mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
b7a75729bf
@ -0,0 +1,149 @@
|
||||
分布式跟踪系统的四大功能模块如何协同工作
|
||||
======
|
||||
|
||||
> 了解分布式跟踪中的主要体系结构决策,以及各部分如何组合在一起。
|
||||
|
||||

|
||||
|
||||
早在十年前,认真研究过分布式跟踪基本上只有学者和一小部分大型互联网公司中的人。对于任何采用微服务的组织来说,它如今成为一种筹码。其理由是确立的:微服务通常会发生让人意想不到的错误,而分布式跟踪则是描述和诊断那些错误的最好方法。
|
||||
|
||||
也就是说,一旦你准备将分布式跟踪集成到你自己的应用程序中,你将很快意识到对于不同的人来说“<ruby>分布式跟踪<rt>Distributed Tracing</rt></ruby>”一词意味着不同的事物。此外,跟踪生态系统里挤满了具有相似内容的重叠项目。本文介绍了分布式跟踪系统中四个(可能)独立的功能模块,并描述了它们间将如何协同工作。
|
||||
|
||||
### 分布式跟踪:一种思维模型
|
||||
|
||||
大多数用于跟踪的思维模型来源于 [Google 的 Dapper 论文][1]。[OpenTracing][2] 使用相似的术语,因此,我们从该项目借用了以下术语:
|
||||
|
||||
![Tracing][3]
|
||||
|
||||
* <ruby>跟踪<rt>Trace</rt></ruby>:事物在分布式系统运行的过程描述。
|
||||
* <ruby>跨度<rt>Span</rt></ruby>:一种命名的定时操作,表示工作流的一部分。跨度可接受键值对标签以及附加到特定跨度实例的细粒度的、带有时间戳的结构化日志。
|
||||
* <ruby>跨度上下文<rt>Span context</rt></ruby>:携带分布式事务的跟踪信息,包括当它通过网络或消息总线将服务传递给服务时。跨度上下文包含跟踪标识符、跨度标识符以及跟踪系统所需传播到下游服务的任何其他数据。
|
||||
|
||||
如果你想要深入研究这种思维模式的细节,请仔细参照 [OpenTracing 技术规范][1]。
|
||||
|
||||
### 四大功能模块
|
||||
|
||||
从应用层分布式跟踪系统的观点来看,现代软件系统架构如下图所示:
|
||||
|
||||
![Tracing][5]
|
||||
|
||||
现代软件系统的组件可分为三类:
|
||||
|
||||
* **应用程序和业务逻辑**:你的代码。
|
||||
* **广泛共享库**:他人的代码
|
||||
* **广泛共享服务**:他人的基础架构
|
||||
|
||||
这三类组件有着不同的需求,驱动着监控应用程序的分布式跟踪系统的设计。最终的设计得到了四个重要的部分:
|
||||
|
||||
* <ruby>跟踪检测 API<rt>A tracing instrumentation API</rt></ruby>:修饰应用程序代码
|
||||
* <ruby>线路协议<rt>Wire protocol</rt></ruby>:在 RPC 请求中与应用程序数据一同发送的规定
|
||||
* <ruby>数据协议<rt>Data protocol</rt></ruby>:将异步信息(带外)发送到你的分析系统的规定
|
||||
* <ruby>分析系统<rt>Analysis system</rt></ruby>:用于处理跟踪数据的数据库和交互式用户界面
|
||||
|
||||
为了更深入的解释这个概念,我们将深入研究驱动该设计的细节。如果你只需要我的一些建议,请跳转至下方的四大解决方案。
|
||||
|
||||
### 需求,细节和解释
|
||||
|
||||
应用程序代码、共享库以及共享式服务在操作上有显著的差别,这种差别严重影响了对其进行检测的请求操作。
|
||||
|
||||
#### 检测应用程序代码和业务逻辑
|
||||
|
||||
在任何特定的微服务中,由微服务开发者编写的大部分代码是应用程序或者商业逻辑。这部分代码规定了特定区域的操作。通常,它包含任何特殊、独一无二的逻辑判断,这些逻辑判断首先证明了创建新型微服务的合理性。基本上按照定义,**该代码通常不会在多个服务中共享或者以其他方式出现。**
|
||||
|
||||
也即是说你仍需了解它,这也意味着需要以某种方式对它进行检测。一些监控和跟踪分析系统使用<ruby>黑盒代理<rt>black-box agents</rt></ruby>自动检测代码,另一些系统更想使用显式的白盒检测工具。对于后者,抽象跟踪 API 提供了许多对于微服务的应用程序代码来说更为实用的优势:
|
||||
|
||||
* 抽象 API 允许你在不重新编写检测代码的条件下换新的监视工具。你可能想要变更云服务提供商、供应商和监测技术,而一大堆不可移植的检测代码将会为该过程增加有意义的开销和麻烦。
|
||||
* 事实证明,除了生产监控之外,该工具还有其他有趣的用途。现有的项目使用相同的跟踪工具来驱动测试工具、分布式调试器、“混沌工程”故障注入器和其他元应用程序。
|
||||
* 但更重要的是,若将应用程序组件提取到共享库中要怎么办呢?由上述内容可得到结论:
|
||||
|
||||
#### 检测共享库
|
||||
|
||||
在大多数应用程序中出现的实用程序代码(处理网络请求、数据库调用、磁盘写操作、线程、并发管理等)通常情况下是通用的,而非特别应用于某个特定应用程序。这些代码会被打包成库和框架,而后就可以被装载到许多的微服务上并且被部署到多种不同的环境中。
|
||||
|
||||
其真正的不同是:对于共享代码,其他人则成为了使用者。大多数用户有不同的依赖关系和操作风格。如果尝试去使用该共享代码,你将会注意到几个常见的问题:
|
||||
|
||||
* 你需要一个 API 来编写检测。然而,你的库并不知道你正在使用哪个分析系统。会有多种选择,并且运行在相同应用下的所有库无法做出不兼容的选择。
|
||||
* 由于这些包封装了所有网络处理代码,因此从请求报头注入和提取跨度上下文的任务往往指向 RPC 库。然而,共享库必须了解到每个应用程序正在使用哪种跟踪协议。
|
||||
* 最后,你不想强制用户使用相互冲突的依赖项。大多数用户有不同的依赖关系和操作风格。即使他们使用 gRPC,绑定的 gRPC 版本是否相同?因此任何你的库附带用于跟踪的监控 API 必定是免于依赖的。
|
||||
|
||||
**因此,一个(a)没有依赖关系、(b)与线路协议无关、(c)使用流行的供应商和分析系统的抽象 API 应该是对检测共享库代码的要求。**
|
||||
|
||||
#### 检测共享式服务
|
||||
|
||||
最后,有时整个服务(或微服务集合体)的通用性足以使许多独立的应用程序使用它们。这种共享式服务通常由第三方托管和管理,例如缓存服务器、消息队列以及数据库。
|
||||
|
||||
从应用程序开发者的角度来看,理解共享式服务本质上是黑盒子是极其重要的。它不可能将你的应用程序监控注入到共享式服务。恰恰相反,托管服务通常会运行它自己的监控方案。
|
||||
|
||||
### 四个方面的解决方案
|
||||
|
||||
因此,抽象的跟踪应用程序接口将会帮助库发出数据并且注入/抽取跨度上下文。标准的线路协议将会帮助黑盒服务相互连接,而标准的数据格式将会帮助分离的分析系统合并其中的数据。让我们来看一下部分有希望解决这些问题的方案。
|
||||
|
||||
#### 跟踪 API:OpenTracing 项目
|
||||
|
||||
如你所见,我们需要一个跟踪 API 来检测应用程序代码。为了将这种工具扩展到大多数进行跨度上下文注入和提取的共享库中,则必须以某种关键方式对 API 进行抽象。
|
||||
|
||||
[OpenTracing][2] 项目主要针对解决库开发者的问题,OpenTracing 是一个与供应商无关的跟踪 API,它没有依赖关系,并且迅速得到了许多监控系统的支持。这意味着,如果库附带了内置的本地 OpenTracing 工具,当监控系统在应用程序启动连接时,跟踪将会自动启动。
|
||||
|
||||
就个人而言,作为一个已经编写、发布和操作开源软件十多年的人,在 OpenTracing 项目上工作并最终解决这个观察性的难题令我十分满意。
|
||||
|
||||
除了 API 之外,OpenTracing 项目还维护了一个不断增长的工具列表,其中一些可以在[这里][6]找到。如果你想参与进来,无论是通过提供一个检测插件,对你自己的 OSS 库进行本地测试,或者仅仅只想问个问题,都可以通过 [Gitter][7] 向我们打招呼。
|
||||
|
||||
#### 线路协议: HTTP 报头 trace-context
|
||||
|
||||
为了监控系统能进行互操作,以及减轻从一个监控系统切换为另外一个时带来的迁移问题,需要标准的线路协议来传播跨度上下文。
|
||||
|
||||
[w3c 分布式跟踪上下文社区小组][8]在努力制定此标准。目前的重点是制定一系列标准的 HTTP 报头。该规范的最新草案可以在[此处][9]找到。如果你对此小组有任何的疑问,[邮件列表][10]和[Gitter 聊天室][11]是很好的解惑地点。
|
||||
|
||||
(LCTT 译注:本文原文发表于 2018 年 5 月,可能现在社区已有不同进展)
|
||||
|
||||
#### 数据协议 (还未出现!!)
|
||||
|
||||
对于黑盒服务,在无法安装跟踪程序或无法与程序进行交互的情况下,需要使用数据协议从系统中导出数据。
|
||||
|
||||
目前这种数据格式和协议的开发工作尚处在初级阶段,并且大多在 w3c 分布式跟踪上下文工作组的上下文中进行工作。需要特别关注的是在标准数据模式中定义更高级别的概念,例如 RPC 调用、数据库语句等。这将允许跟踪系统对可用数据类型做出假设。OpenTracing 项目也通过定义一套[标准标签集][12]来解决这一事务。该计划是为了使这两项努力结果相互配合。
|
||||
|
||||
注意当前有一个中间地带。对于由应用程序开发者操作但不想编译或以其他方式执行代码修改的“网络设备”,动态链接可以帮助避免这种情况。主要的例子就是服务网格和代理,就像 Envoy 或者 NGINX。针对这种情况,可将兼容 OpenTracing 的跟踪器编译为共享对象,然后在运行时动态链接到可执行文件中。目前 [C++ OpenTracing API][13] 提供了该选项。而 JAVA 的 OpenTracing [跟踪器解析][14]也在开发中。
|
||||
|
||||
这些解决方案适用于支持动态链接,并由应用程序开发者部署的的服务。但从长远来看,标准的数据协议可以更广泛地解决该问题。
|
||||
|
||||
#### 分析系统:从跟踪数据中提取有见解的服务
|
||||
|
||||
最后不得不提的是,现在有足够多的跟踪监视解决方案。可以在[此处][15]找到已知与 OpenTracing 兼容的监控系统列表,但除此之外仍有更多的选择。我更鼓励你研究你的解决方案,同时希望你在比较解决方案时发现本文提供的框架能派上用场。除了根据监控系统的操作特性对其进行评级外(更不用提你是否喜欢 UI 和其功能),确保你考虑到了上述三个重要方面、它们对你的相对重要性以及你感兴趣的跟踪系统如何为它们提供解决方案。
|
||||
|
||||
### 结论
|
||||
|
||||
最后,每个部分的重要性在很大程度上取决于你是谁以及正在建立什么样的系统。举个例子,开源库的作者对 OpenTracing API 非常感兴趣,而服务开发者对 trace-context 规范更感兴趣。当有人说一部分比另一部分重要时,他们的意思通常是“一部分对我来说比另一部分重要”。
|
||||
|
||||
然而,事实是:分布式跟踪已经成为监控现代系统所必不可少的事物。在为这些系统进行构建模块时,“尽可能解耦”的老方法仍然适用。在构建像分布式监控系统一样的跨系统的系统时,干净地解耦组件是维持灵活性和前向兼容性地最佳方式。
|
||||
|
||||
感谢你的阅读!现在当你准备好在你自己的应用程序中实现跟踪服务时,你已有一份指南来了解他们正在谈论哪部分部分以及它们之间如何相互协作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/distributed-tracing
|
||||
|
||||
作者:[Ted Young][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[chenmu-kk](https://github.com/chenmu-kk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tedsuo
|
||||
[1]:https://research.google.com/pubs/pub36356.html
|
||||
[2]:http://opentracing.io/
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/tracing1_0.png?itok=dvDTX0JJ (Tracing)
|
||||
[4]:https://github.com/opentracing/specification/blob/master/specification.md
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/tracing2_0.png?itok=yokjNLZk (Tracing)
|
||||
[6]:https://github.com/opentracing-contrib/
|
||||
[7]:https://gitter.im/opentracing/public
|
||||
[8]:https://www.w3.org/community/trace-context/
|
||||
[9]:https://w3c.github.io/distributed-tracing/report-trace-context.html
|
||||
[10]:http://lists.w3.org/Archives/Public/public-trace-context/
|
||||
[11]:https://gitter.im/TraceContext/Lobby
|
||||
[12]:https://github.com/opentracing/specification/blob/master/semantic_conventions.md
|
||||
[13]:https://github.com/opentracing/opentracing-cpp
|
||||
[14]:https://github.com/opentracing-contrib/java-tracerresolver
|
||||
[15]:http://opentracing.io/documentation/pages/supported-tracers
|
||||
[16]:https://events.linuxfoundation.org/kubecon-eu-2018/
|
||||
[17]:https://events.linuxfoundation.org/events/kubecon-cloudnativecon-north-america-2018/
|
||||
@ -0,0 +1,159 @@
|
||||
MidnightBSD:或许是你通往 FreeBSD 的大门
|
||||
======
|
||||
|
||||
|
||||
|
||||
[FreeBSD][1] 是一个开源操作系统,衍生自著名的 <ruby>[伯克利软件套件][2]<rt>Berkeley Software Distribution</rt></ruby>(BSD)。FreeBSD 的第一个版本发布于 1993 年,并且仍然在继续发展。2007 年左右,Lucas Holt 想要利用 OpenStep(现在是 Cocoa)的 Objective-C 框架、widget 工具包和应用程序开发工具的 [GnuStep][3] 实现,来创建一个 FreeBSD 的分支。为此,他开始开发 MidnightBSD 桌面发行版。
|
||||
|
||||
MidnightBSD(以 Lucas 的猫 Midnight 命名)仍然在积极地(尽管缓慢)开发。从 2017 年 8 月开始,可以获得最新的稳定发布版本(0.8.6)(LCTT 译注:截止至本译文发布时,当前是 2019/10/31 发布的 1.2 版)。尽管 BSD 发行版不是你所说的用户友好型发行版,但上手安装是熟悉如何处理 文本(ncurses)安装过程以及通过命令行完成安装的好方法。
|
||||
|
||||
这样,你最终会得到一个非常可靠的 FreeBSD 分支的桌面发行版。这需要花费一点精力,但是如果你是一名正在寻找扩展你的技能的 Linux 用户……这是一个很好的起点。
|
||||
|
||||
我将带你走过安装 MidnightBSD 的流程,如何添加一个图形桌面环境,然后如何安装应用程序。
|
||||
|
||||
### 安装
|
||||
|
||||
正如我所提到的,这是一个文本(ncurses)安装过程,因此在这里找不到可以用鼠标点击的地方。相反,你将使用你键盘的 `Tab` 键和箭头键。在你下载[最新的发布版本][4]后,将它刻录到一个 CD/DVD 或 USB 驱动器,并启动你的机器(或者在 [VirtualBox][5] 中创建一个虚拟机)。安装程序将打开并给你三个选项(图 1)。使用你的键盘的箭头键选择 “Install”,并敲击回车键。
|
||||
|
||||
![MidnightBSD installer][6]
|
||||
|
||||
*图 1: 启动 MidnightBSD 安装程序。*
|
||||
|
||||
在这里要经历相当多的屏幕。其中很多屏幕是一目了然的:
|
||||
|
||||
1. 设置非默认键盘映射(是/否)
|
||||
2. 设置主机名称
|
||||
3. 添加可选系统组件(文档、游戏、32 位兼容性、系统源码代码)
|
||||
4. 对硬盘分区
|
||||
5. 管理员密码
|
||||
6. 配置网络接口
|
||||
7. 选择地区(时区)
|
||||
8. 启用服务(例如 ssh)
|
||||
9. 添加用户(图 2)
|
||||
|
||||
![Adding a user][7]
|
||||
|
||||
*图 2: 向系统添加一个用户。*
|
||||
|
||||
在你向系统添加用户后,你将被进入到一个窗口中(图 3),在这里,你可以处理任何你可能忘记配置或你想重新配置的东西。如果你不需要作出任何更改,选择 “Exit”,然后你的配置就会被应用。
|
||||
|
||||
![Applying your configurations][8]
|
||||
|
||||
*图 3: 应用你的配置。*
|
||||
|
||||
在接下来的窗口中,当出现提示时,选择 “No”,接下来系统将重启。在 MidnightBSD 重启后,你已经为下一阶段的安装做好了准备。
|
||||
|
||||
### 后安装阶段
|
||||
|
||||
当你最新安装的 MidnightBSD 启动时,你将发现你自己处于命令提示符当中。此刻,还没有图形界面。要安装应用程序,MidnightBSD 依赖于 `mport` 工具。比如说你想安装 Xfce 桌面环境。为此,登录到 MidnightBSD 中,并发出下面的命令:
|
||||
|
||||
```
|
||||
sudo mport index
|
||||
sudo mport install xorg
|
||||
```
|
||||
|
||||
你现在已经安装好 Xorg 窗口服务器了,它允许你安装桌面环境。使用命令来安装 Xfce :
|
||||
|
||||
```
|
||||
sudo mport install xfce
|
||||
```
|
||||
|
||||
现在 Xfce 已经安装好。不过,我们必须让它同命令 `startx` 一起启用。为此,让我们先安装 nano 编辑器。发出命令:
|
||||
|
||||
```
|
||||
sudo mport install nano
|
||||
```
|
||||
|
||||
随着 nano 安装好,发出命令:
|
||||
|
||||
```
|
||||
nano ~/.xinitrc
|
||||
```
|
||||
|
||||
这个文件仅包含一行内容:
|
||||
|
||||
```
|
||||
exec startxfce4
|
||||
```
|
||||
|
||||
保存并关闭这个文件。如果你现在发出命令 `startx`, Xfce 桌面环境将会启动。你应该会感到有点熟悉了吧(图 4)。
|
||||
|
||||
![ Xfce][9]
|
||||
|
||||
*图 4: Xfce 桌面界面已准备好服务。*
|
||||
|
||||
因为你不会总是想必须发出命令 `startx`,你希望启用登录守护进程。然而,它却没有安装。要安装这个子系统,发出命令:
|
||||
|
||||
```
|
||||
sudo mport install mlogind
|
||||
```
|
||||
|
||||
当完成安装后,通过在 `/etc/rc.conf` 文件中添加一个项目来在启动时启用 mlogind。在 `rc.conf` 文件的底部,添加以下内容:
|
||||
|
||||
```
|
||||
mlogind_enable=”YES”
|
||||
```
|
||||
|
||||
保存并关闭该文件。现在,当你启动(或重启)机器时,你应该会看到图形登录屏幕。在写这篇文章的时候,在登录后我最后得到一个空白屏幕和讨厌的 X 光标。不幸的是,目前似乎并没有这个问题的解决方法。所以,要访问你的桌面环境,你必须使用 `startx` 命令。
|
||||
|
||||
### 安装应用
|
||||
|
||||
默认情况下,你找不到很多能可用的应用程序。如果你尝试使用 `mport` 安装应用程序,你很快就会感到沮丧,因为只能找到很少的应用程序。为解决这个问题,我们需要使用 `svnlite` 命令来查看检出的可用 mport 软件列表。回到终端窗口,并发出命令:
|
||||
|
||||
```
|
||||
svnlite co http://svn.midnightbsd.org/svn/mports/trunk mports
|
||||
```
|
||||
|
||||
在你完成这些后,你应该看到一个命名为 `~/mports` 的新目录。使用命令 `cd ~/.mports` 更改到这个目录。发出 `ls` 命令,然后你应该看到许多的类别(图 5)。
|
||||
|
||||
![applications][10]
|
||||
|
||||
*图 5: mport 现在可用的应用程序类别。*
|
||||
|
||||
你想安装 Firefox 吗?如果你查看 `www` 目录,你将看到一个 `linux-firefox` 列表。发出命令:
|
||||
|
||||
```
|
||||
sudo mport install linux-firefox
|
||||
```
|
||||
|
||||
现在你应该会在 Xfce 桌面菜单中看到一个 Firefox 项。翻找所有的类别,并使用 `mport` 命令来安装你需要的所有软件。
|
||||
|
||||
### 一个悲哀的警告
|
||||
|
||||
一个悲哀的小警告是,`mport` (通过 `svnlite`)仅能找到的一个办公套件的版本是 OpenOffice 3 。那是非常过时的。尽管在 `~/mports/editors` 目录中能找到 Abiword ,但是它看起来不能安装。甚至在安装 OpenOffice 3 后,它会输出一个执行格式错误。换句话说,你不能使用 MidnightBSD 在办公生产效率方面做很多的事情。但是,嘿嘿,如果你周围正好有一个旧的 Palm Pilot,你可以安装 pilot-link。换句话说,可用的软件不足以构成一个极其有用的桌面发行版……至少对普通用户不是。但是,如果你想在 MidnightBSD 上开发,你将找到很多可用的工具可以安装(查看 `~/mports/devel` 目录)。你甚至可以使用命令安装 Drupal :
|
||||
|
||||
```
|
||||
sudo mport install drupal7
|
||||
```
|
||||
|
||||
当然,在此之后,你将需要创建一个数据库(MySQL 已经安装)、安装 Apache(`sudo mport install apache24`),并配置必要的 Apache 配置。
|
||||
|
||||
显然地,已安装的和可以安装的是一个应用程序、系统和服务的大杂烩。但是随着足够多的工作,你最终可以得到一个能够服务于特殊目的的发行版。
|
||||
|
||||
### 享受 \*BSD 优良
|
||||
|
||||
这就是如何使 MidnightBSD 启动,并使其运行某种有用的桌面发行版的方法。它不像很多其它的 Linux 发行版一样快速简便,但是如果你想要一个促使你思考的发行版,这可能正是你正在寻找的。尽管大多数竞争对手都准备了很多可以安装的应用软件,但 MidnightBSD 无疑是一个 Linux 爱好者或管理员应该尝试的有趣挑战。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/5/midnightbsd-could-be-your-gateway-freebsd
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.freebsd.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Berkeley_Software_Distribution
|
||||
[3]:https://en.wikipedia.org/wiki/GNUstep
|
||||
[4]:http://www.midnightbsd.org/download/
|
||||
[5]:https://www.virtualbox.org/
|
||||
[6]:https://lcom.static.linuxfound.org/sites/lcom/files/midnight_1.jpg (MidnightBSD installer)
|
||||
[7]:https://lcom.static.linuxfound.org/sites/lcom/files/midnight_2.jpg (Adding a user)
|
||||
[8]:https://lcom.static.linuxfound.org/sites/lcom/files/mightnight_3.jpg (Applying your configurations)
|
||||
[9]:https://lcom.static.linuxfound.org/sites/lcom/files/midnight_4.jpg (Xfce)
|
||||
[10]:https://lcom.static.linuxfound.org/sites/lcom/files/midnight_5.jpg (applications)
|
||||
[11]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,150 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11938-1.html)
|
||||
[#]: subject: (Some Advice for How to Make Emacs Tetris Harder)
|
||||
[#]: via: (https://nickdrozd.github.io/2019/01/14/tetris.html)
|
||||
[#]: author: (nickdrozd https://nickdrozd.github.io)
|
||||
|
||||
如何让 Emacs 俄罗斯方块变得更难
|
||||
======
|
||||
|
||||
你知道吗,Emacs 捆绑了一个俄罗斯方块的实现?只需要输入 `M-x tetris` 就行了。
|
||||
|
||||
|
||||
|
||||
在对文本编辑器的讨论中,Emacs 鼓吹者经常提到这一点。“没错,但是你那个编辑器能运行俄罗斯方块吗?”我很好奇,这会让大家相信 Emacs 更优秀吗?比如,为什么有人会关心他们是否可以在文本编辑器中玩游戏呢?“没错,但是你那台吸尘器能播放 mp3 吗?”
|
||||
|
||||
有人说,俄罗斯方块总是很有趣的。像 Emacs 中的所有东西一样,它的源代码是开放的,易于检查和修改,因此 **我们可以使它变得更加有趣**。所谓更加有趣,我的意思是更难。
|
||||
|
||||
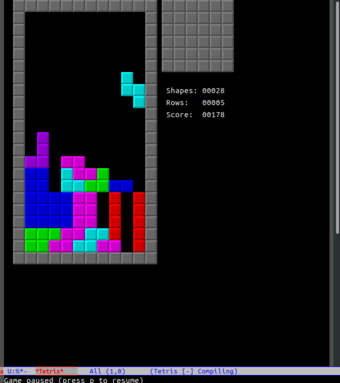
让游戏变得更难的一个最简单的方法就是“隐藏下一个块预览”。你无法在知道下一个块会填满空间的情况下有意地将 S/Z 块放在一个危险的位置——你必须碰碰运气,希望出现最好的情况。下面是没有预览的情况(如你所见,没有预览,我做出的某些选择带来了“可怕的后果”):
|
||||
|
||||
|
||||
|
||||
预览框由一个名为 `tetris-draw-next-shape` [^1] 的函数设置:
|
||||
|
||||
```
|
||||
(defun tetris-draw-next-shape ()
|
||||
(dotimes (x 4)
|
||||
(dotimes (y 4)
|
||||
(gamegrid-set-cell (+ tetris-next-x x)
|
||||
(+ tetris-next-y y)
|
||||
tetris-blank)))
|
||||
(dotimes (i 4)
|
||||
(let ((tetris-shape tetris-next-shape)
|
||||
(tetris-rot 0))
|
||||
(gamegrid-set-cell (+ tetris-next-x
|
||||
(aref (tetris-get-shape-cell i) 0))
|
||||
(+ tetris-next-y
|
||||
(aref (tetris-get-shape-cell i) 1))
|
||||
tetris-shape))))
|
||||
```
|
||||
|
||||
首先,我们引入一个标志,决定是否允许显示下一个预览块 [^2]:
|
||||
|
||||
```
|
||||
(defvar tetris-preview-next-shape nil
|
||||
"When non-nil, show the next block the preview box.")
|
||||
```
|
||||
|
||||
现在的问题是,我们如何才能让 `tetris-draw-next-shape` 遵从这个标志?最明显的方法是重新定义它:
|
||||
|
||||
```
|
||||
(defun tetris-draw-next-shape ()
|
||||
(when tetris-preview-next-shape
|
||||
;; existing tetris-draw-next-shape logic
|
||||
))
|
||||
```
|
||||
|
||||
但这不是理想的解决方案。同一个函数有两个定义,这很容易引起混淆,如果上游版本发生变化,我们必须维护修改后的定义。
|
||||
|
||||
一个更好的方法是使用 **advice**。Emacs 的 advice 类似于 **Python 装饰器**,但是更加灵活,因为 advice 可以从任何地方添加到函数中。这意味着我们可以修改函数而不影响原始的源文件。
|
||||
|
||||
有很多不同的方法使用 Emacs advice([查看手册][4]),但是这里我们只使用 `advice-add` 函数和 `:around` 标志。advice 函数将原始函数作为参数,原始函数可能执行也可能不执行。我们这里,我们让原始函数只有在预览标志是非空的情况下才能执行:
|
||||
|
||||
```
|
||||
(defun tetris-maybe-draw-next-shape (tetris-draw-next-shape)
|
||||
(when tetris-preview-next-shape
|
||||
(funcall tetris-draw-next-shape)))
|
||||
|
||||
(advice-add 'tetris-draw-next-shape :around #'tetris-maybe-draw-next-shape)
|
||||
```
|
||||
|
||||
这段代码将修改 `tetris-draw-next-shape` 的行为,而且它可以存储在配置文件中,与实际的俄罗斯方块代码分离。
|
||||
|
||||
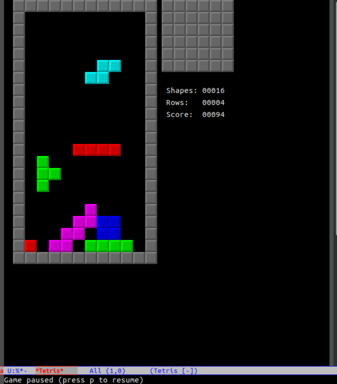
去掉预览框是一个简单的改变。一个更激烈的变化是,**让块随机停止在空中**:
|
||||
|
||||
|
||||
|
||||
本图中,红色的 I 和绿色的 T 部分没有掉下来,它们被固定下来了。这会让游戏变得 **极其困难**,但却很容易实现。
|
||||
|
||||
和前面一样,我们首先定义一个标志:
|
||||
|
||||
```
|
||||
(defvar tetris-stop-midair t
|
||||
"If non-nil, pieces will sometimes stop in the air.")
|
||||
```
|
||||
|
||||
目前,**Emacs 俄罗斯方块的工作方式** 类似这样子:活动部件有 x 和 y 坐标。在每个时钟滴答声中,y 坐标递增(块向下移动一行),然后检查是否有与现存的块重叠。如果检测到重叠,则将该块回退(其 y 坐标递减)并设置该活动块到位。为了让一个块在半空中停下来,我们所要做的就是破解检测函数 `tetris-test-shape`。
|
||||
|
||||
**这个函数内部做什么并不重要** —— 重要的是它是一个返回布尔值的无参数函数。我们需要它在正常情况下返回布尔值 true(否则我们将出现奇怪的重叠情况),但在其他时候也需要它返回 true。我相信有很多方法可以做到这一点,以下是我的方法的:
|
||||
|
||||
```
|
||||
(defun tetris-test-shape-random (tetris-test-shape)
|
||||
(or (and
|
||||
tetris-stop-midair
|
||||
;; Don't stop on the first shape.
|
||||
(< 1 tetris-n-shapes )
|
||||
;; Stop every INTERVAL pieces.
|
||||
(let ((interval 7))
|
||||
(zerop (mod tetris-n-shapes interval)))
|
||||
;; Don't stop too early (it makes the game unplayable).
|
||||
(let ((upper-limit 8))
|
||||
(< upper-limit tetris-pos-y))
|
||||
;; Don't stop at the same place every time.
|
||||
(zerop (mod (random 7) 10)))
|
||||
(funcall tetris-test-shape)))
|
||||
|
||||
(advice-add 'tetris-test-shape :around #'tetris-test-shape-random)
|
||||
```
|
||||
|
||||
这里的硬编码参数使游戏变得更困难,但仍然可玩。当时我在飞机上喝醉了,所以它们可能需要进一步调整。
|
||||
|
||||
顺便说一下,根据我的 `tetris-scores` 文件,我的 **最高分** 是:
|
||||
|
||||
```
|
||||
01389 Wed Dec 5 15:32:19 2018
|
||||
```
|
||||
|
||||
该文件中列出的分数默认最多为五位数,因此这个分数看起来不是很好。
|
||||
|
||||
### 给读者的练习
|
||||
|
||||
1. 使用 advice 修改 Emacs 俄罗斯方块,使得每当方块下移动时就闪烁显示讯息 “OH SHIT”。消息的大小与块堆的高度成比例(当没有块时,消息应该很小的或不存在的,当最高块接近天花板时,消息应该很大)。
|
||||
2. 在这里给出的 `tetris-test-shape-random` 版本中,每隔七格就有一个半空中停止。一个玩家有可能能计算出时间间隔,并利用它来获得优势。修改它,使间隔随机在一些合理的范围内(例如,每 5 到 10 格)。
|
||||
3. 另一个对使用 Tetris 使用 advise 的场景,你可以试试 [autotetris-mode][1]。
|
||||
4. 想出一个有趣的方法来打乱块的旋转机制,然后使用 advice 来实现它。
|
||||
|
||||
[^1]: Emacs 只有一个巨大的全局命名空间,因此函数和变量名一般以包名做前缀以避免冲突。
|
||||
[^2]: 很多人会说你不应该使用已有的命名空间前缀而且应该将自己定义的所有东西都放在一个预留的命名空间中,比如像这样 `my/tetris-preview-next-shape`,然而这样很难看而且没什么意义,因此我不会这么干。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nickdrozd.github.io/2019/01/14/tetris.html
|
||||
|
||||
作者:[nickdrozd][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nickdrozd.github.io
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://nullprogram.com/blog/2014/10/19/
|
||||
[2]: https://nickdrozd.github.io/2019/01/14/tetris.html#fn.1
|
||||
[3]: https://nickdrozd.github.io/2019/01/14/tetris.html#fn.2
|
||||
[4]: https://www.gnu.org/software/emacs/manual/html_node/elisp/Advising-Functions.html
|
||||
[5]: https://nickdrozd.github.io/2019/01/14/tetris.html#fnr.1
|
||||
[6]: https://nickdrozd.github.io/2019/01/14/tetris.html#fnr.2
|
||||
@ -1,21 +1,24 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11913-1.html)
|
||||
[#]: subject: (Zipping files on Linux: the many variations and how to use them)
|
||||
[#]: via: (https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-the-many-variations-and-how-to-use-them.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Zipping files on Linux: the many variations and how to use them
|
||||
在 Linux 上压缩文件:zip 命令的各种变体及用法
|
||||
======
|
||||

|
||||
|
||||
Some of us have been zipping files on Unix and Linux systems for many decades — to save some disk space and package files together for archiving. Even so, there are some interesting variations on zipping that not all of us have tried. So, in this post, we’re going to look at standard zipping and unzipping as well as some other interesting zipping options.
|
||||
> 除了压缩和解压缩文件外,你还可以使用 zip 命令执行许多有趣的操作。这是一些其他的 zip 选项以及它们如何提供帮助。
|
||||
|
||||
### The basic zip command
|
||||

|
||||
|
||||
First, let’s look at the basic **zip** command. It uses what is essentially the same compression algorithm as **gzip** , but there are a couple important differences. For one thing, the gzip command is used only for compressing a single file where zip can both compress files and join them together into an archive. For another, the gzip command zips “in place”. In other words, it leaves a compressed file — not the original file alongside the compressed copy. Here's an example of gzip at work:
|
||||
为了节省一些磁盘空间并将文件打包在一起进行归档,我们中的一些人已经在 Unix 和 Linux 系统上压缩文件数十年了。即使这样,并不是所有人都尝试过一些有趣的压缩工具的变体。因此,在本文中,我们将介绍标准的压缩和解压缩以及其他一些有趣的压缩选项。
|
||||
|
||||
### 基本的 zip 命令
|
||||
|
||||
首先,让我们看一下基本的 `zip` 命令。它使用了与 `gzip` 基本上相同的压缩算法,但是有一些重要的区别。一方面,`gzip` 命令仅用于压缩单个文件,而 `zip` 既可以压缩文件,也可以将多个文件结合在一起成为归档文件。另外,`gzip` 命令是“就地”压缩。换句话说,它会只留下一个压缩文件,而原始文件则没有了。 这是工作中的 `gzip` 示例:
|
||||
|
||||
```
|
||||
$ gzip onefile
|
||||
@ -23,7 +26,7 @@ $ ls -l
|
||||
-rw-rw-r-- 1 shs shs 10514 Jan 15 13:13 onefile.gz
|
||||
```
|
||||
|
||||
And here's zip. Notice how this command requires that a name be provided for the zipped archive where gzip simply uses the original file name and adds the .gz extension.
|
||||
而下面是 `zip`。请注意,此命令要求为压缩存档提供名称,其中 `gzip`(执行压缩操作后)仅使用原始文件名并添加 `.gz` 扩展名。
|
||||
|
||||
```
|
||||
$ zip twofiles.zip file*
|
||||
@ -35,9 +38,9 @@ $ ls -l
|
||||
-rw-rw-r-- 1 shs shs 21289 Jan 15 13:35 twofiles.zip
|
||||
```
|
||||
|
||||
Notice also that the original files are still sitting there.
|
||||
请注意,原始文件仍位于原处。
|
||||
|
||||
The amount of disk space that is saved (i.e., the degree of compression obtained) will depend on the content of each file. The variation in the example below is considerable.
|
||||
所节省的磁盘空间量(即获得的压缩程度)将取决于每个文件的内容。以下示例中的变化很大。
|
||||
|
||||
```
|
||||
$ zip mybin.zip ~/bin/*
|
||||
@ -56,9 +59,9 @@ $ zip mybin.zip ~/bin/*
|
||||
adding: bin/tt (deflated 6%)
|
||||
```
|
||||
|
||||
### The unzip command
|
||||
### unzip 命令
|
||||
|
||||
The **unzip** command will recover the contents from a zip file and, as you'd likely suspect, leave the zip file intact, whereas a similar gunzip command would leave only the uncompressed file.
|
||||
`unzip` 命令将从一个 zip 文件中恢复内容,并且,如你所料,原来的 zip 文件还保留在那里,而类似的 `gunzip` 命令将仅保留未压缩的文件。
|
||||
|
||||
```
|
||||
$ unzip twofiles.zip
|
||||
@ -71,9 +74,9 @@ $ ls -l
|
||||
-rw-rw-r-- 1 shs shs 21289 Jan 15 13:35 twofiles.zip
|
||||
```
|
||||
|
||||
### The zipcloak command
|
||||
### zipcloak 命令
|
||||
|
||||
The **zipcloak** command encrypts a zip file, prompting you to enter a password twice (to help ensure you don't "fat finger" it) and leaves the file in place. You can expect the file size to vary a little from the original.
|
||||
`zipcloak` 命令对一个 zip 文件进行加密,提示你输入两次密码(以确保你不会“胖手指”),然后将该文件原位存储。你可以想到,文件大小与原始文件会有所不同。
|
||||
|
||||
```
|
||||
$ zipcloak twofiles.zip
|
||||
@ -89,11 +92,11 @@ total 204
|
||||
unencrypted version
|
||||
```
|
||||
|
||||
Keep in mind that the original files are still sitting there unencrypted.
|
||||
请记住,压缩包之外的原始文件仍处于未加密状态。
|
||||
|
||||
### The zipdetails command
|
||||
### zipdetails 命令
|
||||
|
||||
The **zipdetails** command is going to show you details — a _lot_ of details about a zipped file, likely a lot more than you care to absorb. Even though we're looking at an encrypted file, zipdetails does display the file names along with file modification dates, user and group information, file length data, etc. Keep in mind that this is all "metadata." We don't see the contents of the files.
|
||||
`zipdetails` 命令将向你显示详细信息:有关压缩文件的详细信息,可能比你想象的要多得多。即使我们正在查看一个加密的文件,`zipdetails` 也会显示文件名以及文件修改日期、用户和组信息、文件长度数据等。请记住,这都是“元数据”。我们看不到文件的内容。
|
||||
|
||||
```
|
||||
$ zipdetails twofiles.zip
|
||||
@ -233,9 +236,9 @@ $ zipdetails twofiles.zip
|
||||
Done
|
||||
```
|
||||
|
||||
### The zipgrep command
|
||||
### zipgrep命令
|
||||
|
||||
The **zipgrep** command is going to use a grep-type feature to locate particular content in your zipped files. If the file is encrypted, you will need to enter the password provided for the encryption for each file you want to examine. If you only want to check the contents of a single file from the archive, add its name to the end of the zipgrep command as shown below.
|
||||
`zipgrep` 命令将使用 `grep` 类的功能来找到压缩文件中的特定内容。如果文件已加密,则需要为要检查的每个文件输入为加密所提供的密码。如果只想检查归档文件中单个文件的内容,请将其名称添加到 `zipgrep` 命令的末尾,如下所示。
|
||||
|
||||
```
|
||||
$ zipgrep hazard twofiles.zip file1
|
||||
@ -243,9 +246,9 @@ $ zipgrep hazard twofiles.zip file1
|
||||
Certain pesticides should be banned since they are hazardous to the environment.
|
||||
```
|
||||
|
||||
### The zipinfo command
|
||||
### zipinfo 命令
|
||||
|
||||
The **zipinfo** command provides information on the contents of a zipped file whether encrypted or not. This includes the file names, sizes, dates and permissions.
|
||||
`zipinfo` 命令提供有关压缩文件内容的信息,无论是否加密。这包括文件名、大小、日期和权限。
|
||||
|
||||
```
|
||||
$ zipinfo twofiles.zip
|
||||
@ -256,9 +259,9 @@ Zip file size: 21313 bytes, number of entries: 2
|
||||
2 files, 116954 bytes uncompressed, 20991 bytes compressed: 82.1%
|
||||
```
|
||||
|
||||
### The zipnote command
|
||||
### zipnote 命令
|
||||
|
||||
The **zipnote** command can be used to extract comments from zip archives or add them. To display comments, just preface the name of the archive with the command. If no comments have been added previously, you will see something like this:
|
||||
`zipnote` 命令可用于从 zip 归档中提取注释或添加注释。要显示注释,只需在命令前面加上归档名称即可。如果之前未添加任何注释,你将看到类似以下内容:
|
||||
|
||||
```
|
||||
$ zipnote twofiles.zip
|
||||
@ -269,21 +272,21 @@ $ zipnote twofiles.zip
|
||||
@ (zip file comment below this line)
|
||||
```
|
||||
|
||||
If you want to add comments, write the output from the zipnote command to a file:
|
||||
如果要添加注释,请先将 `zipnote` 命令的输出写入到文件:
|
||||
|
||||
```
|
||||
$ zipnote twofiles.zip > comments
|
||||
```
|
||||
|
||||
Next, edit the file you've just created, inserting your comments above the **(comment above this line)** lines. Then add the comments using a zipnote command like this one:
|
||||
接下来,编辑你刚刚创建的文件,将注释插入到 `(comment above this line)` 行上方。然后使用像这样的 `zipnote` 命令添加注释:
|
||||
|
||||
```
|
||||
$ zipnote -w twofiles.zip < comments
|
||||
```
|
||||
|
||||
### The zipsplit command
|
||||
### zipsplit 命令
|
||||
|
||||
The **zipsplit** command can be used to break a zip archive into multiple zip archives when the original file is too large — maybe because you're trying to add one of the files to a small thumb drive. The easiest way to do this seems to be to specify the max size for each of the zipped file portions. This size must be large enough to accomodate the largest included file.
|
||||
当归档文件太大时,可以使用 `zipsplit` 命令将一个 zip 归档文件分解为多个 zip 归档文件,这样你就可以将其中某一个文件放到小型 U 盘中。最简单的方法似乎是为每个部分的压缩文件指定最大大小,此大小必须足够大以容纳最大的所包含的文件。
|
||||
|
||||
```
|
||||
$ zipsplit -n 12000 twofiles.zip
|
||||
@ -296,15 +299,11 @@ $ ls twofile*.zip
|
||||
-rw-rw-r-- 1 shs shs 21377 Jan 15 14:27 twofiles.zip
|
||||
```
|
||||
|
||||
Notice how the extracted files are sequentially named "twofile1" and "twofile2".
|
||||
请注意,提取的文件是如何依次命名为 `twofile1` 和 `twofile2` 的。
|
||||
|
||||
### Wrap-up
|
||||
### 总结
|
||||
|
||||
The **zip** command, along with some of its zipping compatriots, provide a lot of control over how you generate and work with compressed file archives.
|
||||
|
||||
**[ Also see:[Invaluable tips and tricks for troubleshooting Linux][1] ]**
|
||||
|
||||
Join the Network World communities on [Facebook][2] and [LinkedIn][3] to comment on topics that are top of mind.
|
||||
`zip` 命令及其一些压缩工具变体,对如何生成和使用压缩文件归档提供了很多控制。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -312,8 +311,8 @@ via: https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-t
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhangxiangping)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11927-1.html)
|
||||
[#]: subject: (12 open source tools for natural language processing)
|
||||
[#]: via: (https://opensource.com/article/19/3/natural-language-processing-tools)
|
||||
[#]: author: (Dan Barker https://opensource.com/users/barkerd427)
|
||||
|
||||
12 种自然语言处理的开源工具
|
||||
======
|
||||
|
||||
> 让我们看看可以用在你自己的 NLP 应用中的十几个工具吧。
|
||||
|
||||

|
||||
|
||||
在过去的几年里,自然语言处理(NLP)推动了聊天机器人、语音助手、文本预测等这些渗透到我们的日常生活中的语音或文本应用程技术的发展。目前有着各种各样开源的 NLP 工具,所以我决定调查一下当前开源的 NLP 工具来帮助你制定开发下一个基于语音或文本的应用程序的计划。
|
||||
|
||||
尽管我并不熟悉所有工具,但我将从我所熟悉的编程语言出发来介绍这些工具(对于我不熟悉的语言,我无法找到大量的工具)。也就是说,出于各种原因,我排除了三种我熟悉的语言之外的工具。
|
||||
|
||||
R 语言可能是没有被包含在内的最重要的语言,因为我发现的大多数库都有一年多没有更新了。这并不一定意味着它们没有得到很好的维护,但我认为它们应该得到更多的更新,以便和同一领域的其他工具竞争。我还选择了最有可能用在生产场景中的语言和工具(而不是在学术界和研究中使用),而我主要是使用 R 作为研究和发现工具。
|
||||
|
||||
我也惊讶地发现 Scala 的很多库都没有更新了。我上次使用 Scala 已经过去了两年了,当时它非常流行。但是大多数库从那个时候就再没有更新过,或者只有少数一些有更新。
|
||||
|
||||
最后,我排除了 C++。 这主要是因为我上次使用 C++ 编写程序已经有很多年了,而我所工作的组织还没有将 C++ 用于 NLP 或任何数据科学方面的工作。
|
||||
|
||||
### Python 工具
|
||||
|
||||
#### 自然语言工具包(NLTK)
|
||||
|
||||
毋庸置疑,[自然语言工具包(NLTK)][2]是我调研过的所有工具中功能最完善的一个。它几乎实现了自然语言处理中多数功能组件,比如分类、令牌化、词干化、标注、分词和语义推理。每一个都有多种不同的实现方式,所以你可以选择具体的算法和方式。同时,它也支持不同的语言。然而,它以字符串的形式表示所有的数据,对于一些简单的数据结构来说可能很方便,但是如果要使用一些高级的功能来说就可能有点困难。它的使用文档有点复杂,但也有很多其他人编写的使用文档,比如[这本很棒的书][3]。和其他的工具比起来,这个工具库的运行速度有点慢。但总的来说,这个工具包非常不错,可以用于需要具体算法组合的实验、探索和实际应用当中。
|
||||
|
||||
#### SpaCy
|
||||
|
||||
[SpaCy][4] 可能是 NLTK 的主要竞争者。在大多数情况下都比 NLTK 的速度更快,但是 SpaCy 的每个自然语言处理的功能组件只有一个实现。SpaCy 把所有的东西都表示为一个对象而不是字符串,从而简化了应用构建接口。这也方便它与多种框架和数据科学工具的集成,使得你更容易理解你的文本数据。然而,SpaCy 不像 NLTK 那样支持多种语言。它确实接口简单,具有简化的选项集和完备的文档,以及用于语言处理和分析各种组件的多种神经网络模型。总的来说,对于需要在生产中表现出色且不需要特定算法的新应用程序,这是一个很不错的工具。
|
||||
|
||||
#### TextBlob
|
||||
|
||||
[TextBlob][5] 是 NLTK 的一个扩展库。你可以通过 TextBlob 用一种更简单的方式来使用 NLTK 的功能,TextBlob 也包括了 Pattern 库中的功能。如果你刚刚开始学习,这将会是一个不错的工具,可以用于对性能要求不太高的生产环境的应用。总体来说,TextBlob 适用于任何场景,但是对小型项目尤佳。
|
||||
|
||||
#### Textacy
|
||||
|
||||
这个工具是我用过的名字最好听的。先重读“ex”再带出“cy”,多读“[Textacy][6]”几次试试。它不仅仅是名字读起来好,同时它本身也是一个很不错的工具。它使用 SpaCy 作为它自然语言处理核心功能,但它在处理过程的前后做了很多工作。如果你想要使用 SpaCy,那么最好使用 Textacy,从而不用去编写额外的附加代码就可以处理不同种类的数据。
|
||||
|
||||
#### PyTorch-NLP
|
||||
|
||||
[PyTorch-NLP][7] 才出现短短的一年,但它已经有一个庞大的社区了。它适用于快速原型开发。当出现了最新的研究,或大公司或者研究人员推出了完成新奇的处理任务的其他工具时,比如图像转换,它就会被更新。总体来说,PyTorch 的目标用户是研究人员,但它也能用于原型开发,或使用最先进算法的初始生产载荷中。基于此基础上的创建的库也是值得研究的。
|
||||
|
||||
### Node.js 工具
|
||||
|
||||
#### Retext
|
||||
|
||||
[Retext][8] 是 [Unified 集合][9]的一部分。Unified 是一个接口,能够集成不同的工具和插件以便它们能够高效的工作。Retext 是 Unified 工具中使用的三种语法之一,另外的两个分别是用于 Markdown 的 Remark 和用于 HTML 的 Rehype。这是一个非常有趣的想法,我很高兴看到这个社区的发展。Retext 没有涉及很多的底层技术,更多的是使用插件去完成你在 NLP 任务中想要做的事情。拼写检查、字形修复、情绪检测和增强可读性都可以用简单的插件来完成。总体来说,如果你不想了解底层处理技术又想完成你的任务的话,这个工具和社区是一个不错的选择。
|
||||
|
||||
#### Compromise
|
||||
|
||||
[Compromise][10] 显然不是最复杂的工具,如果你正在找拥有最先进的算法和最完备的系统的话,它可能不适合你。然而,如果你想要一个性能好、功能广泛、还能在客户端运行的工具的话,Compromise 值得一试。总体来说,它的名字(“折中”)是准确的,因为作者更关注更具体功能的小软件包,而在功能性和准确性上有所折中,这些小软件包得益于用户对使用环境的理解。
|
||||
|
||||
#### Natural
|
||||
|
||||
[Natural][11] 包含了常规自然语言处理库所具有的大多数功能。它主要是处理英文文本,但也包括一些其它语言,它的社区也欢迎支持其它的语言。它能够进行令牌化、词干化、分类、语音处理、词频-逆文档频率计算(TF-IDF)、WordNet、字符相似度计算和一些变换。它和 NLTK 有的一比,因为它想要把所有东西都包含在一个包里头,但它更易于使用,而且不一定专注于研究。总的来说,这是一个非常完整的库,目前仍在活跃开发中,但可能需要对底层实现有更多的了解才能完全发挥效力。
|
||||
|
||||
#### Nlp.js
|
||||
|
||||
[Nlp.js][12] 建立在其他几个 NLP 库之上,包括 Franc 和 Brain.js。它为许多 NLP 组件提供了一个很好的接口,比如分类、情感分析、词干化、命名实体识别和自然语言生成。它也支持一些其它语言,在你处理英语之外的语言时能提供一些帮助。总之,它是一个不错的通用工具,并且提供了调用其他工具的简化接口。在你需要更强大或更灵活的工具之前,这个工具可能会在你的应用程序中用上很长一段时间。
|
||||
|
||||
### Java 工具
|
||||
|
||||
#### OpenNLP
|
||||
|
||||
[OpenNLP][13] 是由 Apache 基金会管理的,所以它可以很方便地集成到其他 Apache 项目中,比如 Apache Flink、Apache NiFi 和 Apache Spark。这是一个通用的 NLP 工具,包含了所有 NLP 组件中的通用功能,可以通过命令行或者以包的形式导入到应用中来使用它。它也支持很多种语言。OpenNLP 是一个很高效的工具,包含了很多特性,如果你用 Java 开发生产环境产品的话,它是个很好的选择。
|
||||
|
||||
#### Stanford CoreNLP
|
||||
|
||||
[Stanford CoreNLP][14] 是一个工具集,提供了统计 NLP、深度学习 NLP 和基于规则的 NLP 功能。这个工具也有许多其他编程语言的版本,所以可以脱离 Java 来使用。它是由高水平的研究机构创建的一个高效的工具,但在生产环境中可能不是最好的。此工具采用双许可证,具有可以用于商业目的的特定许可证。总之,在研究和实验中它是一个很棒的工具,但在生产系统中可能会带来一些额外的成本。比起 Java 版本来说,读者可能对它的 Python 版本更感兴趣。同样,在 Coursera 上最好的机器学习课程之一是斯坦福教授提供的,[点此][15]访问其他不错的资源。
|
||||
|
||||
#### CogCompNLP
|
||||
|
||||
[CogCompNLP][16] 由伊利诺斯大学开发的一个工具,它也有一个相似功能的 Python 版本。它可以用于处理文本,包括本地处理和远程处理,能够极大地缓解你本地设备的压力。它提供了很多处理功能,比如令牌化、词性标注、断句、命名实体标注、词型还原、依存分析和语义角色标注。它是一个很好的研究工具,你可以自己探索它的不同功能。我不确定它是否适合生产环境,但如果你使用 Java 的话,它值得一试。
|
||||
|
||||
* * *
|
||||
|
||||
你最喜欢的开源 NLP 工具和库是什么?请在评论区分享文中没有提到的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/natural-language-processing-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zxp](https://github.com/zhangxiangping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_communication_team.png?itok=CYfZ_gE7 (Chat bubbles)
|
||||
[2]: http://www.nltk.org/
|
||||
[3]: http://www.nltk.org/book_1ed/
|
||||
[4]: https://spacy.io/
|
||||
[5]: https://textblob.readthedocs.io/en/dev/
|
||||
[6]: https://readthedocs.org/projects/textacy/
|
||||
[7]: https://pytorchnlp.readthedocs.io/en/latest/
|
||||
[8]: https://www.npmjs.com/package/retext
|
||||
[9]: https://unified.js.org/
|
||||
[10]: https://www.npmjs.com/package/compromise
|
||||
[11]: https://www.npmjs.com/package/natural
|
||||
[12]: https://www.npmjs.com/package/node-nlp
|
||||
[13]: https://opennlp.apache.org/
|
||||
[14]: https://stanfordnlp.github.io/CoreNLP/
|
||||
[15]: https://opensource.com/article/19/2/learn-data-science-ai
|
||||
[16]: https://github.com/CogComp/cogcomp-nlp
|
||||
236
published/20190407 Manage multimedia files with Git.md
Normal file
236
published/20190407 Manage multimedia files with Git.md
Normal file
@ -0,0 +1,236 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (svtter)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11889-1.html)
|
||||
[#]: subject: (Manage multimedia files with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/manage-multimedia-files-git)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
|
||||
通过 Git 来管理多媒体文件
|
||||
======
|
||||
|
||||
> 在我们有关 Git 鲜为人知的用法系列的最后一篇文章中,了解如何使用 Git 跟踪项目中的大型多媒体文件。
|
||||
|
||||

|
||||
|
||||
Git 是专用于源代码版本控制的工具。因此,Git 很少被用于非纯文本的项目以及行业。然而,异步工作流的优点是十分诱人的,尤其是在一些日益增长的行业中,这种类型的行业把重要的计算和重要的艺术创作结合起来,这包括网页设计、视觉效果、视频游戏、出版、货币设计(是的,这是一个真实的行业)、教育……等等。还有许多行业属于这个类型。
|
||||
|
||||
在这个 Git 系列文章中,我们分享了六种鲜为人知的 Git 使用方法。在最后一篇文章中,我们将介绍将 Git 的优点带到管理多媒体文件的软件。
|
||||
|
||||
### Git 管理多媒体文件的问题
|
||||
|
||||
众所周知,Git 用于处理非文本文件不是很好,但是这并不妨碍我们进行尝试。下面是一个使用 Git 来复制照片文件的例子:
|
||||
|
||||
```
|
||||
$ du -hs
|
||||
108K .
|
||||
$ cp ~/photos/dandelion.tif .
|
||||
$ git add dandelion.tif
|
||||
$ git commit -m 'added a photo'
|
||||
[master (root-commit) fa6caa7] two photos
|
||||
1 file changed, 0 insertions(+), 0 deletions(-)
|
||||
create mode 100644 dandelion.tif
|
||||
$ du -hs
|
||||
1.8M .
|
||||
```
|
||||
|
||||
目前为止没有什么异常。增加一个 1.8MB 的照片到一个目录下,使得目录变成了 1.8 MB 的大小。所以下一步,我们尝试删除文件。
|
||||
|
||||
```
|
||||
$ git rm dandelion.tif
|
||||
$ git commit -m 'deleted a photo'
|
||||
$ du -hs
|
||||
828K .
|
||||
```
|
||||
|
||||
在这里我们可以看到有些问题:删除一个已经被提交的文件,还是会使得存储库的大小扩大到原来的 8 倍(从 108K 到 828K)。我们可以测试多次来得到一个更好的平均值,但是这个简单的演示与我的经验一致。提交非文本文件,在一开始花费空间比较少,但是一个工程活跃地时间越长,人们可能对静态内容修改的会更多,更多的零碎文件会被加和到一起。当一个 Git 存储库变的越来越大,主要的成本往往是速度。拉取和推送的时间,从最初抿一口咖啡的时间到你觉得你可能断网了。
|
||||
|
||||
静态内容导致 Git 存储库的体积不断扩大的原因是什么呢?那些通过文本的构成的文件,允许 Git 只拉取那些修改的部分。光栅图以及音乐文件对 Git 文件而言与文本不同,你可以查看一下 .png 和 .wav 文件中的二进制数据。所以,Git 只不过是获取了全部的数据,并且创建了一个新的副本,哪怕是一张图仅仅修改了一个像素。
|
||||
|
||||
### Git-portal
|
||||
|
||||
在实践中,许多多媒体项目不需要或者不想追踪媒体的历史记录。相对于文本或者代码的部分,项目的媒体部分一般有一个不同的生命周期。媒体资源一般按一个方向产生:一张图片从铅笔草稿开始,以数字绘画的形式抵达它的目的地。然后,尽管文本能够回滚到早起的版本,但是艺术制品只会一直向前发展。工程中的媒体很少被绑定到一个特定的版本。例外情况通常是反映数据集的图形,通常是可以用基于文本的格式(如 SVG)完成的表、图形或图表。
|
||||
|
||||
所以,在许多同时包含文本(无论是叙事散文还是代码)和媒体的工程中,Git 是一个用于文件管理的,可接受的解决方案,只要有一个在版本控制循环之外的游乐场来给艺术家游玩就行。
|
||||
|
||||
![Graphic showing relationship between art assets and Git][2]
|
||||
|
||||
一个启用这个特性的简单方法是 [Git-portal][3],这是一个通过带有 Git 钩子的 Bash 脚本,它可将静态文件从文件夹中移出 Git 的范围,并通过符号链接来取代它们。Git 提交链接文件(有时候称作别名或快捷方式),这种符号链接文件比较小,所以所有的提交都是文本文件和那些代表媒体文件的链接。因为替身文件是符号链接,所以工程还会像预期的运行,因为本地机器会处理他们,转换成“真实的”副本。当用符号链接替换出文件时,Git-portal 维护了项目的结构,因此,如果你认为 Git-portal 不适合你的项目,或者你需要构建项目的一个没有符号链接的版本(比如用于分发),则可以轻松地逆转该过程。
|
||||
|
||||
Git-portal 也允许通过 `rsync` 来远程同步静态资源,所以用户可以设置一个远程存储位置,来做为一个中心的授权源。
|
||||
|
||||
Git-portal 对于多媒体的工程是一个理想的解决方案。类似的多媒体工程包括视频游戏、桌面游戏、需要进行大型 3D 模型渲染和纹理的虚拟现实工程、[带图][4]以及 .odt 输出的书籍、协作型的[博客站点][5]、音乐项目,等等。艺术家在应用程序中以图层(在图形世界中)和曲目(在音乐世界中)的形式执行版本控制并不少见——因此,Git 不会向多媒体项目文件本身添加任何内容。Git 的功能可用于艺术项目的其他部分(例如散文和叙述、项目管理、字幕文件、致谢、营销副本、文档等),而结构化远程备份的功能则由艺术家使用。
|
||||
|
||||
#### 安装 Git-portal
|
||||
|
||||
Git-portal 的 RPM 安装包位于 <https://klaatu.fedorapeople.org/git-portal>,可用于下载和安装。
|
||||
|
||||
此外,用户可以从 Git-portal 的 Gitlab 主页手动安装。这仅仅是一个 Bash 脚本以及一些 Git 钩子(也是 Bash 脚本),但是需要一个快速的构建过程来让它知道安装的位置。
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/slackermedia/git-portal.git git-portal.clone
|
||||
$ cd git-portal.clone
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
#### 使用 Git-portal
|
||||
|
||||
Git-portal 与 Git 一起使用。这意味着,如同 Git 的所有大型文件扩展一样,都需要记住一些额外的步骤。但是,你仅仅需要在处理你的媒体资源的时候使用 Git-portal,所以很容易记住,除非你把大文件都当做文本文件来进行处理(对于 Git 用户很少见)。使用 Git-portal 必须做的一个安装步骤是:
|
||||
|
||||
```
|
||||
$ mkdir bigproject.git
|
||||
$ cd !$
|
||||
$ git init
|
||||
$ git-portal init
|
||||
```
|
||||
|
||||
Git-portal 的 `init` 函数在 Git 存储库中创建了一个 `_portal` 文件夹并且添加到 `.gitignore` 文件中。
|
||||
|
||||
在平日里使用 Git-portal 和 Git 协同十分平滑。一个较好的例子是基于 MIDI 的音乐项目:音乐工作站产生的项目文件是基于文本的,但是 MIDI 文件是二进制数据:
|
||||
|
||||
```
|
||||
$ ls -1
|
||||
_portal
|
||||
song.1.qtr
|
||||
song.qtr
|
||||
song-Track_1-1.mid
|
||||
song-Track_1-3.mid
|
||||
song-Track_2-1.mid
|
||||
$ git add song*qtr
|
||||
$ git-portal song-Track*mid
|
||||
$ git add song-Track*mid
|
||||
```
|
||||
|
||||
如果你查看一下 `_portal` 文件夹,你会发现那里有最初的 MIDI 文件。这些文件在原本的位置被替换成了指向 `_portal` 的链接文件,使得音乐工作站像预期一样运行。
|
||||
|
||||
```
|
||||
$ ls -lG
|
||||
[...] _portal/
|
||||
[...] song.1.qtr
|
||||
[...] song.qtr
|
||||
[...] song-Track_1-1.mid -> _portal/song-Track_1-1.mid*
|
||||
[...] song-Track_1-3.mid -> _portal/song-Track_1-3.mid*
|
||||
[...] song-Track_2-1.mid -> _portal/song-Track_2-1.mid*
|
||||
```
|
||||
|
||||
与 Git 相同,你也可以添加一个目录下的文件。
|
||||
|
||||
```
|
||||
$ cp -r ~/synth-presets/yoshimi .
|
||||
$ git-portal add yoshimi
|
||||
Directories cannot go through the portal. Sending files instead.
|
||||
$ ls -lG _portal/yoshimi
|
||||
[...] yoshimi.stat -> ../_portal/yoshimi/yoshimi.stat*
|
||||
```
|
||||
|
||||
删除功能也像预期一样工作,但是当从 `_portal` 中删除一些东西时,你应该使用 `git-portal rm` 而不是 `git rm`。使用 Git-portal 可以确保文件从 `_portal` 中删除:
|
||||
|
||||
```
|
||||
$ ls
|
||||
_portal/ song.qtr song-Track_1-3.mid@ yoshimi/
|
||||
song.1.qtr song-Track_1-1.mid@ song-Track_2-1.mid@
|
||||
$ git-portal rm song-Track_1-3.mid
|
||||
rm 'song-Track_1-3.mid'
|
||||
$ ls _portal/
|
||||
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
|
||||
```
|
||||
|
||||
如果你忘记使用 Git-portal,那么你需要手动删除 `_portal` 下的文件:
|
||||
|
||||
```
|
||||
$ git-portal rm song-Track_1-1.mid
|
||||
rm 'song-Track_1-1.mid'
|
||||
$ ls _portal/
|
||||
song-Track_1-1.mid* song-Track_2-1.mid* yoshimi/
|
||||
$ trash _portal/song-Track_1-1.mid
|
||||
```
|
||||
|
||||
Git-portal 其它的唯一功能,是列出当前所有的链接并且找到里面可能已经损坏的符号链接。有时这种情况会因为项目文件夹中的文件被移动而发生:
|
||||
|
||||
```
|
||||
$ mkdir foo
|
||||
$ mv yoshimi foo
|
||||
$ git-portal status
|
||||
bigproject.git/song-Track_2-1.mid: symbolic link to _portal/song-Track_2-1.mid
|
||||
bigproject.git/foo/yoshimi/yoshimi.stat: broken symbolic link to ../_portal/yoshimi/yoshimi.stat
|
||||
```
|
||||
|
||||
如果你使用 Git-portal 用于私人项目并且维护自己的备份,以上就是技术方面所有你需要知道关于 Git-portal 的事情了。如果你想要添加一个协作者或者你希望 Git-portal 来像 Git 的方式来管理备份,你可以创建一个远程位置。
|
||||
|
||||
#### 增加 Git-portal 远程位置
|
||||
|
||||
为 Git-portal 增加一个远程位置是通过 Git 已有的远程功能来实现的。Git-portal 实现了 Git 钩子(隐藏在存储库 `.git` 文件夹中的脚本),来寻找你的远程位置上是否存在以 `_portal` 开头的文件夹。如果它找到一个,它会尝试使用 `rsync` 来与远程位置同步文件。Git-portal 在用户进行 Git 推送以及 Git 合并的时候(或者在进行 Git 拉取的时候,实际上是进行一次获取和自动合并),都会执行此操作。
|
||||
|
||||
如果你仅克隆了 Git 存储库,那么你可能永远不会自己添加一个远程位置。这是一个标准的 Git 过程:
|
||||
|
||||
```
|
||||
$ git remote add origin git@gitdawg.com:seth/bigproject.git
|
||||
$ git remote -v
|
||||
origin git@gitdawg.com:seth/bigproject.git (fetch)
|
||||
origin git@gitdawg.com:seth/bigproject.git (push)
|
||||
```
|
||||
|
||||
对你的主要 Git 存储库来说,`origin` 这个名字是一个流行的惯例,将其用于 Git 数据是有意义的。然而,你的 Git-portal 数据是分开存储的,所以你必须创建第二个远程位置来让 Git-portal 了解向哪里推送和从哪里拉取。取决于你的 Git 主机,你可能需要一个单独的服务器,因为空间有限的 Git 主机不太可能接受 GB 级的媒体资产。或者,可能你的服务器仅允许你访问你的 Git 存储库而不允许访问外部的存储文件夹:
|
||||
|
||||
```
|
||||
$ git remote add _portal seth@example.com:/home/seth/git/bigproject_portal
|
||||
$ git remote -v
|
||||
origin git@gitdawg.com:seth/bigproject.git (fetch)
|
||||
origin git@gitdawg.com:seth/bigproject.git (push)
|
||||
_portal seth@example.com:/home/seth/git/bigproject_portal (fetch)
|
||||
_portal seth@example.com:/home/seth/git/bigproject_portal (push)
|
||||
```
|
||||
|
||||
你可能不想为所有用户提供服务器上的个人帐户,也不必这样做。为了提供对托管资源库大文件资产的服务器的访问权限,你可以运行一个 Git 前端,比如 [Gitolite][8] 或者你可以使用 `rrsync` (受限的 rsync)。
|
||||
|
||||
现在你可以推送你的 Git 数据到你的远程 Git 存储库,并将你的 Git-portal 数据到你的远程的门户:
|
||||
|
||||
```
|
||||
$ git push origin HEAD
|
||||
master destination detected
|
||||
Syncing _portal content...
|
||||
sending incremental file list
|
||||
sent 9,305 bytes received 18 bytes 1,695.09 bytes/sec
|
||||
total size is 60,358,015 speedup is 6,474.10
|
||||
Syncing _portal content to example.com:/home/seth/git/bigproject_portal
|
||||
```
|
||||
|
||||
如果你已经安装了 Git-portal,并且配置了 `_portal` 的远程位置,你的 `_portal` 文件夹将会被同步,并且从服务器获取新的内容,以及在每一次推送的时候发送新的内容。尽管你不需要进行 Git 提交或者推送来和服务器同步(用户可以使用直接使用 `rsync`),但是我发现对于艺术性内容的改变,提交是有用的。这将会把艺术家及其数字资产集成到工作流的其余部分中,并提供有关项目进度和速度的有用元数据。
|
||||
|
||||
### 其他选择
|
||||
|
||||
如果 Git-portal 对你而言太过简单,还有一些用于 Git 管理大型文件的其他选择。[Git 大文件存储][9](LFS)是一个名为 git-media 的停工项目的分支,这个分支由 GitHub 维护和支持。它需要特殊的命令(例如 `git lfs track` 来保护大型文件不被 Git 追踪)并且需要用户维护一个 `.gitattributes` 文件来更新哪些存储库中的文件被 LFS 追踪。对于大文件而言,它**仅**支持 HTTP 和 HTTPS 远程主机。所以你必须配置 LFS 服务器,才能使得用户可以通过 HTTP 而不是 SSH 或 `rsync` 来进行鉴权。
|
||||
|
||||
另一个相对 LFS 更灵活的选择是 [git-annex][10]。你可以在我的文章 [管理 Git 中大二进制 blob][11] 中了解更多(忽略其中 git-media 这个已经废弃项目的章节,因为其灵活性没有被它的继任者 Git LFS 延续下来)。Git-annex 是一个灵活且优雅的解决方案。它拥有一个细腻的系统来用于添加、删除、移动存储库中的大型文件。因为它灵活且强大,有很多新的命令和规则需要进行学习,所以建议看一下它的[文档][12]。
|
||||
|
||||
然而,如果你的需求很简单,你可能更加喜欢整合已有技术来进行简单且明显任务的解决方案,则 Git-portal 可能是对于工作而言比较合适的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/manage-multimedia-files-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[svtter](https://github.com/svtter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/video_editing_folder_music_wave_play.png?itok=-J9rs-My (video editing dashboard)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/git-velocity.jpg (Graphic showing relationship between art assets and Git)
|
||||
[3]: http://gitlab.com/slackermedia/git-portal.git
|
||||
[4]: https://www.apress.com/gp/book/9781484241691
|
||||
[5]: http://mixedsignals.ml
|
||||
[6]: mailto:git@gitdawg.com
|
||||
[7]: mailto:seth@example.com
|
||||
[8]: https://opensource.com/article/19/4/file-sharing-git
|
||||
[9]: https://git-lfs.github.com/
|
||||
[10]: https://git-annex.branchable.com/
|
||||
[11]: https://opensource.com/life/16/8/how-manage-binary-blobs-git-part-7
|
||||
[12]: https://git-annex.branchable.com/walkthrough/
|
||||
@ -0,0 +1,189 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mengxinayan)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11935-1.html)
|
||||
[#]: subject: (How to structure a multi-file C program: Part 1)
|
||||
[#]: via: (https://opensource.com/article/19/7/structure-multi-file-c-part-1)
|
||||
[#]: author: (Erik O'Shaughnessy https://opensource.com/users/jnyjnyhttps://opensource.com/users/jnyjnyhttps://opensource.com/users/jim-salterhttps://opensource.com/users/cldxsolutions)
|
||||
|
||||
如何组织构建多文件 C 语言程序(一)
|
||||
======
|
||||
|
||||
> 准备好你喜欢的饮料、编辑器和编译器,放一些音乐,然后开始构建一个由多个文件组成的 C 语言程序。
|
||||
|
||||

|
||||
|
||||
大家常说计算机编程的艺术部分是处理复杂性,部分是命名某些事物。此外,我认为“有时需要添加绘图”是在很大程度上是正确的。
|
||||
|
||||
在这篇文章里,我会编写一个小型 C 程序,命名一些东西,同时处理一些复杂性。该程序的结构大致基于我在 《[如何写一个好的 C 语言 main 函数][2]》 文中讨论的。但是,这次做一些不同的事。准备好你喜欢的饮料、编辑器和编译器,放一些音乐,让我们一起编写一个有趣的 C 语言程序。
|
||||
|
||||
### 优秀 Unix 程序哲学
|
||||
|
||||
首先,你要知道这个 C 程序是一个 [Unix][3] 命令行工具。这意味着它运行在(或者可被移植到)那些提供 Unix C 运行环境的操作系统中。当贝尔实验室发明 Unix 后,它从一开始便充满了[设计哲学][4]。用我自己的话来说就是:程序只做一件事,并做好它,并且对文件进行一些操作。虽然“只做一件事,并做好它”是有意义的,但是“对文件进行一些操作”的部分似乎有点儿不合适。
|
||||
|
||||
事实证明,Unix 中抽象的 “文件” 非常强大。一个 Unix 文件是以文件结束符(EOF)标志为结尾的字节流。仅此而已。文件中任何其它结构均由应用程序所施加而非操作系统。操作系统提供了系统调用,使得程序能够对文件执行一套标准的操作:打开、读取、写入、寻址和关闭(还有其他,但说起来那就复杂了)。对于文件的标准化访问使得不同的程序共用相同的抽象,而且可以一同工作,即使它们是不同的人用不同语言编写的程序。
|
||||
|
||||
具有共享的文件接口使得构建*可组合的*的程序成为可能。一个程序的输出可以作为另一个程序的输入。Unix 家族的操作系统默认在执行程序时提供了三个文件:标准输入(`stdin`)、标准输出(`stdout`)和标准错误(`stderr`)。其中两个文件是只写的:`stdout` 和 `stderr`。而 `stdin` 是只读的。当我们在常见的 Shell 比如 Bash 中使用文件重定向时,可以看到其效果。
|
||||
|
||||
```
|
||||
$ ls | grep foo | sed -e 's/bar/baz/g' > ack
|
||||
```
|
||||
|
||||
这条指令可以被简要地描述为:`ls` 的结果被写入标准输出,它重定向到 `grep` 的标准输入,`grep` 的标准输出重定向到 `sed` 的标准输入,`sed` 的标准输出重定向到当前目录下文件名为 `ack` 的文件中。
|
||||
|
||||
我们希望我们的程序在这个灵活又出色的生态系统中运作良好,因此让我们编写一个可以读写文件的程序。
|
||||
|
||||
### 喵呜喵呜:流编码器/解码器概念
|
||||
|
||||
当我还是一个露着豁牙的孩子懵懵懂懂地学习计算机科学时,学过很多编码方案。它们中的有些用于压缩文件,有些用于打包文件,另一些毫无用处因此显得十分愚蠢。列举最后这种情况的一个例子:[哞哞编码方案][5]。
|
||||
|
||||
为了让我们的程序有个用途,我为它更新了一个 [21 世纪][6] 的概念,并且实现了一个名为“喵呜喵呜” 的编码方案的概念(毕竟网上大家都喜欢猫)。这里的基本的思路是获取文件并且使用文本 “meow” 对每个半字节(半个字节)进行编码。小写字母代表 0,大写字母代表 1。因为它会将 4 个比特替换为 32 个比特,因此会扩大文件的大小。没错,这毫无意义。但是想象一下人们看到经过这样编码后的惊讶表情。
|
||||
|
||||
```
|
||||
$ cat /home/your_sibling/.super_secret_journal_of_my_innermost_thoughts
|
||||
MeOWmeOWmeowMEoW...
|
||||
```
|
||||
|
||||
这非常棒。
|
||||
|
||||
### 最终的实现
|
||||
|
||||
完整的源代码可以在 [GitHub][7] 上面找到,但是我会写下我在编写程序时的思考。目的是说明如何组织构建多文件 C 语言程序。
|
||||
|
||||
既然已经确定了要编写一个编码和解码“喵呜喵呜”格式的文件的程序时,我在 Shell 中执行了以下的命令 :
|
||||
|
||||
```
|
||||
$ mkdir meowmeow
|
||||
$ cd meowmeow
|
||||
$ git init
|
||||
$ touch Makefile # 编译程序的方法
|
||||
$ touch main.c # 处理命令行选项
|
||||
$ touch main.h # “全局”常量和定义
|
||||
$ touch mmencode.c # 实现对喵呜喵呜文件的编码
|
||||
$ touch mmencode.h # 描述编码 API
|
||||
$ touch mmdecode.c # 实现对喵呜喵呜文件的解码
|
||||
$ touch mmdecode.h # 描述解码 API
|
||||
$ touch table.h # 定义编码查找表
|
||||
$ touch .gitignore # 这个文件中的文件名会被 git 忽略
|
||||
$ git add .
|
||||
$ git commit -m "initial commit of empty files"
|
||||
```
|
||||
|
||||
简单的说,我创建了一个目录,里面全是空文件,并且提交到 git。
|
||||
|
||||
即使这些文件中没有内容,你依旧可以从它的文件名推断每个文件的用途。为了避免万一你无法理解,我在每条 `touch` 命令后面进行了简单描述。
|
||||
|
||||
通常,程序从一个简单 `main.c` 文件开始,只有两三个解决问题的函数。然后程序员轻率地向自己的朋友或者老板展示了该程序,然后为了支持所有新的“功能”和“需求”,文件中的函数数量就迅速爆开了。“程序俱乐部”的第一条规则便是不要谈论“程序俱乐部”,第二条规则是尽量减少单个文件中的函数。
|
||||
|
||||
老实说,C 编译器并不关心程序中的所有函数是否都在一个文件中。但是我们并不是为计算机或编译器写程序,我们是为其他人(有时也包括我们)去写程序的。我知道这可能有些奇怪,但这就是事实。程序体现了计算机解决问题所采用的一组算法,当问题的参数发生了意料之外的变化时,保证人们可以理解它们是非常重要的。当在人们修改程序时,发现一个文件中有 2049 函数时他们会诅咒你的。
|
||||
|
||||
因此,优秀的程序员会将函数分隔开,将相似的函数分组到不同的文件中。这里我用了三个文件 `main.c`、`mmencode.c` 和 `mmdecode.c`。对于这样小的程序,也许看起来有些过头了。但是小的程序很难保证一直小下去,因此哥忒拓展做好计划是一个“好主意”。
|
||||
|
||||
但是那些 `.h` 文件呢?我会在后面解释一般的术语,简单地说,它们被称为头文件,同时它们可以包含 C 语言类型定义和 C 预处理指令。头文件中不应该包含任何函数。你可以认为头文件是提供了应用程序接口(API)的定义的一种 `.c` 文件,可以供其它 `.c` 文件使用。
|
||||
|
||||
### 但是 Makefile 是什么呢?
|
||||
|
||||
我知道下一个轰动一时的应用都是你们这些好孩子们用 “终极代码粉碎者 3000” 集成开发环境来编写的,而构建项目是用 Ctrl-Meta-Shift-Alt-Super-B 等一系列复杂的按键混搭出来的。但是如今(也就是今天),使用 `Makefile` 文件可以在构建 C 程序时帮助做很多有用的工作。`Makefile` 是一个包含如何处理文件的方式的文本文件,程序员可以使用其自动地从源代码构建二进制程序(以及其它东西!)
|
||||
|
||||
以下面这个小东西为例:
|
||||
|
||||
```
|
||||
00 # Makefile
|
||||
01 TARGET= my_sweet_program
|
||||
02 $(TARGET): main.c
|
||||
03 cc -o my_sweet_program main.c
|
||||
```
|
||||
|
||||
`#` 符号后面的文本是注释,例如 00 行。
|
||||
|
||||
01 行是一个变量赋值,将 `TARGET` 变量赋值为字符串 `my_sweet_program`。按照惯例,也是我的习惯,所有 `Makefile` 变量均使用大写字母并用下划线分隔单词。
|
||||
|
||||
02 行包含该<ruby>步骤<rt>recipe</rt></ruby>要创建的文件名和其依赖的文件。在本例中,构建<ruby>目标<rt>target</rt></ruby>是 `my_sweet_program`,其依赖是 `main.c`。
|
||||
|
||||
最后的 03 行使用了一个制表符号(`tab`)而不是四个空格。这是将要执行创建目标的命令。在本例中,我们使用 <ruby>C 编译器<rt>C compiler</rt></ruby>前端 `cc` 以编译链接为 `my_sweet_program`。
|
||||
|
||||
使用 `Makefile` 是非常简单的。
|
||||
|
||||
```
|
||||
$ make
|
||||
cc -o my_sweet_program main.c
|
||||
$ ls
|
||||
Makefile main.c my_sweet_program
|
||||
```
|
||||
|
||||
构建我们喵呜喵呜编码器/解码器的 [Makefile][8] 比上面的例子要复杂,但其基本结构是相同的。我将在另一篇文章中将其分解为 Barney 风格。
|
||||
|
||||
### 形式伴随着功能
|
||||
|
||||
我的想法是程序从一个文件中读取、转换它,并将转换后的结果存储到另一个文件中。以下是我想象使用程序命令行交互时的情况:
|
||||
|
||||
```
|
||||
$ meow < clear.txt > clear.meow
|
||||
$ unmeow < clear.meow > meow.tx
|
||||
$ diff clear.txt meow.tx
|
||||
$
|
||||
```
|
||||
|
||||
我们需要编写代码以进行命令行解析和处理输入/输出流。我们需要一个函数对流进行编码并将结果写到另一个流中。最后,我们需要一个函数对流进行解码并将结果写到另一个流中。等一下,我们在讨论如何写一个程序,但是在上面的例子中,我调用了两个指令:`meow` 和 `unmeow`?我知道你可能会认为这会导致越变越复杂。
|
||||
|
||||
### 次要内容:argv[0] 和 ln 指令
|
||||
|
||||
回想一下,C 语言 main 函数的结构如下:
|
||||
|
||||
```
|
||||
int main(int argc, char *argv[])
|
||||
```
|
||||
|
||||
其中 `argc` 是命令行参数的数量,`argv` 是字符指针(字符串)的列表。`argv[0]` 是包含正在执行的程序的文件路径。在 Unix 系统中许多互补功能的程序(比如:压缩和解压缩)看起来像两个命令,但事实上,它们是在文件系统中拥有两个名称的一个程序。这个技巧是通过使用 `ln` 命令创建文件系统链接来实现两个名称的。
|
||||
|
||||
在我笔记本电脑中 `/usr/bin` 的一个例子如下:
|
||||
|
||||
```
|
||||
$ ls -li /usr/bin/git*
|
||||
3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git
|
||||
3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git-receive-pack
|
||||
...
|
||||
```
|
||||
|
||||
这里 `git` 和 `git-receive-pack` 是同一个文件但是拥有不同的名字。我们说它们是相同的文件因为它们具有相同的 inode 值(第一列)。inode 是 Unix 文件系统的一个特点,对它的介绍超越了本文的内容范畴。
|
||||
|
||||
优秀或懒惰的程序可以通过 Unix 文件系统的这个特点达到写更少的代码但是交付双倍的程序。首先,我们编写一个基于其 `argv[0]` 的值而作出相应改变的程序,然后我们确保为导致该行为的名称创建链接。
|
||||
|
||||
在我们的 `Makefile` 中,`unmeow` 链接通过以下的方式来创建:
|
||||
|
||||
```
|
||||
# Makefile
|
||||
...
|
||||
$(DECODER): $(ENCODER)
|
||||
$(LN) -f $< $@
|
||||
...
|
||||
```
|
||||
|
||||
我倾向于在 `Makefile` 中将所有内容参数化,很少使用 “裸” 字符串。我将所有的定义都放置在 `Makefile` 文件顶部,以便可以简单地找到并改变它们。当你尝试将程序移植到新的平台上时,需要将 `cc` 改变为某个 `cc` 时,这会很方便。
|
||||
|
||||
除了两个内置变量 `$@` 和 `$<` 之外,该<ruby>步骤<rt>recipe</rt></ruby>看起来相对简单。第一个便是该步骤的目标的快捷方式,在本例中是 `$(DECODER)`(我能记得这个是因为 `@` 符号看起来像是一个目标)。第二个,`$<` 是规则依赖项,在本例中,它解析为 `$(ENCODER)`。
|
||||
|
||||
事情肯定会变得复杂,但它还在管理之中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/structure-multi-file-c-part-1
|
||||
|
||||
作者:[Erik O'Shaughnessy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[萌新阿岩](https://github.com/mengxinayan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jnyjnyhttps://opensource.com/users/jnyjnyhttps://opensource.com/users/jim-salterhttps://opensource.com/users/cldxsolutions
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_keyboard_coding.png?itok=E0Vvam7A (Programming keyboard.)
|
||||
[2]: https://linux.cn/article-10949-1.html
|
||||
[3]: https://en.wikipedia.org/wiki/Unix
|
||||
[4]: http://harmful.cat-v.org/cat-v/
|
||||
[5]: http://www.jabberwocky.com/software/moomooencode.html
|
||||
[6]: https://giphy.com/gifs/nyan-cat-sIIhZliB2McAo
|
||||
[7]: https://github.com/JnyJny/meowmeow
|
||||
[8]: https://github.com/JnyJny/meowmeow/blob/master/Makefile
|
||||
@ -0,0 +1,208 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11881-1.html)
|
||||
[#]: subject: (How to Go About Linux Boot Time Optimisation)
|
||||
[#]: via: (https://opensourceforu.com/2019/10/how-to-go-about-linux-boot-time-optimisation/)
|
||||
[#]: author: (B Thangaraju https://opensourceforu.com/author/b-thangaraju/)
|
||||
|
||||
如何进行 Linux 启动时间优化
|
||||
======
|
||||
|
||||
![][2]
|
||||
|
||||
> 快速启动嵌入式设备或电信设备,对于时间要求紧迫的应用程序是至关重要的,并且在改善用户体验方面也起着非常重要的作用。这个文章给予一些关于如何增强任意设备的启动时间的重要技巧。
|
||||
|
||||
快速启动或快速重启在各种情况下起着至关重要的作用。为了保持所有服务的高可用性和更好的性能,嵌入式设备的快速启动至关重要。设想有一台运行着没有启用快速启动的 Linux 操作系统的电信设备,所有依赖于这个特殊嵌入式设备的系统、服务和用户可能会受到影响。这些设备维持其服务的高可用性是非常重要的,为此,快速启动和重启起着至关重要的作用。
|
||||
|
||||
一台电信设备的一次小故障或关机,即使只是几秒钟,都可能会对无数互联网上的用户造成破坏。因此,对于很多对时间要求严格的设备和电信设备来说,在它们的设备中加入快速启动的功能以帮助它们快速恢复工作是非常重要的。让我们从图 1 中理解 Linux 启动过程。
|
||||
|
||||
![图 1:启动过程][3]
|
||||
|
||||
### 监视工具和启动过程
|
||||
|
||||
在对机器做出更改之前,用户应注意许多因素。其中包括计算机的当前启动速度,以及占用资源并增加启动时间的服务、进程或应用程序。
|
||||
|
||||
#### 启动图
|
||||
|
||||
为监视启动速度和在启动期间启动的各种服务,用户可以使用下面的命令来安装:
|
||||
|
||||
```
|
||||
sudo apt-get install pybootchartgui
|
||||
```
|
||||
|
||||
你每次启动时,启动图会在日志中保存一个 png 文件,使用户能够查看该 png 文件来理解系统的启动过程和服务。为此,使用下面的命令:
|
||||
|
||||
```
|
||||
cd /var/log/bootchart
|
||||
```
|
||||
|
||||
用户可能需要一个应用程序来查看 png 文件。Feh 是一个面向控制台用户的 X11 图像查看器。不像大多数其它的图像查看器,它没有一个精致的图形用户界面,但它只用来显示图片。Feh 可以用于查看 png 文件。你可以使用下面的命令来安装它:
|
||||
|
||||
```
|
||||
sudo apt-get install feh
|
||||
```
|
||||
|
||||
你可以使用 `feh xxxx.png` 来查看 png 文件。
|
||||
|
||||
|
||||
![图 2:启动图][4]
|
||||
|
||||
图 2 显示了一个正在查看的引导图 png 文件。
|
||||
|
||||
#### systemd-analyze
|
||||
|
||||
但是,对于 Ubuntu 15.10 以后的版本不再需要引导图。为获取关于启动速度的简短信息,使用下面的命令:
|
||||
|
||||
```
|
||||
systemd-analyze
|
||||
```
|
||||
|
||||
![图 3:systemd-analyze 的输出][5]
|
||||
|
||||
图表 3 显示命令 `systemd-analyze` 的输出。
|
||||
|
||||
命令 `systemd-analyze blame` 用于根据初始化所用的时间打印所有正在运行的单元的列表。这个信息是非常有用的,可用于优化启动时间。`systemd-analyze blame` 不会显示服务类型为简单(`Type=simple`)的服务,因为 systemd 认为这些服务应是立即启动的;因此,无法测量初始化的延迟。
|
||||
|
||||
![图 4:systemd-analyze blame 的输出][6]
|
||||
|
||||
图 4 显示 `systemd-analyze blame` 的输出。
|
||||
|
||||
下面的命令打印时间关键的服务单元的树形链条:
|
||||
|
||||
```
|
||||
command systemd-analyze critical-chain
|
||||
```
|
||||
|
||||
图 5 显示命令 `systemd-analyze critical-chain` 的输出。
|
||||
|
||||
![图 5:systemd-analyze critical-chain 的输出][7]
|
||||
|
||||
### 减少启动时间的步骤
|
||||
|
||||
下面显示的是一些可以减少启动时间的各种步骤。
|
||||
|
||||
#### BUM(启动管理器)
|
||||
|
||||
BUM 是一个运行级配置编辑器,允许在系统启动或重启时配置初始化服务。它显示了可以在启动时启动的每个服务的列表。用户可以打开和关闭各个服务。BUM 有一个非常清晰的图形用户界面,并且非常容易使用。
|
||||
|
||||
在 Ubuntu 14.04 中,BUM 可以使用下面的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install bum
|
||||
```
|
||||
|
||||
为在 15.10 以后的版本中安装它,从链接 http://apt.ubuntu.com/p/bum 下载软件包。
|
||||
|
||||
以基本的服务开始,禁用扫描仪和打印机相关的服务。如果你没有使用蓝牙和其它不想要的设备和服务,你也可以禁用它们中一些。我强烈建议你在禁用相关的服务前学习服务的基础知识,因为这可能会影响计算机或操作系统。图 6 显示 BUM 的图形用户界面。
|
||||
|
||||
![图 6:BUM][8]
|
||||
|
||||
#### 编辑 rc 文件
|
||||
|
||||
要编辑 rc 文件,你需要转到 rc 目录。这可以使用下面的命令来做到:
|
||||
|
||||
```
|
||||
cd /etc/init.d
|
||||
```
|
||||
|
||||
然而,访问 `init.d` 需要 root 用户权限,该目录基本上包含的是开始/停止脚本,这些脚本用于在系统运行时或启动期间控制(开始、停止、重新加载、启动启动)守护进程。
|
||||
|
||||
在 `init.d` 目录中的 `rc` 文件被称为<ruby>运行控制<rt>run control</rt></ruby>脚本。在启动期间,`init` 执行 `rc` 脚本并发挥它的作用。为改善启动速度,我们可以更改 `rc` 文件。使用任意的文件编辑器打开 `rc` 文件(当你在 `init.d` 目录中时)。
|
||||
|
||||
例如,通过输入 `vim rc` ,你可以更改 `CONCURRENCY=none` 为 `CONCURRENCY=shell`。后者允许某些启动脚本同时执行,而不是依序执行。
|
||||
|
||||
在最新版本的内核中,该值应该被更改为 `CONCURRENCY=makefile`。
|
||||
|
||||
图 7 和图 8 显示编辑 `rc` 文件前后的启动时间比较。可以注意到启动速度有所提高。在编辑 `rc` 文件前的启动时间是 50.98 秒,然而在对 `rc` 文件进行更改后的启动时间是 23.85 秒。
|
||||
|
||||
但是,上面提及的更改方法在 Ubuntu 15.10 以后的操作系统上不工作,因为使用最新内核的操作系统使用 systemd 文件,而不再是 `init.d` 文件。
|
||||
|
||||
![图 7:对 rc 文件进行更改之前的启动速度][9]
|
||||
|
||||
![图 8:对 rc 文件进行更改之后的启动速度][10]
|
||||
|
||||
#### E4rat
|
||||
|
||||
E4rat 代表 e4 <ruby>减少访问时间<rt>reduced access time</rt></ruby>(仅在 ext4 文件系统的情况下)。它是由 Andreas Rid 和 Gundolf Kiefer 开发的一个项目。E4rat 是一个通过碎片整理来帮助快速启动的应用程序。它还会加速应用程序的启动。E4rat 使用物理文件的重新分配来消除寻道时间和旋转延迟,因而达到较高的磁盘传输速度。
|
||||
|
||||
E4rat 可以 .deb 软件包形式获得,你可以从它的官方网站 http://e4rat.sourceforge.net/ 下载。
|
||||
|
||||
Ubuntu 默认安装的 ureadahead 软件包与 e4rat 冲突。因此必须使用下面的命令安装这几个软件包:
|
||||
|
||||
```
|
||||
sudo dpkg purge ureadahead ubuntu-minimal
|
||||
```
|
||||
|
||||
现在使用下面的命令来安装 e4rat 的依赖关系:
|
||||
|
||||
```
|
||||
sudo apt-get install libblkid1 e2fslibs
|
||||
```
|
||||
|
||||
打开下载的 .deb 文件,并安装它。现在需要恰当地收集启动数据来使 e4rat 工作。
|
||||
|
||||
遵循下面所给的步骤来使 e4rat 正确地运行并提高启动速度。
|
||||
|
||||
* 在启动期间访问 Grub 菜单。这可以在系统启动时通过按住 `shift` 按键来完成。
|
||||
* 选择通常用于启动的选项(内核版本),并按 `e`。
|
||||
* 查找以 `linux /boot/vmlinuz` 开头的行,并在该行的末尾添加下面的代码(在句子的最后一个字母后按空格键):`init=/sbin/e4rat-collect or try - quiet splash vt.handsoff =7 init=/sbin/e4rat-collect
|
||||
`。
|
||||
* 现在,按 `Ctrl+x` 来继续启动。这可以让 e4rat 在启动后收集数据。在这台机器上工作,并在接下来的两分钟时间内打开并关闭应用程序。
|
||||
* 通过转到 e4rat 文件夹,并使用下面的命令来访问日志文件:`cd /var/log/e4rat`。
|
||||
* 如果你没有找到任何日志文件,重复上面的过程。一旦日志文件就绪,再次访问 Grub 菜单,并对你的选项按 `e`。
|
||||
* 在你之前已经编辑过的同一行的末尾输入 `single`。这可以让你访问命令行。如果出现其它菜单,选择恢复正常启动(Resume normal boot)。如果你不知为何不能进入命令提示符,按 `Ctrl+Alt+F1` 组合键。
|
||||
* 在你看到登录提示后,输入你的登录信息。
|
||||
* 现在输入下面的命令:`sudo e4rat-realloc /var/lib/e4rat/startup.log`。此过程需要一段时间,具体取决于机器的磁盘速度。
|
||||
* 现在使用下面的命令来重启你的机器:`sudo shutdown -r now`。
|
||||
* 现在,我们需要配置 Grub 来在每次启动时运行 e4rat。
|
||||
* 使用任意的编辑器访问 grub 文件。例如,`gksu gedit /etc/default/grub`。
|
||||
* 查找以 `GRUB CMDLINE LINUX DEFAULT=` 开头的一行,并在引号之间和任何选项之前添加下面的行:`init=/sbin/e4rat-preload 18`。
|
||||
* 它应该看起来像这样:`GRUB CMDLINE LINUX DEFAULT = init=/sbin/e4rat- preload quiet splash`。
|
||||
* 保存并关闭 Grub 菜单,并使用 `sudo update-grub` 更新 Grub 。
|
||||
* 重启系统,你将发现启动速度有明显变化。
|
||||
|
||||
图 9 和图 10 显示在安装 e4rat 前后的启动时间之间的差异。可注意到启动速度的提高。在使用 e4rat 前启动所用时间是 22.32 秒,然而在使用 e4rat 后启动所用时间是 9.065 秒。
|
||||
|
||||
![图 9:使用 e4rat 之前的启动速度][11]
|
||||
|
||||
![图 10:使用 e4rat 之后的启动速度][12]
|
||||
|
||||
### 一些易做的调整
|
||||
|
||||
使用很小的调整也可以达到良好的启动速度,下面列出其中两个。
|
||||
|
||||
#### SSD
|
||||
|
||||
使用固态设备而不是普通的硬盘或者其它的存储设备将肯定会改善启动速度。SSD 也有助于加快文件传输和运行应用程序方面的速度。
|
||||
|
||||
#### 禁用图形用户界面
|
||||
|
||||
图形用户界面、桌面图形和窗口动画占用大量的资源。禁用图形用户界面是获得良好的启动速度的另一个好方法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensourceforu.com/2019/10/how-to-go-about-linux-boot-time-optimisation/
|
||||
|
||||
作者:[B Thangaraju][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensourceforu.com/author/b-thangaraju/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Screenshot-from-2019-10-07-13-16-32.png?&ssl=1 (Screenshot from 2019-10-07 13-16-32)
|
||||
[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Screenshot-from-2019-10-07-13-16-32.png?fit=700%2C499&ssl=1
|
||||
[3]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-1.png?ssl=1
|
||||
[4]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-2.png?ssl=1
|
||||
[5]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-3.png?ssl=1
|
||||
[6]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-4.png?ssl=1
|
||||
[7]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-5.png?ssl=1
|
||||
[8]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-6.png?ssl=1
|
||||
[9]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-7.png?ssl=1
|
||||
[10]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-8.png?ssl=1
|
||||
[11]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-9.png?ssl=1
|
||||
[12]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-10.png?ssl=1
|
||||
@ -1,26 +1,28 @@
|
||||
自动共享和上传文件到兼容的托管站点
|
||||
======
|
||||

|
||||
前阵子我们写了一个关于[**Transfer.sh**][1]的指南,它允许你使用命令行通过互联网来分享文件。今天,我们来看看另一种文件分享实用工具**Anypaste**。这是一个基于文件类型自动共享和上传文件到兼容托管站点的简单脚本。你不需要去手动登录到托管站点来上传或分享你的文件。Anypaste将会根据你想上传的文件的类型来**自动挑选合适的托管站点**。简单地说,照片将被上传到图像托管站点,视频被传到视频站点,代码被传到pastebins。难道不是很酷的吗?Anypaste是一个完全开源、免费、轻量的脚本,你可以通过命令行完成所有操作。因此,你不需要依靠那些臃肿的,需要消耗大量内存的GUI应用来上传和共享文件。
|
||||
|
||||
### Anypaste-自动共享和上传文件到兼容的托管站点
|
||||
#### 安装
|
||||
正如我所说,这仅仅是一个脚本。所以不存在任何复杂的安装步骤。只需要将脚本下载后放置在你想要运行的位置(例如/usr/bin/anypaste),并将其设置为可执行文件后就可以直接使用了。此外,你也可以通过下面的这两条命令来快速安装Anypaste。
|
||||

|
||||
|
||||
前阵子我们写了一个关于 [Transfer.sh][1]的指南,它允许你使用命令行通过互联网来分享文件。今天,我们来看看另一种文件分享实用工具 Anypaste。这是一个基于文件类型自动共享和上传文件到兼容托管站点的简单脚本。你不需要去手动登录到托管站点来上传或分享你的文件。Anypaste 将会根据你想上传的文件的类型来**自动挑选合适的托管站点**。简单地说,照片将被上传到图像托管站点,视频被传到视频站点,代码被传到 pastebin。难道不是很酷的吗?Anypaste 是一个完全开源、免费、轻量的脚本,你可以通过命令行完成所有操作。因此,你不需要依靠那些臃肿的、需要消耗大量内存的 GUI 应用来上传和共享文件。
|
||||
|
||||
### 安装
|
||||
|
||||
正如我所说,这仅仅是一个脚本。所以不存在任何复杂的安装步骤。只需要将脚本下载后放置在你想要运行的位置(例如 `/usr/bin/`),并将其设置为可执行文件后就可以直接使用了。此外,你也可以通过下面的这两条命令来快速安装 Anypaste。
|
||||
|
||||
```
|
||||
sudo curl -o /usr/bin/anypaste https://anypaste.xyz/sh
|
||||
```
|
||||
```
|
||||
sudo chmod +x /usr/bin/anypaste
|
||||
```
|
||||
|
||||
就是这样简单。如果需要更新老的Anypaste版本,只需要用新的可执行文件覆写旧的即可。
|
||||
就是这样简单。如果需要更新老的 Anypaste 版本,只需要用新的可执行文件覆写旧的即可。
|
||||
|
||||
现在,让我们看看一些实例。
|
||||
|
||||
#### 配置
|
||||
Anypaste开箱即用,并不需要特别的配置。默认的配置文件是 **~/.config/anypaste.conf** ,这个文件在你第一次运行Anypaste时会自动创建。
|
||||
### 配置
|
||||
|
||||
需要配置的选项只有**ap_plugins**。Anypaste使用插件系统去上传文件。每个站点(上传)都由一个特定的插件表示。你可以在anypaste.conf文件中的**ap-plugins directive**位置浏览可用的插件列表。
|
||||
Anypaste 开箱即用,并不需要特别的配置。默认的配置文件是 `~/.config/anypaste.conf`,这个文件在你第一次运行 Anypaste 时会自动创建。
|
||||
|
||||
需要配置的选项只有 `ap_plugins`。Anypaste 使用插件系统上传文件。每个站点(的上传)都由一个特定的插件表示。你可以在 `anypaste.conf` 文件中的 `ap-plugins directive` 位置浏览可用的插件列表。
|
||||
|
||||
```
|
||||
# List of plugins
|
||||
@ -42,13 +44,19 @@ ap_plugins=(
|
||||
)
|
||||
[...]
|
||||
```
|
||||
如果你要安装一个新的插件,将它添加进这个列表中就可以了。如果你想禁用一个默认插件,只需要将它从列表中移除即可。如果多个插件是相互依存的关系,排列中的第一个会被选择,因此**顺序很重要**。
|
||||
#### 用法
|
||||
上传一个简单的文件,例如test.png,可以运行以下命令:
|
||||
|
||||
如果你要安装一个新的插件,将它添加进这个列表中就可以了。如果你想禁用一个默认插件,只需要将它从列表中移除即可。如果有多个兼容的插件,排列中的第一个会被选择,因此**顺序很重要**。
|
||||
|
||||
### 用法
|
||||
|
||||
上传一个简单的文件,例如 `test.png`,可以运行以下命令:
|
||||
|
||||
```
|
||||
anypaste test.png
|
||||
```
|
||||
**输出示例:**
|
||||
|
||||
输出示例:
|
||||
|
||||
```
|
||||
Current file: test.png
|
||||
Attempting to upload with plugin 'tinyimg'
|
||||
@ -59,9 +67,10 @@ Direct Link: https://tinyimg.io/i/Sa1zsjj.png
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
正如输出结果中所看到的,Anypaste通过自动匹配图像文件**test.png**发现了兼容的托管站点(https://tinyimg.io),并将文件上传到了该站点。此外,Anypaste也为我们提供了用于直接浏览/下载该文件的链接。
|
||||
|
||||
不仅png格式文件,你还可以上传任何其他图片格式的文件。例如,下面的命令将会上传gif格式文件:
|
||||
正如输出结果中所看到的,Anypaste 通过自动匹配图像文件 `test.png` 发现了兼容的托管站点(https://tinyimg.io),并将文件上传到了该站点。此外,Anypaste 也为我们提供了用于直接浏览/下载该文件的链接。
|
||||
|
||||
不仅是 png 格式文件,你还可以上传任何其他图片格式的文件。例如,下面的命令将会上传 gif 格式文件:
|
||||
|
||||
```
|
||||
$ anypaste file.gif
|
||||
@ -78,17 +87,21 @@ Direct(ish) Link: https://thumbs.gfycat.com/MisguidedQuaintBergerpicard-size_res
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
你可以将链接分享给你的家庭,朋友和同事们。下图是我刚刚将图片上传到**gfycat**网站的截图。
|
||||
|
||||
[![][2]][3]
|
||||
你可以将链接分享给你的家庭、朋友和同事们。下图是我刚刚将图片上传到 gfycat 网站的截图。
|
||||
|
||||
![][3]
|
||||
|
||||
也可以一次同时上传多个(相同格式或不同格式)文件。
|
||||
|
||||
下面的例子提供参考,这里我会上传两个不同的文件,包含一个图片文件和一个视频文件:
|
||||
|
||||
```
|
||||
anypaste image.png video.mp4
|
||||
```
|
||||
**输出示例:**
|
||||
|
||||
输出示例:
|
||||
|
||||
```
|
||||
Current file: image.png
|
||||
Attempting to upload with plugin 'tinyimg'
|
||||
@ -109,13 +122,16 @@ Delete/Edit: http://sendvid.com/wwy7w96h?secret=39c0af2d-d8bf-4d3d-bad3-ad37432a
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
Anypaste针对两个文件自动发现了与之相兼容的托管站点并成功上传。
|
||||
|
||||
正如你在上述用法介绍部分的例子中注意到的,Anypaste会自动挑选最佳的插件。此外,你可以指定插件进行文件上传,这里提供一个上传**gfycat**类型文件的案例,运行以下命令:
|
||||
Anypaste 针对两个文件自动发现了与之相兼容的托管站点并成功上传。
|
||||
|
||||
正如你在上述用法介绍部分的例子中注意到的,Anypaste 会自动挑选最佳的插件。此外,你可以指定插件进行文件上传,这里提供一个上传到 gfycat 的案例,运行以下命令:
|
||||
|
||||
```
|
||||
anypaste -p gfycat file.gif
|
||||
```
|
||||
**输出示例:**
|
||||
|
||||
输出示例:
|
||||
|
||||
```
|
||||
Current file: file.gif
|
||||
@ -131,15 +147,21 @@ Direct(ish) Link: https://thumbs.gfycat.com/GrayDifferentCollie-size_restricted.
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
|
||||
如果要使用特定插件进行文件上传,可以通过以下命令绕过兼容性检查:
|
||||
|
||||
```
|
||||
anypaste -fp gfycat file.gif
|
||||
```
|
||||
如果你发现在配置文件中忽略了特定的插件,你仍然可以强制Anypaste去使用特定的插件,只不过需要加上'-xp'参数。
|
||||
|
||||
如果你发现在配置文件中忽略了特定的插件,你仍然可以强制 Anypaste 去使用特定的插件,只不过需要加上 `-xp` 参数。
|
||||
|
||||
```
|
||||
anypaste -xp gfycat file.gif
|
||||
```
|
||||
如果想要以交互模式上传文件,可以在命令后加上'-i'标签:
|
||||
|
||||
如果想要以交互模式上传文件,可以在命令后加上 `-i` 标签:
|
||||
|
||||
```
|
||||
$ anypaste -i file.gif
|
||||
Current file: file.gif
|
||||
@ -159,15 +181,16 @@ Direct(ish) Link: https://thumbs.gfycat.com/WaryAshamedBlackbear-size_restricted
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
正如你所见,Anypaste首先询问了我是否需要自动确定插件。因为我不想自动寻找插件,所以我回复了'No'。之后,Anypaste列出了所有可选择的插件,并要求我从列表中选择一个。同样的,你可以上传和共享不同类型的文件,相关文件会被上传到相兼容的站点。
|
||||
|
||||
无论你何时上传一个视频文件,Anypaste都会将其上传到以下站点中的一个:
|
||||
正如你所见,Anypaste 首先询问了我是否需要自动确定插件。因为我不想自动寻找插件,所以我回复了 “No”。之后,Anypaste 列出了所有可选择的插件,并要求我从列表中选择一个。同样的,你可以上传和共享不同类型的文件,相关文件会被上传到相兼容的站点。
|
||||
|
||||
无论你何时上传一个视频文件,Anypaste 都会将其上传到以下站点中的一个:
|
||||
|
||||
1. sendvid
|
||||
2. streamable
|
||||
3. gfycat
|
||||
|
||||
这里注意列表顺序,Anypaste将首先将文件上传到sendvid站点,如果没有sendvid的插件可供使用,Anypaste将会尝试顺序中的另外两个站点。当然你也可以通过更改配置文件来修改顺序。
|
||||
这里注意列表顺序,Anypaste 将首先将文件上传到 sendvid 站点,如果没有 sendvid 的插件可供使用,Anypaste 将会尝试顺序中的另外两个站点。当然你也可以通过更改配置文件来修改顺序。
|
||||
|
||||
图像文件上传站点:
|
||||
|
||||
@ -195,8 +218,9 @@ All files processed. Have a nice day!
|
||||
|
||||
上面列出来的部分站点一段特定的时间后会删除上传的内容,所以在上传和分享内容时应先明确这些站点的条款和条件。
|
||||
|
||||
#### 结论
|
||||
在我看来,识别文件并决定将其上传到何处的想法非常棒,而且开发者也以恰当的方式完美地实现了它。毫无疑问,Anypaste对那些在互联网上需要频繁分享文件的人们非常有用,我希望你也能这么觉得。
|
||||
### 结论
|
||||
|
||||
在我看来,识别文件并决定将其上传到何处的想法非常棒,而且开发者也以恰当的方式完美地实现了它。毫无疑问,Anypaste 对那些在互联网上需要频繁分享文件的人们非常有用,我希望你也能这么觉得。
|
||||
|
||||
这就是今天的全部内容,后面会有越来越多的好东西分享给大家。再见啦!
|
||||
|
||||
@ -206,7 +230,7 @@ via: https://www.ostechnix.com/anypaste-share-upload-files-compatible-hosting-si
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lixin555](https://github.com/lixin555)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
全球化思考:怎样克服交流中的文化差异
|
||||
======
|
||||
|
||||
> 这有一些建议帮助你的全球化开发团队能够更好地理解你们的讨论并能参与其中。
|
||||
|
||||
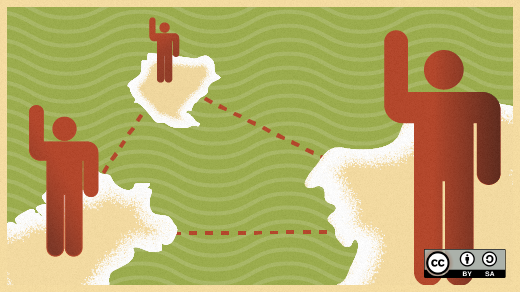
|
||||
|
||||
几周前,我见证了两位同事之间一次有趣的互动,他们分别是 Jason,我们的一位美国员工,和 Raj,一位来自印度的访问工作人员。
|
||||
|
||||
Raj 在印度时,他一般会通过电话参加美国中部时间上午 9 点的每日立会,现在他到美国工作了,就可以和组员们坐在同一间会议室里开会了。Jason 拦下了 Raj,说:“Raj 你要去哪?你不是一直和我们开电话会议吗?你突然出现在会议室里我还不太适应。” Raj 听了说,“是这样吗?没问题。”就回到自己工位前准备和以前一样参加电话会议了。
|
||||
|
||||
我去找 Raj,问他为什么不去参加每日立会,Raj 说 Jason 让自己给组员们打电话参会,而与此同时,Jason 也在会议室等着 Raj 来参加立会。
|
||||
|
||||
到底是哪里出的问题?Jason 明显只是调侃 Raj 终于能来一起开会了,为什么 Raj 没能听懂呢?
|
||||
|
||||
Jason 明显是在开玩笑,但 Raj 把它当真了。这就是在两人互相不了解对方文化语境时发生的一个典型误会。
|
||||
|
||||
我经常会遇到有人在电子邮件的末尾写“请复原”,最开始我很迷惑,“这有什么需要我复原的内容?”后来我才搞懂,“请复原”其实是“请回复”的意思。
|
||||
|
||||
在 Ricardo Fernandez 的TED 演讲“[如何管理跨文化团队][1]” 中,他提到了自己与一位南非同事发生的小故事。那位同事用一句“我一会给你打电话。”结束了两人的 IM 会话,Ricardo 回到办公室后就开始等这位同事的电话,十五分钟后他忍不住主动给这位同事打了电话,问他:“你不是说要给我打电话吗?”,这位同事答到:“是啊,我是说以后有机会给你打电话。”这时 Ricardo 才理解那位同事说的“一会”是“以后”的意思。
|
||||
|
||||
现在是全球化时代,我们的同事很可能不跟我们面对面接触,甚至不在同一座城市,来自不同的国家。越来越多的技术公司拥有全球化的工作场所,和来自世界各地的员工,他们有着不同的背景和经历。这种多样性使得技术公司能够在这个快速发展的科技大环境下拥有更强的竞争力。
|
||||
|
||||
但是这种地域的多样性也会给团队带来挑战。管理和维持高性能的团队发展对于同地协作的团队来说就有着很大难度,对于有着多样背景成员的全球化团队来说,无疑更加困难。成员之间的交流会发生延迟,误解时有发生,成员之间甚至会互相怀疑,这些都会影响着公司的成功。
|
||||
|
||||
到底是什么因素让全球化交流间发生误解呢?我们可以参照 Erin Meyer 的书《[文化地图][2]》,她在书中将全球文化分为八个类型,其中美国文化被分为低语境文化,与之相对的,日本为高语境文化。
|
||||
|
||||
看到这里你可能会问,高、低语境文化到底是什么意思?美国人从小就教育孩子们简洁表达,“直言不讳”是他们的表达准则;另一边,日本人从小学习在高效处理社交线索的同时进行交流,“察言观色”是他们的交流习惯。
|
||||
|
||||
大部分亚洲国家的文化都属于高语境文化。作为一个年轻的移民国家,美国毫不意外地拥有着低语境文化。移民来自于世界各地,拥有着不同的文化背景,他们不得不选择简洁而直接的交流方式,这或许就是其拥有低语境文化的原因。
|
||||
|
||||
### 从文化语境的角度与异国同事交流的三个步骤:
|
||||
|
||||
怎样面临跨文化交流中遇到的挑战?比如说一位美国人与他的日本同事交流,他更应该注重日本同事的非语言线索,同样的日本同事应当更关注美国人直接表达出的信息。如果你也面临类似的挑战,按照下面这三个步骤做,可以帮助你更有效地和异国同事交流,增进与他们的感情。
|
||||
|
||||
#### 认识到文化语境的差异
|
||||
|
||||
跨文化交流的第一步是认识到文化差异,跨文化交流从认识其他文化开始。
|
||||
|
||||
#### 尊重文化语境的差异
|
||||
|
||||
一旦你意识到了文化语境的差异会影响跨文化交流,你要做的就是尊重这些差异。在你遇到一种不同的交流方式时,学会接受差异,学会积极听取他人意见。
|
||||
|
||||
#### 调和文化语境的差异
|
||||
|
||||
只是认识和尊重差异还远远不够,你还需要学会如何调和这些差异。互相理解和换位思考可以增进差异的调和,你还要学着用它们去提高同事间的交流效率,推动生产力。
|
||||
|
||||
### 五种促进不同文化语境间交流的方法
|
||||
|
||||
为了加强组员们之间关系,这么多年来我一直在收集各种各样的方法和建议。这些方法帮助我解决了与外国组员间产生的很多交流问题,下面有其中一些例子:
|
||||
|
||||
#### 与外国组员交流时尽量使用视频会议的形式
|
||||
|
||||
研究表明,交流中约 55% 的内容不是靠语言传递的。肢体语言传达着一种十分微妙的信息,你可以根据它们理解对方的意思,而视频会议中处于异地的组员们能够看到对方的肢体语言。因此,组织远程会议时我一般都会采用视频会议的形式。
|
||||
|
||||
#### 确保每位成员都有机会分享他们的想法
|
||||
|
||||
我虽然喜欢开视频会议,但不是每次都能开的成。如果视频会议对你的团队来说并不常用,大家可能要一些时间去适应,你需要积极鼓励大家参与到其中,先从进行语音会议开始。
|
||||
|
||||
我们有一个外地的组员,每次都和我们进行语音会议,和我们提到她经常会有些想法想要分享,或者想做些贡献,但是我们互相看不到,她不知道该怎样开口。如果你一直在进行语音会议,注意要给组员们足够的时间和机会分享他们的想法。
|
||||
|
||||
#### 互相学习
|
||||
|
||||
通过你身边一两名外国朋友来学习他们的文化,你可以把从一位同事身上学到的应用于所有来自这个国家的同事。我有几位南亚和南美的同事,他们帮助我理解他们的文化,而这些也使得我更加专业。
|
||||
|
||||
对编程人员来说,我建议请你全世界的同行们检查你的代码,这个过程能让你观察到其他文化中人们怎样进行反馈、劝说他人,和最终进行技术决策。
|
||||
|
||||
#### 学会感同身受
|
||||
|
||||
同理心是一段牢固关系的核心。你越能换位思考,就越容易获得信任,来建立长久的关系。你可以在每次会议开始之前和大家闲聊几句,这样大家更容易处于一个放松的状态,如果团队中有很多外国人,要确保大家都能参与进来。
|
||||
|
||||
#### 和你的外国同事们单独见面
|
||||
|
||||
保持长久关系最好的方法是和你的组员们单独见面。如果你的公司可以报销这些费用,那么努力去和组员们见面吧。和一起工作了很长时间的组员们见面能够使你们的关系更加坚固。我所在的公司就有着周期性交换员工的传统,每隔一段时间,世界各地的员工就会来到美国工作,美国员工再到其他分部工作。
|
||||
|
||||
另一种聚齐组员们的机会是研讨会。研讨会创造的不仅是学习和培训的机会,你还可以挤出一些时间和组员们培养感情。
|
||||
|
||||
在如今,全球化经济不断发展,拥有来自不同国家和地区的员工对维持一个公司的竞争力来说越来越重要。即使组员们来自世界各地,团队中会出现一些交流问题,但拥有一支国际化的高绩效团队不是问题。如果你在工作中有什么促进团队交流的小窍门,请在评论中告诉我们吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/think-global-communication-challenges
|
||||
|
||||
作者:[Avindra Fernando][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/avindrafernando
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/watch?v=QIoAkFpN8wQ
|
||||
[2]: https://www.amazon.com/The-Culture-Map-Invisible-Boundaries/dp/1610392507
|
||||
@ -0,0 +1,247 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11691-1.html)
|
||||
[#]: subject: (Easily Upload Text Snippets To Pastebin-like Services From Commandline)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-easily-upload-text-snippets-to-pastebin-like-services-from-commandline/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
从命令行轻松将文本片段上传到类似 Pastebin 的服务中
|
||||
======
|
||||
|
||||

|
||||
|
||||
每当需要在线共享代码片段时,我们想到的第一个便是 Pastebin.com,这是 Paul Dixon 于 2002 年推出的在线文本共享网站。现在,有几种可供选择的文本共享服务可以上传和共享文本片段、错误日志、配置文件、命令输出或任何类型的文本文件。如果你碰巧经常使用各种类似于 Pastebin 的服务来共享代码,那么这对你来说确实是个好消息。向 Wgetpaste 打个招呼吧,它是一个命令行 BASH 实用程序,可轻松地将文本摘要上传到类似 Pastebin 的服务中。使用 Wgetpaste 脚本,任何人都可以与自己的朋友、同事或想在类似 Unix 的系统中的命令行中查看/使用/审查代码的人快速共享文本片段。
|
||||
|
||||
### 安装 Wgetpaste
|
||||
|
||||
Wgetpaste 在 Arch Linux [Community] 存储库中可用。要将其安装在 Arch Linux 及其变体(如 Antergos 和 Manjaro Linux)上,只需运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo pacman -S wgetpaste
|
||||
```
|
||||
|
||||
对于其他发行版,请从 [Wgetpaste 网站][1] 获取源代码,并按如下所述手动安装。
|
||||
|
||||
首先下载最新的 Wgetpaste tar 文件:
|
||||
|
||||
```
|
||||
$ wget http://wgetpaste.zlin.dk/wgetpaste-2.28.tar.bz2
|
||||
```
|
||||
|
||||
提取它:
|
||||
|
||||
```
|
||||
$ tar -xvjf wgetpaste-2.28.tar.bz2
|
||||
```
|
||||
|
||||
它将 tar 文件的内容提取到名为 `wgetpaste-2.28` 的文件夹中。
|
||||
|
||||
转到该目录:
|
||||
|
||||
```
|
||||
$ cd wgetpaste-2.28/
|
||||
```
|
||||
|
||||
将 `wgetpaste` 二进制文件复制到 `$PATH` 中,例如 `/usr/local/bin/`。
|
||||
|
||||
```
|
||||
$ sudo cp wgetpaste /usr/local/bin/
|
||||
```
|
||||
|
||||
最后,使用命令使其可执行:
|
||||
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/wgetpaste
|
||||
```
|
||||
|
||||
### 将文本片段上传到类似 Pastebin 的服务中
|
||||
|
||||
使用 Wgetpaste 上传文本片段很简单。让我向你展示一些示例。
|
||||
|
||||
#### 1、上传文本文件
|
||||
|
||||
要使用 Wgetpaste 上传任何文本文件,只需运行:
|
||||
|
||||
```
|
||||
$ wgetpaste mytext.txt
|
||||
```
|
||||
|
||||
此命令将上传 `mytext.txt` 文件的内容。
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Your paste can be seen here: https://paste.pound-python.org/show/eO0aQjTgExP0wT5uWyX7/
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以通过邮件、短信、whatsapp 或 IRC 等任何媒体共享 pastebin 的 URL。拥有此 URL 的人都可以访问它,并在他们选择的 Web 浏览器中查看文本文件的内容。
|
||||
|
||||
这是 Web 浏览器中 `mytext.txt` 文件的内容:
|
||||
|
||||
|
||||
|
||||
你也可以使用 `tee` 命令显示粘贴的内容,而不是盲目地上传它们。
|
||||
|
||||
为此,请使用如下的 `-t` 选项。
|
||||
|
||||
```
|
||||
$ wgetpaste -t mytext.txt
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
#### 2、将文字片段上传到其他服务
|
||||
|
||||
默认情况下,Wgetpaste 会将文本片段上传到 poundpython(<https://paste.pound-python.org/>)服务。
|
||||
|
||||
要查看支持的服务列表,请运行:
|
||||
|
||||
```
|
||||
$ wgetpaste -S
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Services supported: (case sensitive):
|
||||
Name: | Url:
|
||||
=============|=================
|
||||
bpaste | https://bpaste.net/
|
||||
codepad | http://codepad.org/
|
||||
dpaste | http://dpaste.com/
|
||||
gists | https://api.github.com/gists
|
||||
*poundpython | https://paste.pound-python.org/
|
||||
```
|
||||
|
||||
在这里,`*` 表示默认服务。
|
||||
|
||||
如你所见,Wgetpaste 当前支持五种文本共享服务。我并没有全部尝试,但是我相信所有服务都可以使用。
|
||||
|
||||
要将内容上传到其他服务,例如 bpaste.net,请使用如下所示的 `-s` 选项。
|
||||
|
||||
```
|
||||
$ wgetpaste -s bpaste mytext.txt
|
||||
Your paste can be seen here: https://bpaste.net/show/5199e127e733
|
||||
```
|
||||
|
||||
#### 3、从标准输入读取输入
|
||||
|
||||
Wgetpaste 也可以从标准输入读取。
|
||||
|
||||
```
|
||||
$ uname -a | wgetpaste
|
||||
```
|
||||
|
||||
此命令将上传 `uname -a` 命令的输出。
|
||||
|
||||
#### 4、上传命令及命令的输出
|
||||
|
||||
有时,你可能需要粘贴命令及其输出。为此,请在如下所示的引号内指定命令的内容。
|
||||
|
||||
```
|
||||
$ wgetpaste -c 'ls -l'
|
||||
```
|
||||
|
||||
这会将命令 `ls -l` 及其输出上传到 pastebin 服务。
|
||||
|
||||
当你想让其他人清楚地知道你刚运行的确切命令及其输出时,此功能很有用。
|
||||
|
||||
![][4]
|
||||
|
||||
如你在输出中看到的,我运行了 `ls -l` 命令。
|
||||
|
||||
#### 5、上载系统日志文件、配置文件
|
||||
|
||||
就像我已经说过的,我们可以上载你的系统中任何类型的文本文件,而不仅仅是普通的文本文件,例如日志文件、特定命令的输出等。例如,你刚刚更新了 Arch Linux 机器,最后系统损坏了。你问你的同事该如何解决此问题,他(她)想阅读 `pacman.log` 文件。 这是上传 `pacman.log` 文件内容的命令:
|
||||
|
||||
```
|
||||
$ wgetpaste /var/log/pacman.log
|
||||
```
|
||||
|
||||
与你的同事共享 pastebin URL,以便他/她可以查看 `pacman.log`,并通过查看日志文件来帮助你解决问题。
|
||||
|
||||
通常,日志文件的内容可能太长,你不希望全部共享它们。在这种情况下,只需使用 `cat` 命令读取输出,然后使用 `tail -n` 命令定义要共享的行数,最后将输出通过管道传递到 Wgetpaste,如下所示。
|
||||
|
||||
```
|
||||
$ cat /var/log/pacman.log | tail -n 50 | wgetpaste
|
||||
```
|
||||
|
||||
上面的命令将仅上传 `pacman.log` 文件的“最后 50 行”。
|
||||
|
||||
#### 6、将输入网址转换为短链接
|
||||
|
||||
默认情况下,Wgetpaste 将在输出中显示完整的 pastebin URL。如果要将输入 URL 转换为短链接,只需使用 `-u` 选项。
|
||||
|
||||
```
|
||||
$ wgetpaste -u mytext.txt
|
||||
Your paste can be seen here: http://tinyurl.com/y85d8gtz
|
||||
```
|
||||
|
||||
#### 7、设定语言
|
||||
|
||||
默认情况下,Wgetpaste 将上传“纯文本”中的文本片段。
|
||||
|
||||
要列出指定服务支持的语言,请使用 `-L` 选项。
|
||||
|
||||
```
|
||||
$ wgetpaste -L
|
||||
```
|
||||
|
||||
该命令将列出默认服务(poundpython <https://paste.pound-python.org/>)支持的所有语言。
|
||||
|
||||
我们可以使用 `-l` 选项来改变它。
|
||||
|
||||
```
|
||||
$ wgetpaste -l Bash mytext.txt
|
||||
```
|
||||
|
||||
#### 8、在输出中禁用语法突出显示或 html
|
||||
|
||||
如上所述,文本片段将以特定的语言格式(纯文本、Bash 等)显示。
|
||||
|
||||
但是,你可以更改此行为,以使用 `-r` 选项显示原始文本摘要。
|
||||
|
||||
```
|
||||
$ wgetpaste -r mytext.txt
|
||||
Your raw paste can be seen here: https://paste.pound-python.org/raw/CUJhQ3jEmr2UvfmD2xCL/
|
||||
```
|
||||
|
||||

|
||||
|
||||
如你在上面的输出中看到的,没有语法突出显示,没有 html 格式。只是原始输出。
|
||||
|
||||
#### 9、更改 Wgetpaste 默认值
|
||||
|
||||
所有默认值(`DEFAULT_{NICK,LANGUAGE,EXPIRATION}[_${SERVICE}]` 和 `DEFAULT_SERVICE`)都可以在 `/etc/wgetpaste.conf` 中全局更改,也可以在 `~/.wgetpaste.conf` 文件中针对每个用户更改。但是,这些文件在我的系统中默认情况下并不存在。我想我们需要手动创建它们。开发人员已经在[这里][5]和[这里][6]为这两个文件提供了示例内容。只需使用给定的样本内容手动创建这些文件,并相应地修改参数即可更改 Wgetpaste 的默认设置。
|
||||
|
||||
#### 10、获得帮助
|
||||
|
||||
要显示帮助部分,请运行:
|
||||
|
||||
```
|
||||
$ wgetpaste -h
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-easily-upload-text-snippets-to-pastebin-like-services-from-commandline/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://wgetpaste.zlin.dk/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2018/12/wgetpaste-3.png
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2018/12/wgetpaste-4.png
|
||||
[5]: http://wgetpaste.zlin.dk/zlin.conf
|
||||
[6]: http://wgetpaste.zlin.dk/wgetpaste.example
|
||||
@ -0,0 +1,207 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11711-1.html)
|
||||
[#]: subject: (Install Android 8.1 Oreo on Linux To Run Apps & Games)
|
||||
[#]: via: (https://fosspost.org/tutorials/install-android-8-1-oreo-on-linux)
|
||||
[#]: author: (Python Programmer;Open Source Software Enthusiast. Worked On Developing A Lot Of Free Software. The Founder Of Foss Post;Foss Project. Computer Science Major. )
|
||||
|
||||
在 Linux 上安装安卓 8.1 Oreo 来运行应用程序和游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
[android x86][1] 是一个自由而开源的项目,将谷歌制作的安卓系统从 ARM 架构移植到了 x86 架构,可以让用户在他们的桌面电脑上运行安卓系统来享受所有的安卓功能和应用程序及游戏。
|
||||
|
||||
在前一段时间,android x86 项目完成了安卓 8.1 Oreo 系统的 x86 架构移植。在这篇文章中,我们将解释如何在你的 Linux 系统上安装它,以便你能够随时使用你的安卓 用程序和游戏。
|
||||
|
||||
### 在 Linux 上安装安卓 x86 8.1 Oreo
|
||||
|
||||
#### 准备环境
|
||||
|
||||
首先,让我们下载 android x86 8.1 Oreo 系统镜像。你可以从[这个页面][2]下载它,只需单击 “android-x86_64-8.1-r1.iso” 文件下的 “View” 按钮。
|
||||
|
||||
我们将在我们的 Linux 系统上使用 QEMU 来运行 android x86。QEMU 是一个非常好的模拟器软件,它也是自由而开源的,并且在所有主要的 Linux 发行版存储库中都是可用的。
|
||||
|
||||
在 Ubuntu/Linux Mint/Debian 上安装 QEMU:
|
||||
|
||||
```
|
||||
sudo apt-get install qemu qemu-kvm libvirt-bin
|
||||
```
|
||||
|
||||
在 Fedora 上安装 QEMU:
|
||||
|
||||
```
|
||||
sudo dnf install qemu qemu-kvm
|
||||
```
|
||||
|
||||
对于其它发行版,只需要搜索 “qemu” 和 “qemu-kvm” 软件包,并安装它们。
|
||||
|
||||
在你安装 QEMU 后,我们将需要运行下面的命令来创建 `android.img` 文件,它就像某种分配给安卓系统的磁盘空间。所有安卓文件和系统都将位于该镜像文件中:
|
||||
|
||||
```
|
||||
qemu-img create -f qcow2 android.img 15G
|
||||
```
|
||||
|
||||
我们在这里的意思是,我们想为该安卓系统分配一个最大 15GB 的磁盘空间,但是,你可以更改它到你想要的任意大小(确保它至少大于 5GB)。
|
||||
|
||||
现在,首次启动运行该安卓系统,运行:
|
||||
|
||||
```
|
||||
sudo qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda android.img -cdrom /home/mhsabbagh/android-x86_64-8.1-r1.iso
|
||||
```
|
||||
|
||||
将 `/home/mhsabbagh/android-x86_64-8.1-r1.iso` 替换为你从 android x86 网站下载的文件的路径。关于我们在这里正在使用的其它选项的解释,你可以参考[这篇文章][3]。
|
||||
|
||||
在你运行上面的命令后,该安卓系统将启动:
|
||||
|
||||
![][4]
|
||||
|
||||
#### 安装系统
|
||||
|
||||
从这个窗口中,选择 “Advanced options”, 它将引导到下面的菜单,你应如下在其中选择 “Auto_installation” :
|
||||
|
||||
![][5]
|
||||
|
||||
在这以后,安装器将告知你是否想要继续,选择 “Yes”:
|
||||
|
||||
![][6]
|
||||
|
||||
接下来,安装器将无需你的指示而继续进行:
|
||||
|
||||
![][7]
|
||||
|
||||
最后,你将收到这个信息,它表示你已经成功安装安卓 8.1 :
|
||||
|
||||
![][8]
|
||||
|
||||
现在,关闭 QEMU 窗口即可。
|
||||
|
||||
#### 启动和使用 安卓 8.1 Oreo
|
||||
|
||||
现在,安卓系统已经完全安装在你的 `android.img` 文件中,你应该使用下面的 QEMU 命令来启动它,而不是前面的命令:
|
||||
|
||||
```
|
||||
sudo qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda android.img
|
||||
```
|
||||
|
||||
注意,我们所做的只是移除 `-cdrom` 选项及其参数。这是告诉 QEMU,我们不再想从我们下载的 ISO 文件启动,相反,从这个安装的安卓系统启动。
|
||||
|
||||
你现在能够看到安卓的启动菜单:
|
||||
|
||||
![][9]
|
||||
|
||||
然后,你将进入第一个准备向导,选择你的语言并继续:
|
||||
|
||||
![][10]
|
||||
|
||||
从这里,选择 “Set up as new” 选项:
|
||||
|
||||
![][11]
|
||||
|
||||
然后,安卓将询问你是否想登录到你当前的谷歌账号。这步骤是可选的,但是这很重要,以便你随后可以使用谷歌 Play 商店:
|
||||
|
||||
![][12]
|
||||
|
||||
然后,你将需要接受条款:
|
||||
|
||||
![][13]
|
||||
|
||||
现在,你可以选择你当前的时区:
|
||||
|
||||
![][14]
|
||||
|
||||
系统将询问你是否想启动一些数据收集功能。如果我是你的话,我将简单地全部关闭它们,像这样:
|
||||
|
||||
![][15]
|
||||
|
||||
最后,你将有两种启动类型可供选择,我建议你选择 Launcher3 选项,并使其成为默认项:
|
||||
|
||||
![][16]
|
||||
|
||||
然后,你将看到完整工作的安卓系统主屏幕:
|
||||
|
||||
![][17]
|
||||
|
||||
从现在起,你可以做你想做的任何事情;你可以使用内置的安卓应用程序,或者你可以浏览你的系统设置来根据你的喜好进行调整。你可以更改你的系统的外观和体验,或者你可以像示例一样运行 Chrome :
|
||||
|
||||
![][18]
|
||||
|
||||
你可以开始从谷歌 Play 商店安装一些应用程序程序,像 WhatsApp 和其它的应用程序,以供你自己使用:
|
||||
|
||||
![][19]
|
||||
|
||||
你现在可以用你的系统做任何你想做的事。恭喜!
|
||||
|
||||
### 以后如何轻松地运行安卓 8.1 Oreo
|
||||
|
||||
我们不想总是不得不打开终端窗口,并写那些长长的 QEMU 命令来运行安卓系统,相反,我们想在我们需要时一次单击就运行它。
|
||||
|
||||
为此,我们将使用下面的命令在 `/usr/share/applications` 下创建一个名为 `android.desktop` 的新文件:
|
||||
|
||||
```
|
||||
sudo nano /usr/share/applications/android.desktop
|
||||
```
|
||||
|
||||
并在其中粘贴下面的内容(右键单击然后粘贴):
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=Android 8.1
|
||||
Comment=Run Android 8.1 Oreo on Linux using QEMU
|
||||
Icon=phone
|
||||
Exec=bash -c 'pkexec env DISPLAY=$DISPLAY XAUTHORITY=$XAUTHORITY qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda /home/mhsabbagh/android.img'
|
||||
Terminal=false
|
||||
Type=Application
|
||||
StartupNotify=true
|
||||
Categories=GTK;
|
||||
```
|
||||
|
||||
再强调一次,你必需使用你系统上的本地镜像路径来替换 `/home/mhsabbagh/android.img` 。然后保存文件(`Ctrl+X`,然后按 `Y`,然后按回车)。
|
||||
|
||||
注意,我们需要使用 `pkexec` 来使用 root 权限运行 QEMU ,因为从较新的版本开始,普通用户不允许通过 libvirt 访问 KVM 技术;这就是为什么它将每次要求你输入 root 密码的原因。
|
||||
|
||||
现在,你将在应用程序菜单中看到安卓图标,你可以在你想使用安卓的任何时间来简单地单击该图标,QEMU 程序将启动:
|
||||
|
||||
![][20]
|
||||
|
||||
### 总结
|
||||
|
||||
我们向你展示如何在你的 Linux 系统上安装和运行安卓 8.1 Oreo 。从现在起,在没有其它一些软件的(像 Blutsticks 和类似的方法)的情况下,你可以更容易地完成基于安卓的任务。在这里,你有一个完整工作和功能的安卓系统,你可以随心所欲地操作它,如果一些东西出错,你可以简单地干掉该镜像文件,然后随时再一次重新运行安装程序。
|
||||
|
||||
你之前尝试过 android x86 吗?你的体验如何?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/tutorials/install-android-8-1-oreo-on-linux
|
||||
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fosspost.org/author/mhsabbagh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.android-x86.org/
|
||||
[2]: http://www.android-x86.org/download
|
||||
[3]: https://fosspost.org/tutorials/use-qemu-test-operating-systems-distributions
|
||||
[4]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-16.png?resize=694%2C548&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 40 android 8.1 oreo on linux)
|
||||
[5]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-15.png?resize=673%2C537&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 42 android 8.1 oreo on linux)
|
||||
[6]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-14.png?resize=769%2C469&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 44 android 8.1 oreo on linux)
|
||||
[7]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-13.png?resize=767%2C466&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 46 android 8.1 oreo on linux)
|
||||
[8]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-12.png?resize=750%2C460&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 48 android 8.1 oreo on linux)
|
||||
[9]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-11.png?resize=754%2C456&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 50 android 8.1 oreo on linux)
|
||||
[10]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-10.png?resize=850%2C559&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 52 android 8.1 oreo on linux)
|
||||
[11]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-09.png?resize=850%2C569&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 54 android 8.1 oreo on linux)
|
||||
[12]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-08.png?resize=850%2C562&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 56 android 8.1 oreo on linux)
|
||||
[13]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-07-1.png?resize=850%2C561&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 58 android 8.1 oreo on linux)
|
||||
[14]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-06.png?resize=850%2C569&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 60 android 8.1 oreo on linux)
|
||||
[15]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-05.png?resize=850%2C559&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 62 android 8.1 oreo on linux)
|
||||
[16]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-04.png?resize=850%2C553&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 64 android 8.1 oreo on linux)
|
||||
[17]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-03.png?resize=850%2C571&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 66 android 8.1 oreo on linux)
|
||||
[18]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-02.png?resize=850%2C555&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 68 android 8.1 oreo on linux)
|
||||
[19]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-01.png?resize=850%2C557&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 70 android 8.1 oreo on linux)
|
||||
[20]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-17-1539.png?resize=850%2C557&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 72 android 8.1 oreo on linux)
|
||||
183
published/201912/20190225 Netboot a Fedora Live CD.md
Normal file
183
published/201912/20190225 Netboot a Fedora Live CD.md
Normal file
@ -0,0 +1,183 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11708-1.html)
|
||||
[#]: subject: (Netboot a Fedora Live CD)
|
||||
[#]: via: (https://fedoramagazine.org/netboot-a-fedora-live-cd/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
网络启动一个 Fedora Live CD
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Live CD][1] 对于很多任务是很有用的,例如:
|
||||
|
||||
* 将操作系统安装到一个硬盘驱动器
|
||||
* 修复一个启动加载程序或执行其它救援模式操作
|
||||
* 为 Web 浏览提供一个相适应的最小环境
|
||||
* …以及[更多的东西][2]。
|
||||
|
||||
作为使用 DVD 和 USB 驱动器来存储你的 Live CD 镜像是一个替代方案,你可以上传它们到一个不太可能丢失或损坏的 [iSCSI][3] 服务器中。这个指南向你展示如何加载你的 Live CD 镜像到一个 ISCSI 服务器上,并使用 [iPXE][4] 启动加载程序来访问它们。
|
||||
|
||||
### 下载一个 Live CD 镜像
|
||||
|
||||
```
|
||||
$ MY_RLSE=27
|
||||
$ MY_LIVE=$(wget -q -O - https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/$MY_RLSE/Workstation/x86_64/iso | perl -ne '/(Fedora[^ ]*?-Live-[^ ]*?\.iso)(?{print $^N})/;')
|
||||
$ MY_NAME=fc$MY_RLSE
|
||||
$ wget -O $MY_NAME.iso https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/$MY_RLSE/Workstation/x86_64/iso/$MY_LIVE
|
||||
```
|
||||
|
||||
上面的命令下载 `Fedora-Workstation-Live-x86_64-27-1.6.iso` Fedora Live 镜像,并保存为 `fc27.iso`。更改 `MY_RLSE` 的值来下载其它档案版本。或者,你可以浏览 <https://getfedora.org/> 来下载最新的 Fedora live 镜像。在 21 之前的版本使用不同的命名约定,必需[在这里手动下载][5]。如果你手动下载一个 Live CD 镜像,设置 `MY_NAME` 变量为不带有扩展名的文件的基本名称。用此方法,下面部分中命令将引用正确的文件。
|
||||
|
||||
### 转换 Live CD 镜像
|
||||
|
||||
使用 `livecd-iso-to-disk` 工具来转换 ISO 文件为一个磁盘镜像,并添加 `netroot` 参数到嵌入的内核命令行:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y livecd-tools
|
||||
$ MY_SIZE=$(du -ms $MY_NAME.iso | cut -f 1)
|
||||
$ dd if=/dev/zero of=$MY_NAME.img bs=1MiB count=0 seek=$(($MY_SIZE+512))
|
||||
$ MY_SRVR=server-01.example.edu
|
||||
$ MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
$ MY_LOOP=$(sudo losetup --show --nooverlap --find $MY_NAME.img)
|
||||
$ sudo livecd-iso-to-disk --format --extra-kernel-args netroot=iscsi:$MY_SRVR:::1:iqn.$MY_RVRS:$MY_NAME $MY_NAME.iso $MY_LOOP
|
||||
$ sudo losetup -d $MY_LOOP
|
||||
```
|
||||
|
||||
### 上传 Live 镜像到你的服务器
|
||||
|
||||
在你的 ISCSI 服务器上创建一个目录来存储你的 live 镜像,随后上传你修改的镜像到其中。
|
||||
|
||||
对于 21 及更高发布版本:
|
||||
|
||||
```
|
||||
$ MY_FLDR=/images
|
||||
$ scp $MY_NAME.img $MY_SRVR:$MY_FLDR/
|
||||
```
|
||||
|
||||
对于 21 以前发布版本:
|
||||
|
||||
```
|
||||
$ MY_FLDR=/images
|
||||
$ MY_LOOP=$(sudo losetup --show --nooverlap --find --partscan $MY_NAME.img)
|
||||
$ sudo tune2fs -O ^has_journal ${MY_LOOP}p1
|
||||
$ sudo e2fsck ${MY_LOOP}p1
|
||||
$ sudo dd status=none if=${MY_LOOP}p1 | ssh $MY_SRVR "dd of=$MY_FLDR/$MY_NAME.img"
|
||||
$ sudo losetup -d $MY_LOOP
|
||||
```
|
||||
|
||||
### 定义 iSCSI 目标
|
||||
|
||||
在你的 iSCSI 服务器上运行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
# MY_NAME=fc27
|
||||
# MY_FLDR=/images
|
||||
# MY_SRVR=`hostname`
|
||||
# MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
# cat << END > /etc/tgt/conf.d/$MY_NAME.conf
|
||||
<target iqn.$MY_RVRS:$MY_NAME>
|
||||
backing-store $MY_FLDR/$MY_NAME.img
|
||||
readonly 1
|
||||
allow-in-use yes
|
||||
</target>
|
||||
END
|
||||
# tgt-admin --update ALL
|
||||
```
|
||||
|
||||
### 创建一个可启动 USB 驱动器
|
||||
|
||||
[iPXE][4] 启动加载程序有一个 [sanboot][6] 命令,你可以使用它来连接并启动托管于你 ISCSI 服务器上运行的 live 镜像。它可以以很多不同的[格式][7]编译。最好的工作格式依赖于你正在运行的硬件。例如,下面的说明向你展示如何在一个 USB 驱动器上从 [syslinux][9] 中 [链式加载][8] iPXE。
|
||||
|
||||
首先,下载 iPXE,并以它的 lkrn 格式构建。这应该作为一个工作站上的普通用户完成:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y git
|
||||
$ git clone http://git.ipxe.org/ipxe.git $HOME/ipxe
|
||||
$ sudo dnf groupinstall -y "C Development Tools and Libraries"
|
||||
$ cd $HOME/ipxe/src
|
||||
$ make clean
|
||||
$ make bin/ipxe.lkrn
|
||||
$ cp bin/ipxe.lkrn /tmp
|
||||
```
|
||||
|
||||
接下来,准备一个带有一个 MSDOS 分区表和一个 FAT32 文件系统的 USB 驱动器。下面的命令假设你已经连接将要格式化的 USB 驱动器。**注意:你要格式正确的驱动器!**
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
# dnf install -y parted util-linux dosfstools
|
||||
# echo; find /dev/disk/by-id ! -regex '.*-part.*' -name 'usb-*' -exec readlink -f {} \; | xargs -i bash -c "parted -s {} unit MiB print | perl -0 -ne '/^Model: ([^(]*).*\n.*?([0-9]*MiB)/i && print \"Found: {} = \$2 \$1\n\"'"; echo; read -e -i "$(find /dev/disk/by-id ! -regex '.*-part.*' -name 'usb-*' -exec readlink -f {} \; -quit)" -p "Drive to format: " MY_USB
|
||||
# umount $MY_USB?
|
||||
# wipefs -a $MY_USB
|
||||
# parted -s $MY_USB mklabel msdos mkpart primary fat32 1MiB 100% set 1 boot on
|
||||
# mkfs -t vfat -F 32 ${MY_USB}1
|
||||
```
|
||||
|
||||
最后,在 USB 驱动器上安装并配置 syslinux ,来链式加载 iPXE:
|
||||
|
||||
```
|
||||
# dnf install -y syslinux-nonlinux
|
||||
# syslinux -i ${MY_USB}1
|
||||
# dd if=/usr/share/syslinux/mbr.bin of=${MY_USB}
|
||||
# MY_MNT=$(mktemp -d)
|
||||
# mount ${MY_USB}1 $MY_MNT
|
||||
# MY_NAME=fc27
|
||||
# MY_SRVR=server-01.example.edu
|
||||
# MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
# cat << END > $MY_MNT/syslinux.cfg
|
||||
ui menu.c32
|
||||
default $MY_NAME
|
||||
timeout 100
|
||||
menu title SYSLINUX
|
||||
label $MY_NAME
|
||||
menu label ${MY_NAME^^}
|
||||
kernel ipxe.lkrn
|
||||
append dhcp && sanboot iscsi:$MY_SRVR:::1:iqn.$MY_RVRS:$MY_NAME
|
||||
END
|
||||
# cp /usr/share/syslinux/menu.c32 $MY_MNT
|
||||
# cp /usr/share/syslinux/libutil.c32 $MY_MNT
|
||||
# cp /tmp/ipxe.lkrn $MY_MNT
|
||||
# umount ${MY_USB}1
|
||||
```
|
||||
|
||||
通过简单地编辑 `syslinux.cfg` 文件,并添加附加的菜单项,你应该能够使用这同一个 USB 驱动器来网络启动附加的 ISCSI 目标。
|
||||
|
||||
这仅是加载 IPXE 的一种方法。你可以直接在你的工作站上安装 syslinux 。再一种选项是编译 iPXE 为一个 EFI 可执行文件,并直接放置它到你的 [ESP][10] 中。又一种选项是编译 iPXE 为一个 PXE 加载器,并放置它到你的能够被 DHCP 引用的 TFTP 服务器。最佳的选项依赖于的环境
|
||||
|
||||
### 最后说明
|
||||
|
||||
* 如果你以 IPXE 的 EFI 格式编译 IPXE ,你可能想添加 `–filename \EFI\BOOT\grubx64.efi` 参数到 `sanboot` 命令。
|
||||
* 能够创建自定义 live 镜像。更多信息参考[创建和使用 live CD][11]。
|
||||
* 可以添加 `–overlay-size-mb` 和 `–home-size-mb` 参数到 `livecd-iso-to-disk` 命令来创建永久存储的 live 镜像。然而,如果你有多个并发用户,你将需要设置你的 ISCSI 服务器来管理独立的每个用户的可写覆盖。这与 “[如何构建一个网络启动服务器,部分 4][12]” 一文所示类似。
|
||||
* Live 镜像在它们的内核命令行中支持一个 `persistenthome` 选项(例如, `persistenthome=LABEL=HOME`)。与经过 CHAP 身份验证的 iSCSI 目标一起使用,对于中心控制主目录,`persistenthome` 选项为 NFS 提供一个有趣的替代方案。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/netboot-a-fedora-live-cd/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Live_CD
|
||||
[2]: https://en.wikipedia.org/wiki/Live_CD#Uses
|
||||
[3]: https://en.wikipedia.org/wiki/ISCSI
|
||||
[4]: https://ipxe.org/
|
||||
[5]: https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/
|
||||
[6]: http://ipxe.org/cmd/sanboot/
|
||||
[7]: https://ipxe.org/appnote/buildtargets#boot_type
|
||||
[8]: https://en.wikipedia.org/wiki/Chain_loading
|
||||
[9]: https://www.syslinux.org/wiki/index.php?title=SYSLINUX
|
||||
[10]: https://en.wikipedia.org/wiki/EFI_system_partition
|
||||
[11]: https://docs.fedoraproject.org/en-US/quick-docs/creating-and-using-a-live-installation-image/#proc_creating-and-using-live-cd
|
||||
[12]: https://fedoramagazine.org/how-to-build-a-netboot-server-part-4/
|
||||
|
||||
79
published/201912/20190322 Easy means easy to debug.md
Normal file
79
published/201912/20190322 Easy means easy to debug.md
Normal file
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11693-1.html)
|
||||
[#]: subject: (Easy means easy to debug)
|
||||
[#]: via: (https://arp242.net/weblog/easy.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
简单就是易于调试
|
||||
======
|
||||
|
||||
对于框架、库或者工具来说,怎样做才算是“简单”?也许有很多的定义,但我的理解通常是**易于调试**。我经常见到人们宣传某个特定的程序、框架、库、文件格式或者其它什么东西是简单的,因为他们会说“看,我只需要这么一点工作量就能够完成某项工作,这太简单了”。非常好,但并不完善。
|
||||
|
||||
你可能只编写一次软件,但几乎总要经历好几个调试周期。注意我说的调试周期并不意味着“代码里面有 bug 你需要修复”,而是说“我需要再看一下这份代码来修复 bug”。为了调试代码,你需要理解它,因此“易于调试”延伸来讲就是“易于理解”。
|
||||
|
||||
抽象使得程序易于编写,但往往是以难以理解为代价。有时候这是一个很好的折中,但通常不是。大体上,如果能使程序在日后易于理解和调试,我很乐意花更多的时间来写一些东西,因为这样实际上更省时间。
|
||||
|
||||
简洁并不是让程序易于调试的**唯一**方法,但它也许是最重要的。良好的文档也是,但不幸的是好的文档太少了。(注意,质量并**不**取决于字数!)
|
||||
|
||||
这种影响是真是存在的。难以调试的程序会有更多的 bug,即使最初的 bug 数量与易于调试的程序完全相同,而是因为修复 bug 更加困难、更花时间。
|
||||
|
||||
在公司的环境中,把时间花在难以修复的 bug 上通常被认为是不划算的投资。而在开源的环境下,人们花的时间会更少。(大多数项目都有一个或多个定期的维护者,但成百上千的贡献者提交的仅只是几个补丁)
|
||||
|
||||
---
|
||||
|
||||
这并不全是 1974 年由 Brian W. Kernighan 和 P. J. Plauger 合著的《<ruby>编程风格的元素<rt>The Elements of Programming Style</rt></ruby>》中的观点:
|
||||
|
||||
> 每个人都知道调试比起编写程序困难两倍。当你写程序的时候耍小聪明,那么将来应该怎么去调试?
|
||||
|
||||
我见过许多看起来写起来“极尽精妙”,但却导致难以调试的代码。我会在下面列出几种样例。争论这些东西本身有多坏并不是我的本意,我仅想强调对于“易于使用”和“易于调试”之间的折中。
|
||||
|
||||
* <ruby>ORM<rt>对象关系映射</rt></ruby> 库可以让数据库查询变得简单,代价是一旦你想解决某个问题,事情就变得难以理解。
|
||||
* 许多测试框架让调试变得困难。Ruby 的 rspec 就是一个很好的例子。有一次我不小心使用错了,结果花了很长时间搞清楚**究竟**哪里出了问题(因为它给出错误提示非常含糊)。
|
||||
|
||||
我在《[测试并非万能][1]》这篇文章中写了更多关于以上的例子。
|
||||
* 我用过的许多 JavaScript 框架都很难完全理解。Clever(LCTT 译注:一种 JS 框架)的语句一向很有逻辑,直到某条语句不能如你预期的工作,这时你就只能指望 Stack Overflow 上的某篇文章或 GitHub 上的某个回帖来帮助你了。
|
||||
|
||||
这些函数库**确实**让任务变得非常简单,使用它们也没有什么错。但通常人们都过于关注“易于使用”而忽视了“易于调试”这一点。
|
||||
* Docker 非常棒,并且让许多事情变得非常简单,直到你看到了这条提示:
|
||||
|
||||
```
|
||||
ERROR: for elasticsearch Cannot start service elasticsearch:
|
||||
oci runtime error: container_linux.go:247: starting container process caused "process_linux.go:258:
|
||||
applying cgroup configuration for process caused \"failed to write 898 to cgroup.procs: write
|
||||
/sys/fs/cgroup/cpu,cpuacct/docker/b13312efc203e518e3864fc3f9d00b4561168ebd4d9aad590cc56da610b8dd0e/cgroup.procs:
|
||||
invalid argument\""
|
||||
```
|
||||
|
||||
或者这条:
|
||||
|
||||
```
|
||||
ERROR: for elasticsearch Cannot start service elasticsearch: EOF
|
||||
```
|
||||
|
||||
那么...你怎么看?
|
||||
* `Systemd` 比起 `SysV`、`init.d` 脚本更加简单,因为编写 `systemd` 单元文件比起编写 `shell` 脚本更加方便。这也是 Lennart Poetterin 在他的 [systemd 神话][2] 中解释 `systemd` 为何简单时使用的论点。
|
||||
|
||||
我非常赞同 Poettering 的观点——也可以看 [shell 脚本陷阱][3] 这篇文章。但是这种角度并不全面。单元文件简单的背后意味着 `systemd` 作为一个整体要复杂的多,并且用户确实会受到它的影响。看看我遇到的这个[问题][4]和为它所做的[修复][5]。看起来很简单吗?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/easy.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.arp242.net/testing.html
|
||||
[2]: http://0pointer.de/blog/projects/the-biggest-myths.html
|
||||
[3]:https://www.arp242.net/shell-scripting-trap.html
|
||||
[4]:https://unix.stackexchange.com/q/185495/33645
|
||||
[5]:https://cgit.freedesktop.org/systemd/systemd/commit/?id=6e392c9c45643d106673c6643ac8bf4e65da13c1
|
||||
@ -0,0 +1,186 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11709-1.html)
|
||||
[#]: subject: (How To Set Password Complexity On Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-set-password-complexity-policy-on-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Linux 如何设置密码复杂度?
|
||||
======
|
||||
|
||||
对于 Linux 系统管理员来说,用户管理是最重要的事之一。这涉及到很多因素,实现强密码策略是用户管理的其中一个方面。移步后面的 URL 查看如何 [在 Linux 上生成一个强密码][1]。它会限制系统未授权的用户的访问。
|
||||
|
||||
所有人都知道 Linux 的默认策略很安全,然而我们还是要做一些微调,这样才更安全。弱密码有安全隐患,因此,请特别注意。移步后面的 URL 查看生成的强密码的[密码长度和分值][2]。本文将教你在 Linux 中如何实现最安全的策略。
|
||||
|
||||
在大多数 Linux 系统中,我们可以用 PAM(<ruby>可插拔认证模块<rt>pluggable authentication module</rt></ruby>)来加强密码策略。在下面的路径可以找到这个文件。
|
||||
|
||||
- 在红帽系列的系统中,路径:`/etc/pam.d/system-auth`。
|
||||
- Debian 系列的系统中,路径:`/etc/pam.d/common-password`。
|
||||
|
||||
关于默认的密码过期时间,可以在 `/etc/login.defs` 文件中查看详细信息。
|
||||
|
||||
为了更好理解,我摘取了文件的部分内容:
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MAX_DAYS 99999
|
||||
PASS_MIN_DAYS 0
|
||||
PASS_MIN_LEN 5
|
||||
PASS_WARN_AGE 7
|
||||
```
|
||||
|
||||
详细解释:
|
||||
|
||||
* `PASS_MAX_DAYS`:一个密码可使用的最大天数。
|
||||
* `PASS_MIN_DAYS`:两次密码修改之间最小的间隔天数。
|
||||
* `PASS_MIN_LEN`:密码最小长度。
|
||||
* `PASS_WARN_AGE`:密码过期前给出警告的天数。
|
||||
|
||||
我们将会展示在 Linux 中如何实现下面的 11 个密码策略。
|
||||
|
||||
* 一个密码可使用的最大天数
|
||||
* 两次密码修改之间最小的间隔天数
|
||||
* 密码过期前给出警告的天数
|
||||
* 密码历史记录/拒绝重复使用密码
|
||||
* 密码最小长度
|
||||
* 最少的大写字母个数
|
||||
* 最少的小写字母个数
|
||||
* 最少的数字个数
|
||||
* 最少的其他字符(符号)个数
|
||||
* 账号锁定 — 重试
|
||||
* 账号解锁时间
|
||||
|
||||
### 密码可使用的最大天数是什么?
|
||||
|
||||
这一参数限制一个密码可使用的最大天数。它强制用户在过期前修改他/她的密码。如果他们忘记修改,那么他们会登录不了系统。他们需要联系管理员才能正常登录。这个参数可以在 `/etc/login.defs` 文件中设置。我把这个参数设置为 90 天。
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MAX_DAYS 90
|
||||
```
|
||||
|
||||
### 密码最小天数是什么?
|
||||
|
||||
这个参数限制两次修改之间的最少天数。举例来说,如果这个参数被设置为 15 天,用户今天修改了密码,那么在 15 天之内他都不能修改密码。这个参数可以在 `/etc/login.defs` 文件中设置。我设置为 15 天。
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MIN_DAYS 15
|
||||
```
|
||||
|
||||
### 密码警告天数是什么?
|
||||
|
||||
这个参数控制密码警告的前置天数,在密码即将过期时会给用户警告提示。在警告天数结束前,用户会收到日常警告提示。这可以提醒用户在密码过期前修改他们的密码,否则我们就需要联系管理员来解锁密码。这个参数可以在 `/etc/login.defs` 文件中设置。我设置为 10 天。
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_WARN_AGE 10
|
||||
```
|
||||
|
||||
**注意:** 上面的所有参数仅对新账号有效,对已存在的账号无效。
|
||||
|
||||
### 密码历史或拒绝重复使用密码是什么?
|
||||
|
||||
这个参数控制密码历史。它记录曾经使用过的密码(禁止使用的曾用密码的个数)。当用户设置新的密码时,它会检查密码历史,如果他们要设置的密码是一个曾经使用过的旧密码,将会发出警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置密码历史为 5。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password sufficient pam_unix.so md5 shadow nullok try_first_pass use_authtok remember=5
|
||||
```
|
||||
|
||||
### 密码最小长度是什么?
|
||||
|
||||
这个参数表示密码的最小长度。当用户设置新密码时,系统会检查这个参数,如果新设的密码长度小于这个参数设置的值,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置最小密码长度为 12。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12
|
||||
```
|
||||
|
||||
`try_first_pass retry=3`:在密码设置交互界面,用户有 3 次机会重设密码。
|
||||
|
||||
### 设置最少的大写字母个数?
|
||||
|
||||
这个参数表示密码中至少需要的大写字母的个数。这些是密码强度参数,可以让密码更健壮。当用户设置新密码时,系统会检查这个参数,如果密码中没有大写字母,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置密码(中的大写字母)的最小长度为 1 个字母。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 ucredit=-1
|
||||
```
|
||||
|
||||
### 设置最少的小写字母个数?
|
||||
|
||||
这个参数表示密码中至少需要的小写字母的个数。这些是密码强度参数,可以让密码更健壮。当用户设置新密码时,系统会检查这个参数,如果密码中没有小写字母,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置为 1 个字母。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 lcredit=-1
|
||||
```
|
||||
|
||||
### 设置密码中最少的数字个数?
|
||||
|
||||
这个参数表示密码中至少需要的数字的个数。这些是密码强度参数,可以让密码更健壮。当用户设置新密码时,系统会检查这个参数,如果密码中没有数字,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置为 1 个数字。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 dcredit=-1
|
||||
```
|
||||
|
||||
### 设置密码中最少的其他字符(符号)个数?
|
||||
|
||||
这个参数表示密码中至少需要的特殊符号的个数。这些是密码强度参数,可以让密码更健壮。当用户设置新密码时,系统会检查这个参数,如果密码中没有特殊符号,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置为 1 个字符。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 ocredit=-1
|
||||
```
|
||||
|
||||
### 设置账号锁定?
|
||||
|
||||
这个参数控制用户连续登录失败的最大次数。当达到设定的连续失败登录次数阈值时,锁定账号。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
auth required pam_tally2.so onerr=fail audit silent deny=5
|
||||
account required pam_tally2.so
|
||||
```
|
||||
|
||||
### 设定账号解锁时间?
|
||||
|
||||
这个参数表示用户解锁时间。如果一个用户账号在连续认证失败后被锁定了,当过了设定的解锁时间后,才会解锁。设置被锁定中的账号的解锁时间(900 秒 = 15分钟)。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
auth required pam_tally2.so onerr=fail audit silent deny=5 unlock_time=900
|
||||
account required pam_tally2.so
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-set-password-complexity-policy-on-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-linux-terminal/
|
||||
[2]: https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/
|
||||
73
published/201912/20190711 DevOps for introverted people.md
Normal file
73
published/201912/20190711 DevOps for introverted people.md
Normal file
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (XLCYun)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11725-1.html)
|
||||
[#]: subject: (DevOps for introverted people)
|
||||
[#]: via: (https://opensource.com/article/19/7/devops-introverted-people)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
|
||||
|
||||
内向者的 DevOps
|
||||
======
|
||||
|
||||
> 我们邀请 Opensource.com 的 DevOps 团队,希望他们能够谈一谈作为 DevOps 内向者的休验,同时给 DevOps 外向者一些建议。下面是他们的回答。
|
||||
|
||||

|
||||
|
||||
我们邀请我们的 [DevOps 团队][2] 谈一谈他们作为一个内向者的体验,并给外向者们一些建议。但是在我们开始了解他们的回答之前,让我们先来定义一下这些词汇。
|
||||
|
||||
### “内向者”是什么意思?
|
||||
|
||||
内向者通常指的是一部分人群,当他们和别人相处的时候,会使他们的能量耗尽,而不是激发他们更多的能量。当我们思考我们是如何恢复能量时,这是一个非常有用的词汇:内向者通常需要更多的独处时间来恢复能量,特别是和一群人在一起很长时间后。关于内向者的一个非常大的误解就是他们一定是“害羞的”,但是科学表明,那不过是另一种不同的性格特征。
|
||||
|
||||
内向性与外向性是通过 [Myers Briggs 类型指标][4] 而为人所知的,现在也常常被称作一个 [光谱][5] 的两端。虽然这个世界看起来好像外向者比内向者要多,但是心理学者则倾向于认为大部分人在光谱上的位置是落在 [中间性格或偏内向性格的][6]。
|
||||
|
||||
现在,我们来看看问答。
|
||||
|
||||
### DevOps 技术主管可以通过哪些方式来让内向者感觉他们是团队的一部分并且愿意分享他们的想法?
|
||||
|
||||
“每个人都会不大一样,所以观察敏锐就很重要了。从 GitLab 过来的一个人告诉我,他们的哲学就是如果他们没有提供任何意见,那么他们就是被排除在外的。如果有人在一个会议上没有提供任何的意见,那就想办法让他们加入进来。**当我知道一个内向者对我们将要讨论的会议论题感兴趣的时候,我会提前请他写一些书面文本。有非常多的会议其实是可以避免的,只要通过把讨论放到 Slack 或者 GitLab 上就行了,内向者会更愿意参与进来**。在站立会议中,每个人都会交代最新的进展,在这个环境下,内向者表现得很好。有时候我们在其实会议上会重复做一些事情,仅仅是为了保证每个人都有时间发言。我同时也会鼓励内向者在工作小组或者社区小组面前发言,以此来锻炼他们的这些技能。”—— 丹·巴克
|
||||
|
||||
“**我觉得别人对我做的最好的事情,就是他们保证了当重大问题来临的时候,我拥有必要的技能去回答它**。彼时,我作为一名非常年轻的入伍空军的一员,我需要给我们部队的高级领导做状态简报的汇报。我必须在任何时候都有一些可用的数据点,以及在实现我们确立的目标的过程中,产生延误以及偏差的背后的原因。那样的经历推动着我从一个‘幕后人员’逐渐变得更加愿意和别人分享自己的观点和想法。”—— 克里斯·肖特
|
||||
|
||||
“**通过文化去领导。为你的同僚一起设计和尝试仪式。**你可以为给你的小组或团队设计一个小的每周仪式,甚至给你的部门或组织设计一个年度的大仪式。它的意义在于去尝试一些事物,并观察你在其中的领导角色。去找到你们文化当中的代沟以及对立。回顾团队的信仰和行为。你能从哪里观察到对立?你们的文化中缺失了什么?从一个小陈述开始‘我从 X 和 Y 之间看到了对立’,或者‘我的团队缺少了 Z’。接着,将代沟与对立转换为问题:写下三个‘我们如何能……(How might we's, HMWs)’。”—— 凯瑟琳·路易斯
|
||||
|
||||
“内向者不是一个不同的群体,他们要么是在分享他们的想法之前想得太多或等得太久的一些人,要么就是一些根本不知道发生了什么的人。我就是第一种,我想太多了,有时候还担心我的意见会被其他人嘲笑,或者没有什么意思,或者想偏了。形成那样的思维方式很难,但它同时也在吞噬着我学习更好事物的机会。有一次,我们团队在讨论一个实现问题。我当时的老大一次又一次地问我,为什么我没有作为团队中更具经验的人参与进来,然后我就(集齐了全宇宙的力量之后)开口说我想说的大家都已经说过了。他说,有时候我可以重复说一次,事情纷繁,如果你能够重复一遍你的想法,即使它已经被讨论过了,也会大有裨益。好吧,虽然它不是一种特别信服的方式,但是我知道了至少有人想听听我怎么说,它给了我一点信心。
|
||||
|
||||
“现在,我所使用的让团队中的人发言的方法是**我经常向内向的人求助,即使我知道解决方法,并且在团队会议和讨论中感谢他们来建立他们的自信心,通过给他们时间让他们一点一点的从他们寡言的本性中走出来,从而跟团队分享很多的知识**。他们在外面的世界中可能仍然会有一点点孤立,但是在团队里面,有些会成为我们可以信赖的人。”—— 阿布希什克·塔姆拉卡尔
|
||||
|
||||
“我给参加会议的内向者的建议是,找一个同样要参加会议的朋友或者同事,这样到时你就会有人可以跟你一起舒服地交谈,在会议开始之前,提前跟其他的与会者(朋友、行业联系人、前同事等等)约着见个面或者吃顿饭,**要注意你的疲劳程度,并且照顾好自己**:如果你需要重新恢复能量,就跳过那些社交或者夜晚的活动,在事后回顾中记录一下自己的感受。”—— 伊丽莎白·约瑟夫
|
||||
|
||||
### 和一个内向者倾向的同事一起工作时,有什么提高生产效率的小建议?
|
||||
|
||||
“在保证质量时,生产效率会越来越具备挑战性。在大多数时候,工作中的一个小憩或者轻松随意的交谈,可能正是我们的创造性活动中需要的一个火花。再说一次,我发现当你的团队中有内向者时, Slack 和 Github 会是一个非常有用的用于交换想法以及和其他人互动的媒介。**我同时也发现,结对编程对于大部分的内向者也非常有用,虽然一对一的交流对于他们来说,并不像交税那么频繁,但是生产质量和效率的提升却是重大的**。但是,当一个内向者在独自工作的时间,团队中的所有人都不应该去打断他们。最好是发个邮件,或者使用没有那么强的侵入性的媒介。”—— 丹·巴克
|
||||
|
||||
“给他们趁手的工具,让他们工作并归档他们的工作。**让他们能够在他们的工作上做到最好**。要足够经常地去检查一下,保证他们没有走偏路,但是要记住,相比外向者而言,这样做是更大的一种让人分心的困扰。”—— 克里斯·肖特
|
||||
|
||||
“**当我低着头的时候,不要打断我。真的,别打断我!**当我沉浸在某件事物中时,这样做会造成我至少需要花费两个小时,才能让我的大脑重新回到之前的状态。感觉很痛苦。真的。你可以发个邮件让我去有白板的地方。然后从客户的角度而不是你的角度——通过画图的方式——分享下有什么问题。要知道,可能同时会有十几个客户问题缠绕在我的脑海中,如果你的问题听起来就是‘这样子做会让我在我的领导面前显得很好’的那一类问题,那么相比我脑袋中已经有的真正的客户问题而言,它不会得到更多的关注的。画个图,给我点时间思考。当我准备分享我的看法的时候,保证有多支马克笔可以使用。准备好接受你对问题的假设有可能完全是错误的。”—— 凯瑟琳·路易斯
|
||||
|
||||
“感谢和鼓励就是解决的方法,感谢可能不是一份工作评估,但是感谢能让人舒服地感受到自己并不仅仅是一个活着的独立实体,**因而每个人都能够感觉到自己是被倾听的,而不是被嘲笑或者低估的**。”—— 阿布希什克·塔姆拉卡尔
|
||||
|
||||
### 结语
|
||||
|
||||
在与内向的 DevOps 爱好者的这次交谈中,我们最大的启迪就是平等:其他人需要被怎样对待,就怎样对待他们,同时你想被怎样对待,就去要求别人怎样对待你。无论你是内向还是外向,我们都需要承认我们并非全以相同的一种方式体验这个世界。我们的同事应当被给予足够的空间以完成他们的工作,通过讨论他们的需求作为了解如何支持他们的开始。我们的差异正是我们的社区如此特别的原因,它让我们的工作对更多的人更加的有用。与别人沟通最有效的方式,就是对于你们两者而言都可行的方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/devops-introverted-people
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberg
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_QandAorange_520x292_0311LL.png?itok=qa3hHSou (Q and A letters)
|
||||
[2]: https://opensource.com/devops-team
|
||||
[3]: https://www.inc.com/melanie-curtin/are-you-shy-or-introverted-science-says-this-is-1-primary-difference.html
|
||||
[4]: https://www.myersbriggs.org/my-mbti-personality-type/mbti-basics/extraversion-or-introversion.htm?bhcp=1
|
||||
[5]: https://lifehacker.com/lets-quit-it-with-the-introvert-extrovert-nonsense-1713772952
|
||||
[6]: https://www.psychologytoday.com/us/blog/the-gen-y-guide/201710/the-majority-people-are-not-introverts-or-extroverts
|
||||
@ -0,0 +1,235 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11673-1.html)
|
||||
[#]: subject: (24 sysadmin job interview questions you should know)
|
||||
[#]: via: (https://opensource.com/article/19/7/sysadmin-job-interview-questions)
|
||||
[#]: author: (DirectedSoul https://opensource.com/users/directedsoul)
|
||||
|
||||
24 个必知必会的系统管理员面试问题
|
||||
======
|
||||
|
||||
> 即将进行系统管理员工作面试吗?阅读本文,了解你可能会遇到的一些问题以及可能的答案。
|
||||
|
||||

|
||||
|
||||
作为一个经常与计算机打交道的极客,在硕士毕业后在 IT 行业选择我的职业是很自然的选择。因此,我认为走上系统管理员之路是正确的路径。在我的职业生涯中,我对求职面试过程非常熟悉。现在来看一下对该职位的预期、职业发展道路,以及一系列常见面试问题及我的回答。
|
||||
|
||||
### 系统管理员的典型任务和职责
|
||||
|
||||
组织需要了解系统工作原理的人员,以确保数据安全并保持服务平稳运行。你可能会问:“等等,是不是系统管理员还能做更多的事情?”
|
||||
|
||||
你是对的。现在,一般来说,让我们看一下典型的系统管理员的日常任务。根据公司的需求和人员的技能水平,系统管理员的任务从管理台式机、笔记本电脑、网络和服务器到设计组织的 IT 策略不等。有时,系统管理员甚至负责购买和订购新的 IT 设备。
|
||||
|
||||
那些寻求系统管理工作以作为其职业发展道路的人可能会发现,由于 IT 领域的快速变化是不可避免的,因此难以保持其技能和知识的最新状态。所有人都会想到的下一个自然而然的问题是 IT 专业人员如何掌握最新的更新和技能。
|
||||
|
||||
### 简单的问题
|
||||
|
||||
这是你将遇到的一些最基本的问题,以及我的答案:
|
||||
|
||||
**1、你在 \*nix 服务器上登录后键入的前五个命令是什么?**
|
||||
|
||||
> * `lsblk` 以查看所有的块设备信息
|
||||
> * `who` 查看谁登录到服务器
|
||||
> * `top`,以了解服务器上正在运行的进程
|
||||
> * `df -khT` 以查看服务器上可用的磁盘容量
|
||||
> * `netstat` 以查看哪些 TCP 网络连接处于活动状态
|
||||
|
||||
**2、如何使进程在后台运行,这样做的好处是什么?**
|
||||
|
||||
> 你可以通过在命令末尾添加特殊字符 `&` 来使进程在后台运行。通常,执行时间太长并且不需要用户交互的应用程序可以放到后台,以便我们可以在终端中继续工作。([引文][2])
|
||||
|
||||
**3、以 root 用户身份运行这些命令是好事还是坏事?**
|
||||
|
||||
> 由于两个主要问题,以 root 身份运行(任何命令)是不好的。第一个是*风险*。当你以 **root** 身份登录时,无法避免你由于粗心大意而犯错。如果你尝试以带有潜在危害的方式更改系统,则需要使用 `sudo`,它会引入一个暂停(在你输入密码时),以确保你不会犯错。
|
||||
>
|
||||
> 第二个原因是*安全*。如果你不知道管理员用户的登录信息,则系统更难被攻击。拥有 root 的访问权限意味着你已经能够进行管理员身份下的一半工作任务。
|
||||
|
||||
**4、`rm` 和 `rm -rf` 有什么区别?**
|
||||
|
||||
> `rm` 命令本身仅删除指明的文件(而不删除目录)。使用 `-rf` 标志,你添加了两个附加功能:`-r`(或等价的 `-R`、`--recursive`)标志可以递归删除目录的内容,包括隐藏的文件和子目录;而 `-f`(或 `--force`)标志使 `rm` 忽略不存在的文件,并且从不提示你进行确认。
|
||||
|
||||
**5、有一个大小约为 15GB 的 `Compress.tgz` 文件。你如何列出其内容,以及如何仅提取出特定文件?**
|
||||
|
||||
> 要列出文件的内容:
|
||||
>
|
||||
> `tar tf archive.tgz`
|
||||
>
|
||||
> 要提取特定文件:
|
||||
>
|
||||
> `tar xf archive.tgz filename`
|
||||
|
||||
### 有点难度的问题
|
||||
|
||||
这是你可能会遇到的一些较难的问题,以及我的答案:
|
||||
|
||||
**6、什么是 RAID?什么是 RAID 0、RAID 1、RAID 5、RAID 6 和 RAID 10?**
|
||||
|
||||
> RAID(<ruby>廉价磁盘冗余阵列<rt>Redundant Array of Inexpensive Disks</rt></ruby>)是一种用于提高数据存储性能和/或可靠性的技术。RAID 级别为:
|
||||
>
|
||||
> * RAID 0:也称为磁盘条带化,这是一种分解文件并将数据分布在 RAID 组中所有磁盘驱动器上的技术。它没有防止磁盘失败的保障。([引文][3])
|
||||
> * RAID 1:一种流行的磁盘子系统,通过在两个驱动器上写入相同的数据来提高安全性。RAID 1 被称为*镜像*,它不会提高写入性能,但读取性能可能会提高到每个磁盘性能的总和。另外,如果一个驱动器发生故障,则会使用第二个驱动器,发生故障的驱动器需要手动更换。更换后,RAID 控制器会将可工作的驱动器的内容复制到新驱动器上。
|
||||
> * RAID 5:一种磁盘子系统,可通过计算奇偶校验数据来提高安全性和提高速度。RAID 5 通过跨三个或更多驱动器交错数据(条带化)来实现此目的。在单个驱动器发生故障时,后续读取可以从分布式奇偶校验计算出,从而不会丢失任何数据。
|
||||
> * RAID 6:通过添加另一个奇偶校验块来扩展 RAID 5。此级别至少需要四个磁盘,并且可以在任何两个并发磁盘故障的情况下继续执行读/写操作。RAID 6 不会对读取操作造成性能损失,但由于与奇偶校验计算相关的开销,因此确实会对写入操作造成性能损失。
|
||||
> * RAID 10:RAID 10 也称为 RAID 1 + 0,它结合了磁盘镜像和磁盘条带化功能来保护数据。它至少需要四个磁盘,并且跨镜像对对数据进行条带化。只要每个镜像对中的一个磁盘起作用,就可以检索数据。如果同一镜像对中的两个磁盘发生故障,则所有数据将丢失,因为带区集中没有奇偶校验。([引文][4])
|
||||
|
||||
**7、`ping` 命令使用哪个端口?**
|
||||
|
||||
> `ping` 命令使用 ICMP。具体来说,它使用 ICMP 回显请求和应答包。
|
||||
>
|
||||
> ICMP 不使用 UDP 或 TCP 通信服务:相反,它使用原始的 IP 通信服务。这意味着,ICMP 消息直接承载在 IP 数据报数据字段中。
|
||||
|
||||
**8、路由器和网关之间有什么区别?什么是默认网关?**
|
||||
|
||||
> *路由器*描述的是一种通用技术功能(第 3 层转发)或用于该目的的硬件设备,而*网关*描述的是本地网段的功能(提供到其他地方的连接性)。你还可以说“将路由器设置为网关”。另一个术语是“跳”,它描述了子网之间的转发。
|
||||
>
|
||||
> 术语*默认网关*表示局域网上的路由器,它的责任是作为对局域网外部的计算机通信的第一个联系点。
|
||||
|
||||
**9、解释一下 Linux 的引导过程。**
|
||||
|
||||
> BIOS -> 主引导记录(MBR) -> GRUB -> 内核 -> 初始化 -> 运行级
|
||||
|
||||
**10、服务器启动时如何检查错误消息?**
|
||||
|
||||
> 内核消息始终存储在 kmsg 缓冲区中,可通过 `dmesg` 命令查看。
|
||||
>
|
||||
> 引导出现的问题和错误要求系统管理员结合某些特定命令来查看某些重要文件,这些文件不同版本的 Linux 处理方式不同:
|
||||
>
|
||||
> * `/var/log/boot.log` 是系统引导日志,其中包含系统引导过程中展开的所有内容。
|
||||
> * `/var/log/messages` 存储全局系统消息,包括系统引导期间记录的消息。
|
||||
> * `/var/log/dmesg` 包含内核环形缓冲区信息。
|
||||
|
||||
**11、符号链接和硬链接有什么区别?**
|
||||
|
||||
> *符号链接*(*软链接*)实际是到原始文件的链接,而*硬链接*是原始文件的镜像副本。如果删除原始文件,则该软链接就没有用了,因为它指向的文件不存在了。如果是硬链接,则完全相反。如果删除原始文件,则硬链接仍然包含原始文件中的数据。([引文][5])
|
||||
|
||||
**12、如何更改内核参数?你可能需要调整哪些内核选项?**
|
||||
|
||||
> 要在类 Unix 系统中设置内核参数,请首先编辑文件 `/etc/sysctl.conf`。进行更改后,保存文件并运行 `sysctl -p` 命令。此命令使更改永久生效,而无需重新启动计算机
|
||||
|
||||
**13、解释一下 `/proc` 文件系统。**
|
||||
|
||||
> `/proc` 文件系统是虚拟的,并提供有关内核、硬件和正在运行的进程的详细信息。由于 `/proc` 包含虚拟文件,因此称为“虚拟文件系统”。这些虚拟文件具有独特性。其中大多数显示为零字节。
|
||||
>
|
||||
> 虚拟文件,例如 `/proc/interrupts`、`/proc/meminfo`、`/proc/mounts` 和 `/proc/partitions`,提供了系统硬件的最新信息。其他诸如 `/proc/filesystems` 和 `/proc/sys` 目录提供系统配置信息和接口。
|
||||
|
||||
**14、如何在没有密码的情况下以其他用户身份运行脚本?**
|
||||
|
||||
> 例如,如果你可以编辑 sudoers 文件(例如 `/private/etc/sudoers`),则可以使用 `visudo` 添加以下[内容][2]:
|
||||
>
|
||||
> `user1 ALL =(user2)NOPASSWD:/opt/scripts/bin/generate.sh`
|
||||
|
||||
**15、什么是 UID 0 toor 帐户?是被入侵了么?**
|
||||
|
||||
> `toor` 用户是备用的超级用户帐户,其中 `toor` 是 `root` 反向拼写。它预期与非标准 shell 一起使用,因此 `root` 的默认 shell 不需要更改。
|
||||
>
|
||||
> 此用途很重要。这些 shell 不是基本发行版的一部分,而是从 ports 或软件包安装的,它们安装在 `/usr/local/bin` 中,默认情况下,位于其他文件系统上。如果 root 的 shell 位于 `/usr/local/bin` 中,并且未挂载包含 `/usr/local/bin` 的文件系统,则 root 无法登录以解决问题,并且系统管理员必须重新启动进入单用户模式来输入 shell 程序的路径。
|
||||
|
||||
### 更难的问题
|
||||
|
||||
这是你可能会遇到的甚至更困难的问题:
|
||||
|
||||
**16、`tracert` 如何工作,使用什么协议?**
|
||||
|
||||
> 命令 `tracert`(或 `traceroute`,具体取决于操作系统)使你可以准确地看到在连接到最终目的地的连接链条中所触及的路由器。如果你遇到无法连接或无法 `ping` 通最终目的地的问题,则可以使用 `tracert` 来帮助你确定连接链在何处停止。([引文][6])
|
||||
>
|
||||
> 通过此信息,你可以联系正确的人;无论是你自己的防火墙、ISP、目的地的 ISP 还是中间的某个位置。 `tracert` 命令像 `ping` 一样使用 ICMP 协议,但也可以使用 TCP 三步握手的第一步来发送 SYN 请求以进行响应。
|
||||
|
||||
**17、使用 `chroot` 的主要优点是什么?我们何时以及为什么使用它?在 chroot 环境中,`mount /dev`、`mount /proc` 和 `mount /sys` 命令的作用是什么?**
|
||||
|
||||
> chroot 环境的优点是文件系统与物理主机是隔离的,因为 chroot 在文件系统内部有一个单独的文件系统。区别在于 `chroot` 使用新创建的根目录(`/`)作为其根目录。
|
||||
>
|
||||
> chroot 监狱可让你将进程及其子进程与系统其余部分隔离。它仅应用于不以 root 身份运行的进程,因为 root 用户可以轻松地脱离监狱。
|
||||
>
|
||||
> 该思路是创建一个目录树,在其中复制或链接运行该进程所需的所有系统文件。然后,你可以使用 `chroot()` 系统调用来告诉它根目录现在位于此新树的基点上,然后启动在该 chroot 环境中运行的进程。由于该命令因此而无法引用修改后的根目录之外的路径,因此它无法在这些位置上执行恶意操作(读取、写入等)。([引文][7])
|
||||
|
||||
**18、如何保护你的系统免遭黑客攻击?**
|
||||
|
||||
> 遵循最低特权原则和这些做法:
|
||||
>
|
||||
> * 使用公钥加密,它可提供出色的安全性。
|
||||
> * 增强密码复杂性。
|
||||
> * 了解为什么要对上述规则设置例外。
|
||||
> * 定期检查你的例外情况。
|
||||
> * 让具体的人对失败负责。(它使你保持警惕。)([引文][8])
|
||||
|
||||
**19、什么是 LVM,使用 LVM 有什么好处?**
|
||||
|
||||
> LVM(逻辑卷管理)是一种存储设备管理技术,该技术使用户能够合并和抽象化组件存储设备的物理布局,从而可以更轻松、灵活地进行管理。使用设备映射器的 Linux 内核框架,当前迭代(LVM2)可用于将现有存储设备收集到组中,并根据需要从组合的空间分配逻辑单元。
|
||||
|
||||
**20、什么是粘性端口?**
|
||||
|
||||
> 粘性端口是网络管理员最好的朋友,也是最头痛的事情之一。它们允许你设置网络,以便通过将交换机上的每个端口锁定到特定的 MAC 地址,仅允许一台(或你指定的数字)计算机在该端口上进行连接。
|
||||
|
||||
**21、解释一下端口转发?**
|
||||
|
||||
> 尝试与安全的网络内部的系统进行通信时,从外部进行通信可能非常困难,这是很显然的。因此,在路由器本身或其他连接管理设备中使用端口转发表可以使特定流量自动转发到特定目的地。例如,如果你的网络上运行着一台 Web 服务器,并且想从外部授予对该服务器的访问权限,则可以将端口转发设置为该服务器上的端口 80。这意味着在 Web 浏览器中输入你的(外网)IP 地址的任何人都将立即连接到该服务器的网站。
|
||||
>
|
||||
> 请注意,通常不建议允许从你的网络外部直接访问服务器。
|
||||
|
||||
**22、对于 IDS,误报和漏报是什么?**
|
||||
|
||||
> 当入侵检测系统(IDS)设备为实际上没有发生的入侵生成警报时,这是<ruby>误报(假阳性)<rt>false positive</rt></ruby>。如果设备未生成任何警报,而入侵实际上已发生,则为<ruby>漏报(假阴性)</rt></ruby>。
|
||||
|
||||
**23、解释一下 `:(){ :|:& };:`,如果已经登录系统,如何停止此代码?**
|
||||
|
||||
> 这是一枚复刻炸弹。它分解如下:
|
||||
>
|
||||
> * `:()` 定义了函数,以 `:` 作为函数名,并且空括号表示它不接受任何参数。
|
||||
> * `{}` 是函数定义的开始和结束。
|
||||
> * `:|:` 将函数 `:` 的副本加载到内存中,并将其输出通过管道传递给函数 `:` 的另一个副本,该副本也必须加载到内存中。
|
||||
> * `&` 使前一个命令行成为后台进程,因此即使父进程被自动杀死,子进程也不会被杀死。
|
||||
> * `:` 执行该函数,因此连锁反应开始。
|
||||
>
|
||||
> 保护多用户系统的最佳方法是使用特权访问管理(PAM)来限制用户可以使用的进程数。
|
||||
>
|
||||
> 复刻炸弹的最大问题是它发起了太多进程。因此,如果你已经登录系统,我们有两种尝试解决此问题的方法。一种选择是执行一个 `SIGSTOP` 命令来停止进程,例如:
|
||||
>
|
||||
> `killall -STOP -u user1`
|
||||
>
|
||||
> 如果由于占用了所有进程而无法使用命令行,则必须使用 `exec` 强制其运行:
|
||||
>
|
||||
> `exec killall -STOP -u user1`
|
||||
>
|
||||
> 对于复刻炸弹,最好的选择是防患于未然。
|
||||
|
||||
**24、什么是 OOM 杀手,它如何决定首先杀死哪个进程?**
|
||||
|
||||
> 如果内存被进程彻底耗尽,可能会威胁到系统的稳定性,那么<ruby>内存不足<rt>out of memory</rt></ruby>(OOM)杀手就登场了。
|
||||
>
|
||||
> OOM 杀手首先必须选择要杀死的最佳进程。*最佳*在这里指的是在被杀死时将释放最大内存的进程,并且对系统来说最不重要。主要目标是杀死最少数量的进程,以最大程度地减少造成的损害,同时最大化释放的内存量。
|
||||
>
|
||||
> 为了实现此目标,内核为每个进程维护一个 `oom_score`。你可以在 `/proc` 文件系统中的 `pid` 目录下的看到每个进程的 `oom_score`:
|
||||
>
|
||||
> `$ cat /proc/10292/oom_score`
|
||||
>
|
||||
> 任何进程的 `oom_score` 值越高,在内存不足的情况下被 OOM 杀手杀死的可能性就越高。([引文][9])
|
||||
|
||||
### 总结
|
||||
|
||||
系统管理人员的薪水[差别很大][10],有些网站上说年薪在 70,000 到 100,000 美元之间,具体取决于地点、组织的规模以及你的教育水平以及多年的工作经验。系统管理的职业道路最终归结为你对使用服务器和解决那些酷问题的兴趣。现在,我要说,继续前进,实现你的梦想之路吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/sysadmin-job-interview-questions
|
||||
|
||||
作者:[DirectedSoul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/directedsoul
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_HowToFish_520x292.png?itok=DHbdxv6H (Question and answer.)
|
||||
[2]: https://github.com/trimstray/test-your-sysadmin-skills
|
||||
[3]: https://www.waytoeasylearn.com/2016/05/netapp-filer-tutorial.html
|
||||
[4]: https://searchstorage.techtarget.com/definition/RAID-10-redundant-array-of-independent-disks
|
||||
[5]: https://www.answers.com/Q/What_is_hard_link_and_soft_link_in_Linux
|
||||
[6]: https://www.wisdomjobs.com/e-university/network-administrator-interview-questions.html
|
||||
[7]: https://unix.stackexchange.com/questions/105/chroot-jail-what-is-it-and-how-do-i-use-it
|
||||
[8]: https://serverfault.com/questions/391370/how-to-prevent-zero-day-attacks
|
||||
[9]: https://unix.stackexchange.com/a/153586/8369
|
||||
[10]: https://blog.netwrix.com/2018/07/23/systems-administrator-salary-in-2018-how-much-can-you-earn/
|
||||
200
published/201912/20191004 What-s in an open source name.md
Normal file
200
published/201912/20191004 What-s in an open source name.md
Normal file
@ -0,0 +1,200 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (laingke)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11688-1.html)
|
||||
[#]: subject: (What's in an open source name?)
|
||||
[#]: via: (https://opensource.com/article/19/10/open-source-name-origins)
|
||||
[#]: author: (Joshua Allen Holm https://opensource.com/users/holmja)
|
||||
|
||||
开源软件名称中的故事
|
||||
======
|
||||
|
||||
> 有没有想过你喜欢的开源项目或编程语言的名称来自何处?让我们按字母顺序了解一下流行的技术术语背后的起源故事。
|
||||
|
||||

|
||||
|
||||
GNOME、Java、Jupyter、Python……如果你的朋友或家人曾留意过你的工作对话,他们可能会认为你从事文艺复兴时期的民间文学艺术、咖啡烘焙、天文学或动物学工作。这些开源技术的名称从何而来?我们请我们的作者社区提供意见,并汇总了一些我们最喜欢的技术名称的起源故事。
|
||||
|
||||
### Ansible
|
||||
|
||||
“Ansible”这个名称直接来自科幻小说。Ursula Le Guin 的《Rocannon's World》一书中能进行即时(比光速更快)通信的设备被称为 ansibles(显然来自 “answerable” 一词)。Ansibles 开始流行于科幻小说之中,Orson Scott Card 的《Ender's Game》(后来成为受欢迎的电影)中,该设备控制了许多远程太空飞船。对于控制分布式机器的软件来说,这似乎是一个很好的模型,因此 Michael DeHaan(Ansible 的创建者和创始人)借用了这个名称。
|
||||
|
||||
### Apache
|
||||
|
||||
[Apache][2] 是最初于 1995 年发布的开源 Web 服务器。它的名称与著名的美国原住民部落无关;相反,它是指对原始软件代码的重复补丁。因此称之为,“<ruby>一个修补的<rt>A-patchy</rt></ruby>服务器”。
|
||||
|
||||
### awk
|
||||
|
||||
“awk(1) 代表着 Aho、Weinberger、Kernighan(作者)”—— Michael Greenberg
|
||||
|
||||
### Bash
|
||||
|
||||
“最初的 Unix shell,即 Bourne shell,是以其创造者的名字命名的。在开发出来 Bash 时,csh(发音为 ‘seashell’)实际上更受交互登录用户的欢迎。Bash 项目旨在赋予 Bourne shell 新的生命,使其更适合于交互式使用,因此它被命名为 ‘Bourne again shell’,是‘<ruby>重生<rt>born again</rt></ruby>’的双关语。”——Ken Gaillot
|
||||
|
||||
### C
|
||||
|
||||
在早期,AT&T 的 Ken Thompson 和 Dennis Ritchie 发现可以使用更高级的编程语言(而不是低级的、可移植性更低的汇编编程)来编写操作系统和工具。早期有一个叫做 BCPL(<ruby>基本组合编程语言<rt>Basic Combined programming Language</rt></ruby>)的编程系统,Thompson 创建了一个名为 B 的简化版 BCPL,但 B 的灵活性和速度都不高。然后,Ritchie 把 B 的思想扩展成一种叫做 C 的编译语言。”——Jim Hall
|
||||
|
||||
### dd
|
||||
|
||||
“我想你发表这样一篇文章不能不提到 dd。我的外号叫 Didi。发音正确的话听起来像 ‘dd’。我开始学的是 Unix,然后是 Linux,那是在 1993 年,当时我还是个学生。然后我去了军队,来到了我的部队中少数几个使用 Unix(Ultrix)的部门之一(其它部门主要是 VMS),那里的一个人说:‘这么说,你是一个黑客,对吗?你以为你了解 Unix 吗?好的,那么 dd 这个名字的是怎么来的呢?’我不知道,试着猜道:‘<ruby>数据复印机<rt>Data duplicator</rt></ruby>?’所以他说,‘我要告诉你 dd 的故事。dd 是<ruby>转换<rt>convert</rt></ruby>和<ruby>复制<rt>copy</rt></ruby>的缩写(如今人们仍然可以在手册页中看到),但由于 cc 这个缩写已经被 C 编译器占用,所以它被命名为 dd。’就在几年后,我听闻了关于 JCL 的数据定义和 Unix dd 命令不统一的、半开玩笑的语法的真实故事,某种程度是基于此的。”——Yedidyah Bar David
|
||||
|
||||
### Emacs
|
||||
|
||||
经典的<ruby>反 vi<rt>anti-vi</rt></ruby>编辑器,其名称的真正词源并不明显,因为它源自“<ruby>编辑宏<rt>Editing MACroS</rt></ruby>”。但是,它作为一个伟大的宗教亵渎和崇拜的对象,吸引了许多恶作剧般的缩写,例如“Escape Meta Alt Control Shift”(以调侃其对键盘的大量依赖),“<ruby>8MB 并经常发生内存交换<rt>Eight Megabytes And Constantly Swapping</rt></ruby>”(从那时起就很吃内存了),“<ruby>最终分配了所有的计算机存储空间<rt>Eventually malloc()s All Computer Storage</rt></ruby>”和 “<ruby>EMACS 使一台计算机慢<rt>EMACS Makes A Computer Slow</rt></ruby>”——改编自 Jargon File/Hacker's Dictionary
|
||||
|
||||
### Enarx
|
||||
|
||||
[Enarx][3] 是机密计算领域的一个新项目。该项目的设计原则之一是它应该是“可替代的”。因此最初的名字是“psilocybin”(著名的魔术蘑菇)。一般情况下,经理级别的人可能会对这个名称有所抵触,因此考虑使用新名称。该项目的两位创始人 Mike Bursell 和 Nathaniel McCallum 都是古老语言极客,因此他们考虑了许多不同的想法,包括 тайна(Tayna——俄语中代表秘密或神秘——虽然俄语并不是一门古老的语言,但你就不要在乎这些细节了),crypticon(希腊语的意思是完全私生的),cryptidion(希腊中表示小密室),arconus(拉丁语中表示秘密的褒义形容词),arcanum(拉丁语中表示秘密的中性形容词)和 ærn(盎格鲁撒克逊人表示地方、秘密的地方、壁橱、住所、房子,或小屋的词汇)。最后,由于各种原因,包括域名和 GitHub 项目名称的可用性,他们选择了 enarx,这是两个拉丁词根的组合:en-(表示内部)和 -arx(表示城堡、要塞或堡垒)。
|
||||
|
||||
### GIMP
|
||||
|
||||
没有 [GIMP][4] 我们会怎么样?<ruby>GNU 图像处理项目<rt>GNU Image Manipulation Project</rt></ruby>多年来一直是开源的重要基础。[维基百科][5]指出,“1995 年,[Spencer Kimball][6] 和 [Peter Mattis][7] 在加州大学伯克利分校开始为<ruby>实验计算设施<rt>eXperimental Computing Facility</rt></ruby>开发 GIMP,这是一个为期一个学期的项目。”
|
||||
|
||||
### GNOME
|
||||
|
||||
你有没有想过为什么 GNOME 被称为 GNOME?根据[维基百科][8],GNOME 最初是一个表示“<ruby>GNU 网络对象模型环境<rt>GNU Network Object Model Environment</rt></ruby>”的缩写词。现在,该名称不再表示该项目,并且该项目已被放弃,但这个名称仍然保留了下来。[GNOME 3][9] 是 Fedora、红帽企业版、Ubuntu、Debian、SUSE Linux 企业版等发行版的默认桌面环境。
|
||||
|
||||
### Java
|
||||
|
||||
你能想象这种编程语言还有其它名称吗?Java 最初被称为 Oak,但是遗憾的是,Sun Microsystems 的法律团队由于已有该商标而否决了它。所以开发团队又重新给它命名。[据说][10]该语言的工作组在 1995 年 1 月举行了一次大规模的头脑风暴。许多其它名称也被扔掉了,包括 Silk、DNA、WebDancer 等。该团队不希望新名称与过度使用的术语“web”或“net”有任何关系。取而代之的是,他们在寻找更有活力、更有趣、更容易记住的东西。Java 满足了这些要求,并且奇迹般地,团队同意通过了!
|
||||
|
||||
### Jupyter
|
||||
|
||||
现在许多数据科学家和学生在工作中使用 [Jupyter][11] 笔记本。“Jupyter”这个名字是三种开源计算机语言的融合,这三种语言在这个笔记本中都有使用,在数据科学中也很突出:[Julia][12]、[Python][13] 和 [R][14]。
|
||||
|
||||
### Kubernetes
|
||||
|
||||
Kubernetes 源自希腊语中的舵手。Kubernetes 项目创始人 Craig McLuckie 在 [2015 Hacker News][15] 回应中证实了这种词源。他坚持航海主题,解释说,这项技术可以驱动集装箱,就像舵手或驾驶员驾驶集装箱船一样,因此,他选择了 Kubernetes 这个名字。我们中的许多人仍然在尝试正确的发音(koo-bur-NET-eez),因此 替代使用 K8s 也是可以接受的。有趣的是,它与英语单词“<ruby>行政长官<rt>governor</rt></ruby>”具有相同的词源,也与蒸汽机上的机械负反馈装置相同。
|
||||
|
||||
### KDE
|
||||
|
||||
那 K 桌面呢?KDE 最初代表“<ruby>酷桌面环境<rt>Kool Desktop Environment</rt></ruby>”。 它由 [Matthias Ettrich][16] 于 1996 年创立。根据[维基百科][17]上的说法,该名称是对 Unix 上 <ruby>[通用桌面环境][18]<rt>Common Desktop Environment</rt></ruby>(CDE)一词的调侃。
|
||||
|
||||
### Linux
|
||||
|
||||
[Linux][19] 因其发明者 Linus Torvalds 的名字命名的。Linus 最初想将他的作品命名为“Freax”,因为他认为以他自己的名字命名太自负了。根据[维基百科][19]的说法,“赫尔辛基科技大学 Torvalds 的同事 Ari Lemmke 当时是 FTP 服务器的志愿管理员之一,他并不认为‘Freax’是个好名字。因此,他没有征询 Torvalds 就将服务器上的这个项目命名为‘Linux’。”
|
||||
|
||||
以下是一些最受欢迎的 Linux 发行版。
|
||||
|
||||
#### CentOS
|
||||
|
||||
[CentOS][20] 是<ruby>社区企业操作系统<rt>Community Enterprise Operating System</rt></ruby>的缩写。它包含来自 Red Hat Enterprise Linux 的上游软件包。
|
||||
|
||||
#### Debian
|
||||
|
||||
[Debian][21] Linux 创建于 1993 年 9 月,是其创始人 Ian Murdock 和他当时的女友 Debra Lynn 的名字的混成词。
|
||||
|
||||
#### RHEL
|
||||
|
||||
[Red Hat Linux][22] 得名于它的创始人 Marc Ewing,他戴着一顶祖父送给他的康奈尔大学红色<ruby>软呢帽<rt>fedora</rt></ruby>。红帽公司成立于 1993 年 3 月 26 日。[Fedora Linux][23] 最初是一个志愿者项目,旨在为红帽发行版提供额外的软件,它的名字来自红帽的“Shadowman”徽标。
|
||||
|
||||
#### Ubuntu
|
||||
|
||||
[Ubuntu][24] 旨在广泛分享开源软件,它以非洲哲学“<ruby>人的本质<rt>ubuntu</rt></ruby>”命名,可以翻译为“对他人的人道主义”或“我之所以是我,是因为我们都是这样的人”。
|
||||
|
||||
### Moodle
|
||||
|
||||
开源学习平台 [Moodle][25] 是“<ruby>模块化面向对象动态学习环境<rt>modular object-oriented dynamic learning environment</rt></ruby>”的首字母缩写。Moodle 仍然是领先的线上学习平台。全球有近 10.4 万个注册的 Moodle 网站。
|
||||
|
||||
另外两个流行的开源内容管理系统是 Drupal 和 Joomla。Drupal 的名字来自荷兰语 “druppel”,意思是“掉落”。根据维基百科,Joomla 是斯瓦希里语单词“jumla”的[英式拼写][26],在阿拉伯语、乌尔都语和其他语言中是“在一起”的意思。
|
||||
|
||||
### Mozilla
|
||||
|
||||
[Mozilla][27] 是一个成立于 1998 年的开源软件社区。根据其网站,“Mozilla 项目创建于 1998 年,发布了 Netscape 浏览器套件源代码。其旨在利用互联网上成千上万的程序员的创造力,并推动浏览器市场上前所未有的创新水平。” 这个名字是 [Mosaic] [28] 和 Godzilla 的混成词。
|
||||
|
||||
### Nginx
|
||||
|
||||
“许多技术人员都试图装酷,并将它念成‘n’‘g’‘n’‘x’。实际上,很少的一些人做点基本的调查工作,就可以很快发现该名称实际上应该被念成是“EngineX”,指的是功能强大的 web 服务器,像个引擎。”——Jean Sebastien Tougne
|
||||
|
||||
### Perl
|
||||
|
||||
Perl 的创始人 Larry Wall 最初将他的项目命名为“Pearl”。根据维基百科,Wall 想给这种语言起一个有积极含义的简短名字。在 Perl 正式发布之前,Wall 发现了已有 [PEARL][29] 编程语言,于是更改了名称的拼写。
|
||||
|
||||
### Piet 和 Mondrian
|
||||
|
||||
“有两种编程语言以艺术家 Piet Mondrian 命名。一种叫做‘Piet’,另一种叫做‘Mondrian’。(David Morgan-Mar [写道][30]):‘Piet 是一种编程语言,其中的程序看起来像抽象绘画。该语言以几何抽象艺术的开创者 Piet Mondrian 的名字命名。我曾想将这种语言命名为 Mondrian,但是有人告诉我这会让它看起来像一种很普通的脚本语言。哦,好吧,我想我们不能都是深奥的语言作家。’”——Yuval Lifshitz
|
||||
|
||||
### Python
|
||||
|
||||
Python 编程语言的独特名称来自其创建者 Guido Van Rossum,他是英国六人喜剧团体 Monty Python 的粉丝。
|
||||
|
||||
### Raspberry Pi
|
||||
|
||||
Raspberry Pi 以其微小但强大的功能和对低廉的价格而闻名,在开源社区中是最受欢迎的。但是它可爱(和好吃)的名字是从哪里来的呢?在 70 年代和 80 年代,以水果命名的计算机是一种流行的趋势。苹果、橘子、杏……有人饿了吗?根据创始人 Eben Upton 的 [2012 采访] [31],“<ruby>树莓派<rt>Raspberry Pi</rt></ruby>”这个名称是对这种趋势的致敬。树莓也很小,但却很有味道。名称中的“Pi”暗示着这样的事实:最初,该计算机只能运行 Python。
|
||||
|
||||
### Samba
|
||||
|
||||
[Server Message Block][32] 用于在 Linux 上共享 Windows 文件。
|
||||
|
||||
### ScummVM
|
||||
|
||||
[ScummVM][33](《疯狂大楼》虚拟机的脚本创建实用程序)是一个程序,可以在现代计算机上运行一些经典的计算机冒险游戏。最初,它旨在玩用 SCUMM 构建的 LucasArts 的冒险游戏,该游戏最初用于开发《疯狂大楼》,后来又被用来开发 LucasArts 的其它大多数冒险游戏。目前,ScummVM 支持大量游戏引擎,包括 Sierra Online 的 AGI 和 SCI,但仍保留着名称 ScummVM。
|
||||
|
||||
有一个相关的项目 [ResidualVM][34] 之所以得名,是因为它涵盖了 ScummVM 未涵盖的“<ruby>剩余的<rt>residual</rt></ruby>” LucasArts 冒险游戏。 ResidualVM 涵盖的 LucasArts 游戏是使用 GrimE(Grim Engine)开发的,该引擎最初用于开发 Grim Fandango,因此 ResidualVM 的名称是双关语。
|
||||
|
||||
### SQL
|
||||
|
||||
“你可能知道 SQL 代表<ruby>结构化查询语言<rt>Structured Query Language</rt></ruby>,但你知道为什么它经常被读作‘sequel’吗?它是作为原本的‘QUEL’(<ruby>查询语言<rt>QUEry Language</rt></ruby>)的后续(如<ruby>结局<rt>sequel</rt></ruby>)而创建的。”——Ken Gaillot
|
||||
|
||||
### XFCE
|
||||
|
||||
[XFCE][35] 是由 [Olivier Fourdan][36] 创建的一个流行的桌面。它在 1996 年作为 CDE 的替代品出现,最初是 <ruby>XForms 公共环境<rt>XForms Common Environment</rt></ruby>的缩写。
|
||||
|
||||
### Zsh
|
||||
|
||||
Zsh 是一个交互式登录 shell。1990 年,普林斯顿大学的学生 Paul Falstad 写了该 shell 的第一个版本。他在看到当时在普林斯顿大学担任助教的 Zhong Sha 的登录 ID(zsh)后,觉得这个名字听起来像 [shell 的好名字][37],给它起了这个名字。
|
||||
|
||||
还有更多的项目和名称还没有包括在这个列表中。请一定要在评论中分享你的收藏。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/open-source-name-origins
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[laingke](https://github.com/laingke)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/holmja
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003784_02_os.comcareers_resume_rh1x.png?itok=S3HGxi6E (A person writing.)
|
||||
[2]: https://httpd.apache.org/
|
||||
[3]: https://enarx.io
|
||||
[4]: https://www.gimp.org/
|
||||
[5]: https://en.wikipedia.org/wiki/GIMP
|
||||
[6]: https://en.wikipedia.org/wiki/Spencer_Kimball_(computer_programmer)
|
||||
[7]: https://en.wikipedia.org/wiki/Peter_Mattis
|
||||
[8]: https://en.wikipedia.org/wiki/GNOME
|
||||
[9]: https://www.gnome.org/gnome-3/
|
||||
[10]: https://www.javaworld.com/article/2077265/so-why-did-they-decide-to-call-it-java-.html
|
||||
[11]: https://jupyter.org/
|
||||
[12]: https://julialang.org/
|
||||
[13]: https://www.python.org/
|
||||
[14]: https://www.r-project.org/
|
||||
[15]: https://news.ycombinator.com/item?id=9653797
|
||||
[16]: https://en.wikipedia.org/wiki/Matthias_Ettrich
|
||||
[17]: https://en.wikipedia.org/wiki/KDE
|
||||
[18]: https://sourceforge.net/projects/cdesktopenv/
|
||||
[19]: https://en.wikipedia.org/wiki/Linux
|
||||
[20]: https://www.centos.org/
|
||||
[21]: https://www.debian.org/
|
||||
[22]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[23]: https://getfedora.org/
|
||||
[24]: https://ubuntu.com/about
|
||||
[25]: https://moodle.org/
|
||||
[26]: https://en.wikipedia.org/wiki/Joomla#Historical_background
|
||||
[27]: https://www.mozilla.org/en-US/
|
||||
[28]: https://en.wikipedia.org/wiki/Mosaic_(web_browser)
|
||||
[29]: https://en.wikipedia.org/wiki/PEARL_(programming_language)
|
||||
[30]: http://www.dangermouse.net/esoteric/piet.html
|
||||
[31]: https://www.techspot.com/article/531-eben-upton-interview/
|
||||
[32]: https://www.samba.org/
|
||||
[33]: https://www.scummvm.org/
|
||||
[34]: https://www.residualvm.org/
|
||||
[35]: https://www.xfce.org/
|
||||
[36]: https://en.wikipedia.org/wiki/Olivier_Fourdan
|
||||
[37]: http://www.zsh.org/mla/users/2005/msg00951.html
|
||||
265
published/201912/20191007 Using the Java Persistence API.md
Normal file
265
published/201912/20191007 Using the Java Persistence API.md
Normal file
@ -0,0 +1,265 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (runningwater)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11717-1.html)
|
||||
[#]: subject: (Using the Java Persistence API)
|
||||
[#]: via: (https://opensource.com/article/19/10/using-java-persistence-api)
|
||||
[#]: author: (Stephon Brown https://opensource.com/users/stephb)
|
||||
|
||||
使用 Java 持久化 API
|
||||
======
|
||||
|
||||
> 我们通过为自行车商店构建示例应用程序来学习如何使用 JPA。
|
||||
|
||||

|
||||
|
||||
对应用开发者来说,<ruby>Java 持久化 API<rt>Java Persistence API</rt></ruby>(JPA)是一项重要的 java 功能,需要透彻理解。它为 Java 开发人员定义了如何将对象的方法调用转换为访问、持久化及管理存储在 NoSQL 和关系型数据库中的数据的方案。
|
||||
|
||||
本文通过构建自行车借贷服务的教程示例来详细研究 JPA。此示例会使用 Spring Boot 框架、MongoDB 数据库([已经不开源][2])和 Maven 包管理来构建一个大型应用程序,并且构建一个创建、读取、更新和删除(CRUD)层。这儿我选择 NetBeans 11 作为我的 IDE。
|
||||
|
||||
此教程仅从开源的角度来介绍 Java 持久化 API 的工作原理,不涉及其作为工具的使用说明。这全是关于编写应用程序模式的学习,但对于理解具体的软件实现也很益处。可以从我的 [GitHub 仓库][3]来获取相关代码。
|
||||
|
||||
### Java: 不仅仅是“豆子”
|
||||
|
||||
Java 是一门面向对象的编程语言,自 1996 年发布第一版 Java 开发工具(JDK)起,已经变化了很多很多。要了解其各种发展及其虚拟机本身就是一堂历史课。简而言之,和 Linux 内核很相似,自发布以来,该语言已经向多个方向分支发展。有对社区免费的标准版本、有针对企业的企业版本及由多家供应商提供的开源替代品。主要版本每六个月发布一次,其功能往往差异很大,所以确认选用版本前得先做些研究。
|
||||
|
||||
总而言之,Java 的历史很悠久。本教程重点介绍 Java 11 的开源实现 [JDK 11][4]。因其是仍然有效的长期支持版本之一。
|
||||
|
||||
* **Spring Boot** 是由 Pivotal 公司开发的大型 Spring 框架的一个模块。Spring 是 Java 开发中一个非常流行的框架。它支持各种框架和配置,也为 WEB 应用程序及安全提供了保障。Spring Boot 为快速构建各种类型的 Java 项目提供了基本的配置。本教程使用 Spring Boot 来快速编写控制台应用程序并针对数据库编写测试用例。
|
||||
* **Maven** 是由 Apache 开发的项目/包管理工具。Maven 通过 `POM.xml` 文件来管理包及其依赖项。如果你使用过 NPM 的话,可能会非常熟悉包管理器的功能。此外 Maven 也用来进行项目构建及生成功能报告。
|
||||
* **Lombok** 是一个库,它通过在对象文件里面添加注解来自动创建 getters/setters 方法。像 C# 这些语言已经实现了此功能,Lombok 只是把此功能引入 Java 语言而已。
|
||||
* **NetBeans** 是一款很流行的开源 IDE,专门用于 Java 开发。它的许多工具都随着 Java SE 和 EE 的版本更新而更新。
|
||||
|
||||
我们会用这组工具为一个虚构自行车商店创建一个简单的应用程序。会实现对 `Customer` 和 `Bike` 对象集合的的插入操作。
|
||||
|
||||
### 酿造完美
|
||||
|
||||
导航到 [Spring Initializr][5] 页面。该网站可以生成基于 Spring Boot 和其依赖项的基本项目。选择以下选项:
|
||||
|
||||
1. **项目:** Maven 工程
|
||||
2. **语言:** Java
|
||||
3. **Spring Boot:** 2.1.8(或最稳定版本)
|
||||
4. **项目元数据:** 无论你使用什么名字,其命名约定都是像 `com.stephb` 这样的。
|
||||
* 你可以保留 Artifact 名字为 “Demo”。
|
||||
5. **依赖项:** 添加:
|
||||
* Spring Data MongoDB
|
||||
* Lombok
|
||||
|
||||
点击 **下载**,然后用你的 IDE(例如 NetBeans) 打开此新项目。
|
||||
|
||||
#### 模型层概要
|
||||
|
||||
在项目里面,<ruby>模型<rt>model</rt></ruby>代表从数据库里取出的信息的具体对象。我们关注两个对象:`Customer` 和 `Bike`。首先,在 `src` 目录创建 `dto` 目录;然后,创建两个名为 `Customer.java` 和 `Bike.java` 的 Java 类对象文件。其结构如下示:
|
||||
|
||||
```Java
|
||||
package com.stephb.JavaMongo.dto;
|
||||
|
||||
import lombok.Getter;
|
||||
import lombok.Setter;
|
||||
import org.springframework.data.annotation.Id;
|
||||
|
||||
/**
|
||||
*
|
||||
* @author stephon
|
||||
*/
|
||||
@Getter @Setter
|
||||
public class Customer {
|
||||
|
||||
private @Id String id;
|
||||
private String emailAddress;
|
||||
private String firstName;
|
||||
private String lastName;
|
||||
private String address;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
*Customer.Java*
|
||||
|
||||
```Java
|
||||
package com.stephb.JavaMongo.dto;
|
||||
|
||||
import lombok.Getter;
|
||||
import lombok.Setter;
|
||||
import org.springframework.data.annotation.Id;
|
||||
|
||||
/**
|
||||
*
|
||||
* @author stephon
|
||||
*/
|
||||
@Getter @Setter
|
||||
public class Bike {
|
||||
private @Id String id;
|
||||
private String modelNumber;
|
||||
private String color;
|
||||
private String description;
|
||||
|
||||
@Override
|
||||
public String toString() {
|
||||
return "This bike model is " + this.modelNumber + " is the color " + this.color + " and is " + description;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
*Bike.java*
|
||||
|
||||
如你所见,对象中使用 Lombok 注解来为定义的<ruby>属性<rt>properties</rt></ruby>/<ruby>特性<rt>attributes</rt></ruby>生成 getters/setters 方法。如果你不想对该类的所有特性都生成 getters/setters 方法,可以在属性上专门定义这些注解。这两个类会变成容器,里面携带有数据,无论在何处想显示信息都可以使用。
|
||||
|
||||
#### 配置数据库
|
||||
|
||||
我使用 [Mongo Docker][7] 容器来进行此次测试。如果你的系统上已经安装了 MongoDB,则不必运行 Docker 实例。你也可以登录其官网,选择系统信息,然后按照安装说明来安装 MongoDB。
|
||||
|
||||
安装后,就可以使用命令行、GUI(例如 MongoDB Compass)或用于连接数据源的 IDE 驱动程序来与新的 MongoDB 服务器进行交互。到目前为止,可以开始定义数据层了,用来拉取、转换和持久化数据。需要设置数据库访问属性,请导航到程序中的 `applications.properties` 文件,然后添加如下内容:
|
||||
|
||||
```
|
||||
spring.data.mongodb.host=localhost
|
||||
spring.data.mongodb.port=27017
|
||||
spring.data.mongodb.database=BikeStore
|
||||
```
|
||||
|
||||
#### 定义数据访问对象/数据访问层
|
||||
|
||||
<ruby>数据访问层<rt>data access layer</rt></ruby>(DAL)中的<ruby>数据访问对象<rt>data access objects</rt></ruby>(DAO)定义了与数据库中的数据的交互过程。令人惊叹的就是在使用 `spring-boot-starter` 后,查询数据库的大部分工作已经完成。
|
||||
|
||||
让我们从 `Customer` DAO 开始。在 `src` 下的新目录 `dao` 中创建一个接口文件,然后再创建一个名为 `CustomerRepository.java` 的 Java 类文件,其内容如下示:
|
||||
|
||||
```
|
||||
package com.stephb.JavaMongo.dao;
|
||||
|
||||
import com.stephb.JavaMongo.dto.Customer;
|
||||
import java.util.List;
|
||||
import org.springframework.data.mongodb.repository.MongoRepository;
|
||||
|
||||
/**
|
||||
*
|
||||
* @author stephon
|
||||
*/
|
||||
public interface CustomerRepository extends MongoRepository<Customer, String>{
|
||||
@Override
|
||||
public List<Customer> findAll();
|
||||
public List<Customer> findByFirstName(String firstName);
|
||||
public List<Customer> findByLastName(String lastName);
|
||||
}
|
||||
```
|
||||
|
||||
这个类是一个接口,扩展或继承于 `MongoRepository` 类,而 `MongoRepository` 类依赖于 DTO (`Customer.java`)和一个字符串,它们用来实现自定义函数查询功能。因为你已继承自此类,所以你可以访问许多方法函数,这些函数允许持久化和查询对象,而无需实现或引用自己定义的方法函数。例如,在实例化 `CustomerRepository` 对象后,你就可以直接使用 `Save` 函数。如果你需要扩展更多的功能,也可以重写这些函数。我创建了一些自定义查询来搜索我的集合,这些集合对象是我自定义的元素。
|
||||
|
||||
`Bike` 对象也有一个存储源负责与数据库交互。与 `CustomerRepository` 的实现非常类似。其实现如下所示:
|
||||
|
||||
```
|
||||
package com.stephb.JavaMongo.dao;
|
||||
|
||||
import com.stephb.JavaMongo.dto.Bike;
|
||||
import java.util.List;
|
||||
import org.springframework.data.mongodb.repository.MongoRepository;
|
||||
|
||||
/**
|
||||
*
|
||||
* @author stephon
|
||||
*/
|
||||
public interface BikeRepository extends MongoRepository<Bike,String>{
|
||||
public Bike findByModelNumber(String modelNumber);
|
||||
@Override
|
||||
public List<Bike> findAll();
|
||||
public List<Bike> findByColor(String color);
|
||||
}
|
||||
```
|
||||
|
||||
#### 运行程序
|
||||
|
||||
现在,你已经有了一种结构化数据的方式,可以对数据进行提取、转换和持久化,然后运行这个程序。
|
||||
|
||||
找到 `Application.java` 文件(有可能不是此名称,具体取决于你的应用程序名称,但都会包含有 “application” )。在定义此类的地方,在后面加上 `implements CommandLineRunner`。这将允许你实现 `run` 方法来创建命令行应用程序。重写 `CommandLineRunner` 接口提供的 `run` 方法,并包含如下内容用来测试 `BikeRepository` :
|
||||
|
||||
```
|
||||
package com.stephb.JavaMongo;
|
||||
|
||||
import com.stephb.JavaMongo.dao.BikeRepository;
|
||||
import com.stephb.JavaMongo.dao.CustomerRepository;
|
||||
import com.stephb.JavaMongo.dto.Bike;
|
||||
import java.util.Scanner;
|
||||
import org.springframework.beans.factory.annotation.Autowired;
|
||||
import org.springframework.boot.CommandLineRunner;
|
||||
import org.springframework.boot.SpringApplication;
|
||||
import org.springframework.boot.autoconfigure.SpringBootApplication;
|
||||
|
||||
|
||||
@SpringBootApplication
|
||||
public class JavaMongoApplication implements CommandLineRunner {
|
||||
@Autowired
|
||||
private BikeRepository bikeRepo;
|
||||
private CustomerRepository custRepo;
|
||||
|
||||
public static void main(String[] args) {
|
||||
SpringApplication.run(JavaMongoApplication.class, args);
|
||||
}
|
||||
@Override
|
||||
public void run(String... args) throws Exception {
|
||||
Scanner scan = new Scanner(System.in);
|
||||
String response = "";
|
||||
boolean running = true;
|
||||
while(running){
|
||||
System.out.println("What would you like to create? \n C: The Customer \n B: Bike? \n X:Close");
|
||||
response = scan.nextLine();
|
||||
if ("B".equals(response.toUpperCase())) {
|
||||
String[] bikeInformation = new String[3];
|
||||
System.out.println("Enter the information for the Bike");
|
||||
System.out.println("Model Number");
|
||||
bikeInformation[0] = scan.nextLine();
|
||||
System.out.println("Color");
|
||||
bikeInformation[1] = scan.nextLine();
|
||||
System.out.println("Description");
|
||||
bikeInformation[2] = scan.nextLine();
|
||||
|
||||
Bike bike = new Bike();
|
||||
bike.setModelNumber(bikeInformation[0]);
|
||||
bike.setColor(bikeInformation[1]);
|
||||
bike.setDescription(bikeInformation[2]);
|
||||
|
||||
bike = bikeRepo.save(bike);
|
||||
System.out.println(bike.toString());
|
||||
|
||||
|
||||
} else if ("X".equals(response.toUpperCase())) {
|
||||
System.out.println("Bye");
|
||||
running = false;
|
||||
} else {
|
||||
System.out.println("Sorry nothing else works right now!");
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
其中的 `@Autowired` 注解会自动依赖注入 `BikeRepository` 和 `CustomerRepository` Bean。我们将使用这些类来从数据库持久化和采集数据。
|
||||
|
||||
已经好了。你已经创建了一个命令行应用程序。该应用程序连接到数据库,并且能够以最少的代码执行 CRUD 操作
|
||||
|
||||
### 结论
|
||||
|
||||
从诸如对象和类之类的编程语言概念转换为用于在数据库中存储、检索或更改数据的调用对于构建应用程序至关重要。Java 持久化 API(JPA)正是为 Java 开发人员解决这一难题的重要工具。你正在使用 Java 操纵哪些数据库呢?请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/using-java-persistence-api
|
||||
|
||||
作者:[Stephon Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stephb
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-beans.jpg?itok=3hkjX5We (Coffee beans)
|
||||
[2]: https://www.techrepublic.com/article/mongodb-ceo-tells-hard-truths-about-commercial-open-source/
|
||||
[3]: https://github.com/StephonBrown/SpringMongoJava
|
||||
[4]: https://openjdk.java.net/projects/jdk/11/
|
||||
[5]: https://start.spring.io/
|
||||
[6]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[7]: https://hub.docker.com/_/mongo
|
||||
[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+exception
|
||||
[9]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||
140
published/201912/20191017 How to type emoji on Linux.md
Normal file
140
published/201912/20191017 How to type emoji on Linux.md
Normal file
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11702-1.html)
|
||||
[#]: subject: (How to type emoji on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/10/how-type-emoji-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在 Linux 系统中输入 emoji
|
||||
======
|
||||
|
||||
> 使用 GNOME 桌面可以让你在文字中轻松加入 emoji。
|
||||
|
||||

|
||||
|
||||
emoji 是潜藏在 Unicode 字符空间里的有趣表情图,它们已经风靡于整个互联网。emoji 可以用来在社交媒体上表示自己的心情状态,也可以作为重要文件名的视觉标签,总之它们的各种用法层出不穷。在 Linux 系统中有很多种方式可以输入 Unicode 字符,但 GNOME 桌面能让你更轻松地查找和输入 emoji。
|
||||
|
||||
![Emoji in Emacs][2]
|
||||
|
||||
### 准备工作
|
||||
|
||||
首先,你需要一个运行 [GNOME][3] 桌面的 Linux 系统。
|
||||
|
||||
同时还需要安装一款支持 emoji 的字体。符合这个要求的字体有很多,使用你喜欢的软件包管理器直接搜索 `emoji` 并选择一款安装就可以了。
|
||||
|
||||
例如在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf search emoji
|
||||
emoji-picker.noarch : An emoji selection tool
|
||||
unicode-emoji.noarch : Unicode Emoji Data Files
|
||||
eosrei-emojione-fonts.noarch : A color emoji font
|
||||
twitter-twemoji-fonts.noarch : Twitter Emoji for everyone
|
||||
google-android-emoji-fonts.noarch : Android Emoji font released by Google
|
||||
google-noto-emoji-fonts.noarch : Google “Noto Emoji” Black-and-White emoji font
|
||||
google-noto-emoji-color-fonts.noarch : Google “Noto Color Emoji” colored emoji font
|
||||
[...]
|
||||
```
|
||||
|
||||
对于 Ubuntu 或者 Debian,需要使用 `apt search`。
|
||||
|
||||
在这篇文章中,我会使用 [Google Noto Color Emoji][4] 这款字体为例。
|
||||
|
||||
### 设置
|
||||
|
||||
要开始设置,首先打开 GNOME 的设置面板。
|
||||
|
||||
1、在左边侧栏中,选择“<ruby>地区与语言<rt>Region & Language</rt></ruby>”类别。
|
||||
|
||||
2、点击“<ruby>输入源<rt>Input Sources</rt></ruby>”选项下方的加号(+)打开“<ruby>添加输入源<rt>Add an Input Source</rt></ruby>”面板。
|
||||
|
||||
![Add a new input source][5]
|
||||
|
||||
3、在“<ruby>添加输入源<rt>Add an Input Source</rt></ruby>”面板中,点击底部的菜单按钮。
|
||||
|
||||
![Add an Input Source panel][6]
|
||||
|
||||
4、滑动到列表底部并选择“<ruby>其它<rt>Other</rt></ruby>”。
|
||||
|
||||
5、在“<ruby>其它<rt>Other</rt></ruby>”列表中,找到“<ruby>其它<rt>Other</rt></ruby>(<ruby>快速输入<rt>Typing Booster</rt></ruby>)”。
|
||||
|
||||
![Find Other \(Typing Booster\) in inputs][7]
|
||||
|
||||
6、点击右上角的“<ruby>添加<rt>Add</rt></ruby>”按钮,将输入源添加到 GNOME 桌面。
|
||||
|
||||
以上操作完成之后,就可以关闭设置面板了。
|
||||
|
||||
#### 切换到快速输入
|
||||
|
||||
现在 GNOME 桌面的右上角会出现一个新的图标,一般情况下是当前语言的双字母缩写(例如英语是 en,世界语是 eo,西班牙语是 es,等等)。如果你按下了<ruby>超级键<rt>Super key</rt></ruby>(也就是键盘上带有 Linux 企鹅/Windows 徽标/Mac Command 标志的键)+ 空格键的组合键,就会切换到输入列表中的下一个输入源。在这里,我们只有两个输入源,也就是默认语言和快速输入。
|
||||
|
||||
你可以尝试使用一下这个组合键,观察图标的变化。
|
||||
|
||||
#### 配置快速输入
|
||||
|
||||
在快速输入模式下,点击右上角的输入源图标,选择“<ruby>Unicode 符号和 emoji 联想<rt>Unicode symbols and emoji predictions</rt></ruby>”选项,设置为“<ruby>开<rt>On</rt></ruby>”。
|
||||
|
||||
![Set Unicode symbols and emoji predictions to On][8]
|
||||
|
||||
现在快速输入模式已经可以输入 emoji 了。这正是我们现在所需要的,当然快速输入模式的功能也并不止于此。
|
||||
|
||||
### 输入 emoji
|
||||
|
||||
在快速输入模式下,打开一个文本编辑器,或者网页浏览器,又或者是任意一种支持输入 Unicode 字符的软件,输入“thumbs up”,快速输入模式就会帮你迅速匹配的 emoji 了。
|
||||
|
||||
![Typing Booster searching for emojis][9]
|
||||
|
||||
要退出 emoji 模式,只需要再次使用超级键+空格键的组合键,输入源就会切换回你的默认输入语言。
|
||||
|
||||
### 使用其它切换方式
|
||||
|
||||
如果你觉得“超级键+空格键”这个组合用起来不顺手,你也可以换成其它键的组合。在 GNOME 设置面板中选择“<ruby>设备<rt>Device</rt></ruby>”→“<ruby>键盘<rt>Keyboard</rt></ruby>”。
|
||||
|
||||
在“<ruby>键盘<rt>Keyboard</rt></ruby>”页面中,将“<ruby>切换到下一个输入源<rt>Switch to next input source</rt></ruby>”更改为你喜欢的组合键。
|
||||
|
||||
![Changing keystroke combination in GNOME settings][10]
|
||||
|
||||
### 输入 Unicode
|
||||
|
||||
实际上,现代键盘的设计只是为了输入 26 个字母以及尽可能多的数字和符号。但 ASCII 字符的数量已经比键盘上能看到的字符多得多了,遑论上百万个 Unicode 字符。因此,如果你想要在 Linux 应用程序中输入 Unicode,但又不想使用快速输入,你可以尝试一下 Unicode 输入。
|
||||
|
||||
1. 打开任意一种支持输入 Unicode 字符的软件,但仍然使用你的默认输入语言
|
||||
2. 使用 `Ctrl+Shift+U` 组合键进入 Unicode 输入模式
|
||||
3. 在 Unicode 输入模式下,只需要输入某个 Unicode 字符的对应序号,就实现了对这个 Unicode 字符的输入。例如 `1F44D` 对应的是 👍,而 `2620` 则对应了 ☠。想要查看所有 Unicode 字符的对应序号,可以参考 [Unicode 规范][11]。
|
||||
|
||||
### emoji 的实用性
|
||||
|
||||
emoji 可以让你的文本变得与众不同,这就是它们有趣和富有表现力的体现。同时 emoji 也有很强的实用性,因为它们本质上是 Unicode 字符,在很多支持自定义字体的地方都可以用到它们,而且跟使用其它常规字符没有什么太大的差别。因此,你可以使用 emoji 来对不同的文件做标记,在搜索的时候就可以使用 emoji 把这些文件快速筛选出来。
|
||||
|
||||
![Labeling a file with emoji][12]
|
||||
|
||||
你可以在 Linux 中尽情地使用 emoji,因为 Linux 是一个对 Unicode 友好的环境,未来也会对 Unicode 有着越来越好的支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/how-type-emoji-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc-lead_cat-keyboard.png?itok=fuNmiGV- "A cat under a keyboard."
|
||||
[2]: https://opensource.com/sites/default/files/uploads/emacs-emoji.jpg "Emoji in Emacs"
|
||||
[3]: https://www.gnome.org/
|
||||
[4]: https://www.google.com/get/noto/help/emoji/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/gnome-setting-region-add.png "Add a new input source"
|
||||
[6]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-list.png "Add an Input Source panel"
|
||||
[7]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-other-typing-booster.png "Find Other (Typing Booster) in inputs"
|
||||
[8]: https://opensource.com/sites/default/files/uploads/emoji-input-on.jpg "Set Unicode symbols and emoji predictions to On"
|
||||
[9]: https://opensource.com/sites/default/files/uploads/emoji-input.jpg "Typing Booster searching for emojis"
|
||||
[10]: https://opensource.com/sites/default/files/uploads/gnome-setting-keyboard-switch-input.jpg "Changing keystroke combination in GNOME settings"
|
||||
[11]: http://unicode.org/emoji/charts/full-emoji-list.html
|
||||
[12]: https://opensource.com/sites/default/files/uploads/file-label.png "Labeling a file with emoji"
|
||||
|
||||
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11669-1.html)
|
||||
[#]: subject: (14 SCP Command Examples to Securely Transfer Files in Linux)
|
||||
[#]: via: (https://www.linuxtechi.com/scp-command-examples-in-linux/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
在 Linux 上安全传输文件的 14 SCP 命令示例
|
||||
======
|
||||
|
||||

|
||||
|
||||
SCP(<ruby>安全复制<rt>Secure Copy</rt></ruby>)是 Linux 和 Unix 之类的系统中的命令行工具,用于通过网络安全地跨系统传输文件和目录。当我们使用 `scp` 命令将文件和目录从本地系统复制到远程系统时,则在后端与远程系统建立了 ssh 连接。换句话说,我们可以说 `scp` 在后端使用了相同的 SSH 安全机制,它需要密码或密钥进行身份验证。
|
||||
|
||||
![scp-command-examples-linux][2]
|
||||
|
||||
在本教程中,我们将讨论 14 个有用的 Linux `scp` 命令示例。
|
||||
|
||||
`scp` 命令语法:
|
||||
|
||||
```
|
||||
# scp <选项> <文件或目录> 用户名@目标主机:/<文件夹>
|
||||
|
||||
# scp <选项> 用户名@目标主机:/文件 <本地文件夹>
|
||||
```
|
||||
|
||||
`scp` 命令的第一个语法演示了如何将文件或目录从本地系统复制到特定文件夹下的目标主机。
|
||||
|
||||
`scp` 命令的第二种语法演示了如何将目标主机中的文件复制到本地系统中。
|
||||
|
||||
下面列出了 `scp` 命令中使用最广泛的一些选项,
|
||||
|
||||
* `-C` 启用压缩
|
||||
* `-i` 指定识别文件或私钥
|
||||
* `-l` 复制时限制带宽
|
||||
* `-P` 指定目标主机的 ssh 端口号
|
||||
* `-p` 复制时保留文件的权限、模式和访问时间
|
||||
* `-q` 禁止 SSH 警告消息
|
||||
* `-r` 递归复制文件和目录
|
||||
* `-v` 详细输出
|
||||
|
||||
现在让我们跳入示例!
|
||||
|
||||
### 示例:1)使用 scp 将文件从本地系统复制到远程系统
|
||||
|
||||
假设我们要使用 `scp` 命令将 jdk 的 rpm 软件包从本地 Linux 系统复制到远程系统(172.20.10.8),请使用以下命令,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp jdk-linux-x64_bin.rpm root@linuxtechi:/opt
|
||||
root@linuxtechi's password:
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 27.1MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
上面的命令会将 jdk 的 rpm 软件包文件复制到 `/opt` 文件夹下的远程系统。
|
||||
|
||||
### 示例:2)使用 scp 将文件从远程系统复制到本地系统
|
||||
|
||||
假设我们想将文件从远程系统复制到本地系统下的 `/tmp` 文件夹,执行以下 `scp` 命令,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp root@linuxtechi:/root/Technical-Doc-RHS.odt /tmp
|
||||
root@linuxtechi's password:
|
||||
Technical-Doc-RHS.odt 100% 1109KB 31.8MB/s 00:00
|
||||
[root@linuxtechi ~]$ ls -l /tmp/Technical-Doc-RHS.odt
|
||||
-rwx------. 1 pkumar pkumar 1135521 Oct 19 11:12 /tmp/Technical-Doc-RHS.odt
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:3)使用 scp 传输文件时的详细输出(-v)
|
||||
|
||||
在 `scp` 命令中,我们可以使用 `-v` 选项启用详细输出。使用详细输出,我们可以轻松地发现后台确切发生了什么。这对于调试连接、认证和配置等问题非常有用。
|
||||
|
||||
```
|
||||
root@linuxtechi ~]$ scp -v jdk-linux-x64_bin.rpm root@linuxtechi:/opt
|
||||
Executing: program /usr/bin/ssh host 172.20.10.8, user root, command scp -v -t /opt
|
||||
OpenSSH_7.8p1, OpenSSL 1.1.1 FIPS 11 Sep 2018
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config.d/05-redhat.conf
|
||||
debug1: Reading configuration data /etc/crypto-policies/back-ends/openssh.config
|
||||
debug1: /etc/ssh/ssh_config.d/05-redhat.conf line 8: Applying options for *
|
||||
debug1: Connecting to 172.20.10.8 [172.20.10.8] port 22.
|
||||
debug1: Connection established.
|
||||
…………
|
||||
debug1: Next authentication method: password
|
||||
root@linuxtechi's password:
|
||||
```
|
||||
|
||||
### 示例:4)将多个文件传输到远程系统
|
||||
|
||||
可以使用 `scp` 命令一次性将多个文件复制/传输到远程系统,在 `scp` 命令中指定多个文件,并用空格隔开,示例如下所示
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp install.txt index.html jdk-linux-x64_bin.rpm root@linuxtechi:/mnt
|
||||
root@linuxtechi's password:
|
||||
install.txt 100% 0 0.0KB/s 00:00
|
||||
index.html 100% 85KB 7.2MB/s 00:00
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 25.3MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:5)在两个远程主机之间传输文件
|
||||
|
||||
使用 `scp` 命令,我们可以在两个远程主机之间复制文件和目录,假设我们有一个可以连接到两个远程 Linux 系统的本地 Linux 系统,因此从我的本地 Linux 系统中,我可以使用 `scp` 命令在这两个系统之间复制文件,
|
||||
|
||||
命令语法:
|
||||
|
||||
```
|
||||
# scp 用户名@远程主机1:/<要传输的文件> 用户名@远程主机2:/<文件夹>
|
||||
```
|
||||
|
||||
示例如下:
|
||||
|
||||
```
|
||||
# scp root@linuxtechi:~/backup-Oct.zip root@linuxtechi:/tmp
|
||||
# ssh root@linuxtechi "ls -l /tmp/backup-Oct.zip"
|
||||
-rwx------. 1 root root 747438080 Oct 19 12:02 /tmp/backup-Oct.zip
|
||||
```
|
||||
|
||||
### 示例:6)递归复制文件和目录(-r)
|
||||
|
||||
在 `scp` 命令中使用 `-r` 选项将整个目录从一个系统递归地复制到另一个系统,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -r Downloads root@linuxtechi:/opt
|
||||
```
|
||||
|
||||
使用以下命令验证 `Downloads` 文件夹是否已复制到远程系统,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ ssh root@linuxtechi "ls -ld /opt/Downloads"
|
||||
drwxr-xr-x. 2 root root 75 Oct 19 12:10 /opt/Downloads
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:7)通过启用压缩来提高传输速度(-C)
|
||||
|
||||
在 `scp` 命令中,我们可以通过使用 `-C` 选项启用压缩来提高传输速度,它将自动在源主机上启用压缩并在目标主机上解压缩。
|
||||
|
||||
```
|
||||
root@linuxtechi ~]$ scp -r -C Downloads root@linuxtechi:/mnt
|
||||
```
|
||||
|
||||
在以上示例中,我们正在启用压缩的情况下传输下载目录。
|
||||
|
||||
### 示例:8)复制时限制带宽(-l)
|
||||
|
||||
在 `scp` 命令中使用 `-l` 选项设置复制时对带宽使用的限制。带宽以 Kbit/s 为单位指定,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -l 500 jdk-linux-x64_bin.rpm root@linuxtechi:/var
|
||||
```
|
||||
|
||||
### 示例:9)在 scp 时指定其他 ssh 端口(-P)
|
||||
|
||||
在某些情况下,目标主机上的 ssh 端口会更改,因此在使用 `scp` 命令时,我们可以使用 `-P` 选项指定 ssh 端口号。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -P 2022 jdk-linux-x64_bin.rpm root@linuxtechi:/var
|
||||
```
|
||||
|
||||
在上面的示例中,远程主机的 ssh 端口为 “2022”。
|
||||
|
||||
### 示例:10)复制时保留文件的权限、模式和访问时间(-p)
|
||||
|
||||
从源复制到目标时,在 `scp` 命令中使用 `-p` 选项保留权限、访问时间和模式。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -p jdk-linux-x64_bin.rpm root@linuxtechi:/var/tmp
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 13.5MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:11)在 scp 中以安静模式传输文件(-q)
|
||||
|
||||
在 `scp` 命令中使用 `-q` 选项可禁止显示 ssh 的传输进度、警告和诊断消息。示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -q -r Downloads root@linuxtechi:/var/tmp
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:12)在传输时使用 scp 中的识别文件(-i)
|
||||
|
||||
在大多数 Linux 环境中,首选基于密钥的身份验证。在 `scp` 命令中,我们使用 `-i` 选项指定识别文件(私钥文件),示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -i my_key.pem -r Downloads root@linuxtechi:/root
|
||||
```
|
||||
|
||||
在上面的示例中,`my_key.pem` 是识别文件或私钥文件。
|
||||
|
||||
### 示例:13)在 scp 中使用其他 ssh_config 文件(-F)
|
||||
|
||||
在某些情况下,你使用不同的网络连接到 Linux 系统,可能某些网络位于代理服务器后面,因此在这种情况下,我们必须具有不同的 `ssh_config` 文件。
|
||||
|
||||
通过 `-F` 选项在 `scp` 命令中指定了不同的 `ssh_config` 文件,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -F /home/pkumar/new_ssh_config -r Downloads root@linuxtechi:/root
|
||||
root@linuxtechi's password:
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 16.6MB/s 00:00
|
||||
backup-Oct.zip 100% 713MB 41.9MB/s 00:17
|
||||
index.html 100% 85KB 6.6MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:14)在 scp 命令中使用其他加密方式(-c)
|
||||
|
||||
默认情况下,`scp` 使用 AES-128 加密方式来加密文件。如果你想在 `scp` 命令中使用其他加密方式,请使用 `-c` 选项,后接加密方式名称。
|
||||
|
||||
假设我们要在用 `scp` 命令传输文件时使用 3des-cbc 加密方式,请运行以下 `scp` 命令:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# scp -c 3des-cbc -r Downloads root@linuxtechi:/root
|
||||
```
|
||||
|
||||
使用以下命令列出 `ssh` 和 `scp` 支持的加密方式:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ssh -Q cipher localhost | paste -d , -s -
|
||||
3des-cbc,aes128-cbc,aes192-cbc,aes256-cbc,root@linuxtechi,aes128-ctr,aes192-ctr,aes256-ctr,root@linuxtechi,root@linuxtechi,root@linuxtechi
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
以上就是本教程的全部内容,要获取有关 `scp` 命令的更多详细信息,请参考其手册页。请在下面的评论部分中分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/scp-command-examples-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/10/scp-command-examples-linux.jpg
|
||||
[3]: https://www.linuxtechi.com/cdn-cgi/l/email-protection
|
||||
@ -0,0 +1,467 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11687-1.html)
|
||||
[#]: subject: (How to program with Bash: Logical operators and shell expansions)
|
||||
[#]: via: (https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
怎样用 Bash 编程:逻辑操作符和 shell 扩展
|
||||
======
|
||||
|
||||
> 学习逻辑操作符和 shell 扩展,本文是三篇 Bash 编程系列的第二篇。
|
||||
|
||||

|
||||
|
||||
Bash 是一种强大的编程语言,完美契合命令行和 shell 脚本。本系列(三篇文章,基于我的 [三集 Linux 自学课程][2])讲解如何在 CLI 使用 Bash 编程。
|
||||
|
||||
[第一篇文章][3] 讲解了 Bash 的一些简单命令行操作,包括如何使用变量和控制操作符。第二篇文章探讨文件、字符串、数字等类型和各种各样在执行流中提供控制逻辑的的逻辑运算符,还有 Bash 中的各类 shell 扩展。本系列第三篇也是最后一篇文章,将会探索能重复执行操作的 `for` 、`while` 和 `until` 循环。
|
||||
|
||||
逻辑操作符是程序中进行判断的根本要素,也是执行不同的语句组合的依据。有时这也被称为流控制。
|
||||
|
||||
### 逻辑操作符
|
||||
|
||||
Bash 中有大量的用于不同条件表达式的逻辑操作符。最基本的是 `if` 控制结构,它判断一个条件,如果条件为真,就执行一些程序语句。操作符共有三类:文件、数字和非数字操作符。如果条件为真,所有的操作符返回真值(`0`),如果条件为假,返回假值(`1`)。
|
||||
|
||||
这些比较操作符的函数语法是,一个操作符加一个或两个参数放在中括号内,后面跟一系列程序语句,如果条件为真,程序语句执行,可能会有另一个程序语句列表,该列表在条件为假时执行:
|
||||
|
||||
|
||||
```
|
||||
if [ arg1 operator arg2 ] ; then list
|
||||
或
|
||||
if [ arg1 operator arg2 ] ; then list ; else list ; fi
|
||||
```
|
||||
|
||||
像例子中那样,在比较表达式中,空格不能省略。中括号的每部分,`[` 和 `]`,是跟 `test` 命令一样的传统的 Bash 符号:
|
||||
|
||||
```
|
||||
if test arg1 operator arg2 ; then list
|
||||
```
|
||||
|
||||
还有一个更新的语法能提供一点点便利,一些系统管理员比较喜欢用。这种格式对于不同版本的 Bash 和一些 shell 如 ksh(Korn shell)兼容性稍差。格式如下:
|
||||
|
||||
```
|
||||
if [[ arg1 operator arg2 ]] ; then list
|
||||
```
|
||||
|
||||
#### 文件操作符
|
||||
|
||||
文件操作符是 Bash 中一系列强大的逻辑操作符。图表 1 列出了 20 多种不同的 Bash 处理文件的操作符。在我的脚本中使用频率很高。
|
||||
|
||||
操作符 | 描述
|
||||
---|---
|
||||
`-a filename` | 如果文件存在,返回真值;文件可以为空也可以有内容,但是只要它存在,就返回真值
|
||||
`-b filename` | 如果文件存在且是一个块设备,如 `/dev/sda` 或 `/dev/sda1`,则返回真值
|
||||
`-c filename` | 如果文件存在且是一个字符设备,如 `/dev/TTY1`,则返回真值
|
||||
`-d filename` | 如果文件存在且是一个目录,返回真值
|
||||
`-e filename` | 如果文件存在,返回真值;与上面的 `-a` 相同
|
||||
`-f filename` | 如果文件存在且是一个一般文件,不是目录、设备文件或链接等的其他的文件,则返回 真值
|
||||
`-g filename` | 如果文件存在且 `SETGID` 标记被设置在其上,返回真值
|
||||
`-h filename` | 如果文件存在且是一个符号链接,则返回真值
|
||||
`-k filename` | 如果文件存在且粘滞位已设置,则返回真值
|
||||
`-p filename` | 如果文件存在且是一个命名的管道(FIFO),返回真值
|
||||
`-r filename` | 如果文件存在且有可读权限(它的可读位被设置),返回真值
|
||||
`-s filename` | 如果文件存在且大小大于 0,返回真值;如果一个文件存在但大小为 0,则返回假值
|
||||
`-t fd` | 如果文件描述符 `fd` 被打开且被关联到一个终端设备上,返回真值
|
||||
`-u filename` | 如果文件存在且它的 `SETUID` 位被设置,返回真值
|
||||
`-w filename` | 如果文件存在且有可写权限,返回真值
|
||||
`-x filename` | 如果文件存在且有可执行权限,返回真值
|
||||
`-G filename` | 如果文件存在且文件的组 ID 与当前用户相同,返回真值
|
||||
`-L filename` | 如果文件存在且是一个符号链接,返回真值(同 `-h`)
|
||||
`-N filename` | 如果文件存在且从文件上一次被读取后文件被修改过,返回真值
|
||||
`-O filename` | 如果文件存在且你是文件的拥有者,返回真值
|
||||
`-S filename` | 如果文件存在且文件是套接字,返回真值
|
||||
`file1 -ef file2` | 如果文件 `file1` 和文件 `file2` 指向同一设备的同一 INODE 号,返回真值(即硬链接)
|
||||
`file1 -nt file2` | 如果文件 `file1` 比 `file2` 新(根据修改日期),或 `file1` 存在而 `file2` 不存在,返回真值
|
||||
`file1 -ot file2` | 如果文件 `file1` 比 `file2` 旧(根据修改日期),或 `file1` 不存在而 `file2` 存在
|
||||
|
||||
*图表 1:Bash 文件操作符*
|
||||
|
||||
以测试一个文件存在与否来举例:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; if [ -e $File ] ; then echo "The file $File exists." ; else echo "The file $File does not exist." ; fi
|
||||
The file TestFile1 does not exist.
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
创建一个用来测试的文件,命名为 `TestFile1`。目前它不需要包含任何数据:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ touch TestFile1
|
||||
```
|
||||
|
||||
在这个简短的 CLI 程序中,修改 `$File` 变量的值相比于在多个地方修改表示文件名的字符串的值要容易:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; if [ -e $File ] ; then echo "The file $File exists." ; else echo "The file $File does not exist." ; fi
|
||||
The file TestFile1 exists.
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
现在,运行一个测试来判断一个文件是否存在且长度不为 0(表示它包含数据)。假设你想判断三种情况:
|
||||
|
||||
1. 文件不存在;
|
||||
2. 文件存在且为空;
|
||||
3. 文件存在且包含数据。
|
||||
|
||||
因此,你需要一组更复杂的测试代码 — 为了测试所有的情况,使用 `if-elif-else` 结构中的 `elif` 语句:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; if [ -s $File ] ; then echo "$File exists and contains data." ; fi
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
在这个情况中,文件存在但不包含任何数据。向文件添加一些数据再运行一次:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is file $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; fi
|
||||
TestFile1 exists and contains data.
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
这组语句能返回正常的结果,但是仅仅是在我们已知三种可能的情况下测试某种确切的条件。添加一段 `else` 语句,这样你就可以更精确地测试。把文件删掉,你就可以完整地测试这段新代码:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; rm $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
|
||||
TestFile1 does not exist or is empty.
|
||||
```
|
||||
|
||||
现在创建一个空文件用来测试:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; touch $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
|
||||
TestFile1 does not exist or is empty.
|
||||
```
|
||||
|
||||
向文件添加一些内容,然后再测试一次:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is file $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
|
||||
TestFile1 exists and contains data.
|
||||
```
|
||||
|
||||
现在加入 `elif` 语句来辨别是文件不存在还是文件为空:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; touch $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; elif [ -e $File ] ; then echo "$File exists and is empty." ; else echo "$File does not exist." ; fi
|
||||
TestFile1 exists and is empty.
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; elif [ -e $File ] ; then echo "$File exists and is empty." ; else echo "$File does not exist." ; fi
|
||||
TestFile1 exists and contains data.
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
现在你有一个可以测试这三种情况的 Bash CLI 程序,但是可能的情况是无限的。
|
||||
|
||||
如果你能像保存在文件中的脚本那样组织程序语句,那么即使对于更复杂的命令组合也会很容易看出它们的逻辑结构。图表 2 就是一个示例。 `if-elif-else` 结构中每一部分的程序语句的缩进让逻辑更变得清晰。
|
||||
|
||||
|
||||
```
|
||||
File="TestFile1"
|
||||
echo "This is $File" > $File
|
||||
if [ -s $File ]
|
||||
then
|
||||
echo "$File exists and contains data."
|
||||
elif [ -e $File ]
|
||||
then
|
||||
echo "$File exists and is empty."
|
||||
else
|
||||
echo "$File does not exist."
|
||||
fi
|
||||
```
|
||||
|
||||
*图表 2: 像在脚本里一样重写书写命令行程序*
|
||||
|
||||
对于大多数 CLI 程序来说,让这些复杂的命令变得有逻辑需要写很长的代码。虽然 CLI 可能是用 Linux 或 Bash 内置的命令,但是当 CLI 程序很长或很复杂时,创建一个保存在文件中的脚本将更有效,保存到文件中后,可以随时运行。
|
||||
|
||||
#### 字符串比较操作符
|
||||
|
||||
字符串比较操作符使我们可以对字符串中的字符按字母顺序进行比较。图表 3 列出了仅有的几个字符串比较操作符。
|
||||
|
||||
操作符 | 描述
|
||||
---|---
|
||||
`-z string` | 如果字符串的长度为 0 ,返回真值
|
||||
`-n string` |如果字符串的长度不为 0 ,返回真值
|
||||
`string1 == string2` 或 `string1 = string2` | 如果两个字符串相等,返回真值。处于遵从 POSIX 一致性,在测试命令中应使用一个等号 `=`。与命令 `[[` 一起使用时,会进行如上描述的模式匹配(混合命令)。
|
||||
`string1 != string2` | 两个字符串不相等,返回真值
|
||||
`string1 < string2` | 如果对 `string1` 和 `string2` 按字母顺序进行排序,`string1` 排在 `string2` 前面(即基于地区设定的对所有字母和特殊字符的排列顺序)
|
||||
`string1 > string2` | 如果对 `string1` 和 `string2` 按字母顺序进行排序,`string1` 排在 `string2` 后面
|
||||
|
||||
*图表 3: Bash 字符串逻辑操作符*
|
||||
|
||||
首先,检查字符串长度。比较表达式中 `$MyVar` 两边的双引号不能省略(你仍应该在目录 `~/testdir` 下 )。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ MyVar="" ; if [ -z "" ] ; then echo "MyVar is zero length." ; else echo "MyVar contains data" ; fi
|
||||
MyVar is zero length.
|
||||
[student@studentvm1 testdir]$ MyVar="Random text" ; if [ -z "" ] ; then echo "MyVar is zero length." ; else echo "MyVar contains data" ; fi
|
||||
MyVar is zero length.
|
||||
```
|
||||
|
||||
你也可以这样做:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ MyVar="Random text" ; if [ -n "$MyVar" ] ; then echo "MyVar contains data." ; else echo "MyVar is zero length" ; fi
|
||||
MyVar contains data.
|
||||
[student@studentvm1 testdir]$ MyVar="" ; if [ -n "$MyVar" ] ; then echo "MyVar contains data." ; else echo "MyVar is zero length" ; fi
|
||||
MyVar is zero length
|
||||
```
|
||||
|
||||
有时候你需要知道一个字符串确切的长度。这虽然不是比较,但是也与比较相关。不幸的是,计算字符串的长度没有简单的方法。有很多种方法可以计算,但是我认为使用 `expr`(求值表达式)命令是相对最简单的一种。阅读 `expr` 的手册页可以了解更多相关知识。注意表达式中你检测的字符串或变量两边的引号不要省略。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ MyVar="" ; expr length "$MyVar"
|
||||
0
|
||||
[student@studentvm1 testdir]$ MyVar="How long is this?" ; expr length "$MyVar"
|
||||
17
|
||||
[student@studentvm1 testdir]$ expr length "We can also find the length of a literal string as well as a variable."
|
||||
70
|
||||
```
|
||||
|
||||
关于比较操作符,在我们的脚本中使用了大量的检测两个字符串是否相等(例如,两个字符串是否实际上是同一个字符串)的操作。我使用的是非 POSIX 版本的比较表达式:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ Var1="Hello World" ; Var2="Hello World" ; if [ "$Var1" == "$Var2" ] ; then echo "Var1 matches Var2" ; else echo "Var1 and Var2 do not match." ; fi
|
||||
Var1 matches Var2
|
||||
[student@studentvm1 testdir]$ Var1="Hello World" ; Var2="Hello world" ; if [ "$Var1" == "$Var2" ] ; then echo "Var1 matches Var2" ; else echo "Var1 and Var2 do not match." ; fi
|
||||
Var1 and Var2 do not match.
|
||||
```
|
||||
|
||||
在你自己的脚本中去试一下这些操作符。
|
||||
|
||||
#### 数字比较操作符
|
||||
|
||||
数字操作符用于两个数字参数之间的比较。像其他类操作符一样,大部分都很容易理解。
|
||||
|
||||
操作符 | 描述
|
||||
---|---
|
||||
`arg1 -eq arg2` | 如果 `arg1` 等于 `arg2`,返回真值
|
||||
`arg1 -ne arg2` | 如果 `arg1` 不等于 `arg2`,返回真值
|
||||
`arg1 -lt arg2` | 如果 `arg1` 小于 `arg2`,返回真值
|
||||
`arg1 -le arg2` | 如果 `arg1` 小于或等于 `arg2`,返回真值
|
||||
`arg1 -gt arg2` | 如果 `arg1` 大于 `arg2`,返回真值
|
||||
`arg1 -ge arg2` | 如果 `arg1` 大于或等于 `arg2`,返回真值
|
||||
|
||||
*图表 4: Bash 数字比较逻辑操作符*
|
||||
|
||||
来看几个简单的例子。第一个示例设置变量 `$X` 的值为 1,然后检测 `$X` 是否等于 1。第二个示例中,`$X` 被设置为 0,所以比较表达式返回结果不为真值。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ X=1 ; if [ $X -eq 1 ] ; then echo "X equals 1" ; else echo "X does not equal 1" ; fi
|
||||
X equals 1
|
||||
[student@studentvm1 testdir]$ X=0 ; if [ $X -eq 1 ] ; then echo "X equals 1" ; else echo "X does not equal 1" ; fi
|
||||
X does not equal 1
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
自己来多尝试一下其他的。
|
||||
|
||||
#### 杂项操作符
|
||||
|
||||
这些杂项操作符展示一个 shell 选项是否被设置,或一个 shell 变量是否有值,但是它不显示变量的值,只显示它是否有值。
|
||||
|
||||
操作符 | 描述
|
||||
---|---
|
||||
`-o optname` | 如果一个 shell 选项 `optname` 是启用的(查看内建在 Bash 手册页中的 set `-o` 选项描述下面的选项列表),则返回真值
|
||||
`-v varname` | 如果 shell 变量 `varname` 被设置了值(被赋予了值),则返回真值
|
||||
`-R varname` | 如果一个 shell 变量 `varname` 被设置了值且是一个名字引用,则返回真值
|
||||
|
||||
*图表 5: 杂项 Bash 逻辑操作符*
|
||||
|
||||
自己来使用这些操作符实践下。
|
||||
|
||||
### 扩展
|
||||
|
||||
Bash 支持非常有用的几种类型的扩展和命令替换。根据 Bash 手册页,Bash 有七种扩展格式。本文只介绍其中五种:`~` 扩展、算术扩展、路径名称扩展、大括号扩展和命令替换。
|
||||
|
||||
#### 大括号扩展
|
||||
|
||||
大括号扩展是生成任意字符串的一种方法。(下面的例子是用特定模式的字符创建大量的文件。)大括号扩展可以用于产生任意字符串的列表,并把它们插入一个用静态字符串包围的特定位置或静态字符串的两端。这可能不太好想象,所以还是来实践一下。
|
||||
|
||||
首先,看一下大括号扩展的作用:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo {string1,string2,string3}
|
||||
string1 string2 string3
|
||||
```
|
||||
|
||||
看起来不是很有用,对吧?但是用其他方式使用它,再来看看:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo "Hello "{David,Jen,Rikki,Jason}.
|
||||
Hello David. Hello Jen. Hello Rikki. Hello Jason.
|
||||
```
|
||||
|
||||
这看起来貌似有点用了 — 我们可以少打很多字。现在试一下这个:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo b{ed,olt,ar}s
|
||||
beds bolts bars
|
||||
```
|
||||
|
||||
我可以继续举例,但是你应该已经理解了它的用处。
|
||||
|
||||
#### ~ 扩展
|
||||
|
||||
资料显示,使用最多的扩展是波浪字符(`~`)扩展。当你在命令中使用它(如 `cd ~/Documents`)时,Bash shell 把这个快捷方式展开成用户的完整的家目录。
|
||||
|
||||
使用这个 Bash 程序观察 `~` 扩展的作用:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo ~
|
||||
/home/student
|
||||
[student@studentvm1 testdir]$ echo ~/Documents
|
||||
/home/student/Documents
|
||||
[student@studentvm1 testdir]$ Var1=~/Documents ; echo $Var1 ; cd $Var1
|
||||
/home/student/Documents
|
||||
[student@studentvm1 Documents]$
|
||||
```
|
||||
|
||||
#### 路径名称扩展
|
||||
|
||||
路径名称扩展是展开文件通配模式为匹配该模式的完整路径名称的另一种说法,匹配字符使用 `?` 和 `*`。文件通配指的是在大量操作中匹配文件名、路径和其他字符串时用特定的模式字符产生极大的灵活性。这些特定的模式字符允许匹配字符串中的一个、多个或特定字符。
|
||||
|
||||
* `?` — 匹配字符串中特定位置的一个任意字符
|
||||
* `*` — 匹配字符串中特定位置的 0 个或多个任意字符
|
||||
|
||||
这个扩展用于匹配路径名称。为了弄清它的用法,请确保 `testdir` 是当前工作目录(`PWD`),先执行基本的列出清单命令 `ls`(我家目录下的内容跟你的不一样)。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ ls
|
||||
chapter6 cpuHog.dos dmesg1.txt Documents Music softlink1 testdir6 Videos
|
||||
chapter7 cpuHog.Linux dmesg2.txt Downloads Pictures Templates testdir
|
||||
testdir cpuHog.mac dmesg3.txt file005 Public testdir tmp
|
||||
cpuHog Desktop dmesg.txt link3 random.txt testdir1 umask.test
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
现在列出以 `Do`、`testdir/Documents` 和 `testdir/Downloads` 开头的目录:
|
||||
|
||||
```
|
||||
Documents:
|
||||
Directory01 file07 file15 test02 test10 test20 testfile13 TextFiles
|
||||
Directory02 file08 file16 test03 test11 testfile01 testfile14
|
||||
file01 file09 file17 test04 test12 testfile04 testfile15
|
||||
file02 file10 file18 test05 test13 testfile05 testfile16
|
||||
file03 file11 file19 test06 test14 testfile09 testfile17
|
||||
file04 file12 file20 test07 test15 testfile10 testfile18
|
||||
file05 file13 Student1.txt test08 test16 testfile11 testfile19
|
||||
file06 file14 test01 test09 test18 testfile12 testfile20
|
||||
|
||||
Downloads:
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
然而,并没有得到你期望的结果。它列出了以 `Do` 开头的目录下的内容。使用 `-d` 选项,仅列出目录而不列出它们的内容。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ ls -d Do*
|
||||
Documents Downloads
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
在两个例子中,Bash shell 都把 `Do*` 模式展开成了匹配该模式的目录名称。但是如果有文件也匹配这个模式,会发生什么?
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ touch Downtown ; ls -d Do*
|
||||
Documents Downloads Downtown
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
因此所有匹配这个模式的文件也被展开成了完整名字。
|
||||
|
||||
#### 命令替换
|
||||
|
||||
命令替换是让一个命令的标准输出数据流被当做参数传给另一个命令的扩展形式,例如,在一个循环中作为一系列被处理的项目。Bash 手册页显示:“命令替换可以让你用一个命令的输出替换为命令的名字。”这可能不太好理解。
|
||||
|
||||
命令替换有两种格式:\`command\` 和 `$(command)`。在更早的格式中使用反引号(\`),在命令中使用反斜杠(`\`)来保持它转义之前的文本含义。然而,当用在新版本的括号格式中时,反斜杠被当做一个特殊字符处理。也请注意带括号的格式打开个关闭命令语句都是用一个括号。
|
||||
|
||||
我经常在命令行程序和脚本中使用这种能力,一个命令的结果能被用作另一个命令的参数。
|
||||
|
||||
来看一个非常简单的示例,这个示例使用了这个扩展的两种格式(再一次提醒,确保 `testdir` 是当前工作目录):
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo "Todays date is `date`"
|
||||
Todays date is Sun Apr 7 14:42:46 EDT 2019
|
||||
[student@studentvm1 testdir]$ echo "Todays date is $(date)"
|
||||
Todays date is Sun Apr 7 14:42:59 EDT 2019
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
`-seq` 工具用于一个数字序列:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ seq 5
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
[student@studentvm1 testdir]$ echo `seq 5`
|
||||
1 2 3 4 5
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
现在你可以做一些更有用处的操作,比如创建大量用于测试的空文件。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for I in $(seq -w 5000) ; do touch file-$I ; done
|
||||
```
|
||||
|
||||
`seq` 工具加上 `-w` 选项后,在生成的数字前面会用 0 补全,这样所有的结果都等宽,例如,忽略数字的值,它们的位数一样。这样在对它们按数字顺序进行排列时很容易。
|
||||
|
||||
`seq -w 5000` 语句生成了 1 到 5000 的数字序列。通过把命令替换用于 `for` 语句,`for` 语句就可以使用该数字序列来生成文件名的数字部分。
|
||||
|
||||
#### 算术扩展
|
||||
|
||||
Bash 可以进行整型的数学计算,但是比较繁琐(你一会儿将看到)。数字扩展的语法是 `$((arithmetic-expression))` ,分别用两个括号来打开和关闭表达式。算术扩展在 shell 程序或脚本中类似命令替换;表达式结算后的结果替换了表达式,用于 shell 后续的计算。
|
||||
|
||||
我们再用一个简单的用法来开始:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo $((1+1))
|
||||
2
|
||||
[student@studentvm1 testdir]$ Var1=5 ; Var2=7 ; Var3=$((Var1*Var2)) ; echo "Var 3 = $Var3"
|
||||
Var 3 = 35
|
||||
```
|
||||
|
||||
下面的除法结果是 0,因为表达式的结果是一个小于 1 的整型数字:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ Var1=5 ; Var2=7 ; Var3=$((Var1/Var2)) ; echo "Var 3 = $Var3"
|
||||
Var 3 = 0
|
||||
```
|
||||
|
||||
这是一个我经常在脚本或 CLI 程序中使用的一个简单的计算,用来查看在 Linux 主机中使用了多少虚拟内存。 `free` 不提供我需要的数据:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ RAM=`free | grep ^Mem | awk '{print $2}'` ; Swap=`free | grep ^Swap | awk '{print $2}'` ; echo "RAM = $RAM and Swap = $Swap" ; echo "Total Virtual memory is $((RAM+Swap))" ;
|
||||
RAM = 4037080 and Swap = 6291452
|
||||
Total Virtual memory is 10328532
|
||||
```
|
||||
|
||||
我使用 \` 字符来划定用作命令替换的界限。
|
||||
|
||||
我用 Bash 算术扩展的场景主要是用脚本检查系统资源用量后基于返回的结果选择一个程序运行的路径。
|
||||
|
||||
### 总结
|
||||
|
||||
本文是 Bash 编程语言系列的第二篇,探讨了 Bash 中文件、字符串、数字和各种提供流程控制逻辑的逻辑操作符还有不同种类的 shell 扩展。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_women_computing_5.png?itok=YHpNs_ss (Women in computing and open source v5)
|
||||
[2]: http://www.both.org/?page_id=1183
|
||||
[3]: https://linux.cn/article-11552-1.html
|
||||
336
published/201912/20191023 How to program with Bash- Loops.md
Normal file
336
published/201912/20191023 How to program with Bash- Loops.md
Normal file
@ -0,0 +1,336 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11714-1.html)
|
||||
[#]: subject: (How to program with Bash: Loops)
|
||||
[#]: via: (https://opensource.com/article/19/10/programming-bash-loops)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
怎样用 Bash 编程:循环
|
||||
======
|
||||
|
||||
> 本文是 Bash 编程系列三篇中的最后一篇,来学习使用循环执行迭代的操作。
|
||||
|
||||

|
||||
|
||||
Bash 是一种强大的用于命令行和 shell 脚本的编程语言。本系列的三部分都是基于我的三集 [Linux 自学课程][2] 写的,探索怎么用 CLI 进行 bash 编程。
|
||||
|
||||
本系列的 [第一篇文章][3] 讨论了 bash 编程的一些简单命令行操作,如使用变量和控制操作符。[第二篇文章][4] 探讨了文件、字符串、数字等类型和各种各样在执行流中提供控制逻辑的的逻辑运算符,还有 bash 中不同种类的扩展。本文是第三篇(也是最后一篇),意在考察在各种迭代的操作中使用循环以及怎么合理控制循环。
|
||||
|
||||
### 循环
|
||||
|
||||
我使用过的所有编程语言都至少有两种循环结构来用来执行重复的操作。我经常使用 `for` 循环,然而我发现 `while` 和 `until` 循环也很有用处。
|
||||
|
||||
#### for 循环
|
||||
|
||||
我的理解是,在 bash 中实现的 `for` 命令比大部分语言灵活,因为它可以处理非数字的值;与之形成对比的是,诸如标准 C 语言的 `for` 循环只能处理数字类型的值。
|
||||
|
||||
Bash 版的 `for` 命令基本的结构很简单:
|
||||
|
||||
```
|
||||
for Var in list1 ; do list2 ; done
|
||||
```
|
||||
|
||||
解释一下:“对于 `list1` 中的每一个值,把 `$Var` 设置为那个值,使用该值执行 `list2` 中的程序语句;`list1` 中的值都执行完后,整个循环结束,退出循环。” `list1` 中的值可以是一个简单的显式字符串值,也可以是一个命令执行后的结果(`` 包含其内的命令执行的结果,本系列第二篇文章中有描述)。我经常使用这种结构。
|
||||
|
||||
要测试它,确认 `~/testdir` 仍然是当前的工作目录(PWD)。删除目录下所有东西,来看下这个显式写出值列表的 `for` 循环的简单的示例。这个列表混合了字母和数字 — 但是不要忘了,在 bash 中所有的变量都是字符串或者可以被当成字符串来处理。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ rm *
|
||||
[student@studentvm1 testdir]$ for I in a b c d 1 2 3 4 ; do echo $I ; done
|
||||
a
|
||||
b
|
||||
c
|
||||
d
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
```
|
||||
|
||||
给变量赋予更有意义的名字,变成前面版本的进阶版:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for Dept in "Human Resources" Sales Finance "Information Technology" Engineering Administration Research ; do echo "Department $Dept" ; done
|
||||
Department Human Resources
|
||||
Department Sales
|
||||
Department Finance
|
||||
Department Information Technology
|
||||
Department Engineering
|
||||
Department Administration
|
||||
Department Research
|
||||
```
|
||||
|
||||
创建几个目录(创建时显示一些处理信息):
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for Dept in "Human Resources" Sales Finance "Information Technology" Engineering Administration Research ; do echo "Working on Department $Dept" ; mkdir "$Dept" ; done
|
||||
Working on Department Human Resources
|
||||
Working on Department Sales
|
||||
Working on Department Finance
|
||||
Working on Department Information Technology
|
||||
Working on Department Engineering
|
||||
Working on Department Administration
|
||||
Working on Department Research
|
||||
[student@studentvm1 testdir]$ ll
|
||||
total 28
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Administration
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Engineering
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Finance
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 'Human Resources'
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 'Information Technology'
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Research
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Sales
|
||||
```
|
||||
|
||||
在 `mkdir` 语句中 `$Dept` 变量必须用引号包裹起来;否则名字中间有空格(如 `Information Technology`)会被当做两个独立的目录处理。我一直信奉的一条实践规则:所有的文件和目录都应该为一个单词(中间没有空格)。虽然大部分现代的操作系统可以处理名字中间有空格的情况,但是系统管理员需要花费额外的精力去确保脚本和 CLI 程序能正确处理这些特例。(即使它们很烦人,也务必考虑它们,因为你永远不知道将拥有哪些文件。)
|
||||
|
||||
再次删除 `~/testdir` 下的所有东西 — 再运行一次下面的命令:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ rm -rf * ; ll
|
||||
total 0
|
||||
[student@studentvm1 testdir]$ for Dept in Human-Resources Sales Finance Information-Technology Engineering Administration Research ; do echo "Working on Department $Dept" ; mkdir "$Dept" ; done
|
||||
Working on Department Human-Resources
|
||||
Working on Department Sales
|
||||
Working on Department Finance
|
||||
Working on Department Information-Technology
|
||||
Working on Department Engineering
|
||||
Working on Department Administration
|
||||
Working on Department Research
|
||||
[student@studentvm1 testdir]$ ll
|
||||
total 28
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Administration
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Engineering
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Finance
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Human-Resources
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Information-Technology
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Research
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Sales
|
||||
```
|
||||
|
||||
假设现在有个需求,需要列出一台 Linux 机器上所有的 RPM 包并对每个包附上简短的描述。我为北卡罗来纳州工作的时候,曾经遇到过这种需求。由于当时开源尚未得到州政府的“批准”,而且我只在台式机上使用 Linux,对技术一窍不通的老板(PHB)需要我列出我计算机上安装的所有软件,以便他们可以“批准”一个特例。
|
||||
|
||||
你怎么实现它?有一种方法是,已知 `rpm –qa` 命令提供了 RPM 包的完整描述,包括了白痴老板想要的东西:软件名称和概要描述。
|
||||
|
||||
让我们一步步执行出最后的结果。首先,列出所有的 RPM 包:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ rpm -qa
|
||||
perl-HTTP-Message-6.18-3.fc29.noarch
|
||||
perl-IO-1.39-427.fc29.x86_64
|
||||
perl-Math-Complex-1.59-429.fc29.noarch
|
||||
lua-5.3.5-2.fc29.x86_64
|
||||
java-11-openjdk-headless-11.0.ea.28-2.fc29.x86_64
|
||||
util-linux-2.32.1-1.fc29.x86_64
|
||||
libreport-fedora-2.9.7-1.fc29.x86_64
|
||||
rpcbind-1.2.5-0.fc29.x86_64
|
||||
libsss_sudo-2.0.0-5.fc29.x86_64
|
||||
libfontenc-1.1.3-9.fc29.x86_64
|
||||
<snip>
|
||||
```
|
||||
|
||||
用 `sort` 和 `uniq` 命令对列表进行排序和打印去重后的结果(有些已安装的 RPM 包具有相同的名字):
|
||||
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ rpm -qa | sort | uniq
|
||||
a2ps-4.14-39.fc29.x86_64
|
||||
aajohan-comfortaa-fonts-3.001-3.fc29.noarch
|
||||
abattis-cantarell-fonts-0.111-1.fc29.noarch
|
||||
abiword-3.0.2-13.fc29.x86_64
|
||||
abrt-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-ccpp-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-coredump-helper-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-kerneloops-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-pstoreoops-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-vmcore-2.11.0-1.fc29.x86_64
|
||||
<snip>
|
||||
```
|
||||
|
||||
以上命令得到了想要的 RPM 列表,因此你可以把这个列表作为一个循环的输入信息,循环最终会打印每个 RPM 包的详细信息:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done
|
||||
```
|
||||
|
||||
这段代码产出了多余的信息。当循环结束后,下一步就是提取出白痴老板需要的信息。因此,添加一个 `egrep` 命令用来搜索匹配 `^Name` 或 `^Summary` 的行。脱字符(`^`)表示行首,整个命令表示显示所有以 Name 或 Summary 开头的行。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done | egrep -i "^Name|^Summary"
|
||||
Name : a2ps
|
||||
Summary : Converts text and other types of files to PostScript
|
||||
Name : aajohan-comfortaa-fonts
|
||||
Summary : Modern style true type font
|
||||
Name : abattis-cantarell-fonts
|
||||
Summary : Humanist sans serif font
|
||||
Name : abiword
|
||||
Summary : Word processing program
|
||||
Name : abrt
|
||||
Summary : Automatic bug detection and reporting tool
|
||||
<snip>
|
||||
```
|
||||
|
||||
在上面的命令中你可以试试用 `grep` 代替 `egrep` ,你会发现用 `grep` 不能得到正确的结果。你也可以通过管道把命令结果用 `less` 过滤器来查看。最终命令像这样:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done | egrep -i "^Name|^Summary" > RPM-summary.txt
|
||||
```
|
||||
|
||||
这个命令行程序用到了管道、重定向和 `for` 循环,这些全都在一行中。它把你的 CLI 程序的结果重定向到了一个文件,这个文件可以在邮件中使用或在其他地方作为输入使用。
|
||||
|
||||
这个一次一步构建程序的过程让你能看到每步的结果,以此来确保整个程序以你期望的流程进行且输出你想要的结果。
|
||||
|
||||
白痴老板最终收到了超过 1900 个不同的 RPM 包的清单,我严重怀疑根本就没人读过这个列表。我给了他们想要的东西,没有从他们嘴里听到过任何关于 RPM 包的信息。
|
||||
|
||||
### 其他循环
|
||||
|
||||
Bash 中还有两种其他类型的循环结构:`while` 和 `until` 结构,两者在语法和功能上都类似。这些循环结构的基础语法很简单:
|
||||
|
||||
```
|
||||
while [ expression ] ; do list ; done
|
||||
```
|
||||
|
||||
逻辑解释:表达式(`expression`)结果为 true 时,执行程序语句 `list`。表达式结果为 false 时,退出循环。
|
||||
|
||||
```
|
||||
until [ expression ] ; do list ; done
|
||||
```
|
||||
|
||||
逻辑解释:执行程序语句 `list`,直到表达式的结果为 true。当表达式结果为 true 时,退出循环。
|
||||
|
||||
#### While 循环
|
||||
|
||||
`while` 循环用于当逻辑表达式结果为 true 时执行一系列程序语句。假设你的 PWD 仍是 `~/testdir`。
|
||||
|
||||
最简单的 `while` 循环形式是这个会一直运行下去的循环。下面格式的条件语句永远以 `true` 作为返回。你也可以用简单的 `1` 代替 `true`,结果一样,但是这解释了 true 表达式的用法。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ X=0 ; while [ true ] ; do echo $X ; X=$((X+1)) ; done | head
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
既然你已经学了 CLI 的各部分知识,那就让它变得更有用处。首先,为了防止变量 `$X` 在前面的程序或 CLI 命令执行后有遗留的值,设置 `$X` 的值为 0。然后,因为逻辑表达式 `[ true ]` 的结果永远是 1,即 true,在 `do` 和 `done` 中间的程序指令列表会一直执行 — 或者直到你按下 `Ctrl+C` 抑或发送一个 2 号信号给程序。那些程序指令是算数扩展,用来打印变量 `$X` 当前的值并加 1.
|
||||
|
||||
《[系统管理员的 Linux 哲学][5]》的信条之一是追求优雅,实现优雅的一种方式就是简化。你可以用操作符 `++` 来简化这个程序。在第一个例子中,变量当前的值被打印出来,然后变量的值增加了。可以在变量后加一个 `++` 来表示这个逻辑:
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; while [ true ] ; do echo $((X++)) ; done | head
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
```
|
||||
|
||||
现在删掉程序最后的 `| head` 再运行一次。
|
||||
|
||||
在下面这个版本中,变量在值被打印之前就自增了。这是通过在变量之前添加 `++` 操作符实现的。你能看出区别吗?
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; while [ true ] ; do echo $((++X)) ; done | head
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
```
|
||||
|
||||
你已经把打印变量的值和自增简化到了一条语句。类似 `++` 操作符,也有 `--` 操作符。
|
||||
|
||||
你需要一个在循环到某个特定数字时终止循环的方法。把 true 表达式换成一个数字比较表达式来实现它。这里有一个循环到 5 终止的程序。在下面的示例代码中,你可以看到 `-le` 是 “小于或等于” 的数字逻辑操作符。整个语句的意思:只要 `$X` 的值小于或等于 5,循环就一直运行。当 `$X` 增加到 6 时,循环终止。
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; while [ $X -le 5 ] ; do echo $((X++)) ; done
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
[student@studentvm1 ~]$
|
||||
```
|
||||
|
||||
#### Until 循环
|
||||
|
||||
`until` 命令非常像 `while` 命令。不同之处是,它直到逻辑表达式的值是 `true` 之前,会一直循环。看一下这种结构最简单的格式:
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; until false ; do echo $((X++)) ; done | head
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
[student@studentvm1 ~]$
|
||||
```
|
||||
|
||||
它用一个逻辑比较表达式来计数到一个特定的值:
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; until [ $X -eq 5 ] ; do echo $((X++)) ; done
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
[student@studentvm1 ~]$ X=0 ; until [ $X -eq 5 ] ; do echo $((++X)) ; done
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
[student@studentvm1 ~]$
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
本系列探讨了构建 Bash 命令行程序和 shell 脚本的很多强大的工具。但是这仅仅是你能用 Bash 做的很多有意思的事中的冰山一角,接下来就看你的了。
|
||||
|
||||
我发现学习 Bash 编程最好的方法就是实践。找一个需要多个 Bash 命令的简单项目然后写一个 CLI 程序。系统管理员们要做很多适合 CLI 编程的工作,因此我确信你很容易能找到自动化的任务。
|
||||
|
||||
很多年前,尽管我对其他的 Shell 语言和 Perl 很熟悉,但还是决定用 Bash 做所有系统管理员的自动化任务。我发现,有时稍微搜索一下,我可以用 Bash 实现我需要的所有事情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/programming-bash-loops
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
|
||||
[2]: http://www.both.org/?page_id=1183
|
||||
[3]: https://linux.cn/article-11552-1.html
|
||||
[4]: https://linux.cn/article-11687-1.html
|
||||
[5]: https://www.apress.com/us/book/9781484237298
|
||||
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11657-1.html)
|
||||
[#]: subject: (Get sorted with sort at the command line)
|
||||
[#]: via: (https://opensource.com/article/19/10/get-sorted-sort)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在命令行用 sort 进行排序
|
||||
======
|
||||
|
||||
> 在 Linux、BSD 或 Mac 的终端中使用 sort 命令,按自己的需求重新整理数据。
|
||||
|
||||

|
||||
|
||||
如果你曾经用过数据表应用程序,你就会知道可以按列的内容对行进行排序。例如,如果你有一个费用列表,你可能希望对它们进行按日期或价格升序抑或按类别进行排序。如果你熟悉终端的使用,你不会仅为了排序文本数据就去使用庞大的办公软件。这正是 [sort][2] 命令的用处。
|
||||
|
||||
### 安装
|
||||
|
||||
你不必安装 `sort` ,因为它向来都包含在 [POSIX][3] 系统里。在大多数 Linux 系统中,`sort` 命令来自 GNU 组织打包的实用工具集合中。在其他的 POSIX 系统中,像 BSD 和 Mac,默认的 `sort` 命令不是 GNU 提供的,所以有一些选项可能不一样。本文中我尽量对 GNU 和 BSD 两者的实现都进行说明。
|
||||
|
||||
### 按字母顺序排列行
|
||||
|
||||
`sort` 命令默认会读取文件每行的第一个字符并对每行按字母升序排序后输出。两行中的第一个字符相同的情况下,对下一个字符进行对比。例如:
|
||||
|
||||
```
|
||||
$ cat distro.list
|
||||
Slackware
|
||||
Fedora
|
||||
Red Hat Enterprise Linux
|
||||
Ubuntu
|
||||
Arch
|
||||
1337
|
||||
Mint
|
||||
Mageia
|
||||
Debian
|
||||
$ sort distro.list
|
||||
1337
|
||||
Arch
|
||||
Debian
|
||||
Fedora
|
||||
Mageia
|
||||
Mint
|
||||
Red Hat Enterprise Linux
|
||||
Slackware
|
||||
Ubuntu
|
||||
```
|
||||
|
||||
使用 `sort` 不会改变原文件。`sort` 仅起到过滤的作用,所以如果你希望按排序后的格式保存数据,你需要用 `>` 或 `tee` 进行重定向。
|
||||
|
||||
|
||||
```
|
||||
$ sort distro.list | tee distro.sorted
|
||||
1337
|
||||
Arch
|
||||
Debian
|
||||
[...]
|
||||
$ cat distro.sorted
|
||||
1337
|
||||
Arch
|
||||
Debian
|
||||
[...]
|
||||
```
|
||||
|
||||
### 按列排序
|
||||
|
||||
复杂数据集有时候不止需要对每行的第一个字符进行排序。例如,假设有一个动物列表,每个都有其种和属,用可预见的分隔符分隔每一个“字段”(即数据表中的“单元格”)。这类由数据表导出的格式很常见,CSV(<ryby>以逗号分隔的数据<rt>comma-separated values</rt></ruby>)后缀可以标识这些文件(虽然 CSV 文件不一定用逗号分隔,有分隔符的文件也不一定用 CSV 后缀)。以下数据作为示例:
|
||||
|
||||
```
|
||||
Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
Spheniscus;demersus;Brisson;1760;African
|
||||
Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
Eudyptes;chrysocome;Viellot;1816;Southern Rockhopper
|
||||
Torvaldis;linux;Ewing,L;1996;Tux
|
||||
```
|
||||
|
||||
对于这组示例数据,你可以用 `--field-separator` (在 BSD 和 Mac 用 `-t`,在 GNU 上也可以用简写 `-t` )设置分隔符为分号(因为该示例数据中是用分号而不是逗号,理论上分隔符可以是任意字符),用 `--key`(在 BSD 和 Mac 上用 `-k`,在 GNU 上也可以用简写 `-k`)选项指定哪个字段被排序。例如,对每行第二个字段进行排序(计数以 1 开头而不是 0):
|
||||
|
||||
```
|
||||
sort --field-separator=";" --key=2
|
||||
Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
|
||||
Spheniscus;demersus;Brisson;1760;African
|
||||
Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
Torvaldis;linux;Ewing,L;1996;Tux
|
||||
Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
```
|
||||
|
||||
结果有点不容易读,但是 Unix 以构造命令的管道方式而闻名,所以你可以使用 `column` 命令美化输出结果。使用 GNU `column`:
|
||||
|
||||
```
|
||||
$ sort --field-separator=";" \
|
||||
\--key=2 penguins.list | column --table --separator ";"
|
||||
Megadyptes antipodes Milne-Edwards 1880 Yellow-eyed
|
||||
Eudyptes chrysocome Viellot 1816 Southern Rockhopper
|
||||
Spheniscus demersus Brisson 1760 African
|
||||
Aptenodytes forsteri Miller,JF 1778 Emperor
|
||||
Torvaldis linux Ewing,L 1996 Tux
|
||||
Eudyptula minor Bonaparte 1867 Little Blue
|
||||
Pygoscelis papua Wagler 1832 Gentoo
|
||||
```
|
||||
|
||||
对于初学者可能有点不好理解(但是写起来简单),BSD 和 Mac 上的命令选项:
|
||||
|
||||
```
|
||||
$ sort -t ";" \
|
||||
-k2 penguins.list | column -t -s ";"
|
||||
Megadyptes antipodes Milne-Edwards 1880 Yellow-eyed
|
||||
Eudyptes chrysocome Viellot 1816 Southern Rockhopper
|
||||
Spheniscus demersus Brisson 1760 African
|
||||
Aptenodytes forsteri Miller,JF 1778 Emperor
|
||||
Torvaldis linux Ewing,L 1996 Tux
|
||||
Eudyptula minor Bonaparte 1867 Little Blue
|
||||
Pygoscelis papua Wagler 1832 Gentoo
|
||||
```
|
||||
|
||||
当然 `-k` 不一定非要设为 `2`。任意存在的字段都可以被设为排序的键。
|
||||
|
||||
### 逆序排列
|
||||
|
||||
你可以用 `--reverse`(BSD/Mac 上用 `-r`,GNU 上也可以用简写 `-r`)选项来颠倒已经排好序的列表。
|
||||
|
||||
```
|
||||
$ sort --reverse alphabet.list
|
||||
z
|
||||
y
|
||||
x
|
||||
w
|
||||
[...]
|
||||
```
|
||||
|
||||
你也可以把输出结果通过管道传给命令 [tac][4] 来实现相同的效果。
|
||||
|
||||
### 按月排序(仅 GNU 支持)
|
||||
|
||||
理想情况下,所有人都按照 ISO 8601 标准来写日期:年、月、日。这是一种合乎逻辑的指定精确日期的方法,也可以很容易地被计算机理解。也有很多情况下,人类用其他的方式标注日期,包括用很名字随意的月份。
|
||||
|
||||
幸运的是,GNU `sort` 命令能识别这种写法,并可以按月份的名称正确排序。使用 `--month-sort`(`-M`)选项:
|
||||
|
||||
```
|
||||
$ cat month.list
|
||||
November
|
||||
October
|
||||
September
|
||||
April
|
||||
[...]
|
||||
$ sort --month-sort month.list
|
||||
January
|
||||
February
|
||||
March
|
||||
April
|
||||
May
|
||||
[...]
|
||||
November
|
||||
December
|
||||
```
|
||||
|
||||
月份的全称和简写都可以被识别。
|
||||
|
||||
### 人类可读的数字排序(仅 GNU 支持)
|
||||
|
||||
另一个人类和计算机的常见混淆点是数字的组合。例如,人类通常把 “1024 kilobytes” 写成 “1KB”,因为人类解析 “1 KB” 比 “1024” 要容易且更快(数字越大,这种差异越明显)。对于计算机来说,一个 9 KB 的字符串要比诸如 1 MB 的字符串大(尽管 9 KB 是 1 MB 很小一部分)。GNU `sort` 命令提供了`--human-numeric-sort`(`-h`)选项来帮助正确解析这些值。
|
||||
|
||||
```
|
||||
$ cat sizes.list
|
||||
2M
|
||||
12MB
|
||||
1k
|
||||
9k
|
||||
900
|
||||
7000
|
||||
$ sort --human-numeric-sort
|
||||
900
|
||||
7000
|
||||
1k
|
||||
9k
|
||||
2M
|
||||
12MB
|
||||
```
|
||||
|
||||
有一些情况例外。例如,“16000 bytes” 比 “1 KB” 大,但是 `sort` 识别不了。
|
||||
|
||||
```
|
||||
$ cat sizes0.list
|
||||
2M
|
||||
12MB
|
||||
16000
|
||||
1k
|
||||
$ sort -h sizes0.list
|
||||
16000
|
||||
1k
|
||||
2M
|
||||
12MB
|
||||
```
|
||||
|
||||
逻辑上来说,这个示例中 16000 应该写成 16 KB,所以也不应该全部归咎于GNU `sort`。只要你确保数字的一致性,`--human-numeric-sort` 可以用一种计算机友好的方式解析成人类可读的数字。
|
||||
|
||||
### 随机排序(仅 GNU 支持)
|
||||
|
||||
有时候工具也提供了一些与设计初衷相悖的选项。某种程度上说,`sort` 命令提供对一个文件进行随机排序的能力没有任何意义。这个命令的工作流让这个特性变得很方便。你*可以*用其他的命令,像 [shuf][5] ,或者你可以用现在的命令添加一个选项。不管你认为它是一个臃肿的还是极具创造力的用户体验设计,GNU `sort` 命令提供了对文件进行随机排序的功能。
|
||||
|
||||
最纯粹的随机排序格式选项是 `--random-sort` 或 `-R`(不要跟 `-r` 混淆,`-r` 是 `--reverse` 的简写)。
|
||||
|
||||
```
|
||||
$ sort --random-sort alphabet.list
|
||||
d
|
||||
m
|
||||
p
|
||||
a
|
||||
[...]
|
||||
```
|
||||
|
||||
每次对文件运行随机排序都会有不同的结果。
|
||||
|
||||
### 结语
|
||||
|
||||
GNU 和 BSD 的 `sort` 命令还有很多功能,所以花点时间去了解这些选项。你会惊异于 `sort` 的灵活性,尤其是当它和其他的 Unix 工具一起使用时。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/get-sorted-sort
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl "Coding on a computer"
|
||||
[2]: https://en.wikipedia.org/wiki/Sort_(Unix)
|
||||
[3]: https://en.wikipedia.org/wiki/POSIX
|
||||
[4]: https://opensource.com/article/19/9/tac-command
|
||||
[5]: https://www.gnu.org/software/coreutils/manual/html_node/shuf-invocation.html
|
||||
@ -0,0 +1,222 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11666-1.html)
|
||||
[#]: subject: (How to remove duplicate lines from files with awk)
|
||||
[#]: via: (https://opensource.com/article/19/10/remove-duplicate-lines-files-awk)
|
||||
[#]: author: (Lazarus Lazaridis https://opensource.com/users/iridakos)
|
||||
|
||||
怎样使用 awk 删掉文件中重复的行
|
||||
======
|
||||
|
||||
> 学习怎样使用 awk 的 `!visited[$0]++` 在不重新排序或改变原排列顺序的前提下删掉重复的行。
|
||||
|
||||

|
||||
|
||||
假设你有一个文本文件,你需要删掉所有重复的行。
|
||||
|
||||
### TL;DR
|
||||
|
||||
*要保持原来的排列顺序*删掉重复行,使用:
|
||||
|
||||
```
|
||||
awk '!visited[$0]++' your_file > deduplicated_file
|
||||
```
|
||||
|
||||
### 工作原理
|
||||
|
||||
这个脚本维护一个关联数组,索引(键)为文件中去重后的行,每个索引对应的值为该行出现的次数。对于文件的每一行,如果这行(之前)出现的次数为 0,则值加 1,并打印这行,否则值加 1,不打印这行。
|
||||
|
||||
我之前不熟悉 `awk`,我想弄清楚这么短小的一个脚本是怎么实现的。我调研了下,下面是调研心得:
|
||||
|
||||
* 这个 awk “脚本” `!visited[$0]++` 对输入文件的*每一行*都执行。
|
||||
* `visited[]` 是一个[关联数组][2](又名[映射][3])类型的变量。`awk` 会在第一次执行时初始化它,因此我们不需要初始化。
|
||||
* `$0` 变量的值是当前正在被处理的行的内容。
|
||||
* `visited[$0]` 通过与 `$0`(正在被处理的行)相等的键来访问该映射中的值,即出现次数(我们在下面设置的)。
|
||||
* `!` 对表示出现次数的值取反:
|
||||
* 在 `awk` 中,[任意非零的数或任意非空的字符串的值是 `true`][4]。
|
||||
* [变量默认的初始值为空字符串][5],如果被转换为数字,则为 0。
|
||||
* 也就是说:
|
||||
* 如果 `visited[$0]` 的值是一个比 0 大的数,取反后被解析成 `false`。
|
||||
* 如果 `visited[$0]` 的值为等于 0 的数字或空字符串,取反后被解析成 `true` 。
|
||||
* `++` 表示变量 `visited[$0]` 的值加 1。
|
||||
* 如果该值为空,`awk` 自动把它转换为 `0`(数字) 后加 1。
|
||||
* 注意:加 1 操作是在我们取到了变量的值之后执行的。
|
||||
|
||||
总的来说,整个表达式的意思是:
|
||||
|
||||
* `true`:如果表示出现次数为 0 或空字符串
|
||||
* `false`:如果出现的次数大于 0
|
||||
|
||||
`awk` 由 [模式或表达式和一个与之关联的动作][6] 组成:
|
||||
|
||||
```
|
||||
<模式/表达式> { <动作> }
|
||||
```
|
||||
|
||||
如果匹配到了模式,就会执行后面的动作。如果省略动作,`awk` 默认会打印(`print`)输入。
|
||||
|
||||
> 省略动作等价于 `{print $0}`。
|
||||
|
||||
我们的脚本由一个 `awk` 表达式语句组成,省略了动作。因此这样写:
|
||||
|
||||
```
|
||||
awk '!visited[$0]++' your_file > deduplicated_file
|
||||
```
|
||||
|
||||
等于这样写:
|
||||
|
||||
```
|
||||
awk '!visited[$0]++ { print $0 }' your_file > deduplicated_file
|
||||
```
|
||||
|
||||
对于文件的每一行,如果表达式匹配到了,这行内容被打印到输出。否则,不执行动作,不打印任何东西。
|
||||
|
||||
### 为什么不用 uniq 命令?
|
||||
|
||||
`uniq` 命令仅能对相邻的行去重。这是一个示例:
|
||||
|
||||
```
|
||||
$ cat test.txt
|
||||
A
|
||||
A
|
||||
A
|
||||
B
|
||||
B
|
||||
B
|
||||
A
|
||||
A
|
||||
C
|
||||
C
|
||||
C
|
||||
B
|
||||
B
|
||||
A
|
||||
$ uniq < test.txt
|
||||
A
|
||||
B
|
||||
A
|
||||
C
|
||||
B
|
||||
A
|
||||
```
|
||||
|
||||
### 其他方法
|
||||
|
||||
#### 使用 sort 命令
|
||||
|
||||
我们也可以用下面的 [sort][7] 命令来去除重复的行,但是*原来的行顺序没有被保留*。
|
||||
|
||||
|
||||
```
|
||||
sort -u your_file > sorted_deduplicated_file
|
||||
```
|
||||
|
||||
#### 使用 cat + sort + cut
|
||||
|
||||
上面的方法会产出一个去重的文件,各行是基于内容进行排序的。[通过管道连接命令][8]可以解决这个问题。
|
||||
|
||||
|
||||
```
|
||||
cat -n your_file | sort -uk2 | sort -nk1 | cut -f2-
|
||||
```
|
||||
|
||||
**工作原理**
|
||||
|
||||
假设我们有下面一个文件:
|
||||
|
||||
```
|
||||
abc
|
||||
ghi
|
||||
abc
|
||||
def
|
||||
xyz
|
||||
def
|
||||
ghi
|
||||
klm
|
||||
```
|
||||
|
||||
`cat -n test.txt` 在每行前面显示序号:
|
||||
|
||||
```
|
||||
1 abc
|
||||
2 ghi
|
||||
3 abc
|
||||
4 def
|
||||
5 xyz
|
||||
6 def
|
||||
7 ghi
|
||||
8 klm
|
||||
```
|
||||
|
||||
`sort -uk2` 基于第二列(`k2` 选项)进行排序,对于第二列相同的值只保留一次(`u` 选项):
|
||||
|
||||
```
|
||||
1 abc
|
||||
4 def
|
||||
2 ghi
|
||||
8 klm
|
||||
5 xyz
|
||||
```
|
||||
|
||||
`sort -nk1` 基于第一列排序(`k1` 选项),把列的值作为数字来处理(`-n` 选项):
|
||||
|
||||
```
|
||||
1 abc
|
||||
2 ghi
|
||||
4 def
|
||||
5 xyz
|
||||
8 klm
|
||||
```
|
||||
|
||||
最后,`cut -f2-` 从第二列开始打印每一行,直到最后的内容(`-f2-` 选项:留意 `-` 后缀,它表示这行后面的内容都包含在内)。
|
||||
|
||||
```
|
||||
abc
|
||||
ghi
|
||||
def
|
||||
xyz
|
||||
klm
|
||||
```
|
||||
|
||||
### 参考
|
||||
|
||||
* [GNU awk 用户手册][9]
|
||||
* [awk 中的数组][2]
|
||||
* [Awk — 真值][4]
|
||||
* [Awk 表达式][5]
|
||||
* [Unix 怎么删除文件中重复的行?][10]
|
||||
* [不用排序去掉重复的行(去重)][11]
|
||||
* ['!a[$0]++' 工作原理][12]
|
||||
|
||||
以上为全文。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/remove-duplicate-lines-files-awk
|
||||
|
||||
作者:[Lazarus Lazaridis][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/iridakos
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: http://kirste.userpage.fu-berlin.de/chemnet/use/info/gawk/gawk_12.html
|
||||
[3]: https://en.wikipedia.org/wiki/Associative_array
|
||||
[4]: https://www.gnu.org/software/gawk/manual/html_node/Truth-Values.html
|
||||
[5]: https://ftp.gnu.org/old-gnu/Manuals/gawk-3.0.3/html_chapter/gawk_8.html
|
||||
[6]: http://kirste.userpage.fu-berlin.de/chemnet/use/info/gawk/gawk_9.html
|
||||
[7]: http://man7.org/linux/man-pages/man1/sort.1.html
|
||||
[8]: https://stackoverflow.com/a/20639730/2292448
|
||||
[9]: https://www.gnu.org/software/gawk/manual/html_node/
|
||||
[10]: https://stackoverflow.com/questions/1444406/how-can-i-delete-duplicate-lines-in-a-file-in-unix
|
||||
[11]: https://stackoverflow.com/questions/11532157/remove-duplicate-lines-without-sorting
|
||||
[12]: https://unix.stackexchange.com/questions/159695/how-does-awk-a0-work/159734#159734
|
||||
[13]: https://opensource.com/sites/default/files/uploads/duplicate-cat.jpg (Duplicate cat)
|
||||
[14]: https://iridakos.com/about/
|
||||
[15]: http://creativecommons.org/licenses/by-nc/4.0/
|
||||
@ -0,0 +1,242 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11684-1.html)
|
||||
[#]: subject: (Awk one-liners and scripts to help you sort text files)
|
||||
[#]: via: (https://opensource.com/article/19/11/how-sort-awk)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
帮助你排序文本文件的 Awk 命令行或脚本
|
||||
======
|
||||
|
||||
> Awk 是一个强大的工具,可以执行某些可能由其它常见实用程序(包括 `sort`)来完成的任务。
|
||||
|
||||

|
||||
|
||||
Awk 是个普遍存在的 Unix 命令,用于扫描和处理包含可预测模式的文本。但是,由于它具有函数功能,因此也可以合理地称之为编程语言。
|
||||
|
||||
令人困惑的是,有不止一个 awk。(或者,如果你认为只有一个,那么其它几个就是克隆。)有 `awk`(由Aho、Weinberger 和 Kernighan 编写的原始程序),然后有 `nawk` 、`mawk` 和 GNU 版本的 `gawk`。GNU 版本的 awk 是该实用程序的一个高度可移植的自由软件版本,具有几个独特的功能,因此本文是关于 GNU awk 的。
|
||||
|
||||
虽然它的正式名称是 `gawk`,但在 GNU+Linux 系统上,它的别名是 `awk`,并用作该命令的默认版本。 在其他没有带有 GNU awk 的系统上,你必须先安装它并将其称为 `gawk`,而不是 `awk`。本文互换使用术语 `awk` 和 `gawk`。
|
||||
|
||||
`awk` 既是命令语言又是编程语言,这使其成为一个强大的工具,可以处理原本留给 `sort`、`cut`、`uniq` 和其他常见实用程序的任务。幸运的是,开源中有很多冗余空间,因此,如果你面临是否使用 `awk` 的问题,答案可能是肯定的“随便”。
|
||||
|
||||
`awk` 的灵活之美在于,如果你已经确定使用 `awk` 来完成一项任务,那么无论接下来发生什么,你都可以继续使用 `awk`。这包括对数据排序而不是按交付给你的顺序的永恒需求。
|
||||
|
||||
### 样本数据集
|
||||
|
||||
在探索 `awk` 的排序方法之前,请生成要使用的样本数据集。保持简单,这样你就不会为极端情况和意想不到的复杂性所困扰。这是本文使用的样本集:
|
||||
|
||||
```
|
||||
Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
Spheniscus;demersus;Brisson;1760;African
|
||||
Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
|
||||
Torvaldis;linux;Ewing,L;1996;Tux
|
||||
```
|
||||
|
||||
这是一个很小的数据集,但它提供了多种数据类型:
|
||||
|
||||
* 属名和种名,彼此相关但又是分开的
|
||||
* 姓,有时是以逗号开头的首字母缩写
|
||||
* 代表日期的整数
|
||||
* 任意术语
|
||||
* 所有字段均以分号分隔
|
||||
|
||||
根据你的教育背景,你可能会认为这是二维数组或表格,或者只是行分隔的数据集合。你如何看待它只是你的问题,而 `awk` 只认识文本。由你决定告诉 `awk` 你想如何解析它。
|
||||
|
||||
### 只想排序
|
||||
|
||||
如果你只想按特定的可定义字段(例如电子表格中的“单元格”)对文本数据集进行排序,则可以使用 [sort 命令][2]。
|
||||
|
||||
### 字段和记录
|
||||
|
||||
无论输入的格式如何,都必须在其中找到模式才可以专注于对你重要的数据部分。在此示例中,数据由两个因素定界:行和字段。每行都代表一个新的*记录*,就如你在电子表格或数据库转储中看到的一样。在每一行中,都有用分号(`;`)分隔的不同的*字段*(将其视为电子表格中的单元格)。
|
||||
|
||||
`awk` 一次只处理一条记录,因此,当你在构造发给 `awk` 的这指令时,你可以只关注一行记录。写下你想对一行数据执行的操作,然后在下一行进行测试(无论是心理上还是用 `awk` 进行测试),然后再进行其它的一些测试。最后,你要对你的 `awk` 脚本要处理的数据做好假设,以便可以按你要的数据结构提供给你数据。
|
||||
|
||||
在这个例子中,很容易看到每个字段都用分号隔开。为简单起见,假设你要按每行的第一字段对列表进行排序。
|
||||
|
||||
在进行排序之前,你必须能够让 `awk` 只关注在每行的第一个字段上,因此这是第一步。终端中 awk 命令的语法为 `awk`,后跟相关选项,最后是要处理的数据文件。
|
||||
|
||||
```
|
||||
$ awk --field-separator=";" '{print $1;}' penguins.list
|
||||
Aptenodytes
|
||||
Pygoscelis
|
||||
Eudyptula
|
||||
Spheniscus
|
||||
Megadyptes
|
||||
Eudyptes
|
||||
Torvaldis
|
||||
```
|
||||
|
||||
因为字段分隔符是对 Bash shell 具有特殊含义的字符,所以必须将分号括在引号中或在其前面加上反斜杠。此命令仅用于证明你可以专注于特定字段。你可以使用另一个字段的编号尝试相同的命令,以查看数据的另一个“列”的内容:
|
||||
|
||||
```
|
||||
$ awk --field-separator=";" '{print $3;}' penguins.list
|
||||
Miller,JF
|
||||
Wagler
|
||||
Bonaparte
|
||||
Brisson
|
||||
Milne-Edwards
|
||||
Viellot
|
||||
Ewing,L
|
||||
```
|
||||
|
||||
我们尚未进行任何排序,但这是良好的基础。
|
||||
|
||||
### 脚本编程
|
||||
|
||||
`awk` 不仅仅是命令,它是一种具有索引、数组和函数的编程语言。这很重要,因为这意味着你可以获取要排序的字段列表,将列表存储在内存中,进行处理,然后打印结果数据。对于诸如此类的一系列复杂操作,在文本文件中进行操作会更容易,因此请创建一个名为 `sort.awk` 的新文件并输入以下文本:
|
||||
|
||||
```
|
||||
#!/bin/gawk -f
|
||||
|
||||
BEGIN {
|
||||
FS=";";
|
||||
}
|
||||
```
|
||||
|
||||
这会将该文件建立为 `awk` 脚本,该脚本中包含执行的行。
|
||||
|
||||
`BEGIN` 语句是 `awk` 提供的特殊设置功能,用于只需要执行一次的任务。定义内置变量 `FS`,它代表<ruby>字段分隔符<rt>field separator</rt></ruby>,并且与你在 `awk` 命令中使用 `--field-separator` 设置的值相同,它只需执行一次,因此它包含在 `BEGIN` 语句中。
|
||||
|
||||
#### awk 中的数组
|
||||
|
||||
你已经知道如何通过使用 `$` 符号和字段编号来收集特定字段的值,但是在这种情况下,你需要将其存储在数组中而不是将其打印到终端。这是通过 `awk` 数组完成的。`awk` 数组的重要之处在于它包含键和值。 想象一下有关本文的内容;它看起来像这样:`author:"seth",title:"How to sort with awk",length:1200`。诸如作者、标题和长度之类的元素是键,跟着的内容为值。
|
||||
|
||||
在排序的上下文中这样做的好处是,你可以将任何字段分配为键,将任何记录分配为值,然后使用内置的 `awk` 函数 `asorti()`(按索引排序)按键进行排序。现在,随便假设你*只*想按第二个字段排序。
|
||||
|
||||
*没有*被特殊关键字 `BEGIN` 或 `END` 引起来的 `awk` 语句是在每个记录都要执行的循环。这是脚本的一部分,该脚本扫描数据中的模式并进行相应的处理。每次 `awk` 将注意力转移到一条记录上时,都会执行 `{}` 中的语句(除非以 `BEGIN` 或 `END` 开头)。
|
||||
|
||||
要将键和值添加到数组,请创建一个包含数组的变量(在本示例脚本中,我将其称为 `ARRAY`,虽然不是很原汁原味,但很清楚),然后在方括号中分配给它键,用等号(`=`)连接值。
|
||||
|
||||
```
|
||||
{ # dump each field into an array
|
||||
ARRAY[$2] = $R;
|
||||
}
|
||||
```
|
||||
|
||||
在此语句中,第二个字段的内容(`$2`)用作关键字,而当前记录(`$R`)用作值。
|
||||
|
||||
### asorti() 函数
|
||||
|
||||
除了数组之外,`awk` 还具有一些基本函数,你可以将它们用作常见任务的快速简便的解决方案。GNU awk中引入的函数之一 `asorti()` 提供了按键(*索引*)或值对数组进行排序的功能。
|
||||
|
||||
你只能在对数组进行填充后对其进行排序,这意味着此操作不能对每个新记录都触发,而只能在脚本的最后阶段进行。为此,`awk` 提供了特殊的 `END` 关键字。与 `BEGIN` 相反,`END` 语句仅在扫描了所有记录之后才触发一次。
|
||||
|
||||
将这些添加到你的脚本:
|
||||
|
||||
```
|
||||
END {
|
||||
asorti(ARRAY,SARRAY);
|
||||
# get length
|
||||
j = length(SARRAY);
|
||||
|
||||
for (i = 1; i <= j; i++) {
|
||||
printf("%s %s\n", SARRAY[i],ARRAY[SARRAY[i]])
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`asorti()` 函数获取 `ARRAY` 的内容,按索引对其进行排序,然后将结果放入名为 `SARRAY` 的新数组(我在本文中发明的任意名称,表示“排序的 ARRAY”)。
|
||||
|
||||
接下来,将变量 `j`(另一个任意名称)分配给 `length()` 函数的结果,该函数计算 `SARRAY` 中的项数。
|
||||
|
||||
最后,使用 `for` 循环使用 `printf()` 函数遍历 `SARRAY` 中的每一项,以打印每个键,然后在 `ARRAY` 中打印该键的相应值。
|
||||
|
||||
### 运行该脚本
|
||||
|
||||
要运行你的 `awk` 脚本,先使其可执行:
|
||||
|
||||
```
|
||||
$ chmod +x sorter.awk
|
||||
```
|
||||
|
||||
然后针对 `penguin.list` 示例数据运行它:
|
||||
|
||||
```
|
||||
$ ./sorter.awk penguins.list
|
||||
antipodes Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
chrysocome Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
|
||||
demersus Spheniscus;demersus;Brisson;1760;African
|
||||
forsteri Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
linux Torvaldis;linux;Ewing,L;1996;Tux
|
||||
minor Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
papua Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
```
|
||||
|
||||
如你所见,数据按第二个字段排序。
|
||||
|
||||
这有点限制。最好可以在运行时灵活选择要用作排序键的字段,以便可以在任何数据集上使用此脚本并获得有意义的结果。
|
||||
|
||||
### 添加命令选项
|
||||
|
||||
你可以通过在脚本中使用字面值 `var` 将命令变量添加到 `awk` 脚本中。更改脚本,以使迭代子句在创建数组时使用 `var`:
|
||||
|
||||
```
|
||||
{ # dump each field into an array
|
||||
ARRAY[$var] = $R;
|
||||
}
|
||||
```
|
||||
|
||||
尝试运行该脚本,以便在执行脚本时使用 `-v var` 选项将其按第三字段排序:
|
||||
|
||||
```
|
||||
$ ./sorter.awk -v var=3 penguins.list
|
||||
Bonaparte Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
Brisson Spheniscus;demersus;Brisson;1760;African
|
||||
Ewing,L Torvaldis;linux;Ewing,L;1996;Tux
|
||||
Miller,JF Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
Milne-Edwards Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
Viellot Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
|
||||
Wagler Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
```
|
||||
|
||||
### 修正
|
||||
|
||||
本文演示了如何在纯 GNU awk 中对数据进行排序。你可以对脚本进行改进,以便对你有用,花一些时间在`gawk` 的手册页上研究 [awk 函数][3]并自定义脚本以获得更好的输出。
|
||||
|
||||
这是到目前为止的完整脚本:
|
||||
|
||||
```
|
||||
#!/usr/bin/awk -f
|
||||
# GPLv3 appears here
|
||||
# usage: ./sorter.awk -v var=NUM FILE
|
||||
|
||||
BEGIN { FS=";"; }
|
||||
|
||||
{ # dump each field into an array
|
||||
ARRAY[$var] = $R;
|
||||
}
|
||||
|
||||
END {
|
||||
asorti(ARRAY,SARRAY);
|
||||
# get length
|
||||
j = length(SARRAY);
|
||||
|
||||
for (i = 1; i <= j; i++) {
|
||||
printf("%s %s\n", SARRAY[i],ARRAY[SARRAY[i]])
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/how-sort-awk
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_lead-steps-measure.png?itok=DG7rFZPk (Green graph of measurements)
|
||||
[2]: https://opensource.com/article/19/10/get-sorted-sort
|
||||
[3]: https://www.gnu.org/software/gawk/manual/html_node/Built_002din.html#Built_002din
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hanwckf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11667-1.html)
|
||||
[#]: subject: (Debugging Software Deployments with strace)
|
||||
[#]: via: (https://theartofmachinery.com/2019/11/14/deployment_debugging_strace.html)
|
||||
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||
@ -10,20 +10,20 @@
|
||||
在软件部署中使用 strace 进行调试
|
||||
======
|
||||
|
||||
我的大部分工作都包括部署软件系统,这意味着我需要花费很多时间来解决以下问题:
|
||||

|
||||
|
||||
* 这个软件可以在原始开发者的机器上工作,但是为什么不能在我这里运行?
|
||||
* 这个软件昨天可以在我的机器上工作,但是为什么今天就不行?
|
||||
我的大部分工作都涉及到部署软件系统,这意味着我需要花费很多时间来解决以下问题:
|
||||
|
||||
* 这个软件可以在原开发者的机器上工作,但是为什么不能在我这里运行?
|
||||
* 这个软件昨天可以在我的机器上工作,但是为什么今天就不行?
|
||||
|
||||
|
||||
这是调试的一种类型,但是与传统的软件调试有所不同。传统的调试通常只关心代码的逻辑,但是在软件部署中的调试关注的是程序的代码和它所在的运行环境之间的相互影响。即便问题的根源是代码的逻辑错误,但软件显然可以在别的机器上运行的事实意味着这类问题与运行环境密切相关。
|
||||
这是一种调试的类型,但是与一般的软件调试有所不同。一般的调试通常只关心代码的逻辑,但是在软件部署中的调试关注的是程序的代码和它所在的运行环境之间的相互影响。即便问题的根源是代码的逻辑错误,但软件显然可以在别的机器上运行的事实意味着这类问题与运行环境密切相关。
|
||||
|
||||
所以,在软件部署过程中,我没有使用传统的调试工具(例如 `gdb`),而是选择了其它工具进行调试。我最喜欢的用来解决“为什么这个软件无法在这台机器上运行?”这类问题的工具就是 `strace`。
|
||||
|
||||
### 什么是 `strace`?
|
||||
### 什么是 strace?
|
||||
|
||||
[`strace`][1] 是一个用来“追踪系统调用”的工具。它主要是一个 Linux 工具,但是你也可以在其它系统上使用类似的工具(例如 [DTrace][2] 和 [ktrace][3])。
|
||||
[strace][1] 是一个用来“追踪系统调用”的工具。它主要是一个 Linux 工具,但是你也可以在其它系统上使用类似的工具(例如 [DTrace][2] 和 [ktrace][3])。
|
||||
|
||||
它的基本用法非常简单。只需要在 `strace` 后面跟上你需要运行的命令,它就会显示出该命令触发的所有系统调用(你可能需要先安装好 `strace`):
|
||||
|
||||
@ -37,41 +37,39 @@ exit_group(0) = ?
|
||||
+++ exited with 0 +++
|
||||
```
|
||||
|
||||
这些系统调用都是什么?他们就像是操作系统提供的 API。很久以前,软件拥有直接访问硬件的权限。如果软件需要在屏幕上显示一些东西,它将会与视频硬件的端口和内存映射寄存器纠缠不清。当多任务操作系统变得流行以后,这就导致了混乱的局面,因为不同的应用程序将“争夺”硬件,并且一个应用程序的错误可能致使其它应用程序崩溃,甚至导致整个系统崩溃。所以 CPUs 开始支持多种不同的特权模式 (或者称为“保护环”)。它们让操作系统内核在具有完全硬件访问权限的最高特权模式下运行,于此同时,其它在低特权模式下运行的应用程序必须通过向内核发起系统调用才能够与硬件进行交互。
|
||||
这些系统调用都是什么?它们就像是操作系统内核提供的 API。很久以前,软件拥有直接访问硬件的权限。如果软件需要在屏幕上显示一些东西,它将会与视频硬件的端口和内存映射寄存器纠缠不清。当多任务操作系统变得流行以后,这就导致了混乱的局面,因为不同的应用程序将“争夺”硬件,并且一个应用程序的错误可能致使其它应用程序崩溃,甚至导致整个系统崩溃。所以 CPU 开始支持多种不同的特权模式(或者称为“保护环”)。它们让操作系统内核在具有完全硬件访问权限的最高特权模式下运行,于此同时,其它在低特权模式下运行的应用程序必须通过向内核发起系统调用才能够与硬件进行交互。
|
||||
|
||||
在二进制级别上,发起系统调用相比简单的函数调用有一些区别,但是大部分程序都使用标准库提供的封装函数。例如,POSIX C 标准库包含一个 `write()` 函数,该函数包含用于进行 `write` 系统调用的所有与硬件体系结构相关的代码。
|
||||
|
||||
![][4]
|
||||
|
||||
简单来说,一个应用程序与其环境(计算机系统)的相互影响都是通过系统调用来作用的。所以当软件在一台机器上可以工作但是在另一台机器无法工作的时候,追踪系统调用是一个很好的查错方法。具体地说,你可以通过追踪系统调用分析以下典型操作:
|
||||
简单来说,一个应用程序与其环境(计算机系统)的交互都是通过系统调用来完成的。所以当软件在一台机器上可以工作但是在另一台机器无法工作的时候,追踪系统调用是一个很好的查错方法。具体地说,你可以通过追踪系统调用分析以下典型操作:
|
||||
|
||||
* 控制台输入与输出 (IO)
|
||||
* 网络 IO
|
||||
* 文件系统访问以及文件 IO
|
||||
* 进程/线程 生命周期管理
|
||||
* 进程/线程生命周期管理
|
||||
* 原始内存管理
|
||||
* 访问特定的设备驱动
|
||||
|
||||
|
||||
|
||||
### 什么时候可以使用 `strace`?
|
||||
### 什么时候可以使用 strace?
|
||||
|
||||
理论上,`strace` 适用于任何用户空间程序,因为所有的用户空间程序都需要进行系统调用。`strace` 对于已编译的低级程序最有效果,但如果你可以避免运行时环境和解释器带来的大量额外输出,则仍然可以与 Python 等高级语言程序一起使用。
|
||||
|
||||
当软件在一台机器上正常工作,但在另一台机器上却不能正常工作,同时抛出有关文件、权限或者不能运行某某命令等模糊的错误信息时,`strace` 往往能大显身手。不幸的是,它不能诊断高等级的问题,例如数字证书验证错误等。这些问题通常需要结合 `strace`(有时候是 [`ltrace`][5]),以及其它高级工具(例如使用 `openssl` 命令行工具调试数字证书错误)。
|
||||
当软件在一台机器上正常工作,但在另一台机器上却不能正常工作,同时抛出了有关文件、权限或者不能运行某某命令等模糊的错误信息时,`strace` 往往能大显身手。不幸的是,它不能诊断高等级的问题,例如数字证书验证错误等。这些问题通常需要组合使用 `strace`(有时候是 [`ltrace`][5])和其它高级工具(例如使用 `openssl` 命令行工具调试数字证书错误)。
|
||||
|
||||
本文中的示例基于独立的服务器,但是对系统调用的追踪通常也可以在更复杂的部署平台上完成,仅需要找到合适的工具。
|
||||
|
||||
### 一个简单的例子
|
||||
|
||||
假设你正在尝试运行一个叫做 foo 的服务器应用程序,但是发生了以下情况:
|
||||
假设你正在尝试运行一个叫做 `foo` 的服务器应用程序,但是发生了以下情况:
|
||||
|
||||
```
|
||||
$ foo
|
||||
Error opening configuration file: No such file or directory
|
||||
```
|
||||
|
||||
显然,它没有找到你已经写好的配置文件。之所以会发生这种情况,是因为包管理工具有时候在编译应用程序时指定了自定义的路径,所以你应当遵循特定发行版提供的安装指南。如果错误信息告诉你正确的配置文件应该在什么地方,你就可以在几秒钟内解决这个问题,但事实并非如此。你该如何找到正确的路径?
|
||||
显然,它没有找到你已经写好的配置文件。之所以会发生这种情况,是因为包管理工具有时候在编译应用程序时指定了自定义的路径,所以你应当遵循特定发行版提供的安装指南。如果错误信息告诉你正确的配置文件应该在什么地方,你就可以在几秒钟内解决这个问题,但如果没有告诉你呢?你该如何找到正确的路径?
|
||||
|
||||
如果你有权访问源代码,则可以通过阅读源代码来解决问题。这是一个好的备用计划,但不是最快的解决方案。你还可以使用类似 `gdb` 的单步调试器来观察程序的行为,但使用专门用于展示程序与系统环境交互作用的工具 `strace` 更加有效。
|
||||
|
||||
@ -116,16 +114,14 @@ exit_group(1) = ?
|
||||
+++ exited with 1 +++
|
||||
```
|
||||
|
||||
`strace` 输出的第一页通常是低级的进程启动过程。(你可以看到很多 `mmap`,`mprotect`,`brk` 调用,这是用来分配原始内存和映射动态链接库的。)实际上,在查找错误时,最好从下往上阅读 `strace` 的输出。你可以看到 `write` 调用在最后返回了错误信息。如果你努力了,你将会看到第一个失败的系统调用是 `openat`,它在尝试打开 `/etc/foo/config.json` 时抛出了 `ENOENT` (“No such file or directory”)的错误。现在我们已经知道了配置文件应该放在哪里。
|
||||
`strace` 输出的第一页通常是低级的进程启动过程。(你可以看到很多 `mmap`、`mprotect`、`brk` 调用,这是用来分配原始内存和映射动态链接库的。)实际上,在查找错误时,最好从下往上阅读 `strace` 的输出。你可以看到 `write` 调用在最后返回了错误信息。如果你向上找,你将会看到第一个失败的系统调用是 `openat`,它在尝试打开 `/etc/foo/config.json` 时抛出了 `ENOENT` (“No such file or directory”)的错误。现在我们已经知道了配置文件应该放在哪里。
|
||||
|
||||
这是一个简单的例子,但我敢说在 90% 的情况下,使用 `strace` 进行调试不需要更多复杂的工作。以下是完整的调试步骤:
|
||||
|
||||
1. 从程序中获得含糊不清的错误信息
|
||||
2. 使用 `strace` 运行程序
|
||||
3. 在输出中找到错误信息
|
||||
4. 往前追溯并找到第一个失败的系统调用
|
||||
|
||||
|
||||
1. 从程序中获得含糊不清的错误信息
|
||||
2. 使用 `strace` 运行程序
|
||||
3. 在输出中找到错误信息
|
||||
4. 往前追溯并找到第一个失败的系统调用
|
||||
|
||||
第四步中的系统调用很可能向你显示出问题所在。
|
||||
|
||||
@ -133,27 +129,27 @@ exit_group(1) = ?
|
||||
|
||||
在开始更加复杂的调试之前,这里有一些有用的调试技巧帮助你高效使用 `strace`:
|
||||
|
||||
#### `man` 是你的朋友
|
||||
#### man 是你的朋友
|
||||
|
||||
在很多 *nix 操作系统中,你可以通过 `man syscalls` 查看系统调用的列表。你将会看到类似于 `brk(2)` 之类的东西,这意味着你可以通过运行 `man 2 brk` 得到与此相关的更多信息。
|
||||
|
||||
一个小问题:`man 2 fork` 会显示出在 GNU `libc` 里封装的 `fork()` 手册页,而 `fork()` 现在实际上是由 `clone` 系统调用实现的。`fork` 的语义与 `clone` 相同,但是如果我写了一个含有 `fork()` 的程序并使用 `strace` 去调试它,我将找不到任何关于 `fork` 调用的信息,只能看到 `clone` 调用。只有在将源代码与 `strace` 的输出进行比较的时候,这种问题才会让人感到困惑。
|
||||
一个小问题:`man 2 fork` 会显示出在 GNU `libc` 里封装的 `fork()` 手册页,而 `fork()` 现在实际上是由 `clone` 系统调用实现的。`fork` 的语义与 `clone` 相同,但是如果我写了一个含有 `fork()` 的程序并使用 `strace` 去调试它,我将找不到任何关于 `fork` 调用的信息,只能看到 `clone` 调用。如果将源代码与 `strace` 的输出进行比较的时候,像这种问题会让人感到困惑。
|
||||
|
||||
#### 使用 `-o` 将输出保存到文件
|
||||
#### 使用 -o 将输出保存到文件
|
||||
|
||||
`strace` 可以生成很多输出,所以将输出保存到单独的文件是很有帮助的 (就像上面的例子一样)。它还能够在控制台中避免程序自身的输出与 `strace` 的输出发生混淆。
|
||||
`strace` 可以生成很多输出,所以将输出保存到单独的文件是很有帮助的(就像上面的例子一样)。它还能够在控制台中避免程序自身的输出与 `strace` 的输出发生混淆。
|
||||
|
||||
#### 使用 `-s` 查看更多的参数
|
||||
#### 使用 -s 查看更多的参数
|
||||
|
||||
你可能已经注意到,错误信息的第二部分没有出现在上面的例子中。这是因为 `strace` 默认仅显示字符串参数的前 32 个字节。如果你需要捕获更多参数,请向 `strace` 追加类似于 `-s 128` 之类的参数。
|
||||
|
||||
#### `-y` 使得追踪文件或套接字更加容易
|
||||
#### -y 使得追踪文件或套接字更加容易
|
||||
|
||||
“一切皆文件”意味着 *nix 系统通过文件描述符进行所有 IO 操作,不管是真实的文件还是通过网络或者进程间管道。这对于编程而言是很方便的,但是在追踪系统调用时,你将很难分辨出 `read` 和 `write` 的真实行为。
|
||||
|
||||
`-y` 参数使 `strace` 在注释中注明每个文件描述符的具体指向。
|
||||
|
||||
#### 使用 `-p` 附加到正在运行的进程中
|
||||
#### 使用 -p 附加到正在运行的进程中
|
||||
|
||||
正如我们将在后面的例子中看到的,有时候你想追踪一个正在运行的程序。如果你知道这个程序的进程号为 1337 (可以通过 `ps` 查询),则可以这样操作:
|
||||
|
||||
@ -164,15 +160,15 @@ $ strace -p 1337
|
||||
|
||||
你可能需要 root 权限才能运行。
|
||||
|
||||
#### 使用 `-f` 追踪子进程
|
||||
#### 使用 -f 追踪子进程
|
||||
|
||||
`strace` 默认只追踪一个进程。如果这个进程产生了一个子进程,你将会看到创建子进程的系统调用(一般是 `clone`),但是你看不到子进程内触发的任何调用。
|
||||
|
||||
如果你认为在子进程中存在 bug,则需要使用 `-f` 参数启用子进程追踪功能。这样做的缺点是输出的内容会让人更加困惑。当追踪一个进程时,`strace` 显示的是单个调用事件流。当追踪多个进程的时候,你将会看到以 `<unfinished ...>` 开始的初始调用,接着是一系列针对其它线程的调用,最后才出现以 `<... foocall resumed>` 结束的初始调用。此外,你可以使用 `-ff` 参数将所有的调用分离到不同的文件中(查看 [the `strace` manual][6] 获取更多信息)。
|
||||
如果你认为在子进程中存在错误,则需要使用 `-f` 参数启用子进程追踪功能。这样做的缺点是输出的内容会让人更加困惑。当追踪一个进程时,`strace` 显示的是单个调用事件流。当追踪多个进程的时候,你将会看到以 `<unfinished ...>` 开始的初始调用,接着是一系列针对其它线程的调用,最后才出现以 `<... foocall resumed>` 结束的初始调用。此外,你可以使用 `-ff` 参数将所有的调用分离到不同的文件中(查看 [strace 手册][6] 获取更多信息)。
|
||||
|
||||
#### 使用 `-e` 进行过滤
|
||||
#### 使用 -e 进行过滤
|
||||
|
||||
正如你所看到的,默认的追踪输出是所有的系统调用。你可以使用 `-e` 参数过滤你需要追踪的调用(查看 [the `strace` manual][6])。这样做的好处是运行过滤后的 `strace` 比起使用 `grep` 进行二次过滤要更快。老实说,我大部分时间都不会被打扰。
|
||||
正如你所看到的,默认的追踪输出是所有的系统调用。你可以使用 `-e` 参数过滤你需要追踪的调用(查看 [strace 手册][6])。这样做的好处是运行过滤后的 `strace` 比起使用 `grep` 进行二次过滤要更快。老实说,我大部分时间都不会被打扰。
|
||||
|
||||
#### 并非所有的错误都是不好的
|
||||
|
||||
@ -187,17 +183,17 @@ stat("/usr/bin/uname", {st_mode=S_IFREG|0755, st_size=39584, ...}) = 0
|
||||
...
|
||||
```
|
||||
|
||||
“错误信息之前的最后一次失败调用”这种启发式方法非常适合于查找错误。无论如何,自下而上地工作是有道理的。
|
||||
“错误信息之前的最后一次失败调用”这种启发式方法非常适合于查找错误。无论如何,自下而上地查找是有道理的。
|
||||
|
||||
#### C编程指南非常有助于理解系统调用
|
||||
#### C 编程指南非常有助于理解系统调用
|
||||
|
||||
标准 C 库函数调用不属于系统调用,但它们仅是系统调用之上的唯一一个薄层。所以如果你了解(甚至只是略知一二)如何使用 C 语言,那么阅读系统调用追踪信息就非常容易。例如,如果你在调试网络系统调用,你可以尝试略读 [Beej’s classic Guide to Network Programming][7]。
|
||||
标准 C 库函数调用不属于系统调用,但它们仅是系统调用之上的唯一一个薄层。所以如果你了解(甚至只是略知一二)如何使用 C 语言,那么阅读系统调用追踪信息就非常容易。例如,如果你在调试网络系统调用,你可以尝试略读 [Beej 经典的《网络编程指南》][7]。
|
||||
|
||||
### 一个更复杂的调试例子
|
||||
|
||||
就像我说的那样,简单的调试例子代表我在大部分情况下如何使用 `strace` 。然而,有时候需要一些更加细致的工作,所以这里有一个稍微复杂(且真实)的例子。
|
||||
就像我说的那样,简单的调试例子表现了我在大部分情况下如何使用 `strace`。然而,有时候需要一些更加细致的工作,所以这里有一个稍微复杂(且真实)的例子。
|
||||
|
||||
[`bcron`][8] 是一个任务调度器,它是经典 *nix `cron` 守护程序的一种实现。它已经被安装到一台服务器上,但是当有人尝试编辑作业时间表时,发生了以下情况:
|
||||
[bcron][8] 是一个任务调度器,它是经典 *nix `cron` 守护程序的另一种实现。它已经被安装到一台服务器上,但是当有人尝试编辑作业时间表时,发生了以下情况:
|
||||
|
||||
```
|
||||
# crontab -e -u logs
|
||||
@ -232,9 +228,9 @@ exit_group(111) = ?
|
||||
|
||||
在程序结束之前有一个 `write` 的错误信息,但是这次有些不同。首先,在此之前没有任何相关的失败系统调用。其次,我们看到这个错误信息是由 `read` 从别的地方读取而来的。这看起来像是真正的错误发生在别的地方,而 `bcrontab` 只是在转播这些信息。
|
||||
|
||||
如果你查阅了 `man 2 read`,你将会看到 `read` 的第三个参数 (3) 代表文件描述符,这是 *nix 操作系统用于所有 IO 操作的句柄。你该如何知道文件描述符 3 代表什么?在这种情况下,你可以使用 `-y` 参数运行 `strace`(如上文所述),它将会在注释里告诉你文件描述符的具体指向,但是了解如何从上面这种输出中分析追踪结果是很有用的。
|
||||
如果你查阅了 `man 2 read`,你将会看到 `read` 的第一个参数 (`3`) 是一个文件描述符,这是 *nix 操作系统用于所有 IO 操作的句柄。你该如何知道文件描述符 3 代表什么?在这种情况下,你可以使用 `-y` 参数运行 `strace`(如上文所述),它将会在注释里告诉你文件描述符的具体指向,但是了解如何从上面这种输出中分析追踪结果是很有用的。
|
||||
|
||||
一个文件描述符可以来自于许多系统调用之一(这取决于它是用于控制台、网络套接字还是真实文件等的描述符),但不论如何,我们都可以搜索返回值为 3 的系统调用(例如,在 `strace` 的输出中查找 “=3”)。在这次 `strace` 中可以看到有两个这样的调用:最上面的 `openat` 以及中间的 `socket`。`openat` 打开一个文件,但是紧接着的 `close(3)` 表明其已经被关闭。(注意:文件描述符可以在打开并关闭后重复使用。)所以 `socket` 调用才是与此相关的(它是在 `read` 之前的最后一次),这告诉我们 `brcontab` 正在与一个网络套接字通信。在下一行,`connect` 表明文件描述符 3 是一个连接到 `/var/run/bcron-spool` 的 Unix 域套接字。
|
||||
一个文件描述符可以来自于许多系统调用之一(这取决于它是用于控制台、网络套接字还是真实文件等的描述符),但不论如何,我们都可以搜索返回值为 `3` 的系统调用(例如,在 `strace` 的输出中查找 `=3`)。在这次 `strace` 中可以看到有两个这样的调用:最上面的 `openat` 以及中间的 `socket`。`openat` 打开一个文件,但是紧接着的 `close(3)` 表明其已经被关闭。(注意:文件描述符可以在打开并关闭后重复使用。)所以 `socket` 调用才是与此相关的(它是在 `read` 之前的最后一个),这告诉我们 `brcontab` 正在与一个网络套接字通信。在下一行,`connect` 表明文件描述符 3 是一个连接到 `/var/run/bcron-spool` 的 Unix 域套接字。
|
||||
|
||||
因此,我们需要弄清楚 Unix 套接字的另一侧是哪个进程在监听。有两个巧妙的技巧适用于在服务器部署中调试。一个是使用 `netstat` 或者较新的 `ss`。这两个命令都描述了当前系统中活跃的网络套接字,使用 `-l` 参数可以显示出处于监听状态的套接字,而使用 `-p` 参数可以得到正在使用该套接字的程序信息。(它们还有更多有用的选项,但是这两个已经足够完成工作了。)
|
||||
|
||||
@ -243,7 +239,7 @@ exit_group(111) = ?
|
||||
u_str LISTEN 0 128 /var/run/bcron-spool 1466637 * 0 users:(("unixserver",pid=20629,fd=3))
|
||||
```
|
||||
|
||||
这告诉我们 `/var/run/bcron-spool` 套接字的监听程序是 `unixserver` 这个命令,它的进程 ID 为 20629。(巧合的是,这个程序也使用文件描述符 3 去连接这个套接字。)
|
||||
这告诉我们 `/var/run/bcron-spool` 套接字的监听程序是 `unixserver` 这个命令,它的进程 ID 为 20629。(巧合的是,这个程序也使用文件描述符 `3` 去连接这个套接字。)
|
||||
|
||||
第二个常用的工具就是使用 `lsof` 查找相同的信息。它可以列出当前系统中打开的所有文件(或文件描述符)。或者,我们可以得到一个具体文件的信息:
|
||||
|
||||
@ -277,7 +273,7 @@ rt_sigreturn({mask=[]}) = 43
|
||||
accept(3, NULL, NULL
|
||||
```
|
||||
|
||||
(最后一个 `accept` 调用没有在追踪周期里完成。)不幸的是,这次追踪没有包含我们想要的错误信息。我们没有观察到 `bcrontan` 往套接字发送或接受的任何信息。然而,我们看到了很多进程管理操作(`clone`,`wait4`,`SIGCHLD`,等等)。这个进程产生了子进程,我们猜测真实的工作是由子进程完成的。如果我们想捕获子进程的追踪信息,就必须往 `strace` 追加 `-f` 参数。以下是我们最终使用 `strace -f -o /tmp/trace -p 20629` 找到的错误信息:
|
||||
(最后一个 `accept` 调用没有在追踪期间完成。)不幸的是,这次追踪没有包含我们想要的错误信息。我们没有观察到 `bcrontan` 往套接字发送或接受的任何信息。然而,我们看到了很多进程管理操作(`clone`、`wait4`、`SIGCHLD`,等等)。这个进程产生了子进程,我们猜测真实的工作是由子进程完成的。如果我们想捕获子进程的追踪信息,就必须往 `strace` 追加 `-f` 参数。以下是我们最终使用 `strace -f -o /tmp/trace -p 20629` 找到的错误信息:
|
||||
|
||||
```
|
||||
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied)
|
||||
@ -305,7 +301,9 @@ accept(3, NULL, NULL
|
||||
21470 +++ exited with 111 +++
|
||||
```
|
||||
|
||||
(如果你在这里失败了,你可能需要阅读 [我之前有关 *nix 进程管理和 shell 的文章][9])好的,现在 PID 为 20629 的服务器进程没有权限在 `/var/spool/cron/tmp/spool.21470.1573692319.854640` 创建文件。最可能的原因就是典型的 *nix 文件系统权限设置。让我们检查一下:
|
||||
(如果你在这里迷糊了,你可能需要阅读 [我之前有关 \*nix 进程管理和 shell 的文章][9])
|
||||
|
||||
现在 PID 为 20629 的服务器进程没有权限在 `/var/spool/cron/tmp/spool.21470.1573692319.854640` 创建文件。最可能的原因就是典型的 *nix 文件系统权限设置。让我们检查一下:
|
||||
|
||||
```
|
||||
# ls -ld /var/spool/cron/tmp/
|
||||
@ -330,7 +328,7 @@ via: https://theartofmachinery.com/2019/11/14/deployment_debugging_strace.html
|
||||
作者:[Simon Arneaud][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hanwckf](https://github.com/hanwckf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11654-1.html)
|
||||
[#]: subject: (How to port an awk script to Python)
|
||||
[#]: via: (https://opensource.com/article/19/11/awk-to-python)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
@ -12,13 +12,13 @@
|
||||
|
||||
> 将一个 awk 脚本移植到 Python 主要在于代码风格而不是转译。
|
||||
|
||||
![Woman sitting in front of her laptop][1]
|
||||

|
||||
|
||||
脚本是解决问题的有效方法,而 awk 是编写脚本的出色语言。它特别擅长于简单的文本处理,它可以带你完成配置文件的某些复杂重写或目录中文件名的重新格式化。
|
||||
|
||||
### 何时从 awk 转向 Python
|
||||
|
||||
但是在某写方面,awk 的限制开始显现出来。它没有将文件分解为模块的真正概念,它缺乏质量错误报告,并且缺少了现在被认为是编程语言工作原理的其他内容。当编程语言的这些丰富功能有助于维护关键脚本时,移植将是一个不错的选择。
|
||||
但是在某些方面,awk 的限制开始显现出来。它没有将文件分解为模块的真正概念,它缺乏质量错误报告,并且缺少了现在被认为是编程语言工作原理的其他内容。当编程语言的这些丰富功能有助于维护关键脚本时,移植将是一个不错的选择。
|
||||
|
||||
我最喜欢的完美移植 awk 的现代编程语言是 Python。
|
||||
|
||||
@ -75,7 +75,7 @@ def awk_like_lines(list_of_file_names):
|
||||
|
||||
### 更复杂的 FNR、NR 和行数的 awk 行为
|
||||
|
||||
如果 `FNR`、`NR` 和行数这三个你全部需要,仍然会有问题。如果确实如此,则使用三元组(其中两个项目是数字)会导致混淆。命名参数可使该代码更易于阅读,因此最好使用 `dataclass:
|
||||
如果 `FNR`、`NR` 和行数这三个你全都需要,仍然会有一些问题。如果确实如此,则使用三元组(其中两个项目是数字)会导致混淆。命名参数可使该代码更易于阅读,因此最好使用 `dataclass`:
|
||||
|
||||
```
|
||||
import dataclass
|
||||
@ -95,7 +95,7 @@ def awk_like_lines(list_of_file_names):
|
||||
yield AwkLikeLine(nr=nr, fnr=fnr, line=line)
|
||||
```
|
||||
|
||||
你可能想知道,为什么不总用这种方法呢?用其它方式的的原因是这总是太复杂了。如果你的目标是把一个通用库更容易地从 awk 移植到 Python,请考虑这样做。但是编写一个可以使你确切地了解特定情况所需的循环的方法通常更容易实现,也更容易理解(因而易于维护)。
|
||||
你可能想知道,为什么不一直用这种方法呢?使用其它方式的的原因是总用这种方法太复杂了。如果你的目标是把一个通用库更容易地从 awk 移植到 Python,请考虑这样做。但是编写一个可以使你确切地了解特定情况所需的循环的方法通常更容易实现,也更容易理解(因而易于维护)。
|
||||
|
||||
### 理解 awk 字段
|
||||
|
||||
@ -181,7 +181,7 @@ for line in unique_generator(open("your_file")):
|
||||
|
||||
将 awk 脚本移植到 Python 时,通常是在考虑适当的 Python 代码风格时重新实现核心需求,而不是按条件/操作进行笨拙的音译。考虑原始上下文并产生高质量的 Python 解决方案。虽然有时候使用 awk 的 Bash 单行代码可以完成这项工作,但 Python 编码是通往更易于维护的代码的途径。
|
||||
|
||||
另外,如果你正在编写awk脚本,我相信您也可以学习 Python!如果你有任何疑问,请告诉我。
|
||||
另外,如果你正在编写 awk 脚本,我相信您也可以学习 Python!如果你有任何疑问,请告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -190,7 +190,7 @@ via: https://opensource.com/article/19/11/awk-to-python
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11661-1.html)
|
||||
[#]: subject: (6 Methods to Quickly Check if a Website is up or down from the Linux Terminal)
|
||||
[#]: via: (https://www.2daygeek.com/linux-command-check-website-is-up-down-alive/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
在 Linux Terminal 快速检测网站是否宕机的 6 个方法
|
||||
在 Linux 终端快速检测网站是否宕机的 6 个方法
|
||||
======
|
||||
|
||||
本教程教你怎样在 Linux terminal 快速检测一个网站是否宕机。
|
||||
> 本教程教你怎样在 Linux 终端快速检测一个网站是否宕机。
|
||||
|
||||
你可能已经了解了一些类似的命令,像 ping,curl 和 wget。我们在本教程中又加入了一些其他命令。同时,对于要检测单个和多个主机的信息我们也加入了不同的选项。
|
||||

|
||||
|
||||
本文将帮助你检测网站是否宕机。但是如果你在维护一个网站,希望网站宕掉时得到实时的报警,我推荐你去使用实时网站监控工具。这种工具有很多,有些是免费的,大部分收费。根据你的需求,选择合适的工具。在后续的文章中我们会涉及这个主题。
|
||||
你可能已经了解了一些类似的命令,像 `ping`、`curl` 和 `wget`。我们在本教程中又加入了一些其他命令。同时,我们也加入了不同的选项来检测单个和多个主机的信息。
|
||||
|
||||
本文将帮助你检测网站是否宕机。但是如果你在维护一些网站,希望网站宕掉时得到实时的报警,我推荐你去使用实时网站监控工具。这种工具有很多,有些是免费的,大部分收费。根据你的需求,选择合适的工具。在后续的文章中我们会涉及这个主题。
|
||||
|
||||
### 方法 1:使用 fping 命令检测一个网站是否宕机
|
||||
|
||||
**[fping 命令][1]** 是一个类似 ping 的程序,使用互联网控制消息协议回应请求报文(ICMP echo request)来判断目标主机是否能回应。fping 与 ping 的不同之处在于它可以并行地 ping 任意数量的主机,也可以从一个文本文件读入主机。fping 发送一个 ICMP echo request 后不等待目标主机响应,就以 round-robin 模式向下一个目标主机发请求。如果一个目标主机有响应,那么它就被标记为存活的(active)然后从检查目标列表里去掉。如果一个目标主机在限定的时间和(或)重试次数内没有响应,则被指定为网站无法到达(unreachable)。
|
||||
[fping 命令][1] 是一个类似 `ping` 的程序,使用互联网控制消息协议(ICMP)的<ruby>回应请求报文<rt>echo request</rt></ruby>来判断目标主机是否能回应。`fping` 与 `ping` 的不同之处在于它可以并行地 `ping` 任意数量的主机,也可以从一个文本文件读入主机名称。`fping` 发送一个 ICMP 回应请求后不等待目标主机响应,就以轮询模式向下一个目标主机发请求。如果一个目标主机有响应,那么它就被标记为存活的,然后从检查目标列表里去掉。如果一个目标主机在限定的时间和(或)重试次数内没有响应,则被指定为网站无法到达的。
|
||||
|
||||
```
|
||||
# fping 2daygeek.com linuxtechnews.com magesh.co.in
|
||||
@ -30,7 +32,7 @@ magesh.co.in is alive
|
||||
|
||||
### 方法 2:使用 http 命令检测一个网站是否宕机
|
||||
|
||||
HTTPie(读作 aitch-tee-tee-pie)是一个命令行 HTTP 客户端。**[httpie tool][2]** 是一个可以与 web 服务通过 CLI(command-line interface)进行交互的现代工具。httpie tool 提供了简单的 http 命令,可以通过发送简单的、自然语言语法的任意 HTTP 请求得到多彩的结果输出。HTTPie 可以用来对 HTTP 服务器进行测试、调试和基本的交互。
|
||||
HTTPie(读作 aitch-tee-tee-pie)是一个命令行 HTTP 客户端。[httpie][2] 是一个可以与 web 服务通过 CLI 进行交互的现代工具。httpie 工具提供了简单的 `http` 命令,可以通过发送简单的、自然语言语法的任意 HTTP 请求得到多彩的结果输出。HTTPie 可以用来对 HTTP 服务器进行测试、调试和基本的交互。
|
||||
|
||||
```
|
||||
# http 2daygeek.com
|
||||
@ -49,7 +51,7 @@ Vary: Accept-Encoding
|
||||
|
||||
### 方法 3:使用 curl 命令检测一个网站是否宕机
|
||||
|
||||
**[curl 命令](https://www.2daygeek.com/curl-linux-command-line-download-manager/)** 是一个用于在服务器间通过支持的协议(DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET 和 TFTP)传输数据的工具。这个工具不支持用户交互。curl 也支持使用代理、用户认证、FTP 上传、HTTP post、SSL 连接、cookies、断点续传、Metalink等等。curl 由 libcurl 库提供所有与传输有关的能力。
|
||||
[curl 命令][3] 是一个用于在服务器间通过支持的协议(DICT、FILE、FTP、FTPS、GOPHER、HTTP、HTTPS、IMAP、IMAPS、LDAP、LDAPS、POP3、POP3S、RTMP、RTSP、SCP、SFTP、SMTP、SMTPS、TELNET 和 TFTP)传输数据的工具。这个工具不支持用户交互。`curl` 也支持使用代理、用户认证、FTP 上传、HTTP POST 请求、SSL 连接、cookie、断点续传、Metalink 等等。`curl `由 libcurl 库提供所有与传输有关的能力。
|
||||
|
||||
```
|
||||
# curl -I https://www.magesh.co.in
|
||||
@ -67,7 +69,7 @@ server: cloudflare
|
||||
cf-ray: 535b74123ca4dbf3-LHR
|
||||
```
|
||||
|
||||
如果你只想看 HTTP 状态码而不是返回的全部信息,用下面的 curl 命令:
|
||||
如果你只想看 HTTP 状态码而不是返回的全部信息,用下面的 `curl` 命令:
|
||||
|
||||
```
|
||||
# curl -I "www.magesh.co.in" 2>&1 | awk '/HTTP\// {print $2}'
|
||||
@ -87,7 +89,7 @@ else
|
||||
fi
|
||||
```
|
||||
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果:
|
||||
|
||||
```
|
||||
# sh curl-url-check.sh
|
||||
@ -113,7 +115,7 @@ echo "----------------------------------"
|
||||
done
|
||||
```
|
||||
|
||||
当你把上面脚本内容添加到一个文件后,执行文件,查看结果
|
||||
当你把上面脚本内容添加到一个文件后,执行文件,查看结果:
|
||||
|
||||
```
|
||||
# sh curl-url-check-1.sh
|
||||
@ -130,7 +132,7 @@ www.xyzzz.com is down
|
||||
|
||||
### 方法 4:使用 wget 命令检测一个网站是否宕机
|
||||
|
||||
**[wget 命令][4]** (前身是 Geturl)是一个免费的开源命令行下载工具,通过 HTTP、HTTPS、FTP和其他广泛使用的互联网协议检索文件。wget 是非交互式的命令行工具,由 World Wide Web 和 get 得名。wget 相对于其他工具来说更优秀,功能包括后台运行、递归下载、多文件下载、断点续传、非交互式下载和大文件下载。
|
||||
[wget 命令][4](前身是 Geturl)是一个自由开源的命令行下载工具,通过 HTTP、HTTPS、FTP 和其他广泛使用的互联网协议获取文件。`wget` 是非交互式的命令行工具,由 World Wide Web 和 get 得名。`wget` 相对于其他工具来说更优秀,功能包括后台运行、递归下载、多文件下载、断点续传、非交互式下载和大文件下载。
|
||||
|
||||
```
|
||||
# wget -S --spider https://www.magesh.co.in
|
||||
@ -158,7 +160,7 @@ Remote file exists and could contain further links,
|
||||
but recursion is disabled -- not retrieving.
|
||||
```
|
||||
|
||||
如果你只想看 HTTP 状态码而不是返回的全部结果,用下面的 wget 命令:
|
||||
如果你只想看 HTTP 状态码而不是返回的全部结果,用下面的 `wget` 命令:
|
||||
|
||||
```
|
||||
# wget --spider -S "www.magesh.co.in" 2>&1 | awk '/HTTP\// {print $2}'
|
||||
@ -178,7 +180,7 @@ else
|
||||
fi
|
||||
```
|
||||
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果:
|
||||
|
||||
```
|
||||
# wget-url-check.sh
|
||||
@ -221,7 +223,7 @@ www.xyzzz.com is down
|
||||
|
||||
### 方法 5:使用 lynx 命令检测一个网站是否宕机
|
||||
|
||||
**[lynx][5]** 是一个在可寻址光标字符单元终端上使用的基于文本的高度可配的 web 浏览器,它是最古老的 web 浏览器并且现在仍在开发。
|
||||
[lynx][5] 是一个在<ruby>可寻址光标字符单元终端<rt>cursor-addressable character cell terminals</rt></ruby>上使用的基于文本的高度可配的 web 浏览器,它是最古老的 web 浏览器并且现在仍在活跃开发。
|
||||
|
||||
```
|
||||
# lynx -head -dump http://www.magesh.co.in
|
||||
@ -240,7 +242,7 @@ Server: cloudflare
|
||||
CF-RAY: 535fc5704a43e694-LHR
|
||||
```
|
||||
|
||||
如果你只想看 HTTP 状态码而不是返回的全部结果,用下面的 lynx 命令:
|
||||
如果你只想看 HTTP 状态码而不是返回的全部结果,用下面的 `lynx` 命令:
|
||||
|
||||
```
|
||||
# lynx -head -dump https://www.magesh.co.in 2>&1 | awk '/HTTP\// {print $2}'
|
||||
@ -260,7 +262,7 @@ else
|
||||
fi
|
||||
```
|
||||
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果:
|
||||
|
||||
```
|
||||
# sh lynx-url-check.sh
|
||||
@ -303,7 +305,7 @@ www.xyzzz.com is down
|
||||
|
||||
### 方法 6:使用 ping 命令检测一个网站是否宕机
|
||||
|
||||
**[ping 命令][1]** (Packet Internet Groper)是网络工具的代表,用于在互联网协议(IP)的网络中测试一个目标主机是否可用/可连接。通过向目标主机发送 ICMP 回应请求报文包并等待 ICMP 回应响应报文来检测主机的可用性。它基于已发送的包、接收到的包和丢失了的包来统计结果数据,通常包含最小/平均/最大响应时间。
|
||||
[ping 命令][1](Packet Internet Groper)是网络工具的代表,用于在互联网协议(IP)的网络中测试一个目标主机是否可用/可连接。通过向目标主机发送 ICMP 回应请求报文包并等待 ICMP 回应响应报文来检测主机的可用性。它基于已发送的包、接收到的包和丢失了的包来统计结果数据,通常包含最小/平均/最大响应时间。
|
||||
|
||||
```
|
||||
# ping -c 5 2daygeek.com
|
||||
@ -320,9 +322,9 @@ PING 2daygeek.com (104.27.157.177) 56(84) bytes of data.
|
||||
rtt min/avg/max/mdev = 170.668/213.824/250.295/28.320 ms
|
||||
```
|
||||
|
||||
### 方法 7:使用 telnet 命令检测一个网站是否宕机
|
||||
### 附加 1:使用 telnet 命令检测一个网站是否宕机
|
||||
|
||||
telnet 命令是一个使用 TELNET 协议用于 TCP/IP 网络中多个主机相互通信的古老的网络协议。它通过 23 端口连接其他设备如计算机和网络设备。telnet 是不安全的协议,现在由于用这个协议发送的数据没有经过加密可能被黑客拦截,所以不推荐使用。大家都使用经过加密且非常安全的 SSH 协议来代替 telnet。
|
||||
`telnet` 命令是一个使用 TELNET 协议用于 TCP/IP 网络中多个主机相互通信的古老的网络协议。它通过 23 端口连接其他设备如计算机和网络设备。`telnet` 是不安全的协议,现在由于用这个协议发送的数据没有经过加密可能被黑客拦截,所以不推荐使用。大家都使用经过加密且非常安全的 SSH 协议来代替 `telnet`。
|
||||
|
||||
```
|
||||
# telnet google.com 80
|
||||
@ -335,11 +337,11 @@ telnet> quit
|
||||
Connection closed.
|
||||
```
|
||||
|
||||
### 方法 8:使用 bash 脚本检测一个网站是否宕机
|
||||
### 附加 2:使用 bash 脚本检测一个网站是否宕机
|
||||
|
||||
简而言之,一个 **[shell 脚本][6]** 就是一个包含一系列命令的文件。shell 从文件读取内容按输入顺序逐行在命令行执行。为了让它更有效,我们添加一些条件。这也减轻了 Linux 管理员的负担。
|
||||
简而言之,一个 [shell 脚本][6] 就是一个包含一系列命令的文件。shell 从文件读取内容按输入顺序逐行在命令行执行。为了让它更有效,我们添加一些条件。这也减轻了 Linux 管理员的负担。
|
||||
|
||||
如果你想想用 wget 命令看多个网站的状态,使用下面的 shell 脚本:
|
||||
如果你想想用 `wget` 命令看多个网站的状态,使用下面的 shell 脚本:
|
||||
|
||||
```
|
||||
# vi wget-url-check-2.sh
|
||||
@ -365,7 +367,7 @@ google.co.in is up
|
||||
www.xyzzz.com is down
|
||||
```
|
||||
|
||||
如果你想想用 wget 命令看多个网站的状态,使用下面的 **[shell 脚本][7]**:
|
||||
如果你想用 `wget` 命令看多个网站的状态,使用下面的 [shell 脚本][7]:
|
||||
|
||||
```
|
||||
# vi curl-url-check-2.sh
|
||||
@ -398,7 +400,7 @@ via: https://www.2daygeek.com/linux-command-check-website-is-up-down-alive/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11699-1.html)
|
||||
[#]: subject: (How internet security works: TLS, SSL, and CA)
|
||||
[#]: via: (https://opensource.com/article/19/11/internet-security-tls-ssl-certificate-authority)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brson)
|
||||
|
||||
互联网的安全是如何保证的:TLS、SSL 和 CA
|
||||
======
|
||||
|
||||
> 你的浏览器里的锁的图标的后面是什么?
|
||||
|
||||
![Lock][1]
|
||||
|
||||
每天你都会重复这件事很多次,访问网站,网站需要你用你的用户名或者电子邮件地址和你的密码来进行登录。银行网站、社交网站、电子邮件服务、电子商务网站和新闻网站。这里只在使用了这种机制的网站中列举了其中一小部分。
|
||||
|
||||
每次你登录进一个这种类型的网站时,你实际上是在说:“是的,我信任这个网站,所以我愿意把我的个人信息共享给它。”这些数据可能包含你的姓名、性别、实际地址、电子邮箱地址,有时候甚至会包括你的信用卡信息。
|
||||
|
||||
但是你怎么知道你可以信任这个网站?换个方式问,为了让你可以信任它,网站应该如何保护你的交易?
|
||||
|
||||
本文旨在阐述使网站变得安全的机制。我会首先论述 web 协议 http 和 https,以及<ruby>传输层安全<rt>Transport Layer Security</rt></ruby>(TLS)的概念,后者是<ruby>互联网协议<rt>Internet Protocol</rt></ruby>(IP)层中的加密协议之一。然后,我会解释<ruby>证书颁发机构<rt>certificate authority</rt></ruby>和自签名证书,以及它们如何帮助保护一个网站。最后,我会介绍一些开源的工具,你可以使用它们来创建和管理你的证书。
|
||||
|
||||
### 通过 https 保护路由
|
||||
|
||||
了解一个受保护的网站的最简单的方式就是在交互中观察它,幸运的是,在今天的互联网上,发现一个安全的网站远远比找到一个不安全的网站要简单。但是,因为你已经在 Opensource.com 这个网站上了,我会使用它来作为案例,无论你使用的是哪个浏览器,你应该在你的地址栏旁边看到一个像锁一样的图标。点击这个锁图标,你应该会看见一些和下面这个类似的东西。
|
||||
|
||||
![Certificate information][2]
|
||||
|
||||
默认情况下,如果一个网站使用的是 http 协议,那么它是不安全的。为通过网站主机的路由添加一个配置过的证书,可以把这个网站从一个不安全的 http 网站变为一个安全的 https 网站。那个锁图标通常表示这个网站是受 https 保护的。
|
||||
|
||||
点击证书来查看网站的 CA,根据你的浏览器,你可能需要下载证书来查看它。
|
||||
|
||||
![Certificate information][3]
|
||||
|
||||
在这里,你可以了解有关 Opensource.com 证书的信息。例如,你可以看到 CA 是 DigiCert,并以 Opensource.com 的名称提供给 Red Hat。
|
||||
|
||||
这个证书信息可以让终端用户检查该网站是否可以安全访问。
|
||||
|
||||
> 警告:如果你没有在网站上看到证书标志,或者如果你看见的标志显示这个网站不安全——请不要登录或者做任何需要你个人数据的操作。这种情况非常危险!
|
||||
|
||||
如果你看到的是警告标志,对于大多数面向公众开放的网站来说,这很少见,它通常意味着该证书已经过期或者是该证书是自签名的,而非通过一个受信任的第三方来颁发。在我们进入这些主题之前,我想解释一下 TLS 和 SSL。
|
||||
|
||||
### 带有 TLS 和 SSL 的互联网协议
|
||||
|
||||
TLS 是旧版<ruby>安全套接字层协议<rt>Secure Socket Layer</rt></ruby>(SSL)的最新版本。理解这一点的最好方法就是仔细理解互联网协议的不同协议层。
|
||||
|
||||
![IP layers][4]
|
||||
|
||||
我们知道当今的互联网是由 6 个层面组成的:物理层、数据链路层、网络层、传输层、安全层、应用层。物理层是基础,这一层是最接近实际的硬件设备的。应用层是最抽象的一层,是最接近终端用户的一层。安全层可以被认为是应用层的一部分,TLS 和 SSL,是被设计用来在一个计算机网络中提供通信安全的加密协议,它们位于安全层中。
|
||||
|
||||
这个过程可以确保终端用户使用网络服务时,通信的安全性和保密性。
|
||||
|
||||
### 证书颁发机构和自签名证书
|
||||
|
||||
<ruby>证书颁发机构<rt>Certificate authority</rt></ruby>(CA)是受信任的组织,它可以颁发数字证书。
|
||||
|
||||
TLS 和 SSL 可以使连接更安全,但是这个加密机制需要一种方式来验证它;这就是 SSL/TLS 证书。TLS 使用了一种叫做非对称加密的加密机制,这个机制有一对称为私钥和公钥的安全密钥。(这是一个非常复杂的主题,超出了本文的讨论范围,但是如果你想去了解这方面的东西,你可以阅读“[密码学和公钥密码基础体系简介][5]”)你要知道的基础内容是,证书颁发机构们,比如 GlobalSign、DigiCert 和 GoDaddy,它们是受人们信任的可以颁发证书的供应商,它们颁发的证书可以用于验证网站使用的 TLS/SSL 证书。网站使用的证书是导入到主机服务器里的,用于保护网站。
|
||||
|
||||
然而,如果你只是要测试一下正在开发中的网站或服务,CA 证书可能对你而言太昂贵或者是太复杂了。你必须有一个用于生产目的的受信任的证书,但是开发者和网站管理员需要有一种更简单的方式来测试网站,然后他们才能将其部署到生产环境中;这就是自签名证书的来源。
|
||||
|
||||
自签名证书是一种 TLS/SSL 证书,是由创建它的人而非受信任的 CA 机构颁发的。用电脑生成一个自签名证书很简单,它可以让你在无需购买昂贵的 CA 颁发的证书的情况下测试一个安全网站。虽然自签名证书肯定不能拿到生产环境中去使用,但对于开发和测试阶段来说,这是一种简单灵活的方法。
|
||||
|
||||
### 生成证书的开源工具
|
||||
|
||||
有几种开源工具可以用来管理 TLS/SSL 证书。其中最著名的就是 openssl,这个工具包含在很多 Linux 发行版中和 MacOS 中。当然,你也可以使用其他开源工具。
|
||||
|
||||
| 工具名 | 描述 | 许可证 |
|
||||
| --------- | ------------------------------------------------------------------------------ | --------------------------------- |
|
||||
| [OpenSSL][7] | 实现 TLS 和加密库的最著名的开源工具 | Apache License 2.0 |
|
||||
| [EasyRSA][8] | 用于构建 PKI CA 的命令行实用工具 | GPL v2 |
|
||||
| [CFSSL][9] | 来自 cloudflare 的 PKI/TLS 瑞士军刀 | BSD 2-Clause "Simplified" License |
|
||||
| [Lemur][10] | 来自<ruby>网飞<rt>Netflix</rt></ruby>的 TLS 创建工具 | Apache License 2.0 |
|
||||
|
||||
如果你的目的是扩展和对用户友好,网飞的 Lemur 是一个很有趣的选择。你在[网飞的技术博客][6]上可以查看更多有关它的信息。
|
||||
|
||||
### 如何创建一个 Openssl 证书
|
||||
|
||||
你可以靠自己来创建证书,下面这个案例就是使用 Openssl 生成一个自签名证书。
|
||||
|
||||
1、使用 `openssl` 命令行生成一个私钥:
|
||||
|
||||
```
|
||||
openssl genrsa -out example.key 2048
|
||||
```
|
||||
|
||||
|
||||
|
||||
2、使用在第一步中生成的私钥来创建一个<ruby>证书签名请求<rt>certificate signing request</rt></ruby>(CSR):
|
||||
|
||||
```
|
||||
openssl req -new -key example.key -out example.csr -subj "/C=US/ST=TX/L=Dallas/O=Red Hat/OU=IT/CN=test.example.com"
|
||||
```
|
||||
|
||||
|
||||
|
||||
3、使用你的 CSR 和私钥创建一个证书:
|
||||
|
||||
```
|
||||
openssl x509 -req -days 366 -in example.csr -signkey example.key -out example.crt
|
||||
```
|
||||
|
||||
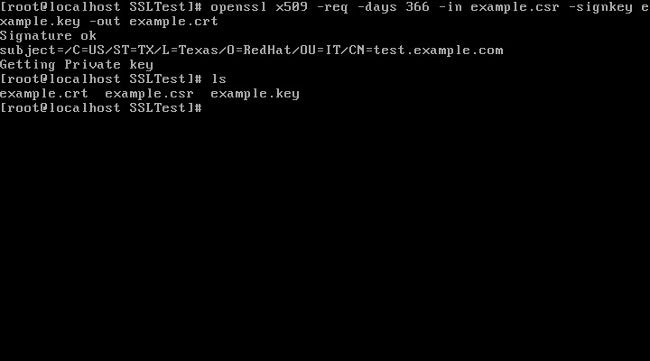
|
||||
|
||||
### 了解更多关于互联网安全的知识
|
||||
|
||||
如果你想要了解更多关于互联网安全和网站安全的知识,请看我为这篇文章一起制作的 Youtube 视频。
|
||||
|
||||
- <https://youtu.be/r0F1Hlcmjsk>
|
||||
|
||||
你有什么问题?发在评论里让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/internet-security-tls-ssl-certificate-authority
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security-lock-password.jpg?itok=KJMdkKum
|
||||
[2]: https://opensource.com/sites/default/files/uploads/1_certificatecheckwebsite.jpg
|
||||
[3]: https://opensource.com/sites/default/files/uploads/2_certificatedisplaywebsite.jpg
|
||||
[4]: https://opensource.com/sites/default/files/uploads/3_internetprotocol.jpg
|
||||
[5]: https://opensource.com/article/18/5/cryptography-pki
|
||||
[6]: https://medium.com/netflix-techblog/introducing-lemur-ceae8830f621
|
||||
[7]: https://www.openssl.org/
|
||||
[8]: https://github.com/OpenVPN/easy-rsa
|
||||
[9]: https://github.com/cloudflare/cfssl
|
||||
[10]: https://github.com/Netflix/lemur
|
||||
225
published/201912/20191125 The many faces of awk.md
Normal file
225
published/201912/20191125 The many faces of awk.md
Normal file
@ -0,0 +1,225 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (luuming)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11658-1.html)
|
||||
[#]: subject: (The many faces of awk)
|
||||
[#]: via: (https://www.networkworld.com/article/3454979/the-many-faces-of-awk.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
千面 awk
|
||||
======
|
||||
|
||||
> `awk` 命令不仅提供了简单的输入字符串筛选功能,还包含提取数据列、打印简单文本、筛选内容——甚至做一些数学计算。
|
||||
|
||||
![Thinkstock][6]
|
||||
|
||||
如果你仅使用 `awk` 选取一行中的特定文本,那么你可能错过了它的很多功能。在这篇文章中,我们会来看看使用 `awk` 可以帮你做一些其他的什么事情,并提供一些例子。
|
||||
|
||||
### 提取数据列
|
||||
|
||||
`awk` 所提供的最简单与最常用的功能便是从文件或管道传输的数据中选取特定的内容。默认使用空格当做分隔符,这非常简单。
|
||||
|
||||
```
|
||||
$ echo one two three four five | awk ‘{print $4}’
|
||||
four
|
||||
$ who | awk ‘{print $1}’
|
||||
jdoe
|
||||
fhenry
|
||||
```
|
||||
|
||||
空格指的是一系列的 `space` 或 `tab` 字符。在下面所展示的命令里,`awk` 从提供的数据中筛选第一和第四项。
|
||||
|
||||
`awk` 命令也可以通过在其后增加文件名参数的方式从文本文件中获取数据。
|
||||
|
||||
```
|
||||
$ awk '{print $1,$5,$NF}' HelenKellerQuote
|
||||
The beautiful heart.
|
||||
```
|
||||
|
||||
(LCTT 译注:“The best and most beautiful things in the world can not be seen or even touched , they must be felt with heart.” ——海伦凯勒)
|
||||
|
||||
在这个例子中,`awk` 挑选了一行中的第一个、第五个和最后一个字段。
|
||||
|
||||
命令中的 `$NF` 指定选取每行的最后一个字段。这是因为 `NF` 代表一行中的<ruby>字段数量<rt>Number of Field</rt></ruby>,也就是 23,而 `$NF` 就代表着那个字段的值,也就是`heart`。最后的句号也包含进去了,因为它是最后一个字符串的一部分。
|
||||
|
||||
字段能以任何有用的形式打印。在这个例子中,我们将字段以日期的格式进行打印输出。
|
||||
|
||||
```
|
||||
$ date | awk '{print $4,$3,$2}'
|
||||
2019 Nov 22
|
||||
```
|
||||
|
||||
如果你省略了 `awk` 命令中字段指示符之间的逗号,输出将会挤成一个字符串。
|
||||
|
||||
```
|
||||
$ date | awk '{print $4 $3 $2}'
|
||||
2019Nov21
|
||||
```
|
||||
|
||||
如果你将通常使用的逗号替换为连字符,`awk` 就会尝试将两个字段的值相减——或许这并不是你想要的。它不会将连字符插入到输出结果中。相反地,它对输出做了一些数学计算。
|
||||
|
||||
```
|
||||
$ date | awk '{print $4-$3-$2}'
|
||||
1997
|
||||
```
|
||||
|
||||
在这个例子中,它将年 “2019” 和日期 “22” 相减,并忽略了中间的 “Nov”。
|
||||
|
||||
如果你想要空格之外的字符作为输出分隔符,你可以通过 `OFS`(<ruby>输出分隔符<rt>output field separator</rt></ruby>)指定分隔符,就像这样:
|
||||
|
||||
```
|
||||
$ date | awk '{OFS="-"; print $4,$3,$2}'
|
||||
2019-Nov-22
|
||||
```
|
||||
|
||||
### 打印简单文本
|
||||
|
||||
你也可以使用 `awk` 简单地显示一些文本。当然了,比起 `awk` 你可能更想使用 `echo` 命令。但换句话说,作为 `awk` 脚本的一部分,打印某些相关性文本将会非常实用。这里有一个没什么用的例子:
|
||||
|
||||
```
|
||||
$ awk 'BEGIN {print "Hello, World" }'
|
||||
Hello, World
|
||||
```
|
||||
|
||||
下面的例子更加合理,添加一行文本标签来更好的辨识数据。
|
||||
|
||||
```
|
||||
$ who | awk 'BEGIN {print "Current logins:"} {print $1}'
|
||||
Current logins:
|
||||
shs
|
||||
nemo
|
||||
```
|
||||
|
||||
### 指定字段分隔符
|
||||
|
||||
不是所有的输入都以空格作为分隔符的。如果你的文本通过其它的字符作为分隔符(例如:逗号、冒号、分号),你可以通过 `-F` 选项(输入分隔符)告诉 `awk`:
|
||||
|
||||
```
|
||||
$ cat testfile
|
||||
a:b:c,d:e
|
||||
$ awk -F : '{print $2,$3}' testfile
|
||||
b c,d
|
||||
```
|
||||
|
||||
下面是一个更加有用的例子——从冒号分隔的 `/etc/passwd` 文件中获取数据:
|
||||
|
||||
```
|
||||
$ awk -F: '{print $1}' /etc/passwd | head -11
|
||||
root
|
||||
daemon
|
||||
bin
|
||||
sys
|
||||
sync
|
||||
games
|
||||
man
|
||||
lp
|
||||
mail
|
||||
news
|
||||
uucp
|
||||
```
|
||||
|
||||
### 筛选内容
|
||||
|
||||
你也可以使用 `awk` 命令评估字段。例如你仅仅想列出 `/etc/passwd` 中的用户账号,就可以对第三个字段做一些筛选。下面的例子中我们只关注大于等于 1000 的 UID:
|
||||
|
||||
```
|
||||
$ awk -F":" ' $3 >= 1000 ' /etc/passwd
|
||||
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
|
||||
shs:x:1000:1000:Sandra Henry-Stocker,,,:/home/shs:/bin/bash
|
||||
nemo:x:1001:1001:Nemo,,,:/home/nemo:/usr/bin/zsh
|
||||
dory:x:1002:1002:Dory,,,:/home/dory:/bin/bash
|
||||
...
|
||||
```
|
||||
|
||||
如果你想为输出增加标题,可以添加 `BEGIN` 从句:
|
||||
|
||||
```
|
||||
$ awk -F":" 'BEGIN {print "user accounts:"} $3 >= 1000 ' /etc/passwd
|
||||
user accounts:
|
||||
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
|
||||
shs:x:1000:1000:Sandra Henry-Stocker,,,:/home/shs:/bin/bash
|
||||
nemo:x:1001:1001:Nemo,,,:/home/nemo:/usr/bin/zsh
|
||||
dory:x:1002:1002:Dory,,,:/home/dory:/bin/bash
|
||||
```
|
||||
|
||||
如果你想要不止一行的标题,你可以通过 `"\n"` 分隔输出:
|
||||
|
||||
```
|
||||
$ awk -F":" 'BEGIN {print "user accounts\n============="} $3 >= 1000 ' /etc/passwd
|
||||
user accounts
|
||||
=============
|
||||
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
|
||||
shs:x:1000:1000:Sandra Henry-Stocker,,,:/home/shs:/bin/bash
|
||||
nemo:x:1001:1001:Nemo,,,:/home/nemo:/usr/bin/zsh
|
||||
dory:x:1002:1002:Dory,,,:/home/dory:/bin/bash
|
||||
```
|
||||
|
||||
### 在 awk 中进行数学计算
|
||||
|
||||
`awk` 提供了惊人的数学计算能力,并且可以开平方,算 `log`,算 `tan` 等等。
|
||||
|
||||
这里有一对例子:
|
||||
|
||||
```
|
||||
$ awk 'BEGIN {print sqrt(2019)}'
|
||||
44.9333
|
||||
$ awk 'BEGIN {print log(2019)}'
|
||||
7.61036
|
||||
```
|
||||
|
||||
想要详细了解 `awk` 的数学计算能力,可以看《[使用 awk 进行数学计算][3]》这篇文章。
|
||||
|
||||
### awk 脚本
|
||||
|
||||
你也可以使用 `awk` 写一套单独的脚本。下面的例子模仿了之前写过的一个,不过还计算了系统里账户的数量。
|
||||
|
||||
```
|
||||
#!/usr/bin/awk -f
|
||||
|
||||
# 这一行是注释
|
||||
|
||||
BEGIN {
|
||||
printf "%s\n","User accounts:"
|
||||
print "=============="
|
||||
FS=":"
|
||||
n=0
|
||||
}
|
||||
|
||||
# 现在开始遍历数据
|
||||
{
|
||||
if ($3 >= 1000) {
|
||||
print $1
|
||||
n ++
|
||||
}
|
||||
}
|
||||
|
||||
END {
|
||||
print "=============="
|
||||
print n " accounts"
|
||||
}
|
||||
```
|
||||
|
||||
注意 `BEGIN` 那一节是如何提供标题、指定字段分隔符和初始化计数器的,它仅在脚本初始化时期执行。这个脚本也包含 `END` 节,它仅在中间所有命令处理完成之后运行,显示了所有中间小节所筛选数据的最终行数(第三个字段大于等于 1000)。
|
||||
|
||||
作为一个长存于 Unix 之上的命令,`awk` 依旧提供着非常有用的服务,这也是我几十年前爱上 Unix 的原因之一。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3454979/the-many-faces-of-awk.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.networkworld.com/article/2974753/doing-math-with-awk.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
[6]:https://images.techhive.com/images/article/2015/09/thinkstockphotos-512100549-100611755-large.jpg
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11716-1.html)
|
||||
[#]: subject: (Create virtual machines with Cockpit in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/create-virtual-machines-with-cockpit-in-fedora/)
|
||||
[#]: author: (Karlis KavacisPaul W. Frields https://fedoramagazine.org/author/karlisk/https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
在 Fedora 中使用 Cockpit 创建虚拟机
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
本文向你展示如何在 Fedora 31 上使用安装 Cockpit 所需软件来创建和管理虚拟机。Cockpit 是一个[交互式管理界面][2],可让你在任何受支持的 Web 浏览器上访问和管理系统。随着 [virt-manager 逐渐被废弃][3],鼓励用户使用 Cockpit 来替换它。
|
||||
|
||||
Cockpit 是一个正在活跃开发的项目,它有许多扩展其工作的插件。例如,其中一个是 “Machines”,它与 libvirtd 交互并允许用户创建和管理虚拟机。
|
||||
|
||||
### 安装软件
|
||||
|
||||
先决所需软件是 `libvirt`、`cockpit` 和 `cockpit-machines`。要将它们安装在 Fedora 31 上,请在终端[使用 sudo][4] 运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install libvirt cockpit cockpit-machines
|
||||
```
|
||||
|
||||
Cockpit 也在 “Headless Management” 软件包组中。该软件组对于仅通过网络访问的基于 Fedora 的服务器很有用。在这里,请使用以下命令进行安装:
|
||||
|
||||
```
|
||||
$ sudo dnf groupinstall "Headless Management"
|
||||
```
|
||||
|
||||
### 设置 Cockpit 服务
|
||||
|
||||
安装了必要的软件包后,就该启用服务了。`libvirtd` 服务运行虚拟机,而 Cockpit 有一个激活的套接字服务,可让你访问 Web GUI:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable libvirtd --now
|
||||
$ sudo systemctl enable cockpit.socket --now
|
||||
```
|
||||
|
||||
这应该足以运行虚拟机并通过 Cockpit 对其进行管理。(可选)如果要从网络上的另一台设备访问并管理计算机,那么需要将该服务开放给网络。为此,请在防火墙配置中添加新规则:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --zone=public --add-service=cockpit --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
要确认服务正在运行并且没有发生任何问题,请检查服务的状态:
|
||||
|
||||
```
|
||||
$ sudo systemctl status libvirtd
|
||||
$ sudo systemctl status cockpit.socket
|
||||
```
|
||||
|
||||
此时一切都应该正常工作。Cockpit Web GUI 应该可通过 <https://localhost:9090> 或 <https://127.0.0.1:9090> 访问。或者,在连接到同一网络的任何其他设备上的 Web 浏览器中输入本地网络 IP。(如果未设置 SSL 证书,那么可能需要允许来自浏览器的连接。)
|
||||
|
||||
### 创建和安装机器
|
||||
|
||||
使用系统的用户名和密码登录界面。你还可以选择是否允许在此会话中将密码用于管理任务。
|
||||
|
||||
选择 “Virtual Machines”,然后选择 “Create VM” 来创建一台新的虚拟机。控制台为你提供几个选项:
|
||||
|
||||
* 使用 Cockpit 的内置库下载操作系统
|
||||
* 使用系统上已下载的安装媒体
|
||||
* 指向系统安装树的 URL
|
||||
* 通过 [PXE][5] 协议通过网络引导媒体
|
||||
|
||||
输入所有必要的参数。然后选择 “Create” 启动新虚拟机。
|
||||
|
||||
此时,将出现一个图形控制台。大多数现代 Web 浏览器都允许你使用键盘和鼠标与 VM 控制台进行交互。现在,你可以完成安装并使用新的 VM,就像[过去通过 virt-manager][6] 一样。
|
||||
|
||||
*照片由 [Miguel Teixeira][7] 发布于 [Flickr][8](CC BY-SA 2.0)*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/create-virtual-machines-with-cockpit-in-fedora/
|
||||
|
||||
作者:[Karlis Kavacis][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/karlisk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/11/create-vm-cockpit-816x345.jpg
|
||||
[2]: https://cockpit-project.org/
|
||||
[3]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/8.0_release_notes/rhel-8_0_0_release#virtualization_4
|
||||
[4]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[5]: https://en.wikipedia.org/wiki/Preboot_Execution_Environment
|
||||
[6]: https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/
|
||||
[7]: https://flickr.com/photos/miguelteixeira/
|
||||
[8]: https://flickr.com/photos/miguelteixeira/2964851828/
|
||||
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hj24)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11701-1.html)
|
||||
[#]: subject: (How to write a Python web API with Flask)
|
||||
[#]: via: (https://opensource.com/article/19/11/python-web-api-flask)
|
||||
[#]: author: (Rachel Waston https://opensource.com/users/rachelwaston)
|
||||
|
||||
如何使用 Flask 编写 Python Web API
|
||||
======
|
||||
|
||||
> 这是一个快速教程,用来展示如何通过 Flask(目前发展最迅速的 Python 框架之一)来从服务器获取数据。
|
||||
|
||||
![spiderweb diagram][1]
|
||||
|
||||
[Python][2] 是一个以语法简洁著称的高级的、面向对象的程序语言。它一直都是一个用来构建 RESTful API 的顶级编程语言。
|
||||
|
||||
[Flask][3] 是一个高度可定制化的 Python 框架,可以为开发人员提供用户访问数据方式的完全控制。Flask 是一个基于 Werkzeug 的 [WSGI][4] 工具包和 Jinja 2 模板引擎的”微框架“。它是一个被设计来开发 RESTful API 的 web 框架。
|
||||
|
||||
Flask 是 Python 发展最迅速的框架之一,很多知名网站如:Netflix、Pinterest 和 LinkedIn 都将 Flask 纳入了它们的开发技术栈。下面是一个简单的示例,展示了 Flask 是如何允许用户通过 HTTP GET 请求来从服务器获取数据的。
|
||||
|
||||
### 初始化一个 Flask 应用
|
||||
|
||||
首先,创建一个你的 Flask 项目的目录结构。你可以在你系统的任何地方来做这件事。
|
||||
|
||||
```
|
||||
$ mkdir tutorial
|
||||
$ cd tutorial
|
||||
$ touch main.py
|
||||
$ python3 -m venv env
|
||||
$ source env/bin/activate
|
||||
(env) $ pip3 install flask-restful
|
||||
Collecting flask-restful
|
||||
Downloading https://files.pythonhosted.org/packages/17/44/6e49...8da4/Flask_RESTful-0.3.7-py2.py3-none-any.whl
|
||||
Collecting Flask>=0.8 (from flask-restful)
|
||||
[...]
|
||||
```
|
||||
|
||||
### 导入 Flask 模块
|
||||
|
||||
然后,在你的 `main.py` 代码中导入 `flask` 模块和它的 `flask_restful` 库:
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
from flask_restful import Resource, Api
|
||||
|
||||
app = Flask(__name__)
|
||||
api = Api(app)
|
||||
|
||||
class Quotes(Resource):
|
||||
def get(self):
|
||||
return {
|
||||
'William Shakespeare': {
|
||||
'quote': ['Love all,trust a few,do wrong to none',
|
||||
'Some are born great, some achieve greatness, and some greatness thrust upon them.']
|
||||
},
|
||||
'Linus': {
|
||||
'quote': ['Talk is cheap. Show me the code.']
|
||||
}
|
||||
}
|
||||
|
||||
api.add_resource(Quotes, '/')
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True)
|
||||
```
|
||||
|
||||
### 运行 app
|
||||
|
||||
Flask 包含一个内建的用于测试的 HTTP 服务器。来测试一下这个你创建的简单的 API:
|
||||
|
||||
```
|
||||
(env) $ python main.py
|
||||
* Serving Flask app "main" (lazy loading)
|
||||
* Environment: production
|
||||
WARNING: This is a development server. Do not use it in a production deployment.
|
||||
Use a production WSGI server instead.
|
||||
* Debug mode: on
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
启动开发服务器时将启动 Flask 应用程序,该应用程序包含一个名为 `get` 的方法来响应简单的 HTTP GET 请求。你可以通过 `wget`、`curl` 命令或者任意的 web 浏览器来测试它。
|
||||
|
||||
```
|
||||
$ curl http://localhost:5000
|
||||
{
|
||||
"William Shakespeare": {
|
||||
"quote": [
|
||||
"Love all,trust a few,do wrong to none",
|
||||
"Some are born great, some achieve greatness, and some greatness thrust upon them."
|
||||
]
|
||||
},
|
||||
"Linus": {
|
||||
"quote": [
|
||||
"Talk is cheap. Show me the code."
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
要查看使用 Python 和 Flask 的类似 Web API 的更复杂版本,请导航至美国国会图书馆的 [Chronicling America][5] 网站,该网站可提供有关这些信息的历史报纸和数字化报纸。
|
||||
|
||||
### 为什么使用 Flask?
|
||||
|
||||
Flask 有以下几个主要的优点:
|
||||
|
||||
1. Python 很流行并且广泛被应用,所以任何熟悉 Python 的人都可以使用 Flask 来开发。
|
||||
2. 它轻巧而简约。
|
||||
3. 考虑安全性而构建。
|
||||
4. 出色的文档,其中包含大量清晰,有效的示例代码。
|
||||
|
||||
还有一些潜在的缺点:
|
||||
|
||||
1. 它轻巧而简约。但如果你正在寻找具有大量捆绑库和预制组件的框架,那么这可能不是最佳选择。
|
||||
2. 如果必须围绕 Flask 构建自己的框架,则你可能会发现维护自定义项的成本可能会抵消使用 Flask 的好处。
|
||||
|
||||
|
||||
如果你要构建 Web 程序或 API,可以考虑选择 Flask。它功能强大且健壮,并且其优秀的项目文档使入门变得容易。试用一下,评估一下,看看它是否适合你的项目。
|
||||
|
||||
在本课中了解更多信息关于 Python 异常处理以及如何以安全的方式进行操作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/python-web-api-flask
|
||||
|
||||
作者:[Rachel Waston][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hj24](https://github.com/hj24)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rachelwaston
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web-cms-build-howto-tutorial.png?itok=bRbCJt1U (spiderweb diagram)
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://palletsprojects.com/p/flask/
|
||||
[4]: https://en.wikipedia.org/wiki/Web_Server_Gateway_Interface
|
||||
[5]: https://chroniclingamerica.loc.gov/about/api
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (algzjh)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11681-1.html)
|
||||
[#]: subject: (An idiot's guide to Kubernetes, low-code developers, and other industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/12/technology-advice-and-other-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
每周开源点评:Kubernetes 傻瓜指南、低代码开发人员和其他行业趋势
|
||||
======
|
||||
> 每周开源社区、市场和行业趋势。
|
||||
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
作为我在具有开源开发模型的企业软件公司担任高级产品营销经理的角色的一部分,我为产品营销人员、经理和其他影响者定期发布有关开源社区,市场和行业趋势的定期更新。这里有该更新中我和他们最喜欢的四篇文章。
|
||||
|
||||
### Kubernetes 傻瓜指南
|
||||
|
||||
- [文章链接][2]
|
||||
|
||||
> Kubernetes 已经发展出了新的特性,这使其成为企业软件的更好的容器平台。安全性和高级网络等元素已被纳入 Kubernetes 上游代码的主体,并且现在可供所有人使用。
|
||||
>
|
||||
> 然而,企业解决方案的其他方面总会有补充需求;比如日志记录和性能监控。这就是像 Istio 等辅助包发挥作用的地方,它带来了额外的功能,但是仍使 Kubernetes 的核心保持了合理的大小和特性集。
|
||||
|
||||
**影响**: 我总是发现,人们很容易把对技术发展的认识视为理所当然。当与你打交道的每个人都处于“最前沿”时,你的观点就会歪曲到这样的程度:你甚至可能会认为对最新的(*此处插入首选技术*)一无所知的人跟不上潮流,而实际上这并没有开始影响他们做自己需要做的事情的能力。那些人不是白痴;他们是我们的朋友、客户、合作伙伴、合作者和社区。
|
||||
|
||||
### Gartner: 采用低代码开发之前应该考虑什么
|
||||
|
||||
- [文章链接][3]
|
||||
|
||||
> 尽管专注于商业 IT 团队,但 Gartner 发现,一个日益重要的开发人员社区是需要快速开发简单应用程序或构建最低可行产品或多体验功能的核心 IT 专业开发人员。当应用程序领导者在传统的应用程序项目中使用低代码时,他们可能希望使用标准的 IT DevOps 自动化方法和低代码工具。
|
||||
|
||||
**影响**: 越来越多的用例和用户体验可以通过需要更少时间和技能来创建的应用程序来处理和交互。而低代码开发人员也可能会结合成一个具有他们自己的规范和亚文化的独特群体。
|
||||
|
||||
### 诺基亚认为云原生对 5G 核心至关重要
|
||||
|
||||
- [文章链接][4]
|
||||
|
||||
> 诺基亚概述了 5G 的五个关键业务目标,这些目标只能通过云原生环境来实现。其中包括:更好的带宽、延迟和密度;通过网络切片将服务扩展到新的企业、行业和[物联网][5]市场;根据敏捷性和效率定义的快速服务部署;超越传统带宽、语音和信息传递的新服务;以及利用端到端网络获取更多收入的数字服务的出现。
|
||||
|
||||
**影响**: 在越来越多的事物连接到网络的情况下,这是最有意义的。4G 主要与越来越多的手机有关;只有当你开始连接其他所有东西时,5G 才是真正必要的。4G 意味着我们的手机上有更丰富的应用程序,而 5G 几乎与手机无关。
|
||||
|
||||
### API:隐藏的业务加速器
|
||||
|
||||
- [文章链接][6]
|
||||
|
||||
> 要想让组织成功地进行数字化转型,API 策略至关重要。从解锁有价值的数据到加快开发时间,API 都是数字时代的幕后英雄。那些已经尝试过 API 的人已经感受到了好处。例如,研究表明,使用 API 的企业中,有 53% 认为它们提高了生产力,而 29% 声称它们的收入增长是使用 API 的直接结果。当 API 被视为存在于一个项目之外的可发现和可重用的产品时,它有助于为持续的变更奠定灵活的基础。
|
||||
|
||||
**影响**: 隐藏的业务加速器实际上是这样一种思想,即功能应该以一种方式进行打包,使其能够在原始提供者没有预料到的环境中进行重新利用和组合。
|
||||
|
||||
我希望你喜欢这份上周给我留下深刻印象的列表,并于下周一回来了解更多开源社区、市场和行业的趋势。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/technology-advice-and-other-industry-trends
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[algzjh](https://github.com/algzjh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr "Person standing in front of a giant computer screen with numbers, data"
|
||||
[2]: https://www.cbronline.com/feature/an-idiots-guide-to-kubernetes
|
||||
[3]: https://www.computerweekly.com/feature/Gartner-What-to-consider-before-adopting-low-code-development
|
||||
[4]: https://www.sdxcentral.com/articles/news/nokia-argues-cloud-native-is-essential-to-5g-core/2019/11/
|
||||
[5]: https://www.sdxcentral.com/5g/iot/ "IoT"
|
||||
[6]: https://www.cbronline.com/opinion/digital-transformation-3
|
||||
@ -1,34 +1,34 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hj24)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11653-1.html)
|
||||
[#]: subject: (Using Ansible to organize your SSH keys in AWS)
|
||||
[#]: via: (https://fedoramagazine.org/using-ansible-to-organize-your-ssh-keys-in-aws/)
|
||||
[#]: author: (Daniel Leite de Abreu https://fedoramagazine.org/author/dabreu/)
|
||||
|
||||
在 AWS 中使用 Ansible 来管理你的 SSH keys
|
||||
在 AWS 中使用 Ansible 来管理你的 SSH 密钥
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
如果你长期使用亚马逊Web服务(AWS)中的实例,你可能会遇到下面这个常见的问题,它不是因为技术性的原因导致的,更多的是因为人类追求方便舒适的天性:当你登录一台你最近没有使用的区域的实例,你最终就会创建一个新的SSH密钥对,久而久之这最终就会造成个人拥有太多密钥,导致管理起来复杂混乱。
|
||||
如果你长期使用亚马逊 Web 服务(AWS)中的实例,你可能会遇到下面这个常见的问题,它不是因为技术性的原因导致的,更多的是因为人类追求方便舒适的天性:当你登录一台你最近没有使用的区域的新实例,你最终会创建一个新的 SSH 密钥对,久而久之这最终就会造成个人拥有太多密钥,导致管理起来复杂混乱。
|
||||
|
||||
本文将会介绍一种在所有区域中使用你的公钥的方法。最近,一篇[Fedora Magazine article][2]介绍了另一种解决方案。但本文中的解决方案可以进一步的以更简洁和可扩展的方式实现自动化。
|
||||
本文将会介绍一种在所有区域中使用你的公钥的方法。最近,一篇 [Fedora Magazine 的文章][2]介绍了另一种解决方案。但本文中的解决方案可以进一步的以更简洁和可扩展的方式实现自动化。
|
||||
|
||||
假设你有一个Fedora 30或31系统,其中存储了你的密钥,并且还安装了Ansible。当这两件事同时满足时,就提供了解决这个问题的办法,甚至它还能做到更多。
|
||||
假设你有一个 Fedora 30 或 31 系统,其中存储了你的密钥,并且还安装了 Ansible。当这两件事同时满足时,就提供了解决这个问题的办法,甚至它还能做到更多。
|
||||
|
||||
使用Ansible的[ec2_key 模块][3],你可以创建一个简单的playbook来在所有区域中维护你的SSH密钥对。如果你需要增加或者删除密钥,在ansible中这就像从文件中添加和删除行一样简单。
|
||||
使用 Ansible 的 [ec2_key 模块][3],你可以创建一个简单的 Ansible 剧本来在所有区域中维护你的 SSH 密钥对。如果你需要增加或者删除密钥,在 Ansible 中这就像从文件中添加和删除行一样简单。
|
||||
|
||||
### 设置和运行 playbook
|
||||
### 设置和运行 Ansible 剧本
|
||||
|
||||
如果要使用playbook,首先需要安装 _ec2_key_ 模块的必要依赖项:
|
||||
如果要使用剧本,首先需要安装 `ec2_key` 模块的必要依赖项:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-boto python3-boto3
|
||||
```
|
||||
|
||||
playbook很简单:你只需要像下面的例子一样,修改其中的密钥及其对应的名称。然后,运行playbook,它会帮你遍历所有列出的公共AWS区域。该示例还包括一些受限区域,以防你有访问权限,只需根据需要来取消对应行的注释,然后,保存文件重新运行playbook即可。
|
||||
该剧本很简单:你只需要像下面的例子一样,修改其中的密钥及其对应的名称。然后,运行该剧本,它会帮你遍历所有列出的公共 AWS 区域。该示例还包括一些你可能要访问的受限区域,只需根据需要来取消对应行的注释,然后,保存文件重新运行剧本即可。
|
||||
|
||||
```
|
||||
---
|
||||
@ -71,34 +71,35 @@ playbook很简单:你只需要像下面的例子一样,修改其中的密钥
|
||||
# - cn-northwest-1 #China (Ningxia)
|
||||
```
|
||||
|
||||
这个playbook需要通过API访问AWS,为此,请使用环境变量,如下所示:
|
||||
这个剧本需要通过 API 访问 AWS,为此,请使用环境变量,如下所示:
|
||||
|
||||
```
|
||||
$ AWS_ACCESS_KEY="aws-access-key-id" AWS_SECRET_KEY="aws-secret-key-id" ansible-playbook ec2-playbook.yml
|
||||
```
|
||||
|
||||
另一个选项是安装aws cli工具并添加凭据,如以前的一篇[Fedora Magazine article][4]文章所述。如果你在线存储它们,这些参数将不建议插入到playbook中!你可以在[GitHub][5]中找到本文的playbook代码。
|
||||
另一个方式是安装 aws 命令行工具并添加凭据,如以前的一篇 [Fedora Magazine 文章][4]所述。如果你在线存储它们,这些参数将**不建议**插入到剧本中!你可以在 [GitHub][5] 中找到本文的剧本代码。
|
||||
|
||||
完成playbook之后,请确认你的密钥在AWS控制台上可用。为此,可以做如下操作:
|
||||
1. 登录你的AWS控制台
|
||||
2. 转到 **EC2 > Key Pairs**
|
||||
3. 您应该会看到列出的密钥。唯一的限制是你必须使用此方法逐个区域来检查。
|
||||
完成该剧本之后,请确认你的密钥在 AWS 控制台上可用。为此,可以做如下操作:
|
||||
|
||||
另一种方法是在shell中使用一个快速命令来为你做这些检查。
|
||||
1. 登录你的 AWS 控制台
|
||||
2. 转到 “EC2 > Key Pairs”
|
||||
3. 你应该会看到列出的密钥。唯一的限制是你必须使用此方法逐个区域来检查。
|
||||
|
||||
首先在playbook上创建一个包含所有区域的变量:
|
||||
另一种方法是在 shell 中使用一个快速命令来为你做这些检查。
|
||||
|
||||
首先在剧本上创建一个包含所有区域的变量:
|
||||
|
||||
```
|
||||
AWS_REGION="us-east-1 us-west-1 us-west-2 ap-east-1 ap-south-1 ap-northeast-2 ap-southeast-1 ap-southeast-2 ap-northeast-1 ca-central-1 eu-central-1 eu-west-1 eu-west-2 eu-west-3 eu-north-1 me-south-1 sa-east-1"
|
||||
```
|
||||
|
||||
然后,执行如下循环,你就可以从aws的API获得结果:
|
||||
然后,执行如下循环,你就可以从 aws 的 API 获得结果:
|
||||
|
||||
```
|
||||
for each in ${AWS_REGION} ; do aws ec2 describe-key-pairs --key-name <YOUR KEY GOES HERE> ; done
|
||||
```
|
||||
|
||||
请记住,要执行上述操作,您需要安装 aws cli。
|
||||
请记住,要执行上述操作,你需要安装 aws 命令行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -107,7 +108,7 @@ via: https://fedoramagazine.org/using-ansible-to-organize-your-ssh-keys-in-aws/
|
||||
作者:[Daniel Leite de Abreu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hj24](https://github.com/hj24)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11660-1.html)
|
||||
[#]: subject: (Why use the Pantheon desktop for Linux Elementary OS)
|
||||
[#]: via: (https://opensource.com/article/19/12/pantheon-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
为何 Elementary OS 中使用 Pantheon 桌面
|
||||
======
|
||||
|
||||
> 本文是 Linux 桌面特别系列的一部分。通过在 Elementary OS 上运行 Pantheon 桌面获得广受喜爱的 Mac OS 特性。
|
||||
|
||||
|
||||
|
||||
你愿意为 Linux 桌面支付 20 美元吗?事实上,我会在下载自由软件时选择支付更多的钱!我这样做的原因是开源是值得的。对于 [Elementary OS][2] 的拷贝,默认价格是 20 美元(你可以选择 1 美元,如果你无法负担,你甚至可以用 0 美元下载)。作为回报,你将获得一个出色且精心制作的发行版,同时拥有它自己的 Pantheon 桌面设计。
|
||||
|
||||
你可能会发现 Pantheon 已包含在软件仓库中,因为它是开源的,但你更可能需要下载并安装 [Elementary][3] Linux 才能体验它。如果你还不准备在计算机上将 Elementary 作为主操作系统,那么可以将其安装到虚拟机中,例如 [GNOME Boxes][4] 中。
|
||||
|
||||
Pantheon 桌面整洁、吸引人,并且有许多用户希望在桌面中获得的东西,但在普通的 Linux 桌面上却无法获得。
|
||||
|
||||
### Pantheon 桌面之旅
|
||||
|
||||
乍一看,Pantheon 桌面看起来有点像 Cinnamon、Budgie 或 GNOME 3 的经典模式。但是,Pantheon 最令人兴奋的功能是极小的接触。它在你很少注意到的地方都表现出色,直到有一天这里成为了你一天都会看的地方,并且会意识到它的工作方式确实改善了你的生活质量,更不用说让你过得愉快多了。
|
||||
|
||||
最明显的例子是“文件名高亮”。几十年来,Mac OS 一直有一个广受欢迎的功能,你可以高亮显示重要文件的名称。人们使用此功能作为快速视觉指示器,来告诉自己哪个文件是这几个的“最佳”版本,或者哪个文件应该发送给朋友,或者哪个文件仍然需要处理。它们可以是任意颜色,可以表示用户想要的任何含义。最重要的是,它是引人注目的视觉元数据。
|
||||
|
||||
从 Mac OS 切换过来用户往往会在 GNOME 和 KDE 以及 Linux 提供的其它桌面里怀念这个功能。Pantheon 悄悄地随手解决了这个问题。
|
||||
|
||||
![A highlighted file in the Pantheon desktop][5]
|
||||
|
||||
当然,那只是其中一个例子。Pantheon 有很多你直到用才会想到的小功能。
|
||||
|
||||
桌面精致而吸引人,有所有其他很多桌面缺少的直观组件。在许多方面,它充分吸取了其他桌面好的想法,并避免实现多余的东西。
|
||||
|
||||
![Pantheon desktop on Elementary OS][6]
|
||||
|
||||
### 自定义 Pantheon 桌面
|
||||
|
||||
Pantheon 桌面表达了如何操作计算机的清晰愿景。这种设计的“问题”(至少在开源之外)是,一个人的偏好可能无法满足另一个人的效率。
|
||||
|
||||
但它是开源的。它可以更改,任何不能改变的东西都可以被丢弃。Pantheon 绝对是针对特定用户群的桌面,但是即使对于那些对桌面应该如何工作抱有自己期望的人,Pantheon 也会比初看上去更加灵活。许多内置设计都具有替代选项,当你无法根据自己的喜好进行调整时,你可以轻松选择其他应用。主题引擎可确保你的替换应用看起来与桌面的其它部分和谐一致,而通常的 Linux 系统兼容性可确保你选择的所有应用都能按预期相互配合。
|
||||
|
||||
![Which one is the guest?][7]
|
||||
|
||||
这些替代品,可使你事半功倍。
|
||||
|
||||
### 受欢迎的补充
|
||||
|
||||
撇开这个桌面的词源不说,此桌面确实是许多 Linux 用户祈祷的答案(LCTT 译注:Pantheon 的意思是“万神庙”)。无论它是否是你的风格,Pantheon 桌面都是 Linux 用户体验中重要且受欢迎的补充。自己尝试一下,看看它是否是你一直期待的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/pantheon-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
|
||||
[2]: https://elementary.io/
|
||||
[3]: http://elementary.io
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-pantheon-highlight.jpg (A highlighted file in the Pantheon desktop)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-pantheon.jpg (Pantheon desktop on Elementary OS)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-pantheon-pcmanfm.jpg (Which one is the guest?)
|
||||
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11664-1.html)
|
||||
[#]: subject: (Dell XPS 13 7390 Review: The Best Laptop For Desktop Linux Users)
|
||||
[#]: via: (https://www.linux.com/articles/dell-xps-13-7390-review-the-best-laptop-for-desktop-linux-user/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Dell XPS 13 7390:最好的 Linux 桌面笔记本
|
||||
======
|
||||
|
||||

|
||||
|
||||
曾经,我们必须进行大量研究、阅读大量评论,才能找到一种在所选的 Linux 桌面发行版上可以以最少的麻烦工作的机器。而如今,这种日子已经一去不复返了,几乎每台机器都可以运行 Linux。Linux 内核社区在设备驱动程序支持方面做得非常出色,可以使一切都开箱即用。
|
||||
|
||||
不过,有的是**可以**运行 Linux d 机器,有的是运行 Linux 的机器。戴尔计算机属于后一类。五年前,Barton George 在戴尔内部启动了一项计划,将桌面版 Linux 引入到消费级的高端戴尔系统。从一台机器开始,到现在整套从产品线的高端笔记本电脑和台式机都可以运行 Linux。
|
||||
|
||||
在这些机器中,XPS 13 是我的最爱。尽管我需要一个功能强大的台式机来处理 4K UHD、多机位视频制作,但我还需要一台超便携的笔记本电脑,可以随身携带,而不必担心笨重的背包和充电器。XPS 13 也是我的第一台笔记本电脑,陪了我 7 年多。因此,是的,这还有一个怀旧因素。
|
||||
|
||||
戴尔几乎每年都会更新其 XPS 产品线,并且最新的[产品展示宣布于 10 月][3]。[XPS 13(7390)] [4] 是该系列的增量更新,而且戴尔非常乐意向我寄来一台测评设备。
|
||||
|
||||

|
||||
|
||||
它由 6 核 Core i7-10710U CPU 所支持。它配备 16GB 内存和 1TB SSD。在 1.10 GHz 的基本频率(可以超频到 4.1 GHz)的情况下,这是一台用于常规工作负载的出色机器。它没有使用任何专用的 GPU,因此它并不适合进行游戏或从源代码进行编译的 Gentoo Linux 或 Arch Linux。但是,我确实设法在上面运行了一些 Steam 游戏。
|
||||
|
||||
如果你想运行 Kubernetes 集群、AI 框架或虚拟现实,那么 Precision 系列中还有更强大的机器,这些机器可以运行 Red Hat Enterprise Linux 和 Ubuntu。
|
||||
|
||||
该机器的底盘与上一代相同。边框保持与上一代一样的薄,依旧比 MacBook 和微软的 Surface Pro 薄。
|
||||
|
||||
它具有三个端口,其中两个是 USB-C Thunderbolt 3,可用于连接 4K 显示器、USB 附件以及用于对等网络的计算机之间的高速数据传输。
|
||||
|
||||
它还具有一个 microSD 插槽。作为视频记者,SD 卡插槽会更有用。大量使用树莓派的用户也会喜欢这种卡。
|
||||
|
||||
它具有 4 个麦克风和一个改进的摄像头,该摄像头现在位于顶部(再见,鼻孔摄像头!)。
|
||||
|
||||
XPS 13(7390)光滑纤薄。它的重量仅为 2.7 磅(1.2kg),可以与苹果的 MacBook Air 相提并论。 这台机器可以成为你的旅行伴侣,并且可以执行日常任务,例如检查电子邮件、浏览网络和写作。
|
||||
|
||||
其 4K UHD 屏幕支持 HDR,这意味着你将可以尽享《The Mandalorian》的全部美妙之处。另外,车载扬声器并没有那么好,听起来有些沉闷。它们适合进行视频聊天或休闲的 YouTube 观看,但是如果你想在今年晚些时候观看《The Witcher》剧集,或者想欣赏 Amazon、Apple Music 或 YouTube Music 的音乐,则需要耳机或外接扬声器。
|
||||
|
||||

|
||||
|
||||
但是,在插入充电线之前,你可以能使用这台机器多少时间?在正常工作量的情况下,它为我提供了大约 7-8 个小时的电池续航时间:我打开了几个选项卡浏览网络,只是看看电影或听音乐。多任务处理,尤其是各种 Web 活动,都会加速消耗电池电量。在 Linux 上进行一些微调可能会给你带来更多的续航时间,而在 Windows 10 上,我可以使用 10 多个小时呢!
|
||||
|
||||
作为仍在从事大量写作工作的视频记者,我非常喜欢键盘。但是,我们这么多年来在 Linux 台式机上听到的触控板故事一直没变:它与 MacBook 或 Windows 上的品质相差甚远。这或许有一天能改变。值得称道的是,他们确实发布了可增强体验的触控板驱动程序,但我没有运行此系统随附的提供的 Ubuntu 18.04 LTS。我全新安装了 Ubuntu 19.10,因为 Gnome 在 18.04 中的运行速度非常慢。我尝试过 openSUSE Tumbleweed、Zorin OS、elementary OS、Fedora、KDE neon 和 Arch Linux。一切正常,尽管有些需要额外的努力才能运行。
|
||||
|
||||
那么,该系统适用于谁?显然,这是给那些想要设计精良的、他们信赖的品牌的高端机器的专业人士打造的。适用于喜欢 MacBook Air,但更喜欢 Linux 台式机生态系统的用户。适用于那些希望使用 Linux 来工作,而不是使 Linux 可以工作的人。
|
||||
|
||||
我使用这台机器一周的时间,进一步说明了为什么我如此喜欢戴尔的 XPS 系列。它们是目前最好的 Linux 笔记本电脑。这款 XPS 13(7390),你值得拥有!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/dell-xps-13-7390-review-the-best-laptop-for-desktop-linux-user/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/wp-content/uploads/2019/12/dell-xps-13-7390-1068x665.jpg (dell-xps-13-7390)
|
||||
[2]: https://www.linux.com/wp-content/uploads/2019/12/dell-xps-13-7390.jpg
|
||||
[3]: https://bartongeorge.io/2019/08/21/please-welcome-the-9th-generation-of-the-xps-13-developer-edition/
|
||||
[4]: https://blog.dell.com/en-us/dells-new-consumer-pc-portfolio-unveiled-ifa-2019/
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11733-1.html)
|
||||
[#]: subject: (Fedora Desktops – Memory Footprints)
|
||||
[#]: via: (https://fedoramagazine.org/fedora-desktops-memory-footprints/)
|
||||
[#]: author: (Troy Dawson https://fedoramagazine.org/author/tdawson/)
|
||||
|
||||
Fedora 上的桌面环境内存占用测试
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 中有 40 多种桌面环境(DE)。每种桌面环境都有自己的优点和缺点。通常,根据功能、外观和其它品质,选择桌面是一件非常个人的偏好。但有时,你选择的桌面环境还会受到硬件限制。
|
||||
|
||||
本文旨在帮助人们根据桌面环境占用的基准内存来比较 Fedora 桌面环境。为了缩小范围,我们仅查看具有正式 Fedora Live 镜像的桌面环境。
|
||||
|
||||
### 安装与系统配置
|
||||
|
||||
每个桌面环境都安装在自己的 KVM 虚拟机上。每个虚拟机都有 1 个 CPU、4GB 内存、15GB virtio 固态磁盘,以及 RHEL 8.0 kvm 上所有其他标准配置。
|
||||
|
||||
用于安装的镜像是标准的 Fedora 31 Live 镜像。对于 GNOME,该镜像是 “Fedora 工作站”。对于其它桌面,使用了相应的 Spin 版本。未对“<ruby>糖葫芦<rt>Sugar On A Stick</rt></ruby>”(SOAS)进行测试,因为它不容易安装到本地驱动器上。
|
||||
|
||||
用 Live CD 启动虚拟机,然后选择“安装到硬盘”。在安装过程中,仅使用默认值。创建了一个 root 用户和一个普通用户。安装并重新启动后,live 镜像已确认不在虚拟 CDROM 中。
|
||||
|
||||
每个桌面环境的设置都没有改动。它们每个都以 Live CD 环境中默认的设置运行。每个桌面环境都是通过普通用户登录的。打开了一个终端,在每台虚拟机中都使用 `sudo` 运行了 `dnf -y update`。在更新后,在该 sudo 终端中,每台虚拟机都运行 `/sbin/shutdown -h now` 以关闭。
|
||||
|
||||
### 测试方式
|
||||
|
||||
每台机器都已启动。桌面环境已通过普通用户登录。打开了三个桌面终端。xterm 从未使用过,始终用的是该桌面环境的终端,例如 konsole。
|
||||
|
||||
在一个终端中,启动 `top` 并按下 `M`,以显示按内存排序的进程。在另一个终端中,一个简单的 `while` 循环每 30 秒显示一次 `free -m`。第三个终端闲置。
|
||||
|
||||
然后,我等待了 5 分钟。这样就可以让所有启动的服务都启动完成。我记录了最终的 `free` 结果,以及 `top` 中最终的前三名内存使用者。
|
||||
|
||||
### 结果
|
||||
|
||||
* Cinnamon
|
||||
* 使用了624 MB
|
||||
* cinnamon 4.8% / Xorg 2.2% / dnfdragora 1.8%
|
||||
* GNOME
|
||||
* 使用了 612 MB
|
||||
* gnome-shell 6.9% / gnome-software 1.8% / ibus-x11 1.5%
|
||||
* KDE
|
||||
* 使用了 733 MB
|
||||
* plasmashell 6.2% / kwin\_x11 3.6% / akonadi\_mailfil 2.9%
|
||||
* LXDE
|
||||
* 使用了 318 MB
|
||||
* Xorg 1.9% / nm-applet 1.8% / dnfdragora 1.8%
|
||||
* LXQt
|
||||
* 使用了 391 MB
|
||||
* lxqt-panel 2.2% / pcmanfm-qt 2.1% / Xorg 2.1%
|
||||
* MATE
|
||||
* 使用了 465 MB
|
||||
* Xorg 2.5% / dnfdragora 1.8% / caja 1.5%
|
||||
* XFCE
|
||||
* 使用了 448 MB
|
||||
* Xorg 2.3% / xfwm4 2.0% / dnfdragora 1.8%
|
||||
|
||||
|
||||
|
||||
### 结论
|
||||
|
||||
我会让数字说明一切。
|
||||
|
||||
请记住,这些数字来自默认的 Live 安装环境。如果删除或添加服务和功能,则内存使用量将发生变化。但是,如果要根据内存消耗确定桌面环境,这是一个很好的基准。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-desktops-memory-footprints/
|
||||
|
||||
作者:[Troy Dawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/tdawson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/11/desktop-memory-footprint-816x346.jpg
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11679-1.html)
|
||||
[#]: subject: (Java vs. Python: Which should you choose?)
|
||||
[#]: via: (https://opensource.com/article/19/12/java-vs-python)
|
||||
[#]: author: (Archit Modi https://opensource.com/users/architmodi)
|
||||
|
||||
Java 与 Python:你应该选择哪个?
|
||||
======
|
||||
|
||||
> 比较世界上最流行的两种编程语言,并在投票中让我们知道你喜欢哪一个。
|
||||
|
||||

|
||||
|
||||
让我们比较一下世界上两种最受欢迎、最强大的编程语言:Java 和 Python!这两种语言有巨大的社区支持和库来执行几乎任何编程任务,尽管选择编程语言通常取决于开发人员的场景。在比较和对比之后,请投票分享你的观点。
|
||||
|
||||
### 是什么?
|
||||
|
||||
* **Java** 是一门通用面向对象的编程语言,主要用于开发从移动端到 Web 到企业级应用的各种应用。
|
||||
* **Python** 是一门高级面向对象的编程语言,主要用于 Web 开发、人工智能、机器学习、自动化和其他数据科学应用。
|
||||
|
||||
### 创建者
|
||||
|
||||
* **Java** 是由 James Gosling(Sun Microsystems)创造的。
|
||||
* **Python** 是由 Guido van Rossum 创造的。
|
||||
|
||||
### 开源状态
|
||||
|
||||
* **Java** 是免费的,(大部分)开源,但商业用途除外。
|
||||
* **Python** 对于所有场景都是免费、开源的。
|
||||
|
||||
### 平台依赖
|
||||
|
||||
* **Java** 根据它的 WORA (“<ruby>一次编写,到处运行<rt>write once, run anywhere</rt></ruby>”)哲学,它是平台无关的。
|
||||
* **Python** 依赖于平台。
|
||||
|
||||
### 编译或解释
|
||||
|
||||
* **Java** 是一门编译语言。Java 程序在编译时转换为字节码,而不是运行时。
|
||||
* **Python** 是一门解释性语言。Python 程序在运行时进行解释。
|
||||
|
||||
### 文件创建
|
||||
|
||||
* **Java**:编译后生成 `<filename>.class` 文件。
|
||||
* **Python**:在运行期,创建 `<filename>.pyc` 文件。
|
||||
|
||||
### 错误类型
|
||||
|
||||
* **Java** 有 2 种错误类型:编译和运行时错误。
|
||||
* **Python** 有 1 种错误类型:回溯(或运行时)错误。
|
||||
|
||||
### 静态或动态类型
|
||||
|
||||
* **Java** 是静态类型。当初始化变量时,需要在程序中指定变量的类型,因为类型检查是在编译时完成的。
|
||||
* **Python** 是动态类型。变量不需要在初始化时指定类型,因为类型检查是在运行时完成的。
|
||||
|
||||
### 语法
|
||||
|
||||
* **Java**:每个语句都需要以分号(`;` )结尾,并且代码块由大括号( `{}` )分隔。
|
||||
* **Python**:代码块通过缩进分隔(用户可以选择要使用的空格数,但在整个块中应保持一致)。
|
||||
|
||||
### 类的数量
|
||||
|
||||
* **Java**:在 Java 中的单个文件中只能存在一个公有顶级类。
|
||||
* **Python**:Python 中的单个文件中可以存在任意数量的类。
|
||||
|
||||
### 代码多少?
|
||||
|
||||
* **Java** 通常比 Python 要写更多代码行。
|
||||
* **Python**通常比 Java 要写更少代码行。
|
||||
|
||||
### 多重继承
|
||||
|
||||
* **Java** 不支持多重继承(从两个或多个基类继承)。
|
||||
* **Python** 支持多重继承,但由于继承复杂性、层次结构、依赖等各种问题,它很少实现。
|
||||
|
||||
### 多线程
|
||||
|
||||
* **Java** 多线程可以支持同时运行的两个或多个并发线程。
|
||||
* **Python** 使用全局解释器锁 (GIL),一次只允许运行单个线程(一个 CPU 核)。
|
||||
|
||||
### 执行速度
|
||||
|
||||
* **Java** 的执行时间通常比 Python 快。
|
||||
* **Python** 的执行时间通常比 Java 慢。
|
||||
|
||||
### Hello world
|
||||
|
||||
Java 的:
|
||||
|
||||
```
|
||||
public class Hello {
|
||||
public static void main([String][3][] args) {
|
||||
[System][4].out.println("Hello Opensource.com from Java!");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python 的:
|
||||
|
||||
```
|
||||
print("Hello Opensource.com from Java!")
|
||||
```
|
||||
|
||||
### 运行程序
|
||||
|
||||
![Java vs. Python][5]
|
||||
|
||||
要运行 java 程序 `Hello.java`,你需要先编译它,这将创建一个 `Hello.class` 文件。只需运行类名 `java Hello`。对于 Python,只需运行文件 `python3 helloworld.py`。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/java-vs-python
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/architmodi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: tmp.Bpi8QYfp8j#poll
|
||||
[3]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[4]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||
[5]: https://opensource.com/sites/default/files/uploads/python-java-hello-world_0.png (Java vs. Python)
|
||||
103
published/201912/20191206 5 cool terminal pagers in Fedora.md
Normal file
103
published/201912/20191206 5 cool terminal pagers in Fedora.md
Normal file
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11676-1.html)
|
||||
[#]: subject: (5 cool terminal pagers in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/5-cool-terminal-pagers-in-fedora/)
|
||||
[#]: author: (Jacob Burns https://fedoramagazine.org/author/jaek/)
|
||||
|
||||
5 个最酷的终端分页器
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
像日志或源代码这样的大文件可能会多达成千上万行,这使得在文件内导航非常困难,尤其是在终端上。此外,大多数终端仿真器的回滚缓冲区只有几百行。这可能使得无法使用打印到标准输出的实用程序(例如 `cat`、`head` 和 `tail`)在终端中浏览大型文件。在计算时代的早期,程序员通过开发用于以虚拟“页面”形式显示文本的实用程序来解决这些问题,该实用程序被形象地描述为<ruby>分页器<rt>pager</rt></ruby>。
|
||||
|
||||
*分页器*提供了许多使文本文件导航更加简单的功能,包括滚动、搜索功能,以及作为命令[管道][2]的一部分而具有的功能。与大多数文本编辑器相比,某些终端分页器不需要加载整个文件即可查看,这使得它们更快,特别是对于非常大的文件。
|
||||
|
||||
在现代 Linux 计算时代,终端仿真器比以往更加复杂。它们提供了对缤纷的色彩、终端尺寸调整以及许多其它功能的支持,这些功能使得辨析屏幕上的文本变得更加轻松和高效。从诸如 `pg` 和 `more` 这样极其简单的 UNIX 实用程序,到涵盖各种使用场景的、功能广泛的复杂程序,终端分页器也经历了类似的演变。考虑到这一点,我们或“多”或“少”地汇总了一些最受欢迎的终端分页实用程序的列表。
|
||||
|
||||
### more
|
||||
|
||||
`more` 是最早的分页器之一,最初在 3.0 BSD 版本中出现。`more` 的第一个实现由 [Daniel Halbert][3] 编写于 1978 年。从那时起,`more` 已成为许多操作系统的普遍功能,包括 Windows、OS/2,MacOS 和大多数 Linux 发行版。
|
||||
|
||||
`more` 是一个非常轻量级的实用程序。util-linux 软件包中提供的版本只有不到 2100 行的 C 语言代码。但是,这种较小的代码大小是有代价的。大多数版本的 `more` 的功能相对有限,不支持向后滚动或搜索。命令也同样精简:按回车键可滚动一行,或按空格键滚动一页。其他一些有用的命令包括:
|
||||
|
||||
* 在阅读时按 `v` 键以在默认的终端编辑器中打开当前文件。
|
||||
* `/模式` 可以让你搜索下一个出现的“模式”。
|
||||
* 以多个文件作为参数调用 `more` 时,`:n` 和 `:p` 将分别打开下一个和上一个文件
|
||||
|
||||
### less
|
||||
|
||||
`less` 最初被认为是 `more` 的继承者,解决了它的一些局限性。`less` 以 `more` 的功能为基础,增加了许多有用的功能,包括向后滚动、向后搜索。它也更适合窗口大小调整。
|
||||
|
||||
`less` 中的导航方式与 `more` 类似,尽管 `less` 也从 `vi` 编辑器借用了一些有用的命令。用户可以使用熟悉的<ruby>主行导航键<rt>home row navigational keys</rt></ruby>(LCTT 译注:指 左手的 `A`、`S`、`D`、`F` 和右手的 `J`、`K`、`L`、`;`,及大拇指所在的空格键)浏览文档。看一眼 `less` 的手册页,就会发现相当多的可用命令。一些特别有用的示例包括:
|
||||
|
||||
* `?模式` 可让你在文件中向后搜索“模式”。
|
||||
* `&模式` 仅显示具有“模式”特征的行。这对于发现自己经常要使用 `$ grep 模式 | less` 的人特别有用。
|
||||
* 使用 `-s`(或 `–sqeueeze-blank-lines`)标志来调用 `less`,使你可以查看空白较大的文本文件。 多个换行符被简化为单个中断行。
|
||||
* 在该程序中调用的 `s 文件名` 将输入保存到 `文件名`中(如果输入来自管道)。
|
||||
* 或者,使用 `-o 文件名` 标志来调用 `less` 将把 `less` 的输入保存到 `文件名` 中。
|
||||
|
||||
随着这些增强的功能也带来了体积的略微增大。在写作本文时,Fedora 随附的 `less` 版本大约有 25000 行源代码。当然,除非是受存储限制最大的系统,在所有其它的系统上这都不是问题。`less` 比 `more` 功能更多。
|
||||
|
||||
### most
|
||||
|
||||
`less` 旨在扩展 `more` 的现有功能,而 `most` 采用另一种方法。`most` 不是在传统的单个文件视图上进行扩展,而是使用户能够将其视图拆分为“窗口”。每个窗口以不同的查看模式包含不同的文件。
|
||||
|
||||
重要的是,`most` 考虑了其输入文本的宽度。默认的查看模式是不换行的(`less` 中的 `-S` 参数),此功能在处理“宽”文件时特别有用。尽管对于某些用户来说,这些设计决策可能代表着与传统的重大偏离,但最终结果却非常强大。
|
||||
|
||||
除了 `more` 提供的导航命令外,`most` 使用直观的助记符进行文件导航。例如,`t` 移至文件的顶部(Top),而 `b` 移至底部(Bottom)。这样,不熟悉 `vi` 及其衍生品的用户会发现 `most` 非常简单好用。
|
||||
|
||||
`most` 的与众不同之处在于它能够快速轻松地拆分窗口和上下文。例如,可以使用以下命令打开两个不同的文本文件:
|
||||
|
||||
```
|
||||
$ most textFile1.txt textFile2.txt
|
||||
```
|
||||
|
||||
为了水平拆分屏幕,请使用组合键 `Ctrl+x, 2` 或 `Ctrl+w, 2`。 `:n` 命令将在给定窗口中打开下一个文件参数,提供两个文件的分屏视图:
|
||||
|
||||
![][4]
|
||||
|
||||
如果在一个窗口中关闭自动换行,它不会影响其他窗口的行为。(行末的)`\` 字符表示换行或折叠,而 `$` 字符表示文件超出了当前窗口的限制。
|
||||
|
||||
### pspg
|
||||
|
||||
使用 SQL 数据库的人员通常需要能够一目了然地检查数据库的内容。许多流行的开源 DBMS(例如 MySQL 和 PostGreSQL)的命令行界面都使用系统默认的分页器来查看无法显示在单个屏幕上的输出。诸如 `more` 和 `less` 之类的实用程序是围绕呈现文本文件的想法而设计的,但是对于更结构化的数据,还有一些不足之处。天真的文本分页程序没有宽的表格数据的概念,当处理大型查询时,这可能会令人感到沮丧。
|
||||
|
||||
[pspg][5] 试图通过为用户提供在查看时冻结列、*原位*排序数据并为输出着色的功能来解决此问题。尽管`pspg` 最初是专门用作 `psql` 的分页器的替代品,但该程序还支持查看 CSV 数据,并且是 `mysql` 和 `pgcli` 的合适的直接替代品。
|
||||
|
||||
### Vim
|
||||
|
||||
在现代的颜色鲜明的终端中,无休止的黑色页面上的灰色文字感觉太过时了。强大的文本编辑器(如 `vim`)提供的语法高亮显示选项对于浏览源代码很有用。此外,`vim` 提供的搜索功能远远超过了竞争对手。考虑到这一点,`vim` 附带了一个 shell 脚本 `less.sh`,该脚本可以使 `vim` 替代传统的分页器。
|
||||
|
||||
要将 `vim` 设置为手册页的[默认分页器][6],请将以下内容添加到 shell 的配置中(如果使用默认的bash shell 的话是 `~/.bashrc`):
|
||||
|
||||
```
|
||||
export MANPAGER="/bin/sh -c \"col -b | vim -c 'set ft=man ts=8 nomod nolist nonu noma' -\""
|
||||
```
|
||||
|
||||
或者,要将 `vim` 设置为系统范围内的默认分页器,请找到 `less.sh` 脚本。(你可以在当前 Fedora 系统上的 `/usr/share/vim/vim81/macros/` 找到它。)将此位置导出为变量 `PAGER` 以将其设置为默认值,或者将其设置为别名以显式调用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-terminal-pagers-in-fedora/
|
||||
|
||||
作者:[Jacob Burns][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/jaek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/11/5-pagers-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/command-line-quick-tips-using-pipes-to-connect-tools/
|
||||
[3]: https://danhalbert.org/more.html
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/11/image-2.png
|
||||
[5]: https://github.com/okbob/pspg
|
||||
[6]: https://zameermanji.com/blog/2012/12/30/using-vim-as-manpager/
|
||||
[7]: https://unsplash.com/@zyljosa?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/s/photos/pages?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,225 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11663-1.html)
|
||||
[#]: subject: (6 Ways to Send Email from the Linux Command Line)
|
||||
[#]: via: (https://www.2daygeek.com/6-ways-to-send-email-from-the-linux-command-line/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Linux 命令行发送邮件的 5 种方法
|
||||
======
|
||||
|
||||
当你需要在 shell 脚本中创建邮件时,就需要用到命令行发送邮件的知识。Linux 中有很多命令可以实现发送邮件。本教程中包含了最流行的 5 个命令行邮件客户端,你可以选择其中一个。这 5 个命令分别是:
|
||||
|
||||
* `mail` / `mailx`
|
||||
* `mutt`
|
||||
* `mpack`
|
||||
* `sendmail`
|
||||
* `ssmtp`
|
||||
|
||||
### 工作原理
|
||||
|
||||
我先从整体上来解释下 Linux 中邮件命令怎么把邮件传递给收件人的。邮件命令撰写邮件并发送给一个本地邮件传输代理(MTA,如 sendmail、Postfix)。邮件服务器和远程邮件服务器之间通信以实际发送和接收邮件。下面的流程可以看得更详细。
|
||||
|
||||
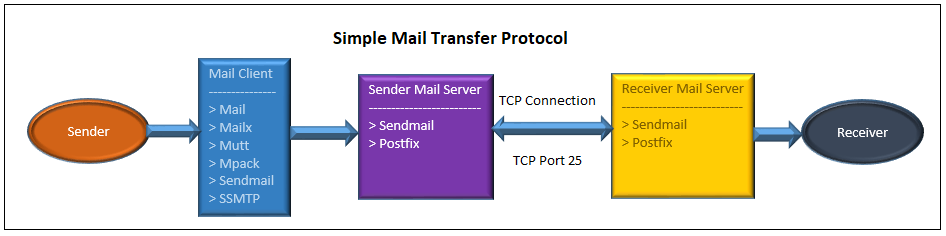
|
||||
|
||||
### 1) 如何在 Linux 上安装 mail/mailx 命令
|
||||
|
||||
`mail` 命令是 Linux 终端发送邮件用的最多的命令。`mailx` 是 `mail` 命令的更新版本,基于 Berkeley Mail 8.1,意在提供 POSIX `mailx` 命令的功能,并支持 MIME、IMAP、POP3、SMTP 和 S/MIME 扩展。mailx 在某些交互特性上更加强大,如缓冲邮件消息、垃圾邮件评分和过滤等。在 Linux 发行版上,`mail` 命令是 `mailx` 命令的软链接。可以运行下面的命令从官方发行版仓库安装 `mail` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mailutils。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mailutils
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo yum install mailx
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo dnf install mailx
|
||||
```
|
||||
|
||||
#### 1a) 如何在 Linux 上使用 mail 命令发送邮件
|
||||
|
||||
`mail` 命令简单易用。如果你不需要发送附件,使用下面的 `mail` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 `mail` 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -a test1.txt -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
- `-a`:用于在基于 Red Hat 的系统上添加附件。
|
||||
- `-A`:用于在基于 Debian 的系统上添加附件。
|
||||
- `-s`:指定消息标题。
|
||||
|
||||
### 2) 如何在 Linux 上安装 mutt 命令
|
||||
|
||||
`mutt` 是另一个很受欢迎的在 Linux 终端发送邮件的命令。`mutt` 是一个小而强大的基于文本的程序,用来在 unix 操作系统下阅读和发送电子邮件,并支持彩色终端、MIME、OpenPGP 和按邮件线索排序的模式。可以运行下面的命令从官方发行版仓库安装 `mutt` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mutt
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo yum install mutt
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo dnf install mutt
|
||||
```
|
||||
|
||||
#### 2b) 如何在 Linux 上使用 mutt 命令发送邮件
|
||||
|
||||
`mutt` 一样简单易用。如果你不需要发送附件,使用下面的 `mutt` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mutt -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 `mutt` 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mutt -s "Subject" 2daygeek@gmail.com -a test1.txt
|
||||
```
|
||||
|
||||
### 3) 如何在 Linux 上安装 mpack 命令
|
||||
|
||||
`mpack` 是另一个很受欢迎的在 Linux 终端上发送邮件的命令。`mpack` 程序会在一个或多个 MIME 消息中对命名的文件进行编码。编码后的消息被发送到一个或多个收件人。可以运行下面的命令从官方发行版仓库安装 `mpack` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mpack
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo yum install mpack
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo dnf install mpack
|
||||
```
|
||||
|
||||
#### 3a) 如何在 Linux 上使用 mpack 命令发送邮件
|
||||
|
||||
`mpack` 同样简单易用。如果你不需要发送附件,使用下面的 `mpack` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mpack -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 mpack 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mpack -s "Subject" 2daygeek@gmail.com -a test1.txt
|
||||
```
|
||||
|
||||
### 4) 如何在 Linux 上安装 sendmail 命令
|
||||
|
||||
sendmail 是一个上广泛使用的通用 SMTP 服务器,你也可以从命令行用 `sendmail` 发邮件。可以运行下面的命令从官方发行版仓库安装 `sendmail` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4]安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo apt-get install sendmail
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo yum install sendmail
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo dnf install sendmail
|
||||
```
|
||||
|
||||
#### 4a) 如何在 Linux 上使用 sendmail 命令发送邮件
|
||||
|
||||
`sendmail` 同样简单易用。使用下面的 `sendmail` 命令发送邮件。
|
||||
|
||||
```
|
||||
$ echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/send-mail.txt
|
||||
```
|
||||
|
||||
```
|
||||
$ sendmail 2daygeek@gmail.com < send-mail.txt
|
||||
```
|
||||
|
||||
### 5) 如何在 Linux 上安装 ssmtp 命令
|
||||
|
||||
`ssmtp` 是类似 `sendmail` 的一个只发送不接收的工具,可以把邮件从本地计算机传递到配置好的 邮件主机(mailhub)。用户可以在 Linux 命令行用 `ssmtp` 把邮件发送到 SMTP 服务器。可以运行下面的命令从官方发行版仓库安装 `ssmtp` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4]安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo apt-get install ssmtp
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo yum install ssmtp
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo dnf install ssmtp
|
||||
```
|
||||
|
||||
### 5a) 如何在 Linux 上使用 ssmtp 命令发送邮件
|
||||
|
||||
`ssmtp` 同样简单易用。使用下面的 `ssmtp` 命令格式发送邮件。
|
||||
|
||||
```
|
||||
$ echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/ssmtp-mail.txt
|
||||
```
|
||||
|
||||
```
|
||||
$ ssmtp 2daygeek@gmail.com < /tmp/ssmtp-mail.txt
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-ways-to-send-email-from-the-linux-command-line/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.2daygeek.com/wp-content/uploads/2019/12/smtp-simple-mail-transfer-protocol.png
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11670-1.html)
|
||||
[#]: subject: (Pekwm: A lightweight Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/pekwm-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Pekwm:一个轻量级的 Linux 桌面
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你是一个觉得传统桌面会妨碍你的极简主义者,那么试试 Pekwm Linux 桌面。
|
||||
|
||||
|
||||
|
||||
假设你想要一个轻量级桌面环境,它只需要能在屏幕上显示图形、四处移动窗口,而别无杂物。你会发现传统桌面的通知、任务栏和系统托盘会妨碍你的工作。你想主要通过终端工作,但也希望运行图形应用。如果听起来像是你的想法,那么 [Pekwm][2] 可能是你一直在寻找的东西。
|
||||
|
||||
Pekwm 的灵感大概来自于 Window Maker 和 Fluxbox 等。它提供了一个应用菜单、窗口装饰、而不是一大堆其他东西。它非常适合极简主义者,即那些希望节省资源的用户和喜欢在终端工作的用户。
|
||||
|
||||
从发行版仓库安装 Pekwm。安装后,请先退出当前桌面会话,以便可以登录到新桌面。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,具体取决于你的设置)将继续登录到以前的桌面,因此需要在登录之前修改它。
|
||||
|
||||
在 GDM 中覆盖之前的桌面:
|
||||
|
||||
![Selecting your desktop in GDM][3]
|
||||
|
||||
在 KDM 中:
|
||||
|
||||
![Selecting your desktop in KDM][4]
|
||||
|
||||
第一次登录 Pekwm 时,你可能会看到黑屏。可能难以置信,但这是正常的。你看到的是一个空白桌面,没有背景壁纸。你可以使用 `feh` 命令设置壁纸(你可能需要从仓库中安装它)。此命令有几个用于设置背景的选项,包括 `--bg-fill` 用壁纸填充屏幕,`--bg-scale` 缩放到合适大小,等等。
|
||||
|
||||
```
|
||||
$ feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg
|
||||
```
|
||||
|
||||
### 应用菜单
|
||||
|
||||
默认情况下,Pekwm 自动生成一个菜单,可在桌面上的任意位置右键单击,从而可让你运行应用。此菜单还提供一些首选项设置,例如选择主题和注销 Pekwm 会话。
|
||||
|
||||
![Pekwm running on Fedora][5]
|
||||
|
||||
### 配置
|
||||
|
||||
Pekwm 主要通过保存在 `$HOME/.pekwm` 下的文本配置文件来配置。`menu` 文件定义你的应用菜单,`keys` 文件定义键盘快捷键,等等。
|
||||
|
||||
`start` 文件是在 Pekwm 启动后执行的 shell 脚本。它类似于传统 Unix 系统上的 `rc.local`。它故意放在最后执行的,因此这里的东西将覆盖之前的一切。这是一个重要文件,它可能是你要设置背景的地方,以便*你的*选择会覆盖正在使用的主题的默认值。
|
||||
|
||||
`start` 文件也是可以启动 dockapp 的地方。dockapp 是一种小程序,它在 Window Maker 和 Fluxbox 引起了人们的关注。它们通常有网络监视器、时钟、音频设置,和其它你可能会在系统托盘或作为一个 KDE plasmoid 或者完整桌面环境中看到的小部件。你可能会在发行版仓库中找到一些 dockapp,或者可以在 [dockapps.net][6] 上在线查找它们。
|
||||
|
||||
你可以在启动时运行 dockapp,将它们列在 `start` 文件中,跟上 `&` 符号:
|
||||
|
||||
|
||||
```
|
||||
feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg
|
||||
wmnd &
|
||||
bubblemon -d &
|
||||
```
|
||||
|
||||
`start` 文件必须[设置为可执行][7],才能在 Pekwm 启动时运行。
|
||||
|
||||
```
|
||||
$ chmod +x $HOME/.pekwm/start
|
||||
```
|
||||
|
||||
### 功能
|
||||
|
||||
Pekwm 的功能不多,但这就是它的美。如果你希望在桌面上运行额外的服务,那么由你来启动这些服务。如果你仍在学习 Linux,这是了解那些与完整的桌面环境捆绑在一起时通常不会注意到的微小 GUI 组件的好方法(像是[任务栏][8])。这也习惯一些 Linux 命令(例如 [nmcli][9])的好方法。
|
||||
|
||||
Pekwm 是一个有趣的窗口管理器。它分散、简洁、轻巧。请试试看!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/pekwm-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
|
||||
[2]: http://www.pekwm.org/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/advent-gdm_1.jpg (Selecting your desktop in GDM)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/advent-enlightenment-kdm_0.jpg (Selecting your desktop in KDM)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-pekwm.jpg (Pekwm running on Fedora)
|
||||
[6]: http://dockapps.net
|
||||
[7]: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
[9]: https://opensource.com/article/19/5/set-static-network-connection-linux
|
||||
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11675-1.html)
|
||||
[#]: subject: (Getting started with the GNOME Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/gnome-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
GNOME Linux 桌面入门
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。GNOME 是大多数现代 Linux 发行版的默认桌面,它干净、简单、组织良好。
|
||||
|
||||
|
||||
|
||||
[GNOME][2] 项目理所应当是 Linux 桌面的宠儿。它起初是专有桌面(当时包括 KDE)的自由开源的桌面替代品,此后一直发展强劲。GNOME 采用了[由 GIMP 项目开发][3]的 GTK+,并将其开发为强大的通用 GTK 框架。该项目开创了用户界面的先声,挑战了桌面“应有”外观的先入之见,并为用户提供了新的范例和选项。
|
||||
|
||||
在大多数主流现代 Linux 发行版(包括 RHEL、Fedora、Debian 和 Ubuntu)中,GNOME 作为默认桌面而广泛使用。如果你的发行版不提供它的某个版本,那么你可以从软件仓库中安装 GNOME。但是,在执行此操作之前,请注意,为了提供完整的桌面体验,这会随桌面一起安装许多 GNOME 应用。如果你在用其他桌面,那么你可能会发现有冗余的应用(两个 PDF 阅读器、两个媒体播放器、两个文件管理器,等等)。如果你只想尝试 GNOME 桌面,请考虑在虚拟机,如 [GNOME Boxes][4],中安装 GNOME 发行版。
|
||||
|
||||
### GNOME 功能
|
||||
|
||||
GNOME 桌面很干净,顶部有一个简单的任务栏,右上角的系统托盘中只有很少的图标。GNOME 上没有桌面图标,这是设计使然。如果你是喜欢在桌面上保存*任何东西*的用户,那么你可能会意识到桌面会定期地变得混乱,而且,更糟糕的是,由于你的应用掩盖了桌面,因此桌面永远不会显示出来。
|
||||
|
||||
GNOME 解决了两个问题:(在功能上)没有桌面,并且动态生成新的虚拟工作区,因此你可以在全屏模式下运行应用。如果你常把屏幕弄乱,那么可能需要一些时间来习惯,但实际上,从各个方面来说,这都是一种改进的工作流程。你将学习如何使文件井井有条(或者将它们分散在家目录中),并且可以像在手机上一样快速地在屏幕之间切换。
|
||||
|
||||
当然,并非所有应用都设计为在全屏模式下运行,因此,如果你更喜欢单击切换窗口,也可以这样做。
|
||||
|
||||
![GNOME running on Debian][5]
|
||||
|
||||
GNOME 哲学褒扬了 Canonical 对常见任务的解决方案。在 GNOME 中,你通常不会发现“回字有四种写法”。你会找到一种或两种官方方法来完成一项任务,你了解了这些方法后,便只需记住这些即可。它非常简单,但由于它在 Linux 上运行,因此在技术上也很灵活(毕竟,你不必因为运行 GNOME 桌面而必须要使用 GNOME 应用)。
|
||||
|
||||
### 应用菜单
|
||||
|
||||
要访问名为“活动”的应用菜单,请在桌面的左上角单击。此菜单将占满整个屏幕,屏幕最左侧有一栏常见应用的 dock,或可以在网格中浏览应用的图标。你可以通过浏览已安装的应用,或输入软件的头几个字母来过滤列表,然后来启动应用。
|
||||
|
||||
![GNOME activities][6]
|
||||
|
||||
### GNOME 应用
|
||||
|
||||
GNOME 不仅是桌面。它是一个桌面以及一组丰富的集成应用,例如 Gedit 文本编辑器、Evince PDF 查看器、Web 浏览器、图像查看器、Nautilus 文件管理器等等。GNOME 应用(例如桌面本身)遵循 [GNOME 人机界面指南][7],因此用户体验既愉悦又一致。无论你是否使用 GNOME 桌面,都可能使用 GTK 应用,也可能会使用 GNOME 应用。
|
||||
|
||||
### GNOME 3 及更高版本
|
||||
|
||||
GNOME 项目进展顺利,还有几个令人兴奋的项目(例如 MATE 和 [Cinnamon][8])。它流行、令人舒适,被视为 Linux 桌面的代表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/gnome-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/custom_gnomes.png?itok=iG98iL8d (Gnomes in a window.)
|
||||
[2]: https://www.gnome.org/
|
||||
[3]: https://www.gtk.org/overview.php
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-gnome.jpg (GNOME running on Debian)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-gnome-activities.jpg (GNOME activities)
|
||||
[7]: https://developer.gnome.org/hig/stable/
|
||||
[8]: https://opensource.com/article/19/11/advent-2019-cinnamon
|
||||
125
published/201912/20191209 Counting down the days using bash.md
Normal file
125
published/201912/20191209 Counting down the days using bash.md
Normal file
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11672-1.html)
|
||||
[#]: subject: (Counting down the days using bash)
|
||||
[#]: via: (https://www.networkworld.com/article/3487712/counting-down-the-days-using-bash.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
用 bash 倒计时日期
|
||||
======
|
||||
|
||||
> 需要知道重要事件发生前有多少天吗?让 Linux bash 和 date 命令可以帮助你!
|
||||
|
||||

|
||||
|
||||
随着即将来临的重要假期,你可能需要提醒你还要准备多久。
|
||||
|
||||
幸运的是,你可以从 `date` 命令获得很多帮助。在本篇中,我们将研究 `date` 和 bash 脚本如何告诉你从今天到你预期的事件之间有多少天。
|
||||
|
||||
首先,在进行之前有几个提示。`date` 命令的 `%j` 选项将以 1 至 366 之间的数字显示当前日期。如你所想的一样,1 月 1 日将显示为 1,12 月 31 日将显示为 365 或 366,这取决于是否是闰年。继续尝试。你应该会看到以下内容:
|
||||
|
||||
```
|
||||
$ date +%j
|
||||
339
|
||||
```
|
||||
|
||||
但是,你可以通过以下方式,在 `date` 命令中得到一年中*任何*一天的数字:
|
||||
|
||||
```
|
||||
$ date -d "Mar 18" +%j
|
||||
077
|
||||
```
|
||||
|
||||
要记住的是,即使该日期是过去的日期,上面命令也会向你显示*当年*的日期。但是,你可以在命令中添加年来修复该问题:
|
||||
|
||||
```
|
||||
$ date -d "Apr 29" +%j
|
||||
119
|
||||
$ date -d "Apr 29 2020" +%j
|
||||
120
|
||||
```
|
||||
|
||||
在闰年中,4 月 29 日将是一年的 120 天,而不是 119 天。
|
||||
|
||||
如果你想倒数圣诞节之前的日子并且不想在挂历上留下指纹,你可以使用以下脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
XMAS=`date -d "Dec 25" +%j`
|
||||
TODAY=`date +%j`
|
||||
DAYS=$(($XMAS - $TODAY))
|
||||
|
||||
case $DAYS in
|
||||
0) echo "It's today! Merry Christmas!";;
|
||||
[0-9]*) echo "$DAYS days remaining";;
|
||||
-[0-9]*) echo "Oops, you missed it";;
|
||||
esac
|
||||
```
|
||||
|
||||
在此脚本中,我们获取 12 月 25 日和今天的日期,然后相减。如果结果是正数,我们将显示剩余天数。如果为零,则发出 “Merry Christmas” 的消息,如果为负,那么仅告诉运行脚本的人他们错过了假期。也许他们沉迷在蛋酒中了。
|
||||
|
||||
`case` 语句由用来打印信息的语句组成,当剩余时间等于 0,或任意数字或以 `-` 符号开头的数字(也就是过去)分别打印不同的信息。
|
||||
|
||||
对于人们想要关注的任何日期,都可以使用相同方法。实际上,我们可以要求运行脚本的人员提供日期,然后让他们知道从现在到那天还有多少天。这个脚本是这样的。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
echo -n "Enter event date (e.g., June 6): "
|
||||
read dt
|
||||
EVENT=`date -d "$dt" +%j`
|
||||
TODAY=`date +%j`
|
||||
DAYS=`expr $EVENT - $TODAY`
|
||||
|
||||
case $DAYS in
|
||||
0) echo "It's today!";;
|
||||
[0-9]*) echo "$DAYS days remaining";;
|
||||
-[0-9]*) echo "Oops, you missed it";;
|
||||
esac
|
||||
```
|
||||
|
||||
使用此脚本会遇到的一个问题,如果运行该脚本的人希望知道到第二年这个特殊日子还有多少天,他们会感到失望。即使他们输入日期时提供了年,`date -d` 命令仍将仅提供今年中的天数,而不会提供从现在到那时的天数。
|
||||
|
||||
计算从今天到某年的日期之间的天数可能有些棘手。你需要包括所有中间年份,并注意那些闰年。
|
||||
|
||||
### 使用 Unix 纪元时间
|
||||
|
||||
计算从现在到某个特殊日期之间的天数的另一种方法是利用 Unix 系统存储日期的方法。如果将自 1970 年 1 月 1 日开始的秒数转换为天数,那么就可以很容易地执行此操作,如下脚本所示:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Enter target date (e.g., Mar 18 2021)> "
|
||||
read target_date
|
||||
today=`echo $(($(date --utc --date "$1" +%s)/86400))`
|
||||
target=`echo $(($(date --utc --date "$target_date" +%s)/86400))`
|
||||
days=`expr $target - $today`
|
||||
echo "$days days until $target_date"
|
||||
```
|
||||
|
||||
解释一下,86400 是一天中的秒数。将自 Unix 纪元开始以来的秒数除该数即为天数。
|
||||
|
||||
```
|
||||
$ ./countdown
|
||||
Enter target date (e.g., Mar 18 2021)> Mar 18 2020
|
||||
104 days until Mar 18 2020
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3487712/counting-down-the-days-using-bash.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,158 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11696-1.html)
|
||||
[#]: subject: (3 easy steps to update your apps to Python 3)
|
||||
[#]: via: (https://opensource.com/article/19/12/update-apps-python-3)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
将你的应用迁移到 Python 3 的三个步骤
|
||||
======
|
||||
|
||||
> Python 2 气数将尽,是时候将你的项目从 Python 2 迁移到 Python 3 了。
|
||||
|
||||

|
||||
|
||||
Python 2.x 很快就要[失去官方支持][2]了,尽管如此,从 Python 2 迁移到 Python 3 却并没有想象中那么难。我在上周用了一个晚上的时间将一个 3D 渲染器的前端代码及其对应的 [PySide][3] 迁移到 Python 3,回想起来,尽管在迁移过程中无可避免地会遇到一些牵一发而动全身的修改,但整个过程相比起痛苦的重构来说简直是出奇地简单。
|
||||
|
||||
每个人都别无选择地有各种必须迁移的原因:或许是觉得已经拖延太久了,或许是依赖了某个在 Python 2 下不再维护的模块。但如果你仅仅是想通过做一些事情来对开源做贡献,那么把一个 Python 2 应用迁移到 Python 3 就是一个简单而又有意义的做法。
|
||||
|
||||
无论你从 Python 2 迁移到 Python 3 的原因是什么,这都是一项重要的任务。按照以下三个步骤,可以让你把任务完成得更加清晰。
|
||||
|
||||
### 1、使用 2to3
|
||||
|
||||
从几年前开始,Python 在你或许还不知道的情况下就已经自带了一个名叫 [2to3][4] 的脚本,它可以帮助你实现大部分代码从 Python 2 到 Python 3 的自动转换。
|
||||
|
||||
下面是一段使用 Python 2.6 编写的代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
mystring = u'abcdé'
|
||||
print ord(mystring[-1])
|
||||
```
|
||||
|
||||
对其执行 2to3 脚本:
|
||||
|
||||
|
||||
```
|
||||
$ 2to3 example.py
|
||||
RefactoringTool: Refactored example.py
|
||||
--- example.py (original)
|
||||
+++ example.py (refactored)
|
||||
@@ -1,5 +1,5 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
-mystring = u'abcdé'
|
||||
-print ord(mystring[-1])
|
||||
+mystring = 'abcdé'
|
||||
+print(ord(mystring[-1]))
|
||||
RefactoringTool: Files that need to be modified:
|
||||
RefactoringTool: example.py
|
||||
```
|
||||
|
||||
在默认情况下,`2to3` 只会对迁移到 Python 3 时必须作出修改的代码进行标示,在输出结果中显示的 Python 3 代码是直接可用的,但你可以在 2to3 加上 `-w` 或者 `--write` 参数,这样它就可以直接按照给出的方案修改你的 Python 2 代码文件了。
|
||||
|
||||
```
|
||||
$ 2to3 -w example.py
|
||||
[...]
|
||||
RefactoringTool: Files that were modified:
|
||||
RefactoringTool: example.py
|
||||
```
|
||||
|
||||
`2to3` 脚本不仅仅对单个文件有效,你还可以把它用于一个目录下的所有 Python 文件,同时它也会递归地对所有子目录下的 Python 文件都生效。
|
||||
|
||||
### 2、使用 Pylint 或 Pyflakes
|
||||
|
||||
有一些不良的代码在 Python 2 下运行是没有异常的,在 Python 3 下运行则会或多或少报出错误,这种情况并不鲜见。因为这些不良代码无法通过语法转换来修复,所以 `2to3` 对它们没有效果,但一旦使用 Python 3 来运行就会产生报错。
|
||||
|
||||
要找出这种问题,你需要使用 [Pylint][5]、[Pyflakes][6](或 [flake8][7] 封装器)这类工具。其中我更喜欢 Pyflakes,它会忽略代码风格上的差异,在这一点上它和 Pylint 不同。尽管代码优美是 Python 的一大特点,但在代码迁移的层面上,“让代码功能保持一致”无疑比“让代码风格保持一致”重要得多。
|
||||
|
||||
以下是 Pyflakes 的输出样例:
|
||||
|
||||
```
|
||||
$ pyflakes example/maths
|
||||
example/maths/enum.py:19: undefined name 'cmp'
|
||||
example/maths/enum.py:105: local variable 'e' is assigned to but never used
|
||||
example/maths/enum.py:109: undefined name 'basestring'
|
||||
example/maths/enum.py:208: undefined name 'EnumValueCompareError'
|
||||
example/maths/enum.py:208: local variable 'e' is assigned to but never used
|
||||
```
|
||||
|
||||
上面这些由 Pyflakes 输出的内容清晰地给出了代码中需要修改的问题。相比之下,Pylint 会输出多达 143 行的内容,而且多数是诸如代码缩进这样无关紧要的问题。
|
||||
|
||||
值得注意的是第 19 行这个容易产生误导的错误。从输出来看你可能会以为 `cmp` 是一个在使用前未定义的变量,实际上 `cmp` 是 Python 2 的一个内置函数,而它在 Python 3 中被移除了。而且这段代码被放在了 `try` 语句块中,除非认真检查这段代码的输出值,否则这个问题很容易被忽略掉。
|
||||
|
||||
```
|
||||
try:
|
||||
result = cmp(self.index, other.index)
|
||||
except:
|
||||
result = 42
|
||||
|
||||
return result
|
||||
```
|
||||
|
||||
在代码迁移过程中,你会发现很多原本在 Python 2 中能正常运行的函数都发生了变化,甚至直接在 Python 3 中被移除了。例如 PySide 的绑定方式发生了变化、`importlib` 取代了 `imp` 等等。这样的问题只能见到一个解决一个,而涉及到的功能需要重构还是直接放弃,则需要你自己权衡。但目前来说,大多数问题都是已知的,并且有[完善的文档记录][8]。所以难的不是修复问题,而是找到问题,从这个角度来说,使用 Pyflake 是很有必要的。
|
||||
|
||||
### 3、修复被破坏的 Python 2 代码
|
||||
|
||||
尽管 `2to3` 脚本能够帮助你把代码修改成兼容 Python 3 的形式,但对于一个完整的代码库,它就显得有点无能为力了,因为一些老旧的代码在 Python 3 中可能需要不同的结构来表示。在这样的情况下,只能人工进行修改。
|
||||
|
||||
例如以下代码在 Python 2.6 中可以正常运行:
|
||||
|
||||
```
|
||||
class CLOCK_SPEED:
|
||||
TICKS_PER_SECOND = 16
|
||||
TICK_RATES = [int(i * TICKS_PER_SECOND)
|
||||
for i in (0.5, 1, 2, 3, 4, 6, 8, 11, 20)]
|
||||
|
||||
class FPS:
|
||||
STATS_UPDATE_FREQUENCY = CLOCK_SPEED.TICKS_PER_SECOND
|
||||
```
|
||||
|
||||
类似 `2to3` 和 Pyflakes 这些自动化工具并不能发现其中的问题,但如果上述代码使用 Python 3 来运行,解释器会认为 `CLOCK_SPEED.TICKS_PER_SECOND` 是未被明确定义的。因此就需要把代码改成面向对象的结构:
|
||||
|
||||
```
|
||||
class CLOCK_SPEED:
|
||||
def TICKS_PER_SECOND():
|
||||
TICKS_PER_SECOND = 16
|
||||
TICK_RATES = [int(i * TICKS_PER_SECOND)
|
||||
for i in (0.5, 1, 2, 3, 4, 6, 8, 11, 20)]
|
||||
return TICKS_PER_SECOND
|
||||
|
||||
class FPS:
|
||||
STATS_UPDATE_FREQUENCY = CLOCK_SPEED.TICKS_PER_SECOND()
|
||||
```
|
||||
|
||||
你也许会认为如果把 `TICKS_PER_SECOND()` 改写为一个构造函数(用 `__init__` 函数设置默认值)能让代码看起来更加简洁,但这样就需要把这个方法的调用形式从 `CLOCK_SPEED.TICKS_PER_SECOND()` 改为 `CLOCK_SPEED()` 了,这样的改动或多或少会对整个库造成一些未知的影响。如果你对整个代码库的结构烂熟于心,那么你确实可以随心所欲地作出这样的修改。但我通常认为,只要我做出了修改,都可能会影响到其它代码中的至少三处地方,因此我更倾向于不使代码的结构发生改变。
|
||||
|
||||
### 坚持信念
|
||||
|
||||
如果你正在尝试将一个大项目从 Python 2 迁移到 Python 3,也许你会觉得这是一个漫长的过程。你可能会费尽心思也找不到一条有用的报错信息,这种情况下甚至会有将代码推倒重建的冲动。但从另一个角度想,代码原本在 Python 2 中就可以运行,要让它能在 Python 3 中继续运行,你需要做的只是对它稍加转换而已。
|
||||
|
||||
但只要你完成了迁移,你就得到了这个模块或者整个应用程序的 Python 3 版本,外加 Python 官方的长期支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/update-apps-python-3
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python-programming-code-keyboard.png?itok=fxiSpmnd "Hands on a keyboard with a Python book "
|
||||
[2]: https://linux.cn/article-11629-1.html
|
||||
[3]: https://pypi.org/project/PySide/
|
||||
[4]: https://docs.python.org/3.1/library/2to3.html
|
||||
[5]: https://opensource.com/article/19/10/python-pylint-introduction
|
||||
[6]: https://pypi.org/project/pyflakes/
|
||||
[7]: https://opensource.com/article/19/5/python-flake8
|
||||
[8]: https://docs.python.org/3.0/whatsnew/3.0.html
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11682-1.html)
|
||||
[#]: subject: (Breaking Linux files into pieces with the split command)
|
||||
[#]: via: (https://www.networkworld.com/article/3489256/breaking-linux-files-into-pieces-with-the-split-command.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
使用 split 命令分割 Linux 文件
|
||||
======
|
||||
|
||||
> 一些简单的 Linux 命令能让你根据需要分割以及重新组合文件,来适应存储或电子邮件附件大小的限制。
|
||||
|
||||
![Marco Verch][1]
|
||||
|
||||
Linux 系统提供了一个非常易于使用的命令来分割文件。在将文件上传到限制大小的存储网站或者作为邮件附件之前,你可能需要执行此操作。要将文件分割为多个文件块,只需使用 `split` 命令。
|
||||
|
||||
```
|
||||
$ split bigfile
|
||||
```
|
||||
|
||||
默认情况下,`split` 命令使用非常简单的命名方案。文件块将被命名为 `xaa`、`xab`、`xac` 等,并且,大概地,如果你将足够大的文件分割,你甚至可能会得到名为 `xza` 和 `xzz` 的块。
|
||||
|
||||
除非你要求,否则该命令将无任何反馈地运行。但是,如果你想在创建文件块时看到反馈,可以使用 `--verbose` 选项。
|
||||
|
||||
```
|
||||
$ split –-verbose bigfile
|
||||
creating file 'xaa'
|
||||
creating file 'xab'
|
||||
creating file 'xac'
|
||||
```
|
||||
|
||||
你还可以给文件命名前缀。例如,要将你原始文件分割并命名为 `bigfile.aa`、`bigfile.ab` 等,你可以将前缀添加到 `split` 命令的末尾,如下所示:
|
||||
|
||||
```
|
||||
$ split –-verbose bigfile bigfile.
|
||||
creating file 'bigfile.aa'
|
||||
creating file 'bigfile.ab'
|
||||
creating file 'bigfile.ac'
|
||||
```
|
||||
|
||||
请注意,上述命令中显示的前缀的末尾会添加一个点。否则,文件将是 `bigfileaa` 之类的名称,而不是 `bigfile.aa`。
|
||||
|
||||
请注意,`split` 命令*不会*删除你的原始文件,只是创建了文件块。如果要指定文件块的大小,可以使用 `-b` 选项将其添加到命令中。例如:
|
||||
|
||||
```
|
||||
$ split -b100M bigfile
|
||||
```
|
||||
|
||||
文件大小可以是 KB、MB,GB,最大可以是 YB!只需使 K、M、G、T、P、E、Z 和 Y 这些合适的字母。
|
||||
|
||||
如果要基于每个块中的行数而不是字节数来拆分文件,那么可以使用 `-l`(行)选项。在此示例中,每个文件将有 1000 行,当然,最后一个文件可能有较少的行。
|
||||
|
||||
```
|
||||
$ split --verbose -l1000 logfile log.
|
||||
creating file 'log.aa'
|
||||
creating file 'log.ab'
|
||||
creating file 'log.ac'
|
||||
creating file 'log.ad'
|
||||
creating file 'log.ae'
|
||||
creating file 'log.af'
|
||||
creating file 'log.ag'
|
||||
creating file 'log.ah'
|
||||
creating file 'log.ai'
|
||||
creating file 'log.aj'
|
||||
```
|
||||
|
||||
如果你需要在远程站点上重新组合文件,那么可以使用如下所示的 `cat` 命令轻松地完成此操作:
|
||||
|
||||
```
|
||||
$ cat x?? > original.file
|
||||
$ cat log.?? > original.file
|
||||
```
|
||||
|
||||
上面所示的分割和组合命令适合于二进制和文本文件。在此示例中,我们将 zip 二进制文件分割为 50KB 的块,之后使用 `cat` 重新组合了它们,然后比较了组合后的文件和原始文件。`diff` 命令验证文件是否相同。
|
||||
|
||||
```
|
||||
$ split --verbose -b50K zip zip.
|
||||
creating file 'zip.aa'
|
||||
creating file 'zip.ab'
|
||||
creating file 'zip.ac'
|
||||
creating file 'zip.ad'
|
||||
creating file 'zip.ae'
|
||||
$ cat zip.a? > zip.new
|
||||
$ diff zip zip.new
|
||||
$ <== 无输出 = 无差别
|
||||
```
|
||||
|
||||
我唯一要提醒的一点的是,如果你经常使用 `split` 并使用默认命名,那么某些文件块可能会覆盖其他的文件块,甚至会比你预期的更多,因为有些是更早之前分割的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489256/breaking-linux-files-into-pieces-with-the-split-command.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/08/chocolate-chunks-100767935-large.jpg
|
||||
[2]: https://creativecommons.org/licenses/by/2.0/legalcode
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11712-1.html)
|
||||
[#]: subject: (Customize your Linux desktop with FVWM)
|
||||
[#]: via: (https://opensource.com/article/19/12/fvwm-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 FVWM 自定义 Linux 桌面
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你正在寻找轻巧、快速且简单的 Linux 窗口管理器,那么 FVWM 可以胜任。但是,如果你正在寻找可以深入、探索和魔改的窗口管理器,那么 FVWM 是必须的。
|
||||
|
||||
|
||||
|
||||
[FVWM][2] 窗口管理器最早脱胎于对 1993 年的 [TWM][3] 的修改。经过几年的迭代,诞生了一个可高度自定义的环境,它可以配置任何行为、动作或事件。它支持自定义键绑定、鼠标手势、主题、脚本等。
|
||||
|
||||
尽管 FVWM 在安装后即可投入使用,但默认分发版本仅提供了极其少的配置。这是开始自定义桌面环境的良好基础,但是,如果你只想将其用作桌面,那么可能要安装由其它用户发布的完整配置版本。FVWM 有几种不同的分发版,包括模仿 Windows 95 的 FVWM95(至少在外观和布局上)。我尝试了 [FVWM-Crystal][4],这是一个具有一些现代 Linux 桌面约定的现代主题。
|
||||
|
||||
可以从 Linux 发行版的软件仓库中安装要尝试的 FVWM 分发版。如果找不到特定的 FVWM 分发版,那么可以安装基础的 FVWM2 包,然后进入 [Box-Look.org][5] 手动下载主题包。这样就需要更多的工作,但比从头开始构建要少。
|
||||
|
||||
安装后,请注销当前的桌面会话,以便你可以登录 FVWM。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该桌面。
|
||||
|
||||
对于 GDM:
|
||||
|
||||
![Select your desktop session in GDM][6]
|
||||
|
||||
对于 KDM:
|
||||
|
||||
![Select your desktop session with KDM][7]
|
||||
|
||||
### FVWM 桌面
|
||||
|
||||
无论你使用什么主题和配置,当你在桌面上单击鼠标左键时,FVWM 至少会显示一个菜单。菜单的内容取决于你所安装的内容。FVWM-Crystal 分发版中的菜单包含对常用首选项的快速访问,例如屏幕分辨率、壁纸设置、窗口装饰等。
|
||||
|
||||
同 FVWM 中的几乎所有东西一样,你可以编辑菜单中你要想的内容,但 FVWM-Crystal 的特色在于其应用菜单栏。应用菜单位于屏幕的左上角,每个图标都包含了相关的应用启动器的菜单。例如,GIMP 图标表示图像编辑器,KDevelop 图标表示集成开发环境(IDE),GNU 图标表示文本编辑器,等等,具体取决于你在系统上安装的程序。
|
||||
|
||||
![FVWM-crystal running on Slackware 14.2][8]
|
||||
|
||||
FVWM-Crystal 还提供了虚拟桌面、任务栏、时钟和应用栏。
|
||||
|
||||
关于背景,你可以使用与 FVWM-Crystal 捆绑在一起的壁纸,也可以使用 `feh` 命令设置自己的壁纸(你可能需要从仓库中安装它)。此命令有一些设置背景的选项,包括 `--bg-scale` 使用你选择的图片缩放填充屏幕,`--bg-fill` 直接填充而不缩放图片,等等。
|
||||
|
||||
```
|
||||
$ feh --bg-scale ~/Pictures/wallpapers/mybackground.jpg
|
||||
```
|
||||
|
||||
大多数配置文件都包含在 `$HOME/.fvwm-crystal` 中,某些系统范围的默认文件位于 `/usr/share/fvwm-crystal`。
|
||||
|
||||
### 自己尝试一下
|
||||
|
||||
FVWM 是大多作为一个桌面构建平台,它也是窗口管理器。它不会为你做到面面俱到,它期望你来配置尽可能的一切。
|
||||
|
||||
如果你正在寻找轻巧、快速且简单的窗口管理器,那么 FVWM 可以胜任。但是,如果你正在寻找可以深入、探索和魔改的窗口管理器,那么 FVWM 是必须的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/fvwm-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: http://www.fvwm.org/
|
||||
[3]: https://en.wikipedia.org/wiki/Twm
|
||||
[4]: https://www.box-look.org/p/1018270/
|
||||
[5]: http://box-look.org
|
||||
[6]: https://opensource.com/sites/default/files/advent-gdm_0.jpg (Select your desktop session in GDM)
|
||||
[7]: https://opensource.com/sites/default/files/advent-kdm.jpg (Select your desktop session with KDM)
|
||||
[8]: https://opensource.com/sites/default/files/advent-fvwm-crystal.jpg (FVWM-crystal running on Slackware 14.2)
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11695-1.html)
|
||||
[#]: subject: (Annotate screenshots on Linux with Ksnip)
|
||||
[#]: via: (https://opensource.com/article/19/12/annotate-screenshots-linux-ksnip)
|
||||
[#]: author: (Clayton Dewey https://opensource.com/users/cedewey)
|
||||
|
||||
在 Linux 上使用 Ksnip 注释截图
|
||||
======
|
||||
|
||||
> Ksnip 让你能轻松地在 Linux 中创建和标记截图。
|
||||
|
||||
![a checklist for a team][1]
|
||||
|
||||
我最近从 MacOS 切换到了 [Elementary OS][2],这是一个专注于易用性和隐私性的 Linux 发行版。作为用户体验设计师和自由软件支持者,我会经常截图并进行注释。在尝试了几种不同的工具之后,到目前为止,我最喜欢的工具是 [Ksnip][3],它是 GPLv2 许可下的一种开源工具。
|
||||
|
||||
![Ksnip screenshot][4]
|
||||
|
||||
### 安装
|
||||
|
||||
使用你首选的包管理器安装 Ksnip。我通过 Apt 安装了它:
|
||||
|
||||
```
|
||||
sudo apt-get install ksnip
|
||||
```
|
||||
|
||||
### 配置
|
||||
|
||||
Ksnip 有许多配置选项,包括:
|
||||
|
||||
* 保存截图的地方
|
||||
* 默认截图的文件名
|
||||
* 图像采集器行为
|
||||
* 光标颜色和宽度
|
||||
* 文字字体
|
||||
|
||||
你也可以将其与你的 Imgur 帐户集成。
|
||||
|
||||
![Ksnip configuration options][5]
|
||||
|
||||
### 用法
|
||||
|
||||
Ksnip 提供了大量的[功能][6]。我最喜欢的 Ksnip 部分是它拥有我需要的所有注释工具(还有一个我没想到的工具!)。
|
||||
|
||||
你可以使用以下注释:
|
||||
|
||||
* 钢笔
|
||||
* 记号笔
|
||||
* 矩形
|
||||
* 椭圆
|
||||
* 文字
|
||||
|
||||
你还可以模糊区域来移除敏感信息。还有使用我最喜欢的新工具:用于在界面上表示步骤的带数字的点。
|
||||
|
||||
### 关于作者
|
||||
|
||||
我非常喜欢 Ksnip,因此我联系了作者 [Damir Porobic][7] 来了解有关该项目的更多信息。
|
||||
|
||||
当我问到是什么启发了他编写 Ksnip 时,他说:
|
||||
|
||||
> “几年前我从 Windows 切换到 Linux,却没有了在 Windows 中常用的 Windows Snipping Tool。当时的所有其他截图工具要么很大(很多按钮和复杂功能),要么缺少诸如注释等关键功能,所以我决定编写一个简单的 Windows Snipping Tool 克隆版,但是随着时间的流逝,它开始有越来越多的功能。“
|
||||
|
||||
这正是我在评估截图工具时发现的。他花时间构建解决方案并免费共享给他人使用,这真是太好了。
|
||||
|
||||
至于 Ksnip 的未来,Damir 希望添加全局快捷方式(至少对于 Windows 是这样)和用于新截图的选项卡,并允许该应用在后台运行。GitHub 上的功能请求列表也越来越多。
|
||||
|
||||
### 帮助的方式
|
||||
|
||||
Damir 最需要的是帮助开发 Ksnip。他和他的妻子很快就会有孩子了,所以他将没有太多的时间放在这个项目上。不过,他可以检查和接受拉取请求。
|
||||
|
||||
此外,此项目还可以通过 Snap 、Flatpak 以及 MacOS 安装包、Windows 安装包等其他安装方式安装。如果你想提供帮助,请查看 Ksnip 的 README 的 [Contribution][8] 部分。
|
||||
|
||||
* * *
|
||||
|
||||
> 此文章最初发表在 [Agaric Tech Cooperative 的博客][9]上,并经允许重新发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/annotate-screenshots-linux-ksnip
|
||||
|
||||
作者:[Clayton Dewey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cedewey
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_hands_team_collaboration.png?itok=u82QepPk (a checklist for a team)
|
||||
[2]: https://elementary.io/
|
||||
[3]: https://github.com/damirporobic/ksnip
|
||||
[4]: https://opensource.com/sites/default/files/uploads/ksnip.png (Ksnip screenshot)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/ksnip-configuration.png (Ksnip configuration options)
|
||||
[6]: https://github.com/DamirPorobic/ksnip#features
|
||||
[7]: https://github.com/damirporobic/
|
||||
[8]: https://github.com/DamirPorobic/ksnip/blob/master/README.md#contribution
|
||||
[9]: https://agaric.coop/blog/annotate-screenshots-linux-ksnip
|
||||
@ -0,0 +1,166 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11678-1.html)
|
||||
[#]: subject: (How to Find High CPU Consumption Processes in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-find-high-cpu-consumption-processes-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 中找出 CPU 占用高的进程
|
||||
======
|
||||
|
||||

|
||||
|
||||
在之前的文章中我们已经讨论过 [如何在 Linux 中找出内存消耗最大的进程][1]。你可能也会遇到在 Linux 系统中找出 CPU 占用高的进程的情形。如果是这样,那么你需要列出系统中 CPU 占用高的进程列表来确定。我认为只有两种方法能实现:使用 [top 命令][2] 和 [ps 命令][3]。出于一些理由,我更倾向于用 `top` 命令而不是 `ps` 命令。但是两个工具都能达到你要的目的,所以你可以根据需求决定使用哪个。这两个工具都被 Linux 系统管理员广泛使用。
|
||||
|
||||
### 1) 怎样使用 top 命令找出 Linux 中 CPU 占用高的进程
|
||||
|
||||
在所有监控 Linux 系统性能的工具中,Linux 的 `top` 命令是最好的也是最知名的一个。`top` 命令提供了 Linux 系统运行中的进程的动态实时视图。它能显示系统的概览信息和 Linux 内核当前管理的进程列表。它显示了大量的系统信息,如 CPU 使用、内存使用、交换内存、运行的进程数、目前系统开机时间、系统负载、缓冲区大小、缓存大小、进程 PID 等等。默认情况下,`top` 命令的输出结果按 CPU 占用进行排序,每 5 秒中更新一次结果。如果你想要一个更清晰的视图来更深入的分析结果,[以批处理模式运行 top 命令][4] 是最好的方法。同时,你需要 [理解 top 命令输出结果的含义][5] ,这样才能解决系统的性能问题。
|
||||
|
||||
```
|
||||
# top -b | head -50
|
||||
|
||||
top - 00:19:17 up 14:23, 1 user, load average: 2.46, 2.18, 1.97
|
||||
Tasks: 306 total, 1 running, 305 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu0 : 10.4 us, 3.0 sy, 0.0 ni, 83.9 id, 0.0 wa, 1.3 hi, 1.3 si, 0.0 st
|
||||
%Cpu1 : 17.0 us, 3.0 sy, 0.0 ni, 78.7 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu2 : 13.0 us, 4.0 sy, 0.0 ni, 81.3 id, 0.0 wa, 0.3 hi, 1.3 si, 0.0 st
|
||||
%Cpu3 : 12.3 us, 3.3 sy, 0.0 ni, 82.5 id, 0.3 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
%Cpu4 : 12.2 us, 3.0 sy, 0.0 ni, 82.8 id, 0.7 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu5 : 6.4 us, 2.7 sy, 0.0 ni, 89.2 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
%Cpu6 : 26.7 us, 3.4 sy, 0.0 ni, 68.6 id, 0.0 wa, 0.7 hi, 0.7 si, 0.0 st
|
||||
%Cpu7 : 15.6 us, 4.0 sy, 0.0 ni, 78.8 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
KiB Mem : 16248556 total, 1448920 free, 8571484 used, 6228152 buff/cache
|
||||
KiB Swap: 17873388 total, 17873388 free, 0 used. 4596044 avail Mem
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
2179 daygeek 20 3106324 613584 327564 S 79.5 3.8 14:19.76 Web Content
|
||||
1714 daygeek 20 4603372 974600 403504 S 20.2 6.0 65:18.91 firefox
|
||||
1227 daygeek 20 4192012 376332 180348 S 13.9 2.3 20:43.26 gnome-shell
|
||||
18324 daygeek 20 3296192 766040 127948 S 6.3 4.7 9:18.12 Web Content
|
||||
1170 daygeek 20 1008264 572036 546180 S 6.0 3.5 18:07.85 Xorg
|
||||
4684 daygeek 20 3363708 1.1g 1.0g S 3.6 7.2 13:49.92 VirtualBoxVM
|
||||
4607 daygeek 20 4591040 1.7g 1.6g S 3.0 11.0 14:09.65 VirtualBoxVM
|
||||
1211 daygeek 9 -11 2865268 21032 16588 S 2.0 0.1 10:46.37 pulseaudio
|
||||
4562 daygeek 20 1096888 28812 21044 S 1.7 0.2 4:42.93 VBoxSVC
|
||||
1783 daygeek 20 3123888 376896 134788 S 1.3 2.3 39:32.56 Web Content
|
||||
3286 daygeek 20 3089736 404088 184968 S 1.0 2.5 41:57.44 Web Content
|
||||
```
|
||||
|
||||
上面的命令的各部分解释:
|
||||
|
||||
* `top`:命令
|
||||
* `-b`:批次档模式
|
||||
* `head -50`:显示输出结果的前 50 个
|
||||
* `PID`:进程的 ID
|
||||
* `USER`:进程的归属者
|
||||
* `PR`:进程的等级
|
||||
* `NI`:进程的 NICE 值
|
||||
* `VIRT`:进程使用的虚拟内存
|
||||
* `RES`:进程使用的物理内存
|
||||
* `SHR`:进程使用的共享内存
|
||||
* `S`:这个值表示进程的状态: `S` = 睡眠,`R` = 运行,`Z` = 僵尸进程
|
||||
* `%CPU`:进程占用的 CPU 比例
|
||||
* `%MEM`:进程使用的 RAM 比例
|
||||
* `TIME+`:进程运行了多长时间
|
||||
* `COMMAND`:进程名字
|
||||
|
||||
如果你想看命令的完整路径而不是命令名字,以运行下面的格式 `top` 命令:
|
||||
|
||||
```
|
||||
# top -c -b | head -50
|
||||
|
||||
top - 00:28:49 up 14:33, 1 user, load average: 2.43, 2.49, 2.23
|
||||
Tasks: 305 total, 1 running, 304 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu0 : 11.7 us, 3.7 sy, 0.0 ni, 82.3 id, 0.0 wa, 1.0 hi, 1.3 si, 0.0 st
|
||||
%Cpu1 : 13.6 us, 3.3 sy, 0.0 ni, 81.1 id, 0.7 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu2 : 10.9 us, 2.6 sy, 0.0 ni, 85.1 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu3 : 16.0 us, 2.6 sy, 0.0 ni, 80.1 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu4 : 9.2 us, 3.6 sy, 0.0 ni, 85.9 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu5 : 15.6 us, 2.9 sy, 0.0 ni, 80.5 id, 0.0 wa, 0.3 hi, 0.7 si, 0.0 st
|
||||
%Cpu6 : 11.6 us, 4.3 sy, 0.0 ni, 82.7 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu7 : 8.0 us, 3.0 sy, 0.0 ni, 87.3 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
KiB Mem : 16248556 total, 1022456 free, 8778508 used, 6447592 buff/cache
|
||||
KiB Swap: 17873388 total, 17873388 free, 0 used. 4201560 avail Mem
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
18527 daygeek 20 3151820 624808 325748 S 52.8 3.8 59:26.72 /usr/lib/firefox/firefox -contentproc -childID 18 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
1714 daygeek 20 4764668 910940 443228 S 21.5 5.6 68:59.33 /usr/lib/firefox/firefox --new-window
|
||||
1227 daygeek 20 4193108 377344 181404 S 11.6 2.3 21:47.36 /usr/bin/gnome-shell
|
||||
1170 daygeek 20 1008820 572700 546844 S 5.6 3.5 19:05.10 /usr/lib/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -background none -noreset -keeptty -verbose 3
|
||||
18324 daygeek 20 3300288 789344 127948 S 5.0 4.9 9:46.89 /usr/lib/firefox/firefox -contentproc -childID 16 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
4684 daygeek 20 3363708 1.1g 1.0g S 3.6 7.2 14:10.18 /usr/lib/virtualbox/VirtualBoxVM --comment CentOS7 --startvm 002f47b8-2af2-48f5-be1d-67b67e03514c --no-startvm-errormsgbox
|
||||
4607 daygeek 20 4591040 1.7g 1.6g S 3.0 11.0 14:28.86 /usr/lib/virtualbox/VirtualBoxVM --comment Ubuntu-18.04 --startvm e8c32dbb-8b01-41b0-977a-bf28b9db1117 --no-startvm-errormsgbox
|
||||
1783 daygeek 20 3132640 451924 132168 S 2.6 2.8 39:49.66 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/l+
|
||||
1211 daygeek 9 -11 2865268 21272 16828 S 2.0 0.1 11:01.29 /usr/bin/pulseaudio --daemonize=no
|
||||
4562 daygeek 20 1096888 28812 21044 S 1.7 0.2 4:49.33 /usr/lib/virtualbox/VBoxSVC --auto-shutdown
|
||||
16865 daygeek 20 3073364 430596 124652 S 1.3 2.7 8:04.02 /usr/lib/firefox/firefox -contentproc -childID 15 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
2179 daygeek 20 2945348 429644 172940 S 1.0 2.6 15:20.90 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 7821 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /us+
|
||||
```
|
||||
|
||||
### 2) 怎样使用 ps 命令找出 Linux 中 CPU 占用高的进程
|
||||
|
||||
`ps` 是<ruby>进程状态<rt>process status</rt></ruby>的缩写,它能显示系统中活跃的/运行中的进程的信息。它提供了当前进程及其详细信息,诸如用户名、用户 ID、CPU 使用率、内存使用、进程启动日期时间、命令名等等的快照。
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%cpu | head
|
||||
|
||||
PID PPID %MEM %CPU CMD
|
||||
18527 1714 4.2 40.3 /usr/lib/firefox/firefox -contentproc -childID 18 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1714 1152 5.6 8.0 /usr/lib/firefox/firefox --new-window
|
||||
18324 1714 4.9 6.3 /usr/lib/firefox/firefox -contentproc -childID 16 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
3286 1714 2.0 5.1 /usr/lib/firefox/firefox -contentproc -childID 14 -isForBrowser -prefsLen 8078 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1783 1714 3.0 4.5 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1227 1152 2.3 2.5 /usr/bin/gnome-shell
|
||||
1170 1168 3.5 2.2 /usr/lib/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -background none -noreset -keeptty -verbose 3
|
||||
16865 1714 2.5 2.1 /usr/lib/firefox/firefox -contentproc -childID 15 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
2179 1714 2.7 1.8 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 7821 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
```
|
||||
|
||||
上面的命令的各部分解释:
|
||||
|
||||
* `ps`:命令名字
|
||||
* `-e`:选择所有进程
|
||||
* `-o`:自定义输出格式
|
||||
* `–sort=-%cpu`:基于 CPU 使用率对输出结果排序
|
||||
* `head`:显示结果的前 10 行
|
||||
* `PID`:进程的 ID
|
||||
* `PPID`:父进程的 ID
|
||||
* `%MEM`:进程使用的 RAM 比例
|
||||
* `%CPU`:进程占用的 CPU 比例
|
||||
* `Command`:进程名字
|
||||
|
||||
如果你只想看命令名字而不是命令的绝对路径,以运行下面的格式 `ps` 命令:
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,%mem,%cpu,comm --sort=-%cpu | head
|
||||
|
||||
PID PPID %MEM %CPU COMMAND
|
||||
18527 1714 4.1 40.4 Web Content
|
||||
1714 1152 5.7 8.0 firefox
|
||||
18324 1714 4.9 6.3 Web Content
|
||||
3286 1714 2.0 5.1 Web Content
|
||||
1783 1714 3.0 4.5 Web Content
|
||||
1227 1152 2.3 2.5 gnome-shell
|
||||
1170 1168 3.5 2.2 Xorg
|
||||
16865 1714 2.4 2.1 Web Content
|
||||
2179 1714 2.7 1.8 Web Content
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-high-cpu-consumption-processes-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-11542-1.html
|
||||
[2]: https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/
|
||||
[3]: https://www.2daygeek.com/linux-ps-command-find-running-process-monitoring/
|
||||
[4]: https://www.2daygeek.com/linux-run-execute-top-command-in-batch-mode/
|
||||
[5]: https://www.2daygeek.com/understanding-linux-top-command-output-usage/
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11698-1.html)
|
||||
[#]: subject: (How to configure Openbox for your Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/openbox-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何为 Linux 桌面配置 Openbox
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。Openbox 窗口管理器占用很小的系统资源、易于配置、使用愉快。
|
||||
|
||||

|
||||
|
||||
你可能不知道你使用过 [Openbox][2] 桌面:尽管 Openbox 本身是一个出色的窗口管理器,但它还是 LXDE 和 LXQT 等桌面环境的窗口管理器“引擎”,它甚至可以管理 KDE 和 GNOME。除了作为多个桌面的基础之外,Openbox 可以说是最简单的窗口管理器之一,可以为那些不想学习那么多配置选项的人配置。通过使用基于菜单的 obconf 的配置应用,可以像在 GNOME 或 KDE 这样的完整桌面中一样轻松地设置所有常用首选项。
|
||||
|
||||
### 安装 Openbox
|
||||
|
||||
你可能会在 Linux 发行版的软件仓库中找到 Openbox,也可以在 [Openbox.org][3] 中找到它。如果你已经在运行其他桌面,那么可以安全地在同一系统上安装 Openbox,因为 Openbox 除了几个配置面板之外,不包括任何捆绑的应用。
|
||||
|
||||
安装后,退出当前桌面会话,以便你可以登录 Openbox 桌面。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,这取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该选择。
|
||||
|
||||
要使用 GDM 覆盖它:
|
||||
|
||||
![Select your desktop session in GDM][4]
|
||||
|
||||
要使用 SDDM 覆盖它:
|
||||
|
||||
![Select your desktop session with KDM][5]
|
||||
|
||||
### 配置 Openbox 桌面
|
||||
|
||||
默认情况下,Openbox 包含 obconf 应用,你可以使用它来选择和安装主题、修改鼠标行为、设置桌面首选项等。你可能会在仓库中发现其他配置应用,如 obmenu,用于配置窗口管理器的其他部分。
|
||||
|
||||
![Openbox Obconf configuration application][6]
|
||||
|
||||
构建你自己的桌面环境相对容易。它有一些所有常见的桌面组件,例如系统托盘 [stalonetray][7]、任务栏 [Tint2][8] 或 [Xfce4-panel][9] 等几乎你能想到的。任意组合应用,直到拥有梦想的开源桌面为止。
|
||||
|
||||
![Openbox][10]
|
||||
|
||||
### 为何使用 Openbox
|
||||
|
||||
Openbox 占用的系统资源很小、易于配置、使用起来很愉悦。它基本不会让你感觉到阻碍,会是一个容易熟悉的系统。你永远不会知道你面前的桌面环境秘密使用了 Openbox 作为窗口管理器(知道如何自定义它会不会很高兴?)。如果开源吸引你,那么试试看 Openbox。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/openbox-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_general_openfield.png?itok=MeVN97oy (open with sky and grass)
|
||||
[2]: http://openbox.org
|
||||
[3]: http://openbox.org/wiki/Openbox:Download
|
||||
[4]: https://opensource.com/sites/default/files/advent-gdm_0.jpg (Select your desktop session in GDM)
|
||||
[5]: https://opensource.com/sites/default/files/advent-kdm.jpg (Select your desktop session with KDM)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-openbox-obconf_675px.jpg (Openbox Obconf configuration application)
|
||||
[7]: https://sourceforge.net/projects/stalonetray/
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
[9]: http://xfce.org
|
||||
[10]: https://opensource.com/sites/default/files/uploads/advent-openbox_675px.jpg (Openbox)
|
||||
@ -0,0 +1,56 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mayunmeiyouming)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11703-1.html)
|
||||
[#]: subject: (What GNOME 2 fans love about the Mate Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/mate-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
GNOME 2 粉丝喜欢 Mate Linux 桌面的什么?
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你还在怀念 GNOME 2,那么 Mate Linux 桌面将满足你的怀旧情怀。
|
||||
|
||||

|
||||
|
||||
如果你以前听过这个传闻:当 GNOME3 第一次发布时,很多 GNOME 用户还没有准备好放弃 GNOME 2。[Mate][2](以<ruby>马黛茶<rt>yerba mate</rt></ruby>植物命名)项目的开始是为了延续 GNOME 2 桌面,刚开始时它使用 GTK 2(GNOME 2 所基于的工具包),然后又合并了 GTK 3。由于 Linux Mint 的简单易用,使得该桌面变得非常流行,并且从那时起,它已经普遍用于 Fedora、Ubuntu、Slackware、Arch 和许多其他 Linux 发行版上。今天,Mate 继续提供一个传统的桌面环境,它的外观和感觉与 GNOME 2 完全一样,使用 GTK 3 工具包。
|
||||
|
||||
你可以在你的 Linux 发行版的软件仓库中找到 Mate,也可以下载并[安装][3]一个把 Mate 作为默认桌面的发行版。不过,在你这样做之前,请注意为了提供完整的桌面体验,所以许多 Mate 应用程序都是随该桌面一起安装的。如果你运行的是不同的桌面,你可能会发现自己有多余的应用程序(两个 PDF 阅读器、两个媒体播放器、两个文件管理器,等等)。所以如果你只想尝试 Mate 桌面,可以在虚拟机(例如 [GNOME box][4])中安装基于 Mate 的发行版。
|
||||
|
||||
### Mate 桌面之旅
|
||||
|
||||
Mate 项目不仅仅可以让你想起来 GNOME 2;它就是 GNOME 2。如果你是 00 年代中期 Linux 桌面的粉丝,至少,你会从中感受到 Mate 的怀旧情怀。我不是 GNOME 2 的粉丝,我更倾向于使用 KDE,但是有一个地方我无法想象没有 GNOME 2:[OpenSolaris][5]。OpenSolaris 项目并没有持续太久,在 Sun Microsystems 被并入 Oracle 之前,Ian Murdock 加入 Sun 时它就显得非常突出,我当时是一个初级的 Solaris 管理员,使用 OpenSolaris 来让自己更多学会那种 Unix 风格。这是我使用过 GNOME 2 的唯一平台(因为我一开始不知道如何更改桌面,后来习惯了它),而今天的 [OpenIndiana project][6] 是 OpenSolaris 的社区延续,它通过 Mate 桌面使用 GNOME 2。
|
||||
|
||||
![Mate on OpenIndiana][7]
|
||||
|
||||
Mate 的布局由左上角的三个菜单组成:应用程序、位置和系统。应用程序菜单提供对系统上安装的所有的应用程序启动器的快速访问。位置菜单提供对常用位置(如家目录、网络文件夹等)的快速访问。系统菜单包含全局选项,如关机和睡眠。右上角是一个系统托盘,屏幕底部有一个任务栏和一个虚拟桌面切换栏。
|
||||
|
||||
就桌面设计而言,这是一种稍微有点奇怪的配置。它从早期的 Linux 桌面、MacFinder 和 Windows 中借用了一些相同的部分,但是又创建了一个独特的配置,这种配置很直观而有些熟悉。Mate 执意保持这个模型,而这正是它的用户喜欢的地方。
|
||||
|
||||
### Mate 和开源
|
||||
|
||||
Mate 是一个最直接的例子,展示了开源如何使开发人员能够对抗项目生命的终结。从理论上讲,GNOME 2 会被 GNOME 3 所取代,但它依然存在,因为一个开发人员建立了该代码的一个分支并继续发展了下去。它的发展势头越来越庞大,更多的开发人员加入进来,并且这个让用户喜爱的桌面比以往任何时候都要更好。并不是所有的软件都有第二次机会,但是开源永远是一个机会,否则就永远没有机会。
|
||||
|
||||
使用和支持开源意味着支持用户和开发人员的自由。而且 Mate 桌面是他们的努力的有力证明。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/mate-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[mayunmeiyouming](https://github.com/mayunmeiyouming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
|
||||
[2]: https://mate-desktop.org/
|
||||
[3]: https://mate-desktop.org/install/
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://en.wikipedia.org/wiki/OpenSolaris
|
||||
[6]: https://www.openindiana.org/documentation/faq/#what-is-openindiana
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-mate-openindiana_675px.jpg (Mate on OpenIndiana)
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11706-1.html)
|
||||
[#]: subject: (Get started with Lumina for your Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-lumina-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 Linux 桌面中开始使用 Lumina
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。Lumina 桌面是让你使用快速、合理的基于 Fluxbox 桌面的捷径,它具有你无法缺少的所有功能。
|
||||
|
||||
|
||||
|
||||
多年来,有一个名为 PC-BSD 的基于 FreeBSD 的桌面操作系统(OS)。它旨在作为一个常规使用的系统,因此值得注意,因为 BSD 主要用于服务器。大多数时候,PC-BSD 默认带 KDE 桌面,但是 KDE 越来越依赖于 Linux 特定的技术,因此 PC-BSD 越来越从 KDE 迁离。PC-BSD 变成了 [Trident][2],它的默认桌面是 [Lumina][3],它是一组小部件,它们使用与 KDE 相同的基于 Qt 的工具包,运行在 Fluxbox 窗口管理器上。
|
||||
|
||||
你可以在 Linux 发行版的软件仓库或 BSD 的 ports 树中找到 Lumina 桌面。如果你安装了 Lumina 并且已经在运行另一个桌面,那么你可能会发现有冗余的应用(两个 PDF 阅读器、两个文件管理器,等等),因为 Lumina 包含一些集成的应用。如果你只想尝试 Lumina 桌面,那么可以在虚拟机如 [GNOME Boxes][4] 中安装基于 Lumina 的 BSD 发行版。
|
||||
|
||||
如果在当前的操作系统上安装 Lumina,那么必须注销当前的桌面会话,才能登录到新的会话。默认情况下,会话管理器(SDDM、GDM、LightDM 或 XDM,取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该桌面。
|
||||
|
||||
在 GDM 中:
|
||||
|
||||
![Selecting your desktop in GDM][5]
|
||||
|
||||
在 SDDM 中:
|
||||
|
||||
![Selecting your desktop in KDM][6]
|
||||
|
||||
### Lumina 桌面
|
||||
|
||||
Lumina 提供了一个简单而轻巧的桌面环境。屏幕底部有一个面板,它的左侧是应用菜单,中间是任务栏,右边是系统托盘。桌面上有图标,可以快速访问常见的应用和路径。
|
||||
|
||||
除了这个基本的桌面结构外,Lumina 还有自定义文件管理器、PDF 查看器,截图工具、媒体播放器、文本编辑器和存档工具。还有一个配置程序可以帮助你自定义 Lumina 桌面,并且右键单击桌面可以找到更多配置选项。
|
||||
|
||||
![Lumina desktop running on Project Trident][7]
|
||||
|
||||
Lumina 与几个 Linux 轻量级桌面非常相似,尤其是 LXQT,不同之处在于 Lumina 完全不依赖于基于 Linux 的桌面框架(例如 ConsoleKit、PolicyKit、D-Bus 或 systemd)。对于你而言,这是否具有优势取决于所运行的操作系统。毕竟,如果你运行的是可以访问这些功能的 Linux,那么使用不使用这些特性的桌面可能就没有多大意义,还会减少功能。如果你运行的是 BSD,那么在 Fluxbox 中运行 Lumina 部件意味着你不必从 ports 安装 Linux 兼容库。
|
||||
|
||||
### 为什么要使用 Lumina
|
||||
|
||||
Lumina 设计简单,它没有很多功能,但是你可以安装 Fluxbox 你喜欢的组件(用于文件管理的 [PCManFM][8]、各种 [LXQt 应用][9]、[Tint2][10] 面板等)。在开源中,开源用户喜欢寻找不要重复发明轮子的方法(几乎与我们喜欢重新发明轮子一样多)。
|
||||
|
||||
Lumina 桌面是让你使用快速、合理的基于 Fluxbox 桌面的捷径,它具有你无法缺少的所有功能,并且你很少需要调整细节。试一试 Lumina 桌面,看看它是否适合你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-lumina-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lightbulb-idea-think-yearbook-lead.png?itok=5ZpCm0Jh (Lightbulb)
|
||||
[2]: https://project-trident.org/
|
||||
[3]: https://lumina-desktop.org/
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-gdm_400x400_1.jpg (Selecting your desktop in GDM)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-kdm_400x400_1.jpg (Selecting your desktop in KDM)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-lumina.jpg (Lumina desktop running on Project Trident)
|
||||
[8]: https://wiki.lxde.org/en/PCManFM
|
||||
[9]: http://lxqt.org
|
||||
[10]: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11730-1.html)
|
||||
[#]: subject: (5 interview questions every Kubernetes job candidate should know)
|
||||
[#]: via: (https://opensource.com/article/19/12/kubernetes-interview-questions)
|
||||
[#]: author: (Jessica Repka https://opensource.com/users/jrepka)
|
||||
|
||||
每个 Kubernetes 应聘者应该知道的 5 个面试题
|
||||
======
|
||||
|
||||
> 如果你是要面试 Kubernetes 相关职位的应聘者,这里给出了要提问的问题以及这些问题的重要性。
|
||||
|
||||

|
||||
|
||||
面试对面试官及候选人来说都很不容易。最近,我发现面试 Kubernetes 相关工作的候选人似乎尤其困难。为什么呢?一方面,很难找到可以回答他们问题的人。而且,不管回答者回答的怎样,都很难确定他们是否有正确的经验。
|
||||
|
||||
跳过这个问题,让我们来看看面试 [Kubernetes][2] 求职者时应该提问的一些问题。
|
||||
|
||||
### Kubernetes 是什么?
|
||||
|
||||
我发现这个问题是面试中最好的问题之一。我经常听到有人说“我用 Kubernetes 工作”,但是当我问道“Kubernetes 是什么”时,从来都没有得到过一个满意答案。
|
||||
|
||||
我最喜欢 [Chris Short][3] 给出的答案:“Kubernetes 就是带有一些 YAML 文件的 API 。”
|
||||
|
||||
虽然他的回答没有错,但我会给你更详细的解释。 Kubernetes 是一个可移植容器的编排工具,用于自动执行管理、监控、扩展和部署容器化应用程序。
|
||||
|
||||
我认为“用于部署容器化应用程序的编排工具”这个回答可能与你期望的答案差不多了。能回答出这个,我觉得已经很不错了。尽管许多人认为 Kubernetes 做了更多更棒的工作,但总的来说,它为其核心功能——容器编排——添加了许多 API。
|
||||
|
||||
我认为,这是你在面试中可以提问的最好的问题之一,因为它至少证明了候选人是否知道 Kubernetes 是什么。
|
||||
|
||||
### Kubernetes 的节点和 Pod 有什么区别?
|
||||
|
||||
该问题揭示了候选人对 Kubernetes 复杂性的初步了解。它将面试对话转换为对体系结构的概述,并可能导向许多有趣的后续细节问题。我已经听到了无数次关于该问题的错误解释了。
|
||||
|
||||
[节点][4] 是工作计算机。该计算机可以是虚拟机(VM)或物理计算机,具体取决于你是在虚拟机监控程序上运行还是在裸机上运行。该节点包含用于运行容器的服务,包括 kubelet、kube-proxy 和容器运行时。
|
||||
|
||||
[Pod][5] 包括:一个或多个**容器**、具有共享**网络**和**存储**,以及有关如何运行一起部署的容器的**规范**。这四个细节都很重要。更进一步,职位申请人应从技术层面解释,Pod 是 Kubernetes 可以创建和管理的最小可部署单元,而不是容器。
|
||||
|
||||
对于这个问题,我听到的最好的简答是:“节点是计算机,而 Pod 是容器运行于其中的东西。”这个区别很重要。Kubernetes 管理员的大部分工作是知道什么时间要部署什么,而节点的部署成本可能非常非常高,具体取决于它们的运行位置。我不希望有人一遍又一遍地部署节点,他们需要做的就是部署一堆 Pod。
|
||||
|
||||
### kubectl 是什么?(你怎么发音?)
|
||||
|
||||
这个问题是我优先级较高的问题之一,但可能与你和你的团队无关。在我的团队中,我们不会使用图形化界面来管理 Kubernetes 环境,我们使用命令行操作。
|
||||
|
||||
那么什么是 [kubectl][6]?它是 Kubernetes 的命令行界面。你可以从该界面获取并设置任何内容,从收集日志和事件到编辑部署环境和机密文件。随机提问候选人关于如何使用此工具对测试候选人对 kubectl 的熟悉度是很有帮助的。
|
||||
|
||||
你是怎么读的?好吧,你随便吧(对此有很大的分歧),但是我很高兴向你介绍我朋友 [Waldo][7] 的精彩视频演示。
|
||||
|
||||
### 命名空间是什么?
|
||||
|
||||
在多次面试中,我都没有得到关于这个问题的答案。我不确定在其他环境中使用的命名空间是否会在我所在的团队经常使用。我在这里给出一个简短的答案:命名空间是 Pod 中的虚拟集群。这种抽象可以使你将多个虚拟集保留在多个环境中以此来进行隔离。
|
||||
|
||||
### 容器是什么?
|
||||
|
||||
了解 Pod 中正在部署的内容总是有帮助的,因为如果都不知道其中部署的是什么,何谈部署?容器是打包代码及其所有依赖项的软件的标准单元。我收到了两个可以接受的答案,其中包括:a)精简的操作系统镜像,以及 b)在受限的操作系统环境中运行的应用程序。如果你可以叫得出使用 [Docker][8] 以外的其他容器的编排软件(例如你最喜欢的公共云的容器服务),则可以得到加分。
|
||||
|
||||
### 其他问题
|
||||
|
||||
如果你想知道为什么我没有在此问题列表中添加更多问题,那么我可以给出一个简单的答案:我所列出的这些问题是在面试候选人时应了解的最基本的问题。接下来的问题应该是基于具体的团队、环境及组织。当你仔细研究这些内容时,尝试寻找有关技术如何相互作用的有趣问题,以了解人们如何应对基础架构挑战。考虑一下你的团队最近遇到的挑战(中断),要求逐步进行部署,或者考虑改善团队积极想要改进的策略(例如减少部署时间)。问题越不抽象,对面试后真正重要的技能的询问就越多。
|
||||
|
||||
没有两个环境是完全相同的。这也适用于面试中。我在每次面试中都会混合提问。我也有一个测试面试者的小环境。我经常发现回答问题是最容易的部分,而你所做的工作才是对你的真正的考验。
|
||||
|
||||
我给面试官的最后一点建议是:如果你遇到一个很有潜力但没有经验的候选人时,请给他们一个证明自己的机会。如果当初没有人看到我的潜力,没有给我机会的话,我不会拥有今天的知识和经验。
|
||||
|
||||
还有哪些重要的问题?请留言告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/kubernetes-interview-questions
|
||||
|
||||
作者:[Jessica Repka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/Morisun029)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jrepka
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/collab-team-pair-programming-code-keyboard.png?itok=kBeRTFL1 (Pair programming)
|
||||
[2]: https://kubernetes.io/
|
||||
[3]: https://twitter.com/ChrisShort
|
||||
[4]: https://kubernetes.io/docs/concepts/architecture/nodes/
|
||||
[5]: https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[6]: https://kubernetes.io/docs/reference/kubectl/kubectl/
|
||||
[7]: https://opensource.com/article/18/12/kubectl-definitive-pronunciation-guide
|
||||
[8]: https://opensource.com/resources/what-docker
|
||||
[9]: https://enterprisersproject.com/article/2019/2/kubernetes-job-interview-questions-how-prepare
|
||||
@ -0,0 +1,207 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11720-1.html)
|
||||
[#]: subject: (Build a retro Apple desktop with the Linux MLVWM)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-mlvwm-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Linux MLVWM 打造复古苹果桌面
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果老式的苹果电脑是用开源 POSIX 构建的呢?你可以通过构建 Macintosh 式的虚拟窗口管理器来实现。
|
||||
|
||||
![Person typing on a 1980's computer][1]
|
||||
|
||||
想象一下穿越到另一段平行历史,Apple II GS 和 MacOS 7 是基于开源 [POSIX][2] 构建的,它使用了与现代 Linux 相同的所有惯例,例如纯文本配置文件和模块化系统设计。这样的操作系统将为其用户带来什么?你可以使用 [Macintosh 式的虚拟窗口管理器(MLVWM)][3]来回答这些问题(甚至更多!)。
|
||||
|
||||
![MLVWM running on Slackware 14.2][4]
|
||||
|
||||
### 安装 MLVWM
|
||||
|
||||
MLVWM 安装并不容易,并且可能不在你的发行版软件仓库中。如果你有时间理解翻译不佳的 README 文件,编辑一些配置文件,收集并调整一些旧的 .xpm 图片,编辑一两个 Xorg 选项,那么你就可以体验 MLVWM。不管怎么说,这是一个新奇的窗口管理器,其最新版本可以追溯到 2000 年。
|
||||
|
||||
要编译 MLVWM,你必须安装 imake,它提供了 `xmkmf` 命令。你可以从发行版的软件仓库中安装 imake,也可以直接从 [Freedesktop.org][5] 获得。假设你已经有 `xmkmf` 命令,请进入包含 MLVWM 源码的目录,然后运行以下命令进行构建:
|
||||
|
||||
```
|
||||
$ xmkmf -a
|
||||
$ make
|
||||
```
|
||||
|
||||
构建后,编译后的 `mlvwm` 二进制文件位于 `mlvwm` 目录中。将其移动到[你的 PATH][6] 的任何位置:
|
||||
|
||||
```
|
||||
$ mv mlvwm/mlvwm /usr/local/bin/
|
||||
```
|
||||
|
||||
#### 编辑配置文件
|
||||
|
||||
现在已经安装好 MLVWM,但是如果不调整几个配置文件并仔细放好所需的图像文件,它将无法正确启动。示例配置文件位于你下载的源代码的 `sample_rc` 目录中。将文件 `Mlvwm-Netscape` 和 `Mlvwm-Xterm` 复制到你的主目录:
|
||||
|
||||
```
|
||||
$ cp sample_rc/Mlvwm-{Netscape,Xterm} $HOME
|
||||
```
|
||||
|
||||
将 `Mlvwmrc` 改名为 `$HOME/.mlvwmrc`(是的,即使示例文件的名称看似是大写字母,但你也必须使用小写的 “m”):
|
||||
|
||||
```
|
||||
$ cp sample_rc/Mlvwmrc $HOME/.mlvwmrc
|
||||
```
|
||||
|
||||
打开 `.mlwmrc` 并找到第 54-55 行,它们定义了 MLVWM 在菜单和 UI 中使用的像素图的路径(`IconPath`):
|
||||
|
||||
```
|
||||
# Set icon search path. It needs before "Style".
|
||||
IconPath /usr/local/include/X11/pixmaps:/home2/tak/bin/pixmap
|
||||
```
|
||||
|
||||
调整路径以匹配你填充图像的路径(我建议使用 `$HOME/.local/share/pixmaps`)。MLVWM 不提供像素图,因此需要你提供构建桌面所需图标。
|
||||
|
||||
即使你有位于系统其他位置的像素图(例如 `/usr/share/pixmaps`),也要这样做,因为你需要调整像素图的大小,你可能也不想在系统范围内执行此操作。
|
||||
|
||||
```
|
||||
# Set icon search path. It needs before "Style".
|
||||
IconPath /home/seth/.local/share/pixmaps
|
||||
```
|
||||
|
||||
#### 选择像素图
|
||||
|
||||
你已将 `.local/share/pixmaps` 目录定义为像素图源路径,但是该目录和图像均不存在。创建目录:
|
||||
|
||||
```
|
||||
$ mkdir -p $HOME/.local/share/pixmaps
|
||||
```
|
||||
|
||||
现在,配置文件将图像分配给菜单项和 UI 元素,但是系统中不存在这些图像。要解决此问题,请通读配置文件并找到每个 .xpm 图像。对于配置中列出的每个图像,将具有相同文件名的图像(或更改配置文件中的文件名)添加到你的 IconPath 目录。
|
||||
|
||||
`.mlvwmrc` 文件的注释很好,因此你可以大致了解要编辑的内容。无论如何,这只是第一步。你可以随时回来更改桌面外观。
|
||||
|
||||
这有些例子。
|
||||
|
||||
此代码块设置屏幕左上角的图标:
|
||||
|
||||
```
|
||||
# Register the menu
|
||||
Menu Apple, Icon label1.xpm, Stick
|
||||
```
|
||||
|
||||
`label1.xpm` 图像实际上在源代码的 `pixmap` 目录中,但我更喜欢使用来自 `/usr/share/pixmaps` 的 `Penguin.xpm`(在 Slackware 上)。无论使用什么,都必须将自定义像素图放在 `~/.local/share/pixmaps` 中,并在配置中更改像素图的名称,或者重命名像素图以匹配配置文件中当前的名称。
|
||||
|
||||
此代码块定义了左侧菜单中列出的应用:
|
||||
|
||||
```
|
||||
"About this Workstation..." NonSelect, Gray, Action About
|
||||
"" NonSelect
|
||||
"Terminal" Icon mini-display.xpm, Action Exec "kterm" exec kterm -ls
|
||||
"Editor" Action Exec "mule" exec mule, Icon mini-edit.xpm
|
||||
"calculator" Action Exec "xcal" exec xcalc, Icon mini-calc.xpm
|
||||
END
|
||||
```
|
||||
|
||||
通过遵循与配置文件中相同的语法,你可以自定义像素图并将自己的应用添加到菜单中(例如,我将 `mule` 更改为 `emacs`)。这是你在 MLVWM GUI 中打开应用的入口,因此请列出你要快速访问的所有内容。你可能还希望包括指向 `/usr/share/applications` 文件夹的快捷方式。
|
||||
|
||||
```
|
||||
"Applications" Icon Penguin.xpm, Action Exec "thunar /usr/share/applications" exec thunar /usr/share/applications
|
||||
```
|
||||
|
||||
完成编辑配置文件并将自己的图像添加到 IconPath 目录后,必须将所有像素图的大小都调整为大约 16x16 像素。(MLVWM 的默认设置不一致,因此存在变化空间。)你可以使用 ImageMagick 进行批量操作:
|
||||
|
||||
```
|
||||
$ for i in ~/.local/share/mlvwm-pixmaps/*xpm ; do convert -resize '16x16^' $i; done
|
||||
```
|
||||
|
||||
### 启动 MLVWM
|
||||
|
||||
最简单的运行 MLVWM 的方式是让 Xorg 完成大部分工作。首先,你必须创建一个 `$HOME/.xinitrc` 文件。我从 Slackware 复制了这个,它也是从 Xorg 拿来的:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# $XConsortium: xinitrc.cpp,v 1.4 91/08/22 11:41:34 rws Exp $
|
||||
|
||||
userresources=$HOME/.Xresources
|
||||
usermodmap=$HOME/.Xmodmap
|
||||
sysresources=/etc/X11/xinit/.Xresources
|
||||
sysmodmap=/etc/X11/xinit/.Xmodmap
|
||||
|
||||
# merge in defaults and keymaps
|
||||
|
||||
if [ -f $sysresources ]; then
|
||||
xrdb -merge $sysresources
|
||||
fi
|
||||
|
||||
if [ -f $sysmodmap ]; then
|
||||
xmodmap $sysmodmap
|
||||
fi
|
||||
|
||||
if [ -f $userresources ]; then
|
||||
xrdb -merge $userresources
|
||||
fi
|
||||
|
||||
if [ -f $usermodmap ]; then
|
||||
xmodmap $usermodmap
|
||||
fi
|
||||
|
||||
# Start the window manager:
|
||||
if [ -z "$DESKTOP_SESSION" -a -x /usr/bin/ck-launch-session ]; then
|
||||
exec ck-launch-session /usr/local/bin/mlvwm
|
||||
else
|
||||
exec /usr/local/bin/mlvwm
|
||||
fi
|
||||
```
|
||||
|
||||
根据此文件,`startx` 命令的默认操作是启动 MLVWM。但是,你的发行版可能对于图形服务器启动(或被终止以重新启动)时会发生的情况有其他做法,因此此文件可能对你没有什么帮助。在许多发行版上,你可以添加 .desktop 文件到 `/usr/share/xsessions` 中,以将其列在 GDM 或 KDM 菜单中,因此创建名为 `mlvwm.desktop` 的文件并输入:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=Mlvwm
|
||||
Comment=Macintosh-like virtual window manager
|
||||
Exec=/usr/local/bin/mlvwm
|
||||
TryExec=ck-launch-session /usr/local/bin/mlvwm
|
||||
Type=Application
|
||||
```
|
||||
|
||||
从桌面会话注销并重新登录到 MLVWM。默认情况下,会话管理器(KDM、GDM 或 LightDM,具体取决于你的设置)将继续登录到以前的桌面,因此在登录之前必须覆盖它。
|
||||
|
||||
对于 GDM:
|
||||
|
||||
![][7]
|
||||
|
||||
对于 SDDM:
|
||||
|
||||
![][8]
|
||||
|
||||
#### 强制启动
|
||||
|
||||
如果 MLVWM 无法启动,请尝试安装 XDM,这是一个轻量级会话管理器,它不会查询 `/usr/share/xsessions` 的内容,而是执行经过身份验证用户的所有 `.xinitrc` 操作。
|
||||
|
||||
![MLVWM][9]
|
||||
|
||||
### 打造自己的复古苹果
|
||||
|
||||
MLVWM 桌面未经打磨、不完美、模仿到位且充满乐趣。你看到的许多菜单项都是未实现的,但你可以使它们变得活跃且有意义。
|
||||
|
||||
这是一次让你时光倒流、改变历史,让老式苹果系列电脑成为开源堡垒的机会。成为一名修正主义者,设计你自己的复古苹果桌面,最重要的是,它有乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-mlvwm-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/1980s-computer-yearbook.png?itok=eGOYEKK- (Person typing on a 1980's computer)
|
||||
[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[3]: http://www2u.biglobe.ne.jp/~y-miyata/mlvwm.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/advent-mlvwm-file.jpg (MLVWM running on Slackware 14.2)
|
||||
[5]: http://cgit.freedesktop.org/xorg/util/imake
|
||||
[6]: https://opensource.com/article/17/6/set-path-linux
|
||||
[7]: https://opensource.com/sites/default/files/advent-gdm_2.jpg
|
||||
[8]: https://opensource.com/sites/default/files/advent-kdm_1.jpg
|
||||
[9]: https://opensource.com/sites/default/files/uploads/advent-mlvwm-chess.jpg (MLVWM)
|
||||
131
published/201912/20191218 How tracking pixels work.md
Normal file
131
published/201912/20191218 How tracking pixels work.md
Normal file
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11721-1.html)
|
||||
[#]: subject: (How tracking pixels work)
|
||||
[#]: via: (https://jvns.ca/blog/how-tracking-pixels-work/)
|
||||
[#]: author: (Julia Evans https://jvns.ca/)
|
||||
|
||||
网络广告商的像素追踪是如何工作的?
|
||||
======
|
||||
|
||||

|
||||
|
||||
昨天,我和一名记者谈到了一个问题:广告商是如何在互联网上对人们进行追踪的?我们津津有味地查看了 Firefox 的开发者工具(虽然我不是一个互联网隐私专家,但至少还会使用开发者工具中的“network”标签页),从中我终于弄明白<ruby>像素追踪<rt>tracking pixels</rt></ruby>在实际中是如何工作的了。
|
||||
|
||||
### 问题:Facebook 怎么知道你逛了 Old Navy?
|
||||
|
||||
我时常听人们说起这种有些诡异的上网经历:你在线上浏览了一个商品,一天之后,竟然看到了同一款靴子(或者是别的什么你当时浏览的商品)的广告。这就是所谓的“再营销”,但它到底是如何实现的呢?
|
||||
|
||||
在本文中,我们来进行一个小实验,看看 Facebook 究竟是怎么知道你在线上浏览了什么商品的。这里使用 Facebook 作为示例,只是因为很容易找到使用了 Facebook 像素追踪技术的网站;其实,几乎所有互联网广告公司都会使用类似的追踪技术。
|
||||
|
||||
### 准备:允许第三方追踪器,同时关闭广告拦截器
|
||||
|
||||
我使用的浏览器是 Firefox,但是 Firefox 默认拦截了很多这种类型的追踪,所以需要修改 Firefox 的隐私设置,才能让这种追踪生效。
|
||||
|
||||
首先,我将隐私设置从默认设置([截图][1])修改为允许第三方追踪器的个性化设置([截图][2]),然后禁用了一些平时运行的隐私保护扩展。
|
||||
|
||||
![截图][1]
|
||||
|
||||
![截图][2]
|
||||
|
||||
### 像素追踪:关键不在于 gif,而在于请求参数
|
||||
|
||||
像素追踪是网站用来追踪你的一个 1x1 大小的 gif。就其本身而言,一个小小的 1x1 gif 显然起不到什么作用。那么,像素追踪到底是如何进行追踪的?其中涉及两个方面:
|
||||
|
||||
1. 通过使用像素追踪上的**请求参数**,网站可以添加额外的信息,比如你正在访问的页面。这样一来,请求的就不是 `https://www.facebook.com/tr/`(这个链接是一个 44 字节大小的 1x1 gif),而是 `https://www.facebook.com/tr/?the_website_you're_on`。(邮件营销人员会使用类似的技巧,通过为像素追踪指定一个独特的 URL,弄清楚你是否打开了某一封邮件。)
|
||||
2. 在发送该请求的同时,还发送了相应的 cookie。这样一来广告商就可以知道,访问 oldnavy.com 的这个人和在同一台电脑上使用 Facebook 的是同一个人。
|
||||
|
||||
### Old Navy 网站上的 Facebook 像素追踪
|
||||
|
||||
为了对此进行验证,我在 Old Navy(GAP 旗下的一个服装品牌)网站上浏览了一个商品,相应的 URL 是 `https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1`(这是一件“男款短绒格子花呢大衣”)。
|
||||
|
||||
在我浏览这个商品的同时,页面上运行的 Javascript(用的应该是[这段代码][4])向 facebook.com 发送了一个请求。在开发者工具中,该请求看上去是这样的:(我屏蔽了大部分 cookie 值,因为其中有一些是我的登录 cookie)
|
||||
|
||||
![][5]
|
||||
|
||||
下面对其进行拆解分析:
|
||||
|
||||
1. 我的浏览器向如下 URL 发送了一个请求;
|
||||
|
||||
```
|
||||
https://www.facebook.com/tr/?id=937725046402747&ev=PageView&dl=https%3A%2F%2Foldnavy.gap.com%2Fbrowse%2Fproduct.do%3Fpid%3D504753002%26cid%3D1125694%26pcid%3Dxxxxxx0%26vid%3D1%26grid%3Dpds_0_109_1%23pdp-page-content&rl=https%3A%2F%2Foldnavy.gap.com%2Fbrowse%2Fcategory.do%3Fcid%3D1135640%26mlink%3D5155%2Cm_mts_a&if=false&ts=1576684838096&sw=1920&sh=1080&v=2.9.15&r=stable&a=tmtealium&ec=0&o=30&fbp=fb.1.1576684798512.1946041422&it=15xxxxxxxxxx4&coo=false&rqm=GET
|
||||
```
|
||||
2. 与该请求同时发送的,还有一个名为 `fr` 的 cookie,取值为
|
||||
|
||||
```
|
||||
10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.
|
||||
```
|
||||
(估计是我的 Facebook 广告追踪 ID)
|
||||
|
||||
在所发送的像素追踪查询字符串里,有三个值得注意的地方:
|
||||
|
||||
* 我当前访问的页面:`https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1#pdp-page-content`
|
||||
* 引导我来到当前页面的上一级页面:`https://oldnavy.gap.com/browse/category.do?cid=1135640&mlink=5155,m_mts_a`;
|
||||
* 作为我的身份标识的 cookie:`10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.`
|
||||
|
||||
### 下面来逛逛 Facebook!
|
||||
|
||||
下面来逛逛 Facebook 吧。我之前已经登入了 Facebook,猜猜看,我的浏览器发送给 Facebook 的 cookie 是什么?
|
||||
|
||||
不出所料,正是之前见过的 `fr` cookie:`10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.`。Facebook 现在一定知道我(Julia Evans,这个 Facebook 账号所关联的人)在几分钟之前访问了 Old Navy 网站,并且浏览了“男款短绒格子花呢大衣”,因为他们可以使用这个 cookie 将数据串联起来。
|
||||
|
||||
### 这里涉及到的是第三方 cookie
|
||||
|
||||
Facebook 用来追踪我访问了哪些网站的 cookie,属于所谓的“第三方 cookie”,因为 Old Navy 的网站使用它为一个第三方(即 facebook.com)确认我的身份。这和用来维持登录状态的“第一方 cookie”有所不同。
|
||||
|
||||
Safari 和 Firefox 默认都会拦截许多第三方 cookie(所以需要更改 Firefox 的隐私设置,才能够进行这个实验),而 Chrome 目前并不进行拦截(很可能是因为 Chrome 的所有者正是一个广告公司)。(LCTT 译注:Chrome 可以设置阻拦)
|
||||
|
||||
### 网站上的像素追踪有很多
|
||||
|
||||
如我所料,网站上的像素追踪有 **很多**。比如,wrangler.com 在我的浏览器里加载了来自不同域的 19 个不同的像素追踪。wrangler.com 上的像素追踪分别来自:`ct.pinterest.com`、`af.monetate.net`、`csm.va.us.criteo.net`、`google-analytics.com`、`dpm.demdex.net`、`google.ca`、`a.tribalfusion.com`、`data.photorank.me`、`stats.g.doubleclick.net`、`vfcorp.dl.sc.omtrdc.net`、`ib.adnxs.com`、`idsync.rlcdn.com`、`p.brsrvr.com`,以及 `adservice.google.com`。
|
||||
|
||||
Firefox 贴心地指出,如果使用 Firefox 的标准隐私设置,其中的大部分追踪器都会被拦截:
|
||||
|
||||
![][8]
|
||||
|
||||
### 浏览器的重要性
|
||||
|
||||
浏览器之所以如此重要,是因为你的浏览器最终决定了发送你的什么信息、发送到哪些网站。Old Navy 网站上的 Javascript 可以请求你的浏览器向 Facebook 发送关于你的追踪信息,但浏览器可以拒绝执行。浏览器的决定可以是:“哈,我知道 facebook.com/tr/ 是一个像素追踪,我不想让我的用户被追踪,所以我不会发送这个请求”。
|
||||
|
||||
浏览器还可以允许用户对上述行为进行配置,方法包括更改浏览器设置,以及安装浏览器扩展(所以才会有如此多的隐私保护扩展)。
|
||||
|
||||
### 摸清其中原理,实为一件趣事
|
||||
|
||||
在我看来,弄清楚 cookie/像素追踪是怎么用于对你进行追踪的,实在是一件趣事(尽管有点吓人)。我之前大概明白其中的道理,但是并没有亲自查看过像素追踪上的 cookie,也没有看过发送的查询参数上究竟包含什么样的信息。
|
||||
|
||||
当然,明白了其中的原理,也就更容易降低被追踪的概率了。
|
||||
|
||||
### 可以采取的措施
|
||||
|
||||
为了尽量避免在互联网上被追踪,我采取了几种简单的措施:
|
||||
|
||||
* 安装一个广告拦截器(比如 ublock origin 之类)。广告拦截器可以针对许多追踪器的域进行拦截。
|
||||
* 使用目前默认隐私保护强度更高的 Firefox/Safari,而不是 Chrome。
|
||||
* 使用 [Facebook Container][9] 这个 Firefox 扩展。该扩展针对 Facebook 进一步采取了防止追踪的措施。
|
||||
|
||||
虽然在互联网上被追踪的方式还有很多(尤其是在使用手机应用的时候,因为在这种情况下,你没有和像对浏览器一样的控制程度),但是能够理解这种追踪方法的工作原理,稍微减少一些被追踪的可能性,也总归是一件好事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/how-tracking-pixels-work/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://jvns.ca/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://jvns.ca/images/trackers.png
|
||||
[2]: https://jvns.ca/images/firefox-insecure-settings.png
|
||||
[3]: https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1
|
||||
[4]: https://developers.facebook.com/docs/facebook-pixel/implementation/
|
||||
[5]: https://jvns.ca/images/fb-old-navy.png
|
||||
[6]: https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1#pdp-page-content
|
||||
[7]: https://oldnavy.gap.com/browse/category.do?cid=1135640&mlink=5155,m_mts_a
|
||||
[8]: https://jvns.ca/images/firefox-helpful.png
|
||||
[9]: https://addons.mozilla.org/en-CA/firefox/addon/facebook-container/
|
||||
@ -0,0 +1,179 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11722-1.html)
|
||||
[#]: subject: (How to Start, Stop & Restart Services in Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/start-stop-restart-services-linux/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
如何在 Ubuntu 和其他 Linux 发行版中启动、停止和重启服务
|
||||
======
|
||||
|
||||

|
||||
|
||||
服务是必不可少的后台进程,它通常随系统启动,并在关机时关闭。如果你是系统管理员,那么你会定期处理服务。如果你是普通桌面用户,你可能会遇到需要重启服务的情况,例如[安装 Barrier 来用于在计算机之间共享鼠标和键盘][1]。或[在使用 ufw 设置防火墙][2]时。
|
||||
|
||||
今天,我将向你展示两种管理服务的方式。你将学习在 Ubuntu 或任何其他 Linux 发行版中启动、停止和重启服务。
|
||||
|
||||
> systemd 与 init
|
||||
>
|
||||
> 如今,Ubuntu 和许多其他发行版都使用 systemd 而不是旧的 init。
|
||||
>
|
||||
> 在 systemd 中,可以使用 `systemctl` 命令管理服务。
|
||||
>
|
||||
> 在 init 中,你可以使用 `service` 命令管理服务。
|
||||
>
|
||||
> 你会注意到,即使你的 Linux 系统使用 systemd,它仍然可以使用 `service` 命令(与 init 系统一起使用的)。这是因为 `service` 命令实际上已重定向到 `systemctl`。systemd 引入了向后兼容性,因为系统管理员们习惯使用 `service` 命令。
|
||||
>
|
||||
> 在本教程中,我将同时展示 `systemctl` 和 `service` 命令。
|
||||
|
||||
我用的是 Ubuntu 18.04,但其他版本的过程也一样。
|
||||
|
||||
### 方法 1:使用 systemd 在 Linux 中管理服务
|
||||
|
||||
我从 systemd 开始,因为它被广泛接受。
|
||||
|
||||
#### 1、列出所有服务
|
||||
|
||||
为了管理服务,你首先需要知道系统上有哪些服务可用。你可以使用 systemd 的命令列出 Linux 系统上的所有服务:
|
||||
|
||||
```
|
||||
systemctl list-unit-files --type service -all
|
||||
```
|
||||
|
||||
![systemctl list-unit-files][3]
|
||||
|
||||
此命令将输出所有服务的状态。服务状态有<ruby>启用<rt>enabled</rt></ruby>、<ruby>禁用<rt>disabled</rt></ruby>、<ruby>屏蔽<rt>masked</rt></ruby>(在取消屏蔽之前处于非活动状态)、<ruby>静态<rt>static</rt></ruby>和<ruby>已生成<rt>generated</rt></ruby>。
|
||||
|
||||
与 [grep 命令][4] 结合,你可以仅显示正在运行的服务:
|
||||
|
||||
```
|
||||
sudo systemctl | grep running
|
||||
```
|
||||
|
||||
![Display running services systemctl][5]
|
||||
|
||||
现在,你知道了如何引用所有不同的服务,你可以开始主动管理它们。
|
||||
|
||||
**注意:** 下列命令中的 `<service-name>` 应该用你想管理的服务名代替。(比如:network-manager、ufw 等)
|
||||
|
||||
#### 2、启动服务
|
||||
|
||||
要在 Linux 中启动服务,你只需使用它的名字:
|
||||
|
||||
```
|
||||
systemctl start <service-name>
|
||||
```
|
||||
|
||||
#### 3、停止服务
|
||||
|
||||
要停止 systemd 服务,可以使用 `systemctl` 命令的 `stop` 选项:
|
||||
|
||||
```
|
||||
systemctl stop <service-name>
|
||||
```
|
||||
|
||||
#### 4、重启服务
|
||||
|
||||
要重启 systemd 服务,可以使用:
|
||||
|
||||
```
|
||||
systemctl restart <service-name>
|
||||
```
|
||||
|
||||
#### 5、检查服务状态
|
||||
|
||||
你可以通过打印服务状态来确认你已经成功执行特定操作:
|
||||
|
||||
```
|
||||
systemctl status <service-name>
|
||||
```
|
||||
|
||||
这将以以下方式输出:
|
||||
|
||||
![systemctl status][6]
|
||||
|
||||
这是 systemd 的内容。现在切换到 init。
|
||||
|
||||
### 方法 2:使用 init 在 Linux 中管理服务
|
||||
|
||||
init 的命令和 systemd 的一样简单。
|
||||
|
||||
#### 1、列出所有服务
|
||||
|
||||
要列出所有 Linux 服务,使用:
|
||||
|
||||
```
|
||||
service --status-all
|
||||
```
|
||||
|
||||
![service –status-all][7]
|
||||
|
||||
前面的 `[ – ]` 代表**禁用**,`[ + ]` 代表**启用**。
|
||||
|
||||
#### 2、启动服务
|
||||
|
||||
要在 Ubuntu 和其他发行版中启动服务,使用命令:
|
||||
|
||||
```
|
||||
service <service-name> start
|
||||
```
|
||||
|
||||
#### 3、停止服务
|
||||
|
||||
停止服务同样简单。
|
||||
|
||||
```
|
||||
service <service-name> stop
|
||||
```
|
||||
|
||||
#### 4、重启服务
|
||||
|
||||
如果你想重启服务,命令是:
|
||||
|
||||
```
|
||||
service <service-name> restart
|
||||
```
|
||||
|
||||
#### 5、检查服务状态
|
||||
|
||||
此外,要检查是否达到了预期的结果,你可以输出服务状态:
|
||||
|
||||
```
|
||||
service <service-name> status
|
||||
```
|
||||
|
||||
这将以以下方式输出:
|
||||
|
||||
![service status][8]
|
||||
|
||||
最重要的是,这将告诉你某项服务是否处于活跃状态(正在运行)。
|
||||
|
||||
### 总结
|
||||
|
||||
今天,我详细介绍了两种在 Ubuntu 或任何其他 Linux 系统上管理服务的非常简单的方法。 希望本文对你有所帮助。
|
||||
|
||||
你更喜欢哪种方法? 让我在下面的评论中知道!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/start-stop-restart-services-linux/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/keyboard-mouse-sharing-between-computers/
|
||||
[2]: https://itsfoss.com/set-up-firewall-gufw/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_list_services.png?ssl=1
|
||||
[4]: https://linuxhandbook.com/grep-command-examples/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_grep_running.jpg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_status.jpg?ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/service_status_all.png?ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/service_status.jpg?ssl=1
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11728-1.html)
|
||||
[#]: subject: (Customize your Linux desktop with KDE Plasma)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-kde-plasma)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 KDE Plasma 定制 Linux 桌面
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你认为没有太多自定义桌面的需要,KDE Plasma 可能适合你。
|
||||
|
||||
![5 pengiuns floating on iceburg][1]
|
||||
|
||||
KDE 社区的 Plasma 桌面是开源桌面环境中的巅峰之作。KDE 很早就进入了 Linux 桌面环境市场,但是由于它的基础 Qt 工具包当时没有完全开放的许可证,因此才有 [GNOME][2] 桌面。在此之后,Qt 开源了,并且 KDE(及其衍生产品,例如 [Trinity 桌面][3])开始蓬勃发展。
|
||||
|
||||
你可能会在发行版的软件仓库中找到 KDE 桌面,或者可以下载并安装将 KDE 作为默认桌面的发行版。在安装之前,请注意,KDE 提供了完整、集成且强大的桌面体验,因此会同时安装几个 KDE 应用。如果你已经在运行其他桌面,那么将发现有几个冗余的应用(两个 PDF 阅读器、多个媒体播放器、两个或多个文件管理器,等等)。如果你只想尝试而不是一直使用 KDE 桌面,那么可以在虚拟机,如 [GNOME Boxes][4] 中安装基于 KDE 的发行版,也可以尝试使用可引导的操作系统,例如 [Porteus][5]。
|
||||
|
||||
### KDE 桌面之旅
|
||||
|
||||
乍一看,[KDE Plasma][6] 桌面相对无聊,但让人感到舒适。它有行业标准的布局:左下角弹出应用菜单,中间是任务栏,右边是系统托盘。这正是你对标准家用或商用计算机的期望。
|
||||
|
||||
![KDE Plasma desktop][7]
|
||||
|
||||
但是,使 KDE 与众不同的是,你几乎可以更改任何想要的东西。Qt 工具包可以以令人惊讶的方式分割和重新排列,这意味着你实质上可以使用 KDE 的部件作为基础来设计自己的桌面。桌面行为的可用设置也很多。KDE 可以充当标准桌面、平铺窗口管理器以及两者之间的任意形式。你可以通过窗口类、角色、类型、标题或它们的任意组合来创建自己的窗口规则,因此,如果希望特定应用的行为不同于其他行为,那么可以创建全局设置的例外。
|
||||
|
||||
此外,它还有丰富的小部件集合,使你可以自定义与桌面交互的方式。它有一个类似 GNOME 的全屏应用启动器,一个类似 Unity 的 dock 启动器和仅有图标的任务栏,以及一个传统的任务栏。你可以在屏幕的任何边缘上创建和放置面板。
|
||||
|
||||
![A slightly customized KDE desktop][8]
|
||||
|
||||
实际上,它有太多的自定义项了,因此 KDE 最常见的批评之一是它的*太过可定制化*,所以请记住,自定义项是可选的。你可以在默认配置下使用 Plasma 桌面,并仅在你认为必要时逐步进行更改。Plasma 桌面配置选项最重要的不是它们的数目,而是它们容易发现和直观,它们都在系统设置应用或者右键单击中。
|
||||
|
||||
事实是,在 KDE 上,几乎绝不会只有一种方法可以完成任何给定的任务,并且它的用户将这个视为其最大的优势。KDE 中没有隐含的工作流,只有默认的。并且可以更改所有默认设置,直到你需要桌面做的成为你的习惯。
|
||||
|
||||
### 一致性和集成
|
||||
|
||||
KDE 社区以一致性和集成为荣,出色的开发人员、社区管理以及 KDE 库使其成为可能。KDE 的开发人员不只是桌面开发人员。它们提供了[惊人的应用集合][9],每个应用都使用 KDE 库创建,这些库扩展并标准化了常见的 Qt 小部件。使用 KDE 几个月后,无论是打开 [DigiKam][10] 进行照片管理,还是打开 Kmail 来检查电子邮件,还是打开 KTorrent 来获取最新的 ISO 或者使用 Dolphin 管理文件,你的肌肉记忆会在你思考之前直接带你进入对应 UI。
|
||||
|
||||
![KDE on Porteus][11]
|
||||
|
||||
### 尝试 KDE
|
||||
|
||||
KDE 适合所有人。使用其默认设置可获得流畅、原始的桌面体验,或对其进行自定义以使其成为自己专属。它是一个稳定、有吸引力且强大的桌面环境,可能有你想要在 Linux 完成要做的事的一切。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-kde-plasma
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
|
||||
[2]: https://opensource.com/article/19/12/gnome-linux-desktop
|
||||
[3]: https://opensource.com/article/19/12/linux-trinity-desktop-environment-tde
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/article/19/6/linux-distros-to-try
|
||||
[6]: https://kde.org/plasma-desktop
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-kde-presskit.jpg (KDE Plasma desktop)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/advent-kde-dock.jpg (A slightly customized KDE desktop)
|
||||
[9]: https://kde.org/applications/
|
||||
[10]: https://opensource.com/life/16/5/how-use-digikam-photo-management
|
||||
[11]: https://opensource.com/sites/default/files/uploads/advent-kde.jpg (KDE on Porteus)
|
||||
@ -0,0 +1,129 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11726-1.html)
|
||||
[#]: subject: (How to Update Grub on Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/update-grub/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 和其它 Linux 发行版上更新 grub
|
||||
======
|
||||
|
||||

|
||||
|
||||
在这篇文章中,你将学习在 Ubuntu 或任何其它 Linux 发行版上更新 grub 。你也将学习一个或两个关于更新这个 grub 过程如何工作的事情。
|
||||
|
||||
### 如何更新 grub
|
||||
|
||||
Ubuntu 和很多其它的 Linux 发行版提供一个易使用的称为 `update-grub` 命令行实用程序。
|
||||
|
||||
为更新 grub ,你所要的全部工作就是使用 `sudo` 在终端中运行这个命令。
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
你应该看到一个像这样的输出:
|
||||
|
||||
```
|
||||
[email protected]:~$ sudo update-grub
|
||||
[sudo] password for abhishek:
|
||||
Sourcing file `/etc/default/grub'
|
||||
Generating grub configuration file ...
|
||||
Found linux image: /boot/vmlinuz-5.0.0-37-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-37-generic
|
||||
Found linux image: /boot/vmlinuz-5.0.0-36-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-36-generic
|
||||
Found linux image: /boot/vmlinuz-5.0.0-31-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-31-generic
|
||||
Found Ubuntu 19.10 (19.10) on /dev/sda4
|
||||
Found MX 19 patito feo (19) on /dev/sdb1
|
||||
Adding boot menu entry for EFI firmware configuration
|
||||
done
|
||||
```
|
||||
|
||||
你可能看到一个类似的称为 `update-grub2` 的命令。不需要在 `update-grub` 和 `update-grub2` 之间感到害怕或不知所措。这两个命令执行相同的动作。
|
||||
|
||||
大约在 10 年前,当 grub2 刚刚被引进时,`update-grub2` 命令也被引进。现在,`update-grub2` 只是一个链接到 `update-grub` 的符号,它们都更新 grub2 配置(因为 grub2 是默认的)。
|
||||
|
||||
#### 不能找到 update-grub 命令?这里是在这种情况下该做什么
|
||||
|
||||
它可能是,你的 Linux 发行版可能没有可用的 `update-grub` 命令。
|
||||
|
||||
在这种情况下你该做什么?你如何在这样一个 Linux 发行版上更新 grub ?
|
||||
|
||||
在这里不需要惊慌。`update-grub` 命令只是一个入口,用于运行 `grub-mkconfig -o /boot/grub/grub.cfg` 来生成 grub2 配置文件。
|
||||
|
||||
这意味着你可以在任意 Linux 发行版上使用下面的命令更新 grub :
|
||||
|
||||
```
|
||||
sudo grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
当然,记住 `update-grub` 命令比上面的命令容易很多,这是为什么它在一开始被创建的原因。
|
||||
|
||||
### update-grub 是如何工作的?
|
||||
|
||||
当你安装一个 Linux 发行版时,它(通常)要求你安装 [grub 启动引导程序][1]。
|
||||
|
||||
grub 的一部分安装在 MBR/ESP 分区上。grub 的剩余部分保留在 Linux 发行版的 `/boot/grub` 目录中。
|
||||
|
||||
依据它的 [man 页面][2],`update-grub` 通过查找 `/boot` 目录来工作。所有以 [vmlinuz-][3] 开头的文件将被作为内核来对待,并且它们将得到一个 grub 菜单项。它也将为与所找到内核版本相同的 [ramdisk][4] 镜像添加 initrd 行。
|
||||
|
||||
它也使用 [os-prober][5] 为其它操作系统查找所有磁盘分区。如果找到其它操作系统,它添加它们到 grub 菜单。
|
||||
|
||||
![Representational image of Grub Menu][6]
|
||||
|
||||
### 为什么你需要更新 grub ?
|
||||
|
||||
在有很多场景下你需要更新 grub。
|
||||
|
||||
假设你修改 grub 配置文件(`/etc/default/grub`)以 [更改默认启动顺序][7] 或减少默认启动时间。除非你更新 grub ,否则你的修改将不会生效。
|
||||
|
||||
另一种情况是,你在同一个电脑系统上安装多个 Linux 发行版。
|
||||
|
||||
例如,在我的 Intel NUC 上,我有两个磁盘。第一个磁盘有 Ubuntu 19.10 ,并且我在其上面安装了 Ubuntu 18.04 。第二个操作系统(Ubuntu 18.04)安装了其自己的 grub ,现在 grub 启动屏幕由 Ubuntu 18.04 grub 控制。
|
||||
|
||||
在第二个磁盘上,我安装了 MX Linux ,但是这次我没有安装 grub。我希望现有的 grub(由 Ubuntu 18.04 控制)来处理所有的操作系统项目。
|
||||
|
||||
现在,在这种情况中,在 Ubuntu 18.04 上的 grub 需要更新,以便它能够看到 [MX Linux][8] 。
|
||||
|
||||
![][9]
|
||||
|
||||
如上图所示,当我更新 grub 时,它在 18.04 上找到很多安装的 Linux 内核, 以及在不同的分区上 Ubntu 19.10 和 MX Linux 。
|
||||
|
||||
如果你想让 MX Linux 控制 grub ,我可以使用 [grub-install][10] 命令来在 MX Linux 上安装 grub,然后在 MX Linux 上的 grub 将开始控制 grub 启动屏幕。你已经明白这点,对吧?
|
||||
|
||||
使用一个像 [Grub Customizer][11] 的 GUI 工具是在 grub 中进行更改的一种简单的方法。
|
||||
|
||||
### 最后…
|
||||
|
||||
最初,我打算保持它为一篇短文作为一种快速提示。但是后来我想解释一些与之相关的东西,以便(相对)新的 Linux 用户能够学到更多,而不仅仅是一个简单命令。
|
||||
|
||||
你喜欢它吗?你有一些问题或建议吗?请随意发表评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/update-grub/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[2]: https://manpages.debian.org/testing/grub-legacy/update-grub.8.en.html
|
||||
[3]: https://www.ibm.com/developerworks/community/blogs/mhhaque/entry/anatomy_of_the_initrd_and_vmlinuz?lang=en
|
||||
[4]: https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[5]: https://packages.debian.org/sid/utils/os-prober
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/grub_screen.png?ssl=1
|
||||
[7]: https://itsfoss.com/grub-customizer-ubuntu/
|
||||
[8]: https://mxlinux.org/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/update_grub.png?ssl=1
|
||||
[10]: https://www.gnu.org/software/grub/manual/grub/html_node/Installing-GRUB-using-grub_002dinstall.html
|
||||
[11]: https://itsfoss.com/customize-grub-linux/
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11718-1.html)
|
||||
[#]: subject: (Why your Python code needs to be beautiful and explicit)
|
||||
[#]: via: (https://opensource.com/article/19/12/zen-python-beauty-clarity)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
为什么 Python 代码要写得美观而明确
|
||||
======
|
||||
|
||||
> 欢迎阅读“Python 光明节(Pythonukkah)”系列文章,这个系列文章将会讨论《Python 之禅》。我们首先来看《Python 之禅》里的前两个原则:美观与明确。
|
||||
|
||||

|
||||
|
||||
早在 1999 年,Python 的贡献者之一,Tim Peters 就提出了《[Python 之禅][2]》,直到二十年后的今天,《Python 之禅》中的 19 条原则仍然对整个社区都产生着深远的影响。为此,就像庆典光明的<ruby>光明节<rt>Hanukkah</rt></ruby>一样,我们举行了这一次的“<ruby>Python 光明节<rt>Pythonukkah</rt></ruby>”。首先,我们会讨论《Python 之禅》中的前两个原则:美观和明确。
|
||||
|
||||
> “Hanukkah is the Festival of Lights,
|
||||
>
|
||||
> Instead of one day of presents, we get eight crazy nights.”
|
||||
>
|
||||
> —亚当·桑德勒,[光明节之歌][3]
|
||||
|
||||
### 美观胜于丑陋
|
||||
|
||||
著名的《[<ruby>计算机程序的构造和解释<rt>Structure and Interpretation of Computer Programs</rt></ruby>][4]》中有这么一句话:<ruby>代码是写给人看的,只是恰好能让机器运行。<rt>Programs must be written for people to read and only incidentally for machines to execute.</rt></ruby>机器并不在乎代码的美观性,但人类在乎。
|
||||
|
||||
阅读美观的代码对人们来说是一种享受,这就要求在整套代码中保持一致的风格。使用诸如 [Black][5]、[flake8][6]、[Pylint][7] 这一类工具能够有效地接近这一个目标。
|
||||
|
||||
但实际上,只有人类自己才知道什么才是真正的美观。因此,代码审查和协同开发是其中的不二法门,同时,在开发过程中倾听别人的意见也是必不可少的。
|
||||
|
||||
最后,个人的主观能动性也很重要,否则一切工具和流程都会变得毫无意义。只有意识到美观的重要性,才能主动编写出美观的代码。
|
||||
|
||||
这就是为什么美观在众多原则当中排到了首位,它让“美”成为了 Python 社区的一种价值。如果有人要问,”我们*真的*在乎美吗?“社区会以代码给出肯定的答案。
|
||||
|
||||
### 明确胜于隐晦
|
||||
|
||||
人类会欢庆光明、惧怕黑暗,那是因为光能够让我们看到难以看清的事物。同样地,尽管有些时候我们会不自觉地把代码写得含糊不清,但明确地编写代码确实能够让我们理解很多抽象的概念。
|
||||
|
||||
“为什么类方法中要将 `self` 显式指定为第一个参数?”
|
||||
|
||||
这个问题已经是老生常谈了,但网络上很多流传已久的回答都是不准确的。在编写<ruby>元类<rt>metaclass</rt></ruby>时,显式指定 `self` 参数就显得毫无意义。如果你没有编写过元类,希望你可以尝试一下,这是很多 Python 程序员的必经之路。
|
||||
|
||||
显式指定 `self` 参数的原因并不是 Python 的设计者不想将这样的元类视为“默认”元类,而是因为第一个参数必须是*显式*的。
|
||||
|
||||
即使 Python 中确实允许非显式的情况存在(例如上下文变量),但我们还是应该提出疑问:某个东西是不是有存在的必要呢?如果非显式地传递参数会不会出现问题呢?有些时候,由于种种原因,这是会有问题的。总之,在写代码时一旦能够优先考虑到明确性,至少意味着能对不明确的地方提出疑问并对结果作出有效的估计。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/zen-python-beauty-clarity
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_python_programming.png?itok=ynSL8XRV "Searching for code"
|
||||
[2]: https://www.python.org/dev/peps/pep-0020/
|
||||
[3]: https://en.wikipedia.org/wiki/The_Chanukah_Song
|
||||
[4]: https://en.wikipedia.org/wiki/Structure_and_Interpretation_of_Computer_Programs
|
||||
[5]: https://opensource.com/article/19/5/python-black
|
||||
[6]: https://opensource.com/article/19/5/python-flake8
|
||||
[7]: https://opensource.com/article/19/10/python-pylint-introduction
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11732-1.html)
|
||||
[#]: subject: (App Highlight: Falkon Open Source Web Browser from KDE)
|
||||
[#]: via: (https://itsfoss.com/falkon-browser/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
应用推荐:来自 KDE 的 Falkon 开源 Web 浏览器
|
||||
======
|
||||
|
||||
> Falkon 是基于 QtWebEngine 的 Web 浏览器,它以前称为 Qupzilla。在本周的“应用推荐”中,我们来看看这个开源软件。
|
||||
|
||||

|
||||
|
||||
### Falkon:适用于 Linux(和 Windows)的开源 Web 浏览器
|
||||
|
||||
![][1]
|
||||
|
||||
首先,[Falkon][2] 并不是一款新的 Web 浏览器。它自 2010 年以来一直在开发中,但被称为 Qupzilla。2017 年,QupZilla 移到 KDE 旗下,并更名为 Falkon。处于 KDE 旗下意味着项目会按照 KDE 标准积极维护。
|
||||
|
||||
它使用 [QtWebEngine][3] 渲染引擎,这是 Chromium 核心的简化版本。
|
||||
|
||||
在本文中,我将仔细研究它提供的功能以及与 Linux 上其他主流 Web 浏览器的不同之处。
|
||||
|
||||
### Falkon 浏览器的功能
|
||||
|
||||
我认为它可能不是流行的浏览器,但我发现它足以浏览现代 Web 服务。让我重点介绍 Falkon 的主要功能,如果你觉得它很有趣,请尝试一下。
|
||||
|
||||
#### 简单的用户界面
|
||||
|
||||
![][4]
|
||||
|
||||
我知道这不完全是一项“功能”,但是用户体验(UX)至关重要。尽管是轻量级的浏览器,但你会拥有一个不错的界面。你不会觉得使用的是一款源自 2000 年早期的浏览器。
|
||||
|
||||
#### AdBlock 扩展
|
||||
|
||||
![][5]
|
||||
|
||||
它附带了 AdBlock 扩展程序,如果你想在浏览网站时摆脱广告,它的效果很好。你还可以自定义 AdBlock 扩展的行为。
|
||||
|
||||
#### DuckDuckGo 作为默认搜索引擎
|
||||
|
||||
如果你不喜欢使用 Google,那么这是一件好事,它将这个[主打隐私的搜索引擎][6]设为默认搜索引擎。
|
||||
|
||||
#### 会话管理器
|
||||
|
||||
![][7]
|
||||
|
||||
Falkon 在浏览器菜单的可用选项中包含了一个有用的会话管理器。你可以用它还原特定的近期会话,这应该能派上用场。
|
||||
|
||||
#### 扩展支持
|
||||
|
||||
![][8]
|
||||
|
||||
它确实支持添加扩展,但你不能从 Chrome/Firefox 插件市场添加扩展。你只能选择有限的一组扩展。
|
||||
|
||||
#### 主题支持
|
||||
|
||||
Falkon 还允许你在某种程度上自定义外观。如果要更改浏览器的外观,可以尝试一下。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 其他基本设置
|
||||
|
||||
![][10]
|
||||
|
||||
我还尝试了其他设置/功能,例如添加书签或管理密码。或者,管理网页的通知。我还试了 YouTube,没有任何问题。
|
||||
|
||||
当然,这不是一个详尽的评测。但是,Falkon 确实拥有浏览器中需要的所有基本功能(除非你有特定要求)。
|
||||
|
||||
### 安装 Falkon 浏览器
|
||||
|
||||
你可以在软件中心轻松找到 Falkon 浏览器。如果没有,你可以从它的[官方下载页面][11]中找到 Flatpak/Snap 包。你还可以在下载页面上找到 Windows 的安装程序。
|
||||
|
||||
[Download Falkon Browser][11]
|
||||
|
||||
### 总结
|
||||
|
||||
作为 KDE 产品,Falkon 是为 KDE 桌面环境量身定制的。一些 KDE 发行版(例如 OpenMandriva)使用 Falkon 作为默认的 Web 浏览器。
|
||||
|
||||
Falkon 浏览器适合那些正在寻求轻巧且功能丰富的 Web 浏览器的人。值得尝试的另一个替代是 [Midori][12]。
|
||||
|
||||
我认为,除非你需要大量的扩展、跨平台同步并且需要访问某些特定于浏览器的网站,不然它是一个很好的替代浏览器。
|
||||
|
||||
你如何看待 Falkon 浏览器?请在下面的评论中让我知道你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/falkon-browser/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/falkon-browser-screenshot.jpg?ssl=1
|
||||
[2]: https://www.falkon.org/
|
||||
[3]: https://wiki.qt.io/QtWebEngine
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/falkon-browser.png?ssl=1
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/falkon-adblock.jpg?ssl=1
|
||||
[6]: https://itsfoss.com/privacy-search-engines/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/session-manager-falkon.jpg?ssl=1
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/falkon-browser-extensions.png?ssl=1
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/falkon-browser-theme.png?ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/falkon-browser-preference.png?ssl=1
|
||||
[11]: https://www.falkon.org/download/
|
||||
[12]: https://itsfoss.com/midori-browser/
|
||||
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11724-1.html)
|
||||
[#]: subject: (Unix is turning 50. What does that mean?)
|
||||
[#]: via: (https://www.networkworld.com/article/3511428/unix-is-turning-50-what-does-that-mean.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Unix 即将迎来 50 岁
|
||||
======
|
||||
|
||||
Unix 时间(又称为“<ruby>纪元时间<rt>epoch time</rt></ruby>”)是自 1970 年 1 月 1 日以来经过的秒数。当 Unix 即将 50 岁时,让我们看一下让内核开发人员担心的地方。
|
||||
|
||||

|
||||
|
||||
对于 Unix 而言,2020 年是重要的一年。在这一年年初,Unix 进入 50 岁。
|
||||
|
||||
尽管 Unix 的某些早期开发早于其“纪元”的正式开始,但 1970 年 1 月 1 日仍然是 POSIX 时间的零点,也是公认的 Unix 的万物之始。自那一刻算起,2020 年 1 月 1 日将是其 50 周年。(LCTT 译注:实际上,在 1971/11/3 出版的第一版《Unix 程序员手册》中,将 1971/1/1 作为 Unix 纪元的开始,并且一秒钟记录 60 个数,但是后来发现这样 32 位整型数字只能记录两年多,后来这个纪元被一再重新定义,改为从 1970/1/1 开始,每秒 1 个数。)
|
||||
|
||||
### Unix 时间与人类时间
|
||||
|
||||
就人类时间而言,50 年是很重要的。就 Unix 时间而言,50 年没有什么特别的。48.7 年同样重要。
|
||||
|
||||
Unix(包括 Linux)系统将日期/时间值存储为自 1970-01-01 00:00:00 UTC 以来经过的秒数(32 位整型)。要确定自该时间以来经过了多少秒钟,看看 Unix 时间值是什么样子,你可以发出如下命令:
|
||||
|
||||
```
|
||||
$ date +%s
|
||||
1576883876
|
||||
```
|
||||
|
||||
`%s` 参数告诉 `date` 命令将当前日期/时间显示为自 1970-01-01 开始以来的秒数。
|
||||
|
||||
### Unix 系统可以管理多少时间?
|
||||
|
||||
要了解 Unix 系统可以容纳多少时间,我们需要查看 32 位字段的容量。可以这样计算:
|
||||
|
||||
```
|
||||
$ echo '2^32' | bc
|
||||
4294967296
|
||||
```
|
||||
|
||||
但是,由于 Unix 需要容纳负数,因此它会为数字的符号保留一位,从而将其减少为:
|
||||
|
||||
```
|
||||
$ echo '2^31' | bc
|
||||
2147483648
|
||||
```
|
||||
|
||||
并且,由于 Unix 计数以 0 开头,这意味着我们有 2,147,483,648 个值,但最大的可能值为 2,147,483,647 个。Unix 日期/时间值不能超过该数字——就像汽车上的里程表可能不能超过 999,999 英里一样。加 1 该值就变为了 -2147483648。(LCTT 译注:此处原文描述有误,已修改。在达到最大值之后,即 2038/1/19 03:14:07,下 1 秒导致符号位变为 1,其余 31 位为 0,即 -2147483648,时间变为 1901/12/13 20:45:52,这就是 Y2K38 问题。)
|
||||
|
||||
### 一年有多少秒?
|
||||
|
||||
大多数年份的秒数可以这样计算:每天的小时数乘以每小时的分钟数乘以每分钟的秒数乘以一年中的天数:
|
||||
|
||||
```
|
||||
$ expr 24 \* 60 \* 60 \* 365
|
||||
31536000
|
||||
```
|
||||
|
||||
在闰年,我们再增加一天:
|
||||
|
||||
```
|
||||
$ expr 24 \* 60 \* 60 \* 366
|
||||
31622400
|
||||
```
|
||||
|
||||
(LCTT 译注:Unix 时间将一天精确定义为 24 * 60 * 60 = 86400 秒,忽略闰秒。)
|
||||
|
||||
### Unix 将如何庆祝其 50 岁生日?
|
||||
|
||||
2020 年 1 月 1 日中午 12:00 是纪元时间的 1577836800。这个计算有些棘手,但主要是因为我们必须适应闰年。自该纪元开始以来,我们经历了 12 个闰年,从 1972 年开始,到上一个闰年是 2016 年。而且,当我们达到 2020 年时,我们将有 38 个常规年份。
|
||||
|
||||
这是使用 `expr` 命令进行的计算,以计算这 50 年的秒数:
|
||||
|
||||
```
|
||||
$ expr 24 \* 60 \* 60 \* 365 \* 38 + 24 \* 60 \* 60 \* 366 \* 12
|
||||
1577836800
|
||||
```
|
||||
|
||||
前半部分是计算 38 个非闰年的秒数。然后,我们加上闰年的 366 天的类似计算。或者,你可以使用前面介绍的每年秒数,然后执行以下操作:
|
||||
|
||||
```
|
||||
$ expr 31536000 \* 38 + 31622400 \* 12
|
||||
1577836800
|
||||
```
|
||||
|
||||
这种跟踪日期和时间的方式使 Unix 系统完全不受 Y2K 恐慌的影响,1999 年末人们开始担心进入 2000 年会对计算机系统造成严重破坏,但是实际遇到的问题比人们担心的少得多。实际上,只有以两位数格式存储年份的应用程序才会将年份变为 00,以表示时间倒退。尽管如此,许多应用程序开发人员还是做了很多额外的繁琐工作,以确保 2000 年到来时,他们的系统不会出现严重问题。
|
||||
|
||||
### Unix 时间何时会遇到问题?
|
||||
|
||||
在 2038 年之前,Unix 系统不会遇到 Y2K 类型的问题,直到如上所述存储的日期将超过其 32 位空间分配。但这距离现在已经只有 18 年了,内核开发人员已经在研究如何避免灾难。但现在开始恐慌还为时过早。
|
||||
|
||||
2038 年的问题有时称为 Y2K38 问题。我们必须在 2038 年 1 月 19 日星期二之前解决这个问题。如果问题到时候仍未解决,则该日期之后的系统可能会认为是 1901 年。解决该问题的一种方法是切换为日期/时间信息的 64 位表示形式。有些人认为,即使那样,也会有比听起来更复杂的问题。无论如何,恐慌还为时过早。并且,与此同时,也许在新年前夜演唱了《Auld Lang Syne》之后,你可以向 Unix 唱《生日快乐》歌了。Unix 50 岁了,这仍然是大事。
|
||||
|
||||
(LCTT 译注:建议阅读一下 Unix 时间的[维基百科][6]页面,有更多有趣和不为人知的信息。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3511428/unix-is-turning-50-what-does-that-mean.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2017/10/birthday-cake-candles-100739452-large.jpg
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
[6]: https://en.wikipedia.org/wiki/Unix_time
|
||||
@ -0,0 +1,147 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11926-1.html)
|
||||
[#]: subject: (Handle Chromium & Firefox sessions with org-mode)
|
||||
[#]: via: (https://acidwords.com/posts/2019-12-04-handle-chromium-and-firefox-sessions-with-org-mode.html)
|
||||
[#]: author: (Sanel Z https://acidwords.com/)
|
||||
|
||||
通过 Org 模式管理 Chromium 和 Firefox 会话
|
||||
======
|
||||
|
||||

|
||||
|
||||
我是[会话管理器][1]的铁粉,它是 Chrome 和 Chromium 的小插件,可以保存所有打开的选项卡,为会话命名,并在需要时恢复会话。
|
||||
|
||||
它非常有用,特别是如果你像我一样,白天的时候需要在多个“思维活动”之间切换——研究、开发或者阅读新闻。或者你只是单纯地希望记住几天前的工作流(和选项卡)。
|
||||
|
||||
在我决定放弃 chromium 上除了 [uBlock Origin][2] 之外的所有扩展后,就必须寻找一些替代品了。我的主要目标是使之与浏览器无关,同时会话链接必须保存在文本文件中,这样我就可以享受所有纯文本的好处了。还有什么比 [org 模式][3]更好呢 ;)
|
||||
|
||||
很久以前我就发现了这个小诀窍:[通过命令行获取当前在谷歌 Chrome 中打开的标签][4] 再加上些 elisp 代码:
|
||||
|
||||
```
|
||||
(require 'cl-lib)
|
||||
|
||||
(defun save-chromium-session ()
|
||||
"Reads chromium current session and generate org-mode heading with items."
|
||||
(interactive)
|
||||
(save-excursion
|
||||
(let* ((cmd "strings ~/'.config/chromium/Default/Current Session' | 'grep' -E '^https?://' | sort | uniq")
|
||||
(ret (shell-command-to-string cmd)))
|
||||
(insert
|
||||
(concat
|
||||
"* "
|
||||
(format-time-string "[%Y-%m-%d %H:%M:%S]")
|
||||
"\n"
|
||||
(mapconcat 'identity
|
||||
(cl-reduce (lambda (lst x)
|
||||
(if (and x (not (string= "" x)))
|
||||
(cons (concat " - " x) lst)
|
||||
lst))
|
||||
(split-string ret "\n")
|
||||
:initial-value (list))
|
||||
"\n"))))))
|
||||
|
||||
(defun restore-chromium-session ()
|
||||
"Restore session, by openning each link in list with (browse-url).
|
||||
Make sure to put cursor on date heading that contains list of urls."
|
||||
(interactive)
|
||||
(save-excursion
|
||||
(beginning-of-line)
|
||||
(when (looking-at "^\\*")
|
||||
(forward-line 1)
|
||||
(while (looking-at "^[ ]+-[ ]+\\(http.?+\\)$")
|
||||
(let* ((ln (thing-at-point 'line t))
|
||||
(ln (replace-regexp-in-string "^[ ]+-[ ]+" "" ln))
|
||||
(ln (replace-regexp-in-string "\n" "" ln)))
|
||||
(browse-url ln))
|
||||
(forward-line 1)))))
|
||||
```
|
||||
|
||||
那么,它的工作原理是什么呢?
|
||||
|
||||
运行上述代码,打开一个新 org 模式文件并调用 `M-x save-chromium-session`。它会创建类似这样的东西:
|
||||
|
||||
```
|
||||
* [2019-12-04 12:14:02]
|
||||
- https://www.reddit.com/r/emacs/comments/...
|
||||
- https://www.reddit.com/r/Clojure
|
||||
- https://news.ycombinator.com
|
||||
```
|
||||
|
||||
也就是任何在 chromium 实例中运行着的 URL。要还原的话,则将光标置于所需日期上然后运行 `M-x restore-chromium-session`。所有标签都应该恢复了。
|
||||
|
||||
以下是我的使用案例,其中的数据是随机生成的:
|
||||
|
||||
```
|
||||
#+TITLE: Browser sessions
|
||||
|
||||
* [2019-12-01 23:15:00]...
|
||||
* [2019-12-02 18:10:20]...
|
||||
* [2019-12-03 19:00:12]
|
||||
- https://www.reddit.com/r/emacs/comments/...
|
||||
- https://www.reddit.com/r/Clojure
|
||||
- https://news.ycombinator.com
|
||||
|
||||
* [2019-12-04 12:14:02]
|
||||
- https://www.reddit.com/r/emacs/comments/...
|
||||
- https://www.reddit.com/r/Clojure
|
||||
- https://news.ycombinator.com
|
||||
```
|
||||
|
||||
请注意,用于读取 Chromium 会话的方法并不完美:`strings` 将从二进制数据库中读取任何类似 URL 字符串的内容,有时这将产生不完整的 URL。不过,你可以很方便地地编辑它们,从而保持会话文件简洁。
|
||||
|
||||
为了真正打开标签,elisp 代码中使用到了 [browse-url][5],它可以通过 `browse-url-browser-function` 变量进一步定制成运行 Chromium、Firefox 或任何其他浏览器。请务必阅读该变量的相关文档。
|
||||
|
||||
别忘了把会话文件放在 git、mercurial 或 svn 中,这样你就再也不会丢失会话历史记录了 :)
|
||||
|
||||
### 那么 Firefox 呢?
|
||||
|
||||
如果你正在使用 Firefox(最近的版本),并且想要获取会话 URL,下面是操作方法。
|
||||
|
||||
首先,下载并编译 [lz4json][6],这是一个可以解压缩 Mozilla lz4json 格式的小工具,Firefox 以这种格式来存储会话数据。会话数据(在撰写本文时)存储在 `$HOME/.mozilla/firefox/<unique-name>/sessionstore-backup /recovery.jsonlz4` 中。
|
||||
|
||||
如果 Firefox 没有运行,则没有 `recovery.jsonlz4`,这种情况下用 `previous.jsonlz4` 代替。
|
||||
|
||||
要提取网址,尝试在终端运行:
|
||||
|
||||
```
|
||||
$ lz4jsoncat recovery.jsonlz4 | grep -oP '"(http.+?)"' | sed 's/"//g' | sort | uniq
|
||||
```
|
||||
|
||||
然后更新 `save-chromium-session` 为:
|
||||
|
||||
```
|
||||
(defun save-chromium-session ()
|
||||
"Reads chromium current session and converts it to org-mode chunk."
|
||||
(interactive)
|
||||
(save-excursion
|
||||
(let* ((path "~/.mozilla/firefox/<unique-name>/sessionstore-backups/recovery.jsonlz4")
|
||||
(cmd (concat "lz4jsoncat " path " | grep -oP '\"(http.+?)\"' | sed 's/\"//g' | sort | uniq"))
|
||||
(ret (shell-command-to-string cmd)))
|
||||
...
|
||||
;; rest of the code is unchanged
|
||||
```
|
||||
|
||||
更新本函数的文档字符串、函数名以及进一步的重构都留作练习。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://acidwords.com/posts/2019-12-04-handle-chromium-and-firefox-sessions-with-org-mode.html
|
||||
|
||||
作者:[Sanel Z][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://acidwords.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://chrome.google.com/webstore/detail/session-manager/mghenlmbmjcpehccoangkdpagbcbkdpc?hl=en-US
|
||||
[2]: https://chrome.google.com/webstore/detail/ublock-origin/cjpalhdlnbpafiamejdnhcphjbkeiagm?hl=en
|
||||
[3]: https://orgmode.org/
|
||||
[4]: https://superuser.com/a/1310873
|
||||
[5]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Browse_002dURL.html
|
||||
[6]: https://github.com/andikleen/lz4json
|
||||
373
published/20191225 8 Commands to Check Memory Usage on Linux.md
Normal file
373
published/20191225 8 Commands to Check Memory Usage on Linux.md
Normal file
@ -0,0 +1,373 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mengxinayan)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11870-1.html)
|
||||
[#]: subject: (8 Commands to Check Memory Usage on Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-commands-check-memory-usage/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
检查 Linux 中内存使用情况的 8 条命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux 并不像 Windows,你经常不会有图形界面可供使用,特别是在服务器环境中。
|
||||
|
||||
作为一名 Linux 管理员,知道如何获取当前可用的和已经使用的资源情况,比如内存、CPU、磁盘等,是相当重要的。如果某一应用在你的系统上占用了太多的资源,导致你的系统无法达到最优状态,那么你需要找到并修正它。
|
||||
|
||||
如果你想找到消耗内存前十名的进程,你需要去阅读这篇文章:[如何在 Linux 中找出内存消耗最大的进程][1]。
|
||||
|
||||
在 Linux 中,命令能做任何事,所以使用相关命令吧。在这篇教程中,我们将会给你展示 8 个有用的命令来即查看在 Linux 系统中内存的使用情况,包括 RAM 和交换分区。
|
||||
|
||||
创建交换分区在 Linux 系统中是非常重要的,如果你想了解如何创建,可以去阅读这篇文章:[在 Linux 系统上创建交换分区][2]。
|
||||
|
||||
下面的命令可以帮助你以不同的方式查看 Linux 内存使用情况。
|
||||
|
||||
* `free` 命令
|
||||
* `/proc/meminfo` 文件
|
||||
* `vmstat` 命令
|
||||
* `ps_mem` 命令
|
||||
* `smem` 命令
|
||||
* `top` 命令
|
||||
* `htop` 命令
|
||||
* `glances` 命令
|
||||
|
||||
### 1)如何使用 free 命令查看 Linux 内存使用情况
|
||||
|
||||
[free 命令][3] 是被 Linux 管理员广泛使用的主要命令。但是它提供的信息比 `/proc/meminfo` 文件少。
|
||||
|
||||
`free` 命令会分别展示物理内存和交换分区内存中已使用的和未使用的数量,以及内核使用的缓冲区和缓存。
|
||||
|
||||
这些信息都是从 `/proc/meminfo` 文件中获取的。
|
||||
|
||||
```
|
||||
# free -m
|
||||
total used free shared buff/cache available
|
||||
Mem: 15867 9199 1702 3315 4965 3039
|
||||
Swap: 17454 666 16788
|
||||
```
|
||||
|
||||
* `total`:总的内存量
|
||||
* `used`:被当前运行中的进程使用的内存量(`used` = `total` – `free` – `buff/cache`)
|
||||
* `free`: 未被使用的内存量(`free` = `total` – `used` – `buff/cache`)
|
||||
* `shared`: 在两个或多个进程之间共享的内存量
|
||||
* `buffers`: 内存中保留用于内核记录进程队列请求的内存量
|
||||
* `cache`: 在 RAM 中存储最近使用过的文件的页缓冲大小
|
||||
* `buff/cache`: 缓冲区和缓存总的使用内存量
|
||||
* `available`: 可用于启动新应用的可用内存量(不含交换分区)
|
||||
|
||||
### 2) 如何使用 /proc/meminfo 文件查看 Linux 内存使用情况
|
||||
|
||||
`/proc/meminfo` 文件是一个包含了多种内存使用的实时信息的虚拟文件。它展示内存状态单位使用的是 kB,其中大部分属性都难以理解。然而它也包含了内存使用情况的有用信息。
|
||||
|
||||
```
|
||||
# cat /proc/meminfo
|
||||
|
||||
MemTotal: 16248572 kB
|
||||
MemFree: 1764576 kB
|
||||
MemAvailable: 3136604 kB
|
||||
Buffers: 234132 kB
|
||||
Cached: 4731288 kB
|
||||
SwapCached: 28516 kB
|
||||
Active: 9004412 kB
|
||||
Inactive: 3552416 kB
|
||||
Active(anon): 8094128 kB
|
||||
Inactive(anon): 2896064 kB
|
||||
Active(file): 910284 kB
|
||||
Inactive(file): 656352 kB
|
||||
Unevictable: 80 kB
|
||||
Mlocked: 80 kB
|
||||
SwapTotal: 17873388 kB
|
||||
SwapFree: 17191328 kB
|
||||
Dirty: 252 kB
|
||||
Writeback: 0 kB
|
||||
AnonPages: 7566736 kB
|
||||
Mapped: 3692368 kB
|
||||
Shmem: 3398784 kB
|
||||
Slab: 278976 kB
|
||||
SReclaimable: 125480 kB
|
||||
SUnreclaim: 153496 kB
|
||||
KernelStack: 23936 kB
|
||||
PageTables: 73880 kB
|
||||
NFS_Unstable: 0 kB
|
||||
Bounce: 0 kB
|
||||
WritebackTmp: 0 kB
|
||||
CommitLimit: 25997672 kB
|
||||
Committed_AS: 24816804 kB
|
||||
VmallocTotal: 34359738367 kB
|
||||
VmallocUsed: 0 kB
|
||||
VmallocChunk: 0 kB
|
||||
Percpu: 3392 kB
|
||||
HardwareCorrupted: 0 kB
|
||||
AnonHugePages: 0 kB
|
||||
ShmemHugePages: 0 kB
|
||||
ShmemPmdMapped: 0 kB
|
||||
HugePages_Total: 0
|
||||
HugePages_Free: 0
|
||||
HugePages_Rsvd: 0
|
||||
HugePages_Surp: 0
|
||||
Hugepagesize: 2048 kB
|
||||
Hugetlb: 0 kB
|
||||
DirectMap4k: 1059088 kB
|
||||
DirectMap2M: 14493696 kB
|
||||
DirectMap1G: 2097152 kB
|
||||
```
|
||||
|
||||
### 3) 如何使用 vmstat 命令查看 Linux 内存使用情况
|
||||
|
||||
[vmstat 命令][4] 是另一个报告虚拟内存统计信息的有用工具。
|
||||
|
||||
`vmstat` 报告的信息包括:进程、内存、页面映射、块 I/O、陷阱、磁盘和 CPU 特性信息。`vmstat` 不需要特殊的权限,并且它可以帮助诊断系统瓶颈。
|
||||
|
||||
```
|
||||
# vmstat
|
||||
|
||||
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
|
||||
r b swpd free buff cache si so bi bo in cs us sy id wa st
|
||||
1 0 682060 1769324 234188 4853500 0 3 25 91 31 16 34 13 52 0 0
|
||||
```
|
||||
|
||||
如果你想详细了解每一项的含义,阅读下面的描述。
|
||||
|
||||
* `procs`:进程
|
||||
* `r`: 可以运行的进程数目(正在运行或等待运行)
|
||||
* `b`: 处于不可中断睡眠中的进程数目
|
||||
* `memory`:内存
|
||||
* `swpd`: 使用的虚拟内存数量
|
||||
* `free`: 空闲的内存数量
|
||||
* `buff`: 用作缓冲区内存的数量
|
||||
* `cache`: 用作缓存内存的数量
|
||||
* `inact`: 不活动的内存数量(使用 `-a` 选项)
|
||||
* `active`: 活动的内存数量(使用 `-a` 选项)
|
||||
* `Swap`:交换分区
|
||||
* `si`: 每秒从磁盘交换的内存数量
|
||||
* `so`: 每秒交换到磁盘的内存数量
|
||||
* `IO`:输入输出
|
||||
* `bi`: 从一个块设备中收到的块(块/秒)
|
||||
* `bo`: 发送到一个块设备的块(块/秒)
|
||||
* `System`:系统
|
||||
* `in`: 每秒的中断次数,包括时钟。
|
||||
* `cs`: 每秒的上下文切换次数。
|
||||
* `CPU`:下面这些是在总的 CPU 时间占的百分比
|
||||
* `us`: 花费在非内核代码上的时间占比(包括用户时间,调度时间)
|
||||
* `sy`: 花费在内核代码上的时间占比 (系统时间)
|
||||
* `id`: 花费在闲置的时间占比。在 Linux 2.5.41 之前,包括 I/O 等待时间
|
||||
* `wa`: 花费在 I/O 等待上的时间占比。在 Linux 2.5.41 之前,包括在空闲时间中
|
||||
* `st`: 被虚拟机偷走的时间占比。在 Linux 2.6.11 之前,这部分称为 unknown
|
||||
|
||||
运行下面的命令查看详细的信息。
|
||||
|
||||
```
|
||||
# vmstat -s
|
||||
|
||||
16248580 K total memory
|
||||
2210256 K used memory
|
||||
2311820 K active memory
|
||||
2153352 K inactive memory
|
||||
11368812 K free memory
|
||||
107584 K buffer memory
|
||||
2561928 K swap cache
|
||||
17873388 K total swap
|
||||
0 K used swap
|
||||
17873388 K free swap
|
||||
44309 non-nice user cpu ticks
|
||||
164 nice user cpu ticks
|
||||
14332 system cpu ticks
|
||||
382418 idle cpu ticks
|
||||
1248 IO-wait cpu ticks
|
||||
1407 IRQ cpu ticks
|
||||
2147 softirq cpu ticks
|
||||
0 stolen cpu ticks
|
||||
1022437 pages paged in
|
||||
260296 pages paged out
|
||||
0 pages swapped in
|
||||
0 pages swapped out
|
||||
1424838 interrupts
|
||||
4979524 CPU context switches
|
||||
1577163147 boot time
|
||||
3318 forks
|
||||
```
|
||||
### 4) 如何使用 ps_mem 命令查看 Linux 内存使用情况
|
||||
|
||||
[ps_mem][5] 是一个用来查看当前内存使用情况的简单的 Python 脚本。该工具可以确定每个程序使用了多少内存(不是每个进程)。
|
||||
|
||||
该工具采用如下的方法计算每个程序使用内存:总的使用 = 程序进程私有的内存 + 程序进程共享的内存。
|
||||
|
||||
计算共享内存是存在不足之处的,该工具可以为运行中的内核自动选择最准确的方法。
|
||||
|
||||
```
|
||||
# ps_mem
|
||||
|
||||
Private + Shared = RAM used Program
|
||||
180.0 KiB + 30.0 KiB = 210.0 KiB xf86-video-intel-backlight-helper (2)
|
||||
192.0 KiB + 66.0 KiB = 258.0 KiB cat (2)
|
||||
312.0 KiB + 38.5 KiB = 350.5 KiB lvmetad
|
||||
380.0 KiB + 25.5 KiB = 405.5 KiB crond
|
||||
392.0 KiB + 32.5 KiB = 424.5 KiB rtkit-daemon
|
||||
852.0 KiB + 117.0 KiB = 969.0 KiB gnome-session-ctl (2)
|
||||
928.0 KiB + 56.5 KiB = 984.5 KiB gvfs-mtp-volume-monitor
|
||||
1.0 MiB + 42.5 KiB = 1.0 MiB dconf-service
|
||||
1.0 MiB + 106.5 KiB = 1.1 MiB gvfs-goa-volume-monitor
|
||||
1.0 MiB + 180.5 KiB = 1.2 MiB gvfsd
|
||||
.
|
||||
.
|
||||
5.3 MiB + 3.0 MiB = 8.3 MiB evolution-addressbook-factory
|
||||
8.5 MiB + 1.2 MiB = 9.7 MiB gnome-session-binary (4)
|
||||
7.5 MiB + 3.1 MiB = 10.5 MiB polkitd
|
||||
7.4 MiB + 3.3 MiB = 10.7 MiB pulseaudio (2)
|
||||
7.0 MiB + 7.0 MiB = 14.0 MiB msm_notifier
|
||||
12.7 MiB + 2.3 MiB = 15.0 MiB evolution-source-registry
|
||||
13.3 MiB + 2.5 MiB = 15.8 MiB gnome-terminal-server
|
||||
15.8 MiB + 1.0 MiB = 16.8 MiB tracker-miner-fs
|
||||
18.7 MiB + 1.8 MiB = 20.5 MiB python3.7
|
||||
16.6 MiB + 4.0 MiB = 20.5 MiB evolution-calendar-factory
|
||||
22.3 MiB + 753.0 KiB = 23.0 MiB gsd-keyboard (2)
|
||||
22.4 MiB + 832.0 KiB = 23.2 MiB gsd-wacom (2)
|
||||
20.8 MiB + 2.5 MiB = 23.3 MiB blueman-tray
|
||||
22.0 MiB + 1.8 MiB = 23.8 MiB blueman-applet
|
||||
23.1 MiB + 934.0 KiB = 24.0 MiB gsd-xsettings (2)
|
||||
23.7 MiB + 1.2 MiB = 24.9 MiB gsd-media-keys (2)
|
||||
23.4 MiB + 1.6 MiB = 25.0 MiB gsd-color (2)
|
||||
23.9 MiB + 1.2 MiB = 25.1 MiB gsd-power (2)
|
||||
16.5 MiB + 8.9 MiB = 25.4 MiB evolution-alarm-notify
|
||||
27.2 MiB + 2.0 MiB = 29.2 MiB systemd-journald
|
||||
28.7 MiB + 2.8 MiB = 31.5 MiB c
|
||||
29.6 MiB + 2.2 MiB = 31.8 MiB chrome-gnome-sh (2)
|
||||
43.9 MiB + 6.8 MiB = 50.7 MiB WebExtensions
|
||||
46.7 MiB + 6.7 MiB = 53.5 MiB goa-daemon
|
||||
86.5 MiB + 55.2 MiB = 141.7 MiB Xorg (2)
|
||||
191.4 MiB + 24.1 MiB = 215.4 MiB notepadqq-bin
|
||||
306.7 MiB + 29.0 MiB = 335.7 MiB gnome-shell (2)
|
||||
601.6 MiB + 77.7 MiB = 679.2 MiB firefox
|
||||
1.0 GiB + 109.7 MiB = 1.1 GiB chrome (15)
|
||||
2.3 GiB + 123.1 MiB = 2.5 GiB Web Content (8)
|
||||
----------------------------------
|
||||
5.6 GiB
|
||||
==================================
|
||||
```
|
||||
|
||||
### 5)如何使用 smem 命令查看 Linux 内存使用情况
|
||||
|
||||
[smem][6] 是一个可以为 Linux 系统提供多种内存使用情况报告的工具。不同于现有的工具,`smem` 可以报告<ruby>比例集大小<rt>Proportional Set Size</rt></ruby>(PSS)、<ruby>唯一集大小<rt>Unique Set Size</rt></ruby>(USS)和<ruby>驻留集大小<rt>Resident Set Size</rt></ruby>(RSS)。
|
||||
|
||||
- 比例集大小(PSS):库和应用在虚拟内存系统中的使用量。
|
||||
- 唯一集大小(USS):其报告的是非共享内存。
|
||||
- 驻留集大小(RSS):物理内存(通常多进程共享)使用情况,其通常高于内存使用量。
|
||||
|
||||
```
|
||||
# smem -tk
|
||||
|
||||
PID User Command Swap USS PSS RSS
|
||||
3383 daygeek cat 0 92.0K 123.0K 1.7M
|
||||
3384 daygeek cat 0 100.0K 129.0K 1.7M
|
||||
1177 daygeek /usr/lib/gnome-session-ctl 0 436.0K 476.0K 4.6M
|
||||
1171 daygeek /usr/bin/dbus-daemon --conf 0 524.0K 629.0K 3.8M
|
||||
1238 daygeek /usr/lib/xdg-permission-sto 0 592.0K 681.0K 5.9M
|
||||
1350 daygeek /usr/lib/gsd-screensaver-pr 0 652.0K 701.0K 5.8M
|
||||
1135 daygeek /usr/lib/gdm-x-session --ru 0 648.0K 723.0K 6.0M
|
||||
.
|
||||
.
|
||||
1391 daygeek /usr/lib/evolution-data-ser 0 16.5M 25.2M 63.3M
|
||||
1416 daygeek caffeine-ng 0 28.7M 31.4M 66.2M
|
||||
4855 daygeek /opt/google/chrome/chrome - 0 38.3M 46.3M 120.6M
|
||||
2174 daygeek /usr/lib/firefox/firefox -c 0 44.0M 50.7M 120.3M
|
||||
1254 daygeek /usr/lib/goa-daemon 0 46.7M 53.3M 80.4M
|
||||
3416 daygeek /opt/google/chrome/chrome - 0 44.7M 54.2M 103.3M
|
||||
4782 daygeek /opt/google/chrome/chrome - 0 57.2M 65.8M 142.3M
|
||||
1137 daygeek /usr/lib/Xorg vt2 -displayf 0 77.2M 129.6M 192.3M
|
||||
3376 daygeek /opt/google/chrome/chrome 0 117.8M 131.0M 210.9M
|
||||
4448 daygeek /usr/lib/firefox/firefox -c 0 124.4M 133.8M 224.1M
|
||||
3558 daygeek /opt/google/chrome/chrome - 0 157.3M 165.7M 242.2M
|
||||
2310 daygeek /usr/lib/firefox/firefox -c 0 159.6M 169.4M 259.6M
|
||||
4331 daygeek /usr/lib/firefox/firefox -c 0 176.8M 186.2M 276.8M
|
||||
4034 daygeek /opt/google/chrome/chrome - 0 179.3M 187.9M 264.6M
|
||||
3911 daygeek /opt/google/chrome/chrome - 0 183.1M 191.8M 269.4M
|
||||
3861 daygeek /opt/google/chrome/chrome - 0 199.8M 208.2M 285.2M
|
||||
2746 daygeek /usr/bin/../lib/notepadqq/n 0 193.5M 217.5M 261.5M
|
||||
1194 daygeek /usr/bin/gnome-shell 0 203.7M 219.0M 285.1M
|
||||
2945 daygeek /usr/lib/firefox/firefox -c 0 294.5M 308.0M 410.2M
|
||||
2786 daygeek /usr/lib/firefox/firefox -c 0 341.2M 354.3M 459.1M
|
||||
4193 daygeek /usr/lib/firefox/firefox -c 0 417.4M 427.6M 519.3M
|
||||
2651 daygeek /usr/lib/firefox/firefox -c 0 417.0M 430.1M 535.6M
|
||||
2114 daygeek /usr/lib/firefox/firefox -c 0 430.6M 473.9M 610.9M
|
||||
2039 daygeek /usr/lib/firefox/firefox -- 0 601.3M 677.5M 840.6M
|
||||
-------------------------------------------------------------------------------
|
||||
90 1 0 4.8G 5.2G 8.0G
|
||||
```
|
||||
|
||||
### 6) 如何使用 top 命令查看 Linux 内存使用情况
|
||||
|
||||
[top 命令][7] 是一个 Linux 系统的管理员最常使用的用于查看进程的资源使用情况的命令。
|
||||
|
||||
该命令会展示了系统总的内存量、当前内存使用量、空闲内存量和缓冲区使用的内存总量。此外,该命令还会展示总的交换空间内存量、当前交换空间的内存使用量、空闲的交换空间内存量和缓存使用的内存总量。
|
||||
|
||||
```
|
||||
# top -b | head -10
|
||||
|
||||
top - 11:04:39 up 40 min, 1 user, load average: 1.59, 1.42, 1.28
|
||||
Tasks: 288 total, 2 running, 286 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 13.3 us, 1.5 sy, 0.0 ni, 84.4 id, 0.0 wa, 0.3 hi, 0.5 si, 0.0 st
|
||||
KiB Mem : 16248572 total, 7755928 free, 4657736 used, 3834908 buff/cache
|
||||
KiB Swap: 17873388 total, 17873388 free, 0 used. 9179772 avail Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
2114 daygeek 20 3182736 616624 328228 R 83.3 3.8 7:09.72 Web Content
|
||||
2039 daygeek 20 4437952 849616 261364 S 13.3 5.2 7:58.54 firefox
|
||||
1194 daygeek 20 4046856 291288 165460 S 4.2 1.8 1:57.68 gnome-shell
|
||||
4034 daygeek 20 808556 273244 88676 S 4.2 1.7 1:44.72 chrome
|
||||
2945 daygeek 20 3309832 416572 150112 S 3.3 2.6 4:04.60 Web Content
|
||||
1137 daygeek 20 564316 197292 183380 S 2.5 1.2 2:55.76 Xorg
|
||||
2651 daygeek 20 3098420 547260 275700 S 1.7 3.4 2:15.96 Web Content
|
||||
2786 daygeek 20 2957112 463912 240744 S 1.7 2.9 3:22.29 Web Content
|
||||
1 root 20 182756 10208 7760 S 0.8 0.1 0:04.51 systemd
|
||||
442 root -51 S 0.8 0:05.02 irq/141-iw+
|
||||
1426 daygeek 20 373660 48948 29820 S 0.8 0.3 0:03.55 python3
|
||||
2174 daygeek 20 2466680 122196 78604 S 0.8 0.8 0:17.75 WebExtensi+
|
||||
```
|
||||
|
||||
### 7) 如何使用 htop 命令查看 Linux 内存使用情况
|
||||
|
||||
[htop 命令][8] 是一个可交互的 Linux/Unix 系统进程查看器。它是一个文本模式应用,且使用它需要 Hisham 开发的 ncurses 库。
|
||||
|
||||
该名令的设计目的使用来代替 `top` 命令。该命令与 `top` 命令很相似,但是其允许你可以垂直地或者水平地的滚动以便可以查看系统中所有的进程情况。
|
||||
|
||||
`htop` 命令拥有不同的颜色,这个额外的优点当你在追踪系统性能情况时十分有用。
|
||||
|
||||
此外,你可以自由地执行与进程相关的任务,比如杀死进程或者改变进程的优先级而不需要其进程号(PID)。
|
||||
|
||||
![][10]
|
||||
|
||||
### 8)如何使用 glances 命令查看 Linux 内存使用情况
|
||||
|
||||
[Glances][11] 是一个 Python 编写的跨平台的系统监视工具。
|
||||
|
||||
你可以在一个地方查看所有信息,比如:CPU 使用情况、内存使用情况、正在运行的进程、网络接口、磁盘 I/O、RAID、传感器、文件系统信息、Docker、系统信息、运行时间等等。
|
||||
|
||||
![][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-commands-check-memory-usage/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[萌新阿岩](https://github.com/mengxinayan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-11542-1.html
|
||||
[2]: https://linux.cn/article-9579-1.html
|
||||
[3]: https://linux.cn/article-8314-1.html
|
||||
[4]: https://linux.cn/article-8157-1.html
|
||||
[5]: https://linux.cn/article-8639-1.html
|
||||
[6]: https://linux.cn/article-7681-1.html
|
||||
[7]: https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/
|
||||
[8]: https://www.2daygeek.com/linux-htop-command-linux-system-performance-resource-monitoring-tool/
|
||||
[9]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2019/12/linux-commands-check-memory-usage-2.jpg
|
||||
[11]: https://www.2daygeek.com/linux-glances-advanced-real-time-linux-system-performance-monitoring-tool/
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/12/linux-commands-check-memory-usage-3.jpg
|
||||
@ -0,0 +1,57 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11875-1.html)
|
||||
[#]: subject: (Top CI/CD resources to set you up for success)
|
||||
[#]: via: (https://opensource.com/article/19/12/cicd-resources)
|
||||
[#]: author: (Jessica Cherry https://opensource.com/users/jrepka)
|
||||
|
||||
顶级 CI / CD 资源,助你成功
|
||||
======
|
||||
|
||||
> 随着企业期望实现无缝、灵活和可扩展的部署,持续集成和持续部署成为 2019 年的关键主题。
|
||||
|
||||
![Plumbing tubes in many directions][1]
|
||||
|
||||
对于 CI/CD 和 DevOps 来说,2019 年是非常棒的一年。Opensource.com 的作者分享了他们专注于无缝、灵活和可扩展部署时是如何朝着敏捷和 scrum 方向发展的。以下是我们 2019 年发布的 CI/CD 文章中的一些重要文章。
|
||||
|
||||
### 学习和提高你的 CI/CD 技能
|
||||
|
||||
我们最喜欢的一些文章集中在 CI/CD 的实操经验上,并涵盖了许多方面。通常以 [Jenkins][2] 管道开始,Bryant Son 的文章《[用 Jenkins 构建 CI/CD 管道][3]》将为你提供足够的经验,以开始构建你的第一个管道。Daniel Oh 在《[用 DevOps 管道进行自动验收测试][4]》一文中,提供了有关验收测试的重要信息,包括可用于自行测试的各种 CI/CD 应用程序。我写的《[安全扫描 DevOps 管道][5]》非常简短,其中简要介绍了如何使用 Jenkins 平台在管道中设置安全性。
|
||||
|
||||
### 交付工作流程
|
||||
|
||||
正如 Jithin Emmanuel 在《[Screwdriver:一个用于持续交付的可扩展构建平台][6]》中分享的,在学习如何使用和提高你的 CI/CD 技能方面,工作流程很重要,特别是当涉及到管道时。Emily Burns 在《[为什么 Spinnaker 对 CI/CD 很重要][7]》中解释了灵活地使用 CI/CD 工作流程准确构建所需内容的原因。Willy-Peter Schaub 还盛赞了为所有产品创建统一管道的想法,以便《[在一个 CI/CD 管道中一致地构建每个产品][8]》。这些文章将让你很好地了解在团队成员加入工作流程后会发生什么情况。
|
||||
|
||||
### CI/CD 如何影响企业
|
||||
|
||||
2019 年也是认识到 CI/CD 的业务影响以及它是如何影响日常运营的一年。Agnieszka Gancarczyk 分享了 Red Hat 《[小型 Scrum vs. 大型 Scrum][9]》的调查结果, 包括受访者对 Scrum、敏捷运动及对团队的影响的不同看法。Will Kelly 的《[持续部署如何影响整个组织][10]》,也提及了开放式沟通的重要性。Daniel Oh 也在《[DevOps 团队必备的 3 种指标仪表板][11]》中强调了指标和可观测性的重要性。最后是 Ann Marie Fred 的精彩文章《[不在生产环境中测试?要在生产环境中测试!][12]》详细说明了在验收测试前在生产环境中测试的重要性。
|
||||
|
||||
感谢许多贡献者在 2019 年与 Opensource 的读者分享他们的见解,我期望在 2020 年里从他们那里了解更多有关 CI/CD 发展的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/cicd-resources
|
||||
|
||||
作者:[Jessica Cherry][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/Morisun029)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jrepka
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/plumbing_pipes_tutorial_how_behind_scenes.png?itok=F2Z8OJV1 (Plumbing tubes in many directions)
|
||||
[2]: https://jenkins.io/
|
||||
[3]: https://linux.cn/article-11546-1.html
|
||||
[4]: https://opensource.com/article/19/4/devops-pipeline-acceptance-testing
|
||||
[5]: https://opensource.com/article/19/7/security-scanning-your-devops-pipeline
|
||||
[6]: https://opensource.com/article/19/3/screwdriver-cicd
|
||||
[7]: https://opensource.com/article/19/8/why-spinnaker-matters-cicd
|
||||
[8]: https://opensource.com/article/19/7/cicd-pipeline-rule-them-all
|
||||
[9]: https://opensource.com/article/19/3/small-scale-scrum-vs-large-scale-scrum
|
||||
[10]: https://opensource.com/article/19/7/organizational-impact-continuous-deployment
|
||||
[11]: https://linux.cn/article-11183-1.html
|
||||
[12]: https://opensource.com/article/19/5/dont-test-production
|
||||
@ -0,0 +1,118 @@
|
||||
如何在 LibreOffice Writer 中创建一个电子书章节模板
|
||||
======
|
||||
|
||||
> 将电子书分成几章,创建电子书会更容易。这是设置模板的分步指南。
|
||||
|
||||

|
||||
|
||||
对于很多人来说,使用 word 程序来撰写和发布一本电子书是一种最好的、最容易的、最熟悉的方法。但是,启动你的 word 程序和打字是不够的 —— 你需要遵循一种格式。
|
||||
|
||||
这就是模板的来源。一个模板确保你的电子书有一个一致的外观和体验。幸运的是,创建模板是快速和容易的,并你在其上花费的时间和努力将带给你一本更好感观的书。
|
||||
|
||||
在这篇文章中,我将陪伴你走过如何使用 LibreOffice Writer 创建一个简单的模板,可以用于一本电子书的各个章节。你可以将这个模板用于 PDF 和 EPUB 书籍,并加以修改来满足你的需要。
|
||||
|
||||
### 我的方法
|
||||
|
||||
为什么我着重于为一个章节创建一个模板,而不是为一整本书创建一个模板?因为编写和管理单独的章节比编写和管理单个庞大而僵化的文档更容易。
|
||||
|
||||
通过关注于单独的章节,你可以专心于你需要编写的东西。你可以很容易地四处移动这些章节,给审阅者发单独一章节比发送你的完整原稿更简单而高效。当你写完一章后,你可以简单地把你的章节拼凑在一起来出版这本书(我将在下面讨论如何做到这一点)。但是不要觉得你被这种方法所束缚 —— 如果你更喜欢在单个文件中编写,简单地调整在这篇文章中描述的步骤就行。
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
### 设置页面
|
||||
|
||||
仅当你计划发布你的电子书为一本 PDF 书时,这是很重要的。设置页面意味着你的书将不包含大量的跨越屏幕的让眼睛疲劳的文本。
|
||||
|
||||
选择 **格式 > 页面** 来打开 **页面样式** 窗口。我的 PDF 电子书通常是 5x8 英寸高(大约 13x20cm ,对于我们这些生活在米制世界的人来说)。我也设置页边距为半英寸(约 1.25 cm)。这些是我较喜欢的尺寸;你可以使用任何适合你的尺寸。
|
||||
|
||||
![LibreOffice Page Style window][2]
|
||||
|
||||
*在 LibreOffice Writer 中的页面样式窗口让你设置页边距和页格式。*
|
||||
|
||||
接下来,添加页脚以显示页码。保持页面样式窗口打开着,并单击 **页脚** 选项卡。选择 **在页脚上** 并单击 **确定** 。
|
||||
|
||||
在该页面上,在页脚中单击,然后选择 **插入 > 字段 > 页码**。不要担心页码的位置和外观;我们接下来会处理。
|
||||
|
||||
### 设置你的样式
|
||||
|
||||
像模板本身一样,样式为你的文档提供一种一致的外观和体验。如果你想更改一个标题的字体或大小,例如,你只需要在一个地方完成它,而不是手动应用格式化到每个标题。
|
||||
|
||||
标准化的 LibreOffice 模板带有许多样式,你可以调整它们以适应你的需要。为此,按 `F11` 来打开 **样式和格式** 窗口。
|
||||
|
||||
![LibreOffice styles and formatting][4]
|
||||
|
||||
*使用样式和格式窗口更改字体和其它细节。*
|
||||
|
||||
在一个样式上右键单击,并选择 **修改** 来编辑它。 这里是我在每本中使用的主要样式:
|
||||
|
||||
样式 | 字体 | 间距 / 对齐方式
|
||||
:-: | :-: | :-:
|
||||
标题 1 | Liberation Sans, 36 pt | 上面 36 pt ,下面 48 pt ,左对齐
|
||||
标题 2 | Liberation Sans, 18 pt | 上面 12 pt ,下面 12 pt ,左对齐
|
||||
标题 3 | Liberation Sans, 14 pt | 上面 12 pt ,下面 12 pt ,左对齐
|
||||
正文 | Liberation Sans, 12 pt | 上面 12 pt ,下面 12 pt ,左对齐
|
||||
页脚 | Liberation Sans, 10 pt | 居中对齐
|
||||
|
||||
|
||||
![LibreOffice styles in action][6]
|
||||
|
||||
*这是当我们应用到电子书内容时的一个选择的样式外观。*
|
||||
|
||||
对于大多数书来说,这通常是最小要求。可以随便更改字体和空格来适应你的要求。
|
||||
|
||||
根据你正在编写书的类型,你可能也想创建或修改项目符合样式,以及数字列表、引号、代码示例、数字符号等等。只需要记住始终如一地使用字体以及其大小。
|
||||
|
||||
### 保存你的模板
|
||||
|
||||
选择 **文件 > 另存为** 。在保持对话框中,从格式列表中选择 “ODF 文本文档模板 (.ott)” 。这将保存模板为一个模板,以后你可以快速调用该模板。
|
||||
|
||||
保存模板的最佳位置是 LibreOffice 模板文件夹。例如,在 Linux 中,那是在你的家目录下,在 `.config/libreoffice/4/user/template` 下。
|
||||
|
||||
### 编写你的书
|
||||
|
||||
在你开始编写前,在你的计算机上创建一个文件夹,它将为你的书保存所有的文件 —— 章节、图像、笔记等等。
|
||||
|
||||
当你准备编写时,启动 LibreOffice Writer 并选择 **文件 > 新建 > 模板** 。然后从列表中选择你的模板,并单击 **打开**。
|
||||
|
||||
![LibreOffice Writer template list][8]
|
||||
|
||||
*从你在 LibreOffice Writer 中设置的列表中选择你的模板,并开始编写。*
|
||||
|
||||
然后用一个描述性名称保存文档。
|
||||
|
||||
建议使用像 “第 1 章” 和 “第 2 章” 这样的惯例 —— 在某些时候,你可能决定重新编排你的章节,当你尝试管理这些章节时,它可能会变得混乱。然而,你可以在文件名称中放置章节数字,像 “第 1 章” 或 “一” 。如果你最后要重新排列全书的章节,像这样重命名更容易。
|
||||
|
||||
无需赘言,开始编写吧。记住在模板中使用样式来格式化文本 —— 这就是为什么你要创建模板,对吧?
|
||||
|
||||
### 发布你的电子书
|
||||
|
||||
在完成编写一堆章节后,并准备发布它们时,创建一个主控文档。把一个主控文档作为你所编写章节的一个容器。使用一个主控文档,你可以快速地组装你的书,并任意重新排序你的章节。LibreOffice 的帮助提供了使用[主控文档][9]的详细信息。
|
||||
|
||||
假设你想生成一个 PDF ,不要只是单击**直接导出到 PDF** 按钮。这将创建一个相当不错的 PDF ,但是你可能想优化它。为此,选择 **文件 > 导出为 PDF** ,并在 PDF 选项窗口中轻微调整。你可以在这篇 [LibreOffice Writer 文档][10] 中学到更多东西。
|
||||
|
||||
如果你想创建一个 EPUB 而不是一个 PDF,或者除了一个 PDF 以外,另外创建一个 EPUB,请安装 [Writer2EPUB][11] 扩展。Opensource.com 的 Bryan Behrenshausen 为这个扩展[分享了一些有用的说明][12] 。
|
||||
|
||||
### 结束语
|
||||
|
||||
我们在这里创建的模板是极简单的,但是你可以将其用于一本简单的书,或者作为构建一个复杂模板的起点。不管怎样,这个模板都会让你快速地开始编写和发布你的电子书。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/creating-ebook-chapter-template-libreoffice-writer
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[2]:https://opensource.com/sites/default/files/images/life-uploads/lo-page-style.png (LibreOffice Page Style window)
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/lo-paragraph-style.png (LibreOffice styles and formatting window)
|
||||
[5]:/file/374466
|
||||
[6]:https://opensource.com/sites/default/files/images/life-uploads/lo-styles-in-action.png (Example of LibreOffice styles)
|
||||
[8]:https://opensource.com/sites/default/files/images/life-uploads/lo-template-list.png (Template list - LibreOffice Writer)
|
||||
[9]:https://help.libreoffice.org/Writer/Working_with_Master_Documents_and_Subdocuments
|
||||
[10]:https://help.libreoffice.org/Common/Export_as_PDF
|
||||
[11]:http://writer2epub.it/en/
|
||||
[12]:https://opensource.com/life/13/8/how-create-ebook-open-source-way
|
||||
230
published/202001/20190405 File sharing with Git.md
Normal file
230
published/202001/20190405 File sharing with Git.md
Normal file
@ -0,0 +1,230 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11768-1.html)
|
||||
[#]: subject: (File sharing with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/file-sharing-git)
|
||||
[#]: author: (Seth Kenlon)
|
||||
|
||||
用 Git 来共享文件
|
||||
======
|
||||
|
||||
> SparkleShare 是一个开源的基于 Git 的 Dropbox 风格的文件共享应用程序。在我们的系列文章中了解有关 Git 鲜为人知的用法。
|
||||
|
||||

|
||||
|
||||
[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
|
||||
|
||||
今天,我们将看看 SparkleShare,它使用 Git 作为文件共享的基础。
|
||||
|
||||
### 用于文件共享的 Git
|
||||
|
||||
Git 的优点之一是它具有固有的分发能力。它可用来建立共享。即使你只是与自己网络上的其他计算机共享资源库,Git 也会为从共享位置获取文件的行为带来透明性。
|
||||
|
||||
随着其界面的发展,Git 变得非常简单。虽然因用户而异,他们坐下来完成一些工作时的共同点仅仅是 `git pull` 或稍微复杂一点的 `git pull && git checkout -b my-branch`。但是,对于某些人来说,将*命令输入*到他们的计算机中的做法完全是令人困惑或烦恼的。计算机旨在使生活变得轻松,它擅长于重复性工作,因此有更简便的方法可以与 Git 共享文件。
|
||||
|
||||
### SparkleShare
|
||||
|
||||
[SparkleShare][3] 项目是一个基于 Git 的跨平台的、开源的 Dropbox 式的文件共享应用程序。它通过将文件拖放到专门指定的 SparkleShare 目录中的简单操作,自动执行所有 Git 命令,触发添加、提交、推送和拉取过程。因为它基于 Git,所以你可以获得基于差异(diff)的快速推送和拉取,并且继承了 Git 版本控制和后端基础设施(如 Git 挂钩)的所有优点。它可以完全自托管,也可以将其与 [GitLab][4]、GitHub、Bitbucket 等 Git 托管服务一起使用。此外,由于它基本上只是一个 Git 的前端,因此你可以在可能没有 SparkleShare 客户端但有 Git 客户端的设备上访问 SparkleShare 中的文件。
|
||||
|
||||
正如你获得 Git 的所有好处一样,你也会受到所有常见的 Git 限制:使用 SparkleShare 存储数百张照片、音乐和视频是不切实际的,因为 Git 是为文本而设计和优化的。Git 当然可以存储二进制文件的大文件,但是因为它可以跟踪历史记录,因此一旦将文件添加到其中,几乎就不可能完全删除它。这在某种程度上限制了 SparkleShare 对某些人的实用性,但使其非常适合许多工作流程,包括[日程安排][5]。
|
||||
|
||||
#### 安装 SparkleShare
|
||||
|
||||
SparkleShare 是跨平台的,可从[网站][6]获得适用于 Windows 和 Mac 的安装程序。对于 Linux,有一个 [Flatpak][7] 安装包,或者你可以在终端中运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo flatpak remote-add flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
$ sudo flatpak install flathub org.sparkleshare.SparkleShare
|
||||
```
|
||||
|
||||
### 创建一个 Git 存储库
|
||||
|
||||
SparkleShare 并不是软件即服务(SaaS)。你在计算机上运行 SparkleShare 与 Git 存储库进行通信,而 SparkleShare 并不存储你的数据。如果你还没有与文件夹同步的 Git 存储库,则必须在启动 SparkleShare 之前创建一个文件夹。你有三个选择:托管的 Git、自托管 Git 或自托管 SparkleShare。
|
||||
|
||||
#### 托管的 Git
|
||||
|
||||
SparkleShare 可以使用你能访问的任何 Git 存储库进行存储,因此,如果你拥有 GitLab 或任何其他托管服务的帐户(或创建一个),则它可以成为 SparkleShare 的后端。例如,开源 [Notabug.org][8] 服务是一个类似于 GitHub 和 GitLab 的 Git 托管服务,但其独特性足以证明 SparkleShare 的灵活性。根据用户界面的不同,不同的托管服务创建新存储库的方法也有所不同,但是所有主要存储库都遵循相同的通用模型。
|
||||
|
||||
首先,在托管服务中找到创建新项目或存储库的按钮,单击它以开始。然后逐步完成存储库的创建过程,为存储库提供名称、隐私级别(存储库通常默认为公共),以及是否使用 `README` 文件初始化存储库。无论你是否需要个 `README` 文件,请初始化建立一个。使用一个文件来创建存储库不是绝对必要的,但是它会强制 Git 主机实例化存储库中的 `master` 分支,这有助于确保前端应用程序(例如 SparkleShare)具有要提交并推送的分支。即使文件是几乎空的 `README` 文件,也可以用来查看该文件以确认你已连接成功。
|
||||
|
||||
![Creating a Git repository][9]
|
||||
|
||||
创建存储库后,获取其用于 SSH 克隆的 URL。就像从 Git 项目获得其 URL 一样,你也可以获取此 URL:导航至存储库页面并查找 “Clone” 按钮或字段。
|
||||
|
||||
![Cloning a URL on GitHub][10]
|
||||
|
||||
*GitHub 的克隆 URL。*
|
||||
|
||||
![Cloning a URL on GitLab][11]
|
||||
|
||||
*GitLab 的克隆 URL。*
|
||||
|
||||
这是 SparkleShare 用于获取数据的地址,因此请记下它。你的 Git 存储库现已配置好。
|
||||
|
||||
#### 自托管的 Git
|
||||
|
||||
你可以使用 SparkleShare 访问你有权访问的任何计算机上的 Git 存储库。除了一个 Git 裸存储库外,无需任何特殊设置。但是,如果你想将对 Git 存储库的访问权授予其他任何人,则应运行 [Gitolite][12] 之类的 Git 管理器或 SparkleShare 自己的 Dazzle 服务器来帮助你管理 SSH 密钥和帐户。至少,创建一个特定于 Git 的用户,以便有权访问你的 Git 存储库的用户不会自动获得对服务器其余部分的访问权限。
|
||||
|
||||
以 Git 用户身份登录服务器(如果你非常擅长管理用户和组权限,则可以以自己的用户登录)并创建存储库:
|
||||
|
||||
```
|
||||
$ mkdir ~/sparkly.git
|
||||
$ cd ~/sparkly.git
|
||||
$ git init --bare .
|
||||
```
|
||||
|
||||
你的 Git 存储库现已配置好。
|
||||
|
||||
#### Dazzle
|
||||
|
||||
SparkleShare 的开发人员提供了一个名为 [Dazzle][13] 的 Git 管理系统,以帮助你自托管 Git 存储库。
|
||||
|
||||
在你的服务器上,将 Dazzle 应用程序下载到你的路径中的某个位置:
|
||||
|
||||
```
|
||||
$ curl https://raw.githubusercontent.com/hbons/Dazzle/master/dazzle.sh --output ~/bin/dazzle
|
||||
$ chmod +x ~/bin/dazzle
|
||||
```
|
||||
|
||||
Dazzle 设置了一个特定于 Git 和 SparkleShare 的用户,并且还基于 SparkleShare 应用程序生成的密钥实现了访问权限。现在,只需设置一个项目:
|
||||
|
||||
```
|
||||
$ dazzle create sparkly
|
||||
```
|
||||
|
||||
你的服务器现在已经配置好,可以用作 SparkleShare 托管了。
|
||||
|
||||
### 配置 SparkleShare
|
||||
|
||||
首次启动 SparkleShare 时,系统会提示你配置 SparkleShare 用于存储的服务器。这个过程可能看起来像一个首次运行的安装向导,但实际上是在 SparkleShare 中设置新共享位置的通常过程。与许多共享驱动器应用程序不同,使用 SparkleShare 可以一次配置多个位置。你配置的第一个共享位置并不比你以后可以配置的任何共享位置更重要,并且你也不用注册 SparkleShare 或任何其他服务。你只是将 SparkleShare 指向 Git 存储库,以便它知道如何使第一个 SparkleShare 文件夹保持同步。
|
||||
|
||||
在第一个屏幕上,给出一个身份信息,SparkleShare 将在代表你进行的 Git 提交记录中使用这些信息。你可以使用任何内容,甚至可以使用不代表任何意义的伪造信息。它仅用于提交消息,如果你对审查 Git 后端进程没有兴趣,你可能甚至看不到它们。
|
||||
|
||||
下一个屏幕提示你选择主机类型。如果你使用的是 GitLab、GitHub、Planio 或 Bitbucket,则可以选择一个适当的。否则,请选择“自己的服务器”。
|
||||
|
||||
![Choosing a Sparkleshare host][14]
|
||||
|
||||
在此屏幕底部,你必须输入 SSH 的克隆 URL。如果你是自托管的 Git,则地址类似于 `<ssh://username@example.com>`,而远程路径是为此目的而创建的 Git 存储库的绝对路径。
|
||||
|
||||
根据上面的自托管示例,我虚构的服务器的地址为 `ssh://git@example.com:22122`(`:22122` 表示一个非标准的 SSH 端口),远程路径为 `/home/git/sparkly.git`。
|
||||
|
||||
如果我改用 Notabug.org 帐户,则上例中的地址为 `ssh://git@notabug.org`,路径为 `seth/sparkly.git`。
|
||||
|
||||
SparkleShare 首次尝试连接到主机时会失败,因为你尚未将 SparkleShare 客户端 ID(特定于 SparkleShare 应用程序的 SSH 密钥)复制到 Git 主机。这是预料之中的,所以不要取消该过程。将 SparkleShare 设置窗口保持打开状态,并从系统任务栏中的 SparkleShare 图标处获取客户端 ID。然后将客户端 ID 复制到剪贴板,以便可以将其添加到 Git 主机。
|
||||
|
||||
![Getting the client ID from Sparkleshare][16]
|
||||
|
||||
#### 将你的客户端 ID 添加到托管的 Git 帐户
|
||||
|
||||
除了较小的 UI 差异外,在任何托管服务上添加 SSH 密钥(所有客户端 ID 都是这样)的过程基本上是相同的。在你的 Git 主机的 Web 仪表板中,导航到你的用户设置,然后找到 “SSH 密钥”类别。单击“添加新密钥”按钮(或类似按钮),然后粘贴你的 SparkleShare 客户端 ID 的内容。
|
||||
|
||||
![Adding an SSH key][17]
|
||||
|
||||
保存密钥。如果你希望其他人(例如协作者或家庭成员)能够访问同一存储库,则他们必须向你提供其 SparkleShare 客户端 ID,以便你可以将其添加到帐户中。
|
||||
|
||||
#### 将你的客户端 ID 添加到自托管的 Git 帐户
|
||||
|
||||
SparkleShare 客户端 ID 只是一个 SSH 密钥,因此将其复制并粘贴到 Git 用户的 `~/.ssh/authorized_keys` 文件中。
|
||||
|
||||
#### 使用 Dazzle 添加你的客户 ID
|
||||
|
||||
如果你使用 Dazzle 管理 SparkleShare 项目,请使用以下命令添加客户端 ID:
|
||||
|
||||
```
|
||||
$ dazzle link
|
||||
```
|
||||
|
||||
当 Dazzle 提示你输入该 ID 时,请粘贴在 SparkleShare 菜单中找到的客户端 ID。
|
||||
|
||||
### 使用 SparkleShare
|
||||
|
||||
将客户端 ID 添加到 Git 主机后,在 SparkleShare 窗口中单击“重试”按钮以完成设置。克隆存储库完成后,你可以关闭 SparkleShare 设置窗口,并在你的家目录中找到一个新的 `SparkleShare` 文件夹。如果你设置了带有托管服务的 Git 存储库,并选择包括 `README` 文件或许可证文件,则可以在 SparkleShare 目录中看到它们。
|
||||
|
||||
![Sparkleshare file manager][18]
|
||||
|
||||
此外,有一些隐藏目录,你可以通过在文件管理器中显示隐藏目录来查看。
|
||||
|
||||
![Showing hidden files in GNOME][19]
|
||||
|
||||
使用 SparkleShare 的方式与使用计算机上任何目录的方式相同:将文件放入其中。每当将文件或目录放入 SparkleShare 文件夹时,它都会在后台复制到你的 Git 存储库。
|
||||
|
||||
#### 排除某些文件
|
||||
|
||||
由于 Git 从设计上就是要记住*一切*,因此你可能希望从记录中排除特定的文件类型。排除一些文件是有原因的。通过定义摆脱 SparkleShare 管理的文件,可以避免意外复制大文件。你还可以为自己设计一种方案,使你可以将存储在一个目录中的逻辑上属于同一个文件(例如,MIDI 文件及其 .flac 导出文件),但是可以自己手动备份大文件,而同时让 SparkleShare 备份基于文本的文件。
|
||||
|
||||
如果在系统的文件管理器中看不到隐藏的文件,请显示它们。导航到你的 SparkleShare 文件夹,然后到代表你的存储库的目录,找到一个名为 `.gitignore` 的文件,然后在文本编辑器中将其打开。你可以在 `.gitignore` 中输入文件扩展名或文件名(每行一个),任何与你列出的文件匹配的文件都会被忽略(如文件名所示)。
|
||||
|
||||
```
|
||||
Thumbs.db
|
||||
$RECYCLE.BIN/
|
||||
.DS_Store
|
||||
._*
|
||||
.fseventsd
|
||||
.Spotlight-V100
|
||||
.Trashes
|
||||
.directory
|
||||
.Trash-*
|
||||
*.wav
|
||||
*.ogg
|
||||
*.flac
|
||||
*.mp3
|
||||
*.m4a
|
||||
*.opus
|
||||
*.jpg
|
||||
*.png
|
||||
*.mp4
|
||||
*.mov
|
||||
*.mkv
|
||||
*.avi
|
||||
*.pdf
|
||||
*.djvu
|
||||
*.epub
|
||||
*.od{s,t}
|
||||
*.cbz
|
||||
```
|
||||
|
||||
你知道最经常遇到哪些文件类型,因此请集中精力处理最有可能潜入你的 SparkleShare 目录的文件。如果你想稍微矫枉过正一些,可以在 Notabug.org 以及整个网上找到 `.gitignore` 文件的好集合。
|
||||
|
||||
通过将这些条目保存在 `.gitignore` 文件中,你可以将不需要发送到 Git 主机的大文件放在 SparkleShare 目录中,SparkleShare 将完全忽略它们。当然,这意味着你需要确保它们可以备份或通过其他方式分发给你的 SparkleShare 协作者。
|
||||
|
||||
### 自动化
|
||||
|
||||
[自动化][20] 是我们与计算机达成的默契之一:计算机执行重复的、无聊的工作,而我们人类要么不擅长做这些,要么不擅长记忆这些。SparkleShare 是一种很好的、简单的自动执行例行数据分发的方法。但不管怎么说,这并不适合每个 Git 存储库。它没有用于高级 Git 功能的接口,它没有暂停按钮或手动管理的操作。没关系,因为它的使用范围是有意限制的。SparkleShare 可以完成它计划要做的事情,它做得很好,而且它是你无需关心的一个 Git 存储库。
|
||||
|
||||
如果你想使用这种稳定的、看不见的自动化,请尝试一下 SparkleShare。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/file-sharing-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_cloud21x_cc.png?itok=5UwC92dO
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://www.sparkleshare.org/
|
||||
[4]: http://gitlab.com
|
||||
[5]: https://opensource.com/article/19/4/calendar-git
|
||||
[6]: http://sparkleshare.org
|
||||
[7]: /business/16/8/flatpak
|
||||
[8]: http://notabug.org
|
||||
[9]: https://opensource.com/sites/default/files/uploads/git-new-repo.jpg (Creating a Git repository)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/github-clone-url.jpg (Cloning a URL on GitHub)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/gitlab-clone-url.jpg (Cloning a URL on GitLab)
|
||||
[12]: http://gitolite.org
|
||||
[13]: https://github.com/hbons/Dazzle
|
||||
[14]: https://opensource.com/sites/default/files/uploads/sparkleshare-host.jpg (Choosing a Sparkleshare host)
|
||||
[15]: mailto:git@notabug.org
|
||||
[16]: https://opensource.com/sites/default/files/uploads/sparkleshare-clientid.jpg (Getting the client ID from Sparkleshare)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/git-ssh-key.jpg (Adding an SSH key)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/sparkleshare-file-manager.jpg (Sparkleshare file manager)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/gnome-show-hidden-files.jpg (Showing hidden files in GNOME)
|
||||
[20]: /downloads/ansible-quickstart
|
||||
226
published/202001/20190406 Run a server with Git.md
Normal file
226
published/202001/20190406 Run a server with Git.md
Normal file
@ -0,0 +1,226 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11795-1.html)
|
||||
[#]: subject: (Run a server with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/server-administration-git)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/seth)
|
||||
|
||||
使用 Git 来管理 Git 服务器
|
||||
======
|
||||
|
||||
> 借助 Gitolite,你可以使用 Git 来管理 Git 服务器。在我们的系列文章中了解这些鲜为人知的 Git 用途。
|
||||
|
||||

|
||||
|
||||
正如我在系列文章中演示的那样,[Git][2] 除了跟踪源代码外,还可以做很多事情。信不信由你,Git 甚至可以管理你的 Git 服务器,因此你可以或多或少地使用 Git 本身来运行 Git 服务器。
|
||||
|
||||
当然,这涉及除日常使用 Git 之外的许多组件,其中最重要的是 [Gitolite][3],该后端应用程序可以管理你使用 Git 的每个细微的配置。Gitolite 的优点在于,由于它使用 Git 作为其前端接口,因此很容易将 Git 服务器管理集成到其他基于 Git 的工作流中。Gitolite 可以精确控制谁可以访问你服务器上的特定存储库以及他们具有哪些权限。你可以使用常规的 Linux 系统工具自行管理此类事务,但是如果有好几个用户和不止一两个仓库,则需要大量的工作。
|
||||
|
||||
Gitolite 的开发人员做了艰苦的工作,使你可以轻松地为许多用户提供对你的 Git 服务器的访问权,而又不让他们访问你的整个环境 —— 而这一切,你可以使用 Git 来完成全部工作。
|
||||
|
||||
Gitolite 并**不是**图形化的管理员和用户面板。优秀的 [Gitea][4] 项目可提供这种体验,但是本文重点介绍 Gitolite 的简单优雅和令人舒适的熟悉感。
|
||||
|
||||
### 安装 Gitolite
|
||||
|
||||
假设你的 Git 服务器运行在 Linux 上,则可以使用包管理器安装 Gitolite(在 CentOS 和 RHEL 上为 `yum`,在 Debian 和 Ubuntu 上为 `apt`,在 OpenSUSE 上为 `zypper` 等)。例如,在 RHEL 上:
|
||||
|
||||
```
|
||||
$ sudo yum install gitolite3
|
||||
```
|
||||
|
||||
许多发行版的存储库提供的仍是旧版本的 Gitolite,但最新版本为版本 3。
|
||||
|
||||
你必须具有对服务器的无密码 SSH 访问权限。如果愿意,你可以使用密码登录服务器,但是 Gitolite 依赖于 SSH 密钥,因此必须配置使用密钥登录的选项。如果你不知道如何配置服务器以进行无密码 SSH 访问,请首先学习如何进行操作(Steve Ovens 的 Ansible 文章的[设置 SSH 密钥身份验证][5]部分对此进行了很好的说明)。这是加强服务器管理的安全以及运行 Gitolite 的重要组成部分。
|
||||
|
||||
### 配置 Git 用户
|
||||
|
||||
如果没有 Gitolite,则如果某人请求访问你在服务器上托管的 Git 存储库时,则必须向该人提供用户帐户。Git 提供了一个特殊的外壳,即 `git-shell`,这是一个仅执行 Git 任务的特别的特定 shell。这可以让你有个只能通过非常受限的 Shell 环境来过滤访问你的服务器的用户。
|
||||
|
||||
这个解决方案是一个办法,但通常意味着用户可以访问服务器上的所有存储库,除非你具有用于组权限的良好模式,并在创建新存储库时严格遵循这些权限。这种方式还需要在系统级别进行大量手动配置,这通常是只有特定级别的系统管理员才能做的工作,而不一定是通常负责 Git 存储库的人员。
|
||||
|
||||
Gitolite 通过为需要访问任何存储库的每个人指定一个用户名来完全回避此问题。默认情况下,该用户名是 `git`,并且由于 Gitolite 的文档中假定使用的是它,因此在学习该工具时保留它是一个很好的默认设置。对于曾经使用过 GitLab 或 GitHub 或任何其他 Git 托管服务的人来说,这也是一个众所周知的约定。
|
||||
|
||||
Gitolite 将此用户称为**托管用户**。在服务器上创建一个帐户以充当托管用户(我习惯使用 `git`,因为这是惯例):
|
||||
|
||||
```
|
||||
$ sudo adduser --create-home git
|
||||
```
|
||||
|
||||
为了控制该 `git` 用户帐户,该帐户必须具有属于你的有效 SSH 公钥。你应该已经进行了设置,因此复制你的公钥(**而不是你的私钥**)添加到 `git` 用户的家目录中:
|
||||
|
||||
```
|
||||
$ sudo cp ~/.ssh/id_ed25519.pub /home/git/
|
||||
$ sudo chown git:git /home/git/id_ed25519.pub
|
||||
```
|
||||
|
||||
如果你的公钥不以扩展名 `.pub` 结尾,则 Gitolite 不会使用它,因此请相应地重命名该文件。切换为该用户帐户以运行 Gitolite 的安装程序:
|
||||
|
||||
```
|
||||
$ sudo su - git
|
||||
$ gitolite setup --pubkey id_ed25519.pub
|
||||
```
|
||||
|
||||
安装脚本运行后,`git` 的家用户目录将有一个 `repository` 目录,该目录(目前)包含存储库 `git-admin.git` 和 `testing.git`。这就是该服务器所需的全部设置,现在请登出 `git` 用户。
|
||||
|
||||
### 使用 Gitolite
|
||||
|
||||
管理 Gitolite 就是编辑 Git 存储库中的文本文件,尤其是 `gitolite-admin.git` 中的。你不会通过 SSH 进入服务器来进行 Git 管理,并且 Gitolite 也建议你不要这样尝试。在 Gitolite 服务器上存储你和你的用户的存储库是个**裸**存储库,因此最好不要使用它们。
|
||||
|
||||
```
|
||||
$ git clone git@example.com:gitolite-admin.git gitolite-admin.git
|
||||
$ cd gitolite-admin.git
|
||||
$ ls -1
|
||||
conf
|
||||
keydir
|
||||
```
|
||||
|
||||
该存储库中的 `conf` 目录包含一个名为 `gitolite.conf` 的文件。在文本编辑器中打开它,或使用 `cat` 查看其内容:
|
||||
|
||||
```
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
```
|
||||
|
||||
你可能对该配置文件的功能有所了解:`gitolite-admin` 代表此存储库,并且 `id_ed25519` 密钥的所有者具有读取、写入和管理 Git 的权限。换句话说,不是将用户映射到普通的本地 Unix 用户(因为所有用户都使用 `git` 用户托管用户身份),而是将用户映射到 `keydir` 目录中列出的 SSH 密钥。
|
||||
|
||||
`testing.git` 存储库使用特殊组符号为访问服务器的每个人提供了全部权限。
|
||||
|
||||
#### 添加用户
|
||||
|
||||
如果要向 Git 服务器添加一个名为 `alice` 的用户,Alice 必须向你发送她的 SSH 公钥。Gitolite 使用文件名的 `.pub` 扩展名左边的任何内容作为该 Git 用户的标识符。不要使用默认的密钥名称值,而是给密钥指定一个指示密钥所有者的名称。如果用户有多个密钥(例如,一个用于笔记本电脑,一个用于台式机),则可以使用子目录来避免文件名冲突。例如,Alice 在笔记本电脑上使用的密钥可能是默认的 `id_rsa.pub`,因此将其重命名为`alice.pub` 或类似名称(或让用户根据其计算机上的本地用户帐户来命名密钥),然后将其放入 `gitolite-admin.git/keydir/work/laptop/` 目录中。如果她从她的桌面计算机发送了另一个密钥,命名为 `alice.pub`(与上一个相同),然后将其添加到 `keydir/home/desktop/` 中。另一个密钥可能放到 `keydir/home/desktop/` 中,依此类推。Gitolite 递归地在 `keydir` 中搜索与存储库“用户”相匹配的 `.pub` 文件,并将所有匹配项视为相同的身份。
|
||||
|
||||
当你将密钥添加到 `keydir` 目录时,必须将它们提交回服务器。这是一件很容易忘记的事情,这里有一个使用自动化的 Git 应用程序(例如 [Sparkleshare][7])的真正的理由,因此任何更改都将立即提交给你的 Gitolite 管理员。第一次忘记提交和推送,在浪费了三个小时的你和你的用户的故障排除时间之后,你会发现 Gitolite 是使用 Sparkleshare 的完美理由。
|
||||
|
||||
```
|
||||
$ git add keydir
|
||||
$ git commit -m 'added alice-laptop-0.pub'
|
||||
$ git push origin HEAD
|
||||
```
|
||||
|
||||
默认情况下,Alice 可以访问 `testing.git` 目录,因此她可以使用该目录测试连接性和功能。
|
||||
|
||||
#### 设置权限
|
||||
|
||||
与用户一样,目录权限和组也是从你可能习惯的的常规 Unix 工具中抽象出来的(或可从在线信息查找)。在 `gitolite-admin.git/conf` 目录中的 `gitolite.conf` 文件中授予对项目的权限。权限分为四个级别:
|
||||
|
||||
* `R` 允许只读。在存储库上具有 `R` 权限的用户可以克隆它,仅此而已。
|
||||
* `RW` 允许用户执行分支的快进推送、创建新分支和创建新标签。对于大多数用户来说,这个基本上就像是一个“普通”的 Git 存储库。
|
||||
* `RW+` 允许可能具有破坏性的 Git 动作。用户可以执行常规的快进推送、回滚推送、变基以及删除分支和标签。你可能想要或不希望将其授予项目中的所有贡献者。
|
||||
* `-` 明确拒绝访问存储库。这与未在存储库的配置中列出的用户相同。
|
||||
|
||||
通过调整 `gitolite.conf` 来创建一个新的存储库或修改现有存储库的权限。例如,授予 Alice 权限来管理一个名为 `widgets.git` 的新存储库:
|
||||
|
||||
```
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo widgets
|
||||
RW+ = alice
|
||||
```
|
||||
|
||||
现在,Alice(也仅有 Alice 一个人)可以克隆该存储库:
|
||||
|
||||
```
|
||||
[alice]$ git clone git@example.com:widgets.git
|
||||
Cloning into 'widgets'...
|
||||
warning: You appear to have cloned an empty repository.
|
||||
```
|
||||
|
||||
在第一次推送时,Alice 必须使用 `-u` 选项将其分支发送到空存储库(如同她在任何 Git 主机上做的一样)。
|
||||
|
||||
为了简化用户管理,你可以定义存储库组:
|
||||
|
||||
```
|
||||
@qtrepo = widgets
|
||||
@qtrepo = games
|
||||
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo @qtrepo
|
||||
RW+ = alice
|
||||
```
|
||||
|
||||
正如你可以创建组存储库一样,你也可以对用户进行分组。默认情况下存在一个用户组:`@all`。如你所料,它包括所有用户,无一例外。你也可以创建自己的组:
|
||||
|
||||
```
|
||||
@qtrepo = widgets
|
||||
@qtrepo = games
|
||||
|
||||
@developers = alice bob
|
||||
|
||||
repo gitolite-admin
|
||||
RW+ = id_ed22519
|
||||
|
||||
repo testing
|
||||
RW+ = @all
|
||||
|
||||
repo @qtrepo
|
||||
RW+ = @developers
|
||||
```
|
||||
|
||||
与添加或修改密钥文件一样,对 `gitolite.conf` 文件的任何更改都必须提交并推送以生效。
|
||||
|
||||
### 创建存储库
|
||||
|
||||
默认情况下,Gitolite 假设存储库的创建是从上至下进行。例如,有权访问 Git 服务器的项目经理创建了一个项目存储库,并通过 Gitolite 管理仓库添加了开发人员。
|
||||
|
||||
实际上,你可能更愿意向用户授予创建存储库的权限。Gitolite 称这些为“<ruby>野生仓库(通配仓库)<rt>wild repos</rt></ruby>”(我不确定这是关于仓库的形成方式的描述,还是指配置文件所需的通配符)。这是一个例子:
|
||||
|
||||
```
|
||||
@managers = alice bob
|
||||
|
||||
repo foo/CREATOR/[a-z]..*
|
||||
C = @managers
|
||||
RW+ = CREATOR
|
||||
RW = WRITERS
|
||||
R = READERS
|
||||
```
|
||||
|
||||
第一行定义了一组用户:该组称为 `@managers`,其中包含用户 `alice` 和 `bob`。下一行设置了通配符允许创建尚不存在的存储库,放在名为 `foo` 的目录下的创建该存储库的用户名的子目录中。例如:
|
||||
|
||||
```
|
||||
[alice]$ git clone git@example.com:foo/alice/cool-app.git
|
||||
Cloning into cool-app'...
|
||||
Initialized empty Git repository in /home/git/repositories/foo/alice/cool-app.git
|
||||
warning: You appear to have cloned an empty repository.
|
||||
```
|
||||
|
||||
野生仓库的创建者可以使用一些机制来定义谁可以读取和写入其存储库,但是他们是有范围限定的。在大多数情况下,Gitolite 假定由一组特定的用户来管理项目权限。一种解决方案是使用 Git 挂钩来授予所有用户对 `gitolite-admin` 的访问权限,以要求管理者批准将更改合并到 master 分支中。
|
||||
|
||||
### 了解更多
|
||||
|
||||
Gitolite 具有比此介绍性文章所涵盖的更多功能,因此请尝试一下。其[文档][8]非常出色,一旦你通读了它,就可以自定义 Gitolite 服务器,以向用户提供你喜欢的任何级别的控制。Gitolite 是一种维护成本低、简单的系统,你可以安装、设置它,然后基本上就可以将其忘却。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/server-administration-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/server_data_system_admin.png?itok=q6HCfNQ8 (computer servers processing data)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://gitolite.com
|
||||
[4]: http://gitea.io
|
||||
[5]: Setting%20up%20SSH%20key%20authentication
|
||||
[6]: mailto:git@example.com
|
||||
[7]: https://opensource.com/article/19/4/file-sharing-git
|
||||
[8]: http://gitolite.com/gitolite/quick_install.html
|
||||
@ -0,0 +1,333 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11810-1.html)
|
||||
[#]: subject: (Getting started with OpenSSL: Cryptography basics)
|
||||
[#]: via: (https://opensource.com/article/19/6/cryptography-basics-openssl-part-1)
|
||||
[#]: author: (Marty Kalin https://opensource.com/users/mkalindepauledu/users/akritiko/users/clhermansen)
|
||||
|
||||
OpenSSL 入门:密码学基础知识
|
||||
======
|
||||
|
||||
> 想要入门密码学的基础知识,尤其是有关 OpenSSL 的入门知识吗?继续阅读。
|
||||
|
||||

|
||||
|
||||
本文是使用 [OpenSSL][2] 的密码学基础知识的两篇文章中的第一篇,OpenSSL 是在 Linux 和其他系统上流行的生产级库和工具包。(要安装 OpenSSL 的最新版本,请参阅[这里][3]。)OpenSSL 实用程序可在命令行使用,程序也可以调用 OpenSSL 库中的函数。本文的示例程序使用的是 C 语言,即 OpenSSL 库的源语言。
|
||||
|
||||
本系列的两篇文章涵盖了加密哈希、数字签名、加密和解密以及数字证书。你可以从[我的网站][4]的 ZIP 文件中找到这些代码和命令行示例。
|
||||
|
||||
让我们首先回顾一下 OpenSSL 名称中的 SSL。
|
||||
|
||||
### OpenSSL 简史
|
||||
|
||||
<ruby>[安全套接字层][5]<rt>Secure Socket Layer</rt></ruby>(SSL)是 Netscape 在 1995 年发布的一种加密协议。该协议层可以位于 HTTP 之上,从而为 HTTPS 提供了 S:<ruby>安全<rt>secure</rt></ruby>。SSL 协议提供了各种安全服务,其中包括两项在 HTTPS 中至关重要的服务:
|
||||
|
||||
* <ruby>对等身份验证<rt>Peer authentication</rt></ruby>(也称为相互质询):连接的每一边都对另一边的身份进行身份验证。如果 Alice 和 Bob 要通过 SSL 交换消息,则每个人首先验证彼此的身份。
|
||||
* <ruby>机密性<rt>Confidentiality</rt></ruby>:发送者在通过通道发送消息之前先对其进行加密。然后,接收者解密每个接收到的消息。此过程可保护网络对话。即使窃听者 Eve 截获了从 Alice 到 Bob 的加密消息(即*中间人*攻击),Eve 会发现他无法在计算上解密此消息。
|
||||
|
||||
反过来,这两个关键 SSL 服务与其他不太受关注的服务相关联。例如,SSL 支持消息完整性,从而确保接收到的消息与发送的消息相同。此功能是通过哈希函数实现的,哈希函数也随 OpenSSL 工具箱一起提供。
|
||||
|
||||
SSL 有多个版本(例如 SSLv2 和 SSLv3),并且在 1999 年出现了一个基于 SSLv3 的类似协议<ruby>传输层安全性<rt>Transport Layer Security</rt></ruby>(TLS)。TLSv1 和 SSLv3 相似,但不足以相互配合工作。不过,通常将 SSL/TLS 称为同一协议。例如,即使正在使用的是 TLS(而非 SSL),OpenSSL 函数也经常在名称中包含 SSL。此外,调用 OpenSSL 命令行实用程序以 `openssl` 开始。
|
||||
|
||||
除了 man 页面之外,OpenSSL 的文档是零零散散的,鉴于 OpenSSL 工具包很大,这些页面很难以查找使用。命令行和代码示例可以将主要主题集中起来。让我们从一个熟悉的示例开始(使用 HTTPS 访问网站),然后使用该示例来选出我们感兴趣的加密部分进行讲述。
|
||||
|
||||
### 一个 HTTPS 客户端
|
||||
|
||||
此处显示的 `client` 程序通过 HTTPS 连接到 Google:
|
||||
|
||||
```
|
||||
/* compilation: gcc -o client client.c -lssl -lcrypto */
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <openssl/bio.h> /* BasicInput/Output streams */
|
||||
#include <openssl/err.h> /* errors */
|
||||
#include <openssl/ssl.h> /* core library */
|
||||
#define BuffSize 1024
|
||||
|
||||
void report_and_exit(const char* msg) {
|
||||
perror(msg);
|
||||
ERR_print_errors_fp(stderr);
|
||||
exit(-1);
|
||||
}
|
||||
|
||||
void init_ssl() {
|
||||
SSL_load_error_strings();
|
||||
SSL_library_init();
|
||||
}
|
||||
|
||||
void cleanup(SSL_CTX* ctx, BIO* bio) {
|
||||
SSL_CTX_free(ctx);
|
||||
BIO_free_all(bio);
|
||||
}
|
||||
|
||||
void secure_connect(const char* hostname) {
|
||||
char name[BuffSize];
|
||||
char request[BuffSize];
|
||||
char response[BuffSize];
|
||||
|
||||
const SSL_METHOD* method = TLSv1_2_client_method();
|
||||
if (NULL == method) report_and_exit("TLSv1_2_client_method...");
|
||||
|
||||
SSL_CTX* ctx = SSL_CTX_new(method);
|
||||
if (NULL == ctx) report_and_exit("SSL_CTX_new...");
|
||||
|
||||
BIO* bio = BIO_new_ssl_connect(ctx);
|
||||
if (NULL == bio) report_and_exit("BIO_new_ssl_connect...");
|
||||
|
||||
SSL* ssl = NULL;
|
||||
|
||||
/* 链路 bio 通道,SSL 会话和服务器端点 */
|
||||
|
||||
sprintf(name, "%s:%s", hostname, "https");
|
||||
BIO_get_ssl(bio, &ssl); /* 会话 */
|
||||
SSL_set_mode(ssl, SSL_MODE_AUTO_RETRY); /* 鲁棒性 */
|
||||
BIO_set_conn_hostname(bio, name); /* 准备连接 */
|
||||
|
||||
/* 尝试连接 */
|
||||
if (BIO_do_connect(bio) <= 0) {
|
||||
cleanup(ctx, bio);
|
||||
report_and_exit("BIO_do_connect...");
|
||||
}
|
||||
|
||||
/* 验证信任库,检查证书 */
|
||||
if (!SSL_CTX_load_verify_locations(ctx,
|
||||
"/etc/ssl/certs/ca-certificates.crt", /* 信任库 */
|
||||
"/etc/ssl/certs/")) /* 其它信任库 */
|
||||
report_and_exit("SSL_CTX_load_verify_locations...");
|
||||
|
||||
long verify_flag = SSL_get_verify_result(ssl);
|
||||
if (verify_flag != X509_V_OK)
|
||||
fprintf(stderr,
|
||||
"##### Certificate verification error (%i) but continuing...\n",
|
||||
(int) verify_flag);
|
||||
|
||||
/* 获取主页作为示例数据 */
|
||||
sprintf(request,
|
||||
"GET / HTTP/1.1\x0D\x0AHost: %s\x0D\x0A\x43onnection: Close\x0D\x0A\x0D\x0A",
|
||||
hostname);
|
||||
BIO_puts(bio, request);
|
||||
|
||||
/* 从服务器读取 HTTP 响应并打印到输出 */
|
||||
while (1) {
|
||||
memset(response, '\0', sizeof(response));
|
||||
int n = BIO_read(bio, response, BuffSize);
|
||||
if (n <= 0) break; /* 0 代表流结束,< 0 代表有错误 */
|
||||
puts(response);
|
||||
}
|
||||
|
||||
cleanup(ctx, bio);
|
||||
}
|
||||
|
||||
int main() {
|
||||
init_ssl();
|
||||
|
||||
const char* hostname = "www.google.com:443";
|
||||
fprintf(stderr, "Trying an HTTPS connection to %s...\n", hostname);
|
||||
secure_connect(hostname);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
可以从命令行编译和执行该程序(请注意 `-lssl` 和 `-lcrypto` 中的小写字母 `L`):
|
||||
|
||||
```
|
||||
gcc -o client client.c -lssl -lcrypto
|
||||
```
|
||||
|
||||
该程序尝试打开与网站 [www.google.com][13] 的安全连接。在与 Google Web 服务器的 TLS 握手过程中,`client` 程序会收到一个或多个数字证书,该程序会尝试对其进行验证(但在我的系统上失败了)。尽管如此,`client` 程序仍继续通过安全通道获取 Google 主页。该程序取决于前面提到的安全工件,尽管在上述代码中只着重突出了数字证书。但其它工件仍在幕后发挥作用,稍后将对它们进行详细说明。
|
||||
|
||||
通常,打开 HTTP(非安全)通道的 C 或 C++ 的客户端程序将使用诸如*文件描述符*或*网络套接字*之类的结构,它们是两个进程(例如,这个 `client` 程序和 Google Web 服务器)之间连接的端点。另一方面,文件描述符是一个非负整数值,用于在程序中标识该程序打开的任何文件类的结构。这样的程序还将使用一种结构来指定有关 Web 服务器地址的详细信息。
|
||||
|
||||
这些相对较低级别的结构不会出现在客户端程序中,因为 OpenSSL 库会将套接字基础设施和地址规范等封装在更高层面的安全结构中。其结果是一个简单的 API。下面首先看一下 `client` 程序示例中的安全性详细信息。
|
||||
|
||||
* 该程序首先加载相关的 OpenSSL 库,我的函数 `init_ssl` 中对 OpenSSL 进行了两次调用:
|
||||
|
||||
```
|
||||
SSL_load_error_strings();
|
||||
SSL_library_init();
|
||||
```
|
||||
* 下一个初始化步骤尝试获取安全*上下文*,这是建立和维护通往 Web 服务器的安全通道所需的信息框架。如对 OpenSSL 库函数的调用所示,在示例中使用了 TLS 1.2:
|
||||
|
||||
```
|
||||
const SSL_METHOD* method = TLSv1_2_client_method(); /* TLS 1.2 */
|
||||
```
|
||||
|
||||
如果调用成功,则将 `method` 指针被传递给库函数,该函数创建类型为 `SSL_CTX` 的上下文:
|
||||
|
||||
```
|
||||
SSL_CTX* ctx = SSL_CTX_new(method);
|
||||
```
|
||||
|
||||
`client` 程序会检查每个关键的库调用的错误,如果其中一个调用失败,则程序终止。
|
||||
* 现在还有另外两个 OpenSSL 工件也在发挥作用:SSL 类型的安全会话,从头到尾管理安全连接;以及类型为 BIO(<ruby>基本输入/输出<rt>Basic Input/Output</rt></ruby>)的安全流,用于与 Web 服务器进行通信。BIO 流是通过以下调用生成的:
|
||||
|
||||
```
|
||||
BIO* bio = BIO_new_ssl_connect(ctx);
|
||||
```
|
||||
|
||||
请注意,这个最重要的上下文是其参数。`BIO` 类型是 C 语言中 `FILE` 类型的 OpenSSL 封装器。此封装器可保护 `client` 程序与 Google 的网络服务器之间的输入和输出流的安全。
|
||||
* 有了 `SSL_CTX` 和 `BIO`,然后程序在 SSL 会话中将它们组合在一起。三个库调用可以完成工作:
|
||||
|
||||
```
|
||||
BIO_get_ssl(bio, &ssl); /* 会话 */
|
||||
SSL_set_mode(ssl, SSL_MODE_AUTO_RETRY); /* 鲁棒性 */
|
||||
BIO_set_conn_hostname(bio, name); /* 准备连接 */
|
||||
```
|
||||
|
||||
安全连接本身是通过以下调用建立的:
|
||||
|
||||
```
|
||||
BIO_do_connect(bio);
|
||||
```
|
||||
|
||||
如果最后一个调用不成功,则 `client` 程序终止;否则,该连接已准备就绪,可以支持 `client` 程序与 Google Web 服务器之间的机密对话。
|
||||
|
||||
在与 Web 服务器握手期间,`client` 程序会接收一个或多个数字证书,以认证服务器的身份。但是,`client` 程序不会发送自己的证书,这意味着这个身份验证是单向的。(Web 服务器通常配置为**不**需要客户端证书)尽管对 Web 服务器证书的验证失败,但 `client` 程序仍通过了连接到 Web 服务器的安全通道继续获取 Google 主页。
|
||||
|
||||
为什么验证 Google 证书的尝试会失败?典型的 OpenSSL 安装目录为 `/etc/ssl/certs`,其中包含 `ca-certificates.crt` 文件。该目录和文件包含着 OpenSSL 自带的数字证书,以此构成<ruby>信任库<rt>truststore</rt></ruby>。可以根据需要更新信任库,尤其是可以包括新信任的证书,并删除不再受信任的证书。
|
||||
|
||||
`client` 程序从 Google Web 服务器收到了三个证书,但是我的计算机上的 OpenSSL 信任库并不包含完全匹配的证书。如目前所写,`client` 程序不会通过例如验证 Google 证书上的数字签名(一个用来证明该证书的签名)来解决此问题。如果该签名是受信任的,则包含该签名的证书也应受信任。尽管如此,`client` 程序仍继续获取页面,然后打印出 Google 的主页。下一节将更详细地介绍这些。
|
||||
|
||||
### 客户端程序中隐藏的安全性
|
||||
|
||||
让我们从客户端示例中可见的安全工件(数字证书)开始,然后考虑其他安全工件如何与之相关。数字证书的主要格式标准是 X509,生产级的证书由诸如 [Verisign][14] 的<ruby>证书颁发机构<rt>Certificate Authority</rt></ruby>(CA)颁发。
|
||||
|
||||
数字证书中包含各种信息(例如,激活日期和失效日期以及所有者的域名),也包括发行者的身份和*数字签名*(这是加密过的*加密哈希*值)。证书还具有未加密的哈希值,用作其标识*指纹*。
|
||||
|
||||
哈希值来自将任意数量的二进制位映射到固定长度的摘要。这些位代表什么(会计报告、小说或数字电影)无关紧要。例如,<ruby>消息摘要版本 5<rt>Message Digest version 5</rt></ruby>(MD5)哈希算法将任意长度的输入位映射到 128 位哈希值,而 SHA1(<ruby>安全哈希算法版本 1<rt>Secure Hash Algorithm version 1</rt></ruby>)算法将输入位映射到 160 位哈希值。不同的输入位会导致不同的(实际上在统计学上是唯一的)哈希值。下一篇文章将会进行更详细的介绍,并着重介绍什么使哈希函数具有加密功能。
|
||||
|
||||
数字证书的类型有所不同(例如根证书、中间证书和最终实体证书),并形成了反映这些证书类型的层次结构。顾名思义,*根*证书位于层次结构的顶部,其下的证书继承了根证书所具有的信任。OpenSSL 库和大多数现代编程语言都具有 X509 数据类型以及处理此类证书的函数。来自 Google 的证书具有 X509 格式,`client` 程序会检查该证书是否为 `X509_V_OK`。
|
||||
|
||||
X509 证书基于<ruby>公共密钥基础结构<rt>public-key infrastructure</rt></ruby>(PKI),其中包括的算法(RSA 是占主导地位的算法)用于生成*密钥对*:公共密钥及其配对的私有密钥。公钥是一种身份:[Amazon][15] 的公钥对其进行标识,而我的公钥对我进行标识。私钥应由其所有者负责保密。
|
||||
|
||||
成对出现的密钥具有标准用途。可以使用公钥对消息进行加密,然后可以使用同一个密钥对中的私钥对消息进行解密。私钥也可以用于对文档或其他电子工件(例如程序或电子邮件)进行签名,然后可以使用该对密钥中的公钥来验证签名。以下两个示例补充了一些细节。
|
||||
|
||||
在第一个示例中,Alice 将她的公钥分发给全世界,包括 Bob。然后,Bob 用 Alice 的公钥加密邮件,然后将加密的邮件发送给 Alice。用 Alice 的公钥加密的邮件将可以用她的私钥解密(假设是她自己的私钥),如下所示:
|
||||
|
||||
```
|
||||
+------------------+ encrypted msg +-------------------+
|
||||
Bob's msg--->|Alice's public key|--------------->|Alice's private key|---> Bob's msg
|
||||
+------------------+ +-------------------+
|
||||
```
|
||||
|
||||
理论上可以在没有 Alice 的私钥的情况下解密消息,但在实际情况中,如果使用像 RSA 这样的加密密钥对系统,则在计算上做不到。
|
||||
|
||||
现在,第二个示例,请对文档签名以证明其真实性。签名算法使用密钥对中的私钥来处理要签名的文档的加密哈希:
|
||||
|
||||
```
|
||||
+-------------------+
|
||||
Hash of document--->|Alice's private key|--->Alice's digital signature of the document
|
||||
+-------------------+
|
||||
```
|
||||
|
||||
假设 Alice 以数字方式签署了发送给 Bob 的合同。然后,Bob 可以使用 Alice 密钥对中的公钥来验证签名:
|
||||
|
||||
```
|
||||
+------------------+
|
||||
Alice's digital signature of the document--->|Alice's public key|--->verified or not
|
||||
+------------------+
|
||||
```
|
||||
|
||||
假若没有 Alice 的私钥,就无法轻松伪造 Alice 的签名:因此,Alice 有必要保密她的私钥。
|
||||
|
||||
在 `client` 程序中,除了数字证书以外,这些安全性都没有明确展示。下一篇文章使用使用 OpenSSL 实用程序和库函数的示例填充更多详细的信息。
|
||||
|
||||
### 命令行的 OpenSSL
|
||||
|
||||
同时,让我们看一下 OpenSSL 命令行实用程序:特别是在 TLS 握手期间检查来自 Web 服务器的证书的实用程序。调用 OpenSSL 实用程序可以使用 `openssl` 命令,然后添加参数和标志的组合以指定所需的操作。
|
||||
|
||||
看看以下命令:
|
||||
|
||||
```
|
||||
openssl list-cipher-algorithms
|
||||
```
|
||||
|
||||
该输出是组成<ruby>加密算法套件<rt>cipher suite<rt></ruby>的相关算法的列表。下面是列表的开头,加了澄清首字母缩写词的注释:
|
||||
|
||||
```
|
||||
AES-128-CBC ## Advanced Encryption Standard, Cipher Block Chaining
|
||||
AES-128-CBC-HMAC-SHA1 ## Hash-based Message Authentication Code with SHA1 hashes
|
||||
AES-128-CBC-HMAC-SHA256 ## ditto, but SHA256 rather than SHA1
|
||||
...
|
||||
```
|
||||
|
||||
下一条命令使用参数 `s_client` 将打开到 [www.google.com][13] 的安全连接,并在屏幕上显示有关此连接的所有信息:
|
||||
|
||||
```
|
||||
openssl s_client -connect www.google.com:443 -showcerts
|
||||
```
|
||||
|
||||
端口号 443 是 Web 服务器用于接收 HTTPS(而不是 HTTP 连接)的标准端口号。(对于 HTTP,标准端口为 80)Web 地址 www.google.com:443 也出现在 `client` 程序的代码中。如果尝试连接成功,则将显示来自 Google 的三个数字证书以及有关安全会话、正在使用的加密算法套件以及相关项目的信息。例如,这是开头的部分输出,它声明*证书链*即将到来。证书的编码为 base64:
|
||||
|
||||
|
||||
```
|
||||
Certificate chain
|
||||
0 s:/C=US/ST=California/L=Mountain View/O=Google LLC/CN=www.google.com
|
||||
i:/C=US/O=Google Trust Services/CN=Google Internet Authority G3
|
||||
-----BEGIN CERTIFICATE-----
|
||||
MIIEijCCA3KgAwIBAgIQdCea9tmy/T6rK/dDD1isujANBgkqhkiG9w0BAQsFADBU
|
||||
MQswCQYDVQQGEwJVUzEeMBwGA1UEChMVR29vZ2xlIFRydXN0IFNlcnZpY2VzMSUw
|
||||
...
|
||||
```
|
||||
|
||||
诸如 Google 之类的主要网站通常会发送多个证书进行身份验证。
|
||||
|
||||
输出以有关 TLS 会话的摘要信息结尾,包括加密算法套件的详细信息:
|
||||
|
||||
```
|
||||
SSL-Session:
|
||||
Protocol : TLSv1.2
|
||||
Cipher : ECDHE-RSA-AES128-GCM-SHA256
|
||||
Session-ID: A2BBF0E4991E6BBBC318774EEE37CFCB23095CC7640FFC752448D07C7F438573
|
||||
...
|
||||
```
|
||||
|
||||
`client` 程序中使用了协议 TLS 1.2,`Session-ID` 唯一地标识了 `openssl` 实用程序和 Google Web 服务器之间的连接。`Cipher` 条目可以按以下方式进行解析:
|
||||
|
||||
* `ECDHE`(<ruby>椭圆曲线 Diffie-Hellman(临时)<rt>Elliptic Curve Diffie Hellman Ephemeral</rt></ruby>)是一种用于管理 TLS 握手的高效的有效算法。尤其是,ECDHE 通过确保连接双方(例如,`client` 程序和 Google Web 服务器)使用相同的加密/解密密钥(称为*会话密钥*)来解决“密钥分发问题”。后续文章会深入探讨该细节。
|
||||
* `RSA`(Rivest Shamir Adleman)是主要的公共密钥密码系统,并以 1970 年代末首次描述了该系统的三位学者的名字命名。这个正在使用的密钥对是使用 RSA 算法生成的。
|
||||
* `AES128`(<ruby>高级加密标准<rt>Advanced Encryption Standard</rt></ruby>)是一种<ruby>块式加密算法<rt>block cipher</rt></ruby>,用于加密和解密<ruby>位块<rt>blocks of bits</rt></ruby>。(另一种算法是<ruby>流式加密算法<rt>stream cipher</rt></ruby>,它一次加密和解密一个位。)这个加密算法是对称加密算法,因为使用同一个密钥进行加密和解密,这首先引起了密钥分发问题。AES 支持 128(此处使用)、192 和 256 位的密钥大小:密钥越大,安全性越好。
|
||||
|
||||
通常,像 AES 这样的对称加密系统的密钥大小要小于像 RSA 这样的非对称(基于密钥对)系统的密钥大小。例如,1024 位 RSA 密钥相对较小,而 256 位密钥则当前是 AES 最大的密钥。
|
||||
* `GCM`(<ruby>伽罗瓦计数器模式<rt>Galois Counter Mode</rt></ruby>)处理在安全对话期间重复应用的加密算法(在这种情况下为 AES128)。AES128 块的大小仅为 128 位,安全对话很可能包含从一侧到另一侧的多个 AES128 块。GCM 非常有效,通常与 AES128 搭配使用。
|
||||
* `SHA256`(<ruby>256 位安全哈希算法<rt>Secure Hash Algorithm 256 bits</rt></ruby>)是我们正在使用的加密哈希算法。生成的哈希值的大小为 256 位,尽管使用 SHA 甚至可以更大。
|
||||
|
||||
加密算法套件正在不断发展中。例如,不久前,Google 使用 RC4 流加密算法(RSA 的 Ron Rivest 后来开发的 Ron's Cipher 版本 4)。 RC4 现在有已知的漏洞,这大概部分导致了 Google 转换为 AES128。
|
||||
|
||||
### 总结
|
||||
|
||||
我们通过安全的 C Web 客户端和各种命令行示例对 OpenSSL 做了首次了解,使一些需要进一步阐明的主题脱颖而出。[下一篇文章会详细介绍][17],从加密散列开始,到对数字证书如何应对密钥分发挑战为结束的更全面讨论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/cryptography-basics-openssl-part-1
|
||||
|
||||
作者:[Marty Kalin][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mkalindepauledu/users/akritiko/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_3reasons.png?itok=k6F3-BqA (A lock on the side of a building)
|
||||
[2]: https://www.openssl.org/
|
||||
[3]: https://www.howtoforge.com/tutorial/how-to-install-openssl-from-source-on-linux/
|
||||
[4]: http://condor.depaul.edu/mkalin
|
||||
[5]: https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[6]: https://en.wikipedia.org/wiki/Netscape
|
||||
[7]: http://www.opengroup.org/onlinepubs/009695399/functions/perror.html
|
||||
[8]: http://www.opengroup.org/onlinepubs/009695399/functions/exit.html
|
||||
[9]: http://www.opengroup.org/onlinepubs/009695399/functions/sprintf.html
|
||||
[10]: http://www.opengroup.org/onlinepubs/009695399/functions/fprintf.html
|
||||
[11]: http://www.opengroup.org/onlinepubs/009695399/functions/memset.html
|
||||
[12]: http://www.opengroup.org/onlinepubs/009695399/functions/puts.html
|
||||
[13]: http://www.google.com
|
||||
[14]: https://www.verisign.com
|
||||
[15]: https://www.amazon.com
|
||||
[16]: http://www.google.com:443
|
||||
[17]: https://opensource.com/article/19/6/cryptography-basics-openssl-part-2
|
||||
@ -0,0 +1,182 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11746-1.html)
|
||||
[#]: subject: (How to make an old computer useful again)
|
||||
[#]: via: (https://opensource.com/article/19/7/how-make-old-computer-useful-again)
|
||||
[#]: author: (Howard Fosdick https://opensource.com/users/howtech)
|
||||
|
||||
如何把你的老爷机重新利用起来
|
||||
======
|
||||
|
||||
> 按照下面各个步骤,让你的老爷机焕然一新。
|
||||
|
||||

|
||||
|
||||
你的地下室里是不是有一台用来落灰的旧电脑?为什么不把它利用起来呢?如果你常用的电脑坏了,又想用一个比手机更大的屏幕上网,这时候一台备用电脑可能就派上用场了。或者,它也可以充当一台全家人共用的廉价备用电脑,甚至还可以改造为一台复古游戏机。
|
||||
|
||||
哪怕是一台有十余年历史的老爷机,只要选对了软件,也可以胜任很多新电脑能够完成的任务。其中的关键在于,要使用开源软件。
|
||||
|
||||
我进行电脑翻新已经有二十年了。在这篇文章里,我会分享一下电脑翻新的技巧。此处讨论的范围包括双核笔记本,以及机龄在 5 到 12 年之间的台式机。
|
||||
|
||||
### 检查硬件
|
||||
|
||||
第一步是检查硬件是否运转正常。如果在这个环节忽略了一个问题,后面可能会让你非常头疼。
|
||||
|
||||
灰尘是电子器件的天敌,所以第一件事应该是打开机箱,清除灰尘。[压缩空气设备][2]这时候可能会派上用场。请注意,进行任何接触电脑的操作时,都应该确保[接地][3]。此外,**不要**用清洁布擦拭任何东西。即使是一次小到你无法察觉的静电放电,也可能会导致电路损毁。
|
||||
|
||||
清洁工作完成之后,关闭机箱,检查是否所有硬件都可以正常工作。需要测试的项目包括:
|
||||
|
||||
* 内存
|
||||
* 硬盘
|
||||
* 主板
|
||||
* 外围设备(DVD 驱动器、USB 接口、声卡,等等)
|
||||
|
||||
首先,将计算机启动界面([UEFI][4] 或者是 [BIOS][5] 界面)上的诊断测试依次运行一遍。如果不知道按哪个功能键进入你电脑的启动界面,可以参考 [这份列表][6]。
|
||||
|
||||
此外,也可以使用诸如 [Hirens BootCD][7] 和 [Ultimate Boot CD][8] 之类的免费资源工具包,进行启动界面覆盖不到的测试。这些资源工具包涵盖了数百个测试程序,并且都是免费的,尽管不都开源。运行这些工具包无需安装任何软件,因为它们都是从 U 盘或者 DVD 驱动器启动的。
|
||||
|
||||
测试一定要彻底!对于内存和硬盘来说,基础测试还不够,应该运行深度测试,哪怕是运行一整夜也无妨。只有这样,才能够查出那些不易发现的瞬时故障。
|
||||
|
||||
如果发现了问题,可以参考我的[硬件故障排除快速指南][9],可以帮你解决最常见的硬件问题。
|
||||
|
||||
### 选择软件
|
||||
|
||||
电脑翻新的关键在于,根据手头的硬件资源,恰如其分地安装软件。最核心的三种硬件资源分别是:
|
||||
|
||||
1. 处理器(内核数、速度)
|
||||
2. 内存
|
||||
3. 显存
|
||||
|
||||
可以在启动时的 UEFI/BIOS 界面上,弄清楚你电脑的硬件资源。记得抄下数据,以免遗忘。接下来,可以在 [CPU Benchmark][10] 网站上查看你的处理器,该网站除了提供 CPU 的背景资料,还提供一个 CPU 的性能分数。
|
||||
|
||||
了解了硬件性能之后,就可以选择能够在硬件上高效运行的软件了。软件的选择涉及四个重要的层面:
|
||||
|
||||
1. 操作系统(OS)
|
||||
2. 桌面环境(DE)
|
||||
3. 浏览器
|
||||
4. 应用
|
||||
|
||||
一个优秀的 Linux 发行版可以满足上述全部四个层面。不要试图使用已经停止维护的 Windows 版本,例如 Windows 8、Vista 或者 XP,哪怕已经安装在电脑上了。恶意软件的[风险][11]你是承受不起的。明智的做法是,使用一个更抗病毒的最新版本操作系统。
|
||||
|
||||
那 Windows 7 呢?[维护宽限期][12]至 2020 年 1 月 14 日结束,也就是说,在此日期之前你还可以获得安全补丁,之后就想都别想了。现在正是迁出 Windows 7 的绝佳时机。
|
||||
|
||||
Linux 的巨大优势在于,有许多专门为过时硬件设计的[发行版][13]。此外,[桌面环境][14]和操作系统在 Linux 的设计中是分开的,你可以自行选择搭配。这一点非常重要,因为桌面环境对低端系统的性能有很大影响。(对于 Windows 和 MacOS 来说,你选择的操作系统版本决定了桌面环境,没得可选。)
|
||||
|
||||
Linux 的另一个好处是,拥有数以千计自由且开源的应用,不需要担心激活或者许可的问题。此外,Linux 是可移植的,可以在不同的分区、硬盘、设备或计算机之间,对操作系统和应用进行复制、移动或克隆。(Windows 则不然,使用注册表将系统捆绑在了所安装的计算机上。)
|
||||
|
||||
### 翻新后的电脑能够做什么?
|
||||
|
||||
这里讨论的是大约在 2006 年到 2013 年之间生产的双核计算机,尤其是装载了 [Intel 酷睿 2][15] CPU 或 [AMD 速龙 64 X2][16] 系列处理器的计算机。它们的 [CPU 分数][10] 大多在 1000 到 4000 分之间。这种电脑卖不了几个钱,但用在运行轻量级 Linux 软件上,性能还是足够的。
|
||||
|
||||
有一点需要注意:你的电脑应该至少拥有 2 GB 内存,如果不够就进行升级。就我翻新过的电脑来说,使用者用到的内存(不包括数据缓存)一般在 0.5 到 2 GB 之间,很少超过 2 GB。如果将内存升级到 2GB,系统就不至于进行**内存交换**,即将硬盘当做内存使用。如果想要获得良好性能,这一点十分关键。
|
||||
|
||||
以我自己为例,我用来写作这篇文章的是一台有十年机龄的翻新电脑。取下 1 GB 内存条之后,它只剩下了 1 GB 内存,然后就慢得像一只乌龟。用它浏览网页,或者是做类似的事情,都让人感到灰心,甚至痛苦。一旦把内存条重新装回去,有了 2 GB 内存,它就立马回到了可以使用的状态。
|
||||
|
||||
一台 2 GB 的双核计算机可以满足大多数人的需求,只要安装的是轻量级发行版和浏览器。你可以用它浏览网页、发送电子邮件、编辑文档和电子表格、观看 YouTube 视频、参与 eBay 拍卖竞标、在社交网络上发帖、听播客、查看相簿、管理家庭收支和个人日程、玩游戏,等等。
|
||||
|
||||
### 翻新电脑的局限
|
||||
|
||||
那么,这些老爷机又有什么局限呢?由于它们的并发性能比不上最先进的计算机,所以应该使用轻量级浏览器,同时拦截广告(广告正是让网页加载变慢的罪魁祸首)。如果可以使用虚拟专用网络(VPN)拦截广告,为处理器免除加载广告的负荷,那就再好不过。此外,还需要禁用视频自动播放、Flash 以及网页动画效果;将浏览器上的标签页控制在少数几个,不要同时打开 20 个;以及下载可以开启/禁用 JavaScript 的浏览器扩展。
|
||||
|
||||
让处理器专注于你目前正在做的事情吧,不要同时打开一堆应用,也不要在后台运行很多程序。图像编辑和视频编辑的高级工具可能会很慢;至于运行虚拟机,还是别想了吧。
|
||||
|
||||
那游戏呢?开源软件仓库提供了数以千计的游戏。这就是我为什么将显存列为三种核心硬件资源之一。如果你的电脑没有独立显卡,那很可能只有 32 或者 64 MB 的显存。可以增加一张显卡,将显存提升到 256 或者 512 MB,这样一来,处理器密集型的游戏就会顺畅很多了。如果不确定你的电脑有多少显存,可以参考[这里][17]。请注意,需要确保显卡与电脑的[显卡插槽][18](AGP、PCI-Express 或者 PCI)相匹配,同时使用正确的[连接线][19](VGA、DVI 或者 HDMI)。
|
||||
|
||||
#### 与 Windows 系统的兼容性如何?
|
||||
|
||||
许多人关心 Linux 与 Windows 系统的兼容性如何。首先,对于任何一个 Windows 程序,都有一个 [Linux 版本的替代品][20]。
|
||||
|
||||
退一步说,即使你真的必须要运行某个特定的 Windows 程序,通常也可以借助 [Wine][21] 在 Linux 上运行。可以在 [Wine 数据库][22] 里查找一下你的应用,看看是否可以在 Wine 上运行,顺便学一些特殊安装技巧。[Winetricks][23] 和 [PlayOnLinux][24] 这两个辅助工具可以帮助你进行安装和配置。
|
||||
|
||||
Wine 的另一个优势是可以运行旧版本 Windows(例如 Vista、XP、ME/98/95 和 3.1)上的程序。我认识一个家伙,搭建了一台特别赞的游戏电脑,然后用来玩 XP 上的老游戏。借助 [DOSBox][26],你甚至还可以运行数以千计的[免费 DOS 程序][25]。但是有一点需要注意,如果 Windows 程序可以运行,那么 Windows [病毒][27]也同样可以。你需要保护 Linux 上的 Wine 环境,正如保护任何其他 Windows 环境一样。
|
||||
|
||||
对了,与 Microsoft Office 的兼容性又如何呢?我使用的是 LibreOffice,经常编辑并交换 Word 和 Excel 文件,完全没有问题。不过,你应该避免使用隐晦或者过于专业的功能。
|
||||
|
||||
### 如何选择发行版?
|
||||
|
||||
假设选择了 Linux 作为操作系统,那么你还需要选择桌面环境、浏览器和各种应用。最简单的方法是,安装一个包含了你所需要的一切的发行版。
|
||||
|
||||
通过从 [live USB][28] U 盘或者 DVD 启动,你无需安装任何程序,就可以尝试不同的发行版。关于在 Linux 或 Windows 上创建可启动的 Linux 的方法,可以参考[这里][29]。
|
||||
|
||||
我进行电脑翻新的目的是做慈善,所以无法指望电脑使用者具备任何相应知识。我需要的发行版应该具有以下特性:
|
||||
|
||||
* 用户友好
|
||||
* 具有轻量级界面
|
||||
* 自带各种轻量级应用
|
||||
* 拥有足够大的软件仓库
|
||||
* 历史表现良好
|
||||
* 拥有庞大的用户社区和活跃的论坛
|
||||
* 通过长期维护版本(而不是滚动发布版本)确保稳定性
|
||||
* 更重视可靠性,而不是尖端功能
|
||||
* 可以通过图形化用户界面进行设置,而不是只能通过文本文件进行设置
|
||||
|
||||
许多发行版都能够满足上面的要求。我曾经尝试成功的有 [Mint/Xfce][30]、[Xubuntu][31] 和 [Lubuntu][32]。前两个发行版使用 Xfce 桌面环境,第三个使用 LXQt。相比 GNOME、Unity、KDE、MATE 和 Cinnamon 这些桌面环境,运行上面这两种桌面环境只需要[更少][33]的处理器和内存资源。
|
||||
|
||||
Xfce 和 LXQt 用起来非常简单,我的客户们之前从未见过 Linux,但是都可以自如使用这些简单的、菜单驱动的用户界面。
|
||||
|
||||
对于旧电脑来说,运行最快速、最高效的浏览器是一件非常重要的事情。[很多人觉得][34] Chromium 是最好的浏览器;此外,我还安装了 Firefox Quantum,因为大家比较熟悉它,并且[它的性能][35]可以和 [Chromium 的性能][36]媲美。我还加上了 Opera,因为它速度快,而且有一些独特功能,比如内置的广告拦截,以及免费的[虚拟专用网络][37]。Opera 是免费的,但并非开源。
|
||||
|
||||
无论你使用什么浏览器,一定要拦截广告和追踪器,尽量降低浏览器的负荷。此外,除非得到你的明确批准,否则视频和 Flash 都不应该被允许运行。
|
||||
|
||||
至于应用,我使用的是 Mint/Xfce、Xubuntu 和 Lubuntu 自带的轻量级应用。它们足以满足一切需求了。
|
||||
|
||||
### 行动起来吧
|
||||
|
||||
你是否会对翻新后的电脑感到满意呢?就我来说,我所使用的两台电脑的机龄都已经超过十年了,其中一个装载的是 Intel 双核处理器([eMachines T5274a][38]),另一个装载的是 AMD 速龙 64 x2 处理器([HP dc5750][39]),两台电脑都有 2 GB 内存。它们和我的另一台具备四核 i5 处理器和 16 GB 内存的电脑一样,完全能够胜任我的办公工作。如果说有什么功能是这两台电脑缺失的,那就是运行虚拟机了。
|
||||
|
||||
我们生活在一个非常神奇的年代。只需要付出一点努力,就可以将一台机龄在 5 到 12 年之间的旧电脑,翻新为一台具备实用价值的机器。还有什么比这更有趣吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/how-make-old-computer-useful-again
|
||||
|
||||
作者:[Howard Fosdick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/howtech
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/1980s-computer-yearbook.png?itok=eGOYEKK- (Person typing on a 1980's computer)
|
||||
[2]: https://www.amazon.com/s/ref=nb_sb_noss_1?url=search-alias%3Daps&field-keywords=compressed+air+for+computers&rh=i%3Aaps%2Ck%3Acompressed+air+for+computers
|
||||
[3]: https://www.wikihow.com/Ground-Yourself-to-Avoid-Destroying-a-Computer-with-Electrostatic-Discharge
|
||||
[4]: https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface
|
||||
[5]: http://en.wikipedia.org/wiki/BIOS
|
||||
[6]: http://www.disk-image.com/faq-bootmenu.htm
|
||||
[7]: http://www.hirensbootcd.org/download/
|
||||
[8]: http://www.ultimatebootcd.com/
|
||||
[9]: http://www.rexxinfo.org/Quick_Guide/Quick_Guide_To_Fixing_Computer_Hardware
|
||||
[10]: http://www.cpubenchmark.net/
|
||||
[11]: https://askleo.com/unsupported-software-really-mean/
|
||||
[12]: http://home.bt.com/tech-gadgets/computing/windows-7/windows-7-support-end-11364081315419
|
||||
[13]: https://fossbytes.com/best-lightweight-linux-distros/
|
||||
[14]: http://en.wikipedia.org/wiki/Desktop_environment
|
||||
[15]: https://en.wikipedia.org/wiki/Intel_Core_2
|
||||
[16]: https://en.wikipedia.org/wiki/Athlon_64_X2
|
||||
[17]: http://www.cyberciti.biz/faq/howto-find-linux-vga-video-card-ram/
|
||||
[18]: https://www.onlinecomputertips.com/support-categories/hardware/493-pci-vs-agp-vs-pci-express-video-cards/
|
||||
[19]: https://silentpc.com/articles/video-connectors
|
||||
[20]: http://wiki.linuxquestions.org/wiki/Linux_software_equivalent_to_Windows_software
|
||||
[21]: https://en.wikipedia.org/wiki/Wine_%28software%29
|
||||
[22]: https://appdb.winehq.org/
|
||||
[23]: https://en.wikipedia.org/wiki/Winetricks
|
||||
[24]: https://en.wikipedia.org/wiki/PlayOnLinux
|
||||
[25]: https://archive.org/details/softwarelibrary_msdos
|
||||
[26]: https://en.wikipedia.org/wiki/DOSBox
|
||||
[27]: https://wiki.winehq.org/FAQ#Is_Wine_malware-compatible.3F
|
||||
[28]: https://www.howtogeek.com/howto/linux/create-a-bootable-ubuntu-usb-flash-drive-the-easy-way/
|
||||
[29]: https://unetbootin.github.io/
|
||||
[30]: https://linuxmint.com/
|
||||
[31]: https://xubuntu.org/
|
||||
[32]: https://lubuntu.me/
|
||||
[33]: https://www.makeuseof.com/tag/best-lean-linux-desktop-environment-lxde-vs-xfce-vs-mate/
|
||||
[34]: https://www.zdnet.com/article/chrome-is-the-most-popular-web-browser-of-all/
|
||||
[35]: https://www.laptopmag.com/articles/firefox-quantum-vs-chrome
|
||||
[36]: https://www.zdnet.com/article/just-how-fast-is-firefox-quantum/
|
||||
[37]: http://en.wikipedia.org/wiki/Virtual_private_network
|
||||
[38]: https://www.cnet.com/products/emachines-t5274/specs/
|
||||
[39]: https://community.spiceworks.com/products/7727-hewlett-packard-dc5750-microtower
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11752-1.html)
|
||||
[#]: subject: (An advanced look at Python interfaces using zope.interface)
|
||||
[#]: via: (https://opensource.com/article/19/9/zopeinterface-python-package)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshezhttps://opensource.com/users/lauren-pritchetthttps://opensource.com/users/sethhttps://opensource.com/users/drmjg)
|
||||
|
||||
借助 zope.interface 深入了解 Python 接口
|
||||
======
|
||||
|
||||
> Zope.interface 可以帮助声明存在哪些接口,是由哪些对象提供的,以及如何查询这些信息。
|
||||
|
||||
![Snake charmer cartoon with a yellow snake and a blue snake][1]
|
||||
|
||||
`zope.interface` 库可以克服 Python 接口设计中的歧义性。让我们来研究一下。
|
||||
|
||||
### 隐式接口不是 Python 之禅
|
||||
|
||||
[Python 之禅][2] 很宽松,但是有点自相矛盾,以至于你可以用它来例证任何东西。让我们来思考其中最著名的原则之一:“显示胜于隐式”。
|
||||
|
||||
传统上,在 Python 中会隐含的一件事是预期的接口。比如函数已经记录了它期望一个“类文件对象”或“序列”。但是什么是类文件对象呢?它支持 `.writelines`吗?`.seek` 呢?什么是一个“序列”?是否支持步进切片,例如 `a[1:10:2]`?
|
||||
|
||||
最初,Python 的答案是所谓的“鸭子类型”,取自短语“如果它像鸭子一样行走,像鸭子一样嘎嘎叫,那么它可能就是鸭子”。换句话说,“试试看”,这可能是你能得到的最具隐式的表达。
|
||||
|
||||
为了使这些内容显式地表达出来,你需要一种方法来表达期望的接口。[Zope][3] Web 框架是最早用 Python 编写的大型系统之一,它迫切需要这些东西来使代码明确呈现出来,例如,期望从“类似用户的对象”获得什么。
|
||||
|
||||
`zope.interface` 由 Zope 开发,但作为单独的 Python 包发布。`Zope.interface` 可以帮助声明存在哪些接口,是由哪些对象提供的,以及如何查询这些信息。
|
||||
|
||||
想象编写一个简单的 2D 游戏,它需要各种东西来支持精灵界面(LCTT 译注:“<ruby>精灵<rt> Sprite</rt></ruby>”是指游戏面板中各个组件)。例如,表示一个边界框,但也要表示对象何时与一个框相交。与一些其他语言不同,在 Python 中,将属性访问作为公共接口一部分是一种常见的做法,而不是实现 getter 和 setter。边界框应该是一个属性,而不是一个方法。
|
||||
|
||||
呈现精灵列表的方法可能类似于:
|
||||
|
||||
```
|
||||
def render_sprites(render_surface, sprites):
|
||||
"""
|
||||
sprites 应该是符合 Sprite 接口的对象列表:
|
||||
* 一个名为 "bounding_box" 的属性,包含了边界框
|
||||
* 一个名为 "intersects" 的方法,它接受一个边界框并返回 True 或 False
|
||||
"""
|
||||
pass # 一些做实际渲染的代码
|
||||
```
|
||||
|
||||
该游戏将具有许多处理精灵的函数。在每个函数中,你都必须在随附文档中指定预期。
|
||||
|
||||
此外,某些函数可能期望使用更复杂的精灵对象,例如具有 Z 序的对象。我们必须跟踪哪些方法需要 Sprite 对象,哪些方法需要 SpriteWithZ 对象。
|
||||
|
||||
如果能够使精灵是显式而直观的,这样方法就可以声明“我需要一个精灵”,并有个严格定义的接口,这不是很好吗?来看看 `zope.interface`。
|
||||
|
||||
```
|
||||
from zope import interface
|
||||
|
||||
class ISprite(interface.Interface):
|
||||
|
||||
bounding_box = interface.Attribute(
|
||||
"边界框"
|
||||
)
|
||||
|
||||
def intersects(box):
|
||||
"它和一个框相交吗?"
|
||||
```
|
||||
|
||||
乍看起来,这段代码有点奇怪。这些方法不包括 `self`,而包含 `self` 是一种常见的做法,并且它有一个**属性**。这是在 `zope.interface` 中声明接口的方法。这看起来很奇怪,因为大多数人不习惯严格声明接口。
|
||||
|
||||
这样做的原因是接口显示了如何调用方法,而不是如何定义方法。因为接口不是超类,所以它们可以用来声明数据属性。
|
||||
|
||||
下面是一个能带有圆形精灵的接口的一个实现:
|
||||
|
||||
```
|
||||
@implementer(ISprite)
|
||||
@attr.s(auto_attribs=True)
|
||||
class CircleSprite:
|
||||
x: float
|
||||
y: float
|
||||
radius: float
|
||||
|
||||
@property
|
||||
def bounding_box(self):
|
||||
return (
|
||||
self.x - self.radius,
|
||||
self.y - self.radius,
|
||||
self.x + self.radius,
|
||||
self.y + self.radius,
|
||||
)
|
||||
|
||||
def intersects(self, box):
|
||||
# 当且仅当至少一个角在圆内时,方框与圆相交
|
||||
top_left, bottom_right = box[:2], box[2:]
|
||||
for choose_x_from (top_left, bottom_right):
|
||||
for choose_y_from (top_left, bottom_right):
|
||||
x = choose_x_from[0]
|
||||
y = choose_y_from[1]
|
||||
if (((x - self.x) ` 2 + (y - self.y) ` 2) <=
|
||||
self.radius ` 2):
|
||||
return True
|
||||
return False
|
||||
```
|
||||
|
||||
这**显式**声明了实现了该接口的 `CircleSprite` 类。它甚至能让我们验证该类是否正确实现了接口:
|
||||
|
||||
```
|
||||
from zope.interface import verify
|
||||
|
||||
def test_implementation():
|
||||
sprite = CircleSprite(x=0, y=0, radius=1)
|
||||
verify.verifyObject(ISprite, sprite)
|
||||
```
|
||||
|
||||
这可以由 pytest、nose 或其他测试框架运行,它将验证创建的精灵是否符合接口。测试通常是局部的:它不会测试仅在文档中提及的内容,甚至不会测试方法是否可以在没有异常的情况下被调用!但是,它会检查是否存在正确的方法和属性。这是对单元测试套件一个很好的补充,至少可以防止简单的拼写错误通过测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/9/zopeinterface-python-package
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshezhttps://opensource.com/users/lauren-pritchetthttps://opensource.com/users/sethhttps://opensource.com/users/drmjg
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/getting_started_with_python.png?itok=MFEKm3gl (Snake charmer cartoon with a yellow snake and a blue snake)
|
||||
[2]: https://en.wikipedia.org/wiki/Zen_of_Python
|
||||
[3]: http://zope.org
|
||||
@ -0,0 +1,107 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11822-1.html)
|
||||
[#]: subject: (How the Linux screen tool can save your tasks – and your sanity – if SSH is interrupted)
|
||||
[#]: via: (https://www.networkworld.com/article/3441777/how-the-linux-screen-tool-can-save-your-tasks-and-your-sanity-if-ssh-is-interrupted.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如果 SSH 被中断,Linux screen 工具如何拯救你的任务以及理智
|
||||
======
|
||||
|
||||
> 当你需要确保长时间运行的任务不会在 SSH 会话中断时被杀死时,Linux screen 命令可以成为救生员。以下是使用方法。
|
||||
|
||||

|
||||
|
||||
如果因 SSH 会话断开而不得不重启一个耗时的进程,那么你可能会很高兴了解一个有趣的工具,可以用来避免此问题:`screen` 工具。
|
||||
|
||||
`screen` 是一个终端多路复用器,它使你可以在单个 SSH 会话中运行多个终端会话,并随时从它们之中脱离或重新接驳。做到这一点的过程非常简单,仅涉及少数命令。
|
||||
|
||||
要启动 `screen` 会话,只需在 SSH 会话中键入 `screen`。 然后,你可以开始启动需要长时间运行的进程,并在适当的时候键入 `Ctrl + A Ctrl + D` 从会话中脱离,然后键入 `screen -r` 重新接驳。
|
||||
|
||||
如果你要运行多个 `screen` 会话,更好的选择是为每个会话指定一个有意义的名称,以帮助你记住正在处理的任务。使用这种方法,你可以在启动每个会话时使用如下命令命名:
|
||||
|
||||
```
|
||||
$ screen -S slow-build
|
||||
```
|
||||
|
||||
一旦运行了多个会话,要重新接驳到一个会话,需要从列表中选择它。在以下命令中,我们列出了当前正在运行的会话,然后再重新接驳其中一个。请注意,一开始这两个会话都被标记为已脱离。
|
||||
|
||||
```
|
||||
$ screen -ls
|
||||
There are screens on:
|
||||
6617.check-backups (09/26/2019 04:35:30 PM) (Detached)
|
||||
1946.slow-build (09/26/2019 02:51:50 PM) (Detached)
|
||||
2 Sockets in /run/screen/S-shs
|
||||
```
|
||||
|
||||
然后,重新接驳到该会话要求你提供分配给会话的名称。例如:
|
||||
|
||||
```
|
||||
$ screen -r slow-build
|
||||
```
|
||||
|
||||
在脱离的会话中,保持运行状态的进程会继续进行处理,而你可以执行其他工作。如果你使用这些 `screen` 会话之一来查询 `screen` 会话情况,可以看到当前重新接驳的会话再次显示为 `Attached`。
|
||||
|
||||
```
|
||||
$ screen -ls
|
||||
There are screens on:
|
||||
6617.check-backups (09/26/2019 04:35:30 PM) (Attached)
|
||||
1946.slow-build (09/26/2019 02:51:50 PM) (Detached)
|
||||
2 Sockets in /run/screen/S-shs.
|
||||
```
|
||||
|
||||
你可以使用 `-version` 选项查询正在运行的 `screen` 版本。
|
||||
|
||||
```
|
||||
$ screen -version
|
||||
Screen version 4.06.02 (GNU) 23-Oct-17
|
||||
```
|
||||
|
||||
### 安装 screen
|
||||
|
||||
如果 `which screen` 未在屏幕上提供信息,则可能你的系统上未安装该工具。
|
||||
|
||||
```
|
||||
$ which screen
|
||||
/usr/bin/screen
|
||||
```
|
||||
|
||||
如果你需要安装它,则以下命令之一可能适合你的系统:
|
||||
|
||||
```
|
||||
sudo apt install screen
|
||||
sudo yum install screen
|
||||
```
|
||||
|
||||
当你需要运行耗时的进程时,如果你的 SSH 会话由于某种原因断开连接,则可能会中断这个耗时的进程,那么 `screen` 工具就会派上用场。而且,如你所见,它非常易于使用和管理。
|
||||
|
||||
以下是上面使用的命令的摘要:
|
||||
|
||||
```
|
||||
screen -S <process description> 开始会话
|
||||
Ctrl+A Ctrl+D 从会话中脱离
|
||||
screen -ls 列出会话
|
||||
screen -r <process description> 重新接驳会话
|
||||
```
|
||||
|
||||
尽管还有更多关于 `screen` 的知识,包括可以在 `screen` 会话之间进行操作的其他方式,但这已经足够帮助你开始使用这个便捷的工具了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3441777/how-the-linux-screen-tool-can-save-your-tasks-and-your-sanity-if-ssh-is-interrupted.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
61
published/202001/20191015 How GNOME uses Git.md
Normal file
61
published/202001/20191015 How GNOME uses Git.md
Normal file
@ -0,0 +1,61 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11806-1.html)
|
||||
[#]: subject: (How GNOME uses Git)
|
||||
[#]: via: (https://opensource.com/article/19/10/how-gnome-uses-git)
|
||||
[#]: author: (Molly de Blanc https://opensource.com/users/mollydb)
|
||||
|
||||
一个非技术人员对 GNOME 项目使用 GitLab 的感受
|
||||
======
|
||||
|
||||
> 将 GNOME 项目集中在 GitLab 上的决定为整个社区(不只是开发人员)带来了好处。
|
||||
|
||||
![red panda][1]
|
||||
|
||||
“您的 GitLab 是什么?”这是我在 [GNOME 基金会][2]工作的第一天被问到的第一个问题之一,该基金会是支持 GNOME 项目(包括[桌面环境][3]、[GTK][4] 和 [GStreamer][5])的非盈利组织。此人问的是我在 [GNOME 的 GitLab 实例][6]上的用户名。我在 GNOME 期间,经常有人要求我提供我的 GitLab。
|
||||
|
||||
我们使用 GitLab 进行几乎所有操作。通常情况下,我会收到一些<ruby>提案<rt>issue</rt></ruby>和参考错误报告,有时还需要修改文件。我不是以开发人员或系统管理员的身份进行此操作的。我参与了“参与度、包容性和多样性(I&D)”团队。我为 GNOME 朋友们撰写新闻通讯,并采访该项目的贡献者。我为 GNOME 活动提供赞助。我不写代码,但我每天都使用 GitLab。
|
||||
|
||||
在过去的二十年中,GNOME 项目的管理采用了各种方式。该项目的不同部分使用不同的系统来跟踪代码更改、协作以及作为项目和社交空间共享信息。但是,该项目决定,它需要更加地一体化,这从构思到完成大约花费了一年的时间。
|
||||
|
||||
GNOME 希望切换到单个工具供整个社区使用的原因很多。外部项目与 GNOME 息息相关,并为它们提供更简单的与资源交互的方式对于项目至关重要,无论是支持社区还是发展生态系统。我们还希望更好地跟踪 GNOME 的指标,即贡献者的数量、贡献的类型和数量以及项目不同部分的开发进度。
|
||||
|
||||
当需要选择一种协作工具时,我们考虑了我们需要的东西。最重要的要求之一是它必须由 GNOME 社区托管。由第三方托管并不是一种选择,因此像 GitHub 和 Atlassian 这样的服务就不在考虑之中。而且,当然了,它必须是自由软件。很快,唯一真正的竞争者出现了,它就是 GitLab。我们希望确保进行贡献很容易。GitLab 具有诸如单点登录的功能,该功能允许人们使用 GitHub、Google、GitLab.com 和 GNOME 帐户登录。
|
||||
|
||||
我们认为 GitLab 是一条出路,我们开始从许多工具迁移到单个工具。GNOME 董事会成员 [Carlos Soriano][7] 领导这项改变。在 GitLab 和 GNOME 社区的大力支持下,我们于 2018 年 5 月完成了该过程。
|
||||
|
||||
人们非常希望迁移到 GitLab 有助于社区的发展,并使贡献更加容易。由于 GNOME 以前使用了许多不同的工具,包括 Bugzilla 和 CGit,因此很难定量地评估这次切换对贡献量的影响。但是,我们可以更清楚地跟踪一些统计数据,例如在 2018 年 6 月至 2018 年 11 月之间关闭了近 10,000 个提案,合并了 7,085 个合并请求。人们感到社区在发展壮大,越来越受欢迎,而且贡献实际上也更加容易。
|
||||
|
||||
人们因不同的原因而开始使用自由软件,重要的是,可以通过为需要软件的人提供更好的资源和更多的支持来公平竞争。Git 作为一种工具已被广泛使用,并且越来越多的人使用这些技能来参与到自由软件当中。自托管的 GitLab 提供了将 Git 的熟悉度与 GitLab 提供的功能丰富、用户友好的环境相结合的绝佳机会。
|
||||
|
||||
切换到 GitLab 已经一年多了,变化确实很明显。持续集成(CI)为开发带来了巨大的好处,并且已经完全集成到 GNOME 的几乎每个部分当中。不进行代码开发的团队也转而使用 GitLab 生态系统进行工作。无论是使用问题跟踪来管理分配的任务,还是使用版本控制来共享和管理资产,就连“参与度、包容性和多样性(I&D)”这样的团队都已经使用了 GitLab。
|
||||
|
||||
一个社区,即使是一个正在开发的自由软件,也很难适应新技术或新工具。在类似 GNOME 的情况下,这尤其困难,该项目[最近已经 22 岁了] [8]。像 GNOME 这样经过了 20 多年建设的项目,太多的人和组织使用了太多的部件,但迁移工作之所以能实现,这要归功于 GNOME 社区的辛勤工作和 GitLab 的慷慨帮助。
|
||||
|
||||
在为使用 Git 进行版本控制的项目工作时,我发现很方便。这是一个令人感觉舒适和熟悉的系统,是一个在工作场所和爱好项目之间保持一致的工具。作为 GNOME 社区的新成员,能够参与并使用 GitLab 真是太好了。作为社区建设者,看到这样结果是令人鼓舞的:越来越多的相关项目加入并进入生态系统;新的贡献者和社区成员对该项目做出了首次贡献;以及增强了衡量我们正在做的工作以了解其成功和成功的能力。
|
||||
|
||||
如此多的做着完全不同的事情(例如他们正在从事的不同工作以及所使用的不同技能)的团队同意汇集在一个工具上(尤其是被认为是跨开源的标准工具),这一点很棒。作为 GNOME 的贡献者,我真的非常感谢我们使用了 GitLab。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/how-gnome-uses-git
|
||||
|
||||
作者:[Molly de Blanc][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mollydb
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/redpanda_firefox_pet_animal.jpg?itok=aSpKsyna (red panda)
|
||||
[2]: https://www.gnome.org/foundation/
|
||||
[3]: https://gnome.org/
|
||||
[4]: https://www.gtk.org/
|
||||
[5]: https://gstreamer.freedesktop.org/
|
||||
[6]: https://gitlab.gnome.org/
|
||||
[7]: https://twitter.com/csoriano1618?lang=en
|
||||
[8]: https://opensource.com/article/19/8/poll-favorite-gnome-version
|
||||
@ -0,0 +1,137 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11774-1.html)
|
||||
[#]: subject: (Open source interior design with Sweet Home 3D)
|
||||
[#]: via: (https://opensource.com/article/19/10/interior-design-sweet-home-3d)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Sweet Home 3D 开放源码室内设计
|
||||
======
|
||||
|
||||
> 在你去真实世界购物前,在虚拟世界中尝试家具布局、配色方案等等。
|
||||
|
||||

|
||||
|
||||
这里有关于如何装饰房间的三大流派:
|
||||
|
||||
1. 购买一堆家具,并把它们塞进房间。
|
||||
2. 仔细测量每件家具,计算房间的理论容量,然后把它们全部塞进房间,忽略你在床上放置一个书架的事实。
|
||||
3. 使用一台计算机进行预先可视化。
|
||||
|
||||
之前,我还实践了鲜为人知的第四个方式:不要家具。然而,自从我成为一个远程工作者,我发现家庭办公需要一些便利的设施,像一张桌子和一张椅子,一个用于存放参考书和技术手册的书架等等。因此,我一直在制定一个使用实际的家具来迁移我的生活和工作空间的计划,在该*计划*上强调由实木制作,而不是牛奶箱子(或胶水和锯末板之类的东西)。我最不想做的一件事:从旧货市场淘到得宝贝带回家时,发现其进不了门,或者比另一件家具大很多。
|
||||
|
||||
是时候做专业人士该做的事了,是时候做视觉预览了。
|
||||
|
||||
### 开放源码室内设计
|
||||
|
||||
[Sweet Home 3D][2] 是一个开源的(GPLv2)室内设计应用程序,可以帮助你绘制你的住宅平面图,然后定义、重新调整大小以及安排家具。你可以使用精确的尺寸来完成这些,精确到一厘米以下,而不使用任何数学运算,仅使用简单的拖拽操作就行。当你完成后,你可以以 3D 方式查看结果。在 Sweet Home 3D 中规划你家的室内设计,就和在 Word 程序中创建基本的表格一样简单。
|
||||
|
||||
### 安装
|
||||
|
||||
Sweet Home 3D 是一个 [Java][3] 应用程序,因此它是平台通用的。它运行在任何可以运行 Java 的操作系统上,包括 Linux、Windows、MacOS 和 BSD 。不用理会你的操作系统,你可以从网站[下载][4]该应用程序。
|
||||
|
||||
* 在 Linux 上,[untar][5] 存档文件。在 `SweetHome3D` 文件上右键单击,并选择**属性**。在**权限**选项卡中,授予文件可执行权限。
|
||||
* 在 MacOS 和 Windows 上,展开存档文件并启动应用程序。当系统提示时,你必需授予它权限来在你的系统上运行。
|
||||
|
||||
![Sweet Home 3D permissions][6]
|
||||
|
||||
在 Linux 上,你也可以像一个 Snap 软件包一样安装 Sweet Home 3D ,前提是你已经安装并启用 **snapd**。
|
||||
|
||||
### 成功的测量
|
||||
|
||||
首先:打开你的卷尺。为充分利用 Sweet Home 3D,你必须知道你所计划的生活空间的实际尺寸。你可能需要测量精度到毫米或 1/16 英寸;你可以自己把握对偏差幅度的容忍度。但是你必需获得基本的尺寸,包括测量墙壁和门窗。
|
||||
|
||||
用你最好的判断力来判断常识。例如,当测量门时,包括门框;虽然从技术上讲它不是*门*本身的一部分,但它可能是你不想用家具遮挡的一部分墙壁空间。
|
||||
|
||||
![Measure twice, execute once][7]
|
||||
|
||||
### 创建一间房间
|
||||
|
||||
当你第一次启动 Sweet Home 3D 时,它会以其默认查看模式来打开一个空白的画布,蓝图视图在顶部面板中,3D 渲染在底部面板中。在我的 [Slackware][8] 桌面计算机上,它可以很好地工作,不过我的桌面计算机也是我的视频编辑和游戏计算机,所以它有一个极好的 3D 渲染显卡。在我的笔记本计算机上,这种视图模式是非常慢的。为了最好的性能(尤其是在一台计没有 3D 渲染的专用计算机上),转到窗口顶部的 **3D 视图** 菜单,并选择 **虚拟访问** 。这个视图模式基于虚拟访客的位置从地面视图渲染你的工作。这意味着你可以控制渲染的内容和时机。
|
||||
|
||||
不管你计算机是否强力,切换到这个视图的有意义的,因为地表以上的 3D 渲染不比蓝图平面图向你提供更多有用的详细信息。在你更改视图模式后,你可以开始设计。
|
||||
|
||||
第一步是定义你家的墙壁。使用**创建墙壁**工具完成,可以在顶部工具栏的**手形**图标右侧找到。绘制墙壁很简单:单击你想要墙壁开始的位置,单击以锚定位置,不断单击锚定,直到你的房间完成。
|
||||
|
||||
![Drawing walls in Sweet Home 3D][9]
|
||||
|
||||
在你闭合墙壁后,按 `Esc` 来退出工具。
|
||||
|
||||
#### 定义一间房间
|
||||
|
||||
Sweet Home 3D 在你如何创建墙壁的问题上是灵活的。你可以先绘制你房子的外部边界,然后再细分内部,或者你可以绘制每个房间作为结成一体的“容器”,最终形成你房子所占的空间量。这种灵活性是能做到的,因为在现实生活中和在 Sweet Home 3D 中,墙壁并不总是用来定义一间房间。为定义一间房间,使用在顶部工具栏的**创建墙壁**按钮右侧的**创建房间**按钮。
|
||||
|
||||
如果房间的地板空间是通过四面墙所定义,你需要做的全部的定义是像一间房间一样在四面墙壁内双击来圈占地方。Sweet Home 3D 将定义该空间为一间房间,并根据你的喜好,以英尺或米为单位向你提供房间的面积。
|
||||
|
||||
对于不规则的房间,你必需使用每次单击来手动定义房间的每个墙角。根据房间形状的复杂性,你可能不得不进行试验来发现你是否需要从你的原点来顺时针或逆时针工作,以避免奇怪的莫比斯条形地板。不过,一般来说,定义一间房间的地板空间是简单的。
|
||||
|
||||
![Defining rooms in Sweet Home 3D][10]
|
||||
|
||||
在你给定房间一层地板后,你可以更改到**箭头**工具,并在房间上双击来给予它一个名称。你也可以设置地板、墙壁、天花板和踢脚线的颜色及纹理。
|
||||
|
||||
![Modifying room floors, ceilings, etc. in Sweet Home 3D][11]
|
||||
|
||||
默认情况下,这些都不会在蓝图视图中渲染。为启用在你蓝图面板中的房间渲染,转到**文件**菜单并选择**首选项**。在**首选项**面板中,设置**平面图中房间渲染**为**地板颜色或纹理**。
|
||||
|
||||
### 门和窗
|
||||
|
||||
在你完成基本的地板平面图后,你可以长期地切换到**箭头**工具。
|
||||
|
||||
你可以在 Sweet Home 3D 的左栏中的**门和窗**类别下找到门和窗。你有很多选择,所以选择最接近你家的东西。
|
||||
|
||||
![Moving a door in Sweet Home 3D][12]
|
||||
|
||||
为放置一扇门或窗到你的平面图中,在你的蓝图平面图中的合适的墙壁上拖拽门或窗。要调整它的位置和大小,请双击门或窗。
|
||||
|
||||
### 添加家具
|
||||
|
||||
随着基本平面图完成,这部分工作感觉像是结束了!从这点继续,你可以摆弄家具布置以及其它装饰。
|
||||
|
||||
你可以在左栏中找到家具,按预期的方式来组织每个房间。你可以拖拽任何项目到你的蓝图平面图中,当你的鼠标悬停在项目的区域上时,使用可视化工具控制方向和大小。在任何项目上双击双击来调整它的颜色和成品表面。
|
||||
|
||||
### 查看和导出
|
||||
|
||||
为了看看你未来的家将会看起来是什么样子,在你的蓝图视图中拖拽“人”图标到一个房间中。
|
||||
|
||||
![Sweet Home 3D rendering][13]
|
||||
|
||||
你可以在现实和空间感受之间找到自己的平衡,你的想象力是你唯一的限制。你可以从 Sweet Home 3D [下载页面][4]获取附加的有用的资源来添加到你的家中。你甚至可以使用**库编辑器**应用程序创建你自己的家具和纹理,它可以从该项目的网站下载。
|
||||
|
||||
Sweet Home 3D 可以导出你的蓝图平面图为 SVG 格式,以便在 [Inkscape][14] 中使用,并且它可以导出你的 3D 模型为 OBJ 格式,以便在 [Blender][15] 中使用。为导出你的蓝图,转到**平面图**菜单,并选择**导出为 SVG 格式**。为导出一个 3D 模型,转到 **3D 视图** 菜单并选择**导出为 OBJ 格式**。
|
||||
|
||||
你也可以拍摄你家的"快照,以便于不打开 Sweet Home 3D 而回顾你的想法。为创建一个快照,转到 **3D 视图**菜单并选择**创建照片**。快照是按照蓝图视图中的人的图标的角度展现的,因此按照需要调整,然后在**创建照片**窗口中单击**创建**按钮。如果你对快照满意,单击**保存**。
|
||||
|
||||
### 甜蜜的家
|
||||
|
||||
在 Sweet Home 3D 中有更多的特色。你可以添加一片天空和一片草坪,为你的照片定位光线,设置天花板高度,给你房子添加另一楼层等等。不管你是打算租一套公寓,还是买一套房子,或是(尚)不存在的房子,Sweet Home 3D 是一款简单迷人的应用程序,当你匆忙购买家具时,它可以帮助你快乐地做出更好的购买选择。因此,你终于可以停止在厨房的柜台上吃早餐以及蹲在地上工作了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/interior-design-sweet-home-3d
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LIFE_housing.png?itok=s7i6pQL1 (Several houses)
|
||||
[2]: http://www.sweethome3d.com/
|
||||
[3]: https://opensource.com/resources/java
|
||||
[4]: http://www.sweethome3d.com/download.jsp
|
||||
[5]: https://opensource.com/article/17/7/how-unzip-targz-file
|
||||
[6]: https://opensource.com/sites/default/files/uploads/sweethome3d-permissions.png (Sweet Home 3D permissions)
|
||||
[7]: https://opensource.com/sites/default/files/images/life/sweethome3d-measure.jpg (Measure twice, execute once)
|
||||
[8]: http://www.slackware.com/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/sweethome3d-walls.jpg (Drawing walls in Sweet Home 3D)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/sweethome3d-rooms.jpg (Defining rooms in Sweet Home 3D)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/sweethome3d-rooms-modify.jpg (Modifying room floors, ceilings, etc. in Sweet Home 3D)
|
||||
[12]: https://opensource.com/sites/default/files/uploads/sweethome3d-move.jpg (Moving a door in Sweet Home 3D)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/sweethome3d-view.jpg (Sweet Home 3D rendering)
|
||||
[14]: http://inkscape.org
|
||||
[15]: http://blender.org
|
||||
204
published/202001/20191017 Intro to the Linux useradd command.md
Normal file
204
published/202001/20191017 Intro to the Linux useradd command.md
Normal file
@ -0,0 +1,204 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11756-1.html)
|
||||
[#]: subject: (Intro to the Linux useradd command)
|
||||
[#]: via: (https://opensource.com/article/19/10/linux-useradd-command)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
Linux useradd 命令介绍
|
||||
======
|
||||
|
||||
> 使用 useradd 命令来添加用户(并且根据需要修改账号)。
|
||||
|
||||

|
||||
|
||||
任何计算机系统中,添加用户都是最重要的事之一;本文着重介绍如何在 Linux 系统中添加用户。
|
||||
|
||||
正式开始之前,我先提三个概念。首先,跟大多数操作系统一样,Linux 用户也需要一个账号才能登录。本文只介绍本地账号,不涉及网络账号,如 LDAP。其次,每个账号都有一个名字(username)和一个对应的数字(用户 ID)。最后,每个用户通常都在一个组内,每个组都有一个名字和一个组 ID。
|
||||
|
||||
你可能已经想到了,Linux 提供了添加用户的命令行工具,就是 `useradd` 命令。有些版本也叫 `adduser`。为了方便使用,很多发行版上这个命令是一个指向 `useradd` 命令的符号链接。
|
||||
|
||||
```
|
||||
$ file `which adduser`
|
||||
/usr/sbin/adduser: symbolic link to useradd
|
||||
```
|
||||
|
||||
来看一下 `useradd`。
|
||||
|
||||
> 注意:本文描述的默认环境是 Red Hat Enterprise Linux 8.0。你可能会发现本文描述的这些文件和某些默认值与某些 Linux 发行版或其他 Unix 操作系统(FreeBSD 或 Solaris)偶尔会有差异。
|
||||
|
||||
### 默认处理
|
||||
|
||||
`useradd` 的基本用法相当简单:提供一个用户名就可以添加一个用户。
|
||||
|
||||
```bash
|
||||
$ sudo useradd sonny
|
||||
```
|
||||
|
||||
在本例中,`useradd` 命令创建了一个名为 `sonny` 的账号。此命令同时创建了一个同名的组,`sonny` 被放进了这个组,这个组也是 `sonny` 账号的主组。命令执行时,根据配置文件 `/etc/default/useradd` 和 `/etc/login.defs` 中的不同设置,也会有其他的参数,如语言和 shell。对于一个私人系统或微小的单服务商业环境,这些参数已经足够了。
|
||||
|
||||
上面两个文件控制 `useradd` 的处理,用户的信息保存在 `/etc` 目录下的一些其他文件中,关于这些信息的讲解会贯穿全文。
|
||||
|
||||
| 文件 | 描述 | 域 (加粗的表示由 useradd 命令设置) |
|
||||
| ------ | ------------------------------------ | ------------------------------------------------------------ |
|
||||
| `passwd` | 存储用户账号信息 | **用户名**:未使用:**UID**:**GID**:**备注**:**家目录**:**shell** |
|
||||
| `shadow` | 存储用户账号的安全信息 | **用户名**:加密密码:上次修改时间:最短使用天数:最长使用天数间:**修改前警示天数**:**过期后宽限时间**:未使用 |
|
||||
| `group` | 存储组信息 | **组名**:未使用:**GID**:**成员列表** |
|
||||
|
||||
### 自定义处理
|
||||
|
||||
当管理员需要更好地控制账号时,可以使用命令行来自定义,如指定一个用户的 ID。
|
||||
|
||||
#### 用户和组 ID
|
||||
|
||||
默认情况下,`useradd` 试图使用相同的用户 ID(UID)和主组 ID(GID),但也不完全是。虽然 UID 与 GID 相同不是必须的,但如果相同,会更方便管理员管理。
|
||||
|
||||
下面的场景就是一个 GID 与 UID 不同的例子。现在我添加另一账号,名为 Timmy。通过使用 `getent` 命令来比较 `sonny` 和 `timmy` 两个账号,显示两个用户和对应的主组。
|
||||
|
||||
```bash
|
||||
$ getent passwd sonny timmy
|
||||
sonny:x:1001:1002:Sonny:/home/sonny:/bin/bash
|
||||
timmy:x:1002:1003::/home/timmy:/bin/bash
|
||||
|
||||
$ getent group sonny timmy
|
||||
sonny:x:1002:
|
||||
timmy:x:1003:
|
||||
```
|
||||
|
||||
不幸的是,两者的 UID 和 GID 都不相同。因为默认的处理是,创建用户时,把下一个可用的 UID 赋给用户,然后把同一个数字作为主组 ID 赋给它。然而,当要使用的组 ID 已经被使用时,就再把下一个可用的 GID 赋给它。为了弄清细节,我猜想 1001 这个 GID 已经被使用了,用一个命令确认了一下。
|
||||
|
||||
```bash
|
||||
$ getent group 1001
|
||||
book:x:1001:alan
|
||||
```
|
||||
|
||||
`book` 的 ID 是 `1001`,因此新创建的用户的 GID 都有偏移量 1。这就是为什么系统管理员在用户创建过程中需要多设置一些值的一个实例。为了解决这个问题,我必须先确定下一个可用的 UID 和 GID 是否相同。确定下一个可用值时,可以使用 `getent group` 和 `getent passwd` 命令,通过 `-u` 参数传递要确认的值。
|
||||
|
||||
```bash
|
||||
$ sudo useradd -u 1004 bobby
|
||||
|
||||
$ getent passwd bobby; getent group bobby
|
||||
bobby:x:1004:1004::/home/bobby:/bin/bash
|
||||
bobby:x:1004:
|
||||
```
|
||||
|
||||
另一个需要指定 ID 的场景是,通过 NFS 访问远程系统上的文件时。对于一个给定的用户,当 NFS 所有客户端和服务系统的 ID 都一样时,管理员更容易控制。在我的文章 [使用 autofs 挂载 NFS][2] 中有详细介绍。
|
||||
|
||||
### 更多自定义
|
||||
|
||||
一些其他的指定用户信息的参数也用得比较频繁。这里是一些你会经常用到的参数的概括例子。
|
||||
|
||||
#### 注释
|
||||
|
||||
注释选项是通过 `-c` 参数指定的一个解释文本字段,可以提供一段简短的描述或其他信息。
|
||||
|
||||
```bash
|
||||
$ sudo useradd -c "Bailey is cool" bailey
|
||||
$ getent passwd bailey
|
||||
bailey:x:1011:1011:Bailey is cool:/home/bailey:/bin/bash
|
||||
```
|
||||
|
||||
#### 组
|
||||
|
||||
一个用户可以被指定一个主组和多个次组。`-g` 参数指定主组名称或 GID。如果不指定,`useradd` 会以用户名创建一个主组(前面演示过)。`-G`(大写)参数用一个逗号分隔的组列表来指定此用户所属的组,这些组就是次组。
|
||||
|
||||
```bash
|
||||
$ sudo useradd -G tgroup,fgroup,libvirt milly
|
||||
$ id milly
|
||||
uid=1012(milly) gid=1012(milly) groups=1012(milly),981(libvirt),4000(fgroup),3000(tgroup)
|
||||
```
|
||||
|
||||
#### 家目录
|
||||
|
||||
`useradd` 的默认处理是,在 `/home` 目录下创建用户的家目录。然而,下面的参数可以改写家目录的基础目录。`-b` 设置另一个可以创建家目录的基础目录。例如指定 `/home2` 而不是 `/home`。
|
||||
|
||||
```bash
|
||||
$ sudo useradd -b /home2 vicky
|
||||
$ getent passwd vicky
|
||||
vicky:x:1013:1013::/home2/vicky:/bin/bash
|
||||
```
|
||||
|
||||
`-d` 参数可以指定一个与用户名不同的家目录。
|
||||
|
||||
```bash
|
||||
$ sudo useradd -d /home/ben jerry
|
||||
$ getent passwd jerry
|
||||
jerry:x:1014:1014::/home/ben:/bin/bash
|
||||
```
|
||||
|
||||
#### 目录模板
|
||||
|
||||
指定 `-k` 参数会在创建新用户时,复制 `/etc/skel` 目录下的所有文件到用户的家目录中。这些文件通常是 shell 配置文件,当然也可以是系统管理员想在新建用户时使用的任何文件。
|
||||
|
||||
#### Shell
|
||||
|
||||
`-s` 参数可以指定 shell。如果不指定,则使用默认的 shell。例如,下面的例子中 ,配置文件中定义的 shell 是 `bash`,但 `wally` 这个用户指定的是 `zsh`。
|
||||
|
||||
```bash
|
||||
SHELL=/bin/bash
|
||||
|
||||
$ sudo useradd -s /usr/bin/zsh wally
|
||||
$ getent passwd wally
|
||||
wally:x:1004:1004::/home/wally:/usr/bin/zsh
|
||||
```
|
||||
|
||||
#### 安全
|
||||
|
||||
安全是用户管理的重中之重,因此 `useradd` 命令也提供了很多关于安全的选项。可以使用 `-e` 参数,以 YYYY-MM-DD 的格式指定一个用户的过期时间。
|
||||
|
||||
```bash
|
||||
$ sudo useradd -e 20191231 sammy
|
||||
$ sudo getent shadow sammy
|
||||
sammy:!!:18171:0:99999:7::20191231:
|
||||
```
|
||||
|
||||
当密码过期时,账号也会自动失效。`-f` 参数指定密码过期后经过几天账号失效。如果设为 0,则立即失效。
|
||||
|
||||
```bash
|
||||
$ sudo useradd -f 30 willy
|
||||
$ sudo getent shadow willy
|
||||
willy:!!:18171:0:99999:7:30::
|
||||
```
|
||||
|
||||
### 实例
|
||||
|
||||
生产环境中,创建一个用户账号时会用到多个参数。例如,我要创建一个 Perry 账号,可能会用下面的命令:
|
||||
|
||||
```bash
|
||||
$ sudo useradd -u 1020 -c "Perry Example" \
|
||||
-G tgroup -b /home2 \
|
||||
-s /usr/bin/zsh \
|
||||
-e 20201201 -f 5 perry
|
||||
```
|
||||
|
||||
查看前面的内容来理解每个选项。用下面的命令确认结果:
|
||||
|
||||
```bash
|
||||
$ getent passwd perry; getent group perry; getent shadow perry; id perry
|
||||
perry:x:1020:1020:Perry Example:/home2/perry:/usr/bin/zsh
|
||||
perry:x:1020:
|
||||
perry:!!:18171:0:99999:7:5:20201201:
|
||||
uid=1020(perry) gid=1020(perry) groups=1020(perry),3000(tgroup)
|
||||
```
|
||||
|
||||
### 一点小建议
|
||||
|
||||
`useradd` 命令是所有 Unix(不仅仅是 Linux)系统管理员都必知必会的命令。由于用户创建不能出错,需要第一次就正确,所以理解它的每一个选项很重要。这意味着你需要有一套深思熟虑的命名约定,包括为整个企业环境而不仅仅是一个单系统预留一个专用的 UID/GID 范围,尤其是你为一个成长中的组织工作时。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/linux-useradd-command
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/connection_people_team_collaboration.png?itok=0_vQT8xV (people in different locations who are part of the same team)
|
||||
[2]: https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (alim0x)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11831-1.html)
|
||||
[#]: subject: (My Linux story: Learning Linux in the 90s)
|
||||
[#]: via: (https://opensource.com/article/19/11/learning-linux-90s)
|
||||
[#]: author: (Mike Harris https://opensource.com/users/mharris)
|
||||
|
||||
我的 Linux 故事:在 90 年代学习 Linux
|
||||
======
|
||||
|
||||
> 这是一个关于我如何在 WiFi 时代之前学习 Linux 的故事,那时的发行版还以 CD 的形式出现。
|
||||
|
||||

|
||||
|
||||
大部分人可能不记得 1996 年时计算产业或日常生活世界的样子。但我很清楚地记得那一年。我那时候是堪萨斯中部一所高中的二年级学生,那是我的自由与开源软件(FOSS)旅程的开端。
|
||||
|
||||
我从这里开始进步。我在 1996 年之前就开始对计算机感兴趣。我在我家的第一台 Apple ][e 上启蒙成长,然后多年之后是 IBM Personal System/2。(是的,在这过程中有一些代际的跨越。)IBM PS/2 有一个非常激动人心的特性:一个 1200 波特的 Hayes 调制解调器。
|
||||
|
||||
我不记得是怎样了,但在那不久之前,我得到了一个本地 [BBS][2] 的电话号码。一旦我拨号进去,我可以得到本地的一些其他 BBS 的列表,我的网络探险就此开始了。
|
||||
|
||||
在 1995 年,[足够幸运][3]的人拥有了家庭互联网连接,每月可以使用不到 30 分钟。那时的互联网不像我们现代的服务那样,通过卫星、光纤、有线电视同轴电缆或任何版本的铜线提供。大多数家庭通过一个调制解调器拨号,它连接到他们的电话线上。(这时离移动电话无处不在的时代还早得很,大多数人只有一部家庭电话。)尽管这还要取决你所在的位置,但我不认为那时有很多独立的互联网服务提供商(ISP),所以大多数人从仅有的几家大公司获得服务,包括 America Online,CompuServe 以及 Prodigy。
|
||||
|
||||
你能获取到的服务速率非常低,甚至在拨号上网革命性地达到了顶峰的 56K,你也只能期望得到最高 3.5Kbps 的速率。如果你想要尝试 Linux,下载一个 200MB 到 800MB 的 ISO 镜像或(更加切合实际的)一套软盘镜像要贡献出时间、决心,以及减少电话的使用。
|
||||
|
||||
我走了一条简单一点的路:在 1996 年,我从一家主要的 Linux 发行商订购了一套 “tri-Linux” CD 集。这些光盘提供了三个发行版,我的这套包含了 Debian 1.1(Debian 的第一个稳定版本)、Red Hat Linux 3.0.3 以及 Slackware 3.1(代号 Slackware '96)。据我回忆,这些光盘是从一家叫做 [Linux Systems Labs][4] 的在线商店购买的。这家在线商店如今已经不存在了,但在 90 年代和 00 年代早期,这样的发行商很常见。这些是多光盘 Linux 套件。这是 1998 年的一套光盘,你可以了解到他们都包含了什么:
|
||||
|
||||
![A tri-linux CD set][5]
|
||||
|
||||
![A tri-linux CD set][6]
|
||||
|
||||
在 1996 年夏天一个命中注定般的日子,那时我住在堪萨斯一个新的并且相对较为乡村的城市,我做出了安装并使用 Linux 的第一次尝试。在 1996 年的整个夏天,我尝试了那套三张 Linux CD 套件里的全部三个发行版。他们都在我母亲的老 Pentium 75MHz 电脑上完美运行。
|
||||
|
||||
我最终选择了 [Slackware][7] 3.1 作为我的首选发行版,相比其它发行版可能更多的是因为它的终端的外观,这是决定选择一个发行版前需要考虑的重要因素。
|
||||
|
||||
我将系统设置完毕并运行了起来。我连接到一家 “不太知名的” ISP(一家这个区域的本地服务商),通过我家的第二条电话线拨号(为了满足我的所有互联网使用而订购)。那就像在天堂一样。我有一台完美运行的双系统(Microsoft Windows 95 和 Slackware 3.1)电脑。我依然拨号进入我所知道和喜爱的 BBS,游玩在线 BBS 游戏,比如 Trade Wars、Usurper 以及 Legend of the Red Dragon。
|
||||
|
||||
我能够记得在 EFNet(IRC)上 #Linux 频道上渡过的日子,帮助其他用户,回答他们的 Linux 问题以及和版主们互动。
|
||||
|
||||
在我第一次在家尝试使用 Linux 系统的 20 多年后,已经是我进入作为 Red Hat 顾问的第五年,我仍然在使用 Linux(现在是 Fedora)作为我的日常系统,并且依然在 IRC 上帮助想要使用 Linux 的人们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/learning-linux-90s
|
||||
|
||||
作者:[Mike Harris][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mharris
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bus-cloud.png?itok=vz0PIDDS (Sky with clouds and grass)
|
||||
[2]: https://en.wikipedia.org/wiki/Bulletin_board_system
|
||||
[3]: https://en.wikipedia.org/wiki/Global_Internet_usage#Internet_users
|
||||
[4]: https://web.archive.org/web/19961221003003/http://lsl.com/
|
||||
[5]: https://opensource.com/sites/default/files/20191026_142009.jpg (A tri-linux CD set)
|
||||
[6]: https://opensource.com/sites/default/files/20191026_142020.jpg (A tri-linux CD set)
|
||||
[7]: http://slackware.com
|
||||
@ -0,0 +1,168 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11735-1.html)
|
||||
[#]: subject: (How to cohost GitHub and GitLab with Ansible)
|
||||
[#]: via: (https://opensource.com/article/19/11/how-host-github-gitlab-ansible)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何使用 Ansible 同步 GitHub 和 GitLab
|
||||
======
|
||||
|
||||
> 通过使用 Ansible 镜像 Git 存储库,保护对重要项目的访问。
|
||||
|
||||

|
||||
|
||||
开源无处不在。它在家里的计算机上、在工作场所的计算机上、在互联网上,并且很多都由 [Git][2] 管理。由于 Git 是分布式的,因此许多人也将其视为一种众包的备份解决方案。从理论上讲,每当有人将 Git 存储库克隆到其本地计算机时,他们就创建了该项目源代码的备份。如果有 100 个人这样做,则存储库就有 100 个备份副本。
|
||||
|
||||
从理论上讲,这可以缓解“灾难”的影响,例如当项目维护者[突然决定删除存储库][3]或[莫名其妙地阻止所有流量][4],导致开发人员们无头苍蝇般地寻找谁拥有主分支的最新版本。类似的,整个代码托管站点也会消失。没有人会想到 Google Code、Microsoft CodePlex 或 Gitorious 会在鼎盛时期将被关闭。
|
||||
|
||||
简而言之,如果在过去的几十年中互联网教给了我们一些东西,那就是依靠互联网神奇地创建备份并不是冗余的最可靠途径。
|
||||
|
||||
此外,对于许多人来说,很多开源项目都托管在 GitHub 上是个问题 —— GitHub 并不是开放平台。许多开发人员和用户都希望支持诸如 GitLab 之类的堆栈并与之交互,它具有开源社区版本。
|
||||
|
||||
### 使用 Ansible 管理 Git
|
||||
|
||||
Git 的去中心方式对于解决这个问题很有用。使用纯 Git,你可以使用一个 `push` 命令轻松地将其推到两个或多个存储库。但是,为了使其在发生意外故障时有用,你必须经常与 Git 存储库进行交互(特别是推送)。此外,即使你可能永远不会自己推送或拉出代码,也可能有一些要备份的存储库。
|
||||
|
||||
但是,使用 Ansible,你可以自动执行项目主分支(或其他任何分支)的 Git 拉取,然后自动进行存储库到“异地”镜像的 Git 推送。换句话说,你可以让你的计算机定期从 GitHub 拉取并推送到 GitLab 或 [Gitolite][5] 或 Gitea(或你喜欢的任何 Git 托管主机)。
|
||||
|
||||
### Ansible 模块
|
||||
|
||||
如果不是因其出色的模块集合,那么 Ansible 就没那么出色。像 Python 的第三方库或 Linux 的应用程序一样,这个技术引擎的一个有用而令人惊讶的简单技巧是,Ansible 以其他人贡献的组件而闻名。因为本文正在研究如何有效和可靠地备份 Git 存储库,所以这里使用的模块是 [Git 模块][6]和 [ini_file][7] 模块。
|
||||
|
||||
首先,创建一个名为 `mirror.yaml` 的文件作为<ruby>剧本<rt>playbook</rt></ruby>。你可以像通常使用 Ansible 一样,从 `name` 和 `task` 条目开始。本示例将 `localhost` 添加到 `hosts` 列表中,以便在控制器计算机(你现在坐在前面的计算机)上运行<ruby>动作<rt>play</rt></ruby>,但是在现实生活中,你可能会在特定的主机或一组网络上的主机上运行它。
|
||||
|
||||
```
|
||||
---
|
||||
- name: "Mirror a Git repo with Ansible"
|
||||
hosts: localhost
|
||||
tasks:
|
||||
```
|
||||
|
||||
### Git 拉取和克隆
|
||||
|
||||
如果要进行备份,则需要最新代码的副本。明显,在 Git 仓库中实现这一目标的方法是执行 `git pull`。 但是,`pull` 会假定克隆已经存在,而写得很好的 Ansible 动作(Ansible 脚本)则尽可能少的假定。最好告诉 Ansible 先克隆存储库。
|
||||
|
||||
将你的第一个任务添加到剧本:
|
||||
|
||||
```
|
||||
---
|
||||
- name: "Mirror a Git repo with Ansible"
|
||||
hosts: localhost
|
||||
vars:
|
||||
git_dir: /tmp/soso.git
|
||||
tasks:
|
||||
|
||||
- name: "Clone the git repo"
|
||||
git:
|
||||
repo: 'https://github.com/ozkl/soso.git'
|
||||
dest: '{{ git_dir }}'
|
||||
clone: yes
|
||||
update: yes
|
||||
```
|
||||
|
||||
这个例子使用了开源的、类似于 Unix 的操作系统 soso 作为我要镜像的存储库。这是一个完全任意的选择,绝不意味着我对该存储库的未来缺乏信心。它还使用变量来引用目标文件夹 `/tmp/soso.git`,这很方便,并且如果以后你希望将它扩展为一个通用的镜像脚本也会受益。在现实生活中,你的工作机上可能会比 `/tmp` 具有更永久的位置,例如 `/home/gitmirrors/soso.git` 或 `/opt/gitmirrors/soso.git`。
|
||||
|
||||
运行你的剧本:
|
||||
|
||||
```
|
||||
$ ansible-playbook mirror.yaml
|
||||
```
|
||||
|
||||
首次运行该剧本时,Ansible 会正确检测到 Git 存储库在本地尚不存在,因此将其克隆。
|
||||
|
||||
```
|
||||
PLAY [Ansible Git mirror] ********
|
||||
|
||||
TASK [Gathering Facts] ***********
|
||||
ok: [localhost]
|
||||
|
||||
TASK [Clone git repo] ************
|
||||
changed: [localhost]
|
||||
|
||||
PLAY RECAP ***********************
|
||||
localhost: ok=2 changed=1 failed=0 [...]
|
||||
```
|
||||
|
||||
如果你再次运行该剧本,Ansible 会正确检测到自上次运行以来没有任何更改,并且会报告未执行任何操作:
|
||||
|
||||
```
|
||||
localhost: ok=2 changed=0 failed=0 [...]
|
||||
```
|
||||
|
||||
接下来,必须指示 Ansible 将存储库推送到另一个 Git 服务器。
|
||||
|
||||
### Git 推送
|
||||
|
||||
Ansible 中的 Git 模块不提供 `push` 功能,因此该过程的一部分是手动的。但是,在将存储库推送到备用镜像之前,你必须具有一个镜像,并且必须将镜像配置为备用<ruby>远程服务器<rt>remote</rt></ruby>。
|
||||
|
||||
首先,必须将备用的远程服务器添加到 Git 配置。因为 Git 配置文件是 INI 样式的配置,所以你可以使用 `ini_file` Ansible 模块轻松地添加所需的信息。将此添加到你的剧本:
|
||||
|
||||
```
|
||||
- name: "Add alternate remote"
|
||||
ini_file: dest={{ git_dir }}/.git/config section='remote \"mirrored\"' option=url value='git@gitlab.com:example/soso-mirror.git'
|
||||
tags: configuration
|
||||
```
|
||||
|
||||
为此,你必须在目标服务器上有一个空的存储库(在本例中为 [GitLab.com][9])。如果需要在剧本中创建目标存储库,可以按照 Steve Ovens 的出色文章《[如何使用 Ansible 通过 SSH 设置 Git 服务器][10]》来完成。
|
||||
|
||||
最后,直接使用 Git 将 HEAD 推送到备用远程服务器:
|
||||
|
||||
```
|
||||
- name: "Push the repo to alternate remote"
|
||||
shell: 'git --verbose --git-dir={{ git_dir }}/.git push mirrored HEAD'
|
||||
```
|
||||
|
||||
像往常一样运行该剧本,然后使该过程自动化,这样你就不必再次直接运行它了。你可以使用变量和特定的 Git 命令来调整脚本以适应你的需求,但是通过常规的拉取和推送操作,可以确保驻留在一台服务器上的重要项目可以安全地镜像到另一台服务器上。
|
||||
|
||||
这是完整的剧本,供参考:
|
||||
|
||||
```
|
||||
---
|
||||
- name: "Mirror a Git repository with Ansible"
|
||||
hosts: localhost
|
||||
vars:
|
||||
git_dir: /tmp/soso.git
|
||||
|
||||
tasks:
|
||||
|
||||
- name: "Clone the Git repo"
|
||||
git:
|
||||
repo: 'https://github.com/ozkl/soso.git'
|
||||
dest: '{{ git_dir }}'
|
||||
clone: yes
|
||||
update: yes
|
||||
|
||||
- name: "Add alternate remote"
|
||||
ini_file: dest={{ git_dir }}/.git/config section='remote \"mirrored\"' option=url value='git@gitlab.com:example/soso-mirror.git'
|
||||
tags: configuration
|
||||
|
||||
- name: "Push the repo to alternate remote"
|
||||
shell: 'git --verbose --git-dir={{ git_dir }}/.git push mirrored HEAD'
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/how-host-github-gitlab-ansible
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
|
||||
[2]: https://opensource.com/resources/what-is-git
|
||||
[3]: https://github.com/AntiMicro/antimicro/issues/3
|
||||
[4]: https://opensource.com/article/19/10/how-community-saved-artwork-creative-commons
|
||||
[5]: https://opensource.com/article/19/4/server-administration-git
|
||||
[6]: https://docs.ansible.com/ansible/latest/modules/git_module.html
|
||||
[7]: https://docs.ansible.com/ansible/latest/modules/ini_file_module.html
|
||||
[8]: mailto:git@gitlab.com
|
||||
[9]: http://GitLab.com
|
||||
[10]: https://opensource.com/article/17/8/ansible-environment-management
|
||||
@ -0,0 +1,395 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11780-1.html)
|
||||
[#]: subject: (Simulate gravity in your Python game)
|
||||
[#]: via: (https://opensource.com/article/19/11/simulate-gravity-python)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在你的 Python 游戏中模拟引力
|
||||
======
|
||||
|
||||
> 学习如何使用 Python 的 Pygame 模块编程电脑游戏,并开始操作引力。
|
||||
|
||||

|
||||
|
||||
真实的世界充满了运动和生活。物理学使得真实的生活如此忙碌和动态。物理学是物质在空间中运动的方式。既然一个电脑游戏世界没有物质,它也就没有物理学规律,使用游戏程序员不得不*模拟*物理学。
|
||||
|
||||
从大多数电脑游戏来说,这里基本上仅有两个方面的物理学是重要的:引力和碰撞。
|
||||
|
||||
当你[添加一个敌人][2]到你的游戏中时,你实现了一些碰撞检测,但是这篇文章要添加更多的东西,因为引力需要碰撞检测。想想为什么引力可能涉及碰撞。如果你不能想到任何原因,不要担心 —— 它会随着你开发示例代码工作而且显然。
|
||||
|
||||
在真实世界中的引力是有质量的物体来相互吸引的倾向性。物体(质量)越大,它施加越大的引力作用。在电脑游戏物理学中,你不必创建质量足够大的物体来证明引力的正确;你可以在电脑游戏世界本身中仅编程一个物体落向假设的最大的对象的倾向。
|
||||
|
||||
### 添加一个引力函数
|
||||
|
||||
记住你的玩家已经有了一个决定动作的属性。使用这个属性来将玩家精灵拉向屏幕底部。
|
||||
|
||||
在 Pygame 中,较高的数字更接近屏幕的底部边缘。
|
||||
|
||||
在真实的世界中,引力影响一切。然而,在平台游戏中,引力是有选择性的 —— 如果你添加引力到你的整个游戏世界,你的所有平台都将掉到地上。反之,你可以仅添加引力到你的玩家和敌人精灵中。
|
||||
|
||||
首先,在你的 `Player` 类中添加一个 `gravity` 函数:
|
||||
|
||||
```
|
||||
def gravity(self):
|
||||
self.movey += 3.2 # 玩家掉落的多快
|
||||
```
|
||||
|
||||
这是一个简单的函数。首先,不管你的玩家是否想运动,你设置你的玩家垂直运动。也就是说,你已经编程你的玩家总是在下降。这基本上就是引力。
|
||||
|
||||
为使引力函数生效,你必须在你的主循环中调用它。这样,当每一个处理循环时,Python 都应用下落运动到你的玩家。
|
||||
|
||||
在这代码中,添加第一行到你的循环中:
|
||||
|
||||
```
|
||||
player.gravity() # 检查引力
|
||||
player.update()
|
||||
```
|
||||
|
||||
启动你的游戏来看看会发生什么。要注意,因为它发生的很快:你是玩家从天空上下落,马上掉出了你的游戏屏幕。
|
||||
|
||||
你的引力模拟是工作的,但是,也许太好了。
|
||||
|
||||
作为一次试验,尝试更改你玩家下落的速度。
|
||||
|
||||
### 给引力添加一个地板
|
||||
|
||||
你的游戏没有办法发现你的角色掉落出世界的问题。在一些游戏中,如果一个玩家掉落出世界,该精灵被删除,并在某个新的位置重生。在另一些游戏中,玩家会丢失分数或一条生命。当一个玩家掉落出世界时,不管你想发生什么,你必须能够侦测出玩家何时消失在屏幕外。
|
||||
|
||||
在 Python 中,要检查一个条件,你可以使用一个 `if` 语句。
|
||||
|
||||
你必需查看你玩家**是否**正在掉落,以及你的玩家掉落的程度。如果你的玩家掉落到屏幕的底部,那么你可以做*一些事情*。简化一下,设置玩家精灵的位置为底部边缘上方 20 像素。
|
||||
|
||||
使你的 `gravity` 函数看起来像这样:
|
||||
|
||||
```
|
||||
def gravity(self):
|
||||
self.movey += 3.2 # 玩家掉落的多快
|
||||
|
||||
if self.rect.y > worldy and self.movey >= 0:
|
||||
self.movey = 0
|
||||
self.rect.y = worldy-ty
|
||||
```
|
||||
|
||||
然后,启动你的游戏。你的精灵仍然下落,但是它停在屏幕的底部。不过,你也许不能*看到*你在地面层之上的精灵。一个简单的解决方法是,在精灵碰撞游戏世界的底部后,通过添加另一个 `-ty` 到它的新 Y 位置,从而使你的精灵弹跳到更高处:
|
||||
|
||||
```
|
||||
def gravity(self):
|
||||
self.movey += 3.2 # 玩家掉落的多快
|
||||
|
||||
if self.rect.y > worldy and self.movey >= 0:
|
||||
self.movey = 0
|
||||
self.rect.y = worldy-ty-ty
|
||||
```
|
||||
|
||||
现在你的玩家在屏幕底部弹跳,恰好在你地面精灵上面。
|
||||
|
||||
你的玩家真正需要的是反抗引力的方法。引力问题是,你不能反抗它,除非你有一些东西来推开引力作用。因此,在接下来的文章中,你将添加地面和平台碰撞以及跳跃能力。在这期间,尝试应用引力到敌人精灵。
|
||||
|
||||
到目前为止,这里是全部的代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# draw a world
|
||||
# add a player and player control
|
||||
# add player movement
|
||||
# add enemy and basic collision
|
||||
# add platform
|
||||
# add gravity
|
||||
|
||||
# GNU All-Permissive License
|
||||
# Copying and distribution of this file, with or without modification,
|
||||
# are permitted in any medium without royalty provided the copyright
|
||||
# notice and this notice are preserved. This file is offered as-is,
|
||||
# without any warranty.
|
||||
|
||||
import pygame
|
||||
import sys
|
||||
import os
|
||||
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
class Platform(pygame.sprite.Sprite):
|
||||
# x location, y location, img width, img height, img file
|
||||
def __init__(self,xloc,yloc,imgw,imgh,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img)).convert()
|
||||
self.image.convert_alpha()
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.y = yloc
|
||||
self.rect.x = xloc
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn a player
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0
|
||||
self.movey = 0
|
||||
self.frame = 0
|
||||
self.health = 10
|
||||
self.score = 1
|
||||
self.images = []
|
||||
for i in range(1,9):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha()
|
||||
img.set_colorkey(ALPHA)
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
def gravity(self):
|
||||
self.movey += 3.2 # how fast player falls
|
||||
|
||||
if self.rect.y > worldy and self.movey >= 0:
|
||||
self.movey = 0
|
||||
self.rect.y = worldy-ty-ty
|
||||
|
||||
def control(self,x,y):
|
||||
'''
|
||||
control player movement
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
Update sprite position
|
||||
'''
|
||||
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
|
||||
# moving left
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > ani*3:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# moving right
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > ani*3:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
|
||||
# collisions
|
||||
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
|
||||
for enemy in enemy_hit_list:
|
||||
self.health -= 1
|
||||
print(self.health)
|
||||
|
||||
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
|
||||
for g in ground_hit_list:
|
||||
self.health -= 1
|
||||
print(self.health)
|
||||
|
||||
class Enemy(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn an enemy
|
||||
'''
|
||||
def __init__(self,x,y,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img))
|
||||
#self.image.convert_alpha()
|
||||
#self.image.set_colorkey(ALPHA)
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.x = x
|
||||
self.rect.y = y
|
||||
self.counter = 0
|
||||
|
||||
def move(self):
|
||||
'''
|
||||
enemy movement
|
||||
'''
|
||||
distance = 80
|
||||
speed = 8
|
||||
|
||||
if self.counter >= 0 and self.counter <= distance:
|
||||
self.rect.x += speed
|
||||
elif self.counter >= distance and self.counter <= distance*2:
|
||||
self.rect.x -= speed
|
||||
else:
|
||||
self.counter = 0
|
||||
|
||||
self.counter += 1
|
||||
|
||||
class Level():
|
||||
def bad(lvl,eloc):
|
||||
if lvl == 1:
|
||||
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
|
||||
enemy_list = pygame.sprite.Group() # create enemy group
|
||||
enemy_list.add(enemy) # add enemy to group
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return enemy_list
|
||||
|
||||
def loot(lvl,lloc):
|
||||
print(lvl)
|
||||
|
||||
def ground(lvl,gloc,tx,ty):
|
||||
ground_list = pygame.sprite.Group()
|
||||
i=0
|
||||
if lvl == 1:
|
||||
while i < len(gloc):
|
||||
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
|
||||
ground_list.add(ground)
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return ground_list
|
||||
|
||||
def platform(lvl,tx,ty):
|
||||
plat_list = pygame.sprite.Group()
|
||||
ploc = []
|
||||
i=0
|
||||
if lvl == 1:
|
||||
ploc.append((0,worldy-ty-128,3))
|
||||
ploc.append((300,worldy-ty-256,3))
|
||||
ploc.append((500,worldy-ty-128,4))
|
||||
|
||||
while i < len(ploc):
|
||||
j=0
|
||||
while j <= ploc[i][2]:
|
||||
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'ground.png')
|
||||
plat_list.add(plat)
|
||||
j=j+1
|
||||
print('run' + str(i) + str(ploc[i]))
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return plat_list
|
||||
|
||||
'''
|
||||
Setup
|
||||
'''
|
||||
worldx = 960
|
||||
worldy = 720
|
||||
|
||||
fps = 40 # frame rate
|
||||
ani = 4 # animation cycles
|
||||
clock = pygame.time.Clock()
|
||||
pygame.init()
|
||||
main = True
|
||||
|
||||
BLUE = (25,25,200)
|
||||
BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
ALPHA = (0,255,0)
|
||||
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = world.get_rect()
|
||||
player = Player() # spawn player
|
||||
player.rect.x = 0
|
||||
player.rect.y = 0
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # how fast to move
|
||||
|
||||
eloc = []
|
||||
eloc = [200,20]
|
||||
gloc = []
|
||||
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
|
||||
tx = 64 #tile size
|
||||
ty = 64 #tile size
|
||||
|
||||
i=0
|
||||
while i <= (worldx/tx)+tx:
|
||||
gloc.append(i*tx)
|
||||
i=i+1
|
||||
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
ground_list = Level.ground( 1,gloc,tx,ty )
|
||||
plat_list = Level.platform( 1,tx,ty )
|
||||
|
||||
'''
|
||||
Main loop
|
||||
'''
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print("LEFT")
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print("RIGHT")
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
|
||||
world.blit(backdrop, backdropbox)
|
||||
player.gravity() # check gravity
|
||||
player.update()
|
||||
player_list.draw(world)
|
||||
enemy_list.draw(world)
|
||||
ground_list.draw(world)
|
||||
plat_list.draw(world)
|
||||
for e in enemy_list:
|
||||
e.move()
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
这是仍在进行中的关于使用 [Pygame][4] 模块来在 [Python 3][3] 在创建电脑游戏的第七部分。先前的文章是:
|
||||
|
||||
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程][5]
|
||||
* [使用 Python 和 Pygame 模块构建一个游戏框架][6]
|
||||
* [如何在你的 Python 游戏中添加一个玩家][7]
|
||||
* [用 Pygame 使你的游戏角色移动起来][8]
|
||||
* [如何向你的 Python 游戏中添加一个敌人][2]
|
||||
* [在 Pygame 游戏中放置平台][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/simulate-gravity-python
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/space_stars_cosmic.jpg?itok=bE94WtN- (Cosmic stars in outer space)
|
||||
[2]: https://linux.cn/article-10883-1.html
|
||||
[3]: https://www.python.org/
|
||||
[4]: https://www.pygame.org
|
||||
[5]: https://linux.cn/article-9071-1.html
|
||||
[6]: https://linux.cn/article-10850-1.html
|
||||
[7]: https://linux.cn/article-10858-1.html
|
||||
[8]: https://linux.cn/article-10874-1.html
|
||||
[9]: https://linux.cn/article-10902-1.html
|
||||
@ -0,0 +1,232 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to write a Python web API with Django)
|
||||
[#]: via: (https://opensource.com/article/19/11/python-web-api-django)
|
||||
[#]: author: (Rachel Waston https://opensource.com/users/rachelwaston)
|
||||
|
||||
如何借助 Django 来编写一个 Python Web API
|
||||
======
|
||||
|
||||
> Django 是 Python API 开发中最流行的框架之一,在这个教程中,我们来学习如何使用它。
|
||||
|
||||

|
||||
|
||||
[Django][2] 所有 Web 框架中最全面的,也是最受欢迎的一个。自 2005 年以来,其流行度大幅上升。
|
||||
|
||||
Django 是由 Django 软件基金会维护,并且获得了社区的大力支持,在全球拥有超过 11,600 名成员。在 Stack Overflow 上,约有 191,000 个带 Django 标签的问题。Spotify、YouTube 和 Instagram 等都使用 Django 来构建应用程序和数据管理。
|
||||
|
||||
本文演示了一个简单的 API,通过它可以使用 HTTP 协议的 GET 方法来从服务器获取数据。
|
||||
|
||||
### 构建一个项目
|
||||
|
||||
首先,为你的 Django 应用程序创建一个目录结构,你可以在系统的任何位置创建:
|
||||
|
||||
```
|
||||
$ mkdir myproject
|
||||
$ cd myproject
|
||||
```
|
||||
|
||||
然后,在项目目录中创建一个虚拟环境来隔离本地包依赖关系:
|
||||
|
||||
```
|
||||
$ python3 -m venv env
|
||||
$ source env/bin/activate
|
||||
```
|
||||
|
||||
在 Windows 上,使用命令 `env\Scripts\activate` 来激活虚拟环境。
|
||||
|
||||
### 安装 Django 和 Django REST framework
|
||||
|
||||
然后,安装 Django 和 Django REST 模块:
|
||||
|
||||
```
|
||||
$ pip3 install django
|
||||
$ pip3 install djangorestframework
|
||||
```
|
||||
|
||||
### 实例化一个新的 Django 项目
|
||||
|
||||
现在你的应用程序已经有了一个工作环境,你必须实例化一个新的 Django 项目。与 [Flask][3] 这样微框架不同的是,Django 有专门的命令来创建(注意第一条命令后的 `.` 字符)。
|
||||
|
||||
```
|
||||
$ django-admin startproject tutorial .
|
||||
$ cd tutorial
|
||||
$ django-admin startapp quickstart
|
||||
```
|
||||
|
||||
Django 使用数据库来管理后端,所以你应该在开始开发之前同步数据库,数据库可以通过 `manage.py` 脚本管理,它是在你运行 `django-admin` 命令时创建的。因为你现在在 `tutorial` 目录,所以使用 `../` 符号来运行脚本,它位于上一层目录:
|
||||
|
||||
```
|
||||
$ python3 ../manage.py makemigrations
|
||||
No changes detected
|
||||
$ python4 ../manage.py migrate
|
||||
Operations to perform:
|
||||
Apply all migrations: admin, auth, contenttypes, sessions
|
||||
Running migrations:
|
||||
Applying contenttypes.0001_initial... OK
|
||||
Applying auth.0001_initial... OK
|
||||
Applying admin.0001_initial... OK
|
||||
Applying admin.0002_logentry_remove_auto_add... OK
|
||||
Applying admin.0003_logentry_add_action_flag_choices... OK
|
||||
Applying contenttypes.0002_remove_content_type_name... OK
|
||||
Applying auth.0002_alter_permission_name_max_length... OK
|
||||
Applying auth.0003_alter_user_email_max_length... OK
|
||||
Applying auth.0004_alter_user_username_opts... OK
|
||||
Applying auth.0005_alter_user_last_login_null... OK
|
||||
Applying auth.0006_require_contenttypes_0002... OK
|
||||
Applying auth.0007_alter_validators_add_error_messages... OK
|
||||
Applying auth.0008_alter_user_username_max_length... OK
|
||||
Applying auth.0009_alter_user_last_name_max_length... OK
|
||||
Applying auth.0010_alter_group_name_max_length... OK
|
||||
Applying auth.0011_update_proxy_permissions... OK
|
||||
Applying sessions.0001_initial... OK
|
||||
```
|
||||
|
||||
### 在 Django 中创建用户
|
||||
|
||||
创建一个名为 `admin`,示例密码为 `password123` 的初始用户:
|
||||
|
||||
```
|
||||
$ python3 ../manage.py createsuperuser \
|
||||
--email admin@example.com \
|
||||
--username admin
|
||||
```
|
||||
|
||||
在提示时创建密码。
|
||||
|
||||
### 在 Django 中实现序列化和视图
|
||||
|
||||
为了使 Django 能够将信息传递给 HTTP GET 请求,必须将信息对象转化为有效的响应数据。Django 为此实现了“序列化类” `serializers`。
|
||||
|
||||
在你的项目中,创建一个名为 `quickstart/serializers.py` 的新模块,使用它来定义一些序列化器,模块将用于数据展示:
|
||||
|
||||
```
|
||||
from django.contrib.auth.models import User, Group
|
||||
from rest_framework import serializers
|
||||
|
||||
class UserSerializer(serializers.HyperlinkedModelSerializer):
|
||||
class Meta:
|
||||
model = User
|
||||
fields = ['url', 'username', 'email', 'groups']
|
||||
|
||||
class GroupSerializer(serializers.HyperlinkedModelSerializer):
|
||||
class Meta:
|
||||
model = Group
|
||||
fields = ['url', 'name']
|
||||
```
|
||||
|
||||
Django 中的[视图][5]是一个接受 Web 请求并返回 Web 响应的函数。响应可以是 HTML、HTTP 重定向、HTTP 错误、JSON 或 XML 文档、图像或 TAR 文件,或者可以是从 Internet 获得的任何其他内容。要创建视图,打开 `quickstart/views.py` 并输入以下代码。该文件已经存在,并且其中包含一些示例文本,保留这些文本并将以下代码添加到文件中:
|
||||
|
||||
```
|
||||
from django.contrib.auth.models import User, Group
|
||||
from rest_framework import viewsets
|
||||
from tutorial.quickstart.serializers import UserSerializer, GroupSerializer
|
||||
|
||||
class UserViewSet(viewsets.ModelViewSet):
|
||||
"""
|
||||
API 允许查看或编辑用户
|
||||
"""
|
||||
queryset = User.objects.all().order_by('-date_joined')
|
||||
serializer_class = UserSerializer
|
||||
|
||||
class GroupViewSet(viewsets.ModelViewSet):
|
||||
"""
|
||||
API 允许查看或编辑组
|
||||
"""
|
||||
queryset = Group.objects.all()
|
||||
serializer_class = GroupSerializer
|
||||
```
|
||||
|
||||
### 使用 Django 生成 URL
|
||||
|
||||
现在,你可以生成 URL 以便人们可以访问你刚起步的 API。在文本编辑器中打开 `urls.py` 并将默认示例代码替换为以下代码:
|
||||
|
||||
```
|
||||
from django.urls import include, path
|
||||
from rest_framework import routers
|
||||
from tutorial.quickstart import views
|
||||
|
||||
router = routers.DefaultRouter()
|
||||
router.register(r'users', views.UserViewSet)
|
||||
router.register(r'groups', views.GroupViewSet)
|
||||
|
||||
# 使用自动路由 URL
|
||||
# 还有登录 URL
|
||||
urlpatterns = [
|
||||
path('', include(router.urls)),
|
||||
path('api-auth/', include('rest_framework.urls', namespace='rest_framework'))
|
||||
]
|
||||
```
|
||||
|
||||
### 调整你的 Django 项目设置
|
||||
|
||||
这个示例项目的设置模块存储在 `tutorial/settings.py` 中,因此在文本编辑器中将其打开,然后在 `INSTALLED_APPS` 列表的末尾添加 `rest_framework`:
|
||||
|
||||
```
|
||||
INSTALLED_APPS = [
|
||||
...
|
||||
'rest_framework',
|
||||
]
|
||||
```
|
||||
|
||||
### 测试 Django API
|
||||
|
||||
现在,你可以测试构建的 API。首先,从命令行启动内置服务器:
|
||||
|
||||
```
|
||||
$ python3 manage.py runserver
|
||||
```
|
||||
|
||||
你可以通过使用 `curl` 导航至 URL `http://localhost:8000/users` 来访问 API:
|
||||
|
||||
```
|
||||
$ curl --get http://localhost:8000/users/?format=json
|
||||
[{"url":"http://localhost:8000/users/1/?format=json","username":"admin","email":"admin@example.com","groups":[]}]
|
||||
```
|
||||
|
||||
使用 Firefox 或你选择的[开源浏览器][6]:
|
||||
|
||||
![一个简单的 Django API][7]
|
||||
|
||||
有关使用 Django 和 Python 的 RESTful API 的更多深入知识,参考出色的 [Django 文档][8]。
|
||||
|
||||
### 为什么要使用 Djago?
|
||||
|
||||
Django 的主要优点:
|
||||
|
||||
1. Django 社区的规模正在不断扩大,因此即使你做一个复杂项目,也会有大量的指导资源。
|
||||
2. 默认包含模板、路由、表单、身份验证和管理工具等功能,你不必寻找外部工具,也不必担心第三方工具会引入兼容性问题。
|
||||
3. 用户、循环和条件的简单结构使你可以专注于编写代码。
|
||||
4. 这是一个成熟且经过优化的框架,它非常快速且可靠。
|
||||
|
||||
Django 的主要缺点:
|
||||
|
||||
1. Django 很复杂!从开发人员视角的角度来看,它可能比简单的框架更难学。
|
||||
2. Django 有一个很大的生态系统。一旦你熟悉它,这会很棒,但是当你深入学习时,它可能会令人感到无所适从。
|
||||
|
||||
对你的应用程序或 API 来说,Django 是绝佳选择。下载并熟悉它,开始开发一个迷人的项目!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/python-web-api-django
|
||||
|
||||
作者:[Rachel Waston][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rachelwaston
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python-programming-code-keyboard.png?itok=fxiSpmnd (Hands on a keyboard with a Python book )
|
||||
[2]: https://www.djangoproject.com/
|
||||
[3]: https://opensource.com/article/19/11/python-web-api-flask
|
||||
[4]: mailto:admin@example.com
|
||||
[5]: https://docs.djangoproject.com/en/2.2/topics/http/views/
|
||||
[6]: https://opensource.com/article/19/7/open-source-browsers
|
||||
[7]: https://opensource.com/sites/default/files/uploads/django-api.png (A simple Django API)
|
||||
[8]: https://docs.djangoproject.com/en/2.2
|
||||
177
published/202001/20191130 7 maker gifts for kids and teens.md
Normal file
177
published/202001/20191130 7 maker gifts for kids and teens.md
Normal file
@ -0,0 +1,177 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11762-1.html)
|
||||
[#]: subject: (7 maker gifts for kids and teens)
|
||||
[#]: via: (https://opensource.com/article/19/11/maker-gifts-kids)
|
||||
[#]: author: (Jess Weichler https://opensource.com/users/cyanide-cupcake)
|
||||
|
||||
给儿童和青少年的 7 件创客礼物
|
||||
======
|
||||
|
||||
> 这份礼物指南使你轻松完成节日礼物的采购,它们可给婴儿、儿童、青少年及年龄更大的人们带来创造和创新能力。
|
||||
|
||||

|
||||
|
||||
还在纠结这个假期给年轻人买什么礼物?这是我精选的开源礼物,这些礼物将激发未来的创意和灵感。
|
||||
|
||||
### 蜂鸟机器人套件
|
||||
|
||||
![Hummingbird Robotics Kit][2]
|
||||
|
||||
**年龄:**8 岁 - 成人
|
||||
|
||||
**这是什么:**[蜂鸟机器人套件][3]是一套完整的机器人套件,带有微控制器、电机、LED 和传感器。机器人的大脑具有特殊的端口,小手可以轻松地将其连接到机器人的组件上。蜂鸟套件并没有身体,而是鼓励用户自己创建一个。
|
||||
|
||||
**为什么我喜欢它:**蜂鸟可以使用多种编程语言 —— 从可视化编程(BirdBlox、MakeCode、Snap)到代码编程(Python 和 Java)—— 可以随着用户编码技能的提高而可扩展。所有组件均与你在电子商店中找到的组件完全相同,没有像其他机器人套件那样被塑料所遮盖。这使机器人的内部工作不再神秘,并在你需要时易于采购更多零件。
|
||||
|
||||
由于没有固定组装项目,因此蜂鸟是发挥创造力的完美机器人。
|
||||
|
||||
蜂鸟具有开源的软件和固件。它适用于 Linux、Windows、Mac、Chromebook、Android 和 iOS。
|
||||
|
||||
**费用:**起价为 99 美元。
|
||||
|
||||
### Makey Makey 经典版
|
||||
|
||||
![Makey Makey Classic][4]
|
||||
|
||||
**年龄:** 6岁 - 成人
|
||||
|
||||
**这是什么:** [Makey Makey 经典版][5]可将任何导电物体(从棉花糖到你的朋友)变成计算机钥匙。
|
||||
|
||||
你可以使用鳄鱼夹将 Makey Makey 连接到你选择的导电物体上。然后,通过同时触摸两个导电物体来闭合接地和任何触发键之间的电路。Makey Makey 是一种安全的方法,可以安全地在家中探索电力,同时创造与计算机进行交互的有趣方式。
|
||||
|
||||
**为什么我喜欢它:** Makey Makey 可以与 Scratch 开发的视频游戏搭配使用,以创建独特的控制器,使用户进一步沉浸在游戏中。从用卫生纸卷和铝箔制成的工具到互动艺术和故事,可能性是无限的。它可以在具有 USB 端口的 Linux、Windows 和 Mac 计算机上使用。
|
||||
|
||||
**费用:** 49.95 美金
|
||||
|
||||
### Arduino Uno
|
||||
|
||||
![Arduino Uno][6]
|
||||
|
||||
**年龄:** 10 岁 - 成人
|
||||
|
||||
**这是什么:** Arduino 是随同电子套件购买的微控制器,也可以单独购买,它们具有多种版本,而我最喜欢 [Arduino Uno][7]。你可以根据需要从任何电子商店购买其他组件,例如 LED、电机和传感器。
|
||||
|
||||
**为什么我喜欢它:** Arduino Uno 的文档很完善,因此创客们很容易在线上找到教程。Arduino 可以实现从简单到复杂的各种电子项目。Arduino 具有开源的固件和硬件。它适用于 Linux、Mac 和 Windows。
|
||||
|
||||
**费用:** 主板的起价为 22.00 美元。总成本取决于项目和技能水平。
|
||||
|
||||
### DIY 创客套件
|
||||
|
||||
![A maker kit assembled in a quick trip to the hardware store][8]
|
||||
|
||||
**年龄**:8 岁 - 成人
|
||||
|
||||
**这是什么:**当今许多创客、发明家和程序员都是从鼓捣碰巧出现在身边东西开始的。你可以快速前往最近的电子产品商店,为家里的年轻人创建一套出色的创客工具包。这是我的创客工具包中的内容:
|
||||
|
||||
* 护目镜
|
||||
* 锤子
|
||||
* 钉子和螺丝
|
||||
* 碎木
|
||||
* 螺丝起子
|
||||
* 电线
|
||||
* LED
|
||||
* 压电蜂鸣器
|
||||
* 马达
|
||||
* 带引线的 AA 电池组
|
||||
* 剪线钳
|
||||
* 纸板
|
||||
* 美纹纸胶带
|
||||
* 废布
|
||||
* 纽扣
|
||||
* 线程
|
||||
* 针
|
||||
* 拉链
|
||||
* 钩子
|
||||
* 一个很酷的工具盒,用来存放所有东西
|
||||
|
||||
**我为什么喜欢它:**还记得小时候,你把父母带回家的空纸箱变成了宇宙飞船、房屋或超级计算机吗?这就是为大孩子们准备的 DIY 创客工具包。
|
||||
|
||||
原始的组件使孩子们可以尝试并运用他们的想象力。DIY 创客工具包可以完全针对接收者定制。可以放入一些接受这份礼品的人可能从未想到过用之发挥创意的某些组件,例如为下水道提供一些 LED 或木工结构。
|
||||
|
||||
**费用:**不等
|
||||
|
||||
### 启发式游戏篮
|
||||
|
||||
![Heuristic play kit][9]
|
||||
|
||||
**年龄:** 8 个月至 5 岁
|
||||
|
||||
**这是什么:**启发式游戏篮充满了由天然、无毒材料制成的有趣物品,可供婴幼儿使用其五种感官进行探索。这是一种开放式、自娱自乐的游戏。其想法是,成年人将监督(但不指导)儿童使用篮子及其物品半小时,然后将篮子拿走,等下一次再玩。
|
||||
|
||||
创建带有常见家用物品的可爱游戏篮很容易。尝试包括质地、声音、气味、形状和重量各不相同的物品。这里有一些想法可以帮助您入门。
|
||||
|
||||
* 漏勺或脊状柳条篮可容纳所有物品
|
||||
* 木勺子
|
||||
* 金属打蛋器和汤匙
|
||||
* 板刷
|
||||
* 海绵
|
||||
* 小型鸡蛋纸箱
|
||||
* 纸板管
|
||||
* 小擀面杖
|
||||
* 带纹理的毛巾
|
||||
* 岩石
|
||||
* 手铃
|
||||
* 钩针桌巾
|
||||
* 带盖的小铁罐
|
||||
|
||||
游戏篮中不应包括任何容易破碎的东西或足够小到可以装入纸巾卷的东西,因为它们有窒息危险,应将所有物品彻底清洁后再交给孩子。
|
||||
|
||||
**我为什么喜欢它:**游戏篮非常适合感官发育,并可以帮助幼儿提出问题和探索周围的世界。这是培养创客思维方式的重要组成部分!
|
||||
|
||||
很容易获得适合这个游戏篮的物品。你可能已经在家中或附近的二手商店里找到了很多有趣的物品。幼儿使用游戏篮的方式与婴儿不同。随着孩子们开始模仿成人生活并通过他们的游戏讲故事,这些物品将随孩子一起成长。
|
||||
|
||||
**费用:**不等
|
||||
|
||||
### 《Hello Ruby》
|
||||
|
||||
![Hello Ruby book cover][10]
|
||||
|
||||
**年龄**:5-8 岁
|
||||
|
||||
**这是什么:** 《[Hello Ruby][11]:编码历险记》是 Linda Liukas 的插图书,通过有趣的故事讲述了一个遇到各种问题和朋友(每个都用一个码代表)的女孩,向孩子们介绍了编程概念。Liukas 还有其他副标题为《互联网探险》和《计算机内的旅程》的《Hello Ruby》系列书籍,而《编码历险记》已以 20 多种语言出版。
|
||||
|
||||
**为什么我喜欢它:**作者在书中附带了许多免费、有趣和无障碍的活动,可以从 Hello Ruby 网站下载和打印这些活动。这些活动教授编码概念、还涉及艺术表达、沟通、甚至时间安排。
|
||||
|
||||
**费用:**精装书的标价为 17.99 美元,但你可以通过本地或在线书店以较低的价格买到这本书。
|
||||
|
||||
### 《编程少女:学会编程和改变世界》
|
||||
|
||||
![Girls Who Code book cover][12]
|
||||
|
||||
**年龄**:10 岁 - 成人
|
||||
|
||||
**内容是什么:**由《编程少女》的创始人 Reshma Saujani 撰写,《[编程少女:学会编程和改变世界][13]》为年轻女孩(以及男孩)提供了科技领域的实用信息。它涵盖了广泛的主题,包括编程语言、用例、术语和词汇、职业选择以及技术行业人士的个人简介和访谈。
|
||||
|
||||
**为什么我喜欢它:**本书以讲述了大多数面向成年人的网站都没有的技术故事。这些技术涉及许多学科,对于年轻人来说,重要的是要了解他们可以使用它来解决现实世界中的问题并有所作为。
|
||||
|
||||
**成本:**精装书的标价为 17.99 美元,平装书的标价为 10.99 美元,但你可以通过本地或在线书店以更低的价格找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/maker-gifts-kids
|
||||
|
||||
作者:[Jess Weichler][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cyanide-cupcake
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_gift_giveaway_box_520x292.png?itok=w1YQhNH1 (Gift box opens with colors coming out)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/hummingbird.png (Hummingbird Robotics Kit)
|
||||
[3]: https://www.birdbraintechnologies.com/hummingbirdbit/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/makeymakey2.jpg (Makey Makey Classic)
|
||||
[5]: https://makeymakey.com/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/arduinouno.jpg (Arduino Uno)
|
||||
[7]: https://www.arduino.cc/
|
||||
[8]: https://opensource.com/sites/default/files/makerbox-makerkit.jpg (A maker kit assembled in a quick trip to the hardware store)
|
||||
[9]: https://opensource.com/sites/default/files/makerbox-sensorykit.jpg (Heuristic play kit)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/helloruby2.jpg (Hello Ruby book cover)
|
||||
[11]: https://www.helloruby.com/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/girlswhocodebook.jpg (Girls Who Code book cover)
|
||||
[13]: https://girlswhocode.com/book/girls-code-learn-code-change-world/
|
||||
@ -0,0 +1,504 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11790-1.html)
|
||||
[#]: subject: (Add jumping to your Python platformer game)
|
||||
[#]: via: (https://opensource.com/article/19/12/jumping-python-platformer-game)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
为你的 Python 平台类游戏添加跳跃功能
|
||||
======
|
||||
|
||||
> 在本期使用 Python Pygame 模块编写视频游戏中,学会如何使用跳跃来对抗重力。
|
||||
|
||||

|
||||
|
||||
在本系列的 [前一篇文章][2] 中,你已经模拟了重力。但现在,你需要赋予你的角色跳跃的能力来对抗重力。
|
||||
|
||||
跳跃是对重力作用的暂时延缓。在这一小段时间里,你是向*上*跳,而不是被重力拉着向下落。但你一旦到达了跳跃的最高点,重力就会重新发挥作用,将你拉回地面。
|
||||
|
||||
在代码中,这种变化被表示为变量。首先,你需要为玩家精灵建立一个变量,使得 Python 能够跟踪该精灵是否正在跳跃中。一旦玩家精灵开始跳跃,他就会再次受到重力的作用,并被拉回最近的物体。
|
||||
|
||||
### 设置跳跃状态变量
|
||||
|
||||
你需要为你的 `Player` 类添加两个新变量:
|
||||
|
||||
* 一个是为了跟踪你的角色是否正在跳跃中,可通过你的玩家精灵是否站在坚实的地面来确定
|
||||
* 一个是为了将玩家带回地面
|
||||
|
||||
将如下两个变量添加到你的 `Player` 类中。在下方的代码中,注释前的部分用于提示上下文,因此只需要添加最后两行:
|
||||
|
||||
```
|
||||
self.movex = 0
|
||||
self.movey = 0
|
||||
self.frame = 0
|
||||
self.health = 10
|
||||
# 此处是重力相关变量
|
||||
self.collide_delta = 0
|
||||
self.jump_delta = 6
|
||||
```
|
||||
|
||||
第一个变量 `collide_delta` 被设为 0 是因为在正常状态下,玩家精灵没有处在跳跃中的状态。另一个变量 `jump_delta` 被设为 6,是为了防止精灵在第一次进入游戏世界时就发生反弹(实际上就是跳跃)。当你完成了本篇文章的示例,尝试把该变量设为 0 看看会发生什么。
|
||||
|
||||
### 跳跃中的碰撞
|
||||
|
||||
如果你是跳到一个蹦床上,那你的跳跃一定非常优美。但是如果你是跳向一面墙会发生什么呢?(千万不要去尝试!)不管你的起跳多么令人印象深刻,当你撞到比你更大更硬的物体时,你都会立马停下。(LCTT 译注:原理参考动量守恒定律)
|
||||
|
||||
为了在你的视频游戏中模拟这一点,你需要在你的玩家精灵与地面等东西发生碰撞时,将 `self.collide_delta` 变量设为 0。如果你的 `self.collide_delta` 不是 0 而是其它的什么值,那么你的玩家就会发生跳跃,并且当你的玩家与墙或者地面发生碰撞时无法跳跃。
|
||||
|
||||
在你的 `Player` 类的 `update` 方法中,将地面碰撞相关代码块修改为如下所示:
|
||||
|
||||
```
|
||||
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
|
||||
for g in ground_hit_list:
|
||||
self.movey = 0
|
||||
self.rect.y = worldy-ty-ty
|
||||
self.collide_delta = 0 # 停止跳跃
|
||||
if self.rect.y > g.rect.y:
|
||||
self.health -=1
|
||||
print(self.health)
|
||||
```
|
||||
|
||||
这段代码块检查了地面精灵和玩家精灵之间发生的碰撞。当发生碰撞时,它会将玩家 Y 方向的坐标值设置为游戏窗口的高度减去一个瓷砖的高度再减去另一个瓷砖的高度。以此保证了玩家精灵是站在地面*上*,而不是嵌在地面里。同时它也将 `self.collide_delta` 设为 0,使得程序能够知道玩家未处在跳跃中。除此之外,它将 `self.movey` 设为 0,使得程序能够知道玩家当前未受到重力的牵引作用(这是游戏物理引擎的奇怪之处,一旦玩家落地,也就没有必要继续将玩家拉向地面)。
|
||||
|
||||
此处 `if` 语句用来检测玩家是否已经落到地面之*下*,如果是,那就扣除一点生命值作为惩罚。此处假定了你希望当你的玩家落到地图之外时失去生命值。这个设定不是必需的,它只是平台类游戏的一种惯例。更有可能的是,你希望这个事件能够触发另一些事件,或者说是一种能够让你的现实世界玩家沉迷于让精灵掉到屏幕之外的东西。一种简单的恢复方式是在玩家精灵掉落到地图之外时,将 `self.rect.y` 重新设置为 0,这样它就会在地图上方重新生成,并落到坚实的地面上。
|
||||
|
||||
### 撞向地面
|
||||
|
||||
模拟的重力使你玩家的 Y 坐标不断增大(LCTT 译注:此处原文中为 0,但在 Pygame 中越靠下方 Y 坐标应越大)。要实现跳跃,完成如下代码使你的玩家精灵离开地面,飞向空中。
|
||||
|
||||
在你的 `Player` 类的 `update` 方法中,添加如下代码来暂时延缓重力的作用:
|
||||
|
||||
```
|
||||
if self.collide_delta < 6 and self.jump_delta < 6:
|
||||
self.jump_delta = 6*2
|
||||
self.movey -= 33 # 跳跃的高度
|
||||
self.collide_delta += 6
|
||||
self.jump_delta += 6
|
||||
```
|
||||
|
||||
根据此代码所示,跳跃使玩家精灵向空中移动了 33 个像素。此处是*负* 33 是因为在 Pygame 中,越小的数代表距离屏幕顶端越近。
|
||||
|
||||
不过此事件视条件而定,只有当 `self.collide_delta` 小于 6(缺省值定义在你 `Player` 类的 `init` 方法中)并且 `self.jump_delta` 也于 6 的时候才会发生。此条件能够保证直到玩家碰到一个平台,才能触发另一次跳跃。换言之,它能够阻止空中二段跳。
|
||||
|
||||
在某些特殊条件下,你可能不想阻止空中二段跳,或者说你允许玩家进行空中二段跳。举个栗子,如果玩家获得了某个战利品,那么在他被敌人攻击到之前,都能够拥有空中二段跳的能力。
|
||||
|
||||
当你完成本篇文章中的示例,尝试将 `self.collide_delta` 和 `self.jump_delta` 设置为 0,从而获得百分之百的几率触发空中二段跳。
|
||||
|
||||
### 在平台上着陆
|
||||
|
||||
目前你已经定义了在玩家精灵摔落地面时的抵抗重力条件,但此时你的游戏代码仍保持平台与地面置于不同的列表中(就像本文中做的很多其他选择一样,这个设定并不是必需的,你可以尝试将地面作为另一种平台)。为了允许玩家精灵站在平台之上,你必须像检测地面碰撞一样,检测玩家精灵与平台精灵之间的碰撞。将如下代码放于你的 `update` 方法中:
|
||||
|
||||
```
|
||||
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
|
||||
for p in plat_hit_list:
|
||||
self.collide_delta = 0 # 跳跃结束
|
||||
self.movey = 0
|
||||
```
|
||||
|
||||
但此处还有一点需要考虑:平台悬在空中,也就意味着玩家可以通过从上面或者从下面接触平台来与之互动。
|
||||
|
||||
确定平台如何与玩家互动取决于你,阻止玩家从下方到达平台也并不稀奇。将如下代码加到上方的代码块中,使得平台表现得像天花板或者说是藤架。只有在玩家精灵跳得比平台上沿更高时才能跳到平台上,但会阻止玩家从平台下方跳上来:
|
||||
|
||||
```
|
||||
if self.rect.y > p.rect.y:
|
||||
self.rect.y = p.rect.y+ty
|
||||
else:
|
||||
self.rect.y = p.rect.y-ty
|
||||
```
|
||||
|
||||
此处 `if` 语句代码块的第一个子句阻止玩家精灵从平台正下方跳到平台上。如果它检测到玩家精灵的坐标比平台更大(在 Pygame 中,坐标更大意味着在屏幕的更下方),那么将玩家精灵新的 Y 坐标设置为当前平台的 Y 坐标加上一个瓷砖的高度。实际效果就是保证玩家精灵距离平台一个瓷砖的高度,防止其从下方穿过平台。
|
||||
|
||||
`else` 子句做了相反的事情。当程序运行到此处时,如果玩家精灵的 Y 坐标*不*比平台的更大,意味着玩家精灵是从空中落下(不论是由于玩家刚刚从此处生成,或者是玩家执行了跳跃)。在这种情况下,玩家精灵的 Y 坐标被设为平台的 Y 坐标减去一个瓷砖的高度(切记,在 Pygame 中更小的 Y 坐标代表在屏幕上的更高处)。这样就能保证玩家在平台*上*,除非他从平台上跳下来或者走下来。
|
||||
|
||||
你也可以尝试其他的方式来处理玩家与平台之间的互动。举个栗子,也许玩家精灵被设定为处在平台的“前面”,他能够无障碍地跳跃穿过平台并站在上面。或者你可以设计一种平台会减缓而又不完全阻止玩家的跳跃过程。甚至你可以通过将不同平台分到不同列表中来混合搭配使用。
|
||||
|
||||
### 触发一次跳跃
|
||||
|
||||
目前为此,你的代码已经模拟了所有必需的跳跃条件,但仍缺少一个跳跃触发器。你的玩家精灵的 `self.jump_delta` 初始值被设置为 6,只有当它比 6 小的时候才会触发更新跳跃的代码。
|
||||
|
||||
为跳跃变量设置一个新的设置方法,在你的 `Player` 类中创建一个 `jump` 方法,并将 `self.jump_delta` 设为小于 6 的值。通过使玩家精灵向空中移动 33 个像素,来暂时减缓重力的作用。
|
||||
|
||||
|
||||
```
|
||||
def jump(self,platform_list):
|
||||
self.jump_delta = 0
|
||||
```
|
||||
|
||||
不管你相信与否,这就是 `jump` 方法的全部。剩余的部分在 `update` 方法中,你已经在前面实现了相关代码。
|
||||
|
||||
要使你游戏中的跳跃功能生效,还有最后一件事情要做。如果你想不起来是什么,运行游戏并观察跳跃是如何生效的。
|
||||
|
||||
问题就在于你的主循环中没有调用 `jump` 方法。先前你已经为该方法创建了一个按键占位符,现在,跳跃键所做的就是将 `jump` 打印到终端。
|
||||
|
||||
### 调用 jump 方法
|
||||
|
||||
在你的主循环中,将*上*方向键的效果从打印一条调试语句,改为调用 `jump` 方法。
|
||||
|
||||
注意此处,与 `update` 方法类似,`jump` 方法也需要检测碰撞,因此你需要告诉它使用哪个 `plat_list`。
|
||||
|
||||
```
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
player.jump(plat_list)
|
||||
```
|
||||
|
||||
如果你倾向于使用空格键作为跳跃键,使用 `pygame.K_SPACE` 替代 `pygame.K_UP` 作为按键。另一种选择,你可以同时使用两种方式(使用单独的 `if` 语句),给玩家多一种选择。
|
||||
|
||||
现在来尝试你的游戏吧!在下一篇文章中,你将让你的游戏卷动起来。
|
||||
|
||||
![Pygame 平台类游戏][3]
|
||||
|
||||
以下是目前为止的所有代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# draw a world
|
||||
# add a player and player control
|
||||
# add player movement
|
||||
# add enemy and basic collision
|
||||
# add platform
|
||||
# add gravity
|
||||
# add jumping
|
||||
|
||||
# GNU All-Permissive License
|
||||
# Copying and distribution of this file, with or without modification,
|
||||
# are permitted in any medium without royalty provided the copyright
|
||||
# notice and this notice are preserved. This file is offered as-is,
|
||||
# without any warranty.
|
||||
|
||||
import pygame
|
||||
import sys
|
||||
import os
|
||||
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
class Platform(pygame.sprite.Sprite):
|
||||
# x 坐标,y 坐标,图像宽度,图像高度,图像文件
|
||||
def __init__(self,xloc,yloc,imgw,imgh,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img)).convert()
|
||||
self.image.convert_alpha()
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.y = yloc
|
||||
self.rect.x = xloc
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
生成一个玩家
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0
|
||||
self.movey = 0
|
||||
self.frame = 0
|
||||
self.health = 10
|
||||
self.collide_delta = 0
|
||||
self.jump_delta = 6
|
||||
self.score = 1
|
||||
self.images = []
|
||||
for i in range(1,9):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha()
|
||||
img.set_colorkey(ALPHA)
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
def jump(self,platform_list):
|
||||
self.jump_delta = 0
|
||||
|
||||
def gravity(self):
|
||||
self.movey += 3.2 # how fast player falls
|
||||
|
||||
if self.rect.y > worldy and self.movey >= 0:
|
||||
self.movey = 0
|
||||
self.rect.y = worldy-ty
|
||||
|
||||
def control(self,x,y):
|
||||
'''
|
||||
控制玩家移动
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
更新精灵位置
|
||||
'''
|
||||
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
|
||||
# 向左移动
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > ani*3:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# 向右移动
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > ani*3:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
|
||||
# 碰撞
|
||||
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
|
||||
for enemy in enemy_hit_list:
|
||||
self.health -= 1
|
||||
#print(self.health)
|
||||
|
||||
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
|
||||
for p in plat_hit_list:
|
||||
self.collide_delta = 0 # stop jumping
|
||||
self.movey = 0
|
||||
if self.rect.y > p.rect.y:
|
||||
self.rect.y = p.rect.y+ty
|
||||
else:
|
||||
self.rect.y = p.rect.y-ty
|
||||
|
||||
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
|
||||
for g in ground_hit_list:
|
||||
self.movey = 0
|
||||
self.rect.y = worldy-ty-ty
|
||||
self.collide_delta = 0 # stop jumping
|
||||
if self.rect.y > g.rect.y:
|
||||
self.health -=1
|
||||
print(self.health)
|
||||
|
||||
if self.collide_delta < 6 and self.jump_delta < 6:
|
||||
self.jump_delta = 6*2
|
||||
self.movey -= 33 # how high to jump
|
||||
self.collide_delta += 6
|
||||
self.jump_delta += 6
|
||||
|
||||
class Enemy(pygame.sprite.Sprite):
|
||||
'''
|
||||
生成一个敌人
|
||||
'''
|
||||
def __init__(self,x,y,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img))
|
||||
self.movey = 0
|
||||
#self.image.convert_alpha()
|
||||
#self.image.set_colorkey(ALPHA)
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.x = x
|
||||
self.rect.y = y
|
||||
self.counter = 0
|
||||
|
||||
|
||||
def move(self):
|
||||
'''
|
||||
敌人移动
|
||||
'''
|
||||
distance = 80
|
||||
speed = 8
|
||||
|
||||
self.movey += 3.2
|
||||
|
||||
if self.counter >= 0 and self.counter <= distance:
|
||||
self.rect.x += speed
|
||||
elif self.counter >= distance and self.counter <= distance*2:
|
||||
self.rect.x -= speed
|
||||
else:
|
||||
self.counter = 0
|
||||
|
||||
self.counter += 1
|
||||
|
||||
if not self.rect.y >= worldy-ty-ty:
|
||||
self.rect.y += self.movey
|
||||
|
||||
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
|
||||
for p in plat_hit_list:
|
||||
self.movey = 0
|
||||
if self.rect.y > p.rect.y:
|
||||
self.rect.y = p.rect.y+ty
|
||||
else:
|
||||
self.rect.y = p.rect.y-ty
|
||||
|
||||
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
|
||||
for g in ground_hit_list:
|
||||
self.rect.y = worldy-ty-ty
|
||||
|
||||
|
||||
class Level():
|
||||
def bad(lvl,eloc):
|
||||
if lvl == 1:
|
||||
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # 生成敌人
|
||||
enemy_list = pygame.sprite.Group() # 创建敌人组
|
||||
enemy_list.add(enemy) # 将敌人添加到敌人组
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return enemy_list
|
||||
|
||||
def loot(lvl,lloc):
|
||||
print(lvl)
|
||||
|
||||
def ground(lvl,gloc,tx,ty):
|
||||
ground_list = pygame.sprite.Group()
|
||||
i=0
|
||||
if lvl == 1:
|
||||
while i < len(gloc):
|
||||
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
|
||||
ground_list.add(ground)
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return ground_list
|
||||
|
||||
def platform(lvl,tx,ty):
|
||||
plat_list = pygame.sprite.Group()
|
||||
ploc = []
|
||||
i=0
|
||||
if lvl == 1:
|
||||
ploc.append((0,worldy-ty-128,3))
|
||||
ploc.append((300,worldy-ty-256,3))
|
||||
ploc.append((500,worldy-ty-128,4))
|
||||
|
||||
while i < len(ploc):
|
||||
j=0
|
||||
while j <= ploc[i][2]:
|
||||
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'ground.png')
|
||||
plat_list.add(plat)
|
||||
j=j+1
|
||||
print('run' + str(i) + str(ploc[i]))
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return plat_list
|
||||
|
||||
'''
|
||||
Setup
|
||||
'''
|
||||
worldx = 960
|
||||
worldy = 720
|
||||
|
||||
fps = 40 # 帧率
|
||||
ani = 4 # 动画循环
|
||||
clock = pygame.time.Clock()
|
||||
pygame.init()
|
||||
main = True
|
||||
|
||||
BLUE = (25,25,200)
|
||||
BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
ALPHA = (0,255,0)
|
||||
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = world.get_rect()
|
||||
player = Player() # 生成玩家
|
||||
player.rect.x = 0
|
||||
player.rect.y = 0
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # how fast to move
|
||||
jump = -24
|
||||
|
||||
eloc = []
|
||||
eloc = [200,20]
|
||||
gloc = []
|
||||
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
|
||||
tx = 64 # 瓷砖尺寸
|
||||
ty = 64 # 瓷砖尺寸
|
||||
|
||||
i=0
|
||||
while i <= (worldx/tx)+tx:
|
||||
gloc.append(i*tx)
|
||||
i=i+1
|
||||
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
ground_list = Level.ground( 1,gloc,tx,ty )
|
||||
plat_list = Level.platform( 1,tx,ty )
|
||||
|
||||
'''
|
||||
主循环
|
||||
'''
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print("LEFT")
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print("RIGHT")
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
player.jump(plat_list)
|
||||
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
|
||||
# world.fill(BLACK)
|
||||
world.blit(backdrop, backdropbox)
|
||||
player.gravity() # 检查重力
|
||||
player.update()
|
||||
player_list.draw(world) # 刷新玩家位置
|
||||
enemy_list.draw(world) # 刷新敌人
|
||||
ground_list.draw(world) # 刷新地面
|
||||
plat_list.draw(world) # 刷新平台
|
||||
for e in enemy_list:
|
||||
e.move()
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
本期是使用 [Pygame][5] 模块在 [Python 3][4] 中创建视频游戏连载系列的第 7 期。往期文章为:
|
||||
|
||||
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程][6]
|
||||
* [使用 Python 和 Pygame 模块构建一个游戏框架][7]
|
||||
* [如何在你的 Python 游戏中添加一个玩家][8]
|
||||
* [用 Pygame 使你的游戏角色移动起来][9]
|
||||
* [如何向你的 Python 游戏中添加一个敌人][10]
|
||||
* [在 Pygame 游戏中放置平台][11]
|
||||
* [在你的 Python 游戏中模拟引力][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/jumping-python-platformer-game
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/arcade_game_gaming.jpg?itok=84Rjk_32 (Arcade games)
|
||||
[2]: https://linux.cn/article-11780-1.html
|
||||
[3]: https://opensource.com/sites/default/files/uploads/pygame-jump.jpg (Pygame platformer)
|
||||
[4]: https://www.python.org/
|
||||
[5]: https://www.pygame.org/
|
||||
[6]: https://linux.cn/article-9071-1.html
|
||||
[7]: https://linux.cn/article-10850-1.html
|
||||
[8]: https://linux.cn/article-10858-1.html
|
||||
[9]: https://linux.cn/article-10874-1.html
|
||||
[10]: https://linux.cn/article-10883-1.html
|
||||
[11]: https://linux.cn/article-10902-1.html
|
||||
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11814-1.html)
|
||||
[#]: subject: (What's your favorite terminal emulator?)
|
||||
[#]: via: (https://opensource.com/article/19/12/favorite-terminal-emulator)
|
||||
[#]: author: (Opensource.com https://opensource.com/users/admin)
|
||||
|
||||
你最喜欢的终端模拟器是什么?
|
||||
======
|
||||
|
||||
> 我们让社区讲述他们在终端仿真器方面的经验。以下是我们收到的一些回复。
|
||||
|
||||

|
||||
|
||||
终端仿真器的偏好可以说明一个人的工作流程。无鼠标操作能力是否必须具备?你想要标签页还是窗口?对于终端仿真器你还有什么选择的原因?是否有酷的因素?欢迎参加调查或给我们留下评论,告诉我们你最喜欢的终端模拟器。你尝试过多少种终端仿真器呢?
|
||||
|
||||
我们让社区讲述他们在终端仿真器方面的经验。以下是我们收到的一些回复。
|
||||
|
||||
“我最喜欢的终端仿真器是用 Powerline 定制的 Tilix。我喜欢它支持在一个窗口中打开多个终端。” —Dan Arel
|
||||
|
||||
“[urxvt][2]。它可以通过文件简单配置,轻巧,并且在大多数程序包管理器存储库中都很容易找到。” —Brian Tomlinson
|
||||
|
||||
“即使我不再使用 GNOME,gnome-terminal 仍然是我的首选。:)” —Justin W. Flory
|
||||
|
||||
“现在 FC31 上的 Terminator。我刚刚开始使用它,我喜欢它的分屏功能,对我来说感觉很轻巧。我正在研究它的插件。” —Marc Maxwell
|
||||
|
||||
“不久前,我切换到了 Tilix,它完成了我需要终端执行的所有工作。:) 多个窗格、通知,很精简,用来运行我的 tmux 会话很棒。” —Kevin Fenzi
|
||||
|
||||
“alacritty。它针对速度进行了优化,是用 Rust 实现的,并且具有很多常规功能,但是老实说,我只关心一个功能:可配置的字形间距,使我可以进一步压缩字体。” —Alexander Sosedkin
|
||||
|
||||
“我是个老古板:KDE Konsole。如果是远程会话,请使用 tmux。” —Marcin Juszkiewicz
|
||||
|
||||
“在 macOS 上用 iTerm2。是的,它是开源的。:-) 在 Linux 上是 Terminator。” —Patrick Mullins
|
||||
|
||||
“我现在已经使用 alacritty 一两年了,但是最近我在全屏模式下使用 cool-retro-term,因为我必须运行一个输出内容有很多的脚本,而它看起来很酷,让我感觉很酷。这对我很重要。” —Nick Childers
|
||||
|
||||
“我喜欢 Tilix,部分是因为它擅长免打扰(我通常全屏运行它,里面是 tmux),而且还提供自定义热链接支持:在我的终端中,像 ‘rhbz#1234’ 之类的文本是将我带到 Bugzilla 的热链接。类似的还有 LaunchPad 提案,OpenStack 的 Gerrit 更改 ID 等。” —Lars Kellogg-Stedman
|
||||
|
||||
“Eterm,在使用 Vintage 配置文件的 cool-retro-term 中,演示效果也最好。” —Ivan Horvath
|
||||
|
||||
“Tilix +1。这是 GNOME 用户最好的选择,我是这么觉得的!” —Eric Rich
|
||||
|
||||
“urxvt。快速、小型、可配置、可通过 Perl 插件扩展,这使其可以无鼠标操作。” —Roman Dobosz
|
||||
|
||||
“Konsole 是最好的,也是 KDE 项目中我唯一使用的应用程序。所有搜索结果都高亮显示是一个杀手级功能,据我所知没有任何其它 Linux 终端有这个功能(如果能证明我错了,那我也很高兴)。最适合搜索编译错误和输出日志。” —Jan Horak
|
||||
|
||||
“我过去经常使用 Terminator。现在我在 Tilix 中克隆了它的主题(深色主题),而感受一样好。它可以在选项卡之间轻松移动。就是这样。” —Alberto Fanjul Alonso
|
||||
|
||||
“我开始使用的是 Terminator,自从差不多过去这三年,我已经完全切换到 Tilix。” —Mike Harris
|
||||
|
||||
“我使用下拉式终端 X。这是 GNOME 3 的一个非常简单的扩展,使我始终可以通过一个按键(对于我来说是`F12`)拉出一个终端。它还支持制表符,这正是我所需要的。 ” —Germán Pulido
|
||||
|
||||
“xfce4-terminal:支持 Wayland、缩放、无边框、无标题栏、无滚动条 —— 这就是我在 tmux 之外全部想要的终端仿真器的功能。我希望我的终端仿真器可以尽可能多地使用屏幕空间,我通常在 tmux 窗格中并排放着编辑器(Vim)和 repl。” —Martin Kourim
|
||||
|
||||
“别问,问就是 Fish ! ;-)” —Eric Schabell
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/favorite-terminal-emulator
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/admin
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_terminals_0.png?itok=XwIRERsn (Terminal window with green text)
|
||||
[2]: https://opensource.com/article/19/10/why-use-rxvt-terminal
|
||||
@ -0,0 +1,320 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11778-1.html)
|
||||
[#]: subject: (Lessons learned from programming in Go)
|
||||
[#]: via: (https://opensource.com/article/19/12/go-common-pitfalls)
|
||||
[#]: author: (Eduardo Ferreira https://opensource.com/users/edufgf)
|
||||
|
||||
Go 并发编程中的经验教训
|
||||
======
|
||||
|
||||
> 通过学习如何定位并发处理的陷阱来避免未来处理这些问题时的困境。
|
||||
|
||||

|
||||
|
||||
在复杂的分布式系统进行任务处理时,你通常会需要进行并发的操作。在 [Mode.net][2] 公司,我们每天都要和实时、快速和灵活的软件打交道。而没有一个高度并发的系统,就不可能构建一个毫秒级的动态地路由数据包的全球专用网络。这个动态路由是基于网络状态的,尽管这个过程需要考虑众多因素,但我们的重点是链路指标。在我们的环境中,链路指标可以是任何跟网络链接的状态和当前属性(如链接延迟)有关的任何内容。
|
||||
|
||||
### 并发探测链接监控
|
||||
|
||||
我们的动态路由算法 [H.A.L.O.][4](<ruby>逐跳自适应链路状态最佳路由<rt>Hop-by-Hop Adaptive Link-State Optimal Routing</rt></ruby>)部分依赖于链路指标来计算路由表。这些指标由位于每个 PoP(<ruby>存活节点<rt>Point of Presence</rt></ruby>)上的独立组件收集。PoP 是表示我们的网络中单个路由实体的机器,通过链路连接并分布在我们的网络拓扑中的各个位置。某个组件使用网络数据包探测周围的机器,周围的机器回复数据包给前者。从接收到的探测包中可以获得链路延迟。由于每个 PoP 都有不止一个临近节点,所以这种探测任务实质上是并发的:我们需要实时测量每个临近连接点的延迟。我们不能串行地处理;为了计算这个指标,必须尽快处理每个探测。
|
||||
|
||||
![latency computation graph][6]
|
||||
|
||||
### 序列号和重置:一个重新排列场景
|
||||
|
||||
我们的探测组件互相发送和接收数据包,并依靠序列号进行数据包处理。这旨在避免处理重复的包或顺序被打乱的包。我们的第一个实现依靠特殊的序列号 0 来重置序列号。这个数字仅在组件初始化时使用。主要的问题是我们考虑了递增的序列号总是从 0 开始。在该组件重启后,包的顺序可能会重新排列,某个包的序列号可能会轻易地被替换成重置之前使用过的值。这意味着,后继的包都会被忽略掉,直到排到重置之前用到的序列值。
|
||||
|
||||
### UDP 握手和有限状态机
|
||||
|
||||
这里的问题是该组件重启前后的序列号是否一致。有几种方法可以解决这个问题,经过讨论,我们选择了实现一个带有清晰状态定义的三步握手协议。这个握手过程在初始化时通过链接建立会话。这样可以确保节点通过同一个会话进行通信且使用了适当的序列号。
|
||||
|
||||
为了正确实现这个过程,我们必须定义一个有清晰状态和过渡的有限状态机。这样我们就可以正确管理握手过程中的所有极端情况。
|
||||
|
||||
![finite state machine diagram][7]
|
||||
|
||||
会话 ID 由握手的初始化程序生成。一个完整的交换顺序如下:
|
||||
|
||||
1. 发送者发送一个 `SYN(ID)` 数据包。
|
||||
2. 接收者存储接收到的 `ID` 并发送一个 `SYN-ACK(ID)`。
|
||||
3. 发送者接收到 `SYN-ACK(ID)` 并发送一个 `ACK(ID)`。它还发送一个从序列号 0 开始的数据包。
|
||||
4. 接收者检查最后接收到的 `ID`,如果 ID 匹配,则接受 `ACK(ID)`。它还开始接受序列号为 0 的数据包。
|
||||
|
||||
### 处理状态超时
|
||||
|
||||
基本上,每种状态下你都需要处理最多三种类型的事件:链接事件、数据包事件和超时事件。这些事件会并发地出现,因此你必须正确处理并发。
|
||||
|
||||
* 链接事件包括网络连接或网络断开的变化,相应的初始化一个链接会话或断开一个已建立的会话。
|
||||
* 数据包事件是控制数据包(`SYN`/`SYN-ACK`/`ACK`)或只是探测响应。
|
||||
* 超时事件在当前会话状态的预定超时时间到期后触发。
|
||||
|
||||
这里面临的最主要的问题是如何处理并发的超时到期和其他事件。这里很容易陷入死锁和资源竞争的陷阱。
|
||||
|
||||
### 第一种方法
|
||||
|
||||
本项目使用的语言是 [Golang][8]。它确实提供了原生的同步机制,如自带的通道和锁,并且能够使用轻量级线程来进行并发处理。
|
||||
|
||||
![gophers hacking together][9]
|
||||
|
||||
*gopher 们聚众狂欢*
|
||||
|
||||
首先,你可以设计两个分别表示我们的会话和超时处理程序的结构体。
|
||||
|
||||
```go
|
||||
type Session struct {
|
||||
State SessionState
|
||||
Id SessionId
|
||||
RemoteIp string
|
||||
}
|
||||
|
||||
type TimeoutHandler struct {
|
||||
callback func(Session)
|
||||
session Session
|
||||
duration int
|
||||
timer *timer.Timer
|
||||
}
|
||||
```
|
||||
|
||||
`Session` 标识连接会话,内有表示会话 ID、临近的连接点的 IP 和当前会话状态的字段。
|
||||
|
||||
`TimeoutHandler` 包含回调函数、对应的会话、持续时间和指向调度计时器的指针。
|
||||
|
||||
每一个临近连接点的会话都包含一个保存调度 `TimeoutHandler` 的全局映射。
|
||||
|
||||
```
|
||||
SessionTimeout map[Session]*TimeoutHandler
|
||||
```
|
||||
|
||||
下面方法注册和取消超时:
|
||||
|
||||
```go
|
||||
// schedules the timeout callback function.
|
||||
func (timeout* TimeoutHandler) Register() {
|
||||
timeout.timer = time.AfterFunc(time.Duration(timeout.duration) * time.Second, func() {
|
||||
timeout.callback(timeout.session)
|
||||
})
|
||||
}
|
||||
|
||||
func (timeout* TimeoutHandler) Cancel() {
|
||||
if timeout.timer == nil {
|
||||
return
|
||||
}
|
||||
timeout.timer.Stop()
|
||||
}
|
||||
```
|
||||
|
||||
你可以使用类似下面的方法来创建和存储超时:
|
||||
|
||||
```go
|
||||
func CreateTimeoutHandler(callback func(Session), session Session, duration int) *TimeoutHandler {
|
||||
if sessionTimeout[session] == nil {
|
||||
sessionTimeout[session] := new(TimeoutHandler)
|
||||
}
|
||||
|
||||
timeout = sessionTimeout[session]
|
||||
timeout.session = session
|
||||
timeout.callback = callback
|
||||
timeout.duration = duration
|
||||
return timeout
|
||||
}
|
||||
```
|
||||
|
||||
超时处理程序创建后,会在经过了设置的 `duration` 时间(秒)后执行回调函数。然而,有些事件会使你重新调度一个超时处理程序(与 `SYN` 状态时的处理一样,每 3 秒一次)。
|
||||
|
||||
为此,你可以让回调函数重新调度一次超时:
|
||||
|
||||
```go
|
||||
func synCallback(session Session) {
|
||||
sendSynPacket(session)
|
||||
|
||||
// reschedules the same callback.
|
||||
newTimeout := NewTimeoutHandler(synCallback, session, SYN_TIMEOUT_DURATION)
|
||||
newTimeout.Register()
|
||||
|
||||
sessionTimeout[state] = newTimeout
|
||||
}
|
||||
```
|
||||
|
||||
这次回调在新的超时处理程序中重新调度自己,并更新全局映射 `sessionTimeout`。
|
||||
|
||||
### 数据竞争和引用
|
||||
|
||||
你的解决方案已经有了。可以通过检查计时器到期后超时回调是否执行来进行一个简单的测试。为此,注册一个超时,休眠 `duration` 秒,然后检查是否执行了回调的处理。执行这个测试后,最好取消预定的超时时间(因为它会重新调度),这样才不会在下次测试时产生副作用。
|
||||
|
||||
令人惊讶的是,这个简单的测试发现了这个解决方案中的一个问题。使用 `cancel` 方法来取消超时并没有正确处理。以下顺序的事件会导致数据资源竞争:
|
||||
|
||||
1. 你有一个已调度的超时处理程序。
|
||||
2. 线程 1:
|
||||
1. 你接收到一个控制数据包,现在你要取消已注册的超时并切换到下一个会话状态(如发送 `SYN` 后接收到一个 `SYN-ACK`)
|
||||
2. 你调用了 `timeout.Cancel()`,这个函数调用了 `timer.Stop()`。(请注意,Golang 计时器的停止不会终止一个已过期的计时器。)
|
||||
3. 线程 2:
|
||||
1. 在取消调用之前,计时器已过期,回调即将执行。
|
||||
2. 执行回调,它调度一次新的超时并更新全局映射。
|
||||
4. 线程 1:
|
||||
1. 切换到新的会话状态并注册新的超时,更新全局映射。
|
||||
|
||||
两个线程并发地更新超时映射。最终结果是你无法取消注册的超时,然后你也会丢失对线程 2 重新调度的超时的引用。这导致处理程序在一段时间内持续执行和重新调度,出现非预期行为。
|
||||
|
||||
### 锁也解决不了问题
|
||||
|
||||
使用锁也不能完全解决问题。如果你在处理所有事件和执行回调之前加锁,它仍然不能阻止一个过期的回调运行:
|
||||
|
||||
```go
|
||||
func (timeout* TimeoutHandler) Register() {
|
||||
timeout.timer = time.AfterFunc(time.Duration(timeout.duration) * time._Second_, func() {
|
||||
stateLock.Lock()
|
||||
defer stateLock.Unlock()
|
||||
|
||||
timeout.callback(timeout.session)
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
现在的区别就是全局映射的更新是同步的,但是这还是不能阻止在你调用 `timeout.Cancel()` 后回调的执行 —— 这种情况出现在调度计时器过期了但是还没有拿到锁的时候。你还是会丢失一个已注册的超时的引用。
|
||||
|
||||
### 使用取消通道
|
||||
|
||||
你可以使用取消通道,而不必依赖不能阻止到期的计时器执行的 golang 函数 `timer.Stop()`。
|
||||
|
||||
这是一个略有不同的方法。现在你可以不用再通过回调进行递归地重新调度;而是注册一个死循环,这个循环接收到取消信号或超时事件时终止。
|
||||
|
||||
新的 `Register()` 产生一个新的 go 线程,这个线程在超时后执行你的回调,并在前一个超时执行后调度新的超时。返回给调用方一个取消通道,用来控制循环的终止。
|
||||
|
||||
```go
|
||||
func (timeout *TimeoutHandler) Register() chan struct{} {
|
||||
cancelChan := make(chan struct{})
|
||||
|
||||
go func () {
|
||||
select {
|
||||
case _ = <- cancelChan:
|
||||
return
|
||||
case _ = <- time.AfterFunc(time.Duration(timeout.duration) * time.Second):
|
||||
func () {
|
||||
stateLock.Lock()
|
||||
defer stateLock.Unlock()
|
||||
|
||||
timeout.callback(timeout.session)
|
||||
} ()
|
||||
}
|
||||
} ()
|
||||
|
||||
return cancelChan
|
||||
}
|
||||
|
||||
func (timeout* TimeoutHandler) Cancel() {
|
||||
if timeout.cancelChan == nil {
|
||||
return
|
||||
}
|
||||
timeout.cancelChan <- struct{}{}
|
||||
}
|
||||
```
|
||||
|
||||
这个方法给你注册的所有超时提供了取消通道。一个取消调用向通道发送一个空结构体并触发取消操作。然而,这并不能解决前面的问题;可能在你通过通道取消之前以及超时线程拿到锁之前,超时时间就已经到了。
|
||||
|
||||
这里的解决方案是,在拿到锁**之后**,检查一下超时范围内的取消通道。
|
||||
|
||||
```go
|
||||
case _ = <- time.AfterFunc(time.Duration(timeout.duration) * time.Second):
|
||||
func () {
|
||||
stateLock.Lock()
|
||||
defer stateLock.Unlock()
|
||||
|
||||
select {
|
||||
case _ = <- handler.cancelChan:
|
||||
return
|
||||
default:
|
||||
timeout.callback(timeout.session)
|
||||
}
|
||||
} ()
|
||||
}
|
||||
```
|
||||
|
||||
最终,这可以确保在拿到锁之后执行回调,不会触发取消操作。
|
||||
|
||||
### 小心死锁
|
||||
|
||||
这个解决方案看起来有效;但是还是有个隐患:[死锁][10]。
|
||||
|
||||
请阅读上面的代码,试着自己找到它。考虑下描述的所有函数的并发调用。
|
||||
|
||||
这里的问题在取消通道本身。我们创建的是无缓冲通道,即发送的是阻塞调用。当你在一个超时处理程序中调用取消函数时,只有在该处理程序被取消后才能继续处理。问题出现在,当你有多个调用请求到同一个取消通道时,这时一个取消请求只被处理一次。当多个事件同时取消同一个超时处理程序时,如连接断开或控制包事件,很容易出现这种情况。这会导致死锁,可能会使应用程序停机。
|
||||
|
||||
![gophers on a wire, talking][11]
|
||||
|
||||
*有人在听吗?*
|
||||
|
||||
(已获得 Trevor Forrey 授权。)
|
||||
|
||||
这里的解决方案是创建通道时指定缓存大小至少为 1,这样向通道发送数据就不会阻塞,也显式地使发送变成非阻塞的,避免了并发调用。这样可以确保取消操作只发送一次,并且不会阻塞后续的取消调用。
|
||||
|
||||
```go
|
||||
func (timeout* TimeoutHandler) Cancel() {
|
||||
if timeout.cancelChan == nil {
|
||||
return
|
||||
}
|
||||
|
||||
select {
|
||||
case timeout.cancelChan <- struct{}{}:
|
||||
default:
|
||||
// can’t send on the channel, someone has already requested the cancellation.
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
在实践中你学到了并发操作时出现的常见错误。由于其不确定性,即使进行大量的测试,也不容易发现这些问题。下面是我们在最初的实现中遇到的三个主要问题:
|
||||
|
||||
#### 在非同步的情况下更新共享数据
|
||||
|
||||
这似乎是个很明显的问题,但如果并发更新发生在不同的位置,就很难发现。结果就是数据竞争,由于一个更新会覆盖另一个,因此对同一数据的多次更新中会有某些更新丢失。在我们的案例中,我们是在同时更新同一个共享映射里的调度超时引用。(有趣的是,如果 Go 检测到在同一个映射对象上的并发读写,会抛出致命错误 — 你可以尝试下运行 Go 的[数据竞争检测器](https://golang.org/doc/articles/race_detector.html))。这最终会导致丢失超时引用,且无法取消给定的超时。当有必要时,永远不要忘记使用锁。
|
||||
|
||||
![gopher assembly line][13]
|
||||
|
||||
*不要忘记同步 gopher 们的工作*
|
||||
|
||||
#### 缺少条件检查
|
||||
|
||||
在不能仅依赖锁的独占性的情况下,就需要进行条件检查。我们遇到的场景稍微有点不一样,但是核心思想跟[条件变量][14]是一样的。假设有个一个生产者和多个消费者使用一个共享队列的经典场景,生产者可以将一个元素添加到队列并唤醒所有消费者。这个唤醒调用意味着队列中的数据是可访问的,并且由于队列是共享的,消费者必须通过锁来进行同步访问。每个消费者都可能拿到锁;然而,你仍然需要检查队列中是否有元素。因为在你拿到锁的瞬间并不知道队列的状态,所以还是需要进行条件检查。
|
||||
|
||||
在我们的例子中,超时处理程序收到了计时器到期时发出的“唤醒”调用,但是它仍需要检查是否已向其发送了取消信号,然后才能继续执行回调。
|
||||
|
||||
![gopher boot camp][15]
|
||||
|
||||
*如果你要唤醒多个 gopher,可能就需要进行条件检查*
|
||||
|
||||
#### 死锁
|
||||
|
||||
当一个线程被卡住,无限期地等待一个唤醒信号,但是这个信号永远不会到达时,就会发生这种情况。死锁可以通过让你的整个程序停机来彻底杀死你的应用。
|
||||
|
||||
在我们的案例中,这种情况的发生是由于多次发送请求到一个非缓冲且阻塞的通道。这意味着向通道发送数据只有在从这个通道接收完数据后才能返回。我们的超时线程循环迅速从取消通道接收信号;然而,在接收到第一个信号后,它将跳出循环,并且再也不会从这个通道读取数据。其他的调用会一直被卡住。为避免这种情况,你需要仔细检查代码,谨慎处理阻塞调用,并确保不会发生线程饥饿。我们例子中的解决方法是使取消调用成为非阻塞调用 — 我们不需要阻塞调用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/go-common-pitfalls
|
||||
|
||||
作者:[Eduardo Ferreira][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/edufgf
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/go-golang.png?itok=OAW9BXny (Goland gopher illustration)
|
||||
[2]: http://mode.net
|
||||
[3]: https://en.wikipedia.org/wiki/Metrics_%28networking%29
|
||||
[4]: https://people.ece.cornell.edu/atang/pub/15/HALO_ToN.pdf
|
||||
[5]: https://en.wikipedia.org/wiki/Point_of_presence
|
||||
[6]: https://opensource.com/sites/default/files/uploads/image2_0_3.png (latency computation graph)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/image3_0.png (finite state machine diagram)
|
||||
[8]: https://golang.org/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/image4.png (gophers hacking together)
|
||||
[10]: https://en.wikipedia.org/wiki/Deadlock
|
||||
[11]: https://opensource.com/sites/default/files/uploads/image5_0_0.jpg (gophers on a wire, talking)
|
||||
[12]: https://golang.org/doc/articles/race_detector.html
|
||||
[13]: https://opensource.com/sites/default/files/uploads/image6.jpeg (gopher assembly line)
|
||||
[14]: https://en.wikipedia.org/wiki/Monitor_%28synchronization%29#Condition_variables
|
||||
[15]: https://opensource.com/sites/default/files/uploads/image7.png (gopher boot camp)
|
||||
@ -0,0 +1,467 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11819-1.html)
|
||||
[#]: subject: (Enable your Python game player to run forward and backward)
|
||||
[#]: via: (https://opensource.com/article/19/12/python-platformer-game-run)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使你的 Python 游戏玩家能够向前和向后跑
|
||||
======
|
||||
> 使用 Pygame 模块来使你的 Python 平台开启侧滚效果,来让你的玩家自由奔跑。
|
||||
|
||||

|
||||
|
||||
这是仍在进行中的关于使用 Pygame 模块来在 Python 3 中在创建电脑游戏的第九部分。先前的文章是:
|
||||
|
||||
* [通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程][2]
|
||||
* [使用 Python 和 Pygame 模块构建一个游戏框架][3]
|
||||
* [如何在你的 Python 游戏中添加一个玩家][4]
|
||||
* [用 Pygame 使你的游戏角色移动起来][5]
|
||||
* [如何向你的 Python 游戏中添加一个敌人][6]
|
||||
* [在 Pygame 游戏中放置平台][12]
|
||||
* [在你的 Python 游戏中模拟引力][7]
|
||||
* [为你的 Python 平台类游戏添加跳跃功能][8]
|
||||
|
||||
在这一系列关于使用 [Pygame][10] 模块来在 [Python 3][9] 中创建电脑游戏的先前文章中,你已经设计了你的关卡设计布局,但是你的关卡的一些部分可能已近超出你的屏幕的可视区域。在平台类游戏中,这个问题的普遍解决方案是,像术语“<ruby>侧滚<rt>side-scroller</rt></ruby>”表明的一样,滚动。
|
||||
|
||||
滚动的关键是当玩家精灵接近屏的幕边缘时,使在玩家精灵周围的平台移动。这样给予一种错觉,屏幕是一个在游戏世界中穿梭追拍的"摄像机"。
|
||||
|
||||
这个滚动技巧需要两个在屏幕边缘的绝对区域,在绝对区域内的点处,在世界滚动期间,你的化身静止不动。
|
||||
|
||||
### 在侧滚动条中放置卷轴
|
||||
|
||||
如果你希望你的玩家能够后退,你需要一个触发点来向前和向后。这两个点仅仅是两个变量。设置它们各个距各个屏幕边缘大约 100 或 200 像素。在你的设置部分中创建变量。在下面的代码中,前两行用于上下文说明,所以仅需要添加这行后的代码:
|
||||
|
||||
```
|
||||
player_list.add(player)
|
||||
steps = 10
|
||||
forwardX = 600
|
||||
backwardX = 230
|
||||
```
|
||||
|
||||
在主循环中,查看你的玩家精灵是否在 `forwardx` 或 `backwardx` 滚动点处。如果是这样,向左或向右移动使用的平台,取决于世界是向前或向后移动。在下面的代码中,代码的最后三行仅供你参考:
|
||||
|
||||
```
|
||||
# scroll the world forward
|
||||
if player.rect.x >= forwardx:
|
||||
scroll = player.rect.x - forwardx
|
||||
player.rect.x = forwardx
|
||||
for p in plat_list:
|
||||
p.rect.x -= scroll
|
||||
|
||||
# scroll the world backward
|
||||
if player.rect.x <= backwardx:
|
||||
scroll = backwardx - player.rect.x
|
||||
player.rect.x = backwardx
|
||||
for p in plat_list:
|
||||
p.rect.x += scroll
|
||||
|
||||
## scrolling code above
|
||||
world.blit(backdrop, backdropbox)
|
||||
player.gravity() # check gravity
|
||||
player.update()
|
||||
```
|
||||
|
||||
启动你的游戏,并尝试它。
|
||||
|
||||
![Scrolling the world in Pygame][11]
|
||||
|
||||
滚动像预期的一样工作,但是你可能注意到一个发生的小问题,当你滚动你的玩家和非玩家精灵周围的世界时:敌人精灵不随同世界滚动。除非你要你的敌人精灵要无休止地追逐你的玩家,你需要修改敌人代码,以便当你的玩家快速撤退时,敌人被留在后面。
|
||||
|
||||
### 敌人卷轴
|
||||
|
||||
在你的主循环中,你必须对卷轴平台为你的敌人的位置的应用相同的规则。因为你的游戏世界将(很可能)有不止一个敌人在其中,该规则应该被应用于你的敌人列表,而不是一个单独的敌人精灵。这是分组类似元素到列表中的优点之一。
|
||||
|
||||
前两行用于上下文注释,所以只需添加这两行后面的代码到你的主循环中:
|
||||
|
||||
```
|
||||
# scroll the world forward
|
||||
if player.rect.x >= forwardx:
|
||||
scroll = player.rect.x - forwardx
|
||||
player.rect.x = forwardx
|
||||
for p in plat_list:
|
||||
p.rect.x -= scroll
|
||||
for e in enemy_list:
|
||||
e.rect.x -= scroll
|
||||
```
|
||||
|
||||
来滚向另一个方向:
|
||||
|
||||
```
|
||||
# scroll the world backward
|
||||
if player.rect.x <= backwardx:
|
||||
scroll = backwardx - player.rect.x
|
||||
player.rect.x = backwardx
|
||||
for p in plat_list:
|
||||
p.rect.x += scroll
|
||||
for e in enemy_list:
|
||||
e.rect.x += scroll
|
||||
```
|
||||
|
||||
再次启动游戏,看看发生什么。
|
||||
|
||||
这里是到目前为止你已经为这个 Python 平台所写所有的代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# draw a world
|
||||
# add a player and player control
|
||||
# add player movement
|
||||
# add enemy and basic collision
|
||||
# add platform
|
||||
# add gravity
|
||||
# add jumping
|
||||
# add scrolling
|
||||
|
||||
# GNU All-Permissive License
|
||||
# Copying and distribution of this file, with or without modification,
|
||||
# are permitted in any medium without royalty provided the copyright
|
||||
# notice and this notice are preserved. This file is offered as-is,
|
||||
# without any warranty.
|
||||
|
||||
import pygame
|
||||
import sys
|
||||
import os
|
||||
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
class Platform(pygame.sprite.Sprite):
|
||||
# x location, y location, img width, img height, img file
|
||||
def __init__(self,xloc,yloc,imgw,imgh,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img)).convert()
|
||||
self.image.convert_alpha()
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.y = yloc
|
||||
self.rect.x = xloc
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn a player
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0
|
||||
self.movey = 0
|
||||
self.frame = 0
|
||||
self.health = 10
|
||||
self.collide_delta = 0
|
||||
self.jump_delta = 6
|
||||
self.score = 1
|
||||
self.images = []
|
||||
for i in range(1,9):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha()
|
||||
img.set_colorkey(ALPHA)
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
def jump(self,platform_list):
|
||||
self.jump_delta = 0
|
||||
|
||||
def gravity(self):
|
||||
self.movey += 3.2 # how fast player falls
|
||||
|
||||
if self.rect.y > worldy and self.movey >= 0:
|
||||
self.movey = 0
|
||||
self.rect.y = worldy-ty
|
||||
|
||||
def control(self,x,y):
|
||||
'''
|
||||
control player movement
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
Update sprite position
|
||||
'''
|
||||
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
|
||||
# moving left
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > ani*3:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# moving right
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > ani*3:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
|
||||
# collisions
|
||||
enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
|
||||
for enemy in enemy_hit_list:
|
||||
self.health -= 1
|
||||
#print(self.health)
|
||||
|
||||
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
|
||||
for p in plat_hit_list:
|
||||
self.collide_delta = 0 # stop jumping
|
||||
self.movey = 0
|
||||
if self.rect.y > p.rect.y:
|
||||
self.rect.y = p.rect.y+ty
|
||||
else:
|
||||
self.rect.y = p.rect.y-ty
|
||||
|
||||
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
|
||||
for g in ground_hit_list:
|
||||
self.movey = 0
|
||||
self.rect.y = worldy-ty-ty
|
||||
self.collide_delta = 0 # stop jumping
|
||||
if self.rect.y > g.rect.y:
|
||||
self.health -=1
|
||||
print(self.health)
|
||||
|
||||
if self.collide_delta < 6 and self.jump_delta < 6:
|
||||
self.jump_delta = 6*2
|
||||
self.movey -= 33 # how high to jump
|
||||
self.collide_delta += 6
|
||||
self.jump_delta += 6
|
||||
|
||||
class Enemy(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn an enemy
|
||||
'''
|
||||
def __init__(self,x,y,img):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.image = pygame.image.load(os.path.join('images',img))
|
||||
self.movey = 0
|
||||
#self.image.convert_alpha()
|
||||
#self.image.set_colorkey(ALPHA)
|
||||
self.rect = self.image.get_rect()
|
||||
self.rect.x = x
|
||||
self.rect.y = y
|
||||
self.counter = 0
|
||||
|
||||
|
||||
def move(self):
|
||||
'''
|
||||
enemy movement
|
||||
'''
|
||||
distance = 80
|
||||
speed = 8
|
||||
|
||||
self.movey += 3.2
|
||||
|
||||
if self.counter >= 0 and self.counter <= distance:
|
||||
self.rect.x += speed
|
||||
elif self.counter >= distance and self.counter <= distance*2:
|
||||
self.rect.x -= speed
|
||||
else:
|
||||
self.counter = 0
|
||||
|
||||
self.counter += 1
|
||||
|
||||
if not self.rect.y >= worldy-ty-ty:
|
||||
self.rect.y += self.movey
|
||||
|
||||
plat_hit_list = pygame.sprite.spritecollide(self, plat_list, False)
|
||||
for p in plat_hit_list:
|
||||
self.movey = 0
|
||||
if self.rect.y > p.rect.y:
|
||||
self.rect.y = p.rect.y+ty
|
||||
else:
|
||||
self.rect.y = p.rect.y-ty
|
||||
|
||||
ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
|
||||
for g in ground_hit_list:
|
||||
self.rect.y = worldy-ty-ty
|
||||
|
||||
|
||||
class Level():
|
||||
def bad(lvl,eloc):
|
||||
if lvl == 1:
|
||||
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
|
||||
enemy_list = pygame.sprite.Group() # create enemy group
|
||||
enemy_list.add(enemy) # add enemy to group
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return enemy_list
|
||||
|
||||
def loot(lvl,lloc):
|
||||
print(lvl)
|
||||
|
||||
def ground(lvl,gloc,tx,ty):
|
||||
ground_list = pygame.sprite.Group()
|
||||
i=0
|
||||
if lvl == 1:
|
||||
while i < len(gloc):
|
||||
ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
|
||||
ground_list.add(ground)
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return ground_list
|
||||
|
||||
def platform(lvl,tx,ty):
|
||||
plat_list = pygame.sprite.Group()
|
||||
ploc = []
|
||||
i=0
|
||||
if lvl == 1:
|
||||
ploc.append((0,worldy-ty-128,3))
|
||||
ploc.append((300,worldy-ty-256,3))
|
||||
ploc.append((500,worldy-ty-128,4))
|
||||
|
||||
while i < len(ploc):
|
||||
j=0
|
||||
while j <= ploc[i][2]:
|
||||
plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'ground.png')
|
||||
plat_list.add(plat)
|
||||
j=j+1
|
||||
print('run' + str(i) + str(ploc[i]))
|
||||
i=i+1
|
||||
|
||||
if lvl == 2:
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
return plat_list
|
||||
|
||||
'''
|
||||
Setup
|
||||
'''
|
||||
worldx = 960
|
||||
worldy = 720
|
||||
|
||||
fps = 40 # frame rate
|
||||
ani = 4 # animation cycles
|
||||
clock = pygame.time.Clock()
|
||||
pygame.init()
|
||||
main = True
|
||||
|
||||
BLUE = (25,25,200)
|
||||
BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
ALPHA = (0,255,0)
|
||||
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = world.get_rect()
|
||||
player = Player() # spawn player
|
||||
player.rect.x = 0
|
||||
player.rect.y = 0
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10
|
||||
forwardx = 600
|
||||
backwardx = 230
|
||||
|
||||
eloc = []
|
||||
eloc = [200,20]
|
||||
gloc = []
|
||||
#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
|
||||
tx = 64 #tile size
|
||||
ty = 64 #tile size
|
||||
|
||||
i=0
|
||||
while i <= (worldx/tx)+tx:
|
||||
gloc.append(i*tx)
|
||||
i=i+1
|
||||
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
ground_list = Level.ground( 1,gloc,tx,ty )
|
||||
plat_list = Level.platform( 1,tx,ty )
|
||||
|
||||
'''
|
||||
Main loop
|
||||
'''
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print("LEFT")
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print("RIGHT")
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
player.jump(plat_list)
|
||||
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
|
||||
# scroll the world forward
|
||||
if player.rect.x >= forwardx:
|
||||
scroll = player.rect.x - forwardx
|
||||
player.rect.x = forwardx
|
||||
for p in plat_list:
|
||||
p.rect.x -= scroll
|
||||
for e in enemy_list:
|
||||
e.rect.x -= scroll
|
||||
|
||||
# scroll the world backward
|
||||
if player.rect.x <= backwardx:
|
||||
scroll = backwardx - player.rect.x
|
||||
player.rect.x = backwardx
|
||||
for p in plat_list:
|
||||
p.rect.x += scroll
|
||||
for e in enemy_list:
|
||||
e.rect.x += scroll
|
||||
|
||||
world.blit(backdrop, backdropbox)
|
||||
player.gravity() # check gravity
|
||||
player.update()
|
||||
player_list.draw(world) #refresh player position
|
||||
enemy_list.draw(world) # refresh enemies
|
||||
ground_list.draw(world) # refresh enemies
|
||||
plat_list.draw(world) # refresh platforms
|
||||
for e in enemy_list:
|
||||
e.move()
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/python-platformer-game-run
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/open_gaming_games_roundup_news.png?itok=KM0ViL0f (Gaming artifacts with joystick, GameBoy, paddle)
|
||||
[2]: https://linux.cn/article-9071-1.html
|
||||
[3]: https://linux.cn/article-10850-1.html
|
||||
[4]: https://linux.cn/article-10858-1.html
|
||||
[5]: https://linux.cn/article-10874-1.html
|
||||
[6]: https://linux.cn/article-10883-1.html
|
||||
[7]: https://linux.cn/article-11780-1.html
|
||||
[8]: https://linux.cn/article-11790-1.html
|
||||
[9]: https://www.python.org/
|
||||
[10]: https://www.pygame.org/news
|
||||
[11]: https://opensource.com/sites/default/files/uploads/pygame-scroll.jpg (Scrolling the world in Pygame)
|
||||
[12]:https://linux.cn/article-10902-1.html
|
||||
@ -0,0 +1,128 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11776-1.html)
|
||||
[#]: subject: (Make VLC More Awesome With These Simple Tips)
|
||||
[#]: via: (https://itsfoss.com/simple-vlc-tips/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
这些简单的技巧使 VLC 更加出色
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果 [VLC][1] 不是最好的播放器,那它也是[最好的开源视频播放器][2]之一。大多数人不知道的是,它不仅仅是视频播放器。
|
||||
|
||||
你可以进行许多复杂的任务,如直播视频、捕捉设备等。只需打开菜单,你就可以看到它有多少选项。
|
||||
|
||||
我们有一个详细的教程,讨论一些[专业的 VLC 技巧][3],但这些对于普通用户太复杂。
|
||||
|
||||
这就是为什么我要写另一篇文章的原因,来向你展示一些可以在 VLC 中使用的简单技巧。
|
||||
|
||||
### 使用这些简单技巧让 VLC 做更多事
|
||||
|
||||
让我们看看除了播放视频文件之外,你还可以使用 VLC 做什么。
|
||||
|
||||
#### 1、使用 VLC 观看 YouTube 视频
|
||||
|
||||
![][4]
|
||||
|
||||
如果你不想在 [YouTube][5] 上观看令人讨厌的广告,或者只想体验没有打扰地观看 YouTube 视频,你可以使用 VLC。
|
||||
|
||||
是的,在 VLC 上流式传输 YouTube 视频是非常容易的。
|
||||
|
||||
只需启动 VLC 播放器,前往媒体设置,然后单击 ”Open Network Stream“ 或使用快捷方式 `CTRL + N`。
|
||||
|
||||
![][6]
|
||||
|
||||
接下来,你只需要粘贴要观看的视频的 URL。有一些选项可以调整,但通常你无需担心这些。如果你好奇,你可以点击 ”Advanced options“ 来探索。
|
||||
|
||||
你还可以通过这种方式向 YouTube 视频添加字幕。然而,[一个更简单的带字幕观看 Youtube 视频的办法是使用 Penguin 字幕播放器][7]。
|
||||
|
||||
#### 2、将视频转换为不同格式
|
||||
|
||||
![][8]
|
||||
|
||||
你可以[在 Linux 命令行使用 ffmpeg 转换视频][9]。你还可以使用图形工具,如 [HandBrake 转换视频格式][10]。
|
||||
|
||||
但是,如果你不想用一个单独的应用来转码视频,你可以使用 VLC 播放器来完成该工作。
|
||||
|
||||
为此,只需点击 VLC 上的媒体选项,然后单击 “Convert/Save”,或者在 VLC 播放器处于活动状态时按下快捷键 `CTRL + R`。接下来,你需要从计算机/硬盘或者 URL 导入你想保存/转换的的视频。
|
||||
|
||||
不管是什么来源,只需选择文件后点击 “Convert/Save” 按钮。你现在会看到另外一个窗口可以更改 “Profile” 设置。点击并选择你想转换的格式(并保存)。
|
||||
|
||||
你还可以在转换之前通过在屏幕底部设置目标文件夹来更改转换文件的存储路径。
|
||||
|
||||
#### 3、从源录制音频/视频
|
||||
|
||||
![Vlc Advanced Controls][11]
|
||||
|
||||
你是否想在 VLC 播放器中录制正在播放的音频/视频?
|
||||
|
||||
如果是的话,有一个简单的解决方案。只需通过 “View”,然后点击 “Advanced Controls”。
|
||||
|
||||
完成后,你会看到一个新按钮(包括 VLC 播放器中的红色录制按钮)。
|
||||
|
||||
#### 4、自动下载字幕
|
||||
|
||||
![][12]
|
||||
|
||||
是的,你可以[使用 VLC 自动下载字幕][13]。你甚至不必在单独的网站上查找字幕。你只需点击
|
||||
“View”->“VLSub”。
|
||||
|
||||
默认情况下,它是禁用的,因此当你单击该选项时,它会被激活,并允许你搜索/下载想要的字幕。
|
||||
|
||||
[VLC 还能让你使用简单的键盘快捷键同步字幕][14]
|
||||
|
||||
#### 5、截图
|
||||
|
||||
![][15]
|
||||
|
||||
你可以在观看视频时使用 VLC 获取一些视频的截图/图像。你只需在视频播放/暂停时右击播放器,你会看到一组选项,点击 “Video”->“Take Snapshot”。
|
||||
|
||||
如果安装了旧版本,你可能在右键时看到截图选项。
|
||||
|
||||
#### 额外技巧:给视频添加音频/视频效果
|
||||
|
||||
在菜单中,进入 “Tools” 选项。单击 “Effects and Filters”,或者在 VLC 播放器窗口中按 `CTRL + E` 打开选项。
|
||||
|
||||
好了,你可以观察你给视频添加的音频和视频效果了。你也许无法实时看到效果,因此你需要调整并保存来看发生了什么。
|
||||
|
||||
![][16]
|
||||
|
||||
我建议在修改视频之前保存一份原始视频备份。
|
||||
|
||||
#### 你最喜欢的 VLC 技巧是什么?
|
||||
|
||||
我分享了一些我最喜欢的 VLC 技巧。你知道什么你经常使用的很酷的 VLC 技巧吗?为什么不和我们分享呢?我可以把它添加到列表中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/simple-vlc-tips/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.videolan.org/
|
||||
[2]: https://itsfoss.com/video-players-linux/
|
||||
[3]: https://itsfoss.com/vlc-pro-tricks-linux/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/youtube-video-stream.jpg?ssl=1
|
||||
[5]: https://www.youtube.com/
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/youtube-video-play.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/penguin-subtitle-player/
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/vlc-video-convert.jpg?ssl=1
|
||||
[9]: https://itsfoss.com/ffmpeg/
|
||||
[10]: https://itsfoss.com/handbrake/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/vlc-advanced-controls.png?ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/vlc-subtitles-automatic.png?ssl=1
|
||||
[13]: https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/
|
||||
[14]: https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/
|
||||
[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/vlc-snapshot.png?ssl=1
|
||||
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/vlc-effects-screenshot.jpg?ssl=1
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user