mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
b799391b68
@ -16,12 +16,8 @@ Linux DNS 查询剖析(第四部分)
|
||||
|
||||
在第四部分中,我将介绍容器如何完成 DNS 查询。你想的没错,也不是那么简单。
|
||||
|
||||
* * *
|
||||
|
||||
### 1) Docker 和 DNS
|
||||
|
||||
============================================================
|
||||
|
||||
在 [Linux DNS 查询剖析(第三部分)][3] 中,我们介绍了 `dnsmasq`,其工作方式如下:将 DNS 查询指向到 localhost 地址 `127.0.0.1`,同时启动一个进程监听 `53` 端口并处理查询请求。
|
||||
|
||||
在按上述方式配置 DNS 的主机上,如果运行了一个 Docker 容器,容器内的 `/etc/resolv.conf` 文件会是怎样的呢?
|
||||
@ -72,29 +68,29 @@ google.com. 112 IN A 172.217.23.14
|
||||
|
||||
在这个问题上,Docker 的解决方案是忽略所有可能的复杂情况,即无论主机中使用什么 DNS 服务器,容器内都使用 Google 的 DNS 服务器 `8.8.8.8` 和 `8.8.4.4` 完成 DNS 查询。
|
||||
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 _<ruby>编排引擎<rt>orchestrators</rt></ruby>_,情况又有些不同。
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 <ruby>编排引擎<rt>orchestrators</rt></ruby>,情况又有些不同。
|
||||
|
||||
### 2) Kubernetes 和 DNS
|
||||
|
||||
在 Kubernetes 中,最小部署单元是 `pod`;`pod` 是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
在 Kubernetes 中,最小部署单元是 pod;它是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
|
||||
Kubernetes 面临的一个额外的挑战是,将 Kubernetes 服务请求(例如,`myservice.kubernetes.io`)通过对应的<ruby>解析器<rt>resolver</rt></ruby>,转发到具体服务地址对应的<ruby>内网地址<rt>private network</rt></ruby>。这里提到的服务地址被称为归属于“<ruby>集群域<rt>cluster domain</rt></ruby>”。集群域可由管理员配置,根据配置可以是 `cluster.local` 或 `myorg.badger` 等。
|
||||
|
||||
在 Kubernetes 中,你可以为 `pod` 指定如下四种 `pod` 内 DNS 查询的方式。
|
||||
在 Kubernetes 中,你可以为 pod 指定如下四种 pod 内 DNS 查询的方式。
|
||||
|
||||
* Default
|
||||
**Default**
|
||||
|
||||
在这种(名称容易让人误解)的方式中,`pod` 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
在这种(名称容易让人误解)的方式中,pod 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
|
||||
如果你希望覆盖 `/etc/resolv.conf` 中的条目,你可以添加到 `kubelet` 的配置中。
|
||||
|
||||
* ClusterFirst
|
||||
**ClusterFirst**
|
||||
|
||||
在 `ClusterFirst` 方式中,遇到 DNS 查询请求会做有选择的转发。根据配置的不同,有以下两种方式:
|
||||
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 `pod` 所在的主机。
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 pod 所在的主机。
|
||||
|
||||
第二种方式相对新一些,你可以在内部 DNS 中配置选择性转发。
|
||||
|
||||
@ -115,27 +111,27 @@ data:
|
||||
|
||||
在 `stubDomains` 条目中,可以为特定域名指定特定的 DNS 服务器;而 `upstreamNameservers` 条目则给出,待查询域名不是集群域子域情况下用到的 DNS 服务器。
|
||||
|
||||
这是通过在一个 `pod` 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
这是通过在一个 pod 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
|
||||

|
||||
|
||||
剩下两种选项都比较小众:
|
||||
|
||||
* ClusterFirstWithHostNet
|
||||
**ClusterFirstWithHostNet**
|
||||
|
||||
适用于 `pod` 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 `pod` 对应主机相同的网络。
|
||||
适用于 pod 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 pod 对应主机相同的网络。
|
||||
|
||||
* None
|
||||
**None**
|
||||
|
||||
`None` 意味着不改变 DNS,但强制要求你在 `pod` <ruby>规范文件<rt>specification</rt></ruby>的 `dnsConfig` 条目中指定 DNS 配置。
|
||||
|
||||
### CoreDNS 即将到来
|
||||
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代 Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
|
||||
如果想了解更多,参考[这里][5]。
|
||||
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 `3.6`,可能有些过时。
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 3.6,可能有些过时。
|
||||
|
||||
### 第四部分总结
|
||||
|
||||
@ -152,14 +148,14 @@ via: https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
|
||||
|
||||
作者:[zwischenzugs][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[3]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
[1]:https://linux.cn/article-9943-1.html
|
||||
[2]:https://linux.cn/article-9949-1.html
|
||||
[3]:https://linux.cn/article-9972-1.html
|
||||
[4]:https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/#impacts-on-pods
|
||||
[5]:https://coredns.io/
|
||||
[6]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||

|
||||
|
||||
**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
|
||||
**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像站点有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像站点后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
|
||||
|
||||
### 强制 APT 包管理器在 Ubuntu 16.04 中使用 IPv4
|
||||
|
||||
@ -11,13 +11,12 @@
|
||||
|
||||
```
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true update
|
||||
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true upgrade
|
||||
```
|
||||
|
||||
瞧!这次更新很快就完成了。
|
||||
|
||||
你还可以使用以下命令在 **/etc/apt/apt.conf.d/99force-ipv4** 中添加以下行,以便将来对所有 **apt-get** 事务保持持久性:
|
||||
你还可以使用以下命令在 `/etc/apt/apt.conf.d/99force-ipv4` 中添加以下行,以便将来对所有 `apt-get` 事务保持持久性:
|
||||
|
||||
```
|
||||
$ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
@ -25,7 +24,7 @@ $ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
|
||||
**免责声明:**
|
||||
|
||||
我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
|
||||
我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四、五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
|
||||
|
||||
希望这有帮助。还有更多的好东西。敬请关注!
|
||||
|
||||
@ -40,7 +39,7 @@ via: https://www.ostechnix.com/how-to-force-apt-package-manager-to-use-ipv4-in-u
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,308 +0,0 @@
|
||||
translating by Flowsnow
|
||||
What is behavior-driven Python?
|
||||
======
|
||||

|
||||
Have you heard about [behavior-driven development][1] (BDD) and wondered what all the buzz is about? Maybe you've caught team members talking in "gherkin" and felt left out of the conversation. Or perhaps you're a Pythonista looking for a better way to test your code. Whatever the circumstance, learning about BDD can help you and your team achieve better collaboration and test automation, and Python's `behave` framework is a great place to start.
|
||||
|
||||
### What is BDD?
|
||||
|
||||
* Submitting forms on a website
|
||||
* Searching for desired results
|
||||
* Saving a document
|
||||
* Making REST API calls
|
||||
* Running command-line interface commands
|
||||
|
||||
|
||||
|
||||
In software, a behavior is how a feature operates within a well-defined scenario of inputs, actions, and outcomes. Products can exhibit countless behaviors, such as:
|
||||
|
||||
Defining a product's features based on its behaviors makes it easier to describe them, develop them, and test them. This is the heart of BDD: making behaviors the focal point of software development. Behaviors are defined early in development using a [specification by example][2] language. One of the most common behavior spec languages is [Gherkin][3], the Given-When-Then scenario format from the [Cucumber][4] project. Behavior specs are basically plain-language descriptions of how a behavior works, with a little bit of formal structure for consistency and focus. Test frameworks can easily automate these behavior specs by "gluing" step texts to code implementations.
|
||||
|
||||
Below is an example of a behavior spec written in Gherkin:
|
||||
```
|
||||
Scenario: Basic DuckDuckGo Search
|
||||
|
||||
Given the DuckDuckGo home page is displayed
|
||||
|
||||
When the user searches for "panda"
|
||||
|
||||
Then results are shown for "panda"
|
||||
|
||||
```
|
||||
|
||||
At a quick glance, the behavior is intuitive to understand. Except for a few keywords, the language is freeform. The scenario is concise yet meaningful. A real-world example illustrates the behavior. Steps declaratively indicate what should happen—without getting bogged down in the details of how.
|
||||
|
||||
The [main benefits of BDD][5] are good collaboration and automation. Everyone can contribute to behavior development, not just programmers. Expected behaviors are defined and understood from the beginning of the process. Tests can be automated together with the features they cover. Each test covers a singular, unique behavior in order to avoid duplication. And, finally, existing steps can be reused by new behavior specs, creating a snowball effect.
|
||||
|
||||
### Python's behave framework
|
||||
|
||||
`behave` is one of the most popular BDD frameworks in Python. It is very similar to other Gherkin-based Cucumber frameworks despite not holding the official Cucumber designation. `behave` has two primary layers:
|
||||
|
||||
1. Behavior specs written in Gherkin `.feature` files
|
||||
2. Step definitions and hooks written in Python modules that implement Gherkin steps
|
||||
|
||||
|
||||
|
||||
As shown in the example above, Gherkin scenarios use a three-part format:
|
||||
|
||||
1. Given some initial state
|
||||
2. When an action is taken
|
||||
3. Then verify the outcome
|
||||
|
||||
|
||||
|
||||
Each step is "glued" by decorator to a Python function when `behave` runs tests.
|
||||
|
||||
### Installation
|
||||
|
||||
As a prerequisite, make sure you have Python and `pip` installed on your machine. I strongly recommend using Python 3. (I also recommend using [`pipenv`][6], but the following example commands use the more basic `pip`.)
|
||||
|
||||
Only one package is required for `behave`:
|
||||
```
|
||||
pip install behave
|
||||
|
||||
```
|
||||
|
||||
Other packages may also be useful, such as:
|
||||
```
|
||||
pip install requests # for REST API calls
|
||||
|
||||
pip install selenium # for Web browser interactions
|
||||
|
||||
```
|
||||
|
||||
The [behavior-driven-Python][7] project on GitHub contains the examples used in this article.
|
||||
|
||||
### Gherkin features
|
||||
|
||||
The Gherkin syntax that `behave` uses is practically compliant with the official Cucumber Gherkin standard. A `.feature` file has Feature sections, which in turn have Scenario sections with Given-When-Then steps. Below is an example:
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
As a gardener,
|
||||
|
||||
I want to carry many cucumbers in a basket,
|
||||
|
||||
So that I don’t drop them all.
|
||||
|
||||
|
||||
|
||||
@cucumber-basket
|
||||
|
||||
Scenario: Add and remove cucumbers
|
||||
|
||||
Given the basket is empty
|
||||
|
||||
When "4" cucumbers are added to the basket
|
||||
|
||||
And "6" more cucumbers are added to the basket
|
||||
|
||||
But "3" cucumbers are removed from the basket
|
||||
|
||||
Then the basket contains "7" cucumbers
|
||||
|
||||
```
|
||||
|
||||
There are a few important things to note here:
|
||||
|
||||
* Both the Feature and Scenario sections have [short, descriptive titles][8].
|
||||
* The lines immediately following the Feature title are comments ignored by `behave`. It is a good practice to put the user story there.
|
||||
* Scenarios and Features can have tags (notice the `@cucumber-basket` mark) for hooks and filtering (explained below).
|
||||
* Steps follow a [strict Given-When-Then order][9].
|
||||
* Additional steps can be added for any type using `And` and `But`.
|
||||
* Steps can be parametrized with inputs—notice the values in double quotes.
|
||||
|
||||
|
||||
|
||||
Scenarios can also be written as templates with multiple input combinations by using a Scenario Outline:
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
|
||||
|
||||
@cucumber-basket
|
||||
|
||||
Scenario Outline: Add cucumbers
|
||||
|
||||
Given the basket has “<initial>” cucumbers
|
||||
|
||||
When "<more>" cucumbers are added to the basket
|
||||
|
||||
Then the basket contains "<total>" cucumbers
|
||||
|
||||
|
||||
|
||||
Examples: Cucumber Counts
|
||||
|
||||
| initial | more | total |
|
||||
|
||||
| 0 | 1 | 1 |
|
||||
|
||||
| 1 | 2 | 3 |
|
||||
|
||||
| 5 | 4 | 9 |
|
||||
|
||||
```
|
||||
|
||||
Scenario Outlines always have an Examples table, in which the first row gives column titles and each subsequent row gives an input combo. The row values are substituted wherever a column title appears in a step surrounded by angle brackets. In the example above, the scenario will be run three times because there are three rows of input combos. Scenario Outlines are a great way to avoid duplicate scenarios.
|
||||
|
||||
There are other elements of the Gherkin language, but these are the main mechanics. To learn more, read the Automation Panda articles [Gherkin by Example][10] and [Writing Good Gherkin][11].
|
||||
|
||||
### Python mechanics
|
||||
|
||||
Every Gherkin step must be "glued" to a step definition, a Python function that provides the implementation. Each function has a step type decorator with the matching string. It also receives a shared context and any step parameters. Feature files must be placed in a directory named `features/`, while step definition modules must be placed in a directory named `features/steps/`. Any feature file can use step definitions from any module—they do not need to have the same names. Below is an example Python module with step definitions for the cucumber basket features.
|
||||
```
|
||||
from behave import *
|
||||
|
||||
from cucumbers.basket import CucumberBasket
|
||||
|
||||
|
||||
|
||||
@given('the basket has "{initial:d}" cucumbers')
|
||||
|
||||
def step_impl(context, initial):
|
||||
|
||||
context.basket = CucumberBasket(initial_count=initial)
|
||||
|
||||
|
||||
|
||||
@when('"{some:d}" cucumbers are added to the basket')
|
||||
|
||||
def step_impl(context, some):
|
||||
|
||||
context.basket.add(some)
|
||||
|
||||
|
||||
|
||||
@then('the basket contains "{total:d}" cucumbers')
|
||||
|
||||
def step_impl(context, total):
|
||||
|
||||
assert context.basket.count == total
|
||||
|
||||
```
|
||||
|
||||
Three [step matchers][12] are available: `parse`, `cfparse`, and `re`. The default and simplest marcher is `parse`, which is shown in the example above. Notice how parametrized values are parsed and passed into the functions as input arguments. A common best practice is to put double quotes around parameters in steps.
|
||||
|
||||
Each step definition function also receives a [context][13] variable that holds data specific to the current scenario being run, such as `feature`, `scenario`, and `tags` fields. Custom fields may be added, too, to share data between steps. Always use context to share data—never use global variables!
|
||||
|
||||
`behave` also supports [hooks][14] to handle automation concerns outside of Gherkin steps. A hook is a function that will be run before or after a step, scenario, feature, or whole test suite. Hooks are reminiscent of [aspect-oriented programming][15]. They should be placed in a special `environment.py` file under the `features/` directory. Hook functions can check the current scenario's tags, as well, so logic can be selectively applied. The example below shows how to use hooks to set up and tear down a Selenium WebDriver instance for any scenario tagged as `@web`.
|
||||
```
|
||||
from selenium import webdriver
|
||||
|
||||
|
||||
|
||||
def before_scenario(context, scenario):
|
||||
|
||||
if 'web' in context.tags:
|
||||
|
||||
context.browser = webdriver.Firefox()
|
||||
|
||||
context.browser.implicitly_wait(10)
|
||||
|
||||
|
||||
|
||||
def after_scenario(context, scenario):
|
||||
|
||||
if 'web' in context.tags:
|
||||
|
||||
context.browser.quit()
|
||||
|
||||
```
|
||||
|
||||
Note: Setup and cleanup can also be done with [fixtures][16] in `behave`.
|
||||
|
||||
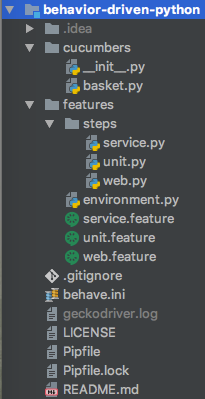
To offer an idea of what a `behave` project should look like, here's the example project's directory structure:
|
||||
|
||||
|
||||
|
||||
Any Python packages and custom modules can be used with `behave`. Use good design patterns to build a scalable test automation solution. Step definition code should be concise.
|
||||
|
||||
### Running tests
|
||||
|
||||
To run tests from the command line, change to the project's root directory and run the `behave` command. Use the `–help` option to see all available options.
|
||||
|
||||
Below are a few common use cases:
|
||||
```
|
||||
# run all tests
|
||||
|
||||
behave
|
||||
|
||||
|
||||
|
||||
# run the scenarios in a feature file
|
||||
|
||||
behave features/web.feature
|
||||
|
||||
|
||||
|
||||
# run all tests that have the @duckduckgo tag
|
||||
|
||||
behave --tags @duckduckgo
|
||||
|
||||
|
||||
|
||||
# run all tests that do not have the @unit tag
|
||||
|
||||
behave --tags ~@unit
|
||||
|
||||
|
||||
|
||||
# run all tests that have @basket and either @add or @remove
|
||||
|
||||
behave --tags @basket --tags @add,@remove
|
||||
|
||||
```
|
||||
|
||||
For convenience, options may be saved in [config][17] files.
|
||||
|
||||
### Other options
|
||||
|
||||
`behave` is not the only BDD test framework in Python. Other good frameworks include:
|
||||
|
||||
* `pytest-bdd` , a plugin for `pytest``behave`, it uses Gherkin feature files and step definition modules, but it also leverages all the features and plugins of `pytest`. For example, it can run Gherkin scenarios in parallel using `pytest-xdist`. BDD and non-BDD tests can also be executed together with the same filters. `pytest-bdd` also offers a more flexible directory layout.
|
||||
|
||||
* `radish` is a "Gherkin-plus" framework—it adds Scenario Loops and Preconditions to the standard Gherkin language, which makes it more friendly to programmers. It also offers rich command line options like `behave`.
|
||||
|
||||
* `lettuce` is an older BDD framework very similar to `behave`, with minor differences in framework mechanics. However, GitHub shows little recent activity in the project (as of May 2018).
|
||||
|
||||
|
||||
|
||||
Any of these frameworks would be good choices.
|
||||
|
||||
Also, remember that Python test frameworks can be used for any black box testing, even for non-Python products! BDD frameworks are great for web and service testing because their tests are declarative, and Python is a [great language for test automation][18].
|
||||
|
||||
This article is based on the author's [PyCon Cleveland 2018][19] talk, [Behavior-Driven Python][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/behavior-driven-python
|
||||
|
||||
作者:[Andrew Knight][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andylpk247
|
||||
[1]:https://automationpanda.com/bdd/
|
||||
[2]:https://en.wikipedia.org/wiki/Specification_by_example
|
||||
[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
|
||||
[4]:https://cucumber.io/
|
||||
[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
|
||||
[6]:https://docs.pipenv.org/
|
||||
[7]:https://github.com/AndyLPK247/behavior-driven-python
|
||||
[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
|
||||
[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
|
||||
[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
|
||||
[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
|
||||
[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
|
||||
[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
|
||||
[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
|
||||
[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
|
||||
[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
|
||||
[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
|
||||
[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
|
||||
[19]:https://us.pycon.org/2018/
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/87/
|
||||
@ -1,110 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
5 cool music player apps
|
||||
======
|
||||
|
||||

|
||||
Do you like music? Then Fedora may have just what you’re looking for. This article introduces different music player apps that run on Fedora. You’re covered whether you have an extensive music library, a small one, or none at all. Here are four graphical application and one terminal-based music player that will have you jamming.
|
||||
|
||||
### Quod Libet
|
||||
|
||||
Quod Libet is a complete manager for your large audio library. If you have an extensive audio library that you would like not just listen to, but also manage, Quod Libet might a be a good choice for you.
|
||||
|
||||
![][1]
|
||||
|
||||
Quod Libet can import music from multiple locations on your disk, and allows you to edit tags of the audio files — so everything is under your control. As a bonus, there are various plugins available for anything from a simple equalizer to a [last.fm][2] sync. You can also search and play music directly from [Soundcloud][3].
|
||||
|
||||
Quod Libet works great on HiDPI screens, and is available as an RPM in Fedora or on [Flathub][4] in case you run [Silverblue][5]. Install it using Gnome Software or the command line:
|
||||
```
|
||||
$ sudo dnf install quodlibet
|
||||
|
||||
```
|
||||
|
||||
### Audacious
|
||||
|
||||
If you like a simple music player that could even look like the legendary Winamp, Audacious might be a good choice for you.
|
||||
|
||||
![][6]
|
||||
|
||||
Audacious probably won’t manage all your music at once, but it works great if you like to organize your music as files. You can also export and import playlists without reorganizing the music files themselves.
|
||||
|
||||
As a bonus, you can make it look likeWinamp. To make it look the same as on the screenshot above, go to Settings / Appearance, select Winamp Classic Interface at the top, and choose the Refugee skin right below. And Bob’s your uncle!
|
||||
|
||||
Audacious is available as an RPM in Fedora, and can be installed using the Gnome Software app or the following command on the terminal:
|
||||
```
|
||||
$ sudo dnf install audacious
|
||||
|
||||
```
|
||||
|
||||
### Lollypop
|
||||
|
||||
Lollypop is a music player that provides great integration with GNOME. If you enjoy how GNOME looks, and would like a music player that’s nicely integrated, Lollypop could be for you.
|
||||
|
||||
![][7]
|
||||
|
||||
Apart from nice visual integration with the GNOME Shell, it woks nicely on HiDPI screens, and supports a dark theme.
|
||||
|
||||
As a bonus, Lollypop has an integrated cover art downloader, and a so-called Party Mode (the note button at the top-right corner) that selects and plays music automatically for you. It also integrates with online services such as [last.fm][2] or [libre.fm][8].
|
||||
|
||||
Available as both an RPM in Fedora or a [Flathub][4] for your [Silverblue][5] workstation, install it using the Gnome Software app or using the terminal:
|
||||
```
|
||||
$ sudo dnf install lollypop
|
||||
|
||||
```
|
||||
|
||||
### Gradio
|
||||
|
||||
What if you don’t own any music, but still like to listen to it? Or you just simply love radio? Then Gradio is here for you.
|
||||
|
||||
![][9]
|
||||
|
||||
Gradio is a simple radio player that allows you to search and play internet radio stations. You can find them by country, language, or simply using search. As a bonus, it’s visually integrated into GNOME Shell, works great with HiDPI screens, and has an option for a dark theme.
|
||||
|
||||
Gradio is available on [Flathub][4] which works with both Fedora Workstation and [Silverblue][5]. Install it using the Gnome Software app.
|
||||
|
||||
### sox
|
||||
|
||||
Do you like using the terminal instead, and listening to some music while you work? You don’t have to leave the terminal thanks to sox.
|
||||
|
||||
![][10]
|
||||
|
||||
sox is a very simple, terminal-based music player. All you need to do is to run a command such as:
|
||||
```
|
||||
$ play file.mp3
|
||||
|
||||
```
|
||||
|
||||
…and sox will play it for you. Apart from individual audio files, sox also supports playlists in the m3u format.
|
||||
|
||||
As a bonus, because sox is a terminal-based application, you can run it over ssh. Do you have a home server with speakers attached to it? Or do you want to play music from a different computer? Try using it together with [tmux][11], so you can keep listening even when the session closes.
|
||||
|
||||
sox is available in Fedora as an RPM. Install it by running:
|
||||
```
|
||||
$ sudo dnf install sox
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-music-player-apps/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/asamalik/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-300x217.png
|
||||
[2]:https://last.fm
|
||||
[3]:https://soundcloud.com/
|
||||
[4]:https://flathub.org/home
|
||||
[5]:https://teamsilverblue.org/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-300x136.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-300x172.png
|
||||
[8]:https://libre.fm
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-300x179.png
|
||||
[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
@ -1,118 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
[Solved] “sub process usr bin dpkg returned an error code 1″ Error in Ubuntu
|
||||
======
|
||||
If you are encountering “sub process usr bin dpkg returned an error code 1” while installing software on Ubuntu Linux, here is how you can fix it.
|
||||
|
||||
One of the common issue in Ubuntu and other Debian based distribution is the broken packages. You try to update the system or install a new package and you encounter an error like ‘Sub-process /usr/bin/dpkg returned an error code’.
|
||||
|
||||
That’s what happened to me the other day. I was trying to install a radio application in Ubuntu when it threw me this error:
|
||||
```
|
||||
Unpacking python-gst-1.0 (1.6.2-1build1) ...
|
||||
Selecting previously unselected package radiotray.
|
||||
Preparing to unpack .../radiotray_0.7.3-5ubuntu1_all.deb ...
|
||||
Unpacking radiotray (0.7.3-5ubuntu1) ...
|
||||
Processing triggers for man-db (2.7.5-1) ...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu5.2) ...
|
||||
Processing triggers for bamfdaemon (0.5.3~bzr0+16.04.20180209-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu3.1) ...
|
||||
Processing triggers for mime-support (3.59ubuntu1) ...
|
||||
Setting up polar-bookshelf (1.0.0-beta56) ...
|
||||
ln: failed to create symbolic link '/usr/local/bin/polar-bookshelf': No such file or directory
|
||||
dpkg: error processing package polar-bookshelf (--configure):
|
||||
subprocess installed post-installation script returned error exit status 1
|
||||
Setting up python-appindicator (12.10.1+16.04.20170215-0ubuntu1) ...
|
||||
Setting up python-gst-1.0 (1.6.2-1build1) ...
|
||||
Setting up radiotray (0.7.3-5ubuntu1) ...
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
The last three lines are of the utmost importance here.
|
||||
```
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
It tells me that the package polar-bookshelf is causing and issue. This might be crucial to how you fix this error here.
|
||||
|
||||
### Fixing Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
![Fix update errors in Ubuntu Linux][1]
|
||||
|
||||
Let’s try to fix this broken error package. I’ll show several methods that you can try one by one. The initial ones are easy to use and simply no-brainers.
|
||||
|
||||
You should try to run sudo apt update and then try to install a new package or upgrade after trying each of the methods discussed here.
|
||||
|
||||
#### Method 1: Reconfigure Package Database
|
||||
|
||||
The first method you can try is to reconfigure the package database. Probably the database got corrupted while installing a package. Reconfiguring often fixes the problem.
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
|
||||
```
|
||||
|
||||
#### Method 2: Use force install
|
||||
|
||||
If a package installation was interrupted previously, you may try to do a force install.
|
||||
```
|
||||
sudo apt-get install -f
|
||||
|
||||
```
|
||||
|
||||
#### Method 3: Try removing the troublesome package
|
||||
|
||||
If it’s not an issue for you, you may try to remove the package manually. Please don’t do it for Linux Kernels (packages starting with linux-).
|
||||
```
|
||||
sudo apt remove
|
||||
|
||||
```
|
||||
|
||||
#### Method 4: Remove post info files of the troublesome package
|
||||
|
||||
This should be your last resort. You can try removing the files associated to the package in question from /var/lib/dpkg/info.
|
||||
|
||||
**You need to know a little about basic Linux commands to figure out what’s happening and how can you use the same with your problem.**
|
||||
|
||||
In my case, I had an issue with polar-bookshelf. So I looked for the files associated with it:
|
||||
```
|
||||
ls -l /var/lib/dpkg/info | grep -i polar-bookshelf
|
||||
-rw-r--r-- 1 root root 2324811 Aug 14 19:29 polar-bookshelf.list
|
||||
-rw-r--r-- 1 root root 2822824 Aug 10 04:28 polar-bookshelf.md5sums
|
||||
-rwxr-xr-x 1 root root 113 Aug 10 04:28 polar-bookshelf.postinst
|
||||
-rwxr-xr-x 1 root root 84 Aug 10 04:28 polar-bookshelf.postrm
|
||||
|
||||
```
|
||||
|
||||
Now all I needed to do was to remove these files:
|
||||
```
|
||||
sudo mv /var/lib/dpkg/info/polar-bookshelf.* /tmp
|
||||
|
||||
```
|
||||
|
||||
Use the sudo apt update and then you should be able to install software as usual.
|
||||
|
||||
#### Which method worked for you (if it worked)?
|
||||
|
||||
I hope this quick article helps you in fixing the ‘E: Sub-process /usr/bin/dpkg returned an error code (1)’ error.
|
||||
|
||||
If it did work for you, which method was it? Did you manage to fix this error with some other method? If yes, please share that to help others with this issue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dpkg-returned-an-error-code-1/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/fix-common-update-errors-ubuntu.jpeg
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to build rpm packages
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
A Simple, Beautiful And Cross-platform Podcast App
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Hegemon – A Modular System Monitor Application Written In Rust
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,88 @@
|
||||
3 open source distributed tracing tools
|
||||
======
|
||||
|
||||
Find performance issues quickly with these tools, which provide a graphical view of what's happening across complex software systems.
|
||||
|
||||

|
||||
|
||||
Distributed tracing systems enable users to track a request through a software system that is distributed across multiple applications, services, and databases as well as intermediaries like proxies. This allows for a deeper understanding of what is happening within the software system. These systems produce graphical representations that show how much time the request took on each step and list each known step.
|
||||
|
||||
A user reviewing this content can determine where the system is experiencing latencies or blockages. Instead of testing the system like a binary search tree when requests start failing, operators and developers can see exactly where the issues begin. This can also reveal where performance changes might be occurring from deployment to deployment. It’s always better to catch regressions automatically by alerting to the anomalous behavior than to have your customers tell you.
|
||||
|
||||
How does this tracing thing work? Well, each request gets a special ID that’s usually injected into the headers. This ID uniquely identifies that transaction. This transaction is normally called a trace. The trace is the overall abstract idea of the entire transaction. Each trace is made up of spans. These spans are the actual work being performed, like a service call or a database request. Each span also has a unique ID. Spans can create subsequent spans called child spans, and child spans can have multiple parents.
|
||||
|
||||
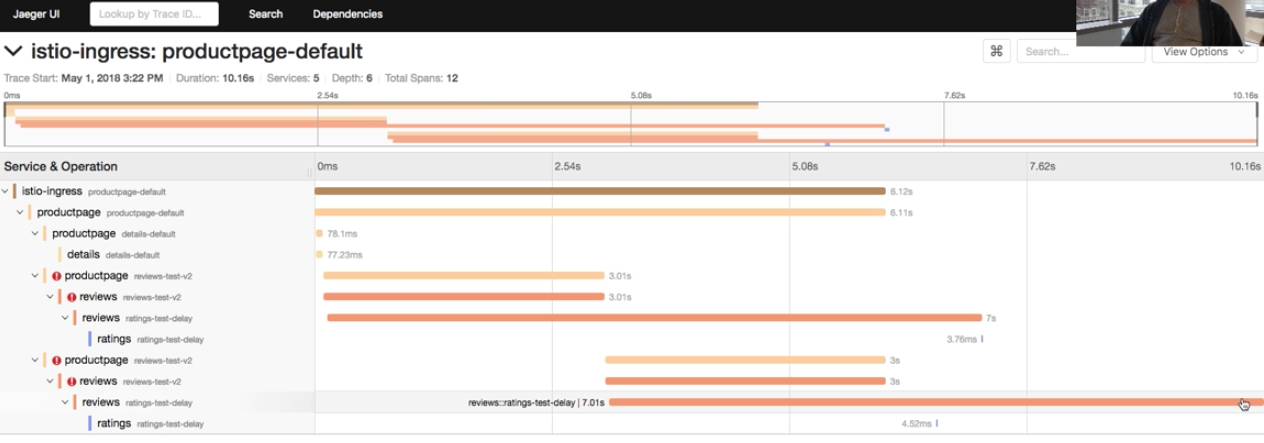
Once a transaction (or trace) has run its course, it can be searched in a presentation layer. There are several tools in this space that we’ll discuss later, but the picture below shows [Jaeger][1] from my [Istio walkthrough][2]. It shows multiple spans of a single trace. The power of this is immediately clear as you can better understand the transaction’s story at a glance.
|
||||
|
||||
|
||||
|
||||
This demo uses Istio’s built-in OpenTracing implementation, so I can get tracing without even modifying my application. It also uses Jaeger, which is OpenTracing-compatible.
|
||||
|
||||
So what is OpenTracing? Let’s find out.
|
||||
|
||||
### OpenTracing API
|
||||
|
||||
[OpenTracing][3] is a spec that grew out of [Zipkin][4] to provide cross-platform compatibility. It offers a vendor-neutral API for adding tracing to applications and delivering that data into distributed tracing systems. A library written for the OpenTracing spec can be used with any system that is OpenTracing-compliant. Zipkin, Jaeger, and Appdash are examples of open source tools that have adopted the open standard, but even proprietary tools like [Datadog][5] and [Instana][6] are adopting it. This is expected to continue as OpenTracing reaches ubiquitous status.
|
||||
|
||||
### OpenCensus
|
||||
|
||||
Okay, we have OpenTracing, but what is this [OpenCensus][7] thing that keeps popping up in my searches? Is it a competing standard, something completely different, or something complementary?
|
||||
|
||||
The answer depends on who you ask. I will do my best to explain the difference (as I understand it): OpenCensus takes a more holistic or all-inclusive approach. OpenTracing is focused on establishing an open API and spec and not on open implementations for each language and tracing system. OpenCensus provides not only the specification but also the language implementations and wire protocol. It also goes beyond tracing by including additional metrics that are normally outside the scope of distributed tracing systems.
|
||||
|
||||
OpenCensus allows viewing data on the host where the application is running, but it also has a pluggable exporter system for exporting data to central aggregators. The current exporters produced by the OpenCensus team include Zipkin, Prometheus, Jaeger, Stackdriver, Datadog, and SignalFx, but anyone can create an exporter.
|
||||
|
||||
From my perspective, there’s a lot of overlap. One isn’t necessarily better than the other, but it’s important to know what each does and doesn’t do. OpenTracing is primarily a spec, with others doing the implementation and opinionation. OpenCensus provides a holistic approach for the local component with more opinionation but still requires other systems for remote aggregation.
|
||||
|
||||
### Tool options
|
||||
|
||||
#### Zipkin
|
||||
|
||||
Zipkin was one of the first systems of this kind. It was developed by Twitter based on the [Google Dapper paper][8] about the internal system Google uses. Zipkin was written using Java, and it can use Cassandra or ElasticSearch as a scalable backend. Most companies should be satisfied with one of those options. The lowest supported Java version is Java 6. It also uses the [Thrift][9] binary communication protocol, which is popular in the Twitter stack and is hosted as an Apache project.
|
||||
|
||||
The system consists of reporters (clients), collectors, a query service, and a web UI. Zipkin is meant to be safe in production by transmitting only a trace ID within the context of a transaction to inform receivers that a trace is in process. The data collected in each reporter is then transmitted asynchronously to the collectors. The collectors store these spans in the database, and the web UI presents this data to the end user in a consumable format. The delivery of data to the collectors can occur in three different methods: HTTP, Kafka, and Scribe.
|
||||
|
||||
The [Zipkin community][10] has also created [Brave][11], a Java client implementation compatible with Zipkin. It has no dependencies, so it won’t drag your projects down or clutter them with libraries that are incompatible with your corporate standards. There are many other implementations, and Zipkin is compatible with the OpenTracing standard, so these implementations should also work with other distributed tracing systems. The popular Spring framework has a component called [Spring Cloud Sleuth][12] that is compatible with Zipkin.
|
||||
|
||||
#### Jaeger
|
||||
|
||||
[Jaeger][1] is a newer project from Uber Technologies that the [CNCF][13] has since adopted as an Incubating project. It is written in Golang, so you don’t have to worry about having dependencies installed on the host or any overhead of interpreters or language virtual machines. Similar to Zipkin, Jaeger also supports Cassandra and ElasticSearch as scalable storage backends. Jaeger is also fully compatible with the OpenTracing standard.
|
||||
|
||||
Jaeger’s architecture is similar to Zipkin, with clients (reporters), collectors, a query service, and a web UI, but it also has an agent on each host that locally aggregates the data. The agent receives data over a UDP connection, which it batches and sends to a collector. The collector receives that data in the form of the [Thrift][14] protocol and stores that data in Cassandra or ElasticSearch. The query service can access the data store directly and provide that information to the web UI.
|
||||
|
||||
By default, a user won’t get all the traces from the Jaeger clients. The system samples 0.1% (1 in 1,000) of traces that pass through each client. Keeping and transmitting all traces would be a bit overwhelming to most systems. However, this can be increased or decreased by configuring the agents, which the client consults with for its configuration. This sampling isn’t completely random, though, and it’s getting better. Jaeger uses probabilistic sampling, which tries to make an educated guess at whether a new trace should be sampled or not. [Adaptive sampling is on its roadmap][15], which will improve the sampling algorithm by adding additional context for making decisions.
|
||||
|
||||
#### Appdash
|
||||
|
||||
[Appdash][16] is a distributed tracing system written in Golang, like Jaeger. It was created by [Sourcegraph][17] based on Google’s Dapper and Twitter’s Zipkin. Similar to Jaeger and Zipkin, Appdash supports the OpenTracing standard; this was a later addition and requires a component that is different from the default component. This adds risk and complexity.
|
||||
|
||||
At a high level, Appdash’s architecture consists mostly of three components: a client, a local collector, and a remote collector. There’s not a lot of documentation, so this description comes from testing the system and reviewing the code. The client in Appdash gets added to your code. Appdash provides Python, Golang, and Ruby implementations, but OpenTracing libraries can be used with Appdash’s OpenTracing implementation. The client collects the spans and sends them to the local collector. The local collector then sends the data to a centralized Appdash server running its own local collector, which is the remote collector for all other nodes in the system.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/distributed-tracing-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.jaegertracing.io/
|
||||
[2]: https://www.youtube.com/watch?v=T8BbeqZ0Rls
|
||||
[3]: http://opentracing.io/
|
||||
[4]: https://zipkin.io/
|
||||
[5]: https://www.datadoghq.com/
|
||||
[6]: https://www.instana.com/
|
||||
[7]: https://opencensus.io/
|
||||
[8]: https://research.google.com/archive/papers/dapper-2010-1.pdf
|
||||
[9]: https://thrift.apache.org/
|
||||
[10]: https://zipkin.io/pages/community.html
|
||||
[11]: https://github.com/openzipkin/brave
|
||||
[12]: https://cloud.spring.io/spring-cloud-sleuth/
|
||||
[13]: https://www.cncf.io/
|
||||
[14]: https://en.wikipedia.org/wiki/Apache_Thrift
|
||||
[15]: https://www.jaegertracing.io/docs/roadmap/#adaptive-sampling
|
||||
[16]: https://github.com/sourcegraph/appdash
|
||||
[17]: https://about.sourcegraph.com/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to use the Scikit-learn Python library for data science projects
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,441 @@
|
||||
How To Find And Delete Duplicate Files In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
I always backup the configuration files or any old files to somewhere in my hard disk before edit or modify them, so I can restore them from the backup if I accidentally did something wrong. But the problem is I forgot to clean up those files and my hard disk is filled with a lot of duplicate files after a certain period of time. I feel either too lazy to clean the old files or afraid that I may delete an important files. If you’re anything like me and overwhelming with multiple copies of same files in different backup directories, you can find and delete duplicate files using the tools given below in Unix-like operating systems.
|
||||
|
||||
**A word of caution:**
|
||||
|
||||
Please be careful while deleting duplicate files. If you’re not careful, it will lead you to [**accidental data loss**][1]. I advice you to pay extra attention while using these tools.
|
||||
|
||||
### Find And Delete Duplicate Files In Linux
|
||||
|
||||
For the purpose of this guide, I am going to discuss about three utilities namely,
|
||||
|
||||
1. Rdfind,
|
||||
2. Fdupes,
|
||||
3. FSlint.
|
||||
|
||||
|
||||
|
||||
These three utilities are free, open source and works on most Unix-like operating systems.
|
||||
|
||||
##### 1. Rdfind
|
||||
|
||||
**Rdfind** , stands for **r** edundant **d** ata **find** , is a free and open source utility to find duplicate files across and/or within directories and sub-directories. It compares files based on their content, not on their file names. Rdfind uses **ranking** algorithm to classify original and duplicate files. If you have two or more equal files, Rdfind is smart enough to find which is original file, and consider the rest of the files as duplicates. Once it found the duplicates, it will report them to you. You can decide to either delete them or replace them with [**hard links** or **symbolic (soft) links**][2].
|
||||
|
||||
**Installing Rdfind**
|
||||
|
||||
Rdfind is available in [**AUR**][3]. So, you can install it in Arch-based systems using any AUR helper program like [**Yay**][4] as shown below.
|
||||
|
||||
```
|
||||
$ yay -S rdfind
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install rdfind
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install rdfind
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
$ sudo yum install rdfind
|
||||
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
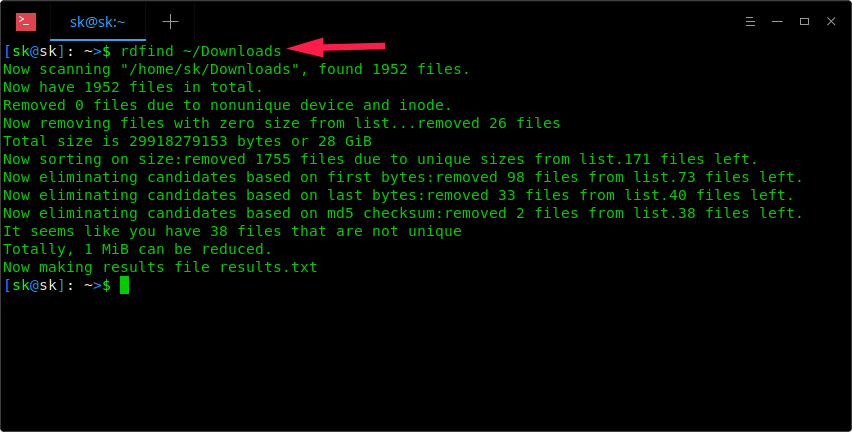
Once installed, simply run Rdfind command along with the directory path to scan for the duplicate files.
|
||||
|
||||
```
|
||||
$ rdfind ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
As you see in the above screenshot, Rdfind command will scan ~/Downloads directory and save the results in a file named **results.txt** in the current working directory. You can view the name of the possible duplicate files in results.txt file.
|
||||
|
||||
```
|
||||
$ cat results.txt
|
||||
# Automatically generated
|
||||
# duptype id depth size device inode priority name
|
||||
DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex
|
||||
DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex
|
||||
[...]
|
||||
DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf
|
||||
DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf
|
||||
# end of file
|
||||
|
||||
```
|
||||
|
||||
By reviewing the results.txt file, you can easily find the duplicates. You can remove the duplicates manually if you want to.
|
||||
|
||||
Also, you can **-dryrun** option to find all duplicates in a given directory without changing anything and output the summary in your Terminal:
|
||||
|
||||
```
|
||||
$ rdfind -dryrun true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Once you found the duplicates, you can replace them with either hardlinks or symlinks.
|
||||
|
||||
To replace all duplicates with hardlinks, run:
|
||||
|
||||
```
|
||||
$ rdfind -makehardlinks true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
To replace all duplicates with symlinks/soft links, run:
|
||||
|
||||
```
|
||||
$ rdfind -makesymlinks true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
You may have some empty files in a directory and want to ignore them. If so, use **-ignoreempty** option like below.
|
||||
|
||||
```
|
||||
$ rdfind -ignoreempty true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
If you don’t want the old files anymore, just delete duplicate files instead of replacing them with hard or soft links.
|
||||
|
||||
To delete all duplicates, simply run:
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
If you do not want to ignore empty files and delete them along with all duplicates, run:
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section:
|
||||
|
||||
```
|
||||
$ rdfind --help
|
||||
|
||||
```
|
||||
|
||||
And, the manual pages:
|
||||
|
||||
```
|
||||
$ man rdfind
|
||||
|
||||
```
|
||||
|
||||
##### 2. Fdupes
|
||||
|
||||
**Fdupes** is yet another command line utility to identify and remove the duplicate files within specified directories and the sub-directories. It is free, open source utility written in **C** programming language. Fdupes identifies the duplicates by comparing file sizes, partial MD5 signatures, full MD5 signatures, and finally performing a byte-by-byte comparison for verification.
|
||||
|
||||
Similar to Rdfind utility, Fdupes comes with quite handful of options to perform operations, such as:
|
||||
|
||||
* Recursively search duplicate files in directories and sub-directories
|
||||
* Exclude empty files and hidden files from consideration
|
||||
* Show the size of the duplicates
|
||||
* Delete duplicates immediately as they encountered
|
||||
* Exclude files with different owner/group or permission bits as duplicates
|
||||
* And a lot more.
|
||||
|
||||
|
||||
|
||||
**Installing Fdupes**
|
||||
|
||||
Fdupes is available in the default repositories of most Linux distributions.
|
||||
|
||||
On Arch Linux and its variants like Antergos, Manjaro Linux, install it using Pacman like below.
|
||||
|
||||
```
|
||||
$ sudo pacman -S fdupes
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install fdupes
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install fdupes
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
$ sudo yum install fdupes
|
||||
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
Fdupes usage is pretty simple. Just run the following command to find out the duplicate files in a directory, for example **~/Downloads**.
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Sample output from my system:
|
||||
|
||||
```
|
||||
/home/sk/Downloads/Hyperledger.pdf
|
||||
/home/sk/Downloads/Hyperledger(1).pdf
|
||||
|
||||
```
|
||||
|
||||
As you can see, I have a duplicate file in **/home/sk/Downloads/** directory. It shows the duplicates from the parent directory only. How to view the duplicates from sub-directories? Just use **-r** option like below.
|
||||
|
||||
```
|
||||
$ fdupes -r ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Now you will see the duplicates from **/home/sk/Downloads/** directory and its sub-directories as well.
|
||||
|
||||
Fdupes can also be able to find duplicates from multiple directories at once.
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads ~/Documents/ostechnix
|
||||
|
||||
```
|
||||
|
||||
You can even search multiple directories, one recursively like below:
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads -r ~/Documents/ostechnix
|
||||
|
||||
```
|
||||
|
||||
The above commands searches for duplicates in “~/Downloads” directory and “~/Documents/ostechnix” directory and its sub-directories.
|
||||
|
||||
Sometimes, you might want to know the size of the duplicates in a directory. If so, use **-S** option like below.
|
||||
|
||||
```
|
||||
$ fdupes -S ~/Downloads
|
||||
403635 bytes each:
|
||||
/home/sk/Downloads/Hyperledger.pdf
|
||||
/home/sk/Downloads/Hyperledger(1).pdf
|
||||
|
||||
```
|
||||
|
||||
Similarly, to view the size of the duplicates in parent and child directories, use **-Sr** option.
|
||||
|
||||
We can exclude empty and hidden files from consideration using **-n** and **-A** respectively.
|
||||
|
||||
```
|
||||
$ fdupes -n ~/Downloads
|
||||
|
||||
$ fdupes -A ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
The first command will exclude zero-length files from consideration and the latter will exclude hidden files from consideration while searching for duplicates in the specified directory.
|
||||
|
||||
To summarize duplicate files information, use **-m** option.
|
||||
|
||||
```
|
||||
$ fdupes -m ~/Downloads
|
||||
1 duplicate files (in 1 sets), occupying 403.6 kilobytes
|
||||
|
||||
```
|
||||
|
||||
To delete all duplicates, use **-d** option.
|
||||
|
||||
```
|
||||
$ fdupes -d ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf
|
||||
[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
|
||||
|
||||
Set 1 of 1, preserve files [1 - 2, all]:
|
||||
|
||||
```
|
||||
|
||||
This command will prompt you for files to preserve and delete all other duplicates. Just enter any number to preserve the corresponding file and delete the remaining files. Pay more attention while using this option. You might delete original files if you’re not be careful.
|
||||
|
||||
If you want to preserve the first file in each set of duplicates and delete the others without prompting each time, use **-dN** option (not recommended).
|
||||
|
||||
```
|
||||
$ fdupes -dN ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
To delete duplicates as they are encountered, use **-I** flag.
|
||||
|
||||
```
|
||||
$ fdupes -I ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
For more details about Fdupes, view the help section and man pages.
|
||||
|
||||
```
|
||||
$ fdupes --help
|
||||
|
||||
$ man fdupes
|
||||
|
||||
```
|
||||
|
||||
##### 3. FSlint
|
||||
|
||||
**FSlint** is yet another duplicate file finder utility that I use from time to time to get rid of the unnecessary duplicate files and free up the disk space in my Linux system. Unlike the other two utilities, FSlint has both GUI and CLI modes. So, it is more user-friendly tool for newbies. FSlint not just finds the duplicates, but also bad symlinks, bad names, temp files, bad IDS, empty directories, and non stripped binaries etc.
|
||||
|
||||
**Installing FSlint**
|
||||
|
||||
FSlint is available in [**AUR**][5], so you can install it using any AUR helpers.
|
||||
|
||||
```
|
||||
$ yay -S fslint
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install fslint
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install fslint
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
```
|
||||
|
||||
$ sudo yum install fslint
|
||||
|
||||
Once it is installed, launch it from menu or application launcher.
|
||||
|
||||
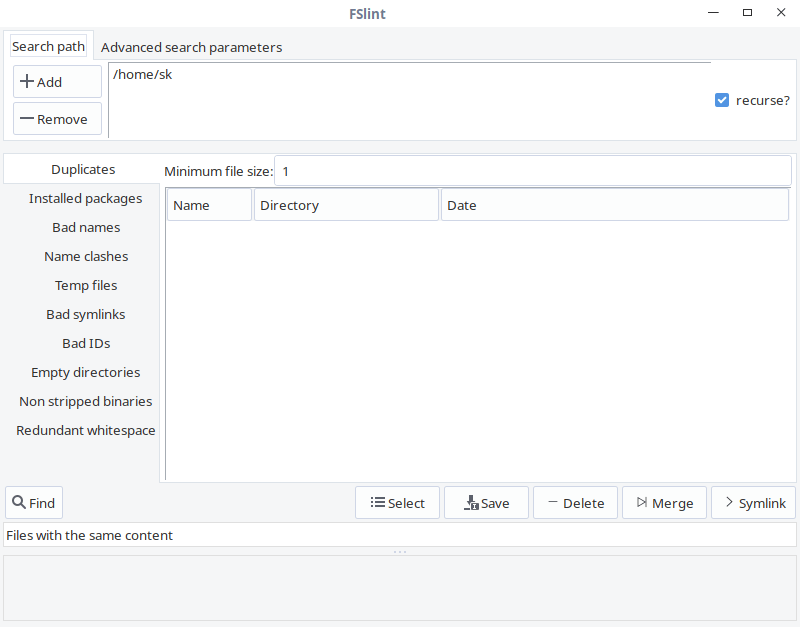
This is how FSlint GUI looks like.
|
||||
|
||||
|
||||
|
||||
As you can see, the interface of FSlint is user-friendly and self-explanatory. In the **Search path** tab, add the path of the directory you want to scan and click **Find** button on the lower left corner to find the duplicates. Check the recurse option to recursively search for duplicates in directories and sub-directories. The FSlint will quickly scan the given directory and list out them.
|
||||
|
||||
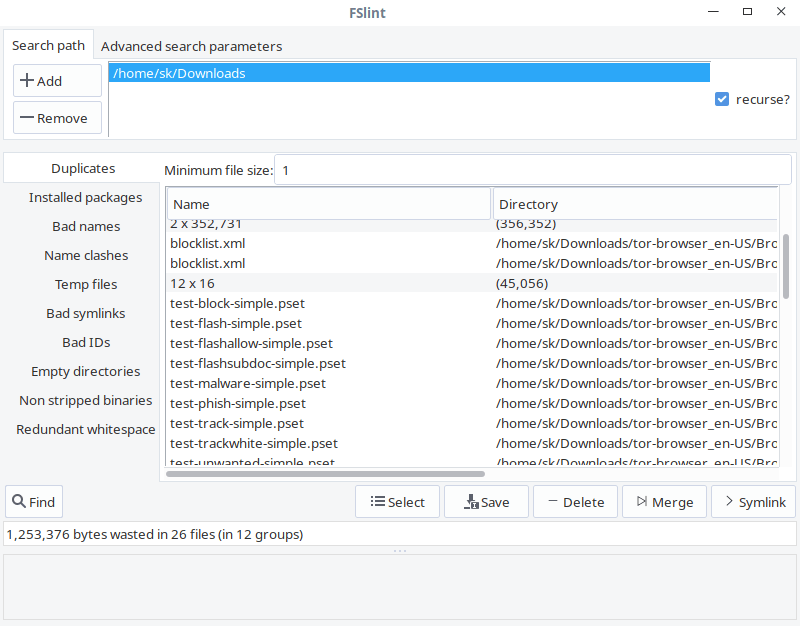
|
||||
|
||||
From the list, choose the duplicates you want to clean and select any one of them given actions like Save, Delete, Merge and Symlink.
|
||||
|
||||
In the **Advanced search parameters** tab, you can specify the paths to exclude while searching for duplicates.
|
||||
|
||||

|
||||
|
||||
**FSlint command line options**
|
||||
|
||||
FSlint provides a collection of the following CLI utilities to find duplicates in your filesystem:
|
||||
|
||||
* **findup** — find DUPlicate files
|
||||
* **findnl** — find Name Lint (problems with filenames)
|
||||
* **findu8** — find filenames with invalid utf8 encoding
|
||||
* **findbl** — find Bad Links (various problems with symlinks)
|
||||
* **findsn** — find Same Name (problems with clashing names)
|
||||
* **finded** — find Empty Directories
|
||||
* **findid** — find files with dead user IDs
|
||||
* **findns** — find Non Stripped executables
|
||||
* **findrs** — find Redundant Whitespace in files
|
||||
* **findtf** — find Temporary Files
|
||||
* **findul** — find possibly Unused Libraries
|
||||
* **zipdir** — Reclaim wasted space in ext2 directory entries
|
||||
|
||||
|
||||
|
||||
All of these utilities are available under **/usr/share/fslint/fslint/fslint** location.
|
||||
|
||||
For example, to find duplicates in a given directory, do:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/findup ~/Downloads/
|
||||
|
||||
```
|
||||
|
||||
Similarly, to find empty directories, the command would be:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/finded ~/Downloads/
|
||||
|
||||
```
|
||||
|
||||
To get more details on each utility, for example **findup** , run:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/findup --help
|
||||
|
||||
```
|
||||
|
||||
For more details about FSlint, refer the help section and man pages.
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/fslint --help
|
||||
|
||||
$ man fslint
|
||||
|
||||
```
|
||||
|
||||
##### Conclusion
|
||||
|
||||
You know now about three tools to find and delete unwanted duplicate files in Linux. Among these three tools, I often use Rdfind. It doesn’t mean that the other two utilities are not efficient, but I am just happy with Rdfind so far. Well, it’s your turn. Which is your favorite tool and why? Let us know them in the comment section below.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
|
||||
[2]: https://www.ostechnix.com/explaining-soft-link-and-hard-link-in-linux-with-examples/
|
||||
[3]: https://aur.archlinux.org/packages/rdfind/
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]: https://aur.archlinux.org/packages/fslint/
|
||||
@ -0,0 +1,97 @@
|
||||
How to Use RAR files in Ubuntu Linux
|
||||
======
|
||||
[RAR][1] is a quite good archive file format. But, it isn’t the best when you’ve got 7-zip offering great compression ratios and Zip files being easily supported across multiple platforms by default. It is one of the most popular archive formats, but, [Ubuntu][2]‘s archive manager does not support extracting RAR files nor does it let you create RAR files.
|
||||
|
||||
Fret not, we have a solution for you. To enable the support to extract RAR files, you need to install **UNRAR** – which is a freeware by [RARLAB][3]. And, to create and manage RAR files, you need to install **RAR** – which is available as a trial.
|
||||
|
||||
![RAR files in Ubuntu Linux][4]
|
||||
|
||||
### Extracting RAR Files
|
||||
|
||||
Unless you have it installed, extracting RAR files will show you an error “Extraction not performed“. Here’s how it should look like ([ **Ubuntu 18.04**][5]):
|
||||
|
||||
![Error in RAR extraction in Ubuntu][6]
|
||||
|
||||
If you want to resolve the error and easily be able to extract RAR files, follow the instructions below to install unrar:
|
||||
|
||||
**- >** Launch the terminal and type in:
|
||||
|
||||
```
|
||||
sudo apt-get install unrar
|
||||
|
||||
```
|
||||
|
||||
-> After installing unrar, you may choose to type in “ **unrar** ” (without the inverted commas) to know more about its usage and how to use RAR files with the help of it.
|
||||
|
||||
The most common usage would obviously be extracting the RAR file you have. So, **you can either perform a right-click on the file and proceed to extract it** from there or you can do it via the terminal with the help of this command:
|
||||
|
||||
```
|
||||
unrar x FileName.rar
|
||||
|
||||
```
|
||||
|
||||
You can see that in action here:
|
||||
|
||||
![Using unrar in Ubuntu][7]
|
||||
|
||||
If the file isn’t present in the Home directory, then you have to navigate to the target folder by using the “ **cd** ” command. For instance, if you have the archive in the Music directory, simply type in “ **cd Music** ” to navigate to the location and then extract the RAR file.
|
||||
|
||||
### Creating & Managing RAR files
|
||||
|
||||
![Using rar archive in Ubuntu Linux][8]
|
||||
|
||||
UNRAR does not let you create RAR files. So, you need to install the RAR command-line tool to be able to create RAR archives.
|
||||
|
||||
To do that, you need to type in the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install rar
|
||||
|
||||
```
|
||||
|
||||
Here, we will help you create a RAR file. In order to do that, follow the command syntax below:
|
||||
|
||||
```
|
||||
rar a ArchiveName File_1 File_2 Dir_1 Dir_2
|
||||
|
||||
```
|
||||
|
||||
When you type a command in this format, it will add every item inside the directory to the archive. In either case, if you want specific files, just mention the exact name/path.
|
||||
|
||||
By default, the RAR files reside in **HOME** directory.
|
||||
|
||||
In the same way, you can update/manage the RAR files. Just type in a command using the following syntax:
|
||||
|
||||
```
|
||||
rar u ArchiveName Filename
|
||||
|
||||
```
|
||||
|
||||
To get the list of commands for the RAR tool, just type “ **rar** ” in the terminal.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Now that you’ve known how to use RAR files on Ubuntu, will you prefer using it over 7-zip, Zip, or Tar.xz?
|
||||
|
||||
Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/use-rar-ubuntu-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://www.rarlab.com/rar_file.htm
|
||||
[2]: https://www.ubuntu.com/
|
||||
[3]: https://www.rarlab.com/
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/rar-ubuntu-linux.png
|
||||
[5]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/extract-rar-error.jpg
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/unrar-rar-extraction.jpg
|
||||
[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/rar-update-create.jpg
|
||||
237
translated/tech/20180528 What is behavior-driven Python.md
Normal file
237
translated/tech/20180528 What is behavior-driven Python.md
Normal file
@ -0,0 +1,237 @@
|
||||
什么是行为驱动的Python?
|
||||
======
|
||||

|
||||
|
||||
您是否听说过[行为驱动开发][1](BDD),并想知道所有的新奇事物是什么? 也许你已经发现了团队成员在使用“gherkin”了,并感到被排除在外无法参与其中。 或许你是一个Python爱好者,正在寻找更好的方法来测试你的代码。 无论在什么情况下,了解BDD都可以帮助您和您的团队实现更好的协作和测试自动化,而Python的`行为`框架是一个很好的起点。
|
||||
|
||||
### 什么是BDD?
|
||||
|
||||
* 在网站上提交表单
|
||||
* 搜索想要的结果
|
||||
* 保存文档
|
||||
* 进行REST API调用
|
||||
* 运行命令行界面命令
|
||||
|
||||
在软件中,行为是指在明确定义的输入,行为和结果场景中功能是如何运转的。 产品可以表现出无数的行为,例如:
|
||||
|
||||
根据产品的行为定义产品的功能可以更容易地描述产品,并对其进行开发和测试。 BDD的核心是:使行为成为软件开发的焦点。 在开发早期使用示例语言的规范来定义行为。 最常见的行为规范语言之一是Gherkin,Cucumber项目中的Given-When-Then场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
|
||||
|
||||
下面是用Gherkin编写的行为规范的示例:
|
||||
|
||||
根据产品的行为定义产品的功能可以更容易地描述产品,开发产品并对其进行测试。 这是BDD的核心:使行为成为软件开发的焦点。 在开发早期使用[示例规范][2]的语言来定义行为。 最常见的行为规范语言之一是[Gherkin][3],[Cucumber][4]项目中的Given-When-Then场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
|
||||
|
||||
下面是用Gherkin编写的行为规范的示例:
|
||||
|
||||
```
|
||||
Scenario: Basic DuckDuckGo Search
|
||||
Given the DuckDuckGo home page is displayed
|
||||
When the user searches for "panda"
|
||||
Then results are shown for "panda"
|
||||
```
|
||||
|
||||
快速浏览一下,行为是直观易懂的。 除少数关键字外,该语言为自由格式。 场景简洁而有意义。 一个真实的例子说明了这种行为。 步骤以声明的方式表明应该发生什么——而不会陷入如何如何的细节中。
|
||||
|
||||
[BDD的主要优点][5]是良好的协作和自动化。 每个人都可以为行为开发做出贡献,而不仅仅是程序员。 从流程开始就定义并理解预期的行为。 测试可以与它们涵盖的功能一起自动化。 每个测试都包含一个单一的,独特的行为,以避免重复。 最后,现有的步骤可以通过新的行为规范重用,从而产生雪球效果。
|
||||
|
||||
### Python的behave框架
|
||||
|
||||
`behave`是Python中最流行的BDD框架之一。 它与其他基于Gherkin的Cucumber框架非常相似,尽管没有得到官方的Cucumber定名。 `behave`有两个主要层:
|
||||
|
||||
1. 用Gherkin的`.feature`文件编写的行为规范
|
||||
2. 用Python模块编写的步骤定义和钩子,用于实现Gherkin步骤
|
||||
|
||||
如上例所示,Gherkin场景有三部分格式:
|
||||
|
||||
1. 鉴于一些初始状态
|
||||
2. 当行为发生时
|
||||
3. 然后验证结果
|
||||
|
||||
当`behave`运行测试时,每个步骤由装饰器“粘合”到Python函数。
|
||||
|
||||
### 安装
|
||||
|
||||
作为先决条件,请确保在你的计算机上安装了Python和`pip`。 我强烈建议使用Python 3.(我还建议使用[`pipenv`][6],但以下示例命令使用更基本的`pip`。)
|
||||
|
||||
`behave`框架只需要一个包:
|
||||
|
||||
```
|
||||
pip install behave
|
||||
```
|
||||
|
||||
其他包也可能有用,例如:
|
||||
```
|
||||
pip install requests # 用于调用REST API
|
||||
pip install selenium # 用于web浏览器交互
|
||||
```
|
||||
|
||||
GitHub上的[behavior-driven-Python][7]项目包含本文中使用的示例。
|
||||
|
||||
### Gherkin特点
|
||||
|
||||
`behave`框架使用的Gherkin语法实际上是符合官方的Cucumber Gherkin标准的。 `.feature`文件包含功能Feature部分,而Feature部分又包含具有Given-When-Then步骤的场景Scenario部分。 以下是一个例子:
|
||||
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
As a gardener,
|
||||
I want to carry many cucumbers in a basket,
|
||||
So that I don’t drop them all.
|
||||
|
||||
@cucumber-basket
|
||||
Scenario: Add and remove cucumbers
|
||||
Given the basket is empty
|
||||
When "4" cucumbers are added to the basket
|
||||
And "6" more cucumbers are added to the basket
|
||||
But "3" cucumbers are removed from the basket
|
||||
Then the basket contains "7" cucumbers
|
||||
```
|
||||
|
||||
这里有一些重要的事情需要注意:
|
||||
|
||||
- Feature和Scenario部分都有[简短的描述性标题][8]。
|
||||
- 紧跟在Feature标题后面的行是会被`behave`框架忽略掉的注释。将功能描述放在那里是一种很好的做法。
|
||||
- Scenarios和Features可以有标签(注意`@cucumber-basket`标记)用于钩子和过滤(如下所述)。
|
||||
- 步骤都遵循[严格的Given-When-Then顺序][9]。
|
||||
- 使用`And`和`Bu`t可以为任何类型添加附加步骤。
|
||||
- 可以使用输入对步骤进行参数化——注意双引号里的值。
|
||||
|
||||
通过使用场景大纲,场景也可以写为具有多个输入组合的模板:
|
||||
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
@cucumber-basket
|
||||
Scenario Outline: Add cucumbers
|
||||
Given the basket has “<initial>” cucumbers
|
||||
When "<more>" cucumbers are added to the basket
|
||||
Then the basket contains "<total>" cucumbers
|
||||
|
||||
Examples: Cucumber Counts
|
||||
| initial | more | total |
|
||||
| 0 | 1 | 1 |
|
||||
| 1 | 2 | 3 |
|
||||
| 5 | 4 | 9 |
|
||||
```
|
||||
|
||||
场景大纲总是有一个Examples表,其中第一行给出列标题,后续每一行给出一个输入组合。 只要列标题出现在由尖括号括起的步骤中,行值就会被替换。 在上面的示例中,场景将运行三次,因为有三行输入组合。 场景大纲是避免重复场景的好方法。
|
||||
|
||||
Gherkin语言还有其他元素,但这些是主要的机制。 想了解更多信息,请阅读Automation Panda这个网站的文章[Gherkin by Example][10]和[Writing Good Gherkin][11]。
|
||||
|
||||
### Python机制
|
||||
|
||||
每个Gherkin步骤必须“粘合”到步骤定义,即提供了实现的Python函数。 每个函数都有一个带有匹配字符串的步骤类型装饰器。 它还接收共享的上下文和任何步骤参数。 功能文件必须放在名为`features/`的目录中,而步骤定义模块必须放在名为`features/steps/`的目录中。 任何功能文件都可以使用任何模块中的步骤定义——它们不需要具有相同的名称。 下面是一个示例Python模块,其中包含cucumber basket功能的步骤定义。
|
||||
|
||||
```
|
||||
from behave import *
|
||||
from cucumbers.basket import CucumberBasket
|
||||
|
||||
@given('the basket has "{initial:d}" cucumbers')
|
||||
def step_impl(context, initial):
|
||||
context.basket = CucumberBasket(initial_count=initial)
|
||||
|
||||
@when('"{some:d}" cucumbers are added to the basket')
|
||||
def step_impl(context, some):
|
||||
context.basket.add(some)
|
||||
|
||||
@then('the basket contains "{total:d}" cucumbers')
|
||||
def step_impl(context, total):
|
||||
assert context.basket.count == total
|
||||
```
|
||||
|
||||
可以使用三个[步骤匹配器][12]:`parse`,`cfparse`和`re`。默认和最简单的匹配器是`parse`,如上例所示。注意如何解析参数化值并将其作为输入参数传递给函数。一个常见的最佳实践是在步骤中给参数加双引号。
|
||||
|
||||
每个步骤定义函数还接收一个[上下文][13]变量,该变量保存当前正在运行的场景的数据,例如`feature`, `scenario`和`tags`字段。也可以添加自定义字段,用于在步骤之间共享数据。始终使用上下文来共享数据——永远不要使用全局变量!
|
||||
|
||||
`behave`框架还支持[钩子][14]来处理Gherkin步骤之外的自动化问题。钩子是一个将在步骤,场景,功能或整个测试套件之前或之后运行的功能。钩子让人联想到[面向方面的编程][15]。它们应放在`features/`目录下的特殊`environment.py`文件中。钩子函数也可以检查当前场景的标签,因此可以有选择地应用逻辑。下面的示例显示了如何使用钩子为标记为`@web`的任何场景生成和销毁一个Selenium WebDriver实例。
|
||||
|
||||
```
|
||||
from selenium import webdriver
|
||||
|
||||
def before_scenario(context, scenario):
|
||||
if 'web' in context.tags:
|
||||
context.browser = webdriver.Firefox()
|
||||
context.browser.implicitly_wait(10)
|
||||
|
||||
def after_scenario(context, scenario):
|
||||
if 'web' in context.tags:
|
||||
context.browser.quit()
|
||||
```
|
||||
|
||||
注意:也可以使用[fixtures][16]进行构建和清理。
|
||||
|
||||
要了解一个`behave`项目应该是什么样子,这里是示例项目的目录结构:
|
||||
|
||||

|
||||
|
||||
任何Python包和自定义模块都可以与`behave`框架一起使用。 使用良好的设计模式构建可扩展的测试自动化解决方案。步骤定义代码应简明扼要。
|
||||
|
||||
### 运行测试
|
||||
|
||||
要从命令行运行测试,请切换到项目的根目录并运行`behave`命令。 使用`-help`选项查看所有可用选项。
|
||||
|
||||
以下是一些常见用例:
|
||||
|
||||
```
|
||||
# run all tests
|
||||
behave
|
||||
|
||||
# run the scenarios in a feature file
|
||||
behave features/web.feature
|
||||
|
||||
# run all tests that have the @duckduckgo tag
|
||||
behave --tags @duckduckgo
|
||||
|
||||
# run all tests that do not have the @unit tag
|
||||
behave --tags ~@unit
|
||||
|
||||
# run all tests that have @basket and either @add or @remove
|
||||
behave --tags @basket --tags @add,@remove
|
||||
```
|
||||
|
||||
为方便起见,选项可以保存在[config][17]文件中。
|
||||
|
||||
### 其他选择
|
||||
|
||||
`behave`不是Python中唯一的BDD测试框架。其他好的框架包括:
|
||||
|
||||
- `pytest-bdd`,`pytest`的插件,和`behave`一样,它使用Gherkin功能文件和步骤定义模块,但它也利用了`pytest`的所有功能和插件。例如,它可以使用`pytest-xdist`并行运行Gherkin场景。 BDD和非BDD测试也可以与相同的过滤器一起执行。 `pytest-bdd`还提供更灵活的目录布局。
|
||||
- `radish`是一个“Gherkin增强版”框架——它将Scenario循环和前提条件添加到标准的Gherkin语言中,这使得它对程序员更友好。它还提供丰富的命令行选项,如`behave`。
|
||||
- `lettuce`是一种较旧的BDD框架,与`behave`非常相似,在框架机制方面存在细微差别。然而,GitHub最近显示该项目的活动很少(截至2018年5月)。
|
||||
|
||||
任何这些框架都是不错的选择。
|
||||
|
||||
另外,请记住,Python测试框架可用于任何黑盒测试,即使对于非Python产品也是如此! BDD框架非常适合Web和服务测试,因为它们的测试是声明性的,而Python是一种[很好的测试自动化语言][18]。
|
||||
|
||||
本文基于作者的[PyCon Cleveland 2018][19]演讲,[行为驱动的Python][20]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/behavior-driven-python
|
||||
|
||||
作者:[Andrew Knight][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andylpk247
|
||||
[1]:https://automationpanda.com/bdd/
|
||||
[2]:https://en.wikipedia.org/wiki/Specification_by_example
|
||||
[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
|
||||
[4]:https://cucumber.io/
|
||||
[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
|
||||
[6]:https://docs.pipenv.org/
|
||||
[7]:https://github.com/AndyLPK247/behavior-driven-python
|
||||
[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
|
||||
[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
|
||||
[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
|
||||
[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
|
||||
[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
|
||||
[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
|
||||
[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
|
||||
[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
|
||||
[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
|
||||
[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
|
||||
[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
|
||||
[19]:https://us.pycon.org/2018/
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/87/
|
||||
108
translated/tech/20180824 5 cool music player apps.md
Normal file
108
translated/tech/20180824 5 cool music player apps.md
Normal file
@ -0,0 +1,108 @@
|
||||
5 个很酷的音乐播放器
|
||||
======
|
||||
|
||||

|
||||
你喜欢音乐吗?那么 Fedora 中可能有你正在寻找的东西。本文介绍在 Fedora 上运行的不同音乐播放器。无论你有大量的音乐库,还是小型音乐库,或者根本没有音乐库,你都会被覆盖到。这里有四个图形程序和一个基于终端的音乐播放器,可以让你挑选。
|
||||
|
||||
### Quod Libet
|
||||
|
||||
Quod Libet 是你的大型音频库的管理员。如果你有一个大量的音频库,你不想只听,但也要管理,Quod Libet 可能是一个很好的选择。
|
||||
|
||||
![][1]
|
||||
|
||||
Quod Libet 可以从磁盘上的多个位置导入音乐,并允许你编辑音频文件的标签 - 因此一切都在你的控制之下。额外地,它还有各种插件可用,从简单的均衡器到 [last.fm][2] 同步。你也可以直接从 [Soundcloud][3] 搜索和播放音乐。
|
||||
|
||||
Quod Libet 在 HiDPI 屏幕上工作得很好,它有 Fedora 的 RPM 包,如果你运行[Silverblue][5],它在 [Flathub][4] 中也有。使用 Gnome Software 或命令行安装它:
|
||||
```
|
||||
$ sudo dnf install quodlibet
|
||||
|
||||
```
|
||||
|
||||
### Audacious
|
||||
|
||||
如果你喜欢简单的音乐播放器,甚至可能看起来像传说中的 Winamp,Audacious 可能是你的不错选择。
|
||||
|
||||
![][6]
|
||||
|
||||
Audacious 可能不会立即管理你的所有音乐,但你如果想将音乐组织为文件,它能做得很好。你还可以导出和导入播放列表,而无需重新组织音乐文件本身。
|
||||
|
||||
额外地,你可以让它看起来像 Winamp。要让它与上面的截图相同,请进入 “Settings/Appearance,”,选择顶部的 “Winamp Classic Interface”,然后选择右下方的 “Refugee” 皮肤。而鲍勃是你的叔叔!这就完成了。
|
||||
|
||||
Audacious 在 Fedora 中作为 RPM 提供,可以使用 Gnome Software 或在终端运行以下命令安装:
|
||||
```
|
||||
$ sudo dnf install audacious
|
||||
|
||||
```
|
||||
|
||||
### Lollypop
|
||||
|
||||
Lollypop 是一个音乐播放器,它与 GNOME 集成良好。如果你喜欢 GNOME 的外观,并且想要一个集成良好的音乐播放器,Lollypop 可能适合你。
|
||||
|
||||
![][7]
|
||||
|
||||
除了与 GNOME Shell 的良好视觉集成之外,它还可以很好地用于 HiDPI 屏幕,并支持黑暗主题。
|
||||
|
||||
额外地,Lollypop 有一个集成的封面下载器和一个所谓的派对模式(右上角的音符按钮),它可以自动选择和播放音乐。它还集成了 [last.fm][2] 或 [libre.fm][8] 等在线服务。
|
||||
|
||||
它有 Fedora 的 RPM 也有用于 [Silverblue][5] 工作站的 [Flathub][4],使用 Gnome Software 或终端进行安装:
|
||||
```
|
||||
$ sudo dnf install lollypop
|
||||
|
||||
```
|
||||
|
||||
### Gradio
|
||||
|
||||
如果你没有任何音乐但仍喜欢听怎么办?或者你只是喜欢收音机?Gradio 就是为你准备的。
|
||||
|
||||
![][9]
|
||||
|
||||
Gradio 是一个简单的收音机,它允许你搜索和播放网络电台。你可以按国家、语言或直接搜索找到它们。额外地,它可视化地集成到了 GNOME Shell 中,可以与 HiDPI 屏幕配合使用,并且可以选择黑暗主题。
|
||||
|
||||
可以在 [Flathub][4] 中找到 Gradio,它同时可以运行在 Fedora Workstation 和 [Silverblue][5] 中。使用 Gnome Software 安装它
|
||||
|
||||
### sox
|
||||
|
||||
你喜欢使用终端在工作时听一些音乐吗?多亏有了 sox,你不必离开终端。
|
||||
|
||||
![][10]
|
||||
|
||||
sox 是一个非常简单的基于终端的音乐播放器。你需要做的就是运行如下命令:
|
||||
```
|
||||
$ play file.mp3
|
||||
|
||||
```
|
||||
|
||||
接着 sox 就会为你播放。除了单独的音频文件外,sox 还支持 m3u 格式的播放列表。
|
||||
|
||||
额外地,因为 sox 是基于终端的程序,你可以在 ssh 中运行它。你有一个带扬声器的家用服务器吗?或者你想从另一台电脑上播放音乐吗?尝试将它与 [tmux][11] 一起使用,这样即使会话关闭也可以继续听。
|
||||
|
||||
sox 在 Fedora 中以 RPM 提供。运行下面的命令安装:
|
||||
```
|
||||
$ sudo dnf install sox
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-music-player-apps/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/asamalik/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-300x217.png
|
||||
[2]:https://last.fm
|
||||
[3]:https://soundcloud.com/
|
||||
[4]:https://flathub.org/home
|
||||
[5]:https://teamsilverblue.org/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-300x136.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-300x172.png
|
||||
[8]:https://libre.fm
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-300x179.png
|
||||
[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
@ -0,0 +1,116 @@
|
||||
[已解决] Ubuntu 中的 “sub process usr bin dpkg returned an error code 1” 错误
|
||||
======
|
||||
如果你在 Ubuntu Linux 上安装软件时遇到 “sub process usr bin dpkg returned an error code 1”,请按照以下步骤进行修复。
|
||||
|
||||
Ubuntu 和其他基于 Debian 的发行版中的一个常见问题是已经损坏的包。你尝试更新系统或安装新软件包时遇到类似 “Sub-process /usr/bin/dpkg returned an error code” 的错误。
|
||||
|
||||
这就是前几天发生在我身上的事。我试图在 Ubuntu 中安装一个电台程序时,它给我了这个错误:
|
||||
```
|
||||
Unpacking python-gst-1.0 (1.6.2-1build1) ...
|
||||
Selecting previously unselected package radiotray.
|
||||
Preparing to unpack .../radiotray_0.7.3-5ubuntu1_all.deb ...
|
||||
Unpacking radiotray (0.7.3-5ubuntu1) ...
|
||||
Processing triggers for man-db (2.7.5-1) ...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu5.2) ...
|
||||
Processing triggers for bamfdaemon (0.5.3~bzr0+16.04.20180209-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu3.1) ...
|
||||
Processing triggers for mime-support (3.59ubuntu1) ...
|
||||
Setting up polar-bookshelf (1.0.0-beta56) ...
|
||||
ln: failed to create symbolic link '/usr/local/bin/polar-bookshelf': No such file or directory
|
||||
dpkg: error processing package polar-bookshelf (--configure):
|
||||
subprocess installed post-installation script returned error exit status 1
|
||||
Setting up python-appindicator (12.10.1+16.04.20170215-0ubuntu1) ...
|
||||
Setting up python-gst-1.0 (1.6.2-1build1) ...
|
||||
Setting up radiotray (0.7.3-5ubuntu1) ...
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
这里最后三行非常重要。
|
||||
```
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
它告诉我 polar-bookshelf 包引发了问题。这可能对你如何修复这个错误至关重要。
|
||||
|
||||
### 修复 Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
![Fix update errors in Ubuntu Linux][1]
|
||||
|
||||
让我们尝试修复这个损坏的错误包。我将展示几种你可以逐一尝试的方法。最初的那些易于使用,几乎不用动脑子。
|
||||
|
||||
你应该尝试运行 sudo apt update,接着尝试安装新的包或尝试升级这里讨论的每个包。
|
||||
|
||||
#### 方法 1:重新配包数据库
|
||||
|
||||
你可以尝试的第一种方法是重新配置包数据库。数据库可能在安装包时损坏了。重新配置通常可以解决问题。
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
|
||||
```
|
||||
|
||||
#### 方法 2:强制安装
|
||||
|
||||
如果是之前中断安装的包,你可以尝试强制安装。
|
||||
```
|
||||
sudo apt-get install -f
|
||||
|
||||
```
|
||||
|
||||
#### 方法3:尝试删除有问题的包
|
||||
|
||||
如果这不是你的问题,你可以尝试手动删除包。请不要在 Linux Kernels(以 linux- 开头的软件包)中执行此操作。
|
||||
```
|
||||
sudo apt remove
|
||||
|
||||
```
|
||||
|
||||
#### 方法 4:删除有问题的包中的信息文件
|
||||
|
||||
这应该是你最后的选择。你可以尝试从 /var/lib/dpkg/info 中删除与相关软件包关联的文件。
|
||||
|
||||
**你需要了解一些基本的 Linux 命令来了解发生了什么以及如何对应你的问题**
|
||||
|
||||
就我而言,我在 polar-bookshelf 中遇到问题。所以我查找了与之关联的文件:
|
||||
```
|
||||
ls -l /var/lib/dpkg/info | grep -i polar-bookshelf
|
||||
-rw-r--r-- 1 root root 2324811 Aug 14 19:29 polar-bookshelf.list
|
||||
-rw-r--r-- 1 root root 2822824 Aug 10 04:28 polar-bookshelf.md5sums
|
||||
-rwxr-xr-x 1 root root 113 Aug 10 04:28 polar-bookshelf.postinst
|
||||
-rwxr-xr-x 1 root root 84 Aug 10 04:28 polar-bookshelf.postrm
|
||||
|
||||
```
|
||||
|
||||
现在我需要做的就是删除这些文件:
|
||||
```
|
||||
sudo mv /var/lib/dpkg/info/polar-bookshelf.* /tmp
|
||||
|
||||
```
|
||||
|
||||
使用 sudo apt update,接着你应该就能像往常一样安装软件了。
|
||||
|
||||
#### 哪种方法适合你(如果有效)?
|
||||
|
||||
我希望这篇快速文章可以帮助你修复 “E: Sub-process /usr/bin/dpkg returned an error code (1)” 的错误
|
||||
|
||||
如果它对你有用,是那种方法?你是否设法使用其他方法修复此错误?如果是,请分享一下以帮助其他人解决此问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dpkg-returned-an-error-code-1/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/fix-common-update-errors-ubuntu.jpeg
|
||||
@ -1,36 +1,24 @@
|
||||
HankChow translating
|
||||
|
||||
How To Find Out Which Port Number A Process Is Using In Linux
|
||||
如何在 Linux 中查看进程占用的端口号
|
||||
======
|
||||
As a Linux administrator, you should know whether the corresponding service is binding/listening with correct port or not.
|
||||
对于 Linux 系统管理员来说,清楚某个服务是否正确地绑定或监听某个端口,是至关重要的。如果你需要处理端口相关的问题,这篇文章可能会对你有用。
|
||||
|
||||
This will help you to easily troubleshoot further when you are facing port related issues.
|
||||
端口是 Linux 系统上特定进程之间逻辑连接的标识,包括物理端口和软件端口。由于 Linux 操作系统是一个软件,因此本文只讨论软件端口。软件端口始终与主机的 IP 地址和相关的通信协议相关联,因此端口常用于区分应用程序。大部分涉及到网络的服务都必须打开一个套接字来监听传入的网络请求,而每个服务都使用一个独立的套接字。
|
||||
|
||||
A port is a logical connection that identifies a specific process on Linux. There are two kind of port are available like, physical and software.
|
||||
**推荐阅读:**
|
||||
**(#)** [在 Linux 上查看进程 ID 的 4 种方法][1]
|
||||
**(#)** [在 Linux 上终止进程的 3 种方法][2]
|
||||
|
||||
Since Linux operating system is a software hence, we are going to discuss about software port.
|
||||
套接字是和 IP 地址,软件端口和协议结合起来使用的,而端口号对传输控制协议(Transmission Control Protocol, TCP)和 用户数据报协议(User Datagram Protocol, UDP)协议都适用,TCP 和 UDP 都可以使用0到65535之间的端口号进行通信。
|
||||
|
||||
Software port is always associated with an IP address of a host and the relevant protocol type for communication. The port is used to distinguish the application.
|
||||
以下是端口分配类别:
|
||||
|
||||
Most of the network related services have to open up a socket to listen incoming network requests. Socket is unique for every service.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [4 Easiest Ways To Find Out Process ID (PID) In Linux][1]
|
||||
**(#)** [3 Easy Ways To Kill Or Terminate A Process In Linux][2]
|
||||
|
||||
Socket is combination of IP address, software Port and protocol. The port numbers area available for both TCP and UDP protocol.
|
||||
|
||||
The Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) use port numbers for communication. It is a value from 0 to 65535.
|
||||
|
||||
Below are port assignments categories.
|
||||
|
||||
* `0-1023:` Well Known Ports or System Ports
|
||||
* `1024-49151:` Registered Ports for applications
|
||||
* `49152-65535:` Dynamic Ports or Private Ports
|
||||
* `0-1023:` 常用端口和系统端口
|
||||
* `1024-49151:` 软件的注册端口
|
||||
* `49152-65535:` 动态端口或私有端口
|
||||
|
||||
|
||||
|
||||
You can check the details of the reserved ports in the /etc/services file on Linux.
|
||||
在 Linux 上的 `/etc/services` 文件可以查看到更多关于保留端口的信息。
|
||||
|
||||
```
|
||||
# less /etc/services
|
||||
@ -89,24 +77,25 @@ lmtp 24/udp # LMTP Mail Delivery
|
||||
|
||||
```
|
||||
|
||||
This can be achieved using the below six methods.
|
||||
可以使用以下六种方法查看端口信息。
|
||||
|
||||
* `ss:` ss is used to dump socket statistics.
|
||||
* `netstat:` netstat is displays a list of open sockets.
|
||||
* `lsof:` lsof – list open files.
|
||||
* `fuser:` fuser – list process IDs of all processes that have one or more files open
|
||||
* `nmap:` nmap – Network exploration tool and security / port scanner
|
||||
* `systemctl:` systemctl – Control the systemd system and service manager
|
||||
* `ss:` ss 可以用于转储套接字统计信息。
|
||||
* `netstat:` netstat 可以显示打开的套接字列表。
|
||||
* `lsof:` lsof 可以列出打开的文件。
|
||||
* `fuser:` fuser 可以列出那些打开了文件的进程的进程 ID。
|
||||
* `nmap:` nmap 是网络检测工具和端口扫描程序。
|
||||
* `systemctl:` systemctl 是 systemd 系统的控制管理器和服务管理器。
|
||||
|
||||
|
||||
|
||||
In this tutorial we are going to find out which port number the SSHD daemon is using.
|
||||
以下我们将找出 `sshd` 守护进程所使用的端口号。
|
||||
|
||||
### Method-1: Using ss Command
|
||||
### 方法1:使用 ss 命令
|
||||
|
||||
ss is used to dump socket statistics. It allows showing information similar to netstat. It can display more TCP and state informations than other tools.
|
||||
`ss` 一般用于转储套接字统计信息。它能够输出类似于 `netstat` 输出的信息,但它可以比其它工具显示更多的 TCP 信息和状态信息。
|
||||
|
||||
它还可以显示所有类型的套接字统计信息,包括 PACKET、TCP、UDP、DCCP、RAW、Unix 域等。
|
||||
|
||||
It can display stats for all kind of sockets such as PACKET, TCP, UDP, DCCP, RAW, Unix domain, etc.
|
||||
|
||||
```
|
||||
# ss -tnlp | grep ssh
|
||||
@ -114,7 +103,7 @@ LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
|
||||
LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
也可以使用端口号来检查。
|
||||
|
||||
```
|
||||
# ss -tnlp | grep ":22"
|
||||
@ -122,11 +111,11 @@ LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
|
||||
LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
|
||||
```
|
||||
|
||||
### Method-2: Using netstat Command
|
||||
### 方法2:使用 netstat 命令
|
||||
|
||||
netstat – Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships.
|
||||
`netstat` 能够显示网络连接、路由表、接口统计信息、伪装连接以及多播成员。
|
||||
|
||||
By default, netstat displays a list of open sockets. If you don’t specify any address families, then the active sockets of all configured address families will be printed. This program is obsolete. Replacement for netstat is ss.
|
||||
默认情况下,`netstat` 会列出打开的套接字。如果不指定任何地址族,则会显示所有已配置地址族的活动套接字。但 `netstat` 已经过时了,一般会使用 `ss` 来替代。
|
||||
|
||||
```
|
||||
# netstat -tnlp | grep ssh
|
||||
@ -134,7 +123,7 @@ tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 997/sshd
|
||||
tcp6 0 0 :::22 :::* LISTEN 997/sshd
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
也可以使用端口号来检查。
|
||||
|
||||
```
|
||||
# netstat -tnlp | grep ":22"
|
||||
@ -142,9 +131,9 @@ tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1208/sshd
|
||||
tcp6 0 0 :::22 :::* LISTEN 1208/sshd
|
||||
```
|
||||
|
||||
### Method-3: Using lsof Command
|
||||
### 方法3:使用 lsof 命令
|
||||
|
||||
lsof – list open files. The Linux lsof command lists information about files that are open by processes running on the system.
|
||||
`lsof` 能够列出打开的文件,并列出系统上被进程打开的文件的相关信息。
|
||||
|
||||
```
|
||||
# lsof -i -P | grep ssh
|
||||
@ -154,7 +143,7 @@ sshd 11584 root 4u IPv6 27627 0t0 TCP *:22 (LISTEN)
|
||||
sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
也可以使用端口号来检查。
|
||||
|
||||
```
|
||||
# lsof -i tcp:22
|
||||
@ -164,9 +153,9 @@ sshd 1208 root 4u IPv6 20921 0t0 TCP *:ssh (LISTEN)
|
||||
sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
|
||||
```
|
||||
|
||||
### Method-4: Using fuser Command
|
||||
### 方法4:使用 fuser 命令
|
||||
|
||||
The fuser utility shall write to standard output the process IDs of processes running on the local system that have one or more named files open.
|
||||
`fuser` 工具会将本地系统上打开了文件的进程的进程 ID 显示在标准输出中。
|
||||
|
||||
```
|
||||
# fuser -v 22/tcp
|
||||
@ -176,11 +165,11 @@ The fuser utility shall write to standard output the process IDs of processes ru
|
||||
root 49339 F.... sshd
|
||||
```
|
||||
|
||||
### Method-5: Using nmap Command
|
||||
### 方法5:使用 nmap 命令
|
||||
|
||||
Nmap (“Network Mapper”) is an open source tool for network exploration and security auditing. It was designed to rapidly scan large networks, although it works fine against single hosts.
|
||||
`nmap`(“Network Mapper”)是一款用于网络检测和安全审计的开源工具。它最初用于对大型网络进行快速扫描,但它对于单个主机的扫描也有很好的表现。
|
||||
|
||||
Nmap uses raw IP packets in novel ways to determine what hosts are available on the network, what services (application name and version) those hosts are offering, what operating systems (and OS versions) they are running, what type of packet filters/firewalls are in use, and dozens of other characteristics.
|
||||
`nmap` 使用原始 IP 数据包来确定网络上可用的主机,这些主机的服务(包括应用程序名称和版本)、主机运行的操作系统(包括操作系统版本等信息)、正在使用的数据包过滤器或防火墙的类型,以及很多其它信息。
|
||||
|
||||
```
|
||||
# nmap -sV -p 22 localhost
|
||||
@ -196,13 +185,13 @@ Service detection performed. Please report any incorrect results at http://nmap.
|
||||
Nmap done: 1 IP address (1 host up) scanned in 0.44 seconds
|
||||
```
|
||||
|
||||
### Method-6: Using systemctl Command
|
||||
### 方法6:使用 systemctl 命令
|
||||
|
||||
systemctl – Control the systemd system and service manager. This is the replacement of old SysV init system management and most of the modern Linux operating systems were adapted systemd.
|
||||
`systemctl` 是 systemd 系统的控制管理器和服务管理器。它取代了旧的 SysV init 系统管理,目前大多数现代 Linux 操作系统都采用了 systemd。
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [chkservice – A Tool For Managing Systemd Units From Linux Terminal][3]
|
||||
**(#)** [How To Check All Running Services In Linux][4]
|
||||
**推荐阅读:**
|
||||
**(#)** [chkservice – Linux 终端上的 systemd 单元管理工具][3]
|
||||
**(#)** [如何查看 Linux 系统上正在运行的服务][4]
|
||||
|
||||
```
|
||||
# systemctl status sshd
|
||||
@ -223,7 +212,7 @@ Sep 23 02:09:15 vps.2daygeek.com sshd[11589]: Connection closed by 103.5.134.167
|
||||
Sep 23 02:09:41 vps.2daygeek.com sshd[11592]: Accepted password for root from 103.5.134.167 port 49902 ssh2
|
||||
```
|
||||
|
||||
The above out will be showing the actual listening port of SSH service when you start the SSHD service recently. Otherwise it won’t because it updates recent logs in the output frequently.
|
||||
以上输出的内容显示了最近一次启动 `sshd` 服务时 `ssh` 服务的监听端口。但它不会将最新日志更新到输出中。
|
||||
|
||||
```
|
||||
# systemctl status sshd
|
||||
@ -250,7 +239,7 @@ Sep 23 12:50:40 vps.2daygeek.com sshd[23911]: Connection closed by 95.210.113.14
|
||||
Sep 23 12:50:40 vps.2daygeek.com sshd[23909]: Connection closed by 95.210.113.142 port 51666 [preauth]
|
||||
```
|
||||
|
||||
Most of the time the above output won’t shows the process actual port number. in this case i would suggest you to check the details using the below command from the journalctl log file.
|
||||
大部分情况下,以上的输出不会显示进程的实际端口号。这时更建议使用以下这个 `journalctl` 命令检查日志文件中的详细信息。
|
||||
|
||||
```
|
||||
# journalctl | grep -i "openssh\|sshd"
|
||||
@ -268,7 +257,7 @@ via: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-usi
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -278,3 +267,4 @@ via: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-usi
|
||||
[2]: https://www.2daygeek.com/kill-terminate-a-process-in-linux-using-kill-pkill-killall-command/
|
||||
[3]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
|
||||
[4]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user