mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Update 20160817 Building a Real-Time Recommendation Engine with Data Science.md
This commit is contained in:
parent
e94405f847
commit
b7774794e8
@ -173,53 +173,69 @@ Below is some example code for how you do this in R, but you can easily do the s
|
||||
下面是用 R 来完成这件事的一些示例代码,但是你可以使用任何你最喜欢的软件来做相同的事,比如 Python 或 Spark。你需要做的只是登录并连接到图表。
|
||||
|
||||
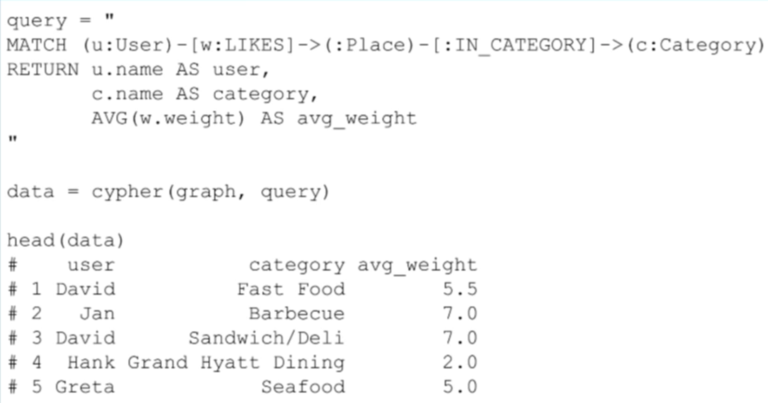
In the following example, I’ve clustered users together based on their similarities. Each user is represented as an observation, and I want to get the average rating that they’ve given each category:
|
||||
|
||||
在下面的例子中,我基于用户的相似性把他们集中起来。每个用户作为一个观察点,然后我想得到他们对每一个目录评分的平均值。
|
||||
|
||||
|
||||
|
||||
Presumably, users who rate the bar category in similar ways are similar in general. Here I’m grabbing the names of users who like places in the same category, the category name, and the average weight of the “likes” relationships, as average weight, and that’s going to give me a table like this:
|
||||
假定用户为酒吧目录评分的方式和一般的评分方式相似。然后我攫取出喜欢相同目录中的地点的用户名,目录名,“喜爱”关系的平均权重,比如平均权重这些信息,从而我可以得到下面这样一个表格:
|
||||
|
||||
|
||||
|
||||
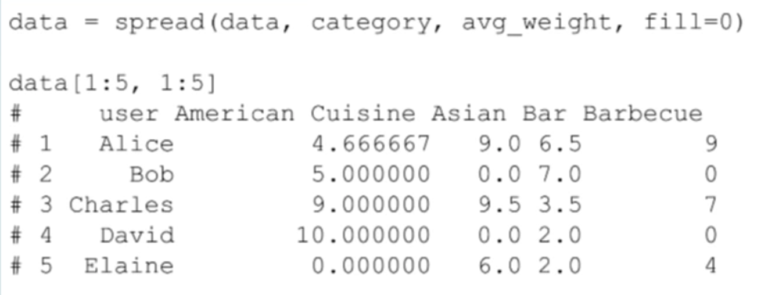
Because we want each user to be an observation, we will have to manipulate the data where each feature is the average weight rating they’ve given restaurants within that category, per category. We’ll then use this to determine how similar they are, and I’m going to use a clustering algorithm to determine users being in different clusters.
|
||||
因为我们把每一个用户都作为一个观察点,我们必须巧妙的处理每一个目录中的数据,这些数据的每一个特性都是用户对目录中餐厅评分的平均权重。接下来,我们将使用这些数据来确定用户的相似性,然后我将使用聚类算法来确定在不同集群中的用户。
|
||||
|
||||
In R this is very straightforward:
|
||||
在 R 中这很直接:
|
||||
|
||||

|
||||
|
||||
For this demonstration we are using k-means, which allows you to easily grab cluster assignments. In summary, I ran a clustering algorithm and now for each user I have a cluster assignment.
|
||||
在这个示例中我们使用 K - 均值聚类算法,这将使你很容易攫取集群分配。总之,我通过运行聚类算法然后分别得到每一个用户的集群分配。
|
||||
|
||||
Bob and David are in the same cluster – they’re in cluster two – and now I’ll be able to see in real time which users have been determined to be in the same cluster.
|
||||
Bob 和 David 在一个相同的集群中 - 他们在集群二中 - 现在我可以实时查看哪些用户被放在了相同的集群中。
|
||||
|
||||
Next we write it into a CSV, which we then load into the graph:
|
||||
接下来我把集群分配写入 CSV 文件中,然后存入图表:
|
||||
|
||||

|
||||
|
||||
We have users and cluster assignments, so the CSV will only have two columns. LOAD CSV is a syntax that’s built into Cypher that allows you to call a CSV from some file path or URL and alias it as something. Then we’ll match on the users that already exist in the graph, grab the user column out of that CSV, and merge on the cluster.
|
||||
我们只有用户和集群分配,因此 CSV 文件只有两列。 LOAD CSV 是 Cypher 中的内建语法,它允许你从一些其他文件路径或者 URL 和别名调用 CSV 。接下来,我们将匹配图表中存在的用户,从 CSV 文件中攫取用户列然后合并到集群中。
|
||||
|
||||
Here we’re creating a new labeled node in the graph, the Cluster ID, which was given by k-means. Next we create relationships between the user and the cluster, which allows us to easily query when we get to the actual recommendation users who are in the same cluster.
|
||||
我们在图表中创建了一个新的标签节点:集群 ID, 这是由 K - 平均聚类算法给出的。接下来我们创建用户和集群间的关系,通过创建这个关系,当我们想要找到在相同集群中的实际推荐用户时,就会很容易做出询问。
|
||||
|
||||
Now we have a new label cluster where users who are in the same cluster have a relationship to that cluster. Below is what our new data model looks like, which is on top of the other data models we explored:
|
||||
我们现在有了一个新的标签集群,在相同集群中的用户和那个集群存在关系。新的数据模型看起来像下面这样,它比我们前面探索的其他数据模型呀更好:
|
||||
|
||||

|
||||
|
||||
Now let’s consider the following query:
|
||||
现在让我们考虑下面的询问:
|
||||
|
||||

|
||||
|
||||
With this Cypher query, we’re going beyond similar users to users in the same cluster. At this point we’ve also deleted those distance relationships:
|
||||
通过这个 Cypher 询问,我们在更远处找到了在同一个集群中的相似用户。由于这个原因,我们删除了“距离”关系:
|
||||
|
||||

|
||||
|
||||
In this query, we’ve taken the user who’s logged in, finding their cluster based on the user-cluster relationship, and finding their neighbors who are in that same cluster.
|
||||
在这个询问中,我们取出已经登录的用户,根据用户-集群关系找到他们所在的集群,找到他们附近和他们在相同集群中的用户。
|
||||
|
||||
We’ve assigned that to some variable cl, and we’re getting other users – which I’ve aliased as a neighbor variable – who have a user-cluster relationship to that same cluster, and then we’re getting the places that neighbor has liked. Again, we’re putting the “likes” on a variable, r, because we’re going want to grab weights off of the relationship to order our results.
|
||||
我们把这些用户分配到变量 c1 中,然后我们得到其他被我取别名为附近变量的用户,这些用户和那个相同的集群存在用户-集群关系,最后我们得到这些附近用户“喜爱”的地点。再次说明,我把“喜爱”放入了变量 r 中,因为我们需要从关系中攫取权重来对结果进行排序。
|
||||
|
||||
All we’ve changed in the query is that instead of using the similarity distance, we’re grabbing users in the same cluster, asserting categories, asserting the terminal and asserting that we’re only grabbing the user who is logged in. We’re collecting all those weights of the :LIKES relationships from their neighbors liking places, getting the category, the absolute value of the distance, ordering that in descending order, and returning those results.
|
||||
在这个询问中,我们所做的改变是,不使用相似性距离,而是攫取在相同集群中的用户,然后对目录、终点以及我们所攫取的登录用户进行声明。我们收集所有的权重:来自附近用户“喜爱”地点的“喜爱”关系,得到的目录,确定的距离值,然后把它们按升序进行排序并返回结果。
|
||||
|
||||
In these examples we’ve been able to take a pretty involved process and persist it in the graph, and then used the results of that algorithm – the results of the clustering algorithm and the clustering assignments – in real time.
|
||||
在这些例子中,我们可以进行一个相当复杂的进程并且在图表中实现进程,然后使用实时算法结果-聚类算法和集群分配的结果。
|
||||
|
||||
Our preferred workflow is to update these clustering assignments however frequently you see fit — for example, nightly or hourly. And, of course, you can use intuition to figure out how often is acceptable to be updating these cluster assignments.
|
||||
我们更喜欢的工作流程是更新这些集群分配,更新频率适合你自己就可以,比如每晚一次或每小时一次。当然,你可以根据直觉来决定多久更新一次这些集群分配是可接受的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user