mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
b71abab503
@ -1,21 +1,34 @@
|
||||
如何在 Linux/Unix 的 Bash 中打开/关闭 ls 命令颜色
|
||||
如何在 Linux/Unix 的 Bash 中打开或关闭 ls 命令颜色显示
|
||||
======
|
||||
|
||||
如何在 Linux或类 Unix 操作系统上的 bash shell 中打开或关闭文件名称颜色(ls 命令颜色)?
|
||||
如何在 Linux 或类 Unix 操作系统上的 bash shell 中打开或关闭文件名称颜色(`ls` 命令颜色)?
|
||||
|
||||
大多数现代 Linux 发行版和 Unix 系统都有定义文件名称颜色的别名。然而,ls 命令负责在屏幕上显示文件、目录和其他文件系统对象的颜色。
|
||||
大多数现代 Linux 发行版和 Unix 系统都有一个定义了文件名称颜色的别名。然后,`ls` 命令负责在屏幕上显示文件、目录和其他文件系统对象的颜色。
|
||||
|
||||
默认情况下,文件类型不会用颜色区分。你需要在 Linux 上将 -color 选项传递给 ls 命令。如果你正在使用基于 OS X 或 BSD 的系统,请将 -G 选项传递给 ls 命令。打开或关闭颜色的语法如下。
|
||||
默认情况下,文件类型不会用颜色区分。你需要在 Linux 上将 `--color` 选项传递给 `ls` 命令。如果你正在使用基于 OS X 或 BSD 的系统,请将 `-G` 选项传递给 `ls` 命令。打开或关闭颜色的语法如下。
|
||||
|
||||
#### 如何关闭 ls 命令的颜色
|
||||
### 如何关闭 ls 命令的颜色
|
||||
|
||||
输入以下命令:
|
||||
|
||||
```
|
||||
$ ls --color=none
|
||||
```
|
||||
|
||||
或者用 `unalias` 命令删除别名:
|
||||
|
||||
```
|
||||
$ unalias ls
|
||||
```
|
||||
|
||||
请注意,下面的 bash shell 别名被定义为用 `ls` 命令显示颜色。这个组合使用 [alias 命令][1]和 [grep 命令][2]:
|
||||
|
||||
```
|
||||
$ alias | grep ls
|
||||
```
|
||||
|
||||
输入以下命令
|
||||
`$ ls --color=none`
|
||||
或者用 unalias 命令删除别名:
|
||||
`$ unalias ls`
|
||||
请注意,下面的 bash shell 别名被定义为用 ls 命令显示颜色。租个组合使用[ alias 命令][1]和[ grep 命令][2]:
|
||||
`$ alias | grep ls`
|
||||
示例输出:
|
||||
|
||||
```
|
||||
alias l='ls -CF'
|
||||
alias la='ls -A'
|
||||
@ -23,41 +36,60 @@ alias ll='ls -alF'
|
||||
alias ls='ls --color=auto'
|
||||
```
|
||||
|
||||
#### 如何打开 ls 命令的颜色
|
||||
### 如何打开 ls 命令的颜色
|
||||
|
||||
使用以下任何一个命令:
|
||||
|
||||
```
|
||||
$ ls --color=auto
|
||||
$ ls --color=tty
|
||||
```
|
||||
如果你想要的话,[定义 bash shell 别名][3]:
|
||||
`alias ls='ls --color=auto'`
|
||||
你可以在 ~/.bash_profile 或 [~/.bashrc file][4] 中添加或删除 ls 别名 。使用文本编辑器(如 vi)编辑文件:
|
||||
`$ vi ~/.bashrc`
|
||||
|
||||
如果你想要的话,[可以定义 bash shell 别名][3]:
|
||||
|
||||
```
|
||||
alias ls='ls --color=auto'
|
||||
```
|
||||
|
||||
你可以在 `~/.bash_profile` 或 [~/.bashrc 文件][4] 中添加或删除 `ls` 别名 。使用文本编辑器(如 vi)编辑文件:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
追加下面的代码:
|
||||
|
||||
```
|
||||
# my ls command aliases #
|
||||
alias ls = 'ls --color=auto'
|
||||
```
|
||||
|
||||
[在 Vi/Vim 文本编辑器中保存并关闭文件][5]。
|
||||
[在 Vi/Vim 文本编辑器中保存并关闭文件即可][5]。
|
||||
|
||||
#### 关于 \*BSD/macOS/Apple OS X 中 ls 命令的注意点
|
||||
### 关于 *BSD/macOS/Apple OS X 中 ls 命令的注意点
|
||||
|
||||
将 `-G` 选项传递给 `ls` 命令以在 {Free、Net、Open} BSD 或 macOS 和 Apple OS X Unix 操作系统家族上启用彩色输出:
|
||||
|
||||
```
|
||||
$ ls -G
|
||||
```
|
||||
|
||||
将 -G 选项传递给 ls 命令以在 {Free、Net、Open} BSD 或 macOS 和 Apple OS X Unix 操作系统家族上启用彩色输出:
|
||||
`$ ls -G`
|
||||
示例输出:
|
||||
[![How to enable colorized output for the ls command in Mac OS X Terminal][6]][7]
|
||||
如何在 Mac OS X 终端中为 ls 命令启用彩色输出
|
||||
|
||||
#### 如何临时跳过 ls 命令彩色输出?
|
||||
[![How to enable colorized output for the ls command in Mac OS X Terminal][6]][7]
|
||||
|
||||
*如何在 Mac OS X 终端中为 ls 命令启用彩色输出*
|
||||
|
||||
### 如何临时跳过 ls 命令彩色输出?
|
||||
|
||||
你可以使用以下任何一种语法[暂时禁用 bash shell 别名][8]:
|
||||
`\ls
|
||||
|
||||
```
|
||||
\ls
|
||||
/bin/ls
|
||||
command ls
|
||||
'ls'`
|
||||
|
||||
'ls'
|
||||
```
|
||||
|
||||
#### 关于作者
|
||||
|
||||
@ -69,7 +101,7 @@ via: https://www.cyberciti.biz/faq/how-to-turn-on-or-off-colors-in-bash/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,25 +1,21 @@
|
||||
KarenMrzhang Tranlating
|
||||
|
||||
Linux / Unix Bash Shell 列出所有内置命令
|
||||
如何列出所有的 Bash Shell 内置命令
|
||||
======
|
||||
|
||||
内置命令包含在 bash shell 本身。我该如何在 Linux / Apple OS X / *BSD / Unix 上像操作系统不用去读大篇的 bash 操作说明页就可以列出所有的内置 bash 命令呢?
|
||||
|
||||
一个 shell 内置函数是一个命令或一个函数,从shell中调用,它直接在shell中执行。 bash shell 是直接执行命令没有调用其他程序的。你可以使用帮助命令查看 Bash 内置命令的信息。以下是几种不同类型的内置命令。
|
||||
内置命令包含在 bash shell 本身里面。我该如何在 Linux / Apple OS X / *BSD / Unix 类操作系统列出所有的内置 bash 命令,而不用去读大篇的 bash 操作说明页?
|
||||
|
||||
shell 内置命令就是一个命令或一个函数,从 shell 中调用,它直接在 shell 中执行。 bash shell 直接执行该命令而无需调用其他程序。你可以使用 `help` 命令查看 Bash 内置命令的信息。以下是几种不同类型的内置命令。
|
||||
|
||||
### 内置命令的类型
|
||||
|
||||
1. Bourne Shell 内置命令:内置命令继承自 Bourne Shell。
|
||||
2. Bash 内置命令:特定于 Bash 的内置命令表。
|
||||
3. 修改 Shell 行为:修改 shell 属性和选择行为的内置命令。
|
||||
4. 特别的内置命令:由 POSIX 特别分类的内置命令。
|
||||
|
||||
|
||||
1. Bourne Shell 内置命令:内置命令继承自 Bourne Shell。
|
||||
2. Bash 内置命令:特定于 Bash 的内置命令表。
|
||||
3. 修改 Shell 行为:修改 shell 属性和可选行为的内置命令。
|
||||
4. 特别的内置命令:由 POSIX 特别分类的内置命令。
|
||||
|
||||
### 如何查看所有 bash 内置命令
|
||||
|
||||
有以下的命令:
|
||||
|
||||
```
|
||||
$ help
|
||||
$ help | less
|
||||
@ -27,6 +23,7 @@ $ help | grep read
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
```
|
||||
GNU bash, version 4.1.5(1)-release (x86_64-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
@ -76,20 +73,32 @@ A star (*) next to a name means that the command is disabled.
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
另外一种选择是使用下列命令:
|
||||
|
||||
```
|
||||
compgen -b
|
||||
compgen -b | more
|
||||
```
|
||||
|
||||
### 查看 Bash 的内置命令信息
|
||||
|
||||
运行以下得到详细信息:
|
||||
|
||||
```
|
||||
help command
|
||||
help read
|
||||
```
|
||||
仅得到所有带简短描述的内置命令的列表,执行如下:
|
||||
|
||||
`$ help -d`
|
||||
要仅得到所有带简短描述的内置命令的列表,执行如下:
|
||||
|
||||
```
|
||||
$ help -d
|
||||
```
|
||||
|
||||
### 查找内置命令的语法和其他选项
|
||||
|
||||
使用下列语法去找出更多的相关内置命令:
|
||||
|
||||
```
|
||||
help name
|
||||
help cd
|
||||
@ -99,7 +108,8 @@ help read
|
||||
help :
|
||||
```
|
||||
|
||||
样例输出:
|
||||
样例输出:
|
||||
|
||||
```
|
||||
:: :
|
||||
Null command.
|
||||
@ -110,9 +120,10 @@ help :
|
||||
Always succeeds
|
||||
```
|
||||
|
||||
### 找出一个命令是内部的(内置的)还是外部的。
|
||||
### 找出一个命令是内部的(内置)还是外部的
|
||||
|
||||
使用 `type` 命令或 `command` 命令:
|
||||
|
||||
使用类型命令或命令命令:
|
||||
```
|
||||
type -a command-name-here
|
||||
type -a cd
|
||||
@ -121,13 +132,14 @@ type -a :
|
||||
type -a ls
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
或者
|
||||
```
|
||||
type -a cd uname : ls uname
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
```
|
||||
cd is a shell builtin
|
||||
uname is /bin/uname
|
||||
@ -142,7 +154,8 @@ l ()
|
||||
|
||||
```
|
||||
|
||||
或者
|
||||
或者:
|
||||
|
||||
```
|
||||
command -V ls
|
||||
command -V cd
|
||||
@ -153,7 +166,7 @@ command -V foo
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是网站站长的发起人和季度系统管理员和 Linux 操作系统/Unix shell 脚本教练。他与全球客户以及包括IT、教育、国防和空间研究以及非营利部门在内的各个行业合作。可以在 [Twitter][2], [Facebook][3], [Google+][4] 上关注他。
|
||||
作者是 nixCraft 网站的发起人和经验丰富的系统管理员,以及 Linux 操作系统/Unix shell 脚本编程培训师。他与全球客户以及包括 IT、教育、国防和空间研究以及非营利部门在内的各个行业合作。可以在 [Twitter][2]、[Facebook][3]、 [Google+][4] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -161,7 +174,7 @@ via: https://www.cyberciti.biz/faq/linux-unix-bash-shell-list-all-builtin-comman
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[KarenMrzhang](https://github.com/KarenMrzhang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
Manjaro Gaming:当 Manjaro 的才华遇上 Linux 游戏
|
||||
======
|
||||
|
||||
[![见见 Manjaro Gaming, 一个专门为游戏者设计的 Linux 发行版,带有 Manjaro 的所有才能。][1]][1]
|
||||
|
||||
[在 Linux 上玩转游戏][2]? 没错,这是非常可行的,我们正致力于为游戏人群打造一个新的 Linux 发行版。
|
||||
|
||||
Manjaro Gaming 是一个专门为游戏人群设计的,带有 Manjaro 所有才能的发行版。之前用过 Manjaro Linux 的人一定知道为什么这对于游戏人群来说是一个如此好的一个消息。
|
||||
|
||||
[Manjaro][3] 是一个 Linux 发行版,它基于最流行的 Linux 发行版之一 —— [Arch Linux][4]。 Arch Linux 因它的前沿性所带来的轻量、强大、高度定制和最新的体验而闻名于世。尽管这些都非常赞,但是也正是因为 Arch Linux 提倡这种 DIY (do it yourself)方式,导致一个主要的缺点,那就是用户想用好它,需要处理一定的技术问题。
|
||||
|
||||
Manjaro 把这些要求全都剥离开去,让 Arch 对新手更亲切,同时也为老手提供了 Arch 所有的高端与强大功能。总之,Manjaro 是一个用户友好型的 Linux 发行版,工作起来行云流水。
|
||||
|
||||
Manjaro 会成为一个强大并且极度适用于游戏的原因:
|
||||
|
||||
* Manjaro 自动检测计算的硬件(例如,显卡)
|
||||
* 自动安装必要的驱动和软件(例如,显示驱动)
|
||||
* 预安装播放媒体文件的编码器
|
||||
* 专用的软件库提供完整测试过的稳定软件包。
|
||||
|
||||
Manjaro Gaming 打包了 Manjaro 的所有强大特性以及各种小工具和软件包,以使得在 Linux 上做游戏即顺畅又享受。
|
||||
|
||||
![Manjaro Gaming 内部][5]
|
||||
|
||||
### 优化
|
||||
|
||||
Manjaro Gaming 做了一些优化:
|
||||
|
||||
* Manjaro Gaming 使用高度定制化的 XFCE 桌面环境,拥有一个黑暗风格主题。
|
||||
* 禁用睡眠模式,防止用手柄上玩游戏或者观看一个长过场动画时计算机自动休眠。
|
||||
|
||||
### 软件
|
||||
|
||||
维持 Manjaro 工作起来行云流水的传统,Manjaro Gaming 打包了各种开源软件包,提供游戏人群经常需要用到的功能。其中一部分软件有:
|
||||
|
||||
* [KdenLIVE][6]:用于编辑游戏视频的视频编辑软件
|
||||
* [Mumble][7]:给游戏人群使用的视频聊天软件
|
||||
* [OBS Studio][8]:用于录制视频或在 [Twitch][9] 上直播游戏用的软件
|
||||
* [OpenShot][10]:Linux 上强大的视频编辑器
|
||||
* [PlayOnLinux][11]:使用 [Wine][12] 作为后端,在 Linux 上运行 Windows 游戏的软件
|
||||
* [Shutter][13]:多种功能的截图工具
|
||||
|
||||
### 模拟器
|
||||
|
||||
Manjaro Gaming 自带很多的游戏模拟器:
|
||||
|
||||
* [DeSmuME][14]:Nintendo DS 任天堂 DS 模拟器
|
||||
* [Dolphin Emulator][15]:GameCube 和 Wii 模拟器
|
||||
* [DOSBox][16]:DOS 游戏模拟器
|
||||
* [FCEUX][17]:任天堂娱乐系统(NES)、 红白机(FC)和 FC 磁盘系统(FDS)模拟器
|
||||
* Gens/GS:世嘉模拟器
|
||||
* [PCSXR][18]:PlayStation 模拟器
|
||||
* [PCSX2][19]:Playstation 2 模拟器
|
||||
* [PPSSPP][20]:PSP 模拟器
|
||||
* [Stella][21]:Atari 2600 VCS (雅达利)模拟器
|
||||
* [VBA-M][22]:Gameboy 和 GameboyAdvance 模拟器
|
||||
* [Yabause][23]:世嘉土星模拟器
|
||||
* [ZSNES][24]:超级任天堂模拟器
|
||||
|
||||
### 其它
|
||||
|
||||
还有一些终端插件 —— Color、ILoveCandy 和 Screenfetch。也包括带有 Retro Conky(LCTT 译注:复古 Conky)风格的 [Conky 管理器][25]。
|
||||
|
||||
注意:上面提到的所有功能并没有全部包含在 Manjaro Gaming 的现行发行版中(版本 16.03)。部分功能计划将在下一版本中纳入 —— Manjaro Gaming 16.06(LCTT 译注:本文发表于 2016 年 5 月)。
|
||||
|
||||
### 下载
|
||||
|
||||
Manjaro Gaming 16.06 将会是 Manjaro Gaming 的第一个正式版本。如果你现在就有兴趣尝试,你可以在 Sourceforge 的[项目页面][26]中下载。去那里然后下载它的 ISO 文件吧。
|
||||
|
||||
你觉得 Gaming Linux 发行版怎么样?想尝试吗?告诉我们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/manjaro-gaming-linux/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2016/06/Manjaro-Gaming.jpg
|
||||
[2]:https://linux.cn/article-7316-1.html
|
||||
[3]:https://manjaro.github.io/
|
||||
[4]:https://www.archlinux.org/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2016/06/Manjaro-Gaming-Inside-1024x576.png
|
||||
[6]:https://kdenlive.org/
|
||||
[7]:https://www.mumble.info
|
||||
[8]:https://obsproject.com/
|
||||
[9]:https://www.twitch.tv/
|
||||
[10]:http://www.openshot.org/
|
||||
[11]:https://www.playonlinux.com
|
||||
[12]:https://www.winehq.org/
|
||||
[13]:http://shutter-project.org/
|
||||
[14]:http://desmume.org/
|
||||
[15]:https://dolphin-emu.org
|
||||
[16]:https://www.dosbox.com/
|
||||
[17]:http://www.fceux.com/
|
||||
[18]:https://pcsxr.codeplex.com
|
||||
[19]:http://pcsx2.net/
|
||||
[20]:http://www.ppsspp.org/
|
||||
[21]:http://stella.sourceforge.net/
|
||||
[22]:http://vba-m.com/
|
||||
[23]:https://yabause.org/
|
||||
[24]:http://www.zsnes.com/
|
||||
[25]:https://itsfoss.com/conky-gui-ubuntu-1304/
|
||||
[26]:https://sourceforge.net/projects/mgame/
|
||||
@ -1,52 +1,53 @@
|
||||
使用 iftop 命令监控网络带宽
|
||||
======
|
||||
系统管理员需要监控 IT 基础设施来确保一切正常运行。我们需要监控硬件也就是内存、硬盘和 CPU 等的性能,我们也必须监控我们的网络。我们需要确保我们的网络不被过度使用,或者我们的程序,网站可能无法正常工作。在本教程中,我们将学习使用 IFTOP。
|
||||
|
||||
系统管理员需要监控 IT 基础设施来确保一切正常运行。我们需要监控硬件,也就是内存、硬盘和 CPU 等的性能,我们也必须监控我们的网络。我们需要确保我们的网络不被过度使用,否则我们的程序,网站可能无法正常工作。在本教程中,我们将学习使用 `iftop`。
|
||||
|
||||
(**推荐阅读**:[**使用 Nagios** 进行资源监控][1]、[**用于检查系统信息的工具**][2] 、[**要监控的重要日志**][3] )
|
||||
|
||||
Iftop 是网络监控工具,它提供实时带宽监控。 Iftop 测量进出各个套接字连接的总数据量,即它捕获通过网络适配器收到或发出的数据包,然后将这些数据相加以得到使用的带宽。
|
||||
`iftop` 是网络监控工具,它提供实时带宽监控。 `iftop` 测量进出各个套接字连接的总数据量,即它捕获通过网络适配器收到或发出的数据包,然后将这些数据相加以得到使用的带宽。
|
||||
|
||||
## 在 Debian/Ubuntu 上安装
|
||||
### 在 Debian/Ubuntu 上安装
|
||||
|
||||
Iftop 存在于 Debian/Ubuntu 的默认仓库中,可以使用下面的命令安装:
|
||||
iftop 存在于 Debian/Ubuntu 的默认仓库中,可以使用下面的命令安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install iftop
|
||||
```
|
||||
|
||||
## 使用 yum 在 RHEL/Centos 上安装
|
||||
### 使用 yum 在 RHEL/Centos 上安装
|
||||
|
||||
要在 CentOS 或 RHEL 上安装 iftop,我们需要启用 EPEL 仓库。要启用仓库,请在终端上运行以下命令:
|
||||
|
||||
### RHEL/CentOS 7
|
||||
**RHEL/CentOS 7:**
|
||||
|
||||
```
|
||||
$ rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-10.noarch.rpm
|
||||
```
|
||||
|
||||
### RHEL/CentOS 6(64位)
|
||||
**RHEL/CentOS 6(64 位):**
|
||||
|
||||
```
|
||||
$ rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
### RHEL/CentOS 6 (64位)
|
||||
**RHEL/CentOS 6 (32 位):**
|
||||
|
||||
```
|
||||
$ rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
epel 仓库安装完成后,我们可以用下面的命令安装 iftop:
|
||||
EPEL 仓库安装完成后,我们可以用下面的命令安装 `iftop`:
|
||||
|
||||
```
|
||||
$ yum install iftop
|
||||
```
|
||||
|
||||
这将在你的系统上安装 iftop。我们现在将用它来监控我们的网络。
|
||||
这将在你的系统上安装 `iftop`。我们现在将用它来监控我们的网络。
|
||||
|
||||
## 使用 IFTOP
|
||||
### 使用 iftop
|
||||
|
||||
可以打开终端窗口,并输入下面的命令使用 iftop:
|
||||
可以打开终端窗口,并输入下面的命令使用 `iftop`:
|
||||
|
||||
```
|
||||
$ iftop
|
||||
@ -60,19 +61,19 @@ $ iftop
|
||||
$ iftop -n
|
||||
```
|
||||
|
||||
这将在屏幕上显示网络信息,但使用 “-n”,则不会显示与 IP 地址相关的名称,只会显示 IP 地址。这个选项能节省一些将 IP 地址解析为名称的带宽。
|
||||
这将在屏幕上显示网络信息,但使用 `-n`,则不会显示与 IP 地址相关的名称,只会显示 IP 地址。这个选项能节省一些将 IP 地址解析为名称的带宽。
|
||||
|
||||
我们也可以看到 iftop 可以使用的所有命令。运行 iftop 后,按下键盘上的 “h” 查看 iftop 可以使用的所有命令。
|
||||
我们也可以看到 `iftop` 可以使用的所有命令。运行 `iftop` 后,按下键盘上的 `h` 查看 `iftop` 可以使用的所有命令。
|
||||
|
||||
![network monitoring][7]
|
||||
|
||||
要监控特定的网络接口,我们可以在 iftop 后加上接口名:
|
||||
要监控特定的网络接口,我们可以在 `iftop` 后加上接口名:
|
||||
|
||||
```
|
||||
$ iftop -I enp0s3
|
||||
```
|
||||
|
||||
如上所述,你可以使用帮助来查看 iftop 可以使用的更多选项。但是这些提到的例子只是可能只是监控网络。
|
||||
如上所述,你可以使用帮助来查看 `iftop` 可以使用的更多选项。但是这些提到的例子只是可能只是监控网络。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -81,7 +82,7 @@ via: http://linuxtechlab.com/monitoring-network-bandwidth-iftop-command/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,33 +1,38 @@
|
||||
# 如何在 Ubuntu 上使用 ZFS 文件系统
|
||||
如何在 Ubuntu 上使用 ZFS 文件系统
|
||||
==============
|
||||
|
||||
在 Linux 系统上,有大量的[文件系统][1]可以使用,那么我们为什么还要尝试一个新的文件系统?他们都工作的很好,不是吗?但是他们并不完全相同,其中的一些文件系统具有非常突出的优点,例如 ZFS。
|
||||

|
||||
|
||||
在 Linux 系统上,有大量的[文件系统][1]可以使用,那么我们为什么还要尝试一个新的文件系统?它们都工作的很好,不是吗?但是它们并不完全相同,其中的一些文件系统具有非常突出的优点,例如 ZFS。
|
||||
|
||||
### 为什么选择 ZFS
|
||||
|
||||
ZFS 非常的优秀。 这是一个真正现代文件系统,内置的功能对于处理大量的数据很有意义。
|
||||
ZFS 非常的优秀。这是一个真正现代的文件系统,内置的功能对于处理大量的数据很有意义。
|
||||
|
||||
现在,如果您正在考虑将 ZFS 用于您的超高速 NVMe SSD,这可能不是一个最佳选择。 它比别的文件系统要慢,不过,这完全没有问题, 它旨在存储大量的数据并保持安全。
|
||||
|
||||
ZFS 消除了建立传统 RAID 阵列(译者注:独立磁盘冗余阵列)的需要。 相反,您可以创建 ZFS 池,甚至可以随时将驱动器添加到这些池中。 ZFS 池的行为操作与 RAID 几乎完全相同,但功能内置于文件系统中。
|
||||
ZFS 消除了建立传统 RAID 阵列(LCTT 译注:独立磁盘冗余阵列)的需要。 相反,您可以创建 ZFS 池,甚至可以随时将驱动器添加到这些池中。 ZFS 池的行为操作与 RAID 几乎完全相同,但功能内置于文件系统中。
|
||||
|
||||
ZFS 也可以替代 LVM (译者注:逻辑盘卷管理),使您能够动态分区和管理分区,而无需处理较低级别的事务,也不必担心相关的风险。
|
||||
ZFS 也可以替代 LVM (LCTT 译注:逻辑盘卷管理),使您能够动态地进行分区和管理分区,而无需处理底层的细节,也不必担心相关的风险。
|
||||
|
||||
这也是一个 CoW (译者注:Copy on Write)文件系统。 没有太多的技术性,这意味着 ZFS 可以保护您的数据免受逐渐损坏的影响。 ZFS 创建文件的校验和,并允许您将这些文件回滚到以前的工作版本。
|
||||
这也是一个 CoW (LCTT 译注:写时复制)文件系统。 这里不会提及太多的技术性,这意味着 ZFS 可以保护您的数据免受逐渐损坏的影响。 ZFS 会创建文件的校验和,并允许您将这些文件回滚到以前的工作版本。
|
||||
|
||||
### 安装 ZFS
|
||||
|
||||
![Install ZFS on Ubuntu][2]
|
||||
|
||||
在 Ubuntu 上安装 ZFS 非常简单,但对于 Ubuntu LTS (译者注:长时间支持版本)和最新版本来说,这个过程稍有不同。
|
||||
在 Ubuntu 上安装 ZFS 非常简单,但对于 Ubuntu LTS (LCTT 译注:长时间支持版本)和最新版本来说,这个过程稍有不同。
|
||||
|
||||
**Ubuntu 16.04 LTS**
|
||||
|
||||
**Ubuntu 16.04 LTS**
|
||||
```
|
||||
sudo apt install zfs
|
||||
sudo apt install zfs
|
||||
```
|
||||
|
||||
**Ubuntu 17.04 and Later**
|
||||
**Ubuntu 17.04 及以后**
|
||||
|
||||
```
|
||||
sudo apt install zfsutils
|
||||
sudo apt install zfsutils
|
||||
```
|
||||
|
||||
当你安装好程序后,可以使用 ZFS 提供的工具创建 ZFS 驱动器和分区。
|
||||
@ -36,11 +41,11 @@ ZFS 也可以替代 LVM (译者注:逻辑盘卷管理),使您能够动态分
|
||||
|
||||
![Create ZFS Pool][3]
|
||||
|
||||
在 ZFS 中,池大致相当于 RAID 。 他们很灵活且易于操作。
|
||||
在 ZFS 中,池大致相当于 RAID 。 它们很灵活且易于操作。
|
||||
|
||||
#### RAID0
|
||||
|
||||
RAID0 只是把你的硬盘集中到一个巨大的驱动器上。 它可以提高你的驱动器速度,(译者注:数据条带化后,并行访问,提高文件读取速度)但是如果你的驱动器有损坏,你可能会失丢失数据。
|
||||
RAID0 只是把你的硬盘集中到一个池子里面,就像一个巨大的驱动器一样。 它可以提高你的驱动器速度,(LCTT 译注:数据条带化后,并行访问,可以提高文件读取速度)但是如果你的驱动器有损坏,你可能会失丢失数据。
|
||||
|
||||
要使用 ZFS 实现 RAID0,只需创建一个普通的池。
|
||||
|
||||
@ -48,9 +53,9 @@ RAID0 只是把你的硬盘集中到一个巨大的驱动器上。 它可以提
|
||||
sudo zpool create your-pool /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
#### RAID1/MIRROR
|
||||
#### RAID1(镜像)
|
||||
|
||||
您可以在 ZFS 中使用 `mirror` 关键字来实现 RAID1 功能。 RAID1 创建一个 1 对 1 的驱动器副本。 这意味着您的数据不断备份。 它也提高了性能。 当然,你将一半的存储空间用于复制。
|
||||
您可以在 ZFS 中使用 `mirror` 关键字来实现 RAID1 功能。 RAID1 会创建一个一对一的驱动器副本。 这意味着您的数据一直在备份。 它也提高了性能。 当然,你将一半的存储空间用于了复制。
|
||||
|
||||
```
|
||||
sudo zpool create your-pool mirror /dev/sdc /dev/sdd
|
||||
@ -58,7 +63,7 @@ sudo zpool create your-pool mirror /dev/sdc /dev/sdd
|
||||
|
||||
#### RAID5/RAIDZ1
|
||||
|
||||
ZFS 将 RAID5 功能实现为 RAIDZ1。 RAID5 要求驱动器至少是 3 个。并允许您通过将备份奇偶校验数据写入驱动器空间的 1/3 来保留 2/3 的存储空间。 如果一个驱动器发生故障,阵列将保持联机状态,但应尽快更换发生故障的驱动器(译者注:与原文翻译略有不同,原文是驱动器的数目是三的倍数,根据 wiki, RAID5 至少需要 3 块驱动器,也可以从下面的命令中猜测)。
|
||||
ZFS 将 RAID5 功能实现为 RAIDZ1。 RAID5 要求驱动器至少是 3 个。并允许您通过将备份奇偶校验数据写入驱动器空间的 1/n(n 是驱动器数),留下的是可用的存储空间。 如果一个驱动器发生故障,阵列仍将保持联机状态,但应尽快更换发生故障的驱动器(LCTT 译注:与原文翻译略有不同,原文是驱动器的数目是三的倍数,根据 wiki, RAID5 至少需要 3 块驱动器,也可以从下面的命令中猜测)。
|
||||
|
||||
```
|
||||
sudo zpool create your-pool raidz1 /dev/sdc /dev/sdd /dev/sde
|
||||
@ -66,15 +71,15 @@ sudo zpool create your-pool raidz1 /dev/sdc /dev/sdd /dev/sde
|
||||
|
||||
#### RAID6/RAIDZ2
|
||||
|
||||
RAID6 与 RAID5 几乎完全相同,但它至少需要四个驱动器。 它将奇偶校验数据加倍,最多允许两个驱动器损坏,而不会导致阵列关闭。(译者注:这里也与原文略有出入,原文是驱动器的数目是四的倍数,根据 wiki ,RAID6 至少需要四个驱动器)
|
||||
RAID6 与 RAID5 几乎完全相同,但它至少需要四个驱动器。 它将奇偶校验数据加倍,最多允许两个驱动器损坏,而不会导致阵列关闭(LCTT 译注:这里也与原文略有出入,原文是驱动器的数目是四的倍数,根据 wiki ,RAID6 至少需要四个驱动器)。
|
||||
|
||||
```
|
||||
sudo zpool create your-pool raidz2 /dev/sdc /dev/sdd /dev/sde /dev/sdf
|
||||
```
|
||||
|
||||
#### RAID10/Striped Mirror
|
||||
#### RAID10(条带化镜像)
|
||||
|
||||
RAID10 旨在通过数据条带化提高存取速度和数据冗余来成为一个两全其美的解决方案。 你至少需要四个驱动器,但只能访问一半的空间。 您可以通过在同一池中创建两个镜像来创建 RAID10 中的池。(译者注:这里也与原文略有出入,原文是驱动器的数目是四的倍数,根据 wiki, RAID10 至少需要四个驱动器)
|
||||
RAID10 旨在通过数据条带化提高存取速度和数据冗余来成为一个两全其美的解决方案。 你至少需要四个驱动器,但只能使用一半的空间。 您可以通过在同一个池中创建两个镜像来创建 RAID10 中的池(LCTT 译注:这里也与原文略有出入,原文是驱动器的数目是四的倍数,根据 wiki, RAID10 至少需要四个驱动器)。
|
||||
|
||||
```
|
||||
sudo zpool create your-pool mirror /dev/sdc /dev/sdd mirror /dev/sde /dev/sdf
|
||||
@ -84,7 +89,7 @@ sudo zpool create your-pool mirror /dev/sdc /dev/sdd mirror /dev/sde /dev/sdf
|
||||
|
||||
![ZFS pool Status][4]
|
||||
|
||||
还有一些管理工具,一旦你创建了你的池,你就必须使用它。 首先,检查你的池的状态。
|
||||
还有一些管理工具,一旦你创建了你的池,你就必须使用它们来操作。 首先,检查你的池的状态。
|
||||
|
||||
```
|
||||
sudo zpool status
|
||||
@ -92,7 +97,7 @@ sudo zpool status
|
||||
|
||||
#### 更新
|
||||
|
||||
当你更新 ZFS 时,你也需要更新你的池。 当您检查他们的状态时,您的池会通知您任何更新。 要更新池,请运行以下命令。
|
||||
当你更新 ZFS 时,你也需要更新你的池。 当您检查它们的状态时,您的池会通知您任何更新。 要更新池,请运行以下命令。
|
||||
|
||||
```
|
||||
sudo zpool upgrade your-pool
|
||||
@ -116,9 +121,9 @@ sudo zpool add your-pool /dev/sdx
|
||||
|
||||
![ZFS in File Browser][5]
|
||||
|
||||
ZFS 在您的池的根文件系统中创建一个目录。 您可以使用 GUI 文件管理器或 CLI (译者注:Command-line interface )按名称浏览它们。
|
||||
ZFS 会在您的池的根文件系统中创建一个目录。 您可以使用 GUI 文件管理器或 CLI 按名称浏览它们。
|
||||
|
||||
ZFS 非常强大,还有很多其他的东西可以用它来做,但这些都是基础。 这是一个优秀的存储负载文件系统,即使它只是一个用于文件的硬盘驱动器的 RAID 阵列。 ZFS 在 NAS 系统上也非常出色。
|
||||
ZFS 非常强大,还有很多其它的东西可以用它来做,但这些都是基础。 这是一个优秀的存储负载文件系统,即使它只是一个用于文件的硬盘驱动器的 RAID 阵列。 ZFS 在 NAS 系统上也非常出色。
|
||||
|
||||
无论 ZFS 的稳定性和可靠性如何,在您的硬盘上实施新的功能时,最好备份您的数据。
|
||||
|
||||
@ -128,7 +133,7 @@ via: https://www.maketecheasier.com/use-zfs-filesystem-ubuntu-linux/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -52,27 +52,27 @@ ibus-setup
|
||||
|
||||
选择 “Yes” 来启动 iBus。你会看到一个像下面的页面。点击 Ok 关闭它。
|
||||
|
||||
[![][2]][3]
|
||||
![][3]
|
||||
|
||||
现在,你将看到 iBus 偏好设置窗口。进入 “Input Method” 选项卡,然后单击 “Add” 按钮。
|
||||
|
||||
[![][2]][4]
|
||||
![][4]
|
||||
|
||||
在列表中选择 “Japanese”:
|
||||
|
||||
[![][2]][5]
|
||||
![][5]
|
||||
|
||||
然后,选择 “Anthy” 并点击添加:
|
||||
|
||||
[![][2]][6]
|
||||
![][6]
|
||||
|
||||
就是这样了。你现在将在输入法栏看到 “Japanese - Anthy”:
|
||||
|
||||
[![][2]][7]
|
||||
![][7]
|
||||
|
||||
根据你的需求在偏好设置中更改日语输入法的选项(点击 “Japanese-Anthy” -> “Preferences”)。
|
||||
|
||||
[![][2]][8]
|
||||
![][8]
|
||||
|
||||
你还可以在键盘绑定中编辑默认的快捷键。完成所有更改后,点击应用并确定。就是这样。从任务栏中的 iBus 图标中选择日语,或者按下 `SUPER + 空格键”(LCTT 译注:SUPER 键通常为 `Command` 或 `Window` 键)来在日语和英语(或者系统中的其他默认语言)之间切换。你可以从 iBus 首选项窗口更改键盘快捷键。
|
||||
|
||||
|
||||
@ -1,37 +1,25 @@
|
||||
为什么说 Python 和 Pygame 最适合初学者
|
||||
为什么说 Python 和 Pygame 最适合编程初学者
|
||||
============================================================
|
||||
|
||||
### 我们有三个理由来说明 Pygame 对初学编程者是最好的选择。
|
||||
|
||||
> 我们有三个理由来说明 Pygame 对初学编程者是最好的选择。
|
||||
|
||||

|
||||
图片来源: [opensource.com](https://opensource.com)
|
||||
|
||||
上个月,[Scott Nesbitt][10] 发表了一篇标题为[ Mozilla 支出 50 万美元来支持开源项目][11]的文章。其中 Phaser,一个基于 HTML/JavaScript 的游戏平台项目,获得了 50,000 美元的奖励。整整一年里,我都在使用 Phaser 平台来教我的小女儿,用来学习的话,它是最简单也是最好的 HTML 游戏开发平台。然而,对于初学者来说,使用[ Pygame ][13]也许效果更好。原因如下:
|
||||
图片来源: [opensource.com](https://opensource.com)
|
||||
|
||||
### 1\. 小段代码块
|
||||
上个月,[Scott Nesbitt][10] 发表了一篇标题为 [Mozilla 支出 50 万美元来支持开源项目][11]的文章。其中一个基于 HTML/JavaScript 的游戏平台项目 Phaser 获得了 50,000 美元的奖励。整整一年里,我都在使用 Phaser 平台来教我的小女儿,用来学习的话,它是最简单也是最好的 HTML 游戏开发平台。然而,对于初学者来说,使用 [Pygame ][13]也许效果更好。原因如下:
|
||||
|
||||
Pygame,基于 Python,[在介绍计算机课程中最流行的语言][14]。Python 非常适合用一小段代码来实现我们的想法,孩子们可以从单个文件和单个代码块起开始学习,在掌握函数 (function) 或类 (class) 对象之前,就可以写出意大利面条似的代码。 很像手指画,所想即所得。
|
||||
### 1、 小段代码块
|
||||
|
||||
更多 Python 资源链接
|
||||
Pygame,基于[计算机课程中最流行的语言][14] Python。Python 非常适合用一小段代码来实现我们的想法,孩子们可以从单个文件和单个代码块起开始学习,在掌握函数(function)或类(class)对象之前,就可以写出意大利面条似的代码。 很像手指画,所想即所得。
|
||||
|
||||
* [Python 是什么?][1]
|
||||
以这样的方式来学习,当编写的代码越来越难于管理的时候,孩子们很自然的就会把代码分解成函数模块和类模块。在学习函数之前就学习了 Python 语言的语法,学生将掌握基本的编程知识,对了解全局作用域和局部作用域起到更好的作用。
|
||||
|
||||
* [最热门 Python IDEs][2]
|
||||
大多数 HTML 游戏在一定程度上会将结构、样式和编程逻辑分为 HTML、CSS 和 JavaScript,并且需要 CSS 和 HTML 的知识。从长远来看,虽然拆分更好,但对初学者来说是个障碍。一旦孩子们发现他们可以用 HTML 和 CSS 快速构建网页,很有可能就会被颜色、字体和图形的视觉刺激分散注意力。即使仅仅只专注于 JavaScript 代码,也需要学习基本的文档结构模型(DOM),以使 JavaScript 代码能够嵌入进去。
|
||||
|
||||
* [最热门 Python GUI 框架][3]
|
||||
### 2、 全局变量更清晰
|
||||
|
||||
* [最新 Python 话题][4]
|
||||
|
||||
* [更多开发资源][5]
|
||||
|
||||
以这样的方式来学习,当编写的代码越来越难于管理的时候,孩子们很自然就的就会把代码分解成函数模块和类模块。在学习函数之前就学习了 Python 语言的语法,学生将掌握基本的编程知识,对了解全局作用域和局部作用域起到更好的作用。
|
||||
|
||||
大多数 HTML 游戏在一定程度上会将结构、样式和编程逻辑分为 HTML、CSS和JavaScript,并且需要 CSS 和 HTML 的知识。从长远来看,虽然拆分更好,但对初学者来说是个障碍。一旦孩子们发现他们可以用 HTML 和 CSS 快速构建网页,很有可能就会被颜色、字体和图形的视觉刺激分散注意力。即使有仅仅只专注于 JavaScript 代码的,也需要学习基本的文档结构模型,以使 JavaScript 代码能够嵌入进去。
|
||||
|
||||
### 2\. 全局变量更清晰
|
||||
|
||||
Python 和 JavaScript 都使用动态类型变量,这意味着变量只有在赋值才能确定其类型为一个字符串、一个整数或一个浮点数,其中 JavaScript 更容易出错。类似于类型变量,JavaScript 和 Python 都有全局变量和局部变量之分。Python 中,如果在函数块内要使用全局变量,就会以 `global` 关键字区分出来。
|
||||
Python 和 JavaScript 都使用动态类型变量,这意味着变量只有在赋值才能确定其类型是一个字符串、一个整数还是一个浮点数,然而在 JavaScript 更容易出错。类似于类型变量,JavaScript 和 Python 都有全局变量和局部变量之分。Python 中,如果在函数块内要使用全局变量,就会以 `global` 关键字区分出来。
|
||||
|
||||
要理解在 Phaser 上教授编程初学者所面临的挑战的话,让我们以基本的[制作您的第一个 Phaser 游戏教程][15]为例子,它是由 Alvin Ourrad 和 Richard Davey 开发制作的。在 JavaScript 中,程序中任何地方都可以访问的全局变量很难追踪调试,常常引起 Bug 且很难解决。因为 Richard 和 Alvin 是专业程序员,所以在这儿特意使用全局变量以使程序简洁。
|
||||
|
||||
@ -49,26 +37,26 @@ var platforms;
|
||||
|
||||
function create() {
|
||||
game.physics.startSystem(Phaser.Physics.ARCADE);
|
||||
…
|
||||
...
|
||||
```
|
||||
|
||||
在他们的 Phaser 编程手册 [《Interphase》][16] 中,Richard Davey 和 Ilija Melentijevic 解释说:在很多 Phaser 项目中通常都会使用全局变量,原因是使用它们完成任务更容易、更快捷。
|
||||
|
||||
> “如果您开发过游戏,只要代码量到一定规模,那么(使用全局变量)这种做法会使您陷入困境的,可是我们为什么还要这样做?原因很简单,仅仅只是要使我们的 Phaser 项目容易完成,更简单而已。”
|
||||
|
||||
针对一个 Phaser 应用程序,虽然可以使用局部变量和拆分代码块来达到关注点隔离这些手段来重构代码,但要使第一次学习编程的小孩能理解,显然很有难度的。
|
||||
针对一个 Phaser 应用程序,虽然可以使用局部变量和拆分代码块来达到关注点隔离这些手段来重构代码,但要使第一次学习编程的小孩能理解,显然很有难度的。
|
||||
|
||||
如果您想教你的孩子学习 JavaScript,或者如果他们已经知道怎样使用像 Python 来编程的话,有个好的 Phaser 课程推荐: [完整的手机游戏开发课程] [17],是由 [ Pablo Farias Navarro ] [18] 开发制作的。虽然标题看着是移动游戏,但实际是关于 JavaScript 和 Phaser 的。JavaScript 和 Phaser 移动应用开发已经转移到 [PhoneGap][19] 话题去了。
|
||||
如果您想教你的孩子学习 JavaScript,或者如果他们已经知道怎样使用像 Python 来编程的话,有个好的 Phaser 课程推荐: [完整的手机游戏开发课程] [17],是由 [Pablo Farias Navarro] [18] 开发制作的。虽然标题看着是移动游戏,但实际是关于 JavaScript 和 Phaser 的。JavaScript 和 Phaser 移动应用开发已经转移到 [PhoneGap][19] 话题去了。
|
||||
|
||||
### 3\. Pygame 无依赖要求
|
||||
### 3、 Pygame 无依赖要求
|
||||
|
||||
由于 [Python Wheels][20] 的出现,Pygame 超级[容易安装][21]。在 Fedora/Red Hat 系统下也可使用 **yum** 包管理器来安装:
|
||||
由于 [Python Wheels][20] 的出现,Pygame 超级[容易安装][21]。在 Fedora/Red Hat 系统下也可使用 `yum` 包管理器来安装:
|
||||
|
||||
```
|
||||
sudo yum install python3-pygame
|
||||
```
|
||||
|
||||
更多消息请参考官网[Pygame 安装说明文档][22]。
|
||||
更多信息请参考官网 [Pygame 安装说明文档][22]。
|
||||
|
||||
相比来说,虽然 Phaser 本身更容易安装,但需要掌握更多的知识。前面提到的,学生需要在 HTML 文档中组装他们的 JavaScript 代码,同时还需要些 CSS。除了这三种语言(HTML、CSS、JavaScript),还需要使用火狐或谷歌开发工具和编辑器。JavaScript 最常用的编辑器有 Sublime、Atom、VS Code(按使用多少排序)等。
|
||||
|
||||
@ -76,31 +64,29 @@ sudo yum install python3-pygame
|
||||
|
||||
### Phaser 和 JavaScript 的优势
|
||||
|
||||
JavaScript 和 Phaser 有着种种的不好,为什么我还继续教授他们?老实说,我考虑了很长一段时间,我在担心着学生学习变量申明提升和变量作用域的揪心。所有我开发出基于 Pygame 和 Python 的课程,随后也开发出一涛基于 Phaser 的。最终,我决定使用 Pablo 预先制定的课程作为起点。
|
||||
JavaScript 和 Phaser 有着种种的不好,为什么我还继续教授他们?老实说,我考虑了很长一段时间,我在担心着学生学习<ruby>变量申明提升<rt>variable hoisting</rt></ruby>和变量作用域的揪心。我开发出基于 Pygame 和 Python 的课程,随后也开发出一涛基于 Phaser 的。最终,我决定使用 Pablo 预先制定的课程作为起点。
|
||||
|
||||
我转用 JavaScript 有两个原因。首先,JavaScript 已经成为正式应用的正式语言。除了 Web 应用外,也可使用于移动和服务应用方面。JavaScript 无处不在,其广泛应用于孩子们每天都能看到的应用中。如果他们的朋友使用 Javascript 来编程,他们很可能也会受影响而使用之。正如我看到了 JavaScript 背后的动力,所以深入研究了可编译成 JavaScript 的替代语言,主要是 Dart 和 TypeScript 两种。虽然我不介意额外的转换步骤,但还是最喜欢 JavaScript。
|
||||
|
||||
最后,我选择使用 Phaser 和 JavaScript 的组合,是因为我意识到上面那些问题在 JavaScript 可以被解决,仅仅只是一些工作量而已。高质量的调试工具和一些大牛们的人的工作使得 JavaScript 成为教育孩子编码的可用和有用的语言。
|
||||
最后,我选择使用 Phaser 和 JavaScript 的组合,是因为我意识到上面那些问题在 JavaScript 可以被解决,仅仅只是一些工作量而已。高质量的调试工具和一些大牛们的工作使得 JavaScript 成为教育孩子编码的可用和有用的语言。
|
||||
|
||||
### 最后话题: Python 对垒 JavaScript
|
||||
|
||||
当家长问我使用的什么语言作为孩子的入门语言时,我会立即推荐 Python 和 Pygame。因为有成千上万的课程可选,而且大多数都是免费的。我为我的儿子选择了 Al Sweigart 的 [使用 Python 和 Pygame 开发游戏][25] 课程,同时也在使用 Allen B. Downey 的 [Python 编程思想:如何像计算机科学家一样思考][7]。在 Android 手机上可以使用 [ Tom Rothame ][27]的[ PAPT Pyame][26] 来安装 Pygame 游戏。
|
||||
当家长问我使用的什么语言作为孩子的入门语言时,我会立即推荐 Python 和 Pygame。因为有成千上万的课程可选,而且大多数都是免费的。我为我的儿子选择了 Al Sweigart 的 [使用 Python 和 Pygame 开发游戏][25] 课程,同时也在使用 Allen B. Downey 的 [Python 编程思想:如何像计算机科学家一样思考][7]。在 Android 手机上可以使用 [Tom Rothame][27] 的 [PAPT Pyame][26] 来安装 Pygame 游戏。
|
||||
|
||||
那是好事。JavaScript 是一门成熟的编程语言,有很多很多辅助工具。但有多年的帮助大儿子使用 Python 创建炫酷游戏经历的我,依然钟情于 Python 和 Pygame。
|
||||
尽管有我的建议, 我总是怀疑孩子们很快就会搬到 JavaScript。这没关系 —— JavaScript 是一门成熟的编程语言,有很多很多辅助工具。但有多年的帮助大儿子使用 Python 创建炫酷游戏经历的我,依然钟情于 Python 和 Pygame。
|
||||
|
||||
### About the author
|
||||
### 关于作者
|
||||
|
||||
[][28]
|
||||
|
||||
Craig Oda - First elected president and co-founder of Tokyo Linux Users Group. Co-author of "Linux Japanese Environment" book published by O'Reilly Japan. Part of core team that established first ISP in Asia. Former VP of product management and product marketing for major Linux company. Partner at Oppkey, developer relations consulting firm in Silicon Valley.[More about me][8]
|
||||
Craig Oda —— 东京 Linux 用户组的首位总裁和共同创始人,奥莱理日本出版的《Linux 日文环境》的共同作者。在亚洲建立了第一个 ISP 的核心团队成员之一。一个大型 Linux 公司的产品管理及市场的前任副总裁。硅谷开发者关系咨询公司 Oppkey 的合作方。[更多][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/pygame
|
||||
|
||||
作者:[Craig Oda ][a]
|
||||
作者:[Craig Oda][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,37 +1,39 @@
|
||||
Linux 中 4 个简单的找出进程 ID(PID)的方法
|
||||
======
|
||||
|
||||
每个人都知道 PID,究竟什么是 PID?为什么你想要 PID?你打算用 PID 做什么?你脑子里有同样的问题吗?如果是这样,你就找对地方了解这些细节了。
|
||||
|
||||
主要地,我们查询 PID 来杀死一个没有响应的程序,它类似于 Windows 任务管理器。 Linux GUI 也提供相同的功能,但 CLI 是执行 kill 操作的有效方法。
|
||||
我们查询 PID 主要是用来杀死一个没有响应的程序,它类似于 Windows 任务管理器一样。 Linux GUI 也提供相同的功能,但 CLI 是执行 `kill` 操作的有效方法。
|
||||
|
||||
### 什么是进程 ID?
|
||||
|
||||
PID 代表进程标识号(process identification),它在大多数操作系统内核(如 Linux、Unix、macOS 和 Windows)中使用。它是在操作系统中创建时自动分配给每个进程的唯一标识号。一个进程是一个正在运行的程序实例。
|
||||
PID 代表<ruby>进程标识号<rt>process identification</rt></ruby>,它在大多数操作系统内核(如 Linux、Unix、macOS 和 Windows)中使用。它是在操作系统中创建时自动分配给每个进程的唯一标识号。一个进程是一个正在运行的程序实例。
|
||||
|
||||
**建议阅读:** [如何查看 Apache Web 服务器在 Linux 中的运行时间][1]
|
||||
|
||||
除了 init 进程外其他所有的进程 ID 每次都会改变,因为 init 始终是系统上的第一个进程,并且是所有其他进程的父进程。它的 PID 是 1。
|
||||
|
||||
PID 默认的最大值是 `32,768`。可以在你的系统上运行 `cat /proc/sys/kernel/pid_max` 来验证。在 32 位系统上,32768 是最大值,但是我们可以在 64 位系统上将其设置为最大 2^22(约 4 百万)内的任何值。
|
||||
PID 默认的最大值是 `32768`。可以在你的系统上运行 `cat /proc/sys/kernel/pid_max` 来验证。在 32 位系统上,`32768` 是最大值,但是我们可以在 64 位系统上将其设置为最大 2^22(约 4 百万)内的任何值。
|
||||
|
||||
你可能会问,为什么我们需要这么多的 PID?因为我们不能立即重用 PID,这就是为什么。另外为了防止可能的错误。
|
||||
|
||||
系统正在运行的进程的 PID 可以通过使用 pidof、pgrep、ps 和 pstree 命令找到。
|
||||
系统正在运行的进程的 PID 可以通过使用 `pidof`、`pgrep`、`ps` 和 `pstree` 命令找到。
|
||||
|
||||
### 方法 1:使用 pidof 命令
|
||||
|
||||
pidof 用于查找正在运行的程序的进程 ID。它在标准输出上打印这些 id。为了演示,我们将在 Debian 9(stretch)系统中找出 Apache2 的进程 ID。
|
||||
`pidof` 用于查找正在运行的程序的进程 ID。它在标准输出上打印这些 id。为了演示,我们将在 Debian 9(stretch)系统中找出 Apache2 的进程 ID。
|
||||
|
||||
```
|
||||
# pidof apache2
|
||||
3754 2594 2365 2364 2363 2362 2361
|
||||
|
||||
```
|
||||
|
||||
从上面的输出中,你可能会遇到难以识别进程 ID 的问题,因为它通过进程名称显示了所有的 PID(包括父进程和子进程)。因此,我们需要找出父 PID(PPID),这是我们要查找的。它可能是第一个数字。在本例中,它是 `3754`,并按降序排列。
|
||||
|
||||
### 方法 2:使用 pgrep 命令
|
||||
|
||||
pgrep 遍历当前正在运行的进程,并将符合选择条件的进程 ID 列到标准输出中。
|
||||
`pgrep` 遍历当前正在运行的进程,并将符合选择条件的进程 ID 列到标准输出中。
|
||||
|
||||
```
|
||||
# pgrep apache2
|
||||
2361
|
||||
@ -41,18 +43,18 @@ pgrep 遍历当前正在运行的进程,并将符合选择条件的进程 ID
|
||||
2365
|
||||
2594
|
||||
3754
|
||||
|
||||
```
|
||||
|
||||
这也与上面的输出类似,但是它将结果从小到大排序,这清楚地说明父 PID 是最后一个。在本例中,它是 `3754`。
|
||||
|
||||
**注意:** 如果你有多个进程的进程 ID,那么在使用 pidof 和 pgrep 识别父进程 ID 时可能会遇到麻烦。
|
||||
**注意:** 如果你有多个进程的进程 ID,那么在使用 `pidof` 和 `pgrep` 识别父进程 ID 时就可能不会很顺利。
|
||||
|
||||
### 方法 3:使用 pstree 命令
|
||||
|
||||
pstree 将运行的进程显示为一棵树。树的根是 pid,如果省略了 pid 那么就是 init。如果在 pstree 命令中指定了用户名,则显示相应用户拥有的所有进程。
|
||||
`pstree` 将运行的进程显示为一棵树。树的根是某个 pid,如果省略了 pid 参数,那么就是 init。如果在 `pstree` 命令中指定了用户名,则显示相应用户拥有的所有进程。
|
||||
|
||||
`pstree` 会将相同的分支放在方括号中,并添加重复计数的前缀来可视化地合并到一起。
|
||||
|
||||
pstree 通过将它们放在方括号中并添加重复计数前缀来可视化地合并相同的分支。
|
||||
```
|
||||
# pstree -p | grep "apache2"
|
||||
|- apache2(3754) -|-apache2(2361)
|
||||
@ -61,21 +63,21 @@ pstree 通过将它们放在方括号中并添加重复计数前缀来可视化
|
||||
| |-apache2(2364)
|
||||
| |-apache2(2365)
|
||||
| `-apache2(2594)
|
||||
|
||||
```
|
||||
|
||||
要单独获取父进程,请使用以下格式。
|
||||
|
||||
```
|
||||
# pstree -p | grep "apache2" | head -1
|
||||
|- apache2(3754) -|-apache2(2361)
|
||||
|
||||
```
|
||||
|
||||
pstree 命令非常简单,因为它分别隔离了父进程和子进程,但这在使用 pidof 和 pgrep 时命令不容易。
|
||||
`pstree` 命令非常简单,因为它分别隔离了父进程和子进程,但这在使用 `pidof` 和 `pgrep` 时命令不容易做到。
|
||||
|
||||
### 方法 4:使用 ps 命令
|
||||
|
||||
ps 显示活动进程的选择信息。它显示进程 ID(pid=PID)、与进程关联的终端(tname=TTY)、以 [DD-]hh:mm:ss 格式(time=TIME)的累计 CPU 时间、以及执行名(ucmd = CMD)。输出默认是未排序的。
|
||||
`ps` 显示活动进程的选择信息。它显示进程 ID(`pid`=PID)、与进程关联的终端(`tname`=TTY)、以 `[DD-]hh:mm:ss` 格式(`time`=TIME)显示的累计 CPU 时间、以及执行名(`ucmd` = CMD)。输出默认是未排序的。
|
||||
|
||||
```
|
||||
# ps aux | grep "apache2"
|
||||
www-data 2361 0.0 0.4 302652 9732 ? S 06:25 0:00 /usr/sbin/apache2 -k start
|
||||
@ -86,10 +88,9 @@ www-data 2365 0.0 0.4 302652 8400 ? S 06:25 0:00 /usr/sbin/apache2 -k start
|
||||
www-data 2594 0.0 0.4 302652 8400 ? S 06:55 0:00 /usr/sbin/apache2 -k start
|
||||
root 3754 0.0 1.4 302580 29324 ? Ss Dec11 0:23 /usr/sbin/apache2 -k start
|
||||
root 5648 0.0 0.0 12784 940 pts/0 S+ 21:32 0:00 grep apache2
|
||||
|
||||
```
|
||||
|
||||
从上面的输出中,我们可以根据进程的启动日期轻松地识别父进程 ID(PPID)。在此例中,apache2 启动于 `Dec11`,它是父进程,其他的是子进程。apache2 的 PID 是 `3754`。
|
||||
从上面的输出中,我们可以根据进程的启动日期轻松地识别父进程 ID(PPID)。在此例中,apache2 启动于 `Dec 11`,它是父进程,其他的是子进程。apache2 的 PID 是 `3754`。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -97,7 +98,7 @@ via: https://www.2daygeek.com/how-to-check-find-the-process-id-pid-ppid-of-a-run
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,11 +3,12 @@
|
||||
|
||||
![Learn xfs commands with examples][1]
|
||||
|
||||
在我们另一篇文章中,我带您领略了一下[什么事 xfs,xfs 的相关特性等内容 ][2]。本文我们来看一些常用的 xfs 管理命令。我们将会通过几个例子来讲解如何创建 xfs 文件系统,如何对 xfs 文件系统进行扩容,如何检测并修复 xfs 文件系统。
|
||||
在我们另一篇文章中,我带您领略了一下[什么是 xfs,xfs 的相关特性等内容][2]。本文我们来看一些常用的 xfs 管理命令。我们将会通过几个例子来讲解如何创建 xfs 文件系统,如何对 xfs 文件系统进行扩容,如何检测并修复 xfs 文件系统。
|
||||
|
||||
### 创建 XFS 文件系统
|
||||
|
||||
`mkfs.xfs` 命令用来创建 xfs 文件系统。无需任何特别的参数,其输出如下:
|
||||
|
||||
```
|
||||
root@kerneltalks # mkfs.xfs /dev/xvdf
|
||||
meta-data=/dev/xvdf isize=512 agcount=4, agsize=1310720 blks
|
||||
@ -25,7 +26,7 @@ realtime =none extsz=4096 blocks=0, rtextents=0
|
||||
|
||||
### 调整 XFS 文件系统容量
|
||||
|
||||
你职能对 XFS 进行扩容而不能缩容。我们使用 `xfs_growfs` 来进行扩容。你需要使用 `-D` 参数指定挂载点的新容量。`-D` 接受一个数字的参数,指定文件系统块的数量。若你没有提供 `-D` 参数,则 `xfs_growfs` 会将文件系统扩到最大。
|
||||
你只能对 XFS 进行扩容而不能缩容。我们使用 `xfs_growfs` 来进行扩容。你需要使用 `-D` 参数指定挂载点的新容量。`-D` 接受一个数字的参数,指定文件系统块的数量。若你没有提供 `-D` 参数,则 `xfs_growfs` 会将文件系统扩到最大。
|
||||
|
||||
```
|
||||
root@kerneltalks # xfs_growfs /dev/xvdf -D 256
|
||||
@ -41,7 +42,7 @@ realtime =none extsz=4096 blocks=0, rtextents=0
|
||||
data size 256 too small, old size is 2883584
|
||||
```
|
||||
|
||||
观察上面的输出中的最后一行。由于我分配的容量要小于现在的容量。它告诉你不能缩减 XFS 文件系统。你只能对他进行扩展。
|
||||
观察上面的输出中的最后一行。由于我分配的容量要小于现在的容量。它告诉你不能缩减 XFS 文件系统。你只能对它进行扩展。
|
||||
|
||||
```
|
||||
root@kerneltalks # xfs_growfs /dev/xvdf -D 2883840
|
||||
@ -59,7 +60,7 @@ data blocks changed from 2883584 to 2883840
|
||||
|
||||
现在我多分配了 1GB 的空间,而且也成功地扩增了容量。
|
||||
|
||||
**1GB 块的计算方式:**
|
||||
**1GB 块的计算方式:**
|
||||
|
||||
当前文件系统 bsize 为 4096,意思是块的大小为 4MB。我们需要 1GB,也就是 256 个块。因此在当前块数,2883584 上加上 256 得到 2883840。因此我为 `-D` 传递参数 2883840。
|
||||
|
||||
@ -76,7 +77,9 @@ xfs_repair: /dev/xvdf contains a mounted and writable filesystem
|
||||
|
||||
fatal error -- couldn't initialize XFS library
|
||||
```
|
||||
|
||||
卸载后运行检查命令。
|
||||
|
||||
```
|
||||
root@kerneltalks # xfs_repair -n /dev/xvdf
|
||||
Phase 1 - find and verify superblock...
|
||||
@ -184,10 +187,10 @@ via: https://kerneltalks.com/commands/xfs-file-system-commands-with-examples/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://c3.kerneltalks.com/wp-content/uploads/2018/01/xfs-commands.png
|
||||
[1]:https://a3.kerneltalks.com/wp-content/uploads/2018/01/xfs-commands.png
|
||||
[2]:https://kerneltalks.com/disk-management/xfs-filesystem-in-linux/
|
||||
@ -1,6 +1,7 @@
|
||||
如何更改 Linux 控制台上的字体
|
||||
======
|
||||

|
||||
|
||||

|
||||
|
||||
我尝试尽可能的保持心灵祥和,然而总有一些事情让我意难平,比如控制台字体太小了。记住我的话,朋友,有一天你的眼睛会退化,无法再看清你编码时用的那些细小字体,到那时你就后悔莫及了。
|
||||
|
||||
@ -8,46 +9,48 @@
|
||||
|
||||
### Linux 控制台是个什么鬼?
|
||||
|
||||
首先让我们来澄清一下我们说的到底是个什么东西。当我提到 Linux 控制台,我指的是 TTY1-6,即你从图形环境用 `Ctrl-Alt-F1` 到 `F6` 切换到的虚拟终端。按下 `Ctrl+Alt+F7` 会切回图形环境。(不过这些热键已经不再通用,你的 Linux 发行版可能有不同的键映射。你的 TTY 的数量也可能不同,你图形环境会话也可能不在 `F7`。比如,Fedora 的默认图形会话是 `F2`,它只有一个额外的终端在 `F1`。) 我觉得能同时拥有 X 会话和终端绘画实在是太酷了。
|
||||
首先让我们来澄清一下我们说的到底是个什么东西。当我提到 Linux 控制台,我指的是 TTY1-6,即你从图形环境用 `Ctrl-Alt-F1` 到 `F6` 切换到的虚拟终端。按下 `Ctrl+Alt+F7` 会切回图形环境。(不过这些热键已经不再通用,你的 Linux 发行版可能有不同的键映射。你的 TTY 的数量也可能不同,你图形环境会话也可能不在 `F7`。比如,Fedora 的默认图形会话是 `F2`,它只有一个额外的终端在 `F1`。) 我觉得能同时拥有 X 会话和终端会话实在是太酷了。
|
||||
|
||||
Linux 控制台是内核的一部分,而且并不运行在 X 会话中。它和你在没有图形环境的无头服务器中用的控制台是一样的。我称呼在图形会话中的 X 终端为终端,而将控制台和 X 终端统称为终端模拟器。
|
||||
Linux 控制台是内核的一部分,而且并不运行在 X 会话中。它和你在没有图形环境的<ruby>无头<rt>headless</rt></ruby>服务器中用的控制台是一样的。我称呼在图形会话中的 X 终端为终端,而将控制台和 X 终端统称为终端模拟器。
|
||||
|
||||
但这还没完。Linux 终端从早期的 ANSI 时代开始已经经历了长久的发展,多亏了 Linux framebuffer,它现在支持 Unicode 并且对图形也有了有限的一些支持。而且出现了很多在控制台下运行的多媒体应用,这些我们在以后的文章中会提到。
|
||||
但这还没完。Linux 终端从早期的 ANSI 时代开始已经经历了长久的发展,多亏了 Linux framebuffer,它现在支持 Unicode 并且对图形也有了有限的一些支持。而且出现了很多在控制台下运行的[多媒体应用][4],这些我们在以后的文章中会提到。
|
||||
|
||||
### 控制台截屏
|
||||
|
||||
获取控制台截屏的最简单方法是让控制台跑在虚拟机内部。然后你可以在宿主系统上使用中意的截屏软件来抓取。不过借助 [fbcat][1] 和 [fbgrab][2] 你也可以直接在控制台上截屏。`fbcat` 会创建一个可移植的像素映射格式 (PPM) 图像; 这是一个高度可移植的未压缩图像格式,可以在所有的操作系统上读取,当然你也可以把它转换成任何喜欢的其他格式。`fbgrab` 则是 `fbcat` 的一个封装脚本,用来生成一个 PNG 文件。不同的人写过多个版本的 `fbgrab`。每个版本的选项都有限而且只能创建截取全屏。
|
||||
获取控制台截屏的最简单方法是让控制台跑在虚拟机内部。然后你可以在宿主系统上使用中意的截屏软件来抓取。不过借助 [fbcat][1] 和 [fbgrab][2] 你也可以直接在控制台上截屏。`fbcat` 会创建一个可移植的像素映射格式(PPM)的图像; 这是一个高度可移植的未压缩图像格式,可以在所有的操作系统上读取,当然你也可以把它转换成任何喜欢的其他格式。`fbgrab` 则是 `fbcat` 的一个封装脚本,用来生成一个 PNG 文件。很多人写过多个版本的 `fbgrab`。每个版本的选项都有限而且只能创建截取全屏。
|
||||
|
||||
`fbcat` 的执行需要 root 权限,而且它的输出需要重定向到文件中。你无需指定文件扩展名,只需要输入文件名就行了:
|
||||
|
||||
```
|
||||
$ sudo fbcat > Pictures/myfile
|
||||
|
||||
```
|
||||
|
||||
在 GIMP 中裁剪后,就得到了图 1。
|
||||
|
||||

|
||||
Figure 1:View after cropping。
|
||||
|
||||
*图 1 : 裁剪后查看*
|
||||
|
||||
如果能在左边空白处有一点填充就好了,如果有读者知道如何实现请在留言框中告诉我。
|
||||
|
||||
`fbgrab` 还有一些选项,你可以通过 `man fbgrab` 来查看,这些选项包括对另一个控制台进行截屏,以及延时截屏。在下面的例子中可以看到,`fbgrab` 截屏跟 `fbcat` 截屏类似,只是你无需明确进行输出重定性了:
|
||||
`fbgrab` 还有一些选项,你可以通过 `man fbgrab` 来查看,这些选项包括对另一个控制台进行截屏,以及延时截屏等。在下面的例子中可以看到,`fbgrab` 截屏跟 `fbcat` 截屏类似,只是你无需明确进行输出重定性了:
|
||||
|
||||
```
|
||||
$ sudo fbgrab Pictures/myOtherfile
|
||||
|
||||
```
|
||||
|
||||
### 查找字体
|
||||
|
||||
就我所知,除了查看字体存储目录 `/usr/share/consolefonts/`(Debian/etc。),`/lib/kbd/consolefonts/` (Fedora),`/usr/share/kbd/consolefonts` (openSUSE),外没有其他方法可以列出已安装的字体了。
|
||||
就我所知,除了查看字体存储目录 `/usr/share/consolefonts/`(Debian 等),`/lib/kbd/consolefonts/` (Fedora),`/usr/share/kbd/consolefonts` (openSUSE)外没有其他方法可以列出已安装的字体了。
|
||||
|
||||
### 更改字体
|
||||
|
||||
可读字体不是什么新概念。我们应该尊重以前的经验!可读性是很重要的。可配置性也很重要,然而现如今却不怎么看重了。
|
||||
|
||||
在 Debian/Ubuntu/ 等系统上,可以运行 `sudo dpkg-reconfigure console-setup` 来设置控制台字体,然后在控制台运行 `setupcon` 命令来让变更生效。`setupcon` 属于 `console-setup` 软件包中的一部分。若你的 Linux 发行版中不包含该工具,可以在 [openSUSE][3] 中下载到它。
|
||||
在 Debian/Ubuntu 等系统上,可以运行 `sudo dpkg-reconfigure console-setup` 来设置控制台字体,然后在控制台运行 `setupcon` 命令来让变更生效。`setupcon` 属于 `console-setup` 软件包中的一部分。若你的 Linux 发行版中不包含该工具,可以在 [openSUSE][3] 中下载到它。
|
||||
|
||||
你也可以直接编辑 `/etc/default/console-setup` 文件。下面这个例子中设置字体为 32 点大小的 Terminus Bold 字体,这是我的最爱,并且严格限制控制台宽度为 80 列。
|
||||
|
||||
```
|
||||
ACTIVE_CONSOLES="/dev/tty[1-6]"
|
||||
CHARMAP="UTF-8"
|
||||
@ -55,22 +58,20 @@ CODESET="guess"
|
||||
FONTFACE="TerminusBold"
|
||||
FONTSIZE="16x32"
|
||||
SCREEN_WIDTH="80"
|
||||
|
||||
```
|
||||
|
||||
这里的 FONTFACE 和 FONTSIZE 的值来自于字体的文件名,`TerminusBold32x16.psf.gz`。是的,你需要反转 FONTSIZE 中值的顺序。计算机就是这么搞笑。然后再运行 `setupcon` 来让新配置生效。可以使用 `showconsolefont` 来查看当前所用字体的所有字符集。要查看完整的选项说明请参考 `man console-setup`。
|
||||
这里的 `FONTFACE` 和 `FONTSIZE` 的值来自于字体的文件名 `TerminusBold32x16.psf.gz`。是的,你需要反转 `FONTSIZE` 中值的顺序。计算机就是这么搞笑。然后再运行 `setupcon` 来让新配置生效。可以使用 `showconsolefont` 来查看当前所用字体的所有字符集。要查看完整的选项说明请参考 `man console-setup`。
|
||||
|
||||
### Systemd
|
||||
|
||||
Systemd 与 `console-setup` 不太一样,除了字体之外,你无需安装任何东西。你只需要编辑 `/etc/vconsole.conf` 然后重启就行了。我在 Fedora 和 openSUSE 系统中安装了一些额外的大型号的 Terminus 字体包,因为默认安装的字体最大只有 16 点而我想要的是 32 点。然后将 `/etc/vconsole.conf` 的内容修改为:
|
||||
Systemd 与 `console-setup` 不太一样,除了字体之外,你无需安装任何东西。你只需要编辑 `/etc/vconsole.conf` 然后重启就行了。我在 Fedora 和 openSUSE 系统中安装了一些额外的大字号的 Terminus 字体包,因为默认安装的字体最大只有 16 点而我想要的是 32 点。然后将 `/etc/vconsole.conf` 的内容修改为:
|
||||
|
||||
```
|
||||
KEYMAP="us"
|
||||
FONT="ter-v32b"
|
||||
|
||||
```
|
||||
|
||||
下周我们还将学习一些更加酷的控制台小技巧,以及一些在控制台上运行的多媒体应用。
|
||||
|
||||
下周我们还将学习一些更加酷的控制台小技巧,以及一些在控制台上运行的[多媒体应用][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -78,7 +79,7 @@ via: https://www.linux.com/learn/intro-to-linux/2018/1/how-change-your-linux-con
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -86,3 +87,4 @@ via: https://www.linux.com/learn/intro-to-linux/2018/1/how-change-your-linux-con
|
||||
[1]:http://jwilk.net/software/fbcat
|
||||
[2]:https://github.com/jwilk/fbcat/blob/master/fbgrab
|
||||
[3]:https://software.opensuse.org/package/console-setup
|
||||
[4]:https://linux.cn/article-9320-1.html
|
||||
69
published/20180122 How to price cryptocurrencies.md
Normal file
69
published/20180122 How to price cryptocurrencies.md
Normal file
@ -0,0 +1,69 @@
|
||||
如何为数字货币定价
|
||||
======
|
||||
|
||||

|
||||
|
||||
预测数字货币价格是一场愚人游戏,然而我想试试。单一数字货币价值的驱动因素目前太多,而且含糊不清,无法根据任何一点进行评估。或许新闻正报道说比特币呈上升趋势,但与此同时,有黑客攻击或是交易所 API 错误,就让比特币的价格下跌。以太坊看起来不够智能?谁知道呢,也许第二天就建立一个新的更智能的 DAO(LCTT 译注:区块链上,基于激励的经济协调机制,以代码作为表达,通过互联网进行传输,允许人们参与数字企业的风险&回报(即分配),代币创建了 DAO 参与者之间的经济链接)将吸引大量参与者。
|
||||
|
||||
那么,您该如何投资呢?又或是更准确的讲,您下注在哪种数字货币上呢?
|
||||
|
||||
理解什么时候买卖和持有数字货币,关键是使用与评估开源项目价值的相关工具。这已经一次又一次地被提及了,但是为了理解当前数字货币的快速发展,您必须回到 Linux 悄然兴起的时候。
|
||||
|
||||
互联网泡沫期间,Linux 出现在大众视野中。那时候,如果您想建立一个 Web 服务器,您必须将一台 Windows 服务器或者 Sun Sparc 工作站运送到一个服务器托管机房,在那里它将为传送 Pets.com(LCTT 译注:一个在线宠物商店,借着互联网繁荣的机会崛起,在互联网泡沫破裂时倒闭)的 HTML 页面而做出努力。与此同时,Linux 就像运行在微软和 Sun 公司平行路径上的货运列车一样,可以让开发人员使用日新月异的操作系统和工具集,快速、轻松地构建一次性项目。相比之下,解决方案提供商的花费比软硬件支出少得多,很快,所有科技巨头的业务由软件转向了服务提供,例如 Sun 公司。
|
||||
|
||||
Linux 的萌发促使整个开源市场蓬勃发展起来。但是有一个关键的问题,您无法从开源软件中赚钱。您可以提供服务,也可以销售使用开源组件的产品,但早期开源者主要是为了提升自我,而不是为了赚钱。
|
||||
|
||||
数字货币几乎完全遵循 Linux 的老路,但数字货币具有一定货币价值。因此,当您在为一个区块链项目工作时,您不是为了公共利益,也不是为了编写自由软件的乐趣,而是您写它的时候期望得到一大笔钱。因此,这掩盖了许多程序员的价值判断。那些给您带来了 Python、PHP、Django 和 Node.js 的人们回来了……而现在他们正在通过编程赚钱。
|
||||
|
||||
### 审查代码库
|
||||
|
||||
今年将是代币销售和数字货币领域大清算的一年。虽然许多公司已经能够摆脱糟糕的或不可用的代码库,但我怀疑开发人员是否能让未来的公司摆脱如此云山雾罩的东西。可以肯定地说,我们可以期待[像这样详细描述 Storj 代码库不足之处的文章成为规范][1],这些评论会让许多所谓的“ICO” 们(LCTT 译注:代币首次发行融资)陷入困境。虽然规模巨大,但 ICO 的资金渠道是有限的,在某种程度上不完整的项目会被更严格的审查。
|
||||
|
||||
这是什么意思呢?这意味着要了解数字货币,您必须像对待创业公司那样对待它。您要看它是否有一个好团队?它是否是一个好产品?是否能运作?会有人想要使用它吗?现在评估整个数字货币的价值还为时过早,但如果我们假设代币将成为未来计算机互相支付的方式,这就让我们摆脱了许多疑问。毕竟,2000 年没有多少人知道 Apache 会在一个竞争激烈的市场上,几乎击败其他所有的 Web 服务器,或者像 Ubuntu 一样常见以至于可以随时可以搭建和拆毁它们。
|
||||
|
||||
理解数字货币价值的关键是忽视泡沫、炒作、恐惧、迷惑和怀疑心理,而是关注其真正的效用。您认为有一天您的手机会为另外一个手机付款,比如游戏内的额外费用吗? 您是否认为信用卡系统会在互联网出现后消失?您是否期望有一天,在生活中花费一点点钱,让自己过得更加舒适?然后,通过一切手段,购买并持有您认为将来可能会使您的生活过得更舒适的东西。如果您认为通过 TCP/IP 互联网的方式并不能够改善您的生活(或是您对其没有足够的了解),那么您可能就不会关注这些。纳斯达克总是开放的,至少在银行的营业时间。
|
||||
|
||||
好的,下面是我的预测。
|
||||
|
||||
### 预测
|
||||
|
||||
以下是我在考虑加密货币的“投资”时应该考虑的事项评估。在我们开始之前,先讲下注意事项:
|
||||
|
||||
* 数字货币不是真正的货币投资,而是投资在未来的技术。这就好比:当您购买数字货币时,我们像是在<ruby>进取号星舰<rt>Starship Enterprise</rt></ruby>的甲板上交换“<ruby>星际信用<rt>Galactic Credit</rt></ruby>”(LCTT 译注:《星球大战》电影中的一种货币)一般。 这是数字货币的唯一不可避免的未来。虽然您可以强制将数字货币附加到各种经济模式中,对其抱有乐观的态度,整个平台是技术乌托邦,并假设各种令人兴奋和不可能的事情将在未来几年来到。如果您有多余的现金,您喜欢《星球大战》,那么您就可以投资这些“黄金”。如果您的兄弟告诉您相关信息,结果您用信用卡买了比特币,那么您可能会要度过一段啃馒头的时间。
|
||||
* 不要相信任何人。没有担保,除了提供不是投资建议的免责声明,而且这绝不是对任何特定数字货币的背书,甚至是普遍概念,但我们必须明白,我在这里写的任何东西都可能是错误的。事实上,任何关于数字货币的文章都可能是错误的,任何试图卖给您吹得天花乱坠的代币的人,几乎肯定是骗子。总之,每个人都是错的,每个人都想要得到您的钱,所以要非常、非常小心。
|
||||
* 您也可以持有。如果您是在 18000 美元的价位买的比特币,您最好还是继续持有下去。 现在您就好像正处于帕斯卡赌注。(LCTT 译注:论述——我不知道上帝是否存在,如果他不存在,作为无神论者没有任何好处,但是如果他存在,作为无神论者我将有很大的坏处。所以,宁愿相信上帝存在)是的,也许您因为数字货币让您赔钱而生气,但也许您只是因为您的愚蠢和自大,但现在您不妨保持信仰,因为没有什么是必然的,或者您可以承认您是有点过于热切。虽然现在您被惩罚,但要相信有比特币之神在注视着您。最终您需要深吸一口气,同意这一切都相当怪异,并坚持下去。
|
||||
|
||||
现在回过头来评估数字货币。
|
||||
|
||||
**比特币** —— 预计明年的涨幅将超过目前的低点。此外,[世界各地的证券交易委员会和其他联邦机构][2]也会开始以实际行动调整加密货币的买卖。现在银行开玩笑说,他们想要降低数字货币的风险。因此,比特币将成为数字黄金,成为投机者稳定,乏味但充满波动的避风港。尽管所有都不能用作真正的货币,但对于我们所需要的东西来说,这已经足够了,我们也可以期待量子计算的产品去改变最古老,最熟悉的加密货币的面貌。
|
||||
|
||||
**以太坊** —— 只要创造者 Vitalik Buterin 不再继续泼冷水,以太坊在价格上可以维持在上千美元。像一个懊悔的<ruby>维克多·弗兰肯斯坦<rt>Victor Frankenstein</rt></ruby>(LCTT 译注:来自《维克多·弗兰肯斯坦》电影的一名角色),Buterin 倾向于做出惊人的事情,然后在网上诋毁他们,这种自我鞭策在充满泡沫和谎言的空间中实际上是非常有用的。以太坊是最接近我们有用的加密货币,但它本质上仍然是分布式应用。这是一个很有用,很聪明的方法,可以很容易地进行实验,但是,没有人用新的分布式数据存储或应用程序取代旧系统。总之,这是一个非常令人兴奋的技术,但是还没有人知道该用它做什么。
|
||||
|
||||
![][3]
|
||||
|
||||
以太坊的价格将何去何从?它将徘徊在 1000 美元左右,今年可能高达 1500 美元,但这是一个原则性的科技项目,但却不是一个保值产品。
|
||||
|
||||
**竞争币**(LCTT 译注:除比特币,以太币之外的所有的数字币,亦称之为山寨币) —— 泡沫的标志之一是当普通人说“我买不起比特币,所以我买了莱特币”这样的话时。这正是我从许多人那里听到的,就好像说“我买不起汉堡,所以我买了一斤木屑,我想孩子们会吃的,对不对?”那您要自担风险。竞争币对于很多人来说是一个风险非常低游戏,就好比您根据一个算法创造出某个竞争币,在市值达到一定水平时卖出,那么您可以赚取一笔不错的利润。况且,大多数竞争币不会在一夜之间消失。 我诚实地推荐以太坊而不是竞争币,但是如果您死磕竞争币,那祝您玩得开心。
|
||||
|
||||
**代币** —— 这是数字货币变得有趣的地方。代币需要研究机构和高校对技术有深入的了解,才能真正的评估。我见过的许多代币都是一场赌博,价格暴涨暴跌。我不会给其命名,但是经验法则是,如果您在公开市场上买了一个代币,那么您可能已经错过了赚钱的机会。截至 2018 年 1 月,代币销售,庄家开始投资一个代币几美分,最后得到百倍的回报。虽然许多创始人谈论他们的产品的神奇之处和他们的团队的强大,但是就是为了单车变摩托,把价值 4 美分一个的代币升值为 20 美分,再升值成一美元。您将收益乘以数百万,就能看到它的吸引力了。
|
||||
|
||||
答案很简单:找到您喜欢的几个项目并潜藏在他们的社区中。评估团队是否有实力,并且很早就知道该如何进入。将钱投入后就当扔掉几个月或几年。但无法保证,因为代币理念太过超前,以至于无法对其评估。
|
||||
|
||||
您正在阅读这篇文章,是因为您希望在这错综复杂的环境下得到一个方向。没关系,我已经跟许多数字货币创始人交谈,知道现在许多人不知道的事情,并且知道合谋和肮脏交易的准则。因此,像我们这样的人,要慢慢地分批购买,就会开始明白这究竟是怎么一回事,也许会从数字货币投资中获利。当数字货币的潜力被完全发掘,我们会得到一个像 Linux 一样的时代。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2018/01/22/how-to-price-cryptocurrencies/
|
||||
|
||||
作者:[John Biggs][a]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/john-biggs/
|
||||
[1]:https://shitcoin.com/storj-not-a-dropbox-killer-1a9f27983d70
|
||||
[2]:http://www.businessinsider.com/bitcoin-price-cryptocurrency-warning-from-sec-cftc-2018-1
|
||||
[3]:https://tctechcrunch2011.files.wordpress.com/2018/01/vitalik-twitter-1312.png?w=525&h=615
|
||||
[4]:https://unsplash.com/photos/pElSkGRA2NU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/cash?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,66 @@
|
||||
开源软件二十年 —— 过去,现在,未来
|
||||
=================================================================
|
||||
|
||||
> 谨以此文纪念 “<ruby>开源软件<rt>open source software</rt></ruby>” 这个名词的二十周年纪念日,开源软件是怎么占有软件的主导地位的 ?以后会如何发展?
|
||||
|
||||

|
||||
|
||||
二十年以前,在 1998 年 2 月,“<ruby>开源<rt>open source</rt></ruby>” 这个词汇第一次出现在“软件”这一名词之前。不久之后,<ruby>开源的定义<rt>Open Source Definition</rt></ruby>(OSD) 这一文档被创建,并成为了撒播 <ruby>开放源代码促进会<rt>Open Source Initiative</rt></ruby>(OSI)的种子。正如 OSD 的作者 [Bruce Perens 所说][9]:
|
||||
|
||||
> “开源”是这场宣传自由软件的既有概念到商业软件,并将许可证化为一系列规则的运动的正式名称。
|
||||
|
||||
二十年后,我们能看到这一运动是非常成功的,甚至超出了当时参与这一活动的任何人的想象。 如今,开源软件无处不在。它是互联网和网络的基础。它为我们所有使用的电脑和移动设备,以及它们所连接的网络提供动力。没有它,云计算和新兴的物联网将不可能发展,甚至不可能出现。它使新的业务方式可以被测试和验证,还可以让像谷歌和 Facebook 这样的大公司在已有的基础之上继续攀登。
|
||||
|
||||
如任何人类的造物一样,它也有黑暗的一面。它也让反乌托邦的监视和必然导致的专制控制的出现成为了可能。它为犯罪分子提供了欺骗受害者的新的途径,还让匿名且大规模的欺凌得以存在。它让有破环性的狂热分子可以暗中组织而不会感到有何不便。这些都是开源的能力之下的黑暗投影。所有的人类工具都是如此,既可以养育人类,亦可以有害于人类。我们需要帮助下一代,让他们能争取无可取代的创新。就如 [费曼所说][10]:
|
||||
|
||||
> 每个人都掌握着一把开启天堂之门的钥匙,但这把钥匙亦能打开地狱之门。
|
||||
|
||||
开源运动已经渐渐成熟。我们讨论和理解它的方式也渐渐的成熟。如果说第一个十年是拥护与非议对立的十年,那么第二个十年就是接纳和适应并存的十年。
|
||||
|
||||
1. 在第一个十年里面,关键问题就是商业模型 —— “我怎样才能自由的贡献代码,且从中受益?” —— 之后,还有更多的人提出了有关管理的难题—— “我怎么才能参与进来,且不受控制 ?”
|
||||
2. 第一个十年的开源项目主要是替代现有的产品;而在第二个十年中,它们更多地是作为更大的解决方案的组成部分。
|
||||
3. 第一个十年的项目往往由非正式的个人组织进行;而在第二个十年中,它们经常由创建于各个项目上的机构经营。
|
||||
4. 第一个十年的开源开发者经常是投入于单一的项目,并经常在业余时间工作。 在第二个十年里,他们越来越多地受雇从事于一个专门的技术 —— 他们成了专业人员。
|
||||
5. 尽管开源一直被认为是提升软件自由度的一种方式,但在第一个十年中,这个运动与那些更喜欢使用“<ruby>自由软件<rt>free software</rt></ruby>”的人产生了冲突。在第二个十年里,随着开源运动的加速发展,这个冲突基本上被忽略了。
|
||||
|
||||
第三个十年会带来什么?
|
||||
|
||||
1. _更复杂的商业模式_ —— 主要的商业模式涉及到将很多开源组件整合而产生的复杂性的解决方案,特别是部署和扩展方面。 开源治理的需求将反映这一点。
|
||||
2. _开源拼图_ —— 开源项目将主要是一系列组件,彼此衔接构成组件堆栈。由此产生的解决方案将是开源组件的拼图。
|
||||
3. _项目族_ —— 越来越多的项目将由诸如 Linux Foundation 和 OpenStack 等联盟/行业协会以及 Apache 和 Software Freedom Conservancy 等机构主办。
|
||||
4. _专业通才_ —— 开源开发人员将越来越多地被雇来将诸多技术集成到复杂的解决方案里,这将有助于一系列的项目的开发。
|
||||
5. _软件自由度降低_ —— 随着新问题的出现,软件自由(将四项自由应用于用户和开发人员之间的灵活性)将越来越多地应用于识别解决方案是否适用于协作社区和独立部署人员。
|
||||
|
||||
2018 年,我将在全球各地的主题演讲中阐述这些内容。欢迎观看 [OSI 20 周年纪念全球巡演][11]!
|
||||
|
||||
_本文最初发表于 [Meshed Insights Ltd.][2] , 已获转载授权,本文,以及我在 OSI 的工作,由 [Patreon patrons][3] 支持_
|
||||
|
||||
### 关于作者
|
||||
|
||||
Simon Phipps - 计算机工业和开源软件专家 Simon Phipps 创办了[公共软件公司][4],这是一个欧洲开源项目的托管公司,以志愿者身份成为 OSI 的总裁,还是 The Document Foundation 的一名总监。 他的作品是由 [Patreon patrons][5] 赞助 —— 如果你想看更多的话,来做赞助人吧! 在超过 30 年的职业生涯中,他一直在参与世界领先的战略层面的开发 ... [关于 Simon Phipps][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/open-source-20-years-and-counting
|
||||
|
||||
作者:[Simon Phipps][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/simonphipps
|
||||
[1]:https://opensource.com/article/18/2/open-source-20-years-and-counting?rate=TZxa8jxR6VBcYukor0FDsTH38HxUrr7Mt8QRcn0sC2I
|
||||
[2]:https://meshedinsights.com/2017/12/21/20-years-and-counting/
|
||||
[3]:https://patreon.com/webmink
|
||||
[4]:https://publicsoftware.eu/
|
||||
[5]:https://patreon.com/webmink
|
||||
[6]:https://opensource.com/users/simonphipps
|
||||
[7]:https://opensource.com/users/simonphipps
|
||||
[8]:https://opensource.com/user/12532/feed
|
||||
[9]:https://perens.com/2017/09/26/on-usage-of-the-phrase-open-source/
|
||||
[10]:https://www.brainpickings.org/2013/07/19/richard-feynman-science-morality-poem/
|
||||
[11]:https://opensource.org/node/905
|
||||
[12]:https://opensource.com/users/simonphipps
|
||||
[13]:https://opensource.com/users/simonphipps
|
||||
[14]:https://opensource.com/users/simonphipps
|
||||
@ -3,94 +3,77 @@ TensorFlow 的简单例子
|
||||
|
||||

|
||||
|
||||
在本次推送中,我们将看一些例子,并从中感受到在定义张量和使用张量做数学计算方面有多么容易,我还会举些别的机器学习相关的例子。
|
||||
在本文中,我们将看一些 TensorFlow 的例子,并从中感受到在定义<ruby>张量<rt>tensor</rt></ruby>和使用张量做数学计算方面有多么容易,我还会举些别的机器学习相关的例子。
|
||||
|
||||
## TensorFlow 是什么?
|
||||
### TensorFlow 是什么?
|
||||
|
||||
TensorFlow 是 Google 为了解决复杂计算耗时过久的问题而开发的一个库。
|
||||
TensorFlow 是 Google 为了解决复杂的数学计算耗时过久的问题而开发的一个库。
|
||||
|
||||
事实上,TensorFlow 能干许多事。比如:
|
||||
|
||||
* 解复杂数学表达式
|
||||
* 机器学习技术。你往其中输入一组数据样本用以训练,接着给出另一组数据样本用以预测基于训练的数据的结果。这就是人工智能了!
|
||||
* 支持 GPU 。你可以使用 GPU (图像处理单元)替代 CPU 以更快的运算。 TensorFlow 有两个版本: CPU 版本和 GPU 版本。
|
||||
|
||||
* 求解复杂数学表达式
|
||||
* 机器学习技术。你往其中输入一组数据样本用以训练,接着给出另一组数据样本基于训练的数据而预测结果。这就是人工智能了!
|
||||
* 支持 GPU 。你可以使用 GPU(图像处理单元)替代 CPU 以更快的运算。TensorFlow 有两个版本: CPU 版本和 GPU 版本。
|
||||
|
||||
开始写例子前,需要了解一些基本知识。
|
||||
|
||||
## 什么是张量?
|
||||
### 什么是张量?
|
||||
|
||||
张量是 TensorFlow 使用的主要的数据块,它很像 TensorFlow 用来处理数据的变量。张量拥有维度和类型的属性。
|
||||
<ruby>张量<rt>tensor</rt></ruby>是 TensorFlow 使用的主要的数据块,它类似于变量,TensorFlow 使用它来处理数据。张量拥有维度和类型的属性。
|
||||
|
||||
维度指张量的行和列数,读到后面你就知道了,可以定义一维张量、二维张量和三维张量。
|
||||
维度指张量的行和列数,读到后面你就知道了,我们可以定义一维张量、二维张量和三维张量。
|
||||
|
||||
类型指张量元素的数据类型。
|
||||
|
||||
## 定义一维张量
|
||||
### 定义一维张量
|
||||
|
||||
可以这样来定义一个张量:创建一个 NumPy (译者注:NumPy 系统是 Python 的一种开源数字扩展,包含一个强大的 N 维数组对象 Array,用来存储和处理大型矩阵 )或者一个 [Python list][1] ,然后使用 tf_convert_to_tensor 函数将其转化成张量。
|
||||
可以这样来定义一个张量:创建一个 NumPy 数组(LCTT 译注:NumPy 系统是 Python 的一种开源数字扩展,包含一个强大的 N 维数组对象 Array,用来存储和处理大型矩阵 )或者一个 [Python 列表][1] ,然后使用 `tf_convert_to_tensor` 函数将其转化成张量。
|
||||
|
||||
可以像下面这样,使用 NumPy 创建一个数组:
|
||||
|
||||
```
|
||||
import numpy as np arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
```
|
||||
|
||||
运行结果显示了这个数组的维度和形状。
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
print(arr)
|
||||
|
||||
print (arr.ndim)
|
||||
|
||||
print (arr.shape)
|
||||
|
||||
print (arr.dtype)
|
||||
|
||||
print(arr.ndim)
|
||||
print(arr.shape)
|
||||
print(arr.dtype)
|
||||
```
|
||||
|
||||
它和 Python list 很像,但是在这里,元素之间没有逗号。
|
||||
它和 Python 列表很像,但是在这里,元素之间没有逗号。
|
||||
|
||||
现在使用 `tf_convert_to_tensor` 函数把这个数组转化为张量。
|
||||
|
||||
现在使用 tf_convert_to_tensor 函数把这个数组转化为张量。
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
tensor = tf.convert_to_tensor(arr,tf.float64)
|
||||
|
||||
print(tensor)
|
||||
|
||||
```
|
||||
|
||||
这次的运行结果显示了张量具体的含义,但是不会展示出张量元素。
|
||||
|
||||
要想看到张量元素,需要像下面这样,运行一个会话:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
tensor = tf.convert_to_tensor(arr,tf.float64)
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
print(sess.run(tensor))
|
||||
|
||||
print(sess.run(tensor[1]))
|
||||
|
||||
```
|
||||
|
||||
## 定义二维张量
|
||||
### 定义二维张量
|
||||
|
||||
定义二维张量,其方法和定义一维张量是一样的,但要这样来定义数组:
|
||||
|
||||
@ -99,227 +82,170 @@ arr = np.array([(1, 5.5, 3, 15, 20),(10, 20, 30, 40, 50), (60, 70, 80, 90, 100)]
|
||||
```
|
||||
|
||||
接着转化为张量:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr = np.array([(1, 5.5, 3, 15, 20),(10, 20, 30, 40, 50), (60, 70, 80, 90, 100)])
|
||||
|
||||
tensor = tf.convert_to_tensor(arr)
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
print(sess.run(tensor))
|
||||
|
||||
```
|
||||
|
||||
现在你应该知道怎么定义张量了,那么,怎么在张量之间跑数学运算呢?
|
||||
|
||||
## 在张量上进行数学运算
|
||||
### 在张量上进行数学运算
|
||||
|
||||
假设我们有以下两个数组:
|
||||
|
||||
```
|
||||
arr1 = np.array([(1,2,3),(4,5,6)])
|
||||
|
||||
arr2 = np.array([(7,8,9),(10,11,12)])
|
||||
|
||||
```
|
||||
|
||||
利用 TenserFlow ,你能做许多数学运算。现在我们需要对这两个数组求和。
|
||||
|
||||
使用加法函数来求和:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr1 = np.array([(1,2,3),(4,5,6)])
|
||||
|
||||
arr2 = np.array([(7,8,9),(10,11,12)])
|
||||
|
||||
arr3 = tf.add(arr1,arr2)
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
tensor = sess.run(arr3)
|
||||
|
||||
print(tensor)
|
||||
|
||||
```
|
||||
|
||||
也可以把数组相乘:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr1 = np.array([(1,2,3),(4,5,6)])
|
||||
|
||||
arr2 = np.array([(7,8,9),(10,11,12)])
|
||||
|
||||
arr3 = tf.multiply(arr1,arr2)
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
tensor = sess.run(arr3)
|
||||
|
||||
print(tensor)
|
||||
|
||||
```
|
||||
|
||||
现在你知道了吧。
|
||||
|
||||
## 三维张量
|
||||
|
||||
我们已经知道了怎么使用一维张量和二维张量,现在,来看一下三维张量吧,不过这次我们不用数字了,而是用一张 RGB 图片。在这张图片上,每一块像素都由 x,y,z 组合表示。
|
||||
我们已经知道了怎么使用一维张量和二维张量,现在,来看一下三维张量吧,不过这次我们不用数字了,而是用一张 RGB 图片。在这张图片上,每一块像素都由 x、y、z 组合表示。
|
||||
|
||||
这些组合形成了图片的宽度、高度以及颜色深度。
|
||||
|
||||
首先使用 matplotlib 库导入一张图片。如果你的系统中没有 matplotlib ,可以 [使用pip][2]来安装它。
|
||||
首先使用 matplotlib 库导入一张图片。如果你的系统中没有 matplotlib ,可以 [使用 pip][2]来安装它。
|
||||
|
||||
将图片放在 Python 文件的同一目录下,接着使用 matplotlib 导入图片:
|
||||
|
||||
```
|
||||
import matplotlib.image as img
|
||||
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
print(myimage.ndim)
|
||||
|
||||
print(myimage.shape)
|
||||
|
||||
```
|
||||
|
||||
从运行结果中,你应该能看到,这张三维图片的宽为 150 、高为 150 、颜色深度为 3 。
|
||||
|
||||
你还可以查看这张图片:
|
||||
|
||||
```
|
||||
import matplotlib.image as img
|
||||
|
||||
import matplotlib.pyplot as plot
|
||||
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
plot.imshow(myimage)
|
||||
|
||||
plot.show()
|
||||
|
||||
```
|
||||
|
||||
真酷!
|
||||
|
||||
那怎么使用 TensorFlow 处理图片呢?超级容易。
|
||||
|
||||
## 使用 TensorFlow 生成或裁剪图片
|
||||
### 使用 TensorFlow 生成或裁剪图片
|
||||
|
||||
首先,向一个占位符赋值:
|
||||
|
||||
```
|
||||
myimage = tf.placeholder("int32",[None,None,3])
|
||||
|
||||
```
|
||||
|
||||
使用裁剪操作来裁剪图像:
|
||||
|
||||
```
|
||||
cropped = tf.slice(myimage,[10,0,0],[16,-1,-1])
|
||||
|
||||
```
|
||||
|
||||
最后,运行这个会话:
|
||||
|
||||
```
|
||||
result = sess.run(cropped, feed\_dict={slice: myimage})
|
||||
|
||||
```
|
||||
|
||||
然后,你就能看到使用 matplotlib 处理过的图像了。
|
||||
|
||||
这是整段代码:
|
||||
|
||||
```
|
||||
import tensorflow as tf
|
||||
|
||||
import matplotlib.image as img
|
||||
|
||||
import matplotlib.pyplot as plot
|
||||
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
slice = tf.placeholder("int32",[None,None,3])
|
||||
|
||||
cropped = tf.slice(myimage,[10,0,0],[16,-1,-1])
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
result = sess.run(cropped, feed_dict={slice: myimage})
|
||||
|
||||
plot.imshow(result)
|
||||
|
||||
plot.show()
|
||||
|
||||
```
|
||||
|
||||
是不是很神奇?
|
||||
|
||||
## 使用 TensorFlow 改变图像
|
||||
### 使用 TensorFlow 改变图像
|
||||
|
||||
在本例中,我们会使用 TensorFlow 做一下简单的转换。
|
||||
|
||||
首先,指定待处理的图像,并初始化 TensorFlow 变量值:
|
||||
|
||||
```
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
image = tf.Variable(myimage,name='image')
|
||||
|
||||
vars = tf.global_variables_initializer()
|
||||
|
||||
```
|
||||
|
||||
然后调用 transpose 函数转换,这个函数用来翻转输入网格的 0 轴和 1 轴。
|
||||
|
||||
```
|
||||
sess = tf.Session()
|
||||
|
||||
flipped = tf.transpose(image, perm=[1,0,2])
|
||||
|
||||
sess.run(vars)
|
||||
|
||||
result=sess.run(flipped)
|
||||
|
||||
```
|
||||
|
||||
接着你就能看到使用 matplotlib 处理过的图像了。
|
||||
|
||||
```
|
||||
import tensorflow as tf
|
||||
|
||||
import matplotlib.image as img
|
||||
|
||||
import matplotlib.pyplot as plot
|
||||
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
image = tf.Variable(myimage,name='image')
|
||||
|
||||
vars = tf.global_variables_initializer()
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
flipped = tf.transpose(image, perm=[1,0,2])
|
||||
|
||||
sess.run(vars)
|
||||
|
||||
result=sess.run(flipped)
|
||||
|
||||
plot.imshow(result)
|
||||
|
||||
plot.show()
|
||||
|
||||
```
|
||||
|
||||
以上例子都向你表明了使用 TensorFlow 有多么容易。
|
||||
@ -330,7 +256,7 @@ via: https://www.codementor.io/likegeeks/define-and-use-tensors-using-simple-ten
|
||||
|
||||
作者:[LikeGeeks][a]
|
||||
译者:[ghsgz](https://github.com/ghsgz)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,74 +0,0 @@
|
||||
translating by wyxplus
|
||||
How to price cryptocurrencies
|
||||
======
|
||||
|
||||

|
||||
|
||||
Predicting cryptocurrency prices is a fool's game, yet this fool is about to try. The drivers of a single cryptocurrency's value are currently too varied and vague to make assessments based on any one point. News is trending up on Bitcoin? Maybe there's a hack or an API failure that is driving it down at the same time. Ethereum looking sluggish? Who knows: Maybe someone will build a new smarter DAO tomorrow that will draw in the big spenders.
|
||||
|
||||
So how do you invest? Or, more correctly, on which currency should you bet?
|
||||
|
||||
The key to understanding what to buy or sell and when to hold is to use the tools associated with assessing the value of open-source projects. This has been said again and again, but to understand the current crypto boom you have to go back to the quiet rise of Linux.
|
||||
|
||||
Linux appeared on most radars during the dot-com bubble. At that time, if you wanted to set up a web server, you had to physically ship a Windows server or Sun Sparc Station to a server farm where it would do the hard work of delivering Pets.com HTML. At the same time, Linux, like a freight train running on a parallel path to Microsoft and Sun, would consistently allow developers to build one-off projects very quickly and easily using an OS and toolset that were improving daily. In comparison, then, the massive hardware and software expenditures associated with the status quo solution providers were deeply inefficient, and very quickly all of the tech giants that made their money on software now made their money on services or, like Sun, folded.
|
||||
|
||||
From the acorn of Linux an open-source forest bloomed. But there was one clear problem: You couldn't make money from open source. You could consult and you could sell products that used open-source components, but early builders built primarily for the betterment of humanity and not the betterment of their bank accounts.
|
||||
|
||||
Cryptocurrencies have followed the Linux model almost exactly, but cryptocurrencies have cash value. Therefore, when you're working on a crypto project you're not doing it for the common good or for the joy of writing free software. You're writing it with the expectation of a big payout. This, therefore, clouds the value judgements of many programmers. The same folks that brought you Python, PHP, Django and Node.js are back… and now they're programming money.
|
||||
|
||||
### Check the codebase
|
||||
|
||||
This year will be the year of great reckoning in the token sale and cryptocurrency space. While many companies have been able to get away with poor or unusable codebases, I doubt developers will let future companies get away with so much smoke and mirrors. It's safe to say we can [expect posts like this one detailing Storj's anemic codebase to become the norm][1] and, more importantly, that these commentaries will sink many so-called ICOs. Though massive, the money trough that is flowing from ICO to ICO is finite and at some point there will be greater scrutiny paid to incomplete work.
|
||||
|
||||
What does this mean? It means to understand cryptocurrency you have to treat it like a startup. Does it have a good team? Does it have a good product? Does the product work? Would someone want to use it? It's far too early to assess the value of cryptocurrency as a whole, but if we assume that tokens or coins will become the way computers pay each other in the future, this lets us hand wave away a lot of doubt. After all, not many people knew in 2000 that Apache was going to beat nearly every other web server in a crowded market or that Ubuntu instances would be so common that you'd spin them up and destroy them in an instant.
|
||||
|
||||
The key to understanding cryptocurrency pricing is to ignore the froth, hype and FUD and instead focus on true utility. Do you think that some day your phone will pay another phone for, say, an in-game perk? Do you expect the credit card system to fold in the face of an Internet of Value? Do you expect that one day you'll move through life splashing out small bits of value in order to make yourself more comfortable? Then by all means, buy and hold or speculate on things that you think will make your life better. If you don't expect the Internet of Value to improve your life the way the TCP/IP internet did (or you do not understand enough to hold an opinion), then you're probably not cut out for this. NASDAQ is always open, at least during banker's hours.
|
||||
|
||||
Still will us? Good, here are my predictions.
|
||||
|
||||
### The rundown
|
||||
|
||||
Here is my assessment of what you should look at when considering an "investment" in cryptocurrencies. There are a number of caveats we must address before we begin:
|
||||
|
||||
* Crypto is not a monetary investment in a real currency, but an investment in a pie-in-the-sky technofuture. That's right: When you buy crypto you're basically assuming that we'll all be on the deck of the Starship Enterprise exchanging them like Galactic Credits one day. This is the only inevitable future for crypto bulls. While you can force crypto into various economic models and hope for the best, the entire platform is techno-utopianist and assumes all sorts of exciting and unlikely things will come to pass in the next few years. If you have spare cash lying around and you like Star Wars, then you're golden. If you bought bitcoin on a credit card because your cousin told you to, then you're probably going to have a bad time.
|
||||
* Don't trust anyone. There is no guarantee and, in addition to offering the disclaimer that this is not investment advice and that this is in no way an endorsement of any particular cryptocurrency or even the concept in general, we must understand that everything I write here could be wrong. In fact, everything ever written about crypto could be wrong, and anyone who is trying to sell you a token with exciting upside is almost certainly wrong. In short, everyone is wrong and everyone is out to get you, so be very, very careful.
|
||||
* You might as well hold. If you bought when BTC was $18,000 you'd best just hold on. Right now you're in Pascal's Wager territory. Yes, maybe you're angry at crypto for screwing you, but maybe you were just stupid and you got in too high and now you might as well keep believing because nothing is certain, or you can admit that you were a bit overeager and now you're being punished for it but that there is some sort of bitcoin god out there watching over you. Ultimately you need to take a deep breath, agree that all of this is pretty freaking weird, and hold on.
|
||||
|
||||
|
||||
|
||||
Now on with the assessments.
|
||||
|
||||
**Bitcoin** - Expect a rise over the next year that will surpass the current low. Also expect [bumps as the SEC and other federal agencies][2] around the world begin regulating the buying and selling of cryptocurrencies in very real ways. Now that banks are in on the joke they're going to want to reduce risk. Therefore, the bitcoin will become digital gold, a staid, boring and volatility proof safe haven for speculators. Although all but unusable as a real currency, it's good enough for what we need it to do and we also can expect quantum computing hardware to change the face of the oldest and most familiar cryptocurrency.
|
||||
|
||||
**Ethereum** - Ethereum could sustain another few thousand dollars on its price as long as Vitalik Buterin, the creator, doesn't throw too much cold water on it. Like a remorseful Victor Frankenstein, Buterin tends to make amazing things and then denigrate them online, a sort of self-flagellation that is actually quite useful in a space full of froth and outright lies. Ethereum is the closest we've come to a useful cryptocurrency, but it is still the Raspberry Pi of distributed computing -- it's a useful and clever hack that makes it easy to experiment but no one has quite replaced the old systems with new distributed data stores or applications. In short, it's a really exciting technology, but nobody knows what to do with it.
|
||||
|
||||
![][3]
|
||||
|
||||
Where will the price go? It will hover around $1,000 and possibly go as high as $1,500 this year, but this is a principled tech project and not a store of value.
|
||||
|
||||
**Altcoins** - One of the signs of a bubble is when average people make statements like "I couldn't afford a Bitcoin so I bought a Litecoin." This is exactly what I've heard multiple times from multiple people and it's akin to saying "I couldn't buy hamburger so I bought a pound of sawdust instead. I think the kids will eat it, right?" Play at your own risk. Altcoins are a very useful low-risk play for many, and if you create an algorithm -- say to sell when the asset hits a certain level -- then you could make a nice profit. Further, most altcoins will not disappear overnight. I would honestly recommend playing with Ethereum instead of altcoins, but if you're dead set on it, then by all means, enjoy.
|
||||
|
||||
**Tokens** - This is where cryptocurrency gets interesting. Tokens require research, education and a deep understanding of technology to truly assess. Many of the tokens I've seen are true crapshoots and are used primarily as pump and dump vehicles. I won't name names, but the rule of thumb is that if you're buying a token on an open market then you've probably already missed out. The value of the token sale as of January 2018 is to allow crypto whales to turn a few cent per token investment into a 100X return. While many founders talk about the magic of their product and the power of their team, token sales are quite simply vehicles to turn 4 cents into 20 cents into a dollar. Multiply that by millions of tokens and you see the draw.
|
||||
|
||||
The answer is simple: find a few projects you like and lurk in their message boards. Assess if the team is competent and figure out how to get in very, very early. Also expect your money to disappear into a rat hole in a few months or years. There are no sure things, and tokens are far too bleeding-edge a technology to assess sanely.
|
||||
|
||||
You are reading this post because you are looking to maintain confirmation bias in a confusing space. That's fine. I've spoken to enough crypto-heads to know that nobody knows anything right now and that collusion and dirty dealings are the rule of the day. Therefore, it's up to folks like us to slowly buy surely begin to understand just what's going on and, perhaps, profit from it. At the very least we'll all get a new Linux of Value when we're all done.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2018/01/22/how-to-price-cryptocurrencies/
|
||||
|
||||
作者:[John Biggs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/john-biggs/
|
||||
[1]:https://shitcoin.com/storj-not-a-dropbox-killer-1a9f27983d70
|
||||
[2]:http://www.businessinsider.com/bitcoin-price-cryptocurrency-warning-from-sec-cftc-2018-1
|
||||
[3]:https://tctechcrunch2011.files.wordpress.com/2018/01/vitalik-twitter-1312.png?w=525&h=615
|
||||
[4]:https://unsplash.com/photos/pElSkGRA2NU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/cash?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,149 @@
|
||||
How writing can change your career for the better, even if you don't identify as a writer
|
||||
======
|
||||
Have you read Marie Kondo's book [The Life-Changing Magic of Tidying Up][1]? Or did you, like me, buy it and read a little bit and then add it to the pile of clutter next to your bed?
|
||||
|
||||
Early in the book, Kondo talks about keeping possessions that "spark joy." In this article, I'll examine ways writing about what we and other people are doing in the open source world can "spark joy," or at least how writing can improve your career in unexpected ways.
|
||||
|
||||
Because I'm a community manager and editor on Opensource.com, you might be thinking, "She just wants us to [write for Opensource.com][2]." And that is true. But everything I will tell you about why you should write is true, even if you never send a story in to Opensource.com. Writing can change your career for the better, even if you don't identify as a writer. Let me explain.
|
||||
|
||||
### How I started writing
|
||||
|
||||
Early in the first decade of my career, I transitioned from a customer service-related role at a tech publishing company into an editing role on Sys Admin Magazine. I was plugging along, happily laying low in my career, and then that all changed when I started writing about open source technologies and communities, and the people in them. But I did _not_ start writing voluntarily. The tl;dr: of it is that my colleagues at Linux New Media eventually talked me into launching our first blog on the [Linux Pro Magazine][3] site. And as it turns out, it was one of the best career decisions I've ever made. I would not be working on Opensource.com today had I not started writing about what other people in open source were doing all those years ago.
|
||||
|
||||
When I first started writing, my goal was to raise awareness of the company I worked for and our publications, while also helping raise the visibility of women in tech. But soon after I started writing, I began seeing unexpected results.
|
||||
|
||||
#### My network started growing
|
||||
|
||||
When I wrote about a person, an organization, or a project, I got their attention. Suddenly the people I wrote about knew who I was. And because I was sharing knowledge—that is to say, I wasn't being a critic—I'd generally become an ally, and in many cases, a friend. I had a platform and an audience, and I was sharing them with other people in open source.
|
||||
|
||||
#### I was learning
|
||||
|
||||
In addition to promoting our website and magazine and growing my network, the research and fact-checking I did when writing articles helped me become more knowledgeable in my field and improve my tech chops.
|
||||
|
||||
#### I started meeting more people IRL
|
||||
|
||||
When I went to conferences, I found that my blog posts helped me meet people. I introduced myself to people I'd written about or learned about during my research, and I met new people to interview. People started knowing who I was because they'd read my articles. Sometimes people were even excited to meet me because I'd highlighted them, their projects, or someone or something they were interested in. I had no idea writing could be so exciting and interesting away from the keyboard.
|
||||
|
||||
#### My conference talks improved
|
||||
|
||||
I started speaking at events about a year after launching my blog. A few years later, I started writing articles based on my talks prior to speaking at events. The process of writing the articles helps me organize my talks and slides, and it was a great way to provide "notes" for conference attendees, while sharing the topic with a larger international audience that wasn't at the event in person.
|
||||
|
||||
### What should you write about?
|
||||
|
||||
Maybe you're interested in writing, but you struggle with what to write about. You should write about two things: what you know, and what you don't know.
|
||||
|
||||
#### Write about what you know
|
||||
|
||||
Writing about what you know can be relatively easy. For example, a script you wrote to help automate part of your daily tasks might be something you don't give any thought to, but it could make for a really exciting article for someone who hates doing that same task every day. That could be a relatively quick, short, and easy article for you to write, and you might not even think about writing it. But it could be a great contribution to the open source community.
|
||||
|
||||
#### Write about what you don't know
|
||||
|
||||
Writing about what you don't know can be much harder and more time consuming, but also much more fulfilling and help your career. I've found that writing about what I don't know helps me learn, because I have to research it and understand it well enough to explain it.
|
||||
|
||||
> "When I write about a technical topic, I usually learn a lot more about it. I want to make sure my article is as good as it can be. So even if I'm writing about something I know well, I'll research the topic a bit more so I can make sure to get everything right." ~Jim Hall, FreeDOS project leader
|
||||
|
||||
For example, I wanted to learn about machine learning, and I thought narrowing down the topic would help me get started. My team mate Jason Baker suggested that I write an article on the [Top 3 machine learning libraries for Python][4], which gave me a focus for research.
|
||||
|
||||
The process of researching that article inspired another article, [3 cool machine learning projects using TensorFlow and the Raspberry Pi][5]. That article was also one of our most popular last year. I'm not an _expert_ on machine learning now, but researching the topic with writing an article in mind allowed me to give myself a crash course in the topic.
|
||||
|
||||
### Why people in tech write
|
||||
|
||||
Now let's look at a few benefits of writing that other people in tech have found. I emailed the Opensource.com writers' list and asked, and here's what writers told me.
|
||||
|
||||
#### Grow your network or your project community
|
||||
|
||||
Xavier Ho wrote for us for the first time last year ("[A programmer's cleaning guide for messy sensor data][6]"). He says: "I've been getting Twitter mentions from all over the world, including Spain, US, Australia, Indonesia, the UK, and other European countries. It shows the article is making some impact... This is the kind of reach I normally don't have. Hope it's really helping someone doing similar work!"
|
||||
|
||||
#### Help people
|
||||
|
||||
Writing about what other people are working on is a great way to help your fellow community members. Antoine Thomas, who wrote "[Linux helped me grow as a musician][7]", says, "I began to use open source years ago, by reading tutorials and documentation. That's why now I share my tips and tricks, experience or knowledge. It helped me to get started, so I feel that it's my turn to help others to get started too."
|
||||
|
||||
#### Give back to the community
|
||||
|
||||
[Jim Hall][8], who started the [FreeDOS project][9], says, "I like to write ... because I like to support the open source community by sharing something neat. I don't have time to be a program maintainer anymore, but I still like to do interesting stuff. So when something cool comes along, I like to write about it and share it."
|
||||
|
||||
#### Highlight your community
|
||||
|
||||
Emilio Velis wrote an article, "[Open hardware groups spread across the globe][10]", about projects in Central and South America. He explains, "I like writing about specific aspects of the open culture that are usually enclosed in my region (Latin America). I feel as if smaller communities and their ideas are hidden from the mainstream, so I think that creating this sense of broadness in participation is what makes some other cultures as valuable."
|
||||
|
||||
#### Gain confidence
|
||||
|
||||
[Don Watkins][11] is one of our regular writers and a [community moderator][12]. He says, "When I first started writing I thought I was an impostor, later I realized that many people feel that way. Writing and contributing to Opensource.com has been therapeutic, too, as it contributed to my self esteem and helped me to overcome feelings of inadequacy. … Writing has given me a renewed sense of purpose and empowered me to help others to write and/or see the valuable contributions that they too can make if they're willing to look at themselves in a different light. Writing has kept me younger and more open to new ideas."
|
||||
|
||||
#### Get feedback
|
||||
|
||||
One of our writers described writing as a feedback loop. He said that he started writing as a way to give back to the community, but what he found was that community responses give back to him.
|
||||
|
||||
Another writer, [Stuart Keroff][13] says, "Writing for Opensource.com about the program I run at school gave me valuable feedback, encouragement, and support that I would not have had otherwise. Thousands upon thousands of people heard about the Asian Penguins because of the articles I wrote for the website."
|
||||
|
||||
#### Exhibit expertise
|
||||
|
||||
Writing can help you show that you've got expertise in a subject, and having writing samples on well-known websites can help you move toward better pay at your current job, get a new role at a different organization, or start bringing in writing income.
|
||||
|
||||
[Jeff Macharyas][14] explains, "There are several ways I've benefitted from writing for Opensource.com. One, is the credibility I can add to my social media sites, resumes, bios, etc., just by saying 'I am a contributing writer to Opensource.com.' … I am hoping that I will be able to line up some freelance writing assignments, using my Opensource.com articles as examples, in the future."
|
||||
|
||||
### Where should you publish your articles?
|
||||
|
||||
That depends. Why are you writing?
|
||||
|
||||
You can always post on your personal blog, but if you don't already have a lot of readers, your article might get lost in the noise online.
|
||||
|
||||
Your project or company blog is a good option—again, you'll have to think about who will find it. How big is your company's reach? Or will you only get the attention of people who already give you their attention?
|
||||
|
||||
Are you trying to reach a new audience? A bigger audience? That's where sites like Opensource.com can help. We attract more than a million page views a month, and more than 700,000 unique visitors. Plus you'll work with editors who will polish and help promote your article.
|
||||
|
||||
We aren't the only site interested in your story. What are your favorite sites to read? They might want to help you share your story, and it's ok to pitch to multiple publications. Just be transparent about whether your article has been shared on other sites when working with editors. Occasionally, editors can even help you modify articles so that you can publish variations on multiple sites.
|
||||
|
||||
#### Do you want to get rich by writing? (Don't count on it.)
|
||||
|
||||
If your goal is to make money by writing, pitch your article to publications that have author budgets. There aren't many of them, the budgets don't tend to be huge, and you will be competing with experienced professional tech journalists who write seven days a week, 365 days a year, with large social media followings and networks. I'm not saying it can't be done—I've done it—but I am saying don't expect it to be easy or lucrative. It's not. (And frankly, I've found that nothing kills my desire to write much like having to write if I want to eat...)
|
||||
|
||||
A couple of people have asked me whether Opensource.com pays for content, or whether I'm asking someone to write "for exposure." Opensource.com does not have an author budget, but I won't tell you to write "for exposure," either. You should write because it meets a need.
|
||||
|
||||
If you already have a platform that meets your needs, and you don't need editing or social media and syndication help: Congratulations! You are privileged.
|
||||
|
||||
### Spark joy!
|
||||
|
||||
Most people don't know they have a story to tell, so I'm here to tell you that you probably do, and my team can help, if you just submit a proposal.
|
||||
|
||||
Most people—myself included—could use help from other people. Sites like Opensource.com offer one way to get editing and social media services at no cost to the writer, which can be hugely valuable to someone starting out in their career, someone who isn't a native English speaker, someone who wants help with their project or organization, and so on.
|
||||
|
||||
If you don't already write, I hope this article helps encourage you to get started. Or, maybe you already write. In that case, I hope this article makes you think about friends, colleagues, or people in your network who have great stories and experiences to share. I'd love to help you help them get started.
|
||||
|
||||
I'll conclude with feedback I got from a recent writer, [Mario Corchero][15], a Senior Software Developer at Bloomberg. He says, "I wrote for Opensource because you told me to :)" (For the record, I "invited" him to write for our [PyCon speaker series][16] last year.) He added, "And I am extremely happy about it—not only did it help me at my workplace by gaining visibility, but I absolutely loved it! The article appeared in multiple email chains about Python and was really well received, so I am now looking to publish the second :)" Then he [wrote for us][17] again.
|
||||
|
||||
I hope you find writing to be as fulfilling as we do.
|
||||
|
||||
You can connect with Opensource.com editors, community moderators, and writers in our Freenode [IRC][18] channel #opensource.com, and you can reach me and the Opensource.com team by email at [open@opensource.com][19].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/career-changing-magic-writing
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:http://tidyingup.com/books/the-life-changing-magic-of-tidying-up-hc
|
||||
[2]:https://opensource.com/how-submit-article
|
||||
[3]:http://linuxpromagazine.com/
|
||||
[4]:https://opensource.com/article/17/2/3-top-machine-learning-libraries-python
|
||||
[5]:https://opensource.com/article/17/2/machine-learning-projects-tensorflow-raspberry-pi
|
||||
[6]:https://opensource.com/article/17/9/messy-sensor-data
|
||||
[7]:https://opensource.com/life/16/9/my-linux-story-musician
|
||||
[8]:https://opensource.com/users/jim-hall
|
||||
[9]:http://www.freedos.org/
|
||||
[10]:https://opensource.com/article/17/6/open-hardware-latin-america
|
||||
[11]:https://opensource.com/users/don-watkins
|
||||
[12]:https://opensource.com/community-moderator-program
|
||||
[13]:https://opensource.com/education/15/3/asian-penguins-Linux-middle-school-club
|
||||
[14]:https://opensource.com/users/jeffmacharyas
|
||||
[15]:https://opensource.com/article/17/5/understanding-datetime-python-primer
|
||||
[16]:https://opensource.com/tags/pycon
|
||||
[17]:https://opensource.com/article/17/9/python-logging
|
||||
[18]:https://opensource.com/article/16/6/getting-started-irc
|
||||
[19]:mailto:open@opensource.com
|
||||
@ -0,0 +1,47 @@
|
||||
Why an involved user community makes for better software
|
||||
======
|
||||

|
||||
|
||||
Imagine releasing a major new infrastructure service based on open source software only to discover that the product you deployed had evolved so quickly that the documentation for the version you released is no longer available. At Bloomberg, we experienced this problem firsthand in our deployment of OpenStack. In late 2016, we spent six months testing and rolling out [Liberty][1] on our OpenStack environment. By that time, Liberty was about a year old, or two versions behind the latest build.
|
||||
|
||||
As our users started taking advantage of its new functionality, we found ourselves unable to solve a few tricky problems and to answer some detailed questions about its API. When we went looking for Liberty's documentation, it was nowhere to be found on the OpenStack website. Liberty, it turned out, had been labeled "end of life" and was no longer supported by the OpenStack developer community.
|
||||
|
||||
The disappearance wasn't intentional, rather the result of a development community that had not anticipated the real-world needs of users. The documentation was stored in the source branch along with the source code, and, as Liberty was superseded by newer versions, it had been deleted. Worse, in the intervening months, the documentation for the newer versions had been completely restructured, and there was no way to easily rebuild it in a useful form. And believe me, we tried.
|
||||
|
||||
The disappearance wasn't intentional, rather the result of a development community that had not anticipated the real-world needs of users. ]After consulting other users and our vendor, we found that OpenStack's development cadence of two releases per year had created some unintended, yet deeply frustrating, consequences. Older releases that were typically still widely in use were being superseded and effectively killed for the purposes of support.
|
||||
|
||||
Eventually, conversations took place between OpenStack users and developers that resulted in changes. Documentation was moved out of the source branch, and users can now build documentation for whatever version they're using—more or less indefinitely. The problem was solved. (I'm especially indebted to my colleague [Chris Morgan][2], who was knee-deep in this effort and first wrote about it in detail for the [OpenStack Superuser blog][3].)
|
||||
|
||||
Many other enterprise users were in the same boat as Bloomberg—running older versions of OpenStack that are three or four versions behind the latest build. There's a good reason for that: On average it takes a reasonably large enterprise about six months to qualify, test, and deploy a new version of OpenStack. And, from my experience, this is generally true of most open source infrastructure projects.
|
||||
|
||||
For most of the past decade, companies like Bloomberg that adopted open source software relied on distribution vendors to incorporate, test, verify, and support much of it. These vendors provide long-term support (LTS) releases, which enable enterprise users to plan for upgrades on a two- or three-year cycle, knowing they'll still have support for a year or two, even if their deployment schedule slips a bit (as they often do). In the past few years, though, infrastructure software has advanced so rapidly that even the distribution vendors struggle to keep up. And customers of those vendors are yet another step removed, so many are choosing to deploy this type of software without vendor support.
|
||||
|
||||
Losing vendor support also usually means there are no LTS releases; OpenStack, Kubernetes, and Prometheus, and many more, do not yet provide LTS releases of their own. As a result, I'd argue that healthy interaction between the development and user community should be high on the list of considerations for adoption of any open source infrastructure. Do the developers building the software pay attention to the needs—and frustrations—of the people who deploy it and make it useful for their enterprise?
|
||||
|
||||
There is a solid model for how this should happen. We recently joined the [Cloud Native Computing Foundation][4], part of The Linux Foundation. It has a formal [end-user community][5], whose members include organizations just like us: enterprises that are trying to make open source software useful to their internal customers. Corporate members also get a chance to have their voices heard as they vote to select a representative to serve on the CNCF [Technical Oversight Committee][6]. Similarly, in the OpenStack community, Bloomberg is involved in the semi-annual Operators Meetups, where companies who deploy and support OpenStack for their own users get together to discuss their challenges and provide guidance to the OpenStack developer community.
|
||||
|
||||
The past few years have been great for open source infrastructure. If you're working for a large enterprise, the opportunity to deploy open source projects like the ones mentioned above has made your company more productive and more agile.
|
||||
|
||||
As large companies like ours begin to consume more open source software to meet their infrastructure needs, they're going to be looking at a long list of considerations before deciding what to use: license compatibility, out-of-pocket costs, and the health of the development community are just a few examples. As a result of our experiences, we'll add the presence of a vibrant and engaged end-user community to the list.
|
||||
|
||||
Increased reliance on open source infrastructure projects has also highlighted a key problem: People in the development community have little experience deploying the software they work on into production environments or supporting the people who use it to get things done on a daily basis. The fast pace of updates to these projects has created some unexpected problems for the people who deploy and use them. There are numerous examples I can cite where open source projects are updated so frequently that new versions will, usually unintentionally, break backwards compatibility.
|
||||
|
||||
As open source increasingly becomes foundational to the operation of so many enterprises, this cannot be allowed to happen, and members of the user community should assert themselves accordingly and press for the creation of formal representation. In the end, the software can only be better.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/important-conversation
|
||||
|
||||
作者:[Kevin P.Fleming][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kpfleming
|
||||
[1]:https://releases.openstack.org/liberty/
|
||||
[2]:https://www.linkedin.com/in/mihalis68/
|
||||
[3]:http://superuser.openstack.org/articles/openstack-at-bloomberg/
|
||||
[4]:https://www.cncf.io/
|
||||
[5]:https://www.cncf.io/people/end-user-community/
|
||||
[6]:https://www.cncf.io/people/technical-oversight-committee/
|
||||
@ -0,0 +1,83 @@
|
||||
Linux ldd Command Explained with Examples
|
||||
=========================================
|
||||
|
||||
If your work involves deep knowledge of executables and shared libraries in Linux, there are several command line tools that you should be aware of. One of those is ldd, which you can use to access shared object dependencies. In this tutorial, we will discuss the basics of this utility using some easy to understand examples.
|
||||
|
||||
Please note that all examples mentioned here have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
### Linux ldd command
|
||||
|
||||
As already mentioned in the beginning, the ldd command prints shared object dependencies. Following is the command's syntax:
|
||||
|
||||
`ldd [option]... file...`
|
||||
|
||||
And here's how the tool's man page explains it:
|
||||
|
||||
```
|
||||
ldd prints the shared objects (shared libraries) required by each program or shared object
|
||||
|
||||
specified on the command line.
|
||||
|
||||
```
|
||||
|
||||
The following Q&A-styled examples should give you a better idea on how ldd works.
|
||||
|
||||
### Q1. How to use ldd?
|
||||
|
||||
Basic usage of ldd is fairly simple - just run the 'ldd' command along with an executable or shared object file name as input.
|
||||
|
||||
`ldd [object-name]`
|
||||
|
||||
For example:
|
||||
|
||||
`ldd test`
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-basic.png)
|
||||
|
||||
So you can see all shared library dependencies have been produced in output.
|
||||
|
||||
### Q2. How to make ldd produce detailed information in output?
|
||||
|
||||
If you want ldd to produce detailed information, including symbol versioning data, you can use the -v command line option. For example, the command
|
||||
|
||||
`ldd -v test`
|
||||
|
||||
produced the following in output when the **-v** command line option was used:
|
||||
|
||||
[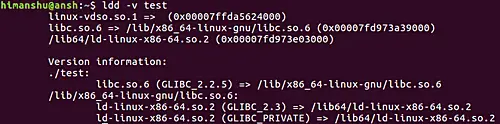](https://www.howtoforge.com/images/command-tutorial/big/ldd-v-option.png)
|
||||
|
||||
### Q3. How to make ldd produce unused direct dependencies?
|
||||
|
||||
For this info, use the **-u** command line option. Here's an example:
|
||||
|
||||
`ldd -u test`
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-u-test.png)
|
||||
|
||||
### Q4. How make ldd perform relocations?
|
||||
|
||||
There are a couple of command line options you can use here: **-d** and **-r**. While the former tells ldd to perform data relocations, the latter makes ldd perform relocations for both data objects and functions. In both cases, the tool reports missing ELF objects (if any).
|
||||
|
||||
`ldd -d`
|
||||
|
||||
`ldd -r`
|
||||
|
||||
### Q5. How get help on ldd?
|
||||
|
||||
The --help command line option makes ldd produce useful usage-related information for the tool.
|
||||
|
||||
`ldd --help`
|
||||
|
||||
[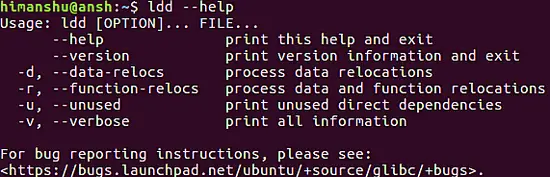](https://www.howtoforge.com/images/command-tutorial/big/ldd-help-option.png)
|
||||
|
||||
### Conclusion
|
||||
|
||||
Agreed, ldd doesn't fall into the category where tools like cd, rm, and mkdir fit in. That's because it's built for a specific purpose, and it does what it promises. The utility offers limited command line options, and we've covered most of them here. To know more, head to ldd's [man page](https://linux.die.net/man/1/ldd).
|
||||
|
||||
* * *
|
||||
|
||||
via: [https://www.howtoforge.com/linux-ldd-command/](https://www.howtoforge.com/linux-ldd-command/)
|
||||
|
||||
作者: [Himanshu Arora](https://www.howtoforge.com/) 选题者: [@lujun9972](https://github.com/lujun9972) 译者: [译者ID](https://github.com/译者ID) 校对: [校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,103 +0,0 @@
|
||||
Translating by erialin
|
||||
|
||||
|
||||
Linux Gunzip Command Explained with Examples
|
||||
======
|
||||
|
||||
We have [already discussed][1] the **gzip** command in Linux. For starters, the tool is used to compress or expand files. To uncompress, the command offers a command line option **-d** , which can be used in the following way:
|
||||
|
||||
gzip -d [compressed-file-name]
|
||||
|
||||
However, there's an entirely different tool that you can use for uncompressing or expanding archives created by gzip. The tool in question is **gunzip**. In this article, we will discuss the gunzip command using some easy to understand examples. Please note that all examples/instructions mentioned in the tutorial have been tested on Ubuntu 16.04.
|
||||
|
||||
### Linux gunzip command
|
||||
|
||||
So now we know that compressed files can be restored using either 'gzip -d' or the gunzip command. The basic syntax of gunzip is:
|
||||
|
||||
gunzip [compressed-file-name]
|
||||
|
||||
The following Q&A-style examples should give you a better idea of how the tool works:
|
||||
|
||||
### Q1. How to uncompress archives using gunzip?
|
||||
|
||||
This is very simple - just pass the name of the archive file as argument to gunzip.
|
||||
|
||||
gunzip [archive-name]
|
||||
|
||||
For example:
|
||||
|
||||
gunzip file1.gz
|
||||
|
||||
[![How to uncompress archives using gunzip][2]][3]
|
||||
|
||||
### Q2. How to make gunzip not delete archive file?
|
||||
|
||||
As you'd have noticed, the gunzip command deletes the archive file after uncompressing it. However, if you want the archive to stay, you can do that using the **-c** command line option.
|
||||
|
||||
gunzip -c [archive-name] > [outputfile-name]
|
||||
|
||||
For example:
|
||||
|
||||
gunzip -c file1.gz > file1
|
||||
|
||||
[![How to make gunzip not delete archive file][4]][5]
|
||||
|
||||
So you can see that the archive file wasn't deleted in this case.
|
||||
|
||||
### Q3. How to make gunzip put the uncompressed file in some other directory?
|
||||
|
||||
We've already discussed the **-c** option in the previous Q &A. To make gunzip put the uncompressed file in a directory other than the present working directory, just provide the absolute path after the redirection operator.
|
||||
|
||||
gunzip -c [compressed-file] > [/complete/path/to/dest/dir/filename]
|
||||
|
||||
Here's an example:
|
||||
|
||||
gunzip -c file1.gz > /home/himanshu/file1
|
||||
|
||||
### More info
|
||||
|
||||
The following details - taken from the common manpage of gzip/gunzip - should be beneficial for those who want to know more about the command:
|
||||
```
|
||||
gunzip takes a list of files on its command line and replaces each file
|
||||
whose name ends with .gz, -gz, .z, -z, or _z (ignoring case) and which
|
||||
begins with the correct magic number with an uncompressed file without
|
||||
the original extension. gunzip also recognizes the special extensions
|
||||
.tgz and .taz as shorthands for .tar.gz and .tar.Z respectively. When
|
||||
compressing, gzip uses the .tgz extension if necessary instead of trun
|
||||
cating a file with a .tar extension.
|
||||
|
||||
gunzip can currently decompress files created by gzip, zip, compress,
|
||||
compress -H or pack. The detection of the input format is automatic.
|
||||
When using the first two formats, gunzip checks a 32 bit CRC. For pack
|
||||
and gunzip checks the uncompressed length. The standard compress format
|
||||
was not designed to allow consistency checks. However gunzip is some
|
||||
times able to detect a bad .Z file. If you get an error when uncom
|
||||
pressing a .Z file, do not assume that the .Z file is correct simply
|
||||
because the standard uncompress does not complain. This generally means
|
||||
that the standard uncompress does not check its input, and happily gen
|
||||
erates garbage output. The SCO compress -H format (lzh compression
|
||||
method) does not include a CRC but also allows some consistency checks.
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As far as basic usage is concerned, there isn't much of a learning curve associated with Gunzip. We've covered pretty much everything that a beginner needs to learn about this command in order to start using it. For more information, head to its [man page][6].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-gunzip-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/linux-gzip-command/
|
||||
[2]:https://www.howtoforge.com/images/linux_gunzip_command/gunzip-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/linux_gunzip_command/gunzip-c.png
|
||||
[5]:https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-c.png
|
||||
[6]:https://linux.die.net/man/1/gzip
|
||||
@ -1,113 +0,0 @@
|
||||
translateing by singledo
|
||||
Processors - Everything You Need to Know
|
||||
======
|
||||

|
||||
|
||||
Our digital devices like Phones, Computers and laptops have grown to become so sophisticated, that they are no longer just devices, they have evolved to become a part of us.
|
||||
|
||||
They perform many tasks with the help of apps and software, But have we ever thought to wonder what powers these software? How do they perform their logic? Where is their brain?
|
||||
|
||||
We already know that a CPU or **Processor** is the brain of any device that must process data or perform logical tasks.
|
||||
|
||||
[![intel processors][1]][1]
|
||||
|
||||
But what are the different **concepts behind Processors**? How are they evaluated? How are some processors faster than the others? And many such questions. So let 's have a look at some major terms involved with processors and see how they affect processing speed.
|
||||
|
||||
### **Architecture**
|
||||
|
||||
Processors come in different architectures, you must have come across different types of programs that say they are for 64Bit or 32Bit. What this means is that those programs support that particular processor architecture.
|
||||
|
||||
If a processor has a 32 Bit Architecture it means that it can process 32 Bits of information in one processing cycle.
|
||||
|
||||
Similarly, a 64 Bit processor will process 64 Bits in one cycle.
|
||||
|
||||
Also, The amount of ram you can use also depends on the architecture. The amount of ram you can use depends upon the amount of memory in powers of 2 ^ architecture of the system.
|
||||
|
||||
For a processor with 16-bit architecture, only 64 KB of ram is accessible. For a 32 Bit processor, the maximum usable ram is 4 GB. And for 64 Bit processor, it is 16 Exa-Byte.
|
||||
|
||||
### **Cores**
|
||||
|
||||
Cores are basically processing units in the computer. They receive instructions and act on it. The more Cores you have, the better your processing speed.
|
||||
|
||||
Imagine it like workers in a factory, The more workers you have the faster you will be able to do work.
|
||||
|
||||
But more workers will require more salary and there will be a little crowd in the factory. processorsSimilarly, having more cores will definitely boost up processing but more cores need more power and they also heat the CPU a little more than those with fewer cores.
|
||||
|
||||
### **Clocking Speed**
|
||||
|
||||
We often hear that a processor is of 1 GHz or 2 GHz or 3 GHz. So what are these GHz?
|
||||
|
||||
[![cpu speed][2]][2]
|
||||
|
||||
GHz is short for GigaHertz. Giga means 'Billion' and Hertz means 'one cycle per second'. So a processor of 2 GHz can perform 2 Billion cycles in one second.
|
||||
|
||||
This is also known as 'frequency' or 'Clocking Speed' of your processor. The higher the number the better it is for your CPU.
|
||||
|
||||
### **CPU Cache**
|
||||
|
||||
CPU cache is a small memory unit inside the processor that stores some memory. Whenever we have to perform some task. Data needs to pass from the RAM to the CPU. Since the CPU works a lot faster than the RAM, most of the time the CPU is idle and waiting for data from the RAM. To solve this the RAM keeps sending data to the CPU Cache continuously.
|
||||
|
||||
You usually get 2-3 Mb of CPU cache in most Mid - Range processors. And up to 6 in high-end ones. The more cache your processor has, the better it is.
|
||||
|
||||
### **Lithography**
|
||||
|
||||
The size of transistors used is the lithographic size of a processor. It is usually measured in NanoMeter and the lesser it is, the more compact your processor will be. This will allow for more cores to fit into the same slot and reduce power consumption.
|
||||
|
||||
The latest Intel processors have a lithograph of 14 Nm.
|
||||
|
||||
### **Thermal Design Power (TDP)**
|
||||
|
||||
It represents the average power, in watts, the processor dissipates when operating at Base Frequency with all cores active under an Intel-defined, high-complexity workload.
|
||||
|
||||
So the lower it is, the better for you. A lower TDP not only uses better power but it also generates less heat.
|
||||
|
||||
[![battery cpu][3]][3]
|
||||
|
||||
Desktop processors usually consume more energy and have a TDP in the range of above 40, Whereas their counterparts Mobile versions consume up to 3 times less energy.
|
||||
|
||||
### **Memory Support(RAM)**
|
||||
|
||||
I had already mentioned that how processor architecture affects the amount of RAM we can use. But that only holds true for theory. In practical application, the amount of ram you can use is usually enough for that specification of a processor. It is usually specified in the processors' specs.
|
||||
[![RAM][4]][4]
|
||||
It also mentions the DDR version number of memory supported.
|
||||
|
||||
### **Overclocking**
|
||||
|
||||
So I already spoke about clocking speed. Now overclocking is the process of forcing your CPU to perform more cycles.
|
||||
|
||||
Gamers usually overclock their processors to get more juice out of their CPU. This surely increases speed but it also increases power consumption and heat generation.
|
||||
|
||||
A lot of High-End Processors allow overclocking. But if we wish to overclock an unsupported Processor, we will have to manually install a new BIOS for our motherboard and do it.
|
||||
|
||||
This may get the job done but it is neither safe nor suggested doing so.
|
||||
|
||||
### **Hyper-Threading**
|
||||
|
||||
When adding cores was not convenient to suite a particular processing need, Hyper-Threading was invented to create virtual cores.
|
||||
|
||||
So when we say that a dual-core processor has Hyper-Threading, it has 2 physical cores and 2 virtual cores. So it is technically a Quad-core processor in the body of a dual-core one.
|
||||
|
||||
### **Conclusion**
|
||||
|
||||
A processor has many variables associated with it. And it is the most important part of any digital device. So it is very important that before selecting a device we carefully examine the specifications of its processor keeping all the above variables in mind.
|
||||
|
||||
Variables like Clock-Speed, Cores, CPU cache and architecture should be maximum. While it is better that variables like TDP and lithography stay as low as possible.
|
||||
|
||||
Still confused about something? Feel free to comment and I will try to reply asap.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/processors-everything-need-know
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/10/download.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/10/download-1.jpg
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/10/download-2.jpg
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/10/images.jpg
|
||||
@ -0,0 +1,181 @@
|
||||
in which the cost of structured data is reduced
|
||||
======
|
||||
Last year I got the wonderful opportunity to attend [RacketCon][1] as it was hosted only 30 minutes away from my home. The two-day conference had a number of great talks on the first day, but what really impressed me was the fact that the entire second day was spent focusing on contribution. The day started out with a few 15- to 20-minute talks about how to contribute to a specific codebase (including that of Racket itself), and after that people just split off into groups focused around specific codebases. Each table had maintainers helping guide other folks towards how to work with the codebase and construct effective patch submissions.
|
||||
|
||||
![lensmen chronicles][2]
|
||||
|
||||
I came away from the conference with a great sense of appreciation for how friendly and welcoming the Racket community is, and how great Racket is as a swiss-army-knife type tool for quick tasks. (Not that it's unsuitable for large projects, but I don't have the opportunity to start any new large projects very frequently.)
|
||||
|
||||
The other day I wanted to generate colored maps of the world by categorizing countries interactively, and Racket seemed like it would fit the bill nicely. The job is simple: show an image of the world with one country selected; when a key is pressed, categorize that country, then show the map again with all categorized countries colored, and continue with the next country selected.
|
||||
|
||||
### GUIs and XML
|
||||
|
||||
I have yet to see a language/framework more accessible and straightforward out of the box for drawing1. Here's the entry point which sets up state and then constructs a canvas that handles key input and display:
|
||||
```
|
||||
(define (main path)
|
||||
(let ([frame (new frame% [label "World color"])]
|
||||
[categorizations (box '())]
|
||||
[doc (call-with-input-file path read-xml/document)])
|
||||
(new (class canvas%
|
||||
(define/override (on-char event)
|
||||
(handle-key this categorizations (send event get-key-code)))
|
||||
(super-new))
|
||||
[parent frame]
|
||||
[paint-callback (draw doc categorizations)])
|
||||
(send frame show #t)))
|
||||
|
||||
```
|
||||
|
||||
While the class system is not one of my favorite things about Racket (most newer code seems to avoid it in favor of [generic interfaces][3] in the rare case that polymorphism is truly called for), the fact that classes can be constructed in a light-weight, anonymous way makes it much less onerous than it could be. This code sets up all mutable state in a [`box`][4] which you use in the way you'd use a `ref` in ML or Clojure: a mutable wrapper around an immutable data structure.
|
||||
|
||||
The world map I'm using is [an SVG of the Robinson projection][5] from Wikipedia. If you look closely there's a call to bind `doc` that calls [`call-with-input-file`][6] with [`read-xml/document`][7] which loads up the whole map file's SVG; just about as easily as you could ask for.
|
||||
|
||||
The data you get back from `read-xml/document` is in fact a [document][8] struct, which contains an `element` struct containing `attribute` structs and lists of more `element` structs. All very sensible, but maybe not what you would expect in other dynamic languages like Clojure or Lua where free-form maps reign supreme. Racket really wants structure to be known up-front when possible, which is one of the things that help it produce helpful error messages when things go wrong.
|
||||
|
||||
Here's how we handle keyboard input; we're displaying a map with one country highlighted, and `key` here tells us what the user pressed to categorize the highlighted country. If that key is in the `categories` hash then we put it into `categorizations`.
|
||||
```
|
||||
(define categories #hash((select . "eeeeff")
|
||||
(#\1 . "993322")
|
||||
(#\2 . "229911")
|
||||
(#\3 . "ABCD31")
|
||||
(#\4 . "91FF55")
|
||||
(#\5 . "2439DF")))
|
||||
|
||||
(define (handle-key canvas categorizations key)
|
||||
(cond [(equal? #\backspace key) (swap! categorizations cdr)]
|
||||
[(member key (dict-keys categories)) (swap! categorizations (curry cons key))]
|
||||
[(equal? #\space key) (display (unbox categorizations))])
|
||||
(send canvas refresh))
|
||||
|
||||
```
|
||||
|
||||
### Nested updates: the bad parts
|
||||
|
||||
Finally once we have a list of categorizations, we need to apply it to the map document and display. We apply a [`fold`][9] reduction over the XML document struct and the list of country categorizations (plus `'select` for the country that's selected to be categorized next) to get back a "modified" document struct where the proper elements have the style attributes applied for the given categorization, then we turn it into an image and hand it to [`draw-pict`][10]:
|
||||
```
|
||||
|
||||
(define (update original-doc categorizations)
|
||||
(for/fold ([doc original-doc])
|
||||
([category (cons 'select (unbox categorizations))]
|
||||
[n (in-range (length (unbox categorizations)) 0 -1)])
|
||||
(set-style doc n (style-for category))))
|
||||
|
||||
(define ((draw doc categorizations) _ context)
|
||||
(let* ([newdoc (update doc categorizations)]
|
||||
[xml (call-with-output-string (curry write-xml newdoc))])
|
||||
(draw-pict (call-with-input-string xml svg-port->pict) context 0 0)))
|
||||
|
||||
```
|
||||
|
||||
The problem is in that pesky `set-style` function. All it has to do is reach deep down into the `document` struct to find the `n`th `path` element (the one associated with a given country), and change its `'style` attribute. It ought to be a simple task. Unfortunately this function ends up being anything but simple:
|
||||
```
|
||||
|
||||
(define (set-style doc n new-style)
|
||||
(let* ([root (document-element doc)]
|
||||
[g (list-ref (element-content root) 8)]
|
||||
[paths (element-content g)]
|
||||
[path (first (drop (filter element? paths) n))]
|
||||
[path-num (list-index (curry eq? path) paths)]
|
||||
[style-index (list-index (lambda (x) (eq? 'style (attribute-name x)))
|
||||
(element-attributes path))]
|
||||
[attr (list-ref (element-attributes path) style-index)]
|
||||
[new-attr (make-attribute (source-start attr)
|
||||
(source-stop attr)
|
||||
(attribute-name attr)
|
||||
new-style)]
|
||||
[new-path (make-element (source-start path)
|
||||
(source-stop path)
|
||||
(element-name path)
|
||||
(list-set (element-attributes path)
|
||||
style-index new-attr)
|
||||
(element-content path))]
|
||||
[new-g (make-element (source-start g)
|
||||
(source-stop g)
|
||||
(element-name g)
|
||||
(element-attributes g)
|
||||
(list-set paths path-num new-path))]
|
||||
[root-contents (list-set (element-content root) 8 new-g)])
|
||||
(make-document (document-prolog doc)
|
||||
(make-element (source-start root)
|
||||
(source-stop root)
|
||||
(element-name root)
|
||||
(element-attributes root)
|
||||
root-contents)
|
||||
(document-misc doc))))
|
||||
|
||||
```
|
||||
|
||||
The reason for this is that while structs are immutable, they don't support functional updates. Whenever you're working with immutable data structures, you want to be able to say "give me a new version of this data, but with field `x` replaced by the value of `(f (lookup x))`". Racket can [do this with dictionaries][11] but not with structs2. If you want a modified version you have to create a fresh one3.
|
||||
|
||||
### Lenses to the rescue?
|
||||
|
||||
![first lensman][12]
|
||||
|
||||
When I brought this up in the `#racket` channel on Freenode, I was helpfully pointed to the 3rd-party [Lens][13] library. Lenses are a general-purpose way of composing arbitrarily nested lookups and updates. Unfortunately at this time there's [a flaw][14] preventing them from working with `xml` structs, so it seemed I was out of luck.
|
||||
|
||||
But then I was pointed to [X-expressions][15] as an alternative to structs. The [`xml->xexpr`][16] function turns the structs into a deeply-nested list tree with symbols and strings in it. The tag is the first item in the list, followed by an associative list of attributes, then the element's children. While this gives you fewer up-front guarantees about the structure of the data, it does work around the lens issue.
|
||||
|
||||
For this to work, we need to compose a new lens based on the "path" we want to use to drill down into the `n`th country and its `style` attribute. The [`lens-compose`][17] function lets us do that. Note that the order here might be backwards from what you'd expect; it works deepest-first (the way [`compose`][18] works for functions). Also note that defining one lens gives us the ability to both get nested values (with [`lens-view`][19]) and update them.
|
||||
```
|
||||
(define (style-lens n)
|
||||
(lens-compose (dict-ref-lens 'style)
|
||||
second-lens
|
||||
(list-ref-lens (add1 (* n 2)))
|
||||
(list-ref-lens 10)))
|
||||
```
|
||||
|
||||
Our `<path>` XML elements are under the 10th item of the root xexpr, (hence the [`list-ref-lens`][20] with 10) and they are interspersed with whitespace, so we have to double `n` to find the `<path>` we want. The [`second-lens`][21] call gets us to that element's attribute alist, and [`dict-ref-lens`][22] lets us zoom in on the `'style` key out of that alist.
|
||||
|
||||
Once we have our lens, it's just a matter of replacing `set-style` with a call to [`lens-set`][23] in our `update` function we had above, and then we're off:
|
||||
```
|
||||
(define (update doc categorizations)
|
||||
(for/fold ([d doc])
|
||||
([category (cons 'select (unbox categorizations))]
|
||||
[n (in-range (length (unbox categorizations)) 0 -1)])
|
||||
(lens-set (style-lens n) d (list (style-for category)))))
|
||||
```
|
||||
|
||||
![second stage lensman][24]
|
||||
|
||||
Often times the trade-off between freeform maps/hashes vs structured data feels like one of convenience vs long-term maintainability. While it's unfortunate that they can't be used with the `xml` structs4, lenses provide a way to get the best of both worlds, at least in some situations.
|
||||
|
||||
The final version of the code clocks in at 51 lines and is is available [on GitLab][25].
|
||||
|
||||
๛
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://technomancy.us/185
|
||||
|
||||
作者:[Phil Hagelberg][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://technomancy.us/
|
||||
[1]:https://con.racket-lang.org/
|
||||
[2]:https://technomancy.us/i/chronicles-of-lensmen.jpg
|
||||
[3]:https://docs.racket-lang.org/reference/struct-generics.html
|
||||
[4]:https://docs.racket-lang.org/reference/boxes.html?q=box#%28def._%28%28quote._~23~25kernel%29._box%29%29
|
||||
[5]:https://commons.wikimedia.org/wiki/File:BlankMap-World_gray.svg
|
||||
[6]:https://docs.racket-lang.org/reference/port-lib.html#(def._((lib._racket%2Fport..rkt)._call-with-input-string))
|
||||
[7]:https://docs.racket-lang.org/xml/index.html?q=read-xml#%28def._%28%28lib._xml%2Fmain..rkt%29._read-xml%2Fdocument%29%29
|
||||
[8]:https://docs.racket-lang.org/xml/#%28def._%28%28lib._xml%2Fmain..rkt%29._document%29%29
|
||||
[9]:https://docs.racket-lang.org/reference/for.html?q=for%2Ffold#%28form._%28%28lib._racket%2Fprivate%2Fbase..rkt%29._for%2Ffold%29%29
|
||||
[10]:https://docs.racket-lang.org/pict/Rendering.html?q=draw-pict#%28def._%28%28lib._pict%2Fmain..rkt%29._draw-pict%29%29
|
||||
[11]:https://docs.racket-lang.org/reference/dicts.html?q=dict-update#%28def._%28%28lib._racket%2Fdict..rkt%29._dict-update%29%29
|
||||
[12]:https://technomancy.us/i/first-lensman.jpg
|
||||
[13]:https://docs.racket-lang.org/lens/lens-guide.html
|
||||
[14]:https://github.com/jackfirth/lens/issues/290
|
||||
[15]:https://docs.racket-lang.org/pollen/second-tutorial.html?q=xexpr#%28part._.X-expressions%29
|
||||
[16]:https://docs.racket-lang.org/xml/index.html?q=xexpr#%28def._%28%28lib._xml%2Fmain..rkt%29._xml-~3exexpr%29%29
|
||||
[17]:https://docs.racket-lang.org/lens/lens-reference.html#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-compose%29%29
|
||||
[18]:https://docs.racket-lang.org/reference/procedures.html#%28def._%28%28lib._racket%2Fprivate%2Flist..rkt%29._compose%29%29
|
||||
[19]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-view%29%29
|
||||
[20]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Flist..rkt%29._list-ref-lens%29%29
|
||||
[21]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Flist..rkt%29._second-lens%29%29
|
||||
[22]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Fdict..rkt%29._dict-ref-lens%29%29
|
||||
[23]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-set%29%29
|
||||
[24]:https://technomancy.us/i/second-stage-lensman.jpg
|
||||
[25]:https://gitlab.com/technomancy/world-color/blob/master/world-color.rkt
|
||||
@ -1,61 +0,0 @@
|
||||
translating by lujun9972
|
||||
Save Some Battery On Our Linux Machines With TLP
|
||||
======
|
||||

|
||||
|
||||
I have always found battery life with Linux to be relatively lesser than windows. Nevertheless, this is [Linux][1] and we always have something up our sleeves.
|
||||
|
||||
Now talking about this small utility called TLP, that can actually save some juice on your device.
|
||||
|
||||
|
||||
|
||||
**TLP - Linux Advanced Power Management** is a small command line utility that can genuinely help extend battery life by performing several tweaks on your Linux system.
|
||||
|
||||
```
|
||||
sudo apt install tlp
|
||||
```
|
||||
|
||||
[][2]
|
||||
|
||||
For other distributions, you can read the instructions from the [official website][3] .
|
||||
|
||||
|
||||
|
||||
After installation is complete, you will have to run the following command to start tlp for the first time only. TLP will automatically start the next time you boot your system.
|
||||
|
||||
[][4]
|
||||
|
||||
Now TLP has started and it has already made the default configurations needed to save battery. We will now see the configurations file. It is located in **/etc/default/tlp**. We need to edit this file to change various configurations.
|
||||
|
||||
There are many options in this file and to enable an option just remove the leading **#** character from that line. There will be instructions about each option and the values that you can allot to it. Some of the things that you will be able to do are -
|
||||
|
||||
* Autosuspend USB devices
|
||||
|
||||
* Define wireless devices to enable/disable at startup
|
||||
|
||||
* Spin down hard drives
|
||||
|
||||
* Switch off wireless devices
|
||||
|
||||
* Set CPU for performance or power savings
|
||||
|
||||
### Conclusion
|
||||
|
||||
TLP is an amazing utility that can help save battery life on Linux systems. I have personally found at least 30-40% of extended battery life when using TLP.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/save-some-battery-on-our-linux-machines-with-tlp
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/linux
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/install-tlp-in-linux.jpeg
|
||||
[3]:http://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/start-tlp-on-linux.jpeg
|
||||
@ -1,3 +1,4 @@
|
||||
translating by wyxplus
|
||||
Become a Hollywood movie hacker with these three command line tools
|
||||
======
|
||||
|
||||
|
||||
@ -1,117 +0,0 @@
|
||||
Manjaro Gaming:当 Manjaro 的才华遇上 Linux 游戏
|
||||
======
|
||||
[![Meet Manjaro Gaming, a Linux distro designed for gamers with the power of Manjaro][1]][1]
|
||||
|
||||
[![见见 Manjaro Gaming, 一个专门为游戏者设计的 Linux 发行版,带有 Manjaro 的所有才能。][1]][1]
|
||||
|
||||
[在 Linux 上玩转游戏][2]? 没错,这是非常可行的,我们正致力于为游戏人群打造一个新的 Linux 发行版。
|
||||
|
||||
Manjaro Gaming 是一个专门为游戏人群设计的,带有 Manjaro 所有才能的发行版。之前用过 Manjaro Linux 的人一定知道为什么这对于游戏人群来说是一个如此好的一个消息。
|
||||
|
||||
[Manjaro][3] 是一个 Linux 发行版,它基于最流行的 Linux 发行版—— [Arch Linux][4]。 Arch Linux 因它的前沿性所带来的轻量、强大、高度定制和最新的体验而闻名于世。尽管这些都非常赞,但是也正是因为 Arch Linux 提倡这种 DIY (do it yourself)方式,导致一个主要的缺点,那就是用户想用好它,需要处理一定的技术问题。
|
||||
|
||||
|
||||
Manjaro 把这些要求全都剥开了去,让 Arch 对新手更亲切,同时也为老手提供了 Arch 所有的高端与强大功能。总之,Manjaro 是一个用户友好型的 Linux 发行版,工作起来行云流水。
|
||||
|
||||
Manjaro 会成为一个强大并且极度适用于游戏的原因:
|
||||
|
||||
* Manjaro 自动检测计算的硬件(例如,显卡)
|
||||
* 自动安装必要的驱动和软件(例如,显示驱动)
|
||||
* 预安装播放媒体文件的编码器
|
||||
* 专用的软件库提供完整测试过的稳定软件包。
|
||||
|
||||
|
||||
Manjaro Gaming 打包了 Manjaro 的所有强大特性以及各种小工具和软件包,以使得在 Linux 上做游戏即顺畅又享受。
|
||||
|
||||
![Inside Manjaro Gaming][5]
|
||||
|
||||
![Manjaro Gaming 中][5]
|
||||
|
||||
#### 小工具
|
||||
|
||||
Manjaro Gaming 中的一些小工具
|
||||
* Manjaro Gaming 使用高度定制化的 XFCE 桌面环境,拥有一个黑暗风格主题。
|
||||
* 禁用睡眠模式,防止用手柄上玩游戏或者观看一个长过场动画时计算机自动休眠。
|
||||
|
||||
|
||||
#### Softwares
|
||||
|
||||
维持 Manjaro 工作起来行云流水的传统,Manjaro Gaming 打包了各种开源软件包,提供游戏人群经常需要用到的功能。其中一部分软件有:
|
||||
* [**KdenLIVE**][6]: 用于编辑游戏视频的视频编辑软件
|
||||
* [**Mumble**][7]: 给游戏人群使用的视频聊天软件
|
||||
* [**OBS Studio**][8]: 用于录制视频或在 [Twitch][9] 上直播游戏用的软件
|
||||
* **[OpenShot][10]**: Linux 上强大的视频编辑器
|
||||
* [**PlayOnLinux**][11]: 使用 [Wine][12] 作为后端,在 Linux 上运行 Windows 游戏的软件
|
||||
* [**Shutter**][13]: 多种功能的截图工具
|
||||
|
||||
|
||||
#### 模拟器
|
||||
Manjaro Gaming comes with a long list of gaming emulators:
|
||||
Manjaro Gaming 自带很多的游戏模拟器:
|
||||
* **[DeSmuME][14]** : Nintendo DS 任天堂 DS 模拟器
|
||||
* **[Dolphin Emulator][15]** : GameCube 和 Wii 模拟器
|
||||
* [**DOSBox**][16]: DOS 游戏模拟器
|
||||
* **[FCEUX][17]** : Nintendo Entertainment System (任天堂娱乐系统, NES), Famicom(FC, 红白机), 和 Famicom Disk System (FC磁盘系统, FDS) 模拟器
|
||||
* **Gens/GS** : Sega Mega Drive(世嘉)模拟器
|
||||
* **[PCSXR][18]** : PlayStation 模拟器
|
||||
* [**PCSX2**][19]: Playstation 2 模拟器
|
||||
* [**PPSSPP**][20]: PSP 模拟器
|
||||
* **[Stella][21]** : Atari 2600 VCS (雅达利)模拟器
|
||||
* [**VBA-M**][22]: Gameboy and GameboyAdvance 模拟器
|
||||
* [**Yabause**][23]: Sega Saturn (世嘉土星)模拟器
|
||||
* **[ZSNES][24]** : Super Nintendo (超级任天堂)模拟器
|
||||
*
|
||||
|
||||
|
||||
|
||||
#### Others
|
||||
|
||||
#### 其它
|
||||
|
||||
还有一些终端插件——Color, ILoveCandy 和 Screenfetch。也包括带有 Retro Conky (译:复古 Conky)风格的 [Conky 管理器][25]。
|
||||
|
||||
**注意:上面提到的所有功能并没有全部包含在 Manjaro Gaming 的现行发行版中(版本 16.03 )。部分功能计划将在下一版本中纳入——Manjaro Gaming 16.06。**
|
||||
|
||||
|
||||
### 下载
|
||||
Manjaro Gaming 16.06 将会是 Manjaro Gaming 的第一个正式版本。如果你现在就有兴趣尝试,你可以在 Sourceforge 的 [project page][26] (译注:项目页面) 中下载。去那然后下载它的 ISO 文件吧。
|
||||
|
||||
你觉得 Gaming Linux 发行版怎么样?想尝试吗?告诉我们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/manjaro-gaming-linux/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2016/06/Manjaro-Gaming.jpg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://manjaro.github.io/
|
||||
[4]:https://www.archlinux.org/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2016/06/Manjaro-Gaming-Inside-1024x576.png
|
||||
[6]:https://kdenlive.org/
|
||||
[7]:https://www.mumble.info
|
||||
[8]:https://obsproject.com/
|
||||
[9]:https://www.twitch.tv/
|
||||
[10]:http://www.openshot.org/
|
||||
[11]:https://www.playonlinux.com
|
||||
[12]:https://www.winehq.org/
|
||||
[13]:http://shutter-project.org/
|
||||
[14]:http://desmume.org/
|
||||
[15]:https://dolphin-emu.org
|
||||
[16]:https://www.dosbox.com/
|
||||
[17]:http://www.fceux.com/
|
||||
[18]:https://pcsxr.codeplex.com
|
||||
[19]:http://pcsx2.net/
|
||||
[20]:http://www.ppsspp.org/
|
||||
[21]:http://stella.sourceforge.net/
|
||||
[22]:http://vba-m.com/
|
||||
[23]:https://yabause.org/
|
||||
[24]:http://www.zsnes.com/
|
||||
[25]:https://itsfoss.com/conky-gui-ubuntu-1304/
|
||||
[26]:https://sourceforge.net/projects/mgame/
|
||||
@ -1,75 +0,0 @@
|
||||
开源软件二十年 —— 过去,现在,未来
|
||||
=================================================================
|
||||
|
||||
### 谨以此文纪念 “开源软件” 这个词的二十年纪念日,开源软件是怎么占有软件的主导地位的 ?以后会如何发展?
|
||||
|
||||

|
||||
图片来自 : opensource.com
|
||||
|
||||
二十年以前,在 1998 年二月,“开源” 这个词汇第一次出现在软件之前。不久之后,如”开源的定义“(OSD)的作者 [Bruce Perens 所说][9], OSD 这一文档被创建,开放源代码促进会( OSI )的种子被播种。
|
||||
|
||||
> “开源”是宣传自由软件的既有概念到商业软件,并对使用一系列规则对许可证进行认证的活动的正式名称。
|
||||
|
||||
二十年后,我们能看到这一运动是非常成功的,甚至超出了当时参与这一活动的任何人的想象。 如今,开源软件无处不在。它是互联网和网络的基础。它为我们所有使用的电脑和移动设备,以及它们所连接的网络提供动力。没有它,云计算和新兴的物联网将不可能发展,甚至不可能出现。它使新的业务方式能被测试和验证,还可以让像谷歌和 Facebook 这样的大公司使用别人的成果继续发展。
|
||||
|
||||
如任何人类的创造物一样,它也有黑暗的一面。它也让反乌托邦的监视和必然导致的专制控制的出现成为了可能。它为犯罪分子提供欺骗受害者的新的途径,还让匿名且大规模的欺凌得以存在。它让有破环性的狂热分子可以暗中组织而不会感到有何不便。这些都是开源的能力之下的黑暗投影。所有的人类工具都是如此,既可以养育人类,亦可以有害于人类。我们需要帮助下一代,让他们能争取无可取代的创新。就如 [费曼所说][10],
|
||||
|
||||
> 每个人都掌握着一把开启天堂之门的钥匙,但这把钥匙亦能打开地狱之门。
|
||||
|
||||
开源运动已经渐渐成熟。我们讨论和理解它的方式也渐渐的成熟。如果说第一个十年拥护与非议对立的十年,那么第二个十年就是接纳和适应并存的十年。
|
||||
|
||||
1. 在第一个十年里面,关键问题就是商业模型 - “我怎样才能自由的贡献代码,且从中受益?” - 之后,还有更多的人提出了有关管理的难题- “我怎么才能参与进来,且不受控制 ?”
|
||||
|
||||
2. 第一个十年的开源项目主要是替代现有的产品; 在第二个十年中,它们更多地是作为更大的解决方案的组成部分。
|
||||
|
||||
3. 第一个十年的项目往往由非正式的个人组织进行; 在第二个十年中,它们经常由逐个项目地创建的机构经营。
|
||||
|
||||
4. 第一个十年的开源开发人员经常是投入于单一的项目,并经常在业余时间工作。 在第二个十年里,他们越来越多地受雇于一个专门的技术 —— 他们成了专业人员。
|
||||
|
||||
5. 尽管开源一直被认为是提升软件自由度的一种方式,但在第一个十年中,这个运动与那些更喜欢使用“自由软件”的人产生了冲突。在第二个十年里,随着开源运动的加速发展,这个冲突基本上被忽略了。
|
||||
|
||||
第三个十年会带来什么?
|
||||
|
||||
1. _更复杂的商业模式_ - 主要的商业模式将通过整合很多开源的,特别是部署和扩展,那部分的开源软件,从而产生的复杂的解决方案。 管理的需求将反映这一点。
|
||||
|
||||
2. _开源拼图_ - 开源项目将主要是一堆组件。 由此产生的解决方案将是开源组建的拼图。
|
||||
|
||||
3. _项目族_ - 越来越多的项目将由诸如 Linux Foundation 和 OpenStack 等联盟/行业协会以及 Apache 和 Software Freedom Conservancy 等机构主办。
|
||||
|
||||
4. _专业通才_ - 开源开发人员将越来越多地被雇来将诸多技术集成到复杂的解决方案里,这将有助于一系列的项目的开发。
|
||||
|
||||
5. _软件自由度降低_ - 随着新问题的出现,软件自由(将四项自由应用于用户和开发人员之间的灵活性)将越来越多地应用于识别适用于协作社区和独立部署人员的解决方案。
|
||||
|
||||
2018年,我将在全球各地的主题演讲中阐述这些内容。欢迎观看 [OSI 20周年纪念全球巡演][11]!
|
||||
|
||||
_本文最初发表于 [Meshed Insights Ltd.][2] , 已获转载授权,本文,以及我在 OSI 的工作,由 [Patreon patrons][3] 支持_
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][12] Simon Phipps - 计算机工业和开源软件专家Simon Phipps创办了[公共软件公司][4],一个欧洲开源项目主管,志愿成为 OSI 的总裁,还是The Document Foundation的一名主管。 他的作品是由 [Patreon patrons][5] 赞助 - 如果你想看更多的话,来做赞助人吧! 在超过30年的职业生涯中,他一直在参与世界领先的战略层面的开发...[关于 Simon Phipps][6][关于我][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/open-source-20-years-and-counting
|
||||
|
||||
作者:[Simon Phipps ][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/simonphipps
|
||||
[1]:https://opensource.com/article/18/2/open-source-20-years-and-counting?rate=TZxa8jxR6VBcYukor0FDsTH38HxUrr7Mt8QRcn0sC2I
|
||||
[2]:https://meshedinsights.com/2017/12/21/20-years-and-counting/
|
||||
[3]:https://patreon.com/webmink
|
||||
[4]:https://publicsoftware.eu/
|
||||
[5]:https://patreon.com/webmink
|
||||
[6]:https://opensource.com/users/simonphipps
|
||||
[7]:https://opensource.com/users/simonphipps
|
||||
[8]:https://opensource.com/user/12532/feed
|
||||
[9]:https://perens.com/2017/09/26/on-usage-of-the-phrase-open-source/
|
||||
[10]:https://www.brainpickings.org/2013/07/19/richard-feynman-science-morality-poem/
|
||||
[11]:https://opensource.org/node/905
|
||||
[12]:https://opensource.com/users/simonphipps
|
||||
[13]:https://opensource.com/users/simonphipps
|
||||
[14]:https://opensource.com/users/simonphipps
|
||||
@ -0,0 +1,22 @@
|
||||
我是被 root@notty 黑了吗?
|
||||
======
|
||||
|
||||
当你在 `ps aux` 的输出中看到 `sshd:root@notty` 时会觉得很奇怪吧,`notty` 算是哪门子的主机,是不是黑客计算机的名字啊。不过不用担心; `notty` 仅仅是表示 `no tty` 而已。
|
||||
|
||||
当你在本地登陆 linux 机器时,登陆终端会在进程列表中显示为 `tty`( 比如。tty7)。若你通过 ssh 登陆一台远程服务器,则会看到类似 `root@pts/0` 这样的东西。
|
||||
|
||||
而若某个连接是由 sftp 或者是由 scp 拷贝文件而创建的,则该连接会会显示成 no tty (notty)。
|
||||
|
||||
如果你仍然想知道服务器上发生了什么事情,可以检查 `ps auxf` 的输出来查看进程树,或者运行 `netstat -vatn` 来检查所有的 TCP 连接。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.sysadminworld.com/2011/ps-aux-shows-sshd-rootnotty/
|
||||
|
||||
作者:[sysadminworld][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.sysadminworld.com
|
||||
@ -0,0 +1,84 @@
|
||||
用示例讲解 Linux Gunzip 命令
|
||||
======
|
||||
|
||||
我们已经讨论过[ Linux 下 **gzip** 命令的用法 ][1]。对于初学者来说,gzip 工具主要用于压缩或者扩展文件。解压时,在 gzip 命令后添加 -d 选项,使用示例如下:
|
||||
|
||||
gzip -d [compressed-file-name]
|
||||
|
||||
不过,在解压或扩展 gzip 创建的压缩文件时,有另一款完全不同的工具可供使用。谈及的这款工具就是 **gunzip**。在本文中,我们会使用一些简单、易于理解的例子来解释 gunzip 命令的用法。文中所有示例及指南都在 Ubuntu 16.04 环境下测试。
|
||||
|
||||
### Linux gunzip 命令
|
||||
|
||||
我们现在知道压缩文件可以用 'gzip -d' 或 gunzip 命令解压。基本的 gunzip 语法为:
|
||||
|
||||
gunzip [compressed-file-name]
|
||||
|
||||
以下的 Q&A 例子将更清晰地展示 gunzip 工具如何工作:
|
||||
|
||||
### Q1. 如何使用 gunzip 解压压缩文件?
|
||||
|
||||
解压命令非常简单,仅仅需要将压缩文件名称作为参数传递到 gunzip 命令后。
|
||||
|
||||
gunzip [archive-name]
|
||||
|
||||
比如:
|
||||
|
||||
gunzip file1.gz
|
||||
|
||||
[![如何使用 gunzip 解压压缩文件?][2]][3]
|
||||
|
||||
### Q2. 如何让 gunzip 不删除原始压缩文件?
|
||||
|
||||
正如你已注意到的那样,gunzip 命令解压后会删除原始压缩文件。如果你想保留原始压缩文件,可以使用 **-c** 选项。
|
||||
|
||||
gunzip -c [archive-name] > [outputfile-name]
|
||||
|
||||
比如:
|
||||
|
||||
gunzip -c file1.gz > file1
|
||||
|
||||
[![如何让 gunzip 不删除原始压缩文件?][4]][5]
|
||||
|
||||
使用这种方式,原压缩文件不会被删除。
|
||||
|
||||
### Q3. 如何用 gunzip 解压文件到其他路径?
|
||||
|
||||
在 Q&A 中我们已经讨论过 **-c** 选项的用法。 使用 gunzip 解压文件到工作目录外的其他路径,仅需要在重定向操作符后添加目标目录的绝对路径即可。
|
||||
|
||||
gunzip -c [compressed-file] > [/complete/path/to/dest/dir/filename]
|
||||
|
||||
示例如下:
|
||||
|
||||
gunzip -c file1.gz > /home/himanshu/file1
|
||||
|
||||
### 更多信息
|
||||
|
||||
以下从 gzip/gunzip man page 中摘录的细节,对于想了解更多的人会有所助益。
|
||||
```
|
||||
gunzip 用命令行列出文件,并且替换每个以正确的幻数开头,后缀名为.gz,-gz,.z,-z,或 _z (忽略) 的压缩文件,删除原始文件。 gunzip 也可识别一些特殊扩展名的压缩文件,如 .tgz 和 .taz 分别是 .tar.gz 和 .tar.Z 的缩写。在压缩时,gzip 在必要情况下使用 .tgz 作为扩展名,而不是只截取为 .tar 作为后缀。
|
||||
|
||||
gunzip 目前可以解压 gzip,zip,compress,compress -H,pack 产生的文件。gunzip 自动检测输入文件格式。在使用前两种压缩格式时,gunzip 会检验 32 位循环冗余校验码(CRC)。对于 pack 包,gunzip 会检验压缩长度。标准压缩格式设计上不允许相容性检测。不过 gunzip 有时可以检测出坏的 .Z 文件。如果你解压 .Z 文件时出错,不要因为标准解压没报错就认为 .Z 文件一定是正确的。这通常意味着标准解压过程不检测它的输入,而是直接产生一个错误的输出。SCO compress -H 格式(lzh 压缩方法)不包括 CRC 校验码,但也允许一些相容性检查。
|
||||
```
|
||||
|
||||
### 结语
|
||||
|
||||
到目前为止提到的 gunzip 基本用法,并不需要过多的学习曲线。我们已包含了一个初学者开始使用它所必须了解的几乎全部知识。想要了解更多的用法,去看 [man page][6] 吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-gunzip-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[erialin](https://github.com/erialin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/linux-gzip-command/
|
||||
[2]:https://www.howtoforge.com/images/linux_gunzip_command/gunzip-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/linux_gunzip_command/gunzip-c.png
|
||||
[5]:https://www.howtoforge.com/images/linux_gunzip_command/big/gunzip-c.png
|
||||
[6]:https://linux.die.net/man/1/gzip
|
||||
@ -0,0 +1,88 @@
|
||||
# 关于处理器你需要知道的每件事
|
||||
|
||||
[![][b]][b]
|
||||
```
|
||||
我们的手机 ,主机以及笔记本电脑已经成长得如此的成熟 ,以至于它们进化成为我们的一部分 ,而不只是一种设备 。
|
||||
在应用和软件的帮助下 ,处理器执行许多任务 。我们是否曾经想过是什么给了这些软件这样的能力 ?它们是如何执行他们的逻辑的 ?它们的大脑在哪 ?
|
||||
我们知道 CPU 或者是处理器是那些需要处理数据和执行逻辑任务设备的大脑 。
|
||||
``
|
||||
[![cpu image][1]][1]
|
||||
```
|
||||
在处理器的深处有那些不一样的概念呢 ? 它们是如何进化的 ? 一些处理器是如何做到比其他处理器更快的 ? 我们来看看关于处理器的主要术语并且它们是如何影响处速度的 ?
|
||||
```
|
||||
## 架构
|
||||
```
|
||||
处理器有不同的架构 ,你一定偶遇过不同种类的那种你说它们是 64 位或 32 位的程序 ,其中的意思是程序支持特定的处理器架构 。
|
||||
如果一颗处理器是 32 位的架构 ,意味着这颗处理器能够在一个处理周期内处理一个 32 位的数据 。同理可得 ,64 位的处理器能够在一个周期内处理一个 64 位的信息 。
|
||||
你可以使用的 RAM 大小决定于处理器的架构 ,你可以使用的 RAM 总量为处理器架构的幂指数 。
|
||||
16 位架构的处理器 ,仅仅有 64 kb 的 RAM 使用 。32 位架构的处理器 ,最大可使用的 RAM 是 4 GB ,64 位架构的处理器的可用 RAM 是 16 Exa-Byte 。
|
||||
```
|
||||
## 内核
|
||||
```
|
||||
在电脑上 ,核心是基本的处理单元 。核心接收指令并且执行指令 。越多的核心带来越快的速度 。把核心当成工厂里的工人 ,越多的工人使工作能够越快的完成 。另一方面 ,工人越多 ,你所付出的薪水也就越多 ,工厂也会越拥挤 ;相对于核心来说 ,越多的合兴消耗更多的能量 ,比核心少的 CPU 更容易发热 。
|
||||
```
|
||||
## 时钟速度
|
||||
[![CPU CLOCK SPEED][2]][2]
|
||||
```
|
||||
GHZ 是 GigaHertz 的简写 ,Giga 意思是 Billon ,Hertz 意思是一秒有几个周期 ,2 GHZ 的处理器意味着处理器一秒能够执行 2 百万个周期 。
|
||||
也被作为 `频率` 或者 `时钟速度` 被熟知 。这项数值越高 ,CPU的性能越好 。
|
||||
```
|
||||
## CPU 缓存
|
||||
```
|
||||
CPU 缓存是处理器内部的一块小的存储单元 ,用来存储一些内存 。不管如何 ,我们都需要执行一些任务 ,数据需要从 RAM 传递到 CPU ,CPU 的工作速度远快于 RAM ,CPU 在大多数时间是在等待从 RAM 传递过来的数据 ,而此时 CPU 是处于空闲状态的 。为了解决这个问题 ,RAM 持续的向 CPU 缓存发送数据 。一般的处理器会有 2 ~ 3 M 的 CPU 缓存 。高端的处理器会有 6 M CPU 缓存 ,越大的缓存 ,意味着处理器更好 。
|
||||
```
|
||||
## 印刷工艺
|
||||
```
|
||||
晶体管的大小就是处理器平板印刷的大小 ,尺寸通常是纳米 ,更小的尺寸意味者更好的兼容性 。这允许你更多的核心 ,更小的面积 ,更小的能量消耗 。
|
||||
这最新的 Intel 处理器有 14 nm 的印刷工艺 。
|
||||
```
|
||||
## 热功耗设计
|
||||
```
|
||||
代表这电池的能量 ,单位是瓦特 。在全核心激活以基本频率来处理 Intel 模式 ,高复杂度的负载是一种浪费处理器的行为 。
|
||||
所以 ,越低的热功耗设计 ,对你越好 。一个低的热功耗设计不仅更好的利用电池能量 ,而且产生更少的热量 。
|
||||
```
|
||||
[![battery][3]][3]
|
||||
```
|
||||
桌面版本的处理器通常消耗更多的能量 ,热功耗消耗的能量能够在 40% 以上 ,相对应的移动版本只有不到桌面版本的 1/3 。
|
||||
```
|
||||
## 内存支持
|
||||
```
|
||||
我们已经提到了处理器的架构是如何影响到我们能够使用的内存总量 。这样我们只掌握了正确的理论 。在实际的应用中 ,RAM 的总量对于处理器的规格来说是足够我们使用的 ,由处理器规格详细规定 ,也包含支持的 DDR 版本的内存 。
|
||||
```
|
||||
[![RAM][4]][4]
|
||||
|
||||
## 超频
|
||||
```
|
||||
前面我们讲过时钟频率 ,超频是程序强迫 CPU 执行更多的周期 。游戏玩家经常会使他们的处理器超频 ,以此来获得更好的性能 。这样确实回增加速度 ,但也会增加消耗的能量 ,产生更多的热量 。
|
||||
一些高端的处理器允许超频 ,如果我们想让一个不支持超平的处理器超频 ,我们需要在主板上安装一个新的 BIOS 。
|
||||
这样通常下回成功 ,但这种情况是不安全的 ,也是不被建议的 。
|
||||
```
|
||||
## 超线程
|
||||
```
|
||||
如果对特定的处理需要添加核心是不合适的 ,那么超线程回建立一个虚拟核心 。
|
||||
当我们说双核处理器有超线程 ,这个双核处理器有两个物理核心和两个虚拟核心 ,在技术上讲 ,一个双核处理器拥有四核核心 。
|
||||
```
|
||||
## 结论
|
||||
```
|
||||
一个处理器有许多相关的数据 ,这是对数字设备来说是最重要的部分 。我们在选择设备时 ,我们应该在脑海中仔细的检查处理器在上面提到的数据 。
|
||||
时钟速度 ,核心数 ,CPU 缓存 ,以及架构是比重最大的数据 。印刷尺寸以及热功耗设计比重要小一些 。
|
||||
仍然有疑惑 ? 欢迎评论 ,我会尽快回复的 。
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/processors-everything-need-know
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[b]:http://www.theitstuff.com/wp-content/uploads/2017/10/processors-all-you-need-to-know.jpg
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/10/download.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/10/download-1.jpg
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/10/download-2.jpg
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/10/images.jpg
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/10/processors-all-you-need-to-know.jpg
|
||||
@ -1,11 +1,11 @@
|
||||
为初学者准备的 Linux ln 命令教程(5 个示例)
|
||||
======
|
||||
|
||||
当我们在命令行上工作时,您可能需要创建文件链接。这时,您可以可以借助一个专用命令,**ln**。本教程中,我们将基于此命令通过一些简明的例子展开讨论。在此之前,有必要明确,本教程所有测试都是基于 Ubuntu 16.04 设备开展的。
|
||||
当我们在命令行上工作时,您可能需要在文件之间创建链接。这时,您可以可以借助一个专用命令,**ln**。本教程中,我们将通过一些简单易理解的例子来讨论此工具的基础知识。在此之前,值得一提的是,本教程所有例子都已在 Ubuntu 16.04 上测试通过。
|
||||
|
||||
### Linux ln 命令
|
||||
|
||||
正如现在你所了解的,ln 命令能够让您链接文件。下面就是 ln 工具的语法(或者使用其他一些可行的语法)。
|
||||
正如你现在所了解的,ln 命令能够让您在文件之间创建链接。下面就是 ln 工具的语法(或者使用其他一些可行的语法)。
|
||||
|
||||
```
|
||||
ln [OPTION]... [-T] TARGET LINK_NAME (1st form)
|
||||
@ -16,32 +16,30 @@ ln [OPTION]... -t DIRECTORY TARGET... (4th form)
|
||||
|
||||
下面是 ln 工具 man 文档描述的内容:
|
||||
```
|
||||
在第一种形式下,创建名为 LINK_NAME 的链接目标。
|
||||
第二种形式为创建链接在当前目录。
|
||||
第三和第四中形式中,在 DIRECTORY 目录下创建链接目标。默认创建硬链接,字符链接需要 --symbolic 选项。默认创建硬链接,目标文件必须存在。字符链接可以保存任何文件。
|
||||
在第一种形式下,为 TARGET 创建一个叫 LINK_NAME 的链接。在第二种形式下,为 TARGET 在当前目录下创建一个链接( LCTT 译注:创建的为同名链接)。在第三和第四中形式中,在 DIRECTORY 目录下为每一个 TARGET 创建链接。默认创建硬链接,符号链接需要 --symbolic 选项。默认创建的每一个目标(新链接的名字)都不能已经存在。当创建硬链接时,TARGET 文件必须存在。符号链接可以保存任意文本,如果之后解析,相对链接的解析与其父目录有关。
|
||||
```
|
||||
|
||||
同故宫下面问答风格的例子,可能会给你更好的理解。但是在此之前,建议您先了解 [软连接和硬链接的区别][1].
|
||||
通过下面问答风格的例子,可能会给你更好的理解。但是在此之前,建议您先了解 [硬链接和软链接的区别][1].
|
||||
|
||||
### Q1. 如何通过 ln 命令创建硬链接?
|
||||
### Q1. 如何使用 ln 命令创建硬链接?
|
||||
|
||||
这很简单,你只需要使用下面的 ln 命令:
|
||||
这很简单,你只需要像下面使用 ln 命令:
|
||||
|
||||
```
|
||||
ln [file] [hard-link-to-file]
|
||||
```
|
||||
|
||||
这里有一个示例:
|
||||
例如:
|
||||
|
||||
```
|
||||
ln test.txt test_hard_link.txt
|
||||
```
|
||||
|
||||
[![如何通过 ln 命令创建硬链接][2]][3]
|
||||
[![如何使用 ln 命令创建硬链接][2]][3]
|
||||
|
||||
如此,您便可以看见一个已经创建好了的硬链接,名为 test_hard_link.txt。
|
||||
如此,您便可以看见一个已经创建好的,名为 test_hard_link.txt 的硬链接。
|
||||
|
||||
### Q2. 如何通过 ln 命令创建软/字符链接?
|
||||
### Q2. 如何使用 ln 命令创建软/符号链接?
|
||||
|
||||
使用 -s 命令行选项
|
||||
|
||||
@ -49,33 +47,35 @@ ln test.txt test_hard_link.txt
|
||||
ln -s [file] [soft-link-to-file]
|
||||
```
|
||||
|
||||
这里有一个示例:
|
||||
例如:
|
||||
|
||||
```
|
||||
ln -s test.txt test_soft_link.txt
|
||||
```
|
||||
|
||||
[![如何通过 ln 命令创建软/字符链接][4]][5]
|
||||
[![如何使用 ln 命令创建软/符号链接][4]][5]
|
||||
|
||||
test_soft_link.txt 文件就是一个软/字符链接,被天蓝色文本 [标识][6]。
|
||||
test_soft_link.txt 文件就是一个软/符号链接,被天蓝色文本 [标识][6]。
|
||||
|
||||
### Q3. 如何通过 ln 命令删除既存的同名目标文件?
|
||||
### Q3. 如何使用 ln 命令删除既存的同名目标文件?
|
||||
|
||||
默认情况下,ln 不允许您在目标文件目录下创建同名链接。
|
||||
默认情况下,ln 不允许您在目标目录下创建已存在的链接。
|
||||
|
||||
[![ln 命令示例][7]][8]
|
||||
|
||||
然而,如果一定要这么做,您可以使用 **-f** 命令行选项忽视此行为。
|
||||
然而,如果一定要这么做,您可以使用 **-f** 命令行选项覆盖此行为。
|
||||
|
||||
[![如何通过 ln 命令创建软/字符链接][9]][10]
|
||||
[![如何使用 ln 命令创建软/符号链接][9]][10]
|
||||
|
||||
**贴士** : 如果您想忽略删除过程中所有的命令行交互,您可以使用 **-i** 选项。
|
||||
**贴士** : 如果您想在此删除过程中有所交互,您可以使用 **-i** 选项。
|
||||
|
||||
### Q4. 如何通过 ln 命令创建既存文件的同名备份?
|
||||
### Q4. 如何使用 ln 命令创建现有文件的同名备份?
|
||||
|
||||
如果您不想通过 ln 删除同名的既存文件,您可以让它为此文件创建备份。使用 **-b** 即可实现此效果。被创建的备份文件,会在其文件名结尾处包含一个(~) 字符标识。
|
||||
如果您不想 ln 删除同名的现有文件,您可以为这些文件创建备份。使用 **-b** 即可实现此效果,以这种方式创建的备份文件,会在其文件名结尾处包含一个波浪号(~)。
|
||||
|
||||
[![如何通过 ln 命令创建既存文件的同名备份][11]][12]
|
||||
[![如何使用 ln 命令创建现有文件的同名备份][11]][12]
|
||||
|
||||
### Q5. 如何在当前目录以外的其它目录创建链接?
|
||||
|
||||
使用 **-t** 选项指定一个文件目录(除了当前目录)。比如:
|
||||
|
||||
@ -83,11 +83,11 @@ test_soft_link.txt 文件就是一个软/字符链接,被天蓝色文本 [标
|
||||
ls test* | xargs ln -s -t /home/himanshu/Desktop/
|
||||
```
|
||||
|
||||
上述命令会为所有 test* 文件(当前目录下的 test* 文件)创建链接到桌面。
|
||||
上述命令会为所有 test* 文件(当前目录下的 test* 文件)创建链接,并放到桌面目录下。
|
||||
|
||||
### 总结
|
||||
|
||||
当然,**ln** 并不是日常必备命令,尤其对于新手。但是了解此命令益处良多,有备无患,万一它哪一天刚好可以拯救你。对于这个命令,我们已经讨论了一些实用的选项,更多详情请查询 [man 文档][13]。
|
||||
当然,尤其对于新手来说,**ln** 并不是日常必备命令。但是,这是一个有用的命令,因为你永远不知道它什么时候能够节省你一天的时间。对于这个命令,我们已经讨论了一些实用的选项,如果你已经完成了这些,可以查询 [man 文档][13] 来了解更多详情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -95,7 +95,7 @@ via: https://www.howtoforge.com/linux-ln-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Locez](https://github.com/locez)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,56 @@
|
||||
TLP 帮助我们的 Linux 机器节能省电
|
||||
======
|
||||

|
||||
|
||||
我发现 Linux 下电池的寿命普遍要比 windows 下要短。尽管如此,这可是 [Linux][1],我们总会有有办法的。
|
||||
|
||||
现在来讲一下这个名叫 TLP 的小工具,它能帮你的设备省点电。
|
||||
|
||||
**TLP - Linux 高级电源管理** 是一个小巧的命令行工具,它通过对 Linux 系统执行一些调整来真正帮助延长电池的寿命。
|
||||
|
||||
```
|
||||
sudo apt install tlp
|
||||
```
|
||||
|
||||
[][2]
|
||||
|
||||
对于其他的发行版,你可以阅读[官方网站 ][3] 上的指南。
|
||||
|
||||
安装完成之后,你只有在第一次的时候需要运行下面命令来启动 tlp。TLP 会在下次启动系统时自动运行。
|
||||
|
||||
[][4]
|
||||
|
||||
现在 TLP 已经被启动起来了,而且已经设置好了节省电池所需要的默认配置。我们可以查看该配置文件。文件路径为 **/etc/default/tlp**。我们需要编辑该文件来修改各项配置。
|
||||
|
||||
配置文件中有很多选项,要启用某个选项的话之胥敖删除行首的 **#** 就行了。每个选项能够赋予什么值都有说明。下面是你可能会用到的选项 -
|
||||
|
||||
* 自动休眠 USB 设备
|
||||
|
||||
* 设定启动时启用/禁用无线设备
|
||||
|
||||
* 降低硬盘转速
|
||||
|
||||
* 关闭无线设备
|
||||
|
||||
* 设置 CPU 以性能优先还是节能优先
|
||||
|
||||
### 结论
|
||||
|
||||
TLP 是一个超棒的工具,可以延长 Linux 系统中电池的寿命。我个人的经验是使用 TLP 能延长至少 30-40% 的电池寿命。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/save-some-battery-on-our-linux-machines-with-tlp
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/linux
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/install-tlp-in-linux.jpeg
|
||||
[3]:http://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/start-tlp-on-linux.jpeg
|
||||
Loading…
Reference in New Issue
Block a user