mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
b68b7c42d0
published
sources
talk
20180319 6 common questions about agile development practices for teams.md20180320 Can we build a social network that serves users rather than advertisers.md20180321 8 tips for better agile retrospective meetings.md
tech
20171012 7 Best eBook Readers for Linux.md20171024 Learn Blockchains by Building One.md20180103 5 ways open source can strengthen your job search.md20180111 How to install software applications on Linux.md20180221 cTop - A CLI Tool For Container Monitoring.md20180313 The Type Command Tutorial With Examples For Beginners.md20180314 How to measure particulate matter with a Raspberry Pi.md20180317 How To Edit Multiple Files Using Vim Editor.md20180318 How To Manage Disk Partitions Using Parted Command.md20180319 A Command Line Productivity Tool For Tracking Work Hours.md20180320 Migrating to Linux- Installing Software.md20180321 Protecting Code Integrity with PGP - Part 6- Using PGP with Git.md20180322 Simple Load Balancing with DNS on Linux.md20180322 chkservice - A Tool For Managing Systemd Units From Linux Terminal.md
translated/tech
20170101 How to resolve mount.nfs- Stale file handle error.md20180209 How to setup and configure network bridge on Debian Linux.md20180314 How to measure particulate matter with a Raspberry Pi.md20180321 How to use Ansible to patch systems and install applications.md20180321 The Command line Personal Assistant For Your Linux System.md
@ -1,79 +1,85 @@
|
||||
Tlog - 录制/播放终端 IO 和会话的工具
|
||||
Tlog:录制/播放终端 IO 和会话的工具
|
||||
======
|
||||
Tlog 是 Linux 中终端 I/O 录制和回放软件包。它用于实现集中式用户会话录制。它将所有经过的消息录制为 JSON 消息。录制为 JSON 格式的主要目的是将数据传送到 Elasticsearch 之类的存储服务,可以从中搜索和查询,以及回放。同时,他们保留所有通过的数据和时序。
|
||||
|
||||
Tlog 包含三个工具,分别是 tlog-rec、tlog-rec-session 和 tlog-play。
|
||||
|
||||
* `Tlog-rec tool` 一般用于录制终端、程序或 shell 的输入或输出。
|
||||
* `Tlog-rec-session tool` 用于录制整个终端会话的 I/O,并保护录制的用户。
|
||||
* `Tlog-rec-session tool` 用于回放录制。
|
||||
Tlog 是 Linux 中终端 I/O 录制和回放软件包。它用于实现一个集中式用户会话录制。它将所有经过的消息录制为 JSON 消息。录制为 JSON 格式的主要目的是将数据传送到 ElasticSearch 之类的存储服务,可以从中搜索和查询,以及回放。同时,它们保留所有通过的数据和时序。
|
||||
|
||||
Tlog 包含三个工具,分别是 `tlog-rec`、tlog-rec-session` 和 `tlog-play`。
|
||||
|
||||
* `tlog-rec` 工具一般用于录制终端、程序或 shell 的输入或输出。
|
||||
* `tlog-rec-session` 工具用于录制整个终端会话的 I/O,包括录制的用户。
|
||||
* `tlog-play` 工具用于回放录制。
|
||||
|
||||
在本文中,我将解释如何在 CentOS 7.4 服务器上安装 Tlog。
|
||||
|
||||
### 安装
|
||||
|
||||
在安装之前,我们需要确保我们的系统满足编译和安装程序的所有软件要求。在第一步中,使用以下命令更新系统仓库和软件包。
|
||||
|
||||
```
|
||||
#yum update
|
||||
# yum update
|
||||
```
|
||||
|
||||
我们需要安装此软件安装所需的依赖项。在安装之前,我已经使用这些命令安装了所有依赖包。
|
||||
|
||||
```
|
||||
#yum install wget gcc
|
||||
#yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
# yum install wget gcc
|
||||
# yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
```
|
||||
|
||||
完成这些安装后,我们可以下载该工具的[源码包][1]并根据需要将其解压到服务器上:
|
||||
|
||||
```
|
||||
#wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
#tar -xvf tlog-3.tar.gz
|
||||
# wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
# tar -xvf tlog-3.tar.gz
|
||||
# cd tlog-3
|
||||
```
|
||||
|
||||
现在,你可以使用我们通常的配置和制作方法开始构建此工具。
|
||||
现在,你可以使用我们通常的配置和编译方法开始构建此工具。
|
||||
|
||||
```
|
||||
#./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
#make install
|
||||
#ldconfig
|
||||
# ./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
# make install
|
||||
# ldconfig
|
||||
```
|
||||
|
||||
最后,你需要运行 `ldconfig`。它会创建必要的链接,并缓存命令行中指定目录中最近的共享库。( /etc/ld.so.conf 中的文件,以及信任的目录 (/lib and /usr/lib))
|
||||
最后,你需要运行 `ldconfig`。它对命令行中指定目录、`/etc/ld.so.conf` 文件,以及信任的目录( `/lib` 和 `/usr/lib`)中最近的共享库创建必要的链接和缓存。
|
||||
|
||||
### Tlog 工作流程图
|
||||
|
||||
![Tlog working process][2]
|
||||
|
||||
首先,用户通过 PAM 进行身份验证登录。名称服务交换机(NSS)提供的 `tlog` 信息是用户的 shell。这初始化了 tlog 部分,并从环境变量/配置文件收集关于实际 shell 的信息,并以 PTY 的形式启动实际的 shell。然后通过 syslog 或 sd-journal 开始录制在终端和 PTY 之间传递的所有内容。
|
||||
首先,用户通过 PAM 进行身份验证登录。名称服务交换器(NSS)提供的 `tlog` 信息是用户的 shell。这初始化了 tlog 部分,并从环境变量/配置文件收集关于实际 shell 的信息,并在 PTY 中启动实际的 shell。然后通过 syslog 或 sd-journal 开始录制在终端和 PTY 之间传递的所有内容。
|
||||
|
||||
### 用法
|
||||
|
||||
你可以使用 `tlog-rec` 录制一个会话并使用 `tlog-play` 回放它来测试新安装的 tlog 是否能够正常录制和回放会话。
|
||||
你可以使用 `tlog-rec` 录制一个会话并使用 `tlog-play` 回放它,以测试新安装的 tlog 是否能够正常录制和回放会话。
|
||||
|
||||
#### 录制到文件中
|
||||
|
||||
要将会话录制到文件中,请在命令行中执行 `tlog-rec`,如下所示:
|
||||
|
||||
```
|
||||
tlog-rec --writer=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令会将我们的终端会话录制到名为 tlog.log 的文件中,并将其保存在命令中指定的路径中。
|
||||
该命令会将我们的终端会话录制到名为 `tlog.log` 的文件中,并将其保存在命令中指定的路径中。
|
||||
|
||||
#### 从文件中回放
|
||||
|
||||
你可以在录制过程中或录制后使用 `tlog-play` 命令回放录制的会话。
|
||||
|
||||
```
|
||||
tlog-play --reader=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令从指定的路径读取先前录制的文件 tlog.log。
|
||||
该命令从指定的路径读取先前录制的文件 `tlog.log`。
|
||||
|
||||
### 总结
|
||||
|
||||
Tlog 是一个开源软件包,可用于实现集中式用户会话录制。它主要是作为一个更大的用户会话录制解决方案的一部分使用,但它被设计为独立且可重用的。该工具可以帮助录制用户所做的一切并将其存储在服务器的某个位置,以备将来参考。你可以从这个[文档][3]中获得关于这个软件包使用的更多细节。我希望这篇文章对你有用。请发表你的宝贵建议和意见。
|
||||
Tlog 是一个开源软件包,可用于实现集中式用户会话录制。它主要是作为一个更大的用户会话录制解决方案的一部分使用,但它被设计为独立且可重用的。该工具可以帮助录制用户所做的一切,并将其存储在服务器的某个位置,以备将来参考。你可以从这个[文档][3]中获得关于这个软件包使用的更多细节。我希望这篇文章对你有用。请发表你的宝贵建议和意见。
|
||||
|
||||
**关于 Saheetha Shameer (作者)**
|
||||
|
||||
### 关于 Saheetha Shameer (作者)
|
||||
我正在担任高级系统管理员。我是一名快速学习者,有轻微的倾向跟随行业中目前和正在出现的趋势。我的爱好包括听音乐、玩策略游戏、阅读和园艺。我对尝试各种美食也有很高的热情 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -82,7 +88,7 @@ via: https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-session
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
6 common questions about agile development practices for teams
|
||||
======
|
||||
|
||||

|
||||
"Any questions?"
|
||||
|
||||
You’ve probably heard a speaker ask this question at the end of their presentation. This is the most important part of the presentation—after all, you didn't attend just to hear a lecture but to participate in a conversation and a community.
|
||||
|
||||
Recently I had the opportunity to hear my fellow Red Hatters present a session called "[Agile in Practice][1]" to a group of technical students at a local university. During the session, software engineer Tomas Tomecek and agile practitioners Fernando Colleone and Pavel Najman collaborated to explain the foundations of agile methodology and showcase best practices for day-to-day activities.
|
||||
|
||||
### 1\. What is the perfect team size?
|
||||
|
||||
Knowing that students attended this session to learn what agile practice is and how to apply it to projects, I wondered how the students' questions would compare to those I hear every day as an agile practitioner at Red Hat. It turns out that the students asked the same questions as my colleagues. These questions drive straight into the core of agile in practice.
|
||||
|
||||
Students wanted to know the size of a small team versus a large team. This issue is relevant to anyone who has ever teamed up to work on a project. Based on Tomas's experience as a tech leader, 12 people working on a project would be considered a large team. In the real world, team size is not often directly correlated to productivity. In some cases, a smaller team located in a single location or time zone might be more productive than a larger team that's spread around the world. Ultimately, the presenters suggested that the ideal team size is probably five people (which aligns with scrum 7, +-2).
|
||||
|
||||
### 2\. What operational challenges do teams face?
|
||||
|
||||
The presenters compared projects supported by local teams (teams with all members in one office or within close proximity to each other) with distributed teams (teams located in different time zones). Engineers prefer local teams when the project requires close cooperation among team members because delays caused by time differences can destroy the "flow" of writing software. At the same time, distributed teams can bring together skill sets that may not be available locally and are great for certain development use cases. Also, there are various best practices to improve cooperation in distributed teams.
|
||||
|
||||
### 3\. How much time is needed to groom the backlog?
|
||||
|
||||
Because this was an introductory talk targeting students who were new to agile, the speakers focused on [Scrum][2] and [Kanban][3] as ways to make agile specific for them. They used the Scrum framework to illustrate a method of writing software and Kanban for a communication and work planning system. On the question of time needed to groom a project's backlog, the speakers explained that there is no fixed rule. Rather, practice makes perfect: During the early stages of development, when a project is new—and especially if some members of the team are new to agile—grooming can consume several hours per week. Over time and with practice, it becomes more efficient.
|
||||
|
||||
### 4\. Is a product owner necessary? What is their role?
|
||||
|
||||
Product owners help facilitate scaling; however, what matters is not the job title, but that you have someone on your team who represents the customer's voice and goals. In many teams, especially those that are part of a larger group of engineering teams working on a single output, a lead engineer can serve as the product owner.
|
||||
|
||||
### 5\. What agile tools do you suggest using? Is specific software necessary to implement Scrum or Kanban in practice?
|
||||
|
||||
Although using proprietary software such as Jira or Trello can be helpful, especially when working with large numbers of contributors working on big enterprise projects, they are not required. Scrum and Kanban can be done with tools as simple as paper cards. The key is to have a clear source of information and strong communication across the entire team. That said, two excellent open source kanban tools are [Taiga][4] and [Wekan][5]. For more information, see [5 open source alternatives to Trello][6] and [Top 7 open source project management tools for agile teams][7].
|
||||
|
||||
### 6\. How can students use agile techniques for school projects?
|
||||
|
||||
The presenters encouraged students to use kanban to visualize and outline tasks to be completed before the end of the project. The key is to create a common board so the entire team can see the status of the project. By using kanban or a similar high-visibility strategy, students won’t get to the end of the project and discover that any particular team member has not been keeping up.
|
||||
|
||||
Scrum practices such as sprints and daily standups are also excellent ways to ensure that everyone is making progress and that the various parts of the project will work together at the end. Regular check-ins and information-sharing are also essential. To learn more about Scrum, see [What is scrum?][8].
|
||||
|
||||
Remember that Kanban and Scrum are just two of many tools and frameworks that make up agile. They may not be the best approach for every situation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/agile-mindset
|
||||
|
||||
作者:[Dominika Bula][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dominika
|
||||
[1]:http://zijemeit.cz/sessions/agile-in-practice/
|
||||
[2]:https://www.scrum.org/resources/what-is-scrum
|
||||
[3]:https://en.wikipedia.org/wiki/Kanban
|
||||
[4]:https://taiga.io/
|
||||
[5]:https://wekan.github.io/
|
||||
[6]:https://opensource.com/alternatives/trello
|
||||
[7]:https://opensource.com/article/18/2/agile-project-management-tools
|
||||
[8]:https://opensource.com/resources/scrum
|
||||
@ -0,0 +1,70 @@
|
||||
Can we build a social network that serves users rather than advertisers?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, open source software is far-reaching and has played a key role driving innovation in our digital economy. The world is undergoing radical change at a rapid pace. People in all parts of the world need a purpose-built, neutral, and transparent online platform to meet the challenges of our time.
|
||||
|
||||
And open principles might just be the way to get us there. What would happen if we married digital innovation with social innovation using open-focused thinking?
|
||||
|
||||
This question is at the heart of our work at [Human Connection][1], a forward-thinking, Germany-based knowledge and action network with a mission to create a truly social network that serves the world. We're guided by the notion that human beings are inherently generous and sympathetic, and that they thrive on benevolent actions. But we haven't seen a social network that has fully supported our natural tendency towards helpfulness and cooperation to promote the common good. Human Connection aspires to be the platform that allows everyone to become an active changemaker.
|
||||
|
||||
In order to achieve the dream of a solution-oriented platform that enables people to take action around social causes by engaging with charities, community groups, and social change activists, Human Connection embraces open values as a vehicle for social innovation.
|
||||
|
||||
Here's how.
|
||||
|
||||
### Transparency first
|
||||
|
||||
Transparency is one of Human Connection's guiding principles. Human Connection invites programmers around the world to jointly work on the platform's source code (JavaScript, Vue, nuxt) by [making their source code available on Github][2] and support the idea of a truly social network by contributing to the code or programming additional functions.
|
||||
|
||||
But our commitment to transparency extends beyond our development practices. In fact—when it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better—making the source code available is just one step towards being transparent.
|
||||
|
||||
To facilitate open dialogue, the Human Connection team holds [regular public meetings online][3]. Here we answer questions, encourage suggestions, and respond to potential concerns. Our Meet The Team events are also recorded and made available to the public afterwards. By being fully transparent with our process, our source code, and our finances, we can protect ourselves against critics or other potential backlashes.
|
||||
|
||||
The commitment to transparency also means that all user contributions that shared publicly on Human Connection will be released under a Creative Commons license and can eventually be downloaded as a data pack. By making crowd knowledge available, especially in a decentralized way, we create the opportunity for social pluralism.
|
||||
|
||||
Guiding all of our organizational decisions is one question: "Does it serve the people and the greater good?" And we use the [UN Charter][4] and the Universal Declaration of Human Rights as a foundation for our value system. As we'll grow bigger, especially with our upcoming open beta launch, it's important for us to stay accountable to that mission. I'm even open to the idea of inviting the Chaos Computer Club or other hacker clubs to verify the integrity of our code and our actions by randomly checking into our platform.
|
||||
|
||||
When it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better, making the source code available is just one step towards being transparent.
|
||||
|
||||
### A collaborative community
|
||||
|
||||
A [collaborative, community-centered approach][5] to programming the Human Connection platform is the foundation for an idea that extends beyond the practical applications of a social network. Our team is driven by finding an answer to the question: "What makes a social network truly social?"
|
||||
|
||||
A network that abandons the idea of a profit-driven algorithm serving advertisers instead of end-users can only thrive by turning to the process of peer production and collaboration. Organizations like [Code Alliance][6] and [Code for America][7], for example, have demonstrated how technology can be created in an open source environment to benefit humanity and disrupt the status quo. Community-driven projects like the map-based reporting platform [FixMyStreet][8] or the [Tasking Manager][9] built for the Humanitarian OpenStreetMap initiative have embraced crowdsourcing as a way to move their mission forward.
|
||||
|
||||
Our approach to building Human Connection has been collaborative from the start. To gather initial data on the necessary functions and the purpose of a truly social network, we collaborated with the National Institute for Oriental Languages and Civilizations (INALCO) at the University Sorbonne in Paris and the Stuttgart Media University in Germany. Research findings from both projects were incorporated into the early development of Human Connection. Thanks to that research, [users will have a whole new set of functions available][10] that put them in control of what content they see and how they engage with others. As early supporters are [invited to the network's alpha version][10], they can experience the first available noteworthy functions. Here are just a few:
|
||||
|
||||
* Linking information to action was one key theme emerging from our research sessions. Current social networks leave users in the information stage. Student groups at both universities saw a need for an action-oriented component that serves our human instinct of working together to solve problems. So we built a ["Can Do" function][11] into our platform. It's one of the ways individuals can take action after reading about a certain topic. "Can Do's" are user-suggested activities in the "Take Action" area that everyone can implement.
|
||||
* The "Versus" function is another defining result. Where traditional social networks are limited to a comment function, our student groups saw the need for a more structured and useful way to engage in discussions and arguments. A "Versus" is a counter-argument to a public post that is displayed separately and provides an opportunity to highlight different opinions around an issue.
|
||||
* Today's social networks don't provide a lot of options to filter content. Research has shown that a filtering option by emotions can help us navigate the social space in accordance with our daily mood and potentially protect our emotional wellbeing by not displaying sad or upsetting posts on a day where we want to see uplifting content only.
|
||||
|
||||
|
||||
|
||||
Human Connection invites changemakers to collaborate on the development of a network with the potential to mobilize individuals and groups around the world to turn negative news into "Can Do's"—and participate in social innovation projects in conjunction with charities and non-profit organizations.
|
||||
|
||||
[Subscribe to our weekly newsletter][12] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/open-social-human-connection
|
||||
|
||||
作者:[Dennis Hack][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dhack
|
||||
[1]:https://human-connection.org/en/
|
||||
[2]:https://github.com/human-connection/
|
||||
[3]:https://youtu.be/tPcYRQcepYE
|
||||
[4]:http://www.un.org/en/charter-united-nations/index.html
|
||||
[5]:https://youtu.be/BQHBno-efRI
|
||||
[6]:http://codealliance.org/
|
||||
[7]:https://www.codeforamerica.org/
|
||||
[8]:http://fixmystreet.org/
|
||||
[9]:https://tasks.hotosm.org/
|
||||
[10]:https://youtu.be/AwSx06DK2oU
|
||||
[11]:https://youtu.be/g2gYLNx686I
|
||||
[12]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,66 @@
|
||||
8 tips for better agile retrospective meetings
|
||||
======
|
||||
|
||||

|
||||
I’ve often thought that retrospectives should be called prospectives, as that term concerns the future rather than focusing on the past. The retro itself is truly future-looking: It’s the space where we can ask the question, “With what we know now, what’s the next experiment we need to try for improving our lives, and the lives of our customers?”
|
||||
|
||||
### What’s a retro supposed to look like?
|
||||
|
||||
There are two significant loops in product development: One produces the desired potentially shippable nugget. The other is where we examine how we’re working—not only to avoid doing what didn’t work so well, but also to determine how we can amplify the stuff we do well—and devise an experiment to pull into the next production loop to improve how our team is delighting our customers. This is the loop on the right side of this diagram:
|
||||
|
||||
|
||||
![Retrospective 1][2]
|
||||
|
||||
### When retros implode
|
||||
|
||||
While attending various teams' iteration retrospective meetings, I saw a common thread of malcontent associated with a relentless focus on continuous improvement.
|
||||
|
||||
One of the engineers put it bluntly: “[Our] continuous improvement feels like we are constantly failing.”
|
||||
|
||||
The teams talked about what worked, restated the stuff that didn’t work (perhaps already feeling like they were constantly failing), nodded to one another, and gave long sighs. Then one of the engineers (already late for another meeting) finally summed up the meeting: “Ok, let’s try not to submit all of the code on the last day of the sprint.” There was no opportunity to amplify the good, as the good was not discussed.
|
||||
|
||||
In effect, here’s what the retrospective felt like:
|
||||
|
||||

|
||||
|
||||
The anti-pattern is where retrospectives become dreaded sessions where we look back at the last iteration, make two columns—what worked and what didn’t work—and quickly come to some solution for the next iteration. There is no [scientific method][3] involved. There is no data gathering and research, no hypothesis, and very little deep thought. The result? You don’t get an experiment or a potential improvement to pull into the next iteration.
|
||||
|
||||
### 8 tips for better retrospectives
|
||||
|
||||
1. Amplify the good! Instead of focusing on what didn’t work well, why not begin the retro by having everyone mention one positive item first?
|
||||
2. Don’t jump to a solution. Thinking about a problem deeply instead of trying to solve it right away might be a better option.
|
||||
3. If the retrospective doesn’t make you feel excited about an experiment, maybe you shouldn’t try it in the next iteration.
|
||||
4. If you’re not analyzing how to improve, ([5 Whys][4], [force-field analysis][5], [impact mapping][6], or [fish-boning][7]), you might be jumping to solutions too quickly.
|
||||
5. Vary your methods. If every time you do a retrospective you ask, “What worked, what didn’t work?” and then vote on the top item from either column, your team will quickly get bored. [Retromat][8] is a great free retrospective tool to help vary your methods.
|
||||
6. End each retrospective by asking for feedback on the retro itself. This might seem a bit meta, but it works: Continually improving the retrospective is recursively improving as a team.
|
||||
7. Remove the impediments. Ask how you are enabling the team's search for improvement, and be prepared to act on any feedback.
|
||||
8. There are no "iteration police." Take breaks as needed. Deriving hypotheses from analysis and coming up with experiments involves creativity, and it can be taxing. Every once in a while, go out as a team and enjoy a nice retrospective lunch.
|
||||
|
||||
|
||||
|
||||
This article was inspired by [Retrospective anti-pattern: continuous improvement should not feel like constantly failing][9], posted at [Podojo.com][10].
|
||||
|
||||
**[See our related story,[How to build a business case for DevOps transformation][11].]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/tips-better-agile-retrospective-meetings
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/catherinelouis
|
||||
[1]:/file/389021
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/retro_1.jpg?itok=bggmHN1Q (Retrospective 1)
|
||||
[3]:https://en.wikipedia.org/wiki/Scientific_method
|
||||
[4]:https://en.wikipedia.org/wiki/5_Whys
|
||||
[5]:https://en.wikipedia.org/wiki/Force-field_analysis
|
||||
[6]:https://opensource.com/open-organization/17/6/experiment-impact-mapping
|
||||
[7]:https://en.wikipedia.org/wiki/Ishikawa_diagram
|
||||
[8]:https://plans-for-retrospectives.com/en/?id=28
|
||||
[9]:http://www.podojo.com/retrospective-anti-pattern-continuous-improvement-should-not-feel-like-constantly-failing/
|
||||
[10]:http://www.podojo.com/
|
||||
[11]:https://opensource.com/article/18/2/how-build-business-case-devops-transformation
|
||||
@ -1,3 +1,5 @@
|
||||
[translating for laujinseoi]
|
||||
|
||||
7 Best eBook Readers for Linux
|
||||
======
|
||||
**Brief:** In this article, we are covering some of the best ebook readers for Linux. These apps give a better reading experience and some will even help in managing your ebooks.
|
||||
|
||||
702
sources/tech/20171024 Learn Blockchains by Building One.md
Normal file
702
sources/tech/20171024 Learn Blockchains by Building One.md
Normal file
@ -0,0 +1,702 @@
|
||||
Learn Blockchains by Building One
|
||||
======
|
||||
|
||||

|
||||
You’re here because, like me, you’re psyched about the rise of Cryptocurrencies. And you want to know how Blockchains work—the fundamental technology behind them.
|
||||
|
||||
But understanding Blockchains isn’t easy—or at least wasn’t for me. I trudged through dense videos, followed porous tutorials, and dealt with the amplified frustration of too few examples.
|
||||
|
||||
I like learning by doing. It forces me to deal with the subject matter at a code level, which gets it sticking. If you do the same, at the end of this guide you’ll have a functioning Blockchain with a solid grasp of how they work.
|
||||
|
||||
### Before you get started…
|
||||
|
||||
Remember that a blockchain is an _immutable, sequential_ chain of records called Blocks. They can contain transactions, files or any data you like, really. But the important thing is that they’re _chained_ together using _hashes_ .
|
||||
|
||||
If you aren’t sure what a hash is, [here’s an explanation][1].
|
||||
|
||||
**_Who is this guide aimed at?_** You should be comfy reading and writing some basic Python, as well as have some understanding of how HTTP requests work, since we’ll be talking to our Blockchain over HTTP.
|
||||
|
||||
**_What do I need?_** Make sure that [Python 3.6][2]+ (along with `pip`) is installed. You’ll also need to install Flask and the wonderful Requests library:
|
||||
|
||||
```
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
```
|
||||
|
||||
Oh, you’ll also need an HTTP Client, like [Postman][3] or cURL. But anything will do.
|
||||
|
||||
**_Where’s the final code?_** The source code is [available here][4].
|
||||
|
||||
* * *
|
||||
|
||||
### Step 1: Building a Blockchain
|
||||
|
||||
Open up your favourite text editor or IDE, personally I ❤️ [PyCharm][5]. Create a new file, called `blockchain.py`. We’ll only use a single file, but if you get lost, you can always refer to the [source code][6].
|
||||
|
||||
#### Representing a Blockchain
|
||||
|
||||
We’ll create a `Blockchain` class whose constructor creates an initial empty list (to store our blockchain), and another to store transactions. Here’s the blueprint for our class:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
def __init__(self):
|
||||
self.chain = []
|
||||
self.current_transactions = []
|
||||
|
||||
def new_block(self):
|
||||
# Creates a new Block and adds it to the chain
|
||||
pass
|
||||
|
||||
def new_transaction(self):
|
||||
# Adds a new transaction to the list of transactions
|
||||
pass
|
||||
|
||||
@staticmethod
|
||||
def hash(block):
|
||||
# Hashes a Block
|
||||
pass
|
||||
|
||||
@property
|
||||
def last_block(self):
|
||||
# Returns the last Block in the chain
|
||||
pass
|
||||
```
|
||||
|
||||
|
||||
Our Blockchain class is responsible for managing the chain. It will store transactions and have some helper methods for adding new blocks to the chain. Let’s start fleshing out some methods.
|
||||
|
||||
#### What does a Block look like?
|
||||
|
||||
Each Block has an index, a timestamp (in Unix time), a list of transactions, a proof (more on that later), and the hash of the previous Block.
|
||||
|
||||
Here’s an example of what a single Block looks like:
|
||||
|
||||
```
|
||||
block = {
|
||||
'index': 1,
|
||||
'timestamp': 1506057125.900785,
|
||||
'transactions': [
|
||||
{
|
||||
'sender': "8527147fe1f5426f9dd545de4b27ee00",
|
||||
'recipient': "a77f5cdfa2934df3954a5c7c7da5df1f",
|
||||
'amount': 5,
|
||||
}
|
||||
],
|
||||
'proof': 324984774000,
|
||||
'previous_hash': "2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824"
|
||||
}
|
||||
```
|
||||
|
||||
At this point, the idea of a chain should be apparent—each new block contains within itself, the hash of the previous Block. This is crucial because it’s what gives blockchains immutability: If an attacker corrupted an earlier Block in the chain then all subsequent blocks will contain incorrect hashes.
|
||||
|
||||
Does this make sense? If it doesn’t, take some time to let it sink in—it’s the core idea behind blockchains.
|
||||
|
||||
#### Adding Transactions to a Block
|
||||
|
||||
We’ll need a way of adding transactions to a Block. Our new_transaction() method is responsible for this, and it’s pretty straight-forward:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
...
|
||||
|
||||
def new_transaction(self, sender, recipient, amount):
|
||||
"""
|
||||
Creates a new transaction to go into the next mined Block
|
||||
:param sender: <str> Address of the Sender
|
||||
:param recipient: <str> Address of the Recipient
|
||||
:param amount: <int> Amount
|
||||
:return: <int> The index of the Block that will hold this transaction
|
||||
"""
|
||||
|
||||
self.current_transactions.append({
|
||||
'sender': sender,
|
||||
'recipient': recipient,
|
||||
'amount': amount,
|
||||
})
|
||||
|
||||
return self.last_block['index'] + 1
|
||||
```
|
||||
|
||||
After new_transaction() adds a transaction to the list, it returns the index of the block which the transaction will be added to—the next one to be mined. This will be useful later on, to the user submitting the transaction.
|
||||
|
||||
#### Creating new Blocks
|
||||
|
||||
When our Blockchain is instantiated we’ll need to seed it with a genesis block—a block with no predecessors. We’ll also need to add a “proof” to our genesis block which is the result of mining (or proof of work). We’ll talk more about mining later.
|
||||
|
||||
In addition to creating the genesis block in our constructor, we’ll also flesh out the methods for new_block(), new_transaction() and hash():
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
from time import time
|
||||
|
||||
|
||||
class Blockchain(object):
|
||||
def __init__(self):
|
||||
self.current_transactions = []
|
||||
self.chain = []
|
||||
|
||||
# Create the genesis block
|
||||
self.new_block(previous_hash=1, proof=100)
|
||||
|
||||
def new_block(self, proof, previous_hash=None):
|
||||
"""
|
||||
Create a new Block in the Blockchain
|
||||
:param proof: <int> The proof given by the Proof of Work algorithm
|
||||
:param previous_hash: (Optional) <str> Hash of previous Block
|
||||
:return: <dict> New Block
|
||||
"""
|
||||
|
||||
block = {
|
||||
'index': len(self.chain) + 1,
|
||||
'timestamp': time(),
|
||||
'transactions': self.current_transactions,
|
||||
'proof': proof,
|
||||
'previous_hash': previous_hash or self.hash(self.chain[-1]),
|
||||
}
|
||||
|
||||
# Reset the current list of transactions
|
||||
self.current_transactions = []
|
||||
|
||||
self.chain.append(block)
|
||||
return block
|
||||
|
||||
def new_transaction(self, sender, recipient, amount):
|
||||
"""
|
||||
Creates a new transaction to go into the next mined Block
|
||||
:param sender: <str> Address of the Sender
|
||||
:param recipient: <str> Address of the Recipient
|
||||
:param amount: <int> Amount
|
||||
:return: <int> The index of the Block that will hold this transaction
|
||||
"""
|
||||
self.current_transactions.append({
|
||||
'sender': sender,
|
||||
'recipient': recipient,
|
||||
'amount': amount,
|
||||
})
|
||||
|
||||
return self.last_block['index'] + 1
|
||||
|
||||
@property
|
||||
def last_block(self):
|
||||
return self.chain[-1]
|
||||
|
||||
@staticmethod
|
||||
def hash(block):
|
||||
"""
|
||||
Creates a SHA-256 hash of a Block
|
||||
:param block: <dict> Block
|
||||
:return: <str>
|
||||
"""
|
||||
|
||||
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
|
||||
block_string = json.dumps(block, sort_keys=True).encode()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
```
|
||||
|
||||
The above should be straight-forward—I’ve added some comments and docstrings to help keep it clear. We’re almost done with representing our blockchain. But at this point, you must be wondering how new blocks are created, forged or mined.
|
||||
|
||||
#### Understanding Proof of Work
|
||||
|
||||
A Proof of Work algorithm (PoW) is how new Blocks are created or mined on the blockchain. The goal of PoW is to discover a number which solves a problem. The number must be difficult to find but easy to verify—computationally speaking—by anyone on the network. This is the core idea behind Proof of Work.
|
||||
|
||||
We’ll look at a very simple example to help this sink in.
|
||||
|
||||
Let’s decide that the hash of some integer x multiplied by another y must end in 0\. So, hash(x * y) = ac23dc...0\. And for this simplified example, let’s fix x = 5\. Implementing this in Python:
|
||||
|
||||
```
|
||||
from hashlib import sha256
|
||||
|
||||
x = 5
|
||||
y = 0 # We don't know what y should be yet...
|
||||
|
||||
while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
|
||||
y += 1
|
||||
|
||||
print(f'The solution is y = {y}')
|
||||
```
|
||||
|
||||
The solution here is y = 21\. Since, the produced hash ends in 0:
|
||||
|
||||
```
|
||||
hash(5 * 21) = 1253e9373e...5e3600155e860
|
||||
```
|
||||
|
||||
The network is able to easily verify their solution.
|
||||
|
||||
#### Implementing basic Proof of Work
|
||||
|
||||
Let’s implement a similar algorithm for our blockchain. Our rule will be similar to the example above:
|
||||
|
||||
> Find a number p that when hashed with the previous block’s solution a hash with 4 leading 0s is produced.
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
|
||||
from time import time
|
||||
from uuid import uuid4
|
||||
|
||||
|
||||
class Blockchain(object):
|
||||
...
|
||||
|
||||
def proof_of_work(self, last_proof):
|
||||
"""
|
||||
Simple Proof of Work Algorithm:
|
||||
- Find a number p' such that hash(pp') contains leading 4 zeroes, where p is the previous p'
|
||||
- p is the previous proof, and p' is the new proof
|
||||
:param last_proof: <int>
|
||||
:return: <int>
|
||||
"""
|
||||
|
||||
proof = 0
|
||||
while self.valid_proof(last_proof, proof) is False:
|
||||
proof += 1
|
||||
|
||||
return proof
|
||||
|
||||
@staticmethod
|
||||
def valid_proof(last_proof, proof):
|
||||
"""
|
||||
Validates the Proof: Does hash(last_proof, proof) contain 4 leading zeroes?
|
||||
:param last_proof: <int> Previous Proof
|
||||
:param proof: <int> Current Proof
|
||||
:return: <bool> True if correct, False if not.
|
||||
"""
|
||||
|
||||
guess = f'{last_proof}{proof}'.encode()
|
||||
guess_hash = hashlib.sha256(guess).hexdigest()
|
||||
return guess_hash[:4] == "0000"
|
||||
```
|
||||
|
||||
To adjust the difficulty of the algorithm, we could modify the number of leading zeroes. But 4 is sufficient. You’ll find out that the addition of a single leading zero makes a mammoth difference to the time required to find a solution.
|
||||
|
||||
Our class is almost complete and we’re ready to begin interacting with it using HTTP requests.
|
||||
|
||||
* * *
|
||||
|
||||
### Step 2: Our Blockchain as an API
|
||||
|
||||
We’re going to use the Python Flask Framework. It’s a micro-framework and it makes it easy to map endpoints to Python functions. This allows us talk to our blockchain over the web using HTTP requests.
|
||||
|
||||
We’ll create three methods:
|
||||
|
||||
* `/transactions/new` to create a new transaction to a block
|
||||
|
||||
* `/mine` to tell our server to mine a new block.
|
||||
|
||||
* `/chain` to return the full Blockchain.
|
||||
|
||||
#### Setting up Flask
|
||||
|
||||
Our “server” will form a single node in our blockchain network. Let’s create some boilerplate code:
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
from textwrap import dedent
|
||||
from time import time
|
||||
from uuid import uuid4
|
||||
|
||||
from flask import Flask
|
||||
|
||||
|
||||
class Blockchain(object):
|
||||
...
|
||||
|
||||
|
||||
# Instantiate our Node
|
||||
app = Flask(__name__)
|
||||
|
||||
# Generate a globally unique address for this node
|
||||
node_identifier = str(uuid4()).replace('-', '')
|
||||
|
||||
# Instantiate the Blockchain
|
||||
blockchain = Blockchain()
|
||||
|
||||
|
||||
@app.route('/mine', methods=['GET'])
|
||||
def mine():
|
||||
return "We'll mine a new Block"
|
||||
|
||||
@app.route('/transactions/new', methods=['POST'])
|
||||
def new_transaction():
|
||||
return "We'll add a new transaction"
|
||||
|
||||
@app.route('/chain', methods=['GET'])
|
||||
def full_chain():
|
||||
response = {
|
||||
'chain': blockchain.chain,
|
||||
'length': len(blockchain.chain),
|
||||
}
|
||||
return jsonify(response), 200
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
```
|
||||
|
||||
A brief explanation of what we’ve added above:
|
||||
|
||||
* Line 15: Instantiates our Node. Read more about Flask [here][7].
|
||||
|
||||
* Line 18: Create a random name for our node.
|
||||
|
||||
* Line 21: Instantiate our Blockchain class.
|
||||
|
||||
* Line 24–26: Create the /mine endpoint, which is a GET request.
|
||||
|
||||
* Line 28–30: Create the /transactions/new endpoint, which is a POST request, since we’ll be sending data to it.
|
||||
|
||||
* Line 32–38: Create the /chain endpoint, which returns the full Blockchain.
|
||||
|
||||
* Line 40–41: Runs the server on port 5000.
|
||||
|
||||
#### The Transactions Endpoint
|
||||
|
||||
This is what the request for a transaction will look like. It’s what the user sends to the server:
|
||||
|
||||
```
|
||||
{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
|
||||
```
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
from textwrap import dedent
|
||||
from time import time
|
||||
from uuid import uuid4
|
||||
|
||||
from flask import Flask, jsonify, request
|
||||
|
||||
...
|
||||
|
||||
@app.route('/transactions/new', methods=['POST'])
|
||||
def new_transaction():
|
||||
values = request.get_json()
|
||||
|
||||
# Check that the required fields are in the POST'ed data
|
||||
required = ['sender', 'recipient', 'amount']
|
||||
if not all(k in values for k in required):
|
||||
return 'Missing values', 400
|
||||
|
||||
# Create a new Transaction
|
||||
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
|
||||
|
||||
response = {'message': f'Transaction will be added to Block {index}'}
|
||||
return jsonify(response), 201
|
||||
```
|
||||
A method for creating Transactions
|
||||
|
||||
#### The Mining Endpoint
|
||||
|
||||
Our mining endpoint is where the magic happens, and it’s easy. It has to do three things:
|
||||
|
||||
1. Calculate the Proof of Work
|
||||
|
||||
2. Reward the miner (us) by adding a transaction granting us 1 coin
|
||||
|
||||
3. Forge the new Block by adding it to the chain
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
|
||||
from time import time
|
||||
from uuid import uuid4
|
||||
|
||||
from flask import Flask, jsonify, request
|
||||
|
||||
...
|
||||
|
||||
@app.route('/mine', methods=['GET'])
|
||||
def mine():
|
||||
# We run the proof of work algorithm to get the next proof...
|
||||
last_block = blockchain.last_block
|
||||
last_proof = last_block['proof']
|
||||
proof = blockchain.proof_of_work(last_proof)
|
||||
|
||||
# We must receive a reward for finding the proof.
|
||||
# The sender is "0" to signify that this node has mined a new coin.
|
||||
blockchain.new_transaction(
|
||||
sender="0",
|
||||
recipient=node_identifier,
|
||||
amount=1,
|
||||
)
|
||||
|
||||
# Forge the new Block by adding it to the chain
|
||||
previous_hash = blockchain.hash(last_block)
|
||||
block = blockchain.new_block(proof, previous_hash)
|
||||
|
||||
response = {
|
||||
'message': "New Block Forged",
|
||||
'index': block['index'],
|
||||
'transactions': block['transactions'],
|
||||
'proof': block['proof'],
|
||||
'previous_hash': block['previous_hash'],
|
||||
}
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
Note that the recipient of the mined block is the address of our node. And most of what we’ve done here is just interact with the methods on our Blockchain class. At this point, we’re done, and can start interacting with our blockchain.
|
||||
|
||||
### Step 3: Interacting with our Blockchain
|
||||
|
||||
You can use plain old cURL or Postman to interact with our API over a network.
|
||||
|
||||
Fire up the server:
|
||||
|
||||
```
|
||||
$ python blockchain.py
|
||||
```
|
||||
|
||||
Let’s try mining a block by making a GET request to http://localhost:5000/mine:
|
||||
|
||||
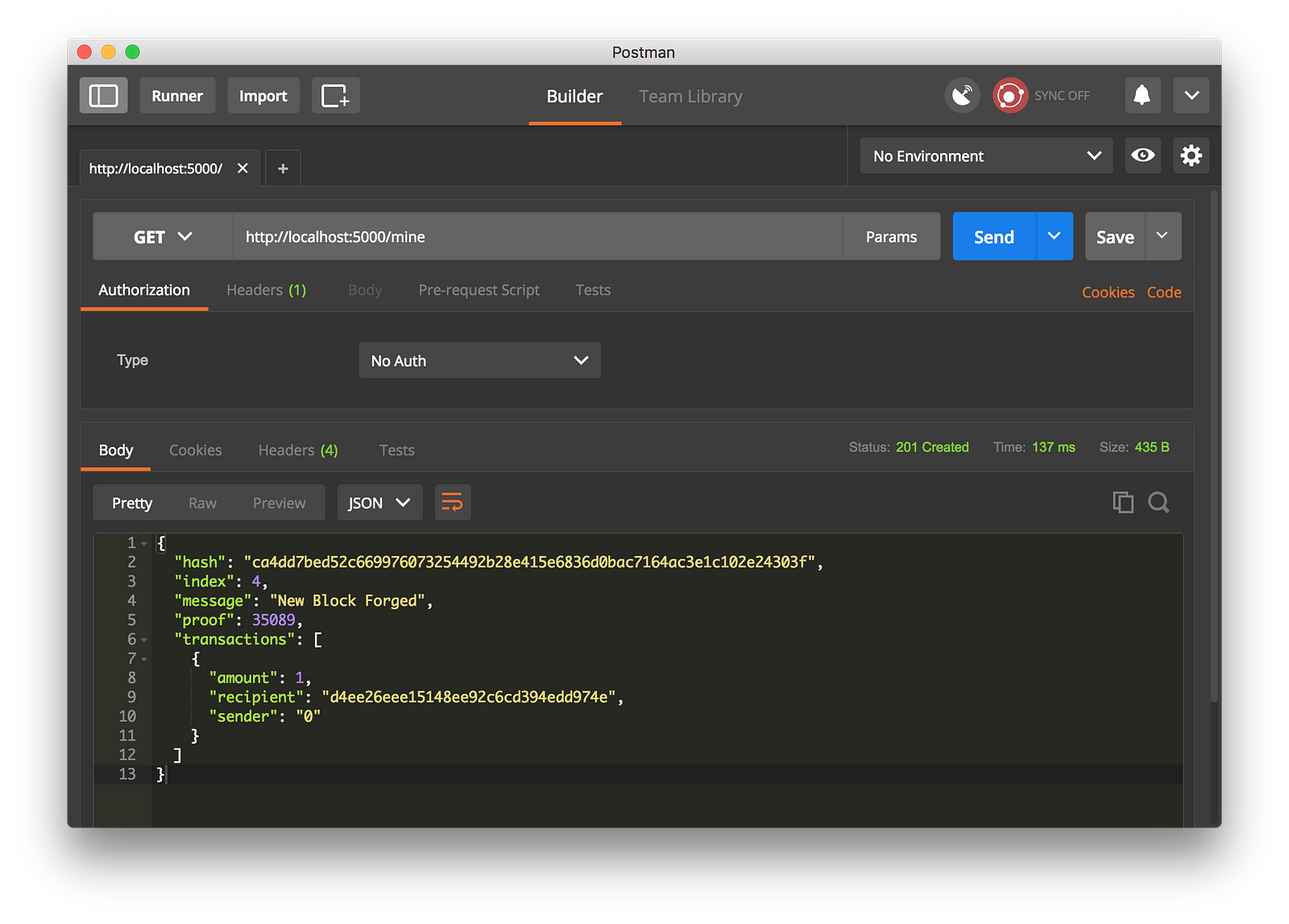
|
||||
Using Postman to make a GET request
|
||||
|
||||
Let’s create a new transaction by making a POST request tohttp://localhost:5000/transactions/new with a body containing our transaction structure:
|
||||
|
||||
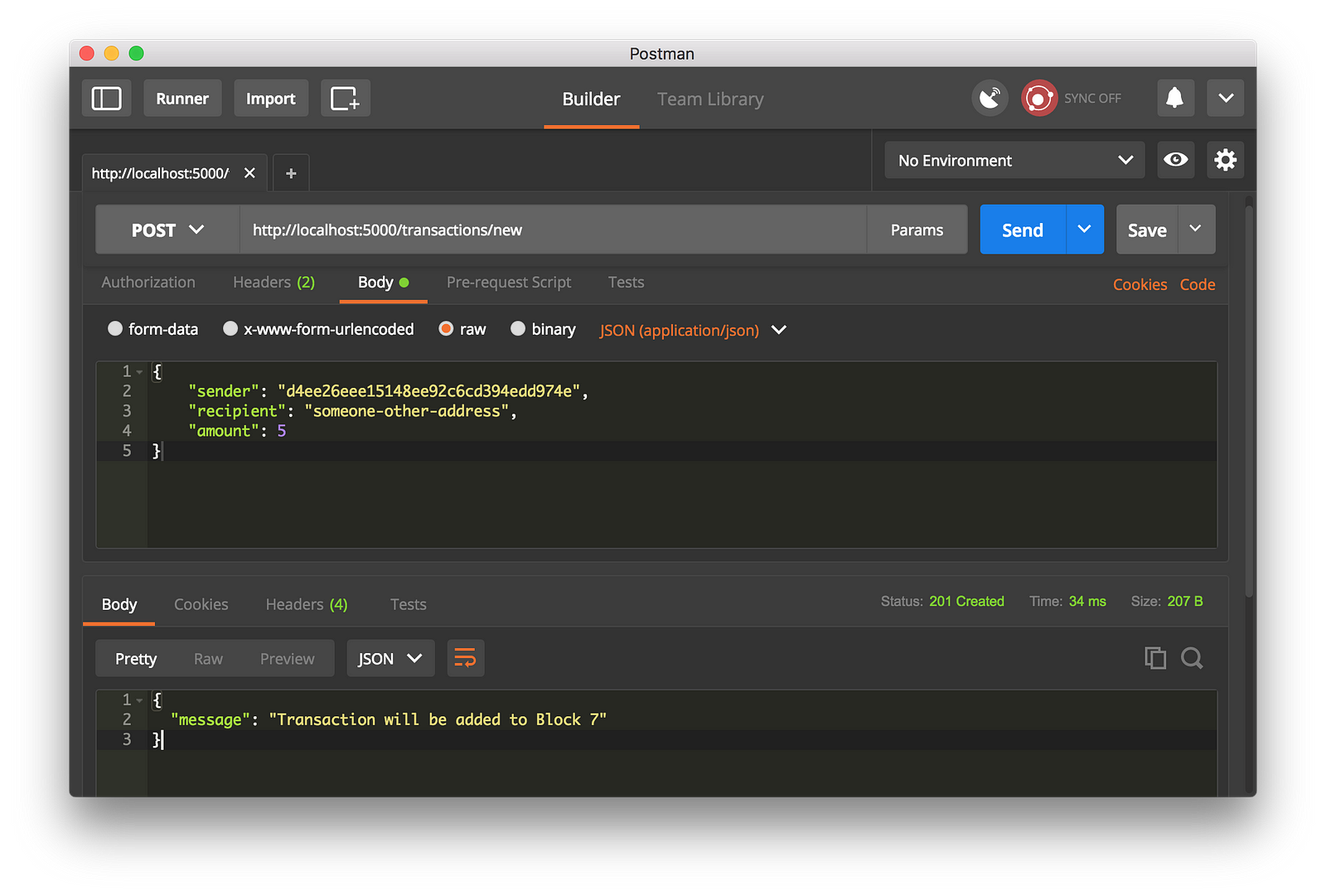
|
||||
Using Postman to make a POST request
|
||||
|
||||
If you aren’t using Postman, then you can make the equivalent request using cURL:
|
||||
|
||||
```
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
|
||||
```
|
||||
I restarted my server, and mined two blocks, to give 3 in total. Let’s inspect the full chain by requesting http://localhost:5000/chain:
|
||||
```
|
||||
{
|
||||
"chain": [
|
||||
{
|
||||
"index": 1,
|
||||
"previous_hash": 1,
|
||||
"proof": 100,
|
||||
"timestamp": 1506280650.770839,
|
||||
"transactions": []
|
||||
},
|
||||
{
|
||||
"index": 2,
|
||||
"previous_hash": "c099bc...bfb7",
|
||||
"proof": 35293,
|
||||
"timestamp": 1506280664.717925,
|
||||
"transactions": [
|
||||
{
|
||||
"amount": 1,
|
||||
"recipient": "8bbcb347e0634905b0cac7955bae152b",
|
||||
"sender": "0"
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"index": 3,
|
||||
"previous_hash": "eff91a...10f2",
|
||||
"proof": 35089,
|
||||
"timestamp": 1506280666.1086972,
|
||||
"transactions": [
|
||||
{
|
||||
"amount": 1,
|
||||
"recipient": "8bbcb347e0634905b0cac7955bae152b",
|
||||
"sender": "0"
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"length": 3
|
||||
```
|
||||
### Step 4: Consensus
|
||||
|
||||
This is very cool. We’ve got a basic Blockchain that accepts transactions and allows us to mine new Blocks. But the whole point of Blockchains is that they should be decentralized. And if they’re decentralized, how on earth do we ensure that they all reflect the same chain? This is called the problem of Consensus, and we’ll have to implement a Consensus Algorithm if we want more than one node in our network.
|
||||
|
||||
#### Registering new Nodes
|
||||
|
||||
Before we can implement a Consensus Algorithm, we need a way to let a node know about neighbouring nodes on the network. Each node on our network should keep a registry of other nodes on the network. Thus, we’ll need some more endpoints:
|
||||
|
||||
1. /nodes/register to accept a list of new nodes in the form of URLs.
|
||||
|
||||
2. /nodes/resolve to implement our Consensus Algorithm, which resolves any conflicts—to ensure a node has the correct chain.
|
||||
|
||||
We’ll need to modify our Blockchain’s constructor and provide a method for registering nodes:
|
||||
|
||||
```
|
||||
...
|
||||
from urllib.parse import urlparse
|
||||
...
|
||||
|
||||
|
||||
class Blockchain(object):
|
||||
def __init__(self):
|
||||
...
|
||||
self.nodes = set()
|
||||
...
|
||||
|
||||
def register_node(self, address):
|
||||
"""
|
||||
Add a new node to the list of nodes
|
||||
:param address: <str> Address of node. Eg. 'http://192.168.0.5:5000'
|
||||
:return: None
|
||||
"""
|
||||
|
||||
parsed_url = urlparse(address)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
```
|
||||
A method for adding neighbouring nodes to our Network
|
||||
|
||||
Note that we’ve used a set() to hold the list of nodes. This is a cheap way of ensuring that the addition of new nodes is idempotent—meaning that no matter how many times we add a specific node, it appears exactly once.
|
||||
|
||||
#### Implementing the Consensus Algorithm
|
||||
|
||||
As mentioned, a conflict is when one node has a different chain to another node. To resolve this, we’ll make the rule that the longest valid chain is authoritative. In other words, the longest chain on the network is the de-facto one. Using this algorithm, we reach Consensus amongst the nodes in our network.
|
||||
|
||||
```
|
||||
...
|
||||
import requests
|
||||
|
||||
|
||||
class Blockchain(object)
|
||||
...
|
||||
|
||||
def valid_chain(self, chain):
|
||||
"""
|
||||
Determine if a given blockchain is valid
|
||||
:param chain: <list> A blockchain
|
||||
:return: <bool> True if valid, False if not
|
||||
"""
|
||||
|
||||
last_block = chain[0]
|
||||
current_index = 1
|
||||
|
||||
while current_index < len(chain):
|
||||
block = chain[current_index]
|
||||
print(f'{last_block}')
|
||||
print(f'{block}')
|
||||
print("\n-----------\n")
|
||||
# Check that the hash of the block is correct
|
||||
if block['previous_hash'] != self.hash(last_block):
|
||||
return False
|
||||
|
||||
# Check that the Proof of Work is correct
|
||||
if not self.valid_proof(last_block['proof'], block['proof']):
|
||||
return False
|
||||
|
||||
last_block = block
|
||||
current_index += 1
|
||||
|
||||
return True
|
||||
|
||||
def resolve_conflicts(self):
|
||||
"""
|
||||
This is our Consensus Algorithm, it resolves conflicts
|
||||
by replacing our chain with the longest one in the network.
|
||||
:return: <bool> True if our chain was replaced, False if not
|
||||
"""
|
||||
|
||||
neighbours = self.nodes
|
||||
new_chain = None
|
||||
|
||||
# We're only looking for chains longer than ours
|
||||
max_length = len(self.chain)
|
||||
|
||||
# Grab and verify the chains from all the nodes in our network
|
||||
for node in neighbours:
|
||||
response = requests.get(f'http://{node}/chain')
|
||||
|
||||
if response.status_code == 200:
|
||||
length = response.json()['length']
|
||||
chain = response.json()['chain']
|
||||
|
||||
# Check if the length is longer and the chain is valid
|
||||
if length > max_length and self.valid_chain(chain):
|
||||
max_length = length
|
||||
new_chain = chain
|
||||
|
||||
# Replace our chain if we discovered a new, valid chain longer than ours
|
||||
if new_chain:
|
||||
self.chain = new_chain
|
||||
return True
|
||||
|
||||
return False
|
||||
```
|
||||
|
||||
The first method valid_chain() is responsible for checking if a chain is valid by looping through each block and verifying both the hash and the proof.
|
||||
|
||||
resolve_conflicts() is a method which loops through all our neighbouring nodes, downloads their chains and verifies them using the above method. If a valid chain is found, whose length is greater than ours, we replace ours.
|
||||
|
||||
Let’s register the two endpoints to our API, one for adding neighbouring nodes and the another for resolving conflicts:
|
||||
|
||||
```
|
||||
@app.route('/nodes/register', methods=['POST'])
|
||||
def register_nodes():
|
||||
values = request.get_json()
|
||||
|
||||
nodes = values.get('nodes')
|
||||
if nodes is None:
|
||||
return "Error: Please supply a valid list of nodes", 400
|
||||
|
||||
for node in nodes:
|
||||
blockchain.register_node(node)
|
||||
|
||||
response = {
|
||||
'message': 'New nodes have been added',
|
||||
'total_nodes': list(blockchain.nodes),
|
||||
}
|
||||
return jsonify(response), 201
|
||||
|
||||
|
||||
@app.route('/nodes/resolve', methods=['GET'])
|
||||
def consensus():
|
||||
replaced = blockchain.resolve_conflicts()
|
||||
|
||||
if replaced:
|
||||
response = {
|
||||
'message': 'Our chain was replaced',
|
||||
'new_chain': blockchain.chain
|
||||
}
|
||||
else:
|
||||
response = {
|
||||
'message': 'Our chain is authoritative',
|
||||
'chain': blockchain.chain
|
||||
}
|
||||
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
At this point you can grab a different machine if you like, and spin up different nodes on your network. Or spin up processes using different ports on the same machine. I spun up another node on my machine, on a different port, and registered it with my current node. Thus, I have two nodes: [http://localhost:5000][9] and http://localhost:5001.
|
||||
|
||||
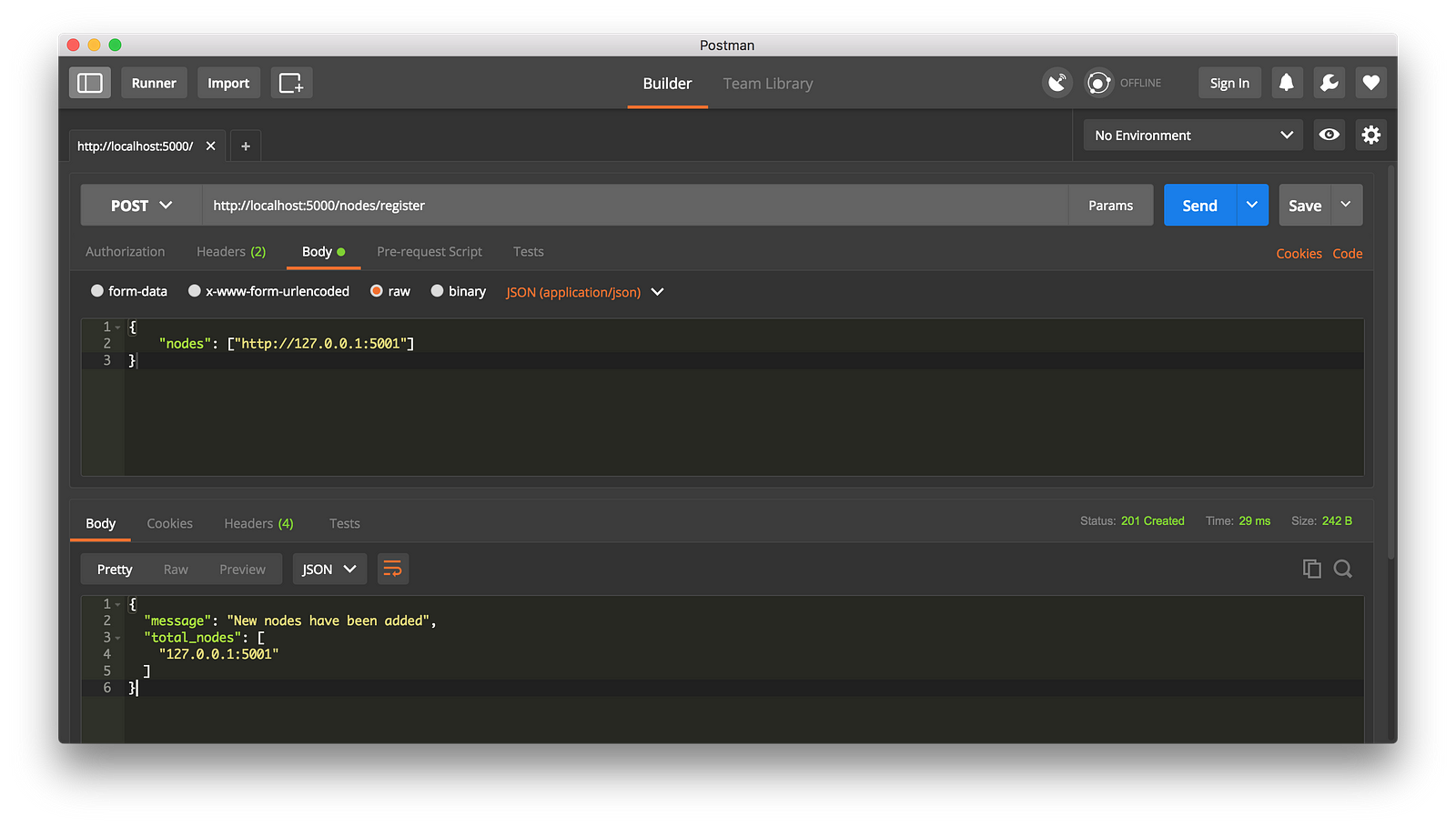
|
||||
Registering a new Node
|
||||
|
||||
I then mined some new Blocks on node 2, to ensure the chain was longer. Afterward, I called GET /nodes/resolve on node 1, where the chain was replaced by the Consensus Algorithm:
|
||||
|
||||
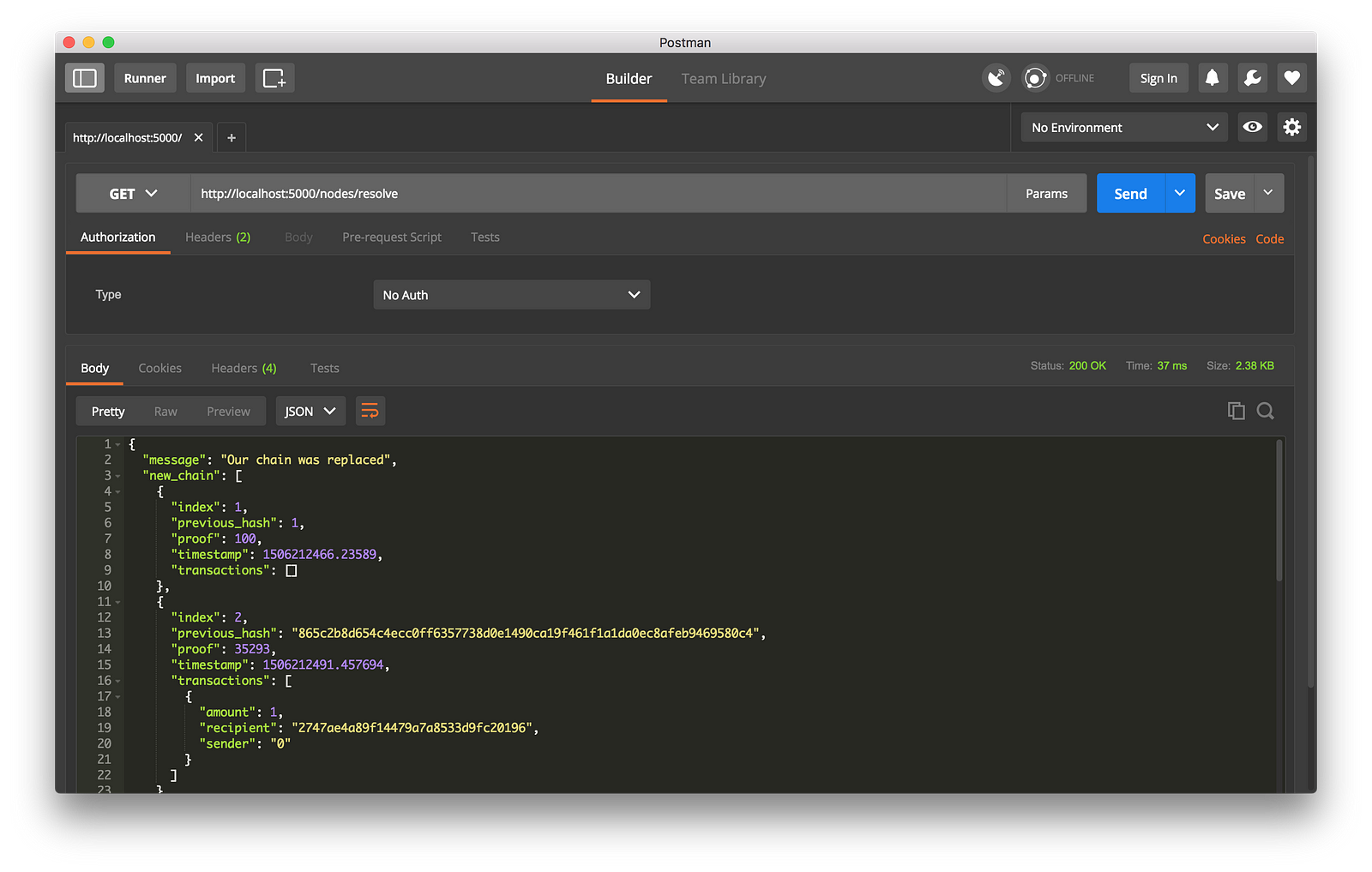
|
||||
Consensus Algorithm at Work
|
||||
|
||||
And that’s a wrap... Go get some friends together to help test out your Blockchain.
|
||||
|
||||
* * *
|
||||
|
||||
I hope that this has inspired you to create something new. I’m ecstatic about Cryptocurrencies because I believe that Blockchains will rapidly change the way we think about economies, governments and record-keeping.
|
||||
|
||||
**Update:** I’m planning on following up with a Part 2, where we’ll extend our Blockchain to have a Transaction Validation Mechanism as well as discuss some ways in which you can productionize your Blockchain.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
|
||||
作者:[Daniel van Flymen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@vanflymen?source=post_header_lockup
|
||||
[1]:https://learncryptography.com/hash-functions/what-are-hash-functions
|
||||
[2]:https://www.python.org/downloads/
|
||||
[3]:https://www.getpostman.com
|
||||
[4]:https://github.com/dvf/blockchain
|
||||
[5]:https://www.jetbrains.com/pycharm/
|
||||
[6]:https://github.com/dvf/blockchain
|
||||
[7]:http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application
|
||||
[8]:http://localhost:5000/transactions/new
|
||||
[9]:http://localhost:5000
|
||||
@ -1,3 +1,5 @@
|
||||
lontow translating
|
||||
|
||||
5 ways open source can strengthen your job search
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating By MjSeven
|
||||
|
||||
How to install software applications on Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by kimii
|
||||
cTop - A CLI Tool For Container Monitoring
|
||||
======
|
||||
Recent days Linux containers are famous, even most of us already working on it and few of us start learning about it.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
The Type Command Tutorial With Examples For Beginners
|
||||
======
|
||||
|
||||
|
||||
@ -1,193 +0,0 @@
|
||||
How to measure particulate matter with a Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
We regularly measure particulate matter in the air at our school in Southeast Asia. The values here are very high, particularly between February and May, when weather conditions are very dry and hot, and many fields burn. These factors negatively affect the quality of the air. In this article, I will show you how to measure particulate matter using a Raspberry Pi.
|
||||
|
||||
### What is particulate matter?
|
||||
|
||||
Particulate matter is fine dust or very small particles in the air. A distinction is made between PM10 and PM2.5: PM10 refers to particles that are smaller than 10µm; PM2.5 refers to particles that are smaller than 2.5µm. The smaller the particles—i.e., anything smaller than 2.5µm—the more dangerous they are to one's health, as they can penetrate into the alveoli and impact the respiratory system.
|
||||
|
||||
The World Health Organization recommends [limiting particulate matter][1] to the following values:
|
||||
|
||||
* Annual average PM10 20 µg/m³
|
||||
* Annual average PM2,5 10 µg/m³ per year
|
||||
* Daily average PM10 50 µg/m³ without permitted days on which exceeding is possible.
|
||||
* Daily average PM2,5 25 µg/m³ without permitted days on which exceeding is possible.
|
||||
|
||||
|
||||
|
||||
These values are below the limits set in most countries. In the European Union, an annual average of 40 µg/m³ for PM10 is allowed.
|
||||
|
||||
### What is the Air Quality Index (AQI)?
|
||||
|
||||
The Air Quality Index indicates how “good” or “bad” air is based on its particulate measurement. Unfortunately, there is no uniform standard for AQI because not all countries calculate it the same way. The Wikipedia article on the [Air Quality Index][2] offers a helpful overview. At our school, we are guided by the classification established by the United States' [Environmental Protection Agency][3].
|
||||
|
||||
|
||||
![Air quality index][5]
|
||||
|
||||
Air quality index
|
||||
|
||||
### What do we need to measure particulate matter?
|
||||
|
||||
Measuring particulate matter requires only two things:
|
||||
|
||||
* A Raspberry Pi (every model works; a model with WiFi is best)
|
||||
* A particulates sensor SDS011
|
||||
|
||||
|
||||
|
||||
![Particulate sensor][7]
|
||||
|
||||
Particulate sensor
|
||||
|
||||
If you are using a Raspberry Pi Zero W, you will also need an adapter cable to a standard USB port because the Zero has only a Micro USB. These are available for about $20. The sensor comes with a USB adapter for the serial interface.
|
||||
|
||||
### Installation
|
||||
|
||||
For our Raspberry Pi we download the corresponding Raspbian Lite Image and [write it on the Micro SD card][8]. (I will not go into the details of setting up the WLAN connection; many tutorials are available online).
|
||||
|
||||
If you want to have SSH enabled after booting, you need to create an empty file named `ssh` in the boot partition. The IP of the Raspberry Pi can best be obtained via your own router/DHCP server. You can then log in via SSH (the default password is raspberry):
|
||||
```
|
||||
$ ssh pi@192.168.1.5
|
||||
|
||||
```
|
||||
|
||||
First we need to install some packages on the Pi:
|
||||
```
|
||||
$ sudo apt install git-core python-serial python-enum lighttpd
|
||||
|
||||
```
|
||||
|
||||
Before we can start, we need to know which serial port the USB adapter is connected to. `dmesg` helps us:
|
||||
```
|
||||
$ dmesg
|
||||
|
||||
[ 5.559802] usbcore: registered new interface driver usbserial
|
||||
|
||||
[ 5.559930] usbcore: registered new interface driver usbserial_generic
|
||||
|
||||
[ 5.560049] usbserial: USB Serial support registered for generic
|
||||
|
||||
[ 5.569938] usbcore: registered new interface driver ch341
|
||||
|
||||
[ 5.570079] usbserial: USB Serial support registered for ch341-uart
|
||||
|
||||
[ 5.570217] ch341 1–1.4:1.0: ch341-uart converter detected
|
||||
|
||||
[ 5.575686] usb 1–1.4: ch341-uart converter now attached to ttyUSB0
|
||||
|
||||
```
|
||||
|
||||
In the last line, you can see our interface: `ttyUSB0`. We now need a small Python script that reads the data and saves it in a JSON file, and then we will create a small HTML page that reads and displays the data.
|
||||
|
||||
### Reading data on the Raspberry Pi
|
||||
|
||||
We first create an instance of the sensor and then read the sensor every 5 minutes, for 30 seconds. These values can, of course, be adjusted. Between the measuring intervals, we put the sensor into a sleep mode to increase its lifespan (according to the manufacturer, the lifespan totals approximately 8000 hours).
|
||||
|
||||
We can download the script with this command:
|
||||
```
|
||||
$ wget -O /home/pi/aqi.py https://raw.githubusercontent.com/zefanja/aqi/master/python/aqi.py
|
||||
|
||||
```
|
||||
|
||||
For the script to run without errors, two small things are still needed:
|
||||
```
|
||||
$ sudo chown pi:pi /var/wwww/html/
|
||||
|
||||
$ echo[] > /var/wwww/html/aqi.json
|
||||
|
||||
```
|
||||
|
||||
Now you can start the script:
|
||||
```
|
||||
$ chmod +x aqi.py
|
||||
|
||||
$ ./aqi.py
|
||||
|
||||
PM2.5:55.3, PM10:47.5
|
||||
|
||||
PM2.5:55.5, PM10:47.7
|
||||
|
||||
PM2.5:55.7, PM10:47.8
|
||||
|
||||
PM2.5:53.9, PM10:47.6
|
||||
|
||||
PM2.5:53.6, PM10:47.4
|
||||
|
||||
PM2.5:54.2, PM10:47.3
|
||||
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
### Run the script automatically
|
||||
|
||||
So that we don’t have to start the script manually every time, we can let it start with a cronjob, e.g., with every restart of the Raspberry Pi. To do this, open the crontab file:
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
and add the following line at the end:
|
||||
```
|
||||
@reboot cd /home/pi/ && ./aqi.py
|
||||
|
||||
```
|
||||
|
||||
Now our script starts automatically with every restart.
|
||||
|
||||
### HTML page for displaying measured values and AQI
|
||||
|
||||
We have already installed a lightweight webserver, `lighttpd`. So we need to save our HTML, JavaScript, and CSS files in the directory `/var/www/html/` so that we can access the data from another computer or smartphone. With the next three commands, we simply download the corresponding files:
|
||||
```
|
||||
$ wget -O /var/wwww/html/index.html https://raw.githubusercontent.com/zefanja/aqi/master/html/index.html
|
||||
|
||||
$ wget -O /var/wwww/html/aqi.js https://raw.githubusercontent.com/zefanja/aqi/master/html/aqi.js
|
||||
|
||||
$ wget -O /var/wwww/html/style.css https://raw.githubusercontent.com/zefanja/aqi/master/html/style.css
|
||||
|
||||
```
|
||||
|
||||
The main work is done in the JavaScript file, which opens our JSON file, takes the last value, and calculates the AQI based on this value. Then the background colors are adjusted according to the scale of the EPA.
|
||||
|
||||
Now you simply open the address of the Raspberry Pi in your browser and look at the current particulates values, e.g., [http://192.168.1.5:][9]
|
||||
|
||||
The page is very simple and can be extended, for example, with a chart showing the history of the last hours, etc. Pull requests are welcome.
|
||||
|
||||
The complete [source code is available on Github][10].
|
||||
|
||||
**[Enter our[Raspberry Pi week giveaway][11] for a chance at this arcade gaming kit.]**
|
||||
|
||||
### Wrapping up
|
||||
|
||||
For relatively little money, we can measure particulate matter with a Raspberry Pi. There are many possible applications, from a permanent outdoor installation to a mobile measuring device. At our school, we use both: There is a sensor that measures outdoor values day and night, and a mobile sensor that checks the effectiveness of the air conditioning filters in our classrooms.
|
||||
|
||||
[Luftdaten.info][12] offers guidance to build a similar sensor. The software is delivered ready to use, and the measuring device is even more compact because it does not use a Raspberry Pi. Great project!
|
||||
|
||||
Creating a particulates sensor is an excellent project to do with students in computer science classes or a workshop.
|
||||
|
||||
What do you use a [Raspberry Pi][13] for?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi
|
||||
|
||||
作者:[Stephan Tetzel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stephan
|
||||
[1]:https://en.wikipedia.org/wiki/Particulates
|
||||
[2]:https://en.wikipedia.org/wiki/Air_quality_index
|
||||
[3]:https://en.wikipedia.org/wiki/United_States_Environmental_Protection_Agency
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/air_quality_index.png?itok=FwmGf1ZS (Air quality index)
|
||||
[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/particulate_sensor.jpg?itok=ddH3bBwO (Particulate sensor)
|
||||
[8]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[9]:http://192.168.1.5/
|
||||
[10]:https://github.com/zefanja/aqi
|
||||
[11]:https://opensource.com/article/18/3/raspberry-pi-week-giveaway
|
||||
[12]:http://luftdaten.info/
|
||||
[13]:https://openschoolsolutions.org/shutdown-servers-case-power-failure%e2%80%8a-%e2%80%8aups-nut-co/
|
||||
@ -0,0 +1,347 @@
|
||||
How To Edit Multiple Files Using Vim Editor
|
||||
======
|
||||
|
||||

|
||||
Sometimes, you will find yourself in a situation where you want to make changes in multiple files or you might want to copy the contents of one file to another. If you’re on GUI mode, you could simply open the files in any graphical text editor, like gedit, and use CTRL+C and CTRL+V to copy/paste the contents. In CLI mode, you can’t use such editors. No worries! Where there is vim editor, there is a way! In this tutorial, we are going to learn to edit multiple files at the same time using Vim editor. Trust me, this is very interesting read.
|
||||
|
||||
### Installing Vim
|
||||
|
||||
Vim editor is available in the official repositories of most Linux distributions. So you can install it using the default package manager. For example, on Arch Linux and its variants you can install it using command:
|
||||
```
|
||||
$ sudo pacman -S vim
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu:
|
||||
```
|
||||
$ sudo apt-get install vim
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
```
|
||||
$ sudo yum install vim
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
$ sudo dnf install vim
|
||||
|
||||
```
|
||||
|
||||
On openSUSE:
|
||||
```
|
||||
$ sudo zypper install vim
|
||||
|
||||
```
|
||||
|
||||
### Edit multiple files at a time using Vim editor in Linux
|
||||
|
||||
Let us now get down to the business. We can do this in two methods.
|
||||
|
||||
#### Method 1
|
||||
|
||||
I have two files namely **file1.txt** and **file2.txt** , with a bunch of random words. Let us have a look at them.
|
||||
```
|
||||
$ cat file1.txt
|
||||
ostechnix
|
||||
open source
|
||||
technology
|
||||
linux
|
||||
unix
|
||||
|
||||
$ cat file2.txt
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
Now, let us edit these two files at a time. To do so, run:
|
||||
```
|
||||
$ vim file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
Vim will display the contents of the files in an order. The first file’s contents will be shown first and then second file and so on.
|
||||
|
||||
![][2]
|
||||
|
||||
**Switch between files**
|
||||
|
||||
To move to the next file, type:
|
||||
```
|
||||
:n
|
||||
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
To go back to previous file, type:
|
||||
```
|
||||
:N
|
||||
|
||||
```
|
||||
|
||||
Vim won’t allow you to move to the next file if there are any unsaved changes. To save the changes in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
Please note that it is double capital letters ZZ (SHIFT+zz).
|
||||
|
||||
To abandon the changes and move to the previous file, type:
|
||||
```
|
||||
:N!
|
||||
|
||||
```
|
||||
|
||||
To view the files which are being currently edited, type:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
You will see the list of loaded files at the bottom.
|
||||
|
||||
![][5]
|
||||
|
||||
To switch to the next file, type **:buffer** followed by the buffer number. For example, to switch to the first file, type:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
**Opening additional files for editing**
|
||||
|
||||
We are currently editing two files namely file1.txt, file2.txt. I want to open another file named **file3.txt** for editing.
|
||||
What will you do? It’s easy! Just type **:e** followed by the file name like below.
|
||||
```
|
||||
:e file3.txt
|
||||
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
Now you can edit file3.txt.
|
||||
|
||||
To view how many files are being edited currently, type:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
Please note that you can not switch between opened files with **:e** using either **:n** or **:N**. To switch to another file, type **:buffer** followed by the file buffer number.
|
||||
|
||||
**Copying contents of one file into another**
|
||||
|
||||
You know how to open and edit multiple files at the same time. Sometimes, you might want to copy the contents of one file into another. It is possible too. Switch to a file of your choice. For example, let us say you want to copy the contents of file1.txt into file2.txt.
|
||||
|
||||
To do so, first switch to file1.txt:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
Place the move cursor in-front of a line that wants to copy and type **yy** to yank(copy) the line. Then. move to file2.txt:
|
||||
```
|
||||
:buffer 2
|
||||
|
||||
```
|
||||
|
||||
Place the mouse cursor where you want to paste the copied lines from file1.txt and type **p**. For example, you want to paste the copied line between line2 and line3. To do so, put the mouse cursor before line and type **p**.
|
||||
|
||||
Sample output:
|
||||
```
|
||||
line1
|
||||
line2
|
||||
ostechnix
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
To save the changes made in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
Again, please note that this is double capital ZZ (SHIFT+z).
|
||||
|
||||
To save the changes in all files and exit vim editor. type:
|
||||
```
|
||||
:wq
|
||||
|
||||
```
|
||||
|
||||
Similarly, you can copy any line from any file to other files.
|
||||
|
||||
**Copying entire file contents into another**
|
||||
|
||||
We know how to copy a single line. What about the entire file contents? That’s also possible. Let us say, you want to copy the entire contents of file1.txt into file2.txt.
|
||||
|
||||
To do so, open the file2.txt first:
|
||||
```
|
||||
$ vim file2.txt
|
||||
|
||||
```
|
||||
|
||||
If the files are already loaded, you can switch to file2.txt by typing:
|
||||
```
|
||||
:buffer 2
|
||||
|
||||
```
|
||||
|
||||
Move the cursor to the place where you wanted to copy the contents of file1.txt. I want to copy the contents of file1.txt after line5 in file2.txt, so I moved the cursor to line 5. Then, type the following command and hit ENTER key:
|
||||
```
|
||||
:r file1.txt
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
Here, **r** means **read**.
|
||||
|
||||
Now you will see the contents of file1.txt is pasted after line5 in file2.txt.
|
||||
```
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
ostechnix
|
||||
open source
|
||||
technology
|
||||
linux
|
||||
unix
|
||||
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
To save the changes in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
To save all changes in all loaded files and exit vim editor, type:
|
||||
```
|
||||
:wq
|
||||
|
||||
```
|
||||
|
||||
#### Method 2
|
||||
|
||||
The another method to open multiple files at once is by using either **-o** or **-O** flags.
|
||||
|
||||
To open multiple files in horizontal windows, run:
|
||||
```
|
||||
$ vim -o file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
To switch between windows, press **CTRL-w w** (i.e Press **CTRL+w** and again press **w** ). Or, you the following shortcuts to move between windows.
|
||||
|
||||
* **CTRL-w k** – top window
|
||||
* **CTRL-w j** – bottom window
|
||||
|
||||
|
||||
|
||||
To open multiple files in vertical windows, run:
|
||||
```
|
||||
$ vim -O file1.txt file2.txt file3.txt
|
||||
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
To switch between windows, press **CTRL-w w** (i.e Press **CTRL+w** and again press **w** ). Or, use the following shortcuts to move between windows.
|
||||
|
||||
* **CTRL-w l** – left window
|
||||
* **CTRL-w h** – right window
|
||||
|
||||
|
||||
|
||||
Everything else is same as described in method 1.
|
||||
|
||||
For example, to list currently loaded files, run:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
To switch between files:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
To open an additional file, type:
|
||||
```
|
||||
:e file3.txt
|
||||
|
||||
```
|
||||
|
||||
To copy entire contents of a file into another:
|
||||
```
|
||||
:r file1.txt
|
||||
|
||||
```
|
||||
|
||||
The only difference in method 2 is once you saved the changes in the current file using **ZZ** , the file will automatically close itself. Also, you need to close the files one by one by typing **:wq**. But, had you followed the method 1, when typing **:wq** all changes will be saved in all files and all files will be closed at once.
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man vim
|
||||
|
||||
```
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
You know now how to edit multiples files using vim editor in Linux. As you can see, editing multiple files is not that difficult. Vim editor has more powerful features. We will write more about Vim editor in the days to come.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-edit-multiple-files-using-vim-editor/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-1-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-5.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-6.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-7.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-8.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-10-1.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-11.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-12.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-13.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/03/Edit-multiple-files-16.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/03/Edit-multiple-files-17.png
|
||||
@ -0,0 +1,435 @@
|
||||
How To Manage Disk Partitions Using Parted Command
|
||||
======
|
||||
We all knows disk partitions is one of the important task for Linux administrator. They can not survive without knowing this.
|
||||
|
||||
In worst cases, at least once in a week they would get this request from dependent team but in big environment admins used to get this request very often.
|
||||
|
||||
You may ask why we need to use parted instead of fdisk? What is the difference? It’s a good question, i will give you more details about this.
|
||||
|
||||
* Parted allow users to create a partition when the disk size is larger than 2TB but fdisk doesn’t allow.
|
||||
* Parted is a higher-level tool than fdisk.
|
||||
* It supports multiple partition table which includes GPT.
|
||||
* It allows users to resize the partition but while shrinking the partition it does not worked as expected and i got error most of the time so, i would advise users to do not shrink the partition.
|
||||
|
||||
|
||||
|
||||
### What Is Parted
|
||||
|
||||
Parted is a program to manipulate disk partitions. It supports multiple partition table formats, including MS-DOS and GPT.
|
||||
|
||||
It allows user to create, delete, resize, shrink, move and copy partitions, reorganizing disk usage, and copying data to new hard disks. GParted is a GUI frontend of parted.
|
||||
|
||||
### How To Install Parted
|
||||
|
||||
Parted package is pre-installed on most of the Linux distribution. If not, use the following commands to install parted package.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [APT-GET Command][1] or [APT Command][2] to install parted.
|
||||
```
|
||||
$ sudo apt install parted
|
||||
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** , use [YUM Command][3] to install parted.
|
||||
```
|
||||
$ sudo yum install parted
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][4] to install parted.
|
||||
```
|
||||
$ sudo dnf install parted
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][5] to install parted.
|
||||
```
|
||||
$ sudo pacman -S parted
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][6] to install parted.
|
||||
```
|
||||
$ sudo zypper in parted
|
||||
|
||||
```
|
||||
|
||||
### How To Launch Parted
|
||||
|
||||
The below parted command picks the `/dev/sda` disk automatically, because this is the first hard drive in this system.
|
||||
```
|
||||
$ sudo parted
|
||||
GNU Parted 3.2
|
||||
Using /dev/sda
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted)
|
||||
|
||||
```
|
||||
|
||||
Also we can go to the corresponding disk by selecting the appropriate disk using below command.
|
||||
```
|
||||
(parted) select /dev/sdb
|
||||
Using /dev/sdb
|
||||
(parted)
|
||||
|
||||
```
|
||||
|
||||
If you wants to go to particular disk, use the following format. In our case we are going to use `/dev/sdb`.
|
||||
```
|
||||
$ sudo parted [Device Name]
|
||||
|
||||
$ sudo parted /dev/sdb
|
||||
GNU Parted 3.2
|
||||
Using /dev/sdb
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted)
|
||||
|
||||
```
|
||||
|
||||
### How To List Available Disks Using Parted Command
|
||||
|
||||
If you don’t know what are the disks are added in your system. Just run the following command, which will display all the available disks name, and other useful information such as Disk Size, Model, Sector Size, Partition Table, Disk Flags, and partition information.
|
||||
```
|
||||
$ sudo parted -l
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sda: 32.2GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 32.2GB 32.2GB primary ext4 boot
|
||||
|
||||
|
||||
Error: /dev/sdb: unrecognised disk label
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: unknown
|
||||
Disk Flags:
|
||||
|
||||
```
|
||||
|
||||
The above error message clearly shows there is no valid disk label for the disk `/dev/sdb`. Hence, we have to set `disk label` first as it doesn’t take any label automatically.
|
||||
|
||||
### How To Create Disk Partition Using Parted Command
|
||||
|
||||
Parted allows us to create primary or extended partition. Procedure is same for both but make sure you have to pass an appropriate partition type like `primary` or `extended` while creating the partition.
|
||||
|
||||
To perform this activity, we have added a new `50GB` hard disk in the system, which falls under `/dev/sdb`.
|
||||
|
||||
In two ways we can create a partition, one is detailed way and other one is single command. In the below example we are going to add one primary partition in detailed way. Make a note, we should set `disk label` first as it doesn’t take any label automatically.
|
||||
|
||||
We are going to create a new partition with `10GB` of disk in the below example.
|
||||
```
|
||||
$ sudo parted /dev/sdb
|
||||
GNU Parted 3.2
|
||||
Using /dev/sdb
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted) mklabel msdos
|
||||
(parted) unit GB
|
||||
(parted) mkpart
|
||||
Partition type? primary/extended? primary
|
||||
File system type? [ext2]? ext4
|
||||
Start? 0.00GB
|
||||
End? 10.00GB
|
||||
(parted) print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 0.00GB 10.0GB 10.0GB primary ext4 lba
|
||||
|
||||
(parted) quit
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can create a new partition using single parted command.
|
||||
|
||||
We are going to create second partition with `10GB` of disk in the below example.
|
||||
```
|
||||
$ sudo parted [Disk Name] [mkpart] [Partition Type] [Filesystem Type] [Partition Start Size] [Partition End Size]
|
||||
|
||||
$ sudo parted /dev/sdb mkpart primary ext4 10.0GB 20.0GB
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
### How To Create A Partition With All Remaining Space
|
||||
|
||||
You have created all required partitions except `/home` and you wants to use all the remaining space to `/home` partition, how to do that? use the following command to create a partition.
|
||||
|
||||
The below command create a new partition with 33.7GB, which starts from `20GB` and ends with `53GB`. `100%` end size will allow users to create a new partition with remaining all available space in the disk.
|
||||
```
|
||||
$ sudo parted [Disk Name] [mkpart] [Partition Type] [Filesystem Type] [Partition Start Size] [Partition End Size]
|
||||
|
||||
$ sudo parted /dev/sdb mkpart primary ext4 20.0GB 100%
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
### How To List All Partitions using Parted
|
||||
|
||||
As you aware of, we have created three partitions in the above step and if you want to list all available partitions on the disk use the print command.
|
||||
```
|
||||
$ sudo parted /dev/sdb print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
3 20.0GB 53.7GB 33.7GB primary ext4
|
||||
|
||||
```
|
||||
|
||||
### How To Create A File System On Partition Using mkfs
|
||||
|
||||
Users can create a file system on the partition using mkfs. Follow the below procedure to create a filesystem using mkfs.
|
||||
```
|
||||
$ sudo mkfs.ext4 /dev/sdb1
|
||||
mke2fs 1.43.4 (31-Jan-2017)
|
||||
Creating filesystem with 2621440 4k blocks and 656640 inodes
|
||||
Filesystem UUID: 415cf467-634c-4403-8c9f-47526bbaa381
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (16384 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
|
||||
```
|
||||
|
||||
Do the same for other partitions as well.
|
||||
```
|
||||
$ sudo mkfs.ext4 /dev/sdb2
|
||||
$ sudo mkfs.ext4 /dev/sdb3
|
||||
|
||||
```
|
||||
|
||||
Create necessary folders and mount the partitions on that.
|
||||
```
|
||||
$ sudo mkdir /par1 /par2 /par3
|
||||
|
||||
$ sudo mount /dev/sdb1 /par1
|
||||
$ sudo mount /dev/sdb2 /par2
|
||||
$ sudo mount /dev/sdb3 /par3
|
||||
|
||||
```
|
||||
|
||||
Run the following command to check newly mounted partitions.
|
||||
```
|
||||
$ df -h /dev/sdb[1-3]
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/sdb1 9.2G 37M 8.6G 1% /par1
|
||||
/dev/sdb2 9.2G 37M 8.6G 1% /par2
|
||||
/dev/sdb3 31G 49M 30G 1% /par3
|
||||
|
||||
```
|
||||
|
||||
### How To Check Free Space On The Disk
|
||||
|
||||
Run the following command to check available free space on the disk. This disk has `25.7GB` of free disk space.
|
||||
```
|
||||
$ sudo parted /dev/sdb print free
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
32.3kB 1049kB 1016kB Free Space
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
3 20.0GB 28.0GB 8001MB primary ext4
|
||||
28.0GB 53.7GB 25.7GB Free Space
|
||||
|
||||
```
|
||||
|
||||
### How To Resize Partition Using Parted Command
|
||||
|
||||
Parted allow users to resize the partitions to big and smaller size. As i told in the beginning of the article, do not shrink partitions because this leads to face disk error issue.
|
||||
|
||||
Run the following command to check disk partitions and available free space. I could see `25.7GB` of free space on this disk.
|
||||
```
|
||||
$ sudo parted /dev/sdb print free
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
32.3kB 1049kB 1016kB Free Space
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
3 20.0GB 28.0GB 8001MB primary ext4
|
||||
28.0GB 53.7GB 25.7GB Free Space
|
||||
|
||||
```
|
||||
|
||||
Run the following command to resize the partition. We are going to resize (increase) the partition 3 end size from `28GB to 33GB`.
|
||||
```
|
||||
$ sudo parted [Disk Name] [resizepart] [Partition Number] [Partition New End Size]
|
||||
|
||||
$ sudo parted /dev/sdb resizepart 3 33.0GB
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
Run the following command to verify whether this partition is increased or not. Yes, i could see the partition 3 got increased from `8GB to 13GB`.
|
||||
```
|
||||
$ sudo parted /dev/sdb print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
3 20.0GB 33.0GB 13.0GB primary ext4
|
||||
|
||||
```
|
||||
|
||||
Resize the file system to grow the resized partition.
|
||||
```
|
||||
$ sudo resize2fs /dev/sdb3
|
||||
resize2fs 1.43.4 (31-Jan-2017)
|
||||
Resizing the filesystem on /dev/sdb3 to 3173952 (4k) blocks.
|
||||
The filesystem on /dev/sdb3 is now 3173952 (4k) blocks long.
|
||||
|
||||
```
|
||||
|
||||
Finally, check whether the mount point has been successfully increased or not.
|
||||
```
|
||||
$ df -h /dev/sdb[1-3]
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/sdb1 9.2G 5.1G 3.6G 59% /par1
|
||||
/dev/sdb2 9.2G 2.1G 6.6G 24% /par2
|
||||
/dev/sdb3 12G 1.1G 11G 10% /par3
|
||||
|
||||
```
|
||||
|
||||
### How To Remove Partition Using Parted Command
|
||||
|
||||
We can simple remove the unused partition (if the partition is no longer use) using rm command. See the procedure below. We are going to remove partition 3 `/dev/sdb3` in this example.
|
||||
```
|
||||
$ sudo parted [Disk Name] [rm] [Partition Number]
|
||||
|
||||
$ sudo parted /dev/sdb rm 3
|
||||
Warning: Partition /dev/sdb3 is being used. Are you sure you want to continue?
|
||||
Yes/No? Yes
|
||||
Error: Partition(s) 3 on /dev/sdb have been written, but we have been unable to inform the kernel of the change, probably because it/they are in use. As a result, the old partition(s) will remain in use.
|
||||
You should reboot now before making further changes.
|
||||
Ignore/Cancel? Ignore
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
We can check the same using below command. Yes, i could see that partition 3 has been removed successfully.
|
||||
```
|
||||
$ sudo parted /dev/sdb print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4
|
||||
|
||||
```
|
||||
|
||||
### How To Set/Change Partition Flag Using Parted Command
|
||||
|
||||
We can easily change the partition flag using below command. We are going to set `lvm` flag to partition 2 `/dev/sdb2`.
|
||||
```
|
||||
$ sudo parted [Disk Name] [set] [Partition Number] [Flags Name] [Flag On/Off]
|
||||
|
||||
$ sudo parted /dev/sdb set 2 lvm on
|
||||
Information: You may need to update /etc/fstab.
|
||||
|
||||
```
|
||||
|
||||
We can verify this modification by listing disk partitions.
|
||||
```
|
||||
$ sudo parted /dev/sdb print
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sdb: 53.7GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
1 1049kB 10.0GB 9999MB primary ext4
|
||||
2 10.0GB 20.0GB 9999MB primary ext4 lvm
|
||||
|
||||
```
|
||||
|
||||
To know list of available flags, use the following command.
|
||||
```
|
||||
$ (parted) help set
|
||||
set NUMBER FLAG STATE change the FLAG on partition NUMBER
|
||||
|
||||
NUMBER is the partition number used by Linux. On MS-DOS disk labels, the primary partitions number from 1 to 4, logical partitions from 5 onwards.
|
||||
FLAG is one of: boot, root, swap, hidden, raid, lvm, lba, hp-service, palo, prep, msftres, bios_grub, atvrecv, diag, legacy_boot, msftdata, irst, esp
|
||||
STATE is one of: on, off
|
||||
|
||||
```
|
||||
|
||||
If you want to know the available options in parted, just navigate to `help` page.
|
||||
```
|
||||
$ sudo parted
|
||||
GNU Parted 3.2
|
||||
Using /dev/sda
|
||||
Welcome to GNU Parted! Type 'help' to view a list of commands.
|
||||
(parted) help
|
||||
align-check TYPE N check partition N for TYPE(min|opt) alignment
|
||||
help [COMMAND] print general help, or help on COMMAND
|
||||
mklabel,mktable LABEL-TYPE create a new disklabel (partition table)
|
||||
mkpart PART-TYPE [FS-TYPE] START END make a partition
|
||||
name NUMBER NAME name partition NUMBER as NAME
|
||||
print [devices|free|list,all|NUMBER] display the partition table, available devices, free space, all found partitions, or a particular partition
|
||||
quit exit program
|
||||
rescue START END rescue a lost partition near START and END
|
||||
resizepart NUMBER END resize partition NUMBER
|
||||
rm NUMBER delete partition NUMBER
|
||||
select DEVICE choose the device to edit
|
||||
disk_set FLAG STATE change the FLAG on selected device
|
||||
disk_toggle [FLAG] toggle the state of FLAG on selected device
|
||||
set NUMBER FLAG STATE change the FLAG on partition NUMBER
|
||||
toggle [NUMBER [FLAG]] toggle the state of FLAG on partition NUMBER
|
||||
unit UNIT set the default unit to UNIT
|
||||
version display the version number and copyright information of GNU Parted
|
||||
(parted) quit
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[2]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[4]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[5]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[6]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,201 @@
|
||||
A Command Line Productivity Tool For Tracking Work Hours
|
||||
======
|
||||
|
||||

|
||||
Keeping track of your work hours will give you an insight about the amount of work you get done in a specific time frame. There are plenty of GUI-based productivity tools available on the Internet for tracking work hours. However, I couldn’t find a good CLI-based tool. Today, I stumbled upon a a simple, yet useful tool named **“Moro”** for tracking work hours. Moro is a Finnish word which means “Hello”. Using Moro, you can find how much time you take to complete a specific task. It is free, open source and written using **NodeJS**.
|
||||
|
||||
### Moro – A Command Line Productivity Tool For Tracking Work Hours
|
||||
|
||||
Since Moro is written using NodeJS, make sure you have installed it on your system. If you haven’t installed it already, follow the link given below to install NodeJS and NPM in your Linux box.
|
||||
|
||||
Once NodeJS and Npm installed, run the following command to install Moro.
|
||||
```
|
||||
$ npm install -g moro
|
||||
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Moro’s working concept is very simple. It saves your work staring time, ending time and the break time in your system. At the end of each day, it will tell you how many hours you have worked!
|
||||
|
||||
When you reached to office, just type:
|
||||
```
|
||||
$ moro
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
💙 Moro \o/
|
||||
|
||||
✔ You clocked in at: 9:20
|
||||
|
||||
```
|
||||
|
||||
Moro will register this time as your starting time.
|
||||
|
||||
When you leave the office, again type:
|
||||
```
|
||||
$ moro
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
💙 Moro \o/
|
||||
|
||||
✔ You clocked out at: 19:22
|
||||
|
||||
ℹ Today looks like this so far:
|
||||
|
||||
┌──────────────────┬─────────────────────────┐
|
||||
│ Today you worked │ 9 Hours and 72 Minutes │
|
||||
├──────────────────┼─────────────────────────┤
|
||||
│ Clock in │ 9:20 │
|
||||
├──────────────────┼─────────────────────────┤
|
||||
│ Clock out │ 19:22 │
|
||||
├──────────────────┼─────────────────────────┤
|
||||
│ Break duration │ 30 minutes │
|
||||
├──────────────────┼─────────────────────────┤
|
||||
│ Date │ 2018-03-19 │
|
||||
└──────────────────┴─────────────────────────┘
|
||||
ℹ Run moro --help to learn how to edit your clock in, clock out or break duration for today
|
||||
|
||||
```
|
||||
|
||||
Moro will registers that time as your ending time.
|
||||
|
||||
Now, More will subtract the starting time from ending time and then subtracts another 30 minutes for break time from the total and gives you the total working hours on that day. Sorry I am really terrible at explaining Math calculations. Let us say you came to work at 10 am in the morning and left 17.30 in the evening. So, the total hours you spent on the office is 7.30 hours (i.e 17.30-10). Then subtract the break time (default is 30 minutes) from the total. Hence, your total working time is 7 hours. Understood? Great!
|
||||
|
||||
**Note:** Don’t confuse “moro” with “more” command like I did while writing this guide.
|
||||
|
||||
To see all your registered hours, run:
|
||||
```
|
||||
$ moro report --all
|
||||
|
||||
```
|
||||
|
||||
Just in case, you forgot to register the start time or end time, you can specify that later on the same.
|
||||
|
||||
For example, to register 10 am as start time, run:
|
||||
```
|
||||
$ moro hi 10:00
|
||||
|
||||
💙 Moro \o/
|
||||
|
||||
✔ You clocked in at: 10:00
|
||||
|
||||
⏰ Working until 18:00 will make it a full (7.5 hours) day
|
||||
|
||||
```
|
||||
|
||||
To register 17.30 as end time:
|
||||
```
|
||||
$ moro bye 17:30
|
||||
|
||||
💙 Moro \o/
|
||||
|
||||
✔ You clocked out at: 17:30
|
||||
|
||||
ℹ Today looks like this so far:
|
||||
|
||||
┌──────────────────┬───────────────────────┐
|
||||
│ Today you worked │ 7 Hours and 0 Minutes │
|
||||
├──────────────────┼───────────────────────┤
|
||||
│ Clock in │ 10:00 │
|
||||
├──────────────────┼───────────────────────┤
|
||||
│ Clock out │ 17:30 │
|
||||
├──────────────────┼───────────────────────┤
|
||||
│ Break duration │ 30 minutes │
|
||||
├──────────────────┼───────────────────────┤
|
||||
│ Date │ 2018-03-19 │
|
||||
└──────────────────┴───────────────────────┘
|
||||
ℹ Run moro --help to learn how to edit your clock in, clock out or break duration for today
|
||||
|
||||
```
|
||||
|
||||
You already know Moro will subtract 30 minutes for break time, by default. If you wanted to set a custom break time, you could simply set it using command:
|
||||
```
|
||||
$ moro break 45
|
||||
|
||||
```
|
||||
|
||||
Now, the break time is 45 minutes.
|
||||
|
||||
To clear all data:
|
||||
```
|
||||
$ moro clear --yes
|
||||
|
||||
💙 Moro \o/
|
||||
|
||||
✔ Database file deleted successfully
|
||||
|
||||
```
|
||||
|
||||
**Add notes**
|
||||
|
||||
Sometimes, you may want to add note while working. Don’t look for a separate note taking application. Moro will help you to add notes. To add a note, just run:
|
||||
```
|
||||
$ moro note mynotes
|
||||
|
||||
```
|
||||
|
||||
To search for the registered notes at later time, simply do:
|
||||
```
|
||||
$ moro search mynotes
|
||||
|
||||
```
|
||||
|
||||
**Change default settings**
|
||||
|
||||
The default full work day is 7.5 hours. Since the developer is from Finland, it’s the official work hours. You can, however, change this settings as per your country’s work hours.
|
||||
|
||||
Say for example, to set it 7 hours, run:
|
||||
```
|
||||
$ moro config --day 7
|
||||
|
||||
```
|
||||
|
||||
Also the default break time can be changed from 30 minutes like below:
|
||||
```
|
||||
$ moro config --break 45
|
||||
|
||||
```
|
||||
|
||||
**Backup your data**
|
||||
|
||||
Like I already said, Moro stores the tracking time data in your home directory, and the file name is **.moro-data.db**.
|
||||
|
||||
You can can, however, save the backup database file to different location. To do so, move the **.more-data.db** file to a different location of your choice and tell Moro to use that database file like below.
|
||||
```
|
||||
$ moro config --database-path /home/sk/personal/moro-data.db
|
||||
|
||||
```
|
||||
|
||||
As per above command, I have assigned the default database file’s location to **/home/sk/personal** directory.
|
||||
|
||||
For help, run:
|
||||
```
|
||||
$ moro --help
|
||||
|
||||
```
|
||||
|
||||
As you can see, Moro is very simple, yet useful to track how much time you’ve spent to get your work done. It is will be useful for freelancers and also anyone who must get things done under a limited time frame.
|
||||
|
||||
And, that’s all for today. Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/moro-a-command-line-productivity-tool-for-tracking-work-hours/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,81 @@
|
||||
Migrating to Linux: Installing Software
|
||||
======
|
||||
|
||||

|
||||
With all the attention you are seeing on Linux and its use on the Internet and in devices like Arduino, Beagle, and Raspberry Pi boards and more, perhaps you are thinking it's time to try it out. This series will help you successfully make the transition to Linux. If you missed the earlier articles in the series, you can find them here:
|
||||
|
||||
[Part 1 - An Introduction][1]
|
||||
|
||||
[Part 2 - Disks, Files, and Filesystems][2]
|
||||
|
||||
[Part 3 - Graphical Environments][3]
|
||||
|
||||
[Part 4 - The Command Line][4]
|
||||
|
||||
[Part 5 - Using sudo][5]
|
||||
|
||||
### Installing software
|
||||
|
||||
To get new software on your computer, the typical approach used to be to get a software product from a vendor and then run an install program. The software product, in the past, would come on physical media like a CD-ROM or DVD. Now we often download the software product from the Internet instead.
|
||||
|
||||
With Linux, software is installed more like it is on your smartphone. Just like going to your phone's app store, on Linux there is a central repository of open source software tools and programs. Just about any program you might want will be in a list of available packages that you can install.
|
||||
|
||||
There isn't a separate install program that you run for each program. Instead you use the package management tools that come with your distribution of Linux. (Remember a Linux distribution is the Linux you install such as Ubuntu, Fedora, Debian, etc.) Each distribution has its own centralized place on the Internet (called a repository) where they store thousands of pre-built applications for you to install.
|
||||
|
||||
You may note that there are a few exceptions to how software is installed on Linux. Sometimes, you will still need to go to a vendor to get their software as the program doesn't exist in your distribution's central repository. This typically is the case when the software isn't open source and/or not free.
|
||||
|
||||
Also keep in mind that if you end up wanting to install a program that is not in your distribution's repositories, things aren't so simple, even if you are installing free and open source programs. This post doesn't get into these more complicated scenarios, and it's best to follow online directions.
|
||||
|
||||
With all the Linux packaging systems and tools out there, it may be confusing to know what's going on. This article should help clear up a few things.
|
||||
|
||||
### Package Managers
|
||||
|
||||
Several packaging systems to manage, install, and remove software compete for use in Linux distributions. The folks behind each distribution choose a package management system to use. Red Hat, Fedora, CentOS, Scientific Linux, SUSE, and others use the Red Hat Package Manager (RPM). Debian, Ubuntu, Linux Mint, and more use the Debian package system, or DPKG for short. Other package systems exist as well, while RPM and DPKG are the most common.
|
||||
|
||||

|
||||
|
||||
Regardless of the package manager you are using, they typically come with a set of tools that are layered on top of one another (Figure 1). At the lowest level is a command-line tool that lets you do anything and everything related to installed software. You can list installed programs, remove programs, install package files, and more.
|
||||
|
||||
This low-level tool isn't always the most convenient to use, so typically there is a command line tool that will find the package in the distribution's central repositories and download and install it along with any dependencies using a single command. Finally, there is usually a graphical application that lets you select what you want with a mouse and click an 'install'' button.
|
||||

|
||||
|
||||
For Red Hat based distributions, which includes Fedora, CentOS, Scientific Linux, and more, the low-level tool is rpm. The high-level tool is called dnf (or yum on older systems). And the graphical installer is called PackageKit (Figure 2) and may appear as "Add/Remove Software" under System Administration.
|
||||

|
||||
|
||||
For Debian based distributions, which includes Debian, Ubuntu, Linux Mint, Elementary OS, and more, the low-level, command-line tool is dpkg. The high-level tool is called apt. The graphical tool to manage installed software on Ubuntu is Ubuntu Software (Figure 3). For Debian and Linux Mint, the graphical tool is called Synaptic, which can also be installed on Ubuntu.
|
||||
|
||||
You can also install a text-based graphical tool on Debian related distributions called aptitude. It is more powerful than Synaptic, and works even if you only have access to the command line. You can try that one if you want access to all the bells and whistles, though with more options, it is more complicated to use than Synaptic. Other distributions may have their own unique tools.
|
||||
|
||||
### Command Line
|
||||
|
||||
Online instructions for installing software on Linux usually describe commands to type in the command line. The instructions are usually easier to understand and can be followed without making a mistake by copying and pasting the command into your command line window. This is opposed to following instructions like, "open this menu, select this program, enter in this search pattern, click this tab, select this program, and click this button," which often get lost in translation.
|
||||
|
||||
Sometimes the Linux installation you are using doesn't have a graphical environment, so it's good to be familiar with installing software packages from the command line. Tables 1 and 2 a few common operations and their associated commands for both RPM and DPKG based systems.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Note that SUSE, which uses RPM like Redhat and Fedora, doesn't have dnf or yum. Instead, it uses a program called zypper for the high-level, command-line tool. Other distributions may have different tools as well, such as, pacman on Arch Linux or emerge on Gentoo. There are many package tools out there, so you may need to look up what works on your distribution.
|
||||
|
||||
These tips should give you a much better idea on how to install programs on your new Linux installation and a better idea how the various package methods on your Linux installation relate to one another.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux"][6]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/3/migrating-linux-installing-software
|
||||
|
||||
作者:[JOHN BONESIO][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
[3]:https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
[4]:https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
[5]:https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,318 @@
|
||||
Protecting Code Integrity with PGP — Part 6: Using PGP with Git
|
||||
======
|
||||
|
||||

|
||||
In this tutorial series, we're providing practical guidelines for using PGP, including basic concepts and generating and protecting your keys. If you missed the previous articles, you can catch up below. In this article, we look at Git's integration with PGP, starting with signed tags, then introducing signed commits, and finally adding support for signed pushes.
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
[Part 4: Moving Your Master Key to Offline Storage][4]
|
||||
|
||||
[Part 5: Moving Subkeys to a Hardware Device][5]
|
||||
|
||||
One of the core features of Git is its decentralized nature -- once a repository is cloned to your system, you have full history of the project, including all of its tags, commits and branches. However, with hundreds of cloned repositories floating around, how does anyone verify that the repository you downloaded has not been tampered with by a malicious third party? You may have cloned it from GitHub or some other official-looking location, but what if someone had managed to trick you?
|
||||
|
||||
Or what happens if a backdoor is discovered in one of the projects you've worked on, and the "Author" line in the commit says it was done by you, while you're pretty sure you had [nothing to do with it][6]?
|
||||
|
||||
To address both of these issues, Git introduced PGP integration. Signed tags prove the repository integrity by assuring that its contents are exactly the same as on the workstation of the developer who created the tag, while signed commits make it nearly impossible for someone to impersonate you without having access to your PGP keys.
|
||||
|
||||
### Checklist
|
||||
|
||||
* Understand signed tags, commits, and pushes (ESSENTIAL)
|
||||
|
||||
* Configure git to use your key (ESSENTIAL)
|
||||
|
||||
* Learn how tag signing and verification works (ESSENTIAL)
|
||||
|
||||
* Configure git to always sign annotated tags (NICE)
|
||||
|
||||
* Learn how commit signing and verification works (ESSENTIAL)
|
||||
|
||||
* Configure git to always sign commits (NICE)
|
||||
|
||||
* Configure gpg-agent options (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
Git implements multiple levels of integration with PGP, first starting with signed tags, then introducing signed commits, and finally adding support for signed pushes.
|
||||
|
||||
#### Understanding Git Hashes
|
||||
|
||||
Git is a complicated beast, but you need to know what a "hash" is in order to have a good grasp on how PGP integrates with it. We'll narrow it down to two kinds of hashes: tree hashes and commit hashes.
|
||||
|
||||
##### Tree hashes
|
||||
|
||||
Every time you commit a change to a repository, git records checksum hashes of all objects in it -- contents (blobs), directories (trees), file names and permissions, etc, for each subdirectory in the repository. It only does this for trees and blobs that have changed with each commit, so as not to re-checksum the entire tree unnecessarily if only a small part of it was touched.
|
||||
|
||||
Then it calculates and stores the checksum of the toplevel tree, which will inevitably be different if any part of the repository has changed.
|
||||
|
||||
##### Commit hashes
|
||||
|
||||
Once the tree hash has been created, git will calculate the commit hash, which will include the following information about the repository and the change being made:
|
||||
|
||||
* The checksum hash of the tree
|
||||
|
||||
* The checksum hash of the tree before the change (parent)
|
||||
|
||||
* Information about the author (name, email, time of authorship)
|
||||
|
||||
* Information about the committer (name, email, time of commit)
|
||||
|
||||
* The commit message
|
||||
|
||||
|
||||
|
||||
|
||||
##### Hashing function
|
||||
|
||||
At the time of writing, git still uses the SHA1 hashing mechanism to calculate checksums, though work is under way to transition to a stronger algorithm that is more resistant to collisions. Note, that git already includes collision avoidance routines, so it is believed that a successful collision attack against git remains impractical.
|
||||
|
||||
#### Annotated tags and tag signatures
|
||||
|
||||
Git tags allow developers to mark specific commits in the history of each git repository. Tags can be "lightweight" \-- more or less just a pointer at a specific commit, or they can be "annotated," which becomes its own object in the git tree. An annotated tag object contains all of the following information:
|
||||
|
||||
* The checksum hash of the commit being tagged
|
||||
|
||||
* The tag name
|
||||
|
||||
* Information about the tagger (name, email, time of tagging)
|
||||
|
||||
* The tag message
|
||||
|
||||
|
||||
|
||||
|
||||
A PGP-signed tag is simply an annotated tag with all these entries wrapped around in a PGP signature. When a developer signs their git tag, they effectively assure you of the following:
|
||||
|
||||
* Who they are (and why you should trust them)
|
||||
|
||||
* What the state of their repository was at the time of signing:
|
||||
|
||||
* The tag includes the hash of the commit
|
||||
|
||||
* The commit hash includes the hash of the toplevel tree
|
||||
|
||||
* Which includes hashes of all files, contents, and subtrees
|
||||
* It also includes all information about authorship
|
||||
|
||||
* Including exact times when changes were made
|
||||
|
||||
|
||||
|
||||
|
||||
When you clone a git repository and verify a signed tag, that gives you cryptographic assurance that all contents in the repository, including all of its history, are exactly the same as the contents of the repository on the developer's computer at the time of signing.
|
||||
|
||||
#### Signed commits
|
||||
|
||||
Signed commits are very similar to signed tags -- the contents of the commit object are PGP-signed instead of the contents of the tag object. A commit signature also gives you full verifiable information about the state of the developer's tree at the time the signature was made. Tag signatures and commit PGP signatures provide exact same security assurances about the repository and its entire history.
|
||||
|
||||
#### Signed pushes
|
||||
|
||||
This is included here for completeness' sake, since this functionality needs to be enabled on the server receiving the push before it does anything useful. As we saw above, PGP-signing a git object gives verifiable information about the developer's git tree, but not about their intent for that tree.
|
||||
|
||||
For example, you can be working on an experimental branch in your own git fork trying out a promising cool feature, but after you submit your work for review, someone finds a nasty bug in your code. Since your commits are properly signed, someone can take the branch containing your nasty bug and push it into master, introducing a vulnerability that was never intended to go into production. Since the commit is properly signed with your key, everything looks legitimate and your reputation is questioned when the bug is discovered.
|
||||
|
||||
Ability to require PGP-signatures during git push was added in order to certify the intent of the commit, and not merely verify its contents.
|
||||
|
||||
#### Configure git to use your PGP key
|
||||
|
||||
If you only have one secret key in your keyring, then you don't really need to do anything extra, as it becomes your default key.
|
||||
|
||||
However, if you happen to have multiple secret keys, you can tell git which key should be used ([fpr] is the fingerprint of your key):
|
||||
```
|
||||
$ git config --global user.signingKey [fpr]
|
||||
|
||||
```
|
||||
|
||||
NOTE: If you have a distinct gpg2 command, then you should tell git to always use it instead of the legacy gpg from version 1:
|
||||
```
|
||||
$ git config --global gpg.program gpg2
|
||||
|
||||
```
|
||||
|
||||
#### How to work with signed tags
|
||||
|
||||
To create a signed tag, simply pass the -s switch to the tag command:
|
||||
```
|
||||
$ git tag -s [tagname]
|
||||
|
||||
```
|
||||
|
||||
Our recommendation is to always sign git tags, as this allows other developers to ensure that the git repository they are working with has not been maliciously altered (e.g. in order to introduce backdoors).
|
||||
|
||||
##### How to verify signed tags
|
||||
|
||||
To verify a signed tag, simply use the verify-tag command:
|
||||
```
|
||||
$ git verify-tag [tagname]
|
||||
|
||||
```
|
||||
|
||||
If you are verifying someone else's git tag, then you will need to import their PGP key. Please refer to the "Trusted Team communication" document in the same repository for guidance on this topic.
|
||||
|
||||
##### Verifying at pull time
|
||||
|
||||
If you are pulling a tag from another fork of the project repository, git should automatically verify the signature at the tip you're pulling and show you the results during the merge operation:
|
||||
```
|
||||
$ git pull [url] tags/sometag
|
||||
|
||||
```
|
||||
|
||||
The merge message will contain something like this:
|
||||
```
|
||||
Merge tag 'sometag' of [url]
|
||||
|
||||
[Tag message]
|
||||
|
||||
# gpg: Signature made [...]
|
||||
# gpg: Good signature from [...]
|
||||
|
||||
```
|
||||
|
||||
#### Configure git to always sign annotated tags
|
||||
|
||||
Chances are, if you're creating an annotated tag, you'll want to sign it. To force git to always sign annotated tags, you can set a global configuration option:
|
||||
```
|
||||
$ git config --global tag.forceSignAnnotated true
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can just train your muscle memory to always pass the -s switch:
|
||||
```
|
||||
$ git tag -asm "Tag message" tagname
|
||||
|
||||
```
|
||||
|
||||
#### How to work with signed commits
|
||||
|
||||
It is easy to create signed commits, but it is much more difficult to incorporate them into your workflow. Many projects use signed commits as a sort of "Committed-by:" line equivalent that records code provenance -- the signatures are rarely verified by others except when tracking down project history. In a sense, signed commits are used for "tamper evidence," and not to "tamper-proof" the git workflow.
|
||||
|
||||
To create a signed commit, you just need to pass the -S flag to the git commit command (it's capital -S due to collision with another flag):
|
||||
```
|
||||
$ git commit -S
|
||||
|
||||
```
|
||||
|
||||
Our recommendation is to always sign commits and to require them of all project members, regardless of whether anyone is verifying them (that can always come at a later time).
|
||||
|
||||
##### How to verify signed commits
|
||||
|
||||
To verify a single commit you can use verify-commit:
|
||||
```
|
||||
$ git verify-commit [hash]
|
||||
|
||||
```
|
||||
|
||||
You can also look at repository logs and request that all commit signatures are verified and shown:
|
||||
```
|
||||
$ git log --pretty=short --show-signature
|
||||
|
||||
```
|
||||
|
||||
##### Verifying commits during git merge
|
||||
|
||||
If all members of your project sign their commits, you can enforce signature checking at merge time (and then sign the resulting merge commit itself using the -S flag):
|
||||
```
|
||||
$ git merge --verify-signatures -S merged-branch
|
||||
|
||||
```
|
||||
|
||||
Note, that the merge will fail if there is even one commit that is not signed or does not pass verification. As it is often the case, technology is the easy part -- the human side of the equation is what makes adopting strict commit signing for your project difficult.
|
||||
|
||||
##### If your project uses mailing lists for patch management
|
||||
|
||||
If your project uses a mailing list for submitting and processing patches, then there is little use in signing commits, because all signature information will be lost when sent through that medium. It is still useful to sign your commits, just so others can refer to your publicly hosted git trees for reference, but the upstream project receiving your patches will not be able to verify them directly with git.
|
||||
|
||||
You can still sign the emails containing the patches, though.
|
||||
|
||||
#### Configure git to always sign commits
|
||||
|
||||
You can tell git to always sign commits:
|
||||
```
|
||||
git config --global commit.gpgSign true
|
||||
|
||||
```
|
||||
|
||||
Or you can train your muscle memory to always pass the -S flag to all git commit operations (this includes --amend).
|
||||
|
||||
#### Configure gpg-agent options
|
||||
|
||||
The GnuPG agent is a helper tool that will start automatically whenever you use the gpg command and run in the background with the purpose of caching the private key passphrase. This way you only have to unlock your key once to use it repeatedly (very handy if you need to sign a bunch of git operations in an automated script without having to continuously retype your passphrase).
|
||||
|
||||
There are two options you should know in order to tweak when the passphrase should be expired from cache:
|
||||
|
||||
* default-cache-ttl (seconds): If you use the same key again before the time-to-live expires, the countdown will reset for another period. The default is 600 (10 minutes).
|
||||
|
||||
* max-cache-ttl (seconds): Regardless of how recently you've used the key since initial passphrase entry, if the maximum time-to-live countdown expires, you'll have to enter the passphrase again. The default is 30 minutes.
|
||||
|
||||
|
||||
|
||||
|
||||
If you find either of these defaults too short (or too long), you can edit your ~/.gnupg/gpg-agent.conf file to set your own values:
|
||||
```
|
||||
# set to 30 minutes for regular ttl, and 2 hours for max ttl
|
||||
default-cache-ttl 1800
|
||||
max-cache-ttl 7200
|
||||
|
||||
```
|
||||
|
||||
##### Bonus: Using gpg-agent with ssh
|
||||
|
||||
If you've created an [A] (Authentication) key and moved it to the smartcard, you can use it with ssh for adding 2-factor authentication for your ssh sessions. You just need to tell your environment to use the correct socket file for talking to the agent.
|
||||
|
||||
First, add the following to your ~/.gnupg/gpg-agent.conf:
|
||||
```
|
||||
enable-ssh-support
|
||||
|
||||
```
|
||||
|
||||
Then, add this to your .bashrc:
|
||||
```
|
||||
export SSH_AUTH_SOCK=$(gpgconf --list-dirs agent-ssh-socket)
|
||||
|
||||
```
|
||||
|
||||
You will need to kill the existing gpg-agent process and start a new login session for the changes to take effect:
|
||||
```
|
||||
$ killall gpg-agent
|
||||
$ bash
|
||||
$ ssh-add -L
|
||||
|
||||
```
|
||||
|
||||
The last command should list the SSH representation of your PGP Auth key (the comment should say cardno:XXXXXXXX at the end to indicate it's coming from the smartcard).
|
||||
|
||||
To enable key-based logins with ssh, just add the ssh-add -L output to ~/.ssh/authorized_keys on remote systems you log in to. Congratulations, you've just made your ssh credentials extremely difficult to steal.
|
||||
|
||||
As a bonus, you can get other people's PGP-based ssh keys from public keyservers, should you need to grant them ssh access to anything:
|
||||
```
|
||||
$ gpg --export-ssh-key [keyid]
|
||||
|
||||
```
|
||||
|
||||
This can come in super handy if you need to allow developers access to git repositories over ssh. Next time, we'll provide tips for protecting your email accounts as well as your PGP keys.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-6-using-pgp-git
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
[5]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device
|
||||
[6]:https://github.com/jayphelps/git-blame-someone-else
|
||||
139
sources/tech/20180322 Simple Load Balancing with DNS on Linux.md
Normal file
139
sources/tech/20180322 Simple Load Balancing with DNS on Linux.md
Normal file
@ -0,0 +1,139 @@
|
||||
Simple Load Balancing with DNS on Linux
|
||||
======
|
||||
|
||||

|
||||
When you have server back ends built of multiple servers, such as clustered or mirrowed web or file servers, a load balancer provides a single point of entry. Large busy shops spend big money on high-end load balancers that perform a wide range of tasks: proxy, caching, health checks, SSL processing, configurable prioritization, traffic shaping, and lots more.
|
||||
|
||||
But you don't want all that. You need a simple method for distributing workloads across all of your servers and providing a bit of failover and don't care whether it is perfectly efficient. DNS round-robin and subdomain delegation with round-robin provide two simple methods to achieve this.
|
||||
|
||||
DNS round-robin is mapping multiple servers to the same hostname, so that when users visit foo.example.com multiple servers are available to handle their requests.
|
||||
|
||||
Subdomain delegation with round-robin is useful when you have multiple subdomains or when your servers are geographically dispersed. You have a primary nameserver, and then your subdomains have their own nameservers. Your primary nameserver refers all subdomain requests to their own nameservers. This usually improves response times, as the DNS protocol will automatically look for the fastest links.
|
||||
|
||||
### Round-Robin DNS
|
||||
|
||||
Round-robin has nothing to do with robins. According to my favorite librarian, it was originally a French phrase, _ruban rond_ , or round ribbon. Way back in olden times, French government officials signed grievance petitions in non-hierarchical circular, wavy, or spoke patterns to conceal whoever originated the petition.
|
||||
|
||||
Round-robin DNS is also non-hierarchical, a simple configuration that takes a list of servers and sends requests to each server in turn. It does not perform true load-balancing as it does not measure loads, and does no health checks, so if one of the servers is down, requests are still sent to that server. Its virtue lies in simplicity. If you have a little cluster of file or web servers and want to spread the load between them in the simplest way, then round-robin DNS is for you.
|
||||
|
||||
All you do is create multiple A or AAAA records, mapping multiple servers to a single host name. This BIND example uses both IPv4 and IPv6 private address classes:
|
||||
```
|
||||
fileserv.example.com. IN A 172.16.10.10
|
||||
fileserv.example.com. IN A 172.16.10.11
|
||||
fileserv.example.com. IN A 172.16.10.12
|
||||
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::10
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::11
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::12
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq uses _/etc/hosts_ for A and AAAA records:
|
||||
```
|
||||
172.16.1.10 fileserv fileserv.example.com
|
||||
172.16.1.11 fileserv fileserv.example.com
|
||||
172.16.1.12 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::10 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::11 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::12 fileserv fileserv.example.com
|
||||
|
||||
```
|
||||
|
||||
Note that these examples are simplified, and there are multiple ways to resolve fully-qualified domain names, so please study up on configuring DNS.
|
||||
|
||||
Use the `dig` command to check your work. Replace `ns.example.com` with your name server:
|
||||
```
|
||||
$ dig @ns.example.com fileserv A fileserv AAA
|
||||
|
||||
```
|
||||
|
||||
That should display both IPv4 and IPv6 round-robin records.
|
||||
|
||||
### Subdomain Delegation and Round-Robin
|
||||
|
||||
Subdomain delegation combined with round-robin is more work to set up, but it has some advantages. Use this when you have multiple subdomains or geographically-dispersed servers. Response times are often quicker, and a down server will not respond, so clients will not get hung up waiting for a reply. A short TTL, such as 60 seconds, helps this.
|
||||
|
||||
This approach requires multiple name servers. In the simplest scenario, you have a primary name server and two subdomains, each with its own name server. Configure your round-robin entries on the subdomain servers, then configure the delegations on your primary server.
|
||||
|
||||
In BIND on your primary name server, you'll need at least two additional configurations, a zone statement, and A/AAAA records in your zone data file. The delegation looks something like this on your primary name server:
|
||||
```
|
||||
ns1.sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
ns2.sub.example.com. IN A 172.16.1.21
|
||||
ns2.sub.example.com. IN AAA fd02:faea:f561:8fa0:1::21
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN NS ns2.sub.example.com.
|
||||
|
||||
```
|
||||
|
||||
Then each of the subdomain servers have their own zone files. The trick here is for each server to return its own IP address. The zone statement in `named.conf` is the same on both servers:
|
||||
```
|
||||
zone "sub.example.com" {
|
||||
type master;
|
||||
file "db.sub.example.com";
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
Then the data files are the same, except that the A/AAAA records use the server's own IP address. The SOA (start of authority) refers to the primary name server:
|
||||
```
|
||||
; first subdomain name server
|
||||
$ORIGIN sub.example.com.
|
||||
$TTL 60
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018123456 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
)
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
|
||||
; second subdomain name server
|
||||
$ORIGIN sub.example.com.
|
||||
$TTL 60
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018234567 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
)
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN A 172.16.1.21
|
||||
ns2.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::21
|
||||
|
||||
```
|
||||
|
||||
Next, make your round-robin entries on the subdomain name servers, and you're done. Now you have multiple name servers handling requests for your subdomains. Again, BIND is complex and has multiple ways to do the same thing, so your homework is to ensure that your configuration fits with the way you use it.
|
||||
|
||||
Subdomain delegations are easier in Dnsmasq. On your primary server, add lines like this in `dnsmasq.conf` to point to the name servers for the subdomains:
|
||||
```
|
||||
server=/sub.example.com/172.16.1.20
|
||||
server=/sub.example.com/172.16.1.21
|
||||
server=/sub.example.com/fd02:faea:f561:8fa0:1::20
|
||||
server=/sub.example.com/fd02:faea:f561:8fa0:1::21
|
||||
|
||||
```
|
||||
|
||||
Then configure round-robin on the subdomain name servers in `/etc/hosts`.
|
||||
|
||||
For way more details and help, refer to these resources:
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][1]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/simple-load-balancing-dns-linux
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,111 @@
|
||||
translating by amwps290
|
||||
chkservice – A Tool For Managing Systemd Units From Linux Terminal
|
||||
======
|
||||
systemd stand for system daemon is a new init system and system manager which is become very popular and widely adapted new standard init system by most of Linux distributions.
|
||||
|
||||
Systemctl is a systemd utility which is help us to manage systemd daemons. It control system startup and services, uses parallelization, socket and D-Bus activation for starting services, offers on-demand starting of daemons, keeps track of processes using Linux control groups, maintains mount and automount points.
|
||||
|
||||
Also it offers logging daemon, utilities to control basic system configuration like the hostname, date, locale, maintain a list of logged-in users and running containers and virtual machines, system accounts, runtime directories and settings, and daemons to manage simple network configuration, network time synchronization, log forwarding, and name resolution.
|
||||
|
||||
### What Is chkservice
|
||||
|
||||
[chkservice][1] is an ncurses-based tool for managing systemd units from the terminal. It provides the user with a comprehensive view of all systemd services and allows them to be changed easily.
|
||||
|
||||
It requires super user privileges to make changes into unit states or sysv scripts.
|
||||
|
||||
### How To Install chkservice In Linux
|
||||
|
||||
We can install chkservice in two ways, either package or manual method.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [APT-GET Command][2] or [APT Command][3]to install chkservice.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:linuxenko/chkservice
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install chkservice
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use [Yaourt Command][4] or [Packer Command][5] to install chkservice from AUR repository.
|
||||
```
|
||||
$ yaourt -S chkservice
|
||||
or
|
||||
$ packer -S chkservice
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][6] to install chkservice.
|
||||
```
|
||||
$ sudo dnf copr enable srakitnican/default
|
||||
$ sudo dnf install chkservice
|
||||
|
||||
```
|
||||
|
||||
For **`Debian Based Systems`** , use [DPKG Command][7] to install chkservice.
|
||||
```
|
||||
$ wget https://github.com/linuxenko/chkservice/releases/download/0.1/chkservice_0.1.0-amd64.deb
|
||||
$ sudo dpkg -i chkservice_0.1.0-amd64.deb
|
||||
|
||||
```
|
||||
|
||||
For **`RPM Based Systems`** , use [DNF Command][8] to install chkservice.
|
||||
```
|
||||
$ sudo yum install https://github.com/linuxenko/chkservice/releases/download/0.1/chkservice_0.1.0-amd64.rpm
|
||||
|
||||
```
|
||||
|
||||
### How To Use chkservice
|
||||
|
||||
Just fire the following command to launch the chkservice tool. The output is split to four parts.
|
||||
|
||||
* **`First Part:`** This part shows about daemons status like, enabled [X] or disabled [] or static [s] or masked -m-
|
||||
* **`Second Part:`** This part shows daemons status like, started [ >] or stopped [=]
|
||||
* **`Third Part:`** This part shows the unit name
|
||||
* **`Fourth Part:`** This part showing the unit short description
|
||||
|
||||
|
||||
```
|
||||
$ sudo chkservice
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
To view help page, hit `?` button. This will shows you available options to manage the systemd services.
|
||||
![][11]
|
||||
|
||||
Select the units, which you want to enable or disable then hit `Space Bar` button.
|
||||
![][12]
|
||||
|
||||
Select the units, which you want to start or stop then hit `s` button.
|
||||
![][13]
|
||||
|
||||
Select the units, which you want to reload then hit `r` button. After hit `r` key, you can see the `updated` message at the top.
|
||||
![][14]
|
||||
|
||||
Hit `q` button to quit the utility.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
|
||||
|
||||
作者:[Ramya Nuvvula][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/ramya/
|
||||
[1]:https://github.com/linuxenko/chkservice
|
||||
[2]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]:https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/
|
||||
[5]:https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/
|
||||
[6]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]:https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/
|
||||
[8]:https://www.2daygeek.com/rpm-command-examples/
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-1.png
|
||||
[11]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-2.png
|
||||
[12]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-3.png
|
||||
[13]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-4.png
|
||||
[14]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-5.png
|
||||
@ -1,16 +1,14 @@
|
||||
translating---geekpi
|
||||
|
||||
How to resolve mount.nfs: Stale file handle error
|
||||
如何解决 mount.nfs:失效的文件句柄错误
|
||||
======
|
||||
Learn how to resolve mount.nfs: Stale file handle error on Linux platform. This is Network File System error can be resolved from client or server end.
|
||||
了解如何解决 mount.nfs:Linux 平台上的失效文件句柄错误。它是可以在客户端或者服务端解决的网络文件系统错误。
|
||||
|
||||
_![][1]_
|
||||
|
||||
When you are using Network File System in your environment, you must have seen`mount.nfs: Stale file handle` error at times. This error denotes that NFS share is unable to mount since something has changed since last good known configuration.
|
||||
当你在你的环境中使用网络文件系统时,你一定不时看到 `mount.nfs:Stale file handle` 错误。此错误表示 NFS 共享无法挂载,因为自上次配置后有些东西已经更改。
|
||||
|
||||
Whenever you reboot NFS server or some of the NFS processes are not running on client or server or share is not properly exported at server; these can be reasons for this error. Moreover its irritating when this error comes to previously mounted NFS share. Because this means configuration part is correct since it was previously mounted. In such case once can try following commands:
|
||||
无论何时你重启 NFS 服务器或某些 NFS 进程未在客户端或服务器上运行,或者共享未在服务器上正确导出,这些都可能是这个错误的原因。此外,当这个错误发生在先前挂载的 NFS 共享上时,它会它令人不快。因为这意味着配置部分是正确的,因为是以前挂载的。在这种情况下,可以尝试下面的命令:
|
||||
|
||||
Make sure NFS service are running good on client and server.
|
||||
确保 NFS 服务在客户端和服务器上运行良好。
|
||||
|
||||
```
|
||||
# service nfs status
|
||||
@ -20,9 +18,9 @@ nfsd (pid 12009 12008 12007 12006 12005 12004 12003 12002) is running...
|
||||
rpc.rquotad (pid 11988) is running...
|
||||
```
|
||||
|
||||
> Stay connected to your favorite windows applications from anywhere on any device with [ windows 7 cloud desktop ][2] from CloudDesktopOnline.com. Get Office 365 with expert support and free migration from [ Apps4Rent.com ][3].
|
||||
>通过 CloudDesktopOnline.com 上的[ Windows 7 云桌面][2]在任意位置的任何设备上保持与你最喜爱的 Windows 程序的连接。从 [Apps4Rent.com][3] 获得有专家支持的 Office 365 和免费迁移。
|
||||
|
||||
If NFS share currently mounted on client, then un-mount it forcefully and try to remount it on NFS client. Check if its properly mounted by `df` command and changing directory inside it.
|
||||
如果 NFS 共享目前挂载在客户端上,则强制卸载它并尝试在 NFS 客户端上重新挂载它。通过 `df` 命令检查它是否正确挂载,并更改其中的目录。
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
@ -34,9 +32,9 @@ If NFS share currently mounted on client, then un-mount it forcefully and try to
|
||||
server:/nfs_share 41943040 892928 41050112 3% /mydata_nfs
|
||||
```
|
||||
|
||||
In above mount command, server can be IP or [hostname ][4]of NFS server.
|
||||
在上面的挂载命令中,服务器可以是 NFS 服务器的 IP 或[主机名][4]。
|
||||
|
||||
If you are getting error while forcefully un-mounting like below :
|
||||
如果你在强制取消挂载时遇到像下面错误:
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
@ -45,7 +43,7 @@ umount: /mydata_nfs: device is busy
|
||||
umount2: Device or resource busy
|
||||
umount: /mydata_nfs: device is busy
|
||||
```
|
||||
Then you can check which all processes or users are using that mount point with `lsof` command like below:
|
||||
然后你可以用 `lsof` 命令来检查哪个进程或用户正在使用该挂载点,如下所示:
|
||||
|
||||
```
|
||||
# lsof |grep mydata_nfs
|
||||
@ -57,9 +55,9 @@ bash 20092 oracle11 cwd unknown
|
||||
bash 25040 oracle11 cwd unknown /mydata_nfs/MUYR (stat: Stale NFS file handle)
|
||||
```
|
||||
|
||||
If you see in above example that 4 PID are using some files on said mount point. Try killing them off to free mount point. Once done you will be able to un-mount it properly.
|
||||
如果你在上面的示例中看到共有 4 个 PID 正在使用该挂载点上的某些文件。尝试杀死它们以释放挂载点。完成后,你将能够正确卸载它。
|
||||
|
||||
Sometimes it still give same error for mount command. Then try mounting after restarting NFS service at client using below command.
|
||||
有时 mount 命令会有相同的错误。接着使用下面的命令在客户端重启 NFS 服务后挂载。
|
||||
|
||||
```
|
||||
# service nfs restart
|
||||
@ -73,18 +71,18 @@ Starting NFS mountd: [ OK ]
|
||||
Starting NFS daemon: [ OK ]
|
||||
```
|
||||
|
||||
Also read : [How to restart NFS step by step in HPUX][5]
|
||||
另请阅读:[如何在 HPUX 中逐步重启 NFS][5]
|
||||
|
||||
Even if this didnt solve your issue, final step is to restart services at NFS server. Caution! This will disconnect all NFS shares which are exported from NFS server. All clients will see mount point disconnect. This step is where 99% you will get your issue resolved. If not then [NFS configurations][6] must be checked, provided you have changed configuration and post that you started seeing this error.
|
||||
即使这没有解决你的问题,最后一步是在 NFS 服务器上重启服务。警告!这将断开从该 NFS 服务器导出的所有 NFS 共享。所有客户端将看到挂载点断开。这一步将 99% 解决你的问题。如果没有,请务必检查[ NFS 配置][6],提供你修改的配置并发布你启动时看到的错误。
|
||||
|
||||
Outputs in above post are from RHEL6.3 server. Drop us your comments related to this post.
|
||||
上面文章中的输出来自 RHEL6.3 服务器。请将你的评论发送给我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/troubleshooting/resolve-mount-nfs-stale-file-handle-error/
|
||||
|
||||
作者:[KernelTalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,36 +1,35 @@
|
||||
How to setup and configure network bridge on Debian Linux
|
||||
======
|
||||
如何在 Debian Linux 上设置和配置网桥
|
||||
=====
|
||||
|
||||
I am new Debian Linux user. I want to setup Bridge for virtualised environments (KVM) running on Debian Linux. How do I setup network bridging in /etc/network/interfaces on Debian Linux 9.x server?
|
||||
我是一个新 Debian Linux 用户,我想为 Debian Linux 上运行的虚拟化环境(KVM)设置网桥。那么我该如何在 Debian Linux 9.x 服务器上的 /etc/network/interfaces 中设置桥接网络呢?
|
||||
|
||||
If you want to assign IP addresses to your virtual machines and make them accessible from your LAN you need to setup network bridge. By default, a private network bridge created when using KVM. You need to set up interfaces manually, avoiding conflicts with, network manager.
|
||||
如何你想为你的虚拟机分配 IP 地址并使其可从你的局域网访问,则需要设置网络桥接器。默认情况下,虚拟机使用 KVM 创建的专用网桥。但你需要手动设置接口,避免与网络管理员发生冲突。
|
||||
|
||||
### How to install the brctl
|
||||
### 怎样安装 brctl
|
||||
|
||||
Type the following [nixcmdn name=”apt”]/[apt-get command][1]:
|
||||
输入以下命令 [nixcmdn name=”apt”]/[apt-get 命令][1]:
|
||||
`$ sudo apt install bridge-utils`
|
||||
|
||||
### How to setup network bridge on Debian Linux
|
||||
### 怎样在 Debian Linux 上设置网桥
|
||||
|
||||
You need to edit /etc/network/interface file. However, I recommend to drop a brand new config in /etc/network/interface.d/ directory. The procedure to configure network bridge on Debian Linux is as follows:
|
||||
你需要编辑 /etc/network/interface 文件。不过,我建议在 /etc/network/interface.d/ 目录下放置一个全新的配置。在 Debian Linux 配置网桥的过程如下:
|
||||
|
||||
#### Step 1 – Find out your physical interface
|
||||
#### 步骤 1 - 找出你的物理接口
|
||||
|
||||
Use the [ip command][2]:
|
||||
使用 [ip 命令][2]:
|
||||
`$ ip -f inet a s`
|
||||
Sample outputs:
|
||||
示例输出如下:
|
||||
```
|
||||
2: eno1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
inet 192.168.2.23/24 brd 192.168.2.255 scope global eno1
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
eno1 是我的物理网卡。
|
||||
|
||||
eno1 is my physical interface.
|
||||
#### 步骤 2 - 更新 /etc/network/interface 文件
|
||||
|
||||
#### Step 2 – Update /etc/network/interface file
|
||||
|
||||
Make sure only lo (loopback is active in /etc/network/interface). Remove any config related to eno1. Here is my config file printed using [cat command][3]:
|
||||
确保只有 lo(loopback 在 /etc/network/interface 中处于活动状态)。(译注:loopback 指本地环回接口,也称为回送地址)删除与 eno1 相关的任何配置。这是我使用 [cat 命令][3] 打印的配置文件:
|
||||
`$ cat /etc/network/interface`
|
||||
```
|
||||
# This file describes the network interfaces available on your system
|
||||
@ -44,11 +43,11 @@ iface lo inet loopback
|
||||
```
|
||||
|
||||
|
||||
#### Step 3 – Configuring bridging (br0) in /etc/network/interfaces.d/br0
|
||||
#### 步骤 3 - 在 /etc/network/interfaces.d/br0 中配置网桥(br0)
|
||||
|
||||
Create a text file using a text editor such as vi command:
|
||||
使用文本编辑器创建一个 text 文件,比如 vi 命令:
|
||||
`$ sudo vi /etc/network/interfaces.d/br0`
|
||||
Append the following config:
|
||||
在其中添加配置:
|
||||
```
|
||||
## static ip config file for br0 ##
|
||||
auto br0
|
||||
@ -68,7 +67,7 @@ iface br0 inet static
|
||||
bridge_fd 0 # no forwarding delay
|
||||
```
|
||||
|
||||
If you want bridge to get an IP address using DHCP:
|
||||
如果你想使用 DHCP 来获得 IP 地址:
|
||||
```
|
||||
## DHCP ip config file for br0 ##
|
||||
auto br0
|
||||
@ -78,35 +77,35 @@ auto br0
|
||||
bridge_ports eno1
|
||||
```
|
||||
|
||||
[在 vi/vim 中保存并关闭文件][4]。
|
||||
|
||||
[Save and close the file in vi/vim][4].
|
||||
#### 步骤 4 - [重新启动网络服务][5]
|
||||
|
||||
#### Step 4 – [Restart networking service in Linux][5]
|
||||
|
||||
Before you restart the networking service make sure firewall is disabled. The firewall may refer to older interface such as eno1. Once service restarted, you must update firewall rule for interface br0. Type the following restart the networking service:
|
||||
在重新启动网络服务之前,请确保防火墙已关闭。防火墙可能会引用较老的接口,例如 eno1。一旦服务重新启动,你必须更新 br0 接口的防火墙规则。键入以下命令重新启动防火墙:
|
||||
`$ sudo systemctl restart network-manager`
|
||||
Verify that service has been restarted:
|
||||
确认服务已经重新启动:
|
||||
`$ systemctl status network-manager`
|
||||
Look for new br0 interface and routing table with the help of [ip command][2]:
|
||||
借助 [ip 命令][2]寻找新的 br0 接口和路由表:
|
||||
`$ ip a s $ ip r $ ping -c 2 cyberciti.biz`
|
||||
Sample outputs:
|
||||
示例输出:
|
||||

|
||||
You can also use the brctl command to view info about your bridges:
|
||||
你可以使用 brctl 命令查看网桥有关信息:
|
||||
`$ brctl show`
|
||||
Show current bridges:
|
||||
显示当前网桥:
|
||||
`$ bridge link`
|
||||

|
||||
|
||||
### About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin, DevOps engineer, and a trainer for the Linux operating system/Unix shell scripting. Get the **latest tutorials on SysAdmin, Linux/Unix and open source topics via[RSS/XML feed][6]** or [weekly email newsletter][7].
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,也是经验丰富的系统管理员,DevOps 工程师以及 Linux 操作系统/ Unix shell 脚本的培训师。通过订阅 [RSS/XML feed][6] 或者 [weekly email newsletter][7]获得**关于 SysAdmin, Linux/Unix 和开源主题的最新教程。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-configuring-bridging-in-debian-linux/
|
||||
|
||||
作者:[Vivek GIte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,188 @@
|
||||
如何使用树莓派测定颗粒物
|
||||
======
|
||||
|
||||

|
||||
我们在东南亚的学校定期测定空气中的颗粒物。这里的测定值非常高,尤其是在二到五月之间,干燥炎热、土地干旱等各种因素都对空气质量产生了不利的影响。我将会在这篇文章中展示如何使用树莓派来测定颗粒物。
|
||||
|
||||
### 什么是颗粒物?
|
||||
|
||||
颗粒物就是粉尘或者空气中的微小颗粒。其中 PM10 和 PM2.5 之间的差别就是 PM10 指的是粒径小于10微米的颗粒,而 PM2.5 指的是粒径小于2.5微米的颗粒。在粒径小于2.5微米的的情况下,由于它们能被吸入肺泡中并且对呼吸系统造成影响,因此颗粒越小,对人的健康危害越大。
|
||||
|
||||
世界卫生组织的建议[颗粒物浓度][1]是:
|
||||
|
||||
* 年均 PM10 不高于20 µg/m³
|
||||
* 年均 PM2.5 不高于10 µg/m³
|
||||
* 不允许超标时,日均 PM10 不高于50 µg/m³
|
||||
* 不允许超标时,日均 PM2.5 不高于25 µg/m³
|
||||
|
||||
以上数值实际上是低于大多数国家的标准的,例如欧盟对于 PM10 所允许的年均值是不高于40 µg/m³。
|
||||
|
||||
### 什么是空气质量指数(AQI, Air Quality Index)?
|
||||
|
||||
空气质量指数按照颗粒物的测定值来评价空气质量的好坏,然而由于各国之间的计算方式有所不同,这个指数并没有统一的标准。维基百科上关于[空气质量指数][2]的词条对此给出了一个概述。我们学校则以[美国环境保护协会][3](EPA, Environment Protection Agency)建立的分类法来作为依据。
|
||||
|
||||
![空气质量指数][5]
|
||||
|
||||
空气质量指数
|
||||
|
||||
### 测定颗粒物需要哪些准备?
|
||||
|
||||
测定颗粒物只需要以下两种器材:
|
||||
* 树莓派(款式不限,最好带有 WiFi)
|
||||
* SDS011 颗粒物传感器
|
||||
|
||||
|
||||
|
||||
![颗粒物传感器][7]
|
||||
|
||||
颗粒物传感器
|
||||
|
||||
如果是只带有 Micro USB的树莓派Zero W,那还需要一根连接到标准 USB 端口的适配线,只需要20美元,而传感器则自带适配串行接口的 USB 适配器。
|
||||
|
||||
### 安装过程
|
||||
|
||||
对于树莓派,只需要下载对应的 Raspbian Lite 镜像并且[写入到 Micro SD 卡][8]上就可以了(网上很多教程都有介绍如何设置 WLAN 连接,我就不细说了)。
|
||||
|
||||
如果要使用 SSH,那还需要在启动分区建立一个名为 `ssh` 的空文件。树莓派的 IP 通过路由器或者 DHCP 服务器获取,随后就可以通过 SSH 登录到树莓派了(默认密码是 raspberry):
|
||||
```
|
||||
$ ssh pi@192.168.1.5
|
||||
|
||||
```
|
||||
|
||||
首先我们需要在树莓派上安装一下这些包:
|
||||
```
|
||||
$ sudo apt install git-core python-serial python-enum lighttpd
|
||||
|
||||
```
|
||||
|
||||
在开始之前,我们可以用 `dmesg` 来获取 USB 适配器连接的串行接口:
|
||||
```
|
||||
$ dmesg
|
||||
|
||||
[ 5.559802] usbcore: registered new interface driver usbserial
|
||||
|
||||
[ 5.559930] usbcore: registered new interface driver usbserial_generic
|
||||
|
||||
[ 5.560049] usbserial: USB Serial support registered for generic
|
||||
|
||||
[ 5.569938] usbcore: registered new interface driver ch341
|
||||
|
||||
[ 5.570079] usbserial: USB Serial support registered for ch341-uart
|
||||
|
||||
[ 5.570217] ch341 1–1.4:1.0: ch341-uart converter detected
|
||||
|
||||
[ 5.575686] usb 1–1.4: ch341-uart converter now attached to ttyUSB0
|
||||
|
||||
```
|
||||
|
||||
在最后一行,可以看到接口 `ttyUSB0`。然后我们需要写一个 Python 脚本来读取传感器的数据并以 JSON 格式存储,在通过一个 HTML 页面就可以把数据展示出来了。
|
||||
|
||||
### 在树莓派上读取数据
|
||||
|
||||
首先创建一个传感器实例,每5分钟读取一次传感器的数据,持续30秒,这些数值后续都可以调整。在每两次测定的间隔,我们把传感器调到睡眠模式以延长它的使用寿命(厂商认为元件的寿命大约8000小时)。
|
||||
|
||||
我们可以使用以下命令来下载 Python 脚本:
|
||||
```
|
||||
$ wget -O /home/pi/aqi.py https://raw.githubusercontent.com/zefanja/aqi/master/python/aqi.py
|
||||
|
||||
```
|
||||
|
||||
另外还需要执行以下两条命令来保证脚本正常运行:
|
||||
```
|
||||
$ sudo chown pi:pi /var/wwww/html/
|
||||
|
||||
$ echo[] > /var/wwww/html/aqi.json
|
||||
|
||||
```
|
||||
|
||||
下面就可以执行脚本了:
|
||||
```
|
||||
$ chmod +x aqi.py
|
||||
|
||||
$ ./aqi.py
|
||||
|
||||
PM2.5:55.3, PM10:47.5
|
||||
|
||||
PM2.5:55.5, PM10:47.7
|
||||
|
||||
PM2.5:55.7, PM10:47.8
|
||||
|
||||
PM2.5:53.9, PM10:47.6
|
||||
|
||||
PM2.5:53.6, PM10:47.4
|
||||
|
||||
PM2.5:54.2, PM10:47.3
|
||||
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
### 自动化执行脚本
|
||||
|
||||
只需要使用诸如 crontab 的服务,我们就不需要每次都手动启动脚本了。按照以下命令打开 crontab 文件:
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
在文件末尾添加这一行:
|
||||
```
|
||||
@reboot cd /home/pi/ && ./aqi.py
|
||||
|
||||
```
|
||||
|
||||
现在我们的脚本就会在树莓派每次重启后自动执行了。
|
||||
|
||||
### 展示颗粒物测定值和空气质量指数的 HTML 页面
|
||||
|
||||
我们在前面已经安装了一个轻量级的 web 服务器 `lighttpd`,所以我们需要把 HTML、JavaScript、CSS 文件放置在 `/var/www/html` 目录中,这样就能通过电脑和智能手机访问到相关数据了。执行下面的三条命令,可以下载到对应的文件:
|
||||
|
||||
```
|
||||
$ wget -O /var/wwww/html/index.html https://raw.githubusercontent.com/zefanja/aqi/master/html/index.html
|
||||
|
||||
$ wget -O /var/wwww/html/aqi.js https://raw.githubusercontent.com/zefanja/aqi/master/html/aqi.js
|
||||
|
||||
$ wget -O /var/wwww/html/style.css https://raw.githubusercontent.com/zefanja/aqi/master/html/style.css
|
||||
|
||||
```
|
||||
|
||||
在 JavaScript 文件中,实现了打开 JSON 文件、提取数据、计算空气质量指数的过程,随后页面的背景颜色将会根据 EPA 的划分标准而变化。
|
||||
|
||||
你只需要用浏览器访问树莓派的地址,就可以看到当前颗粒物浓度值等数据了。[http://192.168.1.5:][9]
|
||||
|
||||
这个页面比较简单而且可扩展,比如可以添加一个展示过去数小时历史数据的表格等等。
|
||||
|
||||
这是[Github上的完整源代码][10]。
|
||||
|
||||
### 总结
|
||||
|
||||
在资金相对紧张的情况下,树莓派是一种选择。除此以外,还有很多可以用来测定颗粒物的应用,包括室外固定装置、移动测定设备等等。我们学校则同时采用了这两种:固定装置在室外测定全天颗粒物浓度,而移动测定设备在室内检测空调过滤器的效果。
|
||||
|
||||
[Luftdaten.info][12]提供了一个如何设计类似的传感器的介绍,其中的软件效果出众,而且因为它没有使用树莓派,所以硬件更是小巧。
|
||||
|
||||
对于学生来说,设计一个颗粒物传感器确实算得上是一个优秀的课外项目。
|
||||
|
||||
你又打算如何使用你的[树莓派][13]呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi
|
||||
|
||||
作者:[Stephan Tetzel][a]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stephan
|
||||
[1]:https://en.wikipedia.org/wiki/Particulates
|
||||
[2]:https://en.wikipedia.org/wiki/Air_quality_index
|
||||
[3]:https://en.wikipedia.org/wiki/United_States_Environmental_Protection_Agency
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/air_quality_index.png?itok=FwmGf1ZS (Air quality index)
|
||||
[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/particulate_sensor.jpg?itok=ddH3bBwO (Particulate sensor)
|
||||
[8]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[9]:http://192.168.1.5/
|
||||
[10]:https://github.com/zefanja/aqi
|
||||
[11]:https://opensource.com/article/18/3/raspberry-pi-week-giveaway
|
||||
[12]:http://luftdaten.info/
|
||||
[13]:https://openschoolsolutions.org/shutdown-servers-case-power-failure%e2%80%8a-%e2%80%8aups-nut-co/
|
||||
@ -0,0 +1,205 @@
|
||||
如何使用 Ansible 打补丁以及安装应用
|
||||
======
|
||||
|
||||

|
||||
你有没有想过,如何打补丁、重启系统,然后继续工作?
|
||||
|
||||
如果你的回答是肯定的,那就需要了解一下 [Ansible][1] 了。它是一个配置管理工具,对于一些复杂的系统管理任务有时候需要几个小时才能完成,又或者对安全性有比较高要求的时候,使用 Ansible 能够大大简化工作流程。
|
||||
|
||||
以我作为系统管理员的经验,打补丁是一项最有难度的工作。每次遇到公共漏洞和暴露(CVE, Common Vulnearbilities and Exposure)通知或者信息安全漏洞预警(IAVA, Information Assurance Vulnerability Alert)时都必须要高度关注安全漏洞,否则安全部门将会严肃追究自己的责任。
|
||||
|
||||
使用 Ansible 可以通过运行[封装模块][2]以缩短打补丁的时间,下面以[yum模块][3]更新系统为例,使用 Ansible 可以执行安装、更新、删除、从其它地方安装(例如持续集成/持续开发中的 `rpmbuild`)。以下是系统更新的任务:
|
||||
```
|
||||
- name: update the system
|
||||
|
||||
yum:
|
||||
|
||||
name: "*"
|
||||
|
||||
state: latest
|
||||
|
||||
```
|
||||
|
||||
在第一行,我们给这个任务命名,这样可以清楚 Ansible 的工作内容。第二行表示使用 `yum` 模块在CentOS虚拟机中执行更新操作。第三行 `name: "*"` 表示更新所有程序。最后一行 `state: latest` 表示更新到最新的 RPM。
|
||||
|
||||
系统更新结束之后,需要重新启动并重新连接:
|
||||
```
|
||||
- name: restart system to reboot to newest kernel
|
||||
|
||||
shell: "sleep 5 && reboot"
|
||||
|
||||
async: 1
|
||||
|
||||
poll: 0
|
||||
|
||||
|
||||
|
||||
- name: wait for 10 seconds
|
||||
|
||||
pause:
|
||||
|
||||
seconds: 10
|
||||
|
||||
|
||||
|
||||
- name: wait for the system to reboot
|
||||
|
||||
wait_for_connection:
|
||||
|
||||
connect_timeout: 20
|
||||
|
||||
sleep: 5
|
||||
|
||||
delay: 5
|
||||
|
||||
timeout: 60
|
||||
|
||||
|
||||
|
||||
- name: install epel-release
|
||||
|
||||
yum:
|
||||
|
||||
name: epel-release
|
||||
|
||||
state: latest
|
||||
|
||||
```
|
||||
|
||||
`shell` 字段中的命令让系统在5秒休眠之后重新启动,我们使用 `sleep` 来保持连接不断开,使用 `async` 设定最大等待时长以避免发生超时,`poll` 设置为0表示直接执行不需要等待执行结果。等待10秒钟,使用 `wait_for_connection` 在虚拟机恢复连接后尽快连接。随后由 `install epel-release` 任务检查 RPM 的安装情况。你可以对这个剧本执行多次来验证它的幂等性,唯一会显示造成影响的是重启操作,因为我们使用了 `shell` 模块。如果不想造成实际的影响,可以在使用 `shell` 模块的时候 `changed_when: False`。
|
||||
|
||||
现在我们已经知道如何对系统进行更新、重启虚拟机、重新连接、安装 RPM 包。下面我们通过 [Ansible Lightbulb][4] 来安装 NGINX:
|
||||
```
|
||||
- name: Ensure nginx packages are present
|
||||
|
||||
yum:
|
||||
|
||||
name: nginx, python-pip, python-devel, devel
|
||||
|
||||
state: present
|
||||
|
||||
notify: restart-nginx-service
|
||||
|
||||
|
||||
|
||||
- name: Ensure uwsgi package is present
|
||||
|
||||
pip:
|
||||
|
||||
name: uwsgi
|
||||
|
||||
state: present
|
||||
|
||||
notify: restart-nginx-service
|
||||
|
||||
|
||||
|
||||
- name: Ensure latest default.conf is present
|
||||
|
||||
template:
|
||||
|
||||
src: templates/nginx.conf.j2
|
||||
|
||||
dest: /etc/nginx/nginx.conf
|
||||
|
||||
backup: yes
|
||||
|
||||
notify: restart-nginx-service
|
||||
|
||||
|
||||
|
||||
- name: Ensure latest index.html is present
|
||||
|
||||
template:
|
||||
|
||||
src: templates/index.html.j2
|
||||
|
||||
dest: /usr/share/nginx/html/index.html
|
||||
|
||||
|
||||
|
||||
- name: Ensure nginx service is started and enabled
|
||||
|
||||
service:
|
||||
|
||||
name: nginx
|
||||
|
||||
state: started
|
||||
|
||||
enabled: yes
|
||||
|
||||
|
||||
|
||||
- name: Ensure proper response from localhost can be received
|
||||
|
||||
uri:
|
||||
|
||||
url: "http://localhost:80/"
|
||||
|
||||
return_content: yes
|
||||
|
||||
register: response
|
||||
|
||||
until: 'nginx_test_message in response.content'
|
||||
|
||||
retries: 10
|
||||
|
||||
delay: 1
|
||||
|
||||
```
|
||||
|
||||
And the handler that restarts the nginx service:
|
||||
```
|
||||
# 安装 nginx 的操作文件
|
||||
|
||||
- name: restart-nginx-service
|
||||
|
||||
service:
|
||||
|
||||
name: nginx
|
||||
|
||||
state: restarted
|
||||
|
||||
```
|
||||
|
||||
在这个角色里,我们使用 RPM 安装了 `nginx`、`python-pip`、`python-devel`、`devel`,用 PIP 安装了 `uwsgi`,接下来使用 `template` 模块复制 `nginx.conf` 和 `index.html` 以显示页面,并确保服务在系统启动时启动。然后就可以使用 `uri` 模块检查到页面的连接了。
|
||||
|
||||
这个是一个系统更新、系统重启、安装 RPM 包的剧本示例,后续可以继续安装 nginx,当然这里可以替换成任何你想要的角色和应用程序。
|
||||
```
|
||||
- hosts: all
|
||||
|
||||
roles:
|
||||
|
||||
- centos-update
|
||||
|
||||
- nginx-simple
|
||||
|
||||
```
|
||||
|
||||
观看演示视频了解了解这个过程。
|
||||
|
||||
[demo](https://asciinema.org/a/166437/embed?)
|
||||
|
||||
这只是关于如何更新系统、重启以及后续工作的示例。简单起见,我只添加了不带[变量][5]的包,当你在操作大量主机的时候,你就需要修改其中的一些设置了:
|
||||
|
||||
这是由于在生产环境中如果你想逐一更新每一台主机的系统,你需要花相当一段时间去等待主机重启才能够继续下去。
|
||||
|
||||
有关 Ansible 进行自动化工作的更多用法,请查阅[其它文章][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/ansible-patch-systems
|
||||
|
||||
作者:[Jonathan Lozada De La Matta][a]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jlozadad
|
||||
[1]:https://www.ansible.com/overview/how-ansible-works
|
||||
[2]:https://docs.ansible.com/ansible/latest/list_of_packaging_modules.html
|
||||
[3]:https://docs.ansible.com/ansible/latest/yum_module.html
|
||||
[4]:https://github.com/ansible/lightbulb/tree/master/examples/nginx-role
|
||||
[5]:https://docs.ansible.com/ansible/latest/playbooks_variables.html
|
||||
[6]:https://opensource.com/tags/ansible
|
||||
@ -0,0 +1,459 @@
|
||||
# 您的 Linux 系统命令行个人助理
|
||||
|
||||

|
||||
|
||||
不久前,我们写了一个名为 [**“Betty”**][1] 的命令行虚拟助手。今天,我偶然发现了一个类似的实用程序,叫做 **“Yoda”**。Yoda 是一个命令行个人助理,可以帮助您在 Linux 中完成一些琐碎的任务。它是用 Python 编写的一个免费的开源应用程序。在本指南中,我们将了解如何在 GNU/Linux 中安装和使用 Yoda。
|
||||
|
||||
### 安装 Yoda,命令行私人助理。
|
||||
|
||||
Yoda 需要 **Python 2** 和 PIP 。如果在您的 Linux 中没有安装 PIP,请参考下面的指南来安装它。只要确保已经安装了 **python2-pip** 。Yoda 可能不支持 Python 3。
|
||||
|
||||
**注意**:我建议你在虚拟环境下试用 Yoda。 不仅仅是 Yoda,总是在虚拟环境中尝试任何 Python 应用程序,让它们不会干扰全局安装的软件包。 您可以按照上文链接中标题为“创建虚拟环境”一节中所述设置虚拟环境。
|
||||
|
||||
在您的系统上安装了 pip 之后,使用下面的命令克隆 Yoda 库。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/yoda-pa/yoda
|
||||
|
||||
```
|
||||
|
||||
上面的命令将在当前工作目录中创建一个名为 “yoda” 的目录,并在其中克隆所有内容。转到 Yoda 目录:
|
||||
|
||||
```
|
||||
$ cd yoda/
|
||||
|
||||
```
|
||||
|
||||
运行以下命令安装Yoda应用程序。
|
||||
|
||||
```
|
||||
$ pip install .
|
||||
|
||||
```
|
||||
|
||||
请注意最后的点(.)。 现在,所有必需的软件包将被下载并安装。
|
||||
|
||||
### 配置 Yoda
|
||||
|
||||
首先,设置配置以将您的信息保存在本地系统上。
|
||||
|
||||
运行下面的命令:
|
||||
|
||||
```
|
||||
$ yoda setup new
|
||||
|
||||
```
|
||||
|
||||
填写下列的问题:
|
||||
|
||||
```
|
||||
Enter your name:
|
||||
Senthil Kumar
|
||||
What's your email id?
|
||||
[email protected]
|
||||
What's your github username?
|
||||
sk
|
||||
Enter your github password:
|
||||
Password:
|
||||
Where shall your config be stored? (Default: ~/.yoda/)
|
||||
|
||||
A configuration file already exists. Are you sure you want to overwrite it? (y/n)
|
||||
y
|
||||
|
||||
```
|
||||
|
||||
你的密码在加密后保存在配置文件中,所以不用担心。
|
||||
|
||||
要检查当前配置,请运行:
|
||||
|
||||
```
|
||||
$ yoda setup check
|
||||
|
||||
```
|
||||
|
||||
你会看到如下的输出。
|
||||
|
||||
```
|
||||
Name: Senthil Kumar
|
||||
Email: [email protected]
|
||||
Github username: sk
|
||||
|
||||
```
|
||||
|
||||
默认情况下,您的信息存储在 **~/.yoda** 目录中。
|
||||
|
||||
要删除现有配置,请执行以下操作:
|
||||
|
||||
```
|
||||
$ yoda setup delete
|
||||
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
Yoda 包含一个简单的聊天机器人。您可以使用下面的聊天命令与它交互。
|
||||
|
||||
```
|
||||
$ yoda chat who are you
|
||||
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
```
|
||||
Yoda speaks:
|
||||
I'm a virtual agent
|
||||
|
||||
$ yoda chat how are you
|
||||
Yoda speaks:
|
||||
I'm doing very well. Thanks!
|
||||
|
||||
```
|
||||
|
||||
以下是我们可以用 Yoda 做的事情:
|
||||
|
||||
**测试网络速度**
|
||||
|
||||
让我们问一下 Yoda 关于互联网速度的问题。运行:
|
||||
|
||||
```
|
||||
$ yoda speedtest
|
||||
Speed test results:
|
||||
Ping: 108.45 ms
|
||||
Download: 0.75 Mb/s
|
||||
Upload: 1.95 Mb/s
|
||||
|
||||
```
|
||||
|
||||
**缩短并展开网址**
|
||||
|
||||
Yoda 还有助于缩短任何网址。
|
||||
|
||||
```
|
||||
$ yoda url shorten https://www.ostechnix.com/
|
||||
Here's your shortened URL:
|
||||
https://goo.gl/hVW6U0
|
||||
|
||||
```
|
||||
|
||||
要展开缩短的网址:
|
||||
|
||||
```
|
||||
$ yoda url expand https://goo.gl/hVW6U0
|
||||
Here's your original URL:
|
||||
https://www.ostechnix.com/
|
||||
|
||||
```
|
||||
|
||||
|
||||
**阅读黑客新闻**
|
||||
|
||||
我是 Hacker News 网站的常客。 如果你像我一样,你可以使用 Yoda 从下面的 Hacker News 网站阅读新闻。
|
||||
|
||||
```
|
||||
$ yoda hackernews
|
||||
News-- 1/513
|
||||
|
||||
Title-- Show HN: a Yelp for iOS developers
|
||||
Description-- I came up with this idea "a Yelp for developers" when talking with my colleagues. My hypothesis is that, it would be very helpful if we know more about a library before choosing to use it. It's similar to that we want to know more about a restaurant by checki…
|
||||
url-- https://news.ycombinator.com/item?id=16636071
|
||||
|
||||
Continue? [press-"y"]
|
||||
|
||||
```
|
||||
|
||||
Yoda 将一次显示一个项目。 要阅读下一条新闻,只需输入 “y” 并按下 ENTER。
|
||||
|
||||
**管理个人日记**
|
||||
|
||||
我们也可以保留个人日记以记录重要事件。
|
||||
|
||||
使用命令创建一个新的日记:
|
||||
|
||||
```
|
||||
$ yoda diary nn
|
||||
Input your entry for note:
|
||||
Today I learned about Yoda
|
||||
|
||||
```
|
||||
|
||||
要创建新笔记,请再次运行上述命令。
|
||||
|
||||
查看所有笔记:
|
||||
|
||||
```
|
||||
$ yoda diary notes
|
||||
Today's notes:
|
||||
----------------
|
||||
Time | Note
|
||||
--------|-----
|
||||
16:41:41| Today I learned about Yoda
|
||||
|
||||
```
|
||||
|
||||
不仅仅是笔记,Yoda 还可以帮助你创建任务。
|
||||
|
||||
要创建新任务,请运行:
|
||||
|
||||
```
|
||||
$ yoda diary nt
|
||||
Input your entry for task:
|
||||
Write an article about Yoda and publish it on OSTechNix
|
||||
|
||||
```
|
||||
|
||||
要查看任务列表,请运行:
|
||||
|
||||
```
|
||||
$ yoda diary tasks
|
||||
Today's agenda:
|
||||
----------------
|
||||
Status | Time | Text
|
||||
-------|---------|-----
|
||||
O | 16:44:03: Write an article about Yoda and publish it on OSTechNix
|
||||
----------------
|
||||
|
||||
Summary:
|
||||
----------------
|
||||
Incomplete tasks: 1
|
||||
Completed tasks: 0
|
||||
|
||||
```
|
||||
|
||||
正如你在上面看到的,我有一个未完成的任务。 要将其标记为已完成,请运行以下命令并输入已完成的任务序列号并按下 ENTER 键:
|
||||
|
||||
```
|
||||
$ yoda diary ct
|
||||
Today's agenda:
|
||||
----------------
|
||||
Number | Time | Task
|
||||
-------|---------|-----
|
||||
1 | 16:44:03: Write an article about Yoda and publish it on OSTechNix
|
||||
Enter the task number that you would like to set as completed
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
您可以随时使用命令分析当前月份的任务:
|
||||
|
||||
```
|
||||
$ yoda diary analyze
|
||||
Percentage of incomplete task : 0
|
||||
Percentage of complete task : 100
|
||||
Frequency of adding task (Task/Day) : 3
|
||||
|
||||
```
|
||||
|
||||
有时候,你可能想要记录一个关于你爱的或者敬佩的人的个人资料。
|
||||
|
||||
**记录关于爱人的笔记**
|
||||
|
||||
首先,您需要设置配置来存储朋友的详细信息。 请运行:
|
||||
|
||||
```
|
||||
$ yoda love setup
|
||||
|
||||
```
|
||||
|
||||
输入你的朋友的详细信息:
|
||||
|
||||
```
|
||||
Enter their name:
|
||||
Abdul Kalam
|
||||
Enter sex(M/F):
|
||||
M
|
||||
Where do they live?
|
||||
Rameswaram
|
||||
|
||||
```
|
||||
|
||||
要查看此人的详细信息,请运行:
|
||||
|
||||
```
|
||||
$ yoda love status
|
||||
{'place': 'Rameswaram', 'name': 'Abdul Kalam', 'sex': 'M'}
|
||||
|
||||
```
|
||||
|
||||
要添加你的爱人的生日:
|
||||
|
||||
```
|
||||
$ yoda love addbirth
|
||||
Enter birthday
|
||||
15-10-1931
|
||||
|
||||
```
|
||||
|
||||
查看生日:
|
||||
|
||||
```
|
||||
$ yoda love showbirth
|
||||
Birthday is 15-10-1931
|
||||
|
||||
```
|
||||
|
||||
你甚至可以添加关于该人的笔记:
|
||||
|
||||
```
|
||||
$ yoda love note
|
||||
Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
|
||||
|
||||
```
|
||||
|
||||
您可以使用命令查看笔记:
|
||||
|
||||
```
|
||||
$ yoda love notes
|
||||
Notes:
|
||||
1: Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
|
||||
|
||||
```
|
||||
|
||||
你也可以写下这个人喜欢的东西:
|
||||
|
||||
```
|
||||
$ yoda love like
|
||||
Add things they like
|
||||
Physics, Aerospace
|
||||
Want to add more things they like? [y/n]
|
||||
n
|
||||
|
||||
```
|
||||
|
||||
要查看他们喜欢的东西,请运行:
|
||||
|
||||
```
|
||||
$ yoda love likes
|
||||
Likes:
|
||||
1: Physics, Aerospace
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
|
||||
**跟踪资金费用**
|
||||
|
||||
您不需要单独的工具来维护您的财务支出。 Yoda 会替您处理好。
|
||||
|
||||
首先,使用命令设置您的金钱支出配置:
|
||||
|
||||
```
|
||||
$ yoda money setup
|
||||
|
||||
```
|
||||
|
||||
输入您的货币代码和初始金额:
|
||||
|
||||
```
|
||||
Enter default currency code:
|
||||
INR
|
||||
{u'USD': 0.015338, u'IDR': 211.06, u'BGN': 0.024436, u'ISK': 1.5305, u'ILS': 0.053402, u'GBP': 0.010959, u'DKK': 0.093063, u'CAD': 0.020041, u'MXN': 0.28748, u'HUF': 3.8873, u'RON': 0.058302, u'MYR': 0.060086, u'SEK': 0.12564, u'SGD': 0.020208, u'HKD': 0.12031, u'AUD': 0.019908, u'CHF': 0.014644, u'KRW': 16.429, u'CNY': 0.097135, u'TRY': 0.06027, u'HRK': 0.092986, u'NZD': 0.021289, u'THB': 0.47854, u'EUR': 0.012494, u'NOK': 0.11852, u'RUB': 0.88518, u'JPY': 1.6332, u'CZK': 0.31764, u'BRL': 0.050489, u'PLN': 0.052822, u'PHP': 0.79871, u'ZAR': 0.1834}
|
||||
₹
|
||||
Indian rupee
|
||||
Enter initial amount:
|
||||
10000
|
||||
|
||||
```
|
||||
|
||||
要查看金钱配置,只需运行:
|
||||
|
||||
```
|
||||
$ yoda money status
|
||||
{'initial_money': 10000, 'currency_code': 'INR'}
|
||||
|
||||
```
|
||||
|
||||
让我们假设你买了一本价值 250 卢比的书。 要添加此费用,请运行:
|
||||
|
||||
```
|
||||
$ yoda money exp
|
||||
Spend 250 INR on books
|
||||
output:
|
||||
|
||||
```
|
||||
|
||||
要查看花费,请运行:
|
||||
|
||||
```
|
||||
$ yoda money exps
|
||||
2018-03-21 17:12:31 INR 250 books
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
|
||||
**创建想法列表**
|
||||
|
||||
创建一个新的想法:
|
||||
|
||||
```
|
||||
$ yoda ideas add --task <task_name> --inside <project_name>
|
||||
|
||||
```
|
||||
|
||||
列出想法:
|
||||
|
||||
```
|
||||
$ yoda ideas show
|
||||
|
||||
```
|
||||
|
||||
从任务中移除一个想法:
|
||||
|
||||
```
|
||||
$ yoda ideas remove --task <task_name> --inside <project_name>
|
||||
|
||||
```
|
||||
|
||||
要完全删除这个想法,请运行:
|
||||
|
||||
```
|
||||
$ yoda ideas remove --project <project_name>
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
|
||||
**学习英语词汇**
|
||||
|
||||
Yoda 帮助你学习随机英语单词并追踪你的学习进度。
|
||||
|
||||
要学习一个新单词,请输入:
|
||||
|
||||
```
|
||||
$ yoda vocabulary word
|
||||
|
||||
```
|
||||
|
||||
它会随机显示一个单词。 按 ENTER 键显示单词的含义。 再一次,Yoda 问你是否已经知道这个词的意思。 如果您已经知道,请输入“是”。 如果您不知道,请输入“否”。 这可以帮助你跟踪你的进度。 使用以下命令来了解您的进度。
|
||||
|
||||
```
|
||||
$ yoda vocabulary accuracy
|
||||
|
||||
```
|
||||
|
||||
此外,Yoda 可以帮助您做其他一些事情,比如找到单词的定义和创建插卡以轻松学习任何内容。 有关更多详细信息和可用选项列表,请参阅帮助部分。
|
||||
|
||||
```
|
||||
$ yoda --help
|
||||
|
||||
```
|
||||
|
||||
更多好的东西来了。请继续关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/yoda-the-command-line-personal-assistant-for-your-linux-system/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/betty-siri-like-commandline-virtual-assistant-linux/
|
||||
Loading…
Reference in New Issue
Block a user