mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
b4cee0b0a4
@ -1,29 +1,28 @@
|
||||
|
||||
我从编程面试中学到的
|
||||
============================================================
|
||||
|
||||
======
|
||||
|
||||

|
||||
聊聊白板编程面试
|
||||
|
||||
在2017年,我参加了[Grace Hopper Celebration][1]‘计算机行业中的女性’这一活动。这个活动是这类科技活动中最大的一个。共有17,000名女性IT工作者参加。
|
||||
*聊聊白板编程面试*
|
||||
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
在 2017 年,我参加了 ‘计算机行业中的女性’ 的[Grace Hopper 庆祝活动][1]。这个活动是这类科技活动中最大的一个。共有 17,000 名女性IT工作者参加。
|
||||
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到 offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
|
||||
为了能更多的帮到像她们一样的白面面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了[prodcast episode][2]上。它们也是这篇文章的主题。
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
|
||||
为了能更多的帮到像她们一样的小白面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了 [prodcast episode][2] 上。它们也是这篇文章的主题。
|
||||
|
||||
为了实习生职位和全职工作,我做过很多次的面试。当我还在大学主修计算机科学时,学校每个秋季学期都有招聘会,第一轮招聘会在校园里举行。(我在第一和最后一轮都搞砸过。)不过,每次面试后,我都会反思哪些方面我能做的更好,我还会和朋友们做模拟面试,这样我就能从他们那儿得到更多的面试反馈。
|
||||
|
||||
不管我们怎么样找工作: 工作中介,网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
不管我们怎么样找工作: 工作中介、网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
|
||||
近年来,我注意到了一些新的不同的面试形式出现了:
|
||||
|
||||
* 与招聘方的一位工程师结对编程
|
||||
* 网络在线测试及在线编码
|
||||
* 白板编程(LCTT译者注: 这种形式应该不新了)
|
||||
|
||||
* 白板编程(LCTT 译注: 这种形式应该不新了)
|
||||
|
||||
我将重点谈谈白板面试,这种形式我经历的最多。我有过很多次面试,有些挺不错的,有些被我搞砸了。
|
||||
|
||||
@ -31,7 +30,7 @@
|
||||
|
||||
首先,我想回顾一下我做的不好的地方。知错能改,善莫大焉。
|
||||
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
|
||||
这里我犯了两个错误:
|
||||
|
||||
@ -41,7 +40,7 @@
|
||||
|
||||
#### 只会默默思考,不去记录想法或和面试官沟通
|
||||
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得要么我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
|
||||
### 想到一个解题方法
|
||||
|
||||
@ -50,30 +49,27 @@
|
||||
这是对我管用的步骤:
|
||||
|
||||
1. 头脑风暴
|
||||
|
||||
2. 写代码
|
||||
|
||||
3. 处理错误路径
|
||||
|
||||
4. 测试
|
||||
|
||||
#### 1\. 头脑风暴
|
||||
#### 1、 头脑风暴
|
||||
|
||||
对我来说,我会首先通过一些例子来视觉化我要解决的问题。比如说如果这个问题和数据结构中的树有关,我就会从树底层的空节点开始思考,如何处理一个节点的情况呢?两个节点呢?三个节点呢?这能帮助你从具体例子里抽象出你的解决方案。
|
||||
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现bug和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),'我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧'
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现 bug 和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),“我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧”。
|
||||
|
||||
#### 2\. 开始写代码,一气呵成
|
||||
#### 2、 开始写代码,一气呵成
|
||||
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总的可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始,未加优化的。(请熟悉算法中的O()的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, ‘还有更好的方法吗?’,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总是可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始的,未加优化的。(请熟悉算法中的 `O()` 的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, “还有更好的方法吗?”,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
|
||||
#### 3\. 错误处理
|
||||
#### 3、 错误处理
|
||||
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,'很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?',这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,“很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?”,这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
|
||||
#### 4\. 测试
|
||||
#### 4、 测试
|
||||
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,‘让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果。。。’
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,“让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果……”
|
||||
|
||||
在你结束之后,面试者有时会问你你将会怎么测试你的代码,你会涉及什么样的测试用例。我建议你用下面不同的分类来组织你的错误用例:
|
||||
|
||||
@ -83,7 +79,7 @@
|
||||
2. 错误用例
|
||||
3. 期望的正常用例
|
||||
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是[How We Test Software at Microsoft][3]。
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是 《[我们在微软如何测试软件][3]》。
|
||||
|
||||
对于错误用例,想一下什么是期望的错误情况并一一写下。
|
||||
|
||||
@ -91,50 +87,45 @@
|
||||
|
||||
### “你还有什么要问我的吗?”
|
||||
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,‘我没什么问题了’,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,“我没什么问题了”,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
|
||||
### 申请一份工作
|
||||
|
||||
|
||||
关于找工作申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
关于找工作和申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
|
||||
我个人并不推荐你用上述的方法去找工作。你会排除很多很好的公司,特别是你是在找实习工作或者入门级的职位时。
|
||||
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web开发?或是人工智能?当在招聘会上与招聘公司沟通是,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web 开发?或是人工智能?当在招聘会上与招聘公司沟通时,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
|
||||
#### 换组
|
||||
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了4轮面试。结果我搞砸了。
|
||||
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快2年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了 4 轮面试。结果我搞砸了。
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快 2 年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
|
||||
我在面试前也没有刷过数据结构和算法题。如果我做了的话,我将会在面试中更有信心。就算你已经在一家公司担任了软件工程师,在你去另外一个组面试前,我强烈建议你在一块白板上演练一下如何写代码。
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我,你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我, 你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到 offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
以上内容来自["Programming interviews"][4] 章节,选自 [The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]
|
||||
以上内容选自 《[The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]》的 “[编程面试][4]”章节,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
微软研究院Software Engineer II, www.thewomenintechshow.com站长,所有观点都只代表本人意见。
|
||||
微软研究院 Software Engineer II, www.thewomenintechshow.com 站长,所有观点都只代表本人意见。
|
||||
|
||||
------------
|
||||
|
||||
via: https://medium.freecodecamp.org/what-i-learned-from-programming-interviews-29ba49c9b851
|
||||
|
||||
作者:[Edaena Salinas ][a]
|
||||
译者:DavidChenLiang (https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Edaena Salinas][a]
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,77 @@
|
||||
如何使用 Apache 构建 URL 缩短服务
|
||||
======
|
||||
> 用 Apache HTTP 服务器的 mod_rewrite 功能创建你自己的短链接。
|
||||
|
||||

|
||||
|
||||
很久以前,人们开始在 Twitter 上分享链接。140 个字符的限制意味着 URL 可能消耗一条推文的大部分(或全部),因此人们使用 URL 缩短服务。最终,Twitter 加入了一个内置的 URL 缩短服务([t.co][1])。
|
||||
|
||||
字符数现在不重要了,但还有其他原因要缩短链接。首先,缩短服务可以提供分析功能 —— 你可以看到你分享的链接的受欢迎程度。它还简化了制作易于记忆的 URL。例如,[bit.ly/INtravel][2] 比<https://www.in.gov/ai/appfiles/dhs-countyMap/dhsCountyMap.html>更容易记住。如果你想预先共享一个链接,但还不知道最终地址,这时 URL 缩短服务可以派上用场。。
|
||||
|
||||
与任何技术一样,URL 缩短服务并非都是正面的。通过屏蔽最终地址,缩短的链接可用于指向恶意或冒犯性内容。但是,如果你仔细上网,URL 缩短服务是一个有用的工具。
|
||||
|
||||
我们之前在网站上[发布过缩短服务的文章][3],但也许你想要运行一些由简单的文本文件支持的缩短服务。在本文中,我们将展示如何使用 Apache HTTP 服务器的 mod_rewrite 功能来设置自己的 URL 缩短服务。如果你不熟悉 Apache HTTP 服务器,请查看 David Both 关于[安装和配置][4]它的文章。
|
||||
|
||||
### 创建一个 VirtualHost
|
||||
|
||||
在本教程中,我假设你购买了一个很酷的域名,你将它专门用于 URL 缩短服务。例如,我的网站是 [funnelfiasco.com][5],所以我买了 [funnelfias.co][6] 用于我的 URL 缩短服务(好吧,它不是很短,但它可以满足我的虚荣心)。如果你不将缩短服务作为单独的域运行,请跳到下一部分。
|
||||
|
||||
第一步是设置将用于 URL 缩短服务的 VirtualHost。有关 VirtualHost 的更多信息,请参阅 [David Both 的文章][7]。这步只需要几行:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
ServerName funnelfias.co
|
||||
</VirtualHost>
|
||||
```
|
||||
|
||||
### 创建重写规则
|
||||
|
||||
此服务使用 HTTPD 的重写引擎来重写 URL。如果你在上面的部分中创建了 VirtualHost,则下面的配置跳到你的 VirtualHost 部分。否则跳到服务器的 VirtualHost 或主 HTTPD 配置。
|
||||
|
||||
```
|
||||
RewriteEngine on
|
||||
RewriteMap shortlinks txt:/data/web/shortlink/links.txt
|
||||
RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
|
||||
```
|
||||
|
||||
第一行只是启用重写引擎。第二行在文本文件构建短链接的映射。上面的路径只是一个例子。你需要使用系统上使用有效路径(确保它可由运行 HTTPD 的用户帐户读取)。最后一行重写 URL。在此例中,它接受任何字符并在重写映射中查找它们。你可能希望重写时使用特定的字符串。例如,如果你希望所有缩短的链接都是 “slX”(其中 X 是数字),则将上面的 `(.+)` 替换为 `(sl\d+)`。
|
||||
|
||||
我在这里使用了临时重定向(HTTP 302)。这能让我稍后更新目标 URL。如果希望短链接始终指向同一目标,则可以使用永久重定向(HTTP 301)。用 `permanent` 替换第三行的 `temp`。
|
||||
|
||||
### 构建你的映射
|
||||
|
||||
编辑配置文件 `RewriteMap` 行中的指定文件。格式是空格分隔的键值存储。在每一行上放一个链接:
|
||||
|
||||
```
|
||||
osdc https://opensource.com/users/bcotton
|
||||
twitter https://twitter.com/funnelfiasco
|
||||
swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
|
||||
```
|
||||
|
||||
### 重启 HTTPD
|
||||
|
||||
最后一步是重启 HTTPD 进程。这是通过 `systemctl restart httpd` 或类似命令完成的(命令和守护进程名称可能因发行版而不同)。你的链接缩短服务现已启动并运行。当你准备编辑映射时,无需重新启动 Web 服务器。你所要做的就是保存文件,Web 服务器将获取到差异。
|
||||
|
||||
### 未来的工作
|
||||
|
||||
此示例为你提供了基本的 URL 缩短服务。如果你想将开发自己的管理接口作为学习项目,它可以作为一个很好的起点。或者你可以使用它分享容易记住的链接到那些容易忘记的 URL。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/apache-url-shortener
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:http://t.co
|
||||
[2]:http://bit.ly/INtravel
|
||||
[3]:https://opensource.com/article/17/3/url-link-shortener
|
||||
[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[5]:http://funnelfiasco.com
|
||||
[6]:http://funnelfias.co
|
||||
[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
@ -0,0 +1,46 @@
|
||||
How Writing Can Expand Your Skills and Grow Your Career
|
||||
======
|
||||
|
||||

|
||||
|
||||
At the recent [Open Source Summit in Vancouver][1], I participated in a panel discussion called [How Writing can Change Your Career for the Better (Even if You don't Identify as a Writer][2]. The panel was moderated by Rikki Endsley, Community Manager and Editor for Opensource.com, and it included VM (Vicky) Brasseur, Open Source Strategy Consultant; Alex Williams, Founder, Editor in Chief, The New Stack; and Dawn Foster, Consultant, The Scale Factory.
|
||||
|
||||
The talk was [inspired by this article][3], in which Rikki examined some ways that writing can "spark joy" and improve your career in unexpected ways. Full disclosure: I have known Rikki for a long time. We worked at the same company for many years, raised our children together, and remain close friends.
|
||||
|
||||
### Write and learn
|
||||
|
||||
As Rikki noted in the talk description, “even if you don't consider yourself to be ‘a writer,’ you should consider writing about your open source contributions, project, or community.” Writing can be a great way to share knowledge and engage others in your work, but it has personal benefits as well. It can help you meet new people, learn new skills, and improve your communication style.
|
||||
|
||||
I find that writing often clarifies for me what I don’t know about a particular topic. The process highlights gaps in my understanding and motivates me to fill in those gaps through further research, reading, and asking questions.
|
||||
|
||||
“Writing about what you don't know can be much harder and more time consuming, but also much more fulfilling and help your career. I've found that writing about what I don't know helps me learn, because I have to research it and understand it well enough to explain it,” Rikki said.
|
||||
|
||||
Writing about what you’ve just learned can be valuable to other learners as well. In her blog, [Julia Evans][4] often writes about learning new technical skills. She has a friendly, approachable style along with the ability to break down topics into bite-sized pieces. In her posts, Evans takes readers through her learning process, identifying what was and was not helpful to her along the way, essentially removing obstacles for her readers and clearing a path for those new to the topic.
|
||||
|
||||
### Communicate more clearly
|
||||
|
||||
Writing can help you practice thinking and speaking more precisely, especially if you’re writing (or speaking) for an international audience. [In this article,][5] for example, Isabel Drost-Fromm provides tips for removing ambiguity for non-native English speakers. Writing can also help you organize your thoughts before a presentation, whether you’re speaking at a conference or to your team.
|
||||
|
||||
“The process of writing the articles helps me organize my talks and slides, and it was a great way to provide ‘notes’ for conference attendees, while sharing the topic with a larger international audience that wasn't at the event in person,” Rikki stated.
|
||||
|
||||
If you’re interested in writing, I encourage you to do it. I highly recommend the articles mentioned here as a way to get started thinking about the story you have to tell. Unfortunately, our discussion at Open Source Summit was not recorded, but I hope we can do another talk in the future and share more ideas.
|
||||
|
||||
Check out the schedule of talks for Open Source Summit Europe and sign up to receive updates:
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/9/how-writing-can-help-you-learn-new-skills-and-grow-your-career
|
||||
|
||||
作者:[Amber Ankerholz][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/aankerholz
|
||||
[1]: https://events.linuxfoundation.org/events/open-source-summit-north-america-2018/
|
||||
[2]: https://ossna18.sched.com/event/FAOF/panel-discussion-how-writing-can-change-your-career-for-the-better-even-if-you-dont-identify-as-a-writer-moderated-by-rikki-endsley-opensourcecom-red-hat?iframe=no#
|
||||
[3]: https://opensource.com/article/18/2/career-changing-magic-writing
|
||||
[4]: https://jvns.ca/
|
||||
[5]: https://www.linux.com/blog/event/open-source-summit-eu/2017/12/technical-writing-international-audience
|
||||
@ -0,0 +1,167 @@
|
||||
Linux Has a Code of Conduct and Not Everyone is Happy With it
|
||||
======
|
||||
**Linux kernel has a new code of conduct (CoC). Linus Torvalds took a break from Linux kernel development just 30 minutes after signing this code of conduct. And since **the writer of this code of conduct has had a controversial past,** it has now become a point of heated discussion. With all the politics involved, not many people are happy with this new CoC.**
|
||||
|
||||
If you do not know already, [Linux creator Linus Torvalds has apologized for his past behavior and has taken a temporary break from Linux kernel development to improve his behavior][1].
|
||||
|
||||
### The new code of conduct for Linux kernel development
|
||||
|
||||
Linux kernel developers have a code of conduct. It’s not like they didn’t have a code before, but the previous [code of conflict][2] is now replaced by this new code of conduct to “help make the kernel community a welcoming environment to participate in.”
|
||||
|
||||
> “In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.”
|
||||
|
||||
You can read the entire code of conduct on this commit page.
|
||||
|
||||
[Linux Code of Conduct][33]
|
||||
|
||||
|
||||
### Was Linus Torvalds forced to apologize and take a break?
|
||||
|
||||
![Linus Torvalds Apologizes][3]
|
||||
|
||||
The code of conduct was signed off by Linus Torvalds and Greg Kroah-Hartman (kind of second-in-command after Torvalds). Dan Williams of Intel and Chris Mason from Facebook were some of the other signees.
|
||||
|
||||
If I have read through the timeline correctly, half an hour after signing this code of conduct, Torvalds sent a [mail apologizing for his past behavior][4]. He also announced taking a temporary break to improve upon his behavior.
|
||||
|
||||
But at this point some people started reading between the lines, with a special attention to this line from his mail:
|
||||
|
||||
> **This week people in our community confronted me about my lifetime of not understanding emotions**. My flippant attacks in emails have been both unprofessional and uncalled for. Especially at times when I made it personal. In my quest for a better patch, this made sense to me. I know now this was not OK and I am truly sorry.
|
||||
|
||||
This particular line could be read as if he was coerced into apologizing and taking a break because of the new code of conduct. Though it could also be a precautionary measure to prevent Torvalds from violating the newly created code of conduct.
|
||||
|
||||
### The controversy around Contributor Convent creator Coraline Ada Ehmke
|
||||
|
||||
The Linux code of conduct is based on the [Contributor Covenant, version 1.4][5]. Contributor Convent has been adopted by hundreds of open source projects. Eclipse, Angular, Ruby, Kubernetes are some of the [many adopters of Contributor Convent][6].
|
||||
|
||||
Contributor Covenant has been created by [Coraline Ada Ehmke][7], a software developer, an open-source advocate, and an [LGBT][8] activist. She has been instrumental in promoting diversity in the open source world.
|
||||
|
||||
Coraline has also been vocal about her stance against [meritocracy][9]. The Latin word meritocracy originally refers to a “system under which advancement within the system turns on “merits”, like intelligence, credentials, and education.” But activists like [Coraline believe][10] that meritocracy is a negative system where the worth of an individual is measured not by their humanity, but solely by their intellectual output.
|
||||
|
||||
[![croraline meritocracy][11]][12]
|
||||
Image credit: Twitter user @nickmon1112
|
||||
|
||||
Remember that [Linus Torvalds has repeatedly said that he cares about the code, not the person who writes it][13]. Clearly, this goes against Coraline’s view on meritocracy.
|
||||
|
||||
Coraline has had a troubled incident in the past with a contributor of [Opal project][14]. There was a [discussion taking place on Twitter][15] where Elia, a core contributor to Opal project from Italy, said “(trans people) not accepting reality is the problem here”.
|
||||
|
||||
Coraline was neither in the discussion nor was she a contributor to the Opal project. But as an LGBT activist, she took it to herself and [demanded that Elia be removed from the Opal Project][16] for his ‘views against trans people’. A lengthy and heated discussion took place on Opal’s GitHub repository. Coraline and her supporters, who never contributed to Opal, tried to coerce the moderators into removing Elia, a core contributor of the project.
|
||||
|
||||
While Elia wasn’t removed from the project, Opal project maintainers agreed to put up a code of conduct in place. And this code of conduct was nothing else but Coraline’s famed Contributor Covenant that she had pitched to the maintainers herself.
|
||||
|
||||
But the story didn’t end here. The Contributor Covenant was then modified and a [new clause added in order to get to Elia][17]. The new clause widened the scope of conduct in public spaces. This malicious change was [spotted by the maintainers][18] and they edited the clause. Opal eventually got rid of the Contributor Covenant and put in place its own guideline.
|
||||
|
||||
This is a classic example of how a few offended people, who never contributed a single line of code to the project, tried to oust its core contributor.
|
||||
|
||||
### People’s reaction on Linux Code of Conduct and Torvalds’ apology
|
||||
|
||||
As soon as Linux code of conduct and Torvalds’ apology went public, Social Media and forums were rife with rumors and [speculations][19]. While many people appreciated this new development, there were some who saw a conspiracy by [SJW infiltrating Linux][20].
|
||||
|
||||
A sarcastic tweet by Caroline only fueled the fire.
|
||||
|
||||
> I can’t wait for the mass exodus from Linux now that it’s been infiltrated by SJWs. Hahahah [pic.twitter.com/eFeY6r4ENv][21]
|
||||
>
|
||||
> — Coraline Ada Ehmke (@CoralineAda) [September 16, 2018][22]
|
||||
|
||||
In the wake of the Linux CoC controversy, Coraline openly said that the Contributor Convent code of conduct is a political document. This did not go down well with the people who want the political stuff out of the open source projects.
|
||||
|
||||
> Some people are saying that the Contributor Covenant is a political document, and they’re right.
|
||||
>
|
||||
> — Coraline Ada Ehmke (@CoralineAda) [September 16, 2018][23]
|
||||
|
||||
Nick Monroe, a freelance journalist, dig up the past of Coraline in order to validate his claim that there is more to Linux CoC than meets the eye. You can go by the entire thread if you want.
|
||||
|
||||
> Alright. You've seen this a million times before. It's a code of conduct blah blah blah
|
||||
>
|
||||
> that has social justice baked right into it. blah blah blah.<https://t.co/KuQqeriYeJ>
|
||||
>
|
||||
> But something is different about this. [pic.twitter.com/8NUL2K1gu2][24]
|
||||
>
|
||||
> — Nick Monroe (@nickmon1112) [September 17, 2018][25]
|
||||
|
||||
Nick wasn’t the only one to disapprove of the new Linux CoC. The [SJW][26] involvement led to more skepticism.
|
||||
|
||||
> I guess the big news in Linux today is that the Linux kernel is now governed by a Code of Conduct and a “post meritocracy” world view.
|
||||
>
|
||||
> In principle these CoCs look great. In practice they are abused tools to hunt people SJWs don’t like. And they don’t like a lot of people.
|
||||
>
|
||||
> — Mark Kern (@Grummz) [September 17, 2018][27]
|
||||
|
||||
While there were many who appreciated Torvalds’ apology, there were a few who blamed Torvalds’ attitude:
|
||||
|
||||
> Am I the only one who thinks Linus Torvalds attitude for decades was a prime contributors to how many of the condescending, rudes, jerks in Linux and open source "communities" behaved? I've never once felt welcomed into the Linux community as a new user.
|
||||
>
|
||||
> — Jonathan Frappier (@jfrappier) [September 17, 2018][28]
|
||||
|
||||
And some were simply not amused with his apology:
|
||||
|
||||
> Oh look, an abusive OSS maintainer finally admitted, after *decades* of abusive and toxic behavior, that his behavior *might* be an issue.
|
||||
>
|
||||
> And a bunch of people I follow are tripping all over themselves to give him cookies for that. 🙄🙄🙄
|
||||
>
|
||||
> — Kelly Ellis (@justkelly_ok) [September 17, 2018][29]
|
||||
|
||||
The entire Torvalds apology episode has raised a genuine concern ;)
|
||||
|
||||
> Do we have to put "I don't/do forgive Linus Torvalds" in our bio now?
|
||||
>
|
||||
> — Verónica. (@maria_fibonacci) [September 17, 2018][30]
|
||||
|
||||
Jokes apart, the genuine concern was raised by Sharp, who had [quit Linux Kernel development][31] in 2015 due to the ‘toxic community’.
|
||||
|
||||
> The real test here is whether the community that built Linus up and protected his right to be verbally abusive will change. Linus not only needs to change himself, but the Linux kernel community needs to change as well. <https://t.co/EG5KO43416>
|
||||
>
|
||||
> — Sage Sharp (@_sagesharp_) [September 17, 2018][32]
|
||||
|
||||
### What do you think of Linux Code of Conduct?
|
||||
|
||||
If you ask my opinion, I do think that a Code of Conduct is the need of the time. It guides people in behaving in a respectable way and helps create a positive environment for all kind of people irrespective of their race, ethnicity, religion, nationality and political views (both left and right).
|
||||
|
||||
What are your views on the entire episode? Do you think the CoC will help Linux kernel development? Or will it deteriorate with the involvement of anti-meritocracy SJWs?
|
||||
|
||||
We don’t have a code of conduct at It’s FOSS but let’s keep the discussion civil :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-code-of-conduct/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://itsfoss.com/torvalds-takes-a-break-from-linux/
|
||||
[2]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/CodeOfConflict?id=ddbd2b7ad99a418c60397901a0f3c997d030c65e
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linus-torvalds-apologizes.jpeg
|
||||
[4]: https://lkml.org/lkml/2018/9/16/167
|
||||
[5]: https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
||||
[6]: https://www.contributor-covenant.org/adopters
|
||||
[7]: https://en.wikipedia.org/wiki/Coraline_Ada_Ehmke
|
||||
[8]: https://en.wikipedia.org/wiki/LGBT
|
||||
[9]: https://en.wikipedia.org/wiki/Meritocracy
|
||||
[10]: https://modelviewculture.com/pieces/the-dehumanizing-myth-of-the-meritocracy
|
||||
[11]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/croraline-meritocracy.jpg
|
||||
[12]: https://pbs.twimg.com/media/DnTTfi7XoAAdk08.jpg
|
||||
[13]: https://arstechnica.com/information-technology/2015/01/linus-torvalds-on-why-he-isnt-nice-i-dont-care-about-you/
|
||||
[14]: https://opalrb.com/
|
||||
[15]: https://twitter.com/krainboltgreene/status/611569515315507200
|
||||
[16]: https://github.com/opal/opal/issues/941
|
||||
[17]: https://github.com/opal/opal/pull/948/commits/817321e27eccfffb3841f663815c17eecb8ef061#diff-a1ee87dafebc22cbd96979f1b2b7e837R11
|
||||
[18]: https://github.com/opal/opal/pull/948#issuecomment-113486020
|
||||
[19]: https://www.reddit.com/r/linux/comments/9go8cp/linus_torvalds_daughter_has_signed_the/
|
||||
[20]: https://snew.github.io/r/linux/comments/9ghrrj/linuxs_new_coc_is_a_piece_of_shit/
|
||||
[21]: https://t.co/eFeY6r4ENv
|
||||
[22]: https://twitter.com/CoralineAda/status/1041441155874009093?ref_src=twsrc%5Etfw
|
||||
[23]: https://twitter.com/CoralineAda/status/1041465346656530432?ref_src=twsrc%5Etfw
|
||||
[24]: https://t.co/8NUL2K1gu2
|
||||
[25]: https://twitter.com/nickmon1112/status/1041668315947708416?ref_src=twsrc%5Etfw
|
||||
[26]: https://www.urbandictionary.com/define.php?term=SJW
|
||||
[27]: https://twitter.com/Grummz/status/1041524170331287552?ref_src=twsrc%5Etfw
|
||||
[28]: https://twitter.com/jfrappier/status/1041486055038492674?ref_src=twsrc%5Etfw
|
||||
[29]: https://twitter.com/justkelly_ok/status/1041522269002985473?ref_src=twsrc%5Etfw
|
||||
[30]: https://twitter.com/maria_fibonacci/status/1041538148121997313?ref_src=twsrc%5Etfw
|
||||
[31]: https://www.networkworld.com/article/2988850/opensource-subnet/linux-kernel-dev-sarah-sharp-quits-citing-brutal-communications-style.html
|
||||
[32]: https://twitter.com/_sagesharp_/status/1041480963287539712?ref_src=twsrc%5Etfw
|
||||
[33]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=8a104f8b5867c682d994ffa7a74093c54469c11f
|
||||
@ -1,3 +1,4 @@
|
||||
sd886393 is dragging this out to translating
|
||||
Free Resources for Securing Your Open Source Code
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
BriFuture is translating
|
||||
|
||||
3 top open source JavaScript chart libraries
|
||||
======
|
||||
|
||||
|
||||
@ -1,142 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Autotrash – A CLI Tool To Automatically Purge Old Trashed Files
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Autotrash** is a command line utility to automatically purge old trashed files. It will purge files that have been in the trash for more then a given number of days. You don’t need to empty the trash folder or do SHIFT+DELETE to permanently purge the files/folders. Autortrash will handle the contents of your Trash folder and delete them automatically after a particular period of time. In a nutshell, Autotrash will never allow your trash to grow too big.
|
||||
|
||||
### Installing Autotrash
|
||||
|
||||
Autotrash is available in the default repositories of Debian-based systems. To install autotrash on Debian, Ubuntu, Linux Mint, run:
|
||||
|
||||
```
|
||||
$ sudo apt-get install autotrash
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install autotrash
|
||||
|
||||
```
|
||||
|
||||
For Arch linux and its variants, you can install it using any AUR helper programs such as [**Yay**][1].
|
||||
|
||||
```
|
||||
$ yay -S autotrash-git
|
||||
|
||||
```
|
||||
|
||||
### Automatically Purge Old Trashed Files
|
||||
|
||||
Whenever you run autotrash, It will scan your **`~/.local/share/Trash/info`** directory and read the **`.trashinfo`** files to find their deletion date. If the files have been in trash folder for more than the defined date, they will be deleted.
|
||||
|
||||
Let me show you some examples.
|
||||
|
||||
To purge files which are in the trash folder for more than 30 days, run:
|
||||
|
||||
```
|
||||
$ autotrash -d 30
|
||||
|
||||
```
|
||||
|
||||
As per above example, if the files in your Trash folder are more than 30-days old, Autotrash will automatically delete them from your Trash. You don’t need to manually delete them. Just send the unnecessary junk to your trash folder and forget about them. Autotrash will take care of the trashed files.
|
||||
|
||||
The above command will only process currently logged-in user’s trash directory. If you want to make autotrash to process trash directories of all users (not just in your home directory), use **-t** option like below.
|
||||
|
||||
```
|
||||
$ autotrash -td 30
|
||||
|
||||
```
|
||||
|
||||
Autotrash also allows you to delete trashed files based on the space left or available on the trash filesystem.
|
||||
|
||||
For example, have a look at the following example.
|
||||
|
||||
```
|
||||
$ autotrash --max-free 1024 -d 30
|
||||
|
||||
```
|
||||
|
||||
As per the above command, autotrash will only purge trashed files that are older than **30 days** from the trash if there is less than **1GB of space left** on the trash filesystem. This can be useful if your trash filesystem is running out of the space.
|
||||
|
||||
We can also purge files from trash, oldest first, till there is at least 1GB of space on the trash filesystem.
|
||||
|
||||
```
|
||||
$ autotrash --min-free 1024
|
||||
|
||||
```
|
||||
|
||||
In this case, there is no restriction on how old trashed files are.
|
||||
|
||||
You can combine both options ( **`--min-free`** and **`--max-free`** ) in a single command like below.
|
||||
|
||||
```
|
||||
$ autotrash --max-free 2048 --min-free 1024 -d 30
|
||||
|
||||
```
|
||||
|
||||
As per the above command, autotrash will start reading the trash if there is less than **2GB** of free space, then start keeping an eye on. At that point, remove files older than 30 days and if there is less than **1GB** of free space after that remove even newer files.
|
||||
|
||||
As you can see, all command should be manually run by the user. You might wonder, how can I automate this task?? That’s easy! Just add autotrash as crontab entry. Now, the commands will automatically run at a scheduled time and purge the files in your trash depending on the defined options.
|
||||
|
||||
To add these commands in crontab file, run:
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
Add the entries, for example:
|
||||
|
||||
```
|
||||
@daily /usr/bin/autotrash -d 30
|
||||
|
||||
```
|
||||
|
||||
Now autotrash will purge files which are in the trash folder for more than 30 days, everyday.
|
||||
|
||||
For more details about scheduling tasks, refer the following links.
|
||||
|
||||
|
||||
+ [A Beginners Guide To Cron Jobs][2]
|
||||
+ [How To Easily And Safely Manage Cron Jobs In Linux][3]
|
||||
|
||||
|
||||
Please be mindful that if you have deleted any important files inadvertently, they will be permanently gone after the defined days, so just be careful.
|
||||
|
||||
Refer man pages to know more about Autotrash.
|
||||
|
||||
```
|
||||
$ man autotrash
|
||||
|
||||
```
|
||||
|
||||
Emptying Trash folder or pressing SHIFT+DELETE to permanently get rid of unnecessary stuffs from the Linux system is no big deal. It will just take a couple seconds. However, if you wanted an extra utility to take care of your junk files, Autotrash might be helpful. Give it a try and see how it works.
|
||||
|
||||
And, that’s all for now. Hope this helps. More good stuffs to come.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/autotrash-a-cli-tool-to-automatically-purge-old-trashed-files/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[2]: https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
[3]: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
heguangzhi translating
|
||||
|
||||
Linux firewalls: What you need to know about iptables and firewalld
|
||||
======
|
||||
Here's how to use the iptables and firewalld tools to manage Linux firewall connectivity rules.
|
||||
|
||||
@ -1,242 +0,0 @@
|
||||
Top 3 Python libraries for data science
|
||||
======
|
||||
Turn Python into a scientific data analysis and modeling tool with these libraries.
|
||||
|
||||

|
||||
|
||||
Python's many attractions—such as efficiency, code readability, and speed—have made it the go-to programming language for data science enthusiasts. Python is usually the preferred choice for data scientists and machine learning experts who want to escalate the functionalities of their applications. (For example, Andrey Bulezyuk used the Python programming language to create an amazing [machine learning application][1].)
|
||||
|
||||
Because of its extensive usage, Python has a huge number of libraries that make it easier for data scientists to complete complicated tasks without many coding hassles. Here are the top 3 Python libraries for data science; check them out if you want to kickstart your career in the field.
|
||||
|
||||
### 1\. NumPy
|
||||
|
||||
[NumPy][2] (short for Numerical Python) is one of the top libraries equipped with useful resources to help data scientists turn Python into a powerful scientific analysis and modelling tool. The popular open source library is available under the BSD license. It is the foundational Python library for performing tasks in scientific computing. NumPy is part of a bigger Python-based ecosystem of open source tools called SciPy.
|
||||
|
||||
The library empowers Python with substantial data structures for effortlessly performing multi-dimensional arrays and matrices calculations. Besides its uses in solving linear algebra equations and other mathematical calculations, NumPy is also used as a versatile multi-dimensional container for different types of generic data.
|
||||
|
||||
Furthermore, it integrates flawlessly with other programming languages like C/C++ and Fortran. The versatility of the NumPy library allows it to easily and swiftly coalesce with an extensive range of databases and tools. For example, let's see how NumPy (abbreviated **np** ) can be used for multiplying two matrices.
|
||||
|
||||
Let's start by importing the library (we'll be using the Jupyter notebook for these examples).
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
```
|
||||
|
||||
Next, let's use the **eye()** function to generate an identity matrix with the stipulated dimensions.
|
||||
|
||||
```
|
||||
matrix_one = np.eye(3)
|
||||
matrix_one
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
|
||||
```
|
||||
array([[1., 0., 0.],
|
||||
[0., 1., 0.],
|
||||
[0., 0., 1.]])
|
||||
```
|
||||
|
||||
Let's generate another 3x3 matrix.
|
||||
|
||||
We'll use the **arange([starting number], [stopping number])** function to arrange numbers. Note that the first parameter in the function is the initial number to be listed and the last number is not included in the generated results.
|
||||
|
||||
Also, the **reshape()** function is applied to modify the dimensions of the originally generated matrix into the desired dimension. For the matrices to be "multiply-able," they should be of the same dimension.
|
||||
|
||||
```
|
||||
matrix_two = np.arange(1,10).reshape(3,3)
|
||||
matrix_two
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
|
||||
```
|
||||
array([[1, 2, 3],
|
||||
[4, 5, 6],
|
||||
[7, 8, 9]])
|
||||
```
|
||||
|
||||
Let's use the **dot()** function to multiply the two matrices.
|
||||
|
||||
```
|
||||
matrix_multiply = np.dot(matrix_one, matrix_two)
|
||||
|
||||
matrix_multiply
|
||||
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
|
||||
```
|
||||
array([[1., 2., 3.],
|
||||
[4., 5., 6.],
|
||||
[7., 8., 9.]])
|
||||
```
|
||||
|
||||
Great!
|
||||
|
||||
We managed to multiply two matrices without using vanilla Python.
|
||||
|
||||
Here is the entire code for this example:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
#generating a 3 by 3 identity matrix
|
||||
matrix_one = np.eye(3)
|
||||
matrix_one
|
||||
#generating another 3 by 3 matrix for multiplication
|
||||
matrix_two = np.arange(1,10).reshape(3,3)
|
||||
matrix_two
|
||||
#multiplying the two arrays
|
||||
matrix_multiply = np.dot(matrix_one, matrix_two)
|
||||
matrix_multiply
|
||||
```
|
||||
|
||||
### 2\. Pandas
|
||||
|
||||
[Pandas][3] is another great library that can enhance your Python skills for data science. Just like NumPy, it belongs to the family of SciPy open source software and is available under the BSD free software license.
|
||||
|
||||
Pandas offers versatile and powerful tools for munging data structures and performing extensive data analysis. The library works well with incomplete, unstructured, and unordered real-world data—and comes with tools for shaping, aggregating, analyzing, and visualizing datasets.
|
||||
|
||||
There are three types of data structures in this library:
|
||||
|
||||
* Series: single-dimensional, homogeneous array
|
||||
* DataFrame: two-dimensional with heterogeneously typed columns
|
||||
* Panel: three-dimensional, size-mutable array
|
||||
|
||||
|
||||
|
||||
For example, let's see how the Panda Python library (abbreviated **pd** ) can be used for performing some descriptive statistical calculations.
|
||||
|
||||
Let's start by importing the library.
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
```
|
||||
|
||||
Let's create a dictionary of series.
|
||||
|
||||
```
|
||||
d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
|
||||
'Irene','Sagar','Simon','James','Rose']),
|
||||
'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
|
||||
'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
|
||||
}
|
||||
```
|
||||
|
||||
Let's create a DataFrame.
|
||||
|
||||
```
|
||||
df = pd.DataFrame(d)
|
||||
```
|
||||
|
||||
Here is a nice table of the output:
|
||||
|
||||
```
|
||||
Name Programming Language Years of Experience
|
||||
0 Alfrick Python 5
|
||||
1 Michael JavaScript 9
|
||||
2 Wendy PHP 1
|
||||
3 Paul C++ 4
|
||||
4 Dusan Java 3
|
||||
5 George Scala 4
|
||||
6 Andreas React 7
|
||||
7 Irene Ruby 9
|
||||
8 Sagar Angular 6
|
||||
9 Simon PHP 8
|
||||
10 James Python 3
|
||||
11 Rose JavaScript 1
|
||||
```
|
||||
|
||||
Here is the entire code for this example:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
#creating a dictionary of series
|
||||
d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
|
||||
'Irene','Sagar','Simon','James','Rose']),
|
||||
'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
|
||||
'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
|
||||
}
|
||||
|
||||
#Create a DataFrame
|
||||
df = pd.DataFrame(d)
|
||||
print(df)
|
||||
```
|
||||
|
||||
### 3\. Matplotlib
|
||||
|
||||
[Matplotlib][4] is also part of the SciPy core packages and offered under the BSD license. It is a popular Python scientific library used for producing simple and powerful visualizations. You can use the Python framework for data science for generating creative graphs, charts, histograms, and other shapes and figures—without worrying about writing many lines of code. For example, let's see how the Matplotlib library can be used to create a simple bar chart.
|
||||
|
||||
Let's start by importing the library.
|
||||
|
||||
```
|
||||
from matplotlib import pyplot as plt
|
||||
```
|
||||
|
||||
Let's generate values for both the x-axis and the y-axis.
|
||||
|
||||
```
|
||||
x = [2, 4, 6, 8, 10]
|
||||
y = [10, 11, 6, 7, 4]
|
||||
```
|
||||
|
||||
Let's call the function for plotting the bar chart.
|
||||
|
||||
```
|
||||
plt.bar(x,y)
|
||||
```
|
||||
|
||||
Let's show the plot.
|
||||
|
||||
```
|
||||
plt.show()
|
||||
```
|
||||
|
||||
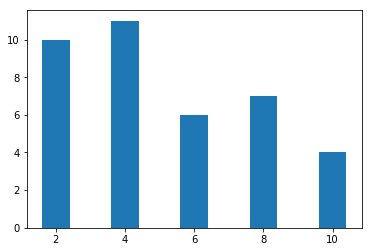
Here is the bar chart:
|
||||
|
||||
|
||||
|
||||
Here is the entire code for this example:
|
||||
|
||||
```
|
||||
#importing Matplotlib Python library
|
||||
from matplotlib import pyplot as plt
|
||||
#same as import matplotlib.pyplot as plt
|
||||
|
||||
#generating values for x-axis
|
||||
x = [2, 4, 6, 8, 10]
|
||||
|
||||
#generating vaues for y-axis
|
||||
y = [10, 11, 6, 7, 4]
|
||||
|
||||
#calling function for plotting the bar chart
|
||||
plt.bar(x,y)
|
||||
|
||||
#showing the plot
|
||||
plt.show()
|
||||
```
|
||||
|
||||
### Wrapping up
|
||||
|
||||
The Python programming language has always done a good job in data crunching and preparation, but less so for complicated scientific data analysis and modeling. The top Python frameworks for [data science][5] help fill this gap, allowing you to carry out complex mathematical computations and create sophisticated models that make sense of your data.
|
||||
|
||||
Which other Python data-mining libraries do you know? What's your experience with them? Please share your comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/top-3-python-libraries-data-science
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
|
||||
[2]: http://www.numpy.org/
|
||||
[3]: http://pandas.pydata.org/
|
||||
[4]: https://matplotlib.org/
|
||||
[5]: https://www.liveedu.tv/guides/data-science/
|
||||
@ -0,0 +1,171 @@
|
||||
Streama – Setup Your Own Streaming Media Server In Minutes
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Streama** is a free, open source application that helps to setup your own personal streaming media server in minutes in Unix-like operating systems. It’s like Netflix, but self-hostable. You can deploy it on your local system or VPS or dedicated server and stream the media files across multiple devices. The media files can be accessed from a web-browser from any system on your network. If you have deployed on your VPS, you can access it from anywhere. Streama works like your own personal Netflix system to stream your TV shows, videos, audios and movies. Streama is a web-based application written using Grails 3 (server-side) with SpringSecurity and all frond-end components are written in AngularJS. The built-in player is completely HTML5-based.
|
||||
|
||||
### Prominent Features
|
||||
|
||||
Streama ships with a lot features as listed below.
|
||||
|
||||
* Easy to install configure. You can either download docker instance and fire up your media server in minutes or install vanilla version on your local or VPS or dedicated server.
|
||||
* Drag and drop support to upload media files.
|
||||
* Live sync watching support. You can watch videos with your friends, family remotely. It doesn’t matter where they are. You can all watch the same video at a time.
|
||||
* Built-in beautiful video player to watch/listen video and audio.
|
||||
* Built-in browser to access the media files in the server.
|
||||
* Multi-user support. You can create individual user accounts to your family members and access the media server simultaneously.
|
||||
* Streama supports pause-play option. Pause the playback at any time and Streama remembers where you left off last time.
|
||||
* Streama can be able to detect similar movies and videos and shows for you to add.
|
||||
* Self-hostable
|
||||
* It is completely free and open source.
|
||||
|
||||
|
||||
|
||||
What do you need more? Streama has everything you to need to setup a full-fledged streaming media server in your Linux box.
|
||||
|
||||
### Setup Your Own Streaming Media Server Using Streama
|
||||
|
||||
Streama requires JAVA 8 or later, preferably **OpenJDK**. And, the recommended OS is **Ubuntu**. For the purpose of this guide, I will be using Ubuntu 18.04 LTS.
|
||||
|
||||
By default, the latest Ubuntu 18.04 includes Open JDK 11. To install default openJDK in Ubuntu 18.04 or later, run:
|
||||
|
||||
```
|
||||
$ sudo apt install default-jdk
|
||||
|
||||
```
|
||||
|
||||
Java 8 is the latest stable Long Time Support version. If you prefer to use Java LTS, run:
|
||||
|
||||
```
|
||||
$ sudo apt install openjdk-8-jdk
|
||||
```
|
||||
|
||||
I have installed openjdk-8-jdk. To check the installed Java version, run:
|
||||
|
||||
```
|
||||
$ java -version
|
||||
openjdk version "1.8.0_181"
|
||||
OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-0ubuntu0.18.04.1-b13)
|
||||
OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
|
||||
```
|
||||
|
||||
Once java installed, create a directory to save Streama executable and yml files.
|
||||
|
||||
```
|
||||
$ sudo mkdir /data
|
||||
|
||||
$ sudo mkdir /data/streama
|
||||
```
|
||||
|
||||
I followed the official documentation, so I used this path – /data/streama. It is optional. You’re free to use any location of your choice.
|
||||
|
||||
Switch to streama directory:
|
||||
|
||||
```
|
||||
$ cd /data/streama
|
||||
```
|
||||
|
||||
Download the latest Streama executable file from [**releases page**][1]. As of writing this guide, the latest version was **v1.6.0-RC8**.
|
||||
|
||||
```
|
||||
$ sudo wget https://github.com/streamaserver/streama/releases/download/v1.6.0-RC8/streama-1.6.0-RC8.war
|
||||
```
|
||||
|
||||
Make it executable:
|
||||
|
||||
```
|
||||
$ sudo chmod +x streama-1.6.0-RC8.war
|
||||
```
|
||||
|
||||
Now, run Streama application using command:
|
||||
|
||||
```
|
||||
$ sudo ./streama-1.6.0-RC8.war
|
||||
```
|
||||
|
||||
If you an output something like below, Streama is working!
|
||||
|
||||
```
|
||||
INFO streama.Application - Starting Application on ubuntuserver with PID 26714 (/data/streama/streama-1.6.0-RC8.war started by root in /data/streama)
|
||||
DEBUG streama.Application - Running with Spring Boot v1.4.4.RELEASE, Spring v4.3.6.RELEASE
|
||||
INFO streama.Application - The following profiles are active: production
|
||||
|
||||
Configuring Spring Security Core ...
|
||||
... finished configuring Spring Security Core
|
||||
|
||||
INFO streama.Application - Started Application in 92.003 seconds (JVM running for 98.66)
|
||||
Grails application running at http://localhost:8080 in environment: production
|
||||
```
|
||||
|
||||
Open your web browser and navigate to URL – **<http://ip-address:8080>**
|
||||
|
||||
You should see Streama login screen. Login with default credentials – **admin/admin**
|
||||
|
||||
|
||||
|
||||
Now, You need to fill out some required base-settings. Click OK button in the next screen and you will be redirected to the settings page. In the Settings page, you need to set some parameters such as the location of the Uploads directory, Streama logo, name of the media server, base URL, allow anonymous access, allow users to download videos. All fields marked with ***** is necessary to fill. Once you provided the details, click **Save settings** button.
|
||||
|
||||

|
||||
|
||||
Congratulations! Your media server is ready to use!
|
||||
|
||||
Here is how Stream dashboard looks like.
|
||||
|
||||

|
||||
|
||||
And, this is the contents management page where you can upload movies, shows, access files via file manager, view the notifications and highlights.
|
||||
|
||||

|
||||
|
||||
### Adding movies/shows
|
||||
|
||||
Let me show you how to add a movie.
|
||||
|
||||
Go to the **“Manage Content”** page from the dashboard and click **“Create New Movie”** link.
|
||||
|
||||
Enter the movie details, such as name, release date, IMDB ID and movie description and click **Save**. These are all optional, you can simply ignore them if you don’t know about the details.
|
||||
|
||||

|
||||
|
||||
We have added the movie details, but we haven’t added the actual movie yet. To do so, click on the red box in the bottom that says – **“No video file yet! Drop file or Click here to add”**.
|
||||
|
||||

|
||||
|
||||
You could either drag and drop the movie file inside this dashboard or click on the red box to manually upload it.
|
||||
|
||||
Choose the movie file to upload and click Upload.
|
||||
|
||||
|
||||
|
||||
Once the upload is completed, you could see the uploaded movie details. Click on the three horizontal lines next to the movie if you want to edit/modify movie details.
|
||||
|
||||

|
||||
|
||||
Similarly, you can create TV shows, videos and audios.
|
||||
|
||||
|
||||
|
||||
And also the movies/shows are started to appear in the home screen of your dashboard. Simply click on it to play the video and enjoy Netflix experience right from your Linux desktop.
|
||||
|
||||
For more details, refer the product’s official website.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/streama-setup-your-own-streaming-media-server-in-minutes/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://github.com/streamaserver/streama/releases
|
||||
@ -0,0 +1,62 @@
|
||||
HankChow translating
|
||||
|
||||
Understand Fedora memory usage with top
|
||||
======
|
||||
|
||||

|
||||
|
||||
Have you used the top utility in a terminal to see memory usage on your Fedora system? If so, you might be surprised to see some of the numbers there. It might look like a lot more memory is consumed than your system has available. This article will explain a little more about memory usage, and how to read these numbers.
|
||||
|
||||
### Memory usage in real terms
|
||||
|
||||
The way the operating system (OS) uses memory may not be self-evident. In fact, some ingenious, behind-the-scenes techniques are at play. They help your OS use memory more efficiently, without involving you.
|
||||
|
||||
Most applications are not self contained. Instead, each relies on sets of functions collected in libraries. These libraries are also installed on the system. In Fedora, the RPM packaging system ensures that when you install an app, any libraries on which it relies are installed, too.
|
||||
|
||||
When an app runs, the OS doesn’t necessarily load all the information it uses into real memory. Instead, it builds a map to the storage where that code is stored, called virtual memory. The OS then loads only the parts it needs. When it no longer needs portions of memory, it might release or swap them out as appropriate.
|
||||
|
||||
This means an app can map a very large amount of virtual memory, while using less real memory on the system at one time. It might even map more RAM than the system has available! In fact, across a whole OS that’s often the case.
|
||||
|
||||
In addition, related applications may rely on the same libraries. The Linux kernel in your Fedora system often shares memory between applications. It doesn’t need to load multiple copies of the same library for related apps. This works similarly for separate instances of the same app, too.
|
||||
|
||||
Without understanding these details, the output of the top application can be confusing. The following example will clarify this view into memory usage.
|
||||
|
||||
### Viewing memory usage in top
|
||||
|
||||
If you haven’t tried yet, open a terminal and run the top command to see some output. Hit **Shift+M** to see the list sorted by memory usage. Your display may look slightly different than this example from a running Fedora Workstation:
|
||||
|
||||
<https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-09-17-14-23-17.png>
|
||||
|
||||
There are three columns showing memory usage to examine: VIRT, RES, and SHR. The measurements are currently shown in kilobytes (KB).
|
||||
|
||||
The VIRT column is the virtual memory mapped for this process. Recall from the earlier description that virtual memory is not actual RAM consumed. For example, the GNOME Shell process gnome-shell is not actually consuming over 3.1 gigabytes of actual RAM. However, it’s built on a number of lower and higher level libraries. The system must map each of those to ensure they can be loaded when necessary.
|
||||
|
||||
The RES column shows you how much actual (resident) memory is consumed by the app. In the case of GNOME Shell, that’s about 180788 KB. The example system has roughly 7704 MB of physical memory, which is why the memory usage shows up as 2.3%.
|
||||
|
||||
However, of that number, at least 88212 KB is shared memory, shown in the SHR column. This memory might be, for example, library functions that other apps also use. This means the GNOME Shell is using about 92 MB on its own not shared with other processes. Notice that other apps in the example share an even higher percentage of their resident memory. In some apps, the shared portion is the vast majority of the memory usage.
|
||||
|
||||
There is a wrinkle here, which is that sometimes processes communicate with each other via memory. That memory is also shared, but can’t necessarily be detected by a utility like top. So yes — even the above clarifications still have some uncertainty!
|
||||
|
||||
### A note about swap
|
||||
|
||||
Your system has another facility it uses to store information, which is swap. Typically this is an area of slower storage (like a hard disk). If the physical memory on the system fills up as needs increase, the OS looks for portions of memory that haven’t been needed in a while. It writes them out to the swap area, where they sit until needed later.
|
||||
|
||||
Therefore, prolonged, high swap usage usually means a system is suffering from too little memory for its demands. Sometimes an errant application may be at fault. Or, if you see this often on your system, consider upgrading your machine’s memory, or restricting what you run.
|
||||
|
||||
Photo courtesy of [Stig Nygaard][1], via [Flickr][2] (CC BY 2.0).
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/understand-fedora-memory-usage-top/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: https://www.flickr.com/photos/stignygaard/
|
||||
[2]: https://www.flickr.com/photos/stignygaard/3138001676/
|
||||
@ -1,82 +0,0 @@
|
||||
如何使用 Apache 构建 URL 缩短器
|
||||
======
|
||||
|
||||

|
||||
|
||||
很久以前,人们开始在 Twitter 上分享链接。140 个字符的限制意味着 URL 可能消耗一条推文的大部分(或全部),因此人们使用 URL 缩短器。最终,Twitter 加入了一个内置的 URL 缩短器([t.co][1])。
|
||||
|
||||
字符数现在不重要了,但还有其他原因要缩短链接。首先,缩短服务可以提供分析 - 你可以看到你分享的链接的受欢迎程度。它还简化了制作易于记忆的 URL。例如,[bit.ly/INtravel][2] 比<https://www.in.gov/ai/appfiles/dhs-countyMap/dhsCountyMap.html>更容易记住。如果你想预先共享一个链接,但还不知道最终地址,这时 URL 缩短器可以派上用场。。
|
||||
|
||||
与任何技术一样,URL 缩短器并非都是正面的。通过屏蔽最终地址,缩短的链接可用于指向恶意或冒犯性内容。但是,如果你仔细上网,URL 缩短器是一个有用的工具。
|
||||
|
||||
我们之前在网站上[发布过缩短器的文章][3],但也许你想要运行一些由简单的文本驱动的缩短器。在本文中,我们将展示如何使用 Apache HTTP 服务器的 mod_rewrite 功能来设置自己的 URL 缩短器。如果你不熟悉 Apache HTTP 服务器,请查看 David Both 关于[安装和配置][4]的文章。
|
||||
|
||||
### 创建一个 VirtualHost
|
||||
|
||||
在本教程中,我假设你购买了一个很酷的域名,你将它专门用于 URL 缩短器。例如,我的网站是 [funnelfiasco.com][5],所以我买了 [funnelfias.co][6] 用于我的 URL 缩短器(好吧,它不是很短,但它可以满足我的虚荣心)。如果你不将缩短器作为单独的域运行,请跳到下一部分。
|
||||
|
||||
第一步是设置将用于 URL 缩短器的 VirtualHost。有关 VirtualHosts 的更多信息,请参[ David Both 的文章][7]。这步只需要几行:
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
|
||||
ServerName funnelfias.co
|
||||
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
### 创建 rewrite
|
||||
|
||||
此服务使用 HTTPD 的重写引擎来重写 URL。如果你在上面的部分中创建了 VirtualHost,则下面的配置跳到你的 VirtualHost 部分。否则跳到服务器的 VirtualHost 或主 HTTPD 配置。
|
||||
```
|
||||
RewriteEngine on
|
||||
|
||||
RewriteMap shortlinks txt:/data/web/shortlink/links.txt
|
||||
|
||||
RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
|
||||
|
||||
```
|
||||
|
||||
第一行只是启用重写引擎。第二行在文本文件构建短链接的映射。上面的路径只是一个例子。你需要使用系统上使用有效路径(确保它可由运行 HTTPD 的用户帐户读取)。最后一行重写 URL。在此例中,它接受任何字符并在重写映射中查找它们。你可能希望重写时使用特定的字符串。例如,如果你希望所有缩短的链接都是 “slX”(其中 X 是数字),则将上面的 `(.+)` 替换为 `(sl\d+)`。
|
||||
|
||||
我在这里使用了临时 (HTTP 302) 重定向。这能让我稍后更新目标 URL。如果希望短链接始终指向同一目标,则可以使用永久 (HTTP 301) 重定向。用 `permanent` 替换第三行的 `temp`。
|
||||
|
||||
### 构建你的映射
|
||||
|
||||
编辑配置文件 “RewriteMap” 行中的指定文件。格式是空格分隔的键值存储。在每一行上放一个链接:
|
||||
```
|
||||
osdc https://opensource.com/users/bcotton
|
||||
|
||||
twitter https://twitter.com/funnelfiasco
|
||||
|
||||
swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
|
||||
|
||||
```
|
||||
|
||||
### 重启 HTTPD
|
||||
|
||||
最后一步是重启 HTTPD 进程。这是通过 `systemctl restart httpd` 或类似命令完成的(命令和守护进程名称可能因发行版而不同)。你的链接缩短器现已启动并运行。当你准备编辑映射时,无需重新启动 Web 服务器。你所要做的就是保存文件,Web 服务器将获取到差异。
|
||||
|
||||
### 未来的工作
|
||||
|
||||
此示例为你提供了基本的 URL 缩短器。如果你想将开发自己的管理接口作为学习项目,它可以作为一个很好的起点。或者你可以使用它分享容易记住的链接到那些容易忘记的 URL。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/apache-url-shortener
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:http://t.co
|
||||
[2]:http://bit.ly/INtravel
|
||||
[3]:https://opensource.com/article/17/3/url-link-shortener
|
||||
[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[5]:http://funnelfiasco.com
|
||||
[6]:http://funnelfias.co
|
||||
[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
@ -0,0 +1,140 @@
|
||||
Autotrash - 一个自动清除旧垃圾的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Autotrash** 是一个命令行程序,它用于自动清除旧的已删除文件。它将清除超过指定天数的在回收站中的文件。你不需要清空回收站或执行 SHIFT+DELETE 以永久清除文件/文件夹。Autortrash 将处理回收站中的内容,并在特定时间段后自动删除它们。简而言之,Autotrash 永远不会让你的垃圾变得太大。
|
||||
|
||||
### 安装 Autotrash
|
||||
|
||||
Autotrash 默认存在于基于 Debian 系统的仓库中。要在 Debian、Ubuntu、Linux Mint 上安装 autotrash,请运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get install autotrash
|
||||
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install autotrash
|
||||
|
||||
```
|
||||
|
||||
对于 Arch linux 及其变体,你可以使用任何 AUR 助手程序, 如 [**Yay**][1] 安装它。
|
||||
|
||||
```
|
||||
$ yay -S autotrash-git
|
||||
|
||||
```
|
||||
|
||||
### 自动清除旧的垃圾文件
|
||||
|
||||
每当你运行 autotrash 时,它会扫描你的 **`~/.local/share/Trash/info`** 目录并读取 **`.trashinfo`** 以找出它们的删除日期。如果文件已在回收站中超过指定的日期,那么就会删除它们。
|
||||
|
||||
让我举几个例子。
|
||||
|
||||
要删除回收站中超过 30 天的文件,请运行:
|
||||
|
||||
```
|
||||
$ autotrash -d 30
|
||||
|
||||
```
|
||||
|
||||
如上例所示,如果回收站中的文件超过 30 天,Autotrash 会自动将其从回收站中删除。你无需手动删除它们。只需将没用的文件放到回收站即可忘记。Autotrash 将处理已删除的文件。
|
||||
|
||||
以上命令仅处理当前登录用户的垃圾目录。如果要使 autotrash 处理所有用户的垃圾目录(不仅仅是在你的家目录中),请使用 **-t** 选项,如下所示。
|
||||
|
||||
```
|
||||
$ autotrash -td 30
|
||||
|
||||
```
|
||||
|
||||
Autotrash 还允许你根据回收站可用容量或磁盘可用空间来删除已删除的文件。
|
||||
|
||||
例如,看下下面的例子。
|
||||
|
||||
```
|
||||
$ autotrash --max-free 1024 -d 30
|
||||
|
||||
```
|
||||
|
||||
根据上面的命令,如果回收站的剩余的空间少于**1GB**,那么 autotrash 将从回收站中清除超过**30 天**的已删除文件。如果你的回收站空间不足,这可能很有用。
|
||||
|
||||
我们还可以从回收站中按最早的时间清除文件直到回收站至少有 1GB 的空间。
|
||||
|
||||
```
|
||||
$ autotrash --min-free 1024
|
||||
|
||||
```
|
||||
|
||||
在这种情况下,对旧的已删除文件没有限制。
|
||||
|
||||
你可以将这两个选项(**`--min-free`** 和 **`--max-free`**)组合在一个命令中,如下所示。
|
||||
|
||||
```
|
||||
$ autotrash --max-free 2048 --min-free 1024 -d 30
|
||||
|
||||
```
|
||||
|
||||
根据上面的命令,如果可用空间小于 **2GB**,autotrash 将读取回收站,接着关注容量。此时,删除超过 30 天的文件,如果少于 **1GB** 的可用空间,则删除更新的文件。
|
||||
|
||||
如你所见,所有命令都应由用户手动运行。你可能想知道,我该如何自动执行此任务?这很容易!只需将 autotrash 添加为 crontab 任务即可。现在,命令将在计划的时间自动运行,并根据定义的选项清除回收站中的文件。
|
||||
|
||||
要在 crontab 中添加这些命令,请运行:
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
添加任务,例如:
|
||||
|
||||
```
|
||||
@daily /usr/bin/autotrash -d 30
|
||||
|
||||
```
|
||||
|
||||
现在,autotrash 将每天清除回收站中超过 30 天的文件。
|
||||
|
||||
有关计划任务的更多详细信息,请参阅以下链接。
|
||||
|
||||
|
||||
+ [Cron 任务的初学者指南]][2]
|
||||
+ [如何在 Linux 中轻松安全地管理 Cron 作业]][3]
|
||||
|
||||
|
||||
请注意,如果你无意中删除了任何重要文件,它们将在规定的日期后永久消失,所以请小心。
|
||||
|
||||
请参阅手册页以了解有关 Autotrash 的更多信息。
|
||||
|
||||
```
|
||||
$ man autotrash
|
||||
|
||||
```
|
||||
|
||||
清空回收站或按 SHIFT+DELETE 永久删除 Linux 系统中没用的东西没什么大不了的。它只需要几秒钟。但是,如果你需要额外的程序来处理垃圾文件,Autotrash 可能会有所帮助。试一下,看看它是如何工作的。
|
||||
|
||||
就是这些了。希望这个有用。还有更多的好东西。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/autotrash-a-cli-tool-to-automatically-purge-old-trashed-files/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[2]: https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
[3]: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
|
||||
@ -0,0 +1,246 @@
|
||||
3 个用于数据科学的顶级 Python 库
|
||||
======
|
||||
|
||||
>使用这些库把 Python 变成一个科学数据分析和建模工具。
|
||||
|
||||
![][7]
|
||||
|
||||
Python 的许多特性,比如开发效率、代码可读性、速度等使之成为了数据科学爱好者的首选编程语言。对于想要升级应用程序功能的数据科学家和机器学习专家来说,Python 通常是最好的选择(比如,Andrey Bulezyuk 使用 Python 语言创造了一个优秀的[机器学习应用程序][1])。
|
||||
|
||||
由于 Python 的广泛使用,因此它拥有大量的库,使得数据科学家能够很容易地完成复杂的任务,而且不会遇到许多编码困难。下面列出 3 个用于数据科学的顶级 Python 库。如果你想在数据科学这一领域开始你的职业生涯,就去了解一下它们吧。
|
||||
|
||||
### NumPy
|
||||
|
||||
[NumPy][2](数值 Python 的简称)是其中一个顶级数据科学库,它拥有许多有用的资源,从而帮助数据科学家把 Python 变成一个强大的科学分析和建模工具。NumPy 是在 BSD 许可证的许可下开源的,它是在科学计算中执行任务的基础 Python 库。SciPy 是一个更大的基于 Python 生态系统的开源工具,而 NumPy 是 SciPy 非常重要的一部分。
|
||||
|
||||
NumPy 为 Python 提供了大量数据结构,从而能够轻松地执行多维数组和矩阵运算。除了用于求解线性代数方程和其它数学计算之外,NumPy 还可以用做不同类型通用数据的多维容器。
|
||||
|
||||
此外,NumPy 还可以和其他编程语言无缝集成,比如 C/C++ 和 Fortran。NumPy 的多功能性使得它可以简单而快速地与大量数据库和工具结合。比如,让我们来看一下如何使用 NumPy(缩写成 `np`)来实现两个矩阵的乘法运算。
|
||||
|
||||
我们首先导入 NumPy 库(在这些例子中,我将使用 Jupyter notebook):
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
```
|
||||
|
||||
接下来,使用 `eye()` 函数来生成指定维数的单位矩阵:
|
||||
|
||||
```
|
||||
matrix_one = np.eye(3)
|
||||
matrix_one
|
||||
```
|
||||
|
||||
输出如下:
|
||||
|
||||
```
|
||||
array([[1., 0., 0.],
|
||||
[0., 1., 0.],
|
||||
[0., 0., 1.]])
|
||||
```
|
||||
|
||||
让我们生成另一个 3x3 矩阵。
|
||||
|
||||
我们使用 `arange([starting number], [stopping number])` 函数来排列数字。注意,函数中的第一个参数是需要列出的初始数字,而后一个数字不包含在生成的结果中。
|
||||
|
||||
另外,使用 `reshape()` 函数把原始生成的矩阵的维度改成我们需要的维度。为了使两个矩阵“可乘”,它们需要有相同的维度。
|
||||
|
||||
```
|
||||
matrix_two = np.arange(1,10).reshape(3,3)
|
||||
matrix_two
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
输出如下:
|
||||
|
||||
```
|
||||
array([[1, 2, 3],
|
||||
[4, 5, 6],
|
||||
[7, 8, 9]])
|
||||
```
|
||||
|
||||
接下来,使用 `dot()` 函数将两个矩阵相乘。
|
||||
|
||||
```
|
||||
matrix_multiply = np.dot(matrix_one, matrix_two)
|
||||
|
||||
matrix_multiply
|
||||
|
||||
```
|
||||
|
||||
相乘后的输出如下:
|
||||
|
||||
```
|
||||
array([[1., 2., 3.],
|
||||
[4., 5., 6.],
|
||||
[7., 8., 9.]])
|
||||
```
|
||||
|
||||
太好了!
|
||||
|
||||
我们成功使用 NumPy 完成了两个矩阵的相乘,而不是使用<ruby>普通冗长<rt>vanilla</rt></ruby>的 Python 代码。
|
||||
|
||||
下面是这个例子的完整代码:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
#生成一个 3x3 单位矩阵
|
||||
matrix_one = np.eye(3)
|
||||
matrix_one
|
||||
#生成另一个 3x3 矩阵以用来做乘法运算
|
||||
matrix_two = np.arange(1,10).reshape(3,3)
|
||||
matrix_two
|
||||
#将两个矩阵相乘
|
||||
matrix_multiply = np.dot(matrix_one, matrix_two)
|
||||
matrix_multiply
|
||||
```
|
||||
|
||||
### Pandas
|
||||
|
||||
[Pandas][3] 是另一个可以提高你的 Python 数据科学技能的优秀库。就和 NumPy 一样,它属于 SciPy 开源软件家族,可以在 BSD 免费许可证许可下使用。
|
||||
|
||||
Pandas 提供了多功能并且很强大的工具用于管理数据结构和执行大量数据分析。该库能够很好的处理不完整、非结构化和无序的真实世界数据,并且提供了用于整形、聚合、分析和可视化数据集的工具
|
||||
|
||||
Pandas 中有三种类型的数据结构:
|
||||
|
||||
* Series: 一维、相同数据类型的数组
|
||||
* DataFrame: 二维异型矩阵
|
||||
* Panel: 三维大小可变数组
|
||||
|
||||
|
||||
|
||||
例如,我们来看一下如何使用 Panda 库(缩写成 `pd`)来执行一些描述性统计计算。
|
||||
|
||||
首先导入该库:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
```
|
||||
|
||||
然后,创建一个<ruby>序列<rt>series</rt></ruby>字典:
|
||||
|
||||
```
|
||||
d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
|
||||
'Irene','Sagar','Simon','James','Rose']),
|
||||
'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
|
||||
'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
|
||||
}
|
||||
```
|
||||
|
||||
接下来,再创建一个<ruby>数据框<rt>DataFrame</rt></ruby>:
|
||||
|
||||
```
|
||||
df = pd.DataFrame(d)
|
||||
```
|
||||
|
||||
输出是一个非常规整的表:
|
||||
|
||||
```
|
||||
Name Programming Language Years of Experience
|
||||
0 Alfrick Python 5
|
||||
1 Michael JavaScript 9
|
||||
2 Wendy PHP 1
|
||||
3 Paul C++ 4
|
||||
4 Dusan Java 3
|
||||
5 George Scala 4
|
||||
6 Andreas React 7
|
||||
7 Irene Ruby 9
|
||||
8 Sagar Angular 6
|
||||
9 Simon PHP 8
|
||||
10 James Python 3
|
||||
11 Rose JavaScript 1
|
||||
```
|
||||
|
||||
下面是这个例子的完整代码:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
#创建一个序列字典
|
||||
d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
|
||||
'Irene','Sagar','Simon','James','Rose']),
|
||||
'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
|
||||
'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
|
||||
}
|
||||
|
||||
#创建一个数据框
|
||||
df = pd.DataFrame(d)
|
||||
print(df)
|
||||
```
|
||||
|
||||
### Matplotlib
|
||||
|
||||
[Matplotlib][4] 也是 Scipy 核心包的一部分,并且在 BSD 许可证下可用。它是一个非常流行的科学库,用于实现简单而强大的可视化。你可以使用这个 Python 数据科学框架来生成曲线图、柱状图、直方图以及各种不同形状的图表,并且不用担心需要写很多行的代码。例如,我们来看一下如何使用 Matplotlib 库来生成一个简单的柱状图。
|
||||
|
||||
首先导入该库:
|
||||
|
||||
```
|
||||
from matplotlib import pyplot as plt
|
||||
```
|
||||
|
||||
然后生成 x 轴和 y 轴的数值:
|
||||
|
||||
```
|
||||
x = [2, 4, 6, 8, 10]
|
||||
y = [10, 11, 6, 7, 4]
|
||||
```
|
||||
|
||||
接下来,调用函数来绘制柱状图:
|
||||
|
||||
```
|
||||
plt.bar(x,y)
|
||||
```
|
||||
|
||||
最后,显示图表:
|
||||
|
||||
```
|
||||
plt.show()
|
||||
```
|
||||
|
||||
柱状图如下:
|
||||
|
||||
![][6]
|
||||
|
||||
下面是这个例子的完整代码:
|
||||
|
||||
```
|
||||
#导入 Matplotlib 库
|
||||
from matplotlib import pyplot as plt
|
||||
#和 import matplotlib.pyplot as plt 一样
|
||||
|
||||
#生成 x 轴的数值
|
||||
x = [2, 4, 6, 8, 10]
|
||||
|
||||
#生成 y 轴的数值
|
||||
y = [10, 11, 6, 7, 4]
|
||||
|
||||
#调用函数来绘制柱状图
|
||||
plt.bar(x,y)
|
||||
|
||||
#显示图表
|
||||
plt.show()
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
Python 编程语言非常擅长数据处理和准备,但是在科学数据分析和建模方面就没有那么优秀了。幸好有这些用于[数据科学][5]的顶级 Python 框架填补了这一空缺,从而你能够进行复杂的数学计算以及创建复杂模型,进而让数据变得更有意义。
|
||||
|
||||
你还知道其它的 Python 数据挖掘库吗?你的使用经验是什么样的?请在下面的评论中和我们分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/top-3-python-libraries-data-science
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
|
||||
[2]: http://www.numpy.org/
|
||||
[3]: http://pandas.pydata.org/
|
||||
[4]: https://matplotlib.org/
|
||||
[5]: https://www.liveedu.tv/guides/data-science/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/matplotlib_barchart.png
|
||||
[7]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr
|
||||
Loading…
Reference in New Issue
Block a user