mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
b31b70fee4
@ -61,6 +61,8 @@ LCTT 的组成
|
||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
||||
* 2017/11/21 鉴于 qhwdw 快速而上佳的翻译质量,提升 qhwdw 为新的 Core 成员。
|
||||
* 2017/11/19 wxy 在上海交大举办的 2017 中国开源年会上做了演讲:《[如何以翻译贡献参与开源社区](https://linux.cn/article-9084-1.html)》。
|
||||
* 2018/01/11 提升 lujun9972 成为核心成员,并加入选题组。
|
||||
|
||||
核心成员
|
||||
-------------------------------
|
||||
@ -88,6 +90,7 @@ LCTT 的组成
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @qhwdw,
|
||||
- 核心成员 @lujun9972
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
为小白准备的重要 Docker 命令说明
|
||||
======
|
||||
在早先的教程中,我们学过了[在 RHEL\ CentOS 7 上安装 Docker 并创建 docker 容器 .][1] 在本教程中,我们会学习管理 docker 容器的其他命令。
|
||||
|
||||
在早先的教程中,我们学过了[在 RHEL CentOS 7 上安装 Docker 并创建 docker 容器][1]。 在本教程中,我们会学习管理 docker 容器的其他命令。
|
||||
|
||||
### Docker 命令语法
|
||||
|
||||
@ -61,7 +62,7 @@ volume Manage Docker volumes
|
||||
wait Block until a container stops, then print its exit code
|
||||
```
|
||||
|
||||
要进一步查看某个 command 支持的选项,运行
|
||||
要进一步查看某个命令支持的选项,运行:
|
||||
|
||||
```
|
||||
$ docker docker-subcommand info
|
||||
@ -77,7 +78,7 @@ $ docker docker-subcommand info
|
||||
$ docker run hello-world
|
||||
```
|
||||
|
||||
结果应该是,
|
||||
结果应该是:
|
||||
|
||||
```
|
||||
Hello from Docker.
|
||||
@ -95,17 +96,17 @@ This message shows that your installation appears to be working correctly.
|
||||
$ docker search Ubuntu
|
||||
```
|
||||
|
||||
我们应该会得到 age 可用的 Ubuntu 镜像的列表。记住,如果你想要的是官方的镜像,经检查 `official` 这一列上是否为 `[OK]`。
|
||||
我们应该会得到可用的 Ubuntu 镜像的列表。记住,如果你想要的是官方的镜像,请检查 `official` 这一列上是否为 `[OK]`。
|
||||
|
||||
### 下载镜像
|
||||
|
||||
一旦搜索并找到了我们想要的镜像,我们可以运行下面语句来下载它,
|
||||
一旦搜索并找到了我们想要的镜像,我们可以运行下面语句来下载它:
|
||||
|
||||
```
|
||||
$ docker pull Ubuntu
|
||||
```
|
||||
|
||||
要查看所有已下载的镜像,运行
|
||||
要查看所有已下载的镜像,运行:
|
||||
|
||||
```
|
||||
$ docker images
|
||||
@ -113,17 +114,17 @@ $ docker images
|
||||
|
||||
### 运行容器
|
||||
|
||||
使用已下载镜像来运行容器,使用下面命令
|
||||
使用已下载镜像来运行容器,使用下面命令:
|
||||
|
||||
```
|
||||
$ docker run -it Ubuntu
|
||||
```
|
||||
|
||||
这里,使用 '-it' 会打开一个 shell 与容器交互。容器启动并运行后,我们就可以像普通机器那样来使用它了,我们可以在容器中执行任何命令。
|
||||
这里,使用 `-it` 会打开一个 shell 与容器交互。容器启动并运行后,我们就可以像普通机器那样来使用它了,我们可以在容器中执行任何命令。
|
||||
|
||||
### 显示所有的 docker 容器
|
||||
|
||||
要列出所有 docker 容器,运行
|
||||
要列出所有 docker 容器,运行:
|
||||
|
||||
```
|
||||
$ docker ps
|
||||
@ -133,7 +134,7 @@ $ docker ps
|
||||
|
||||
### 停止 docker 容器
|
||||
|
||||
要停止 docker 容器,运行
|
||||
要停止 docker 容器,运行:
|
||||
|
||||
```
|
||||
$ docker stop container-id
|
||||
@ -141,7 +142,7 @@ $ docker stop container-id
|
||||
|
||||
### 从容器中退出
|
||||
|
||||
要从容器中退出,执行
|
||||
要从容器中退出,执行:
|
||||
|
||||
```
|
||||
$ exit
|
||||
@ -149,25 +150,19 @@ $ exit
|
||||
|
||||
### 保存容器状态
|
||||
|
||||
容器运行并更改后后(比如安装了 apache 服务器),我们可以保存容器状态。这会在本地系统上保存新创建镜像。
|
||||
容器运行并更改后(比如安装了 apache 服务器),我们可以保存容器状态。这会在本地系统上保存新创建镜像。
|
||||
|
||||
运行下面语句来提交并保存容器状态
|
||||
运行下面语句来提交并保存容器状态:
|
||||
|
||||
```
|
||||
$ docker commit 85475ef774 repository/image_name
|
||||
```
|
||||
|
||||
这里,**commit** 会保存容器状态
|
||||
|
||||
**85475ef774**,是容器的容器 id,
|
||||
|
||||
**repository**,通常为 docker hub 上的用户名 (或者新加的仓库名称)
|
||||
|
||||
**image_name**,新镜像的名称
|
||||
这里,`commit` 命令会保存容器状态,`85475ef774`,是容器的容器 id,`repository`,通常为 docker hub 上的用户名 (或者新加的仓库名称)`image_name`,是新镜像的名称。
|
||||
|
||||
我们还可以使用 `-m` 和 `-a` 来添加更多信息。通过 `-m`,我们可以留个信息说 apache 服务器已经安装好了,而 `-a` 可以添加作者名称。
|
||||
|
||||
**像这样**
|
||||
像这样:
|
||||
|
||||
```
|
||||
docker commit -m "apache server installed"-a "Dan Daniels" 85475ef774 daniels_dan/Cent_container
|
||||
@ -182,7 +177,7 @@ via: http://linuxtechlab.com/important-docker-commands-beginners/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,13 @@
|
||||
|
||||
|
||||
# 在 Linux 的终端上伪造一个好莱坞黑客的屏幕
|
||||
在 Linux 的终端上伪造一个好莱坞黑客的屏幕
|
||||
=============
|
||||
|
||||
摘要:这是一个简单的小工具,可以把你的 Linux 终端变为好莱坞风格的黑客入侵的实时画面。
|
||||
|
||||
|
||||
|
||||
我进去了!
|
||||
我攻进去了!
|
||||
|
||||
你可能会几乎在所有的好莱坞电影里面会听说过这句话,此时的荧幕正在显示着一个入侵的画面。那可能是一个黑色的终端伴随着 ASCII 码、图标和连续不断变化的十六进制编码以及一个黑客正在击打着键盘,仿佛他/她正在打一段愤怒的论坛回复。
|
||||
|
||||
但是那是好莱坞大片!黑客们想要在几分钟之内破解进入一个网络系统除非他花费了几个月的时间来研究它。但是一会儿我将会在旁边留下好莱坞黑客的指责。
|
||||
但是那是好莱坞大片!黑客们想要在几分钟之内破解进入一个网络系统除非他花费了几个月的时间来研究它。不过现在我先把对好莱坞黑客的评论放在一边。
|
||||
|
||||
因为我们将会做相同的事情,我们将会伪装成为一个好莱坞风格的黑客。
|
||||
|
||||
@ -18,17 +15,16 @@
|
||||
|
||||
![在 Linux 上的Hollywood 入侵终端][1]
|
||||
|
||||
看到了吗?就像这样,它甚至在后台播放了一个 Mission Impossible 主题的音乐。此外每次运行这个工具,你都可以获得一个全新且随机的入侵终端
|
||||
看到了吗?就像这样,它甚至在后台播放了一个 Mission Impossible 主题的音乐。此外每次运行这个工具,你都可以获得一个全新且随机的入侵的终端。
|
||||
|
||||
让我们看看如何在 30 秒之内成为一个好莱坞黑客。
|
||||
|
||||
|
||||
|
||||
### 如何安装 Hollywood 入侵终端在 Linux 之上
|
||||
|
||||
这个工具非常适合叫做 Hollywood 。从根本上说,它运行在 Byobu ——一个基于 Window Manager 的文本,而且它会创建随机数量随机尺寸的分屏,并在上面运行混乱的文字应用。
|
||||
这个工具非常适合叫做 Hollywood 。从根本上说,它运行在 Byobu ——一个基于文本的窗口管理器,而且它会创建随机数量、随机尺寸的分屏,并在每个里面运行一个混乱的文字应用。
|
||||
|
||||
Byobu 是一个在 Ubuntu 上由Dustin Kirkland 开发的有趣工具。在其他文章之中还有更多关于它的有趣之处,让我们专心的安装这个工具。
|
||||
[Byobu][2] 是一个在 Ubuntu 上由 Dustin Kirkland 开发的有趣工具。在其他文章之中还有更多关于它的有趣之处,让我们先专注于安装这个工具。
|
||||
|
||||
Ubuntu 用户可以使用简单的命令安装 Hollywood:
|
||||
|
||||
@ -36,7 +32,7 @@ Ubuntu 用户可以使用简单的命令安装 Hollywood:
|
||||
sudo apt install hollywood
|
||||
```
|
||||
|
||||
如果上面的命令不能在你的 Ubuntu 或其他例如 Linux Mint, elementary OS, Zorin OS, Linux Lite 等等基于 Ubuntu 的 Linux 发行版上运行,你可以使用下面的 PPA 来安装:
|
||||
如果上面的命令不能在你的 Ubuntu 或其他例如 Linux Mint、elementary OS、Zorin OS、Linux Lite 等等基于 Ubuntu 的 Linux 发行版上运行,你可以使用下面的 PPA 来安装:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:hollywood/ppa
|
||||
@ -44,17 +40,17 @@ sudo apt-get update
|
||||
sudo apt-get install byobu hollywood
|
||||
```
|
||||
|
||||
你也可以在它的 GitHub 仓库之中获得其源代码:
|
||||
|
||||
[Hollywood 在 GitHub][3]
|
||||
你也可以在它的 GitHub 仓库之中获得其源代码: [Hollywood 在 GitHub][3] 。
|
||||
|
||||
一旦安装好,你可以使用下面的命令运行它,不需要使用 sudo :
|
||||
|
||||
`hollywood`
|
||||
```
|
||||
hollywood
|
||||
```
|
||||
|
||||
因为它会先运行 Byosu ,你将不得不使用 Ctrl+C 两次并再使用 `exit` 命令来停止显示入侵终端的脚本。
|
||||
因为它会先运行 Byosu ,你将不得不使用 `Ctrl+C` 两次并再使用 `exit` 命令来停止显示入侵终端的脚本。
|
||||
|
||||
这是一个伪装好莱坞入侵的视频。订阅我们的 YouTube 频道看更多关于 Linux 的有趣视频。
|
||||
这里面有一个伪装好莱坞入侵的视频。 https://youtu.be/15-hMt8VZ50
|
||||
|
||||
这是一个让你朋友、家人和同事感到吃惊的有趣小工具,甚至你可以在酒吧里给女孩们留下深刻的印象,尽管我不认为这对你在那方面有任何的帮助,
|
||||
|
||||
@ -63,14 +59,13 @@ sudo apt-get install byobu hollywood
|
||||
如果你知道更多有趣的工具,可以在下面的评论栏里分享给我们。
|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://itsfoss.com/hollywood-hacker-screen/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[Drshu](https://github.com/Drshu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,70 @@
|
||||
You GNOME it: Windows and Apple devs get a compelling reason to turn to Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Open Source Insider** The biggest open source story of 2017 was unquestionably Canonical's decision to stop developing its Unity desktop and move Ubuntu to the GNOME Shell desktop.
|
||||
|
||||
What made the story that much more entertaining was how well Canonical pulled off the transition. [Ubuntu 17.10][1] was quite simply one of the best releases of the year and certainly the best release Ubuntu has put out in a good long time. Of course since 17.10 was not an LTS release, the more conservative users - which may well be the majority in Ubuntu's case - still haven't made the transition.
|
||||
|
||||
![Woman takes a hammer to laptop][2]
|
||||
|
||||
Ubuntu 17.10 pulled: Linux OS knackers laptop BIOSes, Intel kernel driver fingered
|
||||
|
||||
Canonical pulled Ubuntu 17.10 downloads from its website last month due to a "bug" that could corrupt BIOS settings on some laptops. Lenovo laptops appear to be the most common source of problems, though users also reported problems with Acer and Dell.
|
||||
|
||||
The bug is actually a result of Canonical's decision to enable the Intel SPI driver, which allows BIOS firmware updates. That sounds nice, but it's not ready for prime time. Clearly. It's also clearly labeled as such and disabled in the upstream kernel. For whatever reason Canonical enabled it and, as it says on the tin, the results were unpredictable.
|
||||
|
||||
According to chatter on the Ubuntu mailing list, a fix is a few days away, with testing happening now. In the mean time, if you've been affected (for what it's worth, I have a Lenovo laptop and was *not* affected) OMGUbuntu has some [instructions that might possibly help][4].
|
||||
|
||||
It's a shame it happened because the BIOS issue seriously mars what was an otherwise fabulous release of Ubuntu.
|
||||
|
||||
Meanwhile, the repercussions of Canonical's move to GNOME are still being felt in the open source world and I believe this will continue to be one of the biggest stories in 2018 for several reasons. The first is that so many have yet to actually make the move to GNOME-based Ubuntu. That will change with 18.04, which is an LTS release set to arrive later this year. Users upgrading between LTS releases will get their first taste of Ubuntu with GNOME come April.
|
||||
|
||||
### You got to have standards: Suddenly it's much, much more accessible
|
||||
|
||||
The second, and perhaps much bigger, reason Ubuntu without Unity will continue to be a big story in the foreseeable future is that with Ubuntu using GNOME Shell, almost all the major distributions out there now ship primarily with GNOME, making GNOME Shell the de facto standard Linux desktop. That's not to say GNOME is the only option, but for a new user, landing on the Ubuntu downloads webpage or the Fedora download page or the Debian download page, the default links will get you GNOME Shell on the desktop.
|
||||
|
||||
That makes it possible for Linux and open source advocates to make a more appealing case for the platform. The ubiquity of GNOME is something that hasn't been the case previously. And it may not be good news for KDE fans, but I believe it's going to have a profound impact on the future of desktop Linux and open source development more generally because it dovetails nicely with something that I believe has been a huge story in 2017 and will continue to be a huge story in 2018 - Flatpak/Snap packages.
|
||||
|
||||
Combine a de facto standard desktop with a standard means of packaging applications and you have a platform that's just as easy to develop for as any other, say Windows or macOS.
|
||||
|
||||
The development tools in GNOME, particularly the APIs and GNOME Builder tool that arrived earlier this year with GNOME 3.20, offer developers a standardised means of targeting the Linux desktop in a way that simply hasn't been possible until now. Combine that with the ability to package applications _independent of distro_ and you have a much more compelling platform for developers.
|
||||
|
||||
That just might mean that developers not currently targeting Linux will be willing to take another look.
|
||||
|
||||
Now this potential utopia has some downsides. As already noted it leaves KDE fans a little out in the cold. It also leaves my favourite distro looking a little less necessary than it used to. I won't be abandoning Arch Linux any time soon, but I'll have a lot harder time making a solid case for Arch with Flatpak/Snap packages having more or less eliminated the need for the Arch User Repository. That's not going to happen overnight, but I do think it will eventually get there.
|
||||
|
||||
### What to look forward to...
|
||||
|
||||
There are two other big stories to watch in 2018. The first is Amazon Linux 2, Amazon's new home-grown Linux distro, based - loosely it seems - on RHEL 7. While Amazon Linux 2 screams vendor lock-in to me, it will certainly appeal to the millions of companies already heavily invested in the AWS system.
|
||||
|
||||
It also appears, from my limited testing, to offer some advantages over other images on EC2. One is speed: AL2 has been tuned to the AWS environment, but perhaps the bigger advantage is the uniformity and ease of moving from development to production entirely through identical containers.
|
||||
|
||||
![Still from Mr Robot][5]
|
||||
|
||||
Mozilla's creepy Mr Robot stunt in Firefox flops in touching tribute to TV show's 2nd season
|
||||
|
||||
The last story worth keeping an eye on is Firefox. The once, and possibly future, darling of open source development had something of a rough year. Firefox 57 with the Quantum code re-write was perhaps the most impressive release since Firefox 1.0, but that was followed up by the rather disastrous Mr Robot tie-in promo fiasco that installed unwanted plugins in users situations, an egregious breach of trust that would have made even Chrome developers blush.
|
||||
|
||||
I think there are going to be a lot more of these sorts of gaffes in 2018. Hopefully not involving Firefox, but as open source projects struggle to find different ways to fund themselves and attain higher levels of recognition, we should expect there to be plenty of ill-advised stunts of this sort.
|
||||
|
||||
I'd say pop some popcorn, because the harder that open source projects try to find money, the more sparks - and disgruntled users - are going fly. ®
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theregister.co.uk/2018/01/08/desktop_linux_open_source_standards_accessible/
|
||||
|
||||
作者:[Scott Gilbertson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://www.theregister.co.uk/2017/10/20/ubuntu_1710/
|
||||
[2]:https://regmedia.co.uk/2017/12/14/shutterstock_laptop_hit.jpg?x=174&y=115&crop=1
|
||||
[3]:https://www.theregister.co.uk/2017/12/21/ubuntu_lenovo_bios/
|
||||
[4]:http://www.omgubuntu.co.uk/2018/01/ubuntu-17-10-lenovo-fix
|
||||
[5]:https://regmedia.co.uk/2017/12/18/mr_robot_still.jpg?x=174&y=115&crop=1
|
||||
[6]:https://www.theregister.co.uk/2017/12/18/mozilla_mr_robot_firefox_promotion/
|
||||
@ -0,0 +1,116 @@
|
||||
How Mycroft used WordPress and GitHub to improve its documentation
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image credits : Photo by Unsplash; modified by Rikki Endsley. CC BY-SA 4.0
|
||||
|
||||
Imagine you've just joined a new technology company, and one of the first tasks you're assigned is to improve and centralize the organization's developer-facing documentation. There's just one catch: That documentation exists in many different places, across several platforms, and differs markedly in accuracy, currency, and style.
|
||||
|
||||
So how did we tackle this challenge?
|
||||
|
||||
### Understanding the scope
|
||||
|
||||
As with any project, we first needed to understand the scope and bounds of the problem we were trying to solve. What documentation was good? What was working? What wasn't? How much documentation was there? What format was it in? We needed to do a **documentation audit**. Luckily, [Aneta Šteflova][1] had recently [published an article on OpenSource.com][2] about this, and it provided excellent guidance.
|
||||
|
||||
![mycroft doc audit][4]
|
||||
|
||||
Mycroft documentation audit, showing source, topic, medium, currency, quality and audience
|
||||
|
||||
Next, every piece of publicly facing documentation was assessed for the topic it covered, the medium it used, currency, and quality. A pattern quickly emerged that different platforms had major deficiencies, allowing us to make a data-driven approach to decommission our existing Jekyll-based sites. The audit also highlighted just how fragmented our documentation sources were--we had developer-facing documentation across no fewer than seven sites. Although search engines were finding this content just fine, the fragmentation made it difficult for developers and users of Mycroft--our primary audiences--to navigate the information they needed. Again, this data helped us make the decision to centralize our documentation on to one platform.
|
||||
|
||||
### Choosing a central platform
|
||||
|
||||
As an organization, we wanted to constrain the number of standalone platforms in use. Over time, maintenance and upkeep of multiple platforms and integration touchpoints becomes cumbersome for any organization, but this is exacerbated for a small startup.
|
||||
|
||||
One of the other business drivers in platform choice was that we had two primary but very different audiences. On one hand, we had highly technical developers who we were expecting would push documentation to its limits--and who would want to contribute to technical documentation using their tools of choice--[Git][5], [GitHub][6], and [Markdown][7]. Our second audience--end users--would primarily consume technical documentation and would want to do so in an inviting, welcoming platform that was visually appealing and provided additional features such as the ability to identify reading time and to provide feedback. The ability to capture feedback was also a key requirement from our side as without feedback on the quality of the documentation, we would not have a solid basis to undertake continuous quality improvement.
|
||||
|
||||
Would we be able to identify one platform that met all of these competing needs?
|
||||
|
||||
We realised that two platforms covered all of our needs:
|
||||
|
||||
* [WordPress][8]: Our existing website is built on WordPress, and we have some reasonably robust WordPress skills in-house. The flexibility of WordPress also fulfilled our requirements for functionality like reading time and the ability to capture user feedback.
|
||||
* [GitHub][9]: Almost [all of Mycroft.AI's source code is available on GitHub][10], and our development team uses this platform daily.
|
||||
|
||||
|
||||
|
||||
But how could we marry the two?
|
||||
|
||||
|
||||
|
||||
|
||||
### Integrating WordPress and GitHub with WordPress GitHub Sync
|
||||
|
||||
Luckily, our COO, [Nate Tomasi][11], spotted a WordPress plugin that promised to integrate the two.
|
||||
|
||||
This was put through its paces on our test website, and it passed with flying colors. It was easy to install, had a straightforward configuration, which just required an OAuth token and webhook with GitHub, and provided two-way integration between WordPress and GitHub.
|
||||
|
||||
It did, however, have a dependency--on Markdown--which proved a little harder to implement. We trialed several Markdown plugins, but each had several quirks that interfered with the rendering of non-Markdown-based content. After several days of frustration, and even an attempt to custom-write a plugin for our needs, we stumbled across [Parsedown Party][12]. There was much partying! With WordPress GitHub Sync and Parsedown Party, we had integrated our two key platforms.
|
||||
|
||||
Now it was time to make our content visually appealing and usable for our user audience.
|
||||
|
||||
### Reading time and feedback
|
||||
|
||||
To implement the reading time and feedback functionality, we built a new [page template for WordPress][13], and leveraged plugins within the page template.
|
||||
|
||||
Knowing the estimated reading time of an article in advance has been [proven to increase engagement with content][14] and provides developers and users with the ability to decide whether to read the content now or bookmark it for later. We tested several WordPress plugins for reading time, but settled on [Reading Time WP][15] because it was highly configurable and could be easily embedded into WordPress page templates. Our decision to place Reading Time at the top of the content was designed to give the user the choice of whether to read now or save for later. With Reading Time in place, we then turned our attention to gathering user feedback and ratings for our documentation.
|
||||
|
||||

|
||||
|
||||
There are several rating and feedback plugins available for WordPress. We needed one that could be easily customized for several use cases, and that could aggregate or summarize ratings. After some experimentation, we settled on [Multi Rating Pro][16] because of its wide feature set, especially the ability to create a Review Ratings page in WordPress--i.e., a central page where staff can review ratings without having to be logged in to the WordPress backend. The only gap we ran into here was the ability to set the display order of rating options--but it will likely be added in a future release.
|
||||
|
||||
The WordPress GitHub Integration plugin also gave us the ability to link back to the GitHub repository where the original Markdown content was held, inviting technical developers to contribute to improving our documentation.
|
||||
|
||||
### Updating the existing documentation
|
||||
|
||||
Now that the "container" for our new documentation had been developed, it was time to update the existing content. Because much of our documentation had grown organically over time, there were no style guidelines to shape how keywords and code were styled. This was tackled first, so that it could be applied to all content. [You can see our content style guidelines on GitHub.][17]
|
||||
|
||||
As part of the update, we also ran several checks to ensure that the content was technically accurate, augmenting the existing documentation with several images for better readability.
|
||||
|
||||
There were also a couple of additional tools that made creating internal links for documentation pieces easier. First, we installed the [WP Anchor Header][18] plugin. This plugin provided a small but important function: adding `id` content in GitHub using the `[markdown-toc][19]` library, then simply copied in to the WordPress content, where they would automatically link to the `id` attributes to each `<h1>`, `<h2>` (and so on) element. This meant that internal anchors could be automatically generated on the command line from the Markdown content in GitHub using the `[markdown-toc][19]` library, then simply copied in to the WordPress content, where they would automatically link to the `id` attributes generated by WP Anchor Header.
|
||||
|
||||
Next, we imported the updated documentation into WordPress from GitHub, and made sure we had meaningful and easy-to-search on slugs, descriptions, and keywords--because what good is excellent documentation if no one can find it?! A final activity was implementing redirects so that people hitting the old documentation would be taken to the new version.
|
||||
|
||||
### What next?
|
||||
|
||||
[Please do take a moment and have a read through our new documentation][20]. We know it isn't perfect--far from it--but we're confident that the mechanisms we've baked into our new documentation infrastructure will make it easier to identify gaps--and resolve them quickly. If you'd like to know more, or have suggestions for our documentation, please reach out to Kathy Reid on [Chat][21] (@kathy-mycroft) or via [email][22].
|
||||
|
||||
_Reprinted with permission from[Mycroft.ai][23]._
|
||||
|
||||
### About the author
|
||||
Kathy Reid - Director of Developer Relations @MycroftAI, President of @linuxaustralia. Kathy Reid has expertise in open source technology management, web development, video conferencing, digital signage, technical communities and documentation. She has worked in a number of technical and leadership roles over the last 20 years, and holds Arts and Science undergraduate degrees... more about Kathy Reid
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/rocking-docs-mycroft
|
||||
|
||||
作者:[Kathy Reid][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kathyreid
|
||||
[1]:https://opensource.com/users/aneta
|
||||
[2]:https://opensource.com/article/17/10/doc-audits
|
||||
[3]:/file/382466
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/mycroft-documentation-audit.png (mycroft documentation audit)
|
||||
[5]:https://git-scm.com/
|
||||
[6]:https://github.com/MycroftAI
|
||||
[7]:https://en.wikipedia.org/wiki/Markdown
|
||||
[8]:https://www.wordpress.org/
|
||||
[9]:https://github.com/
|
||||
[10]:https://github.com/mycroftai
|
||||
[11]:http://mycroft.ai/team/
|
||||
[12]:https://wordpress.org/plugins/parsedown-party/
|
||||
[13]:https://developer.wordpress.org/themes/template-files-section/page-template-files/
|
||||
[14]:https://marketingland.com/estimated-reading-times-increase-engagement-79830
|
||||
[15]:https://jasonyingling.me/reading-time-wp/
|
||||
[16]:https://multiratingpro.com/
|
||||
[17]:https://github.com/MycroftAI/docs-rewrite/blob/master/README.md
|
||||
[18]:https://wordpress.org/plugins/wp-anchor-header/
|
||||
[19]:https://github.com/jonschlinkert/markdown-toc
|
||||
[20]:https://mycroft.ai/documentation
|
||||
[21]:https://chat.mycroft.ai/
|
||||
[22]:mailto:kathy.reid@mycroft.ai
|
||||
[23]:https://mycroft.ai/blog/improving-mycrofts-documentation/
|
||||
@ -1,84 +0,0 @@
|
||||
Anatomy of a Program in Memory
|
||||
============================================================
|
||||
|
||||
Memory management is the heart of operating systems; it is crucial for both programming and system administration. In the next few posts I’ll cover memory with an eye towards practical aspects, but without shying away from internals. While the concepts are generic, examples are mostly from Linux and Windows on 32-bit x86\. This first post describes how programs are laid out in memory.
|
||||
|
||||
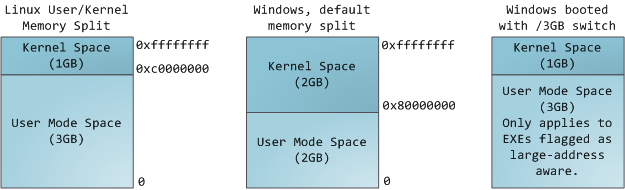
Each process in a multi-tasking OS runs in its own memory sandbox. This sandbox is the virtual address space, which in 32-bit mode is always a 4GB block of memory addresses. These virtual addresses are mapped to physical memory by page tables, which are maintained by the operating system kernel and consulted by the processor. Each process has its own set of page tables, but there is a catch. Once virtual addresses are enabled, they apply to _all software_ running in the machine, _including the kernel itself_ . Thus a portion of the virtual address space must be reserved to the kernel:
|
||||
|
||||
|
||||
|
||||
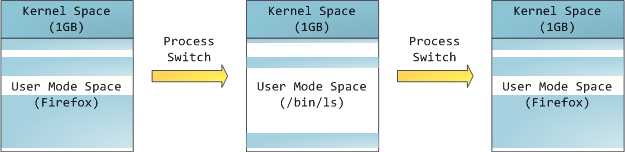
This does not mean the kernel uses that much physical memory, only that it has that portion of address space available to map whatever physical memory it wishes. Kernel space is flagged in the page tables as exclusive to [privileged code][1] (ring 2 or lower), hence a page fault is triggered if user-mode programs try to touch it. In Linux, kernel space is constantly present and maps the same physical memory in all processes. Kernel code and data are always addressable, ready to handle interrupts or system calls at any time. By contrast, the mapping for the user-mode portion of the address space changes whenever a process switch happens:
|
||||
|
||||
|
||||
|
||||
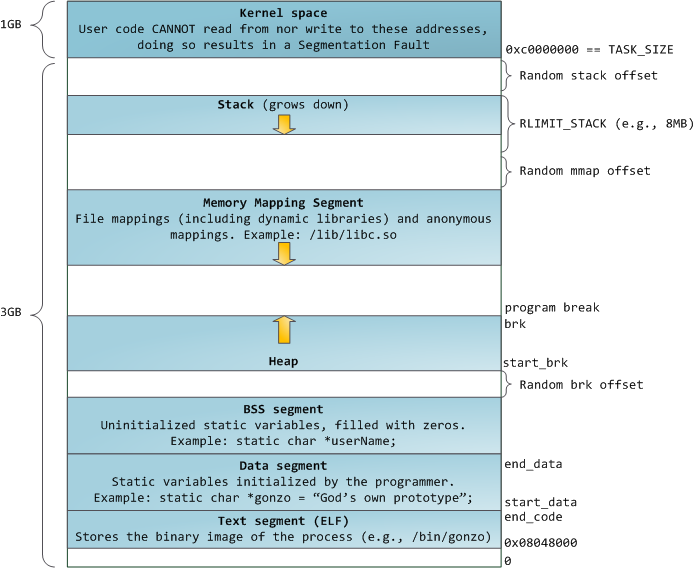
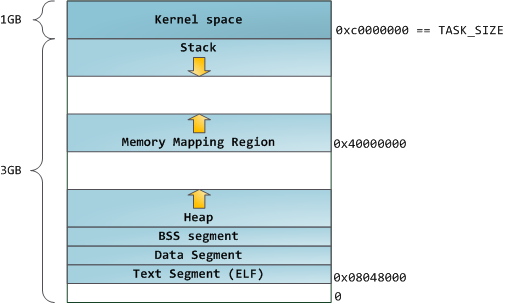
Blue regions represent virtual addresses that are mapped to physical memory, whereas white regions are unmapped. In the example above, Firefox has used far more of its virtual address space due to its legendary memory hunger. The distinct bands in the address space correspond to memory segments like the heap, stack, and so on. Keep in mind these segments are simply a range of memory addresses and _have nothing to do_ with [Intel-style segments][2]. Anyway, here is the standard segment layout in a Linux process:
|
||||
|
||||
|
||||
|
||||
When computing was happy and safe and cuddly, the starting virtual addresses for the segments shown above were exactly the same for nearly every process in a machine. This made it easy to exploit security vulnerabilities remotely. An exploit often needs to reference absolute memory locations: an address on the stack, the address for a library function, etc. Remote attackers must choose this location blindly, counting on the fact that address spaces are all the same. When they are, people get pwned. Thus address space randomization has become popular. Linux randomizes the [stack][3], [memory mapping segment][4], and [heap][5] by adding offsets to their starting addresses. Unfortunately the 32-bit address space is pretty tight, leaving little room for randomization and [hampering its effectiveness][6].
|
||||
|
||||
The topmost segment in the process address space is the stack, which stores local variables and function parameters in most programming languages. Calling a method or function pushes a new stack frame onto the stack. The stack frame is destroyed when the function returns. This simple design, possible because the data obeys strict [LIFO][7] order, means that no complex data structure is needed to track stack contents – a simple pointer to the top of the stack will do. Pushing and popping are thus very fast and deterministic. Also, the constant reuse of stack regions tends to keep active stack memory in the [cpu caches][8], speeding up access. Each thread in a process gets its own stack.
|
||||
|
||||
It is possible to exhaust the area mapping the stack by pushing more data than it can fit. This triggers a page fault that is handled in Linux by [expand_stack()][9], which in turn calls [acct_stack_growth()][10] to check whether it’s appropriate to grow the stack. If the stack size is below <tt>RLIMIT_STACK</tt> (usually 8MB), then normally the stack grows and the program continues merrily, unaware of what just happened. This is the normal mechanism whereby stack size adjusts to demand. However, if the maximum stack size has been reached, we have a stack overflow and the program receives a Segmentation Fault. While the mapped stack area expands to meet demand, it does not shrink back when the stack gets smaller. Like the federal budget, it only expands.
|
||||
|
||||
Dynamic stack growth is the [only situation][11] in which access to an unmapped memory region, shown in white above, might be valid. Any other access to unmapped memory triggers a page fault that results in a Segmentation Fault. Some mapped areas are read-only, hence write attempts to these areas also lead to segfaults.
|
||||
|
||||
Below the stack, we have the memory mapping segment. Here the kernel maps contents of files directly to memory. Any application can ask for such a mapping via the Linux [mmap()][12] system call ([implementation][13]) or [CreateFileMapping()][14] / [MapViewOfFile()][15] in Windows. Memory mapping is a convenient and high-performance way to do file I/O, so it is used for loading dynamic libraries. It is also possible to create an anonymous memory mapping that does not correspond to any files, being used instead for program data. In Linux, if you request a large block of memory via [malloc()][16], the C library will create such an anonymous mapping instead of using heap memory. ‘Large’ means larger than <tt>MMAP_THRESHOLD</tt> bytes, 128 kB by default and adjustable via [mallopt()][17].
|
||||
|
||||
Speaking of the heap, it comes next in our plunge into address space. The heap provides runtime memory allocation, like the stack, meant for data that must outlive the function doing the allocation, unlike the stack. Most languages provide heap management to programs. Satisfying memory requests is thus a joint affair between the language runtime and the kernel. In C, the interface to heap allocation is [malloc()][18] and friends, whereas in a garbage-collected language like C# the interface is the <tt>new</tt> keyword.
|
||||
|
||||
If there is enough space in the heap to satisfy a memory request, it can be handled by the language runtime without kernel involvement. Otherwise the heap is enlarged via the [brk()][19]system call ([implementation][20]) to make room for the requested block. Heap management is [complex][21], requiring sophisticated algorithms that strive for speed and efficient memory usage in the face of our programs’ chaotic allocation patterns. The time needed to service a heap request can vary substantially. Real-time systems have [special-purpose allocators][22] to deal with this problem. Heaps also become _fragmented_ , shown below:
|
||||
|
||||

|
||||
|
||||
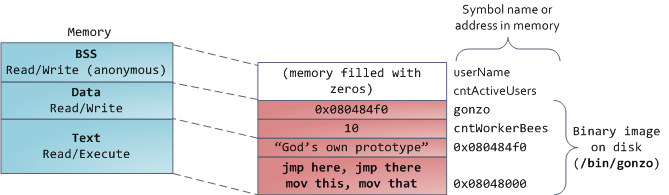
Finally, we get to the lowest segments of memory: BSS, data, and program text. Both BSS and data store contents for static (global) variables in C. The difference is that BSS stores the contents of _uninitialized_ static variables, whose values are not set by the programmer in source code. The BSS memory area is anonymous: it does not map any file. If you say <tt>static int cntActiveUsers</tt>, the contents of <tt>cntActiveUsers</tt> live in the BSS.
|
||||
|
||||
The data segment, on the other hand, holds the contents for static variables initialized in source code. This memory area is not anonymous. It maps the part of the program’s binary image that contains the initial static values given in source code. So if you say <tt>static int cntWorkerBees = 10</tt>, the contents of cntWorkerBees live in the data segment and start out as 10\. Even though the data segment maps a file, it is a private memory mapping, which means that updates to memory are not reflected in the underlying file. This must be the case, otherwise assignments to global variables would change your on-disk binary image. Inconceivable!
|
||||
|
||||
The data example in the diagram is trickier because it uses a pointer. In that case, the _contents_ of pointer <tt>gonzo</tt> – a 4-byte memory address – live in the data segment. The actual string it points to does not, however. The string lives in the text segment, which is read-only and stores all of your code in addition to tidbits like string literals. The text segment also maps your binary file in memory, but writes to this area earn your program a Segmentation Fault. This helps prevent pointer bugs, though not as effectively as avoiding C in the first place. Here’s a diagram showing these segments and our example variables:
|
||||
|
||||
|
||||
|
||||
You can examine the memory areas in a Linux process by reading the file <tt>/proc/pid_of_process/maps</tt>. Keep in mind that a segment may contain many areas. For example, each memory mapped file normally has its own area in the mmap segment, and dynamic libraries have extra areas similar to BSS and data. The next post will clarify what ‘area’ really means. Also, sometimes people say “data segment” meaning all of data + bss + heap.
|
||||
|
||||
You can examine binary images using the [nm][23] and [objdump][24] commands to display symbols, their addresses, segments, and so on. Finally, the virtual address layout described above is the “flexible” layout in Linux, which has been the default for a few years. It assumes that we have a value for <tt>RLIMIT_STACK</tt>. When that’s not the case, Linux reverts back to the “classic” layout shown below:
|
||||
|
||||
|
||||
|
||||
That’s it for virtual address space layout. The next post discusses how the kernel keeps track of these memory areas. Coming up we’ll look at memory mapping, how file reading and writing ties into all this and what memory usage figures mean.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
|
||||
|
||||
作者:[gustavo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
|
||||
[2]:http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729
|
||||
[6]:http://www.stanford.edu/~blp/papers/asrandom.pdf
|
||||
[7]:http://en.wikipedia.org/wiki/Lifo
|
||||
[8]:http://duartes.org/gustavo/blog/post/intel-cpu-caches
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544
|
||||
[11]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692
|
||||
[12]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27
|
||||
[14]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[15]:http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[20]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248
|
||||
[21]:http://g.oswego.edu/dl/html/malloc.html
|
||||
[22]:http://rtportal.upv.es/rtmalloc/
|
||||
[23]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html
|
||||
[24]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
How the Kernel Manages Your Memory
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,458 @@
|
||||
30 Best Sources For Linux / *BSD / Unix Documentation On the Web
|
||||
======
|
||||
Man pages are written by sys-admin and developers for IT techs, and are intended more as a reference than as a how to. Man pages are very useful for people who are already familiar with Linux, Unix, and BSD operating systems. Use man pages when you just need to know the syntax for particular commands or configuration file, but they are not helpful for new Linux users. Man pages are not good for learning something new for the first time. Here are thirty best documentation sites on the web for learning Linux and Unix like operating systems.
|
||||
|
||||
![Dennis Ritchie and Ken Thompson working with UNIX PDP11][1]
|
||||
|
||||
Please note that BSD manpages are usually better as compare to Linux.
|
||||
|
||||
## #1: Red Hat Enterprise Linux
|
||||
|
||||
![Red hat Enterprise Linux Docs][2]
|
||||
|
||||
RHEL is developed by Red Hat and targeted toward the commercial market. It has one of the best documentations covering basis of RHEL to advanced topics like security, SELinux, virtualization, directory server, clustering, JBOSS, HPC, and much more. Red Hat documentation has been translated into twenty-two languages and is available in multi-page HTML, single-page HTML, PDF, and EPUB formats. The good news is you can use the same documentation for CentOS or Scientific Linux (community enterprise distros). All of these documents ship with the OS, so if you don't have a network connection, then you have them there as well. The RHEL docs **covers everything from installation to configuring clusters**. The only downside is you need to be a paid customer. This is perfect for an enterprise company.
|
||||
|
||||
1. RHEL Documentation: [in HTML/PDF format][3]
|
||||
2. Support forums: Only available to Red Hat customer portal to submit a support case.
|
||||
|
||||
|
||||
|
||||
### A Note About CentOS Wiki and Forums
|
||||
|
||||
![Centos Linux Wiki][4]
|
||||
|
||||
CentOS (Community ENTerprise Operating System) is a free rebuild of source packages freely available from a RHEL. It provides truly reliable, free enterprise Linux for personal and other usage. You will get RHEL stability without the cost of certification and support. CentOS wiki divided into Howtos, Tips & Tricks, and much more at the following locations:
|
||||
|
||||
1. [Documentation Wiki][87]
|
||||
2. [Support forum][88]
|
||||
|
||||
## #2: Arch Wiki and Forums
|
||||
|
||||
![Arch Linux wiki and tutorials][5]
|
||||
|
||||
Arch Linux is an independently developed, Linux operating system and it comes with pretty good documentation in form of wiki based site. It is developed collaboratively by a community of Arch users, allowing any user to add and edit content. The articles are divided into various categories like [networking][6], optimization, package management, system administration, X window system, and getting & installing Arch Linux. The official [forums][7] are useful for solving many issues. It has total 40k+ registered users with over 1 million posts. The wiki contains some **general information that can also apply in other Linux distros**.
|
||||
|
||||
1. Arch community Documentation: [Wiki format][8]
|
||||
2. Support forums: [Yes][7]
|
||||
|
||||
|
||||
|
||||
## #3: Gentoo Linux Wiki and Forums
|
||||
|
||||
![Gentoo Linux Handbook and Wiki][9]
|
||||
|
||||
Gentoo Linux is based on the Portage package management system. The Gentoo user compiles the source code locally according to their chosen configuration. The majority of users have configurations and sets of installed programs which are unique to themselves. The Gentoo give you some explanation about the Gentoo Linux and answer most of your questions regarding installations, packages, networking, and much more. Gentoo has **very helpful forum** with over one hundred thirty-four thousand plus users who have posted a total of 5442416 articles.
|
||||
|
||||
1. Gentoo community documentation: [Handbook][10] and [Wiki format][11]
|
||||
2. Support forums: [Yes][12]
|
||||
3. User-supplied documentation available at [gentoo-wiki.com][13]
|
||||
|
||||
|
||||
|
||||
## #4: Ubuntu Wiki and Documentation
|
||||
|
||||
Ubuntu is one of the leading desktop and laptop distro. The official documentation developed and maintained by the Ubuntu Documentation Project. You can access a wealth of information including a getting started Guide. The best part is information contained herein may also work with other Debian-based systems. You will also find the community documentation for Ubuntu created by its users. This is a reference for Ubuntu-related 'Howtos, Tips, Tricks, and Hacks'. Ubuntu Linux has one of the biggest Linux communities on the web. It offers help to the both new and experienced users.
|
||||
|
||||
![Ubuntu Linux Wiki and Forums][14]
|
||||
|
||||
1. Ubuntu community documentation: [wiki format][15].
|
||||
2. Ubuntu official documentation: [wiki format][16].
|
||||
3. Support forums: [Yes][17].
|
||||
|
||||
|
||||
|
||||
## #5: IBM Developer Works
|
||||
|
||||
IBM developer works offers technical resources for Linux programmers and system administrators. It contains hundreds of articles, tutorials, and tips to help developers with Linux programming and application development, as well as Linux system administration.
|
||||
|
||||
![IBM: Technical for Linux programmers and system administrators][18]
|
||||
|
||||
1. IBM Developer Works Documentation: [HTML format][19]
|
||||
2. Support forums: [Yes][20].
|
||||
|
||||
|
||||
|
||||
## #6: FreeBSD Documentation and Handbook
|
||||
|
||||
The FreeBSD handbook is created by the FreeBSD Documentation Project. It describes the installation, administration and day-to-day use of the FreeBSD OS. BSD manpages are usually better as compare to GNU/Linux man pages. The FreeBSD **comes with all the documents** with upto date man pages. The FreeBSD Handbook **covers everything**. The handbook contains some general Unix information that can also apply in other Linux distros. The official FreeBSD forums also provides helps whenever you will get stuck with problems.
|
||||
|
||||
![Freebsd Documentation][21]
|
||||
|
||||
1. FreeBSD Documentation: [HTML/PDF format][90]
|
||||
2. Support forums: [Yes][91].
|
||||
|
||||
|
||||
## #7: Bash Hackers Wiki
|
||||
|
||||
![Bash hackers wiki for bash users][22]
|
||||
This is an excellent resource for bash user. The bash hackers wiki is intended to hold documentations of any kind about the GNU Bash. The main motivation was to provide human-readable documentation and information to not force users to read every bit of the Bash manpage - which is hard sometimes. The wiki is divided into various sections such as - scripting and general information, howtos, coding style, bash syntax, and much more.
|
||||
|
||||
1. Bash hackers [wiki][23] in wiki format
|
||||
|
||||
|
||||
|
||||
## #8: Bash FAQ
|
||||
|
||||
![Bash FAQ: Answers to frequently asked questions about GNU/BASH][24]
|
||||
A wiki designed for new bash users. It has good collections to frequently asked questions on channel #bash on the freenode IRC network. These answers are contributed by the regular members of the channel. Don't forget to check out common mistakes made by Bash programmers, in [BashPitfalls][25] section. The answers given in this FAQ may be slanted toward Bash, or they may be slanted toward the lowest common denominator Bourne shell, depending on who wrote the answer. In most cases, an effort is made to provide both a portable (Bourne) and an efficient (Bash, where appropriate) answer.
|
||||
|
||||
1. Bash FAQ [in wiki ][26] format.
|
||||
|
||||
|
||||
|
||||
## #9: Howtoforge - Linux Tutorials
|
||||
|
||||
![Howtoforge][27]
|
||||
|
||||
Fellow blogger Falko has some great stuff over at How-To Forge. The site provides Linux tutorials about various topic including its famous "The Perfect Server" series. The site is divided into various topics such as web-server, Linux distros, DNS servers, Virtualization, High-availability, Email and anti-spam, FTP servers, programming topics, and much more. The site is also available in German language.
|
||||
|
||||
1. Howtoforge [in html][28] format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #10: OpenBSD FAQ and Documentation
|
||||
|
||||
![OpenBSD Documenation][29]
|
||||
|
||||
OpenBSD is another Unix-like computer operating system based on Berkeley Software Distribution (BSD). It was forked from NetBSD by project. The OpenBSD is well known for the **quality code, documentation** , uncompromising position on software licensing, with strong focus on security. The documenation is divided into various topics such as - installations, package management, firewall setup, user management, networking, disk / RAID management and much more.
|
||||
|
||||
1. OpenBSD [in html][30] format.
|
||||
2. Support forums: No, but [mail lists][31] are available.
|
||||
|
||||
|
||||
|
||||
## #11: Calomel - Open Source Research and Reference
|
||||
|
||||
This amazing site dedicated to documenting open source software, and programs with special focus on OpenBSD. This is one of the cleanest and easy to to navigate website, with focus on the quality content. The site is divided into various server topic such as DNS, OpeBSD, security, web-server, Samba file server, various tools, and much more.
|
||||
|
||||
![Open Source Research and Reference Documentation][32]
|
||||
|
||||
1. Calomel Org [in html][33] format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #12: Slackware Book Project
|
||||
|
||||
![Slackware Linux Book and Documentation ][34]
|
||||
Slackware Linux was my first distro. It was one of the earliest distro based on the Linux kernel and is the oldest currently being maintained. The distro is targeted towards power users with strong focus on stability. Slackware is one of few the most "Unix-like" Linux distribution. The official slackware book is designed to get you started with the Slackware Linux operating system. It's not meant to cover every single aspect of the distribution, but rather to show what it is capable of and give you a basic working knowledge of the system. The book is divided into various topics such as Installation, Network & System Configuration, System administration, Package management, and much more.
|
||||
|
||||
1. Slackware [Linux books in html][35], pdf, and other format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #13: The Linux Documentation Project (TLDP)
|
||||
|
||||
![Linux Learning Site and Documentation ][36]
|
||||
|
||||
The Linux Documentation Project is working towards developing free, high quality documentation for the Linux operating system. The site is created and maintained by volunteers. The site is divided into subject-specific help, longer and in-depth guide books, and much more. I recommend [this document][37] which is both a tutorial and a reference on shell scripting with Bash. The [single list][38] of HOWTOs is also a good starting point for new users.
|
||||
|
||||
1. The Linux [documentation project][39] available in multiple formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #14: Linux Home Networking
|
||||
|
||||
![Linux Home Networking ][40]
|
||||
|
||||
Linux home networking is another good resource for learning Linux. This site covers topics needed for Linux software certification exams, such as the RHCE, and many computer training courses. The site is divided into various topics such as networking, samba file server, wirless networking, web-server, and much more.
|
||||
|
||||
1. Linux [home networking][41] available in html and PDF (with small fee) formats.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #15: Linux Action Show
|
||||
|
||||
![Linux Podcast ][42]
|
||||
|
||||
Linux Action Show ("LAS") is a podcast about Linux. The show is hosted by Bryan Lunduke, Allan Jude, and Chris Fisher. It covers the latest news in the FOSS world. The show reviews various apps and Linux distros. Sometime an interview with a major personal in the open source world is posted on the show.
|
||||
|
||||
1. Linux [action show][43] available in audio/video format.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #16: Commandlinefu
|
||||
|
||||
Commandlinefu lists various shell commands that you may find interesting and useful. All commands can be commented on, discussed and voted up or down. Ths is an awesome resource for all Unix command line users. Don't forget to checkout all [top voted][44] commands here.
|
||||
|
||||
![The best Unix / Linux Commands By Commandlinefu][45]
|
||||
|
||||
1. [Commandlinefu][46] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #17: Debian Administration Tips and Resources
|
||||
|
||||
This site covers topics, tips, and tutorial only related to Debian GNU/Linux. It contain interesting and useful information related to the System Administration. You can contribute an article, tip, or question here. Don't forget to checkout [top articles][47] posted in the hall of fame section.
|
||||
![Debian Linux Adminstration: Tips and Tutorial For Sys Admin][48]
|
||||
|
||||
1. Debian [administration][49] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #18: Catonmat - Sed, Awk, Perl Tutorials
|
||||
|
||||
![Sed, Awk, Perl Tutorials][50]
|
||||
|
||||
This site run by a fellow blogger Peteris Krumins. The main focus is on command line and Unix programming topics such as sed, perl, awk, and others. Don't forget to check out [introduction to sed][51], sed [one liner][52] explained, the definitive [guide][53] to Bash Command line history, and [awk][54] liner explained.
|
||||
|
||||
1. [catonmat][55] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #19: Debian GNU/Linux Documentation and Wiki
|
||||
|
||||
![Debian Linux Tutorials and Wiki][56]
|
||||
|
||||
Debian is another Linux based operating system that primarily uses software released under the GNU General Public. Debian is well known for strict adherence to the philosophies of Unix and free software. It is also one of popular and influential Linux distribution. It is also used as a base for many other distributions such as Ubuntu and others. The Debian project provides its users with proper documentation in an easily accessible form. The site is divided into wiki, installation guide, faqs, and support forum.
|
||||
|
||||
1. Debian GNU/Linux [documentation][57] available in html and other format.
|
||||
2. Debian GNU/Linux [wiki][58]
|
||||
3. Support forums: [Yes][59]
|
||||
|
||||
|
||||
|
||||
## #20: Linux Sea
|
||||
|
||||
The book "Linux Sea" offers a gentle yet technical (from end-user perspective) introduction to the Linux operating system, using Gentoo Linux as the example Linux distribution. It does not nor will it ever talk about the history of the Linux kernel or Linux distributions or dive into details that are less interesting for Linux users.
|
||||
|
||||
1. Linux [sea][60] available in html format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #21: Oreilly Commons
|
||||
|
||||
![Oreilly Free Linux / Unix / Php / Javascript / Ubuntu Books][61]
|
||||
|
||||
The oreilly publishing house has posted quite a few titles in wiki format for all. The purpose of this site is to provide content to communities that would like to create, reference, use, modify, update and revise material from O'Reilly or other sources. The site includes books about Ubuntu, Php, Spamassassin, Linux, and much more all for free.
|
||||
|
||||
1. Oreilly [commons][62] available in wiki format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #22: Ubuntu Pocket Guide
|
||||
|
||||
![Ubuntu Book For New Users][63]
|
||||
|
||||
This book is written by Keir Thomas. This guide/book is a good read for everyday Ubuntu user. The purpose of this book is to introduce you to the Ubuntu operating system, and the philosophy that underpins it. You can download a pdf version from the official site or order a print version using Amazon.
|
||||
|
||||
1. Ubuntu [pocket guide][64] available in pdf and print formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #23: Linux: Rute User's Tutorial and Exposition
|
||||
|
||||
![GNU/LINUX system administration book][65]
|
||||
|
||||
This book covers GNU/LINUX system administration, for popular distributions like RedHat and Debian, as a tutorial for new users and a reference for advanced administrators. It aims to give concise, thorough explanations and practical examples of each aspect of a UNIX system. Anyone who wants a comprehensive text on (what is commercially called) LINUX need look no further-there is little that is not covered here.
|
||||
|
||||
1. Linux: [Rute User's Tutorial and Exposition][66] available in print and html formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #24: Advanced Linux Programming
|
||||
|
||||
![Advanced Linux Programming][67]
|
||||
|
||||
This book is intended for the programmer already familiar with the C programming language. It take a tutorial approach and teach the most important concepts and power features of the GNU/Linux system in application programs. If you're a developer already experienced with programming for the GNU/Linux system, are experienced with another UNIX-like system and are interested in developing GNU/Linux software, or want to make the transition for a non-UNIX environment and are already familiar with the general principles of writing good software, this book is for you. In addition, you will find that this book is equally applicable to C and C++ programming.
|
||||
|
||||
1. Advanced [Linux programming][68] available in print and pdf formats.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #25: LPI 101 Course Notes
|
||||
|
||||
![Linux Professional Institute Certification Books][69]
|
||||
|
||||
LPIC-1/2/3 levels are certification for Linux administrators. This site provides training manuals for LPI 101 and 102 exams. These are licenced under the GNU Free Documentation Licence (FDL). This course material is based on the objectives for the Linux Professionals Institutea€™s LPI 101 and 102 examination. The course is intended to provide you with the skills required for operating and administering Linux systems.
|
||||
|
||||
1. Download LPI [training manuals][70] in pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #26: FOSS Manuals
|
||||
|
||||
FLOSS Manuals is a collection of manuals about free and open source software together with the tools used to create them and the community that uses those tools. They include authors, editors, artists, software developers, activists, and many others. There are manuals that explain how to install and use a range of free and open source softwares, about how to do things (like design or stay safe online) with open source software, and manuals about free culture services that use or support free software and formats. You will find manuals about software such as VLC, [Linux video editing][71], Linux, OLPC / SUGAR, GRAPHICS, and much more.
|
||||
|
||||
![FLOSS Manuals is a collection of manuals about free and open source software][72]
|
||||
|
||||
1. You can browse [FOSS manuals][73] in wiki format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #27: Linux Starter Pack
|
||||
|
||||
![The Linux Starter Pack][74]
|
||||
|
||||
New to the wonderful world of Linux? Looking for an easy way to get started? You can download 130-page guide and get to grips with the OS. This will show you how to install Linux onto your PC, navigate around the desktop, master the most popular Linux programs and fix any problems that may arise.
|
||||
|
||||
1. Download [Linux starter][75] pack in pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #28: Linux.com - The Source of Linux Info
|
||||
|
||||
Linux.com is a product of the Linux Foundation. The side provides news, guides, tutorials and other information about Linux by harnessing the power of Linux users worldwide to inform, collaborate and connect on all matters Linux.
|
||||
|
||||
1. Visit [Linux.com][76] online.
|
||||
2. Support forums: Yes
|
||||
|
||||
|
||||
|
||||
## #29: LWN
|
||||
|
||||
LWN is a site with an emphasis on free software and software for Linux and other Unix-like operating systems. It consists of a weekly issue, separate stories which are published most days, and threaded discussion attached to every story. The site provide comprehensive coverage of development, legal, commercial, and security issues related to Linux and FOSS.
|
||||
|
||||
1. Visit [lwn.net][77] online.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## #30: Mac OS X Related sites
|
||||
|
||||
A quick links to Max OS X related sites:
|
||||
|
||||
* [Mac OS X Hints][78] - This site is dedicated to the Apple's Mac OS X unix operating systems. It has tons of tips, tricks and tutorial about Bash, and OS X
|
||||
* [Mac OS development library][79] - Apple has good collection related to OS X development. Don't forget to checkout [bash shell scripting primer][80].
|
||||
* [Apple kbase][81] - This is like RHN kbase. It provides guides and troublshooting tips for all apple products including OS X.
|
||||
|
||||
|
||||
|
||||
## #30: NetBSD
|
||||
|
||||
NetBSD is another free open source operating system based upon the Berkeley Software Distribution (BSD) Unix operating system. The NetBSD project is primarily focused on high quality design, stability and performance of the system. Due to its portability and Berkeley-style license, NetBSD is often used in embedded systems. This site provides links to the official NetBSD documentation and also links to various external documents.
|
||||
|
||||
1. View [netbsd][82] documentation online in html / pdf format.
|
||||
2. Support forums: No
|
||||
|
||||
|
||||
|
||||
## Your Turn:
|
||||
|
||||
This is my personal list and it is not absolutely definitive, so if you've got your own favorite Unix/Linux specific site, share in the comments below.
|
||||
|
||||
// Image credit: [Flickr photo][83] by PanelSwitchman. Some links are suggested by user on our facebook fan page.
|
||||
|
||||
// For those who celebrate, Merry Christmas! For everyone else, enjoy the weekend.
|
||||
|
||||
## About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][84], [Facebook][85], [Google+][86].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-documentations.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2011/12/unix-pdp11.jpg (Dennis Ritchie and Ken Thompson working with UNIX PDP11)
|
||||
[2]:https://www.cyberciti.biz/media/new/tips/2011/12/redhat-enterprise-linux-docs-150x150.png (Red hat Enterprise Linux Docs)
|
||||
[3]:https://access.redhat.com/documentation/en-us/
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2011/12/centos-linux-wiki-150x150.png (Centos Linux Wiki, Support, Documents)
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2011/12/arch-linux-wiki-150x150.png (Arch Linux wiki and tutorials )
|
||||
[6]:https://wiki.archlinux.org/index.php/Category:Networking_%28English%29
|
||||
[7]:https://bbs.archlinux.org/
|
||||
[8]:https://wiki.archlinux.org/
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2011/12/gentoo-linux-wiki1-150x150.png (Gentoo Linux Handbook and Wiki)
|
||||
[10]:http://www.gentoo.org/doc/en/handbook/
|
||||
[11]:https://wiki.gentoo.org
|
||||
[12]:https://forums.gentoo.org/
|
||||
[13]:http://gentoo-wiki.com
|
||||
[14]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-linux-wiki.png (Ubuntu Linux Wiki and Forums)
|
||||
[15]:https://help.ubuntu.com/community
|
||||
[16]:https://help.ubuntu.com/
|
||||
[17]:https://ubuntuforums.org/
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2011/12/ibm-devel.png (IBM: Technical for Linux programmers and system administrators)
|
||||
[19]:https://www.ibm.com/developerworks/learn/linux/index.html
|
||||
[20]:https://www.ibm.com/developerworks/community/forums/html/public?lang=en
|
||||
[21]:https://www.cyberciti.biz/media/new/tips/2011/12/freebsd-docs.png (Freebsd Documentation)
|
||||
[22]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-hackers-wiki-150x150.png (Bash hackers wiki for bash users)
|
||||
[23]:http://wiki.bash-hackers.org/doku.php
|
||||
[24]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-faq-150x150.png (Bash FAQ: Answers to frequently asked questions about GNU/BASH)
|
||||
[25]:http://mywiki.wooledge.org/BashPitfalls
|
||||
[26]:https://mywiki.wooledge.org/BashFAQ
|
||||
[27]:https://www.cyberciti.biz/media/new/tips/2011/12/howtoforge-150x150.png (Howtoforge tutorials)
|
||||
[28]:https://howtoforge.com/
|
||||
[29]:https://www.cyberciti.biz/media/new/tips/2011/12/openbsd-faq-150x150.png (OpenBSD Documenation)
|
||||
[30]:https://www.openbsd.org/faq/index.html
|
||||
[31]:https://www.openbsd.org/mail.html
|
||||
[32]:https://www.cyberciti.biz/media/new/tips/2011/12/calomel_org.png (Open Source Research and Reference Documentation)
|
||||
[33]:https://calomel.org
|
||||
[34]:https://www.cyberciti.biz/media/new/tips/2011/12/slackware-linux-book-150x150.png (Slackware Linux Book and Documentation )
|
||||
[35]:http://www.slackbook.org/
|
||||
[36]:https://www.cyberciti.biz/media/new/tips/2011/12/tldp-150x150.png (Linux Learning Site and Documentation )
|
||||
[37]:http://tldp.org/LDP/abs/html/index.html
|
||||
[38]:http://tldp.org/HOWTO/HOWTO-INDEX/howtos.html
|
||||
[39]:http://tldp.org/
|
||||
[40]:https://www.cyberciti.biz/media/new/tips/2011/12/linuxhomenetworking-150x150.png (Linux Home Networking )
|
||||
[41]:http://www.linuxhomenetworking.com/
|
||||
[42]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-action-show-150x150.png (Linux Podcast )
|
||||
[43]:http://www.jupiterbroadcasting.com/show/linuxactionshow/
|
||||
[44]:https://www.commandlinefu.com/commands/browse/sort-by-votes
|
||||
[45]:https://www.cyberciti.biz/media/new/tips/2011/12/commandlinefu.png (The best Unix / Linux Commands )
|
||||
[46]:https://commandlinefu.com/
|
||||
[47]:https://www.debian-administration.org/hof
|
||||
[48]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-admin.png (Debian Linux Adminstration: Tips and Tutorial For Sys Admin)
|
||||
[49]:https://www.debian-administration.org/
|
||||
[50]:https://www.cyberciti.biz/media/new/tips/2011/12/catonmat-150x150.png (Sed, Awk, Perl Tutorials)
|
||||
[51]:http://www.catonmat.net/blog/worlds-best-introduction-to-sed/
|
||||
[52]:https://www.catonmat.net/blog/sed-one-liners-explained-part-one/
|
||||
[53]:https://www.catonmat.net/blog/the-definitive-guide-to-bash-command-line-history/
|
||||
[54]:https://www.catonmat.net/blog/awk-one-liners-explained-part-one/
|
||||
[55]:https://catonmat.net/
|
||||
[56]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-wiki-150x150.png (Debian Linux Tutorials and Wiki)
|
||||
[57]:https://www.debian.org/doc/
|
||||
[58]:https://wiki.debian.org/
|
||||
[59]:https://www.debian.org/support
|
||||
[60]:http://swift.siphos.be/linux_sea/
|
||||
[61]:https://www.cyberciti.biz/media/new/tips/2011/12/orelly-150x150.png (Oreilly Free Linux / Unix / Php / Javascript / Ubuntu Books)
|
||||
[62]:http://commons.oreilly.com/wiki/index.php/O%27Reilly_Commons
|
||||
[63]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-guide-150x150.png (Ubuntu Book For New Users)
|
||||
[64]:http://ubuntupocketguide.com/
|
||||
[65]:https://www.cyberciti.biz/media/new/tips/2011/12/rute-150x150.png (GNU/LINUX system administration free book)
|
||||
[66]:https://web.archive.org/web/20160204213406/http://rute.2038bug.com/rute.html.gz
|
||||
[67]:https://www.cyberciti.biz/media/new/tips/2011/12/advanced-linux-programming-150x150.png (Download Advanced Linux Programming PDF version)
|
||||
[68]:https://github.com/MentorEmbedded/advancedlinuxprogramming
|
||||
[69]:https://www.cyberciti.biz/media/new/tips/2011/12/lpic-150x150.png (Download Linux Professional Institute Certification PDF Book)
|
||||
[70]:http://academy.delmar.edu/Courses/ITSC1358/eBooks/LPI-101.LinuxTrainingCourseNotes.pdf
|
||||
[71]://www.cyberciti.biz/faq/top5-linux-video-editing-system-software/
|
||||
[72]:https://www.cyberciti.biz/media/new/tips/2011/12/floss-manuals.png (Download manuals about free and open source software)
|
||||
[73]:https://flossmanuals.net/
|
||||
[74]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-starter-150x150.png (New to Linux? Start Linux starter book [ PDF version ])
|
||||
[75]:http://www.tuxradar.com/linuxstarterpack
|
||||
[76]:https://linux.com
|
||||
[77]:https://lwn.net/
|
||||
[78]:http://hints.macworld.com/
|
||||
[79]:https://developer.apple.com/library/mac/navigation/
|
||||
[80]:https://developer.apple.com/library/mac/#documentation/OpenSource/Conceptual/ShellScripting/Introduction/Introduction.html
|
||||
[81]:https://support.apple.com/kb/index?page=search&locale=en_US&q=
|
||||
[82]:https://www.netbsd.org/docs/
|
||||
[83]:https://www.flickr.com/photos/9479603@N02/3311745151/in/set-72157614479572582/
|
||||
[84]:https://twitter.com/nixcraft
|
||||
[85]:https://facebook.com/nixcraft
|
||||
[86]:https://plus.google.com/+CybercitiBiz
|
||||
[87]:https://wiki.centos.org/
|
||||
[88]:https://www.centos.org/forums/
|
||||
[90]: https://www.freebsd.org/docs.html
|
||||
[91]: https://forums.freebsd.org/
|
||||
@ -0,0 +1,341 @@
|
||||
Let’s Build A Simple Interpreter. Part 1.
|
||||
======
|
||||
|
||||
|
||||
> **" If you don't know how compilers work, then you don't know how computers work. If you're not 100% sure whether you know how compilers work, then you don't know how they work."** -- Steve Yegge
|
||||
|
||||
There you have it. Think about it. It doesn't really matter whether you're a newbie or a seasoned software developer: if you don't know how compilers and interpreters work, then you don't know how computers work. It's that simple.
|
||||
|
||||
So, do you know how compilers and interpreters work? And I mean, are you 100% sure that you know how they work? If you don't. ![][1]
|
||||
|
||||
Or if you don't and you're really agitated about it. ![][2]
|
||||
|
||||
Do not worry. If you stick around and work through the series and build an interpreter and a compiler with me you will know how they work in the end. And you will become a confident happy camper too. At least I hope so. ![][3]
|
||||
|
||||
Why would you study interpreters and compilers? I will give you three reasons.
|
||||
|
||||
1. To write an interpreter or a compiler you have to have a lot of technical skills that you need to use together. Writing an interpreter or a compiler will help you improve those skills and become a better software developer. As well, the skills you will learn are useful in writing any software, not just interpreters or compilers.
|
||||
2. You really want to know how computers work. Often interpreters and compilers look like magic. And you shouldn't be comfortable with that magic. You want to demystify the process of building an interpreter and a compiler, understand how they work, and get in control of things.
|
||||
3. You want to create your own programming language or domain specific language. If you create one, you will also need to create either an interpreter or a compiler for it. Recently, there has been a resurgence of interest in new programming languages. And you can see a new programming language pop up almost every day: Elixir, Go, Rust just to name a few.
|
||||
|
||||
|
||||
|
||||
|
||||
Okay, but what are interpreters and compilers?
|
||||
|
||||
The goal of an **interpreter** or a **compiler** is to translate a source program in some high-level language into some other form. Pretty vague, isn 't it? Just bear with me, later in the series you will learn exactly what the source program is translated into.
|
||||
|
||||
At this point you may also wonder what the difference is between an interpreter and a compiler. For the purpose of this series, let's agree that if a translator translates a source program into machine language, it is a **compiler**. If a translator processes and executes the source program without translating it into machine language first, it is an **interpreter**. Visually it looks something like this:
|
||||
|
||||
![][4]
|
||||
|
||||
I hope that by now you're convinced that you really want to study and build an interpreter and a compiler. What can you expect from this series on interpreters?
|
||||
|
||||
Here is the deal. You and I are going to create a simple interpreter for a large subset of [Pascal][5] language. At the end of this series you will have a working Pascal interpreter and a source-level debugger like Python's [pdb][6].
|
||||
|
||||
You might ask, why Pascal? For one thing, it's not a made-up language that I came up with just for this series: it's a real programming language that has many important language constructs. And some old, but useful, CS books use Pascal programming language in their examples (I understand that that's not a particularly compelling reason to choose a language to build an interpreter for, but I thought it would be nice for a change to learn a non-mainstream language :)
|
||||
|
||||
Here is an example of a factorial function in Pascal that you will be able to interpret with your own interpreter and debug with the interactive source-level debugger that you will create along the way:
|
||||
```
|
||||
program factorial;
|
||||
|
||||
function factorial(n: integer): longint;
|
||||
begin
|
||||
if n = 0 then
|
||||
factorial := 1
|
||||
else
|
||||
factorial := n * factorial(n - 1);
|
||||
end;
|
||||
|
||||
var
|
||||
n: integer;
|
||||
|
||||
begin
|
||||
for n := 0 to 16 do
|
||||
writeln(n, '! = ', factorial(n));
|
||||
end.
|
||||
```
|
||||
|
||||
The implementation language of the Pascal interpreter will be Python, but you can use any language you want because the ideas presented don't depend on any particular implementation language. Okay, let's get down to business. Ready, set, go!
|
||||
|
||||
You will start your first foray into interpreters and compilers by writing a simple interpreter of arithmetic expressions, also known as a calculator. Today the goal is pretty minimalistic: to make your calculator handle the addition of two single digit integers like **3+5**. Here is the source code for your calculator, sorry, interpreter:
|
||||
|
||||
```
|
||||
# Token types
|
||||
#
|
||||
# EOF (end-of-file) token is used to indicate that
|
||||
# there is no more input left for lexical analysis
|
||||
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token type: INTEGER, PLUS, or EOF
|
||||
self.type = type
|
||||
# token value: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', or None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# client string input, e.g. "3+5"
|
||||
self.text = text
|
||||
# self.pos is an index into self.text
|
||||
self.pos = 0
|
||||
# current token instance
|
||||
self.current_token = None
|
||||
|
||||
def error(self):
|
||||
raise Exception('Error parsing input')
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens. One token at a time.
|
||||
"""
|
||||
text = self.text
|
||||
|
||||
# is self.pos index past the end of the self.text ?
|
||||
# if so, then return EOF token because there is no more
|
||||
# input left to convert into tokens
|
||||
if self.pos > len(text) - 1:
|
||||
return Token(EOF, None)
|
||||
|
||||
# get a character at the position self.pos and decide
|
||||
# what token to create based on the single character
|
||||
current_char = text[self.pos]
|
||||
|
||||
# if the character is a digit then convert it to
|
||||
# integer, create an INTEGER token, increment self.pos
|
||||
# index to point to the next character after the digit,
|
||||
# and return the INTEGER token
|
||||
if current_char.isdigit():
|
||||
token = Token(INTEGER, int(current_char))
|
||||
self.pos += 1
|
||||
return token
|
||||
|
||||
if current_char == '+':
|
||||
token = Token(PLUS, current_char)
|
||||
self.pos += 1
|
||||
return token
|
||||
|
||||
self.error()
|
||||
|
||||
def eat(self, token_type):
|
||||
# compare the current token type with the passed token
|
||||
# type and if they match then "eat" the current token
|
||||
# and assign the next token to the self.current_token,
|
||||
# otherwise raise an exception.
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def expr(self):
|
||||
"""expr -> INTEGER PLUS INTEGER"""
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
# we expect the current token to be a single-digit integer
|
||||
left = self.current_token
|
||||
self.eat(INTEGER)
|
||||
|
||||
# we expect the current token to be a '+' token
|
||||
op = self.current_token
|
||||
self.eat(PLUS)
|
||||
|
||||
# we expect the current token to be a single-digit integer
|
||||
right = self.current_token
|
||||
self.eat(INTEGER)
|
||||
# after the above call the self.current_token is set to
|
||||
# EOF token
|
||||
|
||||
# at this point INTEGER PLUS INTEGER sequence of tokens
|
||||
# has been successfully found and the method can just
|
||||
# return the result of adding two integers, thus
|
||||
# effectively interpreting client input
|
||||
result = left.value + right.value
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
|
||||
Save the above code into calc1.py file or download it directly from [GitHub][7]. Before you start digging deeper into the code, run the calculator on the command line and see it in action. Play with it! Here is a sample session on my laptop (if you want to run the calculator under Python3 you will need to replace raw_input with input):
|
||||
```
|
||||
$ python calc1.py
|
||||
calc> 3+4
|
||||
7
|
||||
calc> 3+5
|
||||
8
|
||||
calc> 3+9
|
||||
12
|
||||
calc>
|
||||
```
|
||||
|
||||
For your simple calculator to work properly without throwing an exception, your input needs to follow certain rules:
|
||||
|
||||
* Only single digit integers are allowed in the input
|
||||
* The only arithmetic operation supported at the moment is addition
|
||||
* No whitespace characters are allowed anywhere in the input
|
||||
|
||||
|
||||
|
||||
Those restrictions are necessary to make the calculator simple. Don't worry, you'll make it pretty complex pretty soon.
|
||||
|
||||
Okay, now let's dive in and see how your interpreter works and how it evaluates arithmetic expressions.
|
||||
|
||||
When you enter an expression 3+5 on the command line your interpreter gets a string "3+5". In order for the interpreter to actually understand what to do with that string it first needs to break the input "3+5" into components called **tokens**. A **token** is an object that has a type and a value. For example, for the string "3" the type of the token will be INTEGER and the corresponding value will be integer 3.
|
||||
|
||||
The process of breaking the input string into tokens is called **lexical analysis**. So, the first step your interpreter needs to do is read the input of characters and convert it into a stream of tokens. The part of the interpreter that does it is called a **lexical analyzer** , or **lexer** for short. You might also encounter other names for the same component, like **scanner** or **tokenizer**. They all mean the same: the part of your interpreter or compiler that turns the input of characters into a stream of tokens.
|
||||
|
||||
The method get_next_token of the Interpreter class is your lexical analyzer. Every time you call it, you get the next token created from the input of characters passed to the interpreter. Let's take a closer look at the method itself and see how it actually does its job of converting characters into tokens. The input is stored in the variable text that holds the input string and pos is an index into that string (think of the string as an array of characters). pos is initially set to 0 and points to the character '3'. The method first checks whether the character is a digit and if so, it increments pos and returns a token instance with the type INTEGER and the value set to the integer value of the string '3', which is an integer 3:
|
||||
|
||||
![][8]
|
||||
|
||||
The pos now points to the '+' character in the text. The next time you call the method, it tests if a character at the position pos is a digit and then it tests if the character is a plus sign, which it is. As a result the method increments pos and returns a newly created token with the type PLUS and value '+':
|
||||
|
||||
![][9]
|
||||
|
||||
The pos now points to character '5'. When you call the get_next_token method again the method checks if it's a digit, which it is, so it increments pos and returns a new INTEGER token with the value of the token set to integer 5: ![][10]
|
||||
|
||||
Because the pos index is now past the end of the string "3+5" the get_next_token method returns the EOF token every time you call it:
|
||||
|
||||
![][11]
|
||||
|
||||
Try it out and see for yourself how the lexer component of your calculator works:
|
||||
```
|
||||
>>> from calc1 import Interpreter
|
||||
>>>
|
||||
>>> interpreter = Interpreter('3+5')
|
||||
>>> interpreter.get_next_token()
|
||||
Token(INTEGER, 3)
|
||||
>>>
|
||||
>>> interpreter.get_next_token()
|
||||
Token(PLUS, '+')
|
||||
>>>
|
||||
>>> interpreter.get_next_token()
|
||||
Token(INTEGER, 5)
|
||||
>>>
|
||||
>>> interpreter.get_next_token()
|
||||
Token(EOF, None)
|
||||
>>>
|
||||
```
|
||||
|
||||
So now that your interpreter has access to the stream of tokens made from the input characters, the interpreter needs to do something with it: it needs to find the structure in the flat stream of tokens it gets from the lexer get_next_token. Your interpreter expects to find the following structure in that stream: INTEGER -> PLUS -> INTEGER. That is, it tries to find a sequence of tokens: integer followed by a plus sign followed by an integer.
|
||||
|
||||
The method responsible for finding and interpreting that structure is expr. This method verifies that the sequence of tokens does indeed correspond to the expected sequence of tokens, i.e INTEGER -> PLUS -> INTEGER. After it's successfully confirmed the structure, it generates the result by adding the value of the token on the left side of the PLUS and the right side of the PLUS, thus successfully interpreting the arithmetic expression you passed to the interpreter.
|
||||
|
||||
The expr method itself uses the helper method eat to verify that the token type passed to the eat method matches the current token type. After matching the passed token type the eat method gets the next token and assigns it to the current_token variable, thus effectively "eating" the currently matched token and advancing the imaginary pointer in the stream of tokens. If the structure in the stream of tokens doesn't correspond to the expected INTEGER PLUS INTEGER sequence of tokens the eat method throws an exception.
|
||||
|
||||
Let's recap what your interpreter does to evaluate an arithmetic expression:
|
||||
|
||||
* The interpreter accepts an input string, let's say "3+5"
|
||||
* The interpreter calls the expr method to find a structure in the stream of tokens returned by the lexical analyzer get_next_token. The structure it tries to find is of the form INTEGER PLUS INTEGER. After it's confirmed the structure, it interprets the input by adding the values of two INTEGER tokens because it's clear to the interpreter at that point that what it needs to do is add two integers, 3 and 5.
|
||||
|
||||
Congratulate yourself. You've just learned how to build your very first interpreter!
|
||||
|
||||
Now it's time for exercises.
|
||||
|
||||
![][12]
|
||||
|
||||
You didn't think you would just read this article and that would be enough, did you? Okay, get your hands dirty and do the following exercises:
|
||||
|
||||
1. Modify the code to allow multiple-digit integers in the input, for example "12+3"
|
||||
2. Add a method that skips whitespace characters so that your calculator can handle inputs with whitespace characters like " 12 + 3"
|
||||
3. Modify the code and instead of '+' handle '-' to evaluate subtractions like "7-5"
|
||||
|
||||
|
||||
|
||||
**Check your understanding**
|
||||
|
||||
1. What is an interpreter?
|
||||
2. What is a compiler?
|
||||
3. What's the difference between an interpreter and a compiler?
|
||||
4. What is a token?
|
||||
5. What is the name of the process that breaks input apart into tokens?
|
||||
6. What is the part of the interpreter that does lexical analysis called?
|
||||
7. What are the other common names for that part of an interpreter or a compiler?
|
||||
|
||||
|
||||
|
||||
Before I finish this article, I really want you to commit to studying interpreters and compilers. And I want you to do it right now. Don't put it on the back burner. Don't wait. If you've skimmed the article, start over. If you've read it carefully but haven't done exercises - do them now. If you've done only some of them, finish the rest. You get the idea. And you know what? Sign the commitment pledge to start learning about interpreters and compilers today!
|
||||
|
||||
|
||||
|
||||
_I, ________, of being sound mind and body, do hereby pledge to commit to studying interpreters and compilers starting today and get to a point where I know 100% how they work!_
|
||||
|
||||
Signature:
|
||||
|
||||
Date:
|
||||
|
||||
![][13]
|
||||
|
||||
Sign it, date it, and put it somewhere where you can see it every day to make sure that you stick to your commitment. And keep in mind the definition of commitment:
|
||||
|
||||
> "Commitment is doing the thing you said you were going to do long after the mood you said it in has left you." -- Darren Hardy
|
||||
|
||||
Okay, that's it for today. In the next article of the mini series you will extend your calculator to handle more arithmetic expressions. Stay tuned.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part1/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_i_dont_know.png
|
||||
[2]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_omg.png
|
||||
[3]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_i_know.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_compiler_interpreter.png
|
||||
[5]:https://en.wikipedia.org/wiki/Pascal_%28programming_language%29
|
||||
[6]:https://docs.python.org/2/library/pdb.html
|
||||
[7]:https://github.com/rspivak/lsbasi/blob/master/part1/calc1.py
|
||||
[8]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_lexer1.png
|
||||
[9]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_lexer2.png
|
||||
[10]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_lexer3.png
|
||||
[11]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_lexer4.png
|
||||
[12]:https://ruslanspivak.com/lsbasi-part1/lsbasi_exercises2.png
|
||||
[13]:https://ruslanspivak.com/lsbasi-part1/lsbasi_part1_commitment_pledge.png
|
||||
[14]:http://ruslanspivak.com/lsbaws-part1/ (Part 1)
|
||||
[15]:http://ruslanspivak.com/lsbaws-part2/ (Part 2)
|
||||
[16]:http://ruslanspivak.com/lsbaws-part3/ (Part 3)
|
||||
@ -0,0 +1,244 @@
|
||||
Let’s Build A Simple Interpreter. Part 2.
|
||||
======
|
||||
|
||||
In their amazing book "The 5 Elements of Effective Thinking" the authors Burger and Starbird share a story about how they observed Tony Plog, an internationally acclaimed trumpet virtuoso, conduct a master class for accomplished trumpet players. The students first played complex music phrases, which they played perfectly well. But then they were asked to play very basic, simple notes. When they played the notes, the notes sounded childish compared to the previously played complex phrases. After they finished playing, the master teacher also played the same notes, but when he played them, they did not sound childish. The difference was stunning. Tony explained that mastering the performance of simple notes allows one to play complex pieces with greater control. The lesson was clear - to build true virtuosity one must focus on mastering simple, basic ideas.
|
||||
|
||||
The lesson in the story clearly applies not only to music but also to software development. The story is a good reminder to all of us to not lose sight of the importance of deep work on simple, basic ideas even if it sometimes feels like a step back. While it is important to be proficient with a tool or framework you use, it is also extremely important to know the principles behind them. As Ralph Waldo Emerson said:
|
||||
|
||||
> "If you learn only methods, you'll be tied to your methods. But if you learn principles, you can devise your own methods."
|
||||
|
||||
On that note, let's dive into interpreters and compilers again.
|
||||
|
||||
Today I will show you a new version of the calculator from [Part 1][1] that will be able to:
|
||||
|
||||
1. Handle whitespace characters anywhere in the input string
|
||||
2. Consume multi-digit integers from the input
|
||||
3. Subtract two integers (currently it can only add integers)
|
||||
|
||||
|
||||
|
||||
Here is the source code for your new version of the calculator that can do all of the above:
|
||||
```
|
||||
# Token types
|
||||
# EOF (end-of-file) token is used to indicate that
|
||||
# there is no more input left for lexical analysis
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token type: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token value: non-negative integer value, '+', '-', or None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# client string input, e.g. "3 + 5", "12 - 5", etc
|
||||
self.text = text
|
||||
# self.pos is an index into self.text
|
||||
self.pos = 0
|
||||
# current token instance
|
||||
self.current_token = None
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def error(self):
|
||||
raise Exception('Error parsing input')
|
||||
|
||||
def advance(self):
|
||||
"""Advance the 'pos' pointer and set the 'current_char' variable."""
|
||||
self.pos += 1
|
||||
if self.pos > len(self.text) - 1:
|
||||
self.current_char = None # Indicates end of input
|
||||
else:
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def skip_whitespace(self):
|
||||
while self.current_char is not None and self.current_char.isspace():
|
||||
self.advance()
|
||||
|
||||
def integer(self):
|
||||
"""Return a (multidigit) integer consumed from the input."""
|
||||
result = ''
|
||||
while self.current_char is not None and self.current_char.isdigit():
|
||||
result += self.current_char
|
||||
self.advance()
|
||||
return int(result)
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens.
|
||||
"""
|
||||
while self.current_char is not None:
|
||||
|
||||
if self.current_char.isspace():
|
||||
self.skip_whitespace()
|
||||
continue
|
||||
|
||||
if self.current_char.isdigit():
|
||||
return Token(INTEGER, self.integer())
|
||||
|
||||
if self.current_char == '+':
|
||||
self.advance()
|
||||
return Token(PLUS, '+')
|
||||
|
||||
if self.current_char == '-':
|
||||
self.advance()
|
||||
return Token(MINUS, '-')
|
||||
|
||||
self.error()
|
||||
|
||||
return Token(EOF, None)
|
||||
|
||||
def eat(self, token_type):
|
||||
# compare the current token type with the passed token
|
||||
# type and if they match then "eat" the current token
|
||||
# and assign the next token to the self.current_token,
|
||||
# otherwise raise an exception.
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def expr(self):
|
||||
"""Parser / Interpreter
|
||||
|
||||
expr -> INTEGER PLUS INTEGER
|
||||
expr -> INTEGER MINUS INTEGER
|
||||
"""
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
# we expect the current token to be an integer
|
||||
left = self.current_token
|
||||
self.eat(INTEGER)
|
||||
|
||||
# we expect the current token to be either a '+' or '-'
|
||||
op = self.current_token
|
||||
if op.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
else:
|
||||
self.eat(MINUS)
|
||||
|
||||
# we expect the current token to be an integer
|
||||
right = self.current_token
|
||||
self.eat(INTEGER)
|
||||
# after the above call the self.current_token is set to
|
||||
# EOF token
|
||||
|
||||
# at this point either the INTEGER PLUS INTEGER or
|
||||
# the INTEGER MINUS INTEGER sequence of tokens
|
||||
# has been successfully found and the method can just
|
||||
# return the result of adding or subtracting two integers,
|
||||
# thus effectively interpreting client input
|
||||
if op.type == PLUS:
|
||||
result = left.value + right.value
|
||||
else:
|
||||
result = left.value - right.value
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
Save the above code into the calc2.py file or download it directly from [GitHub][2]. Try it out. See for yourself that it works as expected: it can handle whitespace characters anywhere in the input; it can accept multi-digit integers, and it can also subtract two integers as well as add two integers.
|
||||
|
||||
Here is a sample session that I ran on my laptop:
|
||||
```
|
||||
$ python calc2.py
|
||||
calc> 27 + 3
|
||||
30
|
||||
calc> 27 - 7
|
||||
20
|
||||
calc>
|
||||
```
|
||||
|
||||
The major code changes compared with the version from [Part 1][1] are:
|
||||
|
||||
1. The get_next_token method was refactored a bit. The logic to increment the pos pointer was factored into a separate method advance.
|
||||
2. Two more methods were added: skip_whitespace to ignore whitespace characters and integer to handle multi-digit integers in the input.
|
||||
3. The expr method was modified to recognize INTEGER -> MINUS -> INTEGER phrase in addition to INTEGER -> PLUS -> INTEGER phrase. The method now also interprets both addition and subtraction after having successfully recognized the corresponding phrase.
|
||||
|
||||
In [Part 1][1] you learned two important concepts, namely that of a **token** and a **lexical analyzer**. Today I would like to talk a little bit about **lexemes** , **parsing** , and **parsers**.
|
||||
|
||||
You already know about tokens. But in order for me to round out the discussion of tokens I need to mention lexemes. What is a lexeme? A **lexeme** is a sequence of characters that form a token. In the following picture you can see some examples of tokens and sample lexemes and hopefully it will make the relationship between them clear:
|
||||
|
||||
![][3]
|
||||
|
||||
Now, remember our friend, the expr method? I said before that that's where the interpretation of an arithmetic expression actually happens. But before you can interpret an expression you first need to recognize what kind of phrase it is, whether it is addition or subtraction, for example. That's what the expr method essentially does: it finds the structure in the stream of tokens it gets from the get_next_token method and then it interprets the phrase that is has recognized, generating the result of the arithmetic expression.
|
||||
|
||||
The process of finding the structure in the stream of tokens, or put differently, the process of recognizing a phrase in the stream of tokens is called **parsing**. The part of an interpreter or compiler that performs that job is called a **parser**.
|
||||
|
||||
So now you know that the expr method is the part of your interpreter where both **parsing** and **interpreting** happens - the expr method first tries to recognize ( **parse** ) the INTEGER -> PLUS -> INTEGER or the INTEGER -> MINUS -> INTEGER phrase in the stream of tokens and after it has successfully recognized ( **parsed** ) one of those phrases, the method interprets it and returns the result of either addition or subtraction of two integers to the caller.
|
||||
|
||||
And now it's time for exercises again.
|
||||
|
||||
![][4]
|
||||
|
||||
1. Extend the calculator to handle multiplication of two integers
|
||||
2. Extend the calculator to handle division of two integers
|
||||
3. Modify the code to interpret expressions containing an arbitrary number of additions and subtractions, for example "9 - 5 + 3 + 11"
|
||||
|
||||
|
||||
|
||||
**Check your understanding.**
|
||||
|
||||
1. What is a lexeme?
|
||||
2. What is the name of the process that finds the structure in the stream of tokens, or put differently, what is the name of the process that recognizes a certain phrase in that stream of tokens?
|
||||
3. What is the name of the part of the interpreter (compiler) that does parsing?
|
||||
|
||||
|
||||
|
||||
|
||||
I hope you liked today's material. In the next article of the series you will extend your calculator to handle more complex arithmetic expressions. Stay tuned.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part2/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py
|
||||
[3]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_lexemes.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_exercises.png
|
||||
@ -0,0 +1,340 @@
|
||||
Let’s Build A Simple Interpreter. Part 3.
|
||||
======
|
||||
|
||||
I woke up this morning and I thought to myself: "Why do we find it so difficult to learn a new skill?"
|
||||
|
||||
I don't think it's just because of the hard work. I think that one of the reasons might be that we spend a lot of time and hard work acquiring knowledge by reading and watching and not enough time translating that knowledge into a skill by practicing it. Take swimming, for example. You can spend a lot of time reading hundreds of books about swimming, talk for hours with experienced swimmers and coaches, watch all the training videos available, and you still will sink like a rock the first time you jump in the pool.
|
||||
|
||||
The bottom line is: it doesn't matter how well you think you know the subject - you have to put that knowledge into practice to turn it into a skill. To help you with the practice part I put exercises into [Part 1][1] and [Part 2][2] of the series. And yes, you will see more exercises in today's article and in future articles, I promise :)
|
||||
|
||||
Okay, let's get started with today's material, shall we?
|
||||
|
||||
|
||||
So far, you've learned how to interpret arithmetic expressions that add or subtract two integers like "7 + 3" or "12 - 9". Today I'm going to talk about how to parse (recognize) and interpret arithmetic expressions that have any number of plus or minus operators in it, for example "7 - 3 + 2 - 1".
|
||||
|
||||
Graphically, the arithmetic expressions in this article can be represented with the following syntax diagram:
|
||||
|
||||
![][3]
|
||||
|
||||
What is a syntax diagram? A **syntax diagram** is a graphical representation of a programming language 's syntax rules. Basically, a syntax diagram visually shows you which statements are allowed in your programming language and which are not.
|
||||
|
||||
Syntax diagrams are pretty easy to read: just follow the paths indicated by the arrows. Some paths indicate choices. And some paths indicate loops.
|
||||
|
||||
You can read the above syntax diagram as following: a term optionally followed by a plus or minus sign, followed by another term, which in turn is optionally followed by a plus or minus sign followed by another term and so on. You get the picture, literally. You might wonder what a "term" is. For the purpose of this article a "term" is just an integer.
|
||||
|
||||
Syntax diagrams serve two main purposes:
|
||||
|
||||
* They graphically represent the specification (grammar) of a programming language.
|
||||
* They can be used to help you write your parser - you can map a diagram to code by following simple rules.
|
||||
|
||||
|
||||
|
||||
You've learned that the process of recognizing a phrase in the stream of tokens is called **parsing**. And the part of an interpreter or compiler that performs that job is called a **parser**. Parsing is also called **syntax analysis** , and the parser is also aptly called, you guessed it right, a **syntax analyzer**.
|
||||
|
||||
According to the syntax diagram above, all of the following arithmetic expressions are valid:
|
||||
|
||||
* 3
|
||||
* 3 + 4
|
||||
* 7 - 3 + 2 - 1
|
||||
|
||||
|
||||
|
||||
Because syntax rules for arithmetic expressions in different programming languages are very similar we can use a Python shell to "test" our syntax diagram. Launch your Python shell and see for yourself:
|
||||
```
|
||||
>>> 3
|
||||
3
|
||||
>>> 3 + 4
|
||||
7
|
||||
>>> 7 - 3 + 2 - 1
|
||||
5
|
||||
```
|
||||
|
||||
No surprises here.
|
||||
|
||||
The expression "3 + " is not a valid arithmetic expression though because according to the syntax diagram the plus sign must be followed by a term (integer), otherwise it's a syntax error. Again, try it with a Python shell and see for yourself:
|
||||
```
|
||||
>>> 3 +
|
||||
File "<stdin>", line 1
|
||||
3 +
|
||||
^
|
||||
SyntaxError: invalid syntax
|
||||
```
|
||||
|
||||
It's great to be able to use a Python shell to do some testing but let's map the above syntax diagram to code and use our own interpreter for testing, all right?
|
||||
|
||||
You know from the previous articles ([Part 1][1] and [Part 2][2]) that the expr method is where both our parser and interpreter live. Again, the parser just recognizes the structure making sure that it corresponds to some specifications and the interpreter actually evaluates the expression once the parser has successfully recognized (parsed) it.
|
||||
|
||||
The following code snippet shows the parser code corresponding to the diagram. The rectangular box from the syntax diagram (term) becomes a term method that parses an integer and the expr method just follows the syntax diagram flow:
|
||||
```
|
||||
def term(self):
|
||||
self.eat(INTEGER)
|
||||
|
||||
def expr(self):
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
self.term()
|
||||
while self.current_token.type in (PLUS, MINUS):
|
||||
token = self.current_token
|
||||
if token.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
self.term()
|
||||
elif token.type == MINUS:
|
||||
self.eat(MINUS)
|
||||
self.term()
|
||||
```
|
||||
|
||||
You can see that expr first calls the term method. Then the expr method has a while loop which can execute zero or more times. And inside the loop the parser makes a choice based on the token (whether it's a plus or minus sign). Spend some time proving to yourself that the code above does indeed follow the syntax diagram flow for arithmetic expressions.
|
||||
|
||||
The parser itself does not interpret anything though: if it recognizes an expression it's silent and if it doesn't, it throws out a syntax error. Let's modify the expr method and add the interpreter code:
|
||||
```
|
||||
def term(self):
|
||||
"""Return an INTEGER token value"""
|
||||
token = self.current_token
|
||||
self.eat(INTEGER)
|
||||
return token.value
|
||||
|
||||
def expr(self):
|
||||
"""Parser / Interpreter """
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
result = self.term()
|
||||
while self.current_token.type in (PLUS, MINUS):
|
||||
token = self.current_token
|
||||
if token.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
result = result + self.term()
|
||||
elif token.type == MINUS:
|
||||
self.eat(MINUS)
|
||||
result = result - self.term()
|
||||
|
||||
return result
|
||||
```
|
||||
|
||||
Because the interpreter needs to evaluate an expression the term method was modified to return an integer value and the expr method was modified to perform addition and subtraction at the appropriate places and return the result of interpretation. Even though the code is pretty straightforward I recommend spending some time studying it.
|
||||
|
||||
Le's get moving and see the complete code of the interpreter now, okay?
|
||||
|
||||
Here is the source code for your new version of the calculator that can handle valid arithmetic expressions containing integers and any number of addition and subtraction operators:
|
||||
```
|
||||
# Token types
|
||||
#
|
||||
# EOF (end-of-file) token is used to indicate that
|
||||
# there is no more input left for lexical analysis
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token type: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token value: non-negative integer value, '+', '-', or None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS, '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# client string input, e.g. "3 + 5", "12 - 5 + 3", etc
|
||||
self.text = text
|
||||
# self.pos is an index into self.text
|
||||
self.pos = 0
|
||||
# current token instance
|
||||
self.current_token = None
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
##########################################################
|
||||
# Lexer code #
|
||||
##########################################################
|
||||
def error(self):
|
||||
raise Exception('Invalid syntax')
|
||||
|
||||
def advance(self):
|
||||
"""Advance the `pos` pointer and set the `current_char` variable."""
|
||||
self.pos += 1
|
||||
if self.pos > len(self.text) - 1:
|
||||
self.current_char = None # Indicates end of input
|
||||
else:
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def skip_whitespace(self):
|
||||
while self.current_char is not None and self.current_char.isspace():
|
||||
self.advance()
|
||||
|
||||
def integer(self):
|
||||
"""Return a (multidigit) integer consumed from the input."""
|
||||
result = ''
|
||||
while self.current_char is not None and self.current_char.isdigit():
|
||||
result += self.current_char
|
||||
self.advance()
|
||||
return int(result)
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens. One token at a time.
|
||||
"""
|
||||
while self.current_char is not None:
|
||||
|
||||
if self.current_char.isspace():
|
||||
self.skip_whitespace()
|
||||
continue
|
||||
|
||||
if self.current_char.isdigit():
|
||||
return Token(INTEGER, self.integer())
|
||||
|
||||
if self.current_char == '+':
|
||||
self.advance()
|
||||
return Token(PLUS, '+')
|
||||
|
||||
if self.current_char == '-':
|
||||
self.advance()
|
||||
return Token(MINUS, '-')
|
||||
|
||||
self.error()
|
||||
|
||||
return Token(EOF, None)
|
||||
|
||||
##########################################################
|
||||
# Parser / Interpreter code #
|
||||
##########################################################
|
||||
def eat(self, token_type):
|
||||
# compare the current token type with the passed token
|
||||
# type and if they match then "eat" the current token
|
||||
# and assign the next token to the self.current_token,
|
||||
# otherwise raise an exception.
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def term(self):
|
||||
"""Return an INTEGER token value."""
|
||||
token = self.current_token
|
||||
self.eat(INTEGER)
|
||||
return token.value
|
||||
|
||||
def expr(self):
|
||||
"""Arithmetic expression parser / interpreter."""
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
result = self.term()
|
||||
while self.current_token.type in (PLUS, MINUS):
|
||||
token = self.current_token
|
||||
if token.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
result = result + self.term()
|
||||
elif token.type == MINUS:
|
||||
self.eat(MINUS)
|
||||
result = result - self.term()
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
Save the above code into the calc3.py file or download it directly from [GitHub][4]. Try it out. See for yourself that it can handle arithmetic expressions that you can derive from the syntax diagram I showed you earlier.
|
||||
|
||||
Here is a sample session that I ran on my laptop:
|
||||
```
|
||||
$ python calc3.py
|
||||
calc> 3
|
||||
3
|
||||
calc> 7 - 4
|
||||
3
|
||||
calc> 10 + 5
|
||||
15
|
||||
calc> 7 - 3 + 2 - 1
|
||||
5
|
||||
calc> 10 + 1 + 2 - 3 + 4 + 6 - 15
|
||||
5
|
||||
calc> 3 +
|
||||
Traceback (most recent call last):
|
||||
File "calc3.py", line 147, in <module>
|
||||
main()
|
||||
File "calc3.py", line 142, in main
|
||||
result = interpreter.expr()
|
||||
File "calc3.py", line 123, in expr
|
||||
result = result + self.term()
|
||||
File "calc3.py", line 110, in term
|
||||
self.eat(INTEGER)
|
||||
File "calc3.py", line 105, in eat
|
||||
self.error()
|
||||
File "calc3.py", line 45, in error
|
||||
raise Exception('Invalid syntax')
|
||||
Exception: Invalid syntax
|
||||
```
|
||||
|
||||
|
||||
Remember those exercises I mentioned at the beginning of the article: here they are, as promised :)
|
||||
|
||||
![][5]
|
||||
|
||||
* Draw a syntax diagram for arithmetic expressions that contain only multiplication and division, for example "7 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh 4 / 2 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh 3". Seriously, just grab a pen or a pencil and try to draw one.
|
||||
* Modify the source code of the calculator to interpret arithmetic expressions that contain only multiplication and division, for example "7 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh 4 / 2 * 3".
|
||||
* Write an interpreter that handles arithmetic expressions like "7 - 3 + 2 - 1" from scratch. Use any programming language you're comfortable with and write it off the top of your head without looking at the examples. When you do that, think about components involved: a lexer that takes an input and converts it into a stream of tokens, a parser that feeds off the stream of the tokens provided by the lexer and tries to recognize a structure in that stream, and an interpreter that generates results after the parser has successfully parsed (recognized) a valid arithmetic expression. String those pieces together. Spend some time translating the knowledge you've acquired into a working interpreter for arithmetic expressions.
|
||||
|
||||
|
||||
|
||||
**Check your understanding.**
|
||||
|
||||
1. What is a syntax diagram?
|
||||
2. What is syntax analysis?
|
||||
3. What is a syntax analyzer?
|
||||
|
||||
|
||||
|
||||
|
||||
Hey, look! You read all the way to the end. Thanks for hanging out here today and don't forget to do the exercises. :) I'll be back next time with a new article - stay tuned.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part3/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:http://ruslanspivak.com/lsbasi-part2/ (Part 2)
|
||||
[3]:https://ruslanspivak.com/lsbasi-part3/lsbasi_part3_syntax_diagram.png
|
||||
[4]:https://github.com/rspivak/lsbasi/blob/master/part3/calc3.py
|
||||
[5]:https://ruslanspivak.com/lsbasi-part3/lsbasi_part3_exercises.png
|
||||
240
sources/tech/20160808 Top 10 Command Line Games For Linux.md
Normal file
240
sources/tech/20160808 Top 10 Command Line Games For Linux.md
Normal file
@ -0,0 +1,240 @@
|
||||
Top 10 Command Line Games For Linux
|
||||
======
|
||||
Brief: This article lists the **best command line games for Linux**.
|
||||
|
||||
Linux has never been the preferred operating system for gaming. Though [gaming on Linux][1] has improved a lot lately. You can [download Linux games][2] from a number of resources.
|
||||
|
||||
There are dedicated [Linux distributions for gaming][3]. Yes, they do exist. But, we are not going to see the Linux gaming distributions today.
|
||||
|
||||
Linux has one added advantage over its Windows counterpart. It has got the mighty Linux terminal. You can do a hell lot of things in terminal including playing **command line games**.
|
||||
|
||||
Yeah, hardcore terminal lovers, gather around. Terminal games are light, fast and hell lotta fun to play. And the best thing of all, you've got a lot of classic retro games in Linux terminal.
|
||||
|
||||
[Suggested read: Gaming On Linux:All You Need To Know][20]
|
||||
|
||||
### Best Linux terminal games
|
||||
|
||||
So let's crack this list and see what are some of the best Linux terminal games.
|
||||
|
||||
### 1. Bastet
|
||||
|
||||
Who hasn't spent hours together playing [Tetris][4]? Simple, but totally addictive. Bastet is the Tetris of Linux.
|
||||
|
||||
![Bastet Linux terminal game][5]
|
||||
|
||||
Use the command below to get Bastet:
|
||||
```
|
||||
sudo apt install bastet
|
||||
```
|
||||
|
||||
To play the game, run the below command in terminal:
|
||||
```
|
||||
bastet
|
||||
```
|
||||
|
||||
Use spacebar to rotate the bricks and arrow keys to guide.
|
||||
|
||||
### 2. Ninvaders
|
||||
|
||||
Space Invaders. I remember tussling for high score with my brother on this. One of the best arcade games out there.
|
||||
|
||||
![nInvaders command line game in Linux][6]
|
||||
|
||||
Copy paste the command to install Ninvaders.
|
||||
```
|
||||
sudo apt-get install ninvaders
|
||||
```
|
||||
|
||||
To play this game, use the command below:
|
||||
```
|
||||
ninvaders
|
||||
```
|
||||
|
||||
Arrow keys to move the spaceship. Space bar to shoot at the aliens.
|
||||
|
||||
[Suggested read:Top 10 Best Linux Games eleased in 2016 That You Can Play Today][21]
|
||||
|
||||
|
||||
### 3. Pacman4console
|
||||
|
||||
Yes, the King of the Arcade is here. Pacman4console is the terminal version of the popular arcade hit, Pacman.
|
||||
|
||||
![Pacman4console is a command line Pacman game in Linux][7]
|
||||
|
||||
Use the command to get pacman4console:
|
||||
```
|
||||
sudo apt-get install pacman4console
|
||||
```
|
||||
|
||||
Open a terminal, and I suggest you maximize it. Type the command below to launch the game:
|
||||
```
|
||||
pacman4console
|
||||
```
|
||||
|
||||
Use the arrow keys to control the movement.
|
||||
|
||||
### 4. nSnake
|
||||
|
||||
Remember the snake game in old Nokia phones?
|
||||
|
||||
That game kept me hooked to the phone for a really long time. I used to devise various coiling patterns to manage the grown up snake.
|
||||
|
||||
![nsnake : Snake game in Linux terminal][8]
|
||||
|
||||
We have the [snake game in Linux terminal][9] thanks to [nSnake][9]. Use the command below to install it.
|
||||
```
|
||||
sudo apt-get install nsnake
|
||||
```
|
||||
|
||||
To play the game, type in the below command to launch the game.
|
||||
```
|
||||
nsnake
|
||||
```
|
||||
|
||||
Use arrow keys to move the snake and feed it.
|
||||
|
||||
### 5. Greed
|
||||
|
||||
Greed is little like Tron, minus the speed and adrenaline.
|
||||
|
||||
Your location is denoted by a blinking '@'. You are surrounded by numbers and you can choose to move in any of the 4 directions,
|
||||
|
||||
The direction you choose has a number and you move exactly that number of steps. And you repeat the step again. You cannot revisit the visited spot again and the game ends when you cannot make a move.
|
||||
|
||||
I made it sound more complicated than it really is.
|
||||
|
||||
![Greed : Tron game in Linux command line][10]
|
||||
|
||||
Grab greed with the command below:
|
||||
```
|
||||
sudo apt-get install greed
|
||||
```
|
||||
|
||||
To launch the game use the command below. Then use the arrow keys to play the game.
|
||||
```
|
||||
greed
|
||||
```
|
||||
|
||||
### 6. Air Traffic Controller
|
||||
|
||||
What's better than being a pilot? An air traffic controller. You can simulate an entire air traffic system in your terminal. To be honest, managing air traffic from a terminal kinda feels, real.
|
||||
|
||||
![Air Traffic Controller game in Linux][11]
|
||||
|
||||
Install the game using the command below:
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
Type in the command below to launch the game:
|
||||
```
|
||||
atc
|
||||
```
|
||||
|
||||
ATC is not a child's play. So read the man page using the command below.
|
||||
|
||||
### 7. Backgammon
|
||||
|
||||
Whether You have played [Backgammon][12] before or not, You should check this out. The instructions and control manuals are all so friendly. Play it against computer or your friend if you prefer.
|
||||
|
||||
![Backgammon terminal game in Linux][13]
|
||||
|
||||
Install Backgammon using this command:
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
Type in the below command to launch the game:
|
||||
```
|
||||
backgammon
|
||||
```
|
||||
|
||||
Press 'y' when prompted for rules of the game.
|
||||
|
||||
### 8. Moon Buggy
|
||||
|
||||
Jump. Fire. Hours of fun. No more words.
|
||||
|
||||
![Moon buggy][14]
|
||||
|
||||
Install the game using the command below:
|
||||
```
|
||||
sudo apt-get install moon-buggy
|
||||
```
|
||||
|
||||
Use the below command to start the game:
|
||||
```
|
||||
moon-buggy
|
||||
```
|
||||
|
||||
Press space to jump, 'a' or 'l' to shoot. Enjoy
|
||||
|
||||
### 9. 2048
|
||||
|
||||
Here's something to make your brain flex. [2048][15] is a strategic as well as a highly addictive game. The goal is to get a score of 2048.
|
||||
|
||||
![2048 game in Linux terminal][16]
|
||||
|
||||
Copy paste the commands below one by one to install the game.
|
||||
```
|
||||
wget https://raw.githubusercontent.com/mevdschee/2048.c/master/2048.c
|
||||
|
||||
gcc -o 2048 2048.c
|
||||
```
|
||||
|
||||
Type the below command to launch the game and use the arrow keys to play.
|
||||
```
|
||||
./2048
|
||||
```
|
||||
|
||||
### 10. Tron
|
||||
|
||||
How can this list be complete without a brisk action game?
|
||||
|
||||
![Tron Linux terminal game][17]
|
||||
|
||||
Yes, the snappy Tron is available on Linux terminal. Get ready for some serious nimble action. No installation hassle nor setup hassle. One command will launch the game. All You need is an internet connection.
|
||||
```
|
||||
ssh sshtron.zachlatta.com
|
||||
```
|
||||
|
||||
You can even play this game in multiplayer if there are other gamers online. Read more about [Tron game in Linux][18].
|
||||
|
||||
### Your pick?
|
||||
|
||||
There you have it, people. Top 10 Linux terminal games. I guess it's ctrl+alt+T now. What is Your favorite among the list? Or got some other fun stuff for the terminal? Do share.
|
||||
|
||||
With inputs from [Abhishek Prakash][19].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-command-line-games-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://itsfoss.com/linux-gaming-guide/
|
||||
[2]:https://itsfoss.com/download-linux-games/
|
||||
[3]:https://itsfoss.com/manjaro-gaming-linux/
|
||||
[4]:https://en.wikipedia.org/wiki/Tetris
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/bastet.jpg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/ninvaders.jpg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/pacman.jpg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/nsnake.jpg
|
||||
[9]:https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/greed.jpg
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/atc.jpg
|
||||
[12]:https://en.wikipedia.org/wiki/Backgammon
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/backgammon.jpg
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/moon-buggy.jpg
|
||||
[15]:https://itsfoss.com/2048-offline-play-ubuntu/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/2048.jpg
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/tron.jpg
|
||||
[18]:https://itsfoss.com/play-tron-game-linux-terminal/
|
||||
[19]:https://twitter.com/abhishek_pc
|
||||
[20]:https://itsfoss.com/linux-gaming-guide/
|
||||
[21]:https://itsfoss.com/best-linux-games/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by syys96
|
||||
|
||||
New Year’s resolution: Donate to 1 free software project every month
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,113 +0,0 @@
|
||||
A beginner’s guide to Raspberry Pi 3
|
||||
======
|
||||

|
||||
|
||||
This article is part of a weekly series where I'll create new projects using Raspberry Pi 3. The first article of the series focusses on getting you started and will cover the installation of Raspbian, with PIXEL desktop, setting up networking and some basics.
|
||||
|
||||
### What you need:
|
||||
|
||||
* A Raspberry Pi 3
|
||||
* A 5v 2mAh power supply with mini USB pin
|
||||
* Micro SD card with at least 8GB capacity
|
||||
* Wi-Fi or Ethernet cable
|
||||
* Heat sink
|
||||
* Keyboard and mouse
|
||||
* a PC monitor
|
||||
* A Mac or PC to prepare microSD card.
|
||||
|
||||
|
||||
|
||||
There are many Linux-based operating systems available for Raspberry Pi that you can install directly, but if you're new to the Pi, I suggest NOOBS, the official OS installer for Raspberry Pi that simplifies the process of installing an OS on the device.
|
||||
|
||||
Download NOOBS from [this link][1] on your system. It's a compressed .zip file. If you're on MacOS, just double click on it and MacOS will automatically uncompress the files. If you are on Windows, right-click on it, and select "extract here."
|
||||
|
||||
If you're running desktop Linux, then how to unzip it really depends on the desktop environment you are running, as different DEs have different ways of doing the same thing. So the easiest way is to use the command line.
|
||||
|
||||
`$ unzip NOOBS.zip`
|
||||
|
||||
Irrespective of the operating system, open the unzipped file and check if the file structure looks like this:
|
||||
|
||||
![content][3] Swapnil Bhartiya
|
||||
|
||||
Now plug the Micro SD card to your PC and format it to the FAT32 file system. On MacOS, use the Disk Utility tool and format the Micro SD card:
|
||||
|
||||
![format][4] Swapnil Bhartiya
|
||||
|
||||
On Windows, just right click on the card and choose the formatting option. If you're on desktop Linux, different DEs use different tools, and covering all the DEs is beyond the scope of this story. I have written a tutorial [using the command line interface on Linux][5] to format an SD card with Fat32 file system.
|
||||
|
||||
Once you have the card formatted in the Fat32 partition, just copy the content of the downloaded NOOBS directory into the root directory of the device. If you are on MacOS or Linux, just rsync the content of NOOBS to the SD card. Open Terminal app in MacOS or Linux and run the rsync command in this format:
|
||||
|
||||
`rsync -avzP /path_of_NOOBS /path_of_sdcard`
|
||||
|
||||
Make sure to select the root directory of the sd card. In my case (on MacOS), it was:
|
||||
|
||||
`rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/`
|
||||
|
||||
Or you can copy and paste the content. Just make sure that all the files inside the NOOBS directory are copied into the root directory of the Micro SD Card and not inside any sub-directory.
|
||||
|
||||
Now plug the Micro SD Card into the Raspberry Pi 3, connect the monitor, the keyboard and power supply. If you do have wired network, I recommend using it as you will get faster download speed to download and install the base operating system. The device will boot into NOOBS that offers a couple of distributions to install. Choose Raspbian from the first option and follow the on-screen instructions.
|
||||
|
||||
![raspi config][6] Swapnil Bhartiya
|
||||
|
||||
Once the installation is complete, Pi will reboot, and you will be greeted with Raspbian. Now it's time to configure it and run system updates. In most cases, we use Raspberry Pi in headless mode and manage it remotely over the networking using SSH. Which means you don't have to plug in a monitor or keyboard to manage your Pi.
|
||||
|
||||
First of all, we need to configure the network if you are using Wi-Fi. Click on the network icon on the top panel, and select the network from the list and provide it with the password.
|
||||
|
||||
![wireless][7] Swapnil Bhartiya
|
||||
|
||||
Congrats, you are connected wirelessly. Before we proceed with the next step, we need to find the IP address of the device so we can manage it remotely.
|
||||
|
||||
Open Terminal and run this command:
|
||||
|
||||
`ifconfig`
|
||||
|
||||
Now, note down the IP address of the device in the wlan0 section. It should be listed as "inet addr."
|
||||
|
||||
Now it's time to enable SSH and configure the system. Open the terminal on Pi and open raspi-config tool.
|
||||
|
||||
`sudo raspi-config`
|
||||
|
||||
The default user and password for Raspberry Pi is "pi" and "raspberry" respectively. You'll need the password for the above command. The first option of Raspi Config tool is to change the default password, and I heavily recommend changing the password, especially if you want to use it over the network.
|
||||
|
||||
The second option is to change the hostname, which can be useful if you have more than one Pi on the network. A hostname makes it easier to identify each device on the network.
|
||||
|
||||
Then go to Interfacing Options and enable Camera, SSH, and VNC. If you're using the device for an application that involves multimedia, such as a home theater system or PC, then you may also want to change the audio output option. By default the output is set to HDMI, but if you're using external speakers, you need to change the set-up. Go to the Advanced Option tab of Raspi Config tool, and go to Audio. There choose 3.5mm as the default out.
|
||||
|
||||
[Tip: Use arrow keys to navigate and then Enter key to choose. ]
|
||||
|
||||
Once all these changes are applied, the Pi will reboot. You can unplug the monitor and keyboard from your Pi as we will be managing it over the network. Now open Terminal on your local machine. If you're on Windows, you can use Putty or read my article to install Ubuntu Bash on Windows 10.
|
||||
|
||||
Then ssh into your system:
|
||||
|
||||
`ssh pi@IP_ADDRESS_OF_Pi`
|
||||
|
||||
In my case it was:
|
||||
|
||||
`ssh pi@10.0.0.161`
|
||||
|
||||
Provide it with the password and Eureka!, you are logged into your Pi and can now manage the device from a remote machine. If you want to manage your Raspberry Pi over the Internet, read my article on [enabling RealVNC on your machine][8].
|
||||
|
||||
In the next follow-up article, I will talk about using Raspberry Pi to manage your 3D printer remotely.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network.[Want to Join?][9]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3176488/linux/a-beginner-s-guide-to-raspberry-pi-3.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://www.raspberrypi.org/downloads/noobs/
|
||||
[2]:http://idgenterprise.selz.com
|
||||
[3]:https://images.techhive.com/images/article/2017/03/content-100711633-large.jpg
|
||||
[4]:https://images.techhive.com/images/article/2017/03/format-100711635-large.jpg
|
||||
[5]:http://www.cio.com/article/3176034/linux/how-to-format-an-sd-card-in-linux.html
|
||||
[6]:https://images.techhive.com/images/article/2017/03/raspi-config-100711634-large.jpg
|
||||
[7]:https://images.techhive.com/images/article/2017/03/wireless-100711636-large.jpeg
|
||||
[8]:http://www.infoworld.com/article/3171682/internet-of-things/how-to-access-your-raspberry-pi-remotely-over-the-internet.html
|
||||
[9]:https://www.infoworld.com/contributor-network/signup.html
|
||||
138
sources/tech/20170511 Working with VI editor - The Basics.md
Normal file
138
sources/tech/20170511 Working with VI editor - The Basics.md
Normal file
@ -0,0 +1,138 @@
|
||||
Working with VI editor : The Basics
|
||||
======
|
||||
VI editor is a powerful command line based text editor that was originally created for Unix but has since been ported to various Unix & Linux distributions. In Linux there exists another, advanced version of VI editor called VIM (also known as VI IMproved ). VIM only adds funtionalities to already powefrul VI editor, some of the added functionalities a
|
||||
|
||||
* Support for many more Linux distributions,
|
||||
|
||||
* Support for various coding languages like python, c++, perl etc with features like code folding , code highlighting etc
|
||||
|
||||
* Can be used to edit files over network protocols like ssh and http,
|
||||
|
||||
* Support to edit files inside a compressed archive,
|
||||
|
||||
* Allows screen to split for editing multiple files.
|
||||
|
||||
|
||||
|
||||
|
||||
Now let's discuss the commands/options that we can use with VI/VIM. For the purposes of this tutorial, we are going to use VI as an example but all the commands with VI can be used with VIM as well. But firstly we will start out with the two modes of VI text editor,
|
||||
|
||||
### Command Mode
|
||||
|
||||
This mode allows to handle tasks like saving files, executing a command within vi, copy/cut/paste operations, & tasks like finding/replacing. When in Insert mode, we can press escape to exit into command mode.
|
||||
|
||||
### Insert Mode
|
||||
|
||||
It's where we insert text into the file. To get into insert mode, we will press 'i' in command line mode.
|
||||
|
||||
### Creating a file
|
||||
|
||||
In order to create a file, use
|
||||
|
||||
```
|
||||
$ vi filename
|
||||
```
|
||||
|
||||
Once the file is created & opened, we will enter into what's called a command mode & to enter text into the file, we need to use insert mode. Let's learn in brief about these two modes,
|
||||
|
||||
### Exit out of Vi
|
||||
|
||||
To exit out of Vi from insert mode, we will first press 'Esc' key to exit into command mode & here we can perform following tasks to exit out of vi,
|
||||
|
||||
1. Exit without saving file- to exit out of vi command mode without saving of file, type : `:q!`
|
||||
|
||||
2. Save file & exit - To save a file & exit, type: `:wq`
|
||||
|
||||
Now let's discuss the commands/options that can be used in command mode.
|
||||
|
||||
### Cursor movement
|
||||
|
||||
Use the keys mentioned below to manipulate the cursor position
|
||||
|
||||
1. **k** moves cursor one line up
|
||||
|
||||
2. **j ** moves cursor one line down
|
||||
|
||||
3. **h ** moves cursor to left one character postion
|
||||
|
||||
4. **i** moves cursor to right one character position
|
||||
|
||||
|
||||
|
||||
|
||||
**Note :** If want to move multiple line up or down or left or right, we can use 4k or 5j, which will move cursor 4 lines up or 5 characters right respectively.
|
||||
|
||||
5. **0** cursor will be at begining of the line
|
||||
|
||||
6. **$** cursor will be at the end of a line
|
||||
|
||||
7. ** nG** moves to nth line of the file
|
||||
|
||||
8. **G** moves to last line of the file
|
||||
|
||||
9. **{ ** moves a paragraph back
|
||||
|
||||
10. **}** moves a paragraph forward
|
||||
|
||||
|
||||
|
||||
|
||||
There are several other options that can be used to manage the cursor movement but these should get the work done for you.
|
||||
|
||||
### Editing files
|
||||
|
||||
Now we will learn the options that can be used in command mode to change our mode to Insert mode for editing the files
|
||||
|
||||
1. **i** Inserts text before the current cursor location
|
||||
|
||||
2. **I** Inserts text at the beginning of the current line
|
||||
|
||||
3. ** a ** Inserts text after the current cursor location
|
||||
|
||||
4. **A ** Inserts text at the end of the current line
|
||||
|
||||
5. **o** Creates a new line for text entry below the cursor location
|
||||
|
||||
6. ** O** Creates a new line for text entry above the cursor location
|
||||
|
||||
|
||||
|
||||
|
||||
### Deleting file text
|
||||
|
||||
All of these commands will be excuted from command mode, so if you are in Insert mode exit out to command mode using the 'Esc' key
|
||||
|
||||
1. **dd** will delete the complete line of the cursor, can use a number like 2dd to delete next 2 lines after the cursor
|
||||
|
||||
2. **d$** deletes from cursor position till end of the line
|
||||
|
||||
3. **d^** deletes from cursor position till beginning of line
|
||||
|
||||
4. **dw** deletes from cursor to next word
|
||||
|
||||
|
||||
### Copy & paste commands
|
||||
|
||||
1. **yy** to yank or copy the current line. Can be used with a number to copy a number of lines
|
||||
|
||||
2. **p** paste the copied lines after cursor position
|
||||
|
||||
3. **P** paste the copied lines before the cursor postion
|
||||
|
||||
|
||||
|
||||
|
||||
These were some the basic operations that we can use with VI or VIM editor. In our future tutorials, we leanrn to perform some advanced operations with VI/VIM editors. If having any queries or comments, please leave them in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/working-vi-editor-basics/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
@ -0,0 +1,116 @@
|
||||
Working with Vi/Vim Editor : Advanced concepts
|
||||
======
|
||||
Earlier we have discussed some basics about VI/VIM editor but VI & VIM are both very powerful editors and there are many other functionalities that can be used with these editors. In this tutorial, we are going to learn some advanced uses of VI/VIM editor.
|
||||
|
||||
( **Recommended Read** : [Working with VI editor : The Basics ][1])
|
||||
|
||||
## Opening multiple files with VI/VIM editor
|
||||
|
||||
To open multiple files, command would be same as is for a single file; we just add the file name for second file as well.
|
||||
|
||||
```
|
||||
$ vi file1 file2 file 3
|
||||
```
|
||||
|
||||
Now to browse to next file, we can use
|
||||
|
||||
```
|
||||
$ :n
|
||||
```
|
||||
|
||||
or we can also use
|
||||
|
||||
```
|
||||
$ :e filename
|
||||
```
|
||||
|
||||
## Run external commands inside the editor
|
||||
|
||||
We can run external Linux/Unix commands from inside the vi editor, i.e. without exiting the editor. To issue a command from editor, go back to Command Mode if in Insert mode & we use the BANG i.e. '!' followed by the command that needs to be used. Syntax for running a command is,
|
||||
|
||||
```
|
||||
$ :! command
|
||||
```
|
||||
|
||||
An example for this would be
|
||||
|
||||
```
|
||||
$ :! df -H
|
||||
```
|
||||
|
||||
## Searching for a pattern
|
||||
|
||||
To search for a word or pattern in the text file, we use following two commands in command mode,
|
||||
|
||||
* command '/' searches the pattern in forward direction
|
||||
|
||||
* command '?' searched the pattern in backward direction
|
||||
|
||||
|
||||
Both of these commands are used for same purpose, only difference being the direction they search in. An example would be,
|
||||
|
||||
`$ :/ search pattern` (If at beginning of the file)
|
||||
|
||||
`$ :/ search pattern` (If at the end of the file)
|
||||
|
||||
## Searching & replacing a pattern
|
||||
|
||||
We might be required to search & replace a word or a pattern from our text files. So rather than finding the occurrence of word from whole text file & replace it, we can issue a command from the command mode to replace the word automatically. Syntax for using search & replacement is,
|
||||
|
||||
```
|
||||
$ :s/pattern_to_be_found/New_pattern/g
|
||||
```
|
||||
|
||||
Suppose we want to find word "alpha" & replace it with word "beta", the command would be
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/g
|
||||
```
|
||||
|
||||
If we want to only replace the first occurrence of word "alpha", then the command would be
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/
|
||||
```
|
||||
|
||||
## Using Set commands
|
||||
|
||||
We can also customize the behaviour, the and feel of the vi/vim editor by using the set command. Here is a list of some options that can be use set command to modify the behaviour of vi/vim editor,
|
||||
|
||||
`$ :set ic ` ignores cases while searching
|
||||
|
||||
`$ :set smartcase ` enforce case sensitive search
|
||||
|
||||
`$ :set nu` display line number at the begining of the line
|
||||
|
||||
`$ :set hlsearch ` highlights the matching words
|
||||
|
||||
`$ : set ro ` change the file type to read only
|
||||
|
||||
`$ : set term ` prints the terminal type
|
||||
|
||||
`$ : set ai ` sets auto-indent
|
||||
|
||||
`$ :set noai ` unsets the auto-indent
|
||||
|
||||
Some other commands to modify vi editors are,
|
||||
|
||||
`$ :colorscheme ` its used to change the color scheme for the editor. (for VIM editor only)
|
||||
|
||||
`$ :syntax on ` will turn on the color syntax for .xml, .html files etc. (for VIM editor only)
|
||||
|
||||
This complete our tutorial, do mention your queries/questions or suggestions in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/working-vi-editor-basics/
|
||||
@ -1,7 +1,10 @@
|
||||
translating by Flowsnow
|
||||
|
||||
What Are Bitcoins?
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
**[Bitcoin][1]** is a digital currency or electronic cash the relies on peer to peer technology for completing transactions. Since peer to peer technology is used as the major network, bitcoins provide a community like managed economy. This is to mean, bitcoins eliminate the centralized authority way of managing currency and promotes community management of currency. Most Also of the software related to bitcoin mining and managing of bitcoin digital cash is open source.
|
||||
|
||||
The first Bitcoin software was developed by Satoshi Nakamoto and it's based on open source cryptographic protocol. Bitcoins smallest unit is known as the Satoshi which is basically one-hundredth millionth of a single bitcoin (0.00000001 BTC).
|
||||
|
||||
@ -1,81 +0,0 @@
|
||||
translating by lujun9972
|
||||
Simulate System Loads
|
||||
======
|
||||
Sysadmins often need to discover how the performance of an application is affected when the system is under certain types of load. This means that an artificial load must be re-created. It is, of course, possible to install dedicated tools to do this but this option isn't always desirable or possible.
|
||||
|
||||
Every Linux distribution comes with all the tools needed to create load. They are not as configurable as dedicated tools but they will always be present and you already know how to use them.
|
||||
|
||||
### CPU
|
||||
|
||||
The following command will generate a CPU load by compressing a stream of random data and then sending it to `/dev/null`:
|
||||
```
|
||||
cat /dev/urandom | gzip -9 > /dev/null
|
||||
|
||||
```
|
||||
|
||||
If you require a greater load or have a multi-core system simply keep compressing and decompressing the data as many times as you need e.g.:
|
||||
```
|
||||
cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
|
||||
|
||||
```
|
||||
|
||||
Use `CTRL+C` to end the process.
|
||||
|
||||
### RAM
|
||||
|
||||
The following process will reduce the amount of free RAM. It does this by creating a file system in RAM and then writing files to it. You can use up as much RAM as you need to by simply writing more files.
|
||||
|
||||
First, create a mount point then mount a `ramfs` filesystem there:
|
||||
```
|
||||
mkdir z
|
||||
mount -t ramfs ramfs z/
|
||||
|
||||
```
|
||||
|
||||
Then, use `dd` to create a file under that directory. Here a 128MB file is created:
|
||||
```
|
||||
dd if=/dev/zero of=z/file bs=1M count=128
|
||||
|
||||
```
|
||||
|
||||
The size of the file can be set by changing the following operands:
|
||||
|
||||
* **bs=** Block Size. This can be set to any number followed **B** for bytes, **K** for kilobytes, **M** for megabytes or **G** for gigabytes.
|
||||
* **count=** The number of blocks to write.
|
||||
|
||||
|
||||
|
||||
### Disk
|
||||
|
||||
We will create disk I/O by firstly creating a file, and then use a for loop to repeatedly copy it.
|
||||
|
||||
This command uses `dd` to generate a 1GB file of zeros:
|
||||
```
|
||||
dd if=/dev/zero of=loadfile bs=1M count=1024
|
||||
|
||||
```
|
||||
|
||||
The following command starts a for loop that runs 10 times. Each time it runs it will copy `loadfile` over `loadfile1`:
|
||||
```
|
||||
for i in {1..10}; do cp loadfile loadfile1; done
|
||||
|
||||
```
|
||||
|
||||
If you want it to run for a longer or shorter time change the second number in `{1..10}`.
|
||||
|
||||
If you prefer the process to run forever until you kill it with `CTRL+C` use the following command:
|
||||
```
|
||||
while true; do cp loadfile loadfile1; done
|
||||
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/create-system-load/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
@ -1,61 +0,0 @@
|
||||
translating by lujun9972
|
||||
The most important Firefox command line options
|
||||
======
|
||||
The Firefox web browser supports a number of command line options that it can be run with to customize startup of the web browser.
|
||||
|
||||
You may have come upon some of them in the past, for instance the command -P "profile name" to start the browser with the specified profile, or -private to start a new private browsing session.
|
||||
|
||||
The following guide lists important command line options for Firefox. It is not a complete list of all available options, as many are used only for specific purposes that have little to no value to users of the browser.
|
||||
|
||||
You find the [complete][1] listing of command line options on the Firefox Developer website. Note that many of the command line options work in other Mozilla-based products, even third-party programs, as well.
|
||||
|
||||
### Important Firefox command line options
|
||||
|
||||
![firefox command line][2]
|
||||
|
||||
**Profile specific options**
|
||||
|
||||
* **-CreateProfile profile name** -- This creates a new user profile, but won't start it right away.
|
||||
* **-CreateProfile "profile name profile dir"** -- Same as above, but will specify a custom profile directory on top of that.
|
||||
* **-ProfileManager** , or **-P** -- Opens the built-in profile manager.
|
||||
* - **P "profile name"** -- Starts Firefox with the specified profile. Profile manager is opened if the specified profile does not exist. Works only if no other instance of Firefox is running.
|
||||
* **-no-remote** -- Add this to the -P commands to create a new instance of the browser. This lets you run multiple profiles at the same time.
|
||||
|
||||
|
||||
|
||||
**Browser specific options**
|
||||
|
||||
* **-headless** -- Start Firefox in headless mode. Requires Firefox 55 on Linux, Firefox 56 on Windows and Mac OS X.
|
||||
* **-new-tab URL** -- loads the specified URL in a new tab in Firefox.
|
||||
* **-new-window URL** -- loads the specified URL in a new Firefox window.
|
||||
* **-private** -- Launches Firefox in private browsing mode. Can be used to run Firefox in private browsing mode all the time.
|
||||
* **-private-window** -- Open a private window.
|
||||
* **-private-window URL** -- Open the URL in a new private window. If a private browsing window is open already, open the URL in that window instead.
|
||||
* **-search term** -- Run the search using the default Firefox search engine.
|
||||
* - **url URL** -- Load the URL in a new tab or window. Can be run without -url, and multiple URLs separated by space can be opened using the command.
|
||||
|
||||
|
||||
|
||||
Other options
|
||||
|
||||
* **-safe-mode** -- Starts Firefox in Safe Mode. You may also hold down the Shift-key while opening Firefox to start the browser in Safe Mode.
|
||||
* **-devtools** -- Start Firefox with Developer Tools loaded and open.
|
||||
* **-inspector URL** -- Inspect the specified address in the DOM Inspector.
|
||||
* **-jsconsole** -- Start Firefox with the Browser Console.
|
||||
* **-tray** -- Start Firefox minimized.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/
|
||||
|
||||
作者:[Martin Brinkmann][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ghacks.net/author/martin/
|
||||
[1]:https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options
|
||||
@ -1,155 +0,0 @@
|
||||
translating by lujun9972
|
||||
Install and Use YouTube-DL on Ubuntu 16.04
|
||||
======
|
||||
|
||||
Youtube-dl is a free and open source command line video download tools that can be used to download video from Youtube and other websites like, Facebook, Dailymotion, Google Video, Yahoo and much more. It is based on pygtk and requires Python to run this software. It supports many operating system including, Windows, Mac and Unix. Youtube-dl supports resuming interrupted downloads, channel or playlist download, add custom title, proxy and much more.
|
||||
|
||||
In this tutorial, we will learn how to install and use Youtube-dl and Youtube-dlg on Ubuntu 16.04. We will also learn how to download Youtube video in different quality and formats.
|
||||
|
||||
### Requirements
|
||||
|
||||
* A server running Ubuntu 16.04.
|
||||
* A non-root user with sudo privileges setup on your server.
|
||||
|
||||
|
||||
|
||||
Let's start by updating your system to the latest version with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
After updating, restart the system to apply all these changes.
|
||||
|
||||
### Install Youtube-dl
|
||||
|
||||
By default, Youtube-dl is not available in the Ubuntu-16.04 repository. So you will need to download it from their official website. You can download it with the curl command:
|
||||
|
||||
First, install curl with the following command:
|
||||
|
||||
sudo apt-get install curl -y
|
||||
|
||||
Next, download the youtube-dl binary:
|
||||
|
||||
curl -L https://yt-dl.org/latest/youtube-dl -o /usr/bin/youtube-dl
|
||||
|
||||
Next, change the permission of the youtube-dl binary package with the following command:
|
||||
|
||||
sudo chmod 755 /usr/bin/youtube-dl
|
||||
|
||||
Once youtube-dl is installed, you can proceed to the next step.
|
||||
|
||||
### Use Youtube-dl
|
||||
|
||||
You can list all the available options with youtube-dl, run the following command:
|
||||
|
||||
youtube-dl --h
|
||||
|
||||
Youtube-dl supports many Video formats such as Mp4, WebM, 3gp, and FLV. You can list all the available formats for specific Video with the following command:
|
||||
|
||||
youtube-dl -F https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
|
||||
You should see the all the available formats for this video as below:
|
||||
```
|
||||
[info] Available formats for j_JgXJ-apXs:
|
||||
format code extension resolution note
|
||||
139 m4a audio only DASH audio 56k , m4a_dash container, [[email protected]][1] 48k (22050Hz), 756.44KiB
|
||||
249 webm audio only DASH audio 56k , opus @ 50k, 724.28KiB
|
||||
250 webm audio only DASH audio 69k , opus @ 70k, 902.75KiB
|
||||
171 webm audio only DASH audio 110k , [[email protected]][1], 1.32MiB
|
||||
251 webm audio only DASH audio 122k , opus @160k, 1.57MiB
|
||||
140 m4a audio only DASH audio 146k , m4a_dash container, [[email protected]][1] (44100Hz), 1.97MiB
|
||||
278 webm 256x144 144p 97k , webm container, vp9, 24fps, video only, 1.33MiB
|
||||
160 mp4 256x144 DASH video 102k , avc1.4d400c, 24fps, video only, 731.53KiB
|
||||
133 mp4 426x240 DASH video 174k , avc1.4d4015, 24fps, video only, 1.36MiB
|
||||
242 webm 426x240 240p 221k , vp9, 24fps, video only, 1.74MiB
|
||||
134 mp4 640x360 DASH video 369k , avc1.4d401e, 24fps, video only, 2.90MiB
|
||||
243 webm 640x360 360p 500k , vp9, 24fps, video only, 4.15MiB
|
||||
135 mp4 854x480 DASH video 746k , avc1.4d401e, 24fps, video only, 6.11MiB
|
||||
244 webm 854x480 480p 844k , vp9, 24fps, video only, 7.27MiB
|
||||
247 webm 1280x720 720p 1155k , vp9, 24fps, video only, 9.21MiB
|
||||
136 mp4 1280x720 DASH video 1300k , avc1.4d401f, 24fps, video only, 9.66MiB
|
||||
248 webm 1920x1080 1080p 1732k , vp9, 24fps, video only, 14.24MiB
|
||||
137 mp4 1920x1080 DASH video 2217k , avc1.640028, 24fps, video only, 15.28MiB
|
||||
17 3gp 176x144 small , mp4v.20.3, [[email protected]][1] 24k
|
||||
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
|
||||
43 webm 640x360 medium , vp8.0, [[email protected]][1]
|
||||
18 mp4 640x360 medium , avc1.42001E, [[email protected]][1] 96k
|
||||
22 mp4 1280x720 hd720 , avc1.64001F, [[email protected]][1] (best)
|
||||
|
||||
```
|
||||
|
||||
Next, choose any format you want to download with the flag -f as shown below:
|
||||
|
||||
youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
|
||||
This command will download the Video in mp4 format at 640x360 resolution:
|
||||
```
|
||||
[youtube] j_JgXJ-apXs: Downloading webpage
|
||||
[youtube] j_JgXJ-apXs: Downloading video info webpage
|
||||
[youtube] j_JgXJ-apXs: Extracting video information
|
||||
[youtube] j_JgXJ-apXs: Downloading MPD manifest
|
||||
[download] Destination: B.A. PASS 2 Trailer no 2 _ Filmybox-j_JgXJ-apXs.mp4
|
||||
[download] 100% of 6.90MiB in 00:47
|
||||
|
||||
```
|
||||
|
||||
If you want to download Youtube video in mp3 audio format, then it is also possible with the following command:
|
||||
|
||||
youtube-dl https://www.youtube.com/watch?v=j_JgXJ-apXs -x --audio-format mp3
|
||||
|
||||
You can download all the videos of specific channels by appending the channel's URL as shown below:
|
||||
|
||||
youtube-dl -citw https://www.youtube.com/channel/UCatfiM69M9ZnNhOzy0jZ41A
|
||||
|
||||
If your network is behind the proxy, then you can download the video using --proxy flag as shown below:
|
||||
|
||||
youtube-dl --proxy http://proxy-ip:port https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
|
||||
To download the list of many Youtube videos with the single command, then first save all the Youtube video URL in a file called youtube-list.txt and run the following command to download all the videos:
|
||||
|
||||
youtube-dl -a youtube-list.txt
|
||||
|
||||
### Install Youtube-dl GUI
|
||||
|
||||
If you are looking for a graphical tool for youtube-dl, then youtube-dlg is the best choice for you. youtube-dlg is a free and open source tool for youtube-dl written in wxPython.
|
||||
|
||||
By default, this tool is not available in Ubuntu 16.04 repository. So you will need to add PPA for that.
|
||||
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
|
||||
Next, update your package repository and install youtube-dlg with the following command:
|
||||
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install youtube-dlg -y
|
||||
|
||||
Once Youtube-dl is installed, you can launch it from Unity Dash as shown below:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
[![][4]][5]
|
||||
|
||||
You can now easily download any Youtube video as you wish just paste their URL in the URL field shown in the above image. Youtube-dlg is very useful for those people who don't know command line.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Congratulations! You have successfully installed youtube-dl and youtube-dlg on Ubuntu 16.04 server. You can now easily download any videos from Youtube and any youtube-dl supported sites in any formats and any size.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-and-use-youtube-dl-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/Screenshot-of-youtube-dl-dash.png
|
||||
[3]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dash.png
|
||||
[4]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/Screenshot-of-youtube-dl-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dashboard.png
|
||||
@ -1,3 +1,5 @@
|
||||
translated by hopefully2333
|
||||
|
||||
Meltdown and Spectre Linux Kernel Status
|
||||
============================================================
|
||||
|
||||
|
||||
80
sources/tech/20180108 Debbugs Versioning- Merging.md
Normal file
80
sources/tech/20180108 Debbugs Versioning- Merging.md
Normal file
@ -0,0 +1,80 @@
|
||||
Debbugs Versioning: Merging
|
||||
======
|
||||
One of the key features of Debbugs, the [bug tracking system Debian uses][1], is its ability to figure out which bugs apply to which versions of a package by tracking package uploads. This system generally works well, but when a package maintainer's workflow doesn't match the assumptions of Debbugs, unexpected things can happen. In this post, I'm going to:
|
||||
|
||||
1. introduce how Debbugs tracks versions
|
||||
2. provide an example of a merge-based workflow which Debbugs doesn't handle well
|
||||
3. provide some suggestions on what to do in this case
|
||||
|
||||
|
||||
|
||||
### Debbugs Versioning
|
||||
|
||||
Debbugs tracks versions using a set of one or more [rooted trees][2] which it builds from the ordering of debian/changelog entries. In the simplist case, every upload of a Debian package has changelogs in the same order, and each upload adds just one version. For example, in the case of [dgit][3], to start with the package has this (abridged) version tree:
|
||||
|
||||
![][4]
|
||||
|
||||
the next upload, 3.13, has a changelog with this version ordering: `3.13 3.12 3.11 3.10`, which causes the 3.13 version to be added as a descendant of 3.12, and the version tree now looks like this:
|
||||
|
||||
![][5]
|
||||
|
||||
dgit is being developed while also being used, so new versions with potentially disruptive changes are uploaded to experimental while production versions are uploaded to unstable. For example, the 4.0 experimental upload was based on the 3.10 version, with the changelog ordering `4.0 3.10`. The tree now has two branches, but everything seems as you would expect:
|
||||
|
||||
![][6]
|
||||
|
||||
### Merge based workflows
|
||||
|
||||
Bugfixes in the maintenance version of dgit also are made to the experimental package by merging changes from the production version using git. In this case, some changes which were present in the 3.12 and 3.11 versions are merged using git, corresponds to a git merge flow like this:
|
||||
|
||||
![][7]
|
||||
|
||||
If an upload is prepared with changelog ordering `4.1 4.0 3.12 3.11 3.10`, Debbugs combines this new changelog ordering with the previously known tree, to produce this version tree:
|
||||
|
||||
![][8]
|
||||
|
||||
This looks a bit odd; what happened? Debbugs walks through the new changelog, connecting each of the new versions to the previous version if and only if that version is not already an ancestor of the new version. Because the changelog says that 3.12 is the ancestor of 4.0, that's where the `4.1 4.0` version tree is connected.
|
||||
|
||||
Now, when 4.2 is uploaded, it has the changelog ordering (based on time) `4.2 3.13 4.1 4.0 3.12 3.11 3.10`, which corresponds to this git merge flow:
|
||||
|
||||
![][9]
|
||||
|
||||
Debbugs adds in 3.13 as an ancestor of 4.2, and because 4.1 was not an ancestor of 3.13 in the previous tree, 4.1 is added as an ancestor of 3.13. This results in the following graph:
|
||||
|
||||
![][10]
|
||||
|
||||
Which doesn't seem particularly helpful, because
|
||||
|
||||
![][11]
|
||||
|
||||
is probably the tree that more closely resembles reality.
|
||||
|
||||
### Suggestions on what to do
|
||||
|
||||
Why does this even matter? Bugs which are found in 3.11, and fixed in 3.12 now show up as being found in 4.0 after the 4.1 release, though they weren't found in 4.0 before that release. It also means that 3.13 now shows up as having all of the bugs fixed in 4.2, which might not be what is meant.
|
||||
|
||||
To avoid this, my suggestion is to order the entries in changelogs in the same order that the version graph should be traversed from the leaf version you are releasing to the root. So if the previous version tree is what is wanted, 3.13 should have a changelog with ordering `3.13 3.12 3.11 3.10`, and 4.2 should have a changelog with ordering `4.2 4.1 4.0 3.10`.
|
||||
|
||||
What about making the BTS support DAGs which are not trees? I think something like this would be useful, but I don't personally have a good idea on how this could be specified using the changelog or how bug fixed/found/absent should be propagated in the DAG. If you have better ideas, email me!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.donarmstrong.com/posts/debbugs_merge_versions/
|
||||
|
||||
作者:[Don Armstrong][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.donarmstrong.com/
|
||||
[1]:https://bugs.debian.org
|
||||
[2]:https://en.wikipedia.org/wiki/Tree_%28graph_theory%29#Forest
|
||||
[3]:https://packages.debian.org/dgit
|
||||
[4]:https://www.donarmstrong.com/graph-5d3f559f0fb850f47a5ea54c62b96da18bba46b8.png
|
||||
[5]:https://www.donarmstrong.com/graph-04a0cac92e522aa8816397090f0a23ef51e49379.png
|
||||
[6]:https://www.donarmstrong.com/graph-65493d1d56cbf3a32fc6e061d4d933f609d0dd9d.png
|
||||
[7]:https://www.donarmstrong.com/graph-cc7df2f6e47656a87ca10d313e65a8e3d55fb937.png
|
||||
[8]:https://www.donarmstrong.com/graph-94b259ce6dd4d28c04d692c72f6e021622b5b33a.png
|
||||
[9]:https://www.donarmstrong.com/graph-72f98ac7aa28e7dd40aaccf7742359f5dd2de378.png
|
||||
[10]:https://www.donarmstrong.com/graph-70ebe94be503db5ba97c4693f9e00fbb1dc3c9f7.png
|
||||
[11]:https://www.donarmstrong.com/graph-3f8db089ab21b48bcae9d536c1887b3bc6fc4bcb.png
|
||||
@ -0,0 +1,111 @@
|
||||
How to use syslog-ng to collect logs from remote Linux machines
|
||||
======
|
||||
![linuxhero.jpg][1]
|
||||
|
||||
Image: Jack Wallen
|
||||
|
||||
Let's say your data center is filled with Linux servers and you need to administer them all. Part of that administration job is viewing log files. But if you're looking at numerous machines, that means logging into each machine individually, reading log files, and then moving onto the next. Depending upon how many machines you have, that can take a large chunk of time from your day.
|
||||
|
||||
Or, you could set up a single Linux machine to collect those logs. That would make your day considerably more efficient. To do this, you could opt for a number of different system, one of which is syslog-ng.
|
||||
|
||||
The problem with syslog-ng is that the documentation isn't the easiest to comb through. However, I've taken care of that and am going to lay out the installation and configuration in such a way that you can have syslog-ng up and running in no time. I'll be demonstrating on Ubuntu Server 16.04 on a two system setup:
|
||||
|
||||
* UBUNTUSERVERVM at IP address 192.168.1.118 will serve as log collector
|
||||
* UBUNTUSERVERVM2 will serve as a client, sending log files to the collector
|
||||
|
||||
|
||||
|
||||
Let's install and configure.
|
||||
|
||||
## Installation
|
||||
|
||||
The installation is simple. I'll be installing from the standard repositories, in order to make this as easy as possible. To do this, open up a terminal window and issue the command:
|
||||
```
|
||||
sudo apt install syslog-ng
|
||||
```
|
||||
|
||||
You must issue the above command on both collector and client. Once that's installed, you're ready to configure.
|
||||
|
||||
## Configuration for the collector
|
||||
|
||||
We'll start with the configuration of the log collector. The configuration file is /etc/syslog-ng/syslog-ng.conf. Out of the box, syslog-ng includes a configuration file. We're not going to use that. Let's rename the default config file with the command sudo mv /etc/syslog-ng/syslog-ng.conf /etc/syslog-ng/syslog-ng.conf.BAK. Now create a new configuration file with the command sudo nano /etc/syslog/syslog-ng.conf. In that file add the following:
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
options {
|
||||
time-reap(30);
|
||||
mark-freq(10);
|
||||
keep-hostname(yes);
|
||||
};
|
||||
source s_local { system(); internal(); };
|
||||
source s_network {
|
||||
syslog(transport(tcp) port(514));
|
||||
};
|
||||
destination d_local {
|
||||
file("/var/log/syslog-ng/messages_${HOST}"); };
|
||||
destination d_logs {
|
||||
file(
|
||||
"/var/log/syslog-ng/logs.txt"
|
||||
owner("root")
|
||||
group("root")
|
||||
perm(0777)
|
||||
); };
|
||||
log { source(s_local); source(s_network); destination(d_logs); };
|
||||
```
|
||||
|
||||
Do note that we are working with port 514, so you'll need to make sure it is accessible on your network.
|
||||
|
||||
Save and close the file. The above configuration will dump the desired log files (denoted with system() and internal()) into /var/log/syslog-ng/logs.txt. Because of this, you need to create the directory and file with the following commands:
|
||||
```
|
||||
sudo mkdir /var/log/syslog-ng
|
||||
sudo touch /var/log/syslog-ng/logs.txt
|
||||
```
|
||||
|
||||
Start and enable syslog-ng with the commands:
|
||||
```
|
||||
sudo systemctl start syslog-ng
|
||||
sudo systemctl enable syslog-ng
|
||||
```
|
||||
|
||||
## Configuration for the client
|
||||
|
||||
We're going to do the very same thing on the client (moving the default configuration file and creating a new configuration file). Copy the following text into the new client configuration file:
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
source s_local { system(); internal(); };
|
||||
destination d_syslog_tcp {
|
||||
syslog("192.168.1.118" transport("tcp") port(514)); };
|
||||
log { source(s_local);destination(d_syslog_tcp); };
|
||||
```
|
||||
|
||||
Note: Change the IP address to match the address of your collector server.
|
||||
|
||||
Save and close that file. Start and enable syslog-ng in the same fashion you did on the collector.
|
||||
|
||||
## View the log files
|
||||
|
||||
Head back to your collector and issue the command sudo tail -f /var/log/syslog-ng/logs.txt. You should see output that includes log entries for both collector and client ( **Figure A** ).
|
||||
|
||||
**Figure A**
|
||||
|
||||
![Figure A][3]
|
||||
|
||||
Congratulations, syslog-ng is working. You can now log into your collector to view logs from both the local machine and the remote client. If you have more Linux servers in your data center, walk through the process of installing syslog-ng and setting each of them up as a client to send their logs to the collector, so you no longer have to log into individual machines to view logs.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.techrepublic.com/article/how-to-use-syslog-ng-to-collect-logs-from-remote-linux-machines/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://tr1.cbsistatic.com/hub/i/r/2017/01/11/51204409-68e0-49b8-a637-01af26be85f6/resize/770x/688dfedad4ed30ec4baf548c2adb8cd4/linuxhero.jpg
|
||||
[3]:https://tr4.cbsistatic.com/hub/i/2018/01/09/6a24e5c0-6a29-46d3-8a66-bc72747b5beb/6f94d3e6c6c2121fab6223ed9d8c6aa6/syslognga.jpg
|
||||
@ -0,0 +1,143 @@
|
||||
translating by lujun9972
|
||||
Linux size Command Tutorial for Beginners (6 Examples)
|
||||
======
|
||||
|
||||
As some of you might already know, an object or executable file in Linux consists of several sections (like txt and data). In case you want to know the size of each section, there exists a command line utility - dubbed **size** \- that provides you this information. In this tutorial, we will discuss the basics of this tool using some easy to understand examples.
|
||||
|
||||
But before we do that, it's worth mentioning that all examples mentioned in this article have been tested on Ubuntu 16.04LTS.
|
||||
|
||||
## Linux size command
|
||||
|
||||
The size command basically lists section sizes as well as total size for the input object file(s). Here's the syntax for the command:
|
||||
```
|
||||
size [-A|-B|--format=compatibility]
|
||||
[--help]
|
||||
[-d|-o|-x|--radix=number]
|
||||
[--common]
|
||||
[-t|--totals]
|
||||
[--target=bfdname] [-V|--version]
|
||||
[objfile...]
|
||||
```
|
||||
|
||||
And here's how the man page describes this utility:
|
||||
```
|
||||
The GNU size utility lists the section sizes---and the total size---for each of the object or archive files objfile in its argument list. By default, one line of output is generated for each object file or each module in an archive.
|
||||
|
||||
objfile... are the object files to be examined. If none are specified, the file "a.out" will be used.
|
||||
```
|
||||
|
||||
Following are some Q&A-styled examples that'll give you a better idea about how the size command works.
|
||||
|
||||
## Q1. How to use size command?
|
||||
|
||||
Basic usage of size is very simple. All you have to do is to pass the object/executable file name as input to the tool. Following is an example:
|
||||
|
||||
```
|
||||
size apl
|
||||
```
|
||||
|
||||
Following is the output the above command produced on our system:
|
||||
|
||||
[![How to use size command][1]][2]
|
||||
|
||||
The first three entries are for text, data, and bss sections, with their corresponding sizes. Then comes the total in decimal and hexadecimal formats. And finally, the last entry is for the filename.
|
||||
|
||||
## Q2. How to switch between different output formats?
|
||||
|
||||
The default output format, the man page for size says, is similar to the Berkeley's format. However, if you want, you can go for System V convention as well. For this, you'll have to use the **\--format** option with SysV as value.
|
||||
|
||||
```
|
||||
size apl --format=SysV
|
||||
```
|
||||
|
||||
Here's the output in this case:
|
||||
|
||||
[![How to switch between different output formats][3]][4]
|
||||
|
||||
## Q3. How to switch between different size units?
|
||||
|
||||
By default, the size of sections is displayed in decimal. However, if you want, you can have this information on octal as well as hexadecimal. For this, use the **-o** and **-x** command line options.
|
||||
|
||||
[![How to switch between different size units][5]][6]
|
||||
|
||||
Here's what the man page says about these options:
|
||||
```
|
||||
-d
|
||||
-o
|
||||
-x
|
||||
--radix=number
|
||||
|
||||
Using one of these options, you can control whether the size of each section is given in decimal
|
||||
(-d, or --radix=10); octal (-o, or --radix=8); or hexadecimal (-x, or --radix=16). In
|
||||
--radix=number, only the three values (8, 10, 16) are supported. The total size is always given in
|
||||
two radices; decimal and hexadecimal for -d or -x output, or octal and hexadecimal if you're using
|
||||
-o.
|
||||
```
|
||||
|
||||
## Q4. How to make size command show totals of all object files?
|
||||
|
||||
If you are using size to find out section sizes for multiple files in one go, then if you want, you can also have the tool provide totals of all column values. You can enable this feature using the **-t** command line option.
|
||||
|
||||
```
|
||||
size -t [file1] [file2] ...
|
||||
```
|
||||
|
||||
The following screenshot shows this command line option in action:
|
||||
|
||||
[![How to make size command show totals of all object files][7]][8]
|
||||
|
||||
The last row in the output has been added by the **-t** command line option.
|
||||
|
||||
## Q5. How to make size print total size of common symbols in each file?
|
||||
|
||||
If you are running the size command with multiple input files, and want the command to display common symbols in each file, then you can do this with the **\--common** command line option.
|
||||
|
||||
```
|
||||
size --common [file1] [file2] ...
|
||||
```
|
||||
|
||||
It's also worth mentioning that when using Berkeley format these are included in the bss size.
|
||||
|
||||
## Q6. What are the other available command line options?
|
||||
|
||||
Aside from the ones discussed until now, size also offers some generic command line options like **-v** (for version info) and **-h** (for summary of eligible arguments and options)
|
||||
|
||||
[![What are the other available command line options][9]][10]
|
||||
|
||||
In addition, you can also make size read command-line options from a file. This you can do using the **@file** option. Following are some details related to this option:
|
||||
```
|
||||
The options read are inserted in place of the original @file option. If file does not exist, or
|
||||
cannot be read, then the option will be treated literally, and not removed. Options in file are
|
||||
separated by whitespace. A whitespace character may be included in an option by surrounding the
|
||||
entire option in either single or double quotes. Any character (including a backslash) may be
|
||||
included by prefixing the character to be included with a backslash. The file may itself contain
|
||||
additional @file options; any such options will be processed recursively.
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
|
||||
One thing is clear, the size command isn't for everybody. It's aimed at only those who deal with the structure of object/executable files in Linux. So if you are among the target audience, practice the options we've discussed here, and you should be ready to use the tool on daily basis. For more information on size, head to its [man page][11].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-size-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/size-basic-usage.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/size-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/size-format-option.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/size-format-option.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/size-o-x-options.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/size-o-x-options.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/size-t-option.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/size-t-option.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/size-v-x1.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/size-v-x1.png
|
||||
[11]:https://linux.die.net/man/1/size
|
||||
@ -0,0 +1,155 @@
|
||||
How to install/update Intel microcode firmware on Linux
|
||||
======
|
||||
|
||||
|
||||
I am a new Linux sysadmin. How do I install or update microcode firmware for Intel/AMD CPUs on Linux using the command line option?
|
||||
|
||||
|
||||
A microcode is nothing but CPU firmware provided by Intel or AMD. The Linux kernel can update the CPU's firmware without the BIOS update at boot time. Processor microcode is stored in RAM and kernel update the microcode during every boot. These microcode updates from Intel/AMD needed to fix bugs or apply errata to avoid CPU bugs. This page shows how to install AMD or Intel microcode update using package manager or processor microcode updates supplied by Intel on Linux.
|
||||
|
||||
## How to find out current status of microcode
|
||||
|
||||
|
||||
Run the following command as root user:
|
||||
`# dmesg | grep microcode`
|
||||
Sample outputs:
|
||||
|
||||
[![Verify microcode update on a CentOS RHEL Fedora Ubuntu Debian Linux][1]][1]
|
||||
|
||||
Please note that it is entirely possible that there is no microcode update available for your CPU. In that case it will look as follows:
|
||||
```
|
||||
[ 0.952699] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 0.952773] microcode: Microcode Update Driver: v2.2.
|
||||
|
||||
```
|
||||
|
||||
## How to install Intel microcode firmware on Linux using a package manager
|
||||
|
||||
Tool to transform and deploy CPU microcode update for x86/amd64 comes with Linux. The procedure to install AMD or Intel microcode firmware on Linux is as follows:
|
||||
|
||||
1. Open the terminal app
|
||||
2. Debian/Ubuntu Linux user type: **sudo apt install intel-microcode**
|
||||
3. CentOS/RHEL Linux user type: **sudo yum install microcode_ctl**
|
||||
|
||||
|
||||
|
||||
The package names are as follows for popular Linux distros:
|
||||
|
||||
* microcode_ctl and linux-firmware - CentOS/RHEL microcode update package
|
||||
* intel-microcode - Debian/Ubuntu and clones microcode update package for Intel CPUS
|
||||
* amd64-microcode - Debian/Ubuntu and clones microcode firmware for AMD CPUs
|
||||
* linux-firmware - Arch Linux microcode firmware for AMD CPUs (installed by default and no action is needed on your part)
|
||||
* intel-ucode - Arch Linux microcode firmware for Intel CPUs
|
||||
* microcode_ctl and ucode-intel - Suse/OpenSUSE Linux microcode update package
|
||||
|
||||
|
||||
|
||||
**Warning** : In some cases, microcode update may cause boot issues such as server getting hang or resets automatically at the time of boot. The procedure worked for me, and I am an experienced sysadmin. I do not take responsibility for any hardware failures. Do it at your own risk.
|
||||
|
||||
### Examples
|
||||
|
||||
Type the following [apt command][2]/[apt-get command][3] on a Debian/Ubuntu Linux for Intel CPU:
|
||||
|
||||
`$ sudo apt-get install intel-microcode`
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[![How to install Intel microcode firmware Linux][4]][4]
|
||||
|
||||
You [must reboot the box to activate micocode][5] update:
|
||||
|
||||
`$ sudo reboot`
|
||||
|
||||
Verify it after reboot:
|
||||
|
||||
`# dmesg | grep 'microcode'`
|
||||
|
||||
Sample outputs:
|
||||
|
||||
```
|
||||
[ 0.000000] microcode: microcode updated early to revision 0x1c, date = 2015-02-26
|
||||
[ 1.604672] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 1.604976] microcode: Microcode Update Driver: v2.01 <tigran@aivazian.fsnet.co.uk>, Peter Oruba
|
||||
|
||||
```
|
||||
|
||||
If you are using RHEL/CentOS try installing or updating the following two packages using [yum command][6]:
|
||||
|
||||
```
|
||||
$ sudo yum install linux-firmware microcode_ctl
|
||||
$ sudo reboot
|
||||
$ sudo dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
## How to update/install microcode downloaded from Intel site
|
||||
|
||||
Only use the following method when recommended by your vendor otherwise stick to Linux packages as described above. Most Linux distro maintainer update microcode via the package manager. Package manager method is safe as tested by many users.
|
||||
|
||||
### How to install Intel processor microcode blob for Linux (20180108 release)
|
||||
|
||||
Ok, first visit AMD or [Intel site][7] to grab the latest microcode firmware. In this example, I have a file named ~/Downloads/microcode-20180108.tgz (don't forget to check for checksum) that suppose to help with meltdown/Spectre. First extract it using the tar command:
|
||||
```
|
||||
$ mkdir firmware
|
||||
$ cd firmware
|
||||
$ tar xvf ~/Downloads/microcode-20180108.tgz
|
||||
$ ls -l
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
|
||||
```
|
||||
drwxr-xr-x 2 vivek vivek 4096 Jan 8 12:41 intel-ucode
|
||||
-rw-r--r-- 1 vivek vivek 4847056 Jan 8 12:39 microcode.dat
|
||||
-rw-r--r-- 1 vivek vivek 1907 Jan 9 07:03 releasenote
|
||||
|
||||
```
|
||||
|
||||
Make sure /sys/devices/system/cpu/microcode/reload exits:
|
||||
|
||||
`$ ls -l /sys/devices/system/cpu/microcode/reload`
|
||||
|
||||
You must copy all files from intel-ucode to /lib/firmware/intel-ucode/ using the [cp command][8]:
|
||||
|
||||
`$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/`
|
||||
|
||||
You just copied intel-ucode directory to /lib/firmware/. Write the reload interface to 1 to reload the microcode files:
|
||||
|
||||
`# echo 1 > /sys/devices/system/cpu/microcode/reload`
|
||||
|
||||
Update an existing initramfs so that next time it get loaded via kernel:
|
||||
|
||||
```
|
||||
$ sudo update-initramfs -u
|
||||
$ sudo reboot
|
||||
```
|
||||
Verifying that microcode got updated on boot or reloaded by echo command:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
That is all. You have just updated firmware for your Intel CPU.
|
||||
|
||||
## about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/01/Verify-microcode-update-on-a-CentOS-RHEL-Fedora-Ubuntu-Debian-Linux.jpg
|
||||
[2]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-Intel-microcode-firmware-Linux.jpg
|
||||
[5]:https://www.cyberciti.biz/faq/howto-reboot-linux/
|
||||
[6]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[7]:https://downloadcenter.intel.com/download/27431/Linux-Processor-Microcode-Data-File
|
||||
[8]:https://www.cyberciti.biz/faq/cp-copy-command-in-unix-examples/ (See Linux/Unix cp command examples for more info)
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,126 @@
|
||||
Using Your Own Private Registry with Docker Enterprise Edition
|
||||
======
|
||||
|
||||
![docker trusted registry][1]
|
||||
|
||||
One of the things that makes Docker really cool, particularly compared to using virtual machines, is how easy it is to move around Docker images. If you've already been using Docker, you've almost certainly pulled images from [Docker Hub][2]. Docker Hub is Docker's cloud-based registry service and has tens of thousands of Docker images to choose from. If you're developing your own software and creating your own Docker images though, you'll want your own private Docker registry. This is particularly true if you have images with proprietary licenses, or if you have a complex continuous integration (CI) process for your build system.
|
||||
|
||||
Docker Enterprise Edition includes Docker Trusted Registry (DTR), a highly available registry with secure image management capabilities which was built to run either inside of your own data center or on your own cloud-based infrastructure. In the next few weeks, we'll go over how DTR is a critical component of delivering a secure, repeatable and consistent [software supply chain][3]. You can get started with it today through our [free hosted demo][4] or by downloading and installing the free 30-day trial. The steps to get started with your own installation are below.
|
||||
|
||||
## Setting Up Docker Enterprise Edition
|
||||
|
||||
Docker Trusted Registry runs on top of Universal Control Plane (UCP), so to begin let's install a single-node cluster. If you've already got your own UCP cluster, you can skip this step. On your docker host, run the command:
|
||||
|
||||
```
|
||||
# Pull and install UCP
|
||||
|
||||
docker run -it -rm -v /var/run/docker.sock:/var/run/docker.sock -name ucp docker/ucp:latest install
|
||||
```
|
||||
|
||||
Once UCP is up and running, there are a few more things you should do before you install DTR. Open up your browser against the UCP instance you just installed. There should be a link to it at the end of your log output. If you have already have a Docker Enterprise Edition license, go ahead and upload it through the UI. If you don't, visit the [Docker Store][5] and pick up a free, 30-day trial.
|
||||
|
||||
Once you've got licensing squared away, you're probably going to want to change the port which UCP is running on. Since this is a single node cluster, DTR and UCP are going to want to use the same TCP ports for running their web services. If you've got a UCP swarm with more than one node, this probably isn't a problem because DTR will look for a node which has the required free ports. Inside of UCP, click on Admin Settings -> Cluster Configuration and change the Controller Port to something like 5443.
|
||||
|
||||
## Installing DTR
|
||||
|
||||
We're going to install a simple, single-node instance of Docker Trusted Registry. If you were setting up your DTR for production use, you would likely set things up in High Availability (HA) mode which would require a different type of storage such as a cloud-based object store, or NFS. Since this is a single-node instance, we're going to stick with the default local storage.
|
||||
|
||||
First we need to pull the DTR bootstrap image. The bootstrap image is a tiny, self-contained installer which connects to UCP and sets up all of the containers, volumes, and logical networks required to get DTR up and running.
|
||||
|
||||
Use the command:
|
||||
|
||||
```
|
||||
# Pull and run the DTR bootstrapper
|
||||
|
||||
docker run -it -rm docker/dtr:latest install -ucp-insecure-tls
|
||||
```
|
||||
|
||||
NOTE: Both UCP and DTR by default come with their own certs which won't be recognized by your system. If you've set up UCP with TLS certs which are trusted by your system, you can omit the `-ucp-insecure-tls` option. Alternatively, you can use the `-ucp-ca` option which will let you specify the UCP CA certificate directly.
|
||||
|
||||
The DTR bootstrap image should then ask you for a couple of settings, such as the URL of your UCP installation and your UCP admin username and password. It should only take a minute or two to pull all of the DTR images and set everything up.
|
||||
|
||||
## Keeping Everything Secure
|
||||
|
||||
Once everything is up and running, you're ready to push and pull images to and from
|
||||
|
||||
the registry. Before we do that step though, let's set up our TLS certificates so that we can securely talk to DTR.
|
||||
|
||||
On Linux, we can use these commands (just make certain you change DTR_HOSTNAME to reflect the DTR we just set up):
|
||||
|
||||
```
|
||||
# Pull the CA certificate from DTR (you can use wget if curl is unavailable)
|
||||
|
||||
DTR_HOSTNAME=<Your DTR hostname>
|
||||
|
||||
curl -k https://$(DTR_HOSTNAME)/ca > $(DTR_HOSTNAME).crt
|
||||
|
||||
sudo mkdir /etc/docker/certs.d/$(DTR_HOSTNAME)
|
||||
|
||||
sudo cp $(DTR_HOSTNAME) /etc/docker/certs.d/$(DTR_HOSTNAME)
|
||||
|
||||
# Restart the docker daemon (use `sudo service docker restart` on Ubuntu 14.04)
|
||||
|
||||
sudo systemctl restart docker
|
||||
```
|
||||
|
||||
On Docker for Mac and Windows, we'll set up our client a little bit differently. Go in to Settings -> Daemon and in the Insecure Registries section, enter in your DTR hostname. Click Apply, and your docker daemon should restart and you should be good to go.
|
||||
|
||||
## Pushing and Pulling Images
|
||||
|
||||
We now need to set up a repository to hold an image. This is a little bit different than Docker Hub which automatically creates a repository if one doesn't exist when you do a docker push. To create the repository, point your browser to https://<Your DTR hostname> and then sign-in with your admin credentials when prompted. If you added a license to UCP, that license will automatically have been picked up by DTR. If not, make certain you upload your license now.
|
||||
|
||||
Once you're in, click on the 'New Repository` button and create a new repository.
|
||||
|
||||
We'll create a repo to hold Alpine linux, so type `alpine` in the name field, and click
|
||||
|
||||
`Save` (it's labelled `Create` in DTR 2.5 and newer).
|
||||
|
||||
Now let's go back to our shell and type the commands:
|
||||
|
||||
```
|
||||
# Pull the latest version of Alpine Linux
|
||||
|
||||
docker pull alpine:latest
|
||||
|
||||
# Sign in to your new DTR instance
|
||||
|
||||
docker login <Your DTR hostname>
|
||||
|
||||
# Tag Alpine to be able to push it to your DTR
|
||||
|
||||
docker tag alpine:latest <Your DTR hostname>/admin/alpine:latest
|
||||
|
||||
# Push the image to DTR
|
||||
|
||||
docker push <Your DTR hostname>/admin/alpine:latest
|
||||
```
|
||||
|
||||
And that's it! We just pulled a copy of the latest Alpine Linux, re-tagged it so that we could store it inside of DTR, and then pushed it to our private registry. If you want to pull that image to a different Docker engine, set up your DTR certs as shown above, and issue the command:
|
||||
|
||||
```
|
||||
# Pull the image from DTR
|
||||
|
||||
docker pull <Your DTR hostname>/admin/alpine:latest
|
||||
```
|
||||
|
||||
DTR has a lot of great image management features built right in such as image caching, mirroring, scanning, signing, and even automated supply chain policies. We'll leave these to future blog posts which we can explore in more detail.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2018/01/dtr/
|
||||
|
||||
作者:[Patrick Devine;Rolf Neugebauer;Docker Core Engineering;Matt Bentley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/pdevine/
|
||||
[1]:https://i1.wp.com/blog.docker.com/wp-content/uploads/ccd278d2-29c2-4866-8285-c2fe60b4bd5e-1.jpg?resize=965%2C452&ssl=1
|
||||
[2]:https://hub.docker.com/
|
||||
[3]:https://blog.docker.com/2016/08/securing-enterprise-software-supply-chain-using-docker/
|
||||
[4]:https://www.docker.com/trial
|
||||
[5]:https://store.docker.com/search?offering=enterprise&page=1&q=&type=edition
|
||||
84
translated/tech/20090127 Anatomy of a Program in Memory.md
Normal file
84
translated/tech/20090127 Anatomy of a Program in Memory.md
Normal file
@ -0,0 +1,84 @@
|
||||
剖析内存中的程序
|
||||
============================================================
|
||||
|
||||
内存管理是一个操作系统的核心任务;它对程序员和系统管理员来说也是至关重要的。在接下来的几篇文章中,我将从实践出发着眼于内存管理,并深入到它的内部结构。尽管这些概念很普通,示例也大都来自于 32 位 x86 架构的 Linux 和 Windows 上。第一篇文章描述了在内存中程序如何分布。
|
||||
|
||||
在一个多任务操作系统中的每个进程都运行在它自己的内存“沙箱”中。这个沙箱是一个虚拟地址空间,它在 32 位的模式中它总共有 4GB 的内存地址块。这些虚拟地址是通过内核页表映射到物理地址的,并且这些虚拟地址是由操作系统内核来维护,进而被进程所消费的。每个进程都有它自己的一组页表,但是在它这里仅是一个钩子。一旦虚拟地址被启用,这些虚拟地址将被应用到这台电脑上的 _所有软件_,_包括内核本身_。因此,一部分虚拟地址空间必须保留给内核使用:
|
||||
|
||||

|
||||
|
||||
但是,这并不说内核就使用了很多的物理内存,恰恰相反,它只使用了很少一部分用于去做地址映射。内核空间在内核页表中被标记为仅 [特权代码][1] (ring 2 或更低)独占使用,因此,如果一个用户模式的程序尝试去访问它,将触发一个页面故障错误。在 Linux 中,内核空间是始终存在的,并且在所有进程中都映射相同的物理内存。内核代码和数据总是可寻址的,准备随时去处理中断或者系统调用。相比之下,用户模式中的地址空间,在每次进程切换时都会发生变化:
|
||||
|
||||

|
||||
|
||||
蓝色的区域代表映射到物理地址的虚拟地址空间,白色的区域是尚未映射的部分。在上面的示例中,Firefox 因它令人惊奇的“狂吃”内存而使用了大量的虚拟内存空间。在地址空间中不同的组合对应了不同的内存段,像堆、栈、等等。请注意,这些段只是一系列内存地址的简化表示,它与 [Intel 类型的段][2] _并没有任何关系_ 。不过,这是一个在 Linux 中的标准的段布局:
|
||||
|
||||

|
||||
|
||||
当计算是快乐、安全、讨人喜欢的时候,在机器中的几乎每个进程上,它们的起始虚拟地址段都是完全相同的。这将使远程挖掘安全漏洞变得容易。一个漏洞利用经常需要去引用绝对内存位置:在栈中的一个地址,这个地址可能是一个库的函数,等等。远程攻击必须要“盲选”这个地址,因为地址空间都是相同的。当攻击者们这样做的时候,人们就会受到伤害。因此,地址空间随机化开始流行起来。Linux 随机化栈、内存映射段、以及在堆上增加起始地址偏移量。不幸的是,32 位的地址空间是非常拥挤的,为地址空间随机化留下的空间不多,因此 [妨碍了地址空间随机化的效果][6]。
|
||||
|
||||
在进程地址空间中最高的段是栈,在大多数编程语言中它存储本地变量和函数参数。调用一个方法或者函数将推送一个新的栈帧到这个栈。当函数返回时这个栈帧被删除。这个简单的设计,可能是因为数据严格遵循 [后进先出(LIFO)][7] 的次序,这意味着跟踪栈内容时不需要复杂的数据结构 – 一个指向栈顶的简单指针就可以做到。推送和弹出也因此而非常快且准确。也可能是,持续的栈区重用倾向于在 [CPU 缓存][8] 中保持活跃的栈内存,这样可以加快访问速度。进程中的每个线程都有它自己的栈。
|
||||
|
||||
向栈中推送更多的而不是刚合适的数据可能会耗尽栈的映射区域。这将触发一个页面故障,在 Linux 中它是通过 [expand_stack()][9] 来处理的,它会去调用 [acct_stack_growth()][10] 来检查栈的增长是否正常。如果栈的大小低于 <tt>RLIMIT_STACK</tt> 的值(一般是 8MB 大小),那么这是一个正常的栈增长和程序的合理使用,否则可能是发生了未知问题。这是一个栈大小按需调节的常见机制。但是,栈的大小达到了上述限制,将会发生一个栈溢出,并且,程序将会收到一个段故障错误。当映射的栈为满足需要而扩展后,在栈缩小时,映射区域并不会收缩。就像美国联邦政府的预算一样,它只会扩张。
|
||||
|
||||
动态栈增长是 [唯一例外的情况][11] ,当它去访问一个未映射的内存区域,如上图中白色部分,是允许的。除此之外的任何其它访问未映射的内存区域将在段故障中触发一个页面故障。一些映射区域是只读的,因此,尝试去写入到这些区域也将触发一个段故障。
|
||||
|
||||
在栈的下面,有内存映射段。在这里,内核将文件内容直接映射到内存。任何应用程序都可以通过 Linux 的 [mmap()][12] 系统调用( [实现][13])或者 Windows 的 [CreateFileMapping()][14] / [MapViewOfFile()][15] 来请求一个映射。内存映射是实现文件 I/O 的方便高效的方式。因此,它经常被用于加载动态库。有时候,也被用于去创建一个并不匹配任何文件的匿名内存映射,这种映射经常被用做程序数据的替代。在 Linux 中,如果你通过 [malloc()][16] 去请求一个大的内存块,C 库将会创建这样一个匿名映射而不是使用堆内存。这里的‘大’ 表示是超过了<tt>MMAP_THRESHOLD</tt> 设置的字节数,它的缺省值是 128 kB,可以通过 [mallopt()][17] 去调整这个设置值。
|
||||
|
||||
接下来讲的是“堆”,就在我们接下来的地址空间中,堆提供运行时内存分配,像栈一样,但又不同于栈的是,它分配的数据生存期要长于分配它的函数。大多数编程语言都为程序去提供堆管理支持。因此,满足内存需要是编程语言运行时和内核共同来做的事情。在 C 中,堆分配的接口是 [malloc()][18] ,它是个用户友好的接口,然而在编程语言的垃圾回收中,像 C# 中,这个接口使用 <tt>new</tt> 关键字。
|
||||
|
||||
如果在堆中有足够的空间去满足内存请求,它可以由编程语言运行时来处理内存分配请求,而无需内核参与。否则将通过 [brk()][19] 系统调用([实现][20])来扩大堆以满足内存请求所需的大小。堆的管理是比较 [复杂的][21],在面对我们程序的混乱分配模式时,它通过复杂的算法,努力在速度和内存使用效率之间取得一种平衡。服务一个堆请求所需要的时间可能是非常可观的。实时系统有一个 [特定用途的分配器][22] 去处理这个问题。堆也会出现 _碎片化_ ,如下图所示:
|
||||
|
||||

|
||||
|
||||
最后,我们取得了内存的低位段:BSS、数据、以及程序文本。在 C 中,静态(全局)变量的内容都保存在 BSS 和数据中。它们之间的不同之处在于,BSS 保存 _未初始化的_ 静态变量的内容,它的值在源代码中并没有被程序员设置。BSS 内存区域是_匿名_的:它没有映射到任何文件上。如果你在程序中写这样的语句 <tt>static int cntActiveUsers</tt>,<tt>cntActiveUsers</tt> 的内容就保存在 BSS 中。
|
||||
|
||||
反过来,数据段,用于保存在源代码中静态变量_初始化后_的内容。这个内存区域是_非匿名_的。它映射到程序的二进值镜像上的一部分,这个二进制镜像包含在源代码中给定初始化值的静态变量内容。因此,如果你在程序中写这样的语句 <tt>static int cntWorkerBees = 10</tt>,那么,cntWorkerBees 的内容就保存在数据段中,并且初始值为 10。尽管可以通过数据段映射到一个文件,但是这是一个私有内存映射,意味着,如果在内存中这个文件发生了变化,它并不会将这种变化反映到底层的文件上。必须是这样的,否则,分配的全局变量将会改变你磁盘上的二进制文件镜像,这种做法就太不可思议了!
|
||||
|
||||
用图去展示一个数据段是很困难的,因为它使用一个指针。在那种情况下,指针 <tt>gonzo</tt> 的_内容_ – 保存在数据段上的一个 4 字节的内存地址。它并没有指向一个真实的字符串。而这个字符串存在于文本段中,文本段是只读的,它用于保存你的代码中的类似于字符串常量这样的内容。文本段也映射你的内存中的库,但是,如果你的程序写入到这个区域,将会触发一个段故障错误。尽管在 C 中,它比不上从一开始就避免这种指针错误那么有效,但是,这种机制也有助于避免指针错误。这里有一个展示这些段和示例变量的图:
|
||||
|
||||

|
||||
|
||||
你可以通过读取 <tt>/proc/pid_of_process/maps</tt> 文件来检查 Linux 进程中的内存区域。请记住,一个段可以包含很多的区域。例如,每个内存映射的文件一般都在 mmap 段中的它自己的区域中,而动态库有类似于BSS 和数据一样的额外的区域。下一篇文章中我们将详细说明“区域(area)”的真正含义是什么。此外,有时候人们所说的“数据段(data segment)”是指“数据 + BSS + 堆”。
|
||||
|
||||
你可以使用 [nm][23] 和 [objdump][24] 命令去检查二进制镜像,去显示它们的符号、地址、段、等等。最终,在 Linux 中上面描述的虚拟地址布局是一个“弹性的”布局,这就是这几年来的缺省情况。它假设 <tt>RLIMIT_STACK</tt> 有一个值。如果没有值的话,Linux 将恢复到如下所示的“经典” 布局:
|
||||
|
||||

|
||||
|
||||
这就是虚拟地址空间布局。接下来的文章将讨论内核如何对这些内存区域保持跟踪、内存映射、文件如何读取和写入、以及内存使用数据的意义。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
|
||||
|
||||
作者:[gustavo ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
|
||||
[2]:http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729
|
||||
[6]:http://www.stanford.edu/~blp/papers/asrandom.pdf
|
||||
[7]:http://en.wikipedia.org/wiki/Lifo
|
||||
[8]:http://duartes.org/gustavo/blog/post/intel-cpu-caches
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544
|
||||
[11]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692
|
||||
[12]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27
|
||||
[14]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[15]:http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[20]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248
|
||||
[21]:http://g.oswego.edu/dl/html/malloc.html
|
||||
[22]:http://rtportal.upv.es/rtmalloc/
|
||||
[23]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html
|
||||
[24]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html
|
||||
@ -1,42 +1,42 @@
|
||||
|
||||
Dockers 涉密数据(Secrets) 管理介绍
|
||||
Dockers 涉密信息(Secrets)管理介绍
|
||||
====================================
|
||||
|
||||
容器正在改变我们对应用程序和基础设施的看法。无论容器内的代码量是大还是小,容器架构都会引起代码如何与硬件相互作用方式的改变 —— 它从根本上将其从基础设施中抽象出来。对于容器安全来说,在 Docker 中,容器的安全性有三个关键组成部分,他们相互作用构成本质上更安全的应用程序。
|
||||
|
||||

|
||||
|
||||
构建更安全的应用程序的一个关键因素是与其他应用程序和系统进行安全通信,这通常需要证书、tokens、密码和其他类型的验证信息凭证 —— 通常称为应用程序涉密数据。我们很高兴可以推出 Docker 涉密数据,一个容器的原生解决方案,它是加强容器安全的可信赖交付组件,用户可以在容器平台上直接集成涉密数据分发功能。
|
||||
构建更安全的应用程序的一个关键因素是与系统和其他应用程序进行安全通信,这通常需要证书、tokens、密码和其他类型的验证信息凭证 —— 通常称为应用程序涉密信息。我们很高兴可以推出 Docker 涉密信息,一个容器的原生解决方案,它是加强容器安全的可信赖交付组件,用户可以在容器平台上直接集成涉密信息分发功能。
|
||||
|
||||
有了容器,现在应用程序在多环境下是动态的、可移植的。这使得现存的涉密数据分发的解决方案略显不足,因为它们都是针对静态环境。不幸的是,这导致了应用程序涉密数据应用不善管理的增加,使得不安全的本地解决方案变得十分普遍,比如像 GitHub 嵌入涉密数据到版本控制系统,或者在这之后考虑了其他同样不好的解决方案。
|
||||
有了容器,现在应用程序在多环境下是动态的、可移植的。这使得现存的涉密信息分发的解决方案略显不足,因为它们都是针对静态环境。不幸的是,这导致了应用程序涉密信息管理不善的增加,使得不安全的本地解决方案变得十分普遍,比如像 GitHub 将嵌入涉密信息到版本控制系统,或者在这之后考虑了其他同样不好的解决方案。
|
||||
|
||||
### Docker 涉密数据(Secrets) 管理介绍
|
||||
### Docker 涉密信息(Secrets)管理介绍
|
||||
|
||||
根本上我们认为,如果有一个标准的接口来访问涉密数据,应用程序就更安全了。任何好的解决方案也必须遵循安全性实践,例如在传输的过程中,对涉密数据进行加密;在空闲的时候也对涉密数据 进行加密;防止涉密数据在应用最终使用时被无意泄露;并严格遵守最低权限原则,即应用程序只能访问所需的涉密数据,不能多也不能不少。
|
||||
根本上我们认为,如果有一个标准的接口来访问涉密信息,应用程序就更安全了。任何好的解决方案也必须遵循安全性实践,例如在传输的过程中,对涉密信息进行加密;在空余的时候也对涉密数据进行加密;防止涉密信息在应用最终使用时被无意泄露;并严格遵守最低权限原则,即应用程序只能访问所需的涉密信息,不能多也不能不少。
|
||||
|
||||
通过将涉密数据整合到 docker 的业务流程,我们能够在遵循这些确切的原则下为涉密数据的管理问题提供一种解决方案。
|
||||
通过将涉密信息整合到 Docker 的业务流程,我们能够在遵循这些确切的原则下为涉密信息的管理问题提供一种解决方案。
|
||||
|
||||
下图提供了一个高层次视图,并展示了 Docker swarm mode 体系架构是如何将一种新类型的对象 —— 一个涉密数据对象,安全地传递给我们的容器。
|
||||
下图提供了一个高层次视图,并展示了 Docker swarm mode 体系架构是如何将一种新类型的对象 —— 一个涉密信息对象,安全地传递给我们的容器。
|
||||
|
||||

|
||||
|
||||
在 Docker 中,一个涉密数据是任意的数据块,比如密码、SSH 密钥、TLS 凭证,或者任何其他本质上敏感的数据。当你将一个涉密数据加入集群(通过执行 `docker secret create` )时,利用在引导新集群时自动创建的内置证书颁发机构,Docker 通过相互认证的 TLS 连接将密钥发送给集群管理器。
|
||||
在 Docker 中,一个涉密信息是任意的数据块,比如密码、SSH 密钥、TLS 凭证,或者任何其他本质上敏感的数据。当你将一个涉密信息加入集群(通过执行 `docker secret create` )时,利用在引导新集群时自动创建的内置证书颁发机构,Docker 通过相互认证的 TLS 连接将密钥发送给集群管理器。
|
||||
|
||||
```
|
||||
$ echo "This is a secret" | docker secret create my_secret_data -
|
||||
```
|
||||
|
||||
一旦,涉密数据到达一个管理节点,它将被保存到内部的 Raft 存储区中,该存储区使用 NACL 开源加密库中的 Salsa20、Poly1305 加密算法生成的 256 位密钥进行加密。以确保没有任何数据被永久写入未加密的磁盘。向内部存储写入涉密数据,给予了涉密数据跟其他集群数据一样的高可用性。
|
||||
一旦,涉密信息到达某个管理节点,它将被保存到内部的 Raft 存储区中。该存储区使用 NACL 开源加密库中的 Salsa20、Poly1305 加密算法生成的 256 位密钥进行加密,以确保没有把任何涉密信息数据永久写入未加密的磁盘。向内部存储写入涉密信息,赋予了涉密信息跟其他集群数据一样的高可用性。
|
||||
|
||||
当集群管理器启动的时,包含 涉密数据 的被加密过的 Raft 日志通过每一个节点唯一的数据密钥进行解密。此密钥以及用于与集群其余部分通信的节点的 TLS 证书可以使用一个集群范围的加密密钥进行加密。该密钥称为“解锁密钥”,也使用 Raft 进行传播,将且会在管理器启动的时候被使用。
|
||||
当集群管理器启动的时,包含涉密信息的被加密过的 Raft 日志通过每一个节点唯一的数据密钥进行解密。此密钥以及用于与集群其余部分通信的节点的 TLS 证书可以使用一个集群范围的加密密钥进行加密。该密钥称为“解锁密钥”,也使用 Raft 进行传递,将且会在管理器启动的时候使用。
|
||||
|
||||
当授予新创建或运行的服务权限访问某个涉密数据时,其中一个管理器节点(只有管理人员可以访问被存储的所有涉密数据),将已建立的 TLS 连接分发给正在运行特定服务的节点。这意味着节点自己不能请求涉密数据,并且只有在管理员提供给他们的时候才能访问这些涉密数据 —— 严格地控制请求涉密数据的服务。
|
||||
当授予新创建或运行的服务权限访问某个涉密信息权限时,其中一个管理器节点(只有管理员可以访问被存储的所有涉密信息)会通过已经建立的TLS连接将其分发给正在运行特定服务的节点。这意味着节点自己不能请求涉密信息,并且只有在管理员提供给他们的时候才能访问这些涉密信息 —— 严格地控制请求涉密信息的服务。
|
||||
|
||||
```
|
||||
$ docker service create --name="redis" --secret="my_secret_data" redis:alpine
|
||||
```
|
||||
|
||||
未加密的涉密数据被挂载到一个容器,该容器位于 `/run/secrets/<secret_name>` 的内存文件系统中。
|
||||
未加密的涉密信息被挂载到一个容器,该容器位于 `/run/secrets/<secret_name>` 的内存文件系统中。
|
||||
|
||||
```
|
||||
$ docker exec $(docker ps --filter name=redis -q) ls -l /run/secrets
|
||||
@ -44,7 +44,7 @@ total 4
|
||||
-r--r--r-- 1 root root 17 Dec 13 22:48 my_secret_data
|
||||
```
|
||||
|
||||
如果一个服务被删除或者被重新安排在其他地方,集群管理器将立即通知所有不再需要访问该涉密数据的节点,这些节点将不再有权访问该应用程序的涉密数据。
|
||||
如果一个服务被删除或者被重新安排在其他地方,集群管理器将立即通知所有不再需要访问该涉密信息的节点,这些节点将不再有权访问该应用程序的涉密信息。
|
||||
|
||||
```
|
||||
$ docker service update --secret-rm="my_secret_data" redis
|
||||
@ -54,7 +54,7 @@ $ docker exec -it $(docker ps --filter name=redis -q) cat /run/secrets/my_secret
|
||||
cat: can't open '/run/secrets/my_secret_data': No such file or directory
|
||||
```
|
||||
|
||||
查看 Docker secret 文档以获取更多信息和示例,了解如何创建和管理您的涉密数据。同时,特别推荐 Docker 安全合作团 Laurens Van Houtven (https://www.lvh.io/) 和使这一特性成为现实的团队。
|
||||
查看 Docker Secret 文档以获取更多信息和示例,了解如何创建和管理您的涉密信息。同时,特别推荐 Docker 安全合作团 Laurens Van Houtven (https://www.lvh.io/) 和使这一特性成为现实的团队。
|
||||
|
||||
[Get safer apps for dev and ops w/ new #Docker secrets management][5]
|
||||
|
||||
@ -65,7 +65,7 @@ cat: can't open '/run/secrets/my_secret_data': No such file or directory
|
||||
|
||||
### 通过 Docker 更安全地使用应用程序
|
||||
|
||||
Docker 涉密数据旨在让开发人员和 IT 运营团队可以轻松使用,以用于构建和运行更安全的应用程序。它是是首个被设计为既能保持涉密数据安全又能仅在当被需要涉密数据操作的确切容器需要的使用的容器结构。从使用 Docker Compose 定义应用程序和涉密数据,到 IT 管理人员直接在 Docker Datacenter 中部署的 Compose 文件、涉密数据,networks 和 volumes 都将被加密并安全地跟应用程序一起传输。
|
||||
Docker 涉密信息旨在让开发人员和 IT 运营团队可以轻松使用,以用于构建和运行更安全的应用程序。它是是首个被设计为既能保持涉密信息安全,并且仅在特定的容器需要它来进行必要的涉密信息操作的时候使用。从使用 Docker Compose 定义应用程序和涉密数据,到 IT 管理人员直接在 Docker Datacenter 中部署的 Compose 文件、涉密信息,networks 和 volumes 都将被加密并安全地跟应用程序一起传输。
|
||||
|
||||
更多相关学习资源:
|
||||
|
||||
@ -85,7 +85,7 @@ via: https://blog.docker.com/2017/02/docker-secrets-management/
|
||||
|
||||
作者:[ Ying Li][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[imquanquan](https://github.com/imquanquan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
113
translated/tech/20170502 A beginner-s guide to Raspberry Pi 3.md
Normal file
113
translated/tech/20170502 A beginner-s guide to Raspberry Pi 3.md
Normal file
@ -0,0 +1,113 @@
|
||||
一个树莓派 3 的新手指南
|
||||
======
|
||||

|
||||
|
||||
这篇文章是我的使用树莓派 3 创建新项目的每周系列文章的一部分。该系列的第一篇文章专注于入门,它主要讲使用 PIXEL 桌面去安装树莓派、设置网络以及其它的基本组件。
|
||||
|
||||
### 你需要:
|
||||
|
||||
* 一台树莓派 3
|
||||
* 一个 5v 2mAh 带 USB 接口的电源适配器
|
||||
* 至少 8GB 容量的 Micro SD 卡
|
||||
* Wi-Fi 或者以太网线
|
||||
* 散热片
|
||||
* 键盘和鼠标
|
||||
* 一台 PC 显示器
|
||||
* 一台用于准备 microSD 卡的 Mac 或者 PC
|
||||
|
||||
|
||||
|
||||
现在市面上有很多基于 Linux 操作系统的树莓派,这种树莓派你可以直接安装它,但是,如果你是第一次接触树莓派,我推荐使用 NOOBS,它是树莓派官方的操作系统安装器,它安装操作系统到设备的过程非常简单。
|
||||
|
||||
在你的电脑上从 [这个链接][1] 下载 NOOBS。它是一个 zip 压缩文件。如果你使用的是 MacOS,可以直接双击它,MacOS 会自动解压这个文件。如果你使用的是 Windows,右键单击它,选择“解压到这里”。
|
||||
|
||||
如果你运行的是 Linux,如何去解压 zip 文件取决于你的桌面环境,因为,不同的桌面环境下解压文件的方法不一样,但是,使用命令行可以很容易地完成解压工作。
|
||||
|
||||
`$ unzip NOOBS.zip`
|
||||
|
||||
不管它是什么操作系统,打开解压后的文件,你看到的应该是如下图所示的样子:
|
||||
|
||||
![content][3] Swapnil Bhartiya
|
||||
|
||||
现在,在你的 PC 上插入 Micro SD 卡,将它格式化成 FAT32 格式的文件系统。在 MacOS 上,使用磁盘实用工具去格式化 Micro SD 卡:
|
||||
|
||||
![format][4] Swapnil Bhartiya
|
||||
|
||||
在 Windows 上,只需要右键单击这个卡,然后选择“格式化”选项。如果是在 Linux 上,不同的桌面环境使用不同的工具,就不一一去讲解了。在这里我写了一个教程,[在 Linux 上使用命令行接口][5] 去格式化 SD 卡为 Fat32 文件系统。
|
||||
|
||||
在你拥有了 FAT32 格式的文件系统后,就可以去拷贝下载的 NOOBS 目录的内容到这个卡的根目录下。如果你使用的是 MacOS 或者 Linux,可以使用 rsync 将 NOOBS 的内容传到 SD 卡的根目录中。在 MacOS 或者 Linux 中打开终端应用,然后运行如下的 rsync 命令:
|
||||
|
||||
`rsync -avzP /path_of_NOOBS /path_of_sdcard`
|
||||
|
||||
一定要确保选择了 SD 卡的根目录,在我的案例中(在 MacOS 上),它是:
|
||||
|
||||
`rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/`
|
||||
|
||||
或者你也可以拷贝粘贴 NOOBS 目录中的内容。一定要确保将 NOOBS 目录中的内容全部拷贝到 Micro SD 卡的根目录下,千万不能放到任何的子目录中。
|
||||
|
||||
现在可以插入这张 Micro SD 卡到树莓派 3 中,连接好显示器、键盘鼠标和电源适配器。如果你拥有有线网络,我建议你使用它,因为有线网络下载和安装操作系统更快。树莓派将引导到 NOOBS,它将提供一个供你去选择安装的分发版列表。从第一个选项中选择树莓派,紧接着会出现如下图的画面。
|
||||
|
||||
![raspi config][6] Swapnil Bhartiya
|
||||
|
||||
在你安装完成后,树莓派将重新启动,你将会看到一个欢迎使用树莓派的画面。现在可以去配置它,并且去运行系统更新。大多数情况下,我们都是在没有外设的情况下使用树莓派的,都是使用 SSH 基于网络远程去管理它。这意味着你不需要为了管理树莓派而去为它接上鼠标键盘和显示器。
|
||||
|
||||
开始使用它的第一步是,配置网络(假如你使用的是 Wi-Fi)。点击顶部面板上的网络图标,然后在出现的网络列表中,选择你要配置的网络并为它输入正确的密码。
|
||||
|
||||
![wireless][7] Swapnil Bhartiya
|
||||
|
||||
恭喜您,无线网络的连接配置完成了。在进入下一步的配置之前,你需要找到你的网络为树莓派分配的 IP 地址,因为远程管理会用到它。
|
||||
|
||||
打开一个终端,运行如下的命令:
|
||||
|
||||
`ifconfig`
|
||||
|
||||
现在,记下这个设备的 wlan0 部分的 IP 地址。它一般显示为 “inet addr”
|
||||
|
||||
现在,可以去启用 SSH 了,在树莓派上打开一个终端,然后打开 raspi-config 工具。
|
||||
|
||||
`sudo raspi-config`
|
||||
|
||||
树莓派的默认用户名和密码分别是 “pi” 和 “raspberry”。在上面的命令中你会被要求输入密码。树莓派配置工具的第一个选项是去修改默认密码,我强烈推荐你修改默认密码,尤其是你基于网络去使用它的时候。
|
||||
|
||||
第二个选项是去修改主机名,如果在你的网络中有多个树莓派时,主机名用于区分它们。一个有意义的主机名可以很容易在网络上识别每个设备。
|
||||
|
||||
然后进入到接口选项,去启用摄像头、SSH、以及 VNC。如果你在树莓派上使用了一个涉及到多媒体的应用程序,比如,家庭影院系统或者 PC,你也可以去改变音频输出选项。缺省情况下,它的默认输出到 HDMI 接口,但是,如果你使用外部音响,你需要去改变音频输出设置。转到树莓派配置工具的高级配置选项,选择音频,然后选择 3.5mm 作为默认输出。
|
||||
|
||||
[小提示:使用箭头键去导航,使用回车键去选择]
|
||||
|
||||
一旦所有的改变被应用, 树莓派将要求重新启动。你可以从树莓派上拔出显示器、鼠标键盘,以后可以通过网络来管理它。现在可以在你的本地电脑上打开终端。如果你使用的是 Windows,你可以使用 Putty 或者去读我的文章 - 怎么在 Windows 10 上安装 Ubuntu Bash。
|
||||
|
||||
在你的本地电脑上输入如下的 SSH 命令:
|
||||
|
||||
`ssh pi@IP_ADDRESS_OF_Pi`
|
||||
|
||||
在我的电脑上,这个命令是这样的:
|
||||
|
||||
`ssh pi@10.0.0.161`
|
||||
|
||||
输入它的密码,你登入到树莓派了!现在你可以从一台远程电脑上去管理你的树莓派。如果你希望通过因特网去管理树莓派,可以去阅读我的文章 - [如何在你的计算机上启用 RealVNC][8]。
|
||||
|
||||
在该系列的下一篇文章中,我将讲解使用你的树莓派去远程管理你的 3D 打印机。
|
||||
|
||||
**这篇文章是作为 IDG 投稿网络的一部分发表的。[想加入吗?][9]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3176488/linux/a-beginner-s-guide-to-raspberry-pi-3.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://www.raspberrypi.org/downloads/noobs/
|
||||
[2]:http://idgenterprise.selz.com
|
||||
[3]:https://images.techhive.com/images/article/2017/03/content-100711633-large.jpg
|
||||
[4]:https://images.techhive.com/images/article/2017/03/format-100711635-large.jpg
|
||||
[5]:http://www.cio.com/article/3176034/linux/how-to-format-an-sd-card-in-linux.html
|
||||
[6]:https://images.techhive.com/images/article/2017/03/raspi-config-100711634-large.jpg
|
||||
[7]:https://images.techhive.com/images/article/2017/03/wireless-100711636-large.jpeg
|
||||
[8]:http://www.infoworld.com/article/3171682/internet-of-things/how-to-access-your-raspberry-pi-remotely-over-the-internet.html
|
||||
[9]:https://www.infoworld.com/contributor-network/signup.html
|
||||
80
translated/tech/20170924 Simulate System Loads.md
Normal file
80
translated/tech/20170924 Simulate System Loads.md
Normal file
@ -0,0 +1,80 @@
|
||||
模拟系统负载的方法
|
||||
======
|
||||
系统管理员通常需要探索在不同负载对应用性能的影响。这意味着必须要重复地人为创造负载。当然,你可以通过专门的工具来实现,但有时你可能不想也无法安装新工具。
|
||||
|
||||
每个 Linux 发行版中都自带有创建负载的工具。他们不如专门的工具那么灵活但它们是现成的,而且无需专门学习。
|
||||
|
||||
### CPU
|
||||
|
||||
下面命令会创建 CPU 负荷,方法是通过压缩随机数据并将结果发送到 `/dev/null`:
|
||||
```
|
||||
cat /dev/urandom | gzip -9 > /dev/null
|
||||
|
||||
```
|
||||
|
||||
如果你想要更大的负荷,或者系统有多个核,那么只需要对数据进行压缩和解压就行了,像这样:
|
||||
```
|
||||
cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
|
||||
|
||||
```
|
||||
|
||||
按下 `CTRL+C` 来暂停进程。
|
||||
|
||||
### RAM
|
||||
|
||||
下面命令会减少可用内存的总量。它是是通过在内存中创建文件系统然后往里面写文件来实现的。你可以使用任意多的内存,只需哟往里面写入更多的文件就行了。
|
||||
|
||||
首先,创建一个挂载点,然后将 `ramfs` 文件系统挂载上去:
|
||||
```
|
||||
mkdir z
|
||||
mount -t ramfs ramfs z/
|
||||
|
||||
```
|
||||
|
||||
第二步,使用 `dd` 在该目录下创建文件。这里我们创建了一个 128M 的文件:
|
||||
```
|
||||
dd if=/dev/zero of=z/file bs=1M count=128
|
||||
|
||||
```
|
||||
|
||||
文件的大小可以通过下面这些操作符来修改:
|
||||
|
||||
+ **bs=** 块大小。可以是任何数字后面接上 **B**( 表示字节 ),**K**( 表示 KB),**M**( 表示 MB) 或者 **G**( 表示 GB)。
|
||||
+ **count=** 要写多少个块
|
||||
|
||||
|
||||
|
||||
### Disk
|
||||
|
||||
创建磁盘 I/O 的方法是先创建一个文件,然后使用 for 循环来不停地拷贝它。
|
||||
|
||||
下面使用命令 `dd` 创建了一个充满零的 1G 大小的文件:
|
||||
```
|
||||
dd if=/dev/zero of=loadfile bs=1M count=1024
|
||||
|
||||
```
|
||||
|
||||
下面命令用 for 循环执行 10 次操作。每次都会拷贝 `loadfile` 来覆盖 `loadfile1`:
|
||||
```
|
||||
for i in {1..10}; do cp loadfile loadfile1; done
|
||||
|
||||
```
|
||||
|
||||
通过修改 `{1。.10}` 中的第二个参数来调整运行时间的长短。
|
||||
|
||||
若你想要一直运行,直到按下 `CTRL+C` 来停止,则运行下面命令:
|
||||
```
|
||||
while true; do cp loadfile loadfile1; done
|
||||
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/create-system-load/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
@ -0,0 +1,58 @@
|
||||
最重要的 Firefox 命令行选项
|
||||
======
|
||||
Firefox web 浏览器支持很多命令行选项,可以定制它启动的方式。
|
||||
|
||||
你可能已经接触过一些了,比如 `-P "profile name"` 指定浏览器启动加载时的配置文件,`-private` 开启一个私有会话。
|
||||
|
||||
本指南会列出对 FIrefox 来说比较重要的那些命令行选项。它并不包含所有的可选项,因为很多选项只用于特定的目的,对一般用户来说没什么价值。
|
||||
|
||||
你可以在 Firefox 开发者网站上看到[完整 ][1] 的命令行选项。需要注意的是,很多命令行选项对其他基于 Mozilla 的产品一样有效,甚至对某些第三方的程序也有效。
|
||||
|
||||
### 重要的 Firefox 命令行选项
|
||||
|
||||
![firefox command line][2]
|
||||
|
||||
#### Profile 相关选项
|
||||
|
||||
+ **-CreateProfile profile 名称** -- 创建新的用户配置信息,但并不立即使用它。
|
||||
+ **-CreateProfile "profile 名 存放 profile 的目录"** -- 跟上面一样,只是指定了存放 profile 的目录。
|
||||
+ **-ProfileManager**,或 **-P** -- 打开内置的 profile 管理器。
|
||||
+ - **P "profile 名"** -- 使用 n 指定的 profile 启动 Firefox。若指定的 profile 不存在则会打开 profile 管理器。只有在没有其他 Firefox 实例运行时才有用。
|
||||
+ **-no-remote** -- 与 `-P` 连用来创建新的浏览器实例。它允许你在同一时间运行多个 profile。
|
||||
|
||||
#### 浏览器相关选项
|
||||
|
||||
+ **-headless** -- 以无头模式启动 Firefox。Linux 上需要 Firefox 55 才支持,Windows 和 Mac OS X 上需要 Firefox 56 才支持。
|
||||
+ **-new-tab URL** -- 在 Firefox 的新标签页中加载指定 URL。
|
||||
+ **-new-window URL** -- 在 Firefox 的新窗口中加载指定 URL。
|
||||
+ **-private** -- 以私隐私浏览模式启动 Firefox。可以用来让 Firefox 始终运行在隐私浏览模式下。
|
||||
+ **-private-window** -- 打开一个隐私窗口
|
||||
+ **-private-window URL** -- 在新的隐私窗口中打开 URL。若已经打开了一个隐私浏览窗口,则在那个窗口中打开 URL。
|
||||
+ **-search 单词** -- 使用 FIrefox 默认的搜索引擎进行搜索。
|
||||
+ - **url URL** -- 在新的标签也或窗口中加载 URL。可以省略这里的 `-url`,而且支持打开多个 URL,每个 URL 之间用空格分离。
|
||||
|
||||
|
||||
|
||||
#### 其他 options
|
||||
|
||||
+ **-safe-mode** -- 在安全模式下启动 Firefox。在启动 Firefox 时一直按住 Shift 键也能进入安全模式。
|
||||
+ **-devtools** -- 启动 Firefox,同时加载并打开 Developer Tools。
|
||||
+ **-inspector URL** -- 使用 DOM Inspector 查看指定的 URL
|
||||
+ **-jsconsole** -- 启动 Firefox,同时打开 Browser Console。
|
||||
+ **-tray** -- 启动 Firefox,但保持最小化。
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/
|
||||
|
||||
作者:[Martin Brinkmann][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ghacks.net/author/martin/
|
||||
[1]:https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options
|
||||
@ -0,0 +1,176 @@
|
||||
在 Ubuntu 16.04 上安装并使用 YouTube-DL
|
||||
======
|
||||
|
||||
Youtube-dl 是一个免费而开源的命令行视频下载工具,可以用来从 Youtube 等类似的网站上下载视频,目前它支持的网站除了 Youtube 还有 Facebook,Dailymotion,Google Video,Yahoo 等等。它构架于 pygtk 之上,需要 Python 的支持来运行。它支持很多操作系统,包括 Windows,Mac 以及 Unix。Youtube-dl 还有断点续传,下载整个频道或者整个播放清单中的视频,添加自定义的标题,代理,等等其他功能。
|
||||
|
||||
本文中,我们将来学习如何在 Ubuntu16.04 上安装并使用 Youtube-dl 和 Youtube-dlg。我们还会学习如何以不同质量,不同格式来下载 Youtube 中的视频。
|
||||
|
||||
### 前置需求
|
||||
|
||||
* 一台运行 Ubuntu 16.04 的服务器。
|
||||
* 非 root 用户但拥有 sudo 特权。
|
||||
|
||||
让我们首先用下面命令升级系统到最新版:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
然后重启系统应用这些变更。
|
||||
|
||||
### 安装 Youtube-dl
|
||||
|
||||
默认情况下,Youtube-dl 并不在 Ubuntu-16.04 仓库中。你需要从官网上来下载它。使用 curl 命令可以进行下载:
|
||||
|
||||
首先,使用下面命令安装 curl:
|
||||
|
||||
```
|
||||
sudo apt-get install curl -y
|
||||
```
|
||||
|
||||
然后,下载 youtube-dl 的二进制包:
|
||||
|
||||
```
|
||||
curl -L https://yt-dl.org/latest/youtube-dl -o /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
接着,用下面命令更改 youtube-dl 二进制包的权限:
|
||||
|
||||
```
|
||||
sudo chmod 755 /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
youtube-dl 有算是安装好了,现在可以进行下一步了。
|
||||
|
||||
### 使用 Youtube-dl
|
||||
|
||||
运行下面命令会列出 youtube-dl 的所有可选项:
|
||||
|
||||
```
|
||||
youtube-dl --h
|
||||
```
|
||||
|
||||
Youtube-dl 支持多种视频格式,像 Mp4,WebM,3gp,以及 FLV 都支持。你可以使用下面命令列出指定视频所支持的所有格式:
|
||||
|
||||
```
|
||||
youtube-dl -F https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
如下所示,你会看到该视频所有可能的格式:
|
||||
|
||||
```
|
||||
[info] Available formats for j_JgXJ-apXs:
|
||||
format code extension resolution note
|
||||
139 m4a audio only DASH audio 56k , m4a_dash container, mp4a.40.5@ 48k (22050Hz), 756.44KiB
|
||||
249 webm audio only DASH audio 56k , opus @ 50k, 724.28KiB
|
||||
250 webm audio only DASH audio 69k , opus @ 70k, 902.75KiB
|
||||
171 webm audio only DASH audio 110k , vorbis@128k, 1.32MiB
|
||||
251 webm audio only DASH audio 122k , opus @160k, 1.57MiB
|
||||
140 m4a audio only DASH audio 146k , m4a_dash container, mp4a.40.2@128k (44100Hz), 1.97MiB
|
||||
278 webm 256x144 144p 97k , webm container, vp9, 24fps, video only, 1.33MiB
|
||||
160 mp4 256x144 DASH video 102k , avc1.4d400c, 24fps, video only, 731.53KiB
|
||||
133 mp4 426x240 DASH video 174k , avc1.4d4015, 24fps, video only, 1.36MiB
|
||||
242 webm 426x240 240p 221k , vp9, 24fps, video only, 1.74MiB
|
||||
134 mp4 640x360 DASH video 369k , avc1.4d401e, 24fps, video only, 2.90MiB
|
||||
243 webm 640x360 360p 500k , vp9, 24fps, video only, 4.15MiB
|
||||
135 mp4 854x480 DASH video 746k , avc1.4d401e, 24fps, video only, 6.11MiB
|
||||
244 webm 854x480 480p 844k , vp9, 24fps, video only, 7.27MiB
|
||||
247 webm 1280x720 720p 1155k , vp9, 24fps, video only, 9.21MiB
|
||||
136 mp4 1280x720 DASH video 1300k , avc1.4d401f, 24fps, video only, 9.66MiB
|
||||
248 webm 1920x1080 1080p 1732k , vp9, 24fps, video only, 14.24MiB
|
||||
137 mp4 1920x1080 DASH video 2217k , avc1.640028, 24fps, video only, 15.28MiB
|
||||
17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k
|
||||
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
|
||||
43 webm 640x360 medium , vp8.0, vorbis@128k
|
||||
18 mp4 640x360 medium , avc1.42001E, mp4a.40.2@ 96k
|
||||
22 mp4 1280x720 hd720 , avc1.64001F, mp4a.40.2@192k (best)
|
||||
```
|
||||
|
||||
然后使用 `-f` 指定你想要下载的格式,如下所示:
|
||||
|
||||
```
|
||||
youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
该命令会下载 640x360 分辨率的 mp4 格式的视频:
|
||||
```
|
||||
[youtube] j_JgXJ-apXs: Downloading webpage
|
||||
[youtube] j_JgXJ-apXs: Downloading video info webpage
|
||||
[youtube] j_JgXJ-apXs: Extracting video information
|
||||
[youtube] j_JgXJ-apXs: Downloading MPD manifest
|
||||
[download] Destination: B.A. PASS 2 Trailer no 2 _ Filmybox-j_JgXJ-apXs.mp4
|
||||
[download] 100% of 6.90MiB in 00:47
|
||||
|
||||
```
|
||||
|
||||
如果你想以 mp3 音频的格式下载 Youtube 视频,也可以做到:
|
||||
|
||||
```
|
||||
youtube-dl https://www.youtube.com/watch?v=j_JgXJ-apXs -x --audio-format mp3
|
||||
```
|
||||
|
||||
你也可以下载指定频道中的所有视频,只需要把频道的 URL 放到后面就行,如下所示:
|
||||
|
||||
```
|
||||
youtube-dl -citw https://www.youtube.com/channel/UCatfiM69M9ZnNhOzy0jZ41A
|
||||
```
|
||||
|
||||
若你的网络需要通过代理,那么可以使用 `--proxy` 来下载视频:
|
||||
|
||||
```
|
||||
youtube-dl --proxy http://proxy-ip:port https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
若想一条命令下载多个 Youtube 视频,那么首先把所有要下载的 Youtube 视频 URL 存在一个文件中(假设这个文件叫 youtube-list.txt),然后运行下面命令:
|
||||
|
||||
```
|
||||
youtube-dl -a youtube-list.txt
|
||||
```
|
||||
|
||||
### 安装 Youtube-dl GUI
|
||||
|
||||
若你想要图形化的界面,那么 youtube-dlg 是你最好的选择。youtube-dlg 是一款由 wxPython 所写的免费而开源的 youtube-dl 界面。
|
||||
|
||||
该工具默认也不在 Ubuntu 16.04 仓库中。因此你需要为它添加 PPA。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,更新软件包仓库并安装 youtube-dlg:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install youtube-dlg -y
|
||||
```
|
||||
|
||||
安装好 Youtube-dl 后,就能在 `Unity Dash` 中启动它了:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
[![][4]][5]
|
||||
|
||||
现在你只需要将 URL 粘贴到上图中的 URL 域就能下载视频了。Youtube-dlg 对于那些不太懂命令行的人来说很有用。
|
||||
|
||||
### 结语
|
||||
|
||||
恭喜你!你已经成功地在 Ubuntu 16.04 服务器上安装好了 youtube-dl 和 youtube-dlg。你可以很方便地从 Youtube 及任何 youtube-dl 支持的网站上以任何格式和任何大小下载视频了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-and-use-youtube-dl-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/Screenshot-of-youtube-dl-dash.png
|
||||
[3]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dash.png
|
||||
[4]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/Screenshot-of-youtube-dl-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dashboard.png
|
||||
@ -1,64 +1,65 @@
|
||||
How To Protect Server Against Brute Force Attacks With Fail2ban On Linux
|
||||
如何在Linux上用Fail2ban保护服务器免受暴力攻击
|
||||
======
|
||||
One of the important task for Linux administrator is to protect server against illegitimate attack or access. By default Linux system comes with well-configured firewall such as Iptables, Uncomplicated Firewall (UFW), ConfigServer Security Firewall (CSF), etc, which will prevent many kinds of attacks.
|
||||
|
||||
Any machine which is connected to the internet is a potential target for malicious attacks. There is a tool called fail2ban is available to mitigate illegitimate access on server.
|
||||
Linux管理员的一个重要任务是保护服务器免受非法攻击或访问。 默认情况下,Linux系统带有配置良好的防火墙,比如Iptables,Uncomplicated Firewall(UFW),ConfigServer Security Firewall(CSF)等,可以防止多种攻击。
|
||||
|
||||
### What Is Fail2ban?
|
||||
任何连接到互联网的机器都是恶意攻击的潜在目标。 有一个名为fail2ban的工具可用来缓解服务器上的非法访问。
|
||||
|
||||
[Fail2ban][1] is an intrusion prevention software, framework which protect server against brute force attacks. It's Written in Python programming language. Fail2ban work based on auth log files, by default it will scan the auth log files such as `/var/log/auth.log`, `/var/log/apache/access.log`, etc.. and bans IPs that show the malicious signs, too many password failures, seeking for exploits, etc.
|
||||
### 什么是Fail2ban?
|
||||
|
||||
Generally fail2Ban is used to update firewall rules to reject the IP addresses for a specified amount of time. Also it will send mail notification too. Fail2Ban comes with many filters for various services such as ssh, apache, nginx, squid, named, mysql, nagios, etc,.
|
||||
[Fail2ban][1]是一款入侵防御软件,可以保护服务器免受暴力攻击。 它是用Python编程语言编写的。 Fail2ban基于auth日志文件工作,默认情况下它会扫描所有auth日志文件,如`/var/log/auth.log`,`/var/log/apache/access.log`等,并禁止带有恶意标志的IP,比如密码失败太多,寻找漏洞等等标志。
|
||||
|
||||
Fail2Ban is able to reduce the rate of incorrect authentications attempts however it cannot eliminate the risk that weak authentication presents. this is one of the security for server which will prevent brute force attacks.
|
||||
通常,fail2Ban用于更新防火墙规则,用于在指定的时间内拒绝IP地址。 它也会发送邮件通知。 Fail2Ban为各种服务提供了许多过滤器,如ssh,apache,nginx,squid,named,mysql,nagios等。
|
||||
|
||||
### How to Install Fail2ban In Linux
|
||||
Fail2Ban能够降低错误认证尝试的速度,但是它不能消除弱认证带来的风险。 这只是服务器防止暴力攻击的安全手段之一。
|
||||
|
||||
Fail2ban is already packaged with most of the Linux distribution so, just use you distribution package manager to install it.
|
||||
### 如何在Linux中安装Fail2ban
|
||||
|
||||
Fail2ban已经与大部分Linux发行版打包在一起了,所以只需使用你的发行包版的包管理器来安装它。
|
||||
|
||||
对于**`Debian / Ubuntu`**,使用[APT-GET命令][2]或[APT命令][3]安装。
|
||||
|
||||
For **`Debian/Ubuntu`** , use [APT-GET Command][2] or [APT Command][3] to install tilda.
|
||||
```
|
||||
$ sudo apt install fail2ban
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][4] to install tilda.
|
||||
对于**`Fedora`**,使用[DNF命令][4]安装。
|
||||
|
||||
```
|
||||
$ sudo dnf install fail2ban
|
||||
|
||||
```
|
||||
|
||||
For **`CentOS/RHEL`** systems, enable [EPEL Repository][5] or [RPMForge Repository][6] and use [YUM Command][7] to install Terminator.
|
||||
对于 **`CentOS/RHEL`**,启用[EPEL库][5]或[RPMForge][6]库,使用[YUM命令][7]安装。
|
||||
|
||||
```
|
||||
$ sudo yum install fail2ban
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][8] to install tilda.
|
||||
对于**`Arch Linux`**,使用[Pacman命令][8]安装。
|
||||
|
||||
```
|
||||
$ sudo pacman -S fail2ban
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][9] to install tilda.
|
||||
对于 **`openSUSE`** , 使用[Zypper命令][9]安装.
|
||||
```
|
||||
$ sudo zypper in fail2ban
|
||||
|
||||
```
|
||||
|
||||
### How To Configure Fail2ban
|
||||
### 如何配置Fail2ban
|
||||
|
||||
By default Fail2ban keeps all the configuration files in `/etc/fail2ban/` directory. The main configuration file is `jail.conf`, it contains a set of pre-defined filters. So, don't edit the file and it's not advisable because whenever new update comes the configuration get reset to default.
|
||||
默认情况下,Fail2ban将所有配置文件保存在`/etc/fail2ban/` 目录中。 主配置文件是`jail.conf`,它包含一组预定义的过滤器。 所以,不要编辑文件,这是不可取的,因为只要有新的更新配置就会重置为默认值。
|
||||
|
||||
只需在同一目录下创建一个名为`jail.local`的新配置文件,并根据您的意愿进行修改。
|
||||
|
||||
Just create a new configuration file called `jail.local` in the same directory and modify as per your wish.
|
||||
```
|
||||
# cp /etc/fail2ban/jail.conf /etc/fail2ban/jail.local
|
||||
|
||||
```
|
||||
|
||||
By default most of the option was configured perfectly and if you want to enable access to any particular IP then you can add the IP address into `ignoreip` area, for more then one IP give a speace between the IP address.
|
||||
默认情况下,大多数选项都已经配置的很完美了,如果要启用对任何特定IP的访问,则可以将IP地址添加到`ignoreip` 区域,对于多个ip的情况,用空格隔开ip地址。
|
||||
|
||||
配置文件中的`DEFAULT`部分包含Fail2Ban遵循的基本规则集,您可以根据自己的意愿调整任何参数。
|
||||
|
||||
The `DEFAULT` section contains the basic set of rules that Fail2Ban follow and you can adjust any parameter as per your wish.
|
||||
```
|
||||
# nano /etc/fail2ban/jail.local
|
||||
|
||||
@ -68,19 +69,19 @@ bantime = 600
|
||||
findtime = 600
|
||||
maxretry = 3
|
||||
destemail = 2daygeek@gmail.com
|
||||
|
||||
```
|
||||
|
||||
* **ignoreip :** This section allow us to whitelist the list of IP address and Fail2ban will not ban a host which matches an address in this list
|
||||
* **bantime :** The number of seconds that a host is banned
|
||||
* **findtime :** A host is banned if it has generated "maxretry" during the last "findtime" seconds
|
||||
* **maxretry :** "maxretry" is the number of failures before a host get banned.
|
||||
* **ignoreip:**本部分允许我们列出IP地址列表,Fail2ban不会禁止与列表中的地址匹配的主机
|
||||
* **bantime:**主机被禁止的秒数
|
||||
* **findtime:**如果在上次“findtime”秒期间已经发生了“maxretry”次重试,则主机会被禁止
|
||||
* **maxretry:**“maxretry”是主机被禁止之前的失败次数
|
||||
|
||||
|
||||
|
||||
### How To Configure Service
|
||||
### 如何配置服务
|
||||
|
||||
Fail2ban带有一组预定义的过滤器,用于各种服务,如ssh,apache,nginx,squid,named,mysql,nagios等。 我们不希望对配置文件进行任何更改,只需在服务区域中添加`enabled = true`这一行就可以启用任何服务。 禁用服务时将true改为false即可。
|
||||
|
||||
Fail2ban comes with set of pre-defined filters for various servicess such as ssh, apache, nginx, squid, named, mysql, nagios, etc,. We don't want to make any changes on configuration file and just add following line `enabled = true` in the service area to enable jail to any services. To disable make the line to `false` instead of ture.
|
||||
```
|
||||
# SSH servers
|
||||
[sshd]
|
||||
@ -88,31 +89,29 @@ enabled = true
|
||||
port = ssh
|
||||
logpath = %(sshd_log)s
|
||||
backend = %(sshd_backend)s
|
||||
|
||||
```
|
||||
|
||||
* **enabled :** Determines whether the service is turned on or off.
|
||||
* **port :** It's refering to the particular service. If using the default port, then the service name can be placed here. If using a non-traditional port, this should be the port number.
|
||||
* **logpath :** Gives the location of the service's logs./li>
|
||||
* **backend :** "backend" specifies the backend used to get files modification.
|
||||
* **enabled:** 确定服务是打开还是关闭。
|
||||
* **port :**指的是特定的服务。 如果使用默认端口,则服务名称可以放在这里。 如果使用非传统端口,则应该是端口号。
|
||||
* **logpath:**提供服务日志的位置
|
||||
* **backend:**“后端”指定用于获取文件修改的后端。
|
||||
|
||||
|
||||
|
||||
### Restart Fail2Ban
|
||||
### 重启Fail2Ban
|
||||
|
||||
After making changes restart Fail2Ban to take effect.
|
||||
进行更改后,重新启动Fail2Ban才能生效。
|
||||
```
|
||||
[For SysVinit Systems]
|
||||
# service fail2ban restart
|
||||
|
||||
[For systemd Systems]
|
||||
# systemctl restart fail2ban.service
|
||||
|
||||
```
|
||||
|
||||
### Verify Fail2Ban iptables rules
|
||||
### 验证Fail2Ban iptables规则
|
||||
|
||||
You can confirm whether Fail2Ban iptables rules are added into firewall using below command.
|
||||
你可以使用下面的命令来确认是否在防火墙中成功添加了Fail2Ban iptables规则。
|
||||
```
|
||||
# iptables -L
|
||||
Chain INPUT (policy ACCEPT)
|
||||
@ -136,9 +135,10 @@ target prot opt source destination
|
||||
RETURN all -- anywhere anywhere
|
||||
```
|
||||
|
||||
### How To Test Fail2ban
|
||||
### 如何测试Fail2ban
|
||||
|
||||
我做了一些失败的尝试来测试这个。 为了证实这一点,我要验证`/var/log/fail2ban.log` 文件。
|
||||
|
||||
I have made some failed attempts to test this. To confirm this, I'm going to verify the `/var/log/fail2ban.log` file.
|
||||
```
|
||||
2017-11-05 14:43:22,901 fail2ban.server [7141]: INFO Changed logging target to /var/log/fail2ban.log for Fail2ban v0.9.6
|
||||
2017-11-05 14:43:22,987 fail2ban.database [7141]: INFO Connected to fail2ban persistent database '/var/lib/fail2ban/fail2ban.sqlite3'
|
||||
@ -181,19 +181,17 @@ I have made some failed attempts to test this. To confirm this, I'm going to ver
|
||||
2017-11-05 15:20:12,276 fail2ban.filter [8528]: INFO [sshd] Found 103.5.134.167
|
||||
2017-11-05 15:20:12,380 fail2ban.actions [8528]: NOTICE [sshd] Ban 103.5.134.167
|
||||
2017-11-05 15:21:12,659 fail2ban.actions [8528]: NOTICE [sshd] Unban 103.5.134.167
|
||||
|
||||
```
|
||||
|
||||
To Check list of jail enabled, run the following command.
|
||||
要查看启用的监狱列表,请运行以下命令。
|
||||
```
|
||||
# fail2ban-client status
|
||||
Status
|
||||
|- Number of jail: 2
|
||||
`- Jail list: apache-auth, sshd
|
||||
|
||||
```
|
||||
|
||||
To get the blocked Ip address by running following command.
|
||||
通过运行以下命令来获取禁止的IP地址。
|
||||
```
|
||||
# fail2ban-client status ssh
|
||||
Status for the jail: ssh
|
||||
@ -205,13 +203,11 @@ Status for the jail: ssh
|
||||
|- Currently banned: 1
|
||||
| `- IP list: 192.168.1.115
|
||||
`- Total banned: 1
|
||||
|
||||
```
|
||||
|
||||
To remove blocked IP address from Fail2Ban, run the following command.
|
||||
要从Fail2Ban中删除禁止的IP地址,请运行以下命令。
|
||||
```
|
||||
# fail2ban-client set ssh unbanip 192.168.1.115
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -219,7 +215,7 @@ To remove blocked IP address from Fail2Ban, run the following command.
|
||||
via: https://www.2daygeek.com/how-to-install-setup-configure-fail2ban-on-linux/#
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user