mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
b30d776c38
@ -0,0 +1,49 @@
|
||||
如何在企业中开展开源计划
|
||||
======
|
||||
|
||||
> 有 65% 的企业使用开源软件,并非只有互联网企业才能受惠于开源计划。
|
||||
|
||||

|
||||
|
||||
很多互联网企业如 Google、 Facebook、 Twitter 等,都已经正式建立了开源计划(有的公司中建立了单独的<ruby>开源计划部门<rt>open source program office</rt></ruby>(OSPO)),这是在公司内部消化和支持开源产品的地方。在这样一个实际的部门中,企业可以清晰透明地执行开源策略,这是企业成功开源化的一个必要过程。开源计划部门的职责包括:制定使用、分配、选择和审查代码的相关政策;培育开源社区;培训开发技术人员和确保法律合规。
|
||||
|
||||
互联网企业并不是唯一建立开源计划的企业,有调查发现各种行业中有 [65% 的企业][1]的在使用开源和向开源贡献。在过去几年中 [VMware][2]、 [Amazon][3]、 [Microsoft][4] 等企业,甚至连[英国政府][5]都开始聘用开源管理人员,开展开源计划。可见近年来商业领域乃至政府都十分重视开源策略,在这样的环境下,各界也需要跟上他们的步伐,建立开源计划。
|
||||
|
||||
### 怎样建立开源计划
|
||||
|
||||
虽然根据企业的需求不同,各开源计划部门会有特殊的调整,但下面几个基本步骤是建立每个公司都会经历的,它们是:
|
||||
|
||||
* **选定一位领导者:** 选出一位合适的领导之是建立开源计划的第一步。 [TODO Group][6] 发布了一份[开源人员基础工作任务清单][7],你可以根据这个清单筛选人员。
|
||||
* **确定计划构架:** 开源计划部门可以根据其服务的企业类型的侧重点,来适应不同种类的企业需求,以在各类企业中成功运行。知识型企业可以把开源计划放在法律事务部运行,技术驱动型企业可以把开源计划放在着眼于提高企业效能的部门中,如工程部。其他类型的企业可以把开源计划放在市场部内运行,以此促进开源产品的销售。TODO Group 发布的[开源计划案例][8]或许可以给你些启发。
|
||||
* **制定规章制度:** 开源策略的实施需要有一套规章制度,其中应当具体列出企业成员进行开源工作的标准流程,来减少失误的发生。这个流程应当简洁明了且简单易行,最好可以用设备进行自动化。如果工作人员有质疑标准流程的热情和能力,并提出改进意见,那再好不过了。许多活跃在开源领域的企业中,Google 发布的规章制度十分值得借鉴。你可以参照 [Google 发布的制度][9]起草适用于自己企业的规章制度,用 [TODO 提供其它开源策略][10]也可以参考。
|
||||
|
||||
### 建立开源计划是企业发展中的关键一步
|
||||
|
||||
建立开源计划部门对很多企业来说是关键一步,尤其是对于那些软件公司或是想要转型进入软件领域的公司。不论雇员的满意度或是开发效率上,在开源计划中企业可以获得巨大的利益,这些利益远远大于对开源计划所需要的长期投资。在开源之路上有很多资源可以帮助你成功,例如 TODO Group 的[《怎样创建开源计划》][11]、[《开源计划的价值评估》][12]和[《管理开源计划的几种工具》][13]都很适合初学者阅读。
|
||||
|
||||
随着越来越多的企业形成开源计划,开源社区自身的可持续性逐渐加强,这会对这些企业的开源计划产生积极影响,促进企业的发展,这是企业和开源间的良性循环。我希望以上这些信息能够帮到你,祝你在建立开源计划的路上一路顺风。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-start-open-source-program-your-company
|
||||
|
||||
作者:[Chris Aniszczyk][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/caniszczyk
|
||||
[1]:https://www.blackducksoftware.com/2016-future-of-open-source
|
||||
[2]:http://www.cio.com/article/3095843/open-source-tools/vmware-today-has-a-strong-investment-in-open-source-dirk-hohndel.html
|
||||
[3]:http://fortune.com/2016/12/01/amazon-open-source-guru/
|
||||
[4]:https://opensource.microsoft.com/
|
||||
[5]:https://www.linkedin.com/jobs/view/169669924
|
||||
[6]:http://todogroup.org
|
||||
[7]:https://github.com/todogroup/job-descriptions
|
||||
[8]:https://github.com/todogroup/guides/tree/master/casestudies
|
||||
[9]:https://opensource.google.com/docs/why/
|
||||
[10]:https://github.com/todogroup/policies
|
||||
[11]:https://github.com/todogroup/guides/blob/master/creating-an-open-source-program.md
|
||||
[12]:https://github.com/todogroup/guides/blob/master/measuring-your-open-source-program.md
|
||||
[13]:https://github.com/todogroup/guides/blob/master/tools-for-managing-open-source-programs.md
|
||||
@ -1,4 +1,4 @@
|
||||
注重隐私的开源桌面 YouTube 播放器
|
||||
FreeTube:注重隐私的开源桌面 YouTube 播放器
|
||||
======
|
||||
|
||||

|
||||
@ -13,36 +13,34 @@
|
||||
* 本地存储订阅、历史记录和已保存的视频。
|
||||
* 导入/备份订阅。
|
||||
* 迷你播放器。
|
||||
* 轻/黑暗的主题。
|
||||
* 亮/暗的主题。
|
||||
* 免费、开源。
|
||||
* 跨平台。
|
||||
|
||||
|
||||
|
||||
### 安装 FreeTube
|
||||
|
||||
进入[**发布页面**][1]并根据你使用的操作系统获取版本。在本指南中,我将使用 **.tar.gz** 文件。
|
||||
进入[发布页面][1]并根据你使用的操作系统获取版本。在本指南中,我将使用 **.tar.gz** 文件。
|
||||
|
||||
```
|
||||
$ wget https://github.com/FreeTubeApp/FreeTube/releases/download/v0.1.3-beta/FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
解压下载的归档:
|
||||
|
||||
```
|
||||
$ tar xf FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
进入 Freetube 文件夹:
|
||||
|
||||
```
|
||||
$ cd FreeTube-linux-x64/
|
||||
|
||||
```
|
||||
|
||||
使用命令启动 Freeube:
|
||||
|
||||
```
|
||||
$ ./FreeTub
|
||||
|
||||
```
|
||||
|
||||
这就是 FreeTube 默认界面的样子。
|
||||
@ -51,7 +49,7 @@ $ ./FreeTub
|
||||
|
||||
### 用法
|
||||
|
||||
FreeTube 目前使用 **YouTube API ** 搜索视频。然后,它使用 **Youtube-dl HTTP API** 获取原始视频文件并在基础的 HTML5 视频播放器中播放它们。由于订阅、历史记录和已保存的视频都存储在本地系统中,因此你的详细信息将不会发送给 Google 或其他任何人。
|
||||
FreeTube 目前使用 **YouTube API** 搜索视频。然后,它使用 **Youtube-dl HTTP API** 获取原始视频文件并在基础的 HTML5 视频播放器中播放它们。由于订阅、历史记录和已保存的视频都存储在本地系统中,因此你的详细信息将不会发送给 Google 或其他任何人。
|
||||
|
||||
在搜索框中输入视频名称,然后按下回车键。FreeTube 会根据你的搜索查询列出结果。
|
||||
|
||||
@ -67,9 +65,7 @@ FreeTube 目前使用 **YouTube API ** 搜索视频。然后,它使用 **Youtu
|
||||
|
||||
请注意,FreeTube 仍处于 **beta** 阶段,所以仍然有 bug。如果有任何 bug,请在本指南最后给出的 GitHub 页面上报告。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -77,7 +73,7 @@ via: https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-fo
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,9 @@
|
||||
如何在 Linux 中使用 LVM 创建/扩展交换分区
|
||||
如何在 Linux 中使用 LVM 创建和扩展交换分区
|
||||
======
|
||||
|
||||
我们使用 LVM 进行灵活的卷管理,为什么我们不能将 LVM 用于交换分区呢?
|
||||
|
||||
这让用户在需要时增加交换分区。
|
||||
|
||||
如果你升级系统中的内存,则需要添加更多交换空间。
|
||||
|
||||
这有助于你管理运行需要大量内存的应用的系统。
|
||||
这可以让用户在需要时增加交换分区。如果你升级系统中的内存,则需要添加更多交换空间。这有助于你管理运行需要大量内存的应用的系统。
|
||||
|
||||
可以通过三种方式创建交换分区
|
||||
|
||||
@ -14,13 +11,12 @@
|
||||
* 创建一个新的交换文件
|
||||
* 在现有逻辑卷(LVM)上扩展交换分区
|
||||
|
||||
|
||||
|
||||
建议创建专用交换分区而不是交换文件。
|
||||
|
||||
**建议阅读:**
|
||||
**(#)** [3 种简单的方法在 Linux 中创建或扩展交换空间][1]
|
||||
**(#)** [使用 Shell 脚本在 Linux 中自动创建/删除和挂载交换文件][2]
|
||||
|
||||
* [3 种简单的方法在 Linux 中创建或扩展交换空间][1]
|
||||
* [使用 Shell 脚本在 Linux 中自动创建/删除和挂载交换文件][2]
|
||||
|
||||
Linux 中推荐的交换大小是多少?
|
||||
|
||||
@ -28,47 +24,48 @@ Linux 中推荐的交换大小是多少?
|
||||
|
||||
当物理内存 (RAM) 已满时,将使用 Linux 中的交换空间。当物理内存已满时,内存中的非活动页将移到交换空间。
|
||||
|
||||
这有助于系统连续运行应用程序,但它不被认为是更多内存的替代品。
|
||||
这有助于系统连续运行应用程序,但它不能当做是更多内存的替代品。
|
||||
|
||||
交换空间位于硬盘上,因此它不会像物理内存那样处理请求。
|
||||
交换空间位于硬盘上,因此它不能像物理内存那样处理请求。
|
||||
|
||||
### 如何使用LVM创建交换分区
|
||||
### 如何使用 LVM 创建交换分区
|
||||
|
||||
由于我们已经知道如何创建逻辑卷,所以交换分区也是如此。只需按照以下过程。
|
||||
|
||||
创建你需要的逻辑卷。在我这里,我要创建 `5GB` 的交换分区。
|
||||
|
||||
```
|
||||
$ sudo lvcreate -L 5G -n LogVol_swap1 vg00
|
||||
Logical volume "LogVol_swap1" created.
|
||||
|
||||
```
|
||||
|
||||
格式化新的交换空间。
|
||||
|
||||
```
|
||||
$ sudo mkswap /dev/vg00/LogVol_swap1
|
||||
Setting up swapspace version 1, size = 5 GiB (5368705024 bytes)
|
||||
no label, UUID=d278e9d6-4c37-4cb0-83e5-2745ca708582
|
||||
|
||||
```
|
||||
|
||||
将以下条目添加到 `/etc/fstab` 中。
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
/dev/mapper/vg00-LogVol_swap1 swap swap defaults 0 0
|
||||
|
||||
```
|
||||
|
||||
启用扩展逻辑卷。
|
||||
|
||||
```
|
||||
$ sudo swapon -va
|
||||
swapon: /swapfile: already active -- ignored
|
||||
swapon: /dev/mapper/vg00-LogVol_swap1: found signature [pagesize=4096, signature=swap]
|
||||
swapon: /dev/mapper/vg00-LogVol_swap1: pagesize=4096, swapsize=5368709120, devsize=5368709120
|
||||
swapon /dev/mapper/vg00-LogVol_swap1
|
||||
|
||||
```
|
||||
|
||||
测试交换空间是否已正确添加。
|
||||
|
||||
```
|
||||
$ cat /proc/swaps
|
||||
Filename Type Size Used Priority
|
||||
@ -79,7 +76,6 @@ $ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 1 1 0 0 0 0
|
||||
Swap: 6 0 6
|
||||
|
||||
```
|
||||
|
||||
### 如何使用 LVM 扩展交换分区
|
||||
@ -87,40 +83,41 @@ Swap: 6 0 6
|
||||
只需按照以下过程来扩展 LVM 交换逻辑卷。
|
||||
|
||||
禁用相关逻辑卷的交换。
|
||||
|
||||
```
|
||||
$ sudo swapoff -v /dev/vg00/LogVol_swap1
|
||||
swapoff /dev/vg00/LogVol_swap1
|
||||
|
||||
```
|
||||
|
||||
调整逻辑卷的大小。我将把交换空间从 `5GB 增加到 11GB`。
|
||||
调整逻辑卷的大小。我将把交换空间从 `5GB` 增加到 `11GB`。
|
||||
|
||||
```
|
||||
$ sudo lvresize /dev/vg00/LogVol_swap1 -L +6G
|
||||
Size of logical volume vg00/LogVol_swap1 changed from 5.00 GiB (1280 extents) to 11.00 GiB (2816 extents).
|
||||
Logical volume vg00/LogVol_swap1 successfully resized.
|
||||
|
||||
```
|
||||
|
||||
格式化新的交换空间。
|
||||
|
||||
```
|
||||
$ sudo mkswap /dev/vg00/LogVol_swap1
|
||||
mkswap: /dev/vg00/LogVol_swap1: warning: wiping old swap signature.
|
||||
Setting up swapspace version 1, size = 11 GiB (11811155968 bytes)
|
||||
no label, UUID=2e3b2ee0-ad0b-402c-bd12-5a9431b73623
|
||||
|
||||
```
|
||||
|
||||
启用扩展逻辑卷。
|
||||
|
||||
```
|
||||
$ sudo swapon -va
|
||||
swapon: /swapfile: already active -- ignored
|
||||
swapon: /dev/mapper/vg00-LogVol_swap1: found signature [pagesize=4096, signature=swap]
|
||||
swapon: /dev/mapper/vg00-LogVol_swap1: pagesize=4096, swapsize=11811160064, devsize=11811160064
|
||||
swapon /dev/mapper/vg00-LogVol_swap1
|
||||
|
||||
```
|
||||
|
||||
测试逻辑卷是否已正确扩展。
|
||||
|
||||
```
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
@ -131,7 +128,6 @@ $ cat /proc/swaps
|
||||
Filename Type Size Used Priority
|
||||
/swapfile file 1459804 237024 -1
|
||||
/dev/dm-0 partition 11534332 0 -2
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -140,7 +136,7 @@ via: https://www.2daygeek.com/how-to-create-extend-swap-partition-in-linux-using
|
||||
|
||||
作者:[Ramya Nuvvula][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,111 @@
|
||||
# How will the GDPR impact open source communities?
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
|
||||
|
||||
On May 25, 2018 the [General Data Protection Regulation][1] will go into effect. This new regulation by the European Union will impact how organizations need to protect personal data on a global scale. This could include open source projects, including communities.
|
||||
|
||||
### GDPR details
|
||||
|
||||
The General Data Protection Regulation (GDPR) was approved by the EU Parliament on April 14, 2016, and will be enforced beginning May 25, 2018. The GDPR replaces the Data Protection Directive 95/46/EC that was designed "to harmonize data privacy laws across Europe, to protect and empower all EU citizens data privacy and to reshape the way organizations across the region approach data privacy."
|
||||
|
||||
The aim of the GDPR is to protect the personal data of individuals in the EU in an increasingly data-driven world.
|
||||
|
||||
### To whom does it apply
|
||||
|
||||
One of the biggest changes that comes with the GDPR is an increased territorial scope. The GDPR applies to all organizations processing the personal data of data subjects residing in the European Union, irrelevant to its location.
|
||||
|
||||
While most of the online articles covering the GDPR mention companies selling goods or services, we can also look at this territorial scope with open source projects in mind. There are a few variations, such as a software company (profit) running a community, and a non-profit organization, i.e. an open source software project and its community. Once these communities are run on a global scale, it is most likely that EU-based persons are taking part in this community.
|
||||
|
||||
When such a global community has an online presence, using platforms such as a website, forum, issue tracker etcetera, it is very likely that they are processing personal data of these EU persons, such as their names, e-mail addresses and possibly even more. These activities will trigger a need to comply with the GDPR.
|
||||
|
||||
### GDPR changes and its impact
|
||||
|
||||
The GDPR brings [many changes][2], strengthening data protection and privacy of EU persons, compared to the previous Directive. Some of these changes have a direct impact on a community as described earlier. Let's look at some of these changes.
|
||||
|
||||
#### Consent
|
||||
|
||||
Let's assume that the community in question uses a forum for its members, and also has one or more forms on their website for registration purposes. With the GDPR you will no longer be able to use one lengthy and illegible privacy policy and terms of conditions. For each of those specific purposes, registering on the forum, and on one of those forms, you will need to obtain explicit consent. This consent must be “freely given, specific, informed, and unambiguous.”
|
||||
|
||||
In case of such a form, you could have a checkbox, which should not be pre-checked, with clear text indicating for which purposes the personal data is used, preferably linking to an ‘addendum’ of your existing privacy policy and terms of use.
|
||||
|
||||
#### Right to access
|
||||
|
||||
EU persons get expanded rights by the GDPR. One of them is the right to ask an organization if, where and which personal data is processed. Upon request, they should also be provided with a copy of this data, free of charge, and in an electronic format if this data subject (e.g. EU citizen) asks for it.
|
||||
|
||||
#### Right to be forgotten
|
||||
|
||||
Another right EU citizens get through the GDPR is the "right to be forgotten," also known as data erasure. This means that subject to certain limitation, the organization will have to erase his/her data, and possibly even stop any further processing, including by the organization’s third parties.
|
||||
|
||||
The above three changes imply that your platform(s) software will need to comply with certain aspects of the GDPR as well. It will need to have specific features such as obtaining and storing consent, extracting data and providing a copy in electronic format to a data subject, and finally the means to erase specific data about a data subject.
|
||||
|
||||
#### Breach notification
|
||||
|
||||
Under the GDPR, a data breach occurs whenever personal data is taken or stolen without the authorization of the data subject. Once discovered, you should notify your affected community members within 72 hours unless the personal data breach is unlikely to result in a risk to the rights and freedoms of natural persons. This breach notification is mandatory under the GDPR.
|
||||
|
||||
#### Register
|
||||
|
||||
As an organization, you will become responsible for keeping a register which will include detailed descriptions of all procedures, purposes etc for which you process personal data. This register will act as proof of the organization's compliance with the GDPR’s requirement to maintain a record of personal data processing activities, and will be used for audit purposes.
|
||||
|
||||
#### Fines
|
||||
|
||||
Organizations that do not comply with the GDPR risk fines up to 4% of annual global turnover or €20 million (whichever is greater). According to the GDPR, "this is the maximum fine that can be imposed for the most serious infringements e.g.not having sufficient customer consent to process data or violating the core of Privacy by Design concepts."
|
||||
|
||||
### Final words
|
||||
|
||||
My article should not be used as legal advice or a definite guide to GDPR compliance. I have covered some of the parts of the regulation that could be of impact to an open source community, raising awareness about the GDPR and its impact. Obviously, the regulation contains much more which you will need to know about and possibly comply with.
|
||||
|
||||
As you can probably conclude yourself, you will have to take steps when you are running a global community, to comply with the GDPR. If you already apply robust security standards in your community, such as ISO 27001, NIST or PCI DSS, you should have a head start.
|
||||
|
||||
You can find more information about the GDPR at the following sites/resources:
|
||||
|
||||
* [GDPR Portal][3] (by the EU)
|
||||
|
||||
* [Official Regulation (EU) 2016/679][4] (GDPR, including translations)
|
||||
|
||||
* [What is GDPR? 8 things leaders should know][5] (The Enterprisers Project)
|
||||
|
||||
* [How to avoid a GDPR compliance audit: Best practices][6] (The Enterprisers Project)
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][7]
|
||||
|
||||
Robin Muilwijk \- Robin Muilwijk is Advisor Internet and e-Government. He also serves as a community moderator for Opensource.com, an online publication by Red Hat, and as ambassador for The Open Organization. Robin is also Chair of the eZ Community Board, and Community Manager at [eZ Systems][8]. Robin writes and is active on social media to promote and advocate for open source in our businesses and lives.Follow him on Twitter... [more about Robin Muilwijk][9]
|
||||
|
||||
[More about me][10]
|
||||
|
||||
* [Learn how you can contribute][11]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/gdpr-impact][12]
|
||||
|
||||
作者: [Robin Muilwijk][13] 选题者: [@lujun9972][14] 译者: [译者ID][15] 校对: [校对者ID][16]
|
||||
|
||||
本文由 [LCTT][17] 原创编译,[Linux中国][18] 荣誉推出
|
||||
|
||||
[1]: https://www.eugdpr.org/eugdpr.org.html
|
||||
[2]: https://www.eugdpr.org/key-changes.html
|
||||
[3]: https://www.eugdpr.org/eugdpr.org.html
|
||||
[4]: http://eur-lex.europa.eu/legal-content/EN/TXT/?qid=1520531479111&uri=CELEX:32016R0679
|
||||
[5]: https://enterprisersproject.com/article/2018/4/what-gdpr-8-things-leaders-should-know
|
||||
[6]: https://enterprisersproject.com/article/2017/9/avoiding-gdpr-compliance-audit-best-practices
|
||||
[7]: https://opensource.com/users/robinmuilwijk
|
||||
[8]: http://ez.no
|
||||
[9]: https://opensource.com/users/robinmuilwijk
|
||||
[10]: https://opensource.com/users/robinmuilwijk
|
||||
[11]: https://opensource.com/participate
|
||||
[12]: https://opensource.com/article/18/4/gdpr-impact
|
||||
[13]: https://opensource.com/users/robinmuilwijk
|
||||
[14]: https://github.com/lujun9972
|
||||
[15]: https://github.com/译者ID
|
||||
[16]: https://github.com/校对者ID
|
||||
[17]: https://github.com/LCTT/TranslateProject
|
||||
[18]: https://linux.cn/
|
||||
@ -1,263 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How to build a plotter with Arduino
|
||||
======
|
||||
|
||||

|
||||
Back in school, there was an HP plotter well hidden in a closet in the science department. I got to play with it for a while and always wanted to have one of my own. Fast forward many, many years. Stepper motors are easily available, I am back into doing stuff with electronics and micro-controllers, and I recently saw someone creating displays with engraved acrylic. This triggered me to finally build my own plotter.
|
||||
|
||||
|
||||
![The plotter in action ][2]
|
||||
|
||||
The DIY plotter; see it in action in this [video][3].
|
||||
|
||||
As an old-school 5V guy, I really like the original [Arduino Uno][4]. Here's a list of the other components I used (fyi, I am not affiliated with any of these companies):
|
||||
|
||||
* [FabScan shield][5]: Physically hosts the stepper motor drivers.
|
||||
* [SilentStepSticks][6]: Motor drivers, as the Arduino on its own can't handle the voltage and current that a stepper motor needs. I am using ones with a Trinamic TMC2130 chip, but in standalone mode for now. Those are replacements for the Pololu 4988, but allow for much quieter operation.
|
||||
* [SilentStepStick protectors][7]: Diodes that prevent the turning motor from frying your motor drivers (you want them, believe me).
|
||||
* Stepper motors: I selected NEMA 17 motors with 12V (e.g., models from [Watterott][8] and [SparkFun][9]).
|
||||
* [Linear guide rails][10]
|
||||
* Wooden base plate
|
||||
* Wood screws
|
||||
* GT2 belt
|
||||
* [GT2 timing pulley][11]
|
||||
|
||||
|
||||
|
||||
This is a work in progress that I created as a personal project. If you are looking for a ready-made kit, then check out the [MaXYposi][12] from German Make magazine.
|
||||
|
||||
### Hardware setup
|
||||
|
||||
As you can see here, I started out much too large. This plotter can't comfortably sit on my desk, but it's okay, as I did it for learning purposes (and, as I have to re-do some things, next time I'll use smaller beams).
|
||||
|
||||
|
||||
![Plotter base plate with X-axis and Y-axis rails][14]
|
||||
|
||||
Plotter base plate with X-axis and Y-axis rails
|
||||
|
||||
The belt is mounted on both sides of the rail and then slung around the motor with some helper wheels:
|
||||
|
||||
|
||||
![The belt routing on the motor][16]
|
||||
|
||||
The belt routing on the motor
|
||||
|
||||
I've stacked several components on top of the Arduino. The Arduino is on the bottom, above that is the FabScan shield, next is a StepStick protector on motor slots 1+2, and the SilentStepStick is on top. Note that the SCK and SDI pins are not connected.
|
||||
|
||||
|
||||
![Arduino and Shield][18]
|
||||
|
||||
Arduino stack setup ([larger image][19])
|
||||
|
||||
Be careful to correctly attach the wires to the motor. When in doubt, look at the data sheet or an ohmmeter to figure out which wires belong together.
|
||||
|
||||
### Software setup
|
||||
|
||||
#### The basics
|
||||
|
||||
While software like [grbl][20] can interpret so-called G-codes for tool movement and other things, and I could have just flashed it to the Arduino, I am curious and wanted to better understand things. (My X-Y plotter software is available at [GitHub][21] and comes without any warranty.)
|
||||
|
||||
To drive a stepper motor with the StepStick (or compatible) driver, you basically need to send a high and then a low signal to the respective pin. Or in Arduino terms:
|
||||
```
|
||||
digitalWrite(stepPin, HIGH);
|
||||
|
||||
delayMicroseconds(30);
|
||||
|
||||
digitalWrite(stepPin, LOW);
|
||||
|
||||
```
|
||||
|
||||
Where `stepPin` is the pin number for the stepper: 3 for motor 1 and 6 for motor 2.
|
||||
|
||||
Before the stepper does any work, it must be enabled.
|
||||
```
|
||||
digitalWrite(enPin, LOW);
|
||||
|
||||
```
|
||||
|
||||
Actually, the StepStick knows three states for the pin:
|
||||
|
||||
* Low: Motor is enabled
|
||||
* High: Motor is disabled
|
||||
* Pin not connected: Motor is enabled but goes into an energy-saving mode after a while
|
||||
|
||||
|
||||
|
||||
When a motor is enabled, its coils are powered and it keeps its position. It is almost impossible to manually turn its axis. This is good for precision purposes, but it also means that both motors and driver chips are "flooded" with power and will warm up.
|
||||
|
||||
And last, but not least, we need a way to determine the plotter's direction:
|
||||
```
|
||||
digitalWrite(dirPin, direction);
|
||||
|
||||
```
|
||||
|
||||
The following table lists the functions and the pins
|
||||
|
||||
Function Motor1 Motor2 Enable 2 5 Direction 4 7 Step 3 6
|
||||
|
||||
Before we can use the pins, we need to set them to `OUTPUT` mode in the `setup()` section of the code
|
||||
```
|
||||
pinMode(enPin1, OUTPUT);
|
||||
|
||||
pinMode(stepPin1, OUTPUT);
|
||||
|
||||
pinMode(dirPin1, OUTPUT);
|
||||
|
||||
digitalWrite(enPin1, LOW);
|
||||
|
||||
```
|
||||
|
||||
With this knowledge, we can easily get the stepper to move around:
|
||||
```
|
||||
totalRounds = ...
|
||||
|
||||
for (int rounds =0 ; rounds < 2*totalRounds; rounds++) {
|
||||
|
||||
if (dir==0){ // set direction
|
||||
|
||||
digitalWrite(dirPin2, LOW);
|
||||
|
||||
} else {
|
||||
|
||||
digitalWrite(dirPin2, HIGH);
|
||||
|
||||
}
|
||||
|
||||
delay(1); // give motors some breathing time
|
||||
|
||||
dir = 1-dir; // reverse direction
|
||||
|
||||
for (int i=0; i < 6400; i++) {
|
||||
|
||||
int t = abs(3200-i) / 200;
|
||||
|
||||
digitalWrite(stepPin2, HIGH);
|
||||
|
||||
delayMicroseconds(70 + t);
|
||||
|
||||
digitalWrite(stepPin2, LOW);
|
||||
|
||||
delayMicroseconds(70 + t);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This will make the slider move left and right. This code deals with one stepper, but for an X-Y plotter, we have two axes to consider.
|
||||
|
||||
#### Command interpreter
|
||||
|
||||
I started to implement a simple command interpreter to use path specifications, such as:
|
||||
```
|
||||
"X30|Y30|X-30 Y-30|X-20|Y-20|X20|Y20|X-40|Y-25|X40 Y25
|
||||
|
||||
```
|
||||
|
||||
to describe relative movements in millimeters (1mm equals 80 steps).
|
||||
|
||||
The plotter software implements a _continuous mode_ , which allows a PC to feed large paths (in chunks) to the plotter. (This how I plotted the Hilbert curve in this [video][22].)
|
||||
|
||||
### Building a better pen holder
|
||||
|
||||
In the first image above, the pen was tied to the Y-axis with some metal string. This was not precise and also did not enable the software to raise and lower the hand (this explains the big black dots).
|
||||
|
||||
I have since created a better, more precise pen holder that uses a servo to raise and lower the pen. This new, improved holder can be seen in this picture and in the Hilbert curve video linked above.
|
||||
|
||||
![Servo to raise/lower the pen ][24]
|
||||
|
||||
Close-up view of the servo arm in the upper position raising the pen
|
||||
|
||||
The pen is attached with a little clamp (the one shown is a size 8 clamp typically used to attach cables to walls). The servo arm can raise the pen; when the arm goes down, gravity will lower the pen.
|
||||
|
||||
#### Driving the servo
|
||||
|
||||
Driving the servo is relatively straightforward: Just provide the position and the servo does all the work.
|
||||
```
|
||||
#include <Servo.h>
|
||||
|
||||
|
||||
|
||||
// Servo pin
|
||||
|
||||
#define servoData PIN_A1
|
||||
|
||||
|
||||
|
||||
// Positions
|
||||
|
||||
#define PEN_UP 10
|
||||
|
||||
#define PEN_DOWN 50
|
||||
|
||||
|
||||
|
||||
Servo penServo;
|
||||
|
||||
|
||||
|
||||
void setup() {
|
||||
|
||||
// Attach to servo and raise pen
|
||||
|
||||
penServo.attach(servoData);
|
||||
|
||||
penServo.write(PEN_UP);
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
I am using the servo headers on the Motor 4 place of the FabScan shield, so I've used analog pin 1.
|
||||
|
||||
Lowering the pen is as easy as:
|
||||
```
|
||||
penServo.write(PEN_DOWN);
|
||||
|
||||
```
|
||||
|
||||
### Next steps
|
||||
|
||||
One of my next steps will be to add some end detectors, but I may skip them and use the StallGuard mode of the TMC2130 instead. Those detectors can also be used to implement a `home` command.
|
||||
|
||||
And perhaps in the future I'll add a real Z-axis that can hold an engraver to do wood milling, or PCB drilling, or acrylic engraving, or ... (a laser comes to mind as well).
|
||||
|
||||
This was originally published on the [Some Things to Remember][25] blog and is reprinted with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/diy-plotter-arduino
|
||||
|
||||
作者:[Heiko W.Rupp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pilhuhn
|
||||
[1]:https://opensource.com/file/384786
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/plotter-in-action.png?itok=q9oHrJGr (The plotter in action )
|
||||
[3]:https://twitter.com/pilhuhn/status/948205323726344193
|
||||
[4]:https://en.wikipedia.org/wiki/Arduino#Official_boards
|
||||
[5]:http://www.watterott.com/de/Arduino-FabScan-Shield
|
||||
[6]:http://www.watterott.com/de/SilentStepStick-TMC2130
|
||||
[7]:http://www.watterott.com/de/SilentStepStick-Protector
|
||||
[8]:http://www.watterott.com/de/Schrittmotor-incl-Anschlusskabel
|
||||
[9]:https://www.sparkfun.com/products/9238
|
||||
[10]:https://www.ebay.de/itm/CNC-Set-12x-600mm-Linearfuhrung-Linear-Guide-Rail-Stage-3D-/322917927292?hash=item4b2f68897c
|
||||
[11]:http://www.watterott.com/de/OpenBuilds-GT2-2mm-Aluminium-Timing-Pulley
|
||||
[12]:https://www.heise.de/make/artikel/MaXYposi-Projektseite-zum-universellen-XY-Portalroboter-von-Make-3676050.html
|
||||
[13]:https://opensource.com/file/384776
|
||||
[14]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/entire_plotter.jpg?itok=40iSEs5K (Plotter base plate with X-axis and Y-axis rails)
|
||||
[15]:https://opensource.com/file/384791
|
||||
[16]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/y_motor_detail.jpg?itok=SICJBdRv (The belt routing on the motor)
|
||||
[17]:https://opensource.com/file/384771
|
||||
[18]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/arduino_and_shield.jpg?itok=OFumhpJm
|
||||
[19]:https://www.dropbox.com/s/7bp3bo5g2ujser8/IMG_20180103_110111.jpg?dl=0
|
||||
[20]:https://github.com/gnea/grbl
|
||||
[21]:https://github.com/pilhuhn/xy-plotter
|
||||
[22]:https://twitter.com/pilhuhn/status/949737734654124032
|
||||
[23]:/https://opensource.comfile/384781
|
||||
[24]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/pen_servo.jpg?itok=b2cnwB3P (Servo to raise/lower the pen )
|
||||
[25]:http://pilhuhn.blogspot.com/2018/01/homegrown-xy-plotter-with-arduino.html
|
||||
@ -0,0 +1,141 @@
|
||||
# A gentle introduction to FreeDOS
|
||||
|
||||

|
||||
|
||||
Image credits :
|
||||
|
||||
Jim Hall, CC BY
|
||||
|
||||
## Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
FreeDOS is an old operating system, but it is new to many people. In 1994, several developers and I came together to [create FreeDOS][1]—a complete, free, DOS-compatible operating system you can use to play classic DOS games, run legacy business software, or develop embedded systems. Any program that works on MS-DOS should also run on FreeDOS.
|
||||
|
||||
In 1994, FreeDOS was immediately familiar to anyone who had used Microsoft's proprietary MS-DOS. And that was by design; FreeDOS intended to mimic MS-DOS as much as possible. As a result, DOS users in the 1990s were able to jump right into FreeDOS. But times have changed. Today, open source developers are more familiar with the Linux command line or they may prefer a graphical desktop like [GNOME][2], making the FreeDOS command line seem alien at first.
|
||||
|
||||
New users often ask, "I [installed FreeDOS][3], but how do I use it?" If you haven't used DOS before, the blinking C:\> DOS prompt can seem a little unfriendly. And maybe scary. This gentle introduction to FreeDOS should get you started. It offers just the basics: how to get around and how to look at files. If you want to learn more than what's offered here, visit the [FreeDOS wiki][4].
|
||||
|
||||
## The DOS prompt
|
||||
|
||||
First, let's look at the empty prompt and what it means.
|
||||
|
||||

|
||||
|
||||
DOS is a "disk operating system" created when personal computers ran from floppy disks. Even when computers supported hard drives, it was common in the 1980s and 1990s to switch frequently between the different drives. For example, you might make a backup copy of your most important files to a floppy disk.
|
||||
|
||||
DOS referenced each drive by a letter. Early PCs could have only two floppy drives, which were assigned as the A: and B: drives. The first partition on the first hard drive was the C: drive, and so on for other drives. The C: in the prompt means you are using the first partition on the first hard drive.
|
||||
|
||||
Starting with PC-DOS 2.0 in 1983, DOS also supported directories and subdirectories, much like the directories and subdirectories on Linux filesystems. But unlike Linux, DOS directory names are delimited by \ instead of /. Putting that together with the drive letter, the C:\ in the prompt means you are in the top, or "root," directory of the C: drive.
|
||||
|
||||
The > is the literal prompt where you type your DOS commands, like the $ prompt on many Linux shells. The part before the > tells you the current working directory, and you type commands at the > prompt.
|
||||
|
||||
## Finding your way around in DOS
|
||||
|
||||
The basics of navigating through directories in DOS are very similar to the steps you'd use on the Linux command line. You need to remember only a few commands.
|
||||
|
||||
### Displaying a directory
|
||||
|
||||
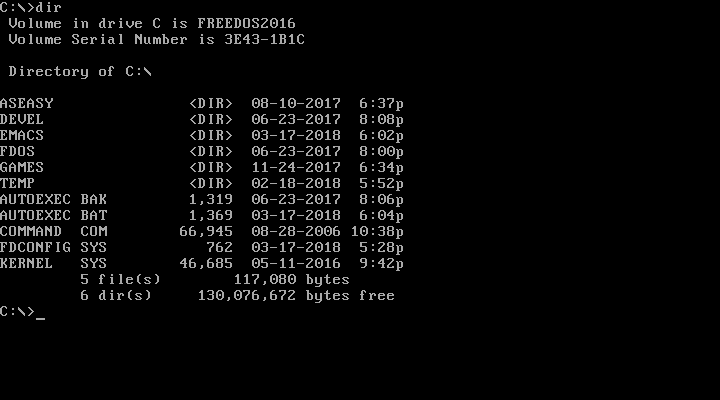
When you want to see the contents of the current directory, use the DIR command. Since DOS commands are not case-sensitive, you could also type dir. By default, DOS displays the details of every file and subdirectory, including the name, extension, size, and last modified date and time.
|
||||
|
||||
|
||||
|
||||
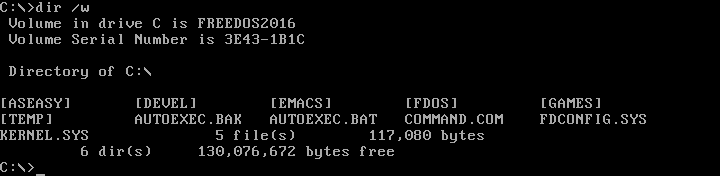
If you don't want the extra details about individual file sizes, you can display a "wide" directory by using the /w option with the DIR command. Note that Linux uses the hyphen (-) or double-hyphen (--) to start command-line options, but DOS uses the slash character (/).
|
||||
|
||||
|
||||
|
||||
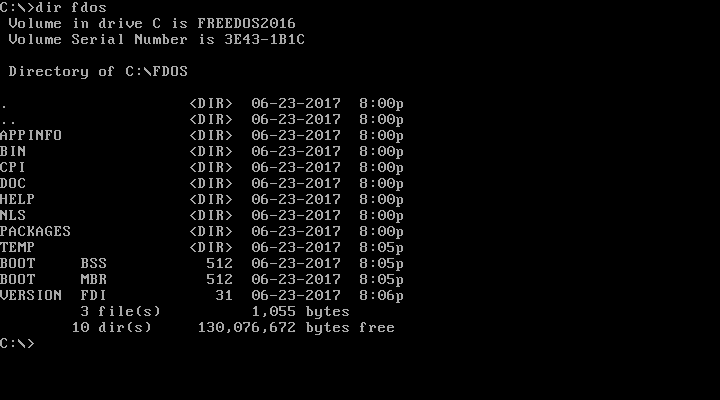
You can look inside a specific subdirectory by passing the pathname as a parameter to DIR. Again, another difference from Linux is that Linux files and directories are case-sensitive, but DOS names are case-insensitive. DOS will usually display files and directories in all uppercase, but you can equally reference them in lowercase.
|
||||
|
||||
|
||||
|
||||
### Changing the working directory
|
||||
|
||||
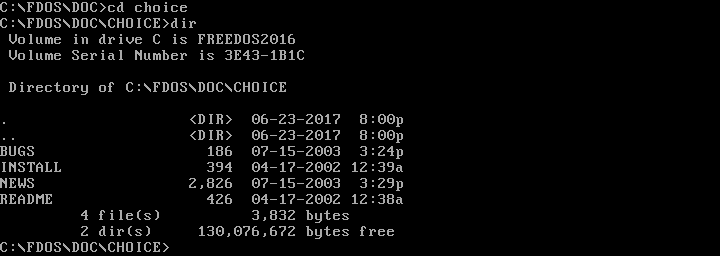
Once you can see the contents of a directory, you can "move into" any other directory. On DOS, you change your working directory with the CHDIR command, also abbreviated as CD. You can change into a subdirectory with a command like CD CHOICE or into a new path with CD \FDOS\DOC\CHOICE.
|
||||
|
||||
|
||||
|
||||
Just like on the Linux command line, DOS uses . to represent the current directory, and .. for the parent directory (one level "up" from the current directory). You can combine these. For example, CD .. changes to the parent directory, and CD ..\.. moves you two levels "up" from the current directory.
|
||||
|
||||
FreeDOS also borrows a feature from Linux: You can use CD - to jump back to your previous working directory. That is handy after you change into a new path to do one thing and want to go back to your previous work.
|
||||
|
||||
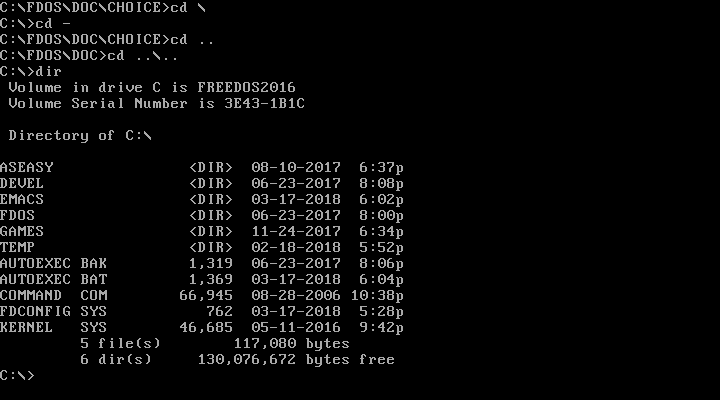
|
||||
|
||||
### Changing the working drive
|
||||
|
||||
Under Linux, the concept of a "drive" is hidden. In Linux and other Unix systems, you "mount" a drive to a directory path, such as /backup, or the system does it for you automatically, such as /var/run/media/user/flashdrive. But DOS is a much simpler system. With DOS, you must change the working drive by yourself.
|
||||
|
||||
Remember that DOS assigns the first partition on the first hard drive as the C: drive, and so on for other drive letters. On modern systems, people rarely divide a hard drive with multiple DOS partitions; they simply use the whole disk—or as much of it as they can assign to DOS. Today, C: is usually the first hard drive, and D: is usually another hard drive or the CD-ROM drive. Other network drives can be mapped to other letters, such as E: or Z: or however you want to organize them.
|
||||
|
||||
Changing drives is easy under DOS. Just type the drive letter followed by a colon (:) on the command line, and DOS will change to that working drive. For example, on my [QEMU][5] system, I set my D: drive to a shared directory in my Linux home directory, where I keep installers for various DOS applications and games I want to test.
|
||||
|
||||
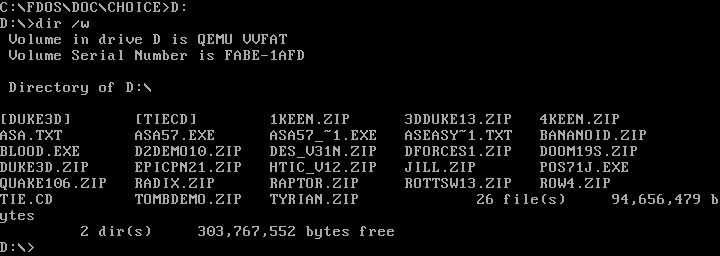
|
||||
|
||||
Be careful that you don't try to change to a drive that doesn't exist. DOS may set the working drive, but if you try to do anything there you'll get the somewhat infamous "Abort, Retry, Fail" DOS error message.
|
||||
|
||||

|
||||
|
||||
## Other things to try
|
||||
|
||||
With the CD and DIR commands, you have the basics of DOS navigation. These commands allow you to find your way around DOS directories and see what other subdirectories and files exist. Once you are comfortable with basic navigation, you might also try these other basic DOS commands:
|
||||
|
||||
* MKDIR or MD to create new directories
|
||||
* RMDIR or RD to remove directories
|
||||
* TREE to view a list of directories and subdirectories in a tree-like format
|
||||
* TYPE and MORE to display file contents
|
||||
* RENAME or REN to rename files
|
||||
* DEL or ERASE to delete files
|
||||
* EDIT to edit files
|
||||
* CLS to clear the screen
|
||||
|
||||
If those aren't enough, you can find a list of [all DOS commands][6] on the FreeDOS wiki.
|
||||
|
||||
In FreeDOS, you can use the /? parameter to get brief instructions to use each command. For example, EDIT /? will show you the usage and options for the editor. Or you can type HELP to use an interactive help system.
|
||||
|
||||
Like any DOS, FreeDOS is meant to be a simple operating system. The DOS filesystem is pretty simple to navigate with only a few basic commands. So fire up a QEMU session, install FreeDOS, and experiment with the DOS command line. Maybe now it won't seem so scary.
|
||||
|
||||
## Related stories:
|
||||
|
||||
* [How to install FreeDOS in QEMU][7]
|
||||
* [How to install FreeDOS on Raspberry Pi][8]
|
||||
* [The origin and evolution of FreeDOS][9]
|
||||
* [Four cool facts about FreeDOS][10]
|
||||
|
||||
## About the author
|
||||
|
||||
[][11]
|
||||
|
||||
Jim Hall \- Jim Hall is an open source software developer and advocate, probably best known as the founder and project coordinator for FreeDOS. Jim is also very active in the usability of open source software, as a mentor for usability testing in GNOME Outreachy, and as an occasional adjunct professor teaching a course on the Usability of Open Source Software. From 2016 to 2017, Jim served as a director on the GNOME Foundation Board of Directors. At work, Jim is Chief Information Officer in local... [more about Jim Hall][12]
|
||||
|
||||
[More about me][13]
|
||||
|
||||
* [Learn how you can contribute][14]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/gentle-introduction-freedos][15]
|
||||
|
||||
作者: [undefined][16] 选题者: [@lujun9972][17] 译者: [译者ID][18] 校对: [校对者ID][19]
|
||||
|
||||
本文由 [LCTT][20] 原创编译,[Linux中国][21] 荣誉推出
|
||||
|
||||
[1]: https://opensource.com/article/17/10/freedos
|
||||
[2]: https://opensource.com/article/17/8/gnome-20-anniversary
|
||||
[3]: http://www.freedos.org/
|
||||
[4]: http://wiki.freedos.org/
|
||||
[5]: https://www.qemu.org/
|
||||
[6]: http://wiki.freedos.org/wiki/index.php/Dos_commands
|
||||
[7]: https://opensource.com/article/17/10/run-dos-applications-linux
|
||||
[8]: https://opensource.com/article/18/3/can-you-run-dos-raspberry-pi
|
||||
[9]: https://opensource.com/article/17/10/freedos
|
||||
[10]: https://opensource.com/article/17/6/freedos-still-cool-today
|
||||
[11]: https://opensource.com/users/jim-hall
|
||||
[12]: https://opensource.com/users/jim-hall
|
||||
[13]: https://opensource.com/users/jim-hall
|
||||
[14]: https://opensource.com/participate
|
||||
[15]: https://opensource.com/article/18/4/gentle-introduction-freedos
|
||||
[16]: undefined
|
||||
[17]: https://github.com/lujun9972
|
||||
[18]: https://github.com/译者ID
|
||||
[19]: https://github.com/校对者ID
|
||||
[20]: https://github.com/LCTT/TranslateProject
|
||||
[21]: https://linux.cn/
|
||||
@ -0,0 +1,146 @@
|
||||
An introduction to the GNU Core Utilities
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image credits :
|
||||
|
||||
[Bella67][1] via Pixabay. [CC0][2].
|
||||
|
||||
Two sets of utilities—the [GNU Core Utilities][3] and util-linux—comprise many of the Linux system administrator's most basic and regularly used tools. Their basic functions allow sysadmins to perform many of the tasks required to administer a Linux computer, including management and manipulation of text files, directories, data streams, storage media, process controls, filesystems, and much more.
|
||||
|
||||
These tools are indispensable because, without them, it is impossible to accomplish any useful work on a Unix or Linux computer. Given their importance, let's examine them.
|
||||
|
||||
### GNU coreutils
|
||||
|
||||
The Linux Terminal
|
||||
|
||||
* [Top 7 terminal emulators for Linux][4]
|
||||
* [10 command-line tools for data analysis in Linux][5]
|
||||
* [Download Now: SSH cheat sheet][6]
|
||||
* [Advanced Linux commands cheat sheet][7]
|
||||
|
||||
To understand the origins of the GNU Core Utilities, we need to take a short trip in the Wayback machine to the early days of Unix at Bell Labs. [Unix was written][8] so Ken Thompson, Dennis Ritchie, Doug McIlroy, and Joe Ossanna could continue with something they had started while working on a large multi-tasking and multi-user computer project called [Multics][9]. That little something was a game called Space Travel. As remains true today, it always seems to be the gamers who drive forward the technology of computing. This new operating system was much more limited than Multics, as only two users could log in at a time, so it was called Unics. This name was later changed to Unix.
|
||||
|
||||
Over time, Unix turned out to be such a success that Bell Labs began essentially giving it away it to universities and later to companies for the cost of the media and shipping. Back in those days, system-level software was shared between organizations and programmers as they worked to achieve common goals within the context of system administration.
|
||||
|
||||
Eventually, the [PHBs][10] at AT&T decided they should make money on Unix and started using more restrictive—and expensive—licensing. This was taking place at a time when software was becoming more proprietary, restricted, and closed. It was becoming impossible to share software with other users and organizations.
|
||||
|
||||
Some people did not like this and fought it with free software. Richard M. Stallman, aka RMS, led a group of rebels who were trying to write an open and freely available operating system they called the GNU Operating System. This group created the GNU Utilities but didn't produce a viable kernel.
|
||||
|
||||
When Linus Torvalds first wrote and compiled the Linux kernel, he needed a set of very basic system utilities to even begin to perform marginally useful work. The kernel does not provide commands or any type of command shell such as Bash. It is useless by itself. So, Linus used the freely available GNU Core Utilities and recompiled them for Linux. This gave him a complete, if quite basic, operating system.
|
||||
|
||||
You can learn about all the individual programs that comprise the GNU Utilities by entering the command info coreutils at a terminal command line. The following list of the core utilities is part of that info page. The utilities are grouped by function to make specific ones easier to find; in the terminal, highlight the group you want more information on and press the Enter key.
|
||||
|
||||
```
|
||||
* Output of entire files:: cat tac nl od base32 base64
|
||||
* Formatting file contents:: fmt pr fold
|
||||
* Output of parts of files:: head tail split csplit
|
||||
* Summarizing files:: wc sum cksum b2sum md5sum sha1sum sha2
|
||||
* Operating on sorted files:: sort shuf uniq comm ptx tsort
|
||||
* Operating on fields:: cut paste join
|
||||
* Operating on characters:: tr expand unexpand
|
||||
* Directory listing:: ls dir vdir dircolors
|
||||
* Basic operations:: cp dd install mv rm shred
|
||||
* Special file types:: mkdir rmdir unlink mkfifo mknod ln link readlink
|
||||
* Changing file attributes:: chgrp chmod chown touch
|
||||
* Disk usage:: df du stat sync truncate
|
||||
* Printing text:: echo printf yes
|
||||
* Conditions:: false true test expr
|
||||
* Redirection:: tee
|
||||
* File name manipulation:: dirname basename pathchk mktemp realpath
|
||||
* Working context:: pwd stty printenv tty
|
||||
* User information:: id logname whoami groups users who
|
||||
* System context:: date arch nproc uname hostname hostid uptime
|
||||
* SELinux context:: chcon runcon
|
||||
* Modified command invocation:: chroot env nice nohup stdbuf timeout
|
||||
* Process control:: kill
|
||||
* Delaying:: sleep
|
||||
* Numeric operations:: factor numfmt seq
|
||||
```
|
||||
|
||||
There are 102 utilities on this list. It covers many of the functions necessary to perform basic tasks on a Unix or Linux host. However, many basic utilities are missing. For example, the mount and umount commands are not in this list. Those and many of the other commands that are not in the GNU coreutils can be found in the util-linux collection.
|
||||
|
||||
### util-linux
|
||||
|
||||
The util-linix package of utilities contains many of the other common commands that sysadmins use. These utilities are distributed by the Linux Kernel Organization, and virtually every one of these 107 commands were originally three separate collections—fileutils, shellutils, and textutils—which were [combined into the single package][11] util-linux in 2003.
|
||||
|
||||
```
|
||||
agetty fsck.minix mkfs.bfs setpriv
|
||||
blkdiscard fsfreeze mkfs.cramfs setsid
|
||||
blkid fstab mkfs.minix setterm
|
||||
blockdev fstrim mkswap sfdisk
|
||||
cal getopt more su
|
||||
cfdisk hexdump mount sulogin
|
||||
chcpu hwclock mountpoint swaplabel
|
||||
chfn ionice namei swapoff
|
||||
chrt ipcmk newgrp swapon
|
||||
chsh ipcrm nologin switch_root
|
||||
colcrt ipcs nsenter tailf
|
||||
col isosize partx taskset
|
||||
colrm kill pg tunelp
|
||||
column last pivot_root ul
|
||||
ctrlaltdel ldattach prlimit umount
|
||||
ddpart line raw unshare
|
||||
delpart logger readprofile utmpdump
|
||||
dmesg login rename uuidd
|
||||
eject look renice uuidgen
|
||||
fallocate losetup reset vipw
|
||||
fdformat lsblk resizepart wall
|
||||
fdisk lscpu rev wdctl
|
||||
findfs lslocks RTC Alarm whereis
|
||||
findmnt lslogins runuser wipefs
|
||||
flock mcookie script write
|
||||
fsck mesg scriptreplay zramctl
|
||||
fsck.cramfs mkfs setarch
|
||||
```
|
||||
|
||||
Some of these utilities have been deprecated and will likely fall out of the collection at some point in the future. You should check [Wikipedia's util-linux page][12] for information on many of the utilities, and the man pages also provide details on the commands.
|
||||
|
||||
### Summary
|
||||
|
||||
These two collections of Linux utilities, the GNU Core Utilities and util-linux, together provide the basic utilities required to administer a Linux system. As I researched this article, I found several interesting utilities I never knew about. Many of these commands are seldom needed, but when you need them, they are indispensable.
|
||||
|
||||
Between these two collections, there are over 200 Linux utilities. While Linux has many more commands, these are the ones needed to manage the basic functions of a typical Linux host.
|
||||
|
||||
### About the author
|
||||
|
||||
[][13]
|
||||
|
||||
David Both \- David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years. David has written articles for... [more about David Both][14]
|
||||
|
||||
[More about me][15]
|
||||
|
||||
* [Learn how you can contribute][16]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/gnu-core-utilities][17]
|
||||
|
||||
作者: [David Both][18] 选题者: [@lujun9972][19] 译者: [译者ID][20] 校对: [校对者ID][21]
|
||||
|
||||
本文由 [LCTT][22] 原创编译,[Linux中国][23] 荣誉推出
|
||||
|
||||
[1]: https://pixabay.com/en/tiny-people-core-apple-apple-half-700921/
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[4]: https://opensource.com/life/17/10/top-terminal-emulators?intcmp=7016000000127cYAAQ
|
||||
[5]: https://opensource.com/article/17/2/command-line-tools-data-analysis-linux?intcmp=7016000000127cYAAQ
|
||||
[6]: https://opensource.com/downloads/advanced-ssh-cheat-sheet?intcmp=7016000000127cYAAQ
|
||||
[7]: https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=7016000000127cYAAQ
|
||||
[8]: https://en.wikipedia.org/wiki/History_of_Unix
|
||||
[9]: https://en.wikipedia.org/wiki/Multics
|
||||
[10]: https://en.wikipedia.org/wiki/Pointy-haired_Boss
|
||||
[11]: https://en.wikipedia.org/wiki/GNU_Core_Utilities
|
||||
[12]: https://en.wikipedia.org/wiki/Util-linux
|
||||
[13]: https://opensource.com/users/dboth
|
||||
[14]: https://opensource.com/users/dboth
|
||||
[15]: https://opensource.com/users/dboth
|
||||
[16]: https://opensource.com/participate
|
||||
[17]: https://opensource.com/article/18/4/gnu-core-utilities
|
||||
[18]: https://opensource.com/users/dboth
|
||||
[19]: https://github.com/lujun9972
|
||||
[20]: https://github.com/译者ID
|
||||
[21]: https://github.com/校对者ID
|
||||
[22]: https://github.com/LCTT/TranslateProject
|
||||
[23]: https://linux.cn/
|
||||
@ -0,0 +1,488 @@
|
||||
# Understanding metrics and monitoring with Python
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
## Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
My reaction when I first came across the terms counter and gauge and the graphs with colors and numbers labeled "mean" and "upper 90" was one of avoidance. It's like I saw them, but I didn't care because I didn't understand them or how they might be useful. Since my job didn't require me to pay attention to them, they remained ignored.
|
||||
|
||||
That was about two years ago. As I progressed in my career, I wanted to understand more about our network applications, and that is when I started learning about metrics.
|
||||
|
||||
The three stages of my journey to understanding monitoring (so far) are:
|
||||
|
||||
* Stage 1: What? (Looks elsewhere)
|
||||
* Stage 2: Without metrics, we are really flying blind.
|
||||
* Stage 3: How do we keep from doing metrics wrong?
|
||||
|
||||
I am currently in Stage 2 and will share what I have learned so far. I'm moving gradually toward Stage 3, and I will offer some of my resources on that part of the journey at the end of this article.
|
||||
|
||||
Let's get started!
|
||||
|
||||
## Software prerequisites
|
||||
|
||||
More Python Resources
|
||||
|
||||
* [What is Python?][1]
|
||||
* [Top Python IDEs][2]
|
||||
* [Top Python GUI frameworks][3]
|
||||
* [Latest Python content][4]
|
||||
* [More developer resources][5]
|
||||
|
||||
All the demos discussed in this article are available on [my GitHub repo][6]. You will need to have docker and docker-compose installed to play with them.
|
||||
|
||||
## Why should I monitor?
|
||||
|
||||
The top reasons for monitoring are:
|
||||
|
||||
* Understanding _normal_ and _abnormal_ system and service behavior
|
||||
* Doing capacity planning, scaling up or down
|
||||
* Assisting in performance troubleshooting
|
||||
* Understanding the effect of software/hardware changes
|
||||
* Changing system behavior in response to a measurement
|
||||
* Alerting when a system exhibits unexpected behavior
|
||||
|
||||
## Metrics and metric types
|
||||
|
||||
For our purposes, a **metric** is an _observed_ value of a certain quantity at a given point in _time_. The total of number hits on a blog post, the total number of people attending a talk, the number of times the data was not found in the caching system, the number of logged-in users on your website—all are examples of metrics.
|
||||
|
||||
They broadly fall into three categories:
|
||||
|
||||
### Counters
|
||||
|
||||
Consider your personal blog. You just published a post and want to keep an eye on how many hits it gets over time, a number that can only increase. This is an example of a **counter** metric. Its value starts at 0 and increases during the lifetime of your blog post. Graphically, a counter looks like this:
|
||||
|
||||
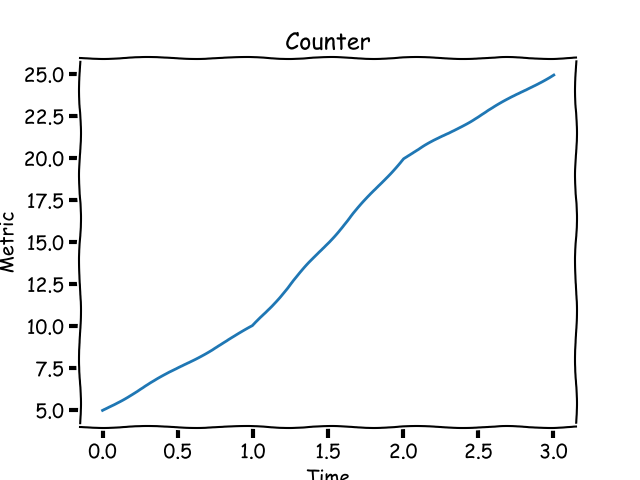
|
||||
|
||||
A counter metric always increases.
|
||||
|
||||
### Gauges
|
||||
|
||||
Instead of the total number of hits on your blog post over time, let's say you want to track the number of hits per day or per week. This metric is called a **gauge** and its value can go up or down. Graphically, a gauge looks like this:
|
||||
|
||||
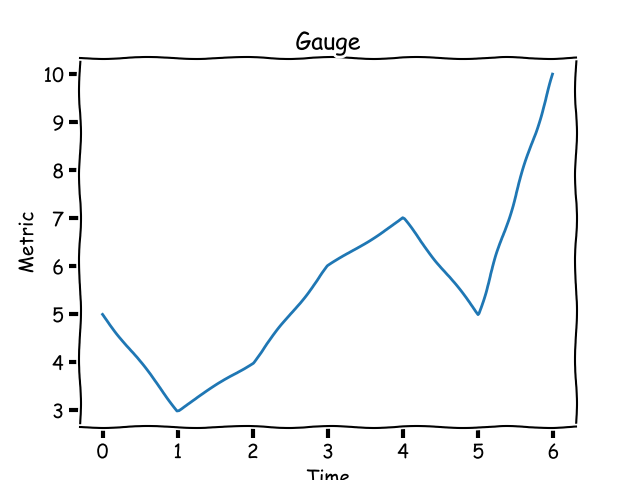
|
||||
|
||||
A gauge metric can increase or decrease.
|
||||
|
||||
A gauge's value usually has a _ceiling_ and a _floor_ in a certain time window.
|
||||
|
||||
### Histograms and timers
|
||||
|
||||
A **histogram** (as Prometheus calls it) or a **timer** (as StatsD calls it) is a metric to track _sampled observations_. Unlike a counter or a gauge, the value of a histogram metric doesn't necessarily show an up or down pattern. I know that doesn't make a lot of sense and may not seem different from a gauge. What's different is what you expect to _do_ with histogram data compared to a gauge. Therefore, the monitoring system needs to know that a metric is a histogram type to allow you to do those things.
|
||||
|
||||
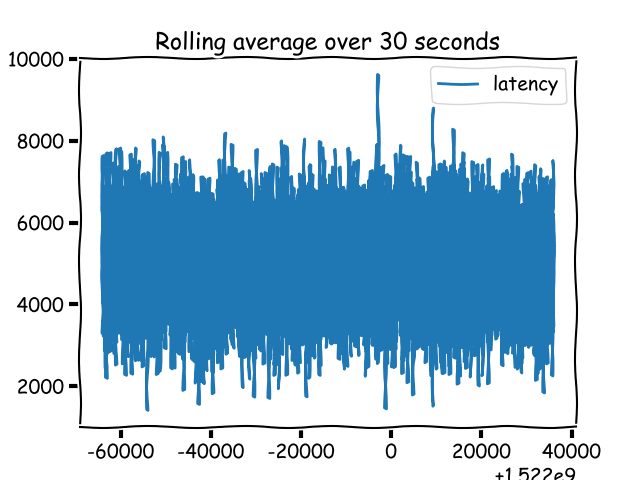
|
||||
|
||||
A histogram metric can increase or decrease.
|
||||
|
||||
## Demo 1: Calculating and reporting metrics
|
||||
|
||||
[Demo 1][7] is a basic web application written using the [Flask][8] framework. It demonstrates how we can _calculate_ and _report_ metrics.
|
||||
|
||||
The src directory has the application in app.py with the src/helpers/middleware.py containing the following:
|
||||
|
||||
```
|
||||
from flask import request
|
||||
import csv
|
||||
import time
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([str(int(time.time())), str(resp_time)])
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def setup_metrics(app):
|
||||
app.before_request(start_timer)
|
||||
app.after_request(stop_timer)
|
||||
```
|
||||
|
||||
When setup_metrics() is called from the application, it configures the start_timer() function to be called before a request is processed and the stop_timer() function to be called after a request is processed but before the response has been sent. In the above function, we write the timestamp and the time it took (in milliseconds) for the request to be processed.
|
||||
|
||||
When we run docker-compose up in the demo1 directory, it starts the web application, then a client container that makes a number of requests to the web application. You will see a src/metrics.csv file that has been created with two columns: timestamp and request_latency.
|
||||
|
||||
Looking at this file, we can infer two things:
|
||||
|
||||
* There is a lot of data that has been generated
|
||||
* No observation of the metric has any characteristic associated with it
|
||||
|
||||
Without a characteristic associated with a metric observation, we cannot say which HTTP endpoint this metric was associated with or which node of the application this metric was generated from. Hence, we need to qualify each metric observation with the appropriate metadata.
|
||||
|
||||
## Statistics 101
|
||||
|
||||
If we think back to high school mathematics, there are a few statistics terms we should all recall, even if vaguely, including mean, median, percentile, and histogram. Let's briefly recap them without judging their usefulness, just like in high school.
|
||||
|
||||
### Mean
|
||||
|
||||
The **mean**, or the average of a list of numbers, is the sum of the numbers divided by the cardinality of the list. The mean of 3, 2, and 10 is (3+2+10)/3 = 5.
|
||||
|
||||
### Median
|
||||
|
||||
The **median** is another type of average, but it is calculated differently; it is the center numeral in a list of numbers ordered from smallest to largest (or vice versa). In our list above (2, 3, 10), the median is 3. The calculation is not very straightforward; it depends on the number of items in the list.
|
||||
|
||||
### Percentile
|
||||
|
||||
The **percentile** is a measure that gives us a measure below which a certain (k) percentage of the numbers lie. In some sense, it gives us an _idea_ of how this measure is doing relative to the k percentage of our data. For example, the 95th percentile score of the above list is 9.29999. The percentile measure varies from 0 to 100 (non-inclusive). The _zeroth_ percentile is the minimum score in a set of numbers. Some of you may recall that the median is the 50th percentile, which turns out to be 3.
|
||||
|
||||
Some monitoring systems refer to the percentile measure as upper_X where _X_ is the percentile; _upper 90_ refers to the value at the 90th percentile.
|
||||
|
||||
### Quantile
|
||||
|
||||
The **q-Quantile** is a measure that ranks q_N_ in a set of _N_ numbers. The value of **q** ranges between 0 and 1 (both inclusive). When **q** is 0.5, the value is the median. The relationship between the quantile and percentile is that the measure at **q** quantile is equivalent to the measure at **100_q_** percentile.
|
||||
|
||||
### Histogram
|
||||
|
||||
The metric **histogram**, which we learned about earlier, is an _implementation detail_ of monitoring systems. In statistics, a histogram is a graph that groups data into _buckets_. Let's consider a different, contrived example: the ages of people reading your blog. If you got a handful of this data and wanted a rough idea of your readers' ages by group, plotting a histogram would show you a graph like this:
|
||||
|
||||
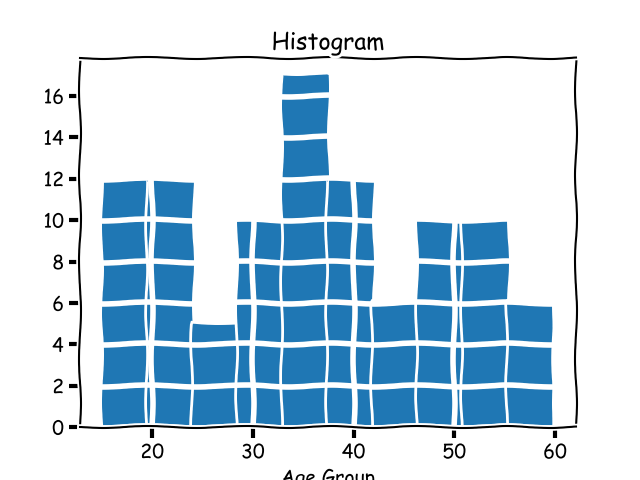
|
||||
|
||||
### Cumulative histogram
|
||||
|
||||
A **cumulative histogram** is a histogram where each bucket's count includes the count of the previous bucket, hence the name _cumulative_. A cumulative histogram for the above dataset would look like this:
|
||||
|
||||
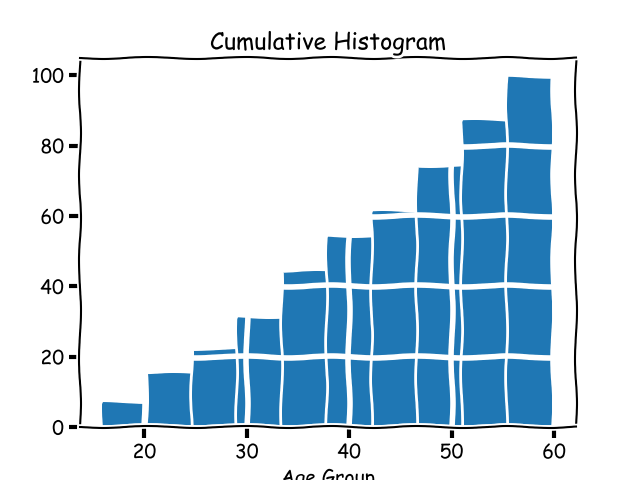
|
||||
|
||||
### Why do we need statistics?
|
||||
|
||||
In Demo 1 above, we observed that there is a lot of data that is generated when we report metrics. We need statistics when working with metrics because there are just too many of them. We don't care about individual values, rather overall behavior. We expect the behavior the values exhibit is a proxy of the behavior of the system under observation.
|
||||
|
||||
## Demo 2: Adding characteristics to metrics
|
||||
|
||||
In our Demo 1 application above, when we calculate and report a request latency, it refers to a specific request uniquely identified by few _characteristics_. Some of these are:
|
||||
|
||||
* The HTTP endpoint
|
||||
* The HTTP method
|
||||
* The identifier of the host/node where it's running
|
||||
|
||||
If we attach these characteristics to a metric observation, we have more context around each metric. Let's explore adding characteristics to our metrics in [Demo 2][9].
|
||||
|
||||
The src/helpers/middleware.py file now writes multiple columns to the CSV file when writing metrics:
|
||||
|
||||
```
|
||||
node_ids = ['10.0.1.1', '10.1.3.4']
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
node_id = node_ids[random.choice(range(len(node_ids)))]
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([
|
||||
str(int(time.time())), 'webapp1', node_id,
|
||||
request.endpoint, request.method, str(response.status_code),
|
||||
str(resp_time)
|
||||
])
|
||||
|
||||
return response
|
||||
```
|
||||
|
||||
Since this is a demo, I have taken the liberty of reporting random IPs as the node IDs when reporting the metric. When we run docker-compose up in the demo2 directory, it will result in a CSV file with multiple columns.
|
||||
|
||||
### Analyzing metrics with pandas
|
||||
|
||||
We'll now analyze this CSV file with [pandas][10]. Running docker-compose up will print a URL that we will use to open a [Jupyter][11] session. Once we upload the Analysis.ipynb notebook into the session, we can read the CSV file into a pandas DataFrame:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
metrics = pd.read_csv('/data/metrics.csv', index_col=0)
|
||||
```
|
||||
|
||||
The index_col specifies that we want to use the timestamp as the index.
|
||||
|
||||
Since each characteristic we add is a column in the DataFrame, we can perform grouping and aggregation based on these columns:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
metrics.groupby(['node_id', 'http_status']).latency.aggregate(np.percentile, 99.999)
|
||||
```
|
||||
|
||||
Please refer to the Jupyter notebook for more example analysis on the data.
|
||||
|
||||
## What should I monitor?
|
||||
|
||||
A software system has a number of variables whose values change during its lifetime. The software is running in some sort of an operating system, and operating system variables change as well. In my opinion, the more data you have, the better it is when something goes wrong.
|
||||
|
||||
Key operating system metrics I recommend monitoring are:
|
||||
|
||||
* CPU usage
|
||||
* System memory usage
|
||||
* File descriptor usage
|
||||
* Disk usage
|
||||
|
||||
Other key metrics to monitor will vary depending on your software application.
|
||||
|
||||
### Network applications
|
||||
|
||||
If your software is a network application that listens to and serves client requests, the key metrics to measure are:
|
||||
|
||||
* Number of requests coming in (counter)
|
||||
* Unhandled errors (counter)
|
||||
* Request latency (histogram/timer)
|
||||
* Queued time, if there is a queue in your application (histogram/timer)
|
||||
* Queue size, if there is a queue in your application (gauge)
|
||||
* Worker processes/threads usage (gauge)
|
||||
|
||||
If your network application makes requests to other services in the context of fulfilling a client request, it should have metrics to record the behavior of communications with those services. Key metrics to monitor include number of requests, request latency, and response status.
|
||||
|
||||
### HTTP web application backends
|
||||
|
||||
HTTP applications should monitor all the above. In addition, they should keep granular data about the count of non-200 HTTP statuses grouped by all the other HTTP status codes. If your web application has user signup and login functionality, it should have metrics for those as well.
|
||||
|
||||
### Long-running processes
|
||||
|
||||
Long-running processes such as Rabbit MQ consumer or task-queue workers, although not network servers, work on the model of picking up a task and processing it. Hence, we should monitor the number of requests processed and the request latency for those processes.
|
||||
|
||||
No matter the application type, each metric should have appropriate **metadata** associated with it.
|
||||
|
||||
## Integrating monitoring in a Python application
|
||||
|
||||
There are two components involved in integrating monitoring into Python applications:
|
||||
|
||||
* Updating your application to calculate and report metrics
|
||||
* Setting up a monitoring infrastructure to house the application's metrics and allow queries to be made against them
|
||||
|
||||
The basic idea of recording and reporting a metric is:
|
||||
|
||||
```
|
||||
def work():
|
||||
requests += 1
|
||||
# report counter
|
||||
start_time = time.time()
|
||||
|
||||
# < do the work >
|
||||
|
||||
# calculate and report latency
|
||||
work_latency = time.time() - start_time
|
||||
...
|
||||
```
|
||||
|
||||
Considering the above pattern, we often take advantage of _decorators_, _context managers_, and _middleware_ (for network applications) to calculate and report metrics. In Demo 1 and Demo 2, we used decorators in a Flask application.
|
||||
|
||||
### Pull and push models for metric reporting
|
||||
|
||||
Essentially, there are two patterns for reporting metrics from a Python application. In the _pull_ model, the monitoring system "scrapes" the application at a predefined HTTP endpoint. In the _push_ model, the application sends the data to the monitoring system.
|
||||
|
||||

|
||||
|
||||
An example of a monitoring system working in the _pull_ model is [Prometheus][12]. [StatsD][13] is an example of a monitoring system where the application _pushes_ the metrics to the system.
|
||||
|
||||
### Integrating StatsD
|
||||
|
||||
To integrate StatsD into a Python application, we would use the [StatsD Python client][14], then update our metric-reporting code to push data into StatsD using the appropriate library calls.
|
||||
|
||||
First, we need to create a client instance:
|
||||
|
||||
```
|
||||
statsd = statsd.StatsClient(host='statsd', port=8125, prefix='webapp1')
|
||||
```
|
||||
|
||||
The prefix keyword argument will add the specified prefix to all the metrics reported via this client.
|
||||
|
||||
Once we have the client, we can report a value for a timer using:
|
||||
|
||||
```
|
||||
statsd.timing(key, resp_time)
|
||||
```
|
||||
|
||||
To increment a counter:
|
||||
|
||||
```
|
||||
statsd.incr(key)
|
||||
```
|
||||
|
||||
To associate metadata with a metric, a key is defined as metadata1.metadata2.metric, where each metadataX is a field that allows aggregation and grouping.
|
||||
|
||||
The demo application [StatsD][15] is a complete example of integrating a Python Flask application with statsd.
|
||||
|
||||
### Integrating Prometheus
|
||||
|
||||
To use the Prometheus monitoring system, we will use the [Promethius Python client][16]. We will first create objects of the appropriate metric class:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY = Histogram('request_latency_seconds', 'Request latency',
|
||||
['app_name', 'endpoint']
|
||||
)
|
||||
```
|
||||
|
||||
The third argument in the above statement is the labels associated with the metric. These labels are what defines the metadata associated with a single metric value.
|
||||
|
||||
To record a specific metric observation:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY.labels('webapp', request.path).observe(resp_time)
|
||||
```
|
||||
|
||||
The next step is to define an HTTP endpoint in our application that Prometheus can scrape. This is usually an endpoint called /metrics:
|
||||
|
||||
```
|
||||
@app.route('/metrics')
|
||||
def metrics():
|
||||
return Response(prometheus_client.generate_latest(), mimetype=CONTENT_TYPE_LATEST)
|
||||
```
|
||||
|
||||
The demo application [Prometheus][17] is a complete example of integrating a Python Flask application with prometheus.
|
||||
|
||||
### Which is better: StatsD or Prometheus?
|
||||
|
||||
The natural next question is: Should I use StatsD or Prometheus? I have written a few articles on this topic, and you may find them useful:
|
||||
|
||||
* [Your options for monitoring multi-process Python applications with Prometheus][18]
|
||||
* [Monitoring your synchronous Python web applications using Prometheus][19]
|
||||
* [Monitoring your asynchronous Python web applications using Prometheus][20]
|
||||
|
||||
## Ways to use metrics
|
||||
|
||||
We've learned a bit about why we want to set up monitoring in our applications, but now let's look deeper into two of them: alerting and autoscaling.
|
||||
|
||||
### Using metrics for alerting
|
||||
|
||||
A key use of metrics is creating alerts. For example, you may want to send an email or pager notification to relevant people if the number of HTTP 500s over the past five minutes increases. What we use for setting up alerts depends on our monitoring setup. For Prometheus we can use [Alertmanager][21] and for StatsD, we use [Nagios][22].
|
||||
|
||||
### Using metrics for autoscaling
|
||||
|
||||
Not only can metrics allow us to understand if our current infrastructure is over- or under-provisioned, they can also help implement autoscaling policies in a cloud infrastructure. For example, if worker process usage on our servers routinely hits 90% over the past five minutes, we may need to horizontally scale. How we would implement scaling depends on the cloud infrastructure. AWS Auto Scaling, by default, allows scaling policies based on system CPU usage, network traffic, and other factors. However, to use application metrics for scaling up or down, we must publish [custom CloudWatch metrics][23].
|
||||
|
||||
## Application monitoring in a multi-service architecture
|
||||
|
||||
When we go beyond a single application architecture, such that a client request can trigger calls to multiple services before a response is sent back, we need more from our metrics. We need a unified view of latency metrics so we can see how much time each service took to respond to the request. This is enabled with [distributed tracing][24].
|
||||
|
||||
You can see an example of distributed tracing in Python in my blog post [Introducing distributed tracing in your Python application via Zipkin][25].
|
||||
|
||||
## Points to remember
|
||||
|
||||
In summary, make sure to keep the following things in mind:
|
||||
|
||||
* Understand what a metric type means in your monitoring system
|
||||
* Know in what unit of measurement the monitoring system wants your data
|
||||
* Monitor the most critical components of your application
|
||||
* Monitor the behavior of your application in its most critical stages
|
||||
|
||||
The above assumes you don't have to manage your monitoring systems. If that's part of your job, you have a lot more to think about!
|
||||
|
||||
## Other resources
|
||||
|
||||
Following are some of the resources I found very useful along my monitoring education journey:
|
||||
|
||||
### General
|
||||
|
||||
* [Monitoring distributed systems][26]
|
||||
* [Observability and monitoring best practices][27]
|
||||
* [Who wants seconds?][28]
|
||||
|
||||
### StatsD/Graphite
|
||||
|
||||
* [StatsD metric types][29]
|
||||
|
||||
### Prometheus
|
||||
|
||||
* [Prometheus metric types][30]
|
||||
* [How does a Prometheus gauge work?][31]
|
||||
* [Why are Prometheus histograms cumulative?][32]
|
||||
* [Monitoring batch jobs in Python][33]
|
||||
* [Prometheus: Monitoring at SoundCloud][34]
|
||||
|
||||
## Avoiding mistakes (i.e., Stage 3 learnings)
|
||||
|
||||
As we learn the basics of monitoring, it's important to keep an eye on the mistakes we don't want to make. Here are some insightful resources I have come across:
|
||||
|
||||
* [How not to measure latency][35]
|
||||
* [Histograms with Prometheus: A tale of woe][36]
|
||||
* [Why averages suck and percentiles are great][37]
|
||||
* [Everything you know about latency is wrong][38]
|
||||
* [Who moved my 99th percentile latency?][39]
|
||||
* [Logs and metrics and graphs][40]
|
||||
* [HdrHistogram: A better latency capture method][41]
|
||||
|
||||
---
|
||||
|
||||
To learn more, attend Amit Saha's talk, [Counter, gauge, upper 90—Oh my!][42], at [PyCon Cleveland 2018][43].
|
||||
|
||||
## About the author
|
||||
|
||||
[][44]
|
||||
|
||||
Amit Saha \- I am a software engineer interested in infrastructure, monitoring and tooling. I am the author of "Doing Math with Python" and creator and the maintainer of Fedora Scientific Spin.
|
||||
|
||||
[More about me][45]
|
||||
|
||||
* [Learn how you can contribute][46]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/metrics-monitoring-and-python][47]
|
||||
|
||||
作者: [Amit Saha][48] 选题者: [@lujun9972][49] 译者: [译者ID][50] 校对: [校对者ID][51]
|
||||
|
||||
本文由 [LCTT][52] 原创编译,[Linux中国][53] 荣誉推出
|
||||
|
||||
[1]: https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]: https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]: https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]: https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]: https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]: https://github.com/amitsaha/python-monitoring-talk
|
||||
[7]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo1
|
||||
[8]: http://flask.pocoo.org/
|
||||
[9]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo2
|
||||
[10]: https://pandas.pydata.org/
|
||||
[11]: http://jupyter.org/
|
||||
[12]: https://prometheus.io/
|
||||
[13]: https://github.com/etsy/statsd
|
||||
[14]: https://pypi.python.org/pypi/statsd
|
||||
[15]: https://github.com/amitsaha/python-monitoring-talk/tree/master/statsd
|
||||
[16]: https://pypi.python.org/pypi/prometheus_client
|
||||
[17]: https://github.com/amitsaha/python-monitoring-talk/tree/master/prometheus
|
||||
[18]: http://echorand.me/your-options-for-monitoring-multi-process-python-applications-with-prometheus.html
|
||||
[19]: https://blog.codeship.com/monitoring-your-synchronous-python-web-applications-using-prometheus/
|
||||
[20]: https://blog.codeship.com/monitoring-your-asynchronous-python-web-applications-using-prometheus/
|
||||
[21]: https://github.com/prometheus/alertmanager
|
||||
[22]: https://www.nagios.org/about/overview/
|
||||
[23]: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
|
||||
[24]: http://opentracing.io/documentation/
|
||||
[25]: http://echorand.me/introducing-distributed-tracing-in-your-python-application-via-zipkin.html
|
||||
[26]: https://landing.google.com/sre/book/chapters/monitoring-distributed-systems.html
|
||||
[27]: http://www.integralist.co.uk/posts/monitoring-best-practices/?imm_mid=0fbebf&cmp=em-webops-na-na-newsltr_20180309
|
||||
[28]: https://www.robustperception.io/who-wants-seconds/
|
||||
[29]: https://github.com/etsy/statsd/blob/master/docs/metric_types.md
|
||||
[30]: https://prometheus.io/docs/concepts/metric_types/
|
||||
[31]: https://www.robustperception.io/how-does-a-prometheus-gauge-work/
|
||||
[32]: https://www.robustperception.io/why-are-prometheus-histograms-cumulative/
|
||||
[33]: https://www.robustperception.io/monitoring-batch-jobs-in-python/
|
||||
[34]: https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud
|
||||
[35]: https://www.youtube.com/watch?v=lJ8ydIuPFeU&feature=youtu.be
|
||||
[36]: http://linuxczar.net/blog/2017/06/15/prometheus-histogram-2/
|
||||
[37]: https://www.dynatrace.com/news/blog/why-averages-suck-and-percentiles-are-great/
|
||||
[38]: https://bravenewgeek.com/everything-you-know-about-latency-is-wrong/
|
||||
[39]: https://engineering.linkedin.com/performance/who-moved-my-99th-percentile-latency
|
||||
[40]: https://grafana.com/blog/2016/01/05/logs-and-metrics-and-graphs-oh-my/
|
||||
[41]: http://psy-lob-saw.blogspot.com.au/2015/02/hdrhistogram-better-latency-capture.html
|
||||
[42]: https://us.pycon.org/2018/schedule/presentation/133/
|
||||
[43]: https://us.pycon.org/2018/
|
||||
[44]: https://opensource.com/users/amitsaha
|
||||
[45]: https://opensource.com/users/amitsaha
|
||||
[46]: https://opensource.com/participate
|
||||
[47]: https://opensource.com/article/18/4/metrics-monitoring-and-python
|
||||
[48]: https://opensource.com/users/amitsaha
|
||||
[49]: https://github.com/lujun9972
|
||||
[50]: https://github.com/译者ID
|
||||
[51]: https://github.com/校对者ID
|
||||
[52]: https://github.com/LCTT/TranslateProject
|
||||
[53]: https://linux.cn/
|
||||
@ -1,347 +0,0 @@
|
||||
How to do math on the Linux command line
|
||||
======
|
||||
|
||||
|
||||
Can you do math on the Linux command line? You sure can! In fact, there are quite a few commands that can make the process easy and some you might even find interesting. Let's look at some very useful commands and syntax for command line math.
|
||||
|
||||
### expr
|
||||
|
||||
First and probably the most obvious and commonly used command for performing mathematical calculations on the command line is the **expr** (expression) command. It can manage addition, subtraction, division, and multiplication. It can also be used to compare numbers. Here are some examples:
|
||||
|
||||
#### Incrementing a variable
|
||||
```
|
||||
$ count=0
|
||||
$ count=`expr $count + 1`
|
||||
$ echo $count
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
#### Performing a simple calculations
|
||||
```
|
||||
$ expr 11 + 123
|
||||
134
|
||||
$ expr 134 / 11
|
||||
12
|
||||
$ expr 134 - 11
|
||||
123
|
||||
$ expr 11 * 123
|
||||
expr: syntax error <== oops!
|
||||
$ expr 11 \* 123
|
||||
1353
|
||||
$ expr 20 % 3
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
Notice that you have to use a \ character in front of * to avoid the syntax error. The % operator is for modulo calculations.
|
||||
|
||||
Here's a slightly more complex example:
|
||||
```
|
||||
participants=11
|
||||
total=156
|
||||
share=`expr $total / $participants`
|
||||
remaining=`expr $total - $participants \* $share`
|
||||
echo $share
|
||||
14
|
||||
echo $remaining
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
If we have 11 participants in some event and 156 prizes to distribute, each participant's fair share of the take is 14, leaving 2 in the pot.
|
||||
|
||||
#### Making comparisons
|
||||
|
||||
Now let's look at the logic for comparisons. These statements may look a little odd at first. They are not setting values, but only comparing the numbers. What **expr** is doing in the examples below is determining whether the statements are true. If the result is 1, the statement is true; otherwise, it's false.
|
||||
```
|
||||
$ expr 11 = 11
|
||||
1
|
||||
$ expr 11 = 12
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
Read them as "Does 11 equal 11?" and "Does 11 equal 12?" and you'll get used to how this works. Of course, no one would be asking if 11 equals 11 on the command line, but they might ask if $age equals 11.
|
||||
```
|
||||
$ age=11
|
||||
$ expr $age = 11
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
If you put the numbers in quotes, you'd actually be doing a string comparison rather than a numeric one.
|
||||
```
|
||||
$ expr "11" = "11"
|
||||
1
|
||||
$ expr "eleven" = "11"
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
In the following examples, we're asking whether 10 is greater than 5 and, then, whether it's greater than 99.
|
||||
```
|
||||
$ expr 10 \> 5
|
||||
1
|
||||
$ expr 10 \> 99
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
Of course, having true comparisons resulting in 1 and false resulting in 0 goes against what we generally expect on Linux systems. The example below shows that using **expr** in this kind of context doesn't work because **if** works with the opposite orientation (0=true).
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Cost to us> "
|
||||
read cost
|
||||
echo -n "Price we're asking> "
|
||||
read price
|
||||
|
||||
if [ `expr $price \> $cost` ]; then
|
||||
echo "We make money"
|
||||
else
|
||||
echo "Don't sell it"
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
Now, let's run this script:
|
||||
```
|
||||
$ ./checkPrice
|
||||
Cost to us> 11.50
|
||||
Price we're asking> 6
|
||||
We make money
|
||||
|
||||
```
|
||||
|
||||
That sure isn't going to help with sales! With a small change, this would work as we'd expect:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Cost to us> "
|
||||
read cost
|
||||
echo -n "Price we're asking> "
|
||||
read price
|
||||
|
||||
if [ `expr $price \> $cost` == 1 ]; then
|
||||
echo "We make money"
|
||||
else
|
||||
echo "Don't sell it"
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
### factor
|
||||
|
||||
The **factor** command works just like you'd probably expect. You feed it a number, and it tells you what its factors are.
|
||||
```
|
||||
$ factor 111
|
||||
111: 3 37
|
||||
$ factor 134
|
||||
134: 2 67
|
||||
$ factor 17894
|
||||
17894: 2 23 389
|
||||
$ factor 1987
|
||||
1987: 1987
|
||||
|
||||
```
|
||||
|
||||
NOTE: The factor command didn't get very far on factoring that last value because 1987 is a **prime number**.
|
||||
|
||||
### jot
|
||||
|
||||
The **jot** command allows you to create a list of numbers. Provide it with the number of values you want to see and the number that you want to start with.
|
||||
```
|
||||
$ jot 8 10
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
|
||||
```
|
||||
|
||||
You can also use **jot** like this. Here we're asking it to decrease the numbers by telling it we want to stop when we get to 2:
|
||||
```
|
||||
$ jot 8 10 2
|
||||
10
|
||||
9
|
||||
8
|
||||
7
|
||||
5
|
||||
4
|
||||
3
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
The **jot** command can be useful if you want to iterate through a series of numbers to create a list for some other purpose.
|
||||
```
|
||||
$ for i in `jot 7 17`; do echo April $i; done
|
||||
April 17
|
||||
April 18
|
||||
April 19
|
||||
April 20
|
||||
April 21
|
||||
April 22
|
||||
April 23
|
||||
|
||||
```
|
||||
|
||||
### bc
|
||||
|
||||
The **bc** command is probably one of the best tools for doing calculations on the command line. Enter the calculation that you want performed, and pipe it to the command like this:
|
||||
```
|
||||
$ echo "123.4+5/6-(7.89*1.234)" | bc
|
||||
113.664
|
||||
|
||||
```
|
||||
|
||||
Notice that **bc** doesn't shy away from precision and that the string you need to enter is fairly straightforward. It can also make comparisons, handle Booleans, and calculate square roots, sines, cosines, tangents, etc.
|
||||
```
|
||||
$ echo "sqrt(256)" | bc
|
||||
16
|
||||
$ echo "s(90)" | bc -l
|
||||
.89399666360055789051
|
||||
|
||||
```
|
||||
|
||||
In fact, **bc** can even calculate pi. You decide how many decimal points you want to see:
|
||||
```
|
||||
$ echo "scale=5; 4*a(1)" | bc -l
|
||||
3.14156
|
||||
$ echo "scale=10; 4*a(1)" | bc -l
|
||||
3.1415926532
|
||||
$ echo "scale=20; 4*a(1)" | bc -l
|
||||
3.14159265358979323844
|
||||
$ echo "scale=40; 4*a(1)" | bc -l
|
||||
3.1415926535897932384626433832795028841968
|
||||
|
||||
```
|
||||
|
||||
And **bc** isn't just for receiving data through pipes and sending answers back. You can also start it interactively and enter the calculations you want it to perform. Setting the scale (as shown below) determines how many decimal places you'll see.
|
||||
```
|
||||
$ bc
|
||||
bc 1.06.95
|
||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||
This is free software with ABSOLUTELY NO WARRANTY.
|
||||
For details type `warranty'.
|
||||
scale=2
|
||||
3/4
|
||||
.75
|
||||
2/3
|
||||
.66
|
||||
quit
|
||||
|
||||
```
|
||||
|
||||
Using **bc** , you can also convert numbers between different bases. The **obase** setting determines the output base.
|
||||
```
|
||||
$ bc
|
||||
bc 1.06.95
|
||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||
This is free software with ABSOLUTELY NO WARRANTY.
|
||||
For details type `warranty'.
|
||||
obase=16
|
||||
16 <=== entered
|
||||
10 <=== response
|
||||
256 <=== entered
|
||||
100 <=== response
|
||||
quit
|
||||
|
||||
```
|
||||
|
||||
One of the easiest ways to convert between hex and decimal is to use **bc** like this:
|
||||
```
|
||||
$ echo "ibase=16; F2" | bc
|
||||
242
|
||||
$ echo "obase=16; 242" | bc
|
||||
F2
|
||||
|
||||
```
|
||||
|
||||
In the first example above, we're converting from hex to decimal by setting the input base (ibase) to hex (base 16). In the second, we're doing the reverse by setting the outbut base (obase) to hex.
|
||||
|
||||
### Easy bash math
|
||||
|
||||
With sets of double-parentheses, we can do some easy math in bash. In the examples below, we create a variable and give it a value and then perform addition, decrement the result, and then square the remaining value.
|
||||
```
|
||||
$ ((e=11))
|
||||
$ (( e = e + 7 ))
|
||||
$ echo $e
|
||||
18
|
||||
|
||||
$ ((e--))
|
||||
$ echo $e
|
||||
17
|
||||
|
||||
$ ((e=e**2))
|
||||
$ echo $e
|
||||
289
|
||||
|
||||
```
|
||||
|
||||
The arithmetic operators allow you to:
|
||||
```
|
||||
+ - Add and subtract
|
||||
++ -- Increment and decrement
|
||||
* / % Multiply, divide, find remainder
|
||||
^ Get exponent
|
||||
|
||||
```
|
||||
|
||||
You can also use both logical and boolean operators:
|
||||
```
|
||||
$ ((x=11)); ((y=7))
|
||||
$ if (( x > y )); then
|
||||
> echo "x > y"
|
||||
> fi
|
||||
x > y
|
||||
|
||||
$ ((x=11)); ((y=7)); ((z=3))
|
||||
$ if (( x > y )) >> (( y > z )); then
|
||||
> echo "letters roll downhill"
|
||||
> fi
|
||||
letters roll downhill
|
||||
|
||||
```
|
||||
|
||||
or if you prefer ...
|
||||
```
|
||||
$ if [ x > y ] << [ y > z ]; then echo "letters roll downhill"; fi
|
||||
letters roll downhill
|
||||
|
||||
```
|
||||
|
||||
Now let's raise 2 to the 3rd power:
|
||||
```
|
||||
$ echo "2 ^ 3"
|
||||
2 ^ 3
|
||||
$ echo "2 ^ 3" | bc
|
||||
8
|
||||
|
||||
```
|
||||
|
||||
### Wrap-up
|
||||
|
||||
There are sure a lot of different ways to work with numbers and perform calculations on the command line on Linux systems. I hope you picked up a new trick or two by reading this post.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3268964/linux/how-to-do-math-on-the-linux-command-line.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -1,47 +0,0 @@
|
||||
如何在企业中开展开源项目
|
||||
======
|
||||
|
||||

|
||||
|
||||
很多互联网企业如 Google, Facebook, Twitter 等,都已经正式建立了数个开源项目(有的公司中建立了单独的开源项目部门)。在这个特定的项目内,开源项目的成本和成果都由公司内部消化。在这样一个实际的部门中,企业可以清晰透明地执行开源策略,这是企业成功开源化的一个必要过程。开源项目部门的职责包括:制定使用、分配、选择和审查代码的相关政策;培训开发技术人员和服从法律法规。
|
||||
|
||||
互联网企业并不是唯一一种运行开源项目的企业,有调查发现产业中 [65% 的企业][1]的运营都与开源相关。在过去几年中 [VMware][2], [Amazon][3], [Microsoft][4] 等企业,甚至连[英国政府][5]都开始聘用开源相关人员,开展开源项目。可见近年来商业领域乃至政府都十分重视开源策略,在这样的环境下,各界也需要跟上他们的步伐,建立开源项目。
|
||||
|
||||
### 怎样建立开源项目
|
||||
|
||||
虽然根据企业的需求不同,各开源部门会有特殊的调整,但下面几个基本步骤是建立每个开源部门都会经历的,它们是:
|
||||
|
||||
* **选定一位领导者:** 选出一位合适的领导之是建立开源项目的第一步。 [TODO Group][6] 发布了一份[开源人员基础工作任务清单][7],你可以根据这个清单筛选人员。
|
||||
* **确定项目构架:** 开源项目可以根据其服务的企业类型改变侧重点,来适应不同种类的企业需求,以在各类企业中成功运行。知识型企业可以把开源项目放在法律事务部运行,技术驱动型企业可以把开源项目放在着眼于提高企业效能的部门中,如工程部。其他类型的企业可以把开源项目放在市场部内运行,以此促进开源产品的销售。TODO Group 发布的[开源项目案例][8]或许可以给你些启发。
|
||||
* **制定规章制度:** 开源策略的实施需要有一套规章制度,其中应当具体列出企业成员进行开源工作的标准流程,来减少失误的发生。这个流程应当简洁明了且简单易行,最好可以用设备进行自动监察。如果工作人员有质疑标准流程的热情和能力,并提出改进意见,那再好不过了。许多活跃在开源领域的企业中,Google 和 TODO 发布的规章制度十分值得借鉴。你可以参照 [Google 发布的制度][9]起草适用于自己企业的规章制度,用 [TODO 的规章制度][10]进行参考。
|
||||
|
||||
### 建立开源项目是企业发展中的关键一步
|
||||
|
||||
建立开源项目部门对很多企业来说是关键一步,尤其是对于那些软件公司或是想要转型进入软件领域的公司。不论雇员的满意度或是开发效率上,在开源项目中企业可以获得巨大的利益,这些利益远远大于对开源项目需要的长期投资。在开源之路上有很多资源可以帮助你成功,例如 TODO Group 的[《怎样创建开源项目》][11],[《开源项目的价值评估》][12]和[《管理开源项目的几种工具》][13]都很适合初学者阅读。
|
||||
|
||||
随着越来越多的企业形成开源项目,开源社区自身的可持续性逐渐加强,这会对这些企业的开源项目产生积极影响,促进企业的发展,这是企业和开源间的良性循环。我希望以上这些信息能够帮到你,祝你在建立开源项目的路上一路顺风。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-start-open-source-program-your-company
|
||||
|
||||
作者:[Chris Aniszczyk][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/caniszczyk
|
||||
[1]:https://www.blackducksoftware.com/2016-future-of-open-source
|
||||
[2]:http://www.cio.com/article/3095843/open-source-tools/vmware-today-has-a-strong-investment-in-open-source-dirk-hohndel.html
|
||||
[3]:http://fortune.com/2016/12/01/amazon-open-source-guru/
|
||||
[4]:https://opensource.microsoft.com/
|
||||
[5]:https://www.linkedin.com/jobs/view/169669924
|
||||
[6]:http://todogroup.org
|
||||
[7]:https://github.com/todogroup/job-descriptions
|
||||
[8]:https://github.com/todogroup/guides/tree/master/casestudies
|
||||
[9]:https://opensource.google.com/docs/why/
|
||||
[10]:https://github.com/todogroup/policies
|
||||
[11]:https://github.com/todogroup/guides/blob/master/creating-an-open-source-program.md
|
||||
[12]:https://github.com/todogroup/guides/blob/master/measuring-your-open-source-program.md
|
||||
[13]:https://github.com/todogroup/guides/blob/master/tools-for-managing-open-source-programs.md
|
||||
262
translated/tech/20180331 How to build a plotter with Arduino.md
Normal file
262
translated/tech/20180331 How to build a plotter with Arduino.md
Normal file
@ -0,0 +1,262 @@
|
||||
如何使用 Arduino 制作一个绘图仪
|
||||
======
|
||||
|
||||

|
||||
在上学时,科学系的壁橱里藏着一台惠普绘图仪。虽然我在上学期间可以经常使用它,但我还是想拥有一台属于自己的绘图仪。许多年之后,步进电机已经很容易获得了,我又在从事电子产品和微控制器方面的工作,最近,我看到有人用丙烯酸塑料(acrylic)制作了一个显示器。这件事启发了我,并最终制作了我自己的绘图仪。
|
||||
|
||||
|
||||
![The plotter in action ][2]
|
||||
|
||||
我 DIY 的绘图仪;在这里看它工作的[视频][3]。
|
||||
|
||||
由于我是一个很怀旧的人,我真的很喜欢最初的 [Arduino Uno][4]。下面是我用到的其它东西的一个清单(仅供参考,其中一些我也不是很满意):
|
||||
|
||||
* [FabScan shield][5]:承载步进电机驱动器。
|
||||
* [SilentStepSticks][6]:步进电机驱动器,因为 Arduino 自身不能处理步进电机所需的电压和电流。因此我使用了一个 Trinamic TMC2130 芯片,但它是工作在单独模式。这些都是为替换 Pololu 4988,但是它们运转更安静。
|
||||
* [SilentStepStick 保护装置][7]:一个防止你的电机驱动器转动过快的二极管(相信我,你肯定会需要它的)。
|
||||
* 步进电机:我选择的是使用 12 V 电压的 NEMA 17 电机(如,来自 [Watterott][8] 和 [SparkFun][9] 的型号)。
|
||||
* [直线导杆][10]
|
||||
* 木制的基板
|
||||
* 木螺丝
|
||||
* GT2 皮带
|
||||
* [GT2 同步滑轮][11]
|
||||
|
||||
|
||||
|
||||
这是我作为个人项目而设计的。如果你想找到一个现成的工具套件,你可以从 German Make 杂志上找到 [MaXYposi][12]。
|
||||
|
||||
### 硬件安装
|
||||
|
||||
正如你所看到的,我刚开始做的太大了。这个绘图仪并不合适放在我的桌子上。但是,没有关系,我只是为了学习它(并且,我也将一些东西进行重新制作,下次我将使用一个更小的横梁)。
|
||||
|
||||
|
||||
![Plotter base plate with X-axis and Y-axis rails][14]
|
||||
|
||||
带 X 轴和 Y 轴轨道的绘图仪基板
|
||||
|
||||
皮带安装在轨道的侧面,并且用它将一些辅助轮和电机挂在一起:
|
||||
|
||||
|
||||
![The belt routing on the motor][16]
|
||||
|
||||
电机上的皮带路由
|
||||
|
||||
我在 Arduino 上堆叠了几个组件。Arduino 在最下面,它之上是 FabScan shield,接着是一个安装在 1 和 2 号电机槽上的 StepStick 保护装置,SilentStepStick 在最上面。注意,SCK 和 SDI 针脚没有连接。
|
||||
|
||||
|
||||
![Arduino and Shield][18]
|
||||
|
||||
Arduino 堆叠配置([高清大图][19])
|
||||
|
||||
注意将电机的连接线接到正确的针脚上。如果有疑问,就去查看它的数据表,或者使用欧姆表去找出哪一对线是正确的。
|
||||
|
||||
### 软件配置
|
||||
|
||||
#### 基础部分
|
||||
|
||||
虽然像 [grbl][20] 这样的软件可以解释诸如像装置移动和其它一些动作的 G-codes,并且,我也可以将它刷进 Arduino 中,但是我很好奇,想更好地理解它是如何工作的。(我的 X-Y 绘图仪软件可以在 [GitHub][21] 上找到,不过我不提供任何保修。)
|
||||
|
||||
使用 StepStick(或者其它兼容的)驱动器去驱动步进电机,基本上只需要发送一个高电平信号或者低电平信号到各自的针脚即可。或者使用 Arduino 的术语:
|
||||
```
|
||||
digitalWrite(stepPin, HIGH);
|
||||
|
||||
delayMicroseconds(30);
|
||||
|
||||
digitalWrite(stepPin, LOW);
|
||||
|
||||
```
|
||||
|
||||
在 `stepPin` 的位置上是步进电机的针脚编号:3 是 1 号电机,而 6 是 2 号电机。
|
||||
|
||||
在步进电机能够工作之前,它必须先被启用。
|
||||
```
|
||||
digitalWrite(enPin, LOW);
|
||||
|
||||
```
|
||||
|
||||
实际上,StepStick 能够理解针脚的三个状态:
|
||||
|
||||
* Low:电机已启用
|
||||
* High:电机已禁用
|
||||
* Pin 未连接:电机已启用,但在一段时间后进入节能模式
|
||||
|
||||
|
||||
|
||||
电机启用后,它的线圈已经有了力量并用来保持位置。这时候几乎不可能用手来转动它的轴。这样可以保证很好的精度,但是也意味着电机和驱动器芯片都“充满着”力量,并且也因此会发热。
|
||||
|
||||
最后,也是很重要的,我们需要一个决定绘图仪方向的方法:
|
||||
```
|
||||
digitalWrite(dirPin, direction);
|
||||
|
||||
```
|
||||
|
||||
下面的表列出了功能和针脚~~(致核对:下面的表格式错误)~~
|
||||
|
||||
Function Motor1 Motor2 Enable 2 5 Direction 4 7 Step 3 6
|
||||
|
||||
在我们使用这些针脚之前,我们需要在代码的 `setup()` 节中设置它的 `OUTPUT` 模式。
|
||||
```
|
||||
pinMode(enPin1, OUTPUT);
|
||||
|
||||
pinMode(stepPin1, OUTPUT);
|
||||
|
||||
pinMode(dirPin1, OUTPUT);
|
||||
|
||||
digitalWrite(enPin1, LOW);
|
||||
|
||||
```
|
||||
|
||||
了解这些知识后,我们可以很容易地让步进电机四处移动:
|
||||
```
|
||||
totalRounds = ...
|
||||
|
||||
for (int rounds =0 ; rounds < 2*totalRounds; rounds++) {
|
||||
|
||||
if (dir==0){ // set direction
|
||||
|
||||
digitalWrite(dirPin2, LOW);
|
||||
|
||||
} else {
|
||||
|
||||
digitalWrite(dirPin2, HIGH);
|
||||
|
||||
}
|
||||
|
||||
delay(1); // give motors some breathing time
|
||||
|
||||
dir = 1-dir; // reverse direction
|
||||
|
||||
for (int i=0; i < 6400; i++) {
|
||||
|
||||
int t = abs(3200-i) / 200;
|
||||
|
||||
digitalWrite(stepPin2, HIGH);
|
||||
|
||||
delayMicroseconds(70 + t);
|
||||
|
||||
digitalWrite(stepPin2, LOW);
|
||||
|
||||
delayMicroseconds(70 + t);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这将使滑块向左和向右移动。这些代码只操纵一个步进电机,但是,对于一个 X-Y 绘图仪,我们要考虑两个轴。
|
||||
|
||||
#### 命令解释器
|
||||
|
||||
我开始做一个简单的命令解释器去使用规范的路径,比如:
|
||||
```
|
||||
"X30|Y30|X-30 Y-30|X-20|Y-20|X20|Y20|X-40|Y-25|X40 Y25
|
||||
|
||||
```
|
||||
|
||||
用毫米来描述相对移动(1 毫米等于 80 步)。
|
||||
|
||||
绘图仪软件实现了一个 _持续模式_ ,这可以允许一台 PC 给它提供一个很大的路径(很多的路径)去绘制。(在这个[视频][22]中展示了如何绘制 Hilbert 曲线)
|
||||
|
||||
### 设计一个好用的握笔器
|
||||
|
||||
在上面的第一张图中,绘图笔是细绳子绑到 Y 轴上的。这样绘图也不精确,并且也无法在软件中实现提笔和下笔(如示例中的大黑点)。
|
||||
|
||||
因此,我设计了一个更好用的、更精确的握笔器,它使用一个伺服器去提笔和下笔。可以在下面的这张图中看到这个新的、改进后的握笔器,上面视频链接中的 Hilbert 曲线就是使用它绘制的。
|
||||
|
||||
![Servo to raise/lower the pen ][24]
|
||||
|
||||
图中的特写镜头就是伺服器臂提起笔的图像
|
||||
|
||||
笔是用一个小夹具固定住的(图上展示的是一个大小为 8 的夹具,它一般用于将线缆固定在墙上)。伺服器臂能够提起笔;当伺服器臂放下来的时候,笔就会被放下来。
|
||||
|
||||
#### 驱动伺服器
|
||||
|
||||
驱动伺服器是非常简单的:只需要提供位置,伺服器就可以完成所有的工作。
|
||||
```
|
||||
#include <Servo.h>
|
||||
|
||||
|
||||
|
||||
// Servo pin
|
||||
|
||||
#define servoData PIN_A1
|
||||
|
||||
|
||||
|
||||
// Positions
|
||||
|
||||
#define PEN_UP 10
|
||||
|
||||
#define PEN_DOWN 50
|
||||
|
||||
|
||||
|
||||
Servo penServo;
|
||||
|
||||
|
||||
|
||||
void setup() {
|
||||
|
||||
// Attach to servo and raise pen
|
||||
|
||||
penServo.attach(servoData);
|
||||
|
||||
penServo.write(PEN_UP);
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我把伺服器接头连接在 FabScan shield 的 4 号电机上,因此,我将用 1 号模拟针脚。
|
||||
|
||||
放下笔也很容易:
|
||||
```
|
||||
penServo.write(PEN_DOWN);
|
||||
|
||||
```
|
||||
|
||||
### 进一步扩展
|
||||
|
||||
我的进一步扩展的其中一项就是添加一些终止检测器,但是,我也可以不用它们,进而使用 TMC2130 的 StallGuard 模式来代替。这些检测器也可以用于去实现一个 `home` 命令。
|
||||
|
||||
以后,我或许还将添加一个真实的 Z 轴,这样它就可以对一个木头进行铣削雕刻,或者钻一个 PCB 板,或者雕刻一块丙烯酸塑料,或者 … (我还想到了用激光)。
|
||||
|
||||
这篇文章最初发布在 [Some Things to Remember][25] 博客中并授权重分发。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/diy-plotter-arduino
|
||||
|
||||
作者:[Heiko W.Rupp][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pilhuhn
|
||||
[1]:https://opensource.com/file/384786
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/plotter-in-action.png?itok=q9oHrJGr "The plotter in action "
|
||||
[3]:https://twitter.com/pilhuhn/status/948205323726344193
|
||||
[4]:https://en.wikipedia.org/wiki/Arduino#Official_boards
|
||||
[5]:http://www.watterott.com/de/Arduino-FabScan-Shield
|
||||
[6]:http://www.watterott.com/de/SilentStepStick-TMC2130
|
||||
[7]:http://www.watterott.com/de/SilentStepStick-Protector
|
||||
[8]:http://www.watterott.com/de/Schrittmotor-incl-Anschlusskabel
|
||||
[9]:https://www.sparkfun.com/products/9238
|
||||
[10]:https://www.ebay.de/itm/CNC-Set-12x-600mm-Linearfuhrung-Linear-Guide-Rail-Stage-3D-/322917927292?hash=item4b2f68897c
|
||||
[11]:http://www.watterott.com/de/OpenBuilds-GT2-2mm-Aluminium-Timing-Pulley
|
||||
[12]:https://www.heise.de/make/artikel/MaXYposi-Projektseite-zum-universellen-XY-Portalroboter-von-Make-3676050.html
|
||||
[13]:https://opensource.com/file/384776
|
||||
[14]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/entire_plotter.jpg?itok=40iSEs5K "Plotter base plate with X-axis and Y-axis rails"
|
||||
[15]:https://opensource.com/file/384791
|
||||
[16]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/y_motor_detail.jpg?itok=SICJBdRv "The belt routing on the motor"
|
||||
[17]:https://opensource.com/file/384771
|
||||
[18]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/arduino_and_shield.jpg?itok=OFumhpJm
|
||||
[19]:https://www.dropbox.com/s/7bp3bo5g2ujser8/IMG_20180103_110111.jpg?dl=0
|
||||
[20]:https://github.com/gnea/grbl
|
||||
[21]:https://github.com/pilhuhn/xy-plotter
|
||||
[22]:https://twitter.com/pilhuhn/status/949737734654124032
|
||||
[23]:/https://opensource.comfile/384781
|
||||
[24]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/pen_servo.jpg?itok=b2cnwB3P "Servo to raise/lower the pen "
|
||||
[25]:http://pilhuhn.blogspot.com/2018/01/homegrown-xy-plotter-with-arduino.html
|
||||
Loading…
Reference in New Issue
Block a user