mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
b2f7dc239d
347
published/20161012 Introduction to FirewallD on CentOS.md
Normal file
347
published/20161012 Introduction to FirewallD on CentOS.md
Normal file
@ -0,0 +1,347 @@
|
|||||||
|
CentOS 上的 FirewallD 简明指南
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
[FirewallD][4] 是 iptables 的前端控制器,用于实现持久的网络流量规则。它提供命令行和图形界面,在大多数 Linux 发行版的仓库中都有。与直接控制 iptables 相比,使用 FirewallD 有两个主要区别:
|
||||||
|
|
||||||
|
1. FirewallD 使用区域和服务而不是链式规则。
|
||||||
|
2. 它动态管理规则集,允许更新规则而不破坏现有会话和连接。
|
||||||
|
|
||||||
|
> FirewallD 是 iptables 的一个封装,可以让你更容易地管理 iptables 规则 - 它并*不是* iptables 的替代品。虽然 iptables 命令仍可用于 FirewallD,但建议使用 FirewallD 时仅使用 FirewallD 命令。
|
||||||
|
|
||||||
|
本指南将向您介绍 FirewallD 的区域和服务的概念,以及一些基本的配置步骤。
|
||||||
|
|
||||||
|
### 安装与管理 FirewallD
|
||||||
|
|
||||||
|
CentOS 7 和 Fedora 20+ 已经包含了 FirewallD,但是默认没有激活。可以像其它的 systemd 单元那样控制它。
|
||||||
|
|
||||||
|
1、 启动服务,并在系统引导时启动该服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl start firewalld
|
||||||
|
sudo systemctl enable firewalld
|
||||||
|
```
|
||||||
|
|
||||||
|
要停止并禁用:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl stop firewalld
|
||||||
|
sudo systemctl disable firewalld
|
||||||
|
```
|
||||||
|
|
||||||
|
2、 检查防火墙状态。输出应该是 `running` 或者 `not running`。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --state
|
||||||
|
```
|
||||||
|
|
||||||
|
3、 要查看 FirewallD 守护进程的状态:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl status firewalld
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出
|
||||||
|
|
||||||
|
```
|
||||||
|
firewalld.service - firewalld - dynamic firewall daemon
|
||||||
|
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled)
|
||||||
|
Active: active (running) since Wed 2015-09-02 18:03:22 UTC; 1min 12s ago
|
||||||
|
Main PID: 11954 (firewalld)
|
||||||
|
CGroup: /system.slice/firewalld.service
|
||||||
|
└─11954 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
|
||||||
|
```
|
||||||
|
|
||||||
|
4、 重新加载 FirewallD 配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
### 配置 FirewallD
|
||||||
|
|
||||||
|
FirewallD 使用 XML 进行配置。除非是非常特殊的配置,你不必处理它们,而应该使用 `firewall-cmd`。
|
||||||
|
|
||||||
|
配置文件位于两个目录中:
|
||||||
|
|
||||||
|
* `/usr/lib/FirewallD` 下保存默认配置,如默认区域和公用服务。 避免修改它们,因为每次 firewall 软件包更新时都会覆盖这些文件。
|
||||||
|
* `/etc/firewalld` 下保存系统配置文件。 这些文件将覆盖默认配置。
|
||||||
|
|
||||||
|
#### 配置集
|
||||||
|
|
||||||
|
FirewallD 使用两个_配置集_:“运行时”和“持久”。 在系统重新启动或重新启动 FirewallD 时,不会保留运行时的配置更改,而对持久配置集的更改不会应用于正在运行的系统。
|
||||||
|
|
||||||
|
默认情况下,`firewall-cmd` 命令适用于运行时配置,但使用 `--permanent` 标志将保存到持久配置中。要添加和激活持久性规则,你可以使用两种方法之一。
|
||||||
|
|
||||||
|
1、 将规则同时添加到持久规则集和运行时规则集中。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-service=http --permanent
|
||||||
|
sudo firewall-cmd --zone=public --add-service=http
|
||||||
|
```
|
||||||
|
|
||||||
|
2、 将规则添加到持久规则集中并重新加载 FirewallD。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-service=http --permanent
|
||||||
|
sudo firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
> `reload` 命令会删除所有运行时配置并应用永久配置。因为 firewalld 动态管理规则集,所以它不会破坏现有的连接和会话。
|
||||||
|
|
||||||
|
### 防火墙的区域
|
||||||
|
|
||||||
|
“区域”是针对给定位置或场景(例如家庭、公共、受信任等)可能具有的各种信任级别的预构建规则集。不同的区域允许不同的网络服务和入站流量类型,而拒绝其他任何流量。 首次启用 FirewallD 后,`public` 将是默认区域。
|
||||||
|
|
||||||
|
区域也可以用于不同的网络接口。例如,要分离内部网络和互联网的接口,你可以在 `internal` 区域上允许 DHCP,但在`external` 区域仅允许 HTTP 和 SSH。未明确设置为特定区域的任何接口将添加到默认区域。
|
||||||
|
|
||||||
|
要找到默认区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --get-default-zone
|
||||||
|
```
|
||||||
|
|
||||||
|
要修改默认区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --set-default-zone=internal
|
||||||
|
```
|
||||||
|
|
||||||
|
要查看你网络接口使用的区域:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --get-active-zones
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
public
|
||||||
|
interfaces: eth0
|
||||||
|
```
|
||||||
|
|
||||||
|
要得到特定区域的所有配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --list-all
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
public (default, active)
|
||||||
|
interfaces: ens160
|
||||||
|
sources:
|
||||||
|
services: dhcpv6-client http ssh
|
||||||
|
ports: 12345/tcp
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
```
|
||||||
|
|
||||||
|
要得到所有区域的配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --list-all-zones
|
||||||
|
```
|
||||||
|
|
||||||
|
示例输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
block
|
||||||
|
interfaces:
|
||||||
|
sources:
|
||||||
|
services:
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
|
||||||
|
...
|
||||||
|
|
||||||
|
work
|
||||||
|
interfaces:
|
||||||
|
sources:
|
||||||
|
services: dhcpv6-client ipp-client ssh
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
#### 与服务一起使用
|
||||||
|
|
||||||
|
FirewallD 可以根据特定网络服务的预定义规则来允许相关流量。你可以创建自己的自定义系统规则,并将它们添加到任何区域。 默认支持的服务的配置文件位于 `/usr/lib /firewalld/services`,用户创建的服务文件在 `/etc/firewalld/services` 中。
|
||||||
|
|
||||||
|
要查看默认的可用服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --get-services
|
||||||
|
```
|
||||||
|
|
||||||
|
比如,要启用或禁用 HTTP 服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-service=http --permanent
|
||||||
|
sudo firewall-cmd --zone=public --remove-service=http --permanent
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 允许或者拒绝任意端口/协议
|
||||||
|
|
||||||
|
比如:允许或者禁用 12345 端口的 TCP 流量。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-port=12345/tcp --permanent
|
||||||
|
sudo firewall-cmd --zone=public --remove-port=12345/tcp --permanent
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 端口转发
|
||||||
|
|
||||||
|
下面是**在同一台服务器上**将 80 端口的流量转发到 12345 端口。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone="public" --add-forward-port=port=80:proto=tcp:toport=12345
|
||||||
|
```
|
||||||
|
|
||||||
|
要将端口转发到**另外一台服务器上**:
|
||||||
|
|
||||||
|
1、 在需要的区域中激活 masquerade。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-masquerade
|
||||||
|
```
|
||||||
|
|
||||||
|
2、 添加转发规则。例子中是将 IP 地址为 :123.456.78.9 的_远程服务器上_ 80 端口的流量转发到 8080 上。
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone="public" --add-forward-port=port=80:proto=tcp:toport=8080:toaddr=123.456.78.9
|
||||||
|
```
|
||||||
|
|
||||||
|
要删除规则,用 `--remove` 替换 `--add`。比如:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --remove-masquerade
|
||||||
|
```
|
||||||
|
|
||||||
|
### 用 FirewallD 构建规则集
|
||||||
|
|
||||||
|
例如,以下是如何使用 FirewallD 为你的服务器配置基本规则(如果您正在运行 web 服务器)。
|
||||||
|
|
||||||
|
1. 将 `eth0` 的默认区域设置为 `dmz`。 在所提供的默认区域中,dmz(非军事区)是最适合于这个程序的,因为它只允许 SSH 和 ICMP。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --set-default-zone=dmz
|
||||||
|
sudo firewall-cmd --zone=dmz --add-interface=eth0
|
||||||
|
```
|
||||||
|
|
||||||
|
2、 把 HTTP 和 HTTPS 添加永久的服务规则到 dmz 区域中:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=dmz --add-service=http --permanent
|
||||||
|
sudo firewall-cmd --zone=dmz --add-service=https --permanent
|
||||||
|
```
|
||||||
|
|
||||||
|
3、 重新加载 FirewallD 让规则立即生效:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --reload
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你运行 `firewall-cmd --zone=dmz --list-all`, 会有下面的输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
dmz (default)
|
||||||
|
interfaces: eth0
|
||||||
|
sources:
|
||||||
|
services: http https ssh
|
||||||
|
ports:
|
||||||
|
masquerade: no
|
||||||
|
forward-ports:
|
||||||
|
icmp-blocks:
|
||||||
|
rich rules:
|
||||||
|
```
|
||||||
|
|
||||||
|
这告诉我们,`dmz` 区域是我们的**默认**区域,它被用于 `eth0` 接口**中所有网络的**源地址**和**端口**。 允许传入 HTTP(端口 80)、HTTPS(端口 443)和 SSH(端口 22)的流量,并且由于没有 IP 版本控制的限制,这些适用于 IPv4 和 IPv6。 不允许**IP 伪装**以及**端口转发**。 我们没有 **ICMP 块**,所以 ICMP 流量是完全允许的。没有**丰富(Rich)规则**,允许所有出站流量。
|
||||||
|
|
||||||
|
### 高级配置
|
||||||
|
|
||||||
|
服务和端口适用于基本配置,但对于高级情景可能会限制较多。 丰富(Rich)规则和直接(Direct)接口允许你为任何端口、协议、地址和操作向任何区域 添加完全自定义的防火墙规则。
|
||||||
|
|
||||||
|
#### 丰富规则
|
||||||
|
|
||||||
|
丰富规则的语法有很多,但都完整地记录在 [firewalld.richlanguage(5)][5] 的手册页中(或在终端中 `man firewalld.richlanguage`)。 使用 `--add-rich-rule`、`--list-rich-rules` 、 `--remove-rich-rule` 和 firewall-cmd 命令来管理它们。
|
||||||
|
|
||||||
|
这里有一些常见的例子:
|
||||||
|
|
||||||
|
允许来自主机 192.168.0.14 的所有 IPv4 流量。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-rich-rule 'rule family="ipv4" source address=192.168.0.14 accept'
|
||||||
|
```
|
||||||
|
|
||||||
|
拒绝来自主机 192.168.1.10 到 22 端口的 IPv4 的 TCP 流量。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-rich-rule 'rule family="ipv4" source address="192.168.1.10" port port=22 protocol=tcp reject'
|
||||||
|
```
|
||||||
|
|
||||||
|
允许来自主机 10.1.0.3 到 80 端口的 IPv4 的 TCP 流量,并将流量转发到 6532 端口上。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-rich-rule 'rule family=ipv4 source address=10.1.0.3 forward-port port=80 protocol=tcp to-port=6532'
|
||||||
|
```
|
||||||
|
|
||||||
|
将主机 172.31.4.2 上 80 端口的 IPv4 流量转发到 8080 端口(需要在区域上激活 masquerade)。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --zone=public --add-rich-rule 'rule family=ipv4 forward-port port=80 protocol=tcp to-port=8080 to-addr=172.31.4.2'
|
||||||
|
```
|
||||||
|
|
||||||
|
列出你目前的丰富规则:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo firewall-cmd --list-rich-rules
|
||||||
|
```
|
||||||
|
|
||||||
|
### iptables 的直接接口
|
||||||
|
|
||||||
|
对于最高级的使用,或对于 iptables 专家,FirewallD 提供了一个直接(Direct)接口,允许你给它传递原始 iptables 命令。 直接接口规则不是持久的,除非使用 `--permanent`。
|
||||||
|
|
||||||
|
要查看添加到 FirewallD 的所有自定义链或规则:
|
||||||
|
|
||||||
|
```
|
||||||
|
firewall-cmd --direct --get-all-chains
|
||||||
|
firewall-cmd --direct --get-all-rules
|
||||||
|
```
|
||||||
|
|
||||||
|
讨论 iptables 的具体语法已经超出了这篇文章的范围。如果你想学习更多,你可以查看我们的 [iptables 指南][6]。
|
||||||
|
|
||||||
|
### 更多信息
|
||||||
|
|
||||||
|
你可以查阅以下资源以获取有关此主题的更多信息。虽然我们希望我们提供的是有效的,但是请注意,我们不能保证外部材料的准确性或及时性。
|
||||||
|
|
||||||
|
* [FirewallD 官方网站][1]
|
||||||
|
* [RHEL 7 安全指南:FirewallD 简介][2]
|
||||||
|
* [Fedora Wiki:FirewallD][3]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linode.com/docs/security/firewalls/introduction-to-firewalld-on-centos
|
||||||
|
|
||||||
|
作者:[Linode][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linode.com/docs/security/firewalls/introduction-to-firewalld-on-centos
|
||||||
|
[1]:http://www.firewalld.org/
|
||||||
|
[2]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Security_Guide/sec-Using_Firewalls.html#sec-Introduction_to_firewalld
|
||||||
|
[3]:https://fedoraproject.org/wiki/FirewallD
|
||||||
|
[4]:http://www.firewalld.org/
|
||||||
|
[5]:https://jpopelka.fedorapeople.org/firewalld/doc/firewalld.richlanguage.html
|
||||||
|
[6]:https://www.linode.com/docs/networking/firewalls/control-network-traffic-with-iptables
|
||||||
184
published/20161128 Managing devices in Linux.md
Normal file
184
published/20161128 Managing devices in Linux.md
Normal file
@ -0,0 +1,184 @@
|
|||||||
|
在 Linux 中管理设备
|
||||||
|
=============
|
||||||
|
|
||||||
|
探索 `/dev` 目录可以让您知道如何直接访问到 Linux 中的设备。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*照片提供:Opensource.com*
|
||||||
|
|
||||||
|
Linux 目录结构中有很多有趣的功能,这次我会讲到 `/dev` 目录一些迷人之处。在继续阅读这篇文章之前,建议你看看我前面的文章。[Linux 文件系统][9],[一切皆为文件][8],这两篇文章介绍了一些有趣的 Linux 文件系统概念。请先看看 - 我会等你看完再回来。
|
||||||
|
|
||||||
|
……
|
||||||
|
|
||||||
|
太好了 !欢迎回来。现在我们可以继续更详尽地探讨 `/dev` 目录。
|
||||||
|
|
||||||
|
### 设备文件
|
||||||
|
|
||||||
|
设备文件也称为[设备特定文件][4]。设备文件用来为操作系统和用户提供它们代表的设备接口。所有的 Linux 设备文件均位于 `/dev` 目录下,是根 (`/`) 文件系统的一个组成部分,因为这些设备文件在操作系统启动过程中必须可以使用。
|
||||||
|
|
||||||
|
关于这些设备文件,要记住的一件重要的事情,就是它们大多不是设备驱动程序。更准确地描述来说,它们是设备驱动程序的门户。数据从应用程序或操作系统传递到设备文件,然后设备文件将它传递给设备驱动程序,驱动程序再将它发给物理设备。反向的数据通道也可以用,从物理设备通过设备驱动程序,再到设备文件,最后到达应用程序或其他设备。
|
||||||
|
|
||||||
|
让我们以一个典型命令的数据流程来直观地看看。
|
||||||
|
|
||||||
|
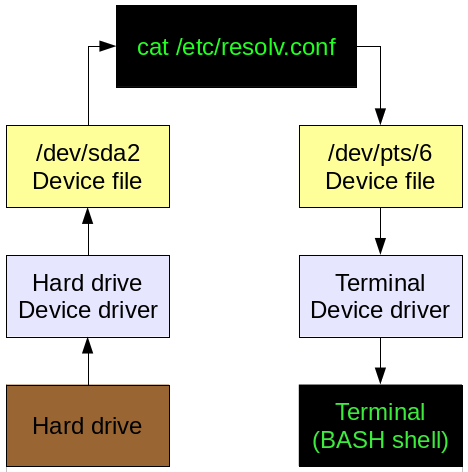
|
||||||
|
|
||||||
|
*图 1:一个典型命令的简单数据流程。*
|
||||||
|
|
||||||
|
在上面的图 1 中,显示一个简单命令的简化数据流程。从一个 GUI 终端仿真器,例如 Konsole 或 xterm 中发出 `cat /etc/resolv.conf` 命令,它会从磁盘中读取 `resolv.conf` 文件,磁盘设备驱动程序处理设备的具体功能,例如在硬盘驱动器上定位文件并读取它。数据通过设备文件传递,然后从命令到设备文件,然后到 6 号伪终端的设备驱动,然后在终端会话中显示。
|
||||||
|
|
||||||
|
当然, `cat` 命令的输出可以以下面的方式被重定向到一个文件, `cat /etc/resolv.conf > /etc/resolv.bak` ,这样会创建该文件的备份。在这种情况下,图 1 左侧的数据流量将保持不变,而右边的数据流量将通过 `/dev/sda2` 设备文件、硬盘设备驱动程序,然后到硬盘驱动器本身。
|
||||||
|
|
||||||
|
这些设备文件使得使用标准流 (STD/IO) 和重定向访问 Linux 或 Unix 计算机上的任何一个设备非常容易。只需将数据流定向到设备文件,即可将数据发送到该设备。
|
||||||
|
|
||||||
|
### 设备文件类别
|
||||||
|
|
||||||
|
设备文件至少可以按两种方式划分。第一种也是最常用的分类是根据与设备相关联的数据流进行划分。比如,tty (teletype) 和串行设备被认为是基于字符的,因为数据流的传送和处理是以一次一个字符或字节进行的;而块类型设备(如硬盘驱动器)是以块为单位传输数据,通常为 256 个字节的倍数。
|
||||||
|
|
||||||
|
您可以在终端上以一个非 root 用户,改变当前工作目录(`PWD`)到 `/dev` ,并显示长目录列表。 这将显示设备文件列表、文件权限及其主、次设备号。 例如,下面的设备文件只是我的 Fedora 24 工作站上 `/dev` 目录中的几个文件。 它们表示磁盘和 tty 设备类型。 注意输出中每行的最左边的字符。 `b` 代表是块类型设备,`c` 代表字符设备。
|
||||||
|
|
||||||
|
```
|
||||||
|
brw-rw---- 1 root disk 8, 0 Nov 7 07:06 sda
|
||||||
|
brw-rw---- 1 root disk 8, 1 Nov 7 07:06 sda1
|
||||||
|
brw-rw---- 1 root disk 8, 16 Nov 7 07:06 sdb
|
||||||
|
brw-rw---- 1 root disk 8, 17 Nov 7 07:06 sdb1
|
||||||
|
brw-rw---- 1 root disk 8, 18 Nov 7 07:06 sdb2
|
||||||
|
crw--w---- 1 root tty 4, 0 Nov 7 07:06 tty0
|
||||||
|
crw--w---- 1 root tty 4, 1 Nov 7 07:07 tty1
|
||||||
|
crw--w---- 1 root tty 4, 10 Nov 7 07:06 tty10
|
||||||
|
crw--w---- 1 root tty 4, 11 Nov 7 07:06 tty11
|
||||||
|
```
|
||||||
|
|
||||||
|
识别设备文件更详细和更明确的方法是使用设备主要以及次要号。 磁盘设备主设备号为 8,将它们指定为 SCSI 块设备。请注意,所有 PATA 和 SATA 硬盘驱动器都由 SCSI 子系统管理,因为旧的 ATA 子系统多年前就由于代码质量糟糕而被认为不可维护。造成的结果就是,以前被称为 “hd[a-z]” 的硬盘驱动器现在被称为 “sd[a-z]”。
|
||||||
|
|
||||||
|
你大概可以从上面的示例中推出磁盘驱动器次设备号的模式。次设备号 0、 16、 32 等等,直到 240,是整个磁盘的号。所以主/次 8/16 表示整个磁盘 `/dev/sdb` , 8/17 是第一个分区的设备文件,`/dev/sdb1`。数字 8/34 代表 `/dev/sdc2`。
|
||||||
|
|
||||||
|
在上面列表中的 tty 设备文件编号更简单一些,从 tty0 到 tty63 。
|
||||||
|
|
||||||
|
Kernel.org 上的 [Linux 下的已分配设备][5]文件是设备类型和主次编号分配的正式注册表。它可以帮助您了解所有当前定义的设备的主要/次要号码。
|
||||||
|
|
||||||
|
### 趣味设备文件
|
||||||
|
|
||||||
|
让我们花几分钟时间,执行几个有趣的实验,演示 Linux 设备文件的强大和灵活性。 大多数 Linux 发行版都有 1 到 7 个虚拟控制台,可用于使用 shell 接口登录到本地控制台会话。 可以使用 `Ctrl-Alt-F1`(控制台 1),`Ctrl-Alt-F2`(控制台 2)等键盘组合键来访问。
|
||||||
|
|
||||||
|
请按 `Ctrl-Alt-F2` 切换到控制台 2。在某些发行版,登录显示的信息包括了与此控制台关联的 tty 设备,但大多不包括。它应该是 tty2,因为你是在控制台 2 中。
|
||||||
|
|
||||||
|
以非 root 用户身份登录。 然后你可以使用 `who am i` 命令 — 是的,就是这个命令,带空格 — 来确定哪个 tty 设备连接到这个控制台。
|
||||||
|
|
||||||
|
在我们实际执行此实验之前,看看 `/dev` 中的 tty2 和 tty3 的设备列表。
|
||||||
|
|
||||||
|
```
|
||||||
|
ls -l /dev/tty[23]
|
||||||
|
```
|
||||||
|
|
||||||
|
有大量的 tty 设备,但我们不关心他们中的大多数,只注意 tty2 和 tty3 设备。 作为设备文件,它们没什么特别之处。它们都只是字符类型设备。我们将使用这些设备进行此实验。 tty2 设备连接到虚拟控制台 2,tty3 设备连接到虚拟控制台 3。
|
||||||
|
|
||||||
|
按 `Ctrl-Alt-F3` 切换到控制台 3。再次以同一非 root 用户身份登录。 现在在控制台 3 上输入以下命令。
|
||||||
|
|
||||||
|
```
|
||||||
|
echo "Hello world" > /dev/tty2
|
||||||
|
```
|
||||||
|
|
||||||
|
按 `Ctrl-Alt-f2` 键以返回到控制台 2。字符串 “Hello world”(没有引号)将显示在控制台 2。
|
||||||
|
|
||||||
|
该实验也可以使用 GUI 桌面上的终端仿真器来执行。 桌面上的终端会话使用 `/dev` 中的伪终端设备,如 `/dev/pts/1`。 使用 Konsole 或 Xterm 打开两个终端会话。 确定它们连接到哪些伪终端,并使用一个向另一个发送消息。
|
||||||
|
|
||||||
|
现在继续实验,使用 `cat` 命令,试试在不同的终端上显示 `/etc/fstab` 文件。
|
||||||
|
|
||||||
|
另一个有趣的实验是使用 `cat` 命令将文件直接打印到打印机。 假设您的打印机设备是 `/dev/usb/lp0`,并且您的打印机可以直接打印 PDF 文件,以下命令将在您的打印机上打印 `test.pdf` 文件。
|
||||||
|
|
||||||
|
```
|
||||||
|
cat test.pdf > /dev/usb/lp0
|
||||||
|
```
|
||||||
|
|
||||||
|
`/dev` 目录包含一些非常有趣的设备文件,这些文件是硬件的入口,人们通常不认为这是硬盘驱动器或显示器之类的设备。 例如,系统存储器 RAM 不是通常被认为是“设备”的东西,而 `/dev/mem` 是通过其可以实现对存储器的直接访问的入口。 下面的例子有一些有趣的结果。
|
||||||
|
|
||||||
|
```
|
||||||
|
dd if=/dev/mem bs=2048 count=100
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的 `dd` 命令提供比简单地使用 `cat` 命令 dump 所有系统的内存提供了更多的控制。 它提供了指定从 `/dev/mem` 读取多少数据的能力,还允许指定从存储器哪里开始读取数据。虽然读取了一些内存,但内核响应了以下错误,在 `/var/log/messages` 中可以看到。
|
||||||
|
|
||||||
|
```
|
||||||
|
Nov 14 14:37:31 david kernel: usercopy: kernel memory exposure attempt detected from ffff9f78c0010000 (dma-kmalloc-512) (2048 bytes)
|
||||||
|
```
|
||||||
|
|
||||||
|
这个错误意味着内核正在通过保护属于其他进程的内存来完成它的工作,这正是它应该工作的方式。 所以,虽然可以使用 `/dev/mem` 来显示存储在 RAM 内存中的数据,但是访问的大多数内存空间是受保护的并且会导致错误。 只可以访问由内核内存管理器分配给运行 `dd` 命令的 BASH shell 的虚拟内存,而不会导致错误。 抱歉,但你不能窥视不属于你的内存,除非你发现了一个可利用的漏洞。
|
||||||
|
|
||||||
|
`/dev` 中还有一些非常有趣的设备文件。 设备文件 `null`,`zero`,`random` 和 `urandom` 不与任何物理设备相关联。
|
||||||
|
|
||||||
|
例如,空设备 `/dev/null` 可以用作来自 shell 命令或程序的输出重定向的目标,以便它们不显示在终端上。 我经常在我的 BASH 脚本中使用这个,以防止向用户展示可能会让他们感到困惑的输出。 `/dev/null` 设备可用于产生一个空字符串。 使用如下所示的 `dd` 命令查看 `/dev/null` 设备文件的一些输出。
|
||||||
|
|
||||||
|
```
|
||||||
|
# dd if=/dev/null bs=512 count=500 | od -c
|
||||||
|
0+0 records in
|
||||||
|
0+0 records out
|
||||||
|
0 bytes copied, 1.5885e-05 s, 0.0 kB/s
|
||||||
|
0000000
|
||||||
|
```
|
||||||
|
|
||||||
|
注意,因为空字符什么也没有所以确实没有可见的输出。 注意看看字节数。
|
||||||
|
|
||||||
|
`/dev/random` 和 `/dev/urandom` 设备也很有趣。 正如它们的名字所暗示的,它们都产生随机输出,不仅仅是数字,而是任何字节组合。 `/dev/urandom` 设备产生的是**确定性**的随机输出,并且非常快。 这意味着输出由算法确定,并使用种子字符串作为起点。 结果,如果原始种子是已知的,则黑客可以再现输出,尽管非常困难,但这是有可能的。 使用命令 `cat /dev/urandom` 可以查看典型的输出,使用 `Ctrl-c` 退出。
|
||||||
|
|
||||||
|
`/dev/random` 设备文件生成**非确定性**的随机输出,但它产生的输出更慢一些。 该输出不是由依赖于先前数字的算法确定的,而是由击键动作和鼠标移动而产生的。 这种方法使得复制特定系列的随机数要困难得多。使用 `cat` 命令去查看一些来自 `/dev/random` 设备文件输出。尝试移动鼠标以查看它如何影响输出。
|
||||||
|
|
||||||
|
正如其名字所暗示的,`/dev/zero` 设备文件产生一个无止境的零作为输出。 注意,这些是八进制零,而不是ASCII字符零(`0`)。 使用如下所示的 `dd` 查看 `/dev/zero` 设备文件中的一些输出
|
||||||
|
|
||||||
|
```
|
||||||
|
# dd if=/dev/zero bs=512 count=500 | od -c
|
||||||
|
0000000 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
|
||||||
|
*
|
||||||
|
500+0 records in
|
||||||
|
500+0 records out
|
||||||
|
256000 bytes (256 kB, 250 KiB) copied, 0.00126996 s, 202 MB/s
|
||||||
|
0764000
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意,此命令的字节数不为零。
|
||||||
|
|
||||||
|
### 创建设备文件
|
||||||
|
|
||||||
|
在过去,在 `/dev` 中的设备文件都是在安装时创建的,导致一个目录中有几乎所有的设备文件,尽管大多数文件永远不会用到。 在不常发生的情况,例如需要新的设备文件,或意外删除后需要重新创建设备文件,可以使用 `mknod` 程序手动创建设备文件。 前提是你必须知道设备的主要和次要号码。
|
||||||
|
|
||||||
|
CentOS 和 RHEL 6、7,以及 Fedora 的所有版本——可以追溯到至少 Fedora 15,使用较新的创建设备文件的方法。 所有设备文件都是在引导时创建的。 这是因为 udev 设备管理器在设备添加和删除发生时会进行检测。这可实现在主机启动和运行时的真正的动态即插即用功能。 它还在引导时执行相同的任务,通过在引导过程的很早的时期检测系统上安装的所有设备。 [Linux.com][6] 上有一篇很棒的对 [udev 的描述][7]。
|
||||||
|
|
||||||
|
回到 `/dev` 中的文件列表,注意文件的日期和时间。 所有文件都是在上次启动时创建的。 您可以使用 `uptime` 或者 `last` 命令来验证这一点。在上面我的设备列表中,所有这些文件都是在 11 月 7 日上午 7:06 创建的,这是我最后一次启动系统。
|
||||||
|
|
||||||
|
当然, `mknod` 命令仍然可用, 但新的 `MAKEDEV` (是的,所有字母大写,在我看来是违背 Linux 使用小写命令名的原则的) 命令提供了一个创建设备文件的更容易的界面。 在当前版本的 Fedora 或 CentOS 7 中,默认情况下不安装 `MAKEDEV` 命令;它安装在 CentOS 6。您可以使用 YUM 或 DNF 来安装 MAKEDEV 包。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
有趣的是,我很久没有创建一个设备文件的需要了。 然而,最近我遇到一个有趣的情况,其中一个我常使用的设备文件没有创建,我不得不创建它。 之后该设备再没出过问题。所以丢失设备文件的情况仍然可以发生,知道如何处理它可能很重要。
|
||||||
|
|
||||||
|
设备文件有无数种,您遇到的设备文件我可能没有涵盖到。 这些信息在所下面引用的资源中有大量的细节信息可用。 关于这些文件的功能和工具,我希望我已经给您一些基本的了解,下一步您自己可以探索更多。
|
||||||
|
|
||||||
|
资源
|
||||||
|
|
||||||
|
- [一切皆文件][1], David Both, Opensource.com
|
||||||
|
- [Linux 文件系统介绍][2], David Both, Opensource.com
|
||||||
|
- [文件系统层次结构][10], The Linux Documentation Project
|
||||||
|
- [设备文件][4], Wikipedia
|
||||||
|
- [Linux 下已分配设备][5], Kernel.org
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/16/11/managing-devices-linux
|
||||||
|
|
||||||
|
作者:[David Both][a]
|
||||||
|
译者:[erlinux](http://www.itxdm.me)
|
||||||
|
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/dboth
|
||||||
|
[1]:https://opensource.com/life/15/9/everything-is-a-file
|
||||||
|
[2]:https://opensource.com/life/16/10/introduction-linux-filesystems
|
||||||
|
[4]:https://en.wikipedia.org/wiki/Device_file
|
||||||
|
[5]:https://www.kernel.org/doc/Documentation/devices.txt
|
||||||
|
[6]:https://www.linux.com/
|
||||||
|
[7]:https://www.linux.com/news/udev-introduction-device-management-modern-linux-system
|
||||||
|
[8]:https://opensource.com/life/15/9/everything-is-a-file
|
||||||
|
[9]:https://opensource.com/life/16/10/introduction-linux-filesystems
|
||||||
|
[10]:http://www.tldp.org/LDP/Linux-Filesystem-Hierarchy/html/dev.html
|
||||||
|
|
||||||
@ -0,0 +1,228 @@
|
|||||||
|
### Android 6.0 Marshmallow
|
||||||
|
|
||||||
|
In October 2015, Google brought Android 6.0 Marshmallow into the world. For the OS's launch, Google commissioned two new Nexus devices: the [Huawei Nexus 6P and LG Nexus 5X][39]. Rather than just the usual speed increase, the new phones also included a key piece of hardware: a fingerprint reader for Marshmallow's new fingerprint API. Marshmallow was also packing a crazy new search feature called "Google Now on Tap," user controlled app permissions, a new data backup system, and plenty of other refinements.
|
||||||
|
|
||||||
|
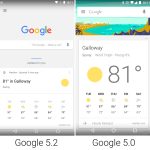
#### The new Google App
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][3]
|
||||||
|
* [
|
||||||
|

|
||||||
|
][4]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][5]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][6]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][7]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][8]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][9]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][10]
|
||||||
|
* [
|
||||||
|

|
||||||
|
][11]
|
||||||
|
|
||||||
|
Marshmallow was the first version of Android after [Google's big logo redesign][40]. The OS was updated accordingly, mainly with a new Google app that added a colorful logo to the search widget, search page, and the app icon.
|
||||||
|
|
||||||
|
Google reverted the app drawer from a paginated horizontal layout back to the single, vertically scrolling sheet. The earliest versions of Android all had vertically scrolling sheets until Google changed to a horizontal page system in Honeycomb. The scrolling single sheet made finding things in a large selection of apps much faster. A "quick scroll" feature, which let you drag on the scroll bar to bring up letter indexing, helped too. This new app drawer layout also carried over to the widget drawer. Given that the old system could easily grow to 15+ pages, this was a big improvement.
|
||||||
|
|
||||||
|
The "suggested apps" bar at the top of Marshmallow's app drawer made finding apps faster, too.
|
||||||
|
This bar changed from time to time and tried to surface the apps you needed when you needed them. It used an algorithm that took into account app usage, apps that are normally launched together, and time of day.
|
||||||
|
|
||||||
|
#### Google Now on Tap—a feature that didn't quite work out
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][12]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][13]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][14]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][15]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][16]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][17]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][18]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][19]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][20]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][21]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][22]
|
||||||
|
|
||||||
|
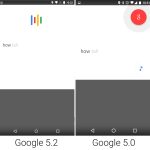
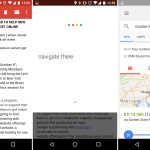
One of Marshmallow's headline features was "Google Now on Tap." With Now on Tap, you could hold down the home button on any screen and Android would send the entire screen to Google for processing. Google would then try to figure out what the screen was about, and a special list of search results would pop up from the bottom of the screen.
|
||||||
|
|
||||||
|
Results yielded by Now on Tap weren't the usual 10 blue links—though there was always a link to a Google Search. Now on Tap could also deep link into other apps using Google's App Indexing feature. The idea was you could call up Now on Tap for a YouTube music video and get a link to the Google Play or Amazon "buy" page. Now on Tapping (am I allowed to verb that?) a news article about an actor could link to his page inside the IMDb app.
|
||||||
|
|
||||||
|
Rather than make this a proprietary feature, Google built a whole new "Assistant API" into Android. The user could pick an "Assist App" which would be granted scads of information upon long-pressing the home button. The Assist app would get all the text that was currently loaded by the app—not just what was immediately on screen—along with all the images and any special metadata the developer wanted to include. This API powered Google Now on Tap, and it also allowed third parties to make Now on Tap rivals if they wished.
|
||||||
|
|
||||||
|
Google hyped Now on Tap during Marshmallow's initial presentation, but in practice, the feature wasn't very useful. Google Search is worthwhile because you're asking it an exact question—you type in whatever you want, and it scours the entire Internet looking for the answer or web page. Now on Tap made things infinitely harder because it didn't even know what question you were asking. You opened Now on Tap with a very specific intent, but you sent Google the very unspecific query of "everything on your screen." Google had to guess what your query was and then tried to deliver useful search results or actions based on that.
|
||||||
|
|
||||||
|
Behind the scenes, Google was probably processing like crazy to brute-force out the result you wanted from an entire page of text and images. But more often than not, Now on Tap yielded what felt like a list of search results for every proper noun on the page. Sifting through the list of results for multiple queries was like being trapped in one of those Bing "[Search Overload][41]" commercials. The lack of any kind of query targeting made Now on Tap feel like you were asking Google to read your mind, and it never could. Google eventually patched in an "Assist" button to the text selection menu, giving Now on Tap some of the query targeting that it desperately needed.
|
||||||
|
|
||||||
|
Calling Now on Tap anything other than a failure is hard. The shortcut to access Now on Tap—long pressing on the home button—basically made it a hidden, hard-to-discover feature that was easy to forget about. We speculate the feature had extremely low usage numbers. Even when users did discover Now on Tap, it failed to read your mind so often that, after a few attempts, most users probably gave up on it.
|
||||||
|
|
||||||
|
With the launch of the Google Pixels in 2016, the company seemingly admitted defeat. It renamed Now on Tap "Screen Search" and demoted it in favor of the Google Assistant. The Assistant—Google's new voice command system—took over On Tap's home button gesture and related it to a second gesture once the voice system was activated. Google also seems to have learned from Now on Tap's poor discoverability. With the Assistant, Google added a set of animated colored dots to the home button that helped users discover and be reminded about the feature.
|
||||||
|
|
||||||
|
#### Permissions
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][23]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][24]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][25]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][26]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][27]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][28]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][29]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][30]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][31]
|
||||||
|
* [
|
||||||
|

|
||||||
|
][32]
|
||||||
|
|
||||||
|
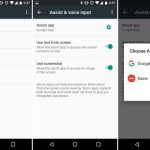
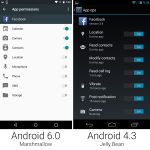
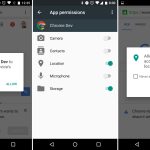
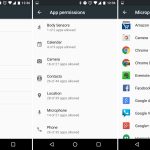
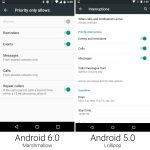
Android 6.0 finally introduced an app permissions system that gave users granular control over what data apps had access to.
|
||||||
|
|
||||||
|
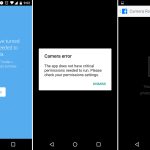
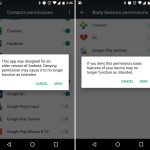
Apps no longer gave you a huge list of permissions at install. With Marshmallow, apps installed without asking for any permissions at all. When apps needed a permission—like access to your location, camera, microphone, or contact list—they asked at the exact time they needed it. During your usage of an app, an "Allow or Deny" dialog popped up anytime the app wanted a new permission. Some app setup flow tackled this by asking for a few key permissions at startup, and everything else popped up as the app needed it. This better communicated to the user what the permissions are for—this app needs camera access because you just tapped on the camera button.
|
||||||
|
|
||||||
|
Besides the in-the-moment "Allow or Deny" dialogs, Marshmallow also added a permissions setting screen. This big list of checkboxes allowed data-conscious users to browse which apps have access to what permissions. They can browse not only by app, but also by permission. For instance, you could see every app that has access to the microphone.
|
||||||
|
|
||||||
|
Google had been experimenting with app permissions for some time, and these screens were basically the rebirth of the hidden "[App Ops][42]" system that was accidentally introduced in Android 4.3 and quickly removed.
|
||||||
|
|
||||||
|
While Google experimented in previous versions, the big difference with Marshmallow's permissions system was that it represented an orderly transition to a permission OS. Android 4.3's App Ops was never meant to be exposed to users, so developers didn't know about it. The result of denying an app a permission in 4.3 was often a weird error message or an outright crash. Marshmallow's system was opt-in for developers—the new permission system only applied to apps that were targeting the Marshmallow SDK, which Google used as a signal that the developer was ready for permission handling. The system also allowed for communication to users when a feature didn't work because of a denied permission. Apps were told when they were denied a permission, and they could instruct the user to turn the permission back on if you wanted to use a feature.
|
||||||
|
|
||||||
|
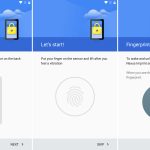
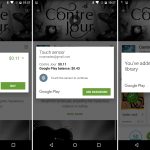
#### The Fingerprint API
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][33]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][34]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][35]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][36]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][37]
|
||||||
|
* [
|
||||||
|

|
||||||
|
][38]
|
||||||
|
|
||||||
|
Before Marshmallow, few OEMs had come up with their own fingerprint solution in response to [Apple's Touch ID][43]. But with Marshmallow, Google finally came up with an ecosystem-wide API for fingerprint recognition. The new system included UI for registering fingerprints, a fingerprint-guarded lock screen, and APIs that allowed apps to protect content behind a fingerprint scan or lock-screen challenge.
|
||||||
|
|
||||||
|
The Play Store was one of the first apps to support the API. Instead of having to enter your password to purchase an app, you could just use your fingerprint. The Nexus 5X and 6P were the first phones to support the fingerprint API with an actual hardware fingerprint reader on the back.
|
||||||
|
|
||||||
|
Later the fingerprint API became one of the rare examples of the Android ecosystem actually cooperating and working together. Every phone with a fingerprint reader uses Google's API, and most banking and purchasing apps are pretty good about supporting it.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/
|
||||||
|
|
||||||
|
作者:[RON AMADEO][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://arstechnica.com/author/ronamadeo
|
||||||
|
[1]:https://www.youtube.com/watch?v=f17qe9vZ8RM
|
||||||
|
[2]:https://www.youtube.com/watch?v=VOn7VrTRlA4&list=PLOU2XLYxmsIJDPXCTt5TLDu67271PruEk&index=11
|
||||||
|
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[25]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[26]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[27]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[28]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[29]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[30]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[31]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[32]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[33]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[34]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[35]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[36]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[37]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[38]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||||
|
[39]:http://arstechnica.com/gadgets/2015/10/nexus-5x-and-nexus-6p-review-the-true-flagships-of-the-android-ecosystem/
|
||||||
|
[40]:http://arstechnica.com/gadgets/2015/09/google-gets-a-new-logo/
|
||||||
|
[41]:https://www.youtube.com/watch?v=9yfMVbaehOE
|
||||||
|
[42]:http://www.androidpolice.com/2013/07/25/app-ops-android-4-3s-hidden-app-permission-manager-control-permissions-for-individual-apps/
|
||||||
|
[43]:http://arstechnica.com/apple/2014/09/ios-8-thoroughly-reviewed/10/#h3
|
||||||
@ -0,0 +1,171 @@
|
|||||||
|
# Behind-the-scenes changes
|
||||||
|
|
||||||
|
Marshmallow expanded on the power-saving JobScheduler APIs that were originally introduced in Lollipop. JobScheduler turned app background processing from a free-for-all that frequently woke up the device to an organized system. JobScheduler was basically a background-processing traffic cop.
|
||||||
|
|
||||||
|
In Marshmallow, Google added a "Doze" mode to save even more power when a device is left alone. If a device was stationary, unplugged, and had its screen off, it would slowly drift into a low-power, disconnected mode that locked down background processing. After a period of time, network access was disabled. Wake locks—an app's request to keep your phone awake so it can do background processing—got ignored. System Alarms (not user-set alarm clock alarms) and the [JobScheduler][25] shut down, too.
|
||||||
|
|
||||||
|
If you've ever put a device in airplane mode and noticed the battery lasts forever, Doze was like an automatic airplane mode that kicked in when you left your device alone—it really did boost battery life. It worked for phones that were left alone on a desk all day or all night, and it was great for tablets, which are often forgotten about on the coffee table.
|
||||||
|
|
||||||
|
The only notification that could punch through Doze mode was a "high priority message" from Google Cloud Messaging. This was meant for texting services so, even if a device is dozing, messages still came through.
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][1]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][2]
|
||||||
|
|
||||||
|
"App Standby" was another power saving feature that more-or-less worked quietly in the background. The idea behind it was simple: if you stopped interacting with an app for a period of time, Android deemed it unimportant and took away its internet access and background processing privileges.
|
||||||
|
|
||||||
|
For the purposes of App Standby, "interacting" with an app meant opening the app, starting a foreground service, or generating a notification. Any one of these actions would reset the Standby timer on an app. For every other edge case, Google added a cryptically-named "Battery Optimizations" screen in the settings. This let users whitelist apps to make them immune from app standby. As for developers, they had an option in Developer Settings called "Inactive apps" which let them manually put an app on standby for testing.
|
||||||
|
|
||||||
|
App Standby basically auto-disabled apps you weren't using, which was a great way to fight battery drain from crapware or forgotten-about apps. Because it was completely silent and automatically happened in the background, it helped even novice users have a well-tuned device.
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][3]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][4]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][5]
|
||||||
|
|
||||||
|
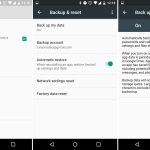
Google tried many app backup schemes over the years, and in Marshmallow it [took another swing][26]. Marshmallow's brute force app backup system aimed to dump the entire app data folder to the cloud. It was possible and technically worked, but app support for it was bad, even among Google apps. Setting up a new Android phone is still a huge hassle, with countless sign-ins and tutorial popups.
|
||||||
|
|
||||||
|
In terms of interface, Marshmallow's backup system used the Google Drive app. In the settings of Google Drive, there's now a "Manage Backups" screen, which showed app data not only from the new system, but also every other app backup scheme Google has tried over the years.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
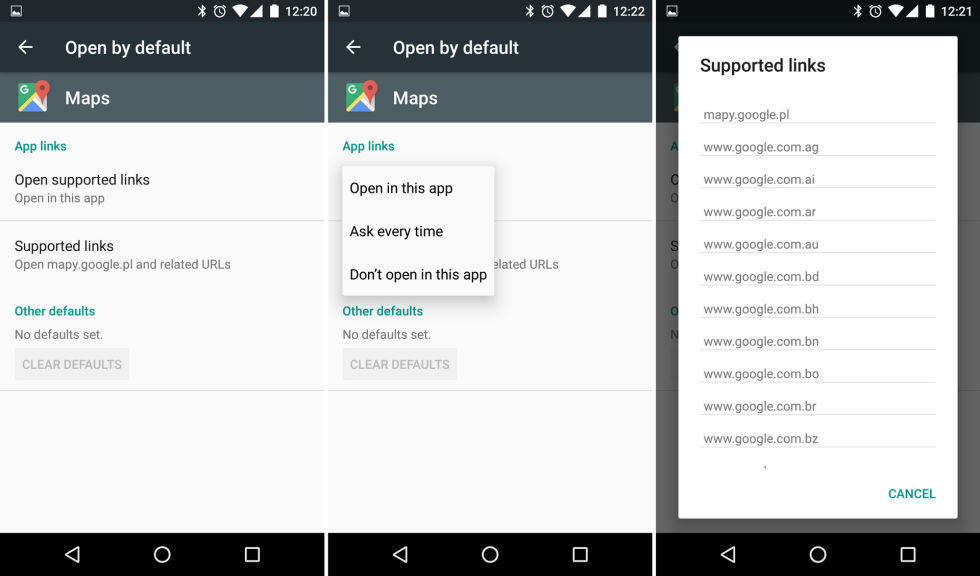
|
Buried in the settings was a new "App linking" feature, which could "link" an app to a website. Before app linking, opening up a Google Maps URL on a fresh install usually popped up an "Open With" dialog box that wanted to know if it should open the URL in a browser or in the Google Maps app.
|
||||||
|
|
||||||
|
This was a silly question, since of course you wanted to use the app instead of the website—that's why you had the app installed. App linking let website owners associate their app with their webpage. If users had the app installed, Android would suppress the "Open With" dialog and use that app instead. To activate app linking, developers just had to throw some JSON code on their website that Android would pick up.
|
||||||
|
|
||||||
|
App linking was great for sites with an obvious app client, like Google Maps, Instagram, and Facebook. For sites with an API and multiple clients, like Twitter, the App Linking settings screen gave users control over the default app association for any URL. Out-of-the-box app linking covered 90 percent of use cases though, which cut down on the annoying pop ups on a new phone.
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][6]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][7]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][8]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][9]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][10]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][11]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][12]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][13]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][14]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][15]
|
||||||
|
|
||||||
|
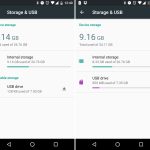
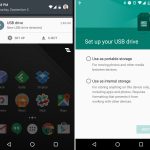
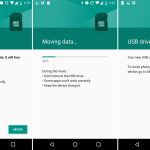
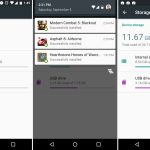
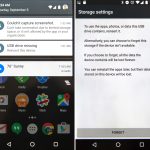
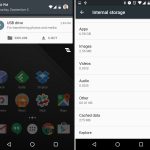
Adoptable storage was one of Marshmallow's best features. It turned SD cards from a janky secondary storage pool into a perfect merged-storage solution. Slide in an SD card, format it, and you instantly had more storage in your device that you never had to think about again.
|
||||||
|
|
||||||
|
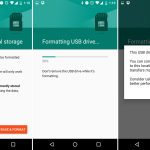
Sliding in a SD card showed a setup notification, and users could choose to format the card as "portable" or "internal" storage. The "Internal" option was the new adoptable storage mode, and it paved over the card with an ext4 file system. The only downside? The card and the data were both "locked" to your phone. You couldn't pull the card out and plug it into anything without formatting it first. Google was going for a set-it-and-forget-it use case with internal storage.
|
||||||
|
|
||||||
|
If you did yank the card out, Android did its best to deal with things. It popped up a message along the lines of "You'd better put that back or else!" along with an option to "forget" the card. Of course "forgetting" the card would result in all sorts of data loss, and it was not recommended.
|
||||||
|
|
||||||
|
The sad part of adoptable storage is that devices that could actually use it didn't come for a long time. Neither Nexus device had an SD card, so for the review we rigged up a USB stick as our adoptable storage. OEMs initially resisted the feature, with [LG and Samsung][27] disabling it on their early 2016 flagships. Samsung stated that "We believe that our users want a microSD card to transfer files between their phone and other devices," which was not possible once the card was formatted to ext4.
|
||||||
|
|
||||||
|
Google's implementation let users choose between portable and internal formatting options. But rather than give users that choice, OEMs completely took the internal storage feature away. Advanced users were unhappy about this, and of course the Android modding scene quickly re-enabled adoptable storage. On the Galaxy S7, modders actually defeated Samsung's SD card lockdown [a day before][28] the device was even officially released!
|
||||||
|
|
||||||
|
#### Volume and Notifications
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|

|
||||||
|
][16]
|
||||||
|
* [
|
||||||
|

|
||||||
|
][17]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][18]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][19]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][20]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][21]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][22]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][23]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][24]
|
||||||
|
|
||||||
|
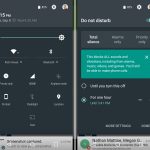
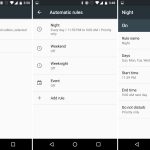
Google walked back the priority notification controls that were in the volume popup in favor of a simpler design. Hitting the volume key popped up a single slider for the current audio source, along with a drop down button that expanded the controls to show all three audio sliders: Notifications, media, and alarms. All the priority notification controls still existed—they just lived in a "do not disturb" quick-settings tile now.
|
||||||
|
|
||||||
|
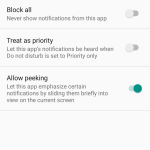
One of the most relieving additions to the notification controls gave users control over Heads-Up notifications—now renamed "Peek" notifications. This feature let notifications pop up over the top portion of the screen, just like on iOS. The idea was that the most important notifications should be elevated over your normal, everyday notifications.
|
||||||
|
|
||||||
|
However, in Lollipop, when this feature was introduced, Google had the terrible idea of letting developers decide if their apps were "important" or not. Of course, every developer thinks its app is the most important thing in the world. So while the feature was originally envisioned for instant messages from your closest contacts, it ended up being hijacked by Facebook "Like" notifications. In Marshmallow, every app got a "treat as priority" checkbox in the notification settings, which gave users an easy ban hammer for unruly apps.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/
|
||||||
|
|
||||||
|
作者:[RON AMADEO][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://arstechnica.com/author/ronamadeo
|
||||||
|
[1]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||||
|
[25]:http://arstechnica.com/gadgets/2014/11/android-5-0-lollipop-thoroughly-reviewed/6/#h2
|
||||||
|
[26]:http://arstechnica.com/gadgets/2015/10/android-6-0-marshmallow-thoroughly-reviewed/6/#h2
|
||||||
|
[27]:http://arstechnica.com/gadgets/2016/02/the-lg-g5-and-galaxy-s7-wont-support-android-6-0s-adoptable-storage/
|
||||||
|
[28]:http://www.androidpolice.com/2016/03/10/modaco-manages-to-get-adoptable-sd-card-storage-working-on-the-galaxy-s7-and-galaxy-s7-edge-no-root-required/
|
||||||
@ -0,0 +1,185 @@
|
|||||||
|
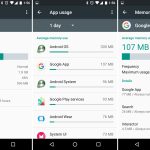
# Monthly security updates
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][31]
|
||||||
|
|
||||||
|
|
||||||
|
A few months before the release of Marshmallow, [vulnerabilities][32] in Android's "Stagefright" media server were disclosed to the public, which could allow for remote code execution on older versions of Android. Android took a beating in the press, with [a billion phones][33] affected by the newly discovered bugs.
|
||||||
|
|
||||||
|
Google responded by starting a monthly Android security update program. Every month it would round up bugs, fix them, and push out new code to AOSP and Nexus devices. OEMs—who were already struggling with updates (possibly due to apathy)—were basically told to "deal with it" and keep up. Every other major operating system has frequent security updates—it's just the cost of being such a huge platform. To accommodate OEMs, Google give them access to the updates a full month ahead of time. After 30 days, security bulletins are posted and Google devices get the updates.
|
||||||
|
|
||||||
|
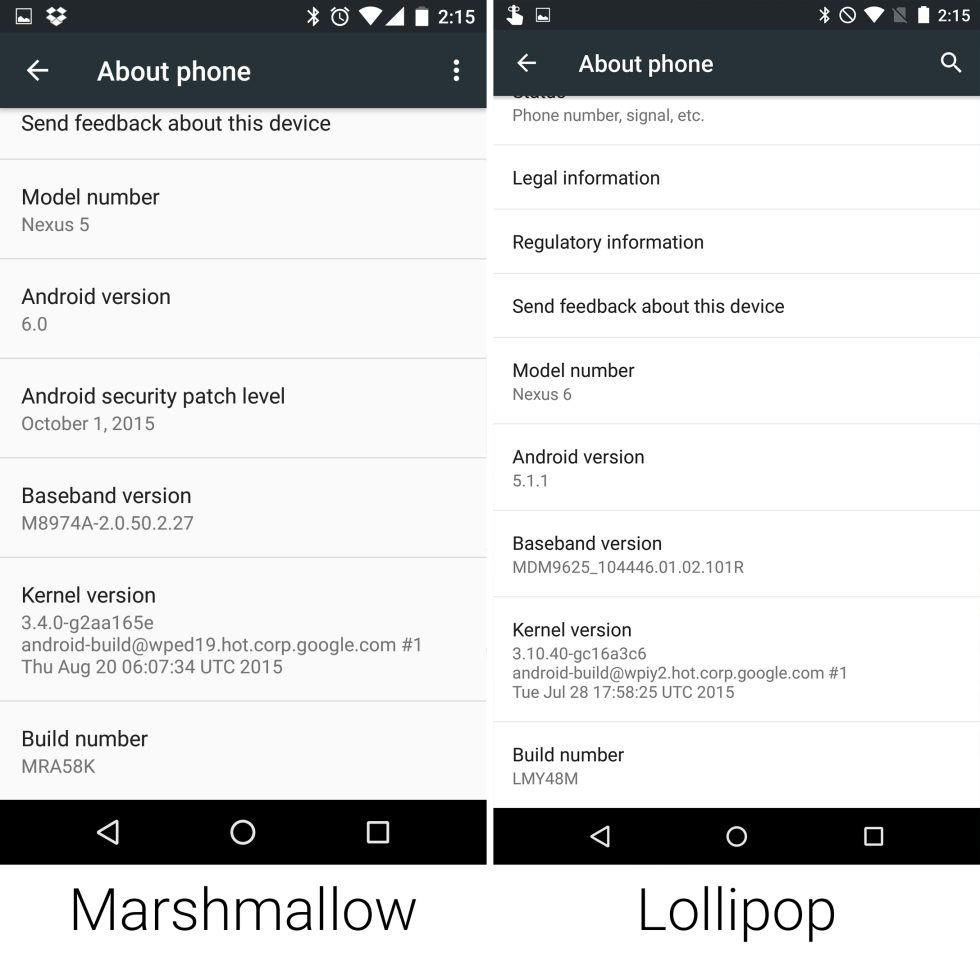
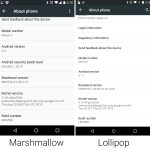
The monthly update program started two months before the release of Marshmallow, but in this major OS update Google added an "Android Security Patch Level" field to the About Phone screen. Rather than use some arcane version number, this was just a date. This let anyone easily see how out of date their phone was, an acted as a nice way to shame slow OEMs.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][2]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][3]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][4]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][5]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][6]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][7]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][8]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][9]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][10]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][11]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][12]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][13]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][14]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][15]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][16]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][17]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][18]
|
||||||
|
|
||||||
|
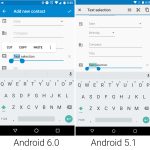
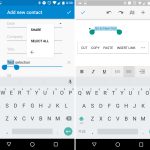
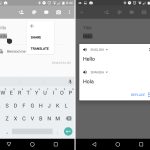
The text selection menu is now a floating toolbar that pops up right next to the text you're selecting. This wasn't just the regular "cut/copy/paste" commands, either. Apps could put special options on the toolbar, like the "add link" option in Google Docs.
|
||||||
|
|
||||||
|
After the standard text commands, an ellipsis button would expose a second menu, and it was here that apps could add extra features to the text selection menu. Using a new "text processing" API, it was now super easy to ship text directly to another app. If you had Google Translate installed, a "translate" option would show up in this menu. Eventually Google Search added an "Assist" option to this menu for Google Now on Tap.
|
||||||
|
|
||||||
|
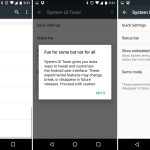
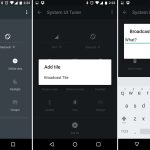
Marshmallow added a hidden settings section called the "System UI Tuner." This section would turn into a catch-all for power user features and experimental items. To access this you had to pull down the notification panel and hold down on the "settings" button for several seconds. The settings gear would spin, and eventually you'd see a message indicating that the System UI Tuner was unlocked. Once it was turned on, you could find it as the bottom of the system settings next to Developer Options.
|
||||||
|
|
||||||
|
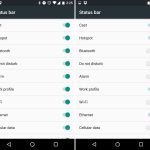
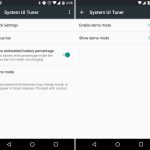
In this first version of the System UI Tuner, users would add custom tiles to the Quick Settings panel, a feature that would later be refined into an API apps could use. For now the feature was very rough, basically allowing users to type a custom command into a text box. System status icons could be individually turned on and off, so if you really hated knowing you were connected to Wi-Fi, you could kill the icon. A popular power user addition was the option for embedding a percentage readout into the battery icon. There was also a "demo" mode for screenshots, which would replace the normal status bar with a fake, clean version.
|
||||||
|
|
||||||
|
### Android 7.0 Nougat, Pixel Phones, and the future
|
||||||
|
|
||||||
|
[Android 7.0 Nougat][34] and [the Pixel Phones][35] came out just a few months ago, and you can read our full reviews for both of them. Both still have a ton of features and implications that we have not seen come to fruition yet, so we'll save a deep "history" dive for when they are actually "history."
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### FURTHER READING
|
||||||
|
|
||||||
|
[Android 7.0 Nougat review—Do more on your gigantic smartphone][25]
|
||||||
|
|
||||||
|
Nougat made serious changes to the [graphics and sensor pipeline][36] for Daydream VR, Google's upcoming smartphone-powered VR experience [we tried][37] but have yet to log any serious time with. A new "Seamless update" feature borrowed an update mechanism from Chrome OS, which uses dual system partitions to quietly update one partition in the background while you're still using the other one. Considering the Pixel phones are the only devices to launch with this and haven't gotten an update yet, we're not sure what that looks like, either.
|
||||||
|
|
||||||
|
|
||||||
|
* [
|
||||||
|
|
||||||
|
][19]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][20]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][21]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][22]
|
||||||
|
* [
|
||||||
|
|
||||||
|
][23]
|
||||||
|
|
||||||
|
One of the most interesting additions to Nougat is a revamp of the app framework to allow for resizable apps. This allowed Google to implement split screen on phones and tablets, picture-in-picture on Android TV, and a mysterious floating windowed mode. We've been able to access the floating window mode with some software trickery, but we've yet to see Google use it in an actual product. Is it being aimed at desktop computing?
|
||||||
|
|
||||||
|
Android and Chrome OS also continue to grow together. Android apps [can run][38] on some Chromebooks now, giving the "Web-only" OS the Play Store and a serious app ecosystem. Rumors continue to swirl that the future of Chrome OS and Android will come even closer together, with the name "[Andromeda][39]"—a portmanteau of "Android" and "Chrome"—being tossed around as the codename for a merged Chrome/Android OS.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
We have yet to see how the historical legacy of the Pixel phones will shake out. Google dove into the hardware pool with the launch of two new smartphone flagships, the Pixel and Pixel XL, only recently. Google had produced co-branded Nexus phones with partners before, but the Pixel line is a "Google" branded product. The company claims it is a full hardware OEM now, using HTC as a contract manufacturer similarly to the way Apple uses Foxconn.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### FURTHER READING
|
||||||
|
|
||||||
|
[Google Pixel review: The best Android phone, even if it is a little pricey][26]</aside>
|
||||||
|
|
||||||
|
With its own hardware comes a change in how Google makes software. The company created the "Google Assistant" as the future of the "OK Google" voice command system. But rather than ship it out to every Android device, the Assistant is an exclusive Pixel feature. Google made some changes to the interface, with a custom "Pixel launcher" home screen app and a new System UI, both of which are Pixel exclusives. We'll have to wait to see what the balance of future features are between "Android" and "Pixel" going forward.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### FURTHER READING
|
||||||
|
|
||||||
|
[Chatting with Google’s Hiroshi Lockheimer about Pixel, Android OEMs, and more][27]</aside>
|
||||||
|
|
||||||
|
With these changes, we're probably at the most uncertain point in Android's history. But ahead of the platform's recent October 2016 event, [Hiroshi Lockheimer][40], SVP of Android, Chrome OS, and Google Play, said he believed we'll all look back fondly on these latest Android developments. Lockheimer is essentially the current king of software at Google, and he thought the newest updates could be the most significant Android happening since the OS debuted eight years earlier. While he wouldn't elaborate much on this sentiment after the unveilings, the fact remains that this time next year we _might_ not even be talking about Android—it could be an Android/Chrome OS hybrid! So as has always been the case since 2008, the next chapter in Android's history looks to be nothing if not interesting.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/
|
||||||
|
|
||||||
|
作者:[RON AMADEO][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://arstechnica.com/author/ronamadeo
|
||||||
|
[1]:http://android-developers.blogspot.com/2015/09/chrome-custom-tabs-smooth-transition.html
|
||||||
|
[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/#
|
||||||
|
[24]:https://cdn.arstechnica.net/wp-content/uploads/2016/10/settings-5.jpg
|
||||||
|
[25]:http://arstechnica.com/gadgets/2016/08/android-7-0-nougat-review-do-more-on-your-gigantic-smartphone/
|
||||||
|
[26]:http://arstechnica.com/gadgets/2016/10/google-pixel-review-bland-pricey-but-still-best-android-phone/
|
||||||
|
[27]:http://arstechnica.com/gadgets/2016/10/chatting-with-googles-hiroshi-lockheimer-about-pixel-android-oems-and-more/
|
||||||
|
[28]:http://arstechnica.com/gadgets/2016/08/android-7-0-nougat-review-do-more-on-your-gigantic-smartphone/
|
||||||
|
[29]:http://arstechnica.com/gadgets/2016/10/google-pixel-review-bland-pricey-but-still-best-android-phone/
|
||||||
|
[30]:http://arstechnica.com/gadgets/2016/10/chatting-with-googles-hiroshi-lockheimer-about-pixel-android-oems-and-more/
|
||||||
|
[31]:https://cdn.arstechnica.net/wp-content/uploads/2016/10/settings-5.jpg
|
||||||
|
[32]:http://arstechnica.com/security/2015/07/950-million-android-phones-can-be-hijacked-by-malicious-text-messages/
|
||||||
|
[33]:http://arstechnica.com/security/2015/10/a-billion-android-phones-are-vulnerable-to-new-stagefright-bugs/
|
||||||
|
[34]:http://arstechnica.com/gadgets/2016/08/android-7-0-nougat-review-do-more-on-your-gigantic-smartphone/
|
||||||
|
[35]:http://arstechnica.com/gadgets/2016/10/google-pixel-review-bland-pricey-but-still-best-android-phone/
|
||||||
|
[36]:http://arstechnica.com/gadgets/2016/08/android-7-0-nougat-review-do-more-on-your-gigantic-smartphone/11/#h1
|
||||||
|
[37]:http://arstechnica.com/gadgets/2016/10/daydream-vr-hands-on-googles-dumb-vr-headset-is-actually-very-clever/
|
||||||
|
[38]:http://arstechnica.com/gadgets/2016/05/if-you-want-to-run-android-apps-on-chromebooks-youll-need-a-newer-model/
|
||||||
|
[39]:http://arstechnica.com/gadgets/2016/09/android-chrome-andromeda-merged-os-reportedly-coming-to-the-pixel-3/
|
||||||
|
[40]:http://arstechnica.com/gadgets/2016/10/chatting-with-googles-hiroshi-lockheimer-about-pixel-android-oems-and-more/
|
||||||
@ -0,0 +1,225 @@
|
|||||||
|
The Cost of Native Mobile App Development is Too Damn High!
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
### A value proposition
|
||||||
|
|
||||||
|
_A tipping point has been reached._ With the exception of a few unique use cases, it no longer makes sense to build and maintain your mobile applications using native frameworks and native development teams.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Average cost of employing iOS, Android, and JavaScript developers in the United States ([http://www.indeed.com/salary][1], [http://www.payscale.com/research/US/Skill=JavaScript/Salary][2])
|
||||||
|
|
||||||
|
The cost of native mobile application development has been spiraling out of control for the past few years. It has become increasingly difficult for new startups without substantial funding to create native apps, MVPs and prototypes. Existing companies, who need to hold on to talent in order to iterate on existing applications or build new applications, are [fighting][6] [tooth][7]and [nail][8] [with companies from all around the world][9] and will do whatever it takes to retain the best of the best.
|
||||||
|
|
||||||
|
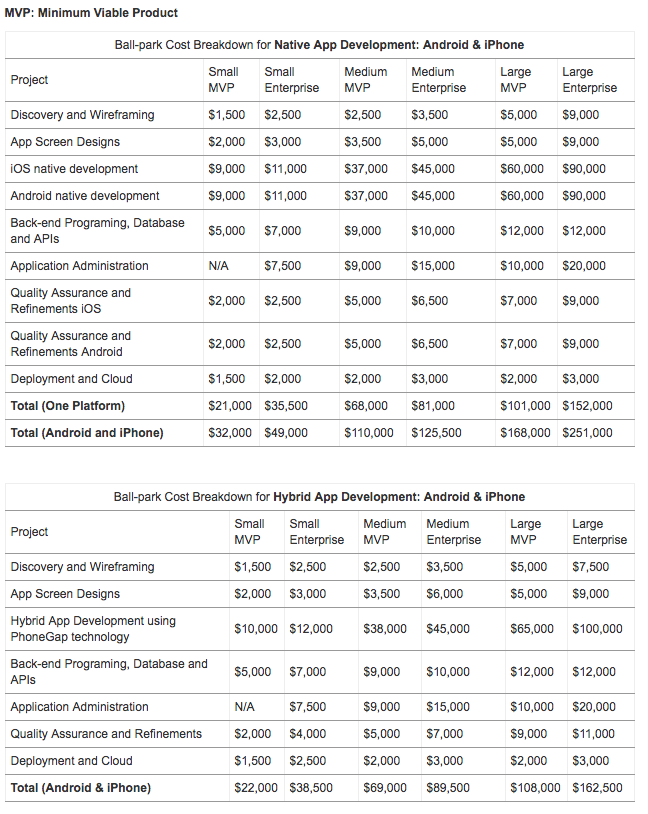
|
||||||
|
|
||||||
|
Cost of developing an MVP early 2015, Native vs Hybrid ([Comomentum.com][3])
|
||||||
|
|
||||||
|
### So what does this mean for all of us?
|
||||||
|
|
||||||
|
If you are a huge company or you are flush with cash, the old thinking was that as long as you threw enough money at native application development, you did not have anything to worry about. This is no longer the case.
|
||||||
|
|
||||||
|
Facebook, the last company in the world who you would think of as behind in the war for talent (because they aren’t), was facing problems with their native app that money could not fix. The application had gotten so large and complex that [they were seeing compilation times of up to 15 minutes for their mobile app][10]. This means that even testing minor user interface changes, like moving something around by a couple of points, could take hours (or even days).
|
||||||
|
|
||||||
|
In addition to the long compilation times, any time they needed to test a small change to their mobile, app it needed to be implemented and tested in two completely different environments (iOS and Android) with teams working with different languages and frameworks, muddying the waters even more.
|
||||||
|
|
||||||
|
Facebook’s solution to this problem is [React Native][11].
|
||||||
|
|
||||||
|
### What about ditching Mobile Apps for Web only?
|
||||||
|
|
||||||
|
[Some people think mobile apps are doomed.][12] While I really enjoy and respect [Eric Elliott][13] and his work, let’s take a look at some recent data and discuss some opposing viewpoints:
|
||||||
|
|
||||||
|
|
||||||
|
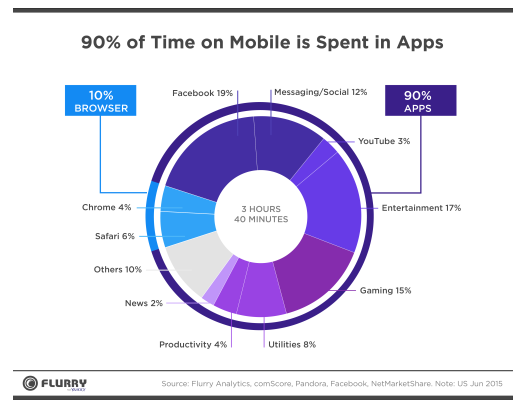
|
||||||
|
|
||||||
|
Time spent in mobile apps (April 2016, [smartinsights.com][4])
|
||||||
|
|
||||||
|
> 90% of Time on Mobile is Spent in Apps
|
||||||
|
|
||||||
|
There are 2.5 billion people on mobile phones in the world right now. [That number is going to be 5 billion sooner than we think.][14] _It is absolutely insane to think that leaving 4.5 billion people out of your business or application makes sense__ in most scenarios._
|
||||||
|
|
||||||
|
The old argument was that native mobile application development was too expensive for most companies. While this was true, the cost of web development is also on the rise, with [the average salary of a JavaScript developer in the US being in the range of $97,000.00][15].
|
||||||
|
|
||||||
|
With the increased complexity and skyrocketing demand for high quality web development, the average price for a JavaScript developer is inching towards that of a Native developer. Arguing that web development is cheaper is no longer a valid argument.
|
||||||
|
|
||||||
|
### What about Hybrid?
|
||||||
|
|
||||||
|
Hybrid apps are HTML5 apps that are wrapped inside of a native container and provide access to native platform features. Cordova and PhoneGap are prime examples.
|
||||||
|
|
||||||
|
_If you’re looking to build an MVP, prototype, or are not worried about the user experience mimicking that of a native app, then a hybrid app may work for you, keeping in mind the entire project will need to be rewritten if you do end up wanting to go native._
|
||||||
|
|
||||||
|
There are many innovative things going on in this space, my favorite being the [Ionic Framework][16]. Hybrid is getting better and better, but it is still not as fluid or natural feeling as Native.
|
||||||
|
|
||||||
|
For many companies, including most serious startups as well as medium and large sized companies, hybrid apps may not deliver the quality that they want and that their customers demand, leaving the feeling unpolished and less professional.
|
||||||
|
|
||||||
|
[While I have read and heard that of the top 100 apps on the app store, zero of them are hybrid,][17] I have not been able to back up this claim with evidence, but I would not doubt if the number were between zero and 5, and this is for a reason.
|
||||||
|
|
||||||
|
> [Our Biggest Mistake Was Betting Too Much On HTML5 ][18]— Mark Zuckerberg
|
||||||
|
|
||||||
|
### The solution
|
||||||
|
|
||||||
|
If you’ve been keeping up with the mobile development landscape you have undoubtedly heard of projects such as [NativeScript][19] and [React Native][20].
|
||||||
|
|
||||||
|
These projects allow you to build native quality mobile applications with JavaScript and use the same fundamental UI building blocks as regular iOS and Android apps.
|
||||||
|
|
||||||
|
With React Native you can have a single engineer or team of engineers specialize in cross platform mobile app development, [native desktop development][21], and even web development [using the existing codebase][22] or [the underlying technology][23], shipping your applications to the App Store, the Play Store, and the Web for a fraction of the traditional cost without losing out on the benefits of native performance and quality.
|
||||||
|
|
||||||
|
It is not unheard of for React Native apps to reuse up to 90% of their code across platforms, though the range is usually between 80% and 90%.
|
||||||
|
|
||||||
|
If your team is using React Native, it eliminates the divide between teams resulting in more consistency in both the UI and the APIs being built, speeding up the development time.
|
||||||
|
|
||||||
|
There is no need for compilation with React Native, as the app updates instantly when saving, also speeding up development time.
|
||||||
|
|
||||||
|
React Native also allows you to use tools such as [Code Push][24] and [AppHub][25] to remotely update your JavaScript code. This means that you can push updates, features, and bug fixes instantly to your users, bypassing the labor of bundling, submitting, and having your app accepted to the App and Google play stores, a process that can take between 2 and 7 days (the App Store being the main pain point in this process). This is something that is not possible with native apps, though is possible with hybrid apps.
|
||||||
|
|
||||||
|
If innovation in this space continues as it has been since it’s release, in the future you will even be able to build for platforms such as the [Apple Watch ][26], [Apple TV][27], and [Tizen][28] to name a few.
|
||||||
|
|
||||||
|
> NativeScript is still fairly new as the framework powering it, Angular 2, [was just released out of beta a few months ago,][29] but it too has a promising future as long as Angular2 holds on to a decent share of the market.
|
||||||
|
|
||||||
|
What you may not know is that some of the most innovative and largest technology companies in the world are betting big on these types of technologies, specifically [React Native.][30]
|
||||||
|
|
||||||
|
I have also spoken to and am working with multiple enterprise and fortune 500 companies currently making the switch to React Native.
|
||||||
|
|
||||||
|
### Notably Using React Native in Production
|
||||||
|
|
||||||
|
Along with the below examples, [here is a list of notable apps using React Native.][31]
|
||||||
|
|
||||||
|
### Facebook
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
React Native Apps by Facebook
|
||||||
|
|
||||||
|
Facebook is now using React Native for both [Ads Manager][32] and [Facebook Groups,][33] and [will be implementing the framework to power it’s news feed.][34]
|
||||||
|
|
||||||
|
Facebook also spends a lot of money creating and maintaining open source projects such as React Native, and t[hey and their open source developers have done a fantastic job lately by creating a lot of awesome projects ][35]that people like me and businesses all around the world benefit greatly from using on a daily basis.
|
||||||
|
|
||||||
|
### Instagram
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Instagram
|
||||||
|
|
||||||
|
React Native has been implemented in parts of the Instagram mobile app.
|
||||||
|
|
||||||
|
### Airbnb
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Airbnb
|
||||||
|
|
||||||
|
Much of Airbnb is being rewritten in React Native (via [Leland Richardson][36])
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Over 90% of the Airbnb Trips Platform is written in React Native (via [spikebrehm][37])
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Vogue
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Vogue Top 10 apps of 2016
|
||||||
|
|
||||||
|
Vogue stands out not only because it was also written in React Native, but [because it was ranked as one of the 10 Best Apps of the Year, according to Apple][38].
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Microsoft
|
||||||
|
|
||||||
|
Microsoft is betting heavily on React Native.
|
||||||
|
|
||||||
|
They have already release multiple open source tools, including [Code Push][39], [React Native VS Code,][40] and [React Native Windows][41], in the shift towards helping developers in the React Native space.
|
||||||
|
|
||||||
|
Their thoughts behind this are that if people are already building their apps using React Native for iOS and Android, and they can reuse up to 90% of their code, then s_hipping to Windows costs them little extra relative to the cost && time already spent building the app in the first place._
|
||||||
|
|
||||||
|
Microsoft has contributed extensively to the React Native ecosystem and have done an excellent job in the Open Source space over the past few years.
|
||||||
|
|
||||||
|
### Conclusion
|
||||||
|
|
||||||
|
React Native and similar technologies are the next step and a paradigm shift in how we will build mobile UIS and mobile applications.
|
||||||
|
|
||||||
|
Companies
|
||||||
|
|
||||||
|
If your company is looking to cut costs and speed up development time without compromising on quality or performance, React Native is ready for prime time and will benefit your bottom line.
|
||||||
|
|
||||||
|
Developers
|
||||||
|
|
||||||
|
If you are a developer and want to enter into an rapidly evolving space with substantial future up side, I would highly recommend looking at adding React Native to your list of things to learn.
|
||||||
|
|
||||||
|
If you know JavaScript, you can hit the ground running very quickly, and I would recommend first trying it out using [Exponent][5] and seeing what you think. Exponent allows developers to easily build, test ,and deploy cross platform React Native apps on both Windows and macOS.
|
||||||
|
|
||||||
|
If you are already a native Developer, you will benefit especially because you will be able to competently dig into the native side of things when needed, something that is not needed often but when needed is a highly valuable skill to have on a team.
|
||||||
|
|
||||||
|
I have spent a lot of my time learning and teaching others about React Native because I am extremely excited about it and it is just plain fun to create apps using the framework.
|
||||||
|
|
||||||
|
Thanks for reading.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Software Developer Specializing in Teaching and Building React Native
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://hackernoon.com/the-cost-of-native-mobile-app-development-is-too-damn-high-4d258025033a
|
||||||
|
|
||||||
|
作者:[Nader Dabit][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://hackernoon.com/@dabit3
|
||||||
|
[1]:http://www.indeed.com/salary
|
||||||
|
[2]:http://www.payscale.com/research/US/Skill=JavaScript/Salary
|
||||||
|
[3]:http://www.comentum.com/mobile-app-development-cost.html
|
||||||
|
[4]:http://www.smartinsights.com/mobile-marketing/mobile-marketing-analytics/mobile-marketing-statistics/attachment/percent-time-spent-on-mobile-apps-2016/
|
||||||
|
[5]:https://medium.com/u/df61a4267d7a
|
||||||
|
[6]:http://www.bizjournals.com/charlotte/how-to/human-resources/2016/12/employers-offer-premium-wages-skilled-workers.html
|
||||||
|
[7]:https://www.cnet.com/news/silicon-valley-talent-wars-engineers-come-get-your-250k-salary/
|
||||||
|
[8]:http://www.nytimes.com/2015/08/19/technology/unicorns-hunt-for-talent-among-silicon-valleys-giants.html
|
||||||
|
[9]:http://blogs.wsj.com/cio/2016/09/30/tech-talent-war-moves-to-africa/
|
||||||
|
[10]:https://devchat.tv/react-native-radio/08-bridging-react-native-components-with-tadeu-zagallo
|
||||||
|
[11]:https://facebook.github.io/react-native/
|
||||||
|
[12]:https://medium.com/javascript-scene/native-apps-are-doomed-ac397148a2c0#.w06yd23ej
|
||||||
|
[13]:https://medium.com/u/c359511de780
|
||||||
|
[14]:http://ben-evans.com/benedictevans/2016/12/8/mobile-is-eating-the-world
|
||||||
|
[15]:http://www.indeed.com/salary?q1=javascript+developer&l1=united+states&tm=1
|
||||||
|
[16]:https://ionicframework.com/
|
||||||
|
[17]:https://medium.com/lunabee-studio/why-hybrid-apps-are-crap-6f827a42f549#.lakqptjw6
|
||||||
|
[18]:https://techcrunch.com/2012/09/11/mark-zuckerberg-our-biggest-mistake-with-mobile-was-betting-too-much-on-html5/
|
||||||
|
[19]:https://www.nativescript.org/
|
||||||
|
[20]:https://facebook.github.io/react-native/
|
||||||
|
[21]:https://github.com/ptmt/react-native-macos
|
||||||
|
[22]:https://github.com/necolas/react-native-web
|
||||||
|
[23]:https://facebook.github.io/react/
|
||||||
|
[24]:http://microsoft.github.io/code-push/
|
||||||
|
[25]:https://apphub.io/
|
||||||
|
[26]:https://github.com/elliottsj/apple-watch-uikit
|
||||||
|
[27]:https://github.com/douglowder/react-native-appletv
|
||||||
|
[28]:https://www.tizen.org/blogs/srsaul/2016/samsung-committed-bringing-react-native-tizen
|
||||||
|
[29]:http://angularjs.blogspot.com/2016/09/angular2-final.html
|
||||||
|
[30]:https://facebook.github.io/react-native/
|
||||||
|
[31]:https://facebook.github.io/react-native/showcase.html
|
||||||
|
[32]:https://play.google.com/store/apps/details?id=com.facebook.adsmanager
|
||||||
|
[33]:https://itunes.apple.com/us/app/facebook-groups/id931735837?mt=8
|
||||||
|
[34]:https://devchat.tv/react-native-radio/40-navigation-in-react-native-with-eric-vicenti
|
||||||
|
[35]:https://code.facebook.com/projects/
|
||||||
|
[36]:https://medium.com/u/41a8b1601c59
|
||||||
|
[37]:https://medium.com/u/71a78c1b069b
|
||||||
|
[38]:http://www.highsnobiety.com/2016/12/08/iphone-apps-best-of-the-year-2016/
|
||||||
|
[39]:http://microsoft.github.io/code-push/
|
||||||
|
[40]:https://github.com/Microsoft/vscode-react-native
|
||||||
|
[41]:https://github.com/ReactWindows/react-native-windows
|
||||||
|
[42]:https://twitter.com/dabit3
|
||||||
|
[43]:http://reactnative.training/
|
||||||
@ -0,0 +1,725 @@
|
|||||||
|
The truth about traditional JavaScript benchmarks
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
It is probably fair to say that [JavaScript][22] is _the most important technology_ these days when it comes to software engineering. To many of us who have been into programming languages, compilers and virtual machines for some time, this still comes a bit as a surprise, as JavaScript is neither very elegant from the language designers point of view, nor very optimizable from the compiler engineers point of view, nor does it have a great standard library. Depending on who you talk to, you can enumerate shortcomings of JavaScript for weeks and still find another odd thing you didn’t know about. Despite what seem to be obvious obstacles, JavaScript is at the core of not only the web today, but it’s also becoming the dominant technology on the server-/cloud-side (via [Node.js][23]), and even finding its way into the IoT space.
|
||||||
|
|
||||||
|
That raises the question, why is JavaScript so popular/successful? There is no one great answer to this I’d be aware of. There are many good reasons to use JavaScript today, probably most importantly the great ecosystem that was built around it, and the huge amount of resources available today. But all of this is actually a consequence to some extent. Why did JavaScript became popular in the first place? Well, it was the lingua franca of the web for ages, you might say. But that was the case for a long time, and people hated JavaScript with passion. Looking back in time, it seems the first JavaScript popularity boosts happened in the second half of the last decade. Unsurprisingly this was the time when JavaScript engines accomplished huge speed-ups on various different workloads, which probably changed the way that many people looked at JavaScript.
|
||||||
|
|
||||||
|
Back in the days, these speed-ups were measured with what is now called _traditional JavaScript benchmarks_, starting with Apple’s [SunSpider benchmark][24], the mother of all JavaScript micro-benchmarks, followed by Mozilla’s [Kraken benchmark][25] and Google’s V8 benchmark. Later the V8 benchmark was superseded by the[Octane benchmark][26] and Apple released its new [JetStream benchmark][27]. These traditional JavaScript benchmarks drove amazing efforts to bring a level of performance to JavaScript that noone would have expected at the beginning of the century. Speed-ups up to a factor of 1000 were reported, and all of a sudden using `<script>` within a website was no longer a dance with the devil, and doing work client-side was not only possible, but even encouraged.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][28]
|
||||||
|
|
||||||
|
|
||||||
|
Now in 2016, all (relevant) JavaScript engines reached a level of performance that is incredible and web apps are as snappy as native apps (or can be as snappy as native apps). The engines ship with sophisticated optimizing compilers, that generate short sequences of highly optimized machine code by speculating on the type/shape that hit certain operations (i.e. property access, binary operations, comparisons, calls, etc.) based on feedback collected about types/shapes seen in the past. Most of these optimizations were driven by micro-benchmarks like SunSpider or Kraken, and static test suites like Octane and JetStream. Thanks to JavaScript-based technologies like [asm.js][29] and [Emscripten][30] it is even possible to compile large C++ applications to JavaScript and run them in your web browser, without having to download or install anything, for example you can play [AngryBots][31] on the web out-of-the-box, whereas in the past gaming on the web required special plugins like Adobe Flash or Chrome’s PNaCl.
|
||||||
|
|
||||||
|
The vast majority of these accomplishments were due to the presence of these micro-benchmarks and static performance test suites, and the vital competition that resulted from having these traditional JavaScript benchmarks. You can say what you want about SunSpider, but it’s clear that without SunSpider, JavaScript performance would likely not be where it is today. Okay, so much for the praise… now on to the flip side of the coin: Any kind of static performance test - be it a micro-benchmark or a large application macro-benchmark - is doomed to become irrelevant over time! Why? Because the benchmark can only teach you so much before you start gaming it. Once you get above (or below) a certain threshold, the general applicability of optimizations that benefit a particular benchmark will decrease exponentially. For example we built Octane as a proxy for performance of real world web applications, and it probably did a fairly good job at that for quite some time, but nowadays the distribution of time in Octane vs. real world is quite different, so optimizing for Octane beyond where it is currently, is likely not going to yield any significant improvements in the real world (neither general web nor Node.js workloads).
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][32]
|
||||||
|
|
||||||
|
|
||||||
|
Since it became more and more obvious that all the traditional benchmarks for measuring JavaScript performance, including the most recent versions of JetStream and Octane, might have outlived their usefulness, we started investigating new ways to measure real-world performance beginning of the year, and added a lot of new profiling and tracing hooks to V8 and Chrome. We especially added mechanisms to see where exactly we spend time when browsing the web, i.e. whether it’s script execution, garbage collection, compilation, etc., and the results of these investigations were highly interesting and surprising. As you can see from the slide above, running Octane spends more than 70% of the time executing JavaScript and collecting garbage, while browsing the web you always spend less than 30% of the time actually executing JavaScript, and never more than 5% collecting garbage. Instead a significant amount of time goes to parsing and compiling, which is not reflected in Octane. So spending a lot of time to optimize JavaScript execution will boost your score on Octane, but won’t have any positive impact on loading [youtube.com][33]. In fact, spending more time on optimizing JavaScript execution might even hurt your real-world performance since the compiler takes more time, or you need to track additional feedback, thus eventually adding more time to the Compile, IC and Runtime buckets.
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][34]
|
||||||
|
|
||||||
|
There’s another set of benchmarks, which try to measure overall browser performance, including JavaScript **and** DOM performance, with the most recent addition being the [Speedometer benchmark][35]. The benchmark tries to capture real world performance more realistically by running a simple [TodoMVC][36] application implemented with different popular web frameworks (it’s a bit outdated now, but a new version is in the makings). The various tests are included in the slide above next to octane (angular, ember, react, vanilla, flight and backbone), and as you can see these seem to be a better proxy for real world performance at this point in time. Note however that this data is already six months old at the time of this writing and things might have changed as we optimized more real world patterns (for example we are refactoring the IC system to reduce overhead significantly, and the [parser is being redesigned][37]). Also note that while this looks like it’s only relevant in the browser space, we have very strong evidence that traditional peak performance benchmarks are also not a good proxy for real world Node.js application performance.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][38]
|
||||||
|
|
||||||
|
|
||||||
|
All of this is probably already known to a wider audience, so I’ll use the rest of this post to highlight a few concrete examples, why I think it’s not only useful, but crucial for the health of the JavaScript community to stop paying attention to static peak performance benchmarks above a certain threshold. So let me run you through a couple of example how JavaScript engines can and do game benchmarks.
|
||||||
|
|
||||||
|
### The notorious SunSpider examples
|
||||||
|
|
||||||
|
A blog post on traditional JavaScript benchmarks wouldn’t be complete without pointing out the obvious SunSpider problems. So let’s start with the prime example of performance test that has limited applicability in real world: The [`bitops-bitwise-and.js`][39] performance test.
|
||||||
|
|
||||||
|
[
|
||||||
|
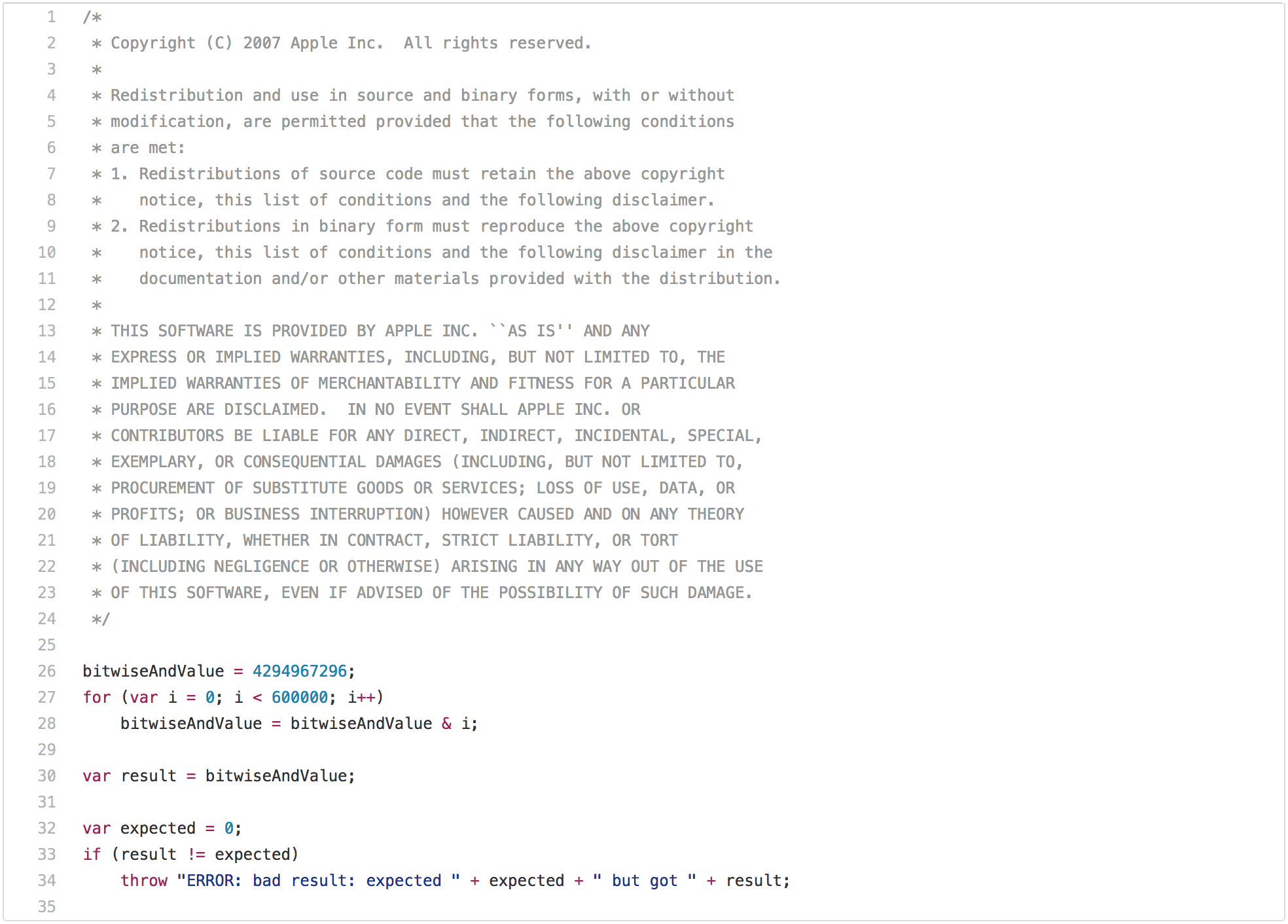
|
||||||
|
][40]
|
||||||
|
|
||||||
|
There are a couple of algorithms that need fast bitwise and, especially in the area of code transpiled from C/C++ to JavaScript, so it does indeed make some sense to be able to perform this operation quickly. However real world web pages will probably not care whether an engine can execute bitwise and in a loop 2x faster than another engine. But staring at this code for another couple of seconds, you’ll probably notice that `bitwiseAndValue` will be `0` after the first loop iteration and will remain `0` for the next 599999 iterations. So once you get this to good performance, i.e. anything below 5ms on decent hardware, you can start gaming this benchmark by trying to recognize that only the first iteration of the loop is necessary, while the remaining iterations are a waste of time (i.e. dead code after [loop peeling][41]). This needs some machinery in JavaScript to perform this transformation, i.e. you need to check that `bitwiseAndValue` is either a regular property of the global object or not present before you execute the script, there must be no interceptor on the global object or it’s prototypes, etc., but if you really want to win this benchmark, and you are willing to go all in, then you can execute this test in less than 1ms. However this optimization would be limited to this special case, and slight modifications of the test would probably no longer trigger it.
|
||||||
|
|
||||||
|
Ok, so that [`bitops-bitwise-and.js`][42] test was definitely the worst example of a micro-benchmark. Let’s move on to something more real worldish in SunSpider, the [`string-tagcloud.js`][43] test, which essentially runs a very early version of the `json.js` polyfill. The test arguably looks a lot more reasonable that the bitwise and test, but looking at the profile of the benchmark for some time immediately reveals that a lot of time is spent on a single `eval` expression (up to 20% of the overall execution time for parsing and compiling plus up to 10% for actually executing the compiled code):
|
||||||
|
|
||||||
|
[
|
||||||
|
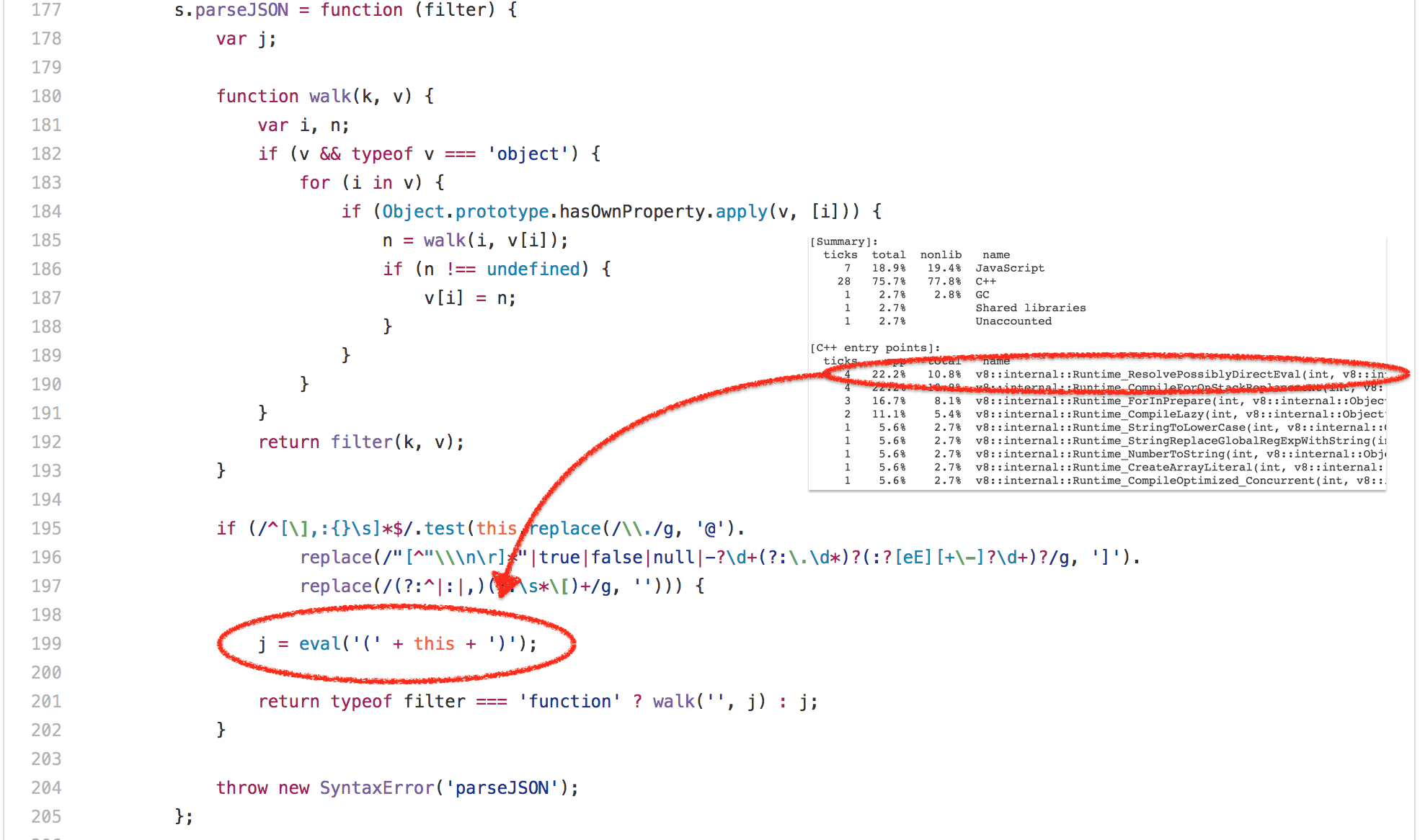
|
||||||
|
][44]
|
||||||
|
|
||||||
|
Looking closer reveals that this `eval` is executed exactly once, and is passed a JSONish string, that contains an array of 2501 objects with `tag` and `popularity` fields:
|
||||||
|
|
||||||
|
```
|
||||||
|
([
|
||||||
|
{
|
||||||
|
"tag": "titillation",
|
||||||
|
"popularity": 4294967296
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"tag": "foamless",
|
||||||
|
"popularity": 1257718401
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"tag": "snarler",
|
||||||
|
"popularity": 613166183
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"tag": "multangularness",
|
||||||
|
"popularity": 368304452
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"tag": "Fesapo unventurous",
|
||||||
|
"popularity": 248026512
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"tag": "esthesioblast",
|
||||||
|
"popularity": 179556755
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"tag": "echeneidoid",
|
||||||
|
"popularity": 136641578
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"tag": "embryoctony",
|
||||||
|
"popularity": 107852576
|
||||||
|
},
|
||||||
|
...
|
||||||
|
])
|
||||||
|
```
|
||||||
|
|
||||||
|
Obviously parsing these object literals, generating native code for it and then executing that code, comes at a high cost. It would be a lot cheaper to just parse the input string as JSON and generate an appropriate object graph. So one trick to speed up this benchmark is to mock with `eval` and try to always interpret the data as JSON first and only fallback to real parse, compile, execute if the attempt to read JSON failed (some additional magic is required to skip the parenthesis, though). Back in 2007, this wouldn’t even be a bad hack, since there was no [`JSON.parse`][45], but in 2017 this is just technical debt in the JavaScript engine and potentially slows down legit uses of `eval`. In fact updating the benchmark to modern JavaScript
|
||||||
|
|
||||||
|
```
|
||||||
|
--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
|
||||||
|
+++ string-tagcloud.js 2016-12-14 09:01:01.033944051 +0100
|
||||||
|
@@ -198,7 +198,7 @@
|
||||||
|
replace(/"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(:?[eE][+\-]?\d+)?/g, ']').
|
||||||
|
replace(/(?:^|:|,)(?:\s*\[)+/g, ''))) {
|
||||||
|
|
||||||
|
- j = eval('(' + this + ')');
|
||||||
|
+ j = JSON.parse(this);
|
||||||
|
|
||||||
|
return typeof filter === 'function' ? walk('', j) : j;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
yields an immediate performance boost, dropping runtime from 36ms to 26ms for V8 LKGR as of today, a 30% improvement!
|
||||||
|
|
||||||
|
```
|
||||||
|
$ node string-tagcloud.js.ORIG
|
||||||
|
Time (string-tagcloud): 36 ms.
|
||||||
|
$ node string-tagcloud.js
|
||||||
|
Time (string-tagcloud): 26 ms.
|
||||||
|
$ node -v
|
||||||
|
v8.0.0-pre
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
This is a common problem with static benchmarks and performance test suites. Today noone would seriously use `eval` to parse JSON data (also for obvious security reaons, not only for the performance issues), but rather stick to [`JSON.parse`][46] for all code written in the last five years. In fact using `eval` to parse JSON would probably be considered a bug in production code today! So the engine writers effort of focusing on performance of newly written code is not reflected in this ancient benchmark, instead it would be beneficial to make `eval`unnecessarily ~~smart~~complex to win on `string-tagcloud.js`.
|
||||||
|
|
||||||
|
Ok, so let’s look at yet another example: the [`3d-cube.js`][47]. This benchmark does a lot of matrix operations, where even the smartest compiler can’t do a lot about it, but just has to execute it. Essentially the benchmark spends a lot of time executing the `Loop` function and functions called by it.
|
||||||
|
|
||||||
|
[
|
||||||
|
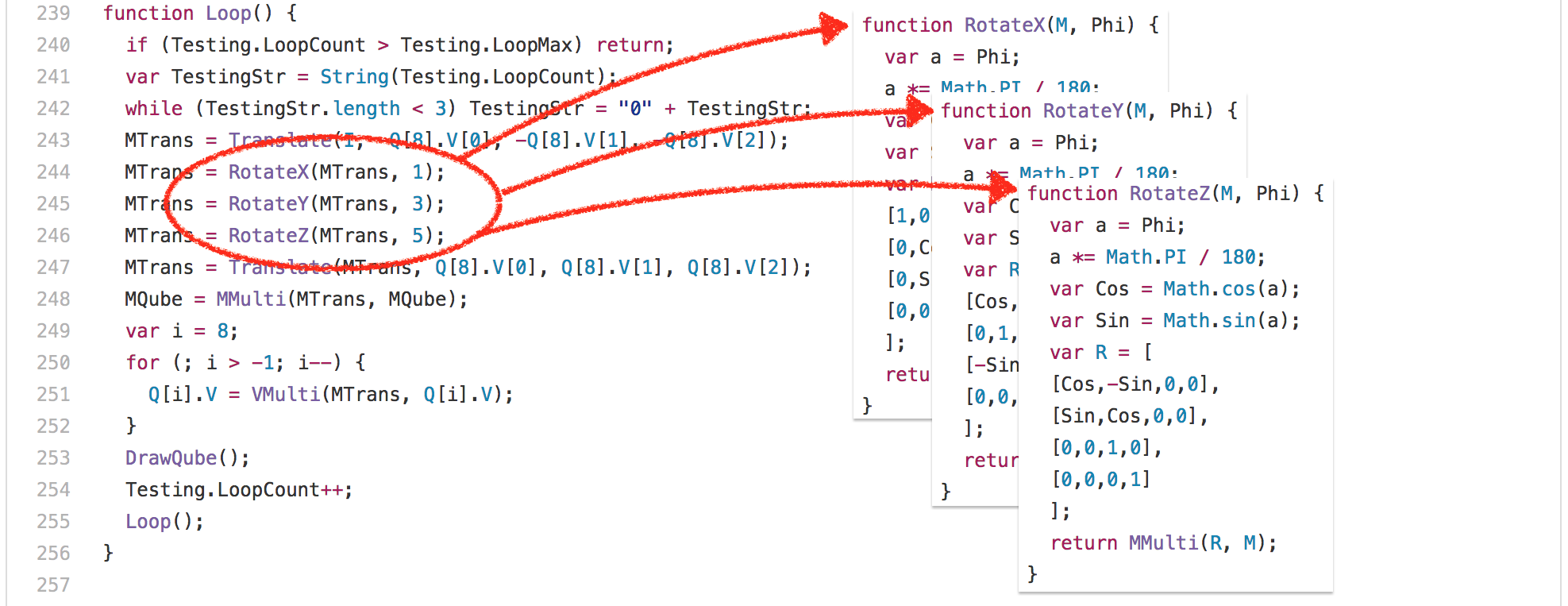
|
||||||
|
][48]
|
||||||
|
|
||||||
|
One interesting observation here is that the `RotateX`, `RotateY` and `RotateZ` functions are always called with the same constant parameter `Phi`.
|
||||||
|
|
||||||
|
[
|
||||||
|
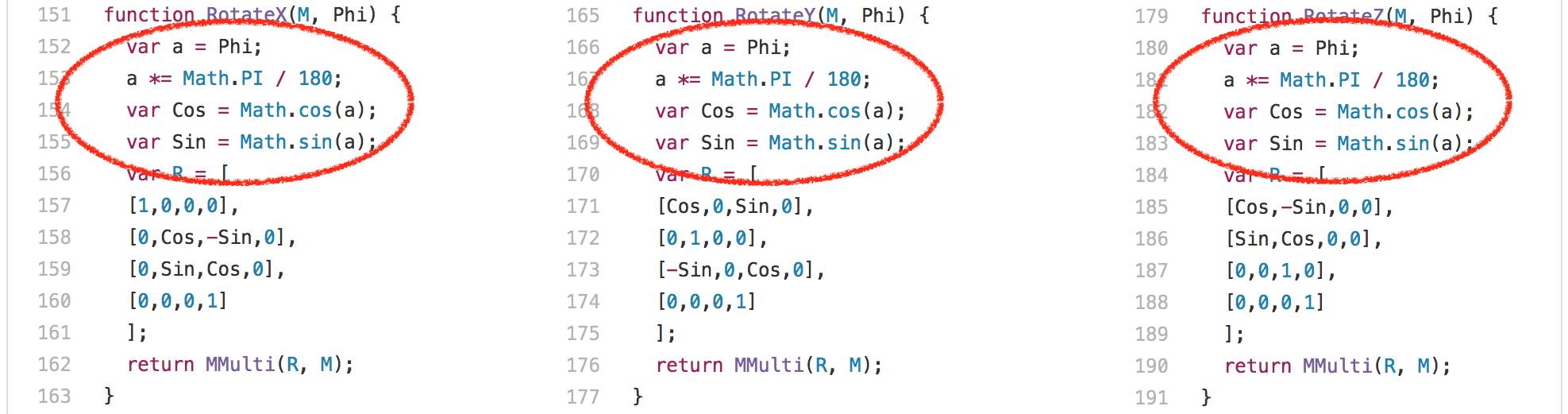
|
||||||
|
][49]
|
||||||
|
|
||||||
|
This means that we basically always compute the same values for [`Math.sin`][50] and [`Math.cos`][51], 204 times each. There are only three different inputs,
|
||||||
|
|
||||||
|
* 0.017453292519943295,
|
||||||
|
* 0.05235987755982989, and
|
||||||
|
* 0.08726646259971647
|
||||||
|
|
||||||
|
obviously. So, one thing you could do here to avoid recomputing the same sine and cosine values all the time is to cache the previously computed values, and in fact, that’s what V8 used to do in the past, and other engines like SpiderMonkey still do. We removed the so-called _transcendental cache_ from V8 because the overhead of the cache was noticable in actual workloads where you don’t always compute the same values in a row, which is unsurprisingly very common in the wild. We took serious hits on the SunSpider benchmark when we removed this benchmark specific optimizations back in 2013 and 2014, but we totally believe that it doesn’t make sense to optimize for a benchmark while at the same time penalizing the real world use case in such a way.
|
||||||
|
|
||||||
|
[
|
||||||
|
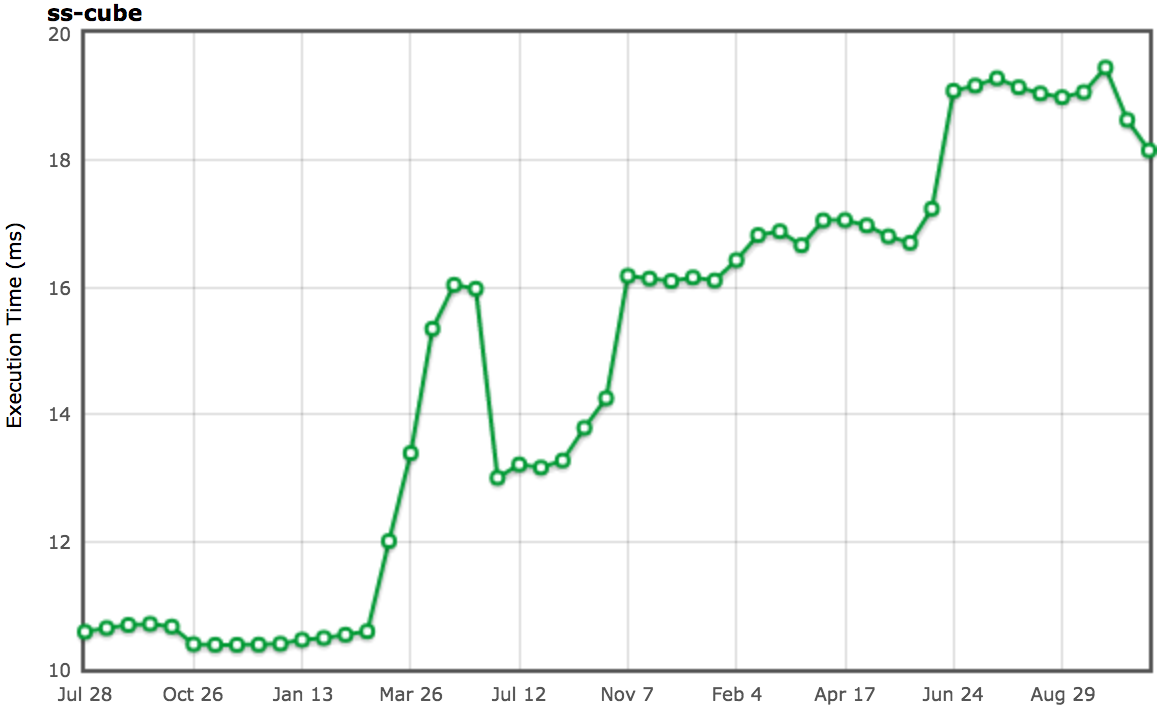
|
||||||
|
][52]
|
||||||
|
|
||||||
|
|
||||||
|
Obviously a better way to deal with the constant sine/cosine inputs is a sane inlining heuristic that tries to balance inlining and take into account different factors like prefer inlining at call sites where constant folding can be beneficial, like in case of the `RotateX`, `RotateY`, and `RotateZ` call sites. But this was not really possible with the Crankshaft compiler for various reasons. With Ignition and TurboFan, this becomes a sensible option, and we are already working on better [inlining heuristics][53].
|
||||||
|
|
||||||
|
### Garbage collection considered harmful
|
||||||
|
|
||||||
|
Besides these very test specific issues, there’s another fundamental problem with the SunSpider benchmark: The overall execution time. V8 on decent Intel hardware runs the whole benchmark in roughly 200ms currently (with the default configuration). A minor GC can take anything between 1ms and 25ms currently (depending on live objects in new space and old space fragmentation), while a major GC pause can easily take 30ms (not even taking into account the overhead from incremental marking), that’s more than 10% of the overall execution time of the whole SunSpider suite! So any engine that doesn’t want to risk a 10-20% slowdown due to a GC cycle has to somehow ensure it doesn’t trigger GC while running SunSpider.
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][54]
|
||||||
|
|
||||||
|
There are different tricks to accomplish this, none of which has any positive impact in real world as far as I can tell. V8 uses a rather simple trick: Since every SunSpider test is run in a new `<iframe>`, which corresponds to a new _native context_ in V8 speak, we just detect rapid `<iframe>` creation and disposal (all SunSpider tests take less than 50ms each), and in that case perform a garbage collection between the disposal and creation, to ensure that we never trigger a GC while actually running a test. This trick works pretty well, and in 99.9% of the cases doesn’t clash with real uses; except every now and then, it can hit you hard if for whatever reason you do something that makes you look like you are the SunSpider test driver to V8, then you can get hit hard by forced GCs, and that can have a negative effect on your application. So rule of thumb: **Don’t let your application look like SunSpider!**
|
||||||
|
|
||||||
|
I could go on with more SunSpider examples here, but I don’t think that’d be very useful. By now it should be clear that optimizing further for SunSpider above the threshold of good performance will not reflect any benefits in real world. In fact the world would probably benefit a lot from not having SunSpider any more, as engines could drop weird hacks that are only useful for SunSpider and can even hurt real world use cases. Unfortunately SunSpider is still being used heavily by the (tech) press to compare what they think is browser performance, or even worse compare phones! So there’s a certain natural interest from phone makers and also from Android in general to have Chrome look somewhat decent on SunSpider (and other nowadays meaningless benchmarks FWIW). The phone makers generate money by selling phones, so getting good reviews is crucial for the success of the phone division or even the whole company, and some of them even went as far as shipping old versions of V8 in their phones that had a higher score on SunSpider, exposing their users to all kinds of unpatched security holes that had long been fixed, and shielding their users from any real world performance benefits that come with more recent V8 versions!
|
||||||
|
|
||||||
|
[
|
||||||
|
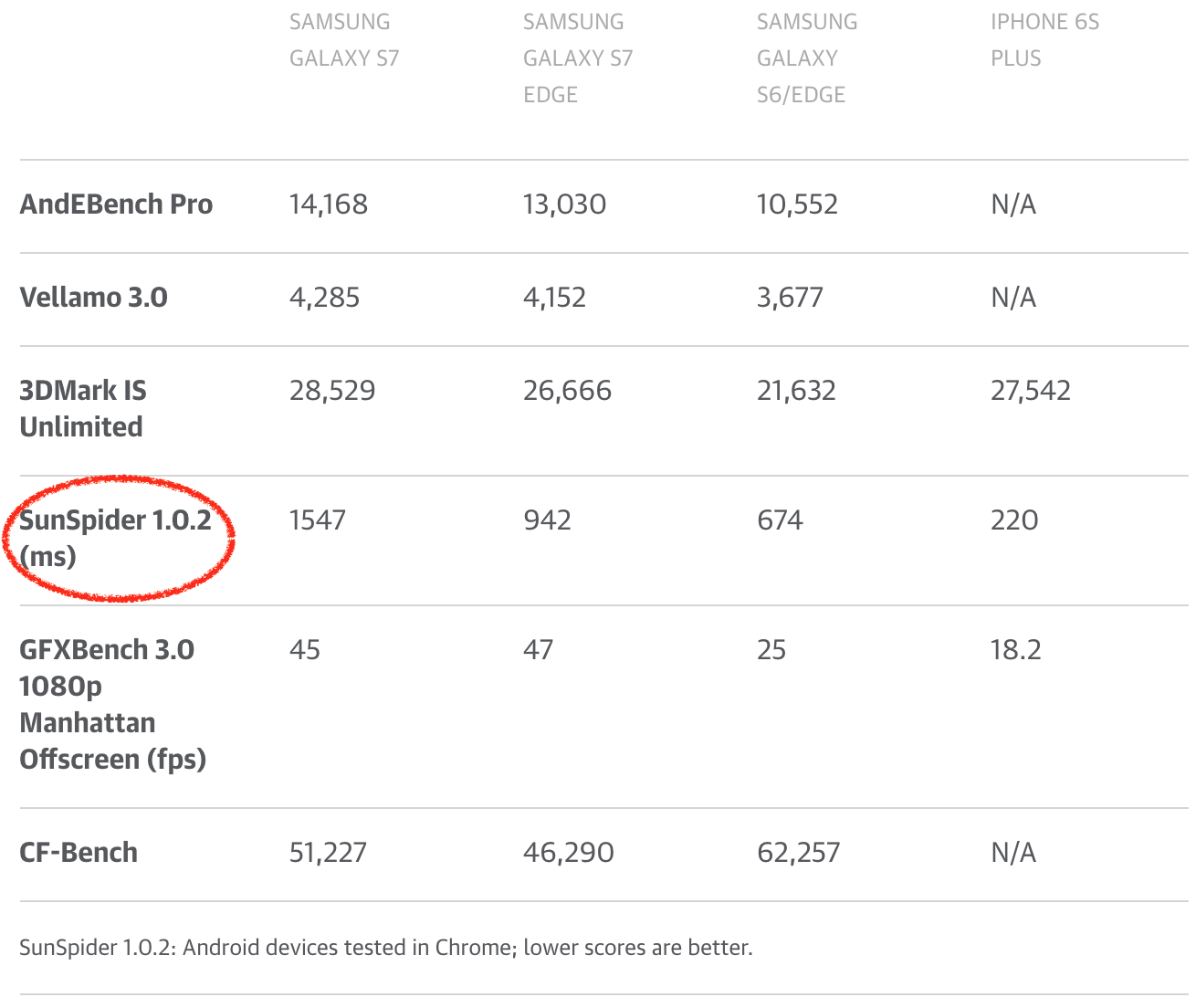
|
||||||
|
][55]
|
||||||
|
|
||||||
|
|
||||||
|
If we as the JavaScript community really want to be serious about real world performance in JavaScript land, we need to make the tech press stop using traditional JavaScript benchmarks to compare browsers or phones. I see that there’s a benefit in being able to just run a benchmark in each browser and compare the number that comes out of it, but then please, please use a benchmark that has something in common with what is relevant today, i.e. real world web pages; if you feel the need to compare two phones via a browser benchmark, please at least consider using [Speedometer][56].
|
||||||
|
|
||||||
|
### Cuteness break!
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
I always loved this in [Myles Borins][57]’ talks, so I had to shamelessly steal his idea. So now that we recovered from the SunSpider rant, let’s go on to check the other classic benchmarks…
|
||||||
|
|
||||||
|
### The not so obvious Kraken case
|
||||||
|
|
||||||
|
The Kraken benchmark was [released by Mozilla in September 2010][58], and it was said to contain snippets/kernels of real world applications, and be less of a micro-benchmark compared to SunSpider. I don’t want to spend too much time on Kraken, because I think it wasn’t as influential on JavaScript performance as SunSpider and Octane, so I’ll highlight one particular example from the [`audio-oscillator.js`][59] test.
|
||||||
|
|
||||||
|
[
|
||||||
|
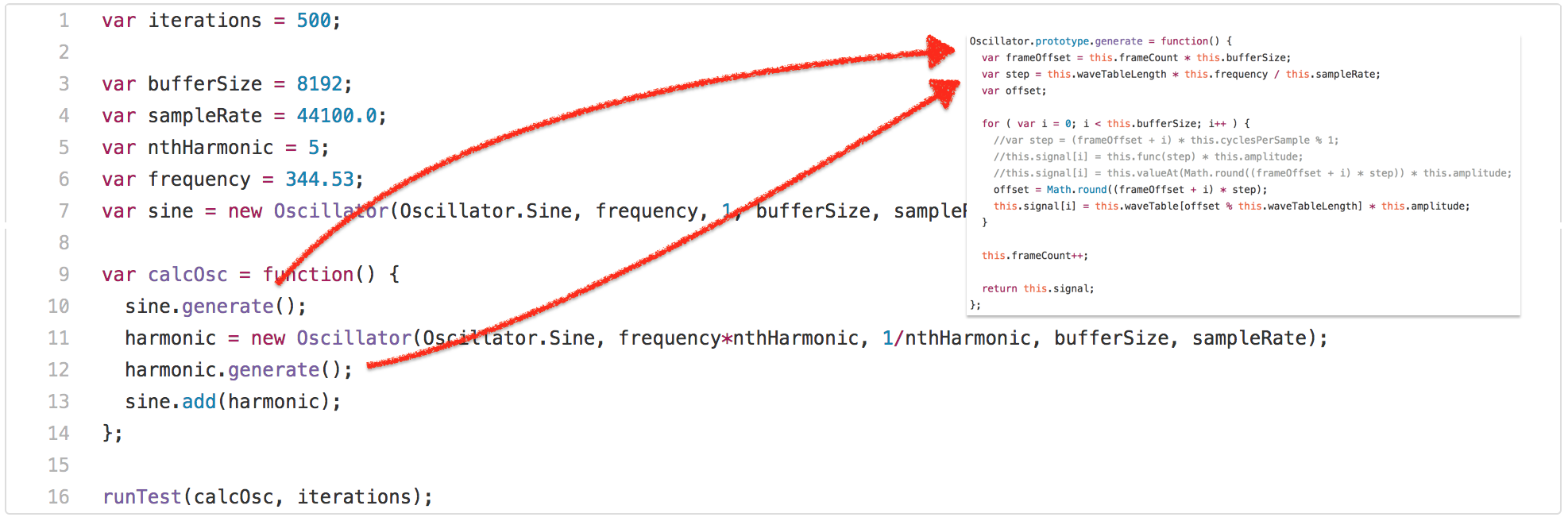
|
||||||
|
][60]
|
||||||
|
|
||||||
|
So the test invokes the `calcOsc` function 500 times. `calcOsc` first calls `generate` on the global `sine``Oscillator`, then creates a new `Oscillator`, calls `generate` on that and adds it to the global `sine` oscillator. Without going into detail why the test is doing this, let’s have a look at the `generate` method on the `Oscillator` prototype.
|
||||||
|
|
||||||
|
[
|
||||||
|
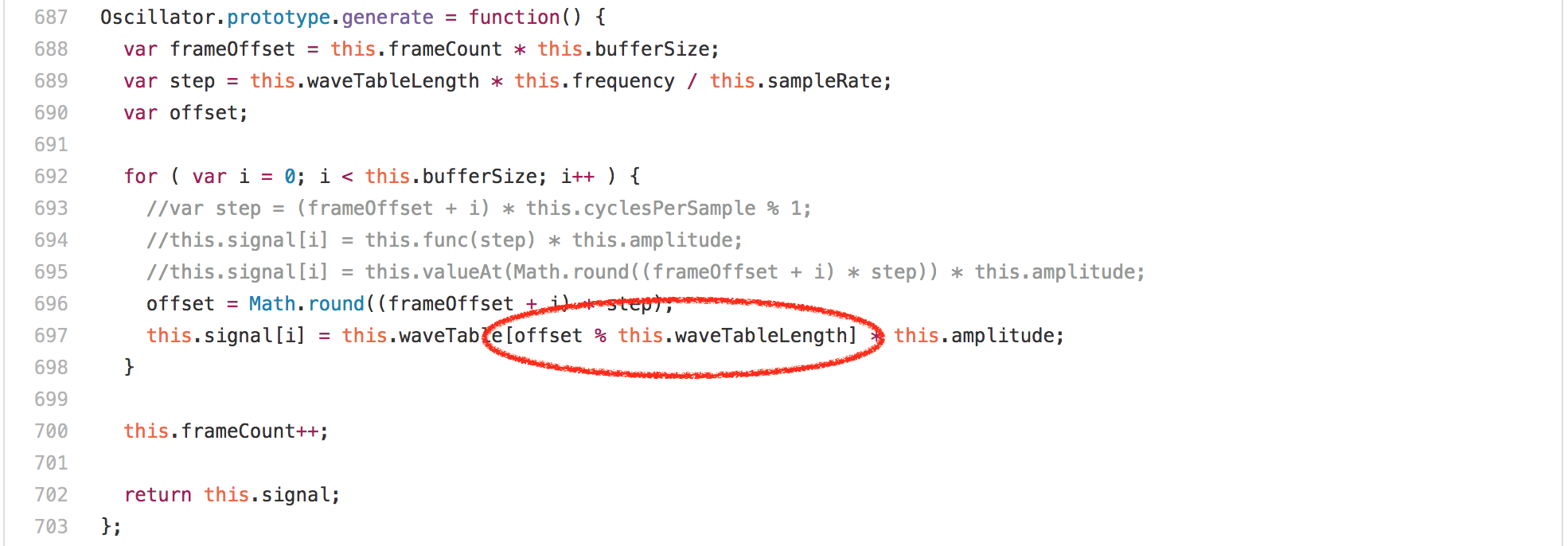
|
||||||
|
][61]
|
||||||
|
|
||||||
|
Looking at the code, you’d expect this to be dominated by the array accesses or the multiplications or the[`Math.round`][62] calls in the loop, but surprisingly what’s completely dominating the runtime of `Oscillator.prototype.generate` is the `offset % this.waveTableLength` expression. Running this benchmark in a profiler on any Intel machine reveals that more than 20% of the ticks are attributed to the `idiv`instruction that we generate for the modulus. One interesting observation however is that the `waveTableLength` field of the `Oscillator` instances always contains the same value 2048, as it’s only assigned once in the `Oscillator` constructor.
|
||||||
|
|
||||||
|
[
|
||||||
|
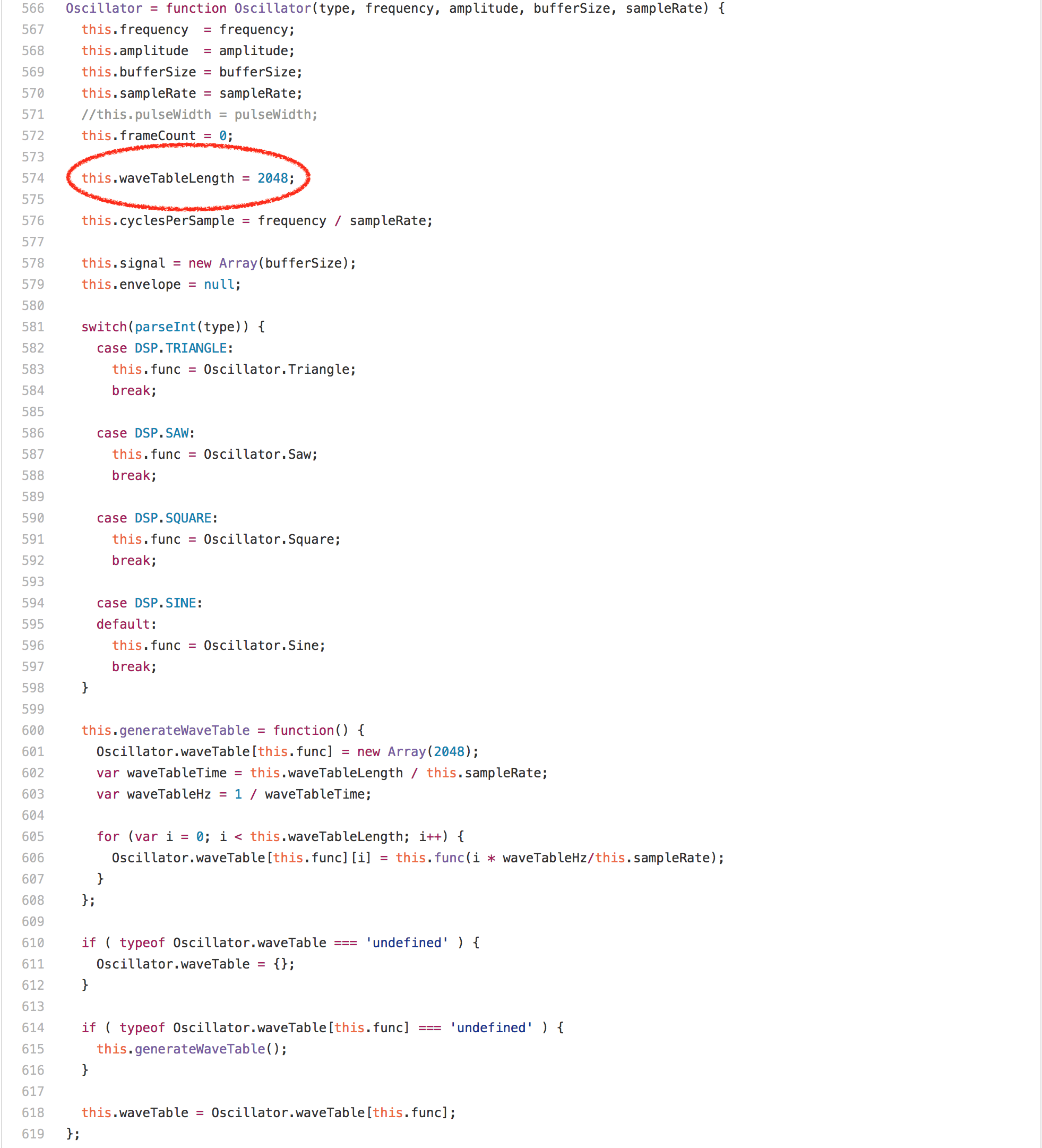
|
||||||
|
][63]
|
||||||
|
|
||||||
|
If we know that the right hand side of an integer modulus operation is a power of two, we can generate [way better code][64] obviously and completely avoid the `idiv` instruction on Intel. So what we needed was a way to get the information that `this.waveTableLength` is always 2048 from the `Oscillator` constructor to the modulus operation in `Oscillator.prototype.generate`. One obvious way would be to try to rely on inlining of everything into the `calcOsc` function and let load/store elimination do the constant propagation for us, but this would not work for the `sine` oscillator, which is allocated outside the `calcOsc` function.
|
||||||
|
|
||||||
|
So what we did instead is add support for tracking certain constant values as right-hand side feedback for the modulus operator. This does make some sense in V8, since we track type feedback for binary operations like `+`, `*` and `%` on uses, which means the operator tracks the types of inputs it has seen and the types of outputs that were produced (see the slides from the round table talk on [Fast arithmetic for dynamic languages][65]recently for some details). Hooking this up with fullcodegen and Crankshaft was even fairly easy back then, the `BinaryOpIC` for `MOD` can also track known power of two right hand sides. In fact running the default configuration of V8 (with Crankshaft and fullcodegen)
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||||
|
[...SNIP...]
|
||||||
|
[BinaryOpIC(MOD:None*None->None) => (MOD:Smi*2048->Smi) @ ~Oscillator.generate+598 at audio-oscillator.js:697]
|
||||||
|
[...SNIP...]
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
shows that the `BinaryOpIC` is picking up the proper constant feedback for the right hand side of the modulus, and properly tracks that the left hand side was always a small integer (a `Smi` in V8 speak), and we also always produced a small integer result. Looking at the generated code using `--print-opt-code --code-comments` quickly reveals that Crankshaft utilizes the feedback to generate an efficient code sequence for the integer modulus in `Oscillator.prototype.generate`:
|
||||||
|
|
||||||
|
```
|
||||||
|
[...SNIP...]
|
||||||
|
;;; <@80,#84> load-named-field
|
||||||
|
0x133a0bdacc4a 330 8b4343 movl rax,[rbx+0x43]
|
||||||
|
;;; <@83,#86> compare-numeric-and-branch
|
||||||
|
0x133a0bdacc4d 333 3d00080000 cmp rax,0x800
|
||||||
|
0x133a0bdacc52 338 0f85ff000000 jnz 599 (0x133a0bdacd57)
|
||||||
|
[...SNIP...]
|
||||||
|
;;; <@90,#94> mod-by-power-of-2-i
|
||||||
|
0x133a0bdacc5b 347 4585db testl r11,r11
|
||||||
|
0x133a0bdacc5e 350 790f jns 367 (0x133a0bdacc6f)
|
||||||
|
0x133a0bdacc60 352 41f7db negl r11
|
||||||
|
0x133a0bdacc63 355 4181e3ff070000 andl r11,0x7ff
|
||||||
|
0x133a0bdacc6a 362 41f7db negl r11
|
||||||
|
0x133a0bdacc6d 365 eb07 jmp 374 (0x133a0bdacc76)
|
||||||
|
0x133a0bdacc6f 367 4181e3ff070000 andl r11,0x7ff
|
||||||
|
[...SNIP...]
|
||||||
|
;;; <@127,#88> deoptimize
|
||||||
|
0x133a0bdacd57 599 e81273cdff call 0x133a0ba8406e
|
||||||
|
[...SNIP...]
|
||||||
|
```
|
||||||
|
|
||||||
|
So you see we load the value of `this.waveTableLength` (`rbx` holds the `this` reference), check that it’s still 2048 (hexadecimal 0x800), and if so just perform a bitwise and with the proper bitmask 0x7ff (`r11` contains the value of the loop induction variable `i`) instead of using the `idiv` instruction (paying proper attention to preserve the sign of the left hand side).
|
||||||
|
|
||||||
|
### The over-specialization issue
|
||||||
|
|
||||||
|
So this trick is pretty damn cool, but as with many benchmark focused tricks, it has one major drawback: It’s over-specialized! As soon as the right hand side ever changes, all optimized code will have to be deoptimized (as the assumption that the right hand is always a certain power of two no longer holds) and any further optimization attempts will have to use `idiv` again, as the `BinaryOpIC` will most likely report feedback in the form `Smi*Smi->Smi` then. For example, let’s assume we instantiate another `Oscillator`, set a different`waveTableLength` on it, and call `generate` for the oscillator, then we’d lose 20% performance even though the actually interesting `Oscillator`s are not affected (i.e. the engine does non-local penalization here).
|
||||||
|
|
||||||
|
```
|
||||||
|
--- audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
|
||||||
|
+++ audio-oscillator.js 2016-12-15 22:02:26.397326067 +0100
|
||||||
|
@@ -1931,6 +1931,10 @@
|
||||||
|
var frequency = 344.53;
|
||||||
|
var sine = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
|
||||||
|
|
||||||
|
+var unused = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
|
||||||
|
+unused.waveTableLength = 1024;
|
||||||
|
+unused.generate();
|
||||||
|
+
|
||||||
|
var calcOsc = function() {
|
||||||
|
sine.generate();
|
||||||
|
```
|
||||||
|
|
||||||
|
Comparing the execution times of the original `audio-oscillator.js` and the version that contains an additional unused `Oscillator` instance with a modified `waveTableLength` shows the expected results:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
|
||||||
|
Time (audio-oscillator-once): 64 ms.
|
||||||
|
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js
|
||||||
|
Time (audio-oscillator-once): 81 ms.
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
This is an example for a pretty terrible performance cliff: Let’s say a developer writes code for a library and does careful tweaking and optimizations using certain sample input values, and the performance is decent. Now a user starts using that library reading through the performance notes, but somehow falls off the performance cliff, because she/he is using the library in a slightly different way, i.e. somehow polluting type feedback for a certain `BinaryOpIC`, and is hit by a 20% slowdown (compared to the measurements of the library author) that neither the library author nor the user can explain, and that seems rather arbitrary.
|
||||||
|
|
||||||
|
Now this is not uncommon in JavaScript land, and unfortunately quite a couple of these cliffs are just unavoidable, because they are due to the fact that JavaScript performance is based on optimistic assumptions and speculation. We have been spending **a lot** of time and energy trying to come up with ways to avoid these performance cliffs, and still provide (nearly) the same performance. As it turns out it makes a lot of sense to avoid `idiv` whenever possible, even if you don’t necessarily know that the right hand side is always a power of two (via dynamic feedback), so what TurboFan does is different from Crankshaft, in that it always checks at runtime whether the input is a power of two, so general case for signed integer modulus, with optimization for (unknown) power of two right hand side looks like this (in pseudo code):
|
||||||
|
|
||||||
|
```
|
||||||
|
if 0 < rhs then
|
||||||
|
msk = rhs - 1
|
||||||
|
if rhs & msk != 0 then
|
||||||
|
lhs % rhs
|
||||||
|
else
|
||||||
|
if lhs < 0 then
|
||||||
|
-(-lhs & msk)
|
||||||
|
else
|
||||||
|
lhs & msk
|
||||||
|
else
|
||||||
|
if rhs < -1 then
|
||||||
|
lhs % rhs
|
||||||
|
else
|
||||||
|
zero
|
||||||
|
```
|
||||||
|
|
||||||
|
And that leads to a lot more consistent and predictable performance (with TurboFan):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
|
||||||
|
Time (audio-oscillator-once): 69 ms.
|
||||||
|
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js
|
||||||
|
Time (audio-oscillator-once): 69 ms.
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
The problem with benchmarks and over-specialization is that the benchmark can give you hints where to look and what to do, but it doesn’t tell you how far you have to go and doesn’t protect the optimization properly. For example, all JavaScript engines use benchmarks as a way to guard against performance regressions, but running Kraken for example wouldn’t protect the general approach that we have in TurboFan, i.e. we could _degrade_ the modulus optimization in TurboFan to the over-specialized version of Crankshaft and the benchmark wouldn’t tell us that we regressed, because from the point of view of the benchmark it’s fine! Now you could extend the benchmark, maybe in the same way that I did above, and try to cover everything with benchmarks, which is what engine implementors do to a certain extent, but that approach doesn’t scale arbitrarily. Even though benchmarks are convenient and easy to use for communication and competition, you’ll also need to leave space for common sense, otherwise over-specialization will dominate everything and you’ll have a really, really fine line of acceptable performance and big performance cliffs.
|
||||||
|
|
||||||
|
There are various other issues with the Kraken tests, but let’s move on the probably most influential JavaScript benchmark of the last five years… the Octane benchmark.
|
||||||
|
|
||||||
|
### A closer look at Octane
|
||||||
|
|
||||||
|
The [Octane benchmark][66] is the successor of the V8 benchmark and was initially [announced by Google in mid 2012][67] and the current version Octane 2.0 was [announced in late 2013][68]. This version contains 15 individual tests, where for two of them - Splay and Mandreel - we measure both the throughput and the latency. These tests range from [Microsofts TypeScript compiler][69] compiling itself, to raw [asm.js][70] performance being measured by the zlib test, to a performance test for the RegExp engine, to a ray tracer, to a full 2D physics engine, etc. See the [description][71] for a detailed overview of the individual benchmark line items. All these line items were carefully chosen to reflect a certain aspect of JavaScript performance that we considered important in 2012 or expected to become important in the near future.
|
||||||
|
|
||||||
|
To a large extent Octane was super successful in achieving its goals of taking JavaScript performance to the next level, it resulted in a healthy competition in 2012 and 2013 where great performance achievements were driven by Octane. But it’s almost 2017 now, and the world looks fairly different than in 2012, really, really different actually. Besides the usual and often cited criticism that most items in Octane are essentially outdated (i.e. ancient versions of TypeScript, zlib being compiled via an ancient version of [Emscripten][72], Mandreel not even being available anymore, etc.), something way more important affects Octanes usefulness:
|
||||||
|
|
||||||
|
We saw big web frameworks winning the race on the web, especially heavy frameworks like [Ember][73] and [AngularJS][74], that use patterns of JavaScript execution, which are not reflected at all by Octane and are often hurt by (our) Octane specific optimizations. We also saw JavaScript winning on the server and tooling front, which means there are large scale JavaScript applications that now often run for weeks if not years, which also not captured by Octane. As stated in the beginning we have hard data that suggests that the execution and memory profile of Octane is completely different than what we see on the web daily.
|
||||||
|
|
||||||
|
So, let’s look into some concrete examples of benchmark gaming that is happening today with Octane, where optimizations are no longer reflected in real world. Note that even though this might sound a bit negative in retrospect, it’s definitely not meant that way! As I said a couple of times already, Octane is an important chapter in the JavaScript performance story, and it played a very important role. All the optimizations that went into JavaScript engines driven by Octane in the past were added on good faith that Octane is a good proxy for real world performance! _Every age has its benchmark, and for every benchmark there comes a time when you have to let go!_
|
||||||
|
|
||||||
|
That being said, let’s get this show on the road and start by looking at the Box2D test, which is based on[Box2DWeb][75], a popular 2D physics engine originally written by Erin Catto, ported to JavaScript. Overall does a lot of floating point math and drove a lot of good optimizations in JavaScript engines, however as it turns out it contains a bug that can be exploited to game the benchmark a bit (blame it on me, I spotted the bug and added the exploit in this case). There’s a function `D.prototype.UpdatePairs` in the benchmark that looks like this (deminified):
|
||||||
|
|
||||||
|
```
|
||||||
|
D.prototype.UpdatePairs = function(b) {
|
||||||
|
var e = this;
|
||||||
|
var f = e.m_pairCount = 0,
|
||||||
|
m;
|
||||||
|
for (f = 0; f < e.m_moveBuffer.length; ++f) {
|
||||||
|
m = e.m_moveBuffer[f];
|
||||||
|
var r = e.m_tree.GetFatAABB(m);
|
||||||
|
e.m_tree.Query(function(t) {
|
||||||
|
if (t == m) return true;
|
||||||
|
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
|
||||||
|
var x = e.m_pairBuffer[e.m_pairCount];
|
||||||
|
x.proxyA = t < m ? t : m;
|
||||||
|
x.proxyB = t >= m ? t : m;
|
||||||
|
++e.m_pairCount;
|
||||||
|
return true
|
||||||
|
},
|
||||||
|
r)
|
||||||
|
}
|
||||||
|
for (f = e.m_moveBuffer.length = 0; f < e.m_pairCount;) {
|
||||||
|
r = e.m_pairBuffer[f];
|
||||||
|
var s = e.m_tree.GetUserData(r.proxyA),
|
||||||
|
v = e.m_tree.GetUserData(r.proxyB);
|
||||||
|
b(s, v);
|
||||||
|
for (++f; f < e.m_pairCount;) {
|
||||||
|
s = e.m_pairBuffer[f];
|
||||||
|
if (s.proxyA != r.proxyA || s.proxyB != r.proxyB) break;
|
||||||
|
++f
|
||||||
|
}
|
||||||
|
}
|
||||||
|
};
|
||||||
|
```
|
||||||
|
|
||||||
|
Some profiling shows that a lot of time is spent in the innocent looking inner function passed to `e.m_tree.Query` in the first loop:
|
||||||
|
|
||||||
|
```
|
||||||
|
function(t) {
|
||||||
|
if (t == m) return true;
|
||||||
|
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
|
||||||
|
var x = e.m_pairBuffer[e.m_pairCount];
|
||||||
|
x.proxyA = t < m ? t : m;
|
||||||
|
x.proxyB = t >= m ? t : m;
|
||||||
|
++e.m_pairCount;
|
||||||
|
return true
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
More precisely the time is not spent in this function itself, but rather operations and builtin library functions triggered by this. As it turned out we spent 4-7% of the overall execution time of the benchmark calling into the [`Compare` runtime function][76], which implements the general case for the [abstract relational comparison][77].
|
||||||
|
|
||||||
|
|
||||||
|
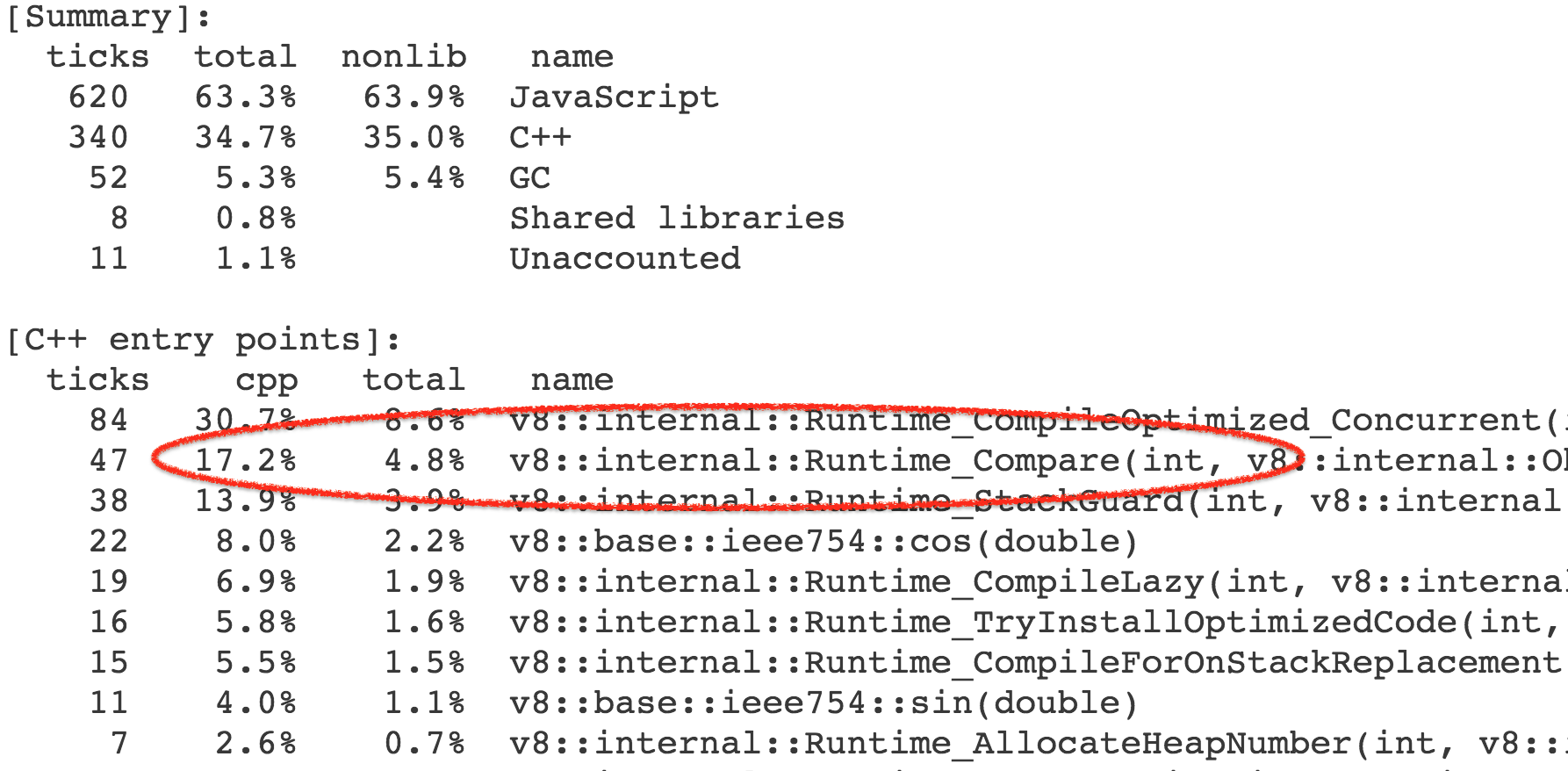
|
||||||
|
|
||||||
|
|
||||||
|
Almost all the calls to the runtime function came from the [`CompareICStub`][78], which is used for the two relational comparisons in the inner function:
|
||||||
|
|
||||||
|
```
|
||||||
|
x.proxyA = t < m ? t : m;
|
||||||
|
x.proxyB = t >= m ? t : m;
|
||||||
|
```
|
||||||
|
|
||||||
|
So these two innocent looking lines of code are responsible for 99% of the time spent in this function! How come? Well, as with so many things in JavaScript, the [abstract relational comparison][79] is not necessarily intuitive to use properly. In this function both `t` and `m` are always instances of `L`, which is a central class in this application, but doesn’t override either any of `Symbol.toPrimitive`, `"toString"`, `"valueOf"` or `Symbol.toStringTag` properties, that are relevant for the abstract relation comparison. So what happens if you write `t < m` is this:
|
||||||
|
|
||||||
|
1. Calls [ToPrimitive][12](`t`, `hint Number`).
|
||||||
|
2. Runs [OrdinaryToPrimitive][13](`t`, `"number"`) since there’s no `Symbol.toPrimitive`.
|
||||||
|
3. Executes `t.valueOf()`, which yields `t` itself since it calls the default [`Object.prototype.valueOf`][14].
|
||||||
|
4. Continues with `t.toString()`, which yields `"[object Object]"`, since the default[`Object.prototype.toString`][15] is being used and no [`Symbol.toStringTag`][16] was found for `L`.
|
||||||
|
5. Calls [ToPrimitive][17](`m`, `hint Number`).
|
||||||
|
6. Runs [OrdinaryToPrimitive][18](`m`, `"number"`) since there’s no `Symbol.toPrimitive`.
|
||||||
|
7. Executes `m.valueOf()`, which yields `m` itself since it calls the default [`Object.prototype.valueOf`][19].
|
||||||
|
8. Continues with `m.toString()`, which yields `"[object Object]"`, since the default[`Object.prototype.toString`][20] is being used and no [`Symbol.toStringTag`][21] was found for `L`.
|
||||||
|
9. Does the comparison `"[object Object]" < "[object Object]"` which yields `false`.
|
||||||
|
|
||||||
|
Same for `t >= m`, which always produces `true` then. So the bug here is that using abstract relational comparison this way just doesn’t make sense. And the way to exploit it is to have the compiler constant-fold it, i.e. similar to applying this patch to the benchmark:
|
||||||
|
|
||||||
|
```
|
||||||
|
--- octane-box2d.js.ORIG 2016-12-16 07:28:58.442977631 +0100
|
||||||
|
+++ octane-box2d.js 2016-12-16 07:29:05.615028272 +0100
|
||||||
|
@@ -2021,8 +2021,8 @@
|
||||||
|
if (t == m) return true;
|
||||||
|
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
|
||||||
|
var x = e.m_pairBuffer[e.m_pairCount];
|
||||||
|
- x.proxyA = t < m ? t : m;
|
||||||
|
- x.proxyB = t >= m ? t : m;
|
||||||
|
+ x.proxyA = m;
|
||||||
|
+ x.proxyB = t;
|
||||||
|
++e.m_pairCount;
|
||||||
|
return true
|
||||||
|
},
|
||||||
|
```
|
||||||
|
|
||||||
|
Because doing so results in a serious speed-up of 13% by not having to do the comparison, and all the propery lookups and builtin function calls triggered by it.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
|
||||||
|
Score (Box2D): 48063
|
||||||
|
$ ~/Projects/v8/out/Release/d8 octane-box2d.js
|
||||||
|
Score (Box2D): 55359
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
So how did we do that? As it turned out we already had a mechanism for tracking the shape of objects that are being compared in the `CompareIC`, the so-called _known receiver_ map tracking (where _map_ is V8 speak for object shape+prototype), but that was limited to abstract and strict equality comparisons. But I could easily extend the tracking to also collect the feedback for abstract relational comparison:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||||
|
[...SNIP...]
|
||||||
|
[CompareIC in ~+557 at octane-box2d.js:2024 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#LT @ 0x1d5a860493a1]
|
||||||
|
[CompareIC in ~+649 at octane-box2d.js:2025 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#GTE @ 0x1d5a860496e1]
|
||||||
|
[...SNIP...]
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
Here the `CompareIC` used in the baseline code tells us that for the LT (less than) and the GTE (greather than or equal) comparisons in the function we’re looking at, it had only seen `RECEIVER`s so far (which is V8 speak for JavaScript objects), and all these receivers had the same map `0x1d5a860493a1`, which corresponds to the map of `L` instances. So in optimized code, we can constant-fold these operations to `false` and `true`respectively as long as we know that both sides of the comparison are instances with the map `0x1d5a860493a1` and noone messed with `L`s prototype chain, i.e. the `Symbol.toPrimitive`, `"valueOf"` and `"toString"` methods are the default ones, and noone installed a `Symbol.toStringTag` accessor property. The rest of the story is _black voodoo magic_ in Crankshaft, with a lot of cursing and initially forgetting to check `Symbol.toStringTag` properly:
|
||||||
|
|
||||||
|
[
|
||||||
|
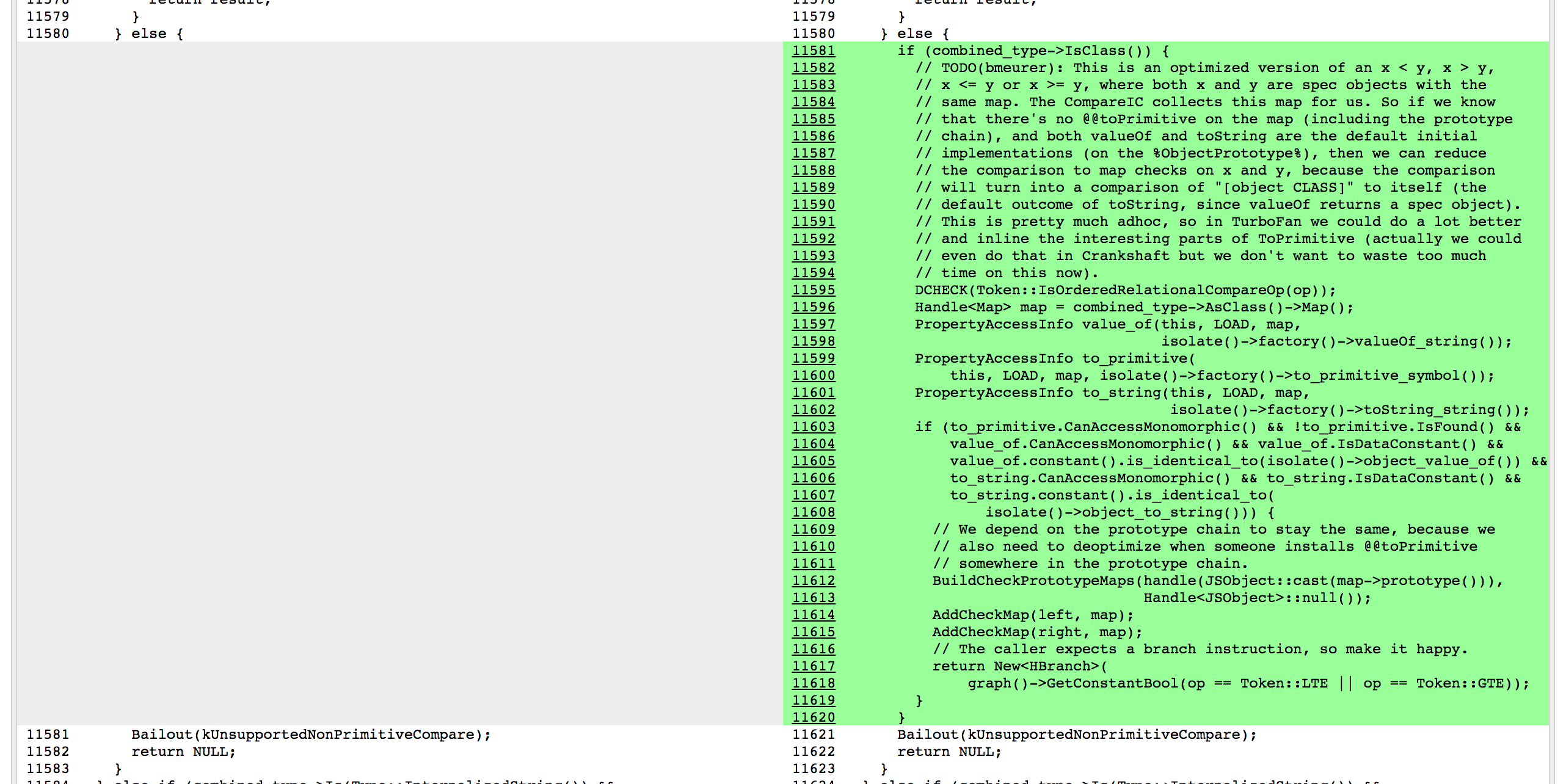
|
||||||
|
][80]
|
||||||
|
|
||||||
|
And in the end there was a rather huge performance boost on this particular benchmark:
|
||||||
|
|
||||||
|
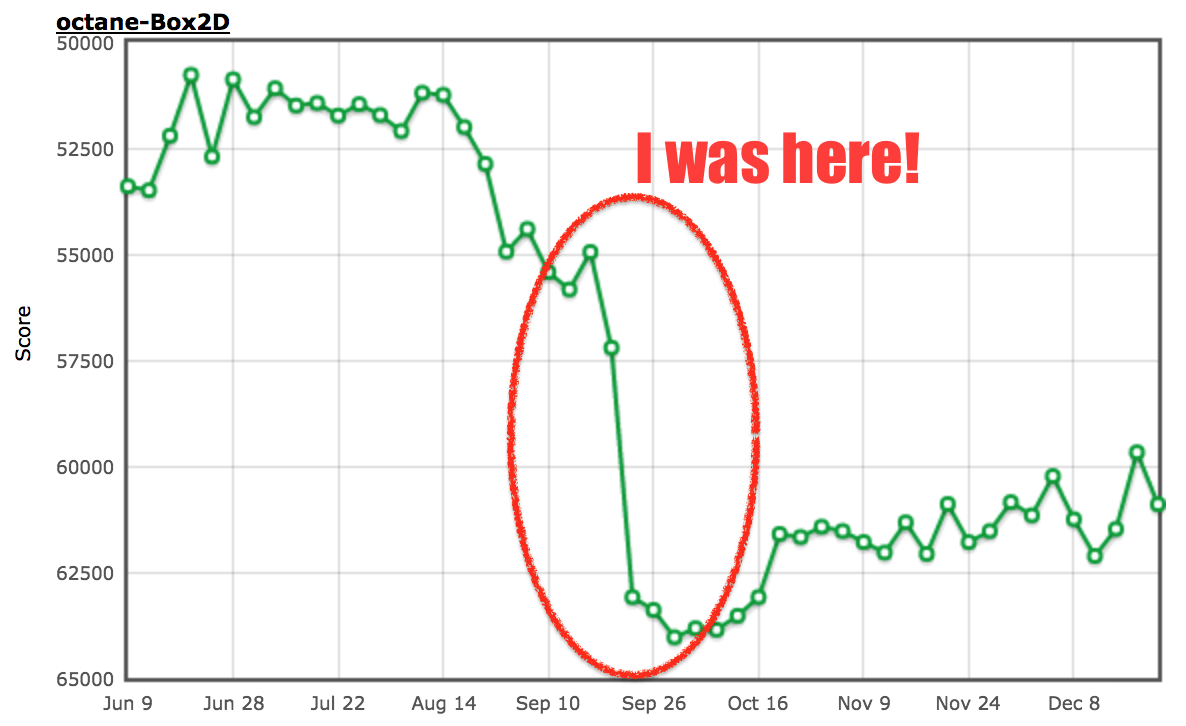
|
||||||
|
|
||||||
|
|
||||||
|
To my defense, back then I was not convinced that this particular behavior would always point to a bug in the original code, so I was even expecting that code in the wild might hit this case fairly often, also because I was assuming that JavaScript developers wouldn’t always care about these kinds of potential bugs. However, I was so wrong, and here I stand corrected! I have to admit that this particular optimization is purely a benchmark thing, and will not help any real code (unless the code is written to benefit from this optimization, but then you could as well write `true` or `false` directly in your code instead of using an always-constant relational comparison). You might wonder why we slightly regressed soon after my patch. That was the period where we threw the whole team at implementing ES2015, which was really a dance with the devil to get all the new stuff in (ES2015 is a monster!) without seriously regressing the traditional benchmarks.
|
||||||
|
|
||||||
|
Enough said about Box2D, let’s have a look at the Mandreel benchmark. Mandreel was a compiler for compiling C/C++ code to JavaScript, it didn’t use the [asm.js][81] subset of JavaScript that is being used by the more recent [Emscripten][82] compiler, and has been deprecated (and more or less disappeared from the internet) since roughly three years now. Nevertheless, Octane still has a version of the [Bullet physics engine][83] compiled via [Mandreel][84]. An interesting test here is the MandreelLatency test, which instruments the Mandreel benchmark with frequent time measurement checkpoints. The idea here was that since Mandreel stresses the VM’s compiler, this test provides an indication of the latency introduced by the compiler, and long pauses between measurement checkpoints lower the final score. In theory that sounds very reasonable, and it does indeed make some sense. However as usual vendors figured out ways to cheat on this benchmark.
|
||||||
|
|
||||||
|
[
|
||||||
|
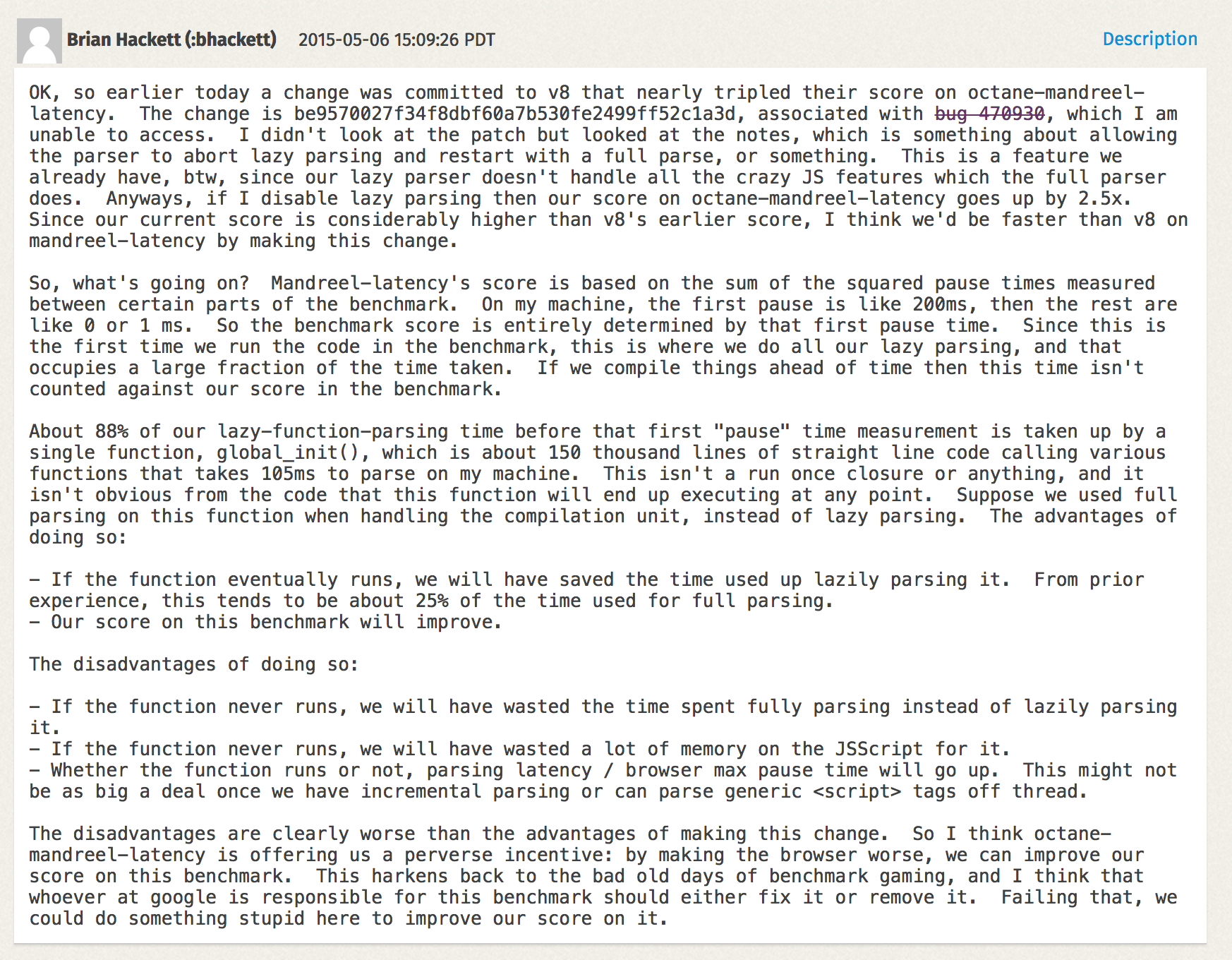
|
||||||
|
][85]
|
||||||
|
|
||||||
|
Mandreel contains a huge initialization function `global_init` that takes an incredible amount of time just parsing this function, and generating baseline code for it. Since engines usually parse various functions in scripts multiple times, one so-called pre-parse step to discover functions inside the script, and then as the function is invoked for the first time a full parse step to actually generate baseline code (or bytecode) for the function. This is called [_lazy parsing_][86] in V8 speak. V8 has some heuristics in place to detect functions that are invoked immediately where pre-parsing is actually a waste of time, but that’s not clear for the `global_init`function in the Mandreel benchmark, thus we’d would have an incredible long pause for pre-parsing + parsing + compiling the big function. So we [added an additional heuristic][87] that would also avoids the pre-parsing for this `global_init` function.
|
||||||
|
|
||||||
|
[
|
||||||
|
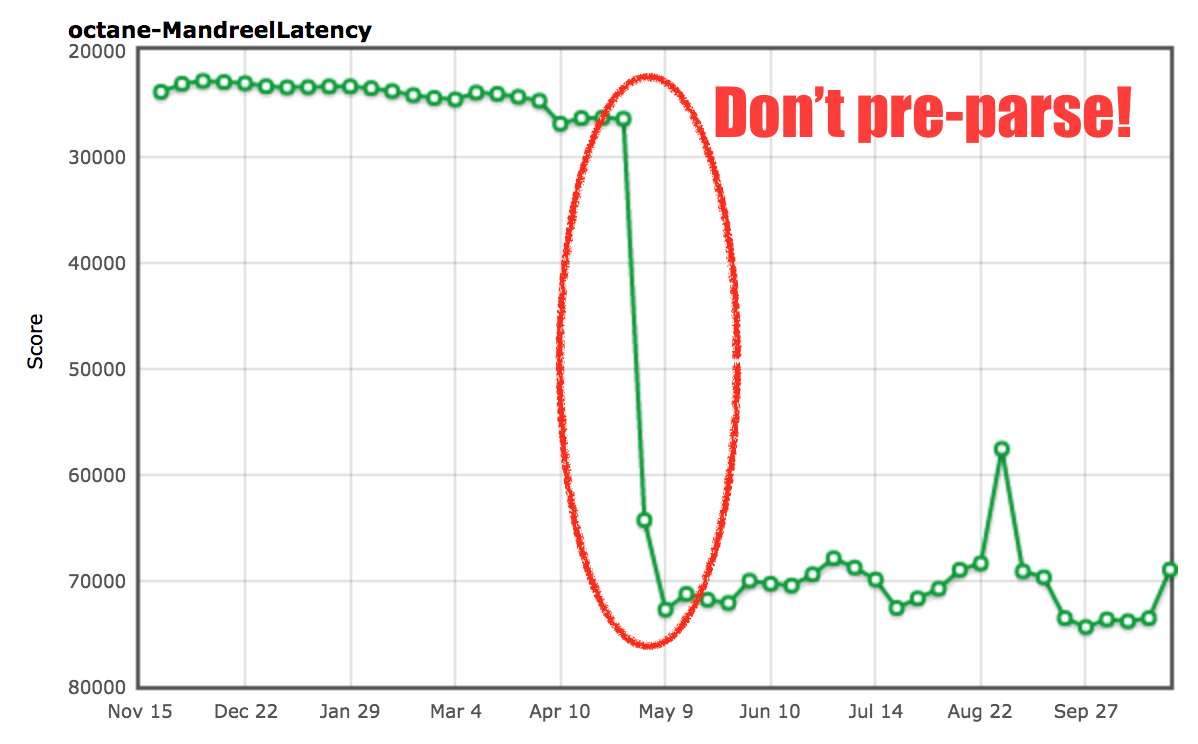
|
||||||
|
][88]
|
||||||
|
|
||||||
|
So we saw an almost 200% improvement just by detecting `global_init` and avoiding the expensive pre-parse step. We are somewhat certain that this should not negatively impact real world use cases, but there’s no guarantee that this won’t bite you on large functions where pre-parsing would be beneficial (because they aren’t immediately executed).
|
||||||
|
|
||||||
|
So let’s look into another slightly less controversial benchmark: the [`splay.js`][89] test, which is meant to be a data manipulation benchmark that deals with splay trees and exercises the automatic memory management subsystem (aka the garbage collector). It comes bundled with a latency test that instruments the Splay code with frequent measurement checkpoints, where a long pause between checkpoints is an indication of high latency in the garbage collector. This test measures the frequency of latency pauses, classifies them into buckets and penalizes frequent long pauses with a low score. Sounds great! No GC pauses, no jank. So much for the theory. Let’s have a look at the benchmark, here’s what’s at the core of the whole splay tree business:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][90]
|
||||||
|
|
||||||
|
This is the core of the splay tree construction, and despite what you might think looking at the full benchmark, this is more or less all that matters for the SplayLatency score. How come? Actually what the benchmark does is to construct huge splay trees, so that the majority of nodes survive, thus making it to old space. With a generational garbage collector like the one in V8 this is super expensive if a program violates the [generational hypothesis][91] leading to extreme pause times for essentially evacuating everything from new space to old space. Running V8 in the old configuration clearly shows this problem:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||||
|
[20872:0x7f26f24c70d0] 10 ms: Scavenge 2.7 (6.0) -> 2.7 (7.0) MB, 1.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 12 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.7 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 14 ms: Scavenge 3.7 (8.0) -> 3.6 (10.0) MB, 0.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 18 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.5 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 22 ms: Scavenge 5.7 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 28 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.3 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 35 ms: Scavenge 9.6 (17.0) -> 9.6 (28.0) MB, 6.9 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 49 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.2 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 65 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.3 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 93 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 17.6 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 126 ms: Scavenge 33.4 (53.5) -> 33.3 (68.0) MB, 31.5 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 151 ms: Scavenge 47.9 (68.0) -> 47.6 (69.5) MB, 15.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 183 ms: Scavenge 49.2 (69.5) -> 49.2 (84.0) MB, 30.9 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 210 ms: Scavenge 63.5 (84.0) -> 62.4 (85.0) MB, 14.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 241 ms: Scavenge 64.7 (85.0) -> 64.6 (99.0) MB, 28.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 268 ms: Scavenge 78.2 (99.0) -> 77.6 (101.0) MB, 16.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 298 ms: Scavenge 80.4 (101.0) -> 80.3 (114.5) MB, 28.2 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 324 ms: Scavenge 93.5 (114.5) -> 92.9 (117.0) MB, 16.4 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 354 ms: Scavenge 96.2 (117.0) -> 96.0 (130.0) MB, 27.6 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 383 ms: Scavenge 108.8 (130.0) -> 108.2 (133.0) MB, 16.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 413 ms: Scavenge 111.9 (133.0) -> 111.7 (145.5) MB, 27.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 440 ms: Scavenge 124.1 (145.5) -> 123.5 (149.0) MB, 17.4 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 473 ms: Scavenge 127.6 (149.0) -> 127.4 (161.0) MB, 29.5 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 502 ms: Scavenge 139.4 (161.0) -> 138.8 (165.0) MB, 18.7 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 534 ms: Scavenge 143.3 (165.0) -> 143.1 (176.5) MB, 28.5 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 561 ms: Scavenge 154.7 (176.5) -> 154.2 (181.0) MB, 19.0 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 594 ms: Scavenge 158.9 (181.0) -> 158.7 (192.0) MB, 29.2 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 622 ms: Scavenge 170.0 (192.5) -> 169.5 (197.0) MB, 19.5 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 655 ms: Scavenge 174.6 (197.0) -> 174.3 (208.0) MB, 28.7 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 683 ms: Scavenge 185.4 (208.0) -> 184.9 (212.5) MB, 19.4 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 715 ms: Scavenge 190.2 (213.0) -> 190.0 (223.5) MB, 27.7 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 743 ms: Scavenge 200.7 (223.5) -> 200.3 (228.5) MB, 19.7 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 774 ms: Scavenge 205.8 (228.5) -> 205.6 (239.0) MB, 27.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 802 ms: Scavenge 216.1 (239.0) -> 215.7 (244.5) MB, 19.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 833 ms: Scavenge 221.4 (244.5) -> 221.2 (254.5) MB, 26.2 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 861 ms: Scavenge 231.5 (255.0) -> 231.1 (260.5) MB, 19.9 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 892 ms: Scavenge 237.0 (260.5) -> 236.7 (270.5) MB, 26.3 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 920 ms: Scavenge 246.9 (270.5) -> 246.5 (276.0) MB, 20.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 951 ms: Scavenge 252.6 (276.0) -> 252.3 (286.0) MB, 25.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 979 ms: Scavenge 262.3 (286.0) -> 261.9 (292.0) MB, 20.3 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1014 ms: Scavenge 268.2 (292.0) -> 267.9 (301.5) MB, 29.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1046 ms: Scavenge 277.7 (302.0) -> 277.3 (308.0) MB, 22.4 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1077 ms: Scavenge 283.8 (308.0) -> 283.5 (317.5) MB, 25.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1105 ms: Scavenge 293.1 (317.5) -> 292.7 (323.5) MB, 20.7 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1135 ms: Scavenge 299.3 (323.5) -> 299.0 (333.0) MB, 24.9 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1164 ms: Scavenge 308.6 (333.0) -> 308.1 (339.5) MB, 20.9 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1194 ms: Scavenge 314.9 (339.5) -> 314.6 (349.0) MB, 25.0 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1222 ms: Scavenge 324.0 (349.0) -> 323.6 (355.5) MB, 21.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1253 ms: Scavenge 330.4 (355.5) -> 330.1 (364.5) MB, 25.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1282 ms: Scavenge 339.4 (364.5) -> 339.0 (371.0) MB, 22.2 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1315 ms: Scavenge 346.0 (371.0) -> 345.6 (380.0) MB, 25.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1413 ms: Mark-sweep 349.9 (380.0) -> 54.2 (305.0) MB, 5.8 / 0.0 ms (+ 87.5 ms in 73 steps since start of marking, biggest step 8.2 ms, walltime since start of marking 131 ms) finalize incremental marking via stack guard GC in old space requested
|
||||||
|
[20872:0x7f26f24c70d0] 1457 ms: Scavenge 65.8 (305.0) -> 65.1 (305.0) MB, 31.0 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1489 ms: Scavenge 69.9 (305.0) -> 69.7 (305.0) MB, 27.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1523 ms: Scavenge 80.9 (305.0) -> 80.4 (305.0) MB, 22.9 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1553 ms: Scavenge 85.5 (305.0) -> 85.3 (305.0) MB, 24.2 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1581 ms: Scavenge 96.3 (305.0) -> 95.7 (305.0) MB, 18.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1616 ms: Scavenge 101.1 (305.0) -> 100.9 (305.0) MB, 29.2 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1648 ms: Scavenge 111.6 (305.0) -> 111.1 (305.0) MB, 22.5 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1678 ms: Scavenge 116.7 (305.0) -> 116.5 (305.0) MB, 25.0 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1709 ms: Scavenge 127.0 (305.0) -> 126.5 (305.0) MB, 20.7 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1738 ms: Scavenge 132.3 (305.0) -> 132.1 (305.0) MB, 23.9 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1767 ms: Scavenge 142.4 (305.0) -> 141.9 (305.0) MB, 19.6 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1796 ms: Scavenge 147.9 (305.0) -> 147.7 (305.0) MB, 23.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1825 ms: Scavenge 157.8 (305.0) -> 157.3 (305.0) MB, 19.9 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1853 ms: Scavenge 163.5 (305.0) -> 163.2 (305.0) MB, 22.2 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1881 ms: Scavenge 173.2 (305.0) -> 172.7 (305.0) MB, 19.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1910 ms: Scavenge 179.1 (305.0) -> 178.8 (305.0) MB, 23.0 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1944 ms: Scavenge 188.6 (305.0) -> 188.1 (305.0) MB, 25.1 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 1979 ms: Scavenge 194.7 (305.0) -> 194.4 (305.0) MB, 28.4 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 2011 ms: Scavenge 204.0 (305.0) -> 203.6 (305.0) MB, 23.4 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 2041 ms: Scavenge 210.2 (305.0) -> 209.9 (305.0) MB, 23.8 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 2074 ms: Scavenge 219.4 (305.0) -> 219.0 (305.0) MB, 24.5 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 2105 ms: Scavenge 225.8 (305.0) -> 225.4 (305.0) MB, 24.7 / 0.0 ms allocation failure
|
||||||
|
[20872:0x7f26f24c70d0] 2138 ms: Scavenge 234.8 (305.0) -> 234.4 (305.0) MB, 23.1 / 0.0 ms allocation failure
|
||||||
|
[...SNIP...]
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
So the key observation here is that allocating the splay tree nodes in old space directly would avoid essentially all the overhead of copying objects around and reduce the number of minor GC cycles to the bare minimum (thereby reducing the pauses caused by the GC). So we came up with a mechanism called [_Allocation Site Pretenuring_][92] that would try to dynamically gather feedback at allocation sites when run in baseline code to decide whether a certain percent of the objects allocated here survives, and if so instrument the optimized code to allocate objects in old space directly - i.e. _pretenure the objects_.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ out/Release/d8 --trace-gc octane-splay.js
|
||||||
|
[20885:0x7ff4d7c220a0] 8 ms: Scavenge 2.7 (6.0) -> 2.6 (7.0) MB, 1.2 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 10 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.6 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 11 ms: Scavenge 3.6 (8.0) -> 3.6 (10.0) MB, 0.9 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 17 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.9 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 20 ms: Scavenge 5.6 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 26 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.5 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 34 ms: Scavenge 9.6 (17.0) -> 9.5 (28.0) MB, 6.8 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 48 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.6 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 64 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.2 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 96 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 19.6 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 153 ms: Scavenge 61.3 (81.5) -> 57.4 (93.5) MB, 27.9 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 432 ms: Scavenge 339.3 (364.5) -> 326.6 (364.5) MB, 12.7 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 666 ms: Scavenge 563.7 (592.5) -> 553.3 (595.5) MB, 20.5 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 825 ms: Mark-sweep 603.9 (644.0) -> 96.0 (528.0) MB, 4.0 / 0.0 ms (+ 92.5 ms in 51 steps since start of marking, biggest step 4.6 ms, walltime since start of marking 160 ms) finalize incremental marking via stack guard GC in old space requested
|
||||||
|
[20885:0x7ff4d7c220a0] 1068 ms: Scavenge 374.8 (528.0) -> 362.6 (528.0) MB, 19.1 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 1304 ms: Mark-sweep 460.1 (528.0) -> 102.5 (444.5) MB, 10.3 / 0.0 ms (+ 117.1 ms in 59 steps since start of marking, biggest step 7.3 ms, walltime since start of marking 200 ms) finalize incremental marking via stack guard GC in old space requested
|
||||||
|
[20885:0x7ff4d7c220a0] 1587 ms: Scavenge 374.2 (444.5) -> 361.6 (444.5) MB, 13.6 / 0.0 ms allocation failure
|
||||||
|
[20885:0x7ff4d7c220a0] 1828 ms: Mark-sweep 485.2 (520.0) -> 101.5 (519.5) MB, 3.4 / 0.0 ms (+ 102.8 ms in 58 steps since start of marking, biggest step 4.5 ms, walltime since start of marking 183 ms) finalize incremental marking via stack guard GC in old space requested
|
||||||
|
[20885:0x7ff4d7c220a0] 2028 ms: Scavenge 371.4 (519.5) -> 358.5 (519.5) MB, 12.1 / 0.0 ms allocation failure
|
||||||
|
[...SNIP...]
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
And indeed that essentially fixed the problem for the SplayLatency benchmark completely and boosted our score by over 250%!
|
||||||
|
|
||||||
|
[
|
||||||
|
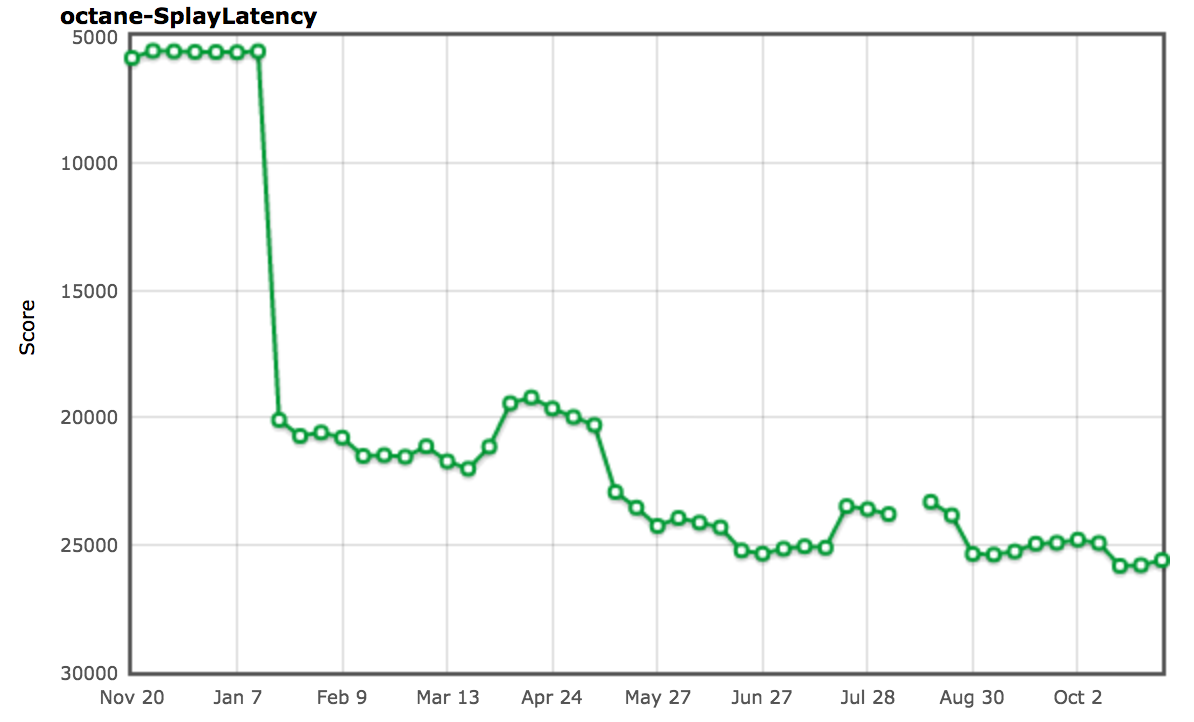
|
||||||
|
][93]
|
||||||
|
|
||||||
|
As mentioned in the [SIGPLAN paper][94] we had good reasons to believe that allocation site pretenuring might be a win for real world applications, and were really looking forward to seeing improvements and extending the mechanism to cover more than just object and array literals. But it didn’t take [long][95] [to][96] [realize][97] that allocation site pretenuring can have a pretty serious negative impact on real world application performance. We actually got a lot of negative press, including a shit storm from Ember.js developers and users, not only because of allocation site pretenuring, but that was big part of the story.
|
||||||
|
|
||||||
|
The fundamental problem with allocation site pretenuring as we learned are factories, which are very common in applications today (mostly because of frameworks, but also for other reasons), and assuming that your object factory is initially used to create the long living objects that form your object model and the views, which transitions the allocation site in your factory method(s) to _tenured_ state, and everything allocated from the factory immediately goes to old space. Now after the initial setup is done, your application starts doing stuff, and as part of that, allocates temporary objects from the factory, that now start polluting old space, eventually leading to expensive major garbage collection cycles, and other negative side effects like triggering incremental marking way too early.
|
||||||
|
|
||||||
|
So we started to reconsider the benchmark driven effort and started looking for real world driven solutions instead, which resulted in an effort called [Orinoco][98] with the goal to incrementally improve the garbage collector; part of that effort is a project called _unified heap_, which will try to avoid copying objects if almost everything in a page survives. I.e. on a high level: If new space is full of live objects, just mark all new space pages as belonging to old space now, and create a fresh new space from empty pages. This might not yield the same score on the SplayLatency benchmark, but it’s a lot better for real world use cases and it automatically adapts to the concrete use case. We are also considering _concurrent marking_ to offload the marking work to a separate thread and thus further reducing the negative impact of incremental marking on both latency and throughput.
|
||||||
|
|
||||||
|
### Cuteness break!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Breathe.
|
||||||
|
|
||||||
|
Ok, I think that should be sufficient to underline the point. I could go on pointing to even more examples where Octane driven improvements turned out to be a bad idea later, and maybe I’ll do that another day. But let’s stop right here for today…
|
||||||
|
|
||||||
|
### Conclusion
|
||||||
|
|
||||||
|
I hope it should be clear by now why benchmarks are generally a good idea, but are only useful to a certain level, and once you cross the line of _useful competition_, you’ll start wasting the time of your engineers or even start hurting your real world performance! If we are serious about performance for the web, we need to start judging browser by real world performance and not their ability to game four year old benchmarks. We need to start educating the (tech) press, or failing that, at least ignore them.
|
||||||
|
|
||||||
|
[
|
||||||
|
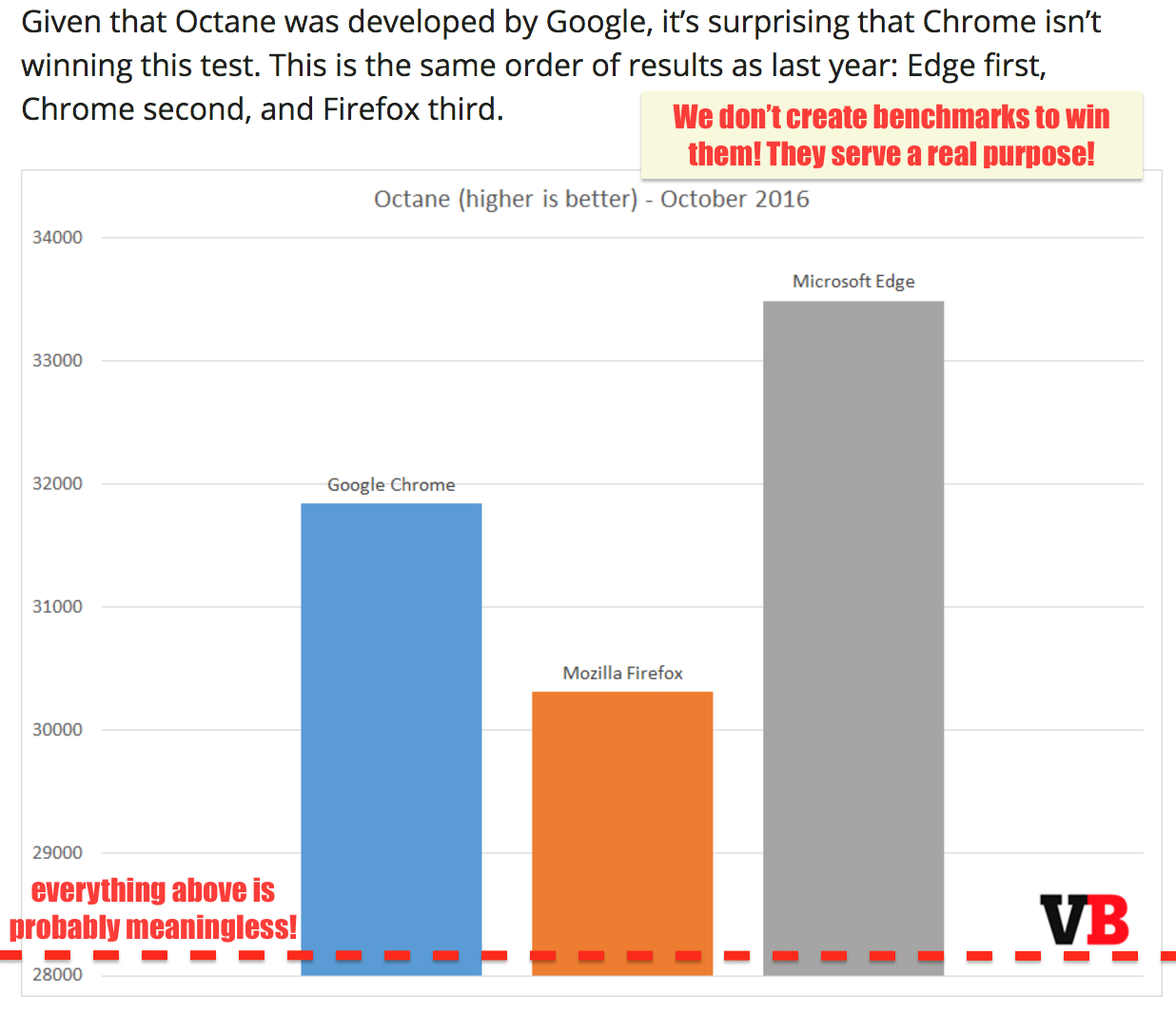
|
||||||
|
][99]
|
||||||
|
|
||||||
|
Noone is afraid of competition, but gaming potentially broken benchmarks is not really useful investment of engineering time. We can do a lot more, and take JavaScript to the next level. Let’s work on meaningful performance tests that can drive competition on areas of interest for the end user and the developer. Additionally let’s also drive meaningful improvements for server and tooling side code running in Node.js (either on V8 or ChakraCore)!
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
One closing comment: Don’t use traditional JavaScript benchmarks to compare phones. It’s really the most useless thing you can do, as the JavaScript performance often depends a lot on the software and not necessarily on the hardware, and Chrome ships a new version every six weeks, so whatever you measure in March maybe irrelevant already in April. And if there’s no way to avoid running something in a browser that assigns a number to a phone, then at least use a recent full browser benchmark that has at least something to do with what people will do with their browsers, i.e. consider [Speedometer benchmark][100].
|
||||||
|
|
||||||
|
Thank you!
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
I am Benedikt Meurer, a software engineer living in Ottobrunn, a municipality southeast of Munich, Bavaria, Germany. I received my diploma in applied computer science with electrical engineering from the Universität Siegen in 2007, and since then I have been working as a research associate at the Lehrstuhl für Compilerbau und Softwareanalyse (and the Lehrstuhl für Mikrosystementwurf in 2007/2008) for five years. In 2013 I joined Google to work on the V8 JavaScript Engine in the Munich office, where I am currently working as tech lead for the JavaScript execution optimization team.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks
|
||||||
|
|
||||||
|
作者:[Benedikt Meurer][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://benediktmeurer.de/
|
||||||
|
[1]:https://www.youtube.com/watch?v=PvZdTZ1Nl5o
|
||||||
|
[2]:https://twitter.com/s3ththompson
|
||||||
|
[3]:https://youtu.be/xCx4uC7mn6Y
|
||||||
|
[4]:https://twitter.com/tverwaes
|
||||||
|
[5]:https://youtu.be/xCx4uC7mn6Y
|
||||||
|
[6]:https://twitter.com/tverwaes
|
||||||
|
[7]:https://arewefastyet.com/#machine=12&view=single&suite=ss&subtest=cube&start=1343350217&end=1415382608
|
||||||
|
[8]:https://www.engadget.com/2016/03/08/galaxy-s7-and-s7-edge-review/
|
||||||
|
[9]:https://arewefastyet.com/#machine=29&view=single&suite=octane&subtest=MandreelLatency&start=1415924086&end=1446461709
|
||||||
|
[10]:https://arewefastyet.com/#machine=12&view=single&suite=octane&subtest=SplayLatency&start=1384889558&end=1415405874
|
||||||
|
[11]:http://venturebeat.com/2016/10/25/browser-benchmark-battle-october-2016-chrome-vs-firefox-vs-edge/3
|
||||||
|
[12]:https://tc39.github.io/ecma262/#sec-toprimitive
|
||||||
|
[13]:https://tc39.github.io/ecma262/#sec-ordinarytoprimitive
|
||||||
|
[14]:https://tc39.github.io/ecma262/#sec-object.prototype.valueof
|
||||||
|
[15]:https://tc39.github.io/ecma262/#sec-object.prototype.toString
|
||||||
|
[16]:https://tc39.github.io/ecma262/#sec-symbol.tostringtag
|
||||||
|
[17]:https://tc39.github.io/ecma262/#sec-toprimitive
|
||||||
|
[18]:https://tc39.github.io/ecma262/#sec-ordinarytoprimitive
|
||||||
|
[19]:https://tc39.github.io/ecma262/#sec-object.prototype.valueof
|
||||||
|
[20]:https://tc39.github.io/ecma262/#sec-object.prototype.toString
|
||||||
|
[21]:https://tc39.github.io/ecma262/#sec-symbol.tostringtag
|
||||||
|
[22]:https://en.wikipedia.org/wiki/JavaScript
|
||||||
|
[23]:https://nodejs.org/
|
||||||
|
[24]:https://webkit.org/perf/sunspider/sunspider.html
|
||||||
|
[25]:http://krakenbenchmark.mozilla.org/
|
||||||
|
[26]:https://developers.google.com/octane
|
||||||
|
[27]:http://browserbench.org/JetStream
|
||||||
|
[28]:https://www.youtube.com/watch?v=PvZdTZ1Nl5o
|
||||||
|
[29]:http://asmjs.org/
|
||||||
|
[30]:https://github.com/kripken/emscripten
|
||||||
|
[31]:http://beta.unity3d.com/jonas/AngryBots
|
||||||
|
[32]:https://youtu.be/xCx4uC7mn6Y
|
||||||
|
[33]:http://youtube.com/
|
||||||
|
[34]:http://browserbench.org/Speedometer
|
||||||
|
[35]:http://browserbench.org/Speedometer
|
||||||
|
[36]:http://todomvc.com/
|
||||||
|
[37]:https://twitter.com/bmeurer/status/806927160300556288
|
||||||
|
[38]:https://youtu.be/xCx4uC7mn6Y
|
||||||
|
[39]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js
|
||||||
|
[40]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js
|
||||||
|
[41]:https://en.wikipedia.org/wiki/Loop_splitting
|
||||||
|
[42]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js
|
||||||
|
[43]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/string-tagcloud.js
|
||||||
|
[44]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/string-tagcloud.js#L199
|
||||||
|
[45]:https://tc39.github.io/ecma262/#sec-json.parse
|
||||||
|
[46]:https://tc39.github.io/ecma262/#sec-json.parse
|
||||||
|
[47]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js
|
||||||
|
[48]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js#L239
|
||||||
|
[49]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js#L151
|
||||||
|
[50]:https://tc39.github.io/ecma262/#sec-math.sin
|
||||||
|
[51]:https://tc39.github.io/ecma262/#sec-math.cos
|
||||||
|
[52]:https://arewefastyet.com/#machine=12&view=single&suite=ss&subtest=cube&start=1343350217&end=1415382608
|
||||||
|
[53]:https://docs.google.com/document/d/1VoYBhpDhJC4VlqMXCKvae-8IGuheBGxy32EOgC2LnT8
|
||||||
|
[54]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/resources/driver-TEMPLATE.html#L70
|
||||||
|
[55]:https://www.engadget.com/2016/03/08/galaxy-s7-and-s7-edge-review/
|
||||||
|
[56]:http://browserbench.org/Speedometer
|
||||||
|
[57]:https://twitter.com/thealphanerd
|
||||||
|
[58]:https://blog.mozilla.org/blog/2010/09/14/release-the-kraken-2
|
||||||
|
[59]:https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator.js
|
||||||
|
[60]:https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator.js
|
||||||
|
[61]:https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator-data.js#L687
|
||||||
|
[62]:https://tc39.github.io/ecma262/#sec-math.round
|
||||||
|
[63]:https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator-data.js#L566
|
||||||
|
[64]:https://graphics.stanford.edu/~seander/bithacks.html#ModulusDivisionEasy
|
||||||
|
[65]:https://docs.google.com/presentation/d/1wZVIqJMODGFYggueQySdiA3tUYuHNMcyp_PndgXsO1Y
|
||||||
|
[66]:https://developers.google.com/octane
|
||||||
|
[67]:https://blog.chromium.org/2012/08/octane-javascript-benchmark-suite-for.html
|
||||||
|
[68]:https://blog.chromium.org/2013/11/announcing-octane-20.html
|
||||||
|
[69]:http://www.typescriptlang.org/
|
||||||
|
[70]:http://asmjs.org/
|
||||||
|
[71]:https://developers.google.com/octane/benchmark
|
||||||
|
[72]:https://github.com/kripken/emscripten
|
||||||
|
[73]:http://emberjs.com/
|
||||||
|
[74]:https://angularjs.org/
|
||||||
|
[75]:https://github.com/hecht-software/box2dweb
|
||||||
|
[76]:https://github.com/v8/v8/blob/5124589642ba12228dcd66a8cb8c84c986a13f35/src/runtime/runtime-object.cc#L884
|
||||||
|
[77]:https://tc39.github.io/ecma262/#sec-abstract-relational-comparison
|
||||||
|
[78]:https://github.com/v8/v8/blob/5124589642ba12228dcd66a8cb8c84c986a13f35/src/x64/code-stubs-x64.cc#L2495
|
||||||
|
[79]:https://tc39.github.io/ecma262/#sec-abstract-relational-comparison
|
||||||
|
[80]:https://codereview.chromium.org/1355113002
|
||||||
|
[81]:http://asmjs.org/
|
||||||
|
[82]:https://github.com/kripken/emscripten
|
||||||
|
[83]:http://bulletphysics.org/wordpress/
|
||||||
|
[84]:http://www.mandreel.com/
|
||||||
|
[85]:https://bugzilla.mozilla.org/show_bug.cgi?id=1162272
|
||||||
|
[86]:https://docs.google.com/presentation/d/1214p4CFjsF-NY4z9in0GEcJtjbyVQgU0A-UqEvovzCs
|
||||||
|
[87]:https://codereview.chromium.org/1102523003
|
||||||
|
[88]:https://arewefastyet.com/#machine=29&view=single&suite=octane&subtest=MandreelLatency&start=1415924086&end=1446461709
|
||||||
|
[89]:https://github.com/chromium/octane/blob/master/splay.js
|
||||||
|
[90]:https://github.com/chromium/octane/blob/master/splay.js#L85
|
||||||
|
[91]:http://www.memorymanagement.org/glossary/g.html
|
||||||
|
[92]:https://research.google.com/pubs/pub43823.html
|
||||||
|
[93]:https://arewefastyet.com/#machine=12&view=single&suite=octane&subtest=SplayLatency&start=1384889558&end=1415405874
|
||||||
|
[94]:https://research.google.com/pubs/pub43823.html
|
||||||
|
[95]:https://bugs.chromium.org/p/v8/issues/detail?id=2935
|
||||||
|
[96]:https://bugs.chromium.org/p/chromium/issues/detail?id=367694
|
||||||
|
[97]:https://bugs.chromium.org/p/v8/issues/detail?id=3665
|
||||||
|
[98]:http://v8project.blogspot.de/2016/04/jank-busters-part-two-orinoco.html
|
||||||
|
[99]:http://venturebeat.com/2016/10/25/browser-benchmark-battle-october-2016-chrome-vs-firefox-vs-edge/3/
|
||||||
|
[100]:http://browserbench.org/Speedometer
|
||||||
406
sources/tech/20161220 TypeScript: the missing introduction.md
Normal file
406
sources/tech/20161220 TypeScript: the missing introduction.md
Normal file
@ -0,0 +1,406 @@
|
|||||||
|
TypeScript: the missing introduction
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
**The following is a guest post by James Henry ([@MrJamesHenry][8]). I am a member of the ESLint Core Team, and a TypeScript evangelist. I am working with Todd on [UltimateAngular][9] to bring you more award-winning Angular and TypeScript courses.**
|
||||||
|
|
||||||
|
> The purpose of this article is to offer an introduction to how we can think about TypeScript, and its role in supercharging our **JavaScript** development.
|
||||||
|
>
|
||||||
|
> We will also try and come up with our own reasonable definitions for a lot of the buzzwords surrounding types and compilation.
|
||||||
|
|
||||||
|
There is huge amount of great stuff in the TypeScript project that we won’t be able to cover within the scope of this blog post. Please read the [official documentation][15] to learn more, and check out the [TypeScript courses over on UltimateAngular][16] to go from total beginner to TypeScript Pro!
|
||||||
|
|
||||||
|
### [Table of contents][17]
|
||||||
|
|
||||||
|
* [Background][10]
|
||||||
|
* [Getting to grips with the buzzwords][11]
|
||||||
|
* [JavaScript - interpreted or compiled?][1]
|
||||||
|
* [Run Time vs Compile Time][2]
|
||||||
|
* [The TypeScript Compiler][3]
|
||||||
|
* [Dynamic vs Static Typing][4]
|
||||||
|
* [TypeScript’s role in our JavaScript workflow][12]
|
||||||
|
* [Our source file is our document, TypeScript is our Spell Check][5]
|
||||||
|
* [TypeScript is a tool which enables other tools][13]
|
||||||
|
* [What is an Abstract Syntax Tree (AST)?][6]
|
||||||
|
* [Example: Renaming symbols in VS Code][7]
|
||||||
|
* [Summary][14]
|
||||||
|
|
||||||
|
### [Background][18]
|
||||||
|
|
||||||
|
TypeScript is an amazingly powerful tool, and really quite easy to get started with.
|
||||||
|
|
||||||
|
It can, however, come across as more complex than it is, because it may simultaneously be introducing us to a whole host of technical concepts related to our JavaScript programs that we may not have considered before.
|
||||||
|
|
||||||
|
Whenever we stray into the area of talking about types, compilers, etc. things can get really confusing, really fast.
|
||||||
|
|
||||||
|
This article is designed as a “what you need to know” guide for a lot of these potentially confusing concepts, so that by the time you dive into the “Getting Started” style tutorials, you are feeling confident with the various themes and terminology that surround the topic.
|
||||||
|
|
||||||
|
### [Getting to grips with the buzzwords][19]
|
||||||
|
|
||||||
|
There is something about running our code in a web browser that makes us _feel_ differently about how it works. “It’s not compiled, right?”, “Well, I definitely know there aren’t any types…”
|
||||||
|
|
||||||
|
Things get even more interesting when we consider that both of those statements are both correct and incorrect at the same time - depending on the context and how you define some of these concepts.
|
||||||
|
|
||||||
|
As a first step, we are going to do exactly that!
|
||||||
|
|
||||||
|
#### [JavaScript - interpreted or compiled?][20]
|
||||||
|
|
||||||
|
Traditionally, developers will often think about a language being a “compiled language” when they are the ones responsible for compiling their own programs.
|
||||||
|
|
||||||
|
> In basic terms, when we compile a program we are converting it from the form we wrote it in, to the form it actually gets run in.
|
||||||
|
|
||||||
|
In a language like Golang, for example, you have a command line tool called `go build`which allows you to compile your `.go` file into a lower-level representation of the code, which can then be executed and run:
|
||||||
|
|
||||||
|
```
|
||||||
|
# We manually compile our .go file into something we can run
|
||||||
|
# using the command line tool "go build"
|
||||||
|
go build ultimate-angular.go
|
||||||
|
# ...then we execute it!
|
||||||
|
./ultimate-angular
|
||||||
|
```
|
||||||
|
|
||||||
|
As authors of JavaScript (ignoring our love of new-fangled build tools and module loaders for a moment), we don’t have such a fundamental compilation step in our workflow.
|
||||||
|
|
||||||
|
We write some code, and load it up in a browser using a `<script>` tag (or a server-side environment such as node.js), and it just runs.
|
||||||
|
|
||||||
|
**Ok, so JavaScript isn’t compiled - it must be an interpreted language, right?**
|
||||||
|
|
||||||
|
Well, actually, all we have determined so far is that JavaScript is not something that we compile _ourselves_, but we’ll come back to this after we briefly look an example of an “interpreted language”.
|
||||||
|
|
||||||
|
> An interpreted computer program is one that is executed like a human reads a book, starting at the top and working down line-by-line.
|
||||||
|
|
||||||
|
The classic example of interpreted programs that we are already familiar with are bash scripts. The bash interpreter in our terminal reads our commands in line-by-line and executes them.
|
||||||
|
|
||||||
|
Now, if we return to thinking about JavaScript and whether or not it is interpreted or compiled, intuitively there are some things about it that just don’t add up when we think about reading and executing a program line-by-line (our simple definition of “interpreted”).
|
||||||
|
|
||||||
|
Take this code as an example:
|
||||||
|
|
||||||
|
```
|
||||||
|
hello();
|
||||||
|
function hello() {
|
||||||
|
console.log('Hello!');
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
This is perfectly valid JavaScript which will print the word “Hello!”, but we have used the `hello()` function before we have even defined it! A simple line-by-line execution of this program would just not be possible, because `hello()` on line 1 does not have any meaning until we reach its declaration on line 2.
|
||||||
|
|
||||||
|
The reason that this, and many other concepts like it, is possible in JavaScript is because our code is actually compiled by the so called “JavaScript engine”, or environment, before it is executed. The exact nature of this compilation process will depend on the specific implementation (e.g. V8, which powers node.js and Google Chrome, will behave slightly differently to SpiderMonkey, which is used by FireFox).
|
||||||
|
|
||||||
|
We will not dig any further into the subtleties of defining “compiled vs interpreted” here (there are a LOT).
|
||||||
|
|
||||||
|
> It’s useful to always keep in mind that the JavaScript code we write is already not the actual code that will be executed by our users, even when we simply have a `<script>` tag in an HTML document.
|
||||||
|
|
||||||
|
#### [Run Time vs Compile Time][21]
|
||||||
|
|
||||||
|
Now that we have properly introduced the idea that compiling a program and running a program are two distinct phases, the terms “Run Time” and “Compile Time” become a little easier to reason about.
|
||||||
|
|
||||||
|
When something happens at **Compile Time**, it is happening during the conversion of our code from what we wrote in our editor/IDE to some other form.
|
||||||
|
|
||||||
|
When something happens at **Run Time**, it is happening during the actual execution of our program. For example, our `hello()` function above is executed at “run time”.
|
||||||
|
|
||||||
|
#### [The TypeScript Compiler][22]
|
||||||
|
|
||||||
|
Now that we understand these key phases in the lifecycle of a program, we can introduce the **TypeScript compiler**.
|
||||||
|
|
||||||
|
The TypeScript compiler is at the core of how TypeScript is able to help us when we write our code. Instead of just including our JavaScript in a `<script>` tag, for example, we will first pass it through the TypeScript compiler so that it can give us helpful hints on how we can improve our program before it runs.
|
||||||
|
|
||||||
|
> We can think about this new step as our own personal “compile time”, which will help us ensure that our program is written in the way we intended, before it even reaches the main JavaScript engine.
|
||||||
|
|
||||||
|
It is a similar process to the one shown in the Golang example above, except that the TypeScript compiler just provides hints based on how we have written our program, and doesn’t turn it into a lower-level executable - it produces pure JavaScript.
|
||||||
|
|
||||||
|
```
|
||||||
|
# One option for passing our source .ts file through the TypeScript
|
||||||
|
# compiler is to use the command line tool "tsc"
|
||||||
|
tsc ultimate-angular.ts
|
||||||
|
|
||||||
|
# ...this will produce a .js file of the same name
|
||||||
|
# i.e. ultimate-angular.js
|
||||||
|
```
|
||||||
|
|
||||||
|
There are many great posts about the different options for integrating the TypeScript compiler into your existing workflow, including the [official documentation][23]. It is beyond the scope of this article to go into those options here.
|
||||||
|
|
||||||
|
#### [Dynamic vs Static Typing][24]
|
||||||
|
|
||||||
|
Just like with “compiled vs interpreted” programs, the existing material on “dynamic vs static typing” can be incredibly confusing.
|
||||||
|
|
||||||
|
Let’s start by taking a step back and refreshing our memory on how much we _already_understand about types from our existing JavaScript code.
|
||||||
|
|
||||||
|
We have the following program:
|
||||||
|
|
||||||
|
```
|
||||||
|
var name = 'James';
|
||||||
|
var sum = 1 + 2;
|
||||||
|
```
|
||||||
|
|
||||||
|
How would we describe this code to somebody?
|
||||||
|
|
||||||
|
“We have declared a variable called `name`, which is assigned the **string** of ‘James’, and we have declared the variable `sum`, which is assigned the value we get when we add the **number** `1` to the **number** `2`.”
|
||||||
|
|
||||||
|
Even in such a simple program, we have already highlighted two of JavaScript’s fundamental types: String and Number.
|
||||||
|
|
||||||
|
As with our introduction to compilation above, we are not going to get bogged down in the academic subtleties of types in programming languages - the key thing is understanding what it means for our JavaScript so that we can then extend it to properly understanding TypeScript.
|
||||||
|
|
||||||
|
We know from our traditional nightly ritual of reading the [latest ECMAScript specification][25]**(LOL, JK - “wat’s an ECMA?”)**, that it makes numerous references to types and their usage in JavaScript.
|
||||||
|
|
||||||
|
Taken directly from the official spec:
|
||||||
|
|
||||||
|
> An ECMAScript language type corresponds to values that are directly manipulated by an ECMAScript programmer using the ECMAScript language.
|
||||||
|
>
|
||||||
|
> The ECMAScript language types are Undefined, Null, Boolean, String, Symbol, Number, and Object.
|
||||||
|
|
||||||
|
We can see that the JavaScript language officially has 7 types, of which we have likely used 6 in just about every real-world program we have ever written (Symbol was first introduced in ES2015, a.k.a. ES6).
|
||||||
|
|
||||||
|
Now, let’s think a bit more deeply about our “name and sum” JavaScript program above.
|
||||||
|
|
||||||
|
We could take our `name` variable which is currently assigned the **string** ‘James’, and reassign it to the current value of our second variable `sum`, which is the **number** `3`.
|
||||||
|
|
||||||
|
```
|
||||||
|
var name = 'James';
|
||||||
|
var sum = 1 + 2;
|
||||||
|
|
||||||
|
name = sum;
|
||||||
|
```
|
||||||
|
|
||||||
|
The `name` variable started out “holding” a string, but now it holds a number. This highlights a fundamental quality of variables and types in JavaScript:
|
||||||
|
|
||||||
|
The _value_ ‘James’ is always one type - a string - but the `name` variable can be assigned any value, and therefore any type. The exact same is true in the case of the `sum`assignment: the _value_ `1` is always a number type, but the `sum` variable could be assigned any possible value.
|
||||||
|
|
||||||
|
> In JavaScript, it is _values_, not variables, which have types. Variables can hold any value, and therefore any _type_, at any time.
|
||||||
|
|
||||||
|
For our purposes, this also just so happens to be the very definition of a **“dynamically typed language”**!
|
||||||
|
|
||||||
|
By contrast, we can think of a **“statically typed language”** as being one in which we can (and very likely have to) associate type information with a particular variable:
|
||||||
|
|
||||||
|
```
|
||||||
|
var name: string = 'James';
|
||||||
|
```
|
||||||
|
|
||||||
|
In this code, we are better able to explicitly declare our _intentions_ for the `name` variable - we want it to always be used as a string.
|
||||||
|
|
||||||
|
And guess what? We have just seen our first bit of TypeScript in action!
|
||||||
|
|
||||||
|
When we reflect on our own code (no programming pun intended), we can likely conclude that even when we are working with dynamic languages like JavaScript, in almost all cases we should have pretty clear intentions for the usage of our variables and function parameters when we first define them. If those variables and parameters are reassigned to hold values of _different_ types to ones we first assigned them to, it is possible that something is not working out as we planned.
|
||||||
|
|
||||||
|
> One great power that the static type annotations from TypeScript give us, as JavaScript authors, is the ability to clearly express our intentions for our variables.
|
||||||
|
>
|
||||||
|
> This improved clarity benefits not only the TypeScript compiler, but also our colleagues and future selves when they come to read and understand our code. Code is _read_ far more than it is written.
|
||||||
|
|
||||||
|
### [TypeScript’s role in our JavaScript workflow][26]
|
||||||
|
|
||||||
|
We have started to see why it is often said that TypeScript is just JavaScript + Static Types. Our so-called “type annotation” `: string` for our `name` variable is used by TypeScript at _compile time_ (in other words, when we pass our code through the TypeScript compiler) to make sure that the rest of the code is true to our original intention.
|
||||||
|
|
||||||
|
Let’s take a look at our program again, and add another explicit annotation, this time for our `sum` variable:
|
||||||
|
|
||||||
|
```
|
||||||
|
var name: string = 'James';
|
||||||
|
var sum: number = 1 + 2;
|
||||||
|
|
||||||
|
name = sum;
|
||||||
|
```
|
||||||
|
|
||||||
|
If we let TypeScript take a look at this code for us, we will now get an error `Type 'number' is not assignable to type 'string'` for our `name = sum` assignment, and we are appropriately warned against shipping _potentially_ problematic code to be executed by our users.
|
||||||
|
|
||||||
|
> Importantly, we can choose to ignore errors from the TypeScript compiler if we want to, because it is just a tool which gives us feedback on our JavaScript code before we ship it to our users.
|
||||||
|
|
||||||
|
The final JavaScript code that the TypeScript compiler will output for us will look exactly the same as our original source above:
|
||||||
|
|
||||||
|
```
|
||||||
|
var name = 'James';
|
||||||
|
var sum = 1 + 2;
|
||||||
|
|
||||||
|
name = sum;
|
||||||
|
```
|
||||||
|
|
||||||
|
The type annotations are all removed for us automatically, and we can now run our code.
|
||||||
|
|
||||||
|
> NOTE: In this example, the TypeScript Compiler would have been able to offer us the exact same error even if we hadn’t provided the explicit type annotations `: string` and `: number`.
|
||||||
|
>
|
||||||
|
> TypeScript is very often able to just _infer_ the type of a variable from the way we have used it!
|
||||||
|
|
||||||
|
#### [Our source file is our document, TypeScript is our Spell Check][27]
|
||||||
|
|
||||||
|
A great analogy for TypeScript’s relationship with our source code, is that of Spell Check’s relationship to a document we are writing in Microsoft Word, for example.
|
||||||
|
|
||||||
|
There are three key commonalities between the two examples:
|
||||||
|
|
||||||
|
1. **It can tell us when stuff we have written is objectively, flat-out wrong:**
|
||||||
|
* _Spell Check_: “we have written a word that does not exist in the dictionary”
|
||||||
|
* _TypeScript_: “we have referenced a symbol (e.g. a variable), which is not declared in our program”
|
||||||
|
|
||||||
|
2. **It can suggest that what we have written _might be_ wrong:**
|
||||||
|
* _Spell Check_: “the tool is not able to fully infer the meaning of a particular clause and suggests rewriting it”
|
||||||
|
* _TypeScript_: “the tool is not able to fully infer the type of a particular variable and warns against using it as is”
|
||||||
|
|
||||||
|
3. **Our source can be used for its original purpose, regardless of if there are errors from the tool or not:**
|
||||||
|
* _Spell Check_: “even if your document has lots of Spell Check errors, you can still print it out and “use” it as document”
|
||||||
|
* _TypeScript_: “even if your source code has TypeScript errors, it will still produce JavaScript code which you can execute”
|
||||||
|
|
||||||
|
### [TypeScript is a tool which enables other tools][28]
|
||||||
|
|
||||||
|
The TypeScript compiler is made up of a couple of different parts or phases. We are going to finish off this article by looking at how one of those parts - **the Parser** - offers us the chance to build _additional developer tools_ on top of what TypeScript already does for us.
|
||||||
|
|
||||||
|
The result of the “parser step” of the compilation process is what is called an **Abstract Syntax Tree**, or **AST** for short.
|
||||||
|
|
||||||
|
#### [What is an Abstract Syntax Tree (AST)?][29]
|
||||||
|
|
||||||
|
We write our programs in a free text form, as this is a great way for us humans to interact with our computers to get them to do the stuff we want them to. We are not so great at manually composing complex data structures!
|
||||||
|
|
||||||
|
However, free text is actually a pretty tricky thing to work with within a compiler in any kind of reasonable way. It may contain things which are unnecessary for the program to function, such as whitespace, or there may be parts which are ambiguous.
|
||||||
|
|
||||||
|
For this reason, we ideally want to convert our programs into a data structure which maps out all of the so-called “tokens” we have used, and where they slot into our program.
|
||||||
|
|
||||||
|
This data structure is exactly what an AST is!
|
||||||
|
|
||||||
|
An AST could be represented in a number of different ways, but let’s take a look at a quick example using our old buddy JSON.
|
||||||
|
|
||||||
|
If we have this incredibly basic source code:
|
||||||
|
|
||||||
|
```
|
||||||
|
var a = 1;
|
||||||
|
```
|
||||||
|
|
||||||
|
The (simplified) output of the TypeScript Compiler’s **Parser** phase will be the following AST:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"pos": 0,
|
||||||
|
"end": 10,
|
||||||
|
"kind": 256,
|
||||||
|
"text": "var a = 1;",
|
||||||
|
"statements": [
|
||||||
|
{
|
||||||
|
"pos": 0,
|
||||||
|
"end": 10,
|
||||||
|
"kind": 200,
|
||||||
|
"declarationList": {
|
||||||
|
"pos": 0,
|
||||||
|
"end": 9,
|
||||||
|
"kind": 219,
|
||||||
|
"declarations": [
|
||||||
|
{
|
||||||
|
"pos": 3,
|
||||||
|
"end": 9,
|
||||||
|
"kind": 218,
|
||||||
|
"name": {
|
||||||
|
"pos": 3,
|
||||||
|
"end": 5,
|
||||||
|
"text": "a"
|
||||||
|
},
|
||||||
|
"initializer": {
|
||||||
|
"pos": 7,
|
||||||
|
"end": 9,
|
||||||
|
"kind": 8,
|
||||||
|
"text": "1"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
The objects in our in our AST are called _nodes_.
|
||||||
|
|
||||||
|
#### [Example: Renaming symbols in VS Code][30]
|
||||||
|
|
||||||
|
Internally, the TypeScript Compiler will use the AST it has produced to power a couple of really important things such as the actual **Type Checking** that occurs when we compile our programs.
|
||||||
|
|
||||||
|
But it does not stop there!
|
||||||
|
|
||||||
|
> We can use the AST to develop our own tooling on top of TypeScript, such as linters, formatters, and analysis tools.
|
||||||
|
|
||||||
|
One great example of a tool built on top of this AST generation is the **Language Server**.
|
||||||
|
|
||||||
|
It is beyond the scope of this article to dive into how the Language Server works, but one absolutely killer feature that it enables for us when we write our programs is that of “renaming symbols”.
|
||||||
|
|
||||||
|
Let’s say that we have the following source code:
|
||||||
|
|
||||||
|
```
|
||||||
|
// The name of the author is James
|
||||||
|
var first_name = 'James';
|
||||||
|
console.log(first_name);
|
||||||
|
```
|
||||||
|
|
||||||
|
After a _thorough_ code review and appropriate bikeshedding, it is decided that we should switch our variable naming convention to use camel case instead of the snake case we are currently using.
|
||||||
|
|
||||||
|
In our code editors, we have long been able to select multiple occurrences of the same text and use multiple cursors to change all of them at once - awesome!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Ah! We have fallen into one of the classic traps that appear when we continue to treat our programs as pieces of text.
|
||||||
|
|
||||||
|
The word “name” in our comment, which we did not want to change, got caught up in our manual matching process. We can see how risky such a strategy would be for code changes in a real-world application!
|
||||||
|
|
||||||
|
As we learned above, when something like TypeScript generates an AST for our program behind the scenes, it no longer has to interact with our program as if it were free text - each token has its own place in the AST, and its usage is clearly mapped.
|
||||||
|
|
||||||
|
We can take advantage of this directly in VS Code using the “rename symbol” option when we right click on our `first_name` variable (TypeScript Language Server plugins are available for other editors).
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Much better! Now our `first_name` variable is the only thing that will be changed, and this change will even happen across multiple files in our project if applicable (as with exported and imported values)!
|
||||||
|
|
||||||
|
### [Summary][31]
|
||||||
|
|
||||||
|
Phew! We have covered a lot in this post.
|
||||||
|
|
||||||
|
We cut through all of the academic distractions to decide on practical definitions for a lot of the terminology that surrounds any discussion on compilers and types.
|
||||||
|
|
||||||
|
We looked at compiled vs interpreted languages, run time vs compile time, dynamic vs static typing, and how Abstract Syntax Trees give us a more optimal way to build tooling for our programs.
|
||||||
|
|
||||||
|
Importantly, we provided a way of thinking about TypeScript as a tool for our _JavaScript_development, and how it in turn can be built upon to offer even more amazing utilities, such as renaming symbols as a way of refactoring code.
|
||||||
|
|
||||||
|
Come join us over on [UltimateAngular][32] to continue the journey and go from total beginner to TypeScript Pro!
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
I'm Todd, I teach the world Angular through @UltimateAngular. Conference speaker and Developer Expert at Google.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://toddmotto.com/typescript-the-missing-introduction
|
||||||
|
|
||||||
|
作者:[Todd][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftoddmotto.com%2Ftypescript-the-missing-introduction%3Futm_source%3Djavascriptweekly%26utm_medium%3Demail&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=toddmotto&tw_p=followbutton
|
||||||
|
[1]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||||
|
[2]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||||
|
[3]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||||
|
[4]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||||
|
[5]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||||
|
[6]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||||
|
[7]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||||
|
[8]:https://twitter.com/MrJamesHenry
|
||||||
|
[9]:https://ultimateangular.com/courses
|
||||||
|
[10]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||||
|
[11]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||||
|
[12]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||||
|
[13]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||||
|
[14]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||||
|
[15]:http://www.typescriptlang.org/docs
|
||||||
|
[16]:https://ultimateangular.com/courses#typescript
|
||||||
|
[17]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#table-of-contents
|
||||||
|
[18]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||||
|
[19]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||||
|
[20]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||||
|
[21]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||||
|
[22]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||||
|
[23]:http://www.typescriptlang.org/docs
|
||||||
|
[24]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||||
|
[25]:http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf
|
||||||
|
[26]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||||
|
[27]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||||
|
[28]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||||
|
[29]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||||
|
[30]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||||
|
[31]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||||
|
[32]:https://ultimateangular.com/courses#typescript
|
||||||
@ -0,0 +1,137 @@
|
|||||||
|
Will Android do for the IoT what it did for mobile?
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Android Things gives the IoT Wings
|
||||||
|
|
||||||
|
### My first 24 hours with Android Things
|
||||||
|
|
||||||
|
Just when I was in the middle of an Android based IoT commercial project running on a Raspberry Pi 3, something awesome happened. Google released the first preview of [Android Things][1], their SDK targeted specifically at (initially) 3 SBC’s (Single Board Computers) — the Pi 3, the Intel Edison and the NXP Pico. To say I was struggling is a bit of an understatement — without even an established port of Android to the Pi, we were at the mercy of the various quirks and omissions of the well-meaning but problematic homebrew distro brigade. One of these problems was a deal breaker too — no touchscreen support, not even for the official one sold by [Element14][2]. I had an idea Android was heading for the Pi already, and earlier a mention in a [commit to the AOSP project from Google][3] got everyone excited for a while. So when, on 12th Dec 2016, without much fanfare I might add, Google announced “Android Things” plus a downloadable SDK, I dived in with both hands, a map and a flashlight, and hung a “do not disturb” sign on my door…
|
||||||
|
|
||||||
|
### Questions?
|
||||||
|
|
||||||
|
I had many questions regarding Googles Android on the Pi, having done extensive work with Android previously and a few Pi projects, including being involved right now in the one mentioned. I’ll try to address these as I proceed, but the first and biggest was answered right away — there is full Android Studio support and the Pi becomes just another regular ADB-addressable device on your list. Yay! The power, convenience and sheer ease of use we get within Android Studio is available at last to real IoT hardware, so we get all the layout previews, debug system, source checkers, automated tests etc. I can’t stress this enough. Up until now, most of my work onboard the Pi had been in Python having SSH’d in using some editor running on the Pi (MC if you really want to know). This worked, and no doubt hardcore Pi/Python heads could point out far better ways of working, but it really felt like I’d timewarped back to the 80’s in terms of software development. My projects involved writing Android software on handsets which controlled the Pi, so this rubbed salt in the wound — I was using Android Studio for “real” Android work, and SSH for the rest. That’s all over now.
|
||||||
|
|
||||||
|
All samples are for the 3 SBC’s, of which the the Pi 3 is just one. The Build.DEVICE constant lets you determine this at runtime, so you see lots of code like:
|
||||||
|
|
||||||
|
```
|
||||||
|
public static String getGPIOForButton() {
|
||||||
|
switch (Build.DEVICE) {
|
||||||
|
case DEVICE_EDISON_ARDUINO:
|
||||||
|
return "IO12";
|
||||||
|
case DEVICE_EDISON:
|
||||||
|
return "GP44";
|
||||||
|
case DEVICE_RPI3:
|
||||||
|
return "BCM21";
|
||||||
|
case DEVICE_NXP:
|
||||||
|
return "GPIO4_IO20";
|
||||||
|
default:
|
||||||
|
throw new IllegalStateException(“Unknown Build.DEVICE “ + Build.DEVICE);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Of keen interest is the GPIO handling. Since I’m only familiar with the Pi, I can only assume the other SBCs work the same way, but this is the set of pins which can be defined as inputs/outputs and is the main interface to the physical outside world. The Pi Linux based OS distros have full and easy support via read and write methods in Python, but for Android you’d have to use the NDK to write C++ drivers, and talk to these via JNI in Java. Not that difficult, but something else to maintain in your build chain. The Pi also designates 2 pins for I2C, the clock and the data, so extra work would be needed handling those. I2C is the really cool bus-addressable system which turns many separate pins of data into one by serialising it. So here’s the kicker — all that’s done directly in Android Things for you. You just _read()_and _write() _to/from whatever GPIO pin you need, and I2C is as easy as this:
|
||||||
|
|
||||||
|
```
|
||||||
|
public class HomeActivity extends Activity {
|
||||||
|
// I2C Device Name
|
||||||
|
private static final String I2C_DEVICE_NAME = ...;
|
||||||
|
// I2C Slave Address
|
||||||
|
private static final int I2C_ADDRESS = ...;
|
||||||
|
|
||||||
|
private I2cDevice mDevice;
|
||||||
|
|
||||||
|
@Override
|
||||||
|
protected void onCreate(Bundle savedInstanceState) {
|
||||||
|
super.onCreate(savedInstanceState);
|
||||||
|
// Attempt to access the I2C device
|
||||||
|
try {
|
||||||
|
PeripheralManagerService manager = new PeripheralManagerService();
|
||||||
|
mDevice = manager.openI2cDevice(I2C_DEVICE_NAME, I2C_ADDRESS)
|
||||||
|
} catch (IOException e) {
|
||||||
|
Log.w(TAG, "Unable to access I2C device", e);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
protected void onDestroy() {
|
||||||
|
super.onDestroy();
|
||||||
|
|
||||||
|
if (mDevice != null) {
|
||||||
|
try {
|
||||||
|
mDevice.close();
|
||||||
|
mDevice = null;
|
||||||
|
} catch (IOException e) {
|
||||||
|
Log.w(TAG, "Unable to close I2C device", e);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### What version of Android is Android Things based on?
|
||||||
|
|
||||||
|
This looks to be Android 7.0, which is fantastic because we get all the material design UI, the optimisations, the security hardening and so on from all the previous versions of Android. It also raises an interesting question — how are future platform updates rolled out, as opposed to your app which you have to manage separately? Remember, these devices may not be connected to the internet. We are no longer in the comfortable space of cellular/WiFi connections being assumed to at least be available, even if sometimes unreliable.
|
||||||
|
|
||||||
|
The other worry was this being an offshoot version of Android in name only, where to accommodate the lowest common denominator, something so simple it could power an Arduino has been released — more of a marketing exercise than a rich OS. That’s quickly put to bed by looking at the [samples][4], actually — some even use SVG graphics as resources, a very recent Android innovation, rather than the traditional bitmap-based graphics, which of course it also handles with ease.
|
||||||
|
|
||||||
|
Inevitably, regular Android will throw up issues when compared with Android Things. For example, there is the permissions conundrum. Mitigated somewhat by the fact Android Things is designed to power fixed hardware devices, so the user wouldn’t normally install apps after it’s been built, it’s nevertheless a problem asking them for permissions on a device which might not have a UI! The solution is to grant all the permissions an app might need at install time. Normally, these devices are one app only, and that app is the one which runs when it powers up.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### What happened to Brillo?
|
||||||
|
|
||||||
|
Brillo was the codename given to Googles previous IoT OS, which sounds a lot like what Android Things used to be called. In fact you see many references to Brillo still, especially in the source code folder names in the GitHub Android Things examples. However, it has ceased to be. All hail the new king!
|
||||||
|
|
||||||
|
### UI Guidelines?
|
||||||
|
|
||||||
|
Google issues extensive guidelines regarding Android smartphone and tablet apps, such as how far apart on screen buttons should be and so on. Sure, its best to follow these where practical, but we’re not in Kansas any more. There is nothing there by default — it’s up the the app author to manage _everything_. This includes the top status bar, the bottom navigation bar — absolutely everything. Years of Google telling Android app authors never to render an onscreen BACK button because the platform will supply one is thrown out, because for Android Things there [might not even be a UI at all!][5]
|
||||||
|
|
||||||
|
### How much support of the Google services we’re used to from smartphones can we expect?
|
||||||
|
|
||||||
|
Quite a bit actually, but not everything. The first preview has no bluetooth support. No NFC, either — both of which are heavily contributing to the IoT revolution. The SBC’s support them, so I can’t see them not being available for too long. Since there’s no notification bar, there can’t be any notifications. No Maps. There’s no default soft keyboard, you have to install one yourself. And since there is no Play Store, you have to get down and dirty with ADB to do this, and many other operations.
|
||||||
|
|
||||||
|
When developing for Android Things I tried to make the same APK I was targeting for the Pi run on a regular handset. This threw up an error preventing it from being installed on anything other than an Android Things device: library “_com.google.android.things_” not present. Kinda makes sense, because only Android Things devices would need this, but it seemed limiting because not only would no smartphones or tablets have it present, but neither would any emulators. It looked like you could only run and test your Android Things apps on physical Android Things devices … until Google helpfully replied to my query on this in the [G+ Google’s IoT Developers Community][6] group with a workaround. Bullet dodged there, then.
|
||||||
|
|
||||||
|
### How can we expect the Android Things ecosystem to evolve now?
|
||||||
|
|
||||||
|
I’d expect to see a lot more porting of traditional Linux server based apps which didn’t really make sense to an Android restricted to smartphones and tablets. For example, a web server suddenly becomes very useful. Some exist already, but nothing like the heavyweights such as Apache or Nginx. IoT devices might not have a local UI, but administering them via a browser is certainly viable, so something to present a web panel this way is needed. Similarly comms apps from the big names — all it needs is a mike and speaker and in theory it’s good to go for any video calling app, like Duo, Skype, FB etc. How far this evolution goes is anyone’s guess. Will there be a Play Store? Will they show ads? Can we be sure they won’t spy on us, or let hackers control them? The IoT from a consumer point of view always was net-connected devices with touchscreens, and everyone’s already used to that way of working from their smartphones.
|
||||||
|
|
||||||
|
I’d also expect to see rapid progress regarding hardware — in particular many more SBC’s at even lower costs. Look at the amazing $5 Raspberry Pi Zero, which unfortunately almost certainly can’t run Android Things due to its limited CPU and RAM. How long until one like this can? It’s pretty obvious, now the bar has been set, any self respecting SBC manufacturer will be aiming for Android Things compatibility, and probably the economies of scale will apply to the peripherals too such as a $2 3" touchscreen. Microwave ovens just won’t sell unless you can watch YouTube on them, and your dishwasher just put in a bid for more powder on eBay since it noticed you’re running low…
|
||||||
|
|
||||||
|
However, I don’t think we can get too carried away here. Knowing a little about Android architecture helps when thinking of it as an all-encompassing IoT OS. It still uses Java, which has been hammered to death in the past with all its garbage-collection induced timing issues. That’s the least of it though. A genuine realtime OS relies on predictable, accurate and rock-solid timing or it can’t be described as “mission critical”. Think about medical applications, safety monitors, industrial controllers etc. With Android, your Activity/Service can, in theory, be killed at any time if the host OS thinks it needs to. Not so bad on a phone — the user restarts the app, kills other apps, or reboots the handset. A heart monitor is a different kettle all together though. If that foreground Activity/Service is watching a GPIO pin, and the signal isn’t dealt with exactly when it is supposed to, we have failed. Some pretty fundamental changes would have to be made to Android to support this, and so far there’s no indication it’s even planned.
|
||||||
|
|
||||||
|
### Those 24 hours
|
||||||
|
|
||||||
|
So, back to my project. I thought I’d take the work I’d done already and just port as much as I could over, waiting for the inevitable roadblock where I had to head over to the G+ group, cap in hand for help. Which, apart from the query about running on non-AT devices, never happened. And it ran great! This project uses some oddball stuff too, custom fonts, prescise timers — all of which appeared perfectly laid out in Android Studio. So its top marks from me, Google — at last I can start giving actual prototypes out rather than just videos and screenshots.
|
||||||
|
|
||||||
|
### The big picture
|
||||||
|
|
||||||
|
The IoT OS landscape today looks very fragmented. There is clearly no market leader and despite all the hype and buzz we hear, it’s still incredibly early days. Can Google do to the IoT with Android Things what it did to mobile, where it’s dominance is now very close to 90%? I believe so, and if that is to happen, this launch of Android Things is exactly how they would go about it.
|
||||||
|
|
||||||
|
Remember all the open vs closed software wars, mainly between Apple who never licence theirs, and Google who can’t give it away for free to enough people? That policy now comes back once more, because the idea of Apple launching a free IoT OS is as far fetched as them giving away their next iPhone for nothing.
|
||||||
|
|
||||||
|
The IoT OS game is wide open for someone to grab, and the opposition won’t even be putting their kit on this time…
|
||||||
|
|
||||||
|
Head over to the [Developer Preview][7] site to get your copy of the Android Things SDK now.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://medium.com/@carl.whalley/will-android-do-for-iot-what-it-did-for-mobile-c9ac79d06c#.hxva5aqi2
|
||||||
|
|
||||||
|
作者:[Carl Whalley][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://medium.com/@carl.whalley
|
||||||
|
[1]:https://developer.android.com/things/index.html
|
||||||
|
[2]:https://www.element14.com/community/docs/DOC-78156/l/raspberry-pi-7-touchscreen-display
|
||||||
|
[3]:http://www.androidpolice.com/2016/05/24/google-is-preparing-to-add-the-raspberry-pi-3-to-aosp-it-will-apparently-become-an-officially-supported-device/
|
||||||
|
[4]:https://github.com/androidthings/sample-simpleui/blob/master/app/src/main/res/drawable/pinout_board_vert.xml
|
||||||
|
[5]:https://developer.android.com/things/sdk/index.html
|
||||||
|
[6]:https://plus.google.com/+CarlWhalley/posts/4tF76pWEs1D
|
||||||
|
[7]:https://developer.android.com/things/preview/index.html
|
||||||
@ -0,0 +1,66 @@
|
|||||||
|
The Do’s and Don’ts of Writing Test cases in Android.
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
In this post, I will try to explain the best practices of writing the test cases based on my experience. I will use Espresso code in this post, but these practices will apply on both unit and instrumentation tests. For the purpose of explaining, I will consider a news application.
|
||||||
|
|
||||||
|
> The features and conditions of the application mentioned below are purely fictitious and are meant purely for the purpose of explaining the best practices and have no resemblance to any application active or removed from Play Store. :P
|
||||||
|
|
||||||
|
The news application will have the following activities.
|
||||||
|
|
||||||
|
* LanguageSelection- When the user launches the application for the very first time, he has to select at least one language. On selecting one or more than one language, the selection will be saved in the shared preferences and the user will be redirected to NewsList activity.
|
||||||
|
* NewsList - When the user lands on the NewsList activity, a request is sent to the server along with the language parameter and the response is shown in the recycler view (which has id _news_list_). In case the language is not present in the shared preference or server does not give a successful response, an error screen will become visible to the user and the recycler view will be gone. The NewsList activity has a button which has the text “Change your Language” if the user had selected only one language and “Change your Languages” if the user had selected more than one language which will always be visible. ( I swear to God that this is a fictional app)
|
||||||
|
* NewsDetail- As the name suggests, this activity is launched when the user clicks on any news list item.
|
||||||
|
|
||||||
|
|
||||||
|
Enough about the great features of the app. Let’s dive into the test cases written for NewsList activity. This is the code which I wrote the very first time.
|
||||||
|
|
||||||
|
|
||||||
|
#### Decide carefully what the test case is about.
|
||||||
|
|
||||||
|
In the first test case_ testClickOnAnyNewsItem()_, if the server does not send a successful response, the test case will fail because the visibility of the recycler view is GONE. But that is not what the test case is about. For this test case to PASS or FAIL, the minimum requirement is that the recycler view should be present and if due to any reason, it is not present, then the test case should not be considered FAILED. The correct code for this test should be something like this.
|
||||||
|
|
||||||
|
|
||||||
|
#### A test case should be complete in itself
|
||||||
|
|
||||||
|
When I started testing, I always tested the activities in the following sequence
|
||||||
|
|
||||||
|
* LanguageSelection
|
||||||
|
* NewsList
|
||||||
|
* NewsDetail
|
||||||
|
|
||||||
|
Since I tested the LanguageSelection activity first, a language was always getting set before the tests for NewsList activity began. But when I tested NewsList activity first, the tests started to fail. The reason for the failure was simple- language was not selected and because of that, the recycler view was not present. Thus, the order of execution of the test cases should not affect the outcome of the test. Therefore before running the test, the language should be saved in the shared preferences. In this case, the test case now becomes independent from LanguageSelection activity test.
|
||||||
|
|
||||||
|
|
||||||
|
#### Avoid conditional coding in test cases.
|
||||||
|
|
||||||
|
Now in the second test case _testChangeLanguageFeature()_, we get the count of the languages selected by the user and based on the count, we write an if-else condition for testing. But the if-else conditions should be written inside your actual code, not in the testing code. Each and every condition should be tested separately. So, in this case, instead of writing only a single test case, we should have written two test cases as follows.
|
||||||
|
|
||||||
|
|
||||||
|
#### The Test cases should be independent of external factors
|
||||||
|
|
||||||
|
In most of the applications, we interact with external agents like network and database. A test case can invoke a request to the server during its execution and the response can be either successful or failed. But due to the failed response from the server, the test case should not be considered failed. Think of it as this way- If a test case fails, then we make some changes in the client code so that the test code works. But in this case, are we going to make any changes in the client code?- NO.
|
||||||
|
|
||||||
|
But you should also not completely avoid testing the network request and response. Since the server is an external agent, there can be a scenario when it can send some wrong response which might result in crashing of the application. Therefore, you should write test cases and cover all the possible responses from the server, even the responses which the server will never send. In this way, all the code will be covered and you make sure that the application handles all the responses gracefully and never crashes down.
|
||||||
|
|
||||||
|
> Writing the test cases in a correct way is as important as writing the code for which the tests are written.
|
||||||
|
|
||||||
|
|
||||||
|
Thanks for reading the article. I hope it helps you write better test cases. You can connect with me on [LinkedIn][1]. You can check out my other medium articles [here][2].
|
||||||
|
|
||||||
|
_For more about programming, follow _[_Mindorks_][3]_ , so you’ll get notified when we write new posts._
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://blog.mindorks.com/the-dos-and-don-ts-of-writing-test-cases-in-android-70f1b5dab3e1#.lfilq9k5e
|
||||||
|
|
||||||
|
作者:[Anshul Jain][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://blog.mindorks.com/@anshuljain?source=post_header_lockup
|
||||||
|
[1]:http://www.linkedin.com/in/anshul-jain-b7082573
|
||||||
|
[2]:https://medium.com/@anshuljain
|
||||||
|
[3]:https://blog.mindorks.com/
|
||||||
@ -0,0 +1,535 @@
|
|||||||
|
How to set up a Continuous Integration server for Android development (Ubuntu + Jenkins + SonarQube)
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
I have recently acquired a new MacBook Pro as my main Android development machine and instead of selling or giving away my old Mac BookPro (13", late 2011, 16GB RAM, 500G SSD, Core i5 2,4GHz, 64Bit) I have wiped it out and turned it into a Continuous Integration Server with dual boot MacOS-Ubuntu.
|
||||||
|
|
||||||
|
The goal of this article is to summarize the installation steps for me as future reference and for any developer that may be interested in setting up its own CI server, I will explain how to:
|
||||||
|
|
||||||
|
* Configure a fresh Ubuntu installation to be able to run the Android SDK.
|
||||||
|
* Install Jenkins CI as a service to pull, compile, and run tests of an Android multi-module project hosted in GitHub.
|
||||||
|
* Install Docker to run a MySQL server and SonarQube in their own containers, to perform static code analysis triggered by Jenkins
|
||||||
|
* Android App configuration requirements.
|
||||||
|
|
||||||
|
### Step 1 — Ubuntu Installation:
|
||||||
|
|
||||||
|
I’m going to use Ubuntu as the SO of the CI because it has a strong community that will provide you support for any issue you may encounter and my personal recommendation is always to use the last LTS version, currently 16.04 LTS. There are plenty of tutorials about how to install it on virtually any hardware so I’m just providing the link to download it.
|
||||||
|
|
||||||
|
[Install Ubuntu Desktop 16.04 LTS][1]
|
||||||
|
|
||||||
|
You may wonder why I’m using the Desktop version instead of the pure server version, this is just a matter of personal preference, I’m not worried of losing a bit of performance and available RAM due to be running the desktop interface because I think that the usability that provides de GUI pays off enough in increased productivity.
|
||||||
|
|
||||||
|
### Step 2 — Remote access management:
|
||||||
|
|
||||||
|
#### SSH-Server:
|
||||||
|
|
||||||
|
Ubuntu desktop is not shipped with the ssh server installed by default, so to be able to manage your server remotely through the command line just install it:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt-get install openssh-server
|
||||||
|
```
|
||||||
|
|
||||||
|
#### NoMachine Remote Desktop:
|
||||||
|
|
||||||
|
Probably your CI is not going to be next to you but closer to your router, other room or even miles away from your current location. I have been dealing with different remote desktop solutions and I have to say that IMHO NoMachine performs the best, it is platform agnostic and works just out of the box just using your ssh credentials. (Obviously you have to install it both in your CI and your machine)
|
||||||
|
|
||||||
|
[NoMachine - Free Remote Access For Everybody
|
||||||
|
Free remote access and desktop sharing software. Access your computer to work on files and transfer documents, watch…www.nomachine.com][2][][3]</section>
|
||||||
|
|
||||||
|
|
||||||
|
### Step 3 — Environment configuration
|
||||||
|
|
||||||
|
Here I’m going to install JAVA8, Git and the Android SDK that are required by Jenkins to pull, compile and run android projects.
|
||||||
|
|
||||||
|
#### SDKMAN!:
|
||||||
|
|
||||||
|
This marvelous command line tool allows you install many popular SDK (eg. Gradle, Groovy, Grails, Kotlin, Scala…), list candidates and switch among different versions in parallel in a really easy and handy way.
|
||||||
|
|
||||||
|
[SDKMAN! the Software Development Kit Manager
|
||||||
|
SDKMAN! is a tool for managing parallel versions of multiple Software Development Kits on most Unix based systems. It…sdkman.io][4][][5]
|
||||||
|
|
||||||
|
They have added recently support for JAVA8 so I preferred to install Java using it instead of using the popular webupd8 repository, so it is up to you to choose whether to install SDKMAN! or not but I’m pretty sure it is a tool that you will use in the near future.
|
||||||
|
|
||||||
|
Installation of SDKMAN! is as easy as executing the following line:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ curl -s "https://get.sdkman.io" | bash
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
#### Oracle JAVA8:
|
||||||
|
|
||||||
|
As we have previously installed SDKMAN! now installing JAVA8 is as easy as:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sdk install java
|
||||||
|
```
|
||||||
|
|
||||||
|
Or using the webupd8 repository:
|
||||||
|
|
||||||
|
[Install Oracle Java 8 In Ubuntu Or Linux Mint Via PPA Repository [JDK8]
|
||||||
|
Oracle Java 8 is now stable. Below you'll find instructions on how to install it in Ubuntu or Debian via a PPA…www.webupd8.org][6][][7]
|
||||||
|
|
||||||
|
#### Git:
|
||||||
|
|
||||||
|
Installing git is straight forward, no more comments needed:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt install git
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
#### Android SDK:
|
||||||
|
|
||||||
|
At the bottom of this page:
|
||||||
|
|
||||||
|
[Download Android Studio and SDK Tools | Android Studio
|
||||||
|
Download the official Android IDE and developer tools to build apps for Android phones, tablets, wearables, TVs, and…developer.android.com][8][][9]
|
||||||
|
|
||||||
|
you can find “_Get just the command line tools_”, copy the link e.g:
|
||||||
|
|
||||||
|
```
|
||||||
|
https://dl.google.com/android/repository/tools_r25.2.3-linux.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
Then download and unzip it at /opt/android-sdk-linux
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd /opt
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo wget https://dl.google.com/android/repository/tools_r25.2.3-linux.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo unzip tools_r25.2.3-linux.zip -d android-sdk-linux
|
||||||
|
```
|
||||||
|
|
||||||
|
As we have used root user to create de directory we need to fix folder permissions to make it readable and writable by our main user:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo chown -R YOUR_USERNAME:YOUR_USERNAME android-sdk-linux/
|
||||||
|
```
|
||||||
|
|
||||||
|
Let’s set the SDK environmental variables editing the /.bashrc file:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd
|
||||||
|
$ nano .bashrc
|
||||||
|
```
|
||||||
|
|
||||||
|
Then add at the bottom (but before SDKMAN! config line) these lines:
|
||||||
|
|
||||||
|
```
|
||||||
|
export ANDROID_HOME="/opt/android-sdk-linux"
|
||||||
|
export PATH="$ANDROID_HOME/tools:$ANDROID_HOME/platform-tools:$PATH"
|
||||||
|
```
|
||||||
|
|
||||||
|
Close the terminal and open a new one to verify that variables have been properly exported:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo $ANDROID_HOME
|
||||||
|
/opt/android-sdk-linux
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
$ android
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Running Android SDK Manager GUI
|
||||||
|
|
||||||
|
|
||||||
|
### Step 4 — Jenkins server:
|
||||||
|
|
||||||
|
Here I’m going to describe how to install the server, configure it, create a Jenkins Job to pull, build and test an Android project and how to get to the console output.
|
||||||
|
|
||||||
|
#### Jenkins installation:
|
||||||
|
|
||||||
|
Jenkins server is available at:
|
||||||
|
|
||||||
|
[Jenkins
|
||||||
|
Jenkins is an open source automation serverjenkins.io][12][][13]
|
||||||
|
|
||||||
|
There are many ways to run Jenkins, executing a .war file, as a linux service, as a Docker container, etc….
|
||||||
|
|
||||||
|
My first thought was to run it using a Docker container but then I realized that it was a nightmare to properly configure code folders, android-sdk folder visibility and USB visibility of physical devices plug to run Android Tests.
|
||||||
|
|
||||||
|
For ease of use I finally decided to use it as service adding the Stable repository key to install and get updates with apt
|
||||||
|
|
||||||
|
```
|
||||||
|
$ wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -
|
||||||
|
```
|
||||||
|
|
||||||
|
Edit the sources.list file and add:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo nano /etc/apt/sources.list
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
#Jenkin Stable
|
||||||
|
deb https://pkg.jenkins.io/debian-stable binary/
|
||||||
|
```
|
||||||
|
|
||||||
|
Then install it:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get update
|
||||||
|
sudo apt-get install jenkins
|
||||||
|
```
|
||||||
|
|
||||||
|
Add user _jenkins_ to your username group to allow it to read and write the Android SDK folder
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo usermod -a -G YOUR_USERNAME jenkins
|
||||||
|
```
|
||||||
|
|
||||||
|
Jenkins service will always start at boot time and will be available at [http://localhost:8080][15]
|
||||||
|
|
||||||
|
Just after installation due to security reasons this screen is shown, just follow the instructions to finally get your Jenkins instance up and running.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Unlocking a successfully installed Jenkins server
|
||||||
|
|
||||||
|
#### Jenkins Configuration:
|
||||||
|
|
||||||
|
After unlocking Jenkins installation you are prompted to install plugins, click “Select plugins to Install” browse and select the following ones to be installed in addition to suggested plugins:
|
||||||
|
|
||||||
|
* JUnit
|
||||||
|
|
||||||
|
[JUnit Plugin - Jenkins - Jenkins Wiki
|
||||||
|
The JUnit plugin provides a publisher that consumes XML test reports generated during the builds and provides some…wiki.jenkins-ci.org][16][][17]
|
||||||
|
|
||||||
|
* JaCoCo
|
||||||
|
|
||||||
|
[JaCoCo Plugin - Jenkins - Jenkins Wiki
|
||||||
|
In order to get the coverage data published to Jenkins, you need to add a JaCoCo publisher and configure it so it will…wiki.jenkins-ci.org][18][][19]
|
||||||
|
|
||||||
|
* EnvInject
|
||||||
|
|
||||||
|
[EnvInject Plugin - Jenkins - Jenkins Wiki
|
||||||
|
Only previous environment variables are available for polling Some plugins provide polling mechanisms (such as SCM…wiki.jenkins-ci.org][20][][21]
|
||||||
|
|
||||||
|
* GitHub plugins
|
||||||
|
|
||||||
|
[GitHub Plugin - Jenkins - Jenkins Wiki
|
||||||
|
This plugin requires that you have an HTTP URL reachable from GitHub, which means it's reachable from the whole…wiki.jenkins-ci.org][22][][23]
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Installing Jenkins plugins
|
||||||
|
|
||||||
|
Create the admin user and complete installation.
|
||||||
|
|
||||||
|
To finish configuration we have to configure ANDROID_HOME and JAVA_HOME environmental variables:
|
||||||
|
|
||||||
|
Go to Manage Jenkins > Configure System
|
||||||
|
|
||||||
|
Scroll down and at Global properties section check the Environment variables box and add _ANDROID_HOME_ and _JAVA_HOME_
|
||||||
|
|
||||||
|
|
||||||
|
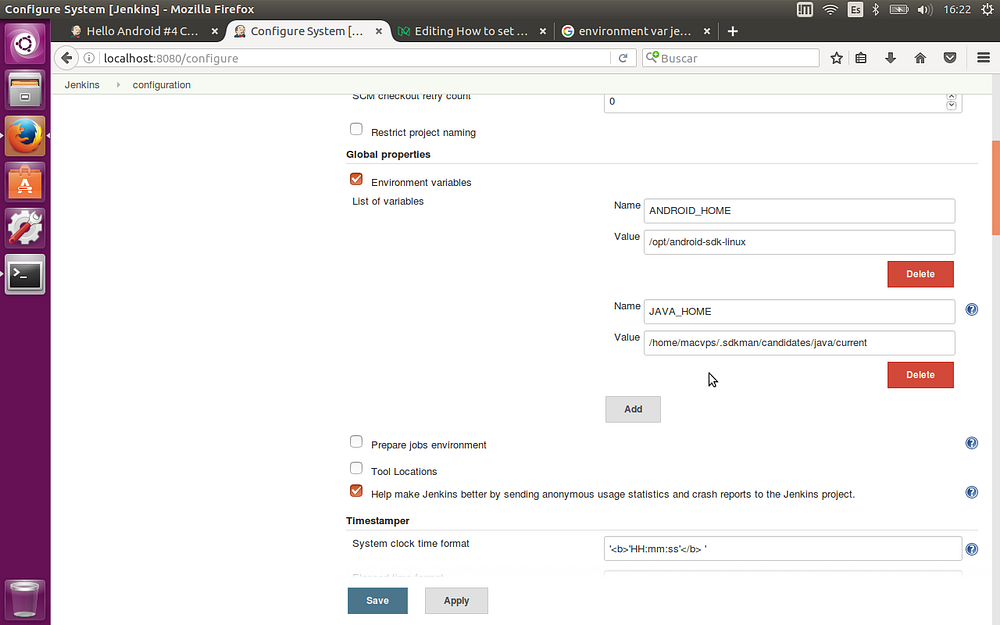
|
||||||
|
|
||||||
|
Adding global environmental variables common to all Jenkins jobs
|
||||||
|
|
||||||
|
#### Creating a “Jenkins Job”
|
||||||
|
|
||||||
|
A Jenkins Job describes a series of steps that are executed consecutively. I have prepared a “Hello Jenkins” Android project in GitHub that you can use to test your Jenkins configuration as you follow this tutorial. It is just a hello world multi-module app with Unit tests, Android tests and includes JaCoCo and SonarQube plugins.
|
||||||
|
|
||||||
|
[pamartineza/helloJenkins
|
||||||
|
helloJenkins - Hello Jenkins project for CI configuration testgithub.com][24][][25]
|
||||||
|
|
||||||
|
First create a new _Freestyle project Job _and give it a name eg. “_Hello_Android_” (Don’t use spaces in Jenkins Job names to avoid future compatibility problems with SonarQube)
|
||||||
|
|
||||||
|
|
||||||
|
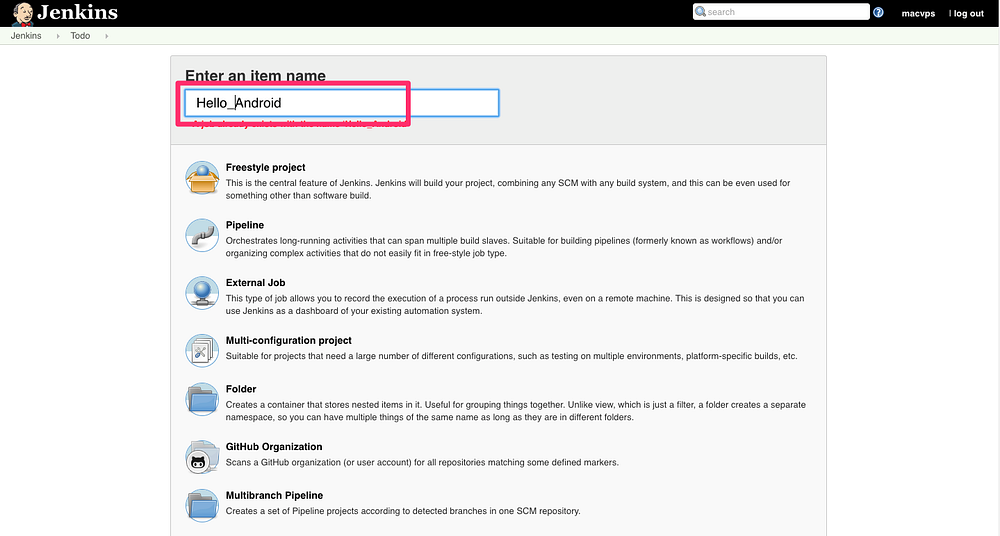
|
||||||
|
|
||||||
|
Creating a Freestyle Jenkins Job
|
||||||
|
|
||||||
|
Then let’s configure it, I’m going to add screenshots of every section:
|
||||||
|
|
||||||
|
General:
|
||||||
|
|
||||||
|
This section is not very interesting for our goals, here you can change the name of the Job, add a description and if using a GitHub project add the project URL, (without *.git, the url of the web not the repo)
|
||||||
|
|
||||||
|
|
||||||
|
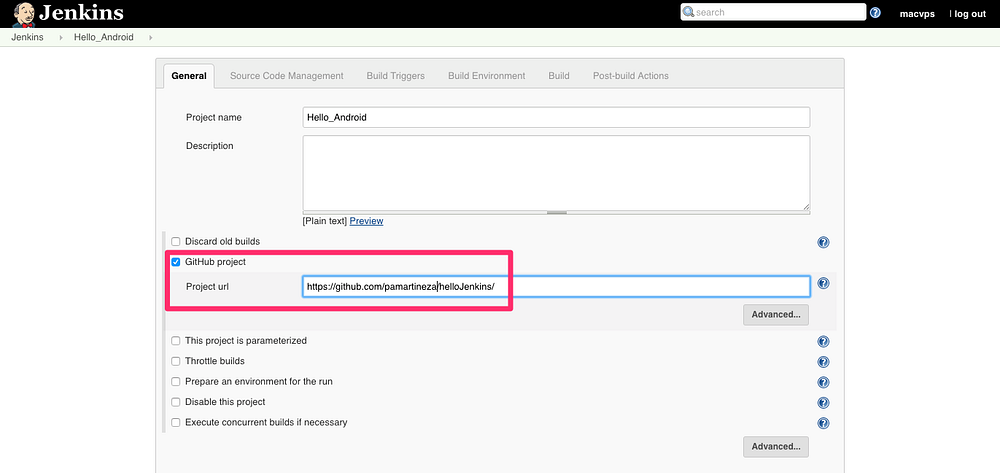
|
||||||
|
|
||||||
|
Project Url Configuration
|
||||||
|
|
||||||
|
Source Code Management:
|
||||||
|
|
||||||
|
Here is where we have to chose our CVS as Git and add the repository url (this time include *.git) and select the branch to pull. As this is a public GitHub repository you don’t need to add credentials but otherwise you will have to add your user and password.
|
||||||
|
|
||||||
|
I recommend you that instead of using your actual GitHub user with full permissions create a new GitHub user with read-only privileges of your private repos to be used exclusively by your Jenkins Jobs.
|
||||||
|
|
||||||
|
In addition if you have enabled Two-Factor authentication Jenkins won’t be able to pull code and again having this exclusively created for Jenkins user will be the solution to pull code from private repos.
|
||||||
|
|
||||||
|
|
||||||
|
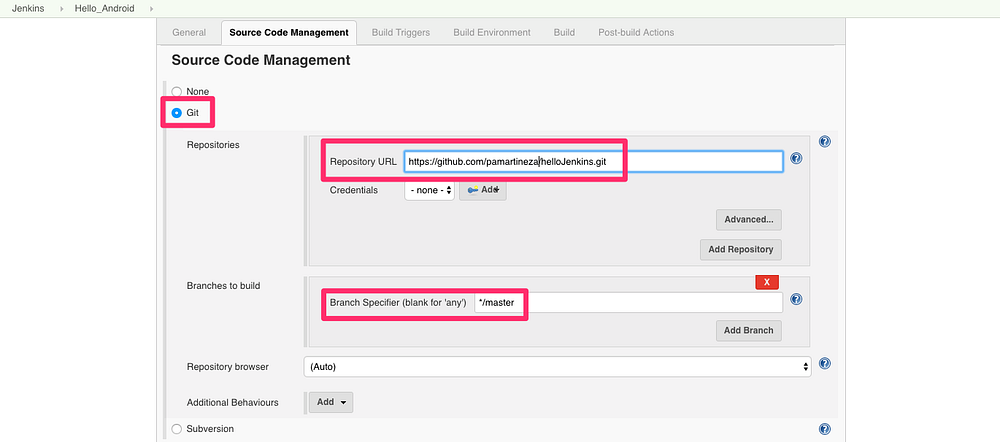
|
||||||
|
|
||||||
|
Repository configuration
|
||||||
|
|
||||||
|
Build Triggers:
|
||||||
|
|
||||||
|
Builds can be triggered manually, remotely, periodically, after another Job build, when changes are detected, etc…
|
||||||
|
|
||||||
|
Ideally the optimal situation is to just trigger a build when a change has been pushed to the repository, GitHub provides a system called Webhooks
|
||||||
|
|
||||||
|
[Webhooks | GitHub Developer Guide
|
||||||
|
Webhooks allow you to build or set up integrations which subscribe to certain events on GitHub.com. When one of those…developer.github.com][26][][27]
|
||||||
|
|
||||||
|
that we can configure to send events to the CI server and then trigger the build, but this obviously requires our CI sever to be online and reachable by GitHub servers.
|
||||||
|
|
||||||
|
Your CI is going to be probably isolated in a private network for security reasons then the only solution is to poll GitHub periodically. In my personal case I just turn on the CI when I’m working, in the following screenshot I have configured it to poll Github every 15 minutes. Polling times are defined with CRON syntax, if you are not familiar with it, press the help button on the right to get an extensive documentation with examples.
|
||||||
|
|
||||||
|
|
||||||
|
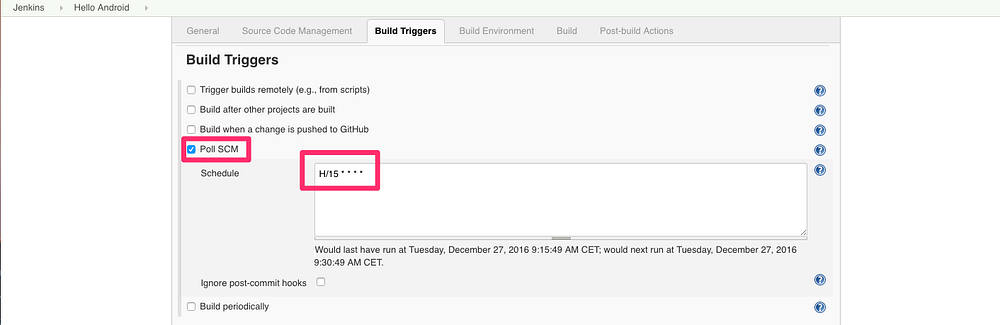
|
||||||
|
|
||||||
|
Repository polling configuration
|
||||||
|
|
||||||
|
Build Environment:
|
||||||
|
|
||||||
|
Here I recommend to configure the build _stuck_ timeout to avoid Jenkins blocking memory and CPU if any unexpected error happens. Here also you can Inject environmental variables, passwords, etc…
|
||||||
|
|
||||||
|
|
||||||
|
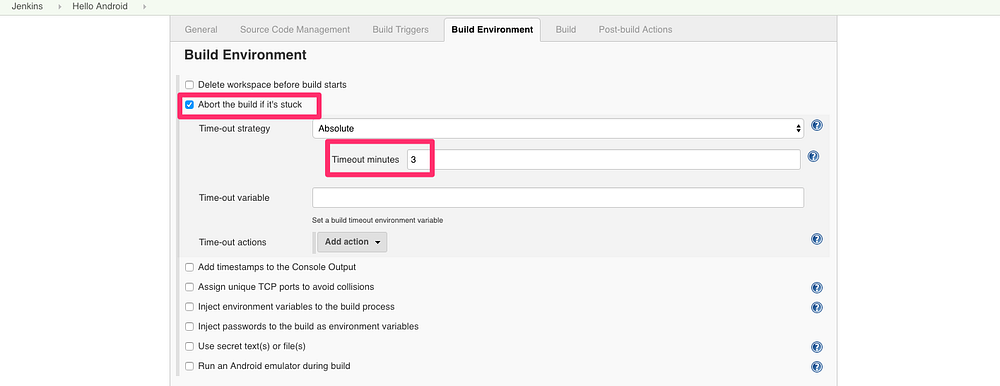
|
||||||
|
|
||||||
|
Build stuck time out
|
||||||
|
|
||||||
|
Build:
|
||||||
|
|
||||||
|
Here is where the magic happens! Add a _Build Step _that _Invokes Gradle Script _select the Gradle Wrapper (Android projects are shipped with a Gradle Wrapper by default, don’t forget to check it into Git) and let’s define which tasks are going to be executed:
|
||||||
|
|
||||||
|
1. clean: Deletes all build outputs of previous builds, this ensures nothing is cached and the freshness of this build.
|
||||||
|
2. assembleDebug: Generates the debug .apk
|
||||||
|
3. test: executes JUnit tests in all modules
|
||||||
|
4. connectedDebugAndroidTest: executes Android Tests on actual android devices connected to the CI. (It is also possible to run Android Test against an Android Emulator installing the Android Emulator Jenkins plugin, but it doesn’t support all emulator versions and its configuration is not trivial at all)
|
||||||
|
|
||||||
|
|
||||||
|
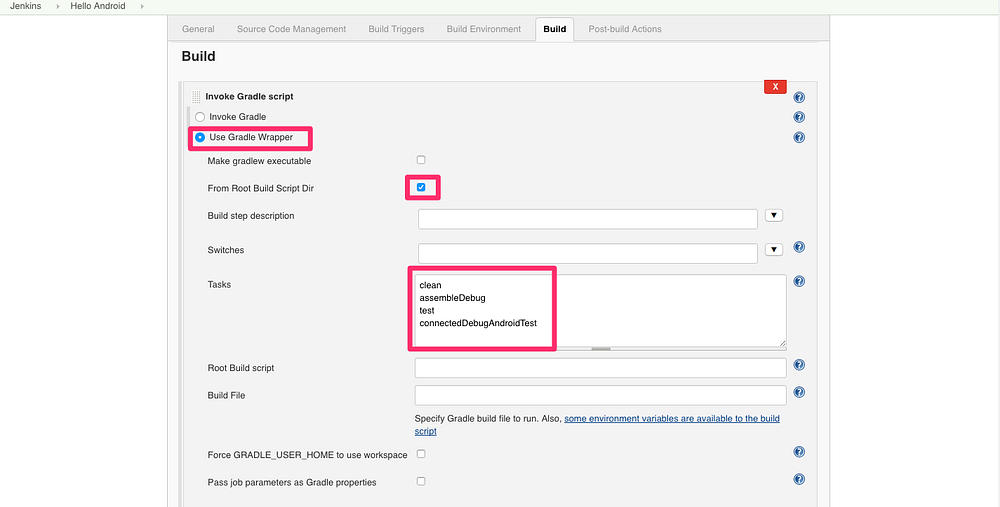
|
||||||
|
|
||||||
|
Gradle tasks definition
|
||||||
|
|
||||||
|
Post-build Actions:
|
||||||
|
|
||||||
|
Here we are going to add _Publish JUnit test result report _this step is provided by the JUnit plugin and collects the .XML reports generated with the outcome of the JUnit tests that will generate a fancy chart with the evolution of tests results in time.
|
||||||
|
|
||||||
|
The path for debug flavor tests results in our app module is:
|
||||||
|
|
||||||
|
app/build/test-results/debug/*.xml
|
||||||
|
|
||||||
|
In multi-module projects the path for test results in other “pure” java modules is:
|
||||||
|
|
||||||
|
*/build/test-results/*.xml
|
||||||
|
|
||||||
|
|
||||||
|
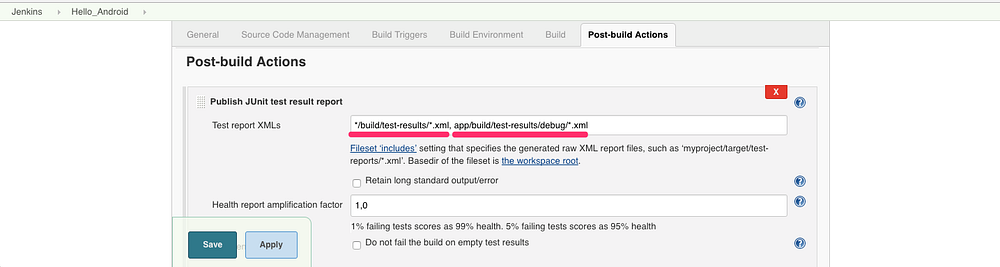
|
||||||
|
|
||||||
|
|
||||||
|
Also add _Record JaCoCo coverage report _that will create a chart to show the evolution of the code coverage
|
||||||
|
|
||||||
|
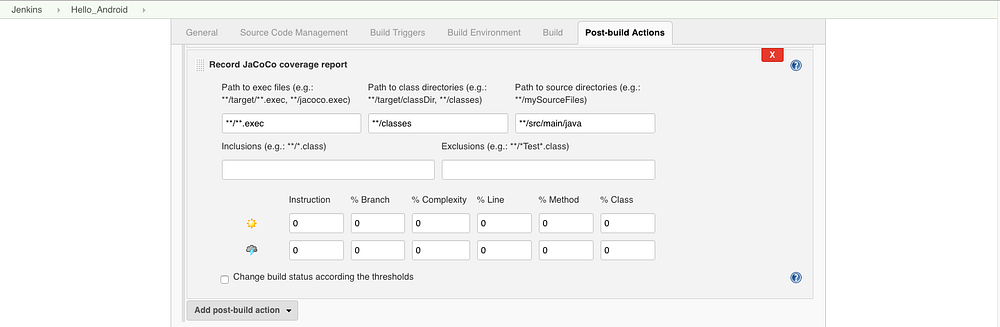
|
||||||
|
|
||||||
|
|
||||||
|
#### Executing a Jenkins Job
|
||||||
|
|
||||||
|
Our Job will execute every 15 minutes if new changes have been pushed to the repository but it can also be triggered manually if you don’t want to wait until next polling or you just want to verify any change in the configuration straight forward. Click _Build Now_ and then current build will be shown in the _Build History _, click on it to see the details.
|
||||||
|
|
||||||
|
|
||||||
|
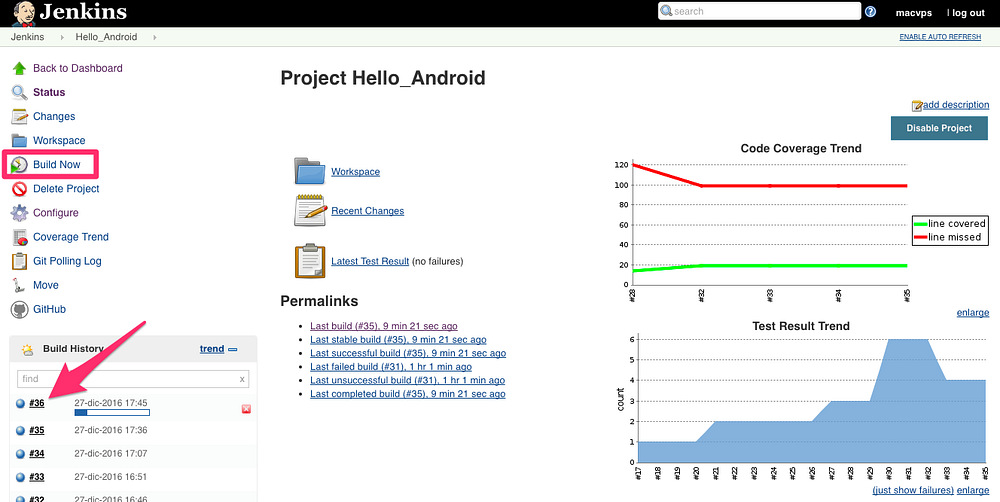
|
||||||
|
|
||||||
|
Manual Job execution
|
||||||
|
|
||||||
|
The most interesting part here is the console output, you can see how Jenkins pulls the code and starts executing the Gradle tasks we have previously defined e.g _clean._
|
||||||
|
|
||||||
|
|
||||||
|
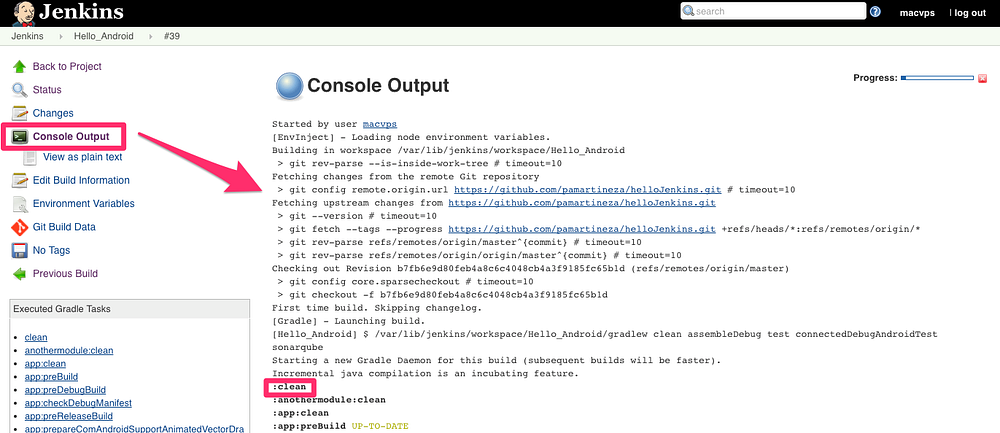
|
||||||
|
|
||||||
|
Beginning of console output
|
||||||
|
|
||||||
|
If everything is OK console output will finish as follows (any repository connectivity problem, failing JUnit or Android test failure would make the build to fail)
|
||||||
|
|
||||||
|
|
||||||
|
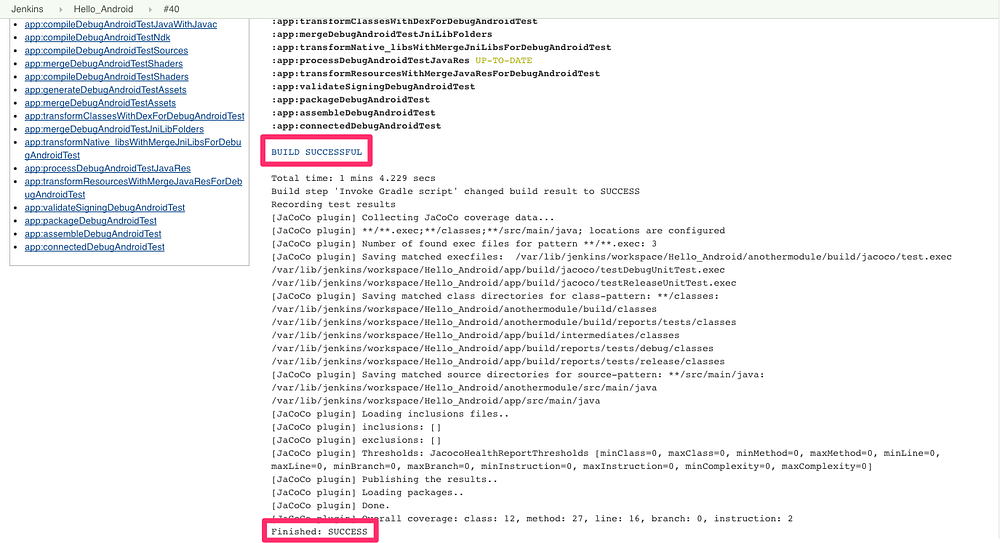
|
||||||
|
|
||||||
|
Yeehaa! build Sucsessful and test results with coverage collected
|
||||||
|
|
||||||
|
### Step 5 — SonarQube
|
||||||
|
|
||||||
|
In this section I will describe how to install and configure SonarQube and its companion MySQL database using Docker containers.
|
||||||
|
|
||||||
|
[Continuous Code Quality | SonarQube
|
||||||
|
The leading open source platform for continuous code qualitywww.sonarqube.org][28][][29]
|
||||||
|
|
||||||
|
SonarQube is a code static analysis tool that helps developers to write cleaner code, detect bugs, learn good practices and it also keeps track of code coverage, tests results, technical debt, etc… all SonarQube detected issues can be imported easily to be fixed into Android Studio/IntelliJ with a plugin:
|
||||||
|
|
||||||
|
[JetBrains Plugin Repository :: SonarQube Community Plugin
|
||||||
|
Edit descriptionplugins.jetbrains.com][30][][31]</section>
|
||||||
|
|
||||||
|
|
||||||
|
#### Installing Docker:
|
||||||
|
|
||||||
|
Installation of Docker is pretty straightforward following official Docker documentation:
|
||||||
|
|
||||||
|
[Install Docker on Ubuntu
|
||||||
|
Instructions for installing Docker on Ubuntudocs.docker.com][32][][33]
|
||||||
|
|
||||||
|
#### Creating Containers:
|
||||||
|
|
||||||
|
MySQL:
|
||||||
|
Let’s create a MySQL 5.7.17 server container called _mysqlserver, _that will allways start at boot time, with a local volume in your user folder, a password and exposed at localhost:3306 _(replace YOUR_USER and YOUR_MYSQL_PASSWORD with your values)_
|
||||||
|
|
||||||
|
```
|
||||||
|
$ docker run --name mysqlserver --restart=always -v /home/YOUR_USER/mysqlVolume:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=YOUR_MYSQL_PASSWORD -p 3306:3306 -d mysql:5.7.17
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
phpMyAdmin:
|
||||||
|
To manage the MySQL server I’m used to phpMyAdmin then nothing more easy than creating another container called _phpmyadmin _linked to our _mysqlserver _container, that also starts at boot time, exposed at localhost:9090 and using the last version available.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ docker run --name phpmyadmin --restart=always --link mysqlserver:db -p 9090:80 -d phpmyadmin/phpmyadmin
|
||||||
|
```
|
||||||
|
|
||||||
|
Using the phpMyAdmin interface at localhost:9090 login as _root and YOUR_MYSQL_PASSWORD _andcreate a database called _sonar_ with _utf8_general_ci _collation. Also create a new user _sonar_ with password _YOUR_SONAR_PASSWORD _and give it all privileges on the _sonar_ database.
|
||||||
|
|
||||||
|
|
||||||
|
SonarQube:
|
||||||
|
Now we are ready to create our SonarQube container called _sonarqube _that starts at boot time, linked to our db, exposed at localhost:9000 and using the 5.6.4 (LTS) version.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ docker run --name sonarqube --restart=always --link mysqlserver:db -p 9000:9000 -p 9092:9092 -e "SONARQUBE_JDBC_URL=jdbc:mysql://db:3306/sonar?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&useConfigs=maxPerformance" -e "SONARQUBE_JDBC_USER=sonar" -e "SONARQUBE_JDBC_PASSWORD=YOUR_SONAR_PASSWORD" -d sonarqube:5.6.4
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
#### SonarQube Configuration:
|
||||||
|
|
||||||
|
If everything is OK browsing to localhost:9000 will lead you to this page:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Now let’s configure necessary plugins and Quality Profiles:
|
||||||
|
|
||||||
|
1. Login at the top right corner (Default administrator login is admin/admin)
|
||||||
|
2. Go to Administration > System > Update Center > Updates Only
|
||||||
|
|
||||||
|
* Update Java plugin if necessary
|
||||||
|
|
||||||
|
3\. Now switch to Available and install the following plugins:
|
||||||
|
|
||||||
|
* Android (provides Android lint rules)
|
||||||
|
* Checkstyle
|
||||||
|
* Findbugs
|
||||||
|
* XML
|
||||||
|
|
||||||
|
4\. Scroll back to the top and press restart button to complete the installation
|
||||||
|
|
||||||
|
|
||||||
|
#### SonarQube Profiles:
|
||||||
|
|
||||||
|
The plugins that we have installed define profiles that are sets of rules used to evaluate the code quality of a project.
|
||||||
|
|
||||||
|
Only 1 profile can be applied to a project at a time but we can make profiles have a parent and therefore inherit rules, so to be able to have all rules evaluated against our project we can create a new custom profile and chain all profiles.
|
||||||
|
|
||||||
|
Let’s do it, go to Quality Profiles > Create and give it a name e.g. CustomAndroidProfile
|
||||||
|
|
||||||
|
Add Android Lint as parent, then switch to the Android Lint profile and add FindBugs Security Minimal as parent, continue this chain until you get this inheritance schema and set the CustomAndroidProfile as the default one:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### Executing the SonarQube Analysis:
|
||||||
|
|
||||||
|
Now that our SonarQube is properly configured we just have to add a new Gradle task, _sonarqube_, to our Jenkins job, that will be executed in last place:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Execute again the Jenkins job and once it has finished let’s see our sonarQube dashboard at localhost:9000 :
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Dashboard with Analysis result
|
||||||
|
|
||||||
|
If we press the project name we can navigate different dashboards, with tons of info, the most important one is probably _Issues.
|
||||||
|
_In the next screenshot I’m showing the detail of a _major _issue that flags an empty constructor method. Here personally what gives me the most important value of using Sonarqube is the explanation shown at the screen bottom when you click on the period … , this is an invaluable way of learning tips and tricks of programming.
|
||||||
|
|
||||||
|
|
||||||
|
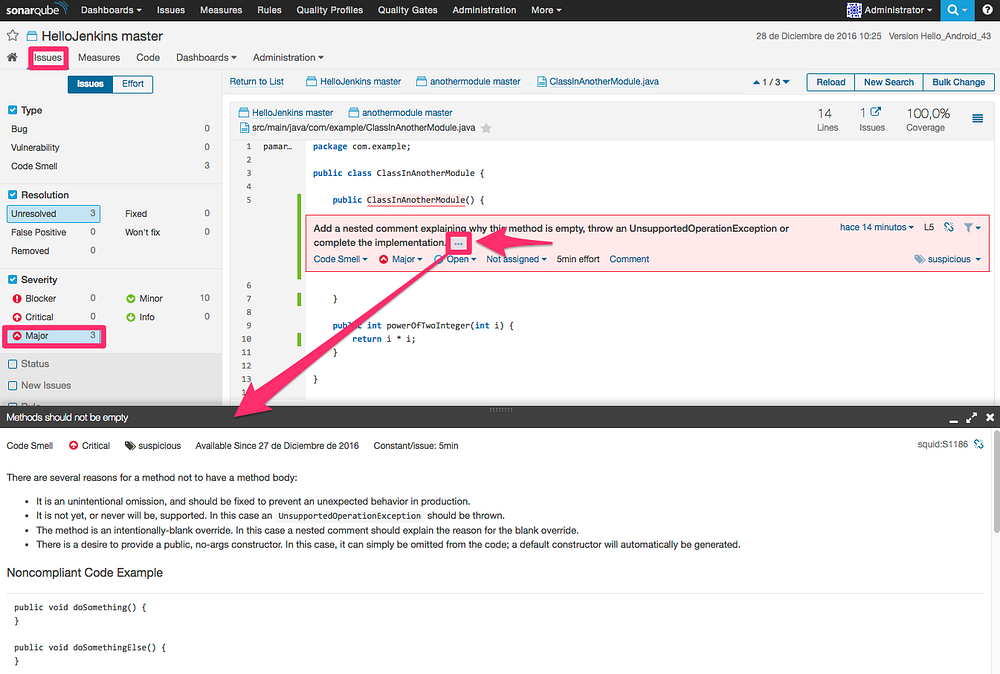
|
||||||
|
|
||||||
|
Getting the explanation of the issue
|
||||||
|
|
||||||
|
### Step 6 — Extra: configuring other Android apps
|
||||||
|
|
||||||
|
Configuring an Android app to get coverage and sonarqube results is just having the JaCoCo and SonarQube plugins applied. Again you can find more details at my demo app HelloJenkins:
|
||||||
|
|
||||||
|
[pamartineza/helloJenkins
|
||||||
|
helloJenkins - Hello Jenkins project for CI configuration testgithub.com][34][][35]
|
||||||
|
|
||||||
|
### The end!
|
||||||
|
|
||||||
|
Yes, you have finally reached the end of this long article! I hope you found it useful. If you find any error or you have any doubt please don’t hesitate to make any comment, I’ll do my best to try to help and if you liked it please share it!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Entrepreneur & CEO at GreenLionSoft · Android Lead @MadridMBC & @Shoptimix · Android, OpenSource and OpenData promoter · Runner · Traveller
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://medium.com/@pamartineza/how-to-set-up-a-continuous-integration-server-for-android-development-ubuntu-jenkins-sonarqube-43c1ed6b08d3#.x6jhcpg98
|
||||||
|
|
||||||
|
作者:[Pablo A. Martínez][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://medium.com/@pamartineza
|
||||||
|
[1]:https://www.ubuntu.com/download/desktop
|
||||||
|
[2]:https://www.nomachine.com/download
|
||||||
|
[3]:https://www.nomachine.com/download
|
||||||
|
[4]:http://sdkman.io/
|
||||||
|
[5]:http://sdkman.io/
|
||||||
|
[6]:http://www.webupd8.org/2012/09/install-oracle-java-8-in-ubuntu-via-ppa.html
|
||||||
|
[7]:http://www.webupd8.org/2012/09/install-oracle-java-8-in-ubuntu-via-ppa.html
|
||||||
|
[8]:https://developer.android.com/studio/index.html
|
||||||
|
[9]:https://developer.android.com/studio/index.html
|
||||||
|
[10]:https://dl.google.com/android/repository/tools_r25.2.3-linux.zip
|
||||||
|
[11]:https://dl.google.com/android/repository/tools_r25.2.3-linux.zip
|
||||||
|
[12]:https://jenkins.io/
|
||||||
|
[13]:https://jenkins.io/
|
||||||
|
[14]:https://pkg.jenkins.io/debian-stable/jenkins.io.key
|
||||||
|
[15]:http://localhost:8080/
|
||||||
|
[16]:https://wiki.jenkins-ci.org/display/JENKINS/JUnit+Plugin
|
||||||
|
[17]:https://wiki.jenkins-ci.org/display/JENKINS/JUnit+Plugin
|
||||||
|
[18]:https://wiki.jenkins-ci.org/display/JENKINS/JaCoCo+Plugin
|
||||||
|
[19]:https://wiki.jenkins-ci.org/display/JENKINS/JaCoCo+Plugin
|
||||||
|
[20]:https://wiki.jenkins-ci.org/display/JENKINS/EnvInject+Plugin
|
||||||
|
[21]:https://wiki.jenkins-ci.org/display/JENKINS/EnvInject+Plugin
|
||||||
|
[22]:https://wiki.jenkins-ci.org/display/JENKINS/GitHub+Plugin
|
||||||
|
[23]:https://wiki.jenkins-ci.org/display/JENKINS/GitHub+Plugin
|
||||||
|
[24]:https://github.com/pamartineza/helloJenkins
|
||||||
|
[25]:https://github.com/pamartineza/helloJenkins
|
||||||
|
[26]:https://developer.github.com/webhooks/
|
||||||
|
[27]:https://developer.github.com/webhooks/
|
||||||
|
[28]:https://www.sonarqube.org/
|
||||||
|
[29]:https://www.sonarqube.org/
|
||||||
|
[30]:https://plugins.jetbrains.com/idea/plugin/7238-sonarqube-community-plugin
|
||||||
|
[31]:https://plugins.jetbrains.com/idea/plugin/7238-sonarqube-community-plugin
|
||||||
|
[32]:https://docs.docker.com/engine/installation/linux/ubuntulinux/
|
||||||
|
[33]:https://docs.docker.com/engine/installation/linux/ubuntulinux/
|
||||||
|
[34]:https://github.com/pamartineza/helloJenkins
|
||||||
|
[35]:https://github.com/pamartineza/helloJenkins
|
||||||
105
sources/tech/20170102 A Guide To Buying A Linux Laptop.md
Normal file
105
sources/tech/20170102 A Guide To Buying A Linux Laptop.md
Normal file
@ -0,0 +1,105 @@
|
|||||||
|
A Guide To Buying A Linux Laptop
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
It goes without saying that if you go to a computer store downtown to [buy a new laptop][5], you will be offered a notebook with Windows preinstalled, or a Mac. Either way, you’ll be forced to pay an extra fee – either for a Microsoft license or for the Apple logo on the back.
|
||||||
|
|
||||||
|
On the other hand, you have the option to buy a laptop and install a distribution of your choice. However, the hardest part may be to find the right hardware that will get along nicely with the operating system.
|
||||||
|
|
||||||
|
On top of that, we also need to consider the availability of drivers for the hardware. So what do you do? The answer is simple: [buy a laptop with Linux preinstalled][6].
|
||||||
|
|
||||||
|
Fortunately, there are several respectable vendors that offer high-quality, well-known brands and distributions and ensure you will not have to worry about the availability of drivers.
|
||||||
|
|
||||||
|
That said, in this article we will list the top 3 machines of our choice based on the intended usage.
|
||||||
|
|
||||||
|
#### Linux Laptops For Home Users
|
||||||
|
|
||||||
|
If you are looking for a laptop that can run an office suite, a modern web browser such as Firefox or Chrome, and has Ethernet/Wifi connectivity, [System76][7] allows you to design your future laptop by choosing the processor type, RAM / storage size, and accessories.
|
||||||
|
|
||||||
|
On top of that, System76 provides Ubuntu lifetime support for all of their laptop models. If this sounds like something that sparks some interest in you, checkout the [Lemur][8] or [Gazelle][9] laptops.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][1]
|
||||||
|
|
||||||
|
Lemur Laptop for Linux
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][2]
|
||||||
|
|
||||||
|
Gazelle Laptop for Linux
|
||||||
|
|
||||||
|
#### Linux Laptops For Developers
|
||||||
|
|
||||||
|
If you are looking for a reliable, nice-looking, and robust laptop for development tasks, you may want to consider [Dell’s XPS 13 Laptops][10].
|
||||||
|
|
||||||
|
This 13-inch beauty features a full HD display and a touchscreen Prices vary depending on the processor generation / model (Intel’s 7th generation i5 and i7), the solid state drive size (128 to 512 GB), and the RAM size (8 to 16 GB).
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][11]
|
||||||
|
|
||||||
|
Dells XPS Laptop for Linux
|
||||||
|
|
||||||
|
These are very important considerations to take into account and Dell has gotten you covered. Unfortunately, the only Linux distribution that is backed by Dell ProSupport on this model is Ubuntu 16.04 LTS (at the time of this writing – December 2016).
|
||||||
|
|
||||||
|
#### Linux Laptops for System Administrators
|
||||||
|
|
||||||
|
Although system administrators can safely undertake the task of installing a distribution on bare-metal hardware, you can avoid the hassle of searching for available drivers by checking out other offers by System76.
|
||||||
|
|
||||||
|
Since you can choose the features of your laptop, being able to add processing power and up to 32 GB of RAM will ensure you can run virtualized environments on and perform all imaginable system administration tasks with it.
|
||||||
|
|
||||||
|
If this sounds like something that sparks some interest in you, checkout the [Kudu][12] or [Oryx Pro][13] laptops.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][3]
|
||||||
|
|
||||||
|
Kudu Linux Laptop
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
Oryx Pro Linux Laptop
|
||||||
|
|
||||||
|
##### Summary
|
||||||
|
|
||||||
|
In this article we have discussed why buying a laptop with Linux preinstalled is a good option for both home users, developers, and system administrators. Once you have made your choice, feel free to relax and think about what you are going to do with the money you saved.
|
||||||
|
|
||||||
|
Can you think of other tips for buying a Linux laptop? Please let us know using the comment form below.
|
||||||
|
|
||||||
|
As always, don’t hesitate to contact us using the form below if you have questions or comments about this article. We look forward to hearing from you!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Gabriel Cánepa is a GNU/Linux sysadmin and web developer from Villa Mercedes, San Luis, Argentina. He works for a worldwide leading consumer product company and takes great pleasure in using FOSS tools to increase productivity in all areas of his daily work.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/buy-linux-laptops/
|
||||||
|
|
||||||
|
作者:[ Gabriel Cánepa][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/gacanepa/
|
||||||
|
[1]:http://www.tecmint.com/wp-content/uploads/2016/11/Lemur-Laptop.png
|
||||||
|
[2]:http://www.tecmint.com/wp-content/uploads/2016/11/Gazelle-Laptop.png
|
||||||
|
[3]:http://www.tecmint.com/wp-content/uploads/2016/11/Kudu-Linux-Laptop.png
|
||||||
|
[4]:http://www.tecmint.com/wp-content/uploads/2016/11/Oryx-Pro-Linux-Laptop.png
|
||||||
|
[5]:http://amzn.to/2fPxTms
|
||||||
|
[6]:http://amzn.to/2fPxTms
|
||||||
|
[7]:https://system76.com/laptops
|
||||||
|
[8]:https://system76.com/laptops/lemur
|
||||||
|
[9]:https://system76.com/laptops/gazelle
|
||||||
|
[10]:http://amzn.to/2fBLMGj
|
||||||
|
[11]:http://www.tecmint.com/wp-content/uploads/2016/11/Dells-XPS-Laptops.png
|
||||||
|
[12]:https://system76.com/laptops/kudu
|
||||||
|
[13]:https://system76.com/laptops/oryx
|
||||||
@ -0,0 +1,105 @@
|
|||||||
|
5 things to watch in Go programming in 2017
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
### What will innovations like dynamic plugins, serverless Go, and HTTP/2 Push mean for your development this year?
|
||||||
|
|
||||||
|
Go 1.8 is due to be released next month and it’s slated to have several new features, including:
|
||||||
|
|
||||||
|
* [HTTP/2 Push][1]
|
||||||
|
* [HTTP Server Graceful Shutdown][2]
|
||||||
|
* [Plugins][3]
|
||||||
|
* [Default GOPATH][4]
|
||||||
|
|
||||||
|
Which of these new features will have the most impact probably depends on how you and your development team use Go. Since Go 1.0 released in 2012, its emphasis on simplicity, concurrency, and built-in support has kept its [popularity][9] pointed up and to the right, so the answers to “_What is Go good for?_” keep multiplying.
|
||||||
|
|
||||||
|
Here I’ll offer some thoughts on a few things from the upcoming release and elsewhere in the Go world that have caught my eye recently. It’s hardly an exhaustive list, so [let me know][10] what else you think is going to be important in Go for 2017.
|
||||||
|
|
||||||
|
### Go’s super deployability + plugins = containers, anyone?
|
||||||
|
|
||||||
|
The [1.8 release][11] planned for next month has several folks I’ve talked with wondering how the addition of dynamic plugins — for loading shared libraries with code that wasn’t part of the program when it was compiled — will affect things like containers. Dynamic plugins should make it simpler to use high-concurrency microservices in containers. You’ll be able to easily load plugins as external processes, with all the added benefits of microservices in containers: protecting your main process from crashes and not having anything messing around in your memory space. Dynamic support for plugins should really be a boon for using containers in Go.
|
||||||
|
|
||||||
|
_For some expert live Go training, sign up for _[_Go Beyond the Basics_][12]_._
|
||||||
|
|
||||||
|
### Cross-platform support will keep pulling in developers
|
||||||
|
|
||||||
|
In the 7 years since Go was open-sourced, it has been adopted across the globe. [Daniel Whitenack][13], a data scientist and engineer who maintains the Go kernel for Jupyter, told me he recently [gave a data science and Go training in Siberia][14], (yes, Siberia! And, yes data science and Go — more on that in a bit . . .) and “was amazed to see how vibrant and active the Go community was there.” Another big reason folks will continue to adopt Go for their projects is cross compilation, which, as several Go experts have explained, [got even easier with the 1.5 release][15]. Developers from other languages such as Python should find the ability to build a bundled, ready-to-deploy application for multiple operating systems with no VM on target platforms a key draw for working in Go.
|
||||||
|
|
||||||
|
Pair this cross-platform support with projected [15% speed improvements in compile time][16] in the 1.8 release, and you can see why Go is a favorite language for startups.
|
||||||
|
|
||||||
|
_Interested in the basics of Go? Check out the _[_Go Fundamentals Learning Path_][17]_ for guidance from O’Reilly experts to get you started._
|
||||||
|
|
||||||
|
### A Go interpreter is in the works; goodbye Read-Eval-Print-Loop
|
||||||
|
|
||||||
|
Some really smart people are working on a [Go Interpreter][18], and I will definitely be watching this. As many of you know too well, there are several Read-Eval-Print-Loop (REPL) solutions out there that can evaluate expressions and make sure your code works as expected, but these methods often mean tolerating inconvenient caveats, or slogging through several to find the one that fits your use case. A robust, consistent interpreter would be great, and as soon as I hear more, I’ll let you know.
|
||||||
|
|
||||||
|
_Working with Go complexities in your development? Watch the _[_Intermediate Go_][19]_ video training from O’Reilly._
|
||||||
|
|
||||||
|
### Serverless for Go — what will that look like?
|
||||||
|
|
||||||
|
Yes, there’s a lot of hype right now around serverless architecture, a.k.a. function as a service (FaaS). But sometimes where there’s smoke there’s fire, so what’s happening in the Go space around serverless? Could we see a serverless service with native support for Go this year?
|
||||||
|
|
||||||
|
AWS Lambda is the most well-known serverless provider, but Google also recently launched [Google Cloud Functions][20]. Both of these FaaS solutions let you run code without managing servers; your code is stored on a cluster of servers managed for you and run only when a triggering event calls it. AWS Lambda currently supports JavaScript, Python, and Java, plus you can launch Go, Ruby, and bash processes. Google Cloud Functions only supports JavaScript, but it seems likely that both Java and Python will soon be supported, too. A lot of IoT devices already make use of a serverless approach, and with Go’s growing adoption by startups, serverless seems a likely spot for growth, so I’m watching what develops to support Go in these serverless solutions.
|
||||||
|
|
||||||
|
There are already [several frameworks that have Go support][21] underway for AWS Lambdas:
|
||||||
|
|
||||||
|
* [λ Gordon][5] — Create, wire and deploy AWS Lambdas using CloudFormation
|
||||||
|
* [Apex][6] — Build, deploy, and manage AWS Lambda functions
|
||||||
|
* [Sparta][7] — A Go framework for AWS Lambda microservices
|
||||||
|
|
||||||
|
There’s also an AWS Lambda alternative that supports Go:
|
||||||
|
|
||||||
|
* [Iron.io][8]: Built on top of Docker and Go; language agnostic; supports Golang, Python, Ruby, PHP, and .NET
|
||||||
|
|
||||||
|
_For more on serverless architecture, watch Mike Roberts’ keynote from the O’Reilly Software Architecture Conference in San Francisco: _[_An Introduction to Serverless_][22]_._
|
||||||
|
|
||||||
|
### Go for Data — no really!
|
||||||
|
|
||||||
|
I hinted at this at the beginning of this article: perhaps surprisingly, a lot of people are using Go for data science and machine learning. There’s some debate about whether this is a good fit, but based on things like the annual Advent Posts for [Gopher Academy for December 2016][23], where you’ll note at least 4 of the 30 posts are on ML or distributed data processing of some kind, it’s happening.
|
||||||
|
|
||||||
|
My earlier point about Go’s easy deployability is probably one key reason data scientists are working with Go: they can more easily show their data models to others in a readable and productionable application. Pair this with the broad adoption of Go (as I mentioned earlier, its popularity is pointed up and to the right!), and you have data folks creating applications that “work and play well with others.” Any applications data scientists build in Go will speak the same language as the rest of the company, or at least fit very well with modern architectures.
|
||||||
|
|
||||||
|
_For more on Go for data science, Daniel Whitenack has written an excellent overview that explains more about how it’s being used: _[_Data Science Gophers_][24]_._
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Supervising Editor at O’Reilly Media, works with an editorial team that covers a wide variety of programming topics.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://medium.com/@sconant/5-things-to-watch-in-go-programming-in-2017-39cd7a7e58e3#.8t4to5jr1
|
||||||
|
|
||||||
|
作者:[Susan Conant][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://medium.com/@sconant?source=footer_card
|
||||||
|
[1]:https://beta.golang.org/doc/go1.8#h2push
|
||||||
|
[2]:https://beta.golang.org/doc/go1.8#http_shutdown
|
||||||
|
[3]:https://beta.golang.org/doc/go1.8#plugin
|
||||||
|
[4]:https://beta.golang.org/doc/go1.8#gopath
|
||||||
|
[5]:https://github.com/jorgebastida/gordon
|
||||||
|
[6]:https://github.com/apex/apex
|
||||||
|
[7]:http://gosparta.io/
|
||||||
|
[8]:https://www.iron.io/
|
||||||
|
[9]:https://github.com/golang/go/wiki/GoUsers
|
||||||
|
[10]:https://twitter.com/SuConant
|
||||||
|
[11]:https://beta.golang.org/doc/go1.8
|
||||||
|
[12]:https://www.safaribooksonline.com/live-training/courses/go-beyond-the-basics/0636920065357/
|
||||||
|
[13]:https://www.oreilly.com/people/1ea0c-daniel-whitenack
|
||||||
|
[14]:https://devfest.gdg.org.ru/en/
|
||||||
|
[15]:https://medium.com/@rakyll/go-1-5-cross-compilation-488092ba44ec#.7s7sxmc4h
|
||||||
|
[16]:https://beta.golang.org/doc/go1.8#compiler
|
||||||
|
[17]:http://shop.oreilly.com/category/learning-path/go-fundamentals.do
|
||||||
|
[18]:https://github.com/go-interpreter
|
||||||
|
[19]:http://shop.oreilly.com/product/0636920047513.do
|
||||||
|
[20]:https://cloud.google.com/functions/docs/
|
||||||
|
[21]:https://github.com/SerifAndSemaphore/go-serverless-list
|
||||||
|
[22]:https://www.safaribooksonline.com/library/view/oreilly-software-architecture/9781491976142/video288473.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=5-things-to-watch-in-go-programming-body-text-cta
|
||||||
|
[23]:https://blog.gopheracademy.com/series/advent-2016/
|
||||||
|
[24]:https://www.oreilly.com/ideas/data-science-gophers
|
||||||
@ -0,0 +1,114 @@
|
|||||||
|
How to Customize Bash Colors and Content in Linux Terminal Prompt
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
Today, Bash is the default shell in most (if not all) modern Linux distributions. However, you may have noticed that the text color in the terminal and the prompt content can be different from one distro to another.
|
||||||
|
|
||||||
|
In case you have been wondering how to customize this for better accessibility or mere whim, keep reading – in this article we will explain how to do just that.
|
||||||
|
|
||||||
|
### The PS1 Bash Environment Variable
|
||||||
|
|
||||||
|
The command prompt and terminal appearance are governed by an environment variable called `PS1`. According to the Bash man page, PS1 represents the primary prompt string which is displayed when the shell is ready to read a command.
|
||||||
|
|
||||||
|
The allowed content in PS1 consists of several backslash-escaped special characters whose meaning is listed in the PROMPTING section of the man page.
|
||||||
|
|
||||||
|
To illustrate, let’s display the current content of `PS1` in our system (this may be somewhat different in your case):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo $PS1
|
||||||
|
[\u@\h \W]\$
|
||||||
|
```
|
||||||
|
|
||||||
|
We will now explain how to customize PS1 as per our needs.
|
||||||
|
|
||||||
|
#### Customizing the PS1 Format
|
||||||
|
|
||||||
|
According to the PROMPTING section in the man page, this is the meaning of each special character:
|
||||||
|
|
||||||
|
1. `\u:` the username of the current user.
|
||||||
|
2. `\h:` the hostname up to the first dot (.) in the Fully-Qualified Domain Name.
|
||||||
|
3. `\W:` the basename of the current working directory, with $HOME abbreviated with a tilde (~).
|
||||||
|
4. `\$:` If the current user is root, display #, $ otherwise.
|
||||||
|
|
||||||
|
For example, we may want to consider adding `\!` If we want to display the history number of the current command, or `\H` if we want to display the FQDN instead of the short server name.
|
||||||
|
|
||||||
|
In the following example we will import both into our current environment by executing this command:
|
||||||
|
|
||||||
|
```
|
||||||
|
PS1="[\u@\H \W \!]\$"
|
||||||
|
```
|
||||||
|
|
||||||
|
When you press Enter you will see that the prompt content changes as shown below. Compare the prompt before and after executing the above command:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][1]
|
||||||
|
|
||||||
|
Customize Linux Terminal Prompt PS1
|
||||||
|
|
||||||
|
Now let’s go one step further and change the color of the user and hostname in command prompt – both the text and its surrounding background.
|
||||||
|
|
||||||
|
Actually, we can customize 3 aspects of the prompt:
|
||||||
|
|
||||||
|
| Text Format | Foreground (text) color | Background color |
|
||||||
|
| 0: normal text | 30: Black | 40: Black |
|
||||||
|
| 1: bold | 31: Red | 41: Red |
|
||||||
|
| 4: Underlined text | 32: Green | 42: Green |
|
||||||
|
| | 33: Yellow | 43: Yellow |
|
||||||
|
| | 34: Blue | 44: Blue |
|
||||||
|
| | 35: Purple | 45: Purple |
|
||||||
|
| | 36: Cyan | 46: Cyan |
|
||||||
|
| | 37: White | 47: White |
|
||||||
|
|
||||||
|
We will use the `\e` special character at the beginning and an `m` at the end to indicate that what follows is a color sequence.
|
||||||
|
|
||||||
|
In this sequence the three values (background, format, and foreground) are separated by commas (if no value is given the default is assumed).
|
||||||
|
|
||||||
|
**Suggested Read:** [Learn Bash Shell Scripting in Linux][2]
|
||||||
|
|
||||||
|
Also, since the value ranges are different, it does not matter which one (background, format, or foreground) you specify first.
|
||||||
|
|
||||||
|
For example, the following `PS1` will cause the prompt to appear in yellow underlined text with red background:
|
||||||
|
|
||||||
|
```
|
||||||
|
PS1="\e[41;4;33m[\u@\h \W]$ "
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][3]
|
||||||
|
|
||||||
|
Change Linux Terminal Color Prompt PS1
|
||||||
|
|
||||||
|
As good as it looks, this customization will only last for the current user session. If you close your terminal or exit the session, the changes will be lost.
|
||||||
|
|
||||||
|
In order to make these changes permanent, you will have to add the following line to `~/.bashrc` or `~/.bash_profile` depending on your distribution:
|
||||||
|
|
||||||
|
```
|
||||||
|
PS1="\e[41;4;33m[\u@\h \W]$ "
|
||||||
|
```
|
||||||
|
|
||||||
|
Feel free to play around with the colors to find what works best for you.
|
||||||
|
|
||||||
|
##### Summary
|
||||||
|
|
||||||
|
In this article we have explained how to customize the color and content of your Bash prompt. If you have questions or suggestions about this post, feel free to use the comment form below to reach us. We look forward to hearing from you!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/customize-bash-colors-terminal-prompt-linux/
|
||||||
|
|
||||||
|
作者:[Aaron Kili][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:http://www.tecmint.com/wp-content/uploads/2017/01/Customize-Linux-Terminal-Prompt.png
|
||||||
|
[2]:http://www.tecmint.com/category/bash-shell/
|
||||||
|
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/Change-Linux-Terminal-Color-Prompt.png
|
||||||
@ -0,0 +1,78 @@
|
|||||||
|
Top 8 systems operations and engineering trends for 2017
|
||||||
|
=================
|
||||||
|
|
||||||
|
Forecasting trends is tricky, especially in the fast-moving world of systems operations and engineering. This year, at our Velocity Conference, we have talked about distributed systems, SRE, containerization, serverless architectures, burnout, and many other topics related to the human and technological challenges of delivering software. Here are some of the trends we see for the next year:
|
||||||
|
|
||||||
|
### 1\. Distributed Systems
|
||||||
|
|
||||||
|
We think this is important enough that we [re-focused the entire Velocity conference on it][1].
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 2\. Site Reliability Engineering
|
||||||
|
|
||||||
|
[Site Reliability Engineering][3]—is it just ops? [Or is it DevOps by another name][4]? Google's profile for an ops professional calls for heavy doses of systems and software engineering. Spread further into the industry by Xooglers at companies like Dropbox, [hiring for SRE positions][5] continues to increase, particularly for web-facing companies with large data centers. In some contexts, the role of SREs becomes more about helping developers operate their own services.
|
||||||
|
|
||||||
|
### 3\. Containerization
|
||||||
|
|
||||||
|
Companies will continue to containerize their software delivery. Docker Inc. itself has positioned Docker as a tool for "[incremental revolution][6]," and containerizing legacy applications has become a common use case in the enterprise. What's the future of Docker? As engineers continue to adopt orchestration tools like Kubernetes and Mesos, the higher level of abstraction may make more room for other flavors of containers (like rkt, Garden, etc.).
|
||||||
|
|
||||||
|
### 4\. Unikernels
|
||||||
|
|
||||||
|
Are unikernels the next step after containerization? Are they unfit for production? Some tout the security and performance benefits of unikernels. Keep an eye out for how unikernels evolve in 2017, [particularly with an eye to what Docker Inc. does][7] in this area (having acquired Unikernel Systems this year).
|
||||||
|
|
||||||
|
### 5\. Serverless
|
||||||
|
|
||||||
|
Serverless architectures treat functions as the basic unit of computation. Some find the term misleading (and reminiscent of "noops"), and prefer to refer to this trend as Functions-as-a-Service. Developers and architects are experimenting with the technology more and more, and expect to see more applications being written in this paradigm. For more on what serverless/FaaS means for operations, check out the free ebook on [Serverless Ops][8] by Michael Hausenblas.
|
||||||
|
|
||||||
|
### 6\. Cloud-Native application development
|
||||||
|
|
||||||
|
Like DevOps, this term has been used and abused by marketers for a long while, but the Cloud Native Computing Foundation makes a strong case for these new sets of tools (often Google-inspired) that take advantage not just of the cloud, but in particular the strengths and opportunities provided by distributed systems—in short, microservices, containerization, and dynamic orchestration.
|
||||||
|
|
||||||
|
### 7\. Monitoring
|
||||||
|
|
||||||
|
As the industry has evolved from Nagios-style monitoring, to streaming metrics and visualizations, we've become great at producing loads of systems data. Interpretation is the next challenge. As such, we are seeing vendors offering machine learning-powered monitoring services, and, more generally, IT operations learning techniques for machine learning systems data. Similarly, as our infrastructure becomes more dynamic and distributed, monitoring becomes less and less about checking the health of individual resources and more about tracing flows between services. As such, distributed tracing has emerged.
|
||||||
|
|
||||||
|
### 8\. DevOps Security
|
||||||
|
|
||||||
|
With DevOpsSec increasing in popularity, [security is quickly becoming a team-wide concern][9]. The classic challenge of DevOps of achieving both velocity and reliability is especially pronounced when companies with security and compliance concerns are feeling the pinch to compete on speed.
|
||||||
|
|
||||||
|
### Tell us about your work
|
||||||
|
|
||||||
|
As an IT operations professional—whether you use the term sysadmin, DevOps, SRE, DBA, etc.—[you’re invited to share your insights][10] to help us learn about the demographics, work environments, tools, and compensation of practitioners in our growing field. All responses are reported in aggregate to assure your anonymity. The survey will require approximately 5–10 minutes to complete. Once we've closed the survey and analyzed the results, we'll share our findings with you. [Take the survey][11].
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Courtney Nash chairs multiple conferences for O'Reilly Media and is the strategic content director focused on areas of modern web operations, high performance applications, and security. An erstwhile academic neuroscientist, she is still fascinated by the brain and how it informs our interactions with and expectations of technology. She's spent 17 years working in the technology industry in a wide variety of roles, ever since moving to Seattle to work at a burgeoning online bookstore. Outside work, Courtney can be found biking, hiking, skiing, ...
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Brian Anderson, Infrastructure and Operations Editor at O’Reilly Media, covers topics essential to the delivery of software — from traditional system administration, to cloud computing, web performance, Docker, and DevOps. He has been working in online education and serving the needs of working learners for more than ten years.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017
|
||||||
|
|
||||||
|
作者:[Courtney Nash][a],[Brian Anderson][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.oreilly.com/people/3f5d7-courtneyw-nash
|
||||||
|
[b]:https://www.oreilly.com/people/brian_anderson
|
||||||
|
[1]:https://www.oreilly.com/ideas/velocity-a-new-direction
|
||||||
|
[2]:https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017?imm_mid=0ec113&cmp=em-webops-na-na-newsltr_20170106
|
||||||
|
[3]:https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||||
|
[4]:http://conferences.oreilly.com/velocity/devops-web-performance-ny/public/content/devops-sre-ama-video
|
||||||
|
[5]:https://www.glassdoor.com/Salaries/site-reliability-engineer-salary-SRCH_KO0,25.htm
|
||||||
|
[6]:http://blog.scottlowe.org/2016/06/21/dockercon-2016-day-2-keynote/
|
||||||
|
[7]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||||
|
[8]:http://www.oreilly.com/webops-perf/free/serverless-ops.csp?intcmp=il-webops-free-lp-na_new_site_top_8_systems_operations_and_engineering_trends_for_2017_body_text_cta
|
||||||
|
[9]:https://www.oreilly.com/learning/devopssec-securing-software-through-continuous-delivery
|
||||||
|
[10]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||||
|
[11]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||||
@ -0,0 +1,379 @@
|
|||||||
|
yangmingming translating
|
||||||
|
12 Useful Commands For Filtering Text for Effective File Operations in Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
In this article, we will review a number of command line tools that act as filters in Linux. A filter is a program that reads standard input, performs an operation upon it and writes the results to standard output.
|
||||||
|
|
||||||
|
For this reason, it can be used to process information in powerful ways such as restructuring output to generate useful reports, modifying text in files and many other system administration tasks.
|
||||||
|
|
||||||
|
With that said, below are some of the useful file or text filters in Linux.
|
||||||
|
|
||||||
|
### 1\. Awk Command
|
||||||
|
|
||||||
|
Awk is a remarkable pattern scanning and processing language, it can be used to build useful filters in Linux. You can start using it by reading through our [Awk series Part 1 to Part 13][7].
|
||||||
|
|
||||||
|
Additionally, also read through the awk man page for more info and usage options:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ man awk
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2\. Sed Command
|
||||||
|
|
||||||
|
sed is a powerful stream editor for filtering and transforming text. We’ve already written a two useful articles on sed, that you can go through it here:
|
||||||
|
|
||||||
|
1. [How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux][1]
|
||||||
|
2. [15 Useful ‘sed’ Command Tips and Tricks for Daily Linux System Administration Tasks][2]
|
||||||
|
|
||||||
|
The sed man page has added control options and instructions:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ man sed
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3\. Grep, Egrep, Fgrep, Rgrep Commands
|
||||||
|
|
||||||
|
These filters output lines matching a given pattern. They read lines from a file or standard input, and print all matching lines by default to standard output.
|
||||||
|
|
||||||
|
Note: The main program is [grep][8], the variations are simply the same as [using specific grep options][9] as below (and they are still being used for backward compatibility):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ egrep = grep -E
|
||||||
|
$ fgrep = grep -F
|
||||||
|
$ rgrep = grep -r
|
||||||
|
```
|
||||||
|
|
||||||
|
Below are some basic grep commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ grep "aaronkilik" /etc/passwd
|
||||||
|
aaronkilik:x:1001:1001::/home/aaronkilik:
|
||||||
|
tecmint@TecMint ~ $ cat /etc/passwd | grep "aronkilik"
|
||||||
|
aaronkilik:x:1001:1001::/home/aaronkilik:
|
||||||
|
```
|
||||||
|
|
||||||
|
You can read more about [What’s Difference Between Grep, Egrep and Fgrep in Linux?][10].
|
||||||
|
|
||||||
|
### 4\. head Command
|
||||||
|
|
||||||
|
head is used to display the first parts of a file, it outputs the first 10 lines by default. You can use the `-n` num flag to specify the number of lines to be displayed:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ head /var/log/auth.log
|
||||||
|
Jan 2 10:45:01 TecMint CRON[3383]: pam_unix(cron:session): session opened for user root by (uid=0)
|
||||||
|
Jan 2 10:45:01 TecMint CRON[3383]: pam_unix(cron:session): session closed for user root
|
||||||
|
Jan 2 10:51:34 TecMint sudo: tecmint : TTY=unknown ; PWD=/home/tecmint ; USER=root ; COMMAND=/usr/lib/linuxmint/mintUpdate/checkAPT.py
|
||||||
|
Jan 2 10:51:34 TecMint sudo: pam_unix(sudo:session): session opened for user root by (uid=0)
|
||||||
|
Jan 2 10:51:39 TecMint sudo: pam_unix(sudo:session): session closed for user root
|
||||||
|
Jan 2 10:55:01 TecMint CRON[4099]: pam_unix(cron:session): session opened for user root by (uid=0)
|
||||||
|
Jan 2 10:55:01 TecMint CRON[4099]: pam_unix(cron:session): session closed for user root
|
||||||
|
Jan 2 11:05:01 TecMint CRON[4138]: pam_unix(cron:session): session opened for user root by (uid=0)
|
||||||
|
Jan 2 11:05:01 TecMint CRON[4138]: pam_unix(cron:session): session closed for user root
|
||||||
|
Jan 2 11:09:01 TecMint CRON[4146]: pam_unix(cron:session): session opened for user root by (uid=0)
|
||||||
|
tecmint@TecMint ~ $ head -n 5 /var/log/auth.log
|
||||||
|
Jan 2 10:45:01 TecMint CRON[3383]: pam_unix(cron:session): session opened for user root by (uid=0)
|
||||||
|
Jan 2 10:45:01 TecMint CRON[3383]: pam_unix(cron:session): session closed for user root
|
||||||
|
Jan 2 10:51:34 TecMint sudo: tecmint : TTY=unknown ; PWD=/home/tecmint ; USER=root ; COMMAND=/usr/lib/linuxmint/mintUpdate/checkAPT.py
|
||||||
|
Jan 2 10:51:34 TecMint sudo: pam_unix(sudo:session): session opened for user root by (uid=0)
|
||||||
|
Jan 2 10:51:39 TecMint sudo: pam_unix(sudo:session): session closed for user root
|
||||||
|
```
|
||||||
|
|
||||||
|
Learn how to use [head command with tail and cat commands][11] for effective usage in Linux.
|
||||||
|
|
||||||
|
### 5\. tail Command
|
||||||
|
|
||||||
|
tail outputs the last parts (10 lines by default) of a file. Use the `-n` num switch to specify the number of lines to be displayed.
|
||||||
|
|
||||||
|
The command below will output the last 5 lines of the specified file:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ tail -n 5 /var/log/auth.log
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on 0.0.0.0 port 22.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on :: port 22.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Received SIGHUP; restarting.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on 0.0.0.0 port 22.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on :: port 22.
|
||||||
|
```
|
||||||
|
|
||||||
|
Additionally, tail has a special option `-f` for [watching changes in a file in real-time][12] (especially log files).
|
||||||
|
|
||||||
|
The following command will enable you monitor changes in the specified file:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ tail -f /var/log/auth.log
|
||||||
|
Jan 6 12:58:01 TecMint sshd[1269]: Server listening on :: port 22.
|
||||||
|
Jan 6 12:58:11 TecMint sshd[1269]: Received SIGHUP; restarting.
|
||||||
|
Jan 6 12:58:12 TecMint sshd[1269]: Server listening on 0.0.0.0 port 22.
|
||||||
|
Jan 6 12:58:12 TecMint sshd[1269]: Server listening on :: port 22.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Received SIGHUP; restarting.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on 0.0.0.0 port 22.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on :: port 22.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Received SIGHUP; restarting.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on 0.0.0.0 port 22.
|
||||||
|
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on :: port 22.
|
||||||
|
```
|
||||||
|
|
||||||
|
Read through the tail man page for a complete list of usage options and instructions:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ man tail
|
||||||
|
```
|
||||||
|
|
||||||
|
### 6\. sort Command
|
||||||
|
|
||||||
|
sort is used to sort lines of a text file or from standard input.
|
||||||
|
|
||||||
|
Below is the content of a file named domains.list:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ cat domains.list
|
||||||
|
tecmint.com
|
||||||
|
tecmint.com
|
||||||
|
news.tecmint.com
|
||||||
|
news.tecmint.com
|
||||||
|
linuxsay.com
|
||||||
|
linuxsay.com
|
||||||
|
windowsmint.com
|
||||||
|
windowsmint.com
|
||||||
|
```
|
||||||
|
|
||||||
|
You can run a simple [sort command][13] to sort the file content like so:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ sort domains.list
|
||||||
|
linuxsay.com
|
||||||
|
linuxsay.com
|
||||||
|
news.tecmint.com
|
||||||
|
news.tecmint.com
|
||||||
|
tecmint.com
|
||||||
|
tecmint.com
|
||||||
|
windowsmint.com
|
||||||
|
windowsmint.com
|
||||||
|
```
|
||||||
|
|
||||||
|
You can use sort command in many ways, go through some of the useful articles on sort command as follows:
|
||||||
|
|
||||||
|
1. [14 Useful Examples of Linux ‘sort’ Command – Part 1][3]
|
||||||
|
2. [7 Interesting Linux ‘sort’ Command Examples – Part 2][4]
|
||||||
|
3. [How to Find and Sort Files Based on Modification Date and Time][5]
|
||||||
|
4. [http://www.tecmint.com/sort-ls-output-by-last-modified-date-and-time/][6]
|
||||||
|
|
||||||
|
### 7\. uniq Command
|
||||||
|
|
||||||
|
uniq command is used to report or omit repeated lines, it filters lines from standard input and writes the outcome to standard output.
|
||||||
|
|
||||||
|
After running sort on an input stream, you can remove repeated lines with uniq as in the example below.
|
||||||
|
|
||||||
|
To indicate the number of occurrences of a line, use the `-c` option and ignore differences in case while comparing by including the `-i` option:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ cat domains.list
|
||||||
|
tecmint.com
|
||||||
|
tecmint.com
|
||||||
|
news.tecmint.com
|
||||||
|
news.tecmint.com
|
||||||
|
linuxsay.com
|
||||||
|
linuxsay.com
|
||||||
|
windowsmint.com
|
||||||
|
tecmint@TecMint ~ $ sort domains.list | uniq -c
|
||||||
|
2 linuxsay.com
|
||||||
|
2 news.tecmint.com
|
||||||
|
2 tecmint.com
|
||||||
|
1 windowsmint.com
|
||||||
|
```
|
||||||
|
|
||||||
|
Read through the uniq man page for further usage info and flags:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ man uniq
|
||||||
|
```
|
||||||
|
|
||||||
|
### 8\. fmt Command
|
||||||
|
|
||||||
|
fmt simple optimal text formatter, it reformats paragraphs in specified file and prints results to the standard output.
|
||||||
|
|
||||||
|
The following is the content extracted from the file domain-list.txt:
|
||||||
|
|
||||||
|
```
|
||||||
|
1.tecmint.com 2.news.tecmint.com 3.linuxsay.com 4.windowsmint.com
|
||||||
|
```
|
||||||
|
|
||||||
|
To reformat the above content to a standard list, run the following command with `-w` switch is used to define the maximum line width:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ cat domain-list.txt
|
||||||
|
1.tecmint.com 2.news.tecmint.com 3.linuxsay.com 4.windowsmint.com
|
||||||
|
tecmint@TecMint ~ $ fmt -w 1 domain-list.txt
|
||||||
|
1.tecmint.com
|
||||||
|
2.news.tecmint.com
|
||||||
|
3.linuxsay.com
|
||||||
|
4.windowsmint.com
|
||||||
|
```
|
||||||
|
|
||||||
|
### 9\. pr Command
|
||||||
|
|
||||||
|
pr command converts text files or standard input for printing. For instance on Debian systems, you can list all installed packages as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ dpkg -l
|
||||||
|
```
|
||||||
|
|
||||||
|
To organize the list in pages and columns ready for printing, issue the following command.
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ dpkg -l | pr --columns 3 -l 20
|
||||||
|
2017-01-06 13:19 Page 1
|
||||||
|
Desired=Unknown/Install ii adduser ii apg
|
||||||
|
| Status=Not/Inst/Conf- ii adwaita-icon-theme ii app-install-data
|
||||||
|
|/ Err?=(none)/Reinst-r ii adwaita-icon-theme- ii apparmor
|
||||||
|
||/ Name ii alsa-base ii apt
|
||||||
|
+++-=================== ii alsa-utils ii apt-clone
|
||||||
|
ii accountsservice ii anacron ii apt-transport-https
|
||||||
|
ii acl ii apache2 ii apt-utils
|
||||||
|
ii acpi-support ii apache2-bin ii apt-xapian-index
|
||||||
|
ii acpid ii apache2-data ii aptdaemon
|
||||||
|
ii add-apt-key ii apache2-utils ii aptdaemon-data
|
||||||
|
2017-01-06 13:19 Page 2
|
||||||
|
ii aptitude ii avahi-daemon ii bind9-host
|
||||||
|
ii aptitude-common ii avahi-utils ii binfmt-support
|
||||||
|
ii apturl ii aview ii binutils
|
||||||
|
ii apturl-common ii banshee ii bison
|
||||||
|
ii archdetect-deb ii baobab ii blt
|
||||||
|
ii aspell ii base-files ii blueberry
|
||||||
|
ii aspell-en ii base-passwd ii bluetooth
|
||||||
|
ii at-spi2-core ii bash ii bluez
|
||||||
|
ii attr ii bash-completion ii bluez-cups
|
||||||
|
ii avahi-autoipd ii bc ii bluez-obexd
|
||||||
|
.....
|
||||||
|
```
|
||||||
|
|
||||||
|
The flags used here are:
|
||||||
|
|
||||||
|
1. `--column` defines number of columns created in the output.
|
||||||
|
2. `-l` specifies page length (default is 66 lines).
|
||||||
|
|
||||||
|
### 10\. tr Command
|
||||||
|
|
||||||
|
This tool translates or deletes characters from standard input and writes results to standard output.
|
||||||
|
|
||||||
|
The syntax for using tr is as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ tr options set1 set2
|
||||||
|
```
|
||||||
|
|
||||||
|
Take a look at the examples below, in the first command, `set1( [:upper:] )` represents the case of input characters (all upper case).
|
||||||
|
|
||||||
|
Then `set2([:lower:])` represents the case in which the resultant characters will be. It’s same thing in the second example and the escape sequence `\n` means print output on a new line:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ echo "WWW.TECMINT.COM" | tr [:upper:] [:lower:]
|
||||||
|
www.tecmint.com
|
||||||
|
tecmint@TecMint ~ $ echo "news.tecmint.com" | tr [:lower:] [:upper:]
|
||||||
|
NEWS.TECMINT.COM
|
||||||
|
```
|
||||||
|
|
||||||
|
### 11\. more Command
|
||||||
|
|
||||||
|
more command is a useful file perusal filter created basically for certificate viewing. It shows file content in a page like format, where users can press [Enter] to view more information.
|
||||||
|
|
||||||
|
You can use it to view large files like so:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ dmesg | more
|
||||||
|
[ 0.000000] Initializing cgroup subsys cpuset
|
||||||
|
[ 0.000000] Initializing cgroup subsys cpu
|
||||||
|
[ 0.000000] Initializing cgroup subsys cpuacct
|
||||||
|
[ 0.000000] Linux version 4.4.0-21-generic (buildd@lgw01-21) (gcc version 5.3.1 20160413 (Ubuntu 5.3.1-14ubuntu2) ) #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 (Ubuntu 4.4.0-21.37-generic
|
||||||
|
4.4.6)
|
||||||
|
[ 0.000000] Command line: BOOT_IMAGE=/boot/vmlinuz-4.4.0-21-generic root=UUID=bb29dda3-bdaa-4b39-86cf-4a6dc9634a1b ro quiet splash vt.handoff=7
|
||||||
|
[ 0.000000] KERNEL supported cpus:
|
||||||
|
[ 0.000000] Intel GenuineIntel
|
||||||
|
[ 0.000000] AMD AuthenticAMD
|
||||||
|
[ 0.000000] Centaur CentaurHauls
|
||||||
|
[ 0.000000] x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
|
||||||
|
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x01: 'x87 floating point registers'
|
||||||
|
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x02: 'SSE registers'
|
||||||
|
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x04: 'AVX registers'
|
||||||
|
[ 0.000000] x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'standard' format.
|
||||||
|
[ 0.000000] x86/fpu: Using 'eager' FPU context switches.
|
||||||
|
[ 0.000000] e820: BIOS-provided physical RAM map:
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009d3ff] usable
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x000000000009d400-0x000000000009ffff] reserved
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x00000000000e0000-0x00000000000fffff] reserved
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x00000000a56affff] usable
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x00000000a56b0000-0x00000000a5eaffff] reserved
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x00000000a5eb0000-0x00000000aaabefff] usable
|
||||||
|
--More--
|
||||||
|
```
|
||||||
|
|
||||||
|
### 12\. less Command
|
||||||
|
|
||||||
|
less is the opposite of more command above but it offers extra features and it’s a little faster with large files.
|
||||||
|
|
||||||
|
Use it in the same way as more:
|
||||||
|
|
||||||
|
```
|
||||||
|
tecmint@TecMint ~ $ dmesg | less
|
||||||
|
[ 0.000000] Initializing cgroup subsys cpuset
|
||||||
|
[ 0.000000] Initializing cgroup subsys cpu
|
||||||
|
[ 0.000000] Initializing cgroup subsys cpuacct
|
||||||
|
[ 0.000000] Linux version 4.4.0-21-generic (buildd@lgw01-21) (gcc version 5.3.1 20160413 (Ubuntu 5.3.1-14ubuntu2) ) #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 (Ubuntu 4.4.0-21.37-generic
|
||||||
|
4.4.6)
|
||||||
|
[ 0.000000] Command line: BOOT_IMAGE=/boot/vmlinuz-4.4.0-21-generic root=UUID=bb29dda3-bdaa-4b39-86cf-4a6dc9634a1b ro quiet splash vt.handoff=7
|
||||||
|
[ 0.000000] KERNEL supported cpus:
|
||||||
|
[ 0.000000] Intel GenuineIntel
|
||||||
|
[ 0.000000] AMD AuthenticAMD
|
||||||
|
[ 0.000000] Centaur CentaurHauls
|
||||||
|
[ 0.000000] x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
|
||||||
|
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x01: 'x87 floating point registers'
|
||||||
|
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x02: 'SSE registers'
|
||||||
|
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x04: 'AVX registers'
|
||||||
|
[ 0.000000] x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'standard' format.
|
||||||
|
[ 0.000000] x86/fpu: Using 'eager' FPU context switches.
|
||||||
|
[ 0.000000] e820: BIOS-provided physical RAM map:
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009d3ff] usable
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x000000000009d400-0x000000000009ffff] reserved
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x00000000000e0000-0x00000000000fffff] reserved
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x00000000a56affff] usable
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x00000000a56b0000-0x00000000a5eaffff] reserved
|
||||||
|
[ 0.000000] BIOS-e820: [mem 0x00000000a5eb0000-0x00000000aaabefff] usable
|
||||||
|
:
|
||||||
|
```
|
||||||
|
|
||||||
|
Learn Why [‘less’ is Faster Than ‘more’ Command][14] for effective file navigation in Linux.
|
||||||
|
|
||||||
|
That’s all for now, do let us know of any [useful command line tools][15] not mentioned here, that act as a text filters in Linux via the comment section below.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/linux-file-operations-commands/
|
||||||
|
|
||||||
|
作者:[Aaron Kili][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||||
|
[2]:http://www.tecmint.com/linux-sed-command-tips-tricks/
|
||||||
|
[3]:http://www.tecmint.com/sort-command-linux/
|
||||||
|
[4]:http://www.tecmint.com/linux-sort-command-examples/
|
||||||
|
[5]:http://www.tecmint.com/find-and-sort-files-modification-date-and-time-in-linux/
|
||||||
|
[6]:http://how%20to%20sort%20output%20of%20%E2%80%98ls%E2%80%99%20command%20by%20last%20modified%20date%20and%20time/
|
||||||
|
[7]:http://www.tecmint.com/category/awk-command/
|
||||||
|
[8]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||||
|
[9]:http://www.tecmint.com/linux-grep-commands-character-classes-bracket-expressions/
|
||||||
|
[10]:http://www.tecmint.com/difference-between-grep-egrep-and-fgrep-in-linux/
|
||||||
|
[11]:http://www.tecmint.com/view-contents-of-file-in-linux/
|
||||||
|
[12]:http://www.tecmint.com/fswatch-monitors-files-and-directory-changes-modifications-in-linux/
|
||||||
|
[13]:http://www.tecmint.com/sort-command-linux/
|
||||||
|
[14]:http://www.tecmint.com/linux-more-command-and-less-command-examples/
|
||||||
|
[15]:http://www.tecmint.com/tag/linux-tricks/
|
||||||
@ -0,0 +1,251 @@
|
|||||||
|
GHLandy Translating
|
||||||
|
|
||||||
|
|
||||||
|
10 Useful Sudoers Configurations for Setting ‘sudo’ in Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
In Linux and other Unix-like operating systems, only the root user can run all commands and perform certain critical operations on the system such as install and update, remove packages, [create users and groups][1], modify important system configuration files and so on.
|
||||||
|
|
||||||
|
However, a system administrator who assumes the role of the root user can permit other normal system users with the help of [sudo command][2] and a few configurations to run some commands as well as carry out a number of vital system operations including the ones mentioned above.
|
||||||
|
|
||||||
|
Alternatively, the system administrator can share the root user password (which is not a recommended method) so that normal system users have access to the root user account via su command.
|
||||||
|
|
||||||
|
sudo allows a permitted user to execute a command as root (or another user), as specified by the security policy:
|
||||||
|
|
||||||
|
1. It reads and parses /etc/sudoers, looks up the invoking user and its permissions,
|
||||||
|
2. then prompts the invoking user for a password (normally the user’s password, but it can as well be the target user’s password. Or it can be skipped with NOPASSWD tag),
|
||||||
|
3. after that, sudo creates a child process in which it calls setuid() to switch to the target user
|
||||||
|
4. next, it executes a shell or the command given as arguments in the child process above.
|
||||||
|
|
||||||
|
Below are ten /etc/sudoers file configurations to modify the behavior of sudo command using Defaults entries.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo cat /etc/sudoers
|
||||||
|
```
|
||||||
|
/etc/sudoers File
|
||||||
|
```
|
||||||
|
#
|
||||||
|
# This file MUST be edited with the 'visudo' command as root.
|
||||||
|
#
|
||||||
|
# Please consider adding local content in /etc/sudoers.d/ instead of
|
||||||
|
# directly modifying this file.
|
||||||
|
#
|
||||||
|
# See the man page for details on how to write a sudoers file.
|
||||||
|
#
|
||||||
|
Defaults env_reset
|
||||||
|
Defaults mail_badpass
|
||||||
|
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
|
||||||
|
Defaults logfile="/var/log/sudo.log"
|
||||||
|
Defaults lecture="always"
|
||||||
|
Defaults badpass_message="Password is wrong, please try again"
|
||||||
|
Defaults passwd_tries=5
|
||||||
|
Defaults insults
|
||||||
|
Defaults log_input,log_output
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Types of Defaults Entries
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults parameter, parameter_list #affect all users on any host
|
||||||
|
Defaults@Host_List parameter, parameter_list #affects all users on a specific host
|
||||||
|
Defaults:User_List parameter, parameter_list #affects a specific user
|
||||||
|
Defaults!Cmnd_List parameter, parameter_list #affects a specific command
|
||||||
|
Defaults>Runas_List parameter, parameter_list #affects commands being run as a specific user
|
||||||
|
```
|
||||||
|
|
||||||
|
For the scope of this guide, we will zero down to the first type of Defaults in the forms below. Parameters may be flags, integer values, strings, or lists.
|
||||||
|
|
||||||
|
You should note that flags are implicitly boolean and can be turned off using the `'!'` operator, and lists have two additional assignment operators, `+=` (add to list) and `-=` (remove from list).
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults parameter
|
||||||
|
OR
|
||||||
|
Defaults parameter=value
|
||||||
|
OR
|
||||||
|
Defaults parameter -=value
|
||||||
|
Defaults parameter +=value
|
||||||
|
OR
|
||||||
|
Defaults !parameter
|
||||||
|
```
|
||||||
|
|
||||||
|
### 1\. Set a Secure PATH
|
||||||
|
|
||||||
|
This is the path used for every command run with sudo, it has two importances:
|
||||||
|
|
||||||
|
1. Used when a system administrator does not trust sudo users to have a secure PATH environment variable
|
||||||
|
2. To separate “root path” and “user path”, only users defined by exempt_group are not affected by this setting.
|
||||||
|
|
||||||
|
To set it, add the line:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2\. Enable sudo on TTY User Login Session
|
||||||
|
|
||||||
|
To enable sudo to be invoked from a real tty but not through methods such as cron or cgi-bin scripts, add the line:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults requiretty
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3\. Run Sudo Command Using a pty
|
||||||
|
|
||||||
|
A few times, attackers can run a malicious program (such as a virus or malware) using sudo, which would again fork a background process that remains on the user’s terminal device even when the main program has finished executing.
|
||||||
|
|
||||||
|
To avoid such a scenario, you can configure sudo to run other commands only from a psuedo-pty using the `use_pty` parameter, whether I/O logging is turned on or not as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults use_pty
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4\. Create a Sudo Log File
|
||||||
|
|
||||||
|
By default, sudo logs through syslog(3). However, to specify a custom log file, use the logfile parameter like so:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults logfile="/var/log/sudo.log"
|
||||||
|
```
|
||||||
|
|
||||||
|
To log hostname and the four-digit year in the custom log file, use log_host and log_year parameters respectively as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults log_host, log_year, logfile="/var/log/sudo.log"
|
||||||
|
```
|
||||||
|
|
||||||
|
Below is an example of a custom sudo log file:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][3]
|
||||||
|
|
||||||
|
Create Custom Sudo Log File
|
||||||
|
|
||||||
|
### 5\. Log Sudo Command Input/Output
|
||||||
|
|
||||||
|
The log_input and log_output parameters enable sudo to run a command in pseudo-tty and log all user input and all output sent to the screen receptively.
|
||||||
|
|
||||||
|
The default I/O log directory is /var/log/sudo-io, and if there is a session sequence number, it is stored in this directory. You can specify a custom directory through the iolog_dir parameter.
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults log_input, log_output
|
||||||
|
```
|
||||||
|
|
||||||
|
There are some escape sequences are supported such as `%{seq}` which expands to a monotonically increasing base-36 sequence number, such as 000001, where every two digits are used to form a new directory, e.g. 00/00/01 as in the example below:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd /var/log/sudo-io/
|
||||||
|
$ ls
|
||||||
|
$ cd 00/00/01
|
||||||
|
$ ls
|
||||||
|
$ cat log
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
Log sudo Input Output
|
||||||
|
|
||||||
|
You can view the rest of the files in that directory using the [cat command][5].
|
||||||
|
|
||||||
|
### 6\. Lecture Sudo Users
|
||||||
|
|
||||||
|
To lecture sudo users about password usage on the system, use the lecture parameter as below.
|
||||||
|
|
||||||
|
It has 3 possible values:
|
||||||
|
|
||||||
|
1. always – always lecture a user.
|
||||||
|
2. once – only lecture a user the first time they execute sudo command (this is used when no value is specified)
|
||||||
|
3. never – never lecture the user.
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
Defaults lecture="always"
|
||||||
|
```
|
||||||
|
|
||||||
|
Additionally, you can set a custom lecture file with the lecture_file parameter, type the appropriate message in the file:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults lecture_file="/path/to/file"
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][6]
|
||||||
|
|
||||||
|
Lecture Sudo Users
|
||||||
|
|
||||||
|
### 7\. Show Custom Message When You Enter Wrong sudo Password
|
||||||
|
|
||||||
|
When a user enters a wrong password, a certain message is displayed on the command line. The default message is “sorry, try again”, you can modify the message using the badpass_message parameter as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults badpass_message="Password is wrong, please try again"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 8\. Increase sudo Password Tries Limit
|
||||||
|
|
||||||
|
The parameter passwd_tries is used to specify the number of times a user can try to enter a password.
|
||||||
|
|
||||||
|
The default value is 3:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults passwd_tries=5
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][7]
|
||||||
|
|
||||||
|
Increase Sudo Password Attempts
|
||||||
|
|
||||||
|
To set a password timeout (default is 5 minutes) using passwd_timeout parameter, add the line below:
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults passwd_timeout=2
|
||||||
|
```
|
||||||
|
|
||||||
|
### 9\. Let Sudo Insult You When You Enter Wrong Password
|
||||||
|
|
||||||
|
In case a user types a wrong password, sudo will display insults on the terminal with the insults parameter. This will automatically turn off the badpass_message parameter.
|
||||||
|
|
||||||
|
```
|
||||||
|
Defaults insults
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][8]
|
||||||
|
|
||||||
|
Let’s Sudo Insult You When Enter Wrong Password
|
||||||
|
|
||||||
|
### 10\. Learn More Sudo Configurations
|
||||||
|
|
||||||
|
Additionally, you can learn more sudo command configurations by reading: [Difference Between su and sudo and How to Configure sudo in Linux][9].
|
||||||
|
|
||||||
|
That’s it! You can share other useful sudo command configurations or [tricks and tips with Linux][10] users out there via the comment section below.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||||
|
|
||||||
|
作者:[Aaron Kili][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||||
|
[2]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||||
|
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/Create-Sudo-Log-File.png
|
||||||
|
[4]:http://www.tecmint.com/wp-content/uploads/2017/01/Log-sudo-Input-Output.png
|
||||||
|
[5]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||||
|
[6]:http://www.tecmint.com/wp-content/uploads/2017/01/Lecture-Sudo-Users.png
|
||||||
|
[7]:http://www.tecmint.com/wp-content/uploads/2017/01/Increase-Sudo-Password-Attempts.png
|
||||||
|
[8]:http://www.tecmint.com/wp-content/uploads/2017/01/Sudo-Insult-Message.png
|
||||||
|
[9]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||||
|
[10]:http://www.tecmint.com/tag/linux-tricks/
|
||||||
@ -1,406 +0,0 @@
|
|||||||
在CentOS 上介绍 FirewallD
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
|
|
||||||
[FirewallD][4] 是iptables的前端控制器,用于实现持久网络流量规则。它提供命令行和图形界面,在大多数Linux发行版的仓库中都有。与直接控制iptables相比,使用 FirewallD 有两个主要区别:
|
|
||||||
|
|
||||||
1. FirewallD 使用 _zones_ 和 _services_ 而不是链式规则。
|
|
||||||
2. 它动态管理规则集,允许更新而不破坏现有会话和连接。
|
|
||||||
|
|
||||||
> FirewallD是 iptables 的一个封装,允许更容易地管理 iptables 规则 - 它并*不是* iptables 的替代品。虽然 iptables 命令仍可用于 FirewallD,但建议仅在 FirewallD 中使用 FirewallD 命令。
|
|
||||||
|
|
||||||
本指南将向您介绍 FirewallD的 zone 和 service 的概念,以及一些基本的配置步骤。
|
|
||||||
|
|
||||||
### 安装与管理 FirewallD
|
|
||||||
|
|
||||||
CentOS 7 和 Fedora 20+ 已经包含了 FirewallD 但是默认没有激活。像其他 systemd 单元那样控制它。
|
|
||||||
|
|
||||||
1. 启动服务,并在启动时启动该服务:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo systemctl start firewalld
|
|
||||||
sudo systemctl enable firewalld
|
|
||||||
```
|
|
||||||
|
|
||||||
要停止并禁用:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo systemctl stop firewalld
|
|
||||||
sudo systemctl disable firewalld
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
2. 检查firewall状态。输出应该是 `running` 或者 `not running`。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --state
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
3. 要查看 FirewallD 守护进程的状态:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo systemctl status firewalld
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
示例输出
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
firewalld.service - firewalld - dynamic firewall daemon
|
|
||||||
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled)
|
|
||||||
Active: active (running) since Wed 2015-09-02 18:03:22 UTC; 1min 12s ago
|
|
||||||
Main PID: 11954 (firewalld)
|
|
||||||
CGroup: /system.slice/firewalld.service
|
|
||||||
└─11954 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
4. 重新加载 FirewallD 配置:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --reload
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
### 配置 FirewallD
|
|
||||||
|
|
||||||
FirewallD 使用 XML 进行配置。除非是非常具体的配置,你不必处理它们,而应该使用 ** firewall-cmd **。
|
|
||||||
|
|
||||||
配置文件位于两个目录中:
|
|
||||||
|
|
||||||
* `/usr/lib/FirewallD` 保存默认配置,如默认 zone 和公共 service。 避免更新它们,因为这些文件将被每个 firewalld 包更新覆盖。
|
|
||||||
* `/etc/firewalld` 保存系统配置文件。 这些文件将覆盖默认配置。
|
|
||||||
|
|
||||||
### 配置集
|
|
||||||
|
|
||||||
FirewallD 使用两个_配置集_:Runtime 和 Permanent。 在重新启动或重新启动 FirewallD 时,不会保留运行时的配置更改,而永久更改不会应用于正在运行的系统。
|
|
||||||
|
|
||||||
默认情况下,`firewall-cmd` 命令适用于运行时配置,但使用 `--permanent` 标志将建立持久配置。要添加和激活永久性规则,你可以使用两种方法之一。
|
|
||||||
|
|
||||||
1. 将规则同时添加到 permanent 和 runtime 中。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-service=http --permanent
|
|
||||||
sudo firewall-cmd --zone=public --add-service=http
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
2. 将规则添加到 permanent 中并重新加载 FirewallD。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-service=http --permanent
|
|
||||||
sudo firewall-cmd --reload
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
> reload 命令会删除所有运行时配置并应用永久配置。因为firewalld 动态管理规则集,所以它不会破坏现有的连接和会话。
|
|
||||||
|
|
||||||
### Firewall Zone
|
|
||||||
|
|
||||||
zone 是针对给定位置或场景(例如家庭、公共、受信任等)可能具有的各种信任级别的预构建规则集。不同的 zone 允许不同的网络服务和入站流量类型,而拒绝其他任何流量。 首次启用 FirewallD 后,_Public_ 将是默认 zone。
|
|
||||||
|
|
||||||
zone 也可以用于不同的网络接口。例如,对于内部网络和Internet的单独接口,你可以在内部 zone 上允许 DHCP,但在外部 zone 仅允许HTTP和SSH。未明确设置为特定区域的任何接口将添加到默认 zone。
|
|
||||||
|
|
||||||
要浏览默认的 zone:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --get-default-zone
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
要修改默认的 zone:
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --set-default-zone=internal
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
要查看你网络接口使用的 zone:
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --get-active-zones
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
示例输出:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
public
|
|
||||||
interfaces: eth0
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
要得到特定 zone 的所有配置:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --list-all
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
示例输出:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
public (default, active)
|
|
||||||
interfaces: ens160
|
|
||||||
sources:
|
|
||||||
services: dhcpv6-client http ssh
|
|
||||||
ports: 12345/tcp
|
|
||||||
masquerade: no
|
|
||||||
forward-ports:
|
|
||||||
icmp-blocks:
|
|
||||||
rich rules:
|
|
||||||
```
|
|
||||||
|
|
||||||
要得到所有 zone 的配置:
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --list-all-zones
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
示例输出:
|
|
||||||
|
|
||||||
```
|
|
||||||
block
|
|
||||||
interfaces:
|
|
||||||
sources:
|
|
||||||
services:
|
|
||||||
ports:
|
|
||||||
masquerade: no
|
|
||||||
forward-ports:
|
|
||||||
icmp-blocks:
|
|
||||||
rich rules:
|
|
||||||
|
|
||||||
...
|
|
||||||
|
|
||||||
work
|
|
||||||
interfaces:
|
|
||||||
sources:
|
|
||||||
services: dhcpv6-client ipp-client ssh
|
|
||||||
ports:
|
|
||||||
masquerade: no
|
|
||||||
forward-ports:
|
|
||||||
icmp-blocks:
|
|
||||||
rich rules:
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
### 与 Service 一起使用
|
|
||||||
|
|
||||||
FirewallD 可以根据特定网络服务的预定义规则允许相关流量。你可以创建自己的自定义系统规则,并将它们添加到任何 zone。 默认支持的服务的配置文件位于 `/usr/lib /firewalld/services`,用户创建的服务文件在`/etc/firewalld/services`中。
|
|
||||||
|
|
||||||
要查看默认的可用服务:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --get-services
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
比如,要启用或禁用 HTTP 服务:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-service=http --permanent
|
|
||||||
sudo firewall-cmd --zone=public --remove-service=http --permanent
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
### 允许或者拒绝任意端口/协议
|
|
||||||
|
|
||||||
比如:允许或者禁用 12345 的 TCP 流量。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-port=12345/tcp --permanent
|
|
||||||
sudo firewall-cmd --zone=public --remove-port=12345/tcp --permanent
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
### 端口转发
|
|
||||||
|
|
||||||
下面是**在同一台服务器上**将 80 端口的流量转发到 12345 端口。
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone="public" --add-forward-port=port=80:proto=tcp:toport=12345
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
要将端口转发到**另外一台服务器上**:
|
|
||||||
|
|
||||||
1. 在需要的 zone 中激活 masquerade。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-masquerade
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
2. 添加转发规则。例子中是将 IP 地址为:123.456.78.9 的_远程服务器上_ 80 端口的流量转发到 8080 上。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone="public" --add-forward-port=port=80:proto=tcp:toport=8080:toaddr=123.456.78.9
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
要删除规则,用 `--remove` 替换 `--add`。比如:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --remove-masquerade
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
### 用 FirewallD 构建规则集
|
|
||||||
|
|
||||||
例如,以下是如何使用 FirewallD 为你的 Linode 配置基本规则(如果您正在运行 web 服务器)。
|
|
||||||
|
|
||||||
1. 将eth0的默认 zone 设置为 _dmz_。 在提供的默认 zone 中,dmz(非军事区)是最适合开始这个程序的,因为它只允许SSH和ICMP。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --set-default-zone=dmz
|
|
||||||
sudo firewall-cmd --zone=dmz --add-interface=eth0
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
2. 为 HTTP 和 HTTPS 添加永久服务规则到 dmz zone 中:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=dmz --add-service=http --permanent
|
|
||||||
sudo firewall-cmd --zone=dmz --add-service=https --permanent
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
3. 重新加载 FirewallD 让规则立即生效:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --reload
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
如果你运行 `firewall-cmd --zone=dmz --list-all`, 会有下面的输出:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
dmz (default)
|
|
||||||
interfaces: eth0
|
|
||||||
sources:
|
|
||||||
services: http https ssh
|
|
||||||
ports:
|
|
||||||
masquerade: no
|
|
||||||
forward-ports:
|
|
||||||
icmp-blocks:
|
|
||||||
rich rules:
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
这告诉我们,**dmz** zone 是我们的**默认** zone,它被分配到 **eth0 接口**中所有网络的**源**和**端口**。 允许传入 HTTP(端口80)、HTTPS(端口443)和 SSH(端口22)的流量,并且由于没有 IP 版本控制的限制,这些适用于 IPv4 和 IPv6。 **不允许伪装**以及**端口转发**。 我们没有** ICMP 块**,所以 ICMP 流量是完全允许的,没有** rich 规则**。 允许所有出站流量。
|
|
||||||
|
|
||||||
### 高级配置
|
|
||||||
|
|
||||||
服务和端口适用于基本配置,但对于高级情景可能会太有限制。 rich 规则和 direct 接口允许你为任何端口、协议、地址和操作向任何 zone 添加完全自定义的防火墙规则。
|
|
||||||
|
|
||||||
### rich 规则
|
|
||||||
|
|
||||||
rich 规则的语法有很多,但都完整地记录在 [firewalld.richlanguage(5)][5] 的手册页中(或在终端中 `man firewalld.richlanguage`)。 使用 `--add-rich-rule`、`--list-rich-rules` 、 `--remove-rich-rule` 和 firewall-cmd 命令来管理它们。
|
|
||||||
|
|
||||||
这里有一些常见的例子:
|
|
||||||
|
|
||||||
允许来自主机 192.168.0.14 的所有IPv4流量。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-rich-rule 'rule family="ipv4" source address=192.168.0.14 accept'
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
拒绝来自主机 192.168.1.10 到 22 端口的 IPv4 的 TCP 流量。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-rich-rule 'rule family="ipv4" source address="192.168.1.10" port port=22 protocol=tcp reject'
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
允许来自主机 10.1.0.3 到 80 端口的IPv4 的 TCP 流量,并将流量转发到 6532 端口上。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-rich-rule 'rule family=ipv4 source address=10.1.0.3 forward-port port=80 protocol=tcp to-port=6532'
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
将主机 172.31.4.2 上 80 端口的 IPv4 流量转发到 8080 端口(需要在 zone 上激活 masquerade)。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --zone=public --add-rich-rule 'rule family=ipv4 forward-port port=80 protocol=tcp to-port=8080 to-addr=172.31.4.2'
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
列出你目前的 rich 规则:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo firewall-cmd --list-rich-rules
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
### iptables 的直接接口
|
|
||||||
|
|
||||||
对于最高级的使用,或对于 iptables 专家,FirewallD 提供了一个直接接口,允许你给它传递原始 iptables 命令。 直接接口规则不是持久的,除非使用 `--permanent`。
|
|
||||||
|
|
||||||
要查看添加到 FirewallD 的所有自定义链或规则:
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
firewall-cmd --direct --get-all-chains
|
|
||||||
firewall-cmd --direct --get-all-rules
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
讨论 iptables 的具体语法已经超出了这篇文章的范围。如果你想学习更多,你可以查看我们的 [iptables 指南][6]。
|
|
||||||
|
|
||||||
### 更多信息
|
|
||||||
|
|
||||||
你可以查阅以下资源以获取有关此主题的更多信息。虽然我们希望我们提供的是有效的,但是请注意,我们不能保证外部材料的准确性或及时性。
|
|
||||||
|
|
||||||
* [FirewallD 官方网站][1]
|
|
||||||
* [RHEL 7 安全指南:FirewallD 简介][2]
|
|
||||||
* [Fedora Wiki:FirewallD][3]
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.linode.com/docs/security/firewalls/introduction-to-firewalld-on-centos
|
|
||||||
|
|
||||||
作者:[Linode][a]
|
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.linode.com/docs/security/firewalls/introduction-to-firewalld-on-centos
|
|
||||||
[1]:http://www.firewalld.org/
|
|
||||||
[2]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Security_Guide/sec-Using_Firewalls.html#sec-Introduction_to_firewalld
|
|
||||||
[3]:https://fedoraproject.org/wiki/FirewallD
|
|
||||||
[4]:http://www.firewalld.org/
|
|
||||||
[5]:https://jpopelka.fedorapeople.org/firewalld/doc/firewalld.richlanguage.html
|
|
||||||
[6]:https://www.linode.com/docs/networking/firewalls/control-network-traffic-with-iptables
|
|
||||||
@ -1,183 +0,0 @@
|
|||||||
### 在 Linux 中管理设备
|
|
||||||
|
|
||||||
探索 /dev 目录如何使您直接访问到 Linux 中的设备。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*照片提供:Opensource.com*
|
|
||||||
|
|
||||||
Linux 目录结构有很多有趣的功能。这个月我涉及了 /dev 目录一些迷人之处。在继续阅读这篇文章之前,建议你看看我前面的文章。[Linux 文件系统][9],[一切皆为文件][8],这两篇文章介绍了一些有趣的 Linux 文件系统概念。请先看看 - 我会等待。
|
|
||||||
|
|
||||||
太好了 !欢迎回来。现在我们可以继续更详尽地探讨 /dev 目录。
|
|
||||||
|
|
||||||
### 设备文件
|
|
||||||
|
|
||||||
设备文件也称为 [special files][4]。设备文件用来为操作系统和用户提供它们代表的设备接口。所有的 Linux 设备文件位于 /dev 目录,是根 (/) 文件系统的一个组成部分,因为这些设备文件在操作系统启动过程中必须用到。
|
|
||||||
|
|
||||||
关于这些设备文件,要记住一件重要的事情,就是它们大多不是设备驱动。更准确地描述来说,它们是对设备驱动程序的门户。数据从应用程序或操作系统传递到设备文件,然后设备文件将它传递给设备驱动程序,驱动再将它发给物理设备。反向数据通道也可以用,从物理设备通过设备驱动程序,再到设备文件,最后到达一个应用程序或其他设备。
|
|
||||||
|
|
||||||
让我们以一个可视化的典型命令看看这数据的流程。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*图 1:一个典型命令的简单数据流。*
|
|
||||||
|
|
||||||
在图 1 中,显示一个简单命令的简化数据流程。从一个 GUI 终端仿真器,例如 Konsole 或 xterm 中发出 **cat /etc/resolv.conf** 命令,从磁盘中读取 resolv.conf 文件,磁盘设备驱动程序处理设备的具体功能,例如在硬盘驱动器上定位文件并读取它。数据通过设备文件传递,然后从命令到设备文件,然后到伪终端 6 的设备驱动,然后在终端会话中显示。
|
|
||||||
|
|
||||||
当然, **cat** 命令的输出可以下面的方式被重定向到一个文件, **cat /etc/resolv.conf > /etc/resolv.bak** ,以创建该文件的备份。在这种情况下,图 1 左侧的数据流量将保持不变,而右边的数据流量将通过 /dev/sda2 设备文件,硬盘设备驱动程序,然后到硬盘驱动器本身。
|
|
||||||
|
|
||||||
这些设备文件使用标准流 (STD/IO) 和重定向,使得访问 Linux 或 Unix 计算机上的任何一个设备非常容易。只需将数据流定向到设备文件,即可将数据发送到该设备。
|
|
||||||
|
|
||||||
### 设备文件类别
|
|
||||||
|
|
||||||
设备文件至少可以按两种方式划分。第一种也是最常用的分类是根据与设备相关联的数据流进行划分。比如,tty (teletype) 和串行设备被认为是基于字符的,因为一次传送和处理数据流的一个字符或字节。 块类型设备(如硬盘驱动器)以块为单位传输数据,通常为 256 个字节的倍数。
|
|
||||||
|
|
||||||
您可以在终端上以一个非 root 用户,改变当前工作目录(PWD)到 /dev ,并显示长目录列表。 这将显示设备文件列表、文件权限及其主次设备号。 例如,下面的设备文件只是我的 Fedora 24 工作站上 /dev 目录中的几个文件。 它们表示磁盘和 tty 设备类型。 注意输出中每行的最左边的字符。 “b” 代表是块类型设备,“c” 代表字符设备。
|
|
||||||
|
|
||||||
```
|
|
||||||
brw-rw---- 1 root disk 8, 0 Nov 7 07:06 sda
|
|
||||||
brw-rw---- 1 root disk 8, 1 Nov 7 07:06 sda1
|
|
||||||
brw-rw---- 1 root disk 8, 16 Nov 7 07:06 sdb
|
|
||||||
brw-rw---- 1 root disk 8, 17 Nov 7 07:06 sdb1
|
|
||||||
brw-rw---- 1 root disk 8, 18 Nov 7 07:06 sdb2
|
|
||||||
crw--w---- 1 root tty 4, 0 Nov 7 07:06 tty0
|
|
||||||
crw--w---- 1 root tty 4, 1 Nov 7 07:07 tty1
|
|
||||||
crw--w---- 1 root tty 4, 10 Nov 7 07:06 tty10
|
|
||||||
crw--w---- 1 root tty 4, 11 Nov 7 07:06 tty11
|
|
||||||
```
|
|
||||||
|
|
||||||
识别设备文件更详细和更明确的方法是使用设备主要以及次要号。 磁盘设备主设备号为 8,将它们指定为 SCSI 块设备。 请注意,所有 PATA 和 SATA 硬盘驱动器都由 SCSI 子系统管理,因为旧的 ATA 子系统多年前被认为是不可维护的,因为它的代码质量差。 造成的结果是,以前被称为 “hd [a-z]” 的硬盘驱动器现在被称为 “sd [a-z]”。
|
|
||||||
|
|
||||||
你大概可以从上面的示例中推出磁盘驱动器次设备号的样式。次设备号 0、 16、 32 等等,直到 240,是整磁盘号。所以主/次 8/16 表示整个磁盘 /dev/sdb , 8/17 是第一个分区的设备文件,/dev/sdb1。数字 8/34 代表 /dev/sdc2。
|
|
||||||
|
|
||||||
在上面列表中的 tty 设备文件编号更简单一些,从 tty0 到 tty63 。
|
|
||||||
|
|
||||||
Kernel.org 上的 [Linux Allocated Devices][5] 文件是设备类型和主次编号分配的正式注册表。 它可以帮助您了解所有当前定义的设备的主要/次要号码。
|
|
||||||
|
|
||||||
### 趣味设备文件
|
|
||||||
|
|
||||||
让我们花几分钟时间,执行几个有趣的实验,演示 Linux 设备文件的强大和灵活性。 大多数 Linux 发行版都有 1 到 7 个虚拟控制台,可用于使用 shell 接口登录到本地控制台会话。 可以使用 Ctrl-Alt-F1(控制台1),Ctrl-Alt-F2(控制台2)等键盘组合键来访问。
|
|
||||||
|
|
||||||
请按 Ctrl-Alt-F2 切换到控制台 2。在某些发行版,登录信息包括与此控制台关联的 tty 设备,但大多不包括。它应该是 tty2,因为你是在控制台 2 中。
|
|
||||||
|
|
||||||
以非 root 用户身份登录。 然后你可以使用 who am i 命令 — 是的,就是这个命令,带空格 — 来确定哪个 tty 设备连接到这个控制台。
|
|
||||||
|
|
||||||
在我们实际执行此实验之前,看看 /dev 中的 tty2 和 tty3 的设备列表。
|
|
||||||
|
|
||||||
```
|
|
||||||
ls -l /dev/tty[23]
|
|
||||||
```
|
|
||||||
|
|
||||||
有大量的 tty 设备,但我们不关心他们中的大多数,只注意 tty2 和 tty3 设备。 作为设备文件,他们没什么特别之处。他们都只是字符类型设备。我们将使用这些设备进行此实验。 tty2 设备连接到虚拟控制台 2,tty3 设备连接到虚拟控制台 3。
|
|
||||||
|
|
||||||
按 Ctrl-Alt-F3 切换到控制台 3。再次以同一非 root 用户身份登陆。 现在在控制台 3 上输入以下命令。
|
|
||||||
|
|
||||||
```
|
|
||||||
echo "Hello world" > /dev/tty2
|
|
||||||
```
|
|
||||||
|
|
||||||
按 Ctrl-Alt-f2 键以返回到控制台 2。字符串 “Hello world”(没有引号)将显示在控制台 2。
|
|
||||||
|
|
||||||
该实验也可以使用 GUI 桌面上的终端仿真器来执行。 桌面上的终端会话使用 /dev 中的伪终端设备,如 /dev/pts/1。 使用 Konsole 或 Xterm 打开两个终端会话。 确定它们连接到哪些伪终端,并使用一个向另一个发送消息。
|
|
||||||
|
|
||||||
现在继续实验,使用 cat 命令,在不同的终端上显示 /etc/fstab 文件。
|
|
||||||
|
|
||||||
另一个有趣的实验是使用 cat 命令将文件直接打印到打印机。 假设您的打印机设备是 /dev/usb/lp0,并且您的打印机可以直接打印 PDF 文件,以下命令将在您的打印机上打印 test.pdf 文件。
|
|
||||||
|
|
||||||
```
|
|
||||||
cat test.pdf > /dev/usb/lp0
|
|
||||||
```
|
|
||||||
|
|
||||||
/dev 目录包含一些非常有趣的设备文件,这些文件是硬件的入口,人们通常不认为这是硬盘驱动器或显示器之类的设备。 例如,系统存储器 RAM 不是通常被认为是“设备”的东西,而 /dev/mem 是通过其可以实现对存储器的直接访问的入口。 下面的例子有一些有趣的结果。
|
|
||||||
|
|
||||||
```
|
|
||||||
dd if=/dev/mem bs=2048 count=100
|
|
||||||
```
|
|
||||||
|
|
||||||
上面的 **dd** 命令提供比简单地使用 **cat** 命令 dump 所有系统的内存提供了更多的控制。 它提供了指定从 /dev/mem 读取多少数据的能力,还允许指定从存储器哪里开始读取数据。 虽然读取了一些内存,但内核响应了以下错误,在 /var/log/messages 中可以找到。
|
|
||||||
|
|
||||||
```
|
|
||||||
Nov 14 14:37:31 david kernel: usercopy: kernel memory exposure attempt detected from ffff9f78c0010000 (dma-kmalloc-512) (2048 bytes)
|
|
||||||
```
|
|
||||||
|
|
||||||
这个错误意味着内核正在通过保护属于其他进程的内存来完成它的工作,这正是它应该工作的方式。 所以,虽然可以使用 /dev/mem 来显示存储在 RAM 内存中的数据,但是访问大多数内存空间是受保护的并且会导致错误。 只可以访问由内核内存管理器分配给运行 **dd** 命令的 BASH shell 的虚拟内存,而不会导致错误。 抱歉,但你不能窥视不属于你的内存,除非你发现了一个可利用的漏洞。
|
|
||||||
|
|
||||||
/dev 中还有一些非常有趣的设备文件。 设备文件 null,zero,random 和 urandom 不与任何物理设备相关联。
|
|
||||||
|
|
||||||
例如,空设备 /dev/null 可以用作来自 shell 命令或程序的输出重定向的目标,以便它们不显示在终端上。 我经常在我的 BASH 脚本中使用这个,以防止向用户展示可能会让他们感到困惑的输出。 /dev/null 设备可用于产生一个空字符串。 使用如下所示的 dd 命令查看 /dev/null 设备文件的一些输出。
|
|
||||||
|
|
||||||
```
|
|
||||||
# dd if=/dev/null bs=512 count=500 | od -c
|
|
||||||
0+0 records in
|
|
||||||
0+0 records out
|
|
||||||
0 bytes copied, 1.5885e-05 s, 0.0 kB/s
|
|
||||||
0000000
|
|
||||||
```
|
|
||||||
|
|
||||||
注意,因为空字符什么也没有所以确实没有可见的输出。 注意字节数。
|
|
||||||
|
|
||||||
/dev/random 和 /dev/urandom 设备也很有趣。 正如他们的名字所暗示的,它们都产生随机输出,而不仅仅是数字,而是任何字节组合。 /dev/urandom 设备产生确定性的随机输出并且非常快。 这意味着输出由算法确定,并使用种子字符串作为起点。 结果,如果原始种子是已知的,则黑客可以再现输出,尽管非常困难,但这是有可能的。 使用命令 **cat /dev/urandom** 可以查看典型输出,使用 Ctrl-c 退出。
|
|
||||||
|
|
||||||
/dev/random 设备文件生成非确定性随机输出,但它产生的输出更慢。 该输出不是由依赖于先前数字的算法确定的,而是由击键和鼠标移动而产生的。 这种方法使得复制特定系列的随机数要困难得多。使用 **cat **命令去查看一些来自 /dev/random 设备文件输出。尝试移动鼠标以查看它如何影响输出。
|
|
||||||
|
|
||||||
正如其名字所暗示的,/dev/zero 设备文件产生一个无止境的零作为输出。 注意,这些是八进制零,而不是ASCII字符零(0)。 使用如下所示的 **dd** 查看 /dev/zero 设备文件中的一些输出
|
|
||||||
|
|
||||||
```
|
|
||||||
# dd if=/dev/zero bs=512 count=500 | od -c
|
|
||||||
0000000 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
|
|
||||||
*
|
|
||||||
500+0 records in
|
|
||||||
500+0 records out
|
|
||||||
256000 bytes (256 kB, 250 KiB) copied, 0.00126996 s, 202 MB/s
|
|
||||||
0764000
|
|
||||||
```
|
|
||||||
|
|
||||||
请注意,此命令的字节数不为零。
|
|
||||||
|
|
||||||
### 创建设备文件
|
|
||||||
|
|
||||||
在过去,在 /dev 中的设备文件都是在安装时创建的,导致一个目录中有几乎所有的设备文件,尽管大多数文件永远不会用到。 在不常发生的情况,例如需要新的设备文件,或意外删除后需要重新创建设备文件,可以使用 **mknod** 程序手动创建设备文件。 前提是你必须知道设备主要和次要号码。
|
|
||||||
|
|
||||||
|
|
||||||
CentOS 和 RHEL 6、7, 以及 Fedora 的所有版本,追溯到至少 Fedora 15,使用较新的创建设备文件的方法。 所有设备文件都是在引导时创建的。 这是因为 udev 设备管理器在设备添加和删除发生时会进行检测。这可实现在主机启动和运行时的真正的动态即插即用功能。 它还在引导时执行相同的任务,通过在引导过程的早期检测系统上安装的所有设备。 [Linux.com][6] 上有很棒的对 [udev 的描述][7].
|
|
||||||
|
|
||||||
回到 /dev 中的文件列表,注意文件的日期和时间。 所有文件都是在上次启动时创建的。 您可以使用 **uptime** 或者 **last** 命令来验证这一点。在上面我的设备列表中,所有这些文件都是在 11 月 7 日上午 7:06 创建的,这是我最后一次启动系统。
|
|
||||||
|
|
||||||
当然, **mknod** 命令仍然可用, 但新的 **MAKEDEV** (是的,所有字母大写,在我看来是违背 Linux 使用小写命令名的原则的) 命令提供了一个更容易的界面,用于创建设备文件,如果需要的话。 在当前版本的 Fedora 或 CentOS 7 中,默认情况下不安装 MAKEDEV 命令; 它安装在 CentOS 6。您可以使用 YUM 或 DNF 来安装 MAKEDEV 包。
|
|
||||||
|
|
||||||
### 结论
|
|
||||||
|
|
||||||
有趣的是,我需要创建一个设备文件已经很长时间了。 然而,最近我遇到一个有趣的情况,其中一个我常使用的设备文件没有创建,我不得不创建它。 之后该设备再出过问题。所以丢失设备文件的情况仍然可以发生,知道如何处理它可能很重要。
|
|
||||||
|
|
||||||
|
|
||||||
设备文件有无数种,您遇到的设备文件我可能没有涵盖到。 这些信息在所下面引用的资源中有大量的细节信息可用。 关于这些文件的功能和工具,我希望我已经给您一些基本的了解,下一步您自己可以探索更多。
|
|
||||||
|
|
||||||
资源
|
|
||||||
|
|
||||||
- [Everything is a file][1], David Both, Opensource.com
|
|
||||||
- [An introduction to Linux filesystems][2], David Both, Opensource.com
|
|
||||||
- [Filesystem Hierarchy][10], The Linux Documentation Project
|
|
||||||
- [Device File][4], Wikipedia
|
|
||||||
- [Linux Allocated Devices][5], Kernel.org
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/16/11/managing-devices-linux
|
|
||||||
|
|
||||||
作者:[David Both][a]
|
|
||||||
译者:[erlinux](http://www.itxdm.me)
|
|
||||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/dboth
|
|
||||||
[1]:https://opensource.com/life/15/9/everything-is-a-file
|
|
||||||
[2]:https://opensource.com/life/16/10/introduction-linux-filesystems
|
|
||||||
[4]:https://en.wikipedia.org/wiki/Device_file
|
|
||||||
[5]:https://www.kernel.org/doc/Documentation/devices.txt
|
|
||||||
[6]:https://www.linux.com/
|
|
||||||
[7]:https://www.linux.com/news/udev-introduction-device-management-modern-linux-system
|
|
||||||
[8]:https://opensource.com/life/15/9/everything-is-a-file
|
|
||||||
[9]:https://opensource.com/life/16/10/introduction-linux-filesystems
|
|
||||||
[10]:http://www.tldp.org/LDP/Linux-Filesystem-Hierarchy/html/dev.html
|
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user