mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
commit
afbfb361e8
@ -1,74 +1,59 @@
|
||||
|
||||
2016 Git 新视界
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
2016 年 Git 发生了 _惊天动地_ 地变化,发布了五大新特性[¹][57] (从 _v2.7_ 到 _v2.11_ )和十六个补丁[²][58]。189 位作者[³][59]贡献了 3676 个提交[⁴][60]到 `master` 分支,比 2015 年多了 15%[⁵][61]!总计有 1545 个文件被修改,其中增加了 276799 行并移除了 100973 行。
|
||||
|
||||
但是,通过统计提交的数量和代码行数来衡量生产力是一种十分愚蠢的方法。除了深度研究过的开发者可以做到凭直觉来判断代码质量的地步,我们普通人来作仲裁难免会因我们常人的判断有失偏颇。
|
||||
|
||||
谨记这一条于心,我决定整理这一年里六个我最喜爱的 Git 特性涵盖的改进,来做一次分类回顾 。这篇文章作为一篇中篇推文有点太过长了,所以我不介意你们直接跳到你们特别感兴趣的特性去。
|
||||
谨记这一条于心,我决定整理这一年里六个我最喜爱的 Git 特性涵盖的改进,来做一次分类回顾。这篇文章作为一篇中篇推文有点太过长了,所以我不介意你们直接跳到你们特别感兴趣的特性去。
|
||||
|
||||
* [完成][41]`[git worktree][25]`[命令][42]
|
||||
* [更多方便的][43]`[git rebase][26]`[选项][44]
|
||||
* `[git lfs][27]`[梦幻的性能加速][45]
|
||||
* `[git diff][28]`[实验性的算法和更好的默认结果][46]
|
||||
* `[git submodules][29]`[差强人意][47]
|
||||
* `[git stash][30]`的[90 个增强][48]
|
||||
* [完成][41] [`git worktree`][25] [命令][42]
|
||||
* [更多方便的][43] [`git rebase`][26] [选项][44]
|
||||
* [`git lfs`][27] [梦幻的性能加速][45]
|
||||
* [`git diff`][28] [实验性的算法和更好的默认结果][46]
|
||||
* [`git submodules`][29] [差强人意][47]
|
||||
* [`git stash`][30] 的[90 个增强][48]
|
||||
|
||||
在我们开始之前,请注意在大多数操作系统上都自带有 Git 的旧版本,所以你需要检查你是否在使用最新并且最棒的版本。如果在终端运行 `git --version` 返回的结果小于 Git `v2.11.0`,请立刻跳转到 Atlassian 的快速指南 [更新或安装 Git][63] 并根据你的平台做出选择。
|
||||
|
||||
###[所需的“引用”]
|
||||
|
||||
在我们进入高质量内容之前还需要做一个短暂的停顿:我觉得我需要为你展示我是如何从公开文档生成统计信息(以及开篇的封面图片)的。你也可以使用下面的命令来对你自己的仓库做一个快速的 *年度回顾*!
|
||||
|
||||
###[`引用` 是需要的]
|
||||
|
||||
在我们进入高质量内容之前还需要做一个短暂的停顿:我觉得我需要为你展示我是如何从公开文档(以及开篇的封面图片)生成统计信息的。你也可以使用下面的命令来对你自己的仓库做一个快速的 *年度回顾*!
|
||||
|
||||
```
|
||||
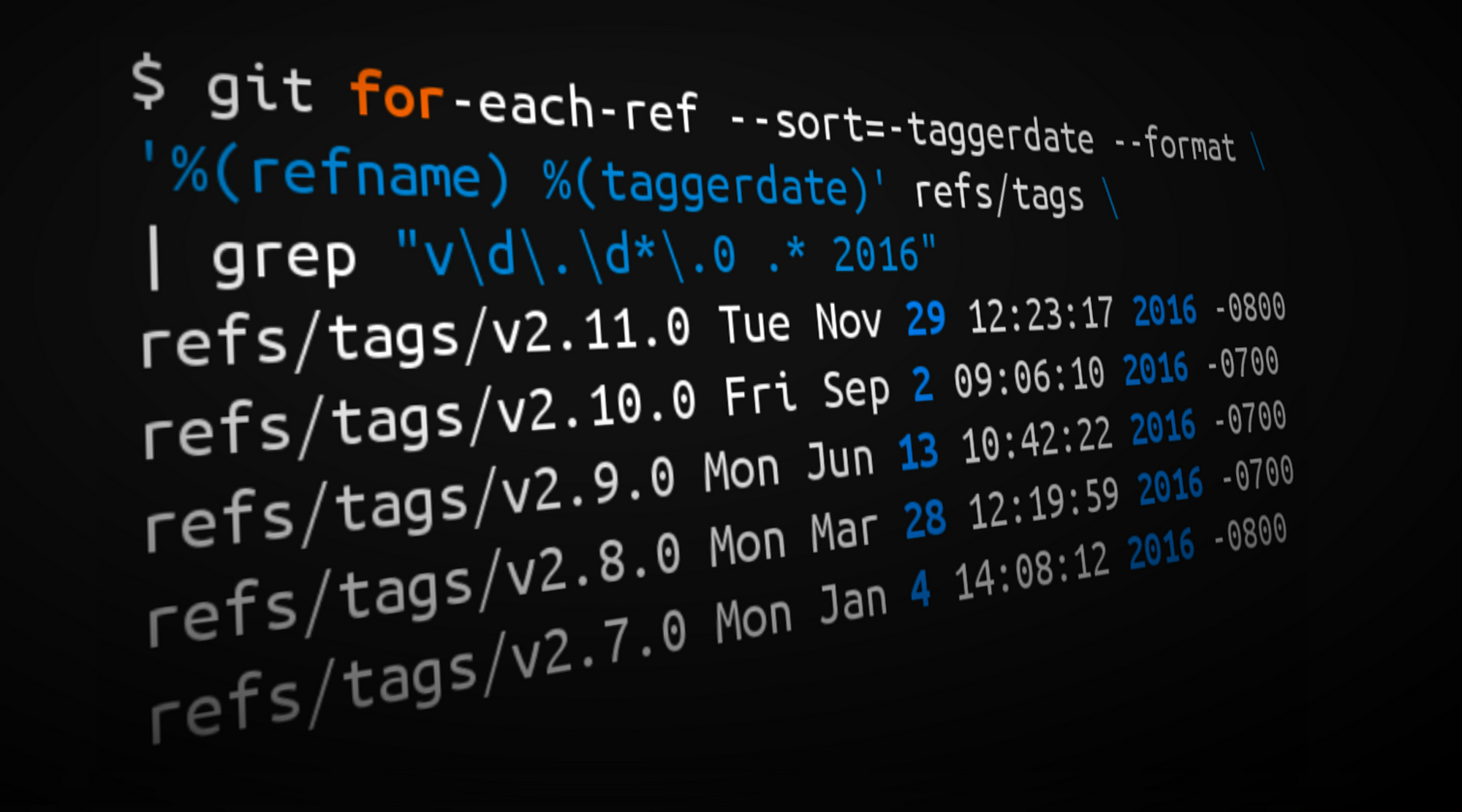
¹ Tags from 2016 matching the form vX.Y.0
|
||||
```
|
||||
>¹ Tags from 2016 matching the form vX.Y.0
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format \
|
||||
'%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.0 .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
² Tags from 2016 matching the form vX.Y.Z
|
||||
```
|
||||
> ² Tags from 2016 matching the form vX.Y.Z
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format '%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.[^0] .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
³ Commits by author in 2016
|
||||
```
|
||||
> ³ Commits by author in 2016
|
||||
|
||||
```
|
||||
$ git shortlog -s -n --since=2016-01-01 --until=2017-01-01
|
||||
```
|
||||
|
||||
```
|
||||
⁴ Count commits in 2016
|
||||
```
|
||||
> ⁴ Count commits in 2016
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2016-01-01 --until=2017-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁵ ... and in 2015
|
||||
```
|
||||
> ⁵ ... and in 2015
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2015-01-01 --until=2016-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁶ Net LOC added/removed in 2016
|
||||
```
|
||||
> ⁶ Net LOC added/removed in 2016
|
||||
|
||||
```
|
||||
$ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
|
||||
@ -79,39 +64,36 @@ $ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
|
||||
|
||||
现在,让我们开始说好的回顾……
|
||||
|
||||
### 完成 Git worktress
|
||||
`git worktree` 命令首次出现于 Git v2.5 但是在 2016 年有了一些显著的增强。两个有价值的新特性在 v2.7 被引入—— `list` 子命令,和为二分搜索增加了命令空间的 refs——而 `lock`/`unlock` 子命令则是在 v2.10被引入。
|
||||
### 完成 Git 工作树(worktree)
|
||||
|
||||
`git worktree` 命令首次出现于 Git v2.5 ,但是在 2016 年有了一些显著的增强。两个有价值的新特性在 v2.7 被引入:`list` 子命令,和为二分搜索增加了命令空间的 refs。而 `lock`/`unlock` 子命令则是在 v2.10 被引入。
|
||||
|
||||
#### 什么是工作树呢?
|
||||
|
||||
[`git worktree`][49] 命令允许你同步地检出和操作处于不同路径下的同一仓库的多个分支。例如,假如你需要做一次快速的修复工作但又不想扰乱你当前的工作区,你可以使用以下命令在一个新路径下检出一个新分支:
|
||||
|
||||
#### 什么是 worktree 呢?
|
||||
`[git worktree][49]` 命令允许你同步地检出和操作处于不同路径下的同一仓库的多个分支。例如,假如你需要做一次快速的修复工作但又不想扰乱你当前的工作区,你可以使用以下命令在一个新路径下检出一个新分支
|
||||
```
|
||||
$ git worktree add -b hotfix/BB-1234 ../hotfix/BB-1234
|
||||
Preparing ../hotfix/BB-1234 (identifier BB-1234)
|
||||
HEAD is now at 886e0ba Merged in bedwards/BB-13430-api-merge-pr (pull request #7822)
|
||||
```
|
||||
|
||||
Worktree 不仅仅是为分支工作。你可以检出多个里程碑(tags)作为不同的工作树来并行构建或测试它们。例如,我从 Git v2.6 和 v2.7 的里程碑中创建工作树来检验不同版本 Git 的行为特征。
|
||||
工作树不仅仅是为分支工作。你可以检出多个里程碑(tags)作为不同的工作树来并行构建或测试它们。例如,我从 Git v2.6 和 v2.7 的里程碑中创建工作树来检验不同版本 Git 的行为特征。
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.6.0 v2.6.0
|
||||
Preparing ../git-v2.6.0 (identifier git-v2.6.0)
|
||||
HEAD is now at be08dee Git 2.6
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.7.0 v2.7.0
|
||||
Preparing ../git-v2.7.0 (identifier git-v2.7.0)
|
||||
HEAD is now at 7548842 Git 2.7
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
/Users/kannonboy/src/git 7548842 [master]
|
||||
/Users/kannonboy/src/git-v2.6.0 be08dee (detached HEAD)
|
||||
/Users/kannonboy/src/git-v2.7.0 7548842 (detached HEAD)
|
||||
```
|
||||
|
||||
```
|
||||
$ cd ../git-v2.7.0 && make
|
||||
```
|
||||
|
||||
@ -119,7 +101,7 @@ $ cd ../git-v2.7.0 && make
|
||||
|
||||
#### 列出工作树
|
||||
|
||||
`git worktree list` 子命令(于 Git v2.7引入)显示所有与当前仓库有关的工作树。
|
||||
`git worktree list` 子命令(于 Git v2.7 引入)显示所有与当前仓库有关的工作树。
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
@ -130,43 +112,41 @@ $ git worktree list
|
||||
|
||||
#### 二分查找工作树
|
||||
|
||||
`[gitbisect][50]` 是一个简洁的 Git 命令,可以让我们对提交记录执行一次二分搜索。通常用来找到哪一次提交引入了一个指定的退化。例如,如果在我的 `master` 分支最后的提交上有一个测试没有通过,我可以使用 `git bisect` 来贯穿仓库的历史来找寻第一次造成这个错误的提交。
|
||||
[`gitbisect`][50] 是一个简洁的 Git 命令,可以让我们对提交记录执行一次二分搜索。通常用来找到哪一次提交引入了一个指定的退化。例如,如果在我的 `master` 分支最后的提交上有一个测试没有通过,我可以使用 `git bisect` 来贯穿仓库的历史来找寻第一次造成这个错误的提交。
|
||||
|
||||
```
|
||||
$ git bisect start
|
||||
```
|
||||
|
||||
```
|
||||
# indicate the last commit known to be passing the tests
|
||||
# (e.g. the latest release tag)
|
||||
# 找到已知通过测试的最后提交
|
||||
# (例如最新的发布里程碑)
|
||||
$ git bisect good v2.0.0
|
||||
```
|
||||
|
||||
```
|
||||
# indicate a known broken commit (e.g. the tip of master)
|
||||
# 找到已知的出问题的提交
|
||||
# (例如在 `master` 上的提示)
|
||||
$ git bisect bad master
|
||||
```
|
||||
|
||||
```
|
||||
# tell git bisect a script/command to run; git bisect will
|
||||
# find the oldest commit between "good" and "bad" that causes
|
||||
# this script to exit with a non-zero status
|
||||
# 告诉 git bisect 要运行的脚本/命令;
|
||||
# git bisect 会在 “good” 和 “bad”范围内
|
||||
# 找到导致脚本以非 0 状态退出的最旧的提交
|
||||
$ git bisect run npm test
|
||||
```
|
||||
|
||||
在后台,bisect 使用 refs 来跟踪 好 与 坏 的提交来作为二分搜索范围的上下界限。不幸的是,对工作树的粉丝来说,这些 refs 都存储在寻常的 `.git/refs/bisect` 命名空间,意味着 `git bisect` 操作如果运行在不同的工作树下可能会互相干扰。
|
||||
在后台,bisect 使用 refs 来跟踪 “good” 与 “bad” 的提交来作为二分搜索范围的上下界限。不幸的是,对工作树的粉丝来说,这些 refs 都存储在寻常的 `.git/refs/bisect` 命名空间,意味着 `git bisect` 操作如果运行在不同的工作树下可能会互相干扰。
|
||||
|
||||
到了 v2.7 版本,bisect 的 refs 移到了 `.git/worktrees/$worktree_name/refs/bisect`, 所以你可以并行运行 bisect 操作于多个工作树中。
|
||||
|
||||
#### 锁定工作树
|
||||
|
||||
当你完成了一颗工作树的工作,你可以直接删除它,然后通过运行 `git worktree prune` 等它被当做垃圾自动回收。但是,如果你在网络共享或者可移除媒介上存储了一颗工作树,如果工作树目录在删除期间不可访问,工作树会被完全清除——不管你喜不喜欢!Git v2.10 引入了 `git worktree lock` 和 `unlock` 子命令来防止这种情况发生。
|
||||
|
||||
```
|
||||
# to lock the git-v2.7 worktree on my USB drive
|
||||
# 在我的 USB 盘上锁定 git-v2.7 工作树
|
||||
$ git worktree lock /Volumes/Flash_Gordon/git-v2.7 --reason \
|
||||
"In case I remove my removable media"
|
||||
```
|
||||
|
||||
```
|
||||
# to unlock (and delete) the worktree when I'm finished with it
|
||||
# 当我完成时,解锁(并删除)该工作树
|
||||
$ git worktree unlock /Volumes/Flash_Gordon/git-v2.7
|
||||
$ rm -rf /Volumes/Flash_Gordon/git-v2.7
|
||||
$ git worktree prune
|
||||
@ -175,32 +155,33 @@ $ git worktree prune
|
||||
`--reason` 标签允许为未来的你留一个记号,描述为什么当初工作树被锁定。`git worktree unlock` 和 `lock` 都要求你指定工作树的路径。或者,你可以 `cd` 到工作树目录然后运行 `git worktree lock .` 来达到同样的效果。
|
||||
|
||||
|
||||
### 更多 Git 变基(rebase)选项
|
||||
|
||||
### 更多 Git `reabse` 选项
|
||||
2016 年三月,Git v2.8 增加了在拉取过程中交互进行 rebase 的命令 `git pull --rebase=interactive` 。对应地,六月份 Git v2.9 发布了通过 `git rebase -x` 命令对执行变基操作而不需要进入交互模式的支持。
|
||||
2016 年三月,Git v2.8 增加了在拉取过程中交互进行变基的命令 `git pull --rebase=interactive` 。对应地,六月份 Git v2.9 发布了通过 `git rebase -x` 命令对执行变基操作而不需要进入交互模式的支持。
|
||||
|
||||
#### Re-啥?
|
||||
|
||||
在我们继续深入前,我假设读者中有些并不是很熟悉或者没有完全习惯变基命令或者交互式变基。从概念上说,它很简单,但是与很多 Git 的强大特性一样,变基散发着听起来很复杂的专业术语的气息。所以,在我们深入前,先来快速的复习一下什么是 rebase。
|
||||
在我们继续深入前,我假设读者中有些并不是很熟悉或者没有完全习惯变基命令或者交互式变基。从概念上说,它很简单,但是与很多 Git 的强大特性一样,变基散发着听起来很复杂的专业术语的气息。所以,在我们深入前,先来快速的复习一下什么是变基(rebase)。
|
||||
|
||||
变基操作意味着将一个或多个提交在一个指定分支上重写。`git rebase` 命令是被深度重载了,但是 rebase 名字的来源事实上还是它经常被用来改变一个分支的基准提交(你基于此提交创建了这个分支)。
|
||||
变基操作意味着将一个或多个提交在一个指定分支上重写。`git rebase` 命令是被深度重载了,但是 rebase 这个名字的来源事实上还是它经常被用来改变一个分支的基准提交(你基于此提交创建了这个分支)。
|
||||
|
||||
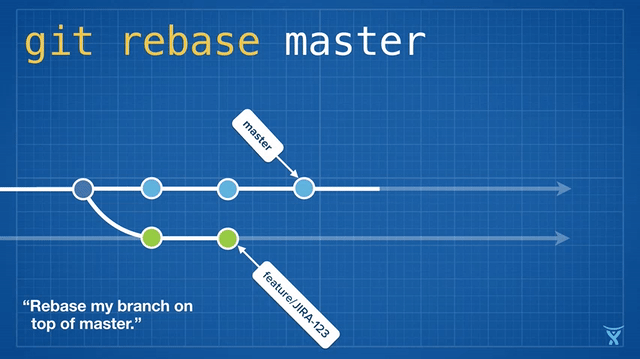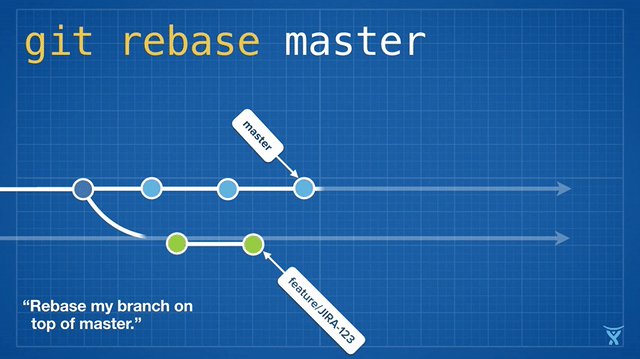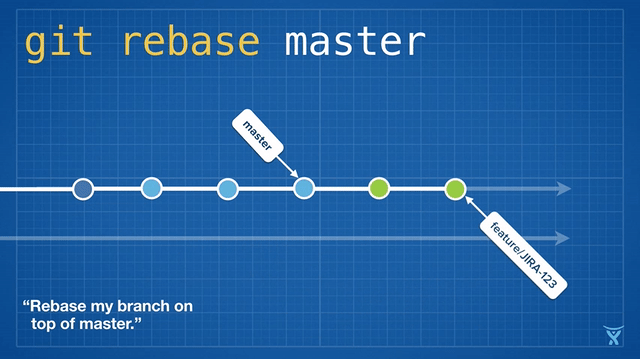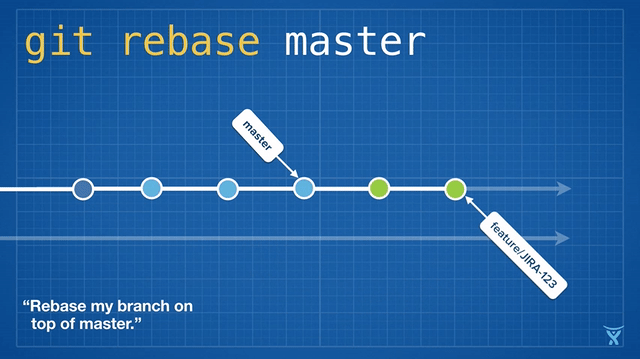
从概念上说,rebase 通过将你的分支上的提交存储为一系列补丁包临时释放了它们,接着将这些补丁包按顺序依次打在目标提交之上。
|
||||
从概念上说,rebase 通过将你的分支上的提交临时存储为一系列补丁包,接着将这些补丁包按顺序依次打在目标提交之上。
|
||||
|
||||
|
||||

|
||||
|
||||
对 master 分支的一个功能分支执行变基操作 (`git reabse master`)是一种通过将 master 分支上最新的改变合并到功能分支的“保鲜法”。对于长期存在的功能分支,规律的变基操作能够最大程度的减少开发过程中出现冲突的可能性和严重性。
|
||||
|
||||
有些团队会选择在合并他们的改动到 master 前立即执行变基操作以实现一次快速合并 (`git merge --ff <feature>`)。对 master 分支快速合并你的提交是通过简单的将 master ref 指向你的重写分支的顶点而不需要创建一个合并提交。
|
||||
|
||||

|
||||

|
||||
|
||||
变基是如此方便和功能强大以致于它已经被嵌入其他常见的 Git 命令中,例如 `git pull`。如果你在本地 master 分支有未推送的提交,运行 `git pull` 命令从 origin 拉取你队友的改动会造成不必要的合并提交。
|
||||
变基是如此方便和功能强大以致于它已经被嵌入其他常见的 Git 命令中,例如拉取操作 `git pull` 。如果你在本地 master 分支有未推送的提交,运行 `git pull` 命令从 origin 拉取你队友的改动会造成不必要的合并提交。
|
||||
|
||||
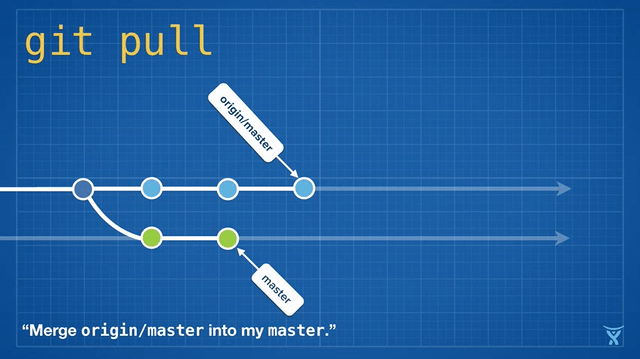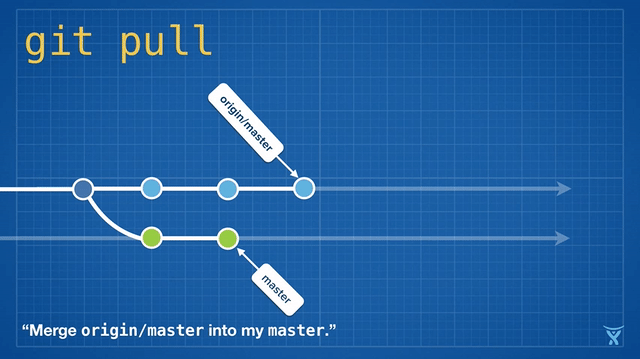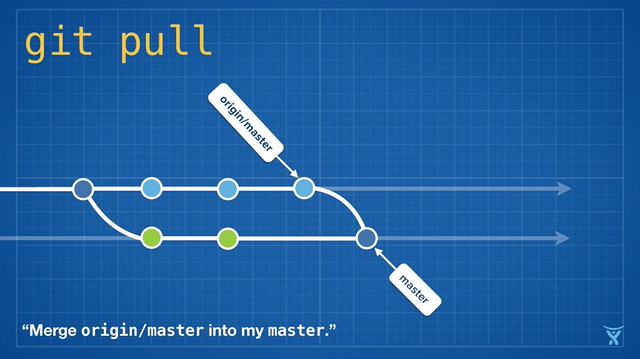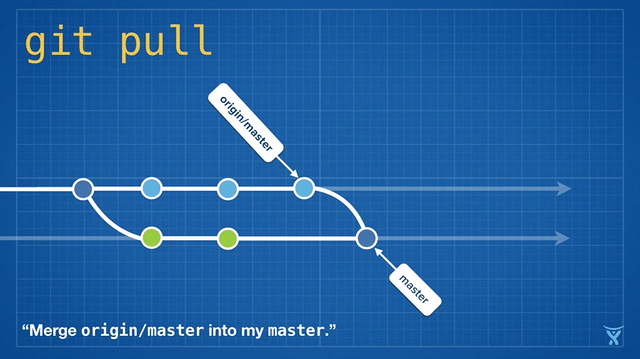
|
||||

|
||||
|
||||
这有点混乱,而且在繁忙的团队,你会获得成堆的不必要的合并提交。`git pull --rebase` 将你本地的提交在你队友的提交上执行变基而不产生一个合并提交。
|
||||
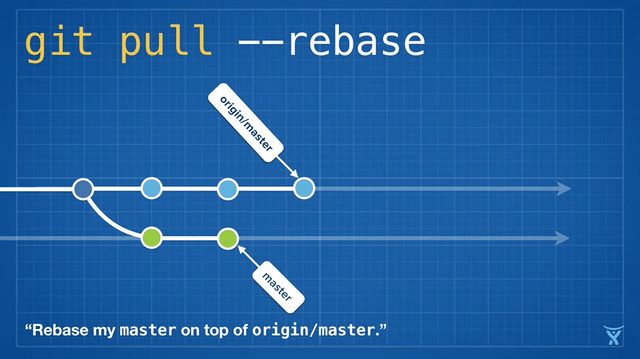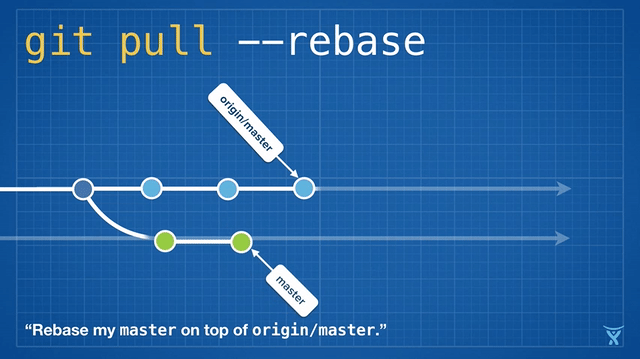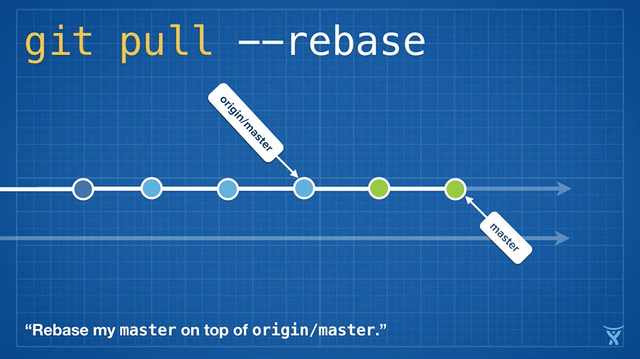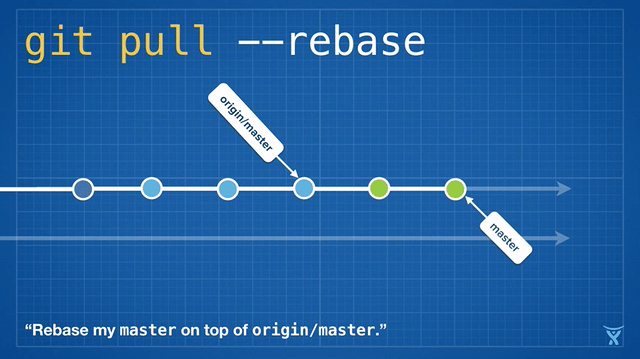
|
||||
|
||||

|
||||
|
||||
这很整洁吧!甚至更酷,Git v2.8 引入了一个新特性,允许你在拉取时 _交互地_ 变基。
|
||||
|
||||
@ -209,18 +190,15 @@ $ git worktree prune
|
||||
交互式变基是变基操作的一种更强大的形态。和标准变基操作相似,它可以重写提交,但它也可以向你提供一个机会让你能够交互式地修改这些将被重新运用在新基准上的提交。
|
||||
|
||||
当你运行 `git rebase --interactive` (或 `git pull --rebase=interactive`)时,你会在你的文本编辑器中得到一个可供选择的提交列表视图。
|
||||
```
|
||||
$ git rebase master --interactive
|
||||
```
|
||||
|
||||
```
|
||||
$ git rebase master --interactive
|
||||
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
pick ed93626 ACE-1294: removed pull request service from test
|
||||
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 commands)
|
||||
#
|
||||
# Commands:
|
||||
@ -238,27 +216,30 @@ pick e68f710 ACE-1294: added testing data to batch email file
|
||||
# If you remove a line here THAT COMMIT WILL BE LOST.
|
||||
```
|
||||
|
||||
注意到每一条提交旁都有一个 `pick`。这是对 rebase 而言,"照原样留下这个提交"。如果你现在就退出文本编辑器,它会执行一次如上文所述的普通变基操作。但是,如果你将 `pick` 改为 `edit` 或者其他 rebase 命令中的一个,变基操作会允许你在它被重新运用前改变它。有效的变基命令有如下几种:
|
||||
* `reword`: 编辑提交信息。
|
||||
* `edit`: 编辑提交了的文件。
|
||||
* `squash`: 将提交与之前的提交(同在文件中)合并,并将提交信息拼接。
|
||||
* `fixup`: 将本提交与上一条提交合并,并且逐字使用上一条提交的提交信息(这很方便,如果你为一个很小的改动创建了第二个提交,而它本身就应该属于上一条提交,例如,你忘记暂存了一个文件)。
|
||||
* `exec`: 运行一条任意的 shell 命令(我们将会在下一节看到本例一次简洁的使用场景)。
|
||||
注意到每一条提交旁都有一个 `pick`。这是对 rebase 而言,“照原样留下这个提交”。如果你现在就退出文本编辑器,它会执行一次如上文所述的普通变基操作。但是,如果你将 `pick` 改为 `edit` 或者其他 rebase 命令中的一个,变基操作会允许你在它被重新运用前改变它。有效的变基命令有如下几种:
|
||||
|
||||
* `reword`:编辑提交信息。
|
||||
* `edit`:编辑提交了的文件。
|
||||
* `squash`:将提交与之前的提交(同在文件中)合并,并将提交信息拼接。
|
||||
* `fixup`:将本提交与上一条提交合并,并且逐字使用上一条提交的提交信息(这很方便,如果你为一个很小的改动创建了第二个提交,而它本身就应该属于上一条提交,例如,你忘记暂存了一个文件)。
|
||||
* `exec`: 运行一条任意的 shell 命令(我们将会在下一节看到本例一次简洁的使用场景)。
|
||||
* `drop`: 这将丢弃这条提交。
|
||||
|
||||
你也可以在文件内重新整理提交,这样会改变他们被重新运用的顺序。这会很顺手当你对不同的主题创建了交错的提交时,你可以使用 `squash` 或者 `fixup` 来将其合并成符合逻辑的原子提交。
|
||||
你也可以在文件内重新整理提交,这样会改变它们被重新应用的顺序。当你对不同的主题创建了交错的提交时这会很顺手,你可以使用 `squash` 或者 `fixup` 来将其合并成符合逻辑的原子提交。
|
||||
|
||||
当你设置完命令并且保存这个文件后,Git 将递归每一条提交,在每个 `reword` 和 `edit` 命令处为你暂停来执行你设计好的改变并且自动运行 `squash`, `fixup`,`exec` 和 `drop`命令。
|
||||
当你设置完命令并且保存这个文件后,Git 将递归每一条提交,在每个 `reword` 和 `edit` 命令处为你暂停来执行你设计好的改变,并且自动运行 `squash`, `fixup`,`exec` 和 `drop` 命令。
|
||||
|
||||
####非交互性式执行
|
||||
|
||||
当你执行变基操作时,本质上你是在通过将你每一条新提交应用于指定基址的头部来重写历史。`git pull --rebase` 可能会有一点危险,因为根据上游分支改动的事实,你的新建历史可能会由于特定的提交遭遇测试失败甚至编译问题。如果这些改动引起了合并冲突,变基过程将会暂停并且允许你来解决它们。但是,整洁的合并改动仍然有可能打断编译或测试过程,留下破败的提交弄乱你的提交历史。
|
||||
|
||||
但是,你可以指导 Git 为每一个重写的提交来运行你的项目测试套件。在 Git v2.9 之前,你可以通过绑定 `git rebase --interactive` 和 `exec` 命令来实现。例如这样:
|
||||
|
||||
```
|
||||
$ git rebase master −−interactive −−exec=”npm test”
|
||||
```
|
||||
|
||||
...会生成在重写每条提交后执行 `npm test` 这样的一个交互式变基计划,保证你的测试仍然会通过:
|
||||
……这会生成一个交互式变基计划,在重写每条提交后执行 `npm test` ,保证你的测试仍然会通过:
|
||||
|
||||
```
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
@ -269,20 +250,17 @@ pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
exec npm test
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
exec npm test
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 command(s))
|
||||
```
|
||||
|
||||
如果出现了测试失败的情况,变基会暂停并让你修复这些测试(并且将你的修改应用于相应提交):
|
||||
|
||||
```
|
||||
291 passing
|
||||
1 failing
|
||||
```
|
||||
|
||||
```
|
||||
1) Host request “after all” hook:
|
||||
1) Host request "after all" hook:
|
||||
Uncaught Error: connect ECONNRESET 127.0.0.1:3001
|
||||
…
|
||||
npm ERR! Test failed.
|
||||
@ -292,91 +270,96 @@ You can fix the problem, and then run
|
||||
```
|
||||
|
||||
这很方便,但是使用交互式变基有一点臃肿。到了 Git v2.9,你可以这样来实现非交互式变基:
|
||||
|
||||
```
|
||||
$ git rebase master -x “npm test”
|
||||
$ git rebase master -x "npm test"
|
||||
```
|
||||
|
||||
简单替换 `npm test` 为 `make`,`rake`,`mvn clean install`,或者任何你用来构建或测试你的项目的命令。
|
||||
可以简单替换 `npm test` 为 `make`,`rake`,`mvn clean install`,或者任何你用来构建或测试你的项目的命令。
|
||||
|
||||
#### 小小警告
|
||||
|
||||
####小小警告
|
||||
就像电影里一样,重写历史可是一个危险的行当。任何提交被重写为变基操作的一部分都将改变它的 SHA-1 ID,这意味着 Git 会把它当作一个全新的提交对待。如果重写的历史和原来的历史混杂,你将获得重复的提交,而这可能在你的团队中引起不少的疑惑。
|
||||
|
||||
为了避免这个问题,你仅仅需要遵照一条简单的规则:
|
||||
|
||||
> _永远不要变基一条你已经推送的提交!_
|
||||
|
||||
坚持这一点你会没事的。
|
||||
|
||||
### Git LFS 的性能提升
|
||||
|
||||
[Git 是一个分布式版本控制系统][64],意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。[Git LFS(Large File Storage 大文件存储)][65] 是一个 Git 拓展包,由 Atlassian、GitHub 和其他一些开源贡献者开发,通过需要时才下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。
|
||||
|
||||
### `Git LFS` 的性能提升
|
||||
[Git 是一个分布式版本控制系统][64],意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。[Git LFS(Large File Storage 大文件存储)][65] 是一个 Git 拓展包,由 Atlassian,GitHub 和其他一些开源贡献者开发,通过消极地下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。
|
||||
|
||||
在 Git 2016 年的五大发布中,Git LFS 自身有四个功能丰富的发布:v1.2 到 v1.5。你可以凭 Git LFS 自身来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
|
||||
在 Git 2016 年的五大发布中,Git LFS 自身就有四个功能版本的发布:v1.2 到 v1.5。你可以仅对 Git LFS 这一项来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
|
||||
|
||||
#### 长期过滤进程
|
||||
|
||||
当你 `git add` 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储前转化文件的内容。Git LFS 通过使用净化过滤器将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
|
||||
当你 `git add` 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储之前转化文件的内容。Git LFS 通过使用净化过滤器(clean filter)将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
|
||||
|
||||
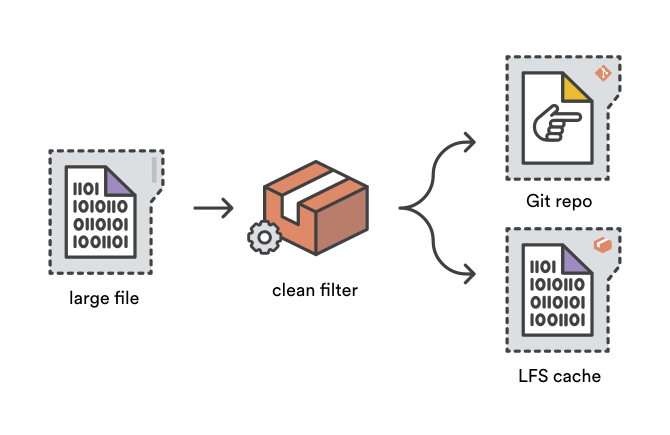
|
||||
|
||||

|
||||
|
||||
污化过滤器是净化过滤器的对立面——正如其名。在 `git checkout` 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
|
||||
污化过滤器(smudge filter)是净化过滤器的对立面——正如其名。在 `git checkout` 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
|
||||
|
||||
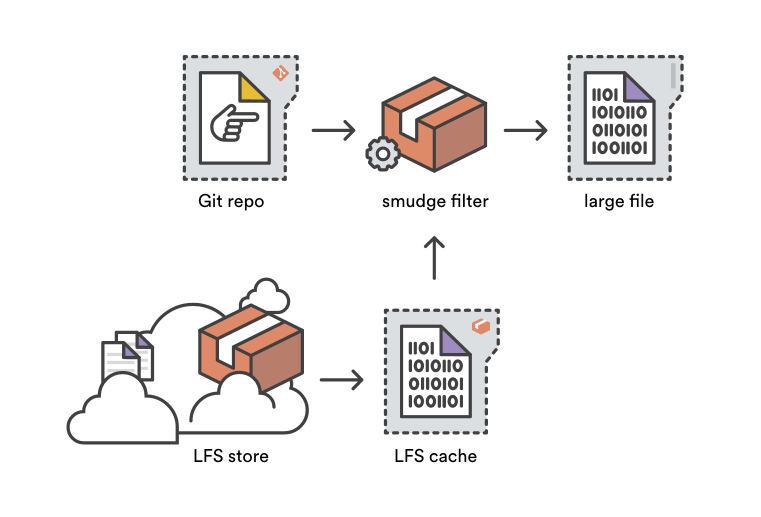
|
||||
|
||||
传统上,污化和净化过滤进程在每个文件被增加和检出时只能被唤起一次。所以,一个项目如果有 1000 个文件在被 Git LFS 追踪 ,做一次全新的检出需要唤起 `git-lfs-smudge` 命令 1000 次。尽管单次操作相对很迅速,但是经常执行 1000 次独立的污化进程总耗费惊人。、
|
||||
|
||||
针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。[Lars Schneider][66],Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
|
||||
> 使用 12k 个文件的测试仓库的过滤进程在 macOS 上快了80 倍,在 Windows 上 快了 58 倍。在 Windows 上,这意味着测试运行了 57 秒而不是 55 分钟。
|
||||
> 这真是一个让人印象深刻的性能增强!
|
||||
针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。[Lars Schneider][66],Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
|
||||
|
||||
> 使用 12k 个文件的测试仓库的过滤进程在 macOS 上快了 80 倍,在 Windows 上 快了 58 倍。在 Windows 上,这意味着测试运行了 57 秒而不是 55 分钟。
|
||||
|
||||
这真是一个让人印象深刻的性能增强!
|
||||
|
||||
#### LFS 专有克隆
|
||||
|
||||
长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两个 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 `git clone` 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
|
||||
长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两次 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 `git clone` 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
|
||||
|
||||
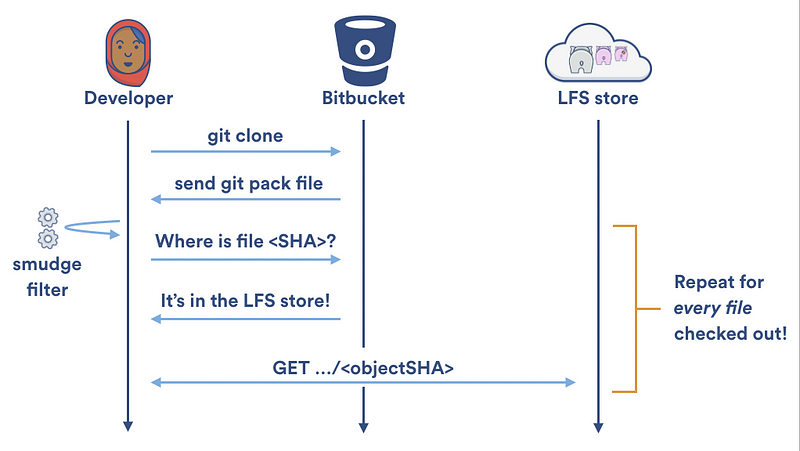
|
||||

|
||||
|
||||
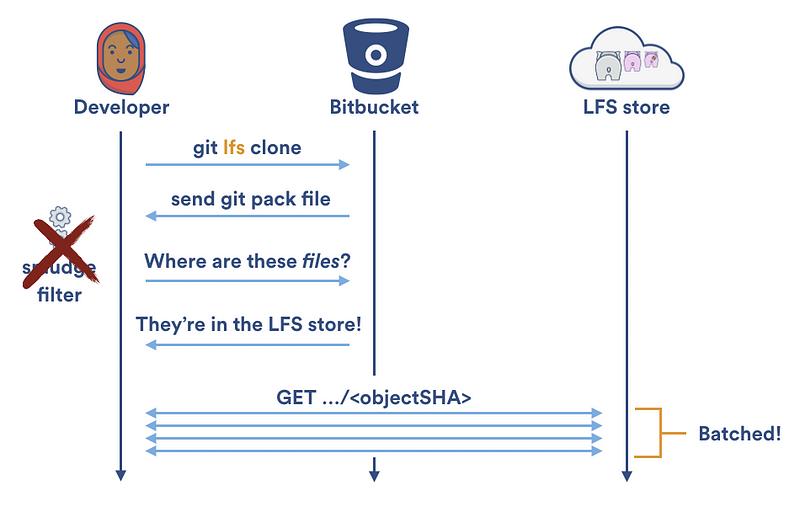
幸运的是,Git LFS v1.2 提供了专门的 `[git lfs clone][51]` 命令。不再是一次下载一个文件; `git lfs clone` 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
|
||||
幸运的是,Git LFS v1.2 提供了专门的 [`git lfs clone`][51] 命令。不再是一次下载一个文件; `git lfs clone` 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
|
||||
|
||||
|
||||

|
||||
|
||||
###自定义传输路由器
|
||||
### 自定义传输路由器(Transfer Adapter)
|
||||
|
||||
正如之前讨论过的,Git LFS 在 v1.5 中 发起了对长期过滤进程的支持。不过,对另外一种可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。
|
||||
正如之前讨论过的,Git LFS 在 v1.5 中提供对长期过滤进程的支持。不过,对另外一种类型的可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器(pluggable transfer adapter)的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。
|
||||
|
||||
直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 [Bitbucket LFS Media Adapter][67] 的托管服务商。这是为了从 Bitbucket 的一个独特的被称为 chunking 的 LFS 存储 API 特性中获利。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块(chunk)。
|
||||

|
||||
直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 [Bitbucket LFS Media Adapter][67] 的托管服务商。这是为了从 Bitbucket 的一个被称为 chunking 的 LFS 存储 API 独特特性中获益。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块(chunk)。
|
||||
|
||||

|
||||
|
||||
分块给予了 Bitbucket 支持的 Git LFS 三大优势:
|
||||
1. 并行下载与上传。默认地,Git LFS 最多并行传输三个文件。但是,如果只有一个文件被单独传输(这也是 Git LFS 污化过滤器的默认行为),它会在一个单独的流中被传输。Bitbucket 的分块允许同一文件的多个文件块同时被上传或下载,经常能够梦幻地提升传输速度。
|
||||
2. 可恢复文件块传输。文件块都在本地缓存,所以如果你的下载或上传被打断,Bitbucket 的自定义 LFS 流媒体路由器会在下一次你推送或拉取时仅为丢失的文件块恢复传输。
|
||||
3. 免重复。Git LFS,正如 Git 本身,是内容索位;每一个 LFS 文件都由它的内容生成的 SHA-256 哈希值认证。所以,哪怕你稍微修改了一位数据,整个文件的 SHA-256 就会修改而你不得不重新上传整个文件。分块允许你仅仅重新上传文件真正被修改的部分。举个例子,想想一下Git LFS 在追踪一个 41M 的电子游戏精灵表。如果我们增加在此精灵表上增加 2MB 的新层并且提交它,传统上我们需要推送整个新的 43M 文件到服务器端。但是,使用 Bitbucket 的自定义传输路由,我们仅仅需要推送 ~7MB:先是 4MB 文件块(因为文件的信息头会改变)和我们刚刚添加的包含新层的 3MB 文件块!其余未改变的文件块在上传过程中被自动跳过,节省了巨大的带宽和时间消耗。
|
||||
|
||||
可自定义的传输路由器是 Git LFS 一个伟大的特性,它们使得不同服务商在不过载核心项目的前提下体验适合其服务器的优化后的传输协议。
|
||||
1. 并行下载与上传。默认地,Git LFS 最多并行传输三个文件。但是,如果只有一个文件被单独传输(这也是 Git LFS 污化过滤器的默认行为),它会在一个单独的流中被传输。Bitbucket 的分块允许同一文件的多个文件块同时被上传或下载,经常能够神奇地提升传输速度。
|
||||
2. 可续传的文件块传输。文件块都在本地缓存,所以如果你的下载或上传被打断,Bitbucket 的自定义 LFS 流媒体路由器会在下一次你推送或拉取时仅为丢失的文件块恢复传输。
|
||||
3. 免重复。Git LFS,正如 Git 本身,是一种可定位的内容;每一个 LFS 文件都由它的内容生成的 SHA-256 哈希值认证。所以,哪怕你稍微修改了一位数据,整个文件的 SHA-256 就会修改而你不得不重新上传整个文件。分块允许你仅仅重新上传文件真正被修改的部分。举个例子,想想一下 Git LFS 在追踪一个 41M 的精灵表格(spritesheet)。如果我们增加在此精灵表格上增加 2MB 的新的部分并且提交它,传统上我们需要推送整个新的 43M 文件到服务器端。但是,使用 Bitbucket 的自定义传输路由,我们仅仅需要推送大约 7MB:先是 4MB 文件块(因为文件的信息头会改变)和我们刚刚添加的包含新的部分的 3MB 文件块!其余未改变的文件块在上传过程中被自动跳过,节省了巨大的带宽和时间消耗。
|
||||
|
||||
### 更佳的 `git diff` 算法与默认值
|
||||
可自定义的传输路由器是 Git LFS 的一个伟大的特性,它们使得不同服务商在不重载核心项目的前提下体验适合其服务器的优化后的传输协议。
|
||||
|
||||
### 更佳的 git diff 算法与默认值
|
||||
|
||||
不像其他的版本控制系统,Git 不会明确地存储文件被重命名了的事实。例如,如果我编辑了一个简单的 Node.js 应用并且将 `index.js` 重命名为 `app.js`,然后运行 `git diff`,我会得到一个看起来像一个文件被删除另一个文件被新建的结果。
|
||||
|
||||

|
||||

|
||||
|
||||
我猜测移动或重命名一个文件从技术上来讲是一次删除后跟一次新建,但这不是对人类最友好的方式来诉说它。其实,你可以使用 `-M` 标志来指示 Git 在计算差异时抽空尝试检测重命名文件。对之前的例子,`git diff -M` 给我们如下结果:
|
||||

|
||||
我猜测移动或重命名一个文件从技术上来讲是一次删除后跟着一次新建,但这不是对人类最友好的描述方式。其实,你可以使用 `-M` 标志来指示 Git 在计算差异时同时尝试检测是否是文件重命名。对之前的例子,`git diff -M` 给我们如下结果:
|
||||
|
||||
第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,`-M` 会考虑任意两个文件都有超过 50% 相似度。这意味着,你需要编辑少于 50% 的行数来确保它们被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,`-M80%`。
|
||||

|
||||
|
||||
到 Git v2.9 版本,如果你使用了 `-M` 标志 `git diff` 和 `git log` 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显示的传递 `--no-renames` 标志来禁用它。
|
||||
第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,`-M` 会处理任意两个超过 50% 相似度的文件。这意味着,你需要编辑少于 50% 的行数来确保它们可以被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,`-M80%`。
|
||||
|
||||
到 Git v2.9 版本,无论你是否使用了 `-M` 标志, `git diff` 和 `git log` 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显式的传递 `--no-renames` 标志来禁用这种行为。
|
||||
|
||||
#### 详细的提交
|
||||
|
||||
你经历过调用 `git commit` 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?verbose 标志就为此而来!
|
||||
你经历过调用 `git commit` 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?`verbose` 标志就为此而来!
|
||||
|
||||
不像这样:
|
||||
```
|
||||
Ah crap, which dependency did I just rev?
|
||||
```
|
||||
|
||||
```
|
||||
Ah crap, which dependency did I just rev?
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with ‘#’ will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
@ -387,15 +370,16 @@ Ah crap, which dependency did I just rev?
|
||||
#
|
||||
```
|
||||
|
||||
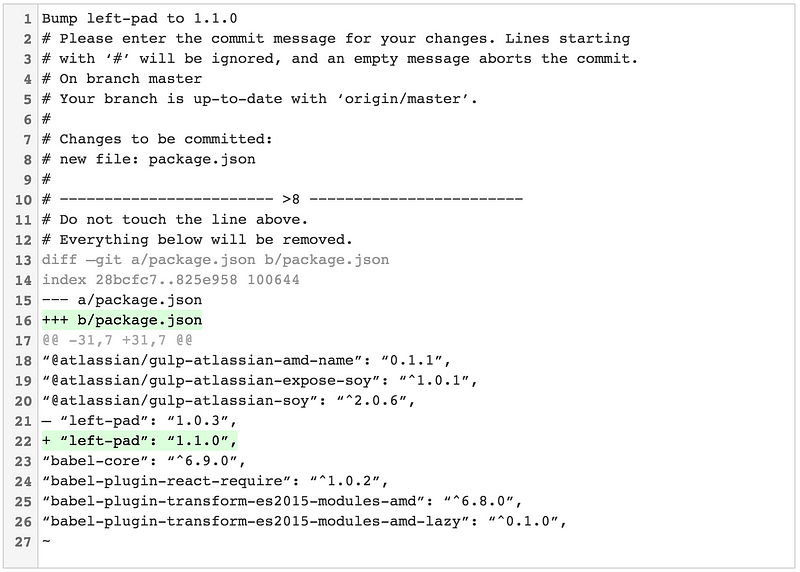
...你可以调用 `git commit --verbose` 来查看你改动造成的内联差异。不用担心,这不会包含在你的提交信息中:
|
||||
……你可以调用 `git commit --verbose` 来查看你改动造成的行内差异。不用担心,这不会包含在你的提交信息中:
|
||||
|
||||
|
||||

|
||||
|
||||
`--verbose` 标志不是最新的,但是直到 Git v2.9 你可以通过 `git config --global commit.verbose true` 永久的启用它。
|
||||
`--verbose` 标志并不是新出现的,但是直到 Git v2.9 你才可以通过 `git config --global commit.verbose true` 永久的启用它。
|
||||
|
||||
#### 实验性的 Diff 改进
|
||||
|
||||
当一个被修改部分前后几行相同时,`git diff` 可能产生一些稍微令人迷惑的输出。如果在一个文件中有两个或者更多相似结构的函数时这可能发生。来看一个有些刻意人为的例子,想象我们有一个 JS 文件包含一个单独的函数:
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
@ -403,15 +387,14 @@ function productName() {
|
||||
}
|
||||
```
|
||||
|
||||
现在想象一下我们刚提交的改动包含一个预谋的 _另一个_可以做相似事情的函数:
|
||||
现在想象一下我们刚提交的改动包含一个我们专门做的 _另一个_可以做相似事情的函数:
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productId() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
return "Bitbucket";
|
||||
@ -420,32 +403,34 @@ function productName() {
|
||||
|
||||
我们希望 `git diff` 显示开头五行被新增,但是实际上它不恰当地将最初提交的第一行也包含进来。
|
||||
|
||||

|
||||

|
||||
|
||||
错误的注释被包含在了 diff 中!这虽不是世界末日,但每次发生这种事情总免不了花费几秒钟的意识去想 _啊?_
|
||||
在十二月,Git v2.11 介绍了一个新的实验性的 diff 选项,`--indent-heuristic`,尝试生成从美学角度来看更赏心悦目的 diff。
|
||||
|
||||

|
||||

|
||||
|
||||
在后台,`--indent-heuristic` 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 "不良" 分数。这是基于试探性的如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲不良)以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。
|
||||
在后台,`--indent-heuristic` 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 “不良” 分数。这是基于启发式的,如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲“不良”),以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。
|
||||
|
||||
这个特性还是实验性的,但是你可以通过应用 `--indent-heuristic` 选项到任何 `git diff` 命令来专门测试它。如果,如果你喜欢尝鲜,你可以这样将其在你的整个系统内启用:
|
||||
|
||||
这个特性还是实验性的,但是你可以通过应用 `--indent-heuristic` 选项到任何 `git diff` 命令来专门测试它。如果,如果你喜欢在刀口上讨生活,你可以这样将其在你的整个系统内使能:
|
||||
```
|
||||
$ git config --global diff.indentHeuristic true
|
||||
```
|
||||
|
||||
### Submodules 差强人意
|
||||
### 子模块(Submodule)差强人意
|
||||
|
||||
子模块允许你从 Git 仓库内部引用和包含其他 Git 仓库。这通常被用在当一些项目管理的源依赖也在被 Git 跟踪时,或者被某些公司用来作为包含一系列相关项目的 [monorepo][68] 的替代品。
|
||||
|
||||
由于某些用法的复杂性以及使用错误的命令相当容易破坏它们的事实,Submodule 得到了一些坏名声。
|
||||
|
||||
|
||||

|
||||
|
||||
但是,它们还是有着它们的用处,而且,我想,仍然对其他方案有依赖时的最好的选择。 幸运的是,2016 对 submodule 用户来说是伟大的一年,在几次发布中落地了许多意义重大的性能和特性提升。
|
||||
但是,它们还是有着它们的用处,而且,我想这仍然是用于需要厂商依赖项的最好选择。 幸运的是,2016 对子模块的用户来说是伟大的一年,在几次发布中落地了许多意义重大的性能和特性提升。
|
||||
|
||||
#### 并行抓取
|
||||
当克隆或则抓取一个仓库时,加上 `--recurse-submodules` 选项意味着任何引用的 submodule 也将被克隆或更新。传统上,这会被串行执行,每次只抓取一个 submodule。直到 Git v2.8,你可以附加 `--jobs=n` 选项来使用 _n_ 个并行线程来抓取 submodules。
|
||||
|
||||
当克隆或则抓取一个仓库时,加上 `--recurse-submodules` 选项意味着任何引用的子模块也将被克隆或更新。传统上,这会被串行执行,每次只抓取一个子模块。直到 Git v2.8,你可以附加 `--jobs=n` 选项来使用 _n_ 个并行线程来抓取子模块。
|
||||
|
||||
我推荐永久的配置这个选项:
|
||||
|
||||
@ -453,30 +438,31 @@ $ git config --global diff.indentHeuristic true
|
||||
$ git config --global submodule.fetchJobs 4
|
||||
```
|
||||
|
||||
...或者你可以选择使用任意程度的平行化。
|
||||
……或者你可以选择使用任意程度的平行化。
|
||||
|
||||
#### 浅层子模块
|
||||
Git v2.9 介绍了 `git clone —shallow-submodules` 标志。它允许你抓取你仓库的完整克隆,然后递归的浅层克隆所有引用的子模块的一个提交。如果你不需要项目的依赖的完整记录时会很有用。
|
||||
#### 浅层化子模块
|
||||
|
||||
例如,一个仓库有着一些混合了的子模块,其中包含有其他方案商提供的依赖和你自己其它的项目。你可能希望初始化时执行浅层子模块克隆然后深度选择几个你想要与之工作的项目。
|
||||
Git v2.9 介绍了 `git clone —shallow-submodules` 标志。它允许你抓取你仓库的完整克隆,然后递归地以一个提交的深度浅层化克隆所有引用的子模块。如果你不需要项目的依赖的完整记录时会很有用。
|
||||
|
||||
另一种情况可能是配置一次持续性的集成或调度工作。Git 需要超级仓库以及每个子模块最新的提交以便能够真正执行构建。但是,你可能并不需要每个子模块全部的历史记录,所以仅仅检索最新的提交可以为你省下时间和带宽。
|
||||
例如,一个仓库有着一些混合了的子模块,其中包含有其他厂商提供的依赖和你自己其它的项目。你可能希望初始化时执行浅层化子模块克隆,然后深度选择几个你想工作与其上的项目。
|
||||
|
||||
另一种情况可能是配置持续集成或部署工作。Git 需要一个包含了子模块的超级仓库以及每个子模块最新的提交以便能够真正执行构建。但是,你可能并不需要每个子模块全部的历史记录,所以仅仅检索最新的提交可以为你省下时间和带宽。
|
||||
|
||||
#### 子模块的替代品
|
||||
|
||||
`--reference` 选项可以和 `git clone` 配合使用来指定另一个本地仓库作为一个目标存储来保存你本地已经存在的又通过网络传输的重复制目标。语法为:
|
||||
`--reference` 选项可以和 `git clone` 配合使用来指定另一个本地仓库作为一个替代的对象存储,来避免跨网络重新复制你本地已经存在的对象。语法为:
|
||||
|
||||
```
|
||||
$ git clone --reference <local repo> <url>
|
||||
```
|
||||
|
||||
直到 Git v2.11,你可以使用 `—reference` 选项与 `—recurse-submodules` 结合来设置子模块替代品从另一个本地仓库指向子模块。其语法为:
|
||||
到 Git v2.11,你可以使用 `—reference` 选项与 `—recurse-submodules` 结合来设置子模块指向一个来自另一个本地仓库的子模块。其语法为:
|
||||
|
||||
```
|
||||
$ git clone --recurse-submodules --reference <local repo> <url>
|
||||
```
|
||||
|
||||
这潜在的可以省下很大数量的带宽和本地磁盘空间,但是如果引用的本地仓库不包含你所克隆自的远程仓库所必需的所有子模块时,它可能会失败。。
|
||||
这潜在的可以省下大量的带宽和本地磁盘空间,但是如果引用的本地仓库不包含你克隆的远程仓库所必需的所有子模块时,它可能会失败。
|
||||
|
||||
幸运的是,方便的 `—-reference-if-able` 选项将会让它优雅地失败,然后为丢失了的被引用的本地仓库的所有子模块回退为一次普通的克隆。
|
||||
|
||||
@ -487,11 +473,11 @@ $ git clone --recurse-submodules --reference-if-able \
|
||||
|
||||
#### 子模块的 diff
|
||||
|
||||
在 Git v2.11 之前,Git 有两种模式来显示对更新了仓库子模块的提交之间的差异。
|
||||
在 Git v2.11 之前,Git 有两种模式来显示对更新你的仓库子模块的提交之间的差异。
|
||||
|
||||
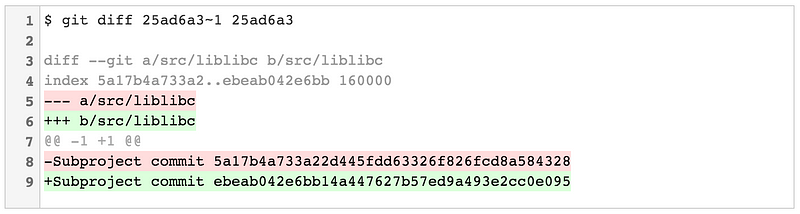
`git diff —-submodule=short` 显示你的项目引用的子模块中的旧提交和新提交( 这也是如果你整体忽略 `--submodule` 选项的默认结果):
|
||||
`git diff —-submodule=short` 显示你的项目引用的子模块中的旧提交和新提交(这也是如果你整体忽略 `--submodule` 选项的默认结果):
|
||||
|
||||
|
||||

|
||||
|
||||
`git diff —submodule=log` 有一点啰嗦,显示更新了的子模块中任意新建或移除的提交的信息中统计行。
|
||||
|
||||
@ -499,15 +485,16 @@ $ git clone --recurse-submodules --reference-if-able \
|
||||
|
||||
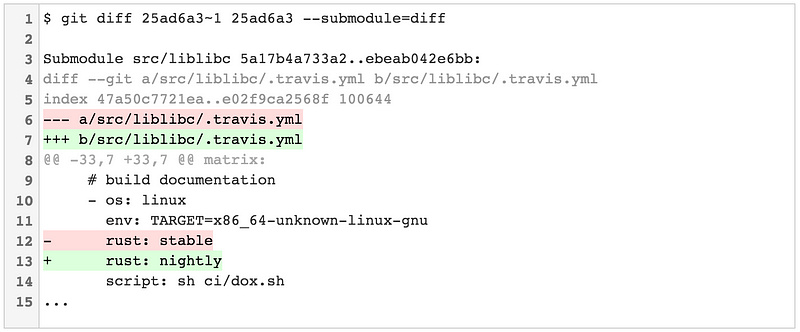
Git v2.11 引入了第三个更有用的选项:`—-submodule=diff`。这会显示更新后的子模块所有改动的完整的 diff。
|
||||
|
||||
|
||||

|
||||
|
||||
### `git stash` 的 90 个增强
|
||||
### git stash 的 90 个增强
|
||||
|
||||
不像 submodules,几乎没有 Git 用户不钟爱 `[git stash][52]`。 `git stash` 临时搁置(或者 _藏匿_)你对工作区所做的改动使你能够先处理其他事情,结束后重新将搁置的改动恢复到先前状态。
|
||||
不像子模块,几乎没有 Git 用户不钟爱 [`git stash`][52]。 `git stash` 临时搁置(或者 _藏匿_)你对工作区所做的改动使你能够先处理其他事情,结束后重新将搁置的改动恢复到先前状态。
|
||||
|
||||
#### 自动搁置
|
||||
|
||||
如果你是 `git rebase` 的粉丝,你可能很熟悉 `--autostash` 选项。它会在变基之前自动搁置工作区所有本地修改然后等变基结束再将其复用。
|
||||
|
||||
```
|
||||
$ git rebase master --autostash
|
||||
Created autostash: 54f212a
|
||||
@ -516,12 +503,14 @@ First, rewinding head to replay your work on top of it...
|
||||
Applied autostash.
|
||||
```
|
||||
|
||||
这很方便,因为它使得你可以在一个不洁的工作区执行变基。有一个方便的配置标志叫做 `rebase.autostash` 可以将这个特性设为默认,你可以这样来全局使能它:
|
||||
这很方便,因为它使得你可以在一个不洁的工作区执行变基。有一个方便的配置标志叫做 `rebase.autostash` 可以将这个特性设为默认,你可以这样来全局启用它:
|
||||
|
||||
```
|
||||
$ git config --global rebase.autostash true
|
||||
```
|
||||
|
||||
`rebase.autostash` 实际上自从 [Git v1.8.4][69] 就可用了,但是 v2.7 引入了通过 `--no-autostash` 选项来取消这个标志的功能。如果你对未暂存的改动使用这个选项,变基会被一条工作树被污染的警告禁止:
|
||||
|
||||
```
|
||||
$ git rebase master --no-autostash
|
||||
Cannot rebase: You have unstaged changes.
|
||||
@ -531,31 +520,37 @@ Please commit or stash them.
|
||||
#### 补丁式搁置
|
||||
|
||||
说到配置标签,Git v2.7 也引入了 `stash.showPatch`。`git stash show` 的默认行为是显示你搁置文件的汇总。
|
||||
|
||||
```
|
||||
$ git stash show
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
将 `-p` 标志传入会将 `git stash show` 变为 "补丁模式",这将会显示完整的 diff:
|
||||
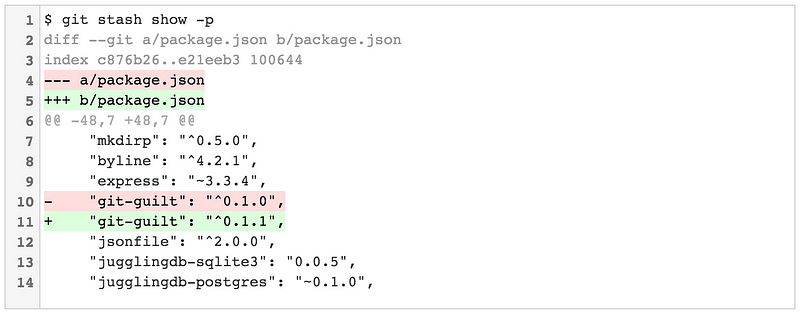
|
||||
将 `-p` 标志传入会将 `git stash show` 变为 “补丁模式”,这将会显示完整的 diff:
|
||||
|
||||

|
||||
|
||||
`stash.showPatch` 将这个行为定为默认。你可以将其全局启用:
|
||||
|
||||
`stash.showPatch` 将这个行为定为默认。你可以将其全局使能:
|
||||
```
|
||||
$ git config --global stash.showPatch true
|
||||
```
|
||||
|
||||
如果你使能 `stash.showPatch` 但却之后决定你仅仅想要查看文件总结,你可以通过传入 `--stat` 选项来重新获得之前的行为。
|
||||
|
||||
```
|
||||
$ git stash show --stat
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
顺便一提:`--no-patch` 是一个有效选项但它不会如你所希望的改写 `stash.showPatch` 的结果。不仅如此,它会传递给用来生成补丁时潜在调用的 `git diff` 命令,然后你会发现完全没有任何输出。
|
||||
顺便一提:`--no-patch` 是一个有效选项但它不会如你所希望的取消 `stash.showPatch`。不仅如此,它会传递给用来生成补丁时潜在调用的 `git diff` 命令,然后你会发现完全没有任何输出。
|
||||
|
||||
#### 简单的搁置标识
|
||||
如果你是 `git stash` 的粉丝,你可能知道你可以搁置多次改动然后通过 `git stash list` 来查看它们:
|
||||
|
||||
如果你惯用 `git stash` ,你可能知道你可以搁置多次改动然后通过 `git stash list` 来查看它们:
|
||||
|
||||
```
|
||||
$ git stash list
|
||||
stash@{0}: On master: crazy idea that might work one day
|
||||
@ -564,11 +559,11 @@ stash@{2}: On master: perf improvement that I forgot I stashed
|
||||
stash@{3}: On master: pop this when we use Docker in production
|
||||
```
|
||||
|
||||
但是,你可能不知道为什么 Git 的搁置有着这么难以理解的标识(`stash@{1}`, `stash@{2}`, 等)也可能将它们勾勒成 "仅仅是 Git 的一个特性吧"。实际上就像很多 Git 特性一样,这些奇怪的标志实际上是 Git 数据模型一个非常巧妙使用(或者说是滥用了的)的特性。
|
||||
但是,你可能不知道为什么 Git 的搁置有着这么难以理解的标识(`stash@{1}`、`stash@{2}` 等),或许你可能将它们勾勒成 “仅仅是 Git 的癖好吧”。实际上就像很多 Git 特性一样,这些奇怪的标志实际上是 Git 数据模型的一个非常巧妙使用(或者说是滥用了的)的结果。
|
||||
|
||||
在后台,`git stash` 命令实际创建了一系列特别的提交目标,这些目标对你搁置的改动做了编码并且维护一个 [reglog][70] 来保存对这些特殊提交的参考。 这也是为什么 `git stash list` 的输出看起来很像 `git reflog` 的输出。当你运行 `git stash apply stash@{1}` 时,你实际上在说,"从stash reflog 的位置 1 上应用这条提交 "
|
||||
在后台,`git stash` 命令实际创建了一系列特定的提交目标,这些目标对你搁置的改动做了编码并且维护一个 [reglog][70] 来保存对这些特殊提交的引用。 这也是为什么 `git stash list` 的输出看起来很像 `git reflog` 的输出。当你运行 `git stash apply stash@{1}` 时,你实际上在说,“从 stash reflog 的位置 1 上应用这条提交。”
|
||||
|
||||
直到 Git v2.11,你不再需要使用完整的 `stash@{n}` 语句。相反,你可以通过一个简单的整数指出搁置在 stash reflog 中的位置来引用它们。
|
||||
到了 Git v2.11,你不再需要使用完整的 `stash@{n}` 语句。相反,你可以通过一个简单的整数指出该搁置在 stash reflog 中的位置来引用它们。
|
||||
|
||||
```
|
||||
$ git stash show 1
|
||||
@ -577,25 +572,26 @@ $ git stash pop 1
|
||||
```
|
||||
|
||||
讲了很多了。如果你还想要多学一些搁置是怎么保存的,我在 [这篇教程][71] 中写了一点这方面的内容。
|
||||
### <2016> <2017>
|
||||
好了,结束了。感谢您的阅读!我希望您享受阅读这份长篇大论,正如我享受在 Git 的源码,发布文档,和 `man` 手册中探险一番来撰写它。如果你认为我忘记了一些重要的事,请留下一条评论或者在 [Twitter][72] 上让我知道,我会努力写一份后续篇章。
|
||||
|
||||
至于 Git 接下来会发生什么,这要靠广大维护者和贡献者了(其中有可能就是你!)。随着日益增长的采用,我猜测简化,改进后的用户体验,和更好的默认结果将会是 2017 年 Git 主要的主题。随着 Git 仓库变得又大又旧,我猜我们也可以看到继续持续关注性能和对大文件、深度树和长历史的改进处理。
|
||||
### </2016> <2017>
|
||||
|
||||
如果你关注 Git 并且很期待能够和一些项目背后的开发者会面,请考虑来 Brussels 花几周时间来参加 [Git Merge][74] 。我会在[那里发言][75]!但是更重要的是,很多维护 Git 的开发者将会出席这次会议而且一年一度的 Git 贡献者峰会很可能会指定来年发展的方向。
|
||||
好了,结束了。感谢您的阅读!我希望您喜欢阅读这份长篇大论,正如我乐于在 Git 的源码、发布文档和 `man` 手册中探险一番来撰写它。如果你认为我忘记了一些重要的事,请留下一条评论或者在 [Twitter][72] 上让我知道,我会努力写一份后续篇章。
|
||||
|
||||
至于 Git 接下来会发生什么,这要靠广大维护者和贡献者了(其中有可能就是你!)。随着 Git 的采用日益增长,我猜测简化、改进的用户体验,和更好的默认结果将会是 2017 年 Git 主要的主题。随着 Git 仓库变得越来越大、越来越旧,我猜我们也可以看到继续持续关注性能和对大文件、深度树和长历史的改进处理。
|
||||
|
||||
如果你关注 Git 并且很期待能够和一些项目背后的开发者会面,请考虑来 Brussels 花几周时间来参加 [Git Merge][74] 。我会在[那里发言][75]!但是更重要的是,很多维护 Git 的开发者将会出席这次会议而且一年一度的 Git 贡献者峰会很可能会指定来年发展的方向。
|
||||
|
||||
或者如果你实在等不及,想要获得更多的技巧和指南来改进你的工作流,请参看这份 Atlassian 的优秀作品: [Git 教程][76] 。
|
||||
|
||||
|
||||
*如果你翻到最下方来找第一节的脚注,请跳转到 [ [引用是需要的] ][77]一节去找生成统计信息的命令。免费的封面图片是由 [ instaco.de ][78] 生成的 ❤️。*
|
||||
封面图片是由 [instaco.de][78] 生成的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/git-in-2016-fad96ae22a15#.t5c5cm48f
|
||||
via: https://medium.com/hacker-daily/git-in-2016-fad96ae22a15
|
||||
|
||||
作者:[Tim Pettersen][a]
|
||||
译者:[xiaow6](https://github.com/xiaow6)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,57 +0,0 @@
|
||||
|
||||
translating by xiaow6
|
||||
|
||||
Why do developers who could work anywhere flock to the world’s most expensive cities?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Politicians and economists [lament][10] that certain alpha regions — SF, LA, NYC, Boston, Toronto, London, Paris — attract all the best jobs while becoming repellently expensive, reducing economic mobility and contributing to further bifurcation between haves and have-nots. But why don’t the best jobs move elsewhere?
|
||||
|
||||
Of course, many of them can’t. The average financier in NYC or London (until Brexit annihilates London’s banking industry, of course…) would be laughed out of the office, and not invited back, if they told their boss they wanted to henceforth work from Chiang Mai.
|
||||
|
||||
But this isn’t true of (much of) the software field. The average web/app developer might have such a request declined; but they would not be laughed at, or fired. The demand for good developers greatly outstrips supply, and in this era of Skype and Slack, there’s nothing about software development that requires meatspace interactions.
|
||||
|
||||
(This is even more true of writers, of course; I did in fact post this piece from Pohnpei. But writers don’t have anything like the leverage of software developers.)
|
||||
|
||||
Some people will tell you that remote teams are inherently less effective and productive than localized ones, or that “serendipitous collisions” are so important that every employee must be forced to the same physical location every day so that these collisions can be manufactured. These people are wrong, as long as the team in question is small — on the order of handfuls, dozens or scores, rather than hundreds or thousands — and flexible.
|
||||
|
||||
I should know: at [HappyFunCorp][11], we work extensively with remote teams, and actively recruit remote developers, and it works out fantastically well. A day in which I interact and collaborate with developers in Stockholm, São Paulo, Shanghai, Brooklyn and New Delhi, from my own home base in San Francisco, is not at all unusual.
|
||||
|
||||
At this point, whether it’s a good idea is almost irrelevant, though. Supply and demand is such that any sufficiently skilled developer could become a so-called digital nomad if they really wanted to. But many who could, do not. I recently spent some time in Reykjavik at a house Airbnb-ed for the month by an ever-shifting crew of temporary remote workers, keeping East Coast time to keep up with their jobs, while spending mornings and weekends exploring Iceland — but almost all of us then returned to live in the Bay Area.
|
||||
|
||||
Economically, of course, this is insane. Moving to and working from Southeast Asia would save us thousands of dollars a month in rent alone. So why do people who could live in Costa Rica on a San Francisco salary, or in Berlin while charging NYC rates, choose not to do so? Why are allegedly hardheaded engineers so financially irrational?
|
||||
|
||||
Of course there are social and cultural reasons. Chiang Mai is very nice, but doesn’t have the Met, or steampunk masquerade parties or 50 foodie restaurants within a 15-minute walk. Berlin is lovely, but doesn’t offer kite surfing, or Sierra hiking or California weather. Neither promises an effectively limitless population of people with whom you share values and a first language.
|
||||
|
||||
And yet I think there’s much more to it than this. I believe there’s a more fundamental economic divide opening than the one between haves and have-nots. I think we are witnessing a growing rift between the world’s Extremistan cities, in which truly extraordinary things can be achieved, and its Mediocristan towns, in which you can work and make money and be happy but never achieve greatness. (Labels stolen from the great Nassim Taleb.)
|
||||
|
||||
The arts have long had Extremistan cities. That’s why aspiring writers move to New York City, and even directors and actors who found international success are still drawn to L.A. like moths to a klieg light. Now it is true of tech, too. Even if you don’t even want to try to (help) build something extraordinary — and the startup myth is so powerful today that it’s a very rare engineer indeed who hasn’t at least dreamed about it — the prospect of being _where great things happen_ is intoxicatingly enticing.
|
||||
|
||||
But the interesting thing about this is that it could, in theory, change; because — as of quite recently — distributed, decentralized teams can, in fact, achieve extraordinary things. The cards are arguably stacked against them, because VCs tend to be quite myopic. But no law dictates that unicorns may only be born in California and a handful of other secondary territories; and it seems likely that, for better or worse, Extremistan is spreading. It would be pleasantly paradoxical if that expansion ultimately leads to _lower_ rents in the Mission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
|
||||
作者:[ Jon Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/jon-evans/
|
||||
[1]:https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/#comments
|
||||
[2]:https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/#
|
||||
[3]:http://twitter.com/share?via=techcrunch&url=http://tcrn.ch/2owXJ0C&text=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F&hashtags=
|
||||
[4]:https://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Ftechcrunch.com%2F2017%2F04%2F02%2Fwhy-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities%2F&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F
|
||||
[5]:https://plus.google.com/share?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[6]:http://www.reddit.com/submit?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F
|
||||
[7]:http://www.stumbleupon.com/badge/?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[8]:mailto:?subject=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities?&body=Article:%20https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[9]:https://share.flipboard.com/bookmarklet/popout?v=2&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F&url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[10]:https://mobile.twitter.com/Noahpinion/status/846054187288866
|
||||
[11]:http://happyfuncorp.com/
|
||||
[12]:https://twitter.com/rezendi
|
||||
[13]:https://techcrunch.com/author/jon-evans/
|
||||
[14]:https://techcrunch.com/2017/04/01/discussing-the-limits-of-artificial-intelligence/
|
||||
@ -1,112 +0,0 @@
|
||||
ictlyh Translating
|
||||
# Recover from a badly corrupt Linux EFI installation
|
||||
|
||||
In the past decade or so, Linux distributions would occasionally fail before, during and after the installation, but I was always able to somehow recover the system and continue working normally. Well, [Solus][1]broke my laptop. Literally.
|
||||
|
||||
GRUB rescue. No luck. Reinstall. No luck still! Ubuntu refused to install, complaining about the target device not being this or that. Wow. Something like this has never happened to me before. Effectively my test machine had become a useless brick. Should we despair? No, absolutely not. Let me show you how you can fix it.
|
||||
|
||||
### Problem in more detail
|
||||
|
||||
It all started with Solus trying to install its own bootloader - goofiboot. No idea what, who or why, but it failed to complete successfully, and I was left with a system that would not boot. After BIOS, I would get a GRUB rescue shell.
|
||||
|
||||

|
||||
|
||||
I tried manually working in the rescue shell, using this and that command, very similar to what I have outlined in my extensive [GRUB2 tutorial][2]. This did not really work. My next attempt was to recover from a live CD, again following my own advice, as I have outlined in my [GRUB2 & EFI tutorial][3]. I set up a new entry, and made sure to mark it active with the efibootmgr utility. Just as we did in the guide, and this has served us well before. Alas, this recovery method did not work, either.
|
||||
|
||||
I tried to perform a complete Ubuntu installation, into the same partition used by Solus, expecting the installer to sort out some of the fine details. But Ubuntu was not able to finish the install. It complained about: failed to install into /target. This was a first. What now?
|
||||
|
||||
### Manually clean up EFI partition
|
||||
|
||||
Obviously, something is very wrong with our EFI partition. Just to briefly recap, if you are using UEFI, then you must have a separate FAT32-formatted partition. This partition is used to store EFI boot images. For instance, when you install Fedora, the Fedora boot image will be copied into the EFI subdirectory. Every operating system is stored into a folder of its own, e.g. /boot/efi/EFI/<os version>/.
|
||||
|
||||

|
||||
|
||||
On my [G50][4] machine, there were multiple entries, from a variety of my distro tests, including: centos, debian, fedora, mx-15, suse, ubuntu, zorin, and many others. There was also a goofiboot folder. However, the efibootmgr was not showing a goofiboot entry in its menu. There was obviously something wrong with the whole thing.
|
||||
|
||||
```
|
||||
sudo efibootmgr -d /dev/sda
|
||||
BootCurrent: 0001
|
||||
Timeout: 0 seconds
|
||||
BootOrder: 0001,0005,2003,0000,2001,2002
|
||||
Boot0000* Lenovo Recovery System
|
||||
Boot0001* ubuntu
|
||||
Boot0003* EFI Network 0 for IPv4 (68-F7-28-4D-D1-A1)
|
||||
Boot0004* EFI Network 0 for IPv6 (68-F7-28-4D-D1-A1)
|
||||
Boot0005* Windows Boot Manager
|
||||
Boot0006* fedora
|
||||
Boot0007* suse
|
||||
Boot0008* debian
|
||||
Boot0009* mx-15
|
||||
Boot2001* EFI USB Device
|
||||
Boot2002* EFI DVD/CDROM
|
||||
Boot2003* EFI Network
|
||||
...
|
||||
```
|
||||
|
||||
P.S. The output above was generated running the command in a LIVE session!
|
||||
|
||||
I decided to clean up all the non-default and non-Microsoft entries and start fresh. Obviously, something was corrupt, and preventing new distros from setting up their own bootloader. So I deleted all the folders in the /boot/efi/EFI partition except Boot and Windows. And then, I also updated the boot manager by removing all the extras.
|
||||
|
||||
```
|
||||
efibootmgr -b <hex> -B <hex>
|
||||
```
|
||||
|
||||
Lastly, I reinstalled Ubuntu and closely monitored the progress with the GRUB installation and setup. This time, things completed fine. There were some errors with several invalid entries, as can be expected, but the whole sequenced completed just fine.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### More reading
|
||||
|
||||
If you don't fancy this manual fix, you may want to read:
|
||||
|
||||
```
|
||||
[Boot-Info][5] page, with automated tools to help you recover your system
|
||||
|
||||
[Boot-repair-cd][6] automatic repair tool download page
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
If you ever encounter a situation where your system is badly botched due to an EFI partition clobbering, then you may want to follow the advice in this guide. Delete all non-default entries. Make sure you do not touch anything Microsoft, if you're multi-booting with Windows. Then update the boot menu accordingly so the baddies are removed. Rerun the installation setup for your desired distro, or try to fix with a less stringent method as explained before.
|
||||
|
||||
I hope this little article saves you some bacon. I was quite annoyed by what Solus did to my system. This is not something that should happen, and the recovery ought to be simpler. However, while things may seem dreadful, the fix is not difficult. You just need to delete the corrupt files and start again. Your data should not be affected, and you will be able to promptly boot into a running system and continue working. There you go.
|
||||
|
||||
Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
My name is Igor Ljubuncic. I'm more or less 38 of age, married with no known offspring. I am currently working as a Principal Engineer with a cloud technology company, a bold new frontier. Until roughly early 2015, I worked as the OS Architect with an engineering computing team in one of the largest IT companies in the world, developing new Linux-based solutions, optimizing the kernel and hacking the living daylights out of Linux. Before that, I was a tech lead of a team designing new, innovative solutions for high-performance computing environments. Some other fancy titles include Systems Expert and System Programmer and such. All of this used to be my hobby, but since 2008, it's a paying job. What can be more satisfying than that?
|
||||
|
||||
From 2004 until 2008, I used to earn my bread by working as a physicist in the medical imaging industry. My work expertise focused on problem solving and algorithm development. To this end, I used Matlab extensively, mainly for signal and image processing. Furthermore, I'm certified in several major engineering methodologies, including MEDIC Six Sigma Green Belt, Design of Experiment, and Statistical Engineering.
|
||||
|
||||
I also happen to write books, including high fantasy and technical work on Linux; mutually inclusive.
|
||||
|
||||
Please see my full list of open-source projects, publications and patents, just scroll down.
|
||||
|
||||
For a complete list of my awards, nominations and IT-related certifications, hop yonder and yonder please.
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/grub2-efi-corrupt-part-recovery.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.dedoimedo.com/computers/solus-1-2-review.html
|
||||
[2]:http://www.dedoimedo.com/computers/grub-2.html
|
||||
[3]:http://www.dedoimedo.com/computers/grub2-efi-recovery.html
|
||||
[4]:http://www.dedoimedo.com/computers/lenovo-g50-distros-second-round.html
|
||||
[5]:https://help.ubuntu.com/community/Boot-Info
|
||||
[6]:https://sourceforge.net/projects/boot-repair-cd/
|
||||
@ -0,0 +1,63 @@
|
||||
|
||||
|
||||
|
||||
为什么可以在任何地方工作的开发者要聚集到世界上最昂贵的城市?
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
政治家和经济学家都在[哀嚎][10]某几个阿尔法地区——三番,洛杉矶,纽约,波士顿,多伦多,伦敦,巴黎——在吸引了所有最好的工作的同时变得令人退却的昂贵,减少了经济变动性而增大了贫富差异。但是为什么那些最好的工作不能搬到其他地区呢?
|
||||
|
||||
当然,很多都不能。工作在纽约或者伦敦(当然,在英国脱欧毁灭伦敦的银行体系之前)普通的金融从业人员如果告诉他们的老板他们想要以后都在清迈工作,将会在办公室里受到嘲笑而且不再受欢迎。
|
||||
|
||||
但是这对(大部分)软件领域不适用。大部分 web/app 开发者如果这样要求的话可能会被拒绝;但是它们至少不会被嘲笑或者被炒。优秀开发者往往供不应求,而且处在 Skype 和 Slack 的时代,软件开发完全可以不依赖物质世界的交互。
|
||||
|
||||
(这一切对作家来说更加正确,真的;事实上我是在波纳配发表的这篇文章。但是作家并不像软件开发者一样具有足够的影响力。)
|
||||
|
||||
有些人会告诉你远程协助的团队天生比本地团队效率和生产力低下一些,或者那些“不经意的灵感碰撞”是如此重要以致于每一位员工每天都必须强制到一个地方来人为的制造这样的碰撞。这些人错了,只要团队的讨论次数不够多——数量级不过一把、一打或者许多,而不是成百上千——也不够专注。
|
||||
|
||||
我应该知道:在 [HappyFunCorp][11] 时,我们广泛的与远程团队工作,而且长期雇佣远程开发者,而结果难以置信的好。我在我三番的家中与斯德哥尔摩,圣保罗,上海,布鲁克林,新德里的开发者交流和合作的一天,完全没有任何不寻常。
|
||||
|
||||
目前为止,不管是不是个好主意,但我有点跑题了。供求关系指出那些拥有足够技能的开发者可以成为被称为“数字流浪者”的人,如果他们愿意的话。但是许多可以做到的却不愿意。最近,我在雷克雅维克的一栋通过 Airbnb 共享的房子和一伙不断变化的临时远程工作团队度过了一段时间,我保持着东海岸时间来跟上他们的工作,也把早上和周末的时光都花费在探索冰岛了——但是最后几乎所有人都回到了湾区生活。
|
||||
|
||||
从经济层面来说,当然,这太疯狂了。搬到东南亚工作光在房租一项上每月就会为我们省下几千美金。 为什么那些可以在哥斯达黎加挣着三番工资,或者在柏林赚着纽约水平薪资的人们,选择不这样做?为什么那些据说冷静固执的工程师在财政方面如此荒谬?
|
||||
|
||||
当然这里有社交和文化原因。清迈很不错,但没有大都会博物馆或者蒸汽朋克化装舞会,也没有 15 分钟脚程可以到的 50 家美食餐厅。柏林也很可爱,但没法提供风筝冲浪或者山脉远足和加州气候。当然也无法保证拥有无数和你一样分享同样价值观和母语的人们。
|
||||
|
||||
但是我觉得原因除了这些还有很多。我相信相比贫富之间的差异,还有一个更基础的经济分水岭存在。我认为我们在目睹世界上可以实现超凡成就的极端斯坦城市和无法成就伟大但可以工作和赚钱的平均斯坦城市之间正在生成巨大的裂缝。(名词是从伟大的纳西姆·塔勒布那里偷来的)
|
||||
(译者注:[平均斯坦与极端斯坦的概念是美国学者纳西姆·塔勒布首先提出来的。他发现在我们所处的世界上,有些事物表现出相当的平均性,大部分个体都靠近均值,离均值越远则个体数量越稀少,与均值的偏离达到一定程度的个体数量将趋近于零。有些事物则表现出相当的极端性,均值这个概念在这个领域没有太多的意义,剧烈偏离均值的个体大量存在,而且偏离程度大得惊人。他把前者称为平均斯坦,把后者称为极端斯坦。][15])
|
||||
|
||||
艺术行业有着悠久历史的极端斯坦城市。这也解释了为什么有抱负的作家纷纷搬到纽约城,而那些已经在国际上大获成功的导演和演员仍然在不断被吸引到洛杉矶,如同飞蛾扑火。现在,这对技术行业同样适用。即使你不曾想试着(帮助)构造一些非凡的事物—— 如今创业神话如此恢弘,很难想象有工程师完全没有梦想过它—— _伟大事物发生的地方_正在以美好的前景如梦如幻的吸引着人们。
|
||||
|
||||
但是关于这一切有趣的是,理论上讲,它会改变;因为——直到最近——分布式的,分散管理的团队实际上可以获得超凡的成就。 情况对这些团队很不利,因为风投的目光趋于短浅。但是没有任何法律指出独角兽公司只能诞生在加州和某些屈指可数的次级领土;而且似乎,不管结果好坏,极端斯坦正在扩散。如果这样的扩散最终可以矛盾的导致米申地区的房租变 _便宜_那就太棒了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
|
||||
作者:[ Jon Evans ][a]
|
||||
译者:[xiaow6](https://github.com/xiaow6)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/jon-evans/
|
||||
[1]:https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/#comments
|
||||
[2]:https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/#
|
||||
[3]:http://twitter.com/share?via=techcrunch&url=http://tcrn.ch/2owXJ0C&text=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F&hashtags=
|
||||
[4]:https://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Ftechcrunch.com%2F2017%2F04%2F02%2Fwhy-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities%2F&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F
|
||||
[5]:https://plus.google.com/share?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[6]:http://www.reddit.com/submit?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F
|
||||
[7]:http://www.stumbleupon.com/badge/?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[8]:mailto:?subject=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities?&body=Article:%20https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[9]:https://share.flipboard.com/bookmarklet/popout?v=2&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F&url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[10]:https://mobile.twitter.com/Noahpinion/status/846054187288866
|
||||
[11]:http://happyfuncorp.com/
|
||||
[12]:https://twitter.com/rezendi
|
||||
[13]:https://techcrunch.com/author/jon-evans/
|
||||
[14]:https://techcrunch.com/2017/04/01/discussing-the-limits-of-artificial-intelligence/
|
||||
[15]:http://blog.sina.com.cn/s/blog_5ba3d8610100q3b1.html
|
||||
@ -1,41 +1,39 @@
|
||||
Windows Trojan hacks into embedded devices to install Mirai
|
||||
Windows 木马黑进嵌入式设备来安装 Mirai
|
||||
============================================================
|
||||
|
||||
> The Trojan tries to authenticate over different protocols with factory default credentials and, if successful, deploys the Mirai bot
|
||||
|
||||
> 木马尝试使用出厂默认凭证对不同协议进行身份验证,如果成功则会部署 Mirai。
|
||||
|
||||

|
||||
|
||||
|
||||
Attackers have started to use Windows and Android malware to hack into embedded devices, dispelling the widely held belief that if such devices are not directly exposed to the Internet they're less vulnerable.
|
||||
攻击者已经开始使用 Windows 和 Android 恶意软件入侵嵌入式设备,这消除了人们广泛认为的如果设备不直接暴露在互联网上,那么它们就不那么脆弱。
|
||||
|
||||
Researchers from Russian antivirus vendor Doctor Web have recently [come across a Windows Trojan program][21] that was designed to gain access to embedded devices using brute-force methods and to install the Mirai malware on them.
|
||||
来自俄罗斯防病毒供应商 Doctor Web 的研究人员最近[遇到了一个 Windows 木马程序][21],它使用暴力方法访问嵌入式设备,并安装 Mirai 恶意软件。
|
||||
|
||||
Mirai is a malware program for Linux-based internet-of-things devices, such as routers, IP cameras, digital video recorders and others. It's used primarily to launch distributed denial-of-service (DDoS) attacks and spreads over Telnet by using factory device credentials.
|
||||
Mirai 是一种用在基于 Linux 的物联网设备的恶意程序,例如路由器、IP 摄像机、数字录像机等。它主要通过使用出厂设备凭据来发动分布式拒绝服务 (DDoS) 攻击并通过 Telnet 传播。
|
||||
|
||||
The Mirai botnet has been used to launch some of the largest DDoS attacks over the past six months. After [its source code was leaked][22], the malware was used to infect more than 500,000 devices.
|
||||
Mirai 的僵尸网络在过去六个月里一直被用来发起最大型的 DDoS 攻击。[它的源代码泄漏][22]之后,恶意软件被用来感染超过 50 万台设备。
|
||||
|
||||
Once installed on a Windows computer, the new Trojan discovered by Doctor Web downloads a configuration file from a command-and-control server. That file contains a range of IP addresses to attempt authentication over several ports including 22 (SSH) and 23 (Telnet).
|
||||
在一台 Windows 上安装之后,Doctor Web 发现的新的木马会从命令控制服务器下载配置文件。该文件包含一系列 IP 地址,用来通过多个端口(包括 22(SSH)和 23(Telnet))尝试进行身份验证。
|
||||
|
||||
#### [■ GET YOUR DAILY SECURITY NEWS: Sign up for CSO's security newsletters][11]
|
||||
#### [■ 获得你的每日安全新闻:注册 CSO 安全通讯][11]
|
||||
|
||||
如果身份验证成功,恶意软件将会根据受害系统的类型执行配置文件中指定的某些命令。在通过 Telnet 访问的 Linux 系统中,木马会下载并执行一个二进制包,然后安装 Mirari。
|
||||
|
||||
If authentication is successful, the malware executes certain commands specified in the configuration file, depending on the type of compromised system. In the case of Linux systems accessed via Telnet, the Trojan downloads and executes a binary package that then installs the Mirai bot.
|
||||
如果受影响的设备未被设计成或被配置为从 Internet 直接访问,那么许多物联网供应商会降低漏洞的严重性。这种思维方式假定局域网是信任和安全的环境。
|
||||
|
||||
Many IoT vendors downplay the severity of vulnerabilities if the affected devices are not intended or configured for direct access from the Internet. This way of thinking assumes that LANs are trusted and secure environments.
|
||||
然而事实并非如此,其他威胁如跨站点请求伪造已经出现了多年。但 Doctor Web 发现的新木马似乎是第一个专门设计用于劫持嵌入式或物联网设备的 Windows 恶意软件。
|
||||
|
||||
This was never really the case, with other threats like cross-site request forgery attacks going around for years. But the new Trojan that Doctor Web discovered appears to be the first Windows malware specifically designed to hijack embedded or IoT devices.
|
||||
Doctor Web 发现的新木马被称为 [Trojan.Mirai.1][23],表明攻击者还可以使用受害的计算机来攻击不能从互联网直接访问的物联网设备。
|
||||
|
||||
This new Trojan found by Doctor Web, dubbed [Trojan.Mirai.1][23], shows that attackers can also use compromised computers to target IoT devices that are not directly accessible from the internet.
|
||||
|
||||
Infected smartphones can be used in a similar way. Researchers from Kaspersky Lab have already [found an Android app][24] designed to perform brute-force password guessing attacks against routers over the local network.
|
||||
受感染的智能手机可以以类似的方式使用。卡巴斯基实验室的研究人员已经[发现了一个 Android 程序][24] 通过本地网络对路由器执行暴力密码猜测攻击。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
|
||||
作者:[ Lucian Constantin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,112 @@
|
||||
# 从损坏的 Linux EFI 安装中恢复
|
||||
|
||||
在过去的十多年里,Linux 发行版在安装前、安装过程中、以及安装后偶尔会失败,但我总是有办法恢复系统并继续正常工作。然而,[Solus][1] 损坏了我的笔记本。
|
||||
|
||||
GRUB 恢复。不行,重装。还不行!Ubuntu 拒绝安装,报错目标设备不是这个或那个。哇。我之前还没有遇到过想这样的事情。我的测试机已变成无用的砖块。我们该失望吗?不,绝对不。让我来告诉你怎样你可以修复它吧。
|
||||
|
||||
### 问题详情
|
||||
|
||||
所有事情都从 Solus 尝试安装它自己的启动引导器 - goofiboot 开始。不知道什么原因、它没有成功完成安装,留给我的就是一个无法启动的系统。BIOS 之后,我有一个 GRUB 恢复终端。
|
||||
|
||||

|
||||
|
||||
我尝试在终端中手动修复,使用类似和我在我的扩展 [GRUB2 指南][2]中介绍的这个或那个命令。但还是不行。然后我尝试按照我在[GRUB2 和 EFI 指南][3]中的建议从 Live CD(译者注:Live CD 是一个完整的计算机可引导安装媒介,它包括在计算机内存中运行的操作系统,而不是从硬盘驱动器加载; CD 本身是只读的。 它允许用户为任何目的运行操作系统,而无需安装它或对计算机的配置进行任何更改)中恢复。我用 efibootmgr 工具创建了一个条目,确保标记它为有效。正如我们之前在指南中做的那样,之前这些是能正常工作的。哎,现在这个方法也不起作用。
|
||||
|
||||
我尝试一次完整的 Ubuntu 安装,把它安装到 Solus 所在的分区,希望安装程序能给我一些有用的信息。但是 Ubuntu 无法按成安装。它报错:failed to install into /target。又回到开始的地方了。怎么办?
|
||||
|
||||
### 手动清除 EFI 分区
|
||||
|
||||
显然,我们的 EFI 分区出现了严重问题。简单回顾以下,如果你使用的是 UEFI,那么你需要一个单独的 FAT-32 格式化分区。该分区用于存储 EFI 引导镜像。例如,当你安装 Fedora 时,Fedora 引导镜像会被拷贝到 EFI 子目录。每个操作系统都会被存储到一个它自己的目录,一般是 /boot/efi/EFI/<操作系统版本>/。
|
||||
|
||||

|
||||
|
||||
在我的 [G50][4] 机器上,这里有很多各种发行版测试条目,包括:centos、debian、fedora、mx-15、suse、Ubuntu、zorin 以及其它。这里也有一个 goofiboot 目录。但是,efibootmgr 并没有在它的菜单中显示 goofiboot 条目。显然这里出现了一些问题。
|
||||
|
||||
```
|
||||
sudo efibootmgr -d /dev/sda
|
||||
BootCurrent: 0001
|
||||
Timeout: 0 seconds
|
||||
BootOrder: 0001,0005,2003,0000,2001,2002
|
||||
Boot0000* Lenovo Recovery System
|
||||
Boot0001* ubuntu
|
||||
Boot0003* EFI Network 0 for IPv4 (68-F7-28-4D-D1-A1)
|
||||
Boot0004* EFI Network 0 for IPv6 (68-F7-28-4D-D1-A1)
|
||||
Boot0005* Windows Boot Manager
|
||||
Boot0006* fedora
|
||||
Boot0007* suse
|
||||
Boot0008* debian
|
||||
Boot0009* mx-15
|
||||
Boot2001* EFI USB Device
|
||||
Boot2002* EFI DVD/CDROM
|
||||
Boot2003* EFI Network
|
||||
...
|
||||
```
|
||||
|
||||
P.S. 上面的输出是在 LIVE 会话中运行命令生成的!
|
||||
|
||||
|
||||
我决定清除所有非默认的以及非微软的条目然后重新开始。显然,有些东西被损坏了,妨碍了新的发行版设置它们自己的启动引导程序。因此我删除了 /boot/efi/EFI 分区下面出 Boot 和 Windows 外的所有目录。同时,我也通过删除所有额外的条目更新了启动管理器。
|
||||
|
||||
```
|
||||
efibootmgr -b <hex> -B <hex>
|
||||
```
|
||||
|
||||
最后,我重新安装了 Ubuntu,并仔细监控 GRUB 安装和配置的过程。这次,成功完成啦。正如预期的那样,几个无效条目出现了一些错误,但整个安装过程完成就好了。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 额外阅读
|
||||
|
||||
如果你不喜欢这种手动修复,你可以阅读:
|
||||
|
||||
```
|
||||
[Boot-Info][5] 手册,里面有帮助你恢复系统的自动化工具
|
||||
|
||||
[Boot-repair-cd][6] 自动恢复工具下载页面
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
如果你遇到由于 EFI 分区破坏而导致系统严重瘫痪的情况,那么你可能需要遵循本指南中的建议。 删除所有非默认条目。 如果你使用 Windows 进行多重引导,请确保不要修改任何和 Microsoft 相关的东西。 然后相应地更新引导菜单,以便删除损坏的条目。 重新运行所需发行版的安装设置,或者尝试用之前介绍的比较不严格的修复方法。
|
||||
|
||||
我希望这篇小文章能帮你节省一些时间。Solus 对我系统的更改使我很懊恼。这些事情本不应该发生,恢复过程也应该更简单。不管怎样,虽然事情似乎很可怕,修复并不是很难。你只需要删除损害的文件然后重新开始。你的数据应该不会受到影响,你也应该能够顺利进入到运行中的系统并继续工作。开始吧。
|
||||
|
||||
加油。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我叫 Igor Ljubuncic。38 岁,已婚,但还没有小孩。我现在是一个云技术公司的首席工程师,前端新手。在 2015 年年初之前,我在世界上最大的 IT 公司之一的工程计算团队担任操作系统架构师,开发新的基于 Linux 的解决方案、优化内核、在 Linux 上实现一些好的想法。在这之前,我是一个为高性能计算环境设计创新解决方案团队的技术主管。其它一些头衔包括系统专家、系统开发员或者类似的。所有这些都是我的爱好,但从 2008 年开始,就是有报酬的工作。还有什么比这更令人满意的呢?
|
||||
|
||||
从 2004 到 2008 年,我通过在医疗图像行业担任物理专家养活自己。我的工作主要关注解决问题和开发算法。为此,我广泛使用 Matlab,主要用于信号和图像处理。另外,我已通过几个主要工程方法的认证,包括 MEDIC Six Sigma Green Belt、实验设计以及统计工程。
|
||||
|
||||
有时候我也会写书,包括 Linux 创新及技术工作。
|
||||
|
||||
往下滚动你可以查看我开源项目的完整列表、发表文章以及专利。
|
||||
|
||||
有关我奖项、提名以及 IT 相关认证的完整列表,稍后也会有。
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/grub2-efi-corrupt-part-recovery.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.dedoimedo.com/computers/solus-1-2-review.html
|
||||
[2]:http://www.dedoimedo.com/computers/grub-2.html
|
||||
[3]:http://www.dedoimedo.com/computers/grub2-efi-recovery.html
|
||||
[4]:http://www.dedoimedo.com/computers/lenovo-g50-distros-second-round.html
|
||||
[5]:https://help.ubuntu.com/community/Boot-Info
|
||||
[6]:https://sourceforge.net/projects/boot-repair-cd/
|
||||
@ -1,4 +1,4 @@
|
||||
python 是慢,但我并不关心
|
||||
python 是慢,但无须过度在意
|
||||
=====================================
|
||||
|
||||
### 对追求生产率而牺牲性能的怒吼
|
||||
@ -35,7 +35,7 @@ python 是慢,但我并不关心
|
||||
|
||||
微服务本来就很慢。微服务的主要概念是用网络调用来打破边界。这意味着你正在使用一个函数调用(几个 cpu 周期)并将它转变为一个网络调用。没有什么比这更影响性能了。和 CPU 相比较,网络调用真的很慢。但是这些大公司仍然选择使用微服务。我所知道的架构里面没有比微服务还要慢的了。微服务最大的弊端就是它的性能,但是最大的长处就是上市的时间。通过在较小的项目和代码库上建立团队,一个公司能够以更快的速度进行迭代和创新。这恰恰表明了,非常大的公司也很在意上市时间,而不仅仅只是只有创业公司。
|
||||
|
||||
#### CPU不是你的瓶颈
|
||||
#### CPU 不是你的瓶颈
|
||||
|
||||

|
||||
|
||||
@ -83,69 +83,70 @@ python 是慢,但我并不关心
|
||||
|
||||

|
||||
|
||||
上述论点的语气可能会让人觉得优化与速度一点也不重要。但事实是,很多时候运行时性能真的很重要。一个例子是,你有一个web应用程序,其中有一个特定的端点需要用很长的时间来响应。你知道这个程序需要多快,并且知道程序需要改进多少。
|
||||
上述论点的语气可能会让人觉得优化与速度一点也不重要。但事实是,很多时候运行时性能真的很重要。一个例子是,你有一个 web 应用程序,其中有一个特定的端点需要用很长的时间来响应。你知道这个程序需要多快,并且知道程序需要改进多少。
|
||||
|
||||
在我们的例子中,发生了两件事:
|
||||
|
||||
1. 我们注意到有一个端点执行缓慢。
|
||||
2. 我们承认它是缓慢,因为我们有一个可以衡量是否足够快的标准,而它要没达到那个标准。
|
||||
|
||||
我们不必在应用程序中微调优化所有内容,只需要让其中每一个都"足够快"。如果一个端点花费了几秒钟来响应,你的用户可能会注意到,但是,他们并不会注意到你将响应时间由35毫秒到25毫秒。"足够好"就是你需要做到的所有事情。_免责声明: 我应该说有一些应用程序,如实时投标程序,确实需要细微优化,每一毫秒都相当重要。但那只是例外,而不是规则。_
|
||||
我们不必在应用程序中微调优化所有内容,只需要让其中每一个都“足够快”。如果一个端点花费了几秒钟来响应,你的用户可能会注意到,但是,他们并不会注意到你将响应时间由 35 毫秒降低到 25 毫秒。“足够好”就是你需要做到的所有事情。_免责声明: 我应该说有**一些**应用程序,如实时投标程序,**确实**需要细微优化,每一毫秒都相当重要。但那只是例外,而不是规则。_
|
||||
|
||||
为了明白如何对端点进行优化,你的第一步将是配置代码,并尝试找出瓶颈在哪。毕竟:
|
||||
|
||||
> 任何除了瓶颈之外的改进都是错觉。 --Gene Kim
|
||||
|
||||
如果你的优化没有触及到瓶颈,你只是浪费你的时间,并没有解决实际问题。在你优化瓶颈之前,你不会得到任何重要的改进。如果你在不知道瓶颈是什么前尝试优化,那么你最终只会在部分代码中玩耍。在测量和确定瓶颈之前优化代码被称为“过早优化”。Donald Knuth经常被归咎于以下引语,但他声称他偷了别人的话:
|
||||
如果你的优化没有触及到瓶颈,你只是浪费你的时间,并没有解决实际问题。在你优化瓶颈之前,你不会得到任何重要的改进。如果你在不知道瓶颈是什么前就尝试优化,那么你最终只会在部分代码中玩耍。在测量和确定瓶颈之前优化代码被称为“过早优化”。人们常提及 Donald Knuth 说的话,但他声称实际是他偷了别人的话:
|
||||
|
||||
> 过早优化是万恶之源。
|
||||
> <ruby>过早优化是万恶之源<rt>Premature optimization is the root of all evil</rt></ruby>。
|
||||
|
||||
在谈到维护代码库时,来自Donald Knuth的更完整的引用是:
|
||||
在谈到维护代码库时,来自 Donald Knuth 的更完整的引用是:
|
||||
|
||||
> 在 97% 的时间里,我们应该忘记微不足道的效率:过早的优化是万恶之源。然而在关
|
||||
> 键的3%,我们不应该错过优化的机会。 ——Donald Knuth
|
||||
> 在 97% 的时间里,我们应该忘记微不足道的效率:**过早的优化是万恶之源**。然而在关
|
||||
> 键的 3%,我们不应该错过优化的机会。 ——Donald Knuth
|
||||
|
||||
换句话说,他所说的是,在大多数时间你应该忘记对你的代码进行优化。它几乎总是足够好。在不是足够好的情况下,我们通常只需要触及3%的代码路径。你的端点快了几纳秒,比如因为你使用了if语句而不是函数,但这并不会使你赢得任何奖项,
|
||||
换句话说,他所说的是,在大多数时间你应该忘记对你的代码进行优化。它几乎总是足够好。在不是足够好的情况下,我们通常只需要触及 3% 的代码路径。你的端点快了几纳秒,比如因为你使用了 if 语句而不是函数,但这并不会使你赢得任何奖项。
|
||||
|
||||
过早的优化包括调用某些更快的函数,或者甚至使用特定的数据结构,因为它通常更快。计算机科学认为,如果一个方法或者算法与另一个具有相同的渐近增长(或者Big-O),那么它们是等价的,即使在实践中要慢两倍。计算机是如此之快,算法随着数据/使用增加而造成的计算增长远远超过实际速度本身。换句话说,如果你有两个O(log n)的函数,但是一个要慢两倍,这实际上并不重要。随着数据规模的增大,它们都以同样的速度"慢下来"。这就是过早优化是万恶之源的原因;它浪费了我们的时间,几乎从来没有真正有助于我们的性能改进。
|
||||
过早的优化包括调用某些更快的函数,或者甚至使用特定的数据结构,因为它通常更快。计算机科学认为,如果一个方法或者算法与另一个具有相同的渐近增长(或者 Big-O),那么它们是等价的,即使在实践中要慢两倍。计算机是如此之快,算法随着数据/使用增加而造成的计算增长远远超过实际速度本身。换句话说,如果你有两个 O(log n) 的函数,但是一个要慢两倍,这实际上并不重要。随着数据规模的增大,它们都以同样的速度“慢下来”。这就是过早优化是万恶之源的原因;它浪费了我们的时间,几乎从来没有真正有助于我们的性能改进。
|
||||
|
||||
就Big-O而言,你可以认为你的程序在所有的语言里都是O(n),其中n是代码或者指令的行数。对于同样的指令,它们以同样的速率增长。对于渐进增长,一种语言的速度快慢并不重要,所有语言都是相同的。在这个逻辑下,你可以说,为你的应用程序选择一种语言仅仅是因为它的“快速”是过早优化的最终形式。你选择的东西据说是快速而不用测量,而不理解瓶颈将在哪里。
|
||||
就 Big-O 而言,你可以认为对你的程序,所有的语言都是 O(n),其中 n 是代码或者指令的行数。对于同样的指令,它们以同样的速率增长。对于渐进增长,一种语言的速度快慢并不重要,所有语言都是相同的。在这个逻辑下,你可以说,为你的应用程序选择一种语言仅仅是因为它的“快速”是过早优化的最终形式。你选择某些预期快速的东西,却没有测量,也不理解瓶颈将在哪里。
|
||||
|
||||
> 为您的应用选择语言只是因为它的“快速”是过早优化的最终形式。
|
||||
> 为您的应用选择语言只是因为它的“快速”,是过早优化的最终形式。
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
### 优化Python
|
||||
### 优化 Python
|
||||
|
||||
我最喜欢Python的一点是,它可以让你一次优化一点点代码。假设你有一个Python的方法,你发现它是你的瓶颈。你对它优化过几次,可能遵循[这里][14]和[那里][15]的一些指导,现在你正处在这样的地步,你很肯定Python本身就是你的瓶颈。Python有调用C代码的能力,这意味着,你可以用C重写这个方法来减少性能问题。你可以一次重写一个这样的方法。这个过程允许你用任何可以编译为C兼容汇编程序的语言编写良好优化的瓶颈方法。这让你能够在大多数时间何用Python编写,只在必要的时候都使用较低级的语言来写代码。
|
||||
我最喜欢 Python 的一点是,它可以让你一次优化一点点代码。假设你有一个 Python 的方法,你发现它是你的瓶颈。你对它优化过几次,可能遵循[这里][14]和[那里][15]的一些指导,现在,你很肯定 Python 本身就是你的瓶颈。Python 有调用 C 代码的能力,这意味着,你可以用 C 重写这个方法来减少性能问题。你可以一次重写一个这样的方法。这个过程允许你用任何可以编译为 C 兼容汇编程序的语言,编写良好优化后的瓶颈方法。这让你能够在大多数时间使用 Python 编写,只在必要的时候都才用较低级的语言来写代码。
|
||||
|
||||
|
||||
有一种叫做Cython的编程语言,它是Python的超集。它几乎是Python和C的合并,是一种渐进类型的语言。任何Python代码都是有新的Cython代码,Cython代码可以编译成C代码。使用Cython,你可以编写一个模块或者一个方法,并逐渐进步到越来越多的C类型和性能。你可以将C类型和Python的鸭子类型合并在一起。使用Cython,你可以获得只在瓶颈处进行优化和在其他所有地方不失去Python的美丽的完美组合。
|
||||
有一种叫做 Cython 的编程语言,它是 Python 的超集。它几乎是 Python 和 C 的合并,是一种渐进类型的语言。任何 Python 代码都是有新的 Cython 代码,Cython 代码可以编译成 C 代码。使用 Cython,你可以编写一个模块或者一个方法,并逐渐进步到越来越多的 C 类型和性能。你可以将 C 类型和 Python 的鸭子类型合并在一起。使用 Cython,你可以获得混合后的完美组合,只在瓶颈处进行优化,同时在其他所有地方不失去 Python 的美丽。
|
||||
|
||||

|
||||
|
||||
星战前夜的一幅截图:用Python编写的space MMO游戏。
|
||||
*星战前夜的一幅截图:用 Python 编写的 space MMO 游戏。*
|
||||
|
||||
当您最终遇到性能问题的Python墙时,你不需要把你的整个代码库用另一种不同的语言来编写。你只需要用Cython重写几个函数几乎就能得到你所需要的性能。这就是[星战前夜][16]采取的策略。这是一个大型多玩家的电脑游戏,在整个堆栈中使用Python和Cython。它们通过优化C/Cython中的瓶颈来实现游戏级别的性能。如果这个策略对他们有用,那么它应该对任何人都有帮助。或者,还有其他方法来优化你的Python。例如,[PyPy][17]是一个Python的JIT实现,它通过使用PyPy交换CPython(默认实现)为长时间运行的应用程序提供重要的运行时改进(如web server)。
|
||||
当您最终遇到性能问题的 Python 墙时,你不需要把你的整个代码库用另一种不同的语言来编写。你只需要用 Cython 重写几个函数,几乎就能得到你所需要的性能。这就是[星战前夜][16]采取的策略。这是一个大型多玩家的电脑游戏,在整个堆栈中使用 Python 和 Cython。它们通过优化 C/Cython 中的瓶颈来实现游戏级别的性能。如果这个策略对他们有用,那么它应该对任何人都有帮助。或者,还有其他方法来优化你的 Python。例如,[PyPy][17] 是一个 Python 的 JIT 实现,它通过使用 PyPy 交换 CPython(默认实现),为长时间运行的应用程序提供重要的运行时改进(如 web server)。
|
||||
|
||||

|
||||
|
||||
让我们回顾一下要点:
|
||||
|
||||
* 优化你最贵的资源。那就是你,而不是计算机。
|
||||
* 选择一种语言/框架/架构来帮助你快速开发(比如Python)。不要仅仅因为某些技术的快而选择它们。
|
||||
* 选择一种语言/框架/架构来帮助你快速开发(比如 Python)。不要仅仅因为某些技术的快而选择它们。
|
||||
* 当你遇到性能问题时,请找到瓶颈所在。
|
||||
* 你的瓶颈很可能不是CPU或者Python本身。
|
||||
* 如何Python成为你的瓶颈(你已经优化过你的算法),那么可以转向热门的Cython或者C。
|
||||
* 你的瓶颈很可能不是 CPU 或者 Python 本身。
|
||||
* 如果 Python 成为你的瓶颈(你已经优化过你的算法),那么可以转向热门的 Cython 或者 C。
|
||||
* 尽情享受可以快速做完事情的乐趣。
|
||||
|
||||
我希望你喜欢阅读这篇文章就像我喜欢写这篇文章一样。如果你想说谢谢,请为我点下赞。另外,如果某个时候你想和我讨论Python,你可以在twitter上艾特我(@nhumrich),或者你可以在[Python slack channel][18]找到我。
|
||||
我希望你喜欢阅读这篇文章,就像我喜欢写这篇文章一样。如果你想说谢谢,请为我点下赞。另外,如果某个时候你想和我讨论 Python,你可以在 twitter 上艾特我(@nhumrich),或者你可以在 [Python slack channel][18] 找到我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:坚持采用持续交付的方法,并为之写了很多工具。同是还是一名Python黑客与技术逛热者,目前是一名devops工程师。
|
||||
作者简介:
|
||||
Nick Humrich -- 坚持采用持续交付的方法,并为之写了很多工具。同是还是一名 Python 黑客与技术狂热者,目前是一名 devops 工程师。
|
||||
|
||||
|
||||
via: https://medium.com/hacker-daily/yes-python-is-slow-and-i-dont-care-13763980b5a1
|
||||
|
||||
Loading…
Reference in New Issue
Block a user