mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
af4e90cd13
@ -3,15 +3,15 @@ Linux 的实用性 VS 行动主义
|
||||
|
||||
*我们使用 Linux 是因为它比其他操作系统更实用,还是其他更高级的理由呢?*
|
||||
|
||||
运行 Linux 的最吸引人的事情之一就是它所提供的自由。 Linux 社区之间的划分在于我们如何看待这种自由。
|
||||
运行 Linux 的最吸引人的事情之一就是它所提供的自由。 Linux 社区之间的分野在于我们如何看待这种自由。
|
||||
|
||||
对一些人来说,使用 Linux 可以享受不受供应商或高软件成本限制的自由。大多数人会称这个是一个实用性的考虑。而其他用户会告诉你,他们享受的是自由软件的自由。那就意味着拥护支持<ruby> [开源软件运动][1]<rt> Free Software Movement</rt> </ruby>的 Linux 发行版,完全避免专有软件和所有相关的东西。
|
||||
对一些人来说,使用 Linux 可以享受到不受供应商限制或避免高昂的软件成本的自由。大多数人会称这个是一个实用性的考虑。而其它用户会告诉你,他们享受的是自由软件的自由。那就意味着拥护支持<ruby> [自由软件运动][1]<rt> Free Software Movement</rt> </ruby>的 Linux 发行版,完全避免专有软件和所有相关的东西。
|
||||
|
||||
在这篇文章中,我将带你比较这两种自由的区别,以及他们如何影响 Linux 的使用。
|
||||
在这篇文章中,我将带你比较这两种自由的区别,以及它们如何影响 Linux 的使用。
|
||||
|
||||
### 专有的问题
|
||||
|
||||
大多数 Linux 用户有一个共同点,就是他们尽量避免使用专有软件。对像我这样的实用主义的爱好者来说,这意味着我能够控制我的软件支出,避免过度依赖特定供应商。当然,我不是一个程序员……所以我对安装软件的调整是十分微小的。但也有一些个别情况,一个应用程序的小调整可以意味着它能否正常工作。
|
||||
大多数 Linux 用户有一个共同点,就是他们尽量避免使用专有软件。对像我这样的实用主义的爱好者来说,这意味着我能够控制我的软件支出,以及避免过度依赖特定供应商。当然,我不是一个程序员……所以我对安装软件的调整是十分微小的。但也有一些个别情况,对应用程序的小调整就意味着它要么能工作,要么不能。
|
||||
|
||||
还有一些 Linux 爱好者,倾向于避开专有软件,因为他们觉得使用它们是不道德的。通常这里主要的问题是使用专有软件会剥夺或者干脆阻碍你的个人自由。像这些用户更喜欢使用 Linux 发行版和软件来支持 [自由软件理念][2] 。虽然它与开源的概念相似并经常直接与之混淆,[但它们之间还是有些差异的][3] 。
|
||||
|
||||
@ -19,21 +19,21 @@ Linux 的实用性 VS 行动主义
|
||||
|
||||
这两种类型的 Linux 爱好者都喜欢使用非专有软件的解决方案。但是,自由软件倡导者根本不会去使用专有软件,而实用主义用户会选择具有最佳性能的工具。这意味着,在有些情况下,这些用户会在他们的非专有操作系统上运行专有应用或代码。
|
||||
|
||||
最终,这两种类型的用户都喜欢使用 Linux 所提供的。但是,我们这样做的原因往往会有所不同。有人认为那些不支持自由软件的人是无知的。我不同意,我认为它是实用方便性的问题。那些喜欢实用方便性的用户根本不关心他们软件的政治问题。
|
||||
最终,这两种类型的用户都喜欢使用 Linux 所提供的非专有解决方案。但是,我们这样做的原因往往会有所不同。有人认为那些不支持自由软件的人是无知的。我不同意这种看法,我认为它是实用方便性的问题。那些喜欢实用方便性的用户根本不关心他们软件的政治问题。
|
||||
|
||||
### 实用方便性
|
||||
|
||||
当你问起绝大多数的人为什么使用他们现在的操作系统,回答通常都集中于实用方便性。方便性可能体现在“它是我一直使用的系统”、“它运行了我需要的软件”。 其他人可能进一步解释说,软件对他们使用操作系统的偏好影响不大,而是对操作系统的熟悉程度,最后,还有硬件兼容性等问题也导致我们使用这个操作系统而不是另一个。
|
||||
当你问起绝大多数的人为什么使用他们现在的操作系统,回答通常都集中于实用方便性。方便性可能体现在“它是我一直使用的系统”,乃至于“它运行了我需要的软件”。 其他人可能进一步解释说,软件对他们使用操作系统的偏好影响不大,而是对操作系统的熟悉程度的问题,最后,还有一些特殊的“商业考虑”或硬件兼容性等问题也导致我们使用这个操作系统而不是另一个。
|
||||
|
||||
这可能会让你们中许多人很惊讶,不过我今天运行桌面 Linux 最大的一个原因是由于我熟悉它。即使我为别人提供 Windows 和 OS X 的支持,实际上我使用这些操作系统时感觉相当沮丧,因为它们根本就不是我习惯的用法。也因此我对那些 Linux 新手表示同情,因为我太懂得踏入陌生的领域是怎样的让人恼火了。我的观点是这样的 —— 熟悉具有价值,而且熟悉加强了实用方便性。
|
||||
这可能会让你们中许多人很惊讶,不过如今我运行桌面 Linux 最大的一个原因是由于我熟悉它。即使我能为别人提供 Windows 和 OS X 的支持,实际上我使用这些操作系统时感觉相当沮丧,因为它们根本就不是我习惯的用法。也因此我对那些 Linux 新手表示同情,因为我太懂得踏入陌生的领域是怎样的让人恼火了。我的观点是这样的 —— 熟悉具有价值,而且熟悉加强了实用方便性。
|
||||
|
||||
现在,如果我们把它和一个自由软件倡导者的需求来比较,你会发现那些人都愿意学习新的甚至更具挑战性的东西,以避免使用非自由软件。对这种用户,我最赞赏的地方,就是他们坚定的采取少数人选择的道路来坚持他们的原则,在我看来,这是十分值得赞赏的。
|
||||
现在,如果我们把它和一个自由软件倡导者的需求来比较,你会发现这种人都愿意学习新的甚至更具挑战性的东西,以避免使用非自由软件。对这种用户,我最赞赏的地方,就是他们坚定的采取少数人选择的道路来坚持他们的原则,在我看来,这是十分值得赞赏的。
|
||||
|
||||
### 自由的价值
|
||||
|
||||
我不羡慕那些自由软件倡导者的一个地方,就是根据<ruby> [自由软件基金会][4] <rt>Free Software Foundation</rt></ruby>规定的标准,为实现自由,他们要始终使用 Linux 发行版和硬件而带来的额外工作。这意味着 Linux 内核需要摆脱专有的驱动支持,而且硬件不需要任何专有代码。当然不是不可能的,但确实很难。
|
||||
我不羡慕那些自由软件倡导者的一个地方,就是根据<ruby> [自由软件基金会][4] <rt>Free Software Foundation</rt></ruby>规定的标准,为实现其自由,他们要始终使用 Linux 发行版和硬件而付出的额外工作。这意味着 Linux 内核需要摆脱专有的驱动支持,而且硬件不需要任何专有代码。当然不是不可能的,但确实很难。
|
||||
|
||||
一个自由软件倡导者可以达到的最好的情况是硬件是“自由兼容”的。有些供应商,可以满足这一需求,但大多提供依赖于 Linux 兼容专有固件的硬件。实用主义用户对自由软件倡导者来说是个搅局者。
|
||||
一个自由软件倡导者可以达到的最好的情况是硬件是“自由兼容”的。有些供应商,可以满足这一需求,但大多提供的硬件依赖于 Linux 兼容的专有固件。实用主义用户对自由软件倡导者来说是个搅局者。
|
||||
|
||||
那么这一切意味着的是,倡导者必须比实用主义的 Linux 爱好者,更加警惕。这本身并不一定是坏事,但如果是打算跳入自由软件的阵营那就要考虑下了。比较而言,实用主义的用户可以不假思索地使用与 Linux 兼容的任何软件或硬件。我不知道你是怎么想的,但在我眼中这样更轻松一点。
|
||||
|
||||
@ -53,7 +53,6 @@ Linux 的实用性 VS 行动主义
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/linux-practicality-vs-activism.html
|
||||
@ -0,0 +1,196 @@
|
||||
用数据科学搭建一个实时推荐引擎
|
||||
======================
|
||||
|
||||
编者注:本文是 2016 年 4 月 Nicole Whilte 在欧洲 [GraphConnect][1] 时所作。这儿我们快速回顾一下她所涉及的内容:
|
||||
- 图数据库推荐基础
|
||||
- 社会化推荐
|
||||
- 相似性推荐
|
||||
- 集群推荐
|
||||
|
||||
今天我们将要讨论的内容是数据科学和图推荐(graph recommendations):
|
||||
|
||||
我在 [Neo4j][2] 任职已经两年了,但实际上我已经使用 Neo4j 和 [Cypher][3] 工作三年了。当我首次发现这个特别的图数据库(graph database)的时候,我还是一个研究生,那时候我在奥斯丁的德克萨斯大学攻读关于社交网络的统计学硕士学位。
|
||||
|
||||
[实时推荐引擎][4]是 Neo4j 中最广泛的用途之一,也是使它如此强大并且容易使用的原因之一。为了探索这个东西,我将通过使用示例数据集来阐述如何将统计学方法并入这些引擎中。
|
||||
|
||||
第一个很简单 - 将 Cypher 用于社交推荐。接下来,我们将看一看相似性推荐,这涉及到可被计算的相似性度量,最后探索的是集群推荐。
|
||||
|
||||
### 图数据库推荐基础
|
||||
|
||||
下面的数据集包含所有达拉斯 Fort Worth 国际机场的餐饮场所,达拉斯 Fort Worth 国际机场是美国主要的机场枢纽之一:
|
||||
|
||||

|
||||
|
||||
我们把节点标记成黄色并按照出入口和航站楼给它们的位置建模。同时我们也按照食物和饮料的主类别将地点分类,其中一些包括墨西哥食物、三明治、酒吧和烤肉。
|
||||
|
||||
让我们做一个简单的推荐。我们想要在机场的某一确定地点找到一种特定食物,大括号中的内容表示是的用户输入,它将进入我们的假想应用程序中。
|
||||
|
||||

|
||||
|
||||
这个英文句子表示成 Cypher 查询:
|
||||
|
||||

|
||||
|
||||
这将提取出该类别中用户所请求的所有地点、航站楼和出入口。然后我们可以计算出用户所在位置到出入口的准确距离,并以升序返回结果。再次说明,这个非常简单的 Cypher 推荐仅仅依据的是用户在机场中的位置。
|
||||
|
||||
### 社交推荐(Social Recommendations)
|
||||
|
||||
让我们来看一下社交推荐。在我们的假想应用程序中,用户可以登录并且可以用和 Facebook 类似的方式标记自己“喜好”的地点,也可以在某地签到。
|
||||
|
||||

|
||||
|
||||
考虑位于我们所研究的第一个模型之上的数据模型,现在让我们在下面的分类中找到用户的朋友喜好的航站楼里面离出入口最近的餐饮场所:
|
||||
|
||||

|
||||
|
||||
MATCH 子句和我们第一次 Cypher 查询的 MATCH 子句相似,只是现在我们依据喜好和朋友来匹配:
|
||||
|
||||

|
||||
|
||||
前三行是完全一样的,但是现在要考虑的是那些登录的用户,我们想要通过 :FRIENDS_WITH 这一关系来找到他们的朋友。仅需通过在 Cypher 中增加一些行内容,我们现在已经把社交层面考虑到了我们的推荐引擎中。
|
||||
|
||||
再次说明,我们仅仅显示了用户明确请求的类别,并且这些类别中的地点与用户进入的地方是相同的航站楼。当然,我们希望按照登录并做出请求的用户来滤过这些目录,然后返回地点的名字、位置以及所在目录。我们也要显示出有多少朋友已经“喜好”那个地点以及那个地点到出入口的确切距离,然后在 RETURN 子句中同时返回所有这些内容。
|
||||
|
||||
### 相似性推荐(Similarity Recommendations)
|
||||
|
||||
现在,让我们看一看相似性推荐引擎:
|
||||
|
||||

|
||||
|
||||
和前面的数据模型相似,用户可以标记“喜好”的地点,但是这一次他们可以用 1 到 10 的整数给地点评分。这是通过前期在 Neo4j 中增加一些属性到关系中建模实现的。
|
||||
|
||||
这将允许我们找到其他相似的用户,比如以上面的 Greta 和 Alice 为例,我们已经查询了他们共同喜好的地点,并且对于每一个地点,我们可以看到他们所设定的权重。大概地,我们可以通过他们的评分来确定他们之间的相似性大小。
|
||||
|
||||
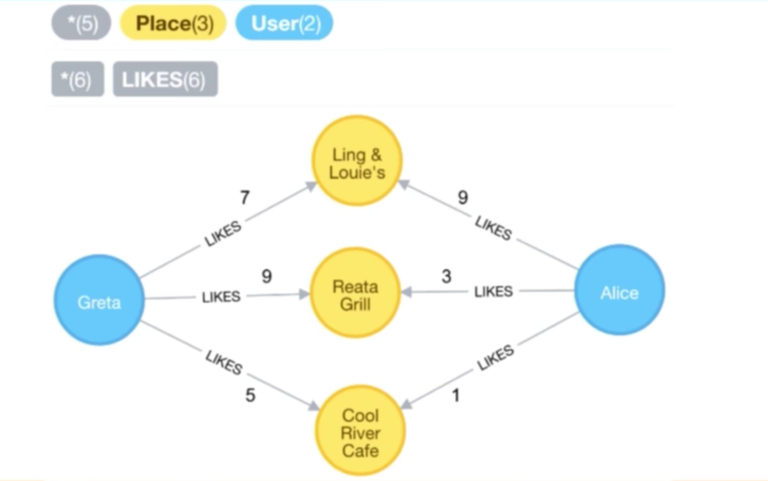
|
||||
|
||||
现在我们有两个向量:
|
||||
|
||||

|
||||
|
||||
现在让我们按照欧几里得距离(Euclidean distance)的定义来计算这两个向量之间的距离:
|
||||
|
||||

|
||||
|
||||
我们把所有的数字带入公式中计算,然后得到下面的相似度,这就是两个用户之间的“距离”:
|
||||
|
||||

|
||||
|
||||
你可以很容易地在 Cypher 中计算两个特定用户的“距离”,特别是如果他们仅仅同时“喜好”一个很小的地点子集。再次说明,这儿我们依据两个用户 Alice 和 Greta 来进行匹配,并尝试去找到他们同时“喜好”的地点:
|
||||
|
||||

|
||||
|
||||
他们都有对最后找到的地点的 :LIKES 关系,然后我们可以在 Cypher 中很容易的计算出他们之间的欧几里得距离,计算方法为他们对各个地点评分差的平方求和再开平方根。
|
||||
|
||||
在两个特定用户的例子中上面这个方法或许能够工作。但是,在实时情况下,当你想要通过和实时数据库中的其他用户比较,从而由一架飞机上的一个用户推断相似用户时,这个方法就不一定能够工作。不用说,至少它不能够很好的工作。
|
||||
|
||||
为了找到解决这个问题的好方法,我们可以预先计算好距离并存入实际关系中:
|
||||
|
||||

|
||||
|
||||
当遇到一个很大的数据集时,我们需要成批处理这件事,在这个很小的示例数据集中,我们可以按照所有用户的迪卡尔乘积(Cartesian product)和他们共同“喜好”的地点来进行匹配。当我们使用 WHERE id(u1) < id(u2) 作为 Cypher 询问的一部分时,它只是来确定我们在左边和右边没有找到相同的对的一个技巧。
|
||||
|
||||
通过用户之间的欧几里得距离,我们创建了他们之间的一种关系,叫做 :DISTANCE,并且设置了一个叫做 euclidean 的欧几里得属性。理论上,我们可以也通过用户间的一些关系来存储其他相似度从而获取不同的相似度,因为在确定的环境下某些相似度可能比其他相似度更有用。
|
||||
|
||||
在 Neo4j 中,的确是对关系属性建模的能力使得完成像这样的事情无比简单。然而,实际上,你不会希望存储每一个可能存在的单一关系,因为你仅仅希望返回离他们“最近”的一些人。
|
||||
|
||||
因此你可以根据一些临界值来存入前几个,从而你不需要构建完整的连通图。这允许你完成一些像下面这样的实时的数据库查询,因为我们已经预先计算好了“距离”并存储在了关系中,在 Cypher 中,我们能够很快的攫取出数据。
|
||||
|
||||

|
||||
|
||||
在这个查询中,我们依据地点和类别来进行匹配:
|
||||
|
||||

|
||||
|
||||
再次说明,前三行是相同的,除了登录用户以外,我们找出了和他们有 :DISTANCE 关系的用户。这是我们前面查看的关系产生的作用 - 实际上,你只需要存储处于前几位的相似用户 :DISTANCE 关系,因此你不需要在 MATCH 子句中攫取大量用户。相反,我们只攫取和那些用户“喜好”的地方有 :DISTANCE 关系的用户。
|
||||
|
||||
这允许我们用少许几行内容表达较为复杂的模型。我们也可以攫取 :LIKES 关系并把它放入到变量中,因为后面我们将使用这些权重来评分。
|
||||
|
||||
在这儿重要的是,我们可以依据“距离”大小将用户按照升序进行排序,因为这是一个距离测度。同时,我们想要找到用户间的最小距离因为距离越小表明他们的相似度最大。
|
||||
|
||||
通过其他按照欧几里得距离大小排序好的用户,我们得到用户评分最高的三个地点并按照用户的平均评分高低来推荐这些地点。换句话说,我们先找出一个活跃用户,然后依据其他用户“喜好”的地点找出和他最相似的其他用户,接下来按照这些相似用户的平均评分把那些地点排序在结果的集合中。
|
||||
|
||||
本质上,我们通过把所有评分相加然后除以收集的用户数目来计算出平均分,然后按照平均评分的升序进行排序。其次,我们按照出入口距离排序。假想地,我猜测应该会有交接点,因此你可以按照出入口距离排序然后再返回名字、类别、出入口和航站楼。
|
||||
|
||||
### 集群推荐(Cluster Recommendations)
|
||||
|
||||
我们最后要讲的一个例子是集群推荐,在 Cypher 中,这可以被想像成一个作为临时解决方案的离线计算工作流。这可能完全基于在[欧洲 GraphConnect 上宣布的新方法][5],但是有时你必须进行一些 Cypher 2.3 版本所没有的算法逼近。
|
||||
|
||||
在这儿你可以使用一些统计软件,把数据从 Neo4j 取出然后放入像 Apache Spark、R 或者 Python 这样的软件中。下面是一段把数据从 Neo4j 中取出的 R 代码,运行该程序,如果正确,写下程序返回结果的给 Neo4j,可以是一个属性、节点、关系或者一个新的标签。
|
||||
|
||||
通过持续把程序运行结果放入到图表中,你可以在一个和我们刚刚看到的查询相似的实时查询中使用它:
|
||||
|
||||

|
||||
|
||||
下面是用 R 来完成这件事的一些示例代码,但是你可以使用任何你最喜欢的软件来做这件事,比如 Python 或 Spark。你需要做的只是登录并连接到图表。
|
||||
|
||||
在下面的例子中,我基于用户的相似性把他们聚合起来。每个用户作为一个观察点,然后得到他们对每一个目录评分的平均值。
|
||||
|
||||
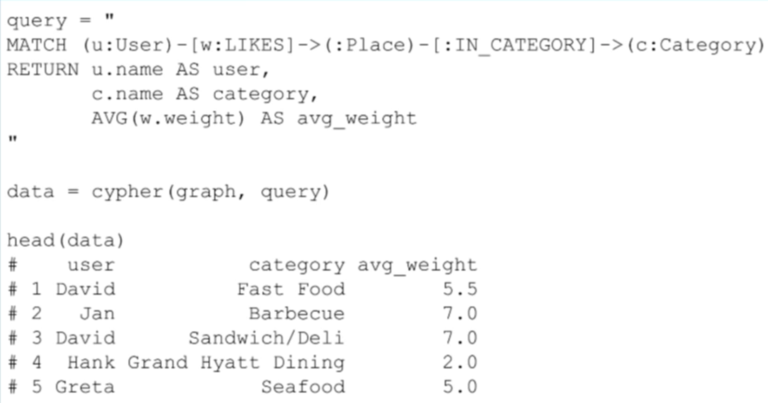
|
||||
|
||||
假定用户对酒吧类评分的方式和一般的评分方式相似。然后我攫取出喜欢相同类别中的地点的用户名、类别名、“喜好”关系的平均权重,比如平均权重这些信息,从而我可以得到下面这样一个表格:
|
||||
|
||||
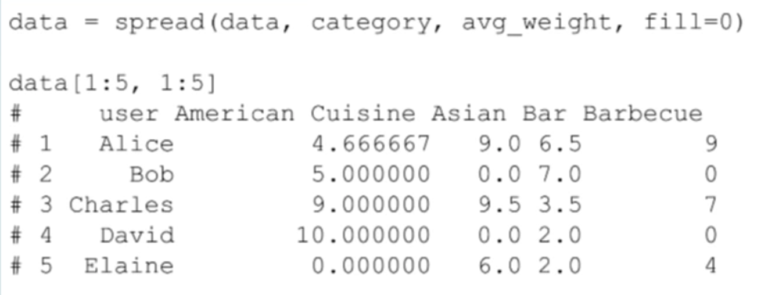
|
||||
|
||||
因为我们把每一个用户都作为一个观察点,所以我们必须巧妙的处理每一个类别中的数据,这些数据的每一个特性都是用户对该类中餐厅评分的平均权重。接下来,我们将使用这些数据来确定用户的相似性,然后我将使用聚类(clustering)算法来确定在不同集群中的用户。
|
||||
|
||||
在 R 中这很直接:
|
||||
|
||||

|
||||
|
||||
在这个示例中我们使用 K-均值(k-means)聚类算法,这将使你很容易攫取集群分配。总之,我通过运行聚类算法然后分别得到每一个用户的集群分配。
|
||||
|
||||
Bob 和 David 在一个相同的集群中 - 他们在集群二中 - 现在我可以实时查看哪些用户被放在了相同的集群中。
|
||||
|
||||
接下来我把集群分配写入 CSV 文件中,然后存入图数据库:
|
||||
|
||||

|
||||
|
||||
我们只有用户和集群分配,因此 CSV 文件只有两列。 LOAD CSV 是 Cypher 中的内建语法,它允许你从一些其他文件路径或者 URL 调用 CSV ,并给它一个别名。接下来,我们将匹配图数据库中存在的用户,从 CSV 文件中攫取用户列然后合并到集群中。
|
||||
|
||||
我们在图表中创建了一个新的标签节点:Cluster ID, 这是由 K-平均聚类算法给出的。接下来我们创建用户和集群间的关系,通过创建这个关系,当我们想要找到在相同集群中的实际推荐用户时,就会很容易进行查询。
|
||||
|
||||
我们现在有了一个新的集群标签,在相同集群中的用户和那个集群存在关系。新的数据模型看起来像下面这样,它比我们前面探索的其他数据模型要更好:
|
||||
|
||||

|
||||
|
||||
现在让我们考虑下面的查询:
|
||||
|
||||

|
||||
|
||||
通过这个 Cypher 查询,我们在更远处找到了在同一个集群中的相似用户。由于这个原因,我们删除了“距离”关系:
|
||||
|
||||

|
||||
|
||||
在这个查询中,我们取出已经登录的用户,根据用户-集群关系找到他们所在的集群,找到他们附近和他们在相同集群中的用户。
|
||||
|
||||
我们把这些用户分配到变量 c1 中,然后我们得到其他被我取别名为 neighbor 变量的用户,这些用户和那个相同集群存在着用户-集群关系,最后我们得到这些附近用户“喜好”的地点。再次说明,我把“喜好”放入了变量 r 中,因为我们需要从关系中攫取权重来对结果进行排序。
|
||||
|
||||
在这个查询中,我们所做的改变是,不使用相似性距离,而是攫取在相同集群中的用户,然后对类别、航站楼以及我们所攫取的登录用户进行声明。我们收集所有的权重:来自附近用户“喜好”地点的“喜好”关系,得到的类别,确定的距离值,然后把它们按升序进行排序并返回结果。
|
||||
|
||||
在这些例子中,我们可以进行一个相当复杂的处理并且将其放到图数据库中,然后我们就可以使用实时算法结果-聚类算法和集群分配的结果。
|
||||
|
||||
我们更喜欢的工作流程是更新这些集群分配,更新频率适合你自己就可以,比如每晚一次或每小时一次。当然,你可以根据直觉来决定多久更新一次这些集群分配是可接受的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://neo4j.com/blog/real-time-recommendation-engine-data-science/
|
||||
|
||||
作者:[Nicole White][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://neo4j.com/blog/contributor/nicole-white/
|
||||
[1]: http://graphconnect.com/
|
||||
[2]: http://neo4j.com/product/
|
||||
[3]: http://neo4j.com/blog/why-database-query-language-matters/#cypher
|
||||
[4]: https://neo4j.com/use-cases/real-time-recommendation-engine/
|
||||
[5]: https://neo4j.com/blog/neo4j-3-0-massive-scale-developer-productivity/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,97 @@
|
||||
监控微服务的五原则
|
||||
====
|
||||
|
||||

|
||||
|
||||
我们对微服务的需求可以归纳为一个词:速度。这种更快提供功能完善且可靠的软件的需求,彻底改变了软件开发模式。毫无疑问,这个改变对软件管理,包括系统监控的方式,都产生了影响。在这篇文章里,我们将重点关注放在有效地监控产品环境中的微服务所需做出的主要改变。我们将为这一新的软件架构拟定 5 条指导性原则来调整你的监控方法。
|
||||
|
||||
监控是微服务控制系统的关键部分,你的软件越复杂,那么你就越难了解其性能及问题排障。鉴于软件交付发生的巨大改变,监控系统同样需要进行彻底的改造,以便在微服务环境下表现更好。下面我们将介绍监控微服务的 5 条原则,如下:
|
||||
|
||||
1. 监控容器及其里面的东西。
|
||||
2. 在服务性能上做监控,而不是容器性能。
|
||||
3. 监控弹性和多地部署的服务。
|
||||
4. 监控 API。
|
||||
5. 将您的监控映射到您的组织结构。
|
||||
|
||||
利用这 5 条原则,你可以在向微服务前进的道路上,建立更有效的对微服务的监控。这些原则,可以让你应对随着微服务而来的技术变化和组织变化。
|
||||
|
||||
### 微服务监控的原则
|
||||
|
||||
#### 1、监控容器及其里面的东西
|
||||
|
||||
容器因构建微服务而凸显其重要性,容器的速度、可移植性和隔离特性让开发者很容易就爱上了微服务模型。容器的好处已经写的够多了,毋庸赘述。
|
||||
|
||||
容器对于其外围的系统来说就像是黑盒子。这对于开发来说大有裨益,从开发环境到生产环境,甚至从开发者的笔记本到云端,为它们带来高度的可移植性。但是当运行起来后,监控和解决服务问题时,这个黑盒子让常规的方法难以奏效了,我们会想:容器里到底在运行着什么?程序和代码运行性能如何?它有什么重要的输出指标吗?从 DevOps 的视角,你需要对容器有更深的了解而不是仅仅知道有一些容器的存在。
|
||||
|
||||

|
||||
|
||||
非容器环境下衡量的典型做法,是让一个代理程序运行在主机或者虚机上的用户空间里,但这并不适用于容器。因为容器的优点是小,将各种进程分离开来,并尽可能的减少依赖关系。
|
||||
|
||||
而且,从规模上看,成千上万的监测代理,对即使是一个中等大小的部署都是一个昂贵的资源浪费和管理的噩梦。对于容器有两个潜在的解决方案:1)要求你的开发人员直接监控他们的代码,或者2)利用一个通用的内核级的检测方法来查看主机上的所有应用程序和容器活动。这里我们不会深入说明,但每一种方法都有其优点和缺点。
|
||||
|
||||
#### 2、 利用业务流程系统提醒服务性能
|
||||
|
||||
理解容器容器中的运行数据并不容易,一个单一容器相比组成一个功能或服务的容器聚合,测量复杂度要低得多。
|
||||
|
||||
这特别适用于应用程序级别的信息,比如哪个请求拥有最短响应时间,或者哪些 URL 遇到最多的错误,但它同样也适用于架构级别的监测,比如哪个服务的容器使用 CPU 资源超过了事先分配的资源数。
|
||||
|
||||
越来越多的软件部署需要一个<ruby>编排系统<rt> orchestration system</rt></ruby>,将应用程序的逻辑规划转化到物理的容器中。常见的编排系统包括 Kubernetes、Mesosphere DC/OS 和 Docker Swarm。团队可以用一个编排系统来(1)定义微服务(2)理解部署的每个服务的当前状态。你可以认为编排系统甚至比容器还重要。容器是短暂的,只有满足你的服务需求才会存在。
|
||||
|
||||
DevOps 团队应该将告警重点放到运行特征上,以尽可能贴近监控服务的体验。如果应用受到了影响,这些告警是评估事态的第一道防线。但是获得这些告警并不容易,除非你的监控系统是基于原生于容器的。
|
||||
|
||||
<ruby>[原生容器][1]<rt>Container-native</rt></ruby>解决方案利用<ruby>编排元数据<rt>orchestration metadata</rt></ruby>来动态聚合容器和应用程序数据,并按每个服务计算监控度量。根据您的编排工具,您可能想在不同层次进行深入检测。比如,在 Kubernetes 里,你通常有 Namespace、ReplicaSet、Pod 和一些其他容器。聚合这些不同的层,对排除逻辑故障是很有必要的,与构成服务的容器的物理部署无关。
|
||||
|
||||

|
||||
|
||||
#### 3、 监控<ruby>弹性<rt>Elastic</rt></ruby>和<ruby>多地部署<rt>Multi-Location</rt></ruby>的服务
|
||||
|
||||
弹性服务不是一个新概念,但是它在原生容器环境中的变化速度比在虚拟环境中快的多。迅速的变化会严重影响检测系统的正常运行。
|
||||
|
||||
监测传统的系统经常需要根据软件部署,手动调整检查指标。这种调整可以是具体的,如定义要捕获的单个指标,或基于应用程序在一个特定的容器中的操作配置要收集的数据。在小规模上(比如几十个容器)我们可以接受,但是再大规模就难以承受了。微服务的集中监控必须能够自由的随弹性服务而增长和缩减,无需人工干预。
|
||||
|
||||
比如,如果 DevOps 团队必须手动定义容器包含哪个服务需要监控,他们毫无疑问会失手,因为 Kubernetes 或者 Mesos 每天都会定期创建新的容器。同样,如果代码发布并置于生产环境时要求运维团队安装一个<ruby>定制的状态端点<rt>custom stats endpoint</rt></ruby>,也给开发者从 Docker 仓库获取基础镜像带来更多的挑战。
|
||||
|
||||
在生产环境中,建立面向跨越多个数据中心或多个云的复杂部署的监控,比如,如果你的服务跨越私有数据中心和 AWS,那么亚马逊的 AWS CloudWatch 就很难做到这一点。这就要求我们建立一个跨不同地域的监控系统,并可在动态的原生容器环境下运行。
|
||||
|
||||
#### 4、 监控 API
|
||||
|
||||
在微服务环境中,API 接口是通用的。本质上,它们是将服务暴露给其它团队的唯一组件。事实上,API 的响应和一致性可以看作是“内部 SLA”,即使还没有定义一个正式的 SLA(服务等级协议)。
|
||||
|
||||
因此,API 接口的监控也是必要的。API 监控可以有不同的形式,但是很显然它绝对不是简单的二进制上下检查。例如,了解像时间函数这样的最常使用的<ruby>端点<rt>endpoint</rt></ruby>是有价值的。这使得团队可以看到服务使用的变化,无论是由于设计变更或用户的改变。
|
||||
|
||||
你也可以记录服务最缓慢的端点,这些可能揭示出重大的问题,或者至少指向需要在系统中做优化的区域。
|
||||
|
||||
最后,跟踪系统服务响应的能力是另一个很重要的能力,它主要是开发者使用,也能帮助你了解整体用户体验,同时将信息基于底层和应用程序视角分成两大部分。
|
||||
|
||||
#### 5、 将您的监控映射到您的组织结构
|
||||
|
||||
这篇文章着重在微服务和监控上,像其他科技文章一样,这是因为很多人都关注此层面。
|
||||
|
||||
对于那些熟悉<ruby>[康威定律][2]<rt> Conway’s law</rt></ruby>的人来说,系统的设计是基于开发团队的组织结构。创造更快,更敏捷的软件的压力推动了团队去思考重新调整他们的开发组织和管理它的规则。
|
||||
|
||||

|
||||
|
||||
所以,如果他们想从这个新的软件架构(微服务)上获益,他们的团队必须将微服务映射到团队自身中。也就是说,他们需要更小的更松散耦合的团队,可以选择自己的方向只要能够满足整个需求即可。在每一个团队中,对于开发语言的使用,bug 的提交甚至工作职责都会有更大的控制能力。
|
||||
|
||||
DevOps 团队对此可以启用一个监控平台:让每一个微服务团队可以有自己的警报,度量指标,和控制面板,同时也要给出整体系统的视图。
|
||||
|
||||
### 总结
|
||||
|
||||
让微服务流行起来的是快捷。开发组织要想更快的为客户提供更多的功能,然后微服务技术就来了,架构转向微服务并且容器的流行让快捷开发成为可能,所有相关的进程理所当然的搭上了这辆火车。
|
||||
|
||||
最后,基本的监控原则需要适应伴随微服务而来的技术和结构。越早认识到这种转变的开发团队,能更早更容易的适应微服务这一新的架构。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thenewstack.io/five-principles-monitoring-microservices/
|
||||
|
||||
作者:[Apurva Dave][a] ,[Loris Degioanni][b]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://thenewstack.io/author/apurvadave/
|
||||
[b]: http://thenewstack.io/author/lorisdegioanni/
|
||||
[1]:https://techcrunch.com/2016/04/27/lets-define-container-native/
|
||||
[2]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
@ -1,29 +1,29 @@
|
||||
如何在 LINUX 和 WINDOWS 之间共享 STEAM 的游戏文件
|
||||
如何在 Linux 和 Windows 之间共享 Steam 的游戏文件
|
||||
============
|
||||
|
||||
[][16]
|
||||
[][16]
|
||||
|
||||
简介:这篇详细的指南将向你展示如何在 Linux 和 Windows 之间共享 Steam 的游戏文件以节省下载的总用时和下载的数据量。
|
||||
简介:这篇详细的指南将向你展示如何在 Linux 和 Windows 之间共享 Steam 的游戏文件以节省下载的总用时和下载的数据量。我们将展示给你它是怎样为我们节约了 83 % 的数据下载量。
|
||||
|
||||
假如你决心成为一名 Linux 平台上的玩家,并且在 [Steam][15] 上拥有同时支持 Linux 和 Windows 平台的游戏,或者基于上面同样的原因,拥有双重启动的系统,则你可以考虑看看这篇文章。
|
||||
假如你决心成为一名 Linux 平台上的玩家,并且在 [Steam][15] 上拥有同时支持 Linux 和 Windows 平台的游戏,或者基于同样的原因,拥有双重启动的系统,则你可以考虑看看这篇文章。
|
||||
|
||||
我们中的许多玩家都拥有双重启动的 Linux 和 Windows。有些人只拥有 Linux 系统,但同时拥有当前还没有被 Linux 平台上的 Steam 支持的游戏。所以我们同时保留这两个系统以便我们可以在忽略平台的前提下玩我们喜爱的游戏。
|
||||
|
||||
幸运的是 [Linux gaming][13] 出现了,越来越多在 Windows 平台上受欢迎的 Steam 游戏在 Linux 平台上的 Steam 中被开发了出来。
|
||||
幸运的是 [Linux 游戏][13]社区应运而生,越来越多在 Windows 平台上受欢迎的 Steam 游戏也发布在 Linux 平台上的 Steam 中。
|
||||
|
||||
我们中的许多人喜欢备份我们的 Steam 游戏,使得我们不再苦苦等待游戏下载完成。这些游戏很大程度上是 Windows 平台下的 Steam 游戏。
|
||||
|
||||
现在,很多游戏也已经登陆了 [Linux 平台上的 Steam][12],例如奇异人生、古墓丽影 2013、中土世界:魔多阴影、幽浮:未知敌人、幽浮 2、与日赛跑、公路救赎、燥热 等等,并且[这份名单一直在增长][11]。甚至还有 [杀出重围:人类分裂][10] 和 [疯狂的麦克斯][9] !!!在一些游戏的 Windows 版发布之后,现在我们不必再等候多年,而只需等待几月左右,便可以听到类似的消息了,这可是大新闻啊!
|
||||
现在,很多游戏也已经登陆了 [Linux 平台上的 Steam][12],例如奇异人生(Life is Strange)、古墓丽影 2013(Tomb Raider 2013)、中土世界:魔多阴影(Shadow of Mordor)、幽浮:未知敌人(XCOM: Enemy Unknown)、幽浮 2、与日赛跑(Race The Sun)、公路救赎(Road Redemption)、燥热(SUPERHOT) 等等,并且[这份名单一直在增长][11]。甚至还有 [杀出重围:人类分裂(Deus Ex: Mankind Divided)][10] 和 [疯狂的麦克斯(Mad Max)][9] !!!在一些游戏的 Windows 版发布之后,现在我们不必再等候多年,而只需等待几月左右,便可以听到类似的消息了,这可是大新闻啊!
|
||||
|
||||
下面的实验性方法将向你展示如何使用你现存的任何平台上游戏文件来在 Steam 上恢复游戏的大部分数据。对于某些游戏,它们在两个平台下有很多相似的文件,利用下面例子中的方法,将减少你在享受这些游戏之前的漫长的等待时间。
|
||||
|
||||
在下面的方法中,我们将一步一步地尝试利用 Steam 自己的备份与恢复或者以手工的方式来达到我们的目的。当涉及到这些方法的时候,我们也将向你展示这两个平台上游戏文件的相同和不同之处,以便你也可以探索并做出你自己的调整。
|
||||
在下面的方法中,我们将一步一步地尝试利用 Steam 自身的备份与恢复功能或者以手工的方式来达到我们的目的。当涉及到这些方法的时候,我们也将向你展示这两个平台上游戏文件的相同和不同之处,以便你也可以探索并做出你自己的调整。
|
||||
|
||||
下面的方法中,我们将使用 Ubuntu 14.04 LTS 和 Windows 10 来执行备份与恢复 Steam 的测试。
|
||||
|
||||
### #1 : Steam 自己的备份与恢复
|
||||
### 1、Steam 自身的备份与恢复
|
||||
|
||||
当我们尝试使用 Windows 平台上 Steam 中《燥热》这个游戏的备份(这些加密文件是 .csd 格式)时,Linux 平台上的 Steam 不能识别这些文件,并重新开始下载整个游戏了!甚至在做了验证性检验后,仍然有很大一部分文件不能被 Steam 识别出来。我们在 Windows 上也做了类似的操作,但结果是一样的!
|
||||
当我们尝试使用 Windows 平台上 Steam 中《燥热(SUPERHOT)》这个游戏的备份(这些加密文件是 .csd 格式)时,Linux 平台上的 Steam 不能识别这些文件,并重新开始下载整个游戏了!甚至在做了验证性检验后,仍然有很大一部分文件不能被 Steam 识别出来。我们在 Windows 上也做了类似的操作,但结果是一样的!
|
||||
|
||||

|
||||
|
||||
@ -31,11 +31,11 @@
|
||||
|
||||
现在到了我们用某些手工的方法来共享 Windows 和 Linux 上的 Steam 游戏的时刻了!
|
||||
|
||||
### #2 : 手工方法
|
||||
### 2、手工方法
|
||||
|
||||
首先,让我们先看看 Linux 下这些游戏文件所处的位置(用户目录在 /home 中):
|
||||
|
||||
这是 Linux 平台上 Steam 游戏的默认安装位置。 `.local` 和 `.steam` 目录默认情况下是不可见的,你必须将它们显现出来。我们将推荐拥有一个自定义的 Steam 安装位置以便更容易地处理这些文件。这里 `SUPERHOT.x86_64` 是 Linux 下原生的可执行文件,与 Windows 中的 `.exe` 文件类似。
|
||||
这是 Linux 平台上 Steam 游戏的默认安装位置。 `.local` 和 `.steam` 目录默认情况下是不可见的,你必须将它们显现出来。我们将推荐使用一个自定义的 Steam 安装位置以便更容易地处理这些文件。这里 `SUPERHOT.x86_64` 是 Linux 下原生的可执行文件,与 Windows 中的 `.exe` 文件类似。
|
||||
|
||||

|
||||
|
||||
@ -43,11 +43,11 @@
|
||||
|
||||

|
||||
|
||||
下面我们来看看这些 `.acf` 格式的文件。“appmanifest_322500.acf”便是那个我们需要的文件。编辑并调整这个文件对 Steam 识别在 “common”这个目录下现存的非加密的原始文件备份大有裨益:
|
||||
下面我们来看看这些 `.acf` 格式的文件。`appmanifest_322500.acf` 便是那个我们需要的文件。编辑并调整这个文件有助于 Steam 识别在 `common` 这个目录下现存的非加密的原始文件备份:
|
||||
|
||||

|
||||
|
||||
为了确认这个文件的相似性,用编辑器打开这个文件并检查它。我们越多地了解这个文件越好。这个[链接是来自 Steam 论坛上的一个帖子][8],它展示了这个文件的主要意义。它类似于下面这样:
|
||||
为了确认这个文件是一样的,用编辑器打开这个文件并检查它。我们越多地了解这个文件越好。这个[链接是来自 Steam 论坛上的一个帖子][8],它展示了这个文件的主要意义。它类似于下面这样:
|
||||
|
||||
```
|
||||
“AppState”
|
||||
@ -80,7 +80,7 @@
|
||||
|
||||

|
||||
|
||||
我们复制了 “SUPERHOT”目录和 .acf 格式的文件(这个文件在 Windows 的 Steam 上格式是一样的)。在复制 .acf 文件和游戏目录到 Linux 中 Steam 它们对应的位置时,我们需要确保 Steam 没有在后台运行。
|
||||
我们复制了 `SUPERHOT` 目录和 `.acf` 格式的清单文件(这个文件在 Windows 的 Steam 上格式是一样的)。在复制 `.acf` 文件和游戏目录到 Linux 中 Steam 它们对应的位置时,我们需要确保 Steam 没有在后台运行。
|
||||
|
||||
在转移完成之后,我们运行 Steam 并看到了这个:
|
||||
|
||||
@ -90,14 +90,14 @@
|
||||
|
||||
我们还进行了其他几种尝试:
|
||||
|
||||
* 我们尝试使用 Linux 下原有的清单文件(.acf)和来自 Windows 的手工备份文件,但结果是 Steam 重新开始下载游戏。
|
||||
* 我们看到当我们将 “SUPERHOT_Data” 这个目录中的 “SH_Data” 更换为 Windows 中的对应目录时,同上面的一样,也重新开始下载整个游戏。
|
||||
* 我们尝试使用 Linux 下原有的清单文件(`.acf`)和来自 Windows 的手工备份文件,但结果是 Steam 重新开始下载游戏。
|
||||
* 我们看到当我们将 `SUPERHOT_Data` 这个目录中的 `SH_Data` 更换为 Windows 中的对应目录时,同上面的一样,也重新开始下载整个游戏。
|
||||
|
||||
### 理解清单目录的一个尝试
|
||||
|
||||
清单目录绝对可以被进一步地被编辑和修改以此来改善上面的结果,使得 Steam 检测出尽可能多的文件。
|
||||
|
||||
在 Github 上有一个[项目][7],包含一个可以生成这些清单文件的 python 脚本。任何 Steam 游戏的 AppID 可以从[SteamDB][6] 上获取到。知晓了游戏的 ID 号后,你便可以用你喜爱的编辑器以下面的格式创建你自己的清单文件 appmanifest_<AppID>.acf”。在上面手工方法中,我们可以看到 SUPERHOT 这个游戏的 AppID 是 322500,所以对应的清单文件名应该是 appmanifest_322500.acf。
|
||||
在 Github 上有一个[项目][7],包含一个可以生成这些清单文件的 python 脚本。任何 Steam 游戏的 AppID 可以从[SteamDB][6] 上获取到。知晓了游戏的 ID 号后,你便可以用你喜爱的编辑器以下面的格式创建你自己的清单文件 `appmanifest_<AppID>.acf`。在上面手工方法中,我们可以看到 SUPERHOT 这个游戏的 AppID 是 322500,所以对应的清单文件名应该是 `appmanifest_322500.acf`。
|
||||
|
||||
下面以我们知晓的信息来尝试对该文件进行一些解释:
|
||||
|
||||
@ -139,10 +139,8 @@
|
||||
via: https://itsfoss.com/share-steam-files-linux-windows/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,63 @@
|
||||
我们大学机房使用的 Fedora 系统
|
||||
==========
|
||||
|
||||

|
||||
|
||||
在[塞尔维亚共和国诺维萨德大学的自然科学系和数学与信息学系][5],我们教学生很多东西。从编程语言的入门到机器学习,所有开设的课程最终目的是让我们的学生能够像专业的开发者和软件工程师一样思考。课程时间紧凑而且学生众多,所以我们必须对现有可利用的资源进行合理调整以满足正常的教学。最终我们决定将机房计算机系统换为 Fedora。
|
||||
|
||||
### 以前的设置
|
||||
|
||||
我们过去的解决方案是在 Ubuntu 系统上面安装 Windows [虚拟机][4]并在虚拟机下安装好教学所需的开发软件。这在当时看起来是一个很不错的主意。然而,这种方法有很多弊端。首先,运行虚拟机导致了严重的计算机性能的浪费,因此导致操作系统性能和运行速度降低。此外,虚拟机有时候会在另一个用户会话里面同时运行。这会导致计算机工作严重缓慢。我们不得不在启动电脑和启动虚拟机上花费宝贵的时间。最后,我们意识到我们的大部分教学所需软件都有对应的 Linux 版本。虚拟机不是必需的。我们需要寻找一个更好的解决办法。
|
||||
|
||||
### 进入 Fedora!
|
||||
|
||||

|
||||
|
||||
*默认运行 Fedora 工作站版本的一个机房的照片*
|
||||
|
||||
我们考虑使用一种简洁的安装替代以前的 Windows 虚拟机方案。我们最终决定使用 Fedora,这有很多原因。
|
||||
|
||||
#### 发展的前沿
|
||||
|
||||
在我们所教授的课程中,我们会用到很多各种各样的开发工具。因此,能够及时获取可用的最新、最好的开发工具很重要。在 Fedora 下,我们发现我们用到的开发工具有 95% 都能够在官方的软件仓库中找到!只有少量的一些工具,我们才需要手动安装。这在 Fedora 下很简单,因为你能获取到几乎所有的现成的开发工具。
|
||||
|
||||
在这个过程中我们意识到我们使用了大量自由、开源的软件和工具。保证这些软件总是能够及时更新通常需要做大量的工作,然而 Fedora 没有这个问题。
|
||||
|
||||
#### 硬件兼容性
|
||||
|
||||
我们机房选择 Fedora 的第二个原因是硬件兼容性。机房现在的电脑还是比较崭新的。过去比较低的内核版本总有些问题。在 Fedora 下,我们总能获得最新的内核版本。正如我们预期的那样,一切运行良好,没有任何问题。
|
||||
|
||||
我们决定使用带有 [GNOME 桌面环境][2]的 Fedora [工作站版本][3]。学生们发现它很容易、直观,可以快速上手。对我们来说,学生有一个简单的环境很重要,这样他们会更多的关注自己的任务和课程本身,而不是一个复杂的或者运行缓慢的用户界面。
|
||||
|
||||
#### 自主的技术支持
|
||||
|
||||
最后一个原因,我们院系高度赞赏自由、开放源代码的软件。使用这些软件,学生们即便在毕业后和工作的时候,仍然能够继续自由地使用它们。在这个过程中,他们通常也对 Fedora 和自由、开源的软件有了一定了解。
|
||||
|
||||
### 转换机房
|
||||
|
||||
我们找来其中的一台电脑,完全手动安装好。包括准备所有必要的脚本和软件,设置远程控制权限和一些其他的重要组成部分。我们也为每一门课程单独设置一个用户账号以方便学生存储他们的文件。
|
||||
|
||||
一台电脑安装配置好后,我们使用一个强大的、免费的、开源的叫做 [CloneZilla][1] 的工具。 CloneZilla 能够制作硬盘镜像以做恢复用。镜像大小约为 11 G。我们用一些带有高速 USB 3.0 接口的闪存来还原磁盘镜像到其余的电脑。我们仅仅利用若干个闪存设备花费了 75 分钟设置好其余的 24 台电脑。
|
||||
|
||||
### 将来的工作
|
||||
|
||||
我们机房现在所有的电脑都完全使用 Fedora (没有虚拟机)。剩下的工作是设置一些管理脚本方便远程安装软件,电脑的开关等等。
|
||||
|
||||
我们由衷地感谢所有 Fedora 的维护人员、软件包管理人员和其他贡献者。我们希望我们的工作能够鼓励其他的学校和大学像我们一样将机房电脑的操作系统转向 Fedora。我们很高兴地确认 Fedora 完全适合我们,同时我们也保证 Fedora 同样会适合您!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-computer-lab-university/
|
||||
|
||||
作者:[Nemanja Milošević][a]
|
||||
译者:[WangYueScream](https://github.com/WangYueScream),[LemonDemo](https://github.com/LemonDemo)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/nmilosev/
|
||||
[1]:http://clonezilla.org/
|
||||
[2]:https://www.gnome.org/
|
||||
[3]:https://getfedora.org/workstation/
|
||||
[4]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[5]:http://www.dmi.rs/
|
||||
@ -1,22 +1,22 @@
|
||||
Linux 中的 DTrace
|
||||
Linux 中的 DTrace :BPF 进入 4.9 内核
|
||||
===========
|
||||
|
||||
|
||||
|
||||
随着 BPF 追踪系统(基于时间采样)最后一个主要功能被合并至 Linux 4.9-rc1 版本的内核中,现在 Linux 内核拥有类似 DTrace 的原生追踪功能。DTrace 是 Solaris 系统中的高级追踪器。对于长期使用 DTrace 的用户和专家,这将是一个振奋人心的里程碑!在 Linux 系统上,现在你可以使用用安全的、低负载的定制追踪系统,通过执行时间的柱状图和频率统计等信息,分析应用的性能以及内核。
|
||||
随着 BPF 追踪系统(基于时间采样)最后一个主要功能被合并至 Linux 4.9-rc1 版本的内核中,现在 Linux 内核拥有类似 DTrace 的原生追踪功能。DTrace 是 Solaris 系统中的高级追踪器。对于长期使用 DTrace 的用户和专家,这将是一个振奋人心的里程碑!现在在 Linux 系统上,你可以在生产环境中使用安全的、低负载的定制追踪系统,通过执行时间的柱状图和频率统计等信息,分析应用的性能以及内核。
|
||||
|
||||
用于 Linux 的追踪工程有很多,但是最终被合并进 Linux 内核的技术从一开始就根本不是一个追踪项目:它是最开始是用于 Berkeley Packet Filter(BPF)的补丁。这些补丁允许 BPF 将软件包重定向,创建软件定义的网络。久而久之,支持追踪事件就被添加进来了,使得程序追踪可用于 Linux 系统。
|
||||
用于 Linux 的追踪项目有很多,但是这个最终被合并进 Linux 内核的技术从一开始就根本不是一个追踪项目:它是最开始是用于伯克利包过滤器(Berkeley Packet Filter)(BPF)的增强功能。这些补丁允许 BPF 重定向数据包,从而创建软件定义网络(SDN)。久而久之,对事件追踪的支持就被添加进来了,使得程序追踪可用于 Linux 系统。
|
||||
|
||||
尽管目前 BPF 没有像 DTrace 一样的高级语言,它所提供的前端已经足够让我创建很多 BPF 工具了,其中有些是基于我以前的 [DTraceToolkit][37]。这个帖子将告诉你怎么去用这些工具,BPF 提供的前端,以及畅谈这项技术将会何去何从。
|
||||
尽管目前 BPF 没有像 DTrace 一样的高级语言,但它所提供的前端已经足够让我创建很多 BPF 工具了,其中有些是基于我以前的 [DTraceToolkit][37]。这个帖子将告诉你怎么去用这些 BPF 提供的前端工具,以及畅谈这项技术将会何去何从。
|
||||
|
||||
### 截图
|
||||
### 示例
|
||||
|
||||
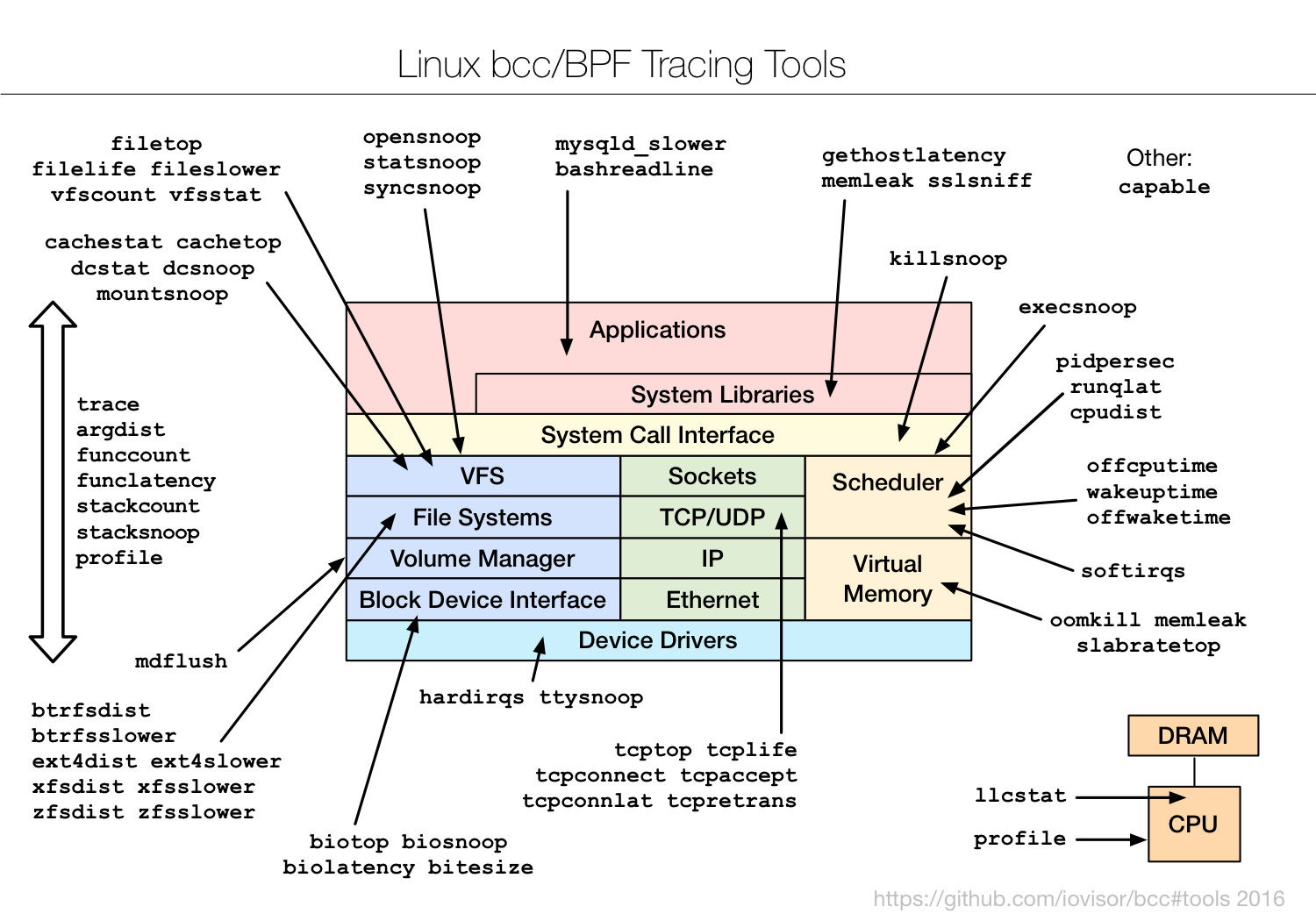
我已经将基于 BPF 的追踪工具添加到了开源的 [bcc][36] 项目里(感谢 PLUMgrid 公司的 Brenden Blanco 带领 bcc 项目的发展)。详见 [bcc 安装][35] 手册。它会在 /usr/share/bcc/tools 目录下添加一系列工具,包括接下来的那些工具。
|
||||
我已经将基于 BPF 的追踪工具添加到了开源的 [bcc][36] 项目里(感谢 PLUMgrid 公司的 Brenden Blanco 带领 bcc 项目的发展)。详见 [bcc 安装][35] 手册。它会在 `/usr/share/bcc/tools` 目录下添加一系列工具,包括接下来的那些工具。
|
||||
|
||||
捕获新进程:
|
||||
|
||||
```
|
||||
# **execsnoop**
|
||||
# execsnoop
|
||||
PCOMM PID RET ARGS
|
||||
bash 15887 0 /usr/bin/man ls
|
||||
preconv 15894 0 /usr/bin/preconv -e UTF-8
|
||||
@ -27,13 +27,12 @@ nroff 15900 0 /usr/bin/locale charmap
|
||||
nroff 15901 0 /usr/bin/groff -mtty-char -Tutf8 -mandoc -rLL=169n -rLT=169n
|
||||
groff 15902 0 /usr/bin/troff -mtty-char -mandoc -rLL=169n -rLT=169n -Tutf8
|
||||
groff 15903 0 /usr/bin/grotty
|
||||
|
||||
```
|
||||
|
||||
硬盘 I/O 延迟的柱状图:
|
||||
|
||||
```
|
||||
# **biolatency -m**
|
||||
# biolatency -m
|
||||
Tracing block device I/O... Hit Ctrl-C to end.
|
||||
^C
|
||||
msecs : count distribution
|
||||
@ -44,13 +43,12 @@ Tracing block device I/O... Hit Ctrl-C to end.
|
||||
16 -> 31 : 100 |**************************************|
|
||||
32 -> 63 : 62 |*********************** |
|
||||
64 -> 127 : 18 |****** |
|
||||
|
||||
```
|
||||
|
||||
追踪常见的 ext4 操作,稍慢于 5ms:
|
||||
追踪慢于 5 毫秒的 ext4 常见操作:
|
||||
|
||||
```
|
||||
# **ext4slower 5**
|
||||
# ext4slower 5
|
||||
Tracing ext4 operations slower than 5 ms
|
||||
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
21:49:45 supervise 3570 W 18 0 5.48 status.new
|
||||
@ -67,26 +65,24 @@ TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
21:49:48 ps 12776 R 832 0 12.02 libprocps.so.4.0.0
|
||||
21:49:48 run 12779 R 128 0 13.21 cut
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
追踪新建的 TCP 活跃连接(connect()):
|
||||
追踪新建的 TCP 活跃连接(`connect()`):
|
||||
|
||||
```
|
||||
# **tcpconnect**
|
||||
# tcpconnect
|
||||
PID COMM IP SADDR DADDR DPORT
|
||||
1479 telnet 4 127.0.0.1 127.0.0.1 23
|
||||
1469 curl 4 10.201.219.236 54.245.105.25 80
|
||||
1469 curl 4 10.201.219.236 54.67.101.145 80
|
||||
1991 telnet 6 ::1 ::1 23
|
||||
2015 ssh 6 fe80::2000:bff:fe82:3ac fe80::2000:bff:fe82:3ac 22
|
||||
|
||||
```
|
||||
|
||||
通过捕获 getaddrinfo()/gethostbyname() 库的调用来追踪 DNS 延迟:
|
||||
通过跟踪 `getaddrinfo()`/`gethostbyname()` 库的调用来追踪 DNS 延迟:
|
||||
|
||||
```
|
||||
# **gethostlatency**
|
||||
# gethostlatency
|
||||
TIME PID COMM LATms HOST
|
||||
06:10:24 28011 wget 90.00 www.iovisor.org
|
||||
06:10:28 28127 wget 0.00 www.iovisor.org
|
||||
@ -96,25 +92,23 @@ TIME PID COMM LATms HOST
|
||||
06:11:16 29195 curl 3.00 www.facebook.com
|
||||
06:11:25 29404 curl 72.00 foo
|
||||
06:11:28 29475 curl 1.00 foo
|
||||
|
||||
```
|
||||
|
||||
按类别划分 VFS 操作的时间间隔统计:
|
||||
|
||||
```
|
||||
# **vfsstat**
|
||||
# vfsstat
|
||||
TIME READ/s WRITE/s CREATE/s OPEN/s FSYNC/s
|
||||
18:35:32: 231 12 4 98 0
|
||||
18:35:33: 274 13 4 106 0
|
||||
18:35:34: 586 86 4 251 0
|
||||
18:35:35: 241 15 4 99 0
|
||||
|
||||
```
|
||||
|
||||
对一个给定的 PID,通过内核和用户堆栈轨迹来追踪 CPU 外的时间(由内核进行统计):
|
||||
对一个给定的 PID,通过内核和用户堆栈轨迹来追踪 CPU 处理之外的时间(由内核进行统计):
|
||||
|
||||
```
|
||||
# **offcputime -d -p 24347**
|
||||
# offcputime -d -p 24347
|
||||
Tracing off-CPU time (us) of PID 24347 by user + kernel stack... Hit Ctrl-C to end.
|
||||
^C
|
||||
[...]
|
||||
@ -142,13 +136,12 @@ Tracing off-CPU time (us) of PID 24347 by user + kernel stack... Hit Ctrl-C to e
|
||||
00007f6733a969b0 read
|
||||
- bash (24347)
|
||||
1450908
|
||||
|
||||
```
|
||||
|
||||
追踪 MySQL 查询延迟(通过 USDT 探针):
|
||||
|
||||
```
|
||||
# **mysqld_qslower `pgrep -n mysqld`**
|
||||
# mysqld_qslower `pgrep -n mysqld`
|
||||
Tracing MySQL server queries for PID 14371 slower than 1 ms...
|
||||
TIME(s) PID MS QUERY
|
||||
0.000000 18608 130.751 SELECT * FROM words WHERE word REGEXP '^bre.*n$'
|
||||
@ -156,101 +149,97 @@ TIME(s) PID MS QUERY
|
||||
4.603549 18608 24.164 SELECT COUNT(*) FROM words
|
||||
9.733847 18608 130.936 SELECT count(*) AS count FROM words WHERE word REGEXP '^bre.*n$'
|
||||
17.864776 18608 130.298 SELECT * FROM words WHERE word REGEXP '^bre.*n$' ORDER BY word
|
||||
|
||||
```
|
||||
|
||||
<!--Using the trace multi-tool to watch login requests, by instrumenting the pam library: -->
|
||||
检测 pam 库并使用多种追踪工具观察登陆请求:
|
||||
监测 pam 库并使用多种追踪工具观察登录请求:
|
||||
|
||||
```
|
||||
# **trace 'pam:pam_start "%s: %s", arg1, arg2'**
|
||||
# trace 'pam:pam_start "%s: %s", arg1, arg2'
|
||||
TIME PID COMM FUNC -
|
||||
17:49:45 5558 sshd pam_start sshd: root
|
||||
17:49:47 5662 sudo pam_start sudo: root
|
||||
17:49:49 5727 login pam_start login: bgregg
|
||||
|
||||
```
|
||||
|
||||
bcc 项目里的很多工具都有帮助信息(-h 选项),并且都应该包含有示例的 man 页面和文本文件。
|
||||
bcc 项目里的很多工具都有帮助信息(`-h` 选项),并且都应该包含有示例的 man 页面和文本文件。
|
||||
|
||||
### 必要的
|
||||
### 必要性
|
||||
|
||||
2014 年,Linux 追踪程序就有一些内核相关的特性(自 ftrace 和 pref_events),但是我们仍然要转储并报告进程数据,因为数十年的老技术会有很大规模的开销。你不能频繁地访问进程名,函数名,堆栈轨迹或内核中的其它任何数据。你不能在将变量保存到一个监测事件里,又在另一个事件里访问它们,这意味着你不能在自定义的地方计算延迟(或者说时间参数)。你也不能创建一个内核之内的延迟柱状图,也不能追踪 USDT 探针,甚至不能写自定义的程序。DTrace 可以做到这些,但仅限于 Solaris 或 BSD 系统。在 Linux 系统中,有些基于树的追踪器,像 SystemTap 就可以满足你的这些需求,但它也有自身的不足。(你可以写一个基于探针的内核模块来满足需求-但实际上没人这么做。)
|
||||
2014 年,Linux 追踪程序就有一些内核相关的特性(来自 `ftrace` 和 `pref_events`),但是我们仍然要转储并报告进程数据,这种几十年前的老技术有很多的限制。你不能频繁地访问进程名、函数名、堆栈轨迹或内核中的任意的其它数据。你不能在将变量保存到一个监测事件里,又在另一个事件里访问它们,这意味着你不能在你需要的地方计算延迟(或者说时间增量)。你也不能创建一个内核内部的延迟柱状图,也不能追踪 USDT 探针,甚至不能写个自定义的程序。DTrace 可以做到所有这些,但仅限于 Solaris 或 BSD 系统。在 Linux 系统中,有些不在主线内核的追踪器,比如 SystemTap 就可以满足你的这些需求,但它也有自身的不足。(理论上说,你可以写一个基于探针的内核模块来满足需求-但实际上没人这么做。)
|
||||
|
||||
2014 年我加入了 Netflix cloud performance 团队。做了这么久的 DTrace 方面的专家,转到 Linux 对我来说简直不可思议。但我确实这么做了,尤其是发现了严重的问题:Netflix cloud 会随着应用,微服务架构和分布式系统的快速变化,性能受到影响。有时要用到系统追踪,而我之前是用的 DTrace。在 Linux 系统上可没有 DTrace,我就开始用 Linux 内核内建的 ftrace 和 perf_events 工具,构建了一个追踪工具([perf-tools][34])。这些工具很有用,但有些工作还是没法完成,尤其是延迟柱状图图以及计算堆栈踪迹。我们需要的是内核追踪程序化。
|
||||
2014 年我加入了 Netflix cloud performance 团队。做了这么久的 DTrace 方面的专家,转到 Linux 对我来说简直不可思议。但我确实这么做了,而且遇到了巨大的挑战:在应用快速变化、采用微服务架构和分布式系统的情况下,调优 Netflix cloud。有时要用到系统追踪,而我之前是用的 DTrace。在 Linux 系统上可没有 DTrace,我就开始用 Linux 内核内建的 `ftrace` 和 `perf_events` 工具,构建了一个追踪工具([perf-tools][34])。这些工具很有用,但有些工作还是没法完成,尤其是延迟柱状图以及堆栈踪迹计数。我们需要的是内核追踪的可程序化。
|
||||
|
||||
### 发生了什么?
|
||||
|
||||
BPF 将程序化的功能添加到现有的内核追踪工具中(tracepoints, kprobes, uprobes)。在 Linux 4.x 系列的内核里,这些功能大大加强了。
|
||||
BPF 将程序化的功能添加到现有的内核追踪工具中(`tracepoints`、`kprobes`、`uprobes`)。在 Linux 4.x 系列的内核里,这些功能大大加强了。
|
||||
|
||||
时间采样是最主要的部分,它被 Linux 4.9-rc1 所采用([patchset][33])。十分感谢 Alexei Starovoitov(致力于 Facebook 中的 BPF 开发),改进 BPF 的主要开发者。
|
||||
时间采样是最主要的部分,它被 Linux 4.9-rc1 所采用([patchset][33])。十分感谢 Alexei Starovoitov(在 Facebook 致力于 BPF 的开发),他是这些 BPF 增强功能的主要开发者。
|
||||
|
||||
Linux 内核现在内建有以下这些特性(添加自 2.6 版本到 4.9 版本):
|
||||
Linux 内核现在内建有以下这些特性(自 2.6 版本到 4.9 版本之间增加):
|
||||
|
||||
* 内核级的动态追踪(BPF 对 kprobes 的支持)
|
||||
* 用户级的动态追踪(BPF 对 uprobes 的支持)
|
||||
* 内核级的静态追踪(BPF 对 tracepoints 的支持)
|
||||
* 时间采样事件(BPF 的 pref_event_open)
|
||||
* PMC 事件(BPF 的 pref_event_open)
|
||||
* 内核级的动态追踪(BPF 对 `kprobes` 的支持)
|
||||
* 用户级的动态追踪(BPF 对 `uprobes` 的支持)
|
||||
* 内核级的静态追踪(BPF 对 `tracepoints` 的支持)
|
||||
* 时间采样事件(BPF 的 `pref_event_open`)
|
||||
* PMC 事件(BPF 的 `pref_event_open`)
|
||||
* 过滤器(通过 BPF 程序)
|
||||
* 调试输出(bpf_trace_printk())
|
||||
* 事件输出(bpf_perf_event_output())
|
||||
* 调试输出(`bpf_trace_printk()`)
|
||||
* 按事件输出(`bpf_perf_event_output()`)
|
||||
* 基础变量(全局的和每个线程的变量,基于 BPF 映射)
|
||||
* 关联数组(通过 BPF 映射)
|
||||
* 频率计数(基于 BPF 映射)
|
||||
* 柱状图(power-of-2, 线性及自定义,基于 BPF 映射)
|
||||
* Timestamps and time deltas (bpf_ktime_get_ns(), and BPF programs)
|
||||
* 时间戳和时间参数(bpf_ktime_get_ns(),和 BPF 程序)
|
||||
* 内核态的堆栈轨迹(BPF stackmap 栈映射)
|
||||
* 用户态的堆栈轨迹 (BPF stackmap 栈映射)
|
||||
* 重写 ring 缓存(pref_event_attr.write_backward)
|
||||
* 柱状图(2 的冥次方、线性及自定义,基于 BPF 映射)
|
||||
* 时间戳和时间增量(`bpf_ktime_get_ns()`,和 BPF 程序)
|
||||
* 内核态的堆栈轨迹(BPF 栈映射)
|
||||
* 用户态的堆栈轨迹 (BPF 栈映射)
|
||||
* 重写 ring 缓存(`pref_event_attr.write_backward`)
|
||||
|
||||
我们采用的前端是 bcc,它同时提供 Python 和 lua 接口。bcc 添加了:
|
||||
|
||||
* 用户级静态追踪(基于 uprobes 的 USDT 探针)
|
||||
* 调试输出(调用 BPF.trace_pipe() 和 BPF.trace_fields() 函数的 Python)
|
||||
* 所有事件输出(BPF_PERF_OUTPUT 宏和 BPF.open_perf_buffer())
|
||||
* 间隔输出(BPF.get_table() 和 table.clear())
|
||||
* 打印柱状图(table.print_log2_hist())
|
||||
* 内核级的 C 结构体导航(bcc 重写 bpf_probe_read() 函数的映射)
|
||||
* 内核级的符号解析(ksym(), ksymaddr())
|
||||
* 用户级的符号解析(usymaddr())
|
||||
* BPF tracepoint 支持(通过 TRACEPOINT_PROBE)
|
||||
* BPF 堆栈轨迹支持(包括针对堆栈框架的 walk 方法)
|
||||
* 其它各种助手宏和方法
|
||||
* 例子(位于 /examples 目录)
|
||||
* 工具(位于 /tools 目录)
|
||||
* 教程(/docs/tutorial*.md)
|
||||
* 参考手册(/docs/reference_guide.md)
|
||||
* 用户级静态追踪(基于 `uprobes` 的 USDT 探针)
|
||||
* 调试输出(Python 中调用 `BPF.trace_pipe()` 和 `BPF.trace_fields()` 函数 )
|
||||
* 按事件输出(`BPF_PERF_OUTPUT` 宏和 `BPF.open_perf_buffer()`)
|
||||
* 间隔输出(`BPF.get_table()` 和 `table.clear()`)
|
||||
* 打印柱状图(`table.print_log2_hist()`)
|
||||
* 内核级的 C 结构体导航(bcc 重写器映射到 `bpf_probe_read()` 函数)
|
||||
* 内核级的符号解析(`ksym()`、 `ksymaddr()`)
|
||||
* 用户级的符号解析(`usymaddr()`)
|
||||
* BPF 跟踪点支持(通过 `TRACEPOINT_PROBE`)
|
||||
* BPF 堆栈轨迹支持(包括针对堆栈框架的 `walk` 方法)
|
||||
* 其它各种辅助宏和方法
|
||||
* 例子(位于 `/examples` 目录)
|
||||
* 工具(位于 `/tools` 目录)
|
||||
* 教程(`/docs/tutorial*.md`)
|
||||
* 参考手册(`/docs/reference_guide.md`)
|
||||
|
||||
直到最新也是最主要的特性被整合进来,我才开始写这篇文章,现在它在 4.9-rc1 内核中。我们还需要去完成一些次要的东西,还有另外一些事情要做,但是现在我们所拥有的已经值得欢呼了。现在 Linux 拥有内建的高级追踪能力。
|
||||
直到最新也是最主要的特性被整合进来,我才开始写这篇文章,现在它在 4.9-rc1 内核中。我们还需要去完成一些次要的东西,还有另外一些事情要做,但是现在我们所拥有的已经值得欢呼了。现在 Linux 拥有了内建的高级追踪能力。
|
||||
|
||||
### 安全性
|
||||
|
||||
设计 BPF 以及改进版时就考虑到产品安全,它被用在大范围的生产环境里。确信的话,你应该能找到一个挂起内核的方法。这个例子是偶然而不是必然,类似的漏洞会被快速修复,尤其是当 BPF 合并入了 Linux。因为 Linux 可是公众的焦点。
|
||||
设计 BPF 及其增强功能时就考虑到生产环境级安全,它被用在大范围的生产环境里。不过你想的话,你还是可以找到一个挂起内核的方法。这种情况是偶然的,而不是必然,类似的漏洞会被快速修复,尤其是当 BPF 合并入了 Linux。因为 Linux 可是公众的焦点。
|
||||
|
||||
在开发过程中我们碰到了一些非 BPF 的漏洞,它们需要被修复:rcu 不可重入,这可能导致内核由于 funccount 挂起,在 4.6 内核版本中这个漏洞被 “bpf: map pre-alloc” 所修复,旧版本内核的漏洞暂时由 bcc 处理。还有一个是 uprobe 的内存计算问题,这导致 uprobe 分配内存失败,在 4.8 内核版本这个漏洞由 “uprobes: Fix the memcg accounting” 补丁所修复,并且该补丁还将被移植到之前版本的内核中(例如,它现在被移植到了 4.4.27 和 4.4.0-45.66 版本中)。
|
||||
在开发过程中我们碰到了一些非 BPF 的漏洞,它们需要被修复:rcu 不可重入,这可能导致内核由于 funccount 挂起,在 4.6 内核版本中这个漏洞被 “bpf: map pre-alloc” 补丁集所修复,旧版本内核的漏洞 bcc 有个临时处理方案。还有一个是 uprobe 的内存计算问题,这导致 uprobe 分配内存失败,在 4.8 内核版本这个漏洞由 “uprobes: Fix the memcg accounting” 补丁所修复,并且该补丁还将被移植到之前版本的内核中(例如,它现在被移植到了 4.4.27 和 4.4.0-45.66 版本中)。
|
||||
|
||||
### 为什么 Linux 追踪很耗时?
|
||||
### 为什么 Linux 追踪用了这么久才加进来?
|
||||
|
||||
首要任务被分到了若干追踪器中间:只有联合使用这些追踪器才能有作用。想要了解更多关于这个或其它方面的问题,可以看一看我在 2014 年写的 [tracing summit talk][32]。我忽视了计数器在部分方案中的效率:有些公司发现其它追踪器(SystemTap 和 LTTng)能满足他们的需求,尽管他们乐于听到 BPF 的开发进程,考虑到他们现有的解决方案,帮助 BPF 的开发就不那么重要了。
|
||||
首要任务被分到了若干追踪器中间:这些不是某个追踪器单个的事情。想要了解更多关于这个或其它方面的问题,可以看一看我在 2014 年 [tracing summit 上的讲话][32]。我忽视了部分方案的反面影响:有些公司发现其它追踪器(SystemTap 和 LTTng)能满足他们的需求,尽管他们乐于听到 BPF 的开发进程,但考虑到他们现有的解决方案,帮助 BPF 的开发就不那么重要了。
|
||||
|
||||
近两年里 BPF 仅在追踪领域得到加强。这一过程原本可以更快的,但早期缺少全职工作于 BPF 追踪的工程师。Alexei Starovoitov (BPF 领导者),Brenden Blanco (bcc 领导者),我还有其它一些开发者,都有其它的事情要做。我在 Netflix 公司花了大量时间(自由工作地),大概有 7% 的时间是花在 BPF 和 bcc 上。某种程度上这不是我的首要任务,因为我还有自己的工作(包括我的 perf-tools,一个工作在旧版本内核上的程序)。
|
||||
BPF 仅在近两年里在追踪领域得到加强。这一过程原本可以更快的,但早期缺少全职从事于 BPF 追踪的工程师。Alexei Starovoitov (BPF 领导者),Brenden Blanco (bcc 领导者),我还有其它一些开发者,都有其它的事情要做。我在 Netflix 公司花了大量时间(志愿地),大概有 7% 的时间是花在 BPF 和 bcc 上。某种程度上这不是我的首要任务,因为我还有自己的工作(包括我的 perf-tools,一个可以工作在旧版本内核上的程序)。
|
||||
|
||||
BPF 追踪已经推出了,已经有科技公司开始关注 BPF 的特点了。但我还是推荐 [Netflix 公司][31]。(如果你为了 BPF 而要聘请我,那我还是十分乐于待在 Netflix 公司的!)
|
||||
现在BPF 追踪器已经推出了,已经有科技公司开始寻找会 BPF 的人了。但我还是推荐 [Netflix 公司][31]。(如果你为了 BPF 而要聘请我,那我还是十分乐于待在 Netflix 公司的!)
|
||||
|
||||
### 使用简单
|
||||
|
||||
DTrace 和 bcc/BPF 现在的最大区别就是哪个更好使用。这取决于你要用 BPF 追踪做什么了。如果你要
|
||||
|
||||
* **使用 BPF tools/metrics**:应该是没什么区别的。工具的表现都差不多,图形用户界面的访问也类似。大部分用户通过这种方式使用 BPF。
|
||||
* **开发 tools/metrics**:bcc 的开发可难多了。DTrace 有一套自己的简单语言,D 语音,和 awk 语言相似,而 bcc 使用已有的带有库的语言(C 语言,Python 和 lua)。一个用 C 和 Python 写的 bcc 工具与仅仅用 D 语言写出来的工具相比,可能要多十多倍行数的代码,或者更多。但是很多 DTrace 工具用 shell 包装来提供参数和差错,会让代码变得十分臃肿。编程的难处是不同的:重写 bcc 更需要巧妙性,这导致某些脚本更加难开发。(尤其是 bpf_probe_read() 这类的函数,需要了解更多 BPF 的内涵知识)。当计划改进 bcc 时,这一情形将得到改善。
|
||||
* **运行常见的命令**:十分相近。用 “dtrace” 命令,DTrace 能做很多事,但 bcc 有各种工具,trace,argdist,funccount,funclatency 等等。
|
||||
* **使用 BPF 工具/度量**:应该是没什么区别的。工具的表现都差不多,图形用户界面都能取得类似度量指标。大部分用户通过这种方式使用 BPF。
|
||||
* **开发工具/度量**:bcc 的开发可难多了。DTrace 有一套自己的简单语言,D 语音,和 awk 语言相似,而 bcc 使用已有的语言(C 语言,Python 和 lua)及其类库。一个用 C 和 Python 写的 bcc 工具与仅仅用 D 语言写出来的工具相比,可能要多十多倍行数的代码,或者更多。但是很多 DTrace 工具用 shell 封装来提供参数和差错检查,会让代码变得十分臃肿。编程的难处是不同的:重写 bcc 更需要巧妙性,这导致某些脚本更加难开发。(尤其是 `bpf_probe_read()` 这类的函数,需要了解更多 BPF 的内涵知识)。当计划改进 bcc 时,这一情形将得到改善。
|
||||
* **运行常见的命令**:十分相近。通过 `dtrace` 命令,DTrace 能做很多事,但 bcc 有各种工具,`trace`、`argdist`、`funccount`、`funclatency` 等等。
|
||||
* **编写自定义的特殊命令**:使用 DTrace 的话,这就没有必要了。允许定制消息快速传递和系统快速响应,DTrace 的高级分析很快。而 bcc 现在受限于它的多种工具以及它们的适用范围。
|
||||
|
||||
简单来说,如果你只使用 BPF 工具的话,就不必关注这些差异了。如果你经验丰富,是个开发者(像我一样),目前 bcc 的使用是比较困难的。
|
||||
简单来说,如果你只使用 BPF 工具的话,就不必关注这些差异了。如果你经验丰富,是个开发者(像我一样),目前 bcc 的使用更难一些。
|
||||
|
||||
举一个 bcc 的 Python 前端的例子,下面是追踪硬盘 I/O 和 打印 I/O 容量柱状图的代码:
|
||||
举一个 bcc 的 Python 前端的例子,下面是追踪硬盘 I/O 并打印出 I/O 大小的柱状图代码:
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
@ -281,16 +270,15 @@ except KeyboardInterrupt:
|
||||
|
||||
# output
|
||||
b["dist"].print_log2_hist("kbytes")
|
||||
|
||||
```
|
||||
|
||||
注意 Python 代码中嵌入的 C 语句(text=)。
|
||||
注意 Python 代码中嵌入的 C 语句(`text=`)。
|
||||
|
||||
这就完成了任务,但仍有改进的空间。好在我们有时间去做:人们使用 Linux 4.9 并能用上 BPF 还得好几个月呢,所以我们有时间来制造工具和前端。
|
||||
|
||||
### 高级语言
|
||||
|
||||
前端越简单,比如高级语言,所改进的可能就越不如你所期望的。绝大多数人使用封装好的工具(和 GUI),仅有少部分人能写出这些工具。但我不反对使用高级语言,比如 SystemTap,毕竟已经开发出来了。
|
||||
前端越简单,比如高级语言,所改进的可能就越不如你所期望的。绝大多数人使用封装好的工具(和图形界面),仅有少部分人能写出这些工具。但我不反对使用高级语言,比如 SystemTap,毕竟已经开发出来了。
|
||||
|
||||
```
|
||||
#!/usr/bin/stap
|
||||
@ -307,12 +295,11 @@ probe syscall.open
|
||||
{
|
||||
printf("%6d %6d %16s %s\n", uid(), pid(), execname(), filename);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
如果拥有整合了语言和脚本的 SystemTap 前端与高性能内核内建的 BPF 后端,会不会令人满意呢?RedHat 公司的 Richard Henderson 已经在进行相关工作了,并且发布了 [初代版本][30]!
|
||||
如果拥有整合了语言和脚本的 SystemTap 前端与高性能的内置在内核中的 BPF 后端,会不会令人满意呢?RedHat 公司的 Richard Henderson 已经在进行相关工作了,并且发布了 [初代版本][30]!
|
||||
|
||||
这是 [ply][29],一个完全新颖的 BPF 高级语言:
|
||||
这是 [ply][29],一个完全新颖的 BPF 高级语言:
|
||||
|
||||
```
|
||||
#!/usr/bin/env ply
|
||||
@ -321,7 +308,6 @@ kprobe:SyS_*
|
||||
{
|
||||
$syscalls[func].count()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这也是一份承诺。
|
||||
@ -330,30 +316,30 @@ kprobe:SyS_*
|
||||
|
||||
### 如何帮助我们
|
||||
|
||||
* **推广**:BPF 追踪目前还没有什么市场方面的进展。尽管有公司了解并在使用它(Facebook,Netflix,Github 和其它公司),但要广为人知尚需时日。分享关于 BPF 产业的文章和资源来帮助我们。
|
||||
* **推广**:BPF 追踪器目前还没有什么市场方面的进展。尽管有公司了解并在使用它(Facebook、Netflix、Github 和其它公司),但要广为人知尚需时日。你可以分享关于 BPF 的文章和资源给业内的其它公司来帮助我们。
|
||||
* **教育**:你可以撰写文章,发表演讲,甚至参与 bcc 文档的编写。分享 BPF 如何解决实际问题以及为公司带来收益的实例。
|
||||
* **解决 bcc 的问题**:参考 [bcc issue list][19],这包含了错误和需要的特性。
|
||||
* **提交错误**:使用 bcc/BPF,提交你发现的错误。
|
||||
* **创造工具**:有很多可视化的工具需要开发,请不要太草率,因为大家会先花几个小时学习使用你做的工具,所以请尽量把工具做的直观好用(参考我的 [文档][18])。就像 Mike Muuss 提及到他自己的 [ping][17] 程序:“要是我早知道这是我一生中最出名的成就,我就多开发一两天,添加更多选项。”
|
||||
* **高级语言**:如果现有的 bcc 前端语言让你很困扰,或者你能弄门更好的语言。要是你想将这门语言内建到 bcc 里面,你需要使用 libbcc。或者你可以帮助进行 SystemTap BPF 或 ply 的工作。
|
||||
* **整合图形界面**:除了 bcc 可以使用的 CLI 命令行工具,怎么让这些信息可视呢?延迟关系,火焰图等等。
|
||||
* **创造工具**:有很多可视化的工具需要开发,但请不要太草率,因为大家会先花几个小时学习使用你做的工具,所以请尽量把工具做的直观好用(参考我的[文档][18])。就像 Mike Muuss 提及到他自己的 [ping][17] 程序:“要是我早知道这是我一生中最出名的成就,我就多开发一两天,添加更多选项。”
|
||||
* **高级语言**:如果现有的 bcc 前端语言让你很困扰,或许你能弄门更好的语言。要是你想将这门语言内建到 bcc 里面,你需要使用 libbcc。或者你可以帮助 SystemTap BPF 或 ply 的工作。
|
||||
* **整合图形界面**:除了 bcc 可以使用的 CLI 命令行工具,怎么让这些信息可视呢?延迟热点图,火焰图等等。
|
||||
|
||||
### 其它追踪器
|
||||
|
||||
那么 SystemTap,ktap,sysdig,LTTng 等追踪器怎么样呢?它们有个共同点,要么使用了 BPF,要么在自己的领域做得更好。会有单独的文章介绍它们自己。
|
||||
那么 SystemTap、ktap、sysdig、LTTng 等追踪器怎么样呢?它们有个共同点,要么使用了 BPF,要么在自己的领域做得更好。会有单独的文章介绍它们自己。
|
||||
|
||||
至于 DTrace ?我们公司目前还在基于 FreeBSD 系统的 CDN 中使用它。
|
||||
|
||||
### 更多 bcc/BPF 的信息
|
||||
### 更多 bcc/BPF 的信息
|
||||
|
||||
我已经写了一篇 [bcc/BPF Tool End-User Tutorial][28],一篇 [bcc Python Developer's Tutorial][27],一篇 [bcc/BPF Reference Guide][26],和已经写好的有用的 [/tools][25],每一个工具都有一个 [example.txt][24] 文件和 [man page][23]。我之前写过的关于 bcc 和 BPF 的文章有:
|
||||
我已经写了一篇《[bcc/BPF 工具最终用户教程][28]》,一篇《[bcc Python 开发者教程][27]》,一篇《[bcc/BPF 参考手册][26]》,并提供了一些有用的[工具][25],每一个工具都有一个 [example.txt][24] 文件和 [man page][23]。我之前写过的关于 bcc 和 BPF 的文章有:
|
||||
|
||||
* [eBPF: One Small Step][16] (以后就叫做 BPF)
|
||||
* [eBPF: One Small Step][16] (后来就叫做 BPF)
|
||||
* [bcc: Taming Linux 4.3+ Tracing Superpowers][15]
|
||||
* [Linux eBPF Stack Trace Hack][14] (现在官方支持追踪堆栈了)
|
||||
* [Linux eBPF Off-CPU Flame Graph][13] (" " ")
|
||||
* [Linux Wakeup and Off-Wake Profiling][12] (" " ")
|
||||
* [Linux Chain Graph Prototype][11] (" " ")
|
||||
* [Linux eBPF Off-CPU Flame Graph][13]
|
||||
* [Linux Wakeup and Off-Wake Profiling][12]
|
||||
* [Linux Chain Graph Prototype][11]
|
||||
* [Linux eBPF/bcc uprobes][10]
|
||||
* [Linux BPF Superpowers][9]
|
||||
* [Ubuntu Xenial bcc/BPF][8]
|
||||
@ -369,22 +355,22 @@ kprobe:SyS_*
|
||||
|
||||
### 致谢
|
||||
|
||||
* Van Jacobson and Steve McCanne,他是最早将 BPF 应用到包过滤的。
|
||||
* Barton P. Miller,Jeffrey K. Hollingsworth,and Jon Cargille,发明了动态追踪,并发表文章《Dynamic Program Instrumentation for Scalable Performance Tools》,可扩展高性能计算协议 (SHPCC),于田纳西州诺克斯维尔市,1994 年 5 月发表。
|
||||
* kerninst (ParaDyn, UW-Madison), an early dynamic tracing tool that showed the value of dynamic tracing (late 1990's).(早期的能够显示动态追踪数值的动态追踪工具,稍晚于 1990 年)
|
||||
* Mathieu Desnoyers (of LTTng),内核的主要开发者,主导 tracepoints 项目。
|
||||
* Van Jacobson 和 Steve McCanne,他们创建了最初用作过滤器的 BPF 。
|
||||
* Barton P. Miller,Jeffrey K. Hollingsworth,and Jon Cargille,发明了动态追踪,并发表论文《Dynamic Program Instrumentation for Scalable Performance Tools》,可扩展高性能计算协议 (SHPCC),于田纳西州诺克斯维尔市,1994 年 5 月发表。
|
||||
* kerninst (ParaDyn, UW-Madison),展示了动态跟踪的价值的早期动态跟踪工具(上世纪 90 年代后期)
|
||||
* Mathieu Desnoyers (在 LTTng),内核的主要开发者,主导 tracepoints 项目。
|
||||
* IBM 开发的作为 DProbes 一部分的 kprobes,DProbes 在 2000 年时曾与 LTT 一起提供 Linux 动态追踪,但没有整合到一起。
|
||||
* Bryan Cantrill, Mike Shapiro, and Adam Leventhal (Sun Microsystems),DTrace 的核心成员,DTrace 是一款很棒的动态追踪工具,安全而且简单(2004 年)。考虑到动态追踪的技术,DTrace 是科技的重要转折点:它很安全,默认安装在 Solaris 以及其它以可靠性著称的系统里。
|
||||
* Bryan Cantrill, Mike Shapiro, and Adam Leventhal (Sun Microsystems),DTrace 的核心开发者,DTrace 是一款很棒的动态追踪工具,安全而且简单(2004 年)。对于动态追踪技术,DTrace 是科技的重要转折点:它很安全,默认安装在 Solaris 以及其它以可靠性著称的系统里。
|
||||
* 来自 Sun Microsystems 的各部门的许多员工,促进了 DTrace,为我们带来了高级系统追踪的意识。
|
||||
* Roland McGrath (at Red Hat),utrace 项目的主要开发者,utrace 变成了后来的 uprobes。
|
||||
* Alexei Starovoitov (PLUMgrid, then Facebook), 加强版 BPF(可编程内核容器)的主要开发者。
|
||||
* 那些帮助反馈,提交代码、测试以及针对增强版 BPF 补丁(搜索 BPF 的 lkml)的 Linux 内核工程师: Wang Nan, Daniel Borkmann, David S. Miller, Peter Zijlstra, 以及其它很多人。
|
||||
* Roland McGrath (在 Red Hat),utrace 项目的主要开发者,utrace 变成了后来的 uprobes。
|
||||
* Alexei Starovoitov (PLUMgrid, 后来是 Facebook),加强版 BPF(可编程内核部件)的主要开发者。
|
||||
* 那些帮助反馈、提交代码、测试以及针对增强版 BPF 补丁(请在 lkml 搜索 BPF)的 Linux 内核工程师: Wang Nan、 Daniel Borkmann、 David S. Miller、 Peter Zijlstra 以及其它很多人。
|
||||
* Brenden Blanco (PLUMgrid),bcc 的主要开发者。
|
||||
* Sasha Goldshtein (Sela) 开发了 bcc 中可用的 tracepoint,和功能最强大的 bcc 工具 trace 及 argdist,帮助 USDT 项目的开发。
|
||||
* Sasha Goldshtein (Sela) 开发了 bcc 中的跟踪点支持,和功能最强大的 bcc 工具 trace 及 argdist,帮助 USDT 项目的开发。
|
||||
* Vicent Martí 和其它 Github 上的工程师,为 bcc 编写了基于 lua 的前端,帮助 USDT 部分项目的开发。
|
||||
* Allan McAleavy, Mark Drayton,和其他的改进 bcc 的贡献者。
|
||||
* Allan McAleavy、 Mark Drayton,和其他的改进 bcc 的贡献者。
|
||||
|
||||
感觉 Netflix 提供环的境和支持,让我能够编写 BPF 和 bcc tracing 并完成它们。开发追踪工具(使用 TNF/prex, DTrace, SystemTap, ktap, ftrace, perf, and now bcc/BPF)和写书、博客以及评论,我已经编写了多年的追踪工具。
|
||||
感觉 Netflix 提供的环境和支持,让我能够编写 BPF 和 bcc 跟踪器并完成它们。我已经编写了多年的追踪工具(使用 TNF/prex、DTrace、SystemTap、ktap、ftrace、perf,现在是 bcc/BPF),并写书、博客以及评论,
|
||||
|
||||
最后,感谢 [Deirdré][20] 编辑了另外一篇文章。
|
||||
|
||||
@ -392,9 +378,9 @@ kprobe:SyS_*
|
||||
|
||||
Linux 没有 DTrace(语言),但它现在有了,或者说拥有了 DTraceTookit(工具)。
|
||||
|
||||
通过内核构建的 BPF 引擎补丁,Linux 4.9 内核有用来支持现代化追踪的最后一项功能。内核支持这一最难的部分已经做完了。今后的任务包括更多的命令行执行工具,可选的高级语言和图形用户界面。
|
||||
通过增强内置的 BPF 引擎,Linux 4.9 内核拥有了用来支持现代化追踪的最后一项能力。内核支持这一最难的部分已经做完了。今后的任务包括更多的命令行执行工具,以及高级语言和图形用户界面。
|
||||
|
||||
对于性能分析产品的客户,这也是一件好事:你能查看延迟柱状图和热点图,CPU 运行和休眠的火焰图,拥有更好的时延断点和更低耗的工具。我们现在用的追踪和处理程序是没有效率的方式。
|
||||
对于性能分析产品的客户,这也是一件好事:你能查看延迟柱状图和热点图,CPU 处理和 CPU 之外的火焰图,拥有更好的时延断点和更低耗的工具。在用户空间按包跟踪和处理是没有效率的方式。
|
||||
|
||||
那么你什么时候会升级到 Linux 4.9 呢?一旦官方发布,新的性能测试工具就来了:`apt-get install bcc-tools` 。
|
||||
|
||||
@ -407,10 +393,8 @@ Brendan
|
||||
via: http://www.brendangregg.com/blog/2016-10-27/dtrace-for-linux-2016.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,121 @@
|
||||
修复 Ubuntu 中“Unable to lock the administration directory (/var/lib/dpkg/)”的问题
|
||||
============================================================
|
||||
|
||||
在 Ubuntu 或者它的衍生版如 Linux Mint(我已经作为日常工作使用的系统)中使用 [apt-get 命令][1]或者其相对更新的[APT 管理工具][2]时,你可能会在命令行中看到一个 `unable to lock the administration directory (/var/lib/dpkg/) is another process using it` 的错误。
|
||||
|
||||
这个错误尤其对那些对这个错误原因不了解的 Linux(Ubuntu)新手而言更加恼人。
|
||||
|
||||
下面是一个例子,展示了出现在 Ubuntu 16.10 上的文件锁定错误:
|
||||
|
||||
```
|
||||
tecmint@TecMint:~$ sudo apt install neofetch
|
||||
[sudo] password for tecmint:
|
||||
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
|
||||
E: Unable to lock the administration directory (/var/lib/dpkg), is another process using it?
|
||||
```
|
||||
|
||||
下面的输出是另外一个可能显示的错误:
|
||||
|
||||
```
|
||||
E: Could not get lock /var/lib/apt/lists/lock - open (11: Resource temporarily unavailable)
|
||||
E: Unable to lock directory /var/lib/apt/lists/
|
||||
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
|
||||
E: Unable to lock the administration directory (/var/lib/dpkg/), is another process using it?
|
||||
```
|
||||
|
||||
你将来遇到这个错误该怎么去解决?一共有几种方法处理这个错误,但是本篇中我们会用两种或许是最简单和最有效的方法来解决它。
|
||||
|
||||
### 1、找出并杀掉所有 apt-get 或者 apt 进程
|
||||
|
||||
运行下面的命令来[生成所有含有 apt 的进程列表][3],你可以使用 `ps` 和 [grep 命令][4]并用管道组合来得到含有 apt 或者 apt-get 的进程。
|
||||
|
||||
```
|
||||
$ ps -A | grep apt
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*找出 apt 以及 apt-get 进程*
|
||||
|
||||
你可以看到上面命令输出的每个 apt-get 或者 apt 进程,使用下面的命令[杀掉每个进程][6]。
|
||||
|
||||
上面截图中的第一列是进程 ID(PID)。
|
||||
|
||||
```
|
||||
$ sudo kill -9 processnumber
|
||||
或者
|
||||
$ sudo kill -SIGKILL processnumber
|
||||
```
|
||||
|
||||
比如,下面命令中的`9`是 `SIGKILL` 的信号数,它会杀掉第一个 apt 进程:
|
||||
|
||||
```
|
||||
$ sudo kill -9 13431
|
||||
或者
|
||||
$ sudo kill -SIGKILL 13431
|
||||
```
|
||||
|
||||
### 2、 删除锁定的文件
|
||||
|
||||
锁定的文件会阻止 Linux 系统中某些文件或者数据的访问,这个概念也存在于 Windows 或者其他的操作系统中。
|
||||
|
||||
一旦你运行了 apt-get 或者 apt 命令,锁定文件将会创建于 `/var/lib/apt/lists/`、`/var/lib/dpkg/`、`/var/cache/apt/archives/` 中。
|
||||
|
||||
这有助于运行中的 apt-get 或者 apt 进程能够避免被其它需要使用相同文件的用户或者系统进程所打断。当该进程执行完毕后,锁定文件将会删除。
|
||||
|
||||
重要提醒:万一你在没有看到 apt-get 或者 apt 进程的情况下在上面两个不同的文件夹中看到了锁定文件,这是因为进程由于某个原因被杀掉了,因此你需要删除锁定文件来避免该错误。
|
||||
|
||||
首先运行下面的命令来移除 `/var/lib/dpkg/` 文件夹下的锁定文件:
|
||||
|
||||
```
|
||||
$ sudo rm /var/lib/dpkg/lock
|
||||
```
|
||||
|
||||
之后像下面这样强制重新配置软件包:
|
||||
|
||||
```
|
||||
$ sudo dpkg --configure -a
|
||||
```
|
||||
|
||||
也可以删除 `/var/lib/apt/lists/` 以及缓存文件夹下的锁定文件:
|
||||
|
||||
```
|
||||
$ sudo rm /var/lib/apt/lists/lock
|
||||
$ sudo rm /var/cache/apt/archives/lock
|
||||
```
|
||||
|
||||
接下来,更新你的软件包源列表:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
或者
|
||||
$ sudo apt-get update
|
||||
```
|
||||
|
||||
总结一下,对于 Ubuntu(以及它的衍生版)用户在使用 apt-get 或者 apt 也叫 [aptitude 命令][7]时遇到的问题,我们已经用两种方法来解决了。
|
||||
|
||||
你有什么可以分享出来的有效的方法来处理这个错误么?在下面的评论区联系我们。
|
||||
|
||||
除此之外,你可能还希望了解[如何找出并杀掉运行的进程][8],你可以阅读这篇[用 kill、pkill、killall 来中止进程][9]指南来了解。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/fix-unable-to-lock-the-administration-directory-var-lib-dpkg-lock
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://linux.cn/article-4933-1.html
|
||||
[2]:https://linux.cn/article-7364-1.html
|
||||
[3]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[4]:http://www.tecmint.com/linux-grep-commands-character-classes-bracket-expressions/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/11/find-apt-processes.png
|
||||
[6]:http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[7]:http://www.tecmint.com/difference-between-apt-and-aptitude/
|
||||
[8]:http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[9]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -0,0 +1,90 @@
|
||||
不常见但是很有用的 gcc 命令行选项(一)
|
||||
===================================================
|
||||
|
||||
在本文中,你可以学习到:
|
||||
|
||||
1. [在每个编译阶段查看中间代码的输出][1]
|
||||
2. [让你的代码可调试和可分析][2]
|
||||
3. [结论][3]
|
||||
|
||||
软件工具通常情况下会提供多个功能以供选择,但是如你所知的,不是所有的功能都能被每个人用到的。公正地讲,这并不是设计上的错误,因为每个用户都会有自己的需求,他们只在他们的领域内使用该工具。然而,深入了解你所使用的工具也是很有益处的,因为你永远不知道它的某个功能会在什么时候派上用场,从而节省下你宝贵的时间。
|
||||
|
||||
举一个例子:编译器。一个优秀的编程语言编译器总是会提供极多的选项,但是用户一般只知道和使用其中很有限的一部分功能。更具体点来说,比如你是 C 语言开发人员,并将 Linux 作为你的开发平台,那么你很有可能会用到 gcc 编译器,这个编译器提供了 (几乎) 数不清的命令行选项列表。
|
||||
|
||||
你知道,你可以让 gcc 保存每个编译阶段的输出吗?你知道用于生成警告的 `-Wall` 选项,它并不会包含一些特殊的警告吗?gcc 的很多命令行选项都不会经常用到,但是它们在某些特定的情况下会变得非常有用,例如,当你在调试代码的时候。
|
||||
|
||||
所以在本文中,我们会介绍这样的几个选项,提供所有必要的细节,并通过简单易懂的例子来解释它们。
|
||||
|
||||
但是在开始前,请注意本文中所有的例子所使用的环境:基于 Ubuntu 16.04 LTS 操作系统,gcc 版本为 5.4.0。
|
||||
|
||||
### 在每个编译阶段查看中间代码的输出
|
||||
|
||||
你知道在通过 gcc 编译 c 语言代码的时候大体上共分为四个阶段吗?分别为预处理 -> 编译 -> 汇编 -> 链接。在每个阶段之后,gcc 都会产生一个将移交给下一个阶段的临时输出文件。但是生成的都是临时文件,因此我们并不能看到它们——我们所看到的只是我们发起编译命令,然后它生成的我们可以直接运行的二进制文件或可执行文件。
|
||||
|
||||
但是比如说在预处理阶段,如果调试时需要查看代码是如何进行处理的,你要怎么做呢?好消息是 gcc 编译器提供了相应的命令行选项,你可以在标准编译命令中使用这些选项获得原本被编译器删除的中间文件。我们所说的选项就是`-sava-temps`。
|
||||
|
||||
以下是 [gcc 手册][4]中对该选项的介绍:
|
||||
|
||||
> 永久存储临时的中间文件,将它们放在当前的文件夹下并根据源文件名称为其命名。因此,用 `-c -save-temps` 命令编译 foo.c 文件时会生成 foo.i foo.s 和 foo.o 文件。即使现在编译器大多使用的是集成的预处理器,这命令也会生成预处理输出文件 foo.i。
|
||||
|
||||
> 当与 `-x` 命令行选项结合使用时,`-save-temps` 命令会避免覆写与中间文件有着相同扩展名的输入源文件。相应的中间文件可以通过在使用 `-save-temps` 命令之前重命名源文件获得。
|
||||
|
||||
以下是怎样使用这个选项的例子:
|
||||
|
||||
```
|
||||
gcc -Wall -save-temps test.c -o test-exec
|
||||
```
|
||||
|
||||
下图为该命令的执行结果,验证其确实产生了中间文件:
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
因此,在截图中你所看到的 test.i、test.s、 test.o 文件都是由 `-save-temps` 选项产生的。这些文件分别对应于预处理、编译和链接阶段。
|
||||
|
||||
### 让你的代码可调试和可分析
|
||||
|
||||
你可以使用专有的工具调试和分析代码。如 [gdb][6] 就是专用于调试的工具,而 [gprof][7] 则是热门的分析工具。但你知道 gcc 特定的命令行选项也可以让你的代码可调试和可分析吗?
|
||||
|
||||
让我们开始调试之路吧!为了能在代码调试中使用 gdb,你需要在编译代码的时候使用 gcc 编译器提供的 `-g` 选项。这个选项让 gcc 生成 gdb 需要的调试信息从而能成功地调试程序。
|
||||
|
||||
如果你想要使用此选项,建议您详细阅读 [gcc 手册][8]提供的有关此选项的详细信息——在某些情况下,其中的一些内容可能是至关重要的。 例如,以下是从手册页中摘录的内容:
|
||||
|
||||
> GCC 允许在使用 `-g` 选项的时候配合使用 `-O` 选项。优化代码采用的便捷方式有时可能会产生意想不到的结果:某些你声明的变量可能不复存在;控制流可能会突然跳转到你未曾预期的位置;一些语句也许不会执行,因为它们已经把常量结果计算了或值已经被保存;一些语句可能会在不同地方执行,因为它们已经被移出循环。
|
||||
|
||||
> 然而优化的输出也是可以调试的。这就使得让优化器可以合理地优化或许有 bug 的代码。
|
||||
|
||||
不只是 gdb,使用 `-g` 选项编译代码,还可以开启使用 Valgrind 内存检测工具,从而完全发挥出该选项的潜力。或许还有一些人不知道,mencheck 工具被程序员们用来检测代码中是否存在内存泄露。你可以在[这里][9]参见这个工具的用法。
|
||||
|
||||
继续往下,为了能够在代码分析中使用 gprof 工具,你需要使用 `-pg` 命令行选项来编译代码。这会让 gcc 生成额外的代码来写入分析信息,gprof 工具需要这些信息来进行代码分析。[gcc 手册][10] 中提到:当编译你需要数据的源文件时,你必须使用这个选项,当然链接时也需要使用它。为了能了解 gprof 分析代码时具体是如何工作的,你可以转到我们的网站[专用教程][11]进行了解。
|
||||
|
||||
**注意**:`-g` 和 `-pg` 选项的用法类似于上一节中使用 `-save-temps` 选项的方式。
|
||||
|
||||
### 结论
|
||||
|
||||
我相信除了 gcc 的专业人士,都可以在这篇文章中得到了一些启发。尝试一下这些选项,然后观察它们是如何工作的。同时,请期待本教程系列的[下一部分][12],我们将会讨论更多有趣和有用的 gcc 命令行选项。
|
||||
|
||||
--------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[dongdongmian](https://github.com/dongdongmian)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options/#see-intermediate-output-during-each-compilation-stage
|
||||
[2]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options/#make-your-code-debugging-and-profiling-ready
|
||||
[3]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options/#conclusion
|
||||
[4]:https://linux.die.net/man/1/gcc
|
||||
[5]:https://www.howtoforge.com/images/uncommon-but-useful-gcc-command-line-options/big/gcc-save-temps.png
|
||||
[6]:https://www.gnu.org/software/gdb/
|
||||
[7]:https://sourceware.org/binutils/docs/gprof/
|
||||
[8]:https://linux.die.net/man/1/gcc
|
||||
[9]:http://valgrind.org/docs/manual/mc-manual.html
|
||||
[10]:https://linux.die.net/man/1/gcc
|
||||
[11]:https://www.howtoforge.com/tutorial/how-to-install-and-use-profiling-tool-gprof/
|
||||
[12]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options-2/
|
||||
@ -0,0 +1,145 @@
|
||||
如何在 Linux 中启用 Shell 脚本的调试模式
|
||||
============================================================
|
||||
|
||||
|
||||
脚本是存储在一个文件的一系列命令。在终端上输入一个个命令,按顺序执行的方法太弱了,使用脚本,系统中的用户可以在一个文件中存储所有命令,反复调用该文件多次重新执行命令。
|
||||
|
||||
在 [学习脚本][1] 或写脚本的初期阶段,我们通常从写小脚本或者几行命令的短脚本开始,调试这样的脚本时我们通常无非就是通过观察它们的输出来确保其正常工作。
|
||||
|
||||
然而,当我们开始写非常长或上千行命令的高级脚本,例如改变系统设置的脚本,[在网络上执行关键备份][2] 等等,我们会意识到仅仅看脚本输出是不足以在脚本中找到 Bug 的!
|
||||
|
||||
因此,在 Linux 系列中这篇介绍 Shell 脚本调试, 我们将看看如何启用 Shell 脚本调试,然后在之后的系列中解释不同的 Shell 脚本调试模式以及如何使用它们。
|
||||
|
||||
### 如何开始写一个脚本
|
||||
|
||||
一个脚本与其它文件的区别是它的首行,它包含 `#!` (She-Bang - 释伴:定义文件类型)和路径名(解释器路径),通知系统该文件是一个命令集合,将被指定程序(解释器)解释。
|
||||
|
||||
下面是不同类型脚本 `首行` 示例:
|
||||
|
||||
```
|
||||
#!/bin/sh [sh 脚本]
|
||||
#!/bin/bash [bash 脚本]
|
||||
#!/usr/bin/perl [perl 程序]
|
||||
#!/bin/awk -f [awk 脚本]
|
||||
```
|
||||
|
||||
注意:如果脚本仅包含一组标准系统命令,没有任何内部 Shell 指令,首行或 `#!` 可以去掉。
|
||||
|
||||
### 如何在 Linux 操作系统执行 Shell 脚本
|
||||
|
||||
|
||||
调用一个脚本脚本的常规语法是:
|
||||
|
||||
```
|
||||
$ 脚本名 参数1 ... 参数N
|
||||
```
|
||||
|
||||
另一种可能的形式是明确指定将执行这个脚本的 Shell,如下:
|
||||
|
||||
```
|
||||
$ shell 脚本名 参数1 ... 参数N
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ /bin/bash 参数1 ... 参数N [bash 脚本]
|
||||
$ /bin/ksh 参数1 ... 参数N [ksh 脚本]
|
||||
$ /bin/sh 参数1 ... 参数N [sh 脚本]
|
||||
```
|
||||
|
||||
对于没有 `#!` 作为首行,仅包含基础系统命令的脚本,示例如下:
|
||||
|
||||
```
|
||||
### 脚本仅包含标准系统命令
|
||||
cd /home/$USER
|
||||
mkdir tmp
|
||||
echo "tmp directory created under /home/$USER"
|
||||
```
|
||||
|
||||
使它可执行并运行,如下:
|
||||
|
||||
```
|
||||
$ chmod +x 脚本名
|
||||
$ ./脚本名
|
||||
```
|
||||
|
||||
### 启用 Shell 脚本调试模式的方法
|
||||
|
||||
下面是主要的 Shell 脚本调试选项:
|
||||
|
||||
- `-v` (verbose 的简称) - 告诉 Shell 读取脚本时显示所有行,激活详细模式。
|
||||
- `-n` (noexec 或 no ecxecution 简称) - 指示 Shell 读取所有命令然而不执行它们,这个选项激活语法检查模式。
|
||||
- `-x` (xtrace 或 execution trace 简称) - 告诉 Shell 在终端显示所有执行的命令和它们的参数。 这个选项是启用 Shell 跟踪模式。
|
||||
|
||||
#### 1、 改变 Shell 脚本首行
|
||||
|
||||
第一个机制是改变 Shell 脚本首行,如下,这会启动脚本调试。
|
||||
|
||||
```
|
||||
#!/bin/sh 选项
|
||||
```
|
||||
|
||||
其中, 选项可以是上面提到的一个或多个调试选项。
|
||||
|
||||
#### 2、 调用 Shell 调试选项
|
||||
|
||||
第二个是使用如下调试选项启动 Shell,这个方法也会打开整个脚本调试。
|
||||
|
||||
```
|
||||
$ shell 选项 参数1 ... 参数N
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ /bin/bash 选项 参数1 ... 参数N
|
||||
```
|
||||
|
||||
#### 3、 使用 Shell 内置命令 set
|
||||
|
||||
第三个方法是使用内置命令 `set` 去调试一个给定的 Shell 脚本部分,如一个函数。这个机制是重要的,因为它让我们可以去调试任何一段 Shell 脚本。
|
||||
|
||||
我们可以如下使用 `set` 命令打开调试模式,其中选项是之前提到的所有调试选项。
|
||||
|
||||
```
|
||||
$ set 选项
|
||||
```
|
||||
|
||||
启用调试模式:
|
||||
|
||||
```
|
||||
$ set -选项
|
||||
```
|
||||
|
||||
禁用调试模式:
|
||||
|
||||
```
|
||||
$ set +选项
|
||||
```
|
||||
|
||||
此外,如果我们在 Shell 脚本不同部分启用了几个调试模式,我们可以一次禁用所有调试模式,如下:
|
||||
|
||||
```
|
||||
$ set -
|
||||
```
|
||||
|
||||
关于启用 Shell 脚本调试模式,先讲这些。正如我们看到的,我们可以调试一整个 Shell 脚本或者特定部分脚本。
|
||||
|
||||
在此系列下面的两篇文章中,我们会举例介绍如何使用 Shell 脚本调试选项,进一步了解 详细(verbose)、语法检查(syntax checking)、 跟踪(tracing)调试模式。
|
||||
|
||||
更重要的是,关于这个指南,欢迎通过下面评论提出任何问题或反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/enable-shell-debug-mode-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[imxieke](https://github.com/imxieke)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/category/bash-shell/
|
||||
[2]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
@ -0,0 +1,156 @@
|
||||
Linux 下清空或删除大文件内容的 5 种方法
|
||||
============================================================
|
||||
|
||||
在 Linux 终端下处理文件时,有时我们想直接清空文件的内容但又不必使用任何 [**Linux 命令行编辑器**][1] 去打开这些文件。那怎样才能达到这个目的呢?在这篇文章中,我们将介绍几种借助一些实用的命令来清空文件内容的方法。
|
||||
|
||||
**注意:**在我们进一步深入了解这些方法之前,请记住: 由于[**在 Linux 中一切皆文件**][2],你需要时刻注意,确保你将要清空的文件不是重要的用户文件或者系统文件。清空重要的系统文件或者配置文件可能会引发严重的应用失败或者系统错误。
|
||||
|
||||
前面已经说道,下面的这些方法都是从命令行中达到清空文件的目的。
|
||||
|
||||
**提示:**在下面的示例中,我们将使用名为 `access.log` 的文件来作为示例样本。
|
||||
|
||||
### 1. 通过重定向到 Null 来清空文件内容
|
||||
|
||||
清空或者让一个文件成为空白的最简单方式,是像下面那样,通过 shell 重定向 `null` (不存在的事物)到该文件:
|
||||
|
||||
```
|
||||
# > access.log
|
||||
```
|
||||
[
|
||||
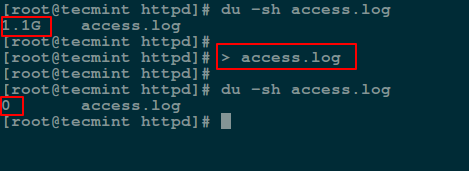
|
||||
][3]
|
||||
|
||||
*在 Linux 下使用 Null 重定向来清空大文件*
|
||||
|
||||
### 2. 使用 ‘true’ 命令重定向来清空文件
|
||||
|
||||
下面我们将使用 `:` 符号,它是 shell 的一个内置命令,等同于 `true` 命令,它可被用来作为一个 no-op(即不进行任何操作)。
|
||||
|
||||
另一种清空文件的方法是将 `:` 或者 `true` 内置命令的输出重定向到文件中,具体如下:
|
||||
|
||||
```
|
||||
# : > access.log
|
||||
或
|
||||
# true > access.log
|
||||
```
|
||||
[
|
||||
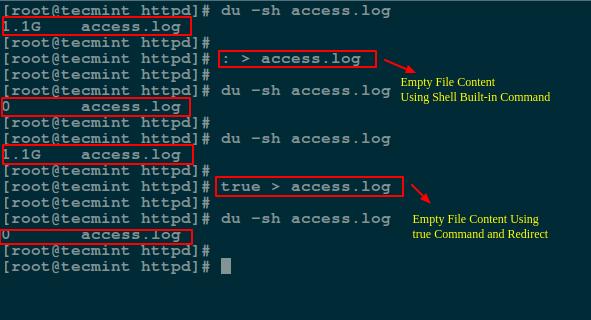
|
||||
][4]
|
||||
|
||||
*使用 Linux 命令清空大文件*
|
||||
|
||||
### 3. 使用 `cat`/`cp`/`dd` 实用工具及 `/dev/null` 设备来清空文件
|
||||
|
||||
在 Linux 中, `null` 设备基本上被用来丢弃某个进程不再需要的输出流,或者作为某个输入流的空白文件,这些通常可以利用重定向机制来达到。
|
||||
|
||||
所以 `/dev/null` 设备文件是一个特殊的文件,它将清空送到它这里来的所有输入,而它的输出则可被视为一个空文件。
|
||||
|
||||
另外,你可以通过使用 [**cat 命令**][5] 显示 `/dev/null` 的内容然后重定向输出到某个文件,以此来达到清空该文件的目的。
|
||||
|
||||
```
|
||||
# cat /dev/null > access.log
|
||||
```
|
||||
[
|
||||
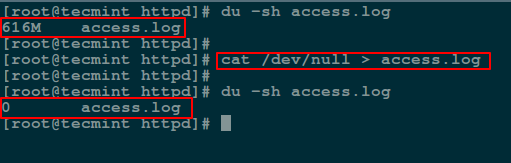
|
||||
][6]
|
||||
|
||||
*使用 cat 命令来清空文件*
|
||||
|
||||
下面,我们将使用 [**cp 命令**][7] 复制 `/dev/null` 的内容到某个文件来达到清空该文件的目的,具体如下所示:
|
||||
|
||||
```
|
||||
# cp /dev/null access.log
|
||||
```
|
||||
[
|
||||
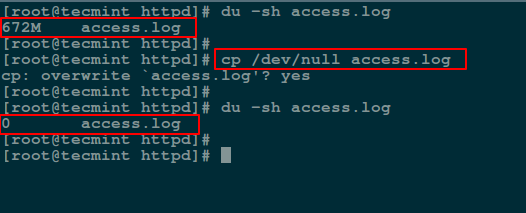
|
||||
][8]
|
||||
|
||||
*使用 cp 命令来清空文件*
|
||||
|
||||
而下面的命令中, `if` 代表输入文件,`of` 代表输出文件。
|
||||
|
||||
```
|
||||
# dd if=/dev/null of=access.log
|
||||
```
|
||||
[
|
||||
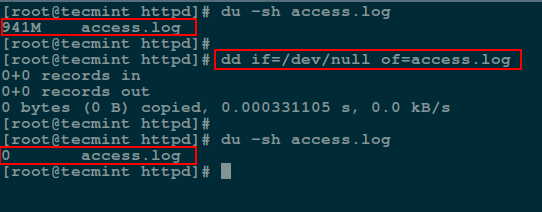
|
||||
][9]
|
||||
|
||||
*使用 dd 命令来清空文件内容*
|
||||
|
||||
### 4. 使用 echo 命令清空文件
|
||||
|
||||
在这里,你可以使用 [**echo 命令**][10] 将空字符串的内容重定向到文件中,具体如下:
|
||||
|
||||
```
|
||||
# echo "" > access.log
|
||||
或者
|
||||
# echo > access.log
|
||||
```
|
||||
[
|
||||
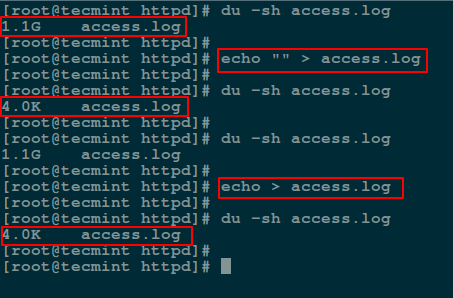
|
||||
][11]
|
||||
|
||||
*使用 echo 命令来清空文件*
|
||||
|
||||
**注意:**你应该记住空字符串并不等同于 `null` 。字符串表明它是一个具体的事物,只不过它的内容可能是空的,但 `null` 则意味着某个事物并不存在。
|
||||
|
||||
基于这个原因,当你将 [echo 命令][12] 的输出作为输入重定向到文件后,使用 [cat 命令][13] 来查看该文件的内容时,你将看到一个空白行(即一个空字符串)。
|
||||
|
||||
要将 null 做为输出输入到文件中,你应该使用 `-n` 选项,这个选项将告诉 echo 不再像上面的那个命令那样输出结尾的那个新行。
|
||||
|
||||
```
|
||||
# echo -n "" > access.log
|
||||
```
|
||||
[
|
||||
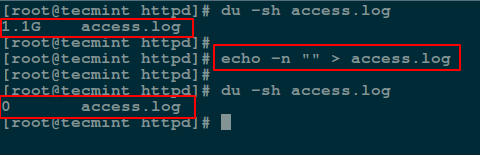
|
||||
][14]
|
||||
|
||||
*使用 Null 重定向来清空文件*
|
||||
|
||||
### 5. 使用 truncate 命令来清空文件内容
|
||||
|
||||
`truncate` 可被用来[**将一个文件缩小或者扩展到某个给定的大小**][15]。
|
||||
|
||||
你可以利用它和 `-s` 参数来特别指定文件的大小。要清空文件的内容,则在下面的命令中将文件的大小设定为 0:
|
||||
|
||||
```
|
||||
# truncate -s 0 access.log
|
||||
```
|
||||
[
|
||||
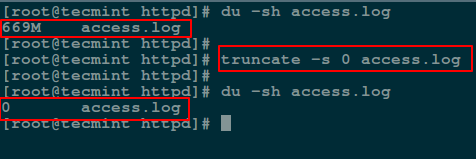
|
||||
][16]
|
||||
|
||||
*在 Linux 中截断文件内容*
|
||||
|
||||
我要介绍的就是这么多了。在本文中,我们介绍了几种通过使用一些简单的命令行工具和 shell 重定向机制来清除或清空文件内容的方法。
|
||||
|
||||
上面介绍的这些可能并不是达到清空文件内容这个目的的所有可行的实践方法,所以你也可以通过下面的评论栏告诉我们本文中尚未提及的其他方法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/empty-delete-file-content-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/linux-command-line-editors/
|
||||
[2]:http://www.tecmint.com/explanation-of-everything-is-a-file-and-types-of-files-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-Large-File-in-Linux.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-Large-File-Using-Linux-Commands.png
|
||||
[5]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Using-cat-Command.png
|
||||
[7]:http://www.tecmint.com/progress-monitor-check-progress-of-linux-commands/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Content-Using-cp-Command.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Content-Using-dd-Command.png
|
||||
[10]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Using-echo-Command.png
|
||||
[12]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[13]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Using-Null-Redirect.png
|
||||
[15]:http://www.tecmint.com/parted-command-to-create-resize-rescue-linux-disk-partitions/
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Truncate-File-Content-in-Linux.png
|
||||
@ -0,0 +1,192 @@
|
||||
不常见但是很有用的 GCC 命令行选项(二)
|
||||
============================================================
|
||||
|
||||
gcc 编译器提供了几乎数不清的命令行选项列表。当然,没有人会使用过或者精通它所有的命令行选项,但是有一些命令行选项是每一个 gcc 用户都应该知道的 - 即使不是必须知道。它们中有一些很常用,其他一些不太常用,但不常用并不意味着它们的用处没前者大。
|
||||
|
||||
在这个系列的文章中,我们集中于一些不常用但是很有用的 gcc 命令行选项,在[第一节][5]已经讲到几个这样的命令行选项。
|
||||
|
||||
不知道你是否能够回想起,在这个系列教程的第一部分的开始,我简要的提到了开发者们通常用来生成警告的 `-Wall` 选项,并不包括一些特殊的警告。如果你不了解这些特殊警告,并且不知道如何生成它们,不用担心,我将在这篇文章中详细讲解关于它们所有的细节。
|
||||
|
||||
除此以外,这篇文章也将涉及与浮点值相关的 gcc 警告选项,以及在 gcc 命令行选项列表变得很大的时候如何更好的管理它们。
|
||||
|
||||
在继续之前,请记住,这个教程中的所有例子、命令和指令都已在 Ubuntu 16.04 LTS 操作系统和 gcc 5.4.0 上测试过。
|
||||
|
||||
### 生成 -Wall 选项不包括的警告
|
||||
|
||||
尽管 gcc 编译器的 `-Wall` 选项涵盖了绝大多数警告标记,依然有一些警告不能生成。为了生成它们,请使用 `-Wextra` 选项。
|
||||
|
||||
比如,下面的代码:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
int main()
|
||||
{
|
||||
int i=0;
|
||||
/* ...
|
||||
some code here
|
||||
...
|
||||
*/
|
||||
|
||||
if(i);
|
||||
return 1;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
我不小心在 `if` 条件后面多打了一个分号。现在,如果使用下面的 gcc 命令来进行编译,不会生成任何警告。
|
||||
|
||||
```
|
||||
gcc -Wall test.c -o test
|
||||
```
|
||||
|
||||
但是如果同时使用 `-Wextra` 选项来进行编译:
|
||||
|
||||
```
|
||||
gcc -Wall -Wextra test.c -o test
|
||||
```
|
||||
|
||||
会生成下面这样一个警告:
|
||||
|
||||
```
|
||||
test.c: In function ‘main’:
|
||||
test.c:10:8: warning: suggest braces around empty body in an ‘if’ statement [-Wempty-body]
|
||||
if(i);
|
||||
```
|
||||
|
||||
从上面的警告清楚的看到, `-Wextra` 选项从内部启用了 `-Wempty-body` 选项,从而可以检测可疑代码并生成警告。下面是这个选项启用的全部警告标记。
|
||||
|
||||
- `-Wclobbered`
|
||||
- `-Wempty-body`
|
||||
- `-Wignored-qualifiers`
|
||||
- `-Wmissing-field-initializers`
|
||||
- `-Wmissing-parameter-type` (仅针对 C 语言)
|
||||
- `-Wold-style-declaration` (仅针对 C 语言)
|
||||
- `-Woverride-init`
|
||||
- `-Wsign-compare`
|
||||
- `-Wtype-limits`
|
||||
- `-Wuninitialized`
|
||||
- `-Wunused-parameter` (只有和 `-Wunused` 或 `-Wall` 选项使用时才会启用)
|
||||
- `-Wunused-but-set-parameter (只有和 `-Wunused` 或 `-Wall` 选项使用时才会生成)
|
||||
|
||||
如果想对上面所提到的标记有更进一步的了解,请查看 [gcc 手册][6]。
|
||||
|
||||
此外,遇到下面这些情况, `-Wextra` 选项也会生成警告:
|
||||
|
||||
* 一个指针和整数 `0` 进行 `<`, `<=`, `>`, 或 `>=` 比较
|
||||
* (仅 C++)一个枚举类型和一个非枚举类型同时出现在一个条件表达式中
|
||||
* (仅 C++)有歧义的虚拟基底
|
||||
* (仅 C++)寄存器类型的数组加下标
|
||||
* (仅 C++)对寄存器类型的变量进行取址
|
||||
* (仅 C++)基类没有在派生类的复制构建函数中进行初始化
|
||||
|
||||
### 浮点值的等值比较时生成警告
|
||||
|
||||
你可能已经知道,浮点值不能进行确切的相等比较(如果不知道,请阅读与浮点值比较相关的 [FAQ][7])。但是如果你不小心这样做了, gcc 编译器是否会报出错误或警告?让我们来测试一下:
|
||||
|
||||
下面是一段使用 `==` 运算符进行浮点值比较的代码:
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
void compare(float x, float y)
|
||||
{
|
||||
if(x == y)
|
||||
{
|
||||
printf("\n EQUAL \n");
|
||||
}
|
||||
}
|
||||
|
||||
int main(void)
|
||||
{
|
||||
compare(1.234, 1.56789);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
使用下面的 gcc 命令(包含 `-Wall` 和 `-Wextra` 选项)来编译这段代码:
|
||||
|
||||
```
|
||||
gcc -Wall -Wextra test.c -o test
|
||||
```
|
||||
|
||||
遗憾的是,上面的命令没有生成任何与浮点值比较相关的警告。快速看一下 gcc 手册,在这种情形下可以使用一个专用的 ```-Wfloat-equal``` 选项。
|
||||
|
||||
下面是包含这个选项的命令:
|
||||
|
||||
```
|
||||
gcc -Wall -Wextra -Wfloat-equal test.c -o test
|
||||
```
|
||||
|
||||
下面是这条命令产生的输出:
|
||||
|
||||
```
|
||||
test.c: In function ‘compare’:
|
||||
test.c:5:10: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
|
||||
if(x == y)
|
||||
```
|
||||
|
||||
正如上面你所看到的输出那样, `-Wfloat-equal` 选项会强制 gcc 编译器生成一个与浮点值比较相关的警告。
|
||||
|
||||
这儿是[gcc 手册][8]关于这一选项的说明:
|
||||
|
||||
> 这背后的想法是,有时,对程序员来说,把浮点值考虑成近似无限精确的实数是方便的。如果你这样做,那么你需要通过分析代码,或者其他方式,算出这种计算方式引入的最大或可能的最大误差,然后进行比较时(以及产生输出时,不过这是一个不同的问题)允许这个误差。特别要指出,不应该检查是否相等,而应该检查两个值是否可能出现范围重叠;这是用关系运算符来做的,所以等值比较可能是搞错了。
|
||||
|
||||
### 如何更好的管理 gcc 命令行选项
|
||||
|
||||
如果在你使用的 gcc 命令中,命令行选项列表变得很大而且很难管理,那么你可以把它放在一个文本文件中,然后把文件名作为 gcc 命令的一个参数。之后,你必须使用 `@file` 命令行选项。
|
||||
|
||||
比如,下面这行是你的 gcc 命令:
|
||||
|
||||
```
|
||||
gcc -Wall -Wextra -Wfloat-equal test.c -o test
|
||||
```
|
||||
|
||||
然后你可以把这三个和警告相关的选项放到一个文件里,文件名叫做 `gcc-options`:
|
||||
|
||||
```
|
||||
$ cat gcc-options
|
||||
-Wall -Wextra -Wfloat-equal
|
||||
```
|
||||
|
||||
这样,你的 gcc 命令会变得更加简洁并且易于管理:
|
||||
|
||||
```
|
||||
gcc @gcc-options test.c -o test
|
||||
```
|
||||
|
||||
下面是 gcc 手册关于 `@file` 的说明:
|
||||
|
||||
> 从文件中读取命令行选项。读取到的选项随之被插入到原始 `@file` 选项所在的位置。如果文件不存在或者无法读取,那么这个选项就会被当成文字处理,而不会被删除。
|
||||
|
||||
> 文件中的选项以空格分隔。选项中包含空白字符的话,可以用一个由单引号或双引号包围完整选项。任何字符(包括反斜杠: '\')均可能通过一个 '\' 前缀而包含在一个选项中。如果该文件本身包含额外的 `@file` 选项,那么它将会被递归处理。
|
||||
|
||||
|
||||
### 结论
|
||||
|
||||
在这个系列的教程中,我们一共讲解了 5 个不常见但是很有用的 gcc 命令行选项: `-Save-temps`、`-g`、 `-Wextra`、`-Wfloat-equal` 以及 `@file`。记得花时间练习使用每一个选项,同时不要忘了浏览 gcc 手册上面所提供的关于它们的全部细节。
|
||||
|
||||
你是否知道或使用其他像这样有用的 gcc 命令行选项,并希望把它们在全世界范围内分享?请在下面的评论区留下所有的细节。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options-2/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options-2/#enable-warnings-that-arent-covered-by-wall
|
||||
[2]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options-2/#enable-warning-fornbspfloating-point-values-in-equity-comparisons
|
||||
[3]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options-2/#how-to-better-manage-gcc-command-line-options
|
||||
[4]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options-2/#conclusion
|
||||
[5]:https://linux.cn/article-8025-1.html
|
||||
[6]:https://linux.die.net/man/1/gcc
|
||||
[7]:https://isocpp.org/wiki/faq/newbie
|
||||
[8]:https://linux.die.net/man/1/gcc
|
||||
@ -0,0 +1,170 @@
|
||||
httpstat:一个检查网站性能的 curl 统计分析工具
|
||||
============================================================
|
||||
|
||||
httpstat 是一个 Python 脚本,它以美妙妥善的方式反映了 curl 统计分析,它是一个单一脚本,兼容 Python 3 ,在用户的系统上不需要安装额外的软件(依赖)。
|
||||
|
||||
从本质上来说它是一个 cURL 工具的封装,意味着你可以在 URL 后使用几个有效的 cURL 选项,但是不包括 `-w`、 `-D`、 `-o`、 `-s` 和 `-S` 选项,这些已经被 httpstat 使用了。
|
||||
|
||||
[
|
||||
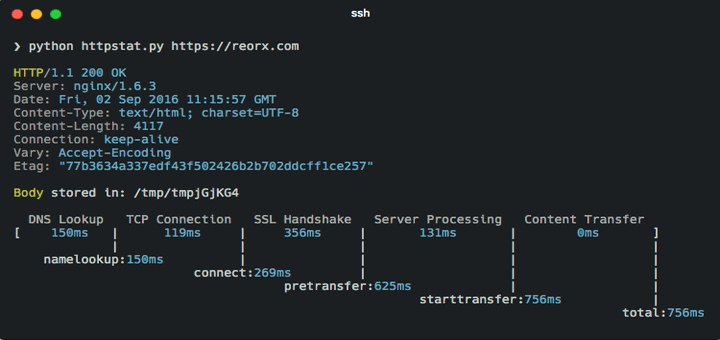
|
||||
][5]
|
||||
|
||||
*httpstat Curl 统计分析工具*
|
||||
|
||||
你可以看到上图的一个 ASCII 表显示了每个过程消耗多长时间,对我来说最重要的一步是“服务器处理(server processing)” – 如果这个数字很高,那么你需要[优化你网站服务器来加速访问速度][6]。
|
||||
|
||||
网站或服务器优化你可以查看我们的文章:
|
||||
|
||||
1. [5 个优化 Apache Web 服务器性能的技巧][1]
|
||||
2. [使 Apache 和 Nginx 性能提升 10 倍][2]
|
||||
3. [如何使用 Gzip 模块提高 Nginx 性能][3]
|
||||
4. [15 个优化 MySQL/MariaDB 性能的建议][4]
|
||||
|
||||
使用下面安装说明和用法来获取 httpstat 检查出你的网站速度。
|
||||
|
||||
### 在 Linux 系统中安装 httpstat
|
||||
|
||||
你可以使用两种合理的方法安装 httpstat :
|
||||
|
||||
1. 使用 [wget 命令][7]直接从它的 Github 仓库获取如下:
|
||||
|
||||
```
|
||||
$ wget -c https://raw.githubusercontent.com/reorx/httpstat/master/httpstat.py
|
||||
```
|
||||
|
||||
2. 使用 `pip`(这个方法允许 httpstat 作为命令安装到你的系统中)像这样:
|
||||
|
||||
```
|
||||
$ sudo pip install httpstat
|
||||
```
|
||||
|
||||
注:确保 `pip` 包已经在系统上安装了,如果没使用你的发行版包管理器 [yum][8] 或 [apt][9]安装它。
|
||||
|
||||
### 在 Linux 中如何使用 httpstat
|
||||
|
||||
`httpstat` 可以根据你安装它的方式来使用,如果你直接下载了它,进入下载目录使用下面的语句运行它:
|
||||
|
||||
```
|
||||
$ python httpstat.py url cURL_options
|
||||
```
|
||||
|
||||
如果你使用 `pip` 来安装它,你可以作为命令来执行它,如下表:
|
||||
|
||||
```
|
||||
$ httpstat url cURL_options
|
||||
```
|
||||
|
||||
查看 `httpstat` 帮助页,命令如下:
|
||||
|
||||
```
|
||||
$ python httpstat.py --help
|
||||
或
|
||||
$ httpstat --help
|
||||
```
|
||||
|
||||
`httpstat` 帮助:
|
||||
|
||||
```
|
||||
Usage: httpstat URL [CURL_OPTIONS]
|
||||
httpstat -h | --help
|
||||
httpstat --version
|
||||
Arguments:
|
||||
URL url to request, could be with or without `http(s)://` prefix
|
||||
Options:
|
||||
CURL_OPTIONS any curl supported options, except for -w -D -o -S -s,
|
||||
which are already used internally.
|
||||
-h --help show this screen.
|
||||
--version show version.
|
||||
Environments:
|
||||
HTTPSTAT_SHOW_BODY Set to `true` to show response body in the output,
|
||||
note that body length is limited to 1023 bytes, will be
|
||||
truncated if exceeds. Default is `false`.
|
||||
HTTPSTAT_SHOW_IP By default httpstat shows remote and local IP/port address.
|
||||
Set to `false` to disable this feature. Default is `true`.
|
||||
HTTPSTAT_SHOW_SPEED Set to `true` to show download and upload speed.
|
||||
Default is `false`.
|
||||
HTTPSTAT_SAVE_BODY By default httpstat stores body in a tmp file,
|
||||
set to `false` to disable this feature. Default is `true`
|
||||
HTTPSTAT_CURL_BIN Indicate the curl bin path to use. Default is `curl`
|
||||
from current shell $PATH.
|
||||
HTTPSTAT_DEBUG Set to `true` to see debugging logs. Default is `false`
|
||||
```
|
||||
|
||||
从上面帮助命令的输出,你可以看出 `httpstat` 已经具备了一些可以影响其行为的环境变量。
|
||||
|
||||
使用它们,只需输出适当的值的这些变量到 `.bashrc` 或 `.zshrc` 文件。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
export HTTPSTAT_SHOW_IP=false
|
||||
export HTTPSTAT_SHOW_SPEED=true
|
||||
export HTTPSTAT_SAVE_BODY=false
|
||||
export HTTPSTAT_DEBUG=true
|
||||
```
|
||||
|
||||
你一旦添加完它们,保存文件然后运行下面的命令使改变生效:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
你可以指定使用 cURL 执行文件的路径,默认使用的是当前 shell 的 [$PATH 环境变量][10]。
|
||||
|
||||
下面是一些展示 `httpstat` 如何工作的例子。
|
||||
|
||||
```
|
||||
$ python httpstat.py google.com
|
||||
或
|
||||
$ httpstat google.com
|
||||
```
|
||||
[
|
||||
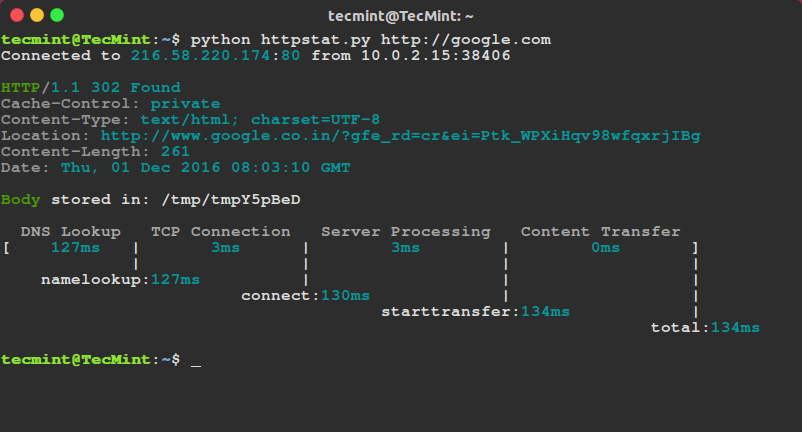
|
||||
][11]
|
||||
|
||||
*httpstat – 展示网站统计分析*
|
||||
|
||||
接下来的命令中:
|
||||
|
||||
1. `-X` 命令标记指定一个客户与 HTTP 服务器连接的请求方法。
|
||||
2. `--data-urlencode` 这个选项将会把数据(这里是 a=b)按 URL 编码的方式编码后再提交。
|
||||
3. `-v` 开启详细模式。
|
||||
|
||||
```
|
||||
$ python httpstat.py httpbin.org/post -X POST --data-urlencode "a=b" -v
|
||||
```
|
||||
|
||||
[
|
||||
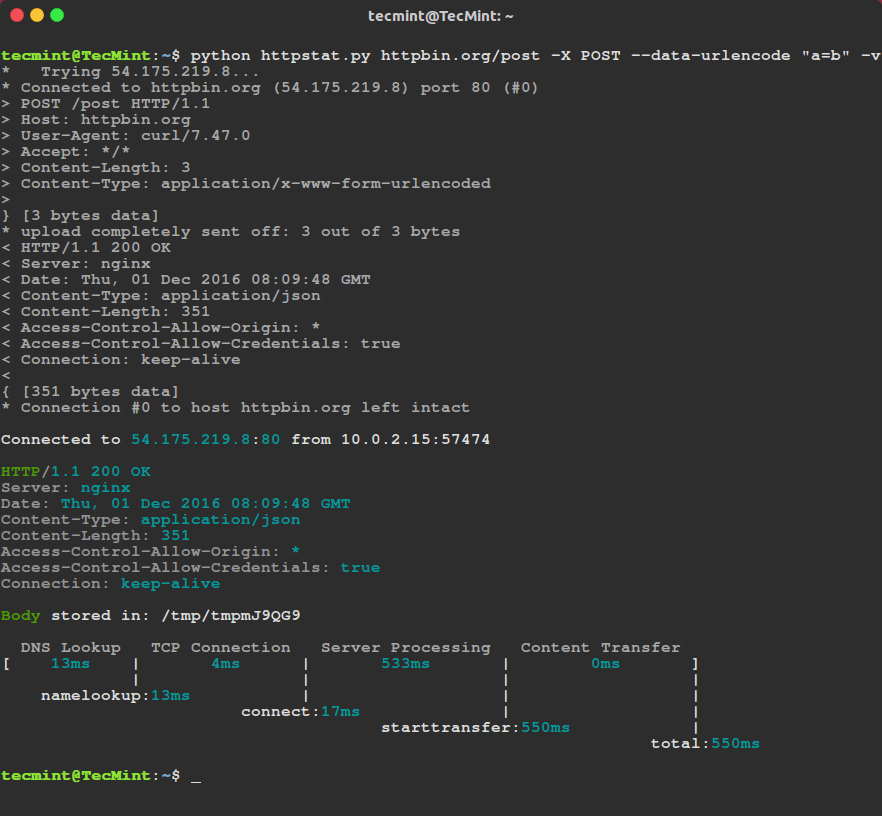
|
||||
][12]
|
||||
|
||||
*httpstat – 定制提交请求*
|
||||
|
||||
你可以查看 cURL 的帮助获取更多有用的高级选项,或者浏览 `httpstat` 的 Github 仓库:[https://github.com/reorx/httpstat][13]
|
||||
|
||||
这篇文章中,我们讲述了一个有效的工具,它以简单和整洁方式来查看 cURL 统计分析。如果你知道任何类似的工具,别犹豫,让我们知道,你也可以问问题或评论这篇文章或 httpstat,通过下面反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/httpstat-curl-statistics-tool-check-website-performance/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/apache-performance-tuning/
|
||||
[2]:http://www.tecmint.com/install-mod_pagespeed-to-boost-apache-nginx-performance/
|
||||
[3]:http://www.tecmint.com/increase-nginx-performance-enable-gzip-compression-module/
|
||||
[4]:https://linux.cn/article-5730-1.html
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/httpstat-Curl-Statistics-Tool.png
|
||||
[6]:http://www.tecmint.com/apache-performance-tuning/
|
||||
[7]:https://linux.cn/article-4129-1.html
|
||||
[8]:https://linux.cn/article-2272-1.html
|
||||
[9]:https://linux.cn/article-7364-1.html
|
||||
[10]:http://www.tecmint.com/set-unset-environment-variables-in-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/12/httpstat.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/httpstat-Post-Request.png
|
||||
[13]:https://github.com/reorx/httpstat
|
||||
@ -0,0 +1,85 @@
|
||||
如何在 Linux 中复制文件到多个目录中
|
||||
============================================================
|
||||
|
||||
[在学习 Linux 的过程中][1],对于新手而言总是会使用几个命令来完成一个简单的任务。对正在熟悉使用终端的人这是很容易理解的行为。然而,如果你想要成为一个老手,学习我说的“快捷命令”会显著减少时间浪费。
|
||||
|
||||
在本篇中,我们会用一个简单的方法在 Linux 中用一个命令来将目录复制到多个文件夹中。
|
||||
|
||||
在 Linux 中,[cp 命令][2]常被用于从一个文件夹中复制文件到另一个中,最简单的语法如下:
|
||||
|
||||
```
|
||||
# cp [options….] source(s) destination
|
||||
```
|
||||
|
||||
另外,你也可以使用[高级复制命令][3],它可以在复制[大的文件或文件夹][4]时显示进度条。
|
||||
|
||||
看下下面的命令,通常你会使用两个不同的命令来将相同的文件复制到不同的文件夹中:
|
||||
|
||||
```
|
||||
# cp -v /home/aaronkilik/bin/sys_info.sh /home/aaronkilik/test
|
||||
# cp -v /home/aaronkilik/bin/sys_info.sh /home/aaronkilik/tmp
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*复制文件到多个文件夹中*
|
||||
|
||||
假设你想要复制一个特定文件到 5 个或者更多的文件夹中,这意味着你需要输入 5 次或者更多的cp命令么?
|
||||
|
||||
要摆脱这个问题,你可以用 cp 命令与 [echo命令][6]、管道、xargs 命令一起使用:
|
||||
|
||||
```
|
||||
# echo /home/aaronkilik/test/ /home/aaronkilik/tmp | xargs -n 1 cp -v /home/aaronkilik/bin/sys_info.sh
|
||||
```
|
||||
|
||||
上面的命令中,目录的路径(dir1、dir2、dir3...dirN)被管道作为输入到 xargs 命令中,含义是:
|
||||
|
||||
1. `-n 1` - 告诉 xargs 命令每个命令行最多使用一个参数,并发送到 cp 命令中。
|
||||
2. `cp` – 用于复制文件。
|
||||
3. `-v` – 启用详细模式来显示更多复制细节。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*在 Linux 中复制文件到多个位置中*
|
||||
|
||||
试试阅读 `cp`、 `echo` 和 `xargs` 的 man 页面来找出所有有用和高级的用法信息:
|
||||
|
||||
```
|
||||
$ man cp
|
||||
$ man echo
|
||||
$ man xargs
|
||||
```
|
||||
|
||||
就是这样了,你可以在下面的评论区给我们发送主题相关的问题或者反馈。你也可以阅读有关 [progress 命令][8]来帮助监控运行中的(cp、mv、dd、[tar][9] 等等)的进度。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Aaron Kili 是一个 Linux 及 F.O.S.S 热衷者,即将成为 Linux 系统管理员、web 开发者,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/copy-file-to-multiple-directories-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/free-online-linux-learning-guide-for-beginners/
|
||||
[2]:http://www.tecmint.com/advanced-copy-command-shows-progress-bar-while-copying-files/
|
||||
[3]:http://www.tecmint.com/advanced-copy-command-shows-progress-bar-while-copying-files/
|
||||
[4]:http://www.tecmint.com/find-top-large-directories-and-files-sizes-in-linux/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/Copy-Files-to-Multiple-Directories.png
|
||||
[6]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/12/Copy-Files-to-Multiple-Directories-in-Linux.png
|
||||
[8]:http://www.tecmint.com/progress-monitor-check-progress-of-linux-commands/
|
||||
[9]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
@ -0,0 +1,79 @@
|
||||
慢动作输出 Linux 命令结果并用彩色显示
|
||||
============================================================
|
||||
|
||||
本篇中,我们会展示一个很酷及简单的方法在屏幕中显示彩色的输出,并且可以为了某个原因减慢输出的速度。
|
||||
|
||||
[lolcat 命令][2]可以满足上面的需求。它基本上通过与 [cat 命令][3]类似的方式将文件或标准输入定向到标准输出来运行,覆盖某个命令的默认屏幕输出颜色,并为其添加彩色。
|
||||
|
||||
### 如何在 Linux 中安装 lolcat 程序
|
||||
|
||||
lolcat 可以在大多数现代 Linux 发行版的默认仓库中得到,但是可用的版本有点老。你可以使用下面的指导来从 git 仓库中安装最新的 lolcat 版本。
|
||||
|
||||
- [安装 lolcat 来在 Linux 中显示彩色输出][1]
|
||||
|
||||
lolcat 安装后,基本的 lolcat 语法是:
|
||||
|
||||
```
|
||||
$ lolcat [options] [files] ...
|
||||
```
|
||||
|
||||
有几个选项可以控制它的行为,下面是一些我们在本指导中会强调的几个最重要的标志:
|
||||
|
||||
1. `-a` - 将每行输出都显示动态效果。
|
||||
2. `-d` – 指定动画效果间隔(显示下一行之前的帧),默认是 12。
|
||||
3. `-s` – 它指定了动画效果的速度(帧速-每秒的显示帧数),默认是 20。
|
||||
4. `-f` – 强制显示彩色以防止标准输出不是 tty。
|
||||
|
||||
你可以在 lolcat 的 man 页可以找到更多的选项:
|
||||
|
||||
```
|
||||
$ man lolcat
|
||||
```
|
||||
|
||||
### 如何在 Linux 中使用 lolcat
|
||||
|
||||
要使用 lolcat,直接将相关命令的输出通过管道给 lolcat,即可见证魔法。
|
||||
|
||||
比如:
|
||||
|
||||
```
|
||||
$ ls -l | lolcat -as 25
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
除此之外你也可以改变默认速度,在下面的命令中,我们会使用一个相对较慢的速度,每秒显示 10 帧:
|
||||
|
||||
```
|
||||
$ ls -l | lolcat -as 10
|
||||
```
|
||||
|
||||
你可以使用任何命令结合 lolcat 在 Linux 终端中输出彩色结果,比如 `ps`、`date` 和 `cal`:
|
||||
|
||||
```
|
||||
$ ps | lolcat
|
||||
$ date | lolcat
|
||||
$ cal | lolcat
|
||||
```
|
||||
|
||||
本篇中,我们了解了如何显著降低屏幕输出的速度,并显示彩色效果。
|
||||
|
||||
通常上,你可以在下面的评论栏中留下任何关于本篇的问题或评论。最后,你可以留下任何你发现的有用命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/add-colors-to-command-output-terminal-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://linux.cn/article-5798-1.html
|
||||
[2]:https://linux.cn/article-5798-1.html
|
||||
[3]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/12/Colorful-Linux-Terminal-Output.gif
|
||||
@ -0,0 +1,58 @@
|
||||
Arch Linux:DIY 用户的终极圣地,纯粹主义者的最后避难所
|
||||
==============
|
||||
|
||||

|
||||
|
||||
让我们翻过一页页 Linux 的新闻报道,你会发现其中对一些冷门的 Linux 发行版的报道数量却出乎预料的多。像 Elementary OS 和 Solus 这样的新发行版因其华丽的界面而被大家所关注,而搭载 MATE 桌面环境的那些系统则因其简洁性而被广泛报道。
|
||||
|
||||
感谢像《黑客军团》这样的电视节目,我完全可以预料到关于 Kali Linux 系统的报道很快就会增加。
|
||||
|
||||
尽管有很多关于 Linux 系统的报道,然而有一个被广泛使用的 Linux 发行版几乎被大家完全遗忘了:Arch Linux 系统!
|
||||
|
||||
关于 Arch 的新闻报道很少的原因有很多,不仅仅是因为它很难安装,而且你还得能在命令行下娴熟地完成各种配置以使其正常运行。更糟糕的是,以大多数的用户的观点来看,其困难是设计之初就没有考虑过其复杂的安装过程会令无数的菜鸟们望而却步。
|
||||
|
||||
这的确很遗憾,在我看来,实际上一旦安装完成后,Arch 比我用过的其它 Linux 发行版易用得多。
|
||||
|
||||
确实如此,Arch 的安装过程很让人蛋疼。有些发行版的安装过程只需要点击“安装”后就可以放手地去干其它事了。Arch 相对来说要花费更多的时间和精力去完成手动分区、手动挂载、生成 fstab 文件等。但是从 Arch 的安装过程中,我们学到很多。它掀开帷幕,让我们弄明白很多背后的东西。事实上,这层掩盖底层细节的帷幕已经彻底消失了,在 Arch 的世界里,你就是帷幕背后的主宰。
|
||||
|
||||
除了大家所熟知的难于安装外,Arch 甚至没有自己默认的桌面环境,虽然这有些让人难以理解,但是 Arch 也因其可定制化而被广泛推崇。你可以自行决定在 Arch 的基础软件包上安装的任何东西。
|
||||
|
||||

|
||||
|
||||
虽然你可以视之为无限可定制性,但也可以说它完全没有定制化。比如,不像 Ubuntu 系统那样,Arch 中几乎没有修改过或是定制开发过的软件包。Arch 的开发者从始至终都使用的是上游开发者提供的软件包。对于部分用户来说,这种情况非常棒。比如,你可以使用“纯粹”的 GNOME 桌面环境。但是,在某些情况下,定制的补丁可以解决一些上游开发者没有处理的很多的缺陷。
|
||||
|
||||
由于 Arch 缺乏一些默认的应用程序和桌面系统,以至于很难形成一致的看法——或者根本不会有什么真正的看法,因为我安装的毫无疑问和你安装的不会一样。我可能选择安装最小化安装配置 Openbox、tint2 和 dmenu,你可能却是使用了最新版的 GNOME 桌面系统。我们都在使用 Arch,但我们的体验却是大相径庭。对于任何发行版来说也有这种情况,但是其它大多数的 Linux 系统都至少有个默认的桌面环境。
|
||||
|
||||
然而对 Arch 的看法还是由很多共性的元素的。比如说,我使用 Arch 系统的主要原因是因为它是一个滚动更新的发行版。这意味着两件事情。首先,Arch 会尽可能的使用最新的内核,只要它们可用,被认为稳定就行。这就意味着我可以在 Arch 系统里测试一些在其它 Linux 发行版中难于测试的东西。滚动版另外一个最大的好处就是所有软件更新就绪就会被即时发布出来。这不仅意味着软件包更新速度更快,而且意味着不会出现破坏掉系统的大规模更新。
|
||||
|
||||
很多用户因为 Arch 是一个滚动发行版认为它不太稳定。但是在我使用了 9 个多月之后,我并不赞同这种观点。
|
||||
|
||||
然而,我从未因为一次升级系统而搞坏过任何东西。我确实有过回滚,因为系统启动分区 /boot 没有挂载,但是后来我发现那完全是自己操作上的失误,我更新后而忘记写入改变。一些暴露出来的缺陷(比如我关于戴尔 XPS 笔记本触摸板又出现以前解决过的问题)很快被修复,并且更新速度要比其它非滚动发行版快得多。总的来说,我认为 Arch 滚动更新的发布模式比其它我在用的发行版要稳定得多。唯一一点我要强调的是查阅维基上的资料,多关注你要更新的内容。
|
||||
|
||||
我怀疑 Arch 之所以没那么受欢迎,主要原因就是你必须要随时小心你的操作。盲目的更新 Arch 系统是极其危险的。但是任何一个发行版的更新都有风险,你只是认为它没有风险而已——因为你别无选择。
|
||||
|
||||
[Arch 的哲学理念][1]是我支持它的另外一个最主要的原因。我认为 Arch 最吸引用户的一点就是:“(Arch)面向的是专业的 Linux 用户,或者是有 DIY 精神,愿意查资料并解决问题的人”。
|
||||
|
||||
随着 Linux 进一步纳入主流,开发者们更需要顺利地渡过每一个艰难的技术领域。那些晦涩难懂的专有软件方面的经验恰恰能反映出用户高深的技术能力。
|
||||
|
||||
尽管在这个时代听起来有些怪怪的,但是事实上我们很多人更愿意自己动手装配一些东西。在这种情形下,Arch 将会是Linux DIY 用户的终极圣地。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: http://www.theregister.co.uk/2016/11/02/arch_linux_taster/
|
||||
|
||||
作者:[Scott Gilbertson][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/1785
|
||||
[1]:https://wiki.archlinux.org/index.php/Arch_Linux
|
||||
[2]:http://www.theregister.co.uk/Author/1785
|
||||
[3]:https://www.linkedin.com/shareArticle?mini=true&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&summary=Last%20refuge%20for%20purists
|
||||
[4]:http://twitter.com/share?text=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&via=theregister
|
||||
[5]:http://www.reddit.com/submit?url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good
|
||||
109
published/The history of Android/13 - The history of Android.md
Normal file
109
published/The history of Android/13 - The history of Android.md
Normal file
@ -0,0 +1,109 @@
|
||||
安卓编年史(13):Android 2.1, update 1——无尽战争的开端
|
||||
================================================================================
|
||||
|
||||
|
||||
### Android 2.1, update 1——无尽战争的开端 ###
|
||||
|
||||
谷歌是第一代 iPhone 的主要合作伙伴——公司为苹果的移动操作系统提供了谷歌地图、搜索,以及 Youtube。在那时,谷歌 CEO 埃里克·施密特是苹果的董事会成员之一。实际上,在最初的苹果发布会上,施密特是在史蒂夫·乔布斯[之后第一个登台的人][1],他还开玩笑说两家公司如此接近,都可以合并成“AppleGoo”了。
|
||||
|
||||
当谷歌开发安卓的时候,两家公司间的关系慢慢变得充满争吵。然而,谷歌很大程度上还是通过拒 iPhone 关键特性于安卓门外,如双指缩放,来取悦苹果。尽管如此,Nexus One 是第一部不带键盘的直板安卓旗舰机,设备被赋予了和iPhone 相同的外观因素。Nexus One 结合了新软件和谷歌的品牌,这是压倒苹果的最后一根稻草。根据沃尔特·艾萨克森为史蒂夫·乔布斯写的传记,2010 年 1 月在看到了 Nexus One 之后,这位苹果的 CEO 震怒了,说道:“如果需要的话我会用尽最后一口气,以及花光苹果在银行里的 400 亿美元,来纠正这个错误……我要摧毁安卓,因为它完全是偷窃来的产品。我愿意为此发起核战争。”
|
||||
|
||||
所有的这些都在秘密地发生,仅在 Nexus One 发布后的几年后才公诸于众。公众们最早在安卓 2.1——推送给 Nexus One 的一个称作 “[2.1 update 1][2]” 的更新,发布后一个月左右捕捉到谷歌和苹果间愈演愈烈的分歧气息。这个更新添加了一个功能,正是 iOS 一直居于安卓之上的功能:双指缩放。
|
||||
|
||||
尽管安卓从 2.0 版本开始就支持多点触控 API 了,但系统的默认应用在乔布斯的命令下依然和这项实用的功能划清界限。在关于 Nexus One 的和解会议谈崩了之后,谷歌再也没有理由拒双指缩放于安卓门外了。谷歌给设备推送了更新,安卓终于补上了不足之处。
|
||||
|
||||
随着谷歌地图、浏览器以及相册中双指缩放的全面启用,谷歌和苹果的智能手机战争也就此拉开序幕。在接下来的几年中,两家公司会变成死敌。双指缩放功能更新的一个月后,苹果开始了它的征途,起诉了所有使用安卓的公司。HTC、摩托罗拉以及三星都被告上法庭,直到现在都还有一些诉讼还没解决。施密特也辞去了苹果董事会的职务。谷歌地图和 Youtube 被从 iPhone 中移除,苹果甚至开始打造自己的地图服务。今天,这两位选手几乎是 “AppleGoo” 竞赛的唯一选手,涉及领域十分广泛:智能手机、平板、笔记本、电影、TV 秀、音乐、书籍、应用、邮件、生产力工具、浏览器、个人助理、云存储、移动广告、即时通讯、地图以及机顶盒……以及不久它们将会在汽车智能、穿戴设备、移动支付,以及客厅娱乐等进行竞争。
|
||||
|
||||
### Android 2.2 Froyo——更快更华丽 ###
|
||||
|
||||
[安卓 2.2][3] 在 2010 年 5 月,也就是 2.1 发布后的四个月后亮相。Froyo(冻酸奶)的亮点主要是底层优化,只为更快的速度。Froyo 最大的改变是增加了 JIT 即时编译。JIT 自动在运行时将 java 字节码转换为原生码,这会给系统全面带来显著的性能改善。
|
||||
|
||||
浏览器同样得到了性能改善,这要感谢整合了来自 Chrome 的 V8 Javascript 引擎。这是安卓浏览器从 Chrome 借鉴的许多特性中的第一个,最终系统内置的浏览器会被移动版 Chrome 彻底替代掉。在那之前,安卓团队还是需要提供一个浏览器。从 Chrome 借鉴特性是条升级的捷径。
|
||||
|
||||
在谷歌专注于让它的平台更快的同时,苹果正在让它的平台更全面。这位谷歌的竞争对手在一个月前发布了 10 英寸的 iPad,先行进入了平板时代。尽管有些搭载 Froyo 和 Gingerbread 的安卓平板发布,但谷歌的官方回应——安卓 3.0 Honeycomb(蜂巢)以及摩托罗拉 Xoom——在 9 个月后才来到。
|
||||
|
||||
|
||||
|
||||
*Froyo 底部添加了双图标停靠栏以及全局搜索。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
Froyo 主屏幕最大的变化是底部的新停靠栏,电话和浏览器图标填充了先前抽屉按钮左右的空白空间。这些新图标都是现有图标的白色定制版本,并且用户没办法自己设置图标。
|
||||
|
||||
默认布局移除了所有图标,屏幕上只留下一个使用提示小部件,引导你点击启动器图标以访问你的应用。谷歌搜索小部件得到了一个谷歌 logo,它同时也是个按钮。点击它可以打开一个搜索界面,你可以限制搜索范围是在互联网、应用或是联系人之内。
|
||||
|
||||
|
||||
|
||||
*下载页面有了“更新所有”按钮,这是个 Flash 应用,一个 flash 驱动的一切皆有可能的网站,以及“移动到 SD”按钮。
|
||||
[[Ryan Paul][4] 供图]*
|
||||
|
||||
还有一些优秀的新功能加入了 Froyo,安卓市场加入了更多的下载控制。有个新的“更新所有”按钮固定在了下载页面底部。谷歌还添加了自动更新特性,只要应用权限没有改变就能够自动安装应用;尽管如此,自动更新默认是关闭的。
|
||||
|
||||
第二张图展示了 Adobe Flash 播放器,它是 Froyo 独有的。这个应用作为插件加入了浏览器,让浏览器能够有“完整的网络”体验。在 2010 年,这意味着网页充满了 Flash 导航和视频。Flash 是安卓相比于 iPhone 最大的不同之一。史蒂夫·乔布斯展开了一场对抗 Flash 的圣战,声称它是一个被淘汰的、充满 bug 的软件,并且苹果不会允许它在 iOS 存在。所以安卓接纳了 Flash 并且让它在安卓上运行,给予用户在安卓上拥有接近可用的 flash 实现。
|
||||
|
||||
在那时,Flash 甚至能够让桌面电脑崩溃,所以在移动设备上一直保持打开状态会带来可怕的体验。为了解决这个问题,安卓浏览器上的 Flash 可以设置为“按需打开”——除非用户点击 Flash 占位图标,否则不会加载 Flash 内容。对 Flash 的支持将会持续到安卓 4.1,Adobe 在那时放弃并且结束了这个项目。Flash 从头到尾从未在安卓上完美运行过。而 Flash在 iPhone 这个最流行的移动设备上的缺失,推动了互联网最终放弃了这个平台。
|
||||
|
||||
最后一张图片显示的是新增的移动应用到 SD 卡功能,在那个手机只有 512 MB内置存储的时代,这个功能十分的必要的。
|
||||
|
||||

|
||||
|
||||
*驾驶模式应用。相机现在可以旋转了。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
相机应用终于更新支持纵向模式了。相机设置被从抽屉中移出,变成一条半透明的按钮带,放在了快门按钮和其他控制键旁边。这个新设计看起来从 Cooliris 相册中获得了许多灵感,半透明的、有弹性的聊天气泡弹出窗口。看到更现代的Cooliris 风格 UI 设计被嫁接到皮革装饰的相机应用确实十分奇怪——从审美上来说一点都不搭。
|
||||
|
||||
|
||||
|
||||
*半残缺的 Facebook 应用是个常见的 2x3 导航页面的优秀范例。谷歌 Goggles 被包含了进来但同样是残缺的。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
不像在安卓 2.0 和 2.1 中包含的 Facebook 客户端,2.2 版本的仍然部分能够工作并且可以登录 Facebook 服务器。Facebook 应用是谷歌那时候设计指南的优秀范例,它建议应用拥有一个含有 3x2 图标方阵的导航页并作为应用主页。
|
||||
|
||||
这是谷歌的第一个标准化尝试,将导航元素从菜单按钮里移到屏幕上,以便用户找到它们。这个设计很实用,但它在打开应用和使用应用之间增加了额外的障碍。谷歌不久后会意识到当用户打开一个应用,显示应用内容而不是中间导航页是个更好的主意。以 Facebook 为例,打开应用直接打开信息订阅会更合适。并且不久后应用设计将会把导航降级到二层位置——先是作为顶部的标签之一,后来谷歌放在了“导航抽屉”,一个含有应用所有功能位置的滑出式面板。
|
||||
|
||||
还有个预装到 Froyo 的应用是谷歌 Goggles,一个视觉搜索应用,它会尝试辨别图片上的主体。它在辨别艺术品、地标以及条形码时很实用,但差不多也就这些了。最先的两个设置屏幕,以及相机界面,这是应用里仅有的现在还能运行的了。由于客户端太旧了,实际上你如今并不能完成一个搜索。应用里也没什么太多可看的,也就一个会返回搜索结果页的相机界面而已。
|
||||
|
||||
|
||||
|
||||
*Twitter 应用,一个充满动画的谷歌和 Twitter 的合作成果。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
Froyo 拥有首个安卓 Twitter 应用,实际上它是谷歌和 Twitter 的合作成果。那时,Twitter 应用是安卓应用阵容里的大缺憾之一。开发者们更偏爱 iPhone,加上苹果占领先机和严格的设计要求,App Store 里可选择的应用远比安卓的有优势。但是谷歌需要一个 Twitter 应用,所以它和 Twitter 合作组建团队让第一个版本问世。
|
||||
|
||||
这个应用代表了谷歌的新设计语言,这意味着它有个中间导航页以及对动画要求的“技术演示”。Twitter 应用甚至比 Cooliris 相册用的动画效果还多——所有东西一直都在动。所有页面顶部和底部的云朵以不同速度持续滚动,底部的 Twitter 小鸟拍动它的翅膀并且左右移动它的头。
|
||||
|
||||
Twitter 应用实际上有点 Action Bar 早期前身的特性,在安卓 3.0 中引入了一条顶部对齐的连续控制条。沿着所有屏幕的顶部有条拥有 Twitter 标志以及如搜索、刷新和发推这样的按钮的蓝色横栏。它和后来的 Action Bar 之间大的区别在于 Twitter / 谷歌这里的设计的右上角缺少“上一级”按钮,实际上它在应用里用了完整的第二个栏位显示你当前所在位置。在上面的第二张图里,你可以看到整条带有“Tweets”标签的专用于显示位置的栏(当然,还有持续滚动的云朵)。第二个栏的 Twitter 标志扮演着另一个导航元素,有时候在当前部分显示额外的下拉区域,有时候显示整个顶级快捷方式集合。
|
||||
|
||||
2.3 Tweet 流看起来和今天的并没有什么不同,除了隐藏的操作按钮(回复,转推等),都在右对齐的箭头按钮里。它们弹出来的是一个聊天气泡菜单,看起来就像导航弹窗。仿 Action Bar 在发推页面有重要作用。它安置着 twitter 标志,剩余字数统计,以及添加照片、拍照,以及提到联系人按钮。
|
||||
|
||||
Twitter 应用甚至还有一对主屏幕小部件,大号的那个占据 8 格,提供了发推栏、更新按钮、一条推文,以及左右箭头来查看更多的推文。小号的显示一条推文以及回复按钮。点击大号的小部件的发推栏立即打开了“新推文”主窗口,这让“更新”按钮变得没有价值。
|
||||
|
||||
|
||||
|
||||
*Google Talk 和新 USB 对话框。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
其他部分,Google Talk(以及没有截图的短信应用)从暗色主题变成了浅色主题,这让它们看起来和现在的更接近现代的应用。USB 存储界面会在你设备接入电脑的时候从一个简单的对话框进入全屏界面。这个界面现在有个一个异形安卓机器人 / USB 闪存盘混合体,而不是之前的纯文字设计。
|
||||
|
||||
尽管安卓 2.2 在用户互动方式上没有什么新特性,但大的 UI 调整会在下两个版本到来。然而在所有的 UI 工作之前,谷歌希望先改进安卓的核心部分。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/13/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.youtube.com/watch?v=9hUIxyE2Ns8#t=3016
|
||||
[2]:http://arstechnica.com/gadgets/2010/02/googles-nexus-one-gets-multitouch/
|
||||
[3]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[4]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,291 +0,0 @@
|
||||
|
||||
### rusking translating
|
||||
|
||||
# Forget Technical Debt —Here'sHowtoBuild Technical Wealth
|
||||
|
||||
[Andrea Goulet][58] and her business partner sat in her living room, casually reviewing their strategic plan, when an episode of This Old House came on television. It was one of those moments where ideas collide to create something new. They’d been looking for a way to communicate their value proposition — cleaning up legacy code and technical debt for other companies. And here they were, face to face with the perfect analogy.
|
||||
|
||||
“We realized that what we were doing transcended clearing out old code, we were actually remodeling software the way you would remodel a house to make it last longer, run better, do more,” says Goulet. “It got me thinking about how companies have to invest in mending their code to get more productivity. Just like you have to put a new roof on a house to make it more valuable. It’s not sexy, but it’s vital, and too many people are doing it wrong.”
|
||||
|
||||
Today, she’s CEO of [Corgibytes][57] — a consulting firm that re-architects and modernizes apps. She’s seen all varieties of broken systems, legacy code, and cases of technical debt so extreme it’s basically digital hoarding. Here, Goulet argues that startups need to shift their mindset away from paying down debt toward building technical wealth, and away from tearing down old code toward deliberately remodeling it. She explains this new approach, and how you can do the impossible — actually recruit amazing engineers to tackle this work.
|
||||
|
||||
### RETHINKING LEGACY CODE
|
||||
|
||||
#
|
||||
|
||||
The most popular definition of legacy code comes from Michael Feathers, author of the aptly titled [Working Effectively with Legacy Code][56][][55]: It's code without test coverage. That’s better than what most people assume — that the term only applies only to really old, archaic systems. But neither definition goes far enough, according to Goulet. “Legacy code has nothing to do with the age of the software. A two year-old app can already be in a legacy state,” she says. “It’s all about how difficult that software is to improve.”
|
||||
|
||||
This means code that isn’t written cleanly, that lacks explanation, that contains zero artifacts of your ideas and decision-making processes. A unit test is one type of artifact, but so is any documentation of the rationale and reasoning used to create that code. If there’s no way to tell what the developer was thinking when you go to improve it — that’s legacy code.
|
||||
|
||||
> Legacy code isn't a technical problem. It's a communication problem.
|
||||
|
||||

|
||||
|
||||
If you linger around in legacy code circles like Goulet does, you’ll find that one particular, and rather obscure adage dubbed [Conway’s Law][54] will make it’s way into nearly every conversation.
|
||||
|
||||
“It’s the law that says your codebase will mirror the communication structures across your organization,” Goulet says. “If you want to fix your legacy code, you can’t do it without also addressing operations, too. That’s the missing link that so many people miss.”
|
||||
|
||||
Goulet and her team dive into a legacy project much like an archaeologist would. They look for artifacts left behind that give them clues into what past developers were thinking. All of these artifacts together provide context to make new decisions.
|
||||
|
||||
The most important artifact? Well organized, intention-revealing, clean code. For example, if you name a variable with generic terms like “foo” or “bar,” you might come back six months later and have no idea what that variable is for.
|
||||
|
||||
If the code isn’t easy to read, a useful artifact is the source control system, because it provides a history of changes to the code and gives developers an opportunity to write about the changes they’re making.
|
||||
|
||||
“A friend of mine says that for commit messages, every summary should be the size of half a tweet, with the description as long as a blog post, if necessary,” says Goulet. “You have the chance to tightly couple your rationale with the code that’s being changed. It doesn’t take a lot of extra time and gives tons of information to people working on the project later, but surprisingly few people do it. It’s common to hear developers get so frustrated about working with a piece of code they run ‘git blame’ in a fit of rage to figure out who wrote that mess, only to find it was themselves.”
|
||||
|
||||
Automated tests are also fertile ground for rationale. “There’s a reason that so many people like Michael Feathers’ definition of legacy code,” Goulet explains. “Test suites, especially when used along with [Behavior Driven Development][53] practices like writing out scenarios, are incredibly useful tools for understanding a developer’s intention.”
|
||||
|
||||
The lesson here is simple: If you want to limit your legacy code down the line, pay attention to the details that will make it easier to understand and work with in the future. Write and run unit, acceptance, approval, and integration tests. Explain your commits. Make it easy for future you (and others) to read your mind.
|
||||
|
||||
That said, legacy code will happen no matter what. For reasons both obvious and unexpected.
|
||||
|
||||
Early on at a startup, there’s usually a heavy push to get features out the door. Developers are under enormous pressure to deliver, and testing falls by the wayside. The Corgibytes team has encountered many companies that simply couldn’t be bothered with testing as they grew — for years.
|
||||
|
||||
Sure, it might not make sense to test compulsively when you’re pushing toward a prototype. But once you have a product and users, you need to start investing in maintenance and incremental improvements. “Too many people say, ‘Don’t worry about the maintenance, the cool things are the features!’” says Goulet. “If you do this, you’re guaranteed to hit a point where you cannot scale. You cannot compete.”
|
||||
|
||||
As it turns out, the second law of thermodynamics applies to code too: You’ll always be hurtling toward entropy. You need to constantly battle the chaos of technical debt. And legacy code is simply one type of debt you’ll accrue over time.
|
||||
|
||||
“Again the house metaphor applies. You have to keep putting away dishes, vacuuming, taking out the trash,” she says. “if you don’t, it’s going to get harder, until eventually you have to call in the HazMat team.”
|
||||
|
||||
Corgibytes gets a lot of calls from CEOs like this one, who said: “Features used to take two weeks to push three years ago. Now they’re taking 12 weeks. My developers are super unproductive.”
|
||||
|
||||
> Technical debt always reflects an operations problem.
|
||||
|
||||
A lot of CTOs will see the problem coming, but it’s hard to convince their colleagues that it’s worth spending money to fix what already exists. It seems like backtracking, with no exciting or new outputs. A lot of companies don’t move to address technical debt until it starts crippling day-to-day productivity, and by then it can be very expensive to pay down.
|
||||
|
||||
### FORGET DEBT, BUILD TECHNICAL WEALTH
|
||||
|
||||
# Recommended Article
|
||||
|
||||
You’re much more likely to get your CEO, investors and other stakeholders on board if you [reframe your technical debt][52] as an opportunity to accumulate technical wealth — [a term recently coined by agile development coach Declan Whelan][51].
|
||||
|
||||
“We need to stop thinking about debt as evil. Technical debt can be very useful when you’re in the early-stage trenches of designing and building your product,” says Goulet. “And when you resolve some debt, you’re giving yourself momentum. When you install new windows in your home, yes you’re spending a bunch of money, but then you save a hundred dollars a month on your electric bill. The same thing happens with code. Only instead of efficiency, you gain productivity that compounds over time.”
|
||||
|
||||
As soon as you see your team not being as productive, you want to identify the technical debt that's holding them back.
|
||||
|
||||
“I talk to so many startups that are killing themselves to acquire talent — they’re hiring so many high-paid engineers just to get more work done,” she says. “Instead, they should have looked at how to make each of their existing engineers more productive. What debt could you have paid off to get that extra productivity?”
|
||||
|
||||
If you change your perspective and focus on wealth building, you’ll end up with a productivity surplus, which can then be reinvested in fixing even more debt and legacy code in a virtuous cycle. Your product will be cruising and getting better all the time.
|
||||
|
||||
> Stop thinking about your software as a project. Start thinking about it as a house you will live in for a long time.
|
||||
|
||||
This is a critical mindset shift, says Goulet. It will take you out of short-term thinking and make you care about maintenance more than you ever have.
|
||||
|
||||
Just like with a house, modernization and upkeep happens in two ways: small, superficial changes (“I bought a new rug!”) and big, costly investments that will pay off over time (“I guess we’ll replace the plumbing...”). You have to think about both to keep your product current and your team running smoothly.
|
||||
|
||||
This also requires budgeting ahead — if you don’t, those bigger purchases are going to hurt. Regular upkeep is the expected cost of home ownership. Shockingly, many companies don’t anticipate maintenance as the cost of doing business.
|
||||
|
||||
This is how Goulet coined the term ‘software remodeling.’ When something in your house breaks, you don’t bulldoze parts of it and rebuild from scratch. Likewise, when you have old, broken code, reaching for a re-write isn’t usually the best option.
|
||||
|
||||
Here are some of the things Corgibytes does when they’re called in to ‘remodel’ a codebase:
|
||||
|
||||
* Break monolithic apps into micro-services that are lighter weight and more easily maintained.
|
||||
* Decouple features from each other to make them more extensible.
|
||||
* Refresh branding and look and feel of the front-end.
|
||||
* Establish automated testing so that code validates itself.
|
||||
* Refactor, or edit, codebases to make them easier to work with.
|
||||
|
||||
Remodeling also gets into DevOps territory. For example, Corgibytes often introduces new clients to [Docker][50], making it much easier and faster to set up new developer environments. When you have 30 engineers on your team, cutting the initial setup time from 10 hours to 10 minutes gives you massive leverage to accomplish more tasks. This type of effort can’t just be about the software itself, it also has to change how it’s built.
|
||||
|
||||
If you know which of these activities will make your code easier to handle and create efficiencies, you should build them into your annual or quarterly roadmap. Don’t expect them to happen on their own. But don’t put pressure on yourself to implement them all right away either. Goulet sees just as many startups hobbled by their obsession with having 100% test coverage from the very beginning.
|
||||
|
||||
To get more specific, there are three types of remodeling work every company should plan on:
|
||||
|
||||
* Automated testing
|
||||
* Continuous delivery
|
||||
* Cultural upgrades
|
||||
|
||||
Let’s take a closer look at each of these.
|
||||
|
||||
Automated Testing
|
||||
|
||||
“One of our clients was going into their Series B and told us they couldn’t hire talent fast enough. We helped them introduce an automated testing framework, and it doubled the productivity of their team in under 3 months,” says Goulet. “They were able to go to their investors and say, ‘We’re getting more with a lean team than we would have if we’d doubled the team.'”
|
||||
|
||||
Automated testing is basically a combination of individual tests. You have unit tests which double-check single lines of code. You have integration tests that make sure different parts of the system are playing nice. And you have acceptance tests that ensure features are working as you envisioned. When you write these tests as automated scripts, you can essentially push a button and have your system validate itself rather than having to comb through and manually click through everything.
|
||||
|
||||
Instituting this before hitting product-market fit is probably premature. But as soon as you have a product you’re happy with, and that users who depend on it, it’s more than worth it to put this framework in place.
|
||||
|
||||
Continuous Delivery
|
||||
|
||||
This is the automation of delivery related tasks that used to be manual. The goal is to be able to deploy a small change as soon as it’s done and make the feedback loop as short as possible. This can give companies a big competitive advantage over their competition, especially in customer service.
|
||||
|
||||
“Let’s say every time you deploy, it’s this big gnarly mess. Entropy is out of control,” says Goulet. “We’ve seen deployments take 12 hours or more because it’s such a cluster. And when this happens, you’re not going to deploy as often. You’re going to postpone shipping features because it’s too painful. You’re going to fall behind and lose to the competition.”
|
||||
|
||||
Other tasks commonly automated during continuous improvement include:
|
||||
|
||||
* Checking for breaks in the build when commits are made.
|
||||
* Rolling back in the event of a failure.
|
||||
* Automated code reviews that check for code quality.
|
||||
* Scaling computing resources up or down based on demand.
|
||||
* Making it easy to set up development, testing, and production environments.
|
||||
|
||||
As a simple example, let’s say a customer sends in a bug report. The more efficient the developer is in fixing that bug and getting it out, the better. The challenge with bug fixes isn’t that making the change is all that difficult, it’s that the system isn’t set up well and the developer wastes a lot of time doing things other than solving problems, which is what they’re best at.
|
||||
|
||||
With continuous improvement, you would become ruthless about determining which tasks are best for the computer and which are best for the human. If a computer is better at it, you automate it. This leaves the developer gleefully solving challenging problems. Customers are happier because their complaints are addressed and fixed quickly. Your backlog of fixes narrows and you’re able to spend more time on new creative ways to improve your app even more. This is the kind of change that generates technical wealth. Because that developer can ship new code as soon as they fix a bug in one step, they have time and bandwidth to do so much more frequently.
|
||||
|
||||
“You have to constantly ask, ‘How can I improve this for my users? How can I make this better? How can I make this more efficient?’ But don’t stop there,” says Goulet. “As soon as you have answers to these questions, you have to ask yourself how you can automate that improvement or efficiency.”
|
||||
|
||||
Cultural Upgrades
|
||||
|
||||
Every day, Corgibytes sees the same problem: A startup that's built an environment that makes it impossible for its developers to be impactful. The CEO looms over their shoulders wondering why they aren’t shipping more often. And the truth is that the culture of the company is working against them. To empower your engineers, you have to look at their environment holistically.
|
||||
|
||||
To make this point, Goulet quotes author Robert Henri:
|
||||
|
||||
> The object isn't to make art, it's to be in that wonderful state which makes art inevitable.
|
||||
|
||||
“That’s how you need to start thinking about your software,” she says. “Your culture can be that state. Your goal should always be to create an environment where art just happens, and that art is clean code, awesome customer service, happy developers, good product-market fit, profitability, etc. It’s all connected.”
|
||||
|
||||
This is a culture that prioritizes the resolution of technical debt and legacy code. That’s what will truly clear the path for your developers to make impact. And that’s what will give you the surplus to build cooler things in the future. You can’t remodel your product without making over the environment it’s developed in. Changing the overall attitude toward investing in maintenance and modernization is the place to start, ideally at the top with the CEO.
|
||||
|
||||
Here are some of Goulet's suggestions for establishing that flow-state culture:
|
||||
|
||||
* Resist the urge to reward “heroes” who work late nights. Praise effectiveness over effort.
|
||||
* Get curious about collaboration techniques, such as Woody Zuill’s [Mob Programming][44][][43].
|
||||
* Follow the four [Modern Agile][42] principles: make users awesome, experiment and learn rapidly, make safety a prerequisite, and deliver value continuously.
|
||||
* Give developers time outside of projects each week for professional development.
|
||||
* Practice [daily shared journals][41] as a way to enable your team to solve problems proactively.
|
||||
* Put empathy at the center of everything you do. At Corgibytes, [Brene Brown’s CourageWorks][40] training has been invaluable.
|
||||
|
||||
If execs and investors balk at this upgrade, frame it in terms of customer service, Goulet says. Tell them how the end product of this change will be a better experience for the people who matter most to them. It’s the most compelling argument you can make.
|
||||
|
||||
### FINDING THE MOST TALENTED REMODELERS
|
||||
|
||||
#
|
||||
|
||||
It’s an industry-wide assumption that badass engineers don’t want to work on legacy code. They want to build slick new features. Sticking them in the maintenance department would be a waste, people say.
|
||||
|
||||
These are misconceptions. You can find incredibly skilled engineers to work on your thorniest debt if you know where and how to look — and how to make them happy when you’ve got them.
|
||||
|
||||
“Whenever we speak at conferences, we poll the audience and ask 'Who loves working on legacy code?' It's pretty consistent that less than 10% of any crowd will raise their hands.” says Goulet. “But when I talked to these people, I found out they were the engineers who liked the most challenging problems.”
|
||||
|
||||
She has clients coming to her with homegrown databases, zero documentation, and no conceivable way to parse out structure. This is the bread and butter of a class of engineers she calls “menders.” Now she has a team of them working for her at Corgibytes who like nothing more than diving into binary files to see what’s really going on.
|
||||
|
||||

|
||||
|
||||
So, how can you find these elite forces? Goulet has tried a lot of things — and a few have worked wonders.
|
||||
|
||||
She launched a community website at [legacycode.rocks][49] that touts the following manifesto: “For too long, those of us who enjoy refactoring legacy code have been treated as second class developers... If you’re proud to work on legacy code, welcome!”
|
||||
|
||||
“I started getting all these emails from people saying, ‘Oh my god, me too!’” she says. “Just getting out there and spreading this message about how valuable this work is drew in the right people.”
|
||||
|
||||
Recommended Article
|
||||
|
||||
She’s also used continuous delivery practices in her recruiting to give these type of developers what they want: Loads of detail and explicit instructions. “It started because I hated repeating myself. If I got more than a few emails asking the same question, I’d put it up on the website, much like I would if I was writing documentation.”
|
||||
|
||||
But over time, she noticed that she could refine the application process even further to help her identify good candidates earlier in the process. For example, her application instructions read, “The CEO is going to review your resume, so make sure to address your cover letter to the CEO” without providing a gender. All letters starting with “Dear Sir,” or "Mr." are immediately trashed. And this is just the beginning of her recruiting gauntlet.
|
||||
|
||||
“This started because I was annoyed at how many times people assumed that because I’m the CEO of a software company, I must be a man,” Goulet said. “So one day, I thought I’d put it on the website as an instruction for applicants to see who was paying attention. To my surprise, it didn’t just muffle the less serious candidates. It amplified the folks who had the particular skills for working with legacy code.”
|
||||
|
||||
Goulet recalls how one candidate emailed her to say, “I inspected the code on your website (I like the site and hey, it’s what I do). There’s a weird artifact that seems to be written in PHP but it appears you’re running Jekyll which is in Ruby. I was really curious what that’s about.”
|
||||
|
||||
It turned out that there was a leftover PHP class name in the HTML, CSS, and JavaScript that Goulet got from her designer that she’d been meaning to getting around to but hadn’t had a chance. Her response: “Are you looking for a job?”
|
||||
|
||||
Another candidate noticed that she had used the term CTO in an instruction, but that title didn’t exist on her team (her business partner is the Chief Code Whisperer). Again, the attention to detail, the curiosity, and the initiative to make it better caught her eye.
|
||||
|
||||
> Menders aren't just detail-oriented, they're compelled by attention to detail.
|
||||
|
||||
Surprisingly, Goulet hasn't been plagued with the recruiting challenges of most tech companies. “Most people apply directly through our website, but when we want to cast a wider net, we use [PowerToFly][48] and [WeWorkRemotely][47]. I really don’t have a need for recruiters at the moment. They have a tough time understanding the nuance of what makes menders different.”
|
||||
|
||||
If they make it through an initial round, Goulet has a candidate read an article called “[Naming is a Process][46]” by Arlo Belshee. It delves into the very granular specifics of working with indebted code. Her only directions: “Read it and tell me what you think.”
|
||||
|
||||
She’s looking for understanding of subtleties in their responses, and also the willingness to take a point of view. It’s been really helpful in separating deep thinkers with conviction from candidates who just want to get hired. She highly recommends choosing a piece of writing that matters to your operations and will demonstrate how passionate, opinionated, and analytical people are.
|
||||
|
||||
Lastly, she’ll have a current team member pair program with the candidate using [Exercism.io][45]. It’s an open-source project that allows developers to learn how to code in different languages with a range of test driven development exercises. The first part of the pair programming session allows the candidate to choose a language to build in. For the next exercise, the interviewer gets to pick the language. They get to see how the person deals with surprise, how flexible they are, and whether they’re willing to admit they don’t know something.
|
||||
|
||||
“When someone has truly transitioned from a practitioner to a master, they freely admit what they don’t know,” says Goulet.
|
||||
|
||||
Having someone code in a language they aren’t that familiar with also gauges their stick-to-it-iveness. “We want someone who will say, ‘I’m going to hammer on this problem until it’s done.’ Maybe they’ll even come to us the next day and say, ‘I kept at it until I figured it out.’ That’s the type of behavior that’s very indicative of success as a mender.”
|
||||
|
||||
> Makers are so lionized in our industry that everyone wants to have them do maintenance too. That's a mistake. The best menders are never the best makers.
|
||||
|
||||
Once she has talented menders in the door, Goulet knows how to set them up for success. Here’s what you can do to make this type of developer happy and productive:
|
||||
|
||||
* Give them a generous amount of autonomy. Hand them assignments where you explain the problem, sure, but never dictate how they should solve it.
|
||||
* If they ask for upgrades to their computers and tooling, do it. They know what they need to maximize efficiency.
|
||||
* Help them [limit their context-switching][39]. They like to focus until something’s done.
|
||||
|
||||
Altogether, this approach has helped Corgibytes build a waiting list of over 20 qualified developers passionate about legacy code.
|
||||
|
||||
### STABILITY IS NOT A DIRTY WORD
|
||||
|
||||
#
|
||||
|
||||
Most startups don’t think past their growth phase. Some may even believe growth should never end. And it doesn’t have to, even when you enter the next stage: Stability. All stability means is that you have the people and processes you need to build technical wealth and spend it on the right priorities.
|
||||
|
||||
“There’s this inflection point between growth and stability where menders must surge, and you start to balance them more equally against the makers focused on new features,” says Goulet. “You have your systems. Now you need them to work better.”
|
||||
|
||||
This means allocating more of your organization’s budget to maintenance and modernization. “You can’t afford to think of maintenance as just another line item,” she says. “It has to become innate to your culture — something important that will yield greater success in the future.”
|
||||
|
||||
Ultimately, the technical wealth you build with these efforts will give rise to a whole new class of developers on your team: scouts that have the time and resources to explore new territory, customer bases and opportunities. When you have the bandwidth to tap into new markets and continuously get better at what you already do — that’s when you’re truly thriving.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://firstround.com/review/forget-technical-debt-heres-how-to-build-technical-wealth/
|
||||
|
||||
作者:[http://firstround.com/][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://firstround.com/
|
||||
[1]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[2]:http://www.courageworks.com/
|
||||
[3]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[4]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[5]:http://mobprogramming.org/
|
||||
[6]:http://exercism.io/
|
||||
[7]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[8]:https://weworkremotely.com/
|
||||
[9]:https://www.powertofly.com/
|
||||
[10]:http://legacycode.rocks/
|
||||
[11]:https://www.docker.com/
|
||||
[12]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[13]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[14]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[15]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[16]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[17]:http://corgibytes.com/
|
||||
[18]:https://www.linkedin.com/in/andreamgoulet
|
||||
[19]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[20]:http://www.courageworks.com/
|
||||
[21]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[22]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[23]:http://mobprogramming.org/
|
||||
[24]:http://mobprogramming.org/
|
||||
[25]:http://exercism.io/
|
||||
[26]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[27]:https://weworkremotely.com/
|
||||
[28]:https://www.powertofly.com/
|
||||
[29]:http://legacycode.rocks/
|
||||
[30]:https://www.docker.com/
|
||||
[31]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[32]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[33]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[34]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[35]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[36]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[37]:http://corgibytes.com/
|
||||
[38]:https://www.linkedin.com/in/andreamgoulet
|
||||
[39]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[40]:http://www.courageworks.com/
|
||||
[41]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[42]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[43]:http://mobprogramming.org/
|
||||
[44]:http://mobprogramming.org/
|
||||
[45]:http://exercism.io/
|
||||
[46]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[47]:https://weworkremotely.com/
|
||||
[48]:https://www.powertofly.com/
|
||||
[49]:http://legacycode.rocks/
|
||||
[50]:https://www.docker.com/
|
||||
[51]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[52]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[53]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[54]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[55]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[56]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[57]:http://corgibytes.com/
|
||||
[58]:https://www.linkedin.com/in/andreamgoulet
|
||||
@ -42,7 +42,7 @@ via: https://www.linux.com/news/build-strong-real-time-streaming-apps-apache-cal
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/aankerholz
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
|
||||
@ -0,0 +1,231 @@
|
||||
Reactive programming vs. Reactive systems
|
||||
============================================================
|
||||
|
||||
>Landing on a set of simple reactive design principles in a sea of constant confusion and overloaded expectations.
|
||||
|
||||

|
||||
|
||||
Download Konrad Malawski's free ebook "[Why Reactive? Foundational Principles for Enterprise Adoption][5]" to dive deeper into the technical aspects and benefits of Reactive.
|
||||
|
||||
Since co-authoring the "[Reactive Manifesto][23]" in 2013, we’ve seen the topic of reactive go from being a virtually unacknowledged technique for constructing applications—used by only fringe projects within a select few corporations—to become part of the overall platform strategy in numerous big players in the middleware field. This article aims to define and clarify the different aspects of reactive by looking at the differences between writing code in a _reactive programming_ style, and the design of _reactive systems_ as a cohesive whole.
|
||||
|
||||
### Reactive is a set of design principles
|
||||
|
||||
One recent indicator of success is that "reactive" has become an overloaded term and is now being associated with several different things to different people—in good company with words like "streaming," "lightweight," and "real-time."
|
||||
|
||||
Consider the following analogy: When looking at an athletic team (think: baseball, basketball, etc.) it’s not uncommon to see it composed of exceptional individuals, yet when they come together something doesn’t click and they lack the synergy to operate effectively as a team and lose to an "inferior" team.From the perspective of this article, reactive is a set of design principles, a way of thinking about systems architecture and design in a distributed environment where implementation techniques, tooling, and design patterns are components of a larger whole—a system.
|
||||
|
||||
This analogy illustrates the difference between a set of reactive applications put together without thought—even though _individually_ they’re great—and a reactive system. In a reactive system, it’s the _interaction between the individual parts_ that makes all the difference, which is the ability to operate individually yet act in concert to achieve their intended result.
|
||||
|
||||
_A reactive system_ is an architectural style that allows multiple individual applications to coalesce as a single unit, reacting to its surroundings, while remaining aware of each other—this could manifest as being able to scale up/down, load balancing, and even taking some of these steps proactively.
|
||||
|
||||
It’s possible to write a single application in a reactive style (i.e. using reactive programming); however, that’s merely one piece of the puzzle. Though each of the above aspects may seem to qualify as "reactive," in and of themselves they do not make a _system_ reactive.
|
||||
|
||||
When people talk about "reactive" in the context of software development and design, they generally mean one of three things:
|
||||
|
||||
* Reactive systems (architecture and design)
|
||||
* Reactive programming (declarative event-based)
|
||||
* Functional reactive programming (FRP)
|
||||
|
||||
We’ll examine what each of these practices and techniques mean, with emphasis on the first two. More specifically, we’ll discuss when to use them, how they relate to each other, and what you can expect the benefits from each to be—particularly in the context of building systems for multicore, cloud, and mobile architectures.
|
||||
|
||||
Let’s start by talking about functional reactive programming, and why we chose to exclude it from further discussions in this article.
|
||||
|
||||
### Functional reactive programming (FRP)
|
||||
|
||||
_Functional reactive programming_, commonly called _FRP_, is most frequently misunderstood. FRP was very [precisely defined][24] 20 years ago by Conal Elliott. The term has most recently been used incorrectly[1][8] to describe technologies like Elm, Bacon.js, and Reactive Extensions (RxJava, Rx.NET, RxJS) amongst others. Most libraries claiming to support FRP are almost exclusively talking about _reactive programming_ and it will therefore not be discussed further.
|
||||
|
||||
### Reactive programming
|
||||
|
||||
_Reactive programming_, not to be confused with _functional reactive programming_, is a subset of asynchronous programming and a paradigm where the availability of new information drives the logic forward rather than having control flow driven by a thread-of-execution.
|
||||
|
||||
It supports decomposing the problem into multiple discrete steps where each can be executed in an asynchronous and non-blocking fashion, and then be composed to produce a workflow—possibly unbounded in its inputs or outputs.
|
||||
|
||||
[Asynchronous][25] is defined by the Oxford Dictionary as “not existing or occurring at the same time,” which in this context means that the processing of a message or event is happening at some arbitrary time, possibly in the future. This is a very important technique in reactive programming since it allows for [non-blocking][26] execution—where threads of execution competing for a shared resource don’t need to wait by blocking (preventing the thread of execution from performing other work until current work is done), and can as such perform other useful work while the resource is occupied. Amdahl’s Law[2][9] tells us that contention is the biggest enemy of scalability, and therefore a reactive program should rarely, if ever, have to block.
|
||||
|
||||
Reactive programming is generally _event-driven_, in contrast to reactive systems, which are _message-driven_—the distinction between event-driven and message-driven is clarified later in this article.
|
||||
|
||||
The application program interface (API) for reactive programming libraries are generally either:
|
||||
|
||||
* Callback-based—where anonymous side-effecting callbacks are attached to event sources, and are being invoked when events pass through the dataflow chain.
|
||||
* Declarative—through functional composition, usually using well-established combinators like _map_, _filter_, _fold_etc.
|
||||
|
||||
Most libraries provide a mix of these two styles, often with the addition of stream-based operators like windowing, counts, triggers, etc.
|
||||
|
||||
It would be reasonable to claim that reactive programming is related to [dataflow programming][27], since the emphasis is on the _flow of data_ rather than the _flow of control_.
|
||||
|
||||
Examples of programming abstractions that support this programming technique are:
|
||||
|
||||
* [Futures/Promises][10]—containers of a single value, many-read/single-write semantics where asynchronous transformations of the value can be added even if it is not yet available.
|
||||
* Streams—as in [reactive streams][11]: unbounded flows of data processing, enabling asynchronous, non-blocking, back-pressured transformation pipelines between a multitude of sources and destinations.
|
||||
* [Dataflow variables][12]—single assignment variables (memory-cells) which can depend on input, procedures and other cells, so that they are automatically updated on change. A practical example is spreadsheets—where the change of the value in a cell ripples through all dependent functions, producing new values downstream.
|
||||
|
||||
Popular libraries supporting the reactive programming techniques on the JVM include, but are not limited to, Akka Streams, Ratpack, Reactor, RxJava, and Vert.x. These libraries implement the reactive streams specification, which is a standard for interoperability between reactive programming libraries on the JVM, and according to its own description is “...an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure.”
|
||||
|
||||
The primary benefits of reactive programming are: increased utilization of computing resources on multicore and multi-CPU hardware; and increased performance by reducing serialization points as per Amdahl’s Law and, by extension, Günther’s Universal Scalability Law[3][13].
|
||||
|
||||
A secondary benefit is one of developer productivity as traditional programming paradigms have all struggled to provide a straightforward and maintainable approach to dealing with asynchronous and non-blocking computation and I/O. Reactive programming solves most of the challenges here since it typically removes the need for explicit coordination between active components.
|
||||
|
||||
Where reactive programming shines is in the creation of components and composition of workflows. In order to take full advantage of asynchronous execution, the inclusion of [back-pressure][28] is crucial to avoid over-utilization, or rather unbounded consumption of resources.
|
||||
|
||||
Even though reactive programming is a very useful piece when constructing modern software, in order to reason about a system at a higher level one has to use another tool: _reactive architecture_—the process of designing reactive systems. Furthermore, it is important to remember that there are many programming paradigms and reactive programming is but one of them, so just as with any tool, it is not intended for any and all use-cases.
|
||||
|
||||
### Event-driven vs. message-driven
|
||||
|
||||
As mentioned previously, reactive programming—focusing on computation through ephemeral dataflow chains—tend to be _event-driven_, while reactive systems—focusing on resilience and elasticity through the communication, and coordination, of distributed systems—is [_message-driven_][29][4][14](also referred to as _messaging_).
|
||||
|
||||
The main difference between a message-driven system with long-lived addressable components, and an event-driven dataflow-driven model, is that messages are inherently directed, events are not. Messages have a clear (single) destination, while events are facts for others to observe. Furthermore, messaging is preferably asynchronous, with the sending and the reception decoupled from the sender and receiver respectively.
|
||||
|
||||
The glossary in the Reactive Manifesto [defines the conceptual difference as][30]:
|
||||
|
||||
> A message is an item of data that is sent to a specific destination. An event is a signal emitted by a component upon reaching a given state. In a message-driven system addressable recipients await the arrival of messages and react to them, otherwise lying dormant. In an event-driven system notification listeners are attached to the sources of events such that they are invoked when the event is emitted. This means that an event-driven system focuses on addressable event sources while a message-driven system concentrates on addressable recipients.
|
||||
|
||||
Messages are needed to communicate across the network and form the basis for communication in distributed systems, while events on the other hand are emitted locally. It is common to use messaging under the hood to bridge an event-driven system across the network by sending events inside messages. This allows maintaining the relative simplicity of the event-driven programming model in a distributed context and can work very well for specialized and well-scoped use cases (e.g., AWS Lambda, Distributed Stream Processing products like Spark Streaming, Flink, Kafka, and Akka Streams over Gearpump, and distributed Publish Subscribe products like Kafka and Kinesis).
|
||||
|
||||
However, it is a trade-off: what one gains in abstraction and simplicity of the programming model, one loses in terms of control. Messaging forces us to embrace the reality and constraints of distributed systems—things like partial failures, failure detection, dropped/duplicated/reordered messages, eventual consistency, managing multiple concurrent realities, etc.—and tackle them head on instead of hiding them behind a leaky abstraction—pretending that the network is not there—as has been done too many times in the past (e.g. EJB, [RPC][31], [CORBA][32], and [XA][33]).
|
||||
|
||||
These differences in semantics and applicability have profound implications in the application design, including things like _resilience_, _elasticity_, _mobility_, _location transparency,_ and _management_ of the complexity of distributed systems, which will be explained further in this article.
|
||||
|
||||
In a reactive system, especially one which uses reactive programming, both events and messages will be present—as one is a great tool for communication (messages), and another is a great way of representing facts (events).
|
||||
|
||||
### Reactive systems and architecture
|
||||
|
||||
_Reactive systems_—as defined by the Reactive Manifesto—is a set of architectural design principles for building modern systems that are well prepared to meet the increasing demands that applications face today.
|
||||
|
||||
The principles of reactive systems are most definitely not new, and can be traced back to the '70s and '80s and the seminal work by Jim Gray and Pat Helland on the [Tandem System][34] and Joe Armstrong and Robert Virding on [Erlang][35]. However, these people were ahead of their time and it is not until the last 5-10 years that the technology industry have been forced to rethink current best practices for enterprise system development and learn to apply the hard-won knowledge of the reactive principles on today’s world of multicore, cloud computing, and the Internet of Things.
|
||||
|
||||
The foundation for a reactive system is _message-passing_, which creates a temporal boundary between components that allows them to be decoupled in _time_—this allows for concurrency—and _space_—which allows for distribution and mobility. This decoupling is a requirement for full [isolation][36]between components, and forms the basis for both _resilience_ and _elasticity_.
|
||||
|
||||
### From programs to systems
|
||||
|
||||
The world is becoming increasingly interconnected. We are no longer building _programs_—end-to-end logic to calculate something for a single operator—as much as we are building _systems_.
|
||||
|
||||
Systems are complex by definition—each consisting of a multitude of components, who in and of themselves also can be systems—which mean software is increasingly dependent on other software to function properly.
|
||||
|
||||
The systems we create today are to be operated on computers small and large, few and many, near each other or half a world away. And at the same time users’ expectations have become harder and harder to meet as everyday human life is increasingly dependent on the availability of systems to function smoothly.
|
||||
|
||||
In order to deliver systems that users—and businesses—can depend on, they have to be _responsive_, for it does not matter if something provides the correct response if the response is not available when it is needed. In order to achieve this, we need to make sure that responsiveness can be maintained under failure (_resilience_) and under load (_elasticity_). To make that happen, we make these systems _message-driven_, and we call them _reactive systems_.
|
||||
|
||||
### The resilience of reactive systems
|
||||
|
||||
Resilience is about responsiveness _under failure_ and is an inherent functional property of the system, something that needs to be designed for, and not something that can be added in retroactively. Resilience is beyond fault-tolerance—it’s not about graceful degradation—even though that is a very useful trait for systems—but about being able to fully recover from failure: to _self-heal_. This requires component isolation and containment of failures in order to avoid failures spreading to neighbouring components—resulting in, often catastrophic, cascading failure scenarios.
|
||||
|
||||
So the key to building resilient, self-healing systems is to allow failures to be: contained, reified as messages, sent to other components (that act as supervisors), and managed from a safe context outside the failed component. Here, being message-driven is the enabler: moving away from strongly coupled, brittle, deeply nested synchronous call chains that everyone learned to suffer through, or ignore. The idea is to decouple the management of failures from the call chain, freeing the client from the responsibility of handling the failures of the server.
|
||||
|
||||
### The elasticity of reactive systems
|
||||
|
||||
[Elasticity][37] is about _responsiveness under load_—meaning that the throughput of a system scales up or down (as well as in or out) automatically to meet varying demand as resources are proportionally added or removed. It is the essential element needed to take advantage of the promises of cloud computing: allowing systems to be resource efficient, cost-efficient, environment-friendly and pay-per-use.
|
||||
|
||||
Systems need to be adaptive—allow intervention-less auto-scaling, replication of state and behavior, load-balancing of communication, failover, and upgrades, without rewriting or even reconfiguring the system. The enabler for this is _location transparency_: the ability to scale the system in the same way, using the same programming abstractions, with the same semantics, _across all dimensions of scale_—from CPU cores to data centers.
|
||||
|
||||
As the Reactive Manifesto [puts it][38]:
|
||||
|
||||
> One key insight that simplifies this problem immensely is to realize that we are all doing distributed computing. This is true whether we are running our systems on a single node (with multiple independent CPUs communicating over the QPI link) or on a cluster of nodes (with independent machines communicating over the network). Embracing this fact means that there is no conceptual difference between scaling vertically on multicore or horizontally on the cluster. This decoupling in space [...], enabled through asynchronous message-passing, and decoupling of the runtime instances from their references is what we call Location Transparency.
|
||||
|
||||
So no matter where the recipient resides, we communicate with it in the same way. The only way that can be done semantically equivalent is via messaging.
|
||||
|
||||
### The productivity of reactive systems
|
||||
|
||||
As most systems are inherently complex by nature, one of the most important aspects is to make sure that a system architecture will impose a minimal reduction of productivity, in the development and maintenance of components, while at the same time reducing the operational _accidental complexity_ to a minimum.
|
||||
|
||||
This is important since during the lifecycle of a system—if not properly designed—it will become harder and harder to maintain, and require an ever-increasing amount of time and effort to understand, in order to localize and to rectify problems.
|
||||
|
||||
Reactive systems are the most _productive_ systems architecture that we know of (in the context of multicore, cloud and mobile architectures):
|
||||
|
||||
* Isolation of failures offer [bulkheads][15] between components, preventing failures to cascade, which limits the scope and severity of failures.
|
||||
* Supervisor hierarchies offer multiple levels of defenses paired with self-healing capabilities, which remove a lot of transient failures from ever incurring any operational cost to investigate.
|
||||
* Message-passing and location transparency allow for components to be taken offline and replaced or rerouted without affecting the end-user experience, reducing the cost of disruptions, their relative urgency, and also the resources required to diagnose and rectify.
|
||||
* Replication reduces the risk of data loss, and lessens the impact of failure on the availability of retrieval and storage of information.
|
||||
* Elasticity allows for conservation of resources as usage fluctuates, allowing for minimizing operational costs when load is low, and minimizing the risk of outages or urgent investment into scalability as load increases.
|
||||
|
||||
Thus, reactive systems allows for the creation systems that cope well under failure, varying load and change over time—all while offering a low cost of ownership over time.
|
||||
|
||||
### How does reactive programming relate to reactive systems?
|
||||
|
||||
Reactive programming is a great technique for managing internal logic and dataflow transformation, locally within the components, as a way of optimizing code clarity, performance and resource efficiency. Reactive systems, being a set of architectural principles, puts the emphasis on distributed communication and gives us tools to tackle resilience and elasticity in distributed systems.
|
||||
|
||||
One common problem with only leveraging reactive programming is that its tight coupling between computation stages in an event-driven callback-based or declarative program makes _resilience_ harder to achieve as its transformation chains are often ephemeral and its stages—the callbacks or combinators—are anonymous, i.e. not addressable.
|
||||
|
||||
This means that they usually handle success or failure directly without signaling it to the outside world. This lack of addressability makes recovery of individual stages harder to achieve as it is typically unclear where exceptions should, or even could, be propagated. As a result, failures are tied to ephemeral client requests instead of to the overall health of the component—if one of the stages in the dataflow chain fails, then the whole chain needs to be restarted, and the client notified. This is in contrast to a message-driven reactive system which has the ability to self-heal, without necessitating notifying the client.
|
||||
|
||||
Another contrast to the reactive systems approach is that pure reactive programming allows decoupling in _time_, but not _space_ (unless leveraging message-passing to distribute the dataflow graph under the hood, across the network, as discussed previously). As mentioned, decoupling in time allows for _concurrency_, but it is decoupling in space that allows for _distribution_, and _mobility_—allowing for not only static but also dynamic topologies—which is essential for _elasticity_.
|
||||
|
||||
A lack of location transparency makes it hard to scale out a program purely based on reactive programming techniques adaptively in an elastic fashion and therefore requires layering additional tools, such as a message bus, data grid, or bespoke network protocols on top. This is where the message-driven programming of reactive systems shines, since it is a communication abstraction that maintains its programming model and semantics across all dimensions of scale, and therefore reduces system complexity and cognitive overhead.
|
||||
|
||||
A commonly cited problem of callback-based programming is that while writing such programs may be comparatively easy, it can have real consequences in the long run.
|
||||
|
||||
For example, systems based on anonymous callbacks provide very little insight when you need to reason about them, maintain them, or most importantly figure out what, where, and why production outages and misbehavior occur.
|
||||
|
||||
Libraries and platforms designed for reactive systems (such as the [Akka][39] project and the [Erlang][40] platform) have long learned this lesson and are relying on long-lived addressable components that are easier to reason about in the long run. When failures occurs, the component is uniquely identifiable along with the message that caused the failure. With the concept of addressability at the core of the component model, monitoring solutions have a _meaningful_ way to present data that is gathered—leveraging the identities that are propagated.
|
||||
|
||||
The choice of a good programming paradigm, one that enforces things like addressability and failure management, has proven to be invaluable in production, as it is designed with the harshness of reality in mind, to _expect and embrace failure_ rather than the lost cause of trying to prevent it.
|
||||
|
||||
All in all, reactive programming is a very useful implementation technique, which can be used in a reactive architecture. Remember that it will only help manage one part of the story: dataflow management through asynchronous and nonblocking execution—usually only within a single node or service. Once there are multiple nodes, there is a need to start thinking hard about things like data consistency, cross-node communication, coordination, versioning, orchestration, failure management, separation of concerns and responsibilities etc.—i.e. system architecture.
|
||||
|
||||
Therefore, to maximize the value of reactive programming, use it as one of the tools to construct a reactive system. Building a reactive system requires more than abstracting away OS-specific resources and sprinkling asynchronous APIs and [circuit breakers][41] on top of an existing, legacy, software stack. It should be about embracing the fact that you are building a distributed system comprising multiple services—that all need to work together, providing a consistent and responsive experience, not just when things work as expected but also in the face of failure and under unpredictable load.
|
||||
|
||||
### Summary
|
||||
|
||||
Enterprises and middleware vendors alike are beginning to embrace reactive, with 2016 witnessing a huge growth in corporate interest in adopting reactive. In this article, we have described reactive systems as being the end goal—assuming the context of multicore, cloud and mobile architectures—for enterprises, with reactive programming serving as one of the important tools.
|
||||
|
||||
Reactive programming offers productivity for developers—through performance and resource efficiency—at the component level for internal logic and dataflow transformation. Reactive systems offer productivity for architects and DevOps practitioners—through resilience and elasticity—at the system level, for building _cloud native_ and other large-scale distributed systems. We recommend combining the techniques of reactive programming within the design principles of reactive systems.
|
||||
|
||||
```
|
||||
1 According to Conal Elliott, the inventor of FRP, in [this presentation][16][↩][17]
|
||||
2 [Amdahl’s Law][18] shows that the theoretical speedup of a system is limited by the serial parts, which means that the system can experience diminishing returns as new resources are added. [↩][19]
|
||||
3 Neil Günter’s [Universal Scalability Law][20] is an essential tool in understanding the effects of contention and coordination in concurrent and distributed systems, and shows that the cost of coherency in a system can lead to negative results, as new resources are added to the system.[↩][21]
|
||||
4 Messaging can be either synchronous (requiring the sender and receiver to be available at the same time) or asynchronous (allowing them to be decoupled in time). Discussing the semantic differences is out scope for this article.[↩][22]
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems
|
||||
|
||||
作者:[Jonas Bonér][a] , [Viktor Klang][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/e0b57-jonas-boner
|
||||
[b]:https://www.oreilly.com/people/f96106d4-4ce6-41d9-9d2b-d24590598fcd
|
||||
[1]:https://www.flickr.com/photos/pixel_addict/2301302732
|
||||
[2]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[3]:https://www.oreilly.com/people/e0b57-jonas-boner
|
||||
[4]:https://www.oreilly.com/people/f96106d4-4ce6-41d9-9d2b-d24590598fcd
|
||||
[5]:http://www.oreilly.com/programming/free/why-reactive.csp?intcmp=il-webops-free-product-na_new_site_reactive_programming_vs_reactive_systems_text_cta
|
||||
[6]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[7]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[8]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-1
|
||||
[9]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-2
|
||||
[10]:https://en.wikipedia.org/wiki/Futures_and_promises
|
||||
[11]:http://reactive-streams.org/
|
||||
[12]:https://en.wikipedia.org/wiki/Oz_(programming_language)#Dataflow_variables_and_declarative_concurrency
|
||||
[13]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-3
|
||||
[14]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-4
|
||||
[15]:http://skife.org/architecture/fault-tolerance/2009/12/31/bulkheads.html
|
||||
[16]:https://begriffs.com/posts/2015-07-22-essence-of-frp.html
|
||||
[17]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-1
|
||||
[18]:https://en.wikipedia.org/wiki/Amdahl%2527s_law
|
||||
[19]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-2
|
||||
[20]:http://www.perfdynamics.com/Manifesto/USLscalability.html
|
||||
[21]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-3
|
||||
[22]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-4
|
||||
[23]:http://www.reactivemanifesto.org/
|
||||
[24]:http://conal.net/papers/icfp97/
|
||||
[25]:http://www.reactivemanifesto.org/glossary#Asynchronous
|
||||
[26]:http://www.reactivemanifesto.org/glossary#Non-Blocking
|
||||
[27]:https://en.wikipedia.org/wiki/Dataflow_programming
|
||||
[28]:http://www.reactivemanifesto.org/glossary#Back-Pressure
|
||||
[29]:http://www.reactivemanifesto.org/glossary#Message-Driven
|
||||
[30]:http://www.reactivemanifesto.org/glossary#Message-Driven
|
||||
[31]:https://christophermeiklejohn.com/pl/2016/04/12/rpc.html
|
||||
[32]:https://queue.acm.org/detail.cfm?id=1142044
|
||||
[33]:https://cs.brown.edu/courses/cs227/archives/2012/papers/weaker/cidr07p15.pdf
|
||||
[34]:http://www.hpl.hp.com/techreports/tandem/TR-86.2.pdf
|
||||
[35]:http://erlang.org/download/armstrong_thesis_2003.pdf
|
||||
[36]:http://www.reactivemanifesto.org/glossary#Isolation
|
||||
[37]:http://www.reactivemanifesto.org/glossary#Elasticity
|
||||
[38]:http://www.reactivemanifesto.org/glossary#Location-Transparency
|
||||
[39]:http://akka.io/
|
||||
[40]:https://www.erlang.org/
|
||||
[41]:http://martinfowler.com/bliki/CircuitBreaker.html
|
||||
@ -0,0 +1,225 @@
|
||||
The (updated) history of Android
|
||||
============================================================
|
||||
|
||||
### Follow the endless iterations from Android 0.5 to Android 7 and beyond.
|
||||
|
||||
|
||||
Google Search was literally everywhere in Lollipop. A new "always-on voice recognition" feature allowed users to say "OK Google" at any time, from any screen, even when the display was off. The Google app was still Google's primary home screen, a feature which debuted in KitKat. The search bar was now present on the new recent apps screen, too.
|
||||
|
||||
Google Now was still the left-most home screen page, but now a Material Design revamp gave it headers with big bold colors and redesigned typography.
|
||||
|
||||
* [
|
||||
|
||||
][1]
|
||||
* [
|
||||
|
||||
][2]
|
||||
* [
|
||||
|
||||
][3]
|
||||
* [
|
||||
|
||||
][4]
|
||||
* [
|
||||
|
||||
][5]
|
||||
* [
|
||||
|
||||
][6]
|
||||
* [
|
||||
|
||||
][7]
|
||||
* [
|
||||
|
||||
][8]
|
||||
|
||||
The Play Store followed a similar path to other Lollipop apps. There was a huge visual refresh with bold colors, new typography, and a fresh layout. It's rare that there's any additional functionality here, just a new coat of paint on everything.
|
||||
|
||||
The Navigation panel for the Play Store could now actually be used for navigation, with entries for each section of the Play Store. Lollipop also typically did away with the overflow button in the action bar, instead deciding to go with a single action button (usually search) and dumping every extra option in the navigation bar. This gave users a single place to look for items instead of having to hunt through two different menus.
|
||||
|
||||
Also new in Lollipop apps was the ability to make the status bar transparent. This allowed the action bar color to bleed right through the status bar, making the bar only slightly darker than the surrounding UI. Some interfaces even used a full-bleed hero image at the top of the screen, which would show through the status bar.
|
||||
|
||||
[
|
||||
|
||||
][38]
|
||||
|
||||
|
||||
Google Calendar was completely re-written, gaining lots of new design touches and losing lots of features. You could no longer pinch zoom to adjust the time scale of views, month view was gone on phones, and week view regressed from a seven-day view to five days. Google would spend the next few versions re-adding some of these features after users complained. "Google Calendar" also doubled down on the "Google" by removing the ability to add third-party accounts directly in the app. Non-Google accounts would now need to be added via Gmail.
|
||||
|
||||
It did look nice, though. In some views, the start of each month came with a header picture, just like a real paper calendar. Events with locations attached showed pictures from those locations. For instance, my "flight to San Francisco" displayed the Golden Gate Bridge. Google Calendar would also pull events out of Gmail and display them right on your calendar.
|
||||
|
||||
* [
|
||||
|
||||
][9]
|
||||
* [
|
||||
|
||||
][10]
|
||||
* [
|
||||
|
||||
][11]
|
||||
* [
|
||||
|
||||
][12]
|
||||
* [
|
||||
|
||||
][13]
|
||||
* [
|
||||
|
||||
][14]
|
||||
* [
|
||||

|
||||
][15]
|
||||
* [
|
||||
|
||||
][16]
|
||||
* [
|
||||
|
||||
][17]
|
||||
* [
|
||||
|
||||
][18]
|
||||
* [
|
||||
|
||||
][19]
|
||||
* [
|
||||
|
||||
][20]
|
||||
|
||||
Other apps all fell under pretty much the same description: not much in the way of new functionality, but big redesigns swapped out the greys of KitKat with bold, bright colors. Hangouts gained the ability to receive Google Voice SMSes, and the clock got a background color that changes with the time of day.
|
||||
|
||||
#### Job Scheduler whips the app ecosystem into shape
|
||||
|
||||
Google decided to focus on battery savings with Lollipop in a project it called "Project Volta." Google started creating more battery tracking tools for itself and developers, starting with the "Battery Historian." This python script took all of Android's battery logging data and spun it into a readable, interactive graph. With its new diagnostic equipment, Google flagged background tasks as a big consumer of battery.
|
||||
|
||||
At I/O 2014, the company noted that enabling airplane mode and turning off the screen allowed an Android phone to run in standby for a month. However, if users enabled everything and started using the device, they wouldn't get through a single day. The takeaway was that if you could just get everything to stop doing stuff, your battery would do a lot better.
|
||||
|
||||
As such, the company created a new API called "JobScheduler," the new traffic cop for background tasks on Android. Before Job Scheduler, every single app was responsible for its background processing, which meant every app would individually wake up the processor and modem, check for connectivity, organize databases, download updates, and upload logs. Everything had its own individual timer, so your phone would be woken up a lot. With JobScheduler, background tasks get batched up from an unorganized free-for-all into an orderly background processing window.
|
||||
|
||||
JobScheduler lets apps specify conditions that their task needs (general connectivity, Wi-Fi, plugged into a wall outlet, etc), and it will send an announcement when those conditions are met. It's like the difference between push e-mail and checking for e-mail every five minutes... but with task requirements. Google also started pushing a "lazier" approach to background tasks. If something can wait until the device is on Wi-Fi, plugged-in, and idle, it should wait until then. You can see the results of this today when, on Wi-Fi, you can plug in an Android phone and only _then_ will it start downloading app updates. You don't instantly need to download app updates; it's best to wait until the user has unlimited power and data.
|
||||
|
||||
#### Device setup gets future-proofed
|
||||
|
||||
* [
|
||||
|
||||
][21]
|
||||
* [
|
||||
|
||||
][22]
|
||||
* [
|
||||
|
||||
][23]
|
||||
* [
|
||||
|
||||
][24]
|
||||
* [
|
||||
|
||||
][25]
|
||||
* [
|
||||
|
||||
][26]
|
||||
* [
|
||||
|
||||
][27]
|
||||
|
||||
Setup was overhauled to not just confirm to the Material Design guidelines, but it was also "future-proofed" so that it can handle any new login and authentication schemes Google cooks up in the future. Remember, part of the entire reasoning for writing "The History of Android" is that older versions of Android don't work anymore. Over the years, Google has upgraded its authentication schemes to use better encryption and two-factor authentication, but adding these new login requirements breaks compatibility with older clients. Lots of Android features require access to Google's cloud infrastructure, so when you can't log in, things like Gmail for Android 1.0 just don't work.
|
||||
|
||||
In Lollipop, setup works much like it did before for the first few screens. You get a "welcome to Android screen" and options to set up cellular and Wi-Fi connectivity. Immediately after this screen, things changed though. As soon as Lollipop hit the internet, it pinged Google's servers to "check for updates." These weren't updates to the OS or to apps, but updates to the setup process about to run. After Android downloaded the newest version of setup, _then_ it asked you to log in with your Google account.
|
||||
|
||||
The benefit of this is evident when trying to log into Lollipop and Kitkat today. Thanks to the updatable setup flow, the "2014" Lollipop OS can handle 2016 improvements, like Google's new "[tap to sign in][39]" 2FA method. KitKat chokes, but luckily it has a "web-browser sign-in" that can handle 2FA.
|
||||
|
||||
Lollipop setup even takes the extreme stance of putting your Google e-mail and password on separate pages. [Google hates passwords][40] and has come up with several [experimental ways][41] to log into Google without one. If your account is setup to not have a password, Lollipop can just skip the password page. If you have a 2FA setup that uses a code, setup can slip the appropriate "enter 2FA code" page into the setup flow. Every piece of signing in is on a single page, so the setup flow is modular. Pages can be added and removed as needed.
|
||||
|
||||
Setup also gave users control over app restoration. Android was doing some kind of data restoration previously to this, but it was impossible to understand because it just picked one of your devices without any user input and started restoring things. A new screen in the setup flow let users see their collection of device profiles in the cloud and pick the appropriate one. You could also choose which apps to restore from that backup. This backup was apps, your home screen layout, and a few minor settings like Wi-Fi hotspots. It wasn't a full app data backup.
|
||||
|
||||
#### Settings
|
||||
|
||||
|
||||
* [
|
||||
|
||||
][28]
|
||||
* [
|
||||
|
||||
][29]
|
||||
* [
|
||||
|
||||
][30]
|
||||
* [
|
||||
|
||||
][31]
|
||||
* [
|
||||
|
||||
][32]
|
||||
* [
|
||||
|
||||
][33]
|
||||
* [
|
||||
|
||||
][34]
|
||||
* [
|
||||
|
||||
][35]
|
||||
|
||||
Setting swapped from a dark theme to a light one. Along with a new look, it got a handy search function. Every screen gave the user access to a magnifying glass, which let them more easily hunt down that elusive option.
|
||||
|
||||
There were a few settings related to Project Volta. "Network Restrictions" allowed users to flag a Wi-Fi connection as metered, which would allow JobScheduler to avoid it for background processing. Also as part of Volta, a "Battery Saver" mode was added. This would limit background tasks and throttle down the CPU, which gave you a long lasting but very sluggish device.
|
||||
|
||||
Multi-user support has been in Android tablets for a while, but Lollipop finally brought it down to Android phones. The settings screen added a new "users" page that let you add additional account or start up a "Guest" account. Guest accounts were temporary—they could be wiped out with a single tap. And unlike a normal account, it didn't try to download every app associated with your account, since it was destined to be wiped out soon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://arstechnica.com/author/ronamadeo
|
||||
[1]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[25]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[26]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[27]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[28]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[29]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[30]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[31]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[32]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[33]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[34]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[35]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
|
||||
[36]:https://cdn.arstechnica.net/wp-content/uploads/2016/10/2-1.jpg
|
||||
[37]:http://arstechnica.com/author/ronamadeo/
|
||||
[38]:https://cdn.arstechnica.net/wp-content/uploads/2016/10/2-1.jpg
|
||||
[39]:http://arstechnica.com/gadgets/2016/06/googles-new-two-factor-authentication-system-tap-yes-to-log-in/
|
||||
[40]:https://www.theguardian.com/technology/2016/may/24/google-passwords-android
|
||||
[41]:http://www.androidpolice.com/2015/12/22/google-appears-to-be-testing-a-new-way-to-log-into-your-account-on-other-devices-with-just-your-phone-no-password-needed/
|
||||
@ -0,0 +1,232 @@
|
||||
The (updated) history of Android
|
||||
============================================================
|
||||
|
||||
> Follow the endless iterations from Android 0.5 to Android 7 and beyond.
|
||||
|
||||
### Android TV
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][2]
|
||||
* [
|
||||
|
||||
][3]
|
||||
* [
|
||||

|
||||
][4]
|
||||
* [
|
||||
|
||||
][5]
|
||||
* [
|
||||
|
||||
][6]
|
||||
* [
|
||||
|
||||
][7]
|
||||
* [
|
||||
|
||||
][8]
|
||||
* [
|
||||
|
||||
][9]
|
||||
* [
|
||||
|
||||
][10]
|
||||
|
||||
November 2014 saw Android continue its march to take over everything with a screen as Google unveiled Android TV. A division inside the company had previously tried to take over the living room with Google TV during the Honeycomb era, but this was a total reboot of the idea directly from the Android team. Android TV took Android 5.0 Lollipop and gave it a Material Design interface purpose-built for the biggest screen in the house. For launch hardware, Google tapped Asus to build the "Nexus Player," an underpowered-but-versatile set top box.
|
||||
|
||||
Android TV was really about three things: video, music, and games. You controlled the TV with a tiny remote consisting only of a D-Pad with 4 buttons: Back, Home, Microphone, and Play/Pause. For games, Asus simply cloned the Xbox 360 controller, giving players a million buttons and a pair of analog sticks.
|
||||
|
||||
The interface was pretty simple. Large horizontally-scrolling media thumbnails occupied the screen, filling the TV with content from YouTube, Google Play, Netflix, Hulu, and other sources. Instead of soiling everything in an app, the thumbnails were actually "recommended" items from many different content sources. Below that you could directly access the apps and settings.
|
||||
|
||||
The voice interface was great. You could ask Android TV to play whatever you wanted, instead of hunting it down through the GUI. You could also run clever search results on content, like "show me movies with Harrison Ford." And instead of app silos, every app could provide content to the indexing service. All these apps were housed in a TV-version of the Play Store. Developers specifically supporting Android TV devices also supported the Google cast protocol, allowing users to beam videos and music from their phones and tablets to the TV.
|
||||
|
||||
### Android 5.1 Lollipop
|
||||
|
||||
* [
|
||||
|
||||
][11]
|
||||
* [
|
||||
|
||||
][12]
|
||||
* [
|
||||
|
||||
][13]
|
||||
* [
|
||||

|
||||
][14]
|
||||
* [
|
||||
|
||||
][15]
|
||||
* [
|
||||

|
||||
][16]
|
||||
* [
|
||||

|
||||
][17]
|
||||
* [
|
||||
|
||||
][18]
|
||||
* [
|
||||

|
||||
][19]
|
||||
* [
|
||||

|
||||
][20]
|
||||
* [
|
||||
|
||||
][21]
|
||||
* [
|
||||
|
||||
][22]
|
||||
* [
|
||||
|
||||
][23]
|
||||
* [
|
||||
|
||||
][24]
|
||||
* [
|
||||
|
||||
][25]
|
||||
* [
|
||||

|
||||
][26]
|
||||
* [
|
||||
|
||||
][27]
|
||||
* [
|
||||

|
||||
][28]
|
||||
* [
|
||||
|
||||
][29]
|
||||
* [
|
||||

|
||||
][30]
|
||||
* [
|
||||
|
||||
][31]
|
||||
|
||||
Android 5.1 came out in March 2015 and was the tiniest of updates. The goal here was mainly to [fix encryption performance][43] on the Nexus 6, along with adding device protection and a few interface tweaks.
|
||||
|
||||
Device protection's only UI addition took the form of a new warning during setup. The feature offered to "Protect your device from reuse" if it was stolen. Once a lock screen was set, device protection would kick in, and could be triggered during a device wipe. If you wiped the phone the way an owner normally would—by unlocking the phone and picking "reset" from the settings—nothing would happen. If you wipe the phone through developer tools though, the device would demand that you "verify a previously-synced Google Account" during the next setup.
|
||||
|
||||
The idea was that a developer would know the pervious Google credentials on the device, but a thief would not so they'd be stuck at setup. In practice this triggered [a cat and mouse game][44] of people finding exploits that get around device protection, and Google getting word of the bug and patching it. Software features added by OEM skins also introduced fun new bugs to get around device protection.
|
||||
|
||||
There was also a whole host of extremely minor UI changes that we have dutifully cataloged in the gallery, above. There's not much to say about them beyond the captions.
|
||||
|
||||
### Android Auto
|
||||
|
||||
* [
|
||||

|
||||
][32]
|
||||
* [
|
||||

|
||||
][33]
|
||||
* [
|
||||
|
||||
][34]
|
||||
* [
|
||||
|
||||
][35]
|
||||
* [
|
||||
|
||||
][36]
|
||||
* [
|
||||
|
||||
][37]
|
||||
* [
|
||||
|
||||
][38]
|
||||
* [
|
||||
|
||||
][39]
|
||||
* [
|
||||
|
||||
][40]
|
||||
* [
|
||||
|
||||
][41]
|
||||
|
||||
Also in March 2015, Google launched "Android Auto," a new Android-inspired interface for car infotainment systems. Android Auto was Google's answer to Apple's CarPlay and worked much the same way. It wasn't a full operating system—it's a "casted" interface that runs on your phone and uses the car's built-in screen as an external monitor. Running Android Auto means having a compatible car, installing the Android Auto app on your phone (Android 5.0 and above), and hooking the phone up to the car with a USB cable.
|
||||
|
||||
Android Auto brought Google's Material Design interface to your existing infotainment system, bringing top-tier software design to a platform that [typically struggles][45] with designing good software. Android Auto was a ground up redesign of the Android interface made specifically to comply with the myriad of infotainment regulations around the world. There was no tradition "home screen" full of app icons, instead Android's navigation bar was changed into an always-on app launcher (almost like a tabbed interface).
|
||||
|
||||
The paired down feature set only really had four sections, from left to right on the navigation bar: Google Maps, a dialer/contacts screen, the "home" section that was a hybrid of Google Now and a notification panel, and a music page. The last button was an "OEM" page that let you exit Android Auto and return to the stock infotainment system (it was also meant to eventually house custom car manufacturer features). There was Google's voice command system, which took the form of a microphone button on the top right of the screen.
|
||||
|
||||
There wasn't much in the way of apps for Android Auto. Only two categories were allowed: music and messaging apps. Infotainment regulations meant customizing the UI wasn't really an option. Messaging apps had no interface and could just plug into the voice system, and music apps couldn't change the interface much, only tweaking the colors and iconography of Google's default "music app" template. What really mattered was delivering the music and messages though, and apps could do that.
|
||||
|
||||
Android Auto hasn't seen much in the way of updates after its initial launch, but it has seen a ton of car manufacturer support. In 2017, there will be [over 100][46] compatible vehicle models.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo/
|
||||
[1]:https://www.youtube.com/watch?v=Ht8yzpIV9M0
|
||||
[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[25]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[26]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[27]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[28]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[29]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[30]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[31]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[32]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[33]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[34]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[35]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[36]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[37]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[38]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[39]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[40]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[41]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/#
|
||||
[42]:http://arstechnica.com/author/ronamadeo/
|
||||
[43]:http://arstechnica.com/gadgets/2015/03/a-look-at-android-5-1-speed-security-tweaks/
|
||||
[44]:http://www.androidpolice.com/2016/08/11/rootjunky-discovers-frp-bypass-method-newer-samsung-phones/
|
||||
[45]:http://www.autoblog.com/2014/10/27/consumer-reports-reliability-infotainment-woes/
|
||||
[46]:http://www.usatoday.com/story/money/cars/2016/10/11/android-auto-comes-more-than-100-car-models-2017/91884366/
|
||||
[47]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/1/
|
||||
[48]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/2/
|
||||
[49]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/
|
||||
[50]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/
|
||||
[51]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/
|
||||
[52]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/33/
|
||||
[53]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/
|
||||
@ -1,119 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
|
||||
>Follow the endless iterations from Android 0.5 to Android 7 and beyond.
|
||||
|
||||
#### ART—The Android Runtime provides a platform for the future
|
||||
|
||||
There aren't too many components that can trace their lineage all the way back to Android 1.0, but in 2014 one of them was Dalvik, the runtime that powers Android apps. Dalvik was originally designed for single-core, low-performance devices, and it prioritized storage and memory usage over performance. Over the years, Google bolted on more and more upgrades to Dalvik, like JIT support, concurrent garbage collection, and multi-process support. But with the advent of multi-core phones that were many times faster than the T-Mobile G1, upgrades could only take Android so far.
|
||||
|
||||
The solution was to replace Dalvik with ART, the Android RunTime, a new app engine written from the ground up for modern smartphone hardware. ART brought an emphasis on performance and UI smoothness. ART brought a switch from JIT (Just-in-time) compilation to AOT (Ahead-of-time) compilation. JIT would compile an app every time it was run, saving storage space since compiled code was never written to disk, but instead it took up more CPU and RAM. AOT would save the compiled code to disk, making app start faster and reducing memory usage. Rather than shipping precompiled code, ART would compile code on the device as part of installation, giving the compiler access to device-specific optimizations. ART also brought support for 64-bit which, in addition to more addressable memory, brings better performance from the 64-bit instruction set (particularly in media and cryptography apps).
|
||||
|
||||
The best part was this change brought these performance improvements and 64-bit support to every java Android app. ART generates code for every java app, thus any improvements to ART automatically come to these apps. ART was also written with future upgrades in mind, so it would be able to evolve along with Android.
|
||||
|
||||
#### A system-wide interface refresh
|
||||
|
||||
|
||||
* [
|
||||
|
||||
][1]
|
||||
* [
|
||||
|
||||
][2]
|
||||
* [
|
||||

|
||||
][3]
|
||||
* [
|
||||
|
||||
][4]
|
||||
* [
|
||||
|
||||
][5]
|
||||
* [
|
||||
|
||||
][6]
|
||||
* [
|
||||
|
||||
][7]
|
||||
* [
|
||||
|
||||
][8]
|
||||
|
||||
Material Design brought a complete overhaul to nearly every interface in Android. For starters, the entire core System UI was changed. Android got a revamped set of buttons that look a bit like a PlayStation controller: triangle, circle, and square buttons now represented back, home, and recent apps, respectively. The status bar was all new thanks to a set of redesigned icons.
|
||||
|
||||
Recent apps got a big revamp, switching from a vertical list of small thumbnails to a cascading view of large, almost fullscreen thumbnails. It also got a new name (which didn't really stick) called "Overview." This definitely seems like something that was inspired by Chrome's tab switcher in past versions.
|
||||
|
||||
Chrome's tab switcher was gone in this release, by the way. In an attempt to put Web apps on even ground with installed apps, Chrome tabs were merged into the Overview list. That's right: the list of recent "apps" now showed recently opened apps mixed in with recently opened websites. In Lollipop, the recent apps list also took a "document centric" approach, meaning apps could put more than one listing into the recent apps list. For instance if you opened two documents in Google Docs, both would be shown in recent apps, allowing you to easily switch between them rather than having to switch back and forth via the app's file list.
|
||||
|
||||
The notification panel was all new. Google brought the "card" motif to the notification panel, storing each item in its own rectangle. Individual notifications changed from a dark background to a white one with better typography and round icons. These new notifications came to the lock screen, changing it from a mostly-useless interstitial screen to a very useful "here's what happened while your were gone" screen.
|
||||
|
||||
Full screen notifications for calls and alarms were banished, replaced with a "heads up" notification that would pop into the top part of the screen. Heads-up notifications also came to "high-priority" app notifications, which were originally intended for IM messages. It was up to developers to decide what was a high-priority notification though, and after developers realized this would make their notifications more noticeable, everyone started forcing them on users. Later versions of Android would fix this by giving users control over the "high-priority" setting.
|
||||
|
||||
Google also added a separate-but-similarly-named "priority" notification system to Lollipop. "Priority" notification was a mode in-between completely silent and "beep for everything" allowing users to flag certain people and apps as "important." Priority mode would only beep for these important people. In the UI, this took the form of a set of notification priority controls attached to the volume popup and a new settings screen for priority notifications. And whenever you were in priority mode, there was a little star in the status bar.
|
||||
|
||||
Quick Settings got a huge series of improvements The controls were now a panel _above_ the notification panel, so that it could be opened with a "double swipe down" gesture. The first pull down would open the notification panel, and the second pull down gesture would shrink the notification panel and open Quick Settings. The layout of the Quick Settings controls changed, dumping the tile layout for a series of buttons floating on a single panel. The top was a very handy brightness slider, followed by buttons for connectivity, auto rotate, the flashlight, GPS, and Chromecast.
|
||||
|
||||
There were also actual in-line panels now in the Quick Settings. It would display Wi-Fi access points, Bluetooth device, and data usage right in the main interface.
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][9]
|
||||
* [
|
||||

|
||||
][10]
|
||||
* [
|
||||
|
||||
][11]
|
||||
* [
|
||||
|
||||
][12]
|
||||
* [
|
||||
|
||||
][13]
|
||||
* [
|
||||
|
||||
][14]
|
||||
* [
|
||||
|
||||
][15]
|
||||
|
||||
The Material Design revamp gave nearly every app a new icon and brought a brighter, white background to the app drawer. There were lots of changes to the default apps loadout. Say "hello" to the new apps: Contacts, Docs, Fit, Messenger, Photos, Play Newsstand, Sheets, and Slides. Say "goodbye" to the dead apps: Gallery, G+ Photos, People, Play Magazines, Email, and Quickoffice.
|
||||
|
||||
Many of these new apps came from Google Drive, which split up from a monolithic app into an app for each product. There was now Drive, Docs, Sheets, and Slides, all from the Drive team. Drive is also responsible for the death of Quickoffice, which was consumed by the Drive team. In the "Google can never make up its mind" category: "People" got renamed back to "Contacts" again, and an SMS app called "Messenger" was reinstated at the behest of cellular carriers. (Those carriers did _not_ like Google Hangouts taking over SMS duties.) We got one genuinely new service: Google Fit, a fitness tracking app that worked on Android phones and Android Wear watches. There was also a revamp of Play Magazines to include websites, so it changes names to "Play Newsstand."
|
||||
|
||||
There were more cases of proprietary Google apps taking over for AOSP.
|
||||
|
||||
* "G+ Photos" became "Google Photos" and took over default picture duties from the AOSP Gallery, which became a dead app. The name change to "Google Photos" was in preparation for Photos being [pulled out of Google+][16] and launching as a standalone service. The Google Photos launch would happen about six months after the launch of Lollipop—for now, this is just the Google+ app spawning a new icon and interface.
|
||||
* Gmail took over POP3, IMAP, and Exchange e-mail duties from the "Email" app. Despite being dead Email still had an app icon, which was a fake—it only displayed a message that told users to setup all e-mail accounts in the Gmail app.
|
||||
* The "People" to "Contacts" change was actually to "Google Contacts" another AOSP replacement app.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo/
|
||||
[1]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[16]:http://arstechnica.com/gadgets/2015/05/google-photos-leaves-google-launches-as-a-standalone-service/
|
||||
@ -144,7 +144,7 @@ via: https://opensource.com/life/15/12/10-kdenlive-tools
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
|
||||
@ -216,7 +216,7 @@ via: http://www.tecmint.com/install-configure-ganglia-monitoring-centos-linux/
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://ganglia.info/
|
||||
|
||||
@ -51,7 +51,7 @@ via: https://www.viget.com/articles/getting-started-with-http-2-part-1?imm_mid=0
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.viget.com/about/team/btinsley
|
||||
[1]:https://twitter.com/home?status=Using%20pizza%20to%20show%20how%20HTTP%2F2%20beats%20HTTP%2F1.1%20when%20your%20orders%20get%20too%20big.%20https%3A%2F%2Fwww.viget.com%2Farticles%2Fgetting-started-with-http-2-part-1
|
||||
|
||||
@ -116,7 +116,7 @@ via: https://code.facebook.com/posts/1671373793181703/apache-spark-scale-a-60-tb
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.facebook.com/sitalkedia
|
||||
[b]: https://www.facebook.com/shuojiew
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
申请翻译
|
||||
|
||||
A Raspberry Pi Hadoop Cluster with Apache Spark on YARN: Big Data 101
|
||||
======
|
||||
|
||||
@ -223,10 +225,10 @@ What do you think? Are you going to build a Raspberry Pi Hadoop Cluster? Want
|
||||
via: https://dqydj.com/raspberry-pi-hadoop-cluster-apache-spark-yarn/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[PK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[popy32](https://github.com/sfantree)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://dqydj.com/about/#contact_us
|
||||
[1]: https://www.raspberrypi.org/downloads/raspbian/
|
||||
|
||||
@ -135,7 +135,7 @@ via: https://www.lifewire.com/how-to-install-the-pycharm-python-ide-in-linux-409
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.lifewire.com/gary-newell-2180098
|
||||
[1]:https://www.jetbrains.com/
|
||||
|
||||
@ -172,7 +172,7 @@ via: https://www.viget.com/articles/getting-started-with-http-2-part-2
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.viget.com/about/team/btinsley
|
||||
[1]:https://twitter.com/home?status=Firmly%20planting%20a%20flag%20in%20the%20sand%20for%20HTTP%2F2%20best%20practices%20for%20front%20end%20development.%20https%3A%2F%2Fwww.viget.com%2Farticles%2Fgetting-started-with-http-2-part-2
|
||||
|
||||
@ -597,6 +597,6 @@ via: https://gorillalogic.com/blog/getting-started-with-ansible/?utm_source=webo
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://gorillalogic.com/author/josehidalgo/
|
||||
|
||||
@ -61,7 +61,7 @@ via: https://www.maketecheasier.com/use-old-xorg-apps-unity-8/
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]:https://www.maketecheasier.com/use-old-xorg-apps-unity-8/#respond
|
||||
|
||||
@ -1,256 +0,0 @@
|
||||
GHLandy Translating
|
||||
|
||||
24 MUST HAVE ESSENTIAL LINUX APPLICATIONS IN 2016
|
||||
=====
|
||||
|
||||
|
||||
[][39]
|
||||
|
||||
Brief: Whare the must have applications for Linux? The answer is subjective and it depends on for what purpose do you use your desktop Linux. But there are still some essentials Linux apps that are more likely to be used by most Linux user. We have listed such best Linux applications that you should have installed in every Linux distribution you use.
|
||||
|
||||
The world of Linux, everything is full of alternatives. You have to choose a distro? You have got several dozens of them. Are you trying to find a decent music player? Alternatives are there too.
|
||||
|
||||
But not all of them are built with the same thing in mind – some of them might target minimalism while others might offer tons of features. Finding the right application for your needs can be quite confusing and a tiresome task. Let’s make that a bit easier.
|
||||
|
||||
### BEST FREE APPLICATIONS FOR LINUX USERS
|
||||
|
||||
I’m putting together a list of essential free Linux applications I prefer to use in different categories. I’m not saying that they are the best, but I have tried lots of applications in each category and finally liked the listed ones better. So, you are more than welcome to mention your favorite applications in the comment section.
|
||||
|
||||
### WEB BROWSER
|
||||
|
||||

|
||||
|
||||
<figcaption>Web Browsers</figcaption>
|
||||
|
||||
### [GOOGLE CHROME][38]
|
||||
|
||||
Google Chrome is a powerful and complete solution for a web browser. It comes with excellent syncing capabilities and offers a vast collection of extensions. If you are accustomed to Google eco-system Google Chrome is for you without any doubt. If you prefer a more open source solution, you may want to try out [Chromium][37], which is the project Google Chrome is based on.
|
||||
|
||||
### [FIREFOX][36]
|
||||
|
||||
If you are not a fan of Google Chrome, you can try out Firefox. It’s been around for a long time and is a very stable and robust web browser.
|
||||
|
||||
### [VIVALDI][35]
|
||||
|
||||
However, if you want something new and different, you can check out Vivaldi. Vivaldi takes a completely fresh approach towards web browser. It’s from former team members of Opera and built on top of the Chromium project. It’s open-source, lightweight and customizable. Though it is still quite new and still missing out some features, it feels amazingly refreshing and does a really decent job.
|
||||
|
||||
Suggested Read[Review] Otter Browser Brings Hope To Opera Lovers
|
||||
|
||||
### DOWNLOAD MANAGER
|
||||
|
||||

|
||||
|
||||
<figcaption>Download Managers</figcaption>
|
||||
|
||||
### [UGET][34]
|
||||
|
||||
uGet is the best download manager I have come across. It is open source and offers everything you can expect from a download manager. uGet offers advanced settings for managing downloads. It can queue and resume downloads, use multiple connections for downloading large files, download files to different directories according to categories and so on.
|
||||
|
||||
### [XDM][33]
|
||||
|
||||
Xtreme Download Manager (XDM) is a powerful and open source tool developed with Java. It has all the basic features of a download manager, including – video grabber, smart scheduler and browser integration.
|
||||
|
||||
Suggested Read4 Best Download Managers For Linux
|
||||
|
||||
### BITTORRENT CLIENT
|
||||
|
||||

|
||||
|
||||
<figcaption>BitTorrent Clients</figcaption>
|
||||
|
||||
### [DELUGE][32]
|
||||
|
||||
Deluge is a open source BitTorrent client. It has a beautiful user interface. If you are used to using uTorrent for Windows, Deluge interface will feel familiar. It has various configuration options as well as plugins support for various tasks.
|
||||
|
||||
### [TRANSMISSION][31]
|
||||
|
||||
Transmission takes the minimal approach. It is an open source BitTorrent client with a minimal user interface. Transmission comes pre-installed with many Linux distributions.
|
||||
|
||||
Suggested ReadTop 5 Torrent Clients For Ubuntu Linux
|
||||
|
||||
### CLOUD STORAGE
|
||||
|
||||

|
||||
|
||||
<figcaption>Cloud Storages</figcaption>
|
||||
|
||||
### [DROPBOX][30]
|
||||
|
||||
Dropbox is one of the most popular cloud storage service available out there. It gives you 2GB free storage to start with. Dropbox has a robust and straight-forward Linux client.
|
||||
|
||||
### [MEGA][29]
|
||||
|
||||
MEGA offers 50GB of free storage. But that is not the best thing about it. The best thing about MEGA is that it has end-to-end encryption support for your files. MEGA has a solid Linux client named MEGAsync.
|
||||
|
||||
Suggested ReadBest Free Cloud Services For Linux
|
||||
|
||||
### COMMUNICATION
|
||||
|
||||

|
||||
|
||||
<figcaption>Communication Apps</figcaption>
|
||||
|
||||
### [PIDGIN][28]
|
||||
|
||||
Pidgin is an open source instant messenger client. It supports many chatting platforms including – Facebook, Google Talk, Yahoo and even IRC. Pidgin is extensible through third-party plugins, that can provide a lots of additional functionalities to Pidgin.
|
||||
|
||||
### [SKYPE][27]
|
||||
|
||||
We all know Skype, it is one of the most popular video chatting platforms. Recently it has [released a brand new desktop client][26] for Linux.
|
||||
|
||||
Suggested ReadBest Messaging Apps Available For Linux In 2016
|
||||
|
||||
### OFFICE SUITE
|
||||
|
||||

|
||||
|
||||
<figcaption>Office Suites</figcaption>
|
||||
|
||||
### [LIBREOFFICE][25]
|
||||
|
||||
LibreOffice is the most actively developed open source office suite for Linux. It has mainly six modules – Writer, Calc, Impress, Draw, Math and Base. And every one of them supports a wide range of file formats. LibreOffice also supports third-party extensions. It is the default office suite for many of the Linux distributions.
|
||||
|
||||
### [WPS OFFICE][24]
|
||||
|
||||
If you want to try out something other than LibreOffice, WPS Office might be your go-to. WPS Office suite includes writer, presentation and spreadsheets support.
|
||||
|
||||
Suggested ReadBest Free and Open Source Alternatives to Microsoft Office
|
||||
|
||||
### MUSIC PLAYER
|
||||
|
||||

|
||||
|
||||
<figcaption>Music Players</figcaption>
|
||||
|
||||
### [LOLLYPOP][23]
|
||||
|
||||
This is a relatively new music player. Lollypop is open source and has a beautiful yet simple user interface. It offers a nice music organizer, scrobbling support, online radio and a party mode. Though it is a simple music player without so many advanced features, it is worth giving it a try.
|
||||
|
||||
### [RHYTHMBOX][22]
|
||||
|
||||
Rhythmbox is the music player mainly developed for GNOME desktop environment but it works on other desktop environments as well. It does all the basic tasks of a music player, including – CD Ripping & Burning, scribbling etc. It also has support for iPod.
|
||||
|
||||
### [CMUS][21]
|
||||
|
||||
If you want minimalism and love your terminal window, cmus is for you. Personally, I’m a fan and user of this one. cmus is a small, fast and powerful console music player for Unix-like operating systems. It has all the basic music player features. And you can also extend its functionalities with additional extensions and scripts.
|
||||
|
||||
Suggested ReadHow To Install Tomahawk Player In Ubuntu 14.04 And Linux Mint 17
|
||||
|
||||
### VIDEO PLAYER
|
||||
|
||||

|
||||
|
||||
<figcaption>Video Players</figcaption>
|
||||
|
||||
### [VLC][20]
|
||||
|
||||
VLC is an open source media player. It is simple, fast, lightweight and really powerful. VLC can play almost any media formats you can throw at it out-of-the-box. It can also stream online medias. It also have some nifty extensions for various tasks like downloading subtitles right from the player.
|
||||
|
||||
### [KODI][19]
|
||||
|
||||
Kodi is a full-fledged media center. Kodi is open source and very popular among its user base. It can handle videos, music, pictures, podcasts and even games, from both local and network media storage. You can even record TV with it. The behavior of Kodi can be customized via add-ons and skins.
|
||||
|
||||
Suggested Read4 Format Factory Alternative In Linux
|
||||
|
||||
### PHOTO EDITOR
|
||||
|
||||

|
||||
|
||||
<figcaption>Photo Editors</figcaption>
|
||||
|
||||
### [GIMP][18]
|
||||
|
||||
GIMP is the Photoshop alternative for Linux. It is open source, full-featured and professional photo editing software. It is packed with a wide range of tools for manipulating images. And on top of that, there is various customization options and third-party plugins for enhancing the experience.
|
||||
|
||||
### [KRITA][17]
|
||||
|
||||
Krita is mainly a painting tool but serves as a photo editing application as well. It is open source and packed with lots of sophisticated and advanced tools.
|
||||
|
||||
Suggested ReadBest Photo Applications For Linux
|
||||
|
||||
### TEXT EDITOR
|
||||
|
||||
Every Linux distribution comes with their own solution for text editors. Generally, they are quite simple and without much functionality. But here are some text editors with enhanced capabilities.
|
||||
|
||||

|
||||
|
||||
<figcaption>Text Editors</figcaption>
|
||||
|
||||
### [ATOM][16]
|
||||
|
||||
Atom is the modern and hackable text editor maintained by GitHub. It is completely open-source and offers everything you can think of to get out of a text editor. You can use it right out-of-the-box or you can customize and tune it just the way you want. And it has a ton of extensions and themes from the community up for grab.
|
||||
|
||||
### [SUBLIME TEXT][15]
|
||||
|
||||
Sublime Text is one of the most popular text editors. Though it is not free, it allows you to use the software for evaluation without any time limit. Sublime Text is a feature-rich and sophisticated piece of software. And of course, it has plugins and themes support.
|
||||
|
||||
Suggested Read4 Best Modern Open Source Code Editors For Linux
|
||||
|
||||
### LAUNCHER
|
||||
|
||||

|
||||
|
||||
<figcaption>Launchers</figcaption>
|
||||
|
||||
### [ALBERT][14]
|
||||
|
||||
Albert is inspired by Alfred (a productivity application for Mac, which is totally kickass by-the-way) and still in the development phase. Albert is fast, extensible and customizable. The goal is to “Access everything with virtually zero effort”. It integrates with your Linux distribution nicely and helps you to boost your productivity.
|
||||
|
||||
### [SYNAPSE][13]
|
||||
|
||||
Synapse has been around for years. It’s a simple launcher that can search and run applications. It can also speed up various workflows like – controlling music, searching files, directories, bookmarks etc., running commands and such.
|
||||
|
||||
[][12][][11][][10][][9][][8][][7][][6][][5][][4][][3]
|
||||
|
||||
As Abhishek advised, we will keep this list of best Linux software updated with our readers’ (i.e. yours) feedback. So, what are your favorite must have Linux applications? Share with us and do suggest more categories of software to add to this list.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://itsfoss.com/essential-linux-applications
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[3]:https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[4]:https://itsfoss.com/image-applications-ubuntu-linux/
|
||||
[5]:https://itsfoss.com/format-factory-alternative-linux/
|
||||
[6]:https://itsfoss.com/install-tomahawk-ubuntu-1404-linux-mint-17/
|
||||
[7]:https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[8]:https://itsfoss.com/best-messaging-apps-linux/
|
||||
[9]:https://itsfoss.com/cloud-services-linux/
|
||||
[10]:https://itsfoss.com/best-torrent-ubuntu/
|
||||
[11]:https://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]:https://itsfoss.com/otter-browser-review/
|
||||
[13]:https://launchpad.net/synapse-project
|
||||
[14]:https://github.com/ManuelSchneid3r/albert
|
||||
[15]:http://www.sublimetext.com/
|
||||
[16]:https://atom.io/
|
||||
[17]:https://krita.org/en/
|
||||
[18]:https://www.gimp.org/
|
||||
[19]:https://kodi.tv/
|
||||
[20]:http://www.videolan.org/
|
||||
[21]:https://cmus.github.io/
|
||||
[22]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[23]:http://gnumdk.github.io/lollypop-web/
|
||||
[24]:https://www.wps.com/
|
||||
[25]:https://www.libreoffice.org/
|
||||
[26]:https://itsfoss.com/skpe-alpha-linux/
|
||||
[27]:https://www.skype.com/
|
||||
[28]:https://www.pidgin.im/
|
||||
[29]:https://mega.nz/
|
||||
[30]:https://www.dropbox.com/
|
||||
[31]:https://transmissionbt.com/
|
||||
[32]:http://deluge-torrent.org/
|
||||
[33]:http://xdman.sourceforge.net/
|
||||
[34]:http://ugetdm.com/
|
||||
[35]:https://vivaldi.com/
|
||||
[36]:https://www.mozilla.org/en-US/firefox
|
||||
[37]:https://www.chromium.org/Home
|
||||
[38]:https://www.google.com/chrome/browser
|
||||
[39]:https://itsfoss.com/wp-content/uploads/2016/10/Essentials-applications-for-every-Linux-user.jpg
|
||||
|
||||
@ -157,7 +157,7 @@ via: https://medium.com/@bartobri/applying-the-linus-tarvolds-good-taste-coding-
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@bartobri?source=post_header_lockup
|
||||
[1]:https://www.ted.com/talks/linus_torvalds_the_mind_behind_linux
|
||||
|
||||
@ -1,209 +0,0 @@
|
||||
Translating by firstadream
|
||||
|
||||
# I don't understand Python's Asyncio
|
||||
|
||||
Recently I started looking into Python's new [asyncio][4] module a bit more. The reason for this is that I needed to do something that works better with evented IO and I figured I might give the new hot thing in the Python world a try. Primarily what I learned from this exercise is that I it's a much more complex system than I expected and I am now at the point where I am very confident that I do not know how to use it properly.
|
||||
|
||||
It's not conceptionally hard to understand and borrows a lot from Twisted, but it has so many elements that play into it that I'm not sure any more how the individual bits and pieces are supposed to go together. Since I'm not clever enough to actually propose anything better I just figured I share my thoughts about what confuses me instead so that others might be able to use that in some capacity to understand it.
|
||||
|
||||
### The Primitives
|
||||
|
||||
<cite>asyncio</cite> is supposed to implement asynchronous IO with the help of coroutines. Originally implemented as a library around the <cite>yield</cite> and <cite>yield from</cite> expressions it's now a much more complex beast as the language evolved at the same time. So here is the current set of things that you need to know exist:
|
||||
|
||||
* event loops
|
||||
* event loop policies
|
||||
* awaitables
|
||||
* coroutine functions
|
||||
* old style coroutine functions
|
||||
* coroutines
|
||||
* coroutine wrappers
|
||||
* generators
|
||||
* futures
|
||||
* concurrent futures
|
||||
* tasks
|
||||
* handles
|
||||
* executors
|
||||
* transports
|
||||
* protocols
|
||||
|
||||
In addition the language gained a few special methods that are new:
|
||||
|
||||
* <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__aenter__</tt> and <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__aexit__</tt> for asynchronous <cite>with</cite> blocks
|
||||
* <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__aiter__</tt> and <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__anext__</tt> for asynchronous iterators (async loops and async comprehensions). For extra fun that protocol already changed once. In 3.5 it returns an awaitable (a coroutine) in Python 3.6 it will return a newfangled async generator.
|
||||
* <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__await__</tt> for custom awaitables
|
||||
|
||||
That's quite a bit to know and the documentation covers those parts. However here are some notes I made on some of those things to understand them better:
|
||||
|
||||
### Event Loops
|
||||
|
||||
The event loop in asyncio is a bit different than you would expect from first look. On the surface it looks like each thread has one event loop but that's not really how it works. Here is how I think this works:
|
||||
|
||||
* if you are the main thread an event loop is created when you call <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.get_event_loop()</tt>
|
||||
* if you are any other thread, a runtime error is raised from <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.get_event_loop()</tt>
|
||||
* You can at any point <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.set_event_loop()</tt> to bind an event loop with the current thread. Such an event loop can be created with the <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.new_event_loop()</tt> function.
|
||||
* Event loops can be used without being bound to the current thread.
|
||||
* <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.get_event_loop()</tt> returns the thread bound event loop, it does not return the currently running event loop.
|
||||
|
||||
The combination of these behaviors is super confusing for a few reasons. First of all you need to know that these functions are delegates to the underlying event loop policy which is globally set. The default is to bind the event loop to the thread. Alternatively one could in theory bind the event loop to a greenlet or something similar if one would so desire. However it's important to know that library code does not control the policy and as such cannot reason that asyncio will scope to a thread.
|
||||
|
||||
Secondly asyncio does not require event loops to be bound to the context through the policy. An event loop can work just fine in isolation. However this is the first problem for library code as a coroutine or something similar does not know which event loop is responsible for scheduling it. This means that if you call <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.get_event_loop()</tt> from within a coroutine you might not get the event loop back that ran you. This is also the reason why all APIs take an optional explicit loop parameter. So for instance to figure out which coroutine is currently running one cannot invoke something like this:
|
||||
|
||||
```
|
||||
def get_task():
|
||||
loop = asyncio.get_event_loop()
|
||||
try:
|
||||
return asyncio.Task.get_current(loop)
|
||||
except RuntimeError:
|
||||
return None
|
||||
|
||||
```
|
||||
|
||||
Instead the loop has to be passed explicitly. This furthermore requires you to pass through the loop explicitly everywhere in library code or very strange things will happen. Not sure what the thinking for that design is but if this is not being fixed (that for instance <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">get_event_loop()</tt> returns the actually running loop) then the only other change that makes sense is to explicitly disallow explicit loop passing and require it to be bound to the current context (thread etc.).
|
||||
|
||||
Since the event loop policy does not provide an identifier for the current context it also is impossible for a library to "key" to the current context in any way. There are also no callbacks that would permit to hook the tearing down of such a context which further limits what can be done realistically.
|
||||
|
||||
### Awaitables and Coroutines
|
||||
|
||||
In my humble opinion the biggest design mistake of Python was to overload iterators so much. They are now being used not just for iteration but also for various types of coroutines. One of the biggest design mistakes of iterators in Python is that <cite>StopIteration</cite> bubbles if not caught. This can cause very frustrating problems where an exception somewhere can cause a generator or coroutine elsewhere to abort. This is a long running issue that Jinja for instance has to fight with. The template engine internally renders into a generator and when a template for some reason raises a <cite>StopIteration</cite> the rendering just ends there.
|
||||
|
||||
Python is slowly learning the lesson of overloading this system more. First of all in 3.something the asyncio module landed and did not have language support. So it was decorators and generators all the way down. To implemented the <cite>yield from</cite> support and more, the <cite>StopIteration</cite>was overloaded once more. This lead to surprising behavior like this:
|
||||
|
||||
```
|
||||
>>> def foo(n):
|
||||
... if n in (0, 1):
|
||||
... return [1]
|
||||
... for item in range(n):
|
||||
... yield item * 2
|
||||
...
|
||||
>>> list(foo(0))
|
||||
[]
|
||||
>>> list(foo(1))
|
||||
[]
|
||||
>>> list(foo(2))
|
||||
[0, 2]
|
||||
|
||||
```
|
||||
|
||||
No error, no warning. Just not the behavior you expect. This is because a <cite>return</cite> with a value from a function that is a generator actually raises a <cite>StopIteration</cite> with a single arg that is not picked up by the iterator protocol but just handled in the coroutine code.
|
||||
|
||||
With 3.5 and 3.6 a lot changed because now in addition to generators we have coroutine objects. Instead of making a coroutine by wrapping a generator there is no a separate object which creates a coroutine directly. It's implemented by prefixing a function with <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">async</tt>. For instance <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">async def x()</tt> will make such a coroutine. Now in 3.6 there will be separate async generators that will raise <cite>AsyncStopIteration</cite> to keep it apart. Additionally with Python 3.5 and later there is now a future import (<tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">generator_stop</tt>) that will raise a <cite>RuntimeError</cite> if code raises <cite>StopIteration</cite> in an iteration step.
|
||||
|
||||
Why am I mentioning all this? Because the old stuff does not really go away. Generators still have <cite>send</cite> and <cite>throw</cite> and coroutines still largely behave like generators. That is a lot of stuff you need to know now for quite some time going forward.
|
||||
|
||||
To unify a lot of this duplication we have a few more concepts in Python now:
|
||||
|
||||
* awaitable: an object with an <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__await__</tt> method. This is for instance implemented by native coroutines and old style coroutines and some others.
|
||||
* coroutinefunction: a function that returns a native coroutine. Not to be confused with a function returning a coroutine.
|
||||
* a coroutine: a native coroutine. Note that old asyncio coroutines are not considered coroutines by the current documentation as far as I can tell. At the very least <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">inspect.iscoroutine</tt> does not consider that a coroutine. It's however picked up by the future/awaitable branches.
|
||||
|
||||
In particularly confusing is that <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.iscoroutinefunction</tt> and <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">inspect.iscoroutinefunction</tt> are doing different things. Same with <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">inspect.iscoroutine</tt> and <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">inspect.iscoroutinefunction</tt>. Note that even though inspect does not know anything about asycnio legacy coroutine functions in the type check, it is apparently aware of them when you check for awaitable status even though it does not conform to <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__await__</tt>.
|
||||
|
||||
### Coroutine Wrappers
|
||||
|
||||
Whenever you run <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">async def</tt> Python invokes a thread local coroutine wrapper. It's set with <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">sys.set_coroutine_wrapper</tt> and it's a function that can wrap this. Looks a bit like this:
|
||||
|
||||
```
|
||||
>>> import sys
|
||||
>>> sys.set_coroutine_wrapper(lambda x: 42)
|
||||
>>> async def foo():
|
||||
... pass
|
||||
...
|
||||
>>> foo()
|
||||
__main__:1: RuntimeWarning: coroutine 'foo' was never awaited
|
||||
42
|
||||
|
||||
```
|
||||
|
||||
In this case I never actually invoke the original function and just give you a hint of what this can do. As far as I can tell this is always thread local so if you swap out the event loop policy you need to figure out separately how to make this coroutine wrapper sync up with the same context if that's something you want to do. New threads spawned will not inherit that flag from the parent thread.
|
||||
|
||||
This is not to be confused with the asyncio coroutine wrapping code.
|
||||
|
||||
### Awaitables and Futures
|
||||
|
||||
Some things are awaitables. As far as I can see the following things are considered awaitable:
|
||||
|
||||
* native coroutines
|
||||
* generators that have the fake <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">CO_ITERABLE_COROUTINE</tt> flag set (we will cover that)
|
||||
* objects with an <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__await__</tt> method
|
||||
|
||||
Essentially these are all objects with an <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__await__</tt> method except that the generators don't for legacy reasons. Where does the <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">CO_ITERABLE_COROUTINE</tt> flag come from? It comes from a coroutine wrapper (now to be confused with <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">sys.set_coroutine_wrapper</tt>) that is <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">@asyncio.coroutine</tt>. That through some indirection will wrap the generator with <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">types.coroutine</tt> (to to be confused with<tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">types.CoroutineType</tt> or <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.coroutine</tt>) which will re-create the internal code object with the additional flag <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">CO_ITERABLE_COROUTINE</tt>.
|
||||
|
||||
So now that we know what those things are, what are futures? First we need to clear up one thing: there are actually two (completely incompatible) types of futures in Python 3. <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.futures.Future</tt> and <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">concurrent.futures.Future</tt>. One came before the other but they are also also both still used even within asyncio. For instance <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.run_coroutine_threadsafe()</tt> will dispatch a coroutine to a event loop running in another thread but it will then return a<tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">concurrent.futures.Future</tt> object instead of a <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.futures.Future</tt> object. This makes sense because only the <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">concurrent.futures.Future</tt> object is thread safe.
|
||||
|
||||
So now that we know there are two incompatible futures we should clarify what futures are in asyncio. Honestly I'm not entirely sure where the differences are but I'm going to call this "eventual" for the moment. It's an object that eventually will hold a value and you can do some handling with that eventual result while it's still computing. Some variations of this are called deferreds, others are called promises. What the exact difference is is above my head.
|
||||
|
||||
What can you do with a future? You can attach a callback that will be invoked once it's ready or you can attach a callback that will be invoked if the future fails. Additionally you can <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">await</tt> it (it implements <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__await__</tt> and is thus awaitable). Additionally futures can be cancelled.
|
||||
|
||||
So how do you get such a future? By calling <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.ensure_future</tt> on an awaitable object. This will also make a good old generator into such a future. However if you read the docs you will read that <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.ensure_future</tt> actually returns a <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">Task</tt>. So what's a task?
|
||||
|
||||
### Tasks
|
||||
|
||||
A task is a future that is wrapping a coroutine in particular. It works like a future but it also has some extra methods to extract the current stack of the contained coroutine. We already saw the tasks mentioned earlier because it's the main way to figure out what an event loop is currently doing via <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">Task.get_current</tt>.
|
||||
|
||||
There is also a difference in how cancellation works for tasks and futures but that's beyond the scope of this. Cancellation is its own entire beast. If you are in a coroutine and you know you are currently running you can get your own task through <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">Task.get_current</tt> as mentioned but this requires knowledge of what event loop you are dispatched on which might or might not be the thread bound one.
|
||||
|
||||
It's not possible for a coroutine to know which loop goes with it. Also the <cite>Task</cite> does not provide that information through a public API. However if you did manage to get hold of a task you can currently access <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">task._loop</tt> to find back to the event loop.
|
||||
|
||||
### Handles
|
||||
|
||||
In addition to all of this there are handles. Handles are opaque objects of pending executions that cannot be awaited but they can be cancelled. In particular if you schedule the execution of a call with <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">call_soon</tt> or <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">call_soon_threadsafe</tt> (and some others) you get that handle you can then use to cancel the execution as a best effort attempt but you can't wait for the call to actually take place.
|
||||
|
||||
### Executors
|
||||
|
||||
Since you can have multiple event loops but it's not obvious what the use of more than one of those things per thread is the obvious assumption can be made that a common setup is to have N threads with an event loop each. So how do you inform another event loop about doing some work? You cannot schedule a callback into an event loop in another thread _and_ get the result back. For that you need to use executors instead.
|
||||
|
||||
Executors come from <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">concurrent.futures</tt> for instance and they allow you to schedule work into threads that itself is not evented. For instance if you use <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">run_in_executor</tt> on the event loop to schedule a function to be called in another thread. The result is then returned as an asyncio coroutine instead of a concurrent coroutine like <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">run_coroutine_threadsafe</tt> would do. I did not yet have enough mental capacity to figure out why those APIs exist, how you are supposed to use and when which one. The documentation suggests that the executor stuff could be used to build multiprocess things.
|
||||
|
||||
### Transports and Protocols
|
||||
|
||||
I always though those would be the confusing things but that's basically a verbatim copy of the same concepts in Twisted. So read those docs if you want to understand them.
|
||||
|
||||
### How to use asyncio
|
||||
|
||||
Now that we know roughly understand asyncio I found a few patterns that people seem to use when they write asyncio code:
|
||||
|
||||
* pass the event loop to all coroutines. That appears to be what a part of the community is doing. Giving a coroutine knowledge about what loop is going to schedule it makes it possible for the coroutine to learn about its task.
|
||||
* alternatively you require that the loop is bound to the thread. That also lets a coroutine learn about that. Ideally support both. Sadly the community is already torn of what to do.
|
||||
* If you want to use contextual data (think thread locals) you are a bit out of luck currently. The most popular workaround is apparently atlassian's <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">aiolocals</tt> which basically requires you to manually propagate contextual information into coroutines spawned since the interpreter does not provide support for this. This means that if you have a utility library spawning coroutines you will lose context.
|
||||
* Ignore that the old coroutine stuff in Python exists. Use 3.5 only with the new <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">async def</tt>keyword and co. In particular you will need that anyways to somewhat enjoy the experience because with older versions you do not have async context managers which turn out to be very necessary for resource management.
|
||||
* Learn to restart the event loop for cleanup. This is something that took me longer to realize than I wish it did but the sanest way to deal with cleanup logic that is written in async code is to restart the event loop a few times until nothing pending is left. Since sadly there is no common pattern to deal with this you will end up with some ugly workaround at time. For instance <cite>aiohttp</cite>'s web support also does this pattern so if you want to combine two cleanup logics you will probably have to reimplement the utility helper that it provides since that helper completely tears down the loop when it's done. This is also not the first library I saw do this :(
|
||||
* Working with subprocesses is non obvious. You need to have an event loop running in the main thread which I suppose is listening in on signal events and then dispatches it to other event loops. This requires that the loop is notified via<tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.get_child_watcher().attach_loop(...)</tt>.
|
||||
* Writing code that supports both async and sync is somewhat of a lost cause. It also gets dangerous quickly when you start being clever and try to support <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">with</tt> and <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">async with</tt> on the same object for instance.
|
||||
* If you want to give a coroutine a better name to figure out why it was not being awaited, setting <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__name__</tt> doesn't help. You need to set <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">__qualname__</tt> instead which is what the error message printer uses.
|
||||
* Sometimes internal type conversations can screw you over. In particular the <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">asyncio.wait()</tt>function will make sure all things passed are futures which means that if you pass coroutines instead you will have a hard time finding out if your coroutine finished or is pending since the input objects no longer match the output objects. In that case the only real sane thing to do is to ensure that everything is a future upfront.
|
||||
|
||||
### Context Data
|
||||
|
||||
Aside from the insane complexity and lack of understanding on my part of how to best write APIs for it my biggest issue is the complete lack of consideration for context local data. This is something that the node community learned by now. <tt class="docutils literal" style="font-family: "Ubuntu Mono", Consolas, "Deja Vu Sans Mono", "Bitstream Vera Sans Mono", Monaco, "Courier New"; font-size: 0.9em; background: rgb(238, 238, 238);">continuation-local-storage</tt> exists but has been accepted as implemented too late. Continuation local storage and similar concepts are regularly used to enforce security policies in a concurrent environment and corruption of that information can cause severe security issues.
|
||||
|
||||
The fact that Python does not even have any store at all for this is more than disappointing. I was looking into this in particular because I'm investigating how to best support [Sentry's breadcrumbs][3] for asyncio and I do not see a sane way to do it. There is no concept of context in asyncio, there is no way to figure out which event loop you are working with from generic code and without monkeypatching the world this information will not be available.
|
||||
|
||||
Node is currently going through the process of [finding a long term solution for this problem][2]. That this is not something to be left ignored can be seen by this being a recurring issue in all ecosystems. It comes up with JavaScript, Python and the .NET environment. The problem [is named async context propagation][1] and solutions go by many names. In Go the context package needs to be used and explicitly passed to all goroutines (not a perfect solution but at least one). .NET has the best solution in the form of local call contexts. It can be a thread context, an web request context, or something similar but it's automatically propagating unless suppressed. This is the gold standard of what to aim for. Microsoft had this solved since more than 15 years now I believe.
|
||||
|
||||
I don't know if the ecosystem is still young enough that logical call contexts can be added but now might still be the time.
|
||||
|
||||
### Personal Thoughts
|
||||
|
||||
Man that thing is complex and it keeps getting more complex. I do not have the mental capacity to casually work with asyncio. It requires constantly updating the knowledge with all language changes and it has tremendously complicated the language. It's impressive that an ecosystem is evolving around it but I can't help but get the impression that it will take quite a few more years for it to become a particularly enjoyable and stable development experience.
|
||||
|
||||
What landed in 3.5 (the actual new coroutine objects) is great. In particular with the changes that will come up there is a sensible base that I wish would have been in earlier versions. The entire mess with overloading generators to be coroutines was a mistake in my mind. With regards to what's in asyncio I'm not sure of anything. It's an incredibly complex thing and super messy internally. It's hard to comprehend how it works in all details. When you can pass a generator, when it has to be a real coroutine, what futures are, what tasks are, how the loop works and that did not even come to the actual IO part.
|
||||
|
||||
The worst part is that asyncio is not even particularly fast. David Beazley's live demo hacked up asyncio replacement is twice as fast as it. There is an enormous amount of complexity that's hard to understand and reason about and then it fails on it's main promise. I'm not sure what to think about it but I know at least that I don't understand asyncio enough to feel confident about giving people advice about how to structure code for it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://lucumr.pocoo.org/2016/10/30/i-dont-understand-asyncio/
|
||||
|
||||
作者:[Armin Ronacher][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://lucumr.pocoo.org/about/
|
||||
[1]:https://docs.google.com/document/d/1tlQ0R6wQFGqCS5KeIw0ddoLbaSYx6aU7vyXOkv-wvlM/edit
|
||||
[2]:https://github.com/nodejs/node-eps/pull/18
|
||||
[3]:https://docs.sentry.io/learn/breadcrumbs/
|
||||
[4]:https://docs.python.org/3/library/asyncio.html
|
||||
@ -105,7 +105,7 @@ via: https://fedoramagazine.org/inkscape-design-imagination/
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://a2batic.id.fedoraproject.org/
|
||||
[1]:https://1504253206.rsc.cdn77.org/wp-content/uploads/2016/10/back1.png
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ucasFL translating
|
||||
How to Install Security Updates Automatically on Debian and Ubuntu
|
||||
============================================================
|
||||
|
||||
@ -76,7 +77,7 @@ via: http://www.tecmint.com/auto-install-security-updates-on-debian-and-ubuntu
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/auto-install-security-patches-updates-on-centos-rhel/
|
||||
|
||||
@ -87,7 +87,7 @@ via: https://itsfoss.com/cloud-focused-linux-distros/
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://itsfoss.com/author/aquil/
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by firstadream
|
||||
|
||||
### [Can Linux containers save IoT from a security meltdown?][28]
|
||||
|
||||

|
||||
@ -139,7 +141,7 @@ via: http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltd
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
[1]:http://hackerboards.com/atom-based-gateway-taps-new-open-source-iot-cloud-platform/
|
||||
|
||||
@ -168,7 +168,7 @@ via: http://opensourceforu.com/2016/11/build-deploy-manage-custom-apps-ibm-bluem
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensourceforu.com/author/mitesh_soni/
|
||||
[1]:http://opensourceforu.com/wp-content/uploads/2016/10/Figure-7-Naming-the-app.jpg
|
||||
|
||||
@ -1,121 +0,0 @@
|
||||
Fix “Unable to lock the administration directory (/var/lib/dpkg/)” in Ubuntu
|
||||
============================================================
|
||||
|
||||
While using the [apt-get command][1] or the relatively new [APT package management tool][2] in Ubuntu Linuxor its derivatives such as Linux Mint (which I actually use as my primary operating system for doing daily work), you might have encountered the error – “unable to lock the administration directory (/var/lib/dpkg/) is another process using it” on the command line.
|
||||
|
||||
This error can be so annoying especially for new Linux (Ubuntu) users who may not know exactly the cause of the error.
|
||||
|
||||
Below is an example, showing the lock file error in Ubuntu 16.10:
|
||||
|
||||
```
|
||||
tecmint@TecMint:~$ sudo apt install neofetch
|
||||
[sudo] password for tecmint:
|
||||
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
|
||||
E: Unable to lock the administration directory (/var/lib/dpkg), is another process using it?
|
||||
```
|
||||
|
||||
The output below is another possible instance of the same error:
|
||||
|
||||
```
|
||||
E: Could not get lock /var/lib/apt/lists/lock - open (11: Resource temporarily unavailable)
|
||||
E: Unable to lock directory /var/lib/apt/lists/
|
||||
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
|
||||
E: Unable to lock the administration directory (/var/lib/dpkg/), is another process using it?
|
||||
```
|
||||
|
||||
How can you solve the above error in case you bump into it in the future? There are several ways of dealing with this error(s), but in this guide, we will go through the two easiest and probably the most effective ways of solving it.
|
||||
|
||||
### 1\. Find and Kill all apt-get or apt Processes
|
||||
|
||||
Run the command below to [generate a list of all processes][3] whose name comprises of the word apt, you will get a list inclusive of all apt or apt-get processes by using `ps` and [grep commands][4] together with a pipeline.
|
||||
|
||||
```
|
||||
$ ps -A | grep apt
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Find apt and apt-get Processes
|
||||
|
||||
For each apt-get or apt process that you can see in the output of the command above, [kill each process][6]using the command below.
|
||||
|
||||
The process ID (PID) is found in the first column from the screenshot above.
|
||||
|
||||
```
|
||||
$ sudo kill -9 processnumber
|
||||
OR
|
||||
$ sudo kill -SIGKILL processnumber
|
||||
```
|
||||
|
||||
For instance, in the command below where `9` is the signal number for the SIGKILL signal, will kill the first apt process:
|
||||
|
||||
```
|
||||
$ sudo kill -9 13431
|
||||
OR
|
||||
$ sudo kill -SIGKILL 13431
|
||||
```
|
||||
|
||||
### 2\. Delete the lock Files
|
||||
|
||||
A lock file simply prevents access to another file(s) or some data on your Linux system, this concept is present in Windows and other operating systems as well.
|
||||
|
||||
Once you run an apt-get or apt command, a lock file is created under the any of these directories /var/lib/apt/lists/, /var/lib/dpkg/ and /var/cache/apt/archives/.
|
||||
|
||||
This helps to avoid the apt-get or apt process that is already running from being interrupted by either a user or other system processes that would need to work with files being used by apt-get or apt. When the process has finished executing, the lock file is then deleted.
|
||||
|
||||
Important: In case a lock is still exiting in the two directories above with no noticeable apt-get or apt process running, this may mean the process was held for one reason or the other, therefore you need to delete the lock files in order to clear the error.
|
||||
|
||||
First execute the command below to remove the lock file in the `/var/lib/dpkg/` directory:
|
||||
|
||||
```
|
||||
$ sudo rm /var/lib/dpkg/lock
|
||||
```
|
||||
|
||||
Afterwards force package(s) to reconfigure like so:
|
||||
|
||||
```
|
||||
$ sudo dpkg --configure -a
|
||||
```
|
||||
|
||||
Alternatively, delete the lock files in the `/var/lib/apt/lists/` and cache directory as below:
|
||||
|
||||
```
|
||||
$ sudo rm /var/lib/apt/lists/lock
|
||||
$ sudo rm /var/cache/apt/archives/lock
|
||||
```
|
||||
|
||||
Next, update your packages sources list as follows:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
OR
|
||||
$ sudo apt-get update
|
||||
```
|
||||
|
||||
In conclusion, we have walked through two important methods to deal with a common problem faced by Ubuntu (and its derivatives) users, while running apt-get or apt as well as [aptitude commands][7].
|
||||
|
||||
Do you have any other reliable methods to share meant for deal with this common error? Then get in touch with us via the feedback form below.
|
||||
|
||||
In addition, you may as well want to learn [how to find and kill running processes][8] and read through a simple guide to [kill, pkill and killall commands to terminate a process][9] in Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/fix-unable-to-lock-the-administration-directory-var-lib-dpkg-lock
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[2]:http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[3]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[4]:http://www.tecmint.com/linux-grep-commands-character-classes-bracket-expressions/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/11/find-apt-processes.png
|
||||
[6]:http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[7]:http://www.tecmint.com/difference-between-apt-and-aptitude/
|
||||
[8]:http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[9]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -236,7 +236,7 @@ via: https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-u
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#prerequisite
|
||||
|
||||
142
sources/tech/20161126 Building Vim from source.md
Normal file
142
sources/tech/20161126 Building Vim from source.md
Normal file
@ -0,0 +1,142 @@
|
||||
翻译中-byzky001
|
||||
Compiling Vim from source is actually not that difficult.
|
||||
Here's what you should do:
|
||||
|
||||
1. First, install all the prerequisite libraries, including Git.
|
||||
For a Debian-like Linux distribution like Ubuntu,
|
||||
that would be the following:
|
||||
|
||||
```sh
|
||||
sudo apt-get install libncurses5-dev libgnome2-dev libgnomeui-dev \
|
||||
libgtk2.0-dev libatk1.0-dev libbonoboui2-dev \
|
||||
libcairo2-dev libx11-dev libxpm-dev libxt-dev python-dev \
|
||||
python3-dev ruby-dev lua5.1 lua5.1-dev libperl-dev git
|
||||
```
|
||||
|
||||
On Ubuntu 16.04, `liblua5.1-dev` is the lua dev package name not `lua5.1-dev`.
|
||||
|
||||
(If you know what languages you'll be using, feel free to leave out
|
||||
packages you won't need, e.g. Python2 `python-dev` or Ruby `ruby-dev`.
|
||||
This principle heavily applies to the whole page.)
|
||||
|
||||
For Fedora 20, that would be the following:
|
||||
|
||||
```sh
|
||||
sudo yum install -y ruby ruby-devel lua lua-devel luajit \
|
||||
luajit-devel ctags git python python-devel \
|
||||
python3 python3-devel tcl-devel \
|
||||
perl perl-devel perl-ExtUtils-ParseXS \
|
||||
perl-ExtUtils-XSpp perl-ExtUtils-CBuilder \
|
||||
perl-ExtUtils-Embed
|
||||
```
|
||||
|
||||
This step is needed to rectify an issue with how Fedora 20 installs XSubPP:
|
||||
|
||||
```sh
|
||||
# symlink xsubpp (perl) from /usr/bin to the perl dir
|
||||
sudo ln -s /usr/bin/xsubpp /usr/share/perl5/ExtUtils/xsubpp
|
||||
```
|
||||
|
||||
2. Remove vim if you have it already.
|
||||
|
||||
```sh
|
||||
sudo apt-get remove vim vim-runtime gvim
|
||||
```
|
||||
|
||||
On Ubuntu 12.04.2 you probably have to remove these packages as well:
|
||||
|
||||
```sh
|
||||
sudo apt-get remove vim-tiny vim-common vim-gui-common vim-nox
|
||||
```
|
||||
|
||||
3. Once everything is installed, getting the source is easy.
|
||||
|
||||
Note: If you are using Python, your config directory might have
|
||||
a machine-specific name (e.g. `config-3.5m-x86_64-linux-gnu`).
|
||||
Check in /usr/lib/python[2/3/3.5] to find yours, and change
|
||||
the `python-config-dir` and/or `python3-config-dir` arguments accordingly.
|
||||
|
||||
Add/remove the flags below to fit your setup. For example, you can leave out
|
||||
`enable-luainterp` if you don't plan on writing any Lua.
|
||||
|
||||
Also, if you're not using vim 8.0,
|
||||
make sure to set the VIMRUNTIMEDIR variable correctly below
|
||||
(for instance, with vim 8.0a, use /usr/share/vim/vim80a).
|
||||
Keep in mind that some vim installations are located directly
|
||||
inside /usr/share/vim; adjust to fit your system:
|
||||
|
||||
```sh
|
||||
cd ~
|
||||
git clone https://github.com/vim/vim.git
|
||||
cd vim
|
||||
./configure --with-features=huge \
|
||||
--enable-multibyte \
|
||||
--enable-rubyinterp=yes \
|
||||
--enable-pythoninterp=yes \
|
||||
--with-python-config-dir=/usr/lib/python2.7/config \
|
||||
--enable-python3interp=yes \
|
||||
--with-python3-config-dir=/usr/lib/python3.5/config \
|
||||
--enable-perlinterp=yes \
|
||||
--enable-luainterp=yes \
|
||||
--enable-gui=gtk2 --enable-cscope --prefix=/usr
|
||||
make VIMRUNTIMEDIR=/usr/share/vim/vim80
|
||||
```
|
||||
On Ubuntu 16.04, Python support was not working due to enabling both Python2 and Python3. Read [answer by chirinosky](http://stackoverflow.com/questions/23023783/vim-compiled-with-python-support-but-cant-see-sys-version) for workaround.
|
||||
|
||||
If you want to be able to easily uninstall vim use `checkinstall`.
|
||||
|
||||
```sh
|
||||
sudo apt-get install checkinstall
|
||||
cd ~/vim
|
||||
sudo checkinstall
|
||||
```
|
||||
|
||||
Otherwise, you can use `make` to install.
|
||||
|
||||
```sh
|
||||
cd ~/vim
|
||||
sudo make install
|
||||
```
|
||||
|
||||
Set vim as your default editor with `update-alternatives`.
|
||||
|
||||
```sh
|
||||
sudo update-alternatives --install /usr/bin/editor editor /usr/bin/vim 1
|
||||
sudo update-alternatives --set editor /usr/bin/vim
|
||||
sudo update-alternatives --install /usr/bin/vi vi /usr/bin/vim 1
|
||||
sudo update-alternatives --set vi /usr/bin/vim
|
||||
```
|
||||
|
||||
4. Double check that you are in fact running the new Vim binary by looking at
|
||||
the output of `vim --version`.
|
||||
|
||||
**If you don't get gvim working (on ubuntu 12.04.1 LTS), try changing
|
||||
`--enable-gui=gtk2` to `--enable-gui=gnome2`**
|
||||
|
||||
If you have problems, double check that you `configure`d using the correct Python config
|
||||
directory, as noted at the beginning of Step 3.
|
||||
|
||||
These `configure` and `make` calls assume a Debian-like distro where Vim's
|
||||
runtime files directory is placed in `/usr/share/vim/vim80/`,
|
||||
which is not Vim's default. Same thing goes for `--prefix=/usr` in the
|
||||
`configure` call. Those values may need to be different with a Linux
|
||||
distro that is not based on Debian. In such a case, try to remove the
|
||||
`--prefix` variable in the `configure` call and the `VIMRUNTIMEDIR` in the
|
||||
`make` call (in other words, go with the defaults).
|
||||
|
||||
If you get stuck, here's some [other useful information on building Vim]
|
||||
(http://vim.wikia.com/wiki/Building_Vim).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
|
||||
作者:[Val Markovic][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/Valloric
|
||||
@ -1,143 +0,0 @@
|
||||
How To Enable Shell Script Debugging Mode in Linux
|
||||
============================================================
|
||||
|
||||
A script is simply a list of commands stored in a file. Instead of running a sequence of commands by typing them one by one all the time on the terminal, a system user can store all of them (commands) in a file and repeatedly invokes the file to re-execute the commands several times.
|
||||
|
||||
While [learning scripting][1] or during the early stages of writing scripts, we normally start by writing small or short scripts with a few lines of commands. And we usually debug such scripts by doing nothing more than looking at their output and ensuring that they work as we intended.
|
||||
|
||||
However, as we begin to write very long and advanced scripts with thousands of lines of commands, for instance scripts that modify system settings, [perform critical backups over networks][2] and many more, we will realize that only looking at the output of a script is not enough to find bugs within a script.
|
||||
|
||||
Therefore, in this shell script debugging in Linux series, we will walk through how to enable shell script debugging, move over to explain the different shell script debugging modes and how to use them in the subsequent series.
|
||||
|
||||
### How To Start A Script
|
||||
|
||||
A script is distinguished from other files by its first line, that contains a `#!` (She-bang – defines the file type) and a path name (path to interpreter) which informs the system that the file is a collection of commands that will be interpreted by the specified program (interpreter).
|
||||
|
||||
Below are examples of the “first lines” in different types of scripts:
|
||||
|
||||
```
|
||||
#!/bin/sh [For sh scripting]
|
||||
#!/bin/bash [For bash scripting]
|
||||
#!/usr/bin/perl [For perl programming]
|
||||
#!/bin/awk -f [For awk scripting]
|
||||
```
|
||||
|
||||
Note: The first line or `#!` can be left out if a script contains only of a set of standard system commands, without any internal shell directives.
|
||||
|
||||
### How To Execute A Shell Script in Linux
|
||||
|
||||
The conventional syntax for invoking a shell script is:
|
||||
|
||||
```
|
||||
$ script_name argument1 ... argumentN
|
||||
```
|
||||
|
||||
Another possible form is by clearly specifying the shell that will execute the script as below:
|
||||
|
||||
```
|
||||
$ shell script_name argument1 ... argumentN
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
$ /bin/bash script_name argument1 ... argumentN [For bash scripting]
|
||||
$ /bin/ksh script_name argument1 ... argumentN [For ksh scripting]
|
||||
$ /bin/sh script_name argument1 ... argumentN [For sh scripting]
|
||||
```
|
||||
|
||||
For scripts that do not have `#!` as the first line and only contain basic system commands such as the one below:
|
||||
|
||||
```
|
||||
#script containing standard system commands
|
||||
cd /home/$USER
|
||||
mkdir tmp
|
||||
echo "tmp directory created under /home/$USER"
|
||||
```
|
||||
|
||||
Simply make it executable and run it as follows:
|
||||
|
||||
```
|
||||
$ chmod +x script_name
|
||||
$ ./script_name
|
||||
```
|
||||
|
||||
### Methods of Enabling Shell Script Debugging Mode
|
||||
|
||||
Below are the primary shell script debugging options:
|
||||
|
||||
1. `-v` (short for verbose) – tells the shell to show all lines in a script while they are read, it activates verbose mode.
|
||||
2. `-n` (short for noexec or no ecxecution) – instructs the shell read all the commands, however doesn’t execute them. This options activates syntax checking mode.
|
||||
3. `-x` (short for xtrace or execution trace) – tells the shell to display all commands and their arguments on the terminal while they are executed. This option enables shell tracing mode.
|
||||
|
||||
#### 1\. Modifying the First Line of a Shell Script
|
||||
|
||||
The first mechanism is by altering the first line of a shell script as below, this will enable debugging of the whole script.
|
||||
|
||||
```
|
||||
#!/bin/sh option(s)
|
||||
```
|
||||
|
||||
In the form above, option can be one or combination of the debugging options above.
|
||||
|
||||
#### 2\. Invoking Shell With Debugging Options
|
||||
|
||||
The second is by invoking the shell with debugging options as follows, this method will also turn on debugging of the entire script.
|
||||
|
||||
```
|
||||
$ shell option(s) script_name argument1 ... argumentN
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
$ /bin/bash option(s) script_name argument1 ... argumentN
|
||||
```
|
||||
|
||||
#### 3\. Using set Shell Built-in Command
|
||||
|
||||
The third method is by using the set built-in command to debug a given section of a shell script such as a function. This mechanism is important, as it allows us to activate debugging at any segment of a shell script.
|
||||
|
||||
We can turn on debugging mode using set command in form below, where option is any of the debugging options.
|
||||
|
||||
```
|
||||
$ set option
|
||||
```
|
||||
|
||||
To enable debugging mode, use:
|
||||
|
||||
```
|
||||
$ set -option
|
||||
```
|
||||
|
||||
To disable debugging mode, use:
|
||||
|
||||
```
|
||||
$ set +option
|
||||
```
|
||||
|
||||
In addition, if we have enabled several debugging modes in different segments of a shell script, we can disable all of them at once like so:
|
||||
|
||||
```
|
||||
$ set -
|
||||
```
|
||||
|
||||
That is it for now with enabling shell script debugging mode. As we have seen, we can either debug an entire shell script or a particular section of a script.
|
||||
|
||||
In the next two episode of this series, we will cover how to use the shell script debugging options to explain verbose, syntax checking and shell tracing debugging modes with examples.
|
||||
|
||||
Importantly, do not forget to ask any questions about this guide or perhaps provide us feedback through the comment section below. Until then, stay connected to Tecmint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/enable-shell-debug-mode-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/category/bash-shell/
|
||||
[2]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
@ -159,7 +159,7 @@ via: https://opensource.com/article/16/11/managing-devices-linux
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/life/15/9/everything-is-a-file
|
||||
|
||||
@ -77,7 +77,7 @@ via: https://insights.ubuntu.com/2016/11/28/mir-is-not-only-about-unity8/
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/guest/
|
||||
[1]:http://voices.canonical.com/kevin.gunn/
|
||||
|
||||
@ -62,7 +62,7 @@ via: https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-fr
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-from-sql-server-to-mysql-as-well/#to-have-control-over-the-platform
|
||||
|
||||
@ -1,111 +0,0 @@
|
||||
dongdongmian 翻译中
|
||||
|
||||
Uncommon but useful GCC command line options
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [See intermediate output during each compilation stage][1]
|
||||
2. [Make your code debugging and profiling ready][2]
|
||||
3. [Conclusion][3]
|
||||
|
||||
Software tools usually offer multiple features, but - as most of you will agree - not all their features are used by everyone. Generally speaking, there's nothing wrong in that, as each user has their own requirement and they use the tools within that sphere only. However, it's always good to keep exploring the tools you use as you never know when one of their features might come in handy, saving you some of your precious time in the process.
|
||||
|
||||
Case in point: compilers. A good programming language compiler always offers plethora of options, but users generally know and use a limited set only. Specifically, if you are C language developer and use Linux as your development platform, it's highly likely that you'd using the gcc compiler, which offers an endless list of command line options.
|
||||
|
||||
Do you know that if you want, you can ask gcc to save the output at each stage of the compilation process? Do you know the -Wall option that you use for generating warnings doesn't cover some specific warnings? There are many command line gcc options that are not commonly used, but can be extremely useful in certain scenarios, for example, while debugging the code.
|
||||
|
||||
So, in this article, we will cover a couple of such options, offering all the required details, and explaining them through easy to understand examples wherever necessary.
|
||||
|
||||
But before we move ahead, please keep in mind that all the examples, command, and instructions mentioned in this tutorial have been tested on Ubuntu 16.04 LTS, and the gcc version that we've used is 5.4.0.
|
||||
|
||||
### See intermediate output during each compilation stage
|
||||
|
||||
Do you know there are, broadly, a total of four stages that your C code goes through when you compile it using the gcc compiler? These are preprocessing, compilation, assembly, and linking. After each stage, gcc produces a temporary output file which is handed over to the next stage. Now, these are all temporary files that are produced, and hence we don't get to see them - all we see is that we've issued the compilation command and it produces the binary/executable that we can run.
|
||||
|
||||
But suppose, if while debugging, there's a requirement to see how the code looked after, say, the preprocessing stage. Then, what would you do? Well, the good thing is that the gcc compiler offers a command line option that you can use in your standard compilation command and you'll get those intermediate files that are deleted by the compiler otherwise. The option we're talking about is -save-temps.
|
||||
|
||||
Here's what the [gcc man page][4] says about this option:
|
||||
|
||||
```
|
||||
Store the usual "temporary" intermediate files permanently; place
|
||||
them in the current directory and name them based on the source
|
||||
file. Thus, compiling foo.c with -c -save-temps produces files
|
||||
foo.i and foo.s, as well as foo.o. This creates a preprocessed
|
||||
foo.i output file even though the compiler now normally uses an
|
||||
integrated preprocessor.
|
||||
|
||||
When used in combination with the -x command-line option,
|
||||
-save-temps is sensible enough to avoid over writing an input
|
||||
source file with the same extension as an intermediate file. The
|
||||
corresponding intermediate file may be obtained by renaming the
|
||||
source file before using -save-temps.
|
||||
```
|
||||
|
||||
Following is an example command that'll give you an idea on how you can use this option:
|
||||
|
||||
gcc -Wall **-save-temps** test.c -o test-exec
|
||||
|
||||
And this is how I verified that all the intermediate files were indeed produced after the above mentioned command was executed:
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
So as you can see in the screenshot above, the test.i, test.s, and test.o files were produced by the -save-temps option. These files correspond to the preprocessing, compiling, and linking stages, respectively.
|
||||
|
||||
### Make your code debugging and profiling ready
|
||||
|
||||
There are dedicated tools that let you debug and profile your source code. For example, [gdb][6] is used for debugging purposes, while [gprof][7] is a popular tool for profiling purposes. But do you know there are specific command line options that gcc offers in order to make your code debugging as well profiling ready?
|
||||
|
||||
Let us start with debugging. To be able to use gdb for code debugging, you'll have to compile your code using the -g command line option provided the gcc compiler. This option basically allows gcc to produce debugging information that's required by gdb to successfully debug your program.
|
||||
|
||||
In case you plan to use this option, you are advised to go through the details the [gcc man page][8] offers on this option - some of that can prove to be vital in some cases. For example, following is an excerpt taken from the man page:
|
||||
|
||||
```
|
||||
GCC allows you to use -g with -O. The shortcuts taken by optimized
|
||||
code may occasionally produce surprising results: some variables
|
||||
you declared may not exist at all; flow of control may briefly move
|
||||
where you did not expect it; some statements may not be executed
|
||||
because they compute constant results or their values are already
|
||||
at hand; some statements may execute in different places because
|
||||
they have been moved out of loops.
|
||||
|
||||
Nevertheless it proves possible to debug optimized output. This
|
||||
makes it reasonable to use the optimizer for programs that might
|
||||
have bugs.
|
||||
```
|
||||
|
||||
Not only gdb, compiling your code using the -g option also opens up the possibility of using Valgrind's memcheck tool to its complete potential. For those who aren't aware, memcheck is used by programmers to check for memory leaks (if any) in their code. You can learn more about this tool [here][9].
|
||||
|
||||
Moving on, to be able to use gprof for code profiling, you have to compile your code using the -pg command line option. It allows gcc to generate extra code to write profiling information, which is required by gprof for code analysis. "You must use this option when compiling the source files you want data about, and you must also use it when linking," the [gcc man page][10] says. To learn more about how to perform code profiling using gprof, head to this [dedicated tutorial][11] on our website.
|
||||
|
||||
**Note**: Usage of both -g and -pg options is similar to the way the -save-temps option was used in the previous section.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Unless you are a gcc pro, I am sure you learned something new with this article. Do give these options a try, and see how they work. Meanwhile, wait for the [next part][12] in this tutorial series where-in we'll discuss more such interesting and useful gcc command line options.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options/
|
||||
|
||||
作者:[ Ansh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options/#see-intermediate-output-during-each-compilation-stage
|
||||
[2]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options/#make-your-code-debugging-and-profiling-ready
|
||||
[3]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options/#conclusion
|
||||
[4]:https://linux.die.net/man/1/gcc
|
||||
[5]:https://www.howtoforge.com/images/uncommon-but-useful-gcc-command-line-options/big/gcc-save-temps.png
|
||||
[6]:https://www.gnu.org/software/gdb/
|
||||
[7]:https://sourceware.org/binutils/docs/gprof/
|
||||
[8]:https://linux.die.net/man/1/gcc
|
||||
[9]:http://valgrind.org/docs/manual/mc-manual.html
|
||||
[10]:https://linux.die.net/man/1/gcc
|
||||
[11]:https://www.howtoforge.com/tutorial/how-to-install-and-use-profiling-tool-gprof/
|
||||
[12]:https://www.howtoforge.com/tutorial/uncommon-but-useful-gcc-command-line-options-2/
|
||||
@ -69,7 +69,7 @@ via: https://medium.com/linode-cube/locking-down-your-linux-server-24d8516ae374#
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/linode-cube/locking-down-your-linux-server-24d8516ae374#.qy8qq4bx2
|
||||
[1]:https://www.linode.com/
|
||||
|
||||
@ -45,7 +45,7 @@ via: https://opensource.com/article/16/12/password-managers
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://opensource.com/users/jason-baker
|
||||
|
||||
@ -1,158 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
5 Ways to Empty or Delete a Large File Content in Linux
|
||||
============================================================
|
||||
|
||||
Occasionally, while dealing with files in Linux terminal, you may want to clear the content of a file without necessarily opening it using any [Linux command line editors][1]. How can this be achieved? In this article, we will go through several different ways of emptying file content with the help of some useful commands.
|
||||
|
||||
Caution: Before we proceed to looking at the various ways, note that because in [Linux everything is a file][2], you must always make sure that the file(s) you are emptying are not important user or system files. Clearing the content of a critical system or configuration file could lead to a fatal application/system error or failure.
|
||||
|
||||
With that said, below are means of clearing file content from the command line.
|
||||
|
||||
Important: For the purpose of this article, we’ve used file `access.log` in the following examples.
|
||||
|
||||
### 1\. Empty File Content by Redirecting to Null
|
||||
|
||||
A easiest way to empty or blank a file content using shell redirect `null` (non-existent object) to the file as below:
|
||||
|
||||
```
|
||||
# > access.log
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Empty Large File Using Null Redirect in Linux
|
||||
|
||||
### 2\. Empty File Using ‘true’ Command Redirection
|
||||
|
||||
Here we will use a symbol `:` is a shell built-in command that is essence equivalent to the `true`command and it can be used as a no-op (no operation).
|
||||
|
||||
Another method is to redirect the output of `:` or `true` built-in command to the file like so:
|
||||
|
||||
```
|
||||
# : > access.log
|
||||
OR
|
||||
# true > access.log
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Empty Large File Using Linux Commands
|
||||
|
||||
### 3\. Empty File Using cat/cp/dd utilities with /dev/null
|
||||
|
||||
In Linux, the `null` device is basically utilized for discarding of unwanted output streams of a process, or else as a suitable empty file for input streams. This is normally done by redirection mechanism.
|
||||
|
||||
And the `/dev/null` device file is therefore a special file that writes-off (removes) any input sent to it or its output is same as that of an empty file.
|
||||
|
||||
Additionally, you can empty contents of a file by redirecting output of `/dev/null` to it (file) as input using [cat command][5]:
|
||||
|
||||
```
|
||||
# cat /dev/null > access.log
|
||||
```
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Empty File Using cat Command
|
||||
|
||||
Next, we will use [cp command][7] to blank a file content as shown.
|
||||
|
||||
```
|
||||
# cp /dev/null access.log
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Empty File Content Using cp Command
|
||||
|
||||
In the following command, `if` means the input file and `of` refers to the output file.
|
||||
|
||||
```
|
||||
# dd if=/dev/null of=access.log
|
||||
```
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Empty File Content Using dd Command
|
||||
|
||||
### 4\. Empty File Using echo Command
|
||||
|
||||
Here, you can use an [echo command][10] with an empty string and redirect it to the file as follows:
|
||||
|
||||
```
|
||||
# echo "" > access.log
|
||||
OR
|
||||
# echo > access.log
|
||||
```
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Empty File Using echo Command
|
||||
|
||||
Note: You should keep in mind that an empty string is not the same as null. A string is already an object much as it may be empty while null simply means non-existence of an object.
|
||||
|
||||
For this reason, when you redirect the out of the [echo command][12] above into the file, and view the file contents using the [cat command][13], is prints an empty line (empty string).
|
||||
|
||||
To send a null output to the file, use the flag `-n` which tells echo to not output the trailing newline that leads to the empty line produced in the previous command.
|
||||
|
||||
```
|
||||
# echo -n "" > access.log
|
||||
```
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Empty File Using Null Redirect
|
||||
|
||||
### 5\. Empty File Using truncate Command
|
||||
|
||||
The truncate command helps to [shrink or extend the size of a file][15] to a defined size.
|
||||
|
||||
You can employ it with the `-s` option that specifies the file size. To empty a file content, use a size of 0 (zero) as in the next command:
|
||||
|
||||
```
|
||||
# truncate -s 0 access.log
|
||||
```
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Truncate File Content in Linux
|
||||
|
||||
That’s it for now, in this article we have covered multiple methods of clearing or emptying file content using simple command line utilities and shell redirection mechanism.
|
||||
|
||||
These are not probably the only available practical ways of doing this, so you can also tell us about any other methods not mentioned in this guide via the feedback section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/empty-delete-file-content-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/linux-command-line-editors/
|
||||
[2]:http://www.tecmint.com/explanation-of-everything-is-a-file-and-types-of-files-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-Large-File-in-Linux.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-Large-File-Using-Linux-Commands.png
|
||||
[5]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Using-cat-Command.png
|
||||
[7]:http://www.tecmint.com/progress-monitor-check-progress-of-linux-commands/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Content-Using-cp-Command.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Content-Using-dd-Command.png
|
||||
[10]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Using-echo-Command.png
|
||||
[12]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[13]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Empty-File-Using-Null-Redirect.png
|
||||
[15]:http://www.tecmint.com/parted-command-to-create-resize-rescue-linux-disk-partitions/
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Truncate-File-Content-in-Linux.png
|
||||
@ -1,3 +1,5 @@
|
||||
translating by dongdongmian
|
||||
|
||||
How to Build an Email Server on Ubuntu Linux
|
||||
============================================================
|
||||
|
||||
@ -110,7 +112,7 @@ via: https://www.linux.com/learn/how-build-email-server-ubuntu-linux
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
|
||||
@ -1,167 +0,0 @@
|
||||
httpstat – A Curl Statistics Tool to Check Website Performance
|
||||
============================================================
|
||||
|
||||
httpstat is a Python script that reflects curl statistics in a fascinating and well-defined way, it is a single file which is compatible with Python 3 and requires no additional software (dependencies) to be installed on a users system.
|
||||
|
||||
It is fundamentally a wrapper of cURL tool, means that you can use several valid cURL options after a URL(s), excluding the options -w, -D, -o, -s, and -S, which are already employed by httpstat.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
httpstat Curl Statistics Tool
|
||||
|
||||
You can see in the above image an ASCII table displaying how long each process took, and for me the most important step is “server processing” – if this number is higher, then you need to [tune your server to speed up website][6].
|
||||
|
||||
For website or server tuning you can check our articles here:
|
||||
|
||||
1. [5 Tips to Tune Performance of Apache Web Server][1]
|
||||
2. [Speed Up Apache and Nginx Performance Upto 10x][2]
|
||||
3. [How to Boost Nginx Performance Using Gzip Module][3]
|
||||
4. [15 Tips to Tune MySQL/MariaDB Performance][4]
|
||||
|
||||
Grab httpstat to check out your website speed using following instillation instructions and usage.
|
||||
|
||||
### Install httpstat in Linux Systems
|
||||
|
||||
You can install httpstat utility using two possible methods:
|
||||
|
||||
1. Get it directly from its Github repo using the [wget command][7] as follows:
|
||||
|
||||
```
|
||||
$ wget -c https://raw.githubusercontent.com/reorx/httpstat/master/httpstat.py
|
||||
```
|
||||
|
||||
2. Using pip (this method allows httpstat to be installed on your system as a command) like so:
|
||||
|
||||
```
|
||||
$ sudo pip install httpstat
|
||||
```
|
||||
|
||||
Note: Make sure pip package installed on the system, if not install it using your distribution package manager [yum][8] or [apt][9].
|
||||
|
||||
### How to Use httpstat in Linux
|
||||
|
||||
httpstat can be used according to the way you installed it, if you directly downloaded it, run it using the following syntax from within the download directory:
|
||||
|
||||
```
|
||||
$ python httpstat.py url cURL_options
|
||||
```
|
||||
|
||||
In case you used pip to install it, you can execute it as a command in the form below:
|
||||
|
||||
```
|
||||
$ httpstat url cURL_options
|
||||
```
|
||||
|
||||
To view the help page for httpstat, issue the command below:
|
||||
|
||||
```
|
||||
$ python httpstat.py --help
|
||||
OR
|
||||
$ httpstat --help
|
||||
```
|
||||
httpstat help
|
||||
```
|
||||
Usage: httpstat URL [CURL_OPTIONS]
|
||||
httpstat -h | --help
|
||||
httpstat --version
|
||||
Arguments:
|
||||
URL url to request, could be with or without `http(s)://` prefix
|
||||
Options:
|
||||
CURL_OPTIONS any curl supported options, except for -w -D -o -S -s,
|
||||
which are already used internally.
|
||||
-h --help show this screen.
|
||||
--version show version.
|
||||
Environments:
|
||||
HTTPSTAT_SHOW_BODY Set to `true` to show response body in the output,
|
||||
note that body length is limited to 1023 bytes, will be
|
||||
truncated if exceeds. Default is `false`.
|
||||
HTTPSTAT_SHOW_IP By default httpstat shows remote and local IP/port address.
|
||||
Set to `false` to disable this feature. Default is `true`.
|
||||
HTTPSTAT_SHOW_SPEED Set to `true` to show download and upload speed.
|
||||
Default is `false`.
|
||||
HTTPSTAT_SAVE_BODY By default httpstat stores body in a tmp file,
|
||||
set to `false` to disable this feature. Default is `true`
|
||||
HTTPSTAT_CURL_BIN Indicate the curl bin path to use. Default is `curl`
|
||||
from current shell $PATH.
|
||||
HTTPSTAT_DEBUG Set to `true` to see debugging logs. Default is `false`
|
||||
```
|
||||
|
||||
From the output of the help command above, you can see that httpstat has a collection of useful environmental variables that influence its behavior.
|
||||
|
||||
To use them, simply export the variables with the appropriate value in the `.bashrc` or `.zshrc` file.
|
||||
|
||||
For instance:
|
||||
|
||||
```
|
||||
export HTTPSTAT_SHOW_IP=false
|
||||
export HTTPSTAT_SHOW_SPEED=true
|
||||
export HTTPSTAT_SAVE_BODY=false
|
||||
export HTTPSTAT_DEBUG=true
|
||||
```
|
||||
|
||||
Once your are done adding them, save the file and run the command below to effect the changes:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
You can as well specify the cURL binary path to use, the default is curl from current shell [$PATH environmental variable][10].
|
||||
|
||||
Below are a few examples showing how httpsat works.
|
||||
|
||||
```
|
||||
$ python httpstat.py google.com
|
||||
OR
|
||||
$ httpstat google.com
|
||||
```
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
httpstat – Showing Website Statistics
|
||||
|
||||
In the next command:
|
||||
|
||||
1. `-x` command flag specifies a custom request method to use while communicating with the HTTP server.
|
||||
2. `--data-urlencode` data posts data (a=b in this case) with URL-encoding turned on.
|
||||
3. `-v` enables a verbose mode.
|
||||
|
||||
```
|
||||
$ python httpstat.py httpbin.org/post -X POST --data-urlencode "a=b" -v
|
||||
```
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
httpstat – Custom Post Request
|
||||
|
||||
You can look through the cURL man page for more useful and advanced options or visit the httpstatGithub repository: [https://github.com/reorx/httpstat][13]
|
||||
|
||||
In this article, we have covered a useful tool for monitoring cURL statistics is a simple and clear way. If you know of any such tools out there, do not hesitate to let us know and you can as well ask a question or make a comment about this article or httpstat via the feedback section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/httpstat-curl-statistics-tool-check-website-performance/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/apache-performance-tuning/
|
||||
[2]:http://www.tecmint.com/install-mod_pagespeed-to-boost-apache-nginx-performance/
|
||||
[3]:http://www.tecmint.com/increase-nginx-performance-enable-gzip-compression-module/
|
||||
[4]:http://www.tecmint.com/mysql-mariadb-performance-tuning-and-optimization/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/httpstat-Curl-Statistics-Tool.png
|
||||
[6]:http://www.tecmint.com/apache-performance-tuning/
|
||||
[7]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[8]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[9]:http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[10]:http://www.tecmint.com/set-unset-environment-variables-in-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/12/httpstat.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/httpstat-Post-Request.png
|
||||
[13]:https://github.com/reorx/httpstat
|
||||
@ -1,269 +0,0 @@
|
||||
The Complete Guide to Flashing Factory Images Using Fastboot
|
||||
==========
|
||||
|
||||

|
||||
|
||||
If your phone has an unlocked [bootloader][31], you can use [Fastboot][32] commands to flash factory images. That may sound like a bunch of technical jargon, but when it comes down to it, this is the best method for updating a [rooted][33] device, fixing a [bricked][34] phone, reverting to stock, or even getting new Android updates before everyone else.
|
||||
|
||||
Much like [ADB][35], Fastboot is a very powerful Android utility that accepts commands through a terminal shell. But if that sounds intimidating, don't worry—because once you've learned your way around things, you'll know so much more about the inner workings of Android, as well as how to fix most common problems.
|
||||
|
||||
### A Note About Samsung Devices
|
||||
|
||||
The process outlined below will work for most Nexus, Pixel, HTC, and Motorola devices, as well as phones and tablets from many other manufacturers. However, Samsung devices use their own firmware-flashing software, so Fastboot isn't the way to go if you own a Galaxy. Instead, it's best to use [Odin][36] to flash firmware on a Samsung device, and we've covered that process at the following link.
|
||||
|
||||
|
||||
### Step 1Install ADB & Fastboot on Your Computer
|
||||
|
||||
First, you'll have to install ADB and Fastboot on your computer, which are the utilities that let you flash images using Fastboot commands. There are several "one-click" and "light" versions of ADB and Fastboot, but I wouldn't recommend using these because they're not updated as frequently as the official utilities, so they might not be fully compatible with newer devices.
|
||||
|
||||
Instead, your best bet is to install the Android SDK Tools from Google. This is the "real" ADB and Fastboot, and it may take a little longer to install, but it's well worth the initial time investment. I've outlined the install process for Windows, Mac, and Linux in _Method 1_ at the following guide, so head over there to get started.
|
||||
|
||||
|
||||
### Step 2Enable OEM Unlocking
|
||||
|
||||
In order to flash images using Fastboot, your device's [bootloader][37] will need to be unlocked. If you've already done this, you can skip ahead to Step 3.
|
||||
|
||||
But before you can unlock your bootloader, there's [a setting that you'll need to enable][38] if your device shipped with [Android Marshmallow or higher][39] preinstalled. To access this setting, start by **[enabling the Developer options menu][18]** on your phone or tablet. Once you've done that, open the Developer options menu, then enable the switch next to "OEM unlocking," and you'll be good to go.
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
If this option is not present on your device, it's likely that your device didn't ship with Android Marshmallow or higher preinstalled. However, if the option is present but grayed out, this usually means that your bootloader cannot be unlocked, which means you won't be able to flash images using Fastboot.
|
||||
|
||||
### Step 3Put Your Phone into Bootloader Mode
|
||||
|
||||
In order to run any Fastboot commands, your phone or tablet will need to be in bootloader mode. This process will vary depending on your device.
|
||||
|
||||
For most phones, start by powering your device completely off. When the screen goes black, press and hold the volume down and power buttons simultaneously, and keep holding them for about 10 seconds.
|
||||
|
||||
If that doesn't work, turn the phone off, then press and hold the volume down button. From there plug a USB data cable into your PC, then simply wait a few seconds.
|
||||
|
||||
If that still didn't work, try repeating the USB cable method, but this time use the volume up button.
|
||||
|
||||
Within moments, you should be greeted by Android's Bootloader menu, which should look something like this:
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
When you see this screen, make sure your phone or tablet is plugged into your computer with a USB data cable. Aside from that, leave the device alone, as the rest of the work will be done on the computer side of things.
|
||||
|
||||
|
||||
### Step 4 Open an ADB Shell on Your Computer
|
||||
|
||||
Navigate to the ADB and Fastboot installation directory on your computer. For Windows users, this can usually be found at _C:\Program Files (x86)\Android\android-sdk\platform-tools_. For Mac and Linux users, it depends on where you extracted your ADB folder when you installed the utility, so search your hard drive for the _platform-tools_ folder if you've forgotten.
|
||||
|
||||
From here, if you're using a Windows PC, hold down the shift button on your keyboard, then right-click any empty space and choose "Open command window here." For Mac and Linux users, simply open a Terminal window, then change directories to the _platform-tools_ folder inside of your ADB installation directory.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
### Step 5Unlock the Bootloader
|
||||
|
||||
This next step is something you only need to do once, so if your bootloader is already unlocked, you can skip ahead. Otherwise, you'll need to run a single Fastboot command—but note that **this will wipe all data on your device**.
|
||||
|
||||
Before we get into this part, note that I'll be listing the commands for Windows users. Mac users will have to add a period and a slash (**./**) before each of these commands, and Linux users will have to add a slash (**/**) to the front.
|
||||
|
||||
So from the ADB shell, type the following command, then hit enter.
|
||||
|
||||
* **fastboot devices**
|
||||
|
||||
If that returns a series of letters and numbers followed by the word "fastboot," then your device is connected properly and you're good to go. Otherwise, refer back to Step 1 to check your ADB and Fastboot installation, and ensure that your device is in bootloader mode as shown in Step 3.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Next up, it's time to unlock your bootloader. Depending on the Android version your device shipped with, this will be done in one of two ways.
|
||||
|
||||
So if your device shipped with Lollipop or lower pre-installed, enter the following command:
|
||||
|
||||
* **fastboot oem unlock**
|
||||
|
||||
If your device shipped with Marshmallow or higher, type the following command, then hit enter:
|
||||
|
||||
* **fastboot flashing unlock**
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
>Sending the bootloader unlock command to a device that shipped with Marshmallow or higher.
|
||||
|
||||
At this point, you'll see a message on your Android device asking if you're sure you'd like to unlock the bootloader. Make sure the "Yes" option is highlighted, and if it's not, use your volume keys to do so. From there, press the power button, then your bootloader will unlock and your phone will reboot back into Fastboot mode.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Bootloader-unlock screen on the Nexus 6P.Image by Dallas Thomas/Gadget Hacks
|
||||
|
||||
### Step 6Download the Factory Images
|
||||
|
||||
Now that your bootloader is unlocked, you're ready to start flashing factory images—but first, you'll have to download the actual images themselves. Below are some links to download the factory images package for common devices.
|
||||
|
||||
* **[Factory images for Nexus or Pixel devices][15]**
|
||||
* **[Factory images for HTC devices][16]**
|
||||
* **[Factory images for Motorola devices][17]**
|
||||
|
||||
With each of the above links, simply locate your device model in the list, then download the latest available firmware on your computer. If your manufacturer is not listed here, try Googling "factory images for `<phone name>`."
|
||||
|
||||
|
||||
### Step 7Flash the Factory Images
|
||||
|
||||
Now it's time to flash the images. The first thing you'll want to do here is extract the factory images archive that you downloaded from your manufacturer's website. For that part, I'd recommend using **[7-Zip][19]**, as it's free and works with most archive formats.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Extracting the factory images archive.
|
||||
|
||||
Next, move all of the contents of the archive to the _platform-tools_ folder inside of your ADB installation directory, then open an ADB Shell window in this folder. For more information on that, refer back to Step 4 above.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Factory image files transferred to the platform-tools folder.
|
||||
|
||||
Aside from that, there are two different approaches you can take when flashing the images. I'll outline both of them in separate sections below.
|
||||
|
||||
|
||||
### Option 1: Use the Flash-All Script
|
||||
|
||||
Most factory images packages will contain a "flash-all" script that applies all of the images in one fell swoop. If you're trying to recover your device from a soft brick, this is the simplest way to go. However, it will unroot your device and wipe all existing data, so if you'd rather avoid that, see Option 2 below.
|
||||
|
||||
But to run the flash-all script, type the following line into the command prompt, then hit enter:
|
||||
|
||||
* **flash-all**
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Sending the "flash-all" command.
|
||||
|
||||
The process will take a few minutes, but when it's done, your phone should automatically reboot and you'll be running complete, 100% stock firmware.
|
||||
|
||||
|
||||
### Option 2: Extract the Images & Flash Them Individually
|
||||
|
||||
For a second option, you can flash the system images individually. This method takes some extra work, but it can be used to un-root, update, or un-brick your device without losing existing data.
|
||||
|
||||
Start by extracting any additional archives from the factory images package. Sometimes, factory images packages can contain a series of three or four nested archives, so make sure to unzip all of them. From there, copy all of the image files to the main _platform-tools_ folder—in other words, don't leave them in any sub-folders.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
All images extracted from factory images package into platform-tools folder.
|
||||
|
||||
From here, there are two images that you can get rid of: _cache.img_ and _userdata.img_. These are the images that will overwrite your data and cache with blank space, so if you don't flash them, your existing data will remain intact.
|
||||
|
||||
Of the remaining images, six make up the core elements of Android: _boot_, _bootloader_, _radio_, _recovery_, _system_, and _vendor_.
|
||||
|
||||
The _boot_ image contains the kernel, so if you just want to get rid of a custom kernel that's causing issues with your device, you only have to flash this one. To do that, type the following command into the ADB shell window:
|
||||
|
||||
* **fastboot flash boot <boot image file name>.img**
|
||||
|
||||
Next is the _bootloader_ image—this is the the interface that you're using to flash images with Fastboot commands. So to update your bootloader, type:
|
||||
|
||||
* **fastboot flash bootloader <bootloader image file name>.img**
|
||||
|
||||
Once you've done that, you should reload the bootloader so that you can continue flashing images on the newer version. To do that, type:
|
||||
|
||||
* **fastboot reboot-bootloader**
|
||||
|
||||
After that, we have the _radio_ image. This one controls connectivity on your device, so if you're having problems with Wi-Fi or mobile data, or if you just want to update your radio, type:
|
||||
|
||||
* **fastboot flash radio <radio image file name>.img**
|
||||
|
||||
Then there's _recovery_. This is something you may or may not want to flash, depending on the modifications you've made. For example, if you've installed TWRP custom recovery, flashing this image will overwrite your modification and replace it with the stock recovery interface. So if you're just updating your modded device, you should skip this one. Otherwise, if you plan to keep your phone stock and want the newer version of stock recovery, type:
|
||||
|
||||
* **fastboot flash recovery <recovery file name>.img**
|
||||
|
||||
Next up is the big one: The _system_ image. This one contains all of the files that make up the actual Android OS. As such, it's the most essential part of any update.
|
||||
|
||||
However you may not be updating your phone. You may just be re-flashing the stock firmware to recover from a soft brick. If this is the case, the system image is often the only image you need to flash in order to fix everything, because it contains the entirety of Android. In other words, if you flash this image and nothing else, it will undo any changes you made with root access and put everything back the way it was.
|
||||
|
||||
So as a cure-all in most soft brick situations, or as a method for getting the core part of an Android update, type:
|
||||
|
||||
* **fastboot flash system <system file name>.img**
|
||||
|
||||
Finally, there's the _vendor_ image. This is only present on newer phones, so don't worry if it's not in your factory images package. But if it's there, it contains a few important files, so type the following line to get this partition updated:
|
||||
|
||||
* **fastboot flash vendor <vendor file name>.img**
|
||||
|
||||
After you've sent any or all of the above commands, you'll be ready to restart your device and boot into Android. To do that, type:
|
||||
|
||||
* **fastboot reboot**
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Flashing the factory images individually.
|
||||
|
||||
At this point, your device should be fully updated, or if you were trying to recover from a soft brick, it should be running flawlessly. And since you now know what each of the core system images actually _does_, you'll have a better sense of how Android works going forward.
|
||||
|
||||
Flashing factory images individually has helped me understand more about Android than any other mod or process. If you think about it, Android is just a series of images written to flash storage, and now that you've dealt with each of them individually, you should be able to identify and resolve root-related issues a lot easier.
|
||||
|
||||
* Follow Gadget Hacks on [Facebook][20], [Twitter][21], [Google+][22], and [YouTube][23]
|
||||
* Follow Android Hacks on [Facebook][24], [Twitter][25], and [Pinterest][26]
|
||||
* Follow WonderHowTo on [Facebook][27], [Twitter][28], [Pinterest][29], and [Google+][30]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://android.wonderhowto.com/how-to/complete-guide-flashing-factory-images-using-fastboot-0175277/
|
||||
|
||||
作者:[ Dallas Thomas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://creator.wonderhowto.com/dallasthomas/
|
||||
[1]:http://img.wonderhowto.com/img/original/95/62/63613181132511/0/636131811325119562.jpg
|
||||
[2]:http://img.wonderhowto.com/img/original/12/37/63615501357234/0/636155013572341237.jpg
|
||||
[3]:http://img.wonderhowto.com/img/original/42/51/63613181192903/0/636131811929034251.jpg
|
||||
[4]:http://img.wonderhowto.com/img/original/06/56/63613181203998/0/636131812039980656.jpg
|
||||
[5]:http://img.wonderhowto.com/img/original/53/86/63613181215032/0/636131812150325386.jpg
|
||||
[6]:http://img.wonderhowto.com/img/original/55/72/63613181234096/0/636131812340965572.jpg
|
||||
[7]:http://img.wonderhowto.com/img/original/81/31/63616200792994/0/636162007929948131.jpg
|
||||
[8]:http://img.wonderhowto.com/img/original/05/92/63616201348448/0/636162013484480592.jpg
|
||||
[9]:http://img.wonderhowto.com/img/original/58/38/63616206141588/0/636162061415885838.jpg
|
||||
[10]:http://img.wonderhowto.com/img/original/47/26/63616206657885/0/636162066578854726.jpg
|
||||
[11]:http://img.wonderhowto.com/img/original/31/31/63616269700533/0/636162697005333131.jpg
|
||||
[12]:http://android.wonderhowto.com/how-to/know-your-android-tools-what-is-fastboot-do-you-use-it-0155640/
|
||||
[13]:http://gs6.wonderhowto.com/how-to/unroot-restore-samsung-galaxy-s6-back-stock-0162155/
|
||||
[14]:http://android.wonderhowto.com/how-to/android-basics-install-adb-fastboot-mac-linux-windows-0164225/
|
||||
[15]:https://developers.google.com/android/images
|
||||
[16]:http://www.htc.com/us/support/rom-downloads.html
|
||||
[17]:https://motorola-global-portal.custhelp.com/cc/cas/sso/redirect/standalone%2Fbootloader%2Frecovery-images
|
||||
[18]:http://android.wonderhowto.com/how-to/android-basics-enable-developer-options-usb-debugging-0161948/
|
||||
[19]:http://www.7-zip.org/download.html
|
||||
[20]:http://facebook.com/gadgethacks/
|
||||
[21]:http://twitter.com/gadgethax
|
||||
[22]:https://plus.google.com/+gadgethacks
|
||||
[23]:https://www.youtube.com/user/OfficialSoftModder/
|
||||
[24]:http://facebook.com/androidhacksdotcom/
|
||||
[25]:http://twitter.com/androidhackscom
|
||||
[26]:https://www.pinterest.com/wonderhowto/android-hacks-mods-tips/
|
||||
[27]:http://facebook.com/wonderhowto/
|
||||
[28]:http://twitter.com/wonderhowto/
|
||||
[29]:http://pinterest.com/wonderhowto/
|
||||
[30]:https://plus.google.com/+wonderhowto
|
||||
[31]:http://android.wonderhowto.com/news/big-android-dictionary-glossary-terms-you-should-know-0165594/
|
||||
[32]:http://android.wonderhowto.com/news/big-android-dictionary-glossary-terms-you-should-know-0165594/
|
||||
[33]:http://android.wonderhowto.com/how-to/android-basics-what-is-root-0167400/
|
||||
[34]:http://android.wonderhowto.com/news/big-android-dictionary-glossary-terms-you-should-know-0165594/
|
||||
[35]:http://android.wonderhowto.com/how-to/know-your-android-tools-what-is-adb-do-you-use-it-0155456/
|
||||
[36]:http://tag.wonderhowto.com/odin/
|
||||
[37]:http://android.wonderhowto.com/news/big-android-dictionary-glossary-terms-you-should-know-0165594/
|
||||
[38]:http://android.wonderhowto.com/news/psa-enable-hidden-setting-before-modding-anything-android-0167840/
|
||||
[39]:http://android.wonderhowto.com/how-to/android-basics-tell-what-android-version-build-number-you-have-0168050/
|
||||
@ -0,0 +1,190 @@
|
||||
9 Open Source/Commercial Software for Data Center Infrastructure Management
|
||||
============================================================
|
||||
|
||||
When a company grows its demand in computing resources grows as well. It works as for regular companies as for providers, including those renting out dedicated servers. When the total number of racks exceed 10 you’ll start facing issues.
|
||||
|
||||
How to inventory servers and spares? How to maintain a data center in a good health, locating and fixing potential threats on time. How to find the rack with broken equipment? How to prepare physical machines to work? Carrying out these tasks manually will take too much time otherwise will require having a huge team of administrators in your IT-department.
|
||||
|
||||
|
||||
However there is a better solution – using a special software that automates Data Center management. Let’s have a review of the tools for running a DC that we have on a market today.
|
||||
|
||||
### 1\. Opendcim
|
||||
|
||||
Currently it’s the one and the only free software in its class. It has an open source-code and designed to be an alternative to commercial DCIM solutions. Allows to keep inventory, draw a DC map and monitor temperature and power consumption.
|
||||
|
||||
On the other hand, it doesn’t support remote power-off, server rebooting, and OS installation functionality. Nevertheless, it is widely used in non-commercial organizations all around the globe.
|
||||
|
||||
Thanks to its open source code, [Opendcims][2] should work fine for the companies having their own developers.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
openDCIM
|
||||
|
||||
### 2\. NOC-PS
|
||||
|
||||
A commercial system, designed for provisioning physical and virtual machines. Has a wide functionality for advance preparation of equipment: OS and other software installation and setting up network configurations, there is WHMCS and Blesta integrations. However, it won’t be your best choice if you need to have a DC map at hand and see the racks location.
|
||||
|
||||
[NOC-PS][4] will cost you a 100€ per year for every 100 dedicated servers bundle. Suits for small-to-middle scale companies.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
NOC-PS
|
||||
|
||||
### 3\. DCImanager
|
||||
|
||||
[DCImanager][6] is a proprietary class solution developed, as announced, considering the needs of DC engineers and hosting providers. Has an integration with popular billing software like WHMCS, Hostbill, BILLmanager.
|
||||
|
||||
Main features are: server provisioning, OS installation from templates, sensors monitoring, traffic and power consumption reports, VLAN management. In addition to said above, Enterprise edition allows you to build a DC map and keep servers and spares inventorying.
|
||||
|
||||
|
||||
You can try a free license for up to 5 physical servers while a yearly license costs 120€ for 100 dedicated machines.
|
||||
|
||||
Depending on edition, can be a good fit for both SMBs and large-scale enterprises.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
DCImanager
|
||||
|
||||
### 4\. EasyDCIM
|
||||
|
||||
[EasyDCIM][9] is a paid software mainly oriented on server provisioning. Brings OS and other software installation features and facilitates DC navigation allowing to draw a scheme of racks.
|
||||
|
||||
Meanwhile the product itself doesn’t include IPs and DNS management, control over the switches. These and other features become available after additional modules installation, both free and paid (including WHMCS integration).
|
||||
|
||||
100 server license starts from $999 per year. Due to the pricing EasyDCIM may be a bit expensive for small companies, while middle and large companies can give it a try.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
EasyDCIM
|
||||
|
||||
### 5\. Ansible Tower
|
||||
|
||||
[Ansible Tower][11] is a Enterprise level computing infrastructure management tool from RedHat. The main idea of this solution was the possibility of a centralized deployment as for servers as for the different user devices.
|
||||
|
||||
Thanks to that Ansible Tower can perform almost any possible program operation with integrated software and has an amazing statistics collecting module. On the dark side we have the lack of integration with popular billing systems and pricing.
|
||||
|
||||
$5000 per year for 100 devices. Will work for large and gigantic companies..
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Ansible Tower
|
||||
|
||||
### 6\. Puppet Enterprise
|
||||
|
||||
Developed on a commercial basis and considered as an accessorial software for IT-departments. Designed for OS and other software installation on servers and user devices both at the initial deployment and a further exploitation stages.
|
||||
|
||||
Unfortunately, inventorying and the more advanced interaction schemes between devices (cable connection, protocols and other) is still under development.
|
||||
|
||||
[Puppet Enterprise][13] has a free and fully-functional version for 10 computers. A yearly license cost is $120 per device.
|
||||
|
||||
Can work for big corporations.
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Puppet Enterprise
|
||||
|
||||
### 7\. Device 42
|
||||
|
||||
Mostly designed for a Data Center monitoring. Has a great tools for inventorying, builds hardware/software dependence map automatically. DC map drawn by [Device 42][15] reflects temperature, spare space and other parameters of a rack as in graphics as marking the racks with specific colour. However software installation and billing integration aren’t supported.
|
||||
|
||||
100 servers license will cost $1499 per year. Probably can be a good shot for middle-to-large companies.
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Device42
|
||||
|
||||
### 8\. CenterOS
|
||||
|
||||
It’s an operating system for a Data Center management with a main focus on equipment inventorying. Besides creating a DC map, schemes of racks and connections a well-thought integrated system of server statuses facilitates managing the internal technical works.
|
||||
|
||||
Another great feature allows to find and reach out to a right person related with a certain piece of equipment within a few clicks (it may be an owner, technician, or manufacturer), what can be truly handful in case of any emergencies.
|
||||
|
||||
**Suggested Read:** [8 Open Source/Commercial Billing Platforms for Hosting Providers][17]
|
||||
|
||||
The source code for [Centeros][18] is closed and pricing is available only upon request.
|
||||
|
||||
A mystery about the pricing complicates determining a target audience of the product, however it’s possible to make an assumption that Centeros is designed mostly for larger companies.
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
CenterOS
|
||||
|
||||
### 9\. LinMin
|
||||
|
||||
It’s an instrument for preparing a physical equipment for a further usager. Uses PXE install the chosen OS and deploys the requested set of additional software afterwards.
|
||||
|
||||
Unlike most of its analogs, [LinMin][20] has a well-developed backup system for hard drives, that speeds up an after-crush recovery and facilitates the mass deployments of the servers with a same configuration.
|
||||
|
||||
Price starts from $1999/year for 100 servers. Middle-to-large companies can keep LinMin in mind.
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
LinMin
|
||||
|
||||
Now let’s summarize everything. I would say that most of the products for automating operations with a high volume of infrastructure, that we have on a market today, can be divided in two categories.
|
||||
|
||||
The first is mainly designed for preparing an equipment for a further exploitation while the second manages inventorying. It’s not so easy to find a universal solution that will contain all the necessary features so you can give up on the many tools with a narrow functionality provided by an equipment manufacturer.
|
||||
|
||||
However now you have a list of such solutions and you are welcome to check it yourself. It’s worth to notice that an open source products is on the list as well, so if you have a good developer, it’s possible to customize it for your specific needs.
|
||||
|
||||
I hope that my review will help you to find a right software for your case and make your life easier. Long life to your servers!
|
||||
|
||||
|
||||
-----------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I'm a technical evangelist at hosting software developing company from Siberia, Russia. I'm curious and like to expand my knowledge whether from new Linux software tools or to Hosting Industry trends, possibilities, journey and opportunities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/data-center-server-management-tools/
|
||||
|
||||
作者:[ Nikita Nesmiyanov][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/nesmiyanov/
|
||||
[1]:http://www.tecmint.com/web-control-panels-to-manage-linux-servers/
|
||||
[2]:http://opendcim.org/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/12/openDCIM.png
|
||||
[4]:http://noc-ps.com/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/NOC-PS.png
|
||||
[6]:https://www.ispsystem.com/software/dcimanager
|
||||
[7]:http://www.tecmint.com/opensource-commercial-control-panels-manage-virtual-machines/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/DCImanager.png
|
||||
[9]:https://www.easydcim.com/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/EasyDCIM.png
|
||||
[11]:https://www.ansible.com/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/Ansible_Tower.png
|
||||
[13]:https://puppet.com/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Puppet-Enterprise.png
|
||||
[15]:http://www.device42.com/
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Device42.png
|
||||
[17]:http://www.tecmint.com/open-source-commercial-billing-software-system-web-hosting/
|
||||
[18]:http://www.centeros.com/
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2016/12/CenterOS.png
|
||||
[20]:http://www.linmin.com/
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2016/12/LinMin.jpg
|
||||
@ -0,0 +1,259 @@
|
||||
GHLandy Translating
|
||||
|
||||
Installation of Red Hat Enterprise Linux (RHEL) 7.3 Guide
|
||||
============================================================
|
||||
|
||||
Red Hat Enterprise Linux is an Open Source Linux distribution developed by Red Hat company, which can run all major processor architectures. Unlike other Linux distributions which are free to download, install and use, RHEL can be downloaded and used, with the exception the 30-day evaluation version, only if you buy a subscription.
|
||||
|
||||
In this tutorial will take a look on how you can install the latest release of RHEL 7.3, on your machine using the 30-day evaluation version of the ISO image downloaded from Red Hat Customer Portal at [https://access.redhat.com/downloads][1].
|
||||
|
||||
If you’re looking for CentOS, go through our [CentOS 7.3 Installation Guide][2].
|
||||
|
||||
To review what’s new in RHEL 7.3 release please read the [version release notes][3].
|
||||
|
||||
#### Pre-Requirements
|
||||
|
||||
This installation will be performed on a UEFI virtualized firmware machine. To perform the installation of RHELon a UEFI machine first you need to instruct the EFI firmware of your motherboard to modify the Boot Ordermenu in order to boot the ISO media from the appropriate drive (DVD or USB stick).
|
||||
|
||||
If the installation is done through a bootable USB media, you need to assure that the bootable USB is created using a UEFI compatible tool, such as [Rufus][4], which can partition your USB drive with a valid GPT partition scheme required by UEFI firmware.
|
||||
|
||||
To modify the motherboard UEFI firmware settings you need to press a special key during your machine initialization POST (Power on Self Test).
|
||||
|
||||
The proper special key needed for this configuration can be obtained by consulting your motherboard vendor manual. Usually, these keys can be F2, F9, F10, F11 or F12 or a combination of Fn with these keys in case your device is a Laptop.
|
||||
|
||||
Besides modifying UEFI Boot Order you need to make sure that QuickBoot/FastBoot and Secure Boot options are disabled in order to properly run RHEL from EFI firmware.
|
||||
|
||||
Some UEFI firmware motherboard models contain an option which allows you to perform the installation of an Operating System from Legacy BIOS or EFI CSM (Compatibility Support Module), a module of the firmware which emulates a BIOS environment. Using this type of installation requires the bootable USB drive to be partitioned in MBR scheme, not GPT style.
|
||||
|
||||
Also, once you install RHEL, or any other OS for that matter, on your UEFI machine from one of these two modes, the OS must run on the same firmware you’ve performed the installation.
|
||||
|
||||
You can’t switch from UEFI to BIOS Legacy or vice-versa. Switching between UEFI and Bios Legacy will render your OS unusable, unable to boot and the OS will require reinstallation.
|
||||
|
||||
### Installation Guide of RHEL 7.3
|
||||
|
||||
1. First, download and burn RHEL 7.3 ISO image on a DVD or create a bootable USB stick using the correct utility.
|
||||
|
||||
Power-on the machine, place the DVD/USB stick in the appropriate drive and instruct UEFI/BIOS, by pressing a special boot key, to boot from the appropriate installation media.
|
||||
|
||||
Once the installation media is detected it will boot-up in RHEL grub menu. From here select Install red hat Enterprise Linux 7.3 and press [Enter] key to continue.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
RHEL 7.3 Boot Menu
|
||||
|
||||
2. The next screen appearing will take you to the welcome screen of RHEL 7.3 From here chose the language that will be used for the installation process and press [Enter] key to move on to the next screen.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Select RHEL 7.3 Language
|
||||
|
||||
3. The next screen that will appear contains a summary of all the items you will need to setup for the installation of RHEL. First hit on DATE & TIME item and choose the physical location of your device from the map.
|
||||
|
||||
Hit on the upper Done button to save the configuration and proceed further with configuring the system.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
RHEL 7.3 Installation Summary
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Select RHEL 7.3 Date and Time
|
||||
|
||||
4. On the next step, configure your system keyboard layout and the and hit on Done button again to go back to the main installer menu.
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
Configure Keyboard Layout
|
||||
|
||||
5. Next, select the language support for your system and hit Done button to move to the next step.
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
Choose Language Support
|
||||
|
||||
6. Leave the Installation Source item as default because in this case we’re performing the installation from our local media drive (DVD/USB image) and click on Software Selection item.
|
||||
|
||||
From here you can choose the base environment and Add-ons for your RHEL OS. Because RHEL is a Linux distribution inclined to be used mostly for servers, the Minimal Installation item is the perfect choice for a system administrator.
|
||||
|
||||
This type of installation is the most recommended in a production environment because only the minimal software required to properly run the OS will be installed.
|
||||
|
||||
This also means a high degree of security and flexibility and a small size footprint on your machine hard drive. All other environments and add-ons listed here can be easily installed afterwards from command line by buying a subscription or by using the DVD image as a source.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
RHEL 7.3 Software Selection
|
||||
|
||||
7. In case you want to install one of the pre-configured server base environments, such as Web Server, File and Print Server, Infrastructure Server, Virtualization Host or Server with a Graphical User Interface, just check the preferred item, choose Add-ons from the right plane and hit on Done button finish this step.
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Select Server with GUI on RHEL 7.3
|
||||
|
||||
8. On the next step hit on Installation Destination item in order to select the device drive where the required partitions, file system and mount points will be created for your system.
|
||||
|
||||
The safest method would be to let the installer automatically configure hard disk partitions. This option will create all basic partitions required for a Linux system (`/boot`, `/boot/efi` and `/(root)` and `swap` in LVM), formatted with the default RHEL 7.3 file system, XFS.
|
||||
|
||||
Keep in mind that if the installation process was started and performed from UEFI firmware, the partition table of the hard disk would be GPT style. Otherwise, if you boot from CSM or BIOS legacy, the hard drive partition table would be old MBR scheme.
|
||||
|
||||
If you’re not satisfied with automatic partitioning you can choose to configure your hard disk partition table and manually create your custom required partitions.
|
||||
|
||||
Anyway, in this tutorial we recommend that you choose to automatically configure partitioning and hit on Donebutton to move on.
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
Choose RHEL 7.3 Installation Drive
|
||||
|
||||
9. Next, disable Kdump service and move to network configuration item.
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Disable Kdump Feature
|
||||
|
||||
10. In Network and Hostname item, setup and apply your machine host name using a descriptive name and enable the network interface by dragging the Ethernet switch button to `ON` position.
|
||||
|
||||
The network IP settings will be automatically pulled and applied in case you have a DHCP server in your network.
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Configure Network Hostname
|
||||
|
||||
11. To statically setup the network interface click on the Configure button and manually configure the IPsettings as illustrated on the below screenshot.
|
||||
|
||||
When you finish setting-up the network interface IP addresses, hit on Save button, then turn `OFF` and `ON` the network interface in order to apply changes.
|
||||
|
||||
Finally, click on Done button to return to the main installation screen.
|
||||
|
||||
[
|
||||
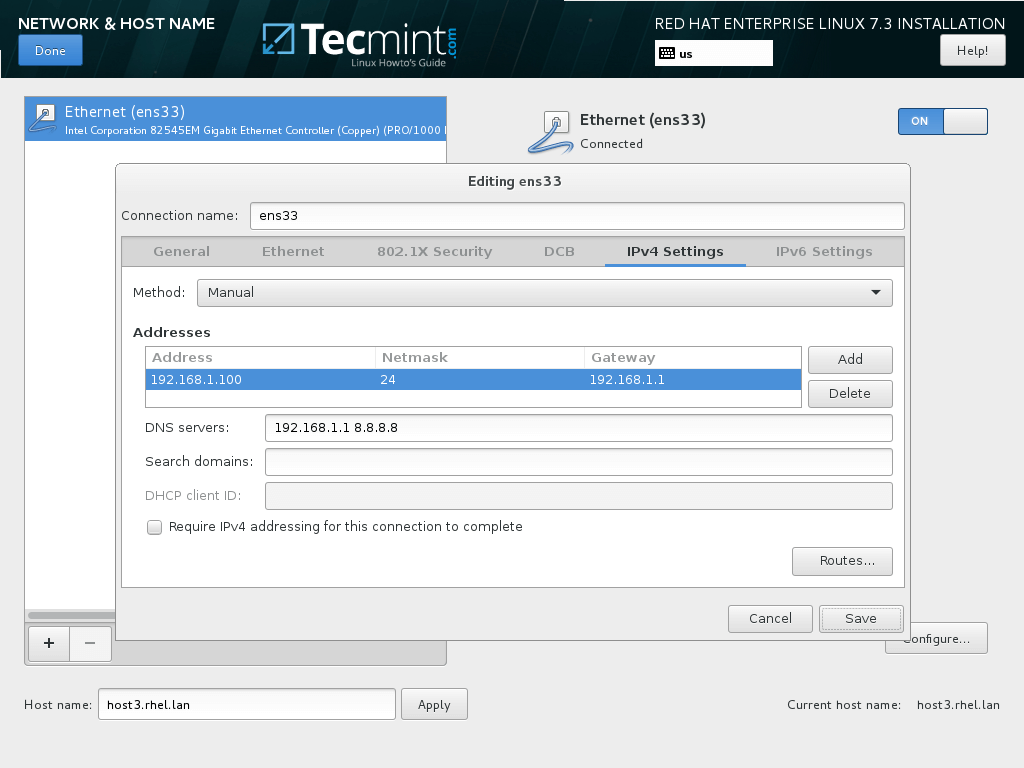
|
||||
][16]
|
||||
|
||||
Configure Network IP Address
|
||||
|
||||
12. Finally, the last item you need to configure from this menu is a Security Policy profile. Select and apply the Default security policy and hit on Done to go back to the main menu.
|
||||
|
||||
Review all your installation items and hit on Begin Installation button in order to start the installation process. Once the installation process has been started you cannot revert changes.
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
Apply Security Policy for RHEL 7.3
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
Begin Installation of RHEL 7.3
|
||||
|
||||
13. During the installation process the User Settings screen will appear on your monitor. First, hit on Root Password item and choose a strong password for the root account.
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
Configure User Settings
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
Set Root Account Password
|
||||
|
||||
14. Finally, create a new user and grant the user with root privileges by checking Make this user administrator. Choose a strong password for this user, hit on Done button to return to the User Settings menu and wait for the installation process to finish.
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
Create New User Account
|
||||
|
||||
[
|
||||

|
||||
][22]
|
||||
|
||||
RHEL 7.3 Installation Process
|
||||
|
||||
15. After the installation process finishes with success, eject the DVD/USB key from the appropriate drive and reboot the machine.
|
||||
|
||||
[
|
||||

|
||||
][23]
|
||||
|
||||
RHEL 7.3 Installation Complete
|
||||
|
||||
[
|
||||

|
||||
][24]
|
||||
|
||||
Booting Up RHEL 7.3
|
||||
|
||||
That’s all! In order to further use Red Hat Enterprise Linux, buy a subscription from Red Hat customer portal and [register your RHEL system using subscription-manager][25] command line.
|
||||
|
||||
------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar
|
||||
|
||||

|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/red-hat-enterprise-linux-7-3-installation-guide/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://access.redhat.com/downloads
|
||||
[2]:http://www.tecmint.com/centos-7-3-installation-guide/
|
||||
[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7-Beta/html/7.3_Release_Notes/chap-Red_Hat_Enterprise_Linux-7.3_Release_Notes-Overview.html
|
||||
[4]:https://rufus.akeo.ie/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Boot-Menu.jpg
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-RHEL-7.3-Language.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Installation-Summary.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-RHEL-7.3-Date-and-Time.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Keyboard-Layout.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/Choose-Language-Support.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Software-Selection.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-Server-with-GUI-on-RHEL-7.3.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2016/12/Choose-RHEL-7.3-Installation-Drive.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Disable-Kdump-Feature.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Network-Hostname.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Network-IP-Address.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2016/12/Apply-Security-Policy-on-RHEL-7.3.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2016/12/Begin-RHEL-7.3-Installation.png
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-User-Settings.png
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2016/12/Set-Root-Account-Password.png
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2016/12/Create-New-User-Account.png
|
||||
[22]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Installation-Process.png
|
||||
[23]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Installation-Complete.png
|
||||
[24]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Booting.png
|
||||
[25]:http://www.tecmint.com/enable-redhat-subscription-reposiories-and-updates-for-rhel-7/
|
||||
@ -0,0 +1,283 @@
|
||||
# Forget Technical Debt —Here'sHowtoBuild Technical Wealth
|
||||
#忘记技术债务——教你如何创造技术财富
|
||||
|
||||
电视里正播放着《老屋》节目,[Andrea Goulet][58]和她商业上的合作伙伴正悠闲地坐在客厅里商讨着他们的战略计划。那正是大家思想的火花碰撞出创新事物的时刻。他们正在寻求一种能够实现自身价值的方式——为其它公司清理遗留代码及科技债务。他们此刻的情景,像极了电视里的剧情。
|
||||
|
||||
“我们意识到我们现在做的工作不仅仅是清理出遗留代码,实际上我们是在用重建老屋的方式来重构软件,让系统运行更持久,更稳定,更高效,”Goulet说。“这让我开始思考着如何让更多的公司花钱来改善他们的代码,以便让他们的系统运行更高效。就好比为了让屋子变得更实用,你不得不使用一个全新的屋顶。这并不吸引人,但却是至关重要的,然而很多人都搞错了。“
|
||||
|
||||
如今,她是[Corgibytes][57]公司的CEO——一家提高软件现代化和进行系统重构方面的咨询公司。她曾经见过各种各样糟糕的系统,遗留代码,以及不计其数的严重的科技债务事件。Goulet认为创业公司需要从偿还债务思维模式向创造科技财富的思维模式转变,并且要从铲除旧代码的方式向逐步修复的方式转变。她解释了这种新的方法,以及如何完成这些看似不可能完成的事情——实际上是聘用大量的工程事来完成这些工作。
|
||||
|
||||
### 反思遗留代码
|
||||
|
||||
关于遗留代码最广泛的定义由Michael Feathers在他的著作[修改代码的艺术][56][][55]一书中提出:遗留代码就是没有被测试的代码。这个定义比大多数人所认为的——遗留代码仅指那些古老陈旧的系统这个说法要妥当得多。但是Goulet认为这两种定义都不够明确。“随时软件周期的生长,遗留代码显得毫无用处。一两年的应用程序,其代码已经进入遗留状态了,”她说。“最重要的是如何提高软件质量的难易程度。”
|
||||
|
||||
这意味着代码写得不够清楚,缺少解释说明,没有任何关于你写的代码构件和做出这个决定的流程。一个单元测试属于一种类型的构件,也包括所有的你写那部分代码的原因以及逻辑推理相关的文档。当你去修复代码的过程中,如果没办法搞清楚原开发者的意图,那些代码就属于遗留代码了。
|
||||
|
||||
> 遗留代码不是技术问题,而是沟通上的问题
|
||||
|
||||

|
||||
|
||||
如果你像Goulet所说的那样迷失在遗留代码里,你会发现每一次的沟通交流过程都会变得像那条鲜为人知的[康威定律][54]所描述的一样。
|
||||
|
||||
Goulet说:“这个定律认为系统的基础架构能反映出你们整个公司的组织沟通结构,如果你想修复你们公司的遗留代码而没有一个好的组织沟通方式是不可能完成的。那是很多人都没注意到的一个重要环节。”
|
||||
|
||||
Goulet和她的团队成员更像是考古学家一样来研究遗留系统项目。他们根据前开发者写的代码构件相关的线索来推断出他们的思想意图。然后再根据这些构件之间的关系来作出新的决策。
|
||||
|
||||
最重要的代码构件是什么呢?良好的代码结构、清晰的思想意图、整洁的代码。例如,如果你使用了通用的名称如”foo“或”bar“来命名一个变量,半年后你再返回来看这段代码时,你根本就看不出这个变量的用途是什么。
|
||||
|
||||
如果代码读起来很困难,可以使用源代码控制系统,这是一个非常有用的构件,因为从该构件可以看出代码的历史修改信息,这为软件开发者写明他们作出本次修改的原因提供一个很好的途径。
|
||||
|
||||
Goulet说:”我一个朋友认为对于代码注释的信息,如有需要,每一个概要部分的内容应该有推文的一半多,而代码的描述信息应该有一篇博客那么长。你得用这个方式来为你修改的代码写一个合理的说明。这也不会浪费太多的时间,并且给后期的项目开发者提供更多有用的信息,但是让人惊讶的是没人会这么做。我们经常听到一些很沮丧的开发人员在调试一段代码的过程中报怨这是谁写的这烂代码,最后发现还不是他们自己写的。“
|
||||
|
||||
使用自动化测试对于理解程序的流程非常有用。Goulet解释道:“很多人都比较认可Michael Feathers提出的关于遗留代码的定义,尤其是我们与[行为驱动开发模式][53]相结合的过程中使用测试套件,比如编写测试场景,这对于理解开发者的意图来说是非常有用的工具。
|
||||
|
||||
理由很简单,如果你想把遗留代码的程度降到最低,你得多注意下代码的易理解性以及将来回顾该代码的一些细节上。编写并运行单元程序、接受、认可,并且进行集成测试,写清楚注释的内容。方便以后你自己或是别人来理解你写的代码。
|
||||
|
||||
尽管如此,由于很多已知的和不可意料的原因,遗留代码仍然会发生。
|
||||
|
||||
在创业公司刚成立初期,公司经常会急于推出很多新的功能。开发人员在巨大的压力下一边完成项目交付一边测试系统缺陷。Corgibytes团队就遇到过好多公司很多年都懒得对系统做详细的测试了。
|
||||
|
||||
确实如此,当你急于开发出系统原型的时候,强制性地去做太多的系统测试也许意义不大。但是,一旦产品开发完成并投入使用后,你就不得投入大量的时间精力来维护及完善系统。“很多人觉得运维没什么好担心的,重要的是产品功能特性上的强大。如果真这样,当系统规模到一定程序的时候,就很难再扩展了。同时也就失去市场竞争力了。
|
||||
|
||||
最后才明白过来,原来热力学第二定律对你们公司的代码也同样适用:你所面临的一切将向熵增的方向发展。你需要与混乱无序的技术债务进行一场无休无止的战斗。并且随着时间的增长,遗留代码也逐渐变成一种简单类型的债务。
|
||||
|
||||
她说:“我们再次拿家来做比喻。你必须坚持每天收拾餐具,打扫卫生,倒垃圾。如果你不这么做,情况将来越来越糟糕,直到有一天你不得不向HazMat团队求助。”
|
||||
|
||||
就跟这种情况一样,Corgibytes团队接到很多公司CEO的求助电话,比如Features公司的CEO在电话里抱怨道:“现在我们公司的开发团队工作效率太低了,三年前只需要两个星期就完成的工作,现在却要花费12个星期。”
|
||||
|
||||
> 技术债务往往反应出公司运作上的问题
|
||||
|
||||
很多公司的CEO明知会发生技术债务的问题,但是他们也难让其它同事相信花钱来修复那些已经存在的问题是很值的。这看起来像是在走回头路,很乏味或者没有新的产品。有些公司直到系统已经严重的影响了日常工作效率时才着手去处理技术债务方面的问题,那时付出的代价就太高了。
|
||||
|
||||
### 忘记债务,创造技术财富
|
||||
|
||||
# 推荐文章
|
||||
|
||||
如果你想把[重构技术债务][52]作为一个积累技术财富的机会-[敏捷开发讲师Declan Whelan最近提到的一个术语][51],你很可能要先说服你们公司的CEO、投资者和其它的股东登上这条财富之船。
|
||||
|
||||
“我们没必要把技术债务想像得很可怕。当产品处于开发设计初期,技术债务反而变得非常有用,”Goulet说。“当你解决一些系统遗留的技术问题时,你会充满成就感。例如,当你在自己家里安装新窗户时,你确实会花费一笔不少的钱,但是之后你每个月就可以节省100美元的电费。程序代码亦是如此。这虽然暂时没有提高工作效率,但是随时时间地推移将为你们公司创造更多的生产率。“
|
||||
|
||||
一旦你意识到项目团队工作不再富有成效时,你必须要确认下是哪些技术债务在拖后腿了。
|
||||
|
||||
“我跟很多不惜一切代价招募英才的初创公司交流过,他们高薪聘请一些工程师来只为了完成更多的工作。”她说。”相反的是,他们应该找出如何让原有的每个工程师都更高效率工作的方法。你需要去解决什么样的技术债务以增加额外的生产率?"
|
||||
|
||||
如果你改变自己的观点并且专注于创造技术财富,你将会看到产能过剩的现象,然后重新把多余的产能投入到修复更多的技术债务和遗留代码的的良性循环中。你们的产品将会走得更远,发展得更好。
|
||||
|
||||
> 别想着把你们公司的软件当作一个项目来看。从现在起,你把它想象成一栋自己要长久居住的房子。
|
||||
|
||||
“这是一个极其重要的思想观念的转变,”Goulet说。“这将带你走出短浅的思维模式,并且你会比之前更加关注产品的维护工作。”
|
||||
|
||||
这就像一栋房子,要实现其现代化的改造方式有两种:小动作,表面上的更改(“我买了一块新的小地毯!”)和大改造,需要很多年才能偿还所有债务(“我假设我们将要替换掉所有的管道...")。你必须考虑好两者才能你们已有的产品和整个团队顺利地运作起来。
|
||||
|
||||
这还需要提前预算好——否则那些较大的花销将会是硬伤。定期维护是最基本的预期费用。让人震惊的是,很多公司在商务上都没把维护成本预算进来。
|
||||
|
||||
这就是Goulet提出软件重构这个术语的原因。当你房子里的一些东西损坏的时候,你不用铲除整个房子而是重新修复坏掉的那一部分就可以了。同样的,当你们公司出现老的,损坏的代码时,重写代码通常不是最明智的选择。
|
||||
|
||||
下面是Corgibytes公司在重构客户代码用到的一些方法:
|
||||
|
||||
* 把大型的应用系统分解成轻量级的更易于维护的微服务。
|
||||
* 相互功能模块之间降低耦合性以便于扩展。
|
||||
* 更新品牌和提升用户前端界面体验。
|
||||
* 集合自动化测试来检查代码可用性。
|
||||
* 重构或者修改代码库来提高易用性。
|
||||
|
||||
系统重构也进入到运维领域。比如,Corgibytes公司经常推荐新客户使用[Docker][50],以便简单快速的部属新的开发环境。当你们公司有30个工程师的时候,把初始化配置时间从10小时减少到10分钟对完成更多的工作很有帮助。系统重构不仅仅是应用于软件开发本身,也包括如何进行系统重构。
|
||||
|
||||
如果你知道有什么新的技术能让你们的代码管理起来更容易,创建更高效,就应该把这它们写入到每年或季度项目规划中。你别指望它们会自动呈现出来。但是也别给自己太大的压力来马上实施它们。Goulets看到很多公司从一开始就这些新的技术进行100%覆盖率测试而陷入困境。
|
||||
|
||||
具体来说,每个公司都应该把以下三种类型的重构工作规划到项目建设中来:
|
||||
|
||||
* 自动化测试
|
||||
* 持续性交付
|
||||
* 文化提升
|
||||
|
||||
咱们来深入的了解下每一项内容
|
||||
|
||||
自动化测试
|
||||
|
||||
“有一位客户即将进行第二轮融资,但是他们却没办法在短期内招聘到足够的人才。我们帮助他们引进了一种自动化测试框架,这让他们的团队在3个月的时间内工作效率翻了一倍,”Goulets说。“这样他们就可以在他们的投资人面前自豪的说,”我们的一个精英团队完成的任务比两个普通的团队要多。“”
|
||||
|
||||
自动化测试从根本上来讲就是单个测试的组合。你可以使用单元测试再次检查某一行代码。可以使用集成测试来确保系统的不同部分都正常运行。还可以使用验收性测试来检验系统的功能特性是否跟你想像的一样。当你把这些测试写成测试脚本后,你只需要简单地用鼠标点一下按钮就可以让系统自行检验了,而不用手工的去梳理并检查每一项功能。
|
||||
|
||||
在产品的市场定位前就来制定自动化测试机制是有些言之过早了。但是如果你有一款信心满满的产品,并且也很依赖客户,那就更应该把这件事考虑在内了。
|
||||
|
||||
持续性交付
|
||||
|
||||
这是与自动化交付相关的工作,过去是需要人工完成。目的是当系统部分修改完成时可以迅速进行部属,并且短期内得到反馈。这给公司在其它竞争对手面前有很大的优势,尤其是在售后服务行业。
|
||||
|
||||
“比如说你每次部属系统时环境都很复杂。熵值无法有效控制,”Goulets说。“我们曾经花了12个小时甚至更多的时间来部属一个很大的集群环境。然而,想必你将来也不会经常干部属新环境这样的工作。因为太折腾人了,而且还推迟了系统功能上线的时间。同时你也落后于其它公司并失去竞争力了。
|
||||
|
||||
在持续性改进的过程中常见的其它自动化任务包括:
|
||||
|
||||
* 在提交完成之后检查中断部分。
|
||||
* 在出现故障时进行回滚操作。
|
||||
* 审查自动化代码的质量。
|
||||
* 根据需求增加或减少服务器硬件资源。
|
||||
* 让开发,测试及生产环境配置简单易懂。
|
||||
|
||||
举一个简单的例子,比如说一个客户提交了一个系统Bug报告。开发团队越高效解决并修复那个Bug越好。对于开发人员来说,修复Bug的挑战根本不是个事儿,这本来也是他们的强项,主要是系统设置上不够完善导致他们浪费太多的时间去处理bug以外的其它问题。
|
||||
|
||||
使用持续改进的方式时,在你决定哪些工作应该让机器去做还是最好丢给研发去完成的时候,你会变得很严肃无情。如果选择让机器去处理,你得使其自动化完成。这样也能让研发很愉快地去解决其它有挑战性的问题。同时客户也会很高兴地看到他们报怨的问题被快速处理了。你的待修复的未完成任务数减少了,之后你就可以把更多的时间投入到运用新的方法来提高公司产品质量上了。
|
||||
|
||||
”你必须时刻问自己,‘我应该如何为我们的客户改善产品功能?如何做得更好?如何让产品运行更高效?’Goulets说。“一旦你回答完这些问题后,你就得询问下自己如何自动去完成那些需要改善的功能”
|
||||
|
||||
提升企业文化
|
||||
|
||||
Corgibytes公司每天都会遇到同样的问题:一家创业公司建立了一个对开发团队毫无影响的文化环境。公司CEO抱着双臂思考着为什么这样的环境对员工没多少改变。然而事实却是公司的企业文化观念与他们是截然相反的。为了激烈你们公司的工程师,你必须全面地了解他们的工作环境。
|
||||
|
||||
为了证明这一点,Goulet引用了作者Robert Henry说过的一段话:
|
||||
|
||||
> 目的不是创造艺术,而是在最美妙的状态下让艺术应运而生。
|
||||
|
||||
“也就是说你得开始思考一下你们公司的产品,“她说。”你们的企业文件就应该跟自己的产品一样。你们的目标是永远创造一个让艺术品应运而生的环境,这件艺术品就是你们公司的代码,一流的售后服务、充满幸福感的员工、良好的市场、盈利能力等等。这些都息息相关。“
|
||||
|
||||
优先考虑公司的技术债务和遗留代码也是一种文化。那才是真正能让开发团队深受影响的方法。同时,这也会让你将来有更多的时间精力去完成更重要的工作。如果你不从根本上改变固有的企业文化环境,你就不可能重构公司产品。改变你所有的对产品维护及现代化上投资的态度是开始实施变革的第一步,最理想情况是从公司的CEO开始转变。
|
||||
|
||||
以下是Goulet关于建立那种流态文化方面提出的建议:
|
||||
|
||||
* 反对公司嘉奖那些加班到深夜的”英雄“。提倡高效率的工作方式。
|
||||
* 了解协同开发技术,比如Woody Zuill提出的[暴徒编程][44][][43]模式。
|
||||
* 遵从4个[现代敏捷开发][42] 原则:用户至上、实践及快速学习、把系统安全放在首位、持续交付价值。
|
||||
* 每周为研发提供项目外的职业发展时间。
|
||||
* 把[日工作记录]作为一种驱动开发团队主动解决问题的方式。
|
||||
* 把同情心放在第一位。Corgibytes公司让员工参加[Brene Brown勇气工厂][40]的培训是非常有用的。
|
||||
|
||||
”如果公司高管和投资者不支持这种文件升级方式,你得从客户服务的角度去说服他们,“Goulet说,”告诉他们通过这次调整后,最终产品将如何给公司的大客户提高更好的体验。这是你能做的一个很有力的论点。“
|
||||
|
||||
### 寻找最具天财的代码重构者
|
||||
|
||||
整个行业都认为那些顶尖的工程师都不愿意去干修复遗留代码的工作。他们只想着去开发新的东西。大家都说把他们留在维护部门真是太浪费人才了。
|
||||
|
||||
其实这些都是误解。如果你知道如何寻找到那些技术精湛的工程师以为他们提供一个愉快的工作环境,你可以安排他们来帮你解决那些最棘手的技术债务问题。
|
||||
|
||||
”每一次开会的时候,我们都会问现场的同事’谁喜欢去干遗留代码的工作?‘但是也只有那么不到10%的同事会举手。“Goulet说。”但是当我跟这些人交流的过程中,我发现这些工程师恰好是喜欢最具挑战性工作的人才。“
|
||||
|
||||
有一位客户来寻求她的帮助,他们使用国产的数据库,没有任何相关文档,也没有一种有效的方法来弄清楚他们公司的产品架构。她称那些类似于面包和黄油的一类工程师为”修正者“。在Corgibytes公司,她有一支这样的修正者团队由她支配,他们没啥爱好,只喜欢通过研究二进制代码来解决技术问题。
|
||||
|
||||

|
||||
|
||||
那么,如何才能找到这些技术人才呢?Goulet尝试过各种各样的方法,其中有一些方法还是富有成效的。
|
||||
|
||||
她创办了一个社区网站[legacycode.rocks][49]并且在招聘启示上写道:”长期招聘那些喜欢重构遗留代码的另类开发人员...如果你以从事处理遗留代码的工作为自豪,欢迎加入!“
|
||||
|
||||
”我刚开始收到很多这些人发来邮件说,’噢,天呐,我也属于这样的开发人员!‘“她说。”我开始发布这条信息,并且告诉他们这份工作是非常有意义的,以吸引合适的人才“
|
||||
|
||||
推荐文章
|
||||
|
||||
在招聘的过程中,她也会使用持续性交付的经验来回答那些另类开发者想知道的信息:包括详细的工作内容以及明确的要求。我这么做的原因是因为我讨厌重复性工作。如果我收到多封邮件来咨询同一个问题,我会把答案发布在网上,我感觉自己更像是在写说明文档一样。”
|
||||
|
||||
但是随着时间的推移,她注意到她会重新定义招聘流程来帮助她识别出更出色的候选人。比如说,她在应聘要求中写道,“公司CEO将会重新审查你的简历,因此确保邮件发送给CEO时”不用写明性别。所有以“尊敬的先生或女士”开头的信件将会被当垃圾处理掉。然后,这只不过是她招聘初期的策略而已。
|
||||
|
||||
“我开始这么做是因为很多申请人把我当成一家软件公司的男性CEO,这让我很厌烦,”Goulet说。“所有,有一天我想我应该它当作应聘要求放到网上,看有多少人注意到这个问题。令我惊讶的是,这让我过滤掉一些不太严谨的申请人。还突显出了很多擅于从事遗留代码方面工作的人。
|
||||
|
||||
Goulet想起一个应聘者发邮件给我说,“我查看了你们网站的代码(我喜欢这个网站以及你们打招呼的方式,这就是我所希望的)。你们的网站架构很奇特,好像是用PHP写的,但是你们却运行在用Ruby语言写的Jekyll下。我真的很好奇那是什么呢。”
|
||||
|
||||
原来是这样的,Goulet从她的设计师那里得知,在HTML、CSS和JavaScript文件中有一个未使用的PHP类名,她一直想解决这个问题,但是一直没机会。她的回复是:“你正在找工作吗?”
|
||||
|
||||
另外一名候选人注意到她曾经在一篇说明文档中使用CTO这个词,但是她的团队里并没有这个头衔(她的合作伙伴是首席代码语者)。其次是那些注重细节、充满求知欲、积极主动的候选者更能引起她的注意。
|
||||
|
||||
> 代码修正者不仅需要注重细节,而且这也是他们必备的品质。
|
||||
|
||||
让人吃惊的是,Goulet从来没有为招募最优秀的代码修正者而感到厌烦过。”大多数人都是通过我们的网站直接投递简历,但是当我们想扩大招聘范围的时候,我们会通过[PowerToFly][48]和[WeWorkRemotely][47]网站进行招聘。我现在确实不需要招募新人马了。他们需要经历一段很艰难的时期才能理解代码修正者的意义是什么。“
|
||||
|
||||
如果他们通过首轮面试,Goulet将会让候选者阅读一篇Arlo Belshee写的文章”[命名是一个过程][46]“。它讲的是非常详细的处理遗留代码的的过程。她最经典的指导方法是:”阅读完这段代码并且告诉我,你是怎么理解的。“
|
||||
|
||||
她将找出对问题的理解很深刻并且也愿意接受文章里提出的观点候选者。这对于筛选出有坚定信念的想被雇用的候选者来说是极其有用的办法。她强力要求候选者找出一段与你操作相关的最关键的代码来证明你是充满激情的、有主见的及善于分析问题的人。
|
||||
|
||||
最后,她会让候选者跟公司里当前的团队成员一起使用[Exercism.io][45]工具进行编程。这是一个开源项目,它允许开发者学习如何在不同的编程语言环境下使用一系列的测试驱动开发的练习进行编程。第一部分的协同编程课程允许候选者选择其中一种语言进行内建。下一个练习中,面试者可以选择一种语言进行编程。他们总能看到那些人处理异常的方法、随机应便的能力以及是否愿意承认某些自己不了解 的技术。
|
||||
|
||||
“当一个人真正的从专家转变为大师的时候,他才会毫不犹豫的承认自己不知道的东西,“Goulet说。
|
||||
|
||||
让他们使用自己不熟悉的编程语言来写代码也能衡量其坚韧不拔的毅力。”我们想听到某个人说,‘我会深入研究这个问题直到彻底解决它。“也许第二天他们仍然会跑过来跟我们说,’我会一直留着这个问题直到我找到答案为止。‘那是作为一个成功的修正者表现出来的一种气质。“
|
||||
|
||||
> 如果你认为产品开发人员在我们这个行业很受追捧,因此很多公司也想让他们来做维护工作。那你可错了。最优秀的维护修正者并不是最好的产品开发工程师。
|
||||
|
||||
如果一个有天赋的修正者在眼前,Goulet懂得如何让他走向成功。下面是如何让这种类型的开发者感到幸福及高效工作的一些方式:
|
||||
|
||||
* 给他们高度的自主权。把问题解释清楚,然后安排他们去完成,但是永不命令他们应该如何去解决问题。
|
||||
* 如果他们要求升级他们的电脑配置和相关工具,尽管去满足他们。他们明白什么样的需求才能最大限度地提高工作效率。
|
||||
* 帮助他们[避免更换任务][39]。他们喜欢全身心投入到某一个任务直至完成。
|
||||
|
||||
总之,这些方法已经帮助Corgibytes公司培养出20几位对遗留代码充满激情的专业开发者。
|
||||
|
||||
### 稳定期没什么不好
|
||||
|
||||
大多数创业公司都都不想跳过他们的成长期。一些公司甚至认为成长期应该是永无止境的。而且,他们觉得也没这个必要,即便他们已经进入到了下一个阶段:稳定期。完全进入到稳定期意味着你可以利用当前的人力资源及管理方法在创造技术财富和消耗资源之间做出一个正确的选择。
|
||||
|
||||
”在成长期和稳定期之间有个转折点就是维护人员必须要足够壮大,并且你开始更公平的对待维护人员以及专注新功能的产品开发人员,“Goulet说。”你们公司的产品开发完成了。现在你得让他们更加稳定地运行。“
|
||||
|
||||
这就意味着要把公司更多的预算分配到产品维护及现代化方面。”你不应该把产品维护当作是一个不值得关注的项目,“她说。”这必须成为你们公司固有的一种企业文化——这将帮助你们公司将来取得更大的成功。“
|
||||
|
||||
最终,你通过这么努力创建的技术财富将会为你的团队带来一大批全新的开发者:他们就像侦查兵一样,有充足的时间和资源去探索新的领域,挖掘新客户资源并且给公司创造更多的机遇。当你们在新的市场领域做得更广泛并且不断发展得更好——那么你们公司已经真正地进入到繁荣发展的状态了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://firstround.com/review/forget-technical-debt-heres-how-to-build-technical-wealth/
|
||||
|
||||
作者:[http://firstround.com/][a]
|
||||
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://firstround.com/
|
||||
[1]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[2]:http://www.courageworks.com/
|
||||
[3]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[4]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[5]:http://mobprogramming.org/
|
||||
[6]:http://exercism.io/
|
||||
[7]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[8]:https://weworkremotely.com/
|
||||
[9]:https://www.powertofly.com/
|
||||
[10]:http://legacycode.rocks/
|
||||
[11]:https://www.docker.com/
|
||||
[12]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[13]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[14]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[15]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[16]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[17]:http://corgibytes.com/
|
||||
[18]:https://www.linkedin.com/in/andreamgoulet
|
||||
[19]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[20]:http://www.courageworks.com/
|
||||
[21]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[22]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[23]:http://mobprogramming.org/
|
||||
[24]:http://mobprogramming.org/
|
||||
[25]:http://exercism.io/
|
||||
[26]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[27]:https://weworkremotely.com/
|
||||
[28]:https://www.powertofly.com/
|
||||
[29]:http://legacycode.rocks/
|
||||
[30]:https://www.docker.com/
|
||||
[31]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[32]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[33]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[34]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[35]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[36]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[37]:http://corgibytes.com/
|
||||
[38]:https://www.linkedin.com/in/andreamgoulet
|
||||
[39]:http://corgibytes.com/blog/2016/04/15/inception-layers/
|
||||
[40]:http://www.courageworks.com/
|
||||
[41]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
|
||||
[42]:https://www.industriallogic.com/blog/modern-agile/
|
||||
[43]:http://mobprogramming.org/
|
||||
[44]:http://mobprogramming.org/
|
||||
[45]:http://exercism.io/
|
||||
[46]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
|
||||
[47]:https://weworkremotely.com/
|
||||
[48]:https://www.powertofly.com/
|
||||
[49]:http://legacycode.rocks/
|
||||
[50]:https://www.docker.com/
|
||||
[51]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
|
||||
[52]:https://www.agilealliance.org/resources/initiatives/technical-debt/
|
||||
[53]:https://en.wikipedia.org/wiki/Behavior-driven_development
|
||||
[54]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[55]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[56]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
|
||||
[57]:http://corgibytes.com/
|
||||
[58]:https://www.linkedin.com/in/andreamgoulet
|
||||
@ -1,84 +0,0 @@
|
||||
我们大学的机房使用 Fedora 系统
|
||||
==========
|
||||
|
||||

|
||||
|
||||
在[塞尔维亚共和国诺维萨德大学的自然科学系和数学与信息学系][5],我们教学生很多东西。从编程语言的入门到机器学习,所有开设的课程最终目的是让我们的学生能够像专业的开发者和软件工程师一样思考。课程时间紧凑而且学生众多,所以我们必须对现有可利用的资源进行合理调整以满足正常的教学。最终我们决定将机房电脑系统换为 Fedora。
|
||||
|
||||
### 以前的设置
|
||||
|
||||
我们过去的解决方案是在 Ubuntu 系统上面安装 Windows [虚拟机][4]并在虚拟机下安装好教学所需的开发软件。这在当时看起来是一个很不错的主意。然而,这种方法有很多弊端。首先,因为运行虚拟机导致了严重的计算机性能的浪费。因为运行虚拟机导致计算机性能利用率不高和操作系统的运行速度降低。此外,虚拟机有时候会在另一个用户会话里面同时运行。这会导致计算机工作效率的严重降低。我们有限的宝贵时间不应该花费在启动电脑和启动虚拟机上。最后,我们意识到我们的大部分教学所需软件都有对应的 Linux 版本。虚拟机不是必需的。我们不得不寻找一个更好的解决办法。
|
||||
|
||||
### 进入 Fedora!
|
||||
|
||||

|
||||
|
||||
默认运行 Fedora 工作站版本的一个机房的照片
|
||||
|
||||
我们思考过暂时替代以前的安装 Windows 虚拟机方案。我们最终决定使用 Fedora 有很多原因。
|
||||
|
||||
#### 发展的前沿
|
||||
|
||||
在我们所教授的课程中,我们会用到很多各种各样的开发工具。因此,我们能及时获取到最新的、最好用的开发工具很重要。在 Fedora 下,我们发现我们用到的开发工具有 95% 都能够在官方的软件仓库中找到。只有少量的一些工具,我们不得不手动安装。这在 Fedora 下很简单,因为你能获取到几乎所有的能开箱即用的开发工具。
|
||||
|
||||
我们意识到在这个过程中我们使用了大量自由、开源的软件和工具。这些软件总是能够及时更新并且可以用来做大量的工作而不仅仅局限于 Fedora 平台。
|
||||
|
||||
#### 硬件兼容性
|
||||
|
||||
我们选择 Fedora 用作机房的第二个原因是硬件兼容性。机房现在的电脑还是比较崭新的。过去比较低的内核版本总有些问题。在 Fedora 下,我们发现我们总能获得最新的内核版本。正如我们预期的那样,一切运行完美,没有任何差错。
|
||||
|
||||
我们决定我们最终会使用带有 [GNOME 桌面环境][2]的 Fedora [工作站版本][3]。学生群体通过使用这个版本的 Fedora 会发现很容易、直观、快速的上手。学生有一个简单舒适的环境对我们很重要,这样他们会更多的关注自己的任务和课程本身而不是一个复杂的或者运行缓慢的用户界面。
|
||||
|
||||
#### 自主的技术支持
|
||||
|
||||
最近,我们院系给予自由、开放源代码的软件很高的评价。通过使用这些软件,学生们即便在毕业后和工作的时候,仍然能够继续自由地使用它们。在这个过程中,他们通常也对 Fedora 和自由、开源的软件有一定了解。
|
||||
|
||||
### 转换机房
|
||||
|
||||
我们将机房的一台电脑完全手动安装。包括准备所有必要的脚本和软件,设置远程控制权限和一些其他的重要组成部分。我们也为每一门课程单独设置一个用户以方便学生存储他们的文件。
|
||||
|
||||
一台电脑安装配置好后,我们使用一个强大的、免费的、开源的叫做 [CloneZilla][1] 的工具。 CloneZilla 能够让我们为硬盘镜像做备份。镜像大小约为 11 G。我们用一些带有高速 USB 3.0 接口的闪存来还原磁盘镜像到剩余的电脑。我们仅仅利用若干个闪存设备花费了 75 分钟设置好剩余的 24 台电脑。
|
||||
|
||||
### 将来的工作
|
||||
|
||||
我们机房现在所有的电脑都完全使用 Fedora (没有虚拟机)。剩下的工作是设置一些管理脚本方便远程安装软件,电脑的开关等等。
|
||||
|
||||
我们由衷地感谢所有 Fedora 的维护人员,包制作人员和其他贡献者。我们希望我们的工作能够鼓励其他的学校和大学像我们一样将机房电脑的操作系统转向 Fedora。我们很高兴地确认了 Fedora 完全适合我们同时我们也担保 Fedora 同样适合你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-computer-lab-university/
|
||||
|
||||
作者:[Nemanja Milošević][a]
|
||||
|
||||
译者:[WangYueScream](https://github.com/WangYueScream)[LemonDemo](https://github.com/LemonDemo)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/nmilosev/
|
||||
[1]:http://clonezilla.org/
|
||||
[2]:https://www.gnome.org/
|
||||
[3]:https://getfedora.org/workstation/
|
||||
[4]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[5]:http://www.dmi.rs/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,68 +0,0 @@
|
||||
Arch Linux: DIY用户的终结圣地
|
||||
|
||||

|
||||
|
||||
深入研究下Linux系统的新闻史,你会发现其中有一些鲜为人知的Linux发行版,而且关于这些操作系统的新闻报道的数量也十分惊人。
|
||||
|
||||
新发行版中的佼佼者,比如Elementary
|
||||
OS和Solus操作系统因其华丽的界面而被大家所关注,并且,任何搭载MATE桌面环境的操作系统都因其简洁性而被广泛报道。
|
||||
|
||||
感谢像《黑客军团》这样的电视节目,我确信关于Kali Linux系统的报道将会飙升。
|
||||
|
||||
尽管有很多关于Linux系统的报道,然而仍然有一个被广泛使用的Linux发行版几乎被大家完全遗忘了:Arch Linux系统。
|
||||
|
||||
关于Arch的新闻报道很少的原因有很多,其中最主要的原因是它很难安装,而且你还得熟练地在命令行下完成各种配置以使其正常运行。更可怕的是,大多数的用户认为最难的是配置系统,复杂的安装过程令无数的菜鸟们望而怯步。
|
||||
|
||||
这的确很遗憾,在我看来,实际上一旦安装完成后,Arch比我用过的其它Linux发行版更容易得多。
|
||||
|
||||
确实如此,Arch的安装过程很让人蛋疼。有些发行版的安装过程只需要点击“安装”后就可以放手地去干其它事了。Arch相对来说要花费更多的时间和精力去完成硬盘分区,手动挂载,生成fstab文件等。但是从Arch的安装过程中,我们学到很多。它掀开帷幕,让我们弄明白很多背后的东西。事实上,这个帷幕已经彻底消失了,在Arch的世界里,你就是帷幕背后的主宰。
|
||||
|
||||
除了大家所熟知的难安装外,Arch甚至没有自己默认的桌面环境,虽然这有些让人难以理解,但是Arch也因其可定制化而被广泛推崇。你可以自行决定在Arch的基础软件包上安装任何东西。
|
||||
|
||||

|
||||
你可以认为Arch是高度可定制化的,或者说它完全没有定制化。比如,不像Ubuntu系统那样,Arch几乎没有修改过或是定制开发后的软件包。Arch的开发者从始至终都使用上游开发者提供的软件包。对于部分用户来说,这种情况非常棒。比如,你可以使用纯粹的未定制化开发过的GNOME桌面环境。但是,在某些情况下,一些上游开发者未更新过的定制化软件包可能存在很多的缺陷。
|
||||
|
||||
由于Arch缺乏一些默认的应用程序和桌面系统,这完全不利于用户管理自己的桌面环境。我曾经使用最小化安装配置Openbox,tint2和dmenu桌面管理工具,但是安装后的效果却跟我很失望。因此,我更倾向于使用最新版的GNOME桌面系统。在使用Arch的过程中,我们会同时安装一个桌面环境,但是这给我们的体验是完全不一样的。对于任何发行版来说,这种做法是正确的,但是大多数的Linux系统都至少会使用一个默认的桌面环境。
|
||||
|
||||
然而Arch还是有很多共性的元素一起构成这个基本系统。比如说,我使用Arch系统的主要原因是因为它是一个滚动更新的发行版。这意味着两件事情。首先,Arch使用最新的稳定版内核。这就意味着我可以在Arch系统里完成在其它Linux发行版中很难完成的测试。滚动版最大的一个好处就是所有可用的软件更新包会被即时发布出来。这不只是说明软件包更新速度快,而且也没有太多的系统升级包会被拆分。
|
||||
|
||||
由于Arch是一个滚动更新的发行版,因此很多用户认为它是不稳定的。但是在我使用了9个多月之后,我并不赞同这种观点。
|
||||
|
||||
我在每一次升级系统的过程中,从未损坏过任何软件。有一次升级系统之后我不得不回滚,因为系统启动分区/boot无法挂载成功,但是后来我发现那完全是自己操作上的失误。一些基本的系统缺陷(比如我关于戴尔XPS笔记本触摸板相关的回归测试方面的问题)已经被修复,并且可用的软件包更新速度要比其它非滚动发行版快得多。总的来说,我认为Arch滚动更新的发布模式比其它我在用的发行版要稳定得多。唯一一点我要强调的是查阅维基上的资料,多关注你要更新的内容。
|
||||
|
||||
你必须要小心你正在做的操作,因为Arch也不是任你肆意胡来的。盲目的更新Arch系统是极其危险的。但是任何一个发行版的更新都有风险。在你别无选择的时候,你得根据实际情况,三思而后行。
|
||||
|
||||
Arch的哲学理念是我支持它的另外一个最主要的原因。我认为Arch最吸引用户的一点就是:Arch面向的是专业的Linux用户,或者是有“自己动手”的态度,并愿意查资料解决问题的任何人。
|
||||
|
||||
随着Linux逐渐成为主流的操作系统,开发者们更需要顺利地渡过每一个艰难的技术领域。那些晦涩难懂的专有软件方面的经验恰恰能反映出用户高深的技术能力。
|
||||
|
||||
尽管在这个时代听起来有些怪怪的,但是事实上我们大多数的用户更愿意自己动手装配一些东西。在这种情形下,Arch将会是Linux DIY用户的终结圣地。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: http://www.theregister.co.uk/2016/11/02/arch_linux_taster/
|
||||
|
||||
作者:[Scott
|
||||
Gilbertson][a]
|
||||
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由
|
||||
[LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/1785
|
||||
|
||||
[1]:https://wiki.archlinux.org/index.php/Arch_Linux
|
||||
|
||||
[2]:http://www.theregister.co.uk/Author/1785
|
||||
|
||||
[3]:https://www.linkedin.com/shareArticle?mini=true&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&summary=Last%20refuge%20for%20purists
|
||||
|
||||
[4]:http://twitter.com/share?text=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&via=theregister
|
||||
|
||||
[5]:http://www.reddit.com/submit?url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good
|
||||
@ -1,104 +0,0 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||

|
||||
|
||||
### Android 2.1, update 1——无尽战争的开端 ###
|
||||
|
||||
谷歌是第一代iPhone的主要合作伙伴——公司为苹果的移动操作系统提供了谷歌地图,搜索,以及Youtube。在那时,谷歌CEO埃里克·施密特是苹果的董事会成员之一。实际上,在最初的苹果发布会上,施密特是在史蒂夫·乔布斯[之后第一个登台的人][1],他还开玩笑说两家公司如此接近,都可以合并成“AppleGoo”了。
|
||||
|
||||
当谷歌开发安卓的时候,两家公司间的关系慢慢变得充满争吵。然而,谷歌很大程度上还是通过拒iPhone关键特性于安卓门外,如双指缩放,来取悦苹果。尽管如此,Nexus One是第一部不带键盘的直板安卓旗舰机,设备被赋予了和iPhone相同的外观因素。Nexus One结合了新软件和谷歌的品牌,这是压倒苹果的最后一根稻草。根据沃尔特·艾萨克森为史蒂夫·乔布斯写的传记,2010年1月在看到了Nexus One之后,这个苹果的CEO震怒了,说道:“如果需要的话我会用尽最后一口气,以及花光苹果在银行里的400亿美元,来纠正这个错误……我要摧毁安卓,因为它完全是偷窃来的产品。我愿意为此进行核战争。”
|
||||
|
||||
所有的这些都在秘密地发生,仅在Nexus One发布后的几年后才公诸于众。公众们最早在安卓2.1——推送给Nexus One的一个称作“[2.1 update 1][2]”的更新,发布后一个月左右捕捉到谷歌和苹果间愈演愈烈的分歧气息。这个更新添加了一个功能,正是iOS一直居于安卓之上的功能:双指缩放。
|
||||
|
||||
尽管安卓从2.0版本开始就支持多点触控API了,默认的系统应用在乔布斯的命令下依然和这项实用的功能划清界限。在关于Nexus One的和解会议谈崩了之后,谷歌再也没有理由拒双指缩放于安卓门外了。谷歌给设备推送了更新,安卓终于补上了不足之处。
|
||||
|
||||
随着谷歌地图,浏览器以及相册中双指缩放的全面启用,谷歌和苹果的智能手机战争也就此拉开序幕。在接下来的几年中,两家公司会变成死敌。双指缩放更新的一个月后,苹果开始了他的征途,起诉了所有使用安卓的公司。HTC,摩托罗拉以及三星都被告上法庭,直到现在都还有一些诉讼还没解决。施密特辞去了苹果董事会的职务。谷歌地图和Youtube被从iPhone中移除,苹果甚至开始打造自己的地图服务。今天,这两位选手几乎是“AppleGoo”竞赛的唯一选手,涉及领域十分广:智能手机,平板,笔记本,电影,TV秀,音乐,书籍,应用,邮件,生产力工具,浏览器,个人助理,云存储,移动广告,即时通讯,地图以及机顶盒……以及不久他们将会在汽车智能,穿戴设备,移动支付,以及客厅娱乐等进行竞争。
|
||||
|
||||
### Android 2.2 Froyo——更快更华丽 ###
|
||||
|
||||
[安卓2.2][3]在2010年5月,也就是2.1发布后的四个月后亮相。Froyo(冻酸奶)的亮点主要是底层优化,只为更快的速度。Froyo最大的改变是增加了JIT编译。JIT自动在运行时将java字节码转换为原生码,这会给系统全面带来显著的性能改善。
|
||||
|
||||
浏览器同样得到了性能改善,这要感谢来自Chrome的V8 Javascript引擎的整合。这是安卓浏览器从Chrome借鉴的许多特性中的第一个,最终系统内置的浏览器会被移动版Chrome彻底替代掉。在那之前,安卓团队还是需要发布一个浏览器。从Chrome借鉴特性是条升级的捷径。
|
||||
|
||||
在谷歌专注于让它的平台更快的同时,苹果正在让它的平台更全面。谷歌的竞争对手在一个月前发布了10英寸的iPad,先行进入了平板时代。尽管有些搭载Froyo和Gingerbread的安卓平板发布,谷歌的官方回应——安卓3.0 Honeycomb(蜂巢)以及摩托罗拉Xoom——在9个月后才来到。
|
||||
|
||||

|
||||
Froyo底部添加了双图标停靠栏以及全局搜索。
|
||||
Ron Amadeo供图
|
||||
|
||||
Froyo主屏幕最大的变化是底部的新停靠栏,电话和浏览器图标填充了先前抽屉按钮左右的空白空间。这些新图标都是现有图标的定制白色版本,并且用户没办法自己设置图标。
|
||||
|
||||
默认布局移除了所有图标,屏幕上只留下一个使用提示小部件,引导你点击启动器图标以访问你的应用。谷歌搜索小部件得到了一个谷歌logo,同时也是个按钮。点击它可以打开一个搜索界面,你可以限制搜索范围在互联网,应用或是联系人之内。
|
||||
|
||||

|
||||
下载页面有了“更新所有”按钮,Flash应用,一个flash驱动的一切皆有可能的网站,以及“移动到SD”按钮。
|
||||
[Ryan Paul][4]供图
|
||||
|
||||
还有一些优秀的新功能加入了Froyo,安卓市场加入了更多的下载控制。有个新的“更新所有”按钮固定在了下载页面底部。谷歌还添加了自动更新特性,只要应用权限没有改变就能够自动安装应用;尽管如此,自动更新默认是关闭的。
|
||||
|
||||
第二张图展示了Adobe Flash播放器,它是Froyo独占的。这个应用作为插件加入了浏览器,让浏览器能够有“完整的网络”体验。在2010年,这意味着网页充满了Flash导航和视频。Flash是安卓相比于iPhone最大的不同之一。史蒂夫·乔布斯展开了一场对抗Flash的圣战,声称它是一个被淘汰的,充满bug的软件,并且苹果不会在iOS上允许它的存在。所以安卓接纳了Flash并且让它在安卓上运行,给予用户在安卓上拥有半可用的flash实现。
|
||||
|
||||
在那时,Flash甚至能够让桌面电脑崩溃,所以在移动设备上一直保持打开状态会带来可怕的体验。为了解决这个问题,安卓浏览器上的Flash可以设置为“按需打开”——除非用户点击Flash占位图标,否则不会加载Flash内容。对Flash的支持将会持续到安卓4.1,Adobe在那时放弃并且结束了这个项目。Flash归根到底从未在安卓上完美运行过。而Flash在iPhone这个最流行的移动设备上的缺失,推动了互联网最终放弃了这个平台。
|
||||
|
||||
最后一张图片显示的是新增的移动应用到SD卡功能,在那个手机只有512MB内置存储的时代,这个功能十分的必要的。
|
||||
|
||||

|
||||
驾驶模式应用。相机现在可以旋转了。
|
||||
Ron Amadeo供图
|
||||
|
||||
相机应用终于更新支持纵向模式了。相机设置被从抽屉中移出,变成一条半透明的按钮带,放在了快门按钮和其他控制键旁边。这个新设计看起来从Cooliris相册中获得了许多灵感,有着半透明,有弹性的聊天气泡弹出窗口。看到更现代的Cooliris风格UI设计被嫁接到皮革装饰的相机应用确实十分奇怪——从审美上来说一点都不搭。
|
||||
|
||||

|
||||
半残缺的Facebook应用是个常见的2x3导航页面的优秀范例。谷歌Goggles被包含了进来但同样是残缺的。
|
||||
Ron Amadeo供图
|
||||
|
||||
不像在安卓2.0和2.1中包含的Facebook客户端,2.2版本的仍然部分能够工作并且登陆Facebook服务器。Facebook应用是个谷歌那时候设计指南的优秀范例,它建议应用拥有一个含有3x2图标方阵的导航页并作为应用主页。
|
||||
|
||||
这是谷歌的第一个标准化尝试,将导航元素从菜单按钮里移到屏幕上,因为用户找不到它们。这个设计很实用,但它在打开应用和使用应用之间增加了额外的障碍。谷歌不久后湖意识到当用户打开一个应用,显示应用内容而不是中间导航页是个更好的主意。以Facebook为例,打开应用直接打开信息订阅会更合适。并且不久后应用设计将会把导航降级到二层位置——先是作为顶部的标签之一,后来谷歌放在了“导航抽屉”,一个含有应用所有功能位置的滑出式面板。
|
||||
|
||||
还有个预装到Froyo的是谷歌Goggles,一个视觉搜索应用,它会尝试辨别图片上的主体。它在辨别艺术品,地标以及条形码时很实用,但差不多也就这些了。最先的两个设置屏幕,以及相机界面,这是应用里唯一现在还能运行的了。由于客户端太旧了,实际上你如今并不能完成一个搜索。应用里也没什么太多可看的,也就一个会返回搜索结果页的相机界面而已。
|
||||
|
||||

|
||||
Twitter应用,一个充满动画的谷歌和Twitter的合作成果。
|
||||
Ron Amadeo供图
|
||||
|
||||
Froyo拥有第一个安卓Twitter应用,实际上它是谷歌和Twitter的合作成果。那时,一个Twitter应用是安卓应用阵容里的大缺憾。开发者们更偏爱iPhone,加上苹果占领先机和严格的设计要求,App Store里可选择的应用远比安卓的有优势。但是谷歌需要一个Twitter应用,所以它和Twitter合作组建团队让第一个版本问世。
|
||||
|
||||
这个应用代表了谷歌的新设计语言,这以为着它有个中间导航页以及对动画要求的“技术演示”。Twitter应用甚至比Cooliris相册用的动画效果还多——所有东西一直都在动。所有页面顶部和底部的云朵以不同速度持续滚动,底部的Twitter小鸟拍动它的翅膀并且左右移动它的头。
|
||||
|
||||
Twitter应用实际上有点Action Bar早期前身的特性,一条顶部对齐的连续控制条在安卓3.0中被引入。沿着所有屏幕的顶部有条拥有Twitter标志和像搜索,刷新和新tweet这样的按钮的蓝色横栏。它和后来的Action Bar之间大的区别在于Twitter/谷歌这里的设计的右上角缺少“上一级”按钮,实际上它在应用里用了完整的第二个栏位显示你当前所在位置。在上面的第二张图里,你可以看到整条带有“Tweets”标签的专用于显示位置的栏(当然,还有持续滚动的云朵)。第二个栏的Twitter标志扮演着另一个导航元素,有时候在当前部分显示额外的下拉区域,有时候显示整个顶级快捷方式集合。
|
||||
|
||||
2.3Tweet流看起来和今天的并没有什么不同,除了隐藏的操作按钮(回复,转推等),都在右对齐的箭头按钮里。它们弹出来是一个聊天气泡菜单,看起来就像导航弹窗。仿action bar在新tweet页面有重要作用。它安置着twitter标志,剩余字数统计,以及添加照片,拍照,以及提到联系人按钮。
|
||||
|
||||
Twitter应用甚至还有一对主屏幕小部件,大号的那个占据8格,给你新建栏,更新按钮,一条tweet,以及左右箭头来查看更多tweet。小号的显示一条tweet以及回复按钮。点击大号小部件的新建栏立即打开了“新Tweet”主窗口,这让“更新”按钮变得没有价值。
|
||||
|
||||

|
||||
Google Talk和新USB对话框。
|
||||
Ron Amadeo供图
|
||||
|
||||
其他部分,Google Talk(以及没有截图的短信应用)从暗色主题变成了浅色主题,这让它们看起来和现在的更接近现在的,更现代的应用。USB存储界面会在你设备接入电脑的时候从一个简单的对话框进入全屏界面。这个界面现在有个一个异形安卓机器人/USB闪存盘混合体,而不是之前的纯文字设计。
|
||||
|
||||
尽管安卓2.2在用户互动方式上没有什么新特性,但大的UI调整会在下两个版本到来。然而在所有的UI工作之前,谷歌希望先改进安卓的核心部分。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/13/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.youtube.com/watch?v=9hUIxyE2Ns8#t=3016
|
||||
[2]:http://arstechnica.com/gadgets/2010/02/googles-nexus-one-gets-multitouch/
|
||||
[3]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[4]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,28 +1,29 @@
|
||||
安卓编年史
|
||||
安卓编年史(14):Android 2.3 Gingerbread——第一次 UI 大变
|
||||
================================================================================
|
||||
### 语音操作——口袋里的超级电脑 ###
|
||||
|
||||
2010年8月,作为语音搜索应用的一项新功能,“[语音命令][1]”登陆了安卓市场。语音命令允许用户向他们的手机发出语音命令,然后安卓会试着去理解他们并完成任务。像“导航至[地址]”这样的命令会打开谷歌地图并且开始逐向导航至你所陈述的目的地。你还可以仅仅通过语音来发送短信或电子邮件,拨打电话,打开网站,获取方向,或是在地图上查看一个地点。
|
||||
2010 年 8 月,作为语音搜索应用的一项新功能,“[语音命令][1]”登陆了安卓市场。语音命令允许用户向他们的手机发出语音命令,然后安卓会试着去理解他们并完成任务。像“导航至[地址]”这样的命令会打开谷歌地图并且开始逐向导航至你所陈述的目的地。你还可以仅仅通过语音来发送短信或电子邮件、拨打电话、打开网站、获取方向,或是在地图上查看一个地点。
|
||||
|
||||
注:youtube视频地址
|
||||
<iframe width="500" height="281" frameborder="0" src="http://www.youtube-nocookie.com/embed/gGbYVvU0Z5s?start=0&wmode=transparent" type="text/html" style="display:block"></iframe>
|
||||
|
||||
语音命令是谷歌新应用设计哲学的顶峰。语音命令是那时候最先进的语音控制软件,秘密在于谷歌并不在设备上做任运算。一般来说,语音识别是对CPU的密集任务要求。实际上,许多语音识别程序仍然有“速度与准确性”设置,用户可以选择他们愿意为语音识别算法运行等待的时间——更多的CPU处理意味着更加准确。
|
||||
语音命令是谷歌新应用设计哲学的顶峰。语音命令是那时候最先进的语音控制软件,秘密在于谷歌并不在设备上做任运算。一般来说,语音识别是 CPU 密集型任务。实际上,许多语音识别程序仍然有“速度与准确性”设置,用户可以选择他们愿意为语音识别算法运行等待的时间——更多的 CPU 处理意味着更加准确。
|
||||
|
||||
谷歌的创新在于没有劳烦手机上能力有限的处理器来进行语音识别运算。当说出一个命令时,用户的声音会被打包并通过互联网发送到谷歌云服务器。在那里,谷歌超算中心的超级计算机分析并解释语音,然后发送回手机。这是很长的一段旅程,但互联网最终还是有足够快的速度在一两秒内完成像这样的任务。
|
||||
|
||||
很多人抛出词语“云计算”来表达“所有东西都被存储在服务器上”,但这才是真正的云计算。谷歌在云端进行这些巨量的运算操作,又因为在这个问题上投入了看似荒唐的CPU资源数目,所以语音识别准确性的唯一限制就是算法本身了。软件不需要由每个用户独立“训练”,因为所有使用语音操作的人无时不刻都在训练它。借助互联网的力量,安卓在你的口袋里放了一部超级电脑,同时相比于已有的解决方案,把语音识别这个工作量从口袋大小的电脑转移到房间大小的电脑上大大提高了准确性。
|
||||
很多人抛出词语“云计算”来表达“所有东西都被存储在服务器上”,但这才是真正的云计算。谷歌在云端进行这些巨量的运算操作,又因为在这个问题上投入了看似荒唐的 CPU 资源数目,所以语音识别准确性的唯一限制就是算法本身了。软件不需要由每个用户独立“训练”,因为所有使用语音操作的人无时不刻都在训练它。借助互联网的力量,安卓在你的口袋里放了一部超级电脑,同时相比于已有的解决方案,把语音识别这个工作量从口袋大小的电脑转移到房间大小的电脑上大大提高了准确性。
|
||||
|
||||
语音识别作为谷歌的项目已经有一段时间了,它的出现都是因为一个800号码。[1-800-GOOG-411][2]是个谷歌从2007年4月起开通的免费电话信息服务。它就像411信息服务一样工作了多年——用户可以拨打这个号码询问电话号码——但是谷歌免费提供这项服务。查询过程中没有人工的干预,411服务由语音识别和文本语音转换引擎驱动。语音命令就是人们教谷歌如何去听之后三年才有实现的可能。
|
||||
语音识别作为谷歌的项目已经有一段时间了,它的出现都是因为一个 800 号码。[1-800-GOOG-411][2]是个谷歌从 2007 年 4 月起开通的免费电话信息服务。它就像 411 信息服务一样工作了多年——用户可以拨打这个号码询问电话号码——但是谷歌免费提供这项服务。查询过程中没有人工的干预,411 服务由语音识别和文本语音转换引擎驱动。在人们教谷歌如何去听之后,又用了三年才有实现语音命令的可能。
|
||||
|
||||
语音识别是谷歌长远思考的极佳范例——公司并不怕在一个可能成不了商业产品的项目上投资多年。今天,语音识别驱动的产品遍布谷歌。它被用在谷歌搜索应用的输入,安卓的语音输入,以及Google.com。同时它还是Google Glass和[Android Wear][3]的默认输入界面。
|
||||
语音识别是谷歌长远思考的极佳范例——公司并不怕在一个可能成不了商业产品的项目上投资多年。今天,语音识别驱动的产品遍布谷歌。它被用在谷歌搜索应用的输入,安卓的语音输入,以及 Google.com。同时它还是 Google Glass 和 [Android Wear][3] 的默认输入界面。
|
||||
|
||||
谷歌甚至还在输入之外的地方使用语音识别。谷歌的语音识别技术被用在了转述Youtube视频上,它能自动生成字幕供听障用户观看。生成的字幕甚至被谷歌做成了索引,所以你可以搜索某句话在视频的哪里说过。语音是许多产品的未来,并且这项长期计划将谷歌带入了屈指可数的拥有自家语音识别服务的公司行列。大部分其它的语音识别产品,像苹果的Siri和三星设备,被迫使用——并且为其支付了授权费——Nuance的语音识别。
|
||||
谷歌甚至还在输入之外的地方使用语音识别。谷歌的语音识别技术被用在了转述 Youtube 视频上,它能自动生成字幕供听障用户观看。生成的字幕甚至被谷歌做成了索引,所以你可以搜索某句话在视频的哪里说过。语音是许多产品的未来,并且这项长期计划将谷歌带入了屈指可数的拥有自家语音识别服务的公司行列。大部分其它的语音识别产品,像苹果的 Siri 和三星设备,只能使用 Nuance 的语音识别,并且为其支付了授权费。
|
||||
|
||||
在计算机听觉系统设立运行之后,谷歌下一步将把这项策略应用到计算机视觉上。这就是为什么像Google Goggles,Google图像搜索和[Project Tango][4]这样的项目存在的原因。就像GOOG-411的那段日子,这些项目还处在早期阶段。当[谷歌的机器人部门][5]造出了机器人,它会需要看和听,谷歌的计算机视觉和听觉项目会给谷歌一个先机。
|
||||
在计算机听觉系统设立运行之后,谷歌下一步将把这项策略应用到计算机视觉上。这就是为什么像 Google Goggles,Google 图像搜索和 [Project Tango][4] 这样的项目存在的原因。就像 GOOG-411 的那段日子,这些项目还处在早期阶段。当[谷歌的机器人部门][5]造出了机器人,它会需要看和听,谷歌的计算机视觉和听觉项目会给谷歌一个先机。
|
||||
|
||||

|
||||
Nexus S,第一部三星制造的Nexus手机。
|
||||
|
||||
*Nexus S,第一部三星制造的 Nexus 手机。*
|
||||
|
||||
### Android 2.3 Gingerbread——第一次UI大变 ###
|
||||
|
||||
|
||||
@ -0,0 +1,117 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||
|
||||
>让我们跟着安卓从 0.5 版本到 7 的无尽迭代来看看它的发展历史。
|
||||
|
||||
#### ART——为未来提供了一个平台的安卓运行时
|
||||
|
||||
安卓里没有多少组件的血统能追溯到 1.0 时代,但在 2014 年 Dalvik 这个驱动安卓应用的运行时是它们中的一员。Dalvik 最初是为单核,低端性能设备设计的,而且存储和内存占用的优先级要高于性能表现。在过去的几年里,谷歌给 Dalvik 扩充了越来越多的更新,比如 JIT 支持,并发垃圾回收,以及多进程支持。但是随着多核手机的出现,它们比 T-Mobile G1 快上很多倍,而这些功能升级扩充只能帮安卓到这里了。
|
||||
|
||||
解决方案就是用 ART 这个安卓运行时替换 Dalvik,这是一个完全为现代智能手机硬件重写的应用引擎。ART 更强调性能表现和用户界面流畅度。ART 带来了一个从 JIT(Just-in-time,即时)编译到 AOT(Ahead-of-time,提前)编译的转变。JIT 会在每次应用运行的时候即时编译,节省存储空间,因为编译后的代码从不写入存储,但它消耗更多的 CPU 和内存资源。AOT 会将编译后的代码保存到存储,让应用启动的时候更快并减少内存使用。ART 会在设备上将编译代码作为安装的一部分进行,而不分发预编译的代码,这样编译器可以进行一些针对特定设备的优化。ART 还带来了 64 位支持,扩大了内存寻址范围,由 64 位指令集带来更佳的性能表现(特别是在媒体和加密应用上)。
|
||||
|
||||
而最好的部分是这个变化将这些性能优化和 64 位支持带给了每个 java 安卓应用。ART 为每个 java 应用生成代码,因此任何对 ART 的改进都自动应用到了这些应用。同时 ART 也是在未来的升级计划下写就,所以它能够和安卓一同进化。
|
||||
|
||||
#### 一个系统层级的界面刷新
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][1]
|
||||
* [
|
||||

|
||||
][2]
|
||||
* [
|
||||

|
||||
][3]
|
||||
* [
|
||||

|
||||
][4]
|
||||
* [
|
||||

|
||||
][5]
|
||||
* [
|
||||

|
||||
][6]
|
||||
* [
|
||||

|
||||
][7]
|
||||
* [
|
||||

|
||||
][8]
|
||||
|
||||
Material Design 带来了一个几乎对安卓所有界面的完全翻新。首先,整个核心系统界面改变了。安卓得到了一个全新的按钮集合,看起来有点像是 PlayStation 的手柄:三角形,圆形以及正方形按钮,分别代表后退,主屏幕,和最近应用。得益于全新的图标集,状态栏也是焕然一新。
|
||||
|
||||
最近应用获得了大翻新。从一个小略缩图纵向列表变成了一个巨大的,几乎全屏的略缩图串联列表。它还获得了一个新名字(也没那么守旧),“概览(Overview)”。这明显是受到了前面版本的 Chrome 标签页切换器效果的启发。
|
||||
|
||||
顺带一说,在这个安卓版本里 Chrome 的标签页切换器效果消失了。作为一种将 Web 应用与本地应用同等对待的尝试,Chrome 标签合并到了概览列表。是的:最近“应用”列表现在显示的是最近打开的应用,加上最近打开的网站。在棒棒糖中,最近应用列表还采取了一种“以文档为中心”的方法,意味着应用可以在最近应用列表中显示多个项目。比如你在 Google Docs 中打开了两个文档,它们都会显示在最近应用中,让你可以在它们之间轻松切换,而不用到应用的文件列表去来回切换。
|
||||
|
||||
通知面板是全新的。谷歌给通知面板带来了“卡片”主题,将每个项目归整到它自己的矩形中。单个通知条目从黑色背景变成了白色背景,有了更佳的排版和圆形图标。这些新通知来到了锁屏上,将它从一个最没用的中间屏变成了很有用的屏幕,用于展示“这里是你不在的时候发生的事情”。
|
||||
|
||||
全屏的通知,比如来电以及闹钟,都被抛弃了,取而代之的是在屏幕顶部弹出一个“抬头”通知。抬头通知也对“高优先级”应用可用,最初这是为即时消息设计的。但是否是高优先级的通知这取决于开发者的决定,在开发者意识到这可以让他们的通知更显眼之后,所有人都开始使用它。之后版本的安卓通过给用户提供“高优先级”的设置解决了这个问题。
|
||||
|
||||
谷歌还给棒棒糖添加了一个单独的,但很相似的“优先”通知系统。“优先”通知是一个介于完全静音和“提醒一切消息”之间的模式,允许用户将特定的联系人和应用标记为重要。优先模式只会为这些重要的人发出提醒。在界面上来看,它采用了音量控制附加通知优先级控制以及设置中心添加一项优先通知新设置的形式。当你处在优先模式的时候,状态栏会有一颗星形标识。
|
||||
|
||||
快速设置获得了一系列的大改善。控制项现在是一块在通知_上面_的面板,所以它可以通过“两次下拉”手势来打开它。第一次下拉会打开通知面板,第二次下拉手势会缩小通知面板并打开快速设置。快速设置的布局变了,抛弃了平铺排列,转为一个单独面板上的一系列浮动按钮。顶部是十分方便的亮度调节条,之后是连接,自动旋转,手电筒,GPS,以及 Chromecast 的按钮。
|
||||
|
||||
快速设置现在还有了实际的内嵌面板。它可以在主界面显示无线网络接入点,蓝牙设备,以及移动数据使用量。
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][9]
|
||||
* [
|
||||

|
||||
][10]
|
||||
* [
|
||||

|
||||
][11]
|
||||
* [
|
||||

|
||||
][12]
|
||||
* [
|
||||

|
||||
][13]
|
||||
* [
|
||||

|
||||
][14]
|
||||
* [
|
||||

|
||||
][15]
|
||||
|
||||
Material Design 革新给了几乎每个应用一个新图标,并带来了一个更明亮,白色背景的应用抽屉。默认应用阵容也有了很大的变化。和这些新应用问声好吧:通讯录,谷歌文档,Fit,信息,照片,Play 报亭,以及谷歌幻灯片。和这些死去的应用说再见吧:相册,G+ 照片,People,Play 杂志,电子邮件,以及 Quickoffice。
|
||||
|
||||
这些新应用中很多来自 Google Drive,从一个单独的大应用分割成每个产品一个应用。现在我们有了云端硬盘,文档,表格,以及幻灯片,都来自于云端硬盘团队。云端硬盘同时也要对 Quickoffice 的死亡负责,云端硬盘团队令它元气大伤。在“谷歌从来没法做好决定”分类下:通讯录从“People”改回了“Contacts”,短信应用在运营商的要求下叫回了“Messenger”。(那些运营商_不_喜欢谷歌环聊插手短信的职能。)我们有项真正的新服务:谷歌健身,一个健康追踪应用,可以在安卓手机和安卓手表上工作。Play 杂志也有了新的设计,添加了网站内容,所以它改名叫“Play 报亭”。
|
||||
|
||||
还有更多的谷歌专有应用接管 AOSP 的例子。
|
||||
|
||||
* “G+ 照片”变成了“谷歌照片”,并取代了 AOSP 的相册成为默认照片应用,而相册也就随之消亡了。改名成“谷歌照片”是为照片应用[退出 Google+][16]并成为独立服务做准备。谷歌照片的发布在棒棒糖发布之后六个月——暂时应用只像是 Google+ 应用换了个图标和界面设计。
|
||||
* Gmail 从电子邮件应用接管了 POP3,IMAP 以及 Exchange 邮件的任务。尽管死掉的电子邮件应用还有个图标,但那是假的——它仅仅只显示一条信息,告诉用户从 Gmail 应用设置电子邮件账户。
|
||||
* “People”到“Contacts”的变化实际上是变为谷歌通讯录,又是一个取代 AOSP 对应应用的例子。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo/
|
||||
[1]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/28/#
|
||||
[16]:http://arstechnica.com/gadgets/2015/05/google-photos-leaves-google-launches-as-a-standalone-service/
|
||||
@ -1,199 +0,0 @@
|
||||
用数据科学搭建一个实时推荐引擎
|
||||
======================
|
||||
|
||||
编者注:本文是 2016 年四月 Nicole Whilte 在欧洲 GraphConnect 时所作。这儿我们快速回顾一下她所涉及的内容:
|
||||
- 【基本图表动力推荐】【1】
|
||||
- 【社会推荐】【2】
|
||||
- 【相似性推荐】【3】
|
||||
- 【集群推荐】【4】
|
||||
|
||||
今天我们将要讨论的内容是数据科学和图表推荐:
|
||||
|
||||
Neo4j 已经伴随我两年了,但实际上我已经使用 Neo4j 和 Cypher 工作三年了。当我首次发现这个特别的图表数据库的时候,我还是一个研究生,那时候我在奥斯丁的德克萨斯大学攻读关于社会网络的统计学硕士学位。
|
||||
|
||||
【实时推荐引擎】【5】是 Neo4j 中广泛使用的一个实例,有一样东西使它如此强大并且容易使用。为了探索这个东西,我将通过使用示例数据集来阐述如何将统计学方法并入这些引擎中。
|
||||
|
||||
第一个很简单 - 仅仅在 Cypher 中关注社会推荐。接下来,我们将看一看相似性推荐,这涉及到可以被计算的相似性度量,最后探索的是集群推荐
|
||||
|
||||
### 基本图表动力推荐
|
||||
|
||||
下面的数据集包含所有达拉斯 Fort Worth 国际机场的餐饮场所,达拉斯 Fort Worth 国际机场是美国主要的机场枢纽之一:
|
||||
|
||||

|
||||
|
||||
我们把节点标记成黄色并按照出入口和终点给它们的位置建模。同时我们也按照食物和饮料的主类别将地点分类,其中一些包括墨西哥食物,三明治,酒吧和烤肉。
|
||||
|
||||
让我们做一个简单的推荐。我们想要在机场的某一确定地点找到一种特定食物,大括号中的内容表示是的用户输入,它将进入我们假想的应用程序中。
|
||||
|
||||

|
||||
|
||||
这个英文句子很好地表示出了 Cypher 查询:
|
||||
|
||||

|
||||
|
||||
这将提取出目录中用户所请求的所有地点,终点和出入口。然后我们可以计算出用户所在位置到出入口的准确距离,并以升序返回结果。再次说明,一个非常简单的 Cypher 推荐仅仅依据用户在机场中的位置。
|
||||
### 社会推荐
|
||||
|
||||
让我们来看一下社会推荐。在我们的假想应用程序中,用户可以登录并且可以用和 Facebook 类似的方式标记自己“喜爱”的地点,也可以查询登记地点。
|
||||
|
||||

|
||||
|
||||
考虑位于我们所探索的第一个模型顶部的数据模型,现在让我们在下面的目录中找到离一些出入口最近的餐饮场所,不考虑用户的朋友想要去哪个终点:
|
||||
|
||||

|
||||
|
||||
匹配项目和我们第一次 Cypher 查询得到的匹配项目相似,只是现在我们依据喜好和朋友来匹配:
|
||||
|
||||

|
||||
|
||||
前三行是完全一样的,但是现在正在考虑的是关于那些登录的用户,我们想要通过喜欢相同的地点这一关系来找到他们的朋友。仅需通过在 Cypher 中增加一些行内容,我们现在已经把社会层面考虑到了我们的推荐引擎中。
|
||||
|
||||
在次说明,我们仅仅显示了用户明确请求的目录,并且这些目录中的地点与用户进入的地方有相同的终点。当然,我们希望通过登录用户做出请求来滤过这些目录,然后返回地点的名字、位置以及所在目录。我们也要显示出有多少朋友已经“喜爱”那个地点以及那个地点到出入口的确切距离,然后在返回项目中同时返回这些内容。
|
||||
|
||||
### 相似性推荐
|
||||
|
||||
现在,让我们看一看相似性推荐引擎:
|
||||
|
||||

|
||||
|
||||
和前面的数据模型相似,用户可以标记“喜爱”的地点,但是这一次他们可以用 1 到 10 的整数给地点评分。这是通过前期在 Neo4j 中增加一些属性到关系中建模实现的。
|
||||
|
||||
这将允许我们找到其他相似的用户,比如以 Greta 和 Alice 为例,我们已经查询了他们共同喜欢的地点,并且对于每一个地点,我们可以看到他们所设定的权重。大概地,我们可以通过他们的评分来确定他们之间的相似性大小。
|
||||
|
||||

|
||||
|
||||
现在我们有两个向量:
|
||||
|
||||

|
||||
|
||||
现在让我们按照欧几里得距离的定义来计算这两个向量之间的距离:
|
||||
|
||||

|
||||
|
||||
|
||||
我们把所有的数字带入公式中计算,然后得到下面的相似度,这就是两个用户之间的“距离”:
|
||||
|
||||

|
||||
|
||||
你可以提前在 Cypher 中计算两个特定用户的“距离”,特别是如果他们仅仅同时“喜爱”一个很小的地点子集。再次说明,这儿我们依据两个用户 Alice 和 Greta 来进行匹配,并尝试去找到他们同时“喜爱”的地点:
|
||||
|
||||

|
||||
|
||||
他们都有对最后找到的地点的“喜爱”关系,然后我们可以在 Cypher 中很容易的计算出他们之间的欧几里得距离,计算方法为他们对各个地点评分差的平方求和再开平方根。
|
||||
|
||||
在两个特定用户的例子中上面这个方法或许能够工作。但是,在实时情况下,当你想要通过和实时数据库中的其他用户比较,从而由一架飞机上的一个用户推断相似用户时,这个方法就不一定能够工作。不用说,至少它不能够很好的工作。
|
||||
|
||||
为了找到解决这个问题的好方法,我们可以预先计算好距离并存入实际关系中:
|
||||
|
||||

|
||||
|
||||
当遇到一个很大的数据集时,我们需要成批处理这件事,在这个很小的示例数据集中,我们可以按照所有用户的迪卡尔乘积和他们共同“喜爱”的地点来进行匹配。当我们使用 WHERE id(u1) < id(u2) 作为 Cypher 询问的一部分时,它只是来确定我们在左边和右边没有找到相同的对的一个技巧。
|
||||
|
||||
通过用户之间的欧几里得距离,我们创建了他们之间的一种关系,叫做“距离”,并且设置了一个欧几里得属性,也叫做“欧几里得”。理论上,我们可以也通过用户间的一些关系来存储其他相似度从而获取不同的相似度,因为在确定的环境下一些相似度可能比其他相似度更有用。
|
||||
|
||||
在 Neo4j 中,的确是关于关系的模型性能力使得完成像这样的事情无比简单。然而,实际上,你不会希望存入每一个可能存在的单一关系,因为你仅仅希望返回离他们“最近”的一些人。
|
||||
|
||||
因此你可以根据一些临界值来存入顶端关系从而你不需要有完整的连通图。这允许你完成一些像下面这样的实时数据库查询,因为我们已经预先计算好了“距离”并存储在了关系中,在 Cypher 中,我们能够很快的攫取出数据。
|
||||
|
||||

|
||||
|
||||
在这个查询中,我们依据地点和目录来进行匹配:
|
||||
|
||||

|
||||
|
||||
再次说明,前三行是相同的,除了登录用户以外,我们找出了有距离关系的用户。这是我们前面查看的关系产生的作用 - 实际上,你只需要存储处于顶端的相似用户“距离”关系,因此你不需要在匹配项目中攫取大量用户。相反,我们只攫取和那些用户“喜爱”的地方有“距离”关系的用户。
|
||||
|
||||
这允许我们用少许几行内容表达较为复杂的模型。我们也可以攫取“喜爱”关系并把它放入到变量中,因为后面我们将使用这些权重来评分。
|
||||
|
||||
在这儿重要的是,我们可以依据“距离”大小将用户按照升序进行排序,因为这是一个距离测度。同时,我们想要找到用户间的最小距离因为距离越小表明他们的相似度最大。
|
||||
|
||||
通过其他按照欧几里得距离大小排序好的用户,我们得到用户评分最高的三个地点并按照用户的平均评分高低来推荐这些地点。用其他的话来说,我们先找出一个积极用户,然后依据其他用户“喜爱”的地点找出和他最相似的其他用户,接下来按照这些相似用户的平均评分把那些地点排序在结果的集合中。
|
||||
|
||||
本质上,我们通过把所有评分相加然后除以收集的用户数目来计算出平均分,然后按照平均评分的升序进行排序。其次,我们按照出入口距离排序。假想地,我猜测应该会有交接点,因此你可以按照出入口距离排序然后再返回名字、目录、出入口和终点。
|
||||
|
||||
### 集群推荐
|
||||
|
||||
我们最后要讲的一个例子是集群推荐,在 Cyphe 中,这可以被想像成一个作为工作区的离线工作流。这可能完全基于在欧洲 GraphConnect 上宣布的新程序,但是有时你必须进行一些 Cypher 2.3 版本没有显示的算法逼近。
|
||||
|
||||
在这儿你可以使用一些统计软件,把数据从 Neo4j 取出然后放入像 Apache Spark, R 或者 Python 这样的软件中。下面是一段把数据从 Neo4j 中取出的 R 代码,运行程序,如果正确,写下程序返回给 Neo4j 的结果,比如一个属性、节点、关系或者一个新的标签。
|
||||
|
||||
通过持续把程序运行结果放入到图表中,你可以在一个和我们刚刚看到的查询相似的实时查询中使用它:
|
||||
|
||||

|
||||
|
||||
下面是用 R 来完成这件事的一些示例代码,但是你可以使用任何你最喜欢的软件来做这件事,比如 Python 或 Spark。你需要做的只是登录并连接到图表。
|
||||
|
||||
在下面的例子中,我基于用户的相似性把他们集中起来。每个用户作为一个观察点,然后得到他们对每一个目录评分的平均值。
|
||||
|
||||

|
||||
|
||||
假定用户对酒吧目录评分的方式和一般的评分方式相似。然后我攫取出喜欢相同目录中的地点的用户名,目录名,“喜爱”关系的平均权重,比如平均权重这些信息,从而我可以得到下面这样一个表格:
|
||||
|
||||

|
||||
|
||||
因为我们把每一个用户都作为一个观察点,所以我们必须巧妙的处理每一个目录中的数据,这些数据的每一个特性都是用户对目录中餐厅评分的平均权重。接下来,我们将使用这些数据来确定用户的相似性,然后我将使用聚类算法来确定在不同集群中的用户。
|
||||
|
||||
在 R 中这很直接:
|
||||
|
||||

|
||||
|
||||
在这个示例中我们使用 K - 均值聚类算法,这将使你很容易攫取集群分配。总之,我通过运行聚类算法然后分别得到每一个用户的集群分配。
|
||||
|
||||
Bob 和 David 在一个相同的集群中 - 他们在集群二中 - 现在我可以实时查看哪些用户被放在了相同的集群中。
|
||||
|
||||
接下来我把集群分配写入 CSV 文件中,然后存入图表:
|
||||
|
||||

|
||||
|
||||
我们只有用户和集群分配,因此 CSV 文件只有两列。 LOAD CSV 是 Cypher 中的内建语法,它允许你从一些其他文件路径或者 URL 和别名调用 CSV 。接下来,我们将匹配图表中存在的用户,从 CSV 文件中攫取用户列然后合并到集群中。
|
||||
|
||||
我们在图表中创建了一个新的标签节点:集群 ID, 这是由 K - 平均聚类算法给出的。接下来我们创建用户和集群间的关系,通过创建这个关系,当我们想要找到在相同集群中的实际推荐用户时,就会很容易进行查询。
|
||||
|
||||
我们现在有了一个新的标签集群,在相同集群中的用户和那个集群存在关系。新的数据模型看起来像下面这样,它比我们前面探索的其他数据模型要更好:
|
||||
|
||||

|
||||
|
||||
现在让我们考虑下面的查询:
|
||||
|
||||

|
||||
|
||||
通过这个 Cypher 查询,我们在更远处找到了在同一个集群中的相似用户。由于这个原因,我们删除了“距离”关系:
|
||||
|
||||

|
||||
|
||||
在这个查询中,我们取出已经登录的用户,根据用户-集群关系找到他们所在的集群,找到他们附近和他们在相同集群中的用户。
|
||||
|
||||
我们把这些用户分配到变量 c1 中,然后我们得到其他被我取别名为附近变量的用户,这些用户和那个相同集群存在用户-集群关系,最后我们得到这些附近用户“喜爱”的地点。再次说明,我把“喜爱”放入了变量 r 中,因为我们需要从关系中攫取权重来对结果进行排序。
|
||||
|
||||
在这个查询中,我们所做的改变是,不使用相似性距离,而是攫取在相同集群中的用户,然后对目录、终点以及我们所攫取的登录用户进行声明。我们收集所有的权重:来自附近用户“喜爱”地点的“喜爱”关系,得到的目录,确定的距离值,然后把它们按升序进行排序并返回结果。
|
||||
|
||||
在这些例子中,我们可以进行一个相当复杂的进程并且在图表中实现进程,然后我们就可以使用实时算法结果-聚类算法和集群分配的结果。
|
||||
|
||||
我们更喜欢的工作流程是更新这些集群分配,更新频率适合你自己就可以,比如每晚一次或每小时一次。当然,你可以根据直觉来决定多久更新一次这些集群分配是可接受的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Nicole White][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://neo4j.com/blog/contributor/nicole-white/
|
||||
[1]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#basic-graph-recommendations
|
||||
[2]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#social-recommendations
|
||||
[3]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#similarity-recommendations
|
||||
[4]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#cluster-recommendations
|
||||
[5]: https://neo4j.com/use-cases/real-time-recommendation-engine/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,96 +0,0 @@
|
||||
监控微服务的5条原则
|
||||
====
|
||||
|
||||

|
||||
|
||||
我们对微服务的需求可以归纳为一个词:速度,提供更多更可靠更快捷的功能的需求,彻底改变了软件开发模式,毫无疑问,这同样改变了软件管理和系统监控的方式。这里,我们着重于有效的监控生产过程中的微服务,我们将为这一新的软件开发模式制定5条原则来调整你的监控方法。
|
||||
|
||||
监控是微服务控制系统的关键部分,你的软件越复杂,那么你就越难了解其性能并解决问题。鉴于微服务给软件部署带来的巨大改变,监控系统同样需要进行彻底的改造。文章接下来介绍监控微服务的5条原则,如下:
|
||||
|
||||
1. 监控容器和里面的东西
|
||||
2. 在服务性能上做监控,而不是容器
|
||||
3. 监控弹性和多变的服务
|
||||
4. 监控开发接口
|
||||
5. 将您的监控映射到您的组织结构
|
||||
|
||||
利用这5条原则,你可以建立更有效的对微服务的监控。这些原则,可以让你定位微服务的技术变化和组织变化。
|
||||
|
||||
### 微服务监控的原则
|
||||
|
||||
#### 1.监控容器和里面的东西
|
||||
|
||||
容器是微服务重要的积木,容器的速度、可移植性和隔离特性让开发者很方便的建立微服务的模型。容器的好处已经写的够多了,在这里我们不再重复。
|
||||
|
||||
容器对于其他的系统来说就像是黑盒子,它的高度的可移植性,对于开发来说简直大有裨益,从开发到生产,甚至从一台笔记本开发直到云端。但是运行起来后,监控和解决服务问题,这个黑盒子让常规的方法失效了,我们会想:容器里到底在运行着什么?这些程序和代码是怎么运行的?它有什么重要的输出指标吗?在开发者的视角,你需要对容器有更深的了解而不是知道一些容器的存在。
|
||||
|
||||

|
||||
|
||||
非容器环境的典型特征,一个代理程序运行在一台主机或者虚机的用户空间,但是容器里不一样。容器的有点是小,讲各种进程分离开来,尽可能的减少依赖关系。
|
||||
|
||||
在规模上看,成千上万的监测代理,对即使是一个中等大小的部署都是一个昂贵的资源浪费和业务流程的噩梦。对于容器有两个潜在的解决方案:1)要求你的开发人员直接提交他们的代码,或者2)利用一个通用的内核级的检测方法来查看主机上的所有应用程序和容器活动。我们不会在这里深入,但每一种方法都有优点和缺点。
|
||||
|
||||
#### 2. 利用业务流程系统提醒服务性能
|
||||
|
||||
理解容器中数据的运行方式并不容易,一个容器的度量值比组成函数或服务的所有容器的聚合信息都要低得多。
|
||||
|
||||
这特别适用于应用程序级别的信息,就像哪个请求拥有最短响应时间或者哪个URLs有最多的错误,同样也适用于基础设施水平监测,比如哪个服务的容器使用CPU资源超过了事先分配的资源数。
|
||||
|
||||
越来越多的软件部署需要一个业务流程系统,将逻辑化的应用程序转化到一个物理的容器中。
|
||||
常见的转化系统包括Kubernetes、Mesosphere DC/OS和Docker Swarm。团队用一个业务流程系统来定义微服务和理解部署每个服务的当前状态。容器是短暂的,只有满足你的服务需求才会存在。
|
||||
|
||||
DevOps团队应该尽可能将重点放到如何更好的监控服务的运行特点上,如果应用受到了影响,这些告警点要放在第一道评估线上。但是能观察到这些告警点也并不容易,除非你的监控系统是容器本地的。
|
||||
|
||||
容器原生解决方案利用业务流程元数据来动态聚合容器和应用程序数据,并计算每个服务基础上的监控度量。根据您的业务流程工具,您可能有不同层次的层次结构想检测。比如,在Kubernetes里,你通常有Namespace、ReplicaSets、Pods和一些其他容器。聚集在这些不同的层有助于故障排除,这与构成服务的容器的物理部署无关。
|
||||
|
||||

|
||||
|
||||
#### 3. 监控弹性和多变的服务
|
||||
|
||||
弹性服务不是一个新概念,但是它在本地容器中的变化速度比在虚拟环境中快的多。迅速的变化会严重影响检测系统的正常运行。
|
||||
|
||||
经常监测系统所需的手动调整指标和单独部署的软件,这种调整可以是具体的,如定义要捕获的单个指标,或收集应用程序在一个特定的容器中操作的配置数据。小规模上我们可以接受,但是数以万计规模的容器就不行了。微服务的集中监控必须能够自由的监控弹性服务的增长和缩减,而且无人工干预。
|
||||
|
||||
比如,开发团队必须手动定义容器包含那个服务做监控使用,他们毫无疑问会把球抛给Kubernetes或者Mesos定期的创建新的容器。同样,如果开发团队需要配置一个自定义的状态点从新代码的产生到付诸生产,那么基础镜像从容器中注册会给开发者带来更多的挑战。
|
||||
|
||||
在生产中,建立一个复杂的跨越多个数据中心或多个云部署的监控,会使你的服务跨越你的死人数据中心,具体的应用,比如亚马逊的AWS CloudWatch。通过动态的本地容器环境,这个实时监控系统,会监控不同区域的数据中心。
|
||||
|
||||
#### 4.监控开发接口
|
||||
|
||||
在微服务环境中,API接口是通用的。它们是一个服务的必备组件,实际上,API的响应和一致性是服务的内部语言,虽然暂时还没人定义它们。
|
||||
|
||||
因此,API接口的监控也是必需的。API监控可以有不同的形式,但是它绝对不是简单的上下检查。例如,了解最常使用的点作为时间函数是有价值的。这使得团队可以看到,服务使用的变化,无论是由于设计变更或用户的改变。
|
||||
|
||||
你也可以记录服务最缓慢的点,这些可以揭示重大的问题,至少,指向需要在系统中做优化的区域。
|
||||
|
||||
最终,跟踪系统服务响应会成为一个很重要的能力,它会帮助开发者了解最终用户体验,同时将信息分成基础设施和应用程序环境两大部分。
|
||||
|
||||
#### 5. 将您的监控映射到您的组织结构
|
||||
|
||||
这篇文章着重在微服务和监控上,像其他科技文章一样,这是因为很多人都关注软件层面。
|
||||
|
||||
对于那些熟悉康威定律的人来说,系统的设计是基于开发团队的组织结构。创造更快,更敏捷的软件的迫力,推动团队思考重新调整他们的组织结构和管理它的规则。
|
||||
|
||||

|
||||
|
||||
如果他们想从新的软件架构比如微服务上获益,那么他们需要更小的更松散更耦合的团队,可以选择自己的方向只要能够满足整个需求即可。在一个团队中,对于什么开发语言的使用,bug的提交甚至工作职责都会有更大的控制能力。
|
||||
|
||||
开发团队可以启用一个监控平台:让每一个微服务团队可以定位自己的警报,指标,和控制面板,同时也要给全局系统的操作一个图表。
|
||||
|
||||
### 总结
|
||||
|
||||
快捷让微服务流行起来。开发组织要想为客户提供更快的更多的功能,然后微服务技术就来了,架构转向微服务并且容器的流行让快捷开发成为可能,所有相关的进程理所当然的搭上了这辆火车。
|
||||
|
||||
最后,基本的监控原则需要适应加入到微服务的技术和结构。越早认识到这种转变的开发团队,能更早更容易的适应微服务这一新的架构。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thenewstack.io/five-principles-monitoring-microservices/
|
||||
|
||||
作者:[Apurva Dave][a] [Loris Degioanni][b]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://thenewstack.io/author/apurvadave/
|
||||
[b]: http://thenewstack.io/author/lorisdegioanni/
|
||||
@ -0,0 +1,240 @@
|
||||
24 款必备的 linux 应用
|
||||
=====
|
||||
|
||||
[][39]
|
||||
|
||||
摘要:Linux 的必备软件有哪些?这将会是一个非常主观的回答,主要取决于你出于什么目的才使用桌面版 Linux。但还是会有一些大部分 Linux 用户都可能会用到的必备软件,这里将会列出在每个发行版中都应该安装的 Linux 软件。
|
||||
|
||||
在 Linux 中,所有一切都是有多种可选方案的。首先,你会选择一个发行版,对吧?你肯能需要尝试过多个发行版才能选出自己喜欢的。你是否还试过很多个音乐播放器?它们还是有很多选择吧?
|
||||
|
||||
并不是每个发行版都这些软件编译成相同的包——有些本身就是为了体积最小化,但其他的可能会提供大量的特性。为自身的需求选择一款正确的应用是一件相当困惑和累人的任务。就让我们来是这个过程变得容易一些吧。
|
||||
|
||||
### Linux 用户最好的自由软件
|
||||
|
||||
在这里,我把自己喜欢用的 Linux 必备软件以几个类型列出来。当然不能说这些事最好的,但在我尝试了大量的各类软件之后,最后才的到这个分类列表。所有,你可以在评论区畅言自己最喜欢的应用。
|
||||
|
||||
### Web浏览器
|
||||
|
||||

|
||||
|
||||
<figcaption>Web 浏览器</figcaption>
|
||||
|
||||
#### [Google Chrome][38]
|
||||
|
||||
Google Chrome 是一个功能完备、性能强悍的 web 浏览器。它具备了非常彪悍的同步功能,同时还提供大量的功能扩展插件。如果那你习惯于 Google 的生态系统,那么 Chrome 绝对是你的不二选择。当然,假如你想要一个开源的解决方案,那么你可以试试 [Chromium][37],Google Chrome 就是基于这个项目来构建的。
|
||||
|
||||
#### [Firefox][36]
|
||||
|
||||
如果你并非 Google Chrome 迷,那就试试 Firefox。它有着比较久的历史,也是一个稳定和健壮的 web 浏览器。
|
||||
|
||||
#### [Vivaldi][35]
|
||||
|
||||
如果说你想尝试新鲜事物并做一些改变,那么,你可以试试 Vivaldi,它是用了全新的 web 浏览器方法,由前 Opera 项目成员基于 Chromium 项目开发出来。它开源、轻量级,同时不失定制性。尽管它还很年轻,缺少特性,但真的让人感觉清爽,可以完成你绝大多数的工作。
|
||||
|
||||
推荐阅读:[[Review] Otter Browser Brings Hope To Opera Lovers](https://itsfoss.com/otter-browser-review/)
|
||||
|
||||
### 下载管理器
|
||||
|
||||

|
||||
|
||||
<figcaption>下载管理器</figcaption>
|
||||
|
||||
#### [Uget][34]
|
||||
|
||||
Uget 是我见过最好的下载管理器了。其源码是开放的,同时在下载管理器中提供了你所想要的一切。其中,高级设置选项可以用来更好的管理下载。它支持排队下载和断店下载、支持多连接来下载大体积文件、支持通过不同分类来下载不同目录,等等。
|
||||
|
||||
#### [Xdm][33]
|
||||
|
||||
Xdm (Xtreme Download Manager,极限下载管理器) 是一个由 Java 开发的功能强大且开源的工具。有着所有下载管理器的必备功能,包括:视频捕获器、智能调度和浏览器集成。
|
||||
|
||||
推荐阅读:[4 Best Download Managers For Linux](https://itsfoss.com/4-best-download-managers-for-linux/)
|
||||
|
||||
#### Bittorrent 客户端
|
||||
|
||||

|
||||
|
||||
<figcaption>BitTorrent 客户端</figcaption>
|
||||
|
||||
#### [Deluge][32]
|
||||
|
||||
Deluge 是一个开源的 BitTorrent 客户端,有着漂亮的用户界面。假如你习惯使用 Windows 下的 uTorrent,你就会知道两者有着很多的相似之处。它有大量的配置选项和插件来帮你应付分钟下载任务。
|
||||
|
||||
#### [Transmission][31]
|
||||
|
||||
Transmission 是最轻量级的 Bittorrent 客户端——开源,有着最轻量级的用户界面。在多数的 Linux 发行版中都预装了 Transmission。
|
||||
|
||||
推荐阅读:[Top 5 Torrent Clients For Ubuntu Linux](https://itsfoss.com/best-torrent-ubuntu/)
|
||||
|
||||
### 云存储
|
||||
|
||||

|
||||
|
||||
<figcaption>云存储</figcaption>
|
||||
|
||||
#### [Dropbox][30]
|
||||
|
||||
Dropbox 是目前最流行云存储服务之一。你注册之后就有 2 GB 的免费空间。Dropbox 直接提供了一个健壮的 Linux 客户端。
|
||||
|
||||
#### [Mega][29]
|
||||
|
||||
Mega 有 50 GB 的免费空间,但其最好的一点却非免费空间之大,而是它位你的文件传输提供了点对点加密。它在 Linux 平台上也有一个稳定的客户端,名为 MEGAsync。
|
||||
|
||||
推荐阅读:[Best Free Cloud Services For Linux](https://itsfoss.com/cloud-services-linux/)
|
||||
|
||||
### 即时消息软件
|
||||
|
||||

|
||||
|
||||
<figcaption>即时消息软件</figcaption>
|
||||
|
||||
#### [Pidgin][28]
|
||||
|
||||
Pidgin是一个开源的即时消息客户端,支持多个聊天平台,包括 Facebook、Google Talk、Yahoo,甚至是 IRC。他还可以通过第三方插件来进行扩展,这样可以把很多功能集成到 Pidgin 中去。
|
||||
|
||||
#### [Skype][27]
|
||||
|
||||
我想,应该所有人到知道 Skype 吧,它是目前最流行的视频聊天平台。近期,它又为 Linux 平台 [发不了一个全新的桌面客户端][26]。
|
||||
|
||||
推荐阅读:[Best Messaging Apps Available For Linux In 2016](https://itsfoss.com/best-messaging-apps-linux/)
|
||||
|
||||
### 办公套件
|
||||
|
||||

|
||||
|
||||
<figcaption>办公套件</figcaption>
|
||||
|
||||
#### [LibreOffice][25]
|
||||
|
||||
LibreOffice 是 Linux 平台下开发活跃度最高的开源软件。它有六大核心模块:Writer (文字处理)、Calc (电子表格)、Impress (文稿演示)、Draw (图像绘制)、Math (数学公式)、Base (数据库),并且,这些模块都支持多种格式。当然,LibreOffice 也是支持第三方扩展的,多数的 Linux 发行版都用它作为默认的办公套件。
|
||||
|
||||
#### [WPS Office][24]
|
||||
|
||||
如果想要尝试 LibreOffice 之外的办公套件,WPS Office 当然是不容错过的,它支持 Writer (文字处理)、presentation (文稿演示)、spreadsheets (电子表格)。
|
||||
|
||||
推荐阅读:[Best Free and Open Source Alternatives to Microsoft Office](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/)
|
||||
|
||||
### 音乐播放器
|
||||
|
||||

|
||||
|
||||
<figcaption>音乐播放器</figcaption>
|
||||
|
||||
##### [Lollypop][23]
|
||||
|
||||
这是一个相对较新的音乐播放器。Lollypop 是开源的,有着非常漂亮的用户界面,提供了非常友好的歌曲管理、播放历史支持、在线电台和派对模式。尽管这是一个很简单的音乐播放器,没有太多的高级特性,但还是值得一试的。
|
||||
|
||||
#### [RhythmBox][22]
|
||||
|
||||
Rhythmbox 最初是为 Gnome 开发的音乐播放器,但现在已经可以很好的在其他的桌面环境中工作。他可以完成音乐播放器的所有基本任务,包括 CD 分离 & 刻录、播放历史等,而且还支持 iPod。
|
||||
|
||||
#### [CMUS][21]
|
||||
|
||||
假如你是极简主义派,并深爱着终端界面,那么 Cmus 很合适你。就个人而言,我很喜欢并一直在用这个软件。它是类 Unix 平台下一个相当小巧、响应速度快、有着功能强大的控制台音乐播放器,具备了音乐播放器所有基本特性。通过额外的扩展和脚本,你也是可以使它功能更加丰富的。
|
||||
|
||||
推荐阅读:[How To Install Tomahawk Player In Ubuntu 14.04 And Linux Mint 17](https://itsfoss.com/install-tomahawk-ubuntu-1404-linux-mint-17/)
|
||||
|
||||
### 视频播放器
|
||||
|
||||

|
||||
|
||||
<figcaption>视频播放器</figcaption>
|
||||
|
||||
#### [VLC][20]
|
||||
|
||||
VLC 是一个开源的媒体播放器,具有简洁、速度快、轻量级但功能强大等特点。它做到了真正的开箱即用,几乎支持所有你想到的的视频格式,而且可以播放在线流媒体哦。当然,它是支持一些非常棒的插件来完成不同的任务的,比方说在播放视频是下载对应的字幕。
|
||||
|
||||
#### [Kodi][19]
|
||||
|
||||
Kodi 是一个功能完备的媒体播放器,开源并流行于其基础用户群中。它可以处理本地或者网络存储中的视频、音乐、图片、播客甚至是游戏,你还有使用它来录制 TV。Kodi 的使用是可以通过附件和不同的皮肤来自定义的。
|
||||
|
||||
推荐阅读:[4 Format Factory Alternative In Linux](https://itsfoss.com/format-factory-alternative-linux/)
|
||||
|
||||
### 图像编辑器
|
||||
|
||||

|
||||
|
||||
<figcaption>图像编辑器</figcaption>
|
||||
|
||||
#### [GIMP][18]
|
||||
|
||||
GIMP 是 Linux 平台下 Photoshop 的替代方案。它是开源的,是一个全功能、专业的图像编辑软件,打包了非常多的工具用来处理各类图像。在此基础上,还有大量的定制选项以及第三方插件可以用了增强用户的使用体验。
|
||||
|
||||
#### [Krita][17]
|
||||
|
||||
Krita 主要是一个绘图工具,但也可以用来编辑图像。他同样也是开源的,也打包了很多精致且高级的工具。
|
||||
|
||||
推荐阅读:[Best Photo Applications For Linux](https://itsfoss.com/image-applications-ubuntu-linux/)
|
||||
|
||||
### 文本编辑器
|
||||
|
||||
每个 Linux 发行版都会自带一个文本编辑器。通常,它的功能相对来说比较简单,没有太多的功能。但还是有一些编辑器具有功能加强的兼容性的。
|
||||
|
||||

|
||||
|
||||
<figcaption>文本编辑器</figcaption>
|
||||
|
||||
#### [Atom][16]
|
||||
|
||||
Atom 是一个现代的可破解的文本编辑器,由 GitHub 进行维护更新。它是完全开源的,提供任何你能想到的一切来完成文本编辑任务。它做到了真正的开箱即用,或者可以进行自定义,让它变成你所需要的样子。同时,你可以重社区获取关于它的大量扩展和主题。
|
||||
|
||||
#### [Sublime Text][15]
|
||||
|
||||
Sublime Text 是主流的文本编辑器之一。尽管它并不免费,它允许你把软件作为评估使用,而且没有时间现在。Sublime Text 是一个功能丰富和复杂的软件。当然,它还有插件和主题支持。
|
||||
|
||||
推荐阅读:[4 Best Modern Open Source Code Editors For Linux](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)
|
||||
|
||||
### 启动器 (Launcher)
|
||||
|
||||

|
||||
|
||||
<figcaption>启动器 (Launcher)</figcaption>
|
||||
|
||||
#### [Albert][14]
|
||||
|
||||
Albert 的灵感来至于 Alfred (Mac 中的一个高效应用,可以做到一切信手拈来),但仍在开发中南。Albert 反应很快,可扩展、可定制。其目标就是“不用思考就使用一切可用资源”。它可以很好的集成到你的 Linux 发行版中,并让你保持高效率。
|
||||
|
||||
#### [Synapse][13]
|
||||
|
||||
Synapse 已有一定历史,是一个简洁的启动器,可以用来搜索和运行应用。它还可以加速各种各样的工作流,比如控制音乐、搜索文件、目录以及书签、运行命令等等。
|
||||
|
||||
正如 Abhishek 所说,我们会一直未读者 (比如,你) 更新这个 Linux 必备软件列表。那么,你最喜欢的 Linux 必备软件是什么呢?随时和我们分享,并想我们这个列表提出更多的软件分类。
|
||||
|
||||
--------------------------------------------------------
|
||||
via: https://itsfoss.com/essential-linux-applications
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[13]:https://launchpad.net/synapse-project
|
||||
[14]:https://github.com/ManuelSchneid3r/albert
|
||||
[15]:http://www.sublimetext.com/
|
||||
[16]:https://atom.io/
|
||||
[17]:https://krita.org/en/
|
||||
[18]:https://www.gimp.org/
|
||||
[19]:https://kodi.tv/
|
||||
[20]:http://www.videolan.org/
|
||||
[21]:https://cmus.github.io/
|
||||
[22]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[23]:http://gnumdk.github.io/lollypop-web/
|
||||
[24]:https://www.wps.com/
|
||||
[25]:https://www.libreoffice.org/
|
||||
[26]:https://itsfoss.com/skpe-alpha-linux/
|
||||
[27]:https://www.skype.com/
|
||||
[28]:https://www.pidgin.im/
|
||||
[29]:https://mega.nz/
|
||||
[30]:https://www.dropbox.com/
|
||||
[31]:https://transmissionbt.com/
|
||||
[32]:http://deluge-torrent.org/
|
||||
[33]:http://xdman.sourceforge.net/
|
||||
[34]:http://ugetdm.com/
|
||||
[35]:https://vivaldi.com/
|
||||
[36]:https://www.mozilla.org/en-US/firefox
|
||||
[37]:https://www.chromium.org/Home
|
||||
[38]:https://www.google.com/chrome/browser
|
||||
[39]:https://itsfoss.com/wp-content/uploads/2016/10/Essentials-applications-for-every-Linux-user.jpg
|
||||
210
translated/tech/20161030 I dont understand Pythons Asyncio.md
Normal file
210
translated/tech/20161030 I dont understand Pythons Asyncio.md
Normal file
@ -0,0 +1,210 @@
|
||||
|
||||
# 雾里看花 Python 之 Asyncio
|
||||
|
||||
|
||||
最近我开始发力钻研 Python 的新 [asyncio][4] 模块。原因是我需要做一些事情,使用事件 IO 会使这些事情工作得更好,炙手可热的 asynio 正好可以用来牛刀小试。从试用的经历来看,该模块比我预想的复杂许多,我现在有足够的信心说,我已经不知道如何恰当地使用 asyncio 了。
|
||||
|
||||
从 Twisted 框架借鉴一些经验来理解 asynio 并非难事,但是,asyncio 包含众多的元素,我开始动摇,不知道如何将这些孤立的零碎拼图组合成一副完整的图画。我已没有足够的智力提出任何更好的建议,在这里,只想分享我的困惑,求大神指点。
|
||||
|
||||
|
||||
#### 原语
|
||||
|
||||
*asyncio* 通过<ruby>协程<rt>coroutines</rt></ruby> 辅助来实现异步 IO。最初它是通过 *yield* 和 *yield from* 表达式实现的一个库,因为 Python 语言本身演进的缘故,现在它已经变成一个更复杂的怪兽。所以,为了在同一个频道讨论下去,你需要了解如下一些术语:
|
||||
|
||||
* 事件循环(event loops)
|
||||
* 事件循环策略(event loop policies)
|
||||
* awaitables
|
||||
* 协程函数(coroutine function)
|
||||
* 老式协程函数(old style coroutine functions)
|
||||
* 协程(coroutines)
|
||||
* 协程封装(coroutine wrappers)
|
||||
* 生成器(generators)
|
||||
* futures
|
||||
* 并发的futures(oncurrent futures)
|
||||
* 任务(tasks)
|
||||
* 句柄(handles)
|
||||
* 执行器(executors)
|
||||
* 传输(transports)
|
||||
* 协议(protocols)
|
||||
|
||||
此外,Python 还新增了一些新的特殊方法:
|
||||
* `__aenter__`和`__aenter__`,用于异步块操作
|
||||
* `__aiter__`和`__anext__ `,用于异步迭代器(异步循环和异步推导)。为了更多的乐趣,协议已经改变一次。 在 Python 3.5 它返回一个awaitable(协程);在 3.6 它返回一个新的异步生成器。
|
||||
* `__await__`,用于自定义的 awaitables
|
||||
|
||||
你还需要了解相当多的内容,文档涵盖了那些部分。尽管如此,我做了一些额外说明以便对其有更好的理解:
|
||||
|
||||
### 事件循环
|
||||
|
||||
asyncio 事件循环和你第一眼看上去的略有不同。表面看,每个线程都有一个事件循环,然而事实并非如此。我认为他们应该按照如下的方式工作:
|
||||
* 如果是主线程,当调用 asyncio.get_event_loop() 时创建一个事件循环。
|
||||
* 如果是其他线程,当调用 asyncio.get_event_loop() 时返回运行时错误。
|
||||
* 当前线程可以使用 asyncio.set_event_loop(),在任何时间节点绑定事件循环。该事件循环可由 asyncio.new_evet_loop() 函数创建。
|
||||
* 事件循环可以在不绑定到当前线程的情况下使用。
|
||||
* asyncio.get_event_loop() 返回绑定线程的事件循环,而非当前运行的事件循环。
|
||||
|
||||
这些行为的组合是超混淆的,主要有以下几个原因。 首先,你需要知道这些函数是全局设置的基础事件循环策略的委托。 默认是将事件循环绑定到线程。 或者,可以在理论上将事件循环绑定到一个 greenlet 或类似的,如果有人想要的话。 然而,重要的是要知道库代码不控制策略,因此不能推断 asyncio 将适用于线程。
|
||||
|
||||
其次,asyncio 不需要通过策略将事件循环绑定到上下文。 事件循环可以单独工作。 但是这正是库代码的第一个问题,因为协同程序或类似的东西不知道哪个事件循环负责调度它。 这意味着,如果从协程中调用 asyncio.get_event_loop(),你可能得不到运行你的事件循环。 这也是所有 API 均采用可选的显式事件循环参数的原因。 举例来说,要弄清楚当前哪个协程正在运行,不能使用如下调用:
|
||||
|
||||
```
|
||||
def get_task():
|
||||
loop = asyncio.get_event_loop()
|
||||
try:
|
||||
return asyncio.Task.get_current(loop)
|
||||
except RuntimeError:
|
||||
return None
|
||||
|
||||
```
|
||||
|
||||
相反,必须显式地传递事件循环。 这进一步要求你在库代码中显式地遍历事件循环,否则可能发生很奇怪的事情。 我不知道这种设计的思想是什么,但如果不解决这个问题(例如 get_event_loop() 返回实际运行的事件循环),那么唯一有意义的其他方案是明确禁止显式事件循环传递,并要求它绑定到当前上下文(线程等)。
|
||||
|
||||
由于事件循环策略不提供当前上下文的标识符,因此库也不可能以任何方式“索引”到当前上下文。 也没有回调函数用来监视这样的上下文的拆除,这进一步限制了实际可以开展的操作。
|
||||
|
||||
### <ruby>等待<rt>Awaitables</rt></ruby>与<ruby>协同<rt>Coroutines</rt></ruby>
|
||||
|
||||
以我的愚见,Python 最大的设计错误是过度重载迭代器。 它们现在不仅用于迭代,而且用于各种类型的协程。 Python 中迭代器最大的设计错误之一是如果 StopIteration 没有被捕获形成的气泡。 这可能导致非常令人沮丧的问题,其中某处的异常可能导致其他地方的生成器或协同程序中止。 这是一个长期运行的问题,基于 Python 的模板引擎如 Jinja,必须奋力解决。 模板引擎在内部渲染为生成器,并且当由于某种原因的模板引起 StopIteration时,该渲染就会在那里结束。
|
||||
|
||||
Python 正在慢慢学习过度重载这个系统的教训。 首先在3.x 版本加入 asyncio 模块,并没有语言支持。 所以自始至终它不过仅仅是装饰器和生成器。 为了实现yield from 等,StopIteration 再次重载。 这导致了令人困惑的行为,像这样:
|
||||
|
||||
```
|
||||
>>> def foo(n):
|
||||
... if n in (0, 1):
|
||||
... return [1]
|
||||
... for item in range(n):
|
||||
... yield item * 2
|
||||
...
|
||||
>>> list(foo(0))
|
||||
[]
|
||||
>>> list(foo(1))
|
||||
[]
|
||||
>>> list(foo(2))
|
||||
[0, 2]
|
||||
|
||||
```
|
||||
|
||||
没有错误,没有警告。 只是不是你期望的行为。 这是因为从一个作为生成器的函数中返回的值实际上引发了一个带有单个参数的 StopIteration,它不是由迭代器协议捕获,而只是在协程代码中处理。
|
||||
|
||||
在 3.5 和 3.6 有很多改变,因为现在除了生成器对象我们还有协程对象。 它不是通过包装一个生成器来生成协程,而是用一个单独的对象直接创建协程。通过用给函数加 `async` 前缀来实现。 例如 `async def x()` 会产生这样的协程。 现在在 3.6,将有单独的异步生成器,它通过触发 AsyncStopIteration 保持其独立性。 此外,对于Python 3.5 和更高版本,导入新的 future 对象(`generator_stop`),如果代码在迭代步骤中触发 StopIteration,它将引发 RuntimeError。
|
||||
|
||||
为什么我提到这一切? 因为老的实现方式并未真的消失。 生成器仍然具有 send 和 throw 方法以及协程仍然在很大程度上表现为生成器。你需要知道这些东西,它们将在未来伴随你相当长的时间。
|
||||
|
||||
为了统一很多这样的重复,现在我们在 Python 中有更多的概念了:
|
||||
|
||||
* awaitable:具有`__await__`方法的对象。 应用于由本地协同程序和旧式协同程序以及一些其他协同程序实现。
|
||||
* coroutinefunction:返回本地协同程序的函数。 不要与返回协程的函数混淆。
|
||||
* a coroutine: 原生的协同程序。 注意,目前为止,当前文档不认为老 asyncio 协程是协同程序。 至少 `inspect.iscoroutine` 不认为它是协程。 尽管它被 future/awaitable 分支接纳。
|
||||
|
||||
特别令人困惑的是 asyncio.iscoroutinefunctio n和 inspect.iscoroutinefunction 正在做不同的事情,这与 inspect.iscoroutine 和 inspect.iscoroutinefunction 相同。 到得注意的是,尽管 inspect 在类型检查中不知道有关 asycnio 遗留协同功能的任何信息,但是当您检查 awaitable 状态时它显然知道它们,即使它与`__await__`不一致。
|
||||
|
||||
|
||||
### <ruby>协程包装器<rt>Coroutine Wrappers</rt></ruby>
|
||||
|
||||
每当你运行 async def ,Python 就会调用一个线程局部 coroutine 包装器。 它由 sys.set_coroutine_wrapper 设置,并且它是可以包装这些东西的一个函数。 看起来有点像如下代码:
|
||||
|
||||
```
|
||||
>>> import sys
|
||||
>>> sys.set_coroutine_wrapper(lambda x: 42)
|
||||
>>> async def foo():
|
||||
... pass
|
||||
...
|
||||
>>> foo()
|
||||
__main__:1: RuntimeWarning: coroutine 'foo' was never awaited
|
||||
42
|
||||
|
||||
```
|
||||
|
||||
在这种情况下,我从来没有实际调用原始的函数,只是给你一个提示,说明这个函数可以做什么。 目前我只能说它总是线程局部有效,所以,如果替换事件循环策略,你需要搞清楚如何让 coroutine 封装在相同的上下文同步更新。创建新线程不会从父线程继承那些标识。
|
||||
|
||||
这不要与 asyncio 协程包装代码混淆。
|
||||
|
||||
### Awaitables 和 Futures
|
||||
|
||||
有些东西是 awaitables。 据我所见,以下概念被认为是awaitable:
|
||||
|
||||
* 原生的协程
|
||||
* 配置了 `CO_ITERABLE_COROUTINE` 标识的生成器(文中有涉及)
|
||||
* 具有`__await__`方法的对象
|
||||
|
||||
|
||||
除了生成器由于遗留的原因不是使用`__await__`方法,其他的对象都使用。 `CO_ITERABLE_COROUTINE` 标志来自哪里? 它来自一个协程包装器(现在与 `sys.set_coroutine_wrapper` 有些混淆),即 `@asyncio.coroutine`。 通过一些间接方法,它使用 types.coroutine(现在与 types.CoroutineType 或asyncio.coroutine 有些混淆)包装生成器,并通过另外一个标志 CO_ITERABLE_COROUTINE 重新创建内部代码对象。
|
||||
|
||||
所以既然我们知道这些东西是什么,那么什么是 future? 首先,我们需要澄清一件事情:在 Python 3 中,实际上有两种(完全不兼容)的 future 类型:`asyncio.futures.Future` 和 `concurrent.futures.Future`。 其中一个出现在另一个之前,但他们都仍然在 asyncio 中使用。 例如,`asyncio.run_coroutine_threadsafe()` 将调度一个协程到在另一个线程中运行的事件循环,但它返回一个 `concurrent.futures.Future` 对象,而不是 `asyncio.futures.Future` 对象。 这是有道理的,因为只有 `concurrent.futures.Future` 对象是线程安全的。
|
||||
|
||||
所以现在我们知道有两个不兼容的 future,我们应该澄清哪个 future 在 asyncio 中。 老实说,我不完全确定差异在哪里,但我打算暂时称之为“最终”。 它是一个最终将持有一个值的对象,当还在计算时你可以对最终结果做一些处理。 future 对象的一些变种称为 deferred,还有一些叫做 promise。 我实在难以理解它们真正的区别。
|
||||
|
||||
你能用一个future对象做什么? 你可以关联一个准备就绪时将被调用的回调函数,或者你可以关联一个失败时将被触发的回调函数。 此外,你可以等待它(它实现`__await__`,因此可以等待),也可以取消它。
|
||||
|
||||
那么你怎样才能得到这样的 future 对象? 通过在 await 对象上调用 `asyncio.ensure_future`。 它会把一个旧版的生成器转变为 future 对象。 然而,如果你阅读文档,你会读到 `asyncio.ensure_future` 实际上返回一个`task`(任务)。 那么问题来了,什么是任务?
|
||||
|
||||
### 任务
|
||||
|
||||
任务是一个包装协同程序的 future 对象。 它的工作方式和 future 类似,但它也有一些额外的方法来提取当前栈中包含的协同程序。 我们已经看到了前面提到的任务,因为它是通过 `Task.get_current` 确定事件循环当前正在做什么的主要方式。
|
||||
|
||||
在如何取消工作上任务和 future 也有区别,但这超出了本文的范围。 取消是它们自己最大的问题。 如果你在一个协程上,并且知道自己正在运行,你可以通过前面提到的 `Task.get_current` 获取自己的任务,但这需要你知道自己被派遣在哪个事件循环,该事件循环可能是也可能不是已绑定的线程。
|
||||
|
||||
协程不可能知道它与哪个循环一起使用。*任务*也没有提供该信息公共 API。 然而,如果你确实可以获得一个任务,你可以访问 `task._loop`,通过它反指到事件循环。
|
||||
|
||||
### 句柄
|
||||
|
||||
除了上面提到的所有一切还有句柄。 句柄是等待执行的不透明对象,不能等待,但可以被取消。 特别是如果你使用 `call_soon` 或者 `call_soon_threadsafe`(还有其他一些)调度一个调用,你可以获得句柄,然后使用它尽力尝试取消执行,但不能等待实际调用生效。
|
||||
|
||||
### <ruby>执行器<rt>Executors</rt></ruby>
|
||||
|
||||
因为你可以有多个事件循环,但这并不意味着每个线程理所当然地应用多个事件循环,最常见的情形还是一个线程一个事件循环。 那么你如何通知另一个事件循环做一些工作? 你不能到另一个线程的事件循环中执行回调函数并获取结果。 这种情况下,你需要使用执行器。
|
||||
|
||||
执行器来自 `concurrent.futures`,它允许你将工作安排到本身未发生事件的线程中。 例如,如果在事件循环中使用 `run_in_executor` 来安编排将在另一个线程中调用的函数。 其返回结果是 asyncio 协程,而不是像 `run_coroutine_threadsafe` 这样的并发协同程序。 我还没有足够的心理能力来弄清楚为什么设计这样的 API,应该如何使用,以及什么时候使用。 文档建议执行器可以用于构建多进程。
|
||||
|
||||
### 传输和协议
|
||||
|
||||
我总是认为传输与协议也凌乱不堪,实际这部分内容基本上是对 Twisted 的逐字拷贝。详情毋庸赘述,请直接阅读相关文档。
|
||||
|
||||
### 如何使用 asyncio
|
||||
|
||||
现在我们已经大致了解 asyncio,我发现了一些模式,人们似乎在写 asyncio 代码时使用:
|
||||
|
||||
* 将事件循环传递给所有协程。 这似乎是社区中一部分人的做法。 把事件循环信息提供给协程为协程获取自己运行的任务提供了可能性。
|
||||
* 或者你要求事件循环绑定到线程,这也能达到同样的目的。 理想情况下两者都支持。 可悲的是,社区已经分化。
|
||||
* 如果想使用上下文数据(如线程本地数据),你可谓是运气不佳。 最流行的变通方法显然是 atlassian 的 `aiolocals`,它基本上需要你手动传递上下文信息到协程,因为解释器不提供支持。 这意味着如果你有一个实用程序库生成协程,你将失去上下文。
|
||||
* 忽略 Python 中的旧协程。 只使用 3.5 版本中 `async def` 和 co 关键字。 你总可能要用到它们,因为在老版本中,没有异步上下文管理器,这是非常必要的资源管理。
|
||||
* 学习重新启动事件循环进行善后清理。 这部分功能和我预想的不同,我花了比较长的时间来厘清它的实现。清理操作的最好方式是不断重启事件循环直到没有等待事件。 遗憾的是没有什么通用的模式来处理清理操作,你只能用一些丑陋的临时方案糊口度日。 例如 aiohttp 的 web 支持也做这个模式,所以如果你想要结合两个清理逻辑,你可能需要重新实现它提供的实用程序助手,因为该助手功能实现后,它彻底破坏了事件循环的设计。 当然,它不是我见过的第一个干这种坏事的库:(。
|
||||
* 使用子进程是不明显的。 你需要一个事件循环在主线程中运行,我想它是在监听信号事件,然后分派到其他事件循环。 这需要通过 `asyncio.get_child_watcher().attach_loop(...)` 通知循环。
|
||||
* 编写同时支持异步和同步的代码在某种程度上注定要失败。 尝试在同一个对象上支持 `with` 和 `async with` 是危险的事情。
|
||||
* 如果你想给 coroutine 一个更好的名字,弄清楚为什么它没有被等待,设置 `__name__`没有帮助。 你需要设置 `__qualname__`。
|
||||
* 有时内部类型交换使你麻痹。 特别是 `asyncio.wait()` 函数将确保所有的事情都是 future,这意味着如果你传递协程,你将很难发现你的协程是否已经完成或者正在等待,因为输入对象不再匹配输出对象。 在这种情况下,唯一真正理智的做法是确保前期一切都是 future。
|
||||
|
||||
### 上下文数据
|
||||
|
||||
除了疯狂的复杂性和缺乏理解如何更好地编写 API,我最大的问题是完全缺乏对上下文本地数据的考虑。这是 Node 社区现在学习的东西。`continuation-local-storage` 存在,但实现的太晚。连续本地存储和类似概念常用于在并发环境中实施安全策略,并且该信息的损坏可能导致严重的安全问题。
|
||||
|
||||
事实上,Python 甚至没有任何存储,这令人失望至极。我正在研究这个内容,因为我正在调查如何最好地支持 [Sentry's breadcrumbs] [3] 的 asyncio,然而我并没有看到一个合理的方式做到这一点。在 asyncio 中没有上下文的概念,没有办法从通用代码中找出您正在使用的事件循环,并且如果没有 monkeypatching(运行环境下的补丁),也无法获取这些信息。
|
||||
|
||||
Node 当前正在经历如何[找到这个问题的长期解决方案] [2]的过程。这个问题不容忽视,因为它在所有生态系统中反复出现过,如 JavaScript,Python 和 .NET 环境。问题[被命名为异步上下文传播] [1],其解决方案有许多名称。在 Go 中,需要使用上下文包,并明确地传递给所有 goroutine(不是一个完美的解决方案,但至少有一个)。.NET 具有本地调用上下文形式的最佳解决方案。它可以是线程上下文,Web 请求上下文或类似的东西,除非被抑制,否则它会自动传播。微软的解决方案是我们的黄金标准。我现在相信,微软在 15 年前已经解决了该问题。
|
||||
|
||||
我不知道生态系统是否还年轻,还可以添加逻辑调用上下文,可能现在仍然为时未晚。
|
||||
|
||||
### 个人感想
|
||||
|
||||
输出 asynio 的 man 帮助是复杂的,并且它变得越来越复杂。 我没有心理能力随便使用 asyncio。 它需要不断地更新所有 Python 语言的变化,这很大程度上使语言本身变得复杂。 令人鼓舞的是,一个生态系统正围绕着它不断发展,只是不知道还需要几年的时间,才能带给开发者愉快和稳定的开发体验。
|
||||
|
||||
3.5 版本引入的东西(新的协程对象)非常棒。 特别是这些变化包括引入了一个合理的基础,这些都是我在早期的版本中一直期盼的。在我心中, 通过生成器实现协程是一个错误。 关于什么是 asyncio,我难以置喙。 这是一个非常复杂的事情,内部令人眼花缭乱。 我很难理解它工作的所有细节。你什么时候可以传递一个生成器,什么时候它必须是一个真正的协程,future 是什么,任务是什么,事件循环如何工作,这甚至还没有触碰到真正的 IO 部分。
|
||||
|
||||
最糟糕的是,asyncio 甚至不是特别快。 David Beazley 演示的他设计的 asyncio 的替代品是原生版本速度的两倍。 asyncio 巨复杂,很难理解,也无法兑现自己在主要特性上的承诺,对于它,我只想说我想静静。我知道,至少我对 asyncio 理解的不够透彻,没有足够的信心对人们为它如何构建代码给出建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://lucumr.pocoo.org/2016/10/30/i-dont-understand-asyncio/
|
||||
|
||||
作者:[Armin Ronacher][a]
|
||||
|
||||
译者:[firstadream](https://github.com/译者ID)
|
||||
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://lucumr.pocoo.org/about/
|
||||
[1]:https://docs.google.com/document/d/1tlQ0R6wQFGqCS5KeIw0ddoLbaSYx6aU7vyXOkv-wvlM/edit
|
||||
[2]:https://github.com/nodejs/node-eps/pull/18
|
||||
[3]:https://docs.sentry.io/learn/breadcrumbs/
|
||||
[4]:https://docs.python.org/3/library/asyncio.html
|
||||
@ -0,0 +1,255 @@
|
||||
The Complete Guide to Flashing Factory Images Using Fastboot
|
||||
==========
|
||||
|
||||

|
||||
|
||||
如果你的手机有一个没有解锁的 [bootloader][31] 的话,你可以用 [Fastboot][32] 命令来刷入出厂镜像。听起来这好像是外行弄不懂的东西,但是当你需要升级被 [root][33] 过的设备,修理坏掉的手机,恢复到原生系统,或者是比别人更早的享受 Android 更新时,它可是最好的办法。
|
||||
|
||||
和 [ADB][35] 类似,Fastboot 是一个强大的 Android 命令行工具。这听起来可能会很恐怖 —— 别担心,一旦你了解了它,你就会知道Android的内部工作原理,以及如何解决最常见的问题。
|
||||
|
||||
### 关于三星设备的注释
|
||||
|
||||
下面的指南对于大多数 Nexus, Pixel, HTC, 以及 Motorola 等众多厂商的手机和平板电脑都适用。但是,三星的设备有自己的刷机软件,所以你的 Galaxy 设备并不支持 Fastboot。对于三星的设备,最好使用 [Odin][36] 来进行刷机工作,我们在下文的链接中提供了相关指南。
|
||||
|
||||
### 第一步 在你的电脑上安装 ADB 和 Fastboot
|
||||
|
||||
首先,你需要在你的电脑上安装 ADB 和 Fastboot,只有有了它们你才能使用 Fastboot 命令刷入镜像。网上有不少 “一键安装版” 或者 “绿色版”的 ADB 和 Fastboot,但是我不建议安装这样的版本,它们没有官方版本更新频繁,所以可能不会适用于新版设备。
|
||||
|
||||
你最好选择安装 Google 的 Android SDK Tools。这才是“真正的' ADB 和 Fastboot。安装 SDK Tools 可能需要一点时间,不过这等待是值得的。在下面的 _方法 1_ 中,我会说明在 Windows, Mac,以及 Linux 中安装这个软件的方法,所以在这里我们先讲后续的工作。
|
||||
|
||||
|
||||
### 第二步 解锁 bootloader
|
||||
|
||||
为了能够使用 Fastboot 刷入镜像,你需要解锁你设备的 [bootloader][37]。如果你已经解锁,你可以跳过这步。
|
||||
|
||||
如果你的设备的 Android 版本在 6.0 以上的话,在你解锁 bootloader 之前,你还[需要开启一项设置][38]。首先你需要**开启开发者选项**。开启之后,进入"开发者选项菜单",然后开启 “OEM 解锁” 选项。之后就可以进行下一步了。
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
如果你的设备没有这个选项,那么你的设备的 Android 版本可能不是 6.0 以上。如果这个选项存在但是是灰色的,这就意味着你的 bootloader 不能解锁,也就是说你不能使用 Fastboot 给你的手机刷入镜像。
|
||||
|
||||
### 第三步 进入 Bootloader 模式
|
||||
|
||||
在使用 Fastboot 软件之前,你还需要让你的设备进入 bootloader 模式。具体进入方式与你的设备有关。
|
||||
|
||||
对于大多数手机,你需要先完全关闭你的手机。在屏幕黑掉以后,同时按住开机键和音量下键大约 10 秒。
|
||||
|
||||
如果这不起效的话,关掉手机,按住音量下键。然后把手机连到电脑上,等上几秒钟。
|
||||
|
||||
如果还不起效的话,改按音量上键,再试试第二种方法。
|
||||
|
||||
很快你就会看见像这样的 bootloader 界面:
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
看到这个界面之后,确保你的设备已经连接到电脑上。之后的工作就都是在电脑上完成了,把手机放在那里就成。
|
||||
|
||||
### 第四步 在你的电脑上为 ADB 打开一个命令行窗口
|
||||
|
||||
转到 ADB 和 Fastboot 的安装目录。对于 Windows 用户来说,这目录通常是 _C:\Program Files (x86)\Android\android-sdk\platform-tools_ 对于 Mac 和 Linux 用户则取决于你设定的安装位置,如果你忘了的话,就在硬盘里搜索 _platform-tools_。
|
||||
|
||||
在此之后,如果你使用 Windows 的话,按住右侧的 Shift 键,在文件管理器的空白处单击右键,然后选择“在此处开启命令行窗口”。如果你用的是 Mac 或者 Linux 那么你仅仅需要打开一个终端,然后转到 _platform-tools_ 下。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
### 第五步 解锁 bootloader
|
||||
|
||||
这一步你仅仅需要做一次,如果你的 bootloader 已经解锁,你可以直接跳过这步。否则你还需要运行一条命令 —— 注意,这条命令会**清空你设备上的数据**。
|
||||
|
||||
在输入命令之前,我需要说明下,下面的命令仅仅对 Windows 适用,Mac 用户需要在命令前加上一个句号和一个斜线(**./**),Linux 用户则需要加上一个斜线(**/**)。
|
||||
|
||||
所以,在 ADB Shell 里输入如下命令,然后按下回车键。
|
||||
|
||||
* **fastboot devices**
|
||||
|
||||
如果程序输出了以 fastboot 结尾的一串字符,那就说明你的设备连接正常可以继续操作。如果没有的话,回到第一步,检查你的 ADB 以及 Fastooot是否正确安装,之后再确定设备是否正确地连到了电脑上。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
之后,解锁你的 bootloader。因为 Android 版本的差别,我们有两种方法来解决这个问题。
|
||||
|
||||
如果你的设备的 Android 版本是 5.0 或者更低版本 ,输入如下命令:
|
||||
|
||||
* **fastboot oem unlock**
|
||||
|
||||
如果你的 Android 版本高于 6.0 的话,输入如下命令,然后按下回车:
|
||||
|
||||
* **fastboot flashing unlock**
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
>将解锁命令发送到 6.0 或者更高版本的 Android 手机上
|
||||
|
||||
在这时,你的 Android 手机会问你是否确定要解锁 bootloader。确定你选中了 “Yes” 的选项,如果没有,使用音量键选中 “Yes”。然后按下电源键,你的设备将会开始解锁,之后会重启到 Fastboot 模式。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Nexus 6P 上的解锁菜单。图像来自 Dallas Thomas/Gadget Hacks
|
||||
|
||||
### 第六步 下载出厂镜像
|
||||
|
||||
现在你的 bootloader 已经解锁。你还需要把你从你的设备厂商下载下来的镜像解压。我推荐 **[7-Zip][19]** 它是免费的,支持大多数格式。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
解压出厂镜像
|
||||
|
||||
下一步,把压缩包中内容移动到 _platform-tools_ 文件夹。之后在这里打开一个命令行窗口。要得到更多信息,请看第四步。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
移动到 platform-tools 的文件
|
||||
|
||||
你有两种刷入镜像的方法。我会在下文分开叙述。
|
||||
|
||||
### 方法一
|
||||
|
||||
大多数出厂镜像都会包含一个 "flash-all" 脚本可以让你一条命令就完成刷机过程。如果你试图让你的黑砖回复正常的话,这是最简单的方法。但是这会让你的手机回到未 root 的状态并会擦除所有数据,如果你不想这样的话,请选择方法二。
|
||||
|
||||
如果要运行 "flash-all" 脚本,输入如下命令,之后敲下回车:
|
||||
|
||||
* **flash-all**
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
运行 "flash-all" 命令
|
||||
|
||||
这需要一点时间,当这步完成之后,你的手机应当自动重启,你可以享受 100% 原生固件。
|
||||
|
||||
### 方法二 手动解压刷入镜像
|
||||
|
||||
你可以手动刷入系统镜像。这么做需要额外的工作,但是它可以不清除数据的情况下反 root,升级设备,或者救回你的砖机。
|
||||
|
||||
首先解压出厂镜像包中的所有压缩文件。通常压缩包里会包含三到四个压缩包,确认你已经解压了所有的压缩文件。之后把这些文件移动到 _platform-tools_ —— 或者说,别把他们放到子文件夹下。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
|
||||
解压后的所有文件
|
||||
|
||||
在这些文件里,有两个镜像是可以直接删除的: _cache.img_ 和 _userdata.img_。就是这两个文件清除了你的设备数据,如果你不刷入这两个镜像,你的数据就不会消失。
|
||||
|
||||
在剩下的文件中,有六个镜像构成了 Android 的核心部分: _boot_, _bootloader_, _radio_, _recovery_, _system_, 和 _vendor_。
|
||||
|
||||
_boot_ 镜像包含了内核,如果你想要换掉一个不太好用的自制内核的话,你仅仅需要刷入这个文件。通过键入如下命令完成工作:
|
||||
|
||||
* **fastboot flash boot <boot image file name>.img**
|
||||
|
||||
下一个就是 _bootloader_ —— 也就是你用来刷入镜像的界面。如果你要升级的话,输入如下命令:
|
||||
|
||||
* **fastboot flash bootloader <bootloader image file name>.img**
|
||||
|
||||
做完这步之后你就可以用新版的 bootloader 刷入镜像。要想如此,输入:
|
||||
|
||||
* **fastboot reboot-bootloader**
|
||||
|
||||
之后就是 _radio_ 镜像。这个镜像和你设备的网络连接有关,如果你手机的 Wi-Fi 或者移动数据出现了毛病。或者你仅仅想升级你的基带固件,输入:
|
||||
|
||||
|
||||
* **fastboot flash radio <radio image file name>.img**
|
||||
|
||||
然后就是 _recovery_。你可以自由选择是否刷入这个镜像,如果你已经刷入 TWRP 的话,刷入这个镜像会恢复到原生 recovery。如果你仅仅要升级你的已经被修改过的设备,你就可以跳过这步。如果你想要新版的原生 recovery ,键入:
|
||||
|
||||
* **fastboot flash recovery <recovery file name>.img**
|
||||
|
||||
下一个可是个大家伙:_system_ 镜像,它包含了 Android 系统所需的全部文件。它是升级过程中最重要的部分。
|
||||
|
||||
如果你不想升级系统仅仅是要换回原生固件或者是救砖的话,你只需要刷入这个镜像,它包含了 Android 的所有文件。换言之,如果你仅仅刷入了这个文件,那你之前对这个设备做的修改都会被取消。
|
||||
|
||||
作为一个救砖的通用方法,以及升级 Android 的方法,键入:
|
||||
|
||||
* **fastboot flash system <system file name>.img**
|
||||
|
||||
最后,就是 _vendor_ 镜像。只有新版的设备才包含这个包。没有的话也不必担心,不过如果有这个文件的话,那它就包含了一些重要的文件,键入如下命令使其更新:
|
||||
|
||||
* **fastboot flash vendor <vendor file name>.img**
|
||||
|
||||
在这之后,你就可以重新启动设备:
|
||||
|
||||
* **fastboot reboot**
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
手动刷入出厂镜像
|
||||
|
||||
至此,你的设备已经完全更新,如果你是救砖的话,你的手机应该已经完好的运行。如果你知道每个系统镜像怎么是干什么的话,你就会更好的理解 Android 是怎么运行的。
|
||||
|
||||
手动刷入镜像比做任何修改已经帮助我更多地理解了 Android。你会发现,Android 就是写进存储设备里的一堆镜像,现在你可以自己处理他们,你也能更好的处理有关 root 的问题。
|
||||
|
||||
* 在[Facebook][20], [Twitter][21], [Google+][22], 以及 [YouTube][23] 关注 Gadget Hacks
|
||||
* 在 [Facebook][24], [Twitter][25], 和 [Pinterest][26] 上关注 Android Hacks
|
||||
* 在 [Facebook][27], [Twitter][28], [Pinterest][29], 还有 [Google+][30] 上关注 WonderHowTo
|
||||
|
||||
|
||||
|
||||
|
||||
via: http://android.wonderhowto.com/how-to/complete-guide-flashing-factory-images-using-fastboot-0175277/
|
||||
|
||||
作者:[ Dallas Thomas][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://creator.wonderhowto.com/dallasthomas/
|
||||
[1]:http://img.wonderhowto.com/img/original/95/62/63613181132511/0/636131811325119562.jpg
|
||||
[2]:http://img.wonderhowto.com/img/original/12/37/63615501357234/0/636155013572341237.jpg
|
||||
[3]:http://img.wonderhowto.com/img/original/42/51/63613181192903/0/636131811929034251.jpg
|
||||
[4]:http://img.wonderhowto.com/img/original/06/56/63613181203998/0/636131812039980656.jpg
|
||||
[5]:http://img.wonderhowto.com/img/original/53/86/63613181215032/0/636131812150325386.jpg
|
||||
[6]:http://img.wonderhowto.com/img/original/55/72/63613181234096/0/636131812340965572.jpg
|
||||
[7]:http://img.wonderhowto.com/img/original/81/31/63616200792994/0/636162007929948131.jpg
|
||||
[8]:http://img.wonderhowto.com/img/original/05/92/63616201348448/0/636162013484480592.jpg
|
||||
[9]:http://img.wonderhowto.com/img/original/58/38/63616206141588/0/636162061415885838.jpg
|
||||
[10]:http://img.wonderhowto.com/img/original/47/26/63616206657885/0/636162066578854726.jpg
|
||||
[11]:http://img.wonderhowto.com/img/original/31/31/63616269700533/0/636162697005333131.jpg
|
||||
[12]:http://android.wonderhowto.com/how-to/know-your-android-tools-what-is-fastboot-do-you-use-it-0155640/
|
||||
[13]:http://gs6.wonderhowto.com/how-to/unroot-restore-samsung-galaxy-s6-back-stock-0162155/
|
||||
[14]:http://android.wonderhowto.com/how-to/android-basics-install-adb-fastboot-mac-linux-windows-0164225/
|
||||
[15]:https://developers.google.com/android/images
|
||||
[16]:http://www.htc.com/us/support/rom-downloads.html
|
||||
[17]:https://motorola-global-portal.custhelp.com/cc/cas/sso/redirect/standalone%2Fbootloader%2Frecovery-images
|
||||
[18]:http://android.wonderhowto.com/how-to/android-basics-enable-developer-options-usb-debugging-0161948/
|
||||
[19]:http://www.7-zip.org/download.html
|
||||
[20]:http://facebook.com/gadgethacks/
|
||||
[21]:http://twitter.com/gadgethax
|
||||
[22]:https://plus.google.com/+gadgethacks
|
||||
[23]:https://www.youtube.com/user/OfficialSoftModder/
|
||||
[24]:http://facebook.com/androidhacksdotcom/
|
||||
[25]:http://twitter.com/androidhackscom
|
||||
[26]:https://www.pinterest.com/wonderhowto/android-hacks-mods-tips/
|
||||
[27]:http://facebook.com/wonderhowto/
|
||||
[28]:http://twitter.com/wonderhowto/
|
||||
[29]:http://pinterest.com/wonderhowto/
|
||||
[30]:https://plus.google.com/+wonderhowto
|
||||
[31]:http://android.wonderhowto.com/news/big-android-dictionary-glossary-terms-you-should-know-0165594/
|
||||
[32]:http://android.wonderhowto.com/news/big-android-dictionary-glossary-terms-you-should-know-0165594/
|
||||
[33]:http://android.wonderhowto.com/how-to/android-basics-what-is-root-0167400/
|
||||
[34]:http://android.wonderhowto.com/news/big-android-dictionary-glossary-terms-you-should-know-0165594/
|
||||
[35]:http://android.wonderhowto.com/how-to/know-your-android-tools-what-is-adb-do-you-use-it-0155456/
|
||||
[36]:http://tag.wonderhowto.com/odin/
|
||||
[37]:http://android.wonderhowto.com/news/big-android-dictionary-glossary-terms-you-should-know-0165594/
|
||||
[38]:http://android.wonderhowto.com/news/psa-enable-hidden-setting-before-modding-anything-android-0167840/
|
||||
[39]:http://android.wonderhowto.com/how-to/android-basics-tell-what-android-version-build-number-you-have-0168050/
|
||||
@ -0,0 +1,170 @@
|
||||
如何在 Shell 脚本中执行语法检查调试模式
|
||||
============================================================
|
||||
|
||||
我们开启了 Shell 脚本调试系列文章,先是解释了不同的调试选项,下面介绍[如何启用 Shell 调试模式][1]。
|
||||
|
||||
写完脚本后,建议在运行脚本之前先检查脚本中的语法,而不是查看它们的输出以确认它们是否正常工作。
|
||||
|
||||
在本系列的这一部分,我们将了解如何使用语法检查调试模式。记住我们之前在本系列的第一部分中解释了不同的调试选项,在这里,我们将使用它们来执行脚本调试。
|
||||
|
||||
#### 启用 verbose 调试模式
|
||||
|
||||
在进入本指导的重点之前,让我们简要地探索下 **verbose 模式**。它可以用 `-v` 调试选项来启用,它会告诉 shell 在读取时显示每行。
|
||||
|
||||
要展示这个如何工作,下面是一个示例脚本来[批量将 PNG 图片转换成 JPG 格式][2]。
|
||||
|
||||
将下面内容输入(或者复制粘贴)到一个文件中。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#convert
|
||||
for image in *.png; do
|
||||
convert "$image" "${image%.png}.jpg"
|
||||
echo "image $image converted to ${image%.png}.jpg"
|
||||
done
|
||||
exit 0
|
||||
```
|
||||
|
||||
接着保存文件,并用下面的命令使脚本可执行:
|
||||
|
||||
```
|
||||
$ chmod +x script.sh
|
||||
```
|
||||
|
||||
我们可以执行脚本并显示它被 Shell 读取到的每一行:
|
||||
|
||||
```
|
||||
$ bash -v script.sh
|
||||
```
|
||||
[
|
||||
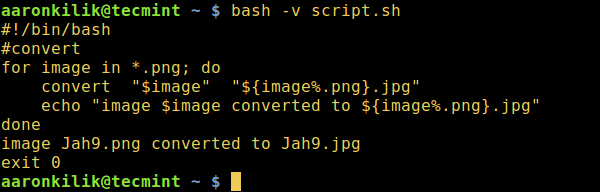
|
||||
][3]
|
||||
|
||||
*显示shell脚本中的所有行*
|
||||
|
||||
#### 在 Shell 脚本中启用语法检查调试模式
|
||||
|
||||
回到我们主题的重点,`-n` 激活语法检查模式。它会让 shell 读取所有的命令,但是不会执行它们,它(shell)只会检查语法。
|
||||
|
||||
一旦 shell 脚本中发现有错误,shell 会在终端中输出错误,不然就不会显示任何东西。
|
||||
|
||||
激活语法检查的命令如下:
|
||||
|
||||
```
|
||||
$ bash -n script.sh
|
||||
```
|
||||
|
||||
因为脚本中的语法是正确的,上面的命令不会显示任何东西。所以,让我们尝试删除结束 for 循环的 `done` 来看下是否会显示错误:
|
||||
|
||||
下面是修改过的含有 bug 的批量将 png 图片转换成 jpg 格式的脚本。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#script with a bug
|
||||
#convert
|
||||
for image in *.png; do
|
||||
convert "$image" "${image%.png}.jpg"
|
||||
echo "image $image converted to ${image%.png}.jpg"
|
||||
exit 0
|
||||
```
|
||||
|
||||
保存文件,接着运行该脚本并执行语法检查:
|
||||
|
||||
```
|
||||
$ bash -n script.sh
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*检查 shell 脚本语法*
|
||||
|
||||
从上面的输出中,我们看到我们的脚本中有一个错误,for 循环缺少了一个结束的 `done` 关键字。shell 脚本从头到尾检查文件,一旦没有找到它(**done**),shell 会打印出一个语法错误:
|
||||
|
||||
```
|
||||
script.sh: line 11: syntax error: unexpected end of file
|
||||
```
|
||||
|
||||
我们可以同时结合 verbose 模式和语法检查模式:
|
||||
|
||||
```
|
||||
$ bash -vn script.sh
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*在脚本中同时启用 verbose 和语法检查*
|
||||
|
||||
另外,我们可以通过修改脚本的首行来启用脚本检查,如下面的例子:
|
||||
|
||||
```
|
||||
#!/bin/bash -n
|
||||
#altering the first line of a script to enable syntax checking
|
||||
#convert
|
||||
for image in *.png; do
|
||||
convert "$image" "${image%.png}.jpg"
|
||||
echo "image $image converted to ${image%.png}.jpg"
|
||||
exit 0
|
||||
```
|
||||
|
||||
如上所示,保存文件并在运行中检查语法:
|
||||
|
||||
```
|
||||
$ ./script.sh
|
||||
script.sh: line 12: syntax error: unexpected end of file
|
||||
```
|
||||
|
||||
此外,我们可以用内置的 set 命令来在脚本中启用调试模式。
|
||||
|
||||
下面的例子中,我们只检查脚本中的 for 循环语法。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#using set shell built-in command to enable debugging
|
||||
#convert
|
||||
#enable debugging
|
||||
set -n
|
||||
for image in *.png; do
|
||||
convert "$image" "${image%.png}.jpg"
|
||||
echo "image $image converted to ${image%.png}.jpg"
|
||||
#disable debugging
|
||||
set +n
|
||||
exit 0
|
||||
```
|
||||
|
||||
再一次保存并执行脚本:
|
||||
|
||||
```
|
||||
$ ./script.sh
|
||||
```
|
||||
|
||||
总的来说,我们应该保证在执行 Shell 脚本之前先检查脚本语法以捕捉错误。
|
||||
|
||||
请在下面的反馈栏中,给我们发送关于这篇指导的任何问题或反馈。在这个系列的第三部分中,我们会解释并使用 shell 追踪调试模式。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Aaron Kili 是一个 Linux 及 F.O.S.S 热衷者,即将是 Linux 系统管理员、web 开发者,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并热心分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/check-syntax-in-shell-script/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/enable-shell-debug-mode-linux/
|
||||
[2]:http://www.tecmint.com/linux-image-conversion-tools/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/12/Show-Shell-Script-Lines.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/12/Check-Syntax-in-Shell-Script.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/Enable-Verbose-and-Syntax-Checking-in-Script.png
|
||||
264
translated/tech/20161215 Installation of CentOS 7.3 Guide.md
Normal file
264
translated/tech/20161215 Installation of CentOS 7.3 Guide.md
Normal file
@ -0,0 +1,264 @@
|
||||
CentOS 7.3安装向导
|
||||
============================================================
|
||||
|
||||
基于Red Hat企业版的最新版本的CentOS 7在今年的11月发布了,包含了许多bug修复、新的包更新、比如Samba、Squid、libreoffice、SELinux、systemd等其他支持第七代Intel酷睿i3、i5、 i7处理器的软件包。
|
||||
|
||||
本指南会向你展示如何在UEFI的机器上使用DVD ISO镜像来安装CentOS 7.3。
|
||||
|
||||
如果你在查找RHEL,看下我们的[RHEL 7.3安装指南][2]
|
||||
|
||||
#### 要求
|
||||
|
||||
1. [下载CentOS 7.3 ISO镜像][1]
|
||||
|
||||
|
||||
要在UEFI的机器上正确安装CentOS 7.3,首先按键((`F2`、 `F11`、 `F12`取决与你的主板类型)进入主板的UEFI的设置,并且确保QuickBoot/FastBoot以及Secure Boot已被禁用。
|
||||
|
||||
### CentOS 7.3安装
|
||||
|
||||
1. 在你从上面的链接下载完成镜像之后,使用[Rufus][3]将它烧录到DVD或者创建一个可启动的UEFI兼容USB盘。
|
||||
|
||||
将USB/DVD放入主板中,重启电脑并用特定的功能键(`F12`、 `F10`,取决于主板供应商)让BIOS/UEFI从DVD/USB启动。
|
||||
|
||||
ISO镜像启动完成后,你机器上会显示一个页面。在菜单中选择Install CentOS 7并按下回车继续。
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
CentOS 7.3启动菜单
|
||||
|
||||
2. 在安装镜像加载到内存完成后,会显示一个欢迎页面。选择你在安装中使用的语言并按下继续按钮。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
选择CentOS 7.3安装语言
|
||||
|
||||
3. 在下一个页面点击日期和时间,从地图中选择你的地理位置。确认日期和时间正确配置了并点击完成按钮来回到主安装界面。
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
CentOS 7.3 安装总结
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
选择日期和时间
|
||||
|
||||
4. 点击键盘菜单进入键盘布局页面。选择或者添加一个键盘布局并点击完成继续。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
选择键盘布局
|
||||
|
||||
5. 接下来,添加或者配置一个你系统中的语言并点击完成进入下一步。
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
选择语言支持
|
||||
|
||||
6. 在这步中,你可以通过选择列表中安全配置来设置你的系统安全策略。
|
||||
|
||||
点击选择配置按钮选择你想要的安全配置并点击应用安全设置按钮到On。点击完成按钮后继续安装流程。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
启用CentOS 7.3 安全策略
|
||||
|
||||
7. 下一步中你可以点击软件选择按钮来配置你的基础机器环境。
|
||||
|
||||
左边的列表是你可以选择安装桌面环境(Gnome、KDE Plasma或者创造型工作站)或者安装一个服务器环境(Web服务器、计算节点、虚拟化主机、基础设施服务器、带图形界面的服务器或者文件及打印服务器)或者执行一个最小化的安装。
|
||||
|
||||
为了随后能自定义你的系统,选择最小化带兼容库安装点击完成按钮继续。
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
CentOS 7.3软件选择
|
||||
|
||||
对于完整的Gnome或者KDE桌面环境,使用下面的截图作为指引。
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
Gnome桌面软件选择
|
||||
|
||||
[
|
||||
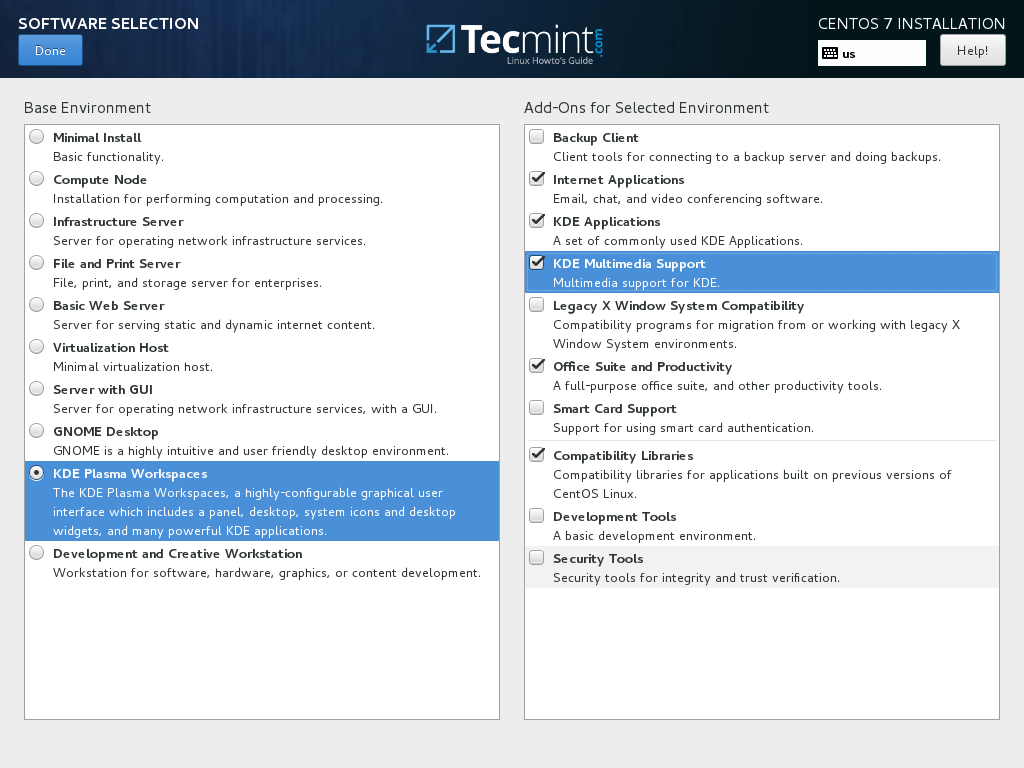
|
||||
][13]
|
||||
|
||||
KDE桌面软件选择
|
||||
|
||||
8. 假设你要在服务器上安装一个图形界面,选择左边那栏带GUI的服务器那项,并在右边那栏中根据你需要提供给客户端的服务选择合适的附加软件。
|
||||
|
||||
你可以选择的服务是非常多样化的,从备份、DNS或者e-mai服务到文件存储服务、FTP、HA或者[监控工具][14]。只选择对你网络设置最重要的服务。
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
选择带GUI的服务器
|
||||
|
||||
9 安装源保持默认,这为了防止你使用了特定的网络比如HTTP、HTTPS、FTP或者NFS协议作为额外的仓库,并点击安装位置来创建一个磁盘分区。
|
||||
|
||||
在设备选择页面,确保你已经选择了本地磁盘。同样,在其他存储选项中确保选择了自动配置分区。
|
||||
|
||||
这个选项可以确保你的磁盘会根据磁盘空间和Linux文件系统层次结构被正确分区。它会为你自动创建/(root)、/home和swap分区。点击完成来应用磁盘分区计划并回到主安装界面。
|
||||
|
||||
重要提醒:如你你想要创建自定义分区及自定义分区大小,你可以选择“I will configure partitioning”选项来创建自定义分区。
|
||||
|
||||
[
|
||||
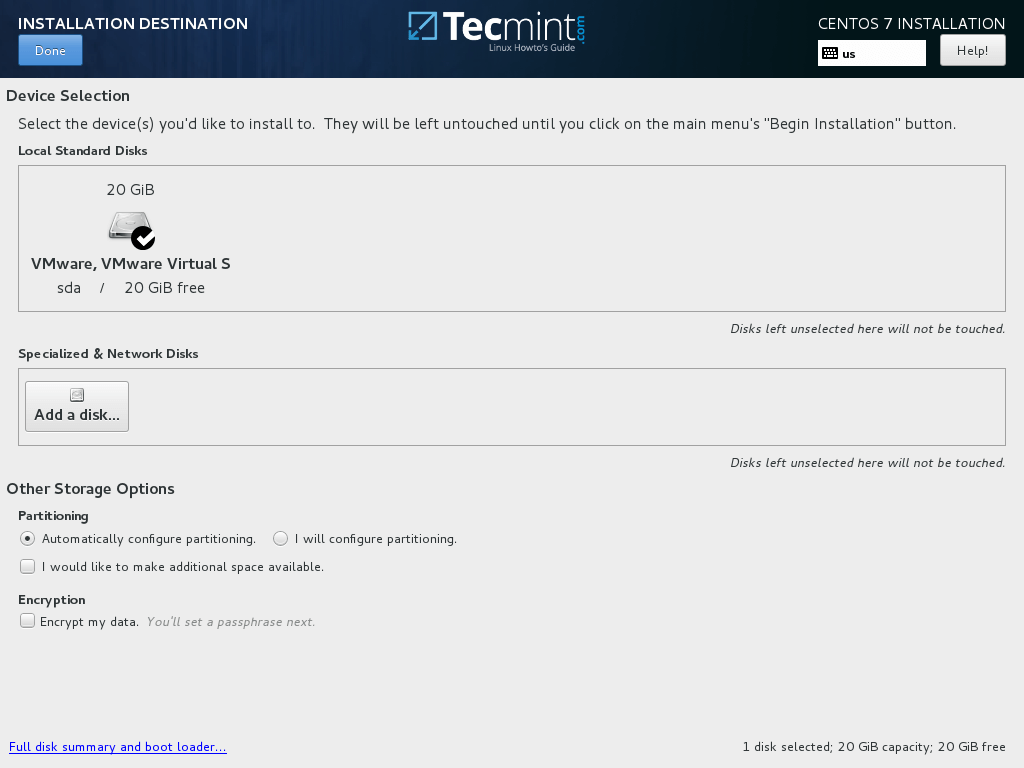
|
||||
][16]
|
||||
|
||||
安装CentOS 7.3安装位置
|
||||
|
||||
10. 接下来,如果你想要释放系统内存,点击KDUMP选项并禁用它。点击完成并回到主安装界面。
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
Kdump选择
|
||||
|
||||
11. 在下一步中设置你的主机名并启用网络服务。点击网络和主机名,在主机名中输入你的FQDN(完整网域名称),万一你在局域网中有一个DHCP服务器将以太网按钮从OFF切换到ON来激活网络接口。
|
||||
|
||||
[
|
||||
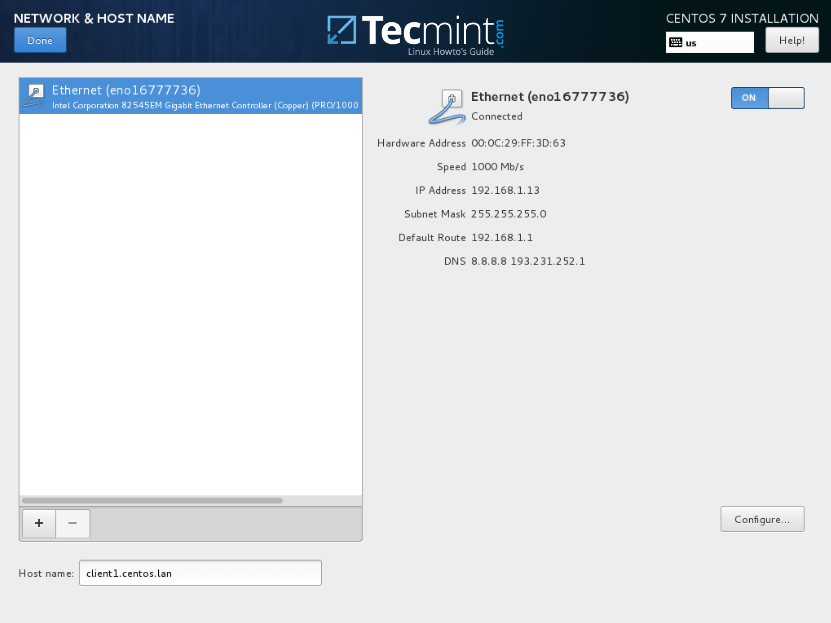
|
||||
][18]
|
||||
|
||||
设置网络及主机名
|
||||
|
||||
12. 为了静态配置你的网络接口,点击配置按钮,手动如截图所示添加IP设置,并点击保存按钮来应用更改。完成后,点击完成按钮来回到主安装菜单。
|
||||
|
||||
[
|
||||
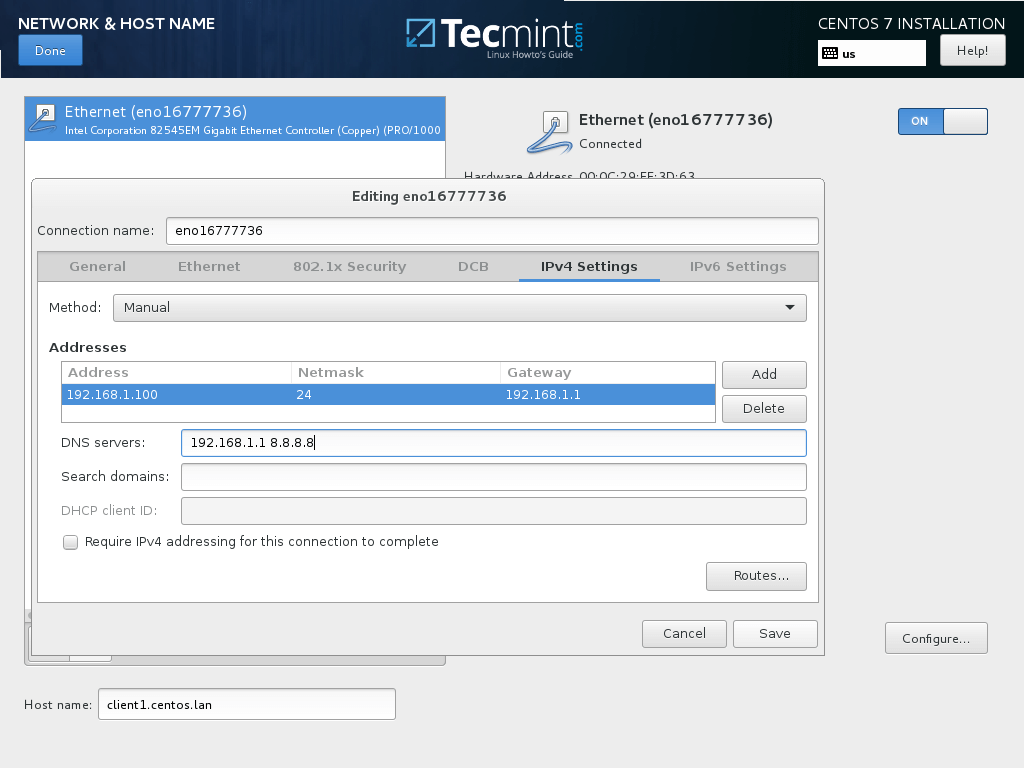
|
||||
][19]
|
||||
|
||||
配置网络和IP地址
|
||||
|
||||
13. 最后检查下所有到目前为止的配置,如果一切没问题,点击开始安装按钮开始安装。
|
||||
|
||||
[
|
||||
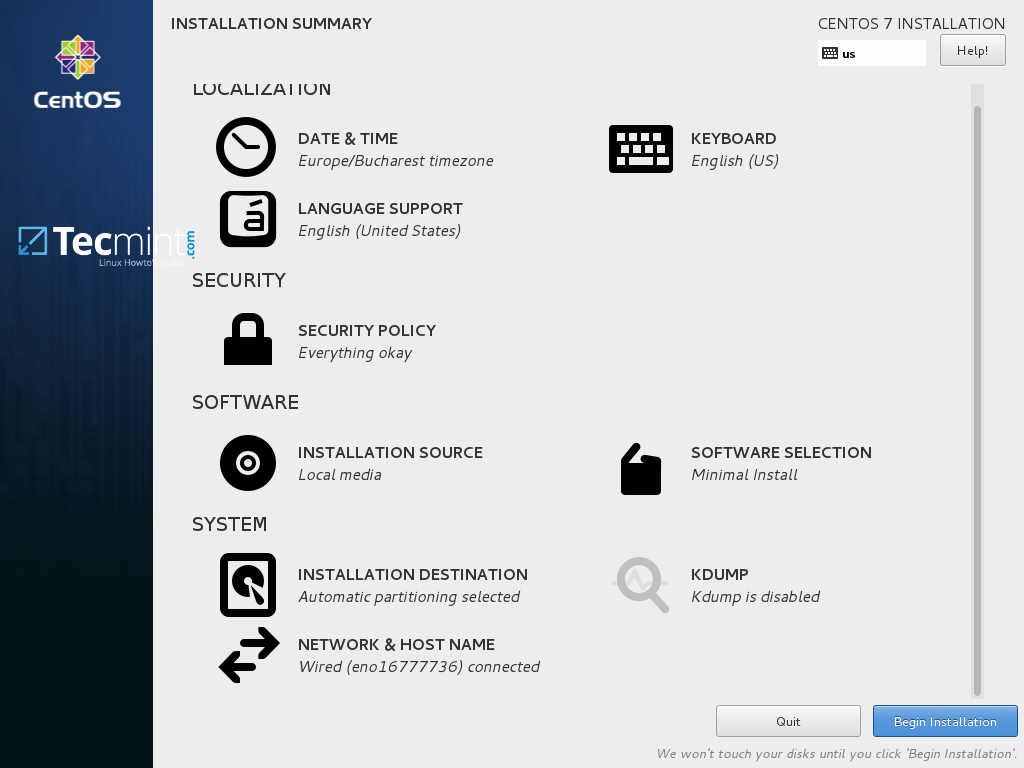
|
||||
][20]
|
||||
|
||||
开始CentOS 7.3安装向导
|
||||
|
||||
14. 开始安装后,一个新的设置用户界面会显示出来。首先点击root密码并添加一个强密码。
|
||||
|
||||
root账户是每个Linux系统的最高管理账户密码,它拥有所有的权限。设置完成后点击完成按回到用户设置界面。
|
||||
|
||||
[
|
||||
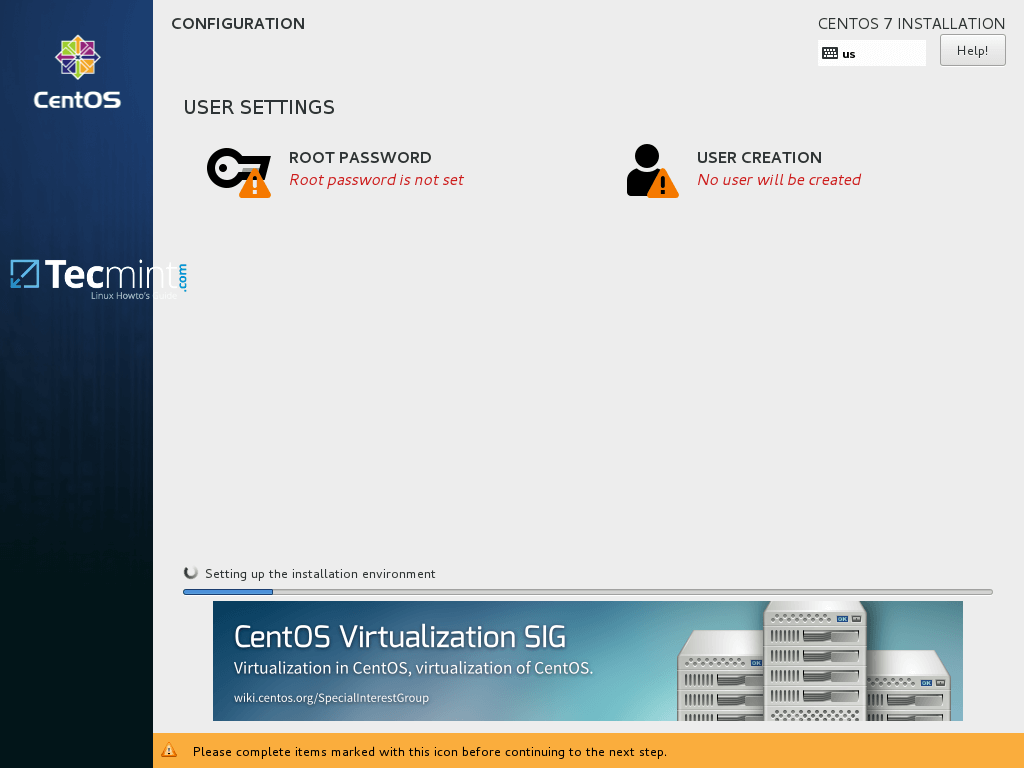
|
||||
][21]
|
||||
|
||||
选择root密码
|
||||
|
||||
[
|
||||
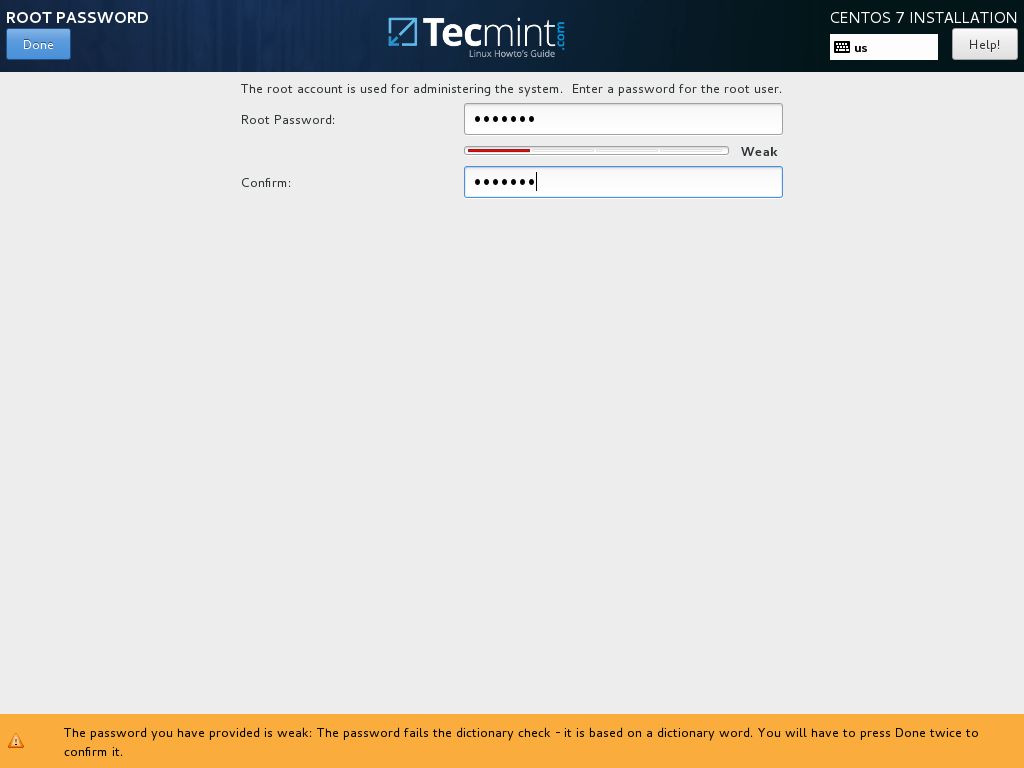
|
||||
][22]
|
||||
|
||||
设置root密码
|
||||
|
||||
15 用root账户运行系统是非常不安全和危险的,因此建议你点击创建用户按钮创建一个新的系统账户来[执行每日的系统任务][23]、
|
||||
|
||||
添加新的用户,并同时选择下面的两个选项来授予用户root权限以及每次在登录系统时手动输入密码。
|
||||
|
||||
当你完成最后一项点击完成按钮并等待安装完成。
|
||||
|
||||
[
|
||||
|
||||
][24]
|
||||
|
||||
创建用户账户
|
||||
|
||||
16. 几分钟后安装程序会报告CentOS已经成功安装在你机器中。要使用系统,你只需要移除安装媒介并重启机器。
|
||||
|
||||
[
|
||||
|
||||
][25]
|
||||
|
||||
CentOS 7.3安装完成
|
||||
|
||||
17. 重启之后,使用安装中创建的用户登录系统,并且用root权限执行下面的命令来执行系统更新。
|
||||
|
||||
```
|
||||
$ sudo yum update
|
||||
```
|
||||
[
|
||||

|
||||
][26]
|
||||
|
||||
更新CentOS 7.3
|
||||
|
||||
所有[yum管理器][27]的问题都选择`yes`,最后再次重启电脑(使用sudo init 6)来应用新的内核升级。
|
||||
|
||||
```
|
||||
$ sudo init 6
|
||||
```
|
||||
|
||||
就是这样!在你的机器中享受最新的CentOS 7.3吧。
|
||||
|
||||
|
||||
------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar
|
||||
|
||||

|
||||
|
||||
我是一个电脑上瘾的家伙,一个开源和linux系统软件的粉丝,有大约4年的Linux桌面,服务器和bash脚本的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/centos-7-3-installation-guide/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1611.iso
|
||||
[2]:http://www.tecmint.com/red-hat-enterprise-linux-7-3-installation-guide/
|
||||
[3]:https://rufus.akeo.ie/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/12/CentOS-7.3-Boot-Menu.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-CentOS-7.3-Installation-Language.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/12/CentOS-7.3-Installation-Summary.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-Date-and-Time.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-Keyboard-Layout.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-Language-Support.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/Enable-CentOS-7-Security-Policy.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/12/CentOs-7.3-Software-Selection.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/Gnome-Desktop-Software-Selection.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2016/12/KDE-Desktop-Software-Selection.png
|
||||
[14]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-Server-with-Gui.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-CentOS-7.3-Installation-Destination.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2016/12/Kdump-Selection.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2016/12/Set-Network-Hostname.png
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Network-and-IP-Address.png
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2016/12/Begin-CentOS-7.3-Installation.png
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-Root-Password.png
|
||||
[22]:http://www.tecmint.com/wp-content/uploads/2016/12/Set-Root-Password.png
|
||||
[23]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[24]:http://www.tecmint.com/wp-content/uploads/2016/12/Create-User-Account.png
|
||||
[25]:http://www.tecmint.com/wp-content/uploads/2016/12/CentO-7.3-Installation-Complete.png
|
||||
[26]:http://www.tecmint.com/wp-content/uploads/2016/12/Update-CentOS-7.3.png
|
||||
[27]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
Loading…
Reference in New Issue
Block a user