mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
ae7d58ccb2
@ -1,37 +1,35 @@
|
||||
使用企业版 Docker 搭建自己的私有注册服务器
|
||||
使用 Docker 企业版搭建自己的私有注册服务器
|
||||
======
|
||||
|
||||
![docker trusted registry][1]
|
||||
|
||||
Docker 真的很酷,特别是和使用虚拟机相比,转移 Docker 镜像十分容易。如果你已准备好使用 Docker,那你肯定已从 [Docker Hub][2] 上拉取完整的镜像。Docker Hub 是 Docker 的云端注册服务器服务,包含成千上万个供选择的 Docker 镜像。如果你开发了自己的软件包并创建了自己的 Docker 镜像,那么你会想有自己的私有注册服务器。如果你有搭配着专有许可的镜像,或想为你的构建系统提供复杂的持续集成(CI)过程,则更应该拥有自己的私有注册服务器。
|
||||
Docker 真的很酷,特别是和使用虚拟机相比,转移 Docker 镜像十分容易。如果你已准备好使用 Docker,那你肯定已从 [Docker Hub][2] 上拉取过完整的镜像。Docker Hub 是 Docker 的云端注册服务器服务,它包含成千上万个供选择的 Docker 镜像。如果你开发了自己的软件包并创建了自己的 Docker 镜像,那么你会想有自己私有的注册服务器。如果你有搭配着专有许可的镜像,或想为你的构建系统提供复杂的持续集成(CI)过程,则更应该拥有自己的私有注册服务器。
|
||||
|
||||
Docker 企业版包括 Docker Trusted Registry(译者注:DTR,Docker 可信注册服务器)。这是一个具有安全镜像管理功能的高可用的注册服务器,为了在你自己的数据中心或基于云端的架构上运行而构建。在接下来的几周,我们将了解 DTR 是提供安全、可重用且连续的[软件供应链][3]的一个关键组件。你可以通过我们的[免费托管小样][4]立即开始使用,或者通过下载安装进行 30 天的免费试用。下面是开始自己安装的步骤。
|
||||
Docker 企业版包括 <ruby>Docker 可信注册服务器<rt>Docker Trusted Registry</rt></ruby>(DTR)。这是一个具有安全镜像管理功能的高可用的注册服务器,为在你自己的数据中心或基于云端的架构上运行而构建。在接下来,我们将了解到 DTR 是提供安全、可重用且连续的[软件供应链][3]的一个关键组件。你可以通过我们的[免费托管小样][4]立即开始使用,或者通过下载安装进行 30 天的免费试用。下面是开始自己安装的步骤。
|
||||
|
||||
## 配置 Docker 企业版
|
||||
### 配置 Docker 企业版
|
||||
|
||||
Docker Trusted Registry 在通用控制面板(UCP)上运行,所以开始前要安装一个单节点集群。如果你已经有了自己的 UCP 集群,可以跳过这一步。在你的 docker 托管主机上,运行以下命令:
|
||||
DTR 运行于通用控制面板(UCP)之上,所以开始前要安装一个单节点集群。如果你已经有了自己的 UCP 集群,可以跳过这一步。在你的 docker 托管主机上,运行以下命令:
|
||||
|
||||
```
|
||||
# 拉取并安装 UCP
|
||||
|
||||
docker run -it -rm -v /var/run/docker.sock:/var/run/docker.sock -name ucp docker/ucp:latest install
|
||||
```
|
||||
|
||||
当 UCP 启动并运行后,在安装 DTR 之前你还有几件事要做。针对刚刚安装的 UCP 实例,打开浏览器。在日志输出的末尾应该有一个链接。如果你已经有了 Docker 企业版的许可证,那就在这个界面上输入它吧。如果你还没有,可以访问 [Docker 商店][5]获取30天的免费试用版。
|
||||
当 UCP 启动并运行后,在安装 DTR 之前你还有几件事要做。针对刚刚安装的 UCP 实例,打开浏览器。在日志输出的末尾应该有一个链接。如果你已经有了 Docker 企业版的许可证,那就在这个界面上输入它吧。如果你还没有,可以访问 [Docker 商店][5]获取 30 天的免费试用版。
|
||||
|
||||
准备好许可证后,你可能会需要改变一下 UCP 运行的端口。因为这是一个单节点集群,DTR 和 UCP 可能会以相同的端口运行他们的 web 服务。如果你拥有不只一个节点的 UCP 集群,这就不是问题,因为 DTR 会寻找有所需空闲端口的节点。在 UCP 中,点击管理员设置 -> 集群配置并修改控制器端口,比如 5443。
|
||||
准备好许可证后,你可能会需要改变一下 UCP 运行的端口。因为这是一个单节点集群,DTR 和 UCP 可能会以相同的端口运行它们的 web 服务。如果你拥有不只一个节点的 UCP 集群,这就不是问题,因为 DTR 会寻找有所需空闲端口的节点。在 UCP 中,点击“管理员设置 -> 集群配置”并修改控制器端口,比如 5443。
|
||||
|
||||
## 安装 DTR
|
||||
### 安装 DTR
|
||||
|
||||
我们要安装一个简单的、单节点的 Docker Trusted Registry 实例。如果你要安装实际生产用途的 DTR,那么你会将其设置为高可用(HA)模式,即需要另一种存储介质,比如基于云端的对象存储或者 NFS(译者注:Network File System,网络文件系统)。因为目前安装的是一个单节点实例,我们依然使用默认的本地存储。
|
||||
我们要安装一个简单的、单节点的 DTR 实例。如果你要安装实际生产用途的 DTR,那么你会将其设置为高可用(HA)模式,即需要另一种存储介质,比如基于云端的对象存储或者 NFS(LCTT 译注:Network File System,网络文件系统)。因为目前安装的是一个单节点实例,我们依然使用默认的本地存储。
|
||||
|
||||
首先我们需要拉取 DTR 的 bootstrap 镜像。Boostrap 镜像是一个微小的独立安装程序,包括连接到 UCP 以及设置和启动 DTR 所需的所有容器、卷和逻辑网络。
|
||||
首先我们需要拉取 DTR 的 bootstrap 镜像。boostrap 镜像是一个微小的独立安装程序,包括了连接到 UCP 以及设置和启动 DTR 所需的所有容器、卷和逻辑网络。
|
||||
|
||||
使用命令:
|
||||
|
||||
```
|
||||
# 拉取并运行 DTR 引导程序
|
||||
|
||||
docker run -it -rm docker/dtr:latest install -ucp-insecure-tls
|
||||
```
|
||||
|
||||
@ -39,55 +37,42 @@ docker run -it -rm docker/dtr:latest install -ucp-insecure-tls
|
||||
|
||||
然后 DTR bootstrap 镜像会让你确定几项设置,比如 UCP 安装的 URL 地址以及管理员的用户名和密码。从拉取所有的 DTR 镜像到设置全部完成,只需要一到两分钟的时间。
|
||||
|
||||
## 保证一切安全
|
||||
### 保证一切安全
|
||||
|
||||
一切都准备好后,就可以向注册服务器推送或者从中拉取镜像了。在做这一步之前,让我们设置 TLS 证书,以便安全的与 DTR 通信。
|
||||
一切都准备好后,就可以向注册服务器推送或者从中拉取镜像了。在做这一步之前,让我们设置 TLS 证书,以便与 DTR 安全地通信。
|
||||
|
||||
在 Linux 上,我们可以使用以下命令(只需确保更改了 DTR_HOSTNAME 变量,来正确映射我们刚刚设置的 DTR):
|
||||
在 Linux 上,我们可以使用以下命令(只需确保更改了 `DTR_HOSTNAME` 变量,来正确映射我们刚刚设置的 DTR):
|
||||
|
||||
```
|
||||
# 从 DTR 拉取 CA 证书(如果 curl 不可用,你可以使用 wget)
|
||||
|
||||
DTR_HOSTNAME=< DTR 主机名>
|
||||
|
||||
curl -k https://$(DTR_HOSTNAME)/ca > $(DTR_HOSTNAME).crt
|
||||
|
||||
sudo mkdir /etc/docker/certs.d/$(DTR_HOSTNAME)
|
||||
|
||||
sudo cp $(DTR_HOSTNAME) /etc/docker/certs.d/$(DTR_HOSTNAME)
|
||||
|
||||
# 重启 docker 守护进程(在 Ubuntu 14.04 上,使用 `sudo service docker restart` 命令)
|
||||
|
||||
sudo systemctl restart docker
|
||||
```
|
||||
|
||||
对于 Mac 和 Windows 版的 Docker,我们会以不同的方式安装客户端。转入设置 -> 守护进程,在 Insecure Registries(译者注:不安全的注册服务器)部分,输入你的 DTR 主机名。点击应用,docker 守护进程应在重启后可以良好使用。
|
||||
对于 Mac 和 Windows 版的 Docker,我们会以不同的方式安装客户端。转入“设置 -> 守护进程”,在“不安全的注册服务器”部分,输入你的 DTR 主机名。点击“应用”,docker 守护进程应在重启后可以良好使用。
|
||||
|
||||
## 推送和拉取镜像
|
||||
### 推送和拉取镜像
|
||||
|
||||
现在我们需要设置一个仓库来存放镜像。这和 Docker Hub 有一点不同,如果你做的 docker 推送仓库中不存在,它会自动创建一个。要创建一个仓库,在浏览器中打开 https://<Your DTR hostname> 并在出现登录提示时使用你的管理员凭据登录。如果你向 UCP 添加了许可证,则 DTR 会自动获取该许可证。如果没有,请现在确认上传你的许可证。
|
||||
现在我们需要设置一个仓库来存放镜像。这和 Docker Hub 有一点不同,如果你做的 docker 推送仓库中不存在,它会自动创建一个。要创建一个仓库,在浏览器中打开 `https://<Your DTR hostname>` 并在出现登录提示时使用你的管理员凭据登录。如果你向 UCP 添加了许可证,则 DTR 会自动获取该许可证。如果没有,请现在确认上传你的许可证。
|
||||
|
||||
进入刚才的网页之后,点击`新建仓库`按钮来创建新的仓库。
|
||||
进入刚才的网页之后,点击“新建仓库”按钮来创建新的仓库。
|
||||
|
||||
我们会创建一个用于存储 Alpine linux 的仓库,所以在名字输入处键入 `alpine`,点击`保存`(在 DTR 2.5 及更高版本中叫`创建`)。
|
||||
我们会创建一个用于存储 Alpine linux 的仓库,所以在名字输入处键入 “alpine”,点击“保存”(在 DTR 2.5 及更高版本中叫“创建”)。
|
||||
|
||||
现在我们回到 shell 界面输入以下命令:
|
||||
|
||||
```
|
||||
# 拉取 Alpine Linux 的最新版
|
||||
|
||||
docker pull alpine:latest
|
||||
|
||||
# 登入新的 DTR 实例
|
||||
|
||||
docker login <Your DTR hostname>
|
||||
|
||||
# 标记上 Alpine 使能推送其至你的 DTR
|
||||
|
||||
docker tag alpine:latest <Your DTR hostname>/admin/alpine:latest
|
||||
|
||||
# 向 DTR 推送镜像
|
||||
|
||||
docker push <Your DTR hostname>/admin/alpine:latest
|
||||
```
|
||||
|
||||
@ -95,22 +80,19 @@ docker push <Your DTR hostname>/admin/alpine:latest
|
||||
|
||||
```
|
||||
# 从 DTR 中拉取镜像
|
||||
|
||||
docker pull <Your DTR hostname>/admin/alpine:latest
|
||||
```
|
||||
|
||||
DTR 具有许多优秀的镜像管理功能,例如图像缓存,镜像,扫描,签名甚至自动化供应链策略。这些功能我们在后期的博客文章中更详细的探讨。
|
||||
|
||||
|
||||
DTR 具有许多优秀的镜像管理功能,例如镜像的缓存、映像、扫描、签名甚至自动化供应链策略。这些功能我们在后期的博客文章中更详细的探讨。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2018/01/dtr/
|
||||
|
||||
作者:[Patrick Devine;Rolf Neugebauer;Docker Core Engineering;Matt Bentley][a]
|
||||
作者:[Patrick Devine][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,35 +1,38 @@
|
||||
CPod:一个开源、跨平台播客应用
|
||||
======
|
||||
|
||||
播客是一个很好的娱乐和获取信息的方式。事实上,我会听十几个不同的播客,包括技术、神秘事件、历史和喜剧。当然,[Linux 播客][1]也在此列表中。
|
||||
|
||||
今天,我们将看一个简单的跨平台应用来收听你的播客。
|
||||
|
||||
![][2]
|
||||
推荐的播客和播客搜索
|
||||
|
||||
*推荐的播客和播客搜索*
|
||||
|
||||
### 应用程序
|
||||
|
||||
[CPod][3] 是 [Zack Guard(z -----)][4] 的作品。**它是一个 [Election][5] 程序**,这使它能够在最大的操作系统(Linux、Windows、Mac OS)上运行。
|
||||
[CPod][3] 是 [Zack Guard(z-------------)][4] 的作品。**它是一个 [Election][5] 程序**,这使它能够在大多数操作系统(Linux、Windows、Mac OS)上运行。
|
||||
|
||||
一个小事:CPod 最初被命名为 Cumulonimbus。
|
||||
> 一个小事:CPod 最初被命名为 Cumulonimbus。
|
||||
|
||||
应用的大部分被两个面板占用,来显示内容和选项。屏幕左侧的小条让你可以使用应用的不同功能。CPod 的不同栏目包括主页、队列、订阅、浏览和设置。
|
||||
|
||||
![cpod settings][6]
|
||||
设置
|
||||
|
||||
*设置*
|
||||
|
||||
### CPod 的功能
|
||||
|
||||
以下是 CPod 提供的功能列表:
|
||||
|
||||
* 简洁,干净的设计
|
||||
* 可在顶级计算机平台上使用
|
||||
* 可在主流计算机平台上使用
|
||||
* 有 Snap 包
|
||||
* 搜索 iTunes 的播客目录
|
||||
* 下载以及无需下载播放节目
|
||||
* 可下载也可无需下载就播放节目
|
||||
* 查看播客信息和节目
|
||||
* 搜索播客的个别节目
|
||||
* 黑暗模式
|
||||
* 深色模式
|
||||
* 改变播放速度
|
||||
* 键盘快捷键
|
||||
* 将你的播客订阅与 gpodder.net 同步
|
||||
@ -39,13 +42,13 @@ CPod:一个开源、跨平台播客应用
|
||||
* 多语言支持
|
||||
|
||||
|
||||
|
||||
![search option in cpod application][7]
|
||||
搜索 ZFS 节目
|
||||
|
||||
*搜索 ZFS 节目*
|
||||
|
||||
### 在 Linux 上体验 CPod
|
||||
|
||||
我最后在两个系统上安装了 CPod:ArchLabs 和 Windows。[Arch 用户仓库][8] 中有两个版本的 CPod。但是,它们都已过时,一个是版本 1.14.0,另一个是 1.22.6。最新版本的 CPod 是 1.27.0。由于 ArchLabs 和 Windows 之间的版本差异,我不得已而有不同的体验。在本文中,我将重点关注 1.27.0,因为它是最新且功能最多的。
|
||||
我最后在两个系统上安装了 CPod:ArchLabs 和 Windows。[Arch 用户仓库][8] 中有两个版本的 CPod。但是,它们都已过时,一个是版本 1.14.0,另一个是 1.22.6。最新版本的 CPod 是 1.27.0。由于 ArchLabs 和 Windows 之间的版本差异,我的体验有所不同。在本文中,我将重点关注 1.27.0,因为它是最新且功能最多的。
|
||||
|
||||
我马上能够找到我最喜欢的播客。我可以粘贴 RSS 源的 URL 来添加 iTunes 列表中没有的那些播客。
|
||||
|
||||
@ -55,7 +58,7 @@ CPod:一个开源、跨平台播客应用
|
||||
|
||||
### 安装 CPod
|
||||
|
||||
在 [GitHub][11]上,你可以下载适用于 Linux 的 AppImage 或 Deb 文件,适用于 Windows 的 .exe 文件或适用于 Mac OS 的 .dmg 文件。
|
||||
在 [GitHub][11] 上,你可以下载适用于 Linux 的 AppImage 或 Deb 文件,适用于 Windows 的 .exe 文件或适用于 Mac OS 的 .dmg 文件。
|
||||
|
||||
你可以使用 [Snap][12] 安装 CPod。你需要做的就是使用以下命令:
|
||||
|
||||
@ -63,14 +66,15 @@ CPod:一个开源、跨平台播客应用
|
||||
sudo snap install cpod
|
||||
```
|
||||
|
||||
就像我之前说的那样,CPod 的 [Arch 用户仓库][8]的版本已经过时了。我已经给其中一个打包者发了消息。如果你使用 Arch(或基于 Arch 的发行版),我建议你这样做。
|
||||
就像我之前说的那样,CPod 的 [Arch 用户仓库][8]的版本已经过时了。我已经给其中一个打包者发了消息。如果你使用 Arch(或基于 Arch 的发行版),我建议你这样做。
|
||||
|
||||
![cpod for Linux pidcasts][13]
|
||||
播放其中一个我最喜欢的播客
|
||||
|
||||
*播放其中一个我最喜欢的播客*
|
||||
|
||||
### 最后的想法
|
||||
|
||||
总的来说,我喜欢 CPod。它外观漂亮,使用简单。事实上,我更喜欢原来的名字 (Cumulonimbus),但是它有点拗口。
|
||||
总的来说,我喜欢 CPod。它外观漂亮,使用简单。事实上,我更喜欢原来的名字(Cumulonimbus),但是它有点拗口。
|
||||
|
||||
我刚刚在程序中遇到两个问题。首先,我希望每个播客都有评分。其次,在打开黑暗模式后,根据长度、日期、下载状态和播放进度对剧集进行排序的菜单不起作用。
|
||||
|
||||
@ -85,23 +89,23 @@ via: https://itsfoss.com/cpod-podcast-app/
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/linux-podcasts/
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/cpod1.1.jpg
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/10/cpod1.1.jpg?w=800&ssl=1
|
||||
[3]: https://github.com/z-------------/CPod
|
||||
[4]: https://github.com/z-------------
|
||||
[5]: https://electronjs.org/
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/cpod2.1.png
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/cpod4.1.jpg
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/10/cpod2.1.png?w=800&ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/10/cpod4.1.jpg?w=800&ssl=1
|
||||
[8]: https://aur.archlinux.org/packages/?O=0&K=cpod
|
||||
[9]: https://latenightlinux.com/
|
||||
[10]: https://itsfoss.com/what-is-zfs/
|
||||
[11]: https://github.com/z-------------/CPod/releases
|
||||
[12]: https://snapcraft.io/cumulonimbus
|
||||
[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/cpod3.1.jpg
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/10/cpod3.1.jpg?w=800&ssl=1
|
||||
[14]: http://reddit.com/r/linuxusersgroup
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
我们都会有文件存储在电脑里 —— 目录、相片、源代码等等。它们是如此之多。也无疑超出了我的记忆范围。要是毫无目标,找到正确的那一个可能会很费时间。在这篇文章里我们来看一下如何在命令行里找到需要的文件,特别是快速找到你想要的那一个。
|
||||
|
||||
好消息是 Linux 命令行专门设计了很多非常有用的命令行工具在你的电脑上查找文件。下面我们看一下它们其中三个:`ls`、`tree` 和 `tree`。
|
||||
好消息是 Linux 命令行专门设计了很多非常有用的命令行工具在你的电脑上查找文件。下面我们看一下它们其中三个:`ls`、`tree` 和 `find`。
|
||||
|
||||
### ls
|
||||
|
||||
|
||||
@ -0,0 +1,186 @@
|
||||
在 Linux 中如何查找一个命令或进程的执行时间
|
||||
======
|
||||
|
||||

|
||||
|
||||
在类 Unix 系统中,你可能知道一个命令或进程开始执行的时间,以及[一个进程运行了多久][1]。 但是,你如何知道这个命令或进程何时结束或者它完成运行所花费的总时长呢? 在类 Unix 系统中,这是非常容易的! 有一个专门为此设计的程序名叫 **GNU time**。 使用 `time` 程序,我们可以轻松地测量 Linux 操作系统中命令或程序的总执行时间。 `time` 命令在大多数 Linux 发行版中都有预装,所以你不必去安装它。
|
||||
|
||||
### 在 Linux 中查找一个命令或进程的执行时间
|
||||
|
||||
要测量一个命令或程序的执行时间,运行:
|
||||
|
||||
```
|
||||
$ /usr/bin/time -p ls
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ time ls
|
||||
```
|
||||
|
||||
输出样例:
|
||||
|
||||
```
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
|
||||
real 0m0.007s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
```
|
||||
|
||||
```
|
||||
$ time ls -a
|
||||
. .bash_logout dir1 file2 mcelog .sudo_as_admin_successful
|
||||
.. .bashrc dir2 .gnupg .profile .wget-hsts
|
||||
.bash_history .cache file1 .local .stack
|
||||
|
||||
real 0m0.008s
|
||||
user 0m0.001s
|
||||
sys 0m0.005s
|
||||
```
|
||||
|
||||
以上命令显示出了 `ls` 命令的总执行时间。 你可以将 `ls` 替换为任何命令或进程,以查找总的执行时间。
|
||||
|
||||
输出详解:
|
||||
|
||||
1. `real` —— 指的是命令或程序所花费的总时间
|
||||
2. `user` —— 指的是在用户模式下程序所花费的时间
|
||||
3. `sys` —— 指的是在内核模式下程序所花费的时间
|
||||
|
||||
|
||||
|
||||
我们也可以将命令限制为仅运行一段时间。参考如下教程了解更多细节:
|
||||
|
||||
- [在 Linux 中如何让一个命令运行特定的时长](https://www.ostechnix.com/run-command-specific-time-linux/)
|
||||
|
||||
### time 与 /usr/bin/time
|
||||
|
||||
你可能注意到了, 我们在上面的例子中使用了两个命令 `time` 和 `/usr/bin/time` 。 所以,你可能会想知道他们的不同。
|
||||
|
||||
首先, 让我们使用 `type` 命令看看 `time` 命令到底是什么。对于那些我们不了解的 Linux 命令,`type` 命令用于查找相关命令的信息。 更多详细信息,[请参阅本指南][2]。
|
||||
|
||||
```
|
||||
$ type -a time
|
||||
time is a shell keyword
|
||||
time is /usr/bin/time
|
||||
```
|
||||
|
||||
正如你在上面的输出中看到的一样,`time` 是两个东西:
|
||||
|
||||
* 一个是 BASH shell 中内建的关键字
|
||||
* 一个是可执行文件,如 `/usr/bin/time`
|
||||
|
||||
由于 shell 关键字的优先级高于可执行文件,当你没有给出完整路径只运行 `time` 命令时,你运行的是 shell 内建的命令。 但是,当你运行 `/usr/bin/time` 时,你运行的是真正的 **GNU time** 命令。 因此,为了执行真正的命令你可能需要给出完整路径。
|
||||
|
||||
在大多数 shell 中如 BASH、ZSH、CSH、KSH、TCSH 等,内建的关键字 `time` 是可用的。 `time` 关键字的选项少于该可执行文件,你可以使用的唯一选项是 `-p`。
|
||||
|
||||
你现在知道了如何使用 `time` 命令查找给定命令或进程的总执行时间。 想进一步了解 GNU time 工具吗? 继续阅读吧!
|
||||
|
||||
### 关于 GNU time 程序的简要介绍
|
||||
|
||||
GNU time 程序运行带有给定参数的命令或程序,并在命令完成后将系统资源使用情况汇总到标准输出。 与 `time` 关键字不同,GNU time 程序不仅显示命令或进程的执行时间,还显示内存、I/O 和 IPC 调用等其他资源。
|
||||
|
||||
`time` 命令的语法是:
|
||||
|
||||
```
|
||||
/usr/bin/time [options] command [arguments...]
|
||||
```
|
||||
|
||||
上述语法中的 `options` 是指一组可以与 `time` 命令一起使用去执行特定功能的选项。 下面给出了可用的选项:
|
||||
|
||||
* `-f, –format` —— 使用此选项可以根据需求指定输出格式。
|
||||
* `-p, –portability` —— 使用简要的输出格式。
|
||||
* `-o file, –output=FILE` —— 将输出写到指定文件中而不是到标准输出。
|
||||
* `-a, –append` —— 将输出追加到文件中而不是覆盖它。
|
||||
* `-v, –verbose` —— 此选项显示 `time` 命令输出的详细信息。
|
||||
* `–quiet` – 此选项可以防止 `time` 命令报告程序的状态.
|
||||
|
||||
当不带任何选项使用 GNU time 命令时,你将看到以下输出。
|
||||
|
||||
```
|
||||
$ /usr/bin/time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2024maxresident)k
|
||||
0inputs+0outputs (0major+73minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
如果你用 shell 关键字 `time` 运行相同的命令, 输出会有一点儿不同:
|
||||
|
||||
```
|
||||
$ time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
|
||||
real 0m0.006s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
```
|
||||
|
||||
有时,你可能希望将系统资源使用情况输出到文件中而不是终端上。 为此, 你可以使用 `-o` 选项,如下所示。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -o file.txt ls
|
||||
dir1 dir2 file1 file2 file.txt mcelog
|
||||
```
|
||||
|
||||
正如你看到的,`time` 命令不会显示到终端上。因为我们将输出写到了`file.txt` 的文件中。 让我们看一下这个文件的内容:
|
||||
|
||||
```
|
||||
$ cat file.txt
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2512maxresident)k
|
||||
0inputs+0outputs (0major+106minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
当你使用 `-o` 选项时, 如果你没有一个名为 `file.txt` 的文件,它会创建一个并把输出写进去。如果文件存在,它会覆盖文件原来的内容。
|
||||
|
||||
你可以使用 `-a` 选项将输出追加到文件后面,而不是覆盖它的内容。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -a file.txt ls
|
||||
```
|
||||
|
||||
`-f` 选项允许用户根据自己的喜好控制输出格式。 比如说,以下命令的输出仅显示用户,系统和总时间。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -f "\t%E real,\t%U user,\t%S sys" ls
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
0:00.00 real, 0.00 user, 0.00 sys
|
||||
```
|
||||
|
||||
请注意 shell 中内建的 `time` 命令并不具有 GNU time 程序的所有功能。
|
||||
|
||||
有关 GNU time 程序的详细说明可以使用 `man` 命令来查看。
|
||||
|
||||
```
|
||||
$ man time
|
||||
```
|
||||
|
||||
想要了解有关 Bash 内建 `time` 关键字的更多信息,请运行:
|
||||
|
||||
```
|
||||
$ help time
|
||||
```
|
||||
|
||||
就到这里吧。 希望对你有所帮助。
|
||||
|
||||
会有更多好东西分享哦。 请关注我们!
|
||||
|
||||
加油哦!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-the-execution-time-of-a-command-or-process-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[caixiangyue](https://github.com/caixiangyue)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/find-long-process-running-linux/
|
||||
[2]: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
@ -1,112 +0,0 @@
|
||||
translating by belitex
|
||||
translating by belitex
|
||||
translating by belitex
|
||||
translating by belitex
|
||||
Directing traffic: Demystifying internet-scale load balancing
|
||||
======
|
||||
Common techniques used to balance network traffic come with advantages and trade-offs.
|
||||

|
||||
Large, multi-site, internet-facing systems, including content-delivery networks (CDNs) and cloud providers, have several options for balancing traffic coming onto their networks. In this article, we'll describe common traffic-balancing designs, including techniques and trade-offs.
|
||||
|
||||
If you were an early cloud computing provider, you could take a single customer web server, assign it an IP address, configure a domain name system (DNS) record to associate it with a human-readable name, and advertise the IP address via the border gateway protocol (BGP), the standard way of exchanging routing information between networks.
|
||||
|
||||
It wasn't load balancing per se, but there probably was load distribution across redundant network paths and networking technologies to increase availability by routing around unavailable infrastructure (giving rise to phenomena like [asymmetric routing][1]).
|
||||
|
||||
### Doing simple DNS load balancing
|
||||
|
||||
As traffic to your customer's service grows, the business' owners want higher availability. You add a second web server with its own publicly accessible IP address and update the DNS record to direct users to both web servers (hopefully somewhat evenly). This is OK for a while until one web server unexpectedly goes offline. Assuming you detect the failure quickly, you can update the DNS configuration (either manually or with software) to stop referencing the broken server.
|
||||
|
||||
Unfortunately, because DNS records are cached, around 50% of requests to the service will likely fail until the record expires from the client caches and those of other nameservers in the DNS hierarchy. DNS records generally have a time to live (TTL) of several minutes or more, so this can create a significant impact on your system's availability.
|
||||
|
||||
Worse, some proportion of clients ignore TTL entirely, so some requests will be directed to your offline web server for some time. Setting very short DNS TTLs is not a great idea either; it means higher load on DNS services plus increased latency because clients will have to perform DNS lookups more often. If your DNS service is unavailable for any reason, access to your service will degrade more quickly with a shorter TTL because fewer clients will have your service's IP address cached.
|
||||
|
||||
### Adding network load balancing
|
||||
|
||||
To work around this problem, you can add a redundant pair of [Layer 4][2] (L4) network load balancers that serve the same virtual IP (VIP) address. They could be hardware appliances or software balancers like [HAProxy][3]. This means the DNS record points only at the VIP and no longer does load balancing.
|
||||
|
||||
![Layer 4 load balancers balance connections across webservers.][5]
|
||||
|
||||
Layer 4 load balancers balance connections from users across two webservers.
|
||||
|
||||
The L4 balancers load-balance traffic from the internet to the backend servers. This is generally done based on a hash (a mathematical function) of each IP packet's 5-tuple: the source and destination IP address and port plus the protocol (such as TCP or UDP). This is fast and efficient (and still maintains essential properties of TCP) and doesn't require the balancers to maintain state per connection. (For more information, [Google's paper on Maglev][6] discusses implementation of a software L4 balancer in significant detail.)
|
||||
|
||||
The L4 balancers can do health-checking and send traffic only to web servers that pass checks. Unlike in DNS balancing, there is minimal delay in redirecting traffic to another web server if one crashes, although existing connections will be reset.
|
||||
|
||||
L4 balancers can do weighted balancing, dealing with backends with varying capacity. L4 balancing gives significant power and flexibility to operators while being relatively inexpensive in terms of computing power.
|
||||
|
||||
### Going multi-site
|
||||
|
||||
The system continues to grow. Your customers want to stay up even if your data center goes down. You build a new data center with its own set of service backends and another cluster of L4 balancers, which serve the same VIP as before. The DNS setup doesn't change.
|
||||
|
||||
The edge routers in both sites advertise address space, including the service VIP. Requests sent to that VIP can reach either site, depending on how each network between the end user and the system is connected and how their routing policies are configured. This is known as anycast. Most of the time, this works fine. If one site isn't operating, you can stop advertising the VIP for the service via BGP, and traffic will quickly move to the alternative site.
|
||||
|
||||
![Serving from multiple sites using anycast][8]
|
||||
|
||||
Serving from multiple sites using anycast.
|
||||
|
||||
This setup has several problems. Its worst failing is that you can't control where traffic flows or limit how much traffic is sent to a given site. You also don't have an explicit way to route users to the nearest site (in terms of network latency), but the network protocols and configurations that determine the routes should, in most cases, route requests to the nearest site.
|
||||
|
||||
### Controlling inbound requests in a multi-site system
|
||||
|
||||
To maintain stability, you need to be able to control how much traffic is served to each site. You can get that control by assigning a different VIP to each site and use DNS to balance them using simple or weighted [round-robin][9].
|
||||
|
||||
![Serving from multiple sites using a primary VIP][11]
|
||||
|
||||
Serving from multiple sites using a primary VIP per site, backed up by secondary sites, with geo-aware DNS.
|
||||
|
||||
You now have two new problems.
|
||||
|
||||
First, using DNS balancing means you have cached records, which is not good if you need to redirect traffic quickly.
|
||||
|
||||
Second, whenever users do a fresh DNS lookup, a VIP connects them to the service at an arbitrary site, which may not be the closest site to them. If your service runs on widely separated sites, individual users will experience wide variations in your system's responsiveness, depending upon the network latency between them and the instance of your service they are using.
|
||||
|
||||
You can solve the first problem by having each site constantly advertise and serve the VIPs for all the other sites (and consequently the VIP for any faulty site). Networking tricks (such as advertising less-specific routes from the backups) can ensure that VIP's primary site is preferred, as long as it is available. This is done via BGP, so we should see traffic move within a minute or two of updating BGP.
|
||||
|
||||
There isn't an elegant solution to the problem of serving users from sites other than the nearest healthy site with capacity. Many large internet-facing services use DNS services that attempt to return different results to users in different locations, with some degree of success. This approach is always somewhat [complex and error-prone][12], given that internet-addressing schemes are not organized geographically, blocks of addresses can change locations (e.g., when a company reorganizes its network), and many end users can be served from a single caching nameserver.
|
||||
|
||||
### Adding Layer 7 load balancing
|
||||
|
||||
Over time, your customers begin to ask for more advanced features.
|
||||
|
||||
While L4 load balancers can efficiently distribute load among multiple web servers, they operate only on source and destination IP addresses, protocol, and ports. They don't know anything about the content of a request, so you can't implement many advanced features in an L4 balancer. Layer 7 (L7) load balancers are aware of the structure and contents of requests and can do far more.
|
||||
|
||||
Some things that can be implemented in L7 load balancers are caching, rate limiting, fault injection, and cost-aware load balancing (some requests require much more server time to process).
|
||||
|
||||
They can also balance based on a request's attributes (e.g., HTTP cookies), terminate SSL connections, and help defend against application layer denial-of-service (DoS) attacks. The downside of L7 balancers at scale is cost—they do more computation to process requests, and each active request consumes some system resources. Running L4 balancers in front of one or more pools of L7 balancers can help with scaling.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Load balancing is a difficult and complex problem. In addition to the strategies described in this article, there are different [load-balancing algorithms][13], high-availability techniques used to implement load balancers, client load-balancing techniques, and the recent rise of service meshes.
|
||||
|
||||
Core load-balancing patterns have evolved alongside the growth of cloud computing, and they will continue to improve as large web services work to improve the control and flexibility that load-balancing techniques offer./p>
|
||||
|
||||
Laura Nolan and Murali Suriar will present [Keeping the Balance: Load Balancing Demystified][14] at [LISA18][15], October 29-31 in Nashville, Tennessee, USA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/internet-scale-load-balancing
|
||||
|
||||
作者:[Laura Nolan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauranolan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.noction.com/blog/bgp-and-asymmetric-routing
|
||||
[2]: https://en.wikipedia.org/wiki/Transport_layer
|
||||
[3]: https://www.haproxy.com/blog/failover-and-worst-case-management-with-haproxy/
|
||||
[4]: /file/412596
|
||||
[5]: https://opensource.com/sites/default/files/uploads/loadbalancing1_l4-network-loadbalancing.png (Layer 4 load balancers balance connections across webservers.)
|
||||
[6]: https://ai.google/research/pubs/pub44824
|
||||
[7]: /file/412601
|
||||
[8]: https://opensource.com/sites/default/files/uploads/loadbalancing2_going-multisite.png (Serving from multiple sites using anycast)
|
||||
[9]: https://en.wikipedia.org/wiki/Round-robin_scheduling
|
||||
[10]: /file/412606
|
||||
[11]: https://opensource.com/sites/default/files/uploads/loadbalancing3_controlling-inbound-requests.png (Serving from multiple sites using a primary VIP)
|
||||
[12]: https://landing.google.com/sre/book/chapters/load-balancing-frontend.html
|
||||
[13]: https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
|
||||
[14]: https://www.usenix.org/conference/lisa18/presentation/suriar
|
||||
[15]: https://www.usenix.org/conference/lisa18
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Browse Stack Overflow From Terminal
|
||||
======
|
||||
|
||||
|
||||
@ -1,265 +0,0 @@
|
||||
Translating by jlztan
|
||||
|
||||
Turn your book into a website and an ePub using Pandoc
|
||||
======
|
||||
Write once, publish twice using Markdown and Pandoc.
|
||||
|
||||

|
||||
|
||||
Pandoc is a command-line tool for converting files from one markup language to another. In my [introduction to Pandoc][1], I explained how to convert text written in Markdown into a website, a slideshow, and a PDF.
|
||||
|
||||
In this follow-up article, I'll dive deeper into [Pandoc][2], showing how to produce a website and an ePub book from the same Markdown source file. I'll use my upcoming e-book, [GRASP Principles for the Object-Oriented Mind][3], which I created using this process, as an example.
|
||||
|
||||
First I will explain the file structure used for the book, then how to use Pandoc to generate a website and deploy it in GitHub. Finally, I demonstrate how to generate its companion ePub book.
|
||||
|
||||
You can find the code in my [Programming Fight Club][4] GitHub repository.
|
||||
|
||||
### Setting up the writing structure
|
||||
|
||||
I do all of my writing in Markdown syntax. You can also use HTML, but the more HTML you introduce the highest risk that problems arise when Pandoc converts Markdown to an ePub document. My books follow the one-chapter-per-file pattern. Declare chapters using the Markdown heading H1 ( **#** ). You can put more than one chapter in each file, but putting them in separate files makes it easier to find content and do updates later.
|
||||
|
||||
The meta-information follows a similar pattern: each output format has its own meta-information file. Meta-information files define information about your documents, such as text to add to your HTML or the license of your ePub. I store all of my Markdown documents in a folder named parts (this is important for the Makefile that generates the website and ePub). As an example, let's take the table of contents, the preface, and the about chapters (divided into the files toc.md, preface.md, and about.md) and, for clarity, we will leave out the remaining chapters.
|
||||
|
||||
My about file might begin like:
|
||||
|
||||
```
|
||||
# About this book {-}
|
||||
|
||||
## Who should read this book {-}
|
||||
|
||||
Before creating a complex software system one needs to create a solid foundation.
|
||||
General Responsibility Assignment Software Principles (GRASP) are guidelines to assign
|
||||
responsibilities to software classes in object-oriented programming.
|
||||
```
|
||||
|
||||
Once the chapters are finished, the next step is to add meta-information to setup the format for the website and the ePub.
|
||||
|
||||
### Generating the website
|
||||
|
||||
#### Create the HTML meta-information file
|
||||
|
||||
The meta-information file (web-metadata.yaml) for my website is a simple YAML file that contains information about the author, title, rights, content for the **< head>** tag, and content for the beginning and end of the HTML file.
|
||||
|
||||
I recommend (at minimum) including the following fields in the web-metadata.yaml file:
|
||||
|
||||
```
|
||||
---
|
||||
title: <a href="/grasp-principles/toc/">GRASP principles for the Object-oriented mind</a>
|
||||
author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
header-includes:
|
||||
- |
|
||||
\```{=html}
|
||||
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
|
||||
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
|
||||
\```
|
||||
include-before:
|
||||
- |
|
||||
\```{=html}
|
||||
<p>If you like this book, please consider
|
||||
spreading the word or
|
||||
<a href="https://www.buymeacoffee.com/programming">
|
||||
buying me a coffee
|
||||
</a>
|
||||
</p>
|
||||
\```
|
||||
include-after:
|
||||
- |
|
||||
```{=html}
|
||||
<div class="footnotes">
|
||||
<hr>
|
||||
<div class="container">
|
||||
<nav class="pagination" role="pagination">
|
||||
<ul>
|
||||
<p>
|
||||
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
|
||||
</p>
|
||||
<p>
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
</p>
|
||||
</ul>
|
||||
</nav>
|
||||
</div>
|
||||
</div>
|
||||
\```
|
||||
---
|
||||
```
|
||||
|
||||
Some variables to note:
|
||||
|
||||
* The **header-includes** variable contains HTML that will be embedded inside the **< head>** tag.
|
||||
* The line after calling a variable must be **\- |**. The next line must begin with triple backquotes that are aligned with the **|** or Pandoc will reject it. **{=html}** tells Pandoc that this is raw text and should not be processed as Markdown. (For this to work, you need to check that the **raw_attribute** extension in Pandoc is enabled. To check, type **pandoc --list-extensions | grep raw** and make sure the returned list contains an item named **+raw_html** ; the plus sign indicates it is enabled.)
|
||||
* The variable **include-before** adds some HTML at the beginning of your website, and I ask readers to consider spreading the word or buying me a coffee.
|
||||
* The **include-after** variable appends raw HTML at the end of the website and shows my book's license.
|
||||
|
||||
|
||||
|
||||
These are only some of the fields available; take a look at the template variables in HTML (my article [introduction to Pandoc][1] covered this for LaTeX but the process is the same for HTML) to learn about others.
|
||||
|
||||
#### Split the website into chapters
|
||||
|
||||
The website can be generated as a whole, resulting in a long page with all the content, or split into chapters, which I think is easier to read. I'll explain how to divide the website into chapters so the reader doesn't get intimidated by a long website.
|
||||
|
||||
To make the website easy to deploy on GitHub Pages, we need to create a root folder called docs (which is the root folder that GitHub Pages uses by default to render a website). Then we need to create folders for each chapter under docs, place the HTML chapters in their own folders, and the file content in a file named index.html.
|
||||
|
||||
For example, the about.md file is converted to a file named index.html that is placed in a folder named about (about/index.html). This way, when users type **http:// <your-website.com>/about/**, the index.html file from the folder about will be displayed in their browser.
|
||||
|
||||
The following Makefile does all of this:
|
||||
|
||||
```
|
||||
# Your book files
|
||||
DEPENDENCIES= toc preface about
|
||||
|
||||
# Placement of your HTML files
|
||||
DOCS=docs
|
||||
|
||||
all: web
|
||||
|
||||
web: setup $(DEPENDENCIES)
|
||||
@cp $(DOCS)/toc/index.html $(DOCS)
|
||||
|
||||
|
||||
# Creation and copy of stylesheet and images into
|
||||
# the assets folder. This is important to deploy the
|
||||
# website to Github Pages.
|
||||
setup:
|
||||
@mkdir -p $(DOCS)
|
||||
@cp -r assets $(DOCS)
|
||||
|
||||
|
||||
# Creation of folder and index.html file on a
|
||||
# per-chapter basis
|
||||
|
||||
$(DEPENDENCIES):
|
||||
@mkdir -p $(DOCS)/$@
|
||||
@pandoc -s --toc web-metadata.yaml parts/$@.md \
|
||||
-c /assets/pandoc.css -o $(DOCS)/$@/index.html
|
||||
|
||||
clean:
|
||||
@rm -rf $(DOCS)
|
||||
|
||||
.PHONY: all clean web setup
|
||||
```
|
||||
|
||||
The option **-c /assets/pandoc.css** declares which CSS stylesheet to use; it will be fetched from **/assets/pandoc.css**. In other words, inside the **< head>** HTML tag, Pandoc adds the following line:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" href="/assets/pandoc.css">
|
||||
```
|
||||
|
||||
To generate the website, type:
|
||||
|
||||
```
|
||||
make
|
||||
```
|
||||
|
||||
The root folder should contain now the following structure and files:
|
||||
|
||||
```
|
||||
.---parts
|
||||
| |--- toc.md
|
||||
| |--- preface.md
|
||||
| |--- about.md
|
||||
|
|
||||
|---docs
|
||||
|--- assets/
|
||||
|--- index.html
|
||||
|--- toc
|
||||
| |--- index.html
|
||||
|
|
||||
|--- preface
|
||||
| |--- index.html
|
||||
|
|
||||
|--- about
|
||||
|--- index.html
|
||||
|
||||
```
|
||||
|
||||
#### Deploy the website
|
||||
|
||||
To deploy the website on GitHub, follow these steps:
|
||||
|
||||
1. Create a new repository
|
||||
2. Push your content to the repository
|
||||
3. Go to the GitHub Pages section in the repository's Settings and select the option for GitHub to use the content from the Master branch
|
||||
|
||||
|
||||
|
||||
You can get more details on the [GitHub Pages][5] site.
|
||||
|
||||
Check out [my book's website][6], generated using this process, to see the result.
|
||||
|
||||
### Generating the ePub book
|
||||
|
||||
#### Create the ePub meta-information file
|
||||
|
||||
The ePub meta-information file, epub-meta.yaml, is similar to the HTML meta-information file. The main difference is that ePub offers other template variables, such as **publisher** and **cover-image**. Your ePub book's stylesheet will probably differ from your website's; mine uses one named epub.css.
|
||||
|
||||
```
|
||||
---
|
||||
title: 'GRASP principles for the Object-oriented Mind'
|
||||
publisher: 'Programming Language Fight Club'
|
||||
author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
cover-image: assets/cover.png
|
||||
stylesheet: assets/epub.css
|
||||
...
|
||||
```
|
||||
|
||||
Add the following content to the previous Makefile:
|
||||
|
||||
```
|
||||
epub:
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
$(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
The command for the ePub target takes all the dependencies from the HTML version (your chapter names), appends to them the Markdown extension, and prepends them with the path to the folder chapters' so Pandoc knows how to process them. For example, if **$(DEPENDENCIES)** was only **preface about** , then the Makefile would call:
|
||||
|
||||
```
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
parts/preface.md parts/about.md -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
Pandoc would take these two chapters, combine them, generate an ePub, and place the book under the Assets folder.
|
||||
|
||||
Here's an [example][7] of an ePub created using this process.
|
||||
|
||||
### Summarizing the process
|
||||
|
||||
The process to create a website and an ePub from a Markdown file isn't difficult, but there are a lot of details. The following outline may make it easier for you to follow.
|
||||
|
||||
* HTML book:
|
||||
* Write chapters in Markdown
|
||||
* Add metadata
|
||||
* Create a Makefile to glue pieces together
|
||||
* Set up GitHub Pages
|
||||
* Deploy
|
||||
* ePub book:
|
||||
* Reuse chapters from previous work
|
||||
* Add new metadata file
|
||||
* Create a Makefile to glue pieces together
|
||||
* Set up GitHub Pages
|
||||
* Deploy
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
|
||||
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kikofernandez
|
||||
[1]: https://opensource.com/article/18/9/intro-pandoc
|
||||
[2]: https://pandoc.org/
|
||||
[3]: https://www.programmingfightclub.com/
|
||||
[4]: https://github.com/kikofernandez/programmingfightclub
|
||||
[5]: https://pages.github.com/
|
||||
[6]: https://www.programmingfightclub.com/grasp-principles/
|
||||
[7]: https://github.com/kikofernandez/programmingfightclub/raw/master/docs/web_assets/demo.epub
|
||||
@ -0,0 +1,73 @@
|
||||
7 command-line tools for writers | Opensource.com
|
||||
======
|
||||
Put away your word processor and start writing from the command line using these open source tools.
|
||||

|
||||
|
||||
For most people (especially non-techies), the act of writing means tapping out words using LibreOffice Writer or another GUI word processing application. But there are many other options available to help anyone communicate their message in writing, especially for the growing number of writers [embracing plaintext][1].
|
||||
|
||||
There's also room in a GUI writer's world for command line tools that can help them write, check their writing, and more—regardless of whether they're banging out an article, blog post, or story; writing a README; or prepping technical documentation.
|
||||
|
||||
Here's a look at some command-line tools that any writer will find useful.
|
||||
|
||||
### Editors
|
||||
|
||||
Yes, you _can_ do actual writing at the command line. I know writers who do their work using editors like [Nano][2], [Vim][3], [Emacs][4], and [Jove][5] in a terminal window. And those editors [aren't the only games in town][6]. Text editors are great because they (at a basic level, anyway) are easy to use and distraction free. They're perfect for tapping out a first draft of anything or even completing a long and complicated writing project.
|
||||
|
||||
If you want a more word processor-like experience at the command line, take a look at [WordGrinder][7] . WordGrinder is a bare-bones word processor, but it has more than enough features for writing and publishing your work. It supports basic formatting and styles, and you can export your writing to formats like Markdown, ODT, LaTeX, and HTML.
|
||||
|
||||
### Spell checkers
|
||||
|
||||
Every writer does (or at least should do) a spelling check on their work at least once. Why? An immutable law of the writing universe states that, no matter how many times you look over your manuscript, a spelling mistake or typo will creep in.
|
||||
|
||||
My favorite command-line spelling checker is [GNU Aspell][8], which I previously [looked at][9] in detail. Aspell checks plaintext documents interactively and not only highlights errors but often puts the best correction at the top of its list of suggestions. Aspell also ignores many markup languages while doing its thing.
|
||||
|
||||
A much older but still useful alternative is [Ispell][10]. It's a bit slower than Aspell, but both utilities work the same way. As you interact with your text file, Ispell suggests corrections. Ispell also has good support for foreign languages.
|
||||
|
||||
### Prose linters
|
||||
|
||||
Software developers use [linters][11] to check their code for errors or bugs. There are also linters for prose that check for style and syntax errors; think of them as the _Elements of Style_ for the command line. While any writer can (and probably should) use one, a prose linter is especially useful for team documentation projects that require a consistent voice and style.
|
||||
|
||||
[Proselint][12] is a comprehensive tool for checking what you're writing. It looks for jargon, hyperbole, incorrect date and time format, misused terms, and [much more][13]. It's also easy to run and ignores markup in a plaintext file.
|
||||
|
||||
[Alex][14] is a simple yet powerful prose linter. Run it against a plaintext document or one formatted with Markdown or HTML. Alex pumps out warnings of "gender favouring, polarising, race related, religion inconsiderate, or other unequal phrasing in text." If you want to give Alex a test drive, there's an [online demo][15].
|
||||
|
||||
### Other tools
|
||||
|
||||
Sometimes you just can't find the right synonym for a word. But you don't need to grab a "dead tree" thesaurus or go to a dedicated website to perfect your word choice. Just run [Aiksaurus][16] against the word you want to replace, and it does the work for you. This utility's main drawback, though, is that it supports English only.
|
||||
|
||||
Even writers with few (if any) technical skills are embracing [Markdown][17] to quickly and easily format their work. Sometimes, though, you need to convert files formatted with Markdown to something else. That's where [Pandoc][18] comes in. You can use it to convert your documents to HTML, Word, LibreOffice Writer, LaTeX, EPUB, and other formats. You can even use Pandoc to produce books and [research papers][19].
|
||||
|
||||
Do you have a favorite command-line tool for writing? Share it with the Opensource.com community by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/command-line-tools-writers
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://plaintextproject.online
|
||||
[2]: https://www.nano-editor.org/
|
||||
[3]: https://www.vim.org
|
||||
[4]: https://www.gnu.org/software/emacs/
|
||||
[5]: https://opensource.com/article/17/1/jove-lightweight-alternative-vim
|
||||
[6]: https://en.wikipedia.org/wiki/List_of_text_editors#Text_user_interface
|
||||
[7]: https://cowlark.com/wordgrinder/
|
||||
[8]: http://aspell.net/
|
||||
[9]: https://opensource.com/article/18/2/how-check-spelling-linux-command-line-aspell
|
||||
[10]: https://www.cs.hmc.edu/~geoff/ispell.html
|
||||
[11]: https://en.wikipedia.org/wiki/Lint_(software)
|
||||
[12]: http://proselint.com/
|
||||
[13]: http://proselint.com/checks/
|
||||
[14]: https://github.com/get-alex/alex
|
||||
[15]: https://alexjs.com/#demo
|
||||
[16]: http://aiksaurus.sourceforge.net/
|
||||
[17]: https://en.wikipedia.org/wiki/Markdown
|
||||
[18]: https://pandoc.org
|
||||
[19]: https://opensource.com/article/18/9/pandoc-research-paper
|
||||
@ -0,0 +1,84 @@
|
||||
How To Change GDM Login Screen Background In Ubuntu
|
||||
======
|
||||
Whenever you log in or lock and unlock your Ubuntu 18.04 LTS desktop, you will be greeted with a plain purple-colored screen. It is the default GDM (GNOME Display Manager) background since Ubuntu version 17.04. Some of you may feel boring to look at this plain background and want to make the Login screen something cool and eye-candy! If so, you’re on the right track. This brief guide describes how to change GDM Login screen background in Ubuntu 18.04 LTS desktop.
|
||||
|
||||
### Change GDM Login Screen Background In Ubuntu
|
||||
|
||||
Here is how the default GDM login screen background image looks like in Ubuntu 18.04 LTS desktop.
|
||||
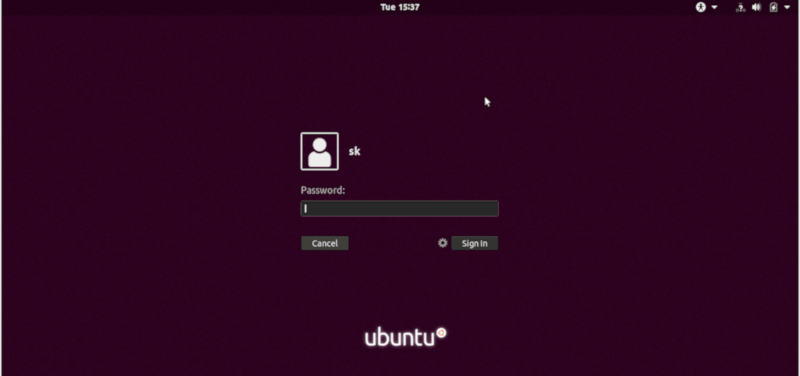
|
||||
|
||||
Whether you like it or not, you will stumbled upon this screen every time you log in or lock and unlock the system. No worries! You can change this background with any beautiful image of your choice.
|
||||
|
||||
Changing desktop wallpaper and user’s profile picture is not a big deal in Ubuntu. We can do it with a few mouse clicks in no time. However, changing Login/Lock screen background need a little bit editing of a file called **ubuntu.css** located under **/usr/share/gnome-shell/theme** directory.
|
||||
|
||||
Before modifying this file, take a backup of this file. So, we can restore it if something went wrong.
|
||||
|
||||
```
|
||||
$ sudo cp /usr/share/gnome-shell/theme/ubuntu.css /usr/share/gnome-shell/theme/ubuntu.css.bak
|
||||
```
|
||||
|
||||
Now, edit ubuntu.css file:
|
||||
|
||||
```
|
||||
$ sudo nano /usr/share/gnome-shell/theme/ubuntu.css
|
||||
```
|
||||
|
||||
Find the following lines under the directive named **“lockDialogGroup”** in the file:
|
||||
|
||||
```
|
||||
#lockDialogGroup {
|
||||
background: #2c001e url(resource:///org/gnome/shell/theme/noise-texture.png);
|
||||
background-repeat: repeat;
|
||||
}
|
||||
```
|
||||

|
||||
|
||||
As you can see, the default image for the GDM login screen is **noise-texture.png**.
|
||||
|
||||
Now, change the background image by adding your image path. You can use either .jpg or .png file. Both format images worked fine for me. After editing the file, the contents of file will look like below:
|
||||
|
||||
```
|
||||
#lockDialogGroup {
|
||||
background: #2c001e url(file:///home/sk/image.png);
|
||||
background-repeat: no-repeat;
|
||||
background-size: cover;
|
||||
background-position: center;
|
||||
}
|
||||
```
|
||||
|
||||
Please pay little attention to the modified version of this directive in the ubuntu.css file. I have marked the changes in bold.
|
||||
|
||||
As you might have noticed, I have changed the line “… **url(resource:///org/gnome/shell/theme/noise-texture.png);** ” with “ **…url(file:///home/sk/image.png);”**. I.e You should change “… **url(resource** …” to “… **url(file**..”.
|
||||
|
||||
Also, I have changed the value of “background-repeat:” parameter from **“repeat”** to **“no-repeat”** and added two more lines. You can simply copy/paste the above lines and change image path with your own in your ubuntu.css file.
|
||||
|
||||
Once you are done, save and close the file. And, reboot your system.
|
||||
|
||||
Here is my GDM login screen with updated backgrounds:
|
||||
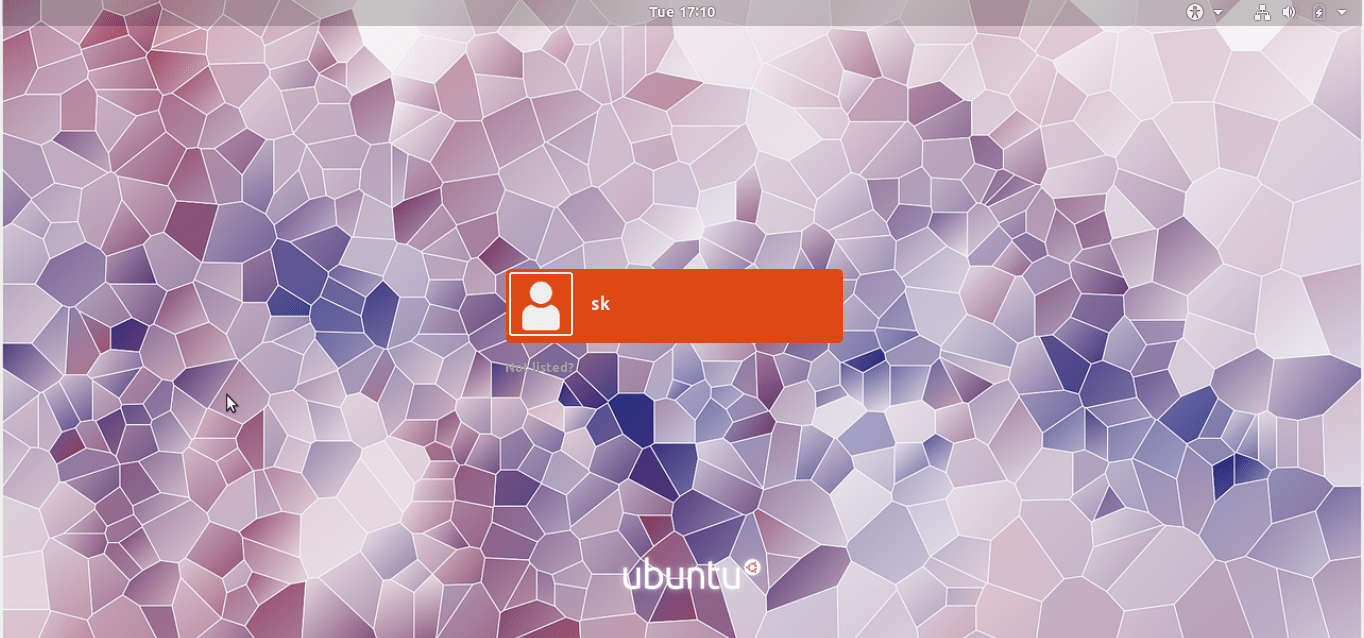
|
||||
|
||||

|
||||
|
||||
Cool, yeah? As you can see, changing GDM login screen is not that difficult either. All you have to do is to change the path of the image in ubuntu.css file and restart your system. It is simple as that. Have fun!
|
||||
|
||||
You can also edit **gdm3.css** file located under **/usr/share/gnome-shell/theme** directory and modify it as shown above to get the same result. Again, don’t forget to take the backup of the file before making any changes.
|
||||
|
||||
And, that’s all now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-change-gdm-login-screen-background-in-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,109 @@
|
||||
流量引导:网络世界的负载均衡解密
|
||||
======
|
||||
|
||||
均衡网络流量的常用技术,它们的优势和利弊权衡。
|
||||
|
||||

|
||||
|
||||
大型的多站点互联网系统,包括内容分发网络(CDN)和云服务提供商,用一些方法来均衡来访的流量。这篇文章我们讲一下常见的流量均衡设计,包括它们的技术手段和利弊权衡。
|
||||
|
||||
如果你很早就用云计算技术来提供服务的话,你可能在单台云服务器上搭建 web 服务,分配一个 IP 地址,然后配置一个给人读的域名(DNS)指向这个 IP 地址,再将 IP 地址通过边界网关协议(BGP)宣告出去,BGP 是在不同网络之间交换路由信息的标准方式。
|
||||
|
||||
这本身并不是负载均衡,但是在冗余的多条网络路径中,很可能是有流量分发的,而且利用网络技术让流量绕过不可用的网络,从而提高了可用性(也引起了[非对称路由][1]的现象)。
|
||||
|
||||
### 简单的 DNS 负载均衡
|
||||
|
||||
随着来自客户的流量变大,老板希望服务是高可用的。你上线第二台 web 服务器,它有自己独立的公网 IP 地址,然后你更新了 DNS 记录,把用户流量引到两台服务器上(内心希望它们均衡地提供服务)。在其中一台服务器出故障之前,这样做一直是没有问题的。假设你能很快地监测到故障,可以更新一下 DNS 配置(手动更新或者通过软件)删除解析到故障机器的记录。
|
||||
|
||||
不幸的是,因为 DNS 记录会被缓存,在客户端缓存和它们依赖的 DNS 服务器上的缓存失效之前,大约一半的请求会失败。DNS 记录都有一个几分钟或更长的生命周期(TTL),所以这种方式会对系统可用性造成严重的影响。
|
||||
|
||||
更糟糕的是,部分客户端会完全忽略 TTL,所以有一些请求会持续被引导到你的故障机器上。设置很短的 TTL 也不是个好办法,因为这意味着更高的 DNS 服务负载,还有更长的访问时延,因为客户端要做更多的 DNS 查询。如果 DNS 服务由于某种原因不可用了,那设置更短的 TTL 会让服务的访问量更快地下降,因为没那么多客户端有你网站 IP 地址的缓存了。
|
||||
|
||||
### 增加网络负载均衡
|
||||
|
||||
要解决上述问题,可以增加一对相互冗余的[四层][2](L4)网络负载均衡器,配置一样的虚拟 IP 地址(VIP)。均衡器可以是硬件的,也可以是像 [HAProxy][3] 这样的软件。域名的 DNS 记录指向 VIP,不再承担负载均衡的功能。
|
||||
|
||||
![Layer 4 load balancers balance connections across webservers.][5]
|
||||
|
||||
四层负载均衡器能够均衡用户和两台 web 服务器的连接
|
||||
|
||||
四层均衡器将网络流量均衡地引导至后端服务器。通常这是基于对 IP 数据包的五元组做散列(数学函数)来完成的,五元组包括:源地址,源端口,目的地址,目的端口,协议(比如 TCP 或 UDP)。这种方法是快速和高效的(还维持了 TCP 的基本属性),而且不需要均衡器维持每个连接的状态。(更多信息请阅读[谷歌发表的 Maglev 论文][6],这篇论文详细讨论了四层软件负载均衡器的实现细节。)
|
||||
|
||||
四层均衡器可以对后端服务做健康检查,只把流量分发到健康的机器上。和使用 DNS 做负载均衡不同的是,在某个后端 web 服务故障的时候,它可以很快地把流量重新分发到其他机器上,虽然故障机器的已有连接会被重置。
|
||||
|
||||
当后端服务器的能力不同时,四层均衡器可以根据权重做流量分发。它为运维人员提供了强大的能力和灵活性,而且硬件成本相对较小。
|
||||
|
||||
### 扩展到多站点
|
||||
|
||||
系统规模在持续增长。你的客户希望能一直使用服务,即使数据中心发生故障的时候。所以你建设了一个新的数据中心,独立部署了一套服务和四层负载均衡器集群,仍然使用同样的 VIP。DNS 的设置不变。
|
||||
|
||||
两个站点的边缘路由器都把自己的地址空间宣告出去,包括 VIP 地址。发往该 VIP 的请求可能到达任何一个站点,取决于用户和系统之间的网络是如何连接的,以及各个网络的路由策略是如何配置的。这就是泛播。大部分时候这种机制可以很好的工作。如果一个站点出问题了,你可以停止通过 BGP 宣告 VIP 地址,客户的请求就会迅速地转移到另外一个站点去。
|
||||
|
||||
![Serving from multiple sites using anycast][8]
|
||||
|
||||
多个站点使用泛播提供服务
|
||||
|
||||
这种设置有一些问题。最大的问题是,不能控制请求流向哪个站点,或者限制某个站点的流量。也没有一个明确的方式把用户的请求转到距离他最近的站点(为了降低网络延迟),不过,网络协议和路由选路配置在大部分情况下应该能把用户请求路由到最近的站点。
|
||||
|
||||
### 控制多站点系统中的入方向请求
|
||||
|
||||
为了维持稳定性,需要能够控制每个站点的流量大小。要实现这种控制,可以给每个站点分配不同的 VIP 地址,然后用简单的或者有权重的 DNS [轮询][9]来做负载均衡。
|
||||
|
||||
![Serving from multiple sites using a primary VIP][11]
|
||||
|
||||
多站点提供服务,每个站点使用一个主 VIP,另外一个站点作为备份。基于能感知地理位置的 DNS。
|
||||
|
||||
现在有两个问题。
|
||||
|
||||
第一,使用 DNS 均衡意味着会有被缓存的记录,如果你要快速重定向流量的话就麻烦了。
|
||||
|
||||
第二,用户每次做新的 DNS 查询,都可能连上任意一个站点,可能不是距离最近的。如果你的服务运行在分布广泛的很多站点上,用户会感受到响应时间有明显的变化,取决于用户和提供服务的站点之间有多大的网络延迟。
|
||||
|
||||
让每个站点都配置上其他所有站点的 VIP 地址,并宣告出去(因此也会包含故障的站点),这样可以解决第一个问题。有一些网络上的小技巧,比如备份站点宣告路由时,不像主站点使用那么具体的目的地址,这样可以保证每个 VIP 的主站点只要可用就会优先提供服务。这是通过 BGP 来实现的,所以我们应该可以看到,流量在 BGP 更新后的一两分钟内就开始转移了。
|
||||
|
||||
即使离用户最近的站点是健康而且有服务能力的,但是用户真正访问到的却不一定是这个站点,这个问题还没有很好的解决方案。很多大型的互联网服务利用 DNS 给不同地域的用户返回不同的解析结果,也能有一定的效果。不过,因为网络地址的结构和地理位置无关,一个地址段也可能会改变所在位置(例如,当一个公司重新规划网络时),而且很多用户可能使用了同一个 DNS 缓存服务器。所以这种方案有一定的复杂度,而且容易出错。
|
||||
|
||||
### 增加七层负载均衡
|
||||
|
||||
又过了一段时间,你的客户开始要更多的高级功能。
|
||||
|
||||
虽然四层负载均衡可以高效地在多个 web 服务器之间分发流量,但是它们只针对源地址、目标地址、协议和端口来操作,请求的内容是什么就不得而知了,所以很多高级功能在四层负载均衡上实现不了。而七层(L7)负载均衡知道请求的内容和结构,所以能做更多的事情。
|
||||
|
||||
七层负载均衡可以实现缓存,限速,错误注入,做负载均衡时可以感知到请求的代价(有些请求需要服务器花更多的时间去处理)。
|
||||
|
||||
七层负载均衡还可以基于请求的属性(比如 HTTP cookies)来分发流量,可以终结 SSL 连接,还可以帮助防御应用层的拒绝服务(DoS)攻击。规模大的 L7 负载均衡的缺点是成本——处理请求需要更多的计算,而且每个活跃的请求都占用一些系统资源。在一个或者多个 L7 均衡器前面运行 L4 均衡器集群,对扩展规模有帮助。
|
||||
|
||||
### 结论
|
||||
|
||||
负载均衡是一个复杂的难题。除了上面说过的策略,还有不同的[负载均衡算法][13],用来实现负载均衡器的高可用技术,客户端负载均衡技术,以及最近兴起的服务网络等等。
|
||||
|
||||
核心的负载均衡模式随着云计算的发展而不断发展,而且,随着大型 web 服务商致力于让负载均衡技术更可控和更灵活,这项技术会持续发展下去。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/internet-scale-load-balancing
|
||||
|
||||
作者:[Laura Nolan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[BeliteX](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauranolan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.noction.com/blog/bgp-and-asymmetric-routing
|
||||
[2]: https://en.wikipedia.org/wiki/Transport_layer
|
||||
[3]: https://www.haproxy.com/blog/failover-and-worst-case-management-with-haproxy/
|
||||
[4]: /file/412596
|
||||
[5]: https://opensource.com/sites/default/files/uploads/loadbalancing1_l4-network-loadbalancing.png "Layer 4 load balancers balance connections across webservers."
|
||||
[6]: https://ai.google/research/pubs/pub44824
|
||||
[7]: /file/412601
|
||||
[8]: https://opensource.com/sites/default/files/uploads/loadbalancing2_going-multisite.png "Serving from multiple sites using anycast"
|
||||
[9]: https://en.wikipedia.org/wiki/Round-robin_scheduling
|
||||
[10]: /file/412606
|
||||
[11]: https://opensource.com/sites/default/files/uploads/loadbalancing3_controlling-inbound-requests.png "Serving from multiple sites using a primary VIP"
|
||||
[12]: https://landing.google.com/sre/book/chapters/load-balancing-frontend.html
|
||||
[13]: https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
|
||||
[14]: https://www.usenix.org/conference/lisa18/presentation/suriar
|
||||
[15]: https://www.usenix.org/conference/lisa18
|
||||
@ -0,0 +1,259 @@
|
||||
使用 Pandoc 将你的书转换成网页和电子书
|
||||
======
|
||||
|
||||
通过 Markdown 和 Pandoc,可以做到编写一次,发布两次。
|
||||
|
||||

|
||||
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。在我的 [Pandoc 简介][1] 一文中,我演示了如何把 Markdown 编写的文本转换为网页、幻灯片和 PDF。
|
||||
|
||||
在这篇后续文章中,我将深入探讨 [Pandoc][2],展示如何从同一 Markdown 源文件生成网页和 ePub 格式的电子书。我将使用我即将发布的电子书-- [面向对象思想的 GRASP 原则][3] 为例进行讲解,这本电子书正是通过以下过程创建的。
|
||||
|
||||
首先,我将解释这本书使用的文件结构,然后介绍如何使用 Pandoc 生成网页并将其部署在 GitHub 上;最后,我演示了如何生成对应的 ePub 格式电子书。
|
||||
|
||||
你可以在我的 GitHub 仓库 [Programming Fight Club][4] 中找到相应代码。
|
||||
|
||||
### 设置图书结构
|
||||
|
||||
我用 Markdown 语法完成了所有的写作,你也可以使用 HTML,但是当 Pandoc 将 Markdown 转换为 ePub 文档时,引入的 HTML 越多,出现问题的风险就越高。我的书按照每章一个文件的形式进行组织,用 Markdown 的 `H1` 标记(`#`)声明每章的标题。你也可以在每个文件中放置多个章节,但将它们放在单独的文件中可以更轻松地查找内容并在以后进行更新。
|
||||
|
||||
元信息遵循类似的模式,每种输出格式都有自己的元信息文件。元信息文件定义有关文档的信息,例如要添加到 HTML 中的文本或 ePub 的许可证。我将所有 Markdown 文档存储在名为 `parts` 的文件夹中(这对于用来生成网页和 ePub 的 Makefile 非常重要)。下面以一个例子进行说明,让我们看一下目录,前言和关于本书(分为 `toc.md`、`preface.md` 和 `about.md` 三个文件)这三部分,为清楚起见,我们将省略其余的章节。
|
||||
|
||||
关于本书这部分内容的开头部分类似:
|
||||
|
||||
```
|
||||
# About this book {-}
|
||||
|
||||
## Who should read this book {-}
|
||||
|
||||
Before creating a complex software system one needs to create a solid foundation.
|
||||
General Responsibility Assignment Software Principles (GRASP) are guidelines to assign
|
||||
responsibilities to software classes in object-oriented programming.
|
||||
```
|
||||
|
||||
每一章完成后,下一步就是添加元信息来设置网页和 ePub 的格式。
|
||||
|
||||
### 生成网页
|
||||
|
||||
#### 创建 HTML 元信息文件
|
||||
|
||||
我创建的网页的元信息文件(`web-metadata.yaml`)是一个简单的 YAML 文件,其中包含 `<head> ` 标签中的作者、标题、和版权等信息,以及 HTML 文件中开头和结尾的内容。
|
||||
|
||||
我建议(至少)包括 `web-metadata.yaml` 文件中的以下字段:
|
||||
|
||||
```
|
||||
---
|
||||
title: <a href="/grasp-principles/toc/">GRASP principles for the Object-oriented mind</a>
|
||||
author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
header-includes:
|
||||
- |
|
||||
\```{=html}
|
||||
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
|
||||
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
|
||||
\```
|
||||
include-before:
|
||||
- |
|
||||
\```{=html}
|
||||
<p>If you like this book, please consider
|
||||
spreading the word or
|
||||
<a href="https://www.buymeacoffee.com/programming">
|
||||
buying me a coffee
|
||||
</a>
|
||||
</p>
|
||||
\```
|
||||
include-after:
|
||||
- |
|
||||
```{=html}
|
||||
<div class="footnotes">
|
||||
<hr>
|
||||
<div class="container">
|
||||
<nav class="pagination" role="pagination">
|
||||
<ul>
|
||||
<p>
|
||||
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
|
||||
</p>
|
||||
<p>
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
</p>
|
||||
</ul>
|
||||
</nav>
|
||||
</div>
|
||||
</div>
|
||||
\```
|
||||
---:
|
||||
```
|
||||
|
||||
下面几个变量需要注意一下:
|
||||
|
||||
- `header-includes` 变量包含将要嵌入 `<head>` 标签的 HTML 文本。
|
||||
- 调用变量后的下一行必须是 `- |`。再往下一行必须以与`|`对齐的三个反引号开始,否则 Pandoc 将无法识别。`{= html}` 告诉 Pandoc 其中的内容是原始文本,不应该作为 Markdown 处理。(为此,需要检查 Pandoc 中的 `raw_attribute` 扩展是否已启用。要进行此检查,键入 `pandoc --list-extensions | grep raw` 并确保返回的列表包含名为 `+ raw_html` 的项目,加号表示已启用。)
|
||||
- 变量 `include-before` 在网页开头添加一些 HTML 文本,此处我要求读者帮忙宣传我的书或给我打赏。
|
||||
- `include-after` 变量在网页末尾添加原始 HTML 文本,同时显示我的图书许可证。
|
||||
|
||||
这些只是其中一部分可用的变量,查看 HTML 中的模板变量(我的文章 [Pandoc简介][1] 中介绍了如何查看 LaTeX 的模版变量,查看 HTML 模版变量的过程是相同的)对其余变量进行了解。
|
||||
|
||||
#### 将网页分成多章
|
||||
|
||||
网页可以作为一个整体生成,这会产生一个包含所有内容的长页面;也可以分成多章,我认为这样会更容易阅读。 我将解释如何将网页划分为多章,以便读者不会被长网页吓到。
|
||||
|
||||
为了使网页易于在 GitHub Pages 上部署,需要创建一个名为 `docs` 的根文件夹(这是 GitHub Pages 默认用于渲染网页的根文件夹)。然后我们需要为 `docs` 下的每一章创建文件夹,将 HTML 内容放在各自的文件夹中,将文件内容放在名为 `index.html` 的文件中。
|
||||
|
||||
例如,`about.md` 文件将转换成名为 `index.html` 的文件,该文件位于名为 `about`(`about/index.html`)的文件夹中。这样,当用户键入 `http://<your-website.com>/about/` 时,文件夹中的 `index.html` 文件将显示在其浏览器中。
|
||||
|
||||
下面的 Makefile 将执行上述所有操作:
|
||||
|
||||
```
|
||||
# Your book files
|
||||
DEPENDENCIES= toc preface about
|
||||
|
||||
# Placement of your HTML files
|
||||
DOCS=docs
|
||||
|
||||
all: web
|
||||
|
||||
web: setup $(DEPENDENCIES)
|
||||
@cp $(DOCS)/toc/index.html $(DOCS)
|
||||
|
||||
|
||||
# Creation and copy of stylesheet and images into
|
||||
# the assets folder. This is important to deploy the
|
||||
# website to Github Pages.
|
||||
setup:
|
||||
@mkdir -p $(DOCS)
|
||||
@cp -r assets $(DOCS)
|
||||
|
||||
|
||||
# Creation of folder and index.html file on a
|
||||
# per-chapter basis
|
||||
|
||||
$(DEPENDENCIES):
|
||||
@mkdir -p $(DOCS)/$@
|
||||
@pandoc -s --toc web-metadata.yaml parts/$@.md \
|
||||
-c /assets/pandoc.css -o $(DOCS)/$@/index.html
|
||||
|
||||
clean:
|
||||
@rm -rf $(DOCS)
|
||||
|
||||
.PHONY: all clean web setup
|
||||
```
|
||||
|
||||
选项 `- c /assets/pandoc.css` 声明要使用的 CSS 样式表,它将从 `/assets/pandoc.cs` 中获取。也就是说,在 `<head>` 标签内,Pandoc 会添加这样一行:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" href="/assets/pandoc.css">
|
||||
```
|
||||
|
||||
使用下面的命令生成网页:
|
||||
|
||||
```
|
||||
make
|
||||
```
|
||||
根文件夹现在应该包含如下所示的文件结构:
|
||||
|
||||
```
|
||||
.---parts
|
||||
| |--- toc.md
|
||||
| |--- preface.md
|
||||
| |--- about.md
|
||||
|
|
||||
|---docs
|
||||
|--- assets/
|
||||
|--- index.html
|
||||
|--- toc
|
||||
| |--- index.html
|
||||
|
|
||||
|--- preface
|
||||
| |--- index.html
|
||||
|
|
||||
|--- about
|
||||
|--- index.html
|
||||
|
||||
```
|
||||
|
||||
#### 部署网页
|
||||
|
||||
通过以下步骤将网页部署到 GitHub 上:
|
||||
|
||||
1. 创建一个新的 GitHub 仓库
|
||||
2. 将内容推送到新创建的仓库
|
||||
3. 找到仓库设置中的 GitHub Pages 部分,选择 `Source` 选项让 GitHub 使用主分支的内容
|
||||
|
||||
你可以在 [GitHub Pages][5] 的网站上获得更多详细信息。
|
||||
|
||||
[我的书的网页][6] 便是通过上述过程生成的,可以在网页上查看结果。
|
||||
|
||||
### 生成电子书
|
||||
|
||||
#### 创建 ePub 格式的元信息文件
|
||||
|
||||
ePub 格式的元信息文件 `epub-meta.yaml` 和 HTML 元信息文件是类似的。主要区别在于 ePub 提供了其他模板变量,例如 `publisher` 和 `cover-image` 。ePub 格式图书的样式表可能与网页所用的不同,在这里我使用一个名为 `epub.css` 的样式表。
|
||||
|
||||
```
|
||||
---
|
||||
title: 'GRASP principles for the Object-oriented Mind'
|
||||
publisher: 'Programming Language Fight Club'
|
||||
author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
cover-image: assets/cover.png
|
||||
stylesheet: assets/epub.css
|
||||
...
|
||||
```
|
||||
|
||||
将以下内容添加到之前的 Makefile 中:
|
||||
|
||||
```
|
||||
epub:
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
$(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
用于产生 ePub 格式图书的命令从 HTML 版本获取所有依赖项(每章的名称),向它们添加 Markdown 扩展,并在它们前面加上每一章的文件夹路径,以便让 Pandoc 知道如何进行处理。例如,如果 `$(DEPENDENCIES` 变量只包含 “前言” 和 “关于本书” 两章,那么 Makefile 将会这样调用:
|
||||
|
||||
```
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
parts/preface.md parts/about.md -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
Pandoc 将提取这两章的内容,然后进行组合,最后生成 ePub 格式的电子书,并放在 `Assets` 文件夹中。
|
||||
|
||||
这是使用此过程创建 ePub 格式电子书的一个 [示例][7]。
|
||||
|
||||
### 过程总结
|
||||
|
||||
从 Markdown 文件创建网页和 ePub 格式电子书的过程并不困难,但有很多细节需要注意。遵循以下大纲可能使你更容易使用 Pandoc。
|
||||
|
||||
- HTML 图书:
|
||||
- 使用 Markdown 语法创建每章内容
|
||||
- 添加元信息
|
||||
- 创建一个 Makefile 将各个部分组合在一起
|
||||
- 设置 GitHub Pages
|
||||
- 部署
|
||||
- ePub 电子书:
|
||||
- 使用之前创建的每一章内容
|
||||
- 添加新的元信息文件
|
||||
- 创建一个 Makefile 以将各个部分组合在一起
|
||||
- 设置 GitHub Pages
|
||||
- 部署
|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
|
||||
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kikofernandez
|
||||
[1]: https://opensource.com/article/18/9/intro-pandoc
|
||||
[2]: https://pandoc.org/
|
||||
[3]: https://www.programmingfightclub.com/
|
||||
[4]: https://github.com/kikofernandez/programmingfightclub
|
||||
[5]: https://pages.github.com/
|
||||
[6]: https://www.programmingfightclub.com/grasp-principles/
|
||||
[7]: https://github.com/kikofernandez/programmingfightclub/raw/master/docs/web_assets/demo.epub
|
||||
@ -1,185 +0,0 @@
|
||||
在linux中如何查找一个命令或进程的执行时间
|
||||
======
|
||||

|
||||
|
||||
你可能知道一个命令或进程开始执行的时间和在类Unix系统中[**一个命令运行了多久**][1]。 但是,你如何知道这个命令或进程何时结束或者它完成运行所花费的总时间呢? 在类Unix系统中,这是非常容易的! 有一个程序专门为此设计名叫 **‘GNU time’**。 使用time程序, 我们可以轻松地测量Linux操作系统中命令或程序的总执行时间。 ‘time’命令在大多数Linux发行版中都有预装, 所以你不必去安装它。
|
||||
|
||||
### 在Linux中查找一个命令或进程的执行时间
|
||||
|
||||
要测量一个命令或程序的执行时间,运行。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -p ls
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ time ls
|
||||
```
|
||||
|
||||
输出样例:
|
||||
|
||||
```
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
|
||||
real 0m0.007s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
|
||||
$ time ls -a
|
||||
. .bash_logout dir1 file2 mcelog .sudo_as_admin_successful
|
||||
.. .bashrc dir2 .gnupg .profile .wget-hsts
|
||||
.bash_history .cache file1 .local .stack
|
||||
|
||||
real 0m0.008s
|
||||
user 0m0.001s
|
||||
sys 0m0.005s
|
||||
```
|
||||
|
||||
以上命令显示出了 **‘ls’** 命令的总执行时间。 你可以将 “ls” 替换为任何命令或进程,以查找总的执行时间。
|
||||
|
||||
输出详解:
|
||||
|
||||
1. **real** -指的是命令或程序所花费的总时间
|
||||
2. **user** – 指的是在用户模式下程序所花费的时间,
|
||||
3. **sys** – 指的是在内核模式下程序所花费的时间。
|
||||
|
||||
|
||||
|
||||
我们也可以将命令限制为仅运行一段时间。
|
||||
|
||||
### time vs /usr/bin/time
|
||||
|
||||
你可能注意到了, 我们在上面的例子中使用了两个命令 **‘time’** and **‘/usr/bin/time’** 。 所以,你可能会想知道他们的不同。
|
||||
|
||||
首先, 让我们使用 ‘type’ 命令看看 ‘time’ 命令到底是什么。对于那些我们不知道的Linux命令, **Type** 命令用于查找相关命令的信息。 更多详细信息, [**请参阅本指南**][2]。
|
||||
|
||||
```
|
||||
$ type -a time
|
||||
time is a shell keyword
|
||||
time is /usr/bin/time
|
||||
```
|
||||
|
||||
正如你在上面的输出中看到的一样, 这两个都是time,
|
||||
|
||||
* 一个是BASH shell中内建的关键字
|
||||
* 一个是可执行文件 如 **/usr/bin/time**
|
||||
|
||||
|
||||
|
||||
由于shell关键字的优先级高于可执行文件, 当你没有给出完整路径只运行`time`命令时, 你运行的是shell内建的命令。 但是,当你运行 `/usr/bin/time`时, 你运行的是真正的 **GNU time** 命令。 因此,为了执行真正的命令你可能需要给出完整路径。
|
||||
|
||||
在大多数shell中如 BASH, ZSH, CSH, KSH, TCSH 等,内建的关键字‘time’是可用的。 ‘time’ 关键字的选项少于可执行文件. 你可以使用的唯一选项是 **-p**。
|
||||
|
||||
你现在知道如何使用 ‘time’ 命令查找给定命令或进程的总执行时间。 想进一步了解 ‘GNU time’ 工具吗? 继续阅读吧!
|
||||
|
||||
### 关于 ‘GNU time’ 程序的简要介绍
|
||||
|
||||
Gnu time程序运行带有给定参数的命令或程序,并在命令完成后将系统资源使用情况汇总到标准输出。 与 ‘time’ 关键字不同, Gnu time程序不仅显示命令或进程的执行时间,还显示内存,I/O和IPC调用等其他资源。
|
||||
|
||||
time 命令的语法是:
|
||||
|
||||
```
|
||||
/usr/bin/time [options] command [arguments...]
|
||||
```
|
||||
|
||||
语法中的‘options’是指一组可以与time命令一起使用去执行特定功能的选项。 下面给出了可用的‘options’。
|
||||
|
||||
* **-f, –format** – 使用此选项可以根据需求指定输出格式。
|
||||
* **-p, –portability** – 使用简要的输出格式。
|
||||
* **-o file, –output=FILE** – 将输出写到指定文件中而不是到标准输出。
|
||||
* **-a, –append** – 将输出追加到文件中而不是覆盖它。
|
||||
* **-v, –verbose** – 此选项显示 ‘time’ 命令输出的详细信息。
|
||||
* **–quiet** – 此选项可以防止 ‘time’ 命令报告程序的状态.
|
||||
|
||||
|
||||
|
||||
当不带任何选项使用 ‘GNU time’ 命令时, 你将看到以下输出。
|
||||
|
||||
```
|
||||
$ /usr/bin/time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2024maxresident)k
|
||||
0inputs+0outputs (0major+73minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
如果你用shell关键字 ‘time’ 运行相同的命令, 输出会有一点儿不同:
|
||||
|
||||
```
|
||||
$ time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
|
||||
real 0m0.006s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
```
|
||||
|
||||
有时,你可能希望将系统资源使用情况输出到文件中而不是终端上。 为此, 你可以使用 **-o** 选项,如下所示。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -o file.txt ls
|
||||
dir1 dir2 file1 file2 file.txt mcelog
|
||||
```
|
||||
|
||||
正如你看到的, time命令不会显示到终端上. 因为我们将输出写到了file.txt的文件中。 让我们看一下这个文件的内容:
|
||||
|
||||
```
|
||||
$ cat file.txt
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2512maxresident)k
|
||||
0inputs+0outputs (0major+106minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
当你使用 **-o** 选项时, 如果你没有一个文件名叫 ‘file.txt’, 它会创建一个并把输出写进去。 如果文件存在, 它会覆盖文件原来的内容。
|
||||
|
||||
你可以使用 **-a** 选项将输出追加到文件后面,而不是覆盖它的内容。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -a file.txt ls
|
||||
```
|
||||
|
||||
**-f** 选项允许用户根据自己的喜好控制输出格式。 比如说, 以下命令的输出仅显示用户,系统和总时间。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -f "\t%E real,\t%U user,\t%S sys" ls
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
0:00.00 real, 0.00 user, 0.00 sys
|
||||
```
|
||||
|
||||
请注意shell中内建的 ‘time’ 命令并不具有Gnu time程序的所有功能。
|
||||
|
||||
有关Gnu time程序的详细说明可以使用man命令来查看。
|
||||
|
||||
```
|
||||
$ man time
|
||||
```
|
||||
|
||||
想要了解有关Bash 内建 ‘Time’ 关键字的更多信息, 请运行:
|
||||
|
||||
```
|
||||
$ help time
|
||||
```
|
||||
|
||||
就到这里吧。 希望对你有所帮助。
|
||||
|
||||
会有更多好东西分享哦。 请关注我们!
|
||||
|
||||
加油哦!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-the-execution-time-of-a-command-or-process-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[caixiangyue](https://github.com/caixiangyue)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/find-long-process-running-linux/
|
||||
[2]: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
Loading…
Reference in New Issue
Block a user