mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
ac1e481ac0
115
published/20150817 Top 5 Torrent Clients For Ubuntu Linux.md
Normal file
115
published/20150817 Top 5 Torrent Clients For Ubuntu Linux.md
Normal file
@ -0,0 +1,115 @@
|
||||
Ubuntu 下五个最好的 BT 客户端
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
在寻找 **Ubuntu 中最好的 BT 客户端**吗?事实上,Linux 桌面平台中有许多 BT 客户端,但是它们中的哪些才是**最好的 Ubuntu 客户端**呢?
|
||||
|
||||
我将会列出 Linux 上最好的五个 BT 客户端,它们都拥有着体积轻盈,功能强大的特点,而且还有令人印象深刻的用户界面。自然,易于安装和使用也是特性之一。
|
||||
|
||||
### Ubuntu 下最好的 BT 客户端 ###
|
||||
|
||||
考虑到 Ubuntu 默认安装了 Transmission,所以我将会从这个列表中排除了 Transmission。但是这并不意味着 Transmission 没有资格出现在这个列表中,事实上,Transmission 是一个非常好的BT客户端,这也正是它被包括 Ubuntu 在内的多个发行版默认安装的原因。
|
||||
|
||||
### Deluge ###
|
||||
|
||||

|
||||
|
||||
[Deluge][1] 被 Lifehacker 评选为 Linux 下最好的 BT 客户端,这说明了 Deluge 是多么的有用。而且,并不仅仅只有 Lifehacker 是 Deluge 的粉丝,纵观多个论坛,你都会发现不少 Deluge 的忠实拥趸。
|
||||
|
||||
快速,时尚而直观的界面使得 Deluge 成为 Linux 用户的挚爱。
|
||||
|
||||
Deluge 可在 Ubuntu 的仓库中获取,你能够在 Ubuntu 软件中心中安装它,或者使用下面的命令:
|
||||
|
||||
sudo apt-get install deluge
|
||||
|
||||
### qBittorrent ###
|
||||
|
||||

|
||||
|
||||
正如它的名字所暗示的,[qBittorrent][2] 是著名的 [Bittorrent][3] 应用的 Qt 版本。如果曾经使用过它,你将会看到和 Windows 下的 Bittorrent 相似的界面。同样轻巧并且有着 BT 客户端的所有标准功能, qBittorrent 也可以在 Ubuntu 的默认仓库中找到。
|
||||
|
||||
它可以通过 Ubuntu 软件仓库安装,或者使用下面的命令:
|
||||
|
||||
sudo apt-get install qbittorrent
|
||||
|
||||
|
||||
### Tixati ###
|
||||
|
||||

|
||||
|
||||
[Tixati][4] 是另一个不错的 Ubuntu 下的 BT 客户端。它有着一个默认的黑暗主题,尽管很多人喜欢,但是我例外。它拥有着一切你能在 BT 客户端中找到的功能。
|
||||
|
||||
除此之外,它还有着数据分析的额外功能。你可以在美观的图表中分析流量以及其它数据。
|
||||
|
||||
- [下载 Tixati][5]
|
||||
|
||||
|
||||
|
||||
### Vuze ###
|
||||
|
||||

|
||||
|
||||
[Vuze][6] 是许多 Linux 以及 Windows 用户最喜欢的 BT 客户端。除了标准的功能,你可以直接在应用程序中搜索种子,也可以订阅系列片源,这样就无需再去寻找新的片源了,因为你可以在侧边栏中的订阅看到它们。
|
||||
|
||||
它还配备了一个视频播放器,可以播放带有字幕的高清视频等等。但是我不认为你会用它来代替那些更好的视频播放器,比如 VLC。
|
||||
|
||||
Vuze 可以通过 Ubuntu 软件中心安装或者使用下列命令:
|
||||
|
||||
sudo apt-get install vuze
|
||||
|
||||
|
||||
|
||||
### Frostwire ###
|
||||
|
||||

|
||||
|
||||
[Frostwire][7] 是一个你应该试一下的应用。它不仅仅是一个简单的 BT 客户端,它还可以应用于安卓,你可以用它通过 Wifi 来共享文件。
|
||||
|
||||
你可以在应用中搜索种子并且播放他们。除了下载文件,它还可以浏览本地的影音文件,并且将它们有条理的呈现在播放器中。这同样适用于安卓版本。
|
||||
|
||||
还有一个特点是:Frostwire 提供了独立音乐人的[合法音乐下载][13]。你可以下载并且欣赏它们,免费而且合法。
|
||||
|
||||
- [下载 Frostwire][8]
|
||||
|
||||
|
||||
|
||||
### 荣誉奖 ###
|
||||
|
||||
在 Windows 中,uTorrent(发音:mu torrent)是我最喜欢的 BT 应用。尽管 uTorrent 可以在 Linux 下运行,但是我还是特意忽略了它。因为在 Linux 下使用 uTorrent 不仅困难,而且无法获得完整的应用体验(运行在浏览器中)。
|
||||
|
||||
可以[在这里][9]阅读 Ubuntu下uTorrent 的安装教程。
|
||||
|
||||
#### 快速提示: ####
|
||||
|
||||
大多数情况下,BT 应用不会默认自动启动。如果想改变这一行为,请阅读[如何管理 Ubuntu 下的自启动程序][10]来学习。
|
||||
|
||||
### 你最喜欢的是什么? ###
|
||||
|
||||
这些是我对于 Ubuntu 下最好的 BT 客户端的意见。你最喜欢的是什么呢?请发表评论。也可以查看与本主题相关的[Ubuntu 最好的下载管理器][11]。如果使用 Popcorn Time,试试 [Popcorn Time 技巧][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-torrent-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Xuanwo](https://github.com/Xuanwo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://deluge-torrent.org/
|
||||
[2]:http://www.qbittorrent.org/
|
||||
[3]:http://www.bittorrent.com/
|
||||
[4]:http://www.tixati.com/
|
||||
[5]:http://www.tixati.com/download/
|
||||
[6]:http://www.vuze.com/
|
||||
[7]:http://www.frostwire.com/
|
||||
[8]:http://www.frostwire.com/downloads
|
||||
[9]:http://sysads.co.uk/2014/05/install-utorrent-3-3-ubuntu-14-04-13-10/
|
||||
[10]:http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
[11]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]:http://itsfoss.com/popcorn-time-tips/
|
||||
[13]:http://www.frostclick.com/wp/
|
||||
|
||||
@ -1,83 +1,82 @@
|
||||
在 Linux 中使用"两个磁盘"创建 RAID 1(镜像) - 第3部分
|
||||
在 Linux 下使用 RAID(三):用两块磁盘创建 RAID 1(镜像)
|
||||
================================================================================
|
||||
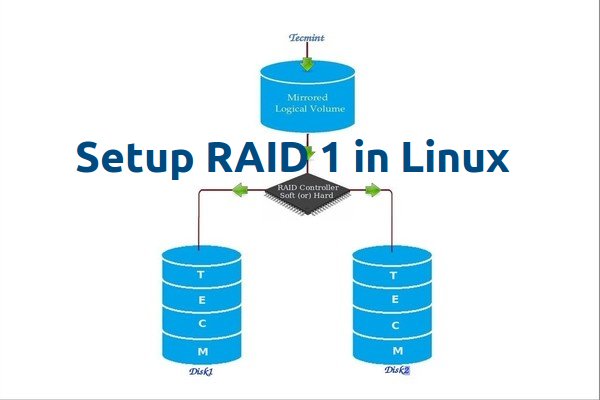
RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁盘中。创建 RAID1 至少需要两个磁盘,它的读取性能或者可靠性比数据存储容量更好。
|
||||
|
||||
**RAID 镜像**意味着相同数据的完整克隆(或镜像),分别写入到两个磁盘中。创建 RAID 1 至少需要两个磁盘,而且仅用于读取性能或者可靠性要比数据存储容量更重要的场合。
|
||||
|
||||
|
||||
|
||||
|
||||
在 Linux 中设置 RAID1
|
||||
*在 Linux 中设置 RAID 1*
|
||||
|
||||
创建镜像是为了防止因硬盘故障导致数据丢失。镜像中的每个磁盘包含数据的完整副本。当一个磁盘发生故障时,相同的数据可以从其它正常磁盘中读取。而后,可以从正在运行的计算机中直接更换发生故障的磁盘,无需任何中断。
|
||||
|
||||
### RAID 1 的特点 ###
|
||||
|
||||
-镜像具有良好的性能。
|
||||
- 镜像具有良好的性能。
|
||||
|
||||
-磁盘利用率为50%。也就是说,如果我们有两个磁盘每个500GB,总共是1TB,但在镜像中它只会显示500GB。
|
||||
- 磁盘利用率为50%。也就是说,如果我们有两个磁盘每个500GB,总共是1TB,但在镜像中它只会显示500GB。
|
||||
|
||||
-在镜像如果一个磁盘发生故障不会有数据丢失,因为两个磁盘中的内容相同。
|
||||
- 在镜像如果一个磁盘发生故障不会有数据丢失,因为两个磁盘中的内容相同。
|
||||
|
||||
-读取数据会比写入性能更好。
|
||||
- 读取性能会比写入性能更好。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 1 至少要有两个磁盘,你也可以添加更多的磁盘,磁盘数需为2,4,6,8等偶数。要添加更多的磁盘,你的系统必须有 RAID 物理适配器(硬件卡)。
|
||||
|
||||
创建 RAID 1 至少要有两个磁盘,你也可以添加更多的磁盘,磁盘数需为2,4,6,8的两倍。为了能够添加更多的磁盘,你的系统必须有 RAID 物理适配器(硬件卡)。
|
||||
这里,我们使用软件 RAID 不是硬件 RAID,如果你的系统有一个内置的物理硬件 RAID 卡,你可以从它的功能界面或使用 Ctrl + I 键来访问它。
|
||||
|
||||
这里,我们使用软件 RAID 不是硬件 RAID,如果你的系统有一个内置的物理硬件 RAID 卡,你可以从它的 UI 组件或使用 Ctrl + I 键来访问它。
|
||||
|
||||
需要阅读: [Basic Concepts of RAID in Linux][1]
|
||||
需要阅读: [介绍 RAID 的级别和概念][1]
|
||||
|
||||
#### 在我的服务器安装 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.226
|
||||
Hostname : rd1.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.226
|
||||
主机名 : rd1.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
|
||||
本文将指导你使用 mdadm (创建和管理 RAID 的)一步一步的建立一个软件 RAID 1 或镜像在 Linux 平台上。但同样的做法也适用于其它 Linux 发行版如 RedHat,CentOS,Fedora 等等。
|
||||
本文将指导你在 Linux 平台上使用 mdadm (用于创建和管理 RAID )一步步的建立一个软件 RAID 1 (镜像)。同样的做法也适用于如 RedHat,CentOS,Fedora 等 Linux 发行版。
|
||||
|
||||
### 第1步:安装所需要的并且检查磁盘 ###
|
||||
### 第1步:安装所需软件并且检查磁盘 ###
|
||||
|
||||
1.正如我前面所说,在 Linux 中我们需要使用 mdadm 软件来创建和管理 RAID。所以,让我们用 yum 或 apt-get 的软件包管理工具在 Linux 上安装 mdadm 软件包。
|
||||
1、 正如我前面所说,在 Linux 中我们需要使用 mdadm 软件来创建和管理 RAID。所以,让我们用 yum 或 apt-get 的软件包管理工具在 Linux 上安装 mdadm 软件包。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
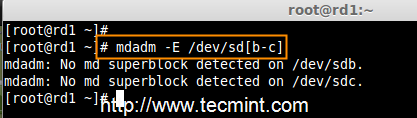
2. 一旦安装好‘mdadm‘包,我们需要使用下面的命令来检查磁盘是否已经配置好。
|
||||
2、 一旦安装好`mdadm`包,我们需要使用下面的命令来检查磁盘是否已经配置好。
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
|
||||
|
||||
检查 RAID 的磁盘
|
||||
|
||||
*检查 RAID 的磁盘*
|
||||
|
||||
正如你从上面图片看到的,没有检测到任何超级块,这意味着还没有创建RAID。
|
||||
|
||||
### 第2步:为 RAID 创建分区 ###
|
||||
|
||||
3. 正如我提到的,我们最少使用两个分区 /dev/sdb 和 /dev/sdc 来创建 RAID1。我们首先使用‘fdisk‘命令来创建这两个分区并更改其类型为 raid。
|
||||
3、 正如我提到的,我们使用最少的两个分区 /dev/sdb 和 /dev/sdc 来创建 RAID 1。我们首先使用`fdisk`命令来创建这两个分区并更改其类型为 raid。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
按照下面的说明
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 按两次回车键默认将整个容量分配给它。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 按 ‘L’,列出所有可用的类型。
|
||||
- 按 ‘t’ 修改分区类型。
|
||||
- 键入 ‘fd’ 设置为Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 修改分区类型。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
创建磁盘分区
|
||||
*创建磁盘分区*
|
||||
|
||||
在创建“/dev/sdb”分区后,接下来按照同样的方法创建分区 /dev/sdc 。
|
||||
|
||||
@ -85,59 +84,59 @@ RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁
|
||||
|
||||

|
||||
|
||||
创建第二个分区
|
||||
*创建第二个分区*
|
||||
|
||||
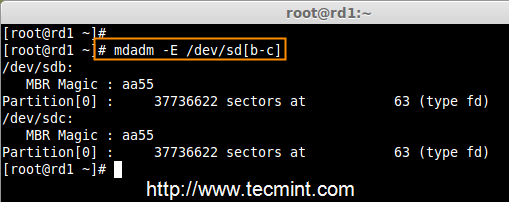
4. 一旦这两个分区创建成功后,使用相同的命令来检查 sdb & sdc 分区并确认 RAID 分区的类型如上图所示。
|
||||
4、 一旦这两个分区创建成功后,使用相同的命令来检查 sdb 和 sdc 分区并确认 RAID 分区的类型如上图所示。
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
|
||||
|
||||
验证分区变化
|
||||
*验证分区变化*
|
||||
|
||||
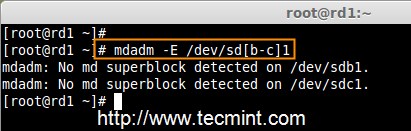
|
||||
|
||||
检查 RAID 类型
|
||||
*检查 RAID 类型*
|
||||
|
||||
**注意**: 正如你在上图所看到的,在 sdb1 和 sdc1 中没有任何对 RAID 的定义,这就是我们没有检测到超级块的原因。
|
||||
|
||||
### 步骤3:创建 RAID1 设备 ###
|
||||
### 第3步:创建 RAID 1 设备 ###
|
||||
|
||||
5.接下来使用以下命令来创建一个名为 /dev/md0 的“RAID1”设备并验证它
|
||||
5、 接下来使用以下命令来创建一个名为 /dev/md0 的“RAID 1”设备并验证它
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[b-c]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
创建RAID设备
|
||||
*创建RAID设备*
|
||||
|
||||
6. 接下来使用如下命令来检查 RAID 设备类型和 RAID 阵列
|
||||
6、 接下来使用如下命令来检查 RAID 设备类型和 RAID 阵列
|
||||
|
||||
# mdadm -E /dev/sd[b-c]1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查 RAID 设备类型
|
||||
*检查 RAID 设备类型*
|
||||
|
||||

|
||||
|
||||
检查 RAID 设备阵列
|
||||
*检查 RAID 设备阵列*
|
||||
|
||||
从上图中,人们很容易理解,RAID1 已经使用的 /dev/sdb1 和 /dev/sdc1 分区被创建,你也可以看到状态为 resyncing。
|
||||
从上图中,人们很容易理解,RAID 1 已经创建好了,使用了 /dev/sdb1 和 /dev/sdc1 分区,你也可以看到状态为 resyncing(重新同步中)。
|
||||
|
||||
### 第4步:在 RAID 设备上创建文件系统 ###
|
||||
|
||||
7. 使用 ext4 为 md0 创建文件系统并挂载到 /mnt/raid1 .
|
||||
7、 给 md0 上创建 ext4 文件系统
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
创建 RAID 设备文件系统
|
||||
*创建 RAID 设备文件系统*
|
||||
|
||||
8. 接下来,挂载新创建的文件系统到“/mnt/raid1”,并创建一些文件,验证在挂载点的数据
|
||||
8、 接下来,挂载新创建的文件系统到“/mnt/raid1”,并创建一些文件,验证在挂载点的数据
|
||||
|
||||
# mkdir /mnt/raid1
|
||||
# mount /dev/md0 /mnt/raid1/
|
||||
@ -146,51 +145,52 @@ RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁
|
||||
|
||||

|
||||
|
||||
挂载 RAID 设备
|
||||
*挂载 RAID 设备*
|
||||
|
||||
9.为了在系统重新启动自动挂载 RAID1,需要在 fstab 文件中添加条目。打开“/etc/fstab”文件并添加以下行。
|
||||
9、为了在系统重新启动自动挂载 RAID 1,需要在 fstab 文件中添加条目。打开`/etc/fstab`文件并添加以下行:
|
||||
|
||||
/dev/md0 /mnt/raid1 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 设备
|
||||
*自动挂载 Raid 设备*
|
||||
|
||||
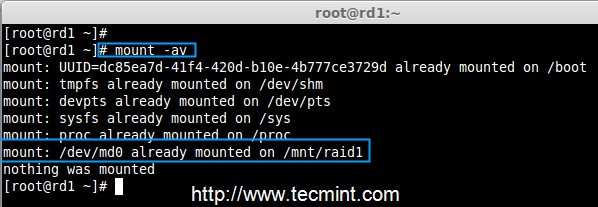
10、 运行`mount -av`,检查 fstab 中的条目是否有错误
|
||||
|
||||
10. 运行“mount -a”,检查 fstab 中的条目是否有错误
|
||||
# mount -av
|
||||
|
||||
|
||||
|
||||
检查 fstab 中的错误
|
||||
*检查 fstab 中的错误*
|
||||
|
||||
11. 接下来,使用下面的命令保存 raid 的配置到文件“mdadm.conf”中。
|
||||
11、 接下来,使用下面的命令保存 RAID 的配置到文件“mdadm.conf”中。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
保存 Raid 的配置
|
||||
*保存 Raid 的配置*
|
||||
|
||||
上述配置文件在系统重启时会读取并加载 RAID 设备。
|
||||
|
||||
### 第5步:在磁盘故障后检查数据 ###
|
||||
|
||||
12.我们的主要目的是,即使在任何磁盘故障或死机时必须保证数据是可用的。让我们来看看,当任何一个磁盘不可用时会发生什么。
|
||||
12、我们的主要目的是,即使在任何磁盘故障或死机时必须保证数据是可用的。让我们来看看,当任何一个磁盘不可用时会发生什么。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
验证 Raid 设备
|
||||
*验证 RAID 设备*
|
||||
|
||||
在上面的图片中,我们可以看到在 RAID 中有2个设备是可用的并且 Active Devices 是2.现在让我们看看,当一个磁盘拔出(移除 sdc 磁盘)或损坏后会发生什么。
|
||||
在上面的图片中,我们可以看到在 RAID 中有2个设备是可用的,并且 Active Devices 是2。现在让我们看看,当一个磁盘拔出(移除 sdc 磁盘)或损坏后会发生什么。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
测试 RAID 设备
|
||||
*测试 RAID 设备*
|
||||
|
||||
现在,在上面的图片中你可以看到,一个磁盘不见了。我从虚拟机上删除了一个磁盘。此时让我们来检查我们宝贵的数据。
|
||||
|
||||
@ -199,9 +199,9 @@ RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁
|
||||
|
||||
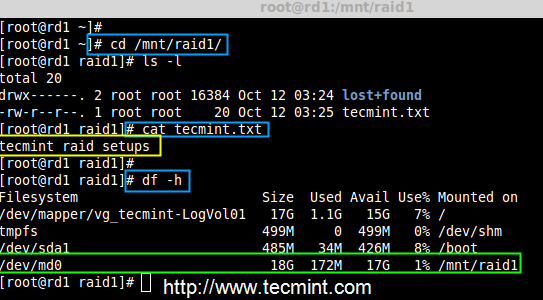
|
||||
|
||||
验证 RAID 数据
|
||||
*验证 RAID 数据*
|
||||
|
||||
你有没有看到我们的数据仍然可用。由此,我们可以知道 RAID 1(镜像)的优势。在接下来的文章中,我们将看到如何设置一个 RAID 5 条带化分布式奇偶校验。希望这可以帮助你了解 RAID 1(镜像)是如何工作的。
|
||||
你可以看到我们的数据仍然可用。由此,我们可以了解 RAID 1(镜像)的优势。在接下来的文章中,我们将看到如何设置一个 RAID 5 条带化分布式奇偶校验。希望这可以帮助你了解 RAID 1(镜像)是如何工作的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -209,9 +209,9 @@ via: http://www.tecmint.com/create-raid1-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
109
published/kde-plasma-5.4.md
Normal file
109
published/kde-plasma-5.4.md
Normal file
@ -0,0 +1,109 @@
|
||||
KDE Plasma 5.4.0 发布,八月特色版
|
||||
=============================
|
||||
|
||||

|
||||
|
||||
2015 年 8 月 25 ,星期二,KDE 发布了 Plasma 5 的一个特色新版本。
|
||||
|
||||
此版本为我们带来了许多非常棒的感受,如优化了对高分辨率的支持,KRunner 自动补全和一些新的 Breeze 漂亮图标。这还为不久以后的技术预览版的 Wayland 桌面奠定了基础。我们还带来了几个新组件,如声音音量部件,显示器校准工具和测试版的用户管理工具。
|
||||
|
||||
###新的音频音量程序
|
||||
|
||||

|
||||
|
||||
新的音频音量程序直接工作于 PulseAudio (Linux 上一个非常流行的音频服务) 之上 ,并且在一个漂亮的简约的界面提供一个完整的音量控制和输出设定。
|
||||
|
||||
###替代的应用控制面板起动器
|
||||
|
||||

|
||||
|
||||
Plasma 5.4 在 kdeplasma-addons 软件包中提供了一个全新的全屏的应用控制面板,它具有应用菜单的所有功能,还支持缩放和全空间键盘导航。新的起动器可以像你目前所用的“最近使用的”或“收藏的文档和联系人”一样简单和快速地查找应用。
|
||||
|
||||
###丰富的艺术图标
|
||||
|
||||

|
||||
|
||||
Plasma 5.4 提供了超过 1400 个的新图标,其中不仅包含 KDE 程序的,而且还为 Inkscape, Firefox 和 Libreoffice 提供 Breeze 主题的艺术图标,可以体验到更加一致和本地化的感觉。
|
||||
|
||||
###KRunner 历史记录
|
||||
|
||||

|
||||
|
||||
KRunner 现在可以记住之前的搜索历史并根据历史记录进行自动补全。
|
||||
|
||||
###Network 程序中实用的图形展示
|
||||
|
||||

|
||||
|
||||
Network 程序现在可以以图形形式显示网络流量了,同时也支持两个新的 VPN 插件:通过 SSH 连接或通过 SSTP 连接。
|
||||
|
||||
###Wayland 技术预览
|
||||
|
||||
随着 Plasma 5.4 ,Wayland 桌面发布了第一个技术预览版。在使用自由图形驱动(free graphics drivers)的系统上可以使用 KWin(Plasma 的 Wayland 合成器和 X11 窗口管理器)通过[内核模式设定][1]来运行 Plasma。现在已经支持的功能需求来自于[手机 Plasma 项目][2],更多的面向桌面的功能还未被完全实现。现在还不能作为替换那些基于 Xorg 的桌面,但可以轻松地对它测试和贡献,以及观看令人激动视频。有关如何在 Wayland 中使用 Plasma 的介绍请到:[KWin 维基页][3]。Wlayland 将随着我们构建的稳定版本而逐步得到改进。
|
||||
|
||||
###其他的改变和添加
|
||||
|
||||
- 优化对高 DPI 支持
|
||||
- 更少的内存占用
|
||||
- 桌面搜索使用了更快的新后端
|
||||
- 便笺增加拖拉支持和键盘导航
|
||||
- 回收站重新支持拖拉
|
||||
- 系统托盘获得更快的可配置性
|
||||
- 文档重新修订和更新
|
||||
- 优化了窄小面板上的数字时钟的布局
|
||||
- 数字时钟支持 ISO 日期
|
||||
- 切换数字时钟 12/24 格式更简单
|
||||
- 日历显示第几周
|
||||
- 任何项目都可以收藏进应用菜单(Kicker),支持收藏文档和 Telepathy 联系人
|
||||
- Telepathy 联系人收藏可以展示联系人的照片和实时状态
|
||||
- 优化程序与容器间的焦点和激活处理
|
||||
- 文件夹视图中各种小修复:更好的默认尺寸,鼠标交互问题以及文本标签换行
|
||||
- 任务管理器更好的呈现起动器默认的应用图标
|
||||
- 可再次通过将程序拖入任务管理器来添加启动器
|
||||
- 可配置中间键点击在任务管理器中的行为:无动作,关闭窗口,启动一个相同的程序的新实例
|
||||
- 任务管理器现在以列排序优先,无论用户是否更倾向于行优先;许多用户更喜欢这样排序是因为它会使更少的任务按钮像窗口一样移来移去
|
||||
- 优化任务管理器的图标和缩放边
|
||||
- 任务管理器中各种小修复:垂直下拉,触摸事件处理现在支持所有系统,组扩展箭头的视觉问题
|
||||
- 提供可用的目的框架技术预览版,可以使用 QuickShare Plasmoid,它可以让许多 web 服务分享文件更容易
|
||||
- 增加了显示器配置工具
|
||||
- 增加的 kwallet-pam 可以在登录时打开 wallet
|
||||
- 用户管理器现在会同步联系人到 KConfig 的设置中,用户账户模块被丢弃了
|
||||
- 应用程序菜单(Kicker)的性能得到改善
|
||||
- 应用程序菜单(Kicker)各种小修复:隐藏/显示程序更加可靠,顶部面板的对齐修复,文件夹视图中 “添加到桌面”更加可靠,在基于 KActivities 的最新模块中有更好的表现
|
||||
- 支持自定义菜单布局 (kmenuedit)和应用程序菜单(Kicker)支持菜单项目分隔
|
||||
- 当在面板中时,改进了文件夹视图,参见 [blog][4]
|
||||
- 将文件夹拖放到桌面容器现在会再次创建一个文件夹视图
|
||||
|
||||
[完整的 Plasma 5.4 变更日志在此](https://www.kde.org/announcements/plasma-5.3.2-5.4.0-changelog.php)
|
||||
|
||||
###Live 镜像
|
||||
|
||||
尝鲜的最简单的方式就是从 U 盘中启动,可以在 KDE 社区 Wiki 中找到 各种 [带有 Plasma 5 的 Live 镜像][5]。
|
||||
|
||||
###下载软件包
|
||||
|
||||
各发行版已经构建了软件包,或者正在构建,wiki 中的列出了各发行版的软件包名:[软件包下载维基页][6]。
|
||||
|
||||
###源码下载
|
||||
|
||||
可以直接从源码中安装 Plasma 5。KDE 社区 Wiki 已经介绍了[怎样编译][7]。
|
||||
|
||||
注意,Plasma 5 与 Plasma 4 不兼容,必须先卸载旧版本,或者安装到不同的前缀处。
|
||||
|
||||
|
||||
- [源代码信息页][8]
|
||||
|
||||
---
|
||||
|
||||
via: https://www.kde.org/announcements/plasma-5.4.0.php
|
||||
|
||||
译者:[Locez](http://locez.com) 校对:[wxy](http://github.com/wxy)
|
||||
|
||||
[1]:https://en.wikipedia.org/wiki/Direct_Rendering_Manager
|
||||
[2]:https://dot.kde.org/2015/07/25/plasma-mobile-free-mobile-platform
|
||||
[3]:https://community.kde.org/KWin/Wayland#Start_a_Plasma_session_on_Wayland
|
||||
[4]:https://blogs.kde.org/2015/06/04/folder-view-panel-popups-are-list-views-again
|
||||
[5]:https://community.kde.org/Plasma/LiveImages
|
||||
[6]:https://community.kde.org/Plasma/Packages
|
||||
[7]:http://community.kde.org/Frameworks/Building
|
||||
[8]:https://www.kde.org/info/plasma-5.4.0.php
|
||||
@ -0,0 +1,87 @@
|
||||
Plasma 5.4 Is Out And It’s Packed Full Of Features
|
||||
================================================================================
|
||||
KDE has [announced][1] a brand new feature release of Plasma 5 — and it’s a corker.
|
||||
|
||||
|
||||
|
||||
Better network details are among the changes
|
||||
|
||||
Plasma 5.4.0 builds on [April’s 5.3.0 milestone][2] in a number of ways, ranging from the inherently technical, Wayland preview session, ahoy, to lavish aesthetic touches, like **1,400 brand new icons**.
|
||||
|
||||
A handful of new components also feature in the release, including a new Plasma Widget for volume control, a monitor calibration tool and an improved user management tool.
|
||||
|
||||
The ‘Kicker’ application menu has been powered up to let you favourite all types of content, not just applications.
|
||||
|
||||
**KRunner now remembers searches** so that it can automatically offer suggestions based on your earlier queries as you type.
|
||||
|
||||
The **network applet displays a graph** to give you a better understanding of your network traffic. It also gains two new VPN plugins for SSH and SSTP connections.
|
||||
|
||||
Minor tweaks to the digital clock see it adapt better in slim panel mode, it gains ISO date support and makes it easier for you to toggle between 12 hour and 24 hour clock. Week numbers have been added to the calendar.
|
||||
|
||||
### Application Dashboard ###
|
||||
|
||||
|
||||
|
||||
The new ‘Application Dashboard’ in KDE Plasma 5.4.0
|
||||
|
||||
**A new full screen launcher, called ‘Application Dashboard’**, is also available.
|
||||
|
||||
This full-screen dash offers the same features as the traditional Application Menu but with “sophisticated scaling to screen size and full spatial keyboard navigation”.
|
||||
|
||||
Like the Unity launch, the new Plasma Application Dashboard helps you quickly find applications, sift through files and contacts based on your previous activity.
|
||||
|
||||
### Changes in KDE Plasma 5.4.0 at a glance ###
|
||||
|
||||
- Improved high DPI support
|
||||
- KRunner autocompletion
|
||||
- KRunner search history
|
||||
- Application Dashboard add on
|
||||
- 1,400 New icons
|
||||
- Wayland tech preview
|
||||
|
||||
For a full list of changes in Plasma 5.4 refer to [this changelog][3].
|
||||
|
||||
### Install Plasma 5.4 in Kubuntu 15.04 ###
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
To **install Plasma 5.4 in Kubuntu 15.04** you will need to add the KDE Backports PPA to your Software Sources.
|
||||
|
||||
Adding the Kubuntu backports PPA **is not strictly advised** as it may upgrade other parts of the KDE desktop, application suite, developer frameworks or Kubuntu specific config files.
|
||||
|
||||
If you like your desktop being stable, don’t proceed.
|
||||
|
||||
The quickest way to upgrade to Plasma 5.4 once it lands in the Kubuntu Backports PPA is to use the Terminal:
|
||||
|
||||
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||
|
||||
sudo apt-get update && sudo apt-get dist-upgrade
|
||||
|
||||
Let the upgrade process complete. Assuming no errors emerge, reboot your computer for changes to take effect.
|
||||
|
||||
If you’re not already using Kubuntu, i.e. you’re using the Unity version of Ubuntu, you should first install the Kubuntu desktop package (you’ll find it in the Ubuntu Software Centre).
|
||||
|
||||
To undo the changes above and downgrade to the most recent version of Plasma available in the Ubuntu archives use the PPA-Purge tool:
|
||||
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
sudo ppa-purge ppa:kubuntu-ppa/backports
|
||||
|
||||
Let us know how your upgrade/testing goes in the comments below and don’t forget to mention the features you hope to see added to the Plasma 5 desktop next.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/plasma-5-4-new-features
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://dot.kde.org/2015/08/25/kde-ships-plasma-540-feature-release-august
|
||||
[2]:http://www.omgubuntu.co.uk/2015/04/kde-plasma-5-3-released-heres-how-to-upgrade-in-kubuntu-15-04
|
||||
[3]:https://www.kde.org/announcements/plasma-5.3.2-5.4.0-changelog.php
|
||||
@ -1,119 +0,0 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Top 5 Torrent Clients For Ubuntu Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Looking for the **best torrent client in Ubuntu**? Indeed there are a number of torrent clients available for desktop Linux. But which ones are the **best Ubuntu torrent clients** among them?
|
||||
|
||||
I am going to list top 5 torrent clients for Linux, which are lightweight, feature rich and have impressive GUI. Ease of installation and using is also a factor.
|
||||
|
||||
### Best torrent programs for Ubuntu ###
|
||||
|
||||
Since Ubuntu comes by default with Transmission, I am going to exclude it from the list. This doesn’t mean that Transmission doesn’t deserve to be on the list. Transmission is a good to have torrent client for Ubuntu and this is the reason why it is the default Torrent application in several Linux distributions, including Ubuntu.
|
||||
|
||||
----------
|
||||
|
||||
### Deluge ###
|
||||
|
||||

|
||||
|
||||
[Deluge][1] has been chosen as the best torrent client for Linux by Lifehacker and that speaks itself of the usefulness of Deluge. And it’s not just Lifehacker who is fan of Deluge, check out any forum and you’ll find a number of people admitting that Deluge is their favorite.
|
||||
|
||||
Fast, sleek and intuitive interface makes Deluge a hot favorite among Linux users.
|
||||
|
||||
Deluge is available in Ubuntu repositories and you can install it in Ubuntu Software Center or by using the command below:
|
||||
|
||||
sudo apt-get install deluge
|
||||
|
||||
----------
|
||||
|
||||
### qBittorrent ###
|
||||
|
||||

|
||||
|
||||
As the name suggests, [qBittorrent][2] is the Qt version of famous [Bittorrent][3] application. You’ll see an interface similar to Bittorrent client in Windows, if you ever used it. Sort of lightweight and have all the standard features of a torrent program, qBittorrent is also available in default Ubuntu repository.
|
||||
|
||||
It could be installed from Ubuntu Software Center or using the command below:
|
||||
|
||||
sudo apt-get install qbittorrent
|
||||
|
||||
----------
|
||||
|
||||
### Tixati ###
|
||||
|
||||

|
||||
|
||||
[Tixati][4] is another nice to have torrent client for Ubuntu. It has a default dark theme which might be preferred by many but not me. It has all the standard features that you can seek in a torrent client.
|
||||
|
||||
In addition to that, there are additional feature of data analysis. You can measure and analyze bandwidth and other statistics in nice charts.
|
||||
|
||||
- [Download Tixati][5]
|
||||
|
||||
----------
|
||||
|
||||
### Vuze ###
|
||||
|
||||

|
||||
|
||||
[Vuze][6] is favorite torrent application of a number of Linux as well as Windows users. Apart from the standard features, you can search for torrents directly in the application. You can also subscribe to episodic content so that you won’t have to search for new contents as you can see it in your subscription in sidebar.
|
||||
|
||||
It also comes with a video player that can play HD videos with subtitles and all. But I don’t think you would like to use it over the better video players such as VLC.
|
||||
|
||||
Vuze can be installed from Ubuntu Software Center or using the command below:
|
||||
|
||||
sudo apt-get install vuze
|
||||
|
||||
----------
|
||||
|
||||
### Frostwire ###
|
||||
|
||||

|
||||
|
||||
[Frostwire][7] is the torrent application you might want to try. It is more than just a simple torrent client. Also available for Android, you can use it to share files over WiFi.
|
||||
|
||||
You can search for torrents from within the application and play them inside the application. In addition to the downloaded files, it can browse your local media and have them organized inside the player. The same is applicable for the Android version.
|
||||
|
||||
An additional feature is that Frostwire also provides access to legal music by indi artists. You can download them and listen to it, for free, for legal.
|
||||
|
||||
- [Download Frostwire][8]
|
||||
|
||||
----------
|
||||
|
||||
### Honorable mention ###
|
||||
|
||||
On Windows, uTorrent (pronounced mu torrent) is my favorite torrent application. While uTorrent may be available for Linux, I deliberately skipped it from the list because installing and using uTorrent in Linux is neither easy nor does it provide a complete application experience (runs with in web browser).
|
||||
|
||||
You can read about uTorrent installation in Ubuntu [here][9].
|
||||
|
||||
#### Quick tip: ####
|
||||
|
||||
Most of the time, torrent applications do not start by default. You might want to change this behavior. Read this post to learn [how to manage startup applications in Ubuntu][10].
|
||||
|
||||
### What’s your favorite? ###
|
||||
|
||||
That was my opinion on the best Torrent clients in Ubuntu. What is your favorite one? Do leave a comment. You can also check the [best download managers for Ubuntu][11] in related posts. And if you use Popcorn Time, check these [Popcorn Time Tips][12].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-torrent-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://deluge-torrent.org/
|
||||
[2]:http://www.qbittorrent.org/
|
||||
[3]:http://www.bittorrent.com/
|
||||
[4]:http://www.tixati.com/
|
||||
[5]:http://www.tixati.com/download/
|
||||
[6]:http://www.vuze.com/
|
||||
[7]:http://www.frostwire.com/
|
||||
[8]:http://www.frostwire.com/downloads
|
||||
[9]:http://sysads.co.uk/2014/05/install-utorrent-3-3-ubuntu-14-04-13-10/
|
||||
[10]:http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
[11]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]:http://itsfoss.com/popcorn-time-tips/
|
||||
65
sources/share/20150826 Five Super Cool Open Source Games.md
Normal file
65
sources/share/20150826 Five Super Cool Open Source Games.md
Normal file
@ -0,0 +1,65 @@
|
||||
Five Super Cool Open Source Games
|
||||
================================================================================
|
||||
In 2014 and 2015, Linux became home to a list of popular commercial titles such as the popular Borderlands, Witcher, Dead Island, and Counter Strike series of games. While this is exciting news, what of the gamer on a budget? Commercial titles are good, but even better are free-to-play alternatives made by developers who know what players like.
|
||||
|
||||
Some time ago, I came across a three year old YouTube video with the ever optimistic title [5 Open Source Games that Don’t Suck][1]. Although the video praises some open source games, I’d prefer to approach the subject with a bit more enthusiasm, at least as far as the title goes. So, here’s my list of five super cool open source games.
|
||||
|
||||
### Tux Racer ###
|
||||
|
||||
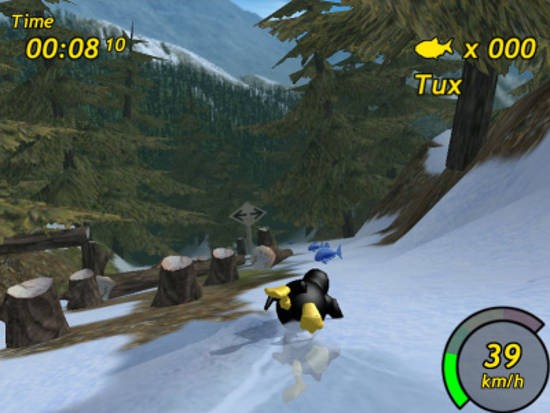
|
||||
|
||||
Tux Racer
|
||||
|
||||
[Tux Racer][2] is the first game on this list because I’ve had plenty of experience with it. On a [recent trip to Mexico][3] that my brother and I took with [Kids on Computers][4], Tux Racer was one of the games that kids and teachers alike enjoyed. In this game, players use the Linux mascot, the penguin Tux, to race on downhill ski slopes in time trials in which players challenge their own personal bests. Currently there’s no multiplayer version available, but that could be subject to change. Available for Linux, OS X, Windows, and Android.
|
||||
|
||||
### Warsow ###
|
||||
|
||||

|
||||
|
||||
Warsow
|
||||
|
||||
The [Warsow][5] website explains: “Set in a futuristic cartoonish world, Warsow is a completely free fast-paced first-person shooter (FPS) for Windows, Linux and Mac OS X. Warsow is the Art of Respect and Sportsmanship Over the Web.” I was reluctant to include games from the FPS genre on this list, because many have played games in this genre, but I was amused by Warsow. It prioritizes lots of movement and the game is fast paced with a set of eight weapons to start with. The cartoonish style makes playing feel less serious and more casual, something for friends and family to play together. However, it boasts competitive play, and when I experienced the game I found there were, indeed, some expert players around. Available for Linux, Windows and OS X.
|
||||
|
||||
### M.A.R.S – A ridiculous shooter ###
|
||||
|
||||

|
||||
|
||||
M.A.R.S. – A ridiculous shooter
|
||||
|
||||
[M.A.R.S – A ridiculous shooter][6] is appealing because of it’s vibrant coloring and style. There is support for two players on the same keyboard, but an online multiplayer version is currently in the works — meaning plans to play with friends have to wait for now. Regardless, it’s an entertaining space shooter with a few different ships and weapons to play as. There are different shaped ships, ranging from shotguns, lasers, scattered shots and more (one of the random ships shot bubbles at my opponents, which was funny amid the chaotic gameplay). There are a few modes of play, such as the standard death match against opponents to score a certain limit or score high, along with other modes called Spaceball, Grave-itation Pit and Cannon Keep. Available for Linux, Windows and OS X.
|
||||
|
||||
### Valyria Tear ###
|
||||
|
||||
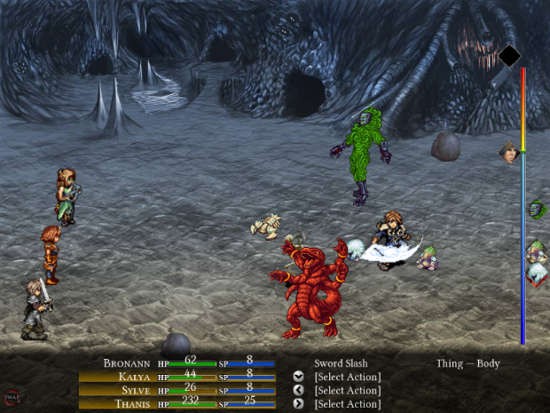
|
||||
|
||||
Valyria Tear
|
||||
|
||||
[Valyria Tear][7] resembles many fan favorite role-playing games (RPGs) spanning the years. The story is set in the usual era of fantasy games, full of knights, kingdoms and wizardry, and follows the main character Bronann. The design team did great work in designing the world and gives players everything expected from the genre: hidden chests, random monster encounters, non-player character (NPC) interaction, and something no RPG would be complete without: grinding for experience on lower level slime monsters until you’re ready for the big bosses. When I gave it a try, time didn’t permit me to play too far into the campaign, but for those interested there is a ‘[Let’s Play][8]‘ series by YouTube user Yohann Ferriera. Available for Linux, Windows and OS X.
|
||||
|
||||
### SuperTuxKart ###
|
||||
|
||||

|
||||
|
||||
SuperTuxKart
|
||||
|
||||
Last but not least is [SuperTuxKart][9], a clone of Mario Kart that is every bit as fun as the original. It started development around 2000-2004 as Tux Kart, but there were errors in its production which led to a cease in development for a few years. Since development picked up again in 2006, it’s been improving, with version 0.9 debuting four months ago. In the game, our old friend Tux starts in the role of Mario and a few other open source mascots. One recognizable face among them is Suzanne, the monkey mascot for Blender. The graphics are solid and gameplay is fluent. While online play is in the planning stages, split screen multiplayer action is available, with up to four players supported on a single computer. Available for Linux, Windows, OS X, AmigaOS 4, AROS and MorphOS.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2015/08/five-super-cool-open-source-games/
|
||||
|
||||
作者:Hunter Banks
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.youtube.com/watch?v=BEKVl-XtOP8
|
||||
[2]:http://tuxracer.sourceforge.net/download.html
|
||||
[3]:http://fossforce.com/2015/07/banks-family-values-texas-linux-fest/
|
||||
[4]:http://www.kidsoncomputers.org/an-amazing-week-in-oaxaca
|
||||
[5]:https://www.warsow.net/download
|
||||
[6]:http://mars-game.sourceforge.net/
|
||||
[7]:http://valyriatear.blogspot.com/
|
||||
[8]:https://www.youtube.com/channel/UCQ5KrSk9EqcT_JixWY2RyMA
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
@ -0,0 +1,110 @@
|
||||
Mosh Shell – A SSH Based Client for Connecting Remote Unix/Linux Systems
|
||||
================================================================================
|
||||
Mosh, which stands for Mobile Shell is a command-line application which is used for connecting to the server from a client computer, over the Internet. It can be used as SSH and contains more feature than Secure Shell. It is an application similar to SSH, but with additional features. The application is written originally by Keith Winstein for Unix like operating system and released under GNU GPL v3.
|
||||
|
||||

|
||||
|
||||
Mosh Shell SSH Client
|
||||
|
||||
#### Features of Mosh ####
|
||||
|
||||
- It is a remote terminal application that supports roaming.
|
||||
- Available for all major UNIX-like OS viz., Linux, FreeBSD, Solaris, Mac OS X and Android.
|
||||
- Intermittent Connectivity supported.
|
||||
- Provides intelligent local echo.
|
||||
- Line editing of user keystrokes supported.
|
||||
- Responsive design and Robust Nature over wifi, cellular and long-distance links.
|
||||
- Remain Connected even when IP changes. It usages UDP in place of TCP (used by SSH). TCP time out when connect is reset or new IP assigned but UDP keeps the connection open.
|
||||
- The Connection remains intact when you resume the session after a long time.
|
||||
- No network lag. Shows users typed key and deletions immediately without network lag.
|
||||
- Same old method to login as it was in SSH.
|
||||
- Mechanism to handle packet loss.
|
||||
|
||||
### Installation of Mosh Shell in Linux ###
|
||||
|
||||
On Debian, Ubuntu and Mint alike systems, you can easily install the Mosh package with the help of [apt-get package manager][1] as shown.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install mosh
|
||||
|
||||
On RHEL/CentOS/Fedora based distributions, you need to turn on third party repository called [EPEL][2], in order to install mosh from this repository using [yum package manager][3] as shown.
|
||||
|
||||
# yum update
|
||||
# yum install mosh
|
||||
|
||||
On Fedora 22+ version, you need to use [dnf package manager][4] to install mosh as shown.
|
||||
|
||||
# dnf install mosh
|
||||
|
||||
### How do I use Mosh Shell? ###
|
||||
|
||||
1. Let’s try to login into remote Linux server using mosh shell.
|
||||
|
||||
$ mosh root@192.168.0.150
|
||||
|
||||

|
||||
|
||||
Mosh Shell Remote Connection
|
||||
|
||||
**Note**: Did you see I got an error in connecting since the port was not open in my remote CentOS 7 box. A quick but not recommended solution I performed was:
|
||||
|
||||
# systemctl stop firewalld [on Remote Server]
|
||||
|
||||
The preferred way is to open a port and update firewall rules. And then connect to mosh on a predefined port. For in-depth details on firewalld you may like to visit this post.
|
||||
|
||||
- [How to Configure Firewalld][5]
|
||||
|
||||
2. Let’s assume that the default SSH port 22 was changed to port 70, in this case you can define custom port with the help of ‘-p‘ switch with mosh.
|
||||
|
||||
$ mosh -p 70 root@192.168.0.150
|
||||
|
||||
3. Check the version of installed Mosh.
|
||||
|
||||
$ mosh --version
|
||||
|
||||

|
||||
|
||||
Check Mosh Version
|
||||
|
||||
4. You can close mosh session type ‘exit‘ on the prompt.
|
||||
|
||||
$ exit
|
||||
|
||||
5. Mosh supports a lot of options, which you may see as:
|
||||
|
||||
$ mosh --help
|
||||
|
||||

|
||||
|
||||
Mosh Shell Options
|
||||
|
||||
#### Cons of Mosh Shell ####
|
||||
|
||||
- Mosh requires additional prerequisite for example, allow direct connection via UDP, which was not required by SSH.
|
||||
- Dynamic port allocation in the range of 60000-61000. The first open fort is allocated. It requires one port per connection.
|
||||
- Default port allocation is a serious security concern, especially in production.
|
||||
- IPv6 connections supported, but roaming on IPv6 not supported.
|
||||
- Scrollback not supported.
|
||||
- No X11 forwarding supported.
|
||||
- No support for ssh-agent forwarding.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Mosh is a nice small utility which is available for download in the repository of most of the Linux Distributions. Though it has a few discrepancies specially security concern and additional requirement it’s features like remaining connected even while roaming is its plus point. My recommendation is Every Linux-er who deals with SSH should try this application and mind it, Mosh is worth a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-mosh-shell-ssh-client-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[4]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[5]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
@ -1,25 +0,0 @@
|
||||
Linux about to gain a new file system – bcachefs
|
||||
================================================================================
|
||||
A five year old file system built by Kent Overstreet, formerly of Google, is near feature complete with all critical components in place. Bcachefs boasts the performance and reliability of the widespread ext4 and xfs as well as the feature list similar to that of btrfs and zfs. Notable features include checksumming, compression, multiple devices, caching and eventually snapshots and other “nifty” features.
|
||||
|
||||
Bcachefs started out as **bcache** which was a block caching layer, the evolution from bcache to a fully featured [copy-on-write][1] file system has been described as a metamorphosis.
|
||||
|
||||
Responding to the self-imposed question “Yet another new filesystem? Why?” Kent Overstreet replies with the following “Well, years ago (going back to when I was still at Google), I and the other people working on bcache realized that what we were working on was, almost by accident, a good chunk of the functionality of a full blown filesystem – and there was a really clean and elegant design to be had there if we took it and ran with it. And a fast one – the main goal of bcachefs to match ext4 and xfs on performance and reliability, but with the features of btrfs/xfs.”
|
||||
|
||||
Overstreet has invited people to use and test bcachefs out on their own systems. To find instructions to use bcachefs on your system check out the mailing list [announcement][2].
|
||||
|
||||
The file system situation on Linux is a fairly drawn out one, Fedora 16 for instance aimed to use btrfs instead of ext4 as the default file system, this switch still has not happened. Currently all of the Debian based distros, including Ubuntu, Mint and elementary OS, still use ext4 as their default file systems and none have even whispered about switching to a new default file system yet.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/08/22/linux-gain-new-file-system-bcachefs/
|
||||
|
||||
作者:[Paul Hill][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/paul_hill/
|
||||
[1]:https://en.wikipedia.org/wiki/Copy-on-write
|
||||
[2]:https://lkml.org/lkml/2015/8/21/22
|
||||
@ -1,676 +0,0 @@
|
||||
Translating by Ezio
|
||||
|
||||
Process of the Linux kernel building
|
||||
================================================================================
|
||||
Introduction
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
I will not tell you how to build and install custom Linux kernel on your machine, you can find many many [resources](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code) that will help you to do it. Instead, we will know what does occur when you are typed `make` in the directory with Linux kernel source code in this part. When I just started to learn source code of the Linux kernel, the [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) file was a first file that I've opened. And it was scary :) This [makefile](https://en.wikipedia.org/wiki/Make_%28software%29) contains `1591` lines of code at the time when I wrote this part and it was [third](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) release candidate.
|
||||
|
||||
This makefile is the the top makefile in the Linux kernel source code and kernel build starts here. Yes, it is big, but moreover, if you've read the source code of the Linux kernel you can noted that all directories with a source code has an own makefile. Of course it is not real to describe how each source files compiled and linked. So, we will see compilation only for the standard case. You will not find here building of the kernel's documentation, cleaning of the kernel source code, [tags](https://en.wikipedia.org/wiki/Ctags) generation, [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler) related stuff and etc. We will start from the `make` execution with the standard kernel configuration file and will finish with the building of the [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
It would be good if you're already familiar with the [make](https://en.wikipedia.org/wiki/Make_%28software%29) util, but I will anyway try to describe all code that will be in this part.
|
||||
|
||||
So let's start.
|
||||
|
||||
Preparation before the kernel compilation
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
There are many things to preparate before the kernel compilation will be started. The main point here is to find and configure
|
||||
the type of compilation, to parse command line arguments that are passed to the `make` util and etc. So let's dive into the top `Makefile` of the Linux kernel.
|
||||
|
||||
The Linux kernel top `Makefile` is responsible for building two major products: [vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (the resident kernel image) and the modules (any module files). The [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) of the Linux kernel starts from the definition of the following variables:
|
||||
|
||||
```Makefile
|
||||
VERSION = 4
|
||||
PATCHLEVEL = 2
|
||||
SUBLEVEL = 0
|
||||
EXTRAVERSION = -rc3
|
||||
NAME = Hurr durr I'ma sheep
|
||||
```
|
||||
|
||||
These variables determine the current version of the Linux kernel and are used in the different places, for example in the forming of the `KERNELVERSION` variable:
|
||||
|
||||
```Makefile
|
||||
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||
```
|
||||
|
||||
After this we can see a couple of the `ifeq` condition that check some of the parameters passed to `make`. The Linux kernel `makefiles` provides a special `make help` target that prints all available targets and some of the command line arguments that can be passed to `make`. For example: `make V=1` - provides verbose builds. The first `ifeq` condition checks if the `V=n` option is passed to make:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin V)", "command line")
|
||||
KBUILD_VERBOSE = $(V)
|
||||
endif
|
||||
ifndef KBUILD_VERBOSE
|
||||
KBUILD_VERBOSE = 0
|
||||
endif
|
||||
|
||||
ifeq ($(KBUILD_VERBOSE),1)
|
||||
quiet =
|
||||
Q =
|
||||
else
|
||||
quiet=quiet_
|
||||
Q = @
|
||||
endif
|
||||
|
||||
export quiet Q KBUILD_VERBOSE
|
||||
```
|
||||
|
||||
If this option is passed to `make` we set the `KBUILD_VERBOSE` variable to the value of the `V` option. Otherwise we set the `KBUILD_VERBOSE` variable to zero. After this we check value of the `KBUILD_VERBOSE` variable and set values of the `quiet` and `Q` variables depends on the `KBUILD_VERBOSE` value. The `@` symbols suppress the output of the command and if it will be set before a command we will see something like this: `CC scripts/mod/empty.o` instead of the `Compiling .... scripts/mod/empty.o`. In the end we just export all of these variables. The next `ifeq` statement checks that `O=/dir` option was passed to the `make`. This option allows to locate all output files in the given `dir`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
|
||||
ifeq ("$(origin O)", "command line")
|
||||
KBUILD_OUTPUT := $(O)
|
||||
endif
|
||||
|
||||
ifneq ($(KBUILD_OUTPUT),)
|
||||
saved-output := $(KBUILD_OUTPUT)
|
||||
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||
&& /bin/pwd)
|
||||
$(if $(KBUILD_OUTPUT),, \
|
||||
$(error failed to create output directory "$(saved-output)"))
|
||||
|
||||
sub-make: FORCE
|
||||
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||
|
||||
skip-makefile := 1
|
||||
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||
endif # ifeq ($(KBUILD_SRC),)
|
||||
```
|
||||
|
||||
We check the `KBUILD_SRC` that represent top directory of the source code of the linux kernel and if it is empty (it is empty every time while makefile executes first time) and the set the `KBUILD_OUTPUT` variable to the value that passed with the `O` option (if this option was passed). In the next step we check this `KBUILD_OUTPUT` variable and if we set it, we do following things:
|
||||
|
||||
* Store value of the `KBUILD_OUTPUT` in the temp `saved-output` variable;
|
||||
* Try to create given output directory;
|
||||
* Check that directory created, in other way print error;
|
||||
* If custom output directory created sucessfully, execute `make` again with the new directory (see `-C` option).
|
||||
|
||||
The next `ifeq` statements checks that `C` or `M` options was passed to the make:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin C)", "command line")
|
||||
KBUILD_CHECKSRC = $(C)
|
||||
endif
|
||||
ifndef KBUILD_CHECKSRC
|
||||
KBUILD_CHECKSRC = 0
|
||||
endif
|
||||
|
||||
ifeq ("$(origin M)", "command line")
|
||||
KBUILD_EXTMOD := $(M)
|
||||
endif
|
||||
```
|
||||
|
||||
The first `C` option tells to the `makefile` that need to check all `c` source code with a tool provided by the `$CHECK` environment variable, by default it is [sparse](https://en.wikipedia.org/wiki/Sparse). The second `M` option provides build for the external modules (will not see this case in this part). As we set this variables we make a check of the `KBUILD_SRC` variable and if it is not set we set `srctree` variable to `.`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
srctree := .
|
||||
endif
|
||||
|
||||
objtree := .
|
||||
src := $(srctree)
|
||||
obj := $(objtree)
|
||||
|
||||
export srctree objtree VPATH
|
||||
```
|
||||
|
||||
That tells to `Makefile` that source tree of the Linux kernel will be in the current directory where `make` command was executed. After this we set `objtree` and other variables to this directory and export these variables. The next step is the getting value for the `SUBARCH` variable that will represent tewhat the underlying archicecture is:
|
||||
|
||||
```Makefile
|
||||
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||
-e s/sun4u/sparc64/ \
|
||||
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||
```
|
||||
|
||||
As you can see it executes [uname](https://en.wikipedia.org/wiki/Uname) utils that prints information about machine, operating system and architecture. As it will get output of the `uname` util, it will parse it and assign to the `SUBARCH` variable. As we got `SUBARCH`, we set the `SRCARCH` variable that provides directory of the certain architecture and `hfr-arch` that provides directory for the header files:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(ARCH),i386)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
ifeq ($(ARCH),x86_64)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
|
||||
hdr-arch := $(SRCARCH)
|
||||
```
|
||||
|
||||
Note that `ARCH` is the alias for the `SUBARCH`. In the next step we set the `KCONFIG_CONFIG` variable that represents path to the kernel configuration file and if it was not set before, it will be `.config` by default:
|
||||
|
||||
```Makefile
|
||||
KCONFIG_CONFIG ?= .config
|
||||
export KCONFIG_CONFIG
|
||||
```
|
||||
|
||||
and the [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29) that will be used during kernel compilation:
|
||||
|
||||
```Makefile
|
||||
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||
else echo sh; fi ; fi)
|
||||
```
|
||||
|
||||
The next set of variables related to the compiler that will be used during Linux kernel compilation. We set the host compilers for the `c` and `c++` and flags for it:
|
||||
|
||||
```Makefile
|
||||
HOSTCC = gcc
|
||||
HOSTCXX = g++
|
||||
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||
HOSTCXXFLAGS = -O2
|
||||
```
|
||||
|
||||
Next we will meet the `CC` variable that represent compiler too, so why do we need in the `HOST*` variables? The `CC` is the target compiler that will be used during kernel compilation, but `HOSTCC` will be used during compilation of the set of the `host` programs (we will see it soon). After this we can see definition of the `KBUILD_MODULES` and `KBUILD_BUILTIN` variables that are used for the determination of the what to compile (kernel, modules or both):
|
||||
|
||||
```Makefile
|
||||
KBUILD_MODULES :=
|
||||
KBUILD_BUILTIN := 1
|
||||
|
||||
ifeq ($(MAKECMDGOALS),modules)
|
||||
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||
endif
|
||||
```
|
||||
|
||||
Here we can see definition of these variables and the value of the `KBUILD_BUILTIN` will depens on the `CONFIG_MODVERSIONS` kernel configuration parameter if we pass only `modules` to the `make`. The next step is including of the:
|
||||
|
||||
```Makefile
|
||||
include scripts/Kbuild.include
|
||||
```
|
||||
|
||||
`kbuild` file. The [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) or `Kernel Build System` is the special infrastructure to manage building of the kernel and its modules. The `kbuild` files has the same syntax that makefiles. The [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) file provides some generic definitions for the `kbuild` system. As we included this `kbuild` files we can see definition of the variables that are related to the different tools that will be used during kernel and modules compilation (like linker, compilers, utils from the [binutils](http://www.gnu.org/software/binutils/) and etc...):
|
||||
|
||||
```Makefile
|
||||
AS = $(CROSS_COMPILE)as
|
||||
LD = $(CROSS_COMPILE)ld
|
||||
CC = $(CROSS_COMPILE)gcc
|
||||
CPP = $(CC) -E
|
||||
AR = $(CROSS_COMPILE)ar
|
||||
NM = $(CROSS_COMPILE)nm
|
||||
STRIP = $(CROSS_COMPILE)strip
|
||||
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||
AWK = awk
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
After definition of these variables we define two variables: `USERINCLUDE` and `LINUXINCLUDE`. They will contain paths of the directories with headers (public for users in the first case and for kernel in the second case):
|
||||
|
||||
```Makefile
|
||||
USERINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||
-I$(srctree)/include/uapi \
|
||||
-Iinclude/generated/uapi \
|
||||
-include $(srctree)/include/linux/kconfig.h
|
||||
|
||||
LINUXINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||
...
|
||||
```
|
||||
|
||||
And the standard flags for the C compiler:
|
||||
|
||||
```Makefile
|
||||
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||
-fno-strict-aliasing -fno-common \
|
||||
-Werror-implicit-function-declaration \
|
||||
-Wno-format-security \
|
||||
-std=gnu89
|
||||
```
|
||||
|
||||
It is the not last compiler flags, they can be updated by the other makefiles (for example kbuilds from `arch/`). After all of these, all variables will be exported to be available in the other makefiles. The following two the `RCS_FIND_IGNORE` and the `RCS_TAR_IGNORE` variables will contain files that will be ignored in the version control system:
|
||||
|
||||
```Makefile
|
||||
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||
-prune -o
|
||||
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||
```
|
||||
|
||||
That's all. We have finished with the all preparations, next point is the building of `vmlinux`.
|
||||
|
||||
Directly to the kernel build
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
As we have finished all preparations, next step in the root makefile is related to the kernel build. Before this moment we will not see in the our terminal after the execution of the `make` command. But now first steps of the compilation are started. In this moment we need to go on the [598](https://github.com/torvalds/linux/blob/master/Makefile#L598) line of the Linux kernel top makefile and we will see `vmlinux` target there:
|
||||
|
||||
```Makefile
|
||||
all: vmlinux
|
||||
include arch/$(SRCARCH)/Makefile
|
||||
```
|
||||
|
||||
Don't worry that we have missed many lines in Makefile that are placed after `export RCS_FIND_IGNORE.....` and before `all: vmlinux.....`. This part of the makefile is responsible for the `make *.config` targets and as I wrote in the beginning of this part we will see only building of the kernel in a general way.
|
||||
|
||||
The `all:` target is the default when no target is given on the command line. You can see here that we include architecture specific makefile there (in our case it will be [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)). From this moment we will continue from this makefile. As we can see `all` target depends on the `vmlinux` target that defined a little lower in the top makefile:
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
```
|
||||
|
||||
The `vmlinux` is is the Linux kernel in an statically linked executable file format. The [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) script links combines different compiled subsystems into vmlinux. The second target is the `vmlinux-deps` that defined as:
|
||||
|
||||
```Makefile
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||
```
|
||||
|
||||
and consists from the set of the `built-in.o` from the each top directory of the Linux kernel. Later, when we will go through all directories in the Linux kernel, the `Kbuild` will compile all the `$(obj-y)` files. It then calls `$(LD) -r` to merge these files into one `built-in.o` file. For this moment we have no `vmlinux-deps`, so the `vmlinux` target will not be executed now. For me `vmlinux-deps` contains following files:
|
||||
|
||||
```
|
||||
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||
init/built-in.o usr/built-in.o
|
||||
arch/x86/built-in.o kernel/built-in.o
|
||||
mm/built-in.o fs/built-in.o
|
||||
ipc/built-in.o security/built-in.o
|
||||
crypto/built-in.o block/built-in.o
|
||||
lib/lib.a arch/x86/lib/lib.a
|
||||
lib/built-in.o arch/x86/lib/built-in.o
|
||||
drivers/built-in.o sound/built-in.o
|
||||
firmware/built-in.o arch/x86/pci/built-in.o
|
||||
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||
net/built-in.o
|
||||
```
|
||||
|
||||
The next target that can be executed is following:
|
||||
|
||||
```Makefile
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
As we can see the `vmlinux-dirs` depends on the two targets: `prepare` and `scripts`. The first `prepare` defined in the top `Makefile` of the Linux kernel and executes three stages of preparations:
|
||||
|
||||
```Makefile
|
||||
prepare: prepare0
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||
|
||||
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||
include/config/auto.conf
|
||||
$(cmd_crmodverdir)
|
||||
prepare2: prepare3 outputmakefile asm-generic
|
||||
```
|
||||
|
||||
The first `prepare0` expands to the `archprepare` that exapnds to the `archheaders` and `archscripts` that defined in the `x86_64` specific [Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile). Let's look on it. The `x86_64` specific makefile starts from the definition of the variables that are related to the archicteture-specific configs ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs) and etc.). After this it defines flags for the compiling of the [16-bit](https://en.wikipedia.org/wiki/Real_mode) code, calculating of the `BITS` variable that can be `32` for `i386` or `64` for the `x86_64` flags for the assembly source code, flags for the linker and many many more (all definitions you can find in the [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)). The first target is `archheaders` in the makefile generates syscall table:
|
||||
|
||||
```Makefile
|
||||
archheaders:
|
||||
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||
```
|
||||
|
||||
And the second target is `archscripts` in this makefile is:
|
||||
|
||||
```Makefile
|
||||
archscripts: scripts_basic
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
We can see that it depends on the `scripts_basic` target from the top [Makefile](https://github.com/torvalds/linux/blob/master/Makefile). At the first we can see the `scripts_basic` target that executes make for the [scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) makefile:
|
||||
|
||||
```Maklefile
|
||||
scripts_basic:
|
||||
$(Q)$(MAKE) $(build)=scripts/basic
|
||||
```
|
||||
|
||||
The `scripts/basic/Makefile` contains targets for compilation of the two host programs: `fixdep` and `bin2`:
|
||||
|
||||
```Makefile
|
||||
hostprogs-y := fixdep
|
||||
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||
always := $(hostprogs-y)
|
||||
|
||||
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||
```
|
||||
|
||||
First program is `fixdep` - optimizes list of dependencies generated by the [gcc](https://gcc.gnu.org/) that tells make when to remake a source code file. The second program is `bin2c` depends on the value of the `CONFIG_BUILD_BIN2C` kernel configuration option and very little C program that allows to convert a binary on stdin to a C include on stdout. You can note here strange notation: `hostprogs-y` and etc. This notation is used in the all `kbuild` files and more about it you can read in the [documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt). In our case the `hostprogs-y` tells to the `kbuild` that there is one host program named `fixdep` that will be built from the will be built from `fixdep.c` that located in the same directory that `Makefile`. The first output after we will execute `make` command in our terminal will be result of this `kbuild` file:
|
||||
|
||||
```
|
||||
$ make
|
||||
HOSTCC scripts/basic/fixdep
|
||||
```
|
||||
|
||||
As `script_basic` target was executed, the `archscripts` target will execute `make` for the [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) makefile with the `relocs` target:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
The `relocs_32.c` and the `relocs_64.c` will be compiled that will contain [relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29) information and we will see it in the `make` output:
|
||||
|
||||
```Makefile
|
||||
HOSTCC arch/x86/tools/relocs_32.o
|
||||
HOSTCC arch/x86/tools/relocs_64.o
|
||||
HOSTCC arch/x86/tools/relocs_common.o
|
||||
HOSTLD arch/x86/tools/relocs
|
||||
```
|
||||
|
||||
There is checking of the `version.h` after compiling of the `relocs.c`:
|
||||
|
||||
```Makefile
|
||||
$(version_h): $(srctree)/Makefile FORCE
|
||||
$(call filechk,version.h)
|
||||
$(Q)rm -f $(old_version_h)
|
||||
```
|
||||
|
||||
We can see it in the output:
|
||||
|
||||
```
|
||||
CHK include/config/kernel.release
|
||||
```
|
||||
|
||||
and the building of the `generic` assembly headers with the `asm-generic` target from the `arch/x86/include/generated/asm` that generated in the top Makefile of the Linux kernel. After the `asm-generic` target the `archprepare` will be done, so the `prepare0` target will be executed. As I wrote above:
|
||||
|
||||
```Makefile
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
```
|
||||
|
||||
Note on the `build`. It defined in the [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) and looks like this:
|
||||
|
||||
```Makefile
|
||||
build := -f $(srctree)/scripts/Makefile.build obj
|
||||
```
|
||||
|
||||
or in our case it is current source directory - `.`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||
```
|
||||
|
||||
The [scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) tries to find the `Kbuild` file by the given directory via the `obj` parameter, include this `Kbuild` files:
|
||||
|
||||
```Makefile
|
||||
include $(kbuild-file)
|
||||
```
|
||||
|
||||
and build targets from it. In our case `.` contains the [Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild) file that generates the `kernel/bounds.s` and the `arch/x86/kernel/asm-offsets.s`. After this the `prepare` target finished to work. The `vmlinux-dirs` also depends on the second target - `scripts` that compiles following programs: `file2alias`, `mk_elfconfig`, `modpost` and etc... After scripts/host-programs compilation our `vmlinux-dirs` target can be executed. First of all let's try to understand what does `vmlinux-dirs` contain. For my case it contains paths of the following kernel directories:
|
||||
|
||||
```
|
||||
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||
drivers sound firmware arch/x86/pci arch/x86/power
|
||||
arch/x86/video net lib arch/x86/lib
|
||||
```
|
||||
|
||||
We can find definition of the `vmlinux-dirs` in the top [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) of the Linux kernel:
|
||||
|
||||
```Makefile
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
Here we remove the `/` symbol from the each directory with the help of the `patsubst` and `filter` functions and put it to the `vmlinux-dirs`. So we have list of directories in the `vmlinux-dirs` and the following code:
|
||||
|
||||
```Makefile
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
The `$@` represents `vmlinux-dirs` here that means that it will go recursively over all directories from the `vmlinux-dirs` and its internal directories (depens on configuration) and will execute `make` in there. We can see it in the output:
|
||||
|
||||
```
|
||||
CC init/main.o
|
||||
CHK include/generated/compile.h
|
||||
CC init/version.o
|
||||
CC init/do_mounts.o
|
||||
...
|
||||
CC arch/x86/crypto/glue_helper.o
|
||||
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||
CC arch/x86/crypto/aes_glue.o
|
||||
...
|
||||
AS arch/x86/entry/entry_64.o
|
||||
AS arch/x86/entry/thunk_64.o
|
||||
CC arch/x86/entry/syscall_64.o
|
||||
```
|
||||
|
||||
Source code in each directory will be compiled and linked to the `built-in.o`:
|
||||
|
||||
```
|
||||
$ find . -name built-in.o
|
||||
./arch/x86/crypto/built-in.o
|
||||
./arch/x86/crypto/sha-mb/built-in.o
|
||||
./arch/x86/net/built-in.o
|
||||
./init/built-in.o
|
||||
./usr/built-in.o
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
Ok, all buint-in.o(s) built, now we can back to the `vmlinux` target. As you remember, the `vmlinux` target is in the top Makefile of the Linux kernel. Before the linking of the `vmlinux` it builds [samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation) and etc., but I will not describe it in this part as I wrote in the beginning of this part.
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
...
|
||||
...
|
||||
+$(call if_changed,link-vmlinux)
|
||||
```
|
||||
|
||||
As you can see main purpose of it is a call of the [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) script is linking of the all `built-in.o`(s) to the one statically linked executable and creation of the [System.map](https://en.wikipedia.org/wiki/System.map). In the end we will see following output:
|
||||
|
||||
```
|
||||
LINK vmlinux
|
||||
LD vmlinux.o
|
||||
MODPOST vmlinux.o
|
||||
GEN .version
|
||||
CHK include/generated/compile.h
|
||||
UPD include/generated/compile.h
|
||||
CC init/version.o
|
||||
LD init/built-in.o
|
||||
KSYM .tmp_kallsyms1.o
|
||||
KSYM .tmp_kallsyms2.o
|
||||
LD vmlinux
|
||||
SORTEX vmlinux
|
||||
SYSMAP System.map
|
||||
```
|
||||
|
||||
and `vmlinux` and `System.map` in the root of the Linux kernel source tree:
|
||||
|
||||
```
|
||||
$ ls vmlinux System.map
|
||||
System.map vmlinux
|
||||
```
|
||||
|
||||
That's all, `vmlinux` is ready. The next step is creation of the [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
Building bzImage
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
The `bzImage` is the compressed Linux kernel image. We can get it with the execution of the `make bzImage` after the `vmlinux` built. In other way we can just execute `make` without arguments and will get `bzImage` anyway because it is default image:
|
||||
|
||||
```Makefile
|
||||
all: bzImage
|
||||
```
|
||||
|
||||
in the [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile). Let's look on this target, it will help us to understand how this image builds. As I already said the `bzImage` target defined in the [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) and looks like this:
|
||||
|
||||
```Makefile
|
||||
bzImage: vmlinux
|
||||
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||
```
|
||||
|
||||
We can see here, that first of all called `make` for the boot directory, in our case it is:
|
||||
|
||||
```Makefile
|
||||
boot := arch/x86/boot
|
||||
```
|
||||
|
||||
The main goal now to build source code in the `arch/x86/boot` and `arch/x86/boot/compressed` directories, build `setup.bin` and `vmlinux.bin`, and build the `bzImage` from they in the end. First target in the [arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) is the `$(obj)/setup.elf`:
|
||||
|
||||
```Makefile
|
||||
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||
$(call if_changed,ld)
|
||||
```
|
||||
|
||||
We already have the `setup.ld` linker script in the `arch/x86/boot` directory and the `SETUP_OBJS` expands to the all source files from the `boot` directory. We can see first output:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/bioscall.o
|
||||
CC arch/x86/boot/cmdline.o
|
||||
AS arch/x86/boot/copy.o
|
||||
HOSTCC arch/x86/boot/mkcpustr
|
||||
CPUSTR arch/x86/boot/cpustr.h
|
||||
CC arch/x86/boot/cpu.o
|
||||
CC arch/x86/boot/cpuflags.o
|
||||
CC arch/x86/boot/cpucheck.o
|
||||
CC arch/x86/boot/early_serial_console.o
|
||||
CC arch/x86/boot/edd.o
|
||||
```
|
||||
|
||||
The next source code file is the [arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S), but we can't build it now because this target depends on the following two header files:
|
||||
|
||||
```Makefile
|
||||
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||
```
|
||||
|
||||
The first is `voffset.h` generated by the `sed` script that gets two addresses from the `vmlinux` with the `nm` util:
|
||||
|
||||
```C
|
||||
#define VO__end 0xffffffff82ab0000
|
||||
#define VO__text 0xffffffff81000000
|
||||
```
|
||||
|
||||
They are start and end of the kernel. The second is `zoffset.h` depens on the `vmlinux` target from the [arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile):
|
||||
|
||||
```Makefile
|
||||
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||
$(call if_changed,zoffset)
|
||||
```
|
||||
|
||||
The `$(obj)/compressed/vmlinux` target depends on the `vmlinux-objs-y` that compiles source code files from the [arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) directory and generates `vmlinux.bin`, `vmlinux.bin.bz2`, and compiles programm - `mkpiggy`. We can see this in the output:
|
||||
|
||||
```Makefile
|
||||
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||
AS arch/x86/boot/compressed/head_64.o
|
||||
CC arch/x86/boot/compressed/misc.o
|
||||
CC arch/x86/boot/compressed/string.o
|
||||
CC arch/x86/boot/compressed/cmdline.o
|
||||
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||
```
|
||||
|
||||
Where the `vmlinux.bin` is the `vmlinux` with striped debuging information and comments and the `vmlinux.bin.bz2` compressed `vmlinux.bin.all` + `u32` size of `vmlinux.bin.all`. The `vmlinux.bin.all` is `vmlinux.bin + vmlinux.relocs`, where `vmlinux.relocs` is the `vmlinux` that was handled by the `relocs` program (see above). As we got these files, the `piggy.S` assembly files will be generated with the `mkpiggy` program and compiled:
|
||||
|
||||
```Makefile
|
||||
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||
AS arch/x86/boot/compressed/piggy.o
|
||||
```
|
||||
|
||||
This assembly files will contain computed offset from a compressed kernel. After this we can see that `zoffset` generated:
|
||||
|
||||
```Makefile
|
||||
ZOFFSET arch/x86/boot/zoffset.h
|
||||
```
|
||||
|
||||
As the `zoffset.h` and the `voffset.h` are generated, compilation of the source code files from the [arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) can be continued:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/header.o
|
||||
CC arch/x86/boot/main.o
|
||||
CC arch/x86/boot/mca.o
|
||||
CC arch/x86/boot/memory.o
|
||||
CC arch/x86/boot/pm.o
|
||||
AS arch/x86/boot/pmjump.o
|
||||
CC arch/x86/boot/printf.o
|
||||
CC arch/x86/boot/regs.o
|
||||
CC arch/x86/boot/string.o
|
||||
CC arch/x86/boot/tty.o
|
||||
CC arch/x86/boot/video.o
|
||||
CC arch/x86/boot/video-mode.o
|
||||
CC arch/x86/boot/video-vga.o
|
||||
CC arch/x86/boot/video-vesa.o
|
||||
CC arch/x86/boot/video-bios.o
|
||||
```
|
||||
|
||||
As all source code files will be compiled, they will be linked to the `setup.elf`:
|
||||
|
||||
```Makefile
|
||||
LD arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
or:
|
||||
|
||||
```
|
||||
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
The last two things is the creation of the `setup.bin` that will contain compiled code from the `arch/x86/boot/*` directory:
|
||||
|
||||
```
|
||||
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||
```
|
||||
|
||||
and the creation of the `vmlinux.bin` from the `vmlinux`:
|
||||
|
||||
```
|
||||
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||
```
|
||||
|
||||
In the end we compile host program: [arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c) that will create our `bzImage` from the `setup.bin` and the `vmlinux.bin`:
|
||||
|
||||
```
|
||||
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||
```
|
||||
|
||||
Actually the `bzImage` is the concatenated `setup.bin` and the `vmlinux.bin`. In the end we will see the output which familiar to all who once build the Linux kernel from source:
|
||||
|
||||
```
|
||||
Setup is 16268 bytes (padded to 16384 bytes).
|
||||
System is 4704 kB
|
||||
CRC 94a88f9a
|
||||
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||
```
|
||||
|
||||
That's all.
|
||||
|
||||
Conclusion
|
||||
================================================================================
|
||||
|
||||
It is the end of this part and here we saw all steps from the execution of the `make` command to the generation of the `bzImage`. I know, the Linux kernel makefiles and process of the Linux kernel building may seem confusing at first glance, but it is not so hard. Hope this part will help you to understand process of the Linux kernel building.
|
||||
|
||||
Links
|
||||
================================================================================
|
||||
|
||||
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||
* [binutils](http://www.gnu.org/software/binutils/)
|
||||
* [gcc](https://gcc.gnu.org/)
|
||||
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,47 +0,0 @@
|
||||
How To Add Hindi And Devanagari Support In Antergos And Arch Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
You might be knowing by now that I have been trying my hands on [Antergos Linux][1] lately. One of the first few things I noticed after installing [Antergos][2] was that **Hindi scripts were not displayed properly** in the default chromium browser.
|
||||
|
||||
This is a strange thing that I never encountered before in my desktop Linux experience ever. First, I thought maybe it could be a browser problem so I went on to install Firefox only to see the same story repeated. Firefox also could not display Hindi properly. Unlike Chromium that displayed nothing, Firefox did display something but it was not readable.
|
||||
|
||||

|
||||
|
||||
Hindi display in Chromium
|
||||
|
||||

|
||||
|
||||
Hindi display in Firefox
|
||||
|
||||
Strange? So no Hindi support in Arch based Antergos Linux by default? I did not verify, but I presume that it would be the same for other Indian languages etc that are also based on Devanagari script.
|
||||
|
||||
I this quick tutorial, I am going to show you how to add Devanagari support so that Hindi and other Indian languages are displayed properly.
|
||||
|
||||
### Add Indian language support in Antergos and Arch Linux ###
|
||||
|
||||
Open a terminal and use the following command:
|
||||
|
||||
sudo yaourt -S ttf-indic-otf
|
||||
|
||||
Enter the password. And it will provide rendering support for Indian languages.
|
||||
|
||||
Restarting Firefox displayed Hindi correctly immediately, but it took a restart to display Hindi. For that reason, I advise that you **restart your system** after installing the Indian fonts.
|
||||
|
||||

|
||||
|
||||
I hope tis quick helped you to read Hindi, Sanskrit, Tamil, Telugu, Malayalam, Bangla and other Indian languages in Antergos and other Arch based Linux distros such as Manjaro Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/display-hindi-arch-antergos/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://antergos.com/
|
||||
[2]:http://itsfoss.com/tag/antergos/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by GOLinux!
|
||||
Mhddfs – Combine Several Smaller Partition into One Large Virtual Storage
|
||||
================================================================================
|
||||
Let’s assume that you have 30GB of movies and you have 3 drives each 20 GB in size. So how will you store?
|
||||
@ -183,4 +184,4 @@ via: http://www.tecmint.com/combine-partitions-into-one-in-linux-using-mhddfs/
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/mount-filesystem-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
How to Run Kali Linux 2.0 In Docker Container
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
Kali Linux is a well known operating system for security testers and ethical hackers. It comes bundled with a large list of security related applications and make it easy to perform penetration testing. Recently, [Kali Linux 2.0][1] is out and it is being considered as one of the most important release for this operating system. On the other hand, Docker technology is getting massive popularity due to its scalability and ease of use. Dockers make it super easy to ship your software applications to your users. Breaking news is that you can now run Kali Linux via Dockers; let’s see how :)
|
||||
|
||||
### Running Kali Linux 2.0 In Docker ###
|
||||
|
||||
**Related Notes**
|
||||
|
||||
If you don’t have docker installed on your system, you can do it by using the following commands:
|
||||
|
||||
**For Ubuntu/Linux Mint/Debian:**
|
||||
|
||||
sudo apt-get install docker
|
||||
|
||||
**For Fedora/RHEL/CentOS:**
|
||||
|
||||
sudo yum install docker
|
||||
|
||||
**For Fedora 22:**
|
||||
|
||||
dnf install docker
|
||||
|
||||
You can start docker service by running:
|
||||
|
||||
sudo docker start
|
||||
|
||||
First of all make sure that docker service is running fine by using the following command:
|
||||
|
||||
sudo docker status
|
||||
|
||||
Kali Linux docker image has been uploaded online by Kali Linux development team, simply run following command to download this image to your system.
|
||||
|
||||
docker pull kalilinux/kali-linux-docker
|
||||
|
||||

|
||||
|
||||
Once download is complete, run following command to find out the Image ID for your downloaded Kali Linux docker image file.
|
||||
|
||||
docker images
|
||||
|
||||

|
||||
|
||||
Now run following command to start your kali Linux docker container from image file (Here replace Image ID with correct one).
|
||||
|
||||
docker run -i -t 198cd6df71ab3 /bin/bash
|
||||
|
||||
It will immediately start the container and will log you into the operating system, you can start working on Kali Linux here.
|
||||
|
||||

|
||||
|
||||
You can verify that container is started/running fine, by using the following command:
|
||||
|
||||
docker ps
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Dockers are the smartest way to deploy and distribute your packages. Kali Linux docker image is pretty handy, does not consume any high amount of space on the disk and it is pretty easy to test this wonderful distro on any docker installed operating system now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/run-kali-linux-2-0-in-docker-container/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
[1]:http://linuxpitstop.com/install-kali-linux-2-0/
|
||||
@ -0,0 +1,294 @@
|
||||
How to set up a system status page of your infrastructure
|
||||
================================================================================
|
||||
If you are a system administrator who is responsible for critical IT infrastructure or services of your organization, you will understand the importance of effective communication in your day-to-day tasks. Suppose your production storage server is on fire. You want your entire team on the same page in order to resolve the issue as fast as you can. While you are at it, you don't want half of all users contacting you asking why they cannot access their documents. When a scheduled maintenance is coming up, you want to notify interested parties of the event ahead of the schedule, so that unnecessary support tickets can be avoided.
|
||||
|
||||
All these require some sort of streamlined communication channel between you, your team and people you serve. One way to achieve that is to maintain a centralized system status page, where the detail of downtime incidents, progress updates and maintenance schedules are reported and chronicled. That way, you can minimize unnecessary distractions during downtime, and also have any interested party informed and opt-in for any status update.
|
||||
|
||||
One good **open-source, self-hosted system status page solution** is [Cachet][1]. In this tutorial, I am going to describe how to set up a self-hosted system status page using Cachet.
|
||||
|
||||
### Cachet Features ###
|
||||
|
||||
Before going into the detail of setting up Cachet, let me briefly introduce its main features.
|
||||
|
||||
- **Full JSON API**: The Cachet API allows you to connect any external program or script (e.g., uptime script) to Cachet to report incidents or update status automatically.
|
||||
- **Authentication**: Cachet supports Basic Auth and API token in JSON API, so that only authorized personnel can update the status page.
|
||||
- **Metrics system**: This is useful to visualize custom data over time (e.g., server load or response time).
|
||||
- **Notification**: Optionally you can send notification emails about reported incidents to anyone who signed up to the status page.
|
||||
- **Multiple languages**: The status page can be translated into 11 different languages.
|
||||
- **Two factor authentication**: This allows you to lock your Cachet admin account with Google's two-factor authentication.
|
||||
- **Cross database support**: You can choose between MySQL, SQLite, Redis, APC, and PostgreSQL for a backend storage.
|
||||
|
||||
In the rest of the tutorial, I explain how to install and configure Cachet on Linux.
|
||||
|
||||
### Step One: Download and Install Cachet ###
|
||||
|
||||
Cachet requires a web server and a backend database to operate. In this tutorial, I am going to use the LAMP stack. Here are distro-specific instructions to install Cachet and LAMP stack.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo apt-get install curl git apache2 mysql-server mysql-client php5 php5-mysql
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R www-data:www-data .
|
||||
|
||||
For more detail on setting up LAMP stack on Debian-based systems, refer to [this tutorial][2].
|
||||
|
||||
#### Fedora, CentOS or RHEL ####
|
||||
|
||||
On Red Hat based systems, you first need to [enable REMI repository][3] (to meet PHP version requirement). Then proceed as follows.
|
||||
|
||||
$ sudo yum install curl git httpd mariadb-server
|
||||
$ sudo yum --enablerepo=remi-php56 install php php-mysql php-mbstring
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R apache:apache .
|
||||
$ sudo firewall-cmd --permanent --zone=public --add-service=http
|
||||
$ sudo firewall-cmd --reload
|
||||
$ sudo systemctl enable httpd.service; sudo systemctl start httpd.service
|
||||
$ sudo systemctl enable mariadb.service; sudo systemctl start mariadb.service
|
||||
|
||||
For more details on setting up LAMP on Red Hat-based systems, refer to [this tutorial][4].
|
||||
|
||||
### Configure a Backend Database for Cachet ###
|
||||
|
||||
The next step is to configure database backend.
|
||||
|
||||
Log in to MySQL/MariaDB server, and create an empty database called 'cachet'.
|
||||
|
||||
$ sudo mysql -uroot -p
|
||||
|
||||
----------
|
||||
|
||||
mysql> create database cachet;
|
||||
mysql> quit
|
||||
|
||||
Now create a Cachet configuration file by using a sample configuration file.
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo mv .env.example .env
|
||||
|
||||
In .env file, fill in database information (i.e., DB_*) according to your setup. Leave other fields unchanged for now.
|
||||
|
||||
APP_ENV=production
|
||||
APP_DEBUG=false
|
||||
APP_URL=http://localhost
|
||||
APP_KEY=SomeRandomString
|
||||
|
||||
DB_DRIVER=mysql
|
||||
DB_HOST=localhost
|
||||
DB_DATABASE=cachet
|
||||
DB_USERNAME=root
|
||||
DB_PASSWORD=<root-password>
|
||||
|
||||
CACHE_DRIVER=apc
|
||||
SESSION_DRIVER=apc
|
||||
QUEUE_DRIVER=database
|
||||
|
||||
MAIL_DRIVER=smtp
|
||||
MAIL_HOST=mailtrap.io
|
||||
MAIL_PORT=2525
|
||||
MAIL_USERNAME=null
|
||||
MAIL_PASSWORD=null
|
||||
MAIL_ADDRESS=null
|
||||
MAIL_NAME=null
|
||||
|
||||
REDIS_HOST=null
|
||||
REDIS_DATABASE=null
|
||||
REDIS_PORT=null
|
||||
|
||||
### Step Three: Install PHP Dependencies and Perform DB Migration ###
|
||||
|
||||
Next, we are going to install necessary PHP dependencies. For that we will use composer. If you do not have composer installed on your system, install it first:
|
||||
|
||||
$ curl -sS https://getcomposer.org/installer | sudo php -- --install-dir=/usr/local/bin --filename=composer
|
||||
|
||||
Now go ahead and install PHP dependencies using composer.
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo composer install --no-dev -o
|
||||
|
||||
Next, perform one-time database migration. This step will populate the empty database we created earlier with necessary tables.
|
||||
|
||||
$ sudo php artisan migrate
|
||||
|
||||
Assuming the database config in /var/www/cachet/.env is correct, database migration should be completed successfully as shown below.
|
||||
|
||||
|
||||
|
||||
Next, create a security key, which will be used to encrypt the data entered in Cachet.
|
||||
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
|
||||
|
||||
The generated app key will be automatically added to the APP_KEY variable of your .env file. No need to edit .env on your own here.
|
||||
|
||||
### Step Four: Configure Apache HTTP Server ###
|
||||
|
||||
Now it's time to configure the web server that Cachet will be running on. As we are using Apache HTTP server, create a new [virtual host][5] for Cachet as follows.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo vi /etc/apache2/sites-available/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
Enable the new Virtual Host and mod_rewrite with:
|
||||
|
||||
$ sudo a2ensite cachet.conf
|
||||
$ sudo a2enmod rewrite
|
||||
$ sudo service apache2 restart
|
||||
|
||||
#### Fedora, CentOS or RHEL ####
|
||||
|
||||
On Red Hat based systems, create a virtual host file as follows.
|
||||
|
||||
$ sudo vi /etc/httpd/conf.d/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
Now reload Apache configuration:
|
||||
|
||||
$ sudo systemctl reload httpd.service
|
||||
|
||||
### Step Five: Configure /etc/hosts for Testing Cachet ###
|
||||
|
||||
At this point, the initial Cachet status page should be up and running, and now it's time to test.
|
||||
|
||||
Since Cachet is configured as a virtual host of Apache HTTP server, we need to tweak /etc/hosts of your client computer to be able to access it. Here the client computer is the one from which you will be accessing the Cachet page.
|
||||
|
||||
Open /etc/hosts, and add the following entry.
|
||||
|
||||
$ sudo vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
<cachet-server-ip-address> cachethost
|
||||
|
||||
In the above, the name "cachethost" must match with ServerName specified in the Apache virtual host file for Cachet.
|
||||
|
||||
### Test Cachet Status Page ###
|
||||
|
||||
Now you are ready to access Cachet status page. Type http://cachethost in your browser address bar. You will be redirected to the initial Cachet setup page as follows.
|
||||
|
||||
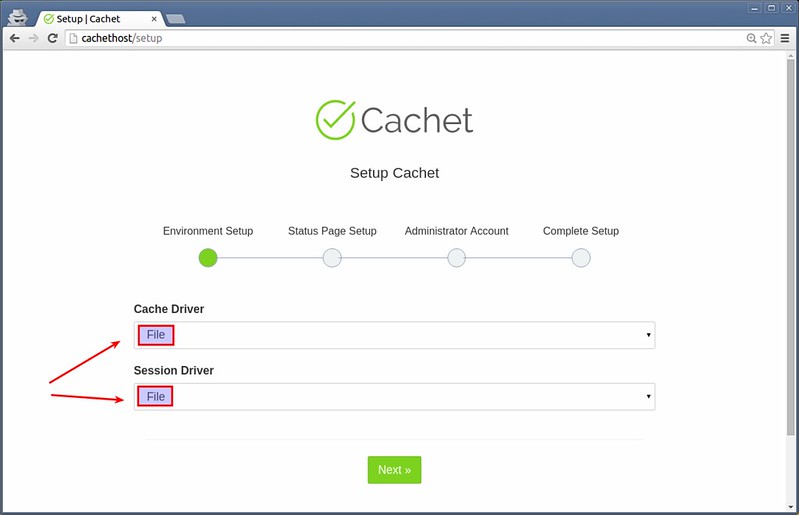
|
||||
|
||||
Choose cache/session driver. Here let's choose "File" for both cache and session drivers.
|
||||
|
||||
Next, type basic information about the status page (e.g., site name, domain, timezone and language), as well as administrator account.
|
||||
|
||||
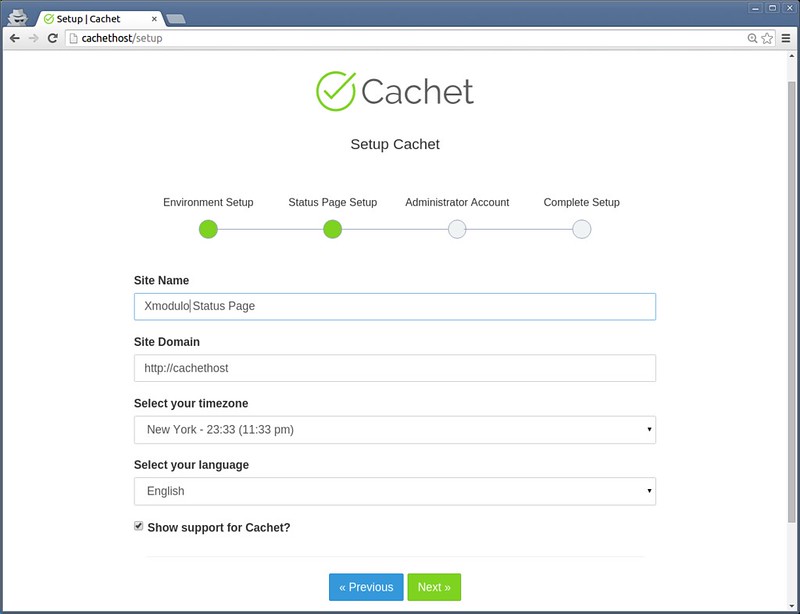
|
||||
|
||||
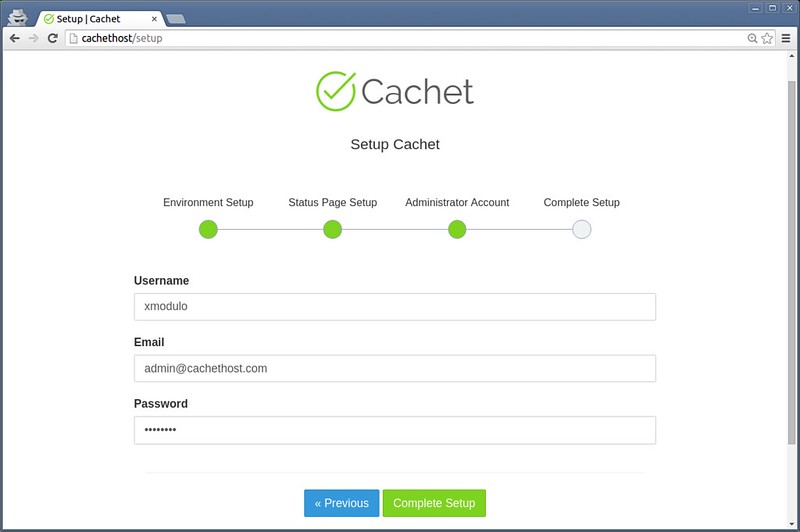
|
||||
|
||||
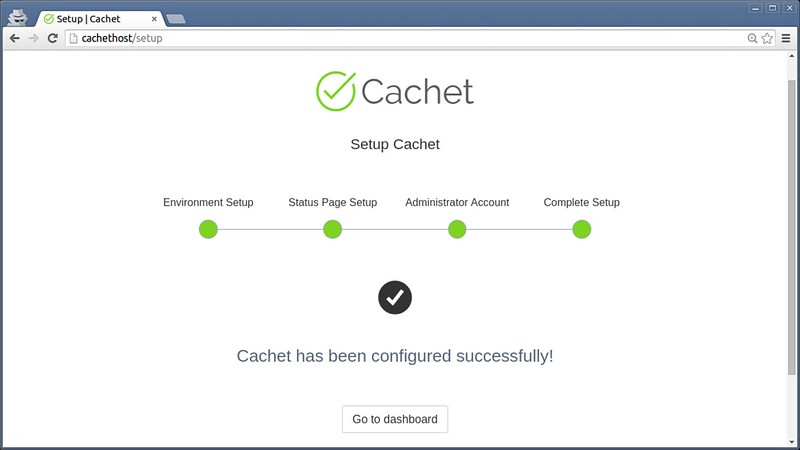
|
||||
|
||||
Your initial status page will finally be ready.
|
||||
|
||||
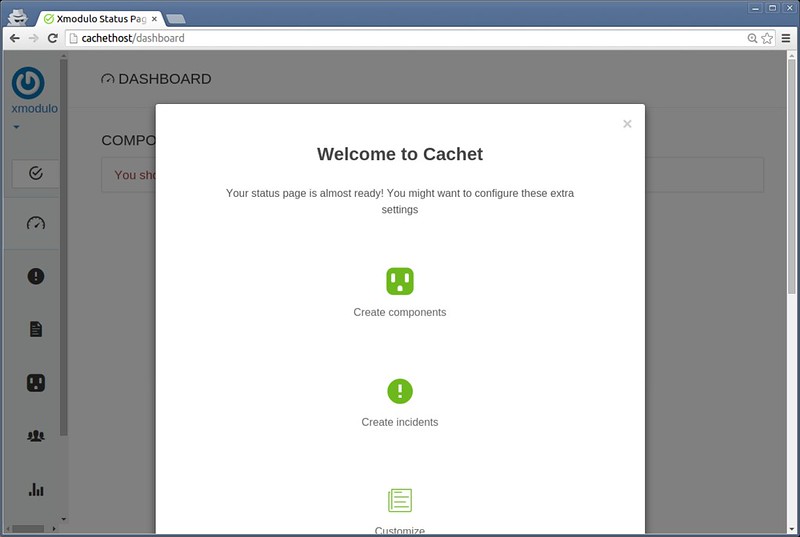
|
||||
|
||||
Go ahead and create components (units of your system), incidents or any scheduled maintenance as you want.
|
||||
|
||||
For example, to add a new component:
|
||||
|
||||
|
||||
|
||||
To add a scheduled maintenance:
|
||||
|
||||
This is what the public Cachet status page looks like:
|
||||
|
||||
|
||||
|
||||
With SMTP integration, you can send out emails on status updates to any subscribers. Also, you can fully customize the layout and style of the status page using CSS and markdown formatting.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Cachet is pretty easy-to-use, self-hosted status page software. One of the nicest features of Cachet is its support for full JSON API. Using its RESTful API, one can easily hook up Cachet with separate monitoring backends (e.g., [Nagios][6]), and feed Cachet with incident reports and status updates automatically. This is far quicker and efficient than manually manage a status page.
|
||||
|
||||
As final words, I'd like to mention one thing. While setting up a fancy status page with Cachet is straightforward, making the best use of the software is not as easy as installing it. You need total commitment from the IT team on updating the status page in an accurate and timely manner, thereby building credibility of the published information. At the same time, you need to educate users to turn to the status page. At the end of the day, it would be pointless to set up a status page if it's not populated well, and/or no one is checking it. Remember this when you consider deploying Cachet in your work environment.
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
As a bonus, here are some useful troubleshooting tips in case you encounter problems while setting up Cachet.
|
||||
|
||||
1. The Cachet page does not load anything, and you are getting the following error.
|
||||
|
||||
production.ERROR: exception 'RuntimeException' with message 'No supported encrypter found. The cipher and / or key length are invalid.' in /var/www/cachet/bootstrap/cache/compiled.php:6695
|
||||
|
||||
**Solution**: Make sure that you create an app key, as well as clear configuration cache as follows.
|
||||
|
||||
$ cd /path/to/cachet
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
2. You are getting the following error while invoking composer command.
|
||||
|
||||
- danielstjules/stringy 1.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- laravel/framework v5.1.8 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- league/commonmark 0.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
|
||||
**Solution**: Make sure to install the required PHP extension mbstring on your system which is compatible with your PHP. On Red Hat based system, since we installed PHP from REMI-56 repository, we install the extension from the same repository.
|
||||
|
||||
$ sudo yum --enablerepo=remi-php56 install php-mbstring
|
||||
|
||||
3. You are getting a blank page while trying to access Cachet status page. The HTTP log shows the following error.
|
||||
|
||||
PHP Fatal error: Uncaught exception 'UnexpectedValueException' with message 'The stream or file "/var/www/cachet/storage/logs/laravel-2015-08-21.log" could not be opened: failed to open stream: Permission denied' in /var/www/cachet/bootstrap/cache/compiled.php:12851
|
||||
|
||||
**Solution**: Try the following commands.
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo php artisan cache:clear
|
||||
$ sudo chmod -R 777 storage
|
||||
$ sudo composer dump-autoload
|
||||
|
||||
If the above solution does not work, try disabling SELinux:
|
||||
|
||||
$ sudo setenforce 0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-system-status-page.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://cachethq.io/
|
||||
[2]:http://xmodulo.com/install-lamp-stack-ubuntu-server.html
|
||||
[3]:http://ask.xmodulo.com/install-remi-repository-centos-rhel.html
|
||||
[4]:http://xmodulo.com/install-lamp-stack-centos.html
|
||||
[5]:http://xmodulo.com/configure-virtual-hosts-apache-http-server.html
|
||||
[6]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 1 - LFCS: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
================================================================================
|
||||
The Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, a new program that aims at helping individuals all over the world to get certified in basic to intermediate system administration tasks for Linux systems. This includes supporting running systems and services, along with first-hand troubleshooting and analysis, and smart decision-making to escalate issues to engineering teams.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 10 - LFCS: Understanding & Learning Basic Shell Scripting and Linux Filesystem Troubleshooting
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new initiative whose purpose is to allow individuals everywhere (and anywhere) to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
@ -99,10 +101,10 @@ Execute Script
|
||||
|
||||
Whenever you need to specify different courses of action to be taken in a shell script, as result of the success or failure of a command, you will use the if construct to define such conditions. Its basic syntax is:
|
||||
|
||||
if CONDITION; then
|
||||
if CONDITION; then
|
||||
COMMANDS;
|
||||
else
|
||||
OTHER-COMMANDS
|
||||
OTHER-COMMANDS
|
||||
fi
|
||||
|
||||
Where CONDITION can be one of the following (only the most frequent conditions are cited here) and evaluates to true when:
|
||||
@ -133,8 +135,8 @@ Where CONDITION can be one of the following (only the most frequent conditions a
|
||||
|
||||
This loop allows to execute one or more commands for each value in a list of values. Its basic syntax is:
|
||||
|
||||
for item in SEQUENCE; do
|
||||
COMMANDS;
|
||||
for item in SEQUENCE; do
|
||||
COMMANDS;
|
||||
done
|
||||
|
||||
Where item is a generic variable that represents each value in SEQUENCE during each iteration.
|
||||
@ -143,8 +145,8 @@ Where item is a generic variable that represents each value in SEQUENCE during e
|
||||
|
||||
This loop allows to execute a series of repetitive commands as long as the control command executes with an exit status equal to zero (successfully). Its basic syntax is:
|
||||
|
||||
while EVALUATION_COMMAND; do
|
||||
EXECUTE_COMMANDS;
|
||||
while EVALUATION_COMMAND; do
|
||||
EXECUTE_COMMANDS;
|
||||
done
|
||||
|
||||
Where EVALUATION_COMMAND can be any command(s) that can exit with a success (0) or failure (other than 0) status, and EXECUTE_COMMANDS can be any program, script or shell construct, including other nested loops.
|
||||
@ -158,7 +160,7 @@ We will demonstrate the use of the if construct and the for loop with the follow
|
||||
Let’s create a file with a list of services that we want to monitor at a glance.
|
||||
|
||||
# cat myservices.txt
|
||||
|
||||
|
||||
sshd
|
||||
mariadb
|
||||
httpd
|
||||
@ -172,10 +174,10 @@ Script to Monitor Linux Services
|
||||
Our shell script should look like.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
# This script iterates over a list of services and
|
||||
# is used to determine whether they are running or not.
|
||||
|
||||
|
||||
for service in $(cat myservices.txt); do
|
||||
systemctl status $service | grep --quiet "running"
|
||||
if [ $? -eq 0 ]; then
|
||||
@ -214,10 +216,10 @@ Services Monitoring Script
|
||||
We could go one step further and check for the existence of myservices.txt before even attempting to enter the for loop.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
# This script iterates over a list of services and
|
||||
# is used to determine whether they are running or not.
|
||||
|
||||
|
||||
if [ -f myservices.txt ]; then
|
||||
for service in $(cat myservices.txt); do
|
||||
systemctl status $service | grep --quiet "running"
|
||||
@ -238,9 +240,9 @@ You may want to maintain a list of hosts in a text file and use a script to dete
|
||||
The read shell built-in command tells the while loop to read myhosts line by line and assigns the content of each line to variable host, which is then passed to the ping command.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
# This script is used to demonstrate the use of a while loop
|
||||
|
||||
|
||||
while read host; do
|
||||
ping -c 2 $host
|
||||
done < myhosts
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 2 - LFCS: How to Install and Use vi/vim as a Full Text Editor
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification in order to help individuals from all over the world to verify they are capable of doing basic to intermediate system administration tasks on Linux systems: system support, first-hand troubleshooting and maintenance, plus intelligent decision-making to know when it’s time to raise issues to upper support teams.
|
||||
@ -295,7 +297,7 @@ Vi Search String in File
|
||||
|
||||
c). vi uses a command (similar to sed’s) to perform substitution operations over a range of lines or an entire file. To change the word “old” to “young” for the entire file, we must enter the following command.
|
||||
|
||||
:%s/old/young/g
|
||||
:%s/old/young/g
|
||||
|
||||
**Notice**: The colon at the beginning of the command.
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 3 - LFCS: How to Archive/Compress Files & Directories, Setting File Attributes and Finding Files in Linux
|
||||
================================================================================
|
||||
Recently, the Linux Foundation started the LFCS (Linux Foundation Certified Sysadmin) certification, a brand new program whose purpose is allowing individuals from all corners of the globe to have access to an exam, which if approved, certifies that the person is knowledgeable in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-level troubleshooting and analysis, plus the ability to decide when to escalate issues to engineering teams.
|
||||
@ -178,9 +180,9 @@ List Archive Content
|
||||
|
||||
Run any of the following commands:
|
||||
|
||||
# gzip -d myfiles.tar.gz [#1]
|
||||
# bzip2 -d myfiles.tar.bz2 [#2]
|
||||
# xz -d myfiles.tar.xz [#3]
|
||||
# gzip -d myfiles.tar.gz [#1]
|
||||
# bzip2 -d myfiles.tar.bz2 [#2]
|
||||
# xz -d myfiles.tar.xz [#3]
|
||||
|
||||
Then
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 4 - LFCS: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
|
||||
================================================================================
|
||||
Last August, the Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators to show, through a performance-based exam, that they can perform overall operational support of Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation – if needed – to other support teams.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 5 - LFCS: How to Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is allowing individuals from all corners of the globe to get certified in basic to intermediate system administration tasks for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 6 - LFCS: Assembling Partitions as RAID Devices – Creating & Managing System Backups
|
||||
================================================================================
|
||||
Recently, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification, a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of performing overall operational support on Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation, when required, to other support teams.
|
||||
@ -24,7 +26,7 @@ However, the actual fault-tolerance and disk I/O performance lean on how the har
|
||||
Our tool of choice for creating, assembling, managing, and monitoring our software RAIDs is called mdadm (short for multiple disks admin).
|
||||
|
||||
---------------- Debian and Derivatives ----------------
|
||||
# aptitude update && aptitude install mdadm
|
||||
# aptitude update && aptitude install mdadm
|
||||
|
||||
----------
|
||||
|
||||
@ -34,7 +36,7 @@ Our tool of choice for creating, assembling, managing, and monitoring our softwa
|
||||
----------
|
||||
|
||||
---------------- On openSUSE ----------------
|
||||
# zypper refresh && zypper install mdadm #
|
||||
# zypper refresh && zypper install mdadm #
|
||||
|
||||
#### Assembling Partitions as RAID Devices ####
|
||||
|
||||
@ -55,7 +57,7 @@ Creating RAID Array
|
||||
After creating RAID array, you an check the status of the array using the following commands.
|
||||
|
||||
# cat /proc/mdstat
|
||||
or
|
||||
or
|
||||
# mdadm --detail /dev/md0 [More detailed summary]
|
||||
|
||||

|
||||
@ -203,16 +205,16 @@ The downside of this backup approach is that the image will have the same size a
|
||||
|
||||
# dd if=/dev/sda of=/system_images/sda.img
|
||||
OR
|
||||
--------------------- Alternatively, you can compress the image file ---------------------
|
||||
# dd if=/dev/sda | gzip -c > /system_images/sda.img.gz
|
||||
--------------------- Alternatively, you can compress the image file ---------------------
|
||||
# dd if=/dev/sda | gzip -c > /system_images/sda.img.gz
|
||||
|
||||
**Restoring the backup from the image file**
|
||||
|
||||
# dd if=/system_images/sda.img of=/dev/sda
|
||||
OR
|
||||
|
||||
--------------------- Depending on your choice while creating the image ---------------------
|
||||
gzip -dc /system_images/sda.img.gz | dd of=/dev/sda
|
||||
OR
|
||||
|
||||
--------------------- Depending on your choice while creating the image ---------------------
|
||||
gzip -dc /system_images/sda.img.gz | dd of=/dev/sda
|
||||
|
||||
Method 2: Backup certain files / directories with tar command – already covered in [Part 3][3] of this series. You may consider using this method if you need to keep copies of specific files and directories (configuration files, users’ home directories, and so on).
|
||||
|
||||
@ -247,7 +249,7 @@ Synchronizing remote → local directories over ssh.
|
||||
|
||||
In this case, switch the source and destination directories from the previous example.
|
||||
|
||||
# rsync -avzhe ssh root@remote_host:/remote_directory/ backups
|
||||
# rsync -avzhe ssh root@remote_host:/remote_directory/ backups
|
||||
|
||||
Please note that these are only 3 examples (most frequent cases you’re likely to run into) of the use of rsync. For more examples and usages of rsync commands can be found at the following article.
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 7 - LFCS: Managing System Startup Process and Services (SysVinit, Systemd and Upstart)
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, an exciting new program whose aim is allowing individuals from all ends of the world to get certified in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-hand problem-finding and analysis, plus the ability to decide when to raise issues to engineering teams.
|
||||
@ -267,7 +269,7 @@ Starting Stoping Services
|
||||
|
||||
Under systemd you can enable or disable a service when it boots.
|
||||
|
||||
# systemctl enable [service] # enable a service
|
||||
# systemctl enable [service] # enable a service
|
||||
# systemctl disable [service] # prevent a service from starting at boot
|
||||
|
||||
The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links in the /etc/systemd/system/multi-user.target.wants directory.
|
||||
@ -315,7 +317,7 @@ For example,
|
||||
|
||||
# My test service - Upstart script demo description "Here goes the description of 'My test service'" author "Dave Null <dave.null@example.com>"
|
||||
# Stanzas
|
||||
|
||||
|
||||
#
|
||||
# Stanzas define when and how a process is started and stopped
|
||||
# See a list of stanzas here: http://upstart.ubuntu.com/wiki/Stanzas#respawn
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 8 - LFCS: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
|
||||
================================================================================
|
||||
Last August, the Linux Foundation started the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is to allow individuals everywhere and anywhere take an exam in order to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus intelligent decision-making to be able to decide when it’s necessary to escalate issues to higher level support teams.
|
||||
@ -191,7 +193,7 @@ Thus, any user should have permission to run /bin/passwd, but only root will be
|
||||
|
||||
|
||||
Change User Password
|
||||
|
||||
|
||||
**Understanding Setgid**
|
||||
|
||||
When the setgid bit is set, the effective GID of the real user becomes that of the group owner. Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory. You will most likely use this approach whenever members of a certain group need access to all the files in a directory, regardless of the file owner’s primary group.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 9 - LFCS: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
|
||||
================================================================================
|
||||
Last August, the Linux Foundation announced the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of succeeding at overall operational support for Linux systems. A Linux Foundation Certified Sysadmin has the expertise to ensure effective system support, first-level troubleshooting and monitoring, including finally issue escalation, when needed, to engineering support teams.
|
||||
@ -85,7 +87,7 @@ rpm is the package management system used by Linux Standard Base (LSB)-compliant
|
||||
yum adds the functionality of automatic updates and package management with dependency management to RPM-based systems. As a high-level tool, like apt-get or aptitude, yum works with repositories.
|
||||
|
||||
- Read More: [20 yum Command Examples][4]
|
||||
-
|
||||
-
|
||||
### Common Usage of Low-Level Tools ###
|
||||
|
||||
The most frequent tasks that you will do with low level tools are as follows:
|
||||
@ -155,7 +157,7 @@ The most frequent tasks that you will do with high level tools are as follows.
|
||||
|
||||
aptitude update will update the list of available packages, and aptitude search will perform the actual search for package_name.
|
||||
|
||||
# aptitude update && aptitude search package_name
|
||||
# aptitude update && aptitude search package_name
|
||||
|
||||
In the search all option, yum will search for package_name not only in package names, but also in package descriptions.
|
||||
|
||||
@ -190,8 +192,8 @@ The option remove will uninstall the package but leaving configuration files int
|
||||
# yum erase package_name
|
||||
|
||||
---Notice the minus sign in front of the package that will be uninstalled, openSUSE ---
|
||||
|
||||
# zypper remove -package_name
|
||||
|
||||
# zypper remove -package_name
|
||||
|
||||
Most (if not all) package managers will prompt you, by default, if you’re sure about proceeding with the uninstallation before actually performing it. So read the onscreen messages carefully to avoid running into unnecessary trouble!
|
||||
|
||||
@ -199,7 +201,7 @@ Most (if not all) package managers will prompt you, by default, if you’re sure
|
||||
|
||||
The following command will display information about the birthday package.
|
||||
|
||||
# aptitude show birthday
|
||||
# aptitude show birthday
|
||||
# yum info birthday
|
||||
# zypper info birthday
|
||||
|
||||
|
||||
@ -0,0 +1,166 @@
|
||||
ictlyh Translating
|
||||
Part 5 - How to Manage System Logs (Configure, Rotate and Import Into Database) in RHEL 7
|
||||
================================================================================
|
||||
In order to keep your RHEL 7 systems secure, you need to know how to monitor all of the activities that take place on such systems by examining log files. Thus, you will be able to detect any unusual or potentially malicious activity and perform system troubleshooting or take another appropriate action.
|
||||
|
||||

|
||||
|
||||
RHCE Exam: Manage System LogsUsing Rsyslogd and Logrotate – Part 5
|
||||
|
||||
In RHEL 7, the [rsyslogd][1] daemon is responsible for system logging and reads its configuration from /etc/rsyslog.conf (this file specifies the default location for all system logs) and from files inside /etc/rsyslog.d, if any.
|
||||
|
||||
### Rsyslogd Configuration ###
|
||||
|
||||
A quick inspection of the [rsyslog.conf][2] will be helpful to start. This file is divided into 3 main sections: Modules (since rsyslog follows a modular design), Global directives (used to set global properties of the rsyslogd daemon), and Rules. As you will probably guess, this last section indicates what gets logged or shown (also known as the selector) and where, and will be our focus throughout this article.
|
||||
|
||||
A typical line in rsyslog.conf is as follows:
|
||||
|
||||

|
||||
|
||||
Rsyslogd Configuration
|
||||
|
||||
In the image above, we can see that a selector consists of one or more pairs Facility:Priority separated by semicolons, where Facility describes the type of message (refer to [section 4.1.1 in RFC 3164][3] to see the complete list of facilities available for rsyslog) and Priority indicates its severity, which can be one of the following self-explanatory words:
|
||||
|
||||
- debug
|
||||
- info
|
||||
- notice
|
||||
- warning
|
||||
- err
|
||||
- crit
|
||||
- alert
|
||||
- emerg
|
||||
|
||||
Though not a priority itself, the keyword none means no priority at all of the given facility.
|
||||
|
||||
**Note**: That a given priority indicates that all messages of such priority and above should be logged. Thus, the line in the example above instructs the rsyslogd daemon to log all messages of priority info or higher (regardless of the facility) except those belonging to mail, authpriv, and cron services (no messages coming from this facilities will be taken into account) to /var/log/messages.
|
||||
|
||||
You can also group multiple facilities using the colon sign to apply the same priority to all of them. Thus, the line:
|
||||
|
||||
*.info;mail.none;authpriv.none;cron.none /var/log/messages
|
||||
|
||||
Could be rewritten as
|
||||
|
||||
*.info;mail,authpriv,cron.none /var/log/messages
|
||||
|
||||
In other words, the facilities mail, authpriv, and cron are grouped and the keyword none is applied to the three of them.
|
||||
|
||||
#### Creating a custom log file ####
|
||||
|
||||
To log all daemon messages to /var/log/tecmint.log, we need to add the following line either in rsyslog.conf or in a separate file (easier to manage) inside /etc/rsyslog.d:
|
||||
|
||||
daemon.* /var/log/tecmint.log
|
||||
|
||||
Let’s restart the daemon (note that the service name does not end with a d):
|
||||
|
||||
# systemctl restart rsyslog
|
||||
|
||||
And check the contents of our custom log before and after restarting two random daemons:
|
||||
|
||||

|
||||
|
||||
Create Custom Log File
|
||||
|
||||
As a self-study exercise, I would recommend you play around with the facilities and priorities and either log additional messages to existing log files or create new ones as in the previous example.
|
||||
|
||||
### Rotating Logs using Logrotate ###
|
||||
|
||||
To prevent log files from growing endlessly, the logrotate utility is used to rotate, compress, remove, and alternatively mail logs, thus easing the administration of systems that generate large numbers of log files.
|
||||
|
||||
Logrotate runs daily as a cron job (/etc/cron.daily/logrotate) and reads its configuration from /etc/logrotate.conf and from files located in /etc/logrotate.d, if any.
|
||||
|
||||
As with the case of rsyslog, even when you can include settings for specific services in the main file, creating separate configuration files for each one will help organize your settings better.
|
||||
|
||||
Let’s take a look at a typical logrotate.conf:
|
||||
|
||||

|
||||
|
||||
Logrotate Configuration
|
||||
|
||||
In the example above, logrotate will perform the following actions for /var/loh/wtmp: attempt to rotate only once a month, but only if the file is at least 1 MB in size, then create a brand new log file with permissions set to 0664 and ownership given to user root and group utmp. Next, only keep one archived log, as specified by the rotate directive:
|
||||
|
||||
|
||||
|
||||
Logrotate Logs Monthly
|
||||
|
||||
Let’s now consider another example as found in /etc/logrotate.d/httpd:
|
||||
|
||||

|
||||
|
||||
Rotate Apache Log Files
|
||||
|
||||
You can read more about the settings for logrotate in its man pages ([man logrotate][4] and [man logrotate.conf][5]). Both files are provided along with this article in PDF format for your reading convenience.
|
||||
|
||||
As a system engineer, it will be pretty much up to you to decide for how long logs will be stored and in what format, depending on whether you have /var in a separate partition / logical volume. Otherwise, you really want to consider removing old logs to save storage space. On the other hand, you may be forced to keep several logs for future security auditing according to your company’s or client’s internal policies.
|
||||
|
||||
#### Saving Logs to a Database ####
|
||||
|
||||
Of course examining logs (even with the help of tools such as grep and regular expressions) can become a rather tedious task. For that reason, rsyslog allows us to export them into a database (OTB supported RDBMS include MySQL, MariaDB, PostgreSQL, and Oracle.
|
||||
|
||||
This section of the tutorial assumes that you have already installed the MariaDB server and client in the same RHEL 7 box where the logs are being managed:
|
||||
|
||||
# yum update && yum install mariadb mariadb-server mariadb-client rsyslog-mysql
|
||||
# systemctl enable mariadb && systemctl start mariadb
|
||||
|
||||
Then use the `mysql_secure_installation` utility to set the password for the root user and other security considerations:
|
||||
|
||||

|
||||
|
||||
Secure MySQL Database
|
||||
|
||||
Note: If you don’t want to use the MariaDB root user to insert log messages to the database, you can configure another user account to do so. Explaining how to do that is out of the scope of this tutorial but is explained in detail in [MariaDB knowledge][6] base. In this tutorial we will use the root account for simplicity.
|
||||
|
||||
Next, download the createDB.sql script from [GitHub][7] and import it into your database server:
|
||||
|
||||
# mysql -u root -p < createDB.sql
|
||||
|
||||

|
||||
|
||||
Save Server Logs to Database
|
||||
|
||||
Finally, add the following lines to /etc/rsyslog.conf:
|
||||
|
||||
$ModLoad ommysql
|
||||
$ActionOmmysqlServerPort 3306
|
||||
*.* :ommysql:localhost,Syslog,root,YourPasswordHere
|
||||
|
||||
Restart rsyslog and the database server:
|
||||
|
||||
# systemctl restart rsyslog
|
||||
# systemctl restart mariadb
|
||||
|
||||
#### Querying the Logs using SQL syntax ####
|
||||
|
||||
Now perform some tasks that will modify the logs (like stopping and starting services, for example), then log to your DB server and use standard SQL commands to display and search in the logs:
|
||||
|
||||
USE Syslog;
|
||||
SELECT ReceivedAt, Message FROM SystemEvents;
|
||||
|
||||

|
||||
|
||||
Query Logs in Database
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have explained how to set up system logging, how to rotate logs, and how to redirect the messages to a database for easier search. We hope that these skills will be helpful as you prepare for the [RHCE exam][8] and in your daily responsibilities as well.
|
||||
|
||||
As always, your feedback is more than welcome. Feel free to use the form below to reach us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-linux-system-logs-using-rsyslogd-and-logrotate/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/wp-content/pdf/rsyslogd.pdf
|
||||
[2]:http://www.tecmint.com/wp-content/pdf/rsyslog.conf.pdf
|
||||
[3]:https://tools.ietf.org/html/rfc3164#section-4.1.1
|
||||
[4]:http://www.tecmint.com/wp-content/pdf/logrotate.pdf
|
||||
[5]:http://www.tecmint.com/wp-content/pdf/logrotate.conf.pdf
|
||||
[6]:https://mariadb.com/kb/en/mariadb/create-user/
|
||||
[7]:https://github.com/sematext/rsyslog/blob/master/plugins/ommysql/createDB.sql
|
||||
[8]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
@ -0,0 +1,25 @@
|
||||
Linux 界将出现一个新的文件系统:bcachefs
|
||||
================================================================================
|
||||
这个有 5 年历史,由 Kent Oberstreet 创建,过去属于谷歌的文件系统,最近完成了关键的组件。Bcachefs 文件系统自称其性能和稳定性与 ext4 和 xfs 相同,而其他方面的功能又可以与 btrfs 和 zfs 相媲美。主要特性包括校验、压缩、多设备支持、缓存、快照与其他好用的特性。
|
||||
|
||||
Bcachefs 来自 **bcache**,这是一个块级缓存层,从 bcaceh 到一个功能完整的[写时复制][1]文件系统,堪称是一项质的转变。
|
||||
|
||||
在自己提出问题“为什么要出一个新的文件系统”中,Kent Oberstreet 作了以下回答:当我还在谷歌的时候,我与其他在 bcache 上工作的同事在偶然的情况下意识到我们正在使用的东西可以成为一个成熟文件系统的功能块,我们可以用 bcache 创建一个拥有干净而优雅设计的文件系统,而最重要的一点是,bcachefs 的主要目的就是在性能和稳定性上能与 ext4 和 xfs 匹敌,同时拥有 btrfs 和 zfs 的特性。
|
||||
|
||||
Overstreet 邀请人们在自己的系统上测试 bcachefs,可以通过邮件列表[通告]获取 bcachefs 的操作指南。
|
||||
|
||||
Linux 生态系统中文件系统几乎处于一家独大状态,Fedora 在第 16 版的时候就想用 btrfs 换掉 ext4 作为其默认文件系统,但是到现在(LCTT:都出到 Fedora 22 了)还在使用 ext4。而几乎所有 Debian 系的发行版(Ubuntu、Mint、elementary OS 等)也使用 ext4 作为默认文件系统,并且这些主流的发生版都没有替换默认文件系统的意思。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/08/22/linux-gain-new-file-system-bcachefs/
|
||||
|
||||
作者:[Paul Hill][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/paul_hill/
|
||||
[1]:https://en.wikipedia.org/wiki/Copy-on-write
|
||||
[2]:https://lkml.org/lkml/2015/8/21/22
|
||||
674
translated/tech/20150728 Process of the Linux kernel building.md
Normal file
674
translated/tech/20150728 Process of the Linux kernel building.md
Normal file
@ -0,0 +1,674 @@
|
||||
如何构建Linux 内核
|
||||
================================================================================
|
||||
介绍
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
我不会告诉你怎么在自己的电脑上去构建、安装一个定制化的Linux 内核,这样的[资料](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code) 太多了,它们会对你有帮助。本文会告诉你当你在内核源码路径里敲下`make` 时会发生什么。当我刚刚开始学习内核代码时,[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 是我打开的第一个文件,这个文件看起来真令人害怕 :)。那时候这个[Makefile](https://en.wikipedia.org/wiki/Make_%28software%29) 还只包含了`1591` 行代码,当我开始写本文是,这个[Makefile](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) 已经是第三个候选版本了。
|
||||
|
||||
这个makefile 是Linux 内核代码的根makefile ,内核构建就始于此处。是的,它的内容很多,但是如果你已经读过内核源代码,你就会发现每个包含代码的目录都有一个自己的makefile。当然了,我们不会去描述每个代码文件是怎么编译链接的。所以我们将只会挑选一些通用的例子来说明问题,而你不会在这里找到构建内核的文档、如何整洁内核代码、[tags](https://en.wikipedia.org/wiki/Ctags) 的生成和[交叉编译](https://en.wikipedia.org/wiki/Cross_compiler) 相关的说明,等等。我们将从`make` 开始,使用标准的内核配置文件,到生成了内核镜像[bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage) 结束。
|
||||
|
||||
如果你已经很了解[make](https://en.wikipedia.org/wiki/Make_%28software%29) 工具那是最好,但是我也会描述本文出现的相关代码。
|
||||
|
||||
让我们开始吧
|
||||
|
||||
|
||||
编译内核前的准备
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
在开始编译前要进行很多准备工作。最主要的就是找到并配置好配置文件,`make` 命令要使用到的参数都需要从这些配置文件获取。现在就让我们深入内核的根`makefile` 吧
|
||||
|
||||
内核的根`Makefile` 负责构建两个主要的文件:[vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (内核镜像可执行文件)和模块文件。内核的 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 从此处开始:
|
||||
|
||||
```Makefile
|
||||
VERSION = 4
|
||||
PATCHLEVEL = 2
|
||||
SUBLEVEL = 0
|
||||
EXTRAVERSION = -rc3
|
||||
NAME = Hurr durr I'ma sheep
|
||||
```
|
||||
|
||||
这些变量决定了当前内核的版本,并且被使用在很多不同的地方,比如`KERNELVERSION` :
|
||||
|
||||
```Makefile
|
||||
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||
```
|
||||
|
||||
接下来我们会看到很多`ifeq` 条件判断语句,它们负责检查传给`make` 的参数。内核的`Makefile` 提供了一个特殊的编译选项`make help` ,这个选项可以生成所有的可用目标和一些能传给`make` 的有效的命令行参数。举个例子,`make V=1` 会在构建过程中输出详细的编译信息,第一个`ifeq` 就是检查传递给make的`V=n` 选项。
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin V)", "command line")
|
||||
KBUILD_VERBOSE = $(V)
|
||||
endif
|
||||
ifndef KBUILD_VERBOSE
|
||||
KBUILD_VERBOSE = 0
|
||||
endif
|
||||
|
||||
ifeq ($(KBUILD_VERBOSE),1)
|
||||
quiet =
|
||||
Q =
|
||||
else
|
||||
quiet=quiet_
|
||||
Q = @
|
||||
endif
|
||||
|
||||
export quiet Q KBUILD_VERBOSE
|
||||
```
|
||||
|
||||
如果`V=n` 这个选项传给了`make` ,系统就会给变量`KBUILD_VERBOSE` 选项附上`V` 的值,否则的话`KBUILD_VERBOSE` 就会为`0`。然后系统会检查`KBUILD_VERBOSE` 的值,以此来决定`quiet` 和`Q` 的值。符号`@` 控制命令的输出,如果它被放在一个命令之前,这条命令的执行将会是`CC scripts/mod/empty.o`,而不是`Compiling .... scripts/mod/empty.o`(注:CC 在makefile 中一般都是编译命令)。最后系统仅仅导出所有的变量。下一个`ifeq` 语句检查的是传递给`make` 的选项`O=/dir`,这个选项允许在指定的目录`dir` 输出所有的结果文件:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
|
||||
ifeq ("$(origin O)", "command line")
|
||||
KBUILD_OUTPUT := $(O)
|
||||
endif
|
||||
|
||||
ifneq ($(KBUILD_OUTPUT),)
|
||||
saved-output := $(KBUILD_OUTPUT)
|
||||
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||
&& /bin/pwd)
|
||||
$(if $(KBUILD_OUTPUT),, \
|
||||
$(error failed to create output directory "$(saved-output)"))
|
||||
|
||||
sub-make: FORCE
|
||||
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||
|
||||
skip-makefile := 1
|
||||
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||
endif # ifeq ($(KBUILD_SRC),)
|
||||
```
|
||||
|
||||
系统会检查变量`KBUILD_SRC`,如果他是空的(第一次执行makefile 时总是空的),并且变量`KBUILD_OUTPUT` 被设成了选项`O` 的值(如果这个选项被传进来了),那么这个值就会用来代表内核源码的顶层目录。下一步会检查变量`KBUILD_OUTPUT` ,如果之前设置过这个变量,那么接下来会做以下几件事:
|
||||
|
||||
* 将变量`KBUILD_OUTPUT` 的值保存到临时变量`saved-output`;
|
||||
* 尝试创建输出目录;
|
||||
* 检查创建的输出目录,如果失败了就打印错误;
|
||||
* 如果成功创建了输出目录,那么就在新目录重新执行`make` 命令(参见选项`-C`)。
|
||||
|
||||
下一个`ifeq` 语句会检查传递给make 的选项`C` 和`M`:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin C)", "command line")
|
||||
KBUILD_CHECKSRC = $(C)
|
||||
endif
|
||||
ifndef KBUILD_CHECKSRC
|
||||
KBUILD_CHECKSRC = 0
|
||||
endif
|
||||
|
||||
ifeq ("$(origin M)", "command line")
|
||||
KBUILD_EXTMOD := $(M)
|
||||
endif
|
||||
```
|
||||
|
||||
第一个选项`C` 会告诉`makefile` 需要使用环境变量`$CHECK` 提供的工具来检查全部`c` 代码,默认情况下会使用[sparse](https://en.wikipedia.org/wiki/Sparse)。第二个选项`M` 会用来编译外部模块(本文不做讨论)。因为设置了这两个变量,系统还会检查变量`KBUILD_SRC`,如果`KBUILD_SRC` 没有被设置,系统会设置变量`srctree` 为`.`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
srctree := .
|
||||
endif
|
||||
|
||||
objtree := .
|
||||
src := $(srctree)
|
||||
obj := $(objtree)
|
||||
|
||||
export srctree objtree VPATH
|
||||
```
|
||||
|
||||
这将会告诉`Makefile` 内核的源码树就在执行make 命令的目录。然后要设置`objtree` 和其他变量为执行make 命令的目录,并且将这些变量导出。接着就是要获取`SUBARCH` 的值,这个变量代表了当前的系统架构(注:一般都指CPU 架构):
|
||||
|
||||
```Makefile
|
||||
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||
-e s/sun4u/sparc64/ \
|
||||
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||
```
|
||||
|
||||
如你所见,系统执行[uname](https://en.wikipedia.org/wiki/Uname) 得到机器、操作系统和架构的信息。因为我们得到的是`uname` 的输出,所以我们需要做一些处理在赋给变量`SUBARCH` 。获得`SUBARCH` 之后就要设置`SRCARCH` 和`hfr-arch`,`SRCARCH`提供了硬件架构相关代码的目录,`hfr-arch` 提供了相关头文件的目录:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(ARCH),i386)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
ifeq ($(ARCH),x86_64)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
|
||||
hdr-arch := $(SRCARCH)
|
||||
```
|
||||
|
||||
注意:`ARCH` 是`SUBARCH` 的别名。如果没有设置过代表内核配置文件路径的变量`KCONFIG_CONFIG`,下一步系统会设置它,默认情况下就是`.config` :
|
||||
|
||||
```Makefile
|
||||
KCONFIG_CONFIG ?= .config
|
||||
export KCONFIG_CONFIG
|
||||
```
|
||||
以及编译内核过程中要用到的[shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
|
||||
```Makefile
|
||||
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||
else echo sh; fi ; fi)
|
||||
```
|
||||
|
||||
接下来就要设置一组和编译内核的编译器相关的变量。我们会设置主机的`C` 和`C++` 的编译器及相关配置项:
|
||||
|
||||
```Makefile
|
||||
HOSTCC = gcc
|
||||
HOSTCXX = g++
|
||||
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||
HOSTCXXFLAGS = -O2
|
||||
```
|
||||
|
||||
下一步会去适配代表编译器的变量`CC`,那为什么还要`HOST*` 这些选项呢?这是因为`CC` 是编译内核过程中要使用的目标架构的编译器,但是`HOSTCC` 是要被用来编译一组`host` 程序的(下面我们就会看到)。然后我们就看看变量`KBUILD_MODULES` 和`KBUILD_BUILTIN` 的定义,这两个变量决定了我们要编译什么东西(内核、模块还是其他):
|
||||
|
||||
```Makefile
|
||||
KBUILD_MODULES :=
|
||||
KBUILD_BUILTIN := 1
|
||||
|
||||
ifeq ($(MAKECMDGOALS),modules)
|
||||
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||
endif
|
||||
```
|
||||
|
||||
在这我们可以看到这些变量的定义,并且,如果们仅仅传递了`modules` 给`make`,变量`KBUILD_BUILTIN` 会依赖于内核配置选项`CONFIG_MODVERSIONS`。下一步操作是引入下面的文件:
|
||||
|
||||
```Makefile
|
||||
include scripts/Kbuild.include
|
||||
```
|
||||
|
||||
文件`kbuild` ,[Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) 或者又叫做 `Kernel Build System`是一个用来管理构建内核和模块的特殊框架。`kbuild` 文件的语法与makefile 一样。文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) 为`kbuild` 系统同提供了一些原生的定义。因为我们包含了这个`kbuild` 文件,我们可以看到和不同工具关联的这些变量的定义,这些工具会在内核和模块编译过程中被使用(比如链接器、编译器、二进制工具包[binutils](http://www.gnu.org/software/binutils/),等等):
|
||||
|
||||
```Makefile
|
||||
AS = $(CROSS_COMPILE)as
|
||||
LD = $(CROSS_COMPILE)ld
|
||||
CC = $(CROSS_COMPILE)gcc
|
||||
CPP = $(CC) -E
|
||||
AR = $(CROSS_COMPILE)ar
|
||||
NM = $(CROSS_COMPILE)nm
|
||||
STRIP = $(CROSS_COMPILE)strip
|
||||
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||
AWK = awk
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
在这些定义好的变量后面,我们又定义了两个变量:`USERINCLUDE` 和`LINUXINCLUDE`。他们包含了头文件的路径(第一个是给用户用的,第二个是给内核用的):
|
||||
|
||||
```Makefile
|
||||
USERINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||
-I$(srctree)/include/uapi \
|
||||
-Iinclude/generated/uapi \
|
||||
-include $(srctree)/include/linux/kconfig.h
|
||||
|
||||
LINUXINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||
...
|
||||
```
|
||||
|
||||
以及标准的C 编译器标志:
|
||||
```Makefile
|
||||
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||
-fno-strict-aliasing -fno-common \
|
||||
-Werror-implicit-function-declaration \
|
||||
-Wno-format-security \
|
||||
-std=gnu89
|
||||
```
|
||||
|
||||
这并不是最终确定的编译器标志,他们还可以在其他makefile 里面更新(比如`arch/` 里面的kbuild)。变量定义完之后,全部会被导出供其他makefile 使用。下面的两个变量`RCS_FIND_IGNORE` 和 `RCS_TAR_IGNORE` 包含了被版本控制系统忽略的文件:
|
||||
|
||||
```Makefile
|
||||
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||
-prune -o
|
||||
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||
```
|
||||
|
||||
这就是全部了,我们已经完成了所有的准备工作,下一个点就是如果构建`vmlinux`.
|
||||
|
||||
直面构建内核
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
现在我们已经完成了所有的准备工作,根makefile(注:内核根目录下的makefile)的下一步工作就是和编译内核相关的了。在我们执行`make` 命令之前,我们不会在终端看到任何东西。但是现在编译的第一步开始了,这里我们需要从内核根makefile的的[598](https://github.com/torvalds/linux/blob/master/Makefile#L598) 行开始,这里可以看到目标`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
all: vmlinux
|
||||
include arch/$(SRCARCH)/Makefile
|
||||
```
|
||||
|
||||
不要操心我们略过的从`export RCS_FIND_IGNORE.....` 到`all: vmlinux.....` 这一部分makefile 代码,他们只是负责根据各种配置文件生成不同目标内核的,因为之前我就说了这一部分我们只讨论构建内核的通用途径。
|
||||
|
||||
目标`all:` 是在命令行如果不指定具体目标时默认使用的目标。你可以看到这里包含了架构相关的makefile(在这里就指的是[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile))。从这一时刻起,我们会从这个makefile 继续进行下去。如我们所见,目标`all` 依赖于根makefile 后面声明的`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
```
|
||||
|
||||
`vmlinux` 是linux 内核的静态链接可执行文件格式。脚本[scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 把不同的编译好的子模块链接到一起形成了vmlinux。第二个目标是`vmlinux-deps`,它的定义如下:
|
||||
|
||||
```Makefile
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||
```
|
||||
|
||||
它是由内核代码下的每个顶级目录的`built-in.o` 组成的。之后我们还会检查内核所有的目录,`kbuild` 会编译各个目录下所有的对应`$obj-y` 的源文件。接着调用`$(LD) -r` 把这些文件合并到一个`build-in.o` 文件里。此时我们还没有`vmloinux-deps`, 所以目标`vmlinux` 现在还不会被构建。对我而言`vmlinux-deps` 包含下面的文件
|
||||
|
||||
```
|
||||
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||
init/built-in.o usr/built-in.o
|
||||
arch/x86/built-in.o kernel/built-in.o
|
||||
mm/built-in.o fs/built-in.o
|
||||
ipc/built-in.o security/built-in.o
|
||||
crypto/built-in.o block/built-in.o
|
||||
lib/lib.a arch/x86/lib/lib.a
|
||||
lib/built-in.o arch/x86/lib/built-in.o
|
||||
drivers/built-in.o sound/built-in.o
|
||||
firmware/built-in.o arch/x86/pci/built-in.o
|
||||
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||
net/built-in.o
|
||||
```
|
||||
|
||||
下一个可以被执行的目标如下:
|
||||
|
||||
```Makefile
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
就像我们看到的,`vmlinux-dir` 依赖于两部分:`prepare` 和`scripts`。第一个`prepare` 定义在内核的根`makefile` ,准备工作分成三个阶段:
|
||||
|
||||
```Makefile
|
||||
prepare: prepare0
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||
|
||||
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||
include/config/auto.conf
|
||||
$(cmd_crmodverdir)
|
||||
prepare2: prepare3 outputmakefile asm-generic
|
||||
```
|
||||
|
||||
第一个`prepare0` 展开到`archprepare` ,后者又展开到`archheader` 和`archscripts`,这两个变量定义在`x86_64` 相关的[Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)。让我们看看这个文件。`x86_64` 特定的makefile从变量定义开始,这些变量都是和特定架构的配置文件 ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs),等等)有关联。变量定义之后,这个makefile 定义了编译[16-bit](https://en.wikipedia.org/wiki/Real_mode)代码的编译选项,根据变量`BITS` 的值,如果是`32`, 汇编代码、链接器、以及其它很多东西(全部的定义都可以在[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)找到)对应的参数就是`i386`,而`64`就对应的是`x86_84`。生成的系统调用列表(syscall table)的makefile 里第一个目标就是`archheaders` :
|
||||
|
||||
```Makefile
|
||||
archheaders:
|
||||
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||
```
|
||||
|
||||
这个makefile 里第二个目标就是`archscripts`:
|
||||
|
||||
```Makefile
|
||||
archscripts: scripts_basic
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
我们可以看到`archscripts` 是依赖于根[Makefile](https://github.com/torvalds/linux/blob/master/Makefile)里的`scripts_basic` 。首先我们可以看出`scripts_basic` 是按照[scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) 的mekefile 执行make 的:
|
||||
|
||||
```Maklefile
|
||||
scripts_basic:
|
||||
$(Q)$(MAKE) $(build)=scripts/basic
|
||||
```
|
||||
|
||||
`scripts/basic/Makefile`包含了编译两个主机程序`fixdep` 和`bin2` 的目标:
|
||||
|
||||
```Makefile
|
||||
hostprogs-y := fixdep
|
||||
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||
always := $(hostprogs-y)
|
||||
|
||||
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||
```
|
||||
|
||||
第一个工具是`fixdep`:用来优化[gcc](https://gcc.gnu.org/) 生成的依赖列表,然后在重新编译源文件的时候告诉make。第二个工具是`bin2c`,他依赖于内核配置选项`CONFIG_BUILD_BIN2C`,并且它是一个用来将标准输入接口(注:即stdin)收到的二进制流通过标准输出接口(即:stdout)转换成C 头文件的非常小的C 程序。你可以注意到这里有些奇怪的标志,如`hostprogs-y`等。这些标志使用在所有的`kbuild` 文件,更多的信息你可以从[documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt) 获得。在我们的用例`hostprogs-y` 中,他告诉`kbuild` 这里有个名为`fixed` 的程序,这个程序会通过和`Makefile` 相同目录的`fixdep.c` 编译而来。执行make 之后,终端的第一个输出就是`kbuild` 的结果:
|
||||
|
||||
```
|
||||
$ make
|
||||
HOSTCC scripts/basic/fixdep
|
||||
```
|
||||
|
||||
当目标`script_basic` 被执行,目标`archscripts` 就会make [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) 下的makefile 和目标`relocs`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
代码`relocs_32.c` 和`relocs_64.c` 包含了[重定位](https://en.wikipedia.org/wiki/Relocation_%28computing%29) 的信息,将会被编译,者可以在`make` 的输出中看到:
|
||||
|
||||
```Makefile
|
||||
HOSTCC arch/x86/tools/relocs_32.o
|
||||
HOSTCC arch/x86/tools/relocs_64.o
|
||||
HOSTCC arch/x86/tools/relocs_common.o
|
||||
HOSTLD arch/x86/tools/relocs
|
||||
```
|
||||
|
||||
在编译完`relocs.c` 之后会检查`version.h`:
|
||||
|
||||
```Makefile
|
||||
$(version_h): $(srctree)/Makefile FORCE
|
||||
$(call filechk,version.h)
|
||||
$(Q)rm -f $(old_version_h)
|
||||
```
|
||||
|
||||
我们可以在输出看到它:
|
||||
|
||||
```
|
||||
CHK include/config/kernel.release
|
||||
```
|
||||
|
||||
以及在内核根Makefiel 使用`arch/x86/include/generated/asm`的目标`asm-generic` 来构建`generic` 汇编头文件。在目标`asm-generic` 之后,`archprepare` 就会被完成,所以目标`prepare0` 会接着被执行,如我上面所写:
|
||||
|
||||
```Makefile
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
```
|
||||
|
||||
注意`build`,它是定义在文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include),内容是这样的:
|
||||
|
||||
```Makefile
|
||||
build := -f $(srctree)/scripts/Makefile.build obj
|
||||
```
|
||||
|
||||
或者在我们的例子中,他就是当前源码目录路径——`.`:
|
||||
```Makefile
|
||||
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||
```
|
||||
|
||||
参数`obj` 会告诉脚本[scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) 那些目录包含`kbuild` 文件,脚本以此来寻找各个`kbuild` 文件:
|
||||
|
||||
```Makefile
|
||||
include $(kbuild-file)
|
||||
```
|
||||
|
||||
然后根据这个构建目标。我们这里`.` 包含了[Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild),就用这个文件来生成`kernel/bounds.s` 和`arch/x86/kernel/asm-offsets.s`。这样目标`prepare` 就完成了它的工作。`vmlinux-dirs` 也依赖于第二个目标——`scripts` ,`scripts`会编译接下来的几个程序:`filealias`,`mk_elfconfig`,`modpost`等等。`scripts/host-programs` 编译完之后,我们的目标`vmlinux-dirs` 就可以开始编译了。第一步,我们先来理解一下`vmlinux-dirs` 都包含了那些东西。在我们的例子中它包含了接下来要使用的内核目录的路径:
|
||||
|
||||
```
|
||||
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||
drivers sound firmware arch/x86/pci arch/x86/power
|
||||
arch/x86/video net lib arch/x86/lib
|
||||
```
|
||||
|
||||
我们可以在内核的根[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 里找到`vmlinux-dirs` 的定义:
|
||||
|
||||
```Makefile
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
这里我们借助函数`patsubst` 和`filter`去掉了每个目录路径里的符号`/`,并且把结果放到`vmlinux-dirs` 里。所以我们就有了`vmlinux-dirs` 里的目录的列表,以及下面的代码:
|
||||
|
||||
```Makefile
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
符号`$@` 在这里代表了`vmlinux-dirs`,这就表明程序会递归遍历从`vmlinux-dirs` 以及它内部的全部目录(依赖于配置),并且在对应的目录下执行`make` 命令。我们可以在输出看到结果:
|
||||
|
||||
```
|
||||
CC init/main.o
|
||||
CHK include/generated/compile.h
|
||||
CC init/version.o
|
||||
CC init/do_mounts.o
|
||||
...
|
||||
CC arch/x86/crypto/glue_helper.o
|
||||
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||
CC arch/x86/crypto/aes_glue.o
|
||||
...
|
||||
AS arch/x86/entry/entry_64.o
|
||||
AS arch/x86/entry/thunk_64.o
|
||||
CC arch/x86/entry/syscall_64.o
|
||||
```
|
||||
|
||||
每个目录下的源代码将会被编译并且链接到`built-io.o` 里:
|
||||
|
||||
```
|
||||
$ find . -name built-in.o
|
||||
./arch/x86/crypto/built-in.o
|
||||
./arch/x86/crypto/sha-mb/built-in.o
|
||||
./arch/x86/net/built-in.o
|
||||
./init/built-in.o
|
||||
./usr/built-in.o
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
好了,所有的`built-in.o` 都构建完了,现在我们回到目标`vmlinux` 上。你应该还记得,目标`vmlinux` 是在内核的根makefile 里。在链接`vmlinux` 之前,系统会构建[samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation)等等,但是如上文所述,我不会在本文描述这些。
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
...
|
||||
...
|
||||
+$(call if_changed,link-vmlinux)
|
||||
```
|
||||
|
||||
你可以看到,`vmlinux` 的调用脚本[scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 的主要目的是把所有的`built-in.o` 链接成一个静态可执行文件、生成[System.map](https://en.wikipedia.org/wiki/System.map)。 最后我们来看看下面的输出:
|
||||
|
||||
```
|
||||
LINK vmlinux
|
||||
LD vmlinux.o
|
||||
MODPOST vmlinux.o
|
||||
GEN .version
|
||||
CHK include/generated/compile.h
|
||||
UPD include/generated/compile.h
|
||||
CC init/version.o
|
||||
LD init/built-in.o
|
||||
KSYM .tmp_kallsyms1.o
|
||||
KSYM .tmp_kallsyms2.o
|
||||
LD vmlinux
|
||||
SORTEX vmlinux
|
||||
SYSMAP System.map
|
||||
```
|
||||
|
||||
以及内核源码树根目录下的`vmlinux` 和`System.map`
|
||||
|
||||
```
|
||||
$ ls vmlinux System.map
|
||||
System.map vmlinux
|
||||
```
|
||||
|
||||
这就是全部了,`vmlinux` 构建好了,下一步就是创建[bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
制作bzImage
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
`bzImage` 就是压缩了的linux 内核镜像。我们可以在构建了`vmlinux` 之后通过执行`make bzImage` 获得`bzImage`。同时我们可以仅仅执行`make` 而不带任何参数也可以生成`bzImage` ,因为它是在[arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) 里预定义的、默认生成的镜像:
|
||||
|
||||
```Makefile
|
||||
all: bzImage
|
||||
```
|
||||
|
||||
让我们看看这个目标,他能帮助我们理解这个镜像是怎么构建的。我已经说过了`bzImage` 师被定义在[arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile),定义如下:
|
||||
|
||||
```Makefile
|
||||
bzImage: vmlinux
|
||||
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||
```
|
||||
|
||||
在这里我们可以看到第一次为boot 目录执行`make`,在我们的例子里是这样的:
|
||||
|
||||
```Makefile
|
||||
boot := arch/x86/boot
|
||||
```
|
||||
|
||||
现在的主要目标是编译目录`arch/x86/boot` 和`arch/x86/boot/compressed` 的代码,构建`setup.bin` 和`vmlinux.bin`,然后用这两个文件生成`bzImage`。第一个目标是定义在[arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) 的`$(obj)/setup.elf`:
|
||||
|
||||
```Makefile
|
||||
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||
$(call if_changed,ld)
|
||||
```
|
||||
|
||||
我们已经在目录`arch/x86/boot`有了链接脚本`setup.ld`,并且将变量`SETUP_OBJS` 扩展到`boot` 目录下的全部源代码。我们可以看看第一个输出:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/bioscall.o
|
||||
CC arch/x86/boot/cmdline.o
|
||||
AS arch/x86/boot/copy.o
|
||||
HOSTCC arch/x86/boot/mkcpustr
|
||||
CPUSTR arch/x86/boot/cpustr.h
|
||||
CC arch/x86/boot/cpu.o
|
||||
CC arch/x86/boot/cpuflags.o
|
||||
CC arch/x86/boot/cpucheck.o
|
||||
CC arch/x86/boot/early_serial_console.o
|
||||
CC arch/x86/boot/edd.o
|
||||
```
|
||||
|
||||
下一个源码文件是[arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S),但是我们不能现在就编译它,因为这个目标依赖于下面两个头文件:
|
||||
|
||||
```Makefile
|
||||
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||
```
|
||||
|
||||
第一个头文件`voffset.h` 是使用`sed` 脚本生成的,包含用`nm` 工具从`vmlinux` 获取的两个地址:
|
||||
|
||||
```C
|
||||
#define VO__end 0xffffffff82ab0000
|
||||
#define VO__text 0xffffffff81000000
|
||||
```
|
||||
|
||||
这两个地址是内核的起始和结束地址。第二个头文件`zoffset.h` 在[arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile) 可以看出是依赖于目标`vmlinux`的:
|
||||
|
||||
```Makefile
|
||||
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||
$(call if_changed,zoffset)
|
||||
```
|
||||
|
||||
目标`$(obj)/compressed/vmlinux` 依赖于变量`vmlinux-objs-y` —— 说明需要编译目录[arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) 下的源代码,然后生成`vmlinux.bin`, `vmlinux.bin.bz2`, 和编译工具 - `mkpiggy`。我们可以在下面的输出看出来:
|
||||
|
||||
```Makefile
|
||||
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||
AS arch/x86/boot/compressed/head_64.o
|
||||
CC arch/x86/boot/compressed/misc.o
|
||||
CC arch/x86/boot/compressed/string.o
|
||||
CC arch/x86/boot/compressed/cmdline.o
|
||||
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||
```
|
||||
|
||||
`vmlinux.bin` 是去掉了调试信息和注释的`vmlinux` 二进制文件,加上了占用了`u32` (注:即4-Byte)的长度信息的`vmlinux.bin.all` 压缩后就是`vmlinux.bin.bz2`。其中`vmlinux.bin.all` 包含了`vmlinux.bin` 和`vmlinux.relocs`(注:vmlinux 的重定位信息),其中`vmlinux.relocs` 是`vmlinux` 经过程序`relocs` 处理之后的`vmlinux` 镜像(见上文所述)。我们现在已经获取到了这些文件,汇编文件`piggy.S` 将会被`mkpiggy` 生成、然后编译:
|
||||
|
||||
```Makefile
|
||||
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||
AS arch/x86/boot/compressed/piggy.o
|
||||
```
|
||||
|
||||
这个汇编文件会包含经过计算得来的、压缩内核的偏移信息。处理完这个汇编文件,我们就可以看到`zoffset` 生成了:
|
||||
|
||||
```Makefile
|
||||
ZOFFSET arch/x86/boot/zoffset.h
|
||||
```
|
||||
|
||||
现在`zoffset.h` 和`voffset.h` 已经生成了,[arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) 里的源文件可以继续编译:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/header.o
|
||||
CC arch/x86/boot/main.o
|
||||
CC arch/x86/boot/mca.o
|
||||
CC arch/x86/boot/memory.o
|
||||
CC arch/x86/boot/pm.o
|
||||
AS arch/x86/boot/pmjump.o
|
||||
CC arch/x86/boot/printf.o
|
||||
CC arch/x86/boot/regs.o
|
||||
CC arch/x86/boot/string.o
|
||||
CC arch/x86/boot/tty.o
|
||||
CC arch/x86/boot/video.o
|
||||
CC arch/x86/boot/video-mode.o
|
||||
CC arch/x86/boot/video-vga.o
|
||||
CC arch/x86/boot/video-vesa.o
|
||||
CC arch/x86/boot/video-bios.o
|
||||
```
|
||||
|
||||
所有的源代码会被编译,他们最终会被链接到`setup.elf` :
|
||||
|
||||
```Makefile
|
||||
LD arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
最后两件事是创建包含目录`arch/x86/boot/*` 下的编译过的代码的`setup.bin`:
|
||||
|
||||
```
|
||||
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||
```
|
||||
|
||||
以及从`vmlinux` 生成`vmlinux.bin` :
|
||||
|
||||
```
|
||||
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||
```
|
||||
|
||||
最后,我们编译主机程序[arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c),它将会用来把`setup.bin` 和`vmlinux.bin` 打包成`bzImage`:
|
||||
|
||||
```
|
||||
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||
```
|
||||
|
||||
实际上`bzImage` 就是把`setup.bin` 和`vmlinux.bin` 连接到一起。最终我们会看到输出结果,就和那些用源码编译过内核的同行的结果一样:
|
||||
|
||||
```
|
||||
Setup is 16268 bytes (padded to 16384 bytes).
|
||||
System is 4704 kB
|
||||
CRC 94a88f9a
|
||||
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||
```
|
||||
|
||||
|
||||
全部结束。
|
||||
|
||||
结论
|
||||
================================================================================
|
||||
|
||||
这就是本文的最后一节。本文我们了解了编译内核的全部步骤:从执行`make` 命令开始,到最后生成`bzImage`。我知道,linux 内核的makefiles 和构建linux 的过程第一眼看起来可能比较迷惑,但是这并不是很难。希望本文可以帮助你理解构建linux 内核的整个流程。
|
||||
|
||||
|
||||
链接
|
||||
================================================================================
|
||||
|
||||
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||
* [binutils](http://www.gnu.org/software/binutils/)
|
||||
* [gcc](https://gcc.gnu.org/)
|
||||
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,46 @@
|
||||
为Antergos与Arch Linux添加印度语和梵文支持
|
||||
================================================================================
|
||||

|
||||
|
||||
你们到目前或许知道,我最近一直在尝试体验[Antergos Linux][1]。在安装完[Antergos][2]后我所首先注意到的一些事情是在默认的Chromium浏览器中**没法正确显示印度语脚本**。
|
||||
|
||||
这是一件奇怪的事情,在我之前桌面Linux的体验中是从未遇到过的。起初,我认为是浏览器的问题,所以我安装了Firefox,然而问题依旧,Firefox也不能正确显示印度语。和Chromium不显示任何东西不同的是,Firefox确实显示了一些东西,但是毫无可读性。
|
||||
|
||||

|
||||
Chromium中的印度语显示
|
||||
|
||||
|
||||

|
||||
Firefox中的印度语显示
|
||||
|
||||
奇怪吧?那么,默认情况下基于Arch的Antergos Linux中没有印度语的支持吗?我没有去验证,但是我假设其它基于梵语脚本的印地语之类会产生同样的问题。
|
||||
|
||||
在这个快速指南中,我打算为大家演示如何来添加梵语支持,以便让印度语和其它印地语都能正确显示。
|
||||
|
||||
### 在Antergos和Arch Linux中添加印地语支持 ###
|
||||
|
||||
打开终端,使用以下命令:
|
||||
|
||||
sudo yaourt -S ttf-indic-otf
|
||||
|
||||
键入密码,它会提供给你对于印地语的译文支持。
|
||||
|
||||
重启Firefox,会马上正确显示印度语了,但是它需要一次重启来显示印度语。因此,我建议你在安装了印地语字体后**重启你的系统**。
|
||||
|
||||

|
||||
|
||||
我希望这篇快速指南能够帮助你,让你可以在Antergos和其它基于Arch的Linux发行版中,如Manjaro Linux,阅读印度语、梵文、泰米尔语、泰卢固语、马拉雅拉姆语、孟加拉语,以及其它印地语。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/display-hindi-arch-antergos/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://antergos.com/
|
||||
[2]:http://itsfoss.com/tag/antergos/
|
||||
Loading…
Reference in New Issue
Block a user