mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
fix confilct
This commit is contained in:
commit
aa4733fda0
@ -2,13 +2,13 @@ Ubuntu中跟踪多个时区的简捷方法
|
||||
================================================================================
|
||||

|
||||
|
||||
**我是否要确保在我醒来时或者安排与*山姆陈*,Ohso的半个开发商,进行Skype通话时,澳大利亚一个关于Chromebook销售的推特已经售罄,我大脑同时在多个时区下工作。**
|
||||
**无论我是要在醒来时发个关于澳大利亚的 Chromebook 销售已经售罄的推特,还是要记着和Ohso的半个开发商山姆陈进行Skype通话,我大脑都需要同时工作在多个时区下。**
|
||||
|
||||
那里头有个问题,如果你认识我,你会知道我的脑容量也就那么丁点,跟金鱼差不多,里头却塞着像Windows Vista这样一个臃肿货(也就是,不是很好)。我几乎记不得昨天之前的事情,更记不得我的门和金门大桥脚之间的时间差!
|
||||
|
||||
作为臂助,我使用一些小部件和菜单项来让我保持同步。在我常规工作日的空间里,我在多个操作系统间游弋,涵盖移动系统和桌面系统,但只有一个让我最快速便捷地设置“世界时钟”。
|
||||
作为臂助,我使用一些小部件和菜单项来让我保持同步。在我常规工作日的空间里,我在多个操作系统间游弋,涵盖移动系统和桌面系统,但只有一个可以让我最快速便捷地设置“世界时钟”。
|
||||
|
||||
**而它刚好是那个名字放在门上方的东西。**
|
||||
**它的名字就是我们标题上提到的那个。**
|
||||
|
||||

|
||||
|
||||
@ -16,10 +16,10 @@ Ubuntu中跟踪多个时区的简捷方法
|
||||
|
||||
Unity中默认的日期-时间指示器提供了添加并查看多个时区的支持,不需要附加组件,不需要额外的包。
|
||||
|
||||
1. 点击时钟小应用,然后uxuanze‘**时间和日期设置**’条目
|
||||
1. 点击时钟小应用,然后选择‘**时间和日期设置**’条目
|
||||
1. 在‘**时钟**’标签中,选中‘**其它位置的时间**’选框
|
||||
1. 点击‘**选择位置**’按钮
|
||||
1. 点击‘**+**’,然后输入位置名称那个
|
||||
1. 点击‘**+**’,然后输入位置名称
|
||||
|
||||
#### 其它桌面环境 ####
|
||||
|
||||
@ -34,13 +34,13 @@ Unity中默认的日期-时间指示器提供了添加并查看多个时区的
|
||||
|
||||

|
||||
|
||||
Cinnamon 2.4中的世界时钟日历
|
||||
*Cinnamon 2.4中的世界时钟日历*
|
||||
|
||||
**XFCE**和**LXDE**就不那么慷慨了,除了自带的“工作区”作为**多个时钟**添加到面板外,每个都需要手动配置以指定位置。两个都支持‘指示器小部件’,所以,如果你没有依赖于Unity,你可以安装/添加单独的日期/时间指示器。
|
||||
**XFCE**和**LXDE**就不那么慷慨了,除了自带的“工作区”作为**多个时钟**添加到面板外,每个都需要手动配置以指定位置。两个都支持‘指示器小部件’,所以,如果你不用Unity的话,你可以安装/添加单独的日期/时间指示器。
|
||||
|
||||
**Budgie**还刚初出茅庐,不足以胜任角落里的需求,因为Pantheon我还没试过——希望你们通过评论来让我知道得更多。
|
||||
**Budgie**还刚初出茅庐,不足以胜任这种角落里的需求,因为Pantheon我还没试过——希望你们通过评论来让我知道得更多。
|
||||
|
||||
#### Desktop Apps, Widgets & Conky Themes桌面应用、不见和Conky主题 ####
|
||||
#### 桌面应用、部件和Conky主题 ####
|
||||
|
||||
当然,面板小部件只是收纳其它国家多个时区的一种方式。如果你不满意通过面板去访问,那里还有各种各样的**桌面应用**可供使用,其中许多都可以跨版本,甚至跨平台使用。
|
||||
|
||||
@ -54,7 +54,7 @@ via: http://www.omgubuntu.co.uk/2014/12/add-time-zones-world-clock-ubuntu
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
CentOS上配置rsyslog客户端用以远程记录日志
|
||||
================================================================================
|
||||
**rsyslog**是一个开源工具,被广泛用于Linux系统以通过TCP/UDP协议转发或接收日志消息。rsyslog守护进程可以被配置称两种环境,一种是配置成日志收集服务器,rsyslog进程可以从网络中收集所有其它主机上的日志数据,这些主机已经将日志配置为发送到服务器。rsyslog的另外一个角色,就是可以配置为客户端,用来过滤和发送内部日志消息到本地文件夹(如/var/log)或一台可以路由到的远程rsyslog服务器上。
|
||||
**rsyslog**是一个开源工具,被广泛用于Linux系统以通过TCP/UDP协议转发或接收日志消息。rsyslog守护进程可以被配置成两种环境,一种是配置成日志收集服务器,rsyslog进程可以从网络中收集其它主机上的日志数据,这些主机会将日志配置为发送到另外的远程服务器。rsyslog的另外一个用法,就是可以配置为客户端,用来过滤和发送内部日志消息到本地文件夹(如/var/log)或一台可以路由到的远程rsyslog服务器上。
|
||||
|
||||
假定你的网络中已经有一台rsyslog服务器[已经起来并且处于运行中][1],本指南将为你展示如何来设置CentOS系统将其内部日志消息路由到一台远程rsyslog服务器上。这将大大改善你的系统磁盘空间的使用,尤其是你还没有一个独立的用于/var目录的大分区。
|
||||
假定你的网络中已经有一台[已经配置好并启动的][1]rsyslog服务器,本指南将为你展示如何来设置CentOS系统将其内部日志消息路由到一台远程rsyslog服务器上。这将大大改善你的系统磁盘空间的使用,尤其是当你还没有一个用于/var目录的独立的大分区。
|
||||
|
||||
### 步骤一: 安装Rsyslog守护进程 ###
|
||||
|
||||
@ -35,9 +35,9 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
*.* @@192.168.1.25:514
|
||||
|
||||
注意,你也可以将rsyslog服务器的IP地址替换成它的DNS名称(FQDN)。
|
||||
注意,你也可以将rsyslog服务器的IP地址替换成它的主机名(FQDN)。
|
||||
|
||||
如果你只想要转发指定设备的日志消息,比如说内核设备,那么你可以在rsyslog配置文件中使用以下声明。
|
||||
如果你只想要转发服务器上的指定设备的日志消息,比如说内核设备,那么你可以在rsyslog配置文件中使用以下声明。
|
||||
|
||||
kern.* @192.168.1.25:514
|
||||
|
||||
@ -51,9 +51,11 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
在另外一种环境中,让我们假定你已经在机器上安装了一个名为“foobar”的应用程序,它会在/var/log下生成foobar.log日志文件。现在,你只想要将它的日志定向到rsyslog服务器,这可以通过像下面这样在rsyslog配置文件中加载imfile模块来实现。
|
||||
####非 syslog 日志的转发
|
||||
|
||||
首先,加载imfile模块,这必须只做一次。
|
||||
在另外一种环境中,让我们假定你已经在机器上安装了一个名为“foobar”的应用程序,它会在/var/log下生成foobar.log日志文件。现在,你想要将它的日志定向到rsyslog服务器,这可以通过像下面这样在rsyslog配置文件中加载imfile模块来实现。
|
||||
|
||||
首先,加载imfile模块,这只需做一次。
|
||||
|
||||
module(load="imfile" PollingInterval="5")
|
||||
|
||||
@ -73,8 +75,7 @@ CentOS上配置rsyslog客户端用以远程记录日志
|
||||
|
||||
### 步骤三: 让Rsyslog进程自动启动 ###
|
||||
|
||||
To automatically start rsyslog client after every system reboot, run the following command to enable it system-wide:
|
||||
要让rsyslog客户端在每次系统重启后自动启动,请运行以下命令来在系统范围启用:
|
||||
要让rsyslog客户端在每次系统重启后自动启动,请运行以下命令:
|
||||
|
||||
**CentOS 7:**
|
||||
|
||||
@ -86,7 +87,7 @@ To automatically start rsyslog client after every system reboot, run the followi
|
||||
|
||||
### 小结 ###
|
||||
|
||||
在本教程中,我演示了如何将CentOS系统转变成rsyslog客户端以强制它发送日志消息到远程rsyslog服务器。这里我假定rsyslog客户端和服务器之间的连接是安全的(如,在有防火墙保护的公司网络中)。不管在任何情况下,都不要配置rsyslog客户端将日志消息通过不安全的网络转发,或者,特别是通过互联网转发,因为syslog协议是一个明文协议。要进行安全传输,可以考虑使用[TLS/SSL][2]来加密日志消息。
|
||||
在本教程中,我演示了如何将CentOS系统转变成rsyslog客户端以强制它发送日志消息到远程rsyslog服务器。这里我假定rsyslog客户端和服务器之间的连接是安全的(如,在有防火墙保护的公司网络中)。不管在任何情况下,都不要配置rsyslog客户端将日志消息通过不安全的网络转发,或者,特别是通过互联网转发,因为syslog协议是一个明文协议。要进行安全传输,可以考虑使用[TLS/SSL][2]来加密日志消息的传输。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -94,7 +95,7 @@ via: http://xmodulo.com/configure-rsyslog-client-centos.html
|
||||
|
||||
作者:[Caezsar M][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -8,7 +8,7 @@
|
||||
|
||||
答: 用 “route -n” 和 “netstat -nr” 命令,我们可以查看默认网关。除了默认的网关信息,这两个命令还可以显示当前的路由表。
|
||||
|
||||
**问:3 如何在Linux上重建初始化内存盘影响文件?**
|
||||
**问:3 如何在Linux上重建初始化内存盘镜像文件?**
|
||||
|
||||
答: 在CentOS 5.X / RHEL 5.X中,可以用mkinitrd命令来创建初始化内存盘文件,举例如下:
|
||||
|
||||
@ -30,7 +30,7 @@
|
||||
|
||||
**问:5 patch命令是什么?如何使用?**
|
||||
|
||||
答: 顾名思义,patch命令就是用来将修改(或补丁)写进文本文件里。Patch命令通常是接收diff的输出并把文件的旧版本转换为新版本。举个例子,Linux内核源代码由百万行代码文件构成,所以无论何时,任何代码贡献者贡献出代码,只需发送改动的部分而不是整个源代码,然后接收者用patch命令将改动写进原始的源代码里。
|
||||
答: 顾名思义,patch命令就是用来将修改(或补丁)写进文本文件里。patch命令通常是接收diff的输出并把文件的旧版本转换为新版本。举个例子,Linux内核源代码由百万行代码文件构成,所以无论何时,任何代码贡献者贡献出代码,只需发送改动的部分而不是整个源代码,然后接收者用patch命令将改动写进原始的源代码里。
|
||||
|
||||
创建一个diff文件给patch使用,
|
||||
|
||||
@ -44,7 +44,7 @@
|
||||
|
||||
**问:6 aspell有什么用 ?**
|
||||
|
||||
答: 顾名思义,aspell就是Linux操作系统上的一款交互式拼写检查器。aspell命令继任了更早的一个名为ispell的程序,并且作为一款嵌入式替代品 ,最重要的是它非常好用。当aspell程序主要被其它一些需要拼写检查能力的程序所使用的时候,在命令行中作为一个独立运行的工具的它也能十分有效。
|
||||
答: 顾名思义,aspell就是Linux操作系统上的一款交互式拼写检查器。aspell命令继任了更早的一个名为ispell的程序,并且作为一款免费替代品 ,最重要的是它非常好用。当aspell程序主要被其它一些需要拼写检查能力的程序所使用的时候,在命令行中作为一个独立运行的工具的它也能十分有效。
|
||||
|
||||
**问:7 如何从命令行查看域SPF记录?**
|
||||
|
||||
@ -56,7 +56,7 @@
|
||||
|
||||
答: # rpm -qf /etc/fstab
|
||||
|
||||
以上命令能列出供应给“/etc/fstab”文件的包。
|
||||
以上命令能列出提供“/etc/fstab”这个文件的包。
|
||||
|
||||
**问:9 哪条命令用来查看bond0的状态?**
|
||||
|
||||
@ -64,7 +64,7 @@
|
||||
|
||||
**问:10 Linux系统中的/proc文件系统有什么用?**
|
||||
|
||||
答: /proc文件系统是一个基于维护关于当前正在运行的内核状态信息的文件系统的随机存取存储器(RAM),其中包括CPU、内存、分区划分、I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的是各种不实际存储信息的文件,它们指向的是内存里的信息。/proc文件系统是由系统自动维护的。
|
||||
答: /proc文件系统是一个基于内存的文件系统,其维护着关于当前正在运行的内核状态信息,其中包括CPU、内存、分区划分、I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的并不是各种实际存储信息的文件,它们指向的是内存里的信息。/proc文件系统是由系统自动维护的。
|
||||
|
||||
**问:11 如何在/usr目录下找出大小超过10MB的文件?**
|
||||
|
||||
@ -78,21 +78,21 @@
|
||||
|
||||
答: # find /var \\! -atime -90
|
||||
|
||||
**问:14 在整个目录树下查找核心文件,如发现则删除它们且不提示确认信息。**
|
||||
**问:14 在整个目录树下查找文件“core”,如发现则无需提示直接删除它们。**
|
||||
|
||||
答: # find / -name core -exec rm {} \;
|
||||
|
||||
**问:15 strings命令有什么作用?**
|
||||
|
||||
答: strings命令用来提取和显示非文本文件的清晰内容。
|
||||
答: strings命令用来提取和显示非文本文件中的文本字符串。(LCTT 译注:当用来分析你系统上莫名其妙出现的二进制程序时,可以从中找到可疑的文件访问,对于追查入侵有用处)
|
||||
|
||||
**问:16 tee filter有什么作用 ?**
|
||||
**问:16 tee 过滤器有什么作用 ?**
|
||||
|
||||
答: tee filter用来向多个目标发送输出内容。它可以向一个文件发送一份输出的拷贝并且如果使用管道的话可以在屏幕上(或一些其它程序)输出其它内容。
|
||||
答: tee 过滤器用来向多个目标发送输出内容。如果用于管道的话,它可以将输出复制一份到一个文件,并复制另外一份到屏幕上(或一些其它程序)。
|
||||
|
||||
linuxtechi@localhost:~$ ll /etc | nl | tee /tmp/ll.out
|
||||
|
||||
在以上例子中,从ll输出的是在 /tmp/ll.out 文件中被捕获的,输出同样在屏幕上显示了出来。
|
||||
在以上例子中,从ll输出可以捕获到 /tmp/ll.out 文件中,并且同样在屏幕上显示了出来。
|
||||
|
||||
**问:17 export PS1 = ”$LOGNAME@`hostname`:\$PWD: 这条命令是在做什么?**
|
||||
|
||||
@ -108,7 +108,7 @@
|
||||
|
||||
**问:20 linux中lspci命令的作用是什么?**
|
||||
|
||||
答: lspci命令用来显示你的系统上PCI总线和附加设备的信息。指定-v,-vv或-vvv来获取详细输出,加上-r参数的话,命令的输出则会更具有易读性。
|
||||
答: lspci命令用来显示你的系统上PCI总线和附加设备的信息。指定-v,-vv或-vvv来获取越来越详细的输出,加上-r参数的话,命令的输出则会更具有易读性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -116,7 +116,7 @@ via: http://www.linuxtechi.com/20-linux-commands-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,11 @@
|
||||
Linux有问必答 - linux如何安装WPS
|
||||
Linux有问必答 - 如何在linux上安装WPS
|
||||
================================================================================
|
||||
> **问题**: 我听说一个好东西Kingsoft Office(译注:就是WPS),所以我想在我的Linux上试试。我怎样才能安装Kingsoft Office呢?
|
||||
|
||||
Kingsoft Office 一套办公套件,支持多个平台,包括Windows, Linux, iOS 和 Android。它包含三个组件:Writer(WPS文字)用来文字处理,Presentation(WPS演示)支持幻灯片,Spereadsheets(WPS表格)为电子表格。使用免费增值模式,其中基础版本是免费使用。比较其他的linux办公套件,如LibreOffice、 OpenOffice,最大优势在于,Kingsoft Office能最好的兼容微软的Office(译注:版权问题?了解下wps和Office的历史问题,可以得到一些结论)。因此如果你需要在windowns和linux平台间交互,Kingsoft office是一个很好的选择。
|
||||
|
||||
Kingsoft Office 是一套办公套件,支持多个平台,包括Windows, Linux, iOS 和 Android。它包含三个组件:Writer(WPS文字)用来文字处理,Presentation(WPS演示)支持幻灯片,Spereadsheets(WPS表格)是电子表格。其使用免费增值模式,其中基础版本是免费使用。比较其他的linux办公套件,如LibreOffice、 OpenOffice,其最大优势在于,Kingsoft Office能最好的兼容微软的Office(译注:版权问题?了解下wps和Office的历史问题,可以得到一些结论)。因此如果你需要在windows和linux平台间交互,Kingsoft office是一个很好的选择。
|
||||
|
||||
### CentOS, Fedora 或 RHEL中安装Kingsoft Office ###
|
||||
|
||||
|
||||
在[官方页面][1]下载RPM文件.官方RPM包只支持32位版本linux,但是你可以在64位中安装。
|
||||
|
||||
需要使用yum命令并用"localinstall"选项来本地安装这个RPM包
|
||||
@ -39,7 +37,7 @@ DEB包同样遇到一堆依赖。因此使用[gdebi][3]命令来代替dpkg来自
|
||||
|
||||
### 启动 Kingsoft Office ###
|
||||
|
||||
安装完成后,你就可以在桌面管理器轻松启动Witer(WPS文字), Presentation(WPS演示), and Spreadsheets(WPS表格),如下图
|
||||
安装完成后,你就可以在桌面管理器轻松启动Witer(WPS文字), Presentation(WPS演示), and Spreadsheets(WPS表格),如下图。
|
||||
|
||||
Ubuntu Unity中:
|
||||
|
||||
@ -49,7 +47,7 @@ GNOME桌面中:
|
||||
|
||||
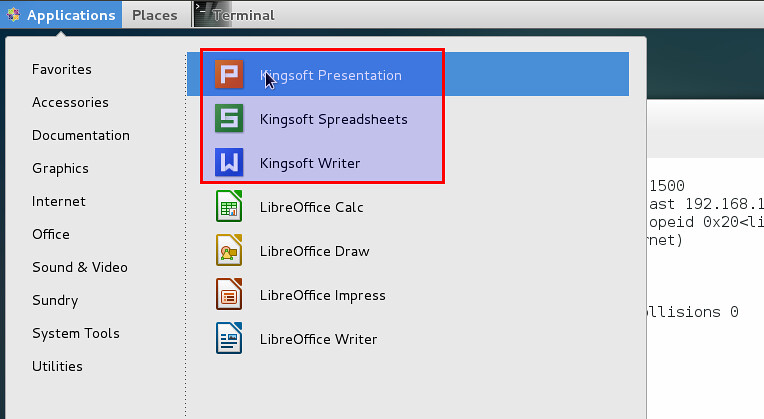
|
||||
|
||||
不但如此,你也可以在命令行中启动Kingsoft Office
|
||||
不但如此,你也可以在命令行中启动Kingsoft Office。
|
||||
|
||||
启动Wirter(WPS文字),使用这个命令:
|
||||
|
||||
@ -74,7 +72,7 @@ GNOME桌面中:
|
||||
via: http://ask.xmodulo.com/install-kingsoft-office-linux.html
|
||||
|
||||
译者:[Vic020/VicYu](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
如何在Linux/类Unix系统中解压tar文件到不同的目录中
|
||||
如何解压 tar 文件到不同的目录中
|
||||
================================================================================
|
||||
我想要解压一个tar文件到一个指定的目录叫/tmp/data。我该如何在Linux或者类Unix的系统中使用tar命令解压一个tar文件到不同的目录中?
|
||||
|
||||
你不必使用cd名切换到其他的目录并解压。可以使用下面的语法解压一个文件:
|
||||
我想要解压一个tar文件到一个叫/tmp/data的指定目录。我该如何在Linux或者类Unix的系统中使用tar命令解压一个tar文件到不同的目录中?
|
||||
|
||||
你不必使用cd命令切换到其他的目录并解压。可以使用下面的语法解压一个文件:
|
||||
|
||||
### 语法 ###
|
||||
|
||||
@ -16,9 +17,9 @@ GNU/tar 语法:
|
||||
|
||||
tar xf file.tar --directory /path/to/directory
|
||||
|
||||
### 示例:解压文件到另一个文件夹中 ###
|
||||
### 示例:解压文件到另一个目录中 ###
|
||||
|
||||
在本例中。我解压$HOME/etc.backup.tar到文件夹/tmp/data中。首先,你需要手动创建这个目录,输入:
|
||||
在本例中。我解压$HOME/etc.backup.tar到/tmp/data目录中。首先,需要手动创建这个目录,输入:
|
||||
|
||||
mkdir /tmp/data
|
||||
|
||||
@ -34,7 +35,7 @@ GNU/tar 语法:
|
||||
|
||||

|
||||
|
||||
Gif 01: tar命令解压文件到不同的目录
|
||||
*Gif 01: tar命令解压文件到不同的目录*
|
||||
|
||||
你也可以指定解压的文件:
|
||||
|
||||
@ -56,8 +57,8 @@ via: http://www.cyberciti.biz/faq/howto-extract-tar-file-to-specific-directory-o
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
@ -0,0 +1,58 @@
|
||||
在 Ubuntu 14.04 中Apache从2.2迁移到2.4的问题
|
||||
================================================================================
|
||||
如果你将**Ubuntu**从12.04升级跨越到了14.04,那么这其中包括了一个重大的升级--**Apache**从2.2版本升级到2.4版本。**Apache**的这次升级带来了许多性能提升,**但是如果继续使用2.2的配置文件会导致很多错误**。
|
||||
|
||||
### 访问控制的改变 ###
|
||||
|
||||
从**Apache 2.4**起,所启用的授权机制比起2.2的只是针对单一数据存储的单一检查更加灵活。过去很难确定哪个 order 授权怎样被使用的,但是授权容器指令的引入解决了这些问题,现在,配置可以控制什么时候授权方法被调用,什么条件决定何时授权访问。
|
||||
|
||||
这就是为什么大多数的升级失败是由于配置错误的原因。2.2的访问控制是基于IP地址、主机名和其他角色,通过使用指令Order,来设置Allow, Deny或 Satisfy;但是2.4,这些一切都通过新的授权方式进行检查。
|
||||
|
||||
为了弄清楚这些,可以来看一些虚拟主机的例子,这些可以在/etc/apache2/sites-enabled/default 或者 /etc/apache2/sites-enabled/*你的网站名称* 中找到:
|
||||
|
||||
旧的2.2虚拟主机配置:
|
||||
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
|
||||
新的2.4虚拟主机配置:
|
||||
|
||||
Require all granted
|
||||
|
||||

|
||||
|
||||
(LCTT 译注:Order、Allow和deny 这些将在之后的版本废弃,请尽量避免使用,Require 指令已可以提供比其更强大和灵活的功能。)
|
||||
|
||||
### .htaccess 问题 ###
|
||||
|
||||
升级后如果一些设置不工作,或者你得到重定向错误,请检查是否这些设置是放在.htaccess文件中。如果Apache 2.4没有使用 .htaccess 文件中的设置,那是因为在2.4中AllowOverride指令的默认是 none,因此忽略了.htaccess文件。你只需要做的就是修改或者添加AllowOverride All命令到你的网站配置文件中。
|
||||
|
||||
上面截图中,可以看见AllowOverride All指令。
|
||||
|
||||
### 丢失配置文件或者模块 ###
|
||||
|
||||
根据我的经验,这次升级带来的另一个问题就是在2.4中,一些旧模块和配置文件不再需要或者不被支持了。你将会收到一条“Apache不能包含相应的文件”的明确警告,你需要做的是在配置文件中移除这些导致问题的配置行。之后你可以搜索和安装相似的模块来替代。
|
||||
|
||||
### 其他需要了解的小改变 ###
|
||||
|
||||
这里还有一些其他的改变需要考虑,虽然这些通常只会发生警告,而不是错误。
|
||||
|
||||
- MaxClients重命名为MaxRequestWorkers,使之有更准确的描述。而异步MPM,如event,客户端最大连接数不等于工作线程数。旧的配置名依然支持。
|
||||
- DefaultType命令无效,使用它已经没有任何效果了。如果使用除了 none 之外的其它配置值,你会得到一个警告。需要使用其他配置设定来替代它。
|
||||
- EnableSendfile默认关闭
|
||||
- FileETag 现在默认为"MTime Size"(没有INode)
|
||||
- KeepAlive 只接受“On”或“Off”值。之前的任何不是“Off”或者“0”的值都被认为是“On”
|
||||
- 单一的 Mutex 已经替代了 Directives AcceptMutex, LockFile, RewriteLock, SSLMutex, SSLStaplingMutex 和 WatchdogMutexPath 等指令。你需要做的是估计一下这些被替代的指令在2.2中的使用情况,来决定是否删除或者使用Mutex来替代。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/apache-migration-2-2-to-2-4-ubuntu-14-04/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://httpd.apache.org/docs/2.4/
|
||||
@ -1,4 +1,4 @@
|
||||
Linux有问必答:在Linux下如何用df命令检查磁盘空间?
|
||||
在 Linux 下你所不知道的 df 命令的那些功能
|
||||
================================================================================
|
||||
> **问题**: 我知道在Linux上我可以用df命令来查看磁盘使用空间。你能告诉我df命令的实际例子使我可以最大限度得利用它吗?
|
||||
|
||||
@ -10,7 +10,7 @@ df命令可以展示任何“mounted”文件系统的磁盘利用率。该命
|
||||
|
||||
### 用人们可读的方式展示 ###
|
||||
|
||||
默认情况下,df命令用1K为块来展示磁盘空间,这不容易解释。“-h”参数使df用更可读的方式打印磁盘空间(例如 100K,200M,3G)。
|
||||
默认情况下,df命令用1K为块来展示磁盘空间,这看起来不是很直观。“-h”参数使df用更可读的方式打印磁盘空间(例如 100K,200M,3G)。
|
||||
|
||||
$ df -h
|
||||
|
||||
@ -28,7 +28,7 @@ df命令可以展示任何“mounted”文件系统的磁盘利用率。该命
|
||||
|
||||
### 展示Inode使用情况 ###
|
||||
|
||||
当你监视磁盘使用情况时,你必须注意的不仅仅是磁盘空间还有“inode”的使用情况。在Linux中,inode是用来存储特定文件的元数据的一种数据结构,在创建一个文件系统时,inode的预先定义数量将被分配。这意味着,一个文件系统可能耗尽空间不只是因为大文件用完了所有可用空间,也可能是因为很多小文件用完了所有可能的inode。用“-i”选项展示inode使用情况。
|
||||
当你监视磁盘使用情况时,你必须注意的不仅仅是磁盘空间还有“inode”的使用情况。在Linux中,inode是用来存储特定文件的元数据的一种数据结构,在创建一个文件系统时,inode的预先定义数量将被分配。这意味着,**一个文件系统可能耗尽空间不只是因为大文件用完了所有可用空间,也可能是因为很多小文件用完了所有可能的inode**。用“-i”选项展示inode使用情况。
|
||||
|
||||
$ df -i
|
||||
|
||||
@ -46,7 +46,8 @@ df命令可以展示任何“mounted”文件系统的磁盘利用率。该命
|
||||
|
||||
### 展示磁盘总利用率 ###
|
||||
|
||||
默认情况下, df命令显示磁盘的单个文件系统的利用率。如果你想知道的所有文件系统的总磁盘使用量,增加“ --total ”选项。
|
||||
默认情况下, df命令显示磁盘的单个文件系统的利用率。如果你想知道的所有文件系统的总磁盘使用量,增加“ --total ”选项(见最下面的汇总行)。
|
||||
|
||||
$ df -h --total
|
||||
|
||||
----------
|
||||
@ -64,7 +65,7 @@ df命令可以展示任何“mounted”文件系统的磁盘利用率。该命
|
||||
|
||||
### 展示文件系统类型 ###
|
||||
|
||||
默认情况下,df命令不现实文件系统类型信息。用“-T”选项来添加文件系统信息到输出中。
|
||||
默认情况下,df命令不显示文件系统类型信息。用“-T”选项来添加文件系统信息到输出中。
|
||||
|
||||
$ df -T
|
||||
|
||||
@ -92,13 +93,13 @@ df命令可以展示任何“mounted”文件系统的磁盘利用率。该命
|
||||
/dev/mapper/ubuntu-root 952893348 591583380 312882756 66% /
|
||||
/dev/sda1 233191 100025 120725 46% /boot
|
||||
|
||||
排除特定的文件系统类型,用“-x <type>”选项。同样,你可以用这个选项多次。
|
||||
排除特定的文件系统类型,用“-x <type>”选项。同样,你可以用这个选项多次来排除多种文件系统类型。
|
||||
|
||||
$ df -x tmpfs
|
||||
|
||||
### 显示一个具体的挂载点磁盘使用情况 ###
|
||||
|
||||
如果你用df指定一个挂载点,它将报告挂载在那个地方的文件系统的磁盘使用情况。如果你指定一个普通文件(或一个目录)而不是一个挂载点,df将现实包含这个文件(或目录)的文件系统的磁盘利用率。
|
||||
如果你用df指定一个挂载点,它将报告挂载在那个地方的文件系统的磁盘使用情况。如果你指定一个普通文件(或一个目录)而不是一个挂载点,df将显示包含这个文件(或目录)的文件系统的磁盘利用率。
|
||||
|
||||
$ df /
|
||||
|
||||
@ -116,9 +117,9 @@ df命令可以展示任何“mounted”文件系统的磁盘利用率。该命
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
/dev/mapper/ubuntu-root 952893348 591583528 312882608 66% /
|
||||
|
||||
### 现实虚拟文件系统的信息 ###
|
||||
### 显示虚拟文件系统的信息 ###
|
||||
|
||||
如果你想显示所有已经存在的文件系统(包括虚拟文件系统)的磁盘空间信息,用“-a”选项。这里,虚拟文件系统是指没有相对应的物理设备的假的文件系统,例如,tmpfs,cgroup虚拟文件系统或FUSE文件安系统。这些虚拟文件系统大小为0,不用“-a”选项将不会被报告出来。
|
||||
如果你想显示所有已经存在的文件系统(包括虚拟文件系统)的磁盘空间信息,用“-a”选项。这里,虚拟文件系统是指没有相对应的物理设备的假文件系统,例如,tmpfs,cgroup虚拟文件系统或FUSE文件安系统。这些虚拟文件系统大小为0,不用“-a”选项将不会被报告出来。
|
||||
|
||||
$ df -a
|
||||
|
||||
@ -149,7 +150,7 @@ df命令可以展示任何“mounted”文件系统的磁盘利用率。该命
|
||||
via: http://ask.xmodulo.com/check-disk-space-linux-df-command.html
|
||||
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
Linux有问必答:如何检查Linux的内存使用状况
|
||||
================================================================================
|
||||
|
||||
>**问题**:我想要监测Linux系统的内存使用状况。有哪些可用的图形界面或者命令行工具来检查当前内存使用情况?
|
||||
|
||||
当涉及到Linux系统性能优化的时候,物理内存是一个最重要的因素。自然的,Linux提供了丰富的选择来监测珍贵的内存资源的使用情况。不同的工具,在监测粒度(例如:全系统范围,每个进程,每个用户),接口方式(例如:图形用户界面,命令行,ncurses)或者运行模式(交互模式,批量处理模式)上都不尽相同。
|
||||
|
||||
下面是一个可供选择的,但并不全面的图形或命令行工具列表,这些工具用来检查Linux平台中已用和可用的内存。
|
||||
|
||||
### 1. /proc/meminfo ###
|
||||
|
||||
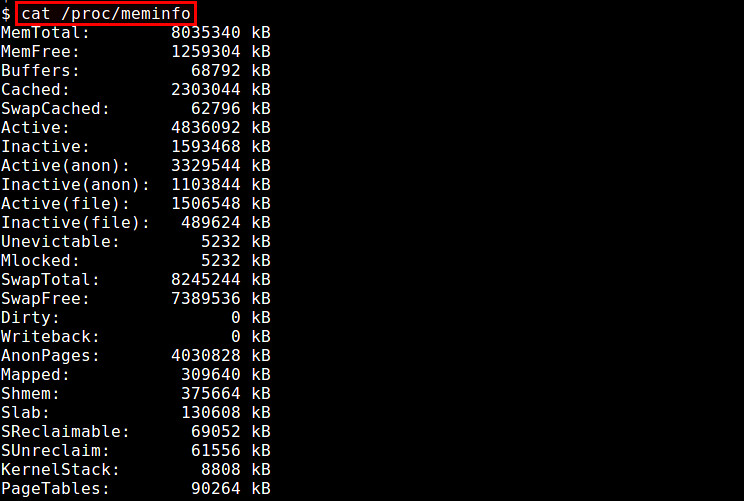
一种最简单的方法是通过“/proc/meminfo”来检查内存使用状况。这个动态更新的虚拟文件事实上是诸如free,top和ps这些与内存相关的工具的信息来源。从可用/闲置物理内存数量到等待被写入缓存的数量或者已写回磁盘的数量,只要是你想要的关于内存使用的信息,“/proc/meminfo”应有尽有。特定进程的内存信息也可以通过“/proc/\<pid>/statm”和“/proc/\<pid>/status”来获取。
|
||||
|
||||
$ cat /proc/meminfo
|
||||
|
||||
|
||||
|
||||
### 2. atop ###
|
||||
|
||||
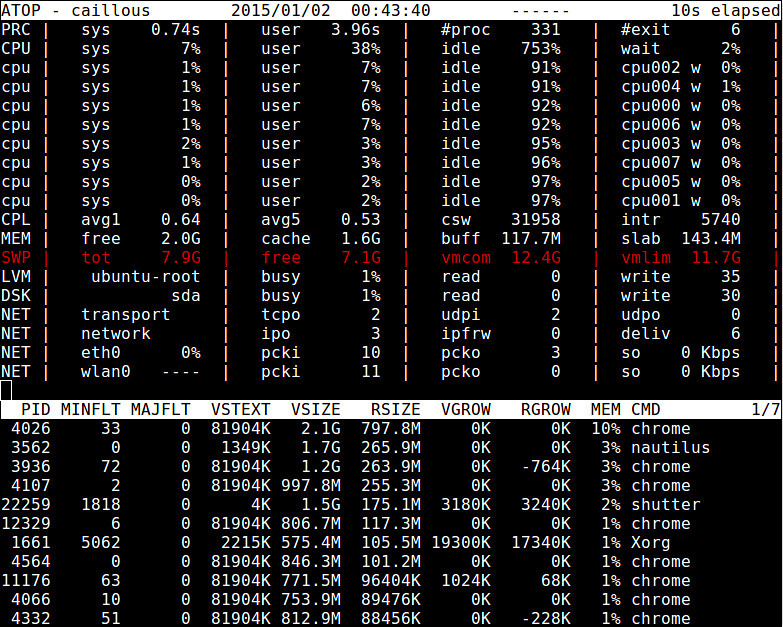
atop命令是用于终端环境的基于ncurses的交互式的系统和进程监测工具。它展示了动态更新的系统资源摘要(CPU, 内存, 网络, 输入/输出, 内核),并且用醒目的颜色把系统高负载的部分以警告信息标注出来。它同样提供了类似于top的线程(或用户)资源使用视图,因此系统管理员可以找到哪个进程或者用户导致的系统负载。内存统计报告包括了总计/闲置内存,缓存的/缓冲的内存和已提交的虚拟内存。
|
||||
|
||||
$ sudo atop
|
||||
|
||||
|
||||
|
||||
### 3. free ###
|
||||
|
||||
free命令是一个用来获得内存使用概况的快速简单的方法,这些信息从“/proc/meminfo”获取。它提供了一个快照,用于展示总计/闲置的物理内存和系统交换区,以及已使用/闲置的内核缓冲区。
|
||||
|
||||
$ free -h
|
||||
|
||||

|
||||
|
||||
### 4. GNOME System Monitor ###
|
||||
|
||||
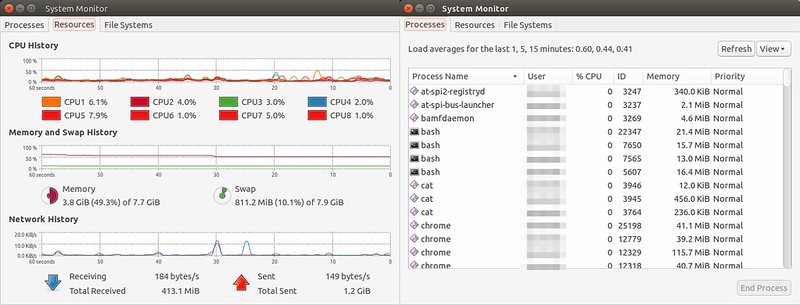
GNOME System Monitor 是一个图形界面应用,它展示了包括CPU,内存,交换区和网络在内的系统资源使用率的较近历史信息。它同时也可以提供一个带有CPU和内存使用情况的进程视图。
|
||||
|
||||
$ gnome-system-monitor
|
||||
|
||||
|
||||
|
||||
### 5. htop ###
|
||||
|
||||
htop命令是一个基于ncurses的交互式的进程视图,它实时展示了每个进程的内存使用情况。它可以报告所有运行中进程的常驻内存大小(RSS)、内存中程序的总大小、库大小、共享页面大小和脏页面大小。你可以横向或者纵向滚动进程列表进行查看。
|
||||
|
||||
$ htop
|
||||
|
||||
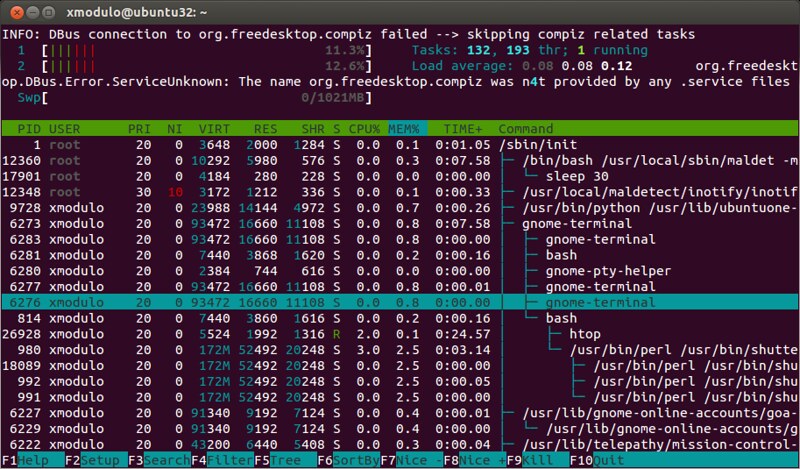
|
||||
|
||||
### 6. KDE System Monitor ###
|
||||
|
||||
就像GNOME桌面拥有GNOME System Monitor一样,KDE桌面也有它自己的对口应用:KDE System Monitor。这个工具的功能与GNOME版本极其相似,也就是说,它同样展示了一个关于系统资源使用情况,以及带有每个进程的CPU/内存消耗情况的实时历史记录。
|
||||
|
||||
$ ksysguard
|
||||
|
||||
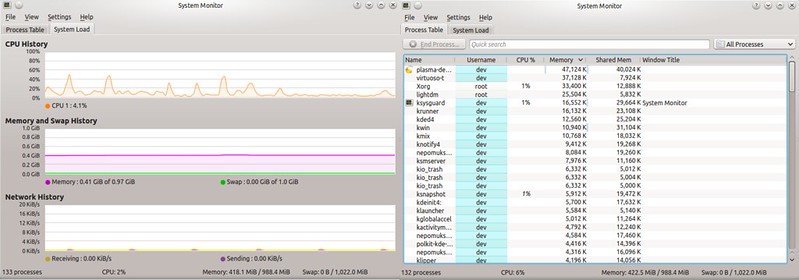
|
||||
|
||||
### 7. memstat ###
|
||||
|
||||
memstat工具对于识别正在消耗虚拟内存的可执行部分、进程和共享库非常有用。给出一个进程识别号,memstat即可识别出与之相关联的可执行部分、数据和共享库究竟使用了多少虚拟内存。
|
||||
|
||||
$ memstat -p <PID>
|
||||
|
||||
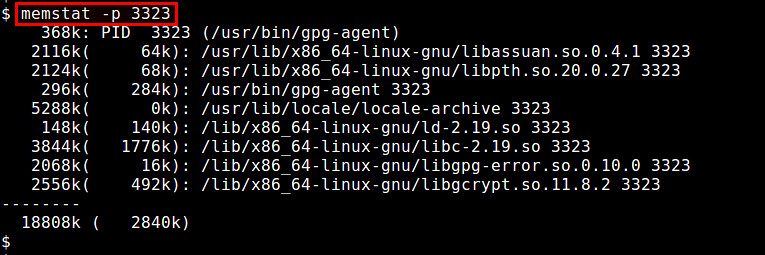
|
||||
|
||||
### 8. nmon ###
|
||||
|
||||
nmon工具是一个基于ncurses系统基准测试工具,它能够以交互方式监测CPU、内存、磁盘I/O、内核、文件系统以及网络资源。对于内存使用状况而言,它能够展示像总计/闲置内存、交换区、缓冲的/缓存的内存,虚拟内存页面换入换出的统计,所有这些都是实时的。
|
||||
|
||||
$ nmon
|
||||
|
||||
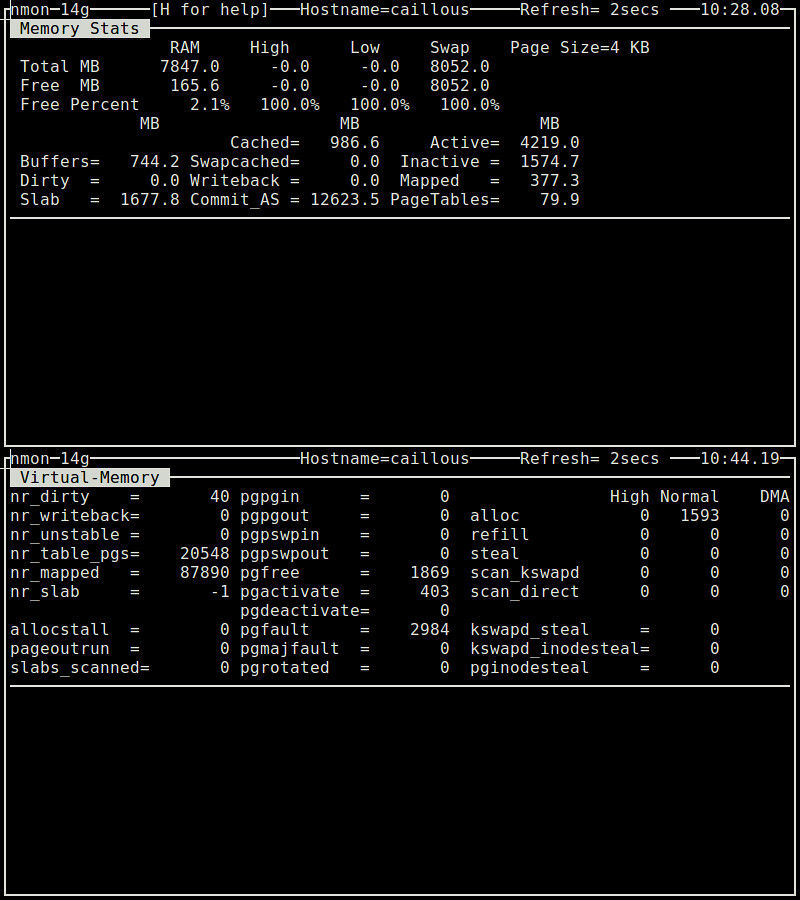
|
||||
|
||||
### 9. ps ###
|
||||
|
||||
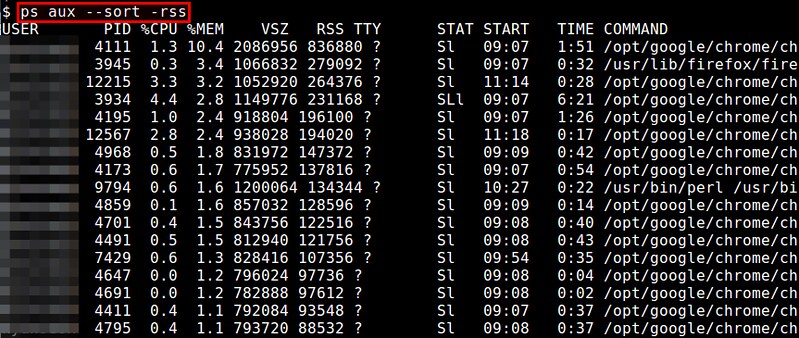
ps命令能够实时展示每个进程的内存使用状况。内存使用报告里包括了 %MEM (物理内存使用百分比), VSZ (虚拟内存使用总量), 和 RSS (物理内存使用总量)。你可以使用“--sort”选项来对进程列表排序。例如,按照RSS降序排序:
|
||||
|
||||
$ ps aux --sort -rss
|
||||
|
||||
|
||||
|
||||
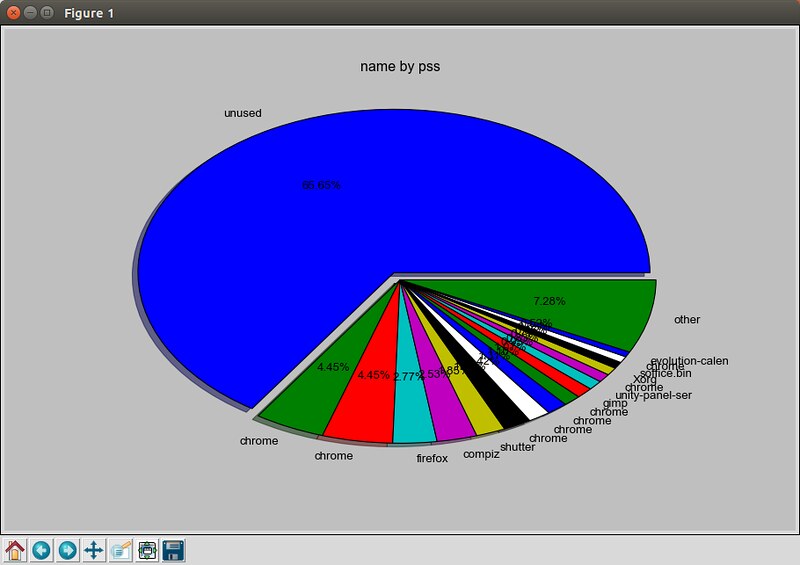
### 10. smem ###
|
||||
|
||||
[smem][1]命令允许你测定不同进程和用户的物理内存使用状况,这些信息来源于“/proc”目录。它利用“按比例分配大小(PSS)”指标来精确量化Linux进程的有效内存使用情况。内存使用分析结果能够输出为柱状图或者饼图类的图形化图表。
|
||||
|
||||
$ sudo smem --pie name -c "pss"
|
||||
|
||||
|
||||
|
||||
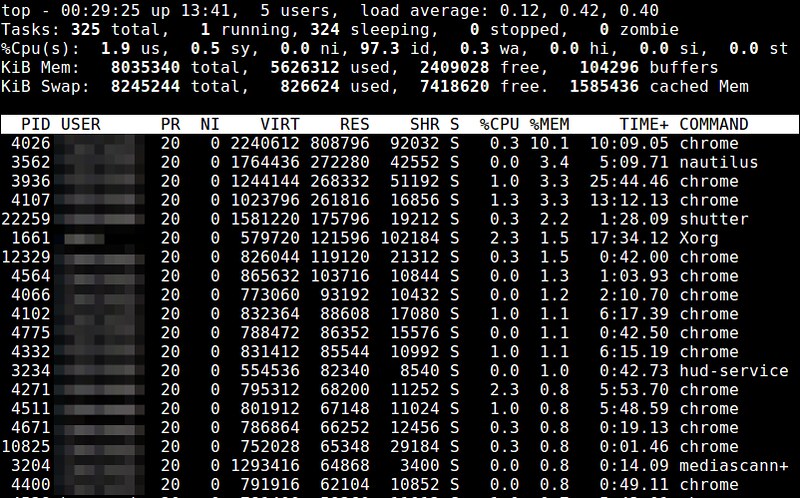
### 11. top ###
|
||||
|
||||
top命令提供了一个运行中进程的实时视图,以及特定进程的各种资源使用统计信息。与内存相关的信息包括 %MEM (内存使用率), VIRT (虚拟内存使用总量), SWAP (换出的虚拟内存使用量), CODE (分配给代码执行的物理内存数量), DATA (分配给非执行的数据的物理内存数量), RES (物理内存使用总量; CODE+DATA), 和 SHR (有可能与其他进程共享的内存数量)。你能够基于内存使用情况或者大小对进程列表进行排序。
|
||||
|
||||
|
||||
|
||||
### 12. vmstat ###
|
||||
|
||||
vmstat命令行工具显示涵盖了CPU、内存、中断和磁盘I/O在内的各种系统活动的瞬时和平均统计数据。对于内存信息而言,命令不仅仅展示了物理内存使用情况(例如总计/已使用内存和缓冲的/缓存的内存),还同样展示了虚拟内存统计数据(例如,内存页的换入/换出,虚拟内存页的换入/换出)
|
||||
|
||||
$ vmstat -s
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-memory-usage-linux.html
|
||||
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/visualize-memory-usage-linux.html
|
||||
@ -0,0 +1,87 @@
|
||||
4个最流行的Linux平台开源代码编辑器
|
||||
===
|
||||
|
||||

|
||||
|
||||
寻找**Linux平台最棒的代码编辑器**?如果你询问那些很早就玩Linux的人,他们会回答是Vi, Vim, Emacs, Nano等。但是,我今天不讨论那些。我将谈论一些新时代尖端、漂亮、时髦而且十分强大, 功能丰富的**最好的Linux平台开源代码编辑器**,它们将会提升你的编程经验。
|
||||
|
||||
### Linux平台最时髦的开源代码编辑器 ###
|
||||
|
||||
我使用Ubuntu作为我的主桌面,所以我提供的安装说明是基于Ubuntu的发行版。但是这并不意味着本文列表就是**Ubuntu最好的文本编辑器**,因为本列表是适用于任何Linux发行版。而且,列表的介绍顺序并没有特定的优先级别。
|
||||
|
||||
#### Brackets ####
|
||||
|
||||

|
||||
|
||||
[Brackets][1]是出自[Adobe][2]的一个开源代码编辑器。它专门关注web设计者的需求,内置支持HTML, CSS和Java Script。它轻量级,但却十分强大,提供在线编辑和实时预览。而且,为了你能更好地体验Brackets,你可以使用许多可用的插件。
|
||||
|
||||
为了[在Ubuntu][3],以及其它基于Ubuntu的发行版,诸如Linux Minit上安装Brackets,你可以使用这个非官方的PPA源:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
|
||||
其他的Linux发行版本,你可以通过下载源代码或相应Linux, OS X和Windows的二进制文件,进行安装。
|
||||
|
||||
- [下载Brackets源码和二进制文件][5]
|
||||
|
||||
#### Atom ####
|
||||
|
||||

|
||||
|
||||
[Atom][5]是为程序员准备的另一个时尚开源代码编辑器。Atom由Github开发,被誉为“21世纪可破解的文本编辑器”。Atom的界面和Sublime Text编辑器十分相似。Sublime Text是一个十分流行但闭源的文本编辑器。
|
||||
|
||||
Atom最近已经发布了 .deb 和 .rpm包,所以在Debian和基于Fedora的Linux版本上安装很简单。当然,你也可以获取它的源代码。
|
||||
|
||||
- [下载Atom .deb][6]
|
||||
- [下载Atom .rpm][7]
|
||||
- [获取Atom源代码][8]
|
||||
|
||||
#### Lime Text ###
|
||||
|
||||

|
||||
|
||||
如果你喜欢Sublime Text,但是你对它的闭源十分反感。别担心,我们有一个[Sublime Text的开源克隆][9],叫做[Lime Text][10]。它基于Go, HTML和QT构造。说它是Sublime Text的克隆,背后原因是Sublime Text2仍有许多bug,而且Sublime Text3到目前为止仍处于测试版本。Sublime Text在开发过程中的bug是否修复,外界并不知情。
|
||||
|
||||
所以,开源爱好者们,你们可以很开心地通过下面的连接获得Lime Text的源码:
|
||||
|
||||
- [获取Lime Text源码][11]
|
||||
|
||||
#### Light Table ####
|
||||
|
||||

|
||||
|
||||
被誉为“下一代的代码编辑器”,[Light Table][12]是另一个时髦,功能丰富的开源编辑器,它更像是一个IDE,而非仅仅是一个文本编辑器。并且,有许多可以提高其性能的扩展方法。内联评价将是你会爱上它的原因。你一定要试用一下看,这样你才会体会它的实用之处。
|
||||
|
||||
- [获取Light Table的源码][13]
|
||||
|
||||
### 你的选择是什么? ###
|
||||
|
||||
在Linux平台,我们不能只局限于这四种代码编辑器。这份列表仅介绍了一些时髦的,可供程序员使用的编辑器。当然,你也有许多其他的选择,比如[Notepad++的替代品Notepadqq][14]或者[SciTE][15]等等。那么,文中这四个编辑器,你最喜欢哪个呢?
|
||||
|
||||
---
|
||||
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://brackets.io/
|
||||
[2]:http://www.adobe.com/
|
||||
[3]:http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]:https://github.com/adobe/brackets/releases
|
||||
[5]:https://atom.io/
|
||||
[6]:https://atom.io/download/deb
|
||||
[7]:https://atom.io/download/rpm
|
||||
[8]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[9]:http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[10]:http://limetext.org/
|
||||
[11]:https://github.com/limetext/lime
|
||||
[12]:http://lighttable.com/
|
||||
[13]:https://github.com/LightTable/LightTable
|
||||
[14]:http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[15]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
@ -1,22 +1,22 @@
|
||||
Ubuntu 15.04即将整合Linux内核3.19分支
|
||||
----
|
||||
*Ubuntu已经开始跟踪一个新的内核分支*
|
||||
*Ubuntu已经开始整合一个新的内核分支*
|
||||
|
||||
|
||||
|
||||
#Linux内核是一个发行版中最重要的组成部分,Ubuntu用户很想知道哪个版本将用于15.04分支的稳定版中,预计几个月后就会发布。
|
||||
Linux内核是一个发行版中最重要的组成部分,Ubuntu用户很想知道哪个版本将用于预计几个月后就会发布的15.04分支的稳定版中。
|
||||
|
||||
Ubuntu和Linux内核开发周期并不同步,所以很难预测最终哪个版本将应用在Ubuntu 15.04中。目前,Ubuntu 15.04(长尾黑颚猴)使用的是Linux内核3.18,但是开发者们已经准备应用3.19分支了。
|
||||
|
||||
“我们的Vivid内核仍然基于v3.18.2的稳定内核上游,但是我们很快将基础变更到v3.18.3。我们也将把我们的非稳定版分支的基础变更到v3.19-rc5,然后上传到我们的团队PPA。”Canonical的Joseph Salisbury[说](1)。
|
||||
“我们的Vivid的内核仍然基于v3.18.2的上游稳定内核,但是我们很快将重新基于v3.18.3内核开发。我们也将把我们的非稳定版分支的基础变更到v3.19-rc5,然后上传到我们的团队PPA。”Canonical的Joseph Salisbury[说](1)。
|
||||
|
||||
Linux内核3.19仍然处于开发阶段,预计还要几个星期才会出稳定版本,但是有充足的时间将它加入到Ubuntu中并测试。不可能等到3.20分支了,举个例子,即使它能在4月23日前发布。
|
||||
Linux内核3.19仍然处于开发阶段,预计还要几个星期才会出稳定版本,但是有充足的时间将它加入到Ubuntu中并测试。但是不可能等到3.20分支了,举个例子,即使它能在4月23日前发布。
|
||||
|
||||
你现在就可以从Softpedia[下载Ubuntu 15.04](2),试用一下。这是一个每日构建版本,会包含发行版中目前已经做出的所有改善。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
via:http://linux.softpedia.com/blog/Ubuntu-15-04-to-Integrate-Linux-Kernel-3-19-Branch-Soon-471121.shtml
|
||||
|
||||
本文发布时间:25 Jan 2015, 20:39 GMT
|
||||
|
||||
@ -24,7 +24,7 @@ via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-W
|
||||
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,36 +1,36 @@
|
||||
Wi-Fi直连的Android实现中的Bug导致拒绝服务
|
||||
Android 中的 Wi-Fi 直连方式的 Bug 会导致拒绝服务
|
||||
----
|
||||
|
||||
*Google标记这个问题为低严重性,并不急着修复*
|
||||
|
||||

|
||||
|
||||
#Android处理Wi-Fi直连连接的方式中的一个漏洞会导致在搜索连接节点的时候设备重启,这个节点可能是其他手机,摄像头,游戏设备,电脑或是打印机等任何设备。
|
||||
Android处理Wi-Fi直连连接的方式中的一个漏洞可以导致在搜索连接节点的时候所连接的设备重启,这个节点可能是其他手机,摄像头,游戏设备,电脑或是打印机等任何设备。
|
||||
|
||||
Wi-Fi直连技术允许无线设备之间直接建立通信,而不用加入到本地网络中。
|
||||
|
||||
##安全公司致力于协调修复这个问题
|
||||
###安全公司致力于协调修复这个问题
|
||||
|
||||
这个漏洞允许攻击者发送一个特定的修改过的802.11侦测响应帧给设备,从而因为WiFi监控类中的一个未处理的异常导致设备重启。
|
||||
|
||||
Core Security通过自己的CoreLabs团队发现了这个下次(CVE-2014-0997),早在2014年9月就汇报给了Google。这家供应商确认了这个问题,却把它列为低严重性,并不提供修复时间表。
|
||||
Core Security通过自己的CoreLabs团队发现了这个瑕疵(CVE-2014-0997),早在2014年9月就汇报给了Google。Google确认了这个问题,却把它列为低严重性,并不提供修复时间表。
|
||||
|
||||
每次Core Security联系Android安全组要求提供修复时间表的时候都会收到同样的答复。最后一次答复是1月20日,意味着这么段时间中都没有补丁。在星期一的时候,这家安全公司公布了他们的发现。
|
||||
每次Core Security联系Android安全组要求提供修复时间表的时候都会收到同样的答复。最后一次答复是1月20日,意味着这么长的时间中都没有补丁。在星期一的时候,这家安全公司公布了他们的发现。
|
||||
|
||||
这家安全公司建立了一个(概念证明)[1]来展示他们研究结果的有效性。
|
||||
这家安全公司建立了一个[概念攻击][1]来展示他们研究结果的有效性。
|
||||
|
||||
根据这个漏洞的技术细节,一些Android设备在收到一个错误的wpa_supplicant事件后可能会进入拒绝服务状态,这些事件让无线驱动和Android平台框架之间的接口有效。
|
||||
|
||||
##Google并不着急结束这个问题
|
||||
###Google并不着急解决这个问题
|
||||
|
||||
Android安全组对于这个问题的放松态度可能是基于这个原因,这种拒绝服务状态只发生在扫描节点这一小段时间。
|
||||
Android安全组对于这个问题的放松态度可能是基于这个原因:这种拒绝服务状态只发生在扫描节点这一小段时间。
|
||||
|
||||
不仅如此,实际上结果也并不严重,因为它会导致设备重启。不存在数据泄漏的风险或是能引起这个问题的攻击,不会吸引攻击者。另一方面,不管怎样都应该提供一个补丁,以减轻任何未来的潜在风险。
|
||||
不仅如此,实际上结果也并不严重,因为它会导致设备重启。不存在数据泄漏的风险或是能引起这个问题的攻击,不会吸引攻击者。但另一方面,不管怎样都应该提供一个补丁,以减轻任何未来的潜在风险。
|
||||
|
||||
Core Security声称在Android 5.0.1及以上版本中没有测试到这个问题,他们发现的受影响的设备有运行移动操作系统版本4.4.4的Nexus 5和4,运行Android 4.2.2的LG D806和Samsung SM-T310,以及4.1.2版本系统的Motorola RAZR HD。
|
||||
Core Security声称在Android 5.0.1及以上版本中没有测试到这个问题,他们发现的受影响的设备有Android系统4.4.4的Nexus 5和4,运行Android 4.2.2的LG D806和Samsung SM-T310,以及4.1.2版本系统的Motorola RAZR HD。
|
||||
|
||||
目前,减轻影响的方式是尽量不用Wi-Fi直连,或者升级到没有漏洞的Android版本。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Bug-In-Wi-Fi-Direct-Android-Implementation-Causes-Denial-of-Service-471299.shtml
|
||||
@ -38,10 +38,8 @@ via:http://news.softpedia.com/news/Bug-In-Wi-Fi-Direct-Android-Implementation-Ca
|
||||
本文发布时间:27 Jan 2015, 09:11 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
在CentOS 7中安装Jetty服务器
|
||||
================================================================================
|
||||
[Jetty][1] 是一款纯Java的HTTP **(Web) 服务器**和Java Servlet容器。 通常在更大的网络框架中,Jetty经常用于设备间的通信。但是其他Web服务器通常给人类传递文件。Jetty是一个Eclipse基金中免费开源项目。这个Web服务器用于如Apache ActiveMQ、 Alfresco、 Apache Geronimo、 Apache Maven、 Apache Spark、Google App Engine、 Eclipse、 FUSE、 Twitter的 Streaming API 和 Zimbra中。
|
||||
[Jetty][1] 是一款纯Java的HTTP **(Web) 服务器**和Java Servlet容器。 通常在更大的网络框架中,Jetty经常用于设备间的通信,而其他Web服务器通常给“人类”传递文件 :D。Jetty是一个Eclipse基金会的免费开源项目。这个Web服务器用于如Apache ActiveMQ、 Alfresco、 Apache Geronimo、 Apache Maven、 Apache Spark、Google App Engine、 Eclipse、 FUSE、 Twitter的 Streaming API 和 Zimbra中。
|
||||
|
||||
这篇文章会解释‘如何在CentOS服务器中安装Jetty服务器’。
|
||||
这篇文章会介绍‘如何在CentOS服务器中安装Jetty服务器’。
|
||||
|
||||
**首先我们要用下面的命令安装JDK:**
|
||||
|
||||
@ -58,7 +58,7 @@
|
||||
|
||||
完成了!
|
||||
|
||||
现在你可以在 **http://<youripaddress>:8080** 中访问了
|
||||
现在你可以在 **http://\<你的 IP 地址>:8080** 中访问了
|
||||
|
||||
就是这样。
|
||||
|
||||
@ -70,7 +70,7 @@ via: http://www.unixmen.com/install-jetty-web-server-centos-7/
|
||||
|
||||
作者:[Jijo][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -21,7 +21,7 @@ Developed in part by two ex-Rackspace engineers, [CoreOS][8] is a lightweight Li
|
||||
CoreOS was quickly adopted by many cloud providers, including Microsoft Azure, Amazon Web Services, DigitalOcean and Google Compute Engine.
|
||||
|
||||
Like CoreOS, Ubuntu Core offers an expedited process for updating components, reducing the amount of time that an administrator would need to manually manage them.
|
||||
|
||||
如同Coreos一样,Ubuntu内核提供了一个快速引擎来更新组件
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2860401/cloud-computing/google-cloud-offers-streamlined-ubuntu-for-docker-use.html
|
||||
@ -40,4 +40,4 @@ via: http://www.infoworld.com/article/2860401/cloud-computing/google-cloud-offer
|
||||
[5]:http://www.itworld.com/article/2695383/open-source-tools/docker-all-geared-up-for-the-enterprise.html
|
||||
[6]:http://www.itworld.com/article/2695501/cloud-computing/google-unleashes-docker-management-tools.html
|
||||
[7]:http://www.itworld.com/article/2696116/open-source-tools/coreos-linux-does-away-with-the-upgrade-cycle.html
|
||||
[8]:https://coreos.com/using-coreos/
|
||||
[8]:https://coreos.com/using-coreos/
|
||||
|
||||
@ -0,0 +1,49 @@
|
||||
WordPress Can Be Used to Leverage Critical Ghost Flaw in Linux
|
||||
-----
|
||||
*Users are advised to apply available patches immediately*
|
||||
|
||||

|
||||
|
||||
**The vulnerability revealed this week by security researchers at Qualys, who dubbed it [Ghost](1), could be taken advantage of through WordPress or other PHP applications to compromise web servers.**
|
||||
|
||||
The glitch is a buffer overflow that can be triggered by an attacker to gain command execution privileges on a Linux machine. It is present in the glibc’s “__nss_hostname_digits_dots()” function that can be used by the “gethostbyname()” function.
|
||||
|
||||
##PHP applications can be used to exploit the glitch
|
||||
|
||||
Marc-Alexandre Montpas at Sucuri says that the problem is significant because these functions are used in plenty of software and server-level mechanism.
|
||||
|
||||
“An example of where this could be a big issue is within WordPress itself: it uses a function named wp_http_validate_url() to validate every pingback’s post URL,” which is carried out through the “gethostbyname()” function wrapper used by PHP applications, he writes in a blog post on Wednesday.
|
||||
|
||||
An attacker could use this method to introduce a malicious URL designed to trigger the vulnerability on the server side and thus obtain access to the machine.
|
||||
|
||||
In fact, security researchers at Trustwave created [proof-of-concept](2) code that would cause the buffer overflow using the pingback feature in WordPress.
|
||||
|
||||
##Multiple Linux distributions are affected
|
||||
|
||||
Ghost is present in glibc versions up to 2.17, which was made available in May 21, 2013. The latest version of glibc is 2.20, available since September 2014.
|
||||
|
||||
However, at that time it was not promoted as a security fix and was not included in many Linux distributions, those offering long-term support (LTS) in particular.
|
||||
|
||||
Among the impacted operating systems are Debian 7 (wheezy), Red Hat Enterprise Linux 6 and 7, CentOS 6 and 7, Ubuntu 12.04. Luckily, Linux vendors have started to distribute updates with the fix that mitigates the risk. Users are advised to waste no time downloading and applying them.
|
||||
|
||||
In order to demonstrate the flaw, Qualys has created an exploit that allowed them remote code execution through the Exim email server. The security company said that it would not release the exploit until the glitch reached its half-life, meaning that the number of the affected systems has been reduced by 50%.
|
||||
|
||||
Vulnerable application in Linux are clockdiff, ping and arping (under certain conditions), procmail, pppd, and Exim mail server.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/WordPress-Can-Be-Used-to-Leverage-Critical-Ghost-Flaw-in-Linux-471730.shtml
|
||||
|
||||
本文发布时间:30 Jan 2015, 17:36 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://news.softpedia.com/news/Linux-Systems-Affected-by-14-year-old-Vulnerability-in-Core-Component-471428.shtml
|
||||
[2]:http://blog.spiderlabs.com/2015/01/ghost-gethostbyname-heap-overflow-in-glibc-cve-2015-0235.html
|
||||
38
sources/news/20150202 The Pirate Bay Is Now Back Online.md
Normal file
38
sources/news/20150202 The Pirate Bay Is Now Back Online.md
Normal file
@ -0,0 +1,38 @@
|
||||
The Pirate Bay Is Now Back Online
|
||||
------
|
||||
*The website was closed for about seven weeks*
|
||||

|
||||
##After being [raided](1) by the police almost two months ago, (in)famous torrent website The Pirate Bay is now back online. Those who thought the website will never return will be either disappointed or happy given that The Pirate Bay seems to live once again.
|
||||
|
||||
In order to celebrate its coming back, The Pirate Bay admins have posted a Phoenix bird on the front page, which signifies the fact that the website can't be killed only damaged.
|
||||
|
||||
About two weeks after The Pirate Bay was raided the domain miraculously came back to life. Soon after a countdown appeared on the temporary homepage of The Pirate Bay indicating that the website is almost ready for a comeback.
|
||||
|
||||
The countdown hinted to February 1, as the possible date for The Pirate Bay's comeback, but it looks like those who manage the website manage to pull it out one day earlier.
|
||||
|
||||
Beginning today, those who have accounts on The Pirate Bay can start downloading the torrents they want. Other than the Phoenix on the front page there are no other messages that might point to the resurrection The Pirate Bay except for the fact that it's now operational.
|
||||
|
||||
Admins of the website said a few weeks ago they will find ways to manage and optimize The Pirate Bay, so that there will be minimal chances for the website to be closed once again. Let's see how it lasts this time.
|
||||
|
||||
##Another version of The Pirate Bay may be launched soon
|
||||
|
||||
In related news, one of the members of the original staff was dissatisfied with the decisions made by the majority regarding some of the changes made in the way admins interact with the website.
|
||||
|
||||
He told [Torrentfreak](2) earlier this week that he, along with a few others, will open his version of The Pirate Bay, which they claim will be the "real" one.
|
||||
|
||||
------
|
||||
via:http://news.softpedia.com/news/The-Pirate-Bay-Is-Now-Back-Online-471802.shtml
|
||||
|
||||
本文发布时间:31 Jan 2015, 22:49 GMT
|
||||
|
||||
作者:[Cosmin Vasile][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/cosmin-vasile
|
||||
[1]:http://news.softpedia.com/news/The-Pirate-Bay-Is-Down-December-9-2014-466987.shtml
|
||||
[2]:http://torrentfreak.com/pirate-bay-back-online-150131/
|
||||
@ -0,0 +1,98 @@
|
||||
Debian Forked over systemd: Birth of Devuan GNU/Linux Distribution
|
||||
================================================================================
|
||||
Debian GNU/Linux distribution is one of the oldest Linux distribution that is currently in working state. init used to be the default central management and configuration platform for Linux operating system before systemd emerged. Systemd from the date of its release has been very much controversial.
|
||||
|
||||
Sooner or later it has replaced init on most of the Linux distribution. Debian remained no exception and Debian 8 codename JESSIE will be having systemd by default. The Debian adaptation of systemd in replacement of init caused polarization. This led to forking of Debian and hence Devuan GNU/Linux distribution born.
|
||||
|
||||
Devuan project started with the primary goal to put back nit and remove controversial systemd. A lot of Linux Distribution are based on Debian or a derivative of Debian and one does not simply fork Debian. Debian will always attract developers.
|
||||
|
||||
### What Devuan is all About? ###
|
||||
|
||||
Devuan in Italian (pronounced Devone in English) suggests “Don’t panic and keep forking Debian”, for Init-Freedom lovers. Developers see Devuan as the beginning of a process which aims at base distribution and is able to protect the freedom of developers and community.
|
||||
|
||||

|
||||
|
||||
Debian Forked over systemd: Birth of Devuan Linux
|
||||
|
||||
Devuan project priority includes – interoperability, diversity and backward compatibility. It will derive its own installer and repos from Debian and modify where ever required. If everything works smooth by the mid of 2015 users can switch to Devuan from Debian 7 and start using devuan repos.
|
||||
|
||||
The process of switching will fairly remain as simple as upgrading a Debian installation. The project will be as minimal as possible and completely in accordance of UNIX philosophy – “Doing one thing and doing it well”. The targeted users of Devuan will be System Admins, Developers and users having experience of Debian.
|
||||
|
||||
The project started by italian developers has raised a fund of 4.5k€ (EUR) in the year 2014. They have moved distro infrastructure from GitHub to GitLab, progress on Loginkit (systemd Logind replaced), discussing Logo and other important aspects useful in long run.
|
||||
|
||||
A few of the Logos are in discussion now are shown in the picture.
|
||||
|
||||

|
||||
|
||||
Devuan Logo Proposals
|
||||
|
||||
Have a look at them here at: [http://without-systemd.org/wiki/index.php/Category:Logo][1]
|
||||
|
||||
The unrest over systemd that gave birth to Devuan is good or bad? Lets have a look.
|
||||
|
||||
### Is Devuan fork a good thing? ###
|
||||
|
||||
Well! difficult to answer that forking such a huge distro is really going to be of any good. A (group of) developer(s) who initially were working with Debian got unsatisfied with systemd and forked it.
|
||||
|
||||
Now the actual number of developers working on Debian/Systemd decreased which is going to affect the productivity of both the projects. Now the same number of developers are working on two different projects.
|
||||
|
||||
What you think would be the fate of Devuan as well as Debian project? Won’t it hinder the progress of either distro and Linux in the long run?
|
||||
|
||||
Please give your [comments][2] about Devuan project.
|
||||
|
||||
注:如果可以在发布文章的时候发布一个调查,就把下面这段发成一个调查,如果不行,就直接嵌入js代码
|
||||
|
||||
<script type="text/javascript" charset="utf-8" src="http://static.polldaddy.com/p/8629256.js"></script>
|
||||
|
||||
Do you think systemd for Debian is
|
||||
|
||||
Good
|
||||
Bad
|
||||
Don't Know
|
||||
Don't Care
|
||||
Other:
|
||||
|
||||
VoteView ResultsPolldaddy.com
|
||||
|
||||
|
||||
**Do you really feel that Debian with systemd will have a bad fate as depicted below**
|
||||
|
||||

|
||||
|
||||
Strip SystmeD
|
||||
|
||||
Time to wait for Devuan 1.0 and lets see what it could contain.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
All the major Linux Distributions Like Fedora, RedHat, openSUSE, SUSE Enterprise, Arch, Megia have already switched to Systemd, Ubuntu and Debian are in the way to replace init with systemd. Only Gentoo and Slack till date have shown no interest in systemd but who knows someday even Gentoo and slack too started moving in the same direction.
|
||||
|
||||
The reputation of Debian as a Linux Distro is something very few have reached the mark. It is blessed by some hundreds of developers and millions of users. The actual question is what percentage of users and developers were not comfortable with systemd. If the percentage is really high then what led debian to switch to systemd. Had it moved against the wishes of its users and developers. If this is the case the chance of success of devuan is pretty fair. Well how many developers put long hours of code punching for the project.
|
||||
|
||||
Hope the fate of this project will not be something like those distros which once was started with high degree of passion and enthusiasm and later the developers got uninterested.
|
||||
|
||||
Post Script : Linus Torvalds do not mind systemd that much.
|
||||
|
||||
**If you need Devuan, then join and support it now!**
|
||||
|
||||
Development : [https://git.devuan.org][3]
|
||||
Donations : [https://devuan.org/donate.html][4]
|
||||
Discussions : [https://mailinglists.dyne.org/cgi-bin/mailman/listinfo/dng][5]
|
||||
Devuan Developers : onelove@devuan.org
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/debian-forked-over-systemd-birth-of-devuan-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://without-systemd.org/wiki/index.php/Category:Logo
|
||||
[2]:http://www.tecmint.com/debian-forked-over-systemd-birth-of-devuan-linux/#comments
|
||||
[3]:https://git.devuan.org/
|
||||
[4]:https://devuan.org/donate.html
|
||||
[5]:https://mailinglists.dyne.org/cgi-bin/mailman/listinfo/dng
|
||||
@ -1,66 +0,0 @@
|
||||
What is a good EPUB reader on Linux
|
||||
================================================================================
|
||||
If the habit on reading books on electronic tablets is still on its way, reading books on a computer is even rarer. It is hard enough to focus on the classics of the 16th century literature, so who needs the Facebook chat pop up sound in the background in addition? But if for some reasons you wish to open an electronic book in your computer, chances are that you will need specific software. Indeed, most editors agreed with using the EPUB format for electronic books (for "Electronic PUBlication"). Hopefully, Linux is not deprived of good programs capable of dealing with such format. In short, here is a non-exhaustive list of good EPUB readers on Linux.
|
||||
|
||||
### 1. Calibre ###
|
||||
|
||||
|
||||
|
||||
Let's dive in with maybe the biggest name of that list: [Calibre][1]. More than just an ebook reader, Calibre is a fully packaged e-library. It supports a plethora of formats (almost every I can think of), integrates a reader, a manager, a meta-data editor which can download covers from the Internet, an EPUB editor, a news reader, and a search engine to download additional books. To top it all, the interface is slick and has nothing to envy to other professional software. The only potential downside is that if you are looking for an EPUB reader, and are not interested in the whole library manager aspect, the program is too heavy for your needs.
|
||||
|
||||
### 2. FBReader ###
|
||||
|
||||
|
||||
|
||||
[FBReader][2] is also a library manager, but in a lighter way than Calibre. The interface is more sober, and is clearly cut in two: (1) the library aspect where you can add files, edit the meta-data, or download new books, and (2) the reader aspect. If you like simplicity, you might enjoy this program. I personally appreciate its straightforward tag and series system for classifying books.
|
||||
|
||||
### 3. Cool Reader ###
|
||||
|
||||

|
||||
|
||||
For all of you who are just looking for a way to visualize the content of an EPUB file, I recommend [Cool Reader][5]. In the spirit of Linux applications which do only one thing and do it well, Cool Reader is optimized to just open an EPUB file, and navigate through it via handy shortcuts. And since it is based on Qt, it also follows Qt's mentality by giving a ton of settings to mess around with.
|
||||
|
||||
### 4. Okular ###
|
||||
|
||||

|
||||
|
||||
Since we were talking about Qt applications, one of KDE's main document viewer, [Okular][3], also has the capacity to view EPUB files, once an EPUB library has been installed on the system. However, this is probably not a very good option if you are not a KDE user.
|
||||
|
||||
### 5. pPub ###
|
||||
|
||||

|
||||
|
||||
[pPub][4] is an old project that you can still find on Github. Its latest change seems to have been made two years ago. However, pPub is one of those programs that really deserve a second life. Written in Python and based on GTK3 and WebKit, pPub is lightweight and intuitive. The interface probably needs a little updating and is beyond sober, but the core is very good. It even supports JavaScript. So please, someone kick that up again.
|
||||
|
||||
### 6. epub ###
|
||||
|
||||
|
||||
|
||||
If all you need is a quick and easy way to check the content of an EPUB file, without caring about any fancy GUI, maybe an EPUB reader with command line interface might just do. [epub][6] is a minimalistic EPUB reader written in Python, which allows you to read an EPUB file in a terminal environment. You can switch between chapter/TOC views, up/down a page, and nothing more. This is as simple as any EPUB reader can possibly get.
|
||||
|
||||
### 7. Sigil ###
|
||||
|
||||
|
||||
|
||||
Finally, last of the list is not actually an EPUB reader, but more of a standalone editor. [Sigil][7] is able to extract the content of an EPUB file, and break it down for what it really is: xhtml text, images, styles, and sometimes audio. The interface is a lot more complex than the one for a basic reader, but remains clear and well thought, on par with the features it provides. I particularly appreciate the tab system. If you are familiar with editing web pages, you will be in know territory here.
|
||||
|
||||
To conclude, there are a lot of open source EPUB readers out there. Some do nothing more, while others go way beyond that. As usual, I recommend using the one that makes the most sense for you to use. If you know more good EPUB readers on Linux that you like, please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/good-epub-reader-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calibre-ebook.com/
|
||||
[2]:http://fbreader.org/
|
||||
[3]:http://okular.kde.org/
|
||||
[4]:https://github.com/sakisds/pPub
|
||||
[5]:http://crengine.sourceforge.net/
|
||||
[6]:https://github.com/rupa/epub
|
||||
[7]:https://github.com/user-none/Sigil
|
||||
@ -1,111 +0,0 @@
|
||||
Best GNOME Shell Themes For Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
Themes are the best way to customize your Linux desktop. If you [install GNOME on Ubuntu 14.04][1] or 14.10, you might want to change the default theme and give it a different look. To help you in this task, I have compiled here a **list of best GNOME shell themes for Ubuntu** or any other Linux OS that has GNOME shell installed on it. But before we see the list, let’s first see how to change install new themes in GNOME Shell.
|
||||
|
||||
### Install themes in GNOME Shell ###
|
||||
|
||||
To install new themes in GNOME with Ubuntu, you can use Gnome Tweak Tool which is available in software repository in Ubuntu. Open a terminal and use the following command:
|
||||
|
||||
sudo apt-get install gnome-tweak-tool
|
||||
|
||||
Alternatively, you can use themes by putting them in ~/.themes directory. I have written a detailed tutorial on [how to install and use themes in GNOME Shell][2], in case you need it.
|
||||
|
||||
### Best GNOME Shell themes ###
|
||||
|
||||
The themes listed here are tested on GNOME Shell 3.10.4 but it should work for all version of GNOME 3 and higher. For the sake of mentioning, the themes are not in any kind of priority order. Let’s have a look at the best GNOME themes:
|
||||
|
||||
#### Numix ####
|
||||
|
||||

|
||||
|
||||
No list can be completed without the mention of [Numix themes][3]. These themes got so popular that it encouraged [Numix team to work on a new Linux OS, Ozon][4]. Considering their design work with Numix theme, it won’t be exaggeration to call it one of the [most beautiful Linux OS][5] releasing in near future.
|
||||
|
||||
To install Numix theme in Ubuntu based distributions, use the following commands:
|
||||
|
||||
sudo apt-add-repository ppa:numix/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install numix-icon-theme-circle
|
||||
|
||||
#### Elegance Colors ####
|
||||
|
||||

|
||||
|
||||
Another beautiful theme from Satyajit Sahoo, who is also a member of Numix team. [Elegance Colors][6] has its own PPA so that you can easily install it:
|
||||
|
||||
sudo add-apt-repository ppa:satyajit-happy/themes
|
||||
sudo apt-get update
|
||||
sudo apt-get install gnome-shell-theme-elegance-colors
|
||||
|
||||
#### Moka ####
|
||||
|
||||

|
||||
|
||||
[Moka][7] is another mesmerizing theme that is always included in the list of beautiful themes. Designed by the same developer who gave us Unity Tweak Tool, Moka is a must try:
|
||||
|
||||
sudo add-apt-repository ppa:moka/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install moka-gnome-shell-theme
|
||||
|
||||
#### Viva ####
|
||||
|
||||

|
||||
|
||||
Based on Gnome’s default Adwaita theme, Viva is a nice theme with shades of black and oranges. You can download Viva from the link below.
|
||||
|
||||
- [Download Viva GNOME Shell Theme][8]
|
||||
|
||||
#### Ciliora-Prima ####
|
||||
|
||||

|
||||
|
||||
Previously known as Zukitwo Dark, Ciliora-Prima has square icons theme. Theme is available in three versions that are slightly different from each other. You can download it from the link below.
|
||||
|
||||
- [Download Ciliora-Prima GNOME Shell Theme][9]
|
||||
|
||||
#### Faience ####
|
||||
|
||||

|
||||
|
||||
Faience has been a popular theme for quite some time and rightly so. You can install Faience using the PPA below for GNOME 3.10 and higher.
|
||||
|
||||
sudo add-apt-repository ppa:tiheum/equinox
|
||||
sudo apt-get update
|
||||
sudo apt-get install faience-theme
|
||||
|
||||
#### Paper [Incomplete] ####
|
||||
|
||||

|
||||
|
||||
Ever since Google talked about Material Design, people have been going gaga over it. Paper GTK theme, by Sam Hewitt (of Moka Project), is inspired by Google Material design and currently under development. Which means you will not have the best experience with Paper at the moment. But if your a bit experimental, like me, you can definitely give it a try.
|
||||
|
||||
sudo add-apt-repository ppa:snwh/pulp
|
||||
sudo apt-get update
|
||||
sudo apt-get install paper-gtk-theme
|
||||
|
||||
That concludes my list. If you are trying to give a different look to your Ubuntu, you should also try the list of [best icon themes for Ubuntu 14.04][10].
|
||||
|
||||
How do you find this list of **best GNOME Shell themes**? Which one is your favorite among the one listed here? And if it’s not listed here, do let us know which theme you think is the best GNOME Shell theme.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/gnome-shell-themes-ubuntu-1404/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/how-to-install-gnome-in-ubuntu-14-04/
|
||||
[2]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[3]:https://numixproject.org/
|
||||
[4]:http://itsfoss.com/numix-linux-distribution/
|
||||
[5]:http://itsfoss.com/new-beautiful-linux-2015/
|
||||
[6]:http://satya164.deviantart.com/art/Gnome-Shell-Elegance-Colors-305966388
|
||||
[7]:http://mokaproject.com/
|
||||
[8]:https://github.com/vivaeltopo/gnome-shell-theme-viva
|
||||
[9]:http://zagortenay333.deviantart.com/art/Ciliora-Prima-Shell-451947568
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -1,88 +0,0 @@
|
||||
su-kaiyao translating
|
||||
|
||||
4 Best Modern Open Source Code Editors For Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Looking for **best programming editors in Linux**? If you ask the old school Linux users, their answer would be Vi, Vim, Emacs, Nano etc. But I am not talking about them. I am going to talk about new age, cutting edge, great looking, sleek and yet powerful, feature rich **best open source code editors for Linux** that would enhance your programming experience.
|
||||
|
||||
### Best modern Open Source editors for Linux ###
|
||||
|
||||
I use Ubuntu as my main desktop and hence I have provided installation instructions for Ubuntu based distributions. But this doesn’t make this list as **best text editors for Ubuntu** because the list is apt for any Linux distribution. Just to add, the list is not in any particular priority order.
|
||||
|
||||
#### Brackets ####
|
||||
|
||||

|
||||
|
||||
[Brackets][1] is an open source code editor from [Adobe][2]. Brackets focuses exclusively on the needs of web designers with built in support for HTML, CSS and Java Script. It’s light weight and yet powerful. It provides you with inline editing and live preview. There are plenty of plugins available to further enhance your experience with Brackets.
|
||||
|
||||
To [install Brackets in Ubuntu][3] and Ubuntu based distributions such as Linux Mint, you can use this unofficial PPA:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
|
||||
For other Linux distributions, you can get the source code as well as binaries for Linux, OS X and Windows on its website.
|
||||
|
||||
- [Download Brackets Source Code and Binaries][5]
|
||||
|
||||
#### Atom ####
|
||||
|
||||

|
||||
|
||||
[Atom][5] is another modern and sleek looking open source editor for programmers. Atom is developed by Github and promoted as a “hackable text editor for the 21st century”. The looks of Atom resembles a lot like Sublime Text editor, a hugely popular but closed source text editors among programmers.
|
||||
|
||||
Atom has recently released .deb and .rpm packages so that one can easily install Atom in Debian and Fedora based Linux distributions. Of course, its source code is available as well.
|
||||
|
||||
- [Download Atom .deb][6]
|
||||
- [Download Atom .rpm][7]
|
||||
- [Get Atom source code][8]
|
||||
|
||||
#### Lime Text ####
|
||||
|
||||

|
||||
|
||||
So you like Sublime Text editor but you are not comfortable with the fact that it is not open source. No worries. We have an [open source clone of Sublime Text][9], called [Lime Text][10]. It is built on Go, HTML and QT. The reason behind cloning of Sublime Text is that there are numerous bugs in Sublime Text 2 and Sublime Text 3 is in beta since forever. There are no transparency in its development, on whether the bugs are being fixed or not.
|
||||
|
||||
So open source lovers, rejoice and get the source code of Lime Text from the link below:
|
||||
|
||||
- [Get Lime Text Source Code][11]
|
||||
|
||||
#### Light Table ####
|
||||
|
||||

|
||||
|
||||
Flaunted as “the next generation code editor”, [Light Table][12] is another modern looking, feature rich open source editor which is more of an IDE than a mere text editor. There are numerous extensions available to enhance its capabilities. Inline evaluation is what you would love in it. You have to use it to believe how useful Light Table actually is.
|
||||
|
||||
- [Get Light Table Source Code][13]
|
||||
|
||||
### What’s your pick? ###
|
||||
|
||||
No, we are not limited to just four code editors in Linux. The list was about modern editors for programmers. Of course you have plenty of other options such as [Notepad++ alternative Notepadqq][14] or [SciTE][15] and many more. So, among these four, which one is your favorite code editor for Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://brackets.io/
|
||||
[2]:http://www.adobe.com/
|
||||
[3]:http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]:https://github.com/adobe/brackets/releases
|
||||
[5]:https://atom.io/
|
||||
[6]:https://atom.io/download/deb
|
||||
[7]:https://atom.io/download/rpm
|
||||
[8]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[9]:http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[10]:http://limetext.org/
|
||||
[11]:https://github.com/limetext/lime
|
||||
[12]:http://lighttable.com/
|
||||
[13]:https://github.com/LightTable/LightTable
|
||||
[14]:http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[15]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
@ -1,82 +0,0 @@
|
||||
[Translating by Stevearzh]
|
||||
Why Mac users don’t switch to Linux
|
||||
================================================================================
|
||||
Linux and Mac users share at least one common thing: they prefer not to use Windows. But after that the two groups part company and tend to go their separate ways. But why don’t more Mac users switch to Linux? Is there something that prevents Mac users from making the jump?
|
||||
|
||||
[Datamation took a look at these questions][1] and tried to answer them. Datamation’s conclusion was that it’s really about the applications and workflow, not the operating system:
|
||||
|
||||
> …there are some instances where replacing existing applications with new options isn’t terribly practical – both in workflow and in overall functionality. This is an area where, sadly, Apple has excelled in. So while it’s hardly “impossible” to get around these issues, they are definitely a large enough challenge that it will give the typical Mac enthusiast pause.
|
||||
>
|
||||
> But outside of Web developers, honestly, I don’t see Mac users “en masse,” seeking to disrupt their workflows for the mere idea of avoiding the upgrade to OS X Yosemite. Granted, having seen Yosemite up close – Mac users who are considered power users will absolutely find this change-up to be hideous. However, despite poor OS X UI changes, the core workflow for existing Mac users will remain largely unchanged and unchallenged.
|
||||
>
|
||||
> No, I believe Linux adoption will continue to be sporadic and random. Ever-growing, but not something that is easily measured or accurately calculated.
|
||||
|
||||
I agree to a certain extent with Datamation’s take on the importance of applications and workflows, both things are important and matter in the choice of a desktop operating system. But I think there’s something more going on with Mac users than just that. I believe that there’s a different mentality that exists between Linux and Mac users, and I think that’s the real reason why many Mac users don’t switch to Linux.
|
||||
|
||||

|
||||
|
||||
### It’s all about control for Linux users ###
|
||||
|
||||
Linux users tend to want control over their computing experience, they want to be able to change things to make them the way that they want them. One simply cannot do that in the same way with OS X or any other Apple products. With Apple you get what they give you for the most part.
|
||||
|
||||
For Mac (and iOS) users this is fine, they seem mostly content to stay within Apple’s walled garden and live according to whatever standards and options Apple gives them. But this is totally unacceptable to most Linux users. People who move to Linux usually come from Windows, and it’s there that they develop their loathing for someone else trying to define or control their computing experiences.
|
||||
|
||||
And once someone like that has tasted the freedom that Linux offers, it’s almost impossible for them to want to go back to living under the thumb of Apple, Microsoft or anyone else. You’d have to pry Linux from their cold, dead fingers before they’d accept the computing experience created for them Apple or Microsoft.
|
||||
|
||||
But you won’t find that same determination to have control among most Mac users. For them it’s mostly about getting the most out of whatever Apple has done with OS X in its latest update. They tend to adjust fairly quickly to new versions of OS X and even when unhappy with Apple’s changes they seem content to continue living within Apple’s walled garden.
|
||||
|
||||
So the need for control is a huge difference between Mac and Linux users. I don’t see it as a problem though since it just reflects the reality of two very different attitudes toward using computers.
|
||||
|
||||
### Mac users need Apple’s support mechanisms ###
|
||||
|
||||
Linux users are also different in the sense that they don’t mind getting their hands dirty by getting “under the hood” of their computers. Along with control comes the personal responsibility of making sure that their Linux systems work well and efficiently, and digging into the operating system is something that many Linux users have no problem doing.
|
||||
|
||||
When a Linux user needs to fix something, chances are they will attempt to do so immediately themselves. If that doesn’t work then they’ll seek additional information online from other Linux users and work through the problem until it has been resolved.
|
||||
|
||||
But Mac users are most likely not going to do that to the same extent. That is probably one of the reasons why Apple stores are so popular and why so many Mac users opt to buy Apple Care when they get a new Mac. A Mac user can simply take his or her computer to the Apple store and ask someone to fix it for them. There they can belly up to the Genius Bar and have their computer looked at by someone Apple has paid to fix it.
|
||||
|
||||
Most Linux users would blanche at the thought of doing such a thing. Who wants some guy you don’t even know to lay hands on your computer and start trying to fix it for you? Some Linux users would shudder at the very idea of such a thing happening.
|
||||
|
||||
So it would be hard for a Mac user to switch to Linux and suddenly be bereft of the support from Apple that he or she was used to getting in the past. Some Mac users might feel very vulnerable and uncertain if they were cut off from the Apple mothership in terms of support.
|
||||
|
||||
### Mac users love Apple’s hardware ###
|
||||
|
||||
The Datamation article focused on software, but I believe that hardware also matters to Mac users. Most Apple customers tend to love Apple’s hardware. When they buy a Mac, they aren’t just buying it for OS X. They are also buying Apple’s industrial design expertise and that can be an important differentiator for Mac users. Mac users are willing to pay more because they perceive that the overall value they are getting from Apple for a Mac is worth it.
|
||||
|
||||
Linux users, on the other hand, seem less concerned by such things. I think they tend to focus more on cost and less on the looks or design of their computer hardware. For them it’s probably about getting the most value from the hardware at the lowest cost. They aren’t in love with the way their computer hardware looks in the same way that some Mac users probably are, and so they don’t make buying decisions based on it.
|
||||
|
||||
I think both points of view on hardware are equally valid. It ultimately gets down to the needs of the individual user and what matters to them when they choose to buy or, in the case of some Linux users, build their computer. Value is the key for both groups, and each has its own perceptions of what constitutes real value in a computer.
|
||||
|
||||
Of course it is [possible to run Linux on a Mac][2], directly or indirectly via virtual machine. So a user that really liked Apple’s hardware does have the option of keeping their Mac but installing Linux on it.
|
||||
|
||||
### Too many Linux distros to choose from? ###
|
||||
|
||||
Another reason that might make it hard for a Mac user to move to Linux is the sheer number of distributions to choose from in the world of Linux. While most Linux users probably welcome the huge diversity of distros available, it could also be very confusing for a Mac user who hasn’t learned to navigate those choices.
|
||||
|
||||
Over time I think a Mac user would learn and adjust by figuring out which distribution worked best for him or her. But in the short term it might be a very daunting hurdle to overcome after being used to OS X for a long period of time. I don’t think it’s insurmountable, but it’s definitely something that is worth mentioning here.
|
||||
|
||||
Of course we do have helpful resources like [DistroWatch][3] and even my own [Desktop Linux Reviews][4] blog that can help people find the right Linux distribution. Plus there are many articles available about “the best Linux distro” and that sort of thing that Mac users can use as resources when trying to figure out the distribution they want to use.
|
||||
|
||||
But one of the reasons why Apple customers buy Macs is the simplicity and all-in-one solution that they offer in terms of the hardware and software being unified by Apple. So I am not sure how many Mac users would really want to spend the time trying to find the right Linux distribution. It might be something that puts them off really considering the switch to Linux.
|
||||
|
||||
### Mac users are apples and Linux users are oranges ###
|
||||
|
||||
I see nothing wrong with Mac and Linux users going their separate ways. I think we’re just talking about two very different groups of people, and it’s a good thing that both groups can find and use the operating system and software that they prefer. Let Mac users enjoy OS X and let Linux users enjoy Linux, and hopefully both groups will be happy and content with their computers.
|
||||
|
||||
Every once in a while a Mac user might stray over to Linux or vice versa, but for the most part I think the two groups live in different worlds and mostly prefer to stay separate and apart from one another. I generally don’t compare the two because when you get right down to it, it’s really just a case of apples and oranges.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jimlynch.com/linux-articles/why-mac-users-dont-switch-to-linux/
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://jimlynch.com/author/Jim/
|
||||
[1]:http://www.datamation.com/open-source/why-linux-isnt-winning-over-mac-users-1.html
|
||||
[2]:http://www.howtogeek.com/187410/how-to-install-and-dual-boot-linux-on-a-mac/
|
||||
[3]:http://distrowatch.com/
|
||||
[4]:http://desktoplinuxreviews.com/
|
||||
@ -0,0 +1,82 @@
|
||||
9 Best IDEs and Code Editors for JavaScript Users
|
||||
================================================================================
|
||||
Web designing and developing is one of the trending sectors in the recent times, where more and more peoples started to search for their career opportunities. But, Getting the right opportunity as a web developer or graphic designer is not just a piece of cake for everyone, It certainly requires a strong mind presence as well as right skills to find the find the right job. There are a lot of websites available today which can help you to get the right job description according to your knowledge. But still if you want to achieve something in this sector you must have some excellent skills like working with different platforms, IDEs and various other tools too.
|
||||
|
||||
Talking about the different platforms and IDEs used for various languages for different purposes, gone is the time when we learn just one IDE and get the optimum solutions for our web design projects easily. Today we are living in the modern lifestyle where competition is getting more and more tough on every single day. Same is the case with the IDEs, IDE is basically a powerful client application for creating and deploying applications. Today we are going to share some best javascript IDE for web designers and developers.
|
||||
|
||||
Please visit this list of best code editors for javascript user and share your thought with us.
|
||||
|
||||
### 1) [Spket][1] ###
|
||||
|
||||
**Spket IDE** is powerful toolkit for JavaScript and XML development. The powerful editor for JavaScript, XUL/XBL and Yahoo! Widget development. The JavaScript editor provides features like code completion, syntax highlighting and content outline that helps developers productively create efficient JavaScript code.
|
||||
|
||||

|
||||
|
||||
### 2) [Ixedit][2] ###
|
||||
|
||||
IxEdit is a JavaScript-based interaction design tool for the web. With IxEdit, designers can practice DOM-scripting without coding to change, add, move, or transform elements dynamically on your web pages.
|
||||
|
||||

|
||||
|
||||
### 3) [Komodo Edit][3] ###
|
||||
|
||||
Komode is free and powerful code editor for Javascript and other programming languages.
|
||||
|
||||

|
||||
|
||||
### 4) [EpicEditor][4] ###
|
||||
|
||||
EpicEditor is an embeddable JavaScript Markdown editor with split fullscreen editing, live previewing, automatic draft saving, offline support, and more. For developers, it offers a robust API, can be easily themed, and allows you to swap out the bundled Markdown parser with anything you throw at it.
|
||||
|
||||

|
||||
|
||||
### 5) [codepress][5] ###
|
||||
|
||||
CodePress is web-based source code editor with syntax highlighting written in JavaScript that colors text in real time while it’s being typed in the browser.
|
||||
|
||||

|
||||
|
||||
### 6) [ACe][6] ###
|
||||
|
||||
Ace is an embeddable code editor written in JavaScript. It matches the features and performance of native editors such as Sublime, Vim and TextMate. It can be easily embedded in any web page and JavaScript application.
|
||||
|
||||

|
||||
|
||||
### 7) [scripted][7] ###
|
||||
|
||||
Scripted is a fast and lightweight code editor with an initial focus on JavaScript editing. Scripted is a browser based editor and the editor itself is served from a locally running Node.js server instance.
|
||||
|
||||

|
||||
|
||||
### 8) [Netbeans][8] ###
|
||||
|
||||
This is another more impressive and useful code editors for javascript and other programming languages.
|
||||
|
||||

|
||||
|
||||
### 9) [Webstorm][9] ###
|
||||
|
||||
This is the smartest ID for javascript. WebStorm is a lightweight yet powerful IDE, perfectly equipped for complex client-side development and server-side development with Node.js.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://devzum.com/2015/01/31/9-best-ides-and-code-editors-for-javascript-users/
|
||||
|
||||
作者:[vikas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://devzum.com/author/vikas/
|
||||
[1]:http://spket.com/
|
||||
[2]:http://www.ixedit.com/
|
||||
[3]:http://komodoide.com/komodo-edit/
|
||||
[4]:http://oscargodson.github.io/EpicEditor/
|
||||
[5]:http://codepress.sourceforge.net/
|
||||
[6]:http://ace.c9.io/#nav=about
|
||||
[7]:https://github.com/scripted-editor/scripted
|
||||
[8]:https://netbeans.org/
|
||||
[9]:http://www.jetbrains.com/webstorm/
|
||||
@ -0,0 +1,34 @@
|
||||
GHOST: Another Security Bug Hits Linux, But is it That Bad?
|
||||
================================================================================
|
||||
> GHOST, a newly announced security vulnerability that affects Linux servers and other systems that use the open source glibc library, is not as dangerous to data privacy as the Shellshock or Heartbleed bugs.
|
||||
|
||||

|
||||
|
||||
Heartbleed is not even a year behind us, and the open source world has been hit with another major security vulnerability in the form of [GHOST][1], which involves holes in the Linux glibc library. This time, though, the actual danger may not live up to the hype.
|
||||
|
||||
The GHOST vulnerability, which was announced last week by security researchers at [Qualys][2], resides in the gethostbyname*() functions of the glibc library. glibc is one of the core building blocks of most Linux systems, and gethostbyname*(), which resolves domain names into IP addresses, is widely used in open source applications.
|
||||
|
||||
Attackers can exploit the GHOST security hole to create a buffer overflow, making it possible to execute any kind of code they want and do all sorts of nasty things.
|
||||
|
||||
All of the above suggests that GHOST is bad news indeed. Fortunately for the open source community, however, the actual risk appears small. As TrendMicro [points out][3], the bug that makes the exploit possible has been fixed in glibc since May 2013, meaning that any Linux servers or PCs running more recent versions of the software are safe from attack.
|
||||
|
||||
In addition, gethostbyname*() has been superseded by newer glibc functions that can better handle modern networking environments. Those include ones that use the IPv6 protocol, which gethostbyname*() doesn't support. As a result, newer applications often don't use the gethostbyname*() functions, and are not at risk.
|
||||
|
||||
And perhaps most importantly, there's currently no known way of executing GHOST attacks through the Web. That greatly reduces opportunities for using this vulnerability to steal the data of unsuspecting users or otherwise wreak havoc.
|
||||
|
||||
All in all, then, GHOST doesn't seem like a vulnerability that will prove as serious as Heartbleed or Shellshock, two other recent security problems that affected widely used open source software.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/020415/ghost-another-security-bug-hits-linux-it-bad
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:https://community.qualys.com/blogs/laws-of-vulnerabilities/2015/01/27/the-ghost-vulnerability
|
||||
[2]:http://qualys.com/
|
||||
[3]:http://blog.trendmicro.com/trendlabs-security-intelligence/not-so-spooky-linux-ghost-vulnerability/
|
||||
@ -0,0 +1,32 @@
|
||||
LinuxQuestions Survey Results Surface Top Open Source Projects
|
||||
================================================================================
|
||||

|
||||
|
||||
Many people in the Linux community look forward to the always highly detailed and reliable results of the annual surveys from LinuxQuestions.org. As [Susan covered in detail in this post][1], this year's [results][2], focused on what readers at the site deem to be the best open source projects, are now available. Most of the people at LinuxQuestions are expert-level users who are on the site to answer questions from newer Linux users.
|
||||
|
||||
In addition to the summary results that Susan provided in her post, below you'll find a graphical snapshot of what the experts took note of on the open source front.
|
||||
|
||||
You can get a very nice graphical summary of the findings from the LinuxQuestions survey [here][3]. Here is a snapshot of the site's determination of the best Linux distributions, where Mint and Slackware fare quite well:
|
||||
|
||||
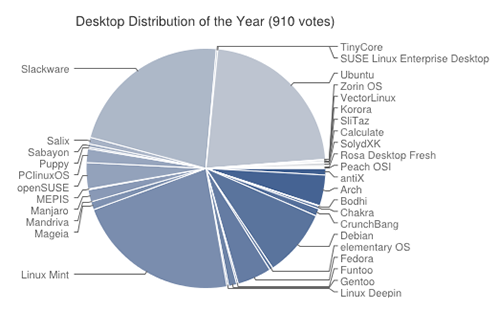
|
||||
|
||||
And below is a snapshot of the site's determination of the best cloud projects. Notably, the LinuxQuestions crowd gives very high praise to ownCloud. Definiitely check into the full results of the survey at the site, see [Susan's summary][4] of winners, and check out all the good graphics [here][5].
|
||||
|
||||
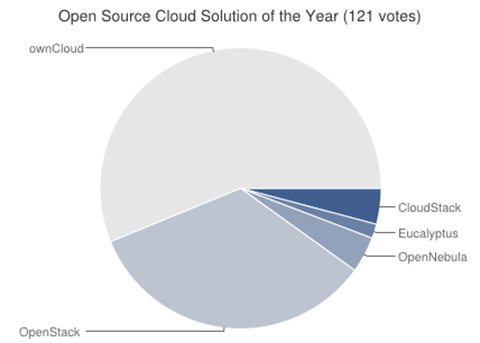
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/linuxquestions-survey-results-surface-top-open-source-projects
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/samdean
|
||||
[1]:http://ostatic.com/blog/lq-members-choice-award-winners-announced
|
||||
[2]:http://www.linuxquestions.org/questions/linux-news-59/2014-linuxquestions-org-members-choice-award-winners-4175532948/
|
||||
[3]:http://www.linuxquestions.org/questions/2014mca.php
|
||||
[4]:http://ostatic.com/blog/lq-members-choice-award-winners-announced
|
||||
[5]:http://www.linuxquestions.org/questions/2014mca.php
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
### Voice Actions—a supercomputer in your pocket ###
|
||||
@ -79,4 +81,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
[5]:http://arstechnica.com/gadgets/2013/12/google-robots-former-android-chief-will-lead-google-robotics-division/
|
||||
[6]:http://arstechnica.com/gadgets/2013/12/lg-g-flex-review-form-over-even-basic-function/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,223 +0,0 @@
|
||||
How to create a software RAID-1 array with mdadm on Linux
|
||||
================================================================================
|
||||
Redundant Array of Independent Disks (RAID) is a storage technology that combines multiple hard disks into a single logical unit to provide fault-tolerance and/or improve disk I/O performance. Depending on how data is stored in an array of disks (e.g., with striping, mirroring, parity, or any combination thereof), different RAID levels are defined (e.g., RAID-0, RAID-1, RAID-5, etc). RAID can be implemented either in software or with a hardware RAID card. On modern Linux, basic software RAID functionality is available by default.
|
||||
|
||||
In this post, we'll discuss the software setup of a RAID-1 array (also known as a "mirroring" array), where identical data is written to the two devices that form the array. While it is possible to implement RAID-1 with partitions on a single physical hard drive (as with other RAID levels), it won't be of much use if that single hard drive fails. In fact, that's why most RAID levels normally use multiple physical drives to provide redundancy. In the event of any single drive failure, the virtual RAID block device should continue functioning without issues, and allow us to replace the faulty drive without significant production downtime and, more importantly, with no data loss. However, it does not replace the need to save periodic system backups in external storage.
|
||||
|
||||
Since the actual storage capacity (size) of a RAID-1 array is the size of the smallest drive, normally (if not always) you will find two identical physical drives in RAID-1 setup.
|
||||
|
||||
### Installing mdadm on Linux ###
|
||||
|
||||
The tool that we are going to use to create, assemble, manage, and monitor our software RAID-1 is called mdadm (short for **m**ultiple **d**isks **adm**in). On Linux distros such as Fedora, CentOS, RHEL or Arch Linux, mdadm is available by default. On Debian-based distros, mdadm can be installed with aptitude or apt-get.
|
||||
|
||||
#### Fedora, CentOS or RHEL ####
|
||||
|
||||
As mdadm comes pre-installed, all you have to do is to start RAID monitoring service, and configure it to auto-start upon boot:
|
||||
|
||||
# systemctl start mdmonitor
|
||||
# systemctl enable mdmonitor
|
||||
|
||||
For CentOS/RHEL 6, use these commands instead:
|
||||
|
||||
# service mdmonitor start
|
||||
# chkconfig mdmonitor on
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
On Debian and its derivatives, mdadm can be installed with **aptitude or apt-get**:
|
||||
|
||||
# aptitude install mdadm
|
||||
|
||||
On Ubuntu, you will be asked to configure postfix MTA for sending out email notifications (as part of RAID monitoring). You can skip it for now.
|
||||
|
||||
On Debian, the installation will start with the following explanatory message to help us decide whether or not we are going to install the root filesystem on a RAID array. What we need to enter on the next screen will depend on this decision. Read it carefully:
|
||||
|
||||
|
||||
|
||||
Since we will not use our RAID-1 for the root filesystem, we will leave the answer blank:
|
||||
|
||||
|
||||
|
||||
When asked whether we want to start (reassemble) our array automatically during each boot, choose "Yes". Note that we will need to add an entry to the /etc/fstab file later in order for the array to be properly mounted during the boot process as well.
|
||||
|
||||

|
||||
|
||||
### Partitioning Hard Drives ###
|
||||
|
||||
Now it's time to prepare the physical devices that will be used in our array. For this setup, I have plugged in two 8 GB USB drives that have been identified as /dev/sdb and /dev/sdc from dmesg output:
|
||||
|
||||
# dmesg | less
|
||||
|
||||
----------
|
||||
|
||||
[ 60.014863] sd 3:0:0:0: [sdb] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
|
||||
[ 75.066466] sd 4:0:0:0: [sdc] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
|
||||
|
||||
We will use fdisk to create a primary partition on each disk that will occupy its entire size. The following steps show how to perform this task on /dev/sdb, and assume that this drive hasn't been partitioned yet (otherwise, we can delete the existing partition(s) to start off with a clean disk):
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
Press 'p' to print the current partition table:
|
||||
|
||||

|
||||
|
||||
(if one or more partitions are found, they can be deleted with 'd' option. Then 'w' option is used to apply the changes).
|
||||
|
||||
Since no partitions are found, we will create a new primary partition ['n'] as a primary partition ['p'], assign the partition number = ['1'] to it, and then indicate its size. You can press Enter key to accept the proposed default values, or enter a value of your choosing, as shown in the image below.
|
||||
|
||||

|
||||
|
||||
Now repeat the same process for /dev/sdc.
|
||||
|
||||
If we have two drives of different sizes, say 750 GB and 1 TB for example, we should create a primary partition of 750 GB on each of them, and use the remaining space on the bigger drive for another purpose, independent of the RAID array.
|
||||
|
||||
### Create a RAID-1 Array ###
|
||||
|
||||
Once you are done with creating the primary partition on each drive, use the following command to create a RAID-1 array:
|
||||
|
||||
# mdadm -Cv /dev/md0 -l1 -n2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
Where:
|
||||
|
||||
- **-Cv**: creates an array and produce verbose output.
|
||||
- **/dev/md0**: is the name of the array.
|
||||
- **-l1** (l as in "level"): indicates that this will be a RAID-1 array.
|
||||
- **-n2**: indicates that we will add two partitions to the array, namely /dev/sdb1 and /dev/sdc1.
|
||||
|
||||
The above command is equivalent to:
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
If alternatively you want to add a spare device in order to replace a faulty disk in the future, you can add '--spare-devices=1 /dev/sdd1' to the above command.
|
||||
|
||||
Answer "y" when prompted if you want to continue creating an array, then press Enter:
|
||||
|
||||
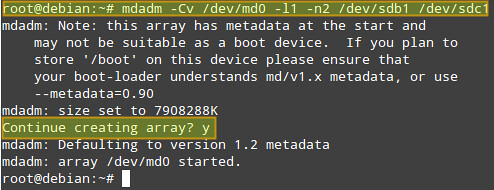
|
||||
|
||||
You can check the progress with the following command:
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
Another way to obtain more information about a RAID array (both while it's being assembled and after the process is finished) is:
|
||||
|
||||
# mdadm --query /dev/md0
|
||||
# mdadm --detail /dev/md0 (or mdadm -D /dev/md0)
|
||||
|
||||
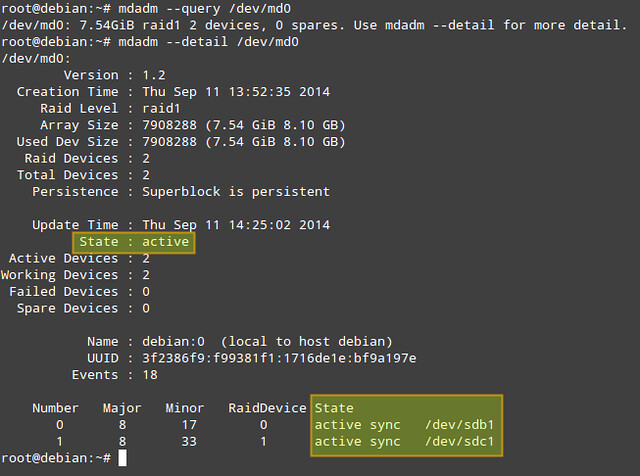
|
||||
|
||||
Of the information provided by 'mdadm -D', perhaps the most useful is that which shows the state of the array. The active state means that there is currently I/O activity happening. Other possible states are clean (all I/O activity has been completed), degraded (one of the devices is faulty or missing), resyncing (the system is recovering from an unclean shutdown such as a power outage), or recovering (a new drive has been added to the array, and data is being copied from the other drive onto it), to name the most common states.
|
||||
|
||||
### Formatting and Mounting a RAID Array ###
|
||||
|
||||
The next step is formatting (with ext4 in this example) the array:
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||
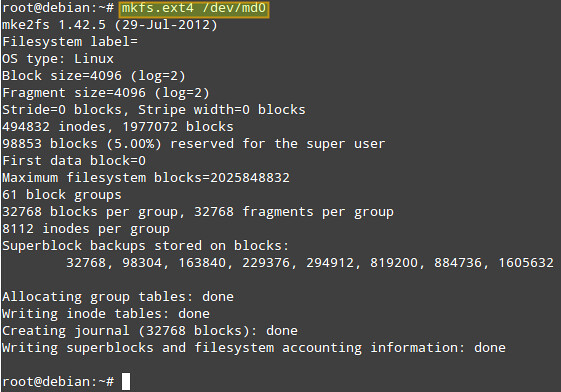
|
||||
|
||||
Now let's mount the array, and verify that it was mounted correctly:
|
||||
|
||||
# mount /dev/md0 /mnt
|
||||
# mount
|
||||
|
||||
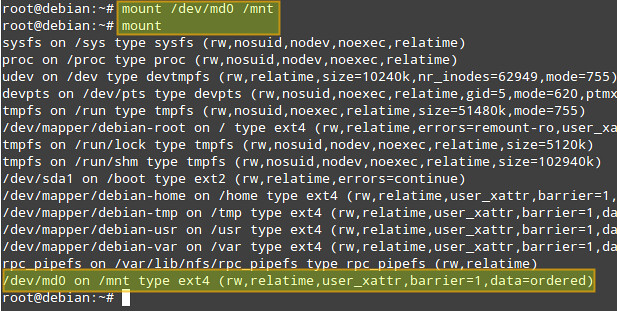
|
||||
|
||||
### Monitor a RAID Array ###
|
||||
|
||||
The mdadm tool comes with RAID monitoring capability built in. When mdadm is set to run as a daemon (which is the case with our RAID setup), it periodically polls existing RAID arrays, and reports on any detected events via email notification or syslog logging. Optionally, it can also be configured to invoke contingency commands (e.g., retrying or removing a disk) upon detecting any critical errors.
|
||||
|
||||
By default, mdadm scans all existing partitions and MD arrays, and logs any detected event to /var/log/syslog. Alternatively, you can specify devices and RAID arrays to scan in mdadm.conf located in /etc/mdadm/mdadm.conf (Debian-based) or /etc/mdadm.conf (Red Hat-based), in the following format. If mdadm.conf does not exist, create one.
|
||||
|
||||
DEVICE /dev/sd[bcde]1 /dev/sd[ab]1
|
||||
|
||||
ARRAY /dev/md0 devices=/dev/sdb1,/dev/sdc1
|
||||
ARRAY /dev/md1 devices=/dev/sdd1,/dev/sde1
|
||||
.....
|
||||
|
||||
# optional email address to notify events
|
||||
MAILADDR your@email.com
|
||||
|
||||
After modifying mdadm configuration, restart mdadm daemon:
|
||||
|
||||
On Debian, Ubuntu or Linux Mint:
|
||||
|
||||
# service mdadm restart
|
||||
|
||||
On Fedora, CentOS/RHEL 7:
|
||||
|
||||
# systemctl restart mdmonitor
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
# service mdmonitor restart
|
||||
|
||||
### Auto-mount a RAID Array ###
|
||||
|
||||
Now we will add an entry in the /etc/fstab to mount the array in /mnt automatically during boot (you can specify any other mount point):
|
||||
|
||||
# echo "/dev/md0 /mnt ext4 defaults 0 2" << /etc/fstab
|
||||
|
||||
To verify that mount works okay, we now unmount the array, restart mdadm, and remount. We can see that /dev/md0 has been mounted as per the entry we just added to /etc/fstab:
|
||||
|
||||
# umount /mnt
|
||||
# service mdadm restart (on Debian, Ubuntu or Linux Mint)
|
||||
or systemctl restart mdmonitor (on Fedora, CentOS/RHEL7)
|
||||
or service mdmonitor restart (on CentOS/RHEL6)
|
||||
# mount -a
|
||||
|
||||
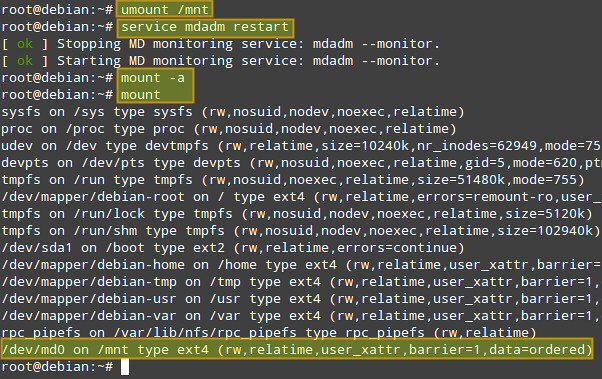
|
||||
|
||||
Now we are ready to access the RAID array via /mnt mount point. To test the array, we'll copy the /etc/passwd file (any other file will do) into /mnt:
|
||||
|
||||
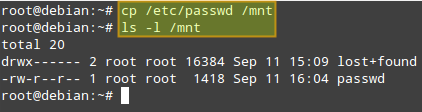
|
||||
|
||||
On Debian, we need to tell the mdadm daemon to automatically start the RAID array during boot by setting the AUTOSTART variable to true in the /etc/default/mdadm file:
|
||||
|
||||
AUTOSTART=true
|
||||
|
||||
### Simulating Drive Failures ###
|
||||
|
||||
We will simulate a faulty drive and remove it with the following commands. Note that in a real life scenario, it is not necessary to mark a device as faulty first, as it will already be in that state in case of a failure.
|
||||
|
||||
First, unmount the array:
|
||||
|
||||
# umount /mnt
|
||||
|
||||
Now, notice how the output of 'mdadm -D /dev/md0' indicates the changes after performing each command below.
|
||||
|
||||
# mdadm /dev/md0 --fail /dev/sdb1 #Marks /dev/sdb1 as faulty
|
||||
# mdadm --remove /dev/md0 /dev/sdb1 #Removes /dev/sdb1 from the array
|
||||
|
||||
Afterwards, when you have a new drive for replacement, re-add the drive again:
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdb1
|
||||
|
||||
The data is then immediately started to be rebuilt onto /dev/sdb1:
|
||||
|
||||

|
||||
|
||||
Note that the steps detailed above apply for systems with hot-swappable disks. If you do not have such technology, you will also have to stop a current array, and shutdown your system first in order to replace the part:
|
||||
|
||||
# mdadm --stop /dev/md0
|
||||
# shutdown -h now
|
||||
|
||||
Then add the new drive and re-assemble the array:
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdb1
|
||||
# mdadm --assemble /dev/md0 /dev/sdb1 /dev/sdc1
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-software-raid1-array-mdadm-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
@ -1,76 +0,0 @@
|
||||
zpl1025
|
||||
Test drive Linux with nothing but a flash drive
|
||||
================================================================================
|
||||

|
||||
Image by : Opensource.com
|
||||
|
||||
Maybe you’ve heard about Linux and are intrigued by it. So intrigued that you want to give it a try. But you might not know where to begin.
|
||||
|
||||
You’ve probably done a bit of research online and have run across terms like dual booting and virtualization. Those terms might mean nothing to you, and you’re definitely not ready to sacrifice the operating system that you’re currently using to give Linux a try. So what can you do?
|
||||
|
||||
If you have a USB flash drive lying around, you can test drive Linux by creating a live USB. It’s a USB flash drive that contains an operating system that can start from the flash drive. It doesn’t take much technical ability to create one. Let’s take a look at how to do that and how to run Linux using a live USB.
|
||||
|
||||
### What you’ll need ###
|
||||
|
||||
Aside from a desktop or laptop computer, you’ll need:
|
||||
|
||||
- A blank USB flash drive—preferably one that has a capacity of 4 GB or more.
|
||||
- An [ISO image][1] (an archive of the contents of a hard disk) of the Linux distribution that you want to try. More about this in a moment.
|
||||
- An application called [Unetbootin][2], an open source tool, cross platform tool that creates a live USB. You don’t need to be running Linux to use it. In the instructions that below, I’m running Unetbootin on a MacBook.
|
||||
|
||||
### Getting to work ###
|
||||
|
||||
Plug your flash drive into a USB port on your computer and then fire up Unetbootin. You’ll be asked for the password that you use to log into your computer.
|
||||
|
||||

|
||||
|
||||
Remember the ISO image that was mentioned a few moments ago? There are two ways you can get one: either by downloading it from the website of the Linux distribution that you want to try, or by having Unetbootin download it for you. To do that latter, click **Select Distribution** at the top of the window, choose the distribution that you want to download, and then click **Select Version** to select the version of the distribution that you want to try.
|
||||
|
||||

|
||||
|
||||
Or, you can download the distribution yourself. Usually, the Linux distributions that I want to try aren’t in the list. If you go the second route, click **Disk image** and then click the button to search for the .iso file that you downloaded.
|
||||
|
||||
Notice the **Space used to preserve files across reboots (Ubuntu only)** option? If you’re testing Ubuntu or one of its derivatives (like Lubuntu or Xubuntu), you can set aside a few megabytes of space on your flash drive to save files like web browser bookmarks or documents that you create. When you load Ubuntu from the flash drive again, you can reuse those files.
|
||||
|
||||

|
||||
|
||||
Once the ISO image is loaded, click **OK**. It takes anywhere from a couple of minutes to 10 minutes for Unetbootin to create the live USB.
|
||||
|
||||

|
||||
|
||||
### Testing out the live USB ###
|
||||
|
||||
This is the point where you have to embrace your inner geek a bit. Not too much, but you will be taking a peek into the innards of your computer by going into the [BIOS][3]. Your computer’s BIOS starts various bits of hardware and controls where the computer’s operating system starts, or boots, from.
|
||||
|
||||
The BIOS usually looks for the operating system in this order (or something like it): hard drive, then CD-ROM or DVD drive, and then an external drive. You’ll want to change that order so that the external drive (in this case, your live USB) is the one that the BIOS checks first.
|
||||
|
||||
To do that, restart your computer with the flash drive plugged into a USB port. When you see the message **Press F2 to enter setup**, do just that. On some computers, the key might be F10.
|
||||
|
||||
In the BIOS, use the right arrow key on your keyboard to navigate to the **Boot** menu. You’ll see a list of drives on your computer. Use the down arrow key on your keyboard to navigate to the item labeled **USB HDD** and then press **F6** to move that item to the top of the list.
|
||||
|
||||
Once you’ve done that, press **F10** to save the changes. You’ll be kicked out of the BIOS and your computer will start up. After a short amount of time, you’ll be presented with a menu listing the options for starting the Linux distribution you’re trying out. Select **Run without installing** (or the menu item closest to it).
|
||||
|
||||
Once the desktop loads, you can connect to a wireless or wired network, browse the web, and give the pre-installed software a whirl. You can also check to see if, for example, your printer or scanner works with the Linux distribution you’re testing. If you really, really want to you can also fiddle at the command line.
|
||||
|
||||
### What to expect ###
|
||||
|
||||
Depending on the Linux distribution you’re testing and the speed of the flash drive you’re using, the operating system might take longer to load and it might run a bit slower than it would if it was installed on your hard drive.
|
||||
|
||||
As well, you’ll only have the basic software that the Linux distribution packs out of the box. You generally get a web browser, a word processor, a text editor, a media player, an image viewer, and a set of utilities. That should be enough to give you a feel for what it’s like to use Linux.
|
||||
|
||||
If you decide that you like using Linux, you can install it from the flash drive by double clicking on the installer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://en.wikipedia.org/wiki/ISO_image
|
||||
[2]:http://unetbootin.sourceforge.net/
|
||||
[3]:http://en.wikipedia.org/wiki/BIOS
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by FSSlc
|
||||
|
||||
How To Use Emoji Anywhere With Twitter's Open Source Library
|
||||
================================================================================
|
||||
> Embed them in webpages and other projects via GitHub.
|
||||
|
||||
@ -1,206 +0,0 @@
|
||||
Translating by shipsw
|
||||
|
||||
|
||||
Auditd - Tool for Security Auditing on Linux Server
|
||||
================================================================================
|
||||
First of all , we wish all our readers **Happy & Prosperous New YEAR 2015** from our Linoxide team. So lets start this new year explaining about Auditd tool.
|
||||
|
||||
Security is one of the main factor that we need to consider. We must maintain it because we don't want someone steal our data. Security includes many things. Audit, is one of it.
|
||||
|
||||
On Linux system, we know that we have a tool named **auditd**. This tool is by default exist in most of Linux operating system. What is auditd tool and how to use it? We will cover it below.
|
||||
|
||||
### What is auditd? ###
|
||||
|
||||
Auditd or audit daemon, is a userspace component to the Linux Auditing System. It’s responsible for writing audit records to the disk.
|
||||
|
||||

|
||||
|
||||
### Installing auditd ###
|
||||
|
||||
On Ubuntu based system , we can use [wajig][1] tool or **apt-get tool** to install auditd.
|
||||
|
||||

|
||||
|
||||
Just follow the instruction to get it done. Once it finish it will install some tools related to auditd tool. Here are the tools :
|
||||
|
||||
- **auditctl ;** is a tool to control the behaviour of the daemon on the fly, adding rules, etc
|
||||
- **/etc/audit/audit.rules ;** is the file that contains audit rules
|
||||
- **aureport ;** is tool to generate and view the audit report
|
||||
- **ausearch ;** is a tool to search various events
|
||||
- **auditspd ;** is a tool which can be used to relay event notifications to other applications instead of writing them to disk in the audit log
|
||||
- **autrace ;** is a command that can be used to trace a process
|
||||
- **/etc/audit/auditd.conf ;** is the configuration file of auditd tool
|
||||
- When the first time we install **auditd**, there will be no rules available yet.
|
||||
|
||||
We can check it using this command :
|
||||
|
||||
$ sudo auditctl -l
|
||||
|
||||

|
||||
|
||||
To add rules on auditd, let’s continue to the section below.
|
||||
|
||||
### How to use it ###
|
||||
|
||||
#### Audit files and directories access ####
|
||||
|
||||
One of the basic need for us to use an audit tool are, how can we know if someone change a file(s) or directories? Using auditd tool, we can do with those commands (please remember, we will need root privileges to configure auditd tool):
|
||||
|
||||
**Audit files**
|
||||
|
||||
$ sudo auditctl -w /etc/passwd -p rwxa
|
||||
|
||||

|
||||
|
||||
**With :**
|
||||
|
||||
- **-w path ;** this parameter will insert a watch for the file system object at path. On the example above, auditd will wacth /etc/passwd file
|
||||
- **-p ; **this parameter describes the permission access type that a file system watch will trigger on
|
||||
- **rwxa ;** are the attributes which bind to -p parameter above. r is read, w is write, x is execute and a is attribute
|
||||
|
||||
#### Audit directories ####
|
||||
|
||||
To audit directories, we will use a similar command. Let’s take a look at the command below :
|
||||
|
||||
$ sudo auditctl -w /production/
|
||||
|
||||

|
||||
|
||||
The above command will watch any access to the **/production folder**.
|
||||
|
||||
Now, if we run **auditctl -l** command again, we will see that new rules are added.
|
||||
|
||||

|
||||
|
||||
Now let’s see the audit log says.
|
||||
|
||||
### Viewing the audit log ###
|
||||
|
||||
After rules are added, now we can see how auditd in action. To view audit log, we can use **ausearch** tool.
|
||||
|
||||
We already add rule to watch /etc/passwd file. Now we will try to use **ausearch** tool to view the audit log.
|
||||
|
||||
$ sudo ausearch -f /etc/passwd
|
||||
|
||||
- **-f** parameter told ausearch to investigate /etc/passwd file
|
||||
- The result is shown below :
|
||||
> **time**->Mon Dec 22 09:39:16 2014
|
||||
> type=PATH msg=audit(1419215956.471:194): item=0 **name="/etc/passwd"** inode=142512 dev=08:01 mode=0100644 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL
|
||||
> type=CWD msg=audit(1419215956.471:194): **cwd="/home/pungki"**
|
||||
> type=SYSCALL msg=audit(1419215956.471:194): arch=40000003 **syscall=5** success=yes exit=3 a0=b779694b a1=80000 a2=1b6 a3=b8776aa8 items=1 ppid=2090 pid=2231 **auid=4294967295 uid=1000 gid=1000** euid=0 suid=0 fsuid=0 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=4294967295 **comm="sudo" exe="/usr/bin/sudo"** key=(null)
|
||||
|
||||
Now let’s we understand the result.
|
||||
|
||||
- **time ;** is when the audit is done
|
||||
- **name ;** is the object name to be audited
|
||||
- **cwd ;** is the current directory
|
||||
- **syscall ;** is related syscall
|
||||
- **auid ;** is the audit user ID
|
||||
- **uid and gid ;** are User ID and Group ID of the user who access the file
|
||||
- **comm ;** is the command that the user is used to access the file
|
||||
- **exe ;** is the location of the command of comm parameter above
|
||||
- The above audit log is the original file.
|
||||
|
||||
Next, we are going to add a new user, to see how the auditd record the activity to /etc/passwd file.
|
||||
|
||||
> **time->**Mon Dec 22 11:25:23 2014
|
||||
> type=PATH msg=audit(1419222323.628:510): item=1 **name="/etc/passwd.lock"** inode=143992 dev=08:01 mode=0100600 ouid=0 ogid=0 rdev=00:00 nametype=DELETE
|
||||
> type=PATH msg=audit(1419222323.628:510): item=0 **name="/etc/"** inode=131073 dev=08:01 mode=040755 ouid=0 ogid=0 rdev=00:00 nametype=PARENT
|
||||
> type=CWD msg=audit(1419222323.628:510): **cwd="/root"**
|
||||
> type=SYSCALL msg=audit(1419222323.628:510): arch=40000003 **syscall=10** success=yes exit=0 a0=bfc0ceec a1=0 a2=bfc0ceec a3=897764c items=2 ppid=2978 pid=2994 **auid=4294967295 uid=0 gid=0** euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=4294967295 **comm="chfn" exe="/usr/bin/chfn"** key=(null)
|
||||
|
||||
As we can see above, that on that particular time, **/etc/passwd was accessed** by user root (uid = 0 and gid = 0) **from** directory /root (cwd = /root). The /etc/passwd file was accessed using **chfn** command which located in **/usr/bin/chfn**
|
||||
|
||||
If we type **man chfn** on the console, we will see more detail about what is chfn.
|
||||
|
||||

|
||||
|
||||
Now we take a look at another example.
|
||||
|
||||
We already told auditd to watch directory /production/ . That is a new directory. So when we try to use ausearch tool at the first time, it found nothing.
|
||||
|
||||

|
||||
|
||||
Next, root account try to list the /production directory using ls command. The second time we use ausearch tool, it will show us some information.
|
||||
|
||||

|
||||
|
||||
> **time->**Mon Dec 22 14:18:28 2014
|
||||
> type=PATH msg=audit(1419232708.344:527): item=0 **name="/production/"** inode=797104 dev=08:01 mode=040755 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL
|
||||
> type=CWD msg=audit(1419232708.344:527): cwd="/root"
|
||||
> type=SYSCALL msg=audit(1419232708.344:527): arch=40000003 syscall=295 success=yes exit=3 a0=ffffff9c a1=95761e8 a2=98800 a3=0 items=1 ppid=3033 pid=3444 **auid=4294967295 uid=0 gid=0** euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=4294967295 **comm="ls" exe="/bin/ls"** key=(null)
|
||||
|
||||
Similar with the previous one, we can determine that **/production folder was looked** by root account (uid=0 gid=0) **using ls command** (comm = ls) and the ls command is **located in /bin/ls folder**.
|
||||
|
||||
### Viewing the audit reports ###
|
||||
|
||||
Once we put the audit rules, it will run automatically. And after a period of time, we want to see how auditd can help us to track them.
|
||||
|
||||
Auditd comes with another tool called **aureport**. As we can guess from its name, **aureport** is a tool that produces summary reports of the audit system log.
|
||||
|
||||
We already told auditd to track /etc/passwd before. And a moment after the auditd parameter is developed, the audit.log file is created.
|
||||
|
||||
To generate the report of audit, we can use aureport tool. Without any parameters, aureport will generate a summary report of audit activity.
|
||||
|
||||
$ sudo aureport
|
||||
|
||||

|
||||
|
||||
As we can see, there are some information available which cover most important area.
|
||||
|
||||
On the picture above we see there are **3 times failed authentication**. Using aureport, we can drill down to that information.
|
||||
|
||||
We can use this command to look deeper on failed authentication :
|
||||
|
||||
$ sudo aureport -au
|
||||
|
||||

|
||||
|
||||
As we can see on the picture above, there are two users which at the particular time are failed to authenticated
|
||||
|
||||
If we want to see all events related to account modification, we can use -m parameter.
|
||||
|
||||
$ sudo aureport -m
|
||||
|
||||

|
||||
|
||||
### Auditd configuration file ###
|
||||
|
||||
Previously we already added :
|
||||
|
||||
- $ sudo auditctl -w /etc/passwd -p rwxa
|
||||
- $ sudo auditctl -w /production/
|
||||
- Now, if we sure the rules are OK, we can add it into
|
||||
|
||||
**/etc/audit/audit.rules** to make them permanently.Here’s how to put them into the /etc/audit/audit.rules fileSample of audit rule file
|
||||
|
||||

|
||||
|
||||
**Then don’t forget to restart auditd daemon.**
|
||||
|
||||
# /etc/init.d/auditd restart
|
||||
|
||||
OR
|
||||
|
||||
# service auditd restart
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Auditd is one of the audit tool that available on Linux system. You can explore more detail about auditd and its related tools by reading its manual page. For example, just type **man auditd** to see more detail about auditd. Or type **man ausearch** to see more detail about ausearch tool.
|
||||
|
||||
**Please be careful before creating rules**. It will increase your log file size significantly if too much information to record.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/auditd-tool-security-auditing/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
[1]:http://linoxide.com/tools/wajig-package-management-debian/
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
Get back your privacy and control over your data in just a few hours: build your own cloud for you and your friends
|
||||
================================================================================
|
||||
40'000+ searches over 8 years! That's my Google Search history. How about yours? (you can find out for yourself [here][1]) With so many data points across such a long time, Google has a very precise idea of what you've been interested in, what's been on your mind, what you are worried about, and how that all changed over the years since you first got that Google account.
|
||||
@ -1110,4 +1111,4 @@ via: https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/
|
||||
[35]:http://owncloud.org/
|
||||
[36]:http://owncloud.org/install/
|
||||
[37]:https://code.google.com/p/k9mail/
|
||||
[38]:http://doc.owncloud.org/server/7.0/user_manual/files/files.html
|
||||
[38]:http://doc.owncloud.org/server/7.0/user_manual/files/files.html
|
||||
|
||||
@ -1,116 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
Linux FAQs with Answers--How to check CPU info on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to know detailed information about the CPU processor of my computer. What are the available methods to check CPU information on Linux?
|
||||
|
||||
Depending on your need, there are various pieces of information you may need to know about the CPU processor(s) of your computer, such as CPU vendor name, model name, clock speed, number of sockets/cores, L1/L2/L3 cache configuration, available processor capabilities (e.g., hardware virtualization, AES, MMX, SSE), and so on. In Linux, there are many command line or GUI-based tools that are used to show detailed information about your CPU hardware.
|
||||
|
||||
### 1. /proc/cpuinfo ###
|
||||
|
||||
The simpliest method is to check /proc/cpuinfo. This virtual file shows the configuration of available CPU hardware.
|
||||
|
||||
$ more /proc/cpuinfo
|
||||
|
||||
|
||||
|
||||
By inspecting this file, you can [identify][1] the number of physical processors, the number of cores per CPU, available CPU flags, and a number of other things.
|
||||
|
||||
### 2. cpufreq-info ###
|
||||
|
||||
The cpufreq-info command (which is part of **cpufrequtils** package) collects and reports CPU frequency information from the kernel/hardware. The command shows the hardware frequency that the CPU currently runs at, as well as the minimum/maximum CPU frequency allowed, CPUfreq policy/statistics, and so on. To check up on CPU #0:
|
||||
|
||||
$ cpufreq-info -c 0
|
||||
|
||||

|
||||
|
||||
### 3. cpuid ###
|
||||
|
||||
The cpuid command-line utility is a dedicated CPU information tool that displays verbose information about CPU hardware by using [CPUID functions][2]. Reported information includes processor type/family, CPU extensions, cache/TLB configuration, power management features, etc.
|
||||
|
||||
$ cpuid
|
||||
|
||||
|
||||
|
||||
### 4. dmidecode ###
|
||||
|
||||
The dmidecode command collects detailed information about system hardware directly from DMI data of the BIOS. Reported CPU information includes CPU vendor, version, CPU flags, maximum/current clock speed, (enabled) core count, L1/L2/L3 cache configuration, and so on.
|
||||
|
||||
$ sudo dmidecode
|
||||
|
||||
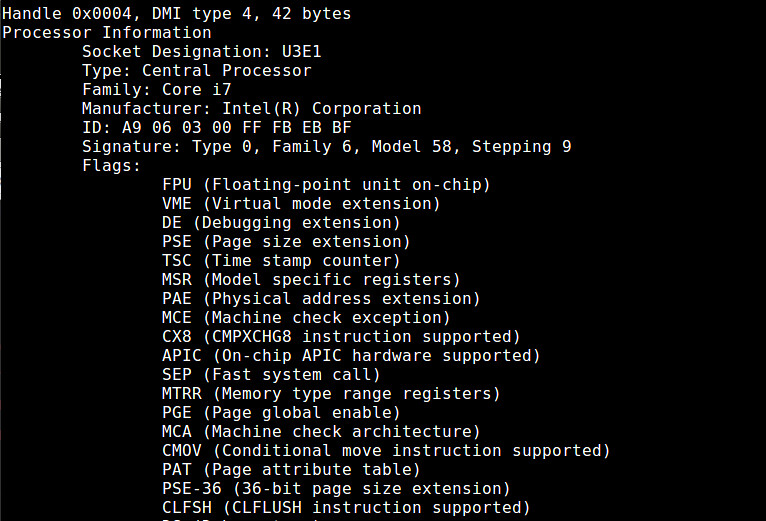
|
||||
|
||||
### 5. hardinfo ###
|
||||
|
||||
The hardinfo is a GUI-based system information tool which can give you an easy-to-understand summary of your CPU hardware, as well as other hardware components of your system.
|
||||
|
||||
$ hardinfo
|
||||
|
||||
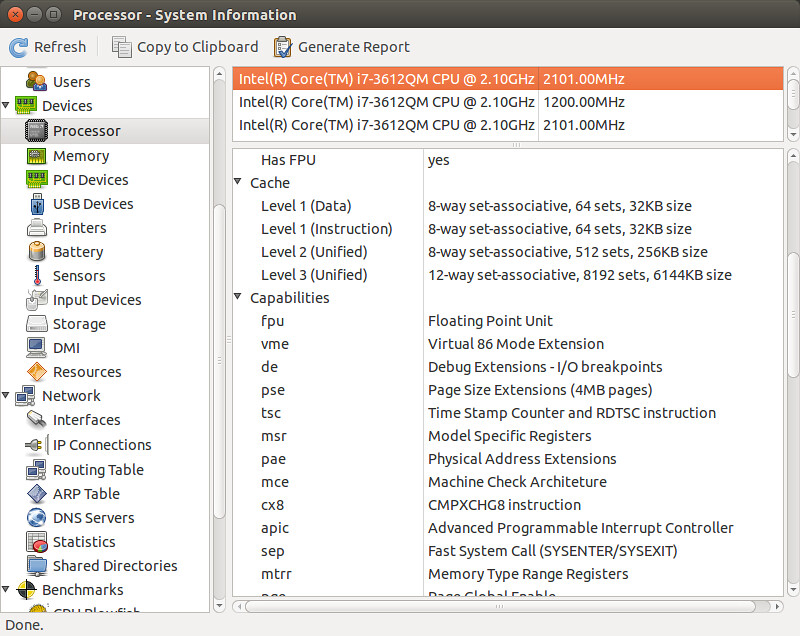
|
||||
|
||||
### 6. i7z ###
|
||||
|
||||
i7z is a real-time CPU reporting tool dedicated to Intel Core i3, i5 and i7 CPUs. It can display various per-core information in real time, such as Turbo Boost states, CPU frequencies, CPU power states, temperature measurements, and so on. i7z runs in either ncurses-based console mode or QT based GUI.
|
||||
|
||||
$ sudo i7z
|
||||
|
||||
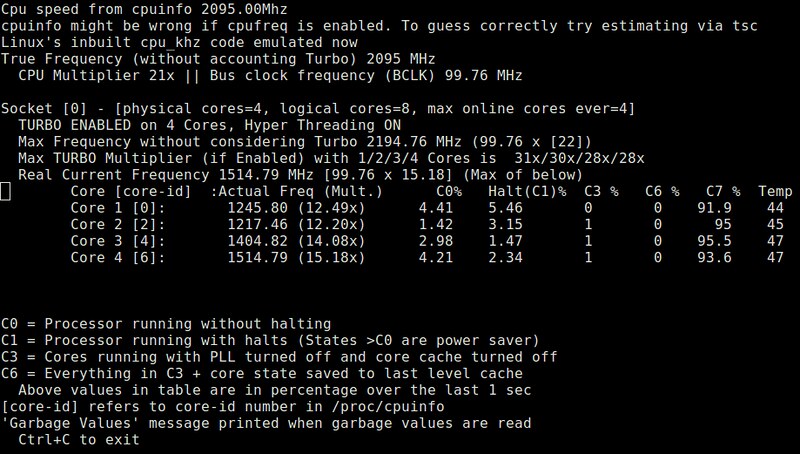
|
||||
|
||||
### 8. likwid-topology ###
|
||||
|
||||
[likwid][3] (Like I Knew What I'm Doing) is a collection of command-line tools to measure, configure and display hardware related properties. Among them is likwid-topology which shows CPU hardware (thread/cache/NUMA) topology information. It can also identify processor families (e.g., Intel Core 2, AMD Shanghai).
|
||||
|
||||
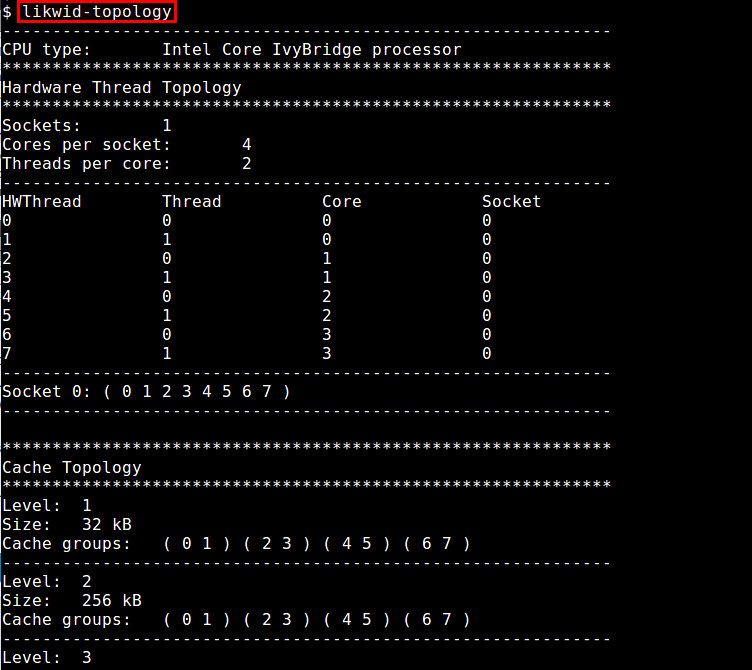
|
||||
|
||||
### 9. lscpu ###
|
||||
|
||||
The lscpu command summarizes /etc/cpuinfo content in a more user-friendly format, e.g., the number of (online/offline) CPUs, cores, sockets, NUMA nodes.
|
||||
|
||||
$ lscpu
|
||||
|
||||
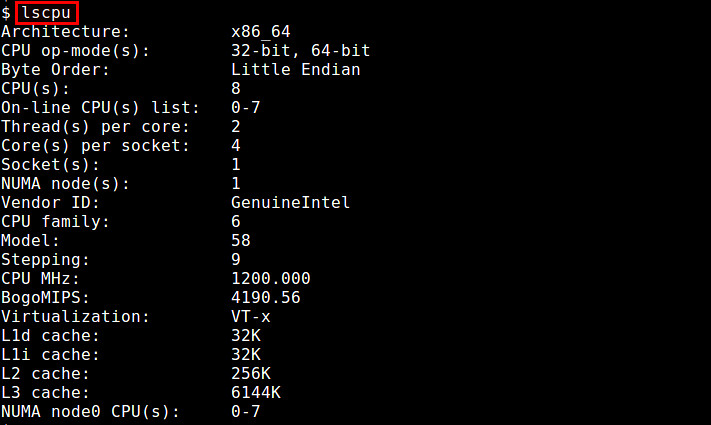
|
||||
|
||||
### 10. lshw ###
|
||||
|
||||
The **lshw** command is a comprehensive hardware query tool. Unlike other tools, lshw requires root privilege because it query DMI information in system BIOS. It can report the total number of cores and enabled cores, but miss out on information such as L1/L2/L3 cache configuration. The GTK version lshw-gtk is also available.
|
||||
|
||||
$ sudo lshw -class processor
|
||||
|
||||
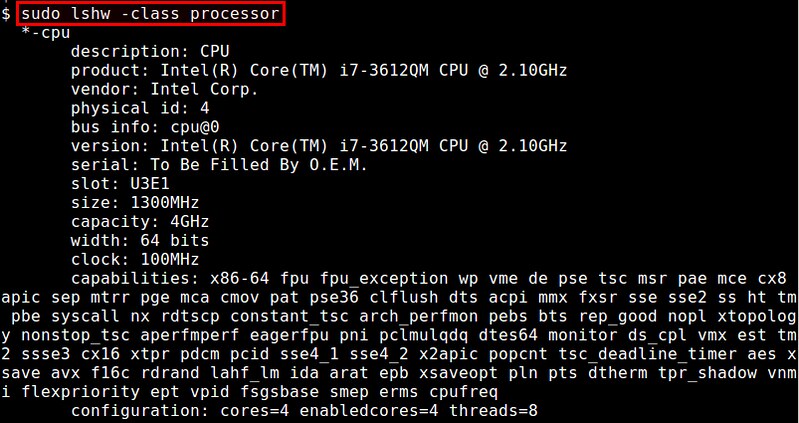
|
||||
|
||||
### 11. lstopo ###
|
||||
|
||||
The lstopo command (contained in [hwloc][4] package) visualizes the topology of the system which is composed of CPUs, cache, memory and I/O devices. This command is useful to identify the processor architecture and NUMA topology of the system.
|
||||
|
||||
$ lstopo
|
||||
|
||||
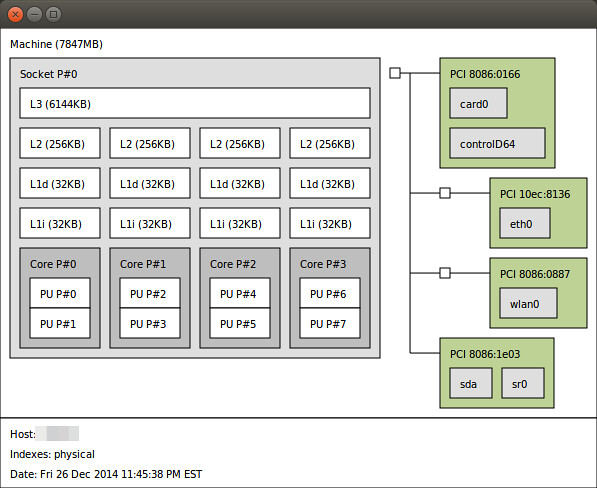
|
||||
|
||||
### 12. numactl ###
|
||||
|
||||
Originally developed to set the NUMA scheduling and memeory placement policy of Linux processes, the numactl command can also show information about NUMA topology of the CPU hardware from the command line.
|
||||
|
||||
$ numactl --hardware
|
||||
|
||||

|
||||
|
||||
### 13. x86info ###
|
||||
|
||||
x86info is a command-line tool for showing x86-based CPU information. Reported information includes CPU model, number of threads/cores, clock speed, TLB cache configuration, supported feature flags, etc.
|
||||
|
||||
$ x86info --all
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-cpu-info-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-find-number-of-cpu-cores-on.html
|
||||
[2]:http://en.wikipedia.org/wiki/CPUID
|
||||
[3]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[4]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
@ -1,120 +0,0 @@
|
||||
4 lvcreate Command Examples on Linux
|
||||
================================================================================
|
||||
Logical volume management (LVM) is a widely-used technique and extremely flexible disk management scheme. It basically contain three basic command :
|
||||
|
||||
a. Creates the physical volumes using **pvcreate**
|
||||
b. Create the volume group and add partition into volume group using **vgcreate**
|
||||
c. Create a new logical volume using **lvcreate**
|
||||
|
||||

|
||||
|
||||
The following examples focus on the command to create a logical volume in an existing volume group, **lvcreate**. **lvcreate** is the command do allocating logical extents from the free physical extent pool of that volume group. Normally logical volumes use up any space available on the underlying physical volumes on a next-free basis. Modifying the logical volume will frees and reallocates space in the physical volumes. The following **lvcreate** command has been tested on linux CentOS 5, CentOS 6, CentOS 7, RHEL 5, RHEl 6 and RHEL 7 version.
|
||||
|
||||
### 4 lvcreate Command Examples on Linux : ###
|
||||
|
||||
1. The following command creates a logical volume 15 gigabytes in size in the volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate -L 15G vg_newlvm
|
||||
|
||||
2. The following command creates a 2500 MB linear logical volume named centos7_newvol in the volume group
|
||||
vg_newlvm, creating the block device /dev/vg_newlvm/centos7_newvol :
|
||||
|
||||
[root@centos7 ~]# lvcreate -L 2500 -n centos7_newvol vg_newlvm
|
||||
|
||||
3. You can use the -l argument of the **lvcreate** command to specify the size of the logical volume in extents. You can also use this argument to specify the percentage of the volume group to use for the logical volume. The following command creates a logical volume called centos7_newvol that uses 50% of the total space in volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate -l 50%VG -n centos7_newvol vg_newlvm
|
||||
|
||||
4. The following command creates a logical volume called centos7_newvol that uses all of the unallocated space in the volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate --name centos7_newvol -l 100%FREE vg_newlvm
|
||||
|
||||
To see more **lvcreate** command options, issue the following command :
|
||||
|
||||
[root@centos7 ~]# lvcreate --help
|
||||
|
||||
----------
|
||||
|
||||
lvcreate: Create a logical volume
|
||||
|
||||
lvcreate
|
||||
[-A|--autobackup {y|n}]
|
||||
[-a|--activate [a|e|l]{y|n}]
|
||||
[--addtag Tag]
|
||||
[--alloc AllocationPolicy]
|
||||
[--cachemode CacheMode]
|
||||
[-C|--contiguous {y|n}]
|
||||
[-d|--debug]
|
||||
[-h|-?|--help]
|
||||
[--ignoremonitoring]
|
||||
[--monitor {y|n}]
|
||||
[-i|--stripes Stripes [-I|--stripesize StripeSize]]
|
||||
[-k|--setactivationskip {y|n}]
|
||||
[-K|--ignoreactivationskip]
|
||||
{-l|--extents LogicalExtentsNumber[%{VG|PVS|FREE}] |
|
||||
-L|--size LogicalVolumeSize[bBsSkKmMgGtTpPeE]}
|
||||
[-M|--persistent {y|n}] [--major major] [--minor minor]
|
||||
[-m|--mirrors Mirrors [--nosync] [{--mirrorlog {disk|core|mirrored}|--corelog}]]
|
||||
[-n|--name LogicalVolumeName]
|
||||
[--noudevsync]
|
||||
[-p|--permission {r|rw}]
|
||||
[--[raid]minrecoveryrate Rate]
|
||||
[--[raid]maxrecoveryrate Rate]
|
||||
[-r|--readahead ReadAheadSectors|auto|none]
|
||||
[-R|--regionsize MirrorLogRegionSize]
|
||||
[-T|--thin [-c|--chunksize ChunkSize]
|
||||
[--discards {ignore|nopassdown|passdown}]
|
||||
[--poolmetadatasize MetadataSize[bBsSkKmMgG]]]
|
||||
[--poolmetadataspare {y|n}]
|
||||
[--thinpool ThinPoolLogicalVolume{Name|Path}]
|
||||
[-t|--test]
|
||||
[--type VolumeType]
|
||||
[-v|--verbose]
|
||||
[-W|--wipesignatures {y|n}]
|
||||
[-Z|--zero {y|n}]
|
||||
[--version]
|
||||
VolumeGroupName [PhysicalVolumePath...]
|
||||
|
||||
lvcreate
|
||||
{ {-s|--snapshot} OriginalLogicalVolume[Path] |
|
||||
[-s|--snapshot] VolumeGroupName[Path] -V|--virtualsize VirtualSize}
|
||||
{-T|--thin} VolumeGroupName[Path][/PoolLogicalVolume]
|
||||
-V|--virtualsize VirtualSize}
|
||||
[-c|--chunksize]
|
||||
[-A|--autobackup {y|n}]
|
||||
[--addtag Tag]
|
||||
[--alloc AllocationPolicy]
|
||||
[-C|--contiguous {y|n}]
|
||||
[-d|--debug]
|
||||
[--discards {ignore|nopassdown|passdown}]
|
||||
[-h|-?|--help]
|
||||
[--ignoremonitoring]
|
||||
[--monitor {y|n}]
|
||||
[-i|--stripes Stripes [-I|--stripesize StripeSize]]
|
||||
[-k|--setactivationskip {y|n}]
|
||||
[-K|--ignoreactivationskip]
|
||||
{-l|--extents LogicalExtentsNumber[%{VG|FREE|ORIGIN}] |
|
||||
-L|--size LogicalVolumeSize[bBsSkKmMgGtTpPeE]}
|
||||
[--poolmetadatasize MetadataVolumeSize[bBsSkKmMgG]]
|
||||
[-M|--persistent {y|n}] [--major major] [--minor minor]
|
||||
[-n|--name LogicalVolumeName]
|
||||
[--noudevsync]
|
||||
[-p|--permission {r|rw}]
|
||||
[-r|--readahead ReadAheadSectors|auto|none]
|
||||
[-t|--test]
|
||||
[--thinpool ThinPoolLogicalVolume[Path]]
|
||||
[-v|--verbose]
|
||||
[--version]
|
||||
[PhysicalVolumePath...]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ehowstuff.com/4-lvcreate-command-examples-on-linux/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ehowstuff.com/author/mhstar/
|
||||
@ -1,91 +0,0 @@
|
||||
translating by KayGuoWhu
|
||||
How to limit network bandwidth on Linux
|
||||
================================================================================
|
||||
If you often run multiple networking applications on your Linux desktop, or share bandwidth among multiple computers at home, you will want to have a better control over bandwidth usage. Otherwise, when you are downloading a big file with a downloader, your interactive SSH session may become sluggish to the point where it's unusable. Or when you sync a big folder over Dropbox, your roommate may complain that video streaming at her computer gets choppy.
|
||||
|
||||
In this tutorial, I am going to describe two different ways to rate limit network traffic on Linux.
|
||||
|
||||
### Rate Limit an Application on Linux ###
|
||||
|
||||
One way to rate limit network traffic is via a command-line tool called [trickle][1]. The trickle command allows you to shape the traffic of any particular program by "pre-loading" a rate-limited socket library at run-time. A nice thing about trickle is that it runs purely in user-space, meaning you don't need root privilege to restrict the bandwidth usage of a program. To be compatible with trickle, the program must use socket interface with no statically linked library. trickle can be handy when you want to rate limit a program which does not have a built-in bandwidth control functionality.
|
||||
|
||||
To install trickle on Ubuntu, Debian and their derivatives:
|
||||
|
||||
$ sudo apt-get install trickle
|
||||
|
||||
To install trickle on Fedora or CentOS/RHEL (with [EPEL repository][2]):
|
||||
|
||||
$ sudo yum install trickle
|
||||
|
||||
Basic usage of trickle is as follows. Simply put, you prepend trickle (with rate) in front of the command you are trying to run.
|
||||
|
||||
$ trickle -d <download-rate> -u <upload-rate> <command>
|
||||
|
||||
This will limit the download and upload rate of <command> to specified values (in KBytes/s).
|
||||
|
||||
For example, set the maximum upload bandwidth of your scp session to 100 KB/s:
|
||||
|
||||
$ trickle -u 100 scp backup.tgz alice@remote_host.com:
|
||||
|
||||
If you want, you can set the maximum download speed (e.g., 300 KB/s) of your Firefox browser by creating a [custom launcher][3] with the following command.
|
||||
|
||||
trickle -d 300 firefox %u
|
||||
|
||||
Finally, trickle can run in a daemon mode, where it can restrict the "aggregate" bandwidth usage of all running programs launched via trickle. To launch trickle as a daemon (i.e., trickled):
|
||||
|
||||
$ sudo trickled -d 1000
|
||||
|
||||
Once the trickled daemon is running in the background, you can launch other programs via trickle. If you launch one program with trickle, its maximum download rate is 1000 KB/s. If you launch another program with trickle, each of them will be rate limited to 500 KB/s, etc.
|
||||
|
||||
### Rate Limit a Network Interface on Linux ###
|
||||
|
||||
Another way to control your bandwidth resource is to enforce bandwidth limit on a per-interface basis. This is useful when you are sharing your upstream Internet connection with someone else. Like anything else, Linux has a tool for you. [wondershaper][4] exactly does that: rate-limit a network interface.
|
||||
|
||||
wondershaper is in fact a shell script which uses [tc][5] to define traffic shaping and QoS for a specific network interface. Outgoing traffic is shaped by being placed in queues with different priorities, while incoming traffic is rate-limited by packet dropping.
|
||||
|
||||
In fact, the stated goal of wondershaper is much more than just adding bandwidth cap to an interface. wondershaper tries to maintain low latency for interactive sessions such as SSH while bulk download or upload is going on. Also, it makes sure that bulk upload (e.g., Dropbox sync) does not suffocate download, and vice versa.
|
||||
|
||||
To install wondershaper on Ubuntu, Debian and their derivatives:
|
||||
|
||||
$ sudo apt-get install wondershaper
|
||||
|
||||
To install wondershaper on Fedora or CentOS/RHEL (with [EPEL repository][6]):
|
||||
|
||||
$ sudo yum install wondershaper
|
||||
|
||||
Basic usage of wondershaper is as follows.
|
||||
|
||||
$ sudo wondershaper <interface> <download-rate> <upload-rate>
|
||||
|
||||
For example, to set the maximum download/upload bandwidth for eth0 to 1000Kbit/s and 500Kbit/s, respectively:
|
||||
|
||||
$ sudo wondershaper eth0 1000 500
|
||||
|
||||
You can remove the rate limit by running:
|
||||
|
||||
$ sudo wondershaper clear eth0
|
||||
|
||||
If you are interested in how wondershaper works, you can read its shell script (/sbin/wondershaper).
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I introduced two different ways to control your bandwidth usages on Linux desktop, on per-application or per-interface basis. Both tools are extremely user-friendly, offering you a quick and easy way to shape otherwise unconstrained traffic. For those of you who want to know more about rate control on Linux, refer to [the Linux bible][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/limit-network-bandwidth-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://monkey.org/~marius/trickle
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[3]:http://xmodulo.com/create-desktop-shortcut-launcher-linux.html
|
||||
[4]:http://lartc.org/wondershaper/
|
||||
[5]:http://lartc.org/manpages/tc.txt
|
||||
[6]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[7]:http://www.lartc.org/lartc.html
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by mtunique
|
||||
Moving to Docker
|
||||
================================================================================
|
||||

|
||||
@ -53,7 +54,7 @@ In the following articles we'll see how to setup a semi-automated Docker based d
|
||||
via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -78,4 +79,4 @@ via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
[20]:
|
||||
|
||||
@ -1,86 +0,0 @@
|
||||
How To Monitor Access Point Signal Strength With wifi-linux
|
||||
================================================================================
|
||||
As a python geek I love exploring new python tools on github that target the linux users. Today I discovered a simple application written in python programming language that can be used to monitor access point signal strength.
|
||||
|
||||
I have been experimenting for about two hours with **wifi-linux** and it works great but I would like to see some unittests in the near future from the author as the command **plot** is not working on my machine and is also causing some errors.
|
||||
|
||||
### What is wifi-linux ###
|
||||
|
||||
According to the official readme.md file on author's github account wifi-linux is a very simple python script which collects RSSI information about wifi access points around you and draws graphics showing RSSI activity.
|
||||
|
||||
The author states that the program also draws RSSI activity graphic and this can be generated with the command plot but unfortunetly it is not working for me. wifi-linux supports other commands such as **bp** to add a breakpoint, **print** to print some statistics and **start changer**.
|
||||
|
||||
The wifi-linux application has the folowing dependencies:
|
||||
|
||||
- dbus-python
|
||||
- gnuplot-py
|
||||
|
||||
So first we have to install all the package dependencies for our project in order to run it in our linux machine.
|
||||
|
||||
### Install pakages required by wifi-linux ###
|
||||
|
||||
I tried to install python-dbus by using the pip tool which is used to manage python packages but it did not work and the reason for this is that pip looks for setup.py, which dbus-python doesn't have. So the following command is not going to work.
|
||||
|
||||
pip install dbus-python
|
||||
|
||||
And to make sure it does not work give it a try. It is a very high probability that you will get the following error displayed on your console.
|
||||
|
||||
IOError: [Errno 2] No such file or directory: '/tmp/pip_build_oltjano/dbus-python/setup.py'
|
||||
|
||||
How did I manage to solve this problem? It is very simple. I installed the the system package for the Python DBUS bindings using the following command.
|
||||
|
||||
sudo apt-get install python-dbus
|
||||
|
||||
The above command will work only in machines that make use of the apt-get package manager such as Debian and Ubuntu.
|
||||
|
||||
Then the second dependency we have to take care is the gnuplot-py. Download it, extract using the tar utility and then run setup.py install to install the python package.
|
||||
|
||||
First step is to download gnuplot-py.
|
||||
|
||||
wget http://prdownloads.sourceforge.net/gnuplot-py/gnuplot-py-1.8.tar.gz
|
||||
|
||||
Then use the tar utility to extract it.
|
||||
|
||||
tar xvf gnuplot-py-1.8.tar.gz
|
||||
|
||||
Then use the cd command to change directory.
|
||||
|
||||
cd gnuplot-py-1.8
|
||||
|
||||
Once there then run the following command to install the package gunplot-py on your system.
|
||||
|
||||
sudo setup.py install
|
||||
|
||||
Once the installation is finished you are ready to run the wifi-linux on your machine. Just download it and use the following command to run the script.
|
||||
|
||||
Download wifi-linux on your local machine by using the following command.
|
||||
|
||||
wget https://github.com/dixel/wifi-linux/archive/master.zip
|
||||
|
||||
Extract the master.zip archive and then use the following command to run the python script list_rsssi.py
|
||||
|
||||
python list_rssi.py
|
||||
|
||||
The following screenshot shows wifi-linux in action.
|
||||
|
||||

|
||||
|
||||
Then the command **bp** is executed to add a breakpoint like shown below.
|
||||
|
||||

|
||||
|
||||
The command **print** can be used to display stats on the console of your machine. An example of its usage is shown below.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/monitor-access-point-signal-strength-wifi-linux/
|
||||
|
||||
作者:[Oltjano Terpollari][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/oltjano/
|
||||
@ -0,0 +1,79 @@
|
||||
How to Bind Apache Tomcat to IPv4 in Centos / Redhat
|
||||
================================================================================
|
||||
Hi all, today we'll learn how to bind tomcat to ipv4 in CentOS 7 Linux Distribution.
|
||||
|
||||
**Apache Tomcat** is an open source web server and servlet container developed by the [Apache Software Foundation][1]. It implements the Java Servlet, JavaServer Pages (JSP), Java Unified Expression Language and Java WebSocket specifications from Sun Microsystems and provides a web server environment for Java code to run in.
|
||||
|
||||
Binding Tomcat to IPv4 is necessary if we have our server not working due to the default binding of our tomcat server to IPv6. As we know IPv6 is the modern way of assigning IP address to a device and is not in complete practice these days but may come into practice in soon future. So, currently we don't need to switch our tomcat server to IPv6 due to no use and we should bind it to IPv4.
|
||||
|
||||
Before thinking to bind to IPv4, we should make sure that we've got tomcat installed in our CentOS 7. Here's is a quick tutorial on [how to install tomcat 8 in CentOS 7.0 Server][2].
|
||||
|
||||
### 1. Switching to user tomcat ###
|
||||
|
||||
First of all, we'll gonna switch user to **tomcat** user. We can do that by running **su - tomcat** in a shell or terminal.
|
||||
|
||||
# su - tomcat
|
||||
|
||||

|
||||
|
||||
### 2. Finding Catalina.sh ###
|
||||
|
||||
Now, we'll First Go to bin directory inside the directory of Apache Tomcat installation which is usually under **/usr/share/apache-tomcat-8.0.x/bin/** where x is sub version of the Apache Tomcat Release. In my case, its **/usr/share/apache-tomcat-8.0.18/bin/** as I have version 8.0.18 installed in my CentOS 7 Server.
|
||||
|
||||
$ cd /usr/share/apache-tomcat-8.0.18/bin
|
||||
|
||||
**Note: Please replace 8.0.18 to the version of Apache Tomcat installed in your system. **
|
||||
|
||||
Inside the bin folder, there is a script file named catalina.sh . Thats the script file which we'll gonna edit and add a line of configuration which will bind tomcat to IPv4 . You can see that file by running **ls** into a terminal or shell.
|
||||
|
||||
$ ls
|
||||
|
||||

|
||||
|
||||
### 3. Configuring Catalina.sh ###
|
||||
|
||||
Now, we'll add **JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"** to that scripting file catalina.sh at the end of the file as shown in the figure below. We can edit the file using our favorite text editing software like nano, vim, etc. Here, we'll gonna use nano.
|
||||
|
||||
$ nano catalina.sh
|
||||
|
||||

|
||||
|
||||
Then, add to the file as shown below:
|
||||
|
||||
**JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"**
|
||||
|
||||

|
||||
|
||||
Now, as we've added the configuration to the file, we'll now save and exit nano.
|
||||
|
||||
### 4. Restarting ###
|
||||
|
||||
Now, we'll restart our tomcat server to get our configuration working. We'll need to first execute shutdown.sh and then startup.sh .
|
||||
|
||||
$ ./shutdown.sh
|
||||
|
||||
Now, well run execute startup.sh as:
|
||||
|
||||
$ ./startup.sh
|
||||
|
||||

|
||||
|
||||
This will restart our tomcat server and the configuration will be loaded which will ultimately bind the server to IPv4.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray, finally we'have got our tomcat server bind to IPv4 running in our CentOS 7 Linux Distribution. Binding to IPv4 is easy and is necessary if your Tomcat server is bind to IPv6 which will infact will make your tomcat server not working as IPv6 is not used these days and may come into practice in coming future. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/bind-apache-tomcat-ipv4-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.apache.org/
|
||||
[2]:http://linoxide.com/linux-how-to/install-tomcat-8-centos-7/
|
||||
@ -0,0 +1,186 @@
|
||||
How to create and show a presentation from the command line on Linux
|
||||
================================================================================
|
||||
When you prepare a talk for audience, the first thing that will probably come to your mind is shiny presentation charts filled with fancy diagrams, graphics and animation effects. Fine. No one can deny the power of visually charming presentation. However, not all presentations need to be Ted talk quality. Often times, the purpose of a presentation is to convey specific information, which can easily be done with textual messages. In such cases, your time can be better spent on gathering information and checking facts, rather than searching for good-looking graphics from Google Image.
|
||||
|
||||
In the world of Linux, you can do presentation in several different ways, e.g., Impress for multimedia-rich content, [Impress.js][1] for stunning visualization, Beamer for hardcore LaTex users, and so on. If you are looking for a simple means to create and show a textual presentation, look no further. [mdp][2] can get the job done for you.
|
||||
|
||||
### What is Mdp? ###
|
||||
|
||||
mdp is an ncurses-based command-line presentation tool for Linux. What I like about mdp is its [markdown][3] support, which makes it easy to create slides with familiar markdown format. Naturally, it becomes painless to publish the slides in HTML format as well. Another plus is its support for UTF-8 character encoding, which comes in handy when showing non-English characters (e.g., Greek or Cyrillic alphabets).
|
||||
|
||||
### Install Mdp on Linux ###
|
||||
|
||||
Installation of mdp is mostly painless due to its light dependency requirement (i.e., ncursesw).
|
||||
|
||||
#### Debian, Ubuntu or their derivatives ####
|
||||
|
||||
$ sudo apt-get install git gcc make libncursesw5-dev
|
||||
$ git clone https://github.com/visit1985/mdp.git
|
||||
$ cd mdp
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
#### Fedora or CentOS/RHEL ####
|
||||
|
||||
$ sudo yum install git gcc make ncurses-devel
|
||||
$ git clone https://github.com/visit1985/mdp.git
|
||||
$ cd mdp
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
#### Arch Linux ####
|
||||
|
||||
On Arch Linux, you can easily install mdp from [AUR][4].
|
||||
|
||||
### Create a Presentation from the Command Line ###
|
||||
|
||||
Once you installed mdp, you can easily create a presentation by using your favorite text editor. If you are familiar with markdown, it will take no time to master mdp. For those of you who are not familiar with markdown, starting with an example is the best way to learn mdp.
|
||||
|
||||
Here is a 6-page sample presentation for your reference.
|
||||
|
||||
%title: Sample Presentation made with mdp (Xmodulo.com)
|
||||
%author: Dan Nanni
|
||||
%date: 2015-01-28
|
||||
|
||||
-> This is a slide title <-
|
||||
=========
|
||||
|
||||
-> mdp is a command-line based presentation tool with markdown support. <-
|
||||
|
||||
*_Features_*
|
||||
|
||||
* Multi-level headers
|
||||
* Code block formatting
|
||||
* Nested quotes
|
||||
* Nested list
|
||||
* Text highlight and underline
|
||||
* Citation
|
||||
* UTF-8 special characters
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of nested list <-
|
||||
|
||||
This is an example of multi-level headers and a nested list.
|
||||
|
||||
# first-level title
|
||||
|
||||
second-level
|
||||
------------
|
||||
|
||||
- *item 1*
|
||||
- sub-item 1
|
||||
- sub-sub-item 1
|
||||
- sub-sub-item 2
|
||||
- sub-sub-item 3
|
||||
- sub-item 2
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of code block formatting <-
|
||||
|
||||
This example shows how to format a code snippet.
|
||||
|
||||
1 /* Hello World program */
|
||||
2
|
||||
3 #include <stdio.h>
|
||||
4
|
||||
5 int main()
|
||||
6 {
|
||||
7 printf("Hello World");
|
||||
8 return 0;
|
||||
9 }
|
||||
|
||||
This example shows inline code: `sudo reboot`
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of nested quotes <-
|
||||
|
||||
This is an example of nested quotes.
|
||||
|
||||
# three-level nested quotes
|
||||
|
||||
> This is the first-level quote.
|
||||
>> This is the second-level quote
|
||||
>> and continues.
|
||||
>>> *This is the third-level quote, and so on.*
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of citations <-
|
||||
|
||||
This example shows how to place a citation inside a presentation.
|
||||
|
||||
This tutorial is published at [Xmodulo](http://xmodulo.com)
|
||||
|
||||
You are welcome to connect with me at [LinkedIn](http://www.linkedin.com/in/xmodulo)
|
||||
|
||||
Pretty cool, huh?
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of UTF-8 special characters <-
|
||||
|
||||
This example shows UTF-8 special characters.
|
||||
|
||||
ae = ä, oe = ö, ue = ü, ss = ß
|
||||
alpha = ?, beta = ?, upsilon = ?, phi = ?
|
||||
Omega = ?, Delta = ?, Sigma = ?
|
||||
|
||||
???????????
|
||||
?rectangle?
|
||||
???????????
|
||||
|
||||
### Show a Presentation from the Command Line ###
|
||||
|
||||
Once you save the above code as slide.md text file, you can show the presentation by simply running:
|
||||
|
||||
$ mdp slide.md
|
||||
|
||||
You can navigate the presentation by pressing Enter/Space/Page-Down/Down-Arrow (next slide), Backspace/Page-Up/Up-Arrow (previous slide), Home (first slide), End (last slide), or numeric-N (N-th slide).
|
||||
|
||||
The title of the presentation appears on top of each slide, and your name and page number are shown at the bottom.
|
||||
|
||||
|
||||
|
||||
This is an example of a nested list and multi-level headers.
|
||||
|
||||
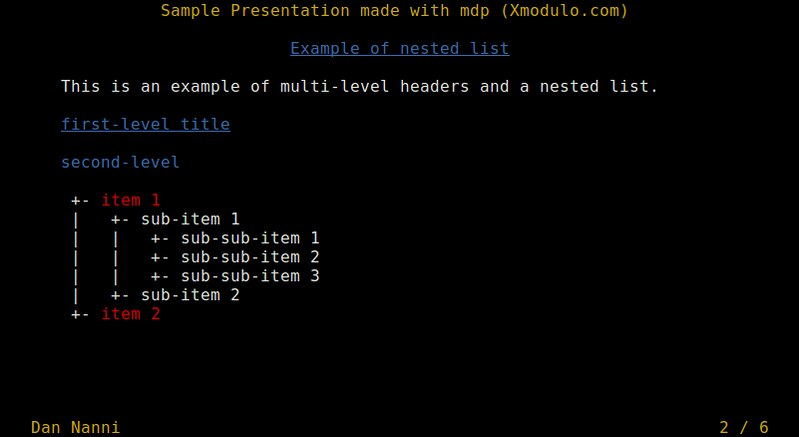
|
||||
|
||||
This is an example of a code snippet and inline code.
|
||||
|
||||
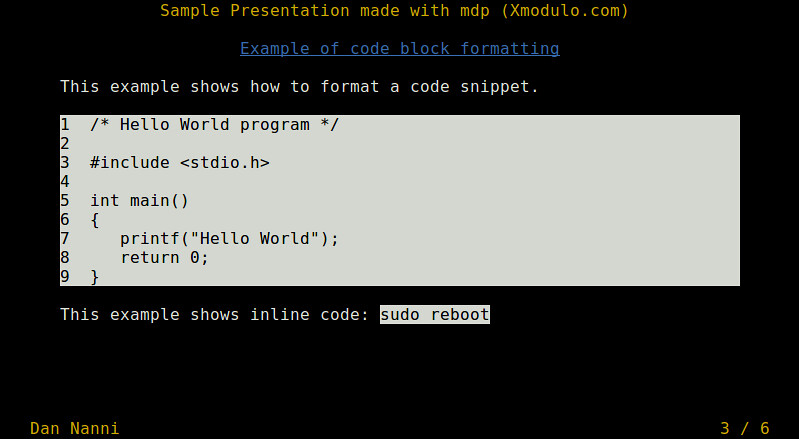
|
||||
|
||||
This is an example of nested quotes.
|
||||
|
||||
|
||||
|
||||
This is an example of placing citations.
|
||||
|
||||
|
||||
|
||||
This is an example of UTF-8 special characters.
|
||||
|
||||
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial, I showed you how to use mdp to create and show a presentation from the command line. Its markdown compatibility saves us the trouble and hassle of having to learn any new formatting, which is an advantage compared to [tpp][5], another command-line presentation tool. Due to its limitations, mdp may not qualify as your default presentation tool, but there should be definitely a use case for that. What do you think of mdp? Do you prefer something else?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/presentation-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://bartaz.github.io/impress.js/
|
||||
[2]:https://github.com/visit1985/mdp
|
||||
[3]:http://daringfireball.net/projects/markdown/
|
||||
[4]:https://aur.archlinux.org/packages/mdp-git/
|
||||
[5]:http://www.ngolde.de/tpp.html
|
||||
@ -0,0 +1,201 @@
|
||||
How to filter BGP routes in Quagga BGP router
|
||||
================================================================================
|
||||
In the [previous tutorial][1], we demonstrated how to turn a CentOS box into a BGP router using Quagga. We also covered basic BGP peering and prefix exchange setup. In this tutorial, we will focus on how we can control incoming and outgoing BGP prefixes by using **prefix-list** and **route-map**.
|
||||
|
||||
As described in earlier tutorials, BGP routing decisions are made based on the prefixes received/advertised. To ensure error-free routing, it is recommended that you use some sort of filtering mechanism to control these incoming and outgoing prefixes. For example, if one of your BGP neighbors starts advertising prefixes which do not belong to them, and you accept such bogus prefixes by mistake, your traffic can be sent to that wrong neighbor, and end up going nowhere (so-called "getting blackholed"). To make sure that such prefixes are not received or advertised to any neighbor, you can use prefix-list and route-map. The former is a prefix-based filtering mechanism, while the latter is a more general prefix-based policy mechanism used to fine-tune actions.
|
||||
|
||||
We will show you how to use prefix-list and route-map in Quagga.
|
||||
|
||||
### Topology and Requirement ###
|
||||
|
||||
In this tutorial, we assume the following topology.
|
||||
|
||||

|
||||
|
||||
Service provider A has already established an eBGP peering with service provider B, and they are exchanging routing information between them. The AS and prefix details are as stated below.
|
||||
|
||||
- **Peering block**: 192.168.1.0/24
|
||||
- **Service provider A**: AS 100, prefix 10.10.0.0/16
|
||||
- **Service provider B**: AS 200, prefix 10.20.0.0/16
|
||||
|
||||
In this scenario, service provider B wants to receive only prefixes 10.10.10.0/23, 10.10.10.0/24 and 10.10.11.0/24 from provider A.
|
||||
|
||||
### Quagga Installation and BGP Peering ###
|
||||
|
||||
In the [previous tutorial][1], we have already covered the method of installing Quagga and setting up BGP peering. So we will not go through the details here. Nonetheless, I am providing a summary of BGP configuration and prefix advertisements:
|
||||
|
||||

|
||||
|
||||
The above output indicates that the BGP peering is up. Router-A is advertising multiple prefixes towards router-B. Router-B, on the other hand, is advertising a single prefix 10.20.0.0/16 to router-A. Both routers are receiving the prefixes without any problems.
|
||||
|
||||
### Creating Prefix-List ###
|
||||
|
||||
In a router, a prefix can be blocked with either an ACL or prefix-list. Using prefix-list is often preferred to ACLs since prefix-list is less processor intensive than ACLs. Also, prefix-list is easier to create and maintain.
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23
|
||||
|
||||
The above command creates prefix-list called 'DEMO-FRFX' that allows only 192.168.0.0/23.
|
||||
|
||||
Another great feature of prefix-list is that we can specify a range of subnet mask(s). Take a look at the following example:
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23 le 24
|
||||
|
||||
The above command creates prefix-list called 'DEMO-PRFX' that permits prefixes between 192.168.0.0/23 and /24, which are 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24. The 'le' operator means less than or equal to. You can also use 'ge' operator for greater than or equal to.
|
||||
|
||||
A single prefix-list statement can have multiple permit/deny actions. Each statement is assigned a sequence number which can be determined automatically or specified manually.
|
||||
|
||||
Multiple prefix-list statements are parsed one by one in the increasing order of sequence numbers. When configuring prefix-list, we should keep in mind that there is always an **implicit deny** at the end of all prefix-list statements. This means that anything that is not explicitly allowed will be denied.
|
||||
|
||||
To allow everything, we can use the following prefix-list statement which allows any prefix starting from 0.0.0.0/0 up to anything with subnet mask /32.
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 0.0.0.0/0 le 32
|
||||
|
||||
Now that we know how to create prefix-list statements, we will create prefix-list called 'PRFX-LST' that will allow prefixes required in our scenario.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# ip prefix-list PRFX-LST permit 10.10.10.0/23 le 24
|
||||
|
||||
### Creating Route-Map ###
|
||||
|
||||
Besides prefix-list and ACLs, there is yet another mechanism called route-map, which can control prefixes in a BGP router. In fact, route-map can fine-tune possible actions more flexibly on the prefixes matched with an ACL or prefix-list.
|
||||
|
||||
Similar to prefix-list, a route-map statement specifies permit or deny action, followed by a sequence number. Each route-map statement can have multiple permit/deny actions with it. For example:
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
|
||||
The above statement creates route-map called 'DEMO-RMAP', and adds permit action with sequence 10. Now we will use match command under sequence 10.
|
||||
|
||||
router-a(config-route-map)# match (press ? in the keyboard)
|
||||
|
||||
----------
|
||||
|
||||
as-path Match BGP AS path list
|
||||
community Match BGP community list
|
||||
extcommunity Match BGP/VPN extended community list
|
||||
interface match first hop interface of route
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
metric Match metric of route
|
||||
origin BGP origin code
|
||||
peer Match peer address
|
||||
probability Match portion of routes defined by percentage value
|
||||
tag Match tag of route
|
||||
|
||||
As we can see, route-map can match many attributes. We will match a prefix in this tutorial.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
|
||||
The match command will match the IP addresses permitted by the prefix-list 'DEMO-PRFX' created earlier (i.e., prefixes 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24).
|
||||
|
||||
Next, we can modify the attributes by using the set command. The following example shows possible use cases of set.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set (press ? in keyboard)
|
||||
|
||||
----------
|
||||
|
||||
aggregator BGP aggregator attribute
|
||||
as-path Transform BGP AS-path attribute
|
||||
atomic-aggregate BGP atomic aggregate attribute
|
||||
comm-list set BGP community list (for deletion)
|
||||
community BGP community attribute
|
||||
extcommunity BGP extended community attribute
|
||||
forwarding-address Forwarding Address
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
local-preference BGP local preference path attribute
|
||||
metric Metric value for destination routing protocol
|
||||
metric-type Type of metric
|
||||
origin BGP origin code
|
||||
originator-id BGP originator ID attribute
|
||||
src src address for route
|
||||
tag Tag value for routing protocol
|
||||
vpnv4 VPNv4 information
|
||||
weight BGP weight for routing table
|
||||
|
||||
As we can see, the set command can be used to change many attributes. For a demonstration purpose, we will set BGP local preference.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
|
||||
Just like prefix-list, there is an implicit deny at the end of all route-map statements. So we will add another permit statement in sequence number 20 to permit everything.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
!
|
||||
route-map DEMO-RMAP permit 20
|
||||
|
||||
The sequence number 20 does not have a specific match command, so it will, by default, match everything. Since the decision is permit, everything will be permitted by this route-map statement.
|
||||
|
||||
If you recall, our requirement is to only allow/deny some prefixes. So in our scenario, the set command is not necessary. We will just use one permit statement as follows.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# route-map RMAP permit 10
|
||||
router-b(config-route-map)# match ip address prefix-list PRFX-LST
|
||||
|
||||
This route-map statement should do the trick.
|
||||
|
||||
### Applying Route-Map ###
|
||||
|
||||
Keep in mind that ACLs, prefix-list and route-map are not effective unless they are applied to an interface or a BGP neighbor. Just like ACLs or prefix-list, a single route-map statement can be used with any number of interfaces or neighbors. However, any one interface or a neighbor can support only one route-map statement for inbound, and one for outbound traffic.
|
||||
|
||||
We will apply the created route-map to the BGP configuration of router-B for neighbor 192.168.1.1 with incoming prefix advertisement.
|
||||
|
||||
router-b# conf terminal
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# neighbor 192.168.1.1 route-map RMAP in
|
||||
|
||||
Now, we check the routes advertised and received by using the following commands.
|
||||
|
||||
For advertised routes:
|
||||
|
||||
show ip bgp neighbor-IP advertised-routes
|
||||
|
||||
For received routes:
|
||||
|
||||
show ip bgp neighbor-IP routes
|
||||
|
||||

|
||||
|
||||
You can see that while router-A is advertising four prefixes towards router-B, router-B is accepting only three prefixes. If we check the range, we can see that only the prefixes that are allowed by route-map are visible on router-B. All other prefixes are discarded.
|
||||
|
||||
**Tip**: If there is no change in the received prefixes, try resetting the BGP session using the command: "clear ip bgp neighbor-IP". In our case:
|
||||
|
||||
clear ip bgp 192.168.1.1
|
||||
|
||||
As we can see, the requirement has been met. We can create similar prefix-list and route-map statements in routers A and B to further control inbound and outbound prefixes.
|
||||
|
||||
I am summarizing the configuration in one place so you can see it all at a glance.
|
||||
|
||||
router bgp 200
|
||||
network 10.20.0.0/16
|
||||
neighbor 192.168.1.1 remote-as 100
|
||||
neighbor 192.168.1.1 route-map RMAP in
|
||||
!
|
||||
ip prefix-list PRFX-LST seq 5 permit 10.10.10.0/23 le 24
|
||||
!
|
||||
route-map RMAP permit 10
|
||||
match ip address prefix-list PRFX-LST
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial, we showed how we can filter BGP routes in Quagga by defining prefix-list and route-map. We also demonstrated how we can combine prefix-list with route-map to fine-control incoming prefixes. You can create your own prefix-list and route-map in a similar way to match your network requirements. These tools are one of the most effective ways to protect the production network from route poisoning and advertisement of bogon routes.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
@ -0,0 +1,52 @@
|
||||
> Vic
|
||||
|
||||
Linux FAQs with Answers--How to fix “Your profile could not be opened correctly” on Google Chrome
|
||||
================================================================================
|
||||
> **Question**: When I open Google Chrome web browser on my Linux box, I have several pop-up messages saying "Your profile could not be opened correctly." This error happens every time I open Google Chrome. How can I solve this error?
|
||||
|
||||
When you see an error message saying "Your profile could not be opened correctly" on your Google Chrome web browser," that is because somehow your profile data on Google Chrome got corrupted. This can happen while you upgrade your Google Chrome browser manually on Linux.
|
||||
|
||||
|
||||
|
||||
Depending on exactly which file got corrupted, you can try one of these methods.
|
||||
|
||||
### Method One ###
|
||||
|
||||
Close all your Chrome browser windows/tabs.
|
||||
|
||||
Go to ~/.config/google-chrome/Default, and remove/rename "Web Data" file as below.
|
||||
|
||||
$ cd ~/.config/google-chrome/Default
|
||||
$ rm "Web Data"
|
||||
|
||||
Re-open Google Chrome browser.
|
||||
|
||||
### Method Two ###
|
||||
|
||||
Close all your Chrome browser windows/tabs.
|
||||
|
||||
Go to ~/.config/google-chrome/"Profile 1", and rename "History" file as below.
|
||||
|
||||
$ cd ~/.config/google-chrome/"Profile 1"
|
||||
$ mv History History.bak
|
||||
|
||||
Re-open Google Chrome browser.
|
||||
|
||||
### Method Three ###
|
||||
|
||||
If the problem still persists, you can remove the Default profile folder (~/.config/google-chrome/Default) altogether. Note that by doing so, you will lose all previously opened Google tabs, imported bookmarks, browsing history, sign-in data, etc.
|
||||
|
||||
Before removing it, first close all your Chrome browser windows/tabs.
|
||||
|
||||
$ rm -rf ~/.config/google-chrome/Default
|
||||
|
||||
After restarting Google Chrome, the folder ~/.config/google-chrome/Default will automatically be re-generated.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/your-profile-could-not-be-opened-correctly-google-chrome.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,377 @@
|
||||
25 Linux Shell Scripting interview Questions & Answers
|
||||
================================================================================
|
||||
### Q:1 What is Shell Script and why it is required ? ###
|
||||
|
||||
Ans: A Shell Script is a text file that contains one or more commands. As a system administrator we often need to issue number of commands to accomplish the task, we can add these all commands together in a text file (Shell Script) to complete daily routine task.
|
||||
|
||||
### Q:2 What is the default login shell and how to change default login shell for a specific user ? ###
|
||||
|
||||
Ans: In Linux like Operating system “/bin/bash” is the default login shell which is assigned while user creation. We can change default shell using the “chsh” command . Example is shown below :
|
||||
|
||||
# chsh <username> -s <new_default_shell>
|
||||
# chsh linuxtechi -s /bin/sh
|
||||
|
||||
### Q:3 What are the different type of variables used in a shell Script ? ###
|
||||
|
||||
Ans: In a shell script we can use two types of variables :
|
||||
|
||||
- System defined variables
|
||||
- User defined variables
|
||||
|
||||
System defined variables are defined or created by Operating System(Linux) itself. These variables are generally defined in Capital Letters and can be viewed by “**set**” command.
|
||||
|
||||
User defined variables are created or defined by system users and the values of variables can be viewed by using the command “`echo $<Name_of_Variable>`”
|
||||
|
||||
### Q:4 How to redirect both standard output and standard error to the same location ? ###
|
||||
|
||||
Ans: There two method to redirect std output and std error to the same location:
|
||||
|
||||
Method:1 2>&1 (# ls /usr/share/doc > out.txt 2>&1 )
|
||||
|
||||
Method:2 &> (# ls /usr/share/doc &> out.txt )
|
||||
|
||||
### Q:5 What is the Syntax of “nested if statement” in shell scripting ? ###
|
||||
|
||||
Ans : Basic Syntax is shown below :
|
||||
|
||||
if [ Condition ]
|
||||
then
|
||||
command1
|
||||
command2
|
||||
…..
|
||||
else
|
||||
if [ condition ]
|
||||
then
|
||||
command1
|
||||
command2
|
||||
….
|
||||
else
|
||||
command1
|
||||
command2
|
||||
…..
|
||||
fi
|
||||
fi
|
||||
|
||||
### Q:6 What is the use of “$?” sign in shell script ? ###
|
||||
|
||||
Ans:While writing a shell script , if you want to check whether previous command is executed successfully or not , then we can use “$?” with if statement to check the exit status of previous command. Basic example is shown below :
|
||||
|
||||
root@localhost:~# ls /usr/bin/shar
|
||||
/usr/bin/shar
|
||||
root@localhost:~# echo $?
|
||||
0
|
||||
|
||||
If exit status is 0 , then command is executed successfully
|
||||
|
||||
root@localhost:~# ls /usr/bin/share
|
||||
|
||||
ls: cannot access /usr/bin/share: No such file or directory
|
||||
root@localhost:~# echo $?
|
||||
2
|
||||
|
||||
If the exit status is other than 0, then we can say command is not executed successfully.
|
||||
|
||||
### Q:7 How to compare numbers in Linux shell Scripting ? ###
|
||||
|
||||
Ans: test command is used to compare numbers in if-then statement. Example is shown below :
|
||||
|
||||
#!/bin/bash
|
||||
x=10
|
||||
y=20
|
||||
|
||||
if [ $x -gt $y ]
|
||||
then
|
||||
echo “x is greater than y”
|
||||
else
|
||||
echo “y is greater than x”
|
||||
fi
|
||||
|
||||
### Q:8 What is the use of break command ? ###
|
||||
|
||||
Ans: The break command is a simple way to escape out of a loop in progress. We can use the break command to exit out from any loop, including while and until loops.
|
||||
|
||||
### Q:9 What is the use of continue command in shell scripting ? ###
|
||||
|
||||
Ans The continue command is identical to break command except it causes the present iteration of the loop to exit, instead of the entire loop. Continue command is useful in some scenarios where error has occurred but we still want to execute the next commands of the loop.
|
||||
|
||||
### Q:10 Tell me the Syntax of “Case statement” in Linux shell scripting ? ###
|
||||
|
||||
Ans: The basic syntax is shown below :
|
||||
|
||||
case word in
|
||||
value1)
|
||||
command1
|
||||
command2
|
||||
…..
|
||||
last_command
|
||||
!!
|
||||
value2)
|
||||
command1
|
||||
command2
|
||||
……
|
||||
last_command
|
||||
;;
|
||||
esac
|
||||
|
||||
### Q:11 What is the basic syntax of while loop in shell scripting ? ###
|
||||
|
||||
Ans: Like the for loop, the while loop repeats its block of commands a number of times. Unlike the for loop, however, the while loop iterates until its while condition is no longer true. The basic syntax is :
|
||||
|
||||
while [ test_condition ]
|
||||
do
|
||||
commands…
|
||||
done
|
||||
|
||||
### Q:12 How to make a shell script executable ? ###
|
||||
|
||||
Ans: Using the chmod command we can make a shell script executable. Example is shown below :
|
||||
|
||||
# chmod a+x myscript.sh
|
||||
|
||||
### Q:13 What is the use of “#!/bin/bash” ? ###
|
||||
|
||||
Ans: #!/bin/bash is the first of a shell script , known as shebang , where # symbol is called hash and ‘!’ is called as bang. It shows that command to be executed via /bin/bash.
|
||||
|
||||
### Q:14 What is the syntax of for loop in shell script ? ###
|
||||
|
||||
Ans: Basic Syntax of for loop is given below :
|
||||
|
||||
for variables in list_of_items
|
||||
do
|
||||
command1
|
||||
command2
|
||||
….
|
||||
last_command
|
||||
done
|
||||
|
||||
### Q:15 How to debug a shell script ? ###
|
||||
|
||||
Ans: A shell script can be debug if we execute the script with ‘-x’ option ( sh -x myscript.sh). Another way to debug a shell script is by using ‘-nv’ option ( sh -nv myscript.sh).
|
||||
|
||||
### Q:16 How compare the strings in shell script ? ###
|
||||
|
||||
Ans: test command is used to compare the text strings. The test command compares text strings by comparing each character in each string.
|
||||
|
||||
### Q:17 What are the Special Variables set by Bourne shell for command line arguments ? ###
|
||||
|
||||
Ans: The following table lists the special variables set by the Bourne shell for command line arguments .
|
||||
|
||||
注:表格部分
|
||||
<table width="659" cellspacing="0" cellpadding="4">
|
||||
<colgroup>
|
||||
<col width="173">
|
||||
<col width="453"> </colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="173" valign="top">
|
||||
<p align="left" class="western">Special Variables</p>
|
||||
</td>
|
||||
<td width="453" valign="top">
|
||||
<p align="left" class="western">Holds</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="173" valign="top">
|
||||
<p align="left" class="western">$0</p>
|
||||
</td>
|
||||
<td width="453" valign="top">
|
||||
<p align="left" class="western">Name of the Script from the command line</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="173" valign="top">
|
||||
<p align="left" class="western">$1</p>
|
||||
</td>
|
||||
<td width="453" valign="top">
|
||||
<p align="left" class="western">First Command-line argument</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="173" valign="top">
|
||||
<p align="left" class="western">$2</p>
|
||||
</td>
|
||||
<td width="453" valign="top">
|
||||
<p align="left" class="western">Second Command-line argument</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="173" valign="top">
|
||||
<p align="left" class="western">…..</p>
|
||||
</td>
|
||||
<td width="453" valign="top">
|
||||
<p align="left" class="western">…….</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="173" valign="top">
|
||||
<p align="left" class="western">$9</p>
|
||||
</td>
|
||||
<td width="453" valign="top">
|
||||
<p align="left" class="western">Ninth Command line argument</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="173" valign="top">
|
||||
<p align="left" class="western">$#</p>
|
||||
</td>
|
||||
<td width="453" valign="top">
|
||||
<p align="left" class="western">Number of Command line arguments</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="173" valign="top">
|
||||
<p align="left" class="western">$*</p>
|
||||
</td>
|
||||
<td width="453" valign="top">
|
||||
<p align="left" class="western">All Command-line arguments, separated with spaces</p>
|
||||
</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Q:18 How to test files in a shell script ? ###
|
||||
|
||||
Ans: test command is used to perform different test on the files. Basic test are listed below :
|
||||
|
||||
注:表格部分
|
||||
<table width="644" cellspacing="0" cellpadding="4">
|
||||
<colgroup>
|
||||
<col width="173">
|
||||
<col width="453"> </colgroup>
|
||||
<tbody>
|
||||
<tr valign="top">
|
||||
<td width="173">
|
||||
<p align="left" class="western">Test</p>
|
||||
</td>
|
||||
<td width="453">
|
||||
<p align="left" class="western">Usage</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
<td width="173">
|
||||
<p align="left" class="western">-d file_name</p>
|
||||
</td>
|
||||
<td width="453">
|
||||
<p align="left" class="western">Returns true if the file exists and is a directory</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
<td width="173">
|
||||
<p align="left" class="western">-e file_name</p>
|
||||
</td>
|
||||
<td width="453">
|
||||
<p align="left" class="western">Returns true if the file exists</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
<td width="173">
|
||||
<p align="left" class="western">-f file_name</p>
|
||||
</td>
|
||||
<td width="453">
|
||||
<p align="left" class="western">Returns true if the file exists and is a regular file</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
<td width="173">
|
||||
<p align="left" class="western">-r file_name</p>
|
||||
</td>
|
||||
<td width="453">
|
||||
<p align="left" class="western">Returns true if the file exists and have read permissions</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
<td width="173">
|
||||
<p align="left" class="western">-s file_name</p>
|
||||
</td>
|
||||
<td width="453">
|
||||
<p align="left" class="western">Returns true if the file exists and is not empty</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
<td width="173">
|
||||
<p align="left" class="western">-w file_name</p>
|
||||
</td>
|
||||
<td width="453">
|
||||
<p align="left" class="western">Returns true if the file exists and have write permissions</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
<td width="173">
|
||||
<p align="left" class="western">-x file_name</p>
|
||||
</td>
|
||||
<td width="453">
|
||||
<p align="left" class="western">Returns true if the file exists and have execute permissions</p>
|
||||
</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Q:19 How to put comments in your shell script ? ###
|
||||
|
||||
Ans: Comments are the messages to yourself and for other users that describe what a script is supposed to do and how its works.To put comments in your script, start each comment line with a hash sign (#) . Example is shown below :
|
||||
|
||||
#!/bin/bash
|
||||
# This is a command
|
||||
echo “I am logged in as $USER”
|
||||
|
||||
### Q:20 How to get input from the terminal for shell script ? ###
|
||||
|
||||
Ans: ‘read’ command reads in data from the terminal (using keyboard). The read command takes in whatever the user types and places the text into the variable you name. Example is shown below :
|
||||
|
||||
# vi /tmp/test.sh
|
||||
|
||||
#!/bin/bash
|
||||
echo ‘Please enter your name’
|
||||
read name
|
||||
echo “My Name is $name”
|
||||
|
||||
# ./test.sh
|
||||
Please enter your name
|
||||
LinuxTechi
|
||||
My Name is LinuxTechi
|
||||
|
||||
### Q:21 How to unset or de-assign variables ? ###
|
||||
|
||||
Ans: ‘unset’ command is used to de-assign or unset a variable. Syntax is shown below :
|
||||
|
||||
# unset <Name_of_Variable>
|
||||
|
||||
### Q:22 How to perform arithmetic operation ? ###
|
||||
|
||||
Ans: There are two ways to perform arithmetic operations :
|
||||
|
||||
1. Using `expr` command (# expr 5 + 2 )
|
||||
2. using a dollar sign and square brackets ( `$[ operation ]` ) Example : test=$[16 + 4] ; test=$[16 + 4]
|
||||
|
||||
### Q:23 Basic Syntax of do-while statement ? ###
|
||||
|
||||
Ans: The do-while statement is similar to the while statement but performs the statements before checking the condition statement. The following is the format for the do-while statement:
|
||||
|
||||
do
|
||||
{
|
||||
statements
|
||||
} while (condition)
|
||||
|
||||
### Q:24 How to define functions in shell scripting ? ###
|
||||
|
||||
Ans: A function is simply a block of of code with a name. When we give a name to a block of code, we can then call that name in our script, and that block will be executed. Example is shown below :
|
||||
|
||||
$ diskusage () { df -h ; }
|
||||
|
||||
### Q:25 How to use bc (bash calculator) in a shell script ? ###
|
||||
|
||||
Ans: Use the below Syntax to use bc in shell script.
|
||||
|
||||
variable=`echo “options; expression” | bc`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/linux-shell-scripting-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,161 @@
|
||||
How To Install / Configure VNC Server On CentOS 7.0
|
||||
================================================================================
|
||||
Hi there, this tutorial is all about how to install or setup [VNC][1] Server on your very CentOS 7. This tutorial also works fine in RHEL 7. In this tutorial, we'll learn what is VNC and how to install or setup [VNC Server][1] on CentOS 7
|
||||
|
||||
As we know, most of the time as a system administrator we are managing our servers over the network. It is very rare that we will need to have a physical access to any of our managed servers. In most cases all we need is to SSH remotely to do our administration tasks. In this article we will configure a GUI alternative to a remote access to our CentOS 7 server, which is VNC. VNC allows us to open a remote GUI session to our server and thus providing us with a full graphical interface accessible from any remote location.
|
||||
|
||||
VNC server is a Free and Open Source Software which is designed for allowing remote access to the Desktop Environment of the server to the VNC Client whereas VNC viewer is used on remote computer to connect to the server .
|
||||
|
||||
**Some Benefits of VNC server are listed below:**
|
||||
|
||||
Remote GUI administration makes work easy & convenient.
|
||||
Clipboard sharing between host CentOS server & VNC-client machine.
|
||||
GUI tools can be installed on the host CentOS server to make the administration more powerful
|
||||
Host CentOS server can be administered through any OS having the VNC-client installed.
|
||||
More reliable over ssh graphics and RDP connections.
|
||||
|
||||
So, now lets start our journey towards the installation of VNC Server. We need to follow the steps below to setup and to get a working VNC.
|
||||
|
||||
First of all we'll need a working Desktop Environment (X-Windows), if we don't have a working GUI Desktop Environment (X Windows) running, we'll need to install it first.
|
||||
|
||||
**Note: The commands below must be running under root privilege. To switch to root please execute "sudo -s" under a shell or terminal without quotes("")**
|
||||
|
||||
### 1. Installing X-Windows ###
|
||||
|
||||
First of all to install [X-Windows][2] we'll need to execute the below commands in a shell or terminal. It will take few minutes to install its packages.
|
||||
|
||||
# yum check-update
|
||||
# yum groupinstall "X Window System"
|
||||
|
||||

|
||||
|
||||
#yum install gnome-classic-session gnome-terminal nautilus-open-terminal control-center liberation-mono-fonts
|
||||
|
||||

|
||||
|
||||
# unlink /etc/systemd/system/default.target
|
||||
# ln -sf /lib/systemd/system/graphical.target /etc/systemd/system/default.target
|
||||
|
||||

|
||||
|
||||
# reboot
|
||||
|
||||
After our machine restarts, we'll get a working CentOS 7 Desktop.
|
||||
|
||||
Now, we'll install VNC Server on our machine.
|
||||
|
||||
### 2. Installing VNC Server Package ###
|
||||
|
||||
Now, we'll install VNC Server package in our CentOS 7 machine. To install VNC Server, we'll need to execute the following command.
|
||||
|
||||
# yum install tigervnc-server -y
|
||||
|
||||

|
||||
|
||||
### 3. Configuring VNC ###
|
||||
|
||||
Then, we'll need to create a configuration file under **/etc/systemd/system/** directory. We can copy the **vncserver@:1.service** file from example file from **/lib/systemd/system/vncserver@.service**
|
||||
|
||||
# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
|
||||
|
||||

|
||||
|
||||
Now we'll open **/etc/systemd/system/vncserver@:1.service** in our favorite text editor (here, we're gonna use **nano**). Then find the below lines of text in that file and replace <USER> with your username. Here, in my case its linoxide so I am replacing <USER> with linoxide and finally looks like below.
|
||||
|
||||
ExecStart=/sbin/runuser -l <USER> -c "/usr/bin/vncserver %i"
|
||||
PIDFile=/home/<USER>/.vnc/%H%i.pid
|
||||
|
||||
TO
|
||||
|
||||
ExecStart=/sbin/runuser -l linoxide -c "/usr/bin/vncserver %i"
|
||||
PIDFile=/home/linoxide/.vnc/%H%i.pid
|
||||
|
||||
If you are creating for root user then
|
||||
|
||||
ExecStart=/sbin/runuser -l root -c "/usr/bin/vncserver %i"
|
||||
PIDFile=/root/.vnc/%H%i.pid
|
||||
|
||||

|
||||
|
||||
Now, we'll need to reload our systemd.
|
||||
|
||||
# systemctl daemon-reload
|
||||
|
||||
Finally, we'll create VNC password for the user . To do so, first you'll need to be sure that you have sudo access to the user, here I will login to user "linoxide" then, execute the following. To login to linoxide we'll run "**su linoxide" without quotes** .
|
||||
|
||||
# su linoxide
|
||||
$ sudo vncpasswd
|
||||
|
||||

|
||||
|
||||
**Make sure that you enter passwords more than 6 characters.**
|
||||
|
||||
### 4. Enabling and Starting the service ###
|
||||
|
||||
To enable service at startup ( Permanent ) execute the commands shown below.
|
||||
|
||||
$ sudo systemctl enable vncserver@:1.service
|
||||
|
||||
Then, start the service.
|
||||
|
||||
$ sudo systemctl start vncserver@:1.service
|
||||
|
||||
### 5. Allowing Firewalls ###
|
||||
|
||||
We'll need to allow VNC services in Firewall now.
|
||||
|
||||
$ sudo firewall-cmd --permanent --add-service vnc-server
|
||||
$ sudo systemctl restart firewalld.service
|
||||
|
||||

|
||||
|
||||
Now you can able to connect VNC server using IP and Port ( Eg : ip-address:1 )
|
||||
|
||||
### 6. Connecting the machine with VNC Client ###
|
||||
|
||||
Finally, we are done installing VNC Server. No, we'll wanna connect the server machine and remotely access it. For that we'll need a VNC Client installed in our computer which will only enable us to remote access the server machine.
|
||||
|
||||

|
||||
|
||||
You can use VNC client like [Tightvnc viewer][3] and [Realvnc viewer][4] to connect Server.
|
||||
To connect with additional users create files with different ports, please go to step 3 to configure and add a new user and port, You'll need to create **vncserver@:2.service** and replace the username in config file and continue the steps by replacing service name for different ports. **Please make sure you logged in as that particular user for creating vnc password**.
|
||||
|
||||
VNC by itself runs on port 5900. Since each user will run their own VNC server, each user will have to connect via a separate port. The addition of a number in the file name tells VNC to run that service as a sub-port of 5900. So in our case, arun's VNC service will run on port 5901 (5900 + 1) and further will run on 5900 + x. Where, x denotes the port specified when creating config file **vncserver@:x.service for the further users**.
|
||||
|
||||
We'll need to know the IP Address and Port of the server to connect with the client. IP addresses are the unique identity number of the machine. Here, my IP address is 96.126.120.92 and port for this user is 1. We can get the public IP address by executing the below command in a shell or terminal of the machine where VNC Server is installed.
|
||||
|
||||
# curl -s checkip.dyndns.org|sed -e 's/.*Current IP Address: //' -e 's/<.*$//'
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally, we installed and configured VNC Server in the machine running CentOS 7 / RHEL 7 (Red Hat Enterprises Linux) . VNC is the most easy FOSS tool for the remote access and also a good alternative to Teamviewer Remote Access. VNC allows a user with VNC client installed to control the machine with VNC Server installed. Here are some commands listed below that are highly useful in VNC . Enjoy !!
|
||||
|
||||
#### Additional Commands : ####
|
||||
|
||||
- To stop VNC service .
|
||||
|
||||
# systemctl stop vncserver@:1.service
|
||||
|
||||
- To disable VNC service from startup.
|
||||
|
||||
# systemctl disable vncserver@:1.service
|
||||
|
||||
- To stop firewall.
|
||||
|
||||
# systemctl stop firewalld.service
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-configure-vnc-server-centos-7-0/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://en.wikipedia.org/wiki/Virtual_Network_Computing
|
||||
[2]:http://en.wikipedia.org/wiki/X_Window_System
|
||||
[3]:http://www.tightvnc.com/
|
||||
[4]:https://www.realvnc.com/
|
||||
@ -0,0 +1,424 @@
|
||||
How To Scan And Check A WordPress Website Security Using WPScan, Nmap, And Nikto
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
Millions of websites are powered by WordPress software and there’s a reason for that. WordPress is the most developer-friendly content management system out there, so you can essentially do anything you want with it. Unfortunately, every day some scary report about a major site being hacked or a sensitive database being compromised hits the web … and freaks everyone out.
|
||||
|
||||
If you haven’t installed WordPress yet, check the following article.
|
||||
On Debian based systems:
|
||||
|
||||
- [How to install WordPress On Ubuntu][1]
|
||||
|
||||
On RPM based systems:
|
||||
|
||||
- [How to install wordpress On CentOS][2]
|
||||
|
||||
Following on from my previous article [How To Secure WordPress Website][3] show you **checklist** allows you to secure your WordPress site with as little effort as possible.
|
||||
|
||||
In this article, will describe to you through the installation of **wpscan** and serve as a guide on how to use wpscan to locate any known vulnerable plugins and themes that may make your site vulnerable to attack. Also, how to install and use **nmap** the free Security Scanner For Network Exploration & Hacking . And at the end we will show you the steps to use **nikto**.
|
||||
|
||||
### WPScan to Test for Vulnerable Plugins and Themes in WordPress ###
|
||||
|
||||
**WPScan** is a black box WordPress Security Scanner written in Ruby which attempts to find known security weaknesses within WordPress installations. Its intended use it to be for security professionals or WordPress administrators to asses the security posture of their WordPress installations. The code base is Open Source and licensed under the GPLv3.
|
||||
|
||||
### Download and Install WPScan ###
|
||||
|
||||
Before we get started with the installation, it is important to note that wpscan will not work on Windows systems, so you will need access to a Linux or OSX installation to proceed. If you only have access to a Windows system you can download Virtualbox and install any Linux distro you like as a Virtual Machine.
|
||||
|
||||
WPScan is hosted on Github, so if it is not already installed we will need to install the git packages before we can continue.
|
||||
|
||||
sudo apt-get install git
|
||||
|
||||
Once git is installed, we need to install the dependencies for wpscan.
|
||||
|
||||
sudo apt-get install libcurl4-gnutls-dev libopenssl-ruby libxml2 libxml2-dev libxslt1-dev ruby-dev ruby1.9.3
|
||||
|
||||
Now we need to clone the wpscan package from github.
|
||||
|
||||
git clone https://github.com/wpscanteam/wpscan.git
|
||||
|
||||
Now we can move to the newly created wpscan directory and install the necessary ruby gems through bundler.
|
||||
|
||||
cd wpscan
|
||||
sudo gem install bundler && bundle install --without test development
|
||||
|
||||
Now that we have wpscan installed, we will walk through using the tool to search for potentially vulnerable files on our WordPress installation. Some of the most important aspects of wpscan are its ability to enumerate not only plugins and themes, but users and timthumb installations as well. WPScan can also perform bruteforce attacks against WordPress– but that is outside of the scope of this article.
|
||||
|
||||
#### Update wpscan ####
|
||||
|
||||
ruby wpscan.rb --update
|
||||
|
||||
#### Enumerate Plugins ####
|
||||
|
||||
To enumerate plugins, all we need to do is launch wpscan with the `--enumerate p` arguments like so.
|
||||
|
||||
ruby wpscan.rb --url http(s)://www.yoursiteurl.com --enumerate p
|
||||
|
||||
or to only display vulnerable plugins:
|
||||
|
||||
ruby wpscan.rb --url http(s)://www.yoursiteurl.com --enumerate vp
|
||||
|
||||
Some example output is posted below:
|
||||
|
||||
| Name: akismet
|
||||
| Location: http://********.com/wp-content/plugins/akismet/
|
||||
|
||||
| Name: audio-player
|
||||
| Location: http://********.com/wp-content/plugins/audio-player/
|
||||
|
|
||||
| * Title: Audio Player - player.swf playerID Parameter XSS
|
||||
| * Reference: http://seclists.org/bugtraq/2013/Feb/35
|
||||
| * Reference: http://secunia.com/advisories/52083
|
||||
| * Reference: http://osvdb.org/89963
|
||||
| * Fixed in: 2.0.4.6
|
||||
|
||||
| Name: bbpress - v2.3.2
|
||||
| Location: http://********.com/wp-content/plugins/bbpress/
|
||||
| Readme: http://********.com/wp-content/plugins/bbpress/readme.txt
|
||||
|
|
||||
| * Title: BBPress - Multiple Script Malformed Input Path Disclosure
|
||||
| * Reference: http://xforce.iss.net/xforce/xfdb/78244
|
||||
| * Reference: http://packetstormsecurity.com/files/116123/
|
||||
| * Reference: http://osvdb.org/86399
|
||||
| * Reference: http://www.exploit-db.com/exploits/22396/
|
||||
|
|
||||
| * Title: BBPress - forum.php page Parameter SQL Injection
|
||||
| * Reference: http://xforce.iss.net/xforce/xfdb/78244
|
||||
| * Reference: http://packetstormsecurity.com/files/116123/
|
||||
| * Reference: http://osvdb.org/86400
|
||||
| * Reference: http://www.exploit-db.com/exploits/22396/
|
||||
|
||||
| Name: contact
|
||||
| Location: http://********.com/wp-content/plugins/contact/
|
||||
|
||||
#### Enumerate Themes ####
|
||||
|
||||
Enumeration of themes works the same as enumeration of plugins, just with the `--enumerate t` argument.
|
||||
|
||||
ruby wpscan.rb --url http(s)://www.host-name.com --enumerate t
|
||||
|
||||
Or to only display vulnerable themes:
|
||||
|
||||
ruby wpscan.rb --url http(s)://www.host-name.com --enumerate vt
|
||||
|
||||
Sample output:
|
||||
|
||||
| Name: path
|
||||
| Location: http://********.com/wp-content/themes/path/
|
||||
| Style URL: http://********.com/wp-content/themes/path/style.css
|
||||
| Description:
|
||||
|
||||
| Name: pub
|
||||
| Location: http://********.com/wp-content/themes/pub/
|
||||
| Style URL: http://********.com/wp-content/themes/pub/style.css
|
||||
| Description:
|
||||
|
||||
| Name: rockstar
|
||||
| Location: http://********.com/wp-content/themes/rockstar/
|
||||
| Style URL: http://********.com/wp-content/themes/rockstar/style.css
|
||||
| Description:
|
||||
|
|
||||
| * Title: WooThemes WooFramework Remote Unauthenticated Shortcode Execution
|
||||
| * Reference: https://gist.github.com/2523147
|
||||
|
||||
| Name: twentyten
|
||||
| Location: http://********.com/wp-content/themes/twentyten/
|
||||
| Style URL: http://********.com/wp-content/themes/twentyten/style.css
|
||||
| Description:
|
||||
|
||||
#### Enumerate Users ####
|
||||
|
||||
WPScan can also be used to enumerate users with valid logins to the WordPress installation. This is usually performed by attackers in order to get a list of users in preparation for a bruteforce attack.
|
||||
|
||||
ruby wpscan.rb --url http(s)://www.host-name.com --enumerate u
|
||||
|
||||
#### Enumerate Timthumb Files ####
|
||||
|
||||
The last function of wpscan we’ll discuss in this article is the ability to enumerate timthumb installations. In recent years, timthumb has become a very common target of attackers due to the numerous vulnerabilities found and posted to online forums, message lists, and advisory boards. Using wpscan to find vulnerable timthumb files is done with the following command.
|
||||
|
||||
ruby wpscan.rb --url http(s)://www.host-name.com --enumerate tt
|
||||
|
||||
### Nmap to Scan for Open Ports on your VPS ###
|
||||
|
||||
**Nmap** is an open source tool for network exploration and security auditing. It was designed to rapidly scan large networks, although it works fine against single hosts. Nmap uses raw IP packets in novel ways to determine what hosts are available on the network, what services (application name and version) those hosts are offering, what operating systems (and OS versions) they are running, what type of packet filters/firewalls are in use, and dozens of other characteristics
|
||||
|
||||
### Download and install nmap on Debian and Ubuntu ###
|
||||
|
||||
To install nmap for Debian and Ubuntu Linux based server systems type the following apt-get command:
|
||||
|
||||
sudo apt-get install nmap
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following NEW packages will be installed:
|
||||
nmap
|
||||
0 upgraded, 1 newly installed, 0 to remove and 2 not upgraded.
|
||||
Need to get 1,643 kB of archives.
|
||||
After this operation, 6,913 kB of additional disk space will be used.
|
||||
Get:1 http://mirrors.service.networklayer.com/ubuntu/ precise/main nmap amd64 5.21-1.1ubuntu1 [1,643 kB]
|
||||
Fetched 1,643 kB in 0s (16.4 MB/s)
|
||||
Selecting previously unselected package nmap.
|
||||
(Reading database ... 56834 files and directories currently installed.)
|
||||
Unpacking nmap (from .../nmap_5.21-1.1ubuntu1_amd64.deb) ...
|
||||
Processing triggers for man-db ...
|
||||
Setting up nmap (5.21-1.1ubuntu1) ...
|
||||
|
||||
#### Examples ####
|
||||
|
||||
To find the nmap version, enter:
|
||||
|
||||
nmap -V
|
||||
|
||||
OR
|
||||
|
||||
nmap --version
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
Nmap version 5.21 ( http://nmap.org )
|
||||
|
||||
### Dowonlad and install nmap on Centos ###
|
||||
|
||||
To install nmap on RHEL based Linux distributions, type the following yum command:
|
||||
|
||||
yum install nmap
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
Loaded plugins: protectbase, rhnplugin, security
|
||||
0 packages excluded due to repository protections
|
||||
Setting up Install Process
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package nmap.x86_64 2:5.51-2.el6 will be installed
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
================================================================================
|
||||
Package Arch Version Repository Size
|
||||
================================================================================
|
||||
Installing:
|
||||
nmap x86_64 2:5.51-2.el6 rhel-x86_64-server-6 2.8 M
|
||||
|
||||
Transaction Summary
|
||||
================================================================================
|
||||
Install 1 Package(s)
|
||||
|
||||
Total download size: 2.8 M
|
||||
Installed size: 0
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
nmap-5.51-2.el6.x86_64.rpm | 2.8 MB 00:00
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Installing : 2:nmap-5.51-2.el6.x86_64 1/1
|
||||
Verifying : 2:nmap-5.51-2.el6.x86_64 1/1
|
||||
|
||||
Installed:
|
||||
nmap.x86_64 2:5.51-2.el6
|
||||
|
||||
Complete!
|
||||
|
||||
#### Examples ####
|
||||
|
||||
To find the nmap version, enter:
|
||||
|
||||
nmap --version
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
Nmap version 5.51 ( http://nmap.org )
|
||||
|
||||
#### Scan Ports with Nmap ####
|
||||
|
||||
You can got a lot of information about your server or host using nmap and it let you to think like someone has malicious intent.
|
||||
|
||||
For this reason, only test it on servers that you own or in situations where you’ve notified the owners.
|
||||
|
||||
The nmap creators actually provide a test server located at:
|
||||
|
||||
scanme.nmap.org
|
||||
|
||||
Some commands may take a long while to complete:
|
||||
|
||||
To scan an IP address or a host name (FQDN), run:
|
||||
|
||||
nmap 192.168.1.1
|
||||
|
||||
Sample outputs:
|
||||
|
||||
|
||||
|
||||
Scan for the host operating system:
|
||||
|
||||
sudo nmap -O 192.168.1.1
|
||||
|
||||
pecify a range with “-” or “/24″ to scan a number of hosts at once:
|
||||
|
||||
sudo nmap -PN xxx.xxx.xxx.xxx-yyy
|
||||
|
||||
Scan a network range for available services:
|
||||
|
||||
sudo nmap -sP network_address_range
|
||||
|
||||
Scan without preforming a reverse DNS lookup on the IP address specified. This should speed up your results in most cases:
|
||||
|
||||
sudo nmap -n remote_host
|
||||
|
||||
Scan a specific port instead of all common ports:
|
||||
|
||||
sudo nmap -p port_number remote_host
|
||||
|
||||
Scan a network and find out which servers and devices are up and running
|
||||
|
||||
This is known as host discovery or ping scan:
|
||||
|
||||
nmap -sP 192.168.1.0/24
|
||||
|
||||
Sample outputs:
|
||||
|
||||
Host 192.168.1.1 is up (0.00035s latency).
|
||||
MAC Address: BC:AE:C5:C3:16:93 (Unknown)
|
||||
Host 192.168.1.2 is up (0.0038s latency).
|
||||
MAC Address: 74:44:01:40:57:FB (Unknown)
|
||||
Host 192.168.1.5 is up.
|
||||
Host nas03 (192.168.1.12) is up (0.0091s latency).
|
||||
MAC Address: 00:11:32:11:15:FC (Synology Incorporated)
|
||||
Nmap done: 256 IP addresses (4 hosts up) scanned in 2.80 second
|
||||
|
||||
Understanding port configuration and how to discover what the attack vectors are on your server is only one step to securing your information and your VPS.
|
||||
|
||||
### Nikto to Scan for vulnerabilities in your website ###
|
||||
|
||||
[Nikto][4] Web-scanner is a open source web-server scanner which can be used to scan the web-servers for malicious programs and files. Nikto can be used to scan the outdated versions of programs too. Nikto will provide us a quick and easy scan to find out the dangerous files and programs in server, At the end of scan result with a log file.
|
||||
|
||||
### Download and install Nikto on Linux server ###
|
||||
|
||||
Perl is pre-installed in linux so all you need to do is download nikto from the [project page][5], unpack it into a directory and start your testing.
|
||||
|
||||
wget https://cirt.net/nikto/nikto-2.1.4.tar.gz
|
||||
|
||||
You can unpack it with an archive manager tool or use tar and gzip together with this command.
|
||||
|
||||
tar zxvf nikto-2.1.4.tar.gz
|
||||
cd nikto-2.1.4
|
||||
perl nikto.pl
|
||||
|
||||
This should be your results from a working installation:
|
||||
|
||||
- ***** SSL support not available (see docs for SSL install) *****
|
||||
- Nikto v2.1.4
|
||||
---------------------------------------------------------------------------
|
||||
+ ERROR: No host specified
|
||||
|
||||
-config+ Use this config file
|
||||
-Cgidirs+ scan these CGI dirs: 'none', 'all', or values like "/cgi/ /cgi-a/"
|
||||
-dbcheck check database and other key files for syntax errors
|
||||
-Display+ Turn on/off display outputs
|
||||
-evasion+ ids evasion technique
|
||||
-Format+ save file (-o) format
|
||||
-host+ target host
|
||||
-Help Extended help information
|
||||
-id+ Host authentication to use, format is id:pass or id:pass:realm
|
||||
-list-plugins List all available plugins
|
||||
-mutate+ Guess additional file names
|
||||
-mutate-options+ Provide extra information for mutations
|
||||
-output+ Write output to this file
|
||||
-nocache Disables the URI cache
|
||||
-nossl Disables using SSL
|
||||
-no404 Disables 404 checks
|
||||
-port+ Port to use (default 80)
|
||||
-Plugins+ List of plugins to run (default: ALL)
|
||||
-root+ Prepend root value to all requests, format is /directory
|
||||
-ssl Force ssl mode on port
|
||||
-Single Single request mode
|
||||
-timeout+ Timeout (default 2 seconds)
|
||||
-Tuning+ Scan tuning
|
||||
-update Update databases and plugins from CIRT.net
|
||||
-vhost+ Virtual host (for Host header)
|
||||
-Version Print plugin and database versions
|
||||
+ requires a value
|
||||
|
||||
Note: This is the short help output. Use -H for full help.
|
||||
|
||||
The error is merely telling us we did not fill in the necessary parameters for a test to run. The SSL support can be enabled by installing the necessary perl ssl module (sudo apt-get install libnet-ssleay-perl).
|
||||
|
||||
#### Update the nikto Database ####
|
||||
|
||||
Before performing any scan we need to update the nikto database packages using.
|
||||
|
||||
/usr/local/bin/nikto.pl -update
|
||||
|
||||
To list the available Plugins for nikto we can use the below command.
|
||||
|
||||
nikto.pl -list-plugins // To list the installed plugins //
|
||||
|
||||
#### Scan for vulnerabilities ####
|
||||
|
||||
For a simple test for we will use test a single url.
|
||||
|
||||
perl nikto.pl -h http://www.host-name.com
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
This will produce fairly verbose output that may be somewhat confusing at first. Take the time to read through the output to understand what each advisory means. Many of the alerts in Nikto will refer to OSVDB numbers. These are Open Source Vulnerability Database ([http://osvdb.org/][6]) designations. You can search on OSVDB for further information about any vulnerabilities identified.
|
||||
|
||||
$ nikto -h http://www.host-name.com
|
||||
- Nikto v2.1.4
|
||||
---------------------------------------------------------------------------
|
||||
+ Target IP: 1.2.3.4
|
||||
+ Target Hostname: host-name.com
|
||||
+ Target Port: 80
|
||||
+ Start Time: 2012-08-11 14:27:31
|
||||
---------------------------------------------------------------------------
|
||||
+ Server: Apache/2.2.22 (FreeBSD) mod_ssl/2.2.22 OpenSSL/1.0.1c DAV/2
|
||||
+ robots.txt contains 4 entries which should be manually viewed.
|
||||
+ mod_ssl/2.2.22 appears to be outdated (current is at least 2.8.31) (may depend on server version)
|
||||
+ ETag header found on server, inode: 5918348, size: 121, mtime: 0x48fc943691040
|
||||
+ mod_ssl/2.2.22 OpenSSL/1.0.1c DAV/2 - mod_ssl 2.8.7 and lower are vulnerable to a remote buffer overflow which may allow a remote shell (difficult to exploit). CVE-2002-0082, OSVDB-756.
|
||||
+ Allowed HTTP Methods: GET, HEAD, POST, OPTIONS, TRACE
|
||||
+ OSVDB-877: HTTP TRACE method is active, suggesting the host is vulnerable to XST
|
||||
+ /lists/admin/: PHPList pre 2.6.4 contains a number of vulnerabilities including remote administrative access, harvesting user info and more. Default login to admin interface is admin/phplist
|
||||
+ OSVDB-2322: /gallery/search.php?searchstring=<script>alert(document.cookie)</script>: Gallery 1.3.4 and below is vulnerable to Cross Site Scripting (XSS). Upgrade to the latest version. http://www.securityfocus.com/bid/8288.
|
||||
+ OSVDB-7022: /calendar.php?year=<script>alert(document.cookie);</script>&month=03&day=05: DCP-Portal v5.3.1 is vulnerable to Cross Site Scripting (XSS). http://www.cert.org/advisories/CA-2000-02.html.
|
||||
+ OSVDB-3233: /phpinfo.php: Contains PHP configuration information
|
||||
+ OSVDB-3092: /system/: This might be interesting...
|
||||
+ OSVDB-3092: /template/: This may be interesting as the directory may hold sensitive files or reveal system information.
|
||||
+ OSVDB-3092: /updates/: This might be interesting...
|
||||
+ OSVDB-3092: /README: README file found.
|
||||
+ 6448 items checked: 1 error(s) and 14 item(s) reported on remote host
|
||||
+ End Time: 2012-08-11 15:52:57 (5126 seconds)
|
||||
---------------------------------------------------------------------------
|
||||
+ 1 host(s) tested
|
||||
$
|
||||
|
||||
**Nikto** is an extremely lightweight, and versatile tool. Because of the fact that Nikto is written in Perl it can be run on almost any host operating system.
|
||||
|
||||
Hope this will will bring you a good idea to scan vulnerbalites for your wordpress website. Following on from my previous article [How To Secure WordPress Website][7] show you **checklist** allows you to secure your WordPress site with as little effort as possible.
|
||||
|
||||
If you have any feedback or comments, feel free to post them in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/scan-check-wordpress-website-security-using-wpscan-nmap-nikto/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/anis/
|
||||
[1]:http://www.unixmen.com/install-wordpress-ubuntu-14-10/
|
||||
[2]:http://www.unixmen.com/install-configure-wordpress-4-0-benny-centos-7/
|
||||
[3]:http://www.unixmen.com/secure-wordpress-website/
|
||||
[4]:http://www.unixmen.com/install-nikto-web-scanner-check-vulnerabilities
|
||||
[5]:https://cirt.net/nikto/
|
||||
[6]:http://osvdb.org/
|
||||
[7]:http://www.unixmen.com/secure-wordpress-website/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user