mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
a9f27994ad
@ -1,4 +1,4 @@
|
||||
CoreOS Linux结束升级周期
|
||||
CoreOS Linux终结升级周期
|
||||
================================================================================
|
||||
> CoreOS发布了他的Linux发行版的商用支持版,并且宣称将废除手动更新。
|
||||
|
||||
@ -10,13 +10,13 @@ CoreOS提供其同名的Linux发行版做为商业服务,开始为一个月100
|
||||
|
||||
商业Linux订阅并不是什么新鲜事:[Red Hat][2]和[Suse][3]都在为他们各自的发行版提供商业订阅。
|
||||
|
||||
因为这些以Linux为基础的公司使用的应用程序和库都是开源和免费提供的,所以订阅的费用不包括软件本身,而收费来自更新,漏洞修复,集成以及发生问题时的技术支持。
|
||||
因为这些以Linux为基础的公司使用的应用程序和库都是开源和免费提供的,所以订阅的费用不包括软件本身,而收费来自更新、漏洞修复、集成以及发生问题时的技术支持。
|
||||
|
||||
CoreOS公司声称,CoreOS将会和这些发行版不同,它将不会有重大更新,而在那些发行版中这些更新通常需要一次更新所有的包。在CoreOS中,它的更新和新特征将会在就绪后自动安装入操作系统中。
|
||||
|
||||
服务中提供了一个叫做CoreUpdate的仪表盘,如果管理员不想自动更新所有包,它可用于标明选取哪些软件包获取更新。
|
||||
|
||||
CoreUpdate可以同时管理多个机器,而且提供了滚回功能——在更新引起问题可使用。
|
||||
CoreUpdate可以同时管理多个机器,而且提供了回滚功能——在更新引起问题可使用。
|
||||
|
||||
CoreOS于去年十二月发布,它的设计旨在[关注][4]开源操作系统内核的新兴使用——用于大量基于云计算的虚拟服务器。
|
||||
|
||||
@ -30,14 +30,14 @@ CoreOS周一还宣布他们收到了来自Kleiner Perkins Caulfield and Byers风
|
||||
|
||||
----------
|
||||
|
||||
Joab Jackson负责IDG新闻服务机构中企业软件和通用技术的新闻。Twitter上关注Joab[@Joab_Jackson][6]。Joab的电子邮箱地址是[Joab_Jackson@idg.com][7]
|
||||
作者Joab Jackson负责IDG新闻服务机构中企业软件和通用技术的新闻。Twitter上关注Joab[@Joab_Jackson][6]。Joab的电子邮箱地址是[Joab_Jackson@idg.com][7]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/s/article/9249460/CoreOS_Linux_ending_the_upgrade_cycle?taxonomyId=122
|
||||
|
||||
译者:[linuhap](https://github.com/linuhap) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[linuhap](https://github.com/linuhap) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,18 @@
|
||||
2q1w2007翻译中
|
||||
法国图卢兹市通过使用Libreoffice省了100万欧元
|
||||
================================================================================
|
||||

|
||||
|
||||
[图卢兹][1],是法国第四大城市,坐落于法国西南部,它通过迁移到开源办公套件[LibreOffice][2]已经节省了一百万欧元。
|
||||
[图卢兹][1]是法国第四大城市,坐落于法国西南部,它通过迁移到开源办公套件[LibreOffice][2]已经节省了一百万欧元。
|
||||
|
||||
迁移到LibreOffice是这个城市新的数字化政策的重要部分。在2011年作出决定后,2012年开始迁移。迁移总共花费了一年半,到今天已有90%的桌面(10000工作人员)运行LibreOffice。
|
||||
迁移到LibreOffice是这个城市新的数字化政策的重要部分。在2011年作出决定后,2012年开始迁移,迁移总共花费了一年半,到今天已有90%的桌面(大约10000工作人员)运行LibreOffice。
|
||||
|
||||
政府每三年的办公软件授权大约要花180万欧元,而迁移总共花了80万欧元。所以城市总共省了100万欧元。
|
||||
政府每三年的办公软件授权大约要花180万欧元,而迁移总共花了80万欧元,所以城市总共省了100万欧元。
|
||||
|
||||
一切起始于Pierre Cohen在2008年被选作卢兹市市长。Cohen是一位IT专家,他的数字化政策起始于对开源软件的特别关注。正式他和他的副手(his associate)Erwane Monthubert的努力下,图卢兹市在2011年决定切换到开源软件。
|
||||
一切起始于Pierre Cohen在2008年被选作卢兹市市长。Cohen是一位IT专家,他的数字化政策起始于对开源软件的特别关注。正是他和他的助手Erwane Monthubert的努力下,图卢兹市在2011年决定切换到开源软件。
|
||||
|
||||
不只是LibreOffice。大多数的图卢兹市的官方门户网站,比如toulouse.fr、toulouse-metropole.fr、toulouse-metropole.fr和data.grandtoulouse.fr,由自由软件支持。Alfresco被选作协同工具。
|
||||
不只是LibreOffice。大多数的图卢兹市的官方门户网站,比如toulouse.fr、toulouse-metropole.fr、toulouse-metropole.fr和data.grandtoulouse.fr,都由自由软件支持。Alfresco被选作协同工具。
|
||||
|
||||
切换到开源软件看起来正在成为欧洲城市的潮流。在临近的西班牙瓦伦西亚和[加那利群岛抛弃了Microsoft Office节省了几百万][3]。[法国首都的警察开发了他们自己的Linux OS][4]基于Ubuntu。列表没有终结,我希望我目前的城市Cote de Azur可以不久后加入这个列表。
|
||||
切换到开源软件看起来正在成为欧洲城市的潮流。在临近的西班牙瓦伦西亚和[加那利群岛抛弃了Microsoft Office节省了几百万][3];[法国首都的警察基于Ubuntu开发了他们自己的Linux OS][4]。这个列表还在继续增长,我希望我目前的城市Cote de Azur可以不久后加入这个列表。
|
||||
|
||||
点[这里][5]阅读所有报道。
|
||||
|
||||
@ -23,7 +22,7 @@ via: http://itsfoss.com/french-city-toulouse-saved-1-million-euro-libreoffice/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[2q1w2007](https://github.com/2q1w2007)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
开源媒体中心‘XBMC’宣布启用新名字
|
||||
开源媒体中心‘XBMC’为什么要改名?
|
||||
================================================================================
|
||||

|
||||
|
||||
早期:项目一开始是运行在Xbox上的视频播放器。
|
||||
|
||||
**一个在Linux平台(以及其他各种平台)上最受欢迎的开源媒体中心软件将启用新名字。**
|
||||
@ -9,23 +10,24 @@ XBMC将不再使用;在项目的下一个重要发布版(第14版)中,
|
||||
|
||||
这个社区项目建立于2002年,用于在Xbox游戏机上播放数字媒体内容。总的来说,在那之后项目一直使用从Xbox衍生出来的名字。早期版本被命名为‘**Xbox媒体播放器**’,然后改成‘**Xbox媒体中心**’以展示新增的功能。在移植到微软游戏机之外的平台后,于2008年确定了首字母缩写‘XBMC’的名称。
|
||||
|
||||
在这个网站早期的时候重复敲过无数次的‘XBMC’。
|
||||
之前,在这个网站上‘XBMC’出现了一遍又一遍。
|
||||
|
||||
为什么要换名字?为什么是现在?‘Kodi’到底有没有什么特殊含义?
|
||||
|
||||
> ‘这个软件仅仅勉强能运行在第一代Xbox上...’
|
||||
|
||||
“*这个软件仅仅勉强能运行在第一代Xbox上,因为之后许多聪明的开发人员仍然在那个平台上开发,它不能在Xbox 360或者Xbox One上运行。*”项目负责人**Nathan Betzen**在XBMC博客上这样解释。
|
||||
“*这个软件仅仅勉强能运行在第一代Xbox上,那是因为许多聪明的开发人员仍然在那个平台上开发,它不能在Xbox 360或者Xbox One上运行。*”项目负责人**Nathan Betzen**在XBMC博客上这样解释。
|
||||
|
||||
如今这个软件已经拥有远远超过以往的功能,包括针对不同市场的插件,游戏功能以及流媒体支持,这已经不能用‘*一个简单的媒体中心*’来包含所有的一切了。
|
||||
|
||||
因为这个原因,Betzen这样总结,“**XB**”和“**MC**”就已经没有有太大意义。
|
||||
|
||||
对于XBMC信徒也无可厚非,名字改动也**解决了许多长期存在的法律风险**。“*我们从来都没有真正在法律意义上拥有过项目名字的使用权...*”Betzen说,并且补充道,XBMC基金会成立于2009年,旨在更好地协助和管理软件开发,一直在面临拥有相似商标的‘其他公司的潜在法律威胁’的情况下运作。
|
||||
对于XBMC信徒也无可厚非,名字改动也**解决了许多长期存在的法律风险**。“*我们从来都没有真正在法律意义上拥有过项目名字的使用权...*”Betzen说,并且补充道,“XBMC基金会成立于2009年,旨在更好地协助和管理软件开发,一直在面临拥有相似商标的‘其他公司的潜在法律威胁’的情况下运作”。
|
||||
|
||||
### 于是乎,Kodi ###
|
||||
|
||||

|
||||
|
||||
新标志(临时)
|
||||
|
||||
即将发布的XBMC 14版本中,项目将正式过渡采用新名字‘Kodi’。除了听起来特别酷以外,这个名字貌似没有什么特殊含义。
|
||||
@ -34,7 +36,7 @@ XBMC将不再使用;在项目的下一个重要发布版(第14版)中,
|
||||
|
||||
“但是”,Betzen这样总结,“我们相信在你的支持以及整个社区的支持下,Kodi,这个我们都热爱的媒体中心或娱乐平台或是不管你叫做什么,将会比以往更加强大。”
|
||||
|
||||
非常正确。关于这次绰号变更的更深层意义,你可以去官方网站溜达一下,链接在下边。
|
||||
非常正确。关于这次代号变更的更深层意义,你可以去官方网站溜达一下,链接在下边。
|
||||
|
||||
- [‘Kodi 14简介′(官方声明贴)][1]
|
||||
|
||||
@ -48,7 +50,7 @@ via: http://www.omgubuntu.co.uk/2014/08/xbmc-renamed-lodi-starting-version-14
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
This Is What’s New In Linux 3.16
|
||||
owen-carter is translating This Is What’s New In Linux 3.16
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -54,4 +54,4 @@ via: http://www.omgubuntu.co.uk/2014/08/linux-kernel-3-16-changes-drivers
|
||||
[4]:https://lwn.net/
|
||||
[5]:http://www.phoronix.com/scan.php?page=news_item&px=MTc1NDM
|
||||
[6]:http://lkml.iu.edu/hypermail/linux/kernel/1406.1/02366.html
|
||||
[7]:http://kernel.ubuntu.com/
|
||||
[7]:http://kernel.ubuntu.com/
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
Lime Text: An Open Source Alternative Of Sublime Text
|
||||
================================================================================
|
||||

|
||||
|
||||
[Sublime Text][1] is one of the best (if not best) text editor for programmers. Packed with numerous feature and great looking interface, Sublime is available for all three major desktop OS i.e. Windows, Mac and Linux.
|
||||
|
||||
But it is not that Sublime Text is perfect. There are bugs, crashes and almost no support. If you have been following Sublime Text development, you know that the beta version of Sublime Text has been out for more than a year now and there is no clear communication to users about its release date. And above all, Sublime Text is neither free nor [Open Source][2].
|
||||
|
||||
All these issues also frustrated [Fredrik Ehnbom][3] and hence he started an Open Source project, [Lime Text][4], on [Github][5] to make a new text editor which looks and works exactly the same way as Sublime Text. On the question of why he decided to “clone” an existing text editor, Frederic mentions:
|
||||
|
||||
> As none of the other text editors I’ve tried come close to the love I had for Sublime Text, I decided I had to create my own.
|
||||
|
||||
Lime Text is built in Go for backend while the frontend is in ermbox, Qt (QML) and HTML/JavaScript. The development is in progress with clear [goals][6] in sight. You can contribute to the project on its [Github page][7].
|
||||
|
||||

|
||||
|
||||
If you want to try the beta version, you can build Lime Text by following the instructions on the [wiki][8]. Meanwhile, if you are looking for other powerful text editors, give [SciTE][9] a go.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/lime-text-open-source-alternative/
|
||||
|
||||
作者:[bhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://www.sublimetext.com/
|
||||
[2]:http://itsfoss.com/category/open-source-software/
|
||||
[3]:https://github.com/quarnster
|
||||
[4]:http://limetext.org/
|
||||
[5]:https://github.com/
|
||||
[6]:https://github.com/limetext/lime/wiki/Goals
|
||||
[7]:https://github.com/limetext/lime/issues
|
||||
[8]:https://github.com/limetext/lime/wiki/Building
|
||||
[9]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
@ -1,199 +0,0 @@
|
||||
How to use variables in shell Scripting
|
||||
================================================================================
|
||||
In every **programming** language **variables** plays an important role , in Linux shell scripting we are using two types of variables : **System Defined Variables** & **User Defined Variables**.
|
||||
|
||||
A variable in a shell script is a means of **referencing** a **numeric** or **character value**. And unlike formal programming languages, a shell script doesn't require you to **declare a type** for your variables
|
||||
|
||||
In this article we will discuss variables, its types and how to set & use variables in shell scripting.
|
||||
|
||||
### System Defined Variables : ###
|
||||
|
||||
These are the variables which are created and maintained by **Operating System(Linux) itself**. Generally these variables are defined in **CAPITAL LETTERS**. We can see these variables by using the command "**$ set**". Some of the system defined variables are given below :
|
||||
|
||||
<table width="100%" cellspacing="1" cellpadding="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><strong> System Defined Variables </strong></td>
|
||||
<td><strong> Meaning </strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> BASH=/bin/bash </td>
|
||||
<td> Shell Name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> BASH_VERSION=4.1.2(1) </td>
|
||||
<td> Bash Version </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> COLUMNS=80 </td>
|
||||
<td> No. of columns for our screen </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> HOME=/home/linuxtechi </td>
|
||||
<td> Home Directory of the User </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> LINES=25 </td>
|
||||
<td> No. of columns for our screen </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> LOGNAME=LinuxTechi </td>
|
||||
<td> LinuxTechi Our logging name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> OSTYPE=Linux </td>
|
||||
<td> OS type </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PATH=/usr/bin:/sbin:/bin:/usr/sbin </td>
|
||||
<td> Path Settings </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PS1=[\u@\h \W]\$ </td>
|
||||
<td> Prompt Settings </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PWD=/home/linuxtechi </td>
|
||||
<td> Current Working Directory </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> SHELL=/bin/bash </td>
|
||||
<td> Shell Name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> USERNAME=linuxtechi </td>
|
||||
<td> User name who is currently login to system </td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
To Print the value of above variables, use **echo command** as shown below :
|
||||
|
||||
# echo $HOME
|
||||
# echo $USERNAME
|
||||
|
||||
We can tap into these environment variables from within your scripts by using the environment variable's name preceded by a dollar sign. This is demonstrated in the following script:
|
||||
|
||||
$ cat myscript
|
||||
|
||||
#!/bin/bash
|
||||
# display user information from the system.
|
||||
echo “User info for userid: $USER”
|
||||
echo UID: $UID
|
||||
echo HOME: $HOME
|
||||
|
||||
Notice that the **environment variables** in the echo commands are replaced by their current values when the script is run. Also notice that we were able to place the **$USER** system variable within the double quotation marks in the first string, and the shell script was still able to figure out what we meant. There is a **drawback** to using this method, however. Look at what happens in this example:
|
||||
|
||||
$ echo “The cost of the item is $15”
|
||||
The cost of the item is 5
|
||||
|
||||
That is obviously not what was intended. Whenever the script sees a dollar sign within quotes, it assumes you're referencing a variable. In this example the script attempted to display the **variable $1** (which was not defined), and then the number 5. To display an actual dollar sign, you **must precede** it with a **backslash character**:
|
||||
|
||||
$ echo “The cost of the item is \$15”
|
||||
The cost of the item is $15
|
||||
|
||||
That's better. The backslash allowed the shell script to interpret the **dollar sign** as an actual dollar sign, and not a variable.
|
||||
|
||||
### User Defined Variables: ###
|
||||
|
||||
These variables are defined by **users**. A shell script allows us to set and use our **own variables** within the script. Setting variables allows you to **temporarily store data** and use it throughout the script, making the shell script more like a real computer program.
|
||||
|
||||
**User variables** can be any text string of up to **20 letters, digits**, or **an underscore character**. User variables are case sensitive, so the variable Var1 is different from the variable var1. This little rule often gets novice script programmers in trouble.
|
||||
|
||||
Values are assigned to user variables using an **equal sign**. No spaces can appear between the variable, the equal sign, and the value (another trouble spot for novices). Here are a few examples of assigning values to user variables:
|
||||
|
||||
var1=10
|
||||
var2=-57
|
||||
var3=testing
|
||||
var4=“still more testing”
|
||||
|
||||
The shell script **automatically determines the data type** used for the variable value. Variables defined within the shell script maintain their values throughout the life of the shell script but are deleted when the shell script completes.
|
||||
|
||||
Just like system variables, user variables can be referenced using the dollar sign:
|
||||
|
||||
$ cat test3
|
||||
#!/bin/bash
|
||||
# testing variables
|
||||
days=10
|
||||
guest="Katie"
|
||||
echo "$guest checked in $days days ago"
|
||||
days=5
|
||||
guest="Jessica"
|
||||
echo "$guest checked in $days days ago"
|
||||
$
|
||||
|
||||
Running the script produces the following output:
|
||||
|
||||
$ chmod u+x test3
|
||||
$ ./test3
|
||||
Katie checked in 10 days ago
|
||||
Jessica checked in 5 days ago
|
||||
$
|
||||
|
||||
Each time the variable is **referenced**, it produces the value currently assigned to it. It's important to remember that when referencing a variable value you use the **dollar sign**, but when referencing the variable to assign a value to it, you do not use the dollar sign. Here's an example of what I mean:
|
||||
|
||||
$ cat test4
|
||||
#!/bin/bash
|
||||
# assigning a variable value to another variable
|
||||
value1=10
|
||||
value2=$value1
|
||||
echo The resulting value is $value2
|
||||
$
|
||||
|
||||
When you use the **value** of the **value1** variable in the assignment statement, you must still use the dollar sign. This code produces the following output:
|
||||
|
||||
$ chmod u+x test4
|
||||
$ ./test4
|
||||
The resulting value is 10
|
||||
$
|
||||
|
||||
If you forget the dollar sign, and make the value2 assignment line look like:
|
||||
|
||||
value2=value1
|
||||
you get the following output:
|
||||
|
||||
$ ./test4
|
||||
The resulting value is value1
|
||||
$
|
||||
|
||||
Without the dollar sign the **shell interprets** the variable name as a **normal text string**, which is most likely not what you wanted.
|
||||
|
||||
### Use of Backtick symbol (`) in shell variables : ###
|
||||
|
||||
The **backtick allows** you to assign the output of a shell command to a variable. While this doesn't seem like much, it is a major building block in **script programming**.You must surround the entire command line command with backtick characters:
|
||||
|
||||
**testing=`date`**
|
||||
|
||||
The shell runs the command within the **backticks** and assigns the output to the variable testing. Here's an example of creating a variable using the output from a normal shell command:
|
||||
|
||||
$ cat test5
|
||||
#!/bin/bash
|
||||
# using the backtick character
|
||||
testing=`date`
|
||||
echo "The date and time are: " $testing
|
||||
$
|
||||
|
||||
The variable testing receives the output from the date command, and it is used in the echo statement to display it. Running the shell script produces the following output:
|
||||
|
||||
$ chmod u+x test5
|
||||
$ ./test5
|
||||
The date and time are: Mon Jan 31 20:23:25 EDT 2011
|
||||
|
||||
**Note** : In bash you can also use the alternative $(…) syntax in place of backtick (`),which has the advantage of being re-entrant.
|
||||
|
||||
Example :
|
||||
|
||||
$ echo " Today’s date & time is :" $(date)
|
||||
Today’s date & time is : Sun Jul 27 16:26:56 IST 2014
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/variables-in-shell-scripting/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -1,84 +0,0 @@
|
||||
[su-kaiyao]翻译中
|
||||
|
||||
Command Line Tuesdays – Part Seven
|
||||
================================================================================
|
||||
Heya geekos. I’ve checked the ‘curriculum’, and we’re at part 7 of 8 as of today. Which means there will be one more – and sadly final – CLT next tuesday. So for today, let’s deal with some **permissions**!
|
||||
|
||||
As we all know, we can have many users using one machine. To protect the users from each other, permissions have been devised. And we have already discussed file permissions, so let’s refresh our memories with a single [click][1].
|
||||
|
||||
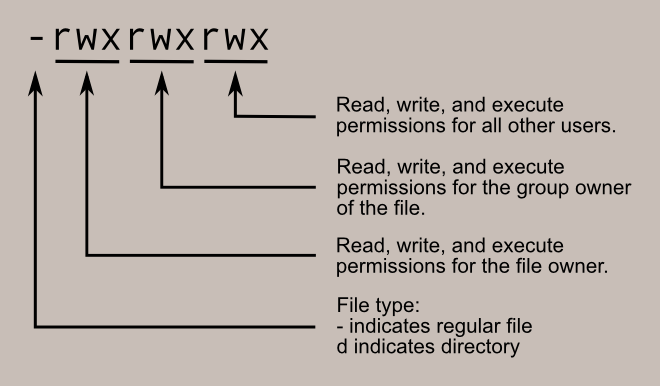
|
||||
|
||||
### chmod ###
|
||||
|
||||
The **chmod** command is used for changing permissions on a directory or a file. To use it, you first type the chmod command, after that you type the permissions specification, and after that the file or directory you’d like to change the permissions of. It can be done in more way, but mr Shotts focuses on the octal notation method.
|
||||
|
||||
Imagine permissions as a series of bits. For every permission slot that’s not empty, there’s a 1, and for every empty one there’s a 0. For example:
|
||||
|
||||
rwx = 111
|
||||
|
||||
rw- = 110
|
||||
|
||||
etc.
|
||||
|
||||
And to see how it looks in binary:
|
||||
|
||||
rwx = 111 —> in binary = 7
|
||||
|
||||
rw- = 110 —> in binary = 6
|
||||
|
||||
r-x = 101 —> in binary = 5
|
||||
|
||||
r– = 100 —> in binary = 4
|
||||
|
||||
Now, if we would like to have a file with read, write and executing permissions for the file owner and for the group owner of the file, but make it unavailable to all other users, we do:
|
||||
|
||||
chmod 770 example_file
|
||||
|
||||
…where example_file is any file you’d like to try this command on. So, you always have to enter three separate digits, for three separate groups known already from our second lesson. The same can be done for directories.
|
||||
|
||||
### su and sudo ###
|
||||
|
||||
It is sometimes needed for a user to become a super user, so he can accomplish a task (usually something like installing software, for example). For temporary accessing to the super user mode, there’s a program called **su**, or substitute user. You just have to type in
|
||||
|
||||
su
|
||||
|
||||
and type your superuser password, and you’re in. However, a word of warning: don’t remember to log out and use it for a short period of time.
|
||||
|
||||
Also there’s an option probably more used in openSUSE and Ubuntu, and it’s called sudo. Sudo is only different in the aspect, that it’s a special command that’s allocated to one specific user. So unlike su, with sudo you can use your user password instead of the superuser’s password. Example:
|
||||
|
||||
sudo zypper in goodiegoodie
|
||||
|
||||
### Changing file and group ownership ###
|
||||
|
||||
To change the owner of the file, you have to run **chown** as a superuser. For example, if I’d want to change ownership from ‘nenad’ to ‘suse’, I do it this way:
|
||||
|
||||
su
|
||||
|
||||
[enter password]
|
||||
|
||||
chown suse example_file
|
||||
|
||||
I can also accomplish the same with changing group ownership, but with a slightly different command **chgrp**. Easy peasy:
|
||||
|
||||
chgrp suse_group example_file
|
||||
|
||||
…and that’s it.
|
||||
|
||||
### Next time ###
|
||||
|
||||
As I already stated, next time we’ll have a photo-finish of sorts. And after that, you’ll be on your own (along with me, wandering through the terminal’s darkness, with only a blinking green cursor as a lighthouse :) ). Until then geekos, remember to…
|
||||
|
||||
…have a lot of fun!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.opensuse.org/2014/08/05/command-line-tuesdays-part-seven/
|
||||
|
||||
作者:[Nenad Latinović][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://news.opensuse.org/author/holden87/
|
||||
[1]:https://news.opensuse.org/2014/07/01/command-line-tuesdays-part-three/
|
||||
@ -1,56 +0,0 @@
|
||||
Linux FAQs with Answers--How to enable and configure desktop sharing on Linux Mint Cinnamon desktop
|
||||
================================================================================
|
||||
> **Question**: I was trying to enable desktop sharing via Vino VNC server (vino-server) on Linux Mint 17 Cinnamon desktop. However, I notice that vino-preferences tool which allows us to configure vino-server (e.g., sharing option, security, notification on/off) no longer exists. Also, I cannot find desktop sharing menu on Cinnamon desktop. How can I configure desktop sharing via vino-server on the latest Linux Mint 17 Cinnamon desktop?
|
||||
|
||||
The latest Linux Mint Cinnamon desktop comes with vino-server pre-installed for VNC desktop sharing, but it's reported that desktop sharing configuration menu is missing.
|
||||
|
||||
An alternative way to configure vino-server and enable desktop sharing is to use dconf-editor's graphical interface.
|
||||
|
||||
First install dconf-editor:
|
||||
|
||||
$ sudo apt-get install dconf-editor
|
||||
|
||||
Launch dconf-editor.
|
||||
|
||||
$ dconf-editor
|
||||
|
||||
Navigate to "org->gnome->desktop->remote-access" on the left panel of dconf-editor. Then you will see various desktop sharing options.
|
||||
|
||||
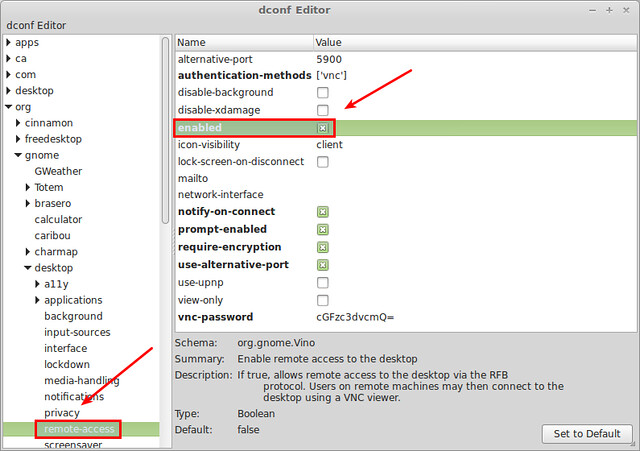
|
||||
|
||||
Most importantly, click on "enabled" to activate desktop remote access. Besides this, you can customize other options.
|
||||
|
||||
For example, you can enable VNC password authentication by changing the following fields:
|
||||
|
||||
- **authentication-methods**: set it to ['vnc']
|
||||
- **vnc-password**: change it to Base64-encoded string of a preferred password.
|
||||
|
||||
In this example, we choose VNC password as "password", and its Base64-encoded string is "cGFzc3dvcmQK".
|
||||
|
||||
$ echo "password" | base64
|
||||
|
||||
> cGFzc3dvcmQK
|
||||
|
||||
Optionally, you can enable other options:
|
||||
|
||||
- **notify-on-connect**: shows a desktop notification when vino-server receives a connection request.
|
||||
- **prompt-enabled**: a remote user is not allowed to access a desktop via VNC until the VNC request is approved by the desktop owner.
|
||||
|
||||
### Troubleshoot ###
|
||||
|
||||
1. I am getting the following error when attempting to start vino-server.
|
||||
|
||||
> ** (vino-server:4280): WARNING **: The desktop sharing service is not enabled, so it should not be run.
|
||||
|
||||
To enable desktop sharing service, use dconf-editor as described above. Alternatively, run the following command.
|
||||
|
||||
# gsettings set org.gnome.Vino enabled true
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/enable-configure-desktop-sharing-linux-mint-cinnamon-desktop.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,39 +0,0 @@
|
||||
Linux FAQs with Answers--How to fix “fatal error: jsoncpp/json/json.h: No such file or directory”
|
||||
================================================================================
|
||||
> **Question**: I am trying compile a C++ application, but I am getting the following error:
|
||||
>
|
||||
> "fatal error: jsoncpp/json/json.h: No such file or directory"
|
||||
>
|
||||
> How can I fix this problem?
|
||||
|
||||
The error indicates that you are missing JsonCpp development files (i.e., JsonCpp library and header files). [JsonCpp][1] is a C++ library for JSON-formatted data manipulation. Here is how to install JsonCpp development files on various Linux distros.
|
||||
|
||||
On Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo apt-get install libjsoncpp-dev
|
||||
|
||||
On Fedora:
|
||||
|
||||
$ sudo yum install jsoncpp-devel
|
||||
|
||||
On CentOS, JsonCpp is not available as a pre-built package. So you can build and install JsonCpp from the source as follows.
|
||||
|
||||
$ sudo yum install cmake
|
||||
$ git clone https://github.com/open-source-parsers/jsoncpp.git
|
||||
$ cd jsoncpp
|
||||
$ mkdir -p build/debug
|
||||
$ cd build/debug
|
||||
$ cmake -DCMAKE_BUILD_TYPE=debug -DJSONCPP_LIB_BUILD_SHARED=OFF -G "Unix Makefiles" ../../
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fix-fatal-error-jsoncpp.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://github.com/open-source-parsers/jsoncpp
|
||||
@ -0,0 +1,46 @@
|
||||
Vic020
|
||||
|
||||
Check Hard drive for bad sectors or bad blocks in linux
|
||||
================================================================================
|
||||
**badblocks** is the command or utility in linux like operating system which can **scan** or test our **hard disk** and **external drive** for **bad sectors**. Bad sectors or **bad blocks** is the space of the disk which can't be used due to the **permanent damage** or OS is unable to access it.
|
||||
|
||||
Badblocks command will detect all **bad blocks(bad sectors)** on our hard disk and save them in a text file so that we can use it with **e2fsck** to configure Operating System(OS) to not store our data on these damaged sectors.
|
||||
|
||||
### Step:1 Use fdisk command to identify your hard drive info ###
|
||||
|
||||
# sudo fdisk -l
|
||||
|
||||
### Step:2 Scan your hard drive for Bad Sectors or Bad Blocks ###
|
||||
|
||||
# sudo badblocks -v /dev/sdb > /tmp/bad-blocks.txt
|
||||
|
||||
Just replace “/dev/sdb” with your own hard disk / partition. When we execute above command a text file “bad-blocks” will be created under /tmp , which will contains all bad blocks.
|
||||
|
||||
Example :
|
||||
|
||||

|
||||
|
||||
### Step:3 Inform OS not to use bad blocks for storing data ###
|
||||
|
||||
Once the scanning is completed , if the bad sectors are reported , then use file “bad-blocks.txt” with e2fsck command and force OS not to use these bad blocks for storing data.
|
||||
|
||||
# sudo e2fsck -l /tmp/bad-blocks.txt /dev/sdb
|
||||
|
||||
Note : Before running e2fsck command , you just make sure the drive is not mounted.
|
||||
|
||||
For any futher help on badblocks & e2fsck command , read their man pages
|
||||
|
||||
# man badblocks
|
||||
# man e2fsck
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/check-hard-drive-for-bad-sector-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,197 @@
|
||||
How to install Puppet server and client on CentOS and RHEL
|
||||
================================================================================
|
||||
As a system administrator acquires more and more systems to manage, automation of mundane tasks gets quite important. Many administrators adopted the way of writing custom scripts, that are simulating complex orchestration software. Unfortunately, scripts get obsolete, people who developed them leave, and without an enormous level of maintenance, after some time these scripts will end up unusable. It is certainly more desirable to share a system that everyone can use, and invest in tools that can be used regardless of one's employer. For that we have several systems available, and in this howto you will learn how to use one of them - Puppet.
|
||||
|
||||
### What is Puppet? ###
|
||||
|
||||
Puppet is an automation software for IT system administrators and consultants. It allows you to automate repetitive tasks such as the installation of applications and services, patch management, and deployments. Configuration for all resources are stored in so called "manifests", that can be applied to multiple machines or just a single server. If you would like to know more information, The Puppet Labs site has a more complete description of [what Puppet is and how it works][1].
|
||||
|
||||
### What are we going to achieve in this tutorial? ###
|
||||
|
||||
We will install and configure a Puppet server, and set up some basic configuration for our client servers. You will discover how to write and manage Puppet manifests and how to push it into your servers.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
Since Puppet is not in basic CentOS or RHEL distribution repositories, we have to add a custom repository provided by Puppet Labs. On all servers in which you want to use Puppet, install the repository by executing following command (RPM file name can change with new release):
|
||||
|
||||
**On CentOS/RHEL 6.5:**
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/6.5/products/x86_64/puppetlabs-release-6-10.noarch.rpm
|
||||
|
||||
**On CentOS/RHEL 7:**
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/7/products/x86_64/puppetlabs-release-7-10.noarch.rpm
|
||||
|
||||
### Server Installation ###
|
||||
|
||||
Install the package "puppet-server" on the server you want to use as a master.
|
||||
|
||||
# yum install puppet-server
|
||||
|
||||
When the installation is done, set the Puppet server to automatically start on boot and turn it on.
|
||||
|
||||
# chkconfig puppetmaster on
|
||||
# service puppetmaster start
|
||||
|
||||
Now when we have the server working, we need to make sure that it is reachable from our network.
|
||||
|
||||
On CentOS/RHEL 6, where iptables is used as firewall, add following line into section ":OUTPUT ACCEPT" of /etc/sysconfig/iptables.
|
||||
|
||||
> -A INPUT -m state --state NEW -m tcp -p tcp --dport 8140 -j ACCEPT
|
||||
|
||||
To apply this change, it's necessary to restart iptables.
|
||||
|
||||
# service iptables restart
|
||||
|
||||
On CentOS/RHEL 7, where firewalld is used, the same thing can be achieved by:
|
||||
|
||||
# firewall-cmd --permanent --zone=public --add-port=8140/tcp
|
||||
# firewall-cmd --reload
|
||||
|
||||
### Client Installation ###
|
||||
|
||||
Install the Puppet client package on your client nodes by executing the following:
|
||||
|
||||
# yum install puppet
|
||||
|
||||
When the installation finishes, make sure that Puppet will start after boot.
|
||||
|
||||
# chkconfig puppet on
|
||||
|
||||
Your Puppet client nodes have to know where the Puppet master server is located. The best practice for this is to use a DNS server, where you can configure the Puppet domain name. If you don't have a DNS server running, you can use the /etc/hosts file, by simply adding the following line:
|
||||
|
||||
> 1.2.3.4 server.your.domain
|
||||
|
||||
> 2.3.4.5 client-node.your.domain
|
||||
|
||||
1.2.3.4 corresponds to the IP address of your Puppet master server, "server.your.domain" is the domain name of your master server (the default is usually the server's hostname), "client-node.your.domain" is your client node. This hosts file should be configured accordingly on all involved servers (both Puppet master and clients).
|
||||
|
||||
When you are done with these settings, we need to show the Puppet client what is its master. By default Puppet looks for a server called "puppet", but this setting is usually inappropriate for your network configuration, therefore we will exchange it for the proper FQDN of the Puppet master server. Open the file /etc/sysconfig/puppet and change the "PUPPET_SERVER" value to your Puppet master server domain name specified in /etc/hosts:
|
||||
|
||||
> PUPPET_SERVER=server.your.domain
|
||||
|
||||
The master server name also has to be defined in the section "[agent]" of /etc/puppet/puppet.conf:
|
||||
|
||||
> server=server.your.domain
|
||||
|
||||
Now you can start your Puppet client:
|
||||
|
||||
# service puppet start
|
||||
|
||||
We need to force our client to check in with the Puppet master by using:
|
||||
|
||||
# puppet agent --test
|
||||
|
||||
You should see something like the following output. Don't panic, this is desired as the server is still not verified on the Puppet master server.
|
||||
|
||||
> Exiting; no certificate found and waitforcert is disabled
|
||||
|
||||
Go back to your puppet master server and check certificate verification requests:
|
||||
|
||||
# puppet cert list
|
||||
|
||||
You should see a list of all the servers that requested a certificate signing from your puppet master. Find the hostname of your client server and sign it using the following command (client-node is the domain name of your client node):
|
||||
|
||||
# puppet cert sign client-node
|
||||
|
||||
At this point you have a working Puppet client and server. Congratulations! However, right now there is nothing for the Puppet master to instruct the client to do. So, let's create some basic manifest and set our client node to install basic utilities.
|
||||
|
||||
Connect back to your Puppet server and make sure the directory /etc/puppet/manifests exists.
|
||||
|
||||
# mkdir -p /etc/puppet/manifests
|
||||
|
||||
Now create the manifest file /etc/puppet/manifests/site.pp with the following content
|
||||
|
||||
node 'client-node' {
|
||||
include custom_utils
|
||||
}
|
||||
|
||||
class custom_utils {
|
||||
package { ["nmap","telnet","vim-enhanced","traceroute"]:
|
||||
ensure => latest,
|
||||
allow_virtual => false,
|
||||
}
|
||||
}
|
||||
|
||||
and restart the puppetmaster service.
|
||||
|
||||
# service puppetmaster restart
|
||||
|
||||
The default refresh interval of the client configuration is 30 minutes, if you want to force the application of your changes manually, execute the following command on your client node:
|
||||
|
||||
# puppet agent -t
|
||||
|
||||
If you would like to change the default client refresh interval, add:
|
||||
|
||||
> runinterval = <yourtime>
|
||||
|
||||
to the "[agent]" section of /etc/puppet/puppet.conf on your client node. This setting can be a time interval in seconds (30 or 30s), minutes (30m), hours (6h), days (2d), or years (5y). Note that a runinterval of 0 means "run continuously" rather than "never run".
|
||||
|
||||
### Tips & Tricks ###
|
||||
|
||||
#### 1. Debugging ####
|
||||
|
||||
It can happen from time to time that you will submit a wrong configuration and you have to debug where the Puppet failed. For that you will always start with either checking logs in /var/log/puppet/ or running the agent manually to see the output:
|
||||
|
||||
# puppet agent -t
|
||||
|
||||
By default "-t" activates verbose mode, so it allows you to see the output of Puppet. This command also has several parameters that might help you identify your problem a bit more. The first useful option is:
|
||||
|
||||
# puppet agent -t --debug
|
||||
|
||||
Debug shows you basically all steps that Puppet goes through during its runtime. It can be really useful during debug of really complicated rules. Another parameter you might find really useful is:
|
||||
|
||||
# puppet agent -t --noop
|
||||
|
||||
This option sets puppet in so called dry-run mode, where no changes are performed. Puppet only writes what it would do on the screen but nothing is written on the disk.
|
||||
|
||||
#### 2. Modules ####
|
||||
|
||||
After some time you find yourself in the situation where you will want to have more complicated manifests. But before you will sit down and start to program them, you should invest some time and browse [https://forge.puppetlabs.com][2]. Forge is a repository of the Puppet community modules and it's very likely that you find the solution for your problem already made there. If not, feel free to write your own and submit it, so other people can benefit from the Puppet modularity.
|
||||
|
||||
Now, let's assume that you have already found a module that would fix your problem. How to install it into the system? It is actually quite easy, because Puppet already contains an interface to download modules directly. Simply type the following command:
|
||||
|
||||
# puppet module install <module_name> --version 0.0.0
|
||||
|
||||
<module_name> is the name of your chosen module, the version is optional (if not specified then the latest release is taken). If you don't remember the name of the module you want to install, you can try to find it by using module search:
|
||||
|
||||
# puppet module search <search_string>
|
||||
|
||||
As a result you will get a list of all modules that contain your search string.
|
||||
|
||||
# puppet module search apache
|
||||
|
||||
----------
|
||||
|
||||
Notice: Searching https://forgeapi.puppetlabs.com ...
|
||||
NAME DESCRIPTION AUTHOR KEYWORDS
|
||||
example42-apache Puppet module for apache @example42 example42, apache
|
||||
puppetlabs-apache Puppet module for Apache @puppetlabs apache web httpd centos rhel ssl wsgi proxy
|
||||
theforeman-apache Apache HTTP server configuration @theforeman foreman apache httpd DEPRECATED
|
||||
|
||||
And if you would like to see what modules you already installed, type:
|
||||
|
||||
# puppet module list
|
||||
|
||||
### Summary ###
|
||||
|
||||
By now, you should have a fully functional Puppet master that is delivering basic configuration to one or more client servers. At this point feel free to add more settings into your configuration to adapt it to your infrastructure. Don't worry about experimenting with Puppet and you will see that it can be a genuine lifesaver.
|
||||
|
||||
Puppet labs is trying to maintain a top quality documentation for their projects, so if you would like to learn more about Puppet and its configuration, I strongly recommend visiting the Puppet project page at [http://docs.puppetlabs.com][3].
|
||||
|
||||
If you have any questions feel free to post them in the comments and I will do my best to answer and advise.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:https://puppetlabs.com/puppet/what-is-puppet/
|
||||
[2]:https://forge.puppetlabs.com/
|
||||
[3]:http://docs.puppetlabs.com/
|
||||
@ -0,0 +1,158 @@
|
||||
How to set up a Samba file server to use with Windows clients
|
||||
================================================================================
|
||||
According to the [Samba][1] project web site, Samba is an open source/free software suite that provides seamless file and print services to SMB/CIFS clients. Unlike other implementations of the SMB/CIFS networking protocol (such as LM Server for HP-UX, LAN Server for OS/2, or VisionFS), Samba (along with its source code) is freely available (at no cost to the end user), and allows for interoperability between Linux/Unix servers and Windows/Unix/Linux clients.
|
||||
|
||||
For these reasons, Samba is the preferred solution for a file server in networks where different operating systems (other than Linux) coexist - the most common setup being the case of multiple Microsoft Windows clients accessing a Linux server where Samba is installed, which is the situation we are going to deal with in this article.
|
||||
|
||||
Please note that on the other hand, if our network consists of only Unix-based clients (such as Linux, AIX, or Solaris, to name a few examples), we can consider using NFS (although Samba is still an option in this case), which has greater reported speeds.
|
||||
|
||||
### Installing Samba in Debian and CentOS ###
|
||||
|
||||
Before we proceed with the installation, we can use our operating system's package management system to look for information about Samba:
|
||||
|
||||
On Debian:
|
||||
|
||||
# aptitude show samba
|
||||
|
||||
On CentOS:
|
||||
|
||||
# yum info samba
|
||||
|
||||
In the following screenshot we can see the output of 'aptitude show samba' ('yum info samba' yields similar results):
|
||||
|
||||
|
||||
|
||||
Now let's install Samba (the screenshot below corresponds to the installation on a Debian 7 [Wheezy] server):
|
||||
|
||||
On Debian:
|
||||
|
||||
# aptitude install samba
|
||||
|
||||
On CentOS:
|
||||
|
||||
# yum install samba
|
||||
|
||||
### Adding Users to Samba ###
|
||||
|
||||
For versions earlier than 4.x, a local Unix account is required for adding users to Samba:
|
||||
|
||||
# adduser <username>
|
||||
|
||||
|
||||
|
||||
Next, we need to add the user to Samba using the smbpasswd command with the '-a' option, which specifies that the username following should be added to the local smbpasswd file. We will be prompted to enter a password (which does not necessarily have to be the same as the password of the local Unix account):
|
||||
|
||||
# smbpassword -a <username>
|
||||
|
||||
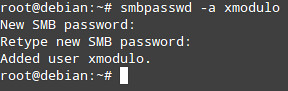
|
||||
|
||||
Finally, we will give access to user xmodulo to a directory within our system that will be used as a Samba share for him (and other users as well, if needed). This is done by opening the /etc/samba/smb.conf file with a text editor (such as Vim), navigating to the end of the file, and creating a section (enclose name between square brackets) with a descriptive name, such as [xmodulo]:
|
||||
|
||||
# SAMBA SHARE
|
||||
[xmodulo]
|
||||
path = /home/xmodulo
|
||||
available = yes
|
||||
valid users = xmodulo
|
||||
read only = no
|
||||
browseable = yes
|
||||
public = yes
|
||||
writeable = yes
|
||||
|
||||
We must now restart Samba and -just in case- check the smb.conf file for syntax errors with the testparm command:
|
||||
|
||||
# service samba restart
|
||||
# testparm
|
||||
|
||||
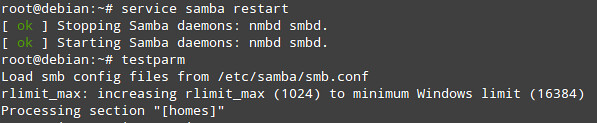
|
||||
|
||||
If there are any errors, they will be reported when testparm ends.
|
||||
|
||||
### Mapping the Samba Share as a Network Drive on a Windows 7 PC ###
|
||||
|
||||
Right click on Computer, and select "Map network drive":
|
||||
|
||||
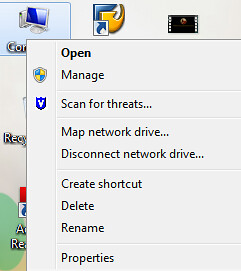
|
||||
|
||||
Type the IP address of the machine where Samba is installed, followed by the name of the share (this is the name that is enclosed between single brackets in the smb.conf file), and make sure that the "Connect using different credentials" checkbox is checked:
|
||||
|
||||
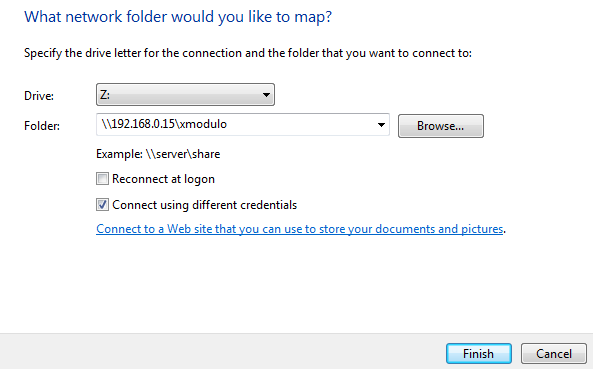
|
||||
|
||||
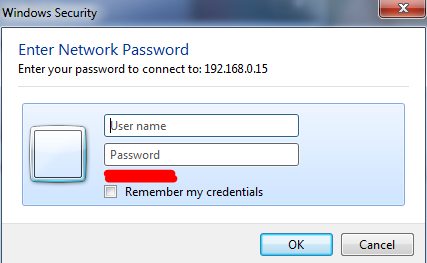
nter the username and password that were set with '**smbpasswd -a**' earlier:
|
||||
|
||||
|
||||
|
||||
Go to Computer and check if the network drive has been added correctly:
|
||||
|
||||
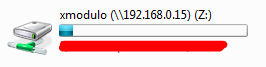
|
||||
|
||||
As a test, let's create a pdf file from the man page of Samba, and save it in the /home/xmodulo directory:
|
||||
|
||||

|
||||
|
||||
Next, we can verify that the file is accessible from Windows:
|
||||
|
||||
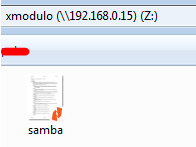
|
||||
|
||||
And we can open it using our default pdf reader:
|
||||
|
||||
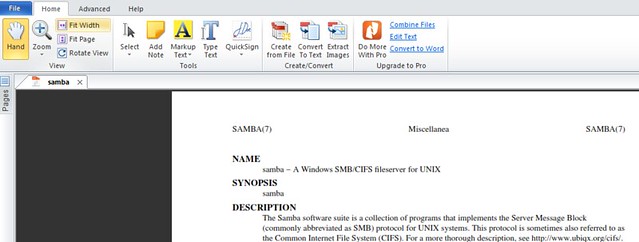
|
||||
|
||||
Finally, let's see if we can save a file from Windows in our newly mapped network drive. We will open the change.log file that lists the features of Notepad++:
|
||||
|
||||
|
||||
|
||||
and try to save it in Z:\ as a plain text file (.txt extension); then let's see if the file is visible in Linux:
|
||||
|
||||

|
||||
|
||||
### Enabling quotas ###
|
||||
|
||||
As a first step, we need to verify whether the current kernel has been compiled with quota support:
|
||||
|
||||
# cat /boot/config-$(uname -r) | grep
|
||||
|
||||
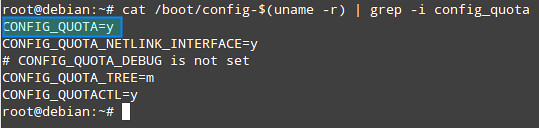
|
||||
|
||||
Each file system has up to five types of quota limits that can be enforced on it: user soft limit, user hard limit, group soft limit, group hard limit, and grace time.
|
||||
|
||||
We will now enable quotas for the /home file system by adding the usrquota and grpquota mount options to the existing defaults option in the line that corresponds to the /home filesystem in the /etc/fstab file, and we will remount the file system in order to apply the changes:
|
||||
|
||||

|
||||
|
||||
Next, we need to create two files that will serve as the databases for user and group quotas: **aquota.user** and **aquota.group**, respectively, in **/home**. Then, we will generate the table of current disk usage per file system with quotas enabled:
|
||||
|
||||
# quotacheck -cug /home
|
||||
# quotacheck -avugm
|
||||
|
||||

|
||||
|
||||
# quota -u <username>
|
||||
# quota -g <groupname>
|
||||
|
||||
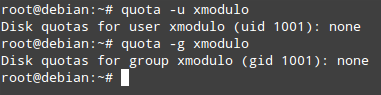
|
||||
|
||||
Finally, the last couple of steps consist of assigning the quotas per user and / or group with the quotatool command (note that this task can also be performed by using edquota, but quotatool is more straightforward and less error-prone).
|
||||
|
||||
To set the soft limits to 4 MB and the hard limit to 5 MB for the user called xmodulo, and 10 MB / 15 MB for the xmodulo group:
|
||||
|
||||
# quotatool -u xmodulo -bq 4M -l '5 Mb' /home
|
||||
# quotatool -g xmodulo -bq 10M -l '15 Mb' /home
|
||||
|
||||
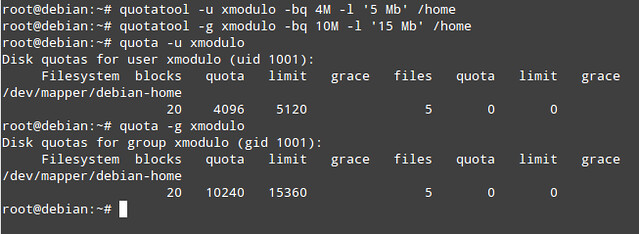
|
||||
|
||||
And we can see the results in Windows 7 (3.98 MB free of 4.00 MB):
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/samba-file-server-windows-clients.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://www.samba.org/
|
||||
@ -0,0 +1,200 @@
|
||||
如何在shell脚本中使用变量
|
||||
================================================================================
|
||||
在每种**编程**语言中,**变量**都扮演了一个重要的角色。在Linux shell脚本编程中,我们使用两种类型的变量:**系统定义的变量**和**用户定义的变量**。
|
||||
|
||||
shell脚本中的变量是用来**调用**一个**数值**或者**字符值**的手段。与正规的编程语言不同的是,shell脚本不要求你去为变量**声明一个类型**。
|
||||
|
||||
在本文中,我们将讨论shell脚本编程中的变量及其类型,以及如何设置和使用这些变量。
|
||||
|
||||
### 系统定义的变量: ###
|
||||
|
||||
这些变量由**操作系统(Linux)自身**创建并维护,通常它们以**大写字母**定义,我们可以通过命令“**$ set**”来查看这些变量。下面列出了部分系统定义的变量:
|
||||
|
||||
<table width="100%" cellspacing="1" cellpadding="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><strong> System Defined Variables </strong></td>
|
||||
<td><strong> Meaning </strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> BASH=/bin/bash </td>
|
||||
<td> Shell Name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> BASH_VERSION=4.1.2(1) </td>
|
||||
<td> Bash Version </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> COLUMNS=80 </td>
|
||||
<td> No. of columns for our screen </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> HOME=/home/linuxtechi </td>
|
||||
<td> Home Directory of the User </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> LINES=25 </td>
|
||||
<td> No. of columns for our screen </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> LOGNAME=LinuxTechi </td>
|
||||
<td> LinuxTechi Our logging name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> OSTYPE=Linux </td>
|
||||
<td> OS type </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PATH=/usr/bin:/sbin:/bin:/usr/sbin </td>
|
||||
<td> Path Settings </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PS1=[\u@\h \W]\$ </td>
|
||||
<td> Prompt Settings </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> PWD=/home/linuxtechi </td>
|
||||
<td> Current Working Directory </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> SHELL=/bin/bash </td>
|
||||
<td> Shell Name </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td> USERNAME=linuxtechi </td>
|
||||
<td> User name who is currently login to system </td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
要打印以上变量的值,可以使用**echo command**命令,如下:
|
||||
|
||||
# echo $HOME
|
||||
# echo $USERNAME
|
||||
|
||||
我们可以通过在环境变量名前前置一个美元符号来从你的脚本里输入环境变量。请看下面脚本演示:
|
||||
|
||||
$ cat myscript
|
||||
|
||||
#!/bin/bash
|
||||
# display user information from the system.
|
||||
echo “User info for userid: $USER”
|
||||
echo UID: $UID
|
||||
echo HOME: $HOME
|
||||
|
||||
注意:echo命令中的**环境变量**在脚本运行时会被它们的值替代。同时注意,我们可以再第一个字符串的双引号中放置**$USER**系统变量,而shell脚本仍然可以明白我们的意思。然而,该方法有一个**缺点**。看下面这个例子:
|
||||
|
||||
$ echo “The cost of the item is $15”
|
||||
The cost of the item is 5
|
||||
|
||||
很明显,那不是我们说希望的。无论何时,当脚本遇见引号中的美元符号时,它都会认为你是在调用一个变量。在本例中,改脚本试着显示**变量$1**(而这个变量并没有定义),然后显示数字5。要显示实际上的美元符号,你**必须前置**一个**反斜线字符**:
|
||||
|
||||
$ echo “The cost of the item is \$15”
|
||||
The cost of the item is $15
|
||||
|
||||
那样好多了。反斜线允许shell脚本将**美元符号**解释成为实际的美元符号,而不是变量。
|
||||
|
||||
### 用户定义的变量: ###
|
||||
|
||||
这些变量由**用户**定义。shell脚本允许我们在脚本中设置并使用我们**自己的变量**。设置变量允许你**临时存储数据**并在脚本中使用,让shell脚本看起来像一个真正的计算机程序。
|
||||
|
||||
**用户变量**可以是任何不超过**20个字母,数字**的文本字符串,或者**一个下划线字符**。用户变量是大小写敏感的,因此,变量Var1和变量var1是不同的变量。这个小规则常常让新手编写脚本时麻烦重重。
|
||||
|
||||
我们可以通过**等于号**为变量赋值。变量,等于号和值(对于新手又是个麻烦的地方)之间不能有空格。下面是几个给用户变量赋值的例子:
|
||||
|
||||
var1=10
|
||||
var2=-57
|
||||
var3=testing
|
||||
var4=“still more testing”
|
||||
|
||||
shell脚本为变量值**自动确定数据类型**。shell脚本内定义的变量会在脚本运行时保留它们的值,当脚本完成后则删除这些值。
|
||||
|
||||
就像系统变量一样,用户变量也可以使用美元符号来调用:
|
||||
|
||||
$ cat test3
|
||||
#!/bin/bash
|
||||
# testing variables
|
||||
days=10
|
||||
guest="Katie"
|
||||
echo "$guest checked in $days days ago"
|
||||
days=5
|
||||
guest="Jessica"
|
||||
echo "$guest checked in $days days ago"
|
||||
$
|
||||
|
||||
运行脚本会产生以下输出:
|
||||
|
||||
$ chmod u+x test3
|
||||
$ ./test3
|
||||
Katie checked in 10 days ago
|
||||
Jessica checked in 5 days ago
|
||||
$
|
||||
|
||||
每次变量被**调用**,它都会产生当前分配给它的值。记住这一点很重要,当调用一个变量值时,你使用**美元符号**,但是当调用一个变量来为其分配一个值时,你不能用美元符号。下面用例子来说明:
|
||||
|
||||
$ cat test4
|
||||
#!/bin/bash
|
||||
# assigning a variable value to another variable
|
||||
value1=10
|
||||
value2=$value1
|
||||
echo The resulting value is $value2
|
||||
$
|
||||
|
||||
当你使用赋值语句中**value1**变量的**值**时,你仍然必须使用美元符号。这段代码产生了如下输出:
|
||||
|
||||
$ chmod u+x test4
|
||||
$ ./test4
|
||||
The resulting value is 10
|
||||
$
|
||||
|
||||
如果你忘了美元符号,而又让value2赋值行看起来像这样:
|
||||
|
||||
value2=value1
|
||||
|
||||
你会获得下面的输出:
|
||||
|
||||
$ ./test4
|
||||
The resulting value is value1
|
||||
$
|
||||
|
||||
没有美元符号,**shell解释**变量名为**普通文本字符串**,这极有可能不是你想要的。
|
||||
|
||||
### 在shell变量中使用反引号(`): ###
|
||||
|
||||
**反引号允许**你将shell命令的输出赋值给变量。虽然这似乎没什么大不了,但它是**脚本编程**中主要的构建基块。你必须使用反引号将整个命令行包含起来:
|
||||
|
||||
**testing=`date`**
|
||||
|
||||
shell会在**反引号**中运行命令,然后将输出结果赋值给变量testing。下面的例子给出了如何使用一个常规shell命令的输出结果来创建一个变量:
|
||||
|
||||
$ cat test5
|
||||
#!/bin/bash
|
||||
# using the backtick character
|
||||
testing=`date`
|
||||
echo "The date and time are: " $testing
|
||||
$
|
||||
|
||||
变量testing接收来自date命令的输出结果,而它又在echo语句中被调用。运行脚本会产生如下输出:
|
||||
|
||||
$ chmod u+x test5
|
||||
$ ./test5
|
||||
The date and time are: Mon Jan 31 20:23:25 EDT 2011
|
||||
|
||||
**注**:在bash中,你也可以选用$(...)语法来替换反引号(`),它有个优点就是可以重用。
|
||||
|
||||
例:
|
||||
|
||||
$ echo " Today’s date & time is :" $(date)
|
||||
Today’s date & time is : Sun Jul 27 16:26:56 IST 2014
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/variables-in-shell-scripting/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,79 @@
|
||||
命令行星期二 – 第七部分
|
||||
==============================================================================================================
|
||||
Heya,geekos,我已经检查了我们的课程,今天我们在八章课程里的第七部分。这意味着下周二我们还有一次课程,但也是最后一次CLT课程。所以,今天,我们讨论一些关于**权限**的问题!
|
||||
|
||||
众所周知,一台机器可能会有多名用户共同使用。为了保证用户之间互不干扰,权限会被分配。我们已经讨论了文件权限的问题,所以让我们用一个简单的[点击](1)回顾一下
|
||||
|
||||

|
||||
|
||||
### chmod ###
|
||||
|
||||
**chmod**命令被用来修改目录或者文件的权限。为了使用它,首先你得输入chmod命令,之后你得输入规范的权限修改,然后你就可以把目录或者文件的权限修改成你想要的。这可以采用多种方式完成,但是Shotts先生关注八进制表示法
|
||||
|
||||
把权限想象成一系列的位,每一个不为空的权限槽就是1,空的权限槽就是0。举个例子:
|
||||
|
||||
rwx = 111
|
||||
|
||||
rw- = 110
|
||||
|
||||
etc.
|
||||
|
||||
看一下二进制表示法:
|
||||
|
||||
rwx = 111 —> in binary = 7
|
||||
|
||||
rw- = 110 —> in binary = 6
|
||||
|
||||
r-x = 101 —> in binary = 5
|
||||
|
||||
r– = 100 —> in binary = 4
|
||||
|
||||
现在,如果你想把一个文件的权限改为:文件所有者和文件所有组拥有读,写,执行权限,但是其他用户没有该文件任何权限,我们可以这样做:
|
||||
|
||||
chmod 770 example_file
|
||||
|
||||
### su 和 sudo ###
|
||||
|
||||
有些时候普通用户想要成为超级用户,这样才能完成一些任务(通常是一些安装软件任务)。为了暂时的获取超级用户权限,我们可以使用**su**程序,输入:
|
||||
|
||||
su
|
||||
|
||||
输入你的超级用户密码,你就成为超级用户了。但是,警告:别忘记退出超级用户模式,仅仅使用它一小段时间
|
||||
|
||||
也有一些选择可能更多的应用于openSUSE和Ubuntu,它叫做sudo,sudo只是在某些方面和su不同,它是分配给制定用户的特殊命令,不像su,你可以用你自己用户的密码执行sudo,而不需要超级用户密码,举个例子:
|
||||
|
||||
sudo zypper in goodiegoodie
|
||||
|
||||
### 修改文件和组所有权 ###
|
||||
|
||||
想要改变文件的所有者,你可以在超级用户模式下运行**chown**,举个例子,如果我想把文件的所有权从‘nenad’改为‘suse’,我可以这样做:
|
||||
|
||||
su
|
||||
|
||||
[enter password]
|
||||
|
||||
chown suse example_file
|
||||
|
||||
同样地,我也可以改变组的所有权,但是是使用稍有不同的**chgrp**命令,很简单:
|
||||
|
||||
chgrp suse_group example_file
|
||||
|
||||
### 下一次 ###
|
||||
|
||||
正如我所阐述的,下一次我们会有各种各样的终点,在这之后,你会有自己的选择(和我一起徜徉在终端的黑暗之中,只有一个绿色的闪烁光标作为灯塔)。在那之前,geekos,记住
|
||||
|
||||
....享受更多的乐趣!
|
||||
|
||||
---------------------------------------------------------------
|
||||
|
||||
via: https://news.opensuse.org/2014/08/05/command-line-tuesdays-part-seven/
|
||||
|
||||
作者:[Nenad Latinović][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://news.opensuse.org/author/holden87/
|
||||
[1]:https://news.opensuse.org/2014/07/01/command-line-tuesdays-part-three/
|
||||
|
||||
@ -0,0 +1,39 @@
|
||||
Linux常见问题与答案——如何修复“fatal error: jsoncpp/json/json.h: No such file or directory”问题
|
||||
================================================================================
|
||||
>**问题**:我试着编译一个C++程序,但是我碰到了以下错误:
|
||||
>
|
||||
>“fatal error: jsoncpp/json/json.h: No such file or directory”
|
||||
>
|
||||
>我怎样修复这个问题呢?
|
||||
|
||||
该错误指出你缺少JsonCpp开发文件(例如,JsonCpp库和头文件)。[JsonCpp][1]是一个用于JSON格式数据复制的C++库。下面给出了在不同Linux发行版上安装JsonCpp开发文件的方法。
|
||||
|
||||
在Debian, Ubuntu或者Linux Mint上:
|
||||
|
||||
$ sudo apt-get install libjsoncpp-dev
|
||||
|
||||
在Fedora上:
|
||||
|
||||
$ sudo yum install jsoncpp-devel
|
||||
|
||||
在CentOS上,没有JsonCpp的预编译包。因此你可以通过以下方法从源码构建一个JsonCpp包并安装。
|
||||
|
||||
$ sudo yum install cmake
|
||||
$ git clone https://github.com/open-source-parsers/jsoncpp.git
|
||||
$ cd jsoncpp
|
||||
$ mkdir -p build/debug
|
||||
$ cd build/debug
|
||||
$ cmake -DCMAKE_BUILD_TYPE=debug -DJSONCPP_LIB_BUILD_SHARED=OFF -G "Unix Makefiles" ../../
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fix-fatal-error-jsoncpp.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://github.com/open-source-parsers/jsoncpp
|
||||
Loading…
Reference in New Issue
Block a user