@@ -48,8 +49,6 @@
[root@centos-007 ~]# yum install java-1.7.0-openjdk-1.7.0.79-2.5.5.2.el7_1
-----------
-
[root@centos-007 ~]# yum install java-1.7.0-openjdk-devel-1.7.0.85-2.6.1.2.el7_1.x86_64
安装完 java 和它的所有依赖后,运行下面的命令设置 JAVA_HOME 环境变量。
@@ -61,8 +60,6 @@
[root@centos-007 ~]# java –version
-----------
-
java version "1.7.0_79"
OpenJDK Runtime Environment (rhel-2.5.5.2.el7_1-x86_64 u79-b14)
OpenJDK 64-Bit Server VM (build 24.79-b02, mixed mode)
@@ -71,7 +68,7 @@
### 安装 MySQL 5.6.x ###
-如果的机器上有其它的 MySQL,建议你先卸载它们并安装这个版本,或者升级它们的模式到指定的版本。因为 Zephyr 前提要求这个指定的主要/最小 MySQL (5.6.x)版本要有 root 用户名。
+如果的机器上有其它的 MySQL,建议你先卸载它们并安装这个版本,或者升级它们的模式(schemas)到指定的版本。因为 Zephyr 前提要求这个指定的 5.6.x 版本的 MySQL ,要有 root 用户名。
可以按照下面的步骤在 CentOS-7.1 上安装 MySQL 5.6 :
@@ -93,10 +90,7 @@
[root@centos-007 ~]# service mysqld start
[root@centos-007 ~]# service mysqld status
-对于全新安装的 MySQL 服务器,MySQL root 用户的密码为空。
-为了安全起见,我们应该重置 MySQL root 用户的密码。
-
-用自动生成的空密码连接到 MySQL 并更改 root 用户密码。
+对于全新安装的 MySQL 服务器,MySQL root 用户的密码为空。为了安全起见,我们应该重置 MySQL root 用户的密码。用自动生成的空密码连接到 MySQL 并更改 root 用户密码。
[root@centos-007 ~]# mysql
mysql> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('your_password');
@@ -224,7 +218,7 @@ via: http://linoxide.com/linux-how-to/setup-zephyr-tool-centos-7-x/
作者:[Kashif Siddique][a]
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20150831 Linux workstation security checklist.md b/published/20150831 Linux workstation security checklist.md
new file mode 100644
index 0000000000..15daaa5382
--- /dev/null
+++ b/published/20150831 Linux workstation security checklist.md
@@ -0,0 +1,509 @@
+来自 Linux 基金会内部的《Linux 工作站安全检查清单》
+================================================================================
+
+### 目标受众
+
+ 这是一套 Linux 基金会为其系统管理员提供的推荐规范。
+
+这个文档用于帮助那些使用 Linux 工作站来访问和管理项目的 IT 设施的系统管理员团队。
+
+如果你的系统管理员是远程员工,你也许可以使用这套指导方针确保系统管理员的系统可以通过核心安全需求,降低你的IT 平台成为攻击目标的风险。
+
+即使你的系统管理员不是远程员工,很多人也会在工作环境中通过便携笔记本完成工作,或者在家中设置系统以便在业余时间或紧急时刻访问工作平台。不论发生何种情况,你都能调整这个推荐规范来适应你的环境。
+
+
+### 限制
+
+但是,这并不是一个详细的“工作站加固”文档,可以说这是一个努力避免大多数明显安全错误而不会导致太多不便的一组推荐基线(baseline)。你也许阅读这个文档后会认为它的方法太偏执,而另一些人也许会认为这仅仅是一些肤浅的研究。安全就像在高速公路上开车 -- 任何比你开的慢的都是一个傻瓜,然而任何比你开的快的人都是疯子。这个指南仅仅是一些列核心安全规则,既不详细又不能替代经验、警惕和常识。
+
+我们分享这篇文档是为了[将开源协作的优势带到 IT 策略文献资料中][18]。如果你发现它有用,我们希望你可以将它用到你自己团体中,并分享你的改进,对它的完善做出你的贡献。
+
+### 结构
+
+每一节都分为两个部分:
+
+- 核对适合你项目的需求
+- 形式不定的提示内容,解释了为什么这么做
+
+#### 严重级别
+
+在清单的每一个项目都包括严重级别,我们希望这些能帮助指导你的决定:
+
+- **关键(ESSENTIAL)** 该项应该在考虑列表上被明确的重视。如果不采取措施,将会导致你的平台安全出现高风险。
+- **中等(NICE)** 该项将改善你的安全形势,但是会影响到你的工作环境的流程,可能会要求养成新的习惯,改掉旧的习惯。
+- **低等(PARANOID)** 留作感觉会明显完善我们平台安全、但是可能会需要大量调整与操作系统交互的方式的项目。
+
+记住,这些只是参考。如果你觉得这些严重级别不能反映你的工程对安全的承诺,你应该调整它们为你所合适的。
+
+## 选择正确的硬件
+
+我们并不会要求管理员使用一个特殊供应商或者一个特殊的型号,所以这一节提供的是选择工作系统时的核心注意事项。
+
+### 检查清单
+
+- [ ] 系统支持安全启动(SecureBoot) _(关键)_
+- [ ] 系统没有火线(Firewire),雷电(thunderbolt)或者扩展卡(ExpressCard)接口 _(中等)_
+- [ ] 系统有 TPM 芯片 _(中等)_
+
+### 注意事项
+
+#### 安全启动(SecureBoot)
+
+尽管它还有争议,但是安全引导能够预防很多针对工作站的攻击(Rootkits、“Evil Maid”,等等),而没有太多额外的麻烦。它并不能阻止真正专门的攻击者,加上在很大程度上,国家安全机构有办法应对它(可能是通过设计),但是有安全引导总比什么都没有强。
+
+作为选择,你也许可以部署 [Anti Evil Maid][1] 提供更多健全的保护,以对抗安全引导所需要阻止的攻击类型,但是它需要更多部署和维护的工作。
+
+#### 系统没有火线(Firewire),雷电(thunderbolt)或者扩展卡(ExpressCard)接口
+
+火线是一个标准,其设计上允许任何连接的设备能够完全地直接访问你的系统内存(参见[维基百科][2])。雷电接口和扩展卡同样有问题,虽然一些后来部署的雷电接口试图限制内存访问的范围。如果你没有这些系统端口,那是最好的,但是它并不严重,它们通常可以通过 UEFI 关闭或内核本身禁用。
+
+#### TPM 芯片
+
+可信平台模块(Trusted Platform Module ,TPM)是主板上的一个与核心处理器单独分开的加密芯片,它可以用来增加平台的安全性(比如存储全盘加密的密钥),不过通常不会用于日常的平台操作。充其量,这个是一个有则更好的东西,除非你有特殊需求,需要使用 TPM 增加你的工作站安全性。
+
+## 预引导环境
+
+这是你开始安装操作系统前的一系列推荐规范。
+
+### 检查清单
+
+- [ ] 使用 UEFI 引导模式(不是传统 BIOS)_(关键)_
+- [ ] 进入 UEFI 配置需要使用密码 _(关键)_
+- [ ] 使用安全引导 _(关键)_
+- [ ] 启动系统需要 UEFI 级别密码 _(中等)_
+
+### 注意事项
+
+#### UEFI 和安全引导
+
+UEFI 尽管有缺点,还是提供了很多传统 BIOS 没有的好功能,比如安全引导。大多数现代的系统都默认使用 UEFI 模式。
+
+确保进入 UEFI 配置模式要使用高强度密码。注意,很多厂商默默地限制了你使用密码长度,所以相比长口令你也许应该选择高熵值的短密码(关于密码短语请参考下面内容)。
+
+基于你选择的 Linux 发行版,你也许需要、也许不需要按照 UEFI 的要求,来导入你的发行版的安全引导密钥,从而允许你启动该发行版。很多发行版已经与微软合作,用大多数厂商所支持的密钥给它们已发布的内核签名,因此避免了你必须处理密钥导入的麻烦。
+
+作为一个额外的措施,在允许某人访问引导分区然后尝试做一些不好的事之前,让他们输入密码。为了防止肩窥(shoulder-surfing),这个密码应该跟你的 UEFI 管理密码不同。如果你经常关闭和启动,你也许不想这么麻烦,因为你已经必须输入 LUKS 密码了(LUKS 参见下面内容),这样会让你您减少一些额外的键盘输入。
+
+## 发行版选择注意事项
+
+很有可能你会坚持一个广泛使用的发行版如 Fedora,Ubuntu,Arch,Debian,或它们的一个类似发行版。无论如何,以下是你选择使用发行版应该考虑的。
+
+### 检查清单
+
+- [ ] 拥有一个强健的 MAC/RBAC 系统(SELinux/AppArmor/Grsecurity) _(关键)_
+- [ ] 发布安全公告 _(关键)_
+- [ ] 提供及时的安全补丁 _(关键)_
+- [ ] 提供软件包的加密验证 _(关键)_
+- [ ] 完全支持 UEFI 和安全引导 _(关键)_
+- [ ] 拥有健壮的原生全磁盘加密支持 _(关键)_
+
+### 注意事项
+
+#### SELinux,AppArmor,和 GrSecurity/PaX
+
+强制访问控制(Mandatory Access Controls,MAC)或者基于角色的访问控制(Role-Based Access Controls,RBAC)是一个用在老式 POSIX 系统的基于用户或组的安全机制扩展。现在大多数发行版已经捆绑了 MAC/RBAC 系统(Fedora,Ubuntu),或通过提供一种机制一个可选的安装后步骤来添加它(Gentoo,Arch,Debian)。显然,强烈建议您选择一个预装 MAC/RBAC 系统的发行版,但是如果你对某个没有默认启用它的发行版情有独钟,装完系统后应计划配置安装它。
+
+应该坚决避免使用不带任何 MAC/RBAC 机制的发行版,像传统的 POSIX 基于用户和组的安全在当今时代应该算是考虑不足。如果你想建立一个 MAC/RBAC 工作站,通常认为 AppArmor 和 PaX 比 SELinux 更容易掌握。此外,在工作站上,很少有或者根本没有对外监听的守护进程,而针对用户运行的应用造成的最高风险,GrSecurity/PaX _可能_ 会比SELinux 提供更多的安全便利。
+
+#### 发行版安全公告
+
+大多数广泛使用的发行版都有一个给它们的用户发送安全公告的机制,但是如果你对一些机密感兴趣,去看看开发人员是否有见于文档的提醒用户安全漏洞和补丁的机制。缺乏这样的机制是一个重要的警告信号,说明这个发行版不够成熟,不能被用作主要管理员的工作站。
+
+#### 及时和可靠的安全更新
+
+多数常用的发行版提供定期安全更新,但应该经常检查以确保及时提供关键包更新。因此应避免使用附属发行版(spin-offs)和“社区重构”,因为它们必须等待上游发行版先发布,它们经常延迟发布安全更新。
+
+现在,很难找到一个不使用加密签名、更新元数据或二者都不使用的发行版。如此说来,常用的发行版在引入这个基本安全机制就已经知道这些很多年了(Arch,说你呢),所以这也是值得检查的。
+
+#### 发行版支持 UEFI 和安全引导
+
+检查发行版是否支持 UEFI 和安全引导。查明它是否需要导入额外的密钥或是否要求启动内核有一个已经被系统厂商信任的密钥签名(例如跟微软达成合作)。一些发行版不支持 UEFI 或安全启动,但是提供了替代品来确保防篡改(tamper-proof)或防破坏(tamper-evident)引导环境([Qubes-OS][3] 使用 Anti Evil Maid,前面提到的)。如果一个发行版不支持安全引导,也没有防止引导级别攻击的机制,还是看看别的吧。
+
+#### 全磁盘加密
+
+全磁盘加密是保护静止数据的要求,大多数发行版都支持。作为一个选择方案,带有自加密硬盘的系统也可以用(通常通过主板 TPM 芯片实现),并提供了类似安全级别而且操作更快,但是花费也更高。
+
+## 发行版安装指南
+
+所有发行版都是不同的,但是也有一些一般原则:
+
+### 检查清单
+
+- [ ] 使用健壮的密码全磁盘加密(LUKS) _(关键)_
+- [ ] 确保交换分区也加密了 _(关键)_
+- [ ] 确保引导程序设置了密码(可以和LUKS一样) _(关键)_
+- [ ] 设置健壮的 root 密码(可以和LUKS一样) _(关键)_
+- [ ] 使用无特权账户登录,作为管理员组的一部分 _(关键)_
+- [ ] 设置健壮的用户登录密码,不同于 root 密码 _(关键)_
+
+### 注意事项
+
+#### 全磁盘加密
+
+除非你正在使用自加密硬盘,配置你的安装程序完整地加密所有存储你的数据与系统文件的磁盘很重要。简单地通过自动挂载的 cryptfs 环(loop)文件加密用户目录还不够(说你呢,旧版 Ubuntu),这并没有给系统二进制文件或交换分区提供保护,它可能包含大量的敏感数据。推荐的加密策略是加密 LVM 设备,以便在启动过程中只需要一个密码。
+
+`/boot`分区将一直保持非加密,因为引导程序需要在调用 LUKS/dm-crypt 前能引导内核自身。一些发行版支持加密的`/boot`分区,比如 [Arch][16],可能别的发行版也支持,但是似乎这样增加了系统更新的复杂度。如果你的发行版并没有原生支持加密`/boot`也不用太在意,内核镜像本身并没有什么隐私数据,它会通过安全引导的加密签名检查来防止被篡改。
+
+#### 选择一个好密码
+
+现代的 Linux 系统没有限制密码口令长度,所以唯一的限制是你的偏执和倔强。如果你要启动你的系统,你将大概至少要输入两个不同的密码:一个解锁 LUKS ,另一个登录,所以长密码将会使你老的更快。最好从丰富或混合的词汇中选择2-3个单词长度,容易输入的密码。
+
+优秀密码例子(是的,你可以使用空格):
+
+- nature abhors roombas
+- 12 in-flight Jebediahs
+- perdon, tengo flatulence
+
+如果你喜欢输入可以在公开场合和你生活中能见到的句子,比如:
+
+- Mary had a little lamb
+- you're a wizard, Harry
+- to infinity and beyond
+
+如果你愿意的话,你也应该带上最少要 10-12个字符长度的非词汇的密码。
+
+除非你担心物理安全,你可以写下你的密码,并保存在一个远离你办公桌的安全的地方。
+
+#### Root,用户密码和管理组
+
+我们建议,你的 root 密码和你的 LUKS 加密使用同样的密码(除非你共享你的笔记本给信任的人,让他应该能解锁设备,但是不应该能成为 root 用户)。如果你是笔记本电脑的唯一用户,那么你的 root 密码与你的 LUKS 密码不同是没有安全优势上的意义的。通常,你可以使用同样的密码在你的 UEFI 管理,磁盘加密,和 root 登录中 -- 知道这些任意一个都会让攻击者完全控制您的系统,在单用户工作站上使这些密码不同,没有任何安全益处。
+
+你应该有一个不同的,但同样强健的常规用户帐户密码用来日常工作。这个用户应该是管理组用户(例如`wheel`或者类似,根据发行版不同),允许你执行`sudo`来提升权限。
+
+换句话说,如果在你的工作站只有你一个用户,你应该有两个独特的、强健(robust)而强壮(strong)的密码需要记住:
+
+**管理级别**,用在以下方面:
+
+- UEFI 管理
+- 引导程序(GRUB)
+- 磁盘加密(LUKS)
+- 工作站管理(root 用户)
+
+**用户级别**,用在以下:
+
+- 用户登录和 sudo
+- 密码管理器的主密码
+
+很明显,如果有一个令人信服的理由的话,它们全都可以不同。
+
+## 安装后的加固
+
+安装后的安全加固在很大程度上取决于你选择的发行版,所以在一个像这样的通用文档中提供详细说明是徒劳的。然而,这里有一些你应该采取的步骤:
+
+### 检查清单
+
+- [ ] 在全局范围内禁用火线和雷电模块 _(关键)_
+- [ ] 检查你的防火墙,确保过滤所有传入端口 _(关键)_
+- [ ] 确保 root 邮件转发到一个你可以收到的账户 _(关键)_
+- [ ] 建立一个系统自动更新任务,或更新提醒 _(中等)_
+- [ ] 检查以确保 sshd 服务默认情况下是禁用的 _(中等)_
+- [ ] 配置屏幕保护程序在一段时间的不活动后自动锁定 _(中等)_
+- [ ] 设置 logwatch _(中等)_
+- [ ] 安装使用 rkhunter _(中等)_
+- [ ] 安装一个入侵检测系统(Intrusion Detection System) _(中等)_
+
+### 注意事项
+
+#### 将模块列入黑名单
+
+将火线和雷电模块列入黑名单,增加一行到`/etc/modprobe.d/blacklist-dma.conf`文件:
+
+ blacklist firewire-core
+ blacklist thunderbolt
+
+重启后的这些模块将被列入黑名单。这样做是无害的,即使你没有这些端口(但也不做任何事)。
+
+#### Root 邮件
+
+默认的 root 邮件只是存储在系统基本上没人读过。确保你设置了你的`/etc/aliases`来转发 root 邮件到你确实能读取的邮箱,否则你也许错过了重要的系统通知和报告:
+
+ # Person who should get root's mail
+ root: bob@example.com
+
+编辑后这些后运行`newaliases`,然后测试它确保能投递到,像一些邮件供应商将拒绝来自不存在的域名或者不可达的域名的邮件。如果是这个原因,你需要配置邮件转发直到确实可用。
+
+#### 防火墙,sshd,和监听进程
+
+默认的防火墙设置将取决于您的发行版,但是大多数都允许`sshd`端口连入。除非你有一个令人信服的合理理由允许连入 ssh,你应该过滤掉它,并禁用 sshd 守护进程。
+
+ systemctl disable sshd.service
+ systemctl stop sshd.service
+
+如果你需要使用它,你也可以临时启动它。
+
+通常,你的系统不应该有任何侦听端口,除了响应 ping 之外。这将有助于你对抗网络级的零日漏洞利用。
+
+#### 自动更新或通知
+
+建议打开自动更新,除非你有一个非常好的理由不这么做,如果担心自动更新将使您的系统无法使用(以前发生过,所以这种担心并非杞人忧天)。至少,你应该启用自动通知可用的更新。大多数发行版已经有这个服务自动运行,所以你不需要做任何事。查阅你的发行版文档了解更多。
+
+你应该尽快应用所有明显的勘误,即使这些不是特别贴上“安全更新”或有关联的 CVE 编号。所有的问题都有潜在的安全漏洞和新的错误,比起停留在旧的、已知的问题上,未知问题通常是更安全的策略。
+
+#### 监控日志
+
+你应该会对你的系统上发生了什么很感兴趣。出于这个原因,你应该安装`logwatch`然后配置它每夜发送在你的系统上发生的任何事情的活动报告。这不会预防一个专业的攻击者,但是一个不错的安全网络功能。
+
+注意,许多 systemd 发行版将不再自动安装一个“logwatch”所需的 syslog 服务(因为 systemd 会放到它自己的日志中),所以你需要安装和启用“rsyslog”来确保在使用 logwatch 之前你的 /var/log 不是空的。
+
+#### Rkhunter 和 IDS
+
+安装`rkhunter`和一个类似`aide`或者`tripwire`入侵检测系统(IDS)并不是那么有用,除非你确实理解它们如何工作,并采取必要的步骤来设置正确(例如,保证数据库在外部介质,从可信的环境运行检测,记住执行系统更新和配置更改后要刷新散列数据库,等等)。如果你不愿在你的工作站执行这些步骤,并调整你如何工作的方式,这些工具只能带来麻烦而没有任何实在的安全益处。
+
+我们建议你安装`rkhunter`并每晚运行它。它相当易于学习和使用,虽然它不会阻止一个复杂的攻击者,它也能帮助你捕获你自己的错误。
+
+## 个人工作站备份
+
+工作站备份往往被忽视,或偶尔才做一次,这常常是不安全的方式。
+
+### 检查清单
+
+- [ ] 设置加密备份工作站到外部存储 _(关键)_
+- [ ] 使用零认知(zero-knowledge)备份工具备份到站外或云上 _(中等)_
+
+### 注意事项
+
+#### 全加密的备份存到外部存储
+
+把全部备份放到一个移动磁盘中比较方便,不用担心带宽和上行网速(在这个时代,大多数供应商仍然提供显著的不对称的上传/下载速度)。不用说,这个移动硬盘本身需要加密(再说一次,通过 LUKS),或者你应该使用一个备份工具建立加密备份,例如`duplicity`或者它的 GUI 版本 `deja-dup`。我建议使用后者并使用随机生成的密码,保存到离线的安全地方。如果你带上笔记本去旅行,把这个磁盘留在家,以防你的笔记本丢失或被窃时可以找回备份。
+
+除了你的家目录外,你还应该备份`/etc`目录和出于取证目的的`/var/log`目录。
+
+尤其重要的是,避免拷贝你的家目录到任何非加密存储上,即使是需要快速的在两个系统上移动文件时,一旦完成你肯定会忘了清除它,从而暴露个人隐私或者安全信息到监听者手中 -- 尤其是把这个存储介质跟你的笔记本放到同一个包里。
+
+#### 有选择的零认知站外备份
+
+站外备份(Off-site backup)也是相当重要的,是否可以做到要么需要你的老板提供空间,要么找一家云服务商。你可以建一个单独的 duplicity/deja-dup 配置,只包括重要的文件,以免传输大量你不想备份的数据(网络缓存、音乐、下载等等)。
+
+作为选择,你可以使用零认知(zero-knowledge)备份工具,例如 [SpiderOak][5],它提供一个卓越的 Linux GUI工具还有更多的实用特性,例如在多个系统或平台间同步内容。
+
+## 最佳实践
+
+下面是我们认为你应该采用的最佳实践列表。它当然不是非常详细的,而是试图提供实用的建议,来做到可行的整体安全性和可用性之间的平衡。
+
+### 浏览
+
+毫无疑问, web 浏览器将是你的系统上最大、最容易暴露的面临攻击的软件。它是专门下载和执行不可信、甚至是恶意代码的一个工具。它试图采用沙箱和代码清洁(code sanitization)等多种机制保护你免受这种危险,但是在之前它们都被击败了多次。你应该知道,在任何时候浏览网站都是你做的最不安全的活动。
+
+有几种方法可以减少浏览器的影响,但这些真实有效的方法需要你明显改变操作您的工作站的方式。
+
+#### 1: 使用两个不同的浏览器 _(关键)_
+
+这很容易做到,但是只有很少的安全效益。并不是所有浏览器都可以让攻击者完全自由访问您的系统 -- 有时它们只能允许某人读取本地浏览器存储,窃取其它标签的活动会话,捕获浏览器的输入等。使用两个不同的浏览器,一个用在工作/高安全站点,另一个用在其它方面,有助于防止攻击者请求整个 cookie 存储的小问题。主要的不便是两个不同的浏览器会消耗大量内存。
+
+我们建议:
+
+##### 火狐用来访问工作和高安全站点
+
+使用火狐登录工作有关的站点,应该额外关心的是确保数据如 cookies,会话,登录信息,击键等等,明显不应该落入攻击者手中。除了少数的几个网站,你不应该用这个浏览器访问其它网站。
+
+你应该安装下面的火狐扩展:
+
+- [ ] NoScript _(关键)_
+ - NoScript 阻止活动内容加载,除非是在用户白名单里的域名。如果用于默认浏览器它会很麻烦(可是提供了真正好的安全效益),所以我们建议只在访问与工作相关的网站的浏览器上开启它。
+
+- [ ] Privacy Badger _(关键)_
+ - EFF 的 Privacy Badger 将在页面加载时阻止大多数外部追踪器和广告平台,有助于在这些追踪站点影响你的浏览器时避免跪了(追踪器和广告站点通常会成为攻击者的目标,因为它们能会迅速影响世界各地成千上万的系统)。
+
+- [ ] HTTPS Everywhere _(关键)_
+ - 这个 EFF 开发的扩展将确保你访问的大多数站点都使用安全连接,甚至你点击的连接使用的是 http://(可以有效的避免大多数的攻击,例如[SSL-strip][7])。
+
+- [ ] Certificate Patrol _(中等)_
+ - 如果你正在访问的站点最近改变了它们的 TLS 证书,这个工具将会警告你 -- 特别是如果不是接近失效期或者现在使用不同的证书颁发机构。它有助于警告你是否有人正尝试中间人攻击你的连接,不过它会产生很多误报。
+
+你应该让火狐成为你打开连接时的默认浏览器,因为 NoScript 将在加载或者执行时阻止大多数活动内容。
+
+##### 其它一切都用 Chrome/Chromium
+
+Chromium 开发者在增加很多很好的安全特性方面走在了火狐前面(至少[在 Linux 上][6]),例如 seccomp 沙箱,内核用户空间等等,这会成为一个你访问的网站与你其它系统之间的额外隔离层。Chromium 是上游开源项目,Chrome 是 Google 基于它构建的专有二进制包(加一句偏执的提醒,如果你有任何不想让谷歌知道的事情都不要使用它)。
+
+推荐你在 Chrome 上也安装**Privacy Badger** 和 **HTTPS Everywhere** 扩展,然后给它一个与火狐不同的主题,以让它告诉你这是你的“不可信站点”浏览器。
+
+#### 2: 使用两个不同浏览器,一个在专用的虚拟机里 _(中等)_
+
+这有点像上面建议的做法,除了您将添加一个通过快速访问协议运行在专用虚拟机内部 Chrome 的额外步骤,它允许你共享剪贴板和转发声音事件(如,Spice 或 RDP)。这将在不可信浏览器和你其它的工作环境之间添加一个优秀的隔离层,确保攻击者完全危害你的浏览器将必须另外打破 VM 隔离层,才能达到系统的其余部分。
+
+这是一个鲜为人知的可行方式,但是需要大量的 RAM 和高速的处理器来处理多增加的负载。这要求作为管理员的你需要相应地调整自己的工作实践而付出辛苦。
+
+#### 3: 通过虚拟化完全隔离你的工作和娱乐环境 _(低等)_
+
+了解下 [Qubes-OS 项目][3],它致力于通过划分你的应用到完全隔离的 VM 中来提供高度安全的工作环境。
+
+### 密码管理器
+
+#### 检查清单
+
+- [ ] 使用密码管理器 _(关键)_
+- [ ] 不相关的站点使用不同的密码 _(关键)_
+- [ ] 使用支持团队共享的密码管理器 _(中等)_
+- [ ] 给非网站类账户使用一个单独的密码管理器 _(低等)_
+
+#### 注意事项
+
+使用好的、唯一的密码对你的团队成员来说应该是非常关键的需求。凭证(credential)盗取一直在发生 — 通过被攻破的计算机、盗取数据库备份、远程站点利用、以及任何其它的方式。凭证绝不应该跨站点重用,尤其是关键的应用。
+
+##### 浏览器中的密码管理器
+
+每个浏览器有一个比较安全的保存密码机制,可以同步到供应商维护的,并使用用户的密码保证数据加密。然而,这个机制有严重的劣势:
+
+1. 不能跨浏览器工作
+2. 不提供任何与团队成员共享凭证的方法
+
+也有一些支持良好、免费或便宜的密码管理器,可以很好的融合到多个浏览器,跨平台工作,提供小组共享(通常是付费服务)。可以很容易地通过搜索引擎找到解决方案。
+
+##### 独立的密码管理器
+
+任何与浏览器结合的密码管理器都有一个主要的缺点,它实际上是应用的一部分,这样最有可能被入侵者攻击。如果这让你不放心(应该这样),你应该选择两个不同的密码管理器 -- 一个集成在浏览器中用来保存网站密码,一个作为独立运行的应用。后者可用于存储高风险凭证如 root 密码、数据库密码、其它 shell 账户凭证等。
+
+这样的工具在团队成员间共享超级用户的凭据方面特别有用(服务器 root 密码、ILO密码、数据库管理密码、引导程序密码等等)。
+
+这几个工具可以帮助你:
+
+- [KeePassX][8],在第2版中改进了团队共享
+- [Pass][9],它使用了文本文件和 PGP,并与 git 结合
+- [Django-Pstore][10],它使用 GPG 在管理员之间共享凭据
+- [Hiera-Eyaml][11],如果你已经在你的平台中使用了 Puppet,在你的 Hiera 加密数据的一部分里面,可以便捷的追踪你的服务器/服务凭证。
+
+### 加固 SSH 与 PGP 的私钥
+
+个人加密密钥,包括 SSH 和 PGP 私钥,都是你工作站中最重要的物品 -- 这是攻击者最想得到的东西,这可以让他们进一步攻击你的平台或在其它管理员面前冒充你。你应该采取额外的步骤,确保你的私钥免遭盗窃。
+
+#### 检查清单
+
+- [ ] 用来保护私钥的强壮密码 _(关键)_
+- [ ] PGP 的主密码保存在移动存储中 _(中等)_
+- [ ] 用于身份验证、签名和加密的子密码存储在智能卡设备 _(中等)_
+- [ ] SSH 配置为以 PGP 认证密钥作为 ssh 私钥 _(中等)_
+
+#### 注意事项
+
+防止私钥被偷的最好方式是使用一个智能卡存储你的加密私钥,绝不要拷贝到工作站上。有几个厂商提供支持 OpenPGP 的设备:
+
+- [Kernel Concepts][12],在这里可以采购支持 OpenPGP 的智能卡和 USB 读取器,你应该需要一个。
+- [Yubikey NEO][13],这里提供 OpenPGP 功能的智能卡还提供很多很酷的特性(U2F、PIV、HOTP等等)。
+
+确保 PGP 主密码没有存储在工作站也很重要,仅使用子密码。主密钥只有在签名其它的密钥和创建新的子密钥时使用 — 不经常发生这种操作。你可以照着 [Debian 的子密钥][14]向导来学习如何将你的主密钥移动到移动存储并创建子密钥。
+
+你应该配置你的 gnupg 代理作为 ssh 代理,然后使用基于智能卡 PGP 认证密钥作为你的 ssh 私钥。我们发布了一个[详尽的指导][15]如何使用智能卡读取器或 Yubikey NEO。
+
+如果你不想那么麻烦,最少要确保你的 PGP 私钥和你的 SSH 私钥有个强健的密码,这将让攻击者很难盗取使用它们。
+
+### 休眠或关机,不要挂起
+
+当系统挂起时,内存中的内容仍然保留在内存芯片中,可以会攻击者读取到(这叫做冷启动攻击(Cold Boot Attack))。如果你离开你的系统的时间较长,比如每天下班结束,最好关机或者休眠,而不是挂起它或者就那么开着。
+
+### 工作站上的 SELinux
+
+如果你使用捆绑了 SELinux 的发行版(如 Fedora),这有些如何使用它的建议,让你的工作站达到最大限度的安全。
+
+#### 检查清单
+
+- [ ] 确保你的工作站强制(enforcing)使用 SELinux _(关键)_
+- [ ] 不要盲目的执行`audit2allow -M`,应该经常检查 _(关键)_
+- [ ] 绝不要 `setenforce 0` _(中等)_
+- [ ] 切换你的用户到 SELinux 用户`staff_u` _(中等)_
+
+#### 注意事项
+
+SELinux 是强制访问控制(Mandatory Access Controls,MAC),是 POSIX许可核心功能的扩展。它是成熟、强健,自从它推出以来已经有很长的路了。不管怎样,许多系统管理员现在仍旧重复过时的口头禅“关掉它就行”。
+
+话虽如此,在工作站上 SELinux 会带来一些有限的安全效益,因为大多数你想运行的应用都是可以自由运行的。开启它有益于给网络提供足够的保护,也有可能有助于防止攻击者通过脆弱的后台服务提升到 root 级别的权限用户。
+
+我们的建议是开启它并强制使用(enforcing)。
+
+##### 绝不`setenforce 0`
+
+使用`setenforce 0`临时把 SELinux 设置为许可(permissive)模式很有诱惑力,但是你应该避免这样做。当你想查找一个特定应用或者程序的问题时,实际上这样做是把整个系统的 SELinux 给关闭了。
+
+你应该使用`semanage permissive -a [somedomain_t]`替换`setenforce 0`,只把这个程序放入许可模式。首先运行`ausearch`查看哪个程序发生问题:
+
+ ausearch -ts recent -m avc
+
+然后看下`scontext=`(源自 SELinux 的上下文)行,像这样:
+
+ scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
+ ^^^^^^^^^^^^^^
+
+这告诉你程序`gpg_pinentry_t`被拒绝了,所以你想排查应用的故障,应该增加它到许可域:
+
+ semange permissive -a gpg_pinentry_t
+
+这将允许你使用应用然后收集 AVC 的其它数据,你可以结合`audit2allow`来写一个本地策略。一旦完成你就不会看到新的 AVC 的拒绝消息,你就可以通过运行以下命令从许可中删除程序:
+
+ semanage permissive -d gpg_pinentry_t
+
+##### 用 SELinux 的用户 staff_r 使用你的工作站
+
+SELinux 带有角色(role)的原生实现,基于用户帐户相关角色来禁止或授予某些特权。作为一个管理员,你应该使用`staff_r`角色,这可以限制访问很多配置和其它安全敏感文件,除非你先执行`sudo`。
+
+默认情况下,用户以`unconfined_r`创建,你可以自由运行大多数应用,没有任何(或只有一点)SELinux 约束。转换你的用户到`staff_r`角色,运行下面的命令:
+
+ usermod -Z staff_u [username]
+
+你应该退出然后登录新的角色,届时如果你运行`id -Z`,你将会看到:
+
+ staff_u:staff_r:staff_t:s0-s0:c0.c1023
+
+在执行`sudo`时,你应该记住增加一个额外标志告诉 SELinux 转换到“sysadmin”角色。你需要用的命令是:
+
+ sudo -i -r sysadm_r
+
+然后`id -Z`将会显示:
+
+ staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
+
+**警告**:在进行这个切换前你应该能很顺畅的使用`ausearch`和`audit2allow`,当你以`staff_r`角色运行时你的应用有可能不再工作了。在写作本文时,已知以下流行的应用在`staff_r`下没有做策略调整就不会工作:
+
+- Chrome/Chromium
+- Skype
+- VirtualBox
+
+切换回`unconfined_r`,运行下面的命令:
+
+ usermod -Z unconfined_u [username]
+
+然后注销再重新回到舒适区。
+
+## 延伸阅读
+
+IT 安全的世界是一个没有底的兔子洞。如果你想深入,或者找到你的具体发行版更多的安全特性,请查看下面这些链接:
+
+- [Fedora 安全指南](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
+- [CESG Ubuntu 安全指南](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
+- [Debian 安全手册](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
+- [Arch Linux 安全维基](https://wiki.archlinux.org/index.php/Security)
+- [Mac OSX 安全](https://www.apple.com/support/security/guides/)
+
+## 许可
+
+这项工作在[创作共用授权4.0国际许可证][0]许可下。
+
+--------------------------------------------------------------------------------
+
+via: https://github.com/lfit/itpol/blob/bbc17d8c69cb8eee07ec41f8fbf8ba32fdb4301b/linux-workstation-security.md
+
+作者:[mricon][a]
+译者:[wyangsun](https://github.com/wyangsun)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://github.com/mricon
+[0]: http://creativecommons.org/licenses/by-sa/4.0/
+[1]: https://github.com/QubesOS/qubes-antievilmaid
+[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
+[3]: https://qubes-os.org/
+[4]: https://xkcd.com/936/
+[5]: https://spideroak.com/
+[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
+[7]: http://www.thoughtcrime.org/software/sslstrip/
+[8]: https://keepassx.org/
+[9]: http://www.passwordstore.org/
+[10]: https://pypi.python.org/pypi/django-pstore
+[11]: https://github.com/TomPoulton/hiera-eyaml
+[12]: http://shop.kernelconcepts.de/
+[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
+[14]: https://wiki.debian.org/Subkeys
+[15]: https://github.com/lfit/ssh-gpg-smartcard-config
+[16]: http://www.pavelkogan.com/2014/05/23/luks-full-disk-encryption/
+[17]: https://en.wikipedia.org/wiki/Cold_boot_attack
+[18]: http://www.linux.com/news/featured-blogs/167-amanda-mcpherson/850607-linux-foundation-sysadmins-open-source-their-it-policies
\ No newline at end of file
diff --git a/published/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md b/published/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md
new file mode 100644
index 0000000000..2f6780cdc2
--- /dev/null
+++ b/published/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md
@@ -0,0 +1,101 @@
+UNIX 家族小史
+================================================================================
+
+
+要记住,当一扇门在你面前关闭的时候,另一扇门就会打开。肯·汤普森([Ken Thompson][1]) 和丹尼斯·里奇([Dennis Richie][2]) 两个人就是这句名言很好的实例。他们俩是**20世纪**最优秀的信息技术专家之二,因为他们创造了最具影响力和创新性的软件之一: **UNIX**。
+
+### UNIX 系统诞生于贝尔实验室 ###
+
+**UNIX** 最开始的名字是 **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice),它有一个大家庭,并不是从石头缝里蹦出来的。UNIX的祖父是 **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem),它的父亲是 **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice),这个系统能支持大量用户通过交互式分时(timesharing)的方式使用大型机。
+
+UNIX 诞生于 **1969** 年,由**肯·汤普森**以及后来加入的**丹尼斯·里奇**共同完成。这两位优秀的研究员和科学家在一个**通用电器 GE**和**麻省理工学院**的合作项目里工作,项目目标是开发一个叫 Multics 的交互式分时系统。
+
+Multics 的目标是整合分时技术以及当时其他先进技术,允许用户在远程终端通过电话(拨号)登录到主机,然后可以编辑文档,阅读电子邮件,运行计算器,等等。
+
+在之后的五年里,AT&T 公司为 Multics 项目投入了数百万美元。他们购买了 GE-645 大型机,聚集了贝尔实验室的顶级研究人员,例如肯·汤普森、 Stuart Feldman、丹尼斯·里奇、道格拉斯·麦克罗伊(M. Douglas McIlroy)、 Joseph F. Ossanna 以及 Robert Morris。但是项目目标太过激进,进度严重滞后。最后,AT&T 高层决定放弃这个项目。
+
+贝尔实验室的管理层决定停止这个让许多研究人员无比纠结的操作系统上的所有遗留工作。不过要感谢汤普森,里奇和一些其他研究员,他们把老板的命令丢到一边,并继续在实验室里满怀热心地忘我工作,最终孵化出前无古人后无来者的 UNIX。
+
+UNIX 的第一声啼哭是在一台 PDP-7 微型机上,它是汤普森测试自己在操作系统设计上的点子的机器,也是汤普森和 里奇一起玩 Space and Travel 游戏的模拟器。
+
+> “我们想要的不仅是一个优秀的编程环境,而是能围绕这个系统形成团体。按我们自己的经验,通过远程访问和分时主机实现的公共计算,本质上不只是用终端输入程序代替打孔机而已,而是鼓励密切沟通。”丹尼斯·里奇说。
+
+UNIX 是第一个靠近理想的系统,在这里程序员可以坐在机器前自由摆弄程序,探索各种可能性并随手测试。在 UNIX 整个生命周期里,它吸引了大量因其他操作系统限制而投身过来的高手做出无私贡献,因此它的功能模型一直保持上升趋势。
+
+UNIX 在 1970 年因为 PDP-11/20 获得了首次资金注入,之后正式更名为 UNIX 并支持在 PDP-11/20 上运行。UNIX 带来的第一次用于实际场景中是在 1971 年,贝尔实验室的专利部门配备来做文字处理。
+
+### UNIX 上的 C 语言革命 ###
+
+丹尼斯·里奇在 1972 年发明了一种叫 “**C**” 的高级编程语言 ,之后他和肯·汤普森决定用 “C” 重写 UNIX 系统,来支持更好的移植性。他们在那一年里编写和调试了差不多 100,000 行代码。在迁移到 “C” 语言后,系统可移植性非常好,只需要修改一小部分机器相关的代码就可以将 UNIX 移植到其他计算机平台上。
+
+UNIX 第一次公开露面是 1973 年丹尼斯·里奇和肯·汤普森在操作系统原理(Operating Systems Principles)上发表的一篇论文,然后 AT&T 发布了 UNIX 系统第 5 版,并授权给教育机构使用,之后在 1975 年第一次以 **$20.000** 的价格授权企业使用 UNIX 第 6 版。应用最广泛的是 1980 年发布的 UNIX 第 7 版,任何人都可以购买授权,只是授权条款非常严格。授权内容包括源代码,以及用 PDP-11 汇编语言写的及其相关内核。反正,各种版本 UNIX 系统完全由它的用户手册确定。
+
+### AIX 系统 ###
+
+在 **1983** 年,**微软**计划开发 **Xenix** 作为 MS-DOS 的多用户版继任者,他们在那一年花了 $8,000 搭建了一台拥有 **512 KB** 内存以及 **10 MB**硬盘并运行 Xenix 的 Altos 586。而到 1984 年为止,全世界 UNIX System V 第二版的安装数量已经超过了 100,000 。在 1986 年发布了包含因特网域名服务的 4.3BSD,而且 **IBM** 宣布 **AIX 系统**的安装数已经超过 250,000。AIX 基于 Unix System V 开发,这套系统拥有 BSD 风格的根文件系统,是两者的结合。
+
+AIX 第一次引入了 **日志文件系统 (JFS)** 以及集成逻辑卷管理器 (Logical Volume Manager ,LVM)。IBM 在 1989 年将 AIX 移植到自己的 RS/6000 平台。2001 年发布的 5L 版是一个突破性的版本,提供了 Linux 友好性以及支持 Power4 服务器的逻辑分区。
+
+在 2004 年发布的 AIX 5.3 引入了支持高级电源虚拟化( Advanced Power Virtualization,APV)的虚拟化技术,支持对称多线程、微分区,以及共享处理器池。
+
+在 2007 年,IBM 同时发布 AIX 6.1 和 Power6 架构,开始加强自己的虚拟化产品。他们还将高级电源虚拟化重新包装成 PowerVM。
+
+这次改进包括被称为 WPARs 的负载分区形式,类似于 Solaris 的 zones/Containers,但是功能更强。
+
+### HP-UX 系统 ###
+
+**惠普 UNIX (Hewlett-Packard’s UNIX,HP-UX)** 源于 System V 第 3 版。这套系统一开始只支持 PA-RISC HP 9000 平台。HP-UX 第 1 版发布于 1984 年。
+
+HP-UX 第 9 版引入了 SAM,一个基于字符的图形用户界面 (GUI),用户可以用来管理整个系统。在 1995 年发布的第 10 版,调整了系统文件分布以及目录结构,变得有点类似 AT&T SVR4。
+
+第 11 版发布于 1997 年。这是 HP 第一个支持 64 位寻址的版本。不过在 2000 年重新发布成 11i,因为 HP 为特定的信息技术用途,引入了操作环境(operating environments)和分级应用(layered applications)的捆绑组(bundled groups)。
+
+在 2001 年发布的 11.20 版宣称支持安腾(Itanium)系统。HP-UX 是第一个使用 ACLs(访问控制列表,Access Control Lists)管理文件权限的 UNIX 系统,也是首先支持内建逻辑卷管理器(Logical Volume Manager)的系统之一。
+
+如今,HP-UX 因为 HP 和 Veritas 的合作关系使用了 Veritas 作为主文件系统。
+
+HP-UX 目前的最新版本是 11iv3, update 4。
+
+### Solaris 系统 ###
+
+Sun 的 UNIX 版本是 **Solaris**,用来接替 1992 年创建的 **SunOS**。SunOS 一开始基于 BSD(伯克利软件发行版,Berkeley Software Distribution)风格的 UNIX,但是 SunOS 5.0 版以及之后的版本都是基于重新包装为 Solaris 的 Unix System V 第 4 版。
+
+SunOS 1.0 版于 1983 年发布,用于支持 Sun-1 和 Sun-2 平台。随后在 1985 年发布了 2.0 版。在 1987 年,Sun 和 AT&T 宣布合作一个项目以 SVR4 为基础将 System V 和 BSD 合并成一个版本。
+
+Solaris 2.4 是 Sun 发布的第一个 Sparc/x86 版本。1994 年 11 月份发布的 SunOS 4.1.4 版是最后一个版本。Solaris 7 是首个 64 位 Ultra Sparc 版本,加入了对文件系统元数据记录的原生支持。
+
+Solaris 9 发布于 2002 年,支持 Linux 特性以及 Solaris 卷管理器(Solaris Volume Manager)。之后,2005 年发布了 Solaris 10,带来许多创新,比如支持 Solaris Containers,新的 ZFS 文件系统,以及逻辑域(Logical Domains)。
+
+目前 Solaris 最新的版本是 第 10 版,最后的更新发布于 2008 年。
+
+### Linux ###
+
+到了 1991 年,用来替代商业操作系统的自由(free)操作系统的需求日渐高涨。因此,**Linus Torvalds** 开始构建一个自由的操作系统,最终成为 **Linux**。Linux 最开始只有一些 “C” 文件,并且使用了阻止商业发行的授权。Linux 是一个类 UNIX 系统但又不尽相同。
+
+2015 年发布了基于 GNU Public License (GPL)授权的 3.18 版。IBM 声称有超过 1800 万行开源代码开源给开发者。
+
+如今 GNU Public License 是应用最广泛的自由软件授权方式。根据开源软件原则,这份授权允许个人和企业自由分发、运行、通过拷贝共享、学习,以及修改软件源码。
+
+### UNIX vs. Linux:技术概要 ###
+
+- Linux 鼓励多样性,Linux 的开发人员来自各种背景,有更多不同经验和意见。
+- Linux 比 UNIX 支持更多的平台和架构。
+- UNIX 商业版本的开发人员针对特定目标平台以及用户设计他们的操作系统。
+- **Linux 比 UNIX 有更好的安全性**,更少受病毒或恶意软件攻击。截止到现在,Linux 上大约有 60-100 种病毒,但是没有任何一种还在传播。另一方面,UNIX 上大约有 85-120 种病毒,但是其中有一些还在传播中。
+- 由于 UNIX 命令、工具和元素很少改变,甚至很多接口和命令行参数在后续 UNIX 版本中一直沿用。
+- 有些 Linux 开发项目以自愿为基础进行资助,比如 Debian。其他项目会维护一个和商业 Linux 的社区版,比如 SUSE 的 openSUSE 以及红帽的 Fedora。
+- 传统 UNIX 是纵向扩展,而另一方面 Linux 是横向扩展。
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/brief-history-aix-hp-ux-solaris-bsd-linux/
+
+作者:[M.el Khamlichi][a]
+译者:[zpl1025](https://github.com/zpl1025)
+校对:[Caroline](https://github.com/carolinewuyan)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.unixmen.com/author/pirat9/
+[1]:http://www.unixmen.com/ken-thompson-unix-systems-father/
+[2]:http://www.unixmen.com/dennis-m-ritchie-father-c-programming-language/
diff --git a/translated/tech/20151020 how to h2 in apache.md b/published/20151020 how to h2 in apache.md
similarity index 55%
rename from translated/tech/20151020 how to h2 in apache.md
rename to published/20151020 how to h2 in apache.md
index 32420d5bf4..add5bb7560 100644
--- a/translated/tech/20151020 how to h2 in apache.md
+++ b/published/20151020 how to h2 in apache.md
@@ -8,45 +8,44 @@ Copyright (C) 2015 greenbytes GmbH
### 源码 ###
-你可以从[这里][1]得到 Apache 发行版。Apache 2.4.17 及其更高版本都支持 HTTP/2。我不会再重复介绍如何构建服务器的指令。在很多地方有很好的指南,例如[这里][2]。
+你可以从[这里][1]得到 Apache 版本。Apache 2.4.17 及其更高版本都支持 HTTP/2。我不会再重复介绍如何构建该服务器的指令。在很多地方有很好的指南,例如[这里][2]。
-(有任何试验的链接?在 Twitter 上告诉我吧 @icing)
+(有任何这个试验性软件包的相关链接?在 Twitter 上告诉我吧 @icing)
-#### 编译支持 HTTP/2 ####
+#### 编译支持 HTTP/2 ####
-在你编译发行版之前,你要进行一些**配置**。这里有成千上万的选项。和 HTTP/2 相关的是:
+在你编译版本之前,你要进行一些**配置**。这里有成千上万的选项。和 HTTP/2 相关的是:
- **--enable-http2**
- 启用在 Apache 服务器内部实现协议的 ‘http2’ 模块。
+ 启用在 Apache 服务器内部实现该协议的 ‘http2’ 模块。
-- **--with-nghttp2=**
+- **--with-nghttp2=\**
指定 http2 模块需要的 libnghttp2 模块的非默认位置。如果 nghttp2 是在默认的位置,配置过程会自动采用。
- **--enable-nghttp2-staticlib-deps**
- 很少用到的选项,你可能用来静态链接 nghttp2 库到服务器。在大部分平台上,只有在找不到共享 nghttp2 库时才有效。
+ 很少用到的选项,你可能想将 nghttp2 库静态链接到服务器里。在大部分平台上,只有在找不到共享 nghttp2 库时才有用。
-如果你想自己编译 nghttp2,你可以到 [nghttp2.org][3] 查看文档。最新的 Fedora 以及其它发行版已经附带了这个库。
+如果你想自己编译 nghttp2,你可以到 [nghttp2.org][3] 查看文档。最新的 Fedora 以及其它版本已经附带了这个库。
#### TLS 支持 ####
-大部分人想在浏览器上使用 HTTP/2, 而浏览器只在 TLS 连接(**https:// 开头的 url)时支持它。你需要一些我下面介绍的配置。但首先你需要的是支持 ALPN 扩展的 TLS 库。
+大部分人想在浏览器上使用 HTTP/2, 而浏览器只在使用 TLS 连接(**https:// 开头的 url)时才支持 HTTP/2。你需要一些我下面介绍的配置。但首先你需要的是支持 ALPN 扩展的 TLS 库。
+ALPN 用来协商(negotiate)服务器和客户端之间的协议。如果你服务器上 TLS 库还没有实现 ALPN,客户端只能通过 HTTP/1.1 通信。那么,可以和 Apache 链接并支持它的是什么库呢?
-ALPN 用来屏蔽服务器和客户端之间的协议。如果你服务器上 TLS 库还没有实现 ALPN,客户端只能通过 HTTP/1.1 通信。那么,和 Apache 连接的到底是什么?又是什么支持它呢?
+- **OpenSSL 1.0.2** 及其以后。
+- ??? (别的我也不知道了)
-- **OpenSSL 1.0.2** 即将到来。
-- ???
-
-如果你的 OpenSSL 库是 Linux 发行版自带的,这里使用的版本号可能和官方 OpenSSL 发行版的不同。如果不确定的话检查一下你的 Linux 发行版吧。
+如果你的 OpenSSL 库是 Linux 版本自带的,这里使用的版本号可能和官方 OpenSSL 版本的不同。如果不确定的话检查一下你的 Linux 版本吧。
### 配置 ###
另一个给服务器的好建议是为 http2 模块设置合适的日志等级。添加下面的配置:
- # 某个地方有这样一行
+ # 放在某个地方的这样一行
LoadModule http2_module modules/mod_http2.so
@@ -62,38 +61,37 @@ ALPN 用来屏蔽服务器和客户端之间的协议。如果你服务器上 TL
那么,假设你已经编译部署好了服务器, TLS 库也是最新的,你启动了你的服务器,打开了浏览器。。。你怎么知道它在工作呢?
-如果除此之外你没有添加其它到服务器配置,很可能它没有工作。
+如果除此之外你没有添加其它的服务器配置,很可能它没有工作。
-你需要告诉服务器在哪里使用协议。默认情况下,你的服务器并没有启动 HTTP/2 协议。因为这是安全路由,你可能要有一套部署了才能继续。
+你需要告诉服务器在哪里使用该协议。默认情况下,你的服务器并没有启动 HTTP/2 协议。因为这样比较安全,也许才能让你已有的部署可以继续工作。
-你用 **Protocols** 命令启用 HTTP/2 协议:
+你可以用新的 **Protocols** 指令启用 HTTP/2 协议:
- # for a https server
+ # 对于 https 服务器
Protocols h2 http/1.1
...
- # for a http server
+ # 对于 http 服务器
Protocols h2c http/1.1
-你可以给一般服务器或者指定的 **vhosts** 添加这个配置。
+你可以给整个服务器或者指定的 **vhosts** 添加这个配置。
#### SSL 参数 ####
-对于 TLS (SSL),HTTP/2 有一些特殊的要求。阅读 [https:// 连接][4]了解更详细的信息。
+对于 TLS (SSL),HTTP/2 有一些特殊的要求。阅读下面的“ https:// 连接”一节了解更详细的信息。
### http:// 连接 (h2c) ###
-尽管现在还没有浏览器支持 HTTP/2 协议, http:// 这样的 url 也能正常工作, 因为有 mod_h[ttp]2 的支持。启用它你只需要做的一件事是在 **httpd.conf** 配置 Protocols :
+尽管现在还没有浏览器支持,但是 HTTP/2 协议也工作在 http:// 这样的 url 上, 而且 mod_h[ttp]2 也支持。启用它你唯一所要做的是在 Protocols 配置中启用它:
- # for a http server
+ # 对于 http 服务器
Protocols h2c http/1.1
-
这里有一些支持 **h2c** 的客户端(和客户端库)。我会在下面介绍:
#### curl ####
-Daniel Stenberg 维护的网络资源命令行客户端 curl 当然支持。如果你的系统上有 curl,有一个简单的方法检查它是否支持 http/2:
+Daniel Stenberg 维护的用于访问网络资源的命令行客户端 curl 当然支持。如果你的系统上有 curl,有一个简单的方法检查它是否支持 http/2:
sh> curl -V
curl 7.43.0 (x86_64-apple-darwin15.0) libcurl/7.43.0 SecureTransport zlib/1.2.5
@@ -126,11 +124,11 @@ Daniel Stenberg 维护的网络资源命令行客户端 curl 当然支持。如
恭喜,如果看到了有 **...101 Switching...** 的行就表示它正在工作!
-有一些情况不会发生到 HTTP/2 的 Upgrade 。如果你的第一个请求没有内容,例如你上传一个文件,就不会触发 Upgrade。[h2c 限制][5]部分有详细的解释。
+有一些情况不会发生 HTTP/2 的升级切换(Upgrade)。如果你的第一个请求有内容数据(body),例如你上传一个文件时,就不会触发升级切换。[h2c 限制][5]部分有详细的解释。
#### nghttp ####
-nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客户端,你可以简单地通过获取资源验证你的安装:
+nghttp2 可以一同编译它自己的客户端和服务器。如果你的系统中有该客户端,你可以简单地通过获取一个资源来验证你的安装:
sh> nghttp -uv http:///
[ 0.001] Connected
@@ -151,7 +149,7 @@ nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客
这和我们上面 **curl** 例子中看到的 Upgrade 输出很相似。
-在命令行参数中隐藏着一种可以使用 **h2c**:的参数:**-u**。这会指示 **nghttp** 进行 HTTP/1 Upgrade 过程。但如果我们不使用呢?
+有另外一种在命令行参数中不用 **-u** 参数而使用 **h2c** 的方法。这个参数会指示 **nghttp** 进行 HTTP/1 升级切换过程。但如果我们不使用呢?
sh> nghttp -v http:///
[ 0.002] Connected
@@ -166,36 +164,33 @@ nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客
:scheme: http
...
-连接马上显示出了 HTTP/2!这就是协议中所谓的直接模式,当客户端发送一些特殊的 24 字节到服务器时就会发生:
+连接马上使用了 HTTP/2!这就是协议中所谓的直接(direct)模式,当客户端发送一些特殊的 24 字节到服务器时就会发生:
0x505249202a20485454502f322e300d0a0d0a534d0d0a0d0a
- or in ASCII: PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
+
+用 ASCII 表示是:
+
+ PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
支持 **h2c** 的服务器在一个新的连接中看到这些信息就会马上切换到 HTTP/2。HTTP/1.1 服务器则认为是一个可笑的请求,响应并关闭连接。
-因此 **直接** 模式只适合于那些确定服务器支持 HTTP/2 的客户端。例如,前一个 Upgrade 过程是成功的。
+因此,**直接**模式只适合于那些确定服务器支持 HTTP/2 的客户端。例如,当前一个升级切换过程成功了的时候。
-**直接** 模式的魅力是零开销,它支持所有请求,即使没有 body 部分(查看[h2c 限制][6])。任何支持 h2c 协议的服务器默认启用了直接模式。如果你想停用它,可以添加下面的配置指令到你的服务器:
+**直接**模式的魅力是零开销,它支持所有请求,即使带有请求数据部分(查看[h2c 限制][6])。
-注:下面这行打删除线
-
- H2Direct off
-
-注:下面这行打删除线
-
-对于 2.4.17 发行版,默认明文连接时启用 **H2Direct** 。但是有一些模块和这不兼容。因此,在下一发行版中,默认会设置为**off**,如果你希望你的服务器支持它,你需要设置它为:
+对于 2.4.17 版本,明文连接时默认启用 **H2Direct** 。但是有一些模块和这不兼容。因此,在下一版本中,默认会设置为**off**,如果你希望你的服务器支持它,你需要设置它为:
H2Direct on
### https:// 连接 (h2) ###
-一旦你的 mod_h[ttp]2 支持 h2c 连接,就是时候一同启用 **h2**,因为现在的浏览器支持它和 **https:** 一同使用。
+当你的 mod_h[ttp]2 可以支持 h2c 连接时,那就可以一同启用 **h2** 兄弟了,现在的浏览器仅支持它和 **https:** 一同使用。
-HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已经提到了 ALNP 扩展。另外的一个要求是不会使用特定[黑名单][7]中的密码。
+HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已经提到了 ALNP 扩展。另外的一个要求是不能使用特定[黑名单][7]中的加密算法。
-尽管现在版本的 **mod_h[ttp]2** 不增强这些密码(以后可能会),大部分客户端会这么做。如果你用不切当的密码在浏览器中打开 **h2** 服务器,你会看到模糊警告**INADEQUATE_SECURITY**,浏览器会拒接连接。
+尽管现在版本的 **mod_h[ttp]2** 不增强这些算法(以后可能会),但大部分客户端会这么做。如果让你的浏览器使用不恰当的算法打开 **h2** 服务器,你会看到不明确的警告**INADEQUATE_SECURITY**,浏览器会拒接连接。
-一个可接受的 Apache SSL 配置类似:
+一个可行的 Apache SSL 配置类似:
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!3DES:!MD5:!PSK
SSLProtocol All -SSLv2 -SSLv3
@@ -203,11 +198,11 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
(是的,这确实很长。)
-这里还有一些应该调整的 SSL 配置参数,但不是必须:**SSLSessionCache**, **SSLUseStapling** 等,其它地方也有介绍这些。例如 Ilya Grigorik 写的一篇博客 [高性能浏览器网络][8]。
+这里还有一些应该调整,但不是必须调整的 SSL 配置参数:**SSLSessionCache**, **SSLUseStapling** 等,其它地方也有介绍这些。例如 Ilya Grigorik 写的一篇超赞的博客: [高性能浏览器网络][8]。
#### curl ####
-再次回到 shell 并使用 curl(查看 [curl h2c 章节][9] 了解要求)你也可以通过 curl 用简单的命令检测你的服务器:
+再次回到 shell 使用 curl(查看上面的“curl h2c”章节了解要求),你也可以通过 curl 用简单的命令检测你的服务器:
sh> curl -v --http2 https:///
...
@@ -220,9 +215,9 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
恭喜你,能正常工作啦!如果还不能,可能原因是:
-- 你的 curl 不支持 HTTP/2。查看[检测][10]。
+- 你的 curl 不支持 HTTP/2。查看上面的“检测 curl”一节。
- 你的 openssl 版本太低不支持 ALPN。
-- 不能验证你的证书,或者不接受你的密码配置。尝试添加命令行选项 -k 停用 curl 中的检查。如果那能工作,还要重新配置你的 SSL 和证书。
+- 不能验证你的证书,或者不接受你的算法配置。尝试添加命令行选项 -k 停用 curl 中的这些检查。如果可以工作,就重新配置你的 SSL 和证书。
#### nghttp ####
@@ -246,11 +241,11 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
The negotiated protocol: http/1.1
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
-这表示 ALPN 能正常工作,但并没有用 h2 协议。你需要像上面介绍的那样在服务器上选中那个协议。如果一开始在 vhost 部分选中不能正常工作,试着在通用部分选中它。
+这表示 ALPN 能正常工作,但并没有用 h2 协议。你需要像上面介绍的那样检查你服务器上的 Protocols 配置。如果一开始在 vhost 部分设置不能正常工作,试着在通用部分设置它。
#### Firefox ####
-Update: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox HTTP/2 指示插件][12]。你可以看到有多少地方用到了 h2(提示:Apache Lounge 用 h2 已经有一段时间了。。。)
+更新: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox 上有个 HTTP/2 指示插件][12]。你可以看到有多少地方用到了 h2(提示:Apache Lounge 用 h2 已经有一段时间了。。。)
你可以在 Firefox 浏览器中打开开发者工具,在那里的网络标签页查看 HTTP/2 连接。当你打开了 HTTP/2 并重新刷新 html 页面时,你会看到类似下面的东西:
@@ -260,9 +255,9 @@ Update: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox HTTP/2 指示
#### Google Chrome ####
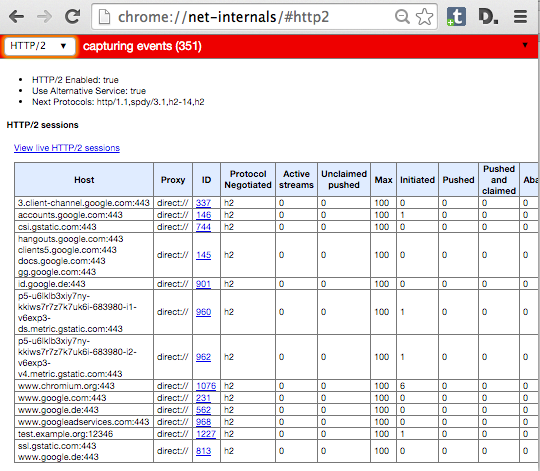
-在 Google Chrome 中,你在开发者工具中看不到 HTTP/2 指示器。相反,Chrome 用特殊的地址 **chrome://net-internals/#http2** 给出了相关信息。
+在 Google Chrome 中,你在开发者工具中看不到 HTTP/2 指示器。相反,Chrome 用特殊的地址 **chrome://net-internals/#http2** 给出了相关信息。(LCTT 译注:Chrome 已经有一个 “HTTP/2 and SPDY indicator” 可以很好的在地址栏识别 HTTP/2 连接)
-如果你在服务器中打开了一个页面并在 Chrome 那个页面查看,你可以看到类似下面这样:
+如果你打开了一个服务器的页面,可以在 Chrome 中查看那个 net-internals 页面,你可以看到类似下面这样:
@@ -276,21 +271,21 @@ Windows 10 中 Internet Explorer 的继任者 Edge 也支持 HTTP/2。你也可
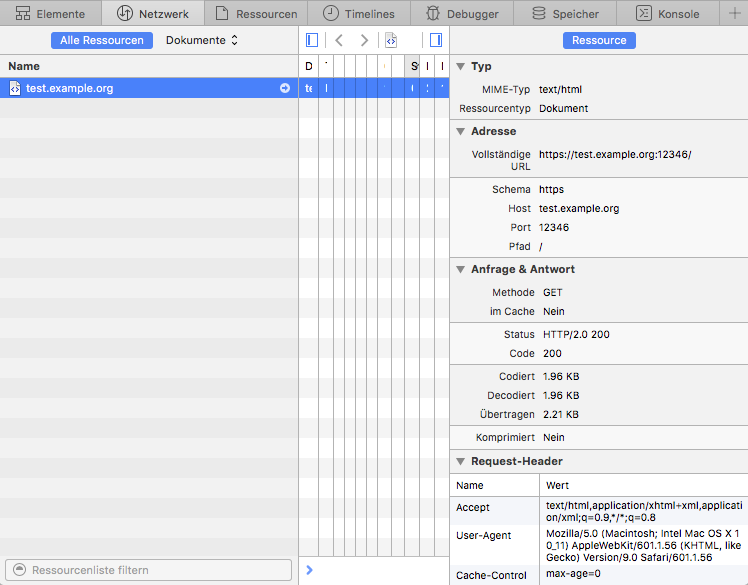
#### Safari ####
-在 Apple 的 Safari 中,打开开发者工具,那里有个网络标签页。重新加载你的服务器页面并在开发者工具中选择显示了加载的行。如果你启用了在右边显示详细试图,看 **状态** 部分。那里显示了 **HTTP/2.0 200**,类似:
+在 Apple 的 Safari 中,打开开发者工具,那里有个网络标签页。重新加载你的服务器上的页面,并在开发者工具中选择显示了加载的那行。如果你启用了在右边显示详细视图,看 **Status** 部分。那里显示了 **HTTP/2.0 200**,像这样:
#### 重新协商 ####
-https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会发生变化。在 Apache httpd 中,你可以通过目录中的配置文件修改 TLS 参数。如果一个要获取特定位置资源的请求到来,配置的 TLS 参数会和当前的 TLS 参数进行对比。如果它们不相同,就会触发重新协商。
+https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会发生变化。在 Apache httpd 中,你可以在 directory 配置中改变 TLS 参数。如果进来一个获取特定位置资源的请求,配置的 TLS 参数会和当前的 TLS 参数进行对比。如果它们不相同,就会触发重新协商。
-这种最常见的情形是密码变化和客户端验证。你可以要求客户访问特定位置时需要通过验证,或者对于特定资源,你可以使用更安全的, CPU 敏感的密码。
+这种最常见的情形是算法变化和客户端证书。你可以要求客户访问特定位置时需要通过验证,或者对于特定资源,你可以使用更安全的、对 CPU 压力更大的算法。
-不管你的想法有多么好,HTTP/2 中都**不可以**发生重新协商。如果有 100 多个请求到同一个地方,什么时候哪个会发生重新协商呢?
+但不管你的想法有多么好,HTTP/2 中都**不可以**发生重新协商。在同一个连接上会有 100 多个请求,那么重新协商该什么时候做呢?
-对于这种配置,现有的 **mod_h[ttp]2** 还不能保证你的安全。如果你有一个站点使用了 TLS 重新协商,别在上面启用 h2!
+对于这种配置,现有的 **mod_h[ttp]2** 还没有办法。如果你有一个站点使用了 TLS 重新协商,别在上面启用 h2!
-当然,我们会在后面的发行版中解决这个问题然后你就可以安全地启用了。
+当然,我们会在后面的版本中解决这个问题,然后你就可以安全地启用了。
### 限制 ###
@@ -298,45 +293,45 @@ https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会
实现除 HTTP 之外协议的模块可能和 **mod_http2** 不兼容。这在其它协议要求服务器首先发送数据时无疑会发生。
-**NNTP** 就是这种协议的一个例子。如果你在服务器中配置了 **mod_nntp_like_ssl**,甚至都不要加载 mod_http2。等待下一个发行版。
+**NNTP** 就是这种协议的一个例子。如果你在服务器中配置了 **mod\_nntp\_like\_ssl**,那么就不要加载 mod_http2。等待下一个版本。
#### h2c 限制 ####
**h2c** 的实现还有一些限制,你应该注意:
-#### 在虚拟主机中拒绝 h2c ####
+##### 在虚拟主机中拒绝 h2c #####
你不能对指定的虚拟主机拒绝 **h2c 直连**。连接建立而没有看到请求时会触发**直连**,这使得不可能预先知道 Apache 需要查找哪个虚拟主机。
-#### 升级请求体 ####
+##### 有请求数据时的升级切换 #####
-对于有 body 部分的请求,**h2c** 升级不能正常工作。那些是 PUT 和 POST 请求(用于提交和上传)。如果你写了一个客户端,你可能会用一个简单的 GET 去处理请求或者用选项 * 去触发升级。
+对于有数据的请求,**h2c** 升级切换不能正常工作。那些是 PUT 和 POST 请求(用于提交和上传)。如果你写了一个客户端,你可能会用一个简单的 GET 或者 OPTIONS * 来处理那些请求以触发升级切换。
-原因从技术层面来看显而易见,但如果你想知道:升级过程中,连接处于半疯状态。请求按照 HTTP/1.1 的格式,而响应使用 HTTP/2。如果请求有一个 body 部分,服务器在发送响应之前需要读取整个 body。因为响应可能需要从客户端处得到应答用于流控制。但如果仍在发送 HTTP/1.1 请求,客户端就还不能处理 HTTP/2 连接。
+原因从技术层面来看显而易见,但如果你想知道:在升级切换过程中,连接处于半疯状态。请求按照 HTTP/1.1 的格式,而响应使用 HTTP/2 帧。如果请求有一个数据部分,服务器在发送响应之前需要读取整个数据。因为响应可能需要从客户端处得到应答用于流控制及其它东西。但如果仍在发送 HTTP/1.1 请求,客户端就仍然不能以 HTTP/2 连接。
-为了使行为可预测,几个服务器实现商决定不要在任何请求体中进行升级,即使 body 很小。
+为了使行为可预测,几个服务器在实现上决定不在任何带有请求数据的请求中进行升级切换,即使请求数据很小。
-#### 升级 302s ####
+##### 302 时的升级切换 #####
-有重定向发生时当前 h2c 升级也不能工作。看起来 mod_http2 之前的重写有可能发生。这当然不会导致断路,但你测试这样的站点也许会让你迷惑。
+有重定向发生时,当前的 h2c 升级切换也不能工作。看起来 mod_http2 之前的重写有可能发生。这当然不会导致断路,但你测试这样的站点也许会让你迷惑。
#### h2 限制 ####
这里有一些你应该意识到的 h2 实现限制:
-#### 连接重用 ####
+##### 连接重用 #####
HTTP/2 协议允许在特定条件下重用 TLS 连接:如果你有带通配符的证书或者多个 AltSubject 名称,浏览器可能会重用现有的连接。例如:
-你有一个 **a.example.org** 的证书,它还有另外一个名称 **b.example.org**。你在浏览器中打开 url **https://a.example.org/**,用另一个标签页加载 **https://b.example.org/**。
+你有一个 **a.example.org** 的证书,它还有另外一个名称 **b.example.org**。你在浏览器中打开 URL **https://a.example.org/**,用另一个标签页加载 **https://b.example.org/**。
-在重新打开一个新的连接之前,浏览器看到它有一个到 **a.example.org** 的连接并且证书对于 **b.example.org** 也可用。因此,它在第一个连接上面向第二个标签页发送请求。
+在重新打开一个新的连接之前,浏览器看到它有一个到 **a.example.org** 的连接并且证书对于 **b.example.org** 也可用。因此,它在第一个连接上面发送第二个标签页的请求。
-这种连接重用是刻意设计的,它使得致力于 HTTP/1 切分效率的站点能够不需要太多变化就能利用 HTTP/2。
+这种连接重用是刻意设计的,它使得使用了 HTTP/1 切分(sharding)来提高效率的站点能够不需要太多变化就能利用 HTTP/2。
-Apache **mod_h[ttp]2** 还没有完全实现这点。如果 **a.example.org** 和 **b.example.org** 是不同的虚拟主机, Apache 不会允许这样的连接重用,并会告知浏览器状态码**421 错误请求**。浏览器会意识到它需要重新打开一个到 **b.example.org** 的连接。这仍然能工作,只是会降低一些效率。
+Apache **mod_h[ttp]2** 还没有完全实现这点。如果 **a.example.org** 和 **b.example.org** 是不同的虚拟主机, Apache 不会允许这样的连接重用,并会告知浏览器状态码 **421 Misdirected Request**。浏览器会意识到它需要重新打开一个到 **b.example.org** 的连接。这仍然能工作,只是会降低一些效率。
-我们期望下一次的发布中能有切当的检查。
+我们期望下一次的发布中能有合适的检查。
Münster, 12.10.2015,
@@ -355,7 +350,7 @@ via: https://icing.github.io/mod_h2/howto.html
作者:[icing][a]
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20150823 How learning data structures and algorithms make you a better developer.md b/published/201511/20150823 How learning data structures and algorithms make you a better developer.md
similarity index 100%
rename from published/20150823 How learning data structures and algorithms make you a better developer.md
rename to published/201511/20150823 How learning data structures and algorithms make you a better developer.md
diff --git a/published/201511/20150827 The Strangest Most Unique Linux Distros.md b/published/201511/20150827 The Strangest Most Unique Linux Distros.md
new file mode 100644
index 0000000000..a7dff335a4
--- /dev/null
+++ b/published/201511/20150827 The Strangest Most Unique Linux Distros.md
@@ -0,0 +1,88 @@
+那些奇特的 Linux 发行版本
+================================================================================
+从大多数消费者所关注的诸如 Ubuntu,Fedora,Mint 或 elementary OS 到更加复杂、轻量级和企业级的诸如 Slackware,Arch Linux 或 RHEL,这些发行版本我都已经见识过了。除了这些,难道没有其他别的了吗?其实 Linux 的生态系统是非常多样化的,对每个人来说,总有一款适合你。下面就让我们讨论一些稀奇古怪的小众 Linux 发行版本吧,它们代表着开源平台真正的多样性。
+
+### Puppy Linux
+
+
+
+它是一个仅有一个普通 DVD 光盘容量十分之一大小的操作系统,这就是 Puppy Linux。整个操作系统仅有 100MB 大小!并且它还可以从内存中运行,这使得它运行极快,即便是在老式的 PC 机上。 在操作系统启动后,你甚至可以移除启动介质!还有什么比这个更好的吗? 系统所需的资源极小,大多数的硬件都会被自动检测到,并且它预装了能够满足你基本需求的软件。[在这里体验 Puppy Linux 吧][1].
+
+### Suicide Linux(自杀 Linux)
+
+
+
+这个名字吓到你了吗?我想应该是。 ‘任何时候 -注意是任何时候-一旦你远程输入不正确的命令,解释器都会创造性地将它重定向为 `rm -rf /` 命令,然后擦除你的硬盘’。它就是这么简单。我真的很想知道谁自信到将[Suicide Linux][2] 安装到生产机上。 **警告:千万不要在生产机上尝试这个!** 假如你感兴趣的话,现在可以通过一个简洁的[DEB 包][3]来获取到它。
+
+### PapyrOS
+
+
+
+它的 “奇怪”是好的方面。PapyrOS 正尝试着将 Android 的 material design 设计语言引入到新的 Linux 发行版本上。尽管这个项目还处于早期阶段,看起来它已经很有前景。该项目的网页上说该系统已经完成了 80%,随后人们可以期待它的第一个 Alpha 发行版本。在该项目被宣告提出时,我们做了 [PapyrOS][4] 的小幅报道,从它的外观上看,它甚至可能会引领潮流。假如你感兴趣的话,可在 [Google+][5] 上关注该项目并可通过 [BountySource][6] 来贡献出你的力量。
+
+### Qubes OS
+
+
+
+Qubes 是一个开源的操作系统,其设计通过使用[安全分级(Security by Compartmentalization)][14]的方法,来提供强安全性。其前提假设是不存在完美的没有 bug 的桌面环境。并通过实现一个‘安全隔离(Security by Isolation)’ 的方法,[Qubes Linux][7]试图去解决这些问题。Qubes 基于 Xen、X 视窗系统和 Linux,并可运行大多数的 Linux 应用,支持大多数的 Linux 驱动。Qubes 入选了 Access Innovation Prize 2014 for Endpoint Security Solution 决赛名单。
+
+### Ubuntu Satanic Edition
+
+
+
+Ubuntu SE 是一个基于 Ubuntu 的发行版本。通过一个含有主题、壁纸甚至来源于某些天才新晋艺术家的重金属音乐的综合软件包,“它同时带来了最好的自由软件和免费的金属音乐” 。尽管这个项目看起来不再积极开发了, Ubuntu Satanic Edition 甚至在其名字上都显得奇异。 [Ubuntu SE (Slightly NSFW)][8]。
+
+### Tiny Core Linux
+
+
+
+Puppy Linux 还不够小?试试这个吧。 Tiny Core Linux 是一个 12MB 大小的图形化 Linux 桌面!是的,你没有看错。一个主要的补充说明:它不是一个完整的桌面,也并不完全支持所有的硬件。它只含有能够启动进入一个非常小巧的 X 桌面,支持有线网络连接的核心部件。它甚至还有一个名为 Micro Core Linux 的没有 GUI 的版本,仅有 9MB 大小。[Tiny Core Linux][9]。
+
+### NixOS
+
+
+
+它是一个资深用户所关注的 Linux 发行版本,有着独特的打包和配置管理方式。在其他的发行版本中,诸如升级的操作可能是非常危险的。升级一个软件包可能会引起其他包无法使用,而升级整个系统感觉还不如重新安装一个。在那些你不能安全地测试由一个配置的改变所带来的结果的更改之上,它们通常没有“重来”这个选项。在 NixOS 中,整个系统由 Nix 包管理器按照一个纯功能性的构建语言的描述来构建。这意味着构建一个新的配置并不会重写先前的配置。大多数其他的特色功能也遵循着这个模式。Nix 相互隔离地存储所有的软件包。有关 NixOS 的更多内容请看[这里][10]。
+
+### GoboLinux
+
+
+
+这是另一个非常奇特的 Linux 发行版本。它与其他系统如此不同的原因是它有着独特的重新整理的文件系统。它有着自己独特的子目录树,其中存储着所有的文件和程序。GoboLinux 没有专门的包数据库,因为其文件系统就是它的数据库。在某些方面,这类重整有些类似于 OS X 上所看到的功能。
+
+### Hannah Montana Linux
+
+
+
+它是一个基于 Kubuntu 的 Linux 发行版本,它有着汉娜·蒙塔娜( Hannah Montana) 主题的开机启动界面、KDM(KDE Display Manager)、图标集、ksplash、plasma、颜色主题和壁纸(I'm so sorry)。[这是它的链接][12]。这个项目现在不再活跃了。
+
+### RLSD Linux
+
+它是一个极其精简、小巧、轻量和安全可靠的,基于 Linux 文本的操作系统。开发者称 “它是一个独特的发行版本,提供一系列的控制台应用和自带的安全特性,对黑客或许有吸引力。” [RLSD Linux][13].
+
+我们还错过了某些更加奇特的发行版本吗?请让我们知晓吧。
+
+--------------------------------------------------------------------------------
+
+via: http://www.techdrivein.com/2015/08/the-strangest-most-unique-linux-distros.html
+
+作者:Manuel Jose
+译者:[FSSlc](https://github.com/FSSlc)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
+[2]:http://qntm.org/suicide
+[3]:http://sourceforge.net/projects/suicide-linux/files/
+[4]:http://www.techdrivein.com/2015/02/papyros-material-design-linux-coming-soon.html
+[5]:https://plus.google.com/communities/109966288908859324845/stream/3262a3d3-0797-4344-bbe0-56c3adaacb69
+[6]:https://www.bountysource.com/teams/papyros
+[7]:https://www.qubes-os.org/
+[8]:http://ubuntusatanic.org/
+[9]:http://tinycorelinux.net/
+[10]:https://nixos.org/
+[11]:http://www.gobolinux.org/
+[12]:http://hannahmontana.sourceforge.net/
+[13]:http://rlsd2.dimakrasner.com/
+[14]:https://en.wikipedia.org/wiki/Compartmentalization_(information_security)
\ No newline at end of file
diff --git a/published/201511/20150831 How to switch from NetworkManager to systemd-networkd on Linux.md b/published/201511/20150831 How to switch from NetworkManager to systemd-networkd on Linux.md
new file mode 100644
index 0000000000..658d6c033d
--- /dev/null
+++ b/published/201511/20150831 How to switch from NetworkManager to systemd-networkd on Linux.md
@@ -0,0 +1,165 @@
+如何在 Linux 上从 NetworkManager 切换为 systemd-network
+================================================================================
+在 Linux 世界里,对 [systemd][1] 的采用一直是激烈争论的主题,它的支持者和反对者之间的战火仍然在燃烧。到了今天,大部分主流 Linux 发行版都已经采用了 systemd 作为默认的初始化(init)系统。
+
+正如其作者所说,作为一个 “从未完成、从未完善、但一直追随技术进步” 的系统,systemd 已经不只是一个初始化进程,它被设计为一个更广泛的系统以及服务管理平台,这个平台是一个包含了不断增长的核心系统进程、库和工具的生态系统。
+
+**systemd** 的其中一部分是 **systemd-networkd**,它负责 systemd 生态中的网络配置。使用 systemd-networkd,你可以为网络设备配置基础的 DHCP/静态 IP 网络。它还可以配置虚拟网络功能,例如网桥、隧道和 VLAN。systemd-networkd 目前还不能直接支持无线网络,但你可以使用 wpa_supplicant 服务配置无线适配器,然后把它和 **systemd-networkd** 联系起来。
+
+在很多 Linux 发行版中,NetworkManager 仍然作为默认的网络配置管理器。和 NetworkManager 相比,**systemd-networkd** 仍处于积极的开发状态,还缺少一些功能。例如,它还不能像 NetworkManager 那样能让你的计算机在任何时候通过多种接口保持连接。它还没有为更高层面的脚本编程提供 ifup/ifdown 钩子函数。但是,systemd-networkd 和其它 systemd 组件(例如用于域名解析的 **resolved**、NTP 的**timesyncd**,用于命名的 udevd)结合的非常好。随着时间增长,**systemd-networkd**只会在 systemd 环境中扮演越来越重要的角色。
+
+如果你对 **systemd-networkd** 的进步感到高兴,从 NetworkManager 切换到 systemd-networkd 是值得你考虑的一件事。如果你强烈反对 systemd,对 NetworkManager 或[基础网络服务][2]感到很满意,那也很好。
+
+但对于那些想尝试 systemd-networkd 的人,可以继续看下去,在这篇指南中学会在 Linux 中怎么从 NetworkManager 切换到 systemd-networkd。
+
+### 需求 ###
+
+systemd 210 及其更高版本提供了 systemd-networkd。因此诸如 Debian 8 "Jessie" (systemd 215)、 Fedora 21 (systemd 217)、 Ubuntu 15.04 (systemd 219) 或更高版本的 Linux 发行版和 systemd-networkd 兼容。
+
+对于其它发行版,在开始下一步之前先检查一下你的 systemd 版本。
+
+ $ systemctl --version
+
+### 从 NetworkManager 切换到 Systemd-networkd ###
+
+从 NetworkManager 切换到 systemd-networkd 其实非常简答(反过来也一样)。
+
+首先,按照下面这样先停用 NetworkManager 服务,然后启用 systemd-networkd。
+
+ $ sudo systemctl disable NetworkManager
+ $ sudo systemctl enable systemd-networkd
+
+你还要启用 **systemd-resolved** 服务,systemd-networkd用它来进行域名解析。该服务还实现了一个缓存式 DNS 服务器。
+
+ $ sudo systemctl enable systemd-resolved
+ $ sudo systemctl start systemd-resolved
+
+当启动后,**systemd-resolved** 就会在 /run/systemd 目录下某个地方创建它自己的 resolv.conf。但是,把 DNS 解析信息存放在 /etc/resolv.conf 是更普遍的做法,很多应用程序也会依赖于 /etc/resolv.conf。因此为了兼容性,按照下面的方式创建一个到 /etc/resolv.conf 的符号链接。
+
+ $ sudo rm /etc/resolv.conf
+ $ sudo ln -s /run/systemd/resolve/resolv.conf /etc/resolv.conf
+
+### 用 systemd-networkd 配置网络连接 ###
+
+要用 systemd-networkd 配置网络服务,你必须指定带.network 扩展名的配置信息文本文件。这些网络配置文件保存到 /etc/systemd/network 并从这里加载。当有多个文件时,systemd-networkd 会按照字母顺序一个个加载并处理。
+
+首先创建 /etc/systemd/network 目录。
+
+ $ sudo mkdir /etc/systemd/network
+
+#### DHCP 网络 ####
+
+首先来配置 DHCP 网络。对于此,先要创建下面的配置文件。文件名可以任意,但记住文件是按照字母顺序处理的。
+
+ $ sudo vi /etc/systemd/network/20-dhcp.network
+
+----------
+
+ [Match]
+ Name=enp3*
+
+ [Network]
+ DHCP=yes
+
+正如你上面看到的,每个网络配置文件包括了一个或多个 “sections”,每个 “section”都用 [XXX] 开头。每个 section 包括了一个或多个键值对。`[Match]` 部分决定这个配置文件配置哪个(些)网络设备。例如,这个文件匹配所有名称以 ens3 开头的网络设备(例如 enp3s0、 enp3s1、 enp3s2 等等)对于匹配的接口,然后启用 [Network] 部分指定的 DHCP 网络配置。
+
+### 静态 IP 网络 ###
+
+如果你想给网络设备分配一个静态 IP 地址,那就新建下面的配置文件。
+
+ $ sudo vi /etc/systemd/network/10-static-enp3s0.network
+
+----------
+
+ [Match]
+ Name=enp3s0
+
+ [Network]
+ Address=192.168.10.50/24
+ Gateway=192.168.10.1
+ DNS=8.8.8.8
+
+正如你猜测的, enp3s0 接口地址会被指定为 192.168.10.50/24,默认网关是 192.168.10.1, DNS 服务器是 8.8.8.8。这里微妙的一点是,接口名 enp3s0 事实上也匹配了之前 DHCP 配置中定义的模式规则。但是,根据词汇顺序,文件 "10-static-enp3s0.network" 在 "20-dhcp.network" 之前被处理,对于 enp3s0 接口静态配置比 DHCP 配置有更高的优先级。
+
+一旦你完成了创建配置文件,重启 systemd-networkd 服务或者重启机器。
+
+ $ sudo systemctl restart systemd-networkd
+
+运行以下命令检查服务状态:
+
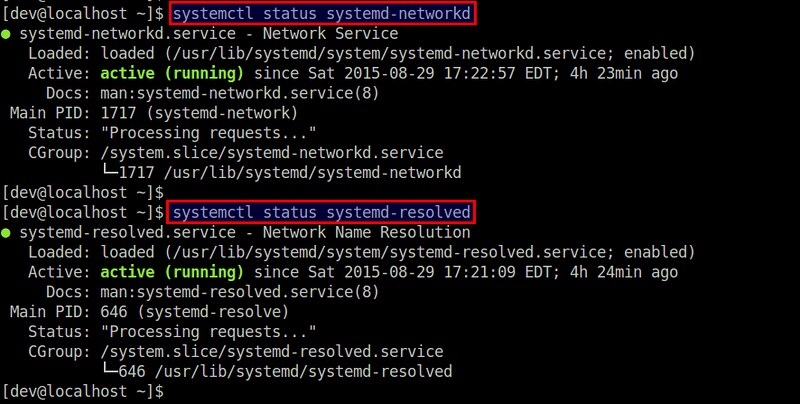
+ $ systemctl status systemd-networkd
+ $ systemctl status systemd-resolved
+
+
+
+### 用 systemd-networkd 配置虚拟网络设备 ###
+
+**systemd-networkd** 同样允许你配置虚拟网络设备,例如网桥、VLAN、隧道、VXLAN、绑定等。你必须在用 .netdev 作为扩展名的文件中配置这些虚拟设备。
+
+这里我展示了如何配置一个桥接接口。
+
+#### Linux 网桥 ####
+
+如果你想创建一个 Linux 网桥(br0) 并把物理接口(eth1) 添加到网桥,你可以新建下面的配置。
+
+ $ sudo vi /etc/systemd/network/bridge-br0.netdev
+
+----------
+
+ [NetDev]
+ Name=br0
+ Kind=bridge
+
+然后按照下面这样用 .network 文件配置网桥接口 br0 和从接口 eth1。
+
+ $ sudo vi /etc/systemd/network/bridge-br0-slave.network
+
+----------
+
+ [Match]
+ Name=eth1
+
+ [Network]
+ Bridge=br0
+
+----------
+
+ $ sudo vi /etc/systemd/network/bridge-br0.network
+
+----------
+
+ [Match]
+ Name=br0
+
+ [Network]
+ Address=192.168.10.100/24
+ Gateway=192.168.10.1
+ DNS=8.8.8.8
+
+最后,重启 systemd-networkd。
+
+ $ sudo systemctl restart systemd-networkd
+
+你可以用 [brctl 工具][3] 来验证是否创建好了网桥 br0。
+
+### 总结 ###
+
+当 systemd 誓言成为 Linux 的系统管理器时,有类似 systemd-networkd 的东西来管理网络配置也就不足为奇。但是在现阶段,systemd-networkd 看起来更适合于网络配置相对稳定的服务器环境。对于桌面/笔记本环境,它们有多种临时有线/无线接口,NetworkManager 仍然是比较好的选择。
+
+对于想进一步了解 systemd-networkd 的人,可以参考官方[man 手册][4]了解完整的支持列表和关键点。
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/switch-from-networkmanager-to-systemd-networkd.html
+
+作者:[Dan Nanni][a]
+译者:[ictlyh](http://mutouxiaogui.cn/blog)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://xmodulo.com/use-systemd-system-administration-debian.html
+[2]:http://xmodulo.com/disable-network-manager-linux.html
+[3]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
+[4]:http://www.freedesktop.org/software/systemd/man/systemd.network.html
diff --git a/published/201511/20150909 Superclass--15 of the world's best living programmers.md b/published/201511/20150909 Superclass--15 of the world's best living programmers.md
new file mode 100644
index 0000000000..89a42d29d7
--- /dev/null
+++ b/published/201511/20150909 Superclass--15 of the world's best living programmers.md
@@ -0,0 +1,427 @@
+超神们:15 位健在的世界级程序员!
+================================================================================
+
+当开发人员说起世界顶级程序员时,他们的名字往往会被提及。
+
+好像现在程序员有很多,其中不乏有许多优秀的程序员。但是哪些程序员更好呢?
+
+虽然这很难客观评价,不过在这个话题确实是开发者们津津乐道的。ITworld 深入程序员社区,避开四溅的争执口水,试图找出可能存在的所谓共识。事实证明,屈指可数的某些名字经常是讨论的焦点。
+
+
+
+*图片来源: [tom_bullock CC BY 2.0][1]*
+
+下面就让我们来看看这些世界顶级的程序员吧!
+
+### 玛格丽特·汉密尔顿(Margaret Hamilton) ###
+
+
+
+*图片来源: [NASA][2]*
+
+**成就: 阿波罗飞行控制软件背后的大脑**
+
+生平: 查尔斯·斯塔克·德雷珀实验室(Charles Stark Draper Laboratory)软件工程部的主任,以她为首的团队负责设计和打造 NASA 的阿波罗的舰载飞行控制器软件和空间实验室(Skylab)的任务。基于阿波罗这段的工作经历,她又后续开发了[通用系统语言(Universal Systems Language)][5]和[开发先于事实( Development Before the Fact)][6]的范例。开创了[异步软件、优先调度和超可靠的软件设计][7]理念。被认为发明了“[软件工程( software engineering)][8]”一词。1986年获[奥古斯塔·埃达·洛夫莱斯奖(Augusta Ada Lovelace Award)][9],2003年获 [NASA 杰出太空行动奖(Exceptional Space Act Award)][10]。
+
+评论:
+
+> “汉密尔顿发明了测试,使美国计算机工程规范了很多” —— [ford_beeblebrox][11]
+
+> “我认为在她之前(不敬地说,包括高德纳(Knuth)在内的)计算机编程是(另一种形式上留存的)数学分支。然而这个宇宙飞船的飞行控制系统明确地将编程带入了一个崭新的领域。” —— [Dan Allen][12]
+
+> “... 她引入了‘软件工程’这个术语 — 并作出了最好的示范。” —— [David Hamilton][13]
+
+> “真是个坏家伙” [Drukered][14]
+
+
+### 唐纳德·克努斯(Donald Knuth),即 高德纳 ###
+
+
+
+*图片来源: [vonguard CC BY-SA 2.0][15]*
+
+**成就: 《计算机程序设计艺术(The Art of Computer Programming,TAOCP)》 作者**
+
+生平: 撰写了[编程理论的权威书籍][16]。发明了数字排版系统 Tex。1971年,[ACM(美国计算机协会)葛丽丝·穆雷·霍普奖(Grace Murray Hopper Award)][17] 的首位获奖者。1974年获 ACM [图灵奖(A. M. Turing)][18],1979年获[美国国家科学奖章(National Medal of Science)][19],1995年获IEEE[约翰·冯·诺依曼奖章(John von Neumann Medal)][20]。1998年入选[计算机历史博物馆(Computer History Museum)名人录(Hall of Fellows)][21]。
+
+评论:
+
+> “... 写的计算机编程艺术(The Art of Computer Programming,TAOCP)可能是有史以来计算机编程方面最大的贡献。”—— [佚名][22]
+
+> “唐·克努斯的 TeX 是我所用过的计算机程序中唯一一个几乎没有 bug 的。真是让人印象深刻!”—— [Jaap Weel][23]
+
+> “如果你要问我的话,我只能说太棒了!” —— [Mitch Rees-Jones][24]
+
+### 肯·汤普逊(Ken Thompson) ###
+
+
+
+*图片来源: [Association for Computing Machinery][25]*
+
+**成就: Unix 之父**
+
+生平:与[丹尼斯·里奇(Dennis Ritchie)][26]共同创造了 Unix。创造了 [B 语言][27]、[UTF-8 字符编码方案][28]、[ed 文本编辑器][29],同时也是 Go 语言的共同开发者。(和里奇)共同获得1983年的[图灵奖(A.M. Turing Award )][30],1994年获 [IEEE 计算机先驱奖( IEEE Computer Pioneer Award)][31],1998年获颁[美国国家科技奖章( National Medal of Technology )][32]。在1997年入选[计算机历史博物馆(Computer History Museum)名人录(Hall of Fellows)][33]。
+
+评论:
+
+> “... 可能是有史以来最能成事的程序员了。Unix 内核,Unix 工具,国际象棋程序世界冠军 Belle,Plan 9,Go 语言。” —— [Pete Prokopowicz][34]
+
+> “肯所做出的贡献,据我所知无人能及,是如此的根本、实用、经得住时间的考验,时至今日仍在使用。” —— [Jan Jannink][35]
+
+
+### 理查德·斯托曼(Richard Stallman) ###
+
+
+
+*图片来源: [Jiel Beaumadier CC BY-SA 3.0][135]*
+
+**成就: Emacs 和 GCC 缔造者**
+
+生平: 成立了 [GNU 工程(GNU Project)] [36],并创造了它的许多核心工具,如 [Emacs、GCC、GDB][37] 和 [GNU Make][38]。还创办了[自由软件基金会(Free Software Foundation)] [39]。1990年荣获 ACM 的[葛丽丝·穆雷·霍普奖( Grace Murray Hopper Award)][40],1998年获 [EFF 先驱奖(Pioneer Award)][41].
+
+评论:
+
+> “... 在 Symbolics 对阵 LMI 的战斗中,独自一人与一众 Lisp 黑客好手对码。” —— [Srinivasan Krishnan][42]
+
+> “通过他在编程上的精湛造诣与强大信念,开辟了一整套编程与计算机的亚文化。” —— [Dan Dunay][43]
+
+> “我可以不赞同这位伟人的很多方面,不必盖棺论定,他不可否认都已经是一位伟大的程序员了。” —— [Marko Poutiainen][44]
+
+> “试想 Linux 如果没有 GNU 工程的前期工作会怎么样。(多亏了)斯托曼的炸弹!” —— [John Burnette][45]
+
+### 安德斯·海尔斯伯格(Anders Hejlsberg) ###
+
+
+
+*图片来源: [D.Begley CC BY 2.0][46]*
+
+**成就: 创造了Turbo Pascal**
+
+生平: [Turbo Pascal 的原作者][47],是最流行的 Pascal 编译器和第一个集成开发环境。而后,[领导了 Turbo Pascal 的继任者 Delphi][48] 的构建。[C# 的主要设计师和架构师][49]。2001年荣获[ Dr. Dobb 的杰出编程奖(Dr. Dobb's Excellence in Programming Award )][50]。
+
+评论:
+
+> “他用汇编语言为当时两个主流的 PC 操作系统(DOS 和 CPM)编写了 [Pascal] 编译器。用它来编译、链接并运行仅需几秒钟而不是几分钟。” —— [Steve Wood][51]
+
+> “我佩服他 - 他创造了我最喜欢的开发工具,陪伴着我度过了三个关键的时期直至我成为一位专业的软件工程师。” —— [Stefan Kiryazov][52]
+
+### Doug Cutting ###
+
+
+
+图片来源: [vonguard CC BY-SA 2.0][53]
+
+**成就: 创造了 Lucene**
+
+生平: [开发了 Lucene 搜索引擎以及 Web 爬虫 Nutch][54] 和用于大型数据集的分布式处理套件 [Hadoop][55]。一位强有力的开源支持者(Lucene、Nutch 以及 Hadoop 都是开源的)。前 [Apache 软件基金(Apache Software Foundation)的理事][56]。
+
+评论:
+
+
+> “...他就是那个既写出了优秀搜索框架(lucene/solr),又为世界开启大数据之门(hadoop)的男人。” —— [Rajesh Rao][57]
+
+> “他在 Lucene 和 Hadoop(及其它工程)的创造/工作中为世界创造了巨大的财富和就业...” —— [Amit Nithianandan][58]
+
+### Sanjay Ghemawat ###
+
+
+
+*图片来源: [Association for Computing Machinery][59]*
+
+**成就: 谷歌核心架构师**
+
+生平: [协助设计和实现了一些谷歌大型分布式系统的功能][60],包括 MapReduce、BigTable、Spanner 和谷歌文件系统(Google File System)。[创造了 Unix 的 ical ][61]日历系统。2009年入选[美国国家工程院(National Academy of Engineering)][62]。2012年荣获 [ACM-Infosys 基金计算机科学奖( ACM-Infosys Foundation Award in the Computing Sciences)][63]。
+
+评论:
+
+
+> “Jeff Dean的僚机。” —— [Ahmet Alp Balkan][64]
+
+### Jeff Dean ###
+
+
+
+*图片来源: [Google][65]*
+
+**成就: 谷歌搜索索引背后的大脑**
+
+生平:协助设计和实现了[许多谷歌大型分布式系统的功能][66],包括网页爬虫,索引搜索,AdSense,MapReduce,BigTable 和 Spanner。2009年入选[美国国家工程院( National Academy of Engineering)][67]。2012年荣获ACM 的[SIGOPS 马克·维瑟奖( SIGOPS Mark Weiser Award)][68]及[ACM-Infosys基金计算机科学奖( ACM-Infosys Foundation Award in the Computing Sciences)][69]。
+
+评论:
+
+> “... 带来了在数据挖掘(GFS、MapReduce、BigTable)上的突破。” —— [Natu Lauchande][70]
+
+> “... 设计、构建并部署 MapReduce 和 BigTable,和以及数不清的其它东西” —— [Erik Goldman][71]
+
+### 林纳斯·托瓦兹(Linus Torvalds) ###
+
+
+
+*图片来源: [Krd CC BY-SA 4.0][72]*
+
+**成就: Linux缔造者**
+
+生平:创造了 [Linux 内核][73]与[开源的版本控制系统 Git][74]。收获了许多奖项和荣誉,包括有1998年的 [EFF 先驱奖(EFF Pioneer Award)][75],2000年荣获[英国电脑学会(British Computer Society)授予的洛夫莱斯勋章(Lovelace Medal)][76],2012年荣获[千禧技术奖(Millenium Technology Prize)][77]还有2014年[IEEE计算机学会( IEEE Computer Society)授予的计算机先驱奖(Computer Pioneer Award)][78]。同样入选了2008年的[计算机历史博物馆( Computer History Museum)名人录(Hall of Fellows)][79]与2012年的[互联网名人堂(Internet Hall of Fame )][80]。
+
+评论:
+
+> “他只用了几年的时间就写出了 Linux 内核,而 GNU Hurd(GNU 开发的内核)历经25年的开发却丝毫没有准备发布的意思。他的成就就是带来了希望。” —— [Erich Ficker][81]
+
+> “托沃兹可能是程序员的程序员。” —— [Dan Allen][82]
+
+> “他真的很棒。” —— [Alok Tripathy][83]
+
+### 约翰·卡马克(John Carmack) ###
+
+
+
+*图片来源: [QuakeCon CC BY 2.0][84]*
+
+**成就: 毁灭战士的缔造者**
+
+生平: ID 社联合创始人,打造了德军总部3D(Wolfenstein 3D)、毁灭战士(Doom)和雷神之锤(Quake)等所谓的即时 FPS 游戏。引领了[切片适配刷新(adaptive tile refresh)][86], [二叉空间分割(binary space partitioning)][87],表面缓存(surface caching)等开创性的计算机图像技术。2001年入选[互动艺术与科学学会名人堂(Academy of Interactive Arts and Sciences Hall of Fame)][88],2007年和2008年荣获工程技术类[艾美奖(Emmy awards)][89]并于2010年由[游戏开发者甄选奖( Game Developers Choice Awards)][90]授予终生成就奖。
+
+评论:
+
+> “他在写第一个渲染引擎的时候不到20岁。这家伙这是个天才。我若有他四分之一的天赋便心满意足了。” —— [Alex Dolinsky][91]
+
+> “... 德军总部3D(Wolfenstein 3D)、毁灭战士(Doom)还有雷神之锤(Quake)在那时都是革命性的,影响了一代游戏设计师。” —— [dniblock][92]
+
+> “一个周末他几乎可以写出任何东西....” —— [Greg Naughton][93]
+
+> “他是编程界的莫扎特... ” —— [Chris Morris][94]
+
+### 法布里斯·贝拉(Fabrice Bellard) ###
+
+
+
+*图片来源: [Duff][95]*
+
+**成就: 创造了 QEMU**
+
+生平: 创造了[一系列耳熟能详的开源软件][96],其中包括硬件模拟和虚拟化的平台 QEMU,用于处理多媒体数据的 FFmpeg,微型C编译器(Tiny C Compiler)和 一个可执行文件压缩软件 LZEXE。2000年和2001年[C语言混乱代码大赛(Obfuscated C Code Contest)的获胜者][97]并在2011年荣获[Google-O'Reilly 开源奖(Google-O'Reilly Open Source Award )][98]。[计算 Pi 最多位数][99]的前世界纪录保持着。
+
+评论:
+
+
+> “我觉得法布里斯·贝拉做的每一件事都是那么显著而又震撼。” —— [raphinou][100]
+
+> “法布里斯·贝拉是世界上最高产的程序员...” —— [Pavan Yara][101]
+
+> “他就像软件工程界的尼古拉·特斯拉(Nikola Tesla)。” —— [Michael Valladolid][102]
+
+> “自80年代以来,他一直高产出一系列的成功作品。” —— [Michael Biggins][103]
+
+### Jon Skeet ###
+
+
+
+*图片来源: [Craig Murphy CC BY 2.0][104]*
+
+**成就: Stack Overflow 的传说级贡献者**
+
+生平: Google 工程师,[深入解析C#(C# in Depth)][105]的作者。保持着[有史以来在 Stack Overflow 上最高的声誉][106],平均每月解答390个问题。
+
+评论:
+
+
+> “他根本不需要调试器,只要他盯一下代码,错误之处自会原形毕露。” —— [Steven A. Lowe][107]
+
+> “如果他的代码没有通过编译,那编译器应该道歉。” —— [Dan Dyer][108]
+
+> “他根本不需要什么编程规范,他的代码就是编程规范。” —— [佚名][109]
+
+### 亚当·安捷罗(Adam D'Angelo) ###
+
+
+
+*图片来源: [Philip Neustrom CC BY 2.0][110]*
+
+**成就: Quora 的创办人之一**
+
+生平: 还是 Facebook 工程师时,[为其搭建了 news feed 功能的基础][111]。直至其离开并联合创始了 Quora,已经成为了 Facebook 的CTO和工程 VP。2001年以高中生的身份在[美国计算机奥林匹克(USA Computing Olympiad)上第八位完成比赛][112]。2004年ACM国际大学生编程大赛(International Collegiate Programming Contest)[获得银牌的团队 - 加利福尼亚技术研究所( California Institute of Technology)][113]的成员。2005年入围 Topcoder 大学生[算法编程挑战赛(Algorithm Coding Competition)][114]。
+
+评论:
+
+> “一位程序设计全才。” —— [佚名][115]
+
+> "我做的每个好东西,他都已有了六个。" —— [马克.扎克伯格(Mark Zuckerberg)][116]
+
+### Petr Mitrechev ###
+
+
+
+*图片来源: [Facebook][117]*
+
+**成就: 有史以来最具竞技能力的程序员之一**
+
+生平: 在国际信息学奥林匹克(International Olympiad in Informatics)中[两次获得金牌][118](2000,2002)。在2006,[赢得 Google Code Jam][119] 同时也是[TopCoder Open 算法大赛冠军][120]。也同样,两次赢得 Facebook黑客杯(Facebook Hacker Cup)([2011][121],[2013][122])。写这篇文章的时候,[TopCoder 榜中排第二][123] (即:Petr)、在 [Codeforces 榜同样排第二][124]。
+
+评论:
+
+> “他是竞技程序员的偶像,即使在印度也是如此...” —— [Kavish Dwivedi][125]
+
+### Gennady Korotkevich ###
+
+
+
+*图片来源: [Ishandutta2007 CC BY-SA 3.0][126]*
+
+**成就: 竞技编程小神童**
+
+生平: 国际信息学奥林匹克(International Olympiad in Informatics)中最小参赛者(11岁),[6次获得金牌][127] (2007-2012)。2013年 ACM 国际大学生编程大赛(International Collegiate Programming Contest)[获胜队伍][128]成员及[2014 Facebook 黑客杯(Facebook Hacker Cup)][129]获胜者。写这篇文章的时候,[Codeforces 榜排名第一][130] (即:Tourist)、[TopCoder榜第一][131]。
+
+评论:
+
+> “一个编程神童!” —— [Prateek Joshi][132]
+
+> “Gennady 真是棒,也是为什么我在白俄罗斯拥有一个强大开发团队的例证。” —— [Chris Howard][133]
+
+> “Tourist 真是天才” —— [Nuka Shrinivas Rao][134]
+
+--------------------------------------------------------------------------------
+
+via: http://www.itworld.com/article/2823547/enterprise-software/158256-superclass-14-of-the-world-s-best-living-programmers.html#slide1
+
+作者:[Phil Johnson][a]
+译者:[martin2011qi](https://github.com/martin2011qi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.itworld.com/author/Phil-Johnson/
+[1]:https://www.flickr.com/photos/tombullock/15713223772
+[2]:https://commons.wikimedia.org/wiki/File:Margaret_Hamilton_in_action.jpg
+[3]:http://klabs.org/home_page/hamilton.htm
+[4]:https://www.youtube.com/watch?v=DWcITjqZtpU&feature=youtu.be&t=3m12s
+[5]:http://www.htius.com/Articles/r12ham.pdf
+[6]:http://www.htius.com/Articles/Inside_DBTF.htm
+[7]:http://www.nasa.gov/home/hqnews/2003/sep/HQ_03281_Hamilton_Honor.html
+[8]:http://www.nasa.gov/50th/50th_magazine/scientists.html
+[9]:https://books.google.com/books?id=JcmV0wfQEoYC&pg=PA321&lpg=PA321&dq=ada+lovelace+award+1986&source=bl&ots=qGdBKsUa3G&sig=bkTftPAhM1vZ_3VgPcv-38ggSNo&hl=en&sa=X&ved=0CDkQ6AEwBGoVChMI3paoxJHWxwIVA3I-Ch1whwPn#v=onepage&q=ada%20lovelace%20award%201986&f=false
+[10]:http://history.nasa.gov/alsj/a11/a11Hamilton.html
+[11]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrswof
+[12]:http://qr.ae/RFEZLk
+[13]:http://qr.ae/RFEZUn
+[14]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrv9u9
+[15]:https://www.flickr.com/photos/44451574@N00/5347112697
+[16]:http://cs.stanford.edu/~uno/taocp.html
+[17]:http://awards.acm.org/award_winners/knuth_1013846.cfm
+[18]:http://amturing.acm.org/award_winners/knuth_1013846.cfm
+[19]:http://www.nsf.gov/od/nms/recip_details.jsp?recip_id=198
+[20]:http://www.ieee.org/documents/von_neumann_rl.pdf
+[21]:http://www.computerhistory.org/fellowawards/hall/bios/Donald,Knuth/
+[22]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answers/3063
+[23]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Jaap-Weel
+[24]:http://qr.ae/RFE94x
+[25]:http://amturing.acm.org/photo/thompson_4588371.cfm
+[26]:https://www.youtube.com/watch?v=JoVQTPbD6UY
+[27]:https://www.bell-labs.com/usr/dmr/www/bintro.html
+[28]:http://doc.cat-v.org/bell_labs/utf-8_history
+[29]:http://c2.com/cgi/wiki?EdIsTheStandardTextEditor
+[30]:http://amturing.acm.org/award_winners/thompson_4588371.cfm
+[31]:http://www.computer.org/portal/web/awards/cp-thompson
+[32]:http://www.uspto.gov/about/nmti/recipients/1998.jsp
+[33]:http://www.computerhistory.org/fellowawards/hall/bios/Ken,Thompson/
+[34]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Pete-Prokopowicz-1
+[35]:http://qr.ae/RFEWBY
+[36]:https://groups.google.com/forum/#!msg/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
+[37]:http://www.emacswiki.org/emacs/RichardStallman
+[38]:https://www.gnu.org/gnu/thegnuproject.html
+[39]:http://www.emacswiki.org/emacs/FreeSoftwareFoundation
+[40]:http://awards.acm.org/award_winners/stallman_9380313.cfm
+[41]:https://w2.eff.org/awards/pioneer/1998.php
+[42]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton/comment/4146397
+[43]:http://qr.ae/RFEaib
+[44]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Marko-Poutiainen
+[45]:http://qr.ae/RFEUqp
+[46]:https://www.flickr.com/photos/begley/2979906130
+[47]:http://www.taoyue.com/tutorials/pascal/history.html
+[48]:http://c2.com/cgi/wiki?AndersHejlsberg
+[49]:http://www.microsoft.com/about/technicalrecognition/anders-hejlsberg.aspx
+[50]:http://www.drdobbs.com/windows/dr-dobbs-excellence-in-programming-award/184404602
+[51]:http://qr.ae/RFEZrv
+[52]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Stefan-Kiryazov
+[53]:https://www.flickr.com/photos/vonguard/4076389963/
+[54]:http://www.wizards-of-os.org/archiv/sprecher/a_c/doug_cutting.html
+[55]:http://hadoop.apache.org/
+[56]:https://www.linkedin.com/in/cutting
+[57]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Shalin-Shekhar-Mangar/comment/2293071
+[58]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answer/Amit-Nithianandan
+[59]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
+[60]:http://research.google.com/pubs/SanjayGhemawat.html
+[61]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat
+[62]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
+[63]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
+[64]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat/answer/Ahmet-Alp-Balkan
+[65]:http://research.google.com/people/jeff/index.html
+[66]:http://research.google.com/people/jeff/index.html
+[67]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
+[68]:http://news.cs.washington.edu/2012/10/10/uw-cse-ph-d-alum-jeff-dean-wins-2012-sigops-mark-weiser-award/
+[69]:http://awards.acm.org/award_winners/dean_2879385.cfm
+[70]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Natu-Lauchande
+[71]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Cosmin-Negruseri/comment/28399
+[72]:https://commons.wikimedia.org/wiki/File:LinuxCon_Europe_Linus_Torvalds_05.jpg
+[73]:http://www.linuxfoundation.org/about/staff#torvalds
+[74]:http://git-scm.com/book/en/Getting-Started-A-Short-History-of-Git
+[75]:https://w2.eff.org/awards/pioneer/1998.php
+[76]:http://www.bcs.org/content/ConWebDoc/14769
+[77]:http://www.zdnet.com/blog/open-source/linus-torvalds-wins-the-tech-equivalent-of-a-nobel-prize-the-millennium-technology-prize/10789
+[78]:http://www.computer.org/portal/web/pressroom/Linus-Torvalds-Named-Recipient-of-the-2014-IEEE-Computer-Society-Computer-Pioneer-Award
+[79]:http://www.computerhistory.org/fellowawards/hall/bios/Linus,Torvalds/
+[80]:http://www.internethalloffame.org/inductees/linus-torvalds
+[81]:http://qr.ae/RFEeeo
+[82]:http://qr.ae/RFEZLk
+[83]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Alok-Tripathy-1
+[84]:https://www.flickr.com/photos/quakecon/9434713998
+[85]:http://doom.wikia.com/wiki/John_Carmack
+[86]:http://thegamershub.net/2012/04/gaming-gods-john-carmack/
+[87]:http://www.shamusyoung.com/twentysidedtale/?p=4759
+[88]:http://www.interactive.org/special_awards/details.asp?idSpecialAwards=6
+[89]:http://www.itworld.com/article/2951105/it-management/a-fly-named-for-bill-gates-and-9-other-unusual-honors-for-tech-s-elite.html#slide8
+[90]:http://www.gamechoiceawards.com/archive/lifetime.html
+[91]:http://qr.ae/RFEEgr
+[92]:http://www.itworld.com/answers/topic/software/question/whos-best-living-programmer#comment-424562
+[93]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton
+[94]:http://money.cnn.com/2003/08/21/commentary/game_over/column_gaming/
+[95]:http://dufoli.wordpress.com/2007/06/23/ammmmaaaazing-night/
+[96]:http://bellard.org/
+[97]:http://www.ioccc.org/winners.html#B
+[98]:http://www.oscon.com/oscon2011/public/schedule/detail/21161
+[99]:http://bellard.org/pi/pi2700e9/
+[100]:https://news.ycombinator.com/item?id=7850797
+[101]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/1718701
+[102]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/2454450
+[103]:http://qr.ae/RFEjhZ
+[104]:https://www.flickr.com/photos/craigmurphy/4325516497
+[105]:http://www.amazon.co.uk/gp/product/1935182471?ie=UTF8&tag=developetutor-21&linkCode=as2&camp=1634&creative=19450&creativeASIN=1935182471
+[106]:http://stackexchange.com/leagues/1/alltime/stackoverflow
+[107]:http://meta.stackexchange.com/a/9156
+[108]:http://meta.stackexchange.com/a/9138
+[109]:http://meta.stackexchange.com/a/9182
+[110]:https://www.flickr.com/photos/philipn/5326344032
+[111]:http://www.crunchbase.com/person/adam-d-angelo
+[112]:http://www.exeter.edu/documents/Exeter_Bulletin/fall_01/oncampus.html
+[113]:http://icpc.baylor.edu/community/results-2004
+[114]:https://www.topcoder.com/tc?module=Static&d1=pressroom&d2=pr_022205
+[115]:http://qr.ae/RFfOfe
+[116]:http://www.businessinsider.com/in-new-alleged-ims-mark-zuckerberg-talks-about-adam-dangelo-2012-9#ixzz369FcQoLB
+[117]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
+[118]:http://stats.ioinformatics.org/people/1849
+[119]:http://googlepress.blogspot.com/2006/10/google-announces-winner-of-global-code_27.html
+[120]:http://community.topcoder.com/tc?module=SimpleStats&c=coder_achievements&d1=statistics&d2=coderAchievements&cr=10574855
+[121]:https://www.facebook.com/notes/facebook-hacker-cup/facebook-hacker-cup-finals/208549245827651
+[122]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
+[123]:http://community.topcoder.com/tc?module=AlgoRank
+[124]:http://codeforces.com/ratings
+[125]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Venkateswaran-Vicky/comment/1960855
+[126]:http://commons.wikimedia.org/wiki/File:Gennady_Korot.jpg
+[127]:http://stats.ioinformatics.org/people/804
+[128]:http://icpc.baylor.edu/regionals/finder/world-finals-2013/standings
+[129]:https://www.facebook.com/hackercup/posts/10152022955628845
+[130]:http://codeforces.com/ratings
+[131]:http://community.topcoder.com/tc?module=AlgoRank
+[132]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi
+[133]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4720779
+[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
+[135]:http://commons.wikimedia.org/wiki/File:Jielbeaumadier_richard_stallman_2010.jpg
\ No newline at end of file
diff --git a/published/20150914 Display Awesome Linux Logo With Basic Hardware Info Using screenfetch and linux_logo Tools.md b/published/201511/20150914 Display Awesome Linux Logo With Basic Hardware Info Using screenfetch and linux_logo Tools.md
similarity index 100%
rename from published/20150914 Display Awesome Linux Logo With Basic Hardware Info Using screenfetch and linux_logo Tools.md
rename to published/201511/20150914 Display Awesome Linux Logo With Basic Hardware Info Using screenfetch and linux_logo Tools.md
diff --git a/translated/tech/20150921 Configure PXE Server In Ubuntu 14.04.md b/published/201511/20150921 Configure PXE Server In Ubuntu 14.04.md
similarity index 70%
rename from translated/tech/20150921 Configure PXE Server In Ubuntu 14.04.md
rename to published/201511/20150921 Configure PXE Server In Ubuntu 14.04.md
index eab3fb5224..8689a180ce 100644
--- a/translated/tech/20150921 Configure PXE Server In Ubuntu 14.04.md
+++ b/published/201511/20150921 Configure PXE Server In Ubuntu 14.04.md
@@ -1,9 +1,9 @@
-
- 在 Ubuntu 14.04 中配置 PXE 服务器
+在 Ubuntu 14.04 中配置 PXE 服务器
================================================================================
+

-PXE(Preboot Execution Environment--预启动执行环境)服务器允许用户从网络中启动 Linux 发行版并且可以同时在数百台 PC 中安装而不需要 Linux ISO 镜像。如果你客户端的计算机没有 CD/DVD 或USB 引导盘,或者如果你想在大型企业中同时安装多台计算机,那么 PXE 服务器可以帮你节省时间和金钱。
+PXE(Preboot Execution Environment--预启动执行环境)服务器允许用户从网络中启动 Linux 发行版并且可以不需要 Linux ISO 镜像就能同时在数百台 PC 中安装。如果你客户端的计算机没有 CD/DVD 或USB 引导盘,或者如果你想在大型企业中同时安装多台计算机,那么 PXE 服务器可以帮你节省时间和金钱。
在这篇文章中,我们将告诉你如何在 Ubuntu 14.04 配置 PXE 服务器。
@@ -11,11 +11,11 @@ PXE(Preboot Execution Environment--预启动执行环境)服务器允许用
开始前,你需要先设置 PXE 服务器使用静态 IP。在你的系统中要使用静态 IP 地址,需要编辑 “/etc/network/interfaces” 文件。
-1. 打开 “/etc/network/interfaces” 文件.
+打开 “/etc/network/interfaces” 文件.
sudo nano /etc/network/interfaces
- 作如下修改:
+作如下修改:
# 回环网络接口
auto lo
@@ -43,23 +43,23 @@ DHCP,TFTP 和 NFS 是 PXE 服务器的重要组成部分。首先,需要更
### 配置 DHCP 服务: ###
-DHCP 代表动态主机配置协议(Dynamic Host Configuration Protocol),并且它主要用于动态分配网络配置参数,如用于接口和服务的 IP 地址。在 PXE 环境中,DHCP 服务器允许客户端请求并自动获得一个 IP 地址来访问网络。
+DHCP 代表动态主机配置协议(Dynamic Host Configuration Protocol),它主要用于动态分配网络配置参数,如用于接口和服务的 IP 地址。在 PXE 环境中,DHCP 服务器允许客户端请求并自动获得一个 IP 地址来访问网络。
-1. 编辑 “/etc/default/dhcp3-server” 文件.
+1、编辑 “/etc/default/dhcp3-server” 文件.
sudo nano /etc/default/dhcp3-server
- 作如下修改:
+作如下修改:
INTERFACES="eth0"
保存 (Ctrl + o) 并退出 (Ctrl + x) 文件.
-2. 编辑 “/etc/dhcp3/dhcpd.conf” 文件:
+2、编辑 “/etc/dhcp3/dhcpd.conf” 文件:
sudo nano /etc/dhcp/dhcpd.conf
- 作如下修改:
+作如下修改:
default-lease-time 600;
max-lease-time 7200;
@@ -74,29 +74,29 @@ DHCP 代表动态主机配置协议(Dynamic Host Configuration Protocol),
保存文件并退出。
-3. 启动 DHCP 服务.
+3、启动 DHCP 服务.
sudo /etc/init.d/isc-dhcp-server start
### 配置 TFTP 服务器: ###
-TFTP 是一种文件传输协议,类似于 FTP。它不用进行用户认证也不能列出目录。TFTP 服务器总是监听网络上的 PXE 客户端。当它检测到网络中有 PXE 客户端请求 PXE 服务器时,它将提供包含引导菜单的网络数据包。
+TFTP 是一种文件传输协议,类似于 FTP,但它不用进行用户认证也不能列出目录。TFTP 服务器总是监听网络上的 PXE 客户端的请求。当它检测到网络中有 PXE 客户端请求 PXE 服务时,它将提供包含引导菜单的网络数据包。
-1. 配置 TFTP 时,需要编辑 “/etc/inetd.conf” 文件.
+1、配置 TFTP 时,需要编辑 “/etc/inetd.conf” 文件.
sudo nano /etc/inetd.conf
- 作如下修改:
+作如下修改:
tftp dgram udp wait root /usr/sbin/in.tftpd /usr/sbin/in.tftpd -s /var/lib/tftpboot
- 保存文件并退出。
+保存文件并退出。
-2. 编辑 “/etc/default/tftpd-hpa” 文件。
+2、编辑 “/etc/default/tftpd-hpa” 文件。
sudo nano /etc/default/tftpd-hpa
- 作如下修改:
+作如下修改:
TFTP_USERNAME="tftp"
TFTP_DIRECTORY="/var/lib/tftpboot"
@@ -105,14 +105,14 @@ TFTP 是一种文件传输协议,类似于 FTP。它不用进行用户认证
RUN_DAEMON="yes"
OPTIONS="-l -s /var/lib/tftpboot"
- 保存文件并退出。
+保存文件并退出。
-3. 使用 `xinetd` 让 boot 服务在每次系统开机时自动启动,并启动tftpd服务。
+3、 使用 `xinetd` 让 boot 服务在每次系统开机时自动启动,并启动tftpd服务。
sudo update-inetd --enable BOOT
sudo service tftpd-hpa start
-4. 检查状态。
+4、检查状态。
sudo netstat -lu
@@ -123,7 +123,7 @@ TFTP 是一种文件传输协议,类似于 FTP。它不用进行用户认证
### 配置 PXE 启动文件 ###
-现在,你需要将 PXE 引导文件 “pxelinux.0” 放在 TFTP 根目录下。为 TFTP 创建一个目录,并复制 syslinux 在 “/usr/lib/syslinux/” 下提供的所有引导程序文件到 “/var/lib/tftpboot/” 下,操作如下:
+现在,你需要将 PXE 引导文件 “pxelinux.0” 放在 TFTP 根目录下。为 TFTP 创建目录结构,并从 “/usr/lib/syslinux/” 复制 syslinux 提供的所有引导程序文件到 “/var/lib/tftpboot/” 下,操作如下:
sudo mkdir /var/lib/tftpboot
sudo mkdir /var/lib/tftpboot/pxelinux.cfg
@@ -135,13 +135,13 @@ TFTP 是一种文件传输协议,类似于 FTP。它不用进行用户认证
PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导并与 TFTP 服务器关联。默认情况下,当一个 PXE 客户端启动时,它会使用自己的 MAC 地址指定要读取的配置文件,所以我们需要创建一个包含可引导内核列表的默认文件。
-编辑 PXE 服务器配置文件使用可用的安装选项。.
+编辑 PXE 服务器配置文件,使用有效的安装选项。
-编辑 “/var/lib/tftpboot/pxelinux.cfg/default,”
+编辑 “/var/lib/tftpboot/pxelinux.cfg/default”:
sudo nano /var/lib/tftpboot/pxelinux.cfg/default
- 作如下修改:
+作如下修改:
DEFAULT vesamenu.c32
TIMEOUT 100
@@ -183,12 +183,12 @@ PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导
### 为 PXE 服务器添加 Ubuntu 14.04 桌面启动镜像 ###
-对于这一步,Ubuntu 内核和 initrd 文件是必需的。要获得这些文件,你需要 Ubuntu 14.04 桌面 ISO 镜像。你可以通过以下命令下载 Ubuntu 14.04 ISO 镜像到 /mnt 目录:
+对于这一步需要 Ubuntu 内核和 initrd 文件。要获得这些文件,你需要 Ubuntu 14.04 桌面 ISO 镜像。你可以通过以下命令下载 Ubuntu 14.04 ISO 镜像到 /mnt 目录:
sudo cd /mnt
sudo wget http://releases.ubuntu.com/14.04/ubuntu-14.04.3-desktop-amd64.iso
-**注意**: 下载用的 URL 可能会改变,因为 ISO 镜像会进行更新。如果上面的网址无法访问,看看这个网站,了解最新的下载链接。
+**注意**: 下载用的 URL 可能会改变,因为 ISO 镜像会进行更新。如果上面的网址无法访问,看看[这个网站][4],了解最新的下载链接。
挂载 ISO 文件,使用以下命令将所有文件复制到 TFTP文件夹中:
@@ -199,9 +199,9 @@ PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导
### 将导出的 ISO 目录配置到 NFS 服务器上 ###
-现在,你需要通过 NFS 协议安装源镜像。你还可以使用 HTTP 和 FTP 来安装源镜像。在这里,我已经使用 NFS 导出 ISO 内容。
+现在,你需要通过 NFS 协议来设置“安装源镜像( Installation Source Mirrors)”。你还可以使用 HTTP 和 FTP 来安装源镜像。在这里,我已经使用 NFS 输出 ISO 内容。
-要配置 NFS 服务器,你需要编辑 “etc/exports” 文件。
+要配置 NFS 服务器,你需要编辑 “/etc/exports” 文件。
sudo nano /etc/exports
@@ -209,7 +209,7 @@ PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导
/var/lib/tftpboot/Ubuntu/14.04/amd64 *(ro,async,no_root_squash,no_subtree_check)
-保存文件并退出。为使更改生效,启动 NFS 服务。
+保存文件并退出。为使更改生效,输出并启动 NFS 服务。
sudo exportfs -a
sudo /etc/init.d/nfs-kernel-server start
@@ -218,9 +218,9 @@ PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导
### 配置网络引导 PXE 客户端 ###
-PXE 客户端可以被任何具备 PXE 网络引导的系统来启用。现在,你的客户端可以启动并安装 Ubuntu 14.04 桌面,需要在系统的 BIOS 中设置 “Boot From Network” 选项。
+PXE 客户端可以是任何支持 PXE 网络引导的计算机系统。现在,你的客户端只需要在系统的 BIOS 中设置 “从网络引导(Boot From Network)” 选项就可以启动并安装 Ubuntu 14.04 桌面。
-现在你可以去做 - 用网络引导启动你的 PXE 客户端计算机,你现在应该看到一个子菜单,显示了我们创建的 Ubuntu 14.04 桌面。
+现在准备出发吧 - 用网络引导启动你的 PXE 客户端计算机,你现在应该看到一个子菜单,显示了我们创建的 Ubuntu 14.04 桌面的菜单项。

@@ -241,7 +241,7 @@ via: https://www.maketecheasier.com/configure-pxe-server-ubuntu/
作者:[Hitesh Jethva][a]
译者:[strugglingyouth](https://github.com/strugglingyouth)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -249,3 +249,4 @@ via: https://www.maketecheasier.com/configure-pxe-server-ubuntu/
[1]:https://en.wikipedia.org/wiki/Preboot_Execution_Environment
[2]:https://help.ubuntu.com/community/PXEInstallServer
[3]:https://www.flickr.com/photos/jhcalderon/3681926417/
+[4]:http://releases.ubuntu.com/14.04/
diff --git a/published/201511/20150929 A Developer's Journey into Linux Containers.md b/published/201511/20150929 A Developer's Journey into Linux Containers.md
new file mode 100644
index 0000000000..7245883635
--- /dev/null
+++ b/published/201511/20150929 A Developer's Journey into Linux Containers.md
@@ -0,0 +1,128 @@
+一位开发者的 Linux 容器之旅
+================================================================================
+
+
+我告诉你一个秘密:使得我的应用程序进入到全世界的 DevOps 云计算之类的东西对我来说仍然有一点神秘。但随着时间流逝,我意识到理解大规模的机器增减和应用程序部署的来龙去脉对一个开发者来说是非常重要的知识。这类似于成为一个专业的音乐家,当然你肯定需要知道如何使用你的乐器,但是,如果你不知道一个录音棚是如何工作的,或者如何适应一个交响乐团,那么你在这样的环境中工作会变得非常困难。
+
+在软件开发的世界里,使你的代码进入我们的更大的世界如同把它编写出来一样重要。DevOps 重要,而且是很重要。
+
+因此,为了弥合开发(Dev)和部署(Ops)之间的空隙,我会从头开始介绍容器技术。为什么是容器?因为有强力的证据表明,容器是机器抽象的下一步:使计算机成为场所而不再是一个东西。理解容器是我们共同的旅程。
+
+在这篇文章中,我会介绍容器化(containerization)背后的概念。包括容器和虚拟机的区别,以及容器构建背后的逻辑以及它是如何适应应用程序架构的。我会探讨轻量级的 Linux 操作系统是如何适应容器生态系统。我还会讨论使用镜像创建可重用的容器。最后我会介绍容器集群如何使你的应用程序可以快速扩展。
+
+在后面的文章中,我会一步一步向你介绍容器化一个示例应用程序的过程,以及如何为你的应用程序容器创建一个托管集群。同时,我会向你展示如何使用 Deis 将你的示例应用程序部署到你本地系统以及多种云供应商的虚拟机上。
+
+让我们开始吧。
+
+### 虚拟机的好处 ###
+
+为了理解容器如何适应事物发展,你首先要了解容器的前任:虚拟机。
+
+[虚拟机][1] (virtual machine (VM))是运行在物理宿主机上的软件抽象。配置一个虚拟机就像是购买一台计算机:你需要定义你想要的 CPU 数目、RAM 和磁盘存储容量。配置好了机器后,你为它加载操作系统,以及你想让虚拟机支持的任何服务器或者应用程序。
+
+虚拟机允许你在一台硬件主机上运行多个模拟计算机。这是一个简单的示意图:
+
+
+
+虚拟机可以让你能充分利用你的硬件资源。你可以购买一台巨大的、轰隆作响的机器,然后在上面运行多个虚拟机。你可以有一个数据库虚拟机以及很多运行相同版本的定制应用程序的虚拟机所构成的集群。你可以在有限的硬件资源获得很多的扩展能力。如果你觉得你需要更多的虚拟机而且你的宿主硬件还有容量,你可以添加任何你需要的虚拟机。或者,如果你不再需要一个虚拟机,你可以关闭该虚拟机并删除虚拟机镜像。
+
+### 虚拟机的局限 ###
+
+但是,虚拟机确实有局限。
+
+如上面所示,假如你在一个主机上创建了三个虚拟机。主机有 12 个 CPU,48 GB 内存和 3TB 的存储空间。每个虚拟机配置为有 4 个 CPU,16 GB 内存和 1TB 存储空间。到现在为止,一切都还好。主机有这个容量。
+
+但这里有个缺陷。所有分配给一个虚拟机的资源,无论是什么,都是专有的。每台机器都分配了 16 GB 的内存。但是,如果第一个虚拟机永不会使用超过 1GB 分配的内存,剩余的 15 GB 就会被浪费在那里。如果第三个虚拟机只使用分配的 1TB 存储空间中的 100GB,其余的 900GB 就成为浪费空间。
+
+这里没有资源的流动。每台虚拟机拥有分配给它的所有资源。因此,在某种方式上我们又回到了虚拟机之前,把大部分金钱花费在未使用的资源上。
+
+虚拟机还有*另一个*缺陷。让它们跑起来需要很长时间。如果你处于基础设施需要快速增长的情形,即使增加虚拟机是自动的,你仍然会发现你的很多时间都浪费在等待机器上线。
+
+### 来到:容器 ###
+
+概念上来说,容器是一个 Linux 进程,Linux 认为它只是一个运行中的进程。该进程只知道它被告知的东西。另外,在容器化方面,该容器进程也分配了它自己的 IP 地址。这点很重要,重要的事情讲三遍,这是第二遍。**在容器化方面,容器进程有它自己的 IP 地址。**一旦给予了一个 IP 地址,该进程就是宿主网络中可识别的资源。然后,你可以在容器管理器上运行命令,使容器 IP 映射到主机中能访问公网的 IP 地址。建立了该映射,无论出于什么意图和目的,容器就是网络上一个可访问的独立机器,从概念上类似于虚拟机。
+
+这是第三遍,容器是拥有不同 IP 地址从而使其成为网络上可识别的独立 Linux 进程。下面是一个示意图:
+
+
+
+容器/进程以动态、合作的方式共享主机上的资源。如果容器只需要 1GB 内存,它就只会使用 1GB。如果它需要 4GB,就会使用 4GB。CPU 和存储空间利用也是如此。CPU、内存和存储空间的分配是动态的,和典型虚拟机的静态方式不同。所有这些资源的共享都由容器管理器来管理。
+
+最后,容器能非常快速地启动。
+
+因此,容器的好处是:**你获得了虚拟机独立和封装的好处,而抛弃了静态资源专有的缺陷**。另外,由于容器能快速加载到内存,在扩展到多个容器时你能获得更好的性能。
+
+### 容器托管、配置和管理 ###
+
+托管容器的计算机运行着被剥离的只剩下主要部分的某个 Linux 版本。现在,宿主计算机流行的底层操作系统是之前提到的 [CoreOS][2]。当然还有其它,例如 [Red Hat Atomic Host][3] 和 [Ubuntu Snappy][4]。
+
+该 Linux 操作系统被所有容器所共享,减少了容器足迹的重复和冗余。每个容器只包括该容器特有的部分。下面是一个示意图:
+
+
+
+你可以用它所需的组件来配置容器。一个容器组件被称为**层(layer)**。层是一个容器镜像,(你会在后面的部分看到更多关于容器镜像的介绍)。你从一个基本层开始,这通常是你想在容器中使用的操作系统。(容器管理器只提供你所要的操作系统在宿主操作系统中不存在的部分。)当你构建你的容器配置时,你需要添加层,例如你想要添加网络服务器时这个层就是 Apache,如果容器要运行脚本,则需要添加 PHP 或 Python 运行时环境。
+
+分层非常灵活。如果应用程序或者服务容器需要 PHP 5.2 版本,你相应地配置该容器即可。如果你有另一个应用程序或者服务需要 PHP 5.6 版本,没问题,你可以使用 PHP 5.6 配置该容器。不像虚拟机,更改一个版本的运行时依赖时你需要经过大量的配置和安装过程;对于容器你只需要在容器配置文件中重新定义层。
+
+所有上面描述的容器的各种功能都由一个称为容器管理器(container manager)的软件控制。现在,最流行的容器管理器是 [Docker][5] 和 [Rocket][6]。上面的示意图展示了容器管理器是 Docker,宿主操作系统是 CentOS 的主机情景。
+
+### 容器由镜像构成 ###
+
+当你需要将我们的应用程序构建到容器时,你就要编译镜像。镜像代表了你的容器需要完成其工作的容器模板。(容器里可以在容器里面,如下图)。镜像存储在注册库(registry)中,注册库通过网络访问。
+
+从概念上讲,注册库类似于一个使用 Java 的人眼中的 [Maven][7] 仓库、使用 .NET 的人眼中的 [NuGet][8] 服务器。你会创建一个列出了你应用程序所需镜像的容器配置文件。然后你使用容器管理器创建一个包括了你的应用程序代码以及从容器注册库中下载的部分资源。例如,如果你的应用程序包括了一些 PHP 文件,你的容器配置文件会声明你会从注册库中获取 PHP 运行时环境。另外,你还要使用容器配置文件声明需要复制到容器文件系统中的 .php 文件。容器管理器会封装你应用程序的所有东西为一个独立容器,该容器将会在容器管理器的管理下运行在宿主计算机上。
+
+这是一个容器创建背后概念的示意图:
+
+
+
+让我们仔细看看这个示意图。
+
+(1)代表一个定义了你容器所需东西以及你容器如何构建的容器配置文件。当你在主机上运行容器时,容器管理器会读取该配置文件,从云上的注册库中获取你需要的容器镜像,(2)将镜像作为层添加到你的容器中。
+
+另外,如果组成镜像需要其它镜像,容器管理器也会获取这些镜像并把它们作为层添加进来。(3)容器管理器会将需要的文件复制到容器中。
+
+如果你使用了配置(provisioning)服务,例如 [Deis][9],你刚刚创建的应用程序容器做成镜像,(4)配置服务会将它部署到你选择的云供应商上,比如类似 AWS 和 Rackspace 云供应商。
+
+### 集群中的容器 ###
+
+好了。这里有一个很好的例子说明了容器比虚拟机提供了更好的配置灵活性和资源利用率。但是,这并不是全部。
+
+容器真正的灵活是在集群中。记住,每个容器有一个独立的 IP 地址。因此,能把它放到负载均衡器后面。将容器放到负载均衡器后面,这就上升了一个层面。
+
+你可以在一个负载均衡容器后运行容器集群以获得更高的性能和高可用计算。这是一个例子:
+
+
+
+假如你开发了一个资源密集型的应用程序,例如图片处理。使用类似 [Deis][9] 的容器配置技术,你可以创建一个包括了你图片处理程序以及你图片处理程序需要的所有资源的容器镜像。然后,你可以部署一个或多个容器镜像到主机上的负载均衡器下。一旦创建了容器镜像,你可以随时使用它。当系统繁忙时可以添加更多的容器实例来满足手中的工作。
+
+这里还有更多好消息。每次添加实例到环境中时,你不需要手动配置负载均衡器以便接受你的容器镜像。你可以使用服务发现技术让容器告知均衡器它可用。然后,一旦获知,均衡器就会将流量分发到新的结点。
+
+### 全部放在一起 ###
+
+容器技术完善了虚拟机缺失的部分。类似 CoreOS、RHEL Atomic、和 Ubuntu 的 Snappy 宿主操作系统,和类似 Docker 和 Rocket 的容器管理技术结合起来,使得容器变得日益流行。
+
+尽管容器变得更加越来越普遍,掌握它们还是需要一段时间。但是,一旦你懂得了它们的窍门,你可以使用类似 [Deis][9] 这样的配置技术使容器创建和部署变得更加简单。
+
+从概念上理解容器和进一步实际使用它们完成工作一样重要。但我认为不实际动手把想法付诸实践,概念也难以理解。因此,我们该系列的下一阶段就是:创建一些容器。
+
+--------------------------------------------------------------------------------
+
+via: https://deis.com/blog/2015/developer-journey-linux-containers
+
+作者:[Bob Reselman][a]
+译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://deis.com/blog
+[1]:https://en.wikipedia.org/wiki/Virtual_machine
+[2]:https://coreos.com/using-coreos/
+[3]:http://www.projectatomic.io/
+[4]:https://developer.ubuntu.com/en/snappy/
+[5]:https://www.docker.com/
+[6]:https://coreos.com/blog/rocket/
+[7]:https://en.wikipedia.org/wiki/Apache_Maven
+[8]:https://www.nuget.org/
+[9]:http://deis.com/learn
\ No newline at end of file
diff --git a/translated/tech/20151007-Fix-Shell-Script-Opens-In-Text Editor In Ubuntu.md b/published/201511/20151007-Fix-Shell-Script-Opens-In-Text Editor In Ubuntu.md
similarity index 52%
rename from translated/tech/20151007-Fix-Shell-Script-Opens-In-Text Editor In Ubuntu.md
rename to published/201511/20151007-Fix-Shell-Script-Opens-In-Text Editor In Ubuntu.md
index f1d9f7253f..da44814e11 100644
--- a/translated/tech/20151007-Fix-Shell-Script-Opens-In-Text Editor In Ubuntu.md
+++ b/published/201511/20151007-Fix-Shell-Script-Opens-In-Text Editor In Ubuntu.md
@@ -1,26 +1,26 @@
-修复Sheell脚本在Ubuntu中用文本编辑器打开的方式
+修复 Shell 脚本在 Ubuntu 中的默认打开方式
================================================================================

-当你双击一个脚本(.sh文件)的时候,你想要做的是什么?通常的想法是执行它。但是在Ubuntu下面却不是这样,或者我应该更确切地说是在Files(Nautilus)中。你可能会疯狂地大叫“运行文件,运行文件”,但是文件没有运行而是用Gedit打开了。
+当你双击一个脚本(.sh文件)的时候,你想要做的是什么?通常的想法是执行它。但是在Ubuntu下面却不是这样,或者我应该更确切地说是在Files(Nautilus)中。你可能会疯狂地大叫“运行文件,运行文件”,但是文件没有运行而是用Gedit打开了。
-我知道你也许会说文件有可执行权限么?我会说是的。脚本有可执行权限但是当我双击它的时候,它还是用文本编辑器打开了。我不希望这样如果你遇到了同样的问题,我想你也许也不需要这样。
+我知道你也许会说文件有可执行权限么?我会说是的。脚本有可执行权限但是当我双击它的时候,它还是用文本编辑器打开了。我不希望这样,如果你遇到了同样的问题,我想你也许也想要这样。
-我知道你或许已经被建议在终端下面运行,我知道这个可行但是这不是一个在GUI下不能运行的借口是么?
+我知道你或许已经被建议在终端下面执行,我知道这个可行,但是这不是一个在GUI下不能运行的借口是么?
这篇教程中,我们会看到**如何在双击后运行shell脚本。**
#### 修复在Ubuntu中shell脚本用文本编辑器打开的方式 ####
-shell脚本用文件编辑器打开的原因是Files(Ubuntu中的文件管理器)中的默认行为设置。在更早的版本中,它或许会询问你是否运行文件或者用编辑器打开。默认的行位在新的版本中被修改了。
+shell脚本用文件编辑器打开的原因是Files(Ubuntu中的文件管理器)中的默认行为设置。在更早的版本中,它或许会询问你是否运行文件或者用编辑器打开。默认的行为在新的版本中被修改了。
要修复这个,进入文件管理器,并在菜单中点击**选项**:

-接下来在**文件选项**中进入**行为**标签中,你会看到**文本文件执行**选项。
+接下来在**文件选项(Files Preferences)**中进入**行为(Behavior)**标签中,你会看到**可执行的文本文件(Executable Text Files)**选项。
-默认情况下,它被设置成“在打开是显示文本文件”。我建议你把它改成“每次询问”,这样你可以选择是执行还是编辑了,当然了你也可以选择默认执行。你可以自行选择。
+默认情况下,它被设置成“在打开时显示文本文件(View executable text files when they are opend)”。我建议你把它改成“每次询问(Ask each time)”,这样你可以选择是执行还是编辑了,当然了你也可以选择“在打开时云可执行文本文件(Run executable text files when they are opend)”。你可以自行选择。

@@ -32,7 +32,7 @@ via: http://itsfoss.com/shell-script-opens-text-editor/
作者:[Abhishek][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/published/201511/20151012 Curious about Linux Try Linux Desktop on the Cloud.md b/published/201511/20151012 Curious about Linux Try Linux Desktop on the Cloud.md
new file mode 100644
index 0000000000..2d2985bc34
--- /dev/null
+++ b/published/201511/20151012 Curious about Linux Try Linux Desktop on the Cloud.md
@@ -0,0 +1,44 @@
+好奇 Linux?试试云端的 Linux 桌面
+================================================================================
+Linux 在桌面操作系统市场上只占据了非常小的份额,从目前的调查结果来看,估计只有2%的市场份额;对比来看,丰富多变的 Windows 系统占据了接近90%的市场份额。对于 Linux 来说,要挑战 Windows 在桌面操作系统市场的垄断,需要有一个让用户学习不同的操作系统的简单方式。如果你相信传统的 Windows 用户会再买一台机器来使用 Linux,那你就太天真了。我们只能去试想用户重新分区,设置引导程序来使用双系统,或者跳过所有步骤回到一个最简单的方法。
+
+
+
+我们实验过一系列让用户试操作 Linux 的无风险的使用方法,不涉及任何分区管理,包括 CD/DVD 光盘、USB 存储棒和桌面虚拟化软件等等。通过实验,我强烈推荐使用 VMware 的 VMware Player 或者 Oracle VirtualBox 虚拟机,对于桌面操作系统或者便携式电脑的用户,这是一种安装运行多操作系统的相对简单而且免费的的方法。每一台虚拟机和其他虚拟机相隔离,但是共享 CPU、内存、网络接口等等。虚拟机仍需要一定的资源来安装运行 Linux,也需要一台相当强劲的主机。但对于一个好奇心不大的人,这样做实在是太麻烦了。
+
+要打破用户传统的使用观念是非常困难的。很多 Windows 用户可以尝试使用 Linux 提供的自由软件,但也有太多要学习的 Linux 系统知识。这会花掉他们相当一部分时间才能习惯 Linux 的工作方式。
+
+当然了,对于一个第一次在 Linux 上操作的新手,有没有一个更高效的方法呢?答案是肯定的,接着往下看看云实验平台。
+
+### LabxNow ###
+
+
+
+LabxNow 提供了一个免费服务,方便广大用户通过浏览器来访问远程 Linux 桌面。开发者将其加强为一个用户个人远程实验室(用户可以在系统里运行、开发任何程序),用户可以在任何地方通过互联网登入远程实验室。
+
+这项服务现在可以为个人用户提供2核处理器,4GB RAM和10GB的固态硬盘,运行在128G RAM的4 AMD 6272处理器上。
+
+#### 配置参数: ####
+
+- 系统镜像:基于 Ubuntu 14.04 的 Xface 4.10,RHEL 6.5,CentOS(Gnome桌面),Oracle
+- 硬件: CPU - 1核或者2核;内存: 512MB, 1GB, 2GB or 4GB
+- 超快的网络数据传输
+- 可以运行在所有流行的浏览器上
+- 可以安装任意程序,可以运行任何程序 – 这是一个非常棒的方法,可以随意做实验学习你想学的任何知识,没有 一点风险
+- 添加、删除、管理、制定虚拟机非常方便
+- 支持虚拟机共享,远程桌面
+
+你所需要的只是一台有稳定网络的设备。不用担心虚拟专用系统(VPS)、域名、或者硬件带来的高费用。LabxNow提供了一个在 Ubuntu、RHEL 和 CentOS 上实验的非常好的方法。它给 Windows 用户提供一个极好的环境,让他们探索美妙的 Linux 世界。说得深入一点,它可以让用户随时随地在里面工作,而没有了要在每台设备上安装 Linux 的压力。点击下面这个链接进入 [www.labxnow.org/labxweb/][1]。
+
+另外还有一些其它服务(大部分是收费服务)可以让用户使用 Linux,包括 Cloudsigma 环境的7天使用权和Icebergs.io (通过HTML5实现root权限)。但是现在,我推荐 LabxNow。
+
+--------------------------------------------------------------------------------
+
+来自: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
+
+译者:[sevenot](https://github.com/sevenot)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:https://www.labxnow.org/labxweb/
diff --git a/published/20151012 How To Use iPhone In Antergos Linux.md b/published/201511/20151012 How To Use iPhone In Antergos Linux.md
similarity index 100%
rename from published/20151012 How To Use iPhone In Antergos Linux.md
rename to published/201511/20151012 How To Use iPhone In Antergos Linux.md
diff --git a/translated/tech/20151012 How to Monitor Stock Prices from Ubuntu Command Line Using Mop.md b/published/201511/20151012 How to Monitor Stock Prices from Ubuntu Command Line Using Mop.md
similarity index 50%
rename from translated/tech/20151012 How to Monitor Stock Prices from Ubuntu Command Line Using Mop.md
rename to published/201511/20151012 How to Monitor Stock Prices from Ubuntu Command Line Using Mop.md
index a5207c3813..50e64ca9ad 100644
--- a/translated/tech/20151012 How to Monitor Stock Prices from Ubuntu Command Line Using Mop.md
+++ b/published/201511/20151012 How to Monitor Stock Prices from Ubuntu Command Line Using Mop.md
@@ -1,22 +1,25 @@
-命令行下使用Mop 监视股票价格
+命令行下使用 Mop 监视股票价格
================================================================================
-有一份隐性收入通常很不错,特别是当你可以轻松的协调业余和全职工作。如果你的日常工作使用了联网的电脑,交易股票是一个很流行的选项来获取额外收入。
+
+
+有一份隐性收入通常很不错,特别是当你可以轻松的协调业余和全职工作。如果你的日常工作使用了联网的电脑,交易股票就是一个获取额外收入的很流行的选项。
+
+但是目前只有很少的股票监视软件可以运行在 linux 上,其中大多数还是基于图形界面的。如果你是一个 Linux 专家,并且大量的工作时间是在没有图形界面的电脑上呢?你是不是就没办法了?不,还是有一些命令行下的股票追踪工具,包括Mop,也就是本文要聊一聊的工具。
-但是目前只有很少的股票监视软件可以用在linux 上,其中大多数还是基于图形界面的。如果你是一个Linux 专家,并且大量的工作时间是在没有图形界面的电脑上呢?你是不是就没办法了?不,这里还有一个命令行下的股票追踪工具,包括Mop,也就是本文要聊一聊的工具。
### Mop ###
-Mop,如上所述,是一个命令行下连续显示和更新美股和独立股票信息的工具。使用GO 实现的,是Michael Dvorkin 大脑的产物。
+Mop,如上所述,是一个命令行下连续显示和更新美股和独立股票信息的工具。使用 GO 语言实现的,是 Michael Dvorkin 的智慧结晶。
+
### 下载安装 ###
-
-因为这个工程使用GO 实现的,所以你要做的第一步是在你的计算机上安装这种编程语言,下面就是在Debian 系系统,比如Ubuntu上安装GO的步骤:
+因为这个项目使用 GO 实现的,所以你要做的第一步是在你的计算机上安装这种编程语言,下面就是在 Debian 系的系统,比如 Ubuntu 上安装 GO 的步骤:
sudo apt-get install golang
mkdir ~/workspace
echo 'export GOPATH="$HOME/workspace"' >> ~/.bashrc
source ~/.bashrc
-GO 安装好后的下一步是安装Mop 工具和配置环境,你要做的是运行下面的命令:
+GO 安装好后的下一步是安装 Mop 工具和配置环境,你要做的是运行下面的命令:
sudo apt-get install git
go get github.com/michaeldv/mop
@@ -24,12 +27,13 @@ GO 安装好后的下一步是安装Mop 工具和配置环境,你要做的是
make install
export PATH="$PATH:$GOPATH/bin"
-完成之后就可以运行下面的命令执行Mop:
+完成之后就可以运行下面的命令执行 Mop:
+
cmd
### 特性 ###
-当你第一次运行Mop 时,你会看到类似下面的输出信息:
+当你第一次运行 Mop 时,你会看到类似下面的输出信息:

@@ -37,19 +41,19 @@ GO 安装好后的下一步是安装Mop 工具和配置环境,你要做的是
### 添加删除股票 ###
-Mop 允许你轻松的从输出列表上添加/删除个股信息。要添加,你全部要做的是按”+“和输入股票名称。举个例子,下图就是添加Facebook (FB) 到列表里。
+Mop 允许你轻松的从输出列表上添加/删除个股信息。要添加,你全部要做的是按“+”和输入股票名称。举个例子,下图就是添加 Facebook (FB) 到列表里。

-因为我按下了”+“键,一列包含文本”Add tickers:“出现了,提示我添加股票名称—— 我添加了FB 然后按下回车。输出列表更新了,我添加的新股票也出现在列表了:
+我按下了“+”键,就出现了包含文本“Add tickers:”的一列,提示我添加股票名称—— 我添加了 FB 然后按下回车。输出列表更新了,我添加的新股票也出现在列表了:

-类似的,你可以使用”-“ 键和提供股票名称删除一个股票。
+类似的,你可以使用“-”键和提供股票名称删除一个股票。
#### 根据价格分组 ####
-还有一个把股票分组的办法:依据他们的股价升跌,你索要做的就是按下”g“ 键。接下来,股票会分组显示:升的在一起使用绿色字体显示,而下跌的股票会黑色字体显示。
+还有一个把股票分组的办法:依据他们的股价升跌,你所要做的就是按下“g”键。接下来,股票会分组显示:升的在一起使用绿色字体显示,而下跌的股票会黑色字体显示。
如下所示:
@@ -57,7 +61,7 @@ Mop 允许你轻松的从输出列表上添加/删除个股信息。要添加,
#### 列排序 ####
-Mop 同时也允许你根据不同的列类型改变排序规则。这种用法需要你按下”o“(这个命令默认使用第一列的值来排序),然后使用左右键来选择你要使用的列。完成之后按下回车对内容重新排序。
+Mop 同时也允许你根据不同的列类型改变排序规则。这种用法需要你按下“o”(这个命令默认使用第一列的值来排序),然后使用左右键来选择你要排序的列。完成之后按下回车对内容重新排序。
举个例子,下面的截图就是根据输出内容的第一列、按照字母表排序之后的结果。
@@ -67,12 +71,13 @@ Mop 同时也允许你根据不同的列类型改变排序规则。这种用法
#### 其他选项 ####
-其它的可用选项包括”p“:暂停市场和股票信息更新,”q“ 或者”esc“ 来退出命令行程序,”?“ 显示帮助页。
+其它的可用选项包括“p”:暂停市场和股票信息更新,“q”或者“esc” 来退出命令行程序,“?”显示帮助页。
+

### 结论 ###
-Mop 是一个基础的股票监控工具,并没有提供太多的特性,只提供了他声称的功能。很明显,这个工具并不是为专业股票交易者提供的,而仅仅为你在只有命令行的机器上得体的提供了一个跟踪股票信息的选择。
+Mop 是一个基础的股票监控工具,并没有提供太多的特性,只提供了它所声称的功能。很明显,这个工具并不是为专业股票交易者提供的,而仅仅为你在只有命令行的机器上得体的提供了一个跟踪股票信息的选择。
--------------------------------------------------------------------------------
@@ -80,7 +85,7 @@ via: https://www.maketecheasier.com/monitor-stock-prices-ubuntu-command-line/
作者:[Himanshu Arora][a]
译者:[oska874](https://github.com/oska874)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201511/20151012 How to Setup DockerUI--a Web Interface for Docker.md b/published/201511/20151012 How to Setup DockerUI--a Web Interface for Docker.md
new file mode 100644
index 0000000000..10ead7542e
--- /dev/null
+++ b/published/201511/20151012 How to Setup DockerUI--a Web Interface for Docker.md
@@ -0,0 +1,113 @@
+用浏览器管理 Docker
+================================================================================
+Docker 越来越流行了。在一个容器里面而不是虚拟机里运行一个完整的操作系统是一种非常棒的技术和想法。docker 已经通过节省工作时间来拯救了成千上万的系统管理员和开发人员。这是一个开源技术,提供一个平台来把应用程序当作容器来打包、分发、共享和运行,而不用关注主机上运行的操作系统是什么。它没有开发语言、框架或打包系统的限制,并且可以在任何时间、任何地点运行,从小型计算机到高端服务器都可以。运行 docker 容器和管理它们可能会花费一点点努力和时间,所以现在有一款基于 web 的应用程序-DockerUI,可以让管理和运行容器变得很简单。DockerUI 是一个对那些不熟悉 Linux 命令行,但又很想运行容器化程序的人很有帮助的工具。DockerUI 是一个开源的基于 web 的应用程序,它最值得称道的是它华丽的设计和用来运行和管理 docker 的简洁的操作界面。
+
+下面会介绍如何在 Linux 上安装配置 DockerUI。
+
+### 1. 安装 docker ###
+
+首先,我们需要安装 docker。我们得感谢 docker 的开发者,让我们可以简单的在主流 linux 发行版上安装 docker。为了安装 docker,我们得在对应的发行版上使用下面的命令。
+
+#### Ubuntu/Fedora/CentOS/RHEL/Debian ####
+
+docker 维护者已经写了一个非常棒的脚本,用它可以在 Ubuntu 15.04/14.10/14.04、 CentOS 6.x/7、 Fedora 22、 RHEL 7 和 Debian 8.x 这几个 linux 发行版上安装 docker。这个脚本可以识别出我们的机器上运行的 linux 的发行版本,然后将需要的源库添加到文件系统、并更新本地的安装源目录,最后安装 docker 及其依赖库。要使用这个脚本安装docker,我们需要在 root 用户或者 sudo 权限下运行如下的命令,
+
+ # curl -sSL https://get.docker.com/ | sh
+
+#### OpenSuse/SUSE Linux 企业版 ####
+
+要在运行了 OpenSuse 13.1/13.2 或者 SUSE Linux Enterprise Server 12 的机器上安装 docker,我们只需要简单的执行zypper 命令。运行下面的命令就可以安装最新版本的docker:
+
+ # zypper in docker
+
+#### ArchLinux ####
+
+docker 在 ArchLinux 的官方源和社区维护的 AUR 库中可以找到。所以在 ArchLinux 上我们有两种方式来安装 docker。使用官方源安装,需要执行下面的 pacman 命令:
+
+ # pacman -S docker
+
+如果要从社区源 AUR 安装 docker,需要执行下面的命令:
+
+ # yaourt -S docker-git
+
+### 2. 启动 ###
+
+安装好 docker 之后,我们需要运行 docker 守护进程,然后才能运行并管理 docker 容器。我们需要使用下列命令来确认 docker 守护进程已经安装并运行了。
+
+#### 在 SysVinit 上####
+
+ # service docker start
+
+#### 在Systemd 上####
+
+ # systemctl start docker
+
+### 3. 安装 DockerUI ###
+
+安装 DockerUI 比安装 docker 要简单很多。我们仅仅需要从 docker 注册库上拉取 dockerui ,然后在容器里面运行。要完成这些,我们只需要简单的执行下面的命令:
+
+ # docker run -d -p 9000:9000 --privileged -v /var/run/docker.sock:/var/run/docker.sock dockerui/dockerui
+
+
+
+在上面的命令里,dockerui 使用的默认端口是9000,我们需要使用`-p` 命令映射默认端口。使用`-v` 标志我们可以指定docker 的 socket。如果主机使用了 SELinux 那么就得使用`--privileged` 标志。
+
+执行完上面的命令后,我们要检查 DockerUI 容器是否运行了,或者使用下面的命令检查:
+
+ # docker ps
+
+
+
+### 4. 拉取 docker 镜像 ###
+
+现在我们还不能直接使用 DockerUI 拉取镜像,所以我们需要在命令行下拉取 docker 镜像。要完成这些我们需要执行下面的命令。
+
+ # docker pull ubuntu
+
+
+
+上面的命令将会从 docker 官方源 [Docker Hub][1]拉取一个标志为 ubuntu 的镜像。类似的我们可以从 Hub 拉取需要的其它镜像。
+
+### 4. 管理 ###
+
+启动了 DockerUI 容器之后,我们可以用它来执行启动、暂停、终止、删除以及 DockerUI 提供的其它操作 docker 容器的命令。
+
+首先,我们需要在 web 浏览器里面打开 dockerui:在浏览器里面输入 http://ip-address:9000 或者 http://mydomain.com:9000,具体要根据你的系统配置。默认情况下登录不需要认证,但是可以配置我们的 web 服务器来要求登录认证。要启动一个容器,我们需要有包含我们要运行的程序的镜像。
+
+#### 创建 ####
+
+创建容器我们需要在 Images 页面里,点击我们想创建的容器的镜像 id。然后点击 `Create` 按钮,接下来我们就会被要求输入创建容器所需要的属性。这些都完成之后,我们需要点击按钮`Create` 完成最终的创建。
+
+
+
+#### 停止 ####
+
+要停止一个容器,我们只需要跳转到`Containers` 页面,然后选取要停止的容器。然后在 Action 的子菜单里面按下 Stop 就行了。
+
+
+
+#### 暂停与恢复 ####
+
+要暂停一个容器,只需要简单的选取目标容器,然后点击 Pause 就行了。恢复一个容器只需要在 Actions 的子菜单里面点击 Unpause 就行了。
+
+#### 删除 ####
+
+类似于我们上面完成的任务,杀掉或者删除一个容器或镜像也是很简单的。只需要检查、选择容器或镜像,然后点击 Kill 或者 Remove 就行了。
+
+### 结论 ###
+
+DockerUI 使用了 docker 远程 API 提供了一个很棒的管理 docker 容器的 web 界面。它的开发者们完全使用 HTML 和 JS 设计、开发了这个应用。目前这个程序还处于开发中,并且还有大量的工作要完成,所以我们并不推荐将它应用在生产环境。它可以帮助用户简单的完成管理容器和镜像,而且只需要一点点工作。如果想要为 DockerUI 做贡献,可以访问它们的 [Github 仓库][2]。如果有问题、建议、反馈,请写在下面的评论框,这样我们就可以修改或者更新我们的内容。谢谢。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/setup-dockerui-web-interface-docker/
+
+作者:[Arun Pyasi][a]
+译者:[oska874](https://github.com/oska874)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://hub.docker.com/
+[2]:https://github.com/crosbymichael/dockerui/
diff --git a/translated/tech/20151012 How to Setup Red Hat Ceph Storage on CentOS 7.0.md b/published/201511/20151012 How to Setup Red Hat Ceph Storage on CentOS 7.0.md
similarity index 81%
rename from translated/tech/20151012 How to Setup Red Hat Ceph Storage on CentOS 7.0.md
rename to published/201511/20151012 How to Setup Red Hat Ceph Storage on CentOS 7.0.md
index 7e6ed0d2c2..4f00be2f90 100644
--- a/translated/tech/20151012 How to Setup Red Hat Ceph Storage on CentOS 7.0.md
+++ b/published/201511/20151012 How to Setup Red Hat Ceph Storage on CentOS 7.0.md
@@ -1,9 +1,8 @@
如何在 CentOS 7.0 上配置 Ceph 存储
-How to Setup Red Hat Ceph Storage on CentOS 7.0
================================================================================
-Ceph 是一个将数据存储在单一分布式计算机集群上的开源软件平台。当你计划构建一个云时,你首先需要决定如何实现你的存储。开源的 CEPH 是红帽原生技术之一,它基于称为 RADOS 的对象存储系统,用一组网关 API 表示块、文件、和对象模式中的数据。由于它自身开源的特性,这种便携存储平台能在公有和私有云上安装和使用。Ceph 集群的拓扑结构是按照备份和信息分布设计的,这内在设计能提供数据完整性。它的设计目标就是容错、通过正确配置能运行于商业硬件和一些更高级的系统。
+Ceph 是一个将数据存储在单一分布式计算机集群上的开源软件平台。当你计划构建一个云时,你首先需要决定如何实现你的存储。开源的 Ceph 是红帽原生技术之一,它基于称为 RADOS 的对象存储系统,用一组网关 API 表示块、文件、和对象模式中的数据。由于它自身开源的特性,这种便携存储平台能在公有云和私有云上安装和使用。Ceph 集群的拓扑结构是按照备份和信息分布设计的,这种内在设计能提供数据完整性。它的设计目标就是容错、通过正确配置能运行于商业硬件和一些更高级的系统。
-Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要求最近的内核以及其它最新的库。在这篇指南中,我们会使用最小化安装的 CentOS-7.0。
+Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它需要最近的内核以及其它最新的库。在这篇指南中,我们会使用最小化安装的 CentOS-7.0。
### 系统资源 ###
@@ -25,11 +24,11 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
### 安装前的配置 ###
-在安装 CEPH 存储之前,我们要在每个节点上完成一些步骤。第一件事情就是确保每个节点的网络已经配置好并且能相互访问。
+在安装 Ceph 存储之前,我们要在每个节点上完成一些步骤。第一件事情就是确保每个节点的网络已经配置好并且能相互访问。
**配置 Hosts**
-要在每个节点上配置 hosts 条目,要像下面这样打开默认的 hosts 配置文件。
+要在每个节点上配置 hosts 条目,要像下面这样打开默认的 hosts 配置文件(LCTT 译注:或者做相应的 DNS 解析)。
# vi /etc/hosts
@@ -46,9 +45,9 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
**配置防火墙**
-如果你正在使用启用了防火墙的限制性环境,确保在你的 CEPH 存储管理节点和客户端节点中开放了以下的端口。
+如果你正在使用启用了防火墙的限制性环境,确保在你的 Ceph 存储管理节点和客户端节点中开放了以下的端口。
-你必须在你的 Admin Calamari 节点开放 80、2003、以及4505-4506 端口,并且允许通过 80 号端口到 CEPH 或 Calamari 管理节点,以便你网络中的客户端能访问 Calamari web 用户界面。
+ 你必须在你的 Admin Calamari 节点开放 80、2003、以及4505-4506 端口,并且允许通过 80 号端口到 CEPH 或 Calamari 管理节点,以便你网络中的客户端能访问 Calamari web 用户界面。
你可以使用下面的命令在 CentOS 7 中启动并启用防火墙。
@@ -62,7 +61,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
#firewall-cmd --zone=public --add-port=4505-4506/tcp --permanent
#firewall-cmd --reload
-在 CEPH Monitor 节点,你要在防火墙中允许通过以下端口。
+在 Ceph Monitor 节点,你要在防火墙中允许通过以下端口。
#firewall-cmd --zone=public --add-port=6789/tcp --permanent
@@ -82,9 +81,9 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
#yum update
#shutdown -r 0
-### 设置 CEPH 用户 ###
+### 设置 Ceph 用户 ###
-现在我们会新建一个单独的 sudo 用户用于在每个节点安装 ceph-deploy工具,并允许该用户无密码访问每个节点,因为它需要在 CEPH 节点上安装软件和配置文件而不会有输入密码提示。
+现在我们会新建一个单独的 sudo 用户用于在每个节点安装 ceph-deploy工具,并允许该用户无密码访问每个节点,因为它需要在 Ceph 节点上安装软件和配置文件而不会有输入密码提示。
运行下面的命令在 ceph-storage 主机上新建有独立 home 目录的新用户。
@@ -100,7 +99,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
### 设置 SSH 密钥 ###
-现在我们会在 ceph 管理节点生成 SSH 密钥并把密钥复制到每个 Ceph 集群节点。
+现在我们会在 Ceph 管理节点生成 SSH 密钥并把密钥复制到每个 Ceph 集群节点。
在 ceph-node 运行下面的命令复制它的 ssh 密钥到 ceph-storage。
@@ -125,7 +124,8 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
### 配置 PID 数目 ###
-要配置 PID 数目的值,我们会使用下面的命令检查默认的内核值。默认情况下,是一个小的最大线程数 32768.
+要配置 PID 数目的值,我们会使用下面的命令检查默认的内核值。默认情况下,是一个小的最大线程数 32768。
+
如下图所示通过编辑系统配置文件配置该值为一个更大的数。

@@ -142,9 +142,9 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
#rpm -Uhv http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm
-
+
-或者创建一个新文件并更新 CEPH 库参数,别忘了替换你当前的 Release 和版本号。
+或者创建一个新文件并更新 Ceph 库参数,别忘了替换你当前的 Release 和版本号。
[root@ceph-storage ~]# vi /etc/yum.repos.d/ceph.repo
@@ -160,7 +160,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
之后更新你的系统并安装 ceph-deploy 软件包。
-### 安装 CEPH-Deploy 软件包 ###
+### 安装 ceph-deploy 软件包 ###
我们运行下面的命令以及 ceph-deploy 安装命令来更新系统以及最新的 ceph 库和其它软件包。
@@ -181,15 +181,16 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要

如果成功执行了上面的命令,你会看到它新建了配置文件。
-现在配置 CEPH 默认的配置文件,用任意编辑器打开它并在会影响你公共网络的 global 参数下面添加以下两行。
+
+现在配置 Ceph 默认的配置文件,用任意编辑器打开它并在会影响你公共网络的 global 参数下面添加以下两行。
#vim ceph.conf
osd pool default size = 1
public network = 45.79.0.0/16
-### 安装 CEPH ###
+### 安装 Ceph ###
-现在我们准备在和 CEPH 集群相关的每个节点上安装 CEPH。我们使用下面的命令在 ceph-storage 和 ceph-node 上安装 CEPH。
+现在我们准备在和 Ceph 集群相关的每个节点上安装 Ceph。我们使用下面的命令在 ceph-storage 和 ceph-node 上安装 Ceph。
#ceph-deploy install ceph-node ceph-storage
@@ -201,7 +202,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
#ceph-deploy mon create-initial
-
+
### 设置 OSDs 和 OSD 守护进程 ###
@@ -223,9 +224,9 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
#ceph-deploy admin ceph-node ceph-storage
-### 测试 CEPH ###
+### 测试 Ceph ###
-我们几乎完成了 CEPH 集群设置,让我们在 ceph 管理节点上运行下面的命令检查正在运行的 ceph 状态。
+我们快完成了 Ceph 集群设置,让我们在 ceph 管理节点上运行下面的命令检查正在运行的 ceph 状态。
#ceph status
#ceph health
@@ -235,7 +236,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
### 总结 ###
-在这篇详细的文章中我们学习了如何使用两台安装了 CentOS 7 的虚拟机设置 CEPH 存储集群,这能用于备份或者作为用于处理其它虚拟机的本地存储。我们希望这篇文章能对你有所帮助。当你试着安装的时候记得分享你的经验。
+在这篇详细的文章中我们学习了如何使用两台安装了 CentOS 7 的虚拟机设置 Ceph 存储集群,这能用于备份或者作为用于处理其它虚拟机的本地存储。我们希望这篇文章能对你有所帮助。当你试着安装的时候记得分享你的经验。
--------------------------------------------------------------------------------
@@ -243,7 +244,7 @@ via: http://linoxide.com/storage/setup-red-hat-ceph-storage-centos-7-0/
作者:[Kashif Siddique][a]
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20151012 Linux FAQs with Answers--How to find information about built-in kernel modules on Linux.md b/published/201511/20151012 Linux FAQs with Answers--How to find information about built-in kernel modules on Linux.md
similarity index 100%
rename from published/20151012 Linux FAQs with Answers--How to find information about built-in kernel modules on Linux.md
rename to published/201511/20151012 Linux FAQs with Answers--How to find information about built-in kernel modules on Linux.md
diff --git a/published/20151012 What is a good IDE for R on Linux.md b/published/201511/20151012 What is a good IDE for R on Linux.md
similarity index 100%
rename from published/20151012 What is a good IDE for R on Linux.md
rename to published/201511/20151012 What is a good IDE for R on Linux.md
diff --git a/published/20151019 Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy.md b/published/201511/20151019 Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy.md
similarity index 100%
rename from published/20151019 Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy.md
rename to published/201511/20151019 Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy.md
diff --git a/published/201511/20151019 Nautilus File Search Is About To Get A Big Power Up.md b/published/201511/20151019 Nautilus File Search Is About To Get A Big Power Up.md
new file mode 100644
index 0000000000..b38d77c28e
--- /dev/null
+++ b/published/201511/20151019 Nautilus File Search Is About To Get A Big Power Up.md
@@ -0,0 +1,38 @@
+Nautilus 的文件搜索将迎来巨大提升
+================================================================================
+
+
+*在Nautilus中搜索零散文件和文件夹将会将会变得相当简单。*
+
+[GNOME文件管理器][1]中正在开发一个新的**搜索过滤器**。它大量使用 GNOME 漂亮的弹出式菜单,以通过简单的方法来缩小搜索结果并精确地找到你所需要的。
+
+开发者Georges Stavracas正致力于开发新的UI,他[说][2]这个新的界面“更干净、更合理、更直观”。
+
+根据他[上传到Youtube][3]的视频来展示的新方式-他还没有嵌入它-他没有错。
+
+> 他在他的博客中写到:“ Nautilus 有非常复杂但是强大的内部组成,它允许我们做很多事情。事实上在代码上存在各种可能。那么,为何它曾经看上去这么糟糕?”
+
+这个问题的部分原因比较令人吃惊:新的搜索过滤器界面向用户展示了“强大的内部组成”。搜索结果可以根据类型、名字或者日期范围来进行过滤。
+
+对于像 Nautilus 这类 app 的任何修改有可能让一些用户不安,因此像这样帮助性的、直接的新UI会带来一些争议。
+
+虽然对于不满的担心貌似会影响进度(毫无疑问,虽然像[移除输入优先搜索][4]的争议自2014年以来一直在争论)。GNOME 3.18 在[上个月发布了][5],给 Nautilus 引入了新的文件进度对话框,以及远程共享的更好整合,包括 Google Drive。
+
+Stavracas 的搜索过滤器还没被合并进 Files 的 trunk 中,但是复刻的搜索 UI 已经初步计划在明年春天的 GNOME 3.20 中实现。
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2015/10/new-nautilus-search-filter-ui
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[Caroline](https://github.com/carolinewuyan)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:https://wiki.gnome.org/Apps/Nautilus
+[2]:http://feaneron.com/2015/10/12/the-new-search-for-gnome-files-aka-nautilus/
+[3]:https://www.youtube.com/watch?v=X2sPRXDzmUw
+[4]:http://www.omgubuntu.co.uk/2014/01/ubuntu-14-04-nautilus-type-ahead-patch
+[5]:http://www.omgubuntu.co.uk/2015/09/gnome-3-18-release-new-features
diff --git a/translated/tech/20151027 How To Install Retro Terminal In Linux.md b/published/201511/20151027 How To Install Retro Terminal In Linux.md
similarity index 85%
rename from translated/tech/20151027 How To Install Retro Terminal In Linux.md
rename to published/201511/20151027 How To Install Retro Terminal In Linux.md
index b3b7b54b62..3284f0d465 100644
--- a/translated/tech/20151027 How To Install Retro Terminal In Linux.md
+++ b/published/201511/20151027 How To Install Retro Terminal In Linux.md
@@ -2,9 +2,9 @@ Linux 下如何安装 Retro Terminal
================================================================================

-你有怀旧情节?那就试试 **安装 retro terminal 应用** [cool-retro-term][1] 来一瞥过去的时光吧。顾名思义,`cool-retro-term` 是一个兼具酷炫和怀旧的终端。
+你有怀旧情节?那就试试 **安装复古终端应用** [cool-retro-term][1] 来一瞥过去的时光吧。顾名思义,`cool-retro-term` 是一个兼具酷炫和怀旧的终端。
-你还记得那段遍地都是 CRT 显示器、终端屏幕闪烁不停的时光吗?现在你并不需要穿越到过去来见证那段时光。假如你观看背景设置在上世纪 90 年代的电影,你就可以看到大量带有绿色或黑底白字的显像管显示器。再加上它们通常带有极客光环,这使得它们看起来更酷。
+你还记得那段遍地都是 CRT 显示器、终端屏幕闪烁不停的时光吗?现在你并不需要穿越到过去来见证那段时光。假如你观看背景设置在上世纪 90 年代的电影,你就可以看到大量带有绿色或黑底白字的显像管显示器。这种极客光环让它们看起来非常酷!
若你已经厌倦了你机器中终端的外表,正寻找某些炫酷且‘新奇’的东西,则 `cool-retro-term` 将会带给你一个复古的终端外表,使你可以重温过去。你也可以改变它的颜色、动画类型并添加一些额外的特效。
@@ -48,7 +48,7 @@ Linux 下如何安装 Retro Terminal
./cool-retro-term
-假如你想使得这个应用可在程序菜单中被快速获取到,以便你不用再每次手动地用命令来启动它,则你可以使用下面的命令:
+假如你想把这个应用放在程序菜单中以便快速找到,这样你就不用再每次手动地用命令来启动它,则你可以使用下面的命令:
sudo cp cool-retro-term.desktop /usr/share/applications
@@ -60,13 +60,13 @@ Linux 下如何安装 Retro Terminal
via: http://itsfoss.com/cool-retro-term/
-作者:[Hossein Heydari][a]
+作者:[Abhishek Prakash][a]
译者:[FSSlc](https://github.com/FSSlc)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-[a]:http://itsfoss.com/author/hossein/
+[a]:http://itsfoss.com/author/abhishek/
[1]:https://github.com/Swordfish90/cool-retro-term
[2]:http://itsfoss.com/tag/antergos/
[3]:https://manjaro.github.io/
diff --git a/published/20151027 How To Show Desktop In GNOME 3.md b/published/201511/20151027 How To Show Desktop In GNOME 3.md
similarity index 100%
rename from published/20151027 How To Show Desktop In GNOME 3.md
rename to published/201511/20151027 How To Show Desktop In GNOME 3.md
diff --git a/translated/tech/20151027 How to Use SSHfs to Mount a Remote Filesystem on Linux.md b/published/201511/20151027 How to Use SSHfs to Mount a Remote Filesystem on Linux.md
similarity index 73%
rename from translated/tech/20151027 How to Use SSHfs to Mount a Remote Filesystem on Linux.md
rename to published/201511/20151027 How to Use SSHfs to Mount a Remote Filesystem on Linux.md
index 9d25041535..cd2274071f 100644
--- a/translated/tech/20151027 How to Use SSHfs to Mount a Remote Filesystem on Linux.md
+++ b/published/201511/20151027 How to Use SSHfs to Mount a Remote Filesystem on Linux.md
@@ -1,6 +1,6 @@
如何在 Linux 上使用 SSHfs 挂载一个远程文件系统
================================================================================
-你有想通过安全 shell 挂载一个远程文件系统到本地的经历吗?如果有的话,SSHfs 也许就是你所需要的。它通过使用 SSH 和 Fuse(LCTT 译注:Filesystem in Userspace,用户态文件系统,是 Linux 中用于挂载某些网络空间,如 SSH,到本地文件系统的模块) 允许你挂载远程计算机(或者服务器)到本地。
+你曾经想过用安全 shell 挂载一个远程文件系统到本地吗?如果有的话,SSHfs 也许就是你所需要的。它通过使用 SSH 和 Fuse(LCTT 译注:Filesystem in Userspace,用户态文件系统,是 Linux 中用于挂载某些网络空间,如 SSH,到本地文件系统的模块) 允许你挂载远程计算机(或者服务器)到本地。
**注意**: 这篇文章假设你明白[SSH 如何工作并在你的系统中配置 SSH][1]。
@@ -16,7 +16,7 @@
如果你使用的不是 Ubuntu,那就在你的发行版软件包管理器中搜索软件包名称。最好搜索和 fuse 或 SSHfs 相关的关键字,因为取决于你运行的系统,软件包名称可能稍微有些不同。
-在你的系统上安装完软件包之后,就该创建 fuse 组了。在你安装 fuse 的时候,应该会在你的系统上创建一个组。如果没有的话,在终端窗口中输入以下命令以便在你的 Linux 系统中创建组:
+在你的系统上安装完软件包之后,就该创建好 fuse 组了。在你安装 fuse 的时候,应该会在你的系统上创建一个组。如果没有的话,在终端窗口中输入以下命令以便在你的 Linux 系统中创建组:
sudo groupadd fuse
@@ -26,7 +26,7 @@

-别担心上面命令的 `$USER`。shell 会自动用你自己的用户名替换。处理了和组相关的事之后,就是时候创建要挂载远程文件的目录了。
+别担心上面命令的 `$USER`。shell 会自动用你自己的用户名替换。处理了和组相关的工作之后,就是时候创建要挂载远程文件的目录了。
mkdir ~/remote_folder
@@ -54,9 +54,9 @@
### 总结 ###
-在 Linux 上有很多工具可以用于访问远程文件并挂载到本地。如之前所说,如果有的话,也只有很少的工具能充分利用 SSH 的强大功能。我希望在这篇指南的帮助下,也能认识到 SSHfs 是一个多么强大的工具。
+在 Linux 上有很多工具可以用于访问远程文件并挂载到本地。但是如之前所说,如果有的话,也只有很少的工具能充分利用 SSH 的强大功能。我希望在这篇指南的帮助下,也能认识到 SSHfs 是一个多么强大的工具。
-你觉得 SSHfs 怎么样呢?在线的评论框里告诉我们吧!
+你觉得 SSHfs 怎么样呢?在下面的评论框里告诉我们吧!
--------------------------------------------------------------------------------
@@ -64,7 +64,7 @@ via: https://www.maketecheasier.com/sshfs-mount-remote-filesystem-linux/
作者:[Derrik Diener][a]
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20151104 How to Create New File Systems or Partitions in the Terminal on Linux.md b/published/201511/20151104 How to Create New File Systems or Partitions in the Terminal on Linux.md
similarity index 74%
rename from translated/tech/20151104 How to Create New File Systems or Partitions in the Terminal on Linux.md
rename to published/201511/20151104 How to Create New File Systems or Partitions in the Terminal on Linux.md
index 2948e8de61..cce93c0d02 100644
--- a/translated/tech/20151104 How to Create New File Systems or Partitions in the Terminal on Linux.md
+++ b/published/201511/20151104 How to Create New File Systems or Partitions in the Terminal on Linux.md
@@ -1,4 +1,3 @@
-
如何在 Linux 终端下创建新的文件系统/分区
================================================================================

@@ -13,8 +12,7 @@

-
-一旦你运行了 `lsblk`,你应该会看到当前系统上每个磁盘的详细列表。看看这个列表,然后找出你想要使用的磁盘。在本文中,我将使用 `sdb` 来进行演示。
+当你运行了 `lsblk`,你应该会看到当前系统上每个磁盘的详细列表。看看这个列表,然后找出你想要使用的磁盘。在本文中,我将使用 `sdb` 来进行演示。
在终端输入这个命令。它会显示一个功能强大的基于终端的分区编辑程序。
@@ -26,9 +24,7 @@
当输入此命令后,你将进入分区编辑器中,然后访问你想改变的磁盘。
-Since hard drive partitions are different, depending on a user’s needs, this part of the guide will go over **how to set up a split Linux home/root system layout**.
-
-由于磁盘分区的不同,这取决于用户的需求,这部分的指南将在 **如何建立一个分布的 Linux home/root 文件分区**。
+由于磁盘分区的不同,这取决于用户的需求,这部分的指南将在 **如何建立一个分离的 Linux home/root 分区布局**。
首先,需要创建根分区。这需要根据磁盘的字节数来进行分割。我测试的磁盘是 32 GB。
@@ -38,7 +34,7 @@ Since hard drive partitions are different, depending on a user’s needs, this p
该程序会要求你输入分区大小。一旦你指定好大小后,按 Enter 键。这将被称为根分区(或 /dev/sdb1)。
-接下来该创建用户分区(/dev/sdb2)了。你需要在 CFdisk 中再选择一些空闲分区。使用箭头选择 [ NEW ] 选项,然后按 Enter 键。输入你用户分区的大小,然后按 Enter 键来创建它。
+接下来该创建 home 分区(/dev/sdb2)了。你需要在 CFdisk 中再选择一些空闲分区。使用箭头选择 [ NEW ] 选项,然后按 Enter 键。输入你的 home 分区的大小,然后按 Enter 键来创建它。

@@ -48,7 +44,7 @@ Since hard drive partitions are different, depending on a user’s needs, this p

-现在,交换分区被创建了,该指定其类型。使用上下箭头来选择它。之后,使用左右箭头选择 [ TYPE ] 。找到 Linux swap 选项,然后按 Enter 键。
+现在,创建了交换分区,该指定其类型。使用上下箭头来选择它。之后,使用左右箭头选择 [ TYPE ] 。找到 Linux swap 选项,然后按 Enter 键。

@@ -56,13 +52,13 @@ Since hard drive partitions are different, depending on a user’s needs, this p
### 使用 mkfs 创建文件系统 ###
-有时候,你并不需要一个完整的分区,你只想要创建一个文件系统而已。你可以在终端直接使用 `mkfs` 命令来实现。
+有时候,你并不需要一个整个重新分区,你只想要创建一个文件系统而已。你可以在终端直接使用 `mkfs` 命令来实现。

-首先,找出你要使用的磁盘。在终端输入 `lsblk` 找出来。它会打印出列表,之后只要找到你想制作文件系统的分区或盘符。
+首先,找出你要使用的磁盘。在终端输入 `lsblk` 找出来。它会打印出列表,之后只要找到你想创建文件系统的分区或盘符。
-在这个例子中,我将使用 `/dev/sdb1` 的第一个分区。只对 `/dev/sdb` 使用 mkfs(将会使用整个分区)。
+在这个例子中,我将使用第二个硬盘的 `/dev/sdb1` 作为第一个分区。可以对 `/dev/sdb` 使用 mkfs(这将会使用整个分区)。

@@ -70,13 +66,13 @@ Since hard drive partitions are different, depending on a user’s needs, this p
sudo mkfs.ext4 /dev/sdb1
-在终端。应当指出的是,`mkfs.ext4` 可以将你指定的任何文件系统改变。
+在终端。应当指出的是,`mkfs.ext4` 可以换成任何你想要使用的的文件系统。
### 结论 ###
虽然使用图形工具编辑文件系统和分区更容易,但终端可以说是更有效的。终端的加载速度更快,点击几个按钮即可。GParted 和其它工具一样,它也是一个完整的工具。我希望在本教程的帮助下,你会明白如何在终端中高效的编辑文件系统。
-你是否更喜欢使用基于终端的方法在 Linux 上编辑分区?为什么或为什么不?在下面告诉我们!
+你是否更喜欢使用基于终端的方法在 Linux 上编辑分区?不管是不是,请在下面告诉我们。
--------------------------------------------------------------------------------
@@ -84,7 +80,7 @@ via: https://www.maketecheasier.com/create-file-systems-partitions-terminal-linu
作者:[Derrik Diener][a]
译者:[strugglingyouth](https://github.com/strugglingyouth)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201511/20151104 Ubuntu Software Centre To Be Replaced in 16.04 LTS.md b/published/201511/20151104 Ubuntu Software Centre To Be Replaced in 16.04 LTS.md
new file mode 100644
index 0000000000..b8b10719bf
--- /dev/null
+++ b/published/201511/20151104 Ubuntu Software Centre To Be Replaced in 16.04 LTS.md
@@ -0,0 +1,53 @@
+Ubuntu 软件中心将在 16.04 LTS 中被替换
+================================================================================
+
+
+*Ubuntu 软件中心将在 Ubuntu 16.04 LTS 中被替换。*
+
+Ubuntu Xenial Xerus 桌面用户将会发现,这个熟悉的(并有些繁琐的)Ubuntu 软件中心将不再可用。
+
+按照目前的计划,GNOME 的 [软件应用(Software application)][1] 将作为基于 Unity 7 的桌面的默认包管理工具。
+
+
+
+*GNOME 软件应用*
+
+作为这次变化的一个结果是,会新开发插件来支持软件中心的评级、评论和应用程序付费的功能。
+
+该决定是在伦敦的 Canonical 总部最近举行的一次桌面峰会中通过的。
+
+“相对于 Ubuntu 软件中心,我们认为我们在 GNOME 软件中心(sic)添加 Snaps 支持上能做的更好。所以,现在看起来我们将使用 GNOME 软件中心来取代 [Ubuntu 软件中心]”,Ubuntu 桌面经理 Will Cooke 在 Ubuntu 在线峰会解释说。
+
+GNOME 3.18 架构与也将出现在 Ubuntu 16.04 中,其中一些应用程序将更新到 GNOME 3.20 , ‘这么做也是有道理的’,Will Cooke 补充说。
+
+我们最近在 Twitter 上做了一项民意调查,询问如何在 Ubuntu 上安装软件。结果表明,只有少数人怀念现在的软件中心...
+
+你使用什么方式在 Ubuntu 上安装软件?
+
+- 软件中心
+- 终端
+
+### 在 Ubuntu 16.04 其他应用程序也将会减少 ###
+
+Ubuntu 软件中心并不是唯一一个在 Xenial Xerus 中被丢弃的。
+
+光盘刻录工具 Brasero 和即时通讯工具 **Empathy** 也将从默认镜像中删除。
+
+虽然这些应用程序还在不断的开发,但随着笔记本减少了光驱以及基于移动网络的聊天服务,它们看起来越来越过时了。
+
+如果你还在使用它们请不要惊慌:Brasero 和 Empathy 将 **仍然可以通过存档在 Ubuntu 上安装**。
+
+也并不全是丢弃和替换,默认还包括了一个新的桌面应用程序:GNOME 日历。
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2015/11/the-ubuntu-software-centre-is-being-replace-in-16-04-lts
+
+作者:[Sam Tran][a]
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/111008502832304483939?rel=author
+[1]:https://wiki.gnome.org/Apps/Software
diff --git a/published/201511/20151105 How to Manage Your To-Do Lists in Ubuntu Using Go For It Application.md b/published/201511/20151105 How to Manage Your To-Do Lists in Ubuntu Using Go For It Application.md
new file mode 100644
index 0000000000..81a298a227
--- /dev/null
+++ b/published/201511/20151105 How to Manage Your To-Do Lists in Ubuntu Using Go For It Application.md
@@ -0,0 +1,84 @@
+如何在 Ubuntu 上用 Go For It 管理您的待办清单
+================================================================================
+
+
+任务管理可以说是工作及日常生活中最重要也最具挑战性的事情之一。当您在工作中承担越来越多的责任时,您的表现将与您管理任务的能力直接挂钩。
+
+若您的工作有部分需要在电脑上完成,那么您一定很乐意知道,有多款应用软件自称可以为您减轻任务管理的负担。即便这些软件中的大多数都是为 Windows 用户服务的,在 Linux 系统中仍然有不少选择。在本文中,我们就来讨论这样一款软件:Go For It.
+
+### Go For It ###
+
+[Go For It][1] (GFI) 由 Manuel Kehl 开发,他声称:“这是款简单易用且时尚优雅的生产力软件,以待办清单(To-Do List)为主打特色,并整合了一个能让你专注于当前事务的定时器。”这款软件的定时器功能尤其有趣,它还可以让您在继续工作之前暂停下来,放松一段时间。
+
+### 下载并安装 ###
+
+使用基于 Debian 系统(如Ubuntu)的用户可以通过运行以下终端命令轻松地安装这款软件:
+
+ sudo add-apt-repository ppa:mank319/go-for-it
+ sudo apt-get update
+ sudo apt-get install go-for-it
+
+以上命令执行完毕后,您就可以使用这条命令运行这款应用软件了:
+
+ go-for-it
+
+### 使用及配置###
+
+当你第一次运行 GFI 时,它的界面是长这样的:
+
+
+
+可以看到,界面由三个标签页组成,分别是*待办* (To-Do),*定时器* (Timer)和*完成* (Done)。*待办*页是一个任务列表(上图所示的4个任务是默认生成的——您可以点击头部的方框删除它们),*定时器*页内含有任务定时器,而*完成*页则是已完成任务的列表。底部有个文本框,您可以在此输入任务描述,并点击“+”号将任务添加到上面的列表中。
+
+举个例子,我将一个名为“MTE-research-work”的任务添加到了列表中,并点击选中了它,如下图所示:
+
+
+
+然后我进入*定时器*页,在这里我可以看到一个为当前“MTE-reaserch-work”任务设定的定时器,定时25分钟。
+
+
+
+当然,您可以将定时器设定为你喜欢的任何值。然而我并没有修改,而是直接点击下方的“开始 (Start)”按钮启动定时器。一旦剩余时间为60秒,GFI 就会给出一个提示。
+
+
+
+一旦时间到,它会提醒我休息5分钟。
+
+
+
+5分钟过后,我可以为我的任务再次开启定时器。
+
+
+
+任务完成以后,您可以点击*定时器*页中的“完成 (Done)”按钮,然后这个任务就会从*待办*页被转移到*完成*页。
+
+
+
+GFI 也能让您稍微调整一些它的设置。例如,下图所示的设置窗口就包含了一些选项,让您修改默认的任务时长,休息时长和提示时刻。
+
+
+
+值得一提的是,GFI 是以 TODO.txt 格式保存待办清单的,这种格式方便了移动设备之间的同步,也让您能使用其他前端程序来编辑任务——更多详情请阅读[这里][2]。
+
+您还可以通过以下视频观看 GFI 的动态展示。
+
+注:youtube 视频
+
+
+### 结论###
+
+正如您所看到的,GFI 是一款简洁明了且易于使用的任务管理软件。虽然它没有提供非常丰富的功能,但它实现了它的承诺,定时器的整合特别有用。如果您正在寻找一款实现了基础功能,并且开源的 Linux 任务管理软件,Go For It 值得您一试。
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/to-do-lists-ubuntu-go-for-it/
+
+作者:[Himanshu Arora][a]
+译者:[Ricky-Gong](https://github.com/Ricky-Gong)
+校对:[Caroline](https://github.com/carolinewuyan)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/himanshu/
+[1]:http://manuel-kehl.de/projects/go-for-it/
+[2]:http://todotxt.com/
diff --git a/translated/tech/20151105 Linux FAQs with Answers--How to change default Java version on Linux.md b/published/201511/20151105 Linux FAQs with Answers--How to change default Java version on Linux.md
similarity index 75%
rename from translated/tech/20151105 Linux FAQs with Answers--How to change default Java version on Linux.md
rename to published/201511/20151105 Linux FAQs with Answers--How to change default Java version on Linux.md
index c48274edf0..a2daadcc11 100644
--- a/translated/tech/20151105 Linux FAQs with Answers--How to change default Java version on Linux.md
+++ b/published/201511/20151105 Linux FAQs with Answers--How to change default Java version on Linux.md
@@ -1,15 +1,13 @@
-Linux又问必答-- 如何在Linux中改变默认的Java版本
+Linux 有问必答:如何在 Linux 中改变默认的 Java 版本
================================================================================
-> **提问**:当我尝试在Linux中运行一个Java程序时,我遇到了一个错误。看上去像程序编译所使用的Javab版本与我本地的不同。我该如何在Linux上切换默认的Java版本?
+> **提问**:当我尝试在Linux中运行一个Java程序时,我遇到了一个错误。看上去像程序编译所使用的Java版本与我本地的不同。我该如何在Linux上切换默认的Java版本?
->
-> Exception in thread "main" java.lang.UnsupportedClassVersionError: com/xmodulo/hmon/gui/NetConf : Unsupported major.minor version 51.0
-当Java程序编译时,编译环境会设置一个“target”变量来设置程序可以运行的最低Java版本。如果你Linux系统上运行的程序不满足最低的JRE版本要求,那么你会在运行的时候遇到下面的错误。
+当Java程序编译时,编译环境会设置一个“target”变量来设置程序可以运行的最低Java版本。如果你Linux系统上运行的程序不能满足最低的JRE版本要求,那么你会在运行的时候遇到下面的错误。
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/xmodulo/hmon/gui/NetConf : Unsupported major.minor version 51.0
-比如,这种情况下程序在Java JRE 1.7下编译,但是系统只有Java JRE 1.6。
+比如,程序在Java JRE 1.7下编译,但是系统只有Java JRE 1.6。
要解决这个问题,你需要改变默认的Java版本到Java JRE 1.7或者更高(假设JRE已经安装了)。
@@ -21,7 +19,7 @@ Linux又问必答-- 如何在Linux中改变默认的Java版本
本例中,总共安装了4个不同的Java版本:OpenJDK JRE 1.6、Oracle Java JRE 1.6、OpenJDK JRE 1.7 和 Oracle Java JRE 1.7。现在默认的Java版本是OpenJDK JRE 1.6。
-如果没有安装需要的Java JRE,你可以参考[这些指导][1]来完成安装。
+如果没有安装需要的Java JRE,你可以参考[这些指导][1]来完成安装。
现在有可用的候选版本,你可以用下面的命令在可用的Java JRE之间**切换默认的Java版本**:
@@ -45,7 +43,7 @@ via: http://ask.xmodulo.com/change-default-java-version-linux.html
作者:[Dan Nanni][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20151105 Linux FAQs with Answers--How to find which shell I am using on Linux.md b/published/201511/20151105 Linux FAQs with Answers--How to find which shell I am using on Linux.md
similarity index 66%
rename from translated/tech/20151105 Linux FAQs with Answers--How to find which shell I am using on Linux.md
rename to published/201511/20151105 Linux FAQs with Answers--How to find which shell I am using on Linux.md
index 675ef43d94..e9e3aeabcc 100644
--- a/translated/tech/20151105 Linux FAQs with Answers--How to find which shell I am using on Linux.md
+++ b/published/201511/20151105 Linux FAQs with Answers--How to find which shell I am using on Linux.md
@@ -1,5 +1,4 @@
-
-Linux 有问必答 - 如何在 Linux 上找到当前正在使用的 shell
+Linux 有问必答:如何知道当前正在使用的 shell 是哪个?
================================================================================
> **问题**: 我经常在命令行中切换 shell。是否有一个快速简便的方法来找出我当前正在使用的 shell 呢?此外,我怎么能找到当前 shell 的版本?
@@ -7,36 +6,30 @@ Linux 有问必答 - 如何在 Linux 上找到当前正在使用的 shell
有多种方式可以查看你目前在使用什么 shell,最简单的方法就是通过使用 shell 的特殊参数。
-其一,[一个名为 "$$" 的特殊参数][1] 表示当前你正在运行的 shell 的 PID。此参数是只读的,不能被修改。所以,下面的命令也将显示你正在运行的 shell 的名字:
+其一,[一个名为 "$$" 的特殊参数][1] 表示当前你正在运行的 shell 实例的 PID。此参数是只读的,不能被修改。所以,下面的命令也将显示你正在运行的 shell 的名字:
$ ps -p $$
-----------
-
PID TTY TIME CMD
21666 pts/4 00:00:00 bash
上述命令可在所有可用的 shell 中工作。
-如果你不使用 csh,使用 shell 的特殊参数 “$$” 可以找出当前的 shell,这表示当前正在运行的 shell 或 shell 脚本的名称。这是 Bash 的一个特殊参数,但也可用在其他 shells 中,如 sh, zsh, tcsh or dash。使用 echo 命令也可以查看你目前正在使用的 shell 的名称。
+如果你不使用 csh,找到当前使用的 shell 的另外一个办法是使用特殊参数 “$0” ,它表示当前正在运行的 shell 或 shell 脚本的名称。这是 Bash 的一个特殊参数,但也可用在其他 shell 中,如 sh、zsh、tcsh 或 dash。使用 echo 命令可以查看你目前正在使用的 shell 的名称。
$ echo $0
-----------
-
bash
-不要将 $SHELL 看成是一个单独的环境变量,它被设置为整个路径下的默认 shell。因此,这个变量并不一定指向你当前使用的 shell。例如,即使你在终端中调用不同的 shell,$SHELL 也保持不变。
+不要被一个叫做 $SHELL 的单独的环境变量所迷惑,它被设置为你的默认 shell 的完整路径。因此,这个变量并不一定指向你当前使用的 shell。例如,即使你在终端中调用不同的 shell,$SHELL 也保持不变。
$ echo $SHELL
-----------
-
/bin/shell

-因此,找出当前的shell,你应该使用 $$ 或 $0,但不是 $ SHELL。
+因此,找出当前的shell,你应该使用 $$ 或 $0,但不是 $SHELL。
### 找出当前 Shell 的版本 ###
@@ -46,8 +39,6 @@ Linux 有问必答 - 如何在 Linux 上找到当前正在使用的 shell
$ bash --version
-----------
-
GNU bash, version 4.3.30(1)-release (x86_64-pc-linux-gnu)
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
@@ -59,23 +50,17 @@ Linux 有问必答 - 如何在 Linux 上找到当前正在使用的 shell
$ zsh --version
-----------
-
zsh 5.0.7 (x86_64-pc-linux-gnu)
**对于** tcsh **shell**:
$ tcsh --version
-----------
-
tcsh 6.18.01 (Astron) 2012-02-14 (x86_64-unknown-linux) options wide,nls,dl,al,kan,rh,nd,color,filec
-对于一些 shells,你还可以使用 shell 特定的变量(例如,$ BASH_VERSION 或 $ ZSH_VERSION)。
+对于某些 shell,你还可以使用 shell 特定的变量(例如,$BASH_VERSION 或 $ZSH_VERSION)。
$ echo $BASH_VERSION
-----------
-
4.3.8(1)-release
--------------------------------------------------------------------------------
@@ -84,7 +69,7 @@ via: http://ask.xmodulo.com/which-shell-am-i-using.html
作者:[Dan Nanni][a]
译者:[strugglingyouth](https://github.com/strugglingyouth)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201511/20151109 Open Source Alternatives to LastPass.md b/published/201511/20151109 Open Source Alternatives to LastPass.md
new file mode 100644
index 0000000000..32819f9a07
--- /dev/null
+++ b/published/201511/20151109 Open Source Alternatives to LastPass.md
@@ -0,0 +1,131 @@
+LastPass 的开源替代品
+================================================================================
+LastPass是一个跨平台的密码管理程序。在Linux平台中,它可作为Firefox, Chrome和Opera浏览器的插件使用。LastPass Sesame支持Ubuntu/Debian与Fedora系统。此外,LastPass还有安装在Firefox Portable的便携版,可将其安装在USB设备上。再加上适用于Ubuntu/Debian, Fedora和openSUSE的LastPass Pocket, 其具有良好的跨平台覆盖性。虽然LastPass备受好评,但它是一个专有软件。此外,LastPass最近被LogMeIn收购。如果你在找一个开源的替代品,这篇文章可能会对你有所帮助。
+
+我们正面临着信息大爆炸。无论你是要在线经营生意,找工作,还是只为了休闲来进行阅读,互联网都是一个海量的信息源。在这种情况下,长期保留信息是很困难的。然而,及时地获取某些特定信息非常重要。密码就是这样的一个例子。
+
+作为一个电脑用户,你可能会面临在不同服务或网站使用相同或不同密码的困境。这个事情非常复杂,因为有些网站会限制你对密码的选择。比如,一个网站可能会限制密码的最小位数,大写字母,数字或者特殊字符,这使得在所有网站使用统一密码变得不可能。更重要的是,不在不同网站中使用同一密码有安全方面的原因。这样就不可避免地意味着人们经常会有很多密码要记。一个解决方案是将所有的密码写下来。然而,这种做法也极度的不安全。
+
+为了解决需要记忆无穷多串密码的问题,目前比较流行的解决方案是使用密码管理软件。事实上,这类软件对于活跃的互联网用户来说极为实用。它使得你获取、管理和安全保存所有密码变得极为容易,而大多数密码都是用软件或文件系统加密过的。因此,用户只需要记住一个简单的密码就可以获取到其它所有密码。密码管理软件鼓励用户对于不同服务去采用独一无二的,非直观的高强度的密码。
+
+为了让大家更深入地了解Linux软件的质量,我将介绍4款优秀的、可替代LastPass的开源软件。
+
+### KeePassX ###
+
+
+
+KeePassX是KeePass的多平台移植,是一款开源、跨平台的密码管理软件。这款软件可以帮助你以安全的方式保管密码。你可以将所有密码保存在一个数据库中,而这个数据库被一个主密码或密码盘来保管。这使得用户只需要记住一个单一的主密码或插入密码盘即可解锁整个数据库。
+
+密码数据库使用AES(即Rijndael)或者TwoFish算法进行加密,密钥长度为256位。
+
+该软件功能包括:
+
+- 管理模式丰富
+ - 通过标题使每条密码更容易被识别
+ - 可设置密码过期时间
+ - 可插入附件
+ - 可为不同分组或密码自定义标志
+ - 在分组中对密码排序
+- 搜索功能:可在特定分组或整个数据库中搜索
+- 自动键入: 这个功能允许你在登录网站时只需要按下几个键。KeePassX可以帮助你输入剩下的密码。自动键入通过读取当前窗口的标题,对密码数据库进行搜索来获取相应的密码
+- 数据库安全性强,用户可通过密码或一个密钥文件(可存储在CD或U盘中)访问数据库(或两者)
+- 安全密码自动生成
+- 具有预防措施,获取用星号隐藏的密码并检查其安全性
+- 加密 - 用256位密钥,通过AES(高级加密标准)或TwoFish算法加密数据库,
+- 密码可以导入或导出。可从PwManager文件(*.pwm)或KWallet文件(*.xml)中导入密码,可导出为文本(*.txt)格式。
+
+---
+- 软件官网:[www.keepassx.org][1]
+- 开发者:KeepassX Team
+- 软件许可证:GNU GPL V2
+- 版本号:0.4.3
+
+### Encryptr ###
+
+
+
+Encryptr是一个开源的、零知识(zero-knowledge)的、基于云端的密码管理/电子钱包软件,以Crypton为基础开发。Crypton是一个Javascript库,允许开发者利用其开发应用来上传文件至服务器,而服务器无法知道用户所存储的文件内容。
+
+Encryptr可将你的敏感信息,比如密码、信用卡数据、PIN码、或认证码存储在云端。然而,由于它基于零知识的Cypton框架开发,Encryptr可保证只有用户才拥有访问或读取秘密信息的权限。
+
+由于其跨平台的特性,Encryptr允许用户随时随地、安全地通过一个账户从云端获取机密信息。
+
+软件特性包括:
+
+- 使用非常安全的零知识Crypton框架,只在你的本地加密/解密数据
+- 易于使用
+- 基于云端
+- 可存储三种类型的数据:密码、信用卡账号以及通用的键值对
+- 可对每条密码设置“备注”项
+- 过滤和搜索密码
+- 对密码进行本地加密缓存,以节省载入时间
+
+---
+- 软件官网: [encryptr.org][2]
+- 开发者: Tommy Williams
+- 软件许可证: GNU GPL v3
+- 版本号: 1.2.0
+
+### RatticDB ###
+
+
+
+RatticDB是一个开源的、基于Django的密码管理服务。
+
+RatticDB被设计为一个“密码生命周期管理工具”而不是单单一个“密码存储工具”。RatticDB致力于及时提醒用户哪些密码在何时需要更改。它不提供应用层面的密码加密。
+
+软件特性包括:
+
+- 简洁的ACL设计
+- 可改变队列功能,可让用户知晓何时需要更改某应用的密码
+- 支持Ansible配置
+
+---
+
+- 软件官网: [rattic.org][3]
+- 开发者: Daniel Hall
+- 软件许可证: GNU GPL v2
+- 版本号: 1.3.1
+
+### Seahorse ###
+
+
+
+Seahorse是一个GnuPG(GNU隐私保护软件)的Gnome前端界面。它的目标是提供一个易于使用密钥管理工具,以及一个易于使用的界面来控制加密操作。
+
+Seahorse是一个工具,用来提供安全传输和数据存储服务。数据加密和数字密钥生成操作可以轻易通过GUI来操作,密钥管理操作也可以轻易通过直观的界面来进行。
+
+此外,Seahorse包含一个Gedit插件,可以使用鹦鹉螺文件管理器管理文件,一个管理剪贴板中事物的小程序,一个存储私密密码的代理,还有一个GnuPG和OpenSSH的密钥管理工具。
+
+软件特性包括:
+
+- 对文本进行加密/解密/签名
+- 管理密钥及密钥环
+- 将密钥及密钥环与密钥服务器同步
+- 密码签名及发布
+- 将密码缓存起来,无需多次重复键入
+- 对密钥及密钥环进行备份
+- 可添加一个GDK支持格式的图片作为OpenGPG图片ID
+- 生成SSH密钥,对其进行验证及储存
+- 多语言支持
+
+---
+
+- 软件官网: [www.gnome.org/projects/seahorse][4]
+- 开发者: Jacob Perkins, Jose Carlos, Garcia Sogo, Jean Schurger, Stef Walter, Adam Schreiber
+- 软件许可证: GNU GPL v2
+- 版本号: 3.18.0
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxlinks.com/article/20151108125950773/LastPassAlternatives.html
+
+译者:[StdioA](https://github.com/StdioA)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.keepassx.org/
+[2]:https://encryptr.org/
+[3]:http://rattic.org/
+[4]:http://www.gnome.org/projects/seahorse/
diff --git a/published/201511/20151116 Linux FAQs with Answers--How to set JAVA_HOME environment variable automatically on Linux.md b/published/201511/20151116 Linux FAQs with Answers--How to set JAVA_HOME environment variable automatically on Linux.md
new file mode 100644
index 0000000000..f9368ec48b
--- /dev/null
+++ b/published/201511/20151116 Linux FAQs with Answers--How to set JAVA_HOME environment variable automatically on Linux.md
@@ -0,0 +1,48 @@
+Linux 有问必答:如何在 Linux 上自动设置 JAVA_HOME 环境变量
+================================================================================
+> **问题**:我需要在我的 Linux 机器上编译 Java 程序。为此我已经安装了 JDK (Java Development Kit),而现在我正试图设置 JAVA\_HOME 环境变量使其指向安装好的 JDK 。关于在 Linux 上设置 JAVA\_HOME 环境变量,最受推崇的办法是什么?
+
+许多 Java 程序或基于 Java 的*集成开发环境* (IDE)都需要设置好 JAVA_HOME 环境变量。该变量应指向 *Java 开发工具包* (JDK)或 *Java 运行时环境* (JRE)的安装目录。JDK 不仅包含了 JRE 提供的一切,还带有用于编译 Java 程序的额外的二进制代码和库文件(例如编译器,调试器及 JavaDoc 文档生成器)。JDK 是用来构建 Java 程序的,如果只是运行已经构建好的 Java 程序,单独一份 JRE 就足够了。
+
+当您正试图设置 JAVA\_HOME 环境变量时,麻烦的事情在于 JAVA\_HOME 变量需要根据以下几点而改变:(1) 您是否安装了 JDK 或 JRE;(2) 您安装了哪个版本;(3) 您安装的是 Oracle JDK 还是 Open JDK。
+
+因此每当您的开发环境或运行时环境发生改变(例如为 JDK 更新版本)时,您需要根据实际情况调整 JAVA\_HOME 变量,而这种做法是繁重且缺乏效率的。
+
+以下 export 命令能为您**自动设置** JAVA\_HOME 环境变量,而无须顾及上述的因素。
+
+若您安装的是 JRE:
+
+ export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))
+
+若您安装的是 JDK:
+
+ export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which javac))))
+
+根据您的情况,将上述命令中的一条写入 ~/.bashrc(或 /etc/profile)文件中,它就会永久地设置好 JAVA\_HOME 变量。
+
+注意,由于 java 或 javac 可以建立起多个层次的符号链接,为此"readlink -f"命令是用来获取它们真正的执行路径的。
+
+举个例子,假如您安装的是 Oracle JRE 7,那么上述的第一条 export 命令将自动设置 JAVA\_HOME 为:
+
+ /usr/lib/jvm/java-7-oracle/jre
+
+若您安装的是 Open JDK 第8版,那么第二条 export 命令将设置 JAVA\_HOME 为:
+
+ /usr/lib/jvm/java-8-openjdk-amd64
+
+
+
+简而言之,这些 export 命令会在您重装/升级您的JDK/JRE,或[更换默认 Java 版本][1]时自动更新 JAVA\_HOME 变量。您不再需要手动调整它。
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/set-java_home-environment-variable-linux.html
+
+作者:[Dan Nanni][a]
+译者:[Ricky-Gong](https://github.com/Ricky-Gong)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:http://ask.xmodulo.com/change-default-java-version-linux.html
diff --git a/published/201511/20151117 N1--The Next Generation Open Source Email Client.md b/published/201511/20151117 N1--The Next Generation Open Source Email Client.md
new file mode 100644
index 0000000000..b2cbb4c4ea
--- /dev/null
+++ b/published/201511/20151117 N1--The Next Generation Open Source Email Client.md
@@ -0,0 +1,48 @@
+N1:下一代开源邮件客户端
+================================================================================
+
+
+当我们谈论到Linux中的邮件客户端,通常 Thunderbird、Geary 和 [Evolution][3] 就会出现在我们的脑海。作为对这些大咖们的挑战,一款新的开源邮件客户端正在涌入市场。
+
+### 设计和功能 ###
+
+[N1][4]是一个设计与功能并重的新一代开源邮件客户端。作为一个开源软件,N1目前支持 Linux 和 Mac OS X,Windows的版本还在开发中。
+
+N1宣传它自己为“可扩展的开源邮件客户端”,因为它包含了 Javascript 插件框架,任何人都可以为它创建强大的新功能。可扩展是一个非常流行的功能,它帮助[开源编辑器Atom][5]变得流行。N1同样把重点放在了可扩展上面。
+
+除了可扩展性,N1同样着重设计了程序的外观。下面N1的截图就是个很好的例子:
+
+
+
+*Mac OS X上的N1客户端。图片来自:N1*
+
+除了这个功能,N1兼容上百个邮件服务提供商,包括Gmail、Yahoo、iCloud、Microsoft Exchange等等,这个桌面应用提供了离线功能。
+
+### 目前只能邀请使用 ###
+
+我不知道为什么每个人都选择了 OnePlus 的‘只能邀请使用’的市场策略。目前,N1桌面端只能被邀请才能下载。你可以用下面的链接请求一个邀请。N1团队会在几天内邮件给你下载链接。
+
+
+- [请求N1邀请][6]
+
+### 感兴趣了么? ###
+
+我并不是桌面邮件客户端的粉丝,但是 N1 的确引起了我的兴趣,让我想要试一试。你呢?
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/n1-open-source-email-client/
+
+作者:[Abhishek][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[Caroline](https://github.com/carolinewuyan)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:https://www.mozilla.org/en-US/thunderbird/
+[2]:https://wiki.gnome.org/Apps/Geary
+[3]:https://help.gnome.org/users/evolution/stable/
+[4]:https://nylas.com/N1/
+[5]:http://itsfoss.com/atom-stable-released/
+[6]:https://invite.nylas.com/download
diff --git a/published/201511/20151123 How to Install NVIDIA 358.16 Driver in Ubuntu 15.10 or 14.04.md b/published/201511/20151123 How to Install NVIDIA 358.16 Driver in Ubuntu 15.10 or 14.04.md
new file mode 100644
index 0000000000..6ec1bdc1ec
--- /dev/null
+++ b/published/201511/20151123 How to Install NVIDIA 358.16 Driver in Ubuntu 15.10 or 14.04.md
@@ -0,0 +1,68 @@
+如何在 Ubuntu 15.10,14.04 中安装 NVIDIA 358.16 驱动程序
+================================================================================
+
+
+[NVIDIA 358.16][1] —— NVIDIA 358 系列的第一个稳定版本已经发布,并对 358.09 中(测试版)做了一些修正,以及一些小的改进。
+
+NVIDIA 358 增加了一个新的 **nvidia-modeset.ko** 内核模块,可以配合 nvidia.ko 内核模块工作来调用 GPU 显示引擎。在以后发布版本中,**nvidia-modeset.ko** 内核驱动程序将被用于模式设置接口的基础,该接口由内核的直接渲染管理器(DRM)所提供。
+
+新的驱动程序也有新的 GLX 协议扩展,以及在 OpenGL 驱动中分配大量内存的系统内存分配新机制。新的 GPU **GeForce 805A** 和 **GeForce GTX 960A** 都支持。NVIDIA 358.16 也支持 X.Org 1.18 服务器和 OpenGL 4.3。
+
+### 如何在 Ubuntu 中安装 NVIDIA 358.16 : ###
+
+> **请不要在生产设备上安装,除非你知道自己在做什么以及如何才能恢复。**
+
+对于官方的二进制文件,请到 [nvidia.com/object/unix.html][1] 查看。
+
+对于那些喜欢 Ubuntu PPA 的,我建议你使用 [显卡驱动 PPA][2]。到目前为止,支持 Ubuntu 16.04, Ubuntu 15.10, Ubuntu 15.04, Ubuntu 14.04。
+
+**1. 添加 PPA.**
+
+通过按 `Ctrl+Alt+T` 快捷键来从 Unity 桌面打开终端。当打启动应用后,粘贴下面的命令并按回车键:
+
+ sudo add-apt-repository ppa:graphics-drivers/ppa
+
+
+
+它会要求你输入密码。输入密码后,密码不会显示在屏幕上,按 Enter 继续。
+
+**2. 刷新并安装新的驱动程序**
+
+添加 PPA 后,逐一运行下面的命令刷新软件库并安装新的驱动程序:
+
+ sudo apt-get update
+
+ sudo apt-get install nvidia-358 nvidia-settings
+
+### (如果需要的话,) 卸载: ###
+
+开机从 GRUB 菜单进入恢复模式,进入根控制台。然后逐一运行下面的命令:
+
+重新挂载文件系统为可写:
+
+ mount -o remount,rw /
+
+删除所有的 nvidia 包:
+
+ apt-get purge nvidia*
+
+最后返回菜单并重新启动:
+
+ reboot
+
+要禁用/删除显卡驱动 PPA,点击系统设置下的**软件和更新**,然后导航到**其他软件**标签。
+
+--------------------------------------------------------------------------------
+
+via: http://ubuntuhandbook.org/index.php/2015/11/install-nvidia-358-16-driver-ubuntu-15-10/
+
+作者:[Ji m][a]
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ubuntuhandbook.org/index.php/about/
+[1]:http://www.nvidia.com/Download/driverResults.aspx/95921/en-us
+[2]:http://www.nvidia.com/object/unix.html
+[3]:https://launchpad.net/~graphics-drivers/+archive/ubuntu/ppa
diff --git a/published/201511/20151123 Install Intel Graphics Installer in Ubuntu 15.10.md b/published/201511/20151123 Install Intel Graphics Installer in Ubuntu 15.10.md
new file mode 100644
index 0000000000..bf6b5c3b11
--- /dev/null
+++ b/published/201511/20151123 Install Intel Graphics Installer in Ubuntu 15.10.md
@@ -0,0 +1,46 @@
+在 Ubuntu 15.10 上安装 Intel Graphics 安装器
+================================================================================
+
+
+Intel 最近发布了一个新版本的 Linux Graphics 安装器。在新版本中,将不支持 Ubuntu 15.04,而必须用 Ubuntu 15.10 Wily。
+
+> Linux 版 Intel® Graphics 安装器可以让你很容易的为你的 Intel Graphics 硬件安装最新版的图形与视频驱动。它能保证你一直使用最新的增强与优化功能,并能够安装到 Intel Graphics Stack 中,来保证你在你的 Intel 图形硬件下,享受到最佳的用户体验。*现在 Linux 版的 Intel® Graphics 安装器支持最新版的 Ubuntu。*
+
+
+
+### 安装 ###
+
+**1.** 从[这个链接页面][1]中下载该安装器。当前支持 Ubuntu 15.10 的版本是1.2.1版。你可以在**系统设置 -> 详细信息**中检查你的操作系统(32位或64位)的类型。
+
+
+
+**2.** 一旦下载完成,到下载目录中点击 .deb 安装包,用 Ubuntu 软件中心打开它,然最后点击“安装”按钮。
+
+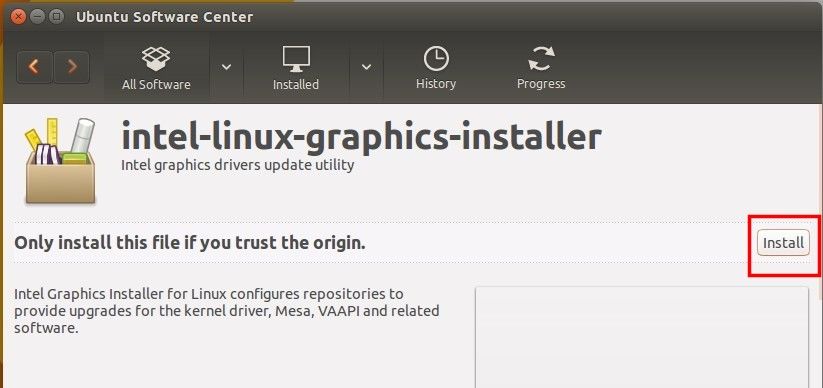
+
+**3.** 为了让系统信任 Intel Graphics 安装器,你需要通过下面的命令来为它添加密钥。
+
+用快捷键`Ctrl+Alt+T`或者在 Unity Dash 中的“应用程序启动器”中打开终端。依次粘贴运行下面的命令。
+
+ wget --no-check-certificate https://download.01.org/gfx/RPM-GPG-KEY-ilg -O - | sudo apt-key add -
+
+ wget --no-check-certificate https://download.01.org/gfx/RPM-GPG-KEY-ilg-2 -O - | sudo apt-key add -
+
+
+
+注意:在运行第一个命令的过程中,如果密钥下载完成后,光标停住不动并且一直闪烁的话,就像上面图片显示的那样,输入你的密码(输入时不会看到什么有变化)然后回车就行了。
+
+最后通过 Unity Dash 或应用程序启动器打开 Intel Graphics 安装器。
+
+--------------------------------------------------------------------------------
+
+via: http://ubuntuhandbook.org/index.php/2015/11/install-intel-graphics-installer-in-ubuntu-15-10/
+
+作者:[Ji m][a]
+译者:[XLCYun](https://github.com/XLCYun)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ubuntuhandbook.org/index.php/about/
+[1]:https://01.org/linuxgraphics/downloads
diff --git a/published/Learn with Linux--Master Your Math with These Linux Apps.md b/published/201511/Learn with Linux--Master Your Math with These Linux Apps.md
similarity index 100%
rename from published/Learn with Linux--Master Your Math with These Linux Apps.md
rename to published/201511/Learn with Linux--Master Your Math with These Linux Apps.md
diff --git a/published/201511/LetsEncrypt.md b/published/201511/LetsEncrypt.md
new file mode 100644
index 0000000000..c1c4a40ea0
--- /dev/null
+++ b/published/201511/LetsEncrypt.md
@@ -0,0 +1,112 @@
+# SSL/TLS 加密新纪元 - Let's Encrypt
+
+根据 Let's Encrypt 官方博客消息,Let's Encrypt 服务将在下周(11 月 16 日)正式对外开放。
+
+Let's Encrypt 项目是由互联网安全研究小组(ISRG,Internet Security Research Group)主导并开发的一个新型数字证书认证机构(CA,Certificate Authority)。该项目旨在开发一个自由且开放的自动化 CA 套件,并向公众提供相关的证书免费签发服务以降低安全通讯的财务、技术和教育成本。在过去的一年中,互联网安全研究小组拟定了 [ACME 协议草案][1],并首次实现了使用该协议的应用套件:服务端 [Boulder][2] 和客户端 [letsencrypt][3]。
+
+至于为什么 Let's Encrypt 让我们如此激动,以及 HTTPS 协议如何保护我们的通讯请参考[浅谈 HTTPS 和 SSL/TLS 协议的背景与基础][4]。
+
+## ACME 协议
+
+Let's Encrypt 的诞生离不开 ACME(Automated Certificate Management Environment,自动证书管理环境)协议的拟定。
+
+说到 ACME 协议,我们不得不提一下传统 CA 的认证方式。Let's Encrypt 服务所签发的证书为域名认证证书(DV,Domain-validated Certificate),签发这类证书需要域名所有者完成以下至少一种挑战(Challenge)以证明自己对域名的所有权:
+
+* 验证申请人对域名的 Whois 信息中邮箱的控制权;
+* 验证申请人对域名的常见管理员邮箱(如以 `admin@`、`postmaster@` 开头的邮箱等)的控制权;
+* 在 DNS 的 TXT 记录中发布一条 CA 提供的字符串;
+* 在包含域名的网址中特定路径发布一条 CA 提供的字符串。
+
+不难发现,其中最容易实现自动化的一种操作必然为最后一条,ACME 协议中的 [Simple HTTP][5] 认证即是用一种类似的方法对从未签发过任何证书的域名进行认证。该协议要求在访问 `http://域名/.well-known/acme-challenge/指定字符串` 时返回特定的字符串。
+
+然而实现该协议的客户端 [letsencrypt][3] 做了更多——它不仅可以通过 ACME 协议配合服务端 [Boulder][2] 的域名进行独立(standalone)的认证工作,同时还可以自动配置常见的服务器软件(目前支持 Nginx 和 Apache)以完成认证。
+
+## Let's Encrypt 免费证书签发服务
+
+对于大多数网站管理员来讲,想要对自己的 Web 服务器进行加密需要一笔不小的支出进行证书签发并且难以配置。根据早些年 SSL Labs 公布的 [2010 年互联网 SSL 调查报告(PDF)][6] 指出超过半数的 Web 服务器没能正确使用 Web 服务器证书,主要的问题有证书不被浏览器信任、证书和域名不匹配、证书过期、证书信任链没有正确配置、使用已知有缺陷的协议和算法等。而且证书过期后的续签和泄漏后的吊销仍需进行繁琐的人工操作。
+
+幸运的是 Let's Encrypt 免费证书签发服务在经历了漫长的开发和测试之后终于来临,在 Let's Encrypt 官方 CA 被广泛信任之前,IdenTrust 的根证书对 Let's Encrypt 的二级 CA 进行了交叉签名使得大部分浏览器已经信任 Let's Encrypt 签发的证书。
+
+## 使用 letsencrypt
+
+由于当前 Let's Encrypt 官方的证书签发服务还未公开,你只能尝试开发版本。这个版本会签发一个 CA 标识为 `happy hacker fake CA` 的测试证书,注意这个证书不受信任。
+
+要获取开发版本请直接 `$ git clone https://github.com/letsencrypt/letsencrypt`。
+
+以下的[使用方法][7]摘自 Let's Encrypt 官方网站。
+
+### 签发证书
+
+`letsencrypt` 工具可以协助你处理证书请求和验证工作。
+
+#### 自动配置 Web 服务器
+
+下面的操作将会自动帮你将新证书配置到 Nginx 和 Apache 中。
+
+```
+$ letsencrypt run
+```
+
+#### 独立签发证书
+
+下面的操作将会将新证书置于当前目录下。
+
+```
+$ letsencrypt -d example.com auth
+```
+
+### 续签证书
+
+默认情况下 `letsencrypt` 工具将协助你跟踪当前证书的有效期限并在需要时自动帮你续签。如果需要手动续签,执行下面的操作。
+
+```
+$ letsencrypt renew --cert-path example-cert.pem
+```
+
+### 吊销证书
+
+列出当前托管的证书菜单以吊销。
+
+```
+$ letsencrypt revoke
+```
+
+你也可以吊销某一个证书或者属于某个私钥的所有证书。
+
+```
+$ letsencrypt revoke --cert-path example-cert.pem
+```
+
+```
+$ letsencrypt revoke --key-path example-key.pem
+```
+
+## Docker 化 letsencrypt
+
+如果你不想让 letsencrypt 自动配置你的 Web 服务器的话,使用 Docker 跑一份独立的版本将是一个不错的选择。你所要做的只是在装有 Docker 的系统中执行:
+
+```
+$ sudo docker run -it --rm -p 443:443 -p 80:80 --name letsencrypt \
+ -v "/etc/letsencrypt:/etc/letsencrypt" \
+ -v "/var/lib/letsencrypt:/var/lib/letsencrypt" \
+ quay.io/letsencrypt/letsencrypt:latest auth
+```
+
+你就可以快速的为自己的 Web 服务器签发一个免费而且受信任的 DV 证书啦!
+
+## Let's Encrypt 的注意事项
+
+* Let's Encrypt 当前发行的 DV 证书仅能验证域名的所有权,并不能验证其所有者身份;
+* Let's Encrypt 不像其他 CA 那样对安全事故有保险赔付;
+* Let's Encrypt 目前不提共 Wildcard 证书;
+* Let's Encrypt 的有效时间仅为 90 天,逾期需要续签(可自动续签)。
+
+对于 Let's Encrypt 的介绍就到这里,让我们一起目睹这场互联网的安全革命吧。
+
+[1]: https://github.com/letsencrypt/acme-spec
+[2]: https://github.com/letsencrypt/boulder
+[3]: https://github.com/letsencrypt/letsencrypt
+[4]: https://linux.cn/article-5175-1.html
+[5]: https://letsencrypt.github.io/acme-spec/#simple-http
+[6]: https://community.qualys.com/servlet/JiveServlet/download/38-1636/Qualys_SSL_Labs-State_of_SSL_2010-v1.6.pdf
+[7]: https://letsencrypt.org/howitworks/
diff --git a/published/20151104 How to Install Redis Server on CentOS 7.md b/published/20151104 How to Install Redis Server on CentOS 7.md
new file mode 100644
index 0000000000..90e090ef39
--- /dev/null
+++ b/published/20151104 How to Install Redis Server on CentOS 7.md
@@ -0,0 +1,239 @@
+如何在 CentOS 7 上安装 Redis 服务器
+================================================================================
+
+大家好,本文的主题是 Redis,我们将要在 CentOS 7 上安装它。编译源代码,安装二进制文件,创建、安装文件。在安装了它的组件之后,我们还会配置 redis ,就像配置操作系统参数一样,目标就是让 redis 运行的更加可靠和快速。
+
+
+
+*Redis 服务器*
+
+Redis 是一个开源的多平台数据存储软件,使用 ANSI C 编写,直接在内存使用数据集,这使得它得以实现非常高的效率。Redis 支持多种编程语言,包括 Lua, C, Java, Python, Perl, PHP 和其他很多语言。redis 的代码量很小,只有约3万行,它只做“很少”的事,但是做的很好。尽管是在内存里工作,但是数据持久化的保存还是有的,而redis 的可靠性就很高,同时也支持集群,这些可以很好的保证你的数据安全。
+
+### 构建 Redis ###
+
+redis 目前没有官方 RPM 安装包,我们需要从源代码编译,而为了要编译就需要安装 Make 和 GCC。
+
+如果没有安装过 GCC 和 Make,那么就使用 yum 安装。
+
+ yum install gcc make
+
+从[官网][1]下载 tar 压缩包。
+
+ curl http://download.redis.io/releases/redis-3.0.4.tar.gz -o redis-3.0.4.tar.gz
+
+解压缩。
+
+ tar zxvf redis-3.0.4.tar.gz
+
+进入解压后的目录。
+
+ cd redis-3.0.4
+
+使用Make 编译源文件。
+
+ make
+
+### 安装 ###
+
+进入源文件的目录。
+
+ cd src
+
+复制 Redis 的服务器和客户端到 /usr/local/bin。
+
+ cp redis-server redis-cli /usr/local/bin
+
+最好也把 sentinel,benchmark 和 check 复制过去。
+
+ cp redis-sentinel redis-benchmark redis-check-aof redis-check-dump /usr/local/bin
+
+创建redis 配置文件夹。
+
+ mkdir /etc/redis
+
+在`/var/lib/redis` 下创建有效的保存数据的目录
+
+ mkdir -p /var/lib/redis/6379
+
+#### 系统参数 ####
+
+为了让 redis 正常工作需要配置一些内核参数。
+
+配置 `vm.overcommit_memory` 为1,这可以避免数据被截断,详情[见此][2]。
+
+ sysctl -w vm.overcommit_memory=1
+
+修改 backlog 连接数的最大值超过 redis.conf 中的 `tcp-backlog` 值,即默认值511。你可以在[kernel.org][3] 找到更多有关基于 sysctl 的 ip 网络隧道的信息。
+
+ sysctl -w net.core.somaxconn=512
+
+取消对透明巨页内存(transparent huge pages)的支持,因为这会造成 redis 使用过程产生延时和内存访问问题。
+
+ echo never > /sys/kernel/mm/transparent_hugepage/enabled
+
+### redis.conf ###
+
+redis.conf 是 redis 的配置文件,然而你会看到这个文件的名字是 6379.conf ,而这个数字就是 redis 监听的网络端口。如果你想要运行超过一个的 redis 实例,推荐用这样的名字。
+
+复制示例的 redis.conf 到 **/etc/redis/6379.conf**。
+
+ cp redis.conf /etc/redis/6379.conf
+
+现在编辑这个文件并且配置参数。
+
+ vi /etc/redis/6379.conf
+
+#### daemonize ####
+
+设置 `daemonize` 为 no,systemd 需要它运行在前台,否则 redis 会突然挂掉。
+
+ daemonize no
+
+#### pidfile ####
+
+设置 `pidfile` 为 /var/run/redis_6379.pid。
+
+ pidfile /var/run/redis_6379.pid
+
+#### port ####
+
+如果不准备用默认端口,可以修改。
+
+ port 6379
+
+#### loglevel ####
+
+设置日志级别。
+
+ loglevel notice
+
+#### logfile ####
+
+修改日志文件路径。
+
+ logfile /var/log/redis_6379.log
+
+#### dir ####
+
+设置目录为 /var/lib/redis/6379
+
+ dir /var/lib/redis/6379
+
+### 安全 ###
+
+下面有几个可以提高安全性的操作。
+
+#### Unix sockets ####
+
+在很多情况下,客户端程序和服务器端程序运行在同一个机器上,所以不需要监听网络上的 socket。如果这和你的使用情况类似,你就可以使用 unix socket 替代网络 socket,为此你需要配置 `port` 为0,然后配置下面的选项来启用 unix socket。
+
+设置 unix socket 的套接字文件。
+
+ unixsocket /tmp/redis.sock
+
+限制 socket 文件的权限。
+
+ unixsocketperm 700
+
+现在为了让 redis-cli 可以访问,应该使用 -s 参数指向该 socket 文件。
+
+ redis-cli -s /tmp/redis.sock
+
+#### requirepass ####
+
+你可能需要远程访问,如果是,那么你应该设置密码,这样子每次操作之前要求输入密码。
+
+ requirepass "bTFBx1NYYWRMTUEyNHhsCg"
+
+#### rename-command ####
+
+想象一下如下指令的输出。是的,这会输出服务器的配置,所以你应该在任何可能的情况下拒绝这种访问。
+
+ CONFIG GET *
+
+为了限制甚至禁止这条或者其他指令可以使用 `rename-command` 命令。你必须提供一个命令名和替代的名字。要禁止的话需要设置替代的名字为空字符串,这样禁止任何人猜测命令的名字会比较安全。
+
+ rename-command FLUSHDB "FLUSHDB_MY_SALT_G0ES_HERE09u09u"
+ rename-command FLUSHALL ""
+ rename-command CONFIG "CONFIG_MY_S4LT_GO3S_HERE09u09u"
+
+
+
+*使用密码通过 unix socket 访问,和修改命令*
+
+#### 快照 ####
+
+默认情况下,redis 会周期性的将数据集转储到我们设置的目录下的 **dump.rdb** 文件。你可以使用 `save` 命令配置转储的频率,它的第一个参数是以秒为单位的时间帧,第二个参数是在数据文件上进行修改的数量。
+
+每隔15分钟并且最少修改过一次键。
+
+ save 900 1
+
+每隔5分钟并且最少修改过10次键。
+
+ save 300 10
+
+每隔1分钟并且最少修改过10000次键。
+
+ save 60 10000
+
+文件 `/var/lib/redis/6379/dump.rdb` 包含了从上次保存以来内存里数据集的转储数据。因为它先创建临时文件然后替换之前的转储文件,这里不存在数据破坏的问题,你不用担心,可以直接复制这个文件。
+
+### 开机时启动 ###
+
+你可以使用 systemd 将 redis 添加到系统开机启动列表。
+
+复制示例的 init_script 文件到 `/etc/init.d`,注意脚本名所代表的端口号。
+
+ cp utils/redis_init_script /etc/init.d/redis_6379
+
+现在我们要使用 systemd,所以在 `/etc/systems/system` 下创建一个单位文件名字为 `redis_6379.service`。
+
+ vi /etc/systemd/system/redis_6379.service
+
+填写下面的内容,详情可见 systemd.service。
+
+ [Unit]
+ Description=Redis on port 6379
+
+ [Service]
+ Type=forking
+ ExecStart=/etc/init.d/redis_6379 start
+ ExecStop=/etc/init.d/redis_6379 stop
+
+ [Install]
+ WantedBy=multi-user.target
+
+现在添加我之前在 `/etc/sysctl.conf` 里面修改过的内存过量使用和 backlog 最大值的选项。
+
+ vm.overcommit_memory = 1
+
+ net.core.somaxconn=512
+
+对于透明巨页内存支持,并没有直接 sysctl 命令可以控制,所以需要将下面的命令放到 `/etc/rc.local` 的结尾。
+
+ echo never > /sys/kernel/mm/transparent_hugepage/enabled
+
+### 总结 ###
+
+这样就可以启动了,通过设置这些选项你就可以部署 redis 服务到很多简单的场景,然而在 redis.conf 还有很多为复杂环境准备的 redis 选项。在一些情况下,你可以使用 [replication][4] 和 [Sentinel][5] 来提高可用性,或者[将数据分散][6]在多个服务器上,创建服务器集群。
+
+谢谢阅读。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/storage/install-redis-server-centos-7/
+
+作者:[Carlos Alberto][a]
+译者:[ezio](https://github.com/oska874)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/carlosal/
+[1]:http://redis.io/download
+[2]:https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
+[3]:https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
+[4]:http://redis.io/topics/replication
+[5]:http://redis.io/topics/sentinel
+[6]:http://redis.io/topics/partitioning
diff --git a/published/20151105 Linus Torvalds Lambasts Open Source Programmers over Insecure Code.md b/published/20151105 Linus Torvalds Lambasts Open Source Programmers over Insecure Code.md
new file mode 100644
index 0000000000..964a9774ca
--- /dev/null
+++ b/published/20151105 Linus Torvalds Lambasts Open Source Programmers over Insecure Code.md
@@ -0,0 +1,35 @@
+开源开发者提交不安全代码,遭 Linus 炮轰
+================================================================================
+
+
+Linus 上个月骂了一个 Linux 开发者,原因是他向 kernel 提交了一份不安全的代码。
+
+Linus 是个 Linux 内核项目非官方的“仁慈的独裁者(benevolent dictator)”(LCTT译注:英国《卫报》曾将乔布斯评价为‘仁慈的独裁者’),这意味着他有权决定将哪些代码合入内核,哪些代码直接丢掉。
+
+在10月28号,一个开源开发者提交的代码未能符合 Torvalds 的要求,于是遭来了[一顿臭骂][1]。Torvalds 在他提交的代码下评论道:“你提交的是什么东西。”
+
+接着他说这个开发者是“毫无能力的神经病”。
+
+Torvalds 为什么会这么生气?他觉得那段代码可以写得更有效率一点,可读性更强一点,编译器编译后跑得更好一点(编译器的作用就是将让人看的代码翻译成让电脑看的代码)。
+
+Torvalds 重新写了一版代码将原来的那份替换掉,并建议所有开发者应该像他那种风格来写代码。
+
+Torvalds 一直在嘲讽那些不符合他观点的人。早在1991年他就攻击过 [Andrew Tanenbaum][2]——那个 Minix 操作系统的作者,而那个 Minix 操作系统被 Torvalds 描述为“脑残”。
+
+但是 Torvalds 在这次嘲讽中表现得更有战略性了:“我想让*每个人*都知道,像他这种代码是完全不能被接收的。”他说他的目的是提醒每个 Linux 开发者,而不是针对那个开发者。
+
+Torvalds 也用这个机会强调了烂代码的安全问题。现在的企业对安全问题很重视,所以安全问题需要在开源开发者心中得到足够重视,甚至需要在代码中表现为最高等级(LCTT 译注:操作系统必须权衡许多因素:安全、处理速度、灵活性、易用性等,而这里 Torvalds 将安全提升为最高优先级了)。骂一下那些提交不安全代码的开发者可以帮助提高 Linux 系统的安全性。
+
+--------------------------------------------------------------------------------
+
+via: http://thevarguy.com/open-source-application-software-companies/110415/linus-torvalds-lambasts-open-source-programmers-over-inse
+
+作者:[Christopher Tozzi][a]
+译者:[bazz2](https://github.com/bazz2)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://thevarguy.com/author/christopher-tozzi
+[1]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
+[2]:https://en.wikipedia.org/wiki/Tanenbaum%E2%80%93Torvalds_debate
diff --git a/published/20151109 How to Monitor the Progress of a Linux Command Line Operation Using PV Command.md b/published/20151109 How to Monitor the Progress of a Linux Command Line Operation Using PV Command.md
new file mode 100644
index 0000000000..37e17b4266
--- /dev/null
+++ b/published/20151109 How to Monitor the Progress of a Linux Command Line Operation Using PV Command.md
@@ -0,0 +1,80 @@
+如何使用 pv 命令监控 linux 命令的执行进度
+================================================================================
+
+
+
+如果你是一个 linux 系统管理员,那么毫无疑问你必须花费大量的工作时间在命令行上:安装和卸载软件,监视系统状态,复制、移动、删除文件,查错,等等。很多时候都是你输入一个命令,然后等待很长时间直到执行完成。也有的时候你执行的命令挂起了,而你只能猜测命令执行的实际情况。
+
+通常 linux 命令不提供和进度相关的信息,而这些信息特别重要,尤其当你只有有限的时间时。然而这并不意味着你是无助的——现在有一个命令,pv,它会显示当前在命令行执行的命令的进度信息。在本文我们会讨论它并用几个简单的例子说明其特性。
+
+### PV 命令 ###
+
+[PV][1] 由Andrew Wood 开发,是 Pipe Viewer 的简称,意思是通过管道显示数据处理进度的信息。这些信息包括已经耗费的时间,完成的百分比(通过进度条显示),当前的速度,全部传输的数据,以及估计剩余的时间。
+
+> "要使用 PV,需要配合合适的选项,把它放置在两个进程之间的管道。命令的标准输入将会通过标准输出传进来的,而进度会被输出到标准错误输出。”
+
+上述解释来自该命令的帮助页。
+
+### 下载和安装 ###
+
+Debian 系的操作系统,如 Ubuntu,可以简单的使用下面的命令安装 PV:
+
+ sudo apt-get install pv
+
+如果你使用了其他发行版本,你可以使用各自的包管理软件在你的系统上安装 PV。一旦 PV 安装好了你就可以在各种场合使用它(详见下文)。需要注意的是下面所有例子都使用的是 pv 1.2.0。
+
+### 特性和用法 ###
+
+我们(在 linux 上使用命令行的用户)的大多数使用场景都会用到的命令是从一个 USB 驱动器拷贝电影文件到你的电脑。如果你使用 cp 来完成上面的任务,你会什么情况都不清楚,直到整个复制过程结束或者出错。
+
+然而pv 命令在这种情景下很有帮助。比如:
+
+ pv /media/himanshu/1AC2-A8E3/fNf.mkv > ./Desktop/fnf.mkv
+
+输出如下:
+
+
+
+所以,如你所见,这个命令显示了很多和操作有关的有用信息,包括已经传输了的数据量,花费的时间,传输速率,进度条,进度的百分比,以及剩余的时间。
+
+`pv` 命令提供了多种显示选项开关。比如,你可以使用`-p` 来显示百分比,`-t` 来显示时间,`-r` 表示传输速率,`-e` 代表eta(LCTT 译注:估计剩余的时间)。好事是你不必记住某一个选项,因为默认这几个选项都是启用的。但是,如果你只要其中某一个信息,那么可以通过控制这几个选项来完成任务。
+
+这里还有一个`-n` 选项来允许 pv 命令显示整数百分比,在标准错误输出上每行显示一个数字,用来替代通常的可视进度条。下面是一个例子:
+
+ pv -n /media/himanshu/1AC2-A8E3/fNf.mkv > ./Desktop/fnf.mkv
+
+
+
+这个特殊的选项非常合适某些情境下的需求,如你想把用管道把输出传给[dialog][2] 命令。
+
+接下来还有一个命令行选项,`-L` 可以让你修改 pv 命令的传输速率。举个例子,使用 -L 选项来限制传输速率为2MB/s。
+
+ pv -L 2m /media/himanshu/1AC2-A8E3/fNf.mkv > ./Desktop/fnf.mkv
+
+
+
+如上图所见,数据传输速度按照我们的要求被限制了。
+
+另一个pv 可以帮上忙的情景是压缩文件。这里有一个例子可以向你解释如何与压缩软件Gzip 一起工作。
+
+ pv /media/himanshu/1AC2-A8E3/fnf.mkv | gzip > ./Desktop/fnf.log.gz
+
+
+
+### 结论 ###
+
+如上所述,pv 是一个非常有用的小工具,它可以在命令没有按照预期执行的情况下帮你节省你宝贵的时间。而且这些显示的信息还可以用在 shell 脚本里。我强烈的推荐你使用这个命令,它值得你一试。
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/monitor-progress-linux-command-line-operation/
+
+作者:[Himanshu Arora][a]
+译者:[ezio](https://github.com/oska874)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/himanshu/
+[1]:http://linux.die.net/man/1/pv
+[2]:http://linux.die.net/man/1/dialog
diff --git a/published/20151109 How to Set Up AWStats On Ubuntu Server.md b/published/20151109 How to Set Up AWStats On Ubuntu Server.md
new file mode 100644
index 0000000000..7bea4e40d8
--- /dev/null
+++ b/published/20151109 How to Set Up AWStats On Ubuntu Server.md
@@ -0,0 +1,107 @@
+如何在 Ubuntu 服务器中配置 AWStats
+================================================================================
+
+
+AWStats 是一个开源的网站分析报告工具,可以生成强大的网站、流媒体、FTP 或邮件服务器的访问统计图。此日志分析器以 CGI 或命令行方式进行工作,并在网页中以图表的形式尽可能的显示你日志中所有的信息。它可以“部分”读取信息文件,以便能够频繁并快速处理大量的日志文件。它支持绝大多数 Web 服务器日志文件格式,包括 Apache,IIS 等。
+
+本文将帮助你在 Ubuntu 上安装配置 AWStats。
+
+### 安装 AWStats 包 ###
+
+默认情况下,AWStats 的包可以在 Ubuntu 仓库中找到。
+
+可以通过运行下面的命令来安装:
+
+ sudo apt-get install awstats
+
+接下来,你需要启用 Apache 的 CGI 模块。
+
+运行以下命令来启动 CGI:
+
+ sudo a2enmod cgi
+
+现在,重新启动 Apache 以使改变生效。
+
+ sudo /etc/init.d/apache2 restart
+
+### 配置 AWStats ###
+
+你需要为你想要查看统计的每个域或网站创建一个配置文件。在这个例子中,我们将为 “test.com” 创建一个配置文件。
+
+要完成此步,你可以通过复制 AWStats 的默认配置文件来配置你要统计的域。
+
+ sudo cp /etc/awstats/awstats.conf /etc/awstats/awstats.test.com.conf
+
+现在,你需要在配置文件中做一些修改:
+
+ sudo nano /etc/awstats/awstats.test.com.conf
+
+像下面这样修改一下:
+
+ # Change to Apache log file, by default it's /var/log/apache2/access.log
+ LogFile="/var/log/apache2/access.log"
+
+ # Change to the website domain name
+ SiteDomain="test.com"
+ HostAliases="www.test.com localhost 127.0.0.1"
+
+ # When this parameter is set to 1, AWStats adds a button on report page to allow to "update" statistics from a web browser
+ AllowToUpdateStatsFromBrowser=1
+
+保存并关闭文件。
+
+修改配置文件后,你需要用服务器的当前日志建立初步统计。你可以这样做:
+
+ sudo /usr/lib/cgi-bin/awstats.pl -config=test.com -update
+
+输出会是这个样子:
+
+
+
+### 为 Apache 配置 AWStats ###
+
+接下来,你需要配置 Apache2 来显示统计数据。现在你需要将 “cgi-bin” 文件夹中的内容复制到 Apache 默认根目录下。默认它是在 “/usr/lib/cgi-bin”。
+
+运行以下命令来完成此步:
+
+ sudo cp -r /usr/lib/cgi-bin /var/www/html/
+ sudo chown www-data:www-data /var/www/html/cgi-bin/
+ sudo chmod -R 755 /var/www/html/cgi-bin/
+
+### 测试 AWStats ###
+
+现在,您可以通过访问 url “http://your-server-ip/cgi-bin/awstats.pl?config=test.com.” 来查看 AWStats 的页面。
+
+它的页面像下面这样:
+
+
+
+### 设置定时任务来更新日志 ###
+
+建议你创建一个定时任务,使用新创建的日志条目定期更新 AWStats 的数据库,然后统计会定期更新。这也将节省你的时间。
+
+要做到这一点,你需要编辑 “/etc/crontab” 文件:
+
+ sudo nano /etc/crontab
+
+添加下面那一行来让 AWStats 每十分钟更新一次。
+
+ */10 * * * * root /usr/lib/cgi-bin/awstats.pl -config=test.com -update
+
+保存并关闭文件。
+
+### 结论 ###
+
+AWStats 是一个非常有用的工具,可以让你对网站的状况了如指掌,并能协助你分析网站。它非常容易安装和配置。如果你有任何疑问,请在下面发表评论。
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/set-up-awstats-ubuntu/
+
+作者:[Hitesh Jethva][a]
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/hiteshjethva/
diff --git a/published/20151123 LNAV--Ncurses based log file viewer.md b/published/20151123 LNAV--Ncurses based log file viewer.md
new file mode 100644
index 0000000000..d51ebe8e76
--- /dev/null
+++ b/published/20151123 LNAV--Ncurses based log file viewer.md
@@ -0,0 +1,81 @@
+LNAV:基于 Ncurses 的日志文件阅读器
+================================================================================
+日志文件导航器(Logfile Navigator,简称 lnav),是一个基于 curses 的,用于查看和分析日志文件的工具。和文本阅读器/编辑器相比, lnav 的好处是它充分利用了可以从日志文件中获取的语义信息,例如时间戳和日志等级。利用这些额外的语义信息, lnav 可以处理像这样的事情:来自不同文件的交错的信息;按照时间生成信息直方图;支持在文件中导航的快捷键。它希望使用这些功能可以使得用户可以快速有效地定位和解决问题。
+
+### lnav 功能 ###
+
+#### 支持以下日志文件格式: ####
+
+Syslog、Apache 访问日志、strace、tcsh 历史以及常见的带时间戳的日志文件。读入文件的时候回自动检测文件格式。
+
+#### 直方图视图: ####
+
+以时间区划来显示日志信息数量。这对于大概了解在一长段时间内发生了什么非常有用。
+
+#### 过滤器: ####
+
+只显示那些匹配或不匹配一些正则表达式的行。对于移除大量你不感兴趣的日志行非常有用。
+
+#### 即时操作: ####
+
+在你输入到时候会同时完成检索;当添加了新日志行的时候会自动加载和搜索;加载行的时候会应用过滤器;另外,还会在你输入 SQL 查询的时候检查其正确性。
+
+#### 自动显示后文: ####
+
+日志文件视图会自动往下滚动到新添加到文件中的行。只需要向上滚动就可以锁定当前视图,然后向下滚动到底部恢复显示后文。
+
+#### 按照日期顺序排序行: ####
+
+从所有文件中加载的日志行会按照日期进行排序。使得你不需要手动从不同文件中收集日志信息。
+
+#### 语法高亮: ####
+
+错误和警告会用红色和黄色显示。高亮还可用于: SQL 关键字、XML 标签、Java 文件行号和括起来的字符串。
+
+#### 导航: ####
+
+有快捷键用于跳转到下一个或上一个错误或警告,按照指定的时间向后或向前翻页。
+
+#### 用 SQL 查询日志: ####
+
+每个日志文件行都相当于数据库中的一行,可以使用 SQL 进行查询。可以使用的列取决于查看的日志文件类型。
+
+#### 命令和搜索历史: ####
+
+会自动保存你之前输入的命令和搜素,因此你可以在会话之间使用它们。
+
+#### 压缩文件: ####
+
+会实时自动检测和解压压缩的日志文件。
+
+### 在 ubuntu 15.10 上安装 lnav ####
+
+打开终端运行下面的命令
+
+ sudo apt-get install lnav
+
+### 使用 lnav ###
+
+如果你想使用 lnav 查看日志,你可以使用下面的命令,默认它会显示 syslogs
+
+ lnav
+
+
+
+如果你想查看特定的日志,那么需要指定路径。如果你想看 CPU 日志,在你的终端里运行下面的命令
+
+ lnav /var/log/cups
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.ubuntugeek.com/lnav-ncurses-based-log-file-viewer.html
+
+作者:[ruchi][a]
+译者:[ictlyh](http://mutouxiaogui.cn/blog/)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.ubuntugeek.com/author/ubuntufix
diff --git a/published/20151125 How to Install GIMP 2.8.16 in Ubuntu 16.04 or 15.10 or 14.04.md b/published/20151125 How to Install GIMP 2.8.16 in Ubuntu 16.04 or 15.10 or 14.04.md
new file mode 100644
index 0000000000..7c2e304403
--- /dev/null
+++ b/published/20151125 How to Install GIMP 2.8.16 in Ubuntu 16.04 or 15.10 or 14.04.md
@@ -0,0 +1,59 @@
+如何在 Ubuntu 16.04,15.10,14.04 中安装 GIMP 2.8.16
+================================================================================
+
+
+GIMP 图像编辑器 2.8.16 版本在其20岁生日时发布了。下面是如何安装或升级 GIMP 在 Ubuntu 16.04, Ubuntu 15.10, Ubuntu 14.04, Ubuntu 12.04 及其衍生版本中,如 Linux Mint 17.x/13, Elementary OS Freya。
+
+GIMP 2.8.16 支持 OpenRaster 文件中的层组,修复了 PSD 中的层组支持以及各种用户界面改进,修复了 OSX 上的构建系统,以及更多新的变化。请阅读 [官方声明][1]。
+
+
+
+### 如何安装或升级: ###
+
+多亏了 Otto Meier,[Ubuntu PPA][2] 中最新的 GIMP 包可用于当前所有的 Ubuntu 版本和其衍生版。
+
+**1. 添加 GIMP PPA**
+
+从 Unity Dash 中打开终端,或通过 Ctrl+Alt+T 快捷键打开。在它打开它后,粘贴下面的命令并回车:
+
+ sudo add-apt-repository ppa:otto-kesselgulasch/gimp
+
+
+
+输入你的密码,密码不会在终端显示,然后回车继续。
+
+**2. 安装或升级编辑器**
+
+在添加了 PPA 后,启动 **Software Updater**(在 Mint 中是 Software Manager)。检查更新后,你将看到 GIMP 的更新列表。点击 “Install Now” 进行升级。
+
+
+
+对于那些喜欢 Linux 命令的,按顺序执行下面的命令,刷新仓库的缓存然后安装 GIMP:
+
+ sudo apt-get update
+
+ sudo apt-get install gimp
+
+**3. (可选的) 卸载**
+
+如果你想卸载或降级 GIMP 图像编辑器。从软件中心直接删除它,或者按顺序运行下面的命令来将 PPA 清除并降级软件:
+
+ sudo apt-get install ppa-purge
+
+ sudo ppa-purge ppa:otto-kesselgulasch/gimp
+
+就这样。玩的愉快!
+
+--------------------------------------------------------------------------------
+
+via: http://ubuntuhandbook.org/index.php/2015/11/how-to-install-gimp-2-8-16-in-ubuntu-16-04-15-10-14-04/
+
+作者:[Ji m][a]
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ubuntuhandbook.org/index.php/about/
+[1]:http://www.gimp.org/news/2015/11/22/20-years-of-gimp-release-of-gimp-2816/
+[2]:https://launchpad.net/~otto-kesselgulasch/+archive/ubuntu/gimp
diff --git a/published/20151125 The tar command explained.md b/published/20151125 The tar command explained.md
new file mode 100644
index 0000000000..22244bf89c
--- /dev/null
+++ b/published/20151125 The tar command explained.md
@@ -0,0 +1,143 @@
+tar 命令使用介绍
+================================================================================
+Linux [tar][1] 命令是归档或分发文件时的强大武器。GNU tar 归档包可以包含多个文件和目录,还能保留其文件权限,它还支持多种压缩格式。Tar 表示 "**T**ape **Ar**chiver",这种格式是 POSIX 标准。
+
+### Tar 文件格式 ###
+
+tar 压缩等级简介:
+
+- **无压缩** 没有压缩的文件用 .tar 结尾。
+- **Gzip 压缩** Gzip 格式是 tar 使用最广泛的压缩格式,它能快速压缩和提取文件。用 gzip 压缩的文件通常用 .tar.gz 或 .tgz 结尾。这里有一些如何[创建][2]和[解压][3] tar.gz 文件的例子。
+- **Bzip2 压缩** 和 Gzip 格式相比 Bzip2 提供了更好的压缩比。创建压缩文件也比较慢,通常采用 .tar.bz2 结尾。
+- **Lzip(LAMA)压缩** Lizp 压缩结合了 Gzip 快速的优势,以及和 Bzip2 类似(甚至更好) 的压缩率。尽管有这些好处,这个格式并没有得到广泛使用。
+- **Lzop 压缩** 这个压缩选项也许是 tar 最快的压缩格式,它的压缩率和 gzip 类似,但也没有广泛使用。
+
+常见的格式是 tar.gz 和 tar.bz2。如果你想快速压缩,那么就是用 gzip。如果归档文件大小比较重要,就是用 tar.bz2。
+
+### tar 命令用来干什么? ###
+
+下面是一些使用 tar 命令的常见情形。
+
+- 备份服务器或桌面系统
+- 文档归档
+- 软件分发
+
+### 安装 tar ###
+
+大部分 Linux 系统默认都安装了 tar。如果没有,这里有安装 tar 的命令。
+
+#### CentOS ####
+
+在 CentOS 中,以 root 用户在 shell 中执行下面的命令安装 tar。
+
+ yum install tar
+
+#### Ubuntu ####
+
+下面的命令会在 Ubuntu 上安装 tar。“sudo” 命令确保 apt 命令是以 root 权限运行的。
+
+ sudo apt-get install tar
+
+#### Debian ####
+
+下面的 apt 命令在 Debian 上安装 tar。
+
+ apt-get install tar
+
+#### Windows ####
+
+tar 命令在 Windows 也可以使用,你可以从 Gunwin 项目[http://gnuwin32.sourceforge.net/packages/gtar.htm][4]中下载它。
+
+### 创建 tar.gz 文件 ###
+
+下面是在 shell 中运行 [tar 命令][5] 的一些例子。下面我会解释这些命令行选项。
+
+ tar pczf myarchive.tar.gz /home/till/mydocuments
+
+这个命令会创建归档文件 myarchive.tar.gz,其中包括了路径 /home/till/mydocuments 中的文件和目录。**命令行选项解释**:
+
+- **[p]** 这个选项表示 “preserve”,它指示 tar 在归档文件中保留文件属主和权限信息。
+- **[c]** 表示创建。要创建文件时不能缺少这个选项。
+- **[z]** z 选项启用 gzip 压缩。
+- **[f]** file 选项告诉 tar 创建一个归档文件。如果没有这个选项 tar 会把输出发送到标准输出( LCTT 译注:如果没有指定,标准输出默认是屏幕,显然你不会想在屏幕上显示一堆乱码,通常你可以用管道符号送到其它程序去)。
+
+#### Tar 命令示例 ####
+
+**示例 1: 备份 /etc 目录**
+
+创建 /etc 配置目录的一个备份。备份保存在 root 目录。
+
+ tar pczvf /root/etc.tar.gz /etc
+
+
+
+要以 root 用户运行命令确保 /etc 中的所有文件都会被包含在备份中。这次,我在命令中添加了 [v] 选项。这个选项表示 verbose,它告诉 tar 显示所有被包含到归档文件中的文件名。
+
+**示例 2: 备份你的 /home 目录**
+
+创建你的 home 目录的备份。备份会被保存到 /backup 目录。
+
+ tar czf /backup/myuser.tar.gz /home/myuser
+
+用你的用户名替换 myuser。这个命令中,我省略了 [p] 选项,也就不会保存权限。
+
+**示例 3: 基于文件的 MySQL 数据库备份**
+
+在大部分 Linux 发行版中,MySQL 数据库保存在 /var/lib/mysql。你可以使用下面的命令来查看:
+
+ ls /var/lib/mysql
+
+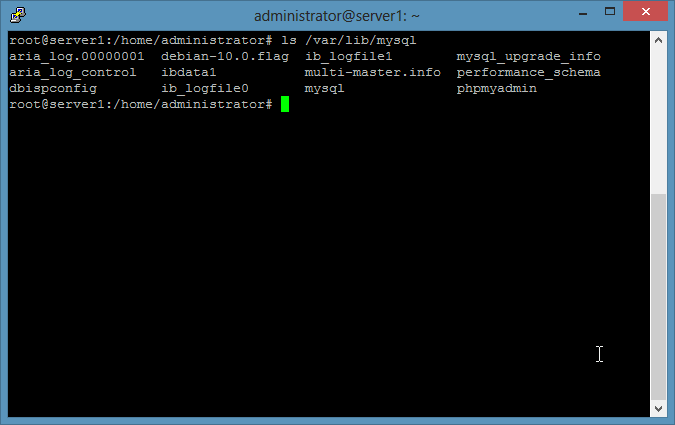
+
+用 tar 备份 MySQL 数据文件时为了保持数据一致性,首先停用数据库服务器。备份会被写到 /backup 目录。
+
+1) 创建 backup 目录
+
+ mkdir /backup
+ chmod 600 /backup
+
+2) 停止 MySQL,用 tar 进行备份并重新启动数据库。
+
+ service mysql stop
+ tar pczf /backup/mysql.tar.gz /var/lib/mysql
+ service mysql start
+ ls -lah /backup
+
+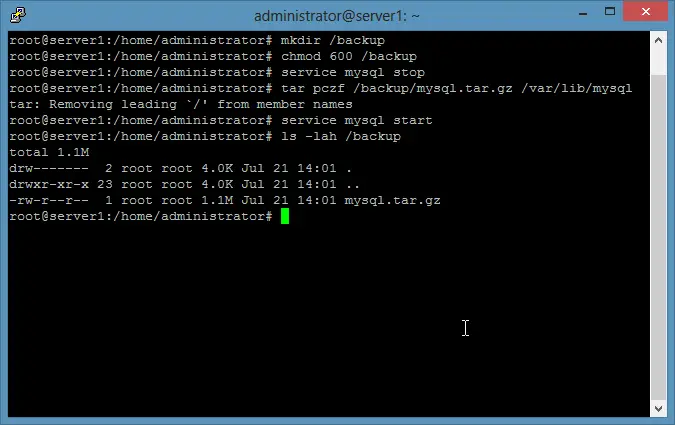
+
+### 提取 tar.gz 文件###
+
+提取 tar.gz 文件的命令是:
+
+ tar xzf myarchive.tar.gz
+
+#### tar 命令选项解释 ####
+
+- **[x]** x 表示提取,提取 tar 文件时这个命令不可缺少。
+- **[z]** z 选项告诉 tar 要解压的归档文件是 gzip 格式。
+- **[f]** 该选项告诉 tar 从一个文件中读取归档内容,本例中是 myarchive.tar.gz。
+
+上面的 tar 命令会安静地提取 tar.gz 文件,除非有错误信息。如果你想要看提取了哪些文件,那么添加 “v” 选项。
+
+ tar xzvf myarchive.tar.gz
+
+**[v]** 选项表示 verbose,它会向你显示解压的文件名。
+
+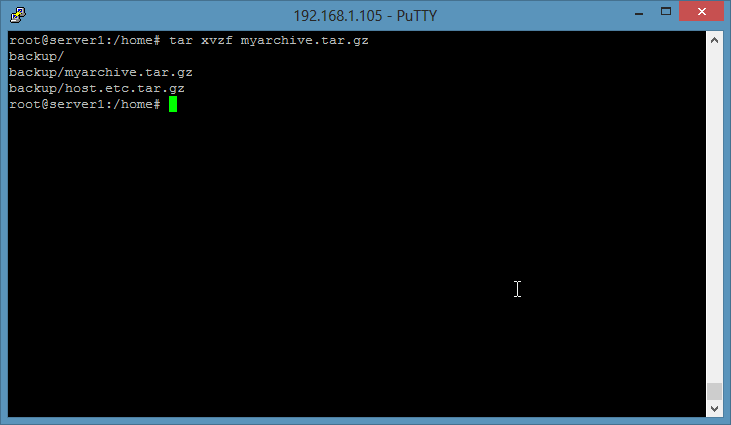
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/tutorial/linux-tar-command/
+
+作者:[howtoforge][a]
+译者:[ictlyh](http://mutouxiaogui.cn/blog/)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com/
+[1]:https://en.wikipedia.org/wiki/Tar_(computing)
+[2]:http://www.faqforge.com/linux/create-tar-gz/
+[3]:http://www.faqforge.com/linux/extract-tar-gz/
+[4]:http://gnuwin32.sourceforge.net/packages/gtar.htm
+[5]:http://www.faqforge.com/linux/tar-command/
\ No newline at end of file
diff --git a/published/20151201 Linux and Unix Port Scanning With netcat [nc] Command.md b/published/20151201 Linux and Unix Port Scanning With netcat [nc] Command.md
new file mode 100644
index 0000000000..f6d69b0cf5
--- /dev/null
+++ b/published/20151201 Linux and Unix Port Scanning With netcat [nc] Command.md
@@ -0,0 +1,95 @@
+使用 netcat [nc] 命令对 Linux 和 Unix 进行端口扫描
+================================================================================
+
+我如何在自己的服务器上找出哪些端口是开放的?如何使用 nc 命令进行端口扫描来替换 [Linux 或类 Unix 中的 nmap 命令][1]?
+
+nmap (“Network Mapper”)是一个用于网络探测和安全审核的开源工具。如果 nmap 没有安装或者你不希望使用 nmap,那你可以用 netcat/nc 命令进行端口扫描。它对于查看目标计算机上哪些端口是开放的或者运行着服务是非常有用的。你也可以使用 [nmap 命令进行端口扫描][2] 。
+
+### 如何使用 nc 来扫描 Linux,UNIX 和 Windows 服务器的端口呢? ###
+
+如果未安装 nmap,试试 nc/netcat 命令,如下所示。-z 参数用来告诉 nc 报告开放的端口,而不是启动连接。在 nc 命令中使用 -z 参数时,你需要在主机名/ip 后面限定端口的范围和加速其运行:
+
+ ### 语法 ###
+ ### nc -z -v {host-name-here} {port-range-here}
+ nc -z -v host-name-here ssh
+ nc -z -v host-name-here 22
+ nc -w 1 -z -v server-name-here port-Number-her
+
+ ### 扫描 1 to 1023 端口 ###
+ nc -zv vip-1.vsnl.nixcraft.in 1-1023
+
+输出示例:
+
+ Connection to localhost 25 port [tcp/smtp] succeeded!
+ Connection to vip-1.vsnl.nixcraft.in 25 port [tcp/smtp] succeeded!
+ Connection to vip-1.vsnl.nixcraft.in 80 port [tcp/http] succeeded!
+ Connection to vip-1.vsnl.nixcraft.in 143 port [tcp/imap] succeeded!
+ Connection to vip-1.vsnl.nixcraft.in 199 port [tcp/smux] succeeded!
+ Connection to vip-1.vsnl.nixcraft.in 783 port [tcp/*] succeeded!
+ Connection to vip-1.vsnl.nixcraft.in 904 port [tcp/vmware-authd] succeeded!
+ Connection to vip-1.vsnl.nixcraft.in 993 port [tcp/imaps] succeeded!
+
+你也可以扫描单个端口:
+
+ nc -zv v.txvip1 443
+ nc -zv v.txvip1 80
+ nc -zv v.txvip1 22
+ nc -zv v.txvip1 21
+ nc -zv v.txvip1 smtp
+ nc -zvn v.txvip1 ftp
+
+ ### 使用1秒的超时值来更快的扫描 ###
+ netcat -v -z -n -w 1 v.txvip1 1-1023
+
+输出示例:
+
+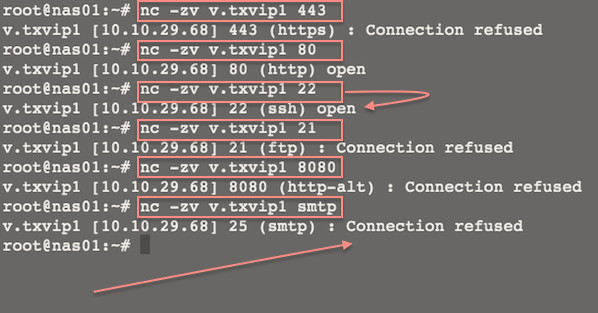
+
+*图01:Linux/Unix:使用 Netcat 来测试 TCP 和 UDP 与服务器建立连接*
+
+1. -z : 端口扫描模式即零 I/O 模式。
+1. -v : 显示详细信息 [使用 -vv 来输出更详细的信息]。
+1. -n : 使用纯数字 IP 地址,即不用 DNS 来解析 IP 地址。
+1. -w 1 : 设置超时值设置为1。
+
+更多例子:
+
+ $ netcat -z -vv www.cyberciti.biz http
+ www.cyberciti.biz [75.126.153.206] 80 (http) open
+ sent 0, rcvd 0
+ $ netcat -z -vv google.com https
+ DNS fwd/rev mismatch: google.com != maa03s16-in-f2.1e100.net
+ DNS fwd/rev mismatch: google.com != maa03s16-in-f6.1e100.net
+ DNS fwd/rev mismatch: google.com != maa03s16-in-f5.1e100.net
+ DNS fwd/rev mismatch: google.com != maa03s16-in-f3.1e100.net
+ DNS fwd/rev mismatch: google.com != maa03s16-in-f8.1e100.net
+ DNS fwd/rev mismatch: google.com != maa03s16-in-f0.1e100.net
+ DNS fwd/rev mismatch: google.com != maa03s16-in-f7.1e100.net
+ DNS fwd/rev mismatch: google.com != maa03s16-in-f4.1e100.net
+ google.com [74.125.236.162] 443 (https) open
+ sent 0, rcvd 0
+ $ netcat -v -z -n -w 1 192.168.1.254 1-1023
+ (UNKNOWN) [192.168.1.254] 989 (ftps-data) open
+ (UNKNOWN) [192.168.1.254] 443 (https) open
+ (UNKNOWN) [192.168.1.254] 53 (domain) open
+
+也可以看看 :
+
+- [使用 nmap 命令扫描网络中开放的端口][3]。
+- 手册页 - [nc(1)][4], [nmap(1)][5]
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/faq/linux-port-scanning/
+
+作者:Vivek Gite
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:https://linux.cn/article-2561-1.html
+[2]:https://linux.cn/article-2561-1.html
+[3]:https://linux.cn/article-2561-1.html
+[4]:http://www.manpager.com/linux/man1/nc.1.html
+[5]:http://www.manpager.com/linux/man1/nmap.1.html
diff --git a/published/20151202 How to use the Linux ftp command to up- and download files on the shell.md b/published/20151202 How to use the Linux ftp command to up- and download files on the shell.md
new file mode 100644
index 0000000000..dbb7e9d189
--- /dev/null
+++ b/published/20151202 How to use the Linux ftp command to up- and download files on the shell.md
@@ -0,0 +1,146 @@
+如何在命令行中使用 ftp 命令上传和下载文件
+================================================================================
+本文中,介绍在 Linux shell 中如何使用 ftp 命令。包括如何连接 FTP 服务器,上传或下载文件以及创建文件夹。尽管现在有许多不错的 FTP 桌面应用,但是在服务器、SSH、远程会话中命令行 ftp 命令还是有很多应用的。比如。需要服务器从 ftp 仓库拉取备份。
+
+### 步骤 1: 建立 FTP 连接 ###
+
+想要连接 FTP 服务器,在命令上中先输入`ftp`然后空格跟上 FTP 服务器的域名 'domain.com' 或者 IP 地址
+
+#### 例如: ####
+
+ ftp domain.com
+
+ ftp 192.168.0.1
+
+ ftp user@ftpdomain.com
+
+**注意: 本例中使用匿名服务器。**
+
+替换下面例子中 IP 或域名为你的服务器地址。
+
+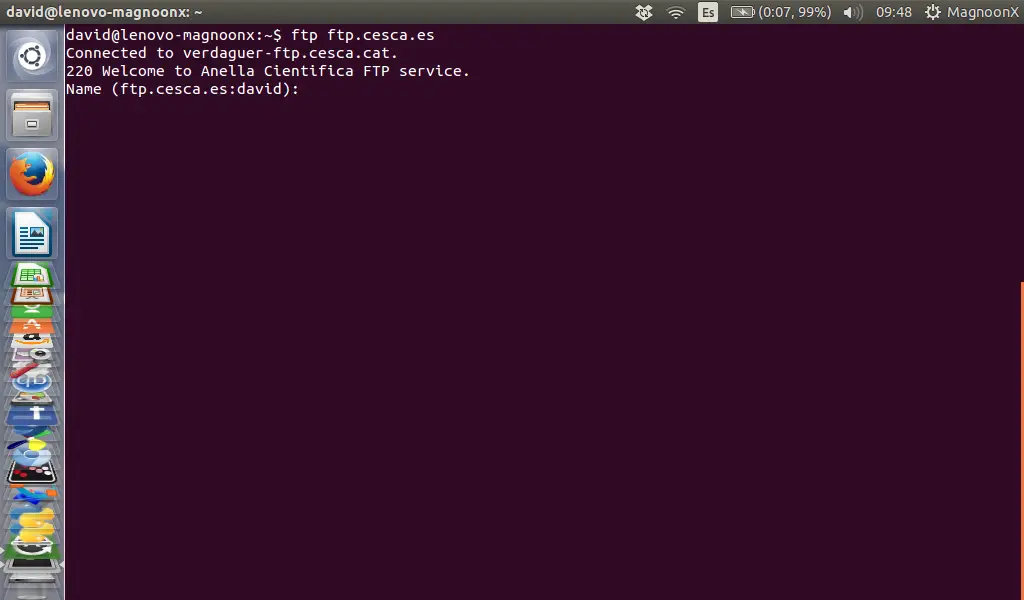
+
+### 步骤 2: 使用用户名密码登录 ###
+
+绝大多数的 FTP 服务器是使用密码保护的,因此这些 FTP 服务器会询问'**username**'和'**password**'.
+
+如果你连接到被称作匿名 FTP 服务器(LCTT 译注:即,并不需要你有真实的用户信息即可使用的 FTP 服务器称之为匿名 FTP 服务器),可以尝试`anonymous`作为用户名以及使用空密码:
+
+ Name: anonymous
+
+ Password:
+
+之后,终端会返回如下的信息:
+
+ 230 Login successful.
+ Remote system type is UNIX.
+ Using binary mode to transfer files.
+ ftp>
+
+登录成功。
+
+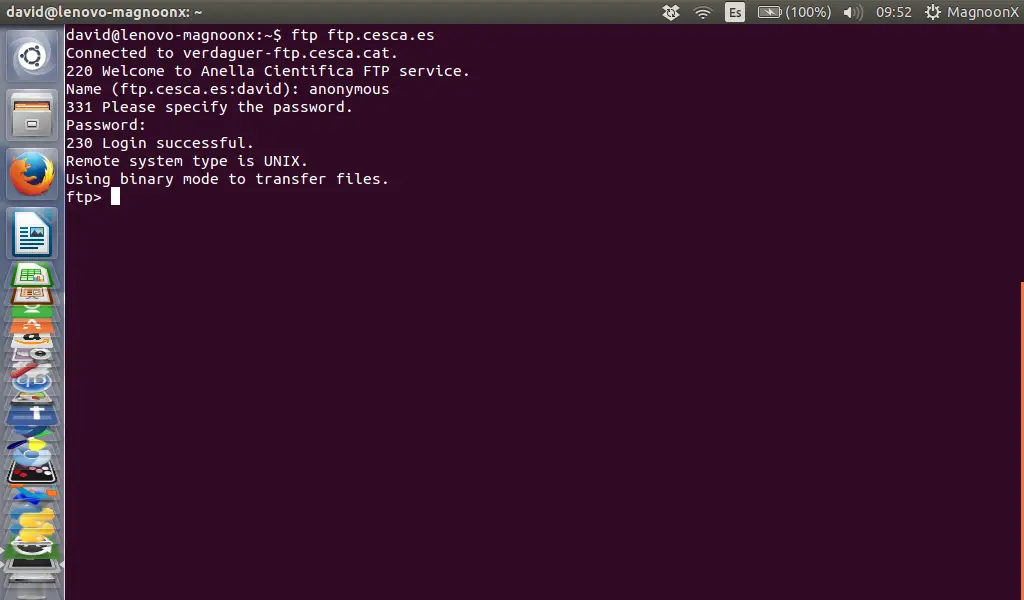
+
+### 步骤 3: 目录操作 ###
+
+FTP 命令可以列出、移动和创建文件夹,如同我们在本地使用我们的电脑一样。`ls`可以打印目录列表,`cd`可以改变目录,`mkdir`可以创建文件夹。
+
+#### 使用安全设置列出目录 ####
+
+ ftp> ls
+
+服务器将返回:
+
+ 200 PORT command successful. Consider using PASV.
+ 150 Here comes the directory listing.
+ directory list
+ ....
+ ....
+ 226 Directory send OK.
+
+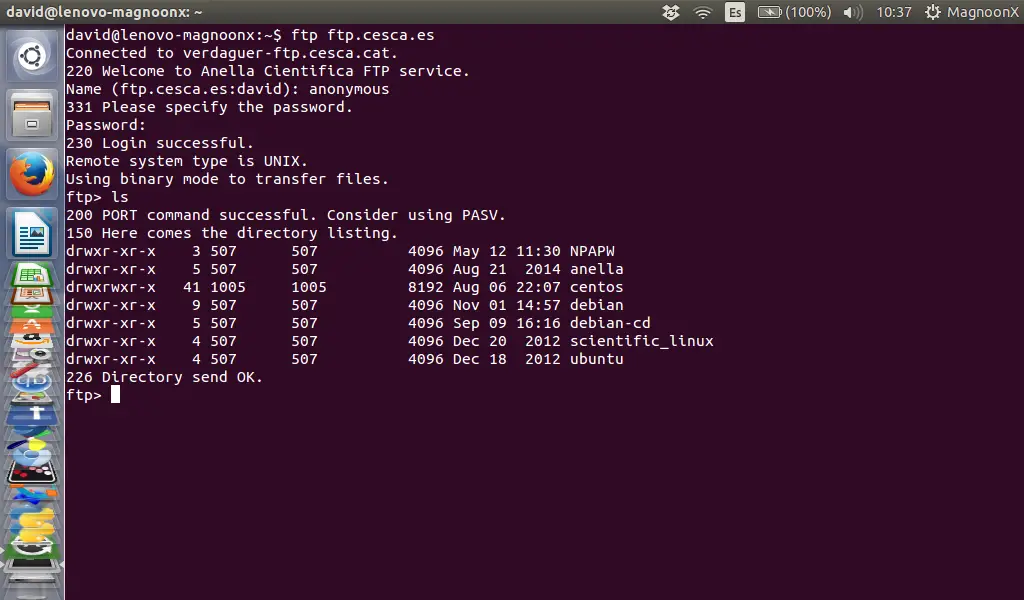
+
+#### 改变目录: ####
+
+改变目录可以输入:
+
+ ftp> cd directory
+
+服务器将会返回:
+
+ 250 Directory succesfully changed.
+
+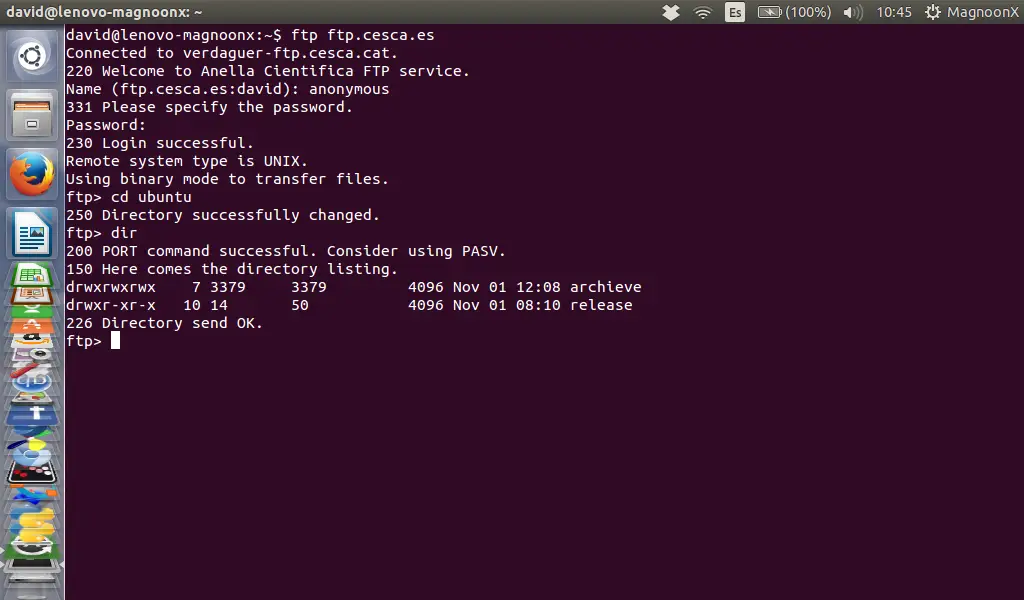
+
+### 步骤 4: 使用 FTP 下载文件 ###
+
+在下载一个文件之前,我们首先需要使用`lcd`命令设定本地接受目录位置。
+
+ lcd /home/user/yourdirectoryname
+
+如果你不指定下载目录,文件将会下载到你登录 FTP 时候的工作目录。
+
+现在,我们可以使用命令 get 来下载文件,比如:
+
+ get file
+
+文件会保存在使用lcd命令设置的目录位置。
+
+服务器返回消息:
+
+ local: file remote: file
+ 200 PORT command successful. Consider using PASV.
+ 150 Opening BINARY mode data connection for file (xxx bytes).
+ 226 File send OK.
+ XXX bytes received in x.xx secs (x.xxx MB/s).
+
+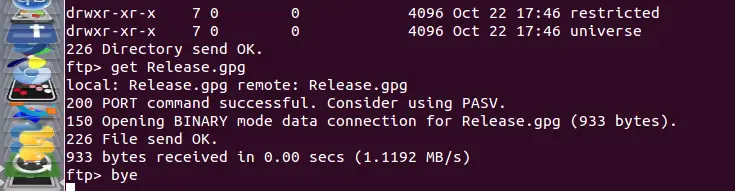
+
+下载多个文件可以使用通配符及 `mget` 命令。例如,下面这个例子我打算下载所有以 .xls 结尾的文件。
+
+ mget *.xls
+
+### 步骤 5: 使用 FTP 上传文件 ###
+
+完成 FTP 连接后,FTP 同样可以上传文件
+
+使用 `put`命令上传文件:
+
+ put file
+
+当文件不再当前本地目录下的时候,可以使用绝对路径:
+
+ put /path/file
+
+同样,可以上传多个文件:
+
+ mput *.xls
+
+### 步骤 6: 关闭 FTP 连接 ###
+
+完成FTP工作后,为了安全起见需要关闭连接。有三个命令可以关闭连接:
+
+ bye
+
+ exit
+
+ quit
+
+任意一个命令可以断开FTP服务器连接并返回:
+
+ 221 Goodbye
+
+
+
+需要更多帮助,在使用 ftp 命令连接到服务器后,可以使用`help`获得更多帮助。
+
+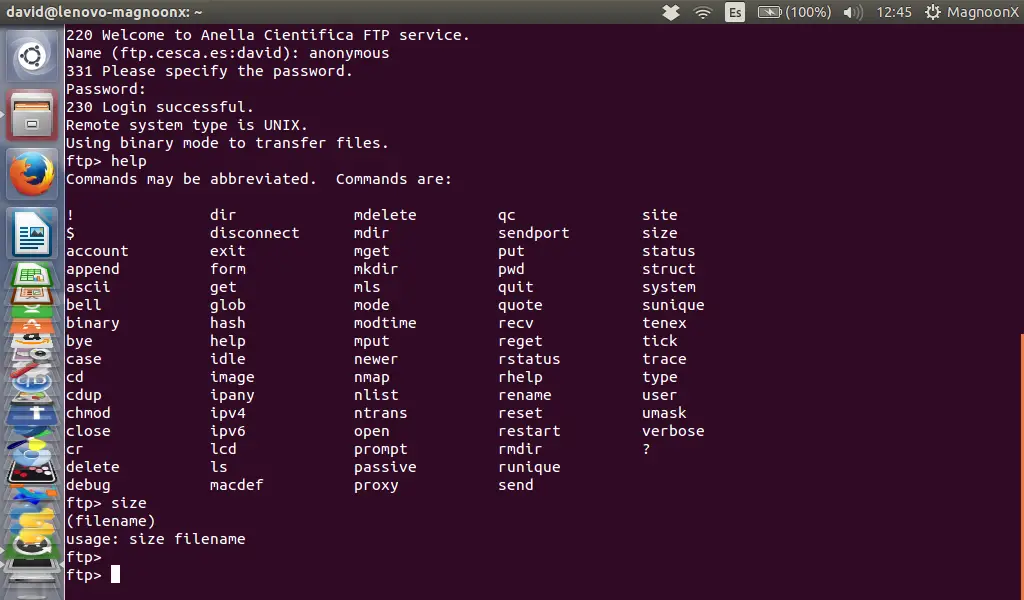
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/tutorial/how-to-use-ftp-on-the-linux-shell/
+
+译者:[VicYu](http://vicyu.net)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20151204 How to Remove Banned IP from Fail2ban on CentOS 6 or CentOS 7.md b/published/20151204 How to Remove Banned IP from Fail2ban on CentOS 6 or CentOS 7.md
new file mode 100644
index 0000000000..a527982122
--- /dev/null
+++ b/published/20151204 How to Remove Banned IP from Fail2ban on CentOS 6 or CentOS 7.md
@@ -0,0 +1,60 @@
+如何在 CentOS 6/7 上移除被 Fail2ban 禁止的 IP
+================================================================================
+
+
+[fail2ban][1] 是一款用于保护你的服务器免于暴力攻击的入侵保护软件。fail2ban 用 python 写成,并广泛用于很多服务器上。fail2ban 会扫描日志文件和 IP 黑名单来显示恶意软件、过多的密码失败尝试、web 服务器利用、wordpress 插件攻击和其他漏洞。如果你已经安装并使用了 fail2ban 来保护你的 web 服务器,你也许会想知道如何在 CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7 中找到被 fail2ban 阻止的 IP,或者你想将 ip 从 fail2ban 监狱中移除。
+
+### 如何列出被禁止的 IP ###
+
+要查看所有被禁止的 ip 地址,运行下面的命令:
+
+ # iptables -L
+ Chain INPUT (policy ACCEPT)
+ target prot opt source destination
+ f2b-AccessForbidden tcp -- anywhere anywhere tcp dpt:http
+ f2b-WPLogin tcp -- anywhere anywhere tcp dpt:http
+ f2b-ConnLimit tcp -- anywhere anywhere tcp dpt:http
+ f2b-ReqLimit tcp -- anywhere anywhere tcp dpt:http
+ f2b-NoAuthFailures tcp -- anywhere anywhere tcp dpt:http
+ f2b-SSH tcp -- anywhere anywhere tcp dpt:ssh
+ f2b-php-url-open tcp -- anywhere anywhere tcp dpt:http
+ f2b-nginx-http-auth tcp -- anywhere anywhere multiport dports http,https
+ ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
+ ACCEPT icmp -- anywhere anywhere
+ ACCEPT all -- anywhere anywhere
+ ACCEPT tcp -- anywhere anywhere tcp dpt:EtherNet/IP-1
+ ACCEPT tcp -- anywhere anywhere tcp dpt:http
+ REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
+
+ Chain FORWARD (policy ACCEPT)
+ target prot opt source destination
+ REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
+
+ Chain OUTPUT (policy ACCEPT)
+ target prot opt source destination
+
+
+ Chain f2b-NoAuthFailures (1 references)
+ target prot opt source destination
+ REJECT all -- 64.68.50.128 anywhere reject-with icmp-port-unreachable
+ REJECT all -- 104.194.26.205 anywhere reject-with icmp-port-unreachable
+ RETURN all -- anywhere anywhere
+
+### 如何从 Fail2ban 中移除 IP ###
+
+ # iptables -D f2b-NoAuthFailures -s banned_ip -j REJECT
+
+我希望这篇教程可以给你在 CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7 中移除被禁止的 ip 一些指导。
+
+--------------------------------------------------------------------------------
+
+via: http://www.ehowstuff.com/how-to-remove-banned-ip-from-fail2ban-on-centos/
+
+作者:[skytech][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.ehowstuff.com/author/skytech/
+[1]:http://www.fail2ban.org/wiki/index.php/Main_Page
diff --git a/translated/tech/RHCE/Part 10 - Setting Up 'NTP (Network Time Protocol) Server' in RHEL or CentOS 7.md b/published/RHCE/Part 10 - Setting Up 'NTP (Network Time Protocol) Server' in RHEL or CentOS 7.md
similarity index 50%
rename from translated/tech/RHCE/Part 10 - Setting Up 'NTP (Network Time Protocol) Server' in RHEL or CentOS 7.md
rename to published/RHCE/Part 10 - Setting Up 'NTP (Network Time Protocol) Server' in RHEL or CentOS 7.md
index 54c4330ae2..404ad003fd 100644
--- a/translated/tech/RHCE/Part 10 - Setting Up 'NTP (Network Time Protocol) Server' in RHEL or CentOS 7.md
+++ b/published/RHCE/Part 10 - Setting Up 'NTP (Network Time Protocol) Server' in RHEL or CentOS 7.md
@@ -1,12 +1,13 @@
-第 10 部分:在 RHEL/CentOS 7 中设置 “NTP(网络时间协议) 服务器”
+RHCE 系列(十):在 RHEL/CentOS 7 中设置 NTP(网络时间协议)服务器
================================================================================
-网络时间协议 - NTP - 是运行在传输层 123 号端口允许计算机通过网络同步准确时间的协议。随着时间的流逝,计算机内部时间会出现漂移,这会导致时间不一致问题,尤其是对于服务器和客户端日志文件,或者你想要备份服务器资源或数据库。
+
+网络时间协议 - NTP - 是运行在传输层 123 号端口的 UDP 协议,它允许计算机通过网络同步准确时间。随着时间的流逝,计算机内部时间会出现漂移,这会导致时间不一致问题,尤其是对于服务器和客户端日志文件,或者你想要复制服务器的资源或数据库。

-在 CentOS 和 RHEL 7 上安装 NTP 服务器
+*在 CentOS 和 RHEL 7 上安装 NTP 服务器*
-#### 要求: ####
+#### 前置要求: ####
- [CentOS 7 安装过程][1]
- [RHEL 安装过程][2]
@@ -17,62 +18,62 @@
- [在 CentOS/RHCE 7 上配置静态 IP][4]
- [在 CentOS/RHEL 7 上停用并移除不需要的服务][5]
-这篇指南会告诉你如何在 CentOS/RHCE 7 上安装和配置 NTP 服务器,并使用 NTP 公共时间服务器池列表中和你服务器地理位置最近的可用节点中同步时间。
+这篇指南会告诉你如何在 CentOS/RHCE 7 上安装和配置 NTP 服务器,并使用 NTP 公共时间服务器池(NTP Public Pool Time Servers)列表中和你服务器地理位置最近的可用节点中同步时间。
#### 步骤一:安装和配置 NTP 守护进程 ####
-1. 官方 CentOS /RHEL 7 库默认提供 NTP 服务器安装包,可以通过使用下面的命令安装。
+1、 官方 CentOS /RHEL 7 库默认提供 NTP 服务器安装包,可以通过使用下面的命令安装。
# yum install ntp
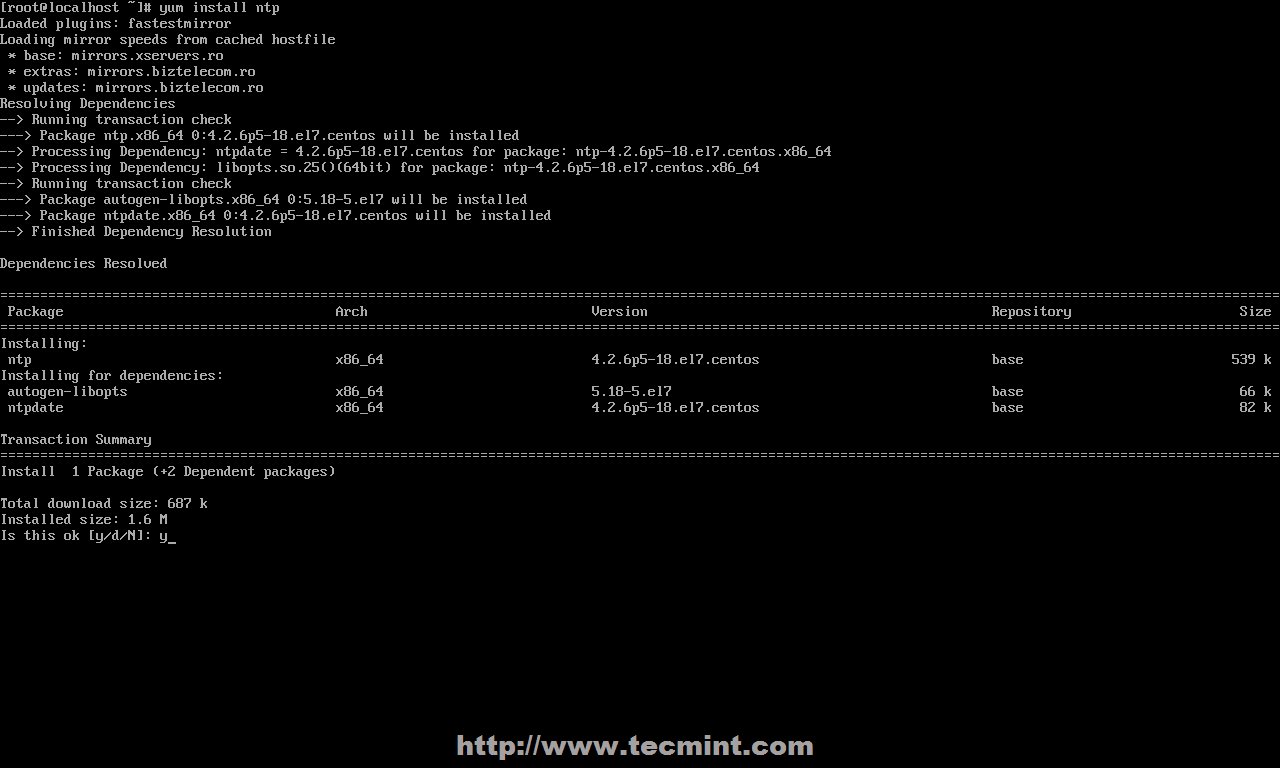
-安装 NTP 服务器
+*安装 NTP 服务器*
-2. 安装完服务器之后,首先到官方 [NTP 公共时间服务器池][6],选择你服务器物理位置所在的洲,然后搜索你的国家位置,然后会出现 NTP 服务器列表。
+2、 安装完服务器之后,首先到官方 [NTP 公共时间服务器池(NTP Public Pool Time Servers)][6],选择你服务器物理位置所在的洲,然后搜索你的国家位置,然后会出现 NTP 服务器列表。

-NTP 服务器池
+*NTP 服务器池*
-3. 然后打开编辑 NTP 守护进程主要配置文件,从 pool.ntp.org 中注释掉默认的公共服务器列表并用类似下面截图提供给你国家的列表替换。
+3、 然后打开编辑 NTP 守护进程的主配置文件,注释掉来自 pool.ntp.org 项目的公共服务器默认列表,并用类似下面截图中提供给你所在国家的列表替换。(LCTT 译注:中国使用 0.cn.pool.ntp.org 等)

-配置 NTP 服务器
+*配置 NTP 服务器*
-4. 下一步,你需要允许客户端从你的网络中和这台服务器同步时间。为了做到这点,添加下面一行到 NTP 配置文件,其中限制语句控制允许哪些网络查询和同步时间 - 根据需要替换网络 IP。
+4、 下一步,你需要允许来自你的网络的客户端和这台服务器同步时间。为了做到这点,添加下面一行到 NTP 配置文件,其中 **restrict** 语句控制允许哪些网络查询和同步时间 - 请根据需要替换网络 IP。
restrict 192.168.1.0 netmask 255.255.255.0 nomodify notrap
nomodify notrap 语句意味着不允许你的客户端配置服务器或者作为同步时间的节点。
-5. 如果你需要额外的信息用于错误处理,以防你的 NTP 守护进程出现问题,添加一个 logfile 语句,用于记录所有 NTP 服务器问题到一个指定的日志文件。
+5、 如果你需要用于错误处理的额外信息,以防你的 NTP 守护进程出现问题,添加一个 logfile 语句,用于记录所有 NTP 服务器问题到一个指定的日志文件。
logfile /var/log/ntp.log

-启用 NTP 日志
+*启用 NTP 日志*
-6. 你编辑完所有上面解释的配置并保存关闭 ntp.conf 文件后,你最终的配置看起来像下面的截图。
+6、 在你编辑完所有上面解释的配置并保存关闭 ntp.conf 文件后,你最终的配置看起来像下面的截图。

-NTP 服务器配置
+*NTP 服务器配置*
### 步骤二:添加防火墙规则并启动 NTP 守护进程 ###
-7. NTP 服务在传输层(第四层)使用 123 号 UDP 端口。它是针对限制可变延迟的影响特别设计的。要在 RHEL/CentOS 7 中开放这个端口,可以对 Firewalld 服务使用下面的命令。
+7、 NTP 服务使用 OSI 传输层(第四层)的 123 号 UDP 端口。它是为了避免可变延迟的影响所特别设计的。要在 RHEL/CentOS 7 中开放这个端口,可以对 Firewalld 服务使用下面的命令。
# firewall-cmd --add-service=ntp --permanent
# firewall-cmd --reload

-在 Firewall 中开放 NTP 端口
+*在 Firewall 中开放 NTP 端口*
-8. 你在防火墙中开放了 123 号端口之后,启动 NTP 服务器并确保系统范围内可用。用下面的命令管理服务。
+8、 你在防火墙中开放了 123 号端口之后,启动 NTP 服务器并确保系统范围内可用。用下面的命令管理服务。
# systemctl start ntpd
# systemctl enable ntpd
@@ -80,34 +81,34 @@ NTP 服务器配置

-启动 NTP 服务
+*启动 NTP 服务*
### 步骤三:验证服务器时间同步 ###
-9. 启动了 NTP 守护进程后,用几分钟等服务器和它的服务器池列表同步时间,然后运行下面的命令验证 NTP 节点同步状态和你的系统时间。
+9、 启动了 NTP 守护进程后,用几分钟等服务器和它的服务器池列表同步时间,然后运行下面的命令验证 NTP 节点同步状态和你的系统时间。
# ntpq -p
# date -R

-验证 NTP 时间同步
+*验证 NTP 时间同步*
-10. 如果你想查询或者和你选择的服务器池同步,你可以使用 ntpdate 命令,后面跟服务器名或服务器地址,类似下面建议的命令行事例。
+10、 如果你想查询或者和你选择的服务器池同步,你可以使用 ntpdate 命令,后面跟服务器名或服务器地址,类似下面建议的命令行示例。
# ntpdate -q 0.ro.pool.ntp.org 1.ro.pool.ntp.org

-同步 NTP 时间
+*同步 NTP 时间*
### 步骤四:设置 Windows NTP 客户端 ###
-11. 如果你的 windows 机器不是域名控制器的一部分,你可以配置 Windows 和你的 NTP服务器同步时间。在任务栏右边 -> 时间 -> 更改日期和时间设置 -> 网络时间标签 -> 更改设置 -> 和一个网络时间服务器检查同步 -> 在 Server 空格输入服务器 IP 或 FQDN -> 马上更新 -> OK。
+11、 如果你的 windows 机器不是域名控制器的一部分,你可以配置 Windows 和你的 NTP服务器同步时间。在任务栏右边 -> 时间 -> 更改日期和时间设置 -> 网络时间标签 -> 更改设置 -> 和一个网络时间服务器检查同步 -> 在 Server 空格输入服务器 IP 或 FQDN -> 马上更新 -> OK。

-和 NTP 同步 Windows 时间
+*和 NTP 同步 Windows 时间*
就是这些。在你的网络中配置一个本地 NTP 服务器能确保你所有的服务器和客户端有相同的时间设置,以防出现网络连接失败,并且它们彼此都相互同步。
@@ -117,7 +118,7 @@ via: http://www.tecmint.com/install-ntp-server-in-centos/
作者:[Matei Cezar][a]
译者:[ictlyh](http://motouxiaogui.cn/blog)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/RHCE/Part 6 - Setting Up Samba and Configure FirewallD and SELinux to Allow File Sharing on Linux or Windows Clients.md b/published/RHCE/Part 6 - Setting Up Samba and Configure FirewallD and SELinux to Allow File Sharing on Linux or Windows Clients.md
similarity index 80%
rename from translated/tech/RHCE/Part 6 - Setting Up Samba and Configure FirewallD and SELinux to Allow File Sharing on Linux or Windows Clients.md
rename to published/RHCE/Part 6 - Setting Up Samba and Configure FirewallD and SELinux to Allow File Sharing on Linux or Windows Clients.md
index cb8fa59954..a439469b81 100644
--- a/translated/tech/RHCE/Part 6 - Setting Up Samba and Configure FirewallD and SELinux to Allow File Sharing on Linux or Windows Clients.md
+++ b/published/RHCE/Part 6 - Setting Up Samba and Configure FirewallD and SELinux to Allow File Sharing on Linux or Windows Clients.md
@@ -1,4 +1,4 @@
-安装 Samba 并配置 Firewalld 和 SELinux 使得能在 Linux 和 Windows 之间共享文件 - 第六部分
+RHCE 系列(六):安装 Samba 并配置 Firewalld 和 SELinux 让 Linux 和 Windows 共享文件
================================================================================
由于计算机很少作为一个独立的系统工作,作为一个系统管理员或工程师,就应该知道如何在有多种类型的服务器之间搭设和维护网络。
@@ -6,9 +6,9 @@

-RHCE 系列第六部分 - 设置 Samba 文件共享
+*RHCE 系列第六部分 - 设置 Samba 文件共享*
-如果有人叫你设置文件服务器用于协作或者配置很可能有多种不同类型操作系统和设备的企业环境,这篇文章就能派上用场。
+如果有人让你设置文件服务器用于协作或者配置很可能有多种不同类型操作系统和设备的企业环境,这篇文章就能派上用场。
由于你可以在网上找到很多关于 Samba 和 NFS 背景和技术方面的介绍,在这篇文章以及后续文章中我们就省略了这些部分直接进入到我们的主题。
@@ -22,7 +22,7 @@ RHCE 系列第六部分 - 设置 Samba 文件共享

-测试安装 Samba
+*测试安装 Samba*
在 box1 中安装以下软件包:
@@ -36,7 +36,7 @@ RHCE 系列第六部分 - 设置 Samba 文件共享
### 步骤二: 设置通过 Samba 进行文件共享 ###
-Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB 是微软和英特尔制定的一种通信协议,CIFS 是其中一个版本,更详细的介绍可以参考[Wiki][6])提供了文件和打印设备,这使得客户端看起来服务器就是一个 Windows 系统(我必须承认写这篇文章的时候我有一点激动,因为这是我多年前作为一个新手 Linux 系统管理员的第一次设置)。
+Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(LCTT 译注:SMB 是微软和英特尔制定的一种通信协议,CIFS 是其中一个版本,更详细的介绍可以参考 [Wiki][6])提供了文件和打印设备,这使得服务器在客户端看起来就是一个 Windows 系统(我必须承认写这篇文章的时候我有一点激动,因为这是我多年前作为一个新手 Linux 系统管理员的第一次设置)。
**添加系统用户并设置权限和属性**
@@ -91,9 +91,9 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
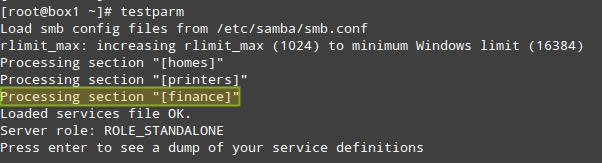
-测试 Samba 配置
+*测试 Samba 配置*
-如果你要添加另一个公开的共享目录(意味着没有任何验证),在 /etc/samba/smb.conf 中创建另一章节,在共享目录名称下面复制上面的章节,只需要把 public=no 更改为 public=yes 并去掉有效用户和写列表命令。
+如果你要添加另一个公开的共享目录(意味着不需要任何验证),在 /etc/samba/smb.conf 中创建另一章节,在共享目录名称下面复制上面的章节,只需要把 public=no 更改为 public=yes 并去掉有效用户(valid users)和写列表(write list)命令。
### 步骤五: 添加 Samba 用户 ###
@@ -102,7 +102,7 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
# smbpasswd -a user1
# smbpasswd -a user2
-最后,重启 Samda,启用系统启动时自动启动服务,并确保共享目录对网络客户端可用:
+最后,重启 Samda,并让系统启动时自动启动该服务,确保共享目录对网络客户端可用:
# systemctl start smb
# systemctl enable smb
@@ -112,7 +112,7 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB

-验证 Samba 共享
+*验证 Samba 共享*
到这里,已经正确安装和配置了 Samba 文件服务器。现在让我们在 RHEL 7 和 Windows 8 客户端中测试该配置。
@@ -120,12 +120,11 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
首先,确保客户端可以访问 Samba 共享:
-# smbclient –L 192.168.0.18 -U user2
-
+ # smbclient –L 192.168.0.18 -U user2

-在 Linux 上挂载 Samba 共享
+*在 Linux 上挂载 Samba 共享*
(为 user1 重复上面的命令)
@@ -135,11 +134,11 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB

-挂载 Samba 网络共享
+*挂载 Samba 网络共享*
(其中 /media/samba 是一个已有的目录)
-或者在 /etc/fstab 文件中添加下面的条目自动挂载:
+或者在 /etc/fstab 文件中添加下面的条目以自动挂载:
**fstab**
@@ -147,7 +146,7 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
//192.168.0.18/finance /media/samba cifs credentials=/media/samba/.smbcredentials,defaults 0 0
-其中隐藏文件 /media/samba/.smbcredentials(它的权限被设置为 600 和 root:root)有两行,指示允许使用共享的账户的用户名和密码:
+其中隐藏文件 /media/samba/.smbcredentials(它的权限被设置为 600 和 root:root)有两行内容,指示允许使用共享的账户的用户名和密码:
**.smbcredentials**
@@ -162,17 +161,17 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB

-在 Samba 共享中创建文件
+*在 Samba 共享中创建文件*
正如你看到的,用权限 0770 和属主 user1:finance 创建了文件。
### 步骤七: 在 Windows 上挂载 Samba 共享 ###
-要在 Windows 上挂载 Samba 共享,进入 ‘我的计算机’ 并选择 ‘计算机’,‘网络驱动映射’。下一步,为要映射的驱动分配一个字母并用不同的认证检查连接(下面的截图使用我的母语西班牙语):
+要在 Windows 上挂载 Samba 共享,进入 ‘我的计算机’ 并选择 ‘计算机’,‘网络驱动映射’。下一步,为要映射的驱动分配一个驱动器盘符并用不同的认证身份检查是否可以连接(下面的截图使用我的母语西班牙语):

-在 Windows 中挂载 Samba 共享
+*在 Windows 中挂载 Samba 共享*
最后,让我们新建一个文件并检查权限和属性:
@@ -188,7 +187,7 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
在这篇文章中我们不仅介绍了如何使用不同操作系统设置 Samba 服务器和两个客户端,也介绍了[如何配置 Firewalld][3] 和 [服务器中的 SELinux][4] 以获取所需的组协作功能。
-最后,同样重要的是,我推荐阅读网上的 [smb.conf man 手册][5] 查看其它可能针对你的情况比本文中介绍的场景更加合适的配置命令。
+最后,同样重要的是,我推荐阅读网上的 [smb.conf man 手册][5] ,查看其它比本文中介绍的场景更加合适你的场景的配置命令。
正如往常,欢迎在下面的评论框中留下你的评论或建议。
@@ -198,7 +197,7 @@ via: http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
作者:[Gabriel Cánepa][a]
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/RHCE/Part 7 - Setting Up NFS Server with Kerberos-based Authentication for Linux Clients.md b/published/RHCE/Part 7 - Setting Up NFS Server with Kerberos-based Authentication for Linux Clients.md
similarity index 82%
rename from translated/tech/RHCE/Part 7 - Setting Up NFS Server with Kerberos-based Authentication for Linux Clients.md
rename to published/RHCE/Part 7 - Setting Up NFS Server with Kerberos-based Authentication for Linux Clients.md
index 5eba70cd7a..a05935f7c1 100644
--- a/translated/tech/RHCE/Part 7 - Setting Up NFS Server with Kerberos-based Authentication for Linux Clients.md
+++ b/published/RHCE/Part 7 - Setting Up NFS Server with Kerberos-based Authentication for Linux Clients.md
@@ -1,11 +1,10 @@
-第七部分 - 在 Linux 客户端配置基于 Kerberos 身份验证的 NFS 服务器
+RHCE 系列(七):在 Linux 客户端配置基于 Kerberos 身份验证的 NFS 服务器
================================================================================
-在本系列的前一篇文章,我们回顾了[如何在可能包括多种类型操作系统的网络上配置 Samba 共享][1]。现在,如果你需要为一组类-Unix 客户端配置文件共享,很自然的你会想到网络文件系统,或简称 NFS。
-
+在本系列的前一篇文章,我们回顾了[如何在可能包括多种类型操作系统的网络上配置 Samba 共享][1]。现在,如果你需要为一组类 Unix 客户端配置文件共享,很自然的你会想到网络文件系统,或简称 NFS。

-RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服务器
+*RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服务器*
在这篇文章中我们会介绍配置基于 Kerberos 身份验证的 NFS 共享的整个流程。假设你已经配置好了一个 NFS 服务器和一个客户端。如果还没有,可以参考 [安装和配置 NFS 服务器][2] - 它列出了需要安装的依赖软件包并解释了在进行下一步之前如何在服务器上进行初始化配置。
@@ -24,28 +23,26 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
#### 创建 NFS 组并配置 NFS 共享目录 ####
-1. 新建一个名为 nfs 的组并给它添加用户 nfsnobody,然后更改 /nfs 目录的权限为 0770,组属主为 nfs。于是,nfsnobody(对应请求用户)在共享目录有写的权限,你就不需要在 /etc/exports 文件中使用 no_root_squash(译者注:设为 root_squash 意味着在访问 NFS 服务器上的文件时,客户机上的 root 用户不会被当作 root 用户来对待)。
+1、 新建一个名为 nfs 的组并给它添加用户 nfsnobody,然后更改 /nfs 目录的权限为 0770,组属主为 nfs。于是,nfsnobody(对应请求用户)在共享目录有写的权限,你就不需要在 /etc/exports 文件中使用 no_root_squash(LCTT 译注:设为 root_squash 意味着在访问 NFS 服务器上的文件时,客户机上的 root 用户不会被当作 root 用户来对待)。
# groupadd nfs
# usermod -a -G nfs nfsnobody
# chmod 0770 /nfs
# chgrp nfs /nfs
-2. 像下面那样更改 export 文件(/etc/exports)只允许从 box1 使用 Kerberos 安全验证的访问(sec=krb5)。
+2、 像下面那样更改 export 文件(/etc/exports)只允许从 box1 使用 Kerberos 安全验证的访问(sec=krb5)。
**注意**:anongid 的值设置为之前新建的组 nfs 的 GID:
**exports – 添加 NFS 共享**
-----------
-
/nfs box1(rw,sec=krb5,anongid=1004)
-3. 再次 exprot(-r)所有(-a)NFS 共享。为输出添加详情(-v)是个好主意,因为它提供了发生错误时解决问题的有用信息:
+3、 再次 exprot(-r)所有(-a)NFS 共享。为输出添加详情(-v)是个好主意,因为它提供了发生错误时解决问题的有用信息:
# exportfs -arv
-4. 重启并启用 NFS 服务器以及相关服务。注意你不需要启动 nfs-lock 和 nfs-idmapd,因为系统启动时其它服务会自动启动它们:
+4、 重启并启用 NFS 服务器以及相关服务。注意你不需要启动 nfs-lock 和 nfs-idmapd,因为系统启动时其它服务会自动启动它们:
# systemctl restart rpcbind nfs-server nfs-lock nfs-idmap
# systemctl enable rpcbind nfs-server
@@ -61,14 +58,12 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
正如你看到的,为了简便,NFS 服务器和 KDC 在同一台机器上,当然如果你有更多可用机器你也可以把它们安装在不同的机器上。两台机器都在 `mydomain.com` 域。
-最后同样重要的是,Kerberos 要求客户端和服务器中至少有一个域名解析的基本模式和[网络时间协议][5]服务,因为 Kerberos 身份验证的安全一部分基于时间戳。
+最后同样重要的是,Kerberos 要求客户端和服务器中至少有一个域名解析的基本方式和[网络时间协议][5]服务,因为 Kerberos 身份验证的安全一部分基于时间戳。
为了配置域名解析,我们在客户端和服务器中编辑 /etc/hosts 文件:
**host 文件 – 为域添加 DNS**
-----------
-
192.168.0.18 box1.mydomain.com box1
192.168.0.20 box2.mydomain.com box2
@@ -82,10 +77,9 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
# chronyc tracking
-

-用 Chrony 同步服务器时间
+*用 Chrony 同步服务器时间*
### 安装和配置 Kerberos ###
@@ -109,7 +103,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服

-创建 Kerberos 数据库
+*创建 Kerberos 数据库*
下一步,使用 kadmin.local 工具为 root 创建管理权限:
@@ -129,7 +123,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服

-添加 Kerberos 到 NFS 服务器
+*添加 Kerberos 到 NFS 服务器*
为 root/admin 获取和缓存票据授权票据(ticket-granting ticket):
@@ -138,7 +132,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
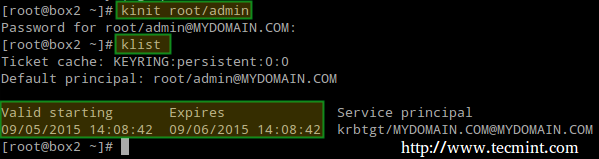
-缓存 Kerberos
+*缓存 Kerberos*
真正使用 Kerberos 之前的最后一步是保存被授权使用 Kerberos 身份验证的规则到一个密钥表文件(在服务器中):
@@ -154,7 +148,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服

-挂载 NFS 共享
+*挂载 NFS 共享*
现在让我们卸载共享,在客户端中重命名密钥表文件(模拟它不存在)然后试着再次挂载共享目录:
@@ -163,7 +157,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服

-挂载/卸载 Kerberos NFS 共享
+*挂载/卸载 Kerberos NFS 共享*
现在你可以使用基于 Kerberos 身份验证的 NFS 共享了。
@@ -177,12 +171,12 @@ via: http://www.tecmint.com/setting-up-nfs-server-with-kerberos-based-authentica
作者:[Gabriel Cánepa][a]
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]:http://www.tecmint.com/author/gacanepa/
-[1]:http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
+[1]:https://linux.cn/article-6550-1.html
[2]:http://www.tecmint.com/configure-nfs-server/
[3]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
[4]:http://www.tecmint.com/firewalld-rules-for-centos-7/
diff --git a/translated/tech/RHCE/Part 8 - RHCE Series--Implementing HTTPS through TLS using Network Security Service NSS for Apache.md b/published/RHCE/Part 8 - RHCE Series--Implementing HTTPS through TLS using Network Security Service NSS for Apache.md
similarity index 62%
rename from translated/tech/RHCE/Part 8 - RHCE Series--Implementing HTTPS through TLS using Network Security Service NSS for Apache.md
rename to published/RHCE/Part 8 - RHCE Series--Implementing HTTPS through TLS using Network Security Service NSS for Apache.md
index 5ff1f9fe65..574e9dc594 100644
--- a/translated/tech/RHCE/Part 8 - RHCE Series--Implementing HTTPS through TLS using Network Security Service NSS for Apache.md
+++ b/published/RHCE/Part 8 - RHCE Series--Implementing HTTPS through TLS using Network Security Service NSS for Apache.md
@@ -1,11 +1,13 @@
-RHCE 系列: 使用网络安全服务(NSS)为 Apache 通过 TLS 实现 HTTPS
+RHCE 系列(八):在 Apache 上使用网络安全服务(NSS)实现 HTTPS
================================================================================
-如果你是一个负责维护和确保 web 服务器安全的系统管理员,你不能不花费最大的精力确保服务器中处理和通过的数据任何时候都受到保护。
+
+如果你是一个负责维护和确保 web 服务器安全的系统管理员,你需要花费最大的精力确保服务器中处理和通过的数据任何时候都受到保护。
+

-RHCE 系列:第八部分 - 使用网络安全服务(NSS)为 Apache 通过 TLS 实现 HTTPS
+*RHCE 系列:第八部分 - 使用网络安全服务(NSS)为 Apache 通过 TLS 实现 HTTPS*
-为了在客户端和服务器之间提供更安全的连接,作为 HTTP 和 SSL(安全套接层)或者最近称为 TLS(传输层安全)的组合,产生了 HTTPS 协议。
+为了在客户端和服务器之间提供更安全的连接,作为 HTTP 和 SSL(Secure Sockets Layer,安全套接层)或者最近称为 TLS(Transport Layer Security,传输层安全)的组合,产生了 HTTPS 协议。
由于一些严重的安全漏洞,SSL 已经被更健壮的 TLS 替代。由于这个原因,在这篇文章中我们会解析如何通过 TLS 实现你 web 服务器和客户端之间的安全连接。
@@ -22,11 +24,11 @@ RHCE 系列:第八部分 - 使用网络安全服务(NSS)为 Apache 通过
# firewall-cmd --permanent –-add-service=http
# firewall-cmd --permanent –-add-service=https
-然后安装一些必须软件包:
+然后安装一些必需的软件包:
# yum update && yum install openssl mod_nss crypto-utils
-**重要**:请注意如果你想使用 OpenSSL 库而不是 NSS(网络安全服务)实现 TLS,你可以在上面的命令中用 mod\_ssl 替换 mod\_nss(使用哪一个取决于你,但在这篇文章中由于更加健壮我们会使用 NSS;例如,它支持最新的加密标准,比如 PKCS #11)。
+**重要**:请注意如果你想使用 OpenSSL 库而不是 NSS(Network Security Service,网络安全服务)实现 TLS,你可以在上面的命令中用 mod\_ssl 替换 mod\_nss(使用哪一个取决于你,但在这篇文章中我们会使用 NSS,因为它更加安全,比如说,它支持最新的加密标准,比如 PKCS #11)。
如果你使用 mod\_nss,首先要卸载 mod\_ssl,反之如此。
@@ -54,15 +56,15 @@ nss.conf – 配置文件
下一步,在 `/etc/httpd/conf.d/nss.conf` 配置文件中做以下更改:
-1. 指定 NSS 数据库目录。你可以使用默认的目录或者新建一个。本文中我们使用默认的:
+1、 指定 NSS 数据库目录。你可以使用默认的目录或者新建一个。本文中我们使用默认的:
NSSCertificateDatabase /etc/httpd/alias
-2. 通过保存密码到数据库目录中的 /etc/httpd/nss-db-password.conf 文件避免每次系统启动时要手动输入密码:
+2、 通过保存密码到数据库目录中的 `/etc/httpd/nss-db-password.conf` 文件来避免每次系统启动时要手动输入密码:
NSSPassPhraseDialog file:/etc/httpd/nss-db-password.conf
-其中 /etc/httpd/nss-db-password.conf 只包含以下一行,其中 mypassword 是后面你为 NSS 数据库设置的密码:
+其中 `/etc/httpd/nss-db-password.conf` 只包含以下一行,其中 mypassword 是后面你为 NSS 数据库设置的密码:
internal:mypassword
@@ -71,27 +73,27 @@ nss.conf – 配置文件
# chmod 640 /etc/httpd/nss-db-password.conf
# chgrp apache /etc/httpd/nss-db-password.conf
-3. 由于 POODLE SSLv3 漏洞,红帽建议停用 SSL 和 TLSv1.0 之前所有版本的 TLS(更多信息可以查看[这里][2])。
+3、 由于 POODLE SSLv3 漏洞,红帽建议停用 SSL 和 TLSv1.0 之前所有版本的 TLS(更多信息可以查看[这里][2])。
确保 NSSProtocol 指令的每个实例都类似下面一样(如果你没有托管其它虚拟主机,很可能只有一条):
NSSProtocol TLSv1.0,TLSv1.1
-4. 由于这是一个自签名证书,Apache 会拒绝重启,并不会识别为有效发行人。由于这个原因,对于这种特殊情况我们还需要添加:
+4、 由于这是一个自签名证书,Apache 会拒绝重启,并不会识别为有效发行人。由于这个原因,对于这种特殊情况我们还需要添加:
NSSEnforceValidCerts off
-5. 虽然并不是严格要求,为 NSS 数据库设置一个密码同样很重要:
+5、 虽然并不是严格要求,为 NSS 数据库设置一个密码同样很重要:
# certutil -W -d /etc/httpd/alias
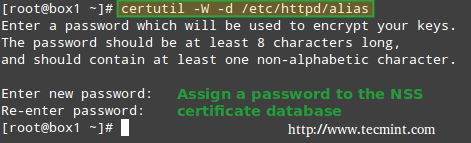
-为 NSS 数据库设置密码
+*为 NSS 数据库设置密码*
### 创建一个 Apache SSL 自签名证书 ###
-下一步,我们会创建一个自签名证书为我们的客户机识别服务器(请注意这个方法对于生产环境并不是最好的选择;对于生产环境你应该考虑购买第三方可信证书机构验证的证书,例如 DigiCert)。
+下一步,我们会创建一个自签名证书来让我们的客户机可以识别服务器(请注意这个方法对于生产环境并不是最好的选择;对于生产环境你应该考虑购买第三方可信证书机构验证的证书,例如 DigiCert)。
我们用 genkey 命令为 box1 创建有效期为 365 天的 NSS 兼容证书。完成这一步后:
@@ -101,19 +103,19 @@ nss.conf – 配置文件

-创建 Apache SSL 密钥
+*创建 Apache SSL 密钥*
你可以使用默认的密钥大小(2048),然后再次选择 Next:

-选择 Apache SSL 密钥大小
+*选择 Apache SSL 密钥大小*
等待系统生成随机比特:

-生成随机密钥比特
+*生成随机密钥比特*
为了加快速度,会提示你在控制台输入随机字符,正如下面的截图所示。请注意当没有从键盘接收到输入时进度条是如何停止的。然后,会让你选择:
@@ -124,35 +126,35 @@ nss.conf – 配置文件
注:youtube 视频
-最后,会提示你输入之前设置的密码到 NSS 证书:
+最后,会提示你输入之前给 NSS 证书设置的密码:
# genkey --nss --days 365 box1

-Apache NSS 证书密码
+*Apache NSS 证书密码*
-在任何时候你都可以用以下命令列出现有的证书:
+需要的话,你可以用以下命令列出现有的证书:
# certutil –L –d /etc/httpd/alias

-列出 Apache NSS 证书
+*列出 Apache NSS 证书*
-然后通过名字删除(除非严格要求,用你自己的证书名称替换 box1):
+然后通过名字删除(如果你真的需要删除的,用你自己的证书名称替换 box1):
# certutil -d /etc/httpd/alias -D -n "box1"
-如果你需要继续的话:
+如果你需要继续进行的话,请继续阅读。
### 测试 Apache SSL HTTPS 连接 ###
-最后,是时候测试到我们服务器的安全连接了。当你用浏览器打开 https://,你会看到著名的信息 “This connection is untrusted”:
+最后,是时候测试到我们服务器的安全连接了。当你用浏览器打开 https://\,你会看到著名的信息 “This connection is untrusted”:

-检查 Apache SSL 连接
+*检查 Apache SSL 连接*
在上面的情况中,你可以点击添加例外(Add Exception) 然后确认安全例外(Confirm Security Exception) - 但先不要这么做。让我们首先来看看证书看它的信息是否和我们之前输入的相符(如截图所示)。
@@ -160,37 +162,37 @@ Apache NSS 证书密码

-确认 Apache SSL 证书详情
+*确认 Apache SSL 证书详情*
-现在你继续,确认例外(限于此次或永久),然后会通过 https 把你带到你 web 服务器的 DocumentRoot 目录,在这里你可以使用你浏览器自带的开发者工具检查连接详情:
+现在你可以继续,确认例外(限于此次或永久),然后会通过 https 把你带到你 web 服务器的 DocumentRoot 目录,在这里你可以使用你浏览器自带的开发者工具检查连接详情:
-在火狐浏览器中,你可以通过在屏幕中右击然后从上下文菜单中选择检查元素(Inspect Element)启动,尤其是通过网络选项卡:
+在火狐浏览器中,你可以通过在屏幕中右击,然后从上下文菜单中选择检查元素(Inspect Element)启动开发者工具,尤其要看“网络”选项卡:

-检查 Apache HTTPS 连接
+*检查 Apache HTTPS 连接*
请注意这和之前显示的在验证过程中输入的信息一致。还有一种方式通过使用命令行工具测试连接:
-左边(测试 SSLv3):
+左图(测试 SSLv3):
# openssl s_client -connect localhost:443 -ssl3
-右边(测试 TLS):
+右图(测试 TLS):
# openssl s_client -connect localhost:443 -tls1

-测试 Apache SSL 和 TLS 连接
+*测试 Apache SSL 和 TLS 连接*
-参考上面的截图了解更相信信息。
+参考上面的截图了解更详细信息。
### 总结 ###
-我确信你已经知道,使用 HTTPS 会增加会在你站点中输入个人信息的访客的信任(从用户名和密码到任何商业/银行账户信息)。
+我想你已经知道,使用 HTTPS 会增加会在你站点中输入个人信息的访客的信任(从用户名和密码到任何商业/银行账户信息)。
-在那种情况下,你会希望获得由可信验证机构签名的证书,正如我们之前解释的(启用的步骤和发送 CSR 到 CA 然后获得签名证书的例子相同);另外的情况,就是像我们的例子中一样使用自签名证书。
+在那种情况下,你会希望获得由可信验证机构签名的证书,正如我们之前解释的(步骤和设置需要启用例外的证书的步骤相同,发送 CSR 到 CA 然后获得返回的签名证书);否则,就像我们的例子中一样使用自签名证书即可。
要获取更多关于使用 NSS 的详情,可以参考关于 [mod-nss][3] 的在线帮助。如果你有任何疑问或评论,请告诉我们。
@@ -200,11 +202,11 @@ via: http://www.tecmint.com/create-apache-https-self-signed-certificate-using-ns
作者:[Gabriel Cánepa][a]
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-[a]:http://www.tecmint.com/install-lamp-in-centos-7/
-[1]:http://www.tecmint.com/author/gacanepa/
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:https://linux.cn/article-5789-1.html
[2]:https://access.redhat.com/articles/1232123
[3]:https://git.fedorahosted.org/cgit/mod_nss.git/plain/docs/mod_nss.html
\ No newline at end of file
diff --git a/translated/tech/RHCE/Part 9 - How to Setup Postfix Mail Server (SMTP) using null-client Configuration.md b/published/RHCE/Part 9 - How to Setup Postfix Mail Server (SMTP) using null-client Configuration.md
similarity index 55%
rename from translated/tech/RHCE/Part 9 - How to Setup Postfix Mail Server (SMTP) using null-client Configuration.md
rename to published/RHCE/Part 9 - How to Setup Postfix Mail Server (SMTP) using null-client Configuration.md
index ccc67dbb30..59d6d9de0c 100644
--- a/translated/tech/RHCE/Part 9 - How to Setup Postfix Mail Server (SMTP) using null-client Configuration.md
+++ b/published/RHCE/Part 9 - How to Setup Postfix Mail Server (SMTP) using null-client Configuration.md
@@ -1,25 +1,25 @@
-第九部分 - 如果使用零客户端配置 Postfix 邮件服务器(SMTP)
+RHCE 系列(九):如何使用无客户端配置 Postfix 邮件服务器(SMTP)
================================================================================
-尽管现在有很多在线联系方式,邮件仍然是一个人传递信息给远在世界尽头或办公室里坐在我们旁边的另一个人的有效方式。
+尽管现在有很多在线联系方式,电子邮件仍然是一个人传递信息给远在世界尽头或办公室里坐在我们旁边的另一个人的有效方式。
-下面的图描述了邮件从发送者发出直到信息到达接收者收件箱的传递过程。
+下面的图描述了电子邮件从发送者发出直到信息到达接收者收件箱的传递过程。
-
+
-邮件如何工作
+*电子邮件如何工作*
-要使这成为可能,背后发生了好多事情。为了使邮件信息从一个客户端应用程序(例如 [Thunderbird][1]、Outlook,或者网络邮件服务,例如 Gmail 或 Yahoo 邮件)到一个邮件服务器,并从其到目标服务器并最终到目标接收人,每个服务器上都必须有 SMTP(简单邮件传输协议)服务。
+要实现这一切,背后发生了好多事情。为了使电子邮件信息从一个客户端应用程序(例如 [Thunderbird][1]、Outlook,或者 web 邮件服务,例如 Gmail 或 Yahoo 邮件)投递到一个邮件服务器,并从其投递到目标服务器并最终到目标接收人,每个服务器上都必须有 SMTP(简单邮件传输协议)服务。
-这就是为什么我们要在这篇博文中介绍如何在 RHEL 7 中设置 SMTP 服务器,从中本地用户发送的邮件(甚至发送到本地用户)被转发到一个中央邮件服务器以便于访问。
+这就是为什么我们要在这篇博文中介绍如何在 RHEL 7 中设置 SMTP 服务器,从本地用户发送的邮件(甚至发送到另外一个本地用户)被转发(forward)到一个中央邮件服务器以便于访问。
-在实际需求中这称为零客户端安装。
+在这个考试的要求中这称为无客户端(null-client)安装。
-在我们的测试环境中将包括一个原始邮件服务器和一个中央服务器或中继主机。
+在我们的测试环境中将包括一个起源(originating)邮件服务器和一个中央服务器或中继主机(relayhost)。
- 原始邮件服务器: (主机名: box1.mydomain.com / IP: 192.168.0.18)
- 中央邮件服务器: (主机名: mail.mydomain.com / IP: 192.168.0.20)
+- 起源邮件服务器: (主机名: box1.mydomain.com / IP: 192.168.0.18)
+- 中央邮件服务器: (主机名: mail.mydomain.com / IP: 192.168.0.20)
-为了域名解析我们在两台机器中都会使用有名的 /etc/hosts 文件:
+我们在两台机器中都会使用你熟知的 `/etc/hosts` 文件做名字解析:
192.168.0.18 box1.mydomain.com box1
192.168.0.20 mail.mydomain.com mail
@@ -28,34 +28,29 @@
首先,我们需要(在两台机器上):
-**1. 安装 Postfix:**
+**1、 安装 Postfix:**
# yum update && yum install postfix
-**2. 启动服务并启用开机自动启动:**
+**2、 启动服务并启用开机自动启动:**
# systemctl start postfix
# systemctl enable postfix
-**3. 允许邮件流量通过防火墙:**
+**3、 允许邮件流量通过防火墙:**
# firewall-cmd --permanent --add-service=smtp
# firewall-cmd --add-service=smtp
-
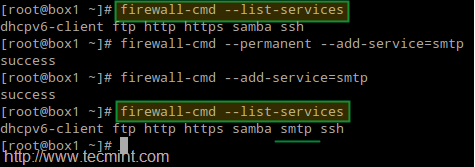
-在防火墙中开通邮件服务器端口
+*在防火墙中开通邮件服务器端口*
-**4. 在 box1.mydomain.com 配置 Postfix**
+**4、 在 box1.mydomain.com 配置 Postfix**
-Postfix 的主要配置文件是 /etc/postfix/main.cf。这个文件本身是一个很大的文本,因为其中包含的注释解析了程序设置的目的。
+Postfix 的主要配置文件是 `/etc/postfix/main.cf`。这个文件本身是一个很大的文本文件,因为其中包含了解释程序设置的用途的注释。
-为了简洁,我们只显示了需要编辑的行(是的,在原始服务器中你需要保留 mydestination 为空;否则邮件会被保存到本地而不是我们实际想要的中央邮件服务器):
-
-**在 box1.mydomain.com 配置 Postfix**
-
-----------
+为了简洁,我们只显示了需要编辑的行(没错,在起源服务器中你需要保留 `mydestination` 为空;否则邮件会被存储到本地,而不是我们实际想要发往的中央邮件服务器):
myhostname = box1.mydomain.com
mydomain = mydomain.com
@@ -64,11 +59,7 @@ Postfix 的主要配置文件是 /etc/postfix/main.cf。这个文件本身是一
mydestination =
relayhost = 192.168.0.20
-**5. 在 mail.mydomain.com 配置 Postfix**
-
-** 在 mail.mydomain.com 配置 Postfix **
-
-----------
+**5、 在 mail.mydomain.com 配置 Postfix**
myhostname = mail.mydomain.com
mydomain = mydomain.com
@@ -83,23 +74,23 @@ Postfix 的主要配置文件是 /etc/postfix/main.cf。这个文件本身是一

-设置 Postfix SELinux 权限
+*设置 Postfix SELinux 权限*
-上面的 SELinux 布尔值会允许 Postfix 在中央服务器写入邮件池。
+上面的 SELinux 布尔值会允许中央服务器上的 Postfix 可以写入邮件池(mail spool)。
-**6. 在两台机子上重启服务以使更改生效:**
+**6、 在两台机子上重启服务以使更改生效:**
# systemctl restart postfix
如果 Postfix 没有正确启动,你可以使用下面的命令进行错误处理。
- # systemctl –l status postfix
- # journalctl –xn
- # postconf –n
+ # systemctl -l status postfix
+ # journalctl -xn
+ # postconf -n
### 测试 Postfix 邮件服务 ###
-为了测试邮件服务器,你可以使用任何邮件用户代理(最常见的简称为 MUA)例如 [mail 或 mutt][2]。
+要测试邮件服务器,你可以使用任何邮件用户代理(Mail User Agent,常简称为 MUA),例如 [mail 或 mutt][2]。
由于我个人喜欢 mutt,我会在 box1 中使用它发送邮件给用户 tecmint,并把现有文件(mailbody.txt)作为信息内容:
@@ -107,7 +98,7 @@ Postfix 的主要配置文件是 /etc/postfix/main.cf。这个文件本身是一

-测试 Postfix 邮件服务器
+*测试 Postfix 邮件服务器*
现在到中央邮件服务器(mail.mydomain.com)以 tecmint 用户登录,并检查是否收到了邮件:
@@ -116,15 +107,15 @@ Postfix 的主要配置文件是 /etc/postfix/main.cf。这个文件本身是一

-检查 Postfix 邮件服务器发送
+*检查 Postfix 邮件服务器发送*
-如果没有收到邮件,检查 root 用户的邮件池查看警告或者错误提示。你也需要使用 [nmap 命令][3]确保两台服务器运行了 SMTP 服务,并在中央邮件服务器中 打开了 25 号端口:
+如果没有收到邮件,检查 root 用户的邮件池看看是否有警告或者错误提示。你也许需要使用 [nmap 命令][3]确保两台服务器运行了 SMTP 服务,并在中央邮件服务器中打开了 25 号端口:
# nmap -PN 192.168.0.20
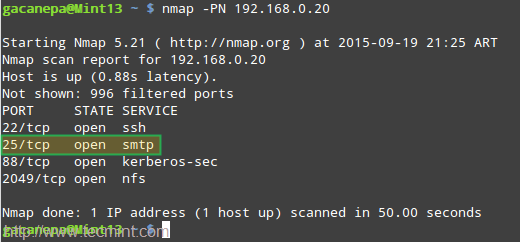
-Postfix 邮件服务器错误处理
+*Postfix 邮件服务器错误处理*
### 总结 ###
@@ -134,7 +125,7 @@ Postfix 邮件服务器错误处理
- [在 CentOS/RHEL 07 上配置仅缓存的 DNS 服务器][4]
-最后,我强烈建议你熟悉 Postfix 的配置文件(main.cf)和这个程序的帮助手册。如果有任何疑问,别犹豫,使用下面的评论框或者我们的论坛 Linuxsay.com 告诉我们吧,你会从世界各地的 Linux 高手中获得几乎及时的帮助。
+最后,我强烈建议你熟悉 Postfix 的配置文件(main.cf)和这个程序的帮助手册。如果有任何疑问,别犹豫,使用下面的评论框或者我们的论坛 Linuxsay.com 告诉我们吧,你会从世界各地的 Linux 高手中获得几乎是及时的帮助。
--------------------------------------------------------------------------------
@@ -142,7 +133,7 @@ via: http://www.tecmint.com/setup-postfix-mail-server-smtp-using-null-client-on-
作者:[Gabriel Cánepa][a]
译者:[ictlyh](https//www.mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/news/20151104 Ubuntu Software Centre To Be Replaced in 16.04 LTS.md b/sources/news/20151104 Ubuntu Software Centre To Be Replaced in 16.04 LTS.md
deleted file mode 100644
index 0e689ede9e..0000000000
--- a/sources/news/20151104 Ubuntu Software Centre To Be Replaced in 16.04 LTS.md
+++ /dev/null
@@ -1,56 +0,0 @@
-Ubuntu Software Centre To Be Replaced in 16.04 LTS
-================================================================================
-
-
-The USC Will Be Replaced
-
-**The Ubuntu Software Centre is to be replaced in Ubuntu 16.04 LTS.**
-
-Users of the Xenial Xerus desktop will find that the familiar (and somewhat cumbersome) Ubuntu Software Centre is no longer available.
-
-GNOME’s [Software application][1] will – according to current plans – take its place as the default and package management utility on the Unity 7-based desktop.
-
-
-
-GNOME Software
-
-New plugins will be created to support the Software Centre’s ratings, reviews and paid app features as a result of the switch.
-
-The decisions were taken at a recent desktop Sprint held at Canonical HQ in London.
-
-“We are more confident in our ability to add support for Snaps to GNOME Software Centre (sic) than we are to Ubuntu Software Centre. And so, right now, it looks like we will be replacing [the USC] with GNOME Software Centre”, explains Ubuntu desktop manager Will Cooke at the Ubuntu Online Summit.
-
-GNOME 3.18 stack will also be included in Ubuntu 16.04, with select app updates to GNOME 3.20 apps taken ‘as and when it makes sense’, adds Will Cooke.
-
-We recently ran a poll on Twitter asking how you install software on Ubuntu. The results suggest that few of you will mourn the passing of the incumbent Software Centre…
-
-注:投票项目
-Which of these do you use to install software on #Ubuntu?
-
-- Software Centre
-- Terminal
-
-### Other Apps Being Dropped in Ubuntu 16.04 ###
-
-The Ubuntu Software Centre is not the only app set to be given the heave-ho in Xenial Xerus.
-
-Disc burning utility Brasero and instant messaging app **Empathy** are also to be removed from the default install image.
-
-Neither app is considered to be under active development, and with the march of laptops lacking optical drives and web and mobile-based chat services, they may also be seen as increasingly obsolete.
-
-If you do have use for them don’t panic: both Brasero and Empathy will **still be available to install on Ubuntu from the archives**.
-
-It’s not all removals and replacements as one new desktop app is set be included by default: GNOME Calendar.
-
---------------------------------------------------------------------------------
-
-via: http://www.omgubuntu.co.uk/2015/11/the-ubuntu-software-centre-is-being-replace-in-16-04-lts
-
-作者:[Sam Tran][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/111008502832304483939?rel=author
-[1]:https://wiki.gnome.org/Apps/Software
\ No newline at end of file
diff --git a/sources/share/20150824 Great Open Source Collaborative Editing Tools.md b/sources/share/20150824 Great Open Source Collaborative Editing Tools.md
index c4746bc482..8f3e2853cb 100644
--- a/sources/share/20150824 Great Open Source Collaborative Editing Tools.md
+++ b/sources/share/20150824 Great Open Source Collaborative Editing Tools.md
@@ -1,3 +1,4 @@
+Translating by H-mudcup
Great Open Source Collaborative Editing Tools
================================================================================
In a nutshell, collaborative writing is writing done by more than one person. There are benefits and risks of collaborative working. Some of the benefits include a more integrated / co-ordinated approach, better use of existing resources, and a stronger, united voice. For me, the greatest advantage is one of the most transparent. That's when I need to take colleagues' views. Sending files back and forth between colleagues is inefficient, causes unnecessary delays and leaves people (i.e. me) unhappy with the whole notion of collaboration. With good collaborative software, I can share notes, data and files, and use comments to share thoughts in real-time or asynchronously. Working together on documents, images, video, presentations, and tasks is made less of a chore.
diff --git a/sources/share/20150901 5 best open source board games to play online.md b/sources/share/20150901 5 best open source board games to play online.md
index c14fecc697..eee49289e0 100644
--- a/sources/share/20150901 5 best open source board games to play online.md
+++ b/sources/share/20150901 5 best open source board games to play online.md
@@ -1,3 +1,4 @@
+translating by tastynoodle
5 best open source board games to play online
================================================================================
I have always had a fascination with board games, in part because they are a device of social interaction, they challenge the mind and, most importantly, they are great fun to play. In my misspent youth, myself and a group of friends gathered together to escape the horrors of the classroom, and indulge in a little escapism. The time provided an outlet for tension and rivalry. Board games help teach diplomacy, how to make and break alliances, bring families and friends together, and learn valuable lessons.
diff --git a/sources/share/20151012 Curious about Linux Try Linux Desktop on the Cloud.md b/sources/share/20151012 Curious about Linux Try Linux Desktop on the Cloud.md
deleted file mode 100644
index 286d6ba816..0000000000
--- a/sources/share/20151012 Curious about Linux Try Linux Desktop on the Cloud.md
+++ /dev/null
@@ -1,44 +0,0 @@
-Curious about Linux? Try Linux Desktop on the Cloud
-================================================================================
-Linux maintains a very small market share as a desktop operating system. Current surveys estimate its share to be a mere 2%; contrast that with the various strains (no pun intended) of Windows which total nearly 90% of the desktop market. For Linux to challenge Microsoft's monopoly on the desktop, there needs to be a simple way of learning about this different operating system. And it would be naive to believe a typical Windows user is going to buy a second machine, tinker with partitioning a hard disk to set up a multi-boot system, or just jump ship to Linux without an easy way back.
-
-
-
-We have examined a number of risk-free ways users can experiment with Linux without dabbling with partition management. Various options include Live CD/DVDs, USB keys and desktop virtualization software. For the latter, I can strongly recommend VMWare (VMWare Player) or Oracle VirtualBox, two relatively easy and free ways of installing and running multiple operating systems on a desktop or laptop computer. Each virtual machine has its own share of CPU, memory, network interfaces etc which is isolated from other virtual machines. But virtual machines still require some effort to get Linux up and running, and a reasonably powerful machine. Too much effort for a mere inquisitive mind.
-
-It can be difficult to break down preconceptions. Many Windows users will have experimented with free software that is available on Linux. But there are many facets to learn on Linux. And it takes time to become accustomed to the way things work in Linux.
-
-Surely there should be an effortless way for a beginner to experiment with Linux for the first time? Indeed there is; step forward the online cloud lab.
-
-### LabxNow ###
-
-
-
-LabxNow provides a free service for general users offering Linux remote desktop over the browser. The developers promote the service as having a personal remote lab (to play around, develop, whatever!) that will be accessible from anywhere, with the internet of course.
-
-The service currently offers a free virtual private server with 2 cores, 4GB RAM and 10GB SSD space. The service runs on a 4 AMD 6272 CPU with 128GB RAM.
-
-#### Features include: ####
-
-- Machine images: Ubuntu 14.04 with Xfce 4.10, RHEL 6.5, CentOS with Gnome, and Oracle
-- Hardware: CPU - 1 or 2 cores; RAM: 512MB, 1GB, 2GB or 4GB
-- Fast network for data transfers
-- Works with all popular browsers
-- Install anything, run anything - an excellent way to experiment and learn all about Linux without any risk
-- Easily add, delete, manage and customize VMs
-- Share VMs, Remote desktop support
-
-All you need is a reasonable Internet connected device. Forget about high cost VPS, domain space or hardware support. LabxNow offers a great way of experimenting with Ubuntu, RHEL and CentOS. It gives Windows users an excellent environment to dip their toes into the wonderful world of Linux. Further, it allows users to do (programming) work from anywhere in the word without having the stress of installing Linux on each machine. Point your web browser at [www.labxnow.org/labxweb/][1].
-
-There are other services (mostly paid services) that allow users to experiment with Linux. These include Cloudsigma which offers a free 7 day trial, and Icebergs.io (full root access via HTML5). But for now, LabxNow gets my recommendation.
-
---------------------------------------------------------------------------------
-
-via: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
-
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[1]:https://www.labxnow.org/labxweb/
\ No newline at end of file
diff --git a/sources/share/20151030 80 Linux Monitoring Tools for SysAdmins.md b/sources/share/20151030 80 Linux Monitoring Tools for SysAdmins.md
deleted file mode 100644
index f9384d4635..0000000000
--- a/sources/share/20151030 80 Linux Monitoring Tools for SysAdmins.md
+++ /dev/null
@@ -1,605 +0,0 @@
-
-translation by strugglingyouth
-80 Linux Monitoring Tools for SysAdmins
-================================================================================
-
-
-The industry is hotting up at the moment, and there are more tools than you can shake a stick at. Here lies the most comprehensive list on the Internet (of Tools). Featuring over 80 ways to your machines. Within this article we outline:
-
-- Command line tools
-- Network related
-- System related monitoring
-- Log monitoring tools
-- Infrastructure monitoring tools
-
-It’s hard work monitoring and debugging performance problems, but it’s easier with the right tools at the right time. Here are some tools you’ve probably heard of, some you probably haven’t – and when to use them:
-
-### Top 10 System Monitoring Tools ###
-
-#### 1. Top ####
-
-
-
-This is a small tool which is pre-installed in many unix systems. When you want an overview of all the processes or threads running in the system: top is a good tool. You can order these processes on different criteria and the default criteria is CPU.
-
-#### 2. [htop][1] ####
-
-
-
-Htop is essentially an enhanced version of top. It’s easier to sort by processes. It’s visually easier to understand and has built in commands for common things you would like to do. Plus it’s fully interactive.
-
-#### 3. [atop][2] ####
-
-Atop monitors all processes much like top and htop, unlike top and htop however it has daily logging of the processes for long-term analysis. It also shows resource consumption by all processes. It will also highlight resources that have reached a critical load.
-
-#### 4. [apachetop][3] ####
-
-Apachetop monitors the overall performance of your apache webserver. It’s largely based on mytop. It displays current number of reads, writes and the overall number of requests processed.
-
-#### 5. [ftptop][4] ####
-
-ftptop gives you basic information of all the current ftp connections to your server such as the total amount of sessions, how many are uploading and downloading and who the client is.
-
-#### 6. [mytop][5] ####
-
-
-
-mytop is a neat tool for monitoring threads and performance of mysql. It gives you a live look into the database and what queries it’s processing in real time.
-
-#### 7. [powertop][6] ####
-
-
-
-powertop helps you diagnose issues that has to do with power consumption and power management. It can also help you experiment with power management settings to achieve the most efficient settings for your server. You switch tabs with the tab key.
-
-#### 8. [iotop][7] ####
-
-
-
-iotop checks the I/O usage information and gives you a top-like interface to that. It displays columns on read and write and each row represents a process. It also displays the percentage of time the process spent while swapping in and while waiting on I/O.
-
-### Network related monitoring ###
-
-#### 9. [ntopng][8] ####
-
-
-
-ntopng is the next generation of ntop and the tool provides a graphical user interface via the browser for network monitoring. It can do stuff such as: geolocate hosts, get network traffic and show ip traffic distribution and analyze it.
-
-#### 10. [iftop][9] ####
-
-
-
-iftop is similar to top, but instead of mainly checking for cpu usage it listens to network traffic on selected network interfaces and displays a table of current usage. It can be handy for answering questions such as “Why on earth is my internet connection so slow?!”.
-
-#### 11. [jnettop][10] ####
-
-
-
-jnettop visualises network traffic in much the same way as iftop does. It also supports customizable text output and a machine-friendly mode to support further analysis.
-
-12. [bandwidthd][11]
-
-
-
-BandwidthD tracks usage of TCP/IP network subnets and visualises that in the browser by building a html page with graphs in png. There is a database driven system that supports searching, filtering, multiple sensors and custom reports.
-
-#### 13. [EtherApe][12] ####
-
-EtherApe displays network traffic graphically, the more talkative the bigger the node. It either captures live traffic or can read it from a tcpdump. The displayed can also be refined using a network filter with pcap syntax.
-
-#### 14. [ethtool][13] ####
-
-
-
-ethtool is used for displaying and modifying some parameters of the network interface controllers. It can also be used to diagnose Ethernet devices and get more statistics from the devices.
-
-#### 15. [NetHogs][14] ####
-
-
-
-NetHogs breaks down network traffic per protocol or per subnet. It then groups by process. So if there’s a surge in network traffic you can fire up NetHogs and see which process is causing it.
-
-#### 16. [iptraf][15] ####
-
-
-
-iptraf gathers a variety of metrics such as TCP connection packet and byte count, interface statistics and activity indicators, TCP/UDP traffic breakdowns and station packet and byte counts.
-
-#### 17. [ngrep][16] ####
-
-
-
-ngrep is grep but for the network layer. It’s pcap aware and will allow to specify extended regular or hexadecimal expressions to match against packets of .
-
-#### 18. [MRTG][17] ####
-
-
-
-MRTG was orginally developed to monitor router traffic, but now it’s able to monitor other network related things as well. It typically collects every five minutes and then generates a html page. It also has the capability of sending warning emails.
-
-#### 19. [bmon][18] ####
-
-
-
-Bmon monitors and helps you debug networks. It captures network related statistics and presents it in human friendly way. You can also interact with bmon through curses or through scripting.
-
-#### 20. traceroute ####
-
-
-
-Traceroute is a built-in tool for displaying the route and measuring the delay of packets across a network.
-
-#### 21. [IPTState][19] ####
-
-IPTState allows you to watch where traffic that crosses your iptables is going and then sort that by different criteria as you please. The tool also allows you to delete states from the table.
-
-#### 22. [darkstat][20] ####
-
-
-
-Darkstat captures network traffic and calculates statistics about usage. The reports are served over a simple HTTP server and gives you a nice graphical user interface of the graphs.
-
-#### 23. [vnStat][21] ####
-
-
-
-vnStat is a network traffic monitor that uses statistics provided by the kernel which ensures light use of system resources. The gathered statistics persists through system reboots. It has color options for the artistic sysadmins.
-
-#### 24. netstat ####
-
-
-
-Netstat is a built-in tool that displays TCP network connections, routing tables and a number of network interfaces. It’s used to find problems in the network.
-
-#### 25. ss ####
-
-Instead of using netstat, it’s however preferable to use ss. The ss command is capable of showing more information than netstat and is actually faster. If you want a summary statistics you can use the command `ss -s`.
-
-#### 26. [nmap][22] ####
-
-
-
-Nmap allows you to scan your server for open ports or detect which OS is being used. But you could also use this for SQL injection vulnerabilities, network discovery and other means related to penetration testing.
-
-#### 27. [MTR][23] ####
-
-
-
-MTR combines the functionality of traceroute and the ping tool into a single network diagnostic tool. When using the tool it will limit the number hops individual packets has to travel while also listening to their expiry. It then repeats this every second.
-
-#### 28. [Tcpdump][24] ####
-
-
-
-Tcpdump will output a description of the contents of the packet it just captured which matches the expression that you provided in the command. You can also save the this data for further analysis.
-
-#### 29. [Justniffer][25] ####
-
-
-
-Justniffer is a tcp packet sniffer. You can choose whether you would like to collect low-level data or high-level data with this sniffer. It also allows you to generate logs in customizable way. You could for instance mimic the access log that apache has.
-
-### System related monitoring ###
-
-#### 30. [nmon][26] ####
-
-
-
-nmon either outputs the data on screen or saves it in a comma separated file. You can display CPU, memory, network, filesystems, top processes. The data can also be added to a RRD database for further analysis.
-
-#### 31. [conky][27] ####
-
-
-
-Conky monitors a plethora of different OS stats. It has support for IMAP and POP3 and even support for many popular music players! For the handy person you could extend it with your own scripts or programs using Lua.
-
-#### 32. [Glances][28] ####
-
-
-
-Glances monitors your system and aims to present a maximum amount of information in a minimum amount of space. It has the capability to function in a client/server mode as well as monitoring remotely. It also has a web interface.
-
-#### 33. [saidar][29] ####
-
-
-
-Saidar is a very small tool that gives you basic information about your system resources. It displays a full screen of the standard system resources. The emphasis for saidar is being as simple as possible.
-
-#### 34. [RRDtool][30] ####
-
-
-
-RRDtool is a tool developed to handle round-robin databases or RRD. RRD aims to handle time-series data like CPU load, temperatures etc. This tool provides a way to extract RRD data in a graphical format.
-
-#### 35. [monit][31] ####
-
-
-
-Monit has the capability of sending you alerts as well as restarting services if they run into trouble. It’s possible to perform any type of check you could write a script for with monit and it has a web user interface to ease your eyes.
-
-#### 36. [Linux process explorer][32] ####
-
-
-
-Linux process explorer is akin to the activity monitor for OSX or the windows equivalent. It aims to be more usable than top or ps. You can view each process and see how much memory usage or CPU it uses.
-
-#### 37. df ####
-
-
-
-df is an abbreviation for disk free and is pre-installed program in all unix systems used to display the amount of available disk space for filesystems which the user have access to.
-
-#### 38. [discus][33] ####
-
-
-
-Discus is similar to df however it aims to improve df by making it prettier using fancy features as colors, graphs and smart formatting of numbers.
-
-#### 39. [xosview][34] ####
-
-
-
-xosview is a classic system monitoring tool and it gives you a simple overview of all the different parts of the including IRQ.
-
-#### 40. [Dstat][35] ####
-
-
-
-Dstat aims to be a replacement for vmstat, iostat, netstat and ifstat. It allows you to view all of your system resources in real-time. The data can then be exported into csv. Most importantly dstat allows for plugins and could thus be extended into areas not yet known to mankind.
-
-#### 41. [Net-SNMP][36] ####
-
-SNMP is the protocol ‘simple network management protocol’ and the Net-SNMP tool suite helps you collect accurate information about your servers using this protocol.
-
-#### 42. [incron][37] ####
-
-Incron allows you to monitor a directory tree and then take action on those changes. If you wanted to copy files to directory ‘b’ once new files appeared in directory ‘a’ that’s exactly what incron does.
-
-#### 43. [monitorix][38] ####
-
-Monitorix is lightweight system monitoring tool. It helps you monitor a single machine and gives you a wealth of metrics. It also has a built-in HTTP server to view graphs and a reporting mechanism of all metrics.
-
-#### 44. vmstat ####
-
-
-
-vmstat or virtual memory statistics is a small built-in tool that monitors and displays a summary about the memory in the machine.
-
-#### 45. uptime ####
-
-This small command that quickly gives you information about how long the machine has been running, how many users currently are logged on and the system load average for the past 1, 5 and 15 minutes.
-
-#### 46. mpstat ####
-
-
-
-mpstat is a built-in tool that monitors cpu usage. The most common command is using `mpstat -P ALL` which gives you the usage of all the cores. You can also get an interval update of the CPU usage.
-
-#### 47. pmap ####
-
-
-
-pmap is a built-in tool that reports the memory map of a process. You can use this command to find out causes of memory bottlenecks.
-
-#### 48. ps ####
-
-
-
-The ps command will give you an overview of all the current processes. You can easily select all processes using the command `ps -A`
-
-#### 49. [sar][39] ####
-
-
-
-sar is a part of the sysstat package and helps you to collect, report and save different system metrics. With different commands it will give you CPU, memory and I/O usage among other things.
-
-#### 50. [collectl][40] ####
-
-
-
-Similar to sar collectl collects performance metrics for your machine. By default it shows cpu, network and disk stats but it collects a lot more. The difference to sar is collectl is able to deal with times below 1 second, it can be fed into a plotting tool directly and collectl monitors processes more extensively.
-
-#### 51. [iostat][41] ####
-
-
-
-iostat is also part of the sysstat package. This command is used for monitoring system input/output. The reports themselves can be used to change system configurations to better balance input/output load between hard drives in your machine.
-
-#### 52. free ####
-
-
-
-This is a built-in command that displays the total amount of free and used physical memory on your machine. It also displays the buffers used by the kernel at that given moment.
-
-#### 53. /Proc file system ####
-
-
-
-The proc file system gives you a peek into kernel statistics. From these statistics you can get detailed information about the different hardware devices on your machine. Take a look at the [full list of the proc file statistics][42]
-
-#### 54. [GKrellM][43] ####
-
-GKrellm is a gui application that monitor the status of your hardware such CPU, main memory, hard disks, network interfaces and many other things. It can also monitor and launch a mail reader of your choice.
-
-#### 55. [Gnome system monitor][44] ####
-
-
-
-Gnome system monitor is a basic system monitoring tool that has features looking at process dependencies from a tree view, kill or renice processes and graphs of all server metrics.
-
-### Log monitoring tools ###
-
-#### 56. [GoAccess][45] ####
-
-
-
-GoAccess is a real-time web log analyzer which analyzes the access log from either apache, nginx or amazon cloudfront. It’s also possible to output the data into HTML, JSON or CSV. It will give you general statistics, top visitors, 404s, geolocation and many other things.
-
-#### 57. [Logwatch][46] ####
-
-Logwatch is a log analysis system. It parses through your system’s logs and creates a report analyzing the areas that you specify. It can give you daily reports with short digests of the activities taking place on your machine.
-
-#### 58. [Swatch][47] ####
-
-
-
-Much like Logwatch Swatch also monitors your logs, but instead of giving reports it watches for regular expression and notifies you via mail or the console when there is a match. It could be used for intruder detection for example.
-
-#### 59. [MultiTail][48] ####
-
-
-
-MultiTail helps you monitor logfiles in multiple windows. You can merge two or more of these logfiles into one. It will also use colors to display the logfiles for easier reading with the help of regular expressions.
-
-#### System tools ####
-
-#### 60. [acct or psacct][49] ####
-
-acct or psacct (depending on if you use apt-get or yum) allows you to monitor all the commands a users executes inside the system including CPU and memory time. Once installed you get that summary with the command ‘sa’.
-
-#### 61. [whowatch][50] ####
-
-Similar to acct this tool monitors users on your system and allows you to see in real time what commands and processes they are using. It gives you a tree structure of all the processes and so you can see exactly what’s happening.
-
-#### 62. [strace][51] ####
-
-
-
-strace is used to diagnose, debug and monitor interactions between processes. The most common thing to do is making strace print a list of system calls made by the program which is useful if the program does not behave as expected.
-
-#### 63. [DTrace][52] ####
-
-
-
-DTrace is the big brother of strace. It dynamically patches live running instructions with instrumentation code. This allows you to do in-depth performance analysis and troubleshooting. However, it’s not for the weak of heart as there is a 1200 book written on the topic.
-
-#### 64. [webmin][53] ####
-
-
-
-Webmin is a web-based system administration tool. It removes the need to manually edit unix configuration files and lets you manage the system remotely if need be. It has a couple of monitoring modules that you can attach to it.
-
-#### 65. stat ####
-
-
-
-Stat is a built-in tool for displaying status information of files and file systems. It will give you information such as when the file was modified, accessed or changed.
-
-#### 66. ifconfig ####
-
-
-
-ifconfig is a built-in tool used to configure the network interfaces. Behind the scenes network monitor tools use ifconfig to set it into promiscuous mode to capture all packets. You can do it yourself with `ifconfig eth0 promisc` and return to normal mode with `ifconfig eth0 -promisc`.
-
-#### 67. [ulimit][54] ####
-
-
-
-ulimit is a built-in tool that monitors system resources and keeps a limit so any of the monitored resources don’t go overboard. For instance making a fork bomb where a properly configured ulimit is in place would be totally fine.
-
-#### 68. [cpulimit][55] ####
-
-CPUlimit is a small tool that monitors and then limits the CPU usage of a process. It’s particularly useful to make batch jobs not eat up too many CPU cycles.
-
-#### 69. lshw ####
-
-
-
-lshw is a small built-in tool extract detailed information about the hardware configuration of the machine. It can output everything from CPU version and speed to mainboard configuration.
-
-#### 70. w ####
-
-W is a built-in command that displays information about the users currently using the machine and their processes.
-
-#### 71. lsof ####
-
-
-
-lsof is a built-in tool that gives you a list of all open files and network connections. From there you can narrow it down to files opened by processes, based on the process name, by a specific user or perhaps kill all processes that belongs to a specific user.
-
-### Infrastructure monitoring tools ###
-
-#### 72. Server Density ####
-
-
-
-Our [server monitoring tool][56]! It has a web interface that allows you to set alerts and view graphs for all system and network metrics. You can also set up monitoring of websites whether they are up or down. Server Density allows you to set permissions for users and you can extend your monitoring with our plugin infrastructure or api. The service already supports Nagios plugins.
-
-#### 73. [OpenNMS][57] ####
-
-
-
-OpenNMS has four main functional areas: event management and notifications; discovery and provisioning; service monitoring and data collection. It’s designed to be customizable to work in a variety of network environments.
-
-#### 74. [SysUsage][58] ####
-
-
-
-SysUsage monitors your system continuously via Sar and other system commands. It also allows notifications to alarm you once a threshold is reached. SysUsage itself can be run from a centralized place where all the collected statistics are also being stored. It has a web interface where you can view all the stats.
-
-#### 75. [brainypdm][59] ####
-
-
-
-brainypdm is a data management and monitoring tool that has the capability to gather data from nagios or another generic source to make graphs. It’s cross-platform, has custom graphs and is web based.
-
-#### 76. [PCP][60] ####
-
-
-
-PCP has the capability of collating metrics from multiple hosts and does so efficiently. It also has a plugin framework so you can make it collect specific metrics that is important to you. You can access graph data through either a web interface or a GUI. Good for monitoring large systems.
-
-#### 77. [KDE system guard][61] ####
-
-
-
-This tool is both a system monitor and task manager. You can view server metrics from several machines through the worksheet and if a process needs to be killed or if you need to start a process it can be done within KDE system guard.
-
-#### 78. [Munin][62] ####
-
-
-
-Munin is both a network and a system monitoring tool which offers alerts for when metrics go beyond a given threshold. It uses RRDtool to create the graphs and it has web interface to display these graphs. Its emphasis is on plug and play capabilities with a number of plugins available.
-
-#### 79. [Nagios][63] ####
-
-
-
-Nagios is system and network monitoring tool that helps you monitor monitor your many servers. It has support for alerting for when things go wrong. It also has many plugins written for the platform.
-
-#### 80. [Zenoss][64] ####
-
-
-
-Zenoss provides a web interface that allows you to monitor all system and network metrics. Moreover it discovers network resources and changes in network configurations. It has alerts for you to take action on and it supports the Nagios plugins.
-
-#### 81. [Cacti][65] ####
-
-
-
-(And one for luck!) Cacti is network graphing solution that uses the RRDtool data storage. It allows a user to poll services at predetermined intervals and graph the result. Cacti can be extended to monitor a source of your choice through shell scripts.
-
-#### 82. [Zabbix][66] ####
-
-
-
-Zabbix is an open source infrastructure monitoring solution. It can use most databases out there to store the monitoring statistics. The Core is written in C and has a frontend in PHP. If you don’t like installing an agent, Zabbix might be an option for you.
-
-### Bonus section: ###
-
-Thanks for your suggestions. It’s an oversight on our part that we’ll have to go back trough and renumber all the headings. In light of that, here’s a short section at the end for some of the Linux monitoring tools recommended by you:
-
-#### 83. [collectd][67] ####
-
-Collectd is a Unix daemon that collects all your monitoring statistics. It uses a modular design and plugins to fill in any niche monitoring. This way collectd stays as lightweight and customizable as possible.
-
-#### 84. [Observium][68] ####
-
-Observium is an auto-discovering network monitoring platform supporting a wide range of hardware platforms and operating systems. Observium focuses on providing a beautiful and powerful yet simple and intuitive interface to the health and status of your network.
-
-#### 85. Nload ####
-
-It’s a command line tool that monitors network throughput. It’s neat because it visualizes the in and and outgoing traffic using two graphs and some additional useful data like total amount of transferred data. You can install it with
-
- yum install nload
-
-or
-
- sudo apt-get install nload
-
-#### 84. [SmokePing][69] ####
-
-SmokePing keeps track of the network latencies of your network and it visualises them too. There are a wide range of latency measurement plugins developed for SmokePing. If a GUI is important to you it’s there is an ongoing development to make that happen.
-
-#### 85. [MobaXterm][70] ####
-
-If you’re working in windows environment day in and day out. You may feel limited by the terminal Windows provides. MobaXterm comes to the rescue and allows you to use many of the terminal commands commonly found in Linux. Which will help you tremendously in your monitoring needs!
-
-#### 86. [Shinken monitoring][71] ####
-
-Shinken is a monitoring framework which is a total rewrite of Nagios in python. It aims to enhance flexibility and managing a large environment. While still keeping all your nagios configuration and plugins.
-
---------------------------------------------------------------------------------
-
-via: https://blog.serverdensity.com/80-linux-monitoring-tools-know/
-
-作者:[Jonathan Sundqvist][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-
-[a]:https://www.serverdensity.com/
-[1]:http://hisham.hm/htop/
-[2]:http://www.atoptool.nl/
-[3]:https://github.com/JeremyJones/Apachetop
-[4]:http://www.proftpd.org/docs/howto/Scoreboard.html
-[5]:http://jeremy.zawodny.com/mysql/mytop/
-[6]:https://01.org/powertop
-[7]:http://guichaz.free.fr/iotop/
-[8]:http://www.ntop.org/products/ntop/
-[9]:http://www.ex-parrot.com/pdw/iftop/
-[10]:http://jnettop.kubs.info/wiki/
-[11]:http://bandwidthd.sourceforge.net/
-[12]:http://etherape.sourceforge.net/
-[13]:https://www.kernel.org/pub/software/network/ethtool/
-[14]:http://nethogs.sourceforge.net/
-[15]:http://iptraf.seul.org/
-[16]:http://ngrep.sourceforge.net/
-[17]:http://oss.oetiker.ch/mrtg/
-[18]:https://github.com/tgraf/bmon/
-[19]:http://www.phildev.net/iptstate/index.shtml
-[20]:https://unix4lyfe.org/darkstat/
-[21]:http://humdi.net/vnstat/
-[22]:http://nmap.org/
-[23]:http://www.bitwizard.nl/mtr/
-[24]:http://www.tcpdump.org/
-[25]:http://justniffer.sourceforge.net/
-[26]:http://nmon.sourceforge.net/pmwiki.php
-[27]:http://conky.sourceforge.net/
-[28]:https://github.com/nicolargo/glances
-[29]:https://packages.debian.org/sid/utils/saidar
-[30]:http://oss.oetiker.ch/rrdtool/
-[31]:http://mmonit.com/monit
-[32]:http://sourceforge.net/projects/procexp/
-[33]:http://packages.ubuntu.com/lucid/utils/discus
-[34]:http://www.pogo.org.uk/~mark/xosview/
-[35]:http://dag.wiee.rs/home-made/dstat/
-[36]:http://www.net-snmp.org/
-[37]:http://inotify.aiken.cz/?section=incron&page=about&lang=en
-[38]:http://www.monitorix.org/
-[39]:http://sebastien.godard.pagesperso-orange.fr/
-[40]:http://collectl.sourceforge.net/
-[41]:http://sebastien.godard.pagesperso-orange.fr/
-[42]:http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
-[43]:http://members.dslextreme.com/users/billw/gkrellm/gkrellm.html
-[44]:http://freecode.com/projects/gnome-system-monitor
-[45]:http://goaccess.io/
-[46]:http://sourceforge.net/projects/logwatch/
-[47]:http://sourceforge.net/projects/swatch/
-[48]:http://www.vanheusden.com/multitail/
-[49]:http://www.gnu.org/software/acct/
-[50]:http://whowatch.sourceforge.net/
-[51]:http://sourceforge.net/projects/strace/
-[52]:http://dtrace.org/blogs/about/
-[53]:http://www.webmin.com/
-[54]:http://ss64.com/bash/ulimit.html
-[55]:https://github.com/opsengine/cpulimit
-[56]:https://www.serverdensity.com/server-monitoring/
-[57]:http://www.opennms.org/
-[58]:http://sysusage.darold.net/
-[59]:http://sourceforge.net/projects/brainypdm/
-[60]:http://www.pcp.io/
-[61]:https://userbase.kde.org/KSysGuard
-[62]:http://munin-monitoring.org/
-[63]:http://www.nagios.org/
-[64]:http://www.zenoss.com/
-[65]:http://www.cacti.net/
-[66]:http://www.zabbix.com/
-[67]:https://collectd.org/
-[68]:http://www.observium.org/
-[69]:http://oss.oetiker.ch/smokeping/
-[70]:http://mobaxterm.mobatek.net/
-[71]:http://www.shinken-monitoring.org/
diff --git a/sources/share/20151204 Review EXT4 vs. Btrfs vs. XFS.md b/sources/share/20151204 Review EXT4 vs. Btrfs vs. XFS.md
new file mode 100644
index 0000000000..d370b87822
--- /dev/null
+++ b/sources/share/20151204 Review EXT4 vs. Btrfs vs. XFS.md
@@ -0,0 +1,65 @@
+Review EXT4 vs. Btrfs vs. XFS
+================================================================================
+
+
+To be honest, one of the things that comes last in people’s thinking is to look at which file system on their PC is being used. Windows users as well as Mac OS X users even have less reason for looking as they have really only 1 choice for their operating system which are NTFS and HFS+. Linux operating system, on the other side, has plenty of various file system options, with the current default is being widely used ext4. However, there is another push for changing the file system to something other which is called btrfs. But what makes btrfs better, what are other file systems, and when can we see the distributions making the change?
+
+Let’s first have a general look at file systems and what they really do, then we will make a small comparison between famous file systems.
+
+### So, What Do File Systems Do? ###
+
+Just in case if you are unfamiliar about what file systems really do, it is actually simple when it is summarized. The file systems are mainly used in order for controlling how the data is stored after any program is no longer using it, how access to the data is controlled, what other information (metadata) is attached to the data itself, etc. I know that it does not sound like an easy thing to be programmed, and it is definitely not. The file systems are continually still being revised for including more functionality while becoming more efficient in what it simply needs to do. Therefore, however, it is a basic need for all computers, it is not quite as basic as it sounds like.
+
+### Why Partitioning? ###
+
+Many people have a vague knowledge of what the partitions are since each operating system has an ability for creating or removing them. It can seem strange that Linux operating system uses more than 1 partition on the same disk, even while using the standard installation procedure, so few explanations are called for them. One of the main goals of having different partitions is achieving higher data security in the disaster case.
+
+By dividing your hard disk into partitions, the data may be grouped and also separated. When the accidents occur, only the data stored in the partition which got the hit will only be damaged, while data on the other partitions will survive most likely. These principles date from the days when the Linux operating system didn’t have a journaled file system and any power failure might have led to a disaster.
+
+The using of partitions will remain for security and the robustness reasons, then the breach on 1 part of the operating system does not automatically mean that whole computer is under risk or danger. This is currently most important factor for the partitioning process. For example, the users create scripts, the programs or web applications which start filling up the disk. If that disk contains only 1 big partition, then entire system may stop functioning if that disk is full. If the users store data on separate partitions, then only that data partition can be affected, while system partitions and the possible other data partitions will keep functioning.
+
+Mind that to have a journaled file system will only provide data security in case if there is a power failure as well as sudden disconnection of the storage devices. Such will not protect the data against the bad blocks and the logical errors in the file system. In such cases, the user should use a Redundant Array of Inexpensive Disks (RAID) solution.
+
+### Why Switch File Systems? ###
+
+The ext4 file system has been an improvement for the ext3 file system that was also an improvement over the ext2 file system. While the ext4 is a very solid file system which has been the default choice for almost all distributions for the past few years, it is made from an aging code base. Additionally, Linux operating system users are seeking many new different features in file systems which ext4 does not handle on its own. There is software which takes care of some of such needs, but in the performance aspect, being able to do such things on the file system level could be faster.
+
+### Ext4 File System ###
+
+The ext4 has some limits which are still a bit impressive. The maximum file size is 16 tebibytes (which is roughly 17.6 terabytes) and is much bigger than any hard drive a regular consumer can currently buy. While, the largest volume/partition you can make with ext4 is 1 exbibyte (which is roughly 1,152,921.5 terabytes). The ext4 is known to bring the speed improvements over ext3 by using multiple various techniques. Like in the most modern file systems, it is a journaling file system that means that it will keep a journal of where the files are mainly located on the disk and of any other changes that happen to the disk. Regardless all of its features, it doesn’t support the transparent compression, the data deduplication, or the transparent encryption. The snapshots are supported technically, but such feature is experimental at best.
+
+### Btrfs File System ###
+
+The btrfs, many of us pronounce it different ways, as an example, Better FS, Butter FS, or B-Tree FS. It is a file system which is completely made from scratch. The btrfs exists because its developers firstly wanted to expand the file system functionality in order to include snapshots, pooling, as well as checksums among the other things. While it is independent from the ext4, it also wants to build off the ideas present in the ext4 that are great for the consumers and the businesses alike as well as incorporate those additional features that will benefit everybody, but specifically the enterprises. For the enterprises who are using very large programs with very large databases, they are having a seemingly continuous file system across the multiple hard drives could be very beneficial as it will make a consolidation of the data much easier. The data deduplication could reduce the amount of the actual space data could occupy, and the data mirroring could become easier with the btrfs as well when there is a single and broad file system which needs to be mirrored.
+
+The user certainly can still choose to create multiple partitions so that he does not need to mirror everything. Considering that the btrfs will be able for spanning over the multiple hard drives, it is a very good thing that it can support 16 times more drive space than the ext4. A maximum partition size of the btrfs file system is 16 exbibytes, as well as maximum file size is 16 exbibytes too.
+
+### XFS File System ###
+
+The XFS file system is an extension of the extent file system. The XFS is a high-performance 64-bit journaling file system. The support of the XFS was merged into Linux kernel in around 2002 and In 2009 Red Hat Enterprise Linux version 5.4 usage of the XFS file system. XFS supports maximum file system size of 8 exbibytes for the 64-bit file system. There is some comparison of XFS file system is XFS file system can’t be shrunk and poor performance with deletions of the large numbers of files. Now, the RHEL 7.0 uses XFS as the default filesystem.
+
+### Final Thoughts ###
+
+Unfortunately, the arrival date for the btrfs is not quite known. But officially, the next-generation file system is still classified as “unstable”, but if the user downloads the latest version of Ubuntu, he will be able to choose to install on a btrfs partition. When the btrfs will be classified actually as “stable” is still a mystery, but users shouldn’t expect the Ubuntu to use the btrfs by default until it’s indeed considered “stable”. It has been reported that Fedora 18 will use the btrfs as its default file system as by the time of its release a file system checker for the btrfs should exist. There is a good amount of work still left for the btrfs, as not all the features are yet implemented and the performance is a little sluggish if we compare it to the ext4.
+
+So, which is better to use? Till now, the ext4 will be the winner despite the identical performance. But why? The answer will be the convenience as well as the ubiquity. The ext4 is still excellent file system for the desktop or workstation use. It is provided by default, so the user can install the operating system on it. Also, the ext4 supports volumes up to 1 Exabyte and files up to 16 Terabyte in size, so there’s still a plenty of room for the growth where space is concerned.
+
+The btrfs might offer greater volumes up to 16 Exabyte and improved fault tolerance, but, till now, it feels more as an add-on file system rather than one integrated into the Linux operating system. For example, the btrfs-tools have to be present before a drive will be formatted with the btrfs, which means that the btrfs is not an option during the Linux operating system installation though that could vary with the distribution.
+
+Even though the transfer rates are so important, there’s more to a just file system than speed of the file transfers. The btrfs has many useful features such as Copy-on-Write (CoW), extensive checksums, snapshots, scrubbing, self-healing data, deduplication, as well as many more good improvements that ensure the data integrity. The btrfs lacks the RAID-Z features of ZFS, so the RAID is still in an experimental state with the btrfs. For pure data storage, however, the btrfs is the winner over the ext4, but time still will tell.
+
+Till the moment, the ext4 seems to be a better choice on the desktop system since it is presented as a default file system, as well as it is faster than the btrfs when transferring files. The btrfs is definitely worth to look into, but to completely switch to replace the ext4 on desktop Linux might be few years later. The data farms and the large storage pools could reveal different stories and show the right differences between ext4, XCF, and btrfs.
+
+If you have a different or additional opinion, kindly let us know by commenting on this article.
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/review-ext4-vs-btrfs-vs-xfs/
+
+作者:[M.el Khamlichi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.unixmen.com/author/pirat9/
diff --git a/sources/talk/20150818 A Linux User Using Windows 10 After More than 8 Years--See Comparison.md b/sources/talk/20150818 A Linux User Using Windows 10 After More than 8 Years--See Comparison.md
index cf472613c4..22a0acdbf1 100644
--- a/sources/talk/20150818 A Linux User Using Windows 10 After More than 8 Years--See Comparison.md
+++ b/sources/talk/20150818 A Linux User Using Windows 10 After More than 8 Years--See Comparison.md
@@ -1,3 +1,4 @@
+sevenot translating
A Linux User Using ‘Windows 10′ After More than 8 Years – See Comparison
================================================================================
Windows 10 is the newest member of windows NT family of which general availability was made on July 29, 2015. It is the successor of Windows 8.1. Windows 10 is supported on Intel Architecture 32 bit, AMD64 and ARMv7 processors.
@@ -341,4 +342,4 @@ via: http://www.tecmint.com/a-linux-user-using-windows-10-after-more-than-8-year
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
[a]:http://www.tecmint.com/author/avishek/
-[1]:https://www.microsoft.com/en-us/software-download/windows10ISO
\ No newline at end of file
+[1]:https://www.microsoft.com/en-us/software-download/windows10ISO
diff --git a/sources/talk/20150820 Why did you start using Linux.md b/sources/talk/20150820 Why did you start using Linux.md
deleted file mode 100644
index 5fb6a8d4fe..0000000000
--- a/sources/talk/20150820 Why did you start using Linux.md
+++ /dev/null
@@ -1,147 +0,0 @@
-Why did you start using Linux?
-================================================================================
-> In today's open source roundup: What got you started with Linux? Plus: IBM's Linux only Mainframe. And why you should skip Windows 10 and go with Linux
-
-### Why did you start using Linux? ###
-
-Linux has become quite popular over the years, with many users defecting to it from OS X or Windows. But have you ever wondered what got people started with Linux? A redditor asked that question and got some very interesting answers.
-
-SilverKnight asked his question on the Linux subreddit:
-
-> I know this has been asked before, but I wanted to hear more from the younger generation why it is that they started using linux and what keeps them here.
->
-> I dont want to discourage others from giving their linux origin stories, because those are usually pretty good, but I was mostly curious about our younger population since there isn't much out there from them yet.
->
-> I myself am 27 and am a linux dabbler. I have installed quite a few different distros over the years but I haven't made the plunge to full time linux. I guess I am looking for some more reasons/inspiration to jump on the bandwagon.
->
-> [More at Reddit][1]
-
-Fellow redditors in the Linux subreddit responded with their thoughts:
-
-> **DoublePlusGood**: "I started using Backtrack Linux (now Kali) at 12 because I wanted to be a "1337 haxor". I've stayed with Linux (Archlinux currently) because it lets me have the endless freedom to make my computer do what I want."
->
-> **Zack**: "I'm a Linux user since, I think, the age of 12 or 13, I'm 15 now.
->
-> It started when I got tired with Windows XP at 11 and the waiting, dammit am I impatient sometimes, but waiting for a basic task such as shutting down just made me tired of Windows all together.
->
-> A few months previously I had started participating in discussions in a channel on the freenode IRC network which was about a game, and as freenode usually goes, it was open source and most of the users used Linux.
->
-> I kept on hearing about this Linux but wasn't that interested in it at the time. However, because the channel (and most of freenode) involved quite a bit of programming I started learning Python.
->
-> A year passed and I was attempting to install GNU/Linux (specifically Ubuntu) on my new (technically old, but I had just got it for my birthday) PC, unfortunately it continually froze, for reasons unknown (probably a bad hard drive, or a lot of dust or something else...).
->
-> Back then I was the type to give up on things, so I just continually nagged my dad to try and install Ubuntu, he couldn't do it for the same reasons.
->
-> After wanting Linux for a while I became determined to get Linux and ditch windows for good. So instead of Ubuntu I tried Linux Mint, being a derivative of Ubuntu(?) I didn't have high hopes, but it worked!
->
-> I continued using it for another 6 months.
->
-> During that time a friend on IRC gave me a virtual machine (which ran Ubuntu) on their server, I kept it for a year a bit until my dad got me my own server.
->
-> After the 6 months I got a new PC (which I still use!) I wanted to try something different.
->
-> I decided to install openSUSE.
->
-> I liked it a lot, and on the same Christmas I obtained a Raspberry Pi, and stuck with Debian on it for a while due to the lack of support other distros had for it."
->
-> **Cqz**: "Was about 9 when the Windows 98 machine handed down to me stopped working for reasons unknown. We had no Windows install disk, but Dad had one of those magazines that comes with demo programs and stuff on CDs. This one happened to have install media for Mandrake Linux, and so suddenly I was a Linux user. Had no idea what I was doing but had a lot of fun doing it, and although in following years I often dual booted with various Windows versions, the FLOSS world always felt like home. Currently only have one Windows installation, which is a virtual machine for games."
->
-> **Tosmarcel**: "I was 15 and was really curious about this new concept called 'programming' and then I stumbled upon this Harvard course, CS50. They told users to install a Linux vm to use the command line. But then I asked myself: "Why doesn't windows have this command line?!". I googled 'linux' and Ubuntu was the top result -Ended up installing Ubuntu and deleted the windows partition accidentally... It was really hard to adapt because I knew nothing about linux. Now I'm 16 and running arch linux, never looked back and I love it!"
->
-> **Micioonthet**: "First heard about Linux in the 5th grade when I went over to a friend's house and his laptop was running MEPIS (an old fork of Debian) instead of Windows XP.
->
-> Turns out his dad was a socialist (in America) and their family didn't trust Microsoft. This was completely foreign to me, and I was confused as to why he would bother using an operating system that didn't support the majority of software that I knew.
->
-> Fast forward to when I was 13 and without a laptop. Another friend of mine was complaining about how slow his laptop was, so I offered to buy it off of him so I could fix it up and use it for myself. I paid $20 and got a virus filled, unusable HP Pavilion with Windows Vista. Instead of trying to clean up the disgusting Windows install, I remembered that Linux was a thing and that it was free. I burned an Ubuntu 12.04 disc and installed it right away, and was absolutely astonished by the performance.
->
-> Minecraft (one of the few early Linux games because it ran on Java), which could barely run at 5 FPS on Vista, ran at an entirely playable 25 FPS on a clean install of Ubuntu.
->
-> I actually still have that old laptop and use it occasionally, because why not? Linux doesn't care how old your hardware is.
->
-> I since converted my dad to Linux and we buy old computers at lawn sales and thrift stores for pennies and throw Linux Mint or some other lightweight distros on them."
->
-> **Webtm**: "My dad had every computer in the house with some distribution on it, I think a couple with OpenSUSE and Debian, and his personal computer had Slackware on it. So I remember being little and playing around with Debian and not really getting into it much. So I had a Windows laptop for a few years and my dad asked me if I wanted to try out Debian. It was a fun experience and ever since then I've been using Debian and trying out distributions. I currently moved away from Linux and have been using FreeBSD for around 5 months now, and I am absolutely happy with it.
->
-> The control over your system is fantastic. There are a lot of cool open source projects. I guess a lot of the fun was figuring out how to do the things I want by myself and tweaking those things in ways to make them do something else. Stability and performance is also a HUGE plus. Not to mention the level of privacy when switching."
->
-> **Wyronaut**: "I'm currently 18, but I first started using Linux when I was 13. Back then my first distro was Ubuntu. The reason why I wanted to check out Linux, was because I was hosting little Minecraft game servers for myself and a couple of friends, back then Minecraft was pretty new-ish. I read that the defacto operating system for hosting servers was Linux.
->
-> I was a big newbie when it came to command line work, so Linux scared me a little, because I had to take care of a lot of things myself. But thanks to google and a few wiki pages I managed to get up a couple of simple servers running on a few older PC's I had lying around. Great use for all that older hardware no one in the house ever uses.
->
-> After running a few game servers I started running a few web servers as well. Experimenting with HTML, CSS and PHP. I worked with those for a year or two. Afterwards, took a look at Java. I made the terrible mistake of watching TheNewBoston video's.
->
-> So after like a week I gave up on Java and went to pick up a book on Python instead. That book was Learn Python The Hard Way by Zed A. Shaw. After I finished that at the fast pace of two weeks, I picked up the book C++ Primer, because at the time I wanted to become a game developer. Went trough about half of the book (~500 pages) and burned out on learning. At that point I was spending a sickening amount of time behind my computer.
->
-> After taking a bit of a break, I decided to pick up JavaScript. Read like 2 books, made like 4 different platformers and called it a day.
->
-> Now we're arriving at the present. I had to go through the horrendous process of finding a school and deciding what job I wanted to strive for when I graduated. I ruled out anything in the gaming sector as I didn't want anything to do with graphics programming anymore, I also got completely sick of drawing and modelling. And I found this bachelor that had something to do with netsec and I instantly fell in love. I picked up a couple books on C to shred this vacation period and brushed up on some maths and I'm now waiting for the new school year to commence.
->
-> Right now, I am having loads of fun with Arch Linux, made couple of different arrangements on different PC's and it's going great!
->
-> In a sense Linux is what also got me into programming and ultimately into what I'm going to study in college starting this september. I probably have my future life to thank for it."
->
-> **Linuxllc**: "You also can learn from old farts like me.
->
-> The crutch, The crutch, The crutch. Getting rid of the crutch will inspired you and have good reason to stick with Linux.
->
-> I got rid of my crutch(Windows XP) back in 2003. Took me only 5 days to get all my computer task back and running at a 100% workflow. Including all my peripheral devices. Minus any Windows games. I just play native Linux games."
->
-> **Highclass**: "Hey I'm 28 not sure if this is the age group you are looking for.
->
-> To be honest, I was always interested in computers and the thought of a free operating system was intriguing even though at the time I didn't fully grasp the free software philosophy, to me it was free as in no cost. I also did not find the CLI too intimidating as from an early age I had exposure to DOS.
->
-> I believe my first distro was Mandrake, I was 11 or 12, I messed up the family computer on several occasions.... I ended up sticking with it always trying to push myself to the next level. Now I work in the industry with Linux everyday.
->
-> /shrug"
->
-> Matto: "My computer couldn't run fast enough for XP (got it at a garage sale), so I started looking for alternatives. Ubuntu came up in Google. I was maybe 15 or 16 at the time. Now I'm 23 and have a job working on a product that uses Linux internally."
->
-> [More at Reddit][2]
-
-### IBM's Linux only Mainframe ###
-
-IBM has a long history with Linux, and now the company has created a Mainframe that features Ubuntu Linux. The new machine is named LinuxOne.
-
-Ron Miller reports for TechCrunch:
-
-> The new mainframes come in two flavors, named for penguins (Linux — penguins — get it?). The first is called Emperor and runs on the IBM z13, which we wrote about in January. The other is a smaller mainframe called the Rockhopper designed for a more “entry level” mainframe buyer.
->
-> You may have thought that mainframes went the way of the dinosaur, but they are still alive and well and running in large institutions throughout the world. IBM as part of its broader strategy to promote the cloud, analytics and security is hoping to expand the potential market for mainframes by running Ubuntu Linux and supporting a range of popular open source enterprise software such as Apache Spark, Node.js, MongoDB, MariaDB, PostgreSQL and Chef.
->
-> The metered mainframe will still sit inside the customer’s on-premises data center, but billing will be based on how much the customer uses the system, much like a cloud model, Mauri explained.
->
-> ...IBM is looking for ways to increase those sales. Partnering with Canonical and encouraging use of open source tools on a mainframe gives the company a new way to attract customers to a small, but lucrative market.
->
-> [More at TechCrunch][3]
-
-### Why you should skip Windows 10 and opt for Linux ###
-
-Since Windows 10 has been released there has been quite a bit of media coverage about its potential to spy on users. ZDNet has listed some reasons why you should skip Windows 10 and opt for Linux instead on your computer.
-
-SJVN reports for ZDNet:
-
-> You can try to turn Windows 10's data-sharing ways off, but, bad news: Windows 10 will keep sharing some of your data with Microsoft anyway. There is an alternative: Desktop Linux.
->
-> You can do a lot to keep Windows 10 from blabbing, but you can't always stop it from talking. Cortana, Windows 10's voice activated assistant, for example, will share some data with Microsoft, even when it's disabled. That data includes a persistent computer ID to identify your PC to Microsoft.
->
-> So, if that gives you a privacy panic attack, you can either stick with your old operating system, which is likely Windows 7, or move to Linux. Eventually, when Windows 7 is no longer supported, if you want privacy you'll have no other viable choice but Linux.
->
-> There are other, more obscure desktop operating systems that are also desktop-based and private. These include the BSD Unix family such as FreeBSD, PCBSD, and NetBSD and eComStation, OS/2 for the 21st century. Your best choice, though, is a desktop-based Linux with a low learning curve.
->
-> [More at ZDNet][4]
-
---------------------------------------------------------------------------------
-
-via: http://www.itworld.com/article/2972587/linux/why-did-you-start-using-linux.html
-
-作者:[Jim Lynch][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://www.itworld.com/author/Jim-Lynch/
-[1]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
-[2]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
-[3]:http://techcrunch.com/2015/08/16/ibm-teams-with-canonical-on-linux-mainframe/
-[4]:http://www.zdnet.com/article/sick-of-windows-spying-on-you-go-linux/
diff --git a/sources/talk/20150827 The Strangest Most Unique Linux Distros.md b/sources/talk/20150827 The Strangest Most Unique Linux Distros.md
deleted file mode 100644
index 83ead1f75e..0000000000
--- a/sources/talk/20150827 The Strangest Most Unique Linux Distros.md
+++ /dev/null
@@ -1,69 +0,0 @@
-FSSlc Translating
-
-The Strangest, Most Unique Linux Distros
-================================================================================
-From the most consumer focused distros like Ubuntu, Fedora, Mint or elementary OS to the more obscure, minimal and enterprise focused ones such as Slackware, Arch Linux or RHEL, I thought I've seen them all. Couldn't have been any further from the truth. Linux eco-system is very diverse. There's one for everyone. Let's discuss the weird and wacky world of niche Linux distros that represents the true diversity of open platforms.
-
-
-
-**Puppy Linux**: An operating system which is about 1/10th the size of an average DVD quality movie rip, that's Puppy Linux for you. The OS is just 100 MB in size! And it can run from RAM making it unusually fast even in older PCs. You can even remove the boot medium after the operating system has started! Can it get any better than that? System requirements are bare minimum, most hardware are automatically detected, and it comes loaded with software catering to your basic needs. [Experience Puppy Linux][1].
-
-
-
-**Suicide Linux**: Did the name scare you? Well it should. 'Any time - any time - you type any remotely incorrect command, the interpreter creatively resolves it into rm -rf / and wipes your hard drive'. Simple as that. I really want to know the ones who are confident enough to risk their production machines with [Suicide Linux][2]. **Warning: DO NOT try this on production machines!** The whole thing is available in a neat [DEB package][3] if you're interested.
-
-
-
-**PapyrOS**: "Strange" in a good way. PapyrOS is trying to adapt the material design language of Android into their brand new Linux distribution. Though the project is in early stages, it already looks very promising. The project page says the OS is 80% complete and one can expect the first Alpha release anytime soon. We did a small write up on [PapyrOS][4] when it was announced and by the looks of it, PapyrOS might even become a trend-setter of sorts. Follow the project on [Google+][5] and contribute via [BountySource][6] if you're interested.
-
-
-
-**Qubes OS**: Qubes is an open-source operating system designed to provide strong security using a Security by Compartmentalization approach. The assumption is that there can be no perfect, bug-free desktop environment. And by implementing a 'Security by Isolation' approach, [Qubes Linux][7] intends to remedy that. Qubes is based on Xen, the X Window System, and Linux, and can run most Linux applications and supports most Linux drivers. Qubes was selected as a finalist of Access Innovation Prize 2014 for Endpoint Security Solution.
-
-
-
-**Ubuntu Satanic Edition**: Ubuntu SE is a Linux distribution based on Ubuntu. "It brings together the best of free software and free metal music" in one comprehensive package consisting of themes, wallpapers, and even some heavy-metal music sourced from talented new artists. Though the project doesn't look actively developed anymore, Ubuntu Satanic Edition is strange in every sense of that word. [Ubuntu SE (Slightly NSFW)][8].
-
-
-
-**Tiny Core Linux**: Puppy Linux not small enough? Try this. Tiny Core Linux is a 12 MB graphical Linux desktop! Yep, you read it right. One major caveat: It is not a complete desktop nor is all hardware completely supported. It represents only the core needed to boot into a very minimal X desktop typically with wired internet access. There is even a version without the GUI called Micro Core Linux which is just 9MB in size. [Tiny Core Linux][9] folks.
-
-
-
-**NixOS**: A very experienced-user focused Linux distribution with a unique approach to package and configuration management. In other distributions, actions such as upgrades can be dangerous. Upgrading a package can cause other packages to break, upgrading an entire system is much less reliable than reinstalling from scratch. And top of all that you can't safely test what the results of a configuration change will be, there's no "Undo" so to speak. In NixOS, the entire operating system is built by the Nix package manager from a description in a purely functional build language. This means that building a new configuration cannot overwrite previous configurations. Most of the other features follow this pattern. Nix stores all packages in isolation from each other. [More about NixOS][10].
-
-
-
-**GoboLinux**: This is another very unique Linux distro. What makes GoboLinux so different from the rest is its unique re-arrangement of the filesystem. It has its own subdirectory tree, where all of its files and programs are stored. GoboLinux does not have a package database because the filesystem is its database. In some ways, this sort of arrangement is similar to that seen in OS X. [Get GoboLinux][11].
-
-
-
-**Hannah Montana Linux**: Here is a Linux distro based on Kubuntu with a Hannah Montana themed boot screen, KDM, icon set, ksplash, plasma, color scheme, and wallpapers (I'm so sorry). [Link][12]. Project not active anymore.
-
-**RLSD Linux**: An extremely minimalistic, small, lightweight and security-hardened, text-based operating system built on Linux. "It's a unique distribution that provides a selection of console applications and home-grown security features which might appeal to hackers," developers claim. [RLSD Linux][13].
-
-Did we miss anything even stranger? Let us know.
-
---------------------------------------------------------------------------------
-
-via: http://www.techdrivein.com/2015/08/the-strangest-most-unique-linux-distros.html
-
-作者:Manuel Jose
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[1]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
-[2]:http://qntm.org/suicide
-[3]:http://sourceforge.net/projects/suicide-linux/files/
-[4]:http://www.techdrivein.com/2015/02/papyros-material-design-linux-coming-soon.html
-[5]:https://plus.google.com/communities/109966288908859324845/stream/3262a3d3-0797-4344-bbe0-56c3adaacb69
-[6]:https://www.bountysource.com/teams/papyros
-[7]:https://www.qubes-os.org/
-[8]:http://ubuntusatanic.org/
-[9]:http://tinycorelinux.net/
-[10]:https://nixos.org/
-[11]:http://www.gobolinux.org/
-[12]:http://hannahmontana.sourceforge.net/
-[13]:http://rlsd2.dimakrasner.com/
diff --git a/sources/talk/20150909 Superclass--15 of the world's best living programmers.md b/sources/talk/20150909 Superclass--15 of the world's best living programmers.md
deleted file mode 100644
index 8959bc42fb..0000000000
--- a/sources/talk/20150909 Superclass--15 of the world's best living programmers.md
+++ /dev/null
@@ -1,391 +0,0 @@
-martin translating...
-
-Superclass: 15 of the world’s best living programmers
-================================================================================
-When developers discuss who the world’s top programmer is, these names tend to come up a lot.
-
-
-
-Image courtesy [tom_bullock CC BY 2.0][1]
-
-It seems like there are lots of programmers out there these days, and lots of really good programmers. But which one is the very best?
-
-Even though there’s no way to really say who the best living programmer is, that hasn’t stopped developers from frequently kicking the topic around. ITworld has solicited input and scoured coder discussion forums to see if there was any consensus. As it turned out, a handful of names did frequently get mentioned in these discussions.
-
-Use the arrows above to read about 15 people commonly cited as the world’s best living programmer.
-
-
-
-Image courtesy [NASA][2]
-
-### Margaret Hamilton ###
-
-**Main claim to fame: The brains behind Apollo’s flight control software**
-
-Credentials: As the Director of the Software Engineering Division at Charles Stark Draper Laboratory, she headed up the team which [designed and built][3] the on-board [flight control software for NASA’s Apollo][4] and Skylab missions. Based on her Apollo work, she later developed the [Universal Systems Language][5] and [Development Before the Fact][6] paradigm. Pioneered the concepts of [asynchronous software, priority scheduling, and ultra-reliable software design][7]. Coined the term “[software engineering][8].” Winner of the [Augusta Ada Lovelace Award][9] in 1986 and [NASA’s Exceptional Space Act Award in 2003][10].
-
-Quotes: “Hamilton invented testing , she pretty much formalised Computer Engineering in the US.” [ford_beeblebrox][11]
-
-“I think before her (and without disrespect including Knuth) computer programming was (and to an extent remains) a branch of mathematics. However a flight control system for a spacecraft clearly moves programming into a different paradigm.” [Dan Allen][12]
-
-“... she originated the term ‘software engineering’ — and offered a great example of how to do it.” [David Hamilton][13]
-
-“What a badass” [Drukered][14]
-
-
-
-Image courtesy [vonguard CC BY-SA 2.0][15]
-
-### Donald Knuth ###
-
-**Main claim to fame: Author of The Art of Computer Programming**
-
-Credentials: Wrote the [definitive book on the theory of programming][16]. Created the TeX digital typesetting system. [First winner of the ACM’s Grace Murray Hopper Award][17] in 1971. Winner of the ACM’s [A. M. Turing][18] Award in 1974, the [National Medal of Science][19] in 1979 and the IEEE’s [John von Neumann Medal][20] in 1995. Named a [Fellow at the Computer History Museum][21] in 1998.
-
-Quotes: “... wrote The Art of Computer Programming which is probably the most comprehensive work on computer programming ever.” [Anonymous][22]
-
-“There is only one large computer program I have used in which there are to a decent approximation 0 bugs: Don Knuth's TeX. That's impressive.” [Jaap Weel][23]
-
-“Pretty awesome if you ask me.” [Mitch Rees-Jones][24]
-
-
-
-Image courtesy [Association for Computing Machinery][25]
-
-### Ken Thompson ###
-
-**Main claim to fame: Creator of Unix**
-
-Credentials: Co-creator, [along with Dennis Ritchie][26], of Unix. Creator of the [B programming language][27], the [UTF-8 character encoding scheme][28], the ed [text editor][29], and co-developer of the Go programming language. Co-winner (along with Ritchie) of the [A.M. Turing Award][30] in 1983, [IEEE Computer Pioneer Award][31] in 1994, and the [National Medal of Technology][32] in 1998. Inducted as a [fellow of the Computer History Museum][33] in 1997.
-
-Quotes: “... probably the most accomplished programmer ever. Unix kernel, Unix tools, world-champion chess program Belle, Plan 9, Go Language.” [Pete Prokopowicz][34]
-
-“Ken's contributions, more than anyone else I can think of, were fundamental and yet so practical and timeless they are still in daily use.“ [Jan Jannink][35]
-
-
-
-Image courtesy Jiel Beaumadier CC BY-SA 3.0
-
-### Richard Stallman ###
-
-**Main claim to fame: Creator of Emacs, GCC**
-
-Credentials: Founded the [GNU Project][36] and created many of its core tools, such as [Emacs, GCC, GDB][37], and [GNU Make][38]. Also founded the [Free Software Foundation][39]. Winner of the ACM's [Grace Murray Hopper Award][40] in 1990 and the [EFF's Pioneer Award in 1998][41].
-
-Quotes: “... there was the time when he single-handedly outcoded several of the best Lisp hackers around, in the Symbolics vs LMI fight.” [Srinivasan Krishnan][42]
-
-“Through his amazing mastery of programming and force of will, he created a whole sub-culture in programming and computers.” [Dan Dunay][43]
-
-“I might disagree on many things with the great man, but he is still one of the most important programmers, alive or dead” [Marko Poutiainen][44]
-
-“Try to imagine Linux without the prior work on the GNu project. Stallman's the bomb, yo.” [John Burnette][45]
-
-
-
-Image courtesy [D.Begley CC BY 2.0][46]
-
-### Anders Hejlsberg ###
-
-**Main claim to fame: Creator of Turbo Pascal**
-
-Credentials: [The original author of what became Turbo Pascal][47], one of the most popular Pascal compilers and the first integrated development environment. Later, [led the building of Delphi][48], Turbo Pascal’s successor. [Chief designer and architect of C#][49]. Winner of [Dr. Dobb's Excellence in Programming Award][50] in 2001.
-
-Quotes: “He wrote the [Pascal] compiler in assembly language for both of the dominant PC operating systems of the day (DOS and CPM). It was designed to compile, link and run a program in seconds rather than minutes.” [Steve Wood][51]
-
-“I revere this guy - he created the development tools that were my favourite through three key periods along my path to becoming a professional software engineer.” [Stefan Kiryazov][52]
-
-
-
-Image courtesy [vonguard CC BY-SA 2.0][53]
-
-### Doug Cutting ###
-
-**Main claim to fame: Creator of Lucene**
-
-Credentials: [Developed the Lucene search engine, as well as Nutch][54], a web crawler, and [Hadoop][55], a set of tools for distributed processing of large data sets. A strong proponent of open-source (Lucene, Nutch and Hadoop are all open-source). Currently [a former director of the Apache Software Foundation][56].
-
-Quotes: “... he is the same guy who has written an exceptional search framework(lucene/solr) and opened the big-data gateway to the world(hadoop).” [Rajesh Rao][57]
-
-“His creation/work on Lucene and Hadoop (among other projects) has created a tremendous amount of wealth and employment for folks in the world….” [Amit Nithianandan][58]
-
-
-
-Image courtesy [Association for Computing Machinery][59]
-
-### Sanjay Ghemawat ###
-
-**Main claim to fame: Key Google architect**
-
-Credentials: [Helped to design and implement some of Google’s large distributed systems][60], including MapReduce, BigTable, Spanner and Google File System. [Created Unix’s ical][61] calendaring system. Elected to the [National Academy of Engineering][62] in 2009. Winner of the [ACM-Infosys Foundation Award in the Computing Sciences][63] in 2012.
-
-Quote: “Jeff Dean's wingman.” [Ahmet Alp Balkan][64]
-
-
-
-Image courtesy [Google][65]
-
-### Jeff Dean ###
-
-**Main claim to fame: The brains behind Google search indexing**
-
-Credentials: Helped to design and implement [many of Google’s large-scale distributed systems][66], including website crawling, indexing and searching, AdSense, MapReduce, BigTable and Spanner. Elected to the [National Academy of Engineering][67] in 2009. 2012 winner of the ACM’s [SIGOPS Mark Weiser Award][68] and the [ACM-Infosys Foundation Award in the Computing Sciences][69].
-
-Quotes: “... for bringing breakthroughs in data mining( GFS, Map and Reduce, Big Table ).” [Natu Lauchande][70]
-
-“... conceived, built, and deployed MapReduce and BigTable, among a bazillion other things” [Erik Goldman][71]
-
-
-
-Image courtesy [Krd CC BY-SA 4.0][72]
-
-### Linus Torvalds ###
-
-**Main claim to fame: Creator of Linux**
-
-Credentials: Created the [Linux kernel][73] and [Git][74], an open source version control system. Winner of numerous awards and honors, including the [EFF Pioneer Award][75] in 1998, the [British Computer Society’s Lovelace Medal][76] in 2000, the [Millenium Technology Prize][77] in 2012 and the [IEEE Computer Society’s Computer Pioneer Award][78] in 2014. Also inducted into the [Computer History Museum’s Hall of Fellows][79] in 2008 and the [Internet Hall of Fame][80] in 2012.
-
-Quotes: “To put into prospective what an achievement this is, he wrote the Linux kernel in a few years while the GNU Hurd (a GNU-developed kernel) has been under development for 25 years and has still yet to release a production-ready example.” [Erich Ficker][81]
-
-“Torvalds is probably the programmer's programmer.” [Dan Allen][82]
-
-“He's pretty darn good.” [Alok Tripathy][83]
-
-
-
-Image courtesy [QuakeCon CC BY 2.0][84]
-
-### John Carmack ###
-
-**Main claim to fame: Creator of Doom**
-
-Credentials: Cofounded id Software and [created such influential FPS games][85] as Wolfenstein 3D, Doom and Quake. Pioneered such ground-breaking computer graphic techniques [adaptive tile refresh][86], [binary space partitioning][87], and surface caching. Inducted into the [Academy of Interactive Arts and Sciences Hall of Fame][88] in 2001, [won Emmy awards][89] in the Engineering & Technology category in 2007 and 2008, and given a lifetime achievement award by the [Game Developers Choice Awards][90] in 2010.
-
-Quotes: “He wrote his first rendering engine before he was 20 years old. The guy's a genius. I wish I were a quarter a programmer he is.” [Alex Dolinsky][91]
-
-“... Wolfenstein 3D, Doom and Quake were revolutionary at the time and have influenced a generation of game designers.” [dniblock][92]
-
-“He can write basically anything in a weekend....” [Greg Naughton][93]
-
-“He is the Mozart of computer coding….” [Chris Morris][94]
-
-
-
-Image courtesy [Duff][95]
-
-### Fabrice Bellard ###
-
-**Main claim to fame: Creator of QEMU**
-
-Credentials: Created a [variety of well-known open-source software programs][96], including QEMU, a platform for hardware emulation and virtualization, FFmpeg, for handling multimedia data, the Tiny C Compiler and LZEXE, an executable file compressor. [Winner of the Obfuscated C Code Contest][97] in 2000 and 2001 and the [Google-O'Reilly Open Source Award][98] in 2011. Former world record holder for [calculating the most number of digits in Pi][99].
-
-Quotes: “I find Fabrice Bellard's work remarkable and impressive.” [raphinou][100]
-
-“Fabrice Bellard is the most productive programmer in the world....” [Pavan Yara][101]
-
-“Hes like the Nikola Tesla of sofware engineering.” [Michael Valladolid][102]
-
-“He's a prolific serial achiever since the 1980s.” M[ichael Biggins][103]
-
-
-
-Image courtesy [Craig Murphy CC BY 2.0][104]
-
-### Jon Skeet ###
-
-**Main claim to fame: Legendary Stack Overflow contributor**
-
-Credentials: Google engineer and author of [C# in Depth][105]. Holds [highest reputation score of all time on Stack Overflow][106], answering, on average, 390 questions per month.
-
-Quotes: “Jon Skeet doesn't need a debugger, he just stares down the bug until the code confesses” [Steven A. Lowe][107]
-
-“When Jon Skeet's code fails to compile the compiler apologises.” [Dan Dyer][108]
-
-“Jon Skeet's code doesn't follow a coding convention. It is the coding convention.” [Anonymous][109]
-
-
-
-Image courtesy [Philip Neustrom CC BY 2.0][110]
-
-### Adam D'Angelo ###
-
-**Main claim to fame: Co-founder of Quora**
-
-Credentials: As an engineer at Facebook, [built initial infrastructure for its news feed][111]. Went on to become CTO and VP of engineering at Facebook, before leaving to co-found Quora. [Eighth place finisher at the USA Computing Olympiad][112] as a high school student in 2001. Member of [California Institute of Technology’s silver medal winning team][113] at the ACM International Collegiate Programming Contest in 2004. [Finalist in the Algorithm Coding Competition][114] of Topcoder Collegiate Challenge in 2005.
-
-Quotes: “An "All-Rounder" Programmer.” [Anonymous][115]
-
-"For every good thing I make he has like six." [Mark Zuckerberg][116]
-
-
-
-Image courtesy [Facebook][117]
-
-### Petr Mitrechev ###
-
-**Main claim to fame: One of the top competitive programmers of all time**
-
-Credentials: [Two-time gold medal winner][118] in the International Olympiad in Informatics (2000, 2002). In 2006, [won the Google Code Jam][119] and was also the [TopCoder Open Algorithm champion][120]. Also, two-time winner of the Facebook Hacker Cup ([2011][121], [2013][122]). At the time of this writing, [the second ranked algorithm competitor on TopCoder][123] (handle: Petr) and also [ranked second by Codeforces][124]
-
-Quote: “He is an idol in competitive programming even here in India…” [Kavish Dwivedi][125]
-
-
-
-Image courtesy [Ishandutta2007 CC BY-SA 3.0][126]
-
-### Gennady Korotkevich ###
-
-**Main claim to fame: Competitive programming prodigy**
-
-Credentials: Youngest participant ever (age 11) and [6 time gold medalist][127] (2007-2012) in the International Olympiad in Informatics. Part of [the winning team][128] at the ACM International Collegiate Programming Contest in 2013 and winner of the [2014 Facebook Hacker Cup][129]. At the time of this writing, [ranked first by Codeforces][130] (handle: Tourist) and [first among algorithm competitors by TopCoder][131].
-
-Quotes: “A programming prodigy!” [Prateek Joshi][132]
-
-“Gennady is definitely amazing, and visible example of why I have a large development team in Belarus.” [Chris Howard][133]
-
-“Tourist is genius” [Nuka Shrinivas Rao][134]
-
---------------------------------------------------------------------------------
-
-via: http://www.itworld.com/article/2823547/enterprise-software/158256-superclass-14-of-the-world-s-best-living-programmers.html#slide1
-
-作者:[Phil Johnson][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://www.itworld.com/author/Phil-Johnson/
-[1]:https://www.flickr.com/photos/tombullock/15713223772
-[2]:https://commons.wikimedia.org/wiki/File:Margaret_Hamilton_in_action.jpg
-[3]:http://klabs.org/home_page/hamilton.htm
-[4]:https://www.youtube.com/watch?v=DWcITjqZtpU&feature=youtu.be&t=3m12s
-[5]:http://www.htius.com/Articles/r12ham.pdf
-[6]:http://www.htius.com/Articles/Inside_DBTF.htm
-[7]:http://www.nasa.gov/home/hqnews/2003/sep/HQ_03281_Hamilton_Honor.html
-[8]:http://www.nasa.gov/50th/50th_magazine/scientists.html
-[9]:https://books.google.com/books?id=JcmV0wfQEoYC&pg=PA321&lpg=PA321&dq=ada+lovelace+award+1986&source=bl&ots=qGdBKsUa3G&sig=bkTftPAhM1vZ_3VgPcv-38ggSNo&hl=en&sa=X&ved=0CDkQ6AEwBGoVChMI3paoxJHWxwIVA3I-Ch1whwPn#v=onepage&q=ada%20lovelace%20award%201986&f=false
-[10]:http://history.nasa.gov/alsj/a11/a11Hamilton.html
-[11]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrswof
-[12]:http://qr.ae/RFEZLk
-[13]:http://qr.ae/RFEZUn
-[14]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrv9u9
-[15]:https://www.flickr.com/photos/44451574@N00/5347112697
-[16]:http://cs.stanford.edu/~uno/taocp.html
-[17]:http://awards.acm.org/award_winners/knuth_1013846.cfm
-[18]:http://amturing.acm.org/award_winners/knuth_1013846.cfm
-[19]:http://www.nsf.gov/od/nms/recip_details.jsp?recip_id=198
-[20]:http://www.ieee.org/documents/von_neumann_rl.pdf
-[21]:http://www.computerhistory.org/fellowawards/hall/bios/Donald,Knuth/
-[22]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answers/3063
-[23]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Jaap-Weel
-[24]:http://qr.ae/RFE94x
-[25]:http://amturing.acm.org/photo/thompson_4588371.cfm
-[26]:https://www.youtube.com/watch?v=JoVQTPbD6UY
-[27]:https://www.bell-labs.com/usr/dmr/www/bintro.html
-[28]:http://doc.cat-v.org/bell_labs/utf-8_history
-[29]:http://c2.com/cgi/wiki?EdIsTheStandardTextEditor
-[30]:http://amturing.acm.org/award_winners/thompson_4588371.cfm
-[31]:http://www.computer.org/portal/web/awards/cp-thompson
-[32]:http://www.uspto.gov/about/nmti/recipients/1998.jsp
-[33]:http://www.computerhistory.org/fellowawards/hall/bios/Ken,Thompson/
-[34]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Pete-Prokopowicz-1
-[35]:http://qr.ae/RFEWBY
-[36]:https://groups.google.com/forum/#!msg/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
-[37]:http://www.emacswiki.org/emacs/RichardStallman
-[38]:https://www.gnu.org/gnu/thegnuproject.html
-[39]:http://www.emacswiki.org/emacs/FreeSoftwareFoundation
-[40]:http://awards.acm.org/award_winners/stallman_9380313.cfm
-[41]:https://w2.eff.org/awards/pioneer/1998.php
-[42]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton/comment/4146397
-[43]:http://qr.ae/RFEaib
-[44]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Marko-Poutiainen
-[45]:http://qr.ae/RFEUqp
-[46]:https://www.flickr.com/photos/begley/2979906130
-[47]:http://www.taoyue.com/tutorials/pascal/history.html
-[48]:http://c2.com/cgi/wiki?AndersHejlsberg
-[49]:http://www.microsoft.com/about/technicalrecognition/anders-hejlsberg.aspx
-[50]:http://www.drdobbs.com/windows/dr-dobbs-excellence-in-programming-award/184404602
-[51]:http://qr.ae/RFEZrv
-[52]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Stefan-Kiryazov
-[53]:https://www.flickr.com/photos/vonguard/4076389963/
-[54]:http://www.wizards-of-os.org/archiv/sprecher/a_c/doug_cutting.html
-[55]:http://hadoop.apache.org/
-[56]:https://www.linkedin.com/in/cutting
-[57]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Shalin-Shekhar-Mangar/comment/2293071
-[58]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answer/Amit-Nithianandan
-[59]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
-[60]:http://research.google.com/pubs/SanjayGhemawat.html
-[61]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat
-[62]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
-[63]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
-[64]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat/answer/Ahmet-Alp-Balkan
-[65]:http://research.google.com/people/jeff/index.html
-[66]:http://research.google.com/people/jeff/index.html
-[67]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
-[68]:http://news.cs.washington.edu/2012/10/10/uw-cse-ph-d-alum-jeff-dean-wins-2012-sigops-mark-weiser-award/
-[69]:http://awards.acm.org/award_winners/dean_2879385.cfm
-[70]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Natu-Lauchande
-[71]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Cosmin-Negruseri/comment/28399
-[72]:https://commons.wikimedia.org/wiki/File:LinuxCon_Europe_Linus_Torvalds_05.jpg
-[73]:http://www.linuxfoundation.org/about/staff#torvalds
-[74]:http://git-scm.com/book/en/Getting-Started-A-Short-History-of-Git
-[75]:https://w2.eff.org/awards/pioneer/1998.php
-[76]:http://www.bcs.org/content/ConWebDoc/14769
-[77]:http://www.zdnet.com/blog/open-source/linus-torvalds-wins-the-tech-equivalent-of-a-nobel-prize-the-millennium-technology-prize/10789
-[78]:http://www.computer.org/portal/web/pressroom/Linus-Torvalds-Named-Recipient-of-the-2014-IEEE-Computer-Society-Computer-Pioneer-Award
-[79]:http://www.computerhistory.org/fellowawards/hall/bios/Linus,Torvalds/
-[80]:http://www.internethalloffame.org/inductees/linus-torvalds
-[81]:http://qr.ae/RFEeeo
-[82]:http://qr.ae/RFEZLk
-[83]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Alok-Tripathy-1
-[84]:https://www.flickr.com/photos/quakecon/9434713998
-[85]:http://doom.wikia.com/wiki/John_Carmack
-[86]:http://thegamershub.net/2012/04/gaming-gods-john-carmack/
-[87]:http://www.shamusyoung.com/twentysidedtale/?p=4759
-[88]:http://www.interactive.org/special_awards/details.asp?idSpecialAwards=6
-[89]:http://www.itworld.com/article/2951105/it-management/a-fly-named-for-bill-gates-and-9-other-unusual-honors-for-tech-s-elite.html#slide8
-[90]:http://www.gamechoiceawards.com/archive/lifetime.html
-[91]:http://qr.ae/RFEEgr
-[92]:http://www.itworld.com/answers/topic/software/question/whos-best-living-programmer#comment-424562
-[93]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton
-[94]:http://money.cnn.com/2003/08/21/commentary/game_over/column_gaming/
-[95]:http://dufoli.wordpress.com/2007/06/23/ammmmaaaazing-night/
-[96]:http://bellard.org/
-[97]:http://www.ioccc.org/winners.html#B
-[98]:http://www.oscon.com/oscon2011/public/schedule/detail/21161
-[99]:http://bellard.org/pi/pi2700e9/
-[100]:https://news.ycombinator.com/item?id=7850797
-[101]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/1718701
-[102]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/2454450
-[103]:http://qr.ae/RFEjhZ
-[104]:https://www.flickr.com/photos/craigmurphy/4325516497
-[105]:http://www.amazon.co.uk/gp/product/1935182471?ie=UTF8&tag=developetutor-21&linkCode=as2&camp=1634&creative=19450&creativeASIN=1935182471
-[106]:http://stackexchange.com/leagues/1/alltime/stackoverflow
-[107]:http://meta.stackexchange.com/a/9156
-[108]:http://meta.stackexchange.com/a/9138
-[109]:http://meta.stackexchange.com/a/9182
-[110]:https://www.flickr.com/photos/philipn/5326344032
-[111]:http://www.crunchbase.com/person/adam-d-angelo
-[112]:http://www.exeter.edu/documents/Exeter_Bulletin/fall_01/oncampus.html
-[113]:http://icpc.baylor.edu/community/results-2004
-[114]:https://www.topcoder.com/tc?module=Static&d1=pressroom&d2=pr_022205
-[115]:http://qr.ae/RFfOfe
-[116]:http://www.businessinsider.com/in-new-alleged-ims-mark-zuckerberg-talks-about-adam-dangelo-2012-9#ixzz369FcQoLB
-[117]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
-[118]:http://stats.ioinformatics.org/people/1849
-[119]:http://googlepress.blogspot.com/2006/10/google-announces-winner-of-global-code_27.html
-[120]:http://community.topcoder.com/tc?module=SimpleStats&c=coder_achievements&d1=statistics&d2=coderAchievements&cr=10574855
-[121]:https://www.facebook.com/notes/facebook-hacker-cup/facebook-hacker-cup-finals/208549245827651
-[122]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
-[123]:http://community.topcoder.com/tc?module=AlgoRank
-[124]:http://codeforces.com/ratings
-[125]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Venkateswaran-Vicky/comment/1960855
-[126]:http://commons.wikimedia.org/wiki/File:Gennady_Korot.jpg
-[127]:http://stats.ioinformatics.org/people/804
-[128]:http://icpc.baylor.edu/regionals/finder/world-finals-2013/standings
-[129]:https://www.facebook.com/hackercup/posts/10152022955628845
-[130]:http://codeforces.com/ratings
-[131]:http://community.topcoder.com/tc?module=AlgoRank
-[132]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi
-[133]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4720779
-[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
diff --git a/sources/talk/20150921 14 tips for teaching open source development.md b/sources/talk/20150921 14 tips for teaching open source development.md
index b2812d44c8..a580f3b776 100644
--- a/sources/talk/20150921 14 tips for teaching open source development.md
+++ b/sources/talk/20150921 14 tips for teaching open source development.md
@@ -69,4 +69,4 @@ via: http://opensource.com/education/15/9/teaching-open-source-development-under
[a]:http://opensource.com/users/mariamkiran
[1]:https://basecamp.com/
-[2]:https://www.mantisbt.org/
\ No newline at end of file
+[2]:https://www.mantisbt.org/
diff --git a/sources/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md b/sources/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md
deleted file mode 100644
index be5c7b9b2e..0000000000
--- a/sources/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md
+++ /dev/null
@@ -1,102 +0,0 @@
-zpl1025 translating
-The Brief History Of Aix, HP-UX, Solaris, BSD, And LINUX
-================================================================================
-
-
-Always remember that when doors close on you, other doors open. [Ken Thompson][1] and [Dennis Richie][2] are a great example for such saying. They were two of the best information technology specialists in the **20th** century as they created the **UNIX** system which is considered one the most influential and inspirational software that ever written.
-
-### The UNIX systems beginning at Bell Labs ###
-
-**UNIX** which was originally called **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice) has a great family and was never born by itself. The grandfather of UNIX was **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem) and the father was the **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice) project which supports interactive timesharing for mainframe computers by huge communities of users.
-
-UNIX was born at **Bell Labs** in **1969** by **Ken Thompson** and later **Dennis Richie**. These two great researchers and scientists worked on a collaborative project with **General Electric** and the **Massachusetts Institute of Technology** to create an interactive timesharing system called the Multics.
-
-Multics was created to combine timesharing with other technological advances, allowing the users to phone the computer from remote terminals, then edit documents, read e-mail, run calculations, and so on.
-
-Over the next five years, AT&T corporate invested millions of dollars in the Multics project. They purchased mainframe computer called GE-645 and they dedicated to the effort of the top researchers at Bell Labs such as Ken Thompson, Stuart Feldman, Dennis Ritchie, M. Douglas McIlroy, Joseph F. Ossanna, and Robert Morris. The project was too ambitious, but it fell troublingly behind the schedule. And at the end, AT&T leaders decided to leave the project.
-
-Bell Labs managers decided to stop any further work on operating systems which made many researchers frustrated and upset. But thanks to Thompson, Richie, and some researchers who ignored their bosses’ instructions and continued working with love on their labs, UNIX was created as one the greatest operating systems of all times.
-
-UNIX started its life on a PDP-7 minicomputer which was a testing machine for Thompson’s ideas about the operating systems design and a platform for Thompsons and Richie’s game simulation that was called Space and Travel.
-
-> “What we wanted to preserve was not just a good environment in which to do programming, but a system around which a fellowship could form. We knew from experience that the essence of communal computing, as supplied by remote-access, time-shared machines, is not just to type programs into a terminal instead of a keypunch, but to encourage close communication”. Dennis Richie Said.
-
-UNIX was so close to be the first system under which the programmer could directly sit down at a machine and start composing programs on the fly, explore possibilities and also test while composing. All through UNIX lifetime, it has had a growing more capabilities pattern by attracting skilled volunteer effort from different programmers impatient with the other operating systems limitations.
-
-UNIX has received its first funding for a PDP-11/20 in 1970, the UNIX operating system was then officially named and could run on the PDP-11/20. The first real job from UNIX was in 1971, it was to support word processing for the patent department at Bell Labs.
-
-### The C revolution on UNIX systems ###
-
-Dennis Richie invented a higher level programming language called “**C**” in **1972**, later he decided with Ken Thompson to rewrite the UNIX in “C” to give the system more portability options. They wrote and debugged almost 100,000 code lines that year. The migration to the “C” language resulted in highly portable software that require only a relatively small machine-dependent code to be then replaced when porting UNIX to another computing platform.
-
-The UNIX was first formally presented to the outside world in 1973 on Operating Systems Principles, where Dennis Ritchie and Ken Thompson delivered a paper, then AT&T released Version 5 of the UNIX system and licensed it to the educational institutions, and then in 1975 they licensed Version 6 of UNIX to companies for the first time with a cost **$20.000**. The most widely used version of UNIX was Version 7 in 1980 where anybody could purchase a license but it was very restrictive terms in this license. The license included the source code, the machine dependents kernel which was written in PDP-11 assembly language. At all, versions of UNIX systems were determined by its user manuals editions.
-
-### The AIX System ###
-
-In **1983**, **Microsoft** had a plan to make a **Xenix** MS-DOS’s multiuser successor, and they created Xenix-based Altos 586 with **512 KB** RAM and **10 MB** hard drive by this year with cost $8,000. By 1984, 100,000 UNIX installations around the world for the System V Release 2. In 1986, 4.3BSD was released that included internet name server and the **AIX system** was announced by **IBM** with Installation base over 250,000. AIX is based on Unix System V, this system has BSD roots and is a hybrid of both.
-
-AIX was the first operating system that introduced a **journaled file system (JFS)** and an integrated Logical Volume Manager (LVM). IBM ported AIX to its RS/6000 platform by 1989. The Version 5L was a breakthrough release that was introduced in 2001 to provide Linux affinity and logical partitioning with the Power4 servers.
-
-AIX introduced virtualization by 2004 in AIX 5.3 with Advanced Power Virtualization (APV) which offered Symmetric multi-threading, micro-partitioning, and shared processor pools.
-
-In 2007, IBM started to enhance its virtualization product, by coinciding with the AIX 6.1 release and the architecture of Power6. They also rebranded Advanced Power Virtualization to PowerVM.
-
-The enhancements included form of workload partitioning that was called WPARs, that are similar to Solaris zones/Containers, but with much better functionality.
-
-### The HP-UX System ###
-
-The **Hewlett-Packard’s UNIX (HP-UX)** was based originally on System V release 3. The system initially ran exclusively on the PA-RISC HP 9000 platform. The Version 1 of HP-UX was released in 1984.
-
-The Version 9, introduced SAM, its character-based graphical user interface (GUI), from which one can administrate the system. The Version 10, was introduced in 1995, and brought some changes in the layout of the system file and directory structure, which made it similar to AT&T SVR4.
-
-The Version 11 was introduced in 1997. It was HP’s first release to support 64-bit addressing. But in 2000, this release was rebranded to 11i, as HP introduced operating environments and bundled groups of layered applications for specific Information Technology purposes.
-
-In 2001, The Version 11.20 was introduced with support for Itanium systems. The HP-UX was the first UNIX that used ACLs (Access Control Lists) for file permissions and it was also one of the first that introduced built-in support for Logical Volume Manager.
-
-Nowadays, HP-UX uses Veritas as primary file system due to partnership between Veritas and HP.
-
-The HP-UX is up to release 11iv3, update 4.
-
-### The Solaris System ###
-
-The Sun’s UNIX version, **Solaris**, was the successor of **SunOS**, which was founded in 1992. SunOS was originally based on the BSD (Berkeley Software Distribution) flavor of UNIX but SunOS versions 5.0 and later were based on Unix System V Release 4 which was rebranded as Solaris.
-
-SunOS version 1.0 was introduced with support for Sun-1 and Sun-2 systems in 1983. Version 2.0 was introduced later in 1985. In 1987, Sun and AT&T announced that they would collaborate on a project to merge System V and BSD into only one release, based on SVR4.
-
-The Solaris 2.4 was first Sparc/x86 release by Sun. The last release of the SunOS was version 4.1.4 announced in November 1994. The Solaris 7 was the first 64-bit Ultra Sparc release and it added native support for file system metadata logging.
-
-Solaris 9 was introduced in 2002, with support for Linux capabilities and Solaris Volume Manager. Then, Solaris 10 was introduced in 2005, and has number of innovations, such as support for its Solaris Containers, new ZFS file system, and Logical Domains.
-
-The Solaris system is presently up to version 10 as the latest update was released in 2008.
-
-### Linux ###
-
-By 1991 there were growing requirements for a free commercial alternative. Therefore **Linus Torvalds** set out to create new free operating system kernel that eventually became **Linux**. Linux started with a small number of “C” files and under a license which prohibited commercial distribution. Linux is a UNIX-like system and is different than UNIX.
-
-Version 3.18 was introduced in 2015 under a GNU Public License. IBM said that more than 18 million lines of code are Open Source and available to developers.
-
-The GNU Public License becomes the most widely available free software license which you can find nowadays. In accordance with the Open Source principles, this license permits individuals and organizations the freedom to distribute, run, share by copying, study, and also modify the code of the software.
-
-### UNIX vs. Linux: Technical Overview ###
-
-- Linux can encourage more diversity, and Linux developers come from wider range of backgrounds with different experiences and opinions.
-- Linux can run on wider range of platforms and also types of architecture than UNIX.
-- Developers of UNIX commercial editions have a specific target platform and audience in mind for their operating system.
-- **Linux is more secure than UNIX** as it is less affected by virus threats or malware attacks. Linux has had about 60-100 viruses to date, but at the same time none of them are currently spreading. On the other hand, UNIX has had 85-120 viruses but some of them are still spreading.
-- With commands of UNIX, tools and elements are rarely changed, and even some interfaces and command lines arguments still remain in later versions of UNIX.
-- Some Linux development projects get funded on a voluntary basis such as Debian. The other projects maintain a community version of commercial Linux distributions such as SUSE with openSUSE and Red Hat with Fedora.
-- Traditional UNIX is about scale up, but on the other hand Linux is about scale out.
-
---------------------------------------------------------------------------------
-
-via: http://www.unixmen.com/brief-history-aix-hp-ux-solaris-bsd-linux/
-
-作者:[M.el Khamlichi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://www.unixmen.com/author/pirat9/
-[1]:http://www.unixmen.com/ken-thompson-unix-systems-father/
-[2]:http://www.unixmen.com/dennis-m-ritchie-father-c-programming-language/
diff --git a/sources/talk/20151019 Nautilus File Search Is About To Get A Big Power Up.md b/sources/talk/20151019 Nautilus File Search Is About To Get A Big Power Up.md
deleted file mode 100644
index 7ce79073c5..0000000000
--- a/sources/talk/20151019 Nautilus File Search Is About To Get A Big Power Up.md
+++ /dev/null
@@ -1,38 +0,0 @@
-Nautilus File Search Is About To Get A Big Power Up
-================================================================================
-
-
-**Finding stray files and folders in Nautilus is about to get a whole lot easier. **
-
-A new **search filter** for the default [GNOME file manager][1] is in development. It makes heavy use of GNOME’s spiffy pop-over menus in an effort to offer a simpler way to narrow in on search results and find exactly what you’re after.
-
-Developer Georges Stavracas is working on the new UI and [describes][2] the new editor as “cleaner, saner and more intuitive”.
-
-Based on a video he’s [uploaded to YouTube][3] demoing the new approach – which he hasn’t made available for embedding – he’s not wrong.
-
-> “Nautilus has very complex but powerful internals, which allows us to do many things. And indeed, there is code for the many options in there. So, why did it used to look so poorly implemented/broken?”, he writes on his blog.
-
-The question is part rhetorical; the new search filter interface surfaces many of these ‘powerful internals’ to yhe user. Searches can be filtered ad **hoc** based on content type, name or by date range.
-
-Changing anything in an app like Nautilus is likely to upset some users, so as helpful and straightforward as the new UI seems it could come in for some heat.
-
-Not that worry of discontent seems to hamper progress (though the outcry at the [removal of ‘type ahead’ search][4] in 2014 still rings loud in many ears, no doubt). GNOME 3.18, [released last month][5], introduced a new file progress dialog to Nautilus and better integration for remote shares, including Google Drive.
-
-Stavracas’ search filter are not yet merged in to Files’ trunk, but the reworked search UI is tentatively targeted for inclusion in GNOME 3.20, due spring next year.
-
---------------------------------------------------------------------------------
-
-via: http://www.omgubuntu.co.uk/2015/10/new-nautilus-search-filter-ui
-
-作者:[Joey-Elijah Sneddon][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/117485690627814051450/?rel=author
-[1]:https://wiki.gnome.org/Apps/Nautilus
-[2]:http://feaneron.com/2015/10/12/the-new-search-for-gnome-files-aka-nautilus/
-[3]:https://www.youtube.com/watch?v=X2sPRXDzmUw
-[4]:http://www.omgubuntu.co.uk/2014/01/ubuntu-14-04-nautilus-type-ahead-patch
-[5]:http://www.omgubuntu.co.uk/2015/09/gnome-3-18-release-new-features
\ No newline at end of file
diff --git a/sources/talk/20151105 Linus Torvalds Lambasts Open Source Programmers over Insecure Code.md b/sources/talk/20151105 Linus Torvalds Lambasts Open Source Programmers over Insecure Code.md
deleted file mode 100644
index 1e37549646..0000000000
--- a/sources/talk/20151105 Linus Torvalds Lambasts Open Source Programmers over Insecure Code.md
+++ /dev/null
@@ -1,35 +0,0 @@
-Linus Torvalds Lambasts Open Source Programmers over Insecure Code
-================================================================================
-
-
-Linus Torvalds's latest rant underscores the high expectations the Linux developer places on open source programmers—as well the importance of security for Linux kernel code.
-
-Torvalds is the unofficial "benevolent dictator" of the Linux kernel project. That means he gets to decide which code contributions go into the kernel, and which ones land in the reject pile.
-
-On Oct. 28, open source coders whose work did not meet Torvalds's expectations faced an [angry rant][1]. "Christ people," Torvalds wrote about the code. "This is just sh*t."
-
-He went on to call the coders "just incompetent and out to lunch."
-
-What made Torvalds so angry? He believed the code could have been written more efficiently. It could have been easier for other programmers to understand and would run better through a compiler, the program that translates human-readable code into the binaries that computers understand.
-
-Torvalds posted his own substitution for the code in question and suggested that the programmers should have written it his way.
-
-Torvalds has a history of lashing out against people with whom he disagrees. It stretches back to 1991, when he famously [flamed Andrew Tanenbaum][2]—whose Minix operating system he later described as a series of "brain-damages." No doubt this latest criticism of fellow open source coders will go down as another example of Torvalds's confrontational personality.
-
-But Torvalds may also have been acting strategically during this latest rant. "I want to make it clear to *everybody* that code like this is completely unacceptable," he wrote, suggesting that his goal was to send a message to all Linux programmers, not just vent his anger at particular ones.
-
-Torvalds also used the incident as an opportunity to highlight the security concerns that arise from poorly written code. Those are issues dear to open source programmers' hearts in an age when enterprises are finally taking software security seriously, and demanding top-notch performance from their code in this regard. Lambasting open source programmers who write insecure code thus helps Linux's image.
-
---------------------------------------------------------------------------------
-
-via: http://thevarguy.com/open-source-application-software-companies/110415/linus-torvalds-lambasts-open-source-programmers-over-inse
-
-作者:[Christopher Tozzi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://thevarguy.com/author/christopher-tozzi
-[1]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
-[2]:https://en.wikipedia.org/wiki/Tanenbaum%E2%80%93Torvalds_debate
\ No newline at end of file
diff --git a/sources/talk/20151117 How bad a boss is Linus Torvalds.md b/sources/talk/20151117 How bad a boss is Linus Torvalds.md
new file mode 100644
index 0000000000..8b10e44584
--- /dev/null
+++ b/sources/talk/20151117 How bad a boss is Linus Torvalds.md
@@ -0,0 +1,77 @@
+How bad a boss is Linus Torvalds?
+================================================================================
+
+
+*Linus Torvalds addressed a packed auditorium of Linux enthusiasts during his speech at the LinuxWorld show in San Jose, California, on August 10, 1999. Credit: James Niccolai*
+
+**It depends on context. In the world of software development, he’s what passes for normal. The question is whether that situation should be allowed to continue.**
+
+I've known Linus Torvalds, Linux's inventor, for over 20 years. We're not chums, but we like each other.
+
+Lately, Torvalds has been getting a lot of flack for his management style. Linus doesn't suffer fools gladly. He has one way of judging people in his business of developing the Linux kernel: How good is your code?
+
+Nothing else matters. As Torvalds said earlier this year at the Linux.conf.au Conference, "I'm not a nice person, and I don't care about you. [I care about the technology and the kernel][1] -- that's what's important to me."
+
+Now, I can deal with that kind of person. If you can't, you should avoid the Linux kernel community, where you'll find a lot of this kind of meritocratic thinking. Which is not to say that I think everything in Linuxland is hunky-dory and should be impervious to calls for change. A meritocracy I can live with; a bastion of male dominance where women are subjected to scorn and disrespect is a problem.
+
+That's why I see the recent brouhaha about Torvalds' management style -- or more accurately, his total indifference to the personal side of management -- as nothing more than standard operating procedure in the world of software development. And at the same time, I see another instance that has come to light as evidence of a need for things to really change.
+
+The first situation arose with the [release of Linux 4.3][2], when Torvalds used the Linux Kernel Mailing List to tear into a developer who had inserted some networking code that Torvalds thought was -- well, let's say "crappy." "[[A]nd it generates [crappy] code.][3] It looks bad, and there's no reason for it." He goes on in this vein for quite a while. Besides the word "crap" and its earthier synonym, he uses the word "idiotic" pretty often.
+
+Here's the thing, though. He's right. I read the code. It's badly written and it does indeed seem to have been designed to use the new "overflow_usub()" function just for the sake of using it.
+
+Now, some people see this diatribe as evidence that Torvalds is a bad-tempered bully. I see a perfectionist who, within his field, doesn't put up with crap.
+
+Many people have told me that this is not how professional programmers should act. People, have you ever worked with top developers? That's exactly how they act, at Apple, Microsoft, Oracle and everywhere else I've known them.
+
+I've heard Steve Jobs rip a developer to pieces. I've cringed while a senior Oracle developer lead tore into a room of new programmers like a piranha through goldfish.
+
+In Accidental Empires, his classic book on the rise of PCs, Robert X. Cringely described Microsoft's software management style when Bill Gates was in charge as a system where "Each level, from Gates on down, screams at the next, goading and humiliating them." Ah, yes, that's the Microsoft I knew and hated.
+
+The difference between the leaders at big proprietary software companies and Torvalds is that he says everything in the open for the whole world to see. The others do it in private conference rooms. I've heard people claim that Torvalds would be fired in their company. Nope. He'd be right where he is now: on top of his programming world.
+
+Oh, and there's another difference. If you get, say, Larry Ellison mad at you, you can kiss your job goodbye. When you get Torvalds angry at your work, you'll get yelled at in an email. That's it.
+
+You see, Torvalds isn't anyone's boss. He's the guy in charge of a project with about 10,000 contributors, but he has zero hiring and firing authority. He can hurt your feelings, but that's about it.
+
+That said, there is a serious problem within both open-source and proprietary software development circles. No matter how good a programmer you are, if you're a woman, the cards are stacked against you.
+
+No case shows this better than that of Sarah Sharp, an Intel developer and formerly a top Linux programmer. [In a post on her blog in October][4], she explained why she had stopped contributing to the Linux kernel more than a year earlier: "I finally realized that I could no longer contribute to a community where I was technically respected, but I could not ask for personal respect.... I did not want to work professionally with people who were allowed to get away with subtle sexist or homophobic jokes."
+
+Who can blame her? I can't. Torvalds, like almost every software manager I've ever known, I'm sorry to say, has permitted a hostile work environment.
+
+He would probably say that it's not his job to ensure that Linux contributors behave with professionalism and mutual respect. He's concerned with the code and nothing but the code.
+
+As Sharp wrote:
+
+> I have the utmost respect for the technical efforts of the Linux kernel community. They have scaled and grown a project that is focused on maintaining some of the highest coding standards out there. The focus on technical excellence, in combination with overloaded maintainers, and people with different cultural and social norms, means that Linux kernel maintainers are often blunt, rude, or brutal to get their job done. Top Linux kernel developers often yell at each other in order to correct each other's behavior.
+>
+> That's not a communication style that works for me. …
+>
+> Many senior Linux kernel developers stand by the right of maintainers to be technically and personally brutal. Even if they are very nice people in person, they do not want to see the Linux kernel communication style change.
+
+She's right.
+
+Where I differ from other observers is that I don't think that this problem is in any way unique to Linux or open-source communities. With five years of work in the technology business and 25 years as a technology journalist, I've seen this kind of immature boy behavior everywhere.
+
+It's not Torvalds' fault. He's a technical leader with a vision, not a manager. The real problem is that there seems to be no one in the software development universe who can set a supportive tone for teams and communities.
+
+Looking ahead, I hope that companies and organizations, such as the Linux Foundation, can find a way to empower community managers or other managers to encourage and enforce civil behavior.
+
+We won't, unfortunately, find that kind of managerial finesse in our pure technical or business leaders. It's not in their DNA.
+
+--------------------------------------------------------------------------------
+
+via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
+
+作者:[Steven J. Vaughan-Nichols][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
+[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
+[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
+[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
+[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
\ No newline at end of file
diff --git a/sources/talk/20151125 20 Years of GIMP Evolution--Step by Step.md b/sources/talk/20151125 20 Years of GIMP Evolution--Step by Step.md
new file mode 100644
index 0000000000..edcef22d7f
--- /dev/null
+++ b/sources/talk/20151125 20 Years of GIMP Evolution--Step by Step.md
@@ -0,0 +1,171 @@
+20 Years of GIMP Evolution: Step by Step
+================================================================================
+注:youtube 视频
+
+
+[GIMP][1] (GNU Image Manipulation Program) – superb open source and free graphics editor. Development began in 1995 as students project of the University of California, Berkeley by Peter Mattis and Spencer Kimball. In 1997 the project was renamed in “GIMP” and became an official part of [GNU Project][2]. During these years the GIMP is one of the best graphics editor and platinum holy wars “GIMP vs Photoshop” – one of the most popular.
+
+The first announce, 21.11.1995:
+
+> From: Peter Mattis
+>
+> Subject: ANNOUNCE: The GIMP
+>
+> Date: 1995-11-21
+>
+> Message-ID: <48s543$r7b@agate.berkeley.edu>
+>
+> Newsgroups: comp.os.linux.development.apps,comp.os.linux.misc,comp.windows.x.apps
+>
+> The GIMP: the General Image Manipulation Program
+> ------------------------------------------------
+>
+> The GIMP is designed to provide an intuitive graphical interface to a
+> variety of image editing operations. Here is a list of the GIMP's
+> major features:
+>
+> Image viewing
+> -------------
+>
+> * Supports 8, 15, 16 and 24 bit color.
+> * Ordered and Floyd-Steinberg dithering for 8 bit displays.
+> * View images as rgb color, grayscale or indexed color.
+> * Simultaneously edit multiple images.
+> * Zoom and pan in real-time.
+> * GIF, JPEG, PNG, TIFF and XPM support.
+>
+> Image editing
+> -------------
+>
+> * Selection tools including rectangle, ellipse, free, fuzzy, bezier
+> and intelligent.
+> * Transformation tools including rotate, scale, shear and flip.
+> * Painting tools including bucket, brush, airbrush, clone, convolve,
+> blend and text.
+> * Effects filters (such as blur, edge detect).
+> * Channel & color operations (such as add, composite, decompose).
+> * Plug-ins which allow for the easy addition of new file formats and
+> new effect filters.
+> * Multiple undo/redo.
+
+GIMP 0.54, 1996
+
+
+
+GIMP 0.54 was required X11 displays, X-server and Motif 1.2 wigdets and supported 8, 15, 16 & 24 color depths with RGB & grayscale colors. Supported images format: GIF, JPEG, PNG, TIFF and XPM.
+
+Basic functionality: rectangle, ellipse, free, fuzzy, bezier, intelligent selection tools, and rotate, scale, shear, clone, blend and flip images.
+
+Extended tools: text operations, effects filters, tools for channel and colors manipulation, undo and redo operations. Since the first version GIMP support the plugin system.
+
+GIMP 0.54 can be ran in Linux, HP-UX, Solaris, SGI IRIX.
+
+### GIMP 0.60, 1997 ###
+
+
+
+This is development release, not for all users. GIMP has the new toolkits – GDK (GIMP Drawing Kit) and GTK (GIMP Toolkit), Motif support is deprecated. GIMP Toolkit is also begin of the GTK+ cross-platform widget toolkit. New features:
+
+- basic layers
+- sub-pixel sampling
+- brush spacing
+- improver airbrush
+- paint modes
+
+### GIMP 0.99, 1997 ###
+
+
+
+Since 0.99 version GIMP has the scripts add macros (Script-Fus) support. GTK and GDK with some improvements has now the new name – GTK+. Other improvements:
+
+- support big images (rather than 100 MB)
+- new native format – XCF
+- new API – write plugins and extensions is easy
+
+### GIMP 1.0, 1998 ###
+
+
+
+GIMP and GTK+ was splitted into separate projects. The GIMP official website has
+reconstructed and contained new tutorials, plugins and documentation. New features:
+
+- tile-based memory management
+- massive changes in plugin API
+- XFC format now support layers, guides and selections
+- web interface
+- online graphics generation
+
+### GIMP 1.2, 2000 ###
+
+New features:
+
+- translation for non-english languages
+- fixed many bugs in GTK+ and GIMP
+- many new plugins
+- image map
+- new toolbox: resize, measure, dodge, burn, smugle, samle colorize and curve bend
+- image pipes
+- images preview before saving
+- scaled brush preview
+- recursive selection by path
+- new navigation window
+- drag’n’drop
+- watermarks support
+
+### GIMP 2.0, 2004 ###
+
+
+
+The biggest change – new GTK+ 2.x toolkit.
+
+### GIMP 2.2, 2004 ###
+
+
+
+Many bugfixes and drag’n’drop support.
+
+### GIMP 2.4, 2007 ###
+
+
+
+New features:
+
+- better drag’n’drop support
+- Ti-Fu was replaced to Script-Fu – the new script interpreter
+- new plugins: photocopy, softglow, neon, cartoon, dog, glob and others
+
+### GIMP 2.6, 2008 ###
+
+New features:
+
+- renew graphics interface
+- new select and tool
+- GEGL (GEneric Graphics Library) integration
+- “The Utility Window Hint” for MDI behavior
+
+### GIMP 2.8, 2012 ###
+
+
+
+New features:
+
+- GUI has some visual changes
+- new save and export menu
+- renew text editor
+- layers group support
+- JPEG2000 and export to PDF support
+- webpage screenshot tool
+
+--------------------------------------------------------------------------------
+
+via: https://tlhp.cf/20-years-of-gimp-evolution/
+
+作者:[Pavlo Rudyi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://tlhp.cf/author/paul/
+[1]:https://gimp.org/
+[2]:http://www.gnu.org/
\ No newline at end of file
diff --git a/sources/talk/20151126 Linux Foundation Explains a 'World without Linux' and Open Source.md b/sources/talk/20151126 Linux Foundation Explains a 'World without Linux' and Open Source.md
new file mode 100644
index 0000000000..90f8b22e32
--- /dev/null
+++ b/sources/talk/20151126 Linux Foundation Explains a 'World without Linux' and Open Source.md
@@ -0,0 +1,51 @@
+Linux Foundation Explains a "World without Linux" and Open Source
+================================================================================
+> The Linux Foundation responds to questions about its "World without Linux" movies, including what the Internet would be like without Linux and other open source software.
+
+
+
+Would the world really be tremendously different if Linux, the open source operating system kernel, did not exist? Would there be no Internet or movies? Those are the questions some viewers of the [Linux Foundation's][1] ongoing "[World without Linux][2]" video series are asking. Here are some answers.
+
+In case you've missed it, the "World without Linux" series is a collection of quirky short films that depict, well, a world without Linux (and open source software more generally). They have emphasized themes like [Linux's role in movie-making][3] and in [serving the Internet][4].
+
+To offer perspective on the series's claims, direction and hidden symbols, Jennifer Cloer, vice president of communications at The Linux Foundation, recently sent The VAR Guy responses to some common queries about the movies. Below are the answers, in her own words.
+
+### The latest episode takes Sam and Annie to the movies. Would today's graphics really be that much different without Linux? ###
+
+In episode #4, we do a bit of a parody on "Avatar." Love it or hate it, the graphics in the real "Avatar" are pretty impressive. In a world without Linux, the graphics would be horrible but we wouldn't even know it because we wouldn't know any better. But in fact, "Avatar" was created using Linux. Weta Digital used one of the world's largest Linux clusters to render the film and do 3D modeling. It's also been reported that "Lord of the Rings," "Fantastic Four" and "King Kong," among others, have used Linux. We hope this episode can bring attention to that work, which hasn't been widely reported.
+
+### Some people criticized the original episode for concluding there would be no Internet without Linux. What's your reaction? ###
+
+We enjoyed the debate that resulted from the debut episode. With more than 100,000 views to date of that episode alone, it brought awareness to the role that Linux plays in society and to the worldwide community of contributors and supporters. Of course the Internet would exist without Linux but it wouldn't be the Internet we know today and it wouldn't have matured at the pace it has. Each episode makes a bold and fun statement about Linux's role in our every day lives. We hope this can help extend the story of Linux to more people around the world.
+
+### Why is Sam and Annie's cat named String? ###
+
+Nothing in the series is a coincidence. Look closely and you'll find all kinds of inside Linux and geek jokes. String is named after String theory and was named by our Linux.com Editor Libby Clark. In physics, string theory is a theoretical framework in which the point-like particles of particle physics are replaced by one-dimensional objects called strings. String theory describes how these strings propagate through space and interact with each other. Kind of like Sam, Annie and String in a World Without Linux.
+
+### What can we expect from the next two episodes and, in particular, the finale? When will it air? ###
+
+In episode #5, we'll go to space and experience what a world without Linux would mean to exploration. It's a wild ride. In the finale, we finally get to see Linus in a world without Linux. There have been clues throughout the series as to what this finale will include but I can't give more than that away since there are ongoing contests to find the clues. And I can't give away the air date for the finale! You'll have to follow #WorldWithoutLinux to learn more.
+
+### Can you give us a hint on the clues in episode #4? ###
+
+There is another reference to the Free Burger Restaurant in this episode. Linux also actually does appear in this world without Linux but in a very covert way; you could say it's like reading Linux in another language. And, of course, just for fun, String makes another appearance.
+
+### Is the series achieving what you hoped? ###
+
+Yes. We're really happy to see people share and engage with these stories. We hope that it's reaching people who might not otherwise know the story of Linux or understand its pervasiveness in the world today. It's really about surfacing this to a broader audience and giving thanks to the worldwide community of developers and companies that support Linux and all the things it makes possible.
+
+--------------------------------------------------------------------------------
+
+via: http://thevarguy.com/open-source-application-software-companies/linux-foundation-explains-world-without-linux-and-open-so
+
+作者:[Christopher Tozzi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://thevarguy.com/author/christopher-tozzi
+[1]:http://linuxfoundation.org/
+[2]:http://www.linuxfoundation.org/world-without-linux
+[3]:http://thevarguy.com/open-source-application-software-companies/new-linux-foundation-video-highlights-role-open-source-3d
+[4]:http://thevarguy.com/open-source-application-software-companies/100715/would-internet-exist-without-linux-yes-without-open-sourc
\ No newline at end of file
diff --git a/sources/talk/20151126 Microsoft and Linux--True Romance or Toxic Love.md b/sources/talk/20151126 Microsoft and Linux--True Romance or Toxic Love.md
new file mode 100644
index 0000000000..92705b4b5c
--- /dev/null
+++ b/sources/talk/20151126 Microsoft and Linux--True Romance or Toxic Love.md
@@ -0,0 +1,77 @@
+Microsoft and Linux: True Romance or Toxic Love?
+================================================================================
+Every now and then, you come across a news story that makes you choke on your coffee or splutter hot latte all over your monitor. Microsoft's recent proclamations of love for Linux is an outstanding example of such a story.
+
+Common sense says that Microsoft and the FOSS movement should be perpetual enemies. In the eyes of many, Microsoft embodies most of the greedy excesses that the Free Software movement rejects. In addition, Microsoft previously has labeled Linux as a cancer and the FOSS community as a "pack of thieves".
+
+We can understand why Microsoft has been afraid of a free operating system. When combined with open-source applications that challenge Microsoft's core line, it threatens Microsoft's grip on the desktop/laptop market.
+
+In spite of Microsoft's fears over its desktop dominance, the Web server marketplace is one arena where Linux has had the greatest impact. Today, the majority of Web servers are Linux boxes. This includes most of the world's busiest sites. The sight of so much unclaimed licensing revenue must be painful indeed for Microsoft.
+
+Handheld devices are another realm where Microsoft has lost ground to free software. At one point, its Windows CE and Pocket PC operating systems were at the forefront of mobile computing. Windows-powered PDA devices were the shiniest and flashiest gadgets around. But, that all ended when Apple released its iPhone. Since then, Android has stepped into the limelight, with Windows Mobile largely ignored and forgotten. The Android platform is built on free and open-source components.
+
+The rapid expansion in Android's market share is due to the open nature of the platform. Unlike with iOS, any phone manufacturer can release an Android handset. And, unlike with Windows Mobile, there are no licensing fees. This has been really good news for consumers. It has led to lots of powerful and cheap handsets appearing from manufacturers all over the world. It's a very definite vindication of the value of FOSS software.
+
+Losing the battle for the Web and mobile computing is a brutal loss for Microsoft. When you consider the size of those two markets combined, the desktop market seems like a stagnant backwater. Nobody likes to lose, especially when money is on the line. And, Microsoft does have a lot to lose. You would expect Microsoft to be bitter about it. And in the past, it has been.
+
+Microsoft has fought back against Linux and FOSS using every weapon at its disposal, from propaganda to patent threats, and although these attacks have slowed the adoption of Linux, they haven't stopped it.
+
+So, you can forgive us for being shocked when Microsoft starts handing out t-shirts and badges that say "Microsoft Loves Linux" at open-source conferences and events. Could it be true? Does Microsoft really love Linux?
+
+Of course, PR slogans and free t-shirts do not equal truth. Actions speak louder than words. And when you consider Microsoft's actions, Microsoft's stance becomes a little more ambiguous.
+
+On the one hand, Microsoft is recruiting hundreds of Linux developers and sysadmins. It's releasing its .NET Core framework as an open-source project with cross-platform support (so that .NET apps can run on OS X and Linux). And, it is partnering with Linux companies to bring popular distros to its Azure platform. In fact, Microsoft even has gone so far as to create its own Linux distro for its Azure data center.
+
+On the other hand, Microsoft continues to launch legal attacks on open-source projects directly and through puppet corporations. It's clear that Microsoft hasn't had some big moral change of heart over proprietary vs. free software, so why the public declarations of adoration?
+
+To state the obvious, Microsoft is a profit-making entity. It's an investment vehicle for its shareholders and a source of income for its employees. Everything it does has a single ultimate goal: revenue. Microsoft doesn't act out of love or even hate (although that's a common accusation).
+
+So the question shouldn't be "does Microsoft really love Linux?" Instead, we should ask how Microsoft is going to profit from all this.
+
+Let's take the open-source release of .NET Core. This move makes it easy to port the .NET runtime to any platform. That extends the reach of Microsoft's .NET framework far beyond the Windows platform.
+
+Opening .NET Core ultimately will make it possible for .NET developers to produce cross-platform apps for OS X, Linux, iOS and even Android--all from a single codebase.
+
+From a developer's perspective, this makes the .NET framework much more attractive than before. Being able to reach many platforms from a single codebase dramatically increases the potential target market for any app developed using the .NET framework.
+
+What's more, a strong Open Source community would provide developers with lots of code to reuse in their own projects. So, the availability of open-source projects would make the .NET framework.
+
+On the plus side, opening .NET Core reduces fragmentation across different platforms and means a wider choice of apps for consumers. That means more choice, both in terms of open-source software and proprietary apps.
+
+From Microsoft's point of view, it would gain a huge army of developers. Microsoft profits by selling training, certification, technical support, development tools (including Visual Studio) and proprietary extensions.
+
+The question we should ask ourselves is does this benefit or hurt the Free Software community?
+
+Widespread adoption of the .NET framework could mean the eventual death of competing open-source projects, forcing us all to dance to Microsoft's tune.
+
+Moving beyond .NET, Microsoft is drawing a lot of attention to its Linux support on its Azure cloud computing platform. Remember, Azure originally was Windows Azure. That's because Windows Server was the only supported operating system. Today, Azure offers support for a number of Linux distros too.
+
+There's one reason for this: paying customers who need and want Linux services. If Microsoft didn't offer Linux virtual machines, those customers would do business with someone else.
+
+It looks like Microsoft is waking up to the fact that Linux is here to stay. Microsoft cannot feasibly wipe it out, so it has to embrace it.
+
+This brings us back to the question of why there is so much buzz about Microsoft and Linux. We're all talking about it, because Microsoft wants us to think about it. After all, all these stories trace back to Microsoft, whether it's through press releases, blog posts or public announcements at conferences. The company is working hard to draw attention to its Linux expertise.
+
+What other possible purpose could be behind Chief Architect Kamala Subramaniam's blog post announcing Azure Cloud Switch? ACS is a custom Linux distro that Microsoft uses to automate the configuration of its switch hardware in the Azure data centers.
+
+ACS is not publicly available. It's intended for internal use in the Azure data center, and it's unlikely that anyone else would be able to find a use for it. In fact, Subramaniam states the same thing herself in her post.
+
+So, Microsoft won't be making any money from selling ACS, and it won't attract a user base by giving it away. Instead, Microsoft gets to draw attention to Linux and Azure, strengthening its position as a Linux cloud computing platform.
+
+Is Microsoft's new-found love for Linux good news for the community?
+
+We shouldn't be slow to forget Microsoft's mantra of Embrace, Extend and Exterminate. Right now, Microsoft is very much in the early stages of embracing Linux. Will Microsoft seek to splinter the community through custom extensions and proprietary "standards"?
+
+Let us know what you think in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxjournal.com/content/microsoft-and-linux-true-romance-or-toxic-love-0
+
+作者:[James Darvell][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxjournal.com/users/james-darvell
\ No newline at end of file
diff --git a/sources/talk/20151201 Cinnamon 2.8 Review.md b/sources/talk/20151201 Cinnamon 2.8 Review.md
new file mode 100644
index 0000000000..0c44eba14f
--- /dev/null
+++ b/sources/talk/20151201 Cinnamon 2.8 Review.md
@@ -0,0 +1,87 @@
+Cinnamon 2.8 Review
+================================================================================
+
+
+Other than Gnome and KDE, Cinnamon is another desktop environment that is used by many people. It is made by the same team that produces Linux Mint (and ships with Linux Mint) and can also be installed on several other distributions. The latest version of this DE – Cinnamon 2.8 – was released earlier this month, and it brings a host of bug fixes and improvements as well as some new features.
+
+I’m going to go over the major improvements made in this release as well as how to update to Cinnamon 2.8 or install it for the first time.
+
+### Improvements to Applets ###
+
+There are several improvements to already existing applets for the panel.
+
+#### Sound Applet ####
+
+
+
+The Sound applet was revamped and now displays track information as well as the media controls on top of the cover art of the audio file. For music players with seeking support (such as Banshee), a progress bar will be displayed in the same region which you can use to change the position of the audio track. Right-clicking on the applet in the panel will display the options to mute input and output devices.
+
+#### Power Applet ####
+
+The Power applet now displays the status of each of the connected batteries and devices using the manufacturer’s data instead of generic names.
+
+#### Window Thumbnails ####
+
+
+
+Cinnamon 2.8 brings the option to show window thumbnails when hovering over the window list in the panel. You can turn it off if you don’t like it, though.
+
+#### Workspace Switcher Applet ####
+
+
+
+Adding the Workspace switcher applet to your panel will show you a visual representation of your workspaces with little rectangles embedded inside to show the position of your windows.
+
+#### System Tray ####
+
+Cinnamon 2.8 brings support for app indicators in the system tray. You can easily disable this in the settings which will force affected apps to fall back to using status icons instead.
+
+### Visual Improvements ###
+
+A host of visual improvements were made in Cinnamon 2.8. The classic and preview Alt + Tab switchers were polished with noticeable improvements, while the Alt + F2 dialog received bug fixes and better auto completion for commands.
+
+Also, the issue with the traditional animation effect for minimizing windows is now sorted and works with multiple panels.
+
+### Nemo Improvements ###
+
+
+
+The default file manager for Cinnamon also received several bug fixes and has a new “Quick-rename” feature for renaming files and directories. This works by clicking the file or directory twice with a short pause in between to rename the files.
+
+Nemo also detects issues with thumbnails automatically and prompts you to quickly fix them.
+
+### Other Notable improvements ###
+
+- Applets now reload themselves automatically once they are updated.
+- Support for multiple monitors was improved significantly.
+- Dialog windows have been improved and now attach themselves to their parent windows.
+- HiDPI dectection has been improved.
+- QT5 applications now look more native and use the default GTK theme.
+- Window management and rendering performance has been improved.
+- There are various bugfixes.
+
+### How to Get Cinnamon 2.8 ###
+
+If you’re running Linux Mint you will get Cinnamon 2.8 as part of the upgrade to Linux Mint 17.3 “Rosa” Cinnamon Edition. The BETA release is already out, so you can grab that if you’d like to get your hands on the new software immediately.
+
+For Arch users, Cinnamon 2.8 is already in the official Arch repositories, so you can just update your packages and do a system-wide upgrade to get the latest version.
+
+Finally, for Ubuntu users, you can install or upgrade to Cinnamon 2.8 by running in turn the following commands:
+
+ sudo add-apt-repository -y ppa:moorkai/cinnamon
+ sudo apt-get update
+ sudo apt-get install cinnamon
+
+Have you tried Cinnamon 2.8? What do you think of it?
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/cinnamon-2-8-review/
+
+作者:[Ayo Isaiah][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/ayoisaiah/
\ No newline at end of file
diff --git a/sources/talk/20151202 KDE vs GNOME vs XFCE Desktop.md b/sources/talk/20151202 KDE vs GNOME vs XFCE Desktop.md
new file mode 100644
index 0000000000..5cfbc31ace
--- /dev/null
+++ b/sources/talk/20151202 KDE vs GNOME vs XFCE Desktop.md
@@ -0,0 +1,53 @@
+KDE vs GNOME vs XFCE Desktop
+================================================================================
+
+
+Over many years, many people spent a long time with Linux desktop using either KDE or GNOME. These two environments have grown through the previous years and each of these desktops continued to expand their current user-base. For example, sleeper desktop environment has been XFCE as XFCE offers more robustness than LXDE that lacks much of XFCE’s polish in the default configuration. The XFCE provides all benefits which users enjoyed in the GNOME 2, but with some lightweight experiences which made it a hit on the older computers.
+
+### The Desktop Theming ###
+
+After the user has fresh installation, the XFCE will be a bit boring, which lacks some certain visual attractiveness to it. So, don’t misunderstand my words here, the XFCE is still having nice looking desktop, but it may be like vanilla in users’ eyes as well as most people who are new to the XFCE desktop environment. The good news here is that while installing new theme to the XFCE, it is a reasonably easy process as you can easily find the right XFCE theme which appeals to you, after that, you can extract that theme to the proper directory. From this point, the XFCE comes with an important tool located under the Appearance for helping the user to select the chosen theme easily throughout the Graphical User Interface (GUID). There’re no other tools that might be required here, and if the user follows the above directions, it will be a bit simple for everyone who is caring to have a try.
+
+On the GNOME desktop, the user should follow the similar above approach. The main key difference for this point is that users have to download and then install GNOME Tweak Tool before proceeding with anything. It does not have any huge barriers under any means, but it is simple valid oversight when the user consider that the XFCE does not require any tweak tool in order for installing and activating the new desktop themes. By being under the GNOME, and especially after installing that Tweak tool which is mentioned above, you will need to go ahead and also to make sure that you have the extension of User Themes installed.
+
+The same as with the XFCE, the user will want to search for, and then download the theme which most appeals personally to him. Then, user can revisit to the GNOME Tweak tool, and click on the Appearance option on left side of that Tweak tool. Then, the user can simply look at the bottom of the page and click on file browse button to right of the Shell Theme. User then can browse to the zipped folder, and click open. In case if this process was successfully done, the user will see an alert that tell him that it was installed without any problems. From this point, user can simply use the pull down menu in order for selecting the theme he wants to use. The same as with the XFCE, process of theme activation is very easy, however, a need to download the non-included application for using a new theme will leave much to be desired.
+
+Finally, there is the process of the KDE desktop theming. The same as with XFCE, there is no need at all to install any extra tools for making it work. This is one area where there is a feeling that the XFCE has to make the KDE the winner. Not only the installing themes in the KDE is accomplished entirely within the Graphical User Interface, but it’s also even possible to click on (Get New Themes) button and user will be able to locate, view, and also install the new themes automatically.
+
+However, it should be noted that the KDE is a bit more robust desktop environment comparing to the XFCE. Therefore, it is a bit reasonable now to see why such extra functionalities could be missing from the desktops which are mainly designed to be minimalist. So, we all have to give the KDE props for such outstanding functionality.
+
+### MATE is not Lightweight Desktop ###
+
+Before continuing with the comparison between the XFCE, the GNOME 3 and the KDE, it should be clear for experts that we can’t touch the MATE desktop as an option in the comparison. MATE can be considered as the GNOME 2 desktop’s next incarnation, but it’s not mainly marketed to be a lightweight or fast desktop. But instead of that, its primary goal is to be more traditional and comfortable desktop environment where the users can feel right at their home to use it.
+
+On the other hand, the XFCE comes with a completely other goal set. The XFCE offers its users a more lightweight and yet still visually appealing desktop experience. Then, for everyone who points out that MATE is a lightweight desktop too, it isn’t really targeting that lightweight desktop crowd. Both options may be dressed up for looking quite attractive with the proper theme installed.
+
+### The Navigation of Desktop ###
+
+The XFCE honestly offers an obvious navigation which is out of the box. Anyone who is used to the traditional Windows or the GNOME 2/MATE desktop experience will be going to have the ability to navigate around the new XFCE installation without any kind of help. Straight away, adding the applets to panel is still very obvious. The same as with locating installed applications, just use the launcher and simply click on any desired application. With an exception of LXDE and MATE, there is no other desktop that can make the navigation that simple. What can be even better is that fact which the control panel is very easy to use, that is a really big benefit to everyone who is new to the desktop environment. If the user prefer older methods to use his desktop, then GNOME is not an option. With the hot corners as well as the no minimize button, plus the other application layout method, it’ll take the most newcomers getting easily used to it.
+
+If the user is coming from, as an example, Windows environment, then he is going to be put off by the inability to add applets to the top of his workspace simply with just a mere right-click. Just instead of this, it can be handled by using extensions. Installing extensions in the GNOME is granted and is a brain-dead easy, based on the easy to use (on/off) toggle switches located on the extensions page of the GNOME. Users have to know, sadly, to actually visit that page to enjoy this functionality.
+
+On the other side, the GNOME is sharing its desire for providing a straight forward and an easy to use control panel, which many of you may think that it is not be a big deal, but it is really something that I by myself find commendable and worth to be mentioned. The KDE offers its users a bit more traditional desktop experience, throughout familiar launchers as well as the ability for getting to the software in more familiar way if they are coming from Windows desktop. The process of adding widgets or applets to the KDE desktop is an easy matter of just right-clicking on the bottom of the desktop. Only the problem with the KDE’s approach is to be that, as many things KDE, the feature which users are actually looking for are hidden. The KDE users might berate my opinion for this, but I still stand by my statement.
+
+In order for adding a Widget, just right-click on “my panel”, just to see the panel options, but not as an immediate method to install Widgets. You will not actually see the Add Widgets until you select the Panel Options, then the Add Widgets. This not a big deal to me, but later for some users, it becomes unnecessary tidbit of confusion. To make things here more convoluted, after the users manage to locate Widgets area they discover later a brand new term called “Activities”. It is in the same area as the Widgets, yet it is somehow in its own area as to what it does.
+
+Now don’t misunderstand me, the Activities feature in the KDE is totally great and actually valued. But to look at it from the usability standpoint, I think that it would be better suited in another menu option in order to not confuse the newbies. User is welcome to differ, but to test this with newbies for some extended periods of time can prove the correct over and over again. The rant against the Activities placement aside, the KDE approach to add new widgets is really great. The same as with the KDE themes, user can’t browse through and install the Widgets automatically via using the provided Graphical User Interface. It is a bit fantastic of functionality, and also it could be celebrated such way. The control panel of the KDE is not as easy as the user might like it to be, yet it is a bit clear that this’s something that they are still working on.
+
+### So, the XFCE is the best desktop, right? ###
+
+I, by myself, actually run GNOME, KDE, and XFCE on my computers in my office and home. I also have some older machines with OpenBox and LXDE too. Each desktop experience can offer something that is a bit useful to me and may help me to use each machine as I see that it is fit. For me, I have a soft spot in my heart for the XFCE as it is one of the desktop environments which I stuck with for years. But in this article, I’m just writing it on my daily use computer which is in fact, GNOME.
+
+The main idea here is that I still feel that the XFCE provides a bit better user experience for users who are looking for stable, traditional, and easy to understand desktop environment. You are also welcome to share with us your opinion in the comments section.
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/kde-vs-gnome-vs-xfce-desktop/
+
+作者:[M.el Khamlichi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.unixmen.com/author/pirat9/
\ No newline at end of file
diff --git a/sources/talk/The history of Android/20 - The history of Android.md b/sources/talk/The history of Android/20 - The history of Android.md
deleted file mode 100644
index 75c89a1abc..0000000000
--- a/sources/talk/The history of Android/20 - The history of Android.md
+++ /dev/null
@@ -1,95 +0,0 @@
-alim0x translating
-
-The history of Android
-================================================================================
-
-Another Market design that was nothing like the old one. This lineup shows the categories page, featured, a top apps list, and an app page.
-Photo by Ron Amadeo
-
-These screenshots give us our first look at the refined version of the Action Bar in Ice Cream Sandwich. Almost every app got a bar at the top of the screen that housed the app icon, title of the screen, several function buttons, and a menu button on the right. The right-aligned menu button was called the "overflow" button, because it housed items that didn't fit on the main action bar. The overflow menu wasn't static, though, it gave the action bar more screen real-estate—like in horizontal mode or on a tablet—and more of the overflow menu items were shown on the action bar as actual buttons.
-
-New in Ice Cream Sandwich was this design style of "swipe tabs," which replaced the 2×3 interstitial navigation screen Google was previously pushing. A tab bar sat just under the Action Bar, with the center title showing the current tab and the left and right having labels for the pages to the left and right of this screen. A swipe in either direction would change tabs, or you could tap on a title to go to that tab.
-
-One really cool design touch on the individual app screen was that, after the pictures, it would dynamically rearrange the page based on your history with that app. If you never installed the app before, the description would be the first box. If you used the app before, the first section would be the reviews bar, which would either invite you to review the app or remind you what you thought of the app last time you installed it. The second section for a previously used app was “What’s New," since an existing user would most likely be interested in changes.
-
-
-Recent apps and the browser were just like Honeycomb, but smaller.
-Photo by Ron Amadeo
-
-Recent apps toned the Tron look way down. The blue outline around the thumbnails was removed, along with the eerie, uneven blue glow in the background. It now looked like a neutral UI piece that would be at home in any time period.
-
-The Browser did its best to bring a tabbed experience to phones. Multi-tab browsing was placed front and center, but instead of wasting precious screen space on a tab strip, a tab button would open a Recent Apps-like interface that would show you your open tabs. Functionally, there wasn't much difference between this and the "window" view that was present in past versions of the Browser. The best addition to the Browser was a "Request desktop site" menu item, which would switch from the default mobile view to the normal site. The Browser showed off the flexibility of Google's Action Bar design, which, despite not having a top-left app icon, still functioned like any other top bar design.
-
-
-Gmail and Google Talk—they're like Honeycomb, but smaller!
-Photo by Ron Amadeo
-
-Gmail and Google Talk both looked like smaller versions of their Honeycomb designs, but with a few tweaks to work better on smaller screens. Gmail featured a dual Action Bar—one on the top of the screen and one on the bottom. The top of the bar showed your current folder, account, and number of unread messages, and tapping on the bar opened a navigation menu. The bottom featured all the normal buttons you would expect along with the overflow button. This dual layout was used in order display more buttons on the surface level, but in landscape mode where vertical space was at a premium, the dual bars merged into a single top bar.
-
-In the message view, the blue bar was "sticky" when you scrolled down. It stuck to the top of the screen, so you could always see who wrote the current message, reply, or star it. Once in a message, the thin, dark gray bar at the bottom showed your current spot in the inbox (or whatever list brought you here), and you could swipe left and right to get to other messages.
-
-Google Talk would let you swipe left and right to change chat windows, just like Gmail, but there the bar was at the top.
-
-
-The new dialer and the incoming call screen, both of which we haven't seen since Gingerbread.
-Photo by Ron Amadeo
-
-Since Honeycomb was only for tablets, some UI pieces were directly preceded by Gingerbread instead. The new Ice Cream Sandwich dialer was, of course, black and blue, and it used smaller tabs that could be swiped through. While Ice Cream Sandwich finally did the sensible thing and separated the main phone and contacts interfaces, the phone app still had its own contacts tab. There were now two spots to view your contact list—one with a dark theme and one with a light theme. With a hardware search button no longer being a requirement, the bottom row of buttons had the voicemail shortcut swapped out for a search icon.
-
-Google liked to have the incoming call interface mirror the lock screen, which meant Ice Cream Sandwich got a circle-unlock design. Besides the usual decline or accept options, a new button was added to the top of the circle, which would let you decline a call by sending a pre-defined text message to the caller. Swiping up and picking a message like "Can't talk now, call you later" was (and still is) much more informative than an endlessly ringing phone.
-
-
-Honeycomb didn't have folders or a texting app, so here's Ice Cream Sandwich versus Gingerbread.
-Photo by Ron Amadeo
-
-Folders were now much easier to make. In Gingerbread, you had to long press on the screen, pick "folders," and then pick "new folder." In Ice Cream Sandwich, just drag one icon on top of another, and a folder is created containing those two icons. It was dead simple and much easier than finding the hidden long-press command.
-
-The design was much improved, too. Gingerbread used a generic beige folder icon, but Ice Cream Sandwich actually showed you what was in the folder by stacking the first three icons on top of each other, drawing a circle around them, and using that as the folder icon. Open folder containers resized to fit the amount of icons in the folder rather than being a full-screen, mostly empty box. It looked way, way better.
-
-
-YouTube switched to a more modern white theme and used a list view instead of the crazy 3D scrolling
-Photo by Ron Amadeo
-
-YouTube was completely redesigned and looked less like something from The Matrix and more like, well, YouTube. It was a simple white list of vertically scrolling videos, just like the website. Making videos on your phone was given prime real estate, with the first button on the action bar dedicated to recording a video. Strangely, different screens used different YouTube logos in the top left, switching between a horizontal YouTube logo and a square one.
-
-YouTube used swipe tabs just about everywhere. They were placed on the main page to browse and view your account and on the video pages to switch between comments, info, and related videos. The 4.0 app showed the first signs of Google+ YouTube integration, placing a "+1" icon next to the traditional rating buttons. Eventually Google+ would completely take over YouTube, turning the comments and author pages into Google+ activity.
-
-
-Ice Cream Sandwich tried to make things easier on everyone. Here is a screen for tracking data usage, the new developer options with tons of analytics enabled, and the intro tutorial.
-Photo by Ron Amadeo
-
-Data Usage allowed users to easily keep track of and control their data usage. The main page showed a graph of this month's data usage, and users could set thresholds to be warned about data consumption or even set a hard usage limit to avoid overage charges. All of this was done easily by dragging the horizontal orange and red threshold lines higher or lower on the chart. The vertical white bars allowed users to select a slice of time in the graph. At the bottom of the page, the data usage for the selected time was broken down by app, so users could select a spike and easily see what app was sucking up all their data. When times got really tough, in the overflow button was an option to restrict all background data. Then, only apps running in the foreground could have access to the Internet connection.
-
-The Developer Options typically only housed a tiny handful of settings, but in Ice Cream Sandwich the section received a huge expansion. Google added all sorts of on-screen diagnostic overlays to help app developers understand what was happening inside their app. You could view CPU usage, pointer location, and view screen updates. There were also options to change the way the system functioned, like control over animation speed, background processing, and GPU rendering.
-
-One of the biggest differences between Android and the iOS is Android's app drawer interface. In Ice Cream Sandwich's quest to be more user-friendly, the initial startup launched a small tutorial showing users where the app drawer was and how to drag icons out of the drawer and onto the homescreen. With the removal of the off-screen menu button and changes like this, Android 4.0 made a big push to be more inviting to new smartphone users and switchers.
-
-
-The "touch to beam" NFC support, Google Earth, and App Info, which would let you disable crapware.
-
-Built into Ice Cream Sandwich was full support for [NFC][1]. While previous devices like the Nexus S had NFC, support was limited and the OS couldn't do much with the chip. 4.0 added a feature called Android Beam, which would let two NFC-equipped Android 4.0 devices transfer data back and forth. NFC would transmit data related to whatever was on the screen at the time, so tapping when a phone displayed a webpage would send that page to the other phone. You could also send contact information, directions, and YouTube links. When the two phones were put together, the screen zoomed out, and tapping on the zoomed-out display would send the information.
-
-In Android, users are not allowed to uninstall system apps, which are often integral to the function of the device. Carriers and OEMs took advantage of this and started putting crapware in the system partition, which they would often stick with software they didn't want. Android 4.0 allowed users to disable any app that couldn't be uninstalled, meaning the app remained on the system but didn't show up in the app drawer and couldn't be run. If users were willing to dig through the settings, this gave them an easy way to take control of their phone.
-
-Android 4.0 can be thought of as the start of the modern Android era. Most of the Google apps released around this time only worked on Android 4.0 and above. There were so many new APIs that Google wanted to take advantage of that—initially at least—support for versions below 4.0 was limited. After Ice Cream Sandwich and Honeycomb, Google was really starting to get serious about software design. In January 2012, the company [finally launched][2] *Android Design*, a design guideline site that taught Android app developers how to create apps to match the look and feel of Android. This was something iOS not only had from the start of third-party app support, but Apple enforced design so seriously that apps that did not meet the guidelines were blocked from the App Store. The fact that Android went three years without any kind of public design documents from Google shows just how bad things used to be. But with Duarte in charge of Android's design revolution, the company was finally addressing basic design needs.
-
-----------
-
-
-
-[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
-
-[@RonAmadeo][t]
-
---------------------------------------------------------------------------------
-
-via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/20/
-
-译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://arstechnica.com/gadgets/2011/02/near-field-communications-a-technology-primer/
-[2]:http://arstechnica.com/business/2012/01/google-launches-style-guide-for-android-developers/
-[a]:http://arstechnica.com/author/ronamadeo
-[t]:https://twitter.com/RonAmadeo
diff --git a/sources/talk/The history of Android/21 - The history of Android.md b/sources/talk/The history of Android/21 - The history of Android.md
deleted file mode 100644
index 265e7a867b..0000000000
--- a/sources/talk/The history of Android/21 - The history of Android.md
+++ /dev/null
@@ -1,103 +0,0 @@
-The history of Android
-================================================================================
-
-Photo by Ron Amadeo
-
-### Google Play and the return of direct-to-consumer device sales ###
-
-On March 6, 2012, Google unified all of its content offerings under the banner of "Google Play." The Android Market became the Google Play Store, Google Books became Google Play Books, Google Music became Google Play Music, and Android Market Movies became Google Play Movies & TV. While the app interfaces didn't change much, all four content apps got new names and icons. Content purchased in the Play Store would be downloaded to the appropriate app, and the Play Store and Play content apps all worked together to provide a fairly organized content experience.
-
-The Google Play update was Google's first big out-of-cycle update. Four packed-in apps were all changed without having to issue a system update—they were all updated through the Android Market/Play Store. Enabling out-of-cycle updates to individual apps was a big focus for Google, and being able to do an update like this was the culmination of an engineering effort that started in the Gingerbread era. Google had been working on "decoupling" the apps from the operating system and making everything portable enough to be distributed through the Android Market/Play Store.
-
-While one or two apps (mostly Maps and Gmail) had previously lived on the Android Market, from here on you'll see a lot more significant updates that have nothing to do with an operating system release. System updates require the cooperation of OEMs and carriers, so they are difficult to push out to every user. Play Store updates are completely controlled by Google, though, providing the company a direct line to users' devices. For the launch of Google Play, the Android Market updated itself to the Google Play Store, and from there, Books, Music, and Movies were all issued Google Play-flavored updates.
-
-The design of the Google Play apps was still all over the place. Each app looked and functioned differently, but for now, a cohesive brand was a good start. And removing "Android" from the branding was necessary because many services were available in the browser and could be used without touching an Android device at all.
-
-In April 2012, Google started [selling devices though the Play Store again][1], reviving the direct-to-customer model it had experimented with for the launch of the Nexus One. While it was only two years after ending the Nexus One sales, Internet shopping was now more common place, and buying something before you could hold it didn't seem as crazy as it did in 2010.
-
-Google also saw how price-conscious consumers became when faced with the Nexus One's $530 price tag. The first device for sale was an unlocked, GSM version of the Galaxy Nexus for $399. From there, price would go even lower. $350 has been the entry-level price for the last two Nexus smartphones, and 7-inch Nexus tablets would come in at only $200 to $220.
-
-Today, the Play Store sells eight different Android devices, four Chromebooks, a thermostat, and tons of accessories, and the device store is the de-facto location for a new Google product launch. New phone launches are so popular, the site usually breaks under the load, and new Nexus phones sell out in a few hours.
-
-### Android 4.1, Jelly Bean—Google Now points toward the future ###
-
-
-The Asus-made Nexus 7, Android 4.1's launch device.
-
-With the release of Android 4.1, Jelly Bean in July 2012, Google settled into an Android release cadence of about every six months. The platform matured to the point where a release every three months was unnecessary, and the slower release cycle gave OEMs a chance to catch their breath. Unlike Honeycomb, point releases were now fairly major updates, with 4.1 bringing major UI and framework changes.
-
-One of the biggest changes in Jelly Bean that you won't be able to see in screenshots is "Project Butter," the name for a concerted effort by Google's engineers to make Android animations run smoothly at 30FPS. Core changes were made, like Vsync and triple buffering, and individual animations were optimized so they could be drawn smoothly. Animation and scrolling smoothness had always been a weak point of Android when compared to iOS. After some work on both the core animation framework and on individual apps, Jelly Bean brought Android a lot closer to iOS' smoothness.
-
-Along with Jelly Bean came the [Nexus][2] 7, a 7-inch tablet manufactured by Asus. Unlike the primarily horizontal Xoom, the Nexus 7 was meant to be used in portrait mode, like a large phone. The Nexus 7 showed that, after almost a year-and-a-half of ecosystem building, Google was ready to commit to the tablet market with a flagship device. Like the Nexus One and GSM Galaxy Nexus, the Nexus 7 was sold online directly by Google. While those earlier devices had shockingly high prices for consumers that were used to carrier subsidies, the Nexus 7 hit a mass market price point of only $200. The price bought you a device with a 7-inch, 1280x800 display, a quad core, 1.2 GHz Tegra 3 processor, 1GB of RAM, and 8GB of storage. The Nexus 7 was such a good value that many wondered if Google was making any money at all on its flagship tablet.
-
-This smaller, lighter, 7-inch form factor would be a huge success for Google, and it put the company in the rare position of being an industry trendsetter. Apple, which started with a 10-inch iPad, was eventually forced to answer the Nexus 7 and tablets like it with the iPad Mini.
-
-
-4.1's new lock screen design, wallpaper, and the new on-press highlight on the system buttons.
-Photo by Ron Amadeo
-
-The Tron look introduced in Honeycomb was toned down a little in Ice Cream Sandwich, and Jelly Bean took things a step further. It started removing blue from large chunks of the operating system. The hint was the on-press highlights on the system buttons, which changed from blue to gray.
-
-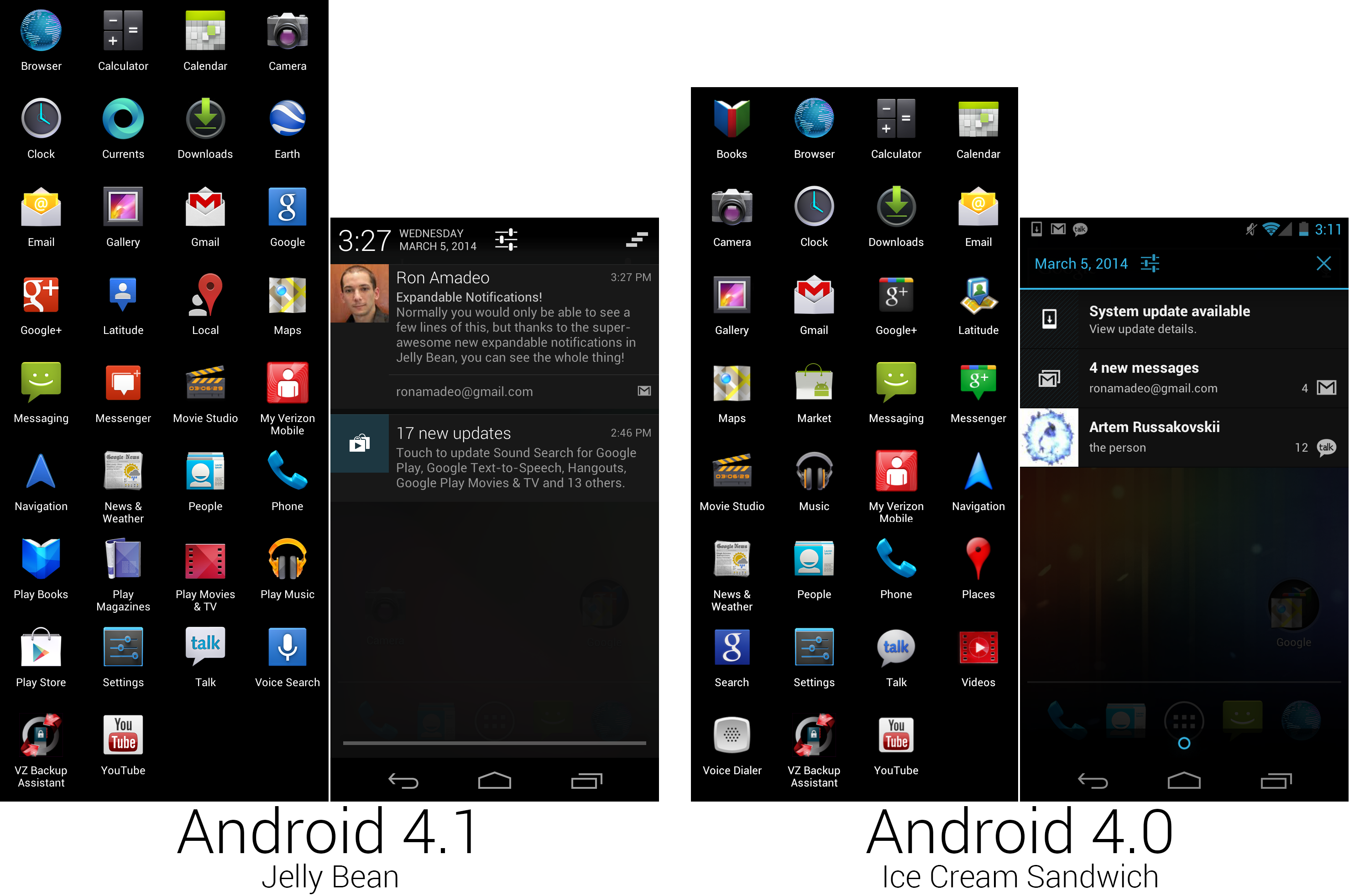
-A composite image of the new app lineup and the new notification panel with expandable notifications.
-Photo by Ron Amadeo
-
-The Notification panel was completely revamped, and we've finally arrived at the design used today in KitKat. The new panel extended to the top of the screen and covered the usual status icons, meaning the status bar was no longer visible when the panel was open. The time was prominently displayed in the top left corner, along with the date and a settings shortcut. The clear all notions button, which was represented by an "X" in Ice Cream Sandwich, changed to a stairstep icon, symbolizing the staggered sliding animation that cleared the notification panel. The bottom handle changed from a circle to a single line that ran the length of the notification panel. All the typography was changed—the notification panel now used bigger, thinner fonts for everything. This was another screen where the blue introduced in Ice Cream Sandwich and Honeycomb was removed. The notification panel was entirely gray now except for on-touch highlights.
-
-There was new functionality in the panel, too. Notifications were now expandable and could show much more information than the previous two-line design. It now showed up to eight lines of text and could even show buttons at the bottom of the notification. The screenshot notification had a share button at the bottom, and you could call directly from a missed call notification, or you could snooze a ringing alarm all from the notification panel. New notifications were expanded by default, but as they piled up they would collapse back to the traditional size. Dragging down on a notification with two fingers would expand it.
-
-
-The new Google Search app, with Google Now cards, voice search, and text search.
-Photo by Ron Amadeo
-
-The biggest feature addition to Jelly Bean for not only Android, but for Google as a whole, was the new version of the Google Search application. This introduced "Google Now," a predictive search feature. Google Now was displayed as several cards that sit below the search box, and it would offer results to searches Google thinks you care about. These were things like Google Maps searches for places you've recently looked at on your desktop computer or calendar appointment locations, the weather, and time at home while traveling.
-
-The new Google Search app could, of course, be launched with the Google icon, but it could also be accessed from any screen with a swipe up from the system bar. Long pressing on the system bar brought up a ring that worked similarly to the lock screen ring. The card section scrolled vertically, and cards could be a swipe away if you didn't want to see them. Voice Search was a big part of the updates. Questions weren't just blindly entered into Google; if Google knew the answer, it would also talk back using a text-To-Speech engine. And old-school text searches were, of course, still supported. Just tap on the bar and start typing.
-
-Google frequently called Google Now "the future of Google Search." Telling Google what you wanted wasn't good enough. Google wanted to know what you wanted before you did. Google Now put all of Google's data mining knowledge about you to work for you, and it was the company's biggest advantage against rival search services like Bing. Smartphones knew more about you than any other device you own, so the service debuted on Android. But Google slowly worked Google Now into Chrome, and eventually it will likely end up on Google.com.
-
-While the functionality was important, it became clear that Google Now was the most important design work to ever come out of the company, too. The white card aesthetic that this app introduced would become the foundation for Google's design of just about everything. Today, this card style is used in the Google Play Store and in all of the Play content apps, YouTube, Google Maps, Drive, Keep, Gmail, Google+, and many others. It's not just Android apps, either. Many of Google's desktop sites and iOS apps are inspired by this design. Design was historically one of Google's weak areas, but Google Now was the point where the company finally got its act together with a cohesive, company-wide design language.
-
-
-Yet another YouTube redesign. Information density went way down.
-Photo by Ron Amadeo
-
-Another version, another YouTube redesign. This time the list view was primarily thumbnail-based, with giant images taking up most of the screen real estate. Information density tanked with the new list design. Before YouTube would display around six items per screen, now it could only display three.
-
-YouTube was one of the first apps to add a sliding drawer to the left side of an app, a feature which would become a standard design style across Google's apps. The drawer has links for your account and channel subscriptions, which allowed Google to kill the tabs-on-top design.
-
-
-Google Play Service's responsibilities versus the rest of Android.
-Photo by Ron Amadeo
-
-### Google Play Services—fragmentation and making OS versions (nearly) obsolete ###
-
-It didn't seem like a big deal at the time, but in September 2012, Google Play Services 1.0 was automatically pushed out to every Android phone running 2.2 and up. It added a few Google+ APIs and support for OAuth 2.0.
-
-While this update might sound boring, Google Play Services would eventually grow to become an integral part of Android. Google Play Services acts as a shim between the normal apps and the installed Android OS, allowing Google to update or replace some core components and add APIs without having to ship out a new Android version.
-
-With Play Services, Google had a direct line to the core of an Android phone without having to go through OEM updates and carrier approval processes. Google used Play Services to add an entirely new location system, a malware scanner, remote wipe capabilities, and new Google Maps APIs, all without shipping an OS update. Like we mentioned at the end of the Gingerbread section, thanks to all the "portable" APIs implemented in Play Services, Gingerbread can still download a modern version of the Play Store and many other Google Apps.
-
-The other big benefit was compatibility with Android's user base. The newest release of an Android OS can take a very long time to get out to the majority of users, which means APIs that get tied to the latest version of the OS won't be any good to developers until the majority of the user base upgrades. Google Play Services is compatible with Froyo and above, which is 99 percent of active devices, and the updates pushed directly to phones through the Play Store. By including APIs in Google Play Services instead of Android, Google can push a new API out to almost all users in about a week. It's [a great solution][3] to many of the problems caused by version fragmentation.
-
-----------
-
-
-
-[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
-
-[@RonAmadeo][t]
-
---------------------------------------------------------------------------------
-
-via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/
-
-译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://arstechnica.com/gadgets/2012/04/unlocked-samsung-galaxy-nexus-can-now-be-purchased-from-google/
-[2]:http://arstechnica.com/gadgets/2012/07/divine-intervention-googles-nexus-7-is-a-fantastic-200-tablet/
-[3]:http://arstechnica.com/gadgets/2013/09/balky-carriers-and-slow-oems-step-aside-google-is-defragging-android/
-[a]:http://arstechnica.com/author/ronamadeo
-[t]:https://twitter.com/RonAmadeo
\ No newline at end of file
diff --git a/sources/talk/yearbook2015/20151208 10 tools for visual effects in Linux with Kdenlive.md b/sources/talk/yearbook2015/20151208 10 tools for visual effects in Linux with Kdenlive.md
new file mode 100644
index 0000000000..bf2ba1ff25
--- /dev/null
+++ b/sources/talk/yearbook2015/20151208 10 tools for visual effects in Linux with Kdenlive.md
@@ -0,0 +1,155 @@
+10 tools for visual effects in Linux with Kdenlive
+================================================================================
+
+Image credits : Seth Kenlon. [CC BY-SA 4.0.][1]
+
+[Kdenlive][2] is one of those applications; you can use it daily for a year and wake up one morning only to realize that you still have only grazed the surface of all of its potential. That's why it's nice every once in a while to sit back and look over some of the lesser-used tricks and tools in Kdenlive. Even though something's not used as often as, say, the Spacer or Razor tools, it still may end up being just the right finishing touch on your latest masterpiece.
+
+Most of the tools I'll discuss here are not officially part of Kdenlive; they are plugins from the [Frei0r][3] package. These are ubiquitous parts of video processing on Linux and Unix, and they usually get installed along with Kdenlive as distributed by most Linux distributions, so they often seem like part of the application. If your install of Kdenlive does not feature some of the tools mentioned here, make sure that you have Frei0r plugins installed.
+
+Since many of the tools in this article affect the look of an image, here is the base image, without effects or adjustment:
+
+
+
+Still image grabbed from a video by Footage Firm, Inc. [CC BY-SA 4.0.][1]
+
+Let's get started.
+
+### 1. Color effect ###
+
+
+
+You can find the **Color Effect** filter in **Add Effect > Misc** context menu. As filters go, it's mostly just a preset; the only controls it has are which filter you want to use.
+
+
+
+Normally that's the kind of filter I avoid, but I have to be honest: Sometimes a plug-and-play solution is exactly what you want. This filter has a few different settings, but the two that make it worth while (at least for me) are the Sepia and XPro effects. Admittedly, controls to adjust how sepia tone the sepia effect is would be nice, but no matter what, when you need a quick and familiar color effect, this is the filter to throw onto a clip. It's immediate, it's easy, and if your client asks for that look, this does the trick every time.
+
+### 2. Colorize ###
+
+
+
+The simplicity of the **Colorize** filter in **Add Effect > Misc** is also its strength. In some editing applications, it takes two filters and some compositing to achieve this simple color-wash effect. It's refreshing that in Kdenlive, it's a matter of one filter with three possible controls (only one of which, strictly speaking, is necessary to achieve the look).
+
+
+
+Its use is intuitive; use the **Hue** slider to set the color. Use the other controls to adjust the luma of the base image as needed.
+
+This is not a filter I use every day, but for ad spots, bumpers, dreamy sequences, or titles, it's the easiest and quickest path to a commonly needed look. Get a company's color, use it as the colorize effect, slap a logo over the top of the screen, and you've just created a winning corporate intro.
+
+### 3. Dynamic Text ###
+
+
+
+For the assistant editor, the Add Effect > Misc > Dynamic **Text** effect is worth the price of Kdenlive. With one mostly pre-set filter, you can add a running timecode burn-in to your project, which is an absolute must-have safety feature when round-tripping your footage through effects and sound.
+
+The controls look more complex than they actually are.
+
+
+
+The font settings are self-explanatory. Placement of the text is controlled by the Horizontal and Vertical Alignment settings; steer clear of the **Size** setting (it controls the size of the "canvas" upon which you are compositing the burn-in, not the size of the burn-in itself).
+
+The text itself doesn't have to be timecode. From the dropdown menu, you can choose from a list of useful text, including frame count (useful for VFX, since animators work in frames), source frame rate, source dimensions, and more.
+
+You are not limited to just one choice. The text field in the control panel will take whatever arbitrary text you put into it, so if you want to burn in more information than just timecode and frame rate (such as **Sc 3 - #timecode# - #meta.media.0.stream.frame_rate#**), then have at it.
+
+### 4. Luminance ###
+
+
+
+The **Add Effect > Misc > Luminance** filter is a no-options filter. Luminance does one thing and it does it well: It drops the chroma values of all pixels in an image so that they are displayed by their luma values. In simpler terms, it's a grayscale filter.
+
+The nice thing about this filter is that it's quick, easy, efficient, and effective. This filter combines particularly well with other related filters (meaning that yes, I'm cheating and including three filters for one).
+
+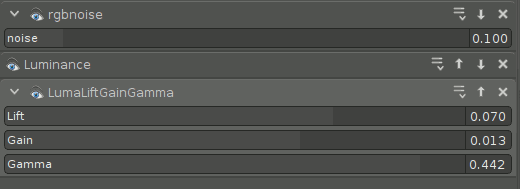
+
+Combining, in this order, the **RGB Noise** for emulated grain, **Luminance** for grayscale, and **LumaLiftGainGamma** for levels can render a textured image that suggests the classic look and feel of [Kodax Tri-X][4] film.
+
+### 5. Mask0mate ###
+
+
+Image by Footage Firm, Inc.
+
+Better known as a four-point garbage mask, the **Add Effect > Alpha Manipulation > Mask0mate** tool is a quick, no-frills way to ditch parts of your frame that you don't need. There isn't much to say about it; it is what it is.
+
+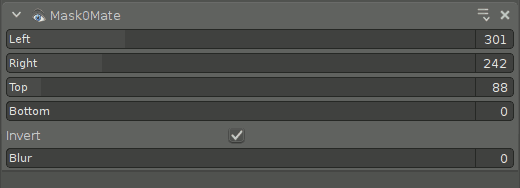
+
+The confusing thing about the effect is that it does not imply compositing. You can pull in the edges all you want, but you won't see it unless you add the **Composite** transition to reveal what's underneath the clip (even if that's nothing). Also, use the **Invert** function for the filter to act like you think it should act (without it, the controls will probably feel backward to you).
+
+### 6. Pr0file ###
+
+
+
+The **Add Effect > Misc > Pr0file** filter is an analytical tool, not something you would actually leave on a clip for final export (unless, of course, you do). Pr0file consists of two components: the Marker, which dictates what area of the image is being analyzed, and the Graph, which displays information about the marked region.
+
+Set the marker using the **X, Y, Tilt**, and **Length** controls. The graphical readout of all the relevant color channel information is displayed as a graph, superimposed over your image.
+
+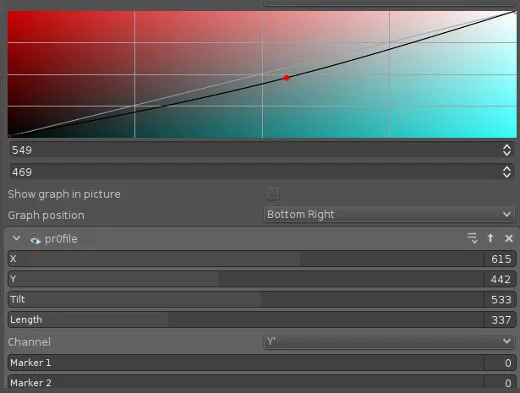
+
+The readout displays a profile of the colors within the region marked. The result is a sort of hyper-specific vectorscope (or oscilloscope, as the case may be) that can help you zero in on problem areas during color correction, or compare regions while color matching.
+
+In other editors, the way to get the same information was simply to temporarily scale your image up to the region you want to analyze, look at your readout, and then hit undo to scale back. Both ways work, but the Pr0file filter does feel a little more elegant.
+
+### 7. Vectorscope ###
+
+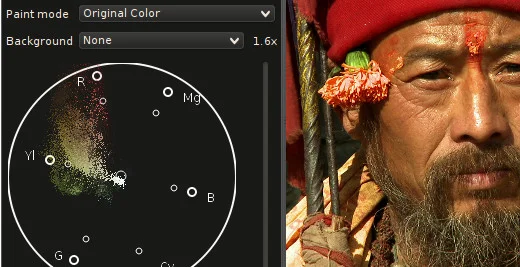
+
+Kdenlive features an inbuilt vectorscope, available from the **View** menu in the main menu bar. A vectorscope is not a filter, it's just another view the footage in your Project Monitor, specifically a view of the color saturation in the current frame. If you are color correcting an image and you're not sure what colors you need to boost or counteract, looking at the vectorscope can be a huge help.
+
+There are several different views available. You can render the vectorscope in traditional green monochrome (like the hardware vectorscopes you'd find in a broadcast control room), or a chromatic view (my personal preference), or subtracted from a color-wheel background, and more.
+
+The vectorscope reads the entire frame, so unlike the Pr0file filter, you are not just getting a reading of one area in the frame. The result is a consolidated view of what colors are most prominent within a frame. Technically, the same sort of information can be intuited by several trial-and-error passes with color correction, or you can just leave your vectorscope open and watch the colors float along the color wheel and make adjustments accordingly.
+
+Aside from how you want the vectorscope to look, there are no controls for this tool. It is a readout only.
+
+### 8. Vertigo ###
+
+
+
+There's no way around it; **Add Effect > Misc > Vertigo** is a gimmicky special effect filter. So unless you're remaking [Fear and Loathing][5] or the movie adaptation of [Dead Island][6], you probably aren't going to use it that much; however, it's one of those high-quality filters that does the exact trick you want when you happen to be looking for it.
+
+The controls are simple. You can adjust how distorted the image becomes and the rate at which it distorts. The overall effect is probably more drunk or vision-quest than vertigo, but it's good.
+
+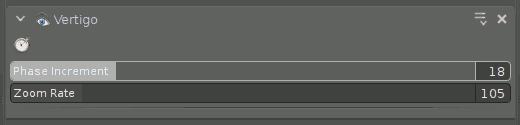
+
+### 9. Vignette ###
+
+
+
+Another beautiful effect, the **Add Effect > Misc > Vignette** darkens the outer edges of the frame to provide a sort of portrait, soft-focus nouveau look. Combined with the Color Effect or the Luminance faux Tri-X trick, this can be a powerful and emotional look.
+
+The softness of the border and the aspect ratio of the iris can be adjusted. The **Clear Center Size** attribute controls the size of the clear area, which has the effect of adjusting the intensity of the vignette effect.
+
+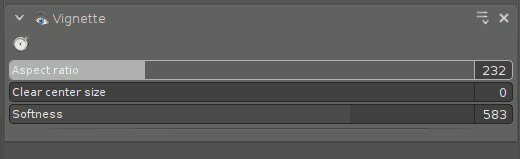
+
+### 10. Volume ###
+
+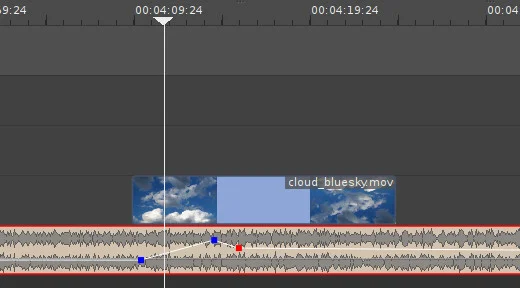
+
+I don't believe in mixing sound within the video editing application, but I do acknowledge that sometimes it's just necessary for a quick fix or, sometimes, even for a tight production schedule. And that's when the **Audio correction > Volume (Keyframable)** effect comes in handy.
+
+The control panel is clunky, and no one really wants to adjust volume that way, so the effect is best when used directly in the timeline. To create a volume change, double-click the volume line over the audio clip, and then click and drag to adjust. It's that simple.
+
+Should you use it? Not really. Sound mixing should be done in a sound mixing application. Will you use it? Absolutely. At some point, you'll get audio that is too loud to play as you edit, or you'll be up against a deadline without a sound engineer in sight. Use it judiciously, watch your levels, and get the show finished.
+
+### Everything else ###
+
+This has been 10 (OK, 13 or 14) effects and tools that Kdenlive has quietly lying around to help your edits become great. Obviously there's a lot more to Kdenlive than just these little tricks. Some are obvious, some are cliché, some are obtuse, but they're all in your toolkit. Get to know them, explore your options, and you might be surprised what a few cheap tricks will get you.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/life/15/12/10-kdenlive-tools
+
+作者:[Seth Kenlon][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/seth
+[1]:https://creativecommons.org/licenses/by-sa/4.0/
+[2]:https://kdenlive.org/
+[3]:http://frei0r.dyne.org/
+[4]:http://www.kodak.com/global/en/professional/products/films/bw/triX2.jhtml
+[5]:https://en.wikipedia.org/wiki/Fear_and_Loathing_in_Las_Vegas_(film)
+[6]:https://en.wikipedia.org/wiki/Dead_Island
\ No newline at end of file
diff --git a/sources/talk/yearbook2015/20151208 5 great Raspberry Pi projects for the classroom.md b/sources/talk/yearbook2015/20151208 5 great Raspberry Pi projects for the classroom.md
new file mode 100644
index 0000000000..c1aa541416
--- /dev/null
+++ b/sources/talk/yearbook2015/20151208 5 great Raspberry Pi projects for the classroom.md
@@ -0,0 +1,96 @@
+5 great Raspberry Pi projects for the classroom
+================================================================================
+
+
+Image by : opensource.com
+
+### 1. Minecraft Pi ###
+
+Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0.][1]
+
+Minecraft is the favorite game of pretty much every teenager in the world—and it's one of the most creative games ever to capture the attention of young people. The version that comes with every Raspberry Pi is not only a creative thinking building game, but comes with a programming interface allowing for additional interaction with the Minecraft world through Python code.
+
+Minecraft: Pi Edition is a great way for teachers to engage students with problem solving and writing code to perform tasks. You can use the Python API to build a house and have it follow you wherever you go, build a bridge wherever you walk, make it rain lava, show the temperature in the sky, and anything else your imagination can create.
+
+Read more in "[Getting Started with Minecraft Pi][2]."
+
+### 2. Reaction game and traffic lights ###
+
+
+
+Courtesy of [Low Voltage Labs][3]. [CC BY-SA 4.0][1].
+
+It's really easy to get started with physical computing on Raspberry Pi—just connect up LEDs and buttons to the GPIO pins, and with a few lines of code you can turn lights on and control things with button presses. Once you know the code to do the basics, it's down to your imagination as to what you do next!
+
+If you know how to flash one light, you can flash three. Pick out three LEDs in traffic light colors and you can code the traffic light sequence. If you know how to use a button to a trigger an event, then you have a pedestrian crossing! Also look out for great pre-built traffic light add-ons like [PI-TRAFFIC][4], [PI-STOP][5], [Traffic HAT][6], and more.
+
+It's not always about the code—this can be used as an exercise in understanding how real world systems are devised. Computational thinking is a useful skill in any walk of life.
+
+
+
+Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0][1].
+
+Next, try wiring up two buttons and an LED and making a two-player reaction game—let the light come on after a random amount of time and see who can press the button first!
+
+To learn more, check out "[GPIO Zero recipes][7]. Everything you need is in [CamJam EduKit 1][8].
+
+### 3. Sense HAT Pixel Pet ###
+
+The Astro Pi—an augmented Raspberry Pi—is going to space this December, but you haven't missed your chance to get your hands on the hardware. The Sense HAT is the sensor board add-on used in the Astro Pi mission and it's available for anyone to buy. You can use it for data collection, science experiments, games and more. Watch this Gurl Geek Diaries video from Raspberry Pi's Carrie Anne for a great way to get started—by bringing to life an animated pixel pet of your own design on the Sense HAT display:
+
+注:youtube 视频
+
+
+Learn more in "[Exploring the Sense HAT][9]."
+
+### 4. Infrared bird box ###
+
+
+Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0.][1]
+
+A great exercise for the whole class to get involved with—place a Raspberry Pi and the NoIR camera module inside a bird box along with some infra-red lights so you can see in the dark, then stream video from the Pi over the network or on the internet. Wait for birds to nest and you can observe them without disturbing them in their habitat.
+
+Learn all about infrared and the light spectrum, and how to adjust the camera focus and control the camera in software.
+
+Learn more in "[Make an infrared bird box.][10]"
+
+### 5. Robotics ###
+
+
+
+Courtesy of Low Voltage Labs. [CC BY-SA 4.0][1].
+
+With a Raspberry Pi and as little as a couple of motors and a motor controller board, you can build your own robot. There is a vast range of robots you can make, from basic buggies held together by sellotape and a homemade chassis, all the way to self-aware, sensor-laden metallic stallions with camera attachments driven by games controllers.
+
+Learn how to control individual motors with something straightforward like the RTK Motor Controller Board (£8/$12), or dive into the new CamJam robotics kit (£17/$25) which comes with motors, wheels and a couple of sensors—great value and plenty of learning potential.
+
+Alternatively, if you'd like something more hardcore, try PiBorg's [4Borg][11] (£99/$150) or [DiddyBorg][12] (£180/$273) or go the whole hog and treat yourself to their DoodleBorg Metal edition (£250/$380)—and build a mini version of their infamous [DoodleBorg tank][13] (unfortunately not for sale).
+
+Check out the [CamJam robotics kit worksheets][14].
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/education/15/12/5-great-raspberry-pi-projects-classroom
+
+作者:[Ben Nuttall][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/bennuttall
+[1]:https://creativecommons.org/licenses/by-sa/4.0/
+[2]:https://opensource.com/life/15/5/getting-started-minecraft-pi
+[3]:http://lowvoltagelabs.com/
+[4]:http://lowvoltagelabs.com/products/pi-traffic/
+[5]:http://4tronix.co.uk/store/index.php?rt=product/product&product_id=390
+[6]:https://ryanteck.uk/hats/1-traffichat-0635648607122.html
+[7]:http://pythonhosted.org/gpiozero/recipes/
+[8]:http://camjam.me/?page_id=236
+[9]:https://opensource.com/life/15/10/exploring-raspberry-pi-sense-hat
+[10]:https://www.raspberrypi.org/learning/infrared-bird-box/
+[11]:https://www.piborg.org/4borg
+[12]:https://www.piborg.org/diddyborg
+[13]:https://www.piborg.org/doodleborg
+[14]:http://camjam.me/?page_id=1035#worksheets
\ No newline at end of file
diff --git a/sources/talk/yearbook2015/20151208 6 creative ways to use ownCloud.md b/sources/talk/yearbook2015/20151208 6 creative ways to use ownCloud.md
new file mode 100644
index 0000000000..969e0637b5
--- /dev/null
+++ b/sources/talk/yearbook2015/20151208 6 creative ways to use ownCloud.md
@@ -0,0 +1,94 @@
+6 creative ways to use ownCloud
+================================================================================
+
+
+Image by : Opensource.com
+
+[ownCloud][1] is a self-hosted open source file sync and share server. Like "big boys" Dropbox, Google Drive, Box, and others, ownCloud lets you access your files, calendar, contacts, and other data. You can synchronize everything (or part of it) between your devices and share files with others. But ownCloud can do much more than its proprietary, [hosted-on-somebody-else's-computer competitors][2].
+
+Let's look at six creative things ownCloud can do. Some of these are possible because ownCloud is open source, whereas others are just unique features it offers.
+
+### 1. A scalable ownCloud Pi cluster ###
+
+Because ownCloud is open source, you can choose between self-hosting on your own server or renting space from a provider you trust—no need to put your files at a big company that stores it who knows where. [Find some ownCloud providers here][3] or grab packages or a virtual machine for [your own server here][4].
+
+
+
+Photo by Jörn Friedrich Dreyer. [CC BY-SA 4.0.][5]
+
+The most creative things we've seen are a [Banana Pi cluster][6] and a [Raspberry Pi cluster][7]. Although ownCloud's scalability is often used to deploy to hundreds of thousands of users, some folks out there take it in a different direction, bringing multiple tiny systems together to make a super-fast ownCloud. Kudos!
+
+### 2. Keep your passwords synced ###
+
+To make ownCloud easier to extend, we have made it extremely modular and have an [ownCloud app store][8]. There you can find things like music and video players, calendars, contacts, productivity apps, games, a sketching app, and much more.
+
+Picking only one app from the almost 200 available is hard, but managing passwords is certainly a unique feature. There are no less than three apps providing this functionality: [Passwords][9], [Secure Container][10], and [Passman][11].
+
+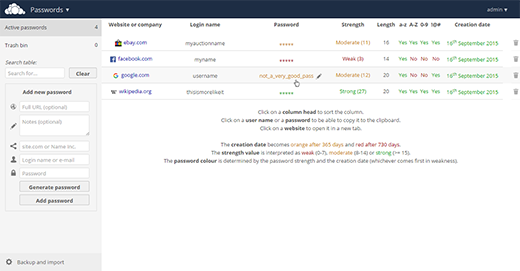
+
+### 3. Store your files where you want ###
+
+External storage allows you to hook your existing data storage into ownCloud, letting you to access files stored on FTP, WebDAV, Amazon S3, and even Dropbox and Google Drive through one interface.
+
+注:youtube 视频
+
+
+The "big boys" like to create their own little walled gardens—Box user can only collaborate with other Box users; and if you want to share your files from Google Drive, your mate needs a Google account or they can't do much. With ownCloud's external storage, you can break these barriers.
+
+A very creative solution is adding Google Drive and Dropbox as external storage. You can work with files on both seamlessly and share them with others through a simple link—no account needed to work with you!
+
+### 4. Get files uploaded ###
+
+Because ownCloud is open source, people contribute interesting features without being limited by corporate requirements. Our contributors have always cared about security and privacy, so ownCloud introduced features such as protecting a public link with a password and setting an expire date [years before anybody else did][12].
+
+Today, ownCloud has the ability to configure a shared link as read-write, which means visitors can seamlessly edit the files you share with them (protected with a password or not) or upload new files to your server without being forced to sign up to another web service that wants their private data.
+
+注:youtube 视频
+
+
+This is great for when people want to share a large file with you. Rather than having to upload it to a third-party site, send you a link, and make you go there and download it (often requiring a login), they can just upload it to a shared folder you provide, and you can get to work right away.
+
+### 5. Get free secure storage ###
+
+We already talked about how many of our contributors care about security and privacy. That's why ownCloud has an app that can encrypt and decrypt stored data.
+
+Using ownCloud to store your files on Dropbox or Google Drive defeats the whole idea of retaking control of your data and keeping it private. The Encryption app changes that. By encrypting data before sending it to these providers and decrypting it upon retrieval, your data is safe as kittens.
+
+### 6. Share your files and stay in control ###
+
+As an open source project, ownCloud has no stake in building walled gardens. Enter Federated Cloud Sharing: a protocol [developed and published by ownCloud][13] that enables different file sync and share servers to talk to one another and exchange files securely. Federated Cloud Sharing has an interesting history. [Twenty-two German universities][14] decided to build a huge cloud for their 500,000 students. But as each university wanted to stay in control of the data of their own students, a creative solution was needed: Federated Cloud Sharing. The solution now connects all these universities so the students can seamlessly work together. At the same time, the system administrators at each university stay in control of the files their students have created and can apply policies, such as storage restrictions, or limitations on what, with whom, and how files can be shared.
+
+注:youtube 视频
+
+
+And this awesome technology isn't limited to German universities: Every ownCloud user can find their [Federated Cloud ID][15] in their user settings and share it with others.
+
+So there you have it. Six ways ownCloud enables people to do special and unique things, all made possible because it is open source and designed to help you liberate your data.
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/life/15/12/6-creative-ways-use-owncloud
+
+作者:[Jos Poortvliet][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jospoortvliet
+[1]:https://owncloud.com/
+[2]:https://blogs.fsfe.org/mk/new-stickers-and-leaflets-no-cloud-and-e-mail-self-defense/
+[3]:https://owncloud.org/providers
+[4]:https://owncloud.org/install/#instructions-server
+[5]:https://creativecommons.org/licenses/by-sa/4.0/
+[6]:http://www.owncluster.de/
+[7]:https://christopherjcoleman.wordpress.com/2013/01/05/host-your-owncloud-on-a-raspberry-pi-cluster/
+[8]:https://apps.owncloud.com/
+[9]:https://apps.owncloud.com/content/show.php/Passwords?content=170480
+[10]:https://apps.owncloud.com/content/show.php/Secure+Container?content=167268
+[11]:https://apps.owncloud.com/content/show.php/Passman?content=166285
+[12]:https://owncloud.com/owncloud45-community/
+[13]:http://karlitschek.de/2015/08/announcing-the-draft-federated-cloud-sharing-api/
+[14]:https://owncloud.com/customer/sciebo/
+[15]:https://owncloud.org/federation/
\ No newline at end of file
diff --git a/sources/talk/yearbook2015/20151208 6 useful LibreOffice extensions.md b/sources/talk/yearbook2015/20151208 6 useful LibreOffice extensions.md
new file mode 100644
index 0000000000..a2c1e393ff
--- /dev/null
+++ b/sources/talk/yearbook2015/20151208 6 useful LibreOffice extensions.md
@@ -0,0 +1,79 @@
+6 useful LibreOffice extensions
+================================================================================
+
+
+Image by : Opensource.com
+
+LibreOffice is the best free office suite around, and as such has been adopted by all major Linux distributions. Although LibreOffice is already packed with features, it can be extended by using specific add-ons, called extensions.
+
+The main LibreOffice extensions website is [extensions.libreoffice.org][1]. Extensions are tools that can be added or removed independently from the main installation, and may add new functionality or make existing functionality easier to use.
+
+### 1. MultiFormatSave ###
+
+MultiFormatSave lets users save a document in the OpenDocument, Microsoft Office (old and new), and/or PDF formats simultaneously, according to user settings. This extension is extremely useful during the migration from Microsoft Office document formats to the [Open Document Format][2] standard, because it offers the option to save in both flavors: ODF for interoperability, and Microsoft Office for compatibility with all users sticking to legacy formats. This makes the migration process softer, and easier to administer.
+
+**[Download MultiFormatSave][3]**
+
+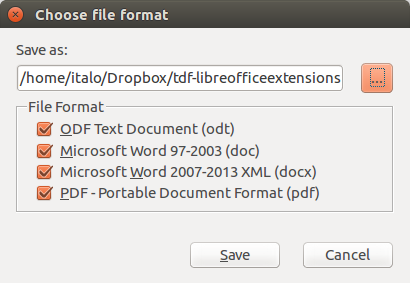
+
+### 2. Alternative dialog Find & Replace for Writer (AltSearch) ###
+
+This extension adds many new features to Writer's find & replace function: searched or replaced text can contain one or more paragraphs; multiple search and replacement in one step; searching: Bookmarks, Notes, Text fields, Cross-references and Reference marks to their content, name or mark and their inserting; searching and inserting Footnote and Endnote; searching object of Table, Pictures and Text frames according to their name; searching out manual page and column break and their set up or deactivation; and searching similarly formatted text, according to cursor point. It is also possible to save and load search and replacement parameters, and execute the batch on several opened documents at the same time.
+
+**[Download Alternative dialog Find & Replace for Writer (AltSearch)][4]**
+
+
+
+### 3. Pepito Cleaner ###
+
+Pepito Cleaner is an extension of LibreOffice created to quickly resolve the most common formatting mistakes of old scans, PDF imports, and every digital text file. By clicking the Pepito Cleaner icon on the LibreOffice toolbar, users will open a window that will analyze the document and show the results broken down by category. This is extremely useful when converting PDF documents to ODF, as it cleans all the cruft left in place by the automatic process.
+
+**[Download Pepito Cleaner][5]**
+
+
+
+### 4. ImpressRunner ###
+
+Impress Runner is a simple extension that transforms an [Impress][6] presentation into an auto-running file. The extension adds two icons, to set and remove the autostart function, which can also be added manually by editing the File | Properties | Custom Properties menu, and adding the term autostart in one of the first four text fields. This extension is especially useful for booths at conferences and events, where the slides are supposed to run unattended.
+
+**[Download ImpressRunner][7]**
+
+### 5. Export as Images ###
+
+The Export as Images extension adds a File menu entry export as Images... in Impress and [Draw][8], to export all slides or pages as images in JPG, PNG, GIF, BMP, and TIFF format, and allows users to choose a file name for exported images, the image size, and other parameters.
+
+**[Download Export as Images][9]**
+
+
+
+### 6. Anaphraseus ###
+
+Anaphraseus is a CAT (Computer-Aided Translation) tool for creating, managing, and using bilingual Translation Memories. Anaphraseus is a LibreOffice macro set available as an extension or a standalone document. Originally, Anaphraseus was developed to work with the Wordfast format, but it can also export and import files in TMX format. Anaphraseus main features are: text segmentation, fuzzy search in Translation Memory, terminology recognition, and TMX Export/Import (OmegaT translation memory format).
+
+**[Download Anaphraseus][10]**
+
+
+
+Do you have a favorite LibreOffice extension to recommend? Let us know about it in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/business/15/12/6-useful-libreoffice-extensions
+
+作者:[Italo Vignoli][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/italovignoli
+[1]:http://extensions.libreoffice.org/
+[2]:http://www.opendocumentformat.org/
+[3]:http://extensions.libreoffice.org/extension-center/multisave-1
+[4]:http://extensions.libreoffice.org/extension-center/alternative-dialog-find-replace-for-writer
+[5]:http://pepitoweb.altervista.org/pepito_cleaner/index.php
+[6]:https://www.libreoffice.org/discover/impress/
+[7]:http://extensions.libreoffice.org/extension-center/impressrunner
+[8]:https://www.libreoffice.org/discover/draw/
+[9]:http://extensions.libreoffice.org/extension-center/export-as-images
+[10]:http://anaphraseus.sourceforge.net/
\ No newline at end of file
diff --git a/sources/talk/yearbook2015/20151208 Top 5 open source community metrics to track.md b/sources/talk/yearbook2015/20151208 Top 5 open source community metrics to track.md
new file mode 100644
index 0000000000..5098151775
--- /dev/null
+++ b/sources/talk/yearbook2015/20151208 Top 5 open source community metrics to track.md
@@ -0,0 +1,79 @@
+Top 5 open source community metrics to track
+================================================================================
+
+
+So you decided to use metrics to track your free, open source software (FOSS) community. Now comes the big question: Which metrics should I be tracking?
+
+To answer this question, you must have an idea of what information you need. For example, you may want to know about the sustainability of the project community. How quickly does the community react to problems? How is the community attracting, retaining, or losing contributors? Once you decide which information you need, you can figure out which traces of community activity are available to provide it. Fortunately, FOSS projects following an open development model tend to leave loads of public data in their software development repositories, which can be analyzed to gather useful data.
+
+In this article, I'll introduce metrics that help provide a multi-faceted view of your project community.
+
+### 1. Activity ###
+
+The overall activity of the community and how it evolves over time is a useful metric for all open source communities. Activity provides a first view of how much the community is doing, and can be used to track different kinds of activity. For example, the number of commits gives a first idea about the volume of the development effort. The number of tickets opened provides insight into how many bugs are reported or new features are proposed. The number of messages in mailing lists or posts in forums gives an idea of how much discussion is being held in public.
+
+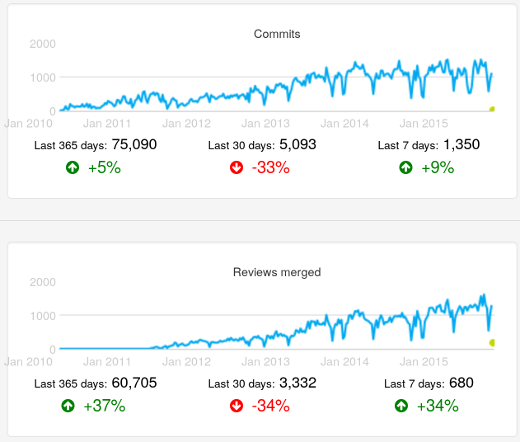
+
+Number of commits and number of merged changes after code review in the OpenStack project, as found in the [OpenStack Activity Dashboard][1]. Evolution over time (weekly data).
+
+### 2. Size ###
+
+The size of the community is the number of people participating in it, but, depending on the kind of participation, size numbers may vary. Usually you're interested in active contributors, which is good news. Active people may leave traces in the repositories of the project, which means you can count contributors who are active in producing code by looking at the **Author** field in git repositories, or count people participating in the resolution of tickets by looking at who is contributing to them.
+
+This basic idea of activity" (somebody did something) can be extended in many ways. One common way to track activity is to look at how many people did a sizable chunk of the activity. Generally most of a project's code contributions, for example, are from a small fraction of the people in the project's community. Knowing about that fraction helps provide an idea of the core group (i.e., the people who help lead the community).
+
+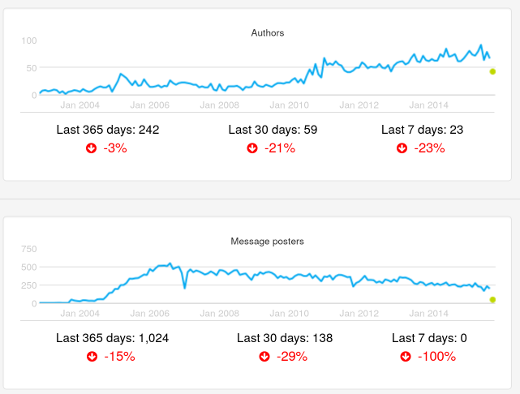
+
+Number of authors and number of posters in mailing lists in the Xen project, as found in the [Xen Project Development Dashboard][2]. Evolution over time (monthly data).
+
+### 3. Performance ###
+
+So far, I have focused on measuring quantities of activities and contributors. You also can analyze how processes and people are performing. For example, you can measure how long processes take to finish. Time to resolve or close tickets shows how the project is reacting to new information that requires action, such as fixing a reported bug or implementing a requested new feature. Time spent in code review—from the moment when a change to the code is proposed to the moment it is accepted—shows how long upgrading a proposed change to the quality standards expected by the community takes.
+
+Other metrics deal with how well the project is coping with pending work, such as the ratio of new to closed tickets, or the backlog of still non-completed code reviews. Those parameters tell us, for example, whether or not the resources put into solving issues is enough.
+
+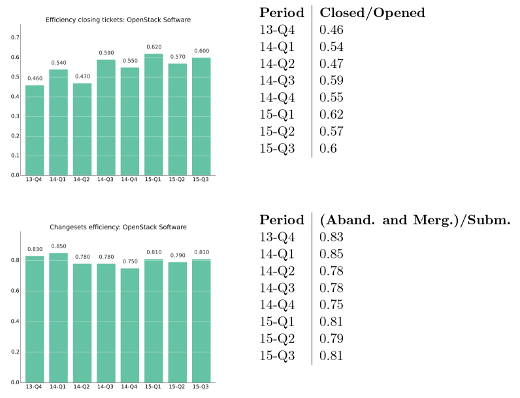
+
+Ratio of tickets closed by tickets opened, and ratio of change proposals accepted or abandoned by new change proposals per quarter. OpenStack project, as shown in the [OpenStack Development Report, 2015-Q3][3] (PDF).
+
+### 4. Demographics ###
+
+Communities change as contributors move in and out. Depending on how people enter and leave a community over time, the age (time since members joined the community) of the community varies. The [community aging chart][4] nicely illustrates these exchanges over time. The chart is structured as a set of horizontal bars, two per "generation" of people joining the community. For each generation, the attracted bar shows how many new people joined the community during the corresponding period of time. The retained bar shows how many people are still active in the community.
+
+The relationship between the two bars for each generation is the retention rate: the fraction of people of that generation who are still in the project. The complete set of attracted bars show how attractive the project was in the past. And the complete set of the retention bars shows the current age structure of the community.
+
+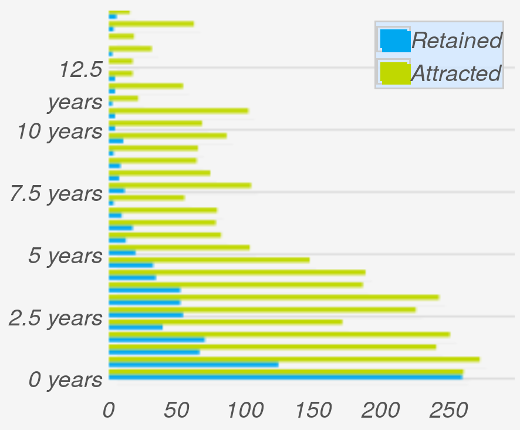
+
+Community aging chart for the Eclipse community, as shown in the [Eclipse Development Dashboard][5]. Generations are defined every six months.
+
+### 5. Diversity ###
+
+Diversity is an important factor in the resiliency of communities. In general, the more diverse communities are—in terms of people or organizations participating—the more resilient they are. For example, when a company decides to leave a FOSS community, the potential problems the departure may cause are much smaller if its employees were contributing 5% of the work rather than 85%.
+
+The [Pony Factor][6], a term defined by [Daniel Gruno][7] for the minimum number of developers performing 50% of the commits. Based on the Pony Factor, the Elephant Factor is the minimum number of companies whose employees perform 50% of the commits. Both numbers provide an indication of how many people or companies the community depends on.
+
+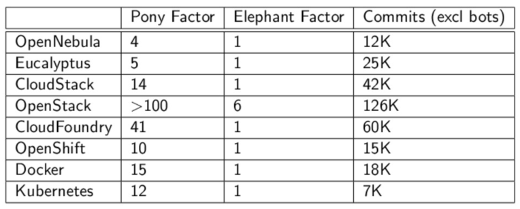
+
+Pony and Elephant Factor for several FOSS projects in the area of cloud computing, as presented in [The quantitative state of the open cloud 2015][8] (slides).
+
+There are many other metrics to help measure a community. When determing which metrics to collect, think about the goals of your community, and which metrics will help you reach them.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/business/15/12/top-5-open-source-community-metrics-track
+
+作者:[Jesus M. Gonzalez-Barahona][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jgbarah
+[1]:http://activity.openstack.org/
+[2]:http://projects.bitergia.com/xen-project-dashboard/
+[3]:http://activity.openstack.org/dash/reports/2015-q3/pdf/2015-q3_OpenStack_report.pdf
+[4]:http://radar.oreilly.com/2014/10/measure-your-open-source-communitys-age-to-keep-it-healthy.html
+[5]:http://dashboard.eclipse.org/demographics.html
+[6]:https://ke4qqq.wordpress.com/2015/02/08/pony-factor-math/
+[7]:https://twitter.com/humbedooh
+[8]:https://speakerdeck.com/jgbarah/the-quantitative-state-of-the-open-cloud-2015-edition
\ No newline at end of file
diff --git a/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md b/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md
deleted file mode 100644
index 2a8bdb2fbd..0000000000
--- a/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md
+++ /dev/null
@@ -1,159 +0,0 @@
-How to Install and Configure Multihomed ISC DHCP Server on Debian Linux
-================================================================================
-Dynamic Host Control Protocol (DHCP) offers an expedited method for network administrators to provide network layer addressing to hosts on a constantly changing, or dynamic, network. One of the most common server utilities to offer DHCP functionality is ISC DHCP Server. The goal of this service is to provide hosts with the necessary network information to be able to communicate on the networks in which the host is connected. Information that is typically served by this service can include: DNS server information, network address (IP), subnet mask, default gateway information, hostname, and much more.
-
-This tutorial will cover ISC-DHCP-Server version 4.2.4 on a Debian 7.7 server that will manage multiple virtual local area networks (VLAN) but can very easily be applied to a single network setup as well.
-
-The test network that this server was setup on has traditionally relied on a Cisco router to manage the DHCP address leases. The network currently has 12 VLANs needing to be managed by one centralized server. By moving this responsibility to a dedicated server, the router can regain resources for more important tasks such as routing, access control lists, traffic inspection, and network address translation.
-
-The other benefit to moving DHCP to a dedicated server will, in a later guide, involve setting up Dynamic Domain Name Service (DDNS) so that new host’s host-names will be added to the DNS system when the host requests a DHCP address from the server.
-
-### Step 1: Installing and Configuring ISC DHCP Server ###
-
-1. To start the process of creating this multi-homed server, the ISC software needs to be installed via the Debian repositories using the ‘apt‘ utility. As with all tutorials, root or sudo access is assumed. Please make the appropriate modifications to the following commands.
-
- # apt-get install isc-dhcp-server [Installs the ISC DHCP Server software]
- # dpkg --get-selections isc-dhcp-server [Confirms successful installation]
- # dpkg -s isc-dhcp-server [Alternative confirmation of installation]
-
-
-
-2. Now that the server software is confirmed installed, it is now necessary to configure the server with the network information that it will need to hand out. At the bare minimum, the administrator needs to know the following information for a basic DHCP scope:
-
-- The network addresses
-- The subnet masks
-- The range of addresses to be dynamically assigned
-
-Other useful information to have the server dynamically assign includes:
-
-- Default gateway
-- DNS server IP addresses
-- The Domain Name
-- Host name
-- Network Broadcast addresses
-
-These are merely a few of the many options that the ISC DHCP server can handle. To get a complete list as well as a description of each option, enter the following command after installing the package:
-
- # man dhcpd.conf
-
-3. Once the administrator has concluded all the necessary information for this server to hand out it is time to configure the DHCP server as well as the necessary pools. Before creating any pools or server configurations though, the DHCP service must be configured to listen on one of the server’s interfaces.
-
-On this particular server, a NIC team has been setup and DHCP will listen on the teamed interfaces which were given the name `'bond0'`. Be sure to make the appropriate changes given the server and environment in which everything is being configured. The defaults in this file are okay for this tutorial.
-
-
-
-This line will instruct the DHCP service to listen for DHCP traffic on the specified interface(s). At this point, it is time to modify the main configuration file to enable the DHCP pools on the necessary networks. The main configuration file is located at /etc/dhcp/dhcpd.conf. Open the file with a text editor to begin:
-
- # nano /etc/dhcp/dhcpd.conf
-
-This file is the configuration for the DHCP server specific options as well as all of the pools/hosts one wishes to configure. The top of the file starts of with a ‘ddns-update-style‘ clause and for this tutorial it will remain set to ‘none‘ however in a future article, Dynamic DNS will be covered and ISC-DHCP-Server will be integrated with BIND9 to enable host name to IP address updates.
-
-4. The next section is typically the area where and administrator can configure global network settings such as the DNS domain name, default lease time for IP addresses, subnet-masks, and much more. Again to know more about all the options be sure to read the man page for the dhcpd.conf file.
-
- # man dhcpd.conf
-
-For this server install, there were a couple of global network options that were configured at the top of the configuration file so that they wouldn’t have to be implemented in every single pool created.
-
-
-
-Lets take a moment to explain some of these options. While they are configured globally in this example, all of them can be configured on a per pool basis as well.
-
-- option domain-name “comptech.local”; – All hosts that this DHCP server hosts, will be a member of the DNS domain name “comptech.local”
-- option domain-name-servers 172.27.10.6; DHCP will hand out DNS server IP of 172.27.10.6 to all of the hosts on all of the networks it is configured to host.
-- option subnet-mask 255.255.255.0; – The subnet mask handed out to every network will be a 255.255.255.0 or a /24
-- default-lease-time 3600; – This is the time in seconds that a lease will automatically be valid. The host can re-request the same lease if time runs out or if the host is done with the lease, they can hand the address back early.
-- max-lease-time 86400; – This is the maximum amount of time in seconds a lease can be held by a host.
-- ping-check true; – This is an extra test to ensure that the address the server wants to assign out isn’t in use by another host on the network already.
-- ping-timeout; – This is how long in second the server will wait for a response to a ping before assuming the address isn’t in use.
-- ignore client-updates; For now this option is irrelevant since DDNS has been disabled earlier in the configuration file but when DDNS is operating, this option will ignore a hosts to request to update its host-name in DNS.
-
-5. The next line in this file is the authoritative DHCP server line. This line means that if this server is to be the server that hands out addresses for the networks configured in this file, then uncomment the authoritative stanza.
-
-This server will be the only authority on all the networks it manages so the global authoritative stanza was un-commented by removing the ‘#’ in front of the keyword authoritative.
-
-
-Enable ISC Authoritative
-
-By default the server is assumed to NOT be an authority on the network. The rationale behind this is security. If someone unknowingly configures the DHCP server improperly or on a network they shouldn’t, it could cause serious connectivity issues. This line can also be used on a per network basis. This means that if the server is not the entire network’s DHCP server, the authoritative line can instead be used on a per network basis rather than in the global configuration as seen in the above screen-shot.
-
-6. The next step is to configure all of the DHCP pools/networks that this server will manage. For brevities sake, this guide will only walk through one of the pools configured. The administrator will need to have gathered all of the necessary network information (ie domain name, network addresses, how many addresses can be handed out, etc).
-
-For this pool the following information was obtained from the network administrator: network id of 172.27.60.0, subnet mask of 255.255.255.0 or a /24, the default gateway for the subnet is 172.27.60.1, and a broadcast address of 172.27.60.255.
-This information is important to building the appropriate network stanza in the dhcpd.conf file. Without further ado, let’s open the configuration file again using a text editor and then add the new network to the server. This must be done with root/sudo!
-
- # nano /etc/dhcp/dhcpd.conf
-
-
-Configure DHCP Pools and Networks
-
-This is the sample created to hand out IP addresses to a network that is used for the creation of VMWare virtual practice servers. The first line indicates the network as well as the subnet mask for that network. Then inside the brackets are all the options that the DHCP server should provide to hosts on this network.
-
-The first stanza, range 172.27.60.50 172.27.60.254;, is the range of dynamically assignable addresses that the DHCP server can hand out to hosts on this network. Notice that the first 49 addresses aren’t in the pool and can be assigned statically to hosts if needed.
-
-The second stanza, option routers 172.27.60.1; , hands out the default gateway address for all hosts on this network.
-
-The last stanza, option broadcast-address 172.27.60.255;, indicates what the network’s broadcast address. This address SHOULD NOT be a part of the range stanza as the broadcast address can’t be assigned to a host.
-
-Some pointers, be sure to always end the option lines with a semi-colon (;) and always make sure each network created is enclosed in curly braces { }.
-
-7. If there are more networks to create, continue creating them with their appropriate options and then save the text file. Once all configurations have been completed, the ISC-DHCP-Server process will need to be restarted in order to apply the new changes. This can be accomplished with the following command:
-
- # service isc-dhcp-server restart
-
-This will restart the DHCP service and then the administrator can check to see if the server is ready for DHCP requests several different ways. The easiest is to simply see if the server is listening on port 67 via the [lsof command][1]:
-
- # lsof -i :67
-
-
-Check DHCP Listening Port
-
-This output indicates that the DHCPD (DHCP Server daemon) is running and listening on port 67. Port 67 in this output was actually converted to ‘bootps‘ due to a port number mapping for port 67 in /etc/services file.
-
-This is very common on most systems. At this point, the server should be ready for network connectivity and can be confirmed by connecting a machine to the network and having it request a DHCP address from the server.
-
-### Step 2: Testing Client Connectivity ###
-
-8. Most systems now-a-days are using Network Manager to maintain network connections and as such the device should be pre-configured to pull DHCP when the interface is active.
-
-However on machines that aren’t using Network Manager, it may be necessary to manually attempt to pull a DHCP address. The next few steps will show how to do this as well as how to see whether the server is handing out addresses.
-
-The ‘[ifconfig][2]‘ utility can be used to check an interface’s configuration. The machine used to test the DHCP server only has one network adapter and it is called ‘eth0‘.
-
- # ifconfig eth0
-
-
-Check Network Interface IP Address
-
-From this output, this machine currently doesn’t have an IPv4 address, great! Let’s instruct this machine to reach out to the DHCP server and request an address. This machine has the DHCP client utility known as ‘dhclient‘ installed. The DHCP client utility may very from system to system.
-
- # dhclient eth0
-
-
-Request IP Address from DHCP
-
-Now the `'inet addr:'` field shows an IPv4 address that falls within the scope of what was configured for the 172.27.60.0 network. Also notice that the proper broadcast address was handed out as well as subnet mask for this network.
-
-Things are looking promising but let’s check the server to see if it was actually the place where this machine received this new IP address. To accomplish this task, the server’s system log file will be consulted. While the entire log file may contain hundreds of thousands of entries, only a few are necessary for confirming that the server is working properly. Rather than using a full text editor, this time a utility known as ‘tail‘ will be used to only show the last few lines of the log file.
-
- # tail /var/log/syslog
-
-
-Check DHCP Logs
-
-Voila! The server recorded handing out an address to this host (HRTDEBXENSRV). It is a safe assumption at this point that the server is working as intended and handing out the appropriate addresses for the networks that it is an authority. At this point the DHCP server is up and running. Configure the other networks, troubleshoot, and secure as necessary.
-
-Enjoy the newly functioning ISC-DHCP-Server and tune in later for more Debian tutorials. In the not too distant future there will be an article on Bind9 and DDNS that will tie into this article.
-
---------------------------------------------------------------------------------
-
-via: http://www.tecmint.com/install-and-configure-multihomed-isc-dhcp-server-on-debian-linux/
-
-作者:[Rob Turner][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.tecmint.com/author/robturner/
-[1]:http://www.tecmint.com/10-lsof-command-examples-in-linux/
-[2]:http://www.tecmint.com/ifconfig-command-examples/
\ No newline at end of file
diff --git a/sources/tech/20150806 Installation Guide for Puppet on Ubuntu 15.04.md b/sources/tech/20150806 Installation Guide for Puppet on Ubuntu 15.04.md
deleted file mode 100644
index ae8df117ef..0000000000
--- a/sources/tech/20150806 Installation Guide for Puppet on Ubuntu 15.04.md
+++ /dev/null
@@ -1,429 +0,0 @@
-Installation Guide for Puppet on Ubuntu 15.04
-================================================================================
-Hi everyone, today in this article we'll learn how to install puppet to manage your server infrastructure running ubuntu 15.04. Puppet is an open source software configuration management tool which is developed and maintained by Puppet Labs that allows us to automate the provisioning, configuration and management of a server infrastructure. Whether we're managing just a few servers or thousands of physical and virtual machines to orchestration and reporting, puppet automates tasks that system administrators often do manually which frees up time and mental space so sysadmins can work on improving other aspects of your overall setup. It ensures consistency, reliability and stability of the automated jobs processed. It facilitates closer collaboration between sysadmins and developers, enabling more efficient delivery of cleaner, better-designed code. Puppet is available in two solutions configuration management and data center automation. They are **puppet open source and puppet enterprise**. Puppet open source is a flexible, customizable solution available under the Apache 2.0 license, designed to help system administrators automate the many repetitive tasks they regularly perform. Whereas puppet enterprise edition is a proven commercial solution for diverse enterprise IT environments which lets us get all the benefits of open source puppet, plus puppet apps, commercial-only enhancements, supported modules and integrations, and the assurance of a fully supported platform. Puppet uses SSL certificates to authenticate communication between master and agent nodes.
-
-In this tutorial, we will cover how to install open source puppet in an agent and master setup running ubuntu 15.04 linux distribution. Here, Puppet master is a server from where all the configurations will be controlled and managed and all our remaining servers will be puppet agent nodes, which is configured according to the configuration of puppet master server. Here are some easy steps to install and configure puppet to manage our server infrastructure running Ubuntu 15.04.
-
-### 1. Setting up Hosts ###
-
-In this tutorial, we'll use two machines, one as puppet master server and another as puppet node agent both running ubuntu 15.04 "Vivid Vervet" in both the machines. Here is the infrastructure of the server that we're gonna use for this tutorial.
-
-puppet master server with IP 44.55.88.6 and hostname : puppetmaster
-puppet node agent with IP 45.55.86.39 and hostname : puppetnode
-
-Now we'll add the entry of the machines to /etc/hosts on both machines node agent and master server.
-
- # nano /etc/hosts
-
- 45.55.88.6 puppetmaster.example.com puppetmaster
- 45.55.86.39 puppetnode.example.com puppetnode
-
-Please note that the Puppet Master server must be reachable on port 8140. So, we'll need to open port 8140 in it.
-
-### 2. Updating Time with NTP ###
-
-As puppet nodes needs to maintain accurate system time to avoid problems when it issues agent certificates. Certificates can appear to be expired if there is time difference, the time of the both the master and the node agent must be synced with each other. To sync the time, we'll update the time with NTP. To do so, here's the command below that we need to run on both master and node agent.
-
- # ntpdate pool.ntp.org
-
- 17 Jun 00:17:08 ntpdate[882]: adjust time server 66.175.209.17 offset -0.001938 sec
-
-Now, we'll update our local repository index and install ntp as follows.
-
- # apt-get update && sudo apt-get -y install ntp ; service ntp restart
-
-### 3. Puppet Master Package Installation ###
-
-There are many ways to install open source puppet. In this tutorial, we'll download and install a debian binary package named as **puppetlabs-release** packaged by the Puppet Labs which will add the source of the **puppetmaster-passenger** package. The puppetmaster-passenger includes the puppet master with apache web server. So, we'll now download the Puppet Labs package.
-
- # cd /tmp/
- # wget https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
-
- --2015-06-17 00:19:26-- https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
- Resolving apt.puppetlabs.com (apt.puppetlabs.com)... 192.155.89.90, 2600:3c03::f03c:91ff:fedb:6b1d
- Connecting to apt.puppetlabs.com (apt.puppetlabs.com)|192.155.89.90|:443... connected.
- HTTP request sent, awaiting response... 200 OK
- Length: 7384 (7.2K) [application/x-debian-package]
- Saving to: ‘puppetlabs-release-trusty.deb’
-
- puppetlabs-release-tr 100%[===========================>] 7.21K --.-KB/s in 0.06s
-
- 2015-06-17 00:19:26 (130 KB/s) - ‘puppetlabs-release-trusty.deb’ saved [7384/7384]
-
-After the download has been completed, we'll wanna install the package.
-
- # dpkg -i puppetlabs-release-trusty.deb
-
- Selecting previously unselected package puppetlabs-release.
- (Reading database ... 85899 files and directories currently installed.)
- Preparing to unpack puppetlabs-release-trusty.deb ...
- Unpacking puppetlabs-release (1.0-11) ...
- Setting up puppetlabs-release (1.0-11) ...
-
-Then, we'll update the local respository index with the server using apt package manager.
-
- # apt-get update
-
-Then, we'll install the puppetmaster-passenger package by running the below command.
-
- # apt-get install puppetmaster-passenger
-
-**Note**: While installing we may get an error **Warning: Setting templatedir is deprecated. See http://links.puppetlabs.com/env-settings-deprecations (at /usr/lib/ruby/vendor_ruby/puppet/settings.rb:1139:in `issue_deprecation_warning')** but we no need to worry, we'll just simply ignore this as it says that the templatedir is deprecated so, we'll simply disbale that setting in the configuration. :)
-
-To check whether puppetmaster has been installed successfully in our Master server not not, we'll gonna try to check its version.
-
- # puppet --version
-
- 3.8.1
-
-We have successfully installed puppet master package in our puppet master box. As we are using passenger with apache, the puppet master process is controlled by apache server, that means it runs when apache is running.
-
-Before continuing, we'll need to stop the Puppet master by stopping the apache2 service.
-
- # systemctl stop apache2
-
-### 4. Master version lock with Apt ###
-
-As We have puppet version as 3.8.1, we need to lock the puppet version update as this will mess up the configurations while updating the puppet. So, we'll use apt's locking feature for that. To do so, we'll need to create a new file **/etc/apt/preferences.d/00-puppet.pref** using our favorite text editor.
-
- # nano /etc/apt/preferences.d/00-puppet.pref
-
-Then, we'll gonna add the entries in the newly created file as:
-
- # /etc/apt/preferences.d/00-puppet.pref
- Package: puppet puppet-common puppetmaster-passenger
- Pin: version 3.8*
- Pin-Priority: 501
-
-Now, it will not update the puppet while running updates in the system.
-
-### 5. Configuring Puppet Config ###
-
-Puppet master acts as a certificate authority and must generate its own certificates which is used to sign agent certificate requests. First of all, we'll need to remove any existing SSL certificates that were created during the installation of package. The default location of puppet's SSL certificates is /var/lib/puppet/ssl. So, we'll remove the entire ssl directory using rm command.
-
- # rm -rf /var/lib/puppet/ssl
-
-Then, we'll configure the certificate. While creating the puppet master's certificate, we need to include every DNS name at which agent nodes can contact the master at. So, we'll edit the master's puppet.conf using our favorite text editor.
-
- # nano /etc/puppet/puppet.conf
-
-The output seems as shown below.
-
- [main]
- logdir=/var/log/puppet
- vardir=/var/lib/puppet
- ssldir=/var/lib/puppet/ssl
- rundir=/var/run/puppet
- factpath=$vardir/lib/facter
- templatedir=$confdir/templates
-
- [master]
- # These are needed when the puppetmaster is run by passenger
- # and can safely be removed if webrick is used.
- ssl_client_header = SSL_CLIENT_S_DN
- ssl_client_verify_header = SSL_CLIENT_VERIFY
-
-Here, we'll need to comment the templatedir line to disable the setting as it has been already depreciated. After that, we'll add the following line at the end of the file under [main].
-
- server = puppetmaster
- environment = production
- runinterval = 1h
- strict_variables = true
- certname = puppetmaster
- dns_alt_names = puppetmaster, puppetmaster.example.com
-
-This configuration file has many options which might be useful in order to setup own configuration. A full description of the file is available at Puppet Labs [Main Config File (puppet.conf)][1].
-
-After editing the file, we'll wanna save that and exit.
-
-Now, we'll gonna generate a new CA certificates by running the following command.
-
- # puppet master --verbose --no-daemonize
-
- Info: Creating a new SSL key for ca
- Info: Creating a new SSL certificate request for ca
- Info: Certificate Request fingerprint (SHA256): F6:2F:69:89:BA:A5:5E:FF:7F:94:15:6B:A7:C4:20:CE:23:C7:E3:C9:63:53:E0:F2:76:D7:2E:E0:BF:BD:A6:78
- ...
- Notice: puppetmaster has a waiting certificate request
- Notice: Signed certificate request for puppetmaster
- Notice: Removing file Puppet::SSL::CertificateRequest puppetmaster at '/var/lib/puppet/ssl/ca/requests/puppetmaster.pem'
- Notice: Removing file Puppet::SSL::CertificateRequest puppetmaster at '/var/lib/puppet/ssl/certificate_requests/puppetmaster.pem'
- Notice: Starting Puppet master version 3.8.1
- ^CNotice: Caught INT; storing stop
- Notice: Processing stop
-
-Now, the certificate is being generated. Once we see **Notice: Starting Puppet master version 3.8.1**, the certificate setup is complete. Then we'll press CTRL-C to return to the shell.
-
-If we wanna look at the cert information of the certificate that was just created, we can get the list by running in the following command.
-
- # puppet cert list -all
-
- + "puppetmaster" (SHA256) 33:28:97:86:A1:C3:2F:73:10:D1:FB:42:DA:D5:42:69:71:84:F0:E2:8A:01:B9:58:38:90:E4:7D:B7:25:23:EC (alt names: "DNS:puppetmaster", "DNS:puppetmaster.example.com")
-
-### 6. Creating a Puppet Manifest ###
-
-The default location of the main manifest is /etc/puppet/manifests/site.pp. The main manifest file contains the definition of configuration that is used to execute in the puppet node agent. Now, we'll create the manifest file by running the following command.
-
- # nano /etc/puppet/manifests/site.pp
-
-Then, we'll add the following lines of configuration in the file that we just opened.
-
- # execute 'apt-get update'
- exec { 'apt-update': # exec resource named 'apt-update'
- command => '/usr/bin/apt-get update' # command this resource will run
- }
-
- # install apache2 package
- package { 'apache2':
- require => Exec['apt-update'], # require 'apt-update' before installing
- ensure => installed,
- }
-
- # ensure apache2 service is running
- service { 'apache2':
- ensure => running,
- }
-
-The above lines of configuration are responsible for the deployment of the installation of apache web server across the node agent.
-
-### 7. Starting Master Service ###
-
-We are now ready to start the puppet master. We can start it by running the apache2 service.
-
- # systemctl start apache2
-
-Here, our puppet master is running, but it isn't managing any agent nodes yet. Now, we'll gonna add the puppet node agents to the master.
-
-**Note**: If you get an error **Job for apache2.service failed. See "systemctl status apache2.service" and "journalctl -xe" for details.** then it must be that there is some problem with the apache server. So, we can see the log what exactly has happened by running **apachectl start** under root or sudo mode. Here, while performing this tutorial, we got a misconfiguration of the certificates under **/etc/apache2/sites-enabled/puppetmaster.conf** file. We replaced **SSLCertificateFile /var/lib/puppet/ssl/certs/server.pem with SSLCertificateFile /var/lib/puppet/ssl/certs/puppetmaster.pem** and commented **SSLCertificateKeyFile** line. Then we'll need to rerun the above command to run apache server.
-
-### 8. Puppet Agent Package Installation ###
-
-Now, as we have our puppet master ready and it needs an agent to manage, we'll need to install puppet agent into the nodes. We'll need to install puppet agent in every nodes in our infrastructure we want puppet master to manage. We'll need to make sure that we have added our node agents in the DNS. Now, we'll gonna install the latest puppet agent in our agent node ie. puppetnode.example.com .
-
-We'll run the following command to download the Puppet Labs package in our puppet agent nodes.
-
- # cd /tmp/
- # wget https://apt.puppetlabs.com/puppetlabs-release-trusty.deb\
-
- --2015-06-17 00:54:42-- https://apt.puppetlabs.com/puppetlabs-release-trusty.deb
- Resolving apt.puppetlabs.com (apt.puppetlabs.com)... 192.155.89.90, 2600:3c03::f03c:91ff:fedb:6b1d
- Connecting to apt.puppetlabs.com (apt.puppetlabs.com)|192.155.89.90|:443... connected.
- HTTP request sent, awaiting response... 200 OK
- Length: 7384 (7.2K) [application/x-debian-package]
- Saving to: ‘puppetlabs-release-trusty.deb’
-
- puppetlabs-release-tr 100%[===========================>] 7.21K --.-KB/s in 0.04s
-
- 2015-06-17 00:54:42 (162 KB/s) - ‘puppetlabs-release-trusty.deb’ saved [7384/7384]
-
-Then, as we're running ubuntu 15.04, we'll use debian package manager to install it.
-
- # dpkg -i puppetlabs-release-trusty.deb
-
-Now, we'll gonna update the repository index using apt-get.
-
- # apt-get update
-
-Finally, we'll gonna install the puppet agent directly from the remote repository.
-
- # apt-get install puppet
-
-Puppet agent is always disabled by default, so we'll need to enable it. To do so we'll need to edit /etc/default/puppet file using a text editor.
-
- # nano /etc/default/puppet
-
-Then, we'll need to change value of **START** to "yes" as shown below.
-
- START=yes
-
-Then, we'll need to save and exit the file.
-
-### 9. Agent Version Lock with Apt ###
-
-As We have puppet version as 3.8.1, we need to lock the puppet version update as this will mess up the configurations while updating the puppet. So, we'll use apt's locking feature for that. To do so, we'll need to create a file /etc/apt/preferences.d/00-puppet.pref using our favorite text editor.
-
- # nano /etc/apt/preferences.d/00-puppet.pref
-
-Then, we'll gonna add the entries in the newly created file as:
-
- # /etc/apt/preferences.d/00-puppet.pref
- Package: puppet puppet-common
- Pin: version 3.8*
- Pin-Priority: 501
-
-Now, it will not update the Puppet while running updates in the system.
-
-### 10. Configuring Puppet Node Agent ###
-
-Next, We must make a few configuration changes before running the agent. To do so, we'll need to edit the agent's puppet.conf
-
- # nano /etc/puppet/puppet.conf
-
-It will look exactly like the Puppet master's initial configuration file.
-
-This time also we'll comment the **templatedir** line. Then we'll gonna delete the [master] section, and all of the lines below it.
-
-Assuming that the puppet master is reachable at "puppet-master", the agent should be able to connect to the master. If not we'll need to use its fully qualified domain name ie. puppetmaster.example.com .
-
- [agent]
- server = puppetmaster.example.com
- certname = puppetnode.example.com
-
-After adding this, it will look alike this.
-
- [main]
- logdir=/var/log/puppet
- vardir=/var/lib/puppet
- ssldir=/var/lib/puppet/ssl
- rundir=/var/run/puppet
- factpath=$vardir/lib/facter
- #templatedir=$confdir/templates
-
- [agent]
- server = puppetmaster.example.com
- certname = puppetnode.example.com
-
-After done with that, we'll gonna save and exit it.
-
-Next, we'll wanna start our latest puppet agent in our Ubuntu 15.04 nodes. To start our puppet agent, we'll need to run the following command.
-
- # systemctl start puppet
-
-If everything went as expected and configured properly, we should not see any output displayed by running the above command. When we run an agent for the first time, it generates an SSL certificate and sends a request to the puppet master then if the master signs the agent's certificate, it will be able to communicate with the agent node.
-
-**Note**: If you are adding your first node, it is recommended that you attempt to sign the certificate on the puppet master before adding your other agents. Once you have verified that everything works properly, then you can go back and add the remaining agent nodes further.
-
-### 11. Signing certificate Requests on Master ###
-
-While puppet agent runs for the first time, it generates an SSL certificate and sends a request for signing to the master server. Before the master will be able to communicate and control the agent node, it must sign that specific agent node's certificate.
-
-To get the list of the certificate requests, we'll run the following command in the puppet master server.
-
- # puppet cert list
-
- "puppetnode.example.com" (SHA256) 31:A1:7E:23:6B:CD:7B:7D:83:98:33:8B:21:01:A6:C4:01:D5:53:3D:A0:0E:77:9A:77:AE:8F:05:4A:9A:50:B2
-
-As we just setup our first agent node, we will see one request. It will look something like the following, with the agent node's Domain name as the hostname.
-
-Note that there is no + in front of it which indicates that it has not been signed yet.
-
-Now, we'll go for signing a certification request. In order to sign a certification request, we should simply run **puppet cert sign** with the **hostname** as shown below.
-
- # puppet cert sign puppetnode.example.com
-
- Notice: Signed certificate request for puppetnode.example.com
- Notice: Removing file Puppet::SSL::CertificateRequest puppetnode.example.com at '/var/lib/puppet/ssl/ca/requests/puppetnode.example.com.pem'
-
-The Puppet master can now communicate and control the node that the signed certificate belongs to.
-
-If we want to sign all of the current requests, we can use the -all option as shown below.
-
- # puppet cert sign --all
-
-### Removing a Puppet Certificate ###
-
-If we wanna remove a host from it or wanna rebuild a host then add it back to it. In this case, we will want to revoke the host's certificate from the puppet master. To do this, we will want to use the clean action as follows.
-
- # puppet cert clean hostname
-
- Notice: Revoked certificate with serial 5
- Notice: Removing file Puppet::SSL::Certificate puppetnode.example.com at '/var/lib/puppet/ssl/ca/signed/puppetnode.example.com.pem'
- Notice: Removing file Puppet::SSL::Certificate puppetnode.example.com at '/var/lib/puppet/ssl/certs/puppetnode.example.com.pem'
-
-If we want to view all of the requests signed and unsigned, run the following command:
-
- # puppet cert list --all
-
- + "puppetmaster" (SHA256) 33:28:97:86:A1:C3:2F:73:10:D1:FB:42:DA:D5:42:69:71:84:F0:E2:8A:01:B9:58:38:90:E4:7D:B7:25:23:EC (alt names: "DNS:puppetmaster", "DNS:puppetmaster.example.com")
-
-### 12. Deploying a Puppet Manifest ###
-
-After we configure and complete the puppet manifest, we'll wanna deploy the manifest to the agent nodes server. To apply and load the main manifest we can simply run the following command in the agent node.
-
- # puppet agent --test
-
- Info: Retrieving pluginfacts
- Info: Retrieving plugin
- Info: Caching catalog for puppetnode.example.com
- Info: Applying configuration version '1434563858'
- Notice: /Stage[main]/Main/Exec[apt-update]/returns: executed successfully
- Notice: Finished catalog run in 10.53 seconds
-
-This will show us all the processes how the main manifest will affect a single server immediately.
-
-If we wanna run a puppet manifest that is not related to the main manifest, we can simply use puppet apply followed by the manifest file path. It only applies the manifest to the node that we run the apply from.
-
- # puppet apply /etc/puppet/manifest/test.pp
-
-### 13. Configuring Manifest for a Specific Node ###
-
-If we wanna deploy a manifest only to a specific node then we'll need to configure the manifest as follows.
-
-We'll need to edit the manifest on the master server using a text editor.
-
- # nano /etc/puppet/manifest/site.pp
-
-Now, we'll gonna add the following lines there.
-
- node 'puppetnode', 'puppetnode1' {
- # execute 'apt-get update'
- exec { 'apt-update': # exec resource named 'apt-update'
- command => '/usr/bin/apt-get update' # command this resource will run
- }
-
- # install apache2 package
- package { 'apache2':
- require => Exec['apt-update'], # require 'apt-update' before installing
- ensure => installed,
- }
-
- # ensure apache2 service is running
- service { 'apache2':
- ensure => running,
- }
- }
-
-Here, the above configuration will install and deploy the apache web server only to the two specified nodes having shortname puppetnode and puppetnode1. We can add more nodes that we need to get deployed with the manifest specifically.
-
-### 14. Configuring Manifest with a Module ###
-
-Modules are useful for grouping tasks together, they are many available in the Puppet community which anyone can contribute further.
-
-On the puppet master, we'll gonna install the **puppetlabs-apache** module using the puppet module command.
-
- # puppet module install puppetlabs-apache
-
-**Warning**: Please do not use this module on an existing apache setup else it will purge your apache configurations that are not managed by puppet.
-
-Now we'll gonna edit the main manifest ie **site.pp** using a text editor.
-
- # nano /etc/puppet/manifest/site.pp
-
-Now add the following lines to install apache under puppetnode.
-
- node 'puppet-node' {
- class { 'apache': } # use apache module
- apache::vhost { 'example.com': # define vhost resource
- port => '80',
- docroot => '/var/www/html'
- }
- }
-
-Then we'll wanna save and exit it. Then, we'll wanna rerun the manifest to deploy the configuration to the agents for our infrastructure.
-
-### Conclusion ###
-
-Finally we have successfully installed puppet to manage our Server Infrastructure running Ubuntu 15.04 "Vivid Vervet" linux operating system. We learned how puppet works, configure a manifest configuration, communicate with nodes and deploy the manifest on the agent nodes with secure SSL certification. Controlling, managing and configuring repeated task in several N number of nodes is very easy with puppet open source software configuration management tool. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-how-to/install-puppet-ubuntu-15-04/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:https://docs.puppetlabs.com/puppet/latest/reference/config_file_main.html
diff --git a/sources/tech/20150817 How to Install OsTicket Ticketing System in Fedora 22 or Centos 7.md b/sources/tech/20150817 How to Install OsTicket Ticketing System in Fedora 22 or Centos 7.md
index 515b15844a..7a56750804 100644
--- a/sources/tech/20150817 How to Install OsTicket Ticketing System in Fedora 22 or Centos 7.md
+++ b/sources/tech/20150817 How to Install OsTicket Ticketing System in Fedora 22 or Centos 7.md
@@ -1,3 +1,4 @@
+translated by iov-wang
How to Install OsTicket Ticketing System in Fedora 22 / Centos 7
================================================================================
In this article, we'll learn how to setup help desk ticketing system with osTicket in our machine or server running Fedora 22 or CentOS 7 as operating system. osTicket is a free and open source popular customer support ticketing system developed and maintained by [Enhancesoft][1] and its contributors. osTicket is the best solution for help and support ticketing system and management for better communication and support assistance with clients and customers. It has the ability to easily integrate with inquiries created via email, phone and web based forms into a beautiful multi-user web interface. osTicket makes us easy to manage, organize and log all our support requests and responses in one single place. It is a simple, lightweight, reliable, open source, web-based and easy to setup and use help desk ticketing system.
@@ -176,4 +177,4 @@ via: http://linoxide.com/linux-how-to/install-osticket-fedora-22-centos-7/
[a]:http://linoxide.com/author/arunp/
[1]:http://www.enhancesoft.com/
[2]:http://osticket.com/download
-[3]:https://github.com/osTicket/osTicket-1.8/releases
\ No newline at end of file
+[3]:https://github.com/osTicket/osTicket-1.8/releases
diff --git a/sources/tech/20150831 Linux workstation security checklist.md b/sources/tech/20150831 Linux workstation security checklist.md
deleted file mode 100644
index 9ef46339d0..0000000000
--- a/sources/tech/20150831 Linux workstation security checklist.md
+++ /dev/null
@@ -1,801 +0,0 @@
-wyangsun translating
-Linux workstation security checklist
-================================================================================
-This is a set of recommendations used by the Linux Foundation for their systems
-administrators. All of LF employees are remote workers and we use this set of
-guidelines to ensure that a sysadmin's system passes core security requirements
-in order to reduce the risk of it becoming an attack vector against the rest
-of our infrastructure.
-
-Even if your systems administrators are not remote workers, chances are that
-they perform a lot of their work either from a portable laptop in a work
-environment, or set up their home systems to access the work infrastructure
-for after-hours/emergency support. In either case, you can adapt this set of
-recommendations to suit your environment.
-
-This, by no means, is an exhaustive "workstation hardening" document, but
-rather an attempt at a set of baseline recommendations to avoid most glaring
-security errors without introducing too much inconvenience. You may read this
-document and think it is way too paranoid, while someone else may think this
-barely scratches the surface. Security is just like driving on the highway --
-anyone going slower than you is an idiot, while anyone driving faster than you
-is a crazy person. These guidelines are merely a basic set of core safety
-rules that is neither exhaustive, nor a replacement for experience, vigilance,
-and common sense.
-
-Each section is split into two areas:
-
-- The checklist that can be adapted to your project's needs
-- Free-form list of considerations that explain what dictated these decisions
-
-## Severity levels
-
-The items in each checklist include the severity level, which we hope will help
-guide your decision:
-
-- _(CRITICAL)_ items should definitely be high on the consideration list.
- If not implemented, they will introduce high risks to your workstation
- security.
-- _(MODERATE)_ items will improve your security posture, but are less
- important, especially if they interfere too much with your workflow.
-- _(LOW)_ items may improve the overall security, but may not be worth the
- convenience trade-offs.
-- _(PARANOID)_ is reserved for items we feel will dramatically improve your
- workstation security, but will probably require a lot of adjustment to the
- way you interact with your operating system.
-
-Remember, these are only guidelines. If you feel these severity levels do not
-reflect your project's commitment to security, you should adjust them as you
-see fit.
-
-## Choosing the right hardware
-
-We do not mandate that our admins use a specific vendor or a specific model, so
-this section addresses core considerations when choosing a work system.
-
-### Checklist
-
-- [ ] System supports SecureBoot _(CRITICAL)_
-- [ ] System has no firewire, thunderbolt or ExpressCard ports _(MODERATE)_
-- [ ] System has a TPM chip _(LOW)_
-
-### Considerations
-
-#### SecureBoot
-
-Despite its controversial nature, SecureBoot offers prevention against many
-attacks targeting workstations (Rootkits, "Evil Maid," etc), without
-introducing too much extra hassle. It will not stop a truly dedicated attacker,
-plus there is a pretty high degree of certainty that state security agencies
-have ways to defeat it (probably by design), but having SecureBoot is better
-than having nothing at all.
-
-Alternatively, you may set up [Anti Evil Maid][1] which offers a more
-wholesome protection against the type of attacks that SecureBoot is supposed
-to prevent, but it will require more effort to set up and maintain.
-
-#### Firewire, thunderbolt, and ExpressCard ports
-
-Firewire is a standard that, by design, allows any connecting device full
-direct memory access to your system ([see Wikipedia][2]). Thunderbolt and
-ExpressCard are guilty of the same, though some later implementations of
-Thunderbolt attempt to limit the scope of memory access. It is best if the
-system you are getting has none of these ports, but it is not critical, as
-they usually can be turned off via UEFI or disabled in the kernel itself.
-
-#### TPM Chip
-
-Trusted Platform Module (TPM) is a crypto chip bundled with the motherboard
-separately from the core processor, which can be used for additional platform
-security (such as to store full-disk encryption keys), but is not normally used
-for day-to-day workstation operation. At best, this is a nice-to-have, unless
-you have a specific need to use TPM for your workstation security.
-
-## Pre-boot environment
-
-This is a set of recommendations for your workstation before you even start
-with OS installation.
-
-### Checklist
-
-- [ ] UEFI boot mode is used (not legacy BIOS) _(CRITICAL)_
-- [ ] Password is required to enter UEFI configuration _(CRITICAL)_
-- [ ] SecureBoot is enabled _(CRITICAL)_
-- [ ] UEFI-level password is required to boot the system _(LOW)_
-
-### Considerations
-
-#### UEFI and SecureBoot
-
-UEFI, with all its warts, offers a lot of goodies that legacy BIOS doesn't,
-such as SecureBoot. Most modern systems come with UEFI mode on by default.
-
-Make sure a strong password is required to enter UEFI configuration mode. Pay
-attention, as many manufacturers quietly limit the length of the password you
-are allowed to use, so you may need to choose high-entropy short passwords vs.
-long passphrases (see below for more on passphrases).
-
-Depending on the Linux distribution you decide to use, you may or may not have
-to jump through additional hoops in order to import your distribution's
-SecureBoot key that would allow you to boot the distro. Many distributions have
-partnered with Microsoft to sign their released kernels with a key that is
-already recognized by most system manufacturers, therefore saving you the
-trouble of having to deal with key importing.
-
-As an extra measure, before someone is allowed to even get to the boot
-partition and try some badness there, let's make them enter a password. This
-password should be different from your UEFI management password, in order to
-prevent shoulder-surfing. If you shut down and start a lot, you may choose to
-not bother with this, as you will already have to enter a LUKS passphrase and
-this will save you a few extra keystrokes.
-
-## Distro choice considerations
-
-Chances are you'll stick with a fairly widely-used distribution such as Fedora,
-Ubuntu, Arch, Debian, or one of their close spin-offs. In any case, this is
-what you should consider when picking a distribution to use.
-
-### Checklist
-
-- [ ] Has a robust MAC/RBAC implementation (SELinux/AppArmor/Grsecurity) _(CRITICAL)_
-- [ ] Publishes security bulletins _(CRITICAL)_
-- [ ] Provides timely security patches _(CRITICAL)_
-- [ ] Provides cryptographic verification of packages _(CRITICAL)_
-- [ ] Fully supports UEFI and SecureBoot _(CRITICAL)_
-- [ ] Has robust native full disk encryption support _(CRITICAL)_
-
-### Considerations
-
-#### SELinux, AppArmor, and GrSecurity/PaX
-
-Mandatory Access Controls (MAC) or Role-Based Access Controls (RBAC) are an
-extension of the basic user/group security mechanism used in legacy POSIX
-systems. Most distributions these days either already come bundled with a
-MAC/RBAC implementation (Fedora, Ubuntu), or provide a mechanism to add it via
-an optional post-installation step (Gentoo, Arch, Debian). Obviously, it is
-highly advised that you pick a distribution that comes pre-configured with a
-MAC/RBAC system, but if you have strong feelings about a distribution that
-doesn't have one enabled by default, do plan to configure it
-post-installation.
-
-Distributions that do not provide any MAC/RBAC mechanisms should be strongly
-avoided, as traditional POSIX user- and group-based security should be
-considered insufficient in this day and age. If you would like to start out
-with a MAC/RBAC workstation, AppArmor and PaX are generally considered easier
-to learn than SELinux. Furthermore, on a workstation, where there are few or
-no externally listening daemons, and where user-run applications pose the
-highest risk, GrSecurity/PaX will _probably_ offer more security benefits than
-SELinux.
-
-#### Distro security bulletins
-
-Most of the widely used distributions have a mechanism to deliver security
-bulletins to their users, but if you are fond of something esoteric, check
-whether the developers have a documented mechanism of alerting the users about
-security vulnerabilities and patches. Absence of such mechanism is a major
-warning sign that the distribution is not mature enough to be considered for a
-primary admin workstation.
-
-#### Timely and trusted security updates
-
-Most of the widely used distributions deliver regular security updates, but is
-worth checking to ensure that critical package updates are provided in a
-timely fashion. Avoid using spin-offs and "community rebuilds" for this
-reason, as they routinely delay security updates due to having to wait for the
-upstream distribution to release it first.
-
-You'll be hard-pressed to find a distribution that does not use cryptographic
-signatures on packages, updates metadata, or both. That being said, fairly
-widely used distributions have been known to go for years before introducing
-this basic security measure (Arch, I'm looking at you), so this is a thing
-worth checking.
-
-#### Distros supporting UEFI and SecureBoot
-
-Check that the distribution supports UEFI and SecureBoot. Find out whether it
-requires importing an extra key or whether it signs its boot kernels with a key
-already trusted by systems manufacturers (e.g. via an agreement with
-Microsoft). Some distributions do not support UEFI/SecureBoot but offer
-alternatives to ensure tamper-proof or tamper-evident boot environments
-([Qubes-OS][3] uses Anti Evil Maid, mentioned earlier). If a distribution
-doesn't support SecureBoot and has no mechanisms to prevent boot-level attacks,
-look elsewhere.
-
-#### Full disk encryption
-
-Full disk encryption is a requirement for securing data at rest, and is
-supported by most distributions. As an alternative, systems with
-self-encrypting hard drives may be used (normally implemented via the on-board
-TPM chip) and offer comparable levels of security plus faster operation, but at
-a considerably higher cost.
-
-## Distro installation guidelines
-
-All distributions are different, but here are general guidelines:
-
-### Checklist
-
-- [ ] Use full disk encryption (LUKS) with a robust passphrase _(CRITICAL)_
-- [ ] Make sure swap is also encrypted _(CRITICAL)_
-- [ ] Require a password to edit bootloader (can be same as LUKS) _(CRITICAL)_
-- [ ] Set up a robust root password (can be same as LUKS) _(CRITICAL)_
-- [ ] Use an unprivileged account, part of administrators group _(CRITICAL)_
-- [ ] Set up a robust user-account password, different from root _(CRITICAL)_
-
-### Considerations
-
-#### Full disk encryption
-
-Unless you are using self-encrypting hard drives, it is important to configure
-your installer to fully encrypt all the disks that will be used for storing
-your data and your system files. It is not sufficient to simply encrypt the
-user directory via auto-mounting cryptfs loop files (I'm looking at you, older
-versions of Ubuntu), as this offers no protection for system binaries or swap,
-which is likely to contain a slew of sensitive data. The recommended
-encryption strategy is to encrypt the LVM device, so only one passphrase is
-required during the boot process.
-
-The `/boot` partition will always remain unencrypted, as the bootloader needs
-to be able to actually boot the kernel before invoking LUKS/dm-crypt. The
-kernel image itself should be protected against tampering with a cryptographic
-signature checked by SecureBoot.
-
-In other words, `/boot` should always be the only unencrypted partition on your
-system.
-
-#### Choosing good passphrases
-
-Modern Linux systems have no limitation of password/passphrase length, so the
-only real limitation is your level of paranoia and your stubbornness. If you
-boot your system a lot, you will probably have to type at least two different
-passwords: one to unlock LUKS, and another one to log in, so having long
-passphrases will probably get old really fast. Pick passphrases that are 2-3
-words long, easy to type, and preferably from rich/mixed vocabularies.
-
-Examples of good passphrases (yes, you can use spaces):
-- nature abhors roombas
-- 12 in-flight Jebediahs
-- perdon, tengo flatulence
-
-You can also stick with non-vocabulary passwords that are at least 10-12
-characters long, if you prefer that to typing passphrases.
-
-Unless you have concerns about physical security, it is fine to write down your
-passphrases and keep them in a safe place away from your work desk.
-
-#### Root, user passwords and the admin group
-
-We recommend that you use the same passphrase for your root password as you
-use for your LUKS encryption (unless you share your laptop with other trusted
-people who should be able to unlock the drives, but shouldn't be able to
-become root). If you are the sole user of the laptop, then having your root
-password be different from your LUKS password has no meaningful security
-advantages. Generally, you can use the same passphrase for your UEFI
-administration, disk encryption, and root account -- knowing any of these will
-give an attacker full control of your system anyway, so there is little
-security benefit to have them be different on a single-user workstation.
-
-You should have a different, but equally strong password for your regular user
-account that you will be using for day-to-day tasks. This user should be member
-of the admin group (e.g. `wheel` or similar, depending on the distribution),
-allowing you to perform `sudo` to elevate privileges.
-
-In other words, if you are the sole user on your workstation, you should have 2
-distinct, robust, equally strong passphrases you will need to remember:
-
-**Admin-level**, used in the following locations:
-
-- UEFI administration
-- Bootloader (GRUB)
-- Disk encryption (LUKS)
-- Workstation admin (root user)
-
-**User-level**, used for the following:
-
-- User account and sudo
-- Master password for the password manager
-
-All of them, obviously, can be different if there is a compelling reason.
-
-## Post-installation hardening
-
-Post-installation security hardening will depend greatly on your distribution
-of choice, so it is futile to provide detailed instructions in a general
-document such as this one. However, here are some steps you should take:
-
-### Checklist
-
-- [ ] Globally disable firewire and thunderbolt modules _(CRITICAL)_
-- [ ] Check your firewalls to ensure all incoming ports are filtered _(CRITICAL)_
-- [ ] Make sure root mail is forwarded to an account you check _(CRITICAL)_
-- [ ] Check to ensure sshd service is disabled by default _(MODERATE)_
-- [ ] Set up an automatic OS update schedule, or update reminders _(MODERATE)_
-- [ ] Configure the screensaver to auto-lock after a period of inactivity _(MODERATE)_
-- [ ] Set up logwatch _(MODERATE)_
-- [ ] Install and use rkhunter _(LOW)_
-- [ ] Install an Intrusion Detection System _(PARANOID)_
-
-### Considerations
-
-#### Blacklisting modules
-
-To blacklist a firewire and thunderbolt modules, add the following lines to a
-file in `/etc/modprobe.d/blacklist-dma.conf`:
-
- blacklist firewire-core
- blacklist thunderbolt
-
-The modules will be blacklisted upon reboot. It doesn't hurt doing this even if
-you don't have these ports (but it doesn't do anything either).
-
-#### Root mail
-
-By default, root mail is just saved on the system and tends to never be read.
-Make sure you set your `/etc/aliases` to forward root mail to a mailbox that
-you actually read, otherwise you may miss important system notifications and
-reports:
-
- # Person who should get root's mail
- root: bob@example.com
-
-Run `newaliases` after this edit and test it out to make sure that it actually
-gets delivered, as some email providers will reject email coming in from
-nonexistent or non-routable domain names. If that is the case, you will need to
-play with your mail forwarding configuration until this actually works.
-
-#### Firewalls, sshd, and listening daemons
-
-The default firewall settings will depend on your distribution, but many of
-them will allow incoming `sshd` ports. Unless you have a compelling legitimate
-reason to allow incoming ssh, you should filter that out and disable the `sshd`
-daemon.
-
- systemctl disable sshd.service
- systemctl stop sshd.service
-
-You can always start it temporarily if you need to use it.
-
-In general, your system shouldn't have any listening ports apart from
-responding to ping. This will help safeguard you against network-level 0-day
-exploits.
-
-#### Automatic updates or notifications
-
-It is recommended to turn on automatic updates, unless you have a very good
-reason not to do so, such as fear that an automatic update would render your
-system unusable (it's happened in the past, so this fear is not unfounded). At
-the very least, you should enable automatic notifications of available updates.
-Most distributions already have this service automatically running for you, so
-chances are you don't have to do anything. Consult your distribution
-documentation to find out more.
-
-You should apply all outstanding errata as soon as possible, even if something
-isn't specifically labeled as "security update" or has an associated CVE code.
-All bugs have the potential of being security bugs and erring on the side of
-newer, unknown bugs is _generally_ a safer strategy than sticking with old,
-known ones.
-
-#### Watching logs
-
-You should have a keen interest in what happens on your system. For this
-reason, you should install `logwatch` and configure it to send nightly activity
-reports of everything that happens on your system. This won't prevent a
-dedicated attacker, but is a good safety-net feature to have in place.
-
-Note, that many systemd distros will no longer automatically install a syslog
-server that `logwatch` needs (due to systemd relying on its own journal), so
-you will need to install and enable `rsyslog` to make sure your `/var/log` is
-not empty before logwatch will be of any use.
-
-#### Rkhunter and IDS
-
-Installing `rkhunter` and an intrusion detection system (IDS) like `aide` or
-`tripwire` will not be that useful unless you actually understand how they work
-and take the necessary steps to set them up properly (such as, keeping the
-databases on external media, running checks from a trusted environment,
-remembering to refresh the hash databases after performing system updates and
-configuration changes, etc). If you are not willing to take these steps and
-adjust how you do things on your own workstation, these tools will introduce
-hassle without any tangible security benefit.
-
-We do recommend that you install `rkhunter` and run it nightly. It's fairly
-easy to learn and use, and though it will not deter a sophisticated attacker,
-it may help you catch your own mistakes.
-
-## Personal workstation backups
-
-Workstation backups tend to be overlooked or done in a haphazard, often unsafe
-manner.
-
-### Checklist
-
-- [ ] Set up encrypted workstation backups to external storage _(CRITICAL)_
-- [ ] Use zero-knowledge backup tools for cloud backups _(MODERATE)_
-
-### Considerations
-
-#### Full encrypted backups to external storage
-
-It is handy to have an external hard drive where one can dump full backups
-without having to worry about such things like bandwidth and upstream speeds
-(in this day and age most providers still offer dramatically asymmetric
-upload/download speeds). Needless to say, this hard drive needs to be in itself
-encrypted (again, via LUKS), or you should use a backup tool that creates
-encrypted backups, such as `duplicity` or its GUI companion, `deja-dup`. I
-recommend using the latter with a good randomly generated passphrase, stored in
-your password manager. If you travel with your laptop, leave this drive at home
-to have something to come back to in case your laptop is lost or stolen.
-
-In addition to your home directory, you should also back up `/etc` and
-`/var/log` for various forensic purposes.
-
-Above all, avoid copying your home directory onto any unencrypted storage, even
-as a quick way to move your files around between systems, as you will most
-certainly forget to erase it once you're done, exposing potentially private or
-otherwise security sensitive data to snooping hands -- especially if you keep
-that storage media in the same bag with your laptop.
-
-#### Selective zero-knowledge backups off-site
-
-Off-site backups are also extremely important and can be done either to your
-employer, if they offer space for it, or to a cloud provider. You can set up a
-separate duplicity/deja-dup profile to only include most important files in
-order to avoid transferring huge amounts of data that you don't really care to
-back up off-site (internet cache, music, downloads, etc).
-
-Alternatively, you can use a zero-knowledge backup tool, such as
-[SpiderOak][5], which offers an excellent Linux GUI tool and has additional
-useful features such as synchronizing content between multiple systems and
-platforms.
-
-## Best practices
-
-What follows is a curated list of best practices that we think you should
-adopt. It is most certainly non-exhaustive, but rather attempts to offer
-practical advice that strikes a workable balance between security and overall
-usability.
-
-### Browsing
-
-There is no question that the web browser will be the piece of software with
-the largest and the most exposed attack surface on your system. It is a tool
-written specifically to download and execute untrusted, frequently hostile
-code. It attempts to shield you from this danger by employing multiple
-mechanisms such as sandboxes and code sanitization, but they have all been
-previously defeated on multiple occasions. You should learn to approach
-browsing websites as the most insecure activity you'll engage in on any given
-day.
-
-There are several ways you can reduce the impact of a compromised browser, but
-the truly effective ways will require significant changes in the way you
-operate your workstation.
-
-#### 1: Use two different browsers
-
-This is the easiest to do, but only offers minor security benefits. Not all
-browser compromises give an attacker full unfettered access to your system --
-sometimes they are limited to allowing one to read local browser storage,
-steal active sessions from other tabs, capture input entered into the browser,
-etc. Using two different browsers, one for work/high security sites, and
-another for everything else will help prevent minor compromises from giving
-attackers access to the whole cookie jar. The main inconvenience will be the
-amount of memory consumed by two different browser processes.
-
-Here's what we recommend:
-
-##### Firefox for work and high security sites
-
-Use Firefox to access work-related sites, where extra care should be taken to
-ensure that data like cookies, sessions, login information, keystrokes, etc,
-should most definitely not fall into attackers' hands. You should NOT use
-this browser for accessing any other sites except select few.
-
-You should install the following Firefox add-ons:
-
-- [ ] NoScript _(CRITICAL)_
- - NoScript prevents active content from loading, except from user
- whitelisted domains. It is a great hassle to use with your default browser
- (though offers really good security benefits), so we recommend only
- enabling it on the browser you use to access work-related sites.
-
-- [ ] Privacy Badger _(CRITICAL)_
- - EFF's Privacy Badger will prevent most external trackers and ad platforms
- from being loaded, which will help avoid compromises on these tracking
- sites from affecting your browser (trackers and ad sites are very commonly
- targeted by attackers, as they allow rapid infection of thousands of
- systems worldwide).
-
-- [ ] HTTPS Everywhere _(CRITICAL)_
- - This EFF-developed Add-on will ensure that most of your sites are accessed
- over a secure connection, even if a link you click is using http:// (great
- to avoid a number of attacks, such as [SSL-strip][7]).
-
-- [ ] Certificate Patrol _(MODERATE)_
- - This tool will alert you if the site you're accessing has recently changed
- their TLS certificates -- especially if it wasn't nearing expiration dates
- or if it is now using a different certification authority. It helps
- alert you if someone is trying to man-in-the-middle your connection,
- but generates a lot of benign false-positives.
-
-You should leave Firefox as your default browser for opening links, as
-NoScript will prevent most active content from loading or executing.
-
-##### Chrome/Chromium for everything else
-
-Chromium developers are ahead of Firefox in adding a lot of nice security
-features (at least [on Linux][6]), such as seccomp sandboxes, kernel user
-namespaces, etc, which act as an added layer of isolation between the sites
-you visit and the rest of your system. Chromium is the upstream open-source
-project, and Chrome is Google's proprietary binary build based on it (insert
-the usual paranoid caution about not using it for anything you don't want
-Google to know about).
-
-It is recommended that you install **Privacy Badger** and **HTTPS Everywhere**
-extensions in Chrome as well and give it a distinct theme from Firefox to
-indicate that this is your "untrusted sites" browser.
-
-#### 2: Use two different browsers, one inside a dedicated VM
-
-This is a similar recommendation to the above, except you will add an extra
-step of running Chrome inside a dedicated VM that you access via a fast
-protocol, allowing you to share clipboards and forward sound events (e.g.
-Spice or RDP). This will add an excellent layer of isolation between the
-untrusted browser and the rest of your work environment, ensuring that
-attackers who manage to fully compromise your browser will then have to
-additionally break out of the VM isolation layer in order to get to the rest
-of your system.
-
-This is a surprisingly workable configuration, but requires a lot of RAM and
-fast processors that can handle the increased load. It will also require an
-important amount of dedication on the part of the admin who will need to
-adjust their work practices accordingly.
-
-#### 3: Fully separate your work and play environments via virtualization
-
-See [Qubes-OS project][3], which strives to provide a high-security
-workstation environment via compartmentalizing your applications into separate
-fully isolated VMs.
-
-### Password managers
-
-#### Checklist
-
-- [ ] Use a password manager _(CRITICAL_)
-- [ ] Use unique passwords on unrelated sites _(CRITICAL)_
-- [ ] Use a password manager that supports team sharing _(MODERATE)_
-- [ ] Use a separate password manager for non-website accounts _(PARANOID)_
-
-#### Considerations
-
-Using good, unique passwords should be a critical requirement for every member
-of your team. Credential theft is happening all the time -- either via
-compromised computers, stolen database dumps, remote site exploits, or any
-number of other means. No credentials should ever be reused across sites,
-especially for critical applications.
-
-##### In-browser password manager
-
-Every browser has a mechanism for saving passwords that is fairly secure and
-can sync with vendor-maintained cloud storage while keeping the data encrypted
-with a user-provided passphrase. However, this mechanism has important
-disadvantages:
-
-1. It does not work across browsers
-2. It does not offer any way of sharing credentials with team members
-
-There are several well-supported, free-or-cheap password managers that are
-well-integrated into multiple browsers, work across platforms, and offer
-group sharing (usually as a paid service). Solutions can be easily found via
-search engines.
-
-##### Standalone password manager
-
-One of the major drawbacks of any password manager that comes integrated with
-the browser is the fact that it's part of the application that is most likely
-to be attacked by intruders. If this makes you uncomfortable (and it should),
-you may choose to have two different password managers -- one for websites
-that is integrated into your browser, and one that runs as a standalone
-application. The latter can be used to store high-risk credentials such as
-root passwords, database passwords, other shell account credentials, etc.
-
-It may be particularly useful to have such tool for sharing superuser account
-credentials with other members of your team (server root passwords, ILO
-passwords, database admin passwords, bootloader passwords, etc).
-
-A few tools can help you:
-
-- [KeePassX][8], which improves team sharing in version 2
-- [Pass][9], which uses text files and PGP and integrates with git
-- [Django-Pstore][10], which uses GPG to share credentials between admins
-- [Hiera-Eyaml][11], which, if you are already using Puppet for your
- infrastructure, may be a handy way to track your server/service credentials
- as part of your encrypted Hiera data store
-
-### Securing SSH and PGP private keys
-
-Personal encryption keys, including SSH and PGP private keys, are going to be
-the most prized items on your workstation -- something the attackers will be
-most interested in obtaining, as that would allow them to further attack your
-infrastructure or impersonate you to other admins. You should take extra steps
-to ensure that your private keys are well protected against theft.
-
-#### Checklist
-
-- [ ] Strong passphrases are used to protect private keys _(CRITICAL)_
-- [ ] PGP Master key is stored on removable storage _(MODERATE)_
-- [ ] Auth, Sign and Encrypt Subkeys are stored on a smartcard device _(MODERATE)_
-- [ ] SSH is configured to use PGP Auth key as ssh private key _(MODERATE)_
-
-#### Considerations
-
-The best way to prevent private key theft is to use a smartcard to store your
-encryption private keys and never copy them onto the workstation. There are
-several manufacturers that offer OpenPGP capable devices:
-
-- [Kernel Concepts][12], where you can purchase both the OpenPGP compatible
- smartcards and the USB readers, should you need one.
-- [Yubikey NEO][13], which offers OpenPGP smartcard functionality in addition
- to many other cool features (U2F, PIV, HOTP, etc).
-
-It is also important to make sure that the master PGP key is not stored on the
-main workstation, and only subkeys are used. The master key will only be
-needed when signing someone else's keys or creating new subkeys -- operations
-which do not happen very frequently. You may follow [the Debian's subkeys][14]
-guide to learn how to move your master key to removable storage and how to
-create subkeys.
-
-You should then configure your gnupg agent to act as ssh agent and use the
-smartcard-based PGP Auth key to act as your ssh private key. We publish a
-[detailed guide][15] on how to do that using either a smartcard reader or a
-Yubikey NEO.
-
-If you are not willing to go that far, at least make sure you have a strong
-passphrase on both your PGP private key and your SSH private key, which will
-make it harder for attackers to steal and use them.
-
-### SELinux on the workstation
-
-If you are using a distribution that comes bundled with SELinux (such as
-Fedora), here are some recommendation of how to make the best use of it to
-maximize your workstation security.
-
-#### Checklist
-
-- [ ] Make sure SELinux is enforcing on your workstation _(CRITICAL)_
-- [ ] Never blindly run `audit2allow -M`, always check _(CRITICAL)_
-- [ ] Never `setenforce 0` _(MODERATE)_
-- [ ] Switch your account to SELinux user `staff_u` _(MODERATE)_
-
-#### Considerations
-
-SELinux is a Mandatory Access Controls (MAC) extension to core POSIX
-permissions functionality. It is mature, robust, and has come a long way since
-its initial roll-out. Regardless, many sysadmins to this day repeat the
-outdated mantra of "just turn it off."
-
-That being said, SELinux will have limited security benefits on the
-workstation, as most applications you will be running as a user are going to
-be running unconfined. It does provide enough net benefit to warrant leaving
-it on, as it will likely help prevent an attacker from escalating privileges
-to gain root-level access via a vulnerable daemon service.
-
-Our recommendation is to leave it on and enforcing.
-
-##### Never `setenforce 0`
-
-It's tempting to use `setenforce 0` to flip SELinux into permissive mode
-on a temporary basis, but you should avoid doing that. This essentially turns
-off SELinux for the entire system, while what you really want is to
-troubleshoot a particular application or daemon.
-
-Instead of `setenforce 0` you should be using `semanage permissive -a
-[somedomain_t]` to put only that domain into permissive mode. First, find out
-which domain is causing troubles by running `ausearch`:
-
- ausearch -ts recent -m avc
-
-and then look for `scontext=` (source SELinux context) line, like so:
-
- scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
- ^^^^^^^^^^^^^^
-
-This tells you that the domain being denied is `gpg_pinentry_t`, so if you
-want to troubleshoot the application, you should add it to permissive domains:
-
- semange permissive -a gpg_pinentry_t
-
-This will allow you to use the application and collect the rest of the AVCs,
-which you can then use in conjunction with `audit2allow` to write a local
-policy. Once that is done and you see no new AVC denials, you can remove that
-domain from permissive by running:
-
- semanage permissive -d gpg_pinentry_t
-
-##### Use your workstation as SELinux role staff_r
-
-SELinux comes with a native implementation of roles that prohibit or grant
-certain privileges based on the role associated with the user account. As an
-administrator, you should be using the `staff_r` role, which will restrict
-access to many configuration and other security-sensitive files, unless you
-first perform `sudo`.
-
-By default, accounts are created as `unconfined_r` and most applications you
-execute will run unconfined, without any (or with only very few) SELinux
-constraints. To switch your account to the `staff_r` role, run the following
-command:
-
- usermod -Z staff_u [username]
-
-You should log out and log back in to enable the new role, at which point if
-you run `id -Z`, you'll see:
-
- staff_u:staff_r:staff_t:s0-s0:c0.c1023
-
-When performing `sudo`, you should remember to add an extra flag to tell
-SELinux to transition to the "sysadmin" role. The command you want is:
-
- sudo -i -r sysadm_r
-
-At which point `id -Z` will show:
-
- staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
-
-**WARNING**: you should be comfortable using `ausearch` and `audit2allow`
-before you make this switch, as it's possible some of your applications will
-no longer work when you're running as role `staff_r`. At the time of writing,
-the following popular applications are known to not work under `staff_r`
-without policy tweaks:
-
-- Chrome/Chromium
-- Skype
-- VirtualBox
-
-To switch back to `unconfined_r`, run the following command:
-
- usermod -Z unconfined_u [username]
-
-and then log out and back in to get back into the comfort zone.
-
-## Further reading
-
-The world of IT security is a rabbit hole with no bottom. If you would like to
-go deeper, or find out more about security features on your particular
-distribution, please check out the following links:
-
-- [Fedora Security Guide](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
-- [CESG Ubuntu Security Guide](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
-- [Debian Security Manual](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
-- [Arch Linux Security Wiki](https://wiki.archlinux.org/index.php/Security)
-- [Mac OSX Security](https://www.apple.com/support/security/guides/)
-
-## License
-This work is licensed under a
-[Creative Commons Attribution-ShareAlike 4.0 International License][0].
-
---------------------------------------------------------------------------------
-
-via: https://github.com/lfit/itpol/blob/master/linux-workstation-security.md#linux-workstation-security-checklist
-
-作者:[mricon][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://github.com/mricon
-[0]: http://creativecommons.org/licenses/by-sa/4.0/
-[1]: https://github.com/QubesOS/qubes-antievilmaid
-[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
-[3]: https://qubes-os.org/
-[4]: https://xkcd.com/936/
-[5]: https://spideroak.com/
-[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
-[7]: http://www.thoughtcrime.org/software/sslstrip/
-[8]: https://keepassx.org/
-[9]: http://www.passwordstore.org/
-[10]: https://pypi.python.org/pypi/django-pstore
-[11]: https://github.com/TomPoulton/hiera-eyaml
-[12]: http://shop.kernelconcepts.de/
-[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
-[14]: https://wiki.debian.org/Subkeys
-[15]: https://github.com/lfit/ssh-gpg-smartcard-config
diff --git a/sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md b/sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md
index c7810d06ef..aca2b04bba 100644
--- a/sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md
+++ b/sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md
@@ -1,3 +1,4 @@
+translated by ivo-wang
How to Configure OpenNMS on CentOS 7.x
================================================================================
Systems management and monitoring services are very important that provides information to view important systems management information that allow us to to make decisions based on this information. To make sure the network is running at its best and to minimize the network downtime we need to improve application performance. So, in this article we will make you understand the step by step procedure to setup OpenNMS in your IT infrastructure. OpenNMS is a free open source enterprise level network monitoring and management platform that provides information to allow us to make decisions in regards to future network and capacity planning.
@@ -216,4 +217,4 @@ via: http://linoxide.com/monitoring-2/install-configure-opennms-centos-7-x/
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-[a]:http://linoxide.com/author/kashifs/
\ No newline at end of file
+[a]:http://linoxide.com/author/kashifs/
diff --git a/sources/tech/20150906 How to install Suricata intrusion detection system on Linux.md b/sources/tech/20150906 How to install Suricata intrusion detection system on Linux.md
index fe4a784d5a..736a6577de 100644
--- a/sources/tech/20150906 How to install Suricata intrusion detection system on Linux.md
+++ b/sources/tech/20150906 How to install Suricata intrusion detection system on Linux.md
@@ -1,3 +1,4 @@
+translated by ivo-wang
How to install Suricata intrusion detection system on Linux
================================================================================
With incessant security threats, intrusion detection system (IDS) has become one of the most critical requirements in today's data center environments. However, as more and more servers upgrade their NICs to 10GB/40GB Ethernet, it is increasingly difficult to implement compute-intensive intrusion detection on commodity hardware at line rates. One approach to scaling IDS performance is **multi-threaded IDS**, where CPU-intensive deep packet inspection workload is parallelized into multiple concurrent tasks. Such parallelized inspection can exploit multi-core hardware to scale up IDS throughput easily. Two well-known open-source efforts in this area are [Suricata][1] and [Bro][2].
@@ -194,4 +195,4 @@ via: http://xmodulo.com/install-suricata-intrusion-detection-system-linux.html
[6]:https://redmine.openinfosecfoundation.org/projects/suricata/wiki/Runmodes
[7]:http://ask.xmodulo.com/view-threads-process-linux.html
[8]:http://xmodulo.com/how-to-compile-and-install-snort-from-source-code-on-ubuntu.html
-[9]:https://redmine.openinfosecfoundation.org/projects/suricata/wiki
\ No newline at end of file
+[9]:https://redmine.openinfosecfoundation.org/projects/suricata/wiki
diff --git a/sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md b/sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
old mode 100644
new mode 100755
index 807cedf01d..43b3b9e219
--- a/sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
+++ b/sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
@@ -1,32 +1,32 @@
-A Repository with 44 Years of Unix Evolution
-================================================================================
-### Abstract ###
+一个涵盖 Unix 44 年进化史的仓库
+=============================================================================
+### 摘要 ###
-The evolution of the Unix operating system is made available as a version-control repository, covering the period from its inception in 1972 as a five thousand line kernel, to 2015 as a widely-used 26 million line system. The repository contains 659 thousand commits and 2306 merges. The repository employs the commonly used Git system for its storage, and is hosted on the popular GitHub archive. It has been created by synthesizing with custom software 24 snapshots of systems developed at Bell Labs, Berkeley University, and the 386BSD team, two legacy repositories, and the modern repository of the open source FreeBSD system. In total, 850 individual contributors are identified, the early ones through primary research. The data set can be used for empirical research in software engineering, information systems, and software archaeology.
+Unix 操作系统的进化历史,可以从一个版本控制的仓库中窥见,时间跨越从 1972 年以 5000 行内核代码的出现,到 2015 年成为一个含有 26,000,000 行代码的被广泛使用的系统。该仓库包含 659,000 条提交,和 2306 次合并。仓库部署被普遍采用的 Git 系统储存其代码,并且在时下流行的 GitHub 上建立了档案。它综合了系统定制软件的 24 个快照,都是开发自贝尔实验室,伯克利大学,386BSD 团队,两个传统的仓库 和 开源 FreeBSD 系统的仓库。总的来说,850 位个人贡献者已经确认,更早些时候的一批人主要做基础研究。这些数据可以用于一些经验性的研究,在软件工程,信息系统和软件考古学领域。
-### 1 Introduction ###
+### 1 介绍 ###
-The Unix operating system stands out as a major engineering breakthrough due to its exemplary design, its numerous technical contributions, its development model, and its widespread use. The design of the Unix programming environment has been characterized as one offering unusual simplicity, power, and elegance [[1][1]]. On the technical side, features that can be directly attributed to Unix or were popularized by it include [[2][2]]: the portable implementation of the kernel in a high level language; a hierarchical file system; compatible file, device, networking, and inter-process I/O; the pipes and filters architecture; virtual file systems; and the shell as a user-selectable regular process. A large community contributed software to Unix from its early days [[3][3]], [[4][4],pp. 65-72]. This community grew immensely over time and worked using what are now termed open source software development methods [[5][5],pp. 440-442]. Unix and its intellectual descendants have also helped the spread of the C and C++ programming languages, parser and lexical analyzer generators (*yacc, lex*), document preparation tools (*troff, eqn, tbl*), scripting languages (*awk, sed, Perl*), TCP/IP networking, and configuration management systems (*SCCS, RCS, Subversion, Git*), while also forming a large part of the modern internet infrastructure and the web.
+Unix 操作系统作为一个主要的工程上的突破而脱颖而出,得益于其模范的设计,大量的技术贡献,它的开发模型和广泛的使用。Unix 编程环境的设计已经被标榜为一个能提供非常简洁,功能强大并且优雅的设计[[1][1]]。在技术方面,许多对 Unix 有直接贡献的,或者因 Unix 而流行的特性就包括[[2][2]]:用高级语言编写的可移植部署的内核;一个分层式设计的文件系统;兼容的文件,设备,网络和进程间 I/O;管道和过滤架构;虚拟文件系统;和用户可选的 shell。很早的时候,就有一个庞大的社区为 Unix 贡献软件[[3][3]],[[4][4]],pp. 65-72]。随时间流走,这个社区不断壮大,并且以现在称为开源软件开发的方式在工作着[[5][5],pp. 440-442]。Unix 和其睿智的晚辈们也将 C 和 C++ 编程语言,分析程序和词法分析生成器(*yacc,lex*),发扬光大了,文档编制工具(*troff,eqn,tbl*),脚本语言(*awk,sed,Perl*),TCP/IP 网络,和配置管理系统(*SCSS,RCS,Subversion,Git*)发扬广大了,同时也形成了大部分的现代互联网基础设施和网络。
-Luckily, important Unix material of historical importance has survived and is nowadays openly available. Although Unix was initially distributed with relatively restrictive licenses, the most significant parts of its early development have been released by one of its right-holders (Caldera International) under a liberal license. Combining these parts with software that was developed or released as open source software by the University of California, Berkeley and the FreeBSD Project provides coverage of the system's development over a period ranging from June 20th 1972 until today.
+幸运的是,一些重要的具有历史意义的 Unix 材料已经保存下来了,现在保持对外开放。尽管 Unix 最初是由相对严格的协议发行,但在早期的开发中,很多重要的部分是通过 Unix 的某个版权拥有者以一个自由的协议发行。然后将这些部分再结合开发的软件或者以开源发行的软件,Berkeley,Californai 大学和 FreeBSD 项目组从 1972 年六月二十日开始到现在,提供了涵盖整个系统的开发。
Curating and processing available snapshots as well as old and modern configuration management repositories allows the reconstruction of a new synthetic Git repository that combines under a single roof most of the available data. This repository documents in a digital form the detailed evolution of an important digital artefact over a period of 44 years. The following sections describe the repository's structure and contents (Section [II][6]), the way it was created (Section [III][7]), and how it can be used (Section [IV][8]).
-### 2 Data Overview ###
+### 2. 数据概览 ###
-The 1GB Unix history Git repository is made available for cloning on [GitHub][9].[1][10] Currently[2][11] the repository contains 659 thousand commits and 2306 merges from about 850 contributors. The contributors include 23 from the Bell Labs staff, 158 from Berkeley's Computer Systems Research Group (CSRG), and 660 from the FreeBSD Project.
+这 1GB 的 Unix 仓库可以从 [GitHub][9] 克隆。[1][10]如今[2][11],这个仓库包含来自 850 个贡献者的 659,000 个提交和 2306 个合并。贡献者有来自 Bell 实验室的 23 个员工,Berkeley 计算机系统研究组(CSRG)的 158 个人,和 FreeBSD 项目的 660 个成员。
-The repository starts its life at a tag identified as *Epoch*, which contains only licensing information and its modern README file. Various tag and branch names identify points of significance.
+这个仓库的生命始于一个 *Epoch* 的标签,这里面只包含了证书信息和现在的 README 文件。其后各种各样的标签和分支记录了很多重要的时刻。
-- *Research-VX* tags correspond to six research editions that came out of Bell Labs. These start with *Research-V1* (4768 lines of PDP-11 assembly) and end with *Research-V7* (1820 mostly C files, 324kLOC).
-- *Bell-32V* is the port of the 7th Edition Unix to the DEC/VAX architecture.
-- *BSD-X* tags correspond to 15 snapshots released from Berkeley.
-- *386BSD-X* tags correspond to two open source versions of the system, with the Intel 386 architecture kernel code mainly written by Lynne and William Jolitz.
-- *FreeBSD-release/X* tags and branches mark 116 releases coming from the FreeBSD project.
+- *Research-VX* 标签对应来自 Bell 实验室六次的研究版本。从 *Research-V1* (PDP-11 4768 行汇编代码)开始,到以 *Research-V7* (大约 324,000 行代码,1820 个 C 文件)结束。
+- *Bell-32V* 是 DEC/VAX 架构的 Unix 第七个版本的一部分。
+- *BSD-X* 标签对应 Berkeley 释出的 15 个快照。
+- *386BSD-X* 标签对应系统的两个开源版本,主要是 Lynne 和 William Jolitz 写的 适用于 Intel 386 架构的内核代码。
+- *FreeBSD-release/X* 标签和分支标记了来自 FreeBSD 项目的 116 个发行版。
-In addition, branches with a *-Snapshot-Development* suffix denote commits that have been synthesized from a time-ordered sequence of a snapshot's files, while tags with a *-VCS-Development* suffix mark the point along an imported version control history branch where a particular release occurred.
+另外,以 *-Snapshot-Development* 为后缀的分支,表示一个被综合的以时间排序的快照文件序列的一些提交,而以一个 *-VCS-Development* 为后缀的标签,标记了有特别发行版出现的历史分支的时刻。
-The repository's history includes commits from the earliest days of the system's development, such as the following.
+仓库的历史包含从系统开发早期的一些提交,比如下面这些。
commit c9f643f59434f14f774d61ee3856972b8c3905b1
Author: Dennis Ritchie
@@ -34,69 +34,69 @@ The repository's history includes commits from the earliest days of the system's
Research V5 development
Work on file usr/sys/dmr/kl.c
-Merges between releases that happened along the system's evolution, such as the development of BSD 3 from BSD 2 and Unix 32/V, are also correctly represented in the Git repository as graph nodes with two parents.
+释出间隙的合并随着系统进化而发生,比如 从 BSD 2 到 BSD 3 的开发,Unix 32/V 也是正确地代表了 Git 仓库里带两个父节点的图形节点。(这太莫名其妙了)
-More importantly, the repository is constructed in a way that allows *git blame*, which annotates source code lines with the version, date, and author associated with their first appearance, to produce the expected code provenance results. For example, checking out the *BSD-4* tag, and running git blame on the kernel's *pipe.c* file will show lines written by Ken Thompson in 1974, 1975, and 1979, and by Bill Joy in 1980. This allows the automatic (though computationally expensive) detection of the code's provenance at any point of time.
+更为重要的是,该仓库的构造方式允许 **git blame**,就是可以给源代码加上注释,如版本,日期和它们第一次出现相关联的作者,这样可以知道任何代码的起源。比如说 **BSD-4** 这个标签,在内核的 *pipe.c* 文件上运行一下 git blame,就会显示代码行由 Ken Thompson 写于 1974,1975 和 1979年,Bill Joy 写于 1980 年。这就可以自动(尽管计算上比较费事)检测出任何时刻出现的代码。
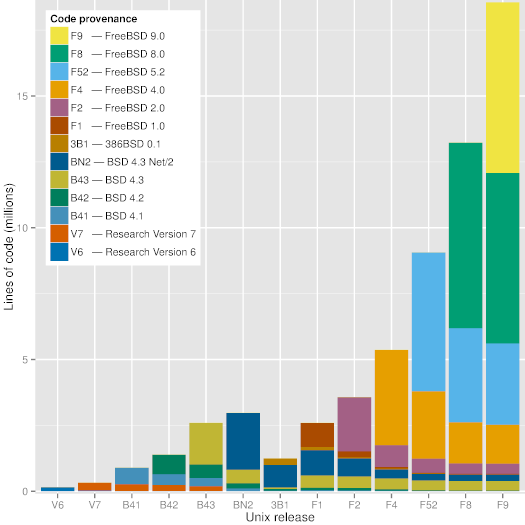
Figure 1: Code provenance across significant Unix releases.
-As can be seen in Figure [1][12], a modern version of Unix (FreeBSD 9) still contains visible chunks of code from BSD 4.3, BSD 4.3 Net/2, and FreeBSD 2.0. Interestingly, the Figure shows that code developed during the frantic dash to create an open source operating system out of the code released by Berkeley (386BSD and FreeBSD 1.0) does not seem to have survived. The oldest code in FreeBSD 9 appears to be an 18-line sequence in the C library file timezone.c, which can also be found in the 7th Edition Unix file with the same name and a time stamp of January 10th, 1979 - 36 years ago.
+如上图[12]所示,现代版本的 Unix(FreeBSD 9)依然有来自 BSD 4.3,BSD 4.3 Net/2 和 BSD 2.0 的代码块。有趣的是,这图片显示有部分代码好像没有保留下来,当时激进地要创造一个脱离于 Berkeyel(386BSD 和 FreeBSD 1.0)释出代码的开源操作系统,其所开发的代码。FreeBSD 9 中最古老的代码是一个 18 行的队列,在 C 库里面的 timezone.c 文件里,该文件也可以在第七版的 Unix 文件里找到,同样的名字,时间戳是 1979 年一月十日 - 36 年前。
-### 3 Data Collection and Processing ###
+### 数据收集和处理 ###
-The goal of the project is to consolidate data concerning the evolution of Unix in a form that helps the study of the system's evolution, by entering them into a modern revision repository. This involves collecting the data, curating them, and synthesizing them into a single Git repository.
+这个项目的目的是以某种方式巩固从数据方面说明 Unix 的进化,通过将其并入一个现代的修订仓库,帮助人们对系统进化的研究。项目工作包括收录数据,分类并综合到一个单独的 Git 仓库里。
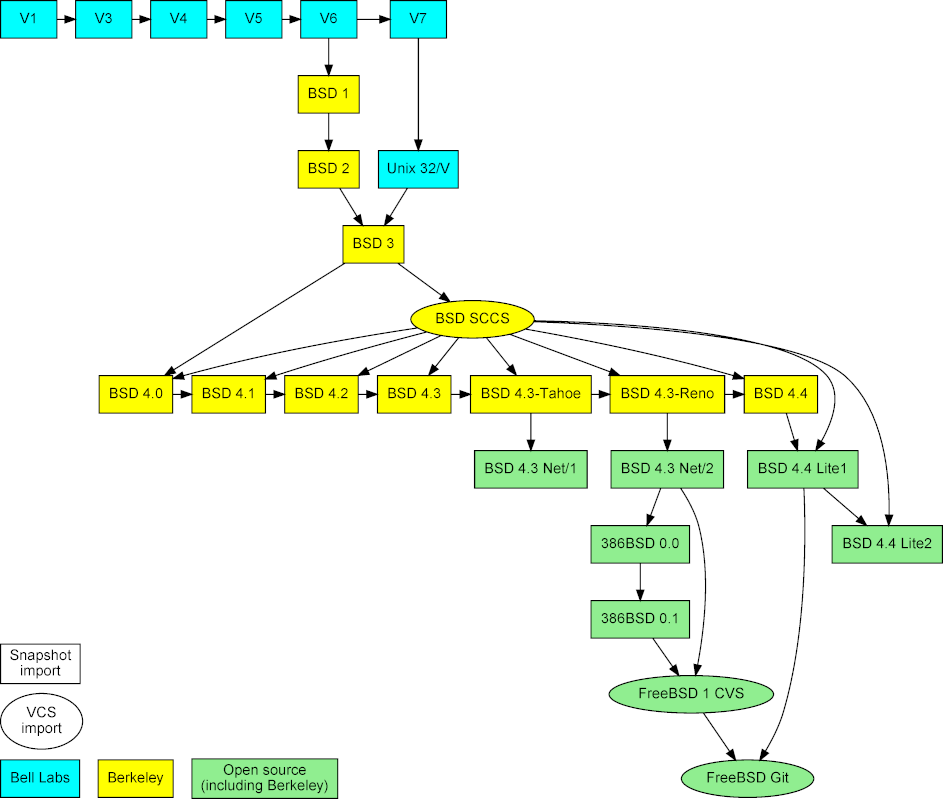
Figure 2: Imported Unix snapshots, repositories, and their mergers.
-The project is based on three types of data (see Figure [2][13]). First, snapshots of early released versions, which were obtained from the [Unix Heritage Society archive][14],[3][15] the [CD-ROM images][16] containing the full source archives of CSRG,[4][17] the [OldLinux site][18],[5][19] and the [FreeBSD archive][20].[6][21] Second, past and current repositories, namely the CSRG SCCS [[6][22]] repository, the FreeBSD 1 CVS repository, and the [Git mirror of modern FreeBSD development][23].[7][24] The first two were obtained from the same sources as the corresponding snapshots.
+项目以三种数据类型为基础(见 Figure [2][13])。首先,早些发布的版本快照,是从 [Unix Heritage Society archive][14] 中获得,[2][15] 在 [CD-ROM 镜像][16] 中包括 CSRG 全部的源包,[4][17] [Oldlinux site],[5][19] 和 [FreeBSD 包][20]。[6][21] 其次,以前的,现在的仓库,也就是 CSRG SCCS [[6][22]] 仓库,FreeBSD 1 CVS 仓库,和[现代 FreeBSD 开发的 Git 镜像][23]。[7][24]前两个都是从相同的源获得而作为对应的快照。
-The last, and most labour intensive, source of data was **primary research**. The release snapshots do not provide information regarding their ancestors and the contributors of each file. Therefore, these pieces of information had to be determined through primary research. The authorship information was mainly obtained by reading author biographies, research papers, internal memos, and old documentation scans; by reading and automatically processing source code and manual page markup; by communicating via email with people who were there at the time; by posting a query on the Unix *StackExchange* site; by looking at the location of files (in early editions the kernel source code was split into `usr/sys/dmr` and `/usr/sys/ken`); and by propagating authorship from research papers and manual pages to source code and from one release to others. (Interestingly, the 1st and 2nd Research Edition manual pages have an "owner" section, listing the person (e.g. *ken*) associated with the corresponding system command, file, system call, or library function. This section was not there in the 4th Edition, and resurfaced as the "Author" section in BSD releases.) Precise details regarding the source of the authorship information are documented in the project's files that are used for mapping Unix source code files to their authors and the corresponding commit messages. Finally, information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26]
+最后,也是最费力的数据源是 **primary research**。释出的快照并没有提供关于它们的源头和每个文件贡献者的信息。因此,这些信息片段需要通过 primary research 验证。至于作者信息主要通过作者的自传,研究论文,内部备忘录和旧文档扫描;通过阅读并且自动处理源代码和帮助页面补充;通过与那个年代的人用电子邮件交流;在 *StackExchange* 网站上贴出疑问;查看文件的位置(在早期的内核源代码版本中,分为 `usr/sys/dmr` 和 `/usr/sys/ken`);从研究论文和帮助手册到源代码,从一个发行版到另一个发行版地宣传中获取。(有趣的是,第一和第二的研究版帮助页面都有一个 “owner” 部分,列出了作者(比如,*Ken*)与对应的系统命令,文件,系统调用,或者功能库。在第四版中这个部分就没了,而在 BSD 发行版中又浮现了 “Author” 部分。)关于作者信息更为详细地写在了项目的文件中,这些文件被用于匹配源代码文件和它们的作者和对应的提交信息。最后,information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26](不好组织这个语言)
-The software and data files that were developed as part of this project, are [available online][27],[9][28] and, with appropriate network, CPU and disk resources, they can be used to recreate the repository from scratch. The authorship information for major releases is stored in files under the project's `author-path` directory. These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author. Multiple authors can also be specified. The regular expressions are processed sequentially, so that a catch-all expression at the end of the file can specify a release's default authors. To avoid repetition, a separate file with a `.au` suffix is used to map author identifiers into their names and emails. One such file has been created for every community associated with the system's evolution: Bell Labs, Berkeley, 386BSD, and FreeBSD. For the sake of authenticity, emails for the early Bell Labs releases are listed in UUCP notation (e.g. `research!ken`). The FreeBSD author identifier map, required for importing the early CVS repository, was constructed by extracting the corresponding data from the project's modern Git repository. In total the commented authorship files (828 rules) comprise 1107 lines, and there are another 640 lines mapping author identifiers to names.
+作为该项目的一部分而开发的软件和数据文件,现在可以[在线获取][27],[9][28],并且,如果有合适的网络环境,CPU 和磁盘资源,可以用来从头构建这样一个仓库。关于主要发行版的所有者信息,都存储在该项目 `author-path` 目录下的文件里。These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author.(这句单词都认识,但是不理解具体意思)也可以制定多个作者。正则表达式是按线性处理的,所以一个文件末尾的匹配一切的表达式可以指定一个发行版的默认作者。为避免重复,一个以 `.au` 后缀的独立文件专门用于映射作者身份到他们的名字和 email。这样一个文件为每个社区建立了一个,以关联系统的进化:Bell 实验室,Berkeley,386BSD 和 FreeBSD。为了真实性的需要,早期 Bell 实验室发行版的 emails 都以 UUCP 注释列出了(e.g. `research!ken`)。FreeBSD 作者的鉴定人图谱,需要导入早期的 CVS 仓库,通过从如今项目的 Git 仓库里解压对应的数据构建。总的来说,注释作者信息的文件(828 rules)包含 1107 行,并且另外 640 映射作者鉴定人到名字。
-The curation of the project's data sources has been codified into a 168-line `Makefile`. It involves the following steps.
+现在项目的数据源被编码成了一个 168 行的 `Makefile`。它包括下面的步骤。
-**Fetching** Copying and cloning about 11GB of images, archives, and repositories from remote sites.
+**Fetching** 从远程站点复制和克隆大约 11GB 的镜像,档案和仓库。
-**Tooling** Obtaining an archiver for old PDP-11 archives from 2.9 BSD, and adjusting it to compile under modern versions of Unix; compiling the 4.3 BSD *compress* program, which is no longer part of modern Unix systems, in order to decompress the 386BSD distributions.
+**Tooling** 从 2.9 BSD 中为旧的 PDP-11 档案获取一个归档器,并作出调整来在现代的 Unix 版本下编译;编译 4.3 BSD *compress* 程序来解压 386BSD 发行版,这个程序不再是现代 Unix 系统的组成部分了。
-**Organizing** Unpacking archives using tar and *cpio*; combining three 6th Research Edition directories; unpacking all 1 BSD archives using the old PDP-11 archiver; mounting CD-ROM images so that they can be processed as file systems; combining the 8 and 62 386BSD floppy disk images into two separate files.
+**Organizing** 用 tar 和 *cpio* 解压缩包;结合第六版的三个目录;用旧的 PDP-11 归档器解压所有的 1 BSD 档案;挂载 CD-ROM 镜像,这样可以作为文件系统处理;组合 8 和 62 386BSD 散乱的磁盘镜像为两个独立的文件。
-**Cleaning** Restoring the 1st Research Edition kernel source code files, which were obtained from printouts through optical character recognition, into a format close to their original state; patching some 7th Research Edition source code files; removing metadata files and other files that were added after a release, to avoid obtaining erroneous time stamp information; patching corrupted SCCS files; processing the early FreeBSD CVS repository by removing CVS symbols assigned to multiple revisions with a custom Perl script, deleting CVS *Attic* files clashing with live ones, and converting the CVS repository into a Git one using *cvs2svn*.
+**Cleaning** 重新存储第一版的内核源代码文件,这个可以通过合适的字符识别从打印输出用获取;给第七版的源代码文件打补丁;移除一个发行版后被添加进来的元数据和其他文件,为避免得到错误的时间戳信息;修复毁坏的 SCCS 文件;通过移除 CVS symbols assigned to multiple revisions with a custom Perl script,删除 CVS *Attr* 文件和用 *cvs2svn* 将 CVS 仓库转换为 Git 仓库,来处理早期的 FreeBSD CVS 仓库。
-An interesting part of the repository representation is how snapshots are imported and linked together in a way that allows *git blame* to perform its magic. Snapshots are imported into the repository as sequential commits based on the time stamp of each file. When all files have been imported the repository is tagged with the name of the corresponding release. At that point one could delete those files, and begin the import of the next snapshot. Note that the *git blame* command works by traversing backwards a repository's history, and using heuristics to detect code moving and being copied within or across files. Consequently, deleted snapshots would create a discontinuity between them, and prevent the tracing of code between them.
+在仓库表述中有一个很有意思的部分就是,如何导入那些快照,并以一种方式联系起来,使得 *git blame* 可以发挥它的魔力。快照导入到仓库是作为一系列的提交实现的,根据每个文件的时间戳。当所有文件导入后,就被用对应发行版的名字给标记了。在这点上,一个人可以删除那些文件,并开始导入下一个快照。注意 *git blame* 命令是通过回溯一个仓库的历史来工作的,并使用启发法来检测文件之间或内部的代码移动和复制。因此,删除掉的快照间会产生中断,防止它们之间的代码被追踪。
-Instead, before the next snapshot is imported, all the files of the preceding snapshot are moved into a hidden look-aside directory named `.ref` (reference). They remain there, until all files of the next snapshot have been imported, at which point they are deleted. Because every file in the `.ref` directory matches exactly an original file, *git blame* can determine how source code moves from one version to the next via the `.ref` file, without ever displaying the `.ref` file. To further help the detection of code provenance, and to increase the representation's realism, each release is represented as a merge between the branch with the incremental file additions (*-Development*) and the preceding release.
+相反,在下一个快照导入之前,之前快照的所有文件都被移动到了一个隐藏的后备目录里,叫做 `.ref`(引用)。它们保存在那,直到下个快照的所有文件都被导入了,这时候它们就会被删掉。因为 `.ref` 目录下的每个文件都完全配对一个原始文件,*git blame* 可以知道多少源代码通过 `.ref` 文件从一个版本移到了下一个,而不用显示出 `.ref` 文件。为了更进一步帮助检测代码起源,同时增加表述的真实性,每个发行版都被表述成了一个合并,介于有增加文件的分支(*-Development*)与之前发行版之间的合并。
-For a period in the 1980s, only a subset of the files developed at Berkeley were under SCCS version control. During that period our unified repository contains imports of both the SCCS commits, and the snapshots' incremental additions. At the point of each release, the SCCS commit with the nearest time stamp is found and is marked as a merge with the release's incremental import branch. These merges can be seen in the middle of Figure [2][29].
+上世纪 80 年代这个时期,只有 Berkeley 开发文件的一个子集是用 SCCS 版本控制的。整个时期内,我们统一的仓库里包含了来自 SCCS 的提交和快照增加的文件。在每个发行版的时间点上,可以发现 SCCS 最近的提交,被标记成一个发行版中增加的导入分支的合并。这些合并可以在 Figure [2][29] 中间看到。
-The synthesis of the various data sources into a single repository is mainly performed by two scripts. A 780-line Perl script (`import-dir.pl`) can export the (real or synthesized) commit history from a single data source (snapshot directory, SCCS repository, or Git repository) in the *Git fast export* format. The output is a simple text format that Git tools use to import and export commits. Among other things, the script takes as arguments the mapping of files to contributors, the mapping between contributor login names and their full names, the commit(s) from which the import will be merged, which files to process and which to ignore, and the handling of "reference" files. A 450-line shell script creates the Git repository and calls the Perl script with appropriate arguments to import each one of the 27 available historical data sources. The shell script also runs 30 tests that compare the repository at specific tags against the corresponding data sources, verify the appearance and disappearance of look-aside directories, and look for regressions in the count of tree branches and merges and the output of *git blame* and *git log*. Finally, *git* is called to garbage-collect and compress the repository from its initial 6GB size down to the distributed 1GB.
+将各种数据资源综合到一个仓库的工作,主要是用两个脚本来完成的。一个 780 行的 Perl 脚本(`import-dir.pl`)可以从一个单独的数据源(快照目录,SCCS 仓库,或者 Git 仓库)中,以 *Git fast export* 格式导出(真实的或者综合的)提交历史。输出是一个简单的文本格式,Git 工具用这个来导入和导出提交。其他方面,这个脚本以一些东西为参数,如文件到贡献者的映射,贡献者登录名和他们的全名间的映射,导入的提交会被合并,哪些文件要处理,哪些文件要忽略,和“引用”文件的处理。一个 450 行的 Shell 脚本创建 Git 仓库,并调用带适当参数的 Perl 脚本,导入 27 个可用的历史数据资源。Shell 脚本也会跑 30 遍测试,比较特定标签的仓库和对应的数据源,确认出现的和没出现的备用目录,并查看分支树和合并的数量,*git blame* 和 *git log* 的输出中的退化。最后,*git* 被调用来作垃圾收集和压缩仓库,从最初的 6GB 降到发行的 1GB。
-### 4 Data Uses ###
+### 4 数据使用 ###
-The data set can be used for empirical research in software engineering, information systems, and software archeology. Through its unique uninterrupted coverage of a period of more than 40 years, it can inform work on software evolution and handovers across generations. With thousandfold increases in processing speed and million-fold increases in storage capacity during that time, the data set can also be used to study the co-evolution of software and hardware technology. The move of the software's development from research labs, to academia, and to the open source community can be used to study the effects of organizational culture on software development. The repository can also be used to study how notable individuals, such as Turing Award winners (Dennis Ritchie and Ken Thompson) and captains of the IT industry (Bill Joy and Eric Schmidt), actually programmed. Another phenomenon worthy of study concerns the longevity of code, either at the level of individual lines, or as complete systems that were at times distributed with Unix (Ingres, Lisp, Pascal, Ratfor, Snobol, TMG), as well as the factors that lead to code's survival or demise. Finally, because the data set stresses Git, the underlying software repository storage technology, to its limits, it can be used to drive engineering progress in the field of revision management systems.
+数据可以用于软件工程,信息系统和软件考古学领域的经验性研究。鉴于它从不间断而独一无二的存在了超过了 40 年,可以供软件的进化和代代更迭参考。伴随那个时代以来在处理速度千倍地增长,存储容量百万倍的扩大,数据同样可以用于软件和硬件技术交叉进化的研究。软件开发从研究中心到大学,到开源社区的转移,可以用来研究组织文化对于软件开发的影响。仓库也可以用于学习开发者编程的影响力,比如 Turing 奖获得者(Dennis Ritchie 和 Ken Thompson)和 IT 产业的大佬(Bill Joy 和 Eric Schmidt)。另一个值得学习的现象是代码的长寿,无论是单行的水平,或是作为那个时代随 Unix 发行的完整的系统(Ingres, Lisp, Pascal, Ratfor, Snobol, TMP),和导致代码存活或消亡的因素。最后,因为数据使 Git 底层软件仓库存储技术感到压力,到了它的限度,这会加速修正管理系统领域的工程进度。
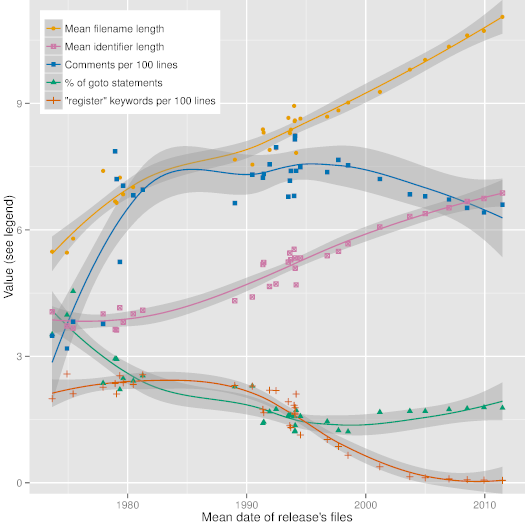
Figure 3: Code style evolution along Unix releases.
-Figure [3][30], which depicts trend lines (obtained with R's local polynomial regression fitting function) of some interesting code metrics along 36 major releases of Unix, demonstrates the evolution of code style and programming language use over very long timescales. This evolution can be driven by software and hardware technology affordances and requirements, software construction theory, and even social forces. The dates in the Figure have been calculated as the average date of all files appearing in a given release. As can be seen in it, over the past 40 years the mean length of identifiers and file names has steadily increased from 4 and 6 characters to 7 and 11 characters, respectively. We can also see less steady increases in the number of comments and decreases in the use of the *goto* statement, as well as the virtual disappearance of the *register* type modifier.
+Figure [3][30] 描述了一些有趣的代码统计,根据 36 个主要 Unix 发行版,验证了代码风格和编程语言的使用在很长的时间尺度上的进化。这种进化是软硬件技术的需求和支持驱动的,软件构筑理论,甚至社会力量。图片中的数据已经计算了在一个所给发行版中出现的文件的平均时间。正如可以从中看到,在过去的 40 年中,验证器和文件名字的长度已经稳定从 4 到 6 个字符增长到 7 到 11 个字符。我们也可以看到在评论数量的少量稳定增加,和 *goto* 表达的使用量减少,同时 *register* 这个类型修改器的消失。
-### 5 Further Work ###
+### 5 未来的工作 ###
-Many things can be done to increase the repository's faithfulness and usefulness. Given that the build process is shared as open source code, it is easy to contribute additions and fixes through GitHub pull requests. The most useful community contribution would be to increase the coverage of imported snapshot files that are attributed to a specific author. Currently, about 90 thousand files (out of a total of 160 thousand) are getting assigned an author through a default rule. Similarly, there are about 250 authors (primarily early FreeBSD ones) for which only the identifier is known. Both are listed in the build repository's unmatched directory, and contributions are welcomed. Furthermore, the BSD SCCS and the FreeBSD CVS commits that share the same author and time-stamp can be coalesced into a single Git commit. Support can be added for importing the SCCS file comment fields, in order to bring into the repository the corresponding metadata. Finally, and most importantly, more branches of open source systems can be added, such as NetBSD OpenBSD, DragonFlyBSD, and *illumos*. Ideally, current right holders of other important historical Unix releases, such as System III, System V, NeXTSTEP, and SunOS, will release their systems under a license that would allow their incorporation into this repository for study.
+可以做很多事情去提高仓库的正确性和有效性。创建进程作为源代码开源了,通过 GitHub 的拉取请求,可以很容易地贡献更多代码和修复。最有用的社区贡献会使得导入的快照文件的覆盖增长,这曾经是隶属于一个具体的作者。现在,大约 90,000 个文件(在 160,000 总量之外)被指定了作者,根据一个默认的规则。类似地,大约有 250 个作者(最初 FreeBSD 那些)是验证器确认的。两个都列在了 build 仓库无配对的目录里,也欢迎贡献数据。进一步,BSD SCCS 和 FreeBSD CVS 的提交,共享相同的作者和时间戳,这些可以结合成一个单独的 Git 提交。导入 SCCS 文件提交的支持会被添加进来,为了引入仓库对应的元数据。最后,最重要的,开源系统的更多分支会添加进来,比如 NetBSD OpenBSD, DragonFlyBSD 和 *illumos*。理想地,其他重要的历史上的 Unix 发行版,它们的版权拥有者,如 System III, System V, NeXTSTEP 和 SunOS,也会在一个协议下释出他们的系统,允许他们的合作伙伴使用仓库用于研究。
-#### Acknowledgements ####
+### 鸣谢 ###
-The author thanks the many individuals who contributed to the effort. Brian W. Kernighan, Doug McIlroy, and Arnold D. Robbins helped with Bell Labs login identifiers. Clem Cole, Era Eriksson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze, and Anatole Shaw helped with BSD login identifiers. The BSD SCCS import code is based on work by H. Merijn Brand and Jonathan Gray.
+本人感谢很多付出努力的人们。 Brian W. Kernighan, Doug McIlroy 和 Arnold D. Robbins 帮助 Bell 实验室开发了登录验证器。 Clem Cole, Era Erikson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze 和 Anatole Shaw 开发了 BSD 的登录验证器。BSD SCCS 导入了 H. Merijn Brand 和 Jonathan Gray 的开发工作的代码。
-This research has been co-financed by the European Union (European Social Fund - ESF) and Greek national funds through the Operational Program "Education and Lifelong Learning" of the National Strategic Reference Framework (NSRF) - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform.
+这次研究通过 National Strategic Reference Framework (NSRF) 的 Operational Program " Education and Lifelong Learning" - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform,由 European Union ( European Social Fund - ESF) 和 Greek national funds 出资赞助。
-### References ###
+### 引用 ###
[[1]][31]
M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
@@ -142,7 +142,7 @@ This research has been co-financed by the European Union (European Social Fund -
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
-译者:[译者ID](https://github.com/译者ID)
+译者:[wi-cuckoo](https://github.com/wi-cuckoo)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -199,4 +199,4 @@ via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.htm
[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
-[53]:https://github.com/dspinellis/unix-history-make
\ No newline at end of file
+[53]:https://github.com/dspinellis/unix-history-make
diff --git a/sources/tech/20151012 How to Setup DockerUI--a Web Interface for Docker.md b/sources/tech/20151012 How to Setup DockerUI--a Web Interface for Docker.md
deleted file mode 100644
index 8e13fdc8d5..0000000000
--- a/sources/tech/20151012 How to Setup DockerUI--a Web Interface for Docker.md
+++ /dev/null
@@ -1,114 +0,0 @@
-translating by Ezio
-
-
-How to Setup DockerUI - a Web Interface for Docker
-================================================================================
-Docker is getting more popularity day by day. The idea of running a complete Operating System inside a container rather than running inside a virtual machine is an awesome technology. Docker has made lives of millions of system administrators and developers pretty easy for getting their work done in no time. It is an open source technology that provides an open platform to pack, ship, share and run any application as a lightweight container without caring on which operating system we are running on the host. It has no boundaries of Language support, Frameworks or packaging system and can be run anywhere, anytime from a small home computers to high-end servers. Running docker containers and managing them may come a bit difficult and time consuming, so there is a web based application named DockerUI which is make managing and running container pretty simple. DockerUI is highly beneficial to people who are not much aware of linux command lines and want to run containerized applications. DockerUI is an open source web based application best known for its beautiful design and ease simple interface for running and managing docker containers.
-
-Here are some easy steps on how we can setup Docker Engine with DockerUI in our linux machine.
-
-### 1. Installing Docker Engine ###
-
-First of all, we'll gonna install docker engine in our linux machine. Thanks to its developers, docker is very easy to install in any major linux distribution. To install docker engine, we'll need to run the following command with respect to which distribution we are running.
-
-#### On Ubuntu/Fedora/CentOS/RHEL/Debian ####
-
-Docker maintainers have written an awesome script that can be used to install docker engine in Ubuntu 15.04/14.10/14.04, CentOS 6.x/7, Fedora 22, RHEL 7 and Debian 8.x distributions of linux. This script recognizes the distribution of linux installed in our machine, then adds the required repository to the filesystem, updates the local repository index and finally installs docker engine and required dependencies from it. To install docker engine using that script, we'll need to run the following command under root or sudo mode.
-
- # curl -sSL https://get.docker.com/ | sh
-
-#### On OpenSuse/SUSE Linux Enterprise ####
-
-To install docker engine in the machine running OpenSuse 13.1/13.2 or SUSE Linux Enterprise Server 12, we'll simply need to execute the zypper command. We'll gonna install docker using zypper command as the latest docker engine is available on the official repository. To do so, we'll run the following command under root/sudo mode.
-
- # zypper in docker
-
-#### On ArchLinux ####
-
-Docker is available in the official repository of Archlinux as well as in the AUR packages maintained by the community. So, we have two options to install docker in archlinux. To install docker using the official arch repository, we'll need to run the following pacman command.
-
- # pacman -S docker
-
-But if we want to install docker from the Archlinux User Repository ie AUR, then we'll need to execute the following command.
-
- # yaourt -S docker-git
-
-### 2. Starting Docker Daemon ###
-
-After docker is installed, we'll now gonna start our docker daemon so that we can run docker containers and manage them. We'll run the following command to make sure that docker daemon is installed and to start the docker daemon.
-
-#### On SysVinit ####
-
- # service docker start
-
-#### On Systemd ####
-
- # systemctl start docker
-
-### 3. Installing DockerUI ###
-
-Installing DockerUI is pretty easy than installing docker engine. We just need to pull the dockerui from the Docker Registry Hub and run it inside a container. To do so, we'll simply need to run the following command.
-
- # docker run -d -p 9000:9000 --privileged -v /var/run/docker.sock:/var/run/docker.sock dockerui/dockerui
-
-
-
-Here, in the above command, as the default port of the dockerui web application server 9000, we'll simply map the default port of it with -p flag. With -v flag, we specify the docker socket. The --privileged flag is required for hosts using SELinux.
-
-After executing the above command, we'll now check if the dockerui container is running or not by running the following command.
-
- # docker ps
-
-
-
-### 4. Pulling an Image ###
-
-Currently, we cannot pull an image directly from DockerUI so, we'll need to pull a docker image from the linux console/terminal. To do so, we'll need to run the following command.
-
- # docker pull ubuntu
-
-
-
-The above command will pull an image tagged as ubuntu from the official [Docker Hub][1]. Similarly, we can pull more images that we require and are available in the hub.
-
-### 4. Managing with DockerUI ###
-
-After we have started the dockerui container, we'll now have fun with it to start, pause, stop, remove and perform many possible activities featured by dockerui with docker containers and images. First of all, we'll need to open the web application using our web browser. To do so, we'll need to point our browser to http://ip-address:9000 or http://mydomain.com:9000 according to the configuration of our system. By default, there is no login authentication needed for the user access but we can configure our web server for adding authentication. To start a container, first we'll need to have images of the required application we want to run a container with.
-
-#### Create a Container ####
-
-To create a container, we'll need to go to the section named Images then, we'll need to click on the image id which we want to create a container of. After clicking on the required image id, we'll need to click on Create button then we'll be asked to enter the required properties for our container. And after everything is set and done. We'll need to click on Create button to finally create a container.
-
-
-
-#### Stop a Container ####
-
-To stop a container, we'll need to move towards the Containers page and then select the required container we want to stop. Now, we'll want to click on Stop option which we can see under Actions drop-down menu.
-
-
-
-#### Pause and Resume ####
-
-To pause a container, we simply select the required container we want to pause by keeping a check mark on the container and then click the Pause option under Actions . This is will pause the running container and then, we can simply resume the container by selecting Unpause option from the Actions drop down menu.
-
-#### Kill and Remove ####
-
-Like we had performed the above tasks, its pretty easy to kill and remove a container or an image. We just need to check/select the required container or image and then select the Kill or Remove button from the application according to our need.
-
-### Conclusion ###
-
-DockerUI is a beautiful utilization of Docker Remote API to develop an awesome web interface for managing docker containers. The developers have designed and developed this application in pure HTML and JS language. It is currently incomplete and is under heavy development so we don't recommend it for the use in production currently. It makes users pretty easy to manage their containers and images with simple clicks without needing to execute lines of commands to do small jobs. If we want to contribute DockerUI, we can simply visit its [Github Repository][2]. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-how-to/setup-dockerui-web-interface-docker/
-
-作者:[Arun Pyasi][a]
-译者:[oska874](https://github.com/oska874)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:https://hub.docker.com/
-[2]:https://github.com/crosbymichael/dockerui/
diff --git a/sources/tech/20151012 Remember sed and awk All Linux admins should.md b/sources/tech/20151012 Remember sed and awk All Linux admins should.md
index c0b3aded0b..67a6641393 100644
--- a/sources/tech/20151012 Remember sed and awk All Linux admins should.md
+++ b/sources/tech/20151012 Remember sed and awk All Linux admins should.md
@@ -1,5 +1,3 @@
-translating by Ezio
-
Remember sed and awk? All Linux admins should
================================================================================

diff --git a/sources/tech/20151022 9 Tips for Improving WordPress Performance.md b/sources/tech/20151022 9 Tips for Improving WordPress Performance.md
deleted file mode 100644
index 8aab6b8f49..0000000000
--- a/sources/tech/20151022 9 Tips for Improving WordPress Performance.md
+++ /dev/null
@@ -1,513 +0,0 @@
-struggling 翻译中...
-9 Tips for Improving WordPress Performance
-================================================================================
-WordPress is the single largest platform for website creation and web application delivery worldwide. About [a quarter][1] of all sites are now built on open-source WordPress software, including sites for eBay, Mozilla, RackSpace, TechCrunch, CNN, MTV, the New York Times, the Wall Street Journal.
-
-WordPress.com, the most popular site for user-created blogs, also runs on WordPress open source software. [NGINX powers WordPress.com][2]. Among WordPress customers, many sites start on WordPress.com and then move to hosted WordPress open-source software; more and more of these sites use NGINX software as well.
-
-WordPress’ appeal is its simplicity, both for end users and for implementation. However, the architecture of a WordPress site presents problems when usage ramps upward – and several steps, including caching and combining WordPress and NGINX, can solve these problems.
-
-In this blog post, we provide nine performance tips to help overcome typical WordPress performance challenges:
-
-- [Cache static resources][3]
-- [Cache dynamic files][4]
-- [Move to NGINX][5]
-- [Add permalink support to NGINX][6]
-- [Configure NGINX for FastCGI][7]
-- [Configure NGINX for W3_Total_Cache][8]
-- [Configure NGINX for WP-Super-Cache][9]
-- [Add security precautions to your NGINX configuration][10]
-- [Configure NGINX to support WordPress Multisite][11]
-
-### WordPress Performance on LAMP Sites ###
-
-Most WordPress sites are run on a traditional LAMP software stack: the Linux OS, Apache web server software, MySQL database software – often on a separate database server – and the PHP programming language. Each of these is a very well-known, widely used, open source tool. Most people in the WordPress world “speak” LAMP, so it’s easy to get help and support.
-
-When a user visits a WordPress site, a browser running the Linux/Apache combination creates six to eight connections per user. As the user moves around the site, PHP assembles each page on the fly, grabbing resources from the MySQL database to answer requests.
-
-LAMP stacks work well for anywhere from a few to, perhaps, hundreds of simultaneous users. However, sudden increases in traffic are common online and – usually – a good thing.
-
-But when a LAMP-stack site gets busy, with the number of simultaneous users climbing into the many hundreds or thousands, it can develop serious bottlenecks. Two main causes of bottlenecks are:
-
-1. The Apache web server – Apache consumes substantial resources for each and every connection. If Apache accepts too many simultaneous connections, memory can be exhausted and performance slows because data has to be paged back and forth to disk. If connections are limited to protect response time, new connections have to wait, which also leads to a poor user experience.
-1. The PHP/MySQL interaction – Together, an application server running PHP and a MySQL database server can serve a maximum number of requests per second. When the number of requests exceeds the maximum, users have to wait. Exceeding the maximum by a relatively small amount can cause a large slowdown in responsiveness for all users. Exceeding it by two or more times can cause significant performance problems.
-
-The performance bottlenecks in a LAMP site are particularly resistant to the usual instinctive response, which is to upgrade to more powerful hardware – more CPUs, more disk space, and so on. Incremental increases in hardware performance can’t keep up with the exponential increases in demand for system resources that Apache and the PHP/MySQL combination experience when they get overloaded.
-
-The leading alternative to a LAMP stack is a LEMP stack – Linux, NGINX, MySQL, and PHP. (In the LEMP acronym, the E stands for the sound at the start of “engine-x.”) We describe a LEMP stack in [Tip 3][12].
-
-### Tip 1. Cache Static Resources ###
-
-Static resources are unchanging files such as CSS files, JavaScript files, and image files. These files often make up half or more of the data on a web page. The remainder of the page is dynamically generated content like comments in a forum, a performance dashboard, or personalized content (think Amazon.com product recommendations).
-
-Caching static resources has two big benefits:
-
-- Faster delivery to the user – The user gets the static file from their browser cache or a caching server closer to them on the Internet. These are sometimes big files, so reducing latency for them helps a lot.
-- Reduced load on the application server – Every file that’s retrieved from a cache is one less request the web server has to process. The more you cache, the more you avoid thrashing because resources have run out.
-
-To support browser caching, set the correct HTTP headers for static files. Look into the HTTP Cache-Control header, specifically the max-age setting, the Expires header, and Entity tags. You can find a good introduction [here][13].
-
-When local caching is enabled and a user requests a previously accessed file, the browser first checks whether the file is in the cache. If so, it asks the web server if the file has changed. If the file hasn’t changed, the web server can respond immediately with code 304 (Not Modified) meaning that the file is unchanged, instead of returning code 200 OK and then retrieving and delivering the changed file.
-
-To support caching beyond the browser, consider the Tips below, and consider a content delivery network (CDN).CDNs are a popular and powerful tool for caching, but we don’t describe them in detail here. Consider a CDN after you implement the other techniques mentioned here. Also, CDNs may be less useful as you transition your site from HTTP/1.x to the new HTTP/2 standard; investigate and test as needed to find the right answer for your site.
-
-If you move to NGINX Plus or the open source NGINX software as part of your software stack, as suggested in [Tip 3][14], then configure NGINX to cache static resources. Use the following configuration, replacing www.example.com with the URL of your web server.
-
- server {
- # substitute your web server's URL for www.example.com
- server_name www.example.com;
- root /var/www/example.com/htdocs;
- index index.php;
-
- access_log /var/log/nginx/example.com.access.log;
- error_log /var/log/nginx/example.com.error.log;
-
- location / {
- try_files $uri $uri/ /index.php?$args;
- }
-
- location ~ \.php$ {
- try_files $uri =404;
- include fastcgi_params;
- # substitute the socket, or address and port, of your WordPress server
- fastcgi_pass unix:/var/run/php5-fpm.sock;
- #fastcgi_pass 127.0.0.1:9000;
- }
-
- location ~* .(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css|rss|atom|js|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
- expires max;
- log_not_found off;
- access_log off;
- }
- }
-
-### Tip 2. Cache Dynamic Files ###
-
-WordPress generates web pages dynamically, meaning that it generates a given web page every time it is requested (even if the result is the same as the time before). This means that users always get the freshest content.
-
-Think of a user visiting a blog post that has comments enabled at the bottom of the post. You want the user to see all comments – even a comment that just came in a moment ago. Dynamic content makes this happen.
-
-But now let’s say that the blog post is getting ten or twenty requests per second. The application server might start to thrash under the pressure of trying to regenerate the page so often, causing big delays. The goal of delivering the latest content to new visitors becomes relevant only in theory, because they’re have to wait so long to get the page in the first place.
-
-To prevent page delivery from slowing down due to increasing load, cache the dynamic file. This makes the file less dynamic, but makes the whole system more responsive.
-
-To enable caching in WordPress, use one of several popular plug-ins – described below. A WordPress caching plug-in asks for a fresh page, then caches it for a brief period of time – perhaps just a few seconds. So, if the site is getting several requests a second, most users get their copy of the page from the cache. This helps the retrieval time for all users:
-
-- Most users get a cached copy of the page. The application server does no work at all.
-- Users who do get a fresh copy get it fast. The application server only has to generate a fresh page every so often. When the server does generate a fresh page (for the first user to come along after the cached page expires), it does this much faster because it’s not overloaded with requests.
-
-You can cache dynamic files for WordPress running on a LAMP stack or on a [LEMP stack][15] (described in [Tip 3][16]). There are several caching plug-ins you can use with WordPress. Here are the most popular caching plug-ins and caching techniques, listed from the simplest to the most powerful:
-
-- [Hyper-Cache][17] and [Quick-Cache][18] – These two plug-ins create a single PHP file for each WordPress page or post. This supports some dynamic functionality while bypassing much WordPress core processing and the database connection, creating a faster user experience. They don’t bypass all PHP processing, so they don’t give the same performance boost as the following options. They also don’t require changes to the NGINX configuration.
-- [WP Super Cache][19] – The most popular caching plug-in for WordPress. It has many settings, which are presented through an easy-to-use interface, shown below. We show a sample NGINX configuration in [Tip 7][20].
-- [W3 Total Cache][21] – This is the second most popular cache plug-in for WordPress. It has even more option settings than WP Super Cache, making it a powerful but somewhat complex option. For a sample NGINX configuration, see [Tip 6][22].
-- [FastCGI][23] – CGI stands for Common Gateway Interface, a language-neutral way to request and receive files on the Internet. FastCGI is not a plug-in but a way to interact with a cache. FastCGI can be used in Apache as well as in NGINX, where it’s the most popular dynamic caching approach; we describe how to configure NGINX to use it in [Tip 5][24].
-
-The documentation for these plug-ins and techniques explains how to configure them in a typical LAMP stack. Configuration options include database and object caching; minification for HTML, CSS, and JavaScript files; and integration options for popular CDNs. For NGINX configuration, see the Tips referenced in the list.
-
-**Note**: Caches do not work for users who are logged into WordPress, because their view of WordPress pages is personalized. (For most sites, only a small minority of users are likely to be logged in.) Also, most caches do not show a cached page to users who have recently left a comment, as that user will want to see their comment appear when they refresh the page. To cache the non-personalized content of a page, you can use a technique called [fragment caching][25], if it’s important to overall performance.
-
-### Tip 3. Move to NGINX ###
-
-As mentioned above, Apache can cause performance problems when the number of simultaneous users rises above a certain point – perhaps hundreds of simultaneous users. Apache allocates substantial resources to each connection, and therefore tends to run out of memory. Apache can be configured to limit connections to avoid exhausting memory, but that means, when the limit is exceeded, new connection requests have to wait.
-
-In addition, Apache loads another copy of the mod_php module into memory for every connection, even if it’s only serving static files (images, CSS, JavaScript, etc.). This consumes even more resources for each connection and limits the capacity of the server further.
-
-To start solving these problems, move from a LAMP stack to a LEMP stack – replace Apache with (e)NGINX. NGINX handles many thousands of simultaneous connections in a fixed memory footprint, so you don’t have to experience thrashing, nor limit simultaneous connections to a small number.
-
-NGINX also deals with static files better, with built-in, easily tuned [caching][26] controls. The load on the application server is reduced, and your site can serve far more traffic with a faster, more enjoyable experience for your users.
-
-You can use NGINX on all the web servers in your deployment, or you can put an NGINX server “in front” of Apache as a reverse proxy – the NGINX server receives client requests, serves static files, and sends PHP requests to Apache, which processes them.
-
-For dynamically generated pages – the core use case for WordPress experience – choose a caching tool, as described in [Tip 2][27]. In the Tips below, you can find NGINX configuration suggestions for FastCGI, W3_Total_Cache, and WP-Super-Cache. (Hyper-Cache and Quick-Cache don’t require changes to NGINX configuration.)
-
-**Tip.** Caches are typically saved to disk, but you can use [tmpfs][28] to store the cache in memory and increase performance.
-
-Setting up NGINX for WordPress is easy. Just follow these four steps, which are described in further detail in the indicated Tips:
-
-1. Add permalink support – Add permalink support to NGINX. This eliminates dependence on the **.htaccess** configuration file, which is Apache-specific. See [Tip 4][29].
-1. Configure for caching – Choose a caching tool and implement it. Choices include FastCGI cache, W3 Total Cache, WP Super Cache, Hyper Cache, and Quick Cache. See Tips [5][30], [6][31], and [7][32].
-1. Implement security precautions – Adopt best practices for WordPress security on NGINX. See [Tip 8][33].
-1. Configure WordPress Multisite – If you use WordPress Multisite, configure NGINX for a subdirectory, subdomain, or multiple-domain architecture. See [Tip 9][34].
-
-### Tip 4. Add Permalink Support to NGINX ###
-
-Many WordPress sites depend on **.htaccess** files, which are required for several WordPress features, including permalink support, plug-ins, and file caching. NGINX does not support **.htaccess** files. Fortunately, you can use NGINX’s simple, yet comprehensive, configuration language to achieve most of the same functionality.
-
-You can enable [Permalinks][35] in WordPress with NGINX by including the following location block in your main [server][36] block. (This location block is also included in other code samples below.)
-
-The **try_files** directive tells NGINX to check whether the requested URL exists as a file ( **$uri**) or directory (**$uri/**) in the document root, **/var/www/example.com/htdocs**. If not, NGINX does a redirect to **/index.php**, passing the query string arguments as parameters.
-
- server {
- server_name example.com www.example.com;
- root /var/www/example.com/htdocs;
- index index.php;
-
- access_log /var/log/nginx/example.com.access.log;
- error_log /var/log/nginx/example.com.error.log;
-
- location / {
- try_files $uri $uri/ /index.php?$args;
- }
- }
-
-### Tip 5. Configure NGINX for FastCGI ###
-
-NGINX can cache responses from FastCGI applications like PHP. This method offers the best performance.
-
-For NGINX open source, compile in the third-party module [ngx_cache_purge][37], which provides cache purging capability, and use the configuration code below. NGINX Plus includes its own implementation of this code.
-
-When using FastCGI, we recommend you install the [Nginx Helper plug-in][38] and use a configuration such as the one below, especially the use of **fastcgi_cache_key** and the location block including **fastcgi_cache_purge**. The plug-in automatically purges your cache when a page or a post is published or modified, a new comment is published, or the cache is manually purged from the WordPress Admin Dashboard.
-
-The Nginx Helper plug-in can also add a short HTML snippet to the bottom of your pages, confirming the cache is working and displaying some statistics. (You can also confirm the cache is functioning properly using the [$upstream_cache_status][39] variable.)
-
-fastcgi_cache_path /var/run/nginx-cache levels=1:2
- keys_zone=WORDPRESS:100m inactive=60m;
-fastcgi_cache_key "$scheme$request_method$host$request_uri";
-
- server {
- server_name example.com www.example.com;
- root /var/www/example.com/htdocs;
- index index.php;
-
- access_log /var/log/nginx/example.com.access.log;
- error_log /var/log/nginx/example.com.error.log;
-
- set $skip_cache 0;
-
- # POST requests and urls with a query string should always go to PHP
- if ($request_method = POST) {
- set $skip_cache 1;
- }
-
- if ($query_string != "") {
- set $skip_cache 1;
- }
-
- # Don't cache uris containing the following segments
- if ($request_uri ~* "/wp-admin/|/xmlrpc.php|wp-.*.php|/feed/|index.php
- |sitemap(_index)?.xml") {
- set $skip_cache 1;
- }
-
- # Don't use the cache for logged in users or recent commenters
- if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+|wp-postpass
- |wordpress_no_cache|wordpress_logged_in") {
- set $skip_cache 1;
- }
-
- location / {
- try_files $uri $uri/ /index.php?$args;
- }
-
- location ~ \.php$ {
- try_files $uri /index.php;
- include fastcgi_params;
- fastcgi_pass unix:/var/run/php5-fpm.sock;
- fastcgi_cache_bypass $skip_cache;
- fastcgi_no_cache $skip_cache;
- fastcgi_cache WORDPRESS;
- fastcgi_cache_valid 60m;
- }
-
- location ~ /purge(/.*) {
- fastcgi_cache_purge WORDPRESS "$scheme$request_method$host$1";
- }
-
- location ~* ^.+\.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css|rss|atom|js|jpg|jpeg|gif|png
- |ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
-
- access_log off;
- log_not_found off;
- expires max;
- }
-
- location = /robots.txt {
- access_log off;
- log_not_found off;
- }
-
- location ~ /\. {
- deny all;
- access_log off;
- log_not_found off;
- }
- }
-
-### Tip 6. Configure NGINX for W3_Total_Cache ###
-
-[W3 Total Cache][40], by Frederick Townes of [W3-Edge][41], is a WordPress caching framework that supports NGINX. It’s an alternative to FastCGI cache with a wide range of option settings.
-
-The caching plug-in offers a variety of caching configurations and also includes options for database and object caching, minification of HTML, CSS, and JavaScript, as well as options to integrate with popular CDNs.
-
-The plug-in handles NGINX configuration by writing to an NGINX configuration file located in the root directory of your domain.
-
- server {
- server_name example.com www.example.com;
-
- root /var/www/example.com/htdocs;
- index index.php;
- access_log /var/log/nginx/example.com.access.log;
- error_log /var/log/nginx/example.com.error.log;
-
- include /path/to/wordpress/installation/nginx.conf;
-
- location / {
- try_files $uri $uri/ /index.php?$args;
- }
-
- location ~ \.php$ {
- try_files $uri =404;
- include fastcgi_params;
- fastcgi_pass unix:/var/run/php5-fpm.sock;
- }
- }
-
-### Tip 7. Configure NGINX for WP Super Cache ###
-
-[WP Super Cache][42] by Donncha O Caoimh, a WordPress developer at [Automattic][43], is a WordPress caching engine that turns dynamic WordPress pages into static HTML files that NGINX can serve very quickly. It was one of the first caching plug-ins for WordPress and has a smaller, more focused range of options than others.
-
-NGINX configurations for WP-Super-Cache can vary depending on your preference. One possible configuration follows.
-
-In the configuration below, the location block with supercache named in it is the WP Super Cache-specific part, and is needed for the configuration to work. The rest of the code is made up of WordPress rules for not caching users who are logged into WordPress, not caching POST requests, and setting expires headers for static assets, plus standard PHP implementation; these parts can be customized to fit your needs.
-
- server {
- server_name example.com www.example.com;
- root /var/www/example.com/htdocs;
- index index.php;
-
- access_log /var/log/nginx/example.com.access.log;
- error_log /var/log/nginx/example.com.error.log debug;
-
- set $cache_uri $request_uri;
-
- # POST requests and urls with a query string should always go to PHP
- if ($request_method = POST) {
- set $cache_uri 'null cache';
- }
- if ($query_string != "") {
- set $cache_uri 'null cache';
- }
-
- # Don't cache uris containing the following segments
- if ($request_uri ~* "(/wp-admin/|/xmlrpc.php|/wp-(app|cron|login|register|mail).php
- |wp-.*.php|/feed/|index.php|wp-comments-popup.php
- |wp-links-opml.php|wp-locations.php |sitemap(_index)?.xml
- |[a-z0-9_-]+-sitemap([0-9]+)?.xml)") {
-
- set $cache_uri 'null cache';
- }
-
- # Don't use the cache for logged-in users or recent commenters
- if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+
- |wp-postpass|wordpress_logged_in") {
- set $cache_uri 'null cache';
- }
-
- # Use cached or actual file if it exists, otherwise pass request to WordPress
- location / {
- try_files /wp-content/cache/supercache/$http_host/$cache_uri/index.html
- $uri $uri/ /index.php;
- }
-
- location = /favicon.ico {
- log_not_found off;
- access_log off;
- }
-
- location = /robots.txt {
- log_not_found off
- access_log off;
- }
-
- location ~ .php$ {
- try_files $uri /index.php;
- include fastcgi_params;
- fastcgi_pass unix:/var/run/php5-fpm.sock;
- #fastcgi_pass 127.0.0.1:9000;
- }
-
- # Cache static files for as long as possible
- location ~*.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css
- |rss|atom|js|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2
- |doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
- expires max;
- log_not_found off;
- access_log off;
- }
- }
-
-### Tip 8. Add Security Precautions to Your NGINX Configuration ###
-
-To protect against attacks, you can control access to key resources and limit the ability of bots to overload the login utility.
-
-Allow only specific IP addresses to access the WordPress Dashboard.
-
- # Restrict access to WordPress Dashboard
- location /wp-admin {
- deny 192.192.9.9;
- allow 192.192.1.0/24;
- allow 10.1.1.0/16;
- deny all;
- }
-
-Only allow uploading of specific types of files to prevent programs with malicious intent from being uploaded and running.
-
- # Deny access to uploads which aren’t images, videos, music, etc.
- location ~* ^/wp-content/uploads/.*.(html|htm|shtml|php|js|swf)$ {
- deny all;
- }
-
-Deny access to **wp-config.php**, the WordPress configuration file. Another way to deny access is to move the file one directory level above the domain root.
-
- # Deny public access to wp-config.php
- location ~* wp-config.php {
- deny all;
- }
-
-Rate limit **wp-login.php** to block against brute force attacks.
-
- # Deny access to wp-login.php
- location = /wp-login.php {
- limit_req zone=one burst=1 nodelay;
- fastcgi_pass unix:/var/run/php5-fpm.sock;
- #fastcgi_pass 127.0.0.1:9000;
- }
-
-### Tip 9. Use NGINX with WordPress Multisite ###
-
-WordPress Multisite, as its name implies, is a version of WordPress software that allows you to manage two or more sites from a single WordPress instance. The [WordPress.com][44] service, which hosts thousands of user blogs, is run from WordPress Multisite.
-
-You can run separate sites from either subdirectories of a single domain or from separate subdomains.
-
-Use this code block to add support for a subdirectory structure.
-
- # Add support for subdirectory structure in WordPress Multisite
- if (!-e $request_filename) {
- rewrite /wp-admin$ $scheme://$host$uri/ permanent;
- rewrite ^(/[^/]+)?(/wp-.*) $2 last;
- rewrite ^(/[^/]+)?(/.*\.php) $2 last;
- }
-
-Use this code block instead of the code block above to add support for a subdirectory structure, substituting your own subdirectory names.
-
- # Add support for subdomains
- server_name example.com *.example.com;
-
-Older versions of WordPress Multisite (3.4 and earlier) use readfile() to serve static content. However, readfile() is PHP code, which causes a significant performance hit when it executes. We can use NGINX to bypass this unnecessary PHP processing. The code snippets below are separated by separator lines (==============).
-
- # Avoid PHP readfile() for /blogs.dir/structure in the subdirectory path.
- location ^~ /blogs.dir {
- internal;
- alias /var/www/example.com/htdocs/wp-content/blogs.dir;
- access_log off;
- log_not_found off;
- expires max;
- }
-
- ============================================================
-
- # Avoid php readfile() for /files/structure in the subdirectory path
- location ~ ^(/[^/]+/)?files/(?.+) {
- try_files /wp-content/blogs.dir/$blogid/files/$rt_file /wp-includes/ms-files.php?file=$rt_file;
- access_log off;
- log_not_found off;
- expires max;
- }
-
- ============================================================
-
- # WPMU files structure for the subdomain path
- location ~ ^/files/(.*)$ {
- try_files /wp-includes/ms-files.php?file=$1 =404;
- access_log off;
- log_not_found off;
- expires max;
- }
-
- ============================================================
-
- # Map blog ID to specific directory
- map $http_host $blogid {
- default 0;
- example.com 1;
- site1.example.com 2;
- site1.com 2;
- }
-
-### Conclusion ###
-
-Scalability is a challenge for more and more site developers as they achieve success with their WordPress sites. (And for new sites that want to head WordPress performance problems off at the pass.) Adding WordPress caching, and combining WordPress and NGINX, are solid answers.
-
-NGINX is not only useful with WordPress sites. NGINX is the [leading web server][45] among the busiest 1,000, 10,000, and 100,000 sites in the world.
-
-For more on NGINX performance, see our recent blog post, [10 Tips for 10x Application Performance][46].
-
-NGINX software comes in two versions:
-
-- NGINX open source software – Like WordPress, this is software you download, configure, and compile yourself.
-- NGINX Plus – NGINX Plus includes a pre-built reference version of the software, as well as service and technical support.
-
-To get started, go to [nginx.org][47] for the open source software or check out [NGINX Plus][48].
-
---------------------------------------------------------------------------------
-
-via: https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/
-
-作者:[Floyd Smith][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.nginx.com/blog/author/floyd/
-[1]:http://w3techs.com/technologies/overview/content_management/all
-[2]:https://www.nginx.com/press/choosing-nginx-growth-wordpresscom/
-[3]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-static
-[4]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-dynamic
-[5]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
-[6]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#permalink
-[7]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
-[8]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
-[9]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
-[10]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#security
-[11]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#multisite
-[12]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
-[13]:http://www.mobify.com/blog/beginners-guide-to-http-cache-headers/
-[14]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
-[15]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#lamp
-[16]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
-[17]:https://wordpress.org/plugins/hyper-cache/
-[18]:https://wordpress.org/plugins/quick-cache/
-[19]:https://wordpress.org/plugins/wp-super-cache/
-[20]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
-[21]:https://wordpress.org/plugins/w3-total-cache/
-[22]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
-[23]:http://www.fastcgi.com/
-[24]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
-[25]:https://css-tricks.com/wordpress-fragment-caching-revisited/
-[26]:https://www.nginx.com/resources/admin-guide/content-caching/
-[27]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-dynamic
-[28]:https://www.kernel.org/doc/Documentation/filesystems/tmpfs.txt
-[29]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#permalink
-[30]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
-[31]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
-[32]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
-[33]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#security
-[34]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#multisite
-[35]:http://codex.wordpress.org/Using_Permalinks
-[36]:http://nginx.org/en/docs/http/ngx_http_core_module.html#server
-[37]:https://github.com/FRiCKLE/ngx_cache_purge
-[38]:https://wordpress.org/plugins/nginx-helper/
-[39]:http://nginx.org/en/docs/http/ngx_http_upstream_module.html#variables
-[40]:https://wordpress.org/plugins/w3-total-cache/
-[41]:http://www.w3-edge.com/
-[42]:https://wordpress.org/plugins/wp-super-cache/
-[43]:http://automattic.com/
-[44]:https://wordpress.com/
-[45]:http://w3techs.com/technologies/cross/web_server/ranking
-[46]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/
-[47]:http://www.nginx.org/en
-[48]:https://www.nginx.com/products/
-[49]:
-[50]:
\ No newline at end of file
diff --git a/sources/tech/20151028 10 Tips for 10x Application Performance.md b/sources/tech/20151028 10 Tips for 10x Application Performance.md
deleted file mode 100644
index a899284450..0000000000
--- a/sources/tech/20151028 10 Tips for 10x Application Performance.md
+++ /dev/null
@@ -1,277 +0,0 @@
-10 Tips for 10x Application Performance
-================================================================================
-Improving web application performance is more critical than ever. The share of economic activity that’s online is growing; more than 5% of the developed world’s economy is now on the Internet (see Resources below for statistics). And our always-on, hyper-connected modern world means that user expectations are higher than ever. If your site does not respond instantly, or if your app does not work without delay, users quickly move on to your competitors.
-
-For example, a study done by Amazon almost 10 years ago proved that, even then, a 100-millisecond decrease in page-loading time translated to a 1% increase in its revenue. Another recent study highlighted the fact that that more than half of site owners surveyed said they lost revenue or customers due to poor application performance.
-
-How fast does a website need to be? For each second a page takes to load, about 4% of users abandon it. Top e-commerce sites offer a time to first interaction ranging from one to three seconds, which offers the highest conversion rate. It’s clear that the stakes for web application performance are high and likely to grow.
-
-Wanting to improve performance is easy, but actually seeing results is difficult. To help you on your journey, this blog post offers you ten tips to help you increase your website performance by as much as 10x. It’s the first in a series detailing how you can increase your application performance with the help of some well-tested optimization techniques, and with a little support from NGINX. This series also outlines potential improvements in security that you can gain along the way.
-
-### Tip #1: Accelerate and Secure Applications with a Reverse Proxy Server ###
-
-If your web application runs on a single machine, the solution to performance problems might seem obvious: just get a faster machine, with more processor, more RAM, a fast disk array, and so on. Then the new machine can run your WordPress server, Node.js application, Java application, etc., faster than before. (If your application accesses a database server, the solution might still seem simple: get two faster machines, and a faster connection between them.)
-
-Trouble is, machine speed might not be the problem. Web applications often run slowly because the computer is switching among different kinds of tasks: interacting with users on thousands of connections, accessing files from disk, and running application code, among others. The application server may be thrashing – running out of memory, swapping chunks of memory out to disk, and making many requests wait on a single task such as disk I/O.
-
-Instead of upgrading your hardware, you can take an entirely different approach: adding a reverse proxy server to offload some of these tasks. A [reverse proxy server][1] sits in front of the machine running the application and handles Internet traffic. Only the reverse proxy server is connected directly to the Internet; communication with the application servers is over a fast internal network.
-
-Using a reverse proxy server frees the application server from having to wait for users to interact with the web app and lets it concentrate on building pages for the reverse proxy server to send across the Internet. The application server, which no longer has to wait for client responses, can run at speeds close to those achieved in optimized benchmarks.
-
-Adding a reverse proxy server also adds flexibility to your web server setup. For instance, if a server of a given type is overloaded, another server of the same type can easily be added; if a server is down, it can easily be replaced.
-
-Because of the flexibility it provides, a reverse proxy server is also a prerequisite for many other performance-boosting capabilities, such as:
-
-- **Load balancing** (see [Tip #2][2]) – A load balancer runs on a reverse proxy server to share traffic evenly across a number of application servers. With a load balancer in place, you can add application servers without changing your application at all.
-- **Caching static files** (see [Tip #3][3]) – Files that are requested directly, such as image files or code files, can be stored on the reverse proxy server and sent directly to the client, which serves assets more quickly and offloads the application server, allowing the application to run faster.
-- **Securing your site** – The reverse proxy server can be configured for high security and monitored for fast recognition and response to attacks, keeping the application servers protected.
-
-NGINX software is specifically designed for use as a reverse proxy server, with the additional capabilities described above. NGINX uses an event-driven processing approach which is more efficient than traditional servers. NGINX Plus adds more advanced reverse proxy features, such as application [health checks][4], specialized request routing, advanced caching, and support.
-
-
-
-### Tip #2: Add a Load Balancer ###
-
-Adding a [load balancer][5] is a relatively easy change which can create a dramatic improvement in the performance and security of your site. Instead of making a core web server bigger and more powerful, you use a load balancer to distribute traffic across a number of servers. Even if an application is poorly written, or has problems with scaling, a load balancer can improve the user experience without any other changes.
-
-A load balancer is, first, a reverse proxy server (see [Tip #1][6]) – it receives Internet traffic and forwards requests to another server. The trick is that the load balancer supports two or more application servers, using [a choice of algorithms][7] to split requests between servers. The simplest load balancing approach is round robin, with each new request sent to the next server on the list. Other methods include sending requests to the server with the fewest active connections. NGINX Plus has [capabilities][8] for continuing a given user session on the same server, which is called session persistence.
-
-Load balancers can lead to strong improvements in performance because they prevent one server from being overloaded while other servers wait for traffic. They also make it easy to expand your web server capacity, as you can add relatively low-cost servers and be sure they’ll be put to full use.
-
-Protocols that can be load balanced include HTTP, HTTPS, SPDY, HTTP/2, WebSocket, [FastCGI][9], SCGI, uwsgi, memcached, and several other application types, including TCP-based applications and other Layer 4 protocols. Analyze your web applications to determine which you use and where performance is lagging.
-
-The same server or servers used for load balancing can also handle several other tasks, such as SSL termination, support for HTTP/1/x and HTTP/2 use by clients, and caching for static files.
-
-NGINX is often used for load balancing; to learn more, please see our [overview blog post][10], [configuration blog post][11], [ebook][12] and associated [webinar][13], and [documentation][14]. Our commercial version, [NGINX Plus][15], supports more specialized load balancing features such as load routing based on server response time and the ability to load balance on Microsoft’s NTLM protocol.
-
-### Tip #3: Cache Static and Dynamic Content ###
-
-Caching improves web application performance by delivering content to clients faster. Caching can involve several strategies: preprocessing content for fast delivery when needed, storing content on faster devices, storing content closer to the client, or a combination.
-
-There are two different types of caching to consider:
-
-- **Caching of static content**. Infrequently changing files, such as image files (JPEG, PNG) and code files (CSS, JavaScript), can be stored on an edge server for fast retrieval from memory or disk.
-- **Caching of dynamic content**. Many Web applications generate fresh HTML for each page request. By briefly caching one copy of the generated HTML for a brief period of time, you can dramatically reduce the total number of pages that have to be generated while still delivering content that’s fresh enough to meet your requirements.
-
-If a page gets ten views per second, for instance, and you cache it for one second, 90% of requests for the page will come from the cache. If you separately cache static content, even the freshly generated versions of the page might be made up largely of cached content.
-
-There are three main techniques for caching content generated by web applications:
-
-- **Moving content closer to users**. Keeping a copy of content closer to the user reduces its transmission time.
-- **Moving content to faster machines**. Content can be kept on a faster machine for faster retrieval.
-- **Moving content off of overused machines**. Machines sometimes operate much slower than their benchmark performance on a particular task because they are busy with other tasks. Caching on a different machine improves performance for the cached resources and also for non-cached resources, because the host machine is less overloaded.
-
-Caching for web applications can be implemented from the inside – the web application server – out. First, caching is used for dynamic content, to reduce the load on application servers. Then, caching is used for static content (including temporary copies of what would otherwise be dynamic content), further off-loading application servers. And caching is then moved off of application servers and onto machines that are faster and/or closer to the user, unburdening the application servers, and reducing retrieval and transmission times.
-
-Improved caching can speed up applications tremendously. For many web pages, static data, such as large image files, makes up more than half the content. It might take several seconds to retrieve and transmit such data without caching, but only fractions of a second if the data is cached locally.
-
-As an example of how caching is used in practice, NGINX and NGINX Plus use two directives to [set up caching][16]: proxy_cache_path and proxy_cache. You specify the cache location and size, the maximum time files are kept in the cache, and other parameters. Using a third (and quite popular) directive, proxy_cache_use_stale, you can even direct the cache to supply stale content when the server that supplies fresh content is busy or down, giving the client something rather than nothing. From the user’s perspective, this may strongly improves your site or application’s uptime.
-
-NGINX Plus has [advanced caching features][17], including support for [cache purging][18] and visualization of cache status on a [dashboard][19] for live activity monitoring.
-
-For more information on caching with NGINX, see the [reference documentation][20] and [NGINX Content Caching][21] in the NGINX Plus Admin Guide.
-
-**Note**: Caching crosses organizational lines between people who develop applications, people who make capital investment decisions, and people who run networks in real time. Sophisticated caching strategies, like those alluded to here, are a good example of the value of a [DevOps perspective][22], in which application developer, architectural, and operations perspectives are merged to help meet goals for site functionality, response time, security, and business results, )such as completed transactions or sales.
-
-### Tip #4: Compress Data ###
-
-Compression is a huge potential performance accelerator. There are carefully engineered and highly effective compression standards for photos (JPEG and PNG), videos (MPEG-4), and music (MP3), among others. Each of these standards reduces file size by an order of magnitude or more.
-
-Text data – including HTML (which includes plain text and HTML tags), CSS, and code such as JavaScript – is often transmitted uncompressed. Compressing this data can have a disproportionate impact on perceived web application performance, especially for clients with slow or constrained mobile connections.
-
-That’s because text data is often sufficient for a user to interact with a page, where multimedia data may be more supportive or decorative. Smart content compression can reduce the bandwidth requirements of HTML, Javascript, CSS and other text-based content, typically by 30% or more, with a corresponding reduction in load time.
-
-If you use SSL, compression reduces the amount of data that has to be SSL-encoded, which offsets some of the CPU time it takes to compress the data.
-
-Methods for compressing text data vary. For example, see the [section on HTTP/2][23] for a novel text compression scheme, adapted specifically for header data. As another example of text compression you can [turn on][24] GZIP compression in NGINX. After you [pre-compress text data][25] on your services, you can serve the compressed .gz version directly using the gzip_static directive.
-
-### Tip #5: Optimize SSL/TLS ###
-
-The Secure Sockets Layer ([SSL][26]) protocol and its successor, the Transport Layer Security (TLS) protocol, are being used on more and more websites. SSL/TLS encrypts the data transported from origin servers to users to help improve site security. Part of what may be influencing this trend is that Google now uses the presence of SSL/TLS as a positive influence on search engine rankings.
-
-Despite rising popularity, the performance hit involved in SSL/TLS is a sticking point for many sites. SSL/TLS slows website performance for two reasons:
-
-1. The initial handshake required to establish encryption keys whenever a new connection is opened. The way that browsers using HTTP/1.x establish multiple connections per server multiplies that hit.
-1. Ongoing overhead from encrypting data on the server and decrypting it on the client.
-
-To encourage the use of SSL/TLS, the authors of HTTP/2 and SPDY (described in the [next section][27]) designed these protocols so that browsers need just one connection per browser session. This greatly reduces one of the two major sources of SSL overhead. However, even more can be done today to improve the performance of applications delivered over SSL/TLS.
-
-The mechanism for optimizing SSL/TLS varies by web server. As an example, NGINX uses [OpenSSL][28], running on standard commodity hardware, to provide performance similar to dedicated hardware solutions. NGINX [SSL performance][29] is well-documented and minimizes the time and CPU penalty from performing SSL/TLS encryption and decryption.
-
-In addition, see [this blog post][30] for details on ways to increase SSL/TLS performance. To summarize briefly, the techniques are:
-
-- **Session caching**. Uses the [ssl_session_cache][31] directive to cache the parameters used when securing each new connection with SSL/TLS.
-- **Session tickets or IDs**. These store information about specific SSL/TLS sessions in a ticket or ID so a connection can be reused smoothly, without new handshaking.
-- **OCSP stapling**. Cuts handshaking time by caching SSL/TLS certificate information.
-
-NGINX and NGINX Plus can be used for SSL/TLS termination – handling encryption and decyption for client traffic, while communicating with other servers in clear text. Use [these steps][32] to set up NGINX or NGINX Plus to handle SSL/TLS termination. Also, here are [specific steps][33] for NGINX Plus when used with servers that accept TCP connections.
-
-### Tip #6: Implement HTTP/2 or SPDY ###
-
-For sites that already use SSL/TLS, HTTP/2 and SPDY are very likely to improve performance, because the single connection requires just one handshake. For sites that don’t yet use SSL/TLS, HTTP/2 and SPDY makes a move to SSL/TLS (which normally slows performance) a wash from a responsiveness point of view.
-
-Google introduced SPDY in 2012 as a way to achieve faster performance on top of HTTP/1.x. HTTP/2 is the recently approved IETF standard based on SPDY. SPDY is broadly supported, but is soon to be deprecated, replaced by HTTP/2.
-
-The key feature of SPDY and HTTP/2 is the use of a single connection rather than multiple connections. The single connection is multiplexed, so it can carry pieces of multiple requests and responses at the same time.
-
-By getting the most out of one connection, these protocols avoid the overhead of setting up and managing multiple connections, as required by the way browsers implement HTTP/1.x. The use of a single connection is especially helpful with SSL, because it minimizes the time-consuming handshaking that SSL/TLS needs to set up a secure connection.
-
-The SPDY protocol required the use of SSL/TLS; HTTP/2 does not officially require it, but all browsers so far that support HTTP/2 use it only if SSL/TLS is enabled. That is, a browser that supports HTTP/2 uses it only if the website is using SSL and its server accepts HTTP/2 traffic. Otherwise, the browser communicates over HTTP/1.x.
-
-When you implement SPDY or HTTP/2, you no longer need typical HTTP performance optimizations such as domain sharding, resource merging, and image spriting. These changes make your code and deployments simpler and easier to manage. To learn more about the changes that HTTP/2 is bringing about, read our [white paper][34].
-
-
-
-As an example of support for these protocols, NGINX has supported SPDY from early on, and [most sites][35] that use SPDY today run on NGINX. NGINX is also [pioneering support][36] for HTTP/2, with [support][37] for HTTP/2 in NGINX open source and NGINX Plus as of September 2015.
-
-Over time, we at NGINX expect most sites to fully enable SSL and to move to HTTP/2. This will lead to increased security and, as new optimizations are found and implemented, simpler code that performs better.
-
-### Tip #7: Update Software Versions ###
-
-One simple way to boost application performance is to select components for your software stack based on their reputation for stability and performance. In addition, because developers of high-quality components are likely to pursue performance enhancements and fix bugs over time, it pays to use the latest stable version of software. New releases receive more attention from developers and the user community. Newer builds also take advantage of new compiler optimizations, including tuning for new hardware.
-
-Stable new releases are typically more compatible and higher-performing than older releases. It’s also easier to keep on top of tuning optimizations, bug fixes, and security alerts when you stay on top of software updates.
-
-Staying with older software can also prevent you from taking advantage of new capabilities. For example, HTTP/2, described above, currently requires OpenSSL 1.0.1. Starting in mid-2016, HTTP/2 will require OpenSSL 1.0.2, which was released in January 2015.
-
-NGINX users can start by moving to the [[latest version of the NGINX open source software][38] or [NGINX Plus][39]; they include new capabilities such as socket sharding and thread pools (see below), and both are constantly being tuned for performance. Then look at the software deeper in your stack and move to the most recent version wherever you can.
-
-### Tip #8: Tune Linux for Performance ###
-
-Linux is the underlying operating system for most web server implementations today, and as the foundation of your infrastructure, Linux represents a significant opportunity to improve performance. By default, many Linux systems are conservatively tuned to use few resources and to match a typical desktop workload. This means that web application use cases require at least some degree of tuning for maximum performance.
-
-Linux optimizations are web server-specific. Using NGINX as an example, here are a few highlights of changes you can consider to speed up Linux:
-
-- **Backlog queue**. If you have connections that appear to be stalling, consider increasing net.core.somaxconn, the maximum number of connections that can be queued awaiting attention from NGINX. You will see error messages if the existing connection limit is too small, and you can gradually increase this parameter until the error messages stop.
-- **File descriptors**. NGINX uses up to two file descriptors for each connection. If your system is serving a lot of connections, you might need to increase sys.fs.file_max, the system-wide limit for file descriptors, and nofile, the user file descriptor limit, to support the increased load.
-- **Ephemeral ports**. When used as a proxy, NGINX creates temporary (“ephemeral”) ports for each upstream server. You can increase the range of port values, set by net.ipv4.ip_local_port_range, to increase the number of ports available. You can also reduce the timeout before an inactive port gets reused with the net.ipv4.tcp_fin_timeout setting, allowing for faster turnover.
-
-For NGINX, check out the [NGINX performance tuning guides][40] to learn how to optimize your Linux system so that it can cope with large volumes of network traffic without breaking a sweat!
-
-### Tip #9: Tune Your Web Server for Performance ###
-
-Whatever web server you use, you need to tune it for web application performance. The following recommendations apply generally to any web server, but specific settings are given for NGINX. Key optimizations include:
-
-- **Access logging**. Instead of writing a log entry for every request to disk immediately, you can buffer entries in memory and write them to disk as a group. For NGINX, add the *buffer=size* parameter to the *access_log* directive to write log entries to disk when the memory buffer fills up. If you add the **flush=time** parameter, the buffer contents are also be written to disk after the specified amount of time.
-- **Buffering**. Buffering holds part of a response in memory until the buffer fills, which can make communications with the client more efficient. Responses that don’t fit in memory are written to disk, which can slow performance. When NGINX buffering is [on][42], you use the *proxy_buffer_size* and *proxy_buffers* directives to manage it.
-- **Client keepalives**. Keepalive connections reduce overhead, especially when SSL/TLS is in use. For NGINX, you can increase the maximum number of *keepalive_requests* a client can make over a given connection from the default of 100, and you can increase the *keepalive_timeout* to allow the keepalive connection to stay open longer, resulting in faster subsequent requests.
-- **Upstream keepalives**. Upstream connections – connections to application servers, database servers, and so on – benefit from keepalive connections as well. For upstream connections, you can increase *keepalive*, the number of idle keepalive connections that remain open for each worker process. This allows for increased connection reuse, cutting down on the need to open brand new connections. For more information about keepalives, refer to this [blog post][41].
-- **Limits**. Limiting the resources that clients use can improve performance and security. For NGINX,the *limit_conn* and *limit_conn_zone* directives restrict the number of connections from a given source, while *limit_rate* constrains bandwidth. These settings can stop a legitimate user from “hogging” resources and also help prevent against attacks. The *limit_req* and *limit_req_zone* directives limit client requests. For connections to upstream servers, use the max_conns parameter to the server directive in an upstream configuration block. This limits connections to an upstream server, preventing overloading. The associated queue directive creates a queue that holds a specified number of requests for a specified length of time after the *max_conns* limit is reached.
-- **Worker processes**. Worker processes are responsible for the processing of requests. NGINX employs an event-based model and OS-dependent mechanisms to efficiently distribute requests among worker processes. The recommendation is to set the value of *worker_processes* to one per CPU. The maximum number of worker_connections (512 by default) can safely be raised on most systems if needed; experiment to find the value that works best for your system.
-- **Socket sharding**. Typically, a single socket listener distributes new connections to all worker processes. Socket sharding creates a socket listener for each worker process, with the kernel assigning connections to socket listeners as they become available. This can reduce lock contention and improve performance on multicore systems. To enable [socket sharding][43], include the reuseport parameter on the listen directive.
-- **Thread pools**. Any computer process can be held up by a single, slow operation. For web server software, disk access can hold up many faster operations, such as calculating or copying information in memory. When a thread pool is used, the slow operation is assigned to a separate set of tasks, while the main processing loop keeps running faster operations. When the disk operation completes, the results go back into the main processing loop. In NGINX, two operations – the read() system call and sendfile() – are offloaded to [thread pools][44].
-
-
-
-**Tip**. When changing settings for any operating system or supporting service, change a single setting at a time, then test performance. If the change causes problems, or if it doesn’t make your site run faster, change it back.
-
-See this [blog post][45] for more details on tuning NGINX.
-
-### Tip #10: Monitor Live Activity to Resolve Issues and Bottlenecks ###
-
-The key to a high-performance approach to application development and delivery is watching your application’s real-world performance closely and in real time. You must be able to monitor activity within specific devices and across your web infrastructure.
-
-Monitoring site activity is mostly passive – it tells you what’s going on, and leaves it to you to spot problems and fix them.
-
-Monitoring can catch several different kinds of issues. They include:
-
-- A server is down.
-- A server is limping, dropping connections.
-- A server is suffering from a high proportion of cache misses.
-- A server is not sending correct content.
-
-A global application performance monitoring tool like New Relic or Dynatrace helps you monitor page load time from remote locations, while NGINX helps you monitor the application delivery side. Application performance data tells you when your optimizations are making a real difference to your users, and when you need to consider adding capacity to your infrastructure to sustain the traffic.
-
-To help identify and resolve issues quickly, NGINX Plus adds [application-aware health checks][46] – synthetic transactions that are repeated regularly and are used to alert you to problems. NGINX Plus also has [session draining][47], which stops new connections while existing tasks complete, and a slow start capability, allowing a recovered server to come up to speed within a load-balanced group. When used effectively, health checks allow you to identify issues before they significantly impact the user experience, while session draining and slow start allow you to replace servers and ensure the process does not negatively affect perceived performance or uptime. The figure shows the built-in NGINX Plus [live activity monitoring][48] dashboard for a web infrastructure with servers, TCP connections, and caching.
-
-
-
-### Conclusion: Seeing 10x Performance Improvement ###
-
-The performance improvements that are available for any one web application vary tremendously, and actual gains depend on your budget, the time you can invest, and gaps in your existing implementation. So, how might you achieve 10x performance improvement for your own applications?
-
-To help guide you on the potential impact of each optimization, here are pointers to the improvement that may be possible with each tip detailed above, though your mileage will almost certainly vary:
-
-- **Reverse proxy server and load balancing**. No load balancing, or poor load balancing, can cause episodes of very poor performance. Adding a reverse proxy server, such as NGINX, can prevent web applications from thrashing between memory and disk. Load balancing can move processing from overburdened servers to available ones and make scaling easy. These changes can result in dramatic performance improvement, with a 10x improvement easily achieved compared to the worst moments for your current implementation, and lesser but substantial achievements available for overall performance.
-- **Caching dynamic and static content**. If you have an overburdened web server that’s doubling as your application server, 10x improvements in peak-time performance can be achieved by caching dynamic content alone. Caching for static files can improve performance by single-digit multiples as well.
-- **Compressing data**. Using media file compression such as JPEG for photos, PNG for graphics, MPEG-4 for movies, and MP3 for music files can greatly improve performance. Once these are all in use, then compressing text data (code and HTML) can improve initial page load times by a factor of two.
-- **Optimizing SSL/TLS**. Secure handshakes can have a big impact on performance, so optimizing them can lead to perhaps a 2x improvement in initial responsiveness, particularly for text-heavy sites. Optimizing media file transmission under SSL/TLS is likely to yield only small performance improvements.
-- **Implementing HTTP/2 and SPDY**. When used with SSL/TLS, these protocols are likely to result in incremental improvements for overall site performance.
-- **Tuning Linux and web server software (such as NGINX)**. Fixes such as optimizing buffering, using keepalive connections, and offloading time-intensive tasks to a separate thread pool can significantly boost performance; thread pools, for instance, can speed disk-intensive tasks by [nearly an order of magnitude][49].
-
-We hope you try out these techniques for yourself. We want to hear the kind of application performance improvements you’re able to achieve. Share your results in the comments below, or tweet your story with the hash tags #NGINX and #webperf!
-
-### Resources for Internet Statistics ###
-
-[Statista.com – Share of the internet economy in the gross domestic product in G-20 countries in 2016][50]
-
-[Load Impact – How Bad Performance Impacts Ecommerce Sales][51]
-
-[Kissmetrics – How Loading Time Affects Your Bottom Line (infographic)][52]
-
-[Econsultancy – Site speed: case studies, tips and tools for improving your conversion rate][53]
-
---------------------------------------------------------------------------------
-
-via: https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
-
-作者:[Floyd Smith][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.nginx.com/blog/author/floyd/
-[1]:https://www.nginx.com/resources/glossary/reverse-proxy-server
-[2]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip2
-[3]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip3
-[4]:https://www.nginx.com/products/application-health-checks/
-[5]:https://www.nginx.com/solutions/load-balancing/
-[6]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip1
-[7]:https://www.nginx.com/resources/admin-guide/load-balancer/
-[8]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
-[9]:https://www.digitalocean.com/community/tutorials/understanding-and-implementing-fastcgi-proxying-in-nginx
-[10]:https://www.nginx.com/blog/five-reasons-use-software-load-balancer/
-[11]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
-[12]:https://www.nginx.com/resources/ebook/five-reasons-choose-software-load-balancer/
-[13]:https://www.nginx.com/resources/webinars/choose-software-based-load-balancer-45-min/
-[14]:https://www.nginx.com/resources/admin-guide/load-balancer/
-[15]:https://www.nginx.com/products/
-[16]:https://www.nginx.com/blog/nginx-caching-guide/
-[17]:https://www.nginx.com/products/content-caching-nginx-plus/
-[18]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&_ga=1.95342300.1348073562.1438712874#proxy_cache_purge
-[19]:https://www.nginx.com/products/live-activity-monitoring/
-[20]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&&&_ga=1.61156076.1348073562.1438712874#proxy_cache
-[21]:https://www.nginx.com/resources/admin-guide/content-caching
-[22]:https://www.nginx.com/blog/network-vs-devops-how-to-manage-your-control-issues/
-[23]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
-[24]:https://www.nginx.com/resources/admin-guide/compression-and-decompression/
-[25]:http://nginx.org/en/docs/http/ngx_http_gzip_static_module.html
-[26]:https://www.digicert.com/ssl.htm
-[27]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
-[28]:http://openssl.org/
-[29]:https://www.nginx.com/blog/nginx-ssl-performance/
-[30]:https://www.nginx.com/blog/improve-seo-https-nginx/
-[31]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_session_cache
-[32]:https://www.nginx.com/resources/admin-guide/nginx-ssl-termination/
-[33]:https://www.nginx.com/resources/admin-guide/nginx-tcp-ssl-termination/
-[34]:https://www.nginx.com/resources/datasheet/datasheet-nginx-http2-whitepaper/
-[35]:http://w3techs.com/blog/entry/25_percent_of_the_web_runs_nginx_including_46_6_percent_of_the_top_10000_sites
-[36]:https://www.nginx.com/blog/how-nginx-plans-to-support-http2/
-[37]:https://www.nginx.com/blog/nginx-plus-r7-released/
-[38]:http://nginx.org/en/download.html
-[39]:https://www.nginx.com/products/
-[40]:https://www.nginx.com/blog/tuning-nginx/
-[41]:https://www.nginx.com/blog/http-keepalives-and-web-performance/
-[42]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_buffering
-[43]:https://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
-[44]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
-[45]:https://www.nginx.com/blog/tuning-nginx/
-[46]:https://www.nginx.com/products/application-health-checks/
-[47]:https://www.nginx.com/products/session-persistence/#session-draining
-[48]:https://www.nginx.com/products/live-activity-monitoring/
-[49]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
-[50]:http://www.statista.com/statistics/250703/forecast-of-internet-economy-as-percentage-of-gdp-in-g-20-countries/
-[51]:http://blog.loadimpact.com/blog/how-bad-performance-impacts-ecommerce-sales-part-i/
-[52]:https://blog.kissmetrics.com/loading-time/?wide=1
-[53]:https://econsultancy.com/blog/10936-site-speed-case-studies-tips-and-tools-for-improving-your-conversion-rate/
\ No newline at end of file
diff --git a/sources/tech/20151104 How to Install Redis Server on CentOS 7.md b/sources/tech/20151104 How to Install Redis Server on CentOS 7.md
deleted file mode 100644
index 6cb66e4f3e..0000000000
--- a/sources/tech/20151104 How to Install Redis Server on CentOS 7.md
+++ /dev/null
@@ -1,236 +0,0 @@
-How to Install Redis Server on CentOS 7
-================================================================================
-Hi everyone, today Redis is the subject of our article, we are going to install it on CentOS 7. Build sources files, install the binaries, create and install files. After installing its components, we will set its configuration as well as some operating system parameters to make it more reliable and faster.
-
-
-
-Redis server
-
-Redis is an open source multi-platform data store written in ANSI C, that uses datasets directly from memory achieving extremely high performance. It supports various programming languages, including Lua, C, Java, Python, Perl, PHP and many others. It is based on simplicity, about 30k lines of code that do "few" things, but do them well. Despite you work on memory, persistence may exist and it has a fairly reasonable support for high availability and clustering, which does good in keeping your data safe.
-
-### Building Redis ###
-
-There is no official RPM package available, we need to build it from sources, in order to do this you will need install Make and GCC.
-
-Install GNU Compiler Collection and Make with yum if it is not already installed
-
- yum install gcc make
-
-Download the tarball from [redis download page][1].
-
- curl http://download.redis.io/releases/redis-3.0.4.tar.gz -o redis-3.0.4.tar.gz
-
-Extract the tarball contents
-
- tar zxvf redis-3.0.4.tar.gz
-
-Enter Redis the directory we have extracted
-
- cd redis-3.0.4
-
-Use Make to build the source files
-
- make
-
-### Install ###
-
-Enter on the src directory
-
- cd src
-
-Copy Redis server and client to /usr/local/bin
-
- cp redis-server redis-cli /usr/local/bin
-
-Its good also to copy sentinel, benchmark and check as well.
-
- cp redis-sentinel redis-benchmark redis-check-aof redis-check-dump /usr/local/bin
-
-Make Redis config directory
-
- mkdir /etc/redis
-
-Create a working and data directory under /var/lib/redis
-
- mkdir -p /var/lib/redis/6379
-
-#### System parameters ####
-
-In order to Redis work correctly you need to set some kernel options
-
-Set the vm.overcommit_memory to 1, which means always, this will avoid data to be truncated, take a look [here][2] for more.
-
- sysctl -w vm.overcommit_memory=1
-
-Change the maximum of backlog connections some value higher than the value on tcp-backlog option of redis.conf, which defaults to 511. You can find more on sysctl based ip networking "tunning" on [kernel.org][3] website.
-
- sysctl -w net.core.somaxconn=512.
-
-Disable transparent huge pages support, that is known to cause latency and memory access issues with Redis.
-
- echo never > /sys/kernel/mm/transparent_hugepage/enabled
-
-### redis.conf ###
-
-Redis.conf is the Redis configuration file, however you will see the file named as 6379.conf here, where the number is the same as the network port is listening to. This name is recommended if you are going to run more than one Redis instance.
-
-Copy sample redis.conf to **/etc/redis/6379.conf**.
-
- cp redis.conf /etc/redis/6379.conf
-
-Now edit the file and set at some of its parameters.
-
- vi /etc/redis/6379.conf
-
-#### daemonize ####
-
-Set daemonize to no, systemd need it to be in foreground, otherwise Redis will suddenly die.
-
- daemonize no
-
-#### pidfile ####
-
-Set the pidfile to redis_6379.pid under /var/run.
-
- pidfile /var/run/redis_6379.pid
-
-#### port ####
-
-Change the network port if you are not going to use the default
-
- port 6379
-
-#### loglevel ####
-
-Set your loglevel.
-
- loglevel notice
-
-#### logfile ####
-
-Set the logfile to /var/log/redis_6379.log
-
- logfile /var/log/redis_6379.log
-
-#### dir ####
-
-Set the directory to /var/lib/redis/6379
-
- dir /var/lib/redis/6379
-
-### Security ###
-
-Here are some actions that you can take to enforce the security.
-
-#### Unix sockets ####
-
-In many cases, the client application resides on the same machine as the server, so there is no need to listen do network sockets. If this is the case you may want to use unix sockets instead, for this you need to set the **port** option to 0, and then enable unix sockets with the following options.
-
-Set the path to the socket file
-
- unixsocket /tmp/redis.sock
-
-Set restricted permission to the socket file
-
- unixsocketperm 700
-
-Now, to have access with redis-cli you should use the -s flag pointing to the socket file
-
- redis-cli -s /tmp/redis.sock
-
-#### requirepass ####
-
-You may need remote access, if so, you should use a password, that will be required before any operation.
-
- requirepass "bTFBx1NYYWRMTUEyNHhsCg"
-
-#### rename-command ####
-
-Imagine the output of the next command. Yes, it will dump the configuration of the server, so you should deny access to this kind information whenever is possible.
-
- CONFIG GET *
-
-To restrict, or even disable this and other commands by using the **rename-command**. You must provide a command name and a replacement. To disable, set the replacement string to "" (blank), this is more secure as it will prevent someone from guessing the command name.
-
- rename-command FLUSHDB "FLUSHDB_MY_SALT_G0ES_HERE09u09u"
- rename-command FLUSHALL ""
- rename-command CONFIG "CONFIG_MY_S4LT_GO3S_HERE09u09u"
-
-
-
-Access through unix sockets with password and command changes
-
-#### Snapshots ####
-
-By default Redis will periodically dump its datasets to **dump.rdb** on the data directory we set. You can configure how often the rdb file will be updated by the save command, the first parameter is a timeframe in seconds and the second is a number of changes performed on the data file.
-
-Every 15 hours if there was at least 1 key change
-
- save 900 1
-
-Every 5 hours if there was at least 10 key changes
-
- save 300 10
-
-Every minute if there was at least 10000 key changes
-
- save 60 10000
-
-The **/var/lib/redis/6379/dump.rdb** file contains a dump of the dataset on memory since last save. Since it creates a temporary file and then replace the original file, there is no problem of corruption and you can always copy it directly without fear.
-
-### Starting at boot ###
-
-You may use systemd to add Redis to the system startup
-
-Copy sample init_script to /etc/init.d, note also the number of the port on the script name
-
- cp utils/redis_init_script /etc/init.d/redis_6379
-
-We are going to use systemd, so create a unit file named redis_6379.service under **/etc/systems/system**
-
- vi /etc/systemd/system/redis_6379.service
-
-Put this content, try man systemd.service for details
-
- [Unit]
- Description=Redis on port 6379
-
- [Service]
- Type=forking
- ExecStart=/etc/init.d/redis_6379 start
- ExecStop=/etc/init.d/redis_6379 stop
-
- [Install]
- WantedBy=multi-user.target
-
-Now add the memory overcommit and maximum backlog options we have set before to the **/etc/sysctl.conf** file.
-
- vm.overcommit_memory = 1
-
- net.core.somaxconn=512
-
-For the transparent huge pages support there is no sysctl directive, so you can put the command at the end of /etc/rc.local
-
- echo never > /sys/kernel/mm/transparent_hugepage/enabled
-
-### Conclusion ###
-
-That's enough to start, with these settings you will be able to deploy Redis server for many simpler scenarios, however there is many options on redis.conf for more complex environments. On some cases, you may use [replication][4] and [Sentinel][5] to provide high availability, [split the data][6] across servers, create a cluster of servers. Thanks for reading!
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/storage/install-redis-server-centos-7/
-
-作者:[Carlos Alberto][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/carlosal/
-[1]:http://redis.io/download
-[2]:https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
-[3]:https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
-[4]:http://redis.io/topics/replication
-[5]:http://redis.io/topics/sentinel
-[6]:http://redis.io/topics/partitioning
\ No newline at end of file
diff --git a/sources/tech/20151104 How to Install SQLite 3.9.1 with JSON Support on Ubuntu 15.04.md b/sources/tech/20151104 How to Install SQLite 3.9.1 with JSON Support on Ubuntu 15.04.md
deleted file mode 100644
index 83fc1c3f30..0000000000
--- a/sources/tech/20151104 How to Install SQLite 3.9.1 with JSON Support on Ubuntu 15.04.md
+++ /dev/null
@@ -1,122 +0,0 @@
-How to Install SQLite 3.9.1 with JSON Support on Ubuntu 15.04
-================================================================================
-Hello and welcome to our today's article on SQLite which is the most widely deployed SQL database engine in the world that comes with zero-configuration, that means no setup or administration needed. SQLite is public-domain software package that provides relational database management system, or RDBMS that is used to store user-defined records in large tables. In addition to data storage and management, database engine process complex query commands that combine data from multiple tables to generate reports and data summaries.
-
-SQLite is very small and light weight that does not require a separate server process or system to operate. It is available on UNIX, Linux, Mac OS-X, Android, iOS and Windows which is being used in various software applications like Opera, Ruby On Rails, Adobe System, Mozilla Firefox, Google Chrome and Skype.
-
-### 1) Basic Requirements: ###
-
-There is are no such complex complex requirements for the installation of SQLite as it mostly comes support all major cross platforms.
-
-So, let's login to your Ubuntu server with sudo or root credentials using your CLI or Secure Shell. Then update your system so that your operating system is upto date with latest packages.
-
-In ubuntu, the below command is to be used for system update.
-
- # apt-get update
-
-If you are starting to deploy SQLite on on a fresh Ubuntu, then make sure that you have installed some basic system management utilities like wget, make, unzip, gcc.
-
-To install wget, make and gcc packages on ubuntu, you use the below command, then press "Y" to allow and proceed with installation of these packages.
-
- # apt-get install wget make gcc
-
-### 2) Download SQLite ###
-
-To download the latest package of SQLite, you can refer to their official [SQLite Download Page][1] as shown below.
-
-
-
-You can copy the link of its resource package and download it on ubuntu server using the wget utility command.
-
- # wget https://www.sqlite.org/2015/sqlite-autoconf-3090100.tar.gz
-
-
-
-After downloading is complete, extract the package and change your current directory to the extracted SQLite folder by using the below command as shown.
-
- # tar -zxvf sqlite-autoconf-3090100.tar.gz
-
-### 3) Installing SQLite ###
-
-Now we are going to install and configure the SQLite package that we downloaded. So, to compile and install SQLite on ubuntu run the configuration script within the same directory where your have extracted the SQLite package as shown below.
-
- root@ubuntu-15:~/sqlite-autoconf-3090100# ./configure –prefix=/usr/local
-
-
-
-Once the package is configuration is done under the mentioned prefix, then run the below command make command to compile the package.
-
- root@ubuntu-15:~/sqlite-autoconf-3090100# make
- source='sqlite3.c' object='sqlite3.lo' libtool=yes \
- DEPDIR=.deps depmode=none /bin/bash ./depcomp \
- /bin/bash ./libtool --tag=CC --mode=compile gcc -DPACKAGE_NAME=\"sqlite\" -DPACKAGE_TARNAME=\"sqlite\" -DPACKAGE_VERSION=\"3.9.1\" -DPACKAGE_STRING=\"sqlite\ 3.9.1\" -DPACKAGE_BUGREPORT=\"http://www.sqlite.org\" -DPACKAGE_URL=\"\" -DPACKAGE=\"sqlite\" -DVERSION=\"3.9.1\" -DSTDC_HEADERS=1 -DHAVE_SYS_TYPES_H=1 -DHAVE_SYS_STAT_H=1 -DHAVE_STDLIB_H=1 -DHAVE_STRING_H=1 -DHAVE_MEMORY_H=1 -DHAVE_STRINGS_H=1 -DHAVE_INTTYPES_H=1 -DHAVE_STDINT_H=1 -DHAVE_UNISTD_H=1 -DHAVE_DLFCN_H=1 -DLT_OBJDIR=\".libs/\" -DHAVE_FDATASYNC=1 -DHAVE_USLEEP=1 -DHAVE_LOCALTIME_R=1 -DHAVE_GMTIME_R=1 -DHAVE_DECL_STRERROR_R=1 -DHAVE_STRERROR_R=1 -DHAVE_POSIX_FALLOCATE=1 -I. -D_REENTRANT=1 -DSQLITE_THREADSAFE=1 -DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_RTREE -g -O2 -c -o sqlite3.lo sqlite3.c
-
-After running make command, to complete the installation of SQLite on ubuntu run the 'make install' command as shown below.
-
- # make install
-
-
-
-### 4) Testing SQLite Installation ###
-
-To confirm the successful installation of SQLite 3.9, run the below command in your command line interface.
-
- # sqlite3
-
-You will the SQLite verion after running the above command as shown.
-
-
-
-### 5) Using SQLite ###
-
-SQLite is very handy to use. To get the detailed information about its usage, simply run the below command in the SQLite console.
-
- sqlite> .help
-
-So here is the list of all its available commands, with their description that you can get help to start using SQLite.
-
-
-
-Now in this last section , we make use of few SQLite commands to create a new database using the SQLite3 command line interface.
-
-To to create a new database run the below command.
-
- # sqlite3 test.db
-
-To create a table within the new database run the below command.
-
- sqlite> create table memos(text, priority INTEGER);
-
-After creating the table, insert some data using the following commands.
-
- sqlite> insert into memos values('deliver project description', 15);
- sqlite> insert into memos values('writing new artilces', 100);
-
-To view the inserted data from the table , run the below command.
-
- sqlite> select * from memos;
- deliver project description|15
- writing new artilces|100
-
-to exit from the sqlite3 type the below command.
-
- sqlite> .exit
-
-
-
-### Conclusion ###
-
-In this article you learned the installation of latest version of SQLite 3.9.1 which enables the recently JSON1 support in its 3.9.0 version and so on. Its is an amazing library that gets embedded inside the application that makes use of it to keep the resources much efficient and lighter. We hope you find this article much helpful, feel free to get back to us if you find any difficulty.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/ubuntu-how-to/install-sqlite-json-ubuntu-15-04/
-
-作者:[Kashif Siddique][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/kashifs/
-[1]:https://www.sqlite.org/download.html
\ No newline at end of file
diff --git a/sources/tech/20151105 How to Manage Your To-Do Lists in Ubuntu Using Go For It Application.md b/sources/tech/20151105 How to Manage Your To-Do Lists in Ubuntu Using Go For It Application.md
deleted file mode 100644
index 8977e0a420..0000000000
--- a/sources/tech/20151105 How to Manage Your To-Do Lists in Ubuntu Using Go For It Application.md
+++ /dev/null
@@ -1,84 +0,0 @@
-How to Manage Your To-Do Lists in Ubuntu Using Go For It Application
-================================================================================
-
-
-Task management is arguably one of the most important and challenging part of professional as well as personal life. Professionally, as you assume more and more responsibility, your performance is directly related to or affected with your ability to manage the tasks you’re assigned.
-
-If your job involves working on a computer, then you’ll be happy to know that there are various applications available that claim to make task management easy for you. While most of them cater to Windows users, there are many options available on Linux, too. In this article we will discuss one such application: Go For It.
-
-### Go For It ###
-
-[Go For It][1] (GFI) is developed by Manuel Kehl, who describes it as a “a simple and stylish productivity app, featuring a to-do list, merged with a timer that keeps your focus on the current task.” The timer feature, specifically, is interesting, as it also makes sure that you take a break from your current task and relax for sometime before proceeding further.
-
-### Download and Installation ###
-
-Users of Debian-based systems, like Ubuntu, can easily install the app by running the following commands in terminal:
-
- sudo add-apt-repository ppa:mank319/go-for-it
- sudo apt-get update
- sudo apt-get install go-for-it
-
-Once done, you can execute the application by running the following command:
-
- go-for-it
-
-### Usage and Configuration ###
-
-Here is how the GFI interface looks when you run the app for the very first time:
-
-
-
-As you can see, the interface consists of three tabs: To-Do, Timer, and Done. While the To-Do tab contains a list of tasks (the 4 tasks shown in the image above are there by default – you can delete them by clicking on the rectangular box in front of them), the Timer tab contains task timer, while Done contains a list of tasks that you’ve finished successfully. Right at the bottom is a text box where you can enter the task text and click “+” to add it to the list above.
-
-For example, I added a task named “MTE-research-work” to the list and selected it by clicking on it in the list – see the screenshot below:
-
-
-
-Then I selected the Timer tab. Here I could see a 25-minute timer for the active task which was “MTE-reaserch-work.”
-
-
-
-Of course, you can change the timer value and set to any time you want. I, however, didn’t change the value and clicked the Start button present below to start the task timer. Once 60 seconds were left, GFI issued a notification indicating the same.
-
-
-
-And once the time was up, I was asked to take a break of five minutes.
-
-
-
-Once those five minutes were over, I could again start the task timer for my task.
-
-
-
-When you’re done with your task, you can click the Done button in the Timer tab. The task is then removed from the To-Do tab and listed in the Done tab.
-
-
-
-GFI also allows you to tweak some of its settings. For example, the settings window shown below contains options to tweak the default task duration, break duration, and reminder time.
-
-
-
-It’s worth mentioning that GFI stores the to-do lists in the Todo.txt format which simplifies synchronization with mobile devices and makes it possible for you to edit tasks using other frontends – read more about it [here][2].
-
-You can also see the GFI app in action in the video below.
-
-注:youtube 视频
-
-
-### Conclusion ###
-
-As you have observed, GFI is an easy to understand and simple to use task management application. Although it doesn’t offer a plethora of features, it does what it claims – the timer integration is especially useful. If you’re looking for a basic, open-source task management tool for Linux, Go For It is worth trying.
-
---------------------------------------------------------------------------------
-
-via: https://www.maketecheasier.com/to-do-lists-ubuntu-go-for-it/
-
-作者:[Himanshu Arora][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.maketecheasier.com/author/himanshu/
-[1]:http://manuel-kehl.de/projects/go-for-it/
-[2]:http://todotxt.com/
\ No newline at end of file
diff --git a/sources/tech/20151109 How to Configure Tripwire IDS on Debian.md b/sources/tech/20151109 How to Configure Tripwire IDS on Debian.md
new file mode 100644
index 0000000000..11e7dbad60
--- /dev/null
+++ b/sources/tech/20151109 How to Configure Tripwire IDS on Debian.md
@@ -0,0 +1,380 @@
+正在翻译:zky001
+How to Configure Tripwire IDS on Debian
+================================================================================
+This article is about Tripwire installation and configuration on Debian OS. It is a host based Intrusion detection system (IDS) for Linux environment. Prime function of tripwire IDS is to detect and report any unauthorized change (files and directories ) on linux system. After tripwire installation, baseline database created first, tripwire monitors and detects changes such as new file addition/creation, file modification and user who changed it etc. If the changes are legitimate, you can accept the changes to update tripwire database.
+
+### Installation and Configuration ###
+
+Tripwire installation on Debian VM is shown below.
+
+ # apt-get install tripwire
+
+
+
+During installation, tripwire prompt for following configuration.
+
+#### Site key Creation ####
+
+Tripwire required a site passphrase to secure the tw.cfg tripwire configuration file and tw.pol tripwire policy file. Tripewire encrypte both files using given passphrase. Site passphrase is must even for a single instance tripwire.
+
+
+
+#### Local Key passphrase ####
+
+Local passphrase is needed for the protection of tripwire database and report files . Local key used by the tripwire to avoid unauthorized modification of tripwire baseline database.
+
+
+
+#### Tripwire configuration path ####
+
+Tripwire configuration saved in the /etc/tripwire/twcfg.txt file. It is used to generate encrypted configuration file tw.cfg.
+
+
+
+**Tripwire Policy path**
+
+Tripwire saves policies in /etc/tripwire/twpol.txt file . It is used for the generation of encrypted policy file tw.pol used by the tripwire.
+
+
+
+Final installation of tripwire is shown in the following snapshot.
+
+
+
+#### Tripwire Configuration file (twcfg.txt) ####
+
+Tripwire configuration file (twcfg.txt) details is given below. Paths of encrypted policy file (tw.pol), site key (site.key) and local key (hostname-local.key) etc are given below.
+
+ ROOT =/usr/sbin
+
+ POLFILE =/etc/tripwire/tw.pol
+
+ DBFILE =/var/lib/tripwire/$(HOSTNAME).twd
+
+ REPORTFILE =/var/lib/tripwire/report/$(HOSTNAME)-$(DATE).twr
+
+ SITEKEYFILE =/etc/tripwire/site.key
+
+ LOCALKEYFILE =/etc/tripwire/$(HOSTNAME)-local.key
+
+ EDITOR =/usr/bin/editor
+
+ LATEPROMPTING =false
+
+ LOOSEDIRECTORYCHECKING =false
+
+ MAILNOVIOLATIONS =true
+
+ EMAILREPORTLEVEL =3
+
+ REPORTLEVEL =3
+
+ SYSLOGREPORTING =true
+
+ MAILMETHOD =SMTP
+
+ SMTPHOST =localhost
+
+ SMTPPORT =25
+
+ TEMPDIRECTORY =/tmp
+
+#### Tripwire Policy Configuration ####
+
+Configure tripwire configuration before generation of baseline database. It is necessary to disable few policies such as /dev , /proc ,/root/mail etc. Detailed policy file twpol.txt is given below.
+
+ @@section GLOBAL
+ TWBIN = /usr/sbin;
+ TWETC = /etc/tripwire;
+ TWVAR = /var/lib/tripwire;
+
+ #
+ # File System Definitions
+ #
+ @@section FS
+
+ #
+ # First, some variables to make configuration easier
+ #
+ SEC_CRIT = $(IgnoreNone)-SHa ; # Critical files that cannot change
+
+ SEC_BIN = $(ReadOnly) ; # Binaries that should not change
+
+ SEC_CONFIG = $(Dynamic) ; # Config files that are changed
+ # infrequently but accessed
+ # often
+
+ SEC_LOG = $(Growing) ; # Files that grow, but that
+ # should never change ownership
+
+ SEC_INVARIANT = +tpug ; # Directories that should never
+ # change permission or ownership
+
+ SIG_LOW = 33 ; # Non-critical files that are of
+ # minimal security impact
+
+ SIG_MED = 66 ; # Non-critical files that are of
+ # significant security impact
+
+ SIG_HI = 100 ; # Critical files that are
+ # significant points of
+ # vulnerability
+
+ #
+ # Tripwire Binaries
+ #
+ (
+ rulename = "Tripwire Binaries",
+ severity = $(SIG_HI)
+ )
+ {
+ $(TWBIN)/siggen -> $(SEC_BIN) ;
+ $(TWBIN)/tripwire -> $(SEC_BIN) ;
+ $(TWBIN)/twadmin -> $(SEC_BIN) ;
+ $(TWBIN)/twprint -> $(SEC_BIN) ;
+ }
+ {
+ /boot -> $(SEC_CRIT) ;
+ /lib/modules -> $(SEC_CRIT) ;
+ }
+
+ (
+ rulename = "Boot Scripts",
+ severity = $(SIG_HI)
+ )
+ {
+ /etc/init.d -> $(SEC_BIN) ;
+ #/etc/rc.boot -> $(SEC_BIN) ;
+ /etc/rcS.d -> $(SEC_BIN) ;
+ /etc/rc0.d -> $(SEC_BIN) ;
+ /etc/rc1.d -> $(SEC_BIN) ;
+ /etc/rc2.d -> $(SEC_BIN) ;
+ /etc/rc3.d -> $(SEC_BIN) ;
+ /etc/rc4.d -> $(SEC_BIN) ;
+ /etc/rc5.d -> $(SEC_BIN) ;
+ /etc/rc6.d -> $(SEC_BIN) ;
+ }
+
+ (
+ rulename = "Root file-system executables",
+ severity = $(SIG_HI)
+ )
+ {
+ /bin -> $(SEC_BIN) ;
+ /sbin -> $(SEC_BIN) ;
+ }
+
+ #
+ # Critical Libraries
+ #
+ (
+ rulename = "Root file-system libraries",
+ severity = $(SIG_HI)
+ )
+ {
+ /lib -> $(SEC_BIN) ;
+ }
+
+ #
+ # Login and Privilege Raising Programs
+ #
+ (
+ rulename = "Security Control",
+ severity = $(SIG_MED)
+ )
+ {
+ /etc/passwd -> $(SEC_CONFIG) ;
+ /etc/shadow -> $(SEC_CONFIG) ;
+ }
+ {
+ #/var/lock -> $(SEC_CONFIG) ;
+ #/var/run -> $(SEC_CONFIG) ; # daemon PIDs
+ /var/log -> $(SEC_CONFIG) ;
+ }
+
+ # These files change the behavior of the root account
+ (
+ rulename = "Root config files",
+ severity = 100
+ )
+ {
+ /root -> $(SEC_CRIT) ; # Catch all additions to /root
+ #/root/mail -> $(SEC_CONFIG) ;
+ #/root/Mail -> $(SEC_CONFIG) ;
+ /root/.xsession-errors -> $(SEC_CONFIG) ;
+ #/root/.xauth -> $(SEC_CONFIG) ;
+ #/root/.tcshrc -> $(SEC_CONFIG) ;
+ #/root/.sawfish -> $(SEC_CONFIG) ;
+ #/root/.pinerc -> $(SEC_CONFIG) ;
+ #/root/.mc -> $(SEC_CONFIG) ;
+ #/root/.gnome_private -> $(SEC_CONFIG) ;
+ #/root/.gnome-desktop -> $(SEC_CONFIG) ;
+ #/root/.gnome -> $(SEC_CONFIG) ;
+ #/root/.esd_auth -> $(SEC_CONFIG) ;
+ # /root/.elm -> $(SEC_CONFIG) ;
+ #/root/.cshrc -> $(SEC_CONFIG) ;
+ #/root/.bashrc -> $(SEC_CONFIG) ;
+ #/root/.bash_profile -> $(SEC_CONFIG) ;
+ # /root/.bash_logout -> $(SEC_CONFIG) ;
+ #/root/.bash_history -> $(SEC_CONFIG) ;
+ #/root/.amandahosts -> $(SEC_CONFIG) ;
+ #/root/.addressbook.lu -> $(SEC_CONFIG) ;
+ #/root/.addressbook -> $(SEC_CONFIG) ;
+ #/root/.Xresources -> $(SEC_CONFIG) ;
+ #/root/.Xauthority -> $(SEC_CONFIG) -i ; # Changes Inode number on login
+ /root/.ICEauthority -> $(SEC_CONFIG) ;
+ }
+
+ #
+ # Critical devices
+ #
+ (
+ rulename = "Devices & Kernel information",
+ severity = $(SIG_HI),
+ )
+ {
+ #/dev -> $(Device) ;
+ #/proc -> $(Device) ;
+ }
+
+#### Tripwire Report ####
+
+**tripwire –check** command checks the twpol.txt file and based on this file generates tripwire report which is shown below. If this is any error in the twpol.txt file, tripwire does not generate report.
+
+
+
+**Report in text form**
+
+ root@VMdebian:/home/labadmin# tripwire --check
+
+ Parsing policy file: /etc/tripwire/tw.pol
+
+ *** Processing Unix File System ***
+
+ Performing integrity check...
+
+ Wrote report file: /var/lib/tripwire/report/VMdebian-20151024-122322.twr
+
+ Open Source Tripwire(R) 2.4.2.2 Integrity Check Report
+
+ Report generated by: root
+
+ Report created on: Sat Oct 24 12:23:22 2015
+
+ Database last updated on: Never
+
+ Report Summary:
+
+ =========================================================
+
+ Host name: VMdebian
+
+ Host IP address: 127.0.1.1
+
+ Host ID: None
+
+ Policy file used: /etc/tripwire/tw.pol
+
+ Configuration file used: /etc/tripwire/tw.cfg
+
+ Database file used: /var/lib/tripwire/VMdebian.twd
+
+ Command line used: tripwire --check
+
+ =========================================================
+
+ Rule Summary:
+
+ =========================================================
+
+ -------------------------------------------------------------------------------
+
+ Section: Unix File System
+
+ -------------------------------------------------------------------------------
+
+ Rule Name Severity Level Added Removed Modified
+
+ --------- -------------- ----- ------- --------
+
+ Other binaries 66 0 0 0
+
+ Tripwire Binaries 100 0 0 0
+
+ Other libraries 66 0 0 0
+
+ Root file-system executables 100 0 0 0
+
+ Tripwire Data Files 100 0 0 0
+
+ System boot changes 100 0 0 0
+
+ (/var/log)
+
+ Root file-system libraries 100 0 0 0
+
+ (/lib)
+
+ Critical system boot files 100 0 0 0
+
+ Other configuration files 66 0 0 0
+
+ (/etc)
+
+ Boot Scripts 100 0 0 0
+
+ Security Control 66 0 0 0
+
+ Root config files 100 0 0 0
+
+ Invariant Directories 66 0 0 0
+
+ Total objects scanned: 25943
+
+ Total violations found: 0
+
+ =========================Object Summary:================================
+
+ -------------------------------------------------------------------------------
+
+ # Section: Unix File System
+
+ -------------------------------------------------------------------------------
+
+ No violations.
+
+ ===========================Error Report:=====================================
+
+ No Errors
+
+ -------------------------------------------------------------------------------
+
+ *** End of report ***
+
+ Open Source Tripwire 2.4 Portions copyright 2000 Tripwire, Inc. Tripwire is a registered
+
+ trademark of Tripwire, Inc. This software comes with ABSOLUTELY NO WARRANTY;
+
+ for details use --version. This is free software which may be redistributed
+
+ or modified only under certain conditions; see COPYING for details.
+
+ All rights reserved.
+
+ Integrity check complete.
+
+### Conclusion ###
+
+In this article, we learned installation and basic configuration of open source IDS tool Tripwire. First it generates baseline database and detects any change (file/folder) by comparing it with already generated baseline. However, tripwire is not live monitoring IDS.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/security/configure-tripwire-ids-debian/
+
+作者:[nido][a]
+译者:[译者zky001](https://github.com/zky001)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/naveeda/
diff --git a/sources/tech/20151109 How to send email notifications using Gmail SMTP server on Linux.md b/sources/tech/20151109 How to send email notifications using Gmail SMTP server on Linux.md
new file mode 100644
index 0000000000..22e8606c6c
--- /dev/null
+++ b/sources/tech/20151109 How to send email notifications using Gmail SMTP server on Linux.md
@@ -0,0 +1,157 @@
+Translating by KnightJoker
+How to send email notifications using Gmail SMTP server on Linux
+================================================================================
+Suppose you want to configure a Linux app to send out email messages from your server or desktop. The email messages can be part of email newsletters, status updates (e.g., [Cachet][1]), monitoring alerts (e.g., [Monit][2]), disk events (e.g., [RAID mdadm][3]), and so on. While you can set up your [own outgoing mail server][4] to deliver messages, you can alternatively rely on a freely available public SMTP server as a maintenance-free option.
+
+One of the most reliable **free SMTP servers** is from Google's Gmail service. All you have to do to send email notifications within your app is to add Gmail's SMTP server address and your credentials to the app, and you are good to go.
+
+One catch with using Gmail's SMTP server is that there are various restrictions in place, mainly to combat spammers and email marketers who often abuse the server. For example, you can send messages to no more than 100 addresses at once, and no more than 500 recipients per day. Also, if you don't want to be flagged as a spammer, you cannot send a large number of undeliverable messages. When any of these limitations is reached, your Gmail account will temporarily be locked out for a day. In short, Gmail's SMTP server is perfectly fine for your personal use, but not meant for commercial bulk emails.
+
+With that being said, let me demonstrate **how to use Gmail's SMTP server in Linux environment**.
+
+### Google Gmail SMTP Server Setting ###
+
+If you want to send emails from your app using Gmail's SMTP server, remember the following details.
+
+- **Outgoing mail server (SMTP server)**: smtp.gmail.com
+- **Use authentication**: yes
+- **Use secure connection**: yes
+- **Username**: your Gmail account ID (e.g., "alice" if your email is alice@gmail.com)
+- **Password**: your Gmail password
+- **Port**: 587
+
+Exact configuration syntax may vary depending on apps. In the rest of this tutorial, I will show you several useful examples of using Gmail SMTP server in Linux.
+
+### Send Emails from the Command Line ###
+
+As the first example, let's try the most basic email functionality: send an email from the command line using Gmail SMTP server. For this, I am going to use a command-line email client called mutt.
+
+First, install mutt:
+
+For Debian-based system:
+
+ $ sudo apt-get install mutt
+
+For Red Hat based system:
+
+ $ sudo yum install mutt
+
+Create a mutt configuration file (~/.muttrc) and specify in the file Gmail SMTP server information as follows. Replace with your own Gmail ID. Note that this configuration is for sending emails only (not receiving emails).
+
+ $ vi ~/.muttrc
+
+----------
+
+ set from = "@gmail.com"
+ set realname = "Dan Nanni"
+ set smtp_url = "smtp://@smtp.gmail.com:587/"
+ set smtp_pass = ""
+
+Now you are ready to send out an email using mutt:
+
+ $ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com
+
+To attach a file in an email, use "-a" option:
+
+ $ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com -a ~/test_attachment.jpg
+
+
+
+Using Gmail SMTP server means that the emails appear as sent from your Gmail account. In other words, a recepient will see your Gmail address as the sender's address. If you want to use your domain as the email sender, you need to use Gmail SMTP relay service instead.
+
+### Send Email Notification When a Server is Rebooted ###
+
+If you are running a [virtual private server (VPS)][5] for some critical website, one recommendation is to monitor VPS reboot activities. As a more practical example, let's consider how to set up email notifications for every reboot event on your VPS. Here I assume you are using systemd on your VPS, and show you how to create a custom systemd boot-time service for automatic email notifications.
+
+First create the following script reboot_notify.sh which takes care of email notifications.
+
+ $ sudo vi /usr/local/bin/reboot_notify.sh
+
+----------
+
+ #!/bin/sh
+
+ echo "`hostname` was rebooted on `date`" | mutt -F /etc/muttrc -s "Notification on `hostname`" alice@yahoo.com
+
+----------
+
+ $ sudo chmod +x /usr/local/bin/reboot_notify.sh
+
+In the script, I use "-F" option to specify the location of system-wide mutt configuration file. So don't forget to create /etc/muttrc file and populate Gmail SMTP information as described earlier.
+
+Now let's create a custom systemd service as follows.
+
+ $ sudo mkdir -p /usr/local/lib/systemd/system
+ $ sudo vi /usr/local/lib/systemd/system/reboot-task.service
+
+----------
+
+ [Unit]
+ Description=Send a notification email when the server gets rebooted
+ DefaultDependencies=no
+ Before=reboot.target
+
+ [Service]
+ Type=oneshot
+ ExecStart=/usr/local/bin/reboot_notify.sh
+
+ [Install]
+ WantedBy=reboot.target
+
+Once the service file is created, enable and start the service.
+
+ $ sudo systemctl enable reboot-task
+ $ sudo systemctl start reboot-task
+
+From now on, you will be receiving a notification email every time the VPS gets rebooted.
+
+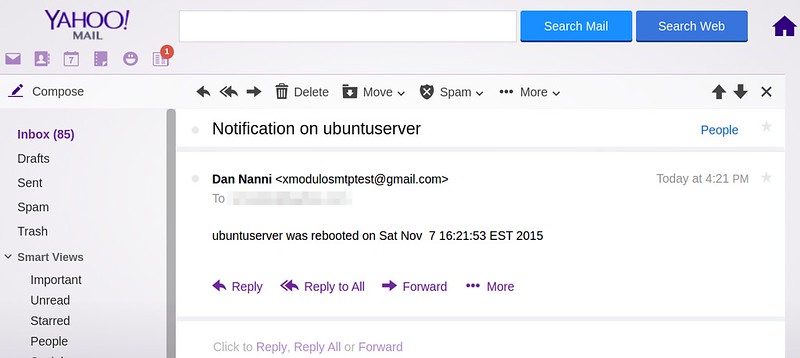
+
+### Send Email Notification from Server Usage Monitoring ###
+
+As a final example, let me present a real-world application called [Monit][6], which is a pretty useful server monitoring application. It comes with comprehensive [VPS][7] monitoring capabilities (e.g., CPU, memory, processes, file system), as well as email notification functions.
+
+If you want to receive email notifications for any event on your VPS (e.g., server overload) generated by Monit, you can add the following SMTP information to Monit configuration file.
+
+ set mailserver smtp.gmail.com port 587
+ username "" password ""
+ using tlsv12
+
+ set mail-format {
+ from: @gmail.com
+ subject: $SERVICE $EVENT at $DATE on $HOST
+ message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
+
+ Yours sincerely,
+ Monit
+ }
+
+ # the person who will receive notification emails
+ set alert alice@yahoo.com
+
+Here is the example email notification sent by Monit for excessive CPU load.
+
+
+
+### Conclusion ###
+
+As you can imagine, there will be so many different ways to take advantage of free SMTP servers like Gmail. But once again, remember that the free SMTP server is not meant for commercial usage, but only for your own personal project. If you are using Gmail SMTP server inside any app, feel free to share your use case.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/send-email-notifications-gmail-smtp-server-linux.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://xmodulo.com/setup-system-status-page.html
+[2]:http://xmodulo.com/server-monitoring-system-monit.html
+[3]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
+[4]:http://xmodulo.com/mail-server-ubuntu-debian.html
+[5]:http://xmodulo.com/go/digitalocean
+[6]:http://xmodulo.com/server-monitoring-system-monit.html
+[7]:http://xmodulo.com/go/digitalocean
\ No newline at end of file
diff --git a/sources/tech/20151109 Install Android On BQ Aquaris Ubuntu Phone In Linux.md b/sources/tech/20151109 Install Android On BQ Aquaris Ubuntu Phone In Linux.md
new file mode 100644
index 0000000000..864068eb91
--- /dev/null
+++ b/sources/tech/20151109 Install Android On BQ Aquaris Ubuntu Phone In Linux.md
@@ -0,0 +1,126 @@
+zpl1025
+Install Android On BQ Aquaris Ubuntu Phone In Linux
+================================================================================
+
+
+If you happen to own the first Ubuntu phone and want to **replace Ubuntu with Android on the bq Aquaris e4.5**, this post is going to help you.
+
+There can be plenty of reasons why you might want to remove Ubuntu and use the mainstream Android OS. One of the foremost reason is that the OS itself is at an early stage and intend to target developers and enthusiasts. Whatever may be your reason, installing Android on bq Aquaris is a piece of cake, thanks to the tools provided by bq.
+
+Let’s see what to do we need to install Android on bq Aquaris.
+
+### Prerequisite ###
+
+- Working Internet connection to download Android factory image and install tools for flashing Android
+- USB data cable
+- A system running Linux
+
+This tutorial is performed using Ubuntu 15.10. But the steps should be applicable to most other Linux distributions.
+
+### Replace Ubuntu with Android in bq Aquaris e4.5 ###
+
+#### Step 1: Download Android firmware ####
+
+First step is to download the Android image for bq Aquaris e4.5. Good thing is that it is available from the bq’s support website. You can download the firmware, around 650 MB in size, from the link below:
+
+- [Download Android for bq Aquaris e4.5][1]
+
+Yes, you would get OTA updates with it. At present the firmware version is 2.0.1 which is based on Android Lolipop. Over time, there could be a new firmware based on Marshmallow and then the above link could be outdated.
+
+I suggest to check the [bq support page and download][2] the latest firmware from there.
+
+Once downloaded, extract it. In the extracted directory, look for **MT6582_Android_scatter.txt** file. We shall be using it later.
+
+#### Step 2: Download flash tool ####
+
+bq has provided its own flash tool, Herramienta MTK Flash Tool, for easier installation of Android or Ubuntu on the device. You can download the tool from the link below:
+
+- [Download MTK Flash Tool][3]
+
+Since the flash tool might be upgraded in future, you can always get the latest version of flash tool from the [bq support page][4].
+
+Once downloaded extract the downloaded file. You should see an executable file named **flash_tool** in it. We shall be using it later.
+
+#### Step 3: Remove conflicting packages (optional) ####
+
+If you are using recent version of Ubuntu or Ubuntu based Linux distributions, you may encounter “BROM ERROR : S_UNDEFINED_ERROR (1001)” later in this tutorial.
+
+To avoid this error, you’ll have to uninstall conflicting package. Use the commands below:
+
+ sudo apt-get remove modemmanager
+
+Restart udev service with the command below:
+
+ sudo service udev restart
+
+Just to check for any possible side effects on kernel module cdc_acm, run the command below:
+
+ lsmod | grep cdc_acm
+
+If the output of the above command is an empty list, you’ll have to reinstall this kernel module:
+
+ sudo modprobe cdc_acm
+
+#### Step 4: Prepare to flash Android ####
+
+Go to the downloaded and extracted flash tool directory (in step 2). Use command line for this purpose because you’ll have to use the root privileges here.
+
+Presuming that you saved it in the Downloads directory, use the command below to go to this directory (in case you do not know how to navigate between directories in command line).
+
+ cd ~/Downloads/SP_Flash*
+
+After that use the command below to run the flash tool as root:
+
+ sudo ./flash_tool
+
+You’ll see a window popped as the one below. Don’t bother about Download Agent field, it will be automatically filled. Just focus on Scatter-loading field.
+
+
+
+Remember we talked about **MT6582_Android_scatter.txt** in step 1? This text file is in the extracted directory of the Andriod firmware you downloaded in step 1. Click on Scatter-loading (in the above picture) and point to MT6582_Android_scatter.txt file.
+
+When you do that, you’ll see several green lines like the one below:
+
+
+
+#### Step 5: Flashing Android ####
+
+We are almost ready. Switch off your phone and connect it to your computer via a USB cable.
+
+Select Firmware Upgrade from the dropdown and after that click on the big download button.
+
+
+
+If everything is correct, you should see a flash status in the bottom of the tool:
+
+
+
+When the procedure is successfully completed, you’ll see a notification like this:
+
+
+
+Unplug your phone and power it on. You should see a white screen with AQUARIS written in the middle and at bottom, “powered by Android” would be displayed. It might take upto 10 minutes before you could configure and start using Android.
+
+Note: If something goes wrong in the process, Press power, volume up, volume down button together and boot in to fast boot mode. Turn off again and connect the cable again. Repeat the process of firmware upgrade. It should work.
+
+### Conclusion ###
+
+Thanks to the tools provided, it becomes easier to **flash Android on bq Ubuntu Phone**. Of course, you can use the same steps to replace Android with Ubuntu. All you need is to download Ubuntu firmware instead of Android.
+
+I hope this tutorial helped you to replace Ubuntu with Android on your bq phone. If you have questions or suggestions, feel free to ask in the comment section below.
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/install-android-ubuntu-phone/
+
+作者:[Abhishek][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5_L/2.0.1_20150623-1900_bq-FW.zip
+[2]:http://www.bq.com/gb/support/aquaris-e4-5
+[3]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5/Ubuntu/Web%20version/Web%20version/SP_Flash_Tool_exe_linux_v5.1424.00.zip
+[4]:http://www.bq.com/gb/support/aquaris-e4-5-ubuntu-edition
diff --git a/sources/tech/20151114 How to Setup Drone - a Continuous Integration Service in Linux.md b/sources/tech/20151114 How to Setup Drone - a Continuous Integration Service in Linux.md
new file mode 100644
index 0000000000..bfcf1e3ae3
--- /dev/null
+++ b/sources/tech/20151114 How to Setup Drone - a Continuous Integration Service in Linux.md
@@ -0,0 +1,317 @@
+How to Setup Drone - a Continuous Integration Service in Linux
+==============================================================
+
+Are you tired of cloning, building, testing, and deploying codes time and again? If yes, switch to continuous integration. Continuous Integration aka CI is practice in software engineering of making frequent commits to the code base, building, testing and deploying as we go. CI helps to quickly integrate new codes into the existing code base. If this process is made automated, then this will speed up the development process as it reduces the time taken for the developer to build and test things manually. [Drone][1] is a free and open source project which provides an awesome environment of continuous integration service and is released under Apache License Version 2.0. It integrates with many repository providers like Github, Bitbucket and Google Code and has the ability to pull codes from the repositories enabling us to build the source code written in number of languages including PHP, Node, Ruby, Go, Dart, Python, C/C++, JAVA and more. It is made such a powerful platform cause it uses containers and docker technology for every build making users a complete control over their build environment with guaranteed isolation.
+
+### 1. Installing Docker ###
+
+First of all, we'll gonna install Docker as its the most vital element for the complete workflow of Drone. Drone does a proper utilization of docker for the purpose of building and testing application. This container technology speeds up the development of the applications. To install docker, we'll need to run the following commands with respective the distribution of linux. In this tutorial, we'll cover the steps with Ubuntu 14.04 and CentOS 7 linux distributions.
+
+#### On Ubuntu ####
+
+To install Docker in Ubuntu, we can simply run the following commands in a terminal or console.
+
+ # apt-get update
+ # apt-get install docker.io
+
+After the installation is done, we'll restart our docker engine using service command.
+
+ # service docker restart
+
+Then, we'll make docker start automatically in every system boot.
+
+ # update-rc.d docker defaults
+
+ Adding system startup for /etc/init.d/docker ...
+ /etc/rc0.d/K20docker -> ../init.d/docker
+ /etc/rc1.d/K20docker -> ../init.d/docker
+ /etc/rc6.d/K20docker -> ../init.d/docker
+ /etc/rc2.d/S20docker -> ../init.d/docker
+ /etc/rc3.d/S20docker -> ../init.d/docker
+ /etc/rc4.d/S20docker -> ../init.d/docker
+ /etc/rc5.d/S20docker -> ../init.d/docker
+
+#### On CentOS ####
+
+First, we'll gonna update every packages installed in our centos machine. We can do that by running the following command.
+
+ # sudo yum update
+
+To install docker in centos, we can simply run the following commands.
+
+ # curl -sSL https://get.docker.com/ | sh
+
+After our docker engine is installed in our centos machine, we'll simply start it by running the following systemd command as systemd is the default init system in centos 7.
+
+ # systemctl start docker
+
+Then, we'll enable docker to start automatically in every system startup.
+
+ # systemctl enable docker
+
+ ln -s '/usr/lib/systemd/system/docker.service' '/etc/systemd/system/multi-user.target.wants/docker.service'
+
+### 2. Installing SQlite Driver ###
+
+It uses SQlite3 database server for storing its data and information by default. It will automatically create a database file named drone.sqlite under /var/lib/drone/ which will handle database schema setup and migration. To setup SQlite3 drivers, we'll need to follow the below steps.
+
+#### On Ubuntu 14.04 ####
+
+As SQlite3 is available on the default respository of Ubuntu 14.04, we'll simply install it by running the following apt command.
+
+ # apt-get install libsqlite3-dev
+
+#### On CentOS 7 ####
+
+To install it on CentOS 7 machine, we'll need to run the following yum command.
+
+ # yum install sqlite-devel
+
+### 3. Installing Drone ###
+
+Finally, after we have installed those dependencies successfully, we'll now go further towards the installation of drone in our machine. In this step, we'll simply download the binary package of it from the official download link of the respective binary formats and then install them using the default package manager.
+
+#### On Ubuntu ####
+
+We'll use wget to download the debian package of drone for ubuntu from the [official Debian file download link][2]. Here is the command to download the required debian package of drone.
+
+ # wget downloads.drone.io/master/drone.deb
+
+ Resolving downloads.drone.io (downloads.drone.io)... 54.231.48.98
+ Connecting to downloads.drone.io (downloads.drone.io)|54.231.48.98|:80... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 7722384 (7.4M) [application/x-debian-package]
+ Saving to: 'drone.deb'
+ 100%[======================================>] 7,722,384 1.38MB/s in 17s
+ 2015-11-06 14:09:28 (456 KB/s) - 'drone.deb' saved [7722384/7722384]
+
+After its downloaded, we'll gonna install it with dpkg package manager.
+
+ # dpkg -i drone.deb
+
+ Selecting previously unselected package drone.
+ (Reading database ... 28077 files and directories currently installed.)
+ Preparing to unpack drone.deb ...
+ Unpacking drone (0.3.0-alpha-1442513246) ...
+ Setting up drone (0.3.0-alpha-1442513246) ...
+ Your system ubuntu 14: using upstart to control Drone
+ drone start/running, process 9512
+
+#### On CentOS ####
+
+In the machine running CentOS, we'll download the RPM package from the [official download link for RPM][3] using wget command as shown below.
+
+ # wget downloads.drone.io/master/drone.rpm
+
+ --2015-11-06 11:06:45-- http://downloads.drone.io/master/drone.rpm
+ Resolving downloads.drone.io (downloads.drone.io)... 54.231.114.18
+ Connecting to downloads.drone.io (downloads.drone.io)|54.231.114.18|:80... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 7763311 (7.4M) [application/x-redhat-package-manager]
+ Saving to: ‘drone.rpm’
+ 100%[======================================>] 7,763,311 1.18MB/s in 20s
+ 2015-11-06 11:07:06 (374 KB/s) - ‘drone.rpm’ saved [7763311/7763311]
+
+Then, we'll install the download rpm package using yum package manager.
+
+ # yum localinstall drone.rpm
+
+### 4. Configuring Port ###
+
+After the installation is completed, we'll gonna configure drone to make it workable. The configuration of drone is inside **/etc/drone/drone.toml** file. By default, drone web interface is exposed under port 80 which is the default port of http, if we wanna change it, we can change it by replacing the value under server block as shown below.
+
+ [server]
+ port=":80"
+
+### 5. Integrating Github ###
+
+In order to run Drone we must setup at least one integration points between GitHub, GitHub Enterprise, Gitlab, Gogs, Bitbucket. In this tutorial, we'll only integrate github but if we wanna integrate other we can do that from the configuration file. In order to integrate github, we'll need to create a new application in our [github settings][4].
+
+
+
+To create, we'll need to click on Register a New Application then fill out the form as shown in the following image.
+
+
+
+We should make sure that **Authorization callback URL** looks like http://drone.linoxide.com/api/auth/github.com under the configuration of the application. Then, we'll click on Register application. After done, we'll note the Client ID and Client Secret key as we'll need to configure it in our drone configuration.
+
+
+
+After thats done, we'll need to edit our drone configuration using a text editor by running the following command.
+
+ # nano /etc/drone/drone.toml
+
+Then, we'll find the [github] section and append the section with the above noted configuration as shown below.
+
+ [github]
+ client="3dd44b969709c518603c"
+ secret="4ee261abdb431bdc5e96b19cc3c498403853632a"
+ # orgs=[]
+ # open=false
+
+
+
+### 6. Configuring SMTP server ###
+
+If we wanna enable drone to send notifications via emails, then we'll need to specify the SMTP configuration of our SMTP server. If we already have an SMTP server, we can use its configuration but as we don't have an SMTP server, we'll need to install an MTA ie Postfix and then specify the SMTP configuration in the drone configuration.
+
+#### On Ubuntu ####
+
+We can install postfix in ubuntu by running the following apt command.
+
+ # apt-get install postfix
+
+#### On CentOS ####
+
+We can install postfix in CentOS by running the following yum command.
+
+ # yum install postfix
+
+After installing, we'll need to edit the configuration of our postfix configuration using a text editor.
+
+ # nano /etc/postfix/main.cf
+
+Then, we'll need to replace the value of myhostname parameter to our FQDN ie drone.linoxide.com .
+
+ myhostname = drone.linoxide.com
+
+Now, we'll gonna finally configure the SMTP section of our drone configuration file.
+
+ # nano /etc/drone/drone.toml
+
+Then, we'll find the [stmp] section and then we'll need to append the setting as follows.
+
+ [smtp]
+ host = "drone.linoxide.com"
+ port = "587"
+ from = "root@drone.linoxide.com"
+ user = "root"
+ pass = "password"
+
+
+
+Note: Here, **user** and **pass** parameters are strongly recommended to be changed according to one's user configuration.
+
+### 7. Configuring Worker ###
+
+As we know that drone utilizes docker for its building and testing task, we'll need to configure docker as the worker for our drone. To do so, we'll need to edit the [worker] section in the drone configuration file.
+
+ # nano /etc/drone/drone.toml
+
+Then, we'll uncomment the following lines and append as shown below.
+
+ [worker]
+ nodes=[
+ "unix:///var/run/docker.sock",
+ "unix:///var/run/docker.sock"
+ ]
+
+Here, we have set only 2 node which means the above configuration is capable of executing only 2 build at a time. In order to increase concurrency, we can increase the number of nodes.
+
+ [worker]
+ nodes=[
+ "unix:///var/run/docker.sock",
+ "unix:///var/run/docker.sock",
+ "unix:///var/run/docker.sock",
+ "unix:///var/run/docker.sock"
+ ]
+
+Here, in the above configuration, drone is configured to process four builds at a time, using the local docker daemon.
+
+### 8. Restarting Drone ###
+
+Finally, after everything is done regarding the installation and configuration, we'll now start our drone server in our linux machine.
+
+#### On Ubuntu ####
+
+To start drone in our Ubuntu 14.04 machine, we'll simply run service command as the default init system of Ubuntu 14.04 is SysVinit.
+
+ # service drone restart
+
+To make drone start automatically in every boot of the system, we'll run the following command.
+
+ # update-rc.d drone defaults
+
+#### On CentOS ####
+
+To start drone in CentOS machine, we'll simply run systemd command as CentOS 7 is shipped with systemd as init system.
+
+ # systemctl restart drone
+
+Then, we'll enable drone to start automatically in every system boot.
+
+ # systemctl enable drone
+
+### 9. Allowing Firewalls ###
+
+As we know drone utilizes port 80 by default and we haven't changed the port, we'll gonna configure our firewall programs to allow port 80 (http) and be accessible from other machines in the network.
+
+#### On Ubuntu 14.04 ####
+
+Iptables is a popular firewall program which is installed in the ubuntu distributions by default. We'll make iptables to expose port 80 so that we can make our Drone web interface accessible in the network.
+
+ # iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
+ # /etc/init.d/iptables save
+
+#### On CentOS 7 ####
+
+As CentOS 7 has systemd installed by default, it contains firewalld running as firewall problem. In order to open the port 80 (http service) on firewalld, we'll need to execute the following commands.
+
+ # firewall-cmd --permanent --add-service=http
+
+ success
+
+ # firewall-cmd --reload
+
+ success
+
+### 10. Accessing Web Interface ###
+
+Now, we'll gonna open the web interface of drone using our favourite web browser. To do so, we'll need to point our web browser to our machine running drone in it. As the default port of drone is 80 and we have also set 80 in this tutorial, we'll simply point our browser to http://ip-address/ or http://drone.linoxide.com according to our configuration. After we have done that correctly, we'll see the first page of it having options to login into our dashboard.
+
+
+
+As we have configured Github in the above step, we'll simply select github and we'll go through the app authentication process and after its done, we'll be forwarded to our Dashboard.
+
+
+
+Here, it will synchronize all our github repository and will ask us to activate the repo which we want to build with drone.
+
+
+
+After its activated, it will ask us to add a new file named .drone.yml in our repository and define the build process and configuration in that file like which image to fetch and which command/script to run while compiling, etc.
+
+We'll need to configure our .drone.yml as shown below.
+
+ image: python
+ script:
+ - python helloworld.py
+ - echo "Build has been completed."
+
+After its done, we'll be able to build our application using the configuration YAML file .drone.yml in our drone appliation. All the commits made into the repository is synced in realtime. It automatically syncs the commit and changes made to the repository. Once the commit is made in the repository, build is automatically started in our drone application.
+
+
+
+After the build is completed, we'll be able to see the output of the build with the output console.
+
+
+
+### Conclusion ###
+
+In this article, we learned to completely setup a workable Continuous Intergration platform with Drone. If we want, we can even get started with the services provided by the official Drone.io project. We can start with free service or paid service according to our requirements. It has changed the world of Continuous integration with its beautiful web interface and powerful bunches of features. It has the ability to integrate with many third party applications and deployment platforms. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/setup-drone-continuous-integration-linux/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://drone.io/
+[2]:http://downloads.drone.io/master/drone.deb
+[3]:http://downloads.drone.io/master/drone.rpm
+[4]:https://github.com/settings/developers
diff --git a/sources/tech/20151117 Install Android On BQ Aquaris Ubuntu Phone In Linux.md b/sources/tech/20151117 Install Android On BQ Aquaris Ubuntu Phone In Linux.md
new file mode 100644
index 0000000000..94e7ef69ce
--- /dev/null
+++ b/sources/tech/20151117 Install Android On BQ Aquaris Ubuntu Phone In Linux.md
@@ -0,0 +1,125 @@
+Install Android On BQ Aquaris Ubuntu Phone In Linux
+================================================================================
+
+
+If you happen to own the first Ubuntu phone and want to **replace Ubuntu with Android on the bq Aquaris e4.5**, this post is going to help you.
+
+There can be plenty of reasons why you might want to remove Ubuntu and use the mainstream Android OS. One of the foremost reason is that the OS itself is at an early stage and intend to target developers and enthusiasts. Whatever may be your reason, installing Android on bq Aquaris is a piece of cake, thanks to the tools provided by bq.
+
+Let’s see what to do we need to install Android on bq Aquaris.
+
+### Prerequisite ###
+
+- Working Internet connection to download Android factory image and install tools for flashing Android
+- USB data cable
+- A system running Linux
+
+This tutorial is performed using Ubuntu 15.10. But the steps should be applicable to most other Linux distributions.
+
+### Replace Ubuntu with Android in bq Aquaris e4.5 ###
+
+#### Step 1: Download Android firmware ####
+
+First step is to download the Android image for bq Aquaris e4.5. Good thing is that it is available from the bq’s support website. You can download the firmware, around 650 MB in size, from the link below:
+
+- [Download Android for bq Aquaris e4.5][1]
+
+Yes, you would get OTA updates with it. At present the firmware version is 2.0.1 which is based on Android Lolipop. Over time, there could be a new firmware based on Marshmallow and then the above link could be outdated.
+
+I suggest to check the [bq support page][2] and download the latest firmware from there.
+
+Once downloaded, extract it. In the extracted directory, look for **MT6582_Android_scatter.txt** file. We shall be using it later.
+
+#### Step 2: Download flash tool ####
+
+bq has provided its own flash tool, Herramienta MTK Flash Tool, for easier installation of Android or Ubuntu on the device. You can download the tool from the link below:
+
+- [Download MTK Flash Tool][3]
+
+Since the flash tool might be upgraded in future, you can always get the latest version of flash tool from the [bq support page][4].
+
+Once downloaded extract the downloaded file. You should see an executable file named **flash_tool** in it. We shall be using it later.
+
+#### Step 3: Remove conflicting packages (optional) ####
+
+If you are using recent version of Ubuntu or Ubuntu based Linux distributions, you may encounter “BROM ERROR : S_UNDEFINED_ERROR (1001)” later in this tutorial.
+
+To avoid this error, you’ll have to uninstall conflicting package. Use the commands below:
+
+ sudo apt-get remove modemmanager
+
+Restart udev service with the command below:
+
+ sudo service udev restart
+
+Just to check for any possible side effects on kernel module cdc_acm, run the command below:
+
+ lsmod | grep cdc_acm
+
+If the output of the above command is an empty list, you’ll have to reinstall this kernel module:
+
+ sudo modprobe cdc_acm
+
+#### Step 4: Prepare to flash Android ####
+
+Go to the downloaded and extracted flash tool directory (in step 2). Use command line for this purpose because you’ll have to use the root privileges here.
+
+Presuming that you saved it in the Downloads directory, use the command below to go to this directory (in case you do not know how to navigate between directories in command line).
+
+ cd ~/Downloads/SP_Flash*
+
+After that use the command below to run the flash tool as root:
+
+ sudo ./flash_tool
+
+You’ll see a window popped as the one below. Don’t bother about Download Agent field, it will be automatically filled. Just focus on Scatter-loading field.
+
+
+
+Remember we talked about **MT6582_Android_scatter.txt** in step 1? This text file is in the extracted directory of the Andriod firmware you downloaded in step 1. Click on Scatter-loading (in the above picture) and point to MT6582_Android_scatter.txt file.
+
+When you do that, you’ll see several green lines like the one below:
+
+
+
+#### Step 5: Flashing Android ####
+
+We are almost ready. Switch off your phone and connect it to your computer via a USB cable.
+
+Select Firmware Upgrade from the dropdown and after that click on the big download button.
+
+
+
+If everything is correct, you should see a flash status in the bottom of the tool:
+
+
+
+When the procedure is successfully completed, you’ll see a notification like this:
+
+
+
+Unplug your phone and power it on. You should see a white screen with AQUARIS written in the middle and at bottom, “powered by Android” would be displayed. It might take upto 10 minutes before you could configure and start using Android.
+
+Note: If something goes wrong in the process, Press power, volume up, volume down button together and boot in to fast boot mode. Turn off again and connect the cable again. Repeat the process of firmware upgrade. It should work.
+
+### Conclusion ###
+
+Thanks to the tools provided, it becomes easier to **flash Android on bq Ubuntu Phone**. Of course, you can use the same steps to replace Android with Ubuntu. All you need is to download Ubuntu firmware instead of Android.
+
+I hope this tutorial helped you to replace Ubuntu with Android on your bq phone. If you have questions or suggestions, feel free to ask in the comment section below.
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/install-android-ubuntu-phone/
+
+作者:[Abhishek][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5_L/2.0.1_20150623-1900_bq-FW.zip
+[2]:http://www.bq.com/gb/support/aquaris-e4-5
+[3]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5/Ubuntu/Web%20version/Web%20version/SP_Flash_Tool_exe_linux_v5.1424.00.zip
+[4]:http://www.bq.com/gb/support/aquaris-e4-5-ubuntu-edition
\ No newline at end of file
diff --git a/sources/tech/20151119 How to Install Revive Adserver on Ubuntu 15.04 or CentOS 7.md b/sources/tech/20151119 How to Install Revive Adserver on Ubuntu 15.04 or CentOS 7.md
new file mode 100644
index 0000000000..3b6277da80
--- /dev/null
+++ b/sources/tech/20151119 How to Install Revive Adserver on Ubuntu 15.04 or CentOS 7.md
@@ -0,0 +1,242 @@
+How to Install Revive Adserver on Ubuntu 15.04 / CentOS 7
+================================================================================
+Revive AdserverHow to Install Revive Adserver on Ubuntu 15.04 / CentOS 7 is a free and open source advertisement management system that enables publishers, ad networks and advertisers to serve ads on websites, apps, videos and manage campaigns for multiple advertiser with many features. Revive Adserver is licensed under GNU Public License which is also known as OpenX Source. It features an integrated banner management interface, URL targeting, geo-targeting and tracking system for gathering statistics. This application enables website owners to manage banners from both in-house advertisement campaigns as well as from paid or third-party sources, such as Google's AdSense. Here, in this tutorial, we'll gonna install Revive Adserver in our machine running Ubuntu 15.04 or CentOS 7.
+
+### 1. Installing LAMP Stack ###
+
+First of all, as Revive Adserver requires a complete LAMP Stack to work, we'll gonna install it. LAMP Stack is the combination of Apache Web Server, MySQL/MariaDB Database Server and PHP modules. To run Revive properly, we'll need to install some PHP modules like apc, zlib, xml, pcre, mysql and mbstring. To setup LAMP Stack, we'll need to run the following command with respect to the distribution of linux we are currently running.
+
+#### On Ubuntu 15.04 ####
+
+ # apt-get install apache2 mariadb-server php5 php5-gd php5-mysql php5-curl php-apc zlibc zlib1g zlib1g-dev libpcre3 libpcre3-dev libapache2-mod-php5 zip
+
+#### On CentOS 7 ####
+
+ # yum install httpd mariadb php php-gd php-mysql php-curl php-mbstring php-xml php-apc zlibc zlib1g zlib1g-dev libpcre3 libpcre3-dev zip
+
+### 2. Starting Apache and MariaDB server ###
+
+We’ll now start our newly installed Apache web server and MariaDB database server in our linux machine. To do so, we'll need to execute the following commands.
+
+#### On Ubuntu 15.04 ####
+
+Ubuntu 15.04 is shipped with Systemd as its default init system, so we'll need to execute the following commands to start apache and mariadb daemons.
+
+ # systemctl start apache2 mysql
+
+After its started, we'll now make it able to start automatically in every system boot by running the following command.
+
+ # systemctl enable apache2 mysql
+
+ Synchronizing state for apache2.service with sysvinit using update-rc.d...
+ Executing /usr/sbin/update-rc.d apache2 defaults
+ Executing /usr/sbin/update-rc.d apache2 enable
+ Synchronizing state for mysql.service with sysvinit using update-rc.d...
+ Executing /usr/sbin/update-rc.d mysql defaults
+ Executing /usr/sbin/update-rc.d mysql enable
+
+#### On CentOS 7 ####
+
+Also in CentOS 7, systemd is the default init system so, we'll run the following command to start them.
+
+ # systemctl start httpd mariadb
+
+Next, we'll enable them to start automatically in every startup of init system using the following command.
+
+ # systemctl enable httpd mariadb
+
+ ln -s '/usr/lib/systemd/system/httpd.service' '/etc/systemd/system/multi-user.target.wants/httpd.service'
+ ln -s '/usr/lib/systemd/system/mariadb.service' '/etc/systemd/system/multi-user.target.wants/mariadb.service'
+
+### 3. Configuring MariaDB ###
+
+#### On CentOS 7/Ubuntu 15.04 ####
+
+Now, as we are starting MariaDB for the first time and no password has been assigned for MariaDB so, we’ll first need to configure a root password for it. Then, we’ll gonna create a new database so that it can store data for our Revive Adserver installation.
+
+To configure MariaDB and assign a root password, we’ll need to run the following command.
+
+ # mysql_secure_installation
+
+This will ask us to enter the password for root but as we haven’t set any password before and its our first time we’ve installed mariadb, we’ll simply press enter and go further. Then, we’ll be asked to set root password, here we’ll hit Y and enter our password for root of MariaDB. Then, we’ll simply hit enter to set the default values for the further configurations.
+
+ ….
+ so you should just press enter here.
+
+ Enter current password for root (enter for none):
+ OK, successfully used password, moving on…
+
+ Setting the root password ensures that nobody can log into the MariaDB
+ root user without the proper authorisation.
+
+ Set root password? [Y/n] y
+ New password:
+ Re-enter new password:
+ Password updated successfully!
+ Reloading privilege tables..
+ … Success!
+ …
+ installation should now be secure.
+ Thanks for using MariaDB!
+
+
+
+### 4. Creating new Database ###
+
+After we have assigned the password to our root user of mariadb server, we'll now create a new database for Revive Adserver application so that it can store its data into the database server. To do so, first we'll need to login to our MariaDB console by running the following command.
+
+ # mysql -u root -p
+
+Then, it will ask us to enter the password of root user which we had just set in the above step. Then, we'll be welcomed into the MariaDB console in which we'll create our new database, database user and assign its password and grant all privileges to create, remove and edit the tables and data stored in it.
+
+ > CREATE DATABASE revivedb;
+ > CREATE USER 'reviveuser'@'localhost' IDENTIFIED BY 'Pa$$worD123';
+ > GRANT ALL PRIVILEGES ON revivedb.* TO 'reviveuser'@'localhost';
+ > FLUSH PRIVILEGES;
+ > EXIT;
+
+
+
+### 5. Downloading Revive Adserver Package ###
+
+Next, we'll download the latest release of Revive Adserver ie version 3.2.2 in the time of writing this article. So, we'll first get the download link from the official Download Page of Revive Adserver ie [http://www.revive-adserver.com/download/][1] then we'll download the compressed zip file using wget command under /tmp/ directory as shown bellow.
+
+ # cd /tmp/
+ # wget http://download.revive-adserver.com/revive-adserver-3.2.2.zip
+
+ --2015-11-09 17:03:48-- http://download.revive-adserver.com/revive-adserver-3.2.2.zip
+ Resolving download.revive-adserver.com (download.revive-adserver.com)... 54.230.119.219, 54.239.132.177, 54.230.116.214, ...
+ Connecting to download.revive-adserver.com (download.revive-adserver.com)|54.230.119.219|:80... connected.
+ HTTP request sent, awaiting response... 200 OK
+ Length: 11663620 (11M) [application/zip]
+ Saving to: 'revive-adserver-3.2.2.zip'
+ revive-adserver-3.2 100%[=====================>] 11.12M 1.80MB/s in 13s
+ 2015-11-09 17:04:02 (906 KB/s) - 'revive-adserver-3.2.2.zip' saved [11663620/11663620]
+
+After the file is downloaded, we'll simply extract its files and directories using unzip command.
+
+ # unzip revive-adserver-3.2.2.zip
+
+Then, we'll gonna move the entire Revive directories including every files from /tmp to the default webroot of Apache Web Server ie /var/www/html/ directory.
+
+ # mv revive-adserver-3.2.2 /var/www/html/reviveads
+
+### 6. Configuring Apache Web Server ###
+
+We'll now configure our Apache Server so that revive will run with proper configuration. To do so, we'll create a new virtualhost by creating a new configuration file named reviveads.conf . The directory here may differ from one distribution to another, here is how we create in the following distributions of linux.
+
+#### On Ubuntu 15.04 ####
+
+ # touch /etc/apache2/sites-available/reviveads.conf
+ # ln -s /etc/apache2/sites-available/reviveads.conf /etc/apache2/sites-enabled/reviveads.conf
+ # nano /etc/apache2/sites-available/reviveads.conf
+
+Now, we'll gonna add the following lines of configuration into this file using our favorite text editor.
+
+
+ ServerAdmin info@reviveads.linoxide.com
+ DocumentRoot /var/www/html/reviveads/
+ ServerName reviveads.linoxide.com
+ ServerAlias www.reviveads.linoxide.com
+
+ Options FollowSymLinks
+ AllowOverride All
+
+ ErrorLog /var/log/apache2/reviveads.linoxide.com-error_log
+ CustomLog /var/log/apache2/reviveads.linoxide.com-access_log common
+
+
+
+
+After done, we'll gonna save the file and exit our text editor. Then, we'll restart our Apache Web server.
+
+ # systemctl restart apache2
+
+#### On CentOS 7 ####
+
+In CentOS, we'll directly create the file reviveads.conf under /etc/httpd/conf.d/ directory using our favorite text editor.
+
+ # nano /etc/httpd/conf.d/reviveads.conf
+
+Then, we'll gonna add the following lines of configuration into the file.
+
+
+ ServerAdmin info@reviveads.linoxide.com
+ DocumentRoot /var/www/html/reviveads/
+ ServerName reviveads.linoxide.com
+ ServerAlias www.reviveads.linoxide.com
+
+ Options FollowSymLinks
+ AllowOverride All
+
+ ErrorLog /var/log/httpd/reviveads.linoxide.com-error_log
+ CustomLog /var/log/httpd/reviveads.linoxide.com-access_log common
+
+
+
+
+Once done, we'll simply save the file and exit the editor. And then, we'll gonna restart our apache web server.
+
+ # systemctl restart httpd
+
+### 7. Fixing Permissions and Ownership ###
+
+Now, we'll gonna fix some file permissions and ownership of the installation path. First, we'll gonna set the ownership of the installation directory to Apache process owner so that apache web server will have full access of the files and directories to edit, create and delete.
+
+#### On Ubuntu 15.04 ####
+
+ # chown www-data: -R /var/www/html/reviveads
+
+#### On CentOS 7 ####
+
+ # chown apache: -R /var/www/html/reviveads
+
+### 8. Allowing Firewall ###
+
+Now, we'll gonna configure our firewall programs to allow port 80 (http) so that our apache web server running Revive Adserver will be accessible from other machines in the network across the default http port ie 80.
+
+#### On Ubuntu 15.04/CentOS 7 ####
+
+As CentOS 7 and Ubuntu 15.04 both has systemd installed by default, it contains firewalld running as firewall program. In order to open the port 80 (http service) on firewalld, we'll need to execute the following commands.
+
+ # firewall-cmd --permanent --add-service=http
+
+ success
+
+ # firewall-cmd --reload
+
+ success
+
+### 9. Web Installation ###
+
+Finally, after everything is done as expected, we'll now be able to access the web interface of the application using a web browser. We can go further towards the web installation, by pointing the web browser to the web server we are running in our linux machine. To do so, we'll need to point our web browser to http://ip-address/ or http://domain.com assigned to our linux machine. Here, in this tutorial, we'll point our browser to http://reviveads.linoxide.com/ .
+
+Here, we'll see the Welcome page of the installation of Revive Adserver with the GNU General Public License V2 as Revive Adserver is released under this license. Then, we'll simply click on I agree button in order to continue the installation.
+
+In the next page, we'll need to enter the required database information in order to connect Revive Adserver with the MariaDB database server. Here, we'll need to enter the database name, user and password that we had set in the above step. In this tutorial, we entered database name, user and password as revivedb, reviveuser and Pa$$worD123 respectively then, we set the hostname as localhost and continue further.
+
+
+
+We'll now enter the required information like administration username, password and email address so that we can use these information to login to the dashboard of our Adserver. After done, we'll head towards the Finish page in which we'll see that we have successfully installed Revive Adserver in our server.
+
+Next, we'll be redirected to the Adverstiser page where we'll add new Advertisers and manage them. Then, we'll be able to navigate to our Dashboard, add new users to the adserver, add new campaign for our advertisers, banners, websites, video ads and everything that its built with.
+
+For enabling more configurations and access towards the administrative settings, we can switch our Dashboard user to the Administrator account. This will add new administrative menus in the dashboard like Plugins, Configuration through which we can add and manage plugins and configure many features and elements of Revive Adserver.
+
+### Conclusion ###
+
+In this article, we learned some information on what is Revive Adserver and how we can setup on linux machine running Ubuntu 15.04 and CentOS 7 distributions. Though Revive Adserver's initial source code was bought from OpenX, currently the code base for OpenX Enterprise and Revive Adserver are completely separate. To extend more features, we can install more plugins which we can also find from [http://www.adserverplugins.com/][2] . Really, this piece of software has changed the way of managing the ads for websites, apps, videos and made it very easy and efficient. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/install-revive-adserver-ubuntu-15-04-centos-7/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:http://www.revive-adserver.com/download/
+[2]:http://www.adserverplugins.com/
\ No newline at end of file
diff --git a/sources/tech/20151123 Data Structures in the Linux Kernel.md b/sources/tech/20151123 Data Structures in the Linux Kernel.md
new file mode 100644
index 0000000000..d344eacd97
--- /dev/null
+++ b/sources/tech/20151123 Data Structures in the Linux Kernel.md
@@ -0,0 +1,203 @@
+Translating by DongShuaike
+
+Data Structures in the Linux Kernel
+================================================================================
+
+Radix tree
+--------------------------------------------------------------------------------
+
+As you already know linux kernel provides many different libraries and functions which implement different data structures and algorithms. In this part we will consider one of these data structures - [Radix tree](http://en.wikipedia.org/wiki/Radix_tree). There are two files which are related to `radix tree` implementation and API in the linux kernel:
+
+* [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)
+* [lib/radix-tree.c](https://github.com/torvalds/linux/blob/master/lib/radix-tree.c)
+
+Lets talk about what a `radix tree` is. Radix tree is a `compressed trie` where a [trie](http://en.wikipedia.org/wiki/Trie) is a data structure which implements an interface of an associative array and allows to store values as `key-value`. The keys are usually strings, but any data type can be used. A trie is different from an `n-tree` because of its nodes. Nodes of a trie do not store keys; instead, a node of a trie stores single character labels. The key which is related to a given node is derived by traversing from the root of the tree to this node. For example:
+
+
+```
+ +-----------+
+ | |
+ | " " |
+ | |
+ +------+-----------+------+
+ | |
+ | |
+ +----v------+ +-----v-----+
+ | | | |
+ | g | | c |
+ | | | |
+ +-----------+ +-----------+
+ | |
+ | |
+ +----v------+ +-----v-----+
+ | | | |
+ | o | | a |
+ | | | |
+ +-----------+ +-----------+
+ |
+ |
+ +-----v-----+
+ | |
+ | t |
+ | |
+ +-----------+
+```
+
+So in this example, we can see the `trie` with keys, `go` and `cat`. The compressed trie or `radix tree` differs from `trie` in that all intermediates nodes which have only one child are removed.
+
+Radix tree in linux kernel is the datastructure which maps values to integer keys. It is represented by the following structures from the file [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h):
+
+```C
+struct radix_tree_root {
+ unsigned int height;
+ gfp_t gfp_mask;
+ struct radix_tree_node __rcu *rnode;
+};
+```
+
+This structure presents the root of a radix tree and contains three fields:
+
+* `height` - height of the tree;
+* `gfp_mask` - tells how memory allocations will be performed;
+* `rnode` - pointer to the child node.
+
+The first field we will discuss is `gfp_mask`:
+
+Low-level kernel memory allocation functions take a set of flags as - `gfp_mask`, which describes how that allocation is to be performed. These `GFP_` flags which control the allocation process can have following values: (`GF_NOIO` flag) means sleep and wait for memory, (`__GFP_HIGHMEM` flag) means high memory can be used, (`GFP_ATOMIC` flag) means the allocation process has high-priority and can't sleep etc.
+
+* `GFP_NOIO` - can sleep and wait for memory;
+* `__GFP_HIGHMEM` - high memory can be used;
+* `GFP_ATOMIC` - allocation process is high-priority and can't sleep;
+
+etc.
+
+The next field is `rnode`:
+
+```C
+struct radix_tree_node {
+ unsigned int path;
+ unsigned int count;
+ union {
+ struct {
+ struct radix_tree_node *parent;
+ void *private_data;
+ };
+ struct rcu_head rcu_head;
+ };
+ /* For tree user */
+ struct list_head private_list;
+ void __rcu *slots[RADIX_TREE_MAP_SIZE];
+ unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
+};
+```
+
+This structure contains information about the offset in a parent and height from the bottom, count of the child nodes and fields for accessing and freeing a node. This fields are described below:
+
+* `path` - offset in parent & height from the bottom;
+* `count` - count of the child nodes;
+* `parent` - pointer to the parent node;
+* `private_data` - used by the user of a tree;
+* `rcu_head` - used for freeing a node;
+* `private_list` - used by the user of a tree;
+
+The two last fields of the `radix_tree_node` - `tags` and `slots` are important and interesting. Every node can contains a set of slots which are store pointers to the data. Empty slots in the linux kernel radix tree implementation store `NULL`. Radix trees in the linux kernel also supports tags which are associated with the `tags` fields in the `radix_tree_node` structure. Tags allow individual bits to be set on records which are stored in the radix tree.
+
+Now that we know about radix tree structure, it is time to look on its API.
+
+Linux kernel radix tree API
+---------------------------------------------------------------------------------
+
+We start from the datastructure initialization. There are two ways to initialize a new radix tree. The first is to use `RADIX_TREE` macro:
+
+```C
+RADIX_TREE(name, gfp_mask);
+````
+
+As you can see we pass the `name` parameter, so with the `RADIX_TREE` macro we can define and initialize radix tree with the given name. Implementation of the `RADIX_TREE` is easy:
+
+```C
+#define RADIX_TREE(name, mask) \
+ struct radix_tree_root name = RADIX_TREE_INIT(mask)
+
+#define RADIX_TREE_INIT(mask) { \
+ .height = 0, \
+ .gfp_mask = (mask), \
+ .rnode = NULL, \
+}
+```
+
+At the beginning of the `RADIX_TREE` macro we define instance of the `radix_tree_root` structure with the given name and call `RADIX_TREE_INIT` macro with the given mask. The `RADIX_TREE_INIT` macro just initializes `radix_tree_root` structure with the default values and the given mask.
+
+The second way is to define `radix_tree_root` structure by hand and pass it with mask to the `INIT_RADIX_TREE` macro:
+
+```C
+struct radix_tree_root my_radix_tree;
+INIT_RADIX_TREE(my_tree, gfp_mask_for_my_radix_tree);
+```
+
+where:
+
+```C
+#define INIT_RADIX_TREE(root, mask) \
+do { \
+ (root)->height = 0; \
+ (root)->gfp_mask = (mask); \
+ (root)->rnode = NULL; \
+} while (0)
+```
+
+makes the same initialziation with default values as it does `RADIX_TREE_INIT` macro.
+
+The next are two functions for inserting and deleting records to/from a radix tree:
+
+* `radix_tree_insert`;
+* `radix_tree_delete`;
+
+The first `radix_tree_insert` function takes three parameters:
+
+* root of a radix tree;
+* index key;
+* data to insert;
+
+The `radix_tree_delete` function takes the same set of parameters as the `radix_tree_insert`, but without data.
+
+The search in a radix tree implemented in two ways:
+
+* `radix_tree_lookup`;
+* `radix_tree_gang_lookup`;
+* `radix_tree_lookup_slot`.
+
+The first `radix_tree_lookup` function takes two parameters:
+
+* root of a radix tree;
+* index key;
+
+This function tries to find the given key in the tree and return the record associated with this key. The second `radix_tree_gang_lookup` function have the following signature
+
+```C
+unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
+ void **results,
+ unsigned long first_index,
+ unsigned int max_items);
+```
+
+and returns number of records, sorted by the keys, starting from the first index. Number of the returned records will not be greater than `max_items` value.
+
+And the last `radix_tree_lookup_slot` function will return the slot which will contain the data.
+
+Links
+---------------------------------------------------------------------------------
+
+* [Radix tree](http://en.wikipedia.org/wiki/Radix_tree)
+* [Trie](http://en.wikipedia.org/wiki/Trie)
+
+--------------------------------------------------------------------------------
+
+via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/radix-tree.md
+
+作者:[0xAX]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
diff --git a/sources/tech/20151123 How to Configure Apache Solr on Ubuntu 14 or 15.md b/sources/tech/20151123 How to Configure Apache Solr on Ubuntu 14 or 15.md
new file mode 100644
index 0000000000..e73bdbeb0a
--- /dev/null
+++ b/sources/tech/20151123 How to Configure Apache Solr on Ubuntu 14 or 15.md
@@ -0,0 +1,133 @@
+How to Configure Apache Solr on Ubuntu 14 / 15
+================================================================================
+Hello and welcome to our today's article on Apache Solr. The brief description about Apache Solr is that it is an Open Source most famous search platform with Apache Lucene at the back end for Web sites that enables you to easily create search engines which searches websites, databases and files. It can index and search multiple sites and return recommendations for related contents based on the searched text.
+
+Solr works with HTTP Extensible Markup Language (XML) that offers application program interfaces (APIs) for Javascript Object Notation, Python, and Ruby. According to the Apache Lucene Project, Solr offers capabilities that have made it popular with administrators including it many featuring like:
+
+- Full Text Search
+- Faceted Navigation
+- Snippet generation/highting
+- Spell Suggestion/Auto complete
+- Custom document ranking/ordering
+
+#### Prerequisites: ####
+
+On a fresh Linux Ubuntu 14/15 with minimal packages installed, you only have to take care of few prerequisites in order to install Apache Solr.
+
+### 1)System Update ###
+
+Login to your Ubuntu server with a non-root sudo user that will be used to perform all the steps to install and use Solr.
+
+After successful login, issue the following command to update your system with latest updates and patches.
+
+ $ sudo apt-get update
+
+### 2) JRE Setup ###
+
+The Solr setup needs Java Runtime Environment to be installed on the system as its basic requirement because solr and tomcat both are the Java based applications. So, we need to install and configure its home environment with latest Java.
+
+To install the latest version on Oracle Java 8, we need to install Python Software Properties using the below command.
+
+ $ sudo apt-get install python-software-properties
+
+Upon completion, run the setup its the repository for the latest version of Java 8.
+
+ $ sudo add-apt-repository ppa:webupd8team/java
+
+Now you are able to install the latest version of Oracle Java 8 with 'wget' by issuing the below commands to update the packages source list and then to install Java.
+
+ $ sudo apt-get update
+
+----------
+
+ $ sudo apt-get install oracle-java8-installer
+
+Accept the Oracle Binary Code License Agreement for the Java SE Platform Products and JavaFX as you will be asked during the Java installation and configuration process by a click on the 'OK' button.
+
+When the installation process complete, run the below command to test the successful installation of Java and check its version.
+
+ kash@solr:~$ java -version
+ java version "1.8.0_66"
+ Java(TM) SE Runtime Environment (build 1.8.0_66-b17)
+ Java HotSpot(TM) 64-Bit Server VM (build 25.66-b17, mixed mode)
+
+The output indicates that we have successfully fulfilled the basic requirement of Solr by installing the Java. Now move to the next step to install Solr.
+
+### Installing Solr ###
+
+Installing Solr on Ubuntu can be done by using two different ways but in this article we prefer to install its latest package from the source.
+
+To install Solr from its source, download its available package with latest version from there Official [Web Page][1], copy the link address and get it using 'wget' command.
+
+ $ wget http://www.us.apache.org/dist/lucene/solr/5.3.1/solr-5.3.1.tgz
+
+Run the command below to extract the archived service into '/bin' folder.
+
+ $ tar -xzf solr-5.3.1.tgz solr-5.3.1/bin/install_solr_service.sh --strip-components=2
+
+Then run the script to start Solr service that will creates a new 'solr' user and then installs solr as a service.
+
+ $ sudo bash ./install_solr_service.sh solr-5.3.1.tgz
+
+
+
+To check the status of Solr service, you use the below command.
+
+ $ service solr status
+
+
+
+### Creating Solr Collection: ###
+
+Now we can create multiple collections using Solr user. To do so just run the below command by mentioning the name of the collection you want to create and by specifying its configuration set as shown.
+
+ $ sudo su - solr -c "/opt/solr/bin/solr create -c myfirstcollection -n data_driven_schema_configs"
+
+
+
+We have successfully created the new core instance directory for our our first collection where we can add new data in it. To view its default schema file in directory '/opt/solr/server/solr/configsets/data_driven_schema_configs/conf' .
+
+### Using Solr Web ###
+
+Apache Solr can be accessible on the default port of Solr that 8983. Open your favorite browser and navigate to http://your_server_ip:8983/solr or http://your-domain.com:8983/solr. Make sure that the port is allowed in your firewall.
+
+ http://172.25.10.171:8983/solr/
+
+
+
+From the Solr Web Console click on the 'Core Admin' button from the left bar, then you will see your first collection that we created earlier using CLI. While you can also create new cores by pointing on the 'Add Core' button.
+
+
+
+You can also add the document and query from the document as shown in below image by selecting your particular collection and pointing the document. Add the data in the specified format as shown in the box.
+
+ {
+ "number": 1,
+ "Name": "George Washington",
+ "birth_year": 1989,
+ "Starting_Job": 2002,
+ "End_Job": "2009-04-30",
+ "Qualification": "Graduation",
+ "skills": "Linux and Virtualization"
+ }
+
+After adding the document click on the 'Submit Document' button.
+
+
+
+### Conclusion ###
+
+You are now able to insert and query data using the Solr web interface after its successful installation on Ubuntu. Now add more collections and insert you own data and documents that you wish to put and manage through Solr. We hope you have got this article much helpful and enjoyed reading this.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/ubuntu-how-to/configure-apache-solr-ubuntu-14-15/
+
+作者:[Kashif][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/kashifs/
+[1]:http://lucene.apache.org/solr/
\ No newline at end of file
diff --git a/sources/tech/20151123 How to Install Cockpit in Fedora or CentOS or RHEL or Arch Linux.md b/sources/tech/20151123 How to Install Cockpit in Fedora or CentOS or RHEL or Arch Linux.md
new file mode 100644
index 0000000000..3f2f392efb
--- /dev/null
+++ b/sources/tech/20151123 How to Install Cockpit in Fedora or CentOS or RHEL or Arch Linux.md
@@ -0,0 +1,148 @@
+How to Install Cockpit in Fedora / CentOS / RHEL/ Arch Linux
+================================================================================
+Cockpit is a free and open source server management software that makes us easy to administer our GNU/Linux servers via its beautiful web interface frontend. Cockpit helps make linux system administrator, system maintainers and DevOps easy to manage their server and to perform simple tasks, such as administering storage, inspecting journals, starting and stopping services and more. Its journal interface adds aroma in flower making people easy to switch between the terminal and web interface. And moreover, it makes easy to manage not only one server but several multiple networked servers from a single place at the same time with just a single click. It is very light weight and has easy to use web based interface. In this tutorial, we'll learn how we can setup Cockpit and use it to manage our server running Fedora, CentOS, Arch Linux and RHEL distributions as their operating system software. Some of the awesome benefits of Cockpit in our GNU/Linux servers are as follows:
+
+1. It consist of systemd service manager for ease.
+1. It has a Journal log viewer to perform troubleshoots and log analysis.
+1. Storage setup including LVM was never easier before.
+1. Basic Network configuration can be applied with Cockpit
+1. We can easily add and remove local users and manage multiple servers.
+
+### 1. Installing Cockpit ###
+
+First of all, we'll need to setup Cockpit in our linux based server. In most of the distributions, the cockpit package is already available in their official repositories. Here, in this tutorial, we'll setup Cockpit in Fedora 22, CentOS 7, Arch Linux and RHEL 7 from their official repositories.
+
+#### On CentOS / RHEL ####
+
+Cockpit is available in the official repository of CenOS and RHEL. So, we'll simply install it using yum manager. To do so, we'll simply run the following command under sudo/root access.
+
+ # yum install cockpit
+
+
+
+#### On Fedora 22/21 ####
+
+Alike, CentOS, it is also available by default in Fedora's official repository, we'll simply install cockpit using dnf package manager.
+
+ # dnf install cockpit
+
+
+
+#### On Arch Linux ####
+
+Cockpit is currently not available in the official repository of Arch Linux but it is available in the Arch User Repository also know as AUR. So, we'll simply run the following yaourt command to install it.
+
+ # yaourt cockpit
+
+
+
+### 2. Starting and Enabling Cockpit ###
+
+After we have successfully installed it, we'll gonna start the cockpit server with our service/daemon manager. As of 2015, most of the linux distributions have adopted Systemd whereas some of the linux distributions still run SysVinit to manage daemon, but Cockpit uses systemd for almost everything from running daemons to services. So, we can only setup Cockpit in the latest releases of linux distributions running Systemd. In order to start Cockpit and make it start in every boot of the system, we'll need to run the following command in a terminal or a console.
+
+ # systemctl start cockpit
+
+ # systemctl enable cockpit.socket
+
+ Created symlink from /etc/systemd/system/sockets.target.wants/cockpit.socket to /usr/lib/systemd/system/cockpit.socket.
+
+### 3. Allowing Firewall ###
+
+After we have started our cockpit server and enable it to start in every boot, we'll now go for configuring firewall. As we have firewall programs running in our server, we'll need to allow ports in order to make cockpit accessible outside of the server.
+
+#### On Firewalld ####
+
+ # firewall-cmd --add-service=cockpit --permanent
+
+ success
+
+ # firewall-cmd --reload
+
+ success
+
+
+
+#### On Iptables ####
+
+ # iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
+
+ # service iptables save
+
+### 4. Accessing Cockpit Web Interface ###
+
+Next, we'll gonna finally access the Cockpit web interface using a web browser. We'll simply need to point our web browser to https://ip-address:9090 or https://server.domain.com:9090 according to the configuration. Here, in our tutorial, we'll gonna point our browser to https://128.199.114.17:9090 as shown in the image below.
+
+
+
+We'll be displayed an SSL certification warning as we are using a self-signed SSL certificate. So, we'll simply ignore it and go forward towards the login page, in chrome/chromium, we'll need to click on Show Advanced and then we'll need to click on **Proceed to 128.199.114.17 (unsafe)** .
+
+
+
+Now, we'll be asked to enter the login details in order to enter into the dashboard. Here, the username and password is the same as that of the login details we use to login to our linux server. After we enter the login details and click on Log In button, we will be welcomed into the Cockpit Dashboard.
+
+
+
+Here, we'll see all the menu and visualization of CPU, Disk, Network, Storage usages of the server. We'll see the dashboard as shown above.
+
+#### Services ####
+
+To manage services, we'll need to click on Services button on the menu situated in the right side of the web page. Then, we'll see the services under 5 categories, Targets, System Services, Sockets, Timers and Paths.
+
+
+
+#### Docker Containers ####
+
+We can even manage docker containers with Cockpit. It is pretty easy to monitor and administer Docker containers with Cockpit. As docker isn't installed and running in our server, we'll need to click on Start Docker.
+
+
+
+Cockpit will automatically install and run docker in our server. After its running, we see the following screen. Then, we can manage the docker images, containers as per our requirement.
+
+
+
+#### Journal Log Viewer ####
+
+Cockpit has a managed log viewer which separates the Errors, Warnings, Notices into different tabs. And we also have a tab All where we can see them all in a single place.
+
+
+
+#### Networking ####
+
+Under the networking section, we see two graphs in which there is the visualization of Sending and Receiving speed. And we can see there the list of available interfaces with option to Add Bond, Bridge, VLAN. If we need to configure an interface, we can do so by simply clicking on the interface name. Below everything, we can see the Journal Log Viewer for Networking.
+
+
+
+#### Storage ####
+
+Now, its easy with Cockpit to see the R/W speed of our hard disk. We can see the Journal log of the Storage in order to perform troubleshoot and fixes. A clear visualization bar of how much space is occupied is shown in the page. We can even Unmount, Format, Delete a partition of a Hard Disk and more. Features like creating RAID Device, Volume Group is also available in it.
+
+
+
+#### Account Management ####
+
+We can easily create new accounts with Cockpit Web Interface. The accounts created in it is applied to the system's user account. We can change password, specify roles, delete, rename user accounts with it.
+
+
+
+#### Live Terminal ####
+
+This is an awesome feature built-in with Cockpit. Yes, we can execute commands, do stuffs with the live terminal provided by Cockpit interface. This makes us really easy to switch between the web interface and terminal according to our need.
+
+
+
+### Conclusion ###
+
+Cockpit is a good free and open source software developed by [Red Hat][1] for making the server management easy and simple. It is best for performing simple system administration tasks and is good for the new system administrators. It is still under pre-release as its stable release hasn't been released yet. So, it is not suitable for production. It is currently developed on the latest release of Fedora, CentOS, Arch Linux, RHEL where systemd is installed by default. If you are willing to install Cockpit in Ubuntu, you can get the PPA access but is currently outdated. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank You !
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/install-cockpit-fedora-centos-rhel-arch-linux/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:http://www.redhat.com/
\ No newline at end of file
diff --git a/sources/tech/20151125 Running a mainline kernel on a cellphone.md b/sources/tech/20151125 Running a mainline kernel on a cellphone.md
new file mode 100644
index 0000000000..c247051def
--- /dev/null
+++ b/sources/tech/20151125 Running a mainline kernel on a cellphone.md
@@ -0,0 +1,40 @@
+Running a mainline kernel on a cellphone
+================================================================================
+
+One of the biggest freedoms associated with free software is the ability to replace a program with an updated or modified version. Even so, of the many millions of people using Linux-powered phones, few are able to run a mainline kernel on those phones, even if they have the technical skills to do the replacement. The sad fact is that no mainstream phone available runs mainline kernels. A session at the 2015 Kernel Summit, led by Rob Herring, explored this problem and what might be done to address it.
+
+When asked, most of the developers in the room indicated that they would prefer to be able to run mainline kernels on their phones — though a handful did say that they would rather not do so. Rob has been working on this problem for the last year and a half in support of Project Ara (mentioned in this article). But the news is not good.
+
+There is, he said, too much out-of-tree code running on a typical handset; mainline kernels simply lack the drivers needed to make that handset work. A typical phone is running 1-3 million lines of out-of-tree code. Almost all of those phones are stuck on the 3.10 kernel — or something even older. There are all kinds of reasons for this, but the simple fact is that things seem to move too quickly in the handset world for the kernel community to keep up. Is that, he asked, something that we care about?
+
+Tim Bird noted that the Nexus 1, one of the original Android phones, never ran a mainline kernel and never will. It broke the promise of open source, making it impossible for users to put a new kernel onto their devices. At this point, no phone supports that ability. Peter Zijlstra wondered about how much of that out-of-tree code was duplicated functionality from one handset to the next; Rob noted that he has run into three independently developed hotplug governors so far.
+
+Dirk Hohndel suggested that few people care. Of the billion phones out there, he said, approximately 27 of them have owners who care about running mainline kernels. The rest just want to get the phone to work. Perhaps developers who are concerned about running mainline kernels are trying to solve the wrong problem.
+
+Chris Mason said that handset vendors are currently facing the same sorts of problems that distributors dealt with many years ago. They are coping with a lot of inefficient, repeated, duplicated work. Once the distributors [Rob Herring] decided to put their work into the mainline instead of carrying it themselves, things got a lot better. The key is to help the phone manufacturers to realize that they can benefit in the same way; that, rather than pressure from users, is how the problem will be solved.
+
+Grant Likely raised concerns about security in a world where phones cannot be upgraded. What we need is a real distribution market for phones. But, as long as the vendors are in charge of the operating software, phones will not be upgradeable. We have a big security mess coming, he said. Peter added that, with Stagefright, that mess is already upon us.
+
+Ted Ts'o said that running mainline kernels is not his biggest concern. He would be happy if the phones on sale this holiday season would be running a 3.18 or 4.1 kernel, rather than being stuck on 3.10. That, he suggested, is a more solvable problem. Steve Rostedt said that would not solve the security problem, but Ted remarked that a newer kernel would at least make it easier to backport fixes. Grant replied that, one year from now, it would all just happen again; shipping newer kernels is just an incremental fix. Kees Cook added that there is not much to be gained from backporting fixes; the real problem is that there are no defenses from bugs (he would expand on this theme in a separate session later in the day).
+
+Rob said that any kind of solution would require getting the vendors on board. That, though, will likely run into trouble with the sort of lockdown that vendors like to apply to their devices. Paolo Bonzini asked whether it would be possible to sue vendors over unfixed security vulnerabilities, especially when the devices are still under warranty. Grant said that upgradeability had to become a market requirement or it simply wasn't going to happen. It might be a nasty security issue that causes this to happen, or carriers might start requiring it. Meanwhile, kernel developers need to keep pushing in that direction. Rob noted that, beyond the advantages noted thus far, the ability to run mainline kernels would help developers to test and validate new features on Android devices.
+
+Josh Triplett asked whether the community would be prepared to do what it would take if the industry were to come around to the idea of mainline kernel support. There would be lots of testing and validation of kernels on handsets required; Android Compatibility Test Suite failures would have to be treated as regressions. Rob suggested that this could be discussed next year, after the basic functionality is in place, but Josh insisted that, if the demand were to show up, we would have to be able to give a good answer.
+
+Tim said that there is currently a big disconnect with the vendor world; vendors are not reporting or contributing anything back to the community at all. They are completely disconnected, so there is no forward progress ever. Josh noted that when vendors do report bugs with the old kernels they are using, the reception tends to be less than friendly. Arnd Bergmann said that what was needed was to get one of the big silicon vendors to commit to the idea and get its hardware to a point where running mainline kernels was possible; that would put pressure on the others. But, he added, that would require the existence of one free GPU driver that got shipped with the hardware — something that does not exist currently.
+
+Rob put up a list of problem areas, but there was not much time for discussion of the particulars. WiFi drivers continue to be an issue, especially with the new features being added in the Android world. Johannes Berg agreed that the new features are an issue; the Android developers do not even talk about them until they ship with the hardware. Support for most of those features does eventually land in the mainline kernel, though.
+
+As things wound down, Ben Herrenschmidt reiterated that the key was to get vendors to realize that working with the mainline kernel is in their own best interest; it saves work in the long run. Mark Brown said that, in past years when the kernel version shipped with Android moved forward more reliably, the benefits of working upstream were more apparent to vendors. Now that things seem to be stuck on 3.10, that pressure is not there in the same way. The session ended with developers determined to improve the situation, but without any clear plan for getting there.
+
+--------------------------------------------------------------------------------
+
+via: https://lwn.net/Articles/662147/
+
+作者:[Jonathan Corbet][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://lwn.net/Articles/KernelSummit2015/
diff --git a/sources/tech/20151130 Useful Linux and Unix Tape Managements Commands For Sysadmins.md b/sources/tech/20151130 Useful Linux and Unix Tape Managements Commands For Sysadmins.md
new file mode 100644
index 0000000000..ff0e0219fb
--- /dev/null
+++ b/sources/tech/20151130 Useful Linux and Unix Tape Managements Commands For Sysadmins.md
@@ -0,0 +1,425 @@
+15 Useful Linux and Unix Tape Managements Commands For Sysadmins
+================================================================================
+Tape devices should be used on a regular basis only for archiving files or for transferring data from one server to another. Usually, tape devices are all hooked up to Unix boxes, and controlled with mt or mtx. You must backup all data to both disks (may be in cloud) and tape device. In this tutorial you will learn about:
+
+- Tape device names
+- Basic commands to manage tape drive
+- Basic backup and restore commands
+
+### Why backup? ###
+
+A backup plant is important:
+
+- Ability to recover from disk failure
+- Accidental file deletion
+- File or file system corruption
+- Complete server destruction, including destruction of on-site backups due to fire or other problems.
+
+You can use tape based archives to backup the whole server and move tapes off-site.
+
+### Understanding tape file marks and block size ###
+
+
+
+Fig.01: Tape file marks
+
+Each tape device can store multiple tape backup files. Tape backup files are created using cpio, tar, dd, and so on. However, tape device can be opened, written data to, and closed by various program. You can store several backups (tapes) on physical tape. Between each tape file is a "tape file mark". This is used to indicate where one tape file ends and another begins on physical tape. You need to use mt command to positions the tape (winds forward and rewinds and marks).
+
+#### How data is stored on a tape ####
+
+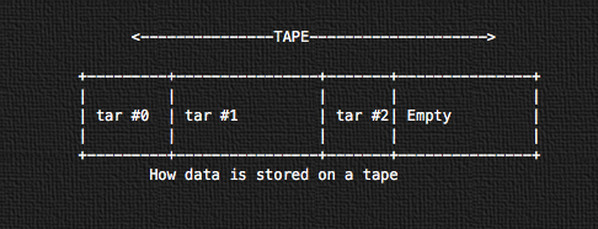
+
+Fig.02: How data is stored on a tape
+
+All data is stored subsequently in sequential tape archive format using tar. The first tape archive will start on the physical beginning of the tape (tar #0). The next will be tar #1 and so on.
+
+### Tape device names on Unix ###
+
+1. /dev/rmt/0 or /dev/rmt/1 or /dev/rmt/[0-127] : Regular tape device name on Unix. The tape is rewound.
+1. /dev/rmt/0n : This is know as no rewind i.e. after using tape, leaves the tape in current status for next command.
+1. /dev/rmt/0b : Use magtape interface i.e. BSD behavior. More-readable by a variety of OS's such as AIX, Windows, Linux, FreeBSD, and more.
+1. /dev/rmt/0l : Set density to low.
+1. /dev/rmt/0m : Set density to medium.
+1. /dev/rmt/0u : Set density to high.
+1. /dev/rmt/0c : Set density to compressed.
+1. /dev/st[0-9] : Linux specific SCSI tape device name.
+1. /dev/sa[0-9] : FreeBSD specific SCSI tape device name.
+1. /dev/esa0 : FreeBSD specific SCSI tape device name that eject on close (if capable).
+
+#### Tape device name examples ####
+
+- The /dev/rmt/1cn indicate that I'm using unity 1, compressed density and no rewind.
+- The /dev/rmt/0hb indicate that I'm using unity 0, high density and BSD behavior.
+- The auto rewind SCSI tape device name on Linux : /dev/st0
+- The non-rewind SCSI tape device name on Linux : /dev/nst0
+- The auto rewind SCSI tape device name on FreeBSD: /dev/sa0
+- The non-rewind SCSI tape device name on FreeBSD: /dev/nsa0
+
+#### How do I list installed scsi tape devices? ####
+
+Type the following commands:
+
+ ## Linux (read man pages for more info) ##
+ lsscsi
+ lsscsi -g
+
+ ## IBM AIX ##
+ lsdev -Cc tape
+ lsdev -Cc adsm
+ lscfg -vl rmt*
+
+ ## Solaris Unix ##
+ cfgadm –a
+ cfgadm -al
+ luxadm probe
+ iostat -En
+
+ ## HP-UX Unix ##
+ ioscan Cf
+ ioscan -funC tape
+ ioscan -fnC tape
+ ioscan -kfC tape
+
+
+Sample outputs from my Linux server:
+
+
+
+Fig.03: Installed tape devices on Linux server
+
+### mt command examples ###
+
+In Linux and Unix-like system, mt command is used to control operations of the tape drive, such as finding status or seeking through files on a tape or writing tape control marks to the tape. You must most of the following command as root user. The syntax is:
+
+ mt -f /tape/device/name operation
+
+#### Setting up environment ####
+
+You can set TAPE shell variable. This is the pathname of the tape drive. The default (if the variable is unset, but not if it is null) is /dev/nsa0 on FreeBSD. It may be overridden with the -f option passed to the mt command as explained below.
+
+ ## Add to your shell startup file ##
+ TAPE=/dev/st1 #Linux
+ TAPE=/dev/rmt/2 #Unix
+ TAPE=/dev/nsa3 #FreeBSD
+ export TAPE
+
+### 1: Display status of the tape/drive ###
+
+ mt status #Use default
+ mt -f /dev/rmt/0 status #Unix
+ mt -f /dev/st0 status #Linux
+ mt -f /dev/nsa0 status #FreeBSD
+ mt -f /dev/rmt/1 status #Unix unity 1 i.e. tape device no. 1
+
+You can use shell loop as follows to poll a system and locate all of its tape drives:
+
+ for d in 0 1 2 3 4 5
+ do
+ mt -f "/dev/rmt/${d}" status
+ done
+
+### 2: Rewinds the tape ###
+
+ mt rew
+ mt rewind
+ mt -f /dev/mt/0 rewind
+ mt -f /dev/st0 rewind
+
+### 3: Eject the tape ###
+
+ mt off
+ mt offline
+ mt eject
+ mt -f /dev/mt/0 off
+ mt -f /dev/st0 eject
+
+### 4: Erase the tape (rewind the tape and, if applicable, unload the tape) ###
+
+ mt erase
+ mt -f /dev/st0 erase #Linux
+ mt -f /dev/rmt/0 erase #Unix
+
+### 5: Retensioning a magnetic tape cartridge ###
+
+If errors occur when a tape is being read, you can retension the tape, clean the tape drive, and then try again as follows:
+
+ mt retension
+ mt -f /dev/rmt/1 retension #Unix
+ mt -f /dev/st0 retension #Linux
+
+### 6: Writes n EOF marks in the current position of tape ###
+
+ mt eof
+ mt weof
+ mt -f /dev/st0 eof
+
+### 7: Forward space count files i.e. jumps n EOF marks ###
+
+The tape is positioned on the first block of the next file i.e. tape will position on first block of the field (see fig.01):
+
+ mt fsf
+ mt -f /dev/rmt/0 fsf
+ mt -f /dev/rmt/1 fsf 1 #go 1 forward file/tape (see fig.01)
+
+### 8: Backward space count files i.e. rewinds n EOF marks ###
+
+The tape is positioned on the first block of the next file i.e. tape positions after EOF mark (see fig.01):
+
+ mt bsf
+ mt -f /dev/rmt/1 bsf
+ mt -f /dev/rmt/1 bsf 1 #go 1 backward file/tape (see fig.01)
+
+Here is a list of the tape position commands:
+
+ fsf Forward space count files. The tape is positioned on the first block of the next file.
+
+ fsfm Forward space count files. The tape is positioned on the last block of the previous file.
+
+ bsf Backward space count files. The tape is positioned on the last block of the previous file.
+
+ bsfm Backward space count files. The tape is positioned on the first block of the next file.
+
+ asf The tape is positioned at the beginning of the count file. Positioning is done by first rewinding the tape and then spacing forward over count filemarks.
+
+ fsr Forward space count records.
+
+ bsr Backward space count records.
+
+ fss (SCSI tapes) Forward space count setmarks.
+
+ bss (SCSI tapes) Backward space count setmarks.
+
+### Basic backup commands ###
+
+Let us see commands to backup and restore files
+
+### 9: To backup directory (tar format) ###
+
+ tar cvf /dev/rmt/0n /etc
+ tar cvf /dev/st0 /etc
+
+### 10: To restore directory (tar format) ###
+
+ tar xvf /dev/rmt/0n -C /path/to/restore
+ tar xvf /dev/st0 -C /tmp
+
+### 11: List or check tape contents (tar format) ###
+
+ mt -f /dev/st0 rewind; dd if=/dev/st0 of=-
+
+ ## tar format ##
+ tar tvf {DEVICE} {Directory-FileName}
+ tar tvf /dev/st0
+ tar tvf /dev/st0 desktop
+ tar tvf /dev/rmt/0 foo > list.txt
+
+### 12: Backup partition with dump or ufsdump ###
+
+ ## Unix backup c0t0d0s2 partition ##
+ ufsdump 0uf /dev/rmt/0 /dev/rdsk/c0t0d0s2
+
+ ## Linux backup /home partition ##
+ dump 0uf /dev/nst0 /dev/sda5
+ dump 0uf /dev/nst0 /home
+
+ ## FreeBSD backup /usr partition ##
+ dump -0aL -b64 -f /dev/nsa0 /usr
+
+### 12: Restore partition with ufsrestore or restore ###
+
+ ## Unix ##
+ ufsrestore xf /dev/rmt/0
+ ## Unix interactive restore ##
+ ufsrestore if /dev/rmt/0
+
+ ## Linux ##
+ restore rf /dev/nst0
+ ## Restore interactive from the 6th backup on the tape media ##
+ restore isf 6 /dev/nst0
+
+ ## FreeBSD restore ufsdump format ##
+ restore -i -f /dev/nsa0
+
+### 13: Start writing at the beginning of the tape (see fig.02) ###
+
+ ## This will overwrite all data on tape ##
+ mt -f /dev/st1 rewind
+
+ ### Backup home ##
+ tar cvf /dev/st1 /home
+
+ ## Offline and unload tape ##
+ mt -f /dev/st0 offline
+
+To restore from the beginning of the tape:
+
+ mt -f /dev/st0 rewind
+ tar xvf /dev/st0
+ mt -f /dev/st0 offline
+
+### 14: Start writing after the last tar (see fig.02) ###
+
+ ## This will kee all data written so far ##
+ mt -f /dev/st1 eom
+
+ ### Backup home ##
+ tar cvf /dev/st1 /home
+
+ ## Unload ##
+ mt -f /dev/st0 offline
+
+### 15: Start writing after tar number 2 (see fig.02) ###
+
+ ## To wrtite after tar number 2 (should be 2+1)
+ mt -f /dev/st0 asf 3
+ tar cvf /dev/st0 /usr
+
+ ## asf equivalent command done using fsf ##
+ mt -f /dev/sf0 rewind
+ mt -f /dev/st0 fsf 2
+
+To restore tar from tar number 2:
+
+ mt -f /dev/st0 asf 3
+ tar xvf /dev/st0
+ mt -f /dev/st0 offline
+
+### How do I verify backup tapes created using tar? ###
+
+It is important that you do regular full system restorations and service testing, it's the only way to know for sure that the entire system is working correctly. See our [tutorial on verifying tar command tape backups][1] for more information.
+
+### Sample shell script ###
+
+ #!/bin/bash
+ # A UNIX / Linux shell script to backup dirs to tape device like /dev/st0 (linux)
+ # This script make both full and incremental backups.
+ # You need at two sets of five tapes. Label each tape as Mon, Tue, Wed, Thu and Fri.
+ # You can run script at midnight or early morning each day using cronjons.
+ # The operator or sys admin can replace the tape every day after the script has done.
+ # Script must run as root or configure permission via sudo.
+ # -------------------------------------------------------------------------
+ # Copyright (c) 1999 Vivek Gite
+ # This script is licensed under GNU GPL version 2.0 or above
+ # -------------------------------------------------------------------------
+ # This script is part of nixCraft shell script collection (NSSC)
+ # Visit http://bash.cyberciti.biz/ for more information.
+ # -------------------------------------------------------------------------
+ # Last updated on : March-2003 - Added log file support.
+ # Last updated on : Feb-2007 - Added support for excluding files / dirs.
+ # -------------------------------------------------------------------------
+ LOGBASE=/root/backup/log
+
+ # Backup dirs; do not prefix /
+ BACKUP_ROOT_DIR="home sales"
+
+ # Get todays day like Mon, Tue and so on
+ NOW=$(date +"%a")
+
+ # Tape devie name
+ TAPE="/dev/st0"
+
+ # Exclude file
+ TAR_ARGS=""
+ EXCLUDE_CONF=/root/.backup.exclude.conf
+
+ # Backup Log file
+ LOGFIILE=$LOGBASE/$NOW.backup.log
+
+ # Path to binaries
+ TAR=/bin/tar
+ MT=/bin/mt
+ MKDIR=/bin/mkdir
+
+ # ------------------------------------------------------------------------
+ # Excluding files when using tar
+ # Create a file called $EXCLUDE_CONF using a text editor
+ # Add files matching patterns such as follows (regex allowed):
+ # home/vivek/iso
+ # home/vivek/*.cpp~
+ # ------------------------------------------------------------------------
+ [ -f $EXCLUDE_CONF ] && TAR_ARGS="-X $EXCLUDE_CONF"
+
+ #### Custom functions #####
+ # Make a full backup
+ full_backup(){
+ local old=$(pwd)
+ cd /
+ $TAR $TAR_ARGS -cvpf $TAPE $BACKUP_ROOT_DIR
+ $MT -f $TAPE rewind
+ $MT -f $TAPE offline
+ cd $old
+ }
+
+ # Make a partial backup
+ partial_backup(){
+ local old=$(pwd)
+ cd /
+ $TAR $TAR_ARGS -cvpf $TAPE -N "$(date -d '1 day ago')" $BACKUP_ROOT_DIR
+ $MT -f $TAPE rewind
+ $MT -f $TAPE offline
+ cd $old
+ }
+
+ # Make sure all dirs exits
+ verify_backup_dirs(){
+ local s=0
+ for d in $BACKUP_ROOT_DIR
+ do
+ if [ ! -d /$d ];
+ then
+ echo "Error : /$d directory does not exits!"
+ s=1
+ fi
+ done
+ # if not; just die
+ [ $s -eq 1 ] && exit 1
+ }
+
+ #### Main logic ####
+
+ # Make sure log dir exits
+ [ ! -d $LOGBASE ] && $MKDIR -p $LOGBASE
+
+ # Verify dirs
+ verify_backup_dirs
+
+ # Okay let us start backup procedure
+ # If it is Monday make a full backup;
+ # For Tue to Fri make a partial backup
+ # Weekend no backups
+ case $NOW in
+ Mon) full_backup;;
+ Tue|Wed|Thu|Fri) partial_backup;;
+ *) ;;
+ esac > $LOGFIILE 2>&1
+
+### A note about third party backup utilities ###
+
+Both Linux and Unix-like system provides many third-party utilities which you can use to schedule the creation of backups including tape backups such as:
+
+- Amanda
+- Bacula
+- rsync
+- duplicity
+- rsnapshot
+
+See also
+
+- Man pages - [mt(1)][2], [mtx(1)][3], [tar(1)][4], [dump(8)][5], [restore(8)][6]
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/hardware/unix-linux-basic-tape-management-commands/
+
+作者:Vivek Gite
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.cyberciti.biz/faq/unix-verify-tape-backup/
+[2]:http://www.manpager.com/linux/man1/mt.1.html
+[3]:http://www.manpager.com/linux/man1/mtx.1.html
+[4]:http://www.manpager.com/linux/man1/tar.1.html
+[5]:http://www.manpager.com/linux/man8/dump.8.html
+[6]:http://www.manpager.com/linux/man8/restore.8.html
\ No newline at end of file
diff --git a/sources/tech/20151202 8 things to do after installing openSUSE Leap 42.1.md b/sources/tech/20151202 8 things to do after installing openSUSE Leap 42.1.md
new file mode 100644
index 0000000000..bbd79c19a3
--- /dev/null
+++ b/sources/tech/20151202 8 things to do after installing openSUSE Leap 42.1.md
@@ -0,0 +1,108 @@
+8 things to do after installing openSUSE Leap 42.1
+================================================================================
+
+Credit: [Metropolitan Transportation/Flicrk][1]
+
+> You've installed openSUSE on your PC. Here's what to do next.
+
+[openSUSE Leap is indeed a huge leap][2], allowing users to run a distro that has the same DNA of SUSE Linux Enterprise. Like any other operating system, some work is needed to get it set up for optimal use.
+
+Following are some of the things that I did after installing openSUSE Leap on my PC (these are not applicable for server installations). None of them are mandatory, and you may be fine with the basic install. But if you need more out of your openSUSE Leap, follow me.
+
+### 1. Adding Packman repository ###
+
+Due to software patents and licences, openSUSE, like many Linux distributions, doesn't offer many applications, codecs, and drivers through official repositories (repos). Instead, these are made available through 3rd party or community repos. The first and most important repository is 'Packman'. Since these repos are not enabled by default, we have to add them. You can do so either using YaST (one of the gems of openSUSE) or by command line (instructions below).
+
+
+Adding Packman repositories.
+
+Using YaST, go to the Software Repositories section. Click on the 'Add’ button and select 'Community Repositories.' Click 'next.' And once the repos are loaded, select the Packman Repository. Click 'OK,' then import the trusted GnuPG key by clicking on the 'Trust' button.
+
+Or, using the terminal you can add and enable the Packman repo using the following command:
+
+ zypper ar -f -n packmanhttp://ftp.gwdg.de/pub/linux/misc/packman/suse/openSUSE_Leap_42.1/ packman
+
+Once the repo is added, you have access to many more packages. To install any application or package, open YaST Software Manager, search for the package and install it.
+
+### 2. Install VLC ###
+
+VLC is the Swiss Army knife of media players and can play virtually any media file. You can install VLC from YaST Software Manager or from software.opensuse.org. You will need to install two packages: vlc and vlc-codecs.
+
+If using terminal, run the following command:
+
+ sudo zypper install vlc vlc-codecs
+
+### 3. Install Handbrake ###
+
+If you need to transcode or convert your video files from one format to another, [Handbrake is the tools for you][3]. Handbrake is available through repositories we enabled, so just search for it in YaST and install.
+
+If you are using the terminal, run the following command:
+
+ sudo zypper install handbrake-cli handbrake-gtk
+
+(Pro tip: VLC can also transcode audio and video files.)
+
+### 4. Install Chrome ###
+
+OpenSUSE comes with Firefox as the default browser. But since Firefox isn't capable of playing restricted media such as Netflix, I recommend installing Chrome. This takes some extra work. First you need to import the trusted key from Google. Open the terminal app and run the 'wget' command to download the key:
+
+ wget https://dl.google.com/linux/linux_signing_key.pub
+
+Then import the key:
+
+ sudo rpm --import linux_signing_key.pub
+
+Now head over to the [Google Chrome website][4] and download the 64 bit .rpm file. Once downloaded run the following command to install the browser:
+
+ sudo zypper install /PATH_OF_GOOGLE_CHROME.rpm
+
+### 5. Install Nvidia drivers ###
+
+OpenSUSE Leap will work out of the box even if you have Nvidia or ATI graphics cards. However, if you do need the proprietary drivers for gaming or any other purpose, you can install such drivers, but some extra work is needed.
+
+First you need to add the Nvidia repositories; it's the same procedure we used to add Packman repositories using YaST. The only difference is that you will choose Nvidia from the Community Repositories section. Once it's added, go to **Software Management > Extras** and select 'Extras/Install All Matching Recommended Packages'.
+
+
+
+It will open a dialogue box showing all the packages it's going to install, click OK and follow the instructions. You can also run the following command after adding the Nvidia repository to install the needed Nvidia drivers:
+
+ sudo zypper inr
+
+(Note: I have never used AMD/ATI cards so I have no experience with them.)
+
+### 6. Install media codecs ###
+
+Once you have VLC installed you won't need to install media codecs, but if you are using other apps for media playback you will need to install such codecs. Some developers have written scripts/tools which makes it a much easier process. Just go to [this page][5] and install the entire pack by clicking on the appropriate button. It will open YaST and install the packages automatically (of source you will have to give the root password and trust the GnuPG key, as usual).
+
+### 7. Install your preferred email client ###
+
+OpenSUSE comes with Kmail or Evolution, depending on the Desktop Environment you installed on the system. I run Plasma, which comes with Kmail, and this email client leaves a lot to be desired. I suggest trying Thunderbird or Evolution mail. All major email clients are available through official repositories. You can also check my [handpicked list of the best email clients for Linux][7].
+
+### 8. Enable Samba services from Firewall ###
+
+OpenSUSE offers a much more secure system out of the box, compared to other distributions. But it also requires a little bit more work for a new user. If you are using Samba protocol to share files within your local network then you will have to allow that service from the Firewall.
+
+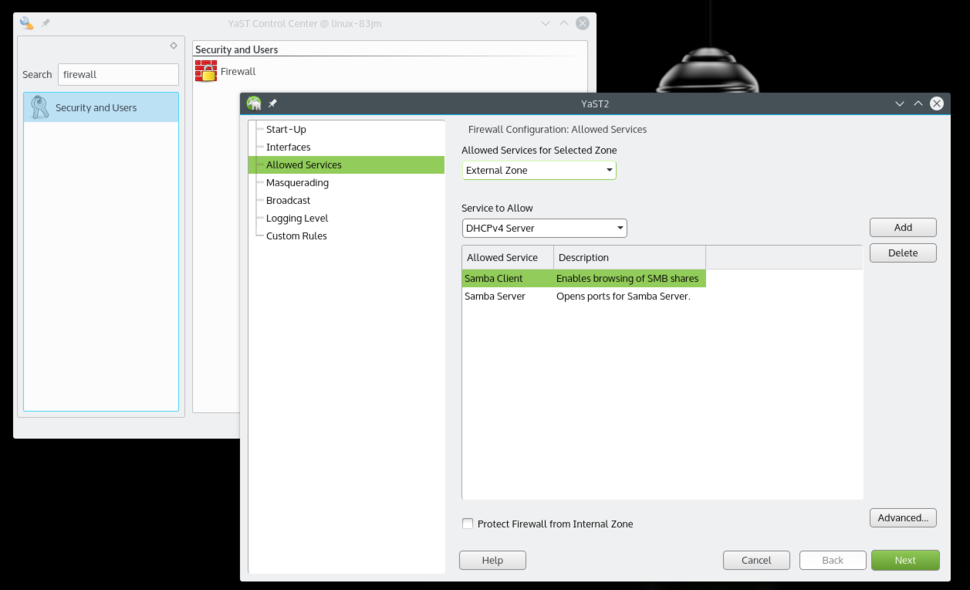
+Allow Samba Client and Server from Firewall settings.
+
+Open YaST and search for Firewall. Once in Firewall settings, go to 'Allowed Services' where you will see a drop down list under 'Service to allow.' Select 'Samba Client,' then click 'Add.' Do the same with the 'Samba Server' option. Once both are added, click 'Next,' then click 'Finish,' and now you will be able to share folders from your openSUSE system and also access other machines over the local network.
+
+That's pretty much all that I did on my new openSUSE system to set it up just the way I like it. If you have any questions, please feel free to ask in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: http://www.itworld.com/article/3003865/open-source-tools/8-things-to-do-after-installing-opensuse-leap-421.html
+
+作者:[Swapnil Bhartiya][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.itworld.com/author/Swapnil-Bhartiya/
+[1]:https://www.flickr.com/photos/mtaphotos/11200079265/
+[2]:https://www.linux.com/news/software/applications/865760-opensuse-leap-421-review-the-most-mature-linux-distribution
+[3]:https://www.linux.com/learn/tutorials/857788-how-to-convert-videos-in-linux-using-the-command-line
+[4]:https://www.google.com/intl/en/chrome/browser/desktop/index.html#brand=CHMB&utm_campaign=en&utm_source=en-ha-na-us-sk&utm_medium=ha
+[5]:http://opensuse-community.org/
+[6]:http://www.itworld.com/article/2875981/the-5-best-open-source-email-clients-for-linux.html
\ No newline at end of file
diff --git a/sources/tech/20151202 A new Mindcraft moment.md b/sources/tech/20151202 A new Mindcraft moment.md
new file mode 100644
index 0000000000..79930e8202
--- /dev/null
+++ b/sources/tech/20151202 A new Mindcraft moment.md
@@ -0,0 +1,43 @@
+A new Mindcraft moment?
+=======================
+
+Credit:Jonathan Corbet
+
+It is not often that Linux kernel development attracts the attention of a mainstream newspaper like The Washington Post; lengthy features on the kernel community's approach to security are even more uncommon. So when just such a feature hit the net, it attracted a lot of attention. This article has gotten mixed reactions, with many seeing it as a direct attack on Linux. The motivations behind the article are hard to know, but history suggests that we may look back on it as having given us a much-needed push in a direction we should have been going for some time.
+
+Think back, a moment, to the dim and distant past — April 1999, to be specific. An analyst company named Mindcraft issued a report showing that Windows NT greatly outperformed Red Hat Linux 5.2 and Apache for web-server workloads. The outcry from the Linux community, including from a very young LWN, was swift and strong. The report was a piece of Microsoft-funded FUD trying to cut off an emerging threat to its world-domination plans. The Linux system had been deliberately configured for poor performance. The hardware chosen was not well supported by Linux at the time. And so on.
+
+Once people calmed down a bit, though, one other fact came clear: the Mindcraft folks, whatever their motivations, had a point. Linux did, indeed, have performance problems that were reasonably well understood even at the time. The community then did what it does best: we sat down and fixed the problems. The scheduler got exclusive wakeups, for example, to put an end to thethundering-herd problem in the acceptance of connection requests. Numerous other little problems were fixed. Within a year or so, the kernel's performance on this kind of workload had improved considerably.
+
+The Mindcraft report, in other words, was a much-needed kick in the rear that got the community to deal with issues that had been neglected until then.
+
+The Washington Post article seems clearly slanted toward a negative view of the Linux kernel and its contributors. It freely mixes kernel problems with other issues (the AshleyMadison.com breakin, for example) that were not kernel vulnerabilities at all. The fact that vendors seem to have little interest in getting security fixes to their customers is danced around like a huge elephant in the room. There are rumors of dark forces that drove the article in the hopes of taking Linux down a notch. All of this could well be true, but it should not be allowed to overshadow the simple fact that the article has a valid point.
+
+We do a reasonable job of finding and fixing bugs. Problems, whether they are security-related or not, are patched quickly, and the stable-update mechanism makes those patches available to kernel users. Compared to a lot of programs out there (free and proprietary alike), the kernel is quite well supported. But pointing at our ability to fix bugs is missing a crucial point: fixing security bugs is, in the end, a game of whack-a-mole. There will always be more moles, some of which we will not know about (and will thus be unable to whack) for a long time after they are discovered and exploited by attackers. These bugs leave our users vulnerable, even if the commercial side of Linux did a perfect job of getting fixes to users — which it decidedly does not.
+
+The point that developers concerned about security have been trying to make for a while is that fixing bugs is not enough. We must instead realize that we will never fix them all and focus on making bugs harder to exploit. That means restricting access to information about the kernel, making it impossible for the kernel to execute code in user-space memory, instrumenting the kernel to detect integer overflows, and all the other things laid out in Kees Cook's Kernel Summit talk at the end of October. Many of these techniques are well understood and have been adopted by other operating systems; others will require innovation on our part. But, if we want to adequately defend our users from attackers, these changes need to be made.
+
+Why hasn't the kernel adopted these technologies already? The Washington Post article puts the blame firmly on the development community, and on Linus Torvalds in particular. The culture of the kernel community prioritizes performance and functionality over security and is unwilling to make compromises if they are needed to improve the security of the kernel. There is some truth to this claim; the good news is that attitudes appear to be shifting as the scope of the problem becomes clear. Kees's talk was well received, and it clearly got developers thinking and talking about the issues.
+
+The point that has been missed is that we do not just have a case of Linus fending off useful security patches. There simply are not many such patches circulating in the kernel community. In particular, the few developers who are working in this area have never made a serious attempt to get that work integrated upstream. Getting any large, intrusive patch set merged requires working with the kernel community, making the case for the changes, splitting the changes into reviewable pieces, dealing with review comments, and so on. It can be tiresome and frustrating, but it's how the kernel works, and it clearly results in a more generally useful, more maintainable kernel in the long run.
+
+Almost nobody is doing that work to get new security technologies into the kernel. One might cite a "chilling effect" from the hostile reaction such patches can receive, but that is an inadequate answer: developers have managed to merge many changes over the years despite a difficult initial reaction. Few security developers are even trying.
+
+Why aren't they trying? One fairly obvious answer is that almost nobody is being paid to try. Almost all of the work going into the kernel is done by paid developers and has been for many years. The areas that companies see fit to support get a lot of work and are well advanced in the kernel. The areas that companies think are not their problem are rather less so. The difficulties in getting support for realtime development are a clear case in point. Other areas, such as documentation, tend to languish as well. Security is clearly one of those areas. There are a lot of reasons why Linux lags behind in defensive security technologies, but one of the key ones is that the companies making money on Linux have not prioritized the development and integration of those technologies.
+
+There are signs that things might be changing a bit. More developers are showing interest in security-related issues, though commercial support for their work is still less than it should be. The reaction against security-related changes might be less knee-jerk negative than it used to be. Efforts like the Kernel Self Protection Project are starting to work on integrating existing security technologies into the kernel.
+
+We have a long way to go, but, with some support and the right mindset, a lot of progress can be made in a short time. The kernel community can do amazing things when it sets its mind to it. With luck, the Washington Post article will help to provide the needed impetus for that sort of setting of mind. History suggests that we will eventually see this moment as a turning point, when we were finally embarrassed into doing work that has clearly needed doing for a while. Linux should not have a substandard security story for much longer.
+
+---------------------------
+
+via: https://lwn.net/Articles/663474/
+
+作者:Jonathan Corbet
+
+译者:[译者ID](https://github.com/译者ID)
+
+校对:[校对者ID](https://github.com/校对者ID)
+
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/tech/20151204 How to Install Laravel PHP Framework on CentOS 7 or Ubuntu 15.04.md b/sources/tech/20151204 How to Install Laravel PHP Framework on CentOS 7 or Ubuntu 15.04.md
new file mode 100644
index 0000000000..1e14ff6a7b
--- /dev/null
+++ b/sources/tech/20151204 How to Install Laravel PHP Framework on CentOS 7 or Ubuntu 15.04.md
@@ -0,0 +1,176 @@
+translating by NearTan
+How to Install Laravel PHP Framework on CentOS 7 / Ubuntu 15.04
+================================================================================
+Hi All, In this article we are going to setup Laravel on CentOS 7 and Ubuntu 15.04. If you are a PHP web developer then you don't need to worry about of all modern PHP frameworks, Laravel is the easiest to get up and running that saves your time and effort and makes web development a joy. Laravel embraces a general development philosophy that sets a high priority on creating maintainable code by following some simple guidelines, you should be able to keep a rapid pace of development and be free to change your code with little fear of breaking existing functionality.
+
+Laravel's PHP framework installation is not a big deal. You can simply follow the step by step guide in this article for your CentOS 7 or Ubuntu 15 server.
+
+### 1) Server Requirements ###
+
+Laravel depends upon a number of prerequisites that must be setup before installing it. Those prerequisites includes some basic tuning parameter of server like your system update, sudo rights and installation of required packages.
+
+Once you are connected to your server make sure to configure the fully qualified domain name then run the commands below to enable EPEL Repo and update your server.
+
+#### CentOS-7 ####
+
+ # yum install epel-release
+
+----------
+
+ # rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
+ # rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
+
+----------
+
+ # yum update
+
+#### Ubuntu ####
+
+ # apt-get install python-software-properties
+ # add-apt-repository ppa:ondrej/php5
+
+----------
+
+ # apt-get update
+
+----------
+
+ # apt-get install -y php5 mcrypt php5-mcrypt php5-gd
+
+### 2) Firewall Setup ###
+
+System Firewall and SELinux setup is an important part regarding the security of your applications in production. You can make firewall off if you are working on test server and keep SELinux to permissive mode using the below command, so that you installing setup won't be affected by it.
+
+ # setenforce 0
+
+### 3) Apache, MariaDB, PHP Setup ###
+
+Laravel installation requires a complete LAMP stack with OpenSSL, PDO, Mbstring and Tokenizer PHP Extensions. If you are already running LAMP server then you can skip this step to move on and just make sure that the required PHP extensions are installed.
+
+To install AMP stack you can use the below commands on your respective server.
+
+#### CentOS ####
+
+ # yum install httpd mariadb-server php56w php56w-mysql php56w-mcrypt php56w-dom php56w-mbstring
+
+To start and enable Apache web and MySQL/Mariadb services at bootup on CentOS 7 , we will use below commands.
+
+ # systemctl start httpd
+ # systemctl enable httpd
+
+----------
+
+ #systemctl start mysqld
+ #systemctl enable mysqld
+
+After starting MariaDB service, we will configure its secured password with below command.
+
+ #mysql_secure_installation
+
+#### Ubuntu ####
+
+ # apt-get install mysql-server apache2 libapache2-mod-php5 php5-mysql
+
+### 4) Install Composer ###
+
+Now we are going to install composer that is one of the most important requirement before starting the Laravel installation that helps in installing Laravel's dependencies.
+
+#### CentOS/Ubuntu ####
+
+Run the below commands to setup 'composer' in CentOS/Ubuntu.
+
+ # curl -sS https://getcomposer.org/installer | php
+ # mv composer.phar /usr/local/bin/composer
+ # chmod +x /usr/local/bin/composer
+
+
+
+### 5) Installing Laravel ###
+
+Laravel's installation package can be downloaded from github using the command below.
+
+# wget https://github.com/laravel/laravel/archive/develop.zip
+
+To extract the archived package and move into the document root directory use below commands.
+
+ # unzip develop.zip
+
+----------
+
+ # mv laravel-develop /var/www/
+
+Now use the following compose command that will install all required dependencies for Laravel within its directory.
+
+ # cd /var/www/laravel-develop/
+ # composer install
+
+
+
+### 6) Key Encryption ###
+
+For encrypter service, we will be generating a 32 digit encryption key using the command below.
+
+ # php artisan key:generate
+
+ Application key [Lf54qK56s3qDh0ywgf9JdRxO2N0oV9qI] set successfully
+
+Now put this key into the 'app.php' file as shown below.
+
+ # vim /var/www/laravel-develop/config/app.php
+
+
+
+### 7) Virtua Host and Ownership ###
+
+After composer installation assign the permissions and apache user ownership to the document root directory as shown.
+
+ # chmod 775 /var/www/laravel-develop/app/storage
+
+----------
+
+ # chown -R apache:apache /var/www/laravel-develop
+
+Open the default configuration file of apache web server using any editor to add the following lines at the end file for new virtual host entry.
+
+ # vim /etc/httpd/conf/httpd.conf
+
+----------
+
+ ServerName laravel-develop
+ DocumentRoot /var/www/laravel/public
+
+ start Directory /var/www/laravel
+ AllowOverride All
+ Directory close
+
+Now the time is to restart apache web server services as shown below and then open your web browser to check your localhost page.
+
+#### CentOS ####
+
+ # systemctl restart httpd
+
+#### Ubuntu ####
+
+ # service apache2 restart
+
+### 8) Laravel 5 Web Access ###
+
+Open your web browser and give your server IP or Fully Qualified Domain name and you will see the default web page of Laravel 5 frame work.
+
+
+
+### Conclusion ###
+
+Laravel Framework is a great tool to develop your web applications. So, at the end of this article you have learned its installation setup on Ubuntu 15 and CentOS 7 , Now start using this awesome PHP framework that provides you a lot of more features and comfort in your development work. Feel free to comment us back for your valuable suggestions an feedback to guide you in more specific and easiest way.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/install-laravel-php-centos-7-ubuntu-15-04/
+
+作者:[Kashif][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/kashifs/
diff --git a/sources/tech/20151204 Install and Configure Munin monitoring server in Linux.md b/sources/tech/20151204 Install and Configure Munin monitoring server in Linux.md
new file mode 100644
index 0000000000..314d721e38
--- /dev/null
+++ b/sources/tech/20151204 Install and Configure Munin monitoring server in Linux.md
@@ -0,0 +1,145 @@
+Install and Configure Munin monitoring server in Linux
+================================================================================
+
+
+Munin is an excellent system monitoring tool similar to [RRD tool][1] which will give you ample information about system performance in multiple fronts like **disk, network, process, system and users**. These are some of the default properties Munin monitors.
+
+### How Munin works? ###
+
+Munin works in a client-server model. Munin server process on main server try to collect data from client daemon which is running locally(Munin can monitor it’ss own resources) or from remote client(Munin can monitor hundreds of machines) and displays them in graphs on its web interface.
+
+### Configuring Munin in nutshell ###
+
+This is of two steps as we have to configure both server and client.
+1)Install Munin server package and configure it so that it get data from clients.
+2)Configure Munin client so that server will connect to client daemon for data collocation.
+
+### Install munin server in Linux ###
+
+Munin server installation on Ubuntu/Debian based machines
+
+ apt-get install munin apache2
+
+Munin server installation on Redhat/Centos based machines. Make sure that you [enable EPEL repo][2] before installing Munin on Redhat based machines as by default Redhat based machines do not have Munin in their repos.
+
+ yum install munin httpd
+
+### Configuring Munin server in Linux ###
+
+Below are the steps we have to do in order to bring server up.
+
+1. Add host details which need monitoring in /etc/munin/munin.conf
+1. Configure apache web server to include munin details.
+1. Create User name and password for web interface
+1. Restart apache server
+
+**Step 1**: Add hosts entry in this file in **/etc/munin/munin.conf**. Go to end of the file and a client to monitor. Here in this example, I added my DB server and its IP address to monitor
+
+Example:
+
+ [db.linuxnix.com]
+ address 192.168.1.25
+ use_node_name yes
+
+Save the file and exit.
+
+**Step 2**: Edit/create munin.conf file in /etc/apache2/conf.d folder to include Munin Apache related configs. In another note, by default other Munin web related configs are kept in /var/www/munin folder.
+
+ vi /etc/apache2/conf.d/munin.conf
+
+Content:
+
+ Alias /munin /var/www/munin
+
+ Order allow,deny
+ Allow from localhost 127.0.0.0/8 ::1
+ AllowOverride None
+ Options ExecCGI FollowSymlinks
+ AddHandler cgi-script .cgi
+ DirectoryIndex index.cgi
+ AuthUserFile /etc/munin/munin.passwd
+ AuthType basic
+ AuthName "Munin stats"
+ require valid-user
+
+ ExpiresActive On
+ ExpiresDefault M310
+
+
+
+Save the file and exit
+
+**Step 3**: Now create a username and password for viewing muning graphs:
+
+ htpasswd -c /etc/munin/munin-htpasswd munin
+
+**Note**: For Redhat/Centos machines replace “**apache2**” with “**httpd**” in each path to access your config files.
+
+**Step 3**: Restart Apache server so that Munin configurations are picked-up by Apache.
+
+#### Ubuntu/Debian based: ####
+
+ service apache2 restart
+
+#### Centos/Redhat based: ####
+
+ service httpd restart
+
+### Install and configure Munin client in Linux ###
+
+**Step 1**: Install Munin client in Linux
+
+ apt-get install munin-node
+
+**Note**: If you want to monitor your Munin server, then you have to install munin-node on that as well.
+
+**Step 2**: Configure client by editing munin-node.conf file.
+
+ vi /etc/munin/munin-node.conf
+
+Example:
+
+ allow ^127\.0\.0\.1$
+ allow ^10\.10\.20\.20$
+
+----------
+
+ # Which address to bind to;
+ host *
+
+----------
+
+ # And which port
+ port 4949
+
+**Note**: 10.10.20.20 is my Munin server and it connections to 4949 port on client to get its data.
+
+**Step 3**: Restart munin-node on client server
+
+ service munin-node restart
+
+### Testing connection ###
+
+check if you are able to connect client from server on 4949 port, other wise you have to open that port on client machine.
+
+ telnet db.linuxnix.com 4949
+
+Accessing Munin web interface
+
+ http://munin.linuxnix.com/munin/index.html
+
+Hope this helps to configure basic Munin server.
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxnix.com/install-and-configure-munin-monitoring-server-in-linux/
+
+作者:[Surendra Anne][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxnix.com/author/surendra/
+[1]:http://www.linuxnix.com/network-monitoringinfo-gathering-tools-in-linux/
+[2]:http://www.linuxnix.com/how-to-install-and-enable-epel-repo-in-rhel-centos-oracle-scentific-linux/
diff --git a/sources/tech/20151206 NetworkManager and privacy in the IPv6 internet.md b/sources/tech/20151206 NetworkManager and privacy in the IPv6 internet.md
new file mode 100644
index 0000000000..b485db2927
--- /dev/null
+++ b/sources/tech/20151206 NetworkManager and privacy in the IPv6 internet.md
@@ -0,0 +1,54 @@
+NetworkManager and privacy in the IPv6 internet
+======================
+
+IPv6 is gaining momentum. With growing use of the protocol concerns about privacy that were not initially anticipated arise. The Internet community actively publishes solutions to them. What’s the current state and how does NetworkManager catch up? Let’s figure out!
+
+
+
+## The identity of a IPv6-connected host
+
+The IPv6 enabled nodes don’t need a central authority similar to IPv4 [DHCP](https://tools.ietf.org/html/rfc2132) servers to configure their addresses. They discover the networks they are in and [complete the addresses themselves](https://tools.ietf.org/html/rfc4862) by generating the host part. This makes the network configuration simpler and scales better to larger networks. However, there’s some drawbacks to this approach. Firstly, the node needs to ensure that its address doesn’t collide with an address of any other node on the network. Secondly, if the node uses the same host part of the address in every network it enters then its movement can be tracked and the privacy is at risk.
+
+Internet Engineering Task Force (IETF), the organization behind the Internet standards, [acknowledged this problem](https://tools.ietf.org/html/draft-iesg-serno-privacy-00) and recommends against use of hardware serial numbers to identify the node in the network.
+
+But what does the actual implementation look like?
+
+The problem of address uniqueness is addressed with [Duplicate Address Detection](https://tools.ietf.org/html/rfc4862#section-5.4) (DAD) mechanism. When a node creates an address for itself it first checks whether another node uses the same address using the [Neighbor Discovery Protocol](https://tools.ietf.org/html/rfc4861) (a mechanism not unlike IPv4 [ARP](https://tools.ietf.org/html/rfc826) protocol). When it discovers the address is already used, it must discard it.
+
+The other problem (privacy) is a bit harder to solve. An IP address (be it IPv4 or IPv6) address consists of a network part and the host part. The host discovers the relevant network parts and is supposed generate the host part. Traditionally it just uses an Interface Identifier derived from the network hardware’s (MAC) address. The MAC address is set at manufacturing time and can uniquely identify the machine. This guarantees the address is stable and unique. That’s a good thing for address collision avoidance but a bad thing for privacy. The host part remaining constant in different network means that the machine can be uniquely identified as it enters different networks. This seemed like non-issue at the time the protocol was designed, but the privacy concerns arose as the IPv6 gained popularity. Fortunately, there’s a solution to this problem.
+
+## Enter privacy extensions
+
+It’s no secret that the biggest problem with IPv4 is that the addresses are scarce. This is no longer true with IPv6 and in fact an IPv6-enabled host can use addresses quite liberally. There’s absolutely nothing wrong with having multiple IPv6 addresses attached to the same interface. On the contrary, it’s a pretty standard situation. At the very minimum each node has an address that is used for contacting nodes on the same hardware link called a link-local address. When the network contains a router that connects it to other networks in the internet, a node has an address for every network it’s directly connected to. If a host has more addresses in the same network the node accepts incoming traffic for all of them. For the outgoing connections which, of course, reveal the address to the remote host, the kernel picks the fittest one. But which one is it?
+
+With privacy extensions enabled, as defined by [RFC4941](https://tools.ietf.org/html/rfc4941), a new address with a random host part is generated every now and then. The newest one is used for new outgoing connections while the older ones are deprecated when they’re unused. This is a nifty trick — the host does not reveal the stable address as it’s not used for outgoing connections, but still accepts connections to it from the hosts that are aware of it.
+
+There’s a downside to this. Certain applications tie the address to the user identity. Consider a web application that issues a HTTP Cookie for the user during the authentication but only accepts it for the connections that come from the address that conducted the authentications. As the kernel generates a new temporary address, the server would reject the requests that use it, effectively logging the user out. It could be argued that the address is not an appropriate mechanism for establishing user’s identity but that’s what some real-world applications do.
+
+## Privacy stable addressing to the rescue
+
+Another approach would be needed to cope with this. There’s a need for an address that is unique (of course), stable for a particular network but still changes when user enters another network so that tracking is not possible. The RFC7217 introduces a mechanism that provides exactly this.
+
+Creation of a privacy stable address relies on a pseudo-random key that’s only known the host itself and never revealed to other hosts in the network. This key is then hashed using a cryptographically secure algorithm along with values specific for a particular network connection. It includes an identifier of the network interface, the network prefix and possibly other values specific to the network such as the wireless SSID. The use of the secret key makes it impossible to predict the resulting address for the other hosts while the network-specific data causes it to be different when entering a different network.
+
+This also solves the duplicate address problem nicely. The random key makes collisions unlikely. If, in spite of this, a collision occurs then the hash can be salted with a DAD failure counter and a different address can be generated instead of failing the network connectivity. Now that’s clever.
+
+Using privacy stable address doesn’t interfere with the privacy extensions at all. You can use the [RFC7217](https://tools.ietf.org/html/rfc7217) stable address while still employing the RFC4941 temporary addresses at the same time.
+
+## Where does NetworkManager stand?
+
+We’ve already enabled the privacy extensions with the release NetworkManager 1.0.4. They’re turned on by default; you can control them with ipv6.ip6-privacy property.
+
+With the release of NetworkManager 1.2, we’re adding the stable privacy addressing. It’s supposed to address the situations where the privacy extensions don’t make the cut. The use of the feature is controlled with the ipv6.addr-gen-mode property. If it’s set to stable-privacy then stable privacy addressing is used. Setting it to “eui64” or not setting it at all preserves the traditional default behavior.
+
+Stay tuned for NetworkManager 1.2 release in early 2016! If you want to try the bleeding-edge snapshot, give Fedora Rawhide a try. It will eventually become Fedora 24.
+
+*I’d like to thank Hannes Frederic Sowa for a valuable feedback. The article would make less sense without his corrections. Hannes also created the in-kernel implementation of the RFC7217 mechanism which can be used when the networking is not managed by NetworkManager.*
+
+--------------------------------------------------------------------------------
+
+via: https://blogs.gnome.org/lkundrak/2015/12/03/networkmanager-and-privacy-in-the-ipv6-internet/
+作者:[Lubomir Rintel]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/sources/tech/20151206 Supporting secure DNS in glibc.md b/sources/tech/20151206 Supporting secure DNS in glibc.md
new file mode 100644
index 0000000000..8933c3c891
--- /dev/null
+++ b/sources/tech/20151206 Supporting secure DNS in glibc.md
@@ -0,0 +1,46 @@
+Supporting secure DNS in glibc
+========================
+
+Credit: Jonathan Corbet
+
+One of the many weak links in Internet security is the domain name system (DNS); it is subject to attacks that, among other things, can mislead applications regarding the IP address of a system they wish to connect to. That, in turn, can cause connections to go to the wrong place, facilitating man-in-the-middle attacks and more. The DNSSEC protocol extensions are meant to address this threat by setting up a cryptographically secure chain of trust for DNS information. When DNSSEC is set up properly, applications should be able to trust the results of domain lookups. As the discussion over an attempt to better integrate DNSSEC into the GNU C Library shows, though, ensuring that DNS lookups are safe is still not a straightforward problem.
+
+In a sense, the problem was solved years ago; one can configure a local nameserver to perform full DNSSEC verification and use that server via glibc calls in applications. DNSSEC can even be used to increase security in other areas; it can, for example, carry SSH or TLS key fingerprints, allowing applications to verify that they are talking to the right server. Things get tricky, though, when one wants to be sure that DNS results claiming to have DNSSEC verification are actually what they claim to be — when one wants the security that DNSSEC is meant to provide, in other words.
+
+The /etc/resolv.conf problem
+
+Part of the problem, from the glibc perspective, is that glibc itself does not do DNSSEC verification. Instead, it consults /etc/resolv.conf and asks the servers found therein to do the lookup and verification; the results are then returned to the application. If the application is using the low-level res_query() interface, those results may include the "authenticated data" (AD) flag (if the nameserver has set it) indicating that DNSSEC verification has been successfully performed. But glibc knows nothing about the trustworthiness of the nameserver that has provided those results, so it cannot tell the application anything about whether they should really be trusted.
+
+One of the first steps suggested by glibc maintainer Carlos O'Donell is to add an option (dns-strip-dnssec-ad-bit) to the resolv.conf file telling glibc to unconditionally remove the AD bit. This option could be set by distributions to indicate that the DNS lookup results cannot be trusted at a DNSSEC level. Once things have been set up so that the results can be trusted, that option can be removed. In the meantime, though, applications would have a way to judge the DNS lookup results they get from glibc, something that does not exist now.
+
+What would a trustworthy setup look like? The standard picture looks something like this: there is a local nameserver, accessed via the loopback interface, as the only entry in /etc/resolv.conf. That nameserver would be configured to do verification and, in the case that verification fails, simply return no results at all. There would, in almost all cases, be no need to worry about whether applications see the AD bit or not; if the results are not trustworthy, applications will simply not see them at all. A number of distributions are moving toward this model, but the situation is still not as simple as some might think.
+
+One problem is that this scheme makes /etc/resolv.conf into a central point of trust for the system. But, in a typical Linux system, there are no end of DHCP clients, networking scripts, and more that will make changes to that file. As Paul Wouters pointed out, locking down this file in the short term is not really an option. Sometimes those changes are necessary: when a diskless system is booting, it may need name-resolution service before it is at a point where it can start up its own nameserver. A system's entire DNS environment may change depending on which network it is attached to. Systems in containers may be best configured to talk to a nameserver on the host. And so on.
+
+So there seems to be a general belief that /etc/resolv.conf cannot really be trusted on current systems. Ideas to add secondary configuration files (/etc/secure-resolv.conf or whatever) have been floated, but they don't much change the basic nature of the situation. Beyond that, some participants felt that even a local nameserver running on the loopback interface is not really trustworthy; Zack Weinberg suggested that administrators might intentionally short out DNSSEC validation, for example.
+
+Since the configuration cannot be trusted on current systems, the reasoning goes, glibc needs to have a way to indicate to applications when the situation has improved and things can be trusted. That could include the AD-stripping option described above (or, conversely, an explicit "this nameserver is trusted" option); that, of course, would require that the system be locked down to a level where surprising changes to /etc/resolv.conf no longer happen. A variant, as suggested by Petr Spacek, is to have a way for an application to ask glibc whether it is talking to a local nameserver or not.
+
+Do it in glibc?
+
+An alternative would be to dispense with the nameserver and have glibc do DNSSEC validation itself. There is, however, resistance to putting a big pile of cryptographic code into glibc itself. That would increase the size of the library and, it is felt, increase the attack surface of any application using it. A variant of this idea, suggested by Zack, would be to put the validation code into the name-service caching daemon (nscd) instead. Since nscd is part of glibc, it is under the control of the glibc developers and there could be a certain amount of confidence that DNSSEC validation is being performed properly. The location of the nscd socket is well known, so the /etc/resolv.confissues don't come into play. Carlos worried, though, that this approach might deter adoption by users who do not want the caching features of nscd; in his mind, that seems to rule out the nscd option.
+
+So, in the short term, at least, it seems unlikely that glibc will take on the full task of performing validated DNSSEC lookups. That means that, if security-conscious applications are going to use glibc for their name lookups, the library will have to provide an indication of how trustworthy the results received from a separate nameserver are. And that will almost certainly require explicit action on the part of the distributor and/or system administrator. As Simo Sorce put it:
+
+A situation in which glibc does not use an explicit configuration option to signal applications that it is using a trusted resolver is not useful ... no scratch that, it is actively harmful, because applications developers will quickly realize they cannot trust any information coming from glibc and will simply not use it for DNSSEC related information.
+
+Configuring a system to properly use DNSSEC involves change to many of the components of that system — it is a distribution-wide problem that will take time to solve fully. The role that glibc plays in this transition is likely to be relatively small, but it is an important one: glibc is probably the only place where applications can receive some assurance that their DNS results are trustworthy without implementing their own resolver code. Running multiple DNSSEC implementations on a system seems like an unlikely path to greater security, so it would be good to get this right.
+
+The glibc project has not yet chosen a path by which it intends to get things right, though some sort of annotation in /etc/resolv.conf looks like a likely outcome. Any such change would then have to get into a release; given the conservative nature of glibc development, it may already be late for the 2.23 release, which is likely to happen in February. So higher DNSSEC awareness in glibc may not happen right away, but there is at least some movement in that direction.
+
+---------------------------
+
+via: https://lwn.net/Articles/663474/
+
+作者:Jonathan Corbet
+
+译者:[译者ID](https://github.com/译者ID)
+
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/tech/20151208 How to Customize Time and Date Format in Ubuntu Panel.md b/sources/tech/20151208 How to Customize Time and Date Format in Ubuntu Panel.md
new file mode 100644
index 0000000000..a9e72c626b
--- /dev/null
+++ b/sources/tech/20151208 How to Customize Time and Date Format in Ubuntu Panel.md
@@ -0,0 +1,65 @@
+How to Customize Time & Date Format in Ubuntu Panel
+================================================================================
+
+
+This quick tutorial is going to show you how to customize your Time & Date indicator in Ubuntu panel, though there are already a few options available in the settings page.
+
+
+
+To get started, search for and install **dconf Editor** in Ubuntu Software Center. Then launch the software and follow below steps:
+
+**1.** When dconf Editor launches, navigate to **com -> canonical -> indicator -> datetime**. Set the value of **time-format** to **custom**.
+
+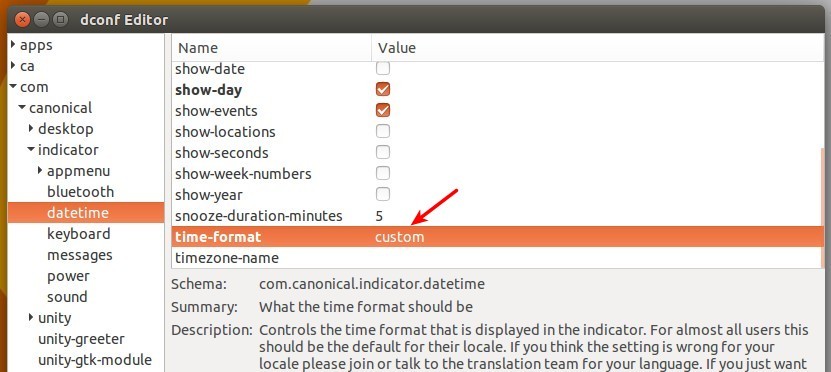
+
+You can also do this via a command in terminal:
+
+ gsettings set com.canonical.indicator.datetime time-format 'custom'
+
+**2.** Now you can customize the Time & Date format by editing the value of **custom-time-format**.
+
+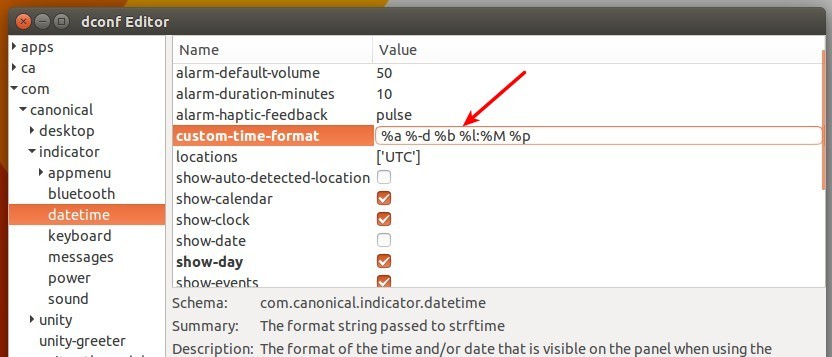
+
+You can also do this via command:
+
+ gsettings set com.canonical.indicator.datetime custom-time-format 'FORMAT_VALUE_HERE'
+
+Interpreted sequences are:
+
+- %a = abbreviated weekday name
+- %A = full weekday name
+- %b = abbreviated month name
+- %B = full month name
+- %d = day of month
+- %l = hour ( 1..12), %I = hour (01..12)
+- %k = hour ( 1..23), %H = hour (01..23)
+- %M = minute (00..59)
+- %p = AM or PM, %P = am or pm.
+- %S = second (00..59)
+- open terminal and run command `man date` to get more details.
+
+Some examples:
+
+custom time format value: **%a %H:%M %m/%d/%Y**
+
+
+
+**%a %r %b %d or %a %I:%M:%S %p %b %d**
+
+
+
+**%a %-d %b %l:%M %P %z**
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://ubuntuhandbook.org/index.php/2015/12/time-date-format-ubuntu-panel/
+
+作者:[Ji m][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ubuntuhandbook.org/index.php/about/
\ No newline at end of file
diff --git a/sources/tech/20151208 How to Install Bugzilla with Apache and SSL on FreeBSD 10.2.md b/sources/tech/20151208 How to Install Bugzilla with Apache and SSL on FreeBSD 10.2.md
new file mode 100644
index 0000000000..2b543d3444
--- /dev/null
+++ b/sources/tech/20151208 How to Install Bugzilla with Apache and SSL on FreeBSD 10.2.md
@@ -0,0 +1,268 @@
+Translating by ZTinoZ
+How to Install Bugzilla with Apache and SSL on FreeBSD 10.2
+================================================================================
+Bugzilla is open source web base application for bug tracker and testing tool, develop by mozilla project, and licensed under Mozilla Public License. It is used by high tech company like mozilla, redhat and gnome. Bugzilla was originally created by Terry Weissman in 1998. It written in perl, use MySQL as the database back-end. It is a server software designed to help you manage software development. Bugzilla has a lot of features, optimized database, excellent security, advanced search tool, integrated with email capabilities etc.
+
+In this tutorial we will install bugzilla 5.0 with apache for the web server, and enable SSL for it. Then install mysql51 as the database system on freebsd 10.2.
+
+#### Prerequisite ####
+
+ FreeBSD 10.2 - 64bit.
+ Root privileges.
+
+### Step 1 - Update System ###
+
+Log in to the freebsd server with ssl login, and update the repository database :
+
+ sudo su
+ freebsd-update fetch
+ freebsd-update install
+
+### Step 2 - Install and Configure Apache ###
+
+In this step we will install apache from the freebsd repositories with pkg command. Then configure apache by editing file "httpd.conf" on apache24 directory, configure apache to use SSL, and CGI support.
+
+Install apache with pkg command :
+
+ pkg install apache24
+
+Go to the apache directory and edit the file "httpd.conf" with nanao editor :
+
+ cd /usr/local/etc/apache24
+ nano -c httpd.conf
+
+Uncomment the list line below :
+
+ #Line 70
+ LoadModule authn_socache_module libexec/apache24/mod_authn_socache.so
+
+ #Line 89
+ LoadModule socache_shmcb_module libexec/apache24/mod_socache_shmcb.so
+
+ # Line 117
+ LoadModule expires_module libexec/apache24/mod_expires.so
+
+ #Line 141 to enabling SSL
+ LoadModule ssl_module libexec/apache24/mod_ssl.so
+
+ # Line 162 for cgi support
+ LoadModule cgi_module libexec/apache24/mod_cgi.so
+
+ # Line 174 to enable mod_rewrite
+ LoadModule rewrite_module libexec/apache24/mod_rewrite.so
+
+ # Line 219 for the servername configuration
+ ServerName 127.0.0.1:80
+
+Save and exit.
+
+Next, we need to install mod perl from freebsd repository, and then enable it :
+
+ pkg install ap24-mod_perl2
+
+To enable mod_perl, edit httpd.conf and add to the "Loadmodule" line below :
+
+ nano -c httpd.conf
+
+Add line below :
+
+ # Line 175
+ LoadModule perl_module libexec/apache24/mod_perl.so
+
+Save and exit.
+
+And before start apache, add it to start at boot time with sysrc command :
+
+ sysrc apache24_enable=yes
+ service apache24 start
+
+### Step 3 - Install and Configure MySQL Database ###
+
+We will use mysql51 for the database back-end, and it is support for perl module for mysql. Install mysql51 with pkg command below :
+
+ pkg install p5-DBD-mysql51 mysql51-server mysql51-client
+
+Now we must add mysql to the boot time, and then start and configure the root password for mysql.
+
+Run command below to do it all :
+
+ sysrc mysql_enable=yes
+ service mysql-server start
+ mysqladmin -u root password aqwe123
+
+Note :
+
+mysql password : aqwe123
+
+
+
+Next, we will log in to the mysql shell with user root and password that we've configured above, then we will create new database and user for bugzilla installation.
+
+Log in to the mysql shell with command below :
+
+ mysql -u root -p
+ password: aqwe123
+
+Add the database :
+
+ create database bugzilladb;
+ create user bugzillauser@localhost identified by 'bugzillauser@';
+ grant all privileges on bugzilladb.* to bugzillauser@localhost identified by 'bugzillauser@';
+ flush privileges;
+ \q
+
+
+
+Database for bugzilla is created, database "bugzilladb" with user "bugzillauser" and password "bugzillauser@".
+
+### Step 4 - Generate New SSL Certificate ###
+
+Generate new self signed ssl certificate on directory "ssl" for bugzilla site.
+
+Go to the apache24 directory and create new directory "ssl" on it :
+
+ cd /usr/local/etc/apache24/
+ mkdir ssl; cd ssl
+
+Next, generate the certificate file with openssl command, then change the permission of the certificate file :
+
+ sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /usr/local/etc/apache24/ssl/bugzilla.key -out /usr/local/etc/apache24/ssl/bugzilla.crt
+ chmod 600 *
+
+### Step 5 - Configure Virtualhost ###
+
+We will install bugzilla on directory "/usr/local/www/bugzilla", so we must create new virtualhost configuration for it.
+
+Go to the apache directory and create new directory called "vhost" for virtualhost file :
+
+ cd /usr/local/etc/apache24/
+ mkdir vhost; cd vhost
+
+Now create new file "bugzilla.conf" for the virtualhost file :
+
+ nano -c bugzilla.conf
+
+Paste configuration below :
+
+
+ ServerName mybugzilla.me
+ ServerAlias www.mybuzilla.me
+ DocumentRoot /usr/local/www/bugzilla
+ Redirect permanent / https://mybugzilla.me/
+
+
+ Listen 443
+
+ ServerName mybugzilla.me
+ DocumentRoot /usr/local/www/bugzilla
+
+ ErrorLog "/var/log/mybugzilla.me-error_log"
+ CustomLog "/var/log/mybugzilla.me-access_log" common
+
+ SSLEngine On
+ SSLCertificateFile /usr/local/etc/apache24/ssl/bugzilla.crt
+ SSLCertificateKeyFile /usr/local/etc/apache24/ssl/bugzilla.key
+
+
+ AddHandler cgi-script .cgi
+ Options +ExecCGI
+ DirectoryIndex index.cgi index.html
+ AllowOverride Limit FileInfo Indexes Options
+ Require all granted
+
+
+
+Save and exit.
+
+If all is done, create new directory for bugzilla installation and then enable the bugzilla virtualhost by adding the virtualhost configuration to httpd.conf file.
+
+Run command below on "apache24" directory :
+
+ mkdir -p /usr/local/www/bugzilla
+ cd /usr/local/etc/apache24/
+ nano -c httpd.conf
+
+In the end of the line, add configuration below :
+
+ Include etc/apache24/vhost/*.conf
+
+Save and exit.
+
+Now test the apache configuration with "apachectl" command and restart it :
+
+ apachectl configtest
+ service apache24 restart
+
+### Step 6 - Install Bugzilla ###
+
+We can install bugzilla manually by downloading the source, or install it from freebsd repository. In this step we will install bugzilla from freebsd repository with pkg command :
+
+ pkg install bugzilla50
+
+If it's done, go to the bugzilla installation directory and install all perl module that needed by bugzilla.
+
+ cd /usr/local/www/bugzilla
+ ./install-module --all
+
+Wait it until all is finished, it is take the time.
+
+Next, generate the configuration file "localconfig" by executing "checksetup.pl" file on bugzilla installation directory.
+
+ ./checksetup.pl
+
+You will see the error message about the database configuration, so edit the file "localconfig" with nano editor :
+
+ nano -c localconfig
+
+Now add the database that was created on step 3.
+
+ #Line 57
+ $db_name = 'bugzilladb';
+
+ #Line 60
+ $db_user = 'bugzillauser';
+
+ #Line 67
+ $db_pass = 'bugzillauser@';
+
+Save and exit.
+
+Then run "checksetup.pl" again :
+
+ ./checksetup.pl
+
+You will be prompt about mail and administrator account, fill all of it with your email, user and password.
+
+
+
+In the last, we need to change the owner of the installation directory to user "www", then restart apache with service command :
+
+ cd /usr/local/www/
+ chown -R www:www bugzilla
+ service apache24 restart
+
+Now Bugzilla is installed, you can see it by visiting mybugzilla.me and you will be redirect to the https connection.
+
+Bugzilla home page.
+
+
+
+Bugzilla admin panel.
+
+
+
+### Conclusion ###
+
+Bugzilla is web based application help you to manage the software development. It is written in perl and use MySQL as the database system. Bugzilla used by mozilla, redhat, gnome etc for help their software development. Bugzilla has a lot of features and easy to configure and install.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/tools/install-bugzilla-apache-ssl-freebsd-10-2/
+
+作者:[Arul][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arulm/
diff --git a/sources/tech/20151215 How to Install Light Table 0.8 in Ubuntu 14.04, 15.10.md b/sources/tech/20151215 How to Install Light Table 0.8 in Ubuntu 14.04, 15.10.md
new file mode 100644
index 0000000000..5424c7cd68
--- /dev/null
+++ b/sources/tech/20151215 How to Install Light Table 0.8 in Ubuntu 14.04, 15.10.md
@@ -0,0 +1,104 @@
+How to Install Light Table 0.8 in Ubuntu 14.04, 15.10
+================================================================================
+
+
+The Light Table IDE has just reached a new stable release after more than one year of development. Now it provides 64-bit only binary for Linux.
+
+Changes in LightTable 0.8.0:
+
+- CHANGED: We have switched to Electron from NW.js
+- CHANGED: LT’s releases and self-updating processes are completely in the open on Github
+- ADDED: LT can be built from source with provided scripts across supported platforms
+- ADDED: Most of LT’s node libraries are installed as npm dependencies instead of as forked libraries
+- ADDED: Significant documentation. See more below
+- FIX: Major usability issues on >= OSX 10.10
+- CHANGED: 32-bit linux is no longer an official download. Building from source will still be supported
+- FIX: ClojureScript eval for modern versions of ClojureScript
+- More details at [github.com/LightTable/LightTable/releases][1]
+
+
+
+### How to Install Light Table 0.8.0 in Ubuntu: ###
+
+Below steps show you how to install the official binary in Ubuntu. Works on all current Ubuntu releases (**64-bit only**).
+
+Before getting started, please make a backup if you have a previous release installed.
+
+**1.** Download the Linux binary from link below:
+
+- [lighttable-0.8.0-linux.tar.gz][2]
+
+**2.** Open terminal from Unity Dash, App Launcher, or via Ctrl+Alt+T keys. When it opens, paste below command and hit enter:
+
+ gksudo file-roller ~/Downloads/lighttable-0.8.0-linux.tar.gz
+
+
+
+Install `gksu` from Ubuntu Software Center if the command does not work.
+
+**3.** Previous command opens the downloaded archive via Archive Manager using root user privilege.
+
+When it opens, do:
+
+- right-click and rename the folder name to **LightTable**
+- extract it to **Computer -> /opt/** directory.
+
+
+
+Finally you should have the LightTable installed to /opt/ directory:
+
+
+
+**4.** Create a launcher so you can start LightTable from Unity Dash or App Launcher.
+
+Open terminal and run below command to create & edit a launcher file for LightTable:
+
+ gksudo gedit /usr/share/applications/lighttable.desktop
+
+When the file opens via Gedit text editor, paste below and save the file:
+
+ [Desktop Entry]
+ Version=1.0
+ Type=Application
+ Name=Light Table
+ GenericName=Text Editor
+ Comment=Open source IDE that modify, from running programs to embed websites and games
+ Exec=/opt/LightTable/LightTable %F
+ Terminal=false
+ MimeType=text/plain;
+ Icon=/opt/LightTable/resources/app/core/img/lticon.png
+ Categories=TextEditor;Development;Utility;
+ StartupNotify=true
+ Actions=Window;Document;
+
+ Name[en_US]=Light Table
+
+ [Desktop Action Window]
+ Name=New Window
+ Exec=/opt/LightTable/LightTable -n
+ OnlyShowIn=Unity;
+
+ [Desktop Action Document]
+ Name=New File
+ Exec=/opt/LightTable/LightTable --command new_file
+ OnlyShowIn=Unity;
+
+So it looks like:
+
+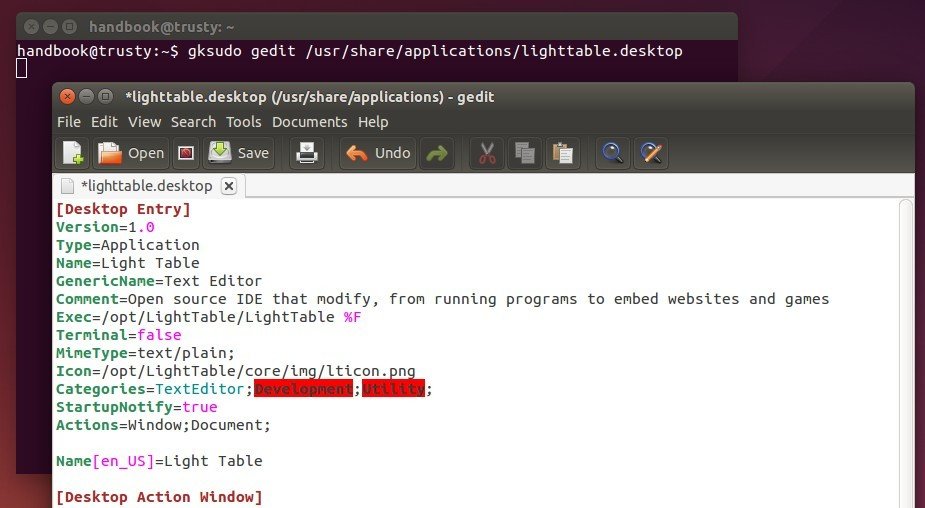
+
+Finally launch the IDE from Unity Dash or Application Launcher and enjoy!
+
+--------------------------------------------------------------------------------
+
+via: http://ubuntuhandbook.org/index.php/2015/12/install-light-table-0-8-ubuntu-14-04/
+
+作者:[Ji m][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ubuntuhandbook.org/index.php/about/
+[1]:https://github.com/LightTable/LightTable/releases
+[2]:https://github.com/LightTable/LightTable/releases/download/0.8.0/lighttable-0.8.0-linux.tar.gz
\ No newline at end of file
diff --git a/sources/tech/20151215 How to block network traffic by country on Linux.md b/sources/tech/20151215 How to block network traffic by country on Linux.md
new file mode 100644
index 0000000000..1f2d39f04d
--- /dev/null
+++ b/sources/tech/20151215 How to block network traffic by country on Linux.md
@@ -0,0 +1,110 @@
+How to block network traffic by country on Linux
+================================================================================
+As a system admin who maintains production Linux servers, there are circumstances where you need to **selectively block or allow network traffic based on geographic locations**. For example, you are experiencing denial-of-service attacks mostly originating from IP addresses registered with a particular country. You want to block SSH logins from unknown foreign countries for security reasons. Your company has a distribution right to online videos, which requires it to legally stream to particular countries only. You need to prevent any local host from uploading documents to any non-US remote cloud storage due to geo-restriction company policies.
+
+All these scenarios require an ability to set up a firewall which does **country-based traffic filtering**. There are a couple of ways to do that. For one, you can use TCP wrappers to set up conditional blocking for individual applications (e.g., SSH, NFS, httpd). The downside is that the application you want to protect must be built with TCP wrappers support. Besides, TCP wrappers are not universally available across different platforms (e.g., Arch Linux [dropped][2] its support). An alternative approach is to set up [ipset][3] with country-based GeoIP information and apply it to iptables rules. The latter approach is more promising as the iptables-based filtering is application-agnostic and easy to set up.
+
+In this tutorial, I am going to present **another iptables-based GeoIP filtering which is implemented with xtables-addons**. For those unfamiliar with it, xtables-addons is a suite of extensions for netfilter/iptables. Included in xtables-addons is a module called xt_geoip which extends the netfilter/iptables to filter, NAT or mangle packets based on source/destination countries. For you to use xt_geoip, you don't need to recompile the kernel or iptables, but only need to build xtables-addons as modules, using the current kernel build environment (/lib/modules/`uname -r`/build). Reboot is not required either. As soon as you build and install xtables-addons, xt_geoip is immediately usable with iptables.
+
+As for the comparison between xt_geoip and ipset, the [official source][3] mentions that xt_geoip is superior to ipset in terms of memory foot print. But in terms of matching speed, hash-based ipset might have an edge.
+
+In the rest of the tutorial, I am going to show **how to use iptables/xt_geoip to block network traffic based on its source/destination countries**.
+
+### Install Xtables-addons on Linux ###
+
+Here is how you can compile and install xtables-addons on various Linux platforms.
+
+To build xtables-addons, you need to install a couple of dependent packages first.
+
+#### Install Dependencies on Debian, Ubuntu or Linux Mint ####
+
+ $ sudo apt-get install iptables-dev xtables-addons-common libtext-csv-xs-perl pkg-config
+
+#### Install Dependencies on CentOS, RHEL or Fedora ####
+
+CentOS/RHEL 6 requires EPEL repository being set up first (for perl-Text-CSV_XS).
+
+ $ sudo yum install gcc-c++ make automake kernel-devel-`uname -r` wget unzip iptables-devel perl-Text-CSV_XS
+
+#### Compile and Install Xtables-addons ####
+
+Download the latest `xtables-addons` source code from the [official site][4], and build/install it as follows.
+
+ $ wget http://downloads.sourceforge.net/project/xtables-addons/Xtables-addons/xtables-addons-2.10.tar.xz
+ $ tar xf xtables-addons-2.10.tar.xz
+ $ cd xtables-addons-2.10
+ $ ./configure
+ $ make
+ $ sudo make install
+
+Note that for Red Hat based systems (CentOS, RHEL, Fedora) which have SELinux enabled by default, it is necessary to adjust SELinux policy as follows. Otherwise, SELinux will prevent iptables from loading xt_geoip module.
+
+ $ sudo chcon -vR --user=system_u /lib/modules/$(uname -r)/extra/*.ko
+ $ sudo chcon -vR --type=lib_t /lib64/xtables/*.so
+
+### Install GeoIP Database for Xtables-addons ###
+
+The next step is to install GeoIP database which will be used by xt_geoip for IP-to-country mapping. Conveniently, the xtables-addons source package comes with two helper scripts for downloading GeoIP database from MaxMind and converting it into a binary form recognized by xt_geoip. These scripts are found in geoip folder inside the source package. Follow the instructions below to build and install GeoIP database on your system.
+
+ $ cd geoip
+ $ ./xt_geoip_dl
+ $ ./xt_geoip_build GeoIPCountryWhois.csv
+ $ sudo mkdir -p /usr/share/xt_geoip
+ $ sudo cp -r {BE,LE} /usr/share/xt_geoip
+
+According to [MaxMind][5], their GeoIP database is 99.8% accurate on a country-level, and the database is updated every month. To keep the locally installed GeoIP database up-to-date, you want to set up a monthly [cron job][6] to refresh the local GeoIP database as often.
+
+### Block Network Traffic Originating from or Destined to a Country ###
+
+Once xt_geoip module and GeoIP database are installed, you can immediately use the geoip match options in iptables command.
+
+ $ sudo iptables -m geoip --src-cc country[,country...] --dst-cc country[,country...]
+
+Countries you want to block are specified using [two-letter ISO3166 code][7] (e.g., US (United States), CN (China), IN (India), FR (France)).
+
+For example, if you want to block incoming traffic from Yemen (YE) and Zambia (ZM), the following iptables command will do.
+
+ $ sudo iptables -I INPUT -m geoip --src-cc YE,ZM -j DROP
+
+If you want to block outgoing traffic destined to China (CN), run the following command.
+
+ $ sudo iptables -A OUTPUT -m geoip --dst-cc CN -j DROP
+
+The matching condition can also be "negated" by prepending "!" to "--src-cc" or "--dst-cc". For example:
+
+If you want to block all incoming non-US traffic on your server, run this:
+
+ $ sudo iptables -I INPUT -m geoip ! --src-cc US -j DROP
+
+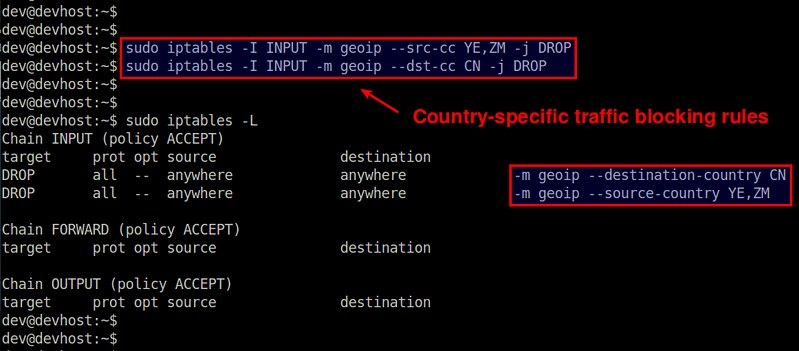
+
+#### For Firewall-cmd Users ####
+
+Some distros such as CentOS/RHEL 7 or Fedora have replaced iptables with firewalld as the default firewall service. On such systems, you can use firewall-cmd to block traffic using xt_geoip similarly. The above three examples can be rewritten with firewall-cmd as follows.
+
+ $ sudo firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -m geoip --src-cc YE,ZM -j DROP
+ $ sudo firewall-cmd --direct --add-rule ipv4 filter OUTPUT 0 -m geoip --dst-cc CN -j DROP
+ $ sudo firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -m geoip ! --src-cc US -j DROP
+
+### Conclusion ###
+
+In this tutorial, I presented iptables/xt_geoip which is an easy way to filter network packets based on their source/destination countries. This can be a useful arsenal to deploy in your firewall system if needed. As a final word of caution, I should mention that GeoIP-based traffic filtering is not a foolproof way to ban certain countries on your server. GeoIP database is by nature inaccurate/incomplete, and source/destination geography can easily be spoofed using VPN, Tor or any compromised relay hosts. Geography-based filtering can even block legitimate traffic that should not be banned. Understand this limitation before you decide to deploy it in your production environment.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/block-network-traffic-by-country-linux.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:https://www.archlinux.org/news/dropping-tcp_wrappers-support/
+[2]:http://xmodulo.com/block-unwanted-ip-addresses-linux.html
+[3]:http://xtables-addons.sourceforge.net/geoip.php
+[4]:http://xtables-addons.sourceforge.net/
+[5]:https://support.maxmind.com/geoip-faq/geoip2-and-geoip-legacy-databases/how-accurate-are-your-geoip2-and-geoip-legacy-databases/
+[6]:http://ask.xmodulo.com/add-cron-job-linux.html
+[7]:https://en.wikipedia.org/wiki/ISO_3166-1
\ No newline at end of file
diff --git a/sources/tech/20151215 How to enable Software Collections (SCL) on CentOS.md b/sources/tech/20151215 How to enable Software Collections (SCL) on CentOS.md
new file mode 100644
index 0000000000..1d5340a3aa
--- /dev/null
+++ b/sources/tech/20151215 How to enable Software Collections (SCL) on CentOS.md
@@ -0,0 +1,107 @@
+Translating by bianjp
+
+How to enable Software Collections (SCL) on CentOS
+================================================================================
+Red Hat Enterprise Linux (RHEL) and its community fork, CentOS, offer 10-year life cycle, meaning that each version of RHEL/CentOS is updated with security patches for up to 10 years. While such long life cycle guarantees much needed system compatibility and reliability for enterprise users, a downside is that core applications and run-time environments grow antiquated as the underlying RHEL/CentOS version becomes close to end-of-life (EOF). For example, CentOS 6.5, whose EOL is dated to November 30th 2020, comes with python 2.6.6 and MySQL 5.1.73, which are already pretty old by today's standard.
+
+On the other hand, attempting to manually upgrade development toolchains and run-time environments on RHEL/CentOS may potentially break your system unless all dependencies are resolved correctly. Under normal circumstances, manual upgrade is not recommended unless you know what you are doing.
+
+The [Software Collections][1] (SCL) repository came into being to help with RHEL/CentOS users in this situation. The SCL is created to provide RHEL/CentOS users with a means to easily and safely install and use multiple (and potentially more recent) versions of applications and run-time environments "without" messing up the existing system. This is in contrast to other third party repositories which could cause conflicts among installed packages.
+
+The latest SCL offers:
+
+- Python 3.3 and 2.7
+- PHP 5.4
+- Node.js 0.10
+- Ruby 1.9.3
+- Perl 5.16.3
+- MariaDB and MySQL 5.5
+- Apache httpd 2.4.6
+
+In the rest of the tutorial, let me show you how to set up the SCL repository and how to install and enable the packages from the SCL.
+
+### Set up the Software Collections (SCL) Repository ###
+
+The SCL is available on CentOS 6.5 and later. To set up the SCL, simply run:
+
+ $ sudo yum install centos-release-SCL
+
+To enable and run applications from the SCL, you also need to install the following package.
+
+ $ sudo yum install scl-utils-build
+
+You can browse a complete list of packages available from the SCL repository by running:
+
+ $ yum --disablerepo="*" --enablerepo="scl" list available
+
+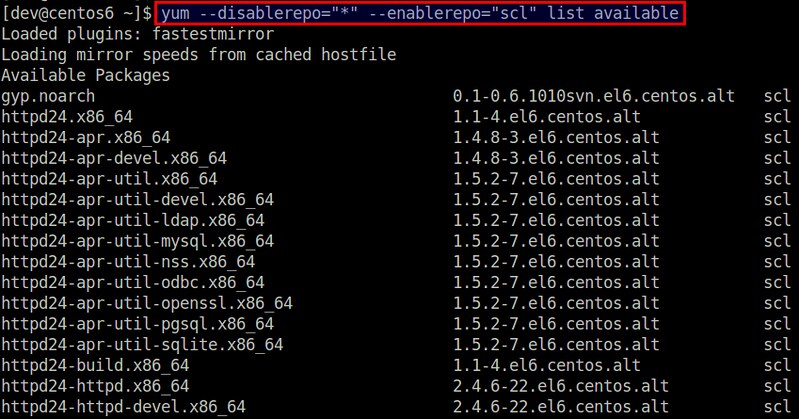
+
+### Install and Enable a Package from the SCL ###
+
+Now that you have set up the SCL, you can go ahead and install any package from the SCL.
+
+You can search for SCL packages with:
+
+ $ yum --disablerepo="*" --enablerepo="scl" search
+
+Let's say you want to install python 3.3.
+
+Go ahead and install it as usual with yum:
+
+ $ sudo yum install python33
+
+At any time you can check the list of packages you installed from the SCL by running:
+
+ $ scl --list
+
+----------
+
+ python33
+
+A nice thing about the SCL is that installing a package from the SCL does NOT overwrite any system files, and is guaranteed to not cause any conflicts with other system libraries and applications.
+
+For example, if you check the default python version after installing python33, you will see that the default version is still the same:
+
+ $ python --version
+
+----------
+
+ Python 2.6.6
+
+If you want to try an installed SCL package, you need to explicitly enable it "on a per-command basis" using scl:
+
+ $ scl enable
+
+For example, to enable python33 package for python command:
+
+ $ scl enable python33 'python --version'
+
+----------
+
+ Python 3.3.2
+
+If you want to run multiple commands while enabling python33 package, you can actually create an SCL-enabled bash session as follows.
+
+ $ scl enable python33 bash
+
+Within this bash session, the default python will be switched to 3.3 until you type exit and kill the session.
+
+
+
+In short, the SCL is somewhat similar to the virtualenv of Python, but is more general in that you can enable/disable SCL sessions for a far greater number of applications than just Python.
+
+For more detailed instructions on the SCL, refer to the official [quick start guide][2].
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/enable-software-collections-centos.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:https://www.softwarecollections.org/
+[2]:https://www.softwarecollections.org/docs/
\ No newline at end of file
diff --git a/sources/tech/20151215 Linux Desktop Fun--Summon Swarms Of Penguins To Waddle About The Desktop.md b/sources/tech/20151215 Linux Desktop Fun--Summon Swarms Of Penguins To Waddle About The Desktop.md
new file mode 100644
index 0000000000..b544517f5e
--- /dev/null
+++ b/sources/tech/20151215 Linux Desktop Fun--Summon Swarms Of Penguins To Waddle About The Desktop.md
@@ -0,0 +1,101 @@
+translation by strugglingyouth
+Linux Desktop Fun: Summon Swarms Of Penguins To Waddle About The Desktop
+================================================================================
+XPenguins is a program for animating cute cartoons animals in your root window. By default it will be penguins they drop in from the top of the screen, walk along the tops of your windows, up the side of your windows, levitate, skateboard, and do other similarly exciting things. Now you can send an army of cute little penguins to invade the screen of someone else on your network.
+
+### Install XPenguins ###
+
+Open a command-line terminal (select Applications > Accessories > Terminal), and then type the following commands to install XPenguins program. First, type the command apt-get update to tell apt to refresh its package information by querying the configured repositories and then install the required program:
+
+ $ sudo apt-get update
+ $ sudo apt-get install xpenguins
+
+### How do I Start XPenguins Locally? ###
+
+Type the following command:
+
+ $ xpenguins
+
+Sample outputs:
+
+
+
+An army of cute little penguins invading the screen
+
+
+
+Linux: Cute little penguins walking along the tops of your windows
+
+
+
+Xpenguins Screenshot
+
+Be careful when you move windows as the little guys squash easily. If you send the program an interupt signal (Ctrl-C) they will burst.
+
+### Themes ###
+
+To list themes, enter:
+
+ $ xpenguins -l
+
+Sample outputs:
+
+ Big Penguins
+ Bill
+ Classic Penguins
+ Penguins
+ Turtles
+
+You can use alternative themes as follows:
+
+ $ xpenguins --theme "Big Penguins" --theme "Turtles"
+
+You can install additional themes as follows:
+
+ $ cd /tmp
+ $ wget http://xpenguins.seul.org/xpenguins_themes-1.0.tar.gz
+ $ tar -zxvf xpenguins_themes-1.0.tar.gz
+ $ mkdir ~/.xpenguins
+ $ mv -v themes ~/.xpenguins/
+ $ xpenguins -l
+
+Sample outputs:
+
+ Lemmings
+ Sonic the Hedgehog
+ The Simpsons
+ Winnie the Pooh
+ Worms
+ Big Penguins
+ Bill
+ Classic Penguins
+ Penguins
+ Turtles
+
+To start with a random theme, enter:
+
+ $ xpenguins --random-theme
+
+To load all available themes and run them simultaneously, enter:
+
+ $ xpenguins --all
+
+More links and information:
+
+- [XPenguins][1] home page.
+- man penguins
+- More Linux / UNIX desktop fun with [Steam Locomotive][2] and [Terminal ASCII Aquarium][3].
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/tips/linux-cute-little-xpenguins-walk-along-tops-ofyour-windows.html
+
+作者:Vivek Gite
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://xpenguins.seul.org/
+[2]:http://www.cyberciti.biz/tips/displays-animations-when-accidentally-you-type-sl-instead-of-ls.html
+[3]:http://www.cyberciti.biz/tips/linux-unix-apple-osx-terminal-ascii-aquarium.html
diff --git a/sources/tech/20151215 Linux or Unix Desktop Fun--Text Mode ASCII-art Box and Comment Drawing.md b/sources/tech/20151215 Linux or Unix Desktop Fun--Text Mode ASCII-art Box and Comment Drawing.md
new file mode 100644
index 0000000000..db254d3858
--- /dev/null
+++ b/sources/tech/20151215 Linux or Unix Desktop Fun--Text Mode ASCII-art Box and Comment Drawing.md
@@ -0,0 +1,201 @@
+Linux / Unix Desktop Fun: Text Mode ASCII-art Box and Comment Drawing
+================================================================================
+Boxes command is a text filter and a little known tool that can draw any kind of ASCII art box around its input text or code for fun and profit. You can quickly create email signatures, or create regional comments in any programming language. This command was intended to be used with the vim text editor, but can be tied to any text editor which supports filters, as well as from the command line as a standalone tool.
+
+### Task: Install boxes ###
+
+Use the [apt-get command][1] to install boxes under Debian / Ubuntu Linux:
+
+ $ sudo apt-get install boxes
+
+Sample outputs:
+
+ Reading package lists... Done
+ Building dependency tree
+ Reading state information... Done
+ The following NEW packages will be installed:
+ boxes
+ 0 upgraded, 1 newly installed, 0 to remove and 6 not upgraded.
+ Need to get 0 B/59.8 kB of archives.
+ After this operation, 205 kB of additional disk space will be used.
+ Selecting previously deselected package boxes.
+ (Reading database ... 224284 files and directories currently installed.)
+ Unpacking boxes (from .../boxes_1.0.1a-2.3_amd64.deb) ...
+ Processing triggers for man-db ...
+ Setting up boxes (1.0.1a-2.3) ...
+
+RHEL / CentOS / Fedora Linux users, use the [yum command to install boxes][2] (first [enable EPEL repo as described here][3]):
+
+ # yum install boxes
+
+Sample outputs:
+
+ Loaded plugins: rhnplugin
+ Setting up Install Process
+ Resolving Dependencies
+ There are unfinished transactions remaining. You might consider running yum-complete-transaction first to finish them.
+ --> Running transaction check
+ ---> Package boxes.x86_64 0:1.1-8.el6 will be installed
+ --> Finished Dependency Resolution
+ Dependencies Resolved
+ ==========================================================================
+ Package Arch Version Repository Size
+ ==========================================================================
+ Installing:
+ boxes x86_64 1.1-8.el6 epel 64 k
+ Transaction Summary
+ ==========================================================================
+ Install 1 Package(s)
+ Total download size: 64 k
+ Installed size: 151 k
+ Is this ok [y/N]: y
+ Downloading Packages:
+ boxes-1.1-8.el6.x86_64.rpm | 64 kB 00:00
+ Running rpm_check_debug
+ Running Transaction Test
+ Transaction Test Succeeded
+ Running Transaction
+ Installing : boxes-1.1-8.el6.x86_64 1/1
+ Installed:
+ boxes.x86_64 0:1.1-8.el6
+ Complete!
+
+FreeBSD user can use the port as follows:
+
+ cd /usr/ports/misc/boxes/ && make install clean
+
+Or, add the package using the pkg_add command:
+
+ # pkg_add -r boxes
+
+### Draw any kind of box around some given text ###
+
+Type the following command:
+
+ echo "This is a test" | boxes
+
+Or specify the name of the design to use:
+
+ echo -e "\n\tVivek Gite\n\tvivek@nixcraft.com\n\twww.cyberciti.biz" | boxes -d dog
+
+Sample outputs:
+
+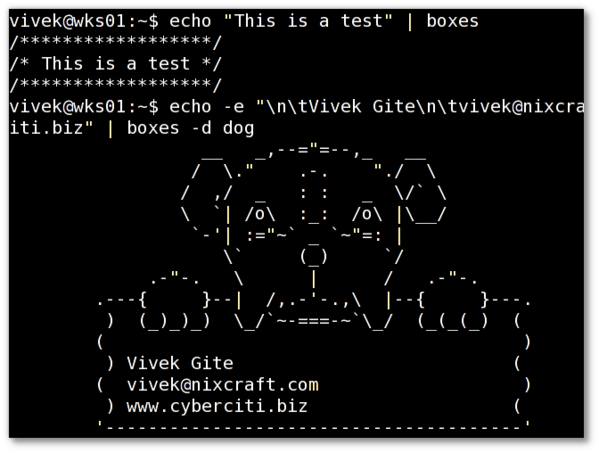
+
+Fig.01: Unix / Linux: Boxes Command To Draw Various Designs
+
+#### How do I list all designs? ####
+
+The syntax is:
+
+ boxes option
+ pipe | boxes options
+ echo "text" | boxes -d foo
+ boxes -l
+
+The -d design option sets the name of the design to use. The syntax is:
+
+ echo "Text" | boxes -d design
+ pipe | boxes -d desig
+
+The -l option list designs. It produces a listing of all available box designs in the config file, along with a sample box and information about it's creator:
+
+ boxes -l
+ boxes -l | more
+ boxes -l | less
+
+Sample outputs:
+
+ 43 Available Styles in "/etc/boxes/boxes-config":
+ -------------------------------------------------
+ ada-box (Neil Bird ):
+ ---------------
+ -- --
+ -- --
+ ---------------
+ ada-cmt (Neil Bird ):
+ --
+ -- regular Ada
+ -- comments
+ --
+ boy (Joan G. Stark ):
+ .-"""-.
+ / .===. \
+ \/ 6 6 \/
+ ( \___/ )
+ _________ooo__\_____/______________
+ / \
+ | joan stark spunk1111@juno.com |
+ | VISIT MY ASCII ART GALLERY: |
+ | http://www.geocities.com/SoHo/7373/ |
+ \_______________________ooo_________/ jgs
+ | | |
+ |_ | _|
+ | | |
+ |__|__|
+ /-'Y'-\
+ (__/ \__)
+ ....
+ ...
+ output truncated
+ ..
+
+### How do I filter text via boxes while using vi/vim text editor? ###
+
+You can use any external command with vi or vim. In this example, [insert current date and time][4], enter:
+
+ !!date
+
+OR
+
+ :r !date
+
+You need to type above command in Vim to read the output from the date command. This will insert the date and time after the current line:
+
+ Tue Jun 12 00:05:38 IST 2012
+
+You can do the same with boxes command. Create a sample shell script or a c program as follows:
+
+ #!/bin/bash
+ Purpose: Backup mysql database to remote server.
+ Author: Vivek Gite
+ Last updated on: Tue Jun, 12 2012
+
+Now type the following (move cursor to the second line i.e. line which starts with "Purpose: ...")
+
+ 3!!boxes
+
+And voila you will get the output as follows:
+
+ #!/bin/bash
+ /****************************************************/
+ /* Purpose: Backup mysql database to remote server. */
+ /* Author: Vivek Gite */
+ /* Last updated on: Tue Jun, 12 2012 */
+ /****************************************************/
+
+This video will give you an introduction to boxes command:
+
+注:youtube 视频
+
+
+(Video:01: boxes command in action. BTW, this is my first video so go easy on me and let me know what you think.)
+
+See also
+
+- boxes man page
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/tips/unix-linux-draw-any-kind-of-boxes-around-text-editor.html
+
+作者:Vivek Gite
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
+[2]:http://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
+[3]:http://www.cyberciti.biz/faq/fedora-sl-centos-redhat6-enable-epel-repo/
+[4]:http://www.cyberciti.biz/faq/vim-inserting-current-date-time-under-linux-unix-osx/
\ No newline at end of file
diff --git a/sources/tech/20151215 Securi-Pi--Using the Raspberry Pi as a Secure Landing Point.md b/sources/tech/20151215 Securi-Pi--Using the Raspberry Pi as a Secure Landing Point.md
new file mode 100644
index 0000000000..7388b7693e
--- /dev/null
+++ b/sources/tech/20151215 Securi-Pi--Using the Raspberry Pi as a Secure Landing Point.md
@@ -0,0 +1,501 @@
+translating by ezio
+
+
+
+Securi-Pi: Using the Raspberry Pi as a Secure Landing Point
+================================================================================
+
+Like many LJ readers these days, I've been leading a bit of a techno-nomadic lifestyle as of the past few years—jumping from network to network, access point to access point, as I bounce around the real world while maintaining my connection to the Internet and other networks I use on a daily basis. As of late, I've found that more and more networks are starting to block outbound ports like SMTP (port 25), SSH (port 22) and others. It becomes really frustrating when you drop into a local coffee house expecting to be able to fire up your SSH client and get a few things done, and you can't, because the network's blocking you.
+
+However, I have yet to run across a network that blocks HTTPS outbound (port 443). After a bit of fiddling with a Raspberry Pi 2 I have at home, I was able to get a nice clean solution that lets me hit various services on the Raspberry Pi via port 443—allowing me to walk around blocked ports and hobbled networks so I can do the things I need to do. In a nutshell, I have set up this Raspberry Pi to act as an OpenVPN endpoint, SSH endpoint and Apache server—with all these services listening on port 443 so networks with restrictive policies aren't an issue.
+
+### Notes
+This solution will work on most networks, but firewalls that do deep packet inspection on outbound traffic still can block traffic that's tunneled using this method. However, I haven't been on a network that does that...yet. Also, while I use a lot of cryptography-based solutions here (OpenVPN, HTTPS, SSH), I haven't done a strict security audit of this setup. DNS may leak information, for example, and there may be other things I haven't thought of. I'm not recommending this as a way to hide all your traffic—I just use this so that I can connect to the Internet in an unfettered way when I'm out and about.
+
+### Getting Started
+Let's start off with what you need to put this solution together. I'm using this on a Raspberry Pi 2 at home, running the latest Raspbian, but this should work just fine on a Raspberry Pi Model B, as well. It fits within the 512MB of RAM footprint quite easily, although performance may be a bit slower, because the Raspberry Pi Model B has a single-core CPU as opposed to the Pi 2's quad-core. My Raspberry Pi 2 is behind my home's router/firewall, so I get the added benefit of being able to access my machines at home. This also means that any traffic I send to the Internet appears to come from my home router's IP address, so this isn't a solution designed to protect anonymity. If you don't have a Raspberry Pi, or don't want this running out of your home, it's entirely possible to run this out of a small cloud server too. Just make sure that the server's running Debian or Ubuntu, as these instructions are targeted at Debian-based distributions.
+
+
+
+Figure 1. The Raspberry Pi, about to become an encrypted network endpoint.
+
+### Installing and Configuring BIND
+Once you have your platform up and running—whether it's a Raspberry Pi or otherwise—next you're going to install BIND, the nameserver that powers a lot of the Internet. You're going to install BIND as a caching nameserver only, and not have it service incoming requests from the Internet. Installing BIND will give you a DNS server to point your OpenVPN clients at, once you get to the OpenVPN step. Installing BIND is easy; it's just a simple `apt-get `command to install it:
+
+```
+root@test:~# apt-get install bind9
+Reading package lists... Done
+Building dependency tree
+Reading state information... Done
+The following extra packages will be installed:
+ bind9utils
+Suggested packages:
+ bind9-doc resolvconf ufw
+The following NEW packages will be installed:
+ bind9 bind9utils
+0 upgraded, 2 newly installed, 0 to remove and
+ ↪0 not upgraded.
+Need to get 490 kB of archives.
+After this operation, 1,128 kB of additional disk
+ ↪space will be used.
+Do you want to continue [Y/n]? y
+```
+
+There are a couple minor configuration changes that need to be made to one of the config files of BIND before it can operate as a caching nameserver. Both changes are in `/etc/bind/named.conf.options`. First, you're going to uncomment the "forwarders" section of this file, and you're going to add a nameserver on the Internet to which to forward requests. In this case, I'm going to add Google's DNS (8.8.8.8). The "forwarders" section of the file should look like this:
+
+```
+forwarders {
+ 8.8.8.8;
+};
+```
+
+The second change you're going to make allows queries from your internal network and localhost. Simply add this line to the bottom of the configuration file, right before the `}`; that ends the file:
+
+```
+allow-query { 192.168.1.0/24; 127.0.0.0/16; };
+```
+
+That line above allows this DNS server to be queried from the network it's on (in this case, my network behind my firewall) and localhost. Next, you just need to restart BIND:
+
+```
+root@test:~# /etc/init.d/bind9 restart
+[....] Stopping domain name service...: bind9waiting
+ ↪for pid 13209 to die
+. ok
+[ ok ] Starting domain name service...: bind9.
+```
+
+Now you can test `nslookup` to make sure your server works:
+
+```
+root@test:~# nslookup
+> server localhost
+Default server: localhost
+Address: 127.0.0.1#53
+> www.google.com
+Server: localhost
+Address: 127.0.0.1#53
+
+Non-authoritative answer:
+Name: www.google.com
+Address: 173.194.33.176
+Name: www.google.com
+Address: 173.194.33.177
+Name: www.google.com
+Address: 173.194.33.178
+Name: www.google.com
+Address: 173.194.33.179
+Name: www.google.com
+Address: 173.194.33.180
+```
+
+That's it! You've got a working nameserver on this machine. Next, let's move on to OpenVPN.
+
+### Installing and Configuring OpenVPN
+
+OpenVPN is an open-source VPN solution that relies on SSL/TLS for its key exchange. It's also easy to install and get working under Linux. Configuration of OpenVPN can be a bit daunting, but you're not going to deviate from the default configuration by much. To start, you're going to run an apt-get command and install OpenVPN:
+
+```
+root@test:~# apt-get install openvpn
+Reading package lists... Done
+Building dependency tree
+Reading state information... Done
+The following extra packages will be installed:
+ liblzo2-2 libpkcs11-helper1
+Suggested packages:
+ resolvconf
+The following NEW packages will be installed:
+ liblzo2-2 libpkcs11-helper1 openvpn
+0 upgraded, 3 newly installed, 0 to remove and
+ ↪0 not upgraded.
+Need to get 621 kB of archives.
+After this operation, 1,489 kB of additional disk
+ ↪space will be used.
+Do you want to continue [Y/n]? y
+```
+
+Now that OpenVPN is installed, you're going to configure it. OpenVPN is SSL-based, and it relies on both server and client certificates to work. To generate these certificates, you need to configure a Certificate Authority (CA) on the machine. Luckily, OpenVPN ships with some wrapper scripts known as "easy-rsa" that help to bootstrap this process. You'll start by making a directory on the filesystem for the easy-rsa scripts to reside in and by copying the scripts from the template directory there:
+
+```
+root@test:~# mkdir /etc/openvpn/easy-rsa
+root@test:~# cp -rpv
+ ↪/usr/share/doc/openvpn/examples/easy-rsa/2.0/*
+ ↪/etc/openvpn/easy-rsa/
+ ```
+
+Next, copy the vars file to a backup copy:
+
+```
+root@test:/etc/openvpn/easy-rsa# cp vars vars.bak
+```
+
+Now, edit vars so it's got information pertinent to your installation. I'm going specify only the lines that need to be edited, with sample data, below:
+
+```
+KEY_SIZE=4096
+KEY_COUNTRY="US"
+KEY_PROVINCE="CA"
+KEY_CITY="Silicon Valley"
+KEY_ORG="Linux Journal"
+KEY_EMAIL="bill.childers@linuxjournal.com"
+```
+
+The next step is to source the vars file, so that the environment variables in the file are in your current environment:
+
+```
+root@test:/etc/openvpn/easy-rsa# source ./vars
+NOTE: If you run ./clean-all, I will be doing a
+ ↪rm -rf on /etc/openvpn/easy-rsa/keys
+ ```
+
+### Building the Certificate Authority
+
+You're now going to run clean-all to ensure a clean working environment, and then you're going to build the CA. Note that I'm changing changeme prompts to something that's appropriate for this installation:
+
+```
+root@test:/etc/openvpn/easy-rsa# ./clean-all
+root@test:/etc/openvpn/easy-rsa# ./build-ca
+Generating a 4096 bit RSA private key
+...................................................++
+...................................................++
+writing new private key to 'ca.key'
+-----
+You are about to be asked to enter information that
+will be incorporated into your certificate request.
+What you are about to enter is what is called a
+Distinguished Name or a DN.
+There are quite a few fields but you can leave some
+blank. For some fields there will be a default value,
+If you enter '.', the field will be left blank.
+-----
+Country Name (2 letter code) [US]:
+State or Province Name (full name) [CA]:
+Locality Name (eg, city) [Silicon Valley]:
+Organization Name (eg, company) [Linux Journal]:
+Organizational Unit Name (eg, section)
+ ↪[changeme]:SecTeam
+Common Name (eg, your name or your server's hostname)
+ ↪[changeme]:test.linuxjournal.com
+Name [changeme]:test.linuxjournal.com
+Email Address [bill.childers@linuxjournal.com]:
+```
+
+### Building the Server Certificate
+
+Once the CA is created, you need to build the OpenVPN server certificate:
+
+```root@test:/etc/openvpn/easy-rsa#
+ ↪./build-key-server test.linuxjournal.com
+Generating a 4096 bit RSA private key
+...................................................++
+writing new private key to 'test.linuxjournal.com.key'
+-----
+You are about to be asked to enter information that
+will be incorporated into your certificate request.
+What you are about to enter is what is called a
+Distinguished Name or a DN.
+There are quite a few fields but you can leave some
+blank. For some fields there will be a default value,
+If you enter '.', the field will be left blank.
+-----
+Country Name (2 letter code) [US]:
+State or Province Name (full name) [CA]:
+Locality Name (eg, city) [Silicon Valley]:
+Organization Name (eg, company) [Linux Journal]:
+Organizational Unit Name (eg, section)
+ ↪[changeme]:SecTeam
+Common Name (eg, your name or your server's hostname)
+ ↪[test.linuxjournal.com]:
+Name [changeme]:test.linuxjournal.com
+Email Address [bill.childers@linuxjournal.com]:
+
+Please enter the following 'extra' attributes
+to be sent with your certificate request
+A challenge password []:
+An optional company name []:
+Using configuration from
+ ↪/etc/openvpn/easy-rsa/openssl-1.0.0.cnf
+Check that the request matches the signature
+Signature ok
+The Subject's Distinguished Name is as follows
+countryName :PRINTABLE:'US'
+stateOrProvinceName :PRINTABLE:'CA'
+localityName :PRINTABLE:'Silicon Valley'
+organizationName :PRINTABLE:'Linux Journal'
+organizationalUnitName:PRINTABLE:'SecTeam'
+commonName :PRINTABLE:'test.linuxjournal.com'
+name :PRINTABLE:'test.linuxjournal.com'
+emailAddress
+ ↪:IA5STRING:'bill.childers@linuxjournal.com'
+Certificate is to be certified until Sep 1
+ ↪06:23:59 2025 GMT (3650 days)
+Sign the certificate? [y/n]:y
+
+1 out of 1 certificate requests certified, commit? [y/n]y
+Write out database with 1 new entries
+Data Base Updated
+```
+
+The next step may take a while—building the Diffie-Hellman key for the OpenVPN server. This takes several minutes on a conventional desktop-grade CPU, but on the ARM processor of the Raspberry Pi, it can take much, much longer. Have patience, as long as the dots in the terminal are proceeding, the system is building its Diffie-Hellman key (note that many dots are snipped in these examples):
+
+```
+root@test:/etc/openvpn/easy-rsa# ./build-dh
+Generating DH parameters, 4096 bit long safe prime,
+ ↪generator 2
+This is going to take a long time
+....................................................+
+
+```
+
+### Building the Client Certificate
+
+Now you're going to generate a client key for your client to use when logging in to the OpenVPN server. OpenVPN is typically configured for certificate-based auth, where the client presents a certificate that was issued by an approved Certificate Authority:
+
+```
+root@test:/etc/openvpn/easy-rsa# ./build-key
+ ↪bills-computer
+Generating a 4096 bit RSA private key
+...................................................++
+...................................................++
+writing new private key to 'bills-computer.key'
+-----
+You are about to be asked to enter information that
+will be incorporated into your certificate request.
+What you are about to enter is what is called a
+Distinguished Name or a DN. There are quite a few
+fields but you can leave some blank.
+For some fields there will be a default value,
+If you enter '.', the field will be left blank.
+-----
+Country Name (2 letter code) [US]:
+State or Province Name (full name) [CA]:
+Locality Name (eg, city) [Silicon Valley]:
+Organization Name (eg, company) [Linux Journal]:
+Organizational Unit Name (eg, section)
+ ↪[changeme]:SecTeam
+Common Name (eg, your name or your server's hostname)
+ ↪[bills-computer]:
+Name [changeme]:bills-computer
+Email Address [bill.childers@linuxjournal.com]:
+
+Please enter the following 'extra' attributes
+to be sent with your certificate request
+A challenge password []:
+An optional company name []:
+Using configuration from
+ ↪/etc/openvpn/easy-rsa/openssl-1.0.0.cnf
+Check that the request matches the signature
+Signature ok
+The Subject's Distinguished Name is as follows
+countryName :PRINTABLE:'US'
+stateOrProvinceName :PRINTABLE:'CA'
+localityName :PRINTABLE:'Silicon Valley'
+organizationName :PRINTABLE:'Linux Journal'
+organizationalUnitName:PRINTABLE:'SecTeam'
+commonName :PRINTABLE:'bills-computer'
+name :PRINTABLE:'bills-computer'
+emailAddress
+ ↪:IA5STRING:'bill.childers@linuxjournal.com'
+Certificate is to be certified until
+ ↪Sep 1 07:35:07 2025 GMT (3650 days)
+Sign the certificate? [y/n]:y
+
+1 out of 1 certificate requests certified,
+ ↪commit? [y/n]y
+Write out database with 1 new entries
+Data Base Updated
+root@test:/etc/openvpn/easy-rsa#
+```
+
+Now you're going to generate an HMAC code as a shared key to increase the security of the system further:
+
+```
+root@test:~# openvpn --genkey --secret
+ ↪/etc/openvpn/easy-rsa/keys/ta.key
+```
+
+### Configuration of the Server
+
+Finally, you're going to get to the meat of configuring the OpenVPN server. You're going to create a new file, /etc/openvpn/server.conf, and you're going to stick to a default configuration for the most part. The main change you're going to do is to set up OpenVPN to use TCP rather than UDP. This is needed for the next major step to work—without OpenVPN using TCP for its network communication, you can't get things working on port 443. So, create a new file called /etc/openvpn/server.conf, and put the following configuration in it: Garrick, shrink below.
+
+```
+port 1194
+proto tcp
+dev tun
+ca easy-rsa/keys/ca.crt
+cert easy-rsa/keys/test.linuxjournal.com.crt ## or whatever
+ ↪your hostname was
+key easy-rsa/keys/test.linuxjournal.com.key ## Hostname key
+ ↪- This file should be kept secret
+management localhost 7505
+dh easy-rsa/keys/dh4096.pem
+tls-auth /etc/openvpn/certs/ta.key 0
+server 10.8.0.0 255.255.255.0 # The server will use this
+ ↪subnet for clients connecting to it
+ifconfig-pool-persist ipp.txt
+push "redirect-gateway def1 bypass-dhcp" # Forces clients
+ ↪to redirect all traffic through the VPN
+push "dhcp-option DNS 192.168.1.1" # Tells the client to
+ ↪use the DNS server at 192.168.1.1 for DNS -
+ ↪replace with the IP address of the OpenVPN
+ ↪machine and clients will use the BIND
+ ↪server setup earlier
+keepalive 30 240
+comp-lzo # Enable compression
+persist-key
+persist-tun
+status openvpn-status.log
+verb 3
+```
+
+And last, you're going to enable IP forwarding on the server, configure OpenVPN to start on boot and start the OpenVPN service:
+
+```
+root@test:/etc/openvpn/easy-rsa/keys# echo
+ ↪"net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
+root@test:/etc/openvpn/easy-rsa/keys# sysctl -p
+ ↪/etc/sysctl.conf
+net.core.wmem_max = 12582912
+net.core.rmem_max = 12582912
+net.ipv4.tcp_rmem = 10240 87380 12582912
+net.ipv4.tcp_wmem = 10240 87380 12582912
+net.core.wmem_max = 12582912
+net.core.rmem_max = 12582912
+net.ipv4.tcp_rmem = 10240 87380 12582912
+net.ipv4.tcp_wmem = 10240 87380 12582912
+net.core.wmem_max = 12582912
+net.core.rmem_max = 12582912
+net.ipv4.tcp_rmem = 10240 87380 12582912
+net.ipv4.tcp_wmem = 10240 87380 12582912
+net.ipv4.ip_forward = 0
+net.ipv4.ip_forward = 1
+
+root@test:/etc/openvpn/easy-rsa/keys# update-rc.d
+ ↪openvpn defaults
+update-rc.d: using dependency based boot sequencing
+
+root@test:/etc/openvpn/easy-rsa/keys#
+ ↪/etc/init.d/openvpn start
+[ ok ] Starting virtual private network daemon:.
+```
+
+### Setting Up OpenVPN Clients
+
+Your client installation depends on the host OS of your client, but you'll need to copy your client certs and keys created above to your client, and you'll need to import those certificates and create a configuration for that client. Each client and client OS does it slightly differently and documenting each one is beyond the scope of this article, so you'll need to refer to the documentation for that client to get it running. Refer to the Resources section for OpenVPN clients for each major OS.
+
+### Installing SSLH—the "Magic" Protocol Multiplexer
+
+The really interesting piece of this solution is SSLH. SSLH is a protocol multiplexer—it listens on port 443 for traffic, and then it can analyze whether the incoming packet is an SSH packet, HTTPS or OpenVPN, and it can forward that packet onto the proper service. This is what enables this solution to bypass most port blocks—you use the HTTPS port for all of this traffic, since HTTPS is rarely blocked.
+
+To start, `apt-get` install SSLH:
+
+```
+root@test:/etc/openvpn/easy-rsa/keys# apt-get
+ ↪install sslh
+Reading package lists... Done
+Building dependency tree
+Reading state information... Done
+The following extra packages will be installed:
+ apache2 apache2-mpm-worker apache2-utils
+ ↪apache2.2-bin apache2.2-common
+ libapr1 libaprutil1 libaprutil1-dbd-sqlite3
+ ↪libaprutil1-ldap libconfig9
+Suggested packages:
+ apache2-doc apache2-suexec apache2-suexec-custom
+ ↪openbsd-inetd inet-superserver
+The following NEW packages will be installed:
+ apache2 apache2-mpm-worker apache2-utils
+ ↪apache2.2-bin apache2.2-common
+ libapr1 libaprutil1 libaprutil1-dbd-sqlite3
+ ↪libaprutil1-ldap libconfig9 sslh
+0 upgraded, 11 newly installed, 0 to remove
+ ↪and 0 not upgraded.
+Need to get 1,568 kB of archives.
+After this operation, 5,822 kB of additional
+ ↪disk space will be used.
+Do you want to continue [Y/n]? y
+```
+
+After SSLH is installed, the package installer will ask you if you want to run it in inetd or standalone mode. Select standalone mode, because you want SSLH to run as its own process. If you don't have Apache installed, the Debian/Raspbian package of SSLH will pull it in automatically, although it's not strictly required. If you already have Apache running and configured, you'll want to make sure it only listens on localhost's interface and not all interfaces (otherwise, SSLH can't start because it can't bind to port 443). After installation, you'll receive an error that looks like this:
+
+```
+[....] Starting ssl/ssh multiplexer: sslhsslh disabled,
+ ↪please adjust the configuration to your needs
+[FAIL] and then set RUN to 'yes' in /etc/default/sslh
+ ↪to enable it. ... failed!
+failed!
+```
+
+This isn't an error, exactly—it's just SSLH telling you that it's not configured and can't start. Configuring SSLH is pretty simple. Its configuration is stored in `/etc/default/sslh`, and you just need to configure the `RUN` and `DAEMON_OPTS` variables. My SSLH configuration looks like this:
+
+```
+# Default options for sslh initscript
+# sourced by /etc/init.d/sslh
+
+# Disabled by default, to force yourself
+# to read the configuration:
+# - /usr/share/doc/sslh/README.Debian (quick start)
+# - /usr/share/doc/sslh/README, at "Configuration" section
+# - sslh(8) via "man sslh" for more configuration details.
+# Once configuration ready, you *must* set RUN to yes here
+# and try to start sslh (standalone mode only)
+
+RUN=yes
+
+# binary to use: forked (sslh) or single-thread
+ ↪(sslh-select) version
+DAEMON=/usr/sbin/sslh
+
+DAEMON_OPTS="--user sslh --listen 0.0.0.0:443 --ssh
+ ↪127.0.0.1:22 --ssl 127.0.0.1:443 --openvpn
+ ↪127.0.0.1:1194 --pidfile /var/run/sslh/sslh.pid"
+ ```
+
+ Save the file and start SSLH:
+
+```
+ root@test:/etc/openvpn/easy-rsa/keys#
+ ↪/etc/init.d/sslh start
+[ ok ] Starting ssl/ssh multiplexer: sslh.
+```
+
+Now, you should be able to ssh to port 443 on your Raspberry Pi, and have it forward via SSLH:
+
+```
+$ ssh -p 443 root@test.linuxjournal.com
+root@test:~#
+```
+
+SSLH is now listening on port 443 and can direct traffic to SSH, Apache or OpenVPN based on the type of packet that hits it. You should be ready to go!
+
+### Conclusion
+
+Now you can fire up OpenVPN and set your OpenVPN client configuration to port 443, and SSLH will route it to the OpenVPN server on port 1194. But because you're talking to your server on port 443, your VPN traffic won't get blocked. Now you can land at a strange coffee shop, in a strange town, and know that your Internet will just work when you fire up your OpenVPN and point it at your Raspberry Pi. You'll also gain some encryption on your link, which will improve the privacy of your connection. Enjoy surfing the Net via your new landing point!
+
+Resources
+
+Installing and Configuring OpenVPN: [https://wiki.debian.org/OpenVPN](https://wiki.debian.org/OpenVPN) and [http://cryptotap.com/articles/openvpn](http://cryptotap.com/articles/openvpn)
+
+OpenVPN client downloads: [https://openvpn.net/index.php/open-source/downloads.html](https://openvpn.net/index.php/open-source/downloads.html)
+
+OpenVPN Client for iOS: [https://itunes.apple.com/us/app/openvpn-connect/id590379981?mt=8](https://itunes.apple.com/us/app/openvpn-connect/id590379981?mt=8)
+
+OpenVPN Client for Android: [https://play.google.com/store/apps/details?id=net.openvpn.openvpn&hl=en](https://play.google.com/store/apps/details?id=net.openvpn.openvpn&hl=en)
+
+Tunnelblick for Mac OS X (OpenVPN client): [https://tunnelblick.net](https://tunnelblick.net)
+
+SSLH—Protocol Multiplexer: [http://www.rutschle.net/tech/sslh.shtml](http://www.rutschle.net/tech/sslh.shtml) and [https://github.com/yrutschle/sslh](https://github.com/yrutschle/sslh)
+
+
+----------
+via: http://www.linuxjournal.com/content/securi-pi-using-raspberry-pi-secure-landing-point?page=0,0
+
+作者:[Bill Childers][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxjournal.com/users/bill-childers
+
+
diff --git a/sources/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md b/sources/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md
deleted file mode 100644
index 6d0f65223f..0000000000
--- a/sources/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md
+++ /dev/null
@@ -1,229 +0,0 @@
-Part 9 - LFCS: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
-================================================================================
-Last August, the Linux Foundation announced the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of succeeding at overall operational support for Linux systems. A Linux Foundation Certified Sysadmin has the expertise to ensure effective system support, first-level troubleshooting and monitoring, including finally issue escalation, when needed, to engineering support teams.
-
-
-
-Linux Foundation Certified Sysadmin – Part 9
-
-Watch the following video that explains about the Linux Foundation Certification Program.
-
-注:youtube 视频
-
-
-This article is a Part 9 of 10-tutorial long series, today in this article we will guide you about Linux Package Management, that are required for the LFCS certification exam.
-
-### Package Management ###
-
-In few words, package management is a method of installing and maintaining (which includes updating and probably removing as well) software on the system.
-
-In the early days of Linux, programs were only distributed as source code, along with the required man pages, the necessary configuration files, and more. Nowadays, most Linux distributors use by default pre-built programs or sets of programs called packages, which are presented to users ready for installation on that distribution. However, one of the wonders of Linux is still the possibility to obtain source code of a program to be studied, improved, and compiled.
-
-**How package management systems work**
-
-If a certain package requires a certain resource such as a shared library, or another package, it is said to have a dependency. All modern package management systems provide some method of dependency resolution to ensure that when a package is installed, all of its dependencies are installed as well.
-
-**Packaging Systems**
-
-Almost all the software that is installed on a modern Linux system will be found on the Internet. It can either be provided by the distribution vendor through central repositories (which can contain several thousands of packages, each of which has been specifically built, tested, and maintained for the distribution) or be available in source code that can be downloaded and installed manually.
-
-Because different distribution families use different packaging systems (Debian: *.deb / CentOS: *.rpm / openSUSE: *.rpm built specially for openSUSE), a package intended for one distribution will not be compatible with another distribution. However, most distributions are likely to fall into one of the three distribution families covered by the LFCS certification.
-
-**High and low-level package tools**
-
-In order to perform the task of package management effectively, you need to be aware that you will have two types of available utilities: low-level tools (which handle in the backend the actual installation, upgrade, and removal of package files), and high-level tools (which are in charge of ensuring that the tasks of dependency resolution and metadata searching -”data about the data”- are performed).
-
-注:表格
-
-
-
-
-
-
-
-
-
-
-
DISTRIBUTION
-
LOW-LEVEL TOOL
-
HIGH-LEVEL TOOL
-
-
-
Debian and derivatives
-
dpkg
-
apt-get / aptitude
-
-
-
CentOS
-
rpm
-
yum
-
-
-
openSUSE
-
rpm
-
zypper
-
-
-
-
-Let us see the descrption of the low-level and high-level tools.
-
-dpkg is a low-level package manager for Debian-based systems. It can install, remove, provide information about and build *.deb packages but it can’t automatically download and install their corresponding dependencies.
-
-- Read More: [15 dpkg Command Examples][1]
-
-apt-get is a high-level package manager for Debian and derivatives, and provides a simple way to retrieve and install packages, including dependency resolution, from multiple sources using the command line. Unlike dpkg, apt-get does not work directly with *.deb files, but with the package proper name.
-
-- Read More: [25 apt-get Command Examples][2]
-
-aptitude is another high-level package manager for Debian-based systems, and can be used to perform management tasks (installing, upgrading, and removing packages, also handling dependency resolution automatically) in a fast and easy way. It provides the same functionality as apt-get and additional ones, such as offering access to several versions of a package.
-
-rpm is the package management system used by Linux Standard Base (LSB)-compliant distributions for low-level handling of packages. Just like dpkg, it can query, install, verify, upgrade, and remove packages, and is more frequently used by Fedora-based distributions, such as RHEL and CentOS.
-
-- Read More: [20 rpm Command Examples][3]
-
-yum adds the functionality of automatic updates and package management with dependency management to RPM-based systems. As a high-level tool, like apt-get or aptitude, yum works with repositories.
-
-- Read More: [20 yum Command Examples][4]
--
-### Common Usage of Low-Level Tools ###
-
-The most frequent tasks that you will do with low level tools are as follows:
-
-**1. Installing a package from a compiled (*.deb or *.rpm) file**
-
-The downside of this installation method is that no dependency resolution is provided. You will most likely choose to install a package from a compiled file when such package is not available in the distribution’s repositories and therefore cannot be downloaded and installed through a high-level tool. Since low-level tools do not perform dependency resolution, they will exit with an error if we try to install a package with unmet dependencies.
-
- # dpkg -i file.deb [Debian and derivative]
- # rpm -i file.rpm [CentOS / openSUSE]
-
-**Note**: Do not attempt to install on CentOS a *.rpm file that was built for openSUSE, or vice-versa!
-
-**2. Upgrading a package from a compiled file**
-
-Again, you will only upgrade an installed package manually when it is not available in the central repositories.
-
- # dpkg -i file.deb [Debian and derivative]
- # rpm -U file.rpm [CentOS / openSUSE]
-
-**3. Listing installed packages**
-
-When you first get your hands on an already working system, chances are you’ll want to know what packages are installed.
-
- # dpkg -l [Debian and derivative]
- # rpm -qa [CentOS / openSUSE]
-
-If you want to know whether a specific package is installed, you can pipe the output of the above commands to grep, as explained in [manipulate files in Linux – Part 1][6] of this series. Suppose we need to verify if package mysql-common is installed on an Ubuntu system.
-
- # dpkg -l | grep mysql-common
-
-
-
-Check Installed Packages
-
-Another way to determine if a package is installed.
-
- # dpkg --status package_name [Debian and derivative]
- # rpm -q package_name [CentOS / openSUSE]
-
-For example, let’s find out whether package sysdig is installed on our system.
-
- # rpm -qa | grep sysdig
-
-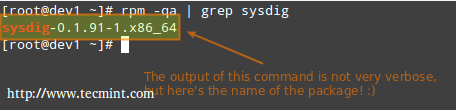
-
-Check sysdig Package
-
-**4. Finding out which package installed a file**
-
- # dpkg --search file_name
- # rpm -qf file_name
-
-For example, which package installed pw_dict.hwm?
-
- # rpm -qf /usr/share/cracklib/pw_dict.hwm
-
-
-
-Query File in Linux
-
-### Common Usage of High-Level Tools ###
-
-The most frequent tasks that you will do with high level tools are as follows.
-
-**1. Searching for a package**
-
-aptitude update will update the list of available packages, and aptitude search will perform the actual search for package_name.
-
- # aptitude update && aptitude search package_name
-
-In the search all option, yum will search for package_name not only in package names, but also in package descriptions.
-
- # yum search package_name
- # yum search all package_name
- # yum whatprovides “*/package_name”
-
-Let’s supposed we need a file whose name is sysdig. To know that package we will have to install, let’s run.
-
- # yum whatprovides “*/sysdig”
-
-
-
-Check Package Description
-
-whatprovides tells yum to search the package the will provide a file that matches the above regular expression.
-
- # zypper refresh && zypper search package_name [On openSUSE]
-
-**2. Installing a package from a repository**
-
-While installing a package, you may be prompted to confirm the installation after the package manager has resolved all dependencies. Note that running update or refresh (according to the package manager being used) is not strictly necessary, but keeping installed packages up to date is a good sysadmin practice for security and dependency reasons.
-
- # aptitude update && aptitude install package_name [Debian and derivatives]
- # yum update && yum install package_name [CentOS]
- # zypper refresh && zypper install package_name [openSUSE]
-
-**3. Removing a package**
-
-The option remove will uninstall the package but leaving configuration files intact, whereas purge will erase every trace of the program from your system.
-# aptitude remove / purge package_name
-# yum erase package_name
-
- ---Notice the minus sign in front of the package that will be uninstalled, openSUSE ---
-
- # zypper remove -package_name
-
-Most (if not all) package managers will prompt you, by default, if you’re sure about proceeding with the uninstallation before actually performing it. So read the onscreen messages carefully to avoid running into unnecessary trouble!
-
-**4. Displaying information about a package**
-
-The following command will display information about the birthday package.
-
- # aptitude show birthday
- # yum info birthday
- # zypper info birthday
-
-
-
-Check Package Information
-
-### Summary ###
-
-Package management is something you just can’t sweep under the rug as a system administrator. You should be prepared to use the tools described in this article at a moment’s notice. Hope you find it useful in your preparation for the LFCS exam and for your daily tasks. Feel free to leave your comments or questions below. We will be more than glad to get back to you as soon as possible.
-
---------------------------------------------------------------------------------
-
-via: http://www.tecmint.com/linux-package-management/
-
-作者:[Gabriel Cánepa][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://www.tecmint.com/author/gacanepa/
-[1]:http://www.tecmint.com/dpkg-command-examples/
-[2]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
-[3]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
-[4]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
-[5]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
\ No newline at end of file
diff --git a/sources/tech/Learn with Linux/Learn with Linux--Learning Music.md b/sources/tech/Learn with Linux/Learn with Linux--Learning Music.md
index e6467eb810..f9675d59ce 100644
--- a/sources/tech/Learn with Linux/Learn with Linux--Learning Music.md
+++ b/sources/tech/Learn with Linux/Learn with Linux--Learning Music.md
@@ -1,16 +1,17 @@
+bazz2
Learn with Linux: Learning Music
================================================================================

-This article is part of the [Learn with Linux][1] series:
+[Linux 学习系列][1]的所有文章:
-- [Learn with Linux: Learning to Type][2]
-- [Learn with Linux: Physics Simulation][3]
-- [Learn with Linux: Learning Music][4]
-- [Learn with Linux: Two Geography Apps][5]
-- [Learn with Linux: Master Your Math with These Linux Apps][6]
+- [Linux 教学之教你练打字][2]
+- [Linux 教学之物理模拟][3]
+- [Linux 教学之教你玩音乐][4]
+- [Linux 教学之两款地理软件][5]
+- [Linux 教学之掌握数学][6]
-Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
+引言:Linux 提供大量的教学软件和工具,面向各个年级段以及年龄段,提供大量学科的练习实践,其中大多数是可以与用户进行交互的。本“Linux 教学”系列就来介绍一些教学软件。
Learning music is a great pastime. Training your ears to identify scales and chords and mastering an instrument or your own voice requires lots of practise and could become difficult. Music theory is extensive. There is much to memorize, and to turn it into a “skill” you will need diligence. Linux offers exceptional software to help you along your musical journey. They will not help you become a professional musician instantly but could ease the process of learning, being a great aide and reference point.
@@ -152,4 +153,4 @@ via: https://www.maketecheasier.com/linux-learning-music/
[10]:http://sourceforge.net/projects/tete/files/latest/download
[11]:http://sourceforge.net/projects/jalmus/files/Jalmus-2.3/
[12]:http://tuxguitar.herac.com.ar/
-[13]:http://www.linuxlinks.com/article/20090517041840856/PianoBooster.html
\ No newline at end of file
+[13]:http://www.linuxlinks.com/article/20090517041840856/PianoBooster.html
diff --git a/sources/tech/Learn with Linux/Learn with Linux--Physics Simulation.md b/sources/tech/Learn with Linux/Learn with Linux--Physics Simulation.md
deleted file mode 100644
index 2a8415dda7..0000000000
--- a/sources/tech/Learn with Linux/Learn with Linux--Physics Simulation.md
+++ /dev/null
@@ -1,107 +0,0 @@
-Learn with Linux: Physics Simulation
-================================================================================
-
-
-This article is part of the [Learn with Linux][1] series:
-
-- [Learn with Linux: Learning to Type][2]
-- [Learn with Linux: Physics Simulation][3]
-- [Learn with Linux: Learning Music][4]
-- [Learn with Linux: Two Geography Apps][5]
-- [Learn with Linux: Master Your Math with These Linux Apps][6]
-
-Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
-
-Physics is an interesting subject, and arguably the most enjoyable part of any Physics class/lecture are the demonstrations. It is really nice to see physics in action, yet the experiments do not need to be restricted to the classroom. While Linux offers many great tools for scientists to support or conduct experiments, this article will concern a few that would make learning physics easier or more fun.
-
-### 1. Step ###
-
-[Step][7] is an interactive physics simulator, part of [KDEEdu, the KDE Education Project][8]. Nobody could better describe what Step does than the people who made it. According to the project webpage, “[Step] works like this: you place some bodies on the scene, add some forces such as gravity or springs, then click “Simulate” and Step shows you how your scene will evolve according to the laws of physics. You can change every property of bodies/forces in your experiment (even during simulation) and see how this will change the outcome of the experiment. With Step, you can not only learn but feel how physics works!”
-
-While of course it requires Qt and loads of KDE-specific dependencies to work, projects like this (and KDEEdu itself) are part of the reason why KDE is such an awesome environment (if you don’t mind running a heavier desktop, of course).
-
-Step is in the Debian repositories; to install it on derivatives, simply type
-
- sudo apt-get install step
-
-into a terminal. On a KDE system it should have minimal dependencies and install in seconds.
-
-Step has a simple interface, and it lets you jump right into simulations.
-
-
-
-You will find all available objects on the left-hand side. You can have different particles, gas, shaped objects, springs, and different forces in action. (1) If you select an object, a short description of it will appear on the right-hand side (2). On the right you will also see an overview of the “world” you have created (the objects it contains) (3), the properties of the currently selected object (4), and the steps you have taken so far (5).
-
-
-
-Once you have placed all you wanted on the canvas, just press “Simulate,” and watch the events unfold as the objects interact with each other.
-
-
-
-
-
-
-
-To get to know Step better you only need to press F1. The KDE Help Center offers a great and detailed Step handbook.
-
-### 2. Lightspeed ###
-
-Lightspeed is a simple GTK+ and OpenGL based simulator that is meant to demonstrate the effect of how one might observe a fast moving object. Lightspeed will simulate these effects based on Einstein’s special relativity. According to [their sourceforge page][9] “When an object accelerates to more than a few million meters per second, it begins to appear warped and discolored in strange and unusual ways, and as it approaches the speed of light (299,792,458 m/s) the effects become more and more bizarre. In addition, the manner in which the object is distorted varies drastically with the viewpoint from which it is observed.”
-
-These effects which come into play at relative velocities are:
-
-- **The Lorentz contraction** – causes the object to appear shorter
-- **The Doppler red/blue shift** – alters the hues of color observed
-- **The headlight effect** – brightens or darkens the object
-- **Optical aberration** – deforms the object in unusual ways
-
-Lightspeed is in the Debian repositories; to install it, simply type:
-
- sudo apt-get install lightspeed
-
-The user interface is very simple. You get a shape (more can be downloaded from sourceforge) which would move along the x-axis (animation can be started by processing “A” or by selecting it from the object menu).
-
-
-
-You control the speed of its movement with the right-hand side slider and watch how it deforms.
-
-
-
-Some simple controls will allow you to add more visual elements
-
-
-
-The viewing angles can be adjusted by pressing either the left, middle or right button and dragging the mouse or from the Camera menu that also offers some other adjustments like background colour or graphics mode.
-
-### Notable mention: Physion ###
-
-Physion looks like an interesting project and a great looking software to simulate physics in a much more colorful and fun way than the above examples would allow. Unfortunately, at the time of writing, the [official website][10] was experiencing problems, and the download page was unavailable.
-
-Judging from their Youtube videos, Physion must be worth installing once a download line becomes available. Until then we can just enjoy the this video demo.
-
-注:youtube 视频
-
-
-Do you have another favorite physics simulation/demonstration/learning applications for Linux? Please share with us in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://www.maketecheasier.com/linux-physics-simulation/
-
-作者:[Attila Orosz][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.maketecheasier.com/author/attilaorosz/
-[1]:https://www.maketecheasier.com/series/learn-with-linux/
-[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
-[3]:https://www.maketecheasier.com/linux-physics-simulation/
-[4]:https://www.maketecheasier.com/linux-learning-music/
-[5]:https://www.maketecheasier.com/linux-geography-apps/
-[6]:https://www.maketecheasier.com/learn-linux-maths/
-[7]:https://edu.kde.org/applications/all/step
-[8]:https://edu.kde.org/
-[9]:http://lightspeed.sourceforge.net/
-[10]:http://www.physion.net/
\ No newline at end of file
diff --git a/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 4--Grep Count Lines If a String or Word Matches.md b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 4--Grep Count Lines If a String or Word Matches.md
new file mode 100644
index 0000000000..cc11cf85c2
--- /dev/null
+++ b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 4--Grep Count Lines If a String or Word Matches.md
@@ -0,0 +1,33 @@
+Grep Count Lines If a String / Word Matches
+================================================================================
+How do I count lines if given word or string matches for each input file under Linux or UNIX operating systems?
+
+You need to pass the -c or --count option to suppress normal output. It will display a count of matching lines for each input file:
+
+ $ grep -c vivek /etc/passwd
+
+OR
+
+ $ grep -w -c vivek /etc/passwd
+
+Sample outputs:
+
+ 1
+
+However, with the -v or --invert-match option it will count non-matching lines, enter:
+
+ $ grep -c vivek /etc/passwd
+
+Sample outputs:
+
+ 45
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/faq/grep-count-lines-if-a-string-word-matches/
+
+作者:Vivek Gite
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
\ No newline at end of file
diff --git a/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 5--Grep From Files and Display the File Name.md b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 5--Grep From Files and Display the File Name.md
new file mode 100644
index 0000000000..6fa9dc7a27
--- /dev/null
+++ b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 5--Grep From Files and Display the File Name.md
@@ -0,0 +1,67 @@
+Grep From Files and Display the File Name
+================================================================================
+How do I grep from a number of files and display the file name only?
+
+When there is more than one file to search it will display file name by default:
+
+ grep "word" filename
+ grep root /etc/*
+
+Sample outputs:
+
+ /etc/bash.bashrc: See "man sudo_root" for details.
+ /etc/crontab:17 * * * * root cd / && run-parts --report /etc/cron.hourly
+ /etc/crontab:25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
+ /etc/crontab:47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
+ /etc/crontab:52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
+ /etc/group:root:x:0:
+ grep: /etc/gshadow: Permission denied
+ /etc/logrotate.conf: create 0664 root utmp
+ /etc/logrotate.conf: create 0660 root utmp
+
+The first name is file name (e.g., /etc/crontab, /etc/group). The -l option will only print filename if th
+
+ grep -l "string" filename
+ grep -l root /etc/*
+
+Sample outputs:
+
+ /etc/aliases
+ /etc/arpwatch.conf
+ grep: /etc/at.deny: Permission denied
+ /etc/bash.bashrc
+ /etc/bash_completion
+ /etc/ca-certificates.conf
+ /etc/crontab
+ /etc/group
+
+You can suppress normal output; instead print the name of each input file from **which no output would normally have been** printed:
+
+ grep -L "word" filename
+ grep -L root /etc/*
+
+Sample outputs:
+
+ /etc/apm
+ /etc/apparmor
+ /etc/apparmor.d
+ /etc/apport
+ /etc/apt
+ /etc/avahi
+ /etc/bash_completion.d
+ /etc/bindresvport.blacklist
+ /etc/blkid.conf
+ /etc/bluetooth
+ /etc/bogofilter.cf
+ /etc/bonobo-activation
+ /etc/brlapi.key
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/faq/grep-from-files-and-display-the-file-name/
+
+作者:Vivek Gite
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
\ No newline at end of file
diff --git a/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 6--How To Find Files by Content Under UNIX.md b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 6--How To Find Files by Content Under UNIX.md
new file mode 100644
index 0000000000..3d5943fc07
--- /dev/null
+++ b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 6--How To Find Files by Content Under UNIX.md
@@ -0,0 +1,66 @@
+How To Find Files by Content Under UNIX
+================================================================================
+I had written lots of code in C for my school work and saved it as source code under /home/user/c/*.c and *.h. How do I find files by content such as string or words (function name such as main() under UNIX shell prompt?
+
+You need to use the following tools:
+
+[a] **grep command** : print lines matching a pattern.
+
+[b] **find command**: search for files in a directory hierarchy.
+
+### [grep Command To Find Files By][1] Content ###
+
+Type the command as follows:
+
+ grep 'string' *.txt
+ grep 'main(' *.c
+ grep '#include' *.c
+ grep 'getChar*' *.c
+ grep -i 'ultra' *.conf
+ grep -iR 'ultra' *.conf
+
+Where
+
+- **-i** : Ignore case distinctions in both the PATTERN (match valid, VALID, ValID string) and the input files (math file.c FILE.c FILE.C filename).
+- **-R** : Read all files under each directory, recursively
+
+### Highlighting searched patterns ###
+
+You can highlight patterns easily while searching large number of files:
+
+ $ grep --color=auto -iR 'getChar();' *.c
+
+### Displaying file names and line number for searched patterns ###
+
+You may also need to display filenames and numbers:
+
+ $ grep --color=auto -iRnH 'getChar();' *.c
+
+Where,
+
+- **-n** : Prefix each line of output with the 1-based line number within its input file.
+- **-H** Print the file name for each match. This is the default when there is more than one file to search.
+
+ $grep --color=auto -nH 'DIR' *
+
+Sample output:
+
+
+
+Fig.01: grep command displaying searched pattern
+
+You can also use find command:
+
+ $ find . -name "*.c" -print | xargs grep "main("
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/faq/unix-linux-finding-files-by-content/
+
+作者:Vivek Gite
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.cyberciti.biz/faq/howto-search-find-file-for-text-string/
\ No newline at end of file
diff --git a/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 7--Linux or UNIX View Only Configuration File Directives Uncommented Lines of a Config File.md b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 7--Linux or UNIX View Only Configuration File Directives Uncommented Lines of a Config File.md
new file mode 100644
index 0000000000..d7d520326e
--- /dev/null
+++ b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 7--Linux or UNIX View Only Configuration File Directives Uncommented Lines of a Config File.md
@@ -0,0 +1,151 @@
+Linux / UNIX View Only Configuration File Directives ( Uncommented Lines of a Config File )
+================================================================================
+Most Linux and UNIX-like system configuration files are documented using comments, but some time I just need to see line of configuration text in a config file. How can I view just the uncommented configuration file directives from squid.conf or httpd.conf file? How can I strip out comments and blank lines on a Linux or Unix-like systems?
+
+To view just the uncommented lines of text in a config file use the grep, sed, awk, perl or any other text processing utility provided by UNIX / BSD / OS X / Linux operating systems.
+
+### grep command example to strip out command ###
+
+You can use the gerp command as follows:
+
+ $ grep -v "^#" /path/to/config/file
+ $ grep -v "^#" /etc/apache2/apache2.conf
+
+Sample outputs:
+
+ ServerRoot "/etc/apache2"
+
+ LockFile /var/lock/apache2/accept.lock
+
+ PidFile ${APACHE_PID_FILE}
+
+ Timeout 300
+
+ KeepAlive On
+
+ MaxKeepAliveRequests 100
+
+ KeepAliveTimeout 15
+
+
+
+ StartServers 5
+ MinSpareServers 5
+ MaxSpareServers 10
+ MaxClients 150
+ MaxRequestsPerChild 0
+
+
+
+ StartServers 2
+ MinSpareThreads 25
+ MaxSpareThreads 75
+ ThreadLimit 64
+ ThreadsPerChild 25
+ MaxClients 150
+ MaxRequestsPerChild 0
+
+
+
+ StartServers 2
+ MaxClients 150
+ MinSpareThreads 25
+ MaxSpareThreads 75
+ ThreadLimit 64
+ ThreadsPerChild 25
+ MaxRequestsPerChild 0
+
+
+ User ${APACHE_RUN_USER}
+ Group ${APACHE_RUN_GROUP}
+
+
+ AccessFileName .htaccess
+
+
+ Order allow,deny
+ Deny from all
+ Satisfy all
+
+
+ DefaultType text/plain
+
+
+ HostnameLookups Off
+
+ ErrorLog /var/log/apache2/error.log
+
+ LogLevel warn
+
+ Include /etc/apache2/mods-enabled/*.load
+ Include /etc/apache2/mods-enabled/*.conf
+
+ Include /etc/apache2/httpd.conf
+
+ Include /etc/apache2/ports.conf
+
+ LogFormat "%v:%p %h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" vhost_combined
+ LogFormat "%h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" combined
+ LogFormat "%h %l %u %t \"%r\" %>s %O" common
+ LogFormat "%{Referer}i -> %U" referer
+ LogFormat "%{User-agent}i" agent
+
+ CustomLog /var/log/apache2/other_vhosts_access.log vhost_combined
+
+
+
+ Include /etc/apache2/conf.d/
+
+ Include /etc/apache2/sites-enabled/
+
+To suppress blank lines use [egrep command][1], run:
+
+ egrep -v "^#|^$" /etc/apache2/apache2.conf
+ ## or pass it to the page such as more or less ##
+ egrep -v "^#|^$" /etc/apache2/apache2.conf | less
+
+ ## Bash function ######################################
+ ## or create function or alias and use it as follows ##
+ ## viewconfig /etc/squid/squid.conf ##
+ #######################################################
+ viewconfig(){
+ local f="$1"
+ [ -f "$1" ] && command egrep -v "^#|^$" "$f" || echo "Error $1 file not found."
+ }
+
+Sample output:
+
+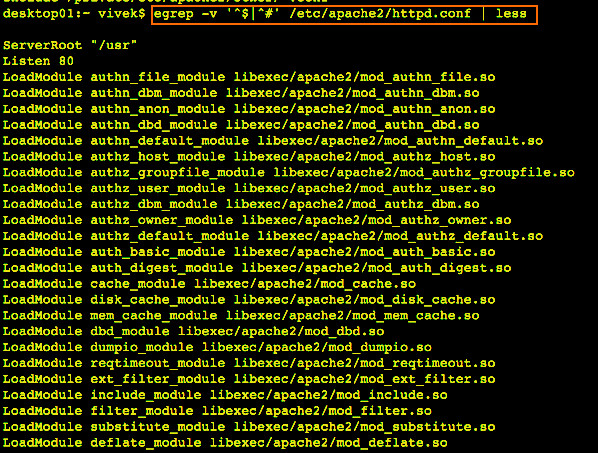
+
+Fig.01: Unix/Linux Egrep Strip Out Comments Blank Lines
+
+### Understanding grep/egrep command line options ###
+
+The -v option invert the sense of matching, to select non-matching lines. This option should work under all posix based systems. The regex ^$ matches and removes all blank lines and ^# matches and removes all comments that starts with a "#".
+
+### sed Command example ###
+
+GNU / sed command can be used as follows:
+
+ $ sed '/ *#/d; /^ *$/d' /path/to/file
+ $ sed '/ *#/d; /^ *$/d' /etc/apache2/apache2.conf
+
+GNU or BSD sed can update your config file too. The syntax is as follows to edit files in-place, saving backups with the specified extension such as .bak:
+
+ sed -i'.bak.2015.12.27' '/ *#/d; /^ *$/d' /etc/apache2/apache2.conf
+
+For more info see man pages - [grep(1)][2], [sed(1)][3]
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/faq/shell-display-uncommented-lines-only/
+
+作者:Vivek Gite
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.cyberciti.biz/faq/grep-regular-expressions/
+[2]:http://www.manpager.com/linux/man1/grep.1.html
+[3]:http://www.manpager.com/linux/man1/sed.1.html
\ No newline at end of file
diff --git a/translated/news/20151208 Apple Swift Programming Language Comes To Linux.md b/translated/news/20151208 Apple Swift Programming Language Comes To Linux.md
new file mode 100644
index 0000000000..fe2089345d
--- /dev/null
+++ b/translated/news/20151208 Apple Swift Programming Language Comes To Linux.md
@@ -0,0 +1,43 @@
+
+苹果编程语言Swift开始支持Linux
+================================================================================
+
+
+苹果也开源了?是的,苹果编程语言Swift已经开源了。其实我们并不应该感到意外,因为[在六个月以前苹果就已经宣布了这个消息][1]。
+
+苹果宣布这周将推出开源Swift社区。一个专用于开源Swift社区的[新网站][2]已经就位,网站首页显示以下信息:
+
+> 我们对Swift开源感到兴奋。在苹果推出了编程语言Swift之后,它很快成为历史上增长最快的语言之一。Swift可以编写出难以置信的又快又安全的软件。目前,Swift是开源的,你能帮助做出随处可用的最好的通用编程语言。
+
+[swift.org][2]这个网站将会作为一站式网站,它会提供各种资料的下载,包括各种平台,社区指南,最新消息,入门教程,贡献开源Swift的说明,文件和一些其他的指南。 如果你正期待着学习Swift,那么必须收藏这个网站。
+
+在苹果的这次宣布中,一个用于方便分享和构建代码的包管理器已经可用了。
+
+对于所有的Linux使用者来说,最重要的是,源代码已经可以从[Github][3]获得了.你可以从以下链接Checkout它:
+Most important of all for Linux users, the source code is now available at [Github][3]. You can check it out from the link below:
+
+- [苹果Swift源代码][3]
+
+除此之外,对于ubuntu 14.04和15.10版本还有预编译的二进制文件。
+
+- [ubuntu系统的Swift二进制文件][4]
+
+不要急着去使用它们,因为这些都是发展分支而且不适合于专用机器。因此现在避免使用,一旦发布了Linux下Swift的稳定版本,我希望ubuntu会把它包含在[umake][5]中靠近[Visual Studio][6]的地方。
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/swift-open-source-linux/
+
+作者:[Abhishek][a]
+译者:[Flowsnow](https://github.com/Flowsnow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://itsfoss.com/apple-open-sources-swift-programming-language-linux/
+[2]:https://swift.org/
+[3]:https://github.com/apple
+[4]:https://swift.org/download/#latest-development-snapshots
+[5]:https://wiki.ubuntu.com/ubuntu-make
+[6]:http://itsfoss.com/install-visual-studio-code-ubuntu/
diff --git a/translated/share/20151030 80 Linux Monitoring Tools for SysAdmins.md b/translated/share/20151030 80 Linux Monitoring Tools for SysAdmins.md
new file mode 100644
index 0000000000..7c16ca9fc8
--- /dev/null
+++ b/translated/share/20151030 80 Linux Monitoring Tools for SysAdmins.md
@@ -0,0 +1,604 @@
+
+为 Linux 系统管理员准备的80个监控工具
+================================================================================
+
+
+随着行业的不断发展,有许多比你想象中更棒的工具。这里列着网上最全的(工具)。拥有超过80种方式来管理你的机器。在本文中,我们主要讲述以下方面:
+
+- 命令行工具
+- 与网络相关的
+- 系统相关的监控工具
+- 日志监控工具
+- 基础设施监控工具
+
+监控和调试性能问题非常困难,但用对了正确的工具有时也是很容易的。下面是一些你可能听说过的工具,当你使用它们时可能存在一些问题:
+
+### 十大系统监控工具 ###
+
+#### 1. Top ####
+
+
+
+这是一个被预安装在许多 UNIX 系统中的小工具。当你想要查看在系统中运行的进程或线程时:top 是一个很好的工具。你可以对这些进程以不同的标准进行排序,默认是以 CPU 进行排序的。
+
+#### 2. [htop][1] ####
+
+
+
+HTOP 实质上是 top 的增强版本。它更容易对进程排序。它在视觉上更容易理解并且已经内建了许多通用的命令。它也是完全交互的。
+
+#### 3. [atop][2] ####
+
+Atop 和 top,htop 非常相似,它也能监控所有进程,但不同于 top 和 htop 的是,它会记录进程的日志供以后分析。它也能显示所有进程的资源消耗。它还会高亮显示已经达到临界负载的资源。
+
+#### 4. [apachetop][3] ####
+
+Apachetop 会监视 apache 网络服务器的整体性能。它主要是基于 mytop。它会显示当前 reads, writes 的数量以及 requests 进程的总数。
+
+#### 5. [ftptop][4] ####
+
+ftptop 给你提供了当前所有连接到 ftp 服务器的基本信息,如会话总数,正在上传和下载的客户端数量以及客户端信息。
+
+#### 6. [mytop][5] ####
+
+
+
+mytop 是一个很方便的工具,用于监控线程和 mysql 的性能。它给了你一个实时的数据库查询处理结果。
+
+#### 7. [powertop][6] ####
+
+
+
+powertop 可以帮助你诊断与电量消耗和电源管理相关的问题。它也可以帮你进行电源管理设置,以实现对你服务器最有效的配置。你可以使用 tab 键进行选项切换。
+
+#### 8. [iotop][7] ####
+
+
+
+iotop 用于检查 I/O 的使用情况,并为你提供了一个类似 top 的界面来显示。它每列显示读和写的速率,每行代表一个进程。当出现等待 I/O 交换时,它也显示进程消耗时间的百分比。
+
+### 与网络相关的监控 ###
+
+#### 9. [ntopng][8] ####
+
+
+
+ntopng 是 ntop 的升级版,它提供了一个能使用浏览器进行网络监控的图形用户界面。它还有其他用途,如:定位主机,显示网络流量和 ip 流量分布并能进行分析。
+
+#### 10. [iftop][9] ####
+
+
+
+iftop 类似于 top,但它主要不是检查 cpu 的使用率而是监听网卡的流量,并以表格的形式显示当前的使用量。像“为什么我的网速这么慢呢?!”这样的问题它可以直接回答。
+
+#### 11. [jnettop][10] ####
+
+
+
+jnettop 以相同的方式来监测网络流量但比 iftop 更形象。它还支持自定义的文本输出并能以友好的交互方式来快速分析日志。
+
+#### 12. [bandwidthd][11] ####
+
+
+
+bandwidthd 可以跟踪 TCP/IP 网络子网的使用情况并能在浏览器中通过 png 图片形象化的构建一个 HTML 页面。它有一个数据库驱动系统,支持搜索,过滤,多传感器和自定义报表。
+
+#### 13. [EtherApe][12] ####
+
+EtherApe 以图形化显示网络流量,可以支持更多的节点。它可以捕获实时流量信息,也可以从 tcpdump 进行读取。也可以使用具有 pcap 语法的网络过滤显示特定信息。
+
+#### 14. [ethtool][13] ####
+
+
+
+ethtool 用于显示和修改网络接口控制器的一些参数。它也可以用来诊断以太网设备,并获得更多的统计数据。
+
+#### 15. [NetHogs][14] ####
+
+
+
+NetHogs 打破了网络流量按协议或子网进行统计的原理。它以进程组来计算。所以,当网络流量猛增时,你可以使用 NetHogs 查看是由哪个进程造成的。
+
+#### 16. [iptraf][15] ####
+
+
+
+iptraf 收集的各种指标,如 TCP 连接数据包和字节数,接口界面和活动指标,TCP/UDP 通信故障,站内数据包和字节数。
+
+#### 17. [ngrep][16] ####
+
+
+
+ngrep 就是 grep 但是相对于网络层的。pcap 意识到后允许其指定扩展规则或十六进制表达式来匹配数据包。
+
+#### 18. [MRTG][17] ####
+
+
+
+MRTG 最初被开发来监控路由器的流量,但现在它也能够监控网络相关的东西。它每五分钟收集一次,然后产生一个 HTML 页面。它还具有发送邮件报警的能力。
+
+#### 19. [bmon][18] ####
+
+
+
+Bmon 能监控并帮助你调试网络。它能捕获网络相关的统计数据,并以友好的方式进行展示。你还可以与 bmon 通过脚本进行交互。
+
+#### 20. traceroute ####
+
+
+
+Traceroute 一个内置工具,能测试路由和数据包在网络中的延迟。
+
+#### 21. [IPTState][19] ####
+
+IPTState 可以让你跨越 iptables 来监控流量,并通过你指定的条件来进行排序。该工具还允许你从表中删除状态信息。
+
+#### 22. [darkstat][20] ####
+
+
+
+Darkstat 能捕获网络流量并计算统计的数据。该报告需要在浏览器中进行查看,它为你提供了一个非常棒的图形用户界面。
+
+#### 23. [vnStat][21] ####
+
+
+
+vnStat 是一个网络流量监控工具,它的数据统计是由内核进行提供的,其消耗的系统资源非常少。系统重新启动后,它收集的数据仍然存在。它具有颜色选项供系统管理员使用。
+
+#### 24. netstat ####
+
+
+
+netstat 是一个内置的工具,它能显示 TCP 网络连接,路由表和网络接口数量,被用来在网络中查找问题。
+
+#### 25. ss ####
+
+并非 netstat,最好使用 ss。ss 命令能够显示的信息比 netstat 更多,也更快。如果你想查看统计结果的总信息,你可以使用命令 `ss -s`。
+
+#### 26. [nmap][22] ####
+
+
+
+Nmap 可以扫描你服务器开放的端口并且可以检测正在使用哪个操作系统。但你也可以使用 SQL 注入漏洞,网络发现和渗透测试相关的其他手段。
+
+#### 27. [MTR][23] ####
+
+
+
+MTR 结合了 traceroute 和 ping 的功能到一个网络诊断工具上。当使用该工具时,它会限制单个数据包的跳数,同时也监视它们的到期时间。然后每秒进行重复。
+
+#### 28. [Tcpdump][24] ####
+
+
+
+Tcpdump 将输出一个你在命令中匹配并捕获到的数据包的信息。你还可以将此数据保存并进一步分析。
+
+#### 29. [Justniffer][25] ####
+
+
+
+Justniffer 是 tcp 数据包嗅探器。使用此嗅探器你可以选择收集低级别的数据还是高级别的数据。它也可以让你以自定义方式生成日志。比如模仿 Apache 的访问日志。
+
+### 与系统有关的监控 ###
+
+#### 30. [nmon][26] ####
+
+
+
+nmon 将数据输出到屏幕上的,或将其保存在一个以逗号分隔的文件中。你可以查看 CPU,内存,网络,文件系统,top 进程。数据也可以被添加到 RRD 数据库中用于进一步分析。
+
+#### 31. [conky][27] ####
+
+
+
+Conky 能监视不同操作系统并统计数据。它支持 IMAP 和 POP3, 甚至许多流行的音乐播放器!出于方便不同的人,你可以使用自己的 Lua 脚本或程序来进行扩展。
+
+#### 32. [Glances][28] ####
+
+
+
+使用 Glances 监控你的系统,其旨在使用最小的空间为你呈现最多的信息。它可以在客户端/服务器端模式下运行,也有远程监控的能力。它也有一个 Web 界面。
+
+#### 33. [saidar][29] ####
+
+
+
+Saidar 是一个非常小的工具,为你提供有关系统资源的基础信息。它将系统资源在全屏进行显示。重点是 saidar 会尽可能的简化。
+
+#### 34. [RRDtool][30] ####
+
+
+
+RRDtool 是用来处理 RRD 数据库的工具。RRDtool 旨在处理时间序列数据,如 CPU 负载,温度等。该工具提供了一种方法来提取 RRD 数据并以图形界面显示。
+
+#### 35. [monit][31] ####
+
+
+
+如果出现故障时,monit 有发送警报以及重新启动服务的功能。它可以对任何类型进行检查,你可以为 monit 写一个脚本,它有一个 Web 用户界面来分担你眼睛的压力。
+
+#### 36. [Linux process explorer][32] ####
+
+
+
+Linux process explorer 是类似 OSX 或 Windows 的在线监视器。它比 top 或 ps 的使用范围更广。你可以查看每个进程的内存消耗以及 CPU 的使用情况。
+
+#### 37. df ####
+
+
+
+df 是 disk free 的缩写,它是所有 UNIX 系统预装的程序,用来显示用户有访问权限的文件系统的可用磁盘空间。
+
+#### 38. [discus][33] ####
+
+
+
+Discus 类似于 df,它的目的是通过使用更吸引人的特性,如颜色,图形和数字来对 df 进行改进。
+
+#### 39. [xosview][34] ####
+
+
+
+xosview 是一款经典的系统监控工具,它给你提供包括 IRQ 的各个不同部分的总览。
+
+#### 40. [Dstat][35] ####
+
+
+
+Dstat 旨在替代 vmstat,iostat,netstat 和 ifstat。它可以让你查实时查看所有的系统资源。这些数据可以导出为 CSV。最重要的是 dstat 允许使用插件,因此其可以扩展到更多领域。
+
+#### 41. [Net-SNMP][36] ####
+
+SNMP 是“简单网络管理协议”,Net-SNMP 工具套件使用该协议可帮助你收集服务器的准确信息。
+
+#### 42. [incron][37] ####
+
+Incron 允许你监控一个目录树,然后对这些变化采取措施。如果你想将目录‘a’中的新文件复制到目录‘b’,这正是 incron 能做的。
+
+#### 43. [monitorix][38] ####
+
+Monitorix 是轻量级的系统监控工具。它可以帮助你监控一台机器,并为你提供丰富的指标。它也有一个内置的 HTTP 服务器,来查看图表和所有指标的报告。
+
+#### 44. vmstat ####
+
+
+
+vmstat(virtual memory statistics)是一个小的内置工具,能监控和显示机器的内存。
+
+#### 45. uptime ####
+
+这个小程序能快速显示你机器运行了多久,目前有多少用户登录和系统过去1分钟,5分钟和15分钟的平均负载。
+
+#### 46. mpstat ####
+
+
+
+mpstat 是一个内置的工具,能监视 cpu 的使用情况。最常见的使用方法是 `mpstat -P ALL`,它给你提供 cpu 的使用情况。你也可以间隔更新 cpu 的使用情况。
+
+#### 47. pmap ####
+
+
+
+pmap 是一个内置的工具,报告一个进程的内存映射。你可以使用这个命令来找出内存瓶颈的原因。
+
+#### 48. ps ####
+
+
+
+该命令将给你当前所有进程的概述。你可以使用 `ps -A` 命令查看所有进程。
+
+#### 49. [sar][39] ####
+
+
+
+sar 是 sysstat 包的一部分,可以帮助你收集,报告和保存不同系统的指标。使用不同的参数,它会给你提供 CPU, 内存 和 I/O 使用情况及其他东西。
+
+#### 50. [collectl][40] ####
+
+
+
+类似于 sar,collectl 收集你机器的性能指标。默认情况下,显示 cpu,网络和磁盘统计数据,但它实际收集了很多信息。与 sar 不同的是,collectl 能够处理比秒更小的单位,它可以被直接送入绘图工具并且 collectl 的监控过程更广泛。
+
+#### 51. [iostat][41] ####
+
+
+
+iostat 也是 sysstat 包的一部分。此命令用于监控系统的输入/输出。其报告可以用来进行系统调优,以更好地调节你机器上硬盘的输入/输出负载。
+
+#### 52. free ####
+
+
+
+这是一个内置的命令用于显示你机器上可用的内存大小以及已使用的内存大小。它还可以显示某时刻内核所使用的缓冲区大小。
+
+#### 53. /Proc 文件系统 ####
+
+
+
+proc 文件系统可以让你查看内核的统计信息。从这些统计数据可以得到你机器上不同硬件设备的详细信息。看看这个 [ proc文件统计的完整列表 ][42]。
+
+#### 54. [GKrellM][43] ####
+
+GKrellm 是一个图形应用程序来监控你硬件的状态信息,像CPU,内存,硬盘,网络接口以及其他的。它也可以监视并启动你所选择的邮件阅读器。
+
+#### 55. [Gnome 系统监控器][44] ####
+
+
+
+Gnome 系统监控器是一个基本的系统监控工具,其能通过一个树状结构来查看进程的依赖关系,能杀死及调整进程优先级,还能以图表形式显示所有服务器的指标。
+
+### 日志监控工具 ###
+
+#### 56. [GoAccess][45] ####
+
+
+
+GoAccess 是一个实时的网络日志分析器,它能分析 apache, nginx 和 amazon cloudfront 的访问日志。它也可以将数据输出成 HTML,JSON 或 CSV 格式。它会给你一个基本的统计信息,访问量,404页面,访客位置和其他东西。
+
+#### 57. [Logwatch][46] ####
+
+Logwatch 是一个日志分析系统。它通过分析系统的日志,并为你所指定的区域创建一个分析报告。它每天给你一个报告可以让你花费更少的时间来分析日志。
+
+#### 58. [Swatch][47] ####
+
+
+
+像 Logwatch 一样,Swatch 也监控你的日志,但不是给你一个报告,它会匹配你定义的正则表达式,当匹配到后会通过邮件或控制台通知你。它可用于检测入侵者。
+
+#### 59. [MultiTail][48] ####
+
+
+
+MultiTail 可帮助你在多窗口下监控日志文件。你可以将这些日志文件合并成一个。它也像正则表达式一样使用不同的颜色来显示日志文件以方便你阅读。
+
+#### 系统工具 ####
+
+#### 60. [acct or psacct][49] ####
+
+acct 也称 psacct(取决于如果你使用 apt-get 还是 yum)可以监控所有用户执行的命令,包括 CPU 和内存在系统内所使用的时间。一旦安装完成后你可以使用命令 ‘sa’ 来查看。
+
+#### 61. [whowatch][50] ####
+
+类似 acct,这个工具监控系统上所有的用户,并允许你实时查看他们正在执行的命令及运行的进程。它将所有进程以树状结构输出,这样你就可以清楚地看到到底发生了什么。
+
+#### 62. [strace][51] ####
+
+
+
+strace 被用于诊断,调试和监控程序之间的相互调用过程。最常见的做法是用 strace 打印系统调用的程序列表,其可以看出程序是否像预期那样被执行了。
+
+#### 63. [DTrace][52] ####
+
+
+
+DTrace 可以说是 strace 的大哥。它动态地跟踪与检测代码实时运行的指令。它允许你深入分析其性能和诊断故障。但是,它并不简单,大约有1200本书中提到过它。
+
+#### 64. [webmin][53] ####
+
+
+
+Webmin 是一个基于 Web 的系统管理工具。它不需要手动编辑 UNIX 配置文件,并允许你远程管理系统。它有一对监控模块用于连接它。
+
+#### 65. stat ####
+
+
+
+Stat 是一个内置的工具,用于显示文件和文件系统的状态信息。它会显示文件被修改,访问或更改的信息。
+
+#### 66. ifconfig ####
+
+
+
+ifconfig 是一个内置的工具用于配置网络接口。大多数网络监控工具背后都使用 ifconfig 将其设置成混乱模式来捕获所有的数据包。你可以手动执行 `ifconfig eth0 promisc` 并使用 `ifconfig eth0 -promisc` 返回正常模式。
+
+#### 67. [ulimit][54] ####
+
+
+
+ulimit 是一个内置的工具,可监控系统资源,并可以限制任何监控资源不得超标。比如做一个 fork 炸弹,如果使用 ulimit 正确配置了将完全不受影响。
+
+#### 68. [cpulimit][55] ####
+
+CPULimit 是一个小工具用于监控并限制进程对 CPU 的使用率。其特别有用,能限制批处理作业对 CPU 的使用率保持在一定范围。
+
+#### 69. lshw ####
+
+
+
+lshw 是一个小的内置工具能提取关于本机硬件配置的详细信息。它可以输出 CPU 版本和主板配置。
+
+#### 70. w ####
+
+w 是一个内置命令用于显示当前登录用户的信息及他们所运行的进程。
+
+#### 71. lsof ####
+
+
+
+lsof 是一个内置的工具可让你列出所有打开的文件和网络连接。从那里你可以看到文件是由哪个进程打开的,基于进程名,可通过一个特定的用户来杀死属于某个用户的所有进程。
+
+### 基础架构监控工具 ###
+
+#### 72. Server Density ####
+
+
+
+我们的 [服务器监控工具][56]!它有一个 web 界面,使你可以进行报警设置并可以通过图表来查看所有系统的网络指标。你还可以设置监控的网站,无论是否在线。Server Density 允许你设置用户的权限,你可以根据我们的插件或 api 来扩展你的监控。该服务已经支持 Nagios 的插件了。
+
+#### 73. [OpenNMS][57] ####
+
+
+
+OpenNMS 主要有四个功能区:事件管理和通知;发现和配置;服务监控和数据收集。其设计可被在多种网络环境中定制。
+
+#### 74. [SysUsage][58] ####
+
+
+
+SysUsage 通过 Sar 和其他系统命令持续监控你的系统。一旦达到阈值它也可以进行报警通知。SysUsage 本身也可以收集所有的统计信息并存储在一个地方。它有一个 Web 界面可以让你查看所有的统计数据。
+
+#### 75. [brainypdm][59] ####
+
+
+
+brainypdm 是一个数据管理和监控工具,它能收集来自 nagios 或其它公共资源的数据并以图表显示。它是跨平台的,其基于 Web 并可自定义图形。
+
+#### 76. [PCP][60] ####
+
+
+
+PCP 可以收集来自多个主机的指标,并且效率很高。它也有一个插件框架,所以你可以把它收集的对你很重要的指标使用插件来管理。你可以通过任何一个 Web 界面或 GUI 访问图形数据。它比较适合大型监控系统。
+
+#### 77. [KDE 系统保护][61] ####
+
+
+
+这个工具既是一个系统监控器也是一个任务管理器。你可以通过工作表来查看多台机器的服务指标,如果一个进程需要被杀死或者你需要启动一个进程,它可以在 KDE 系统保护中来完成。
+
+#### 78. [Munin][62] ####
+
+
+
+Munin 既是一个网络也是系统监控工具,当一个指标超出给定的阈值时它会提供报警机制。它运用 RRDtool 创建图表,并且它也有 Web 界面来显示这些图表。它更强调的是即插即用的功能并且有许多可用的插件。
+
+#### 79. [Nagios][63] ####
+
+
+
+Nagios 是系统和网络监控工具,可帮助你监控多台服务器。当发生错误时它也有报警功能。它的平台也有很多的插件。
+
+#### 80. [Zenoss][64] ####
+
+
+
+Zenoss 提供了一个 Web 界面,使你可以监控所有的系统和网络指标。此外,它能自动发现网络资源和修改网络配置。并且会提醒你采取行动,它也支持 Nagios 的插件。
+
+#### 81. [Cacti][65] ####
+
+
+
+(和上一个一样!) Cacti 是一个网络图形解决方案,其使用 RRDtool 进行数据存储。它允许用户在预定的时间间隔进行投票服务并将结果以图形显示。Cacti 可以通过 shell 脚本扩展来监控你所选择的来源。
+
+#### 82. [Zabbix][66] ####
+
+
+
+Zabbix 是一个开源的基础设施监控解决方案。它使用了许多数据库来存放监控统计信息。其核心是用 C 语言编写,并在前端中使用 PHP。如果你不喜欢安装代理,Zabbix 可能是一个最好选择。
+
+### 附加部分: ###
+
+感谢您的建议。这是我们的一个附加部分,由于我们需要重新编排所有的标题,鉴于此,这是在最后的一个简短部分,根据您的建议添加的一些 Linux 监控工具:
+
+#### 83. [collectd][67] ####
+
+Collectd 是一个 Unix 守护进程来收集所有的监控数据。它采用了模块化设计并使用插件来填补一些缺陷。这样能使 collectd 保持轻量级并可进行定制。
+
+#### 84. [Observium][68] ####
+
+Observium 是一个自动发现网络的监控平台,支持普通的硬件平台和操作系统。Observium 专注于提供一个优美,功能强大,简单直观的界面来显示网络的健康和状态。
+
+#### 85. Nload ####
+
+这是一个命令行工具来监控网络的吞吐量。它很整洁,因为它使用两个图表和其他一些有用的数据类似传输的数据总量来对进出站流量进行可视化。你可以使用如下方法安装它:
+
+ yum install nload
+
+或者
+
+ sudo apt-get install nload
+
+#### 86. [SmokePing][69] ####
+
+SmokePing 可以跟踪你网络延迟,并对他们进行可视化。SmokePing 有一个流行的延迟测量插件。如果图形用户界面对你来说非常重要,现在有一个正在开发中的插件来实现此功能。
+
+#### 87. [MobaXterm][70] ####
+
+如果你整天在 windows 环境下工作。你可能会觉得 Windows 下受终端窗口的限制。MobaXterm 正是由此而来的,它允许你使用多个在 Linux 中相似的终端。这将会极大地帮助你在监控方面的需求!
+
+#### 88. [Shinken monitoring][71] ####
+
+Shinken 是一个监控框架,其是由 python 对 Nagios 进行完全重写的。它的目的是增强灵活性和管理更大环境。但仍保持所有的 nagios 配置和插件。
+
+--------------------------------------------------------------------------------
+
+via: https://blog.serverdensity.com/80-linux-monitoring-tools-know/
+
+作者:[Jonathan Sundqvist][a]
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+
+[a]:https://www.serverdensity.com/
+[1]:http://hisham.hm/htop/
+[2]:http://www.atoptool.nl/
+[3]:https://github.com/JeremyJones/Apachetop
+[4]:http://www.proftpd.org/docs/howto/Scoreboard.html
+[5]:http://jeremy.zawodny.com/mysql/mytop/
+[6]:https://01.org/powertop
+[7]:http://guichaz.free.fr/iotop/
+[8]:http://www.ntop.org/products/ntop/
+[9]:http://www.ex-parrot.com/pdw/iftop/
+[10]:http://jnettop.kubs.info/wiki/
+[11]:http://bandwidthd.sourceforge.net/
+[12]:http://etherape.sourceforge.net/
+[13]:https://www.kernel.org/pub/software/network/ethtool/
+[14]:http://nethogs.sourceforge.net/
+[15]:http://iptraf.seul.org/
+[16]:http://ngrep.sourceforge.net/
+[17]:http://oss.oetiker.ch/mrtg/
+[18]:https://github.com/tgraf/bmon/
+[19]:http://www.phildev.net/iptstate/index.shtml
+[20]:https://unix4lyfe.org/darkstat/
+[21]:http://humdi.net/vnstat/
+[22]:http://nmap.org/
+[23]:http://www.bitwizard.nl/mtr/
+[24]:http://www.tcpdump.org/
+[25]:http://justniffer.sourceforge.net/
+[26]:http://nmon.sourceforge.net/pmwiki.php
+[27]:http://conky.sourceforge.net/
+[28]:https://github.com/nicolargo/glances
+[29]:https://packages.debian.org/sid/utils/saidar
+[30]:http://oss.oetiker.ch/rrdtool/
+[31]:http://mmonit.com/monit
+[32]:http://sourceforge.net/projects/procexp/
+[33]:http://packages.ubuntu.com/lucid/utils/discus
+[34]:http://www.pogo.org.uk/~mark/xosview/
+[35]:http://dag.wiee.rs/home-made/dstat/
+[36]:http://www.net-snmp.org/
+[37]:http://inotify.aiken.cz/?section=incron&page=about&lang=en
+[38]:http://www.monitorix.org/
+[39]:http://sebastien.godard.pagesperso-orange.fr/
+[40]:http://collectl.sourceforge.net/
+[41]:http://sebastien.godard.pagesperso-orange.fr/
+[42]:http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
+[43]:http://members.dslextreme.com/users/billw/gkrellm/gkrellm.html
+[44]:http://freecode.com/projects/gnome-system-monitor
+[45]:http://goaccess.io/
+[46]:http://sourceforge.net/projects/logwatch/
+[47]:http://sourceforge.net/projects/swatch/
+[48]:http://www.vanheusden.com/multitail/
+[49]:http://www.gnu.org/software/acct/
+[50]:http://whowatch.sourceforge.net/
+[51]:http://sourceforge.net/projects/strace/
+[52]:http://dtrace.org/blogs/about/
+[53]:http://www.webmin.com/
+[54]:http://ss64.com/bash/ulimit.html
+[55]:https://github.com/opsengine/cpulimit
+[56]:https://www.serverdensity.com/server-monitoring/
+[57]:http://www.opennms.org/
+[58]:http://sysusage.darold.net/
+[59]:http://sourceforge.net/projects/brainypdm/
+[60]:http://www.pcp.io/
+[61]:https://userbase.kde.org/KSysGuard
+[62]:http://munin-monitoring.org/
+[63]:http://www.nagios.org/
+[64]:http://www.zenoss.com/
+[65]:http://www.cacti.net/
+[66]:http://www.zabbix.com/
+[67]:https://collectd.org/
+[68]:http://www.observium.org/
+[69]:http://oss.oetiker.ch/smokeping/
+[70]:http://mobaxterm.mobatek.net/
+[71]:http://www.shinken-monitoring.org/
diff --git a/translated/share/20151123 7 ways hackers can use Wi-Fi against you.md b/translated/share/20151123 7 ways hackers can use Wi-Fi against you.md
new file mode 100644
index 0000000000..623886b896
--- /dev/null
+++ b/translated/share/20151123 7 ways hackers can use Wi-Fi against you.md
@@ -0,0 +1,69 @@
+黑客利用Wi-Fi侵犯你隐私的七种方法
+================================================================================
+
+
+### 黑客利用Wi-Fi侵犯你隐私的七种方法 ###
+
+Wi-Fi — 既然方便又危险的东西!这里给大家介绍一下通过Wi-Fi连接泄露身份信息的七种方法和预防措施。
+
+
+
+### 利用免费热点 ###
+
+它们似乎无处不在,而且它们的数量会在[下一个四年里增加四倍][1]。但是它们当中很多都是不值得信任的,从你的登录凭证、email甚至更加敏感的账户,都能被黑客用一款名叫“sniffers”的软件截获 — 这款软件能截获到任何你通过该连接提交的信息。防止被黑客盯上的最好办法就是使用VPN(virtual private network),它能保护你的数据隐私它会加密你所输入的信息。
+
+
+
+### 网上银行 ###
+
+你可能认为没有人需要自己被提醒不要使用免费Wi-Fi来操作网上银行, 但网络安全厂商卡巴斯基实验室表示[全球超过100家银行因为网络黑客而损失9亿美元][2],由此可见还是有很多人因此受害。如果你真的想要在一家咖吧里使用免费真实的Wi-Fi,那么你应该向服务员确认网络名称。[在店里用路由器设置一个开放的无线连接][3]并将它的网络名称设置成店名是一件相当简单的事。
+
+
+
+### 始终开着Wi-Fi开关 ###
+
+如果你手机的Wi-Fi开关一直开着的,你会自动被连接到一个不安全的网络中去,你甚至都没有意识到。你可以利用你手机的[基于位置的Wi-Fi功能][4],如果它是可用的,那它会在你离开你所保存的网络范围后自动关闭你的Wi-Fi开关并在你回去之后再次开启。
+
+
+
+### 不使用防火墙 ###
+
+防火墙是你的第一道抵御恶意入侵的防线,它能有效地让你的电脑网络通畅并阻挡黑客和恶意软件。你应该时刻开启它除非你的杀毒软件有它自己的防火墙。
+
+
+
+### 浏览非加密网页 ###
+
+说起来很难过,[世界上排名前100万个网站中55%是不加密的][5],一个未加密的网站则会让传输的数据暴露在黑客的眼下。如果一个网页是安全的,你的浏览器则会有标明(比如说火狐浏览器是一把绿色的挂锁、Chrome蓝旗则是个绿色的图标)。但是一个安全的网站不能让你免于被劫持的风险,它能通过公共网络从你访问过的网站上窃取cookies,无论是不是正当网站与否。
+
+
+
+### 不更新你的安全防护软件 ###
+
+如果你想要确保你自己的网络是受保护的,就更新的路由器固件。你要做的就是进入你的路由器管理页面去检查,通常你能在厂商的官方网页上下载到最新的固件版本。
+
+
+
+### 不保护你的家用Wi-Fi ###
+
+不用说,设置一个复杂的密码和更改无线连接的默认名都是非常重要的。你还可以过滤你的MAC地址来让你的路由器只承认那些确认过的设备。
+
+**Josh Althuser**是一个开源支持者、网络架构师和科技企业家。在过去12年里,他花了很多时间去倡导使用开源软件来管理团队和项目,同时为网络应用程序提供企业级咨询并帮助它们走向市场。你可以联系[他的推特][6].
+
+--------------------------------------------------------------------------------
+
+via: http://www.networkworld.com/article/3003170/mobile-security/7-ways-hackers-can-use-wi-fi-against-you.html
+
+作者:[Josh Althuser][a]
+译者:[ZTinoZ](https://github.com/ZTinoZ)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://twitter.com/JoshAlthuser
+[1]:http://www.pcworld.com/article/243464/number_of_wifi_hotspots_to_quadruple_by_2015_says_study.html
+[2]:http://www.nytimes.com/2015/02/15/world/bank-hackers-steal-millions-via-malware.html?hp&action=click&pgtype=Homepage&module=first-column-region%C2%AEion=top-news&WT.nav=top-news&_r=3
+[3]:http://news.yahoo.com/blogs/upgrade-your-life/banking-online-not-hacked-182159934.html
+[4]:http://pocketnow.com/2014/10/15/should-you-leave-your-smartphones-wifi-on-or-turn-it-off
+[5]:http://www.cnet.com/news/chrome-becoming-tool-in-googles-push-for-encrypted-web/
+[6]:https://twitter.com/JoshAlthuser
diff --git a/translated/share/20151130 eSpeak--Text To Speech Tool For Linux.md b/translated/share/20151130 eSpeak--Text To Speech Tool For Linux.md
new file mode 100644
index 0000000000..271866ff47
--- /dev/null
+++ b/translated/share/20151130 eSpeak--Text To Speech Tool For Linux.md
@@ -0,0 +1,64 @@
+eSpeak: Linux文本转语音工具
+================================================================================
+
+
+[eSpeak][1]是Linux的命令行工具,能把文本转变成语音。这是一款用C语言写就的精致的语音合成器,提供英语和其它多种语言支持。
+
+eSpeak从标准输入或者输入文件中读取文本。虽然语音输出与真人声音相去甚远,但是,在你项目有用得到的地方,eSpeak仍不失为一个精致快捷的工具。
+
+eSpeak部分主要特性如下:
+
+- 为Linux和Windows准备的命令行工具
+- 从文件或者标准输入中把文本读出来
+- 提供给其它程序使用的共享库版本
+- 为Windows提供SAPI5版本,在screen-readers或者其它支持Windows SAPI5接口程序的支持下,eSpeak仍然能正常使用
+- 可移植到其它平台,包括安卓,OSX等
+- 多种特色声音提供选择
+- 语音输出可保存为[.WAV][2]格式的文件
+- 部分SSML([Speech Synthesis Markup Language][3])能为HTML所支持
+- 体积小巧,整个程序包括语言支持等占用不足2MB
+- 可以实现文本到音素编码的转化,能被其它语音合成引擎吸纳为前端工具
+- 可作为生成和调制音素数据的开发工具
+
+### 安装eSpeak ###
+
+基于Ubuntu的系统中,在终端运行以下命令安装eSpeak:
+
+ sudo apt-get install espeak
+
+eSpeak is an old tool and I presume that it should be available in the repositories of other Linux distributions such as Arch Linux, Fedora etc. You can install eSpeak easily using dnf, pacman etc.eSpeak是一个古老的工具,我推测它应该能在其它众多Linux发行版如Arch,Fedora中运行。使用dnf,pacman等命令就能轻易安装。
+
+eSpeak用法如下:输入espeak按enter键运行程序。输入字符按enter转换为语音输出(译补)。使用Ctrl+C来关闭运行中的程序。
+
+
+
+还有其它可以的选项,可以通过程序帮助进行查看。
+
+### GUI版本:Gespeaker ###
+
+如果你更倾向于使用GUI版本,可以安装Gespeaker,它为eSpeak提供了GTK界面。
+
+使用以下命令来安装Gespeaker:
+
+ sudo apt-get install gespeaker
+
+操作接口简明易用,你完全可以自行探索。
+
+
+
+虽然这个工具不能为大部分计算所用,但是当你的项目需要把文本转换成语音,espeak还是挺方便使用的。需则用之吧~
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/espeak-text-speech-linux/
+
+作者:[Abhishek][a]
+译者:[译者ID](https://github.com/soooogreen)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://espeak.sourceforge.net/
+[2]:http://en.wikipedia.org/wiki/WAV
+[3]:http://en.wikipedia.org/wiki/Speech_Synthesis_Markup_Language
diff --git a/translated/talk/20150820 Why did you start using Linux.md b/translated/talk/20150820 Why did you start using Linux.md
new file mode 100644
index 0000000000..aa48db697c
--- /dev/null
+++ b/translated/talk/20150820 Why did you start using Linux.md
@@ -0,0 +1,144 @@
+年轻人,你为啥使用 linux
+================================================================================
+> 今天的开源综述:是什么带你进入 linux 的世界?号外:IBM 基于 Linux 的大型机。以及,你应该抛弃 win10 选择 Linux 的原因。
+
+### 当初你为何使用 Linux? ###
+
+Linux 越来越流行,很多 OS X 或 Windows 用户都转移到 Linux 阵营了。但是你知道是什么让他们开始使用 Linux 的吗?一个 Reddit 用户在网站上问了这个问题,并且得到了很多有趣的回答。
+
+一个名为 SilverKnight 的用户在 Reddit 的 Linux 板块上问了如下问题:
+
+> 我知道这个问题肯定被问过了,但我还是想听听年轻一代使用 Linux 的原因,以及是什么让他们坚定地成为 Linux 用户。
+>
+> 我无意阻止大家讲出你们那些精彩的 Linux 故事,但是我还是对那些没有经历过什么精彩故事的新人的想法比较感兴趣。
+>
+> 我27岁,半吊子 Linux 用户,这些年装过不少发行版,但没有投入全部精力去玩 Linux。我正在找更多的、能让我全身心投入到 Linux 潮流的理由,或者说激励。
+>
+> [详见 Reddit][1]
+
+以下是网站上的回复:
+
+> **DoublePlusGood**:我12岁开始使用 Backtrack(现在改名为 Kali),因为我想成为一名黑客(LCTT 译注:原文1337 haxor,1337 是 leet 的火星文写法,意为'火星文',haxor 为 hackor 的火星文写法,意为'黑客',另一种写法是 1377 h4x0r,满满的火星文文化)。我现在一直使用 ArchLinux,因为它给我无限自由,让我对我的电脑可以为所欲为。
+>
+> **Zack**:我记得是12、3岁的时候使用 Linux,现在15岁了。
+>
+> 我11岁的时候就对 Windows XP 感到不耐烦,一个简单的功能,比如关机,TMD 都要让我耐心等着它慢慢完成。
+>
+> 在那之前几个月,我在 freenode IRC 聊天室参与讨论了一个游戏,它是一个开源项目,大多数用户使用 Linux。
+>
+> 我不断听到 Linux 但当时对它还没有兴趣。然而由于这些聊天频道(大部分在 freenode 上)谈论了很多编程话题,我就开始学习 python 了。
+>
+> 一年后我尝试着安装 GNU/Linux (主要是 ubuntu)到我的新电脑(其实不新,但它是作为我的生日礼物被我得到的)。不幸的是它总是不能正常工作,原因未知,也许硬盘坏了,也许灰尘太多了。
+>
+> 那时我放弃自己解决这个问题,然后缠着老爸给我的电脑装上 Ubuntu,他也无能为力,原因同上。
+>
+> 在追求 Linux 一段时间后,我打算抛弃 Windows,使用 Linux Mint 代替 Ubuntu,本来没抱什么希望,但 Linux Mint 竟然能跑起来!
+>
+> 于是这个系统我用了6个月。
+>
+> 那段时间我的一个朋友给了我一台虚拟机,跑 Ubuntu 的,我用了一年,直到我爸给了我一台服务器。
+>
+> 6个月后我得到一台新 PC(现在还在用)。于是起想折腾点不一样的东西。
+>
+> 我打算装 openSUSE。
+>
+> 我很喜欢这个系统。然后在圣诞节的时候我得到树莓派,上面只能跑 Debian,还不能支持其它发行版。
+>
+> **Cqz**:我9岁的时候有一次玩 Windows 98,结果这货当机了,原因未知。我没有 Windows 安装盘,但我爸的一本介绍编程的杂志上有一张随书附赠的光盘,这张光盘上刚好有 Mandrake Linux 的安装软件,于是我瞬间就成为了 Linux 用户。我当时还不知道自己在玩什么,但是玩得很嗨皮。这些年我虽然在电脑上装了多种 Windows 版本,但是 FLOSS 世界才是我的家。现在我只把 Windows 装在虚拟机上,用来玩游戏。
+>
+> **Tosmarcel**:15岁那年对'编程'这个概念很好奇,然后我开始了哈佛课程'CS50',这个课程要我们安装 Linux 虚拟机用来执行一些命令。当时我问自己为什么 Windows 没有这些命令?于是我 Google 了 Linux,搜索结果出现了 Ubuntu,在安装 Ubuntu。的时候不小心把 Windows 分区给删了。。。当时对 Linux 毫无所知,适应这个系统非常困难。我现在16岁,用 ArchLinux,不想用回 Windows,我爱 ArchLinux。
+>
+> **Micioonthet**:第一次听说 Linux 是在我5年级的时候,当时去我一朋友家,他的笔记本装的就是 MEPIS(Debian的一个比较老的衍生版),而不是 XP。
+>
+> 原来是他爸爸是个美国的社会学家,而他全家都不信任微软。我对这些东西完全陌生,这系统完全没有我熟悉的软件,我很疑惑他怎么能使用。
+>
+> 我13岁那年还没有自己的笔记本电脑,而我另一位朋友总是抱怨他的电脑有多慢,所以我打算把它买下来并修好它。我花了20美元买下了这台装着 Windows Vista 系统、跑满病毒、完全无法使用的惠普笔记本。我不想重装讨厌的 Windows 系统,记得 Linux 是免费的,所以我刻了一张 Ubuntu 14.04 光盘,马上把它装起来,然后我被它的高性能给震精了。
+>
+> 我的世界(由于它允运行在 JAVA 上,所以当时它是 Linux 下为数不多的几个游戏之一)在 Vista 上只能跑5帧每秒,而在 Ubuntu 上能跑到25帧。
+>
+> 我到现在还会偶尔使用一下那台笔记本,Linux 可不会在乎你的硬件设备有多老。
+>
+> 之后我把我爸也拉入 Linux 行列,我们会以很低的价格买老电脑,装上 Linux Mint 或其他轻量级发行版,这省了好多钱。
+>
+> **Webtm**:我爹每台电脑都会装多个发行版,有几台是 opensuse 和 Debian,他的个人电脑装的是 Slackware。所以我记得很小的时候一直在玩 debian,但没有投入很多精力,我用了几年的 Windows,然后我爹问我有没有兴趣试试 debian。这是个有趣的经历,在那之后我一直使用 debian。而现在我不用 Linux,转投 freeBSD,5个月了,用得很开心。
+>
+> 完全控制自己的系统是个很奇妙的体验。开源届有好多酷酷的软件,我认为在自己解决一些问题并且利用这些工具解决其他事情的过程是最有趣的。当然稳定和高效也是吸引我的地方。更不用说它的保密级别了。
+>
+> **Wyronaut**:我今年18,第一次玩 Linux 是13岁,当时玩的 Ubuntu,为啥要碰 Linux?因为我想搭一个'我的世界'的服务器来和小伙伴玩游戏,当时'我的世界'可是个新鲜玩意儿。而搭个私服需要用 Linux 系统。
+>
+> 当时我还是个新手,对着 Linux 的命令行有些傻眼,因为很多东西都要我自己处理。还是多亏了 Google 和维基,我成功地在多台老 PC 上部署了一些简单的服务器,那些早已无人问津的老古董机器又能发挥余热了。
+>
+> 跑过游戏服务器后,我又开始跑 web 服务器,先是跑了几年 HTML,CSS 和 PHP,之后受 TheNewBoston 视频的误导转到了 JAVA。
+>
+> 一周后放弃 JAVA 改用 Python,当时学习 Python 用的书名叫《Learn Python The Hard Way》,作者是 Zed A. Shaw。我花了两周学完 Python,然后开始看《C++ Primer》,因为我想做游戏开发。看到一半(大概500页)的时候我放弃了。那个时候我有点讨厌玩电脑了。
+>
+> 这样中断了一段时间之后,我决定学习 JavaScript,读了2本书,试了4个平台,然后又不玩了。
+>
+> 现在到了不得不找一所学校并决定毕业后找什么样工作的糟糕时刻。我不想玩图形界面编程,所以我不会进游戏行业。我也不喜欢画画和建模。然后我发现了一个涉及网络安全的专业,于是我立刻爱上它了。我挑了很多 C 语言的书来度过这个假期,并且复习了一下数学来迎接新的校园生活。
+>
+> 目前我玩 archlinux,不同 PC 上跑着不同任务,它们运行很稳定。
+>
+> 可以说 Linux 带我进入编程的世界,而反过来,我最终在学校要学的就是 Linux。我估计会终生感谢 Linux。
+>
+> **Linuxllc**:你们可以学学像我这样的老头。
+>
+> 扔掉 Windows!扔掉 Windows!扔掉 Windows!给自己一个坚持使用 Linux 的理由,那就是完全,彻底,远离,Windows。
+>
+> 我在 2003 年放弃 Windows,只用了5天就把所有电脑跑成 Linux,包括所有的外围设备(LCTT 译注:比如打印机?)。我不玩 Windows 里的游戏,只玩 Linux 里的。
+>
+> **Highclass**:我28岁,不知道还是不是你要找的年轻人类型。
+>
+> 老实说我对电脑挺感兴趣的,当我还没接触'自由软件哲学'的时候,我认为 free 是免费的意思。我也不认为命令行界面很让人难以接受,因为我小时候就接触过 DOS 系统。
+>
+> 我第一个发行版是 Mandrake,在我11岁还是12岁那年我把家里的电脑弄得乱七八糟,然后我一直折腾那台电脑,试着让我技的技能提升一个台阶。现在我在一家公司全职使用 Linux。(请允许我耸个肩)。
+>
+> **Matto**:我的电脑是旧货市场淘回来的,装 XP,跑得慢,于是我想换个系统。Google 了一下,发现 Ubuntu。当年我15、6岁,现在23了,就职的公司内部使用 Linux。
+>
+> [更多评论移步 Reddit][2]
+
+### IBM 的 Linux 大型机 ###
+
+IBM 很久前就用 Linux 了。现在这家公司退推出一款机器专门使用 Ubuntu,机器名叫 LinuxOne。
+
+Ron Miller 在 TecchCrunch 博客上说:
+
+> 新的大型机包括两款机型,都是以企鹅名称命名的(Linux 的吉祥物就是一只企鹅,懂18摸的命名用意了没?)第一款叫帝企鹅,使用 IBM z13 机型,我们早在1月份就介绍过了。另一款稍微小一点,名叫跳岩企鹅,供入门级买家使用。
+>
+> 也许你会以为大型机就像恐龙一样早就灭绝了,但世界上许多大型机构中都还在使用它们,它们还健在。作为发展云技术战略的一部分,数据分析与安全有望于提升 Ubuntu 大型机的市场,这种大型机能提供一系列开源的企业级软件,比如 Apache Spark,Node.js,MongoDB,MariaDB,PostgreSQL 和 Chef。
+>
+> 大型机还会存在于客户预置的数据中心中,但是市场的大小取决于会有多少客户使用这种类似于云服务的系统。Mauri 解释道,IBM 正在寻求增加大型机销量的途径,与 Canonical 公司合作,鼓励使用开源工具,都能为大型机打开一个小的,却能赚钱的市场。
+>
+>
+> [详情移步 TechCrunch][3]
+
+### 你为什么要放弃 Windows10 而选择 Linux ###
+
+自从 Windows10 出来以后,各种媒体都报道过它的隐藏间谍功能。ZDNet 列出了一些放弃 Windows10 的理由。
+
+SJVN 在 ZDNet 的报告:
+
+> 你试试关掉 Windows10 的数据分享功能,坏消息来了:window10 会继续把你的数据分享给微软公司。请选择 Linux 吧。
+>
+> 你可以有很多方法不让 Windows10 泄露你的秘密,但你不能阻止它交谈。Cortana,win10 小娜,语音助手,就算你把她关了,她也会把数据发给微软公司。这些数据包括你的电脑 ID,微软用它来识别你的 PC 机。
+>
+> 所以如果这些泄密给你带来了烦恼,你可以使用老版本 Windows7,或者换到 Linux。然而,当 Windows7 不再提供技术支持的那天到来,如果你还想保留隐私,最终你还是只能选择 Linux。
+>
+> 这里还有些小众的桌面系统能保护你的隐私,比如 BSD 家族的 FreeBSD,PCBSD,NetBSD,eComStation,OS/2。但是,最好的选择还是 Linux,它提供最低的学习曲线。
+>
+> [详情移步 ZDNet][4]
+
+--------------------------------------------------------------------------------
+
+via: http://www.itworld.com/article/2972587/linux/why-did-you-start-using-linux.html
+
+作者:[Jim Lynch][a]
+译者:[bazz2](https://github.com/bazz2)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.itworld.com/author/Jim-Lynch/
+[1]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
+[2]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
+[3]:http://techcrunch.com/2015/08/16/ibm-teams-with-canonical-on-linux-mainframe/
+[4]:http://www.zdnet.com/article/sick-of-windows-spying-on-you-go-linux/
diff --git a/translated/talk/20151124 Review--5 memory debuggers for Linux coding.md b/translated/talk/20151124 Review--5 memory debuggers for Linux coding.md
new file mode 100644
index 0000000000..b49ba9e40a
--- /dev/null
+++ b/translated/talk/20151124 Review--5 memory debuggers for Linux coding.md
@@ -0,0 +1,299 @@
+点评:Linux编程中五款内存调试器
+================================================================================
+
+Credit: [Moini][1]
+
+作为一个程序员,我知道我总在犯错误——事实是,怎么可能会不犯错的!程序员也是人啊。有的错误能在编码过程中及时发现,而有些却得等到软件测试才显露出来。然而,有一类错误并不能在这两个时期被排除,从而导致软件不能正常运行,甚至是提前中止。
+
+想到了吗?我说的就是内存相关的错误。手动调试这些错误不仅耗时,而且很难发现并纠正。值得一提的是,这种错误非常地常见,特别是在一些软件里,这些软件是用C/C++这类允许[手动管理内存][2]的语言编写的。
+
+幸运的是,现行有一些编程工具能够帮你找到软件程序中这些内存相关的错误。在这些工具集中,我评定了五款Linux可用的,流行、免费并且开源的内存调试器:Dmalloc、Electric Fence、 Memcheck、 Memwatch以及Mtrace。日常编码过程中我已经把这五个调试器用了个遍,所以这些点评是建立在我的实际体验之上的。
+
+### [Dmalloc][3] ###
+
+**开发者**:Gray Watson
+
+**点评版本**:5.5.2
+
+**Linux支持**:所有种类
+
+**许可**:知识共享署名-相同方式共享许可证3.0
+
+Dmalloc是Gray Watson开发的一款内存调试工具。它实现成库,封装了标准内存管理函数如**malloc(), calloc(), free()**等,使得程序员得以检测出有问题的代码。
+
+
+Dmalloc
+
+如同工具的网页所列,这个调试器提供的特性包括内存泄漏跟踪、[重复释放(double free)][4]错误跟踪、以及[越界写入(fence-post write)][5]检测。其它特性包括文件/行号报告、普通统计记录。
+
+#### 更新内容 ####
+
+5.5.2版本是一个[bug修复发行版][6],同时修复了构建和安装的问题。
+
+#### 有何优点 ####
+
+Dmalloc最大的优点是可以进行任意配置。比如说,你可以配置以支持C++程序和多线程应用。Dmalloc还提供一个有用的功能:运行时可配置,这表示在Dmalloc执行时,可以轻易地使能或者禁能它提供的特性。
+
+你还可以配合[GNU Project Debugger (GDB)][7]来使用Dmalloc,只需要将dmalloc.gdb文件(位于Dmalloc源码包中的contrib子目录里)的内容添加到你的主目录中的.gdbinit文件里即可。
+
+另外一个优点让我对Dmalloc爱不释手的是它有大量的资料文献。前往官网的[Documentation标签][8],可以获取任何内容,有关于如何下载、安装、运行,怎样使用库,和Dmalloc所提供特性的细节描述,及其输入文件的解释。里面还有一个章节介绍了一般问题的解决方法。
+
+#### 注意事项 ####
+
+跟Mtrace一样,Dmalloc需要程序员改动他们的源代码。比如说你可以(必须的)添加头文件**dmalloc.h**,工具就能汇报产生问题的调用的文件或行号。这个功能非常有用,因为它节省了调试的时间。
+
+除此之外,还需要在编译你的程序时,把Dmalloc库(编译源码包时产生的)链接进去。
+
+然而,还有点更麻烦的事,需要设置一个环境变量,命名为**DMALLOC_OPTION**,以供工具在运行时配置内存调试特性,以及输出文件的路径。可以手动为该环境变量分配一个值,不过初学者可能会觉得这个过程有点困难,因为你想使能的Dmalloc特性是存在于这个值之中的——表示为各自的十六进制值的累加。[这里][9]有详细介绍。
+
+一个比较简单方法设置这个环境变量是使用[Dmalloc实用指令][10],这是专为这个目的设计的方法。
+
+#### 总结 ####
+
+Dmalloc真正的优势在于它的可配置选项。而且高度可移植,曾经成功移植到多种操作系统如AIX、BSD/OS、DG/UX、Free/Net/OpenBSD、GNU/Hurd、HPUX、Irix、Linux、MS-DOG、NeXT、OSF、SCO、Solaris、SunOS、Ultrix、Unixware甚至Unicos(运行在Cray T3E主机上)。虽然Dmalloc有很多东西需要学习,但是它所提供的特性值得为之付出。
+
+### [Electric Fence][15] ###
+
+**开发者**:Bruce Perens
+
+**点评版本**:2.2.3
+
+**Linux支持**:所有种类
+
+**许可**:GNU 通用公共许可证 (第二版)
+
+Electric Fence是Bruce Perens开发的一款内存调试工具,它以库的形式实现,你的程序需要链接它。Electric Fence能检测出[栈][11]内存溢出和访问已经释放的内存。
+
+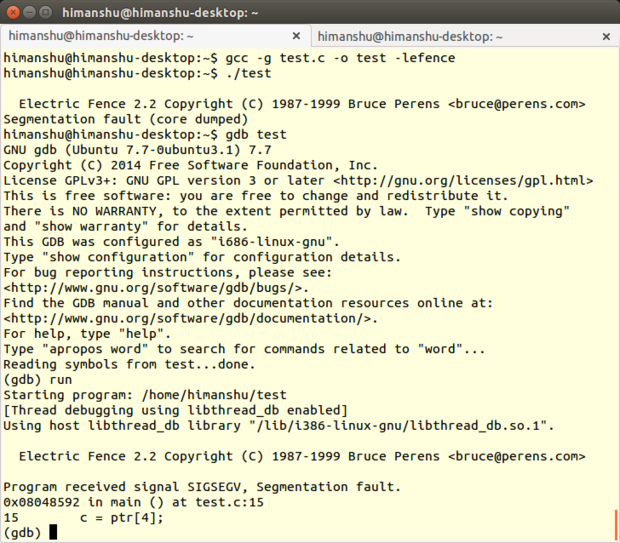
+Electric Fence
+
+顾名思义,Electric Fence在每个申请的缓存边界建立了fence(防护),任何非法内存访问都会导致[段错误][12]。这个调试工具同时支持C和C++编程。
+
+
+#### 更新内容 ####
+
+2.2.3版本修复了工具的构建系统,使得-fno-builtin-malloc选项能真正传给[GNU Compiler Collection (GCC)][13]。
+
+#### 有何优点 ####
+
+我喜欢Electric Fence首要的一点是(Memwatch、Dmalloc和Mtrace所不具有的),这个调试工具不需要你的源码做任何的改动,你只需要在编译的时候把它的库链接进你的程序即可。
+
+其次,Electric Fence实现一个方法,确认导致越界访问(a bounds violation)的第一个指令就是引起段错误的原因。这比在后面再发现问题要好多了。
+
+不管是否有检测出错误,Electric Fence经常会在输出产生版权信息。这一点非常有用,由此可以确定你所运行的程序已经启用了Electric Fence。
+
+#### 注意事项 ####
+
+另一方面,我对Electric Fence真正念念不忘的是它检测内存泄漏的能力。内存泄漏是C/C++软件最常见也是最难隐秘的问题之一。不过,Electric Fence不能检测出堆内存溢出,而且也不是线程安全的。
+
+基于Electric Fence会在用户分配内存区的前后分配禁止访问的虚拟内存页,如果你过多的进行动态内存分配,将会导致你的程序消耗大量的额外内存。
+
+Electric Fence还有一个局限是不能明确指出错误代码所在的行号。它所能做只是在监测到内存相关错误时产生段错误。想要定位行号,需要借助[The Gnu Project Debugger (GDB)][14]这样的调试工具来调试你启用了Electric Fence的程序。
+
+最后一点,Electric Fence虽然能检测出大部分的缓冲区溢出,有一个例外是,如果所申请的缓冲区大小不是系统字长的倍数,这时候溢出(即使只有几个字节)就不能被检测出来。
+
+#### 总结 ####
+
+尽管有那么多的局限,但是Electric Fence的优点却在于它的易用性。程序只要链接工具一次,Electric Fence就可以在监测出内存相关问题的时候报警。不过,如同前面所说,Electric Fence需要配合像GDB这样的源码调试器使用。
+
+
+### [Memcheck][16] ###
+
+**开发者**:[Valgrind开发团队][17]
+
+**点评版本**:3.10.1
+
+**Linux支持**:所有种类
+
+**许可**:通用公共许可证
+
+[Valgrind][18]是一个提供好几款调试和Linux程序性能分析工具的套件。虽然Valgrind和编写语言各不相同(有Java、Perl、Python、Assembly code、ortran、Ada等等)的程序配合工作,但是它所提供的工具大部分都意在支持C/C++所编写的程序。
+
+Memcheck作为内存错误检测器,是一款最受欢迎的Memcheck工具。它能够检测出诸多问题诸如内存泄漏、无效的内存访问、未定义变量的使用以及栈内存分配和释放相关的问题等。
+
+#### 更新内容 ####
+
+工具套件(3.10.1)的[发行版][19]是一个副版本,主要修复了3.10.0版本发现的bug。除此之外,从主版本backport一些包,修复了缺失的AArch64 ARMv8指令和系统调用。
+
+#### 有何优点 ####
+
+同其它所有Valgrind工具一样,Memcheck也是基本的命令行实用程序。它的操作非常简单:通常我们会使用诸如prog arg1 arg2格式的命令来运行程序,而Memcheck只要求你多加几个值即可,就像valgrind --leak-check=full prog arg1 arg2。
+
+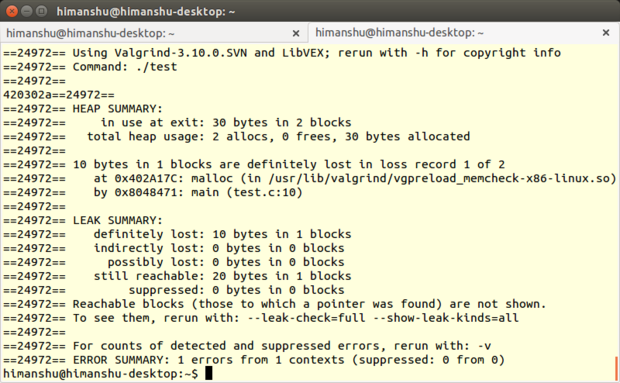
+Memcheck
+
+(注意:因为Memcheck是Valgrind的默认工具所以无需提及Memcheck。但是,需要在编译程序之初带上-g参数选项,这一步会添加调试信息,使得Memcheck的错误信息会包含正确的行号。)
+
+我真正倾心于Memcheck的是它提供了很多命令行选项(如上所述的--leak-check选项),如此不仅能控制工具运转还可以控制它的输出。
+
+举个例子,可以开启--track-origins选项,以查看程序源码中未初始化的数据。可以开启--show-mismatched-frees选项让Memcheck匹配内存的分配和释放技术。对于C语言所写的代码,Memcheck会确保只能使用free()函数来释放内存,malloc()函数来申请内存。而对C++所写的源码,Memcheck会检查是否使用了delete或delete[]操作符来释放内存,以及new或者new[]来申请内存。
+
+Memcheck最好的特点,尤其是对于初学者来说的,是它会给用户建议使用那个命令行选项能让输出更加有意义。比如说,如果你不使用基本的--leak-check选项,Memcheck会在输出时建议“使用--leak-check=full重新运行,查看更多泄漏内存细节”。如果程序有未初始化的变量,Memcheck会产生信息“使用--track-origins=yes,查看未初始化变量的定位”。
+
+Memcheck另外一个有用的特性是它可以[创建抑制文件(suppression files)][20],由此可以忽略特定不能修正的错误,这样Memcheck运行时就不会每次都报警了。值得一提的是,Memcheck会去读取默认抑制文件来忽略系统库(比如C库)中的报错,这些错误在系统创建之前就已经存在了。可以选择创建一个新的抑制文件,或是编辑现有的(通常是/usr/lib/valgrind/default.supp)。
+
+Memcheck还有高级功能,比如可以使用[定制内存分配器][22]来[检测内存错误][21]。除此之外,Memcheck提供[监控命令][23],当用到Valgrind的内置gdbserver,以及[客户端请求][24]机制(不仅能把程序的行为告知Memcheck,还可以进行查询)时可以使用。
+
+#### 注意事项 ####
+
+毫无疑问,Memcheck可以节省很多调试时间以及省去很多麻烦。但是它使用了很多内存,导致程序执行变慢([由资料可知][25],大概花上20至30倍时间)。
+
+除此之外,Memcheck还有其它局限。根据用户评论,Memcheck明显不是[线程安全][26]的;它不能检测出 [静态缓冲区溢出][27];还有就是,一些Linux程序如[GNU Emacs][28],目前还不能使用Memcheck。
+
+如果有兴趣,可以在[这里][29]查看Valgrind详尽的局限性说明。
+
+#### 总结 ####
+
+无论是对于初学者还是那些需要高级特性的人来说,Memcheck都是一款便捷的内存调试工具。如果你仅需要基本调试和错误核查,Memcheck会非常容易上手。而当你想要使用像抑制文件或者监控指令这样的特性,就需要花一些功夫学习了。
+
+虽然罗列了大量的局限性,但是Valgrind(包括Memcheck)在它的网站上声称全球有[成千上万程序员][30]使用了此工具。开发团队称收到来自超过30个国家的用户反馈,而这些用户的工程代码有的高达2.5千万行。
+
+### [Memwatch][31] ###
+
+**开发者**:Johan Lindh
+
+**点评版本**:2.71
+
+**Linux支持**:所有种类
+
+**许可**:GNU通用公共许可证
+
+Memwatch是由Johan Lindh开发的内存调试工具,虽然它主要扮演内存泄漏检测器的角色,但是它也具有检测其它如[重复释放跟踪和内存错误释放][32]、缓冲区溢出和下溢、[野指针][33]写入等等内存相关问题的能力(根据网页介绍所知)。
+
+Memwatch支持用C语言所编写的程序。可以在C++程序中使用它,但是这种做法并不提倡(由Memwatch源码包随附的Q&A文件中可知)。
+
+#### 更新内容 ####
+
+这个版本添加了ULONG_LONG_MAX以区分32位和64位程序。
+
+#### 有何优点 ####
+
+跟Dmalloc一样,Memwatch也有优秀的文献资料。参考USING文件,可以学习如何使用Memwatch,可以了解Memwatch是如何初始化、如何清理以及如何进行I/O操作的,等等不一而足。还有一个FAQ文件,旨在帮助用户解决使用过程遇到的一般问题。最后还有一个test.c文件提供工作案例参考。
+
+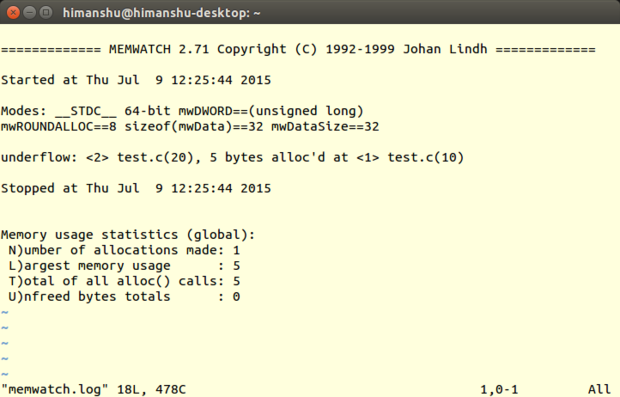
+Memwatch
+
+不同于Mtrace,Memwatch的输出产生的日志文件(通常是memwatch.log)是人类可阅读格式。而且,Memwatch每次运行时总会拼接内存调试输出到此文件末尾,而不是进行覆盖(译改)。如此便可在需要之时,轻松查看之前的输出信息。
+
+同样值得一提的是当你执行了启用Memwatch的程序,Memwatch会在[标准输出][34]中产生一个单行输出,告知发现了错误,然后你可以在日志文件中查看输出细节。如果没有产生错误信息,就可以确保日志文件不会写入任何错误,多次运行的话能实际节省时间。
+
+另一个我喜欢的优点是Memwatch同样在源码中提供一个方法,你可以据此获取Memwatch的输出信息,然后任由你进行处理(参考Memwatch源码中的mwSetOutFunc()函数获取更多有关的信息)。
+
+#### 注意事项 ####
+
+跟Mtrace和Dmalloc一样,Memwatch也需要你往你的源文件里增加代码:你需要把memwatch.h这个头文件包含进你的代码。而且,编译程序的时候,你需要连同memwatch.c一块编译;或者你可以把已经编译好的目标模块包含起来,然后在命令行定义MEMWATCH和MW_STDIO变量。不用说,想要在输出中定位行号,-g编译器选项也少不了。
+
+还有一些没有具备的特性。比如Memwatch不能检测出往一块已经被释放的内存写入操作,或是在分配的内存块之外的读取操作。而且,Memwatch也不是线程安全的。还有一点,正如我在开始时指出,在C++程序上运行Memwatch的结果是不能预料的。
+
+#### 总结 ####
+
+Memcheck可以检测很多内存相关的问题,在处理C程序时是非常便捷的调试工具。因为源码小巧,所以可以从中了解Memcheck如何运转,有需要的话可以调试它,甚至可以根据自身需求扩展升级它的功能。
+
+### [Mtrace][35] ###
+
+**开发者**: Roland McGrath and Ulrich Drepper
+
+**点评版本**: 2.21
+
+**Linux支持**:所有种类
+
+**许可**:GNU通用公共许可证
+
+Mtrace是[GNU C库][36]中的一款内存调试工具,同时支持Linux C和C++程序,检测由malloc()和free()函数的不对等调用所引起的内存泄漏问题。
+
+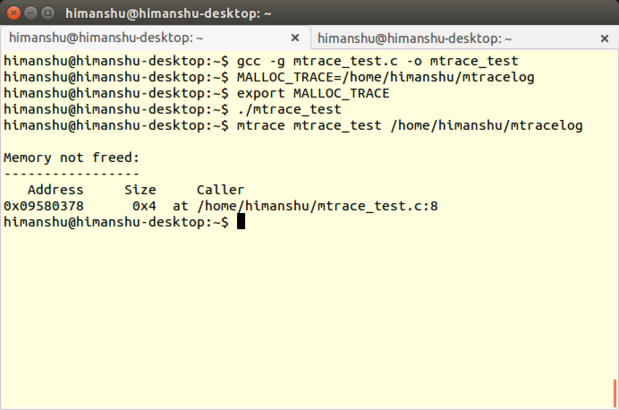
+Mtrace
+
+Mtrace实现为对mtrace()函数的调用,跟踪程序中所有malloc/free调用,在用户指定的文件中记录相关信息。文件以一种机器可读的格式记录数据,所以有一个Perl脚本(同样命名为mtrace)用来把文件转换并展示为人类可读格式。
+
+#### 更新内容 ####
+
+[Mtrace源码][37]和[Perl文件][38]同GNU C库(2.21版本)一起释出,除了更新版权日期,其它别无改动。
+
+#### 有何优点 ####
+
+Mtrace最优秀的特点是非常简单易学。你只需要了解在你的源码中如何以及何处添加mtrace()及其对立的muntrace()函数,还有如何使用Mtrace的Perl脚本。后者非常简单,只需要运行指令mtrace (例子见开头截图最后一条指令)。
+
+Mtrace另外一个优点是它的可收缩性,体现在,不仅可以使用它来调试完整的程序,还可以使用它来检测程序中独立模块的内存泄漏。只需在每个模块里调用mtrace()和muntrace()即可。
+
+最后一点,因为Mtrace会在mtace()(在源码中添加的函数)执行时被触发,因此可以很灵活地[使用信号][39]动态地(在程序执行周期内)使能Mtrace。
+
+#### 注意事项 ####
+
+因为mtrace()和mauntrace()函数(在mcheck.h文件中声明,所以必须在源码中包含此头文件)的调用是Mtrace运行(mauntrace()函数并非[总是必要][40])的根本,因此Mtrace要求程序员至少改动源码一次。
+
+了解需要在编译程序的时候带上-g选项([GCC][41]和[G++][42]编译器均由提供),才能使调试工具在输出展示正确的行号。除此之外,有些程序(取决于源码体积有多大)可能会花很长时间进行编译。最后,带-g选项编译会增加了可执行文件的内存(因为提供了额外的调试信息),因此记得程序需要在测试结束,不带-g选项重新进行编译。
+
+使用Mtrace,你需要掌握Linux环境变量的基本知识,因为在程序执行之前,需要把用户指定文件(mtrace()函数用以记载全部信息)的路径设置为环境变量MALLOC_TRACE的值。
+
+Mtrace在检测内存泄漏和尝试释放未经过分配的内存方面存在局限。它不能检测其它内存相关问题如非法内存访问、使用未初始化内存。而且,[有人抱怨][43]Mtrace不是[线程安全][44]的。
+
+### 总结 ###
+
+不言自明,我在此讨论的每款内存调试器都有其优点和局限。所以,哪一款适合你取决于你所需要的特性,虽然有时候容易安装和使用也是一个决定因素。
+
+要想捕获软件程序中的内存泄漏,Mtrace最适合不过了。它还可以节省时间。由于Linux系统已经预装了此工具,对于不能联网或者不可以下载第三方调试调试工具的情况,Mtrace也是极有助益的。
+
+另一方面,相比Mtrace,,Dmalloc不仅能检测更多错误类型,还你呢个提供更多特性,比如运行时可配置、GDB集成。而且,Dmalloc不像这里所说的其它工具,它是线程安全的。更不用说它的详细资料了,这让Dmalloc成为初学者的理想选择。
+
+虽然Memwatch的资料比Dmalloc的更加丰富,而且还能检测更多的错误种类,但是你只能在C语言写就的软件程序上使用它。一个让Memwatch脱颖而出的特性是它允许在你的程序源码中处理它的输出,这对于想要定制输出格式来说是非常有用的。
+
+如果改动程序源码非你所愿,那么使用Electric Fence吧。不过,请记住,Electric Fence只能检测两种错误类型,而此二者均非内存泄漏。还有就是,需要了解GDB基础以最大程序发挥这款内存调试工具的作用。
+
+Memcheck可能是这当中综合性最好的了。相比这里所说其它工具,它检测更多的错误类型,提供更多的特性,而且不需要你的源码做任何改动。但请注意,基本功能并不难上手,但是想要使用它的高级特性,就必须学习相关的专业知识了。
+
+--------------------------------------------------------------------------------
+
+via: http://www.computerworld.com/article/3003957/linux/review-5-memory-debuggers-for-linux-coding.html
+
+作者:[Himanshu Arora][a]
+译者:[译者ID](https://github.com/soooogreen)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.computerworld.com/author/Himanshu-Arora/
+[1]:https://openclipart.org/detail/132427/penguin-admin
+[2]:https://en.wikipedia.org/wiki/Manual_memory_management
+[3]:http://dmalloc.com/
+[4]:https://www.owasp.org/index.php/Double_Free
+[5]:https://stuff.mit.edu/afs/sipb/project/gnucash-test/src/dmalloc-4.8.2/dmalloc.html#Fence-Post%20Overruns
+[6]:http://dmalloc.com/releases/notes/dmalloc-5.5.2.html
+[7]:http://www.gnu.org/software/gdb/
+[8]:http://dmalloc.com/docs/
+[9]:http://dmalloc.com/docs/latest/online/dmalloc_26.html#SEC32
+[10]:http://dmalloc.com/docs/latest/online/dmalloc_23.html#SEC29
+[11]:https://en.wikipedia.org/wiki/Memory_management#Dynamic_memory_allocation
+[12]:https://en.wikipedia.org/wiki/Segmentation_fault
+[13]:https://en.wikipedia.org/wiki/GNU_Compiler_Collection
+[14]:http://www.gnu.org/software/gdb/
+[15]:https://launchpad.net/ubuntu/+source/electric-fence/2.2.3
+[16]:http://valgrind.org/docs/manual/mc-manual.html
+[17]:http://valgrind.org/info/developers.html
+[18]:http://valgrind.org/
+[19]:http://valgrind.org/docs/manual/dist.news.html
+[20]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.suppfiles
+[21]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.mempools
+[22]:http://stackoverflow.com/questions/4642671/c-memory-allocators
+[23]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.monitor-commands
+[24]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.clientreqs
+[25]:http://valgrind.org/docs/manual/valgrind_manual.pdf
+[26]:http://sourceforge.net/p/valgrind/mailman/message/30292453/
+[27]:https://msdn.microsoft.com/en-us/library/ee798431%28v=cs.20%29.aspx
+[28]:http://www.computerworld.com/article/2484425/linux/5-free-linux-text-editors-for-programming-and-word-processing.html?nsdr=true&page=2
+[29]:http://valgrind.org/docs/manual/manual-core.html#manual-core.limits
+[30]:http://valgrind.org/info/
+[31]:http://www.linkdata.se/sourcecode/memwatch/
+[32]:http://www.cecalc.ula.ve/documentacion/tutoriales/WorkshopDebugger/007-2579-007/sgi_html/ch09.html
+[33]:http://c2.com/cgi/wiki?WildPointer
+[34]:https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
+[35]:http://www.gnu.org/software/libc/manual/html_node/Tracing-malloc.html
+[36]:https://www.gnu.org/software/libc/
+[37]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.c;h=df10128b872b4adc4086cf74e5d965c1c11d35d2;hb=HEAD
+[38]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.pl;h=0737890510e9837f26ebee2ba36c9058affb0bf1;hb=HEAD
+[39]:http://webcache.googleusercontent.com/search?q=cache:s6ywlLtkSqQJ:www.gnu.org/s/libc/manual/html_node/Tips-for-the-Memory-Debugger.html+&cd=1&hl=en&ct=clnk&gl=in&client=Ubuntu
+[40]:http://www.gnu.org/software/libc/manual/html_node/Using-the-Memory-Debugger.html#Using-the-Memory-Debugger
+[41]:http://linux.die.net/man/1/gcc
+[42]:http://linux.die.net/man/1/g++
+[43]:https://sourceware.org/ml/libc-help/2014-05/msg00008.html
+[44]:https://en.wikipedia.org/wiki/Thread_safety
diff --git a/translated/talk/The history of Android/20 - The history of Android.md b/translated/talk/The history of Android/20 - The history of Android.md
new file mode 100644
index 0000000000..9ef34f1f63
--- /dev/null
+++ b/translated/talk/The history of Android/20 - The history of Android.md
@@ -0,0 +1,93 @@
+安卓编年史
+================================================================================
+
+和之前完全不同的市场设计。以上是分类,特色,热门应用以及应用详情页面。
+Ron Amadeo 供图
+
+这些截图给了我们冰淇淋三明治中新版操作栏的第一印象。几乎所有的应用顶部都有一条栏,带有应用图标,当前界面标题,一些功能按钮,右边还有一个菜单按钮。这个右对齐的菜单按钮被称为“更多操作”,因为里面存放着无法放置到主操作栏的项目。不过更多操作菜单并不是固定不变的,它给了操作栏节省了更多的屏幕空间——比如在横屏模式或在平板上时,更多操作菜单的项目会像通常的按钮一样显示在操作栏上。
+
+冰淇凌三明治中新增了“滑动标签页”设计,替换掉了谷歌之前推行的2×3方阵导航屏幕。一个标签页栏放置在了操作栏下方,位于中间的标签显示的是当前页面,左右侧的两个标签显示的是对应的当前页面的左右侧页面。向左右滑动可以切换标签页,或者你可以点击指定页面的标签跳转过去。
+
+应用详情页面有个很赞的设计,在应用截图后,会根据你关于那个应用的历史动态地重新布局页面。如果你从来没有安装过该应用,应用描述会优先显示。如果你曾安装过这个应用,第一部分将会是评价栏,它会邀请你评价该应用或者提醒你上次你安装该应用时的评价是什么。之前使用过的应用页面第二部分是“新特性”,因为一个老用户最关心的应该是应用有什么变化。
+
+
+最近应用和浏览器和蜂巢中的类似,但是是小号的。
+Ron Amadeo 供图
+
+最近应用的电子风格外观被移除了。略缩图周围的蓝色的轮廓线被去除了,同时去除的还有背景怪异的,不均匀的蓝色光晕。它现在看起来是个中立型的界面,在任何时候看起来都很舒适。
+
+浏览器尽了最大的努力把标签页体验带到手机上来。多标签浏览受到了关注,操作栏上引入的一个标签页按钮会打开一个类似最近应用的界面,显示你打开的标签页,而不是浪费宝贵的屏幕空间引入一个标签条。从功能上来说,这个和之前的浏览器中的“窗口”视图没什么差别。浏览器最佳的改进是菜单中的“请求桌面版站点”选项,这让你可以从默认的移动站点视图切换到正常站点。浏览器展示了谷歌的操作栏设计的灵活性,尽管这里没有左上角的应用图标,功能上来说和其他的顶栏设计相似。
+
+
+Gmail 和 Google Talk —— 它们和蜂巢中的相似,但是更小!
+Ron Amadeo 供图
+
+Gmail 和 Google Talk 看起来都像是之前蜂巢中的设计的缩小版,但是有些小调整让它们在小屏幕上表现更佳。Gmail 以双操作栏为特色——一个在屏幕顶部,一个在底部。顶部操作栏显示当前文件夹,账户,以及未读消息数目,点击顶栏可以打开一个导航菜单。底部操作栏有你期望出现在更多操作中的选项。使用双操作栏布局是为了在界面显示更多的按钮,但是在横屏模式下纵向空间有限,双操作栏就是合并成一个顶部操作栏。
+
+在邮件视图下,往下滚动屏幕时蓝色栏有“粘性”。它会固定在屏幕顶部,所以你一直可以看到该邮件是谁写的,回复它,或者给它加星标。一旦处于邮件消息界面,底部细长的,深灰色栏会显示你当前在收件箱(或你所在的某个列表)的位置,并且你可以向左或向右滑动来切换到其他邮件。
+
+Google Talk 允许你像在 Gmail 中那样左右滑动来切换聊天窗口,但是这里显示栏是在顶部。
+
+
+新的拨号和来电界面,都是姜饼以来我们还没见过的。
+Ron Amadeo 供图
+
+因为蜂巢只给平板使用,所以一些界面设计直接超前于姜饼。冰淇淋三明治的新拨号界面就是如此,黑色和蓝色相间,并且使用了可滑动切换的小标签。尽管冰淇淋三明治终于做了对的事情并将电话主体和联系人独立开来,但电话应用还是有它自己的联系人标签。现在有两个地方可以看到你的联系人列表——一个有着暗色主题,另一个有着亮色主题。由于实体搜索按钮不再是硬性要求,底部的按钮栏的语音信息快捷方式被替换为了搜索图标。
+
+谷歌几乎就是把来电界面做成了锁屏界面的镜像,这意味着冰淇淋三明治有着一个环状解锁设计。除了通常的接受和挂断选项,圆环的顶部还添加了一个按钮,让你可以挂断来电并给对方发送一条预先定义好的信息。向上滑动并选择一条信息如“现在无法接听,一会回电”,相比于一直响个不停的手机而言这样做的信息交流更加丰富。
+
+
+蜂巢没有文件夹和信息应用,所以这里是冰淇淋三明治和姜饼的对比。
+Ron Amadeo 供图
+
+现在创建文件夹更加方便了。在姜饼中,你得长按屏幕,选择“文件夹”选项,再点击“新文件夹”。在冰淇淋三明治中,你只要将一个图标拖拽到另一个图标上面,就会自动创建一个文件夹,并包含这两个图标。这简直不能更简单了,比寻找隐藏的长按命令容易多了。
+
+设计上也有很大的改进。姜饼使用了一个通用的米黄色文件夹图标,但冰淇淋三明治直接显示出了文件夹中的头三个应用,把它们的图标叠在一起,在外侧画一个圆圈,并将其设置为文件夹图标。打开文件夹容器将自动调整大小以适应文件夹中的应用图标数目,而不是显示一个全屏的,大部分都是空的对话框。这看起来好得多得多。
+
+
+Youtube 转换到一个更加现代的白色主题,使用了列表视图替换疯狂的 3D 滚动视图。
+Ron Amadeo 供图
+
+Youtube 经过了完全的重新设计,看起来没那么像是来自黑客帝国的产物,更像是,嗯,Youtube。它现在就是一个简单的垂直滚动的白色视频列表,就像网站的那样。在你手机上制作视频受到了重视,操作栏的第一个按钮专用于拍摄视频。奇怪的是,不同的界面左上角使用了不同的 Youtube 标志,在水平的 Youtube 标志和方形标志之间切换。
+
+Youtube 几乎在所有地方都使用了滑动标签页。它们被放置在主页面以在浏览和账户间切换,放置在视频页面以在评论,介绍和相关视频之间切换。4.0 版本的应用显示出 Google+ Youtube 集成的第一个信号,通常的评分按钮旁边放置了 “+1” 图标。最终 Google+ 会完全占据 Youtube,将评论和作者页面变成 Google+ 活动。
+
+
+冰淇淋三明治试着让事情对所有人都更加简单。这里是数据使用量追踪,打开许多数据的新开发者选项,以及使用向导。
+Ron Amadeo 供图
+
+数据使用量允许用户更轻松地追踪和控制他们的数据使用。主页面显示一个月度使用量图表,用户可以设置数据使用警告值或者硬性使用限制以避免超量使用产生费用。所有的这些只需简单地拖动橙色和红色水平限制线在图表上的位置即可。纵向的白色把手允许用户选择图表上的一段指定时间段。在页面底部,选定时间段内的数据使用量又细分到每个应用,所以用户可以选择一个数据使用高峰并轻松地查看哪个应用在消耗大量流量。当流量紧张的时候,更多操作按钮中有个限制所有后台流量的选项。设置之后只用在前台运行的程序有权连接互联网。
+
+开发者选项通常只有一点点设置选项,但是在冰淇淋三明治中,这部分有非常多选项。谷歌添加了所有类型的屏幕诊断显示浮层来帮助开发者理解他们的应用中发生了什么。你可以看到 CPU 使用率,触摸点位置,还有视图界面更新。还有些选项可以更改系统功能,比如控制动画速度,后台处理,以及 GPU 渲染。
+
+安卓和 iOS 之间最大的区别之一就是应用抽屉界面。在冰淇淋三明治对更加用户友好的追求下,设备第一次初始化启动会启动一个小教程,向用户展示应用抽屉的位置以及如何将应用图标从应用抽屉拖拽到主屏幕。随着实体菜单按键的移除和像这样的改变,安卓 4.0 做了很大的努力变得对新智能手机用户和转换过来的用户更有吸引力。
+
+
+“触摸分享”NFC 支持,Google Earth,以及应用信息,让你可以禁用垃圾软件。
+
+冰淇淋三明治内置对 [NFC][1] 的完整支持。尽管之前的设备,比如 Nexus S 也拥有 NFC,得到的支持是有限的并且系统并不能利用芯片做太多事情。4.0 添加了一个“Android Beam”功能,两台拥有 NFC 的安卓 4.0 设备可以借此在设备间来回传输数据。NFC 会传输关于此事屏幕显示的数据,因此在手机显示一个网页的时候使用该功能会将该页面传送给另一部手机。你还可以发送联系人信息,方向导航,以及 Youtube 链接。当两台手机放在一起时,屏幕显示会缩小,点击缩小的界面会发送相关信息。
+
+I在安卓中,用户不允许删除系统应用,以保证系统完整性。运营商和 OEM 利用该特性并开始将垃圾软件放入系统分区,经常有一些没用的应用存在系统中。安卓 4.0 允许用户禁用任何不能被卸载的应用,意味着该应用还存在于系统中但是不显示在应用抽屉里并且不能运行。如果用户愿意深究设置项,这给了他们一个简单的途径来拿回手机的控制权。
+
+安卓 4.0 可以看做是现代安卓时代的开始。大部分这时发布的谷歌应用只能在安卓 4.0 及以上版本运行。4.0 还有许多谷歌想要好好利用的新 API——至少最初想要——对 4.0 以下的版本的支持就有限了。在冰淇淋三明治和蜂巢之后,谷歌真的开始认真对待软件设计。在2012年1月,谷歌[最终发布了][2] *Android Design*,一个教安卓开发者如何创建符合安卓外观和感觉的应用的设计指南站点。这是 iOS 在有第三方应用支持开始就在做的事情,苹果还严肃地对待应用的设计,不符合指南的应用都被 App Store 拒之门外。安卓三年以来谷歌没有给出任何公共设计规范文档的事实,足以说明事情有多糟糕。但随着在 Duarte 掌控下的安卓设计革命,谷歌终于发布了基本设计需求。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/20/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://arstechnica.com/gadgets/2011/02/near-field-communications-a-technology-primer/
+[2]:http://arstechnica.com/business/2012/01/google-launches-style-guide-for-android-developers/
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/talk/The history of Android/21 - The history of Android.md b/translated/talk/The history of Android/21 - The history of Android.md
new file mode 100644
index 0000000000..48cd8880be
--- /dev/null
+++ b/translated/talk/The history of Android/21 - The history of Android.md
@@ -0,0 +1,104 @@
+安卓编年史
+================================================================================
+
+Ron Amadeo 供图
+
+### Google Play 和直接面向消费者出售设备的回归 ###
+
+2012年3月6日,谷歌将旗下提供的所有内容统一到 “Google Play”。安卓市场变为了 Google Play 商店,Google Books 变为 Google Play Books,Google Music 变为 Google Play Music,还有 Android Market Movies 变为 Google Play Movies & TV。尽管应用界面的变化不是很大,这四个内容应用都获得了新的名称和图标。在 Play 商店购买的内容会下载到对应的应用中,Play 商店和 Play 内容应用一道给用户提供了易管理的内容体验。
+
+Google Play 更新是谷歌第一个大的更新周期外更新。四个自带应用都没有通过系统更新获得升级,它们都是直接通过安卓市场/ Play商店更新的。对单独的应用启用周期外更新是谷歌的重大关注点之一,而能够实现这样的更新,是自姜饼时代开始的工程努力的顶峰。谷歌一直致力于对应用从系统“解耦”,从而让它们能够通过安卓市场/ Play 商店进行分发。
+
+尽管一两个应用(主要是地图和 Gmail)之前就在安卓市场上,从这里开始你会看到许多更重大的更新,而其和系统发布无关。系统更新需要 OEM 厂商和运营商的合作,所以很难保证推送到每个用户手上。而 Play 商店更新则完全掌握在谷歌手上,给了谷歌一条直接到达用户设备的途径。因为 Google Play 的发布,安卓市场对自身升级到了 Google Play Store,在那之后,图书,音乐以及电影应用都下发了 Google Play 式的更新。
+
+Google Play 系列应用的设计仍然不尽相同。每个应用的外观和功能各有差异,但暂且来说,一个统一的品牌标识是个好的开始。从品牌标识中去除“安卓”字样是很有必要的,因为很多服务是在浏览器中提供的,不需要安卓设备也能使用。
+
+2012年4月,谷歌[再次开始通过 Play 商店销售设备][1],恢复在 Nexus One 发布时尝试的直接面向消费者销售的方式。尽管距 Nexus One 销售结束仅有两年,但往上购物现在更加寻常,在接触到物品之前就购买它并不像在2010年时听起来那么疯狂。
+
+谷歌也看到了价格敏感的用户在面对 Nexus One 530美元的价格时的反应。第一部销售的设备是无锁的,GSM 版本的 Galaxy Nexus,价格399美元。在那之后,价格变得更低。350美元成为了最近两台 Nexus 设备的入门价,7英寸 Nexus 平板的价格更是只有200美元到220美元。
+
+今天,Play 商店销售八款不同的安卓设备,四款 Chromebook,一款自动调温器,以及许多配件,设备商店已经是谷歌新产品发布的实际地点了。新产品发布总是如此受欢迎,站点往往无法承载如此大的流量,新 Nexus 手机也在几小时内售空。
+
+### 安卓 4.1,果冻豆——Google Now指明未来
+
+
+华硕制造的 Nexus 7,安卓 4.1 的首发设备。
+
+随着2012年7月安卓 4.1 果冻豆的发布,谷歌的安卓发布节奏进入每六个月一发布的轨道。平台已经成熟,三个月的发布周期就没那么必要了,更长的发布周期也给了 OEM 厂商足够的时间跟上谷歌的节奏。和蜂巢不同,小数点后的更新发布现在是主要更新,4.1 带来了主要的界面更新和框架变化。
+
+果冻豆最大的变化之一,并且你在截图中看不到的是“黄油计划”,谷歌工程师齐心努力让安卓的动画顺畅地跑在 30FPS 上。还有一些核心变化,像垂直同步和三重缓冲,每个动画都经过优化以流畅地绘制。动画和顺滑滚动一直是安卓和 iOS 相比之下的弱点。经过在核心动画框架和单独的应用上的努力,果冻豆让安卓的流畅度大幅接近 iOS。
+
+和果冻豆一起到来的还有 [Nexus][2] 7,由华硕生产的7英寸平板。不像之前主要是横屏模式的 Xoom,Nexus 7 主要以竖屏模式使用,像个大一号的手机。Nexus 7 展现了经过一年半的生态建设,谷歌已经准备好了给平板市场带来一部旗舰设备。和 Nexus One 和 GSM Galaxy Nexus 一样,Nexus 7 直接由谷歌在线销售。尽管那些早先的设备对习惯于运营商补贴的消费者来说拥有惊人的高价,Nexus 7 以仅仅 200 美元的价格推向大众市场。这个价格给你带来一部7英寸,1280x800 英寸显示屏,四核 1.2GHz Tegra 3 处理器,1GB 内存,8GB 内置存储的设备。Nexus 7 的性价比如此之高,许多人都想知道谷歌到底有没有在其旗舰平板上赚到钱。
+
+更小,更轻,7英寸,这些因素促成了谷歌巨大的成功,并且将谷歌带向了引领行业潮流的位置。一开始制造10英寸 iPad 的苹果,最终也不得不推出和 Nexus 7 相似的 iPad Mini 来应对。
+
+
+4.1 的新锁屏设计,壁纸,以及系统按钮新的点击高亮。
+Ron Amadeo 供图
+
+蜂巢引入的电子风格在冰淇淋三明治中有所减少,果冻豆在此之上走得更远。它开始从系统中大范围地移除蓝色。迹象就是系统按钮的点击高亮从蓝色变为了灰色。
+
+
+新应用阵容合成图以及新的消息可展开通知面板。
+Ron Amadeo 供图
+
+通知中心面板完全重制了,这个设计一直沿用到今天的奇巧巧克力(KitKat)。新面板扩展到了屏幕顶部,并且覆盖了状态栏图标,这意味着通知面板打开的时候不再能看到状态栏。时间突出显示在左上角,旁边是日期和设置按钮。清除所有通知按钮,冰淇淋三明治中显示为一个“X”按钮,现在变为阶梯状的按钮,象征着清除所有通知的时候消息交错滑动的动画效果。底部的面板把手从一个小圆换成了一条直线,和面板等宽。所有的排版都发生了变化——通知面板的所有项现在都使用了更大,更细的字体。通知面板是另一个从冰淇淋三明治和蜂巢中引入的蓝色元素被移除的屏幕。除了触摸高亮之外整个通知面板都是灰色的。
+
+通知面板也引入了新功能。相较于之前的两行设计,现在的通知消息可以展开以显示更多信息。通知消息可以显示最多8行文本,甚至还能在消息底部显示按钮。屏幕截图通知消息底部有个分享按钮,你也可以直接从未接来电通知拨号,或者将一个正在响铃的闹钟小睡,这些都可以在通知面板完成。新通知消息默认展开,但当它们堆叠到一起时会恢复原来的尺寸。在通知消息上双指向下滑动可以展开消息。
+
+
+新谷歌搜索应用,带有 Google Now 卡片,语音搜索,以及文字搜索。
+Ron Amadeo 供图
+
+果冻豆中不止对安卓而言,也是对谷歌来说最大的特性,是新版谷歌搜索应用。它带来了“Google Now”,一个预测性搜索功能。Google Now 在搜索框下面显示为几张卡片,它会提供谷歌认为你所关心的事物的搜索结果。就比如谷歌地图搜索你最近在桌面电脑查找的地点或日历的约会地点,天气,以及旅行时回家的时间。
+
+新版谷歌搜索应用自然可以从谷歌图标启动,但它还可以在任意屏幕从系统栏上滑访问。长按系统栏会唤出一个类似锁屏解锁的环。卡片部分纵向滚动,如果你不想看到它们,可以滑动消除它们。语音搜索是更新的一个大部分。提问不是无脑地输入进谷歌,如果谷歌知道答案,它还会用文本语音转换引擎回答你。传统的文字搜索当然也受支持。只需点击搜索栏然后开始输入即可。
+
+谷歌经常将 Google Now 称作“谷歌搜索的未来”。告诉谷歌你想要什么这还不够好。谷歌想要在你之前知道你想要什么。Google Now 用谷歌所有的数据挖掘关于你的知识为你服务,这也是谷歌对抗搜索引擎竞争对手,比如必应,最大的优势所在。智能手机比你拥有的其它设备更了解你,所以该服务在安卓上首次亮相。但谷歌慢慢也将 Google Now 加入 Chrome,最终似乎会到达 Google.com。
+
+尽管功能很重要,但同时 Google Now 是谷歌产品有史以来最重要的设计工作也是毋庸置疑的。谷歌搜索应用引入的白色卡片审美将会成为几乎所有谷歌产品设计的基础。今天,卡片风格被用在 Google Play 商店以及所有的 Play 内容应用,Youtube,谷歌地图,Drive,Keep,Gmail,Google+以及其它产品。同时也不限于安卓应用。不少谷歌的桌面站点和 iOS 应用也以此设计为灵感。设计是谷歌历史中的弱项之一,但 Google Now 开始谷歌最终在设计上采取了行动,带来一个统一的,全公司范围的设计语言。
+
+
+又一个 Youtube 的重新设计,信息密度有所下降。
+Ron Amadeo 供图
+
+又一个版本,又一个 Youtube 的重新设计。这次列表视图主要基于略缩图,大大的图片占据了屏幕的大部分。信息密度在新列表设计中有所下降。之前 Youtube 每屏大约能显示6个项目,现在只能显示3个。
+
+Youtube 是首批在应用左侧加入滑动抽屉的应用之一,该特性会成为谷歌应用的标准设计风格。抽屉中有你的账户的链接和订阅频道,这让谷歌可以去除页面顶部标签页设计。
+
+
+Google Play 服务的职责以及安卓的剩余部分职责。
+Ron Amadeo 供图
+
+### Google Play Services—fragmentation and making OS versions (nearly) obsolete ###
+### Google Play 服务——碎片化和让系统版本(几乎)过时 ###
+
+碎片化那时候看起来这并不是个大问题,但2012年12月,Google Play 服务 1.0 面向所有安卓2.2及以上版本的手机推出。它添加了一些 Google+ API 和对 OAuth 2.0 的支持。
+
+尽管这个升级听起来很无聊,但 Google Play 服务最终会成长为安卓整体的一部分。Google Play 服务扮演着正常应用和安卓系统的中间角色,使得谷歌可以升级或替换一些核心组件,并在不发布新安卓版本的前提下添加 API。
+
+有了 Play 服务,谷歌有了直接接触安卓手机核心部分的能力,而不用通过 OEM 更新一集运营商批准的过程。谷歌使用 Play 服务添加了全新的位置系统,恶意软件扫描,远程擦除功能,以及新的谷歌地图 API,所有的这一切都不用通过发布一个系统更新实现。正如我们在姜饼部分的结尾提到的,感谢 Play 服务里这些“可移植的”API 实现,姜饼仍然能够下载现代版本的 Play 商店和许多其他的谷歌应用。
+
+另一个巨大的益处是安卓用户基础的兼容性。最新版本的安卓系统要经过很长时间到达大多数用户手中,这意味着最新版本系统绑定的 API 在大多数用户升级之前对开发者来说没有任何意义。Google Play 服务兼容冻酸奶及以上版本,换句话说就是99%的活跃设备,并且更新可以直接通过 Play 商店直接推送到手机上。通过将 API 包含在 Google Play 服务中而不是安卓中,谷歌可以在一周内将新 API 推送到几乎所有用户手中。这对许多版本碎片化引起的问题来说是个[伟大的解决方案][3]。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://arstechnica.com/gadgets/2012/04/unlocked-samsung-galaxy-nexus-can-now-be-purchased-from-google/
+[2]:http://arstechnica.com/gadgets/2012/07/divine-intervention-googles-nexus-7-is-a-fantastic-200-tablet/
+[3]:http://arstechnica.com/gadgets/2013/09/balky-carriers-and-slow-oems-step-aside-google-is-defragging-android/
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md b/translated/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md
new file mode 100644
index 0000000000..5dcea06611
--- /dev/null
+++ b/translated/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md
@@ -0,0 +1,164 @@
+debian linux上安装配置 ISC DHCP Server
+================================================================================
+动态主机控制协议(DHCP)给网络管理员提供一种便捷的方式,为不断变化的网络主机或是动态网络提供网络层地址。其中最常用的DHCP服务工具是 ISC DHCP Server。DHCP服务的目的是给主机提供必要的网络信息以便能够和其他连接在网络中的主机互相通信。DHCP服务一般包括以下信息:DNS服务器信息,网络地址(IP),子网掩码,默认网关信息,主机名等等。
+
+本教程介绍4.2.4版的ISC-DHCP-Server如何在Debian7.7上管理多个虚拟局域网(VLAN),它也可以非常容易的配置的用于单一网络。
+
+测试用的网络是通过思科路由器使用传统的方式来管理DHCP租约地址的,目前有12个VLANs需要通过路由器的集中式服务器来管理。把DHCP的任务转移到一个专用的服务器上面,路由器可以收回相应的资源,把资源用到更重要的任务上,比如路由寻址,访问控制列表,流量监测以及网络地址转换等。
+
+另一个将DHCP服务转移到专用服务器的好处,以后会讲到,它可以建立动态域名服务器(DDNS)这样当主机从服务器请求DHCP地址的时候,新主机的主机名将被添加到DNS系统里面。
+
+### 安装和配置ISC DHCP Server###
+
+1. 使用apt工具用来安装Debian软件仓库中的ISC软件,来创建这个多宿主服务器。与其他教程一样需要使用root或者sudo访问权限。请适当的修改,以便使用下面的命令。(译者注:下面中括号里面是注释,使用的时候请删除,#表示使用的root权限)
+
+
+ # apt-get install isc-dhcp-server [安装 the ISC DHCP Server 软件]
+ # dpkg --get-selections isc-dhcp-server [确认软件已经成功安装]
+ # dpkg -s isc-dhcp-server [用另一种方式确认成功安装]
+
+
+
+2. 确认服务软件已经安装完成,现在需要一些网络的需求来配置服务器,这样服务器才能够根据我们的需要来分发网络信息。作为管理员最起码需要了解的DHCP信息如下:
+- 网络地址
+- 子网掩码
+- 动态分配的地址范围
+
+其他一些服务器动态分配的有用信息包括:
+- 默认网关
+- DNS服务器IP地址
+- 域名
+- 主机名
+- 网络广播地址
+
+
+这只是能让ISC DHCP server处理的选项中非常少的一部分。如果你想查看所有选项及其描述需要在安装好软件后输入以下命令:
+ # man dhcpd.conf
+
+3. 一旦管理员已经确定了这台服务器需要分发的需求信息,那么是时候配置服务器并且分配必要的地址池了。在配置任何地址池或服务器配置之前,DHCP服务必须配置好,来侦听这台服务器上面的一个接口。
+
+在这台特定的服务器上,设置好网卡后,DHCP会侦听名称名为`'bond0'`的接口。请适根据你的实际情况来更改服务器以及网络环境。下面的配置都是针对本教程的。
+
+
+
+这行指定的是DHCP服务侦听接口(一个或多个)上的DHCP流量。修改主要的配置文件分配适合的DHCP地址池到所需要的网络上。配置文件所在置/etc/dhcp/dhcpd.conf。用文本编辑器打开这个文件
+ # nano /etc/dhcp/dhcpd.conf
+
+这个配置文件可以配置我们所需要的地址池/主机。文件顶部有‘ddns-update-style‘这样一句,在本教程中它设置为‘none‘。在以后的教程中动态DNS,ISC-DHCP-Server 将被整合到 BIND9,它能够使主机名更新到IP地址。
+
+4. 接下来的部分是管理员配置全局网络设置,如DNS域名,默认的租约时间,IP地址,子网的掩码,以及更多的区域。如果你想了解所有的选项,请阅读man手册中的dhcpd.conf文件,命令如下:
+
+ # man dhcpd.conf
+
+
+对于这台服务器,我们需要在顶部配置一些全局网络设置,这样就不用到每个地址池中去单独设置了。
+
+
+
+
+我们花一点时间来解释一下这些选项,在本教程中虽然它们是一些全局设置,但是也可以为单独的为某一个地址池进行配置。
+
+- option domain-name “comptech.local”; – 所有使用这台DHCP服务器的主机,都将成为DNS域名为“comptech.local”的一员
+
+- option domain-name-servers 172.27.10.6; DHCP向所有配置这台DHCP服务器的的网络主机分发DNS服务器地址为172.27.10.6
+
+- option subnet-mask 255.255.255.0; – 分派子网掩码到每一个网络设备 255.255.255.0 或a /24
+
+- default-lease-time 3600; – 默认有效的地址租约时间(单位是秒)。如果租约时间耗尽,那么主机可以重新申请租约。如果租约完成,那么相应的地址也将被尽快回收。
+
+- max-lease-time 86400; – 这是一台主机最大的租约时间(单位为秒)。
+
+- ping-check true; – 这是一个额外的测试,以确保服务器分发出的网络地址不是当前网络中另一台主机已使用的网络地址。
+
+- ping-timeout; – 如果地址以前没有使用过,可以用这个选项来检测2个ping返回值之间的时间长度。
+
+- ignore client-updates; 现在这个选项是可以忽略的,因为DDNS在前面已在配置文件中已经被禁用,但是当DDNS运行时,这个选项会忽略更新其DNS主机名的请求。
+
+5. 文件中下面一行是权威DHCP所在行。这行的意义是如果服务器是为文件中所配置的网络分发地址的服务器,那么取消注释权威字节(authoritative stanza)来实现。
+
+通过去掉关键字authoritative 前面的‘#’,取消注释全局权威字节。这台服务器将是它所管理网络里面的唯一权威。
+
+
+开启 ISC Authoritative
+
+默认情况下服务器被假定为不是网络上的权威。之所以这样做是出于安全考虑。如果有人因为不了解DHCP服务的配置,导致配置不当或配置到一个不该出现的网络里面,这都将带来非常严重的重连接问题。这行还可用在每个网络中单独配置使用。也就是说如果这台服务器不是整个网络的DHCP服务器,authoritative行可以用在每个单独的网络中,而不是像上面截图中那样的全局配置。
+
+6. 这一步是配置服务器将要管理的所有DHCP地址池/网络。简短起见,本教程只配置了地址池。作为管理员需要收集一些必要的网络信息(比如域名,网络地址,有多少地址能够被分发等等)
+
+以下这个地址池所用到的信息都是管理员收集整理的:网络id 172.27.60.0, 子网掩码 255.255.255.0 or a /24, 默认子网网关172.27.60.1,广播地址 172.27.60.255.0
+
+以上这些信息用于构建hcpd.conf文件中新的网络非常重要。使用文本编辑器修改配置文件添加新的网络进去,这里我们需要使用root或sudo访问权限。网络非常重要。使用文本编辑器修改配置文件添加新的网络进去,这里我们需要使用root或sudo访问权限。
+
+ # nano /etc/dhcp/dhcpd.conf
+
+
+配置DHCP的地址池和网络
+
+当前这个例子是给用VMWare创建的虚拟服务器分配IP地址。第一行显示是该网络的子网掩码。括号里面的内容是DHCP服务器应该提供给网络上面主机的所有选项。
+
+第一节, range 172.27.60.50 172.27.60.254;这一行显示的是,DHCP服务在这个网络上能够给主机动态分发的地址范围。
+
+第二节,option routers 172.27.60.1;这里显示的是网络里面所有的主机分发默认网关地址。
+
+最后一节, option broadcast-address 172.27.60.255;,显示当前网络的广播地址。这个地址不能被包含在要分发放的地址范围内,因为广播地址不能分配到一个主机上面。
+
+必须要强调的是每行的结尾必须要用(;)来结束,所有创建的网络必须要在{}里面。
+
+7. 如果是创建多个网络,连续的创建完它们的相应选项后保存文本文件即可。配置完成以后如果有更改,ISC-DHCP-Server进程需要重启来使新的更改生效。重启进程可以通过下面的命令来完成:
+ # service isc-dhcp-server restart
+
+这条命令将重启DHCP服务,管理员能够使用几种不同的方式来检查服务器是否已经可以处理dhcp请求。最简单的方法是通过lsof命令[1]来查看服务器是否在侦听67端口,命令如下:
+
+ # lsof -i :67
+
+
+检查DHCP侦听端口
+
+这里输出的结果表明DHCPD(DHCP服务守护进程)正在运行并且侦听67端口。由于/etc/services文件中67端口是端口映射,所以输出中的67端口实际上被转换成了“bootps”。
+
+在大多数的系统中这是非常常见的,现在服务器应该已经为网络连接做好准备,我们可以将一台主机接入网络请求DHCP地址来验证服务是否正常。
+
+### 测试客户端连接 ###
+
+8. 现在许多系统使用网络管理器来维护网络连接状态,因此这个设备应该预先配置好的,只要对应的接口处于活跃状态就能够获取DHCP。
+
+然而当一台设备无法使用网络管理器时,它可能需要手动获取DHCP地址。下面的几步将演示怎样手动获取以及如何查看服务器是否已经按需要分发地址。
+
+ ‘[ifconfig][2]‘工具能够用来检查接口的配置。这台被用来测试的DHCP服务器的设备,它只有一个网络适配器(网卡),这块网卡被命名为‘eth0‘。
+
+ # ifconfig eth0
+
+
+检查网络接口IP地址
+
+从输出结果上看,这台设备目前没IPv4地址,这样很好便于测试。我们把这台设备连接到DHCP服务器并发出一个请求。这台设备上已经安装了一个名为‘dhclient‘ 的DHCP客户端工具。因为操作系统各不相同,所以这个客户端软件也是互不一样的。
+ # dhclient eth0
+
+
+从DHCP请求IP地址
+
+当前 `'inet addr:'` 字段中显示了属于172.27.60.0网络地址范围内的IPv4地址。值得欣慰的是当前网络还配置了正确的子网掩码并且分发了广播地址。
+
+到这里看起来还都不错,让我们来测试一下,看看这台设备收到新IP地址是不是由服务器发出的。这里我们参照服务器的日志文件来完成这个任务。虽然这个日志的内容有几十万条,但是里面只有几条是用来确定服务器是否正常工作的。这里我们使用一个工具‘tail’,它只显示日志文件的最后几行,这样我们就可以不用拿一个文本编辑器去查看所有的日志文件了。命令如下:
+
+ # tail /var/log/syslog
+
+
+检查DHCP日志文件
+
+OK!服务器记录表明它分发了一个地址给这台主机(HRTDEBXENSRV)。服务器按预期运行,给它充当权威的网络分发适合的网络地址。至此DHCP服务器搭建成功并且运行。如果有需要你可以继续配置其他的网络,排查故障,确保安全。
+
+在以后的Debian教程中我会讲一些新的 ISC-DHCP-Server 功能。有时间的话我将写一篇关于Bind9和DDNS的教程,融入到这篇文章里面。
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/install-and-configure-multihomed-isc-dhcp-server-on-debian-linux/
+
+作者:[Rob Turner][a]
+译者:[ivo-wang](https://github.com/ivo-wang)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/robturner/
+[1]:http://www.tecmint.com/10-lsof-command-examples-in-linux/
+[2]:http://www.tecmint.com/ifconfig-command-examples/
diff --git a/translated/tech/20150831 How to switch from NetworkManager to systemd-networkd on Linux.md b/translated/tech/20150831 How to switch from NetworkManager to systemd-networkd on Linux.md
deleted file mode 100644
index 1a1fe6b35a..0000000000
--- a/translated/tech/20150831 How to switch from NetworkManager to systemd-networkd on Linux.md
+++ /dev/null
@@ -1,202 +0,0 @@
-如何在 Linux 中从 NetworkManager 切换为 systemd-network
-How to switch from NetworkManager to systemd-networkd on Linux
-================================================================================
-在 Linux 世界里, [systemd][1] 的采用一直是激烈争论的主题,它的支持者和反对者之间的战火仍然在燃烧。到了今天,大部分主流 Linux 发行版都已经采用了 systemd 作为默认初始化系统。
-In the world of Linux, adoption of [systemd][1] has been a subject of heated controversy, and the debate between its proponents and critics is still going on. As of today, most major Linux distributions have adopted systemd as a default init system.
-
-正如其作者所说,作为一个 “从未完成、从未完善、但一直追随技术进步” 的系统,systemd 已经不只是一个初始化进程,它被设计为一个更广泛的系统以及服务管理平台,这个;平台包括了不断增长的核心系统进程、库和工具的生态系统。
-Billed as a "never finished, never complete, but tracking progress of technology" by its author, systemd is not just the init daemon, but is designed as a more broad system and service management platform which encompasses the growing ecosystem of core system daemons, libraries and utilities.
-
-**systemd** 的其中一部分是 **systemd-networkd**,它负责 systemd 生态中的网络配置。使用 systemd-networkd,你可以为网络设备配置基础的 DHCP/静态 IP 网络。它还可以配置虚拟网络功能,例如网桥、隧道和 VLAN。systemd-networkd 目前还不能直接支持无线网络,但你可以使用 wpa_supplicant 服务配置无线适配器,然后用 **systemd-networkd** 挂钩起来。
-One of many additions to **systemd** is **systemd-networkd**, which is responsible for network configuration within the systemd ecosystem. Using systemd-networkd, you can configure basic DHCP/static IP networking for network devices. It can also configure virtual networking features such as bridges, tunnels or VLANs. Wireless networking is not directly handled by systemd-networkd, but you can use wpa_supplicant service to configure wireless adapters, and then hook it up with **systemd-networkd**.
-
-在很多 Linux 发行版中,NetworkManager 仍然作为默认的网络配置管理器。和 NetworkManager 相比,**systemd-networkd** 仍处于活跃的开发状态,还缺少一些功能。例如,它还不能像 NetworkManager 那样能在任何时候让你的计算机在多种接口之间保持连接。它还没有为高级脚本提供 ifup/ifdown 钩子函数。但是,systemd-networkd 和其它 systemd 组件(例如用于域名解析的 **resolved**、NTP 的**timesyncd**,用于命名的 udevd)结合的非常好。随着时间增长,**systemd-networkd**只会在 systemd 环境中扮演越来越重要的角色。
-On many Linux distributions, NetworkManager has been and is still used as a default network configuration manager. Compared to NetworkManager, **systemd-networkd** is still under active development, and missing features. For example, it does not have NetworkManager's intelligence to keep your computer connected across various interfaces at all times. It does not provide ifup/ifdown hooks for advanced scripting. Yet, systemd-networkd is integrated well with the rest of systemd components (e.g., **resolved** for DNS, **timesyncd** for NTP, udevd for naming), and the role of **systemd-networkd** may only grow over time in the systemd environment.
-
-如果你对 **systemd-networkd** 的进步感到高兴,从 NetworkManager 切换到 systemd-networkd 是值得你考虑的一件事。如果你强烈反对 systemd,对 NetworkManager 或[基础网络服务][2]感到很满意,那也很好。
-If you are happy with the way **systemd** is evolving, one thing you can consider is to switch from NetworkManager to systemd-networkd. If you are feverishly against systemd, and perfectly happy with NetworkManager or [basic network service][2], that is totally cool.
-
-但对于那些想尝试 systemd-networkd 的人,可以继续看下去,在这篇指南中学会在 Linux 中怎么从 NetworkManager 切换到 systemd-networkd。
-But for those of you who want to try out systemd-networkd, you can read on, and find out in this tutorial how to switch from NetworkManager to systemd-networkd on Linux.
-
-### 需求 ###
-### Requirement ###
-
-systemd 210 或更高版本提供了 systemd-networkd。因此诸如 Debian 8 "Jessie" (systemd 215)、 Fedora 21 (systemd 217)、 Ubuntu 15.04 (systemd 219) 或更高版本的 Linux 发行版和 systemd-networkd 兼容。
-systemd-networkd is available in systemd version 210 and higher. Thus distributions like Debian 8 "Jessie" (systemd 215), Fedora 21 (systemd 217), Ubuntu 15.04 (systemd 219) or later are compatible with systemd-networkd.
-
-对于其它发行版,在开始下一步之前先检查一下你的 systemd 版本。
-For other distributions, check the version of your systemd before proceeding.
-
- $ systemctl --version
-
-### 从 NetworkManager 切换到 Systemd-networkd ###
-### Switch from Network Manager to Systemd-Networkd ###
-
-从 NetworkManager 切换到 systemd-networkd 其实非常简答(反过来也一样)。
-It is relatively straightforward to switch from Network Manager to systemd-networkd (and vice versa).
-
-首先,按照下面这样先停用 NetworkManager 服务,然后启用 systemd-networkd。
-First, disable Network Manager service, and enable systemd-networkd as follows.
-
- $ sudo systemctl disable NetworkManager
- $ sudo systemctl enable systemd-networkd
-
-你还要启用 **systemd-resolved** 服务,systemd-networkd用它来进行域名解析。该服务还实现了一个缓存式 DNS 服务器。
-You also need to enable **systemd-resolved** service, which is used by systemd-networkd for network name resolution. This service implements a caching DNS server.
-
- $ sudo systemctl enable systemd-resolved
- $ sudo systemctl start systemd-resolved
-
-一旦启动,**systemd-resolved** 就会在 /run/systemd 目录下某个地方创建它自己的 resolv.conf。但是,把 DNS 解析信息存放在 /etc/resolv.conf 是更普遍的做法,很多应用程序也会依赖于 /etc/resolv.conf。因此为了兼容性,按照下面的方式创建一个到 /etc/resolv.conf 的符号链接。
-Once started, **systemd-resolved** will create its own resolv.conf somewhere under /run/systemd directory. However, it is a common practise to store DNS resolver information in /etc/resolv.conf, and many applications still rely on /etc/resolv.conf. Thus for compatibility reason, create a symlink to /etc/resolv.conf as follows.
-
- $ sudo rm /etc/resolv.conf
- $ sudo ln -s /run/systemd/resolve/resolv.conf /etc/resolv.conf
-
-### 用 systemd-networkd 配置网络连接 ###
-### Configure Network Connections with Systemd-networkd ###
-
-要用 systemd-networkd 配置网络服务,你必须指定带.network 扩展名的配置信息文本文件。这些网络配置文件保存到 /etc/systemd/network 并从这里加载。当有多个文件时,systemd-networkd 会按照词汇顺序一个个加载并处理。
-To configure network devices with systemd-networkd, you must specify configuration information in text files with .network extension. These network configuration files are then stored and loaded from /etc/systemd/network. When there are multiple files, systemd-networkd loads and processes them one by one in lexical order.
-
-首先创建 /etc/systemd/network 目录。
-Let's start by creating a folder /etc/systemd/network.
-
- $ sudo mkdir /etc/systemd/network
-
-#### DHCP 网络 ####
-#### DHCP Networking ####
-
-首先来配置 DHCP 网络。对于此,先要创建下面的配置文件。文件名可以任意,但记住文件是按照词汇顺序处理的。
-Let's configure DHCP networking first. For this, create the following configuration file. The name of a file can be arbitrary, but remember that files are processed in lexical order.
-
- $ sudo vi /etc/systemd/network/20-dhcp.network
-
-----------
-
- [Match]
- Name=enp3*
-
- [Network]
- DHCP=yes
-
-正如你上面看到的,每个网络配置文件包括了一个多多个 “sections”,每个 “section”都用 [XXX] 开头。每个 section 包括了一个或多个键值对。[Match] 部分决定这个配置文件配置哪个(些)网络设备。例如,这个文件匹配所有名称以 ens3 开头的网络设备(例如 enp3s0、 enp3s1、 enp3s2 等等)对于匹配的接口,然后启用 [Network] 部分指定的 DHCP 网络配置。
-As you can see above, each network configuration file contains one or more "sections" with each section preceded by [XXX] heading. Each section contains one or more key/value pairs. The [Match] section determine which network device(s) are configured by this configuration file. For example, this file matches any network interface whose name starts with ens3 (e.g., enp3s0, enp3s1, enp3s2, etc). For matched interface(s), it then applies DHCP network configuration specified under [Network] section.
-
-### 静态 IP 网络 ###
-### Static IP Networking ###
-
-如果你想给网络设备分配一个静态 IP 地址,那就新建下面的配置文件。
-If you want to assign a static IP address to a network interface, create the following configuration file.
-
- $ sudo vi /etc/systemd/network/10-static-enp3s0.network
-
-----------
-
- [Match]
- Name=enp3s0
-
- [Network]
- Address=192.168.10.50/24
- Gateway=192.168.10.1
- DNS=8.8.8.8
-
-正如你猜测的, enp3s0 接口地址会被指定为 192.168.10.50/24,默认网关是 192.168.10.1, DNS 服务器是 8.8.8.8。这里微妙的一点是,接口名 enp3s0 事实上也匹配了之前 DHCP 配置中定义的模式规则。但是,根据词汇顺序,文件 "10-static-enp3s0.network" 在 "20-dhcp.network" 之前被处理,对于 enp3s0 接口静态配置比 DHCP 配置有更高的优先级。
-As you can guess, the interface enp3s0 will be assigned an address 192.168.10.50/24, a default gateway 192.168.10.1, and a DNS server 8.8.8.8. One subtlety here is that the name of an interface enp3s0, in facts, matches the pattern rule defined in the earlier DHCP configuration as well. However, since the file "10-static-enp3s0.network" is processed before "20-dhcp.network" according to lexical order, the static configuration takes priority over DHCP configuration in case of enp3s0 interface.
-
-一旦你完成了创建配置文件,重启 systemd-networkd 服务或者重启机器。
-Once you are done with creating configuration files, restart systemd-networkd service or reboot.
-
- $ sudo systemctl restart systemd-networkd
-
-运行以下命令检查服务状态:
-Check the status of the service by running:
-
- $ systemctl status systemd-networkd
- $ systemctl status systemd-resolved
-
-
-
-### 用 systemd-networkd 配置虚拟网络设备 ###
-### Configure Virtual Network Devices with Systemd-networkd ###
-
-**systemd-networkd** 同样允许你配置虚拟网络设备,例如网桥、VLAN、隧道、VXLAN、绑定等。你必须在用 .netdev 作为扩展名的文件中配置这些虚拟设备。
-**systemd-networkd** also allows you to configure virtual network devices such as bridges, VLANs, tunnel, VXLAN, bonding, etc. You must configure these virtual devices in files with .netdev extension.
-
-这里我展示了如何配置一个桥接接口。
-Here I'll show how to configure a bridge interface.
-
-#### Linux 网桥 ####
-#### Linux Bridge ####
-
-如果你想创建一个 Linux 网桥(br0) 并把物理接口(eth1) 添加到网桥,你可以新建下面的配置。
-If you want to create a Linux bridge (br0) and add a physical interface (eth1) to the bridge, create the following configuration.
-
- $ sudo vi /etc/systemd/network/bridge-br0.netdev
-
-----------
-
- [NetDev]
- Name=br0
- Kind=bridge
-
-然后按照下面这样用 .network 文件配置网桥接口 br0 和从接口 eth1。
-Then configure the bridge interface br0 and the slave interface eth1 using .network files as follows.
-
- $ sudo vi /etc/systemd/network/bridge-br0-slave.network
-
-----------
-
- [Match]
- Name=eth1
-
- [Network]
- Bridge=br0
-
-----------
-
- $ sudo vi /etc/systemd/network/bridge-br0.network
-
-----------
-
- [Match]
- Name=br0
-
- [Network]
- Address=192.168.10.100/24
- Gateway=192.168.10.1
- DNS=8.8.8.8
-
-最后,重启 systemd-networkd。
-Finally, restart systemd-networkd:
-
- $ sudo systemctl restart systemd-networkd
-
-你可以用 [brctl 工具][3] 来验证是否创建了网桥 br0。
-You can use [brctl tool][3] to verify that a bridge br0 has been created.
-
-### 总结 ###
-### Summary ###
-
-当 systemd 誓言成为 Linux 的系统管理器时,有类似 systemd-networkd 的东西来管理网络配置也就不足为奇。但是在现阶段,systemd-networkd 看起来更适合于网络配置相对稳定的服务器环境。对于桌面/笔记本环境,它们有多种临时有线/无线接口,NetworkManager 仍然是比较好的选择。
-When systemd promises to be a system manager for Linux, it is no wonder something like systemd-networkd came into being to manage network configurations. At this stage, however, systemd-networkd seems more suitable for a server environment where network configurations are relatively stable. For desktop/laptop environments which involve various transient wired/wireless interfaces, NetworkManager may still be a preferred choice.
-
-对于想进一步了解 systemd-networkd 的人,可以参考官方[man 手册][4]了解完整的支持列表和关键点。
-For those who want to check out more on systemd-networkd, refer to the official [man page][4] for a complete list of supported sections and keys.
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/switch-from-networkmanager-to-systemd-networkd.html
-
-作者:[Dan Nanni][a]
-译者:[ictlyh](http://mutouxiaogui.cn/blog)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/nanni
-[1]:http://xmodulo.com/use-systemd-system-administration-debian.html
-[2]:http://xmodulo.com/disable-network-manager-linux.html
-[3]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
-[4]:http://www.freedesktop.org/software/systemd/man/systemd.network.html
diff --git a/translated/tech/20150929 A Developer's Journey into Linux Containers.md b/translated/tech/20150929 A Developer's Journey into Linux Containers.md
deleted file mode 100644
index a71b5e8fb3..0000000000
--- a/translated/tech/20150929 A Developer's Journey into Linux Containers.md
+++ /dev/null
@@ -1,128 +0,0 @@
-开发者的 Linux 容器之旅
-================================================================================
-
-
-我告诉你一个秘密:使得我的应用程序进入到全世界的所有云计算的东西,对我来说仍然有一点神秘。但随着时间流逝,我意识到理解大规模机器配置和应用程序部署的来龙去脉对一个开发者来说是非常重要的知识。这类似于成为一个专业的音乐家。你当然需要知道如何使用你的乐器。但是,如果你不知道一个录音室是如何工作的,或者你如何适应一个交响乐团,你在这样的环境中工作会变得非常困难。
-
-在软件开发的世界里,使你的代码进入我们更大的世界正如写出它来一样重要。开发重要,而且是很重要。
-
-因此,为了弥合开发和部署之间的间隔,我会从头开始介绍容器技术。为什么是容器?因为有强有力的证据表明,容器是机器抽象的下一步:使计算机成为场所而不再是一个东西。理解容器是我们共同的旅程。
-
-在这篇文章中,我会介绍容器化背后的概念。容器和虚拟机的区别。以及容器构建背后的逻辑以及它是如何适应应用程序架构的。我会探讨轻量级的 Linux 操作系统是如何适应容器生态系统。我还会讨论使用镜像创建可重用的容器。最后我会介绍容器集群如何使你的应用程序可以快速扩展。
-
-在后面的文章中,我会一步一步向你介绍容器化一个事例应用程序的过程,以及如何为你的应用程序容器创建一个托管集群。同时,我会向你展示如何使用 Deis 将你的事例应用程序部署到你本地系统以及多种云供应商的虚拟机上。
-
-让我们开始吧。
-
-### 虚拟机的好处 ###
-
-为了理解容器如何适应事物发展,你首先要了解容器的前者:虚拟机
-
-[虚拟机][1] 是运行在物理宿主机上的软件抽象。配置一个虚拟机就像是购买一台计算机:你需要定义你想要的 CPU 数目,RAM 和磁盘存储容量。配置好了机器后,你把它加载到操作系统,然后是你想让虚拟机支持的任何服务器或者应用程序。
-
-虚拟机允许你在一台硬件主机上运行多个模拟计算机。这是一个简单的示意图:
-
-
-
-虚拟机使得能充分利用你的硬件资源。你可以购买一台大型机然后在上面运行多个虚拟机。你可以有一个数据库虚拟机以及很多运行相同版本定制应用程序的虚拟机构成的集群。你可以在有限的硬件资源获得很多的扩展能力。如果你觉得你需要更多的虚拟机而且你的宿主硬件还有容量,你可以添加任何你想要的。或者,如果你不再需要一个虚拟机,你可以关闭该虚拟机并删除虚拟机镜像。
-
-### 虚拟机的局限 ###
-
-但是,虚拟机确实有局限。
-
-如上面所示,假如你在一个主机上创建了三个虚拟机。主机有 12 个 CPU,48 GB 内存和 3TB 的存储空间。每个虚拟机配置为有 4 个 CPU,16 GB 内存和 1TB 存储空间。到现在为止,一切都还好。主机有这个容量。
-
-但这里有个缺陷。所有分配给一个虚拟机的资源,无论是什么,都是专有的。每台机器都分配了 16 GB 的内存。但是,如果第一个虚拟机永不会使用超过 1GB 分配的内存,剩余的 15 GB 就会被浪费在那里。如果第三天虚拟机只使用分配的 1TB 存储空间中的 100GB,其余的 900GB 就成为浪费空间。
-
-这里没有资源的流动。每台虚拟机拥有分配给它的所有资源。因此,在某种方式上我们又回到了虚拟机之前,把大部分金钱花费在未使用的资源上。
-
-虚拟机还有*另一个*缺陷。扩展他们需要很长时间。如果你处于基础设施需要快速增长的情形,即使虚拟机配置是自动的,你仍然会发现你的很多时间都浪费在等待机器上线。
-
-### 来到:容器 ###
-
-概念上来说,容器是 Linux 中认为只有它自己的一个进程。该进程只知道告诉它的东西。另外,在容器化方面,该容器进程也分配了它自己的 IP 地址。这点很重要,我会再次重复。**在容器化方面,容器进程有它自己的 IP 地址**。一旦给予了一个 IP 地址,该进程就是宿主网络中可识别的资源。然后,你可以在容器管理器上运行命令,使容器 IP 映射到主机中能访问公网的 IP 地址。该映射发生时,对于任何意图和目的,一个容器就是网络上一个可访问的独立机器,概念上类似于虚拟机。
-
-再次说明,容器是拥有不同 IP 地址从而使其成为网络上可识别的独立 Linux 进程。下面是一个示意图:
-
-
-
-容器/进程以动态合作的方式共享主机上的资源。如果容器只需要 1GB 内存,它就只会使用 1GB。如果它需要 4GB,就会使用 4GB。CPU 和存储空间利用也是如此。CPU,内存和存储空间的分配是动态的,和典型虚拟机的静态方式不同。所有这些资源的共享都由容器管理器管理。
-
-最后,容器能快速启动。
-
-因此,容器的好处是:**你获得了虚拟机独立和封装的好处而抛弃了专有静态资源的缺陷**。另外,由于容器能快速加载到内存,在扩展到多个容器时你能获得更好的性能。
-
-### 容器托管、配置和管理 ###
-
-托管容器的计算机运行着被剥离的只剩下主要部分的 Linux 版本。现在,宿主计算机流行的底层操作系统是上面提到的 [CoreOS][2]。当然还有其它,例如 [Red Hat Atomic Host][3] 和 [Ubuntu Snappy][4]。
-
-所有容器之间共享Linux 操作系统,减少了容器足迹的重复和冗余。每个容器只包括该容器唯一的部分。下面是一个示意图:
-
-
-
-你用它所需的组件配置容器。一个容器组件被称为**层**。一层是一个容器镜像,(你会在后面的部分看到更多关于容器镜像的介绍)。你从一个基本层开始,这通常是你想在容器中使用的操作系统。(容器管理器只提供你想要的操作系统在宿主操作系统中不存在的部分。)当你构建配置你的容器时,你会添加层,例如你想要添加网络服务器 Apache,如果容器要运行脚本,则需要添加 PHP 或 Python 运行时。
-
-分层非常灵活。如果应用程序或者服务容器需要 PHP 5.2 版本,你相应地配置该容器即可。如果你有另一个应用程序或者服务需要 PHP 5.6 版本,没问题,你可以使用 PHP 5.6 配置该容器。不像虚拟机,更改一个版本的运行时依赖时你需要经过大量的配置和安装过程;对于容器你只需要在容器配置文件中重新定义层。
-
-所有上面描述的容器多功能性都由一个称为容器管理器的软件控制。现在,最流行的容器管理器是 [Docker][5] 和 [Rocket][6]。上面的示意图展示了容器管理器是 Docker,宿主操作系统是 CentOS 的主机情景。
-
-### 容器由镜像构成 ###
-
-当你需要将我们的应用程序构建到容器时,你就会编译镜像。镜像代表了需要完成容器工作的容器模板。(容器里的容器)。镜像被保存在网络上的注册表里。
-
-从概念上讲,注册表类似于一个使用 Java 的人眼中的 [Maven][7] 仓库,使用 .NET 的人眼中的 [NuGet][8] 服务器。你会创建一个列出了你应用程序所需镜像的容器配置文件。然后你使用容器管理器创建一个包括了你应用程序代码以及从注册表中下载的构成资源的容器。例如,如果你的应用程序包括了一些 PHP 文件,你的容器配置文件会声明你会从注册表中获取 PHP 运行时。另外,你还要使用容器配置文件声明需要复制到容器文件系统中的 .php 文件。容器管理器会封装你应用程序的所有东西为一个独立容器。该容器将会在容器管理器的管理下运行在宿主计算机上。
-
-这是一个容器创建背后概念的示意图:
-
-
-
-让我们仔细看看这个示意图。
-
-(1)表示一个定义了你容器所需东西以及你容器如何构建的容器配置文件。当你在主机上运行容器时,容器管理器会读取配置文件从云上的注册表中获取你需要的容器镜像,(2)作为层将镜像添加到你的容器。
-
-另外,如果组成镜像需要其它镜像,容器管理器也会获取这些镜像并把它们作为层添加进来。(3)容器管理器会将需要的文件复制到容器中。
-
-如果你使用了配置服务,例如 [Deis][9],你刚刚创建的应用程序容器作为镜像存在(4)配置服务会将它部署到你选择的云供应商上。类似 AWS 和 Rackspace 云供应商。
-
-### 集群中的容器 ###
-
-好了。这里有一个很好的例子说明了容器比虚拟机提供了更好的配置灵活性和资源利用率。但是,这并不是全部。
-
-容器真正灵活是在集群中。记住,每个容器有一个独立的 IP 地址。因此,能把它放到负载均衡器后面。将容器放到负载均衡器后面,就上升了一个层次。
-
-你可以在一个负载均衡容器后运行容器集群以获得更高的性能和高可用计算。这是一个例子:
-
-
-
-假如你开发了一个进行资源密集型工作的应用程序。例如图片处理。使用类似 [Deis][9] 的容器配置技术,你可以创建一个包括了你图片处理程序以及你图片处理程序需要的所有资源的容器镜像。然后,你可以部署一个或多个容器镜像到主机上的负载均衡器。一旦创建了容器镜像,你可以在系统快要刷爆时把它放到一边,为了满足手中的工作时添加更多的容器实例。
-
-这里还有更多好消息。你不需要每次添加实例到环境中时手动配置负载均衡器以便接受你的容器镜像。你可以使用服务发现技术告知均衡器你容器的可用性。然后,一旦获知,均衡器就会将流量分发到新的结点。
-
-### 全部放在一起 ###
-
-容器技术完善了虚拟机不包括的部分。类似 CoreOS、RHEL Atomic、和 Ubuntu 的 Snappy 宿主操作系统,和类似 Docker 和 Rocket 的容器管理技术结合起来,使得容器变得日益流行。
-
-尽管容器变得更加越来越普遍,掌握它们还是需要一段时间。但是,一旦你懂得了它们的窍门,你可以使用类似 [Deis][9] 的配置技术使容器创建和部署变得更加简单。
-
-概念上理解容器和进一步实际使用它们完成工作一样重要。但我认为不实际动手把想法付诸实践,概念也难以理解。因此,我们该系列的下一阶段就是:创建一些容器。
-
---------------------------------------------------------------------------------
-
-via: https://deis.com/blog/2015/developer-journey-linux-containers
-
-作者:[Bob Reselman][a]
-译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://deis.com/blog
-[1]:https://en.wikipedia.org/wiki/Virtual_machine
-[2]:https://coreos.com/using-coreos/
-[3]:http://www.projectatomic.io/
-[4]:https://developer.ubuntu.com/en/snappy/
-[5]:https://www.docker.com/
-[6]:https://coreos.com/blog/rocket/
-[7]:https://en.wikipedia.org/wiki/Apache_Maven
-[8]:https://www.nuget.org/
-[9]:http://deis.com/learn
\ No newline at end of file
diff --git a/translated/tech/20151022 9 Tips for Improving WordPress Performance.md b/translated/tech/20151022 9 Tips for Improving WordPress Performance.md
new file mode 100644
index 0000000000..9c105df42a
--- /dev/null
+++ b/translated/tech/20151022 9 Tips for Improving WordPress Performance.md
@@ -0,0 +1,520 @@
+
+提高 WordPress 性能的9个技巧
+================================================================================
+
+关于建站和 web 应用程序交付,WordPress 是全球最大的一个平台。全球大约 [四分之一][1] 的站点现在正在使用开源 WordPress 软件,包括 eBay, Mozilla, RackSpace, TechCrunch, CNN, MTV,纽约时报,华尔街日报。
+
+WordPress.com,对于用户创建博客平台是最流行的,其也运行在WordPress 开源软件上。[NGINX powers WordPress.com][2]。许多 WordPress 用户刚开始在 WordPress.com 上建站,然后移动到搭载着 WordPress 开源软件的托管主机上;其中大多数站点都使用 NGINX 软件。
+
+WordPress 的吸引力是它的简单性,无论是安装启动或者对于终端用户的使用。然而,当使用量不断增长时,WordPress 站点的体系结构也存在一定的问题 - 这里几个方法,包括使用缓存以及组合 WordPress 和 NGINX,可以解决这些问题。
+
+在这篇博客中,我们提供了9个技巧来进行优化,以帮助你解决 WordPress 中一些常见的性能问题:
+
+- [缓存静态资源][3]
+- [缓存动态文件][4]
+- [使用 NGINX][5]
+- [添加支持 NGINX 的链接][6]
+- [为 NGINX 配置 FastCGI][7]
+- [为 NGINX 配置 W3_Total_Cache][8]
+- [为 NGINX 配置 WP-Super-Cache][9]
+- [为 NGINX 配置安全防范措施][10]
+- [配置 NGINX 支持 WordPress 多站点][11]
+
+### 在 LAMP 架构下 WordPress 的性能 ###
+
+大多数 WordPress 站点都运行在传统的 LAMP 架构下:Linux 操作系统,Apache Web 服务器软件,MySQL 数据库软件 - 通常是一个单独的数据库服务器 - 和 PHP 编程语言。这些都是非常著名的,广泛应用的开源工具。大多数人都将 WordPress “称为” LAMP,并且很容易寻求帮助和支持。
+
+当用户访问 WordPress 站点时,浏览器为每个用户创建六到八个连接来运行 Linux/Apache 的组合。当用户请求连接时,每个页面的 PHP 文件开始飞速的从 MySQL 数据库争夺资源来响应请求。
+
+LAMP 对于数百个并发用户依然能照常工作。然而,流量突然增加是常见的并且 - 通常是 - 一件好事。
+
+但是,当 LAMP 站点变得繁忙时,当同时在线的用户达到数千个时,它的瓶颈就会被暴露出来。瓶颈存在主要是两个原因:
+
+1. Apache Web 服务器 - Apache 为每一个连接需要消耗大量资源。如果 Apache 接受了太多的并发连接,内存可能会耗尽,性能急剧降低,因为数据必须使用磁盘进行交换。如果以限制连接数来提高响应时间,新的连接必须等待,这也导致了用户体验变得很差。
+
+1. PHP/MySQL 的交互 - 总之,一个运行 PHP 和 MySQL 数据库服务器的应用服务器上每秒的请求量不能超过最大限制。当请求的数量超过最大连接数时,用户必须等待。超过最大连接数时也会增加所有用户的响应时间。超过其两倍以上时会出现明显的性能问题。
+
+ LAMP 架构的网站一般都会出现性能瓶颈,这时就需要升级硬件了 - 加 CPU,扩大磁盘空间等等。当 Apache 和 PHP/MySQL 的架构负载运行后,在硬件上不断的提升无法保证对系统资源指数增长的需求。
+
+最先取代 LAMP 架构的是 LEMP 架构 – Linux, NGINX, MySQL, 和 PHP。 (这是 LEMP 的缩写,E 代表着 “engine-x.” 的发音。) 我们在 [技巧 3][12] 中会描述 LEMP 架构。
+
+### 技巧 1. 缓存静态资源 ###
+
+静态资源是指不变的文件,像 CSS,JavaScript 和图片。这些文件往往在网页的数据中占半数以上。页面的其余部分是动态生成的,像在论坛中评论,仪表盘的性能,或个性化的内容(可以看看Amazon.com 产品)。
+
+缓存静态资源有两大好处:
+
+- 更快的交付给用户 - 用户从他们浏览器的缓存或者从互联网上离他们最近的缓存服务器获取静态文件。有时候文件较大,因此减少等待时间对他们来说帮助很大。
+
+- 减少应用服务器的负载 - 从缓存中检索到的每个文件会让 web 服务器少处理一个请求。你的缓存越多,用户等待的时间越短。
+
+要让浏览器缓存文件,需要早在静态文件中设置正确的 HTTP 首部。当看到 HTTP Cache-Control 首部时,特别设置了 max-age,Expires 首部,以及 Entity 标记。[这里][13] 有详细的介绍。
+
+当启用本地缓存然后用户请求以前访问过的文件时,浏览器首先检查该文件是否在缓存中。如果在,它会询问 Web 服务器该文件是否改变过。如果该文件没有改变,Web 服务器将立即响应一个304状态码(未改变),这意味着该文件没有改变,而不是返回状态码200 OK,然后继续检索并发送已改变的文件。
+
+为了支持浏览器以外的缓存,可以考虑下面的方法,内容分发网络(CDN)。CDN 是一种流行且强大的缓存工具,但我们在这里不详细描述它。可以想一下 CDN 背后的支撑技术的实现。此外,当你的站点从 HTTP/1.x 过渡到 HTTP/2 协议时,CDN 的用处可能不太大;根据需要调查和测试,找到你网站需要的正确方法。
+
+如果你转向 NGINX Plus 或开源的 NGINX 软件作为架构的一部分,建议你考虑 [技巧 3][14],然后配置 NGINX 缓存静态资源。使用下面的配置,用你 Web 服务器的 URL 替换 www.example.com。
+
+ server {
+ # substitute your web server's URL for www.example.com
+ server_name www.example.com;
+ root /var/www/example.com/htdocs;
+ index index.php;
+
+ access_log /var/log/nginx/example.com.access.log;
+ error_log /var/log/nginx/example.com.error.log;
+
+ location / {
+ try_files $uri $uri/ /index.php?$args;
+ }
+
+ location ~ \.php$ {
+ try_files $uri =404;
+ include fastcgi_params;
+ # 使用你 WordPress 服务器的套接字,地址和端口来替换
+ fastcgi_pass unix:/var/run/php5-fpm.sock;
+ #fastcgi_pass 127.0.0.1:9000;
+ }
+
+ location ~* .(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css|rss|atom|js|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
+ expires max;
+ log_not_found off;
+ access_log off;
+ }
+ }
+
+### 技巧 2. 缓存动态文件 ###
+
+WordPress 是动态生成的网页,这意味着每次请求时它都要生成一个给定的网页(即使和前一次的结果相同)。这意味着用户随时获得的是最新内容。
+
+想一下,当用户访问一个帖子时,并在文章底部有用户的评论时。你希望用户能够看到所有的评论 - 即使评论刚刚发布。动态内容就是处理这种情况的。
+
+但现在,当帖子每秒出现十几二十几个请求时。应用服务器可能每秒需要频繁生成页面导致其压力过大,造成延误。为了给用户提供最新的内容,每个访问理论上都是新的请求,因此他们也不得不在首页等待。
+
+为了防止页面由于负载过大变得缓慢,需要缓存动态文件。这需要减少文件的动态内容来提高整个系统的响应速度。
+
+要在 WordPress 中启用缓存中,需要使用一些流行的插件 - 如下所述。WordPress 的缓存插件需要刷新页面,然后将其缓存短暂时间 - 也许只有几秒钟。因此,如果该网站每秒中只有几个请求,那大多数用户获得的页面都是缓存的副本。这也有助于提高所有用户的检索时间:
+
+- 大多数用户获得页面的缓存副本。应用服务器没有做任何工作。
+- 用户很快会得到一个新的副本。应用服务器只需每隔一段时间刷新页面。当服务器产生一个新的页面(对于第一个用户访问后,缓存页过期),它这样做要快得多,因为它的请求不会超载。
+
+你可以缓存运行在 LAMP 架构或者 [LEMP 架构][15] 上 WordPress 的动态文件(在 [技巧 3][16] 中说明了)。有几个缓存插件,你可以在 WordPress 中使用。这里有最流行的缓存插件和缓存技术,从最简单到最强大的:
+
+- [Hyper-Cache][17] 和 [Quick-Cache][18] – 这两个插件为每个 WordPress 页面创建单个 PHP 文件。它支持的一些动态函数会绕过多个 WordPress 与数据库的连接核心处理,创建一个更快的用户体验。他们不会绕过所有的 PHP 处理,所以使用以下选项他们不能给出相同的性能提升。他们也不需要修改 NGINX 的配置。
+
+- [WP Super Cache][19] – 最流行的 WordPress 缓存插件。它有许多功能,它的界面非常简洁,如下图所示。我们展示了 NGINX 一个简单的配置实例在 [技巧 7][20] 中。
+
+- [W3 Total Cache][21] – 这是第二大最受欢迎的 WordPress 缓存插件。它比 WP Super Cache 的功能更强大,但它有些配置选项比较复杂。一个 NGINX 的简单配置,请看 [技巧 6][22]。
+
+- [FastCGI][23] – CGI 代表通用网关接口,在因特网上发送请求和接收文件。它不是一个插件只是一种能直接使用缓存的方法。FastCGI 可以被用在 Apache 和 Nginx 上,它也是最流行的动态缓存方法;我们在 [技巧 5][24] 中描述了如何配置 NGINX 来使用它。
+
+这些插件的技术文档解释了如何在 LAMP 架构中配置它们。配置选项包括数据库和对象缓存;也包括使用 HTML,CSS 和 JavaScript 来构建 CDN 集成环境。对于 NGINX 的配置,请看列表中的提示技巧。
+
+**注意**:WordPress 不能缓存用户的登录信息,因为它们的 WordPress 页面都是不同的。(对于大多数网站来说,只有一小部分用户可能会登录),大多数缓存不会对刚刚评论过的用户显示缓存页面,只有当用户刷新页面时才会看到他们的评论。若要缓存页面的非个性化内容,如果它对整体性能来说很重要,可以使用一种称为 [fragment caching][25] 的技术。
+
+### 技巧 3. 使用 NGINX ###
+
+如上所述,当并发用户数超过某一值时 Apache 会导致性能问题 – 可能数百个用户同时使用。Apache 对于每一个连接会消耗大量的资源,因而容易耗尽内存。Apache 可以配置连接数的值来避免耗尽内存,但是这意味着,超过限制时,新的连接请求必须等待。
+
+此外,Apache 使用 mod_php 模块将每一个连接加载到内存中,即使只有静态文件(图片,CSS,JavaScript 等)。这使得每个连接消耗更多的资源,从而限制了服务器的性能。
+
+开始解决这些问题吧,从 LAMP 架构迁到 LEMP 架构 – 使用 NGINX 取代 Apache 。NGINX 仅消耗很少量的内存就能处理成千上万的并发连接数,所以你不必经历颠簸,也不必限制并发连接数。
+
+NGINX 处理静态文件的性能也较好,它有内置的,简单的 [缓存][26] 控制策略。减少应用服务器的负载,你的网站的访问速度会更快,用户体验更好。
+
+你可以在部署的所有 Web 服务器上使用 NGINX,或者你可以把一个 NGINX 服务器作为 Apache 的“前端”来进行反向代理 - NGINX 服务器接收客户端请求,将请求的静态文件直接返回,将 PHP 请求转发到 Apache 上进行处理。
+
+对于动态页面的生成 - WordPress 核心体验 - 选择一个缓存工具,如 [技巧 2][27] 中描述的。在下面的技巧中,你可以看到 FastCGI,W3_Total_Cache 和 WP-Super-Cache 在 NGINX 上的配置示例。 (Hyper-Cache 和 Quick-Cache 不需要改变 NGINX 的配置。)
+
+**技巧** 缓存通常会被保存到磁盘上,但你可以用 [tmpfs][28] 将缓存放在内存中来提高性能。
+
+为 WordPress 配置 NGINX 很容易。按照这四个步骤,其详细的描述在指定的技巧中:
+
+1.添加永久的支持 - 添加对 NGINX 的永久支持。此步消除了对 **.htaccess** 配置文件的依赖,这是 Apache 特有的。参见 [技巧 4][29]
+2.配置缓存 - 选择一个缓存工具并安装好它。可选择的有 FastCGI cache,W3 Total Cache, WP Super Cache, Hyper Cache, 和 Quick Cache。请看技巧 [5][30], [6][31], 和 [7][32].
+3.落实安全防范措施 - 在 NGINX 上采用对 WordPress 最佳安全的做法。参见 [技巧 8][33]。
+4.配置 WordPress 多站点 - 如果你使用 WordPress 多站点,在 NGINX 下配置子目录,子域,或多个域的结构。见 [技巧9][34]。
+
+### 技巧 4. 添加支持 NGINX 的链接 ###
+
+许多 WordPress 网站依靠 **.htaccess** 文件,此文件依赖 WordPress 的多个功能,包括永久支持,插件和文件缓存。NGINX 不支持 **.htaccess** 文件。幸运的是,你可以使用 NGINX 的简单而全面的配置文件来实现大部分相同的功能。
+
+你可以在使用 NGINX 的 WordPress 中通过在主 [server][36] 块下添加下面的 location 块中启用 [永久链接][35]。(此 location 块在其他代码示例中也会被包括)。
+
+**try_files** 指令告诉 NGINX 检查请求的 URL 在根目录下是作为文件(**$uri**)还是目录(**$uri/**),**/var/www/example.com/htdocs**。如果都不是,NGINX 将重定向到 **/index.php**,通过查询字符串参数判断是否作为参数。
+
+ server {
+ server_name example.com www.example.com;
+ root /var/www/example.com/htdocs;
+ index index.php;
+
+ access_log /var/log/nginx/example.com.access.log;
+ error_log /var/log/nginx/example.com.error.log;
+
+ location / {
+ try_files $uri $uri/ /index.php?$args;
+ }
+ }
+
+### 技巧 5. 在 NGINX 中配置 FastCGI ###
+
+NGINX 可以从 FastCGI 应用程序中缓存响应,如 PHP 响应。此方法可提供最佳的性能。
+
+对于开源的 NGINX,第三方模块 [ngx_cache_purge][37] 提供了缓存清除能力,需要手动编译,配置代码如下所示。NGINX Plus 已经包含了此代码的实现。
+
+当使用 FastCGI 时,我们建议你安装 [NGINX 辅助插件][38] 并使用下面的配置文件,尤其是要使用 **fastcgi_cache_key** 并且 location 块下要包括 **fastcgi_cache_purge**。当页面被发布或有改变时,甚至有新评论被发布时,该插件会自动清除你的缓存,你也可以从 WordPress 管理控制台手动清除。
+
+NGINX 的辅助插件还可以添加一个简短的 HTML 代码到你网页的底部,确认缓存是否正常并显示一些统计工作。(你也可以使用 [$upstream_cache_status][39] 确认缓存功能是否正常。)
+
+fastcgi_cache_path /var/run/nginx-cache levels=1:2
+ keys_zone=WORDPRESS:100m inactive=60m;
+fastcgi_cache_key "$scheme$request_method$host$request_uri";
+
+ server {
+ server_name example.com www.example.com;
+ root /var/www/example.com/htdocs;
+ index index.php;
+
+ access_log /var/log/nginx/example.com.access.log;
+ error_log /var/log/nginx/example.com.error.log;
+
+ set $skip_cache 0;
+
+ # POST 请求和查询网址的字符串应该交给 PHP
+ if ($request_method = POST) {
+ set $skip_cache 1;
+ }
+
+ if ($query_string != "") {
+ set $skip_cache 1;
+ }
+
+ #以下 uris 中包含的部分不缓存
+ if ($request_uri ~* "/wp-admin/|/xmlrpc.php|wp-.*.php|/feed/|index.php
+ |sitemap(_index)?.xml") {
+ set $skip_cache 1;
+ }
+
+ #用户不能使用缓存登录或缓存最近的评论
+ if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+|wp-postpass
+ |wordpress_no_cache|wordpress_logged_in") {
+ set $skip_cache 1;
+ }
+
+ location / {
+ try_files $uri $uri/ /index.php?$args;
+ }
+
+ location ~ \.php$ {
+ try_files $uri /index.php;
+ include fastcgi_params;
+ fastcgi_pass unix:/var/run/php5-fpm.sock;
+ fastcgi_cache_bypass $skip_cache;
+ fastcgi_no_cache $skip_cache;
+ fastcgi_cache WORDPRESS;
+ fastcgi_cache_valid 60m;
+ }
+
+ location ~ /purge(/.*) {
+ fastcgi_cache_purge WORDPRESS "$scheme$request_method$host$1";
+ }
+
+ location ~* ^.+\.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css|rss|atom|js|jpg|jpeg|gif|png
+ |ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
+
+ access_log off;
+ log_not_found off;
+ expires max;
+ }
+
+ location = /robots.txt {
+ access_log off;
+ log_not_found off;
+ }
+
+ location ~ /\. {
+ deny all;
+ access_log off;
+ log_not_found off;
+ }
+ }
+
+### 技巧 6. 为 NGINX 配置 W3_Total_Cache ###
+
+[W3 Total Cache][40], 是 Frederick Townes 的 [W3-Edge][41] 下的, 是一个支持 NGINX 的 WordPress 缓存框架。其有众多选项配置,可以替代 FastCGI 缓存。
+
+缓存插件提供了各种缓存配置,还包括数据库和对象的缓存,对 HTML,CSS 和 JavaScript,可选择性的与流行的 CDN 整合。
+
+使用插件时,需要将其配置信息写入位于你的域的根目录的 NGINX 配置文件中。
+
+ server {
+ server_name example.com www.example.com;
+
+ root /var/www/example.com/htdocs;
+ index index.php;
+ access_log /var/log/nginx/example.com.access.log;
+ error_log /var/log/nginx/example.com.error.log;
+
+ include /path/to/wordpress/installation/nginx.conf;
+
+ location / {
+ try_files $uri $uri/ /index.php?$args;
+ }
+
+ location ~ \.php$ {
+ try_files $uri =404;
+ include fastcgi_params;
+ fastcgi_pass unix:/var/run/php5-fpm.sock;
+ }
+ }
+
+### 技巧 7. 为 NGINX 配置 WP Super Cache ###
+
+[WP Super Cache][42] 是由 Donncha O Caoimh 完成的, [Automattic][43] 上的一个 WordPress 开发者, 这是一个 WordPress 缓存引擎,它可以将 WordPress 的动态页面转变成静态 HTML 文件,以使 NGINX 可以很快的提供服务。它是第一个 WordPress 缓存插件,和其他的相比,它更专注于某一特定的领域。
+
+配置 NGINX 使用 WP Super Cache 可以根据你的喜好而进行不同的配置。以下是一个示例配置。
+
+在下面的配置中,location 块中使用了名为 WP Super Cache 的超级缓存中部分配置来工作。代码的其余部分是根据 WordPress 的规则不缓存用户登录信息,不缓存 POST 请求,并对静态资源设置过期首部,再加上标准的 PHP 实现;这部分可以进行定制,来满足你的需求。
+
+
+ server {
+ server_name example.com www.example.com;
+ root /var/www/example.com/htdocs;
+ index index.php;
+
+ access_log /var/log/nginx/example.com.access.log;
+ error_log /var/log/nginx/example.com.error.log debug;
+
+ set $cache_uri $request_uri;
+
+ # POST 请求和查询网址的字符串应该交给 PHP
+ if ($request_method = POST) {
+ set $cache_uri 'null cache';
+ }
+ if ($query_string != "") {
+ set $cache_uri 'null cache';
+ }
+
+ #以下 uris 中包含的部分不缓存
+ if ($request_uri ~* "(/wp-admin/|/xmlrpc.php|/wp-(app|cron|login|register|mail).php
+ |wp-.*.php|/feed/|index.php|wp-comments-popup.php
+ |wp-links-opml.php|wp-locations.php |sitemap(_index)?.xml
+ |[a-z0-9_-]+-sitemap([0-9]+)?.xml)") {
+
+ set $cache_uri 'null cache';
+ }
+
+ #用户不能使用缓存登录或缓存最近的评论
+ if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+
+ |wp-postpass|wordpress_logged_in") {
+ set $cache_uri 'null cache';
+ }
+
+ #当请求的文件存在时使用缓存,否则将请求转发给WordPress
+ location / {
+ try_files /wp-content/cache/supercache/$http_host/$cache_uri/index.html
+ $uri $uri/ /index.php;
+ }
+
+ location = /favicon.ico {
+ log_not_found off;
+ access_log off;
+ }
+
+ location = /robots.txt {
+ log_not_found off
+ access_log off;
+ }
+
+ location ~ .php$ {
+ try_files $uri /index.php;
+ include fastcgi_params;
+ fastcgi_pass unix:/var/run/php5-fpm.sock;
+ #fastcgi_pass 127.0.0.1:9000;
+ }
+
+ # 尽可能的缓存静态文件
+ location ~*.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css
+ |rss|atom|js|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2
+ |doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
+ expires max;
+ log_not_found off;
+ access_log off;
+ }
+ }
+
+### 技巧 8. 为 NGINX 配置安全防范措施 ###
+
+为了防止攻击,可以控制对关键资源的访问以及当机器超载时进行登录限制。
+
+只允许特定的 IP 地址访问 WordPress 的仪表盘。
+
+ #对访问 WordPress 的仪表盘进行限制
+ location /wp-admin {
+ deny 192.192.9.9;
+ allow 192.192.1.0/24;
+ allow 10.1.1.0/16;
+ deny all;
+ }
+
+只允许上传特定类型的文件,以防止恶意代码被上传和运行。
+
+ #当上传的不是图像,视频,音乐等时,拒绝访问。
+ location ~* ^/wp-content/uploads/.*.(html|htm|shtml|php|js|swf)$ {
+ deny all;
+ }
+
+拒绝其他人访问 WordPress 的配置文件 **wp-config.php**。拒绝其他人访问的另一种方法是将该文件的一个目录移到域的根目录下。
+
+ # 拒绝其他人访问 wp-config.php
+ location ~* wp-config.php {
+ deny all;
+ }
+
+对 **wp-login.php** 进行限速来防止暴力攻击。
+
+ # 拒绝访问 wp-login.php
+ location = /wp-login.php {
+ limit_req zone=one burst=1 nodelay;
+ fastcgi_pass unix:/var/run/php5-fpm.sock;
+ #fastcgi_pass 127.0.0.1:9000;
+ }
+
+### 技巧 9. 配置 NGINX 支持 WordPress 多站点 ###
+
+WordPress 多站点,顾名思义,使用同一个版本的 WordPress 从单个实例中允许你管理两个或多个网站。[WordPress.com][44] 运行的就是 WordPress 多站点,其主机为成千上万的用户提供博客服务。
+
+你可以从单个域的任何子目录或从不同的子域来运行独立的网站。
+
+使用此代码块添加对子目录的支持。
+
+ # 在 WordPress 中添加支持子目录结构的多站点
+ if (!-e $request_filename) {
+ rewrite /wp-admin$ $scheme://$host$uri/ permanent;
+ rewrite ^(/[^/]+)?(/wp-.*) $2 last;
+ rewrite ^(/[^/]+)?(/.*\.php) $2 last;
+ }
+
+使用此代码块来替换上面的代码块以添加对子目录结构的支持,子目录名自定义。
+
+ # 添加支持子域名
+ server_name example.com *.example.com;
+
+旧版本(3.4以前)的 WordPress 多站点使用 readfile() 来提供静态内容。然而,readfile() 是 PHP 代码,它会导致在执行时性能会显著降低。我们可以用 NGINX 来绕过这个非必要的 PHP 处理。该代码片段在下面被(==============)线分割出来了。
+
+ # 避免 PHP readfile() 在 /blogs.dir/structure 子目录中
+ location ^~ /blogs.dir {
+ internal;
+ alias /var/www/example.com/htdocs/wp-content/blogs.dir;
+ access_log off;
+ log_not_found off;
+ expires max;
+ }
+
+ ============================================================
+
+ # 避免 PHP readfile() 在 /files/structure 子目录中
+ location ~ ^(/[^/]+/)?files/(?.+) {
+ try_files /wp-content/blogs.dir/$blogid/files/$rt_file /wp-includes/ms-files.php?file=$rt_file;
+ access_log off;
+ log_not_found off;
+ expires max;
+ }
+
+ ============================================================
+
+ # WPMU 文件结构的子域路径
+ location ~ ^/files/(.*)$ {
+ try_files /wp-includes/ms-files.php?file=$1 =404;
+ access_log off;
+ log_not_found off;
+ expires max;
+ }
+
+ ============================================================
+
+ # 地图博客 ID 在特定的目录下
+ map $http_host $blogid {
+ default 0;
+ example.com 1;
+ site1.example.com 2;
+ site1.com 2;
+ }
+
+### 结论 ###
+
+可扩展性对许多站点的开发者来说是一项挑战,因为这会让他们在 WordPress 站点中取得成功。(对于那些想要跨越 WordPress 性能问题的新站点。)为 WordPress 添加缓存,并将 WordPress 和 NGINX 结合,是不错的答案。
+
+NGINX 不仅对 WordPress 网站是有用的。世界上排名前 1000,10,000和100,000网站中 NGINX 也是作为 [领先的 web 服务器][45] 被使用。
+
+欲了解更多有关 NGINX 的性能,请看我们最近的博客,[关于 10x 应用程序的 10 个技巧][46]。
+
+NGINX 软件有两个版本:
+
+- NGINX 开源的软件 - 像 WordPress 一样,此软件你可以自行下载,配置和编译。
+- NGINX Plus - NGINX Plus 包括一个预构建的参考版本的软件,以及服务和技术支持。
+
+想要开始,先到 [nginx.org][47] 下载开源软件并了解下 [NGINX Plus][48]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/
+
+作者:[Floyd Smith][a]
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.nginx.com/blog/author/floyd/
+[1]:http://w3techs.com/technologies/overview/content_management/all
+[2]:https://www.nginx.com/press/choosing-nginx-growth-wordpresscom/
+[3]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-static
+[4]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-dynamic
+[5]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
+[6]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#permalink
+[7]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
+[8]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
+[9]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
+[10]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#security
+[11]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#multisite
+[12]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
+[13]:http://www.mobify.com/blog/beginners-guide-to-http-cache-headers/
+[14]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
+[15]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#lamp
+[16]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
+[17]:https://wordpress.org/plugins/hyper-cache/
+[18]:https://wordpress.org/plugins/quick-cache/
+[19]:https://wordpress.org/plugins/wp-super-cache/
+[20]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
+[21]:https://wordpress.org/plugins/w3-total-cache/
+[22]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
+[23]:http://www.fastcgi.com/
+[24]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
+[25]:https://css-tricks.com/wordpress-fragment-caching-revisited/
+[26]:https://www.nginx.com/resources/admin-guide/content-caching/
+[27]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-dynamic
+[28]:https://www.kernel.org/doc/Documentation/filesystems/tmpfs.txt
+[29]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#permalink
+[30]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
+[31]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
+[32]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
+[33]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#security
+[34]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#multisite
+[35]:http://codex.wordpress.org/Using_Permalinks
+[36]:http://nginx.org/en/docs/http/ngx_http_core_module.html#server
+[37]:https://github.com/FRiCKLE/ngx_cache_purge
+[38]:https://wordpress.org/plugins/nginx-helper/
+[39]:http://nginx.org/en/docs/http/ngx_http_upstream_module.html#variables
+[40]:https://wordpress.org/plugins/w3-total-cache/
+[41]:http://www.w3-edge.com/
+[42]:https://wordpress.org/plugins/wp-super-cache/
+[43]:http://automattic.com/
+[44]:https://wordpress.com/
+[45]:http://w3techs.com/technologies/cross/web_server/ranking
+[46]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/
+[47]:http://www.nginx.org/en
+[48]:https://www.nginx.com/products/
+[49]:
+[50]:
diff --git a/translated/tech/20151028 10 Tips for 10x Application Performance.md b/translated/tech/20151028 10 Tips for 10x Application Performance.md
new file mode 100644
index 0000000000..55cd24bd9a
--- /dev/null
+++ b/translated/tech/20151028 10 Tips for 10x Application Performance.md
@@ -0,0 +1,279 @@
+10 Tips for 10x Application Performance
+
+将程序性能提高十倍的10条建议
+================================================================================
+
+提高web 应用的性能从来没有比现在更关键过。网络经济的比重一直在增长;全球经济超过5% 的价值是在因特网上产生的(数据参见下面的资料)。我们的永远在线、超级连接的世界意味着用户的期望值也处于历史上的最高点。如果你的网站不能及时的响应,或者你的app 不能无延时的工作,用户会很快的投奔到你的竞争对手那里。
+
+举一个例子,一份亚马逊十年前做过的研究可以证明,甚至在那个时候,网页加载时间每减少100毫秒,收入就会增加1%。另一个最近的研究特别强调一个事实,即超过一半的网站拥有着在调查中说他们会因为应用程序性能的问题流失用户。
+
+网站到底需要多块呢?对于页面加载,每增加1秒钟就有4%的用户放弃使用。顶级的电子商务站点的页面在第一次交互时可以做到1秒到3秒加载时间,而这是提供最高舒适度的速度。很明显这种利害关系对于web 应用来说很高,而且在不断的增加。
+
+想要提高效率很简单,但是看到实际结果很难。要在旅途上帮助你,这篇blog 会给你提供10条最高可以10倍的提升网站性能的建议。这是系列介绍提高应用程序性能的第一篇文章,包括测试充分的优化技术和一点NGIX 的帮助。这个系列给出了潜在的提高安全性的帮助。
+
+### Tip #1: 通过反向代理来提高性能和增加安全性 ###
+
+如果你的web 应用运行在单个机器上,那么这个办法会明显的提升性能:只需要添加一个更快的机器,更好的处理器,更多的内存,更快的磁盘阵列,等等。然后新机器就可以更快的运行你的WordPress 服务器, Node.js 程序, Java 程序,以及其它程序。(如果你的程序要访问数据库服务器,那么这个办法还是很简单:添加两个更快的机器,以及在两台电脑之间使用一个更快的链路。)
+
+问题是,机器速度可能并不是问题。web 程序运行慢经常是因为计算机一直在不同的任务之间切换:和用户的成千上万的连接,从磁盘访问文件,运行代码,等等。应用服务器可能会抖动-内存不足,将内存数据写会磁盘,以及多个请求等待一个任务完成,如磁盘I/O。
+
+你可以采取一个完全不同的方案来替代升级硬件:添加一个反向代理服务器来分担部分任务。[反向代理服务器][1] 位于运行应用的机器的前端,是用来处理网络流量的。只有反向代理服务器是直接连接到互联网的;和程序的通讯都是通过一个快速的内部网络完成的。
+
+使用反向代理服务器可以将应用服务器从等待用户与web 程序交互解放出来,这样应用服务器就可以专注于为反向代理服务器构建网页,让其能够传输到互联网上。而应用服务器就不需要在能带客户端的响应,可以运行与接近优化过的性能水平。
+
+添加方向代理服务器还可以给你的web 服务器安装带来灵活性。比如,一个已知类型的服务器已经超载了,那么就可以轻松的添加另一个相同的服务器;如果某个机器宕机了,也可以很容易的被替代。
+
+因为反向代理带来的灵活性,所以方向代理也是一些性能加速功能的必要前提,比如:
+
+- **负载均衡** (参见 [Tip #2][2]) – 负载均衡运行在方向代理服务器上,用来将流量均衡分配给一批应用。有了合适的负载均衡,你就可以在不改变程序的前提下添加应用服务器。
+- **缓存静态文件** (参见 [Tip #3][3]) – 直接读取的文件,比如图像或者代码,可以保存在方向代理服务器,然后直接发给客户端,这样就可以提高速度、分担应用服务器的负载,可以让应用运行的更快
+- **网站安全** – 反响代理服务器可以提高网站安全性,以及快速的发现和响应攻击,保证应用服务器处于被保护状态。
+
+NGINX 软件是一个专门设计的反响代理服务器,也包含了上述的多种功能。NGINX 使用事件驱动的方式处理问题,着回避传统的服务器更加有效率。NGINX plus 天价了更多高级的反向代理特性,比如程序[健康度检查][4],专门用来处理request 路由,高级缓冲和相关支持。
+
+
+
+### Tip #2: 添加负载平衡 ###
+
+添加一个[负载均衡服务器][5] 是一个相当简单的用来提高性能和网站安全性的的方法。使用负载均衡讲流量分配到多个服务器,是用来替代只使用一个巨大且高性能web 服务器的方案。即使程序写的不好,或者在扩容方面有困难,只使用负载均衡服务器就可以很好的提高用户体验。
+
+负载均衡服务器首先是一个反响代理服务器(参见[Tip #1][6])——它接收来自互联网的流量,然后转发请求给另一个服务器。小戏法是负载均衡服务器支持两个或多个应用服务器,使用[分配算法][7]将请求转发给不同服务器。最简单的负载均衡方法是轮转法,只需要将新的请求发给列表里的下一个服务器。其它的方法包括将请求发给负载最小的活动连接。NGINX plus 拥有将特定用户的会话分配给同一个服务器的[能力][8].
+
+负载均衡可以很好的提高性能是因为它可以避免某个服务器过载而另一些服务器却没有流量来处理。它也可以简单的扩展服务器规模,因为你可以添加多个价格相对便宜的服务器并且保证它们被充分利用了。
+
+可以进行负载均衡的协议包括HTTP, HTTPS, SPDY, HTTP/2, WebSocket,[FastCGI][9],SCGI,uwsgi, memcached,以及集中其它的应用类型,包括采用TCP 第4层协议的程序。分析你的web 应用来决定那些你要使用以及那些地方的性能不足。
+
+相同的服务器或服务器群可以被用来进行负载均衡,也可以用来处理其它的任务,如SSL 终止,提供对客户端使用的HTTP/1/x 和 HTTP/2 ,以及缓存静态文件。
+
+NGINX 经常被用来进行负载均衡;要想了解更多的情况可以访问我们的[overview blog post][10], [configuration blog post][11], [ebook][12] 以及相关网站 [webinar][13], 和 [documentation][14]。我们的商业版本 [NGINX Plus][15] 支持更多优化了的负载均衡特性,如基于服务器响应时间的加载路由和Microsoft’s NTLM 协议上的负载均衡。
+
+### Tip #3: 缓存静态和动态的内容 ###
+
+缓存通过加速内容的传输速度来提高web 应用的性能。它可以采用一下集中策略:当需要的时候预处理要传输的内容,保存数据到速度更快的设备,把数据存储在距离客户端更近的位置,或者结合起来使用。
+
+下面要考虑两种不同类型数据的缓冲:
+
+- **静态内容缓存**。不经常变化的文件,比如图像(JPEG,PNG) 和代码(CSS,JavaScript),可以保存在边缘服务器,这样就可以快速的从内存和磁盘上提取。
+- **动态内容缓存**。很多web 应用回针对每个网页请求生成不同的HTML 页面。在短时间内简单的缓存每个生成HTML 内容,就可以很好的减少要生成的内容的数量,这完全可以达到你的要求。
+
+举个例子,如果一个页面每秒会被浏览10次,你将它缓存1 秒,99%请求的页面都会直接从缓存提取。如果你将将数据分成静态内容,甚至新生成的页面可能都是由这些缓存构成的。
+
+下面由是web 应用发明的三种主要的缓存技术:
+
+- **缩短数据与用户的距离**。把一份内容的拷贝放的离用户更近点来减少传输时间。
+- **提高内容服务器的速度**。内容可以保存在一个更快的服务器上来减少提取文件的时间。
+- **从过载服务器拿走数据**。机器经常因为要完成某些其它的任务而造成某个任务的执行速度比测试结果要差。将数据缓存在不同的机器上可以提高缓存资源和非缓存资源的效率,而这知识因为主机没有被过度使用。
+
+对web 应用的缓存机制可以web 应用服务器内部实现。第一,缓存动态内容是用来减少应用服务器加载动态内容的时间。然后,缓存静态内容(包括动态内容的临时拷贝)是为了更进一步的分担应用服务器的负载。而且缓存之后会从应用服务器转移到对用户而言更快、更近的机器,从而减少应用服务器的压力,减少提取数据和传输数据的时间。
+
+改进过的缓存方案可以极大的提高应用的速度。对于大多数网页来说,静态数据,比如大图像文件,构成了超过一半的内容。如果没有缓存,那么这可能会花费几秒的时间来提取和传输这类数据,但是采用了缓存之后不到1秒就可以完成。
+
+举一个在实际中缓存是如何使用的例子, NGINX 和NGINX Plus使用了两条指令来[设置缓存机制][16]:proxy_cache_path 和 proxy_cache。你可以指定缓存的位置和大小,文件在缓存中保存的最长时间和其他一些参数。使用第三条(而且是相当受欢迎的一条)指令,proxy_cache_use_stale,如果服务器提供新鲜内容是忙或者挂掉之类的信息,你甚至可以让缓存提供旧的内容,这样客户端就不会一无所得。从用户的角度来看这可以很好的提高你的网站或者应用的上线时间。
+
+NGINX plus 拥有[高级缓存特性][17],包括对[缓存清除][18]的支持和在[仪表盘][19]上显示缓存状态信息。
+
+要想获得更多关于NGINX 的缓存机制的信息可以浏览NGINX Plus 管理员指南中的 [reference documentation][20] 和 [NGINX Content Caching][21] 。
+
+**注意**:缓存机制分布于应用开发者、投资决策者以及实际的系统运维人员之间。本文提到的一些复杂的缓存机制从[DevOps 的角度][23]来看很具有价值,即对集应用开发者、架构师以及运维操作人员的功能为一体的工程师来说可以满足他们对站点功能性、响应时间、安全性和商业结果,如完成的交易数。
+
+### Tip #4: 压缩数据 ###
+
+压缩是一个具有很大潜力的提高性能的加速方法。现在已经有一些针对照片(JPEG 和PNG)、视频(MPEG-4)和音乐(MP3)等各类文件精心设计和高压缩率的标准。每一个标准都或多或少的减少了文件的大小。
+
+文本数据 —— 包括HTML(包含了纯文本和HTL 标签),CSS和代码,比如Javascript —— 经常是未经压缩就传输的。压缩这类数据会在对应用程序性能的感觉上,特别是处于慢速或受限的移动网络的客户端,产生不成比例的影响。
+
+这是因为文本数据经常是用户与网页交互的有效数据,而多媒体数据可能更多的是起提供支持或者装饰的作用。聪明的内容压缩可以减少HTML,Javascript,CSS和其他文本内容对贷款的要求,通常可以减少30% 甚至更多的带宽和相应的页面加载时间。
+
+如果你是用SSL,压缩可以减少需要进行SSL 编码的的数据量,而这些编码操作会占用一些CPU时间而抵消了压缩数据减少的时间。
+
+压缩文本数据的方法很多,举个例子,在定义小说文本压缩模式的[HTTP/2 部分]就专门为适应头数据。另一个例子是可以在NGINX 里打开使用GZIP 压缩文本。你在你的服务里[预压缩文本数据][25]之后,你就可以直接使用gzip_static 指令来处理压缩过的.gz 版本。
+
+### Tip #5: 优化 SSL/TLS ###
+
+安全套接字([SSL][26]) 协议和它的继承者,传输层安全(TLS)协议正在被越来越多的网站采用。SSL/TLS 对从原始服务器发往用户的数据进行加密提高了网站的安全性。影响这个趋势的部分原因是Google 正在使用SSL/TLS,这在搜索引擎排名上是一个正面的影响因素。
+
+尽管SSL/TLS 越来越流行,但是使用加密对速度的影响也让很多网站望而却步。SSL/TLS 之所以让网站变的更慢,原因有二:
+
+1. 任何一个连接第一次连接时的握手过程都需要传递密钥。而采用HTTP/1.x 协议的浏览器在建立多个连接时会对每个连接重复上述操作。
+2. 数据在传输过程中需要不断的在服务器加密、在客户端解密。
+
+要鼓励使用SSL/TLS,HTTP/2 和SPDY(在[下一章][27]会描述)的作者设计新的协议来让浏览器只需要对一个浏览器会话使用一个连接。这会大大的减少上述两个原因中的一个浪费的时间。然而现在可以用来提高应用程序使用SSL/TLS 传输数据的性能的方法不止这些。
+
+web 服务器有对应的机制优化SSL/TLS 传输。举个例子,NGINX 使用[OpenSSL][28]运行在普通的硬件上提供接近专用硬件的传输性能。NGINX [SSL 性能][29] 有详细的文档,而且把对SSL/TLS 数据进行加解密的时间和CPU 占用率降低了很多。
+
+更进一步,在这篇[blog][30]有详细的说明如何提高SSL/TLS 性能,可以总结为一下几点:
+
+- **会话缓冲**。使用指令[ssl_session_cache][31]可以缓存每个新的SSL/TLS 连接使用的参数。
+- **会话票据或者ID**。把SSL/TLS 的信息保存在一个票据或者ID 里可以流畅的复用而不需要重新握手。
+- **OCSP 分割**。通过缓存SSL/TLS 证书信息来减少握手时间。
+
+NGINX 和NGINX Plus 可以被用作SSL/TLS 终结——处理客户端流量的加密和解密,而同时和其他服务器进行明文通信。使用[这几步][32] 来设置NGINX 和NGINX Plus 处理SSL/TLS 终止。同时,这里还有一些NGINX Plus 和接收TCP 连接的服务器一起使用时的[特有的步骤][33]
+
+### Tip #6: 使用 HTTP/2 或 SPDY ###
+
+对于已经使用了SSL/TLS 的站点,HTTP/2 和SPDY 可以很好的提高性能,因为每个连接只需要一次握手。而对于没有使用SSL/TLS 的站点来说,HTTP/2 和SPDY会在响应速度上有些影响(通常会将度效率)。
+
+Google 在2012年开始把SPDY 作为一个比HTTP/1.x 更快速的协议来推荐。HTTP/2 是目前IETF 标准,他也基于SPDY。SPDY 已经被广泛的支持了,但是很快就会被HTTP/2 替代。
+
+SPDY 和HTTP/2 的关键是用单连接来替代多路连接。单个连接是被复用的,所以它可以同时携带多个请求和响应的分片。
+
+通过使用一个连接这些协议可以避免过多的设置和管理多个连接,就像浏览器实现了HTTP/1.x 一样。单连接在对SSL 特别有效,这是因为它可以最小化SSL/TLS 建立安全链接时的握手时间。
+
+SPDY 协议需要使用SSL/TLS, 而HTTP/2 官方并不需要,但是目前所有支持HTTP/2的浏览器只有在使能了SSL/TLS 的情况下才会使用它。这就意味着支持HTTP/2 的浏览器只有在网站使用了SSL 并且服务器接收HTTP/2 流量的情况下才会启用HTTP/2。否则的话浏览器就会使用HTTP/1.x 协议。
+
+当你实现SPDY 或者HTTP/2时,你不再需要通常的HTTP 性能优化方案,比如域分隔资源聚合,以及图像登记。这些改变可以让你的代码和部署变得更简单和更易于管理。要了解HTTP/2 带来的这些变化可以浏览我们的[白皮书][34]。
+
+
+
+作为支持这些协议的一个样例,NGINX 已经从一开始就支持了SPDY,而且[大部分使用SPDY 协议的网站][35]都运行的是NGINX。NGINX 同时也[很早][36]对HTTP/2 的提供了支持,从2015 年9月开始开源NGINX 和NGINX Plus 就[支持][37]它了。
+
+经过一段时间,我们NGINX 希望更多的站点完全是能SSL 并且向HTTP/2 迁移。这将会提高安全性,同时新的优化手段也会被发现和实现,更简单的代码表现的更加优异。
+
+### Tip #7: 升级软件版本 ###
+
+一个提高应用性能的简单办法是根据软件的稳定性和性能的评价来选在你的软件栈。进一步说,因为高性能组件的开发者更愿意追求更高的性能和解决bug ,所以值得使用最新版本的软件。新版本往往更受开发者和用户社区的关注。更新的版本往往会利用到新的编译器优化,包括对新硬件的调优。
+
+稳定的新版本通常比旧版本具有更好的兼容性和更高的性能。一直进行软件更新,可以非常简单的保持软件保持最佳的优化,解决掉bug,以及安全性的提高。
+
+一直使用旧版软件也会组织你利用新的特性。比如上面说到的HTTP/2,目前要求OpenSSL 1.0.1.在2016 年中期开始将会要求1.0.2 ,而这是在2015年1月才发布的。
+
+NGINX 用户可以开始迁移到[NGINX 最新的开源软件][38] 或者[NGINX Plus][39];他们都包含了罪行的能力,如socket分区和线程池(见下文),这些都已经为性能优化过了。然后好好看看的你软件栈,把他们升级到你能能升级道德最新版本吧。
+
+### Tip #8: linux 系统性能调优 ###
+
+linux 是大多数web 服务器使用操作系统,而且作为你的架构的基础,Linux 表现出明显可以提高性能的机会。默认情况下,很多linux 系统都被设置为使用很少的资源,匹配典型的桌面应用负载。这就意味着web 应用需要最少一些等级的调优才能达到最大效能。
+
+Linux 优化是转变们针对web 服务器方面的。以NGINX 为例,这里有一些在加速linux 时需要强调的变化:
+
+- **缓冲队列**。如果你有挂起的连接,那么你应该考虑增加net.core.somaxconn 的值,它代表了可以缓存的连接的最大数量。如果连接线直太小,那么你将会看到错误信息,而你可以逐渐的增加这个参数知道错误信息停止出现。
+- **文件描述符**。NGINX 对一个连接使用最多2个文件描述符。如果你的系统有很多连接,你可能就需要提高sys.fs.file_max ,增加系统对文件描述符数量整体的限制,这样子才能支持不断增加的负载需求。
+- **临时端口**。当使用代理时,NGINX 会为每个上游服务器创建临时端口。你可以设置net.ipv4.ip_local_port_range 来提高这些端口的范围,增加可用的端口。你也可以减少非活动的端口的超时判断来重复使用端口,这可以通过net.ipv4.tcp_fin_timeout 来设置,这可以快速的提高流量。
+
+对于NGINX 来说,可以查阅[NGINX 性能调优指南][40]来学习如果优化你的Linux 系统,这样子它就可以很好的适应大规模网络流量而不会超过工作极限。
+
+### Tip #9: web 服务器性能调优 ###
+
+无论你是用哪种web 服务器,你都需要对它进行优化来提高性能。下面的推荐手段可以用于任何web 服务器,但是一些设置是针对NGINX的。关键的优化手段包括:
+
+- **f访问日志**。不要把每个请求的日志都直接写回磁盘,你可以在内存将日志缓存起来然后一批写回磁盘。对于NGINX 来说添加给指令*access_log* 添加参数 *buffer=size* 可以让系统在缓存满了的情况下才把日志写到此哦按。如果你添加了参数**flush=time** ,那么缓存内容会每隔一段时间再写回磁盘。
+- **缓存**。缓存掌握了内存中的部分资源知道满了位置,这可以让与客户端的通信更加高效。与内存中缓存不匹配的响应会写回磁盘,而这就会降低效能。当NGINX [启用][42]了缓存机制后,你可以使用指令*proxy_buffer_size* 和 *proxy_buffers* 来管理缓存。
+- **客户端保活**。保活连接可以减少开销,特别是使用SSL/TLS时。对于NGINX 来说,你可以增加*keepalive_requests* 的值,从默认值100 开始修改,这样一个客户端就可以转交一个指定的连接,而且你也可以通过增加*keepalive_timeout* 的值来允许保活连接存活更长时间,结果就是让后来的请求处理的更快速。
+- **上游保活**。上游的连接——即连接到应用服务器、数据库服务器等机器的连接——同样也会收益于连接保活。对于上游连接老说,你可以增加*保活时间*,即每个工人进程的空闲保活连接个数。这就可以提高连接的复用次数,减少需要重新打开全新的连接次数。更多关于保活连接的信息可以参见[blog][41].
+- **限制**。限制客户端使用的资源可以提高性能和安全性。对于NGINX 来说指令*limit_conn* 和 *limit_conn_zone* 限制了每个源的连接数量,而*limit_rate* 限制了带宽。这些限制都可以阻止合法用户*攫取* 资源,同时夜避免了攻击。指令*limit_req* 和 *limit_req_zone* 限制了客户端请求。对于上游服务器来说,可以在上游服务器的配置块里使用max_conns 可以限制连接到上游服务器的连接。 这样可以避免服务器过载。关联的队列指令会创建一个队列来在连接数抵达*max_conn* 限制时在指定的长度的时间内保存特定数量的请求。
+- **工人进程**。工人进程负责处理请求。NGINX 采用事件驱动模型和依赖操作系统的机制来有效的讲请求分发给不同的工人进程。这条建议推荐设置每个CPU 的参数*worker_processes* 。如果需要的话,工人连接的最大数(默认512)可以安全在大部分系统增加,是指找到最适合你的系统的值。
+- **套接字分割**。通常一个套接字监听器会把新连接分配给所有工人进程。套接字分割会未每个工人进程创建一个套接字监听器,这样一来以内核分配连接给套接字就成为可能了。折可以减少锁竞争,并且提高多核系统的性能,要使能[套接字分隔][43]需要在监听指令里面加上复用端口参数。
+- **线程池**。一个计算机进程可以处理一个缓慢的操作。对于web 服务器软件来说磁盘访问会影响很多更快的操作,比如计算或者在内存中拷贝。使用了线程池之后慢操作可以分配到不同的任务集,而主进程可以一直运行快速操作。当磁盘操作完成后结果会返回给主进程的循环。在NGINX理有两个操作——read()系统调用和sendfile() ——被分配到了[线程池][44]
+
+
+
+**技巧**。当改变任务操作系统或支持服务的设置时,一次只改变一个参数然后测试性能。如果修改引起问题了,或者不能让你的系统更快那么就改回去。
+
+在[blog][45]可以看到更详细的NGINX 调优方法。
+
+### Tip #10: 监视系统活动来解决问题和瓶颈 ###
+
+在应用开发中要使得系统变得非常高效的关键是监视你的系统在现实世界运行的性能。你必须能通过特定的设备和你的web 基础设施上监控程序活动。
+
+监视活动是最积极的——他会告诉你发生了什么,把问题留给你发现和最终解决掉。
+
+监视可以发现集中不同的问题。它们包括:
+
+- 服务器宕机。
+- 服务器出问题一直在丢失连接。
+- 服务器出现大量的缓存未命中。
+- 服务器没有发送正确的内容。
+
+应用的总体性能监控工具,比如New Relic 和Dynatrace,可以帮助你监控到从远处加载网页的时间,二NGINX 可以帮助你监控到应用发送的时 间。当你需要考虑为基础设施添加容量以满足流量需求时,应用性能数据可以告诉你你的优化措施的确起作用了。
+
+为了帮助开发者快速的发现、解决问题,NGINX Plus 增加了[应用感知健康度检查][46] ——对重复出现的常规事件进行综合分析并在问题出现时向你发出警告。NGINX Plus 同时提供[会话过滤][47] 功能,折可以组织当前任务未完成之前不接受新的连接,另一个功能是慢启动,允许一个从错误恢复过来的服务器追赶上负载均衡服务器群的速度。当有使用得当时,健康度检查可以让你在问题变得严重到影响用户体验前就发现它,而会话过滤和慢启动可以让你替换服务器,并且这个过程不会对性能和正常运行时间产生负面影响。这个表格就展示了NGINX Plus 内建模块在web 基础设施[监视活活动][48]的仪表盘,包括了服务器群,TCP 连接和缓存等信息。
+
+
+
+### 总结: 看看10倍性能提升的效果 ###
+
+这些性能提升方案对任何一个web 应用都可用并且效果都很好,而实际效果取决于你的预算,如你能花费的时间,目前实现方案的差距。所以你该如何对你自己的应用实现10倍性能提升?
+
+为了指导你了解每种优化手段的潜在影响,这里是是上面详述的每个优化方法的关键点,虽然你的里程肯定大不相同:
+
+- **反向代理服务器和负载均衡**。没有负载均衡或者负载均衡很差都会造成间断的极低性能。增加一个反向代理,比如NGINX可以避免web应用程序在内存和磁盘之间抖动。负载均衡可以将过载服务器的任务转移到空闲的服务器,还可以轻松的进行扩容。这些改变都可以产生巨大的性能提升,很容易就可以比你现在的实现方案的最差性能提高10倍,对于总体性能来说可能提高的不多,但是也是有实质性的提升。
+- **缓存动态和静态数据**。如果你又一个web 服务器负担过重,那么毫无疑问肯定是你的应用服务器,只通过缓存动态数据就可以在峰值时间提高10倍的性能。缓存静态文件可以提高个位数倍的性能。
+- **压缩数据**。使用媒体文件压缩格式,比如图像格式JPEG,图形格式PNG,视频格式MPEG-4,音乐文件格式MP3可以极大的提高性能。一旦这些都用上了,然后压缩文件数据可以提高初始页面加载速度提高两倍。
+- **优化SSL/TLS**。安全握手会对性能产生巨大的影响,对他们的优化可能会对初始响应特别是重文本站点产生2倍的提升。优化SSL/TLS 下媒体文件只会产生很小的性能提升。
+- **使用HTTP/2 和SPDY*。当你使用了SSL/TLS,这些协议就可以提高整个站点的性能。
+- **对linux 和web 服务器软件进行调优**。比如优化缓存机制,使用保活连接,分配时间敏感型任务到不同的线程池可以明显的提高性能;举个例子,线程池可以加速对磁盘敏感的任务[近一个数量级][49].
+
+我们希望你亲自尝试这些技术。我们希望这些提高应用性能的手段可以被你实现。请在下面评论栏分享你的结果 或者在标签#NGINX 和#webperf 下tweet 你的故事。
+### 网上资源 ###
+
+[Statista.com – Share of the internet economy in the gross domestic product in G-20 countries in 2016][50]
+
+[Load Impact – How Bad Performance Impacts Ecommerce Sales][51]
+
+[Kissmetrics – How Loading Time Affects Your Bottom Line (infographic)][52]
+
+[Econsultancy – Site speed: case studies, tips and tools for improving your conversion rate][53]
+
+--------------------------------------------------------------------------------
+
+via: https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
+
+作者:[Floyd Smith][a]
+译者:[Ezio]](https://github.com/oska874)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.nginx.com/blog/author/floyd/
+[1]:https://www.nginx.com/resources/glossary/reverse-proxy-server
+[2]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip2
+[3]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip3
+[4]:https://www.nginx.com/products/application-health-checks/
+[5]:https://www.nginx.com/solutions/load-balancing/
+[6]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip1
+[7]:https://www.nginx.com/resources/admin-guide/load-balancer/
+[8]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
+[9]:https://www.digitalocean.com/community/tutorials/understanding-and-implementing-fastcgi-proxying-in-nginx
+[10]:https://www.nginx.com/blog/five-reasons-use-software-load-balancer/
+[11]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
+[12]:https://www.nginx.com/resources/ebook/five-reasons-choose-software-load-balancer/
+[13]:https://www.nginx.com/resources/webinars/choose-software-based-load-balancer-45-min/
+[14]:https://www.nginx.com/resources/admin-guide/load-balancer/
+[15]:https://www.nginx.com/products/
+[16]:https://www.nginx.com/blog/nginx-caching-guide/
+[17]:https://www.nginx.com/products/content-caching-nginx-plus/
+[18]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&_ga=1.95342300.1348073562.1438712874#proxy_cache_purge
+[19]:https://www.nginx.com/products/live-activity-monitoring/
+[20]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&&&_ga=1.61156076.1348073562.1438712874#proxy_cache
+[21]:https://www.nginx.com/resources/admin-guide/content-caching
+[22]:https://www.nginx.com/blog/network-vs-devops-how-to-manage-your-control-issues/
+[23]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
+[24]:https://www.nginx.com/resources/admin-guide/compression-and-decompression/
+[25]:http://nginx.org/en/docs/http/ngx_http_gzip_static_module.html
+[26]:https://www.digicert.com/ssl.htm
+[27]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
+[28]:http://openssl.org/
+[29]:https://www.nginx.com/blog/nginx-ssl-performance/
+[30]:https://www.nginx.com/blog/improve-seo-https-nginx/
+[31]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_session_cache
+[32]:https://www.nginx.com/resources/admin-guide/nginx-ssl-termination/
+[33]:https://www.nginx.com/resources/admin-guide/nginx-tcp-ssl-termination/
+[34]:https://www.nginx.com/resources/datasheet/datasheet-nginx-http2-whitepaper/
+[35]:http://w3techs.com/blog/entry/25_percent_of_the_web_runs_nginx_including_46_6_percent_of_the_top_10000_sites
+[36]:https://www.nginx.com/blog/how-nginx-plans-to-support-http2/
+[37]:https://www.nginx.com/blog/nginx-plus-r7-released/
+[38]:http://nginx.org/en/download.html
+[39]:https://www.nginx.com/products/
+[40]:https://www.nginx.com/blog/tuning-nginx/
+[41]:https://www.nginx.com/blog/http-keepalives-and-web-performance/
+[42]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_buffering
+[43]:https://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
+[44]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
+[45]:https://www.nginx.com/blog/tuning-nginx/
+[46]:https://www.nginx.com/products/application-health-checks/
+[47]:https://www.nginx.com/products/session-persistence/#session-draining
+[48]:https://www.nginx.com/products/live-activity-monitoring/
+[49]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
+[50]:http://www.statista.com/statistics/250703/forecast-of-internet-economy-as-percentage-of-gdp-in-g-20-countries/
+[51]:http://blog.loadimpact.com/blog/how-bad-performance-impacts-ecommerce-sales-part-i/
+[52]:https://blog.kissmetrics.com/loading-time/?wide=1
+[53]:https://econsultancy.com/blog/10936-site-speed-case-studies-tips-and-tools-for-improving-your-conversion-rate/
diff --git a/translated/tech/20151104 How to Install SQLite 3.9.1 with JSON Support on Ubuntu 15.04.md b/translated/tech/20151104 How to Install SQLite 3.9.1 with JSON Support on Ubuntu 15.04.md
new file mode 100644
index 0000000000..b79dc3657e
--- /dev/null
+++ b/translated/tech/20151104 How to Install SQLite 3.9.1 with JSON Support on Ubuntu 15.04.md
@@ -0,0 +1,121 @@
+如何在Ubuntu 15.04 上安装带JSON 支持的SQLite 3.9.1
+================================================================================
+欢迎阅读我们关于SQLite 的文章,SQLite 是当今时间上使用最广泛的SQL 数据库引擎,它他基本不需要配置,不需要安装或者管理就可以运行。SQLite 是一个是开放领域的软件,是关系数据库的管理系统,或者说RDBMS,用来在大表存储用户定义的记录。对于数据存储和管理来说,数据库引擎要处理复杂的查询命令,这些命令可能会从多个表获取数据然后生成报告的数据总结。
+
+SQLite 是一个非常小、轻量级,不需要分离的服务进程或系统。他可以运行在UNIX,Linux,Mac OS-X,Android,iOS 和Windows 上,已经被大量的软件程序使用,如Opera, Ruby On Rails, Adobe System, Mozilla Firefox, Google Chrome 和 Skype。
+
+### 1) 基本需求: ###
+
+在几乎全部支持SQLite 的平台上安装SQLite 基本上没有复杂的要求。
+
+所以让我们在CLI 或者Secure Shell 上使用sudo 或者root 权限登录Ubuntu 服务器。然后更新系统,这样子就可以让操作系统的软件更新到新版本。
+
+在Ubuntu 上,下面的命令是用来更新系统的软件源的。
+
+ # apt-get update
+
+如果你要在新安装的Ubuntu 上部署SQLite,那么你需要安装一些基础的系统管理工具,如wget, make, unzip, gcc。
+
+要安装wget,可以使用下面的命令,然后输入Y 如果系统提示的话:
+
+ # apt-get install wget make gcc
+
+### 2) 下载 SQLite ###
+
+要下载SQLite 最好是在[SQLite 官网][1]下载,如下所示
+
+
+
+你也可以直接复制资源的连接然后再命令行使用wget 下载,如下所示:
+
+ # wget https://www.sqlite.org/2015/sqlite-autoconf-3090100.tar.gz
+
+
+
+下载完成之后,解压缩安装包,切换工作目录到解压缩后的SQLite 目录,使用下面的命令。
+
+ # tar -zxvf sqlite-autoconf-3090100.tar.gz
+
+### 3) 安装 SQLite ###
+
+现在我们要开始安装、配置刚才下载的SQLite。所以在Ubuntu 上编译、安装SQLite,运行配置脚本。
+
+ root@ubuntu-15:~/sqlite-autoconf-3090100# ./configure –prefix=/usr/local
+
+
+
+配置要上面的prefix 之后,运行下面的命令编译安装包。
+
+ root@ubuntu-15:~/sqlite-autoconf-3090100# make
+source='sqlite3.c' object='sqlite3.lo' libtool=yes \
+DEPDIR=.deps depmode=none /bin/bash ./depcomp \
+/bin/bash ./libtool --tag=CC --mode=compile gcc -DPACKAGE_NAME=\"sqlite\" -DPACKAGE_TARNAME=\"sqlite\" -DPACKAGE_VERSION=\"3.9.1\" -DPACKAGE_STRING=\"sqlite\ 3.9.1\" -DPACKAGE_BUGREPORT=\"http://www.sqlite.org\" -DPACKAGE_URL=\"\" -DPACKAGE=\"sqlite\" -DVERSION=\"3.9.1\" -DSTDC_HEADERS=1 -DHAVE_SYS_TYPES_H=1 -DHAVE_SYS_STAT_H=1 -DHAVE_STDLIB_H=1 -DHAVE_STRING_H=1 -DHAVE_MEMORY_H=1 -DHAVE_STRINGS_H=1 -DHAVE_INTTYPES_H=1 -DHAVE_STDINT_H=1 -DHAVE_UNISTD_H=1 -DHAVE_DLFCN_H=1 -DLT_OBJDIR=\".libs/\" -DHAVE_FDATASYNC=1 -DHAVE_USLEEP=1 -DHAVE_LOCALTIME_R=1 -DHAVE_GMTIME_R=1 -DHAVE_DECL_STRERROR_R=1 -DHAVE_STRERROR_R=1 -DHAVE_POSIX_FALLOCATE=1 -I. -D_REENTRANT=1 -DSQLITE_THREADSAFE=1 -DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_RTREE -g -O2 -c -o sqlite3.lo sqlite3.c
+
+运行完上面的命令之后,要在Ubuntu 上完成SQLite 的安装得运行下面的命令。
+
+ # make install
+
+
+
+### 4) 测试 SQLite 安装 ###
+
+要保证SQLite 3.9 安装成功了,运行下面的命令。
+
+ # sqlite3
+
+SQLite 的版本会显示在命令行。
+
+
+
+### 5) 使用 SQLite ###
+
+SQLite 很容易上手。要获得详细的使用方法,在SQLite 控制台里输入下面的命令。
+
+ sqlite> .help
+
+这里会显示全部可用的命令和详细说明。
+
+
+
+现在开始最后一部分,使用一点SQLite 命令创建数据库。
+
+要创建一个新的数据库需要运行下面的命令。
+
+ # sqlite3 test.db
+
+然后创建一张新表。
+
+ sqlite> create table memos(text, priority INTEGER);
+
+接着使用下面的命令插入数据。
+
+ sqlite> insert into memos values('deliver project description', 15);
+ sqlite> insert into memos values('writing new artilces', 100);
+
+要查看插入的数据可以运行下面的命令。
+
+ sqlite> select * from memos;
+ deliver project description|15
+ writing new artilces|100
+
+或者使用下面的命令离开。
+
+ sqlite> .exit
+
+
+### 结论 ###
+
+通过本文你可以了解如果安装支持JSON1 的最新版的SQLite,SQLite 从3.9.0 开始支持JSON1。这是一个非常棒的库,可以用来获取内嵌到应用程序,利用它可以很有效而且很轻量的管理资源。我们希望你能觉得本文有所帮助,请自由的像我们反馈你遇到的问题和困难。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/ubuntu-how-to/install-sqlite-json-ubuntu-15-04/
+
+作者:[Kashif Siddique][a]
+译者:[译者ID](https://github.com/oska874)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/kashifs/
+[1]:https://www.sqlite.org/download.html
diff --git a/translated/tech/20151109 How to Install GitLab on Ubuntu or Fedora or Debian.md b/translated/tech/20151109 How to Install GitLab on Ubuntu or Fedora or Debian.md
new file mode 100644
index 0000000000..524fc1e2c1
--- /dev/null
+++ b/translated/tech/20151109 How to Install GitLab on Ubuntu or Fedora or Debian.md
@@ -0,0 +1,178 @@
+如何在 Ubuntu / Fedora / Debian 中安装 GitLab
+================================================================================
+在 Git 问世之前,分布式版本控制从来都不是一件简单的事。Git 是一个免费、开源的软件,旨在轻松且快速地对从小规模到非常巨大的项目进行管理。Git 最开始由 Linus Torvalds 开发,他同时也是著名的 Linux 内核的创建者。在 git 和分布式版本控制系统领域中,[GitLab][1] 是一个极棒的新产品。它是一个基于 web 的 Git 仓库管理应用,包含代码审查、wiki、问题跟踪等诸多功能。使用 GitLab 可以很方便、快速地创建、审查、部署及托管代码。与 Github 类似,尽管它也提供在其官方的服务器托管免费的代码仓库,但它也可以运行在我们自己的服务器上。GitLab 有两个不同的版本:社区版(Community Edition)和企业版(Enterprise Edition)。社区本完全免费且开源,遵循 MIT 协议;而企业版则遵循一个专有的协议,包含一些社区版中没有的功能。下面介绍的是有关如何在我们自己的运行着 Ubuntu、Fedora 或 Debian 操作系统的机子上安装 GitLab 社区版的简单步骤。
+
+### 1. 安装先决条件 ###
+
+首先,我们需要安装 GitLab 所依赖的软件包。我们将安装 `curl`,用以下载我们所需的文件;安装`openssh-server` ,以此来通过 ssh 协议登陆到我们的机子上;安装`ca-certificates`,用它来添加 CA 认证;以及 `postfix`,把它作为一个 MTA(Mail Transfer Agent,邮件传输代理)。
+
+注: 若要安装 GitLab 社区版,我们需要一个至少包含 2 GB 内存和 2 核 CPU 的 linux 机子。
+
+#### 在 Ubuntu 14 .04/Debian 8.x 中 ####
+
+鉴于这些依赖包都可以在 Ubuntu 14.04 和 Debian 8.x 的官方软件仓库中获取到,我们只需通过使用 `apt-get` 包管理器来安装它们。为此,我们需要在一个终端或控制台中执行下面的命令:
+
+ # apt-get install curl openssh-server ca-certificates postfix
+
+
+
+#### 在 Fedora 22 中 ####
+
+在 Fedora 22 中,由于 `yum` 已经被弃用了,所以默认的包管理器是 `dnf`。为了安装上面那些需要的软件包,我们只需运行下面的 dnf 命令:
+
+ # dnf install curl openssh-server postfix
+
+
+
+### 2. 打开并开启服务 ###
+
+现在,我们将使用我们默认的 init 系统来打开 sshd 和 postfix 服务。并且我们将使得它们在每次系统启动时被自动开启。
+
+#### 在 Ubuntu 14.04 中 ####
+
+由于 SysVinit 在 Ubuntu 14.04 中作为 init 系统被安装,我们将使用 service 命令来开启 sshd 和 postfix 守护进程:
+
+ # service sshd start
+ # service postfix start
+
+现在,为了使得它们在每次开机启动时被自动开启,我们需要运行下面的 update-rc.d 命令:
+
+ # update-rc.d sshd enable
+ # update-rc.d postfix enable
+
+#### 在 Fedora 22/Debian 8.x 中 ####
+
+鉴于 Fedora 22 和 Debi 8.x 已经用 Systemd 代替了 SysVinit 来作为默认的 init 系统,我们只需运行下面的命令来开启 sshd 和 postfix 服务:
+
+ # systemctl start sshd postfix
+
+现在,为了使得它们在每次开机启动时被自动地开启,我们需要运行下面的 systemctl 命令:
+
+ # systemctl enable sshd postfix
+
+ 从 /etc/systemd/system/multi-user.target.wants/sshd.service 建立软链接到 /usr/lib/systemd/system/sshd.service.
+ 从 /etc/systemd/system/multi-user.target.wants/postfix.service 建立软链接到 /usr/lib/systemd/system/postfix.service.
+
+### 3. 下载 GitLab ###
+
+现在,我们将使用 curl 从官方的 GitLab 社区版仓库下载二进制安装文件。首先,为了得到所需文件的下载链接,我们需要浏览到该软件仓库的页面。为此,我们需要在运行着相应操作系统的 linux 机子上运行下面的命令。
+
+#### 在 Ubuntu 14.04 中 ####
+
+由于 Ubuntu 和 Debian 使用相同格式的 debian 文件,我们需要在 [https://packages.gitlab.com/gitlab/gitlab-ce?filter=debs][2] 下搜索所需版本的 GitLab,然后点击有着 ubuntu/trusty 标签的链接,这是因为我们运作着 Ubuntu 14.04。接着一个新的页面将会出现,我们将看到一个下载按钮,然后我们在它的上面右击,得到文件的链接,然后像下面这样使用 curl 来下载它。
+
+ # curl https://packages.gitlab.com/gitlab/gitlab-ce/packages/ubuntu/trusty/gitlab-ce_8.1.2-ce.0_amd64.deb
+
+
+
+#### 在 Debian 8.x 中 ####
+
+与 Ubuntu 类似,我们需要在 [https://packages.gitlab.com/gitlab/gitlab-ce?filter=debs][3] 页面中搜索所需版本的 GitLab,然后点击带有 debian/jessie 标签的链接,这是因为我们运行的是 Debian 8.x。接着,一个新的页面将会出现,然后我们在下载按钮上右击,得到文件的下载链接。最后我们像下面这样使用 curl 来下载该文件。
+
+ # curl https://packages.gitlab.com/gitlab/gitlab-ce/packages/debian/jessie/gitlab-ce_8.1.2-ce.0_amd64.deb/download
+
+
+
+#### 在 Fedora 22 中####
+
+由于 Fedora 使用 rpm 文件来作为软件包,我们将在 [https://packages.gitlab.com/gitlab/gitlab-ce?filter=rpms][4] 页面下搜索所需版本的 GitLab,然后点击所需发行包的链接,这里由于我们运行的是 Fedora 22,所以我们将选择带有 el/7 标签的发行包。一个新的页面将会出现,在其中我们可以看到一个下载按钮,我们将右击它,得到所需文件的链接,然后像下面这样使用 curl 来下载它。
+
+ # curl https://packages.gitlab.com/gitlab/gitlab-ce/packages/el/7/gitlab-ce-8.1.2-ce.0.el7.x86_64.rpm/download
+
+
+
+### 4. 安装 GitLab ###
+
+在相应的软件源被添加到我们的 linux 机子上之后,现在我们将使用相应 linux 发行版本中的默认包管理器来安装 GitLab 社区版。
+
+#### 在 Ubuntu 14.04/Debian 8.x 中 ####
+
+要在运行着 Ubuntu 14.04 或 Debian 8.x linux 发行版本的机子上安装 GitLab 社区版,我们只需运行如下的命令:
+
+ # dpkg -i gitlab-ce_8.1.2-ce.0_amd64.deb
+
+
+
+#### 在 Fedora 22 中 ####
+
+我们只需执行下面的 dnf 命令来在我们的 Fedora 22 机子上安装 GitLab。
+
+ # dnf install gitlab-ce-8.1.2-ce.0.el7.x86_64.rpm
+
+
+
+### 5. 配置和开启 GitLab ###
+
+由于 GitLab 社区版已经成功地安装在我们的 linux 系统中了,接下来我们将要配置和开启它了。为此,我们需要运行下面的命令,这在 Ubuntu、Debian 和 Fedora 发行版本上都一样:
+
+ # gitlab-ctl reconfigure
+
+
+
+### 6. 允许通过防火墙 ###
+
+假如在我们的 linux 机子中已经启用了防火墙程序,为了使得 GitLab 社区版的 web 界面可以通过网络进行访问,我们需要允许 80 端口通过防火墙,这个端口是 GitLab 社区版的默认端口。为此,我们需要运行下面的命令。
+
+#### 在 Iptables 中 ####
+
+Ubuntu 14.04 默认安装和使用 Iptables。所以,我们将运行下面的 iptables 命令来打开 80 端口:
+
+ # iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
+
+ # /etc/init.d/iptables save
+
+#### 在 Firewalld 中 ####
+
+由于 Fedora 22 和 Debian 8.x 默认安装了 systemd,它包含了作为防火墙程序的 firewalld。为了使得 80 端口(http 服务) 能够通过 firewalld,我们需要执行下面的命令。
+
+ # firewall-cmd --permanent --add-service=http
+
+ success
+
+ # firewall-cmd --reload
+
+ success
+
+### 7. 访问 GitLab Web 界面 ###
+
+最后,我们将访问 GitLab 社区版的 web 界面。为此,我们需要将我们的 web 浏览器指向 GitLab 服务器的网址,根据我们的配置,可能是 http://ip-address/ 或 http://domain.com/ 的格式。在我们成功指向该网址后,我们将会看到下面的页面。
+
+
+
+现在,为了登陆进面板,我们需要点击登陆按钮,它将询问我们的用户名和密码。然后我们将输入默认的用户名和密码,即 **root** 和 **5iveL!fe** 。在登陆进控制面板后,我们将被强制要求为我们的 GitLab root 用户输入新的密码。
+
+
+
+### 8. 创建仓库 ###
+
+在我们成功地更改密码并登陆到我们的控制面板之后,现在,我们将为我们的新项目创建一个新的仓库。为此,我们需要来到项目栏,然后点击 **新项目** 绿色按钮。
+
+
+
+接着,我们将被询问给我们的项目输入所需的信息和设定,正如下面展示的那样。我们甚至可以从其他的 git 仓库提供商和仓库中导入我们的项目。
+
+
+
+做完这些后,我们将能够使用任何包含基本 git 命令行的 Git 客户端来访问我们的 Git 仓库。我们可以看到在仓库中进行的任何活动,例如创建一个里程碑,管理 issue,合并请求,管理成员,便签,Wiki 等。
+
+
+
+### 总结 ###
+
+GitLab 是一个用来管理 git 仓库的很棒的开源 web 应用。它有着漂亮,响应式的带有诸多酷炫功能的界面。它还打包有许多酷炫功能,例如管理群组,分发密钥,连续集成,查看日志,广播消息,钩子,系统 OAuth 应用,模板等。(注:OAuth 是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资源(如照片,视频,联系人列表),而无需将用户名和密码提供给第三方应用。--- 摘取自 [维基百科上的 OAuth 词条](https://zh.wikipedia.org/wiki/OAuth)) 它还可以和大量的工具进行交互如 Slack,Hipchat,LDAP,JIRA,Jenkins,很多类型的钩子和一个完整的 API。它至少需要 2 GB 的内存和 2 核 CPU 来流畅运行,支持多达 500 个用户,但它也可以被扩展到多个活动的服务器上。假如你有任何的问题,建议,回馈,请将它们写在下面的评论框中,以便我们可以提升或更新我们的内容。谢谢!
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/install-gitlab-on-ubuntu-fedora-debian/
+
+作者:[Arun Pyasi][a]
+译者:[FSSlc](https://github.com/FSSlc)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://about.gitlab.com/
+[2]:https://packages.gitlab.com/gitlab/gitlab-ce?filter=debs
+[3]:https://packages.gitlab.com/gitlab/gitlab-ce?filter=debs
+[4]:https://packages.gitlab.com/gitlab/gitlab-ce?filter=rpms
\ No newline at end of file
diff --git a/translated/tech/20151116 Linux FAQs with Answers--How to install Node.js on Linux.md b/translated/tech/20151116 Linux FAQs with Answers--How to install Node.js on Linux.md
new file mode 100644
index 0000000000..8ccca22632
--- /dev/null
+++ b/translated/tech/20151116 Linux FAQs with Answers--How to install Node.js on Linux.md
@@ -0,0 +1,92 @@
+Linux 有问必答 - 如何在 Linux 上安装 Node.js
+================================================================================
+> **问题**: 如何在你的 Linux 发行版上安装 Node.js?
+
+[Node.js][1] 是建立在谷歌的 V8 JavaScript 引擎服务器端的软件平台上。在构建高性能的服务器端应用程序上,Node.js 在 JavaScript 中已是首选方案。是什么让使用 Node.js 库和应用程序的 [庞大生态系统][2] 来开发服务器后台变得如此流行。Node.js 自带一个被称为 npm 的命令行工具可以让你轻松地安装它,进行版本控制并使用 npm 的在线仓库来管理 Node.js 库和应用程序的依赖关系。
+
+在本教程中,我将介绍 **如何在主流 Linux 发行版上安装 Node.js,包括Debian,Ubuntu,Fedora 和 CentOS** 。
+
+Node.js 在一些发行版上作为预构建的程序包(如,Fedora 或 Ubuntu),而在其他发行版上你需要源码安装。由于 Node.js 发展比较快,建议从源码安装最新版而不是安装一个过时的预构建的程序包。最新的 Node.js 自带 npm(Node.js 的包管理器),让你可以轻松的安装 Node.js 的外部模块。
+
+### 在 Debian 上安装 Node.js on ###
+
+从 Debian 8 (Jessie)开始,Node.js 已被纳入官方软件仓库。因此,你可以使用如下方式安装它:
+
+ $ sudo apt-get install npm
+
+在 Debian 7 (Wheezy) 以前的版本中,你需要使用下面的方式来源码安装:
+
+ $ sudo apt-get install python g++ make
+ $ wget http://nodejs.org/dist/node-latest.tar.gz
+ $ tar xvfvz node-latest.tar.gz
+ $ cd node-v0.10.21 (replace a version with your own)
+ $ ./configure
+ $ make
+ $ sudo make install
+
+### 在 Ubuntu 或 Linux Mint 中安装 Node.js ###
+
+Node.js 被包含在 Ubuntu(13.04 及更高版本)。因此,安装非常简单。以下方式将安装 Node.js 和 npm。
+
+ $ sudo apt-get install npm
+ $ sudo ln -s /usr/bin/nodejs /usr/bin/node
+
+而 Ubuntu 中的 Node.js 可能版本比较老,你可以从 [其 PPA][3] 中安装最新的版本。
+
+ $ sudo apt-get install python-software-properties python g++ make
+ $ sudo add-apt-repository -y ppa:chris-lea/node.js
+ $ sudo apt-get update
+ $ sudo apt-get install npm
+
+### 在 Fedora 中安装 Node.js ###
+
+Node.js 被包含在 Fedora 的 base 仓库中。因此,你可以在 Fedora 中用 yum 安装 Node.js。
+
+ $ sudo yum install npm
+
+如果你想安装 Node.js 的最新版本,可以按照以下步骤使用源码来安装。
+
+ $ sudo yum groupinstall 'Development Tools'
+ $ wget http://nodejs.org/dist/node-latest.tar.gz
+ $ tar xvfvz node-latest.tar.gz
+ $ cd node-v0.10.21 (replace a version with your own)
+ $ ./configure
+ $ make
+ $ sudo make install
+
+### 在 CentOS 或 RHEL 中安装 Node.js ###
+
+在 CentOS 使用 yum 包管理器来安装 Node.js,首先启用 EPEL 软件库,然后运行:
+
+ $ sudo yum install npm
+
+如果你想在 CentOS 中安装最新版的 Node.js,其安装步骤和在 Fedora 中的相同。
+
+### 在 Arch Linux 上安装 Node.js ###
+
+Node.js is available in the Arch Linux community repository. Thus installation is as simple as running:
+
+Node.js 在 Arch Linux 的社区库中可以找到。所以安装很简单,只要运行:
+
+ $ sudo pacman -S nodejs npm
+
+### 检查 Node.js 的版本 ###
+
+一旦你已经安装了 Node.js,你可以使用如下所示的方法检查 Node.js 的版本。
+
+ $ node --version
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/install-node-js-linux.html
+
+作者:[Dan Nanni][a]
+译者:[strugglingyou](https://github.com/strugglingyou)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:http://nodejs.org/
+[2]:https://www.npmjs.com/
+[3]:https://launchpad.net/~chris-lea/+archive/node.js
diff --git a/translated/tech/20151117 Install PostgreSQL 9.4 And phpPgAdmin On Ubuntu 15.10.md b/translated/tech/20151117 Install PostgreSQL 9.4 And phpPgAdmin On Ubuntu 15.10.md
new file mode 100644
index 0000000000..7fd4414127
--- /dev/null
+++ b/translated/tech/20151117 Install PostgreSQL 9.4 And phpPgAdmin On Ubuntu 15.10.md
@@ -0,0 +1,317 @@
+在 Ubuntu 15.10 上安装 PostgreSQL 9.4 和 phpPgAdmin
+================================================================================
+
+
+### 简介 ###
+
+[PostgreSQL][1] 是一款强大的,开源对象关系型数据库系统。它支持所有的主流操作系统,包括 Linux、Unix(AIX、BSD、HP-UX,SGI IRIX、Mac OS、Solaris、Tru64) 以及 Windows 操作系统。
+
+下面是 **Ubuntu** 发起者 **Mark Shuttleworth** 对 PostgreSQL 的一段评价。
+
+> PostgreSQL 真的是一款很好的数据库系统。刚开始我们使用它的时候,并不确定它能否胜任工作。但我错的太离谱了。它很强壮、快速,在各个方面都很专业。
+>
+> — Mark Shuttleworth.
+
+在这篇简短的指南中,让我们来看看如何在 Ubuntu 15.10 服务器中安装 PostgreSQL 9.4。
+
+### 安装 PostgreSQL ###
+
+默认仓库中就有可用的 PostgreSQL。在终端中输入下面的命令安装它。
+
+ sudo apt-get install postgresql postgresql-contrib
+
+如果你需要其它的版本,按照下面那样先添加 PostgreSQL 仓库然后再安装。
+
+**PostgreSQL apt 仓库** 支持 amd64 和 i386 架构的 Ubuntu 长期支持版(10.04、12.04 和 14.04),以及非长期支持版(14.04)。对于其它非长期支持版,该软件包虽然不能完全支持,但使用和 LTS 版本近似的也能正常工作。
+
+#### Ubuntu 14.10 系统: ####
+
+新建文件**/etc/apt/sources.list.d/pgdg.list**;
+
+ sudo vi /etc/apt/sources.list.d/pgdg.list
+
+用下面一行添加仓库:
+
+ deb http://apt.postgresql.org/pub/repos/apt/ utopic-pgdg main
+
+**注意**: 上面的库只能用于 Ubuntu 14.10。还没有升级到 Ubuntu 15.04 和 15.10。
+
+**Ubuntu 14.04**,添加下面一行:
+
+ deb http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg main
+
+**Ubuntu 12.04**,添加下面一行:
+
+ deb http://apt.postgresql.org/pub/repos/apt/ precise-pgdg main
+
+导入库签名密钥:
+
+ wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc
+
+----------
+
+ sudo apt-key add -
+
+更新软件包列表:
+
+ sudo apt-get update
+
+然后安装需要的版本。
+
+ sudo apt-get install postgresql-9.4
+
+### 访问 PostgreSQL 命令窗口 ###
+
+默认的数据库名称和数据库用户名称都是 “**postgres**”。切换到 postgres 用户进行 postgresql 相关的操作:
+
+ sudo -u postgres psql postgres
+
+#### 事例输出: ####
+
+ psql (9.4.5)
+ Type "help" for help.
+ postgres=#
+
+要退出 postgresql 窗口,在 **psql** 窗口输入 **\q** 退出到终端。
+
+### 设置 “postgres” 用户密码 ###
+
+登录到 postgresql 窗口,
+
+ sudo -u postgres psql postgres
+
+用下面的命令为用户 postgres 设置密码:
+
+ postgres=# \password postgres
+ Enter new password:
+ Enter it again:
+ postgres=# \q
+
+要安装 PostgreSQL Adminpack,在 postgresql 窗口输入下面的命令:
+
+ sudo -u postgres psql postgres
+
+----------
+
+ postgres=# CREATE EXTENSION adminpack;
+ CREATE EXTENSION
+
+在 **psql** 窗口输入 **\q** 从 postgresql 窗口退回到终端。
+
+### 创建新用户和数据库 ###
+
+例如,让我们创建一个新的用户,名为 “**senthil**”,密码是 “**ubuntu**”,以及名为 “**mydb**” 的数据库。
+
+ sudo -u postgres createuser -D -A -P senthil
+
+----------
+
+ sudo -u postgres createdb -O senthil mydb
+
+### 删除用户和数据库 ###
+
+要删除数据库,首先切换到 postgres 用户:
+
+ sudo -u postgres psql postgres
+
+输入命令:
+
+ $ drop database
+
+要删除一个用户,输入下面的命令:
+
+ $ drop user
+
+### 配置 PostgreSQL-MD5 验证 ###
+
+**MD5 验证** 要求用户提供一个 MD5 加密的密码用于认证。首先编辑 **/etc/postgresql/9.4/main/pg_hba.conf** 文件:
+
+ sudo vi /etc/postgresql/9.4/main/pg_hba.conf
+
+按照下面所示添加或修改行
+
+ [...]
+ # TYPE DATABASE USER ADDRESS METHOD
+ # "local" is for Unix domain socket connections only
+ local all all md5
+ # IPv4 local connections:
+ host all all 127.0.0.1/32 md5
+ host all all 192.168.1.0/24 md5
+ # IPv6 local connections:
+ host all all ::1/128 md5
+ [...]
+
+其中, 192.168.1.0/24 是我的本地网络 IP 地址。用你自己的地址替换。
+
+重启 postgresql 服务以使更改生效:
+
+ sudo systemctl restart postgresql
+
+或者,
+
+ sudo service postgresql restart
+
+### 配置 PostgreSQL TCP/IP 配置 ###
+
+默认情况下,没有启用 TCP/IP 连接,因此其它计算机的用户不能访问 postgresql。为了允许其它计算机的用户访问,编辑文件 **/etc/postgresql/9.4/main/postgresql.conf:**
+
+ sudo vi /etc/postgresql/9.4/main/postgresql.conf
+
+找到下面一行:
+
+ [...]
+ #listen_addresses = 'localhost'
+ [...]
+ #port = 5432
+ [...]
+
+取消改行的注释,然后设置你 postgresql 服务器的 IP 地址,或者设置为 ‘*’ 监听所有用户。你应该谨慎设置所有远程用户都可以访问 PostgreSQL。
+
+ [...]
+ listen_addresses = '*'
+ [...]
+ port = 5432
+ [...]
+
+重启 postgresql 服务保存更改:
+
+ sudo systemctl restart postgresql
+
+或者,
+
+ sudo service postgresql restart
+
+### 用 phpPgAdmin 管理 PostgreSQL ###
+
+[**phpPgAdmin**][2] 是基于 web 用 PHP 写的 PostgreSQL 管理工具。
+
+默认仓库中有可用的 phpPgAdmin。用下面的命令安装 phpPgAdmin:
+
+ sudo apt-get install phppgadmin
+
+默认情况下,你可以在本地系统的 web 浏览器用 **http://localhost/phppgadmin** 访问 phppgadmin。
+
+要访问远程系统,在 Ubuntu 15.10 上做如下操作:
+
+编辑文件 **/etc/apache2/conf-available/phppgadmin.conf**,
+
+ sudo vi /etc/apache2/conf-available/phppgadmin.conf
+
+找到 **Require local** 的一行在这行前面添加 **#** 注释掉它。
+
+ #Require local
+
+添加下面的一行:
+
+ allow from all
+
+保存并退出文件。
+
+然后重启 apache 服务。
+
+ sudo systemctl restart apache2
+
+对于 Ubuntu 14.10 及之前版本:
+
+编辑 **/etc/apache2/conf.d/phppgadmin**:
+
+ sudo nano /etc/apache2/conf.d/phppgadmin
+
+注释掉下面一行:
+
+ [...]
+ #allow from 127.0.0.0/255.0.0.0 ::1/128
+
+取消下面一行的注释使所有系统都可以访问 phppgadmin。
+
+ allow from all
+
+编辑 **/etc/apache2/apache2.conf**:
+
+ sudo vi /etc/apache2/apache2.conf
+
+添加下面一行:
+
+ Include /etc/apache2/conf.d/phppgadmin
+
+然后重启 apache 服务。
+
+ sudo service apache2 restart
+
+### 配置 phpPgAdmin ###
+
+编辑文件 **/etc/phppgadmin/config.inc.php**, 做以下更改。下面大部分选项都带有解释。认真阅读以便了解为什么要更改这些值。
+
+ sudo nano /etc/phppgadmin/config.inc.php
+
+找到下面一行:
+
+ $conf['servers'][0]['host'] = '';
+
+按照下面这样更改:
+
+ $conf['servers'][0]['host'] = 'localhost';
+
+找到这一行:
+
+ $conf['extra_login_security'] = true;
+
+更改值为 **false**。
+
+ $conf['extra_login_security'] = false;
+
+找到这一行:
+
+ $conf['owned_only'] = false;
+
+更改值为 **true**。
+
+ $conf['owned_only'] = true;
+
+保存并关闭文件。重启 postgresql 服务和 Apache 服务。
+
+ sudo systemctl restart postgresql
+
+----------
+
+ sudo systemctl restart apache2
+
+或者,
+
+ sudo service postgresql restart
+
+ sudo service apache2 restart
+
+现在打开你的浏览器并导航到 **http://ip-address/phppgadmin**。你会看到以下截图。
+
+
+
+用你之前创建的用户登录。我之前已经创建了一个名为 “**senthil**” 的用户,密码是 “**ubuntu**”,因此我以 “senthil” 用户登录。
+
+
+
+然后你就可以访问 phppgadmin 面板了。
+
+
+
+用 postgres 用户登录:
+
+
+
+就是这样。现在你可以用 phppgadmin 可视化创建、删除或者更改数据库了。
+
+加油!
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/install-postgresql-9-4-and-phppgadmin-on-ubuntu-15-10/
+
+作者:[SK][a]
+译者:[ictlyh](http://mutouxiaogui.cn/blog/)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.twitter.com/ostechnix
+[1]:http://www.postgresql.org/
+[2]:http://phppgadmin.sourceforge.net/doku.php
\ No newline at end of file
diff --git a/translated/tech/20151117 Linux 101--Get the most out of Systemd.md b/translated/tech/20151117 Linux 101--Get the most out of Systemd.md
new file mode 100644
index 0000000000..1a382479ec
--- /dev/null
+++ b/translated/tech/20151117 Linux 101--Get the most out of Systemd.md
@@ -0,0 +1,171 @@
+Linux 101:最有效地使用 Systemd
+================================================================================
+干嘛要这么做?
+
+- 理解现代 Linux 发行版中的显著变化;
+- 看看 Systemd 是如何取代 SysVinit 的;
+- 处理好*单元* (unit)和新的 journal 日志。
+
+吐槽邮件,人身攻击,死亡威胁——Lennart Poettering,Systemd 的作者,对收到这些东西早就习以为常了。这位 Red Hat 公司的员工最近在 Google+ 上怒斥 FOSS 社区([http://tinyurl.com/poorlennart][1])的本质,悲痛且失望地表示:“那真是个令人恶心的地方”。他着重指出 Linus Torvalds 在邮件列表上言辞刻薄的帖子,并谴责这位内核的领导者为在线讨论定下基调,并使得人身攻击及贬抑之辞成为常态。
+
+但为何 Poettering 会遭受如此多的憎恨?为何就这么个搞搞开源软件的人要忍受这等愤怒?答案就在于他的软件的重要性。如今大多数发行版中,Systemd 是 Linux 内核发起的第一个程序,并且它还扮演多种角色。它会启动系统服务,处理用户登陆,每隔特定的时间执行一些任务,还有很多很多。它在不断地成长,并逐渐成为 Linux 的某种“基础系统”——提供系统启动和发行版维护所需的所有工具。
+
+如今,在以下几点上 Systemd 颇具争议:它逃避了一些确立好的 Unix 传统,例如纯文本的日志文件;它被看成是个“大一统”的项目,试图接管一切;它还是我们这个操作系统的支柱的重要革新。然而大多数主流发行版已经接受了(或即将接受)它,因此它就保留了下来。而且它确实是有好处的:更快地启动,更简单地管理那些有依赖的服务程序,提供强大且安全的日志系统等。
+
+因此在这篇教程中,我们将探索 Systemd 的特性,并向您展示如何最有效地利用这些特性。即便您此刻并不是这款软件的粉丝,读完本文后您至少可以更加了解和适应它。
+
+
+
+**这部没正经的动画片来自[http://tinyurl.com/m2e7mv8][2],它把 Systemd 塑造成一只狂暴的动物,吞噬它路过的一切。大多数批评者的言辞可不像这只公仔一样柔软。**
+
+### 启动及服务 ###
+
+大多数主流发行版要么已经采用 Systemd,要么即将在下个发布中采用(如 Debian 和 Ubuntu)。在本教程中,我们使用 Fedora 21——该发行版已经是 Systemd 的优秀实验场地——的一个预览版进行演示,但不论您用哪个发行版,要用到的命令和注意事项都应该是一样的。这是 Systemd 的一个加分点:它消除了不同发行版之间许多细微且琐碎的区别。
+
+在终端中输入 **ps ax | grep systemd**,看到第一行,其中的数字 **1** 表示它的进程号是1,也就是说它是 Linux 内核发起的第一个程序。因此,内核一旦检测完硬件并组织好了内存,就会运行 **/usr/lib/systemd/systemd** 可执行程序,这个程序会按顺序依次发起其他程序。(在还没有 Systemd 的日子里,内核会去运行 **/sbin/init**,随后这个程序会在名为 SysVinit 的系统中运行其余的各种启动脚本。)
+
+Systemd 的核心是一个叫*单元* (unit)的概念,它是一些存有关于服务(在运行在后台的程序),设备,挂载点,和操作系统其他方面信息的配置文件。Systemd 的其中一个目标就是简化这些事物之间的相互作用,因此如果你有程序需要在某个挂载点被创建或某个设备被接入后开始运行,Systemd 可以让这一切正常运作起来变得相当容易。(在没有 Systemd 的日子里,要使用脚本来把这些事情调配好,那可是相当丑陋的。)要列出您 Linux 系统上的所有单元,输入以下命令:
+
+ systemctl list-unit-files
+
+现在,**systemctl** 是与 Systemd 交互的主要工具,它有不少选项。在单元列表中,您会注意到这儿有一些格式:被使能的单元显示为绿色,被禁用的显示为红色。标记为“static”的单元不能直接启用,它们是其他单元所依赖的对象。若要限制输出列表只包含服务,使用以下命令:
+
+ systemctl list-unit-files --type=service
+
+注意,一个单元显示为“enabled”,并不等于对应的服务正在运行,而只能说明它可以被开启。要获得某个特定服务的信息,以 GDM (the Gnome Display Manager) 为例,输入以下命令:
+
+ systemctl status gdm.service
+
+这条命令提供了许多有用的信息:一段人类可读的服务描述,单元配置文件的位置,启动的时间,进程号,以及它所从属的 CGroups (用以限制各组进程的资源开销)。
+
+如果您去查看位于 **/usr/lib/systemd/system/gdm.service** 的单元配置文件,您可以看到多种选项,包括要被运行的二进制文件(“ExecStart”那一行),相冲突的其他单元(即不能同时进入运行的单元),以及需要在本单元执行前进入运行的单元(“After”那一行)。一些单元有附加的依赖选项,例如“Requires”(必要的依赖)和“Wants”(可选的依赖)。
+
+此处另一个有趣的选项是:
+
+ Alias=display-manager.service
+
+当您启动 **gdm.service** 后,您将可以通过 **systemctl status display-manager.service** 来查看它的状态。当您知道有*显示管理程序* (display manager)在运行并想对它做点什么,但您不关心那究竟是 GDM,KDM,XDM 还是什么别的显示管理程序时,这个选项会非常有用。
+
+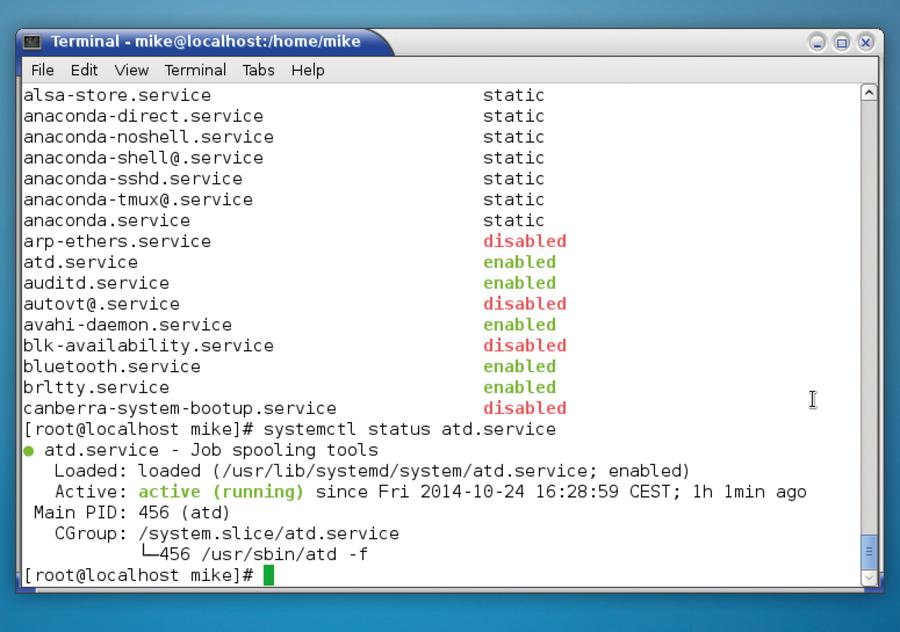
+
+**使用 systemctl status 命令后面跟一个单元名,来查看对应的服务有什么情况。**
+
+### “目标”锁定 ###
+
+如果您在 **/usr/lib/systemd/system** 目录中输入 **ls** 命令,您将看到各种以 **.target** 结尾的文件。一个*启动目标* (target)是一种将多个单元聚合在一起以致于将它们同时启动的方式。例如,对大多数类 Unix 操作系统而言有一种“多用户”状态,意思是系统已被成功启动,后台服务正在运行,并且已准备好让一个或多个用户登陆并工作——至少在文本模式下。(其他状态包括用于进行管理工作的单用户状态,以及用于机器关机的重启状态。)
+
+如果您打开 **multi-user.target** 文件一探究竟,您可能期待看到的是一个要被启动的单元列表。但您会发现这个文件内部几乎空空如也——其实,一个服务会通过 **WantedBy** 选项让自己成为启动目标的依赖。因此如果您去打开 **avahi-daemon.service**, **NetworkManager.service** 及其他 **.service** 文件看看,您将在 Install 段看到这一行:
+
+ WantedBy=multi-user.target
+
+因此,切换到多用户启动目标会使能那些包含上述语句的单元。还有其他一些启动目标可用(例如 **emergency.target** 用于一个紧急情况使用的 shell,以及 **halt.target** 用于机器关机),您可以用以下方式轻松地在它们之间切换:
+
+ systemctl isolate emergency.target
+
+在许多方面,这些都很像 SysVinit 中的*运行级* (runlevel),如文本模式的 **multi-user.target** 类似于第3运行级,**graphical.target** 类似于第5运行级,**reboot.target** 类似于第6运行级,诸如此类。
+
+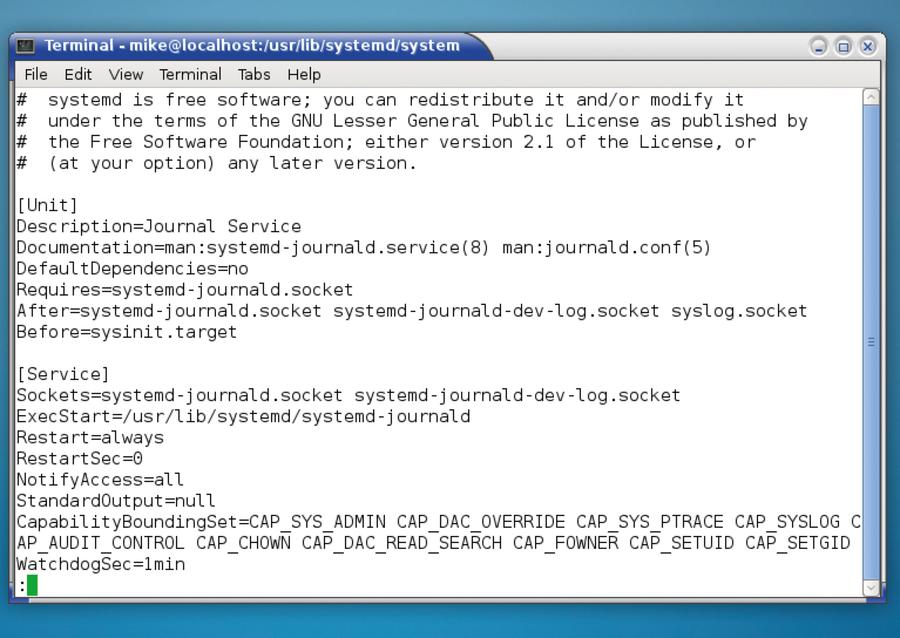
+
+**与传统的脚本相比,单元配置文件也许看起来很陌生,但并不难以理解。**
+
+### 开启与停止 ###
+
+现在您也许陷入了沉思:我们已经看了这么多,但仍没看到如何停止和开启服务!这其实是有原因的。从外部看,Systemd 也许很复杂,像野兽一般难以驾驭。因此在您开始摆弄它之间,有必要从宏观的角度看看它是如何工作的。实际用来管理服务的命令非常简单:
+
+ systemctl stop cups.service
+ systemctl start cups.service
+
+(若某个单元被禁用了,您可以先通过 **systemctl enable** 加该单元名的方式将其使能。这种做法会为该单元创建一个符号链接,并将其放置在当前启动目标的 .wants 目录下,这些 .wants 目录在**/etc/systemd/system** 文件夹中。)
+
+还有两个有用的命令是 **systemctl restart** 和 **systemctl reload**,后面接单元名。后者要求单元重新加载它的配置文件。Systemd 的绝大部分都有良好的文档,因此您可以查看手册 (**man systemctl**) 了解每条命令的细节。
+
+> ### 定时器单元:取代 Cron ###
+>
+> 除了系统初始化和服务管理,Systemd 还染指其他方面。在很大程度上,它能够完成 **cron** 的工作,而且可以说是以更灵活的方式(并带有更易读的语法)。**cron** 是一个以规定时间间隔执行任务的程序——例如清楚临时文件,刷新缓存等。
+>
+> 如果您再次进入 **/usr/lib/systemd/system** 目录,您会看到那儿有多个 **.timer** 文件。用 **less** 来查看这些文件,您会发现它们与 **.service** 和 **.target** 文件有着相似的结构,而区别在于 **[Timer]** 段。举个例子:
+>
+> [Timer]
+> OnBootSec=1h
+> OnUnitActiveSec=1w
+>
+> **OnBootSec** 选项告诉 Systemd 在系统启动一小时后启动这个单元。第二个选项的意思是:自那以后每周启动这个单元一次。关于定时器有大量选项您可以设置——输入 **man systemd.time** 查看完整列表。
+>
+> Systemd 的时间精度默认为一分钟。也就是说,它会在设定时刻的一分钟内运行单元,但不一定精确到那一秒。这么做是基于电源管理方面的原因,但如果您需要一个没有任何延时且精确到毫秒的定时器,您可以添加以下一行:
+>
+> AccuracySec=1us
+>
+> 另外, **WakeSystem** 选项(可以被设置为 true 或 false)决定了定时器是否可以唤醒处于休眠状态的机器。
+
+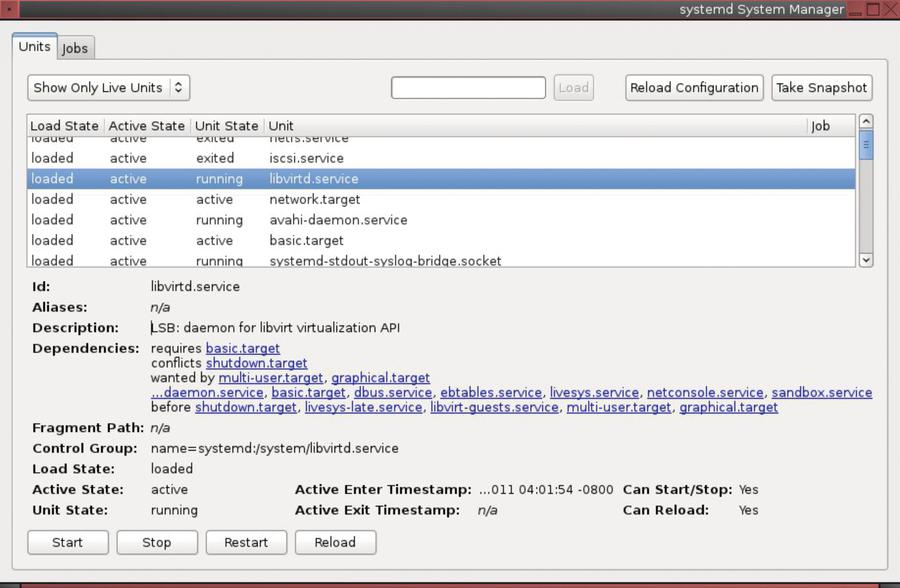
+
+**存在一个 Systemd 的图形界面程序,即便它已有多年未被积极维护。**
+
+### 日志文件:向 journald 问声好 ###
+
+Systemd 的第二个主要部分是 journal 。这是个日志系统,类似于 syslog 但也有些显著区别。如果您是个 Unix 日志管理模式的 粉丝,准备好热血沸腾吧:这是个二进制日志,因此您不能使用常规的命令行文本处理工具来解析它。这个设计决定不出意料地在网上引起了激烈的争论,但它的确有些优点。例如,日志可以被更系统地组织,带有更多元数据,因此可以更容易地根据可执行文件名和进程号等过滤出信息。
+
+要查看整个 journal,输入以下命令:
+
+ journalctl
+
+像许多其他的 Systemd 命令一样,该命令将输出通过管道的方式引向 **less** 程序,因此您可以使用空格键向下滚动,“/”(斜杠)键查找,以及其他熟悉的快捷键。您也能在此看到少许颜色,像红色的警告及错误信息。
+
+以上命令会输出很多信息。为了限制其只输出当前启动的消息,使用如下命令:
+
+ journalctl -b
+
+这就是 Systemd 大放异彩的地方!您想查看自上次启动以来的全部消息吗?试试 **journalctl -b -1** 吧。再上一次的?用 **-2** 替换 **-1** 吧。那自某个具体时间,例如2014年10月24日16:38以来的呢?
+
+ journalctl -b --since=”2014-10-24 16:38”
+
+即便您对二进制日志感到遗憾,那依然是个有用的特性,并且对许多系统管理员来说,构建类似的过滤器比起写正则表达式而言容易多了。
+
+我们已经可以根据特定的时间来准确查找日志了,那可以根据特定程序吗?对单元而言,试试这个:
+
+ journalctl -u gdm.service
+
+(注意:这是个查看 X server 产生的日志的好办法。)那根据特定的进程号?
+
+ journalctl _PID=890
+
+您甚至可以请求只看某个可执行文件产生的消息:
+
+ journalctl /usr/bin/pulseaudio
+
+若您想将输出的消息限制在某个优先级,可以使用 **-p** 选项。该选项参数为 0 的话只会显示紧急消息(也就是说,是时候向 **\$DEITY** 祈求保佑了),为 7 的话会显示所有消息,包括调试消息。请查看手册 (**man journalctl**) 获取更多关于优先级的信息。
+
+值得指出的是,您也可以将多个选项结合在一起,若想查看在当前启动中由 GDM 服务输出的优先级数小于等于 3 的消息,请使用下述命令:
+
+ journalctl -u gdm.service -p 3 -b
+
+最后,如果您仅仅想打开一个随 journal 持续更新的终端窗口,就像在没有 Systemd 时使用 tail 命令实现的那样,输入 **journalctl -f** 就好了。
+
+
+
+**二进制日志并不流行,但 journal 的确有它的优点,如非常方便的信息查找及过滤。**
+
+> ### 没有 Systemd 的生活?###
+>
+> 如果您就是完全不能接收 Systemd,您仍然有一些主流发现版中的选择。尤其是 Slackware,作为历史最为悠久的发行版,目前还没有做出改变,但它的主要开发者并没有将其从未来规划中移除。一些不出名的发行版也在坚持使用 SysVinit 。
+>
+> 但这又将持续多久呢?Gnome 正越来越依赖于 Systemd,其他的主流桌面环境也会步其后尘。这也是引起 BSD 社区一阵恐慌的原因:Systemd 与 Linux 内核紧密相连,导致在某种程度上,桌面环境正变得越来越不可移植。一种折中的解决方案也许会以 Uselessd ([http://uselessd.darknedgy.net][3]) 的形式到来:一种裁剪版的 Systemd,纯粹专注于启动和监控进程,而不消耗整个基础系统。
+>
+> 
+>
+> 若您不喜欢 Systemd,可以尝试一下 Gentoo 发行版,它将 Systemd 作为初始化工具的一种选择,但并不强制用户使用 Systemd。
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxvoice.com/linux-101-get-the-most-out-of-systemd/
+
+作者:[Mike Saunders][a]
+译者:[Ricky-Gong](https://github.com/Ricky-Gong)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxvoice.com/author/mike/
+[1]:http://tinyurl.com/poorlennart
+[2]:http://tinyurl.com/m2e7mv8
+[3]:http://uselessd.darknedgy.net/
diff --git a/translated/tech/20151119 Going Beyond Hello World Containers is Hard Stuff.md b/translated/tech/20151119 Going Beyond Hello World Containers is Hard Stuff.md
new file mode 100644
index 0000000000..c42b278787
--- /dev/null
+++ b/translated/tech/20151119 Going Beyond Hello World Containers is Hard Stuff.md
@@ -0,0 +1,334 @@
+要超越Hello World 容器是件困难的事情
+================================================================================
+
+在[我的上一篇文章里][1], 我介绍了Linux 容器背后的技术的概念。我写了我知道的一切。容器对我来说也是比较新的概念。我写这篇文章的目的就是鼓励我真正的来学习这些东西。
+
+我打算在使用中学习。首先实践,然后上手并记录下我是怎么走过来的。我假设这里肯定有很多想"Hello World" 这种类型的知识帮助我快速的掌握基础。然后我能够更进一步,构建一个微服务容器或者其它东西。
+
+我的意思是还会比着更难吗,对吧?
+
+错了。
+
+可能对某些人来说这很简单,因为他们会耗费大量的时间专注在操作工作上。但是对我来说实际上是很困难的,可以从我在Facebook 上的状态展示出来的挫折感就可以看出了。
+
+但是还有一个好消息:我最终让它工作了。而且他工作的还不错。所以我准备分享向你分享我如何制作我的第一个微服务容器。我的痛苦可能会节省你不少时间呢。
+
+如果你曾经发现或者从来都没有发现自己处在这种境地:像我这样的人在这里解决一些你不需要解决的问题。
+
+让我们开始吧。
+
+
+### 一个缩略图微服务 ###
+
+我设计的微服务在理论上很简单。以JPG 或者PNG 格式在HTTP 终端发布一张数字照片,然后获得一个100像素宽的缩略图。
+
+下面是它实际的效果:
+
+
+
+我决定使用NodeJS 作为我的开发语言,使用[ImageMagick][2] 来转换缩略图。
+
+我的服务的第一版的逻辑如下所示:
+
+
+
+我下载了[Docker Toolbox][3],用它安装了Docker 的快速启动终端。Docker 快速启动终端使得创建容器更简单了。终端会启动一个装好了Docker 的Linux 虚拟机,它允许你在一个终端里运行Docker 命令。
+
+虽然在我的例子里,我的操作系统是Mac OS X。但是Windows 下也有相同的工具。
+
+我准备使用Docker 快速启动终端里为我的微服务创建一个容器镜像,然后从这个镜像运行容器。
+
+Docker 快速启动终端就运行在你使用的普通终端里,就像这样:
+
+
+
+### 第一个小问题和第一个大问题###
+
+所以我用NodeJS 和ImageMagick 瞎搞了一通然后让我的服务在本地运行起来了。
+
+然后我创建了Dockerfile,这是Docker 用来构建容器的配置脚本。(我会在后面深入介绍构建和Dockerfile)
+
+这是我运行Docker 快速启动终端的命令:
+
+ $ docker build -t thumbnailer:0.1
+
+获得如下回应:
+
+ docker: "build" requires 1 argument.
+
+呃。
+
+我估摸着过了15分钟:我忘记了在末尾参数输入一个点`.`。
+
+正确的指令应该是这样的:
+
+ $ docker build -t thumbnailer:0.1 .
+
+
+但是这不是我最后一个问题。
+
+我让这个镜像构建好了,然后我Docker 快速启动终端输入了[`run` 命令][4]来启动容器,名字叫`thumbnailer:0.1`:
+
+ $ docker run -d -p 3001:3000 thumbnailer:0.1
+
+参数`-p 3001:3000` 让NodeJS 微服务在Docker 内运行在端口3000,而在主机上则是3001。
+
+到目前卡起来都很好,对吧?
+
+错了。事情要马上变糟了。
+
+我指定了在Docker 快速启动中端里用命令`docker-machine` 运行的Docker 虚拟机的ip地址:
+
+ $ docker-machine ip default
+
+这句话返回了默认虚拟机的IP地址,即运行docker 的虚拟机。对于我来说,这个ip 地址是192.168.99.100。
+
+我浏览网页http://192.168.99.100:3001/ ,然后找到了我创建的上传图片的网页:
+
+
+
+我选择了一个文件,然后点击上传图片的按钮。
+
+但是它并没有工作。
+
+终端告诉我他无法找到我的微服务需要的`/upload` 目录。
+
+现在开始记住,我已经在此耗费了将近一天的时间-从浪费时间到研究问题。我此时感到了一些挫折感。
+
+然后灵光一闪。某人记起来微服务不应该自己做任何数据持久化的工作!保存数据应该是另一个服务的工作。
+
+所以容器找不到目录`/upload` 的原因到底是什么?这个问题的根本就是我的微服务在基础设计上就有问题。
+
+让我们看看另一幅图:
+
+
+
+我为什么要把文件保存到磁盘?微服务按理来说是很快的。为什么不能让我的全部工作都在内存里完成?使用内存缓冲可以解决“找不到目录”这个问题,而且可以提高我的应用的性能。
+
+这就是我现在所做的。下面是我的计划:
+
+
+
+这是我用NodeJS 写的在内存工作、生成缩略图的代码:
+
+ // Bind to the packages
+ var express = require('express');
+ var router = express.Router();
+ var path = require('path'); // used for file path
+ var im = require("imagemagick");
+
+ // Simple get that allows you test that you can access the thumbnail process
+ router.get('/', function (req, res, next) {
+ res.status(200).send('Thumbnailer processor is up and running');
+ });
+
+ // This is the POST handler. It will take the uploaded file and make a thumbnail from the
+ // submitted byte array. I know, it's not rocket science, but it serves a purpose
+ router.post('/', function (req, res, next) {
+ req.pipe(req.busboy);
+ req.busboy.on('file', function (fieldname, file, filename) {
+ var ext = path.extname(filename)
+
+ // Make sure that only png and jpg is allowed
+ if(ext.toLowerCase() != '.jpg' && ext.toLowerCase() != '.png'){
+ res.status(406).send("Service accepts only jpg or png files");
+ }
+
+ var bytes = [];
+
+ // put the bytes from the request into a byte array
+ file.on('data', function(data) {
+ for (var i = 0; i < data.length; ++i) {
+ bytes.push(data[i]);
+ }
+ console.log('File [' + fieldname + '] got bytes ' + bytes.length + ' bytes');
+ });
+
+ // Once the request is finished pushing the file bytes into the array, put the bytes in
+ // a buffer and process that buffer with the imagemagick resize function
+ file.on('end', function() {
+ var buffer = new Buffer(bytes,'binary');
+ console.log('Bytes got ' + bytes.length + ' bytes');
+
+ //resize
+ im.resize({
+ srcData: buffer,
+ height: 100
+ }, function(err, stdout, stderr){
+ if (err){
+ throw err;
+ }
+ // get the extension without the period
+ var typ = path.extname(filename).replace('.','');
+ res.setHeader("content-type", "image/" + typ);
+ res.status(200);
+ // send the image back as a response
+ res.send(new Buffer(stdout,'binary'));
+ });
+ });
+ });
+ });
+
+ module.exports = router;
+
+好了,回到正轨,已经可以在我的本地机器正常工作了。我该去休息了。
+
+但是,在我测试把这个微服务当作一个普通的Node 应用运行在本地时...
+
+
+
+它工作的很好。现在我要做的就是让他在容器里面工作。
+
+第二天我起床后喝点咖啡,然后创建一个镜像——这次没有忘记那个"."!
+
+ $ docker build -t thumbnailer:01 .
+
+我从缩略图工程的根目录开始构建。构建命令使用了根目录下的Dockerfile。它是这样工作的:把Dockerfile 放到你想构建镜像的地方,然后系统就默认使用这个Dockerfile。
+
+下面是我使用的Dockerfile 的内容:
+
+ FROM ubuntu:latest
+ MAINTAINER bob@CogArtTech.com
+
+ RUN apt-get update
+ RUN apt-get install -y nodejs nodejs-legacy npm
+ RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
+ RUN apt-get clean
+
+ COPY ./package.json src/
+
+ RUN cd src && npm install
+
+ COPY . /src
+
+ WORKDIR src/
+
+ CMD npm start
+
+这怎么可能出错呢?
+
+### 第二个大问题 ###
+
+我运行了`build` 命令,然后出了这个错:
+
+ Do you want to continue? [Y/n] Abort.
+
+ The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
+
+我猜测微服务出错了。我回到本地机器,从本机启动微服务,然后试着上传文件。
+
+然后我从NodeJS 获得了这个错误:
+
+ Error: spawn convert ENOENT
+
+怎么回事?之前还是好好的啊!
+
+我搜索了我能想到的所有的错误原因。差不多4个小时后,我想:为什么不重启一下机器呢?
+
+重启了,你猜猜结果?错误消失了!(译注:万能的重启)
+
+继续。
+
+### 将精灵关进瓶子 ###
+
+跳回正题:我需要完成构建工作。
+
+我使用[`rm` 命令][5]删除了虚拟机里所有的容器。
+
+ $ docker rm -f $(docker ps -a -q)
+
+`-f` 在这里的用处是强制删除运行中的镜像。
+
+然后删除了全部Docker 镜像,用的是[命令`rmi`][6]:
+
+ $ docker rmi if $(docker images | tail -n +2 | awk '{print $3}')
+
+我重新执行了命令构建镜像,安装容器,运行微服务。然后过了一个充满自我怀疑和沮丧的一个小时,我告诉我自己:这个错误可能不是微服务的原因。
+
+所以我重新看到了这个错误:
+
+ Do you want to continue? [Y/n] Abort.
+
+ The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
+
+这太打击我了:构建脚本好像需要有人从键盘输入Y! 但是,这是一个非交互的Dockerfile 脚本啊。这里并没有键盘。
+
+回到Dockerfile,脚本元来时这样的:
+
+ RUN apt-get update
+ RUN apt-get install -y nodejs nodejs-legacy npm
+ RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
+ RUN apt-get clean
+
+The second `apt-get` command is missing the `-y` flag which causes "yes" to be given automatically where usually it would be prompted for.
+第二个`apt-get` 忘记了`-y` 标志,这才是错误的根本原因。
+
+I added the missing `-y` to the command:
+我在这条命令后面添加了`-y` :
+
+ RUN apt-get update
+ RUN apt-get install -y nodejs nodejs-legacy npm
+ RUN apt-get install -y imagemagick libmagickcore-dev libmagickwand-dev
+ RUN apt-get clean
+
+猜一猜结果:经过将近两天的尝试和痛苦,容器终于正常工作了!整整两天啊!
+
+我完成了构建工作:
+
+ $ docker build -t thumbnailer:0.1 .
+
+启动了容器:
+
+ $ docker run -d -p 3001:3000 thumbnailer:0.1
+
+Got the IP address of the Virtual Machine:
+获取了虚拟机的IP 地址:
+
+ $ docker-machine ip default
+
+在我的浏览器里面输入 http://192.168.99.100:3001/ :
+
+上传页面打开了。
+
+我选择了一个图片,然后得到了这个:
+
+
+
+工作了!
+
+在容器里面工作了,我的第一次啊!
+
+### 这意味着什么? ###
+
+很久以前,我接受了这样一个道理:当你刚开始尝试某项技术时,即使是最简单的事情也会变得很困难。因此,我压抑了要成为房间里最聪明的人的欲望。然而最近几天尝试容器的过程就是一个充满自我怀疑的旅程。
+
+但是你想知道一些其它的事情吗?这篇文章是我在凌晨2点完成的,而每一个折磨的小时都值得了。为什么?因为这段时间你将自己全身心投入了喜欢的工作里。这件事很难,对于所有人来说都不是很容易就获得结果的。但是不要忘记:你在学习技术,运行世界的技术。
+
+P.S. 了解一下Hello World 容器的两段视频,这里会有 [Raziel Tabib’s][7] 的精彩工作内容。
+
+注:youtube视频
+
+
+千万被忘记第二部分...
+
+注:youtube视频
+
+
+--------------------------------------------------------------------------------
+
+via: https://deis.com/blog/2015/beyond-hello-world-containers-hard-stuff
+
+作者:[Bob Reselman][a]
+译者:[Ezio](https://github.com/oska874)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://deis.com/blog
+[1]:http://deis.com/blog/2015/developer-journey-linux-containers
+[2]:https://github.com/rsms/node-imagemagick
+[3]:https://www.docker.com/toolbox
+[4]:https://docs.docker.com/reference/commandline/run/
+[5]:https://docs.docker.com/reference/commandline/rm/
+[6]:https://docs.docker.com/reference/commandline/rmi/
+[7]:http://twitter.com/RazielTabib
diff --git a/translated/tech/20151122 Doubly linked list in the Linux Kernel.md b/translated/tech/20151122 Doubly linked list in the Linux Kernel.md
new file mode 100644
index 0000000000..631d918813
--- /dev/null
+++ b/translated/tech/20151122 Doubly linked list in the Linux Kernel.md
@@ -0,0 +1,258 @@
+Linux 内核里的数据结构——双向链表
+================================================================================
+
+双向链表
+--------------------------------------------------------------------------------
+
+
+Linux 内核自己实现了双向链表,可以在[include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h)找到定义。我们将会从双向链表数据结构开始`内核的数据结构`。为什么?因为它在内核里使用的很广泛,你只需要在[free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
+
+首先让我们看一下在[include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 里的主结构体:
+
+```C
+struct list_head {
+ struct list_head *next, *prev;
+};
+```
+
+你可能注意到这和你以前见过的双向链表的实现方法是不同的。举个例子来说,在[glib](http://www.gnu.org/software/libc/) 库里是这样实现的:
+
+```C
+struct GList {
+ gpointer data;
+ GList *next;
+ GList *prev;
+};
+```
+
+通常来说一个链表会包含一个指向某个项目的指针。但是内核的实现并没有这样做。所以问题来了:`链表在哪里保存数据呢?`。实际上内核里实现的链表实际上是`侵入式链表`。侵入式链表并不在节点内保存数据-节点仅仅包含指向前后节点的指针,然后把数据是附加到链表的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
+
+比如:
+
+```C
+struct nmi_desc {
+ spinlock_t lock;
+ struct list_head head;
+};
+```
+
+让我们看几个例子来理解一下在内核里是如何使用`list_head` 的。如上所述,在内核里有实在很多不同的地方用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动API 被用来编写处理小型硬件和虚拟设备的小驱动。这些驱动共享相同的主设备号:
+
+```C
+#define MISC_MAJOR 10
+```
+
+但是都有各自不同的次设备号。比如:
+
+```
+ls -l /dev | grep 10
+crw------- 1 root root 10, 235 Mar 21 12:01 autofs
+drwxr-xr-x 10 root root 200 Mar 21 12:01 cpu
+crw------- 1 root root 10, 62 Mar 21 12:01 cpu_dma_latency
+crw------- 1 root root 10, 203 Mar 21 12:01 cuse
+drwxr-xr-x 2 root root 100 Mar 21 12:01 dri
+crw-rw-rw- 1 root root 10, 229 Mar 21 12:01 fuse
+crw------- 1 root root 10, 228 Mar 21 12:01 hpet
+crw------- 1 root root 10, 183 Mar 21 12:01 hwrng
+crw-rw----+ 1 root kvm 10, 232 Mar 21 12:01 kvm
+crw-rw---- 1 root disk 10, 237 Mar 21 12:01 loop-control
+crw------- 1 root root 10, 227 Mar 21 12:01 mcelog
+crw------- 1 root root 10, 59 Mar 21 12:01 memory_bandwidth
+crw------- 1 root root 10, 61 Mar 21 12:01 network_latency
+crw------- 1 root root 10, 60 Mar 21 12:01 network_throughput
+crw-r----- 1 root kmem 10, 144 Mar 21 12:01 nvram
+brw-rw---- 1 root disk 1, 10 Mar 21 12:01 ram10
+crw--w---- 1 root tty 4, 10 Mar 21 12:01 tty10
+crw-rw---- 1 root dialout 4, 74 Mar 21 12:01 ttyS10
+crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
+crw------- 1 root root 10, 137 Mar 21 12:01 vhci
+```
+
+现在让我们看看它是如何使用链表的。首先看一下结构体`miscdevice`:
+
+```C
+struct miscdevice
+{
+ int minor;
+ const char *name;
+ const struct file_operations *fops;
+ struct list_head list;
+ struct device *parent;
+ struct device *this_device;
+ const char *nodename;
+ mode_t mode;
+};
+```
+
+可以看到结构体的第四个变量`list` 是所有注册过的设备的链表。在源代码文件的开始可以看到这个链表的定义:
+
+```C
+static LIST_HEAD(misc_list);
+```
+
+它实际上是对用`list_head` 类型定义的变量的扩展。
+
+```C
+#define LIST_HEAD(name) \
+ struct list_head name = LIST_HEAD_INIT(name)
+```
+
+然后使用宏`LIST_HEAD_INIT` 进行初始化,这会使用变量`name` 的地址来填充`prev`和`next` 结构体的两个变量。
+
+```C
+#define LIST_HEAD_INIT(name) { &(name), &(name) }
+```
+
+现在来看看注册杂项设备的函数`misc_register`。它在开始就用 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
+
+```C
+INIT_LIST_HEAD(&misc->list);
+```
+
+作用和宏`LIST_HEAD_INIT`一样。
+
+```C
+static inline void INIT_LIST_HEAD(struct list_head *list)
+{
+ list->next = list;
+ list->prev = list;
+}
+```
+
+在函数`device_create` 创建了设备后我们就用下面的语句将设备添加到设备链表:
+
+```
+list_add(&misc->list, &misc_list);
+```
+
+内核文件`list.h` 提供了项链表添加新项的API 接口。我们来看看它的实现:
+
+
+```C
+static inline void list_add(struct list_head *new, struct list_head *head)
+{
+ __list_add(new, head, head->next);
+}
+```
+
+实际上就是使用3个指定的参数来调用了内部函数`__list_add`:
+
+* new - 新项。
+* head - 新项将会被添加到`head`之前.
+* head->next - `head` 之后的项。
+
+`__list_add`的实现非常简单:
+
+```C
+static inline void __list_add(struct list_head *new,
+ struct list_head *prev,
+ struct list_head *next)
+{
+ next->prev = new;
+ new->next = next;
+ new->prev = prev;
+ prev->next = new;
+}
+```
+
+我们会在`prev`和`next` 之间添加一个新项。所以我们用宏`LIST_HEAD_INIT`定义的`misc` 链表会包含指向`miscdevice->list` 的向前指针和向后指针。
+
+这里有一个问题:如何得到列表的内容呢?这里有一个特殊的宏:
+
+```C
+#define list_entry(ptr, type, member) \
+ container_of(ptr, type, member)
+```
+
+使用了三个参数:
+
+* ptr - 指向链表头的指针;
+* type - 结构体类型;
+* member - 在结构体内类型为`list_head` 的变量的名字;
+
+比如说:
+
+```C
+const struct miscdevice *p = list_entry(v, struct miscdevice, list)
+```
+
+然后我们就可以使用`p->minor` 或者 `p->name`来访问`miscdevice`。让我们来看看`list_entry` 的实现:
+
+```C
+#define list_entry(ptr, type, member) \
+ container_of(ptr, type, member)
+```
+
+如我们所见,它仅仅使用相同的参数调用了宏`container_of`。初看这个宏挺奇怪的:
+
+```C
+#define container_of(ptr, type, member) ({ \
+ const typeof( ((type *)0)->member ) *__mptr = (ptr); \
+ (type *)( (char *)__mptr - offsetof(type,member) );})
+```
+
+首先你可以注意到花括号内包含两个表达式。编译器会执行花括号内的全部语句,然后返回最后的表达式的值。
+
+举个例子来说:
+
+```
+#include
+
+int main() {
+ int i = 0;
+ printf("i = %d\n", ({++i; ++i;}));
+ return 0;
+}
+```
+
+最终会打印`2`
+
+下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是`container_of`中的0.实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
+
+```C
+#include
+
+struct s {
+ int field1;
+ char field2;
+ char field3;
+};
+
+int main() {
+ printf("%p\n", &((struct s*)0)->field3);
+ return 0;
+}
+```
+
+结果显示`0x5`。
+
+下一个宏`offsetof` 会计算从结构体的某个变量的相对于结构体起始地址的偏移。它的实现和上面类似:
+
+```C
+#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
+```
+
+现在我们来总结一下宏`container_of`。只需要知道结构体里面类型为`list_head` 的变量的名字和结构体容器的类型,它可以通过结构体的变量`list_head`获得结构体的起始地址。在宏定义的第一行,声明了一个指向结构体成员变量`ptr`的指针`__mptr`,并且把`ptr` 的地址赋给它。现在`ptr` 和`__mptr` 指向了同一个地址。从技术上讲我们并不需要这一行,但是它可以方便的进行类型检查。第一行保证了特定的结构体(参数`type`)包含成员变量`member`。第二行代码会用宏`offsetof`计算成员变量相对于结构体起始地址的偏移,然后从结构体的地址减去这个偏移,最后就得到了结构体。
+
+当然了`list_add` 和 `list_entry`不是``提供的唯一功能。双向链表的实现还提供了如下API:
+
+* list_add
+* list_add_tail
+* list_del
+* list_replace
+* list_move
+* list_is_last
+* list_empty
+* list_cut_position
+* list_splice
+* list_for_each
+* list_for_each_entry
+
+等等很多其它API。
+
+via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
+
+译者:[Ezio](https://github.com/oska874)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20151123 Assign Multiple IP Addresses To One Interface On Ubuntu 15.10.md b/translated/tech/20151123 Assign Multiple IP Addresses To One Interface On Ubuntu 15.10.md
new file mode 100644
index 0000000000..fd61e5a939
--- /dev/null
+++ b/translated/tech/20151123 Assign Multiple IP Addresses To One Interface On Ubuntu 15.10.md
@@ -0,0 +1,236 @@
+在 Ubuntu 15.10 上为单个网卡设置多个 IP 地址
+================================================================================
+有时候你可能想在你的网卡上使用多个 IP 地址。遇到这种情况你会怎么办呢?买一个新的网卡并分配一个新的 IP?不,这没有必要(至少在小网络中)。现在我们可以在 Ubuntu 系统中为一个网卡分配多个 IP 地址。想知道怎么做到的?跟着我往下看,其实并不难。
+
+这个方法也适用于 Debian 以及它的衍生版本。
+
+### 临时添加 IP 地址 ###
+
+首先,让我们找到网卡的 IP 地址。在我的 Ubuntu 15.10 服务器版中,我只使用了一个网卡。
+
+运行下面的命令找到 IP 地址:
+
+ sudo ip addr
+
+**事例输出:**
+
+ 1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default
+ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
+ inet 127.0.0.1/8 scope host lo
+ valid_lft forever preferred_lft forever
+ inet6 ::1/128 scope host
+ valid_lft forever preferred_lft forever
+ 2: enp0s3: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
+ link/ether 08:00:27:2a:03:4b brd ff:ff:ff:ff:ff:ff
+ inet 192.168.1.103/24 brd 192.168.1.255 scope global enp0s3
+ valid_lft forever preferred_lft forever
+ inet6 fe80::a00:27ff:fe2a:34e/64 scope link
+ valid_lft forever preferred_lft forever
+
+或
+
+ sudo ifconfig
+
+**事例输出:**
+
+ enp0s3 Link encap:Ethernet HWaddr 08:00:27:2a:03:4b
+ inet addr:192.168.1.103 Bcast:192.168.1.255 Mask:255.255.255.0
+ inet6 addr: fe80::a00:27ff:fe2a:34e/64 Scope:Link
+ UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
+ RX packets:186 errors:0 dropped:0 overruns:0 frame:0
+ TX packets:70 errors:0 dropped:0 overruns:0 carrier:0
+ collisions:0 txqueuelen:1000
+ RX bytes:21872 (21.8 KB) TX bytes:9666 (9.6 KB)
+ lo Link encap:Local Loopback
+ inet addr:127.0.0.1 Mask:255.0.0.0
+ inet6 addr: ::1/128 Scope:Host
+ UP LOOPBACK RUNNING MTU:65536 Metric:1
+ RX packets:217 errors:0 dropped:0 overruns:0 frame:0
+ TX packets:217 errors:0 dropped:0 overruns:0 carrier:0
+ collisions:0 txqueuelen:0
+ RX bytes:38793 (38.7 KB) TX bytes:38793 (38.7 KB)
+
+正如你在上面看到的,我的网卡名称是 **enp0s3**,它的 IP 地址是 **192.168.1.103**。
+
+现在让我们来为网卡添加一个新的 IP 地址,例如说 **192.168.1.104**。
+
+打开你的终端并运行下面的命令添加额外的 IP。
+
+ sudo ip addr add 192.168.1.104/24 dev enp0s3
+
+用命令检查是否启用了新的 IP:
+
+ sudo ip address show enp0s3
+
+**样例输出:**
+
+ 2: enp0s3: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
+ link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
+ inet 192.168.1.103/24 brd 192.168.1.255 scope global enp0s3
+ valid_lft forever preferred_lft forever
+ inet 192.168.1.104/24 scope global secondary enp0s3
+ valid_lft forever preferred_lft forever
+ inet6 fe80::a00:27ff:fe2a:34e/64 scope link
+ valid_lft forever preferred_lft forever
+
+类似地,你可以添加想要的任意多的 IP 地址。
+
+让我们 ping 一下这个 IP 地址验证一下。
+
+ sudo ping 192.168.1.104
+
+**样例输出**
+
+ PING 192.168.1.104 (192.168.1.104) 56(84) bytes of data.
+ 64 bytes from 192.168.1.104: icmp_seq=1 ttl=64 time=0.901 ms
+ 64 bytes from 192.168.1.104: icmp_seq=2 ttl=64 time=0.571 ms
+ 64 bytes from 192.168.1.104: icmp_seq=3 ttl=64 time=0.521 ms
+ 64 bytes from 192.168.1.104: icmp_seq=4 ttl=64 time=0.524 ms
+
+好极了,它能工作!
+
+要删除 IP,只需要运行:
+
+ sudo ip addr del 192.168.1.104/24 dev enp0s3
+
+再检查一下是否删除了 IP。
+
+ sudo ip address show enp0s3
+
+**样例输出:**
+
+ 2: enp0s3: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
+ link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
+ inet 192.168.1.103/24 brd 192.168.1.255 scope global enp0s3
+ valid_lft forever preferred_lft forever
+ inet6 fe80::a00:27ff:fe2a:34e/64 scope link
+ valid_lft forever preferred_lft forever
+
+可以看到已经没有了!!
+
+也许你已经知道,你重启系统后会丢失这些设置。那么怎么设置才能永久有效呢?这也很简单。
+
+### 添加永久 IP 地址 ###
+
+Ubuntu 系统的网卡配置文件是 **/etc/network/interfaces**。
+
+让我们来看看上面文件的具体内容。
+
+ sudo cat /etc/network/interfaces
+
+**输出样例:**
+
+ # This file describes the network interfaces available on your system
+ # and how to activate them. For more information, see interfaces(5).
+ source /etc/network/interfaces.d/*
+ # The loopback network interface
+ auto lo
+ iface lo inet loopback
+ # The primary network interface
+ auto enp0s3
+ iface enp0s3 inet dhcp
+
+正如你在上面输出中看到的,网卡启用了 DHCP。
+
+现在,让我们来分配一个额外的地址,例如 **192.168.1.104/24**。
+
+编辑 **/etc/network/interfaces**:
+
+ sudo nano /etc/network/interfaces
+
+按照黑色字体标注的添加额外的 IP 地址。
+
+ # This file describes the network interfaces available on your system
+ # and how to activate them. For more information, see interfaces(5).
+ source /etc/network/interfaces.d/*
+ # The loopback network interface
+ auto lo
+ iface lo inet loopback
+ # The primary network interface
+ auto enp0s3
+ iface enp0s3 inet dhcp
+ iface enp0s3 inet static
+ address 192.168.1.104/24
+
+保存并关闭文件。
+
+无需重启运行下面的命令使更改生效。
+
+ sudo ifdown enp0s3 && sudo ifup enp0s3
+
+**样例输出:**
+
+ Killed old client process
+ Internet Systems Consortium DHCP Client 4.3.1
+ Copyright 2004-2014 Internet Systems Consortium.
+ All rights reserved.
+ For info, please visit https://www.isc.org/software/dhcp/
+ Listening on LPF/enp0s3/08:00:27:2a:03:4e
+ Sending on LPF/enp0s3/08:00:27:2a:03:4e
+ Sending on Socket/fallback
+ DHCPRELEASE on enp0s3 to 192.168.1.1 port 67 (xid=0x225f35)
+ Internet Systems Consortium DHCP Client 4.3.1
+ Copyright 2004-2014 Internet Systems Consortium.
+ All rights reserved.
+ For info, please visit https://www.isc.org/software/dhcp/
+ Listening on LPF/enp0s3/08:00:27:2a:03:4e
+ Sending on LPF/enp0s3/08:00:27:2a:03:4e
+ Sending on Socket/fallback
+ DHCPDISCOVER on enp0s3 to 255.255.255.255 port 67 interval 3 (xid=0xdfb94764)
+ DHCPREQUEST of 192.168.1.103 on enp0s3 to 255.255.255.255 port 67 (xid=0x6447b9df)
+ DHCPOFFER of 192.168.1.103 from 192.168.1.1
+ DHCPACK of 192.168.1.103 from 192.168.1.1
+ bound to 192.168.1.103 -- renewal in 35146 seconds.
+
+**注意**:如果你从远程连接到服务器,把上面的两个命令放到**一行**中**非常重要**,因为第一个命令会断掉你的连接。而采用这种方式可以存活你的 ssh 会话。
+
+现在,让我们用下面的命令来检查一下是否添加了新的 IP:
+
+ sudo ip address show enp0s3
+
+**输出样例:**
+
+ 2: enp0s3: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
+ link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
+ inet 192.168.1.103/24 brd 192.168.1.255 scope global enp0s3
+ valid_lft forever preferred_lft forever
+ inet 192.168.1.104/24 brd 192.168.1.255 scope global secondary enp0s3
+ valid_lft forever preferred_lft forever
+ inet6 fe80::a00:27ff:fe2a:34e/64 scope link
+ valid_lft forever preferred_lft forever
+
+很好!我们已经添加了额外的 IP。
+
+再次 ping IP 地址进行验证。
+
+ sudo ping 192.168.1.104
+
+**样例输出:**
+
+ PING 192.168.1.104 (192.168.1.104) 56(84) bytes of data.
+ 64 bytes from 192.168.1.104: icmp_seq=1 ttl=64 time=0.137 ms
+ 64 bytes from 192.168.1.104: icmp_seq=2 ttl=64 time=0.050 ms
+ 64 bytes from 192.168.1.104: icmp_seq=3 ttl=64 time=0.054 ms
+ 64 bytes from 192.168.1.104: icmp_seq=4 ttl=64 time=0.067 ms
+
+好极了!它能正常工作。就是这样。
+
+想知道怎么给 CentOS/RHEL/Scientific Linux/Fedora 系统添加额外的 IP 地址,可以点击下面的链接。
+
+注:此篇文章以前做过选题:20150205 Linux Basics--Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7.md
+- [Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7][1]
+
+周末愉快!
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/assign-multiple-ip-addresses-to-one-interface-on-ubuntu-15-10/
+
+作者:[SK][a]
+译者:[ictlyh](http://mutouxiaogui.cn/blog/)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.unixmen.com/author/sk/
+[1]:http://www.unixmen.com/linux-basics-assign-multiple-ip-addresses-single-network-interface-card-centos-7/
\ No newline at end of file
diff --git a/translated/tech/20151123 How to access Dropbox from the command line in Linux.md b/translated/tech/20151123 How to access Dropbox from the command line in Linux.md
new file mode 100644
index 0000000000..6c5f73e596
--- /dev/null
+++ b/translated/tech/20151123 How to access Dropbox from the command line in Linux.md
@@ -0,0 +1,97 @@
+Linux 中如何从命令行访问 Dropbox
+================================================================================
+在当今这个多设备的环境下,云存储无处不在。无论身处何方,人们都想通过多种设备来从云存储中获取所需的内容。由于优雅的 UI 和完美的跨平台兼容性,Dropbox 已成为最为广泛使用的云存储服务。 Dropbox 的流行已引发了一系列官方或非官方 Dropbox 客户端的出现,它们支持不同的操作系统平台。
+
+当然 Linux 平台下也有着自己的 Dropbox 客户端: 既有命令行的,也有图形界面。[Dropbox Uploader][1] 是一个简单易用的 Dropbox 命令行客户端,它是用 BASH 脚本语言所编写的。在这篇教程中,我将描述 **在 Linux 中如何使用 Dropbox Uploader 通过命令行来访问 Dropbox**。
+
+### Linux 中安装和配置 Dropbox Uploader ###
+
+要使用 Dropbox Uploader,你需要下载该脚本并使其可被执行。
+
+ $ wget https://raw.github.com/andreafabrizi/Dropbox-Uploader/master/dropbox_uploader.sh
+ $ chmod +x dropbox_uploader.sh
+
+请确保你已经在系统中安装了 `curl`,因为 Dropbox Uploader 通过 curl 来运行 Dropbox 的 API。
+
+要配置 Dropbox Uploader,只需运行 dropbox_uploader.sh 即可。当你第一次运行这个脚本时,它将询问你,以使得它可以访问你的 Dropbox 账户。
+
+ $ ./dropbox_uploader.sh
+
+
+
+如上图所指示的那样,你需要通过浏览器访问 [https://www.dropbox.com/developers/apps][2] 页面,并创建一个新的 Dropbox app。接着像下图那样填入新 app 的相关信息,并输入 app 的名称,它与 Dropbox Uploader 所生成的 app 名称类似。
+
+
+
+在你创建好一个新的 app 之后,你将在下一个页面看到 app key 和 app secret。请记住它们。
+
+
+
+然后在正运行着 dropbox_uploader.sh 的终端窗口中输入 app key 和 app secret。然后 dropbox_uploader.sh 将产生一个 oAUTH 网址(例如,https://www.dropbox.com/1/oauth/authorize?oauth_token=XXXXXXXXXXXX)。
+
+
+
+接着通过浏览器访问那个 oAUTH 网址,并同意访问你的 Dropbox 账户。
+
+
+
+这便完成了 Dropbox Uploader 的配置。若要确认 Dropbox Uploader 是否真的被成功地认证了,可以运行下面的命令。
+
+ $ ./dropbox_uploader.sh info
+
+----------
+
+ Dropbox Uploader v0.12
+
+ > Getting info...
+
+ Name: Dan Nanni
+ UID: XXXXXXXXXX
+ Email: my@email_address
+ Quota: 2048 Mb
+ Used: 13 Mb
+ Free: 2034 Mb
+
+### Dropbox Uploader 示例 ###
+
+要显示根目录中的所有内容,运行:
+
+ $ ./dropbox_uploader.sh list
+
+要列出某个特定文件夹中的所有内容,运行:
+
+ $ ./dropbox_uploader.sh list Documents/manuals
+
+要上传一个本地文件到一个远程的 Dropbox 文件夹,使用:
+
+ $ ./dropbox_uploader.sh upload snort.pdf Documents/manuals
+
+要从 Dropbox 下载一个远程的文件到本地,使用:
+
+ $ ./dropbox_uploader.sh download Documents/manuals/mysql.pdf ./mysql.pdf
+
+要从 Dropbox 下载一个完整的远程文件夹到一个本地的文件夹,运行:
+
+ $ ./dropbox_uploader.sh download Documents/manuals ./manuals
+
+要在 Dropbox 上创建一个新的远程文件夹,使用:
+
+ $ ./dropbox_uploader.sh mkdir Documents/whitepapers
+
+要完全删除 Dropbox 中某个远程的文件夹(包括它所含的所有内容),运行:
+
+ $ ./dropbox_uploader.sh delete Documents/manuals
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/access-dropbox-command-line-linux.html
+
+作者:[Dan Nanni][a]
+译者:[FSSlc](https://github.com/FSSlc)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://www.andreafabrizi.it/?dropbox_uploader
+[2]:https://www.dropbox.com/developers/apps
diff --git a/translated/tech/20151123 How to install Android Studio on Ubuntu 15.04 or CentOS 7.md b/translated/tech/20151123 How to install Android Studio on Ubuntu 15.04 or CentOS 7.md
new file mode 100644
index 0000000000..11d2e9b5b4
--- /dev/null
+++ b/translated/tech/20151123 How to install Android Studio on Ubuntu 15.04 or CentOS 7.md
@@ -0,0 +1,139 @@
+如何在 Ubuntu 15.04 / CentOS 7 上安装 Android Studio
+================================================================================
+随着最近几年智能手机的进步,安卓成为了最大的手机平台之一,也有很多免费的用于开发安卓应用的工具。Android Studio 是基于 [IntelliJ IDEA][1] 用于开发安卓应用的集成开发环境。它是 Google 2014 年发布的免费开源软件,继 Eclipse 之后成为主要的 IDE。
+
+在这篇文章,我们一起来学习如何在 Ubuntu 15.04 和 CentOS 7 上安装 Android Studio。
+
+### 在 Ubuntu 15.04 上安装 ###
+
+我们可以用两种方式安装 Android Studio。第一种是配置必须的库然后再安装它;另一种是从 Android 官方网站下载然后再本地编译安装。在下面的例子中,我们会使用命令行设置库并安装它。在继续下一步之前,我们需要确保我们已经安装了 JDK 1.6 或者更新版本。
+
+这里,我打算安装 JDK 1.8。
+
+ $ sudo add-apt-repository ppa:webupd8team/java
+
+ $ sudo apt-get update
+
+ $ sudo apt-get install oracle-java8-installer oracle-java8-set-default
+
+验证 java 是否安装成功:
+
+ poornima@poornima-Lenovo:~$ java -version
+
+现在,设置安装 Android Studio 需要的库
+
+ $ sudo apt-add-repository ppa:paolorotolo/android-studio
+
+
+
+ $ sudo apt-get update
+
+ $ sudo apt-get install android-studio
+
+上面的安装命令会在 /opt 目录下面安装 Android Studio。
+
+现在,运行下面的命令启动安装窗口:
+
+ $ /opt/android-studio/bin/studio.sh
+
+这会激活安装窗口。下面的截图展示了安装 Android Studio 的过程。
+
+
+
+
+
+
+
+你点击了 Finish 按钮之后,就会显示同意协议页面。当你接受协议之后,它就开始下载需要的组件。
+
+
+
+这一步之后就完成了 Android Studio 的安装。当你重启 Android Studio 时,你会看到下面的欢迎界面,从这里你可以开始用 Android Studio 工作了。
+
+
+
+### 在 CentOS 7 上安装 ###
+
+现在再让我们来看看如何在 CentOS 7 上安装 Android Studio。这里你同样需要安装 JDK 1.6 或者更新版本。如果你不是 root 用户,记得在命令前面使用 ‘sudo’。你可以下载[最新版本][2]的 JDK。如果你已经安装了一个比较旧的版本,在安装新的版本之前你需要先卸载旧版本。在下面的例子中,我会通过下载需要的 rpm 包安装 JDK 1.8.0_65。
+
+ [root@li1260-39 ~]# rpm -ivh jdk-8u65-linux-x64.rpm
+ Preparing... ################################# [100%]
+ Updating / installing...
+ 1:jdk1.8.0_65-2000:1.8.0_65-fcs ################################# [100%]
+ Unpacking JAR files...
+ tools.jar...
+ plugin.jar...
+ javaws.jar...
+ deploy.jar...
+ rt.jar...
+ jsse.jar...
+ charsets.jar...
+ localedata.jar...
+ jfxrt.jar...
+
+如果没有正确设置 Java 路径,你会看到错误信息。因此,设置正确的路径:
+
+ export JAVA_HOME=/usr/java/jdk1.8.0_25/
+ export PATH=$PATH:$JAVA_HOME
+
+检查是否安装了正确的版本:
+
+ [root@li1260-39 ~]# java -version
+ java version "1.8.0_65"
+ Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
+ Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
+
+如果你安装 Android Studio 的时候看到任何类似 “unable-to-run-mksdcard-sdk-tool:” 的错误信息,你可能要在 CentOS 7 64 位系统中安装以下软件包:
+
+ glibc.i686
+
+ glibc-devel.i686
+
+ libstdc++.i686
+
+ zlib-devel.i686
+
+ ncurses-devel.i686
+
+ libX11-devel.i686
+
+ libXrender.i686
+
+ libXrandr.i686
+
+通过从 [Android 网站][3] 下载 IDE 文件然后解压安装 studio 也是一样的。
+
+ [root@li1260-39 tmp]# unzip android-studio-ide-141.2343393-linux.zip
+
+移动 android-studio 目录到 /opt 目录
+
+ [root@li1260-39 tmp]# mv /tmp/android-studio/ /opt/
+
+需要的话你可以创建一个到 studio 可执行文件的符号链接用于快速启动。
+
+ [root@li1260-39 tmp]# ln -s /opt/android-studio/bin/studio.sh /usr/local/bin/android-studio
+
+现在在终端中启动 studio:
+
+ [root@localhost ~]#studio
+
+之后用于完成安装的截图和前面 Ubuntu 安装过程中的是一样的。安装完成后,你就可以开始开发你自己的 Android 应用了。
+
+### 总结 ###
+
+虽然发布不到一年,但是 Android Studio 已经替代 Eclipse 成为了安装开发最主要的 IDE。它是唯一一个能支持之后 Google 提供的 Android SDKs 和其它 Android 特性的官方 IDE 工具。那么,你还在等什么呢?赶快安装 Android Studio 然后体验开发安装应用的乐趣吧。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/tools/install-android-studio-ubuntu-15-04-centos-7/
+
+作者:[B N Poornima][a]
+译者:[ictlyh](http://mutouxiaogui.cn/blog/)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/bnpoornima/
+[1]:https://www.jetbrains.com/idea/
+[2]:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
+[3]:http://developer.android.com/sdk/index.html
\ No newline at end of file
diff --git a/translated/tech/20151126 How to Install Nginx as Reverse Proxy for Apache on FreeBSD 10.2.md b/translated/tech/20151126 How to Install Nginx as Reverse Proxy for Apache on FreeBSD 10.2.md
new file mode 100644
index 0000000000..83877c8488
--- /dev/null
+++ b/translated/tech/20151126 How to Install Nginx as Reverse Proxy for Apache on FreeBSD 10.2.md
@@ -0,0 +1,327 @@
+
+如何在FreeBSD 10.2上安装Nginx作为Apache的反向代理
+================================================================================
+Nginx是一款免费的,开源的HTTP和反向代理服务器, 以及一个代理POP3/IMAP的邮件服务器. Nginx是一款高性能的web服务器,其特点是丰富的功能,简单的结构以及低内存的占用. 第一个版本由 Igor Sysoev在2002年发布,然而到现在为止很多大的科技公司都在使用,包括 Netflix, Github, Cloudflare, WordPress.com等等
+
+在这篇教程里我们会 "**在freebsd 10.2系统上,安装和配置Nginx网络服务器作为Apache的反向代理**". Apache 会用PHP在8080端口上运行,并且我们需要在80端口配置Nginx的运行,用来接收用户/访问者的请求.如果网页的用户请求来自于浏览器的80端口, 那么Nginx会用Apache网络服务器和PHP来通过这个请求,并运行在8080端口.
+
+#### 前提条件 ####
+
+- FreeBSD 10.2.
+- Root 权限.
+
+### 步骤 1 - 更新系统 ###
+
+使用SSH证书登录到你的FreeBSD服务器以及使用下面命令来更新你的系统 :
+
+ freebsd-update fetch
+ freebsd-update install
+
+### 步骤 2 - 安装 Apache ###
+
+Apache是现在使用范围最广的网络服务器以及开源的HTTP服务器.在FreeBSD里Apache是未被默认安装的, 但是我们可以直接从端口下载,或者解压包在"/usr/ports/www/apache24" 目录下,再或者直接从PKG命令的FreeBSD系统信息库安装。在本教程中,我们将使用PKG命令从FreeBSD的库中安装:
+
+ pkg install apache24
+
+### 步骤 3 - 安装 PHP ###
+
+一旦成功安装Apache, 接着将会安装PHP并由一个用户处理一个PHP的文件请求. 我们将会用到如下的PKG命令来安装PHP :
+
+ pkg install php56 mod_php56 php56-mysql php56-mysqli
+
+### 步骤 4 - 配置 Apache 和 PHP ###
+
+一旦所有都安装好了, 我们将会配置Apache在8080端口上运行, 并让PHP与Apache一同工作. 为了配置Apache,我们可以编辑 "httpd.conf"这个配置文件, 然而PHP我们只需要复制PHP的配置文件 php.ini 在 "/usr/local/etc/"目录下.
+
+进入到 "/usr/local/etc/" 目录 并且复制 php.ini-production 文件到 php.ini :
+
+ cd /usr/local/etc/
+ cp php.ini-production php.ini
+
+下一步, 在Apache目录下通过编辑 "httpd.conf"文件来配置Apache :
+
+ cd /usr/local/etc/apache24
+ nano -c httpd.conf
+
+端口配置在第 **52**行 :
+
+ Listen 8080
+
+服务器名称配置在第 **219** 行:
+
+ ServerName 127.0.0.1:8080
+
+在第 **277**行,如果目录需要,添加的DirectoryIndex文件,Apache将直接作用于它 :
+
+ DirectoryIndex index.php index.html
+
+在第 **287**行下,配置Apache通过添加脚本来支持PHP :
+
+
+ SetHandler application/x-httpd-php
+
+
+ SetHandler application/x-httpd-php-source
+
+
+保存然后退出.
+
+现在用sysrc命令,来添加Apache作为开机启动项目 :
+
+ sysrc apache24_enable=yes
+
+然后用下面的命令测试Apache的配置 :
+
+ apachectl configtest
+
+如果到这里都没有问题的话,那么就启动Apache吧 :
+
+ service apache24 start
+
+如果全部完毕, 在"/usr/local/www/apache24/data" 目录下,创建一个phpinfo文件是验证PHP在Apache下完美运行的好方法 :
+
+ cd /usr/local/www/apache24/data
+ echo "" > info.php
+
+现在就可以访问 freebsd 的服务器 IP : 192.168.1.123:8080/info.php.
+
+
+
+Apache 是使用 PHP 在 8080端口下运行的.
+
+### 步骤 5 - 安装 Nginx ###
+
+Nginx 以低内存的占用作为一款高性能的web服务器以及反向代理服务器.在这个步骤里,我们将会使用Nginx作为Apache的反向代理, 因此让我们用pkg命令来安装它吧 :
+
+ pkg install nginx
+
+### 步骤 6 - 配置 Nginx ###
+
+一旦 Nginx 安装完毕, 在 "**nginx.conf**" 文件里,我们需要做一个新的配置文件来替换掉原来的nginx文件. 更改到 "/usr/local/etc/nginx/"目录下 并且默认备份到 nginx.conf 文件:
+
+ cd /usr/local/etc/nginx/
+ mv nginx.conf nginx.conf.oroginal
+
+现在就可以创建一个新的 nginx 配置文件了 :
+
+ nano -c nginx.conf
+
+然后粘贴下面的配置:
+
+ user www;
+ worker_processes 1;
+ error_log /var/log/nginx/error.log;
+
+ events {
+ worker_connections 1024;
+ }
+
+ http {
+ include mime.types;
+ default_type application/octet-stream;
+
+ log_format main '$remote_addr - $remote_user [$time_local] "$request" '
+ '$status $body_bytes_sent "$http_referer" '
+ '"$http_user_agent" "$http_x_forwarded_for"';
+ access_log /var/log/nginx/access.log;
+
+ sendfile on;
+ keepalive_timeout 65;
+
+ # Nginx cache configuration
+ proxy_cache_path /var/nginx/cache levels=1:2 keys_zone=my-cache:8m max_size=1000m inactive=600m;
+ proxy_temp_path /var/nginx/cache/tmp;
+ proxy_cache_key "$scheme$host$request_uri";
+
+ gzip on;
+
+ server {
+ #listen 80;
+ server_name _;
+
+ location /nginx_status {
+
+ stub_status on;
+ access_log off;
+ }
+
+ # redirect server error pages to the static page /50x.html
+ #
+ error_page 500 502 503 504 /50x.html;
+ location = /50x.html {
+ root /usr/local/www/nginx-dist;
+ }
+
+ # proxy the PHP scripts to Apache listening on 127.0.0.1:8080
+ #
+ location ~ \.php$ {
+ proxy_pass http://127.0.0.1:8080;
+ include /usr/local/etc/nginx/proxy.conf;
+ }
+ }
+
+ include /usr/local/etc/nginx/vhost/*;
+
+ }
+
+保存退出.
+
+下一步, 在nginx目录下面,创建一个 **proxy.conf** 文件,使其作为反向代理 :
+
+ cd /usr/local/etc/nginx/
+ nano -c proxy.conf
+
+粘贴如下配置 :
+
+ proxy_buffering on;
+ proxy_redirect off;
+ proxy_set_header Host $host;
+ proxy_set_header X-Real-IP $remote_addr;
+ proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
+ client_max_body_size 10m;
+ client_body_buffer_size 128k;
+ proxy_connect_timeout 90;
+ proxy_send_timeout 90;
+ proxy_read_timeout 90;
+ proxy_buffers 100 8k;
+ add_header X-Cache $upstream_cache_status;
+
+保存退出.
+
+最后一步, 为 nginx 的高速缓存创建一个 "/var/nginx/cache"的新目录 :
+
+ mkdir -p /var/nginx/cache
+
+### 步骤 7 - 配置 Nginx 的虚拟主机 ###
+
+在这个步骤里面,我们需要创建一个新的虚拟主机域 "saitama.me", 以跟文件 "/usr/local/www/saitama.me" 和日志文件一同放在 "/var/log/nginx" 目录下.
+
+我们必须做的第一件事情就是创建新的目录来存放虚拟主机文件, 在这里我们将用到一个"**vhost**"的新文件. 并创建它 :
+
+ cd /usr/local/etc/nginx/
+ mkdir vhost
+
+创建好vhost 目录, 那么我们就进入这个目录并创建一个新的虚拟主机文件. 这里我取名为 "**saitama.conf**" :
+
+ cd vhost/
+ nano -c saitama.conf
+
+粘贴如下虚拟主机的配置 :
+
+ server {
+ # Replace with your freebsd IP
+ listen 192.168.1.123:80;
+
+ # Document Root
+ root /usr/local/www/saitama.me;
+ index index.php index.html index.htm;
+
+ # Domain
+ server_name www.saitama.me saitama.me;
+
+ # Error and Access log file
+ error_log /var/log/nginx/saitama-error.log;
+ access_log /var/log/nginx/saitama-access.log main;
+
+ # Reverse Proxy Configuration
+ location ~ \.php$ {
+ proxy_pass http://127.0.0.1:8080;
+ include /usr/local/etc/nginx/proxy.conf;
+
+ # Cache configuration
+ proxy_cache my-cache;
+ proxy_cache_valid 10s;
+ proxy_no_cache $cookie_PHPSESSID;
+ proxy_cache_bypass $cookie_PHPSESSID;
+ proxy_cache_key "$scheme$host$request_uri";
+
+ }
+
+ # Disable Cache for the file type html, json
+ location ~* .(?:manifest|appcache|html?|xml|json)$ {
+ expires -1;
+ }
+
+ # Enable Cache the file 30 days
+ location ~* .(jpg|png|gif|jpeg|css|mp3|wav|swf|mov|doc|pdf|xls|ppt|docx|pptx|xlsx)$ {
+ proxy_cache_valid 200 120m;
+ expires 30d;
+ proxy_cache my-cache;
+ access_log off;
+ }
+
+ }
+
+保存退出.
+
+下一步, 为nginx和虚拟主机创建一个新的日志目录 "/var/log/" :
+
+ mkdir -p /var/log/nginx/
+
+如果一切顺利, 在文件的根目录下创建文件 saitama.me :
+
+ cd /usr/local/www/
+ mkdir saitama.me
+
+### 步骤 8 - 测试 ###
+
+在这个步骤里面,我们只是测试我们的nginx和虚拟主机的配置.
+
+用如下命令测试nginx的配置 :
+
+ nginx -t
+
+如果一切都没有问题, 用 sysrc 命令添加nginx为启动项,并且启动nginx和重启apache:
+
+ sysrc nginx_enable=yes
+ service nginx start
+ service apache24 restart
+
+一切完毕后, 在 saitama.me 目录下,添加一个新的phpinfo文件来验证php的正常运行 :
+
+ cd /usr/local/www/saitama.me
+ echo "" > info.php
+
+然后便访问这个文档 : **www.saitama.me/info.php**.
+
+
+
+Nginx 作为Apache的反向代理正在运行了,PHP也同样在进行工作了.
+
+这是另一种结果 :
+
+Test .html 文件无缓存.
+
+ curl -I www.saitama.me
+
+
+
+Test .css 文件只有三十天的缓存.
+
+ curl -I www.saitama.me/test.css
+
+
+
+Test .php 文件正常缓存 :
+
+ curl -I www.saitama.me/info.php
+
+
+
+全部完成.
+
+### 总结 ###
+
+Nginx 是最广泛的 HTTP 和反向代理的服务器. 拥有丰富的高性能和低内存/RAM的使用功能. Nginx使用了太多的缓存, 我们可以在网络上缓存静态文件使得网页加速, 并且在用户需要的时候再缓存php文件. 这样Nginx 的轻松配置和使用,可以让它用作HTTP服务器 或者 apache的反向代理.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/install-nginx-reverse-proxy-apache-freebsd-10-2/
+
+作者:[Arul][a]
+译者:[KnightJoker](https://github.com/KnightJoker)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arulm/
\ No newline at end of file
diff --git a/translated/tech/20151201 Backup (System Restore Point) your Ubuntu or Linux Mint with SystemBack.md b/translated/tech/20151201 Backup (System Restore Point) your Ubuntu or Linux Mint with SystemBack.md
new file mode 100644
index 0000000000..7e0ccc87c7
--- /dev/null
+++ b/translated/tech/20151201 Backup (System Restore Point) your Ubuntu or Linux Mint with SystemBack.md
@@ -0,0 +1,39 @@
+# 使用SystemBack备份你的Ubuntu/Linux Mint(系统还原)
+
+系统还原对于任何一款允许用户还原电脑到之前状态(包括文件系统,安装的应用,以及系统设置)的操作系统来说,都是必备功能,可以处理系统故障以及其他的问题。有的时候安装一个程序或者驱动可能让你的系统黑屏。系统还原则让你电脑里面的系统文件(译者注:是系统文件,并非普通文件,详情请看**注意**部分)和程序恢复到之前工作正常时候的状态,进而让你远离那让人头痛的排障过程了。而且它也不会影响你的文件,照片或者其他数据。简单的系统备份还原工具[Systemback](https://launchpad.net/systemback)让你很容易地创建系统备份以及用户配置文件。如果遇到问题,你可以傻瓜式还原。它还有一些额外的特征包括系统复制,系统安装以及Live系统创建。
+
+截图
+
+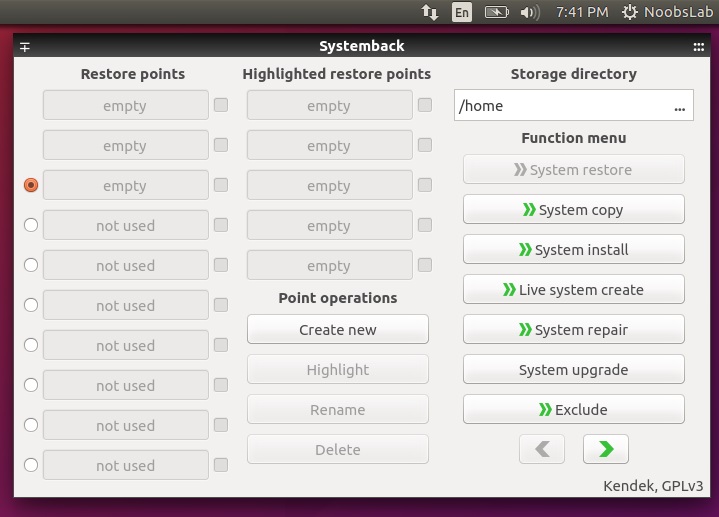
+
+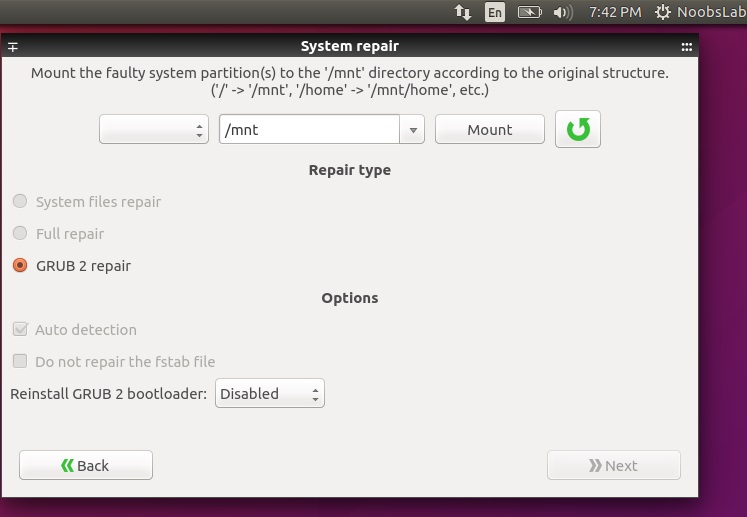
+
+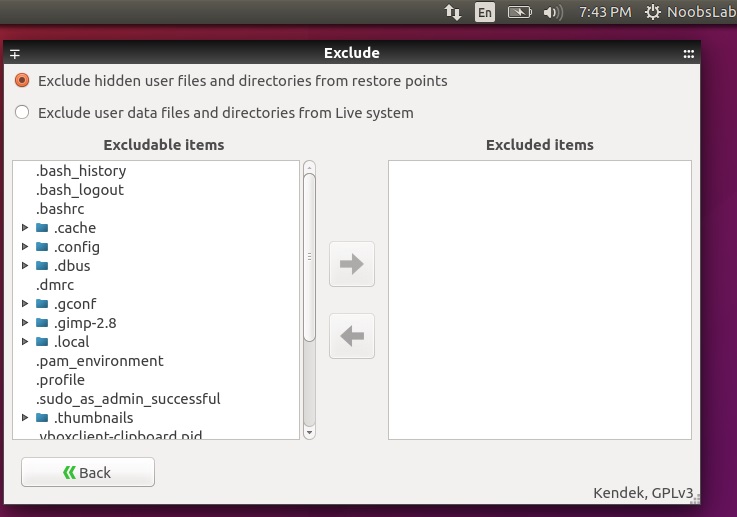
+
+
+
+**注意**:使用系统还原不会还原你的文件,音乐,电子邮件或者其他任何类型的私人文件。对不同用户来讲,这既是优点又是缺点。坏消息是它不会还原你意外删除的文件,不过你可以通过一个文件恢复程序来解决这个问题。如果你的计算机上没有系统还原点,那么系统还原工具就不会奏效了。(最后一句没有太理解)
+
+> > >适用于Ubuntu 15.10 Wily/16.04/15.04 Vivid/14.04 Trusty/Linux Mint 14.x/其他Ubuntu衍生版,打开终端,将下面这些命令复制过去:
+
+终端命令:
+
+```
+sudo add-apt-repository ppa:nemh/systemback
+sudo apt-get update
+sudo apt-get install systemback
+
+```
+
+大功告成。
+
+--------------------------------------------------------------------------------
+
+via: http://www.noobslab.com/2015/11/backup-system-restore-point-your.html
+
+译者:[DongShuaike](https://github.com/DongShuaike)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:https://launchpad.net/systemback
diff --git a/translated/tech/20151201 How to Install The Latest Arduino IDE 1.6.6 in Ubuntu.md b/translated/tech/20151201 How to Install The Latest Arduino IDE 1.6.6 in Ubuntu.md
new file mode 100644
index 0000000000..668b9c3a80
--- /dev/null
+++ b/translated/tech/20151201 How to Install The Latest Arduino IDE 1.6.6 in Ubuntu.md
@@ -0,0 +1,78 @@
+如何再Ubuntu中安装最新的Arduino IDE 1.6.6
+================================================================================
+
+
+> 本篇教程会教你如何在现在的Ubuntu发布版中安装最新的 Arduino IDE,目前的版本为1.6.6。
+
+开源的Arduino IDE发布了1.6.6,并带来了很多的改变。新的发布已经切换到Java 8,它与IDE绑定并且再编译时需要它。具体见[RELEASE NOTE][1]。
+
+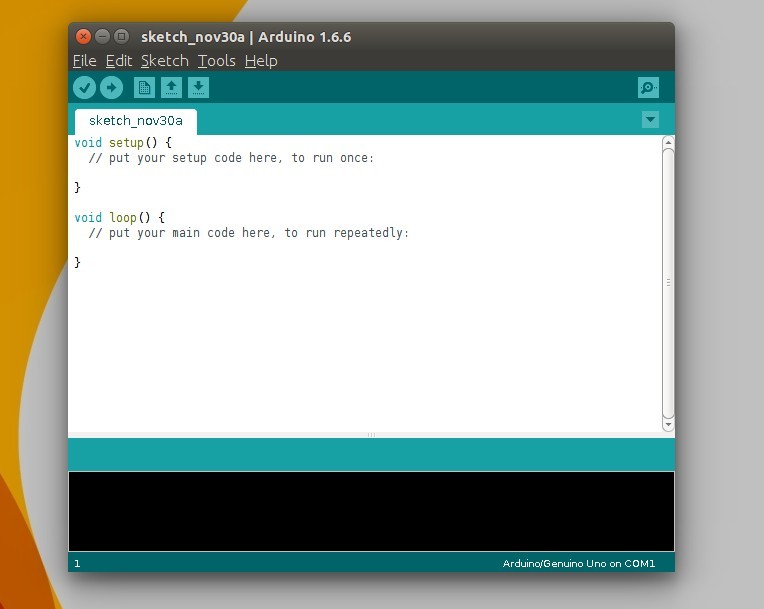
+
+对于那些不想使用软件中心的1.0.5旧版本的人而言,你可以使用下面的步骤再所有的Ubuntu发行版中安装Ardunino。
+
+注:下面这个说明下面的代码颜色,这个发布的时候要对照一下原文,写点说明,因为颜色在md里标识不出来
+> **用红字替换将来的版本**
+
+**1.** Download the latest packages, **Linux 32-bit or Linux 64-bit**, from the official link below:
+**1.** 从下面的官方链接下载最新的包 **Linux 32-bit 或者 Linux 64-bit**。
+
+- [www.arduino.cc/en/Main/Software][2]
+
+不知道你系统的类型?进入系统设置->详细->概览。
+
+**2.** 从Unity Dash、App Launcher或者Ctrl+Alt+T打开终端。打开后,一个个运行下面的命令:
+
+进入下载文件夹:
+
+ cd ~/Downloads
+
+
+
+使用tar命令解压
+
+注:arduino-1.6.6-*.tar.xz 为红色部分
+ tar -xvf arduino-1.6.6-*.tar.xz
+
+
+
+将解压后的文件移动到**/opt/**下:
+
+注:arduino-1.6.6 为红色部分
+ sudo mv arduino-1.6.6 /opt
+
+
+
+**3.** 现在IDE已经与最新的Java绑定使用了。但是最好位程序设置一个桌面图标/启动方式:
+
+进入安装目录
+
+注:arduino-1.6.6 为红色部分
+ cd /opt/arduino-1.6.6/
+
+在这个目录给install.sh可执行权限
+
+ chmod +x install.sh
+
+最后运行脚本同事安装桌面快捷方式和启动图标:
+
+ ./install.sh
+
+下图中我用“&&”同事运行这三个命令:
+
+
+
+最后从Unity Dash、程序启动器或者桌面快捷方式运行Arduino IDE。
+
+--------------------------------------------------------------------------------
+
+via: http://ubuntuhandbook.org/index.php/2015/11/install-arduino-ide-1-6-6-ubuntu/
+
+作者:[Ji m][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ubuntuhandbook.org/index.php/about/
+[1]:https://www.arduino.cc/en/Main/ReleaseNotes
+[2]:https://www.arduino.cc/en/Main/Software
diff --git a/translated/tech/20151201 How to use Mutt email client with encrypted passwords.md b/translated/tech/20151201 How to use Mutt email client with encrypted passwords.md
new file mode 100644
index 0000000000..1e8a032a04
--- /dev/null
+++ b/translated/tech/20151201 How to use Mutt email client with encrypted passwords.md
@@ -0,0 +1,138 @@
+如何使用加密过密码的Mutt邮件客户端
+================================================================================
+Mutt是一个开源的Linux/UNIX终端环境下的邮件客户端。连同[Alpine][1],Mutt有充分的理由在Linux命令行热衷者中有最忠诚的追随者。想一下你对邮件客户端的期待的事情,Mutt拥有:多协议支持(e.g., POP3, IMAP and SMTP),S/MIME和PGP/GPG集成,线程会话,颜色编码,可定制宏/快捷键,等等。另外,基于命令行的Mutt相比笨重的web浏览器(如:Gmail,Ymail)或可视化邮件客户端(如:Thunderbird,MS Outlook)是一个轻量访问电子邮件的选择。
+
+当你想使用Mutt通过公司的SMTP/IMAP服务器访问或发送邮件,或取代网页邮件服务,可能所关心的一个问题是如何保护您的邮件凭据(如:SMTP/IMAP密码)存储在一个纯文本Mutt配置文件(~/.muttrc)。
+
+对于一些人安全的担忧,确实有一个容易的方法来**加密Mutt配置文件***,防止这种风险。在这个教程中,我描述了如何加密Mutt敏感配置,比如SMTP/IMAP密码使用GnuPG(GPG),一个开源的OpenPGP实现。
+
+### 第一步 (可选):创建GPG密钥 ###
+
+因为我们将要使用GPG加密Mutt配置文件,如果你没有,第一步就是创建一个GPG密钥(公有/私有 密钥对)。如果有,忽略这步。
+
+创建一个新GPG密钥,输入下面的。
+
+ $ gpg --gen-key
+
+选择密钥类型(RSA),密钥长度(2048 bits),和过期时间(0,不过期)。当出现用户ID提示时,输入你的名字(Dan Nanni) 和邮箱地址(myemail@email.com)关联到私有/公有密钥对。最后,输入一个密码来保护你的私钥。
+
+
+
+生成一个GPG密钥需要大量的随机字节熵,所以在生成密钥期间确保在你的系统上执行一些随机行为(如:打键盘,移动鼠标或者读写磁盘)。根据密钥长度决定生成GPG密钥要花几分钟或更多时间。
+
+
+
+### 第二部:加密Mutt敏感配置 ###
+
+下一步,在~/.mutt目录创建一个新的文本文件,然后把一些你想隐藏的Mutt敏感配置放进去。这个例子里,我指定了SMTP/IMAP密码。
+
+ $ mkdir ~/.mutt
+ $ vi ~/.mutt/password
+
+----------
+
+ set smtp_pass="XXXXXXX"
+ set imap_pass="XXXXXXX"
+
+现在gpg用你的公钥加密这个文件如下。
+
+ $ gpg -r myemail@email.com -e ~/.mutt/password
+
+这将创建~/.mutt/password.gpg,这个是一个GPG加密原始版本文件。
+
+继续删除~/.mutt/password,只保留GPG加密版本。
+
+### 第三部:创建完整Mutt配置文件 ###
+
+由于你已经在一个单独的文件加密了Mutt敏感配置,你可以在~/.muttrc指定其余的Mutt配置。然后增加下面这行在~/.muttrc末尾。
+
+ source "gpg -d ~/.mutt/password.gpg |"
+
+当你使用Mutt,这行将解密~/.mutt/password.gpg,然后将解密内容应用到你的Mutt配置。
+
+下面展示一个完整Mutt配置例子,这允许你用Mutt访问Gmail,没有暴露你的SMTP/IMAP密码。取代你用Gmail ID登陆你的账户。
+
+ set from = "yourgmailaccount@gmail.com"
+ set realname = "Your Name"
+ set smtp_url = "smtp://yourgmailaccount@smtp.gmail.com:587/"
+ set imap_user = "yourgmailaccount@gmail.com"
+ set folder = "imaps://imap.gmail.com:993"
+ set spoolfile = "+INBOX"
+ set postponed = "+[Google Mail]/Drafts"
+ set trash = "+[Google Mail]/Trash"
+ set header_cache =~/.mutt/cache/headers
+ set message_cachedir =~/.mutt/cache/bodies
+ set certificate_file =~/.mutt/certificates
+ set move = no
+ set imap_keepalive = 900
+
+ # encrypted IMAP/SMTP passwords
+ source "gpg -d ~/.mutt/password.gpg |"
+
+### 第四部(可选):配置GPG代理 ###
+
+这时候,你将可以使用加密了IMAP/SMTP密码的Mutt。无论如何,每次你运行Mutt,你都要先被提示输入一个GPG密码来使用你的私钥解密IMAP/SMTP密码。
+
+
+
+如果你想避免这样的GPG密码提示,你可以部署gpg代理。运行一个后台程序,gpg代理安全的缓存你的GPG密码,无需手工干预gpg自动从gpg代理获得你的GPG密码。如果你正在使用Linux桌面,你可以使用桌面特定方式来配置一些东西等价于gpg代理,例如,GNOME桌面的gnome-keyring-daemon。
+
+你可以在基于Debian系统安装gpg代理:
+
+$ sudo apt-get install gpg-agent
+
+gpg代理是基于Red Hat系统预装的。
+
+现在增加下面这些道你的.bashrc文件。
+
+ envfile="$HOME/.gnupg/gpg-agent.env"
+ if [[ -e "$envfile" ]] && kill -0 $(grep GPG_AGENT_INFO "$envfile" | cut -d: -f 2) 2>/dev/null; then
+ eval "$(cat "$envfile")"
+ else
+ eval "$(gpg-agent --daemon --allow-preset-passphrase --write-env-file "$envfile")"
+ fi
+ export GPG_AGENT_INFO
+
+重载.bashrc,或单纯的登出然后登陆回来。
+
+ $ source ~/.bashrc
+
+现在确认GPG_AGENT_INFO环境变量已经设置妥当。
+
+ $ echo $GPG_AGENT_INFO
+
+----------
+
+ /tmp/gpg-0SKJw8/S.gpg-agent:942:1
+
+并且,当你输入gpg-agent命令时,你应该看到下面的信息。
+
+ $ gpg-agent
+
+----------
+
+ gpg-agent: gpg-agent running and available
+
+一旦gpg-agent启动运行,它将会在第一次提示你输入密码时缓存你的GPG密码。随后你运行Mutt多次,你将不会被提示要GPG密码(gpg-agent一直开着,缓存就不会过期)。
+
+
+
+### 结论 ###
+
+在这个指导里,我提出一个方法加密Mutt敏感配置如SMTP/IMAP密码使用GnuPG。注意,如果你想在Mutt上使用GnuPG或者登陆你的邮件信息,你可以参考[官方指南][2]在使用GPG与Mutt结合。
+
+如果你知道任何使用Mutt的安全技巧,随时分享他。
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/mutt-email-client-encrypted-passwords.html
+
+作者:[Dan Nanni][a]
+译者:[wyangsun](https://github.com/wyangsun)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://xmodulo.com/gmail-command-line-linux-alpine.html
+[2]:http://dev.mutt.org/trac/wiki/MuttGuide/UseGPG
diff --git a/translated/tech/20151204 Linux or Unix--jobs Command Examples.md b/translated/tech/20151204 Linux or Unix--jobs Command Examples.md
new file mode 100644
index 0000000000..fbb52a2544
--- /dev/null
+++ b/translated/tech/20151204 Linux or Unix--jobs Command Examples.md
@@ -0,0 +1,197 @@
+
+Linux / Unix: jobs 命令示例
+================================================================================
+
+我是个新的 Linux 或 Unix 用户。如何在 Linux 或类 Unix 系统中使用 BASH/KSH/TCSH 或者基于 POSIX 的 shell 来查看当前正在进行的作业?在 Unix/Linux 上怎样显示当前作业的状态?
+
+作业控制的是什么,停止/暂停进程(命令)的执行并按你的要求继续/恢复它们的执行。这是根据你的操作系统和 shell 如,bash/ksh 或 POSIX shell 来执行的。
+
+shell 会将当前所执行的作业保存在一个表中,可以用 jobs 命令来显示。
+
+### 目的 ###
+
+> 在当前 shell 会话中显示作业的状态。
+
+### 语法 ###
+
+其基本语法如下:
+
+ jobs
+
+或
+
+ jobs jobID
+
+或者
+
+ jobs [options] jobID
+
+### 启动一些作业来进行示范 ###
+
+在开始使用 jobs 命令前,你需要在系统上先启动多个作业。执行以下命令来启动作业:
+
+ ## 启动 xeyes, calculator, 和 gedit 文本编辑器 ###
+ xeyes &
+ gnome-calculator &
+ gedit fetch-stock-prices.py &
+
+最后,在前台运行 ping 命令:
+
+ ping www.cyberciti.biz
+
+按 **Ctrl-Z** 键来暂停 ping 命令的作业。
+
+### jobs 命令示例 ###
+
+要在当前 shell 显示作业的状态,请输入:
+
+ $ jobs
+
+输出示例:
+
+ [1] 7895 Running gpass &
+ [2] 7906 Running gnome-calculator &
+ [3]- 7910 Running gedit fetch-stock-prices.py &
+ [4]+ 7946 Stopped ping cyberciti.biz
+
+要显示进程 ID 或作业名称请使用 “P” 选项,输入:
+
+ $ jobs -p %p
+
+或者
+
+ $ jobs %p
+
+输出示例:
+
+ [4]- Stopped ping cyberciti.biz
+
+字符 % 后加一个作业。在这个例子中,你需要使用作业的名称来暂停它,如 %ping。
+
+### 如何显示进程 ID 不包含其他正常的信息? ###
+
+通过 jobs 命令的 -l(小写的 L)选项列出每个作业的详细信息,运行:
+
+ $ jobs -l
+
+示例输出:
+
+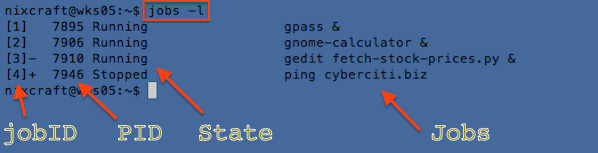
+Fig.01: 在 shell 中显示 jobs 的状态
+
+### 如何只列出最近一次状态改变的进程? ###
+
+首先,启动一个新的工作如下所示:
+
+ $ sleep 100 &
+
+现在,只显示作业最近一次的状态(停止或退出),输入:
+
+ $ jobs -n
+
+示例输出:
+
+ [5]- Running sleep 100 &
+
+### 仅显示进程 ID(PID) ###
+
+通过 jobs 命令的 -p 选项仅显示 PID:
+
+ $ jobs -p
+
+示例输出:
+
+ 7895
+ 7906
+ 7910
+ 7946
+ 7949
+
+### 怎样只显示正在运行的作业呢? ###
+
+通过 jobs 命令的 -r 选项只显示正在运行的作业,输入:
+
+ $ jobs -r
+
+示例输出:
+
+ [1] Running gpass &
+ [2] Running gnome-calculator &
+ [3]- Running gedit fetch-stock-prices.py &
+
+### 怎样只显示已经停止工作的作业? ###
+
+通过 jobs 命令的 -s 选项只显示停止工作的作业,输入:
+
+ $ jobs -s
+
+示例输出:
+
+ [4]+ Stopped ping cyberciti.biz
+
+要继续执行 ping cyberciti.biz 作业,输入以下 bg 命令:
+
+ $ bg %4
+
+### jobs 命令选项 ###
+
+摘自 [bash(1)][1] 命令 man 手册页:
+
+注:表格
+
+
+
+
Option
+
Description
+
+
+
-l
+
Show process id's in addition to the normal information.
+
+
+
-p
+
Show process id's only.
+
+
+
-n
+
Show only processes that have changed status since the last notification are printed.
+
+
+
-r
+
Restrict output to running jobs only.
+
+
+
-s
+
Restrict output to stopped jobs only.
+
+
+
-x
+
COMMAND is run after all job specifications that appear in ARGS have been replaced with the process ID of that job's process group leader./td>
+
+
+
+
+### 关于 /usr/bin/jobs 和 shell 内建的说明 ###
+
+输入以下 type 命令找出是否 jobs 命令是 shell 的内建命令或是外部命令:
+
+ $ type -a jobs
+
+输出示例:
+
+ jobs is a shell builtin
+ jobs is /usr/bin/jobs
+
+在几乎所有情况下,jobs 命令都是作为 BASH/KSH/POSIX shell 内建命令被实现的。/usr/bin/jobs 命令不能被用在当前 shell 中。/usr/bin/jobs 命令工作在不同的环境中不共享父 bash/ksh 的 shells 来执行作业。
+
+--------------------------------------------------------------------------------
+
+via:
+
+作者:Vivek Gite
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.manpager.com/linux/man1/bash.1.html
diff --git a/translated/tech/20151208 How to renew the ISPConfig 3 SSL Certificate.md b/translated/tech/20151208 How to renew the ISPConfig 3 SSL Certificate.md
new file mode 100644
index 0000000000..a2ce4f1d1c
--- /dev/null
+++ b/translated/tech/20151208 How to renew the ISPConfig 3 SSL Certificate.md
@@ -0,0 +1,58 @@
+如何更新ISPConfig 3 SSL证书
+================================================================================
+本教程描述了如何再ISPConfig 3控制面板中更新SSL证书。有两个可选的方法:
+
+- 用OpenSSL创建一个新的OpenSSL证书和CSR。
+- 用ISPConfig updater更新SSL证书
+
+我将会用手工的方法更新ssl证书。
+
+### 1)用OpenSSL创建一个新的ISPConfig 3 SSL 证书 ###
+
+用root用户登录你的服务器。在创建一个新的SSL证书之前,备份现有的。SSL证书是安全敏感的,因此我将它存储在/root/目录下。
+
+ tar pcfz /root/ispconfig_ssl_backup.tar.gz /usr/local/ispconfig/interface/ssl
+ chmod 600 /root/ispconfig_ssl_backup.tar.gz
+
+> 现在创建一个新的SSL证书密钥,证书请求(csr)和自签发证书。
+
+ cd /usr/local/ispconfig/interface/ssl
+ openssl genrsa -des3 -out ispserver.key 4096
+ openssl req -new -key ispserver.key -out ispserver.csr
+ openssl x509 -req -days 3650 -in ispserver.csr \
+ -signkey ispserver.key -out ispserver.crt
+ openssl rsa -in ispserver.key -out ispserver.key.insecure
+ mv ispserver.key ispserver.key.secure
+ mv ispserver.key.insecure ispserver.key
+
+重启apache来加载新的SSL证书
+
+ service apache2 restart
+
+### 2)用ISPConfig安装器来更新SSL证书 ###
+
+另一个获取新的SSL证书的替代方案是使用ISPConfig更新脚本。下载ISPConfig到/tmp目录下,解压包并运行脚本。
+
+ cd /tmp
+ wget http://www.ispconfig.org/downloads/ISPConfig-3-stable.tar.gz
+ tar xvfz ISPConfig-3-stable.tar.gz
+ cd ispconfig3_install/install
+ php -q update.php
+
+更新脚本会在更新时询问下面的额问题:
+
+ Create new ISPConfig SSL certificate (yes,no) [no]:
+
+这里回答“yes”,SSL证书创建对话框就会启动。
+
+--------------------------------------------------------------------------------
+
+via: http://www.faqforge.com/linux/how-to-renew-the-ispconfig-3-ssl-certificate/
+
+作者:[Till][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.faqforge.com/author/till/
diff --git a/translated/tech/20151208 Install Wetty on Centos or RHEL 6.X.md b/translated/tech/20151208 Install Wetty on Centos or RHEL 6.X.md
new file mode 100644
index 0000000000..330a6cc8e6
--- /dev/null
+++ b/translated/tech/20151208 Install Wetty on Centos or RHEL 6.X.md
@@ -0,0 +1,62 @@
+
+在 Centos/RHEL 6.X 上安装 Wetty
+================================================================================
+
+
+Wetty 是什么?
+
+作为系统管理员,如果你是在 Linux 桌面下,你可能会使用一个软件来连接远程服务器,像 GNOME 终端(或类似的),如果你是在 Windows 下,你可能会使用像 Putty 这样的 SSH 客户端来连接,并同时可以在浏览器中查收邮件等做其他事情。
+
+### 第1步: 安装 epel 源 ###
+
+ # wget http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
+ # rpm -ivh epel-release-6-8.noarch.rpm
+
+### 第2步:安装依赖 ###
+
+ # yum install epel-release git nodejs npm -y
+
+### 第3步:在安装完依赖后,克隆 GitHub 仓库 ###
+
+ # git clone https://github.com/krishnasrinivas/wetty
+
+### 第4步:运行 Wetty ###
+
+ # cd wetty
+ # npm install
+
+### 第5步:从 Web 浏览器启动 Wetty 并访问 Linux 终端 ###
+
+ # node app.js -p 8080
+
+### 第6步:为 Wetty 安装 HTTPS 证书 ###
+
+ # openssl req -x509 -newkey rsa:2048 -keyout key.pem -out cert.pem -days 365 -nodes (complete this)
+
+### Step 7: 通过 HTTPS 来使用 Wetty ###
+
+ # nohup node app.js --sslkey key.pem --sslcert cert.pem -p 8080 &
+
+### Step 8: 为 wetty 添加一个用户 ###
+
+ # useradd
+ # Passwd
+
+### 第9步:访问 wetty ###
+
+ http://Your_IP-Address:8080
+ give the credential have created before for wetty and access
+
+到此结束!
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/install-wetty-centosrhel-6-x/
+
+作者:[Debojyoti Das][a]
+译者:[strugglingyouth](https://github.com/strugglingyouth)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.unixmen.com/author/debjyoti/
diff --git a/translated/tech/20151210 Getting started with Docker by Dockerizing this Blog.md.md b/translated/tech/20151210 Getting started with Docker by Dockerizing this Blog.md.md
new file mode 100644
index 0000000000..a74af87b6f
--- /dev/null
+++ b/translated/tech/20151210 Getting started with Docker by Dockerizing this Blog.md.md
@@ -0,0 +1,464 @@
+通过Dockerize这篇博客来开启我们的Docker之旅
+===
+>这篇文章将包含Docker的基本概念,以及如何通过创建一个定制的Dockerfile来Dockerize一个应用
+>作者:Benjamin Cane,2015-12-01 10:00:00
+
+Docker是2年前从某个idea中孕育而生的有趣技术,世界各地的公司组织都积极使用它来部署应用。在今天的文章中,我将教你如何通过"Dockerize"一个现有的应用,来开始我们的Docker运用。问题中的应用指的就是这篇博客!
+
+## 什么是Docker?
+
+当我们开始学习Docker基本概念时,让我们先去搞清楚什么是Docker以及它为什么这么流行。Docker是一个操作系统容器管理工具,它通过将应用打包在操作系统容器中,来方便我们管理和部署应用。
+
+### 容器 vs. 虚拟机
+
+容器虽和虚拟机并不完全相似,但它也是一种提供**操作系统虚拟化**的方式。但是,它和标准的虚拟机还是有不同之处的。
+
+标准虚拟机一般会包括一个完整的操作系统,操作系统包,最后还有一至两个应用。这都得益于为虚拟机提供硬件虚拟化的管理程序。这样一来,一个单一的服务器就可以将许多独立的操作系统作为虚拟客户机运行了。
+
+容器和虚拟机很相似,它们都支持在单一的服务器上运行多个操作环境,只是,在容器中,这些环境并不是一个个完整的操作系统。容器一般只包含必要的操作系统包和一些应用。它们通常不会包含一个完整的操作系统或者硬件虚拟化程序。这也意味着容器比传统的虚拟机开销更少。
+
+容器和虚拟机常被误认为是两种抵触的技术。虚拟机采用同一个物理服务器,来提供全功能的操作环境,该环境会和其余虚拟机一起共享这些物理资源。容器一般用来隔离运行中的应用进程,运行进程将在单独的主机中运行,以保证隔离后的进程之间不能相互影响。事实上,容器和**BSD Jails**以及`chroot`进程的相似度,超过了和完整虚拟机的相似度。
+
+### Docker在容器的上层提供了什么
+
+Docker不是一个容器运行环境,事实上,只是一个容器技术,并不包含那些帮助Docker支持[Solaris Zones](https://blog.docker.com/2015/08/docker-oracle-solaris-zones/)和[BSD Jails](https://wiki.freebsd.org/Docker)的技术。Docker提供管理,打包和部署容器的方式。虽然一定程度上,虚拟机多多少少拥有这些类似的功能,但虚拟机并没有完整拥有绝大多数的容器功能,即使拥有,这些功能用起来都并没有Docker来的方便。
+
+现在,我们应该知道Docker是什么了,然后,我们将从安装Docker,并部署一个公共的预构建好的容器开始,学习Docker是如何工作的。
+
+## 从安装开始
+
+默认情况下,Docker并不会自动被安装在您的计算机中,所以,第一步就是安装Docker包;我们的教学机器系统是Ubuntu 14.0.4,所以,我们将使用Apt包管理器,来执行安装操作。
+
+```
+# apt-get install docker.io
+Reading package lists... Done
+Building dependency tree
+Reading state information... Done
+The following extra packages will be installed:
+ aufs-tools cgroup-lite git git-man liberror-perl
+Suggested packages:
+ btrfs-tools debootstrap lxc rinse git-daemon-run git-daemon-sysvinit git-doc
+ git-el git-email git-gui gitk gitweb git-arch git-bzr git-cvs git-mediawiki
+ git-svn
+The following NEW packages will be installed:
+ aufs-tools cgroup-lite docker.io git git-man liberror-perl
+0 upgraded, 6 newly installed, 0 to remove and 0 not upgraded.
+Need to get 7,553 kB of archives.
+After this operation, 46.6 MB of additional disk space will be used.
+Do you want to continue? [Y/n] y
+```
+
+为了检查当前是否有容器运行,我们可以执行`docker`命令,加上`ps`选项
+
+```
+# docker ps
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+```
+
+`docker`命令中的`ps`功能类似于Linux的`ps`命令。它将显示可找到的Docker容器以及各自的状态。由于我们并没有开启任何Docker容器,所以命令没有显示任何正在运行的容器。
+
+## 部署一个预构建好的nginx Docker容器
+
+我比较喜欢的Docker特性之一就是Docker部署预先构建好的容器的方式,就像`yum`和`apt-get`部署包一样。为了更好地解释,我们来部署一个运行着nginx web服务器的预构建容器。我们可以继续使用`docker`命令,这次选择`run`选项。
+
+```
+# docker run -d nginx
+Unable to find image 'nginx' locally
+Pulling repository nginx
+5c82215b03d1: Download complete
+e2a4fb18da48: Download complete
+58016a5acc80: Download complete
+657abfa43d82: Download complete
+dcb2fe003d16: Download complete
+c79a417d7c6f: Download complete
+abb90243122c: Download complete
+d6137c9e2964: Download complete
+85e566ddc7ef: Download complete
+69f100eb42b5: Download complete
+cd720b803060: Download complete
+7cc81e9a118a: Download complete
+```
+
+`docker`命令的`run`选项,用来通知Docker去寻找一个指定的Docker镜像,然后开启运行着该镜像的容器。默认情况下,Docker容器在前台运行,这意味着当你运行`docker run`命令的时候,你的shell会被绑定到容器的控制台以及运行在容器中的进程。为了能在后台运行该Docker容器,我们可以使用`-d` (**detach**)标志。
+
+再次运行`docker ps`命令,可以看到nginx容器正在运行。
+
+```
+# docker ps
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+f6d31ab01fc9 nginx:latest nginx -g 'daemon off 4 seconds ago Up 3 seconds 443/tcp, 80/tcp desperate_lalande
+```
+
+从上面的打印信息中,我们可以看到正在运行的名为`desperate_lalande`的容器,它是由`nginx:latest image`(译者注:nginx最新版本的镜像)构建而来得。
+
+### Docker镜像
+
+镜像是Docker的核心特征之一,类似于虚拟机镜像。和虚拟机镜像一样,Docker镜像是一个被保存并打包的容器。当然,Docker不只是创建镜像,它还可以通过Docker仓库发布这些镜像,Docker仓库和包仓库的概念差不多,它让Docker能够模仿`yum`部署包的方式来部署镜像。为了更好地理解这是怎么工作的,我们来回顾`docker run`执行后的输出。
+
+```
+# docker run -d nginx
+Unable to find image 'nginx' locally
+```
+
+我们可以看到第一条信息是,Docker不能在本地找到名叫nginx的镜像。这是因为当我们执行`docker run`命令时,告诉Docker运行一个基于nginx镜像的容器。既然Docker要启动一个基于特定镜像的容器,那么Docker首先需要知道那个指定镜像。在检查远程仓库之前,Docker首先检查本地是否存在指定名称的本地镜像。
+
+因为系统是崭新的,不存在nginx镜像,Docker将选择从Docker仓库下载之。
+
+```
+Pulling repository nginx
+5c82215b03d1: Download complete
+e2a4fb18da48: Download complete
+58016a5acc80: Download complete
+657abfa43d82: Download complete
+dcb2fe003d16: Download complete
+c79a417d7c6f: Download complete
+abb90243122c: Download complete
+d6137c9e2964: Download complete
+85e566ddc7ef: Download complete
+69f100eb42b5: Download complete
+cd720b803060: Download complete
+7cc81e9a118a: Download complete
+```
+
+这就是第二部分打印信息显示给我们的内容。默认,Docker会使用[Docker Hub](https://hub.docker.com/)仓库,该仓库由Docker公司维护。
+
+和Github一样,在Docker Hub创建公共仓库是免费的,私人仓库就需要缴纳费用了。当然,部署你自己的Docker仓库也是可以实现的,事实上只需要简单地运行`docker run registry`命令就行了。但在这篇文章中,我们的重点将不是讲解如何部署一个定制的注册服务。
+
+### 关闭并移除容器
+
+在我们继续构建定制容器之前,我们先清理Docker环境,我们将关闭先前的容器,并移除它。
+
+我们利用`docker`命令和`run`选项运行一个容器,所以,为了停止该相同的容器,我们简单地在执行`docker`命令时,使用`kill`选项,并指定容器名。
+
+```
+# docker kill desperate_lalande
+desperate_lalande
+```
+
+当我们再次执行`docker ps`,就不再有容器运行了
+
+```
+# docker ps
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+```
+
+但是,此时,我们这是停止了容器;虽然它不再运行,但仍然存在。默认情况下,`docker ps`只会显示正在运行的容器,如果我们附加`-a` (all) 标识,它会显示所有运行和未运行的容器。
+
+```
+# docker ps -a
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+f6d31ab01fc9 5c82215b03d1 nginx -g 'daemon off 4 weeks ago Exited (-1) About a minute ago desperate_lalande
+```
+
+为了能完整地移除容器,我们在用`docker`命令时,附加`rm`选项。
+
+```
+# docker rm desperate_lalande
+desperate_lalande
+```
+
+虽然容器被移除了;但是我们仍拥有可用的**nginx**镜像(译者注:镜像缓存)。如果我们重新运行`docker run -d nginx`,Docker就无需再次拉取nginx镜像,即可启动容器。这是因为我们本地系统中已经保存了一个副本。
+
+为了列出系统中所有的本地镜像,我们运行`docker`命令,附加`images`选项。
+
+```
+# docker images
+REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
+nginx latest 9fab4090484a 5 days ago 132.8 MB
+```
+
+## 构建我们自己的镜像
+
+截至目前,我们已经使用了一些基础的Docker命令来开启,停止和移除一个预构建好的普通镜像。为了"Dockerize"这篇博客,我们需要构建我们自己的镜像,也就是创建一个**Dockerfile**。
+
+在大多数虚拟机环境中,如果你想创建一个机器镜像,首先,你需要建立一个新的虚拟机,安装操作系统,安装应用,最后将其转换为一个模板或者镜像。但在Docker中,所有这些步骤都可以通过Dockerfile实现全自动。Dockerfile是向Docker提供构建指令去构建定制镜像的方式。在这一章节,我们将编写能用来部署这篇博客的定制Dockerfile。
+
+### 理解应用
+
+我们开始构建Dockerfile之前,第一步要搞明白,我们需要哪些东西来部署这篇博客。
+
+博客本质上是由静态站点生成器生成的静态HTML页面,这个静态站点是我编写的,名为**hamerkop**。这个生成器很简单,它所做的就是生成该博客站点。所有的博客源码都被我放在了一个公共的[Github仓库](https://github.com/madflojo/blog)。为了部署这篇博客,我们要先从Github仓库把博客内容拉取下来,然后安装**Python**和一些**Python**模块,最后执行`hamerkop`应用。我们还需要安装**nginx**,来运行生成后的内容。
+
+截止目前,这些还是一个简单的Dockerfile,但它却给我们展示了相当多的[Dockerfile语法]((https://docs.docker.com/v1.8/reference/builder/))。我们需要克隆Github仓库,然后使用你最喜欢的编辑器编写Dockerfile;我选择`vi`
+
+```
+# git clone https://github.com/madflojo/blog.git
+Cloning into 'blog'...
+remote: Counting objects: 622, done.
+remote: Total 622 (delta 0), reused 0 (delta 0), pack-reused 622
+Receiving objects: 100% (622/622), 14.80 MiB | 1.06 MiB/s, done.
+Resolving deltas: 100% (242/242), done.
+Checking connectivity... done.
+# cd blog/
+# vi Dockerfile
+```
+
+### FROM - 继承一个Docker镜像
+
+第一条Dockerfile指令是`FROM`指令。这将指定一个现存的镜像作为我们的基础镜像。这也从根本上给我们提供了继承其他Docker镜像的途径。在本例中,我们还是从刚刚我们使用的**nginx**开始,如果我们想重新开始,我们可以通过指定`ubuntu:latest`来使用**Ubuntu** Docker镜像。
+
+```
+## Dockerfile that generates an instance of http://bencane.com
+
+FROM nginx:latest
+MAINTAINER Benjamin Cane
+```
+
+除了`FROM`指令,我还使用了`MAINTAINER`,它用来显示Dockerfile的作者。
+
+Docker支持使用`#`作为注释,我将经常使用该语法,来解释Dockerfile的部分内容。
+
+### 运行一次测试构建
+
+因为我们继承了**nginx** Docker镜像,我们现在的Dockerfile也就包括了用来构建**nginx**镜像的[Dockerfile](https://github.com/nginxinc/docker-nginx/blob/08eeb0e3f0a5ee40cbc2bc01f0004c2aa5b78c15/Dockerfile)中所有指令。这意味着,此时我们可以从该Dockerfile中构建出一个Docker镜像,然后从该镜像中运行一个容器。虽然,最终的镜像和**nginx**镜像本质上是一样的,但是我们这次是通过构建Dockerfile的形式,然后我们将讲解Docker构建镜像的过程。
+
+想要从Dockerfile构建镜像,我们只需要在运行`docker`命令的时候,加上**build**选项。
+
+```
+# docker build -t blog /root/blog
+Sending build context to Docker daemon 23.6 MB
+Sending build context to Docker daemon
+Step 0 : FROM nginx:latest
+ ---> 9fab4090484a
+Step 1 : MAINTAINER Benjamin Cane
+ ---> Running in c97f36450343
+ ---> 60a44f78d194
+Removing intermediate container c97f36450343
+Successfully built 60a44f78d194
+```
+
+上面的例子,我们使用了`-t` (**tag**)标识给镜像添加"blog"的标签。本质上我们只是在给镜像命名,如果我们不指定标签,就只能通过Docker分配的**Image ID**来访问镜像了。本例中,从Docker构建成功的信息可以看出,**Image ID**值为`60a44f78d194`。
+
+除了`-t`标识外,我还指定了目录`/root/blog`。该目录被称作"构建目录",它将包含Dockerfile,以及其他需要构建该容器的文件。
+
+现在我们构建成功,下面我们开始定制该镜像。
+
+### 使用RUN来执行apt-get
+
+用来生成HTML页面的静态站点生成器是用**Python**语言编写的,所以,在Dockerfile中需要做的第一件定制任务是安装Python。我们将使用Apt包管理器来安装Python包,这意味着在Dockerfile中我们要指定运行`apt-get update`和`apt-get install python-dev`;为了完成这一点,我们可以使用`RUN`指令。
+
+```
+## Dockerfile that generates an instance of http://bencane.com
+
+FROM nginx:latest
+MAINTAINER Benjamin Cane
+
+## Install python and pip
+RUN apt-get update
+RUN apt-get install -y python-dev python-pip
+```
+
+如上所示,我们只是简单地告知Docker构建镜像的时候,要去执行指定的`apt-get`命令。比较有趣的是,这些命令只会在该容器的上下文中执行。这意味着,即使容器中安装了`python-dev`和`python-pip`,但主机本身并没有安装这些。说的更简单点,`pip`命令将只在容器中执行,出了容器,`pip`命令不存在。
+
+还有一点比较重要的是,Docker构建过程中不接受用户输入。这说明任何被`RUN`指令执行的命令必须在没有用户输入的时候完成。由于很多应用在安装的过程中需要用户的输入信息,所以这增加了一点难度。我们例子,`RUN`命令执行的命令都不需要用户输入。
+
+### 安装Python模块
+
+**Python**安装完毕后,我们现在需要安装Python模块。如果在Docker外做这些事,我们通常使用`pip`命令,然后参考博客Git仓库中名叫`requirements.txt`的文件。在之前的步骤中,我们已经使用`git`命令成功地将Github仓库"克隆"到了`/root/blog`目录;这个目录碰巧也是我们创建`Dockerfile`的目录。这很重要,因为这意味着Dokcer在构建过程中可以访问Git仓库中的内容。
+
+当我们执行构建后,Docker将构建的上下文环境设置为指定的"构建目录"。这意味着目录中的所有文件都可以在构建过程中被使用,目录之外的文件(构建环境之外)是不能访问的。
+
+为了能安装需要的Python模块,我们需要将`requirements.txt`从构建目录拷贝到容器中。我们可以在`Dockerfile`中使用`COPY`指令完成这一需求。
+
+```
+## Dockerfile that generates an instance of http://bencane.com
+
+FROM nginx:latest
+MAINTAINER Benjamin Cane
+
+## Install python and pip
+RUN apt-get update
+RUN apt-get install -y python-dev python-pip
+
+## Create a directory for required files
+RUN mkdir -p /build/
+
+## Add requirements file and run pip
+COPY requirements.txt /build/
+RUN pip install -r /build/requirements.txt
+```
+
+在`Dockerfile`中,我们增加了3条指令。第一条指令使用`RUN`在容器中创建了`/build/`目录。该目录用来拷贝生成静态HTML页面需要的一切应用文件。第二条指令是`COPY`指令,它将`requirements.txt`从"构建目录"(`/root/blog`)拷贝到容器中的`/build/`目录。第三条使用`RUN`指令来执行`pip`命令;安装`requirements.txt`文件中指定的所有模块。
+
+当构建定制镜像时,`COPY`是条重要的指令。如果在Dockerfile中不指定拷贝文件,Docker镜像将不会包含requirements.txt文件。在Docker容器中,所有东西都是隔离的,除非在Dockerfile中指定执行,否则容器中不会包括需要的依赖。
+
+### 重新运行构建
+
+现在,我们让Docker执行了一些定制任务,现在我们尝试另一次blog镜像的构建。
+
+```
+# docker build -t blog /root/blog
+Sending build context to Docker daemon 19.52 MB
+Sending build context to Docker daemon
+Step 0 : FROM nginx:latest
+ ---> 9fab4090484a
+Step 1 : MAINTAINER Benjamin Cane
+ ---> Using cache
+ ---> 8e0f1899d1eb
+Step 2 : RUN apt-get update
+ ---> Using cache
+ ---> 78b36ef1a1a2
+Step 3 : RUN apt-get install -y python-dev python-pip
+ ---> Using cache
+ ---> ef4f9382658a
+Step 4 : RUN mkdir -p /build/
+ ---> Running in bde05cf1e8fe
+ ---> f4b66e09fa61
+Removing intermediate container bde05cf1e8fe
+Step 5 : COPY requirements.txt /build/
+ ---> cef11c3fb97c
+Removing intermediate container 9aa8ff43f4b0
+Step 6 : RUN pip install -r /build/requirements.txt
+ ---> Running in c50b15ddd8b1
+Downloading/unpacking jinja2 (from -r /build/requirements.txt (line 1))
+Downloading/unpacking PyYaml (from -r /build/requirements.txt (line 2))
+
+Successfully installed jinja2 PyYaml mistune markdown MarkupSafe
+Cleaning up...
+ ---> abab55c20962
+Removing intermediate container c50b15ddd8b1
+Successfully built abab55c20962
+```
+
+上述输出所示,我们可以看到构建成功了,我们还可以看到另外一个有趣的信息` ---> Using cache`。这条信息告诉我们,Docker在构建该镜像时使用了它的构建缓存。
+
+### Docker构建缓存
+
+当Docker构建镜像时,它不仅仅构建一个单独的镜像;事实上,在构建过程中,它会构建许多镜像。从上面的输出信息可以看出,在每一"步"执行后,Docker都在创建新的镜像。
+
+```
+ Step 5 : COPY requirements.txt /build/
+ ---> cef11c3fb97c
+```
+
+上面片段的最后一行可以看出,Docker在告诉我们它在创建一个新镜像,因为它打印了**Image ID**;`cef11c3fb97c`。这种方式有用之处在于,Docker能在随后构建**blog**镜像时将这些镜像作为缓存使用。这很有用处,因为这样,Docker就能加速同一个容器中新构建任务的构建流程。从上面的例子中,我们可以看出,Docker没有重新安装`python-dev`和`python-pip`包,Docker则使用了缓存镜像。但是由于Docker并没有找到执行`mkdir`命令的构建缓存,随后的步骤就被一一执行了。
+
+Docker构建缓存一定程度上是福音,但有时也是噩梦。这是因为使用缓存或者重新运行指令的决定在一个很狭窄的范围内执行。比如,如果`requirements.txt`文件发生了修改,Docker会在构建时检测到该变化,然后Docker会重新执行该执行那个点往后的所有指令。这得益于Docker能查看`requirements.txt`的文件内容。但是,`apt-get`命令的执行就是另一回事了。如果提供Python包的**Apt** 仓库包含了一个更新的python-pip包;Docker不会检测到这个变化,转而去使用构建缓存。这会导致之前旧版本的包将被安装。虽然对`python-pip`来说,这不是主要的问题,但对使用了某个致命攻击缺陷的包缓存来说,这是个大问题。
+
+出于这个原因,抛弃Docker缓存,定期地重新构建镜像是有好处的。这时,当我们执行Docker构建时,我简单地指定`--no-cache=True`即可。
+
+## 部署博客的剩余部分
+
+Python包和模块安装后,接下来我们将拷贝需要用到的应用文件,然后运行`hamerkop`应用。我们只需要使用更多的`COPY` and `RUN`指令就可完成。
+
+```
+## Dockerfile that generates an instance of http://bencane.com
+
+FROM nginx:latest
+MAINTAINER Benjamin Cane
+
+## Install python and pip
+RUN apt-get update
+RUN apt-get install -y python-dev python-pip
+
+## Create a directory for required files
+RUN mkdir -p /build/
+
+## Add requirements file and run pip
+COPY requirements.txt /build/
+RUN pip install -r /build/requirements.txt
+
+## Add blog code nd required files
+COPY static /build/static
+COPY templates /build/templates
+COPY hamerkop /build/
+COPY config.yml /build/
+COPY articles /build/articles
+
+## Run Generator
+RUN /build/hamerkop -c /build/config.yml
+```
+
+现在我们已经写出了剩余的构建指令,我们再次运行另一次构建,并确保镜像构建成功。
+
+```
+# docker build -t blog /root/blog/
+Sending build context to Docker daemon 19.52 MB
+Sending build context to Docker daemon
+Step 0 : FROM nginx:latest
+ ---> 9fab4090484a
+Step 1 : MAINTAINER Benjamin Cane
+ ---> Using cache
+ ---> 8e0f1899d1eb
+Step 2 : RUN apt-get update
+ ---> Using cache
+ ---> 78b36ef1a1a2
+Step 3 : RUN apt-get install -y python-dev python-pip
+ ---> Using cache
+ ---> ef4f9382658a
+Step 4 : RUN mkdir -p /build/
+ ---> Using cache
+ ---> f4b66e09fa61
+Step 5 : COPY requirements.txt /build/
+ ---> Using cache
+ ---> cef11c3fb97c
+Step 6 : RUN pip install -r /build/requirements.txt
+ ---> Using cache
+ ---> abab55c20962
+Step 7 : COPY static /build/static
+ ---> 15cb91531038
+Removing intermediate container d478b42b7906
+Step 8 : COPY templates /build/templates
+ ---> ecded5d1a52e
+Removing intermediate container ac2390607e9f
+Step 9 : COPY hamerkop /build/
+ ---> 59efd1ca1771
+Removing intermediate container b5fbf7e817b7
+Step 10 : COPY config.yml /build/
+ ---> bfa3db6c05b7
+Removing intermediate container 1aebef300933
+Step 11 : COPY articles /build/articles
+ ---> 6b61cc9dde27
+Removing intermediate container be78d0eb1213
+Step 12 : RUN /build/hamerkop -c /build/config.yml
+ ---> Running in fbc0b5e574c5
+Successfully created file /usr/share/nginx/html//2011/06/25/checking-the-number-of-lwp-threads-in-linux
+Successfully created file /usr/share/nginx/html//2011/06/checking-the-number-of-lwp-threads-in-linux
+
+Successfully created file /usr/share/nginx/html//archive.html
+Successfully created file /usr/share/nginx/html//sitemap.xml
+ ---> 3b25263113e1
+Removing intermediate container fbc0b5e574c5
+Successfully built 3b25263113e1
+```
+
+### 运行定制的容器
+
+成功的一次构建后,我们现在就可以通过运行`docker`命令和`run`选项来运行我们定制的容器,和之前我们启动nginx容器一样。
+
+```
+# docker run -d -p 80:80 --name=blog blog
+5f6c7a2217dcdc0da8af05225c4d1294e3e6bb28a41ea898a1c63fb821989ba1
+```
+
+我们这次又使用了`-d` (**detach**)标识来让Docker在后台运行。但是,我们也可以看到两个新标识。第一个新标识是`--name`,这用来给容器指定一个用户名称。之前的例子,我们没有指定名称,因为Docker随机帮我们生成了一个。第二个新标识是`-p`,这个标识允许用户从主机映射一个端口到容器中的一个端口。
+
+之前我们使用的基础**nginx**镜像分配了80端口给HTTP服务。默认情况下,容器内的端口通道并没有绑定到主机系统。为了让外部系统能访问容器内部端口,我们必须使用`-p`标识将主机端口映射到容器内部端口。上面的命令,我们通过`-p 8080:80`语法将主机80端口映射到容器内部的80端口。
+
+经过上面的命令,我们的容器似乎成功启动了,我们可以通过执行`docker ps`核实。
+
+```
+# docker ps
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+d264c7ef92bd blog:latest nginx -g 'daemon off 3 seconds ago Up 3 seconds 443/tcp, 0.0.0.0:80->80/tcp blog
+```
+
+## 总结
+
+截止目前,我们拥有了正在运行的定制Docker容器。虽然在这篇文章中,我们只接触了一些Dockerfile指令用法,但是我们还是要讨论所有的指令。我们可以检查[Docker's reference page](https://docs.docker.com/v1.8/reference/builder/)来获取所有的Dockerfile指令用法,那里对指令的用法说明得很详细。
+
+另一个比较好的资源是[Dockerfile Best Practices page](https://docs.docker.com/engine/articles/dockerfile_best-practices/),它有许多构建定制Dockerfile的最佳练习。有些技巧非常有用,比如战略性地组织好Dockerfile中的命令。上面的例子中,我们将`articles`目录的`COPY`指令作为Dockerfile中最后的`COPY`指令。这是因为`articles`目录会经常变动。所以,将那些经常变化的指令尽可能地放在最后面的位置,来最优化那些可以被缓存的步骤。
+
+通过这篇文章,我们涉及了如何运行一个预构建的容器,以及如何构建,然后部署定制容器。虽然关于Docker你还有许多需要继续学习的地方,但我想这篇文章给了你如何继续开始的好建议。当然,如果你认为还有一些需要继续补充的内容,在下面评论即可。
+
+--------------------------------------
+via:http://bencane.com/2015/12/01/getting-started-with-docker-by-dockerizing-this-blog/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+bencane%2FSAUo+%28Benjamin+Cane%29
+
+作者:Benjamin Cane
+
+译者:[su-kaiyao](https://github.com/su-kaiyao)
+
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
diff --git a/translated/tech/20151214 Linux or Unix Desktop Fun--Christmas Tree For Your Terminal.md b/translated/tech/20151214 Linux or Unix Desktop Fun--Christmas Tree For Your Terminal.md
new file mode 100644
index 0000000000..dbbab5ef8c
--- /dev/null
+++ b/translated/tech/20151214 Linux or Unix Desktop Fun--Christmas Tree For Your Terminal.md
@@ -0,0 +1,84 @@
+Linux / Unix桌面之趣:终端上的圣诞树
+================================================================================
+给你的Linux或Unix控制台创造一棵圣诞树玩玩吧。在此之前,需要先安装一个Perl模块,命名为Acme::POE::Tree。这是一棵很喜庆的圣诞树,我已经在Linux、OSX和类Unix系统上验证过了。
+
+
+### 安装 Acme::POE::Tree ###
+
+安装perl模块最简单的办法就是使用cpan(Perl综合典藏网)。打开终端,把下面的指令敲进去便可安装Acme::POE::Tree。
+
+ ## 以root身份运行 ##
+ perl -MCPAN -e 'install Acme::POE::Tree'
+
+**案例输出:**
+
+ Installing /home/vivek/perl5/man/man3/POE::NFA.3pm
+ Installing /home/vivek/perl5/man/man3/POE::Kernel.3pm
+ Installing /home/vivek/perl5/man/man3/POE::Loop.3pm
+ Installing /home/vivek/perl5/man/man3/POE::Resource.3pm
+ Installing /home/vivek/perl5/man/man3/POE::Filter::Map.3pm
+ Installing /home/vivek/perl5/man/man3/POE::Resource::SIDs.3pm
+ Installing /home/vivek/perl5/man/man3/POE::Loop::IO_Poll.3pm
+ Installing /home/vivek/perl5/man/man3/POE::Pipe::TwoWay.3pm
+ Appending installation info to /home/vivek/perl5/lib/perl5/x86_64-linux-gnu-thread-multi/perllocal.pod
+ RCAPUTO/POE-1.367.tar.gz
+ /usr/bin/make install -- OK
+ RCAPUTO/Acme-POE-Tree-1.022.tar.gz
+ Has already been unwrapped into directory /home/vivek/.cpan/build/Acme-POE-Tree-1.022-uhlZUz
+ RCAPUTO/Acme-POE-Tree-1.022.tar.gz
+ Has already been prepared
+ Running make for R/RC/RCAPUTO/Acme-POE-Tree-1.022.tar.gz
+ cp lib/Acme/POE/Tree.pm blib/lib/Acme/POE/Tree.pm
+ Manifying 1 pod document
+ RCAPUTO/Acme-POE-Tree-1.022.tar.gz
+ /usr/bin/make -- OK
+ Running make test
+ PERL_DL_NONLAZY=1 "/usr/bin/perl" "-MExtUtils::Command::MM" "-MTest::Harness" "-e" "undef *Test::Harness::Switches; test_harness(0, 'blib/lib', 'blib/arch')" t/*.t
+ t/01_basic.t .. ok
+ All tests successful.
+ Files=1, Tests=2, 6 wallclock secs ( 0.09 usr 0.03 sys + 0.53 cusr 0.06 csys = 0.71 CPU)
+ Result: PASS
+ RCAPUTO/Acme-POE-Tree-1.022.tar.gz
+ Tests succeeded but one dependency not OK (Curses)
+ RCAPUTO/Acme-POE-Tree-1.022.tar.gz
+ [dependencies] -- NA
+
+### 在Shell中显示圣诞树 ###
+
+只需要在终端上运行以下命令:
+
+ perl -MAcme::POE::Tree -e 'Acme::POE::Tree->new()->run()'
+
+**案例输出**
+
+
+
+Gif 01: 一棵用Perl写的喜庆圣诞树
+
+### 树的定制 ###
+
+以下是我的脚本文件tree.pl的内容:
+
+ #!/usr/bin/perl
+
+ use Acme::POE::Tree;
+ my $tree = Acme::POE::Tree->new(
+ {
+ star_delay => 1.5, # shimmer star every 1.5 sec
+ light_delay => 2, # twinkle lights every 2 sec
+ run_for => 10, # automatically exit after 10 sec
+ }
+ );
+ $tree->run();
+
+这样就可以通过修改star_delay、run_for和light_delay参数的值来自定义你的树了。一棵提供消遣的终端圣诞树就此诞生。
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/open-source/command-line-hacks/linux-unix-desktop-fun-christmas-tree-for-your-terminal/
+
+作者:Vivek Gite
+译者:[soooogreen](https://github.com/soooogreen)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20151215 Fix--Cannot establish FTP connection to an SFTP server.md b/translated/tech/20151215 Fix--Cannot establish FTP connection to an SFTP server.md
new file mode 100644
index 0000000000..79e26abd64
--- /dev/null
+++ b/translated/tech/20151215 Fix--Cannot establish FTP connection to an SFTP server.md
@@ -0,0 +1,49 @@
+修复:无法与SFTP服务器建立FTP连接
+================================================================================
+### 问题 ###
+
+有一天我要连接到我的web服务器。我使用[FileZilla][1]连接到FTP服务器。当我输入主机名和密码后来连接服务器后,我得到了下面的错误。
+
+> Error: Cannot establish FTP connection to an SFTP server. Please select proper protocol.
+>
+> Error: Critical error: Could not connect to server
+
+
+
+### 原因 ###
+
+看见错误信息后我意识到了我的错误。我尝试与一台SFTP服务器建立一个[FTP][2]连接。很明显我没有使用一个正确的协议(应该是SFTP而不是FTP)。
+
+如你在上图所见,FileZilla默认使用的是FTP协议。
+
+### 解决“Cannot establish FTP connection to an SFTP server”的方案 ###
+
+解决方案很简单。使用SFTP协议而不是FTP。一个你或许要面对的问题是把协议修改成SFTP。这就是我要帮助你的。
+
+再FileZilla菜单中,进入 **文件->站点管理**.
+
+
+
+在站点管理中,进入通用选项并选择SFTP协议。同样填上主机、端口号、用户密码等。
+
+
+
+我希望你从这里可以开始处理。
+
+我希望本篇教程可以帮助你修复“Cannot establish FTP connection to an SFTP server. Please select proper protocol.”这个问题。在相关的文章中,你可以读[了解在Linux中如何设置FTP][4]。
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/fix-establish-ftp-connection-sftp-server/
+
+作者:[Abhishek][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:https://filezilla-project.org/
+[2]:https://en.wikipedia.org/wiki/File_Transfer_Protocol
+[3]:https://en.wikipedia.org/wiki/SSH_File_Transfer_Protocol
+[4]:http://itsfoss.com/set-ftp-server-linux/
diff --git a/translated/tech/20151215 Linux or UNIX Desktop Fun--Let it Snow On Your Desktop.md b/translated/tech/20151215 Linux or UNIX Desktop Fun--Let it Snow On Your Desktop.md
new file mode 100644
index 0000000000..c47ff21da0
--- /dev/null
+++ b/translated/tech/20151215 Linux or UNIX Desktop Fun--Let it Snow On Your Desktop.md
@@ -0,0 +1,75 @@
+Linux/Unix桌面趣事:让桌面下雪
+================================================================================
+在这个节日里感到孤独么?试一下Xsnow吧。它是一个可以在Unix/Linux桌面下下雪的app。圣诞老人和他的驯鹿会在屏幕中奔跑,伴随着雪片让你感受到节日的感觉。
+
+我第一次是再13、4年前安装的它。它最初是在1984年Macintosh系统中创造的。你可以用下面的方法来安装:
+
+### 安装 xsnow ###
+
+Debian/Ubuntu/Mint用户用下面的命令:
+
+ $ sudo apt-get install xsnow
+
+Freebsd用户输入下面的命令:
+
+ # cd /usr/ports/x11/xsnow/
+ # make install clean
+
+或者尝试添加包:
+
+ # pkg_add -r xsnow
+
+#### 其他发行版的方法 ####
+
+1. Fedora/RHEL/CentOS在[rpmfusion][1]仓库中找找。
+2. Gentoo用户试下Gentoo portage也就是[emerge -p xsnow][2]
+3. Opensuse用户使用yast搜索xsnow
+
+### 我该如何使用xsnow? ###
+
+打开终端(程序 > 附件 > 终端),输入下面的额命令启动xsnow:
+
+ $ xsnow
+
+示例输出:
+
+
+
+图01: 在Linux和Unix桌面中显示雪花
+
+你可以设置背景位蓝色,并让它下白雪,输入:
+
+ $ xsnow -bg blue -sc snow
+
+设置最大的雪片数量,并让它尽可能快地运行,输入:
+
+ $ xsnow -snowflakes 10000 -delay 0
+
+不要显示圣诞树和圣诞老人满屏幕地跑,输入:
+
+ $ xsnow -notrees -nosanta
+
+关于xsnow更多的信息和选项,在命令行下输入man xsnow查看手册:
+
+ $ man xsnow
+
+建议阅读
+
+- 官网[下载 Xsnow][1]
+- 注意[MS-Windows][2]和[Mac OS X version][3]有一次性的共享软件费用。
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/tips/linux-unix-xsnow.html
+
+作者:Vivek Gite
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://rpmfusion.org/Configuration
+[2]:http://www.gentoo.org/doc/en/handbook/handbook-x86.xml?part=2&chap=1
+[3]:http://dropmix.xs4all.nl/rick/Xsnow/
+[4]:http://dropmix.xs4all.nl/rick/WinSnow/
+[5]:http://dropmix.xs4all.nl/rick/MacOSXSnow/
diff --git a/translated/tech/20151215 Linux or UNIX Desktop Fun--Steam Locomotive.md b/translated/tech/20151215 Linux or UNIX Desktop Fun--Steam Locomotive.md
new file mode 100644
index 0000000000..d97f0f3c68
--- /dev/null
+++ b/translated/tech/20151215 Linux or UNIX Desktop Fun--Steam Locomotive.md
@@ -0,0 +1,40 @@
+Linux/Unix 桌面趣事:蒸汽火车
+================================================================================
+一个[最常见的错误][1]是把ls输入成了sl。我已经设置了[一个alias][2],也就是alias sl=ls。但是你也许就错过了带汽笛的蒸汽小火车了。
+
+sl是一个玩笑软件或是一个Unix游戏。它会在你错误地把“ls”输入成“sl”(Steam Locomotive)后出现一辆蒸汽火车穿过你的屏幕。
+
+### 安装 sl ###
+
+在Debian/Ubuntu下输入下面的命令:
+
+ # apt-get install sl
+
+它同样也在Freebsd和其他类Unix的操作系统上存在。下面把ls输错成sl:
+
+ $ sl
+
+
+
+图01: 如果你把“ls”输入成“sl”蒸汽火车会穿过你的屏幕。
+
+It also supports the following options:
+它同样支持下面的选项:
+
+- **-a** : 似乎发生了意外。你会哭喊求助的人们感到难过。
+- **-l** : 显示小一点的火车
+- **-F** : 它飞走
+- **-e** : 允许被Ctrl+C终端
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/tips/displays-animations-when-accidentally-you-type-sl-instead-of-ls.html
+
+作者:Vivek Gite
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.cyberciti.biz/tips/my-10-unix-command-line-mistakes.html
+[2]:http://bash.cyberciti.biz/guide/Create_and_use_aliases
diff --git a/translated/tech/20151215 Linux or UNIX Desktop Fun--Terminal ASCII Aquarium.md b/translated/tech/20151215 Linux or UNIX Desktop Fun--Terminal ASCII Aquarium.md
new file mode 100644
index 0000000000..ed26f49783
--- /dev/null
+++ b/translated/tech/20151215 Linux or UNIX Desktop Fun--Terminal ASCII Aquarium.md
@@ -0,0 +1,65 @@
+Linux/Unix桌面趣事:终端ASCII水族箱
+================================================================================
+你可以在你的终端中使用ASCIIQuarium安全地欣赏海洋的神秘了。它是一个用perl写的ASCII艺术水族箱/海洋动画。
+
+### 安装 Term::Animation ###
+
+
+首先你需要安装名为Term-Animation的perl模块。打开终端(选择程序 > 附件 > 终端),并输入:
+
+ $ sudo apt-get install libcurses-perl
+ $ cd /tmp
+ $ wget http://search.cpan.org/CPAN/authors/id/K/KB/KBAUCOM/Term-Animation-2.4.tar.gz
+ $ tar -zxvf Term-Animation-2.4.tar.gz
+ $ cd Term-Animation-2.4/
+ $ perl Makefile.PL && make && make test
+ $ sudo make install
+
+### 下载安装ASCIIQuarium ###
+
+接着再终端中输入:
+
+ $ cd /tmp
+ $ wget http://www.robobunny.com/projects/asciiquarium/asciiquarium.tar.gz
+ $ tar -zxvf asciiquarium.tar.gz
+ $ cd asciiquarium_1.0/
+ $ sudo cp asciiquarium /usr/local/bin
+ $ sudo chmod 0755 /usr/local/bin/asciiquarium
+
+### 我怎么浏览ASCII水族箱? ###
+
+输入下面的命令:
+
+ $ /usr/local/bin/asciiquarium
+
+或者
+
+ $ perl /usr/local/bin/asciiquarium
+
+
+
+### 相关媒体 ###
+
+注:youtube 视频
+
+
+[视频01: ASCIIQuarium - Linux/Unix桌面上的海洋动画][1]
+
+### 下载:ASCII Aquarium的KDE和Mac OS X版本 ###
+
+[下载asciiquarium][2]。如果你运行的是Mac OS X,试下一个可以直接使用已经打包好的[版本][3]。对于KDE用户,试试基于Asciiquarium的[KDE屏幕保护程序][4]
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/tips/linux-unix-apple-osx-terminal-ascii-aquarium.html
+
+作者:Vivek Gite
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://youtu.be/MzatWgu67ok
+[2]:http://www.robobunny.com/projects/asciiquarium/html/
+[3]:http://habilis.net/macasciiquarium/
+[4]:http://kde-look.org/content/show.php?content=29207
diff --git a/translated/tech/20151215 Linux or Unix Desktop Fun--Cat And Mouse Chase All Over Your Screen.md b/translated/tech/20151215 Linux or Unix Desktop Fun--Cat And Mouse Chase All Over Your Screen.md
new file mode 100644
index 0000000000..e08d21ae49
--- /dev/null
+++ b/translated/tech/20151215 Linux or Unix Desktop Fun--Cat And Mouse Chase All Over Your Screen.md
@@ -0,0 +1,91 @@
+Linux/Unix桌面趣事:猫和老鼠在屏幕中追逐
+================================================================================
+Oneko是一个有趣的app。它会把你的光标变成一直老鼠,并在后面创建一个可爱的小猫,并且始终在老鼠光标后面追着。单词“neko”再日语中的意思是老鼠。它最初是作为Macintosh桌面附件由一位日本人开发的。
+
+### 安装 oneko ###
+
+试下下面的命令:
+
+ $ sudo apt-get install oneko
+
+示例输出:
+
+ [sudo] password for vivek:
+ Reading package lists... Done
+ Building dependency tree
+ Reading state information... Done
+ The following NEW packages will be installed:
+ oneko
+ 0 upgraded, 1 newly installed, 0 to remove and 10 not upgraded.
+ Need to get 38.6 kB of archives.
+ After this operation, 168 kB of additional disk space will be used.
+ Get:1 http://debian.osuosl.org/debian/ squeeze/main oneko amd64 1.2.sakura.6-7 [38.6 kB]
+ Fetched 38.6 kB in 1s (25.9 kB/s)
+ Selecting previously deselected package oneko.
+ (Reading database ... 274152 files and directories currently installed.)
+ Unpacking oneko (from .../oneko_1.2.sakura.6-7_amd64.deb) ...
+ Processing triggers for menu ...
+ Processing triggers for man-db ...
+ Setting up oneko (1.2.sakura.6-7) ...
+ Processing triggers for menu ...
+
+FreeBSD用户输入下面的命令安装oneko:
+
+ # cd /usr/ports/games/oneko
+ # make install clean
+
+### 我该如何使用oneko? ###
+
+Simply type the following command:
+输入下面的命令:
+
+ $ oneko
+
+你可以把猫变成“tora-neko”,一只像白老虎条纹的猫:
+
+ $ oneko -tora
+
+### 不喜欢猫? ###
+
+你可以用狗代替猫:
+
+ $ oneko -dog
+
+下面可以用樱花代替猫:
+
+ $ oneko -sakura
+
+用大道寺代替猫:
+
+ $ oneko -tomoyo
+
+### 查看相关媒体 ###
+
+这个教程同样也有视频格式:
+
+注:youtube 视频
+
+
+(Video.01: 示例 - 在Linux下安装和使用oneko)
+
+### 其他选项 ###
+
+You can pass the following options:
+你可以传入下面的选项
+
+1.**-tofocus**:让猫再聚焦的窗口顶部奔跑。当聚焦的窗口不在视野中时,猫像平常那样追逐老鼠。
+2. **-position 坐标** :指定X和Y来调整猫相对老鼠的位置
+3. **-rv**:将前景色和背景色对调
+4. **-fg 颜色** : 前景色 (比如 oneko -dog -fg red)。
+5. **-bg 颜色** : 背景色 (比如 oneko -dog -bg green)。
+6. 查看oneko的手册获取更多信息。
+
+--------------------------------------------------------------------------------
+
+via: http://www.cyberciti.biz/open-source/oneko-app-creates-cute-cat-chasing-around-your-mouse/
+
+作者:Vivek Gite
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md b/translated/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md
new file mode 100644
index 0000000000..2781dde63d
--- /dev/null
+++ b/translated/tech/LFCS/Part 9 - LFCS--Linux Package Management with Yum RPM Apt Dpkg Aptitude and Zypper.md
@@ -0,0 +1,230 @@
+Flowsnow translating...
+LFCS系列第九讲: 使用Yum, RPM, Apt, Dpkg, Aptitude, Zypper进行Linux包管理
+================================================================================
+去年八月, Linux基金会宣布了一个全新的LFCS(Linux Foundation Certified Sysadmin,Linux基金会认证系统管理员)认证计划,这对广大系统管理员来说是一个很好的机会,管理员们可以通过绩效考试来表明自己可以成功支持Linux系统的整体运营。 当需要的时候一个Linux基金会认证的系统管理员有足够的专业知识来确保系统高效运行,提供第一手的故障诊断和监视,并且为工程师团队在问题升级时提供智能决策。
+
+
+
+Linux基金会认证系统管理员 – 第九讲
+
+请观看下面关于Linux基金会认证计划的演示。
+
+注:youtube 视频
+
+
+本文是本系列十套教程中的第九讲,今天在这篇文章中我们会引导你学习Linux包管理,这也是LFCS认证考试所需要的。
+
+### 包管理 ###
+
+简单的说,包管理是系统中安装和维护软件的一种方法,其中维护也包含更新和卸载。
+
+在Linux早期,程序只以源代码的方式发行,还带有所需的用户使用手册和必备的配置文件,甚至更多。现如今,大多数发行商使用默认的预装程序或者被称为包的程序集合。用户使用这些预装程序或者包来安装该发行版本。然而,Linux最伟大的一点是我们仍然能够获得程序的源代码用来学习、改进和编译。
+
+**包管理系统是如何工作的**
+
+如果某一个包需要一定的资源,如共享库,或者需要另一个包,据说就会存在依赖性问题。所有现在的包管理系统提供了一些解决依赖性的方法,以确保当安装一个包时,相关的依赖包也安装好了
+
+**打包系统**
+
+几乎所有安装在现代Linux系统上的软件都会在互联网上找到。它要么能够通过中央库(中央库能包含几千个包,每个包都已经构建、测试并且维护好了)发行商得到,要么能够直接得到可以下载和手动安装的源代码。
+
+由于不同的发行版使用不同的打包系统(Debian的*.deb文件/ CentOS的*.rpm文件/ openSUSE的专门为openSUSE构建的*.rpm文件),因此为一个发行版本开发的包会与其他发行版本不兼容。然而,大多数发行版本都可能是LFCS认证的三个发行版本之一。
+
+**高级和低级打包工具**
+
+为了有效地进行包管理的任务,你需要知道,你将有两种类型的实用工具:低级工具(能在后端实际安装,升级,卸载包文件),以及高级工具(负责确保能很好的执行依赖性解决和元数据检索的任务,元数据也称为关于数据的数据)。
+
+注:表格
+
+