mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
a7a9a6ee70
@ -1,39 +1,40 @@
|
||||
|
||||
如何在 Linux 中使用 Fio 来测评硬盘性能
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fio(Flexible I/O Tester) 是一款由 Jens Axboe 开发的用于测评和压力/硬件验证的[免费开源][1]的软件
|
||||
Fio(Flexible I/O Tester) 是一款由 Jens Axboe 开发的用于测评和压力/硬件验证的[自由开源][1]的软件。
|
||||
|
||||
它支持 19 种不同类型的 I/O 引擎 (sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio, 以及更多), I/O 优先级(针对较新的 Linux 内核),I/O 速度,复刻或线程任务,和其他更多的东西。它能够在块设备和文件上工作。
|
||||
它支持 19 种不同类型的 I/O 引擎 (sync、mmap、libaio、posixaio、SG v3、splice、null、network、 syslet、guasi、solarisaio,以及更多), I/O 优先级(针对较新的 Linux 内核),I/O 速度,fork 的任务或线程任务等等。它能够在块设备和文件上工作。
|
||||
|
||||
Fio 接受一种非常简单易于理解的文本格式作为任务描述。软件默认包含了许多示例任务文件。 Fio 展示了所有类型的 I/O 性能信息,包括完整的 IO 延迟和百分比。
|
||||
Fio 接受一种非常简单易于理解的文本格式的任务描述。软件默认包含了几个示例任务文件。 Fio 展示了所有类型的 I/O 性能信息,包括完整的 IO 延迟和百分比。
|
||||
|
||||
它被广泛的应用在非常多的地方,包括测评、QA,以及验证用途。它支持 Linux 、 FreeBSD 、 NetBSD、 OpenBSD、 OS X、 OpenSolaris、 AIX、 HP-UX、 Android 以及 Windows。
|
||||
它被广泛的应用在非常多的地方,包括测评、QA,以及验证用途。它支持 Linux 、FreeBSD 、NetBSD、 OpenBSD、 OS X、 OpenSolaris、 AIX、 HP-UX、 Android 以及 Windows。
|
||||
|
||||
在这个教程,我们将使用 Ubuntu 16 ,你需要拥有这台电脑的 sudo 或 root 权限。我们将完整的进行安装和 Fio 的使用。
|
||||
在这个教程,我们将使用 Ubuntu 16 ,你需要拥有这台电脑的 `sudo` 或 root 权限。我们将完整的进行安装和 Fio 的使用。
|
||||
|
||||
### 使用源码安装 Fio
|
||||
|
||||
我们要去克隆 Github 上的仓库。安装所需的依赖,然后我们将会从源码构建应用。首先,确保我们安装了 Git 。
|
||||
我们要去克隆 GitHub 上的仓库。安装所需的依赖,然后我们将会从源码构建应用。首先,确保我们安装了 Git 。
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
CentOS 用户可以执行下述命令:
|
||||
|
||||
```
|
||||
sudo yum install git
|
||||
```
|
||||
|
||||
现在,我们切换到 /opt 目录,并从 Github 上克隆仓库:
|
||||
现在,我们切换到 `/opt` 目录,并从 Github 上克隆仓库:
|
||||
|
||||
```
|
||||
cd /opt
|
||||
git clone https://github.com/axboe/fio
|
||||
```
|
||||
|
||||
你应该会看到下面这样的输出
|
||||
你应该会看到下面这样的输出:
|
||||
|
||||
```
|
||||
Cloning into 'fio'...
|
||||
@ -45,7 +46,7 @@ Resolving deltas: 100% (16251/16251), done.
|
||||
Checking connectivity... done.
|
||||
```
|
||||
|
||||
现在,我们通过在 opt 目录下输入下方的命令切换到 Fio 的代码目录:
|
||||
现在,我们通过在 `/opt` 目录下输入下方的命令切换到 Fio 的代码目录:
|
||||
|
||||
```
|
||||
cd fio
|
||||
@ -61,7 +62,7 @@ cd fio
|
||||
|
||||
### 在 Ubuntu 上安装 Fio
|
||||
|
||||
对于 Ubuntu 和 Debian 来说, Fio 已经在主仓库内。你可以很容易的使用类似 yum 和 apt-get 的标准包管理器来安装 Fio。
|
||||
对于 Ubuntu 和 Debian 来说, Fio 已经在主仓库内。你可以很容易的使用类似 `yum` 和 `apt-get` 的标准包管理器来安装 Fio。
|
||||
|
||||
对于 Ubuntu 和 Debian ,你只需要简单的执行下述命令:
|
||||
|
||||
@ -69,7 +70,8 @@ cd fio
|
||||
sudo apt-get install fio
|
||||
```
|
||||
|
||||
对于 CentOS/Redhat 你只需要简单执行下述命令:
|
||||
对于 CentOS/Redhat 你只需要简单执行下述命令。
|
||||
|
||||
在 CentOS ,你可能在你能安装 Fio 前需要去安装 EPEL 仓库到你的系统中。你可以通过执行下述命令来安装它:
|
||||
|
||||
```
|
||||
@ -124,23 +126,20 @@ Run status group 0 (all jobs):
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%
|
||||
|
||||
|
||||
```
|
||||
|
||||
### 执行随机读测试
|
||||
|
||||
我们将要执行一个随机读测试,我们将会尝试读取一个随机的 2GB 文件。
|
||||
|
||||
```
|
||||
|
||||
sudo fio --name=randread --ioengine=libaio --iodepth=16 --rw=randread --bs=4k --direct=0 --size=512M --numjobs=4 --runtime=240 --group_reporting
|
||||
|
||||
|
||||
```
|
||||
|
||||
你应该会看到下面这样的输出
|
||||
```
|
||||
你应该会看到下面这样的输出:
|
||||
|
||||
```
|
||||
...
|
||||
fio-2.2.10
|
||||
Starting 4 processes
|
||||
@ -176,15 +175,13 @@ Run status group 0 (all jobs):
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=521587/871, merge=0/1142, ticks=96664/612, in_queue=97284, util=99.85%
|
||||
|
||||
|
||||
```
|
||||
|
||||
最后,我们想要展示一个简单的随机读-写测试来看一看 Fio 返回的输出类型。
|
||||
|
||||
### 读写性能测试
|
||||
|
||||
下述命令将会测试 USB Pen 驱动器 (/dev/sdc1) 的随机读写性能:
|
||||
下述命令将会测试 USB Pen 驱动器 (`/dev/sdc1`) 的随机读写性能:
|
||||
|
||||
```
|
||||
sudo fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=random_read_write.fio --bs=4k --iodepth=64 --size=4G --readwrite=randrw --rwmixread=75
|
||||
@ -213,8 +210,6 @@ Disk stats (read/write):
|
||||
sda: ios=774141/258944, merge=1463/899, ticks=748800/150316, in_queue=900720, util=99.35%
|
||||
```
|
||||
|
||||
We hope you enjoyed this tutorial and enjoyed following along, Fio is a very useful tool and we hope you can use it in your next debugging activity. If you enjoyed reading this post feel free to leave a comment of questions. Go ahead and clone the repo and play around with the code.
|
||||
|
||||
我们希望你能喜欢这个教程并且享受接下来的内容,Fio 是一个非常有用的工具,并且我们希望你能在你下一次 Debugging 活动中使用到它。如果你喜欢这个文章,欢迎留下评论和问题。
|
||||
|
||||
|
||||
@ -224,7 +219,7 @@ via: https://wpmojo.com/how-to-use-fio-to-measure-disk-performance-in-linux/
|
||||
|
||||
作者:[Alex Pearson][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,58 +1,52 @@
|
||||
# [Google 为树莓派 Zero W 发布了基于TensorFlow 的视觉识别套件][26]
|
||||
|
||||
Google 为树莓派 Zero W 发布了基于TensorFlow 的视觉识别套件
|
||||
===============
|
||||
|
||||

|
||||
|
||||
Google 发行了一个 45 美元的 “AIY Vision Kit”,它是运行在树莓派 Zero W 上的基于 TensorFlow 的视觉识别开发套件,它使用了一个带 Movidius 芯片的 “VisionBonnet” 板。
|
||||
|
||||
为加速设备上的神经网络,Google 的 AIY 视频套件继承了早期树莓派上运行的 [AIY 项目][7] 的语音/AI 套件,这个型号的树莓派随五月份的 MagPi 杂志一起赠送。与语音套件和老的 Google 硬纸板 VR 查看器一样,这个新的 AIY 视觉套件也使用一个硬纸板包装。这个套件和 [Cloud Vision API][8] 是不一样的,它使用了一个在 2015 年演示过的基于树莓派的 GoPiGo 机器人,它完全在本地的处理能力上运行,而不需要使用一个云端连接。这个 AIY 视觉套件现在可以 45 美元的价格去预订,将在 12 月份发货。
|
||||
为加速该设备上的神经网络,Google 的 AIY 视频套件继承了早期树莓派上运行的 [AIY 项目][7] 的语音/AI 套件,这个型号的树莓派随五月份的 MagPi 杂志一起赠送。与语音套件和老的 Google 硬纸板 VR 查看器一样,这个新的 AIY 视觉套件也使用一个硬纸板包装。这个套件和 [Cloud Vision API][8] 是不一样的,它使用了一个在 2015 年演示过的基于树莓派的 GoPiGo 机器人,它完全在本地的处理能力上运行,而不需要使用一个云端连接。这个 AIY 视觉套件现在可以 45 美元的价格去预订,将在 12 月份发货。
|
||||
|
||||
[][9] [][10]
|
||||
|
||||
[][9] [][10]
|
||||
**AIY 视觉套件,完整包装(左)和树莓派 Zero W**
|
||||
(点击图片放大)
|
||||
*AIY 视觉套件,完整包装(左)和树莓派 Zero W*
|
||||
|
||||
这个套件的主要处理部分除了所需要的 [树莓派 Zero W][21] 单片机之外 —— 一个基于 ARM11 的 1 GHz 的 Broadcom BCM2836 片上系统,另外的就是 Google 最新的 VisionBonnet RPi 附件板。这个 VisionBonnet pHAT 附件板使用了一个 Movidius MA2450,它是 [Movidius Myriad 2 VPU][22] 版的处理器。在 VisionBonnet 上,处理器为神经网络运行了 Google 的开源机器学习库 [TensorFlow][23]。因为这个芯片,使得视觉处理的速度最高达每秒 30 帧。
|
||||
|
||||
这个套件的主要处理部分除了所需要的 [树莓派 Zero W][21] 单片机之外 —— 一个基于 ARM11 的 1 GHz 的 Broadcom BCM2836 片上系统,另外的就是 Google 最新的 VisionBonnet RPi 附件板。这个 VisionBonnet pHAT 附件板使用了一个 Movidius MA2450,它是 [Movidius Myriad 2 VPU][22] 版的处理器。在 VisionBonnet 上,处理器为神经网络运行了 Google 的开源机器学习库 [TensorFlow][23]。因为这个芯片,便得视觉处理的速度最高达每秒 30 帧。
|
||||
|
||||
这个 AIY 视觉套件要求用户提供一个树莓派 Zero W、一个 [树莓派摄像机 v2][11]、以及一个 16GB 的 micro SD 卡,它用来下载基于 Linux 的 OS 镜像。这个套件包含了 VisionBonnet、一个 RGB 街机风格的按钮、一个压电扬声器、一个广角镜头套件、以及一个包裹它们的硬纸板。还有一些就是线缆、支架、安装螺母、以及连接部件。
|
||||
这个 AIY 视觉套件要求用户提供一个树莓派 Zero W、一个 [树莓派摄像机 v2][11]、以及一个 16GB 的 micro SD 卡,它用来下载基于 Linux 的 OS 镜像。这个套件包含了 VisionBonnet、一个 RGB 街机风格的按钮、一个压电扬声器、一个广角镜头套件、以及一个包裹它们的硬纸板。还有一些就是线缆、支架、安装螺母,以及连接部件。
|
||||
|
||||
|
||||
[][12] [][13]
|
||||
**AIY 视觉套件组件(左)和 VisonBonnet 附件板**
|
||||
(点击图片放大)
|
||||
|
||||
*AIY 视觉套件组件(左)和 VisonBonnet 附件板*
|
||||
|
||||
有三个可用的神经网络模型。一个是通用的模型,它可以识别常见的 1,000 个东西,一个是面部检测模型,它可以对 “快乐程度” 进行评分,从 “悲伤” 到 “大笑”,还有一个模型可以用来辨别图像内容是狗、猫、还是人。这个 1,000-image 模型源自 Google 的开源 [MobileNets][24],它是基于 TensorFlow 家族的计算机视觉模型,它设计用于资源受限的移动或者嵌入式设备。
|
||||
|
||||
MobileNet 模型是低延时、低功耗,和参数化的,以满足资源受限的不同使用案例。Google 说,这个模型可以用于构建分类、检测、嵌入、以及分隔。在本月的早些时候,Google 发布了一个开发者预览版,它是一个对 Android 和 iOS 移动设备友好的 [TensorFlow Lite][14] 库,它与 MobileNets 和 Android 神经网络 API 是兼容的。
|
||||
有三个可用的神经网络模型。一个是通用的模型,它可以识别常见的 1000 个东西,一个是面部检测模型,它可以对 “快乐程度” 进行评分,从 “悲伤” 到 “大笑”,还有一个模型可以用来辨别图像内容是狗、猫、还是人。这个 1000 个图片模型源自 Google 的开源 [MobileNets][24],它是基于 TensorFlow 家族的计算机视觉模型,它设计用于资源受限的移动或者嵌入式设备。
|
||||
|
||||
MobileNet 模型是低延时、低功耗,和参数化的,以满足资源受限的不同使用情景。Google 说,这个模型可以用于构建分类、检测、嵌入、以及分隔。在本月的早些时候,Google 发布了一个开发者预览版,它是一个对 Android 和 iOS 移动设备友好的 [TensorFlow Lite][14] 库,它与 MobileNets 和 Android 神经网络 API 是兼容的。
|
||||
|
||||
[][15]
|
||||
**AIY 视觉套件包装图**
|
||||
(点击图像放大)
|
||||
|
||||
*AIY 视觉套件包装图*
|
||||
|
||||
除了提供这三个模型之外,AIY 视觉套件还提供了基本的 TensorFlow 代码和一个编译器,因此用户可以去开发自己的模型。另外,Python 开发者可以写一些新软件去定制 RGB 按钮颜色、压电元素声音、以及在 VisionBonnet 上的 4x GPIO 针脚,它可以添加另外的指示灯、按钮、或者伺服机构。Potential 模型包括识别食物、基于可视化输入来打开一个狗门、当你的汽车偏离车道时发出文本信息、或者根据识别到的人的面部表情来播放特定的音乐。
|
||||
|
||||
|
||||
[][16] [][17]
|
||||
**Myriad 2 VPU 结构图(左)和参考板**
|
||||
(点击图像放大)
|
||||
|
||||
*Myriad 2 VPU 结构图(左)和参考板*
|
||||
|
||||
Movidius Myriad 2 处理器在一个标称 1W 的功耗下提供每秒万亿次浮点运算的性能。在被 Intel 收购之前,这个芯片最早出现在 Tango 项目的参考平台上,并内置在 2016 年 5 月由 Movidius 首次亮相的、Ubuntu 驱动的 USB 的 [Fathom][25] 神经网络处理棒中。根据 Movidius 的说法,Myriad 2 目前已经在 “市场上数百万的设备上使用”。
|
||||
|
||||
**更多信息**
|
||||
|
||||
AIY 视觉套件可以在 Micro Center 上预订,价格为 $44.99,预计在 12 月初发货。更多信息请参考 AIY 视觉套件的 [公告][18]、[Google 博客][19]、以及 [Micro Center 购物页面][20]。
|
||||
AIY 视觉套件可以在 Micro Center 上预订,价格为 $44.99,预计在(2017 年) 12 月初发货。更多信息请参考 AIY 视觉套件的 [公告][18]、[Google 博客][19]、以及 [Micro Center 购物页面][20]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
|
||||
作者:[ Eric Brown][a]
|
||||
作者:[Eric Brown][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
563
published/20180306 How To Check All Running Services In Linux.md
Normal file
563
published/20180306 How To Check All Running Services In Linux.md
Normal file
@ -0,0 +1,563 @@
|
||||
如何查看 Linux 中所有正在运行的服务
|
||||
======
|
||||
|
||||
有许多方法和工具可以查看 Linux 中所有正在运行的服务。大多数管理员会在 System V(SysV)初始化系统中使用 `service service-name status` 或 `/etc/init.d/service-name status`,而在 systemd 初始化系统中使用 `systemctl status service-name`。
|
||||
|
||||
以上命令可以清楚地显示该服务是否在服务器上运行,这也是每个 Linux 管理员都该知道的非常简单和基础的命令。
|
||||
|
||||
如果你对系统环境并不熟悉,也不清楚系统在运行哪些服务,你会如何检查?
|
||||
|
||||
是的,我们的确有必要这样检查一下。这将有助于我们了解系统上运行了什么服务,以及哪些是必要的、哪些需要被禁用。
|
||||
|
||||
init(<ruby>初始化<rt>initialization</rt></ruby>的简称)是在系统启动期间运行的第一个进程。`init` 是一个守护进程,它将持续运行直至关机。
|
||||
|
||||
大多数 Linux 发行版都使用如下的初始化系统之一:
|
||||
|
||||
- System V 是更老的初始化系统
|
||||
- Upstart 是一个基于事件的传统的初始化系统的替代品
|
||||
- systemd 是新的初始化系统,它已经被大多数最新的 Linux 发行版所采用
|
||||
|
||||
### 什么是 System V(SysV)
|
||||
|
||||
SysV(意即 System V) 初始化系统是早期传统的初始化系统和系统管理器。由于 sysVinit 系统上一些长期悬而未决的问题,大多数最新的发行版都适用于 systemd 系统。
|
||||
|
||||
### 什么是 Upstart 初始化系统
|
||||
|
||||
Upstart 是一个基于事件的 /sbin/init 的替代品,它控制在启动时的任务和服务的开始,在关机时停止它们,并在系统运行时监控它们。
|
||||
|
||||
它最初是为 Ubuntu 发行版开发的,但其是以适合所有 Linux 发行版的开发为目标的,以替换过时的 System-V 初始化系统。
|
||||
|
||||
### 什么是 systemd
|
||||
|
||||
systemd 是一个新的初始化系统以及系统管理器,它已成为大多数 Linux 发行版中非常流行且广泛适应的新的标准初始化系统。`systemctl` 是一个 systemd 管理工具,它可以帮助我们管理 systemd 系统。
|
||||
|
||||
### 方法一:如何在 System V(SysV)系统中查看运行的服务
|
||||
|
||||
以下命令可以帮助我们列出 System V(SysV) 系统中所有正在运行的服务。
|
||||
|
||||
如果服务很多,我建议使用文件查看命令,如 `less`、`more` 等,以便得到清晰的结果。
|
||||
|
||||
```
|
||||
# service --status-all
|
||||
或
|
||||
# service --status-all | more
|
||||
或
|
||||
# service --status-all | less
|
||||
```
|
||||
|
||||
```
|
||||
abrt-ccpp hook is installed
|
||||
abrtd (pid 2131) is running...
|
||||
abrt-dump-oops is stopped
|
||||
acpid (pid 1958) is running...
|
||||
atd (pid 2164) is running...
|
||||
auditd (pid 1731) is running...
|
||||
Frequency scaling enabled using ondemand governor
|
||||
crond (pid 2153) is running...
|
||||
hald (pid 1967) is running...
|
||||
htcacheclean is stopped
|
||||
httpd is stopped
|
||||
Table: filter
|
||||
Chain INPUT (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
1 ACCEPT all ::/0 ::/0 state RELATED,ESTABLISHED
|
||||
2 ACCEPT icmpv6 ::/0 ::/0
|
||||
3 ACCEPT all ::/0 ::/0
|
||||
4 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:80
|
||||
5 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:21
|
||||
6 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:22
|
||||
7 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:25
|
||||
8 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2082
|
||||
9 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2086
|
||||
10 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2083
|
||||
11 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2087
|
||||
12 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:10000
|
||||
13 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
1 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
|
||||
iptables: Firewall is not running.
|
||||
irqbalance (pid 1826) is running...
|
||||
Kdump is operational
|
||||
lvmetad is stopped
|
||||
mdmonitor is stopped
|
||||
messagebus (pid 1929) is running...
|
||||
SUCCESS! MySQL running (24376)
|
||||
rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
|
||||
named is stopped
|
||||
netconsole module not loaded
|
||||
Usage: startup.sh { start | stop }
|
||||
Configured devices:
|
||||
lo eth0 eth1
|
||||
Currently active devices:
|
||||
lo eth0
|
||||
ntpd is stopped
|
||||
portreserve (pid 1749) is running...
|
||||
master (pid 2107) is running...
|
||||
Process accounting is disabled.
|
||||
quota_nld is stopped
|
||||
rdisc is stopped
|
||||
rngd is stopped
|
||||
rpcbind (pid 1840) is running...
|
||||
rsyslogd (pid 1756) is running...
|
||||
sandbox is stopped
|
||||
saslauthd is stopped
|
||||
smartd is stopped
|
||||
openssh-daemon (pid 9859) is running...
|
||||
svnserve is stopped
|
||||
vsftpd (pid 4008) is running...
|
||||
xinetd (pid 2031) is running...
|
||||
zabbix_agentd (pid 2150 2149 2148 2147 2146 2140) is running...
|
||||
```
|
||||
|
||||
执行以下命令,可以只查看正在运行的服务:
|
||||
|
||||
```
|
||||
# service --status-all | grep running
|
||||
```
|
||||
|
||||
```
|
||||
crond (pid 535) is running...
|
||||
httpd (pid 627) is running...
|
||||
mysqld (pid 911) is running...
|
||||
rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
|
||||
rsyslogd (pid 449) is running...
|
||||
saslauthd (pid 492) is running...
|
||||
sendmail (pid 509) is running...
|
||||
sm-client (pid 519) is running...
|
||||
openssh-daemon (pid 478) is running...
|
||||
xinetd (pid 485) is running...
|
||||
```
|
||||
|
||||
运行以下命令以查看指定服务的状态:
|
||||
|
||||
```
|
||||
# service --status-all | grep httpd
|
||||
httpd (pid 627) is running...
|
||||
```
|
||||
|
||||
或者,使用以下命令也可以查看指定服务的状态:
|
||||
|
||||
```
|
||||
# service httpd status
|
||||
httpd (pid 627) is running...
|
||||
```
|
||||
|
||||
使用以下命令查看系统启动时哪些服务会被启用:
|
||||
|
||||
```
|
||||
# chkconfig --list
|
||||
```
|
||||
|
||||
```
|
||||
crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
htcacheclean 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
httpd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
|
||||
ip6tables 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
modules_dep 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
named 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
netconsole 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
netfs 0:off 1:off 2:off 3:off 4:on 5:on 6:off
|
||||
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
nmb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
nscd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
portreserve 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
quota_nld 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
rdisc 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
restorecond 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
rpcbind 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
saslauthd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
|
||||
sendmail 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
smb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
snmpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
snmptrapd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
udev-post 0:off 1:on 2:on 3:off 4:on 5:on 6:off
|
||||
winbind 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
xinetd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
||||
|
||||
xinetd based services:
|
||||
chargen-dgram: off
|
||||
chargen-stream: off
|
||||
daytime-dgram: off
|
||||
daytime-stream: off
|
||||
discard-dgram: off
|
||||
discard-stream: off
|
||||
echo-dgram: off
|
||||
echo-stream: off
|
||||
finger: off
|
||||
ntalk: off
|
||||
rsync: off
|
||||
talk: off
|
||||
tcpmux-server: off
|
||||
time-dgram: off
|
||||
time-stream: off
|
||||
```
|
||||
|
||||
### 方法二:如何在 System V(SysV)系统中查看运行的服务
|
||||
|
||||
另外一种在 Linux 系统上列出运行的服务的方法是使用 initctl 命令:
|
||||
|
||||
```
|
||||
# initctl list
|
||||
rc stop/waiting
|
||||
tty (/dev/tty3) start/running, process 1740
|
||||
tty (/dev/tty2) start/running, process 1738
|
||||
tty (/dev/tty1) start/running, process 1736
|
||||
tty (/dev/tty6) start/running, process 1746
|
||||
tty (/dev/tty5) start/running, process 1744
|
||||
tty (/dev/tty4) start/running, process 1742
|
||||
plymouth-shutdown stop/waiting
|
||||
control-alt-delete stop/waiting
|
||||
rcS-emergency stop/waiting
|
||||
readahead-collector stop/waiting
|
||||
kexec-disable stop/waiting
|
||||
quit-plymouth stop/waiting
|
||||
rcS stop/waiting
|
||||
prefdm stop/waiting
|
||||
init-system-dbus stop/waiting
|
||||
ck-log-system-restart stop/waiting
|
||||
readahead stop/waiting
|
||||
ck-log-system-start stop/waiting
|
||||
splash-manager stop/waiting
|
||||
start-ttys stop/waiting
|
||||
readahead-disable-services stop/waiting
|
||||
ck-log-system-stop stop/waiting
|
||||
rcS-sulogin stop/waiting
|
||||
serial stop/waiting
|
||||
```
|
||||
|
||||
### 方法三:如何在 systemd 系统中查看运行的服务
|
||||
|
||||
以下命令帮助我们列出 systemd 系统中所有服务:
|
||||
|
||||
```
|
||||
# systemctl
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
sys-devices-virtual-block-loop0.device loaded active plugged /sys/devices/virtual/block/loop0
|
||||
sys-devices-virtual-block-loop1.device loaded active plugged /sys/devices/virtual/block/loop1
|
||||
sys-devices-virtual-block-loop2.device loaded active plugged /sys/devices/virtual/block/loop2
|
||||
sys-devices-virtual-block-loop3.device loaded active plugged /sys/devices/virtual/block/loop3
|
||||
sys-devices-virtual-block-loop4.device loaded active plugged /sys/devices/virtual/block/loop4
|
||||
sys-devices-virtual-misc-rfkill.device loaded active plugged /sys/devices/virtual/misc/rfkill
|
||||
sys-devices-virtual-tty-ttyprintk.device loaded active plugged /sys/devices/virtual/tty/ttyprintk
|
||||
sys-module-fuse.device loaded active plugged /sys/module/fuse
|
||||
sys-subsystem-net-devices-enp0s3.device loaded active plugged 82540EM Gigabit Ethernet Controller (PRO/1000 MT Desktop Adapter)
|
||||
-.mount loaded active mounted Root Mount
|
||||
dev-hugepages.mount loaded active mounted Huge Pages File System
|
||||
dev-mqueue.mount loaded active mounted POSIX Message Queue File System
|
||||
run-user-1000-gvfs.mount loaded active mounted /run/user/1000/gvfs
|
||||
run-user-1000.mount loaded active mounted /run/user/1000
|
||||
snap-core-3887.mount loaded active mounted Mount unit for core
|
||||
snap-core-4017.mount loaded active mounted Mount unit for core
|
||||
snap-core-4110.mount loaded active mounted Mount unit for core
|
||||
snap-gping-13.mount loaded active mounted Mount unit for gping
|
||||
snap-termius\x2dapp-8.mount loaded active mounted Mount unit for termius-app
|
||||
sys-fs-fuse-connections.mount loaded active mounted FUSE Control File System
|
||||
sys-kernel-debug.mount loaded active mounted Debug File System
|
||||
acpid.path loaded active running ACPI Events Check
|
||||
cups.path loaded active running CUPS Scheduler
|
||||
systemd-ask-password-plymouth.path loaded active waiting Forward Password Requests to Plymouth Directory Watch
|
||||
systemd-ask-password-wall.path loaded active waiting Forward Password Requests to Wall Directory Watch
|
||||
init.scope loaded active running System and Service Manager
|
||||
session-c2.scope loaded active running Session c2 of user magi
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
anacron.service loaded active running Run anacron jobs
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
apparmor.service loaded active exited AppArmor initialization
|
||||
apport.service loaded active exited LSB: automatic crash report generation
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
console-setup.service loaded active exited Set console font and keymap
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
postfix.service loaded active exited Postfix Mail Transport Agent
|
||||
```
|
||||
* `UNIT` 相应的 systemd 单元名称
|
||||
* `LOAD` 相应的单元是否被加载到内存中
|
||||
* `ACTIVE` 该单元是否处于活动状态
|
||||
* `SUB` 该单元是否处于运行状态(LCTT 译注:是较于 ACTIVE 更加详细的状态描述,不同的单元类型有不同的状态。)
|
||||
* `DESCRIPTION` 关于该单元的简短描述
|
||||
|
||||
以下选项可根据类型列出单元:
|
||||
|
||||
```
|
||||
# systemctl list-units --type service
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
anacron.service loaded active running Run anacron jobs
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
apparmor.service loaded active exited AppArmor initialization
|
||||
apport.service loaded active exited LSB: automatic crash report generation
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
console-setup.service loaded active exited Set console font and keymap
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
fwupd.service loaded active running Firmware update daemon
|
||||
getty@tty1.service loaded active running Getty on tty1
|
||||
grub-common.service loaded active exited LSB: Record successful boot for GRUB
|
||||
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
|
||||
keyboard-setup.service loaded active exited Set the console keyboard layout
|
||||
kmod-static-nodes.service loaded active exited Create list of required static device nodes for the current kernel
|
||||
```
|
||||
|
||||
以下选项可帮助您根据状态列出单位,输出与前例类似但更直截了当:
|
||||
|
||||
```
|
||||
# systemctl list-unit-files --type service
|
||||
|
||||
UNIT FILE STATE
|
||||
accounts-daemon.service enabled
|
||||
acpid.service disabled
|
||||
alsa-restore.service static
|
||||
alsa-state.service static
|
||||
alsa-utils.service masked
|
||||
anacron-resume.service enabled
|
||||
anacron.service enabled
|
||||
apache-htcacheclean.service disabled
|
||||
apache-htcacheclean@.service disabled
|
||||
apache2.service enabled
|
||||
apache2@.service disabled
|
||||
apparmor.service enabled
|
||||
apport-forward@.service static
|
||||
apport.service generated
|
||||
apt-daily-upgrade.service static
|
||||
apt-daily.service static
|
||||
aptik-battery-monitor.service generated
|
||||
atop.service enabled
|
||||
atopacct.service enabled
|
||||
autovt@.service enabled
|
||||
avahi-daemon.service enabled
|
||||
bluetooth.service enabled
|
||||
```
|
||||
|
||||
运行以下命令以查看指定服务的状态:
|
||||
|
||||
```
|
||||
# systemctl | grep apache2
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
```
|
||||
|
||||
或者,使用以下命令也可查看指定服务的状态:
|
||||
|
||||
```
|
||||
# systemctl status apache2
|
||||
● apache2.service - The Apache HTTP Server
|
||||
Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: enabled)
|
||||
Drop-In: /lib/systemd/system/apache2.service.d
|
||||
└─apache2-systemd.conf
|
||||
Active: active (running) since Tue 2018-03-06 12:34:09 IST; 8min ago
|
||||
Process: 2786 ExecReload=/usr/sbin/apachectl graceful (code=exited, status=0/SUCCESS)
|
||||
Main PID: 1171 (apache2)
|
||||
Tasks: 55 (limit: 4915)
|
||||
CGroup: /system.slice/apache2.service
|
||||
├─1171 /usr/sbin/apache2 -k start
|
||||
├─2790 /usr/sbin/apache2 -k start
|
||||
└─2791 /usr/sbin/apache2 -k start
|
||||
|
||||
Mar 06 12:34:08 magi-VirtualBox systemd[1]: Starting The Apache HTTP Server...
|
||||
Mar 06 12:34:09 magi-VirtualBox apachectl[1089]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.0.2.15. Set the 'ServerName' directive globally to suppre
|
||||
Mar 06 12:34:09 magi-VirtualBox systemd[1]: Started The Apache HTTP Server.
|
||||
Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloading The Apache HTTP Server.
|
||||
Mar 06 12:39:10 magi-VirtualBox apachectl[2786]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using fe80::7929:4ed1:279f:4d65. Set the 'ServerName' directive gl
|
||||
Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloaded The Apache HTTP Server.
|
||||
```
|
||||
|
||||
执行以下命令,只查看正在运行的服务:
|
||||
```
|
||||
# systemctl | grep running
|
||||
acpid.path loaded active running ACPI Events Check
|
||||
cups.path loaded active running CUPS Scheduler
|
||||
init.scope loaded active running System and Service Manager
|
||||
session-c2.scope loaded active running Session c2 of user magi
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
fwupd.service loaded active running Firmware update daemon
|
||||
getty@tty1.service loaded active running Getty on tty1
|
||||
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
|
||||
lightdm.service loaded active running Light Display Manager
|
||||
ModemManager.service loaded active running Modem Manager
|
||||
NetworkManager.service loaded active running Network Manager
|
||||
polkit.service loaded active running Authorization Manager
|
||||
```
|
||||
|
||||
使用以下命令查看系统启动时会被启用的服务列表:
|
||||
|
||||
```
|
||||
# systemctl list-unit-files | grep enabled
|
||||
acpid.path enabled
|
||||
cups.path enabled
|
||||
accounts-daemon.service enabled
|
||||
anacron-resume.service enabled
|
||||
anacron.service enabled
|
||||
apache2.service enabled
|
||||
apparmor.service enabled
|
||||
atop.service enabled
|
||||
atopacct.service enabled
|
||||
autovt@.service enabled
|
||||
avahi-daemon.service enabled
|
||||
bluetooth.service enabled
|
||||
console-setup.service enabled
|
||||
cron.service enabled
|
||||
cups-browsed.service enabled
|
||||
cups.service enabled
|
||||
display-manager.service enabled
|
||||
dns-clean.service enabled
|
||||
friendly-recovery.service enabled
|
||||
getty@.service enabled
|
||||
gpu-manager.service enabled
|
||||
keyboard-setup.service enabled
|
||||
lightdm.service enabled
|
||||
ModemManager.service enabled
|
||||
network-manager.service enabled
|
||||
networking.service enabled
|
||||
NetworkManager-dispatcher.service enabled
|
||||
NetworkManager-wait-online.service enabled
|
||||
NetworkManager.service enabled
|
||||
```
|
||||
|
||||
`systemd-cgtop` 按资源使用情况(任务、CPU、内存、输入和输出)列出控制组:
|
||||
|
||||
```
|
||||
# systemd-cgtop
|
||||
|
||||
Control Group Tasks %CPU Memory Input/s Output/s
|
||||
/ - - 1.5G - -
|
||||
/init.scope 1 - - - -
|
||||
/system.slice 153 - - - -
|
||||
/system.slice/ModemManager.service 3 - - - -
|
||||
/system.slice/NetworkManager.service 4 - - - -
|
||||
/system.slice/accounts-daemon.service 3 - - - -
|
||||
/system.slice/acpid.service 1 - - - -
|
||||
/system.slice/apache2.service 55 - - - -
|
||||
/system.slice/aptik-battery-monitor.service 1 - - - -
|
||||
/system.slice/atop.service 1 - - - -
|
||||
/system.slice/atopacct.service 1 - - - -
|
||||
/system.slice/avahi-daemon.service 2 - - - -
|
||||
/system.slice/colord.service 3 - - - -
|
||||
/system.slice/cron.service 1 - - - -
|
||||
/system.slice/cups-browsed.service 3 - - - -
|
||||
/system.slice/cups.service 2 - - - -
|
||||
/system.slice/dbus.service 6 - - - -
|
||||
/system.slice/fwupd.service 5 - - - -
|
||||
/system.slice/irqbalance.service 1 - - - -
|
||||
/system.slice/lightdm.service 7 - - - -
|
||||
/system.slice/polkit.service 3 - - - -
|
||||
/system.slice/repowerd.service 14 - - - -
|
||||
/system.slice/rsyslog.service 4 - - - -
|
||||
/system.slice/rtkit-daemon.service 3 - - - -
|
||||
/system.slice/snapd.service 8 - - - -
|
||||
/system.slice/system-getty.slice 1 - - - -
|
||||
```
|
||||
|
||||
同时,我们可以使用 `pstree` 命令(输出来自 SysVinit 系统)查看正在运行的服务:
|
||||
|
||||
```
|
||||
# pstree
|
||||
init-+-crond
|
||||
|-httpd---2*[httpd]
|
||||
|-kthreadd/99149---khelper/99149
|
||||
|-2*[mingetty]
|
||||
|-mysqld_safe---mysqld---9*[{mysqld}]
|
||||
|-rsyslogd---3*[{rsyslogd}]
|
||||
|-saslauthd---saslauthd
|
||||
|-2*[sendmail]
|
||||
|-sshd---sshd---bash---pstree
|
||||
|-udevd
|
||||
`-xinetd
|
||||
```
|
||||
|
||||
我们还可以使用 `pstree` 命令(输出来自 systemd 系统)查看正在运行的服务:
|
||||
|
||||
```
|
||||
# pstree
|
||||
systemd─┬─ModemManager─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─NetworkManager─┬─dhclient
|
||||
│ ├─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─accounts-daemon─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─acpid
|
||||
├─agetty
|
||||
├─anacron
|
||||
├─apache2───2*[apache2───26*[{apache2}]]
|
||||
├─aptd───{gmain}
|
||||
├─aptik-battery-m
|
||||
├─atop
|
||||
├─atopacctd
|
||||
├─avahi-daemon───avahi-daemon
|
||||
├─colord─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─cron
|
||||
├─cups-browsed─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─cupsd
|
||||
├─dbus-daemon
|
||||
├─fwupd─┬─{GUsbEventThread}
|
||||
│ ├─{fwupd}
|
||||
│ ├─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─gnome-keyring-d─┬─{gdbus}
|
||||
│ ├─{gmain}
|
||||
│ └─{timer}
|
||||
```
|
||||
|
||||
### 方法四:如何使用 chkservice 在 systemd 系统中查看正在运行的服务
|
||||
|
||||
`chkservice` 是一个管理系统单元的终端工具,需要超级用户权限。
|
||||
|
||||
```
|
||||
# chkservice
|
||||
```
|
||||
|
||||
![][1]
|
||||
|
||||
要查看帮助页面,请按下 `?` ,它将显示管理 systemd 服务的可用选项。
|
||||
|
||||
![][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-1.png
|
||||
[2]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-2.png
|
||||
@ -0,0 +1,58 @@
|
||||
老树发新芽:微服务
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果我告诉你有这样一种软件架构,一个应用程序的组件通过基于网络的通讯协议为其它组件提供服务,我估计你可能会说它是 …
|
||||
|
||||
是的,它和你编程的年限有关。如果你从上世纪九十年代就开始了你的编程生涯,那么你肯定会说它是 <ruby>[面向服务的架构][1]<rt> Service-Oriented Architecture</rt></ruby>(SOA)。但是,如果你是个年青人,并且在云上获得初步的经验,那么,你将会说:“哦,你说的是 <ruby>[微服务][2]<rt>Microservices</rt></ruby>。”
|
||||
|
||||
你们都没错。如果想真正地了解它们的差别,你需要深入地研究这两种架构。
|
||||
|
||||
在 SOA 中,服务是一个功能,它是定义好的、自包含的、并且是不依赖上下文和其它服务的状态的功能。总共有两种服务。一种是消费者服务,它从另外类型的服务 —— 提供者服务 —— 中请求一个服务。一个 SOA 服务可以同时扮演这两种角色。
|
||||
|
||||
SOA 服务可以与其它服务交换数据。两个或多个服务也可以彼此之间相互协调。这些服务执行基本的任务,比如创建一个用户帐户、提供登录功能、或验证支付。
|
||||
|
||||
与其说 SOA 是模块化一个应用程序,还不如说它是把分布式的、独立维护和部署的组件,组合成一个应用程序。然后在服务器上运行这些组件。
|
||||
|
||||
早期版本的 SOA 使用面向对象的协议进行组件间通讯。例如,微软的 <ruby>[分布式组件对象模型][3]<rt> Distributed Component Object Model</rt></ruby>(DCOM) 和使用 <ruby>[通用对象请求代理架构][5]<rt>Common Object Request Broker Architecture</rt></ruby>(CORBA) 规范的 <ruby>[对象请求代理][4]<rt> Object Request Broker</rt></ruby>(ORB)。
|
||||
|
||||
用于消息服务的最新的版本,有 <ruby>[Java 消息服务][6]<rt> Java Message Service</rt></ruby>(JMS)或者 <ruby>[高级消息队列协议][7]<rt>Advanced Message Queuing Protocol</rt></ruby>(AMQP)。这些服务通过<ruby>企业服务总线<rt>Enterprise Service Bus</rt></ruby>(ESB) 进行连接。基于这些总线,来传递和接收可扩展标记语言(XML)格式的数据。
|
||||
|
||||
[微服务][2] 是一个架构样式,其中的应用程序以松散耦合的服务或模块组成。它适用于开发大型的、复杂的应用程序的<ruby>持续集成<rt>Continuous Integration</rt></ruby>/<ruby>持续部署<rt>Continuous Deployment</rt></ruby>(CI/CD)模型。一个应用程序就是一堆模块的汇总。
|
||||
|
||||
每个微服务提供一个应用程序编程接口(API)端点。它们通过轻量级协议连接,比如,<ruby>[表述性状态转移][8]<rt> REpresentational State Transfer</rt></ruby>(REST),或 [gRPC][9]。数据倾向于使用 <ruby>[JavaScript 对象标记][10]<rt> JavaScript Object Notation</rt></ruby>(JSON)或 [Protobuf][11] 来表示。
|
||||
|
||||
这两种架构都可以用于去替代以前老的整体式架构,整体式架构的应用程序被构建为单个的、自治的单元。例如,在一个客户机 —— 服务器模式中,一个典型的 Linux、Apache、MySQL、PHP/Python/Perl (LAMP) 服务器端应用程序将去处理 HTTP 请求、运行子程序、以及从底层的 MySQL 数据库中检索/更新数据。所有这些应用程序“绑”在一起提供服务。当你改变了任何一个东西,你都必须去构建和部署一个新版本。
|
||||
|
||||
使用 SOA,你可以只改变需要的几个组件,而不是整个应用程序。使用微服务,你可以做到一次只改变一个服务。使用微服务,你才能真正做到一个解耦架构。
|
||||
|
||||
微服务也比 SOA 更轻量级。不过 SOA 服务是部署到服务器和虚拟机上,而微服务是部署在容器中。协议也更轻量级。这使得微服务比 SOA 更灵活。因此,它更适合于要求敏捷性的电商网站。
|
||||
|
||||
说了这么多,到底意味着什么呢?微服务就是 SOA 在容器和云计算上的变种。
|
||||
|
||||
老式的 SOA 并没有离我们远去,而因为我们不断地将应用程序搬迁到容器中,所以微服务架构将越来越流行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blogs.dxc.technology/2018/05/08/everything-old-is-new-again-microservices/
|
||||
|
||||
作者:[Cloudy Weather][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blogs.dxc.technology/author/steven-vaughan-nichols/
|
||||
[1]:https://www.service-architecture.com/articles/web-services/service-oriented_architecture_soa_definition.html
|
||||
[2]:http://microservices.io/
|
||||
[3]:https://technet.microsoft.com/en-us/library/cc958799.aspx
|
||||
[4]:https://searchmicroservices.techtarget.com/definition/Object-Request-Broker-ORB
|
||||
[5]:http://www.corba.org/
|
||||
[6]:https://docs.oracle.com/javaee/6/tutorial/doc/bncdq.html
|
||||
[7]:https://www.amqp.org/
|
||||
[8]:https://www.service-architecture.com/articles/web-services/representational_state_transfer_rest.html
|
||||
[9]:https://grpc.io/
|
||||
[10]:https://www.json.org/
|
||||
[11]:https://github.com/google/protobuf/
|
||||
@ -1,40 +1,41 @@
|
||||
UKTools - 安装最新 Linux 内核的简便方法
|
||||
UKTools:安装最新 Linux 内核的简便方法
|
||||
======
|
||||
|
||||
Ubuntu 中有许多实用程序可以将 Linux 内核升级到最新的稳定版本。我们之前已经写过关于这些实用程序的文章,例如 Linux Kernel Utilities (LKU), Ubuntu Kernel Upgrade Utility (UKUU) 和 Ubunsys。
|
||||
Ubuntu 中有许多实用程序可以将 Linux 内核升级到最新的稳定版本。我们之前已经写过关于这些实用程序的文章,例如 Linux Kernel Utilities (LKU)、 Ubuntu Kernel Upgrade Utility (UKUU) 和 Ubunsys。
|
||||
|
||||
另外还有一些其它实用程序可供使用。我们计划在其它文章中包含这些,例如 `ubuntu-mainline-kernel.sh` 和从主线内核手动安装的方式。
|
||||
|
||||
另外还有一些其它实用程序可供使用。我们计划在其它文章中包含这些,例如 ubuntu-mainline-kernel.sh 和 manual method from mainline kernel.
|
||||
今天我们还会教你类似的使用工具 —— UKTools。你可以尝试使用这些实用程序中的任何一个来将 Linux 内核升级至最新版本。
|
||||
|
||||
今天我们还会教你类似的使用工具 -- UKTools。你可以尝试使用这些实用程序中的任何一个来将 Linux 内核升级至最新版本。
|
||||
|
||||
最新的内核版本附带了安全漏洞修复和一些改进,因此,最好保持最新的内核版本以获得可靠,安全和更好的硬件性能。
|
||||
最新的内核版本附带了安全漏洞修复和一些改进,因此,最好保持最新的内核版本以获得可靠、安全和更好的硬件性能。
|
||||
|
||||
有时候最新的内核版本可能会有一些漏洞,并且会导致系统崩溃,这是你的风险。我建议你不要在生产环境中安装它。
|
||||
|
||||
**建议阅读:**
|
||||
**(#)** [Linux 内核实用程序(LKU)- 在 Ubuntu/LinuxMint 中编译,安装和更新最新内核的一组 Shell 脚本][1]
|
||||
**(#)** [Ukuu - 在基于 Ubuntu 的系统中安装或升级 Linux 内核的简便方法][2]
|
||||
**(#)** [6 种检查系统上正在运行的 Linux 内核版本的方法][3]
|
||||
**建议阅读:**
|
||||
|
||||
- [Linux 内核实用程序(LKU)- 在 Ubuntu/LinuxMint 中编译,安装和更新最新内核的一组 Shell 脚本][1]
|
||||
- [Ukuu - 在基于 Ubuntu 的系统中安装或升级 Linux 内核的简便方法][2]
|
||||
- [6 种检查系统上正在运行的 Linux 内核版本的方法][3]
|
||||
|
||||
### 什么是 UKTools
|
||||
|
||||
[UKTools][4] 意思是 Ubuntu 内核工具,它包含两个 shell 脚本 `ukupgrade` 和 `ukpurge`。
|
||||
|
||||
ukupgrade 意思是 “Ubuntu Kernel Upgrade”,它允许用户将 Linux 内核升级到 Ubuntu/Mint 的最新稳定版本以及基于 [kernel.ubuntu.com][5] 的衍生版本。
|
||||
`ukupgrade` 意思是 “Ubuntu Kernel Upgrade”,它允许用户将 Linux 内核升级到 Ubuntu/Mint 的最新稳定版本以及基于 [kernel.ubuntu.com][5] 的衍生版本。
|
||||
|
||||
ukpurge 意思是 “Ubuntu Kernel Purge”,它允许用户在机器中删除旧的 Linux 内核镜像或头文件,用于 Ubuntu/Mint 和其衍生版本。它将只保留三个内核版本。
|
||||
`ukpurge` 意思是 “Ubuntu Kernel Purge”,它允许用户在机器中删除旧的 Linux 内核镜像或头文件,用于 Ubuntu/Mint 和其衍生版本。它将只保留三个内核版本。
|
||||
|
||||
此实用程序没有 GUI,但它看起来非常简单直接,因此,新手可以在没有任何问题的情况下进行升级。
|
||||
|
||||
我正在运行 Ubuntu 17.10,目前的内核版本如下:
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
Linux ubuntu 4.13.0-39-generic #44-Ubuntu SMP Thu Apr 5 14:25:01 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
|
||||
|
||||
```
|
||||
|
||||
运行以下命令来获取系统上已安装内核的列表(Ubuntu 及其衍生产品)。目前我持有 `7` 个内核。
|
||||
|
||||
```
|
||||
$ dpkg --list | grep linux-image
|
||||
ii linux-image-4.13.0-16-generic 4.13.0-16.19 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
|
||||
@ -52,7 +53,6 @@ ii linux-image-extra-4.13.0-37-generic 4.13.0-37.42 amd64 Linux kernel extra mod
|
||||
ii linux-image-extra-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
|
||||
ii linux-image-extra-4.13.0-39-generic 4.13.0-39.44 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
|
||||
ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
|
||||
|
||||
```
|
||||
|
||||
### 如何安装 UKTools
|
||||
@ -60,18 +60,19 @@ ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
|
||||
在 Ubuntu 及其衍生产品上,只需运行以下命令来安装 UKTools 即可。
|
||||
|
||||
在你的系统上运行以下命令来克隆 UKTools 仓库:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/usbkey9/uktools
|
||||
|
||||
```
|
||||
|
||||
进入 uktools 目录:
|
||||
|
||||
```
|
||||
$ cd uktools
|
||||
|
||||
```
|
||||
|
||||
运行 Makefile 以生成必要的文件。此外,这将自动安装最新的可用内核。只需重新启动系统即可使用最新的内核。
|
||||
运行 `Makefile` 以生成必要的文件。此外,这将自动安装最新的可用内核。只需重新启动系统即可使用最新的内核。
|
||||
|
||||
```
|
||||
$ sudo make
|
||||
[sudo] password for daygeek:
|
||||
@ -188,30 +189,30 @@ done
|
||||
|
||||
Thanks for using this script! Hope it helped.
|
||||
Give it a star: https://github.com/MarauderXtreme/uktools
|
||||
|
||||
```
|
||||
|
||||
重新启动系统以激活最新的内核。
|
||||
|
||||
```
|
||||
$ sudo shutdown -r now
|
||||
|
||||
```
|
||||
|
||||
一旦系统重新启动,重新检查内核版本。
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
Linux ubuntu 4.16.7-041607-generic #201805021131 SMP Wed May 2 15:34:55 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
|
||||
|
||||
```
|
||||
|
||||
此 make 命令会将下面的文件放到 `/usr/local/bin` 目录中。
|
||||
|
||||
```
|
||||
do-kernel-upgrade
|
||||
do-kernel-purge
|
||||
|
||||
```
|
||||
|
||||
要移除旧内核,运行以下命令:
|
||||
|
||||
```
|
||||
$ do-kernel-purge
|
||||
|
||||
@ -364,10 +365,10 @@ run-parts: executing /etc/kernel/postrm.d/initramfs-tools 4.13.0-37-generic /boo
|
||||
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
|
||||
|
||||
Thanks for using this script!!!
|
||||
|
||||
```
|
||||
|
||||
使用以下命令重新检查已安装内核的列表。它将只保留三个旧的内核。
|
||||
|
||||
```
|
||||
$ dpkg --list | grep linux-image
|
||||
ii linux-image-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
|
||||
@ -376,14 +377,13 @@ ii linux-image-extra-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel extra mod
|
||||
ii linux-image-extra-4.13.0-39-generic 4.13.0-39.44 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
|
||||
ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
|
||||
ii linux-image-unsigned-4.16.7-041607-generic 4.16.7-041607.201805021131 amd64 Linux kernel image for version 4.16.7 on 64 bit x86 SMP
|
||||
|
||||
```
|
||||
|
||||
下次你可以调用 `do-kernel-upgrade` 实用程序来安装新的内核。如果有任何新内核可用,那么它将安装。如果没有,它将报告当前没有可用的内核更新。
|
||||
|
||||
```
|
||||
$ do-kernel-upgrade
|
||||
Kernel up to date. Finishing
|
||||
|
||||
```
|
||||
|
||||
再次运行 `do-kernel-purge` 命令以确认。如果发现超过三个内核,那么它将移除。如果不是,它将报告没有删除消息。
|
||||
@ -400,7 +400,6 @@ Linux Kernel 4.16.7-041607 Generic (linux-image-4.16.7-041607-generic)
|
||||
Nothing to remove!
|
||||
|
||||
Thanks for using this script!!!
|
||||
|
||||
```
|
||||
|
||||
|
||||
@ -411,7 +410,7 @@ via: https://www.2daygeek.com/uktools-easy-way-to-install-latest-stable-linux-ke
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,51 +1,52 @@
|
||||
献给 Debian 和 Ubuntu 用户的一组实用程序
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
你使用的是基于 Debian 的系统吗?如果是,太好了!我今天在这里给你带来了一个好消息。先向 **“Debian-goodies”** 打个招呼,这是一组基于 Debian 系统(比如:Ubuntu, Linux Mint)的有用工具。这些实用工具提供了一些额外的有用的命令,这些命令在基于 Debian 的系统中默认不可用。通过使用这些工具,用户可以找到哪些程序占用更多磁盘空间,更新系统后需要重新启动哪些服务,在一个包中搜索与模式匹配的文件,根据搜索字符串列出已安装的包等等。在这个简短的指南中,我们将讨论一些有用的 Debian 的好东西。
|
||||
你使用的是基于 Debian 的系统吗?如果是,太好了!我今天在这里给你带来了一个好消息。先向 “Debian-goodies” 打个招呼,这是一组基于 Debian 系统(比如:Ubuntu、Linux Mint)的有用工具。这些实用工具提供了一些额外的有用的命令,这些命令在基于 Debian 的系统中默认不可用。通过使用这些工具,用户可以找到哪些程序占用更多磁盘空间,更新系统后需要重新启动哪些服务,在一个软件包中搜索与模式匹配的文件,根据搜索字符串列出已安装的包等等。在这个简短的指南中,我们将讨论一些有用的 Debian 的好东西。
|
||||
|
||||
### Debian-goodies – 给 Debian 和 Ubuntu 用户的实用程序
|
||||
|
||||
debian-goodies 包可以在 Debian 和其衍生的 Ubuntu 以及其它 Ubuntu 变体(如 Linux Mint)的官方仓库中找到。要安装 debian-goodies,只需简单运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get install debian-goodies
|
||||
|
||||
```
|
||||
|
||||
debian-goodies 安装完成后,让我们继续看一看一些有用的实用程序。
|
||||
|
||||
#### **1. Checkrestart**
|
||||
#### 1、 checkrestart
|
||||
|
||||
让我从我最喜欢的 **“checkrestart”** 实用程序开始。安装某些安全更新时,某些正在运行的应用程序可能仍然会使用旧库。要彻底应用安全更新,你需要查找并重新启动所有这些更新。这就是 Checkrestart 派上用场的地方。该实用程序将查找哪些进程仍在使用旧版本的库,然后,你可以重新启动服务。
|
||||
让我从我最喜欢的 `checkrestart` 实用程序开始。安装某些安全更新时,某些正在运行的应用程序可能仍然会使用旧库。要彻底应用安全更新,你需要查找并重新启动所有这些更新。这就是 `checkrestart` 派上用场的地方。该实用程序将查找哪些进程仍在使用旧版本的库,然后,你可以重新启动服务。
|
||||
|
||||
在进行库更新后,要检查哪些守护进程应该被重新启动,运行:
|
||||
|
||||
```
|
||||
$ sudo checkrestart
|
||||
[sudo] password for sk:
|
||||
Found 0 processes using old versions of upgraded files
|
||||
|
||||
```
|
||||
|
||||
由于我最近没有执行任何安全更新,因此没有显示任何内容。
|
||||
|
||||
请注意,Checkrestart 实用程序确实运行良好。但是,有一个名为 “needrestart” 的类似工具可用于最新的 Debian 系统。Needrestart 的灵感来自 checkrestart 实用程序,它完成了同样的工作。 Needrestart 得到了积极维护,并支持容器(LXC, Docker)等新技术。
|
||||
请注意,`checkrestart` 实用程序确实运行良好。但是,有一个名为 `needrestart` 的类似的新工具可用于最新的 Debian 系统。`needrestart` 的灵感来自 `checkrestart` 实用程序,它完成了同样的工作。 `needrestart` 得到了积极维护,并支持容器(LXC、 Docker)等新技术。
|
||||
|
||||
以下是 Needrestart 的特点:
|
||||
以下是 `needrestart` 的特点:
|
||||
|
||||
* 支持(当不要求)systemd
|
||||
* 二进制黑名单(即显示管理员)
|
||||
* 试图检测挂起的内核升级
|
||||
* 尝试检测基于解释器的守护进程所需的重启(支持 Perl, Python, Ruby)
|
||||
* 支持(但不要求)systemd
|
||||
* 二进制程序的黑名单(例如:用于图形显示的显示管理器)
|
||||
* 尝试检测挂起的内核升级
|
||||
* 尝试检测基于解释器的守护进程所需的重启(支持 Perl、Python、Ruby)
|
||||
* 使用钩子完全集成到 apt/dpkg 中
|
||||
|
||||
它在默认仓库中也可以使用。所以,你可以使用如下命令安装它:
|
||||
|
||||
```
|
||||
$ sudo apt-get install needrestart
|
||||
|
||||
```
|
||||
|
||||
现在,你可以使用以下命令检查更新系统后需要重新启动的守护程序列表:
|
||||
|
||||
```
|
||||
$ sudo needrestart
|
||||
Scanning processes...
|
||||
@ -60,26 +61,26 @@ No services need to be restarted.
|
||||
No containers need to be restarted.
|
||||
|
||||
No user sessions are running outdated binaries.
|
||||
|
||||
```
|
||||
|
||||
好消息是 Needrestart 同样也适用于其它 Linux 发行版。例如,你可以从 Arch Linux 及其衍生版的 AUR 或者其它任何 AUR 帮助程序来安装,就像下面这样:
|
||||
|
||||
```
|
||||
$ yaourt -S needrestart
|
||||
|
||||
```
|
||||
|
||||
在 fedora:
|
||||
在 Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install needrestart
|
||||
|
||||
```
|
||||
|
||||
#### 2. Check-enhancements
|
||||
#### 2、 check-enhancements
|
||||
|
||||
Check-enhancements 实用程序用于查找那些用于增强已安装的包的软件包。此实用程序将列出增强其它包但不是必须运行它的包。你可以通过 “-ip” 或 “–installed-packages” 选项来查找增强单个包或所有已安装包的软件包。
|
||||
`check-enhancements` 实用程序用于查找那些用于增强已安装的包的软件包。此实用程序将列出增强其它包但不是必须运行它的包。你可以通过 `-ip` 或 `–installed-packages` 选项来查找增强单个包或所有已安装包的软件包。
|
||||
|
||||
例如,我将列出增强 gimp 包功能的包:
|
||||
|
||||
```
|
||||
$ check-enhancements gimp
|
||||
gimp => gimp-data: Installed: (none) Candidate: 2.8.22-1
|
||||
@ -102,10 +103,10 @@ gimp => gimp-help-sl: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-help-sv: Installed: (none) Candidate: 2.8.2-0.1
|
||||
gimp => gimp-plugin-registry: Installed: (none) Candidate: 7.20140602ubuntu3
|
||||
gimp => xcftools: Installed: (none) Candidate: 1.0.7-6
|
||||
|
||||
```
|
||||
|
||||
要列出增强所有已安装包的,请运行:
|
||||
|
||||
```
|
||||
$ check-enhancements -ip
|
||||
autoconf => autoconf-archive: Installed: (none) Candidate: 20170928-2
|
||||
@ -114,12 +115,12 @@ ca-certificates => ca-cacert: Installed: (none) Candidate: 2011.0523-2
|
||||
cryptsetup => mandos-client: Installed: (none) Candidate: 1.7.19-1
|
||||
dpkg => debsig-verify: Installed: (none) Candidate: 0.18
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
#### 3. dgrep
|
||||
#### 3、 dgrep
|
||||
|
||||
顾名思义,`dgrep` 用于根据给定的正则表达式搜索制指定包的所有文件。例如,我将在 Vim 包中搜索包含正则表达式 “text” 的文件。
|
||||
|
||||
顾名思义,dgrep 用于根据给定的正则表达式搜索制指定包的所有文件。例如,我将在 Vim 包中搜索包含正则表达式 “text” 的文件。
|
||||
```
|
||||
$ sudo dgrep "text" vim
|
||||
Binary file /usr/bin/vim.tiny matches
|
||||
@ -131,44 +132,44 @@ Binary file /usr/bin/vim.tiny matches
|
||||
/usr/share/doc/vim-tiny/copyright: context diff will do. The e-mail address to be used is
|
||||
/usr/share/doc/vim-tiny/copyright: On Debian systems, the complete text of the GPL version 2 license can be
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
dgrep 支持大多数 grep 的选项。参阅以下指南以了解 grep 命令。
|
||||
`dgrep` 支持大多数 `grep` 的选项。参阅以下指南以了解 `grep` 命令。
|
||||
|
||||
* [献给初学者的 Grep 命令教程][2]
|
||||
|
||||
#### 4 dglob
|
||||
#### 4、 dglob
|
||||
|
||||
`dglob` 实用程序生成与给定模式匹配的包名称列表。例如,找到与字符串 “vim” 匹配的包列表。
|
||||
|
||||
dglob 实用程序生成与给定模式匹配的包名称列表。例如,找到与字符串 “vim” 匹配的包列表。
|
||||
```
|
||||
$ sudo dglob vim
|
||||
vim-tiny:amd64
|
||||
vim:amd64
|
||||
vim-common:all
|
||||
vim-runtime:all
|
||||
|
||||
```
|
||||
|
||||
默认情况下,dglob 将仅显示已安装的软件包。如果要列出所有包(包括已安装的和未安装的),使用 **-a** 标志。
|
||||
默认情况下,`dglob` 将仅显示已安装的软件包。如果要列出所有包(包括已安装的和未安装的),使用 `-a` 标志。
|
||||
|
||||
```
|
||||
$ sudo dglob vim -a
|
||||
|
||||
```
|
||||
|
||||
#### 5. debget
|
||||
#### 5、 debget
|
||||
|
||||
`debget` 实用程序将在 APT 的数据库中下载一个包的 .deb 文件。请注意,它只会下载给定的包,不包括依赖项。
|
||||
|
||||
**debget** 实用程序将在 APT 的数据库中下载一个包的 .deb 文件。请注意,它只会下载给定的包,不包括依赖项。
|
||||
```
|
||||
$ debget nano
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 nano amd64 2.9.3-2 [231 kB]
|
||||
Fetched 231 kB in 2s (113 kB/s)
|
||||
|
||||
```
|
||||
|
||||
#### 6. dpigs
|
||||
#### 6、 dpigs
|
||||
|
||||
这是此次集合中另一个有用的实用程序。`dpigs` 实用程序将查找并显示那些占用磁盘空间最多的已安装包。
|
||||
|
||||
这是此次集合中另一个有用的实用程序。**dpigs** 实用程序将查找并显示那些占用磁盘空间最多的已安装包。
|
||||
```
|
||||
$ dpigs
|
||||
260644 linux-firmware
|
||||
@ -181,64 +182,66 @@ $ dpigs
|
||||
28420 vim-runtime
|
||||
25971 gcc-7
|
||||
24349 g++-7
|
||||
|
||||
```
|
||||
|
||||
如你所见,linux-firmware 包占用的磁盘空间最多。默认情况下,它将显示占用磁盘空间的 **前 10 个**包。如果要显示更多包,例如 20 个,运行以下命令:
|
||||
|
||||
```
|
||||
$ dpigs -n 20
|
||||
|
||||
```
|
||||
|
||||
#### 7. debman
|
||||
|
||||
**debman** 实用程序允许你轻松查看二进制文件 **.deb** 中的手册页而不提取它。你甚至不需要安装 .deb 包。以下命令显示 nano 包的手册页。
|
||||
`debman` 实用程序允许你轻松查看二进制文件 .deb 中的手册页而不提取它。你甚至不需要安装 .deb 包。以下命令显示 nano 包的手册页。
|
||||
|
||||
```
|
||||
$ debman -f nano_2.9.3-2_amd64.deb nano
|
||||
|
||||
```
|
||||
如果你没有 .deb 软件包的本地副本,使用 **-p** 标志下载并查看包的手册页。
|
||||
|
||||
如果你没有 .deb 软件包的本地副本,使用 `-p` 标志下载并查看包的手册页。
|
||||
|
||||
```
|
||||
$ debman -p nano nano
|
||||
|
||||
```
|
||||
|
||||
**建议阅读:**
|
||||
[每个 Linux 用户都应该知道的 3 个 man 的替代品][3]
|
||||
|
||||
#### 8. debmany
|
||||
- [每个 Linux 用户都应该知道的 3 个 man 的替代品][3]
|
||||
|
||||
#### 8、 debmany
|
||||
|
||||
安装的 Debian 包不仅包含手册页,还包括其它文件,如确认、版权和自述文件等。`debmany` 实用程序允许你查看和读取那些文件。
|
||||
|
||||
安装的 Debian 包不仅包含手册页,还包括其它文件,如确认,版权和 read me (自述文件)等。**debmany** 实用程序允许你查看和读取那些文件。
|
||||
```
|
||||
$ debmany vim
|
||||
|
||||
```
|
||||
|
||||
![][1]
|
||||
|
||||
使用方向键选择要查看的文件,然后按 ENTER 键查看所选文件。按 **q** 返回主菜单。
|
||||
使用方向键选择要查看的文件,然后按回车键查看所选文件。按 `q` 返回主菜单。
|
||||
|
||||
如果未安装指定的软件包,debmany 将从 APT 数据库下载并显示手册页。应安装 **dialog** 包来阅读手册页。
|
||||
如果未安装指定的软件包,`debmany` 将从 APT 数据库下载并显示手册页。应安装 `dialog` 包来阅读手册页。
|
||||
|
||||
#### 9. popbugs
|
||||
#### 9、 popbugs
|
||||
|
||||
如果你是开发人员,**popbugs** 实用程序将非常有用。它将根据你使用的包显示一个定制的发布关键 bug 列表(使用热门竞赛数据)。对于那些不关心的人,Popular-contest 包设置了一个 cron (定时)任务,它将定期匿名向 Debian 开发人员提交有关该系统上最常用的 Debian 软件包的统计信息。这些信息有助于 Debian 做出决定,例如哪些软件包应该放在第一张 CD 上。它还允许 Debian 改进未来的发行版本,以便为新用户自动安装最流行的软件包。
|
||||
如果你是开发人员,`popbugs` 实用程序将非常有用。它将根据你使用的包显示一个定制的发布关键 bug 列表(使用 popularity-contest 数据)。对于那些不关心的人,popularity-contest 包设置了一个 cron (定时)任务,它将定期匿名向 Debian 开发人员提交有关该系统上最常用的 Debian 软件包的统计信息。这些信息有助于 Debian 做出决定,例如哪些软件包应该放在第一张 CD 上。它还允许 Debian 改进未来的发行版本,以便为新用户自动安装最流行的软件包。
|
||||
|
||||
要生成严重 bug 列表并在默认 Web 浏览器中显示结果,运行:
|
||||
|
||||
```
|
||||
$ popbugs
|
||||
|
||||
```
|
||||
|
||||
此外,你可以将结果保存在文件中,如下所示。
|
||||
|
||||
```
|
||||
$ popbugs --output=bugs.txt
|
||||
|
||||
```
|
||||
|
||||
#### 10. which-pkg-broke
|
||||
#### 10、 which-pkg-broke
|
||||
|
||||
此命令将显示给定包的所有依赖项以及安装每个依赖项的时间。通过使用此信息,你可以在升级系统或软件包之后轻松找到哪个包可能会在什么时间损坏了另一个包。
|
||||
|
||||
此命令将显示给定包的所有依赖项以及安装每个依赖项的时间。通过使用此信息,你可以在升级系统或软件包之后轻松找到哪个包可能会在什么时间损坏另一个包。
|
||||
```
|
||||
$ which-pkg-broke vim
|
||||
Package <debconf-2.0> has no install time info
|
||||
@ -253,15 +256,14 @@ libgcc1:amd64 Wed Apr 25 08:08:42 2018
|
||||
liblzma5:amd64 Wed Apr 25 08:08:42 2018
|
||||
libdb5.3:amd64 Wed Apr 25 08:08:42 2018
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
#### 11. dhomepage
|
||||
#### 11、 dhomepage
|
||||
|
||||
`dhomepage` 实用程序将在默认 Web 浏览器中显示给定包的官方网站。例如,以下命令将打开 Vim 编辑器的主页。
|
||||
|
||||
dhomepage 实用程序将在默认 Web 浏览器中显示给定包的官方网站。例如,以下命令将打开 Vim 编辑器的主页。
|
||||
```
|
||||
$ dhomepage vim
|
||||
|
||||
```
|
||||
|
||||
这就是全部了。Debian-goodies 是你武器库中必备的工具。即使我们不经常使用所有这些实用程序,但它们值得学习,我相信它们有时会非常有用。
|
||||
@ -278,7 +280,7 @@ via: https://www.ostechnix.com/debian-goodies-a-set-of-useful-utilities-for-debi
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,18 +2,16 @@
|
||||
============================================================
|
||||
|
||||

|
||||
>欧洲核子研究组织(简称 CERN)依靠开源技术处理大型强子对撞机生成的大量数据。ATLAS(超环面仪器,如图所示)是一种探测基本粒子的通用探测器。(图片来源:CERN)[经许可使用][2]
|
||||
|
||||
>欧洲核子研究组织(简称 CERN)依靠开源技术处理大型强子对撞机生成的大量数据。ATLAS(超环面仪器,如图所示)是一种探测基本粒子的通用探测器。(图片来源:CERN)
|
||||
|
||||
[CERN][3]
|
||||
|
||||
[CERN][6] 无需过多介绍了吧。CERN 创建了万维网和大型强子对撞机(LHC),这是世界上最大的粒子加速器,就是通过它发现了 [希格斯玻色子][7]。负责该组织 IT 操作系统和基础架构的 Tim Bell 表示,他的团队的目标是“为全球 13000 名物理学家提供计算设施,以分析这些碰撞、了解宇宙的构成以及是如何运转的。”
|
||||
[CERN][6] 无需过多介绍了吧。CERN 创建了<ruby>万维网<rt>World Wide Web</rt></ruby>(WWW)和<ruby>大型强子对撞机<rt>Large Hadron Collider</rt></ruby>(LHC),这是世界上最大的<ruby>粒子加速器<rt>particle accelerator</rt></ruby>,就是通过它发现了 <ruby>[希格斯玻色子][7]<rt>Higgs boson</rt></ruby>。负责该组织 IT 操作系统和基础架构的 Tim Bell 表示,他的团队的目标是“为全球 13000 名物理学家提供计算设施,以分析这些碰撞,了解宇宙的构成以及是如何运转的。”
|
||||
|
||||
CERN 正在进行硬核科学研究,尤其是大型强子对撞机,它在运行时 [生成大量数据][8]。“CERN 目前存储大约 200 PB 的数据,当加速器运行时,每月有超过 10 PB 的数据产生。这必然会给计算基础架构带来极大的挑战,包括存储大量数据,以及能够在合理的时间范围内处理数据,对于网络、存储技术和高效计算架构都是很大的压力。“Bell 说到。
|
||||
|
||||
### [tim-bell-cern.png][4]
|
||||

|
||||
|
||||

|
||||
Tim Bell, CERN [经许可使用][1] Swapnil Bhartiya
|
||||
*Tim Bell, CERN*
|
||||
|
||||
大型强子对撞机的运作规模和它产生的数据量带来了严峻的挑战,但 CERN 对这些问题并不陌生。CERN 成立于 1954 年,已经 60 余年了。“我们一直面临着难以解决的计算能力挑战,但我们一直在与开源社区合作解决这些问题。”Bell 说,“即使在 90 年代,当我们发明万维网时,我们也希望与人们共享,使其能够从 CERN 的研究中受益,开源是做这件事的再合适不过的工具了。”
|
||||
|
||||
@ -29,19 +27,20 @@ CERN 帮助 CentOS 提供基础架构,他们还组织了 CentOS DoJo 活动(
|
||||
|
||||
除了 OpenStack 和 CentOS 之外,CERN 还是其他开源项目的深度用户,包括用于配置管理的 Puppet、用于监控的 Grafana 和 InfluxDB,等等。
|
||||
|
||||
“我们与全球约 170 个实验室合作。因此,每当我们发现一个开源项目的可完善之处,其他实验室便可以很容易地采纳使用。“Bell 说,”与此同时,我们也向其他项目学习。当像 eBay 和 Rackspace 这样大规模的安装提高了解决方案的可扩展性时,我们也从中受益,也可以扩大规模。“
|
||||
“我们与全球约 170 个实验室合作。因此,每当我们发现一个开源项目的改进之处,其他实验室便可以很容易地采纳使用。”Bell 说,“与此同时,我们也向其他项目学习。当像 eBay 和 Rackspace 这样大规模的装机量提高了解决方案的可扩展性时,我们也从中受益,也可以扩大规模。“
|
||||
|
||||
### 解决现实问题
|
||||
|
||||
2012 年左右,CERN 正在研究如何为大型强子对撞机扩展计算能力,但难点是人员而不是技术。CERN 雇用的员工人数是固定的。“我们必须找到一种方法来扩展计算能力,而不需要大量额外的人来管理。”Bell 说,“OpenStack 为我们提供了一个自动的 API 驱动和软件定义的基础架构。”OpenStack 还帮助 CERN 检查与服务交付相关的问题,然后使其自动化,而无需增加员工。
|
||||
|
||||
“我们目前在日内瓦和布达佩斯的两个数据中心运行大约 280000 个核心(cores)和 7000 台服务器。我们正在使用软件定义的基础架构使一切自动化,这使我们能够在保持员工数量不变的同时继续添加更多的服务器。“Bell 说。
|
||||
“我们目前在日内瓦和布达佩斯的两个数据中心运行大约 280000 个处理器核心和 7000 台服务器。我们正在使用软件定义的基础架构使一切自动化,这使我们能够在保持员工数量不变的同时继续添加更多的服务器。“Bell 说。
|
||||
|
||||
随着时间的推移,CERN 将面临更大的挑战。大型强子对撞机有一个到 2035 年的蓝图,包括一些重要的升级。“我们的加速器运转三到四年,然后会用 18 个月或两年的时间来升级基础架构。在这维护期间我们会做一些计算能力的规划。“Bell 说。CERN 还计划升级高亮度大型强子对撞机,会允许更高光度的光束。与目前的 CERN 的规模相比,升级意味着计算需求需增加约 60 倍。
|
||||
随着时间的推移,CERN 将面临更大的挑战。大型强子对撞机有一个到 2035 年的蓝图,包括一些重要的升级。“我们的加速器运转三到四年,然后会用 18 个月或两年的时间来升级基础架构。在这维护期间我们会做一些计算能力的规划。
|
||||
”Bell 说。CERN 还计划升级高亮度大型强子对撞机,会允许更高光度的光束。与目前的 CERN 的规模相比,升级意味着计算需求需增加约 60 倍。
|
||||
|
||||
“根据摩尔定律,我们可能只能满足需求的四分之一,因此我们必须找到相应的扩展计算能力和存储基础架构的方法,并找到自动化和解决方案,例如 OpenStack,将有助于此。”Bell 说。
|
||||
|
||||
“当我们开始使用大型强子对撞机并观察我们如何提供计算能力时,很明显我们无法将所有内容都放入 CERN 的数据中心,因此我们设计了一个分布式网格结构:位于中心的 CERN 和围绕着它的级联结构。“Bell 说,“全世界约有 12 个大型一级数据中心,然后是 150 所小型大学和实验室。他们从大型强子对撞机的数据中收集样本,以帮助物理学家理解和分析数据。“
|
||||
“当我们开始使用大型强子对撞机并观察我们如何提供计算能力时,很明显我们无法将所有内容都放入 CERN 的数据中心,因此我们设计了一个分布式网格结构:位于中心的 CERN 和围绕着它的级联结构。”Bell 说,“全世界约有 12 个大型一级数据中心,然后是 150 所小型大学和实验室。他们从大型强子对撞机的数据中收集样本,以帮助物理学家理解和分析数据。”
|
||||
|
||||
这种结构意味着 CERN 正在进行国际合作,数百个国家正致力于分析这些数据。归结为一个基本原则,即开源不仅仅是共享代码,还包括人们之间的协作、知识共享,以实现个人、组织或公司无法单独实现的目标。这就是开源世界的希格斯玻色子。
|
||||
|
||||
@ -49,9 +48,9 @@ CERN 帮助 CentOS 提供基础架构,他们还组织了 CentOS DoJo 活动(
|
||||
|
||||
via: https://www.linux.com/blog/2018/5/how-cern-using-linux-open-source
|
||||
|
||||
作者:[SWAPNIL BHARTIYA ][a]
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,25 @@
|
||||
使用 MQTT 实现项目数据收发
|
||||
使用 MQTT 在项目中实现数据收发
|
||||
======
|
||||
|
||||
> 从开源数据到开源事件流,了解一下 MQTT 发布/订阅(pubsub)线路协议。
|
||||
|
||||

|
||||
|
||||
去年 11 月我们购买了一辆电动汽车,同时也引发了有趣的思考:我们应该什么时候为电动汽车充电?对于电动汽车充电所用的电,我希望能够对应最小的二氧化碳排放,归结为一个特定的问题:对于任意给定时刻,每千瓦时对应的二氧化碳排放量是多少,一天中什么时间这个值最低?
|
||||
|
||||
|
||||
### 寻找数据
|
||||
|
||||
我住在纽约州,大约 80% 的电力消耗可以自给自足,主要来自天然气、水坝(大部分来自于<ruby>尼亚加拉<rt>Niagara</rt></ruby>大瀑布)、核能发电,少部分来自风力、太阳能和其它化石燃料发电。非盈利性组织 [<ruby>纽约独立电网运营商<rt>New York Independent System Operator</rt></ruby>][1] (NYISO) 负责整个系统的运作,实现发电机组发电与用电之间的平衡,同时也是纽约路灯系统的监管部门。
|
||||
我住在纽约州,大约 80% 的电力消耗可以自给自足,主要来自天然气、水坝(大部分来自于<ruby>尼亚加拉<rt>Niagara</rt></ruby>大瀑布)、核能发电,少部分来自风力、太阳能和其它化石燃料发电。非盈利性组织 [<ruby>纽约独立电网运营商<rt>New York Independent System Operator</rt></ruby>][1] (NYISO)负责整个系统的运作,实现发电机组发电与用电之间的平衡,同时也是纽约路灯系统的监管部门。
|
||||
|
||||
尽管没有为公众提供公开 API,NYISO 还是尽责提供了[不少公开数据][2]供公众使用。每隔 5 分钟汇报全州各个发电机组消耗的燃料数据。数据以 CSV 文件的形式发布于公开的档案库中,全天更新。如果你了解不同燃料对发电瓦数的贡献比例,你可以比较准确的估计任意时刻的二氧化碳排放情况。
|
||||
|
||||
在构建收集处理公开数据的工具时,我们应该时刻避免过度使用这些资源。相比将这些数据打包并发送给所有人,我们有更好的方案。我们可以创建一个低开销的<ruby>事件流<rt>event stream</rt></ruby>,人们可以订阅并第一时间得到消息。我们可以使用 [MQTT][3] 实现该方案。我的 ([ny-power.org][4]) 项目目标是收录到 [Home Assistant][5] 项目中;后者是一个开源的<ruby>家庭自动化<rt>home automation</rt></ruby>平台,拥有数十万用户。如果所有用户同时访问 CSV 文件服务器,估计 NYISO 不得不增加访问限制。
|
||||
在构建收集处理公开数据的工具时,我们应该时刻避免过度使用这些资源。相比将这些数据打包并发送给所有人,我们有更好的方案。我们可以创建一个低开销的<ruby>事件流<rt>event stream</rt></ruby>,人们可以订阅并第一时间得到消息。我们可以使用 [MQTT][3] 实现该方案。我的项目([ny-power.org][4])目标是收录到 [Home Assistant][5] 项目中;后者是一个开源的<ruby>家庭自动化<rt>home automation</rt></ruby>平台,拥有数十万用户。如果所有用户同时访问 CSV 文件服务器,估计 NYISO 不得不增加访问限制。
|
||||
|
||||
### MQTT 是什么?
|
||||
|
||||
MQTT 是一个<ruby>发布订阅线协议<rt>publish/subscription wire protocol</rt></ruby>,为小规模设备设计。发布订阅系统工作原理类似于消息总线。你将一条消息发布到一个<ruby>主题<rt>topic</rt></ruby>上,那么所有订阅了该主题的客户端都可以获得该消息的一份拷贝。对于消息发送者而言,无需知道哪些人在订阅消息;你只需将消息发布到一系列主题,同时订阅一些你感兴趣的主题。就像参加了一场聚会,你选取并加入感兴趣的对话。
|
||||
MQTT 是一个<ruby>发布订阅线路协议<rt>publish/subscription wire protocol</rt></ruby>,为小规模设备设计。发布订阅系统工作原理类似于消息总线。你将一条消息发布到一个<ruby>主题<rt>topic</rt></ruby>上,那么所有订阅了该主题的客户端都可以获得该消息的一份拷贝。对于消息发送者而言,无需知道哪些人在订阅消息;你只需将消息发布到一系列主题,并订阅一些你感兴趣的主题。就像参加了一场聚会,你选取并加入感兴趣的对话。
|
||||
|
||||
MQTT 可应用构建极为高效的应用。客户端订阅有限的几个主题,也只收到他们感兴趣的内容。不仅节省了处理时间,还降低了网络带宽使用。
|
||||
MQTT 能够构建极为高效的应用。客户端订阅有限的几个主题,也只收到它们感兴趣的内容。不仅节省了处理时间,还降低了网络带宽使用。
|
||||
|
||||
作为一个开放标准,MQTT 有很多开源的客户端和服务端实现。对于你能想到的每种编程语言,都有对应的客户端库;甚至有嵌入到 Arduino 的库,可以构建传感器网络。服务端可供选择的也很多,我的选择是 Eclipse 项目提供的 [Mosquitto][6] 服务端,这是因为它体积小、用 C 编写,可以承载数以万计的订阅者。
|
||||
|
||||
@ -34,7 +35,7 @@ MQTT 还有一些有趣的特性,其中之一是<ruby>遗嘱<rt>last-will-and-
|
||||
|
||||
NYSO 公布的 CSV 文件中有一个是实时的燃料混合使用情况。每 5 分钟,NYSO 发布这 5 分钟内发电使用的燃料类型和相应的发电量(以兆瓦为单位)。
|
||||
|
||||
The CSV file looks something like this:
|
||||
这个 CSV 文件看起来像这样:
|
||||
|
||||
| 时间戳 | 时区 | 燃料类型 | 兆瓦为单位的发电量 |
|
||||
| --- | --- | --- | --- |
|
||||
@ -65,7 +66,6 @@ ny-power/upstream/fuel-mix/Other Fossil Fuels {"units": "MW", "value": 4, "ts":
|
||||
ny-power/upstream/fuel-mix/Wind {"units": "MW", "value": 41, "ts": "05/09/2018 00:05:00"}
|
||||
ny-power/upstream/fuel-mix/Other Renewables {"units": "MW", "value": 226, "ts": "05/09/2018 00:05:00"}
|
||||
ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
```
|
||||
|
||||
这种直接的转换是种不错的尝试,可将公开数据转换为公开事件。我们后续会继续将数据转换为二氧化碳排放强度,但这些原始数据还可被其它应用使用,用于其它计算用途。
|
||||
@ -74,7 +74,7 @@ ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2
|
||||
|
||||
主题和<ruby>主题结构<rt>topic structure</rt></ruby>是 MQTT 的一个主要特色。与其它标准的企业级消息总线不同,MQTT 的主题无需事先注册。发送者可以凭空创建主题,唯一的限制是主题的长度,不超过 220 字符。其中 `/` 字符有特殊含义,用于创建主题的层次结构。我们即将看到,你可以订阅这些层次中的一些分片。
|
||||
|
||||
基于开箱即用的 Mosquitto,任何一个客户端都可以向任何主题发布消息。在原型设计过程中,这种方式十分便利;但一旦部署到生产环境,你需要增加<ruby>访问控制列表<rt>access control list, ACL</rt></ruby>只允许授权的应用发布消息。例如,任何人都能以只读的方式访问我的应用的主题层级,但只有那些具有特定<ruby>凭证<rt>credentials</rt></ruby>的客户端可以发布内容。
|
||||
基于开箱即用的 Mosquitto,任何一个客户端都可以向任何主题发布消息。在原型设计过程中,这种方式十分便利;但一旦部署到生产环境,你需要增加<ruby>访问控制列表<rt>access control list</rt></ruby>(ACL)只允许授权的应用发布消息。例如,任何人都能以只读的方式访问我的应用的主题层级,但只有那些具有特定<ruby>凭证<rt>credentials</rt></ruby>的客户端可以发布内容。
|
||||
|
||||
主题中不包含<ruby>自动样式<rt>automatic schema</rt></ruby>,也没有方法查找客户端可以发布的全部主题。因此,对于那些从 MQTT 总线消费数据的应用,你需要让其直接使用已知的主题和消息格式样式。
|
||||
|
||||
@ -87,8 +87,8 @@ ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2
|
||||
* `#` 以递归方式匹配,直到字符串结束
|
||||
* `+` 匹配下一个 `/` 之前的内容
|
||||
|
||||
|
||||
为便于理解,下面给出几个例子:
|
||||
|
||||
```
|
||||
ny-power/# - 匹配 ny-power 应用发布的全部主题
|
||||
ny-power/upstream/# - 匹配全部原始数据的主题
|
||||
@ -107,6 +107,7 @@ ny-power/+/+/Hydro - 匹配全部两次层级之后为 Hydro 类型的主题(
|
||||
利用[<ruby>美国能源情报署<rt>U.S. Energy Information Administration</rt></ruby>][7] 给出的 2016 年纽约各类燃料发电及排放情况,我们可以给出各类燃料的[平均排放率][8],单位为克/兆瓦时。
|
||||
|
||||
上述结果被封装到一个专用的微服务中。该微服务订阅 `ny-power/upstream/fuel-mix/+`,即数据泵中燃料组成情况的原始数据,接着完成计算并将结果(单位为克/千瓦时)发布到新的主题层次结构上:
|
||||
|
||||
```
|
||||
ny-power/computed/co2 {"units": "g / kWh", "value": 152.9486, "ts": "05/09/2018 00:05:00"}
|
||||
```
|
||||
@ -123,7 +124,6 @@ ny-power/computed/co2 {"units": "g / kWh", "value": 152.9486, "ts": "05/09/2018
|
||||
|
||||
```
|
||||
mosquitto_sub -h mqtt.ny-power.org -t ny-power/# -v
|
||||
|
||||
```
|
||||
|
||||
只要我编写或调试 MQTT 应用,我总会在一个终端中运行 `mosquitto_sub`。
|
||||
@ -132,7 +132,7 @@ mosquitto_sub -h mqtt.ny-power.org -t ny-power/# -v
|
||||
|
||||
到目前为止,我们已经有提供公开事件流的应用,可以用微服务或命令行工具访问该应用。但考虑到互联网仍占据主导地位,因此让用户可以从浏览器直接获取事件流是很重要。
|
||||
|
||||
MQTT 的设计者已经考虑到了这一点。协议标准支持三种不同的传输协议:[TCP][10],[UDP][11] 和 [WebSockets][12]。主流浏览器都支持 WebSockets,可以维持持久连接,用于实时应用。
|
||||
MQTT 的设计者已经考虑到了这一点。协议标准支持三种不同的传输协议:[TCP][10]、[UDP][11] 和 [WebSockets][12]。主流浏览器都支持 WebSockets,可以维持持久连接,用于实时应用。
|
||||
|
||||
Eclipse 项目提供了 MQTT 的一个 JavaScript 实现,叫做 [Paho][13],可包含在你的应用中。工作模式为与服务器建立连接、建立一些订阅,然后根据接收到的消息进行响应。
|
||||
|
||||
@ -187,21 +187,19 @@ function onMessageArrived(message) {
|
||||
};
|
||||
Plotly.newPlot('co2_graph', plot, layout);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
上述应用订阅了不少主题,因为我们将要呈现若干种不同类型的数据;其中 `ny-power/computed/co2` 主题为我们提供当前二氧化碳排放的参考值。一旦收到该主题的新消息,网站上的相应内容会被相应替换。
|
||||
|
||||
|
||||
![NYISO 二氧化碳排放图][15]
|
||||
|
||||
[ny-power.org][4] 网站提供的 NYISO 二氧化碳排放图。
|
||||
*[ny-power.org][4] 网站提供的 NYISO 二氧化碳排放图。*
|
||||
|
||||
`ny-power/archive/co2/24h` 主题提供了时间序列数据,用于为 [Plotly][16] 线表提供数据。`ny-power/upstream/fuel-mix` 主题提供当前燃料组成情况,为漂亮的柱状图提供数据。
|
||||
|
||||
![NYISO 燃料组成情况][18]
|
||||
|
||||
[ny-power.org][4] 网站提供的燃料组成情况。
|
||||
*[ny-power.org][4] 网站提供的燃料组成情况。*
|
||||
|
||||
这是一个动态网站,数据不从服务器拉取,而是结合 MQTT 消息总线,监听对外开放的 WebSocket。就像数据泵和打包器程序那样,网站页面也是一个发布订阅客户端,只不过是在你的浏览器中执行,而不是在公有云的微服务上。
|
||||
|
||||
@ -223,8 +221,8 @@ via: https://opensource.com/article/18/6/mqtt
|
||||
|
||||
作者:[Sean Dague][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,156 @@
|
||||
用以检查 Linux 内存使用的 5 个命令
|
||||
======
|
||||
|
||||
> 对于 Linux 管理员来说,检查系统内存用量是一个重要的技能。Jack 给出了解决这个问题的五种不同方式。
|
||||
|
||||

|
||||
|
||||
Linux 操作系统包含大量工具,所有这些工具都可以帮助你管理系统。从简单的文件和目录工具到非常复杂的安全命令,在 Linux 中没有多少是你做不了的。而且,尽管普通桌面用户可能不需要在命令行熟悉这些工具,但对于 Linux 管理员来说,它们是必需的。为什么?首先,你在某些时候不得不使用没有 GUI 的 Linux 服务器。其次,命令行工具通常比 GUI 替代工具提供更多的功能和灵活性。
|
||||
|
||||
确定内存使用情况是你可能需要的技能,尤其是某个应用程序变得异常和占用系统内存时。当发生这种情况时,知道有多种工具可以帮助你进行故障排除十分方便的。或者,你可能需要收集有关 Linux 交换分区的信息,或者有关安装的内存的详细信息?对于这些也有相应的命令。让我们深入了解各种 Linux 命令行工具,以帮助你检查系统内存使用情况。这些工具并不是非常难以使用,在本文中,我将向你展示五种不同的方法来解决这个问题。
|
||||
|
||||
我将在 [Ubuntu 18.04 服务器平台][1]上进行演示,但是你应该在你选择的发行版中找到对应的所有命令。更妙的是,你不需要安装任何东西(因为大多数这些工具都包含 Linux 系统中)。
|
||||
|
||||
话虽如此,让我们开始工作吧。
|
||||
|
||||
### top
|
||||
|
||||
我想从最常用的工具开始。`top` 命令提供正在运行的系统的实时动态视图,它检查每个进程的内存使用情况。这非常重要,因为你可以轻松地看到同一命令的多个示例消耗不同的内存量。虽然你无法在没有显示器的服务器上看到这种情况,但是你已经注意到打开 Chrome 使你的系统速度变慢了。运行 `top` 命令以查看 Chrome 有多个进程在运行(每个选项卡一个 - 图 1)。
|
||||
|
||||
![top][3]
|
||||
|
||||
*图1:top 命令中出现多个 Chrome 进程。*
|
||||
|
||||
Chrome 并不是唯一显示多个进程的应用。你看到图 1 中的 Firefox 了吗?那是 Firefox 的主进程,而 Web Content 进程是其打开的选项卡。在输出的顶部,你将看到系统统计信息。在我的机器上([System76 Leopard Extreme][5]),我总共有 16GB 可用 RAM,其中只有超过 10GB 的 RAM 正在使用中。然后,你可以整理该列表,查看每个进程使用的内存百分比。
|
||||
|
||||
`top` 最好的地方之一就是发现可能已经失控的服务的进程 ID 号(PID)。有了这些 PID,你可以对有问题的任务进行故障排除(或 `kill`)。
|
||||
|
||||
如果你想让 `top` 显示更友好的内存信息,使用命令 `top -o %MEM`,这会使 `top` 按进程所用内存对所有进程进行排序(图 2)。
|
||||
|
||||
![top][7]
|
||||
|
||||
*图 2:在 top 命令中按使用内存对进程排序*
|
||||
|
||||
`top` 命令还为你提供有关使用了多少交换空间的实时更新。
|
||||
|
||||
### free
|
||||
|
||||
然而有时候,`top` 命令可能不能满足你的需求。你可能只需要查看系统的可用和已用内存。对此,Linux 还有 `free` 命令。`free` 命令显示:
|
||||
|
||||
* 可用和已使用的物理内存总量
|
||||
* 系统中交换内存的总量
|
||||
* 内核使用的缓冲区和缓存
|
||||
|
||||
在终端窗口中,输入 `free` 命令。它的输出不是实时的,相反,你将获得的是当前空闲和已用内存的即时快照(图 3)。
|
||||
|
||||
![free][9]
|
||||
|
||||
*图 3 :free 命令的输出简单明了。*
|
||||
|
||||
当然,你可以通过添加 `-m` 选项来让 `free` 显示得更友好一点,就像这样:`free -m`。这将显示内存的使用情况,以 MB 为单位(图 4)。
|
||||
|
||||
![free][11]
|
||||
|
||||
*图 4:free 命令以一种更易于阅读的形式输出。*
|
||||
|
||||
当然,如果你的系统是很新的,你将希望使用 `-g` 选项(以 GB 为单位),比如 `free -g`。
|
||||
|
||||
如果你需要知道内存总量,你可以添加 `-t` 选项,比如:`free -mt`。这将简单地计算每列中的内存总量(图 5)。
|
||||
|
||||
![total][13]
|
||||
|
||||
*图 5:为你提供空闲的内存列。*
|
||||
|
||||
### vmstat
|
||||
|
||||
另一个非常方便的工具是 `vmstat`。这个特殊的命令是一个报告虚拟内存统计信息的小技巧。`vmstat` 命令将报告关于:
|
||||
|
||||
* 进程
|
||||
* 内存
|
||||
* 分页
|
||||
* 阻塞 IO
|
||||
* 中断
|
||||
* 磁盘
|
||||
* CPU
|
||||
|
||||
使用 `vmstat` 的最佳方法是使用 `-s` 选项,如 `vmstat -s`。这将在单列中报告统计信息(这比默认报告更容易阅读)。`vmstat` 命令将提供比你需要的更多的信息(图 6),但更多的总是更好的(在这种情况下)。
|
||||
|
||||
![vmstat][15]
|
||||
|
||||
*图 6:使用 vmstat 命令来检查内存使用情况。*
|
||||
|
||||
### dmidecode
|
||||
|
||||
如果你想找到关于已安装的系统内存的详细信息,该怎么办?为此,你可以使用 `dmidecode` 命令。这个特殊的工具是 DMI 表解码器,它将系统的 DMI 表内容转储成人类可读的格式。如果你不清楚 DMI 表是什么,那么可以这样说,它可以用来描述系统的构成(以及系统的演变)。
|
||||
|
||||
要运行 `dmidecode` 命令,你需要 `sudo` 权限。因此输入命令 `sudo dmidecode -t 17`。该命令的输出(图 7)可能很长,因为它显示所有内存类型设备的信息。因此,如果你无法上下滚动,则可能需要将该命令的输出发送到一个文件中,比如:`sudo dmidecode -t 17> dmi_infoI`,或将其传递给 `less` 命令,如 `sudo dmidecode | less`。
|
||||
|
||||
![dmidecode][17]
|
||||
|
||||
*图 7:dmidecode 命令的输出。*
|
||||
|
||||
### /proc/meminfo
|
||||
|
||||
你可能会问自己:“这些命令从哪里获取这些信息?”在某些情况下,它们从 `/proc/meminfo` 文件中获取。猜到了吗?你可以使用命令 `less /proc/meminfo` 直接读取该文件。通过使用 `less` 命令,你可以在长长的输出中向上和向下滚动,以准确找到你需要的内容(图 8)。
|
||||
|
||||
![/proc/meminfo][19]
|
||||
|
||||
*图 8:less /proc/meminfo 命令的输出。*
|
||||
|
||||
关于 `/proc/meminfo` 你应该知道:这不是一个真实的文件。相反 `/proc/meminfo` 是一个虚拟文件,包含有关系统的实时动态信息。特别是,你需要检查以下值:
|
||||
|
||||
* 全部内存(`MemTotal`)
|
||||
* 空闲内存(`MemFree`)
|
||||
* 可用内存(`MemAvailable`)
|
||||
* 缓冲区(`Buffers`)
|
||||
* 文件缓存(`Cached`)
|
||||
* 交换缓存(`SwapCached`)
|
||||
* 全部交换区(`SwapTotal`)
|
||||
* 空闲交换区(`SwapFree`)
|
||||
|
||||
如果你想使用 `/proc/meminfo`,你可以连接 egrep 命令使用它:`egrep --color'Mem | Cache | Swap'/proc/meminfo`。这将生成一个易于阅读的列表,其中包含 `Mem`、 `Cache` 和 `Swap` 等内容的条目将是彩色的(图 9)。
|
||||
|
||||
![/proc/meminfo][21]
|
||||
|
||||
*图 9:让 /proc/meminfo 更容易阅读。*
|
||||
|
||||
### 继续学习
|
||||
|
||||
你要做的第一件事就是阅读每个命令的手册页(例如 `man top`、`man free`、`man vmstat`、`man dmidecode`)。从命令的手册页开始,对于如何在 Linux 上使用一个工具,它总是一个很好的学习方法。
|
||||
|
||||
通过 Linux 基金会和 edX 的免费 [“Linux 简介”][22]课程了解有关 Linux 的更多知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/5-commands-checking-memory-usage-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.ubuntu.com/download/server
|
||||
[2]:/files/images/memory1jpg
|
||||
[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_1.jpg?itok=fhhhUL_l (top)
|
||||
[4]:/licenses/category/used-permission
|
||||
[5]:https://system76.com/desktops/leopard
|
||||
[6]:/files/images/memory2jpg
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_2.jpg?itok=zuVkQfvv (top)
|
||||
[8]:/files/images/memory3jpg
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_3.jpg?itok=rvuQp3t0 (free)
|
||||
[10]:/files/images/memory4jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_4.jpg?itok=K_luLLPt (free)
|
||||
[12]:/files/images/memory5jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_5.jpg?itok=q50atcsX (total)
|
||||
[14]:/files/images/memory6jpg
|
||||
[15]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_6.jpg?itok=bwFnUVmy (vmstat)
|
||||
[16]:/files/images/memory7jpg
|
||||
[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_7.jpg?itok=UNHIT_P6 (dmidecode)
|
||||
[18]:/files/images/memory8jpg
|
||||
[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_8.jpg?itok=t87jvmJJ (/proc/meminfo)
|
||||
[20]:/files/images/memory9jpg
|
||||
[21]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_9.jpg?itok=t-iSMEKq (/proc/meminfo)
|
||||
[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,21 +1,24 @@
|
||||
如何在 Git 中重置、恢复、和返回到以前的状态
|
||||
如何在 Git 中重置、恢复,返回到以前的状态
|
||||
======
|
||||
|
||||
> 用简洁而优雅的 Git 命令撤销仓库中的改变。
|
||||
|
||||

|
||||
|
||||
使用 Git 工作时其中一个鲜为人知(和没有意识到)的方面就是,如何很容易地返回到你以前的位置 —— 也就是说,在仓库中如何很容易地去撤销那怕是重大的变更。在本文中,我们将带你了解如何去重置、恢复、和完全回到以前的状态,做到这些只需要几个简单而优雅的 Git 命令。
|
||||
使用 Git 工作时其中一个鲜为人知(和没有意识到)的方面就是,如何轻松地返回到你以前的位置 —— 也就是说,在仓库中如何很容易地去撤销那怕是重大的变更。在本文中,我们将带你了解如何去重置、恢复和完全回到以前的状态,做到这些只需要几个简单而优雅的 Git 命令。
|
||||
|
||||
### reset
|
||||
### 重置
|
||||
|
||||
我们从 Git 的 `reset` 命令开始。确实,你应该能够想到它就是一个 "回滚" — 它将你本地环境返回到前面的提交。这里的 "本地环境" 一词,我们指的是你的本地仓库、暂存区、以及工作目录。
|
||||
我们从 Git 的 `reset` 命令开始。确实,你应该能够认为它就是一个 “回滚” —— 它将你本地环境返回到之前的提交。这里的 “本地环境” 一词,我们指的是你的本地仓库、暂存区以及工作目录。
|
||||
|
||||
先看一下图 1。在这里我们有一个在 Git 中表示一系列状态的提交。在 Git 中一个分支就是简单的一个命名的、可移动指针到一个特定的提交。在这种情况下,我们的 master 分支是链中指向最新提交的一个指针。
|
||||
先看一下图 1。在这里我们有一个在 Git 中表示一系列提交的示意图。在 Git 中一个分支简单来说就是一个命名的、指向一个特定的提交的可移动指针。在这里,我们的 master 分支是指向链中最新提交的一个指针。
|
||||
|
||||
![Local Git environment with repository, staging area, and working directory][2]
|
||||
|
||||
图 1:有仓库、暂存区、和工作目录的本地环境
|
||||
*图 1:有仓库、暂存区、和工作目录的本地环境*
|
||||
|
||||
如果看一下我们的 master 分支是什么,可以看一下到目前为止我们产生的提交链。
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
b764644 File with three lines
|
||||
@ -23,41 +26,49 @@ b764644 File with three lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
如果我们想回滚到前一个提交会发生什么呢?很简单 —— 我们只需要移动分支指针即可。Git 提供了为我们做这个动作的命令。例如,如果我们重置 master 为当前提交回退两个提交的位置,我们可以使用如下之一的方法:
|
||||
如果我们想回滚到前一个提交会发生什么呢?很简单 —— 我们只需要移动分支指针即可。Git 提供了为我们做这个动作的 `reset` 命令。例如,如果我们重置 master 为当前提交回退两个提交的位置,我们可以使用如下之一的方法:
|
||||
|
||||
`$ git reset 9ef9173`(使用一个绝对的提交 SHA1 值 9ef9173)
|
||||
```
|
||||
$ git reset 9ef9173
|
||||
```
|
||||
|
||||
或
|
||||
(使用一个绝对的提交 SHA1 值 `9ef9173`)
|
||||
|
||||
`$ git reset current~2`(在 “current” 标签之前,使用一个相对值 -2)
|
||||
或:
|
||||
|
||||
```
|
||||
$ git reset current~2
|
||||
```
|
||||
(在 “current” 标签之前,使用一个相对值 -2)
|
||||
|
||||
图 2 展示了操作的结果。在这之后,如果我们在当前分支(master)上运行一个 `git log` 命令,我们将看到只有一个提交。
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
|
||||
9ef9173 File with one line
|
||||
|
||||
```
|
||||
|
||||
![After reset][4]
|
||||
|
||||
图 2:在 `reset` 之后
|
||||
*图 2:在 `reset` 之后*
|
||||
|
||||
`git reset` 命令也包含使用一个你最终满意的提交内容去更新本地环境的其它部分的选项。这些选项包括:`hard` 在仓库中去重置指向的提交,用提交的内容去填充工作目录,并重置暂存区;`soft` 仅重置仓库中的指针;而 `mixed`(默认值)将重置指针和暂存区。
|
||||
`git reset` 命令也包含使用一些选项,可以让你最终满意的提交内容去更新本地环境的其它部分。这些选项包括:`hard` 在仓库中去重置指向的提交,用提交的内容去填充工作目录,并重置暂存区;`soft` 仅重置仓库中的指针;而 `mixed`(默认值)将重置指针和暂存区。
|
||||
|
||||
这些选项在特定情况下非常有用,比如,`git reset --hard <commit sha1 | reference>` 这个命令将覆盖本地任何未提交的更改。实际上,它重置了(清除掉)暂存区,并用你重置的提交内容去覆盖了工作区中的内容。在你使用 `hard` 选项之前,一定要确保这是你真正地想要做的操作,因为这个命令会覆盖掉任何未提交的更改。
|
||||
|
||||
### revert
|
||||
### 恢复
|
||||
|
||||
`git revert` 命令的实际结果类似于 `reset`,但它的方法不同。`reset` 命令是在(默认)链中向后移动分支的指针去“撤销”更改,`revert` 命令是在链中添加一个新的提交去“取消”更改。再次查看图 1 可以非常轻松地看到这种影响。如果我们在链中的每个提交中向文件添加一行,一种方法是使用 `reset` 使那个提交返回到仅有两行的那个版本,如:`git reset HEAD~1`。
|
||||
`git revert` 命令的实际结果类似于 `reset`,但它的方法不同。`reset` 命令(默认)是在链中向后移动分支的指针去“撤销”更改,`revert` 命令是在链中添加一个新的提交去“取消”更改。再次查看图 1 可以非常轻松地看到这种影响。如果我们在链中的每个提交中向文件添加一行,一种方法是使用 `reset` 使那个提交返回到仅有两行的那个版本,如:`git reset HEAD~1`。
|
||||
|
||||
另一个方法是添加一个新的提交去删除第三行,以使最终结束变成两行的版本 —— 实际效果也是取消了那个更改。使用一个 `git revert` 命令可以实现上述目的,比如:
|
||||
|
||||
另一个方法是添加一个新的提交去删除第三行,以使最终结束变成两行的版本 — 实际效果也是取消了那个更改。使用一个 `git revert` 命令可以实现上述目的,比如:
|
||||
```
|
||||
$ git revert HEAD
|
||||
|
||||
```
|
||||
|
||||
因为它添加了一个新的提交,Git 将提示如下的提交信息:
|
||||
|
||||
```
|
||||
Revert "File with three lines"
|
||||
|
||||
@ -74,6 +85,7 @@ This reverts commit b764644bad524b804577684bf74e7bca3117f554.
|
||||
图 3(在下面)展示了 `revert` 操作完成后的结果。
|
||||
|
||||
如果我们现在运行一个 `git log` 命令,我们将看到前面的提交之前的一个新提交。
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
11b7712 Revert "File with three lines"
|
||||
@ -83,6 +95,7 @@ b764644 File with three lines
|
||||
```
|
||||
|
||||
这里是工作目录中这个文件当前的内容:
|
||||
|
||||
```
|
||||
$ cat <filename>
|
||||
Line 1
|
||||
@ -91,31 +104,34 @@ Line 2
|
||||
|
||||
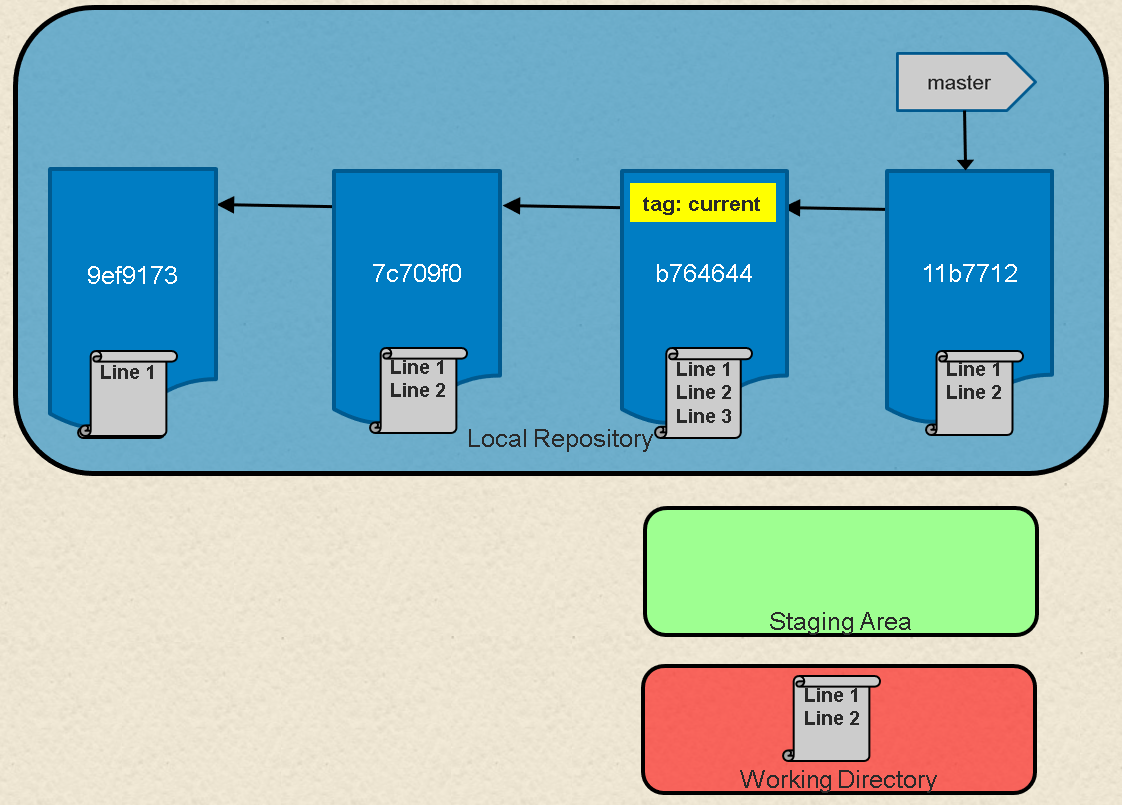
|
||||
|
||||
#### Revert 或 reset 如何选择?
|
||||
*图 3 `revert` 操作之后*
|
||||
|
||||
#### 恢复或重置如何选择?
|
||||
|
||||
为什么要优先选择 `revert` 而不是 `reset` 操作?如果你已经将你的提交链推送到远程仓库(其它人可以已经拉取了你的代码并开始工作),一个 `revert` 操作是让他们去获得更改的非常友好的方式。这是因为 Git 工作流可以非常好地在分支的末端添加提交,但是当有人 `reset` 分支指针之后,一组提交将再也看不见了,这可能会是一个挑战。
|
||||
|
||||
当我们以这种方式使用 Git 工作时,我们的基本规则之一是:在你的本地仓库中使用这种方式去更改还没有推送的代码是可以的。如果提交已经推送到了远程仓库,并且可能其它人已经使用它来工作了,那么应该避免这些重写提交历史的更改。
|
||||
|
||||
总之,如果你想回滚、撤销、或者重写其它人已经在使用的一个提交链的历史,当你的同事试图将他们的更改合并到他们拉取的原始链上时,他们可能需要做更多的工作。如果你必须对已经推送并被其他人正在使用的代码做更改,在你做更改之前必须要与他们沟通,让他们先合并他们的更改。然后在没有需要去合并的侵入操作之后,他们再拉取最新的副本。
|
||||
总之,如果你想回滚、撤销或者重写其它人已经在使用的一个提交链的历史,当你的同事试图将他们的更改合并到他们拉取的原始链上时,他们可能需要做更多的工作。如果你必须对已经推送并被其他人正在使用的代码做更改,在你做更改之前必须要与他们沟通,让他们先合并他们的更改。然后在这个侵入操作没有需要合并的内容之后,他们再拉取最新的副本。
|
||||
|
||||
你可能注意到了,在我们做了 `reset` 操作之后,原始的提交链仍然在那个位置。我们移动了指针,然后 `reset` 代码回到前一个提交,但它并没有删除任何提交。换句话说就是,只要我们知道我们所指向的原始提交,我们能够通过简单的返回到分支的原始链的头部来“恢复”指针到前面的位置:
|
||||
|
||||
你可能注意到了,在我们做了 `reset` 操作之后,原始的链仍然在那个位置。我们移动了指针,然后 `reset` 代码回到前一个提交,但它并没有删除任何提交。换句话说就是,只要我们知道我们所指向的原始提交,我们能够通过简单的返回到分支的原始头部来“恢复”指针到前面的位置:
|
||||
```
|
||||
git reset <sha1 of commit>
|
||||
|
||||
```
|
||||
|
||||
当提交被替换之后,我们在 Git 中做的大量其它操作也会发生类似的事情。新提交被创建,有关的指针被移动到一个新的链,但是老的提交链仍然存在。
|
||||
|
||||
### Rebase
|
||||
### 变基
|
||||
|
||||
现在我们来看一个分支变基。假设我们有两个分支 — master 和 feature — 提交链如下图 4 所示。Master 的提交链是 `C4->C2->C1->C0` 和 feature 的提交链是 `C5->C3->C2->C1->C0`.
|
||||
现在我们来看一个分支变基。假设我们有两个分支:master 和 feature,提交链如下图 4 所示。master 的提交链是 `C4->C2->C1->C0` 和 feature 的提交链是 `C5->C3->C2->C1->C0`。
|
||||
|
||||
![Chain of commits for branches master and feature][6]
|
||||
|
||||
图 4:master 和 feature 分支的提交链
|
||||
*图 4:master 和 feature 分支的提交链*
|
||||
|
||||
如果我们在分支中看它的提交记录,它们看起来应该像下面的这样。(为了易于理解,`C` 表示提交信息)
|
||||
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
@ -131,9 +147,10 @@ f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
我给人讲,在 Git 中,可以将 `rebase` 认为是 “将历史合并”。从本质上来说,Git 将一个分支中的每个不同提交尝试“重放”到另一个分支中。
|
||||
我告诉人们在 Git 中,可以将 `rebase` 认为是 “将历史合并”。从本质上来说,Git 将一个分支中的每个不同提交尝试“重放”到另一个分支中。
|
||||
|
||||
因此,我们使用基本的 Git 命令,可以变基一个 feature 分支进入到 master 中,并将它拼入到 `C4` 中(比如,将它插入到 feature 的链中)。操作命令如下:
|
||||
|
||||
因此,我们使用基本的 Git 命令,可以 rebase 一个 feature 分支进入到 master 中,并将它拼入到 `C4` 中(比如,将它插入到 feature 的链中)。操作命令如下:
|
||||
```
|
||||
$ git checkout feature
|
||||
$ git rebase master
|
||||
@ -147,9 +164,10 @@ Applying: C5
|
||||
|
||||
![Chain of commits after the rebase command][8]
|
||||
|
||||
图 5:`rebase` 命令完成后的提交链
|
||||
*图 5:`rebase` 命令完成后的提交链*
|
||||
|
||||
接着,我们看一下提交历史,它应该变成如下的样子。
|
||||
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
@ -168,25 +186,27 @@ f33ae68 C1
|
||||
|
||||
注意那个 `C3'` 和 `C5'`— 在 master 分支上已处于提交链的“顶部”,由于产生了更改而创建了新提交。但是也要注意的是,rebase 后“原始的” `C3` 和 `C5` 仍然在那里 — 只是再没有一个分支指向它们而已。
|
||||
|
||||
如果我们做了这个 rebase,然后确定这不是我们想要的结果,希望去撤销它,我们可以做下面示例所做的操作:
|
||||
如果我们做了这个变基,然后确定这不是我们想要的结果,希望去撤销它,我们可以做下面示例所做的操作:
|
||||
|
||||
```
|
||||
$ git reset 79768b8
|
||||
|
||||
```
|
||||
|
||||
由于这个简单的变更,现在我们的分支将重新指向到做 `rebase` 操作之前一模一样的位置 —— 完全等效于撤销操作(图 6)。
|
||||
|
||||
![After undoing rebase][10]
|
||||
|
||||
图 6:撤销 `rebase` 操作之后
|
||||
*图 6:撤销 `rebase` 操作之后*
|
||||
|
||||
如果你想不起来之前一个操作指向的一个分支上提交了什么内容怎么办?幸运的是,Git 命令依然可以帮助你。用这种方式可以修改大多数操作的指针,Git 会记住你的原始提交。事实上,它是在 `.git` 仓库目录下,将它保存为一个特定的名为 `ORIG_HEAD ` 的文件中。在它被修改之前,那个路径是一个包含了大多数最新引用的文件。如果我们 `cat` 这个文件,我们可以看到它的内容。
|
||||
|
||||
```
|
||||
$ cat .git/ORIG_HEAD
|
||||
79768b891f47ce06f13456a7e222536ee47ad2fe
|
||||
```
|
||||
|
||||
我们可以使用 `reset` 命令,正如前面所述,它返回指向到原始的链。然后它的历史将是如下的这样:
|
||||
|
||||
```
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
@ -196,7 +216,8 @@ f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
在 reflog 中是获取这些信息的另外一个地方。这个 reflog 是你本地仓库中相关切换或更改的详细描述清单。你可以使用 `git reflog` 命令去查看它的内容:
|
||||
在 reflog 中是获取这些信息的另外一个地方。reflog 是你本地仓库中相关切换或更改的详细描述清单。你可以使用 `git reflog` 命令去查看它的内容:
|
||||
|
||||
```
|
||||
$ git reflog
|
||||
79768b8 HEAD@{0}: reset: moving to 79768b
|
||||
@ -216,10 +237,10 @@ f33ae68 HEAD@{13}: commit: C1
|
||||
5043e79 HEAD@{14}: commit (initial): C0
|
||||
```
|
||||
|
||||
你可以使用日志中列出的、你看到的相关命名格式,去 reset 任何一个东西:
|
||||
你可以使用日志中列出的、你看到的相关命名格式,去重置任何一个东西:
|
||||
|
||||
```
|
||||
$ git reset HEAD@{1}
|
||||
|
||||
```
|
||||
|
||||
一旦你理解了当“修改”链的操作发生后,Git 是如何跟踪原始提交链的基本原理,那么在 Git 中做一些更改将不再是那么可怕的事。这就是强大的 Git 的核心能力之一:能够很快速、很容易地尝试任何事情,并且如果不成功就撤销它们。
|
||||
@ -233,7 +254,7 @@ via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,34 +1,34 @@
|
||||
比特币是一个邪教 — Adam Caudill
|
||||
比特币是一个邪教
|
||||
======
|
||||
经过这些年,比特币社区已经发生了非常大的变化;社区成员从闭着眼睛都能讲解 [Merkle 树][1] 的技术迷们,变成了被一夜爆富欲望驱使的投机者和由一些连什么是 Merkle 树都不懂的人所领导的企图寻求 10 亿美元估值的区块链初创公司。随着时间的流逝,围绕比特币和其它加密货币形成了一个狂热,他们认为比特币和其它加密货币远比实际的更重要;他们相信常见的货币(法定货币)正在成为过去,而加密货币将从根本上改变世界经济。
|
||||
|
||||
每一年他们的队伍都在壮大,而他们对加密货币的看法也在变得更加宏伟,那怕是因为[使用新技术][2]而使它陷入困境的情况下。虽然我坚信设计优良的加密货币可以使金钱的跨境流动更容易,并且在大规模通胀的领域提供一个更稳定的选择,但现实情况是,我们并没有做到这些。实际上,正是价值的巨大不稳定性才使得投机者赚钱。那些宣扬美元和欧元即将死去的人,已经完全抛弃了对现实世界客观公正的看法。
|
||||
经过这些年,比特币社区已经发生了非常大的变化;社区成员从闭着眼睛都能讲解 [梅克尔树][1] 的技术迷们,变成了被一夜爆富欲望驱使的投机者和由一些连什么是梅克尔树都不懂的人所领导的企图寻求 10 亿美元估值的区块链初创公司。随着时间的流逝,围绕比特币和其它加密货币形成了一股热潮,他们认为比特币和其它加密货币远比实际的更重要;他们相信常见的货币(法定货币)正在成为过去,而加密货币将从根本上改变世界经济。
|
||||
|
||||
每一年他们的队伍都在壮大,而他们对加密货币的看法也在变得更加宏伟,那怕是对该技术的[新奇的用法][2]而使它陷入了困境。虽然我坚信设计优良的加密货币可以使金钱的跨境流动更容易,并且在大规模通胀的领域提供一个更稳定的选择,但现实情况是,我们并没有做到这些。实际上,正是价值的巨大不稳定性才使得投机者赚钱。那些宣扬美元和欧元即将死去的人,已经完全抛弃了对现实世界客观公正的看法。
|
||||
|
||||
### 一点点背景 …
|
||||
|
||||
比特币发行那天,我读了它的白皮书 —— 它使用有趣的 [Merkle 树][1] 去创建一个公共账簿和一个非常合理的共识协议 —— 由于它新颖的特性引起了密码学领域中许多人的注意。在白皮书发布后的几年里,比特币变得非常有价值,并由此吸引了许多人将它视为是一种投资,和那些认为它将改变一切的忠实追随者(和发声者)。这篇文章将讨论的正是后者。
|
||||
比特币发行那天,我读了它的白皮书 —— 它使用有趣的 [梅克尔树][1] 去创建一个公共账簿和一个非常合理的共识协议 —— 由于它新颖的特性引起了密码学领域中许多人的注意。在白皮书发布后的几年里,比特币变得非常有价值,并由此吸引了许多人将它视为是一种投资,和那些认为它将改变一切的忠实追随者(和发声者)。这篇文章将讨论的正是后者。
|
||||
|
||||
昨天,有人在推特上发布了一个最近的比特币区块的哈希,下面成千上万的推文和其它讨论让我相信,比特币已经跨越界线进入了真正的邪教领域。
|
||||
昨天(2018/6/20),有人在推特上发布了一个最近的比特币区块的哈希,下面成千上万的推文和其它讨论让我相信,比特币已经跨越界线进入了真正的邪教领域。
|
||||
|
||||
一切都源于 Mark Wilcox 的这个推文:
|
||||
一切都源于 Mark Wilcox 的[这个推文][9]:
|
||||
|
||||
> #00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a
|
||||
> — Mark Wilcox (@mwilcox) June 19, 2018
|
||||
> [#00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a][8]
|
||||
|
||||
张贴的这个值是 [比特币 #528249 号区块][3] 的哈希值。前导零是挖矿过程的结果;挖掘一个区块就是把区块内容与一个 nonce(和其它数据)组合起来,然后做哈希运算,并且它至少有一定数量的前导零才能被验证为有效区块。如果它不是正确的数字,你可以更换 nonce 再试。重复这个过程直到哈希值的前导零数量是正确的数字之后,你就有了一个有效的区块。让人们感到很兴奋的部分是接下来的 21e800。
|
||||
> — Mark Wilcox (@mwilcox) [June 19, 2018][9]
|
||||
|
||||
张贴的这个值是 [比特币 #528249 号区块][3] 的哈希值。前导零是挖矿过程的结果;挖掘一个区块就是把区块内容与一个<ruby>现时数<rt>nonce</rt></ruby>(和其它数据)组合起来,然后做哈希运算,并且它至少有一定数量的前导零才能被验证为有效区块。如果它不是正确的数字,你可以更换现时数再试。重复这个过程直到哈希值的前导零数量是正确的数字之后,你就有了一个有效的区块。让人们感到很兴奋的部分是接下来的 `21e800`。
|
||||
|
||||
一些人说这是一个有意义的编号,挖掘出这个区块的人实际上的难度远远超出当前所看到的,不仅要调整前导零的数量,还要匹配接下来的 24 位 —— 它要求非常强大的计算能力。如果有人能够以蛮力去实现它,这将表明有些事情很严重,比如,在计算或密码学方面的重大突破。
|
||||
|
||||
你一定会有疑问,为什么 21e800 如此重要 —— 一个你问了肯定会后悔的问题。有人说它是参考了 [E8 理论][4](一个广受批评的提出标准场理论的论文),或是表示总共存在 2100000000 枚比特币(`21 x 10^8` 就是 2,100,000,000)。还有其它说法,因为太疯狂了而没有办法写出来。另一个重要的事实是,在前导零后面有 21e8 的区块平均每年被挖掘出一次 —— 这些从来没有人认为是很重要的。
|
||||
你一定会有疑问,为什么 `21e800` 如此重要 —— 一个你问了肯定会后悔的问题。有人说它是参考了 [E8 理论][4](一个广受批评的提出标准场理论的论文),或是表示总共存在 2,100,000,000 枚比特币(`21 x 10^8` 就是 2,100,000,000)。还有其它说法,因为太疯狂了而没有办法写出来。另一个重要的事实是,在前导零后面有 21e8 的区块平均每年被挖掘出一次 —— 这些从来没有人认为是很重要的。
|
||||
|
||||
这就引出了有趣的地方:关于这是如何发生的[理论][5]。
|
||||
|
||||
* 一台量子计算机,它能以某种方式用不可思议的速度做哈希运算。尽管在量子计算机的理论中还没有迹象表明它能够做这件事。哈希是量子计算机认为很安全的东西之一。
|
||||
* 一台量子计算机,它能以某种方式用不可思议的速度做哈希运算。尽管在量子计算机的理论中还没有迹象表明它能够做这件事。哈希是量子计算机认为安全的东西之一。
|
||||
* 时间旅行。是的,真的有人这么说,有人从未来穿梭回到现在去挖掘这个区块。我认为这种说法太荒谬了,都懒得去解释它为什么是错误的。
|
||||
* 中本聪回来了。尽管事实上他的私钥没有任何活动,一些人从理论上认为他回来了,他能做一些没人能做的事情。这些理论是无法解释他如何做到的。
|
||||
|
||||
|
||||
|
||||
> 因此,总的来说(按我的理解)中本聪,为了知道和计算他做的事情,根据现代科学,他可能是以下之一:
|
||||
>
|
||||
> A) 使用了一台量子计算机
|
||||
@ -37,39 +37,35 @@
|
||||
>
|
||||
> — Crypto Randy Marsh [REKT] (@nondualrandy) [June 21, 2018][6]
|
||||
|
||||
如果你觉得所有的这一切听起来像 [命理学][7],不止你一个人是这样想的。
|
||||
如果你觉得所有的这一切听起来像 <ruby>[命理学][7]<rt>numerology</rt></ruby>,不止你一个人是这样想的。
|
||||
|
||||
所有围绕有特殊意义的区块哈希的讨论,也引发了对在某种程度上比较有趣的东西的讨论。比特币的创世区块,它是第一个比特币区块,有一个不寻常的属性:早期的比特币要求哈希值的前 32 位是零;而创始区块的前导零有 43 位。因为由代码产生的创世区块从不会发布,它不知道它是如何产生的,也不知道是用什么类型的硬件产生的。中本聪有学术背景,因此可能他有比那个时候大学中常见设备更强大的计算能力。从这一点上说,只是对古怪的创世区块的历史有点好奇,仅此而已。
|
||||
所有围绕有特殊意义的区块哈希的讨论,也引发了对在某种程度上比较有趣的东西的讨论。比特币的创世区块,它是第一个比特币区块,有一个不寻常的属性:早期的比特币要求哈希值的前 32 <ruby>位<rt>bit</rt></ruby>是零;而创始区块的前导零有 43 位。因为产生创世区块的代码从未发布过,不知道它是如何产生的,也不知道是用什么类型的硬件产生的。中本聪有学术背景,因此可能他有比那个时候大学中常见设备更强大的计算能力。从这一点上说,只是对古怪的创世区块的历史有点好奇,仅此而已。
|
||||
|
||||
### 关于哈希运算的简单题外话
|
||||
|
||||
这种喧嚣始于比特币区块的哈希运算;因此理解哈希是什么很重要,并且要理解一个非常重要的属性,一个哈希是单向加密函数,它能够基于给定的数据创建一个伪随机输出。
|
||||
这种喧嚣始于比特币区块的哈希运算;因此理解哈希是什么很重要,并且要理解一个非常重要的属性,哈希是单向加密函数,它能够基于给定的数据创建一个伪随机输出。
|
||||
|
||||
这意味着什么呢?基于本文讨论的目的,对于每个给定的输入你将得到一个随机的输出。随机数有时看起来很有趣,很简单,因为它是随机的结果,并且人类大脑可以很容易从任何东西中找到顺序。当你从随机数据中开始查看顺序时,你就会发现有趣的事情 —— 这些东西毫无意义,因为它们只是简单地随机数。当人们把重要的意义归属到随机数据上时,它将告诉你很多这些参与者观念相关的东西,而不是数据本身。
|
||||
|
||||
### 币的邪教
|
||||
### 币之邪教
|
||||
|
||||
首先,我们来定义一组术语:
|
||||
|
||||
* 邪教:一个宗教崇拜和直接向一个特定的人或物虔诚的体系。
|
||||
* 宗教:有人认为是至高无上的追求或兴趣。
|
||||
* <ruby>邪教<rt>Cult</rt></ruby>:一个宗教崇拜和直接向一个特定的人或物虔诚的体系。
|
||||
* <ruby>宗教<rt>Religion</rt></ruby>:有人认为是至高无上的追求或兴趣。
|
||||
|
||||
<ruby>币之邪教<rt>Cult of the Coin</rt></ruby>有许多圣人,或许没有人比<ruby>中本聪<rt>Satoshi Nakamoto</rt></ruby>更伟大,他是比特币创始者(们)的假名。(对他的)狂热拥戴,要归因于他的能力和理解力远超过一般的研究人员,认为他的远见卓视无人能比,他影响了世界新经济的秩序。当将中本聪的神秘本质和未知的真实身份结合起来时,狂热的追随着们将中本聪视为一个真正值得尊敬的人物。
|
||||
|
||||
当然,除了追随其他圣人的追捧者之外,毫无疑问这些追捧者认为自己是正确的。任何对他们的圣人的批评都被认为也是对他们的批评。例如,那些追捧 EOS 的人,可能会视中本聪为一个开发了失败项目的黑客,而对 EOS 那怕是最轻微的批评,他们也会作出激烈的反应,之所以反应如此强烈,仅仅是因为攻击了他们心目中的神。那些追捧 IOTA 的人的反应也一样;还有更多这样的例子。
|
||||
|
||||
币的狂热追捧者中的许多圣人,或许没有人比中本聪更伟大,他是比特币创始人的假名。强力的护卫、赋予能力和理解力远超过一般的研究人员,认为他的远见卓视无人能比,他影响了世界新经济的秩序。当将中本聪的神秘本质和未知的真实身份结合起来时,狂热的追随着们将中本聪视为一个真正的值的尊敬的人物。
|
||||
|
||||
当然,除了追随其他圣人的追捧者之外,毫无疑问这些追捧者认为自己是正确的。任何对他们的圣人的批评都被认为也是对他们的批评。例如,那些追捧 EOS 的人,可能会认为中本聪是开发了一个失败项目的黑客,而对 EOS 那怕是最轻微的批评,他们也会作出激烈的反应,之所以反应如此强烈,仅仅是因为攻击了他们心目中的神。那些追捧 IOTA 的人的反应也一样;还有更多这样的例子。
|
||||
|
||||
这些追随着在讨论问题时已经失去了理性和客观,他们的狂热遮盖了他们的视野。任何对这些项目和项目背后的人的讨论,如果不是溢美之词,必然以某种程序的刻薄言辞结束,对于一个技术的讨论那种做法是毫无道理的。
|
||||
这些追随者在讨论问题时已经失去了理性和客观,他们的狂热遮盖了他们的视野。任何对这些项目和项目背后的人的讨论,如果不是溢美之词,必然以某种程序的刻薄言辞结束,对于一个技术的讨论那种做法是毫无道理的。
|
||||
|
||||
这很危险,原因很多:
|
||||
|
||||
* 开发者 & 研究者对缺陷视而不见。由于追捧者的大量赞美,这些参与开发的人对自己的能力开始膨胀,并将一些批评看作是无端的攻击 —— 因为他们认为自己是不可能错的。
|
||||
* 开发者 & 研究者对缺陷视而不见。由于追捧者的大量赞美,这些参与开发的人对自己的能力的看法开始膨胀,并将一些批评看作是无端的攻击 —— 因为他们认为自己是不可能错的。
|
||||
* 真正的问题是被攻击。技术问题不再被看作是需要去解决的问题和改进的机会,他们认为是来自那些想去破坏项目的人的攻击。
|
||||
* 用一枚币来控制他们。追随者们通常会结盟,而圣人仅有一个。承认其它项目的优越,意味着认同自己项目的缺陷或不足,而这是他们不愿意做的事情。
|
||||
* 阻止真实的进步。进化是很残酷的,它要求死亡,项目失败,以及承认这些失败的原因。如果忽视失败的教训,如果不允许那些应该去死亡的事情发生,进步就会停止。
|
||||
|
||||
|
||||
* 物以类聚,人以币分。追随者们通常会结盟到一起,而圣人仅有一个。承认其它项目的优越,意味着认同自己项目的缺陷或不足,而这是他们不愿意做的事情。
|
||||
* 阻止真实的进步。进化是很残酷的,死亡是必然会有的,项目可能失败,也要承认这些失败的原因。如果忽视失败的教训,如果不允许那些应该去死亡的事情发生,进步就会停止。
|
||||
|
||||
许多围绕加密货币和相关区块链项目的讨论已经开始变得越来越”有毒“,善意的人想在不受攻击的情况下进行技术性讨论越来越不可能。随着对真正缺陷的讨论,那些在其它环境中注定要失败的缺陷,在没有做任何的事实分析的情况下即刻被判定为异端已经成为了惯例,善意的人参与其中的代价变得极其昂贵。至少有些人已经意识到极其严重的安全漏洞,由于高“毒性”的环境,他们选择保持沉默。
|
||||
|
||||
@ -79,7 +75,10 @@
|
||||
|
||||
[注意:这种行为有许多例子可以引用,但是为了保护那些因批评项目而成为被攻击目标的人,我选择尽可能少的列出这种例子。我看到许多我很尊敬的人、许多我认为是朋友的人成为这种恶毒攻击的受害者 —— 我不想引起人们对这些攻击的注意和重新引起对他们的攻击。]
|
||||
|
||||
---
|
||||
关于作者:
|
||||
|
||||
我是一个资深应用安全顾问、研究员和具有超过 15 年的经验的软件开发者。我主要关注的是应用程序安全、安全通信和加密, 虽然我经常由于无聊而去研究新的领域。我通常会写了一些关于我的研究和安全、开发和软件设计,和我当前吸引了我注意力的爱好的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -88,7 +87,7 @@ via: https://adamcaudill.com/2018/06/21/bitcoin-is-a-cult/
|
||||
作者:[Adam Caudill][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -100,3 +99,5 @@ via: https://adamcaudill.com/2018/06/21/bitcoin-is-a-cult/
|
||||
[5]:https://medium.com/@coop__soup/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a-cd4b67d446be
|
||||
[6]:https://twitter.com/nondualrandy/status/1009609117768605696?ref_src=twsrc%5Etfw
|
||||
[7]:https://en.wikipedia.org/wiki/Numerology
|
||||
[8]:https://twitter.com/hashtag/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a?src=hash&ref_src=twsrc%5Etfw
|
||||
[9]:https://twitter.com/mwilcox/status/1009160832398262273?ref_src=twsrc%5Etfw
|
||||
@ -3,28 +3,28 @@ netdev 第一天:IPsec!
|
||||
|
||||
嗨!和去年一样,今年我又参加了 [netdev 会议][3]。([这里][14]是我上一年所做的笔记)。
|
||||
|
||||
在今天的会议中,我学到了很多有关 IPsec 的知识,所以下面我将介绍它们!其中 Sowmini Varadhan 和 [Paul Wouters][5] 做了一场关于 IPsec 的专题研讨会。本文中的错误 100% 都是我的错:)。
|
||||
在今天的会议中,我学到了很多有关 IPsec 的知识,所以下面我将介绍它们!其中 Sowmini Varadhan 和 [Paul Wouters][5] 做了一场关于 IPsec 的专题研讨会。本文中的错误 100% 都是我的错 :)。
|
||||
|
||||
### 什么是 IPsec?
|
||||
|
||||
IPsec 是一个用来加密 IP 包的协议。某些 VPN 已经是通过使用 IPsec 来实现的。直到今天我才真正意识到 VPN 使用了不只一种协议,原来我以为 VPN 只是一个通用术语,指的是“你的数据包将被加密,然后通过另一台服务器去发送“。VPN 可以使用一系列不同的协议(OpenVPN、PPTP、SSTP、IPsec 等)以不同的方式来实现。
|
||||
|
||||
为什么 IPsec 和其他的 VPN 协议如此不同呢?(或者说,为什么在本次 netdev 会议中,将会给出 IPsec 的教学而不是其他的协议呢?)我的理解是有 2 点使得它如此不同:
|
||||
为什么 IPsec 和其他的 VPN 协议如此不同呢?(或者说,为什么在本次 netdev 会议会有 IPsec 的教程,而不是其他的协议呢?)我的理解是有 2 点使得它如此不同:
|
||||
|
||||
* 它是一个 IETF 标准,例如可以在文档 [RFC 6071][1] 等中查到(你知道 IETF 是制定 RFC 标准的组织吗?我也是直到今天才知道的!)。
|
||||
|
||||
* 它在 Linux 内核中被实现了(所以这才是为什么本次 netdev 会议中有关于它的教学,因为 netdev 是一个跟 Linux 内核网络有关的会议 :))。
|
||||
* 它在 Linux 内核中被实现了(所以这才是为什么本次 netdev 会议中有关于它的教程,因为 netdev 是一个跟 Linux 内核网络有关的会议 :))。
|
||||
|
||||
### IPsec 是如何工作的?
|
||||
|
||||
假如说你的笔记本正使用 IPsec 来加密数据包并通过另一台设备来发送它们,那这是怎么工作的呢?对于 IPsec 来说,它有 2 个部分:一个是用户空间部分,另一个是内核空间部分。
|
||||
|
||||
IPsec 的用户空间部分负责**密钥的交换**,使用名为 [IKE][6] ("internet key exchange",网络密钥传输)的协议。总的来说,当你打开一个 VPN 连接的时候,你需要与 VPN 服务器通信,并且和它协商使用一个密钥来进行加密。
|
||||
IPsec 的用户空间部分负责**密钥的交换**,使用名为 [IKE][6] (<ruby>网络密钥传输<rt>internet key exchange</rt></ruby>)的协议。总的来说,当你打开一个 VPN 连接的时候,你需要与 VPN 服务器通信,并且和它协商使用一个密钥来进行加密。
|
||||
|
||||
IPsec 的内核部分负责数据包的实际加密工作——一旦使用 `IKE` 生成了一个密钥,IPsec 的用户空间部分便会告诉内核使用哪个密钥来进行加密。然后内核便会使用该密钥来加密数据包!
|
||||
IPsec 的内核部分负责数据包的实际加密工作 —— 一旦使用 IKE 生成了一个密钥,IPsec 的用户空间部分便会告诉内核使用哪个密钥来进行加密。然后内核便会使用该密钥来加密数据包!
|
||||
|
||||
### 安全策略以及安全关联
|
||||
(译者注:security association 我翻译为安全关联, 参考自 https://zh.wikipedia.org/wiki/%E5%AE%89%E5%85%A8%E9%97%9C%E8%81%AF)
|
||||
|
||||
(LCTT 译注:security association 我翻译为安全关联, 参考自 https://zh.wikipedia.org/wiki/%E5%AE%89%E5%85%A8%E9%97%9C%E8%81%AF )
|
||||
|
||||
IPSec 的内核部分有两个数据库:**安全策略数据库**(SPD)和**安全关联数据库**(SAD)。
|
||||
|
||||
@ -33,7 +33,9 @@ IPSec 的内核部分有两个数据库:**安全策略数据库**(SPD)和*
|
||||
而在我眼中,安全关联数据库存放有用于各种不同 IP 的加密密钥。
|
||||
|
||||
查看这些数据库的方式却是非常不直观的,需要使用一个名为 `ip xfrm` 的命令,至于 `xfrm` 是什么意思呢?我也不知道!
|
||||
(译者注:我在 https://www.allacronyms.com/XFMR/Transformer 上查到 xfmr 是 Transformer 的简写,又根据 man7 上 http://man7.org/linux/man-pages/man8/ip-xfrm.8.html 的简介, 我认为这个说法可信。)
|
||||
|
||||
(LCTT 译注:我在 https://www.allacronyms.com/XFMR/Transformer 上查到 xfmr 是 Transformer 的简写,又根据 [man7](http://man7.org/linux/man-pages/man8/ip-xfrm.8.html) 上的简介, 我认为这个说法可信。)
|
||||
|
||||
```
|
||||
# security policy database
|
||||
$ sudo ip xfrm policy
|
||||
@ -42,7 +44,6 @@ $ sudo ip x p
|
||||
# security association database
|
||||
$ sudo ip xfrm state
|
||||
$ sudo ip x s
|
||||
|
||||
```
|
||||
|
||||
### 为什么 IPsec 被实现在 Linux 内核中而 TLS 没有?
|
||||
@ -53,11 +54,10 @@ IPsec 更容易在内核实现的原因是使用 IPsec 你可以更少频率地
|
||||
|
||||
而对于 TLS 来说,则存在一些问题:
|
||||
|
||||
a. 当你每一打开一个 TLS 连接时,每次你都要做新的密钥交换,并且 TLS 连接存活时间较短。
|
||||
|
||||
a. 当你每打开一个 TLS 连接时,每次你都要做新的密钥交换,并且 TLS 连接存活时间较短。
|
||||
b. 当你需要开始做加密时,使用 IPsec 没有一个自然的协议边界,你只需要加密给定 IP 范围内的每个 IP 包即可,但如果使用 TLS,你需要查看 TCP 流,辨别 TCP 包是否是一个数据包,然后决定是否加密它。
|
||||
|
||||
实际上存在一个补丁用于 [在 Linux 内核中实现 TLS][7],它让用户空间做密钥交换,然后传给内核密钥,所以很明显,使用 TLS 不是不可能的,但它是一个新事物,并且我认为相比使用 IPsec,使用 TLS 更加复杂。
|
||||
实际上有一个补丁用于 [在 Linux 内核中实现 TLS][7],它让用户空间做密钥交换,然后传给内核密钥,所以很明显,使用 TLS 不是不可能的,但它是一个新事物,并且我认为相比使用 IPsec,使用 TLS 更加复杂。
|
||||
|
||||
### 使用什么软件来实现 IPsec 呢?
|
||||
|
||||
@ -65,33 +65,29 @@ b. 当你需要开始做加密时,使用 IPsec 没有一个自然的协议边
|
||||
|
||||
有些让人迷糊的是,尽管 Libreswan 和 Strongswan 是不同的程序包,但它们都会安装一个名为 `ipsec` 的二进制文件来管理 IPsec 连接,并且这两个 `ipsec` 二进制文件并不是相同的程序(尽管它们担任同样的角色)。
|
||||
|
||||
在上面的“IPsec 如何工作”部分,我已经描述了 Strongswan 和 Libreswan 做了什么——使用 IKE 做密钥交换,并告诉内核有关如何使用密钥来做加密。
|
||||
在上面的“IPsec 如何工作”部分,我已经描述了 Strongswan 和 Libreswan 做了什么 —— 使用 IKE 做密钥交换,并告诉内核有关如何使用密钥来做加密。
|
||||
|
||||
### VPN 不是只能使用 IPsec 来实现!
|
||||
|
||||
在本文的开头我说“IPsec 是一个 VPN 协议”,这是对的,但你并不必须使用 IPsec 来实现 VPN!实际上有两种方式来使用 IPsec:
|
||||
|
||||
1. “传输模式”,其中 IP 表头没有改变,只有 IP 数据包的内容被加密。这种模式有点类似于使用 TLS -- 你直接告诉服务器你正在通信(而不是通过一个 VPN 服务器或其他设备),只有 IP 包里的内容被加密。
|
||||
1. “传输模式”,其中 IP 表头没有改变,只有 IP 数据包的内容被加密。这种模式有点类似于使用 TLS —— 你直接告诉服务器你正在通信(而不是通过一个 VPN 服务器或其他设备),只有 IP 包里的内容被加密。
|
||||
2. ”隧道模式“,其中 IP 表头和它的内容都被加密了,并且被封装进另一个 UDP 包内。这个模式被 VPN 所使用 —— 你获取你正传送给一个秘密网站的包,然后加密它,并将它送给你的 VPN 服务器,然后 VPN 服务器再传送给你。
|
||||
|
||||
2. ”隧道模式“,其中 IP 表头和它的内容都被加密了,并且被封装进另一个 UDP 包内。这个模式被 VPN 所使用 -- 你获取你正传送给一个秘密网站的包,然后加密它,并将它送给你的 VPN 服务器,然后 VPN 服务器再传送给你。
|
||||
### 投机的 IPsec
|
||||
|
||||
### opportunistic IPsec
|
||||
今天我学到了 IPsec “传输模式”的一个有趣应用,它叫做 “投机的 IPsec”(通过它,你可以通过开启一个 IPsec 连接来直接和你要通信的主机连接,而不是通过其他的中介服务器),现在已经有一个“投机的 IPsec” 服务器了,它位于 [http://oe.libreswan.org/][8]。
|
||||
|
||||
今天我学到了 IPsec “传输模式”的一个有趣应用,它叫做 “opportunistic IPsec”(通过它,你可以通过开启一个 IPsec 连接来直接和你要通信的主机连接,而不是通过其他的中介服务器),现在已经有一个 opportunistic IPsec 服务器了,它位于 [http://oe.libreswan.org/][8]。
|
||||
|
||||
我认为当你在你的电脑上设定好 `libreswan` 和 unbound DNS 程序后,当你连接到 [http://oe.libreswan.org][8] 时,主要发生了如下的几件事:
|
||||
我认为当你在你的电脑上设定好 `libreswan` 和 `unbound` DNS 程序后,当你连接到 [http://oe.libreswan.org][8] 时,主要发生了如下的几件事:
|
||||
|
||||
1. `unbound` 做一次 DNS 查询来获取 `oe.libreswan.org` (`dig ipseckey oe.libreswan.org`) 的 IPSECKEY 记录,以便获取到公钥来用于该网站(这需要 DNSSEC 是安全的,并且当我获得足够多这方面的知识后,我将用另一篇文章来说明它。假如你想看到相关的结果,并且如果你只是使用 dig 命令来运行此次 DNS 查询的话,它也可以工作)。
|
||||
|
||||
2. `unbound` 将公钥传给 `libreswan` 程序,然后 `libreswan` 使用它来和运行在 `oe.libreswan.org` 网站上的 IKE 服务器做一次密钥交换。
|
||||
|
||||
3. `libreswan` 完成了密钥交换,将加密密钥传给内核并告诉内核当和 `oe.libreswan.org` 做通信时使用该密钥。
|
||||
|
||||
4. 你的连接现在被加密了!即便它是 HTTP 连接!有趣吧!
|
||||
|
||||
### IPsec 和 TLS 相互借鉴
|
||||
|
||||
在今天的教程中听到一个有趣的花絮是 IPsec 和 TLS 协议实际上总是从对方学习 -- 正如他们说在 TLS 出现前, IPsec 的 IKE 协议有着完美的正向加密,而 IPsec 也从 TLS 那里学了很多。很高兴能听到不同的网络协议之间是如何从对方那里学习并与时俱进的事实!
|
||||
在今天的教程中听到一个有趣的花絮是 IPsec 和 TLS 协议实际上总是从对方学习 —— 正如他们说在 TLS 出现前, IPsec 的 IKE 协议有着完美的正向加密,而 IPsec 也从 TLS 那里学了很多。很高兴能听到不同的网络协议之间是如何从对方那里学习并与时俱进的事实!
|
||||
|
||||
### IPsec 是有趣的!
|
||||
|
||||
@ -103,9 +99,9 @@ b. 当你需要开始做加密时,使用 IPsec 没有一个自然的协议边
|
||||
|
||||
via: https://jvns.ca/blog/2018/07/11/netdev-day-1--ipsec/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -118,3 +114,4 @@ via: https://jvns.ca/blog/2018/07/11/netdev-day-1--ipsec/
|
||||
[6]:https://en.wikipedia.org/wiki/Internet_Key_Exchange
|
||||
[7]:https://blog.filippo.io/playing-with-kernel-tls-in-linux-4-13-and-go/
|
||||
[8]:http://oe.libreswan.org/
|
||||
[14]:https://jvns.ca/categories/netdev/
|
||||
@ -0,0 +1,171 @@
|
||||
系统管理员的 SELinux 指南:这个大问题的 42 个答案
|
||||
======
|
||||
|
||||
> 获取有关生活、宇宙和除了有关 SELinux 的重要问题的答案
|
||||
|
||||

|
||||
|
||||
> “一个重要而普遍的事实是,事情并不总是你看上去的那样 …”
|
||||
> ―Douglas Adams,《银河系漫游指南》
|
||||
|
||||
安全、坚固、遵从性、策略是末世中系统管理员的四骑士。除了我们的日常任务之外 —— 监控、备份、实施、调优、更新等等 —— 我们还需要负责我们的系统安全。即使这些系统是第三方提供商告诉我们该禁用增强安全性的系统。这看起来像《碟中碟》中 [Ethan Hunt][1] 的工作一样。
|
||||
|
||||
面对这种窘境,一些系统管理员决定去[服用蓝色小药丸][2],因为他们认为他们永远也不会知道如生命、宇宙、以及其它一些大问题的答案。而我们都知道,它的答案就是这个 **[42][3]**。
|
||||
|
||||
按《银河系漫游指南》的精神,这里是关于在你的系统上管理和使用 [SELinux][4] 这个大问题的 42 个答案。
|
||||
|
||||
1. SELinux 是一个标签系统,这意味着每个进程都有一个标签。每个文件、目录、以及系统对象都有一个标签。策略规则负责控制标签化的进程和标签化的对象之间的访问。由内核强制执行这些规则。
|
||||
2. 两个最重要的概念是:标签化(文件、进程、端口等等)和类型强制(基于不同的类型隔离不同的的进程)。
|
||||
3. 正确的标签格式是 `user:role:type:level`(可选)。
|
||||
4. <ruby>多级别安全<rt>Multi-Level Security</rt></ruby>(MLS)强制的目的是基于它们所使用数据的安全级别,对进程(域)强制实施控制。比如,一个秘密级别的进程是不能读取极机密级别的数据。
|
||||
5. <ruby>多类别安全<rt>Multi-Category Security</rt></ruby>(MCS)强制相互保护相似的进程(如虚拟机、OpenShift gears、SELinux 沙盒、容器等等)。
|
||||
6. 在启动时改变 SELinux 模式的内核参数有:
|
||||
* `autorelabel=1` → 强制给系统重新标签化
|
||||
* `selinux=0` → 内核不加载 SELinux 基础设施的任何部分
|
||||
* `enforcing=0` → 以<ruby>许可<rt>permissive</rt></ruby>模式启动
|
||||
7. 如果给整个系统重新标签化:
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
# reboot
|
||||
```
|
||||
如果系统标签中有大量的错误,为了能够让 autorelabel 成功,你可以用许可模式引导系统。
|
||||
8. 检查 SELinux 是否启用:`# getenforce`
|
||||
9. 临时启用/禁用 SELinux:`# setenforce [1|0]`
|
||||
10. SELinux 状态工具:`# sestatus`
|
||||
11. 配置文件:`/etc/selinux/config`
|
||||
12. SELinux 是如何工作的?这是一个为 Apache Web Server 标签化的示例:
|
||||
* 二进制文件:`/usr/sbin/httpd`→`httpd_exec_t`
|
||||
* 配置文件目录:`/etc/httpd`→`httpd_config_t`
|
||||
* 日志文件目录:`/var/log/httpd` → `httpd_log_t`
|
||||
* 内容目录:`/var/www/html` → `httpd_sys_content_t`
|
||||
* 启动脚本:`/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
|
||||
* 进程:`/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
|
||||
* 端口:`80/tcp, 443/tcp` → `httpd_t, http_port_t`
|
||||
|
||||
在 `httpd_t` 安全上下文中运行的一个进程可以与具有 `httpd_something_t` 标签的对象交互。
|
||||
13. 许多命令都可以接收一个 `-Z` 参数去查看、创建、和修改安全上下文:
|
||||
* `ls -Z`
|
||||
* `id -Z`
|
||||
* `ps -Z`
|
||||
* `netstat -Z`
|
||||
* `cp -Z`
|
||||
* `mkdir -Z`
|
||||
|
||||
当文件被创建时,它们的安全上下文会根据它们父目录的安全上下文来创建(可能有某些例外)。RPM 可以在安装过程中设定安全上下文。
|
||||
14. 这里有导致 SELinux 出错的四个关键原因,它们将在下面的 15 - 21 条中展开描述:
|
||||
* 标签化问题
|
||||
* SELinux 需要知道一些东西
|
||||
* SELinux 策略或者应用有 bug
|
||||
* 你的信息可能被损坏
|
||||
15. 标签化问题:如果在 `/srv/myweb` 中你的文件没有被正确的标签化,访问可能会被拒绝。这里有一些修复这类问题的方法:
|
||||
* 如果你知道标签:`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
|
||||
* 如果你知道和它有相同标签的文件:`# semanage fcontext -a -e /srv/myweb /var/www`
|
||||
* 恢复安全上下文(对于以上两种情况):`# restorecon -vR /srv/myweb`
|
||||
16. 标签化问题:如果你是移动了一个文件,而不是去复制它,那么这个文件将保持原始的环境。修复这类问题:
|
||||
* 使用标签来改变安全上下文:`# chcon -t httpd_system_content_t /var/www/html/index.html`
|
||||
* 使用参考文件的标签来改变安全上下文:`# chcon --reference /var/www/html/ /var/www/html/index.html`
|
||||
* 恢复安全上下文(对于以上两种情况):`# restorecon -vR /var/www/html/`
|
||||
17. 如果 SELinux 需要知道 HTTPD 在 8585 端口上监听,使用下列命令告诉 SELinux:`# semanage port -a -t http_port_t -p tcp 8585`
|
||||
18. SELinux 需要知道是否允许在运行时改变 SELinux 策略部分,而无需重写 SELinux 策略。例如,如果希望 httpd 去发送邮件,输入:`# setsebool -P httpd_can_sendmail 1`
|
||||
19. SELinux 需要知道 SELinux 设置的关闭或打开的一系列布尔值:
|
||||
* 查看所有的布尔值:`# getsebool -a`
|
||||
* 查看每个布尔值的描述:`# semanage boolean -l`
|
||||
* 设置某个布尔值:`# setsebool [_boolean_] [1|0]`
|
||||
* 将它配置为永久值,添加 `-P` 标志。例如:`# setsebool httpd_enable_ftp_server 1 -P`
|
||||
20. SELinux 策略/应用可能有 bug,包括:
|
||||
* 不寻常的代码路径
|
||||
* 配置
|
||||
* 重定向 `stdout`
|
||||
* 泄露的文件描述符
|
||||
* 可执行内存
|
||||
* 错误构建的库
|
||||
|
||||
开一个工单(但不要提交 Bugzilla 报告;使用 Bugzilla 没有对应的服务)
|
||||
21. 你的信息可能被损坏了,假如你被限制在某个区域,尝试这样做:
|
||||
* 加载内核模块
|
||||
* 关闭 SELinux 的强制模式
|
||||
* 写入 `etc_t/shadow_t`
|
||||
* 修改 iptables 规则
|
||||
22. 用于开发策略模块的 SELinux 工具:`# yum -y install setroubleshoot setroubleshoot-server`。安装完成之后重引导机器或重启 `auditd` 服务。
|
||||
23. 使用 `journalctl` 去列出所有与 `setroubleshoot` 相关的日志:`# journalctl -t setroubleshoot --since=14:20`
|
||||
24. 使用 `journalctl` 去列出所有与特定 SELinux 标签相关的日志。例如:`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
|
||||
25. 当 SELinux 错误发生时,使用`setroubleshoot` 的日志,并尝试找到某些可能的解决方法。例如:从 `journalctl` 中:
|
||||
```
|
||||
Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
|
||||
|
||||
***** Plugin restorecon (99.5 confidence) suggests ************************
|
||||
|
||||
If you want to fix the label,
|
||||
/var/www/html/index.html default label should be httpd_syscontent_t.
|
||||
Then you can restorecon.
|
||||
Do
|
||||
# /sbin/restorecon -v /var/www/html/index.html
|
||||
```
|
||||
26. 日志:SELinux 记录的信息全在这些地方:
|
||||
* `/var/log/messages`
|
||||
* `/var/log/audit/audit.log`
|
||||
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
|
||||
27. 日志:在审计日志中查找 SELinux 错误:`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
|
||||
28. 针对特定的服务,搜索 SELinux 的<ruby>访问向量缓存<rt>Access Vector Cache</rt></ruby>(AVC)信息:`# ausearch -m avc -c httpd`
|
||||
29. `audit2allow` 实用工具可以通过从日志中搜集有关被拒绝的操作,然后生成 SELinux 策略允许的规则,例如:
|
||||
* 产生一个人类可读的关于为什么拒绝访问的描述:`# audit2allow -w -a`
|
||||
* 查看允许被拒绝的类型强制规则:`# audit2allow -a`
|
||||
* 创建一个自定义模块:`# audit2allow -a -M mypolicy`,其中 `-M` 选项将创建一个特定名称的强制类型文件(.te),并编译这个规则到一个策略包(.pp)中:`mypolicy.pp mypolicy.te`
|
||||
* 安装自定义模块:`# semodule -i mypolicy.pp`
|
||||
30. 配置单个进程(域)运行在许可模式:`# semanage permissive -a httpd_t`
|
||||
31. 如果不再希望一个域在许可模式中:`# semanage permissive -d httpd_t`
|
||||
32. 禁用所有的许可域:`# semodule -d permissivedomains`
|
||||
33. 启用 SELinux MLS 策略:`# yum install selinux-policy-mls`。
|
||||
在 `/etc/selinux/config` 中:
|
||||
```
|
||||
SELINUX=permissive
|
||||
SELINUXTYPE=mls
|
||||
```
|
||||
确保 SELinux 运行在许可模式:`# setenforce 0`
|
||||
|
||||
使用 `fixfiles` 脚本来确保在下一次重启时文件将被重新标签化:`# fixfiles -F onboot # reboot`
|
||||
34. 创建一个带有特定 MLS 范围的用户:`# useradd -Z staff_u john`
|
||||
|
||||
使用 `useradd` 命令,映射新用户到一个已存在的 SELinux 用户(上面例子中是 `staff_u`)。
|
||||
35. 查看 SELinux 和 Linux 用户之间的映射:`# semanage login -l`
|
||||
36. 为用户定义一个指定的范围:`# semanage login --modify --range s2:c100 john`
|
||||
37. 调整用户家目录上的标签(如果需要的话):`# chcon -R -l s2:c100 /home/john`
|
||||
38. 列出当前类别:`# chcat -L`
|
||||
39. 修改类别或者创建你自己的分类,修改如下文件:`/etc/selinux/_<selinuxtype>_/setrans.conf`
|
||||
40. 以某个特定的文件、角色和用户安全上下文来运行一个命令或者脚本:`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
|
||||
* `-t` 是文件安全上下文
|
||||
* `-r` 是角色安全上下文
|
||||
* `-u` 是用户安全上下文
|
||||
41. 在容器中禁用 SELinux:
|
||||
* 使用 Podman:`# podman run --security-opt label=disable ...`
|
||||
* 使用 Docker:`# docker run --security-opt label=disable ...`
|
||||
42. 如果需要给容器提供完全访问系统的权限:
|
||||
* 使用 Podman:`# podman run --privileged ...`
|
||||
* 使用 Docker:`# docker run --privileged ...`
|
||||
|
||||
就这些了,你已经知道了答案。因此请相信我:**不用恐慌,去打开 SELinux 吧**。
|
||||
|
||||
### 作者简介
|
||||
|
||||
Alex Callejas 是位于墨西哥城的红帽公司拉丁美洲区的一名技术客服经理。作为一名系统管理员,他已有超过 10 年的经验。在基础设施强化方面具有很强的专业知识。对开源抱有热情,通过在不同的公共事件和大学中分享他的知识来支持社区。天生的极客,当然他一般选择使用 Fedora Linux 发行版。[这里][11]有更多关于他的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
|
||||
作者:[Alex Callejas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw), [FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/darkaxl
|
||||
[1]:https://en.wikipedia.org/wiki/Ethan_Hunt
|
||||
[2]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
|
||||
[3]:https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29
|
||||
[4]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
173
published/20180731 A sysadmin-s guide to Bash.md
Normal file
173
published/20180731 A sysadmin-s guide to Bash.md
Normal file
@ -0,0 +1,173 @@
|
||||
面向系统管理员的 Bash 指南
|
||||
======
|
||||
|
||||
> 使 Bash 工作的更好的技巧。
|
||||
|
||||

|
||||
|
||||
每个行业都有一个该行业的大师们最常使用的工具。 对于许多系统管理员来说,这个工具就是他们的 [shell][1]。 在大多数 Linux 和其他类 Unix 系统上,默认的 shell 是 Bash。
|
||||
|
||||
Bash 是一个相当古老的程序——它起源于 20 世纪 80 年代后期——但它建立在更多更老的 shell 上,比如 C shell(csh),csh 至少是它 10 年前的前辈了。 因为 shell 的概念是那么古老,所以有大量的神秘知识等待着系统管理员去吸收领悟,使其生活更轻松。
|
||||
|
||||
我们来看看一些基础知识。
|
||||
|
||||
在某些时候,谁曾经无意中以 root 身份运行命令并导致某种问题? *举手*
|
||||
|
||||
我很确定我们很多人一度都是那个人。 这很痛苦。 这里有一些非常简单的技巧可以防止你再次碰上这类问题。
|
||||
|
||||
### 使用别名
|
||||
|
||||
首先,为 `mv` 和 `rm` 等命令设置别名,指向 `mv -i` 和 `rm -i`。 这将确保在运行 `rm -f /boot` 时至少需要你确认。 在 Red Hat 企业版 Linux 中,如果你使用 root 帐户,则默认设置这些别名。
|
||||
|
||||
如果你还要为普通用户帐户设置这些别名,只需将这两行放入家目录下名为 `.bashrc` 的文件中(这些也适用于 `sudo` ):
|
||||
|
||||
```
|
||||
alias mv='mv -i'
|
||||
alias rm='rm -i'
|
||||
```
|
||||
|
||||
### 让你的 root 提示符脱颖而出
|
||||
|
||||
你可以采取的防止意外发生的另一项措施是确保你很清楚在使用 root 帐户。 在日常工作中,我通常会让 root 提示符从日常使用的提示符中脱颖而出。
|
||||
|
||||
如果将以下内容放入 root 的家目录中的 `.bashrc` 文件中,你将看到一个黑色背景上的红色的 root 提示符,清楚地表明你(或其他任何人)应该谨慎行事。
|
||||
|
||||
```
|
||||
export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"
|
||||
```
|
||||
|
||||
实际上,你应该尽可能避免以 root 用户身份登录,而是通过 `sudo` 运行大多数系统管理命令,但这是另一回事。
|
||||
|
||||
使用了一些小技巧用于防止使用 root 帐户时的“不小心的副作用”之后,让我们看看 Bash 可以帮助你在日常工作中做的一些好事。
|
||||
|
||||
### 控制你的历史
|
||||
|
||||
你可能知道在 Bash 中你按向上的箭头时能看见和重新使用你之前所有(好吧,大多数)的命令。这是因为这些命令已经保存到了你家目录下的名为 `.bash_history` 的文件中。这个历史文件附带了一组有用的设置和命令。
|
||||
|
||||
首先,你可以通过键入 `history` 来查看整个最近的命令历史记录,或者你可以通过键入 `history 30` 将其限制为最近 30 个命令。不过这技巧太平淡无奇了(LCTT 译注: vanilla 原为香草,后引申没拓展的、标准、普通的,比如 vanilla C++ compiler 意为标准 C++ 编译器)。 你可以更好地控制 Bash 保存的内容以及保存方式。
|
||||
|
||||
例如,如果将以下内容添加到 `.bashrc`,那么任何以空格开头的命令都不会保存到历史记录列表中:
|
||||
|
||||
```
|
||||
HISTCONTROL=ignorespace
|
||||
```
|
||||
|
||||
如果你需要以明文形式将密码传递给一个命令,这就非常有用。 (是的,这太可怕了,但它仍然会发生。)
|
||||
|
||||
如果你不希望经常执行的命令充斥在历史记录中,请使用:
|
||||
|
||||
```
|
||||
HISTCONTROL=ignorespace:erasedups
|
||||
```
|
||||
|
||||
这样,每次使用一个命令时,都会从历史记录文件中删除之前出现的所有相同命令,并且只将最后一次调用保存到历史记录列表中。
|
||||
|
||||
我特别喜欢的历史记录设置是 `HISTTIMEFORMAT` 设置。 这将在历史记录文件中在所有的条目前面添加上时间戳。 例如,我使用:
|
||||
|
||||
```
|
||||
HISTTIMEFORMAT="%F %T "
|
||||
```
|
||||
|
||||
当我输入 `history 5` 时,我得到了很好的完整信息,如下所示:
|
||||
|
||||
```
|
||||
1009 2018-06-11 22:34:38 cat /etc/hosts
|
||||
1010 2018-06-11 22:34:40 echo $foo
|
||||
1011 2018-06-11 22:34:42 echo $bar
|
||||
1012 2018-06-11 22:34:44 ssh myhost
|
||||
1013 2018-06-11 22:34:55 vim .bashrc
|
||||
```
|
||||
|
||||
这使我更容易浏览我的命令历史记录并找到我两天前用来建立到我家实验室的 SSH 连接(我一次又一次地忘记......)。
|
||||
|
||||
### Bash 最佳实践
|
||||
|
||||
我将在编写 Bash 脚本时最好的(或者至少是好的,我不要求无所不知)11 项实践列出来。
|
||||
|
||||
11、 Bash 脚本可能变得复杂,不过注释也很方便。 如果你在考虑是否要添加注释,那就添加一个注释。 如果你在周末之后回来并且不得不花时间搞清楚你上周五想要做什么,那你是忘了添加注释。
|
||||
|
||||
10、 用花括号括起所有变量名,比如 `${myvariable}`。 养成这个习惯可以使用 `${variable}_suffix` 这种用法了,还能提高整个脚本的一致性。
|
||||
|
||||
9、 计算表达式时不要使用反引号;请改用 `$()` 语法。 所以使用:
|
||||
|
||||
```
|
||||
for file in $(ls); do
|
||||
```
|
||||
|
||||
而不使用:
|
||||
|
||||
```
|
||||
for file in `ls`; do
|
||||
```
|
||||
|
||||
前一个方式是可嵌套的,更易于阅读的,还能让一般的系统管理员群体感到满意。 不要使用反引号。
|
||||
|
||||
8、 一致性是好的。 选择一种风格并在整个脚本中坚持下去。 显然,我喜欢人们选择 `$()` 语法而不是反引号,并将其变量包在花括号中。 我更喜欢人们使用两个或四个空格而不是制表符来缩进,但即使你选择了错误的方式,也要一贯地错下去。
|
||||
|
||||
7、 为 Bash 脚本使用适当的<ruby>[释伴][3]<rt>shebang</rt></ruby>(LCTT 译注:**Shebang**,也称为 **Hashbang** ,是一个由井号和叹号构成的字符序列 `#!` ,其出现在文本文件的第一行的前两个字符。 在文件中存在释伴的情况下,类 Unix 操作系统的程序载入器会分析释伴后的内容,将这些内容作为解释器指令,并调用该指令,并将载有释伴的文件路径作为该解释器的参数)。 因为我正在编写Bash脚本,只打算用 Bash 执行它们,所以我经常使用 `#!/usr/bin/bash` 作为我的释伴。 不要使用 `#!/bin/sh` 或 `#!/usr/bin/sh`。 你的脚本会被执行,但它会以兼容模式运行——可能会产生许多意外的副作用。 (当然,除非你想要兼容模式。)
|
||||
|
||||
6、 比较字符串时,在 `if` 语句中给变量加上引号是个好主意,因为如果你的变量是空的,Bash 会为这样的行抛出一个错误:
|
||||
|
||||
```
|
||||
if [ ${myvar} == "foo" ]; then
|
||||
echo "bar"
|
||||
fi
|
||||
```
|
||||
|
||||
对于这样的行,将判定为 `false`:
|
||||
|
||||
```
|
||||
if [ "${myvar}" == "foo" ]; then
|
||||
echo "bar"
|
||||
fi
|
||||
```
|
||||
|
||||
此外,如果你不确定变量的内容(例如,在解析用户输入时),请给变量加引号以防止解释某些特殊字符,并确保该变量被视为单个单词,即使它包含空格。
|
||||
|
||||
5、 我想这是一个品味问题,但我更喜欢使用双等号( `==` ),即使是比较 Bash 中的字符串。 这是一致性的问题,尽管对于字符串比较,只有一个等号会起作用,我的思维立即变为“单个 `=` 是一个赋值运算符!”
|
||||
|
||||
4、 使用适当的退出代码。 确保如果你的脚本无法执行某些操作,则会向用户显示已写好的失败消息(最好提供解决问题的方法)并发送非零退出代码:
|
||||
|
||||
```
|
||||
# we have failed
|
||||
echo "Process has failed to complete, you need to manually restart the whatchamacallit"
|
||||
exit 1
|
||||
```
|
||||
|
||||
这样可以更容易地以编程方式从另一个脚本调用你的脚本并验证其成功完成。
|
||||
|
||||
3、 使用 Bash 的内置机制为变量提供合理的默认值,或者如果未定义你希望定义的变量,则抛出错误:
|
||||
|
||||
```
|
||||
# this sets the value of $myvar to redhat, and prints 'redhat'
|
||||
echo ${myvar:=redhat}
|
||||
```
|
||||
|
||||
```
|
||||
# this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined
|
||||
${myvar:?The variable myvar is undefined, dear reader}
|
||||
```
|
||||
|
||||
2、 特别是如果你正在编写大型脚本,或者是如果你与其他人一起开发该大型脚本,请考虑在函数内部定义变量时使用 `local` 关键字。 `local` 关键字将创建一个局部变量,该变量只在该函数中可见。 这限制了变量冲突的可能性。
|
||||
|
||||
1、 每个系统管理员有时必须这样做:在控制台上调试一些东西,可能是数据中心的真实服务器,也可能是虚拟化平台的虚拟服务器。 如果你必须以这种方式调试脚本,你会感谢你自己记住了这个:不要让你的脚本中的行太长!
|
||||
|
||||
在许多系统上,控制台的默认宽度仍为 80 个字符。 如果你需要在控制台上调试脚本并且该脚本有很长的行,那么你将成为一个悲伤的熊猫。 此外,具有较短行的脚本—— 默认值仍为 80 个字符——在普通编辑器中也更容易阅读和理解!
|
||||
|
||||
我真的很喜欢 Bash。 我可以花几个小时写这篇文章或与其他爱好者交流优秀的技巧。 就希望你们能在评论中留下赞美。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/admin-guide-bash
|
||||
|
||||
作者:[Maxim Burgerhout][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/wzzrd
|
||||
[1]:http://www.catb.org/jargon/html/S/shell.html
|
||||
[2]:https://en.wikipedia.org/wiki/C_shell
|
||||
[3]:https://linux.cn/article-3664-1.html
|
||||
@ -0,0 +1,136 @@
|
||||
如何在 Linux 上使用 pbcopy 和 pbpaste 命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
由于 Linux 和 Mac OS X 是基于 *Nix 的系统,因此许多命令可以在两个平台上运行。但是,某些命令可能在两个平台上都没有,比如 `pbcopy` 和 `pbpast`。这些命令仅在 Mac OS X 平台上可用。`pbcopy` 命令将标准输入复制到剪贴板。然后,你可以在任何地方使用 `pbpaste` 命令粘贴剪贴板内容。当然,上述命令可能有一些 Linux 替代品,例如 `xclip`。 `xclip` 与 `pbcopy` 完全相同。但是,从 Mac OS 切换到 Linux 的发行版的人将会找不到这两个命令,不过仍然想使用它们。别担心!这个简短的教程描述了如何在 Linux 上使用 `pbcopy` 和 `pbpaste` 命令。
|
||||
|
||||
### 安装 xclip / xsel
|
||||
|
||||
就像我已经说过的那样,Linux 中没有 `pbcopy` 和 `pbpaste` 命令。但是,我们可以通过 shell 别名使用 xclip 和/或 xsel 命令复制 `pbcopy` 和 `pbpaste` 命令的功能。xclip 和 xsel 包存在于大多数 Linux 发行版的默认存储库中。请注意,你无需安装这两个程序。只需安装上述任何一个程序即可。
|
||||
|
||||
要在 Arch Linux 及其衍生产版上安装它们,请运行:
|
||||
|
||||
```
|
||||
$ sudo pacman xclip xsel
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf xclip xsel
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt install xclip xsel
|
||||
```
|
||||
|
||||
安装后,你需要为 `pbcopy` 和 `pbpaste` 命令创建别名。为此,请编辑 `~/.bashrc`:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
如果要使用 xclip,请粘贴以下行:
|
||||
|
||||
```
|
||||
alias pbcopy='xclip -selection clipboard'
|
||||
alias pbpaste='xclip -selection clipboard -o'
|
||||
```
|
||||
|
||||
如果要使用 xsel,请在 `~/.bashrc` 中粘贴以下行。
|
||||
|
||||
```
|
||||
alias pbcopy='xsel --clipboard --input'
|
||||
alias pbpaste='xsel --clipboard --output'
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
接下来,运行以下命令以更新 `~/.bashrc` 中的更改。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
ZSH 用户将上述行粘贴到 `~/.zshrc` 中。
|
||||
|
||||
### 在 Linux 上使用 pbcopy 和 pbpaste 命令
|
||||
|
||||
让我们看一些例子。
|
||||
|
||||
`pbcopy` 命令将文本从 stdin 复制到剪贴板缓冲区。例如,看看下面的例子。
|
||||
|
||||
```
|
||||
$ echo "Welcome To OSTechNix!" | pbcopy
|
||||
```
|
||||
|
||||
上面的命令会将文本 “Welcome to OSTechNix” 复制到剪贴板中。你可以稍后访问此内容并使用如下所示的 `pbpaste` 命令将其粘贴到任何位置。
|
||||
|
||||
```
|
||||
$ echo `pbpaste`
|
||||
Welcome To OSTechNix!
|
||||
```
|
||||
|
||||
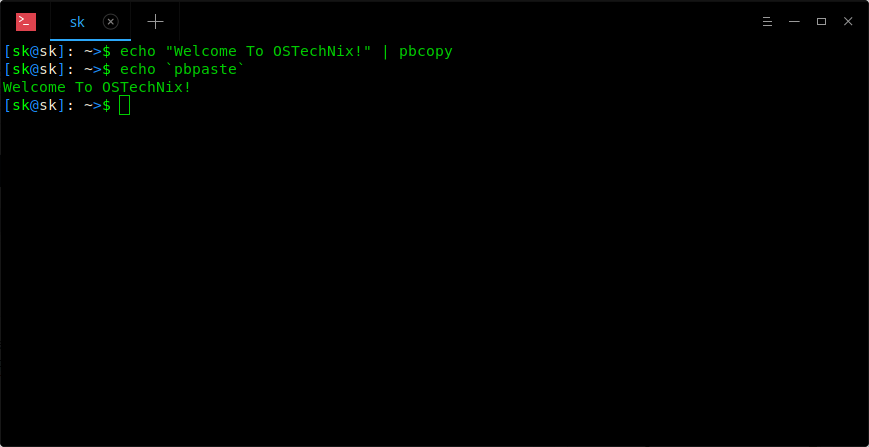
|
||||
|
||||
以下是一些其他例子。
|
||||
|
||||
我有一个名为 `file.txt` 的文件,其中包含以下内容。
|
||||
|
||||
```
|
||||
$ cat file.txt
|
||||
Welcome To OSTechNix!
|
||||
```
|
||||
|
||||
你可以直接将文件内容复制到剪贴板中,如下所示。
|
||||
|
||||
```
|
||||
$ pbcopy < file.txt
|
||||
```
|
||||
|
||||
现在,只要你用其他文件的内容更新了剪切板,那么剪切板中的内容就可用了。
|
||||
|
||||
要从剪贴板检索内容,只需输入:
|
||||
|
||||
```
|
||||
$ pbpaste
|
||||
Welcome To OSTechNix!
|
||||
```
|
||||
|
||||
你还可以使用管道字符将任何 Linux 命令的输出发送到剪贴板。看看下面的例子。
|
||||
|
||||
```
|
||||
$ ps aux | pbcopy
|
||||
```
|
||||
|
||||
现在,输入 `pbpaste` 命令以显示剪贴板中 `ps aux` 命令的输出。
|
||||
|
||||
```
|
||||
$ pbpaste
|
||||
```
|
||||
|
||||
|
||||
|
||||
使用 `pbcopy` 和 `pbpaste` 命令可以做更多的事情。我希望你现在对这些命令有一个基本的想法。
|
||||
|
||||
就是这些了。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
52
published/20180801 Cross-Site Request Forgery.md
Normal file
52
published/20180801 Cross-Site Request Forgery.md
Normal file
@ -0,0 +1,52 @@
|
||||
CSRF(跨站请求伪造)简介
|
||||
======
|
||||

|
||||
|
||||
设计 Web 程序时,安全性是一个主要问题。我不是在谈论 DDoS 保护、使用强密码或两步验证。我说的是对网络程序的最大威胁。它被称为**CSRF**, 是 **Cross Site Resource Forgery** (跨站请求伪造)的缩写。
|
||||
|
||||
### 什么是 CSRF?
|
||||
|
||||
[][1]
|
||||
|
||||
首先,**CSRF** 是 Cross Site Resource Forgery 的缩写。它通常发音为 “sea-surf”,也经常被称为 XSRF。CSRF 是一种攻击类型,在受害者不知情的情况下,在受害者登录的 Web 程序上执行各种操作。这些行为可以是任何事情,从简单地点赞或评论社交媒体帖子到向人们发送垃圾消息,甚至从受害者的银行账户转移资金。
|
||||
|
||||
### CSRF 如何工作?
|
||||
|
||||
**CSRF** 攻击尝试利用所有浏览器上的一个简单的常见漏洞。每次我们对网站进行身份验证或登录时,会话 cookie 都会存储在浏览器中。因此,每当我们向网站提出请求时,这些 cookie 就会自动发送到服务器,服务器通过匹配与服务器记录一起发送的 cookie 来识别我们。这样就知道是我们了。
|
||||
|
||||
[][2]
|
||||
|
||||
这意味着我将在知情或不知情的情况下发出请求。由于 cookie 也被发送并且它们将匹配服务器上的记录,服务器认为我在发出该请求。
|
||||
|
||||
CSRF 攻击通常以链接的形式出现。我们可以在其他网站上点击它们或通过电子邮件接收它们。单击这些链接时,会向服务器发出不需要的请求。正如我之前所说,服务器认为我们发出了请求并对其进行了身份验证。
|
||||
|
||||
#### 一个真实世界的例子
|
||||
|
||||
为了把事情看得更深入,想象一下你已登录银行的网站。并在 **yourbank.com/transfer** 上填写表格。你将接收者的帐号填写为 1234,填入金额 5,000 并单击提交按钮。现在,我们将有一个 **yourbank.com/transfer/send?to=1234&amount=5000** 的请求。因此服务器将根据请求进行操作并转账。现在想象一下你在另一个网站上,然后点击一个链接,用黑客的帐号作为参数打开上面的 URL。这笔钱现在会转账给黑客,服务器认为你做了交易。即使你没有。
|
||||
|
||||
[][3]
|
||||
|
||||
#### CSRF 防护
|
||||
|
||||
CSRF 防护非常容易实现。它通常将一个称为 CSRF 令牌的令牌发送到网页。每次发出新请求时,都会发送并验证此令牌。因此,向服务器发出的恶意请求将通过 cookie 身份验证,但 CSRF 验证会失败。大多数 Web 框架为防止 CSRF 攻击提供了开箱即用的支持,而 CSRF 攻击现在并不像以前那样常见。
|
||||
|
||||
### 总结
|
||||
|
||||
CSRF 攻击在 10 年前是一件大事,但如今我们看不到太多。过去,Youtube、纽约时报和 Netflix 等知名网站都容易受到 CSRF 的攻击。然而,CSRF 攻击的普遍性和发生率最近有减少。尽管如此,CSRF 攻击仍然是一种威胁,重要的是,你要保护自己的网站或程序免受攻击。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/understanding-csrf-cross-site-request-forgery
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-what-is-cross-site-forgery_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/cookies-set-by-website-chrome_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-hacking-bank-account_orig.jpg
|
||||
@ -0,0 +1,69 @@
|
||||
Mu 入门:一个面向初学者的 Python 编辑器
|
||||
======
|
||||
> 相识 Mu —— 一个可以使学生学习 Python 更轻松的开源编辑器。
|
||||
|
||||

|
||||
|
||||
Mu 是一个给初学者的 Python 编辑器,它旨在使学习体验更加愉快。它使学生能够在早期体验成功,这在你学习任何新知识的时候都很重要。
|
||||
|
||||
如果你曾试图教年轻人如何编程,你会立即把握到 [Mu][1] 的重要性。大多数编程工具都是由开发人员为开发人员编写的,不管他们的年龄如何,它们并不适合初学者。然而,Mu 是由老师为学生写的。
|
||||
|
||||
### Mu 的起源
|
||||
|
||||
Mu 是 [Nicholas Tollervey][2] 的心血结晶(我听过他 5 月份在 PyCon2018 上发言)。Nicholas 是一位受过古典音乐训练的音乐家,在担任音乐老师期间,他在职业生涯早期就开始对 Python 和开发感兴趣。他还写了 [Python in Education][3],这是一本可以从 O'Reilly 下载的免费书。
|
||||
|
||||
Nicholas 曾经寻找过一个更简单的 Python 编程界面。他想要一些没有其他编辑器(甚至是 Python 附带的 IDLE3 编辑器 )复杂性的东西,所以他与 Raspberry Pi 基金会(赞助他的工作)的教育总监 [Carrie Ann Philbin][4] 合作开发了 Mu 。
|
||||
|
||||
Mu 是一个用 Python 编写的开源程序(在 [GNU GPLv3][5] 许可证下)。它最初是为 [Micro:bit][6] 迷你计算机开发的,但是其他老师的反馈和请求促使他将 Mu 重写为通用的 Python 编辑器。
|
||||
|
||||
### 受音乐启发
|
||||
|
||||
Nicholas 对 Mu 的启发来自于他教授音乐的方法。他想知道如果我们按照教授音乐的方式教授编程会如何,并立即看出了差别。与编程不同,我们没有音乐训练营,我们也不会书上学习如何演奏乐器,比如说如何演奏长笛。
|
||||
|
||||
Nicholas 说,Mu “旨在成为真实的东西”,因为没有人可以在 30 分钟内学习 Python。当他开发 Mu 时,他与老师一起工作,观察编程俱乐部,并观看中学生使用 Python。他发现少即多,保持简单可以改善成品的功能。Nicholas 说,Mu 只有大约 3,000 行代码。
|
||||
|
||||
### 使用 Mu
|
||||
|
||||
要尝试它,[下载][7] Mu 并按照 [Linux、Windows 和 Mac OS] [8]的简易安装说明进行操作。如果像我一样,你想[在 Raspberry Pi 上安装] [9],请在终端中输入以下内容:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install mu
|
||||
```
|
||||
|
||||
从编程菜单启动 Mu。然后你就可以选择如何使用 Mu。
|
||||
|
||||
|
||||
|
||||
我选择了Python 3,它启动了编写代码的环境。Python shell 直接在下面,它允许你查看代码执行。
|
||||
|
||||
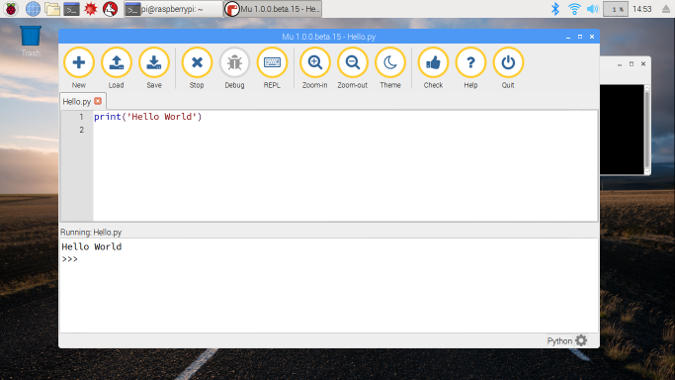
|
||||
|
||||
菜单使用和理解非常简单,这实现了 Mu 的目标 —— 让编写代码对初学者简单。
|
||||
|
||||
在 Mu 用户的网站上可找到[教程][10]和其他资源。在网站上,你还可以看到一些帮助开发 Mu 的[志愿者][11]的名字。如果你想成为其中之一并[为 Mu 的发展做出贡献][12],我们非常欢迎您。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://codewith.mu
|
||||
[2]:https://us.pycon.org/2018/speaker/profile/194/
|
||||
[3]:https://www.oreilly.com/programming/free/python-in-education.csp
|
||||
[4]:https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7
|
||||
[5]:https://mu.readthedocs.io/en/latest/license.html
|
||||
[6]:http://microbit.org/
|
||||
[7]:https://codewith.mu/en/download
|
||||
[8]:https://codewith.mu/en/howto/install_with_python
|
||||
[9]:https://codewith.mu/en/howto/install_raspberry_pi
|
||||
[10]:https://codewith.mu/en/tutorials/
|
||||
[11]:https://codewith.mu/en/thanks
|
||||
[12]:https://mu.readthedocs.io/en/latest/contributing.html
|
||||
@ -0,0 +1,77 @@
|
||||
使用 EduBlocks 轻松学习 Python 编程
|
||||
======
|
||||
|
||||
> EduBlocks 提供了 Scratch 式的图形界面来编写 Python 3 代码。
|
||||
|
||||

|
||||
|
||||
如果你正在寻找一种方法将你的学生(或你自己)从使用 [Scratch][1] 编程转移到学习 [Python][2],我建议你了解一下 [EduBlocks][3]。它为 Python 3 编程带来了熟悉的拖放式图形用户界面(GUI)。
|
||||
|
||||
从 Scratch 过渡到 Python 的一个障碍是缺少拖放式 GUI,而正是这种拖放式 GUI 使得 Scratch 成为 K-12 学校的首选程序。EduBlocks 的拖放版的 Python 3 改变了这种范式。它的目的是“帮助教师在较早的时候向儿童介绍基于文本的编程语言,如 Python。”
|
||||
|
||||
EduBlocks 的硬件要求非常适中 —— 一个树莓派和一条互联网连接 —— 应该可以在许多教室中使用。
|
||||
|
||||
EduBlocks 是由来自英国的 14 岁 Python 开发人员 Joshua Lowe 开发的。我看到 Joshua 在 2018 年 5 月的 [PyCon 2018][4] 上展示了他的项目。
|
||||
|
||||
### 入门
|
||||
|
||||
安装 EduBlocks 很容易。该网站提供了清晰的安装说明,你可以在项目的 [GitHub][5] 仓库中找到详细的截图。
|
||||
|
||||
使用以下命令在 Raspberry Pi 命令行安装 EduBlocks:
|
||||
|
||||
```
|
||||
curl -sSL get.edublocks.org | bash
|
||||
```
|
||||
|
||||
### 在 EduBlocks 中编程
|
||||
|
||||
安装完成后,从桌面快捷方式或 Raspberry Pi 上的“编程”菜单启动 EduBlocks。
|
||||
|
||||

|
||||
|
||||
启动程序后,你可以使用 EduBlocks 的拖放界面开始创建 Python 3 代码。它的菜单有清晰的标签。你可以通过单击 **Samples** 菜单按钮使用示例代码。你还可以通过单击 **Theme** 为你的编程界面选择不同的配色方案。使用 **Save** 菜单,你可以保存你的作品,然后 **Download** 你的 Python 代码。单击 **Run** 来执行并测试你的代码。
|
||||
|
||||
你可以通过单击最右侧的 **Blockly** 按钮来查看代码。它让你在 ”Blockly” 界面和普通的 Python 代码视图之间切换(正如你在任何其他 Python 编辑器中看到的那样)。
|
||||
|
||||
|
||||
|
||||
EduBlocks 附带了一系列代码库,包括 [EduPython][6]、[Minecraft] [7]、[Sonic Pi] [8]、[GPIO Zero][9] 和 [Sense Hat][10]。
|
||||
|
||||
### 学习和支持
|
||||
|
||||
该项目维护了一个[学习门户网站][11],其中包含教程和其他资源,可以轻松地 [hack][12] 树莓派版本的 Minecraft,编写 GPIOZero 和 Sonic Pi,并使用 Micro:bit 代码编辑器控制 LED。可以在 Twitter [@edu_blocks][13] 和 [@all_about_code][14] 以及 [email][15] 提供对 EduBlocks 的支持。
|
||||
|
||||
为了更深入的了解,你可以在 [GitHub][16] 上访问 EduBlocks 的源代码。该程序在 GNU Affero Public License v3.0 下[许可][17]。EduBlocks 的创建者(项目负责人 [Joshua Lowe][18] 和开发人员 [Chris Dell][19] 和 [Les Pounder][20])希望它成为一个社区项目,并邀请人们提出问题,提供反馈,以及提交 pull request 以向项目添加功能或修复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/edublocks
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://scratch.mit.edu/
|
||||
[2]:https://www.python.org/
|
||||
[3]:https://edublocks.org/
|
||||
[4]:https://us.pycon.org/2018/about/
|
||||
[5]:https://github.com/AllAboutCode/EduBlocks
|
||||
[6]:https://edupython.tuxfamily.org/
|
||||
[7]:https://minecraft.net/en-us/edition/pi/
|
||||
[8]:https://sonic-pi.net/
|
||||
[9]:https://gpiozero.readthedocs.io/en/stable/
|
||||
[10]:https://www.raspberrypi.org/products/sense-hat/
|
||||
[11]:https://edublocks.org/learn.html
|
||||
[12]:https://edublocks.org/resources/1.pdf
|
||||
[13]:https://twitter.com/edu_blocks?lang=en
|
||||
[14]:https://twitter.com/all_about_code
|
||||
[15]:mailto:support@edublocks.org
|
||||
[16]:https://github.com/allaboutcode/edublocks
|
||||
[17]:https://github.com/AllAboutCode/EduBlocks/blob/tarball-install/LICENSE
|
||||
[18]:https://github.com/JoshuaLowe1002
|
||||
[19]:https://twitter.com/cjdell?lang=en
|
||||
[20]:https://twitter.com/biglesp?lang=en
|
||||
@ -1,4 +1,4 @@
|
||||
20 questions DevOps job candidates should be prepared to answer
|
||||
Translating by FelixYFZ 20 questions DevOps job candidates should be prepared to answer
|
||||
======
|
||||
|
||||

|
||||
|
||||
@ -0,0 +1,68 @@
|
||||
3 pitfalls everyone should avoid with hybrid multi-cloud, part 2
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article was co-written with [Roel Hodzelmans][1].
|
||||
|
||||
Cloud hype is all around you—you're told it's critical to ensuring a digital future for your business. Whether you choose cloud, hybrid cloud, or hybrid multi-cloud, you have numerous decisions to make, even as you continue the daily work of enhancing your customers' experience and agile delivery of your applications (including legacy applications)—likely some of your business' most important resources.
|
||||
|
||||
In this series, we explain three pitfalls everyone should avoid when transitioning to hybrid multi-cloud environments. [In part one][2], we defined the different cloud types and explained the differences between hybrid cloud and multi-cloud. Here, in part two, we will dive into the first pitfall: Why cost is not always the best motivator for moving to the cloud.
|
||||
|
||||
### Why not?
|
||||
|
||||
When looking at hybrid or multi-cloud strategies for your business, don't let cost become the obvious motivator. There are a few other aspects of any migration strategy that you should review when putting your plan together. But often budget rules the conversations.
|
||||
|
||||
When giving this talk three times at conferences, we've asked our audience to answer a live, online questionnaire about their company, customers, and experiences in the field. Over 73% of respondents said cost was the driving factor in their business' decision to move to hybrid or multi-cloud.
|
||||
|
||||
But, if you already have full control of your on-premises data centers, yet perpetually underutilize and overpay for resources, how can you expect to prevent those costs from rolling over into your cloud strategy?
|
||||
|
||||
There are three main (and often forgotten, ignored, and unaccounted for) reasons cost shouldn't be the primary motivating factor for migrating to the cloud: labor costs, overcapacity, and overpaying for resources. They are important points to consider when developing a hybrid or multi-cloud strategy.
|
||||
|
||||
### Labor costs
|
||||
|
||||
Imagine a utility company making the strategic decision to move everything to the cloud within the next three years. The company kicks off enthusiastically, envisioning huge cost savings, but soon runs into labor cost issues that threaten to blow up the budget.
|
||||
|
||||
One of the most overlooked aspects of moving to the cloud is the cost of labor to migrate existing applications and data. A Forrester study reports that labor costs can consume [over 50% of the total cost of a public cloud migration][3]. Forrester says, "customer-facing apps for systems of engagement… typically employ lots of new code rather than migrating existing code to cloud platforms."
|
||||
|
||||
Step back and analyze what's essential to your customer success and move only that to the cloud. Then, evaluate all your non-essential applications and, over time, consider moving them to commercial, off-the-shelf solutions that require little labor cost.
|
||||
|
||||
### Overcapacity
|
||||
|
||||
"More than 80% of in-house data centers have [way more server capacity than is necessary][4]," reports Business Insider. This amazing bit of information should shock you to your core.
|
||||
|
||||
What exactly is "way more" in this context?
|
||||
|
||||
One hint comes from Deutsche Bank CTO Pat Healey, presenting at Red Hat Summit 2017. He talks about ordering hardware for the financial institution's on-premises data center, only to find out later that [usage numbers were in the single digits][5].
|
||||
|
||||
Healey is not alone; many companies have these problems. They don't do routine assessments, such as checking electricity, cooling, licensing, and other factors, to see how much capacity they are using on a consistent basis.
|
||||
|
||||
### Overpaying
|
||||
|
||||
Companies are paying an average of 36% more for cloud services than they need to, according to the Business Insider article mentioned above.
|
||||
|
||||
One reason is that public cloud providers enthusiastically support customers coming agnostically into their cloud. As customers leverage more of the platform's cloud-native features, they reach a monetary threshold, and technical support drops off dramatically.
|
||||
|
||||
It's a classic case of vendor lock-in, where the public cloud provider knows it is cost-prohibitive for the customer to migrate off its cloud, so it doesn't feel compelled to provide better service.
|
||||
|
||||
### Coming up
|
||||
|
||||
In part three of this series, we'll discuss the second of three pitfalls that everyone should avoid with hybrid multi-cloud. Stay tuned to learn why you should take care with moving everything to the cloud.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/users/roelh
|
||||
[2]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[3]:https://www.techrepublic.com/article/labor-costs-can-make-up-50-of-public-cloud-migration-is-it-worth-it/
|
||||
[4]:http://www.businessinsider.com/companies-waste-62-billion-on-the-cloud-by-paying-for-storage-they-dont-need-according-to-a-report-2017-11
|
||||
[5]:https://youtu.be/SPRUJ5Z-Aew
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Why moving all your workloads to the cloud is a bad idea
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,94 @@
|
||||
Becoming a successful programmer in an underrepresented community
|
||||
======
|
||||
|
||||
|
||||
|
||||
Becoming a programmer from an underrepresented community like Cameroon is tough. Many Africans don't even know what computer programming is—and a lot who do think it's only for people from Western or Asian countries.
|
||||
|
||||
I didn't own a computer until I was 18, and I didn't start programming until I was a 19-year-old high school senior, and had to write a lot of code on paper because I couldn't be carrying my big desktop to school. I have learned a lot over the past five years as I've moved up the ladder to become a successful programmer from an underrepresented community. While these lessons are from my experience in Africa, many apply to other underrepresented communities, including women.
|
||||
|
||||
### 1\. Learn how to code
|
||||
|
||||
This is obvious: To be a successful programmer, you first have to be a programmer. In an African community, this may not be very easy. To learn how to code you need a computer and probably internet, too, which aren't very common for Africans to have. I didn't own a desktop computer until I was 18 years old—and I didn't own a laptop until I was about 20, and some may have still considered me privileged. Some students don't even know what a computer looks like until they get to the university.
|
||||
|
||||
You still have to find a way to learn how to code. Before I had a computer, I used to walk for miles to see a friend who had one. He wasn't very interested in it, so I spent a lot of time with it. I also visited cybercafes regularly, which consumed most of my pocket money.
|
||||
|
||||
Take advantage of local programming communities, as this could be one of your greatest sources of motivation. When you're working on your own, you may feel like a ninja, but that may be because you do not interact much with other programmers. Attend tech events. Make sure you have at least one friend who is better than you. See that person as a competitor and work hard to beat them, even though they may be working as hard as you are. Even if you never win, you'll be growing in skill as a programmer.
|
||||
|
||||
### 2\. Don't read too much into statistics
|
||||
|
||||
A lot of smart people in underrepresented communities never even make it to the "learning how to code" part because they take statistics as hard facts. I remember when I was aspiring to be a hacker, I used to get discouraged about the statistic that there are far fewer black people than white people in technology. If you google the "top 50 computer programmers of all time," there probably won't be many (if any) black people on the list. Most of the inspiring names in tech, like Ada Lovelace, Linus Torvalds, and Bill Gates, are white.
|
||||
|
||||
Growing up, I always believed technology was a white person's thing. I used to think I couldn't do it. When I was young, I never saw a science fiction movie with a black man as a hacker or an expert in computing. It was always white people. I remember when I got to high school and our teacher wrote that programming was part of our curriculum, I thought that was a joke—I wondered, "since when and how will that even be possible?" I wasn't far from the truth. Our teachers couldn't program at all.
|
||||
|
||||
Statistics also say that a lot of the amazing, inspiring programmers you look up to, no matter what their color, started coding at the age of 13. But you didn't even know programming existed until you were 19. You ask yourself questions like: How am I going to catch up? Do I even have the intelligence for this? When I was 13, I was still playing stupid, childish games—how can I compete with this?
|
||||
|
||||
This may make you conclude that white people are naturally better at tech. That's wrong. Yes, the statistics are correct, but they're just statistics. And they can change. Make them change. Your environment contributes a lot to the things you do while growing up. How can you compare yourself to someone whose parents got him a computer before he was nine—when you didn't even see one until you were 19? That's a 10-year gap. And that nine-year-old kid also had a lot of people to coach him.
|
||||
|
||||
How can you compare yourself to someone whose parents got him a computer before he was nine—when you didn't even see one until you were 19?
|
||||
|
||||
You can be a great software engineer regardless of your background. It may be a little harder because you may not have the resources or opportunities people in the western world have, but it's not impossible.
|
||||
|
||||
### 3\. Have a local hero or mentor
|
||||
|
||||
I think having someone in your life to look up to is one of the most important things. We all admire people like Linus Torvalds and Bill Gates but trying to make them your role models can be demotivating. Bill Gates began coding at age 13 and formed his first venture at age 17. I'm 24 and still trying to figure out what I want to do with my life. Those stories always make me wonder why I'm not better yet, rather than looking for reasons to get better.
|
||||
|
||||
Having a local hero or mentor is more helpful. Because you're both living in the same community, there's a greater chance there won't be such a large gap to discourage you. A local mentor probably started coding around the age you did and was unlikely to start a big venture at a very young age.
|
||||
|
||||
I've always admired the big names in tech and still do. But I never saw them as mentors. First, because their stories seemed like fantasy to me, and second, I couldn't reach them. I chose my mentors and role models to be those near my reach. Choosing a role model doesn't mean you just want to get to where they are and stop. Success is step by step, and you need a role model for each stage you're trying to reach. When you attain a stage, get another role model for the next stage.
|
||||
|
||||
You probably can't get one-on-one advice from someone like Bill Gates. You can get the advice they're giving to the public at conferences, which is great, too. I always follow smart people. But advice that makes the most impact is advice that is directed to you. Advice that takes into consideration your goals and circumstances. You can get that only from someone you have direct access to.
|
||||
|
||||
I'm a product of many mentors at different stages of my life. One is [Nyah Check][1] , who was a year ahead of me at the university, but in terms of skill and experience, he was two to three years ahead. I heard stories about him when I was still in high school. He made people want to be great programmers, not just focus on getting a 4.0 GPA. He was one of the first people in French-speaking Africa to participate in [Google Summer of Code][2] . While still at the university, he traveled abroad more times than many lecturers would dream of—without spending a dime. He could write code that even our course instructors couldn't understand. He co-founded [Google Developer Group Buea][3] and created an elite programmers club that helped many students learn to code. He started a lot of other communities, like the [Docker Buea meetup][4] that I'm the lead organizer for.
|
||||
|
||||
These things inspired me. I wanted to be like him and knew what I would gain by becoming friends with him. Discussions with him were always very inspiring—he talked about programming and his adventures traveling the world for conferences. I learned a lot from him, and I think he taught me well. Now younger students want to be around me for the same reasons I wanted to learn from him.
|
||||
|
||||
### 4\. Get involved with open source
|
||||
|
||||
If you're in Africa and want to gain top skills from top engineers, your best bet is to join an open source project. The tech ecosystem in Africa is small and mostly made of startups, so getting experience in a field you love might not be easy. It's rare for startups in Africa to be working with machine learning, distributed computing, or containers and technologies like Kubernetes. Unless your passion is web development, your best bet is joining an open source project. I've learned most of what I know by being part of the [OpenMRS][5] community. I've also contributed to other open source projects including [LibreHealth][6], [Coala][7], and [Kubernetes][8]. Along with gaining tech skills, you'll be building your network of influential people. Most of my peers know about Linus Torvalds from books, but I have a picture with him.
|
||||
|
||||
Participate in open source outreach programs like Google Summer of Code, [Google Code-in][9], [Outreachy][10], or [Linux Foundation Networking Internships][11]. These opportunities help you gain skills that may not be available in startups.
|
||||
|
||||
I participated in Google Summer of Code twice as a student, and I'm now a mentor. I've been a Google Code-in org admin, and I'm volunteering as an open source developer. All these activities help me learn new things.
|
||||
|
||||
### 5\. Take advantage of diversity programs while you can
|
||||
|
||||
Diversity programs are great, but if you're like me, you may not like to benefit very much from them. If you're on a team of five and the basis of your offer is that you're a black person and the other four are white, you might wonder if you're really good enough. You won't want people to think a foundation sponsored your trip because you're black rather than because you add as much value as anyone else. It's never only that you're a minority—it's because the sponsoring organization thinks you're an exceptional minority. You're not the only person who applied for the diversity scholarship, and not everyone that applied won the award. Take advantage of diversity opportunities while you can and build your knowledge base and network.
|
||||
|
||||
When people ask me why the Linux Foundation sponsored my trip to the Open Source Summit, I say: "I was invited to give a talk at their conference, but they have diversity scholarships you can apply for." How cool does that sound?
|
||||
|
||||
Attend as many conferences as you can—diversity scholarships can help. Learn all you can learn. Practice what you learn. Get to know people. Apply to give talks. Start small. My right leg used to shake whenever I stood in front of a crowd to give a speech, but with practice, I've gotten better.
|
||||
|
||||
### 6\. Give back
|
||||
|
||||
Always find a way to give back. Mentor someone. Take up an active role in a community. These are the ways I give back to my community. It isn't only a moral responsibility—it's a win-win because you can learn a lot while helping others get closer to their dreams.
|
||||
|
||||
I was part of a Programming Language meetup organized by Google Developer Group Buea where I mentored 15 students in Java programming (from beginner to intermediate). After the program was over, I created a Java User Group to keep the Java community together. I recruited two members from the meetup to join me as volunteer developers at LibreHealth, and under my guidance, they made useful commits to the project. They were later accepted as Google Summer of Code students, and I was assigned to mentor them during the program. I'm also the lead organizer for Docker Buea, the official Docker meetup in Cameroon, and I'm also Docker Campus Ambassador.
|
||||
|
||||
Taking up leadership roles in this community has forced me to learn. As Docker Campus Ambassador, I'm supposed to train students on how to use Docker. Because of this, I've learned a lot of cool stuff about Docker and containers in general.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/becoming-successful-programmer
|
||||
|
||||
作者:[lvange Larry][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ivange94
|
||||
[1]:https://github.com/Ch3ck
|
||||
[2]:https://summerofcode.withgoogle.com/
|
||||
[3]:http://www.gdgbuea.net/
|
||||
[4]:https://www.meetup.com/Docker-Buea/?_cookie-check=EnOn1Ct-CS4o1YOw
|
||||
[5]:https://openmrs.org/
|
||||
[6]:https://librehealth.io/
|
||||
[7]:https://coala.io/#/home'
|
||||
[8]:https://kubernetes.io/
|
||||
[9]:https://codein.withgoogle.com/archive/
|
||||
[10]:https://www.outreachy.org/
|
||||
[11]:https://wiki.lfnetworking.org/display/LN/LF+Networking+Internships
|
||||
[12]:http://sched.co/FAND
|
||||
[13]:https://ossna18.sched.com/
|
||||
@ -0,0 +1,70 @@
|
||||
Building more trustful teams in four steps
|
||||
======
|
||||
|
||||

|
||||
|
||||
Robin Dreeke's The Code of Trust is a helpful guide to developing trustful relationships, and it's particularly useful to people working in open organizations (where trust is fundamental to any kind of work). As its title implies, Dreeke's book presents a "code" or set of principles people can follow when attempting to establish trust. I explained those in [the first installment of this review][1]. In this article, then, I'll outline what Dreeke (a former FBI agent) calls "The Four Steps to Inspiring Trust"—a set of practices for enacting the principles. In other words, the Steps make the Code work in the real world.
|
||||
|
||||
### The Four Steps
|
||||
|
||||
#### 1\. Align your goals
|
||||
|
||||
First, determine your primary goal—what you want to achieve and what sacrifices you are willing to make to achieve those goals. Learn the goals of others. Look for ways to align your goals with their goals, to make parts of their goals a part of yours. "You'll achieve the power that only combined forces can attain," Dreeke writes. For example, in the sales manager seminar I once ran regularly, I mentioned that if a sales manager helps a salesman reach his sales goals, the manager will reach his goals automatically. Also, if a salesman helps his customer reach his goals, the salesman will reach his goals automatically. This is aligning goals. (For more on this, see an [earlier article][2] I wrote about how companies can determine when to compete and when to cooperate).
|
||||
|
||||
This couldn't be more true in open organizations, which depend on both internal and external contributors a great deal. What are those contributors' goals? Everyone must understand these if an open organization is going to be successful.
|
||||
|
||||
When aligning goals, try to avoid having strong opinions on the topic at hand. This leads to inflexibility, Dreeke says, and reduces the chance of generating options that align with other people's goals. To find their goals, consider what their fears or concerns are. Then try to help them overcome those fears or concerns.
|
||||
|
||||
If you can't get them to align with your goals, then you should choose to not align with them and instead remove them from the team. Dreeke recommends doing this in a way that allows you to stay approachable for other projects. In one issue, goals might not be aligned; in other issues, they may.
|
||||
|
||||
Dreeke also notes that many people believe being successful means carefully narrowing your focus to your own goals. "But that's one of those lazy shortcuts that slow you down," Dreeke writes. Success, Dreeke says, arrives faster when you inspire others to merge their goals with yours, then forge ahead together. In that respect, if you place heavy attention on other people and their goals while doing the same with yours, success in opening someone up comes far sooner. This all sounds very much like advice for activating transparency, inclusivity, and collaboration—key open organization principles.
|
||||
|
||||
#### 2\. Apply the power of context
|
||||
|
||||
Dreeke recommends really getting to know your partners, discovering "their desires, beliefs, personality traits, behaviors, and demographic characteristics." Those are key influences that define their context.
|
||||
|
||||
To achieve trust, you must find a plan that achieves their goals along with yours.
|
||||
|
||||
People only trust those who know them (including these beliefs, goals, and personalities). Once known, you can match their goals with yours. To achieve trust, you must find a plan that achieves their goals along with yours (see above). If you try to push your goals on them, they'll become defensive and information exchange will shut down. If that happens, no good ideas will materialize.
|
||||
|
||||
#### 3\. Craft your encounter
|
||||
|
||||
When you meet with potential allies, plan the meeting meticulously—especially the first meeting. Create the perfect environment for it. Know in advance: 1. the proper atmosphere and mood required, 2. the special nature of the occasion, 3. the perfect time and location, 4. your opening remark, and 5. your plan of what to offer the other person (and what to ask for at that time). Creating the best possible environment for every interaction sets the stage for success.
|
||||
|
||||
Dreeke explains the difference between times for planning and thinking and times for simply performing (like when you meet a stranger for the first time). If you are not well prepared, the fear and emotions of the moment could be overwhelming. To reduce that emotion, planning, preparing and role playing can be very helpful.
|
||||
|
||||
Later in the book, Dreeke discusses "toxic situations," suggesting you should not ignore toxic situations, as they'll more than likely get worse if you do. People could become emotional and say irrational things. You must address the toxic situation by helping people stay rational. Then try to laser in on interactions between your goals and theirs. What does the person want to achieve? Suspending your ego gives you "the freedom to laser-in" on others' points of view and places where their goals can lead to joint ultimate goals, Dreeke says. Stay focused on their context, not your ego, in toxic situations.
|
||||
|
||||
Some leaders think it is best to strongly confront toxic people, maybe embarrassing them in front of others. That might feel good at the time, but "kicking ass in a crowd" just builds people's defenses, Dreeke says. To build a productive plan, he says, you need "shields down," so information will be shared.
|
||||
|
||||
Show others you speak their language—not only for understanding, but also to demonstrate reason, respect, and consideration.
|
||||
|
||||
"Trust leaders take no interest in their own power," Dreeke argues, as they are deeply interested and invested in others. By helping others, their trust develops. For toxic people, the opposite is true: They want power. Unfortunately, this desire for power just espouses more fear and distrust. Dreeke says that to combat a toxic environment, trust leaders do not "fight fire with fire" which spreads the toxicity. They "fight fire with water" to reduce it. In movies, fights are exciting; in real life they are counterproductive.
|
||||
|
||||
#### 4\. Connect
|
||||
|
||||
Finally, show others you speak their language—not only for understanding, but also to demonstrate reason, respect, and consideration. Speak about what they want to hear (namely, issues that focus on them and their needs). The speed of trust is directly opposed to the speed of speech, Dreeke says. People who speak slowly and carefully build trust faster than people who rush their speaking.
|
||||
|
||||
Importantly, Dreeke also covers a way to get people to like you. It doesn't involve directly getting people to like you personally; it involves getting people to like themselves. Show more respect for them than they might even feel about themselves. Praise them for qualities about themselves that they hadn't thought about. That will open the doors to a trusting relationship.
|
||||
|
||||
### Putting it together
|
||||
|
||||
I've spent my entire career attempting to build trust globally, throughout the business communities in which I've worked. I have no experience in the intelligence community, but I do see great similarities in spite of the different working environment. The book has given me new insights I never considered (like the section on "crafting your encounter," for example). I recommend people pick up the book and read it thoroughly, as there is other helpful advice in it that I couldn't cover in this short article.
|
||||
|
||||
As I [mentioned in Part 1][1], following Dreeke's Code of Trust can lead to building strong trust networks or communities. Those trust communities are exactly what we are trying to create in open organizations.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/8/steps-trust
|
||||
|
||||
作者:[Ron McFarland][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ron-mcfarland
|
||||
[1]:https://opensource.com/open-organization/18/7/the-code-of-trust-1
|
||||
[2]:https://opensource.com/open-organization/17/6/collaboration-vs-competition-part-1
|
||||
@ -0,0 +1,180 @@
|
||||
3 tips for moving your team to a microservices architecture
|
||||
======
|
||||

|
||||
|
||||
Microservices are gaining in popularity and providing new ways for tech companies to improve their services for end users. But what impact does the shift to microservices have on team culture and morale? What issues should CTOs, developers, and project managers consider when the best technological choice is a move to microservices?
|
||||
|
||||
Below you’ll find key advice and insight from CTOs and project leads as they reflect on their experiences with team culture and microservices.
|
||||
|
||||
### You can't build successful microservices without a successful team culture
|
||||
|
||||
When I was working with Java developers, there was tension within the camp about who got to work on the newest and meatiest features. Our engineering leadership had decided that we would exclusively use Java to build all new microservices.
|
||||
|
||||
There were great reasons for this decision, but as I will explain later, such a restrictive decision come with some repercussions. Communicating the “why” of technical decisions can go a long way toward creating a culture where people feel included and informed.
|
||||
|
||||
When you're organizing and managing a team around microservices, it’s always challenging to balance the mood, morale, and overall culture. In most cases, the leadership needs to balance the risk of team members using new technology against the needs of the client and the business itself.
|
||||
|
||||
This dilemma, and many others like it, has led CTOs to ask themselves questions such as: How much freedom should I give my team when it comes to adopting new technologies? And perhaps even more importantly, how can I manage the overarching culture within my camp?
|
||||
|
||||
### Give every team member a chance to thrive
|
||||
|
||||
When the engineering leaders in the example above decided that Java was the best technology to use when building microservices, the decision was best for the company: Java is performant, and many of the senior people on the team were well-versed with it. However, not everyone on the team had experience with Java.
|
||||
|
||||
The problem was, our team was split into two camps: the Java guys and the JavaScript guys. As time went by and exciting new projects came up, we’d always reach for Java to get the job done. Before long, some annoyance within the JavaScript camp crept in: “Why do the Java guys always get to work on the exciting new projects while we’re left to do the mundane front-end tasks like implementing third-party analytics tools? We want a big, exciting project to work on too!”
|
||||
|
||||
Like most rifts, it started out small, but it grew worse over time.
|
||||
|
||||
The lesson I learned from that experience was to take your team’s expertise and favored technologies into account when choosing a de facto tech stack for your microservices and when adjusting your team's level of freedom to pick and choose their tools.
|
||||
|
||||
Sure, you need some structure, but if you’re too restrictive—or worse, blind to the desire of team members to innovate with different technologies—you may have a rift of your own to manage.
|
||||
|
||||
So evaluate your team closely and come up with a plan that empowers everyone. That way, every section of your team can get involved in major projects, and nobody will feel like they’re being left on the bench.
|
||||
|
||||
### Technology choices: stability vs. flexibility
|
||||
|
||||
Let’s say you hire a new junior developer who is excited about some brand new, fresh-off-the-press JavaScript framework.
|
||||
|
||||
That framework, while sporting some technical breakthroughs, may not have proven itself in production environments, and it probably doesn’t have great support available. CTOs have to make a difficult choice: Okaying that move for the morale of the team, or declining it to protect the company and its bottom line and to keep the project stable as the deadline approaches.
|
||||
|
||||
The answer depends on a lot of different factors (which also means there is no single correct answer).
|
||||
|
||||
### Technological freedom
|
||||
|
||||
“We give our team and ourselves 100% freedom in considering technology choices. We eventually identified two or three technologies not to use in the end, primarily due to not wanting to complicate our deployment story,” said [Benjamin Curtis][1], co-founder of [Honeybadger][2].
|
||||
|
||||
“In other words, we considered introducing new languages and new approaches into our tech stack when creating our microservices, and we actually did deploy a production microservice on a different stack at one point. [While we do generally] stick with technologies that we know in order to simplify our ops stack, we periodically revisit that decision to see if potential performance or reliability benefits would be gained by adopting a new technology, but so far we haven't made a change,” Curtis continued.
|
||||
|
||||
When I spoke with [Stephen Blum][3], CTO at [PubNub][4], he expressed a similar view, welcoming pretty much any technology that cuts the mustard: “We're totally open with it. We want to continue to push forward with new open source technologies that are available, and we only have a couple of constraints with the team that are very fair: [It] must run in container environment, and it has to be cost-effective.”
|
||||
|
||||
### High freedom, high responsibility
|
||||
|
||||
[Sumo Logic][5] CTO [Christian Beedgen][6] and chief architect [Stefan Zier][7] expanded on this topic, agreeing that if you’re going to give developers freedom to choose their technology, it must come with a high level of responsibility attached. “It’s really important that [whoever builds] the software takes full ownership for it. In other words, they not only build software, but they also run the software and remain responsible for the whole lifecycle.”
|
||||
|
||||
Beedgen and Zier recommend implementing a system that resembles a federal government system, keeping those freedoms in check by heightening responsibility: “[You need] a federal culture, really. You've got to have a system where multiple, independent teams can come together towards the greater goal. That limits the independence of the units to some degree, as they have to agree that there is potentially a federal government of some sort. But within those smaller groups, they can make as many decisions on their own as they like within guidelines established on a higher level.”
|
||||
|
||||
Decentralized, federal, or however you frame it, this approach to structuring microservice teams gives each team and each team member the freedom they want, without enabling anyone to pull the project apart.
|
||||
|
||||
However, not everyone agrees.
|
||||
|
||||
### Restrict technology to simplify things
|
||||
|
||||
[Darby Frey][8], co-founder of [Lead Honestly][9], takes a more restrictive approach to technology selection.
|
||||
|
||||
“At my last company we had a lot of services and a fairly small team, and one of the main things that made it work, especially for the team size that we had, was that every app was the same. Every backend service was a Ruby app,” he explained.
|
||||
|
||||
Frey explained that this helped simplify the lives of his team members: “[Every service has] the same testing framework, the same database backend, the same background job processing tool, et cetera. Everything was the same.
|
||||
|
||||
“That meant that when an engineer would jump around between apps, they weren’t having to learn a new pattern or learn a different language each time,” Frey continued, “So we're very aware and very strict about keeping that commonality.”
|
||||
|
||||
While Frey is sympathetic to developers wanting to introduce a new language, admitting that he “loves the idea of trying new things,” he feels that the cons still outweigh the pros.
|
||||
|
||||
“Having a polyglot architecture can increase the development and maintenance costs. If it's just all the same, you can focus on business value and business features and not have to be super siloed in how your services operate. I don't think everybody loves that decision, but at the end of the day, when they have to fix something on a weekend or in the middle of the night, they appreciate it,” said Frey.
|
||||
|
||||
### Centralized or decentralized organization
|
||||
|
||||
How your team is structured is also going to impact your microservices engineering culture—for better or worse.
|
||||
|
||||
For example, it’s common for software engineers to write the code before shipping it off to the operations team, who in turn deploy it to the servers. But when things break (and things always break!), an internal conflict occurs.
|
||||
|
||||
Because operation engineers don’t write the code themselves, they rarely understand problems when they first arise. As a result, they need to get in touch with those who did code it: the software engineers. So right from the get-go, you’ve got a middleman relaying messages between the problem and the team that can fix that problem.
|
||||
|
||||
To add an extra layer of complexity, because software engineers aren’t involved with operations, they often can’t fully appreciate how their code affects the overall operation of the platform. They learn of issues only when operations engineers complain about them.
|
||||
|
||||
As you can see, this is a relationship that’s destined for constant conflict.
|
||||
|
||||
### Navigating conflict
|
||||
|
||||
One way to attack this problem is by following the lead of Netflix and Amazon, both of which favor decentralized governance. Software development thought leaders James Lewis and Martin Fowler feel that decentralized governance is the way to go when it comes to microservice team organization, as they explain in a [blog post][10].
|
||||
|
||||
“One of the consequences of centralized governance is the tendency to standardize on single technology platforms. Experience shows that this approach is constricting—not every problem is a nail and not every solution a hammer,” the article reads. “Perhaps the apogee of decentralized governance is the ‘build it, run it’ ethos popularized by Amazon. Teams are responsible for all aspects of the software they build, including operating the software 24/7.”
|
||||
|
||||
Netflix, Lewis and Fowler write, is another company pushing higher levels of responsibility on development teams. They hypothesize that, because they’ll be responsible and called upon should anything go wrong later down the line, more care will be taken during the development and testing stages to ensure each microservice is in ship shape.
|
||||
|
||||
“These ideas are about as far away from the traditional centralized governance model as it is possible to be,” they conclude.
|
||||
|
||||
### Who's on weekend pager duty?
|
||||
|
||||
When considering a centralized or decentralized culture, think about how it impacts your team members when problems inevitably crop up at inopportune times. A decentralized system implies that each decentralized team takes responsibility for one service or one set of services. But that also creates a problem: Silos.
|
||||
|
||||
That’s one reason why Lead Honestly's Frey isn’t a proponent of the concept of decentralized governance.
|
||||
|
||||
“The pattern of ‘a single team is responsible for a particular service’ is something you see a lot in microservice architectures. We don't do that, for a couple of reasons. The primary business reason is that we want teams that are responsible not for specific code but for customer-facing features. A team might be responsible for order processing, so that will touch multiple code bases but the end result for the business is that there is one team that owns the whole thing end to end, so there are fewer cracks for things to fall through,” Frey explained.
|
||||
|
||||
The other main reason, he continued, is that developers can take more ownership of the overall project: “They can actually think about [the project] holistically.”
|
||||
|
||||
Nathan Peck, developer advocate for container services at Amazon Web Services, [explained this problem in more depth][11]. In essence, when you separate the software engineers and the operations engineers, you make life harder for your team whenever an issue arises with the code—which is bad news for end users, too.
|
||||
|
||||
But does decentralization need to lead to separation and siloization?
|
||||
|
||||
Peck explained that his solution lies in [DevOps][12], a model aimed at tightening the feedback loop by bringing these two teams closer together, strengthening team culture and communication in the process. Peck describes this as the “you build it, you run it” approach.
|
||||
|
||||
However, that doesn’t mean teams need to get siloed or distanced away from partaking in certain tasks, as Frey suggests might happen.
|
||||
|
||||
“One of the most powerful approaches to decentralized governance is to build a mindset of ‘DevOps,’” Peck wrote. “[With this approach], engineers are involved in all parts of the software pipeline: writing code, building it, deploying the resulting product, and operating and monitoring it in production. The DevOps way contrasts with the older model of separating development teams from operations teams by having development teams ship code ‘over the wall’ to operations teams who were then responsible to run it and maintain it.”
|
||||
|
||||
DevOps, as [Armory][13] CTO [Isaac Mosquera][14] explained, is an agile software development framework and culture that’s gaining traction thanks to—well, pretty much everything that Peck said.
|
||||
|
||||
Interestingly, Mosquera feels that this approach actually flies in the face of [Conway’s Law][15]:
|
||||
|
||||
_" Organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations." — M. Conway_
|
||||
|
||||
“Instead of communication driving software design, now software architecture drives communication. Not only do teams operate and organize differently, but it requires a new set of tooling and process to support this type of architecture; i.e., DevOps,” Mosquera explained.
|
||||
|
||||
[Chris McFadden][16], VP of engineering at [SparkPost][17], offers an interesting example that might be worth following. At SparkPost, you’ll find decentralized governance—but you won’t find a one-team-per-service culture.
|
||||
|
||||
“The team that is developing these microservices started off as one team, but they’re now split up into three teams under the same larger group. Each team has some level of responsibility around certain domains and certain expertise, but the ownership of these services is not restricted to any one of these teams,” McFadden explained.
|
||||
|
||||
This approach, McFadden continued, allows any team to work on anything from new features to bug fixes to production issues relating to any of those services. There’s total flexibility and not a silo in sight.
|
||||
|
||||
“It allows [the teams to be] a little more flexible both in terms of new product development as well, just because you're not getting too restricted and that's based on our size as a company and as an engineering team. We really need to retain some flexibility,” he said.
|
||||
|
||||
However, size might matter here. McFadden admitted that if SparkPost was a lot larger, “then it would make more sense to have a single, larger team own one of those microservices.”
|
||||
|
||||
“[It's] better, I think, to have a little bit more broad responsibility for these services and it gives you a little more flexibility. At least that works for us at this time, where we are as an organization,” he said.
|
||||
|
||||
### A successful microservices engineering culture is a balancing act
|
||||
|
||||
When it comes to technology, freedom—with responsibility—looks to be the most rewarding path. Team members with differing technological preferences will come and go, while new challenges may require you to ditch technologies that have previously served you well. Software development is constantly in flux, so you’ll need to continually balance the needs of your team are new devices, technologies, and clients emerge.
|
||||
|
||||
As for structuring your teams, a decentralized yet un-siloed approach that leverages DevOps and instills a “you build it, you run it” mentality seems to be popular, although other schools of thought do exist. As usual, you’re going to have to experiment to see what suits your team best.
|
||||
|
||||
Here’s a quick recap on how to ensure your team culture meshes well with a microservices architecture:
|
||||
|
||||
* **Be sustainable, yet flexible** : Balance sustainability without forgetting about flexibility and the need for your team to be innovative when the right opportunity comes along. However, there’s a distinct difference of opinion over how you should achieve that balance.
|
||||
|
||||
* **Give equal opportunities** : Don’t favor one section of your team over another. If you’re going to impose restrictions, make sure it’s not going to fundamentally alienate team members from the get-go. Think about how your product roadmap is shaping up and forecast how it will be built and who’s going to do the work.
|
||||
|
||||
* **Structure your team to be agile, yet responsible** : Decentralized governance and agile development is the flavor of the day for a good reason, but don’t forget to install a sense of responsibility within each team.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/microservices-team-challenges
|
||||
|
||||
作者:[Jake Lumetta][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://twitter.com/stympy?lang=en
|
||||
[2]:https://www.honeybadger.io/
|
||||
[3]:https://twitter.com/stephenlb
|
||||
[4]:https://www.pubnub.com/
|
||||
[5]:http://sumologic.com/
|
||||
[6]:https://twitter.com/raychaser
|
||||
[7]:https://twitter.com/stefanzier
|
||||
[8]:https://twitter.com/darbyfrey
|
||||
[9]:https://leadhonestly.com/
|
||||
[10]:https://martinfowler.com/articles/microservices.html#ProductsNotProjects
|
||||
[11]:https://medium.com/@nathankpeck/microservice-principles-decentralized-governance-4cdbde2ff6ca
|
||||
[12]:https://opensource.com/resources/devops
|
||||
[13]:http://armory.io/
|
||||
[14]:https://twitter.com/imosquera
|
||||
[15]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[16]:https://twitter.com/cristoirmac
|
||||
[17]:https://www.sparkpost.com/
|
||||
56
sources/talk/20180809 How do tools affect culture.md
Normal file
56
sources/talk/20180809 How do tools affect culture.md
Normal file
@ -0,0 +1,56 @@
|
||||
How do tools affect culture?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Most of the DevOps community talks about how tools don’t matter much. The culture has to change first, the argument goes, which might modify how the tools are used.
|
||||
|
||||
I agree and disagree with that concept. I believe the relationship between tools and culture is more symbiotic and bidirectional than unidirectional. I have discovered this through real-world transformations across several companies now. I admit it’s hard to determine whether the tools changed the culture or whether the culture changed how the tools were used.
|
||||
|
||||
### Violating principles
|
||||
|
||||
Some tools violate core principles of modern development and operations. The primary violation I have seen are tools that require GUI interactions. This often separates operators from the value pipeline in a way that is cognitively difficult to overcome. If everything in your infrastructure is supposed to be configured and deployed through a value pipeline, then taking someone out of that flow inherently changes their perspective and engagement. Making manual modifications also injects risk into the system that creates unpredictability and undermines the value of the pipeline.
|
||||
|
||||
I’ve heard it said that these tools are fine and can be made to work within the new culture, and I’ve tried this in the past. Screen scraping and form manipulation tools have been used to attempt automation with some systems I’ve integrated. This is very fragile and doesn’t work on all systems. It ultimately required a lot of manual intervention.
|
||||
|
||||
Another system from a large vendor providing integrated monitoring and ticketing solutions for infrastructure seemed to implement its API as an afterthought, and this resulted in the system being unable to handle the load from the automated system. This required constant manual recoveries and sometimes the tedious task of manually closing errant tickets that shouldn’t have been created or that weren’t closed properly.
|
||||
|
||||
The individuals maintaining these systems experienced great frustration and often expressed a lack of confidence in the overall DevOps transformation. In one of these instances, we introduced a modern tool for monitoring and alerting, and the same individuals suddenly developed a tremendous amount of confidence in the overall DevOps transformation. I believe this is because tools can reinforce culture and improve it when a similar tool that lacks modern capabilities would otherwise stymie motivation and engagement.
|
||||
|
||||
### Choosing tools
|
||||
|
||||
At the NAIC (National Association of Insurance Commissioners), we’ve adopted a practice of evaluating new and existing tools based on features we believe reinforce the core principles of our value pipeline. We currently have seven items on our list:
|
||||
|
||||
* REST API provided and fully functional (possesses all application functionality)
|
||||
* Ability to provision immutably (can be installed, configured, and started without human intervention)
|
||||
* Ability to provide all configuration through static files
|
||||
* Open source code
|
||||
* Uses open standards when available
|
||||
* Offered as Software as a Service (SaaS) or hosted (we don't run anything)
|
||||
* Deployable to public cloud (based on licensing and cost)
|
||||
|
||||
|
||||
|
||||
This is a prioritized list. Each item gets rated green, yellow, or red to indicate how much each statement applies to a particular technology. This creates a visual that makes it quite clear how the different candidates compare to one another. We then use this to make decisions about which tools we should use. We don’t make decisions solely on these criteria, but they do provide a clearer picture and help us know when we’re sacrificing principles. Transparency is a core principle in our culture, and this system helps reinforce that in our decision-making process.
|
||||
|
||||
We use green, yellow, and red because there’s not normally a clear binary representation of these criteria within each tool. For example, some tools have an incomplete API, which would result in yellow being applied. If the tool uses open standards like OpenAPI and there’s no other applicable open standard, then it would receive green for “Uses open standards when available.” However, a tracing system that uses OpenAPI and not OpenTracing would receive a yellow rating.
|
||||
|
||||
This type of system creates a common understanding of what is valued when it comes to tool selection, and it helps avoid unknowingly violating core principles of your value pipeline. We recently used this method to select [GitLab][1] as our version control and continuous integration system, and it has drastically improved our culture for many reasons. I estimated 50 users for the first year, and we’re already over 120 in just the first few months.
|
||||
|
||||
The tools we used previously didn’t allow us to contribute back our own features, collaborate transparently, or automate so completely. We’ve also benefited from GitLab’s culture influencing ours. Its [handbook][2] and open communication have been invaluable to our growth. Tools, and the companies that make them, can and will influence your company’s culture. What are you willing to allow in?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/how-tools-affect-culture
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/barkerd427
|
||||
[1]:https://about.gitlab.com/
|
||||
[2]:https://about.gitlab.com/handbook/
|
||||
@ -1,601 +0,0 @@
|
||||
A Collection Of Useful BASH Scripts For Heavy Commandline Users
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, I have stumbled upon a collection of useful BASH scripts for heavy commandline users. These scripts, known as **Bash-Snippets** , might be quite helpful for those who live in Terminal all day. Want to check the weather of a place where you live? This script will do that for you. Wondering what is the Stock price? You can run the script that displays the current details of a stock. Feel bored? You can watch some youtube videos. All from commandline. You don’t need to install any heavy memory consumable GUI applications.
|
||||
|
||||
As of writing this, Bash-Snippets provides the following 19 useful tools:
|
||||
|
||||
1. **Cheat** – Linux Commands cheat sheet.
|
||||
2. **Cloudup** – A tool to backup your GitHub repositories to bitbucket.
|
||||
3. **Crypt** – Encrypt and decrypt files.
|
||||
4. **Cryptocurrency** – Converts Cryptocurrency based on realtime exchange rates of the top 10 cryptos.
|
||||
5. **Currency** – Currency converter.
|
||||
6. **Geo** – Provides the details of wan, lan, router, dns, mac, and ip.
|
||||
7. **Lyrics** – Grab lyrics for a given song quickly from the command line.
|
||||
8. **Meme** – Command line meme creator.
|
||||
9. **Movies** – Search and display a movie details.
|
||||
10. **Newton** – Performs numerical calculations all the way up to symbolic math parsing.
|
||||
11. **Qrify** – Turns the given string into a qr code.
|
||||
12. **Short** – URL Shortner
|
||||
13. **Siteciphers** – Check which ciphers are enabled / disabled for a given https site.
|
||||
14. **Stocks** – Provides certain Stock details.
|
||||
15. **Taste** – Recommendation engine that provides three similar items like the supplied item (The items can be books, music, artists, movies, and games etc).
|
||||
16. **Todo** – Command line todo manager.
|
||||
17. **Transfer** – Quickly transfer files from the command line.
|
||||
18. **Weather** – Displays weather details of your place.
|
||||
19. **Youtube-Viewer** – Watch YouTube from Terminal.
|
||||
|
||||
|
||||
|
||||
The author might add more utilities and/or features in future, so I recommend you to keep an eye on the project’s website or GitHub page for future updates.
|
||||
|
||||
### Bash-Snippets – A Collection Of Useful BASH Scripts For Heavy Commandline Users
|
||||
|
||||
#### Installation
|
||||
|
||||
You can install these scripts on any OS that supports BASH.
|
||||
|
||||
First, clone the GIT repository using command:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
Go to the cloned directory:
|
||||
```
|
||||
$ cd Bash-Snippets/
|
||||
|
||||
```
|
||||
|
||||
Git checkout to the latest stable release:
|
||||
```
|
||||
$ git checkout v1.22.0
|
||||
|
||||
```
|
||||
|
||||
Finally, install the Bash-Snippets using command:
|
||||
```
|
||||
$ sudo ./install.sh
|
||||
|
||||
```
|
||||
|
||||
This will ask you which scripts to install. Just type **Y** and press ENTER key to install the respective script. If you don’t want to install a particular script, type **N** and hit ENTER.
|
||||
```
|
||||
Do you wish to install currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
To install all scripts, run:
|
||||
```
|
||||
$ sudo ./install.sh all
|
||||
|
||||
```
|
||||
|
||||
To install a specific script, say currency, run:
|
||||
```
|
||||
$ sudo ./install.sh currency
|
||||
|
||||
```
|
||||
|
||||
You can also install it using [**Linuxbrew**][1] package manager.
|
||||
|
||||
To installs all tools, run:
|
||||
```
|
||||
$ brew install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
To install specific tools:
|
||||
```
|
||||
$ brew install bash-snippets --without-all-tools --with-newton --with-weather
|
||||
|
||||
```
|
||||
|
||||
Also, there is a PPA for Debian-based systems such as Ubuntu, Linux Mint.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:navanchauhan/bash-snippets
|
||||
$ sudo apt update
|
||||
$ sudo apt install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
**An active Internet connection is required** to use these tools. The usage is fairly simple. Let us see how to use some of these scripts. I assume you have installed all scripts.
|
||||
|
||||
**1\. Currency – Currency Converter**
|
||||
|
||||
This script converts the currency based on realtime exchange rates. Enter the base currency code and the currency to exchange to, and the amount being exchanged one by one as shown below.
|
||||
```
|
||||
$ currency
|
||||
What is the base currency: INR
|
||||
What currency to exchange to: USD
|
||||
What is the amount being exchanged: 10
|
||||
|
||||
=========================
|
||||
| INR to USD
|
||||
| Rate: 0.015495
|
||||
| INR: 10
|
||||
| USD: .154950
|
||||
=========================
|
||||
|
||||
```
|
||||
|
||||
You can also pass all arguments in a single command as shown below.
|
||||
```
|
||||
$ currency INR USD 10
|
||||
|
||||
```
|
||||
|
||||
Refer the following screenshot.
|
||||
|
||||
[![Bash-Snippets][2]][3]
|
||||
|
||||
**2\. Stocks – Display stock price details**
|
||||
|
||||
If you want to check a stock price details, mention the stock item as shown below.
|
||||
```
|
||||
$ stocks Intel
|
||||
|
||||
INTC stock info
|
||||
=============================================
|
||||
| Exchange Name: NASDAQ
|
||||
| Latest Price: 34.2500
|
||||
| Close (Previous Trading Day): 34.2500
|
||||
| Price Change: 0.0000
|
||||
| Price Change Percentage: 0.00%
|
||||
| Last Updated: Jul 12, 4:00PM EDT
|
||||
=============================================
|
||||
|
||||
```
|
||||
|
||||
The above output the **Intel stock** details.
|
||||
|
||||
**3\. Weather – Display Weather details**
|
||||
|
||||
Let us check the Weather details by running the following command:
|
||||
```
|
||||
$ weather
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![][4]
|
||||
|
||||
As you see in the above screenshot, it provides the 3 day weather forecast. Without any arguments, it will display the weather details based on your IP address. You can also bring the weather details of a particular city or country like below.
|
||||
```
|
||||
$ weather Chennai
|
||||
|
||||
```
|
||||
|
||||
Also, you can view the moon phase by entering the following command:
|
||||
```
|
||||
$ weather moon
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
![][5]
|
||||
|
||||
**4\. Crypt – Encrypt and Decrypt files**
|
||||
|
||||
This script is a wrapper for openssl that allows you to encrypt and decrypt files quickly and easily.
|
||||
|
||||
To encrypt a file, use the following command:
|
||||
```
|
||||
$ crypt -e [original file] [encrypted file]
|
||||
|
||||
```
|
||||
|
||||
For example, the following command will encrypt a file called **ostechnix.txt** , and save it as **encrypt_ostechnix.txt **in the current working directory.
|
||||
```
|
||||
$ crypt -e ostechnix.txt encrypt_ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
Enter the password for the file twice.
|
||||
```
|
||||
Encrypting ostechnix.txt...
|
||||
enter aes-256-cbc encryption password:
|
||||
Verifying - enter aes-256-cbc encryption password:
|
||||
Successfully encrypted
|
||||
|
||||
```
|
||||
|
||||
The above command will encrypt the given file using **AES 256 level encryption**. The password will not be saved in plain text. You can encrypt .pdf, .txt, .docx, .doc, .png, .jpeg type files.
|
||||
|
||||
To decrypt the file, use the following command:
|
||||
```
|
||||
$ crypt -d [encrypted file] [output file]
|
||||
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
$ crypt -d encrypt_ostechnix.txt ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
Enter the password to decrypt.
|
||||
```
|
||||
Decrypting encrypt_ostechnix.txt...
|
||||
enter aes-256-cbc decryption password:
|
||||
Successfully decrypted
|
||||
|
||||
```
|
||||
|
||||
**5\. Movies – Find Movie details**
|
||||
|
||||
Using this script, you can find a movie details.
|
||||
|
||||
The following command displays the details of a movie called “mother”.
|
||||
```
|
||||
$ movies mother
|
||||
|
||||
==================================================
|
||||
| Title: Mother
|
||||
| Year: 2009
|
||||
| Tomato: 95%
|
||||
| Rated: R
|
||||
| Genre: Crime, Drama, Mystery
|
||||
| Director: Bong Joon Ho
|
||||
| Actors: Hye-ja Kim, Bin Won, Goo Jin, Je-mun Yun
|
||||
| Plot: A mother desperately searches for the killer who framed her son for a girl's horrific murder.
|
||||
==================================================
|
||||
|
||||
```
|
||||
|
||||
**6\. Display similar items like the supplied item**
|
||||
|
||||
To use this script, you need to get the API key **[here][6]**. No worries, it is completely FREE! Once the you got the API, add the following line to your **~/.bash_profile** : **export TASTE_API_KEY=”yourAPIKeyGoesHere”**``
|
||||
|
||||
Now, you can view the similar item like the supplied item as shown below:
|
||||
```
|
||||
$ taste -i Red Hot Chilli Peppers
|
||||
|
||||
```
|
||||
|
||||
**7\. Short – Shorten URLs**
|
||||
|
||||
This script shortens the given URL.
|
||||
```
|
||||
$ short <URL>
|
||||
|
||||
```
|
||||
|
||||
**8\. Geo – Display the details of your network**
|
||||
|
||||
This script helps you to find out the details of your network, such as wan, lan, router, dns, mac, and ip geolocation.
|
||||
|
||||
For example, to find out your LAN ip, run:
|
||||
```
|
||||
$ geo -l
|
||||
|
||||
```
|
||||
|
||||
Sample output from my system:
|
||||
```
|
||||
192.168.43.192
|
||||
|
||||
```
|
||||
|
||||
To find your Wan IP:
|
||||
```
|
||||
$ geo -w
|
||||
|
||||
```
|
||||
|
||||
For more details, just type ‘geo’ in the Terminal.
|
||||
```
|
||||
$ geo
|
||||
Geo
|
||||
Description: Provides quick access for wan, lan, router, dns, mac, and ip geolocation data
|
||||
Usage: geo [flag]
|
||||
-w Returns WAN IP
|
||||
-l Returns LAN IP(s)
|
||||
-r Returns Router IP
|
||||
-d Returns DNS Nameserver
|
||||
-m Returns MAC address for interface. Ex. eth0
|
||||
-g Returns Current IP Geodata
|
||||
Examples:
|
||||
geo -g
|
||||
geo -wlrdgm eth0
|
||||
Custom Geo Output =>
|
||||
[all] [query] [city] [region] [country] [zip] [isp]
|
||||
Example: geo -a 8.8.8.8 -o city,zip,isp
|
||||
-o [options] Returns Specific Geodata
|
||||
-a [address] For specific ip in -s
|
||||
-v Returns Version
|
||||
-h Returns Help Screen
|
||||
-u Updates Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
**9\. Cheat – Display cheatsheets of Linux commands**
|
||||
|
||||
Want to refer the cheatsheet of Linux command? Well, it is also possible. The following command will display the cheatsheet of **curl** command:
|
||||
```
|
||||
$ cheat curl
|
||||
|
||||
```
|
||||
|
||||
Just replace **curl** with the command of your choice to display its cheatsheet. This can be very useful for the quick reference to any command you want to use.
|
||||
|
||||
**10\. Youtube-Viewer – Watch YouTube videos**
|
||||
|
||||
Using this script, you can search or watch youtube videos right from the Terminal.
|
||||
|
||||
Let us watch some **Ed Sheeran** videos.
|
||||
```
|
||||
$ ytview Ed Sheeran
|
||||
|
||||
```
|
||||
|
||||
Choose the video you want to play from the list. The selected will play in your default media player.
|
||||
|
||||
![][7]
|
||||
|
||||
To view recent videos by an artist, you can use:
|
||||
```
|
||||
$ ytview -c [channel name]
|
||||
|
||||
```
|
||||
|
||||
To search for videos, just enter:
|
||||
```
|
||||
$ ytview -s [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
or just,
|
||||
```
|
||||
$ ytview [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
**11\. cloudup – Backup GitHub repositories to bitbucket**
|
||||
|
||||
Have you hosted any project on GitHub? Great! You can backup the GitHub repositories to **bitbucket** , a web-based hosting service used for source code and development projects, at any time.
|
||||
|
||||
You can either backup all github repositories of the designated user at once with the **-a** option. Or run it with no flags and backup individual repositories.
|
||||
|
||||
To backup GitHub repository, run:
|
||||
```
|
||||
$ cloudup
|
||||
|
||||
```
|
||||
|
||||
You will be asked to enter your GitHub username, name of the repository to backup, and bitbucket username and password etc.
|
||||
|
||||
**12\. Qrify – Convert Strings into QR code**
|
||||
|
||||
This script converts any given string of text into a QR code. This is useful for sending links or saving a string of commands to your phone
|
||||
```
|
||||
$ qrify convert this text into qr code
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
![][8]
|
||||
|
||||
Cool, isn’t it?
|
||||
|
||||
**13\. Cryptocurrency**
|
||||
|
||||
It displays the top ten cryptocurrencies realtime exchange rates.
|
||||
|
||||
Type the following command and hit ENTER to run it:
|
||||
```
|
||||
$ cryptocurrency
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
**14\. Lyrics**
|
||||
|
||||
This script grabs the lyrics for a given song quickly from the command line.
|
||||
|
||||
Say for example, I am going to fetch the lyrics of **“who is it”** song, a popular song sung by **Michael Jackson**.
|
||||
```
|
||||
$ lyrics -a michael jackson -s who is it
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
**15\. Meme**
|
||||
|
||||
This script allows you to create simple memes from command line. It is quite faster than GUI-based meme generators.
|
||||
|
||||
To create a meme, just type:
|
||||
```
|
||||
$ meme -f mymeme
|
||||
Enter the name for the meme's background (Ex. buzz, doge, blb ): buzz
|
||||
Enter the text for the first line: THIS IS A
|
||||
Enter the text for the second line: MEME
|
||||
|
||||
```
|
||||
|
||||
This will create jpg file in your current working directory.
|
||||
|
||||
**16\. Newton**
|
||||
|
||||
Tired of solving complex Maths problems? Here you go. The Newton script will perform numerical calculations all the way up to symbolic math parsing.
|
||||
|
||||
![][11]
|
||||
|
||||
**17\. Siteciphers**
|
||||
|
||||
This script helps you to check which ciphers are enabled / disabled for a given https site.
|
||||
```
|
||||
$ siteciphers google.com
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
**18\. Todo**
|
||||
|
||||
It allows you to create everyday tasks directly from the Terminal.
|
||||
|
||||
Let us create some tasks.
|
||||
```
|
||||
$ todo -a The first task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To add another task, simply re-run the above command with the task name.
|
||||
```
|
||||
$ todo -a The second task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). The second task Tue Jun 26 14:52:29 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To view the list of tasks, run:
|
||||
```
|
||||
$ todo -g
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). A The second task Tue Jun 26 14:51:46 IST 2018
|
||||
|
||||
```
|
||||
|
||||
Once you completed a task, remove it from the list as shown below.
|
||||
```
|
||||
$ todo -r 2
|
||||
Sucessfully removed task number 2
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To clear all tasks, run:
|
||||
```
|
||||
$ todo -c
|
||||
Tasks cleared.
|
||||
|
||||
```
|
||||
|
||||
**19\. Transfer**
|
||||
|
||||
The transfer script allows you to quickly and easily transfer files and directories over Internet.
|
||||
|
||||
Let us upload a file.
|
||||
```
|
||||
$ transfer test.txt
|
||||
Uploading test.txt
|
||||
################################################################################################################################################ 100.0%
|
||||
Success!
|
||||
Transfer Download Command: transfer -d desiredOutputDirectory ivmfj test.txt
|
||||
Transfer File URL: https://transfer.sh/ivmfj/test.txt
|
||||
|
||||
```
|
||||
|
||||
The file will be uploaded to transfer.sh site. Transfer.sh allows you to upload files up to **10 GB** in one go. All shared files automatically expire after **14 days**. As you can see, anyone can download the file either by visiting the second URL via a web browser or using the transfer command (it is installed in his/her system, of course).
|
||||
|
||||
Now remove the file from your system.
|
||||
```
|
||||
$ rm -fr test.txt
|
||||
|
||||
```
|
||||
|
||||
Now, you can download the file from transfer.sh site at any time (within 14 days) like below.
|
||||
```
|
||||
$ transfer -d Downloads ivmfj test.txt
|
||||
|
||||
```
|
||||
|
||||
For more details about this utility, refer our following guide.
|
||||
|
||||
##### Getting help
|
||||
|
||||
If you don’t know how to use a particular script, just type that script’s name and press ENTER. You will see the usage details. The following example displays the help section of **Qrify** script.
|
||||
```
|
||||
$ qrify
|
||||
Qrify
|
||||
Usage: qrify [stringtoturnintoqrcode]
|
||||
Description: Converts strings or urls into a qr code.
|
||||
-u Update Bash-Snippet Tools
|
||||
-m Enable multiline support (feature not working yet)
|
||||
-h Show the help
|
||||
-v Get the tool version
|
||||
Examples:
|
||||
qrify this is a test string
|
||||
qrify -m two\\nlines
|
||||
qrify github.com # notice no http:// or https:// this will fail
|
||||
|
||||
```
|
||||
|
||||
#### Updating scripts
|
||||
|
||||
You can update the installed tools at any time suing -u option. The following command updates “weather” tool.
|
||||
```
|
||||
$ weather -u
|
||||
|
||||
```
|
||||
|
||||
#### Uninstall
|
||||
|
||||
You can uninstall these tools as shown below.
|
||||
|
||||
Git clone the repository:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
Go to the Bash-Snippets directory:
|
||||
```
|
||||
$ cd Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
And uninstall the scripts by running the following command:
|
||||
```
|
||||
$ sudo ./uninstall.sh
|
||||
|
||||
```
|
||||
|
||||
Type **y** and hit ENTER to remove each script.
|
||||
```
|
||||
Do you wish to uninstall currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
**Also read: **
|
||||
|
||||
And, that’s all for now folks. I must admit that I’m very impressed when testing this scripts. I really liked the idea of combing all useful scripts into a single package. Kudos to the developer. Give it a try, you won’t be disappointed.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/collection-useful-bash-scripts-heavy-commandline-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_001.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_002-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_003.png
|
||||
[6]:https://tastedive.com/account/api_access
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/07/ytview-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_005.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/07/cryptocurrency.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/07/lyrics.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/07/newton.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/07/siteciphers.png
|
||||
@ -1,151 +0,0 @@
|
||||
fuowang 翻译中
|
||||
|
||||
Arch Linux Applications Automatic Installation Script
|
||||
======
|
||||
|
||||

|
||||
|
||||
Howdy Archers! Today, I have stumbled upon an useful utility called **“ArchI0”** , a CLI menu-based Arch Linux applications automatic installation script. This script provides an easiest way to install all essential applications for your Arch-based distribution. Please note that **this script is meant for noobs only**. Intermediate and advanced users can easily figure out [**how to use pacman**][1] to get things done. If you want to learn how Arch Linux works, I suggest you to manually install all software one by one. For those who are still noobs and wanted an easy and quick way to install all essential applications for their Arch-based systems, make use of this script.
|
||||
|
||||
### ArchI0 – Arch Linux Applications Automatic Installation Script
|
||||
|
||||
The developer of this script has created two scripts namely **ArchI0live** and **ArchI0**. You can use ArchI0live script to test without installing it. This might be helpful to know what actually is in this script before installing it on your system.
|
||||
|
||||
### Install ArchI0
|
||||
|
||||
To install this script, Git cone the ArchI0 script repository using command:
|
||||
```
|
||||
$ git clone https://github.com/SifoHamlaoui/ArchI0.git
|
||||
|
||||
```
|
||||
|
||||
The above command will clone the ArchI0 GtiHub repository contents in a folder called ArchI0 in your current directory. Go to the directory using command:
|
||||
```
|
||||
$ cd ArchI0/
|
||||
|
||||
```
|
||||
|
||||
Make the script executable using command:
|
||||
```
|
||||
$ chmod +x ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
Run the script with command:
|
||||
```
|
||||
$ sudo ./ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
We need to run this script as root or sudo user, because installing applications requires root privileges.
|
||||
|
||||
> **Note:** For those wondering what all are those commands for at the beginning of the script, the first command downloads **figlet** , because the script logo is shown using figlet. The 2nd command install **Leafpad** which is used to open and read the license file. The 3rd command install **wget** to download files from sourceforge. The 4th and 5th commands are to download and open the License File on leafpad. And, the final and 6th command is used to close the license file after reading it.
|
||||
|
||||
Type your Arch Linux system’s architecture and hit ENTER key. When it asks to install the script, type y and hit ENTER.
|
||||
|
||||
![][3]
|
||||
|
||||
Once it is installed, you will be redirected to the main menu.
|
||||
|
||||
![][4]
|
||||
|
||||
As you see in the above screenshot, ArchI0 has 13 categories and contains 90 easy-to-install programs under those categories. These 90 programs are just enough to setup a full-fledged Arch Linux desktop to perform day-to-day activities. To know about this script, type **a** and to exit this script type **q**.
|
||||
|
||||
After installing it, you don’t need to run the ArchI0live script. You can directly launch it using the following command:
|
||||
```
|
||||
$ sudo ArchI0
|
||||
|
||||
```
|
||||
|
||||
It will ask you each time to choose your Arch Linux distribution architecture.
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
Preparing To Run Script
|
||||
Checking For ROOT: PASSED
|
||||
What Is Your OS Architecture? {32/64} 64
|
||||
|
||||
```
|
||||
|
||||
From now on, you can install the program of your choice from the categories listed in the main menu. To view the list of available programs under a specific category, enter the category number. Say for example, to view the list of available programs under **Text Editors** category, type **1** and hit ENTER.
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ R00T MENU ]
|
||||
Make A Choice
|
||||
1) Text Editors
|
||||
2) FTP/Torrent Applications
|
||||
3) Download Managers
|
||||
4) Network managers
|
||||
5) VPN clients
|
||||
6) Chat Applications
|
||||
7) Image Editors
|
||||
8) Video editors/Record
|
||||
9) Archive Handlers
|
||||
10) Audio Applications
|
||||
11) Other Applications
|
||||
12) Development Environments
|
||||
13) Browser/Web Plugins
|
||||
14) Dotfiles
|
||||
15) Usefull Links
|
||||
------------------------
|
||||
a) About ArchI0 Script
|
||||
q) Leave ArchI0 Script
|
||||
|
||||
Choose An Option: 1
|
||||
|
||||
```
|
||||
|
||||
Next, choose the application you want to install. To return to main menu, type **q** and hit ENTER.
|
||||
|
||||
I want to install Emacs, so I type **3**.
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ TEXT EDITORS ]
|
||||
[ Option ] [ Description ]
|
||||
1) GEdit
|
||||
2) Geany
|
||||
3) Emacs
|
||||
4) VIM
|
||||
5) Kate
|
||||
---------------------------
|
||||
q) Return To Main Menu
|
||||
|
||||
Choose An Option: 3
|
||||
|
||||
```
|
||||
|
||||
Now, Emacs will be installed on your Arch Linux system.
|
||||
|
||||
![][5]
|
||||
|
||||
Press ENTER key to return to main menu after installing the applications of your choice.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Undoubtedly, this script makes the Arch Linux user’s life easier, particularly the beginner’s. If you are looking for a fast and easy way to install applications without using pacman, then this script might be a good choice. Give it a try and let us know what you think about this script in the comment section below.
|
||||
|
||||
And, that’s all. Hope this tool helps. We will be posting useful guides every day. If you find our guides useful, please share them on your social, professional networks and support OSTechNix.
|
||||
|
||||
Cheers!!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/archi0-arch-linux-applications-automatic-installation-script/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_003.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_004-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/pacman-as-superuser_005.png
|
||||
@ -1,71 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Linux command line tools for working with non-Linux users
|
||||
======
|
||||

|
||||
I spend most of my computing life in the Shell (command line, terminal or whatever you want to call it on your platform of choice). This can be a bit challenging, though, when I need to work with large groups of other people, especially in big enterprise companies that -- well -- use anything but the Shell.
|
||||
|
||||
The problems that crop up are made worse when other people within your company use a different platform than you. I tend to use Linux. If I'm doing a lot of my daily work from a Linux terminal and the bulk of my co-workers use Windows 10 (entirely from the GUI side), things can get … problematic.
|
||||
|
||||
**Also on Network World:**[ **11 pointless but awesome Linux terminal tricks**][1]
|
||||
|
||||
Luckily, over the past few years, I've figured out how to deal with these problems. I've found ways to make using a Linux (or other Unix-like systems) Shell much more doable within a non-Unix, corporate environment. These tools/tips apply equally well for SysAdmins working on a company's servers as they do for developers or marketing people.
|
||||
|
||||
## Command line tools for working with non-Linux users
|
||||
|
||||
Let's start by focusing on the two areas that seem to be the hardest to solve for many people in big companies: document compatibility and enterprise instant messaging.
|
||||
|
||||
### Document compatibility between Linux and non-Linux systems
|
||||
|
||||
One of the biggest issues that crops up is that of simple word processing document compatibility.
|
||||
|
||||
Let's say your company has standardized on Microsoft Office. This makes you sad. But do not lose hope! There are ways to make this (mostly) work -- even from the Shell.
|
||||
|
||||
Two tools are critical in my arsenal: [Pandoc][2] and [Wordgrinder][3].
|
||||
|
||||
Wordgrinder is a simple, straight-to-the-point word processor. It may not be as full-featured as LibreOffice (or, really, any major GUI word-processing application), but it's fast. It's stable. And it supports just enough features (and file formats) to get the job done. In fact, I write the majority of my articles and books entirely in Wordgrinder.
|
||||
|
||||
But there's a problem (you knew there had to be).
|
||||
|
||||
Wordgrinder doesn't support .doc (or .docx) files. That means it can't read most files that your Windows- and MS Office-using co-workers send you.
|
||||
|
||||
That's where Pandoc comes in. It's a simple document converter that takes a wide range of files as input (MS Word, LibreOffice, HTML, markdown, etc.) and converts them to something else. The number of formats supported here is absolutely phenomenal -- PDF, ePub, various slideshow formats. It really makes converting documents between formats a breeze.
|
||||
|
||||
That's not to say I don't occasionally encounter formatting or feature issues. Converting a Word document that has a lot of custom formatting, some scripting, and an embedded chart? Yeah, a lot of that will be lost in the process.
|
||||
|
||||
But in practical terms, the combination of Pandoc (for converting files) and Wordgrinder (for document editing) has proven quite capable and powerful.
|
||||
|
||||
### Corporate instant messaging between Linux and non-Linux systems
|
||||
|
||||
Every company likes to standardize on an instant messaging system -- something for all employees to use to keep in real-time contact.
|
||||
|
||||
From the command line, this can get tricky. What if your company uses Google Hangouts? Or how about Novell GroupWise Messenger? Neither have officially supported, terminal-based clients.
|
||||
|
||||
Thank goodness, then, for [Finch & Hangups][4].
|
||||
|
||||
Finch is sort of the terminal version of Pidgin (the open-source, multi-protocol messenger client). It supports a wide variety of protocols, including Novell GroupWise, (the soon to be dead) AOL Instant Messenger, and a bunch of others.
|
||||
|
||||
And Hangups is an open implementation of a Google Hangouts client -- complete with message history and a nice tabbed interface.
|
||||
|
||||
Neither of these solutions will provide you with voice or video chat capabilities, but for text-based messaging, they work delightfully well. They aren't perfect (the user interface of Finch takes some getting used to), but they're definitely good enough to keep in touch with your co-workers.
|
||||
|
||||
Will these solutions allow you to spend your entire work day within the comforts of a text-only Shell? Probably not. Personally, I find that (with these tools, and others) I can comfortably spend roughly 80 percent of my day in a text-only interface.
|
||||
|
||||
Which feels pretty darn great.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3235688/linux/linux-command-line-tools-for-working-with-non-linux-users.html
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Bryan-Lunduke/
|
||||
[1]:http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html#tk.nww-fsb
|
||||
[2]:https://www.youtube.com/watch?v=BkTYHChkDoE
|
||||
[3]:https://www.youtube.com/watch?v=WnMyamBgKFE
|
||||
[4]:https://www.youtube.com/watch?v=19lbWnYOsTc
|
||||
@ -1,3 +1,5 @@
|
||||
Translatin by imquanquan
|
||||
|
||||
Here are some amazing advantages of Go that you don’t hear much about
|
||||
============================================================
|
||||
|
||||
@ -220,4 +222,4 @@ via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that
|
||||
[19]:https://golang.org/src/encoding/json/encode.go
|
||||
[20]:https://tour.golang.org/
|
||||
[21]:https://github.com/kirillrogovoy/
|
||||
[22]:https://twitter.com/krogovoy
|
||||
[22]:https://twitter.com/krogovoy
|
||||
|
||||
@ -1,262 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
API Star: Python 3 API Framework – Polyglot.Ninja()
|
||||
======
|
||||
For building quick APIs in Python, I have mostly depended on [Flask][1]. Recently I came across a new API framework for Python 3 named “API Star” which seemed really interesting to me for several reasons. Firstly the framework embraces modern Python features like type hints and asyncio. And then it goes ahead and uses these features to provide awesome development experience for us, the developers. We will get into those features soon but before we begin, I would like to thank Tom Christie for all the work he has put into Django REST Framework and now API Star.
|
||||
|
||||
Now back to API Star – I feel very productive in the framework. I can choose to write async codes based on asyncio or I can choose a traditional backend like WSGI. It comes with a command line tool – `apistar` to help us get things done faster. There’s (optional) support for both Django ORM and SQLAlchemy. There’s a brilliant type system that enables us to define constraints on our input and output and from these, API Star can auto generate api schemas (and docs), provide validation and serialization feature and a lot more. Although API Star is heavily focused on building APIs, you can also build web applications on top of it fairly easily. All these might not make proper sense until we build something all by ourselves.
|
||||
|
||||
### Getting Started
|
||||
|
||||
We will start by installing API Star. It would be a good idea to create a virtual environment for this exercise. If you don’t know how to create a virtualenv, don’t worry and go ahead.
|
||||
```
|
||||
pip install apistar
|
||||
|
||||
```
|
||||
|
||||
If you’re not using a virtual environment or the `pip` command for your Python 3 is called `pip3`, then please use `pip3 install apistar` instead.
|
||||
|
||||
Once we have the package installed, we should have access to the `apistar` command line tool. We can create a new project with it. Let’s create a new project in our current directory.
|
||||
```
|
||||
apistar new .
|
||||
|
||||
```
|
||||
|
||||
Now we should have two files created – `app.py` – which contains the main application and then `test.py` for our tests. Let’s examine our `app.py` file:
|
||||
```
|
||||
from apistar import Include, Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
from apistar.handlers import docs_urls, static_urls
|
||||
|
||||
|
||||
def welcome(name=None):
|
||||
if name is None:
|
||||
return {'message': 'Welcome to API Star!'}
|
||||
return {'message': 'Welcome to API Star, %s!' % name}
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'GET', welcome),
|
||||
Include('/docs', docs_urls),
|
||||
Include('/static', static_urls)
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
Before we dive into the code, let’s run the app and see if it works. If we navigate to `http://127.0.0.1:8080/` we will get this following response:
|
||||
```
|
||||
{"message": "Welcome to API Star!"}
|
||||
|
||||
```
|
||||
|
||||
And if we navigate to: `http://127.0.0.1:8080/?name=masnun`
|
||||
```
|
||||
{"message": "Welcome to API Star, masnun!"}
|
||||
|
||||
```
|
||||
|
||||
Similarly if we navigate to: `http://127.0.0.1:8080/docs/`, we will see auto generated docs for our API.
|
||||
|
||||
Now let’s look at the code. We have a `welcome` function that takes a parameter named `name` which has a default value of `None`. API Star is a smart api framework. It will try to find the `name` key in the url path or query string and pass it to our function. It also generates the API docs based on it. Pretty nice, no?
|
||||
|
||||
We then create a list of `Route` and `Include` instances and pass the list to the `App` instance. `Route` objects are used to define custom user routing. `Include` , as the name suggests, includes/embeds other routes under the path provided to it.
|
||||
|
||||
### Routing
|
||||
|
||||
Routing is simple. When constructing the `App` instance, we need to pass a list as the `routes` argument. This list should comprise of `Route` or `Include` objects as we just saw above. For `Route`s, we pass a url path, http method name and the request handler callable (function or otherwise). For the `Include` instances, we pass a url path and a list of `Routes` instance.
|
||||
|
||||
##### Path Parameters
|
||||
|
||||
We can put a name inside curly braces to declare a url path parameter. For example `/user/{user_id}` defines a path where the `user_id` is a path parameter or a variable which will be injected into the handler function (actually callable). Here’s a quick example:
|
||||
```
|
||||
from apistar import Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
|
||||
def user_profile(user_id: int):
|
||||
return {'message': 'Your profile id is: {}'.format(user_id)}
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/user/{user_id}', 'GET', user_profile),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
If we visit `http://127.0.0.1:8080/user/23` we will get a response like this:
|
||||
```
|
||||
{"message": "Your profile id is: 23"}
|
||||
|
||||
```
|
||||
|
||||
But if we try to visit `http://127.0.0.1:8080/user/some_string` – it will not match. Because the `user_profile` function we defined, we added a type hint for the `user_id` parameter. If it’s not integer, the path doesn’t match. But if we go ahead and delete the type hint and just use `user_profile(user_id)`, it will match this url. This is again API Star is being smart and taking advantages of typing.
|
||||
|
||||
#### Including / Grouping Routes
|
||||
|
||||
Sometimes it might make sense to group certain urls together. Say we have a `user` module that deals with user related functionality. It might be better to group all the user related endpoints under the `/user` path. For example – `/user/new`, `/user/1`, `/user/1/update` and what not. We can easily create our handlers and routes in a separate module or package even and then include them in our own routes.
|
||||
|
||||
Let’s create a new module named `user`, the file name would be `user.py`. Let’s put these codes in this file:
|
||||
```
|
||||
from apistar import Route
|
||||
|
||||
|
||||
def user_new():
|
||||
return {"message": "Create a new user"}
|
||||
|
||||
|
||||
def user_update(user_id: int):
|
||||
return {"message": "Update user #{}".format(user_id)}
|
||||
|
||||
|
||||
def user_profile(user_id: int):
|
||||
return {"message": "User Profile for: {}".format(user_id)}
|
||||
|
||||
|
||||
user_routes = [
|
||||
Route("/new", "GET", user_new),
|
||||
Route("/{user_id}/update", "GET", user_update),
|
||||
Route("/{user_id}/profile", "GET", user_profile),
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
Now we can import our `user_routes` from within our main app file and use it like this:
|
||||
```
|
||||
from apistar import Include
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
from user import user_routes
|
||||
|
||||
routes = [
|
||||
Include("/user", user_routes)
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
Now `/user/new` will delegate to `user_new` function.
|
||||
|
||||
### Accessing Query String / Query Parameters
|
||||
|
||||
Any parameters passed in the query parameters can be injected directly into handler function. Say for the url `/call?phone=1234`, the handler function can define a `phone` parameter and it will receive the value from the query string / query parameters. If the url query string doesn’t include a value for `phone`, it will get `None` instead. We can also set a default value to the parameter like this:
|
||||
```
|
||||
def welcome(name=None):
|
||||
if name is None:
|
||||
return {'message': 'Welcome to API Star!'}
|
||||
return {'message': 'Welcome to API Star, %s!' % name}
|
||||
|
||||
```
|
||||
|
||||
In the above example, we set a default value to `name` which is `None` anyway.
|
||||
|
||||
### Injecting Objects
|
||||
|
||||
By type hinting a request handler, we can have different objects injected into our views. Injecting request related objects can be helpful for accessing them directly from inside the handler. There are several built in objects in the `http` package from API Star itself. We can also use it’s type system to create our own custom objects and have them injected into our functions. API Star also does data validation based on the constraints specified.
|
||||
|
||||
Let’s define our own `User` type and have it injected in our request handler:
|
||||
```
|
||||
from apistar import Include, Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
from apistar import typesystem
|
||||
|
||||
|
||||
class User(typesystem.Object):
|
||||
properties = {
|
||||
'name': typesystem.string(max_length=100),
|
||||
'email': typesystem.string(max_length=100),
|
||||
'age': typesystem.integer(maximum=100, minimum=18)
|
||||
}
|
||||
|
||||
required = ["name", "age", "email"]
|
||||
|
||||
|
||||
def new_user(user: User):
|
||||
return user
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'POST', new_user),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
Now if we send this request:
|
||||
|
||||
```
|
||||
curl -X POST \
|
||||
http://127.0.0.1:8080/ \
|
||||
-H 'Cache-Control: no-cache' \
|
||||
-H 'Content-Type: application/json' \
|
||||
-d '{"name": "masnun", "email": "masnun@gmail.com", "age": 12}'
|
||||
```
|
||||
|
||||
Guess what happens? We get an error saying age must be equal to or greater than 18. The type system is allowing us intelligent data validation as well. If we enable the `docs` url, we will also get these parameters automatically documented there.
|
||||
|
||||
### Sending a Response
|
||||
|
||||
If you have noticed so far, we can just pass a dictionary and it will be JSON encoded and returned by default. However, we can set the status code and any additional headers by using the `Response` class from `apistar`. Here’s a quick example:
|
||||
```
|
||||
from apistar import Route, Response
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
|
||||
def hello():
|
||||
return Response(
|
||||
content="Hello".encode("utf-8"),
|
||||
status=200,
|
||||
headers={"X-API-Framework": "API Star"},
|
||||
content_type="text/plain"
|
||||
)
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'GET', hello),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
It should send a plain text response along with a custom header. Please note that the `content` should be bytes, not string. That’s why I encoded it.
|
||||
|
||||
### Moving On
|
||||
|
||||
I just walked through some of the features of API Star. There’s a lot more of cool stuff in API Star. I do recommend going through the [Github Readme][2] for learning more about different features offered by this excellent framework. I shall also try to cover short, focused tutorials on API Star in the coming days.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://polyglot.ninja/api-star-python-3-api-framework/
|
||||
|
||||
作者:[MASNUN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://polyglot.ninja/author/masnun/
|
||||
[1]:http://polyglot.ninja/rest-api-best-practices-python-flask-tutorial/
|
||||
[2]:https://github.com/encode/apistar
|
||||
@ -0,0 +1,87 @@
|
||||
3 pitfalls everyone should avoid with hybrid multicloud
|
||||
======
|
||||

|
||||
|
||||
This article was co-written with [Roel Hodzelmans][1].
|
||||
|
||||
We're all told the cloud is the way to ensure a digital future for our businesses. But which cloud? From cloud to hybrid cloud to hybrid multi-cloud, you need to make choices, and these choices don't preclude the daily work of enhancing your customers' experience or agile delivery of the applications they need.
|
||||
|
||||
This article is the first in a four-part series on avoiding pitfalls in hybrid multi-cloud computing. Let's start by examining multi-cloud, hybrid cloud, and hybrid multi-cloud and what makes them different from one another.
|
||||
|
||||
### Hybrid vs. multi-cloud
|
||||
|
||||
There are many conversations you may be having in your business around moving to the cloud. For example, you may want to take your on-premises computing capacity and turn it into your own private cloud. You may wish to provide developers with a cloud-like experience using the same resources you already have. A more traditional reason for expansion is to use external computing resources to augment those in your own data centers. The latter leads you to the various public cloud providers, as well as to our first definition, multi-cloud.
|
||||
|
||||
#### Multi-cloud
|
||||
|
||||
Multi-cloud means using multiple clouds from multiple providers for multiple tasks.
|
||||
|
||||
![Multi-cloud][3]
|
||||
|
||||
Figure 1. Multi-cloud IT with multiple isolated cloud environments
|
||||
|
||||
Typically, multi-cloud refers to the use of several different public clouds in order to achieve greater flexibility, lower costs, avoid vendor lock-in, or use specific regional cloud providers.
|
||||
|
||||
A challenge of the multi-cloud approach is achieving consistent policies, compliance, and management with different providers involved.
|
||||
|
||||
Multi-cloud is mainly a strategy to expand your business while leveraging multi-vendor cloud solutions and spreading the risk of lock-in. Figure 1 shows the isolated nature of cloud services in this model, without any sort of coordination between the services and business applications. Each is managed separately, and applications are isolated to services found in their environments.
|
||||
|
||||
#### Hybrid cloud
|
||||
|
||||
Hybrid cloud solves issues where isolation and coordination are central to the solution. It is a combination of one or more public and private clouds with at least a degree of workload portability, integration, orchestration, and unified management.
|
||||
|
||||
![Hybrid cloud][5]
|
||||
|
||||
Figure 2. Hybrid clouds may be on or off premises, but must have a degree of interoperability
|
||||
|
||||
The key issue here is that there is an element of interoperability, migration potential, and a connection between tasks running in public clouds and on-premises infrastructure, even if it's not always seamless or otherwise fully implemented.
|
||||
|
||||
If your cloud model is missing portability, integration, orchestration, and management, then it's just a bunch of clouds, not a hybrid cloud.
|
||||
|
||||
The cloud environments in Fig. 2 include at least one private and public cloud. They can be off or on premises, but they have some degree of the following:
|
||||
|
||||
* Interoperability
|
||||
* Application portability
|
||||
* Data portability
|
||||
* Common management
|
||||
|
||||
|
||||
|
||||
As you can probably guess, combining multi-cloud and hybrid cloud results in a hybrid multi-cloud. But what does that look like?
|
||||
|
||||
### Hybrid multi-cloud
|
||||
|
||||
Hybrid multi-cloud pulls together multiple clouds and provides the tools to ensure interoperability between the various services in hybrid and multi-cloud solutions.
|
||||
|
||||
![Hybrid multi-cloud][7]
|
||||
|
||||
Figure 3. Hybrid multi-cloud solutions using open technologies
|
||||
|
||||
Bringing these together can be a serious challenge, but the result ensures better use of resources without isolation in their respective clouds.
|
||||
|
||||
Fig. 3 shows an example of hybrid multi-cloud based on open technologies for interoperability, workload portability, and management.
|
||||
|
||||
### Moving forward: Pitfalls of hybrid multi-cloud
|
||||
|
||||
In part two of this series, we'll look at the first of three pitfalls to avoid with hybrid multi-cloud. Namely, why cost is not always the obvious motivator when determining how to transition your business to the cloud.
|
||||
|
||||
This article is based on "[3 pitfalls everyone should avoid with hybrid multi-cloud][8]," a talk the authors will be giving at [Red Hat Summit 2018][9], which will be held May 8-10 in San Francisco. [Register by May 7][9] to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/users/roelh
|
||||
[3]:https://opensource.com/sites/default/files/u128651/multi-cloud.png (Multi-cloud)
|
||||
[5]:https://opensource.com/sites/default/files/u128651/hybrid-cloud.png (Hybrid cloud)
|
||||
[7]:https://opensource.com/sites/default/files/u128651/hybrid-multicloud.png (Hybrid multi-cloud)
|
||||
[8]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=153892
|
||||
[9]:https://www.redhat.com/en/summit/2018
|
||||
@ -1,141 +0,0 @@
|
||||
# A gentle introduction to FreeDOS
|
||||
|
||||

|
||||
|
||||
Image credits :
|
||||
|
||||
Jim Hall, CC BY
|
||||
|
||||
## Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
FreeDOS is an old operating system, but it is new to many people. In 1994, several developers and I came together to [create FreeDOS][1]—a complete, free, DOS-compatible operating system you can use to play classic DOS games, run legacy business software, or develop embedded systems. Any program that works on MS-DOS should also run on FreeDOS.
|
||||
|
||||
In 1994, FreeDOS was immediately familiar to anyone who had used Microsoft's proprietary MS-DOS. And that was by design; FreeDOS intended to mimic MS-DOS as much as possible. As a result, DOS users in the 1990s were able to jump right into FreeDOS. But times have changed. Today, open source developers are more familiar with the Linux command line or they may prefer a graphical desktop like [GNOME][2], making the FreeDOS command line seem alien at first.
|
||||
|
||||
New users often ask, "I [installed FreeDOS][3], but how do I use it?" If you haven't used DOS before, the blinking C:\> DOS prompt can seem a little unfriendly. And maybe scary. This gentle introduction to FreeDOS should get you started. It offers just the basics: how to get around and how to look at files. If you want to learn more than what's offered here, visit the [FreeDOS wiki][4].
|
||||
|
||||
## The DOS prompt
|
||||
|
||||
First, let's look at the empty prompt and what it means.
|
||||
|
||||

|
||||
|
||||
DOS is a "disk operating system" created when personal computers ran from floppy disks. Even when computers supported hard drives, it was common in the 1980s and 1990s to switch frequently between the different drives. For example, you might make a backup copy of your most important files to a floppy disk.
|
||||
|
||||
DOS referenced each drive by a letter. Early PCs could have only two floppy drives, which were assigned as the A: and B: drives. The first partition on the first hard drive was the C: drive, and so on for other drives. The C: in the prompt means you are using the first partition on the first hard drive.
|
||||
|
||||
Starting with PC-DOS 2.0 in 1983, DOS also supported directories and subdirectories, much like the directories and subdirectories on Linux filesystems. But unlike Linux, DOS directory names are delimited by \ instead of /. Putting that together with the drive letter, the C:\ in the prompt means you are in the top, or "root," directory of the C: drive.
|
||||
|
||||
The > is the literal prompt where you type your DOS commands, like the $ prompt on many Linux shells. The part before the > tells you the current working directory, and you type commands at the > prompt.
|
||||
|
||||
## Finding your way around in DOS
|
||||
|
||||
The basics of navigating through directories in DOS are very similar to the steps you'd use on the Linux command line. You need to remember only a few commands.
|
||||
|
||||
### Displaying a directory
|
||||
|
||||
When you want to see the contents of the current directory, use the DIR command. Since DOS commands are not case-sensitive, you could also type dir. By default, DOS displays the details of every file and subdirectory, including the name, extension, size, and last modified date and time.
|
||||
|
||||
|
||||
|
||||
If you don't want the extra details about individual file sizes, you can display a "wide" directory by using the /w option with the DIR command. Note that Linux uses the hyphen (-) or double-hyphen (--) to start command-line options, but DOS uses the slash character (/).
|
||||
|
||||
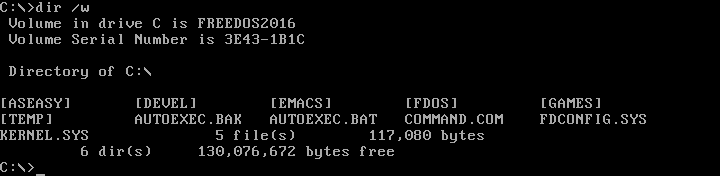
|
||||
|
||||
You can look inside a specific subdirectory by passing the pathname as a parameter to DIR. Again, another difference from Linux is that Linux files and directories are case-sensitive, but DOS names are case-insensitive. DOS will usually display files and directories in all uppercase, but you can equally reference them in lowercase.
|
||||
|
||||
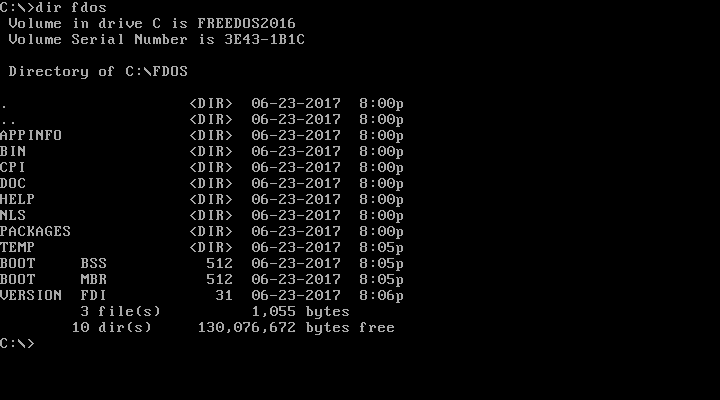
|
||||
|
||||
### Changing the working directory
|
||||
|
||||
Once you can see the contents of a directory, you can "move into" any other directory. On DOS, you change your working directory with the CHDIR command, also abbreviated as CD. You can change into a subdirectory with a command like CD CHOICE or into a new path with CD \FDOS\DOC\CHOICE.
|
||||
|
||||
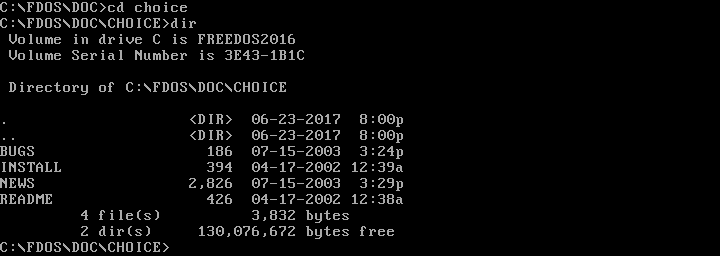
|
||||
|
||||
Just like on the Linux command line, DOS uses . to represent the current directory, and .. for the parent directory (one level "up" from the current directory). You can combine these. For example, CD .. changes to the parent directory, and CD ..\.. moves you two levels "up" from the current directory.
|
||||
|
||||
FreeDOS also borrows a feature from Linux: You can use CD - to jump back to your previous working directory. That is handy after you change into a new path to do one thing and want to go back to your previous work.
|
||||
|
||||
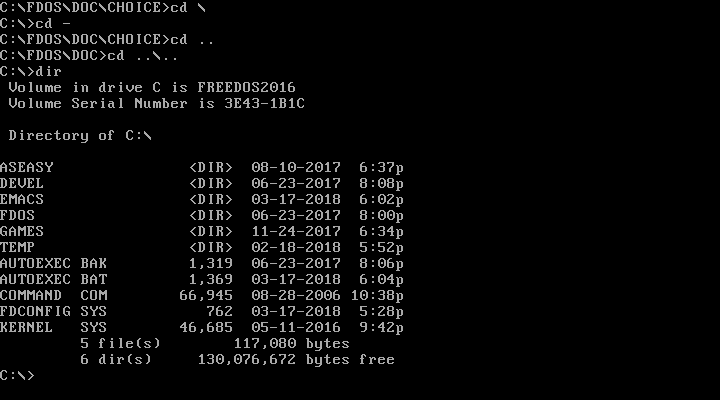
|
||||
|
||||
### Changing the working drive
|
||||
|
||||
Under Linux, the concept of a "drive" is hidden. In Linux and other Unix systems, you "mount" a drive to a directory path, such as /backup, or the system does it for you automatically, such as /var/run/media/user/flashdrive. But DOS is a much simpler system. With DOS, you must change the working drive by yourself.
|
||||
|
||||
Remember that DOS assigns the first partition on the first hard drive as the C: drive, and so on for other drive letters. On modern systems, people rarely divide a hard drive with multiple DOS partitions; they simply use the whole disk—or as much of it as they can assign to DOS. Today, C: is usually the first hard drive, and D: is usually another hard drive or the CD-ROM drive. Other network drives can be mapped to other letters, such as E: or Z: or however you want to organize them.
|
||||
|
||||
Changing drives is easy under DOS. Just type the drive letter followed by a colon (:) on the command line, and DOS will change to that working drive. For example, on my [QEMU][5] system, I set my D: drive to a shared directory in my Linux home directory, where I keep installers for various DOS applications and games I want to test.
|
||||
|
||||
|
||||
|
||||
Be careful that you don't try to change to a drive that doesn't exist. DOS may set the working drive, but if you try to do anything there you'll get the somewhat infamous "Abort, Retry, Fail" DOS error message.
|
||||
|
||||

|
||||
|
||||
## Other things to try
|
||||
|
||||
With the CD and DIR commands, you have the basics of DOS navigation. These commands allow you to find your way around DOS directories and see what other subdirectories and files exist. Once you are comfortable with basic navigation, you might also try these other basic DOS commands:
|
||||
|
||||
* MKDIR or MD to create new directories
|
||||
* RMDIR or RD to remove directories
|
||||
* TREE to view a list of directories and subdirectories in a tree-like format
|
||||
* TYPE and MORE to display file contents
|
||||
* RENAME or REN to rename files
|
||||
* DEL or ERASE to delete files
|
||||
* EDIT to edit files
|
||||
* CLS to clear the screen
|
||||
|
||||
If those aren't enough, you can find a list of [all DOS commands][6] on the FreeDOS wiki.
|
||||
|
||||
In FreeDOS, you can use the /? parameter to get brief instructions to use each command. For example, EDIT /? will show you the usage and options for the editor. Or you can type HELP to use an interactive help system.
|
||||
|
||||
Like any DOS, FreeDOS is meant to be a simple operating system. The DOS filesystem is pretty simple to navigate with only a few basic commands. So fire up a QEMU session, install FreeDOS, and experiment with the DOS command line. Maybe now it won't seem so scary.
|
||||
|
||||
## Related stories:
|
||||
|
||||
* [How to install FreeDOS in QEMU][7]
|
||||
* [How to install FreeDOS on Raspberry Pi][8]
|
||||
* [The origin and evolution of FreeDOS][9]
|
||||
* [Four cool facts about FreeDOS][10]
|
||||
|
||||
## About the author
|
||||
|
||||
[][11]
|
||||
|
||||
Jim Hall \- Jim Hall is an open source software developer and advocate, probably best known as the founder and project coordinator for FreeDOS. Jim is also very active in the usability of open source software, as a mentor for usability testing in GNOME Outreachy, and as an occasional adjunct professor teaching a course on the Usability of Open Source Software. From 2016 to 2017, Jim served as a director on the GNOME Foundation Board of Directors. At work, Jim is Chief Information Officer in local... [more about Jim Hall][12]
|
||||
|
||||
[More about me][13]
|
||||
|
||||
* [Learn how you can contribute][14]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/gentle-introduction-freedos][15]
|
||||
|
||||
作者: [undefined][16] 选题者: [@lujun9972][17] 译者: [译者ID][18] 校对: [校对者ID][19]
|
||||
|
||||
本文由 [LCTT][20] 原创编译,[Linux中国][21] 荣誉推出
|
||||
|
||||
[1]: https://opensource.com/article/17/10/freedos
|
||||
[2]: https://opensource.com/article/17/8/gnome-20-anniversary
|
||||
[3]: http://www.freedos.org/
|
||||
[4]: http://wiki.freedos.org/
|
||||
[5]: https://www.qemu.org/
|
||||
[6]: http://wiki.freedos.org/wiki/index.php/Dos_commands
|
||||
[7]: https://opensource.com/article/17/10/run-dos-applications-linux
|
||||
[8]: https://opensource.com/article/18/3/can-you-run-dos-raspberry-pi
|
||||
[9]: https://opensource.com/article/17/10/freedos
|
||||
[10]: https://opensource.com/article/17/6/freedos-still-cool-today
|
||||
[11]: https://opensource.com/users/jim-hall
|
||||
[12]: https://opensource.com/users/jim-hall
|
||||
[13]: https://opensource.com/users/jim-hall
|
||||
[14]: https://opensource.com/participate
|
||||
[15]: https://opensource.com/article/18/4/gentle-introduction-freedos
|
||||
[16]: undefined
|
||||
[17]: https://github.com/lujun9972
|
||||
[18]: https://github.com/译者ID
|
||||
[19]: https://github.com/校对者ID
|
||||
[20]: https://github.com/LCTT/TranslateProject
|
||||
[21]: https://linux.cn/
|
||||
@ -1,489 +0,0 @@
|
||||
Translating by qhwdw
|
||||
# Understanding metrics and monitoring with Python
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
## Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
My reaction when I first came across the terms counter and gauge and the graphs with colors and numbers labeled "mean" and "upper 90" was one of avoidance. It's like I saw them, but I didn't care because I didn't understand them or how they might be useful. Since my job didn't require me to pay attention to them, they remained ignored.
|
||||
|
||||
That was about two years ago. As I progressed in my career, I wanted to understand more about our network applications, and that is when I started learning about metrics.
|
||||
|
||||
The three stages of my journey to understanding monitoring (so far) are:
|
||||
|
||||
* Stage 1: What? (Looks elsewhere)
|
||||
* Stage 2: Without metrics, we are really flying blind.
|
||||
* Stage 3: How do we keep from doing metrics wrong?
|
||||
|
||||
I am currently in Stage 2 and will share what I have learned so far. I'm moving gradually toward Stage 3, and I will offer some of my resources on that part of the journey at the end of this article.
|
||||
|
||||
Let's get started!
|
||||
|
||||
## Software prerequisites
|
||||
|
||||
More Python Resources
|
||||
|
||||
* [What is Python?][1]
|
||||
* [Top Python IDEs][2]
|
||||
* [Top Python GUI frameworks][3]
|
||||
* [Latest Python content][4]
|
||||
* [More developer resources][5]
|
||||
|
||||
All the demos discussed in this article are available on [my GitHub repo][6]. You will need to have docker and docker-compose installed to play with them.
|
||||
|
||||
## Why should I monitor?
|
||||
|
||||
The top reasons for monitoring are:
|
||||
|
||||
* Understanding _normal_ and _abnormal_ system and service behavior
|
||||
* Doing capacity planning, scaling up or down
|
||||
* Assisting in performance troubleshooting
|
||||
* Understanding the effect of software/hardware changes
|
||||
* Changing system behavior in response to a measurement
|
||||
* Alerting when a system exhibits unexpected behavior
|
||||
|
||||
## Metrics and metric types
|
||||
|
||||
For our purposes, a **metric** is an _observed_ value of a certain quantity at a given point in _time_. The total of number hits on a blog post, the total number of people attending a talk, the number of times the data was not found in the caching system, the number of logged-in users on your website—all are examples of metrics.
|
||||
|
||||
They broadly fall into three categories:
|
||||
|
||||
### Counters
|
||||
|
||||
Consider your personal blog. You just published a post and want to keep an eye on how many hits it gets over time, a number that can only increase. This is an example of a **counter** metric. Its value starts at 0 and increases during the lifetime of your blog post. Graphically, a counter looks like this:
|
||||
|
||||
|
||||
|
||||
A counter metric always increases.
|
||||
|
||||
### Gauges
|
||||
|
||||
Instead of the total number of hits on your blog post over time, let's say you want to track the number of hits per day or per week. This metric is called a **gauge** and its value can go up or down. Graphically, a gauge looks like this:
|
||||
|
||||
|
||||
|
||||
A gauge metric can increase or decrease.
|
||||
|
||||
A gauge's value usually has a _ceiling_ and a _floor_ in a certain time window.
|
||||
|
||||
### Histograms and timers
|
||||
|
||||
A **histogram** (as Prometheus calls it) or a **timer** (as StatsD calls it) is a metric to track _sampled observations_. Unlike a counter or a gauge, the value of a histogram metric doesn't necessarily show an up or down pattern. I know that doesn't make a lot of sense and may not seem different from a gauge. What's different is what you expect to _do_ with histogram data compared to a gauge. Therefore, the monitoring system needs to know that a metric is a histogram type to allow you to do those things.
|
||||
|
||||
|
||||
|
||||
A histogram metric can increase or decrease.
|
||||
|
||||
## Demo 1: Calculating and reporting metrics
|
||||
|
||||
[Demo 1][7] is a basic web application written using the [Flask][8] framework. It demonstrates how we can _calculate_ and _report_ metrics.
|
||||
|
||||
The src directory has the application in app.py with the src/helpers/middleware.py containing the following:
|
||||
|
||||
```
|
||||
from flask import request
|
||||
import csv
|
||||
import time
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([str(int(time.time())), str(resp_time)])
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def setup_metrics(app):
|
||||
app.before_request(start_timer)
|
||||
app.after_request(stop_timer)
|
||||
```
|
||||
|
||||
When setup_metrics() is called from the application, it configures the start_timer() function to be called before a request is processed and the stop_timer() function to be called after a request is processed but before the response has been sent. In the above function, we write the timestamp and the time it took (in milliseconds) for the request to be processed.
|
||||
|
||||
When we run docker-compose up in the demo1 directory, it starts the web application, then a client container that makes a number of requests to the web application. You will see a src/metrics.csv file that has been created with two columns: timestamp and request_latency.
|
||||
|
||||
Looking at this file, we can infer two things:
|
||||
|
||||
* There is a lot of data that has been generated
|
||||
* No observation of the metric has any characteristic associated with it
|
||||
|
||||
Without a characteristic associated with a metric observation, we cannot say which HTTP endpoint this metric was associated with or which node of the application this metric was generated from. Hence, we need to qualify each metric observation with the appropriate metadata.
|
||||
|
||||
## Statistics 101
|
||||
|
||||
If we think back to high school mathematics, there are a few statistics terms we should all recall, even if vaguely, including mean, median, percentile, and histogram. Let's briefly recap them without judging their usefulness, just like in high school.
|
||||
|
||||
### Mean
|
||||
|
||||
The **mean**, or the average of a list of numbers, is the sum of the numbers divided by the cardinality of the list. The mean of 3, 2, and 10 is (3+2+10)/3 = 5.
|
||||
|
||||
### Median
|
||||
|
||||
The **median** is another type of average, but it is calculated differently; it is the center numeral in a list of numbers ordered from smallest to largest (or vice versa). In our list above (2, 3, 10), the median is 3. The calculation is not very straightforward; it depends on the number of items in the list.
|
||||
|
||||
### Percentile
|
||||
|
||||
The **percentile** is a measure that gives us a measure below which a certain (k) percentage of the numbers lie. In some sense, it gives us an _idea_ of how this measure is doing relative to the k percentage of our data. For example, the 95th percentile score of the above list is 9.29999. The percentile measure varies from 0 to 100 (non-inclusive). The _zeroth_ percentile is the minimum score in a set of numbers. Some of you may recall that the median is the 50th percentile, which turns out to be 3.
|
||||
|
||||
Some monitoring systems refer to the percentile measure as upper_X where _X_ is the percentile; _upper 90_ refers to the value at the 90th percentile.
|
||||
|
||||
### Quantile
|
||||
|
||||
The **q-Quantile** is a measure that ranks q_N_ in a set of _N_ numbers. The value of **q** ranges between 0 and 1 (both inclusive). When **q** is 0.5, the value is the median. The relationship between the quantile and percentile is that the measure at **q** quantile is equivalent to the measure at **100_q_** percentile.
|
||||
|
||||
### Histogram
|
||||
|
||||
The metric **histogram**, which we learned about earlier, is an _implementation detail_ of monitoring systems. In statistics, a histogram is a graph that groups data into _buckets_. Let's consider a different, contrived example: the ages of people reading your blog. If you got a handful of this data and wanted a rough idea of your readers' ages by group, plotting a histogram would show you a graph like this:
|
||||
|
||||
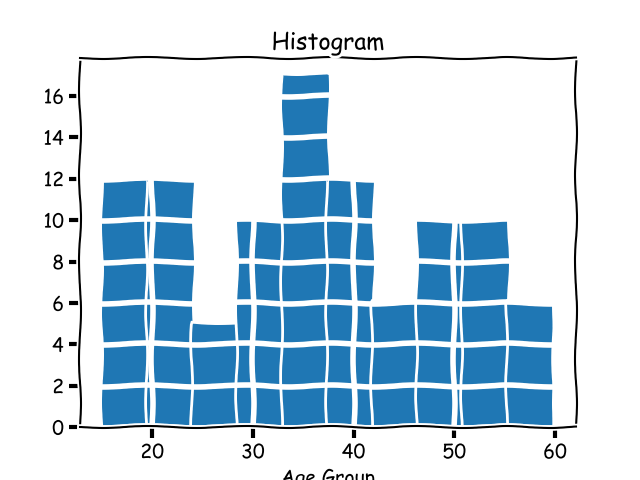
|
||||
|
||||
### Cumulative histogram
|
||||
|
||||
A **cumulative histogram** is a histogram where each bucket's count includes the count of the previous bucket, hence the name _cumulative_. A cumulative histogram for the above dataset would look like this:
|
||||
|
||||
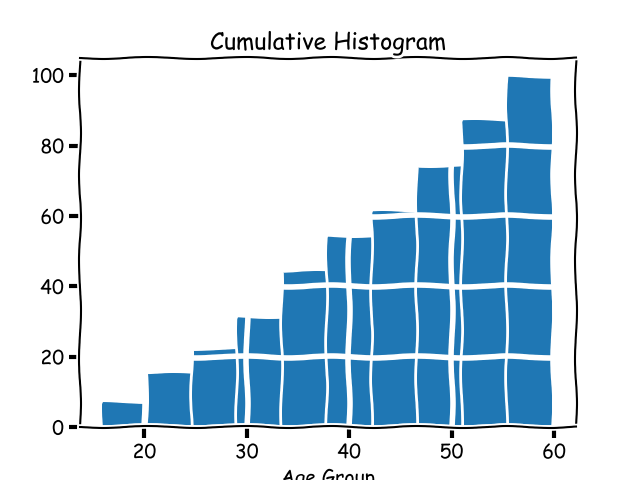
|
||||
|
||||
### Why do we need statistics?
|
||||
|
||||
In Demo 1 above, we observed that there is a lot of data that is generated when we report metrics. We need statistics when working with metrics because there are just too many of them. We don't care about individual values, rather overall behavior. We expect the behavior the values exhibit is a proxy of the behavior of the system under observation.
|
||||
|
||||
## Demo 2: Adding characteristics to metrics
|
||||
|
||||
In our Demo 1 application above, when we calculate and report a request latency, it refers to a specific request uniquely identified by few _characteristics_. Some of these are:
|
||||
|
||||
* The HTTP endpoint
|
||||
* The HTTP method
|
||||
* The identifier of the host/node where it's running
|
||||
|
||||
If we attach these characteristics to a metric observation, we have more context around each metric. Let's explore adding characteristics to our metrics in [Demo 2][9].
|
||||
|
||||
The src/helpers/middleware.py file now writes multiple columns to the CSV file when writing metrics:
|
||||
|
||||
```
|
||||
node_ids = ['10.0.1.1', '10.1.3.4']
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
node_id = node_ids[random.choice(range(len(node_ids)))]
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([
|
||||
str(int(time.time())), 'webapp1', node_id,
|
||||
request.endpoint, request.method, str(response.status_code),
|
||||
str(resp_time)
|
||||
])
|
||||
|
||||
return response
|
||||
```
|
||||
|
||||
Since this is a demo, I have taken the liberty of reporting random IPs as the node IDs when reporting the metric. When we run docker-compose up in the demo2 directory, it will result in a CSV file with multiple columns.
|
||||
|
||||
### Analyzing metrics with pandas
|
||||
|
||||
We'll now analyze this CSV file with [pandas][10]. Running docker-compose up will print a URL that we will use to open a [Jupyter][11] session. Once we upload the Analysis.ipynb notebook into the session, we can read the CSV file into a pandas DataFrame:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
metrics = pd.read_csv('/data/metrics.csv', index_col=0)
|
||||
```
|
||||
|
||||
The index_col specifies that we want to use the timestamp as the index.
|
||||
|
||||
Since each characteristic we add is a column in the DataFrame, we can perform grouping and aggregation based on these columns:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
metrics.groupby(['node_id', 'http_status']).latency.aggregate(np.percentile, 99.999)
|
||||
```
|
||||
|
||||
Please refer to the Jupyter notebook for more example analysis on the data.
|
||||
|
||||
## What should I monitor?
|
||||
|
||||
A software system has a number of variables whose values change during its lifetime. The software is running in some sort of an operating system, and operating system variables change as well. In my opinion, the more data you have, the better it is when something goes wrong.
|
||||
|
||||
Key operating system metrics I recommend monitoring are:
|
||||
|
||||
* CPU usage
|
||||
* System memory usage
|
||||
* File descriptor usage
|
||||
* Disk usage
|
||||
|
||||
Other key metrics to monitor will vary depending on your software application.
|
||||
|
||||
### Network applications
|
||||
|
||||
If your software is a network application that listens to and serves client requests, the key metrics to measure are:
|
||||
|
||||
* Number of requests coming in (counter)
|
||||
* Unhandled errors (counter)
|
||||
* Request latency (histogram/timer)
|
||||
* Queued time, if there is a queue in your application (histogram/timer)
|
||||
* Queue size, if there is a queue in your application (gauge)
|
||||
* Worker processes/threads usage (gauge)
|
||||
|
||||
If your network application makes requests to other services in the context of fulfilling a client request, it should have metrics to record the behavior of communications with those services. Key metrics to monitor include number of requests, request latency, and response status.
|
||||
|
||||
### HTTP web application backends
|
||||
|
||||
HTTP applications should monitor all the above. In addition, they should keep granular data about the count of non-200 HTTP statuses grouped by all the other HTTP status codes. If your web application has user signup and login functionality, it should have metrics for those as well.
|
||||
|
||||
### Long-running processes
|
||||
|
||||
Long-running processes such as Rabbit MQ consumer or task-queue workers, although not network servers, work on the model of picking up a task and processing it. Hence, we should monitor the number of requests processed and the request latency for those processes.
|
||||
|
||||
No matter the application type, each metric should have appropriate **metadata** associated with it.
|
||||
|
||||
## Integrating monitoring in a Python application
|
||||
|
||||
There are two components involved in integrating monitoring into Python applications:
|
||||
|
||||
* Updating your application to calculate and report metrics
|
||||
* Setting up a monitoring infrastructure to house the application's metrics and allow queries to be made against them
|
||||
|
||||
The basic idea of recording and reporting a metric is:
|
||||
|
||||
```
|
||||
def work():
|
||||
requests += 1
|
||||
# report counter
|
||||
start_time = time.time()
|
||||
|
||||
# < do the work >
|
||||
|
||||
# calculate and report latency
|
||||
work_latency = time.time() - start_time
|
||||
...
|
||||
```
|
||||
|
||||
Considering the above pattern, we often take advantage of _decorators_, _context managers_, and _middleware_ (for network applications) to calculate and report metrics. In Demo 1 and Demo 2, we used decorators in a Flask application.
|
||||
|
||||
### Pull and push models for metric reporting
|
||||
|
||||
Essentially, there are two patterns for reporting metrics from a Python application. In the _pull_ model, the monitoring system "scrapes" the application at a predefined HTTP endpoint. In the _push_ model, the application sends the data to the monitoring system.
|
||||
|
||||

|
||||
|
||||
An example of a monitoring system working in the _pull_ model is [Prometheus][12]. [StatsD][13] is an example of a monitoring system where the application _pushes_ the metrics to the system.
|
||||
|
||||
### Integrating StatsD
|
||||
|
||||
To integrate StatsD into a Python application, we would use the [StatsD Python client][14], then update our metric-reporting code to push data into StatsD using the appropriate library calls.
|
||||
|
||||
First, we need to create a client instance:
|
||||
|
||||
```
|
||||
statsd = statsd.StatsClient(host='statsd', port=8125, prefix='webapp1')
|
||||
```
|
||||
|
||||
The prefix keyword argument will add the specified prefix to all the metrics reported via this client.
|
||||
|
||||
Once we have the client, we can report a value for a timer using:
|
||||
|
||||
```
|
||||
statsd.timing(key, resp_time)
|
||||
```
|
||||
|
||||
To increment a counter:
|
||||
|
||||
```
|
||||
statsd.incr(key)
|
||||
```
|
||||
|
||||
To associate metadata with a metric, a key is defined as metadata1.metadata2.metric, where each metadataX is a field that allows aggregation and grouping.
|
||||
|
||||
The demo application [StatsD][15] is a complete example of integrating a Python Flask application with statsd.
|
||||
|
||||
### Integrating Prometheus
|
||||
|
||||
To use the Prometheus monitoring system, we will use the [Promethius Python client][16]. We will first create objects of the appropriate metric class:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY = Histogram('request_latency_seconds', 'Request latency',
|
||||
['app_name', 'endpoint']
|
||||
)
|
||||
```
|
||||
|
||||
The third argument in the above statement is the labels associated with the metric. These labels are what defines the metadata associated with a single metric value.
|
||||
|
||||
To record a specific metric observation:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY.labels('webapp', request.path).observe(resp_time)
|
||||
```
|
||||
|
||||
The next step is to define an HTTP endpoint in our application that Prometheus can scrape. This is usually an endpoint called /metrics:
|
||||
|
||||
```
|
||||
@app.route('/metrics')
|
||||
def metrics():
|
||||
return Response(prometheus_client.generate_latest(), mimetype=CONTENT_TYPE_LATEST)
|
||||
```
|
||||
|
||||
The demo application [Prometheus][17] is a complete example of integrating a Python Flask application with prometheus.
|
||||
|
||||
### Which is better: StatsD or Prometheus?
|
||||
|
||||
The natural next question is: Should I use StatsD or Prometheus? I have written a few articles on this topic, and you may find them useful:
|
||||
|
||||
* [Your options for monitoring multi-process Python applications with Prometheus][18]
|
||||
* [Monitoring your synchronous Python web applications using Prometheus][19]
|
||||
* [Monitoring your asynchronous Python web applications using Prometheus][20]
|
||||
|
||||
## Ways to use metrics
|
||||
|
||||
We've learned a bit about why we want to set up monitoring in our applications, but now let's look deeper into two of them: alerting and autoscaling.
|
||||
|
||||
### Using metrics for alerting
|
||||
|
||||
A key use of metrics is creating alerts. For example, you may want to send an email or pager notification to relevant people if the number of HTTP 500s over the past five minutes increases. What we use for setting up alerts depends on our monitoring setup. For Prometheus we can use [Alertmanager][21] and for StatsD, we use [Nagios][22].
|
||||
|
||||
### Using metrics for autoscaling
|
||||
|
||||
Not only can metrics allow us to understand if our current infrastructure is over- or under-provisioned, they can also help implement autoscaling policies in a cloud infrastructure. For example, if worker process usage on our servers routinely hits 90% over the past five minutes, we may need to horizontally scale. How we would implement scaling depends on the cloud infrastructure. AWS Auto Scaling, by default, allows scaling policies based on system CPU usage, network traffic, and other factors. However, to use application metrics for scaling up or down, we must publish [custom CloudWatch metrics][23].
|
||||
|
||||
## Application monitoring in a multi-service architecture
|
||||
|
||||
When we go beyond a single application architecture, such that a client request can trigger calls to multiple services before a response is sent back, we need more from our metrics. We need a unified view of latency metrics so we can see how much time each service took to respond to the request. This is enabled with [distributed tracing][24].
|
||||
|
||||
You can see an example of distributed tracing in Python in my blog post [Introducing distributed tracing in your Python application via Zipkin][25].
|
||||
|
||||
## Points to remember
|
||||
|
||||
In summary, make sure to keep the following things in mind:
|
||||
|
||||
* Understand what a metric type means in your monitoring system
|
||||
* Know in what unit of measurement the monitoring system wants your data
|
||||
* Monitor the most critical components of your application
|
||||
* Monitor the behavior of your application in its most critical stages
|
||||
|
||||
The above assumes you don't have to manage your monitoring systems. If that's part of your job, you have a lot more to think about!
|
||||
|
||||
## Other resources
|
||||
|
||||
Following are some of the resources I found very useful along my monitoring education journey:
|
||||
|
||||
### General
|
||||
|
||||
* [Monitoring distributed systems][26]
|
||||
* [Observability and monitoring best practices][27]
|
||||
* [Who wants seconds?][28]
|
||||
|
||||
### StatsD/Graphite
|
||||
|
||||
* [StatsD metric types][29]
|
||||
|
||||
### Prometheus
|
||||
|
||||
* [Prometheus metric types][30]
|
||||
* [How does a Prometheus gauge work?][31]
|
||||
* [Why are Prometheus histograms cumulative?][32]
|
||||
* [Monitoring batch jobs in Python][33]
|
||||
* [Prometheus: Monitoring at SoundCloud][34]
|
||||
|
||||
## Avoiding mistakes (i.e., Stage 3 learnings)
|
||||
|
||||
As we learn the basics of monitoring, it's important to keep an eye on the mistakes we don't want to make. Here are some insightful resources I have come across:
|
||||
|
||||
* [How not to measure latency][35]
|
||||
* [Histograms with Prometheus: A tale of woe][36]
|
||||
* [Why averages suck and percentiles are great][37]
|
||||
* [Everything you know about latency is wrong][38]
|
||||
* [Who moved my 99th percentile latency?][39]
|
||||
* [Logs and metrics and graphs][40]
|
||||
* [HdrHistogram: A better latency capture method][41]
|
||||
|
||||
---
|
||||
|
||||
To learn more, attend Amit Saha's talk, [Counter, gauge, upper 90—Oh my!][42], at [PyCon Cleveland 2018][43].
|
||||
|
||||
## About the author
|
||||
|
||||
[][44]
|
||||
|
||||
Amit Saha \- I am a software engineer interested in infrastructure, monitoring and tooling. I am the author of "Doing Math with Python" and creator and the maintainer of Fedora Scientific Spin.
|
||||
|
||||
[More about me][45]
|
||||
|
||||
* [Learn how you can contribute][46]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/metrics-monitoring-and-python][47]
|
||||
|
||||
作者: [Amit Saha][48] 选题者: [@lujun9972][49] 译者: [译者ID][50] 校对: [校对者ID][51]
|
||||
|
||||
本文由 [LCTT][52] 原创编译,[Linux中国][53] 荣誉推出
|
||||
|
||||
[1]: https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]: https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]: https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]: https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]: https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]: https://github.com/amitsaha/python-monitoring-talk
|
||||
[7]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo1
|
||||
[8]: http://flask.pocoo.org/
|
||||
[9]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo2
|
||||
[10]: https://pandas.pydata.org/
|
||||
[11]: http://jupyter.org/
|
||||
[12]: https://prometheus.io/
|
||||
[13]: https://github.com/etsy/statsd
|
||||
[14]: https://pypi.python.org/pypi/statsd
|
||||
[15]: https://github.com/amitsaha/python-monitoring-talk/tree/master/statsd
|
||||
[16]: https://pypi.python.org/pypi/prometheus_client
|
||||
[17]: https://github.com/amitsaha/python-monitoring-talk/tree/master/prometheus
|
||||
[18]: http://echorand.me/your-options-for-monitoring-multi-process-python-applications-with-prometheus.html
|
||||
[19]: https://blog.codeship.com/monitoring-your-synchronous-python-web-applications-using-prometheus/
|
||||
[20]: https://blog.codeship.com/monitoring-your-asynchronous-python-web-applications-using-prometheus/
|
||||
[21]: https://github.com/prometheus/alertmanager
|
||||
[22]: https://www.nagios.org/about/overview/
|
||||
[23]: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
|
||||
[24]: http://opentracing.io/documentation/
|
||||
[25]: http://echorand.me/introducing-distributed-tracing-in-your-python-application-via-zipkin.html
|
||||
[26]: https://landing.google.com/sre/book/chapters/monitoring-distributed-systems.html
|
||||
[27]: http://www.integralist.co.uk/posts/monitoring-best-practices/?imm_mid=0fbebf&cmp=em-webops-na-na-newsltr_20180309
|
||||
[28]: https://www.robustperception.io/who-wants-seconds/
|
||||
[29]: https://github.com/etsy/statsd/blob/master/docs/metric_types.md
|
||||
[30]: https://prometheus.io/docs/concepts/metric_types/
|
||||
[31]: https://www.robustperception.io/how-does-a-prometheus-gauge-work/
|
||||
[32]: https://www.robustperception.io/why-are-prometheus-histograms-cumulative/
|
||||
[33]: https://www.robustperception.io/monitoring-batch-jobs-in-python/
|
||||
[34]: https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud
|
||||
[35]: https://www.youtube.com/watch?v=lJ8ydIuPFeU&feature=youtu.be
|
||||
[36]: http://linuxczar.net/blog/2017/06/15/prometheus-histogram-2/
|
||||
[37]: https://www.dynatrace.com/news/blog/why-averages-suck-and-percentiles-are-great/
|
||||
[38]: https://bravenewgeek.com/everything-you-know-about-latency-is-wrong/
|
||||
[39]: https://engineering.linkedin.com/performance/who-moved-my-99th-percentile-latency
|
||||
[40]: https://grafana.com/blog/2016/01/05/logs-and-metrics-and-graphs-oh-my/
|
||||
[41]: http://psy-lob-saw.blogspot.com.au/2015/02/hdrhistogram-better-latency-capture.html
|
||||
[42]: https://us.pycon.org/2018/schedule/presentation/133/
|
||||
[43]: https://us.pycon.org/2018/
|
||||
[44]: https://opensource.com/users/amitsaha
|
||||
[45]: https://opensource.com/users/amitsaha
|
||||
[46]: https://opensource.com/participate
|
||||
[47]: https://opensource.com/article/18/4/metrics-monitoring-and-python
|
||||
[48]: https://opensource.com/users/amitsaha
|
||||
[49]: https://github.com/lujun9972
|
||||
[50]: https://github.com/译者ID
|
||||
[51]: https://github.com/校对者ID
|
||||
[52]: https://github.com/LCTT/TranslateProject
|
||||
[53]: https://linux.cn/
|
||||
@ -1,3 +1,5 @@
|
||||
icecoobe translating
|
||||
|
||||
How To Check System Hardware Manufacturer, Model And Serial Number In Linux
|
||||
======
|
||||
Getting system hardware information is not a problem for Linux GUI and Windows users but CLI users facing trouble to get this details.
|
||||
|
||||
@ -0,0 +1,330 @@
|
||||
Tuptime - A Tool To Report The Historical Uptime Of Linux System
|
||||
======
|
||||
Beginning of this month we written an article about system uptime that helps user to check how long your Linux system has been running without downtime? when the system is up and what date. This can be done using 11 methods.
|
||||
|
||||
uptime is one of the very famous commands, which everyone use when there is a requirement to check the Linux server uptime.
|
||||
|
||||
But it won’t shows historical and statistical running time of Linux system, that’s why tuptime is came to picture.
|
||||
|
||||
server uptime is very important when the server running with critical applications such as online portals.
|
||||
|
||||
**Suggested Read :** [11 Methods To Find System/Server Uptime In Linux][1]
|
||||
|
||||
### What Is tuptime?
|
||||
|
||||
[Tuptime][2] is a tool for report the historical and statistical running time of the system, keeping it between restarts. Like uptime command but with more interesting output.
|
||||
|
||||
### tuptime Features
|
||||
|
||||
* Count system startups
|
||||
* Register first boot time (a.k.a. installation time)
|
||||
* Count nicely and accidentally shutdowns
|
||||
* Uptime and downtime percentage since first boot time
|
||||
* Accumulated system uptime, downtime and total
|
||||
* Largest, shortest and average uptime and downtime
|
||||
* Current uptime
|
||||
* Print formatted table or list with most of the previous values
|
||||
* Register used kernels
|
||||
* Narrow reports since and/or until a given startup or timestamp
|
||||
* Reports in csv
|
||||
|
||||
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Make sure your system should have installed Python3 as a prerequisites. If no, install it using your distribution package manager.
|
||||
|
||||
**Suggested Read :** [3 Methods To Install Latest Python3 Package On CentOS 6 System][3]
|
||||
|
||||
### How To Install tuptime
|
||||
|
||||
Few distributions offer tuptime package but it may be bit older version. I would advise you to install latest available version to avail all the features using the below method.
|
||||
|
||||
Clone tuptime repository from github.
|
||||
```
|
||||
# git clone https://github.com/rfrail3/tuptime.git
|
||||
|
||||
```
|
||||
|
||||
Copy executable file from `tuptime/src/tuptime` to `/usr/bin/` and assign 755 permission.
|
||||
```
|
||||
# cp tuptime/src/tuptime /usr/bin/tuptime
|
||||
# chmod 755 /usr/bin/tuptime
|
||||
|
||||
```
|
||||
|
||||
All scripts, units and related files are provided inside this repo so, copy and past the necessary files in the appropriate location to get full functionality of tuptime utility.
|
||||
|
||||
Add tuptime user because it doesn’t run as a daemon, at least, it only need execution when the init manager startup and shutdown the system.
|
||||
```
|
||||
# useradd -d /var/lib/tuptime -s /bin/sh tuptime
|
||||
|
||||
```
|
||||
|
||||
Change owner of the db file.
|
||||
```
|
||||
# chown -R tuptime:tuptime /var/lib/tuptime
|
||||
|
||||
```
|
||||
|
||||
Copy cron file from `tuptime/src/tuptime` to `/usr/bin/` and assign 644 permission.
|
||||
```
|
||||
# cp tuptime/src/cron.d/tuptime /etc/cron.d/tuptime
|
||||
# chmod 644 /etc/cron.d/tuptime
|
||||
|
||||
```
|
||||
|
||||
Add system service file based on your system initsystem. Use the below command to check if your system is running with systemd or init.
|
||||
```
|
||||
# ps -p 1
|
||||
PID TTY TIME CMD
|
||||
1 ? 00:00:03 systemd
|
||||
|
||||
# ps -p 1
|
||||
PID TTY TIME CMD
|
||||
1 ? 00:00:00 init
|
||||
|
||||
```
|
||||
|
||||
If is a system with systemd, copy service file and enable it.
|
||||
```
|
||||
# cp tuptime/src/systemd/tuptime.service /lib/systemd/system/
|
||||
# chmod 644 /lib/systemd/system/tuptime.service
|
||||
# systemctl enable tuptime.service
|
||||
|
||||
```
|
||||
|
||||
If have upstart system, copy the file:
|
||||
```
|
||||
# cp tuptime/src/init.d/redhat/tuptime /etc/init.d/tuptime
|
||||
# chmod 755 /etc/init.d/tuptime
|
||||
# chkconfig --add tuptime
|
||||
# chkconfig tuptime on
|
||||
|
||||
```
|
||||
|
||||
If have init system, copy the file:
|
||||
```
|
||||
# cp tuptime/src/init.d/debian/tuptime /etc/init.d/tuptime
|
||||
# chmod 755 /etc/init.d/tuptime
|
||||
# update-rc.d tuptime defaults
|
||||
# /etc/init.d/tuptime start
|
||||
|
||||
```
|
||||
|
||||
### How To Use tuptime
|
||||
|
||||
Make sure you should run the command with a privileged user. Intially you will get output similar to this.
|
||||
```
|
||||
# tuptime
|
||||
System startups: 1 since 02:48:00 AM 04/12/2018
|
||||
System shutdowns: 0 ok - 0 bad
|
||||
System uptime: 100.0 % - 26 days, 5 hours, 31 minutes and 52 seconds
|
||||
System downtime: 0.0 % - 0 seconds
|
||||
System life: 26 days, 5 hours, 31 minutes and 52 seconds
|
||||
|
||||
Largest uptime: 26 days, 5 hours, 31 minutes and 52 seconds from 02:48:00 AM 04/12/2018
|
||||
Shortest uptime: 26 days, 5 hours, 31 minutes and 52 seconds from 02:48:00 AM 04/12/2018
|
||||
Average uptime: 26 days, 5 hours, 31 minutes and 52 seconds
|
||||
|
||||
Largest downtime: 0 seconds
|
||||
Shortest downtime: 0 seconds
|
||||
Average downtime: 0 seconds
|
||||
|
||||
Current uptime: 26 days, 5 hours, 31 minutes and 52 seconds since 02:48:00 AM 04/12/2018
|
||||
|
||||
```
|
||||
|
||||
### Details:
|
||||
|
||||
* **`System startups:`** Total number of system startups from since to until date. Until is joined if is used in a narrow range.
|
||||
* **`System shutdowns:`** Total number of shutdowns done correctly or incorrectly. The separator usually points to the state of last shutdown () bad.
|
||||
* **`System uptime:`** Percentage of uptime and time counter.
|
||||
* **`System downtime:`** Percentage of downtime and time counter.
|
||||
* **`System life:`** Time counter since first startup date until last.
|
||||
* **`Largest/Shortest uptime:`** Time counter and date with the largest/shortest uptime register.
|
||||
* **`Largest/Shortest downtime:`** Time counter and date with the largest/shortest downtime register.
|
||||
* **`Average uptime/downtime:`** Time counter with the average time.
|
||||
* **`Current uptime:`** Actual time counter and date since registered boot date.
|
||||
|
||||
|
||||
|
||||
If you do the same a few days after some reboot, the output may will be more similar to this.
|
||||
```
|
||||
# tuptime
|
||||
System startups: 3 since 02:48:00 AM 04/12/2018
|
||||
System shutdowns: 0 ok -> 2 bad
|
||||
System uptime: 97.0 % - 28 days, 4 hours, 6 minutes and 0 seconds
|
||||
System downtime: 3.0 % - 20 hours, 54 minutes and 22 seconds
|
||||
System life: 29 days, 1 hour, 0 minutes and 23 seconds
|
||||
|
||||
Largest uptime: 26 days, 5 hours, 32 minutes and 57 seconds from 02:48:00 AM 04/12/2018
|
||||
Shortest uptime: 1 hour, 31 minutes and 12 seconds from 02:17:11 AM 05/11/2018
|
||||
Average uptime: 9 days, 9 hours, 22 minutes and 0 seconds
|
||||
|
||||
Largest downtime: 20 hours, 51 minutes and 58 seconds from 08:20:57 AM 05/08/2018
|
||||
Shortest downtime: 2 minutes and 24 seconds from 02:14:47 AM 05/11/2018
|
||||
Average downtime: 10 hours, 27 minutes and 11 seconds
|
||||
|
||||
Current uptime: 1 hour, 31 minutes and 12 seconds since 02:17:11 AM 05/11/2018
|
||||
|
||||
```
|
||||
|
||||
Enumerate as table each startup number, startup date, uptime, shutdown date, end status and downtime. Multiple order options can be combined together.
|
||||
```
|
||||
# tuptime -t
|
||||
No. Startup Date Uptime Shutdown Date End Downtime
|
||||
|
||||
1 02:48:00 AM 04/12/2018 26 days, 5 hours, 32 minutes and 57 seconds 08:20:57 AM 05/08/2018 BAD 20 hours, 51 minutes and 58 seconds
|
||||
2 05:12:55 AM 05/09/2018 1 day, 21 hours, 1 minute and 52 seconds 02:14:47 AM 05/11/2018 BAD 2 minutes and 24 seconds
|
||||
3 02:17:11 AM 05/11/2018 1 hour, 34 minutes and 33 seconds
|
||||
|
||||
```
|
||||
|
||||
Enumerate as list each startup number, startup date, uptime, shutdown date, end status and offtime. Multiple order options can be combined together.
|
||||
```
|
||||
# tuptime -l
|
||||
Startup: 1 at 02:48:00 AM 04/12/2018
|
||||
Uptime: 26 days, 5 hours, 32 minutes and 57 seconds
|
||||
Shutdown: BAD at 08:20:57 AM 05/08/2018
|
||||
Downtime: 20 hours, 51 minutes and 58 seconds
|
||||
|
||||
Startup: 2 at 05:12:55 AM 05/09/2018
|
||||
Uptime: 1 day, 21 hours, 1 minute and 52 seconds
|
||||
Shutdown: BAD at 02:14:47 AM 05/11/2018
|
||||
Downtime: 2 minutes and 24 seconds
|
||||
|
||||
Startup: 3 at 02:17:11 AM 05/11/2018
|
||||
Uptime: 1 hour, 34 minutes and 36 seconds
|
||||
|
||||
```
|
||||
|
||||
To print kernel information with tuptime output.
|
||||
```
|
||||
# tuptime -k
|
||||
System startups: 3 since 02:48:00 AM 04/12/2018
|
||||
System shutdowns: 0 ok -> 2 bad
|
||||
System uptime: 97.0 % - 28 days, 4 hours, 11 minutes and 25 seconds
|
||||
System downtime: 3.0 % - 20 hours, 54 minutes and 22 seconds
|
||||
System life: 29 days, 1 hour, 5 minutes and 47 seconds
|
||||
System kernels: 1
|
||||
|
||||
Largest uptime: 26 days, 5 hours, 32 minutes and 57 seconds from 02:48:00 AM 04/12/2018
|
||||
...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
|
||||
Shortest uptime: 1 hour, 36 minutes and 36 seconds from 02:17:11 AM 05/11/2018
|
||||
...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
|
||||
Average uptime: 9 days, 9 hours, 23 minutes and 48 seconds
|
||||
|
||||
Largest downtime: 20 hours, 51 minutes and 58 seconds from 08:20:57 AM 05/08/2018
|
||||
...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
|
||||
Shortest downtime: 2 minutes and 24 seconds from 02:14:47 AM 05/11/2018
|
||||
...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
|
||||
Average downtime: 10 hours, 27 minutes and 11 seconds
|
||||
|
||||
Current uptime: 1 hour, 36 minutes and 36 seconds since 02:17:11 AM 05/11/2018
|
||||
...with kernel: Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
|
||||
|
||||
```
|
||||
|
||||
Change the date format. By default it’s printed based on system locales.
|
||||
```
|
||||
# tuptime -d %d/%m/%y %H:%M:%S
|
||||
System startups: 3 since 12/04/18
|
||||
System shutdowns: 0 ok -> 2 bad
|
||||
System uptime: 97.0 % - 28 days, 4 hours, 15 minutes and 18 seconds
|
||||
System downtime: 3.0 % - 20 hours, 54 minutes and 22 seconds
|
||||
System life: 29 days, 1 hour, 9 minutes and 41 seconds
|
||||
|
||||
Largest uptime: 26 days, 5 hours, 32 minutes and 57 seconds from 12/04/18
|
||||
Shortest uptime: 1 hour, 40 minutes and 30 seconds from 11/05/18
|
||||
Average uptime: 9 days, 9 hours, 25 minutes and 6 seconds
|
||||
|
||||
Largest downtime: 20 hours, 51 minutes and 58 seconds from 08/05/18
|
||||
Shortest downtime: 2 minutes and 24 seconds from 11/05/18
|
||||
Average downtime: 10 hours, 27 minutes and 11 seconds
|
||||
|
||||
Current uptime: 1 hour, 40 minutes and 30 seconds since 11/05/18
|
||||
|
||||
```
|
||||
|
||||
Print information about the internals of tuptime. It’s good for debugging how it gets the variables.
|
||||
```
|
||||
# tuptime -v
|
||||
INFO:Arguments: {'endst': 0, 'seconds': None, 'table': False, 'csv': False, 'ts': None, 'silent': False, 'order': False, 'since': 0, 'kernel': False, 'reverse': False, 'until': 0, 'db_file': '/var/lib/tuptime/tuptime.db', 'lst': False, 'tu': None, 'date_format': '%X %x', 'update': True}
|
||||
INFO:Linux system
|
||||
INFO:uptime = 5773.54
|
||||
INFO:btime = 1526019431
|
||||
INFO:kernel = Linux-2.6.32-696.23.1.el6.x86_64-x86_64-with-centos-6.9-Final
|
||||
INFO:Execution user = 0
|
||||
INFO:Directory exists = /var/lib/tuptime
|
||||
INFO:DB file exists = /var/lib/tuptime/tuptime.db
|
||||
INFO:Last btime from db = 1526019431
|
||||
INFO:Last uptime from db = 5676.04
|
||||
INFO:Drift over btime = 0
|
||||
INFO:System wasn't restarted. Updating db values...
|
||||
System startups: 3 since 02:48:00 AM 04/12/2018
|
||||
System shutdowns: 0 ok -> 2 bad
|
||||
System uptime: 97.0 % - 28 days, 4 hours, 11 minutes and 2 seconds
|
||||
System downtime: 3.0 % - 20 hours, 54 minutes and 22 seconds
|
||||
System life: 29 days, 1 hour, 5 minutes and 25 seconds
|
||||
|
||||
Largest uptime: 26 days, 5 hours, 32 minutes and 57 seconds from 02:48:00 AM 04/12/2018
|
||||
Shortest uptime: 1 hour, 36 minutes and 14 seconds from 02:17:11 AM 05/11/2018
|
||||
Average uptime: 9 days, 9 hours, 23 minutes and 41 seconds
|
||||
|
||||
Largest downtime: 20 hours, 51 minutes and 58 seconds from 08:20:57 AM 05/08/2018
|
||||
Shortest downtime: 2 minutes and 24 seconds from 02:14:47 AM 05/11/2018
|
||||
Average downtime: 10 hours, 27 minutes and 11 seconds
|
||||
|
||||
Current uptime: 1 hour, 36 minutes and 14 seconds since 02:17:11 AM 05/11/2018
|
||||
|
||||
```
|
||||
|
||||
Print a quick reference of the command line parameters.
|
||||
```
|
||||
# tuptime -h
|
||||
Usage: tuptime [options]
|
||||
|
||||
Options:
|
||||
-h, --help show this help message and exit
|
||||
-c, --csv csv output
|
||||
-d DATE_FORMAT, --date=DATE_FORMAT
|
||||
date format output
|
||||
-f FILE, --filedb=FILE
|
||||
database file
|
||||
-g, --graceful register a gracefully shutdown
|
||||
-k, --kernel print kernel information
|
||||
-l, --list enumerate system life as list
|
||||
-n, --noup avoid update values
|
||||
-o TYPE, --order=TYPE
|
||||
order enumerate by []
|
||||
-r, --reverse reverse order
|
||||
-s, --seconds output time in seconds and epoch
|
||||
-S SINCE, --since=SINCE
|
||||
restric since this register number
|
||||
-t, --table enumerate system life as table
|
||||
--tsince=TIMESTAMP restrict since this epoch timestamp
|
||||
--tuntil=TIMESTAMP restrict until this epoch timestamp
|
||||
-U UNTIL, --until=UNTIL
|
||||
restrict until this register number
|
||||
-v, --verbose verbose output
|
||||
-V, --version show version
|
||||
-x, --silent update values into db without output
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/tuptime-a-tool-to-report-the-historical-and-statistical-running-time-of-linux-system/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
|
||||
[2]:https://github.com/rfrail3/tuptime/
|
||||
[3]:https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/
|
||||
@ -1,288 +0,0 @@
|
||||
translating by Flowsnow
|
||||
Getting started with the Python debugger
|
||||
======
|
||||
|
||||

|
||||
|
||||
The Python ecosystem is rich with many tools and libraries that improve developers’ lives. For example, the Magazine has previously covered how to [enhance your Python with a interactive shell][1]. This article focuses on another tool that saves you time and improves your Python skills: the Python debugger.
|
||||
|
||||
### Python Debugger
|
||||
|
||||
The Python standard library provides a debugger called pdb. This debugger provides most features needed for debugging such as breakpoints, single line stepping, inspection of stack frames, and so on.
|
||||
|
||||
A basic knowledge of pdb is useful since it’s part of the standard library. You can use it in environments where you can’t install another enhanced debugger.
|
||||
|
||||
#### Running pdb
|
||||
|
||||
The easiest way to run pdb is from the command line, passing the program to debug as an argument. Considering the following script:
|
||||
```
|
||||
# pdb_test.py
|
||||
#!/usr/bin/python3
|
||||
|
||||
from time import sleep
|
||||
|
||||
def countdown(number):
|
||||
for i in range(number, 0, -1):
|
||||
print(i)
|
||||
sleep(1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
seconds = 10
|
||||
countdown(seconds)
|
||||
|
||||
```
|
||||
|
||||
You can run pdb from the command line like this:
|
||||
```
|
||||
$ python3 -m pdb pdb_test.py
|
||||
> /tmp/pdb_test.py(1)<module>()
|
||||
-> from time import sleep
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
Another way to use pdb is to set a breakpoint in the program. To do this, import the pdb module and use the set_trace function:
|
||||
```
|
||||
1 # pdb_test.py
|
||||
2 #!/usr/bin/python3
|
||||
3
|
||||
4 from time import sleep
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
16 countdown(seconds)
|
||||
|
||||
$ python3 pdb_test.py
|
||||
> /tmp/pdb_test.py(6)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
The script stops at the breakpoint, and pdb displays the next line in the script. You can also execute the debugger after a failure. This is known as postmortem debugging.
|
||||
|
||||
#### Navigate the execution stack
|
||||
|
||||
A common use case in debugging is to navigate the execution stack. Once the Python debugger is running, the following commands are useful :
|
||||
|
||||
+ w(here) : Shows which line is currently executed and where the execution stack is.
|
||||
|
||||
|
||||
```
|
||||
$ python3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) w
|
||||
/tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
+ l(ist) : Shows more context (code) around the current the location.
|
||||
|
||||
|
||||
```
|
||||
$ python3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) l
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 -> print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
+ u(p)/d(own) : Navigate the call stack up or down.
|
||||
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) up
|
||||
> /tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
(Pdb) down
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
#### Stepping through a program
|
||||
|
||||
pdb provides the following commands to execute and step through code:
|
||||
|
||||
+ n(ext): Continue execution until the next line in the current function is reached, or it returns
|
||||
+ s(tep): Execute the current line and stop at the first possible occasion (either in a function that is called or in the current function)
|
||||
+ c(ontinue): Continue execution, only stopping at a breakpoint.
|
||||
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) n
|
||||
10
|
||||
> /tmp/test_pdb.py(11)countdown()
|
||||
-> sleep(1)
|
||||
(Pdb) n
|
||||
> /tmp/test_pdb.py(8)countdown()
|
||||
-> for i in range(number, 0, -1):
|
||||
(Pdb) n
|
||||
> /tmp/test_pdb.py(9)countdown()
|
||||
-> import pdb; pdb.set_trace()
|
||||
(Pdb) s
|
||||
--Call--
|
||||
> /usr/lib64/python3.6/pdb.py(1584)set_trace()
|
||||
-> def set_trace():
|
||||
(Pdb) c
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) c
|
||||
9
|
||||
> /tmp/test_pdb.py(9)countdown()
|
||||
-> import pdb; pdb.set_trace()
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
The example shows the difference between next and step. Indeed, when using step the debugger stepped into the pdb module source code, whereas next would have just executed the set_trace function.
|
||||
|
||||
#### Examine variables content
|
||||
|
||||
Where pdb is really useful is examining the content of variables stored in the execution stack. For example, the a(rgs) command prints the variables of the current function, as shown below:
|
||||
```
|
||||
py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) where
|
||||
/tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) args
|
||||
number = 10
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
pdb prints the value of the variable number, in this case 10.
|
||||
|
||||
Another command that can be used to print variables value is p(rint).
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) list
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 -> print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
(Pdb) print(seconds)
|
||||
10
|
||||
(Pdb) p i
|
||||
10
|
||||
(Pdb) p number - i
|
||||
0
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
As shown in the example’s last command, print can evaluate an expression before displaying the result.
|
||||
|
||||
The [Python documentation][2] contains the reference and examples for each of the pdb commands. This is a useful read for someone starting with the Python debugger.
|
||||
|
||||
### Enhanced debugger
|
||||
|
||||
Some enhanced debuggers provide a better user experience. Most add useful extra features to pdb, such as syntax highlighting, better tracebacks, and introspection. Popular choices of enhanced debuggers include [IPython’s ipdb][3] and [pdb++][4].
|
||||
|
||||
These examples show you how to install these two debuggers in a virtual environment. These examples use a new virtual environment, but in the case of debugging an application, the application’s virtual environment should be used.
|
||||
|
||||
#### Install IPython’s ipdb
|
||||
|
||||
To install the IPython ipdb, use pip in the virtual environment:
|
||||
```
|
||||
$ python3 -m venv .test_pdb
|
||||
$ source .test_pdb/bin/activate
|
||||
(test_pdb)$ pip install ipdb
|
||||
|
||||
```
|
||||
|
||||
To call ipdb inside a script, you must use the following command. Note that the module is called ipdb instead of pdb:
|
||||
```
|
||||
import ipdb; ipdb.set_trace()
|
||||
|
||||
```
|
||||
|
||||
IPython’s ipdb is also available in Fedora packages, so you can install it using Fedora’s package manager dnf:
|
||||
```
|
||||
$ sudo dnf install python3-ipdb
|
||||
|
||||
```
|
||||
|
||||
#### Install pdb++
|
||||
|
||||
You can install pdb++ similarly:
|
||||
```
|
||||
$ python3 -m venv .test_pdb
|
||||
$ source .test_pdb/bin/activate
|
||||
(test_pdb)$ pip install pdbp
|
||||
|
||||
```
|
||||
|
||||
pdb++ overrides the pdb module, and therefore you can use the same syntax to add a breakpoint inside a program:
|
||||
```
|
||||
import pdb; pdb.set_trace()
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
Learning how to use the Python debugger saves you time when investigating problems with an application. It can also be useful to understand how a complex part of an application or some libraries work, and thereby improve your Python developer skills.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/getting-started-python-debugger/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://fedoramagazine.org/enhance-python-interactive-shell
|
||||
[2]:https://docs.python.org/3/library/pdb.html
|
||||
[3]:https://github.com/gotcha/ipdb
|
||||
[4]:https://github.com/antocuni/pdb
|
||||
@ -0,0 +1,336 @@
|
||||
How To Add Additional IP (Secondary IP) In Ubuntu System
|
||||
======
|
||||
Linux admin should be aware of this because it’s a routine task. Many of you wondering why we need to add more than one IP address in server? why we need add this to single network card? am i right?
|
||||
|
||||
Also you can have a question like, how to assign multiple IP addresses to single network card in linux. In this article you can get an answer for this.
|
||||
|
||||
When we setup a new server, ideally it will have one IP address, which is server main IP address and linked with server hostname.
|
||||
|
||||
We should not host any application in server main IP address, which is not advisable. If you want to host any application on server, we should add additional IP or Secondary IP for that.
|
||||
|
||||
This is the best practices in industry, this allows users to install SSL certificate. Most of the system comes with single network card, which is more than enough to add additional IP address.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [9 Methods To Check Your Public IP Address In Linux Command Line][1]
|
||||
**(#)** [3 Easy Ways To Check DNS (Domain Name Server) Records In Linux Terminal][2]
|
||||
**(#)** [Check DNS (Domain Name Server) Records On Linux Using Dig Command][3]
|
||||
**(#)** [Check DNS (Domain Name Server) Records On Linux Using Nslookup Command][4]
|
||||
**(#)** [Check DNS (Domain Name Server) Records On Linux Using Host Command][5]
|
||||
|
||||
We can add IP address in the same interface or create sub interface on the same device then add IP in that. By default interface name comes `ethX (eth0)` till Ubuntu 14.04 LTS but from Ubuntu 15.10 network interfaces names have been changed from `ethX` to `enXXXXX` (For server ens33 & For desktop enp0s3).
|
||||
|
||||
In this article we will teach you how to perform this on Ubuntu and it is derivative.
|
||||
|
||||
**`Make a note:`** You should not add IP address entry after DNS details. If so, DNS wont work.
|
||||
|
||||
### How To Add Secondary IP Address Temporarily In Ubuntu 14.04 LTS
|
||||
|
||||
Before adding IP address in system. Just verify the server main IP address by running any of the below commands.
|
||||
```
|
||||
# ifconfig
|
||||
|
||||
or
|
||||
|
||||
# ip addr
|
||||
|
||||
eth0 Link encap:Ethernet HWaddr 08:00:27:98:b7:36
|
||||
inet addr:192.168.56.150 Bcast:192.168.56.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::a00:27ff:fe98:b736/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:4 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:105 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:902 (902.0 B) TX bytes:16423 (16.4 KB)
|
||||
|
||||
eth1 Link encap:Ethernet HWaddr 08:00:27:6a:cf:d3
|
||||
inet addr:10.0.3.15 Bcast:10.0.3.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::a00:27ff:fe6a:cfd3/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:80 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:146 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:8698 (8.6 KB) TX bytes:17047 (17.0 KB)
|
||||
|
||||
lo Link encap:Local Loopback
|
||||
inet addr:127.0.0.1 Mask:255.0.0.0
|
||||
inet6 addr: ::1/128 Scope:Host
|
||||
UP LOOPBACK RUNNING MTU:65536 Metric:1
|
||||
RX packets:25 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:25 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1
|
||||
RX bytes:1730 (1.7 KB) TX bytes:1730 (1.7 KB)
|
||||
|
||||
```
|
||||
|
||||
As i can see, the server main IP address is `192.168.56.150` so, i’m going to assign next IP `192.168.56.151` as a secondary IP. This can be done using below method.
|
||||
```
|
||||
# ip addr add 192.168.56.151/24 broadcast 192.168.56.255 dev eth0 label eth0:1
|
||||
|
||||
```
|
||||
|
||||
Fire the following command to check newly added IP address. If you reboot the server then the newly added IP address go off because we have added this temporarily.
|
||||
```
|
||||
# ip addr
|
||||
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: eth0: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:98:b7:36 brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.56.150/24 brd 192.168.56.255 scope global eth0
|
||||
valid_lft forever preferred_lft forever
|
||||
inet 192.168.56.151/24 brd 192.168.56.255 scope global secondary eth0:1
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe98:b736/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
3: eth1: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:6a:cf:d3 brd ff:ff:ff:ff:ff:ff
|
||||
inet 10.0.3.15/24 brd 10.0.3.255 scope global eth1
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe6a:cfd3/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
```
|
||||
|
||||
### How To Add Secondary IP Address Permanently In Ubuntu 14.04 LTS
|
||||
|
||||
To add secondary IP address permanently on Ubuntu system, just edit `/etc/network/interfaces` file and add the requires IP details.
|
||||
```
|
||||
# vi /etc/network/interfaces
|
||||
|
||||
# The loopback network interface
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
|
||||
# The primary network interface
|
||||
auto eth0
|
||||
iface eth0 inet static
|
||||
address 192.168.56.150
|
||||
netmask 255.255.255.0
|
||||
network 192.168.56.0
|
||||
broadcast 192.168.56.255
|
||||
gateway 192.168.56.1
|
||||
|
||||
auto eth0:1
|
||||
iface eth0:1 inet static
|
||||
address 192.168.56.151
|
||||
netmask 255.255.255.0
|
||||
|
||||
```
|
||||
|
||||
Save and close the file then restart the network interface
|
||||
```
|
||||
# service networking restart
|
||||
or
|
||||
# ifdown eth0:1 && ifup eth0:1
|
||||
|
||||
```
|
||||
|
||||
Verify the newly added IP address.
|
||||
```
|
||||
# ifconfig
|
||||
eth0 Link encap:Ethernet HWaddr 08:00:27:98:b7:36
|
||||
inet addr:192.168.56.150 Bcast:192.168.56.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::a00:27ff:fe98:b736/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:5 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:84 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:962 (962.0 B) TX bytes:11905 (11.9 KB)
|
||||
|
||||
eth0:1 Link encap:Ethernet HWaddr 08:00:27:98:b7:36
|
||||
inet addr:192.168.56.151 Bcast:192.168.56.255 Mask:255.255.255.0
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
|
||||
eth1 Link encap:Ethernet HWaddr 08:00:27:6a:cf:d3
|
||||
inet addr:10.0.3.15 Bcast:10.0.3.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::a00:27ff:fe6a:cfd3/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:4924 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:3185 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:4037636 (4.0 MB) TX bytes:422516 (422.5 KB)
|
||||
|
||||
lo Link encap:Local Loopback
|
||||
inet addr:127.0.0.1 Mask:255.0.0.0
|
||||
inet6 addr: ::1/128 Scope:Host
|
||||
UP LOOPBACK RUNNING MTU:65536 Metric:1
|
||||
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1
|
||||
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
|
||||
|
||||
```
|
||||
|
||||
### How To Add Secondary IP Address Temporarily In Ubuntu 16.04 LTS
|
||||
|
||||
As discussed in the beginning of the article, network interfaces names have been changed
|
||||
from ‘ethX’ to ‘enXXXX’ (enp0s3) since Ubuntu 15.10 so, replace your interface name instead of us.
|
||||
|
||||
Let me check the IP information on my system before performing this.
|
||||
```
|
||||
# ifconfig
|
||||
or
|
||||
# ip addr
|
||||
|
||||
enp0s3: flags=4163 mtu 1500
|
||||
inet 192.168.56.201 netmask 255.255.255.0 broadcast 192.168.56.255
|
||||
inet6 fe80::a00:27ff:fe97:132e prefixlen 64 scopeid 0x20
|
||||
ether 08:00:27:97:13:2e txqueuelen 1000 (Ethernet)
|
||||
RX packets 7 bytes 420 (420.0 B)
|
||||
RX errors 0 dropped 0 overruns 0 frame 0
|
||||
TX packets 294 bytes 24747 (24.7 KB)
|
||||
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
||||
|
||||
enp0s8: flags=4163 mtu 1500
|
||||
inet 10.0.3.15 netmask 255.255.255.0 broadcast 10.0.3.255
|
||||
inet6 fe80::344b:6259:4dbe:eabb prefixlen 64 scopeid 0x20
|
||||
ether 08:00:27:12:e8:c1 txqueuelen 1000 (Ethernet)
|
||||
RX packets 1 bytes 590 (590.0 B)
|
||||
RX errors 0 dropped 0 overruns 0 frame 0
|
||||
TX packets 97 bytes 10209 (10.2 KB)
|
||||
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
||||
|
||||
lo: flags=73 mtu 65536
|
||||
inet 127.0.0.1 netmask 255.0.0.0
|
||||
inet6 ::1 prefixlen 128 scopeid 0x10
|
||||
loop txqueuelen 1000 (Local Loopback)
|
||||
RX packets 325 bytes 24046 (24.0 KB)
|
||||
RX errors 0 dropped 0 overruns 0 frame 0
|
||||
TX packets 325 bytes 24046 (24.0 KB)
|
||||
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
||||
|
||||
```
|
||||
|
||||
As i can see, the server main IP address is `192.168.56.201` so, i’m going to assign next IP `192.168.56.202` as a secondary IP. This can be done using below command.
|
||||
```
|
||||
# ip addr add 192.168.56.202/24 broadcast 192.168.56.255 dev enp0s3
|
||||
|
||||
```
|
||||
|
||||
Run the below command to check if the new IP has been assigned or not. This will go off when you reboot the machine.
|
||||
```
|
||||
# ip addr
|
||||
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: enp0s3: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:97:13:2e brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.56.201/24 brd 192.168.56.255 scope global enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet 192.168.56.202/24 brd 192.168.56.255 scope global secondary enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe97:132e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
3: enp0s8: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:12:e8:c1 brd ff:ff:ff:ff:ff:ff
|
||||
inet 10.0.3.15/24 brd 10.0.3.255 scope global dynamic enp0s8
|
||||
valid_lft 86353sec preferred_lft 86353sec
|
||||
inet6 fe80::344b:6259:4dbe:eabb/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
```
|
||||
|
||||
### How To Add Secondary IP Address Permanently In Ubuntu 16.04 LTS
|
||||
|
||||
To add secondary IP address permanently on Ubuntu system, just edit `/etc/network/interfaces` file and add the requires IP details.
|
||||
|
||||
We should not add secondary IP address after dns-nameservers because it wont work and add the IP details in the below format.
|
||||
|
||||
Moreover we don’t need to add sub interface (how we did previously in Ubuntu 14.04 LTS).
|
||||
```
|
||||
# vi /etc/network/interfaces
|
||||
|
||||
# interfaces(5) file used by ifup(8) and ifdown(8)
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
|
||||
# The primary network interface
|
||||
auto enp0s3
|
||||
iface enp0s3 inet static
|
||||
address 192.168.56.201
|
||||
netmask 255.255.255.0
|
||||
|
||||
iface enp0s3 inet static
|
||||
address 192.168.56.202
|
||||
netmask 255.255.255.0
|
||||
|
||||
gateway 192.168.56.1
|
||||
network 192.168.56.0
|
||||
broadcast 192.168.56.255
|
||||
dns-nameservers 8.8.8.8 8.8.4.4
|
||||
dns-search 2daygeek.local
|
||||
|
||||
```
|
||||
|
||||
Save and close the file then restart the network interface
|
||||
```
|
||||
# systemctl restart networking
|
||||
or
|
||||
# ifdown enp0s3 && ifup enp0s3
|
||||
|
||||
```
|
||||
|
||||
Run the below command to check if the new IP has been assigned or not.
|
||||
```
|
||||
# ip addr
|
||||
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: enp0s3: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:97:13:2e brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.56.201/24 brd 192.168.56.255 scope global enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet 192.168.56.202/24 brd 192.168.56.255 scope global secondary enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe97:132e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
3: enp0s8: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:12:e8:c1 brd ff:ff:ff:ff:ff:ff
|
||||
inet 10.0.3.15/24 brd 10.0.3.255 scope global dynamic enp0s8
|
||||
valid_lft 86353sec preferred_lft 86353sec
|
||||
inet6 fe80::344b:6259:4dbe:eabb/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
```
|
||||
|
||||
Also, let me ping the new IP address.
|
||||
```
|
||||
# ping 192.168.56.202 -c 4
|
||||
PING 192.168.56.202 (192.168.56.202) 56(84) bytes of data.
|
||||
64 bytes from 192.168.56.202: icmp_seq=1 ttl=64 time=0.019 ms
|
||||
64 bytes from 192.168.56.202: icmp_seq=2 ttl=64 time=0.087 ms
|
||||
64 bytes from 192.168.56.202: icmp_seq=3 ttl=64 time=0.034 ms
|
||||
64 bytes from 192.168.56.202: icmp_seq=4 ttl=64 time=0.042 ms
|
||||
|
||||
--- 192.168.56.202 ping statistics ---
|
||||
4 packets transmitted, 4 received, 0% packet loss, time 3068ms
|
||||
rtt min/avg/max/mdev = 0.019/0.045/0.087/0.026 ms
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-add-additional-ip-secondary-ip-in-ubuntu-debian-system/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/check-find-server-public-ip-address-linux/
|
||||
[2]:https://www.2daygeek.com/check-find-dns-records-of-domain-in-linux-terminal/
|
||||
[3]:https://www.2daygeek.com/dig-command-check-find-dns-records-lookup-linux/
|
||||
[4]:https://www.2daygeek.com/nslookup-command-check-find-dns-records-lookup-linux/
|
||||
[5]:https://www.2daygeek.com/host-command-check-find-dns-records-lookup-linux/
|
||||
@ -1,218 +0,0 @@
|
||||
BriFuture is translating
|
||||
|
||||
Twitter Sentiment Analysis using NodeJS
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
If you want to know how people feel about something, there is no better place than Twitter. It is a continuous stream of opinion, with around 6,000 new tweets being created every second. The internet is quick to react to events and if you want to be updated with the latest and hottest, Twitter is the place to be.
|
||||
|
||||
Now, we live in an age where data is king and companies put Twitter's data to good use. From gauging the reception of their new products to trying to predict the next market trend, analysis of Twitter data has many uses. Businesses use it to market their product that to the right customers, to gather feedback on their brand and improve or to assess the reasons for the failure of a product or promotional campaign. Not only businesses, many political and economic decisions are made based on observation of people's opinion. Today, I will try and give you a taste of simple [sentiment analysis][1] of tweets to determine whether a tweet is positive, negative or neutral. It won't be as sophisticated as those used by professionals, but nonetheless, it will give you an idea about opinion mining.
|
||||
|
||||
We will be using NodeJs since JavaScript is ubiquitous nowadays and is one of the easiest languages to get started with.
|
||||
|
||||
### Prerequisite:
|
||||
|
||||
* NodeJs and NPM installed
|
||||
|
||||
* A little experience with NodeJs and NPM packages
|
||||
|
||||
* some familiarity with the command line.
|
||||
|
||||
Alright, that's it. Let's get started.
|
||||
|
||||
### Getting Started
|
||||
|
||||
Make a new directory for your project and go inside the directory. Open a terminal (or command line). Go inside the newly created directory and run the `npm init -y` command. This will create a `package.json` in your directory. Now we can install the npm packages we need. We just need to create a new file named `index.js` and then we are all set to start coding.
|
||||
|
||||
### Getting the tweets
|
||||
|
||||
Well, we want to analyze tweets and for that, we need programmatic access to Twitter. For this, we will use the [twit][2] package. So, let's install it with the `npm i twit` command. We also need to register an App through our account to gain access to the Twitter API. Head over to this [link][3], fill in all the details and copy ‘Consumer Key’, ‘Consumer Secret’, ‘Access token’ and ‘Access Token Secret’ from 'Keys and Access Token' tabs in a `.env` file like this:
|
||||
|
||||
```
|
||||
# .env
|
||||
# replace the stars with values you copied
|
||||
CONSUMER_KEY=************
|
||||
CONSUMER_SECRET=************
|
||||
ACCESS_TOKEN=************
|
||||
ACCESS_TOKEN_SECRET=************
|
||||
|
||||
```
|
||||
|
||||
Now, let's begin.
|
||||
|
||||
Open `index.js` in your favorite code editor. We need to install the `dotenv`package to read from `.env` file with the command `npm i dotenv`. Alright, let's create an API instance.
|
||||
|
||||
```
|
||||
const Twit = require('twit');
|
||||
const dotenv = require('dotenv');
|
||||
|
||||
dotenv.config();
|
||||
|
||||
const { CONSUMER_KEY
|
||||
, CONSUMER_SECRET
|
||||
, ACCESS_TOKEN
|
||||
, ACCESS_TOKEN_SECRET
|
||||
} = process.env;
|
||||
|
||||
const config_twitter = {
|
||||
consumer_key: CONSUMER_KEY,
|
||||
consumer_secret: CONSUMER_SECRET,
|
||||
access_token: ACCESS_TOKEN,
|
||||
access_token_secret: ACCESS_TOKEN_SECRET,
|
||||
timeout_ms: 60*1000
|
||||
};
|
||||
|
||||
let api = new Twit(config_twitter);
|
||||
|
||||
```
|
||||
|
||||
Here we have established a connection to the Twitter with the required configuration. But we are not doing anything with it. Let's define a function to get tweets.
|
||||
|
||||
```
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, tweet_mode: 'extended'});
|
||||
return tweets.data.statuses.map(tweet => tweet.full_text);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This is an async function because of the `api.get` the function returns a promise and instead of chaining `then`s, I wanted an easy way to extract the text of the tweets. It accepts two arguments -q and count, `q` being the query or keyword we want to search for and `count` is the number of tweets we want the `api` to return.
|
||||
|
||||
So now we have an easy way to get the full texts from the tweets. But we still have a problem, the text that we will get now may contain some links or may be truncated if it's a retweet. So we will write another function that will extract and return the text of the tweets, even for retweets and remove the links if any.
|
||||
|
||||
```
|
||||
function get_text(tweet) {
|
||||
let txt = tweet.retweeted_status ? tweet.retweeted_status.full_text : tweet.full_text;
|
||||
return txt.split(/ |\n/).filter(v => !v.startsWith('http')).join(' ');
|
||||
}
|
||||
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, 'tweet_mode': 'extended'});
|
||||
return tweets.data.statuses.map(get_text);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
So, now we have the text of tweets. Our next step is getting the sentiment from the text. For this, we will use another package from `npm` - [`sentiment`][4]package. Let's install it like the other packages and add to our script.
|
||||
|
||||
```
|
||||
const sentiment = require('sentiment')
|
||||
|
||||
```
|
||||
|
||||
Using `sentiment` is very easy. We will just have to call the `sentiment`function on the text that we want to analyze and it will return us the comparative score of the text. If the score is below 0, it expresses a negative sentiment, a score above 0 is positive and 0, as you may have guessed, is neutral. So based on this, we will print the tweets in different colors - green for positive, red for negative and blue for neutral. For this, we will use the [`colors`][5] package. Let's install it like the other packages and add to our script.
|
||||
|
||||
```
|
||||
const colors = require('colors/safe');
|
||||
|
||||
```
|
||||
|
||||
Alright, now let us bring it all together in a `main` function.
|
||||
|
||||
```
|
||||
async function main() {
|
||||
let keyword = \* define the keyword that you want to search for *\;
|
||||
let count = \* define the count of tweets you want *\;
|
||||
let tweets = await get_tweets(keyword, count);
|
||||
for (tweet of tweets) {
|
||||
let score = sentiment(tweet).comparative;
|
||||
tweet = `${tweet}\n`;
|
||||
if (score > 0) {
|
||||
tweet = colors.green(tweet);
|
||||
} else if (score < 0) {
|
||||
tweet = colors.red(tweet);
|
||||
} else {
|
||||
tweet = colors.blue(tweet);
|
||||
}
|
||||
console.log(tweet);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
And finally, execute the `main` function.
|
||||
|
||||
```
|
||||
main();
|
||||
|
||||
```
|
||||
|
||||
There you have it, a short script of analyzing the basic sentiments of a tweet.
|
||||
|
||||
```
|
||||
\\ full script
|
||||
const Twit = require('twit');
|
||||
const dotenv = require('dotenv');
|
||||
const sentiment = require('sentiment');
|
||||
const colors = require('colors/safe');
|
||||
|
||||
dotenv.config();
|
||||
|
||||
const { CONSUMER_KEY
|
||||
, CONSUMER_SECRET
|
||||
, ACCESS_TOKEN
|
||||
, ACCESS_TOKEN_SECRET
|
||||
} = process.env;
|
||||
|
||||
const config_twitter = {
|
||||
consumer_key: CONSUMER_KEY,
|
||||
consumer_secret: CONSUMER_SECRET,
|
||||
access_token: ACCESS_TOKEN,
|
||||
access_token_secret: ACCESS_TOKEN_SECRET,
|
||||
timeout_ms: 60*1000
|
||||
};
|
||||
|
||||
let api = new Twit(config_twitter);
|
||||
|
||||
function get_text(tweet) {
|
||||
let txt = tweet.retweeted_status ? tweet.retweeted_status.full_text : tweet.full_text;
|
||||
return txt.split(/ |\n/).filter(v => !v.startsWith('http')).join(' ');
|
||||
}
|
||||
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, 'tweet_mode': 'extended'});
|
||||
return tweets.data.statuses.map(get_text);
|
||||
}
|
||||
|
||||
async function main() {
|
||||
let keyword = 'avengers';
|
||||
let count = 100;
|
||||
let tweets = await get_tweets(keyword, count);
|
||||
for (tweet of tweets) {
|
||||
let score = sentiment(tweet).comparative;
|
||||
tweet = `${tweet}\n`;
|
||||
if (score > 0) {
|
||||
tweet = colors.green(tweet);
|
||||
} else if (score < 0) {
|
||||
tweet = colors.red(tweet);
|
||||
} else {
|
||||
tweet = colors.blue(tweet)
|
||||
}
|
||||
console.log(tweet)
|
||||
}
|
||||
}
|
||||
|
||||
main();
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://boostlog.io/@anshulc95/twitter-sentiment-analysis-using-nodejs-5ad1331247018500491f3b6a
|
||||
|
||||
作者:[Anshul Chauhan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://boostlog.io/@anshulc95
|
||||
[1]:https://en.wikipedia.org/wiki/Sentiment_analysis
|
||||
[2]:https://github.com/ttezel/twit
|
||||
[3]:https://boostlog.io/@anshulc95/apps.twitter.com
|
||||
[4]:https://www.npmjs.com/package/sentiment
|
||||
[5]:https://www.npmjs.com/package/colors
|
||||
[6]:https://boostlog.io/tags/nodejs
|
||||
[7]:https://boostlog.io/tags/twitter
|
||||
[8]:https://boostlog.io/@anshulc95
|
||||
@ -1,204 +0,0 @@
|
||||
[Moelf](https://github.com/moelf/) Translating
|
||||
Don’t Install Yaourt! Use These Alternatives for AUR in Arch Linux
|
||||
======
|
||||
**Brief: Yaourt had been the most popular AUR helper, but it is not being developed anymore. In this article, we list out some of the best alternatives to Yaourt for Arch based Linux distributions. **
|
||||
|
||||
[Arch User Repository][1] popularly known as AUR is the community-driven software repository for Arch users. Debian/Ubuntu users can think of AUR as the equivalent of PPA.
|
||||
|
||||
It contains the packages that are not directly endorsed by [Arch Linux][2]. If someone develops a software or package for Arch Linux, it can be provided through this community repositories. This enables the end-user to access more software than what they get by default.
|
||||
|
||||
So, how do you use AUR then? Well, you need a different tool to install software from AUR. Arch’s package manager [pacman][3] doesn’t support it directly. These ‘special tools’ are called [AUR helpers][4].
|
||||
|
||||
Yaourt (Yet AnOther User Repository Tool) is/was a wrapper for pacman that helps to install AUR packages on Arch Linux. It uses the same syntax as pacman. Yaourt has great support for Arch User Repository for searching, installing, conflict resolution and dependency maintenance.
|
||||
|
||||
However, Yaourt development has been slow lately and is [listed][5] as “Discontinued or problematic” on Arch Wiki. [Many Arch User believe it’s not secure][6] and hence go towards a different AUR helper.
|
||||
|
||||
![AUR Helpers other than Yaourt][7]
|
||||
|
||||
In this article, we will see the best Yaourt alternatives that you can use for installing software from AUR.
|
||||
|
||||
### Best AUR helpers to use AUR
|
||||
|
||||
I am deliberating omitting some of the other popular AUR helpers like trizen or packer because they too have been flagged as ‘discontinued or problematic’.
|
||||
|
||||
#### 1\. aurman
|
||||
|
||||
[aurman][8] is one of the best AUR helpers and serves pretty well as an alternative to Yaourt. It has almost similar syntax to pacman with support for all pacman operations. You can search the AUR, resolve dependencies, check PKGBUILD content before a package build etc.
|
||||
|
||||
##### Features of aurman
|
||||
|
||||
* aurman supports all pacman operations and incorporates reliable dependency resolving, conflict detection and split package support.
|
||||
* Threaded sudo loop runs in the background saving you from entering your password each time.
|
||||
* Provides development package support and distincts between explictily and inlicitly installed packages.
|
||||
* Support for searching of AUR packages and repositories.
|
||||
* You can see and edit the PKGBUILDs before starting AUR package build.
|
||||
* It can also be used as a standalone [dependency solver][9].
|
||||
|
||||
|
||||
|
||||
##### Installing aurman
|
||||
```
|
||||
git clone https://aur.archlinux.org/aurman.git
|
||||
cd aurman
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### Using aurman
|
||||
|
||||
Searching for an application through aurman in Arch User Repository is done in the following manner:
|
||||
```
|
||||
aurman -Ss <package-name>
|
||||
|
||||
```
|
||||
|
||||
Installing an application using aurman:
|
||||
```
|
||||
aurman -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
#### 2\. yay
|
||||
|
||||
[yay][10] is the next best AUR helper written in Go with the objective of providing an interface of pacman with minimal user input, yaourt like search and with almost no dependencies.
|
||||
|
||||
##### Features of yay
|
||||
|
||||
* yay provides AUR table completion and download the PKGBUILD from ABS or AUR.
|
||||
* Supports search narrowing and no sourcing of PKGBUILD.
|
||||
* The binary has no additional dependencies than pacman.
|
||||
* Provides advanced dependency solver and remove make dependencies at the end of the build process.
|
||||
* Supports colored output when you enable Color option in the /etc/pacman.conf file.
|
||||
* It can be made to support only AUR package or only repo packages.
|
||||
|
||||
|
||||
|
||||
##### Installing yay
|
||||
|
||||
You can install yay by cloning the git repo and building it. Use the below command to install yay in Arch Linux :
|
||||
```
|
||||
git clone https://aur.archlinux.org/yay.git
|
||||
cd yay
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### Using yay
|
||||
|
||||
Searching an application through Yay in AUR:
|
||||
```
|
||||
yay -Ss <package-name>
|
||||
|
||||
```
|
||||
|
||||
Installing an application:
|
||||
```
|
||||
yay -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
#### 3\. pakku
|
||||
|
||||
[Pakku][11] is another pacman wrapper which is still in its initial stage. However, just because its new doesn’t mean its lacking any of the features supported by other AUR helper. It does its job pretty nice and along with searching and installing applications from AUR, it removes dependencies after a build.
|
||||
|
||||
##### Features of pakku
|
||||
|
||||
* Searching and installing packages from Arch User Repository.
|
||||
* Viewing files and changes between builds.
|
||||
* Building packages from official repositories and removing make dependencies after a build.
|
||||
* PKGBUILD retrieving and Pacman integration.
|
||||
* Pacman-like user interface and pacman options supports.
|
||||
* Pacman configuration supports and no PKGBUILD sourcing.
|
||||
|
||||
|
||||
|
||||
##### Installing pakku
|
||||
```
|
||||
git clone https://aur.archlinux.org/pakku.git
|
||||
cd pakku
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### Using pakku
|
||||
|
||||
You can search an application from AUR using below command.:
|
||||
```
|
||||
pakku -Ss spotify
|
||||
|
||||
```
|
||||
|
||||
And then the package can be installed similar to pacman:
|
||||
```
|
||||
pakku -S spotify
|
||||
|
||||
```
|
||||
|
||||
#### 4\. aurutils
|
||||
|
||||
[aurutils][12] is basically a collection of scripts that automates the usage of Arch User Repository. It can search AUR, check updates for different applications installed and settle up dependencies issues.
|
||||
|
||||
##### Features of aurutils
|
||||
|
||||
* aurutils uses a local repository which gives it a benefit of pacman file support, and all packages works with –asdeps.
|
||||
* There can be multiple repos for different tasks.
|
||||
* Update local repository in one go with aursync -u
|
||||
* pkgbase, long format and raw support for aursearch
|
||||
* Ability to ignore package
|
||||
|
||||
|
||||
|
||||
##### Installing aurutils
|
||||
```
|
||||
git clone https://aur.archlinux.org/aurutils.git
|
||||
cd aurutils
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### Using aurutils
|
||||
|
||||
Searching an application via aurutils:
|
||||
```
|
||||
aurutils -Ss <package-name>
|
||||
|
||||
```
|
||||
|
||||
Installing a package from AUR:
|
||||
```
|
||||
aurutils -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
All of these packages can directly be installed if you are already using Yaourt or any other AUR helper.
|
||||
|
||||
#### Final Words on AUR helpers
|
||||
|
||||
Arch Linux has some [more AUR helper][4] that can automate certain tasks for the Arch User Repository. Many users are still using Yaourt for their AUR-work and
|
||||
|
||||
The choice differs for each user and we would like to know which one you use for your Arch Linux. Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-aur-helpers/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
[2]:https://www.archlinux.org/
|
||||
[3]:https://wiki.archlinux.org/index.php/pacman
|
||||
[4]:https://wiki.archlinux.org/index.php/AUR_helpers
|
||||
[5]:https://wiki.archlinux.org/index.php/AUR_helpers#Comparison_table
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/4azqyb/whats_so_bad_with_yaourt/
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/no-yaourt-arch-800x450.jpeg
|
||||
[8]:https://github.com/polygamma/aurman
|
||||
[9]:https://github.com/polygamma/aurman/wiki/Using-aurman-as-dependency-solver
|
||||
[10]:https://github.com/Jguer/yay
|
||||
[11]:https://github.com/kitsunyan/pakku
|
||||
[12]:https://github.com/AladW/aurutils
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
View The Contents Of An Archive Or Compressed File Without Extracting It
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by leemeans
|
||||
Setting Up a Timer with systemd in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,499 @@
|
||||
50 Best Ubuntu Apps You Should Be Using Right Now
|
||||
======
|
||||
**Brief: A comprehensive list of best Ubuntu apps for all kind of users. These software will help you in getting a better experience with your Linux desktop.**
|
||||
|
||||
I have written about [things to do after installing Ubuntu][1] several times in the past. Each time I suggest installing the essential applications in Ubuntu.
|
||||
|
||||
But the question arises, what are the essential Ubuntu applications? There is no set answer here. It depends on your need and the kind of work you do on your Ubuntu desktop.
|
||||
|
||||
Still, I have been asked to suggest some good Ubuntu apps by a number of readers. This is the reason I have created this comprehensive list of Ubuntu applications you can use regularly.
|
||||
|
||||
The list has been divided into respective categories for ease of reading and ease of comprehension.
|
||||
|
||||
### Best Ubuntu apps for a better Ubuntu experience
|
||||
|
||||
![Best Ubuntu Apps][2]
|
||||
|
||||
Of course, you don’t have to use all of these applications. Just go through this list of essential Ubuntu software, read the description and then install the ones you need or are inclined to use. Just keep this page bookmarked for future reference or simply search on Google with term ‘best ubuntu apps itsfoss’.
|
||||
|
||||
The best Ubuntu application list is intended for average Ubuntu user. Therefore not all the applications here are open source. I have also marked the slightly complicated applications that might not be suitable for a beginner. The list should be valid for Ubuntu 16.04,18.04 and other versions.
|
||||
|
||||
Unless exclusively mentioned, the software listed here are available in Ubuntu Software Center.
|
||||
|
||||
If you don’t find any application in the software center or if it is missing installation instruction, let me know and I’ll add the installation procedure.
|
||||
|
||||
Enough talk! Let’s see what are the best apps for Ubuntu.
|
||||
|
||||
#### Web Browser
|
||||
|
||||
Ubuntu comes with Firefox as the default web browser. Since the Quantum release, Firefox has improved drastically. Personally, I always use more than one web browser for the sake of distinguishing between different type of works.
|
||||
|
||||
##### Google Chrome
|
||||
|
||||
![Google Chrome Logo][3]
|
||||
|
||||
Google Chrome is the most used web browser on the internet for a reason. With your Google account, it allows you seamless syncing across devices. Plenty of extensions and apps further enhance its capabilities. You can [download Chrome in Ubuntu from its website][4].
|
||||
|
||||
##### Brave
|
||||
|
||||
![brave browser][5]
|
||||
|
||||
Google Chrome might be the most used web browser but it’s a privacy invader. An [alternative browser][6] is [Brave][7] that blocks ads and tracking scripts by default. This provides you with a faster and secure web browsing experience.
|
||||
|
||||
#### Music applications
|
||||
|
||||
![best music apps ubuntu][8]
|
||||
|
||||
Ubuntu has Rhythmbox as the default music player which is not at all a bad choice for the default music player. However, you can definitely install a better music player.
|
||||
|
||||
##### Sayonara
|
||||
|
||||
[Sayonara][9] is a small, lightweight music player with a nice dark user interface. It comes with all the essential features you would expect in a standard music player. It integrates well with the Ubuntu desktop environment and doesn’t eat up your RAM.
|
||||
|
||||
##### Audacity
|
||||
|
||||
[Audacity][10] is more of an audio editor than an audio player. You can record and edit audio with this free and open source tool. It is available for Linux, Windows and macOS. You can install it from the Software Center.
|
||||
|
||||
##### MusicBrainz Picard
|
||||
|
||||
[Picard][11] is not a music player, it is a music tagger. If you have tons of local music files, Picard allows you to automatically update the music files with correct tracks, album, artist info and album cover art.
|
||||
|
||||
#### Streaming Music Applications
|
||||
|
||||
![Streaming Music app Ubuntu][12]
|
||||
|
||||
In this age of the internet, music listening habit has surely changed. People these days rely more on streaming music players rather than storing hundreds of local music files. Let’s see some apps you can use for streaming music.
|
||||
|
||||
##### Spotify
|
||||
|
||||
[Spotify][13] is the king of streaming music. And the good thing is that it has a native Linux app. The [Spotify app on Ubuntu][14] integrates well with the media key and sound menu along with the desktop notification. Do note that Spotify may or may not be available in your country.
|
||||
|
||||
##### Nuvola music player
|
||||
|
||||
[Nuvola][15] is not a streaming music service like Spotify. It is a desktop music player that allows you to use several streaming music services in one application. You can use Spotify, Deezer, Google Play Music, Amazon Cloud Player and many more such services.
|
||||
|
||||
#### Video Players
|
||||
|
||||
![Video players for Linux][16]
|
||||
|
||||
Ubuntu has the default GNOME video player (previously known as Totem) which is okay but it doesn’t support various media codecs. There are certainly other video players better than the GNOME video player.
|
||||
|
||||
##### VLC
|
||||
|
||||
The free and open source software [VLC][17] is the king of video players. It supports almost all possible media codecs. It also allows you to increase the volume up to 200%. It can also resume playing from the last known position. There are so many [VLC tricks][18] you can use to get the most of it.
|
||||
|
||||
##### MPV
|
||||
|
||||
[MPV][19] is a video player that deserves more attention. A sleek minimalist GUI and plenty of features, MPV has everything you would expect from a good video player. You can even use it in the command line. If you are not happy with VLC, you should surely give MPV a try.
|
||||
|
||||
#### Cloud Storage Service
|
||||
|
||||
Local backups are fine but cloud storage gives an additional degree of freedom. You don’t have to carry a USB key with you all the time or worry about a hard disk crash with cloud services.
|
||||
|
||||
##### Dropbox
|
||||
|
||||
![Dropbox logo][20]
|
||||
|
||||
[Dropbox][21] is one of the most popular Cloud service providers. You get 2GB of free storage with the option to get more by referring others. Dropbox provides a native Linux client and you can download it from its website. It creates a local folder on your system that is synced with the cloud servers.
|
||||
|
||||
##### pCloud
|
||||
|
||||
![pCloud icon][22]
|
||||
|
||||
[pCloud][23] is another good cloud storage service for Linux. It also has a native Linux client that you can download from its website. You get up to 20GB of free storage and if you need more, the pricing is better than Dropbox. pCloud is based in Switzerland, a country renowned for strict data privacy laws.
|
||||
|
||||
#### Image Editors
|
||||
|
||||
I am sure that you would need a photo editor at some point in time. Here are some of the best Ubuntu apps for editing images.
|
||||
|
||||
##### GIMP
|
||||
|
||||
![gimp icon][24]
|
||||
|
||||
[GIMP][25] is a free and open source image editor available for Linux, Windows and macOS. It’s the best alternative for Adobe Photoshop in Linux. You can use it for all kind of image editing. There are plenty of resources available on the internet to help you with Gimp.
|
||||
|
||||
##### Inkscape
|
||||
|
||||
![inkscape icon][26]
|
||||
|
||||
[Inkscape][27] is also a free and open source image editor specifically focusing on vector graphics. You can design vector arts and logo on it. You can compare it to Adobe Illustrator. Like Gimp, Inkscape too has plenty of tutorials available online.
|
||||
|
||||
#### Paint applications
|
||||
|
||||
Painting applications are not the same as image editors though their functionalities overlap at times. Here are some paint apps you can use in Ubuntu.
|
||||
![Painting apps for Ubuntu Linux][28]
|
||||
|
||||
##### Krita
|
||||
|
||||
[Krita][29] is a free and open source digital painting application. You can create digital art, comics and animation with it. It’s a professional grade software and is even used as the primary software in art schools.
|
||||
|
||||
##### Pinta
|
||||
|
||||
[Pinta][30] might not be as feature rich as Krita but that’s deliberate. You can think of Pinta as Microsoft Paint for Linux. You can draw, paint, add text and do other such small tasks you do in a paint application.
|
||||
|
||||
#### Photography applications
|
||||
|
||||
Amateur photographer or a professional? You have plenty of [photography tools][31] at your disposal. Here are some recommended applications.
|
||||
|
||||
##### digiKam
|
||||
|
||||
![digikam][32]
|
||||
|
||||
With open source software [digiKam][33], you can handle your high-end camera images in a professional manner. digiKam provides all the tools required for viewing, managing, editing, enhancing, organizing, tagging and sharing photographs.
|
||||
|
||||
##### Darktable
|
||||
|
||||
![Darktable icon][34]
|
||||
|
||||
[darktable][35] is an open source photography workflow application with a special focus on raw image development. This is the best alternative you can get for Adobe Lightroom. It is also available for Windows and macOS.
|
||||
|
||||
#### Video editors
|
||||
|
||||
![Video editors Ubuntu][36]
|
||||
|
||||
There is no dearth of [video editors for Linux][37] but I won’t go in detail here. Take a look at some of the feature-rich yet relatively simple to use video editors for Ubuntu.
|
||||
|
||||
##### Kdenlive
|
||||
|
||||
[Kdenlive][38] is the best all-purpose video editor for Linux. It has enough features that compare it to iMovie or Movie Maker.
|
||||
|
||||
##### Shotcut
|
||||
|
||||
[Shotcut][39] is another good choice for a video editor. It is an open source software with all the features you can expect in a standard video editor.
|
||||
|
||||
#### Image and video converter
|
||||
|
||||
If you need to [convert the file format][40] of your images and videos, here are some of my recommendations.
|
||||
|
||||
##### Xnconvert
|
||||
|
||||
![xnconvert logo][41]
|
||||
|
||||
[Xnconvert][42] is an excellent batch image conversion tool. You can bulk resize images, convert the file type and rename them.
|
||||
|
||||
##### Handbrake
|
||||
|
||||
![Handbrake Logo][43]
|
||||
|
||||
[HandBrake][44] is an easy to use open source tool for converting videos from a number of formats to a few modern, popular formats.
|
||||
|
||||
#### Screenshot and screen recording tools
|
||||
|
||||
![Screenshot and recorders Ubuntu][45]
|
||||
|
||||
Here are the best Ubuntu apps for taking screenshots and recording your screen.
|
||||
|
||||
##### Shutter
|
||||
|
||||
[Shutter][46] is my go-to tool for taking screenshots. You can also do some quick editing to those screenshots such as adding arrows, text or resizing the images. The screenshots you see on It’s FOSS have been edited with Shutter. Definitely one of the best apps for Ubuntu.
|
||||
|
||||
##### Kazam
|
||||
|
||||
[Kazam][47] is my favorite [screen recorder for Linux][48]. It’s a tiny tool that allows you to record the entire window, an application window or a selected area. You can also use shortcuts to pause or resume recording. The tutorials on [It’s FOSS YouTube channel][49] have been recorded with Kazam.
|
||||
|
||||
#### Office suites
|
||||
|
||||
I cannot imagine that you could use a computer without a document editor. And why restrict yourself to just one document editor? Go for a complete office suite.
|
||||
|
||||
##### LibreOffice
|
||||
|
||||
![LibreOffice logo][50]
|
||||
|
||||
[LibreOffice][51] comes preinstalled on Ubuntu and it is undoubtedly the [best open source office software][52]. It’s a complete package comprising of a document editor, spreadsheet tool, presentation software, maths tool and a graphics tool. You can even edit some PDF files with LibreOffice.
|
||||
|
||||
##### WPS Office
|
||||
|
||||
![WPS Office logo][53]
|
||||
|
||||
[WPS Office][54] has gained popularity for being a Microsoft Office clone. It has an interface identical to Microsoft Office and it claims to be more compatible with MS Office. If you are looking for something similar to the Microsoft Office, WPS Office is a good choice.
|
||||
|
||||
#### Downloading tools
|
||||
|
||||
![Downloading software Ubuntu][55]
|
||||
|
||||
If you often download videos or other big files from the internet, these tools will help you.
|
||||
|
||||
##### youtube-dl
|
||||
|
||||
This is one of the rare Ubuntu application on the list that is command line based. If you want to download videos from YouTube, DailyMotion or other video websites, youtube-dl is an excellent choice. It provides plenty of [advanced option for video downloading][56].
|
||||
|
||||
##### uGet
|
||||
|
||||
[uGet][57] is a feature rich [download manager for Linux][58]. It allows you to pause and resume your downloads, schedule your downloads, monitor clipboard for downloadable content. A perfect tool if you have a slow, inconsistent internet or daily data limit.
|
||||
|
||||
#### Code Editors
|
||||
|
||||
![Coding apps for Ubuntu][59]
|
||||
|
||||
If you are into programming, the default Gedit text editor might not be sufficient for your coding needs. Here are some of the better code editors for you.
|
||||
|
||||
##### Atom
|
||||
|
||||
[Atom][60] is a free and [open source code editor][61] from GitHub. Even before it was launched its first stable version, it became a hot favorite among coders for its UI, features and vast range of plugins.
|
||||
|
||||
##### Visual Studio Code
|
||||
|
||||
[VS Code][62] is an open source code editor from Microsoft. Don’t worry about Microsoft, VS Code is an awesome editor for web development. It also supports a number of other programming languages.
|
||||
|
||||
#### PDF and eBooks related applications
|
||||
|
||||
![eBook Management tools in Ubuntu][63]
|
||||
|
||||
In this digital age, you cannot only rely on the real paper books especially when there are plenty of free eBooks available. Here are some Ubuntu apps for managing PDFs and eBooks.
|
||||
|
||||
##### Calibre
|
||||
|
||||
If you are a bibliophile and collect eBooks, you should use [Calibre][64]. It is an eBook manager with all the necessary software for [creating eBooks][65], converting eBook formats and managing an eBook library.
|
||||
|
||||
##### Okular
|
||||
|
||||
Okular is mostly a PDF viewer with options for editing PDF files. You can do some basic [PDF editing on Linux][66] with Okular such as adding pop-ups notes, inline notes, freehand line drawing, highlighter, stamp etc.
|
||||
|
||||
#### Messaging applications
|
||||
|
||||
![Messaging apps for Ubuntu][67]
|
||||
|
||||
I believe you use at least one [messaging app on Linux][68]. Here are my recommendations.
|
||||
|
||||
##### Skype
|
||||
|
||||
[Skype][69] is the most popular video chatting application. It is also used by many companies and businesses for interviews and meetings. This makes Skype one of the must-have applications for Ubuntu.
|
||||
|
||||
##### Rambox
|
||||
|
||||
[Rambox][70] is not a messaging application on its own. But it allows you to use Skype, Viber, Facebook Messanger, WhatsApp, Slack and a number of other messaging applications from a single application window.
|
||||
|
||||
#### Notes and To-do List applications
|
||||
|
||||
Need a to-do list app or simple an app for taking notes? Have a look at these:
|
||||
|
||||
##### Simplenote
|
||||
|
||||
![Simplenote logo][71]
|
||||
|
||||
[Simplenote][72] is a free and open source note taking application from WordPress creators [Automattic][73]. It is available for Windows, Linux, macOS, iOS and Android. Your notes are synced to a cloud server and you can access them on any device. You can download the DEB file from its website.
|
||||
|
||||
##### Remember The Milk
|
||||
|
||||
![Remember The Milk logo][74]
|
||||
|
||||
[Remember The Milk][75] is a popular to-do list application. It is available for Windows, Linux, macOS, iOS and Android. Your to-do list is accessible on all the devices you own. You can also access it from a web browser. It also has an official native application for Linux that you can download from its website.
|
||||
|
||||
#### Password protection and encryption
|
||||
|
||||
![Encryption software Ubuntu][76]
|
||||
|
||||
If there are other people regularly using your computer perhaps you would like to add an extra layer of security by password protecting files and folders.
|
||||
|
||||
##### EncryptPad
|
||||
|
||||
[EncryptPad][77] is an open source text editor that allows you to lock your files with a password. You can choose the type of encryption. There is also a command line version of this tool.
|
||||
|
||||
##### Gnome Encfs Manager
|
||||
|
||||
Gnome Encfs Manager allows you to [lock folders with a password in Linux][78]. You can keep whatever files you want in a secret folder and then lock it with a password.
|
||||
|
||||
#### Gaming
|
||||
|
||||
![Gaming on Ubuntu][79]
|
||||
|
||||
[Gaming on Linux][80] is a lot better than what it used to be a few years ago. You can enjoy plenty of games on Linux without going back to Windows.
|
||||
|
||||
##### Steam
|
||||
|
||||
[Steam][81] is a digital distribution platform that allows you to purchase (if required) games. Steam has over 1500 [games for Linux][82]. You can download the Steam client from the Software Center.
|
||||
|
||||
##### PlayOnLinux
|
||||
|
||||
[PlayOnLinux][83] allows you to run Windows games on Linux over WINE compatibility layer. Don’t expect too much out of it because not every game will run flawlessly with PlayOnLinux.
|
||||
|
||||
#### Package Managers [Intermediate to advanced users]
|
||||
|
||||
![Package Management tools Ubuntu][84]
|
||||
|
||||
Ubuntu Software Center is more than enough for an average Ubuntu user’s software needs but you can have more control on it using these applications.
|
||||
|
||||
##### Gdebi
|
||||
|
||||
Gedbi is a tiny packagae manager that you can use for installing DEB files. It is faster than the Software Center and it also handles dependency issues.
|
||||
|
||||
##### Synaptic
|
||||
|
||||
Synaptic was the default GUI package manager for most Linux distributions a decade ago. It still is in some Linux distributions. This powerful package manager is particularly helpful in [finding installed applications and removing them][85].
|
||||
|
||||
#### Backup and Recovery tools
|
||||
|
||||
![Backup and data recovery tools for Ubuntu][86]
|
||||
|
||||
Backup and recovery tools are must-have software for any system. Let’s see what softwares you must have on Ubuntu.
|
||||
|
||||
##### Timeshift
|
||||
|
||||
Timeshift is a tool that allows you to [take a snapshot of your system][87]. This allows you to restore your system to a previous state in case of an unfortunate incident when your system configuration is messed up. Note that it’s not the best tool for your personal data backup though. For that, you can use Ubuntu’s default Deja Dup (also known as Backups) tool.
|
||||
|
||||
##### TestDisk [Intermediate Users]
|
||||
|
||||
This is another command line tool on this list of best Ubuntu application. [TestDisk][88] allows you to [recover data on Linux][89]. If you accidentally deleted files, there are still chances that you can get it back using TestDisk.
|
||||
|
||||
#### System Tweaking and Management Tools
|
||||
|
||||
![System Maintenance apps Ubuntu][90]
|
||||
|
||||
##### GNOME/Unity Tweak Tool
|
||||
|
||||
These Tweak tools are a must for every Ubuntu user. They allow you to access some advanced system settings. Best of all, you can [change themes in Ubuntu][91] using these tweak tools.
|
||||
|
||||
##### UFW Firewall
|
||||
|
||||
[UFW][92] stands for Uncomplicated Firewall and rightly so. UFW has predefined firewall settings for Home, Work and Public networks.
|
||||
|
||||
##### Stacer
|
||||
|
||||
If you want to free up space on Ubuntu, try Stacer. This graphical tool allows you to [optimize your Ubuntu system][93] by removing unnecessary files and completely uninstalling software. Download Stacer from [its website][94].
|
||||
|
||||
#### Other Utilities
|
||||
|
||||
![Utilities Ubuntu][95]
|
||||
|
||||
In the end, I’ll list some of my other favorite Ubuntu apps that I could not put into a certain category.
|
||||
|
||||
##### Neofetch
|
||||
|
||||
One more command line tool! Neofetch displays your system information such as [Ubuntu version][96], desktop environment, theme, icons, RAM etc info along with [ASCII logo of the distribution][97]. Use this command for installing Neofetch.
|
||||
```
|
||||
sudo apt install neofetch
|
||||
|
||||
```
|
||||
|
||||
##### Etcher
|
||||
|
||||
Ubuntu has a live USB creator tool installed already but Etcher is a better application for this task. It is also available for Windows and macOS. You can download it [from its website][98].
|
||||
|
||||
##### gscan2pdf
|
||||
|
||||
I use this tiny tool for the sole purpose of [converting images into PDF][99]. You can use it for combining multiple images into one PDF file as well.
|
||||
|
||||
##### Audio Recorder
|
||||
|
||||
Another tiny yet essential Ubuntu application for [recording audio on Ubuntu][100]. You can use it to record sound from system microphone, from music player or from any other source.
|
||||
|
||||
### Your suggestions for essential Ubuntu applications?
|
||||
|
||||
I would like to conclude my list of best Ubuntu apps here. I know that you might not need or use all of them but I am certain that you would like most of the software listed here.
|
||||
|
||||
Did you find some useful applications that you didn’t know about before? If you would have to suggest your favorite Ubuntu application, which one would it be?
|
||||
|
||||
In the end, if you find this article useful, please share it on social media, Reddit, Hacker News or other community or forums you visit regularly. This way you help us grow :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-ubuntu-apps/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/best-ubuntu-apps-featured.jpeg
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/google-chrome.jpeg
|
||||
[4]:https://www.google.com/chrome/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/brave-browser-icon.jpeg
|
||||
[6]:https://itsfoss.com/open-source-browsers-linux/
|
||||
[7]:https://brave.com/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/music-apps-ubuntu.jpeg
|
||||
[9]:https://itsfoss.com/sayonara-music-player/
|
||||
[10]:https://www.audacityteam.org/
|
||||
[11]:https://itsfoss.com/musicbrainz-picard/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/streaming-music-apps-ubuntu.jpeg
|
||||
[13]:https://www.spotify.com//
|
||||
[14]:https://itsfoss.com/install-spotify-ubuntu-1404/
|
||||
[15]:https://tiliado.eu/nuvolaplayer/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Video-Players-linux.jpg
|
||||
[17]:https://www.videolan.org/index.html
|
||||
[18]:https://itsfoss.com/vlc-pro-tricks-linux/
|
||||
[19]:https://mpv.io/
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/dropbox-icon.jpeg
|
||||
[21]:https://www.dropbox.com/
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/pcloud-icon.jpeg
|
||||
[23]:https://itsfoss.com/recommends/pcloud/
|
||||
[24]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/gimp-icon.jpeg
|
||||
[25]:https://www.gimp.org/
|
||||
[26]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/inkscape-icon.jpeg
|
||||
[27]:https://inkscape.org/en/
|
||||
[28]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/paint-apps-ubuntu.jpeg
|
||||
[29]:https://krita.org/en/
|
||||
[30]:https://pinta-project.com/pintaproject/pinta/
|
||||
[31]:https://itsfoss.com/image-applications-ubuntu-linux/
|
||||
[32]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/digikam-icon.jpeg
|
||||
[33]:https://www.digikam.org/
|
||||
[34]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/darktable-icon.jpeg
|
||||
[35]:https://www.darktable.org/
|
||||
[36]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/video-editing-apps-ubuntu.jpeg
|
||||
[37]:https://itsfoss.com/best-video-editing-software-linux/
|
||||
[38]:https://kdenlive.org/en/
|
||||
[39]:https://shotcut.org/
|
||||
[40]:https://itsfoss.com/format-factory-alternative-linux/
|
||||
[41]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/xnconvert-logo.jpeg
|
||||
[42]:https://www.xnview.com/en/xnconvert/
|
||||
[43]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/handbrake-logo.jpeg
|
||||
[44]:https://handbrake.fr/
|
||||
[45]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/screen-recording-ubuntu-apps.jpeg
|
||||
[46]:http://shutter-project.org/
|
||||
[47]:https://launchpad.net/kazam
|
||||
[48]:https://itsfoss.com/best-linux-screen-recorders/
|
||||
[49]:https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[50]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/libre-office-logo.jpeg
|
||||
[51]:https://www.libreoffice.org/download/download/
|
||||
[52]:https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[53]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/wps-office-logo.jpeg
|
||||
[54]:http://wps-community.org/
|
||||
[55]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/download-apps-ubuntu.jpeg
|
||||
[56]:https://itsfoss.com/download-youtube-linux/
|
||||
[57]:http://ugetdm.com/
|
||||
[58]:https://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[59]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/coding-apps-ubuntu.jpeg
|
||||
[60]:https://atom.io/
|
||||
[61]:https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[62]:https://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
[63]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/pdf-management-apps-ubuntu.jpeg
|
||||
[64]:https://calibre-ebook.com/
|
||||
[65]:https://itsfoss.com/create-ebook-calibre-linux/
|
||||
[66]:https://itsfoss.com/pdf-editors-linux/
|
||||
[67]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/messaging-apps-ubuntu.jpeg
|
||||
[68]:https://itsfoss.com/best-messaging-apps-linux/
|
||||
[69]:https://www.skype.com/en/
|
||||
[70]:https://rambox.pro/
|
||||
[71]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/simplenote-logo.jpeg
|
||||
[72]:http://simplenote.com/
|
||||
[73]:https://automattic.com/
|
||||
[74]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/remember-the-milk-logo.jpeg
|
||||
[75]:https://itsfoss.com/remember-the-milk-linux/
|
||||
[76]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/encryption-apps-ubuntu.jpeg
|
||||
[77]:https://itsfoss.com/encryptpad-encrypted-text-editor-linux/
|
||||
[78]:https://itsfoss.com/password-protect-folder-linux/
|
||||
[79]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/gaming-ubuntu.jpeg
|
||||
[80]:https://itsfoss.com/linux-gaming-guide/
|
||||
[81]:https://store.steampowered.com/
|
||||
[82]:https://itsfoss.com/free-linux-games/
|
||||
[83]:https://www.playonlinux.com/en/
|
||||
[84]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/package-management-apps-ubuntu.jpeg
|
||||
[85]:https://itsfoss.com/how-to-add-remove-programs-in-ubuntu/
|
||||
[86]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/backup-recovery-tools-ubuntu.jpeg
|
||||
[87]:https://itsfoss.com/backup-restore-linux-timeshift/
|
||||
[88]:https://www.cgsecurity.org/wiki/TestDisk
|
||||
[89]:https://itsfoss.com/recover-deleted-files-linux/
|
||||
[90]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/system-maintenance-apps-ubuntu.jpeg
|
||||
[91]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[92]:https://wiki.ubuntu.com/UncomplicatedFirewall
|
||||
[93]:https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[94]:https://github.com/oguzhaninan/Stacer
|
||||
[95]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/utilities-apps-ubuntu.jpeg
|
||||
[96]:https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[97]:https://itsfoss.com/display-linux-logo-in-ascii/
|
||||
[98]:https://etcher.io/
|
||||
[99]:https://itsfoss.com/convert-multiple-images-pdf-ubuntu-1304/
|
||||
[100]:https://itsfoss.com/record-streaming-audio/
|
||||
@ -1,198 +0,0 @@
|
||||
translating by Flowsnow
|
||||
A sysadmin's guide to Bash
|
||||
======
|
||||
|
||||

|
||||
|
||||
Each trade has a tool that masters in that trade wield most often. For many sysadmins, that tool is their [shell][1]. On the majority of Linux and other Unix-like systems out there, the default shell is Bash.
|
||||
|
||||
Bash is a fairly old program—it originated in the late 1980s—but it builds on much, much older shells, like the C shell ([csh][2]), which is easily 10 years its senior. Because the concept of a shell is that old, there is an enormous amount of arcane knowledge out there waiting to be consumed to make any sysadmin guy's or gal's life a lot easier.
|
||||
|
||||
Let's take a look at some of the basics.
|
||||
|
||||
Who has, at some point, unintentionally ran a command as root and caused some kind of issue? raises hand
|
||||
|
||||
I'm pretty sure a lot of us have been that guy or gal at one point. Very painful. Here are some very simple tricks to prevent you from hitting that stone a second time.
|
||||
|
||||
### Use aliases
|
||||
|
||||
First, set up aliases for commands like **`mv`** and **`rm`** that point to `mv -I` and `rm -I`. This will make sure that running `rm -f /boot` at least asks you for confirmation. In Red Hat Enterprise Linux, these aliases are set up by default if you use the root account.
|
||||
|
||||
If you want to set those aliases for your normal user account as well, just drop these two lines into a file called .bashrc in your home directory (these will also work with sudo):
|
||||
```
|
||||
alias mv='mv -i'
|
||||
|
||||
alias rm='rm -i'
|
||||
|
||||
```
|
||||
|
||||
### Make your root prompt stand out
|
||||
|
||||
Another thing you can do to prevent mishaps is to make sure you are aware when you are using the root account. I usually do that by making the root prompt stand out really well from the prompt I use for my normal, everyday work.
|
||||
|
||||
If you drop the following into the .bashrc file in root's home directory, you will have a root prompt that is red on black, making it crystal clear that you (or anyone else) should tread carefully.
|
||||
```
|
||||
export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"
|
||||
|
||||
```
|
||||
|
||||
In fact, you should refrain from logging in as root as much as possible and instead run the majority of your sysadmin commands through sudo, but that's a different story.
|
||||
|
||||
Having implemented a couple of minor tricks to help prevent "unintentional side-effects" of using the root account, let's look at a couple of nice things Bash can help you do in your daily work.
|
||||
|
||||
### Control your history
|
||||
|
||||
You probably know that when you press the Up arrow key in Bash, you can see and reuse all (well, many) of your previous commands. That is because those commands have been saved to a file called .bash_history in your home directory. That history file comes with a bunch of settings and commands that can be very useful.
|
||||
|
||||
First, you can view your entire recent command history by typing **`history`** , or you can limit it to your last 30 commands by typing **`history 30`**. But that's pretty vanilla. You have more control over what Bash saves and how it saves it.
|
||||
|
||||
For example, if you add the following to your .bashrc, any commands that start with a space will not be saved to the history list:
|
||||
```
|
||||
HISTCONTROL=ignorespace
|
||||
|
||||
```
|
||||
|
||||
This can be useful if you need to pass a password to a command in plaintext. (Yes, that is horrible, but it still happens.)
|
||||
|
||||
If you don't want a frequently executed command to show up in your history, use:
|
||||
```
|
||||
HISTCONTROL=ignorespace:erasedups
|
||||
|
||||
```
|
||||
|
||||
With this, every time you use a command, all its previous occurrences are removed from the history file, and only the last invocation is saved to your history list.
|
||||
|
||||
A history setting I particularly like is the **`HISTTIMEFORMAT`** setting. This will prepend all entries in your history file with a timestamp. For example, I use:
|
||||
```
|
||||
HISTTIMEFORMAT="%F %T "
|
||||
|
||||
```
|
||||
|
||||
When I type **`history 5`** , I get nice, complete information, like this:
|
||||
```
|
||||
1009 2018-06-11 22:34:38 cat /etc/hosts
|
||||
|
||||
1010 2018-06-11 22:34:40 echo $foo
|
||||
|
||||
1011 2018-06-11 22:34:42 echo $bar
|
||||
|
||||
1012 2018-06-11 22:34:44 ssh myhost
|
||||
|
||||
1013 2018-06-11 22:34:55 vim .bashrc
|
||||
|
||||
```
|
||||
|
||||
That makes it a lot easier to browse my command history and find the one I used two days ago to set up an SSH tunnel to my home lab (which I forget again, and again, and again…).
|
||||
|
||||
### Best Bash practices
|
||||
|
||||
I'll wrap this up with my top 11 list of the best (or good, at least; I don't claim omniscience) practices when writing Bash scripts.
|
||||
|
||||
11. Bash scripts can become complicated and comments are cheap. If you wonder whether to add a comment, add a comment. If you return after the weekend and have to spend time figuring out what you were trying to do last Friday, you forgot to add a comment.
|
||||
|
||||
|
||||
10. Wrap all your variable names in curly braces, like **`${myvariable}`**. Making this a habit makes things like `${variable}_suffix` possible and improves consistency throughout your scripts.
|
||||
|
||||
|
||||
9. Do not use backticks when evaluating an expression; use the **`$()`** syntax instead. So use:
|
||||
```
|
||||
for file in $(ls); do
|
||||
```
|
||||
|
||||
|
||||
not
|
||||
```
|
||||
for file in `ls`; do
|
||||
|
||||
```
|
||||
|
||||
The former option is nestable, more easily readable, and keeps the general sysadmin population happy. Do not use backticks.
|
||||
|
||||
|
||||
|
||||
8. Consistency is good. Pick one style of doing things and stick with it throughout your script. Obviously, I would prefer if people picked the **`$()`** syntax over backticks and wrapped their variables in curly braces. I would prefer it if people used two or four spaces—not tabs—to indent, but even if you choose to do it wrong, do it wrong consistently.
|
||||
|
||||
|
||||
7. Use the proper shebang for a Bash script. As I'm writing Bash scripts with the intention of only executing them with Bash, I most often use **`#!/usr/bin/bash`** as my shebang. Do not use **`#!/bin/sh`** or **`#!/usr/bin/sh`**. Your script will execute, but it'll run in compatibility mode—potentially with lots of unintended side effects. (Unless, of course, compatibility mode is what you want.)
|
||||
|
||||
|
||||
6. When comparing strings, it's a good idea to quote your variables in if-statements, because if your variable is empty, Bash will throw an error for lines like these:
|
||||
```
|
||||
if [ ${myvar} == "foo" ]; then
|
||||
|
||||
echo "bar"
|
||||
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
And will evaluate to false for a line like this:
|
||||
```
|
||||
if [ "${myvar}" == "foo" ]; then
|
||||
|
||||
echo "bar"
|
||||
|
||||
fi
|
||||
```
|
||||
|
||||
Also, if you are unsure about the contents of a variable (e.g., when you are parsing user input), quote your variables to prevent interpretation of some special characters and make sure the variable is considered a single word, even if it contains whitespace.
|
||||
|
||||
|
||||
|
||||
5. This is a matter of taste, I guess, but I prefer using the double equals sign ( **`==`** ) even when comparing strings in Bash. It's a matter of consistency, and even though—for string comparisons only—a single equals sign will work, my mind immediately goes "single equals is an assignment operator!"
|
||||
|
||||
|
||||
4. Use proper exit codes. Make sure that if your script fails to do something, you present the user with a written failure message (preferably with a way to fix the problem) and send a non-zero exit code:
|
||||
```
|
||||
# we have failed
|
||||
|
||||
echo "Process has failed to complete, you need to manually restart the whatchamacallit"
|
||||
|
||||
exit 1
|
||||
|
||||
```
|
||||
|
||||
This makes it easier to programmatically call your script from yet another script and verify its successful completion.
|
||||
|
||||
|
||||
|
||||
3. Use Bash's built-in mechanisms to provide sane defaults for your variables or throw errors if variables you expect to be defined are not defined:
|
||||
```
|
||||
# this sets the value of $myvar to redhat, and prints 'redhat'
|
||||
|
||||
echo ${myvar:=redhat}
|
||||
|
||||
# this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined
|
||||
|
||||
${myvar:?The variable myvar is undefined, dear reader}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. Especially if you are writing a large script, and especially if you work on that large script with others, consider using the **`local`** keyword when defining variables inside functions. The **`local`** keyword will create a local variable, that is one that's visible only within that function. This limits the possibility of clashing variables.
|
||||
|
||||
|
||||
1. Every sysadmin must do it sometimes: debug something on a console, either a real one in a data center or a virtual one through a virtualization platform. If you have to debug a script that way, you will thank yourself for remembering this: Do not make the lines in your scripts too long!
|
||||
|
||||
On many systems, the default width of a console is still 80 characters. If you need to debug a script on a console and that script has very long lines, you'll be a sad panda. Besides, a script with shorter lines—the default is still 80 characters—is a lot easier to read and understand in a normal editor, too!
|
||||
|
||||
|
||||
|
||||
|
||||
I truly love Bash. I can spend hours writing about it or exchanging nice tricks with fellow enthusiasts. Make sure you drop your favorites in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/admin-guide-bash
|
||||
|
||||
作者:[Maxim Burgerhout][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/wzzrd
|
||||
[1]:http://www.catb.org/jargon/html/S/shell.html
|
||||
[2]:https://en.wikipedia.org/wiki/C_shell
|
||||
@ -1,138 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Use Pbcopy And Pbpaste Commands On Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Since Linux and Mac OS X are *Nix based systems, many commands would work on both platforms. However, some commands may not available in on both platforms, for example **pbcopy** and **pbpaste**. These commands are exclusively available only on Mac OS X platform. The Pbcopy command will copy the standard input into clipboard. You can then paste the clipboard contents using Pbpaste command wherever you want. Of course, there could be some Linux alternatives to the above commands, for example **Xclip**. The Xclip will do exactly same as Pbcopy. But, the distro-hoppers who switched to Linux from Mac OS would miss this command-pair and still prefer to use them. No worries! This brief tutorial describes how to use Pbcopy and Pbpaste commands on Linux.
|
||||
|
||||
### Install Xclip / Xsel
|
||||
|
||||
Like I already said, Pbcopy and Pbpaste commands are not available in Linux. However, we can replicate the functionality of pbcopy and pbpaste commands using Xclip and/or Xsel commands via shell aliasing. Both Xclip and Xsel packages available in the default repositories of most Linux distributions. Please note that you need not to install both utilities. Just install any one of the above utilities.
|
||||
|
||||
To install them on Arch Linux and its derivatives, run:
|
||||
```
|
||||
$ sudo pacman xclip xsel
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
$ sudo dnf xclip xsel
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt install xclip xsel
|
||||
|
||||
```
|
||||
|
||||
Once installed, you need create aliases for pbcopy and pbpaste commands. To do so, edit your **~/.bashrc** file:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
If you want to use Xclip, paste the following lines:
|
||||
```
|
||||
alias pbcopy='xclip -selection clipboard'
|
||||
alias pbpaste='xclip -selection clipboard -o'
|
||||
|
||||
```
|
||||
|
||||
If you want to use xsel, paste the following lines in your ~/.bashrc file.
|
||||
```
|
||||
alias pbcopy='xsel --clipboard --input'
|
||||
alias pbpaste='xsel --clipboard --output'
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Next, run the following command to update the changes in ~/.bashrc file.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
The ZSH users paste the above lines in **~/.zshrc** file.
|
||||
|
||||
### Use Pbcopy And Pbpaste Commands On Linux
|
||||
|
||||
Let us see some examples.
|
||||
|
||||
The pbcopy command will copy the text from stdin into clipboard buffer. For example, have a look at the following example.
|
||||
```
|
||||
$ echo "Welcome To OSTechNix!" | pbcopy
|
||||
|
||||
```
|
||||
|
||||
The above command will copy the text “Welcome To OSTechNix” into clipboard. You can access this content later and paste them anywhere you want using Pbpaste command like below.
|
||||
```
|
||||
$ echo `pbpaste`
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
Here are some other use cases.
|
||||
|
||||
I have a file named **file.txt** with the following contents.
|
||||
```
|
||||
$ cat file.txt
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
You can directly copy the contents of a file into a clipboard as shown below.
|
||||
```
|
||||
$ pbcopy < file.txt
|
||||
|
||||
```
|
||||
|
||||
Now, the contents of the file is available in the clipboard as long as you updated with another file’s contents.
|
||||
|
||||
To retrieve the contents from clipboard, simply type:
|
||||
```
|
||||
$ pbpaste
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
You can also send the output of any Linux command to clip board using pipeline character. Have a look at the following example.
|
||||
```
|
||||
$ ps aux | pbcopy
|
||||
|
||||
```
|
||||
|
||||
Now, type “pbpaste” command at any time to display the output of “ps aux” command from the clipboard.
|
||||
```
|
||||
$ pbpaste
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
There is much more you can do with Pbcopy and Pbpaste commands. I hope you now got a basic idea about these commands.
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,55 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Cross-Site Request Forgery
|
||||
======
|
||||

|
||||
Security is a major concern when designing web apps. And I am not talking about DDOS protection, using a strong password or 2 step verification. I am talking about the biggest threat to a web app. It is known as **CSRF** short for **Cross Site Resource Forgery**.
|
||||
|
||||
### What is CSRF?
|
||||
|
||||
[][1]
|
||||
|
||||
First thing first, **CSRF** is short for Cross Site Resource Forgery. It is commonly pronounced as sea-surf and often referred to as XSRF. CSRF is a type of attack where various actions are performed on the web app where the victim is logged in without the victim's knowledge. These actions could be anything ranging from simply liking or commenting on a social media post to sending abusive messages to people or even transferring money from the victim’s bank account.
|
||||
|
||||
### How CSRF works?
|
||||
|
||||
**CSRF** attacks try to bank upon a simple common vulnerability in all browsers. Every time, we authenticate or log in to a website, session cookies are stored in the browser. So whenever we make a request to the website these cookies are automatically sent to the server where the server identifies us by matching the cookie we sent with the server’s records. So that way it knows it’s us.
|
||||
|
||||
[][2]
|
||||
|
||||
This means that any request made by me, knowingly or unknowingly, will be fulfilled. Since the cookies are being sent and they will match the records on the server, the server thinks I am making that request.
|
||||
|
||||
|
||||
|
||||
CSRF attacks usually come in form of links. We may click them on other websites or receive them as email. On clicking these links, an unwanted request is made to the server. And as I previously said, the server thinks we made the request and authenticates it.
|
||||
|
||||
#### A Real World Example
|
||||
|
||||
To put things into perspective, imagine you are logged into your bank’s website. And you fill up a form on the page at **yourbank.com/transfer** . You fill in the account number of the receiver as 1234 and the amount of 5,000 and you click on the submit button. Now, a request will be made to **yourbank.com/transfer/send?to=1234&amount=5000** . So the server will act upon the request and make the transfer. Now just imagine you are on another website and you click on a link that opens up the above URL with the hacker’s account number. That money is now transferred to the hacker and the server thinks you made the transaction. Even though you didn’t.
|
||||
|
||||
[][3]
|
||||
|
||||
#### Protection against CSRF
|
||||
|
||||
CSRF protection is very easy to implement. It usually involves sending a token called the CSRF token to the webpage. This token is sent and verified on the server with every new request made. So malicious requests made by the server will pass cookie authentication but fail CSRF authentication. Most web frameworks provide out of the box support for preventing CSRF attacks and CSRF attacks are not as commonly seen today as they were some time back.
|
||||
|
||||
### Conclusion
|
||||
|
||||
CSRF attacks were a big thing 10 years back but today we don’t see too many of them. In the past, famous sites such as Youtube, The New York Times and Netflix have been vulnerable to CSRF. However, popularity and occurrence of CSRF attacks have decreased lately. Nevertheless, CSRF attacks are still a threat and it is important, you protect your website or app from it.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/understanding-csrf-cross-site-request-forgery
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-what-is-cross-site-forgery_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/cookies-set-by-website-chrome_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-hacking-bank-account_orig.jpg
|
||||
@ -1,71 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Getting started with Mu, a Python editor for beginners
|
||||
======
|
||||
|
||||

|
||||
|
||||
Mu is a Python editor for beginning programmers, designed to make the learning experience more pleasant. It gives students the ability to experience success early on, which is important anytime you're learning something new.
|
||||
|
||||
If you have ever tried to teach young people how to program, you will immediately grasp the importance of [Mu][1]. Most programming tools are written by developers for developers and aren't well-suited for beginning programmers, regardless of their age. Mu, however, was written by a teacher for students.
|
||||
|
||||
### Mu's origins
|
||||
|
||||
Mu is the brainchild of [Nicholas Tollervey][2] (who I heard speak at PyCon2018 in May). Nicholas is a classically trained musician who became interested in Python and development early in his career while working as a music teacher. He also wrote [Python in Education][3], a free book you can download from O'Reilly.
|
||||
|
||||
Nicholas was looking for a simpler interface for Python programming. He wanted something without the complexity of other editors—even the IDLE3 editor that comes with Python—so he worked with [Carrie Ann Philbin][4] , director of education at the Raspberry Pi Foundation (which sponsored his work), to develop Mu.
|
||||
|
||||
Mu is an open source application (licensed under [GNU GPLv3][5]) written in Python. It was originally developed to work with the [Micro:bit][6] mini-computer, but feedback and requests from other teachers spurred him to rewrite Mu into a generic Python editor.
|
||||
|
||||
### Inspired by music
|
||||
|
||||
Nicholas' inspiration for Mu came from his approach to teaching music. He wondered what would happen if we taught programming the way we teach music and immediately saw the disconnect. Unlike with programming, we don't have music boot camps and we don't learn to play an instrument from a book on, say, how to play the flute.
|
||||
|
||||
Nicholas says, Mu "aims to be the real thing," because no one can learn Python in 30 minutes. As he developed Mu, he worked with teachers, observed coding clubs, and watched secondary school students as they worked with Python. He found that less is more and keeping things simple improves the finished product's functionality. Mu is only about 3,000 lines of code, Nicholas says.
|
||||
|
||||
### Using Mu
|
||||
|
||||
To try it out, [download][7] Mu and follow the easy installation instructions for [Linux, Windows, and Mac OS][8]. If, like me, you want to [install it on Raspberry Pi][9], enter the following in the terminal:
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install mu
|
||||
|
||||
```
|
||||
|
||||
Launch Mu from the Programming menu. Then you'll have a choice about how you will use Mu.
|
||||
|
||||

|
||||
|
||||
I chose Python 3, which launches an environment to write code; the Python shell is directly below, which allows you to see the code execution.
|
||||
|
||||

|
||||
|
||||
The menu is very simple to use and understand, which achieves Mu's purpose—making coding easy for beginning programmers.
|
||||
|
||||
[Tutorials][10] and other resources are available on the Mu users' website. On the site, you can also see names of some of the [volunteers][11] who helped develop Mu. If you would like to become one of them and [contribute to Mu's development][12], you are most welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://codewith.mu
|
||||
[2]:https://us.pycon.org/2018/speaker/profile/194/
|
||||
[3]:https://www.oreilly.com/programming/free/python-in-education.csp
|
||||
[4]:https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7
|
||||
[5]:https://mu.readthedocs.io/en/latest/license.html
|
||||
[6]:http://microbit.org/
|
||||
[7]:https://codewith.mu/en/download
|
||||
[8]:https://codewith.mu/en/howto/install_with_python
|
||||
[9]:https://codewith.mu/en/howto/install_raspberry_pi
|
||||
[10]:https://codewith.mu/en/tutorials/
|
||||
[11]:https://codewith.mu/en/thanks
|
||||
[12]:https://mu.readthedocs.io/en/latest/contributing.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
UNIX curiosities
|
||||
======
|
||||
Recently I've been doing more UNIXy things in various tools I'm writing, and I hit two interesting issues. Neither of these are "bugs", but behaviors that I wasn't expecting.
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
Learn Python programming the easy way with EduBlocks
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you are you looking for a way to move your students (or yourself) from programming in [Scratch][1] to learning [Python][2], I recommend you look into [EduBlocks][3]. It brings a familiar drag-and-drop graphical user interface (GUI) to Python 3 programming.
|
||||
|
||||
One of the barriers when transitioning from Scratch to Python is the absence of the drag-and-drop GUI that has made Scratch the go-to application in K-12 schools. EduBlocks' drag-and-drop version of Python 3 changes that paradigm. It aims to "help teachers to introduce text-based programming languages, like Python, to children at an earlier age."
|
||||
|
||||
The hardware requirements for EduBlocks are quite modest—a Raspberry Pi and an internet connection—and should be available in many classrooms.
|
||||
|
||||
EduBlocks was developed by Joshua Lowe, a 14-year-old Python developer from the United Kingdom. I saw Joshua demonstrate his project at [PyCon 2018][4] in May 2018.
|
||||
|
||||
### Getting started
|
||||
|
||||
It's easy to install EduBlocks. The website provides clear installation instructions, and you can find detailed screenshots in the project's [GitHub][5] repository.
|
||||
|
||||
Install EduBlocks from the Raspberry Pi command line by issuing the following command:
|
||||
```
|
||||
curl -sSL get.edublocks.org | bash
|
||||
|
||||
```
|
||||
|
||||
### Programming EduBlocks
|
||||
|
||||
Once the installation is complete, launch EduBlocks from either the desktop shortcut or the Programming menu on the Raspberry Pi.
|
||||
|
||||

|
||||
|
||||
Once you launch the application, you can start creating Python 3 code with EduBlocks' drag-and-drop interface. Its menus are clearly labeled. You can start with sample code by clicking the **Samples** menu button. You can also choose a different color scheme for your programming palette by clicking **Theme**. With the **Save** menu, you can save your code as you work, then **Download** your Python code. Click **Run** to execute and test your code.
|
||||
|
||||
You can see your code by clicking the **Blockly** button at the far right. It allows you to toggle between the "Blockly" interface and the normal Python code view (as you would see in any other Python editor).
|
||||
|
||||

|
||||
|
||||
EduBlocks comes with a range of code libraries, including [EduPython][6], [Minecraft][7], [Sonic Pi][8], [GPIO Zero][9], and [Sense Hat][10].
|
||||
|
||||
### Learning and support
|
||||
|
||||
The project maintains a [learning portal][11] with tutorials and other resources for easily [hacking][12] the version of Minecraft that comes with Raspberry Pi, programming the GPIOZero and Sonic Pi, and controlling LEDs with the Micro:bit code editor. Support for EduBlocks is available on Twitter [@edu_blocks][13] and [@all_about_code][14] and through [email][15].
|
||||
|
||||
For a deeper dive, you can access EduBlocks' source code on [GitHub][16]; the application is [licensed][17] under GNU Affero General Public License v3.0. EduBlocks' creators (project lead [Joshua Lowe][18] and fellow developers [Chris Dell][19] and [Les Pounder][20]) want it to be a community project and invite people to open issues, provide feedback, and submit pull requests to add features or fixes to the project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/edublocks
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://scratch.mit.edu/
|
||||
[2]:https://www.python.org/
|
||||
[3]:https://edublocks.org/
|
||||
[4]:https://us.pycon.org/2018/about/
|
||||
[5]:https://github.com/AllAboutCode/EduBlocks
|
||||
[6]:https://edupython.tuxfamily.org/
|
||||
[7]:https://minecraft.net/en-us/edition/pi/
|
||||
[8]:https://sonic-pi.net/
|
||||
[9]:https://gpiozero.readthedocs.io/en/stable/
|
||||
[10]:https://www.raspberrypi.org/products/sense-hat/
|
||||
[11]:https://edublocks.org/learn.html
|
||||
[12]:https://edublocks.org/resources/1.pdf
|
||||
[13]:https://twitter.com/edu_blocks?lang=en
|
||||
[14]:https://twitter.com/all_about_code
|
||||
[15]:mailto:support@edublocks.org
|
||||
[16]:https://github.com/allaboutcode/edublocks
|
||||
[17]:https://github.com/AllAboutCode/EduBlocks/blob/tarball-install/LICENSE
|
||||
[18]:https://github.com/JoshuaLowe1002
|
||||
[19]:https://twitter.com/cjdell?lang=en
|
||||
[20]:https://twitter.com/biglesp?lang=en
|
||||
@ -1,3 +1,5 @@
|
||||
translating by pityonline
|
||||
|
||||
What is CI/CD?
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,111 @@
|
||||
5 reasons the i3 window manager makes Linux better
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the nicest things about Linux (and open source software in general) is the freedom to choose among different alternatives to address our needs.
|
||||
|
||||
I've been using Linux for a long time, but I was never entirely happy with the desktop environment options available. Until last year, [Xfce][1] was the closest to what I consider a good compromise between features and performance. Then I found [i3][2], an amazing piece of software that changed my life.
|
||||
|
||||
I3 is a tiling window manager. The goal of a window manager is to control the appearance and placement of windows in a windowing system. Window managers are often used as part a full-featured desktop environment (such as GNOME or Xfce), but some can also be used as standalone applications.
|
||||
|
||||
A tiling window manager automatically arranges the windows to occupy the whole screen in a non-overlapping way. Other popular tiling window managers include [wmii][3] and [xmonad][4].
|
||||
|
||||
![i3 tiled window manager screenshot][6]
|
||||
|
||||
Screenshot of i3 with three tiled windows
|
||||
|
||||
Following are the top five reasons I use the i3 window manager and recommend it for a better Linux desktop experience.
|
||||
|
||||
### 1\. Minimalism
|
||||
|
||||
I3 is fast. It is neither bloated nor fancy. It is designed to be simple and efficient. As a developer, I value these features, as I can use the extra capacity to power my favorite development tools or test stuff locally using containers or virtual machines.
|
||||
|
||||
In addition, i3 is a window manager and, unlike full-featured desktop environments, it does not dictate the applications you should use. Do you want to use Thunar from Xfce as your file manager? GNOME's gedit to edit text? I3 does not care. Pick the tools that make the most sense for your workflow, and i3 will manage them all in the same way.
|
||||
|
||||
### 2\. Screen real estate
|
||||
|
||||
As a tiling window manager, i3 will automatically "tile" or position the windows in a non-overlapping way, similar to laying tiles on a wall. Since you don't need to worry about window positioning, i3 generally makes better use of your screen real estate. It also allows you to get to what you need faster.
|
||||
|
||||
There are many useful cases for this. For example, system administrators can open several terminals to monitor or work on different remote systems simultaneously; and developers can use their favorite IDE or editor and a few terminals to test their programs.
|
||||
|
||||
In addition, i3 is flexible. If you need more space for a particular window, enable full-screen mode or switch to a different layout, such as stacked or tabbed.
|
||||
|
||||
### 3\. Keyboard-driven workflow
|
||||
|
||||
I3 makes extensive use of keyboard shortcuts to control different aspects of your environment. These include opening the terminal and other programs, resizing and positioning windows, changing layouts, and even exiting i3. When you start using i3, you need to memorize a few of those shortcuts to get around and, with time, you'll use more of them.
|
||||
|
||||
The main benefit is that you don't often need to switch contexts from the keyboard to the mouse. With practice, it means you'll improve the speed and efficiency of your workflow.
|
||||
|
||||
For example, to open a new terminal, press `<SUPER>+<ENTER>`. Since the windows are automatically positioned, you can start typing your commands right away. Combine that with a nice terminal-driven text editor (e.g., Vim) and a keyboard-focused browser for a fully keyboard-driven workflow.
|
||||
|
||||
In i3, you can define shortcuts for everything. Here are some examples:
|
||||
|
||||
* Open terminal
|
||||
* Open browser
|
||||
* Change layouts
|
||||
* Resize windows
|
||||
* Control music player
|
||||
* Switch workspaces
|
||||
|
||||
|
||||
|
||||
Now that I am used to this workflow, I can't see myself going back to a regular desktop environment.
|
||||
|
||||
### 4\. Flexibility
|
||||
|
||||
I3 strives to be minimal and use few system resources, but that does not mean it can't be pretty. I3 is flexible and can be customized in several ways to improve the visual experience. Because i3 is a window manager, it doesn't provide tools to enable customizations; you need external tools for that. Some examples:
|
||||
|
||||
* Use `feh` to define a background picture for your desktop.
|
||||
* Use a compositor manager such as `compton` to enable effects like window fading and transparency.
|
||||
* Use `dmenu` or `rofi` to enable customizable menus that can be launched from a keyboard shortcut.
|
||||
* Use `dunst` for desktop notifications.
|
||||
|
||||
|
||||
|
||||
I3 is fully configurable, and you can control every aspect of it by updating the default configuration file. From changing all keyboard shortcuts, to redefining the name of the workspaces, to modifying the status bar, you can make i3 behave in any way that makes the most sense for your needs.
|
||||
|
||||
![i3 with rofi menu and dunst desktop notifications][8]
|
||||
|
||||
i3 with `rofi` menu and `dunst` desktop notifications
|
||||
|
||||
Finally, for more advanced users, i3 provides a full interprocess communication ([IPC][9]) interface that allows you to use your favorite language to develop scripts or programs for even more customization options.
|
||||
|
||||
### 5\. Workspaces
|
||||
|
||||
In i3, a workspace is an easy way to group windows. You can group them in different ways according to your workflow. For example, you can put the browser on one workspace, the terminal on another, an email client on a third, etc. You can even change i3's configuration to always assign specific applications to their own workspaces.
|
||||
|
||||
Switching workspaces is quick and easy. As usual in i3, do it with a keyboard shortcut. Press `<SUPER>+num` to switch to workspace `num`. If you get into the habit of always assigning applications/groups of windows to the same workspace, you can quickly switch between them, which makes workspaces a very useful feature.
|
||||
|
||||
In addition, you can use workspaces to control multi-monitor setups, where each monitor gets an initial workspace. If you switch to that workspace, you switch to that monitor—without moving your hand off the keyboard.
|
||||
|
||||
Finally, there is another, special type of workspace in i3: the scratchpad. It is an invisible workspace that shows up in the middle of the other workspaces by pressing a shortcut. This is a convenient way to access windows or programs that you frequently use, such as an email client or your music player.
|
||||
|
||||
### Give it a try
|
||||
|
||||
If you value simplicity and efficiency and are not afraid of working with the keyboard, i3 is the window manager for you. Some say it is for advanced users, but that is not necessarily the case. You need to learn a few basic shortcuts to get around at the beginning, but they'll soon feel natural and you'll start using them without thinking.
|
||||
|
||||
This article just scratches the surface of what i3 can do. For more details, consult [i3's documentation][10].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/i3-tiling-window-manager
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rgerardi
|
||||
[1]:https://xfce.org/
|
||||
[2]:https://i3wm.org/
|
||||
[3]:https://code.google.com/archive/p/wmii/
|
||||
[4]:https://xmonad.org/
|
||||
[5]:/file/406476
|
||||
[6]:https://opensource.com/sites/default/files/uploads/i3_screenshot.png (i3 tiled window manager screenshot)
|
||||
[7]:/file/405161
|
||||
[8]:https://opensource.com/sites/default/files/uploads/rofi_dunst.png (i3 with rofi menu and dunst desktop notifications)
|
||||
[9]:https://i3wm.org/docs/ipc.html
|
||||
[10]:https://i3wm.org/docs/userguide.html
|
||||
@ -0,0 +1,90 @@
|
||||
5 applications to manage your to-do list on Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
Effective management of your to-do list can do wonders for your productivity. Some prefer just keeping a to-do list in a text file, or even just using a notepad and pen. For users that want more out of their to-do list, they often turn to an application. In this article we highlight 4 graphical applications and a terminal-based tool for managing your to-do list.
|
||||
|
||||
### GNOME To Do
|
||||
|
||||
[GNOME To Do][1] is a personal task manager designed specifically for the GNOME desktop (Fedora Workstation’s default desktop). When comparing GNOME To Do with some others in this list, it is has a range of neat features.
|
||||
|
||||
GNOME To Do provides organization of tasks by lists, and the ability to assign a colour to that list. Additionally, individual tasks can be assigned due dates & priorities, and notes for each task. Futhermore, GNOME To Do has extensions, allowing even more features, including support for [todo.txt][2] and syncing with online services such as [todoist][3].
|
||||
|
||||
![][4]
|
||||
|
||||
Install GNOME To Do either by using the Software application, or using the following command in the Terminal:
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Getting things GNOME!
|
||||
|
||||
Before GNOME To Do existed, the go-to application for tracking tasks on GNOME was [Getting things GNOME!][5] This older-style GNOME application has a multiple window layout, allowing you to show the details of multiple tasks at the same time. Rather than having lists of tasks, GTG has the ability to add sub-tasks to tasks and even to sub-tasks. GTG also has the ability to add due dates and start dates. Syncing to other apps and services is also possible in GTG via plugins.
|
||||
|
||||
![][6]
|
||||
|
||||
Install Getting Things GNOME either by using the Software application, or using the following command in the Terminal:
|
||||
```
|
||||
sudo dnf install gtg
|
||||
|
||||
```
|
||||
|
||||
### Go For It!
|
||||
|
||||
[Go For It!][7] is a super-simple task management application. It is used to simply create a list of tasks, and mark them as done when completed. It does not have the ability to group tasks, or create sub-tasks. By default, Go For It! stored tasks in the todo.txt format, allowing simpler syncing to online services and other applications. Additionally, Go For It! contains a simple timer to track how much time you have spent on the current task.
|
||||
|
||||
![][8]
|
||||
|
||||
Go For It is available to download from the Flathub application repository. To install, simply [enable Flathub as a software source][9], and then install via the Software application.
|
||||
|
||||
### Agenda
|
||||
|
||||
If you are looking for a no-fuss super simple to-do application, look no further than [Agenda][10]. Create tasks, mark them as complete, and then delete them from your list. Agenda shows all tasks (completed or open) until you remove them.
|
||||
|
||||
![][11]
|
||||
|
||||
Agenda is available to download from the Flathub application repository. To install, simply [enable Flathub as a software source][9], and then install via the Software application.
|
||||
|
||||
### Taskwarrior
|
||||
|
||||
[Taskwarrior][12] is a flexible command-line task management program. It is highly customizable, but can also be used “right out of the box.” Using simple commands, you can create tasks, mark them as complete, and list current open tasks. Additionally, tasks can be tagged, added to projects, searched and filtered. Furthermore, you can set up recurring tasks, and apply due dates to tasks.
|
||||
|
||||
[This previous article on the Fedora Magazine][13] provides a good overview of getting started with Taskwarrior.
|
||||
|
||||
![][14]
|
||||
|
||||
Install Taskwarrior with this command in the Terminal:
|
||||
```
|
||||
sudo dnf install task
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[1]:https://wiki.gnome.org/Apps/Todo/
|
||||
[2]:http://todotxt.org/
|
||||
[3]:https://en.todoist.com/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/08/gnome-todo.png
|
||||
[5]:https://wiki.gnome.org/Apps/GTG
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/gtg.png
|
||||
[7]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/08/goforit.png
|
||||
[9]:https://fedoramagazine.org/install-flathub-apps-fedora/
|
||||
[10]:https://github.com/dahenson/agenda
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/08/agenda.png
|
||||
[12]:https://taskwarrior.org/
|
||||
[13]:https://fedoramagazine.org/getting-started-taskwarrior/
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2018/08/taskwarrior.png
|
||||
@ -0,0 +1,106 @@
|
||||
translated by hopefully2333
|
||||
|
||||
5 open source role-playing games for Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games are often not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
|
||||
|
||||
So, can someone who only uses free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website in order to install and play it.
|
||||
|
||||
This article looks at role-playing games. I have already written about [arcade-style games][1], [board & card games][2], [puzzle games][3], and [racing & flying games][4]. In the final article in this series, I plan to cover strategy and simulation games.
|
||||
|
||||
### Endless Sky
|
||||
|
||||
|
||||
|
||||
[Endless Sky][5] is an open source clone of the [Escape Velocity][6] series from Ambrosia Software. Players captain a spaceship and travel between worlds delivering trade goods or passengers, taking on other missions along the way, or they can turn to piracy and steal from cargo ships. The game lets the player decide how they want to experience the game, and the extremely large map of solar systems is theirs to explore as they see fit. Endless Sky is one of those games that defies normal genre classifications, but this action, role-playing, space simulation, trading game is well worth checking out.
|
||||
|
||||
To install Endless Sky, run the following command:
|
||||
|
||||
On Fedora: `dnf install endless-sky`
|
||||
|
||||
On Debian/Ubuntu: `apt install endless-sky`
|
||||
|
||||
### FreeDink
|
||||
|
||||
|
||||
|
||||
[FreeDink][7] is the open source version of [Dink Smallwood][8], an action role-playing game released by RTSoft in 1997. Dink Smallwood became freeware in 1999, and the source code was released in 2003. In 2008 the game's data files, minus a few sound files, were also released under an open license. FreeDink replaces those sound files with alternatives to provide a complete game. Gameplay is similar to Nintendo's [The Legend of Zelda][9] series. The player's character, the eponymous Dink Smallwood, explores an over-world map filled with hidden items and caves as he moves from one quest to another. Due to its age, FreeDink is not going to stand up to modern commercial games, but it is still a fun game with an amusing story. The game can be expanded by using [D-Mods][10], which are add-on modules that provide additional quests, but the D-Mods do vary greatly in complexity, quality, and age-appropriateness; the main game is suitable for teenagers, but some of the add-ons are for adult audiences.
|
||||
|
||||
To install FreeDink, run the following command:
|
||||
|
||||
On Fedora: `dnf install freedink`
|
||||
|
||||
On Debian/Ubuntu: `apt install freedink`
|
||||
|
||||
### ManaPlus
|
||||
|
||||
|
||||
|
||||
Technically not a game in itself, [ManaPlus][11] is a client for accessing various massive multi-player online role-playing games. [The Mana World][12] and [Evol Online][13] are the two of the open source games available, but other servers are out there. The games feature 2D sprite graphics reminiscent of Super Nintendo games. While none of the games supported by ManaPlus are as popular as some of the commercial alternatives, they do have interesting worlds and at least a few players are online most of the time. Players are unlikely to run into massive groups of other players, but there are usually enough people around to make the games [MMORPG][14]s, not single-player games that require a connection to a server. The Mana World and Evol Online developers have joined together for future development, but for now, The Mana World's legacy server and Evol Online offer different experiences.
|
||||
|
||||
To install ManaPlus, run the following command:
|
||||
|
||||
On Fedora: `dnf install manaplus`
|
||||
|
||||
On Debian/Ubuntu: `apt install manaplus`
|
||||
|
||||
### Minetest
|
||||
|
||||
|
||||
|
||||
Explore and build in an open-ended world with [Minetest][15], a clone of Minecraft. Just like the game it is based on, Minetest provides an open-ended world where players can explore and build whatever they wish. Minetest provides a wide variety of block types and tools, making it a good alternative to Minecraft for anyone wanting a more open alternative. Beyond what comes with the basic game, Minetest can be extended with [add-on modules][16], which add even more options.
|
||||
|
||||
To install Minetest, run the following command:
|
||||
|
||||
On Fedora: `dnf install minetest`
|
||||
|
||||
On Debian/Ubuntu: `apt install minetest`
|
||||
|
||||
### NetHack
|
||||
|
||||
|
||||
|
||||
[NetHack][17] is a classic [Roguelike][18] role-playing game. Players explore a multi-level dungeon as one of several different character races, classes, and alignments. The object of the game is to retrieve the Amulet of Yendor. Players begin on the first level of the dungeon and try to work their way towards the bottom, with each level being randomly generated, which makes for a unique game experience each time. While this game features either ASCII graphics or basic tile graphics, the depth of game-play more than makes up for the primitive graphics. Players who want less primitive graphics might want to check out [Vulture for NetHack][19], which offers better graphics along with sound effects and background music.
|
||||
|
||||
To install NetHack, run the following command:
|
||||
|
||||
On Fedora: `dnf install nethack`
|
||||
|
||||
On Debian/Ubuntu: `apt install nethack-x11 or apt install nethack-console`
|
||||
|
||||
Did I miss one of your favorite open source role-playing games? Share it in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/role-playing-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://opensource.com/article/18/6/puzzle-games-linux
|
||||
[4]:https://opensource.com/article/18/7/racing-flying-games-linux
|
||||
[5]:https://endless-sky.github.io/
|
||||
[6]:https://en.wikipedia.org/wiki/Escape_Velocity_(video_game)
|
||||
[7]:http://www.gnu.org/software/freedink/
|
||||
[8]:http://www.rtsoft.com/pages/dink.php
|
||||
[9]:https://en.wikipedia.org/wiki/The_Legend_of_Zelda
|
||||
[10]:http://www.dinknetwork.com/files/category_dmod/
|
||||
[11]:http://manaplus.org/
|
||||
[12]:http://www.themanaworld.org/
|
||||
[13]:http://evolonline.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Massively_multiplayer_online_role-playing_game
|
||||
[15]:https://www.minetest.net/
|
||||
[16]:https://wiki.minetest.net/Mods
|
||||
[17]:https://www.nethack.org/
|
||||
[18]:https://en.wikipedia.org/wiki/Roguelike
|
||||
[19]:http://www.darkarts.co.za/vulture-for-nethack
|
||||
@ -0,0 +1,334 @@
|
||||
Getting started with Postfix, an open source mail transfer agent
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Postfix][1] is a great program that routes and delivers email to accounts that are external to the system. It is currently used by approximately [33% of internet mail servers][2]. In this article, I'll explain how you can use Postfix to send mail using Gmail with two-factor authentication enabled.
|
||||
|
||||
Before you get Postfix up and running, however, you need to have some items lined up. Following are instructions on how to get it working on a number of distros.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
* An installed OS (Ubuntu/Debian/Fedora/Centos/Arch/FreeBSD/OpenSUSE)
|
||||
* A Google account with two-factor authentication
|
||||
* A working internet connection
|
||||
|
||||
|
||||
|
||||
### Step 1: Prepare Google
|
||||
|
||||
Open a web browser and log into your Google account. Once you’re in, go to your settings by clicking your picture and selecting "Google Account.” Click “Sign-in & security” and scroll down to "App passwords.” Use your password to log in. Then you can create a new app password (I named mine "postfix Setup”).
|
||||
|
||||
|
||||
|
||||
Note the crazy password (shown below), which I will use throughout this article.
|
||||
|
||||
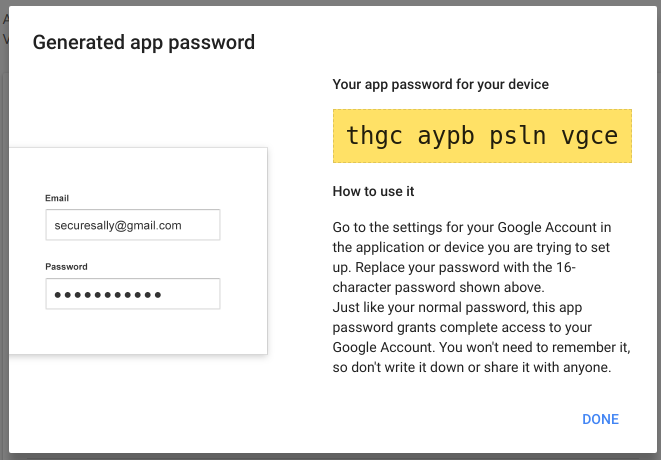
|
||||
|
||||
### Step 2: Install Postfix
|
||||
|
||||
Before you can configure the mail client, you need to install it. You must also install either the `mailutils` or `mailx` utility, depending on the OS you're using. Here's how to install it for each OS:
|
||||
|
||||
**Debian/Ubuntu** :
|
||||
```
|
||||
apt-get update && apt-get install postfix mailutils
|
||||
|
||||
```
|
||||
|
||||
**Fedora** :
|
||||
```
|
||||
dnf update && dnf install postfix mailx
|
||||
|
||||
```
|
||||
|
||||
**Centos** :
|
||||
```
|
||||
yum update && yum install postfix mailx cyrus-sasl cyrus-sasl-plain
|
||||
|
||||
```
|
||||
|
||||
**Arch** :
|
||||
```
|
||||
pacman -Sy postfix mailutils
|
||||
|
||||
```
|
||||
|
||||
**FreeBSD** :
|
||||
```
|
||||
portsnap fetch extract update
|
||||
|
||||
cd /usr/ports/mail/postfix
|
||||
|
||||
make config
|
||||
|
||||
```
|
||||
|
||||
In the configuration dialog, select "SASL support." All other options can remain the same.
|
||||
|
||||
From there: `make install clean`
|
||||
|
||||
Install `mailx` from the binary package: `pkg install mailx`
|
||||
|
||||
**OpenSUSE** :
|
||||
```
|
||||
zypper update && zypper install postfix mailx cyrus-sasl
|
||||
|
||||
```
|
||||
|
||||
### Step 3: Set up Gmail authentication
|
||||
|
||||
Once you've installed Postfix, you can set up Gmail authentication. Since you have created the app password, you need to put it in a configuration file and lock it down so no one else can see it. Fortunately, this is simple to do:
|
||||
|
||||
**Ubuntu/Debian/Fedora/Centos/Arch/OpenSUSE** :
|
||||
```
|
||||
vim /etc/postfix/sasl_passwd
|
||||
|
||||
```
|
||||
|
||||
Add this line:
|
||||
```
|
||||
[smtp.gmail.com]:587 ben.heffron@gmail.com:thgcaypbpslnvgce
|
||||
|
||||
```
|
||||
|
||||
Save and close the file. Since your Gmail password is stored as plaintext, make the file accessible only by root to be extra safe.
|
||||
```
|
||||
chmod 600 /etc/postfix/sasl_passwd
|
||||
|
||||
```
|
||||
|
||||
**FreeBSD** :
|
||||
```
|
||||
vim /usr/local/etc/postfix/sasl_passwd
|
||||
|
||||
```
|
||||
|
||||
Add this line:
|
||||
```
|
||||
[smtp.gmail.com]:587 ben.heffron@gmail.com:thgcaypbpslnvgce
|
||||
|
||||
```
|
||||
|
||||
Save and close the file. Since your Gmail password is stored as plaintext, make the file accessible only by root to be extra safe.
|
||||
```
|
||||
chmod 600 /usr/local/etc/postfix/sasl_passwd
|
||||
|
||||
```
|
||||
|
||||
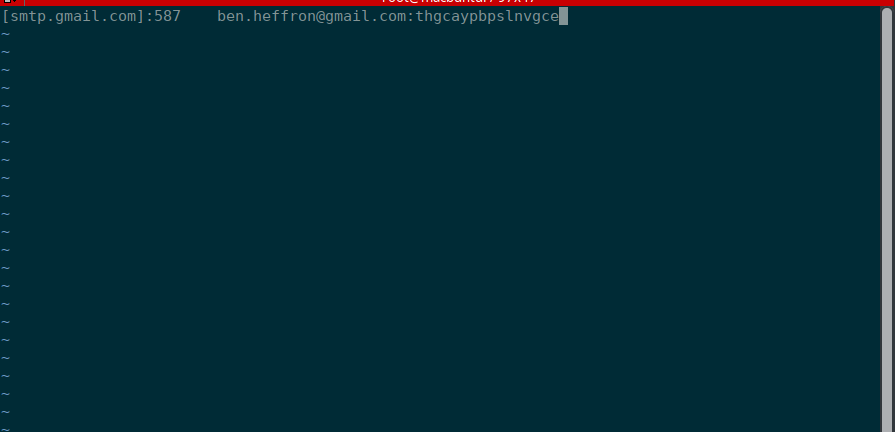
|
||||
|
||||
### Step 4: Get Postfix moving
|
||||
|
||||
This step is the "meat and potatoes"—everything you've done so far has been preparation.
|
||||
|
||||
Postfix gets its configuration from the `main.cf` file, so the settings in this file are critical. For Google, it is mandatory to enable the correct SSL settings.
|
||||
|
||||
Here are the six options you need to enter or update on the `main.cf` to make it work with Gmail (from the [SASL readme][3]):
|
||||
|
||||
* The **smtp_sasl_auth_enable** setting enables client-side authentication. We will configure the client’s username and password information in the second part of the example.
|
||||
* The **relayhost** setting forces the Postfix SMTP to send all remote messages to the specified mail server instead of trying to deliver them directly to their destination.
|
||||
* With the **smtp_sasl_password_maps** parameter, we configure the Postfix SMTP client to send username and password information to the mail gateway server.
|
||||
* Postfix SMTP client SASL security options are set using **smtp_sasl_security_options** , with a whole lot of options. In this case, it will be nothing; otherwise, Gmail won’t play nicely with Postfix.
|
||||
* The **smtp_tls_CAfile** is a file containing CA certificates of root CAs trusted to sign either remote SMTP server certificates or intermediate CA certificates.
|
||||
* From the [configure settings page:][4] **stmp_use_tls** uses TLS when a remote SMTP server announces STARTTLS support, the default is not using TLS.
|
||||
|
||||
|
||||
|
||||
**Ubuntu/Debian/Arch**
|
||||
|
||||
These three OSes keep their files (certificates and `main.cf`) in the same location, so this is all you need to put in there:
|
||||
```
|
||||
vim /etc/postfix/main.cf
|
||||
|
||||
```
|
||||
|
||||
If the following values aren’t there, add them:
|
||||
```
|
||||
relayhost = [smtp.gmail.com]:587
|
||||
|
||||
smtp_use_tls = yes
|
||||
|
||||
smtp_sasl_auth_enable = yes
|
||||
|
||||
smtp_sasl_security_options =
|
||||
|
||||
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
|
||||
|
||||
smtp_tls_CAfile = /etc/ssl/certs/ca-certificates.crt
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
**Fedora/CentOS**
|
||||
|
||||
These two OSes are based on the same underpinnings, so they share the same updates.
|
||||
```
|
||||
vim /etc/postfix/main.cf
|
||||
|
||||
```
|
||||
|
||||
If the following values aren’t there, add them:
|
||||
```
|
||||
relayhost = [smtp.gmail.com]:587
|
||||
|
||||
smtp_use_tls = yes
|
||||
|
||||
smtp_sasl_auth_enable = yes
|
||||
|
||||
smtp_sasl_security_options =
|
||||
|
||||
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
|
||||
|
||||
smtp_tls_CAfile = /etc/ssl/certs/ca-bundle.crt
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
**OpenSUSE**
|
||||
```
|
||||
vim /etc/postfix/main.cf
|
||||
|
||||
```
|
||||
|
||||
If the following values aren’t there, add them:
|
||||
```
|
||||
relayhost = [smtp.gmail.com]:587
|
||||
|
||||
smtp_use_tls = yes
|
||||
|
||||
smtp_sasl_auth_enable = yes
|
||||
|
||||
smtp_sasl_security_options =
|
||||
|
||||
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
|
||||
|
||||
smtp_tls_CAfile = /etc/ssl/ca-bundle.pem
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
OpenSUSE also requires that you modify the Postfix master process configuration file `master.cf`. Open it for editing:
|
||||
```
|
||||
vim /etc/postfix/master.cf
|
||||
|
||||
```
|
||||
|
||||
Uncomment the line that reads:
|
||||
```
|
||||
#tlsmgr unix - - n 1000? 1 tlsmg
|
||||
|
||||
```
|
||||
|
||||
It should look like this:
|
||||
```
|
||||
tlsmgr unix - - n 1000? 1 tlsmg
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
**FreeBSD**
|
||||
```
|
||||
vim /usr/local/etc/postfix/main.cf
|
||||
|
||||
```
|
||||
|
||||
If the following values aren’t there, add them:
|
||||
```
|
||||
relayhost = [smtp.gmail.com]:587
|
||||
|
||||
smtp_use_tls = yes
|
||||
|
||||
smtp_sasl_auth_enable = yes
|
||||
|
||||
smtp_sasl_security_options =
|
||||
|
||||
smtp_sasl_password_maps = hash:/usr/local/etc/postfix/sasl_passwd
|
||||
|
||||
smtp_tls_CAfile = /etc/mail/certs/cacert.pem
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
### Step 5: Set up the password file
|
||||
|
||||
Remember that password file you created? Now you need to feed it into Postfix using `postmap`. This is part of the `mailutils` or `mailx` utilities.
|
||||
|
||||
**Debian, Ubuntu, Fedora, CentOS, OpenSUSE, Arch Linux**
|
||||
```
|
||||
postmap /etc/postfix/sasl_passwd
|
||||
|
||||
```
|
||||
|
||||
**FreeBSD**
|
||||
```
|
||||
postmap /usr/local/etc/postfix/sasl_passwd
|
||||
|
||||
```
|
||||
|
||||
### Step 6: Get Postfix grooving
|
||||
|
||||
To get all the settings and configurations working, you must restart Postfix.
|
||||
|
||||
**Debian, Ubuntu, Fedora, CentOS, OpenSUSE, Arch Linux**
|
||||
|
||||
These guys make it simple to restart:
|
||||
```
|
||||
systemctl restart postfix.service
|
||||
|
||||
```
|
||||
|
||||
**FreeBSD**
|
||||
|
||||
To start Postfix at startup, edit `/etc/rc.conf`:
|
||||
```
|
||||
vim /etc/rc.conf
|
||||
|
||||
```
|
||||
|
||||
Add the line:
|
||||
```
|
||||
postfix_enable=YES
|
||||
|
||||
```
|
||||
|
||||
Save and close the file. Then start Postfix by running:
|
||||
```
|
||||
service postfix start
|
||||
|
||||
```
|
||||
|
||||
### Step 7: Test it
|
||||
|
||||
Now for the big finale—time to test it to see if it works. The `mail` command is another tool installed with `mailutils` or `mailx`.
|
||||
```
|
||||
echo Just testing my sendmail gmail relay" | mail -s "Sendmail gmail Relay" ben.heffron@gmail.com
|
||||
|
||||
```
|
||||
|
||||
This is what I used to test my settings, and then it came up in my Gmail.
|
||||
|
||||
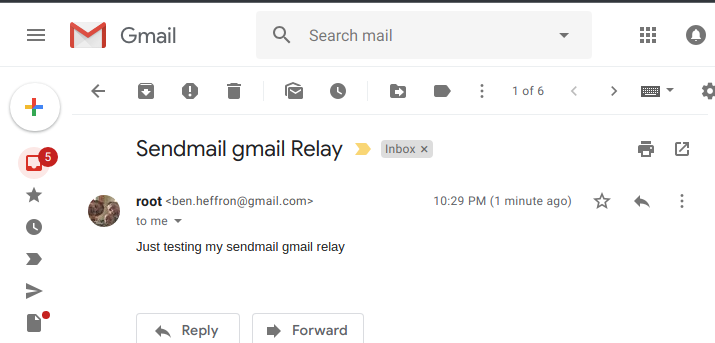
|
||||
|
||||
Now you can use Gmail with two-factor authentication in your Postfix setup.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/postfix-open-source-mail-transfer-agent
|
||||
|
||||
作者:[Ben Heffron][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/elheffe
|
||||
[1]:http://www.postfix.org/start.html
|
||||
[2]:http://www.securityspace.com/s_survey/data/man.201806/mxsurvey.html
|
||||
[3]:http://www.postfix.org/SASL_README.html
|
||||
[4]:http://www.postfix.org/postconf.5.html#smtp_tls_security_level
|
||||
@ -0,0 +1,130 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Switch Between Multiple PHP Versions In Ubuntu
|
||||
======
|
||||
|
||||

|
||||
|
||||
Sometimes, the most recent version of an installed package might not work as you expected. Your application may not compatible with the updated package and support only a specific old version of package. In such cases, you can simply downgrade the problematic package to its earlier working version in no time. Refer our old guides on how to downgrade a package in Ubuntu and its variants [**here**][1] and how to downgrade a package in Arch Linux and its derivatives [**here**][2]. However, you need not to downgrade some packages. We can use multiple versions at the same time. For instance, let us say you are testing a PHP application in [**LAMP stack**][3] deployed in Ubuntu 18.04 LTS. After a while you find out that the application worked fine in PHP5.6, but not in PHP 7.2 (Ubuntu 18.04 LTS installs PHP 7.x by default). Are you going to reinstall PHP or the whole LAMP stack again? Not necessary, though. You don’t even have to downgrade the PHP to its earlier version. In this brief tutorial, I will show you how to switch between multiple PHP versions in Ubuntu 18.04 LTS. It’s not that difficult as you may think. Read on.
|
||||
|
||||
### Switch Between Multiple PHP Versions
|
||||
|
||||
To check the default installed version of PHP, run:
|
||||
```
|
||||
$ php -v
|
||||
PHP 7.2.7-0ubuntu0.18.04.2 (cli) (built: Jul 4 2018 16:55:24) ( NTS )
|
||||
Copyright (c) 1997-2018 The PHP Group
|
||||
Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies
|
||||
with Zend OPcache v7.2.7-0ubuntu0.18.04.2, Copyright (c) 1999-2018, by Zend Technologies
|
||||
|
||||
```
|
||||
|
||||
As you can see, the installed version of PHP is 7.2.7. After testing your application for couple days, you find out that your application doesn’t support PHP7.2. In such cases, it is a good idea to have both PHP5.x version and PHP7.x version, so that you can easily switch between to/from any supported version at any time.
|
||||
|
||||
You don’t need to remove PHP7.x or reinstall LAMP stack. You can use both PHP5.x and 7.x versions together.
|
||||
|
||||
I assume you didn’t uninstall php5.6 in your system yet. Just in case, you removed it already, you can install it again using a PPA like below.
|
||||
|
||||
You can install PHP5.6 from a PPA:
|
||||
```
|
||||
$ sudo add-apt-repository -y ppa:ondrej/php
|
||||
$ sudo apt update
|
||||
$ sudo apt install php5.6
|
||||
|
||||
```
|
||||
|
||||
#### Switch from PHP7.x to PHP5.x
|
||||
|
||||
First disable PHP7.2 module using command:
|
||||
```
|
||||
$ sudo a2dismod php7.2
|
||||
Module php7.2 disabled.
|
||||
To activate the new configuration, you need to run:
|
||||
systemctl restart apache2
|
||||
|
||||
```
|
||||
|
||||
Next, enable PHP5.6 module:
|
||||
```
|
||||
$ sudo a2enmod php5.6
|
||||
|
||||
```
|
||||
|
||||
Set PHP5.6 as default version:
|
||||
```
|
||||
$ sudo update-alternatives --set php /usr/bin/php5.6
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can run the following command to to set which system wide version of PHP you want to use by default.
|
||||
```
|
||||
$ sudo update-alternatives --config php
|
||||
|
||||
```
|
||||
|
||||
Enter the selection number to set it as default version or simply press ENTER to keep the current choice.
|
||||
|
||||
In case, you have installed other PHP extensions, set them as default as well.
|
||||
```
|
||||
$ sudo update-alternatives --set phar /usr/bin/phar5.6
|
||||
|
||||
```
|
||||
|
||||
Finally, restart your Apache web server:
|
||||
```
|
||||
$ sudo systemctl restart apache2
|
||||
|
||||
```
|
||||
|
||||
Now, check if PHP5.6 is the default version or not:
|
||||
```
|
||||
$ php -v
|
||||
PHP 5.6.37-1+ubuntu18.04.1+deb.sury.org+1 (cli)
|
||||
Copyright (c) 1997-2016 The PHP Group
|
||||
Zend Engine v2.6.0, Copyright (c) 1998-2016 Zend Technologies
|
||||
with Zend OPcache v7.0.6-dev, Copyright (c) 1999-2016, by Zend Technologies
|
||||
|
||||
```
|
||||
|
||||
#### Switch from PHP5.x to PHP7.x
|
||||
|
||||
Likewise, you can switch from PHP5.x to PHP7.x version as shown below.
|
||||
```
|
||||
$ sudo a2enmod php7.2
|
||||
|
||||
$ sudo a2dismod php5.6
|
||||
|
||||
$ sudo update-alternatives --set php /usr/bin/php7.2
|
||||
|
||||
$ sudo systemctl restart apache2
|
||||
|
||||
```
|
||||
|
||||
**A word of caution:**
|
||||
|
||||
The final stable PHP5.6 version has reached the [**end of active support**][4] as of 19 Jan 2017. However, PHP 5.6 will continue to receive support for critical security issues until 31 Dec 2018. So, It is recommended to upgrade all your PHP applications to be compatible with PHP7.x as soon as possible.
|
||||
|
||||
If you want prevent PHP to be automatically upgraded in future, refer the following guide.
|
||||
|
||||
And, that’s all for now. Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-switch-between-multiple-php-versions-in-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/how-to-downgrade-a-package-in-ubuntu/
|
||||
[2]:https://www.ostechnix.com/downgrade-package-arch-linux/
|
||||
[3]:https://www.ostechnix.com/install-apache-mariadb-php-lamp-stack-ubuntu-16-04/
|
||||
[4]:http://php.net/supported-versions.php
|
||||
@ -0,0 +1,176 @@
|
||||
Perform robust unit tests with PyHamcrest
|
||||
======
|
||||
|
||||

|
||||
|
||||
At the base of the [testing pyramid][1] are unit tests. Unit tests test one unit of code at a time—usually one function or method.
|
||||
|
||||
Often, a single unit test is designed to test one particular flow through a function, or a specific branch choice. This enables easy mapping of a unit test that fails and the bug that made it fail.
|
||||
|
||||
Ideally, unit tests use few or no external resources, isolating them and making them faster.
|
||||
|
||||
_Good_ tests increase developer productivity by catching bugs early and making testing faster. _Bad_ tests decrease developer productivity.
|
||||
|
||||
Unit test suites help maintain high-quality products by signaling problems early in the development process. An effective unit test catches bugs before the code has left the developer machine, or at least in a continuous integration environment on a dedicated branch. This marks the difference between good and bad unit tests:tests increase developer productivity by catching bugs early and making testing faster.tests decrease developer productivity.
|
||||
|
||||
Productivity usually decreases when testing _incidental features_. The test fails when the code changes, even if it is still correct. This happens because the output is different, but in a way that is not part of the function's contract.
|
||||
|
||||
A good unit test, therefore, is one that helps enforce the contract to which the function is committed.
|
||||
|
||||
If a unit test breaks, the contract is violated and should be either explicitly amended (by changing the documentation and tests), or fixed (by fixing the code and leaving the tests as is).
|
||||
|
||||
While limiting tests to enforce only the public contract is a complicated skill to learn, there are tools that can help.
|
||||
|
||||
One of these tools is [Hamcrest][2], a framework for writing assertions. Originally invented for Java-based unit tests, today the Hamcrest framework supports several languages, including [Python][3].
|
||||
|
||||
Hamcrest is designed to make test assertions easier to write and more precise.
|
||||
```
|
||||
def add(a, b):
|
||||
|
||||
return a + b
|
||||
|
||||
|
||||
|
||||
from hamcrest import assert_that, equal_to
|
||||
|
||||
|
||||
|
||||
def test_add():
|
||||
|
||||
assert_that(add(2, 2), equal_to(4))
|
||||
|
||||
```
|
||||
|
||||
This is a simple assertion, for simple functionality. What if we wanted to assert something more complicated?
|
||||
```
|
||||
def test_set_removal():
|
||||
|
||||
my_set = {1, 2, 3, 4}
|
||||
|
||||
my_set.remove(3)
|
||||
|
||||
assert_that(my_set, contains_inanyorder([1, 2, 4]))
|
||||
|
||||
assert_that(my_set, is_not(has_item(3)))
|
||||
|
||||
```
|
||||
|
||||
Note that we can succinctly assert that the result has `1`, `2`, and `4` in any order since sets do not guarantee order.
|
||||
|
||||
We also easily negate assertions with `is_not`. This helps us write _precise assertions_ , which allow us to limit ourselves to enforcing public contracts of functions.
|
||||
|
||||
Sometimes, however, none of the built-in functionality is _precisely_ what we need. In those cases, Hamcrest allows us to write our own matchers.
|
||||
|
||||
Imagine the following function:
|
||||
```
|
||||
def scale_one(a, b):
|
||||
|
||||
scale = random.randint(0, 5)
|
||||
|
||||
pick = random.choice([a,b])
|
||||
|
||||
return scale * pick
|
||||
|
||||
```
|
||||
|
||||
We can confidently assert that the result divides into at least one of the inputs evenly.
|
||||
|
||||
A matcher inherits from `hamcrest.core.base_matcher.BaseMatcher`, and overrides two methods:
|
||||
```
|
||||
class DivisibleBy(hamcrest.core.base_matcher.BaseMatcher):
|
||||
|
||||
|
||||
|
||||
def __init__(self, factor):
|
||||
|
||||
self.factor = factor
|
||||
|
||||
|
||||
|
||||
def _matches(self, item):
|
||||
|
||||
return (item % self.factor) == 0
|
||||
|
||||
|
||||
|
||||
def describe_to(self, description):
|
||||
|
||||
description.append_text('number divisible by')
|
||||
|
||||
description.append_text(repr(self.factor))
|
||||
|
||||
```
|
||||
|
||||
Writing high-quality `describe_to` methods is important, since this is part of the message that will show up if the test fails.
|
||||
```
|
||||
def divisible_by(num):
|
||||
|
||||
return DivisibleBy(num)
|
||||
|
||||
```
|
||||
|
||||
By convention, we wrap matchers in a function. Sometimes this gives us a chance to further process the inputs, but in this case, no further processing is needed.
|
||||
```
|
||||
def test_scale():
|
||||
|
||||
result = scale_one(3, 7)
|
||||
|
||||
assert_that(result,
|
||||
|
||||
any_of(divisible_by(3),
|
||||
|
||||
divisible_by(7)))
|
||||
|
||||
```
|
||||
|
||||
Note that we combined our `divisible_by` matcher with the built-in `any_of` matcher to ensure that we test only what the contract commits to.
|
||||
|
||||
While editing this article, I heard a rumor that the name "Hamcrest" was chosen as an anagram for "matches". Hrm...
|
||||
```
|
||||
>>> assert_that("matches", contains_inanyorder(*"hamcrest")
|
||||
|
||||
Traceback (most recent call last):
|
||||
|
||||
File "<stdin>", line 1, in <module>
|
||||
|
||||
File "/home/moshez/src/devops-python/build/devops/lib/python3.6/site-packages/hamcrest/core/assert_that.py", line 43, in assert_that
|
||||
|
||||
_assert_match(actual=arg1, matcher=arg2, reason=arg3)
|
||||
|
||||
File "/home/moshez/src/devops-python/build/devops/lib/python3.6/site-packages/hamcrest/core/assert_that.py", line 57, in _assert_match
|
||||
|
||||
raise AssertionError(description)
|
||||
|
||||
AssertionError:
|
||||
|
||||
Expected: a sequence over ['h', 'a', 'm', 'c', 'r', 'e', 's', 't'] in any order
|
||||
|
||||
but: no item matches: 'r' in ['m', 'a', 't', 'c', 'h', 'e', 's']
|
||||
|
||||
```
|
||||
|
||||
Researching more, I found the source of the rumor: It is an anagram for "matchers".
|
||||
```
|
||||
>>> assert_that("matchers", contains_inanyorder(*"hamcrest"))
|
||||
|
||||
>>>
|
||||
|
||||
```
|
||||
|
||||
If you are not yet writing unit tests for your Python code, now is a good time to start. If you are writing unit tests for your Python code, using Hamcrest will allow you to make your assertion _precise_ —neither more nor less than what you intend to test. This will lead to fewer false positives when modifying code and less time spent modifying tests for working code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/robust-unit-tests-hamcrest
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/moshez
|
||||
[1]:https://martinfowler.com/bliki/TestPyramid.html
|
||||
[2]:http://hamcrest.org/
|
||||
[3]:https://www.python.org/
|
||||
@ -0,0 +1,77 @@
|
||||
6 Reasons Why Linux Users Switch to BSD
|
||||
======
|
||||
Thus far I have written several articles about [BSD][1] for It’s FOSS. There is always at least one person in the comments asking “Why bother with BSD?” I figure that the best way to respond was to write an article on the topic.
|
||||
|
||||
### Why use BSD over Linux?
|
||||
|
||||
In preparation for this article, I chatted with several BSD users, some of whom moved to BSD after using Linux for years. The points in this article are based on the opinions of real BSD users. This article hopes to offer a different viewpoint.
|
||||
|
||||
![why use bsd over linux][2]
|
||||
|
||||
#### 1\. BSD is More than Just a Kernel
|
||||
|
||||
Several people pointed out that BSD offers an operating system that is one big cohesive package to the end-user. They point out that the named “Linux” refers to just the kernel. A Linux distro consists of the aforementioned kernel and a number of different applications and packages selected by the creator of that distro. Sometimes installing new packages can cause incompatibility, which will lead to system crashes.
|
||||
|
||||
A typical BSD consists of a kernel and all of the packages that it needs to get things done. The majority of these packages are actively developed by the project. This leads to tighter integration and improved responsiveness.
|
||||
|
||||
#### 2\. Packages are More Trustworthy
|
||||
|
||||
Speaking of packages, another point that the BSD users raised was the trustworthiness of packages. In Linux, packages are available from a bunch of different sources, some provided by distro developers and others by third parties. [Ubuntu][3] and [other distros][4] have encountered issues with malware hidden in third-party apps.
|
||||
|
||||
In BSD, all packages are provided by “a centralized package/ports system with every package getting built as part of a single repository with security systems in place each step of the way”. This ensures that a hacker can’t sneak malicious software into a seemingly-safe application and lends to the long-term stability of BSD.
|
||||
|
||||
#### 3\. Slow Change = Better Long-Term Stability
|
||||
|
||||
If development was a race, Linux would be the rabbit and BSD the turtle. Even the slowest Linux distro releases a new version at least once a year (except Debian, of course). In the BSD world, major releases take longer. This means that there is more of a focus on getting things right then getting them pushed out to the user.
|
||||
|
||||
This also means that changes to the operating system happen over time. The Linux world has experienced several rapid and major changes that we still feel to this day (cough, [systemD][5], cough). Like with Debian, long development cycles help BSD to test new ideas to make sure they work properly before making them permanent. It also helps to produce code less likely to have issues.
|
||||
|
||||
#### 4\. Linux is Too Cluttered
|
||||
|
||||
None of the BSD users made this point outright, but it was suggested by many of their experiences. Many of them bounced from Linux distro to Linux distro in the quest to find one that worked for them. In many instances, they could not get all of their hardware or software to work correctly. Then, they decided to give BSD a try and everything just worked.
|
||||
|
||||
When it came to choosing which BSD they were going to use, the choice was fairly easy. There are only half a dozen BSDs that are being actively developed. Of those BSDs, each one has a specific purpose. “[OpenBSD][6] security, [FreeBSD][7] more desktop/server, [NetBSD][8] “run on anything and everything”, [DragonFlyBSD][9] scaling and performance.” Meanwhile, the Linux world is full of distros that just add a theme or icon pack to an existing distro. The smaller number of BSD projects means that there is less duplication of effort and more overall focus.
|
||||
|
||||
#### 5\. ZFS Support
|
||||
|
||||
One BSD user noted that one of the main reasons that he switched to BSD was [ZFS][10]. In fact almost all of the people I talked to mentioned ZFS support on BSD as the reason they did not return to Linux.
|
||||
|
||||
This is an area where Linux will lose out on for the time being. While [OpenZFS][11] is available on some Linux distros, ZFS is built into the BSD kernels. This alone means that ZFS will have better performance on BSD. While there have been several attempts to get ZFS into the Linux kernel, licensing issues will be solved first.
|
||||
|
||||
#### 6\. License
|
||||
|
||||
There was also a difference of opinion on licenses. The general idea held by many is the GPL is not truly free because it put limits on how you can make use of the software. Some also think that the GPL is “too large and difficult to interpret which can lead to legal problems down the road if a person is not careful when developing a product with this license”.
|
||||
|
||||
On the other hand, the BSD license only has three clauses and allows anyone to “take the software, make changes, and do whatever you want with it, but it also offers protection to the developer”.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
These are just a few of the reason why people use BSD over Linux. If you want, you can read some of the other comments [here][12]. If you are a BSD user and feel I missed something important, please comment below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/why-use-bsd/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://itsfoss.com/category/bsd/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/why-BSD.png
|
||||
[3]:https://itsfoss.com/snapstore-cryptocurrency-saga/
|
||||
[4]:https://www.bleepingcomputer.com/news/security/malware-found-in-arch-linux-aur-package-repository/
|
||||
[5]:https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[6]:https://www.openbsd.org/
|
||||
[7]:https://www.freebsd.org/
|
||||
[8]:http://netbsd.org/
|
||||
[9]:http://www.dragonflybsd.org/
|
||||
[10]:https://en.wikipedia.org/wiki/ZFS
|
||||
[11]:http://open-zfs.org/wiki/Main_Page
|
||||
[12]:https://discourse.trueos.org/t/why-do-you-guys-use-bsd/2601
|
||||
[13]:http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,77 @@
|
||||
translating---geekpi
|
||||
|
||||
Automatically Switch To Light / Dark Gtk Themes Based On Sunrise And Sunset Times With AutomaThemely
|
||||
======
|
||||
If you're looking for an easy way of automatically changing the Gtk theme based on sunrise and sunset times, give [AutomaThemely][3] a try.
|
||||
|
||||
|
||||
|
||||
**AutomaThemely is a Python application that automatically changes Gnome themes according to light and dark hours, useful if you want to use a dark Gtk theme at night and a light Gtk theme during the day.**
|
||||
|
||||
**While the application is made for the Gnome desktop, it also works with Unity**. AutomaThemely does not support changing the Gtk theme for desktop environments that don't make use of the `org.gnome.desktop.interface Gsettings` , like Cinnamon, or changing the icon theme, at least not yet. It also doesn't support setting the Gnome Shell theme.
|
||||
|
||||
Besides automatically changing the Gtk3 theme, **AutomaThemely can also automatically switch between dark and light themes for Atom editor and VSCode, as well as between light and dark syntax highlighting for Atom editor.** This is obviously also done based the time of day.
|
||||
|
||||
[![AutomaThemely Atom VSCode][1]][2]
|
||||
AutomaThemely Atom and VSCode theme / syntax settings
|
||||
|
||||
The application uses your IP address to determine your location in order to retrieve the sunrise and sunset times, and requires a working Internet connection for this. However, you can disable automatic location from the application user interface, and enter your location manually.
|
||||
|
||||
From the AutomaThemely user interface you can also enter a time offset (in minutes) for the sunrise and sunset times, and enable or disable notifications on theme changes.
|
||||
|
||||
### Downloading / installing AutomaThemely
|
||||
|
||||
**Ubuntu 18.04** : using the link above, download the Python 3.6 DEB which includes dependencies (python3.6-automathemely_1.2_all.deb).
|
||||
|
||||
**Ubuntu 16.04:** you'll need to download and install the AutomaThemely Python 3.5 DEB which DOES NOT include dependencies (python3.5-no_deps-automathemely_1.2_all.deb), and install the dependencies (`requests` , `astral` , `pytz` , `tzlocal` and `schedule`) separately, using PIP3:
|
||||
```
|
||||
sudo apt install python3-pip
|
||||
python3 -m pip install --user requests astral pytz tzlocal schedule
|
||||
|
||||
```
|
||||
|
||||
The AutomaThemely download page also includes RPM packages for Python 3.5 or 3.6, with and without dependencies. Install the package appropriate for your Python version. If you download the package that includes dependencies and they are not available on your system, grab the "no_deps" package and install the Python3 dependencies using PIP3, as explained above.
|
||||
|
||||
### Using AutomaThemely to change to light / dark Gtk themes based on Sun times
|
||||
|
||||
Once installed, run AutomaThemely once to generate the configuration file. Either click on the AutomaThemely menu entry or run this in a terminal:
|
||||
```
|
||||
automathemely
|
||||
|
||||
```
|
||||
|
||||
This doesn't run any GUI, it only generates the configuration file.
|
||||
|
||||
Using AutomaThemely is a bit counter intuitive. You'll get an AutomaThemely icon in your menu but clicking it does not open any window / GUI. If you use Gnome or some other Gnome-based desktop that supports jumplists / quicklists, you can right click the AutomaThemely icon in the menu (or you can pin it to Dash / dock and right click it there) and select Manage Settings to launch the GUI:
|
||||
|
||||
|
||||
|
||||
You can also launch the AutomaThemely GUI from the command line, using:
|
||||
```
|
||||
automathemely --manage
|
||||
|
||||
```
|
||||
|
||||
**Once you configure the themes you want to use, you'll need to update the Sun times and restart the AutomaThemely scheduler**. You can do this by right clicking on the AutomaThemely icon (should work in Unity / Gnome) and selecting `Update sun times` , and then `Restart the scheduler` . You can also do this from a terminal, using these commands:
|
||||
```
|
||||
automathemely --update
|
||||
automathemely --restart
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/automatically-switch-to-light-dark-gtk.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://4.bp.blogspot.com/-K2-1K_MIWv0/W2q9GEWYA6I/AAAAAAAABUg/-z_gTMSHlxgN-ZXDvUGIeTQ8I72WrRq0ACLcBGAs/s640/automathemely-settings_2.png (AutomaThemely Atom VSCode)
|
||||
[2]:https://4.bp.blogspot.com/-K2-1K_MIWv0/W2q9GEWYA6I/AAAAAAAABUg/-z_gTMSHlxgN-ZXDvUGIeTQ8I72WrRq0ACLcBGAs/s1600/automathemely-settings_2.png
|
||||
[3]:https://github.com/C2N14/AutomaThemely
|
||||
142
sources/tech/20180810 How To Remove Or Disable Ubuntu Dock.md
Normal file
142
sources/tech/20180810 How To Remove Or Disable Ubuntu Dock.md
Normal file
@ -0,0 +1,142 @@
|
||||
How To Remove Or Disable Ubuntu Dock
|
||||
======
|
||||
|
||||

|
||||
|
||||
**If you want to replace the Ubuntu Dock in Ubuntu 18.04 with some other dock (like Plank dock for example) or panel, and you want to remove or disable the Ubuntu Dock, here's what you can do and how.**
|
||||
|
||||
Ubuntu Dock - the bar on the left-hand side of the screen which can be used to pin applications and access installed applications -
|
||||
|
||||
|
||||
### How to access the Activities Overview without Ubuntu Dock
|
||||
|
||||
Without Ubuntu Dock, you may have no way of accessing the Activities / installed application list (which can be accessed from Ubuntu Dock by clicking on Show Applications button at the bottom of the dock). For example if you want to use Plank dock.
|
||||
|
||||
Obviously, that's not the case if you install Dash to Panel extension to use it instead Ubuntu Dock, because Dash to Panel provides a button to access the Activities Overview / installed applications.
|
||||
|
||||
Depending on what you plan to use instead of Ubuntu Dock, if there's no way of accessing the Activities Overview, you can enable the Activities Overview Hot Corner option and simply move your mouse to the upper left corner of the screen to open the Activities. Another way of accessing the installed application list is using a keyboard shortcut: `Super + A` .
|
||||
|
||||
If you want to enable the Activities Overview hot corner, use this command:
|
||||
```
|
||||
gsettings set org.gnome.shell enable-hot-corners true
|
||||
|
||||
```
|
||||
|
||||
If later you want to undo this and disable the hot corners, you need to use this command:
|
||||
```
|
||||
gsettings set org.gnome.shell enable-hot-corners false
|
||||
|
||||
```
|
||||
|
||||
You can also enable or disable the Activities Overview Hot Corner option by using the Gnome Tweaks application (the option is in the `Top Bar` section of Gnome Tweaks), which can be installed by using this command:
|
||||
```
|
||||
sudo apt install gnome-tweaks
|
||||
|
||||
```
|
||||
|
||||
### How to remove or disable Ubuntu Dock
|
||||
|
||||
Below you'll find 4 ways of getting rid of Ubuntu Dock which work in Ubuntu 18.04.
|
||||
|
||||
**Option 1: Remove the Gnome Shell Ubuntu Dock package.**
|
||||
|
||||
The easiest way of getting rid of the Ubuntu Dock is to remove the package.
|
||||
|
||||
This completely removes the Ubuntu Dock extension from your system, but it also removes the `ubuntu-desktop` meta package. There's no immediate issue if you remove the `ubuntu-desktop` meta package because does nothing by itself. The `ubuntu-meta` package depends on a large number of packages which make up the Ubuntu Desktop. Its dependencies won't be removed and nothing will break. The issue is that if you want to upgrade to a newer Ubuntu version, any new `ubuntu-desktop` dependencies won't be installed.
|
||||
|
||||
As a way around this, you can simply install the `ubuntu-desktop` meta package before upgrading to a newer Ubuntu version (for example if you want to upgrade from Ubuntu 18.04 to 18.10).
|
||||
|
||||
If you're ok with this and want to remove the Ubuntu Dock extension package from your system, use the following command:
|
||||
```
|
||||
sudo apt remove gnome-shell-extension-ubuntu-dock
|
||||
|
||||
```
|
||||
|
||||
If later you want to undo the changes, simply install the extension back using this command:
|
||||
```
|
||||
sudo apt install gnome-shell-extension-ubuntu-dock
|
||||
|
||||
```
|
||||
|
||||
Or to install the `ubuntu-desktop` meta package back (this will install any ubuntu-desktop dependencies you may have removed, including Ubuntu Dock), you can use this command:
|
||||
```
|
||||
sudo apt install ubuntu-desktop
|
||||
|
||||
```
|
||||
|
||||
**Option 2: Install and use the vanilla Gnome session instead of the default Ubuntu session.**
|
||||
|
||||
Another way to get rid of Ubuntu Dock is to install and use the vanilla Gnome session. Installing the vanilla Gnome session will also install other packages this session depends on, like Gnome Documents, Maps, Music, Contacts, Photos, Tracker and more.
|
||||
|
||||
By installing the vanilla Gnome session, you'll also get the default Gnome GDM login / lock screen theme instead of the Ubuntu defaults as well as Adwaita Gtk theme and icons. You can easily change the Gtk and icon theme though, by using the Gnome Tweaks application.
|
||||
|
||||
Furthermore, the AppIndicators extension will be disabled by default (so applications that make use of the AppIndicators tray won't show up on the top panel), but you can enable this by using Gnome Tweaks (under Extensions, enable the Ubuntu appindicators extension).
|
||||
|
||||
In the same way, you can also enable or disable Ubuntu Dock from the vanilla Gnome session, which is not possible if you use the Ubuntu session (disabling Ubuntu Dock from Gnome Tweaks when using the Ubuntu session does nothing).
|
||||
|
||||
If you don't want to install these extra packages required by the vanilla Gnome session, this option of removing Ubuntu Dock is not for you so check out the other options.
|
||||
|
||||
If you are ok with this though, here's what you need to do. To install the vanilla Gnome session in Ubuntu, use this command:
|
||||
```
|
||||
sudo apt install vanilla-gnome-desktop
|
||||
|
||||
```
|
||||
|
||||
After the installation finishes, reboot your system and on the login screen, after you click on your username, click the gear icon next to the `Sign in` button, and select `GNOME` instead of `Ubuntu` , then proceed to login:
|
||||
|
||||
|
||||
|
||||
In case you want to undo this and remove the vanilla Gnome session, you can purge the vanilla Gnome package and then remove the dependencies it installed (second command) using the following commands:
|
||||
```
|
||||
sudo apt purge vanilla-gnome-desktop
|
||||
sudo apt autoremove
|
||||
|
||||
```
|
||||
|
||||
Then reboot and select Ubuntu in the same way, from the GDM login screen.
|
||||
|
||||
**Option 3: Permanently hide the Ubuntu Dock from your desktop instead of removing it.**
|
||||
|
||||
If you prefer to permanently hide the Ubuntu Dock from showing up on your desktop instead of uninstalling it or using the vanilla Gnome session, you can easily do this using Dconf Editor. The drawback to this is that Ubuntu Dock will still use some system resources even though you're not using in on your desktop, but you'll also be able to easily revert this without installing or removing any packages.
|
||||
|
||||
Ubuntu Dock is only hidden from your desktop though. When you go in overlay mode (Activities), you'll still see and be able to use Ubuntu Dock from there.
|
||||
|
||||
To permanently hide Ubuntu Dock, use Dconf Editor to navigate to `/org/gnome/shell/extensions/dash-to-dock` and disable (set them to false) the following options: `autohide` , `dock-fixed` and `intellihide` .
|
||||
|
||||
You can achieve this from the command line if you wish, buy running the commands below:
|
||||
```
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock autohide false
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed false
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide false
|
||||
|
||||
```
|
||||
In case you change your mind and you want to undo this, you can either use Dconf Editor and re-enable (set them to true) autohide, dock-fixed and intellihide from `/org/gnome/shell/extensions/dash-to-dock` , or you can use these commands:
|
||||
```
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock autohide true
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed true
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide true
|
||||
|
||||
```
|
||||
|
||||
**Option 4: Use Dash to Panel extension.**
|
||||
|
||||
You can install Dash to Panel from
|
||||
|
||||
If you change your mind and you want Ubuntu Dock back, you can either disable Dash to Panel by using Gnome Tweaks app, or completely remove Dash to Panel by clicking the X button next to it from here:
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/how-to-remove-or-disable-ubuntu-dock.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://bugs.launchpad.net/ubuntu/+source/gnome-tweak-tool/+bug/1713020
|
||||
[2]:https://www.linuxuprising.com/2018/05/gnome-shell-dash-to-panel-v14-brings.html
|
||||
[3]:https://extensions.gnome.org/extension/1160/dash-to-panel/
|
||||
@ -0,0 +1,78 @@
|
||||
translating---geekpi
|
||||
|
||||
Image creation applications for Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
Feeling creative? There are a multitude of applications available for Fedora to aid your creativity. From digital painting, vectors, to pixel art there is something for everyone to get creative this weekend. This article highlights a selection of the applications available for Fedora for creating awesome images.
|
||||
|
||||
### Vector graphics: Inkscape
|
||||
|
||||
[Inkscape][1] is a well known and loved Open Source vector graphics editor. SVG is the primary file format of Inkscape, so all your drawings will scale no-problems! Inkscape has been around for many years, so there is a solid community and [mountains of tutorials and other resources][2] for getting started.
|
||||
|
||||
Being a vector graphics editor, Inkscape is better suited towards simpler illustrations (for example a simple comics style). However, using vector blurs, some artists create some [amazing vector drawings][3].
|
||||
|
||||
![][4]
|
||||
|
||||
Install Inkscape from the Software application in Fedora Workstation, or use the following command in Terminal:
|
||||
```
|
||||
sudo dnf install inkscape
|
||||
|
||||
```
|
||||
|
||||
### Digital Painting: Krita & Mypaint
|
||||
|
||||
[Krita][5] is a popular image creation application for digital painting, raster illustration, and texturing. Additionally, Krita is an active project, with a vibrant community — so [lots of tutorials to get started][6]. Krita features multiple brush engines, a UI with pop-up palletes, a wrap-around mode for creating seamless patterns, filters, layers, and much more.
|
||||
|
||||
![][7]
|
||||
|
||||
Install Krita from the Software application in Fedora Workstation, or use the following command in Terminal:
|
||||
```
|
||||
sudo dnf install krita
|
||||
|
||||
```
|
||||
|
||||
[Mypaint][8] is another amazing digital painting application available for Fedora. Like Krita, it has multiple brushes and the ability to use layers.
|
||||
|
||||
![][9]
|
||||
|
||||
Install Mypaint from the Software application in Fedora Workstation, or use the following command in Terminal:
|
||||
```
|
||||
sudo dnf install mypaint
|
||||
|
||||
```
|
||||
|
||||
### Pixel Art: Libresprite
|
||||
|
||||
[Libresprite][10] is an application designed for the creation of pixel art and pixel animations. It supports a range of colour modes and exports to many formats (including animated GIF). Additionally, Libresprite has drawing tools designed for the creation of pixel art: the polygon tool, and contour & shading tools.
|
||||
|
||||
![][11]
|
||||
|
||||
Libresprite is available to download from the Flathub application repository. To install, simply [enable Flathub as a software source][12], and then install via the Software application.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/image-creation-applications-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[1]:http://inkscape.org
|
||||
[2]:https://inkscape.org/en/learn/tutorials/
|
||||
[3]:https://inkscape.org/en/gallery/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/08/inkscape.png
|
||||
[5]:https://krita.org/en/
|
||||
[6]:https://docs.krita.org/en/
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/krita.jpg
|
||||
[8]:http://mypaint.org/about/
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/mypaint.png
|
||||
[10]:https://github.com/LibreSprite/LibreSprite
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/08/libresprite.gif
|
||||
[12]:https://fedoramagazine.org/install-flathub-apps-fedora/
|
||||
@ -0,0 +1,105 @@
|
||||
Strawberry: Quality sound, open source music player
|
||||
======
|
||||
|
||||

|
||||
|
||||
I recently received an email from [Jonas Kvinge][1] who forked the [Clementine open source music player][2]. Jonas writes:
|
||||
|
||||
I started working on a modified version of Clementine already in 2013, but because of other priorities, I did not pick up the work again before last year. I had not decided then if I was creating a fork, or contributing to Clementine. I ended up doing both. I started to see that I wanted the program development in a different direction. My focus was to create a music player for playing local music files, and not having to maintain support for multiple internet features that I did not use, and some which I did not want in the program at all… I also saw more and more that I disagree with the authors of Clementine and some statements that have been made regarding high-resolution audio.
|
||||
|
||||
Jonas and I are definitely working from the same perspective, at least in relation to high-resolution music files. Back in late 2016, [I looked at Clementine][3], and though it was in many ways delightful, it definitely missed the boat with respect to working with a dedicated high-resolution digital-analog converter (DAC) for music enjoyment. But that’s OK; Clementine just wasn’t built for me. Nor, it appears, was it for Jonas.
|
||||
|
||||
So, given that Jonas and I share an interest in being able to play back high-resolution audio on a dedicated listening device, I thought I’d best give [Strawberry][4], Jonas’ fork of Clementine, a try. I grabbed the [2018/07/16 release for Ubuntu][5] from Jonas’ site. It was a .deb and very straightforward to install.
|
||||
```
|
||||
sudo dpkg -i strawberry_0.2.1-27-gb2c26eb_amd64.deb
|
||||
|
||||
```
|
||||
|
||||
As usual, some necessary packages weren’t installed on my system, so I used `apt install -f` to remedy that.
|
||||
|
||||
Apt recommended the following packages:
|
||||
```
|
||||
graphicsmagick-dbg gxine xine-ui
|
||||
|
||||
```
|
||||
|
||||
and installed the following packages:
|
||||
```
|
||||
libgraphicsmagick-q16-3 libiso9660-10 liblastfm5-1 libqt5concurrent5 libvcdinfo0 libxine2 libxine2-bin libxine2-doc libxine2-ffmpeg libxine2-misc-plugins libxine2-plugins
|
||||
|
||||
```
|
||||
|
||||
Once that was all in hand, I started up Strawberry and saw this:
|
||||
|
||||
|
||||
|
||||
I verified that I could point Strawberry at ALSA in general and at my dedicated DAC in particular.
|
||||
|
||||
|
||||
|
||||
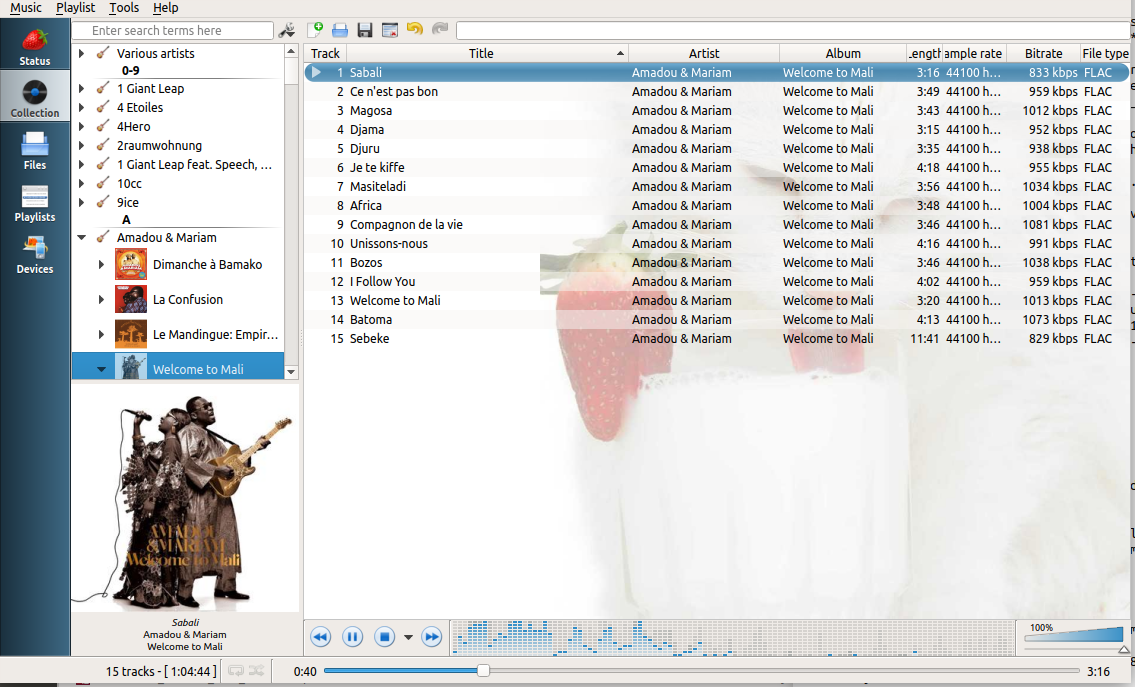
|
||||
|
||||
Then I was ready to update my collection, which took less than a minute (Clementine was similarly fast).
|
||||
|
||||
The only thing I noticed that seemed a little odd was that Strawberry provided a software volume control, which isn’t of great interest to me (my hardware has a nice shiny knob on top for just that purpose).
|
||||
|
||||
|
||||
|
||||
And then I got down to some quality listening. One of the things I found I liked right away is the status button (see the strawberry at the top left of the UI). This verifies the details of the currently playing track, as shown in the screen capture to the left. Note that the effective bit rate, bit rate, and word length are shown, as well as other useful information.
|
||||
|
||||
The sound is glorious, as is customary with well-recorded high-resolution material (for those of you inclined to argue about the merits of high-resolution audio, before you post your opinions, whether pro or con, please read [this article][6], which actually treats the topic in a scientific fashion).
|
||||
|
||||
What’s cool about Strawberry, besides audio quality? Well, it’s fun to see the spectrum analyzer operating on the bottom of the screen. The overall responsiveness is smooth and quick; the album cover slides up once the music starts. There isn’t a lot of wasted space in the UI. And, as Jonas says:
|
||||
|
||||
For many people, Clementine will still be a better choice since it has features such as scrobbling and internet services, which Strawberry lacks and I do not plan to include.
|
||||
|
||||
Evidently, this is a player focused on the quality of the music, rather than the quantity. I’ll be using this player more in the future; it’s right up my alley.
|
||||
|
||||
### Fine sound collections
|
||||
|
||||
On the topic of music, especially interesting and unusual music, many thanks to [Michael Lavorgna over at Audiostream][7], who mentions these two fine online sound collections: [Cultural Equity][8] and [Smithsonian Folkways Recordings][9]. What great sources for stuff that is of historical interest and just plain fun.
|
||||
|
||||
Also thanks to Michael for reminding me about [Ektoplazm][10], a fine free music portal for those interested in “psytrance, techno, and downtempo music.” I’ve downloaded a few albums from this site in the past, and when the mood strikes, I really appreciate what it has to offer. It's especially wonderful that the music files are available in [FLAC][11].
|
||||
|
||||
### And more music…
|
||||
|
||||
In my last article, I spent so much time building that I didn’t have any time for listening. But since then, I’ve been to my favorite record store and picked up four new albums, some of which came with downloads. First up is [Jon Hopkins’][12] [Singularity][12]. I’ve been picking up the odd Jon Hopkins album since [Linn Records][13] (by the way, a great site for Linux users to buy downloads since no bloatware is required) was experimenting with a more broad-based music offering and introduced me to Jon. Some of his work is [available on Bandcamp][14] these days (including Singularity) which is a fine Linux-friendly site. For me, this is a great album—not really ambient, not really beatless, not really anything except what it is. Huge powerful swaths of music, staggering bass. Great fun! Go listen on [Bandcamp][14].
|
||||
|
||||
And if, like me, you have bought a few [Putumayo Music][15] albums over the years, keep your eyes peeled for Putumayo’s absolutely wonderful vinyl LP release of [_Vintage Latino_][16]. This great LP of vintage salsa and cha-cha is also available there to buy as a CD; you can listen to [1:00 clips on Bandcamp][17].
|
||||
|
||||
[Bombino][18] was in town last night. I had other stuff to do, but a friend went to the concert and loved it. I have three of his albums now; the last two I purchased on that fine open source medium, the vinyl LP, which came with downloads as well. His most recent album, _Deran_ , is more than worth it; check it out on the link above.
|
||||
<https://www.youtube.com/embed/1PTj1qIqcWM>
|
||||
|
||||
Last but by no means least, I managed to find a copy of [Nils Frahm’s _All Melody_][19] on vinyl (which includes a download code). I’ve been enjoying the high-resolution digital version of this album that I bought earlier this year, but it’s great fun to have it on vinyl.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/strawberry-new-open-source-music-player
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://github.com/jonaski
|
||||
[2]:https://www.clementine-player.org/
|
||||
[3]:https://opensource.com/life/16/10/4-open-music-players-compared
|
||||
[4]:http://www.strawbs.org/
|
||||
[5]:http://builds.jkvinge.net/ubuntu/bionic/strawberry_0.2.1-27-gb2c26eb_amd64.deb
|
||||
[6]:http://www.aes.org/e-lib/browse.cfm?elib=18296
|
||||
[7]:https://www.audiostream.com/content/alan-lomax-17000-sound-recordings-online-free
|
||||
[8]:http://research.culturalequity.org/audio-guide.jsp
|
||||
[9]:https://folkways.si.edu/radio-and-playlists/smithsonian
|
||||
[10]:http://www.ektoplazm.com/
|
||||
[11]:https://xiph.org/flac/
|
||||
[12]:https://pitchfork.com/reviews/albums/jon-hopkins-singularity/
|
||||
[13]:http://www.linnrecords.com/
|
||||
[14]:https://jonhopkins.bandcamp.com/album/singularity
|
||||
[15]:https://www.putumayo.com/
|
||||
[16]:https://www.putumayo.com/product-page/vintage-latino
|
||||
[17]:https://putumayo.bandcamp.com/album/vintage-latino
|
||||
[18]:http://www.bombinomusic.com/
|
||||
[19]:https://www.youtube.com/watch?v=1PTj1qIqcWM
|
||||
@ -0,0 +1,77 @@
|
||||
Use Plank On Multiple Monitors Without Creating Multiple Docks With autoplank
|
||||
======
|
||||
|
||||
|
||||
|
||||
**[autoplank][1] is a small tool written in Go which adds multi-monitor support to Plank dock without having to create [multiple][2] docks.**
|
||||
|
||||
**When you move your mouse cursor to the bottom of a monitor, autoplank detect your mouse movement using** `xdotool` and it automatically moves Plank to that monitor. This tool **only works if Plank is set to run at the bottom of the screen** , at least for now.
|
||||
|
||||
There's a slight delay until Plank actually shows up on the monitor where the mouse is though. The developer says this is intentional, to make sure you actually want to access Plank on that monitor. The time delay before showing plank is not currently configurable, but that may change in the future.
|
||||
|
||||
autoplank should work with elementary OS, as well as any desktop environment or Linux distribution you use Plank dock on.
|
||||
|
||||
Plank is a simple dock that shows icons of running applications / windows. The application allows pinning applications to the dock, and comes with a few built-in simple "docklets": a clipboard manager, clock, CPU monitor, show desktop and trash. To access its settings, hold down the `Ctrl` key while right clicking anywhere on the Plank dock, and then clicking on `Preferences` .
|
||||
|
||||
Plank is used by default in elementary OS, but it can be used on any desktop environment or Linux distribution you wish.
|
||||
|
||||
### Install autoplank
|
||||
|
||||
On its GitHub page, it's mentioned that you need Go 1.8 or newer to build autoplank but I was able to successfully build it with Go 1.6 in Ubuntu 16.04 (elementary OS 0.4 Loki).
|
||||
|
||||
The developer has said on
|
||||
|
||||
**1\. Install required dependencies.**
|
||||
|
||||
To build autoplank you'll need Go (`golang-go` in Debian, Ubuntu, elementary OS, etc.). To get the latest Git code you'll also need `git` , and for detecting the monitor on which you move the mose, you'll also need to install `xdotool` .
|
||||
|
||||
Install these in Ubuntu, Debian, elementary OS and so on, by using this command:
|
||||
```
|
||||
sudo apt install git golang-go xdotool
|
||||
|
||||
```
|
||||
|
||||
**2\. Get the latest autoplank from[Git][1], build it, and install it in** `/usr/local/bin` :
|
||||
```
|
||||
git clone https://github.com/abiosoft/autoplank
|
||||
cd autoplank
|
||||
go build -o autoplank
|
||||
sudo mv autoplank /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
You can remove the autoplank folder from your home directory now.
|
||||
|
||||
When you want to uninstall autoplank, simply remove the `/usr/local/bin/autoplank` binary (`sudo rm /usr/local/bin/autoplank`).
|
||||
|
||||
**3\. Add autoplank to startup.**
|
||||
|
||||
If you want to try autoplank before adding it to startup or creating a systemd service for it, you can simply type `autoplank` in a terminal to start it.
|
||||
|
||||
To have autoplank work between reboots, you'll need to add it to your startup applications. The exact steps for doing this depend on your desktop environments, so I won't tell you exactly how to do that for every desktop environment, but remember to use `/usr/local/bin/autoplank` as the executable in Startup Applications.
|
||||
|
||||
In elementary OS, you can open `System Settings` , then in `Applications` , on the `Startup` tab, click the `+` button in the bottom left-hand side corner of the window, then add `/usr/local/bin/autoplank` in the `Type in a custom command` field:
|
||||
|
||||
|
||||
|
||||
**Another way of using autoplank is by creating a systemd service for it, as explained[here][3].** Using a systemd service for autoplank has the advantage of restarting autoplank if it crashes for whatever reason. Use either the systemd service or add autoplank to your startup applications (don't use both).
|
||||
|
||||
**4\. After you do this, logout, login and autoplank should be running so you can move the mouse at the bottom of a monitor to move Plank dock there.**
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/use-plank-on-multiple-monitors-without.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/abiosoft/autoplank
|
||||
[2]:https://answers.launchpad.net/plank/+question/204593
|
||||
[3]:https://github.com/abiosoft/autoplank#optional-create-a-service
|
||||
[4]:https://www.reddit.com/r/elementaryos/comments/95a879/autoplank_use_plank_on_multimonitor_setup/e3r9saq/
|
||||
129
sources/tech/20180812 Ubuntu 18.04 Vs. Fedora 28.md
Normal file
129
sources/tech/20180812 Ubuntu 18.04 Vs. Fedora 28.md
Normal file
@ -0,0 +1,129 @@
|
||||
Ubuntu 18.04 Vs. Fedora 28
|
||||
======
|
||||

|
||||
|
||||
Hello folks. Today I'll highlight some of the features and differences between the two popular Linux distros; **Ubuntu 18.04** and **Fedora 28** . Each has their own package management; Ubuntu uses DEB while Fedora uses RPM, but both of them features the same [Desktop Environment][3] ([GNOME][4]) and aims to provide quality desktop experience for the Linux users.
|
||||
|
||||
**Ubuntu 18.04** is the latest Ubuntu [LTS][1] release and comes equipped with GNOME desktop. So is Fedora 28 that also features GNOME desktop, but both of them provides a unique desktop experience when it comes down to their software management and of course their User Interfaces too.
|
||||
|
||||
### Quick Facts
|
||||
|
||||
Did you know that Ubuntu which is based on Debian, provides the latest software earlier than the latter one? An example is the popular web browser Firefox Quantum found on Ubuntu while Debian follows behind on the ESR (Extended Support Release) version of the same web browser.
|
||||
|
||||
|
||||
|
||||
The same applies to Fedora which provides cutting-edge software to the end users and also acts as the testing platform for the next stable RHEL (Red Hat Enterprise Linux) release.
|
||||
|
||||
### Desktop overview
|
||||
|
||||
Fedora provides vanilla GNOME desktop experience while Ubuntu 18.04 have tweaked certain aspects of the desktop to enable long-time Unity users a smooth transition to GNOME Desktop Environment.
|
||||
|
||||
_Canonical decided to save development time by ditching Unity and switching to GNOME desktop (starting from Ubuntu [17.10][2]) so they can focus more on IoT.
|
||||
_
|
||||
|
||||
So on Fedora, we have a clean icon-less desktop, a hidden panel on the overview and its look featuring GNOME default theme: Adwaita.
|
||||
|
||||
[][5]
|
||||
|
||||
Whereas Ubuntu features its classic desktop style with icons, a panel on the left mimicking its traditional dock, and customized window looks (also traditional) with Ubuntu Ambiance theme set as its default look and feel.
|
||||
|
||||
[][6]
|
||||
|
||||
However, learning to use one of them and then switching to another won't cost you time. Instead, they are designed with simplicity and user-friendliness in mind so any newbie can feel right at home with either of the two Linux distros.
|
||||
|
||||
|
||||
|
||||
But it's not just the looks or UI that determines the user's decision to choose a Linux distro. Other factors come into the role too, and below are more sub-topics describing all about software management between the two Linux OS.
|
||||
|
||||
### Software center
|
||||
|
||||
Ubuntu uses dpkg; Debian Package Management, for distributing software to end users while Fedora uses Red Hat Package Management called rpm. Both are very popular package management among the Linux community and their command line tools are easy to use too.
|
||||
|
||||
[][7]
|
||||
|
||||
But each Linux distro quite varies when it comes to the software that's being distributed. Canonical releases new Ubuntu versions every six months; usually in the month of April and then on October. So for each release, the developers maintain a development schedule, after a new Ubuntu release, it enters into "freeze" state where its development on testing new software is halted.
|
||||
|
||||
|
||||
|
||||
Whereas, Fedora also following the same six months release cycle, pretty much mimics a rolling release Linux distro (though it is not one of those). Almost all software packages are updated regularly so users get the opportunity to try out the latest software, unlike Ubuntu. However, this invites "instability" on the user's side as software bugs are more commonly faced but not critical enough to render the system unusable.
|
||||
|
||||
### Software updates
|
||||
|
||||
I've mentioned above about Ubuntu "freeze" state. Well, I'll be exaggerating more about this state since it has some significant importance on the way Ubuntu software is updated... So, once a new version of Ubuntu is released, its development (testing new software) is halted.
|
||||
|
||||
_The development for the next upcoming Ubuntu release begins where it'll go through the phases of "daily builds" then "beta release" and finally shipping the new Ubuntu release to the end users._
|
||||
|
||||
In this "freeze" state Ubuntu maintainers no longer add the latest software (unless it fixes serious security issues) to its package repository. So Ubuntu users get more "bug fixes" updates than "feature" updates, which is great since the system would remain stable without disrupting user's productivity.
|
||||
|
||||
|
||||
|
||||
Fedora aims to provide cutting-edge software to the end users so users get more "feature" updates than on Ubuntu. Also, measures are taken by the developers to maintain its system stability. For instance, on computer start up the user will be given at most three working kernels (latest one on the top) choices so if one fails to start the user can revert to the other two previous working kernels.
|
||||
|
||||
### Snaps and flatpak
|
||||
|
||||
Both are new and cool sexy tools for distributing software across multiple Linux distributions. Ubuntu provides **snaps** out of the box while **flatpak** goes to Fedora. The most popular among the two is snaps where more popular and proprietary applications are finding their way on snap store. Flatpak too is gaining traction with more apps added onto its platform.
|
||||
|
||||
|
||||
|
||||
Unfortunately, both of them are still new and there are some "window theme-breaking" rants dispersed around the Internet. But still, switching between the two tools isn't nerve wrecking as they are easy to use.
|
||||
|
||||
### Apps showdown
|
||||
|
||||
Below are some of the common apps available on Ubuntu and Fedora, they are compared between the two platforms:
|
||||
|
||||
#### Calculator
|
||||
|
||||
The program launches faster on Fedora than on Ubuntu. The reason is on Fedora, calculator program is natively installed while on Ubuntu the snap version of the same program is installed.
|
||||
|
||||
#### System Monitor
|
||||
|
||||
This might sound nerdy but I find it necessary and intuitive to observe my computer performance and kill offending processes if any. The program's launch time is the same as above ie., faster on Fedora (natively installed) and slower on Ubuntu (snap version).
|
||||
|
||||
#### Help
|
||||
|
||||
I've mentioned above that Ubuntu provides a tweaked version of the GNOME Desktop Environment (for long time Unity users migration ease). Unfortunately, Ubuntu developers have either forgotten or ignored to update the Help program since it's somewhat confusing to look at the documentation (getting started videos) and finding out the demonstration videos and the actual environment varies a tad-bit slightly.
|
||||
|
||||
[][8]
|
||||
|
||||
### Conclusion
|
||||
|
||||
Ubuntu and Fedora are two popular Linux distros. Each has their own eye-candy features, so choosing between the two would be quite a challenge for newbies. I recommend trying both of them out so you can later find out which tools provided by the two Linux distro better suits you.
|
||||
|
||||
|
||||
|
||||
I hope you had a good read and let me know what I missed out/your opinions in the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/ubuntu-1804-vs-fedora-28
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/ubuntu-1804-codename-announced-bionic-beaver
|
||||
[2]:http://www.linuxandubuntu.com/home/what-new-is-going-to-be-in-ubuntu-1704-zesty-zapus
|
||||
[3]:http://www.linuxandubuntu.com/home/5-best-linux-desktop-environments-with-pros-cons
|
||||
[4]:http://www.linuxandubuntu.com/home/walkthrough-on-how-to-use-gnome-boxes
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-18-04-gnome_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-gnome-18-04_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-software-center_2_orig.jpg
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-18-04-help-manual_orig.jpg
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/ubuntu-1804-vs-fedora-28
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
@ -0,0 +1,81 @@
|
||||
5 of the Best Linux Educational Software and Games for Kids
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux is a very powerful operating system, and that explains why it powers most of the servers on the Internet. Though it may not be the best OS in terms of user friendliness, its diversity is commendable. Everyone has their own need for Linux. Be it for coding, educational purposes or the internet of things (IoT), you’ll always find a suitable Linux distro for every use. To that end, many have dubbed Linux as the OS for future computing.
|
||||
|
||||
Because the future belongs to the kids of today, introducing them to Linux is the best way to prepare them for what the future holds. This OS may not have a reputation for popular games such as FIFA or PES; however, it offers the best educational software and games for kids. These are five of the best Linux educational software to keep your kids ahead of the game.
|
||||
|
||||
**Related** : [The Beginner’s Guide to Using a Linux Distro][1]
|
||||
|
||||
### 1. GCompris
|
||||
|
||||
If you’re looking for the best educational software for kids, [GCompris][2] should be your starting point. This software is specifically designed for kids education and is ideal for kids between two and ten years old. As the pinnacle of all Linux educational software suites for children, GCompris offers about 100 activities for kids. It packs everything you want for your kids from reading practice to science, geography, drawing, algebra, quizzes, and more.
|
||||
|
||||
![Linux educational software and games][3]
|
||||
|
||||
GCompris even has activities for helping your kids learn computer peripherals. If your kids are young and you want them to learn alphabets, colors, and shapes, GCompris has programmes for those, too. What’s more, it also comes with helpful games for kids such as chess, tic-tac-toe, memory, and hangman. GCompris is not a Linux-only app. It’s also available for Windows and Android.
|
||||
|
||||
### 2. TuxMath
|
||||
|
||||
Most students consider math a tough subject. You can change that perception by acquainting your kids with mathematical skills through Linux software applications such as [TuxMath][4]. TuxMath is a top-rated educational Math tutorial game for kids. In this game your role is to help Tux the penguin of Linux protect his planet from a rain of mathematical problems.
|
||||
|
||||
![linux-educational-software-tuxmath-1][5]
|
||||
|
||||
By finding the answer, you help Tux save the planet by destroying the asteroids with your laser before they make an impact. The difficulty of the math problems increases with each level you pass. This game is ideal for kids, as it can help them rack their brains for solutions. Besides making them good at math, it also helps them improve their mental agility.
|
||||
|
||||
### 3. Sugar on a Stick
|
||||
|
||||
[Sugar on a Stick][6] is a dedicated learning program for kids – a brand new pedagogy that has gained a lot of traction. This program provides your kids with a fully-fledged learning platform where they can gain skills in creating, exploring, discovering and also reflecting on ideas. Just like GCompris, Sugar on a Stick comes with a host of learning resources for kids, including games and puzzles.
|
||||
|
||||
![linux-educational-software-sugar-on-a-stick][7]
|
||||
|
||||
The best thing about Sugar on a Stick is that you can set it up on a USB Drive. All you need is an X86-based PC, then plug in the USB, and boot the distro from it. Sugar on a Stick is a project by Sugar Labs – a non-profit organization that is run by volunteers.
|
||||
|
||||
### 4. KDE Edu Suite
|
||||
|
||||
[KDE Edu Suite][8] is a package of software for different user purposes. With a host of applications from different fields, the KDE community has proven that it isn’t just serious about empowering adults; it also cares about bringing the young generation to speed with everything surrounding them. It comes packed with various applications for kids ranging from science to math, geography, and more.
|
||||
|
||||
![linux-educational-software-kde-1][9]
|
||||
|
||||
The KDE Suite can be used for adult needs based on necessities, as a school teaching software, or as a kid’s leaning app. It offers a huge software package and is free to download. The KDE Edu suite can be installed on most GNU/Linux Distros.
|
||||
|
||||
### 5. Tux Paint
|
||||
|
||||
![linux-educational-software-tux-paint-2][10]
|
||||
|
||||
[Tux Paint][11] is another great Linux educational software for kids. This award-winning drawing program is used in schools around the world to help children nurture the art of drawing. It comes with a clean, easy-to-use interface and fun sound effects that help children use the program. There is also an encouraging cartoon mascot that guides kids as they use the program. Tux Paint comes with a variety of drawing tools that help kids unleash their creativity.
|
||||
|
||||
### Summing Up
|
||||
|
||||
Due to the popularity of these educational software for kids, many institutions have embraced these programs as teaching aids in schools and kindergartens. A typical example is [Edubuntu][12], an Ubuntu-derived distro that is widely used by teachers and parents for educating kids.
|
||||
|
||||
Tux Paint is another great example that has grown in popularity over the years and is being used in schools to teach children how to draw. This list is by no means exhaustive. There are hundreds of other Linux educational software and games that can be very useful for your kids.
|
||||
|
||||
If you know of any other great Linux educational software and games for kids, share with us in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/5-best-linux-software-packages-for-kids/
|
||||
|
||||
作者:[Kenneth Kimari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/kennkimari/
|
||||
[1]:https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/ (The Beginner’s Guide to Using a Linux Distro)
|
||||
[2]:http://www.gcompris.net/downloads-en.html
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg (Linux educational software and games)
|
||||
[4]:https://tuxmath.en.uptodown.com/ubuntu
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg (linux-educational-software-tuxmath-1)
|
||||
[6]:http://wiki.sugarlabs.org/go/Sugar_on_a_Stick/Downloads
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png (linux-educational-software-sugar-on-a-stick)
|
||||
[8]:https://edu.kde.org/
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg (linux-educational-software-kde-1)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg (linux-educational-software-tux-paint-2)
|
||||
[11]:http://www.tuxpaint.org/
|
||||
[12]:http://edubuntu.org/
|
||||
@ -0,0 +1,65 @@
|
||||
Convert file systems with Fstransform
|
||||
======
|
||||
|
||||

|
||||
|
||||
Few people know that they can convert their filesystems from one type to another without losing data, i.e. non-destructively. It may sound like magic, but [Fstransform][1] can convert an ext2, ext3, ext4, jfs, reiserfs or xfs partition to another type from the list in almost any combination. More importantly, it does so in-place, without formatting or copying data anywhere. Atop of all this goodness, there is a little bonus: Fstransform can also handle ntfs, btrfs, fat and exfat partitions as well.
|
||||
|
||||
### Before you run it
|
||||
|
||||
There are certain caveats and limitations in Fstransform, so it is strongly advised to back up before attempting a conversion. Additionally, there are some limitations to be aware of when using Fstransform:
|
||||
|
||||
* Both the source and target filesystems must be supported by your Linux kernel. Sounds like an obvious thing and exposes zero risk in case you want to use ext2, ext3, ext4, reiserfs, jfs and xfs partitions. Fedora supports all of that just fine.
|
||||
* Upgrading ext2 to ext3 or ext4 does not require Fstransform. Use the Tune2fs utility instead.
|
||||
* The device with source file system must have at least 5% of free space.
|
||||
* You need to be able to unmount the source filesystem before you begin.
|
||||
* The more data your source file system stores, the longer the conversion will last. The actual speed depends on your device, but expect it to be around one gigabyte per minute. The large amount of hard links can also slow down the conversion.
|
||||
* Although Fstransform is proved to be stable, please back up data on your source filesystem.
|
||||
|
||||
|
||||
|
||||
### Installation instructions
|
||||
|
||||
Fstransform is already a part of Fedora. Install with the command:
|
||||
```
|
||||
sudo dnf install fstransform
|
||||
|
||||
```
|
||||
|
||||
### Time to convert something
|
||||
|
||||
![][2]
|
||||
|
||||
The syntax of the fstransform command is very simple: fstransform <source device> <target file system>. Keep in mind that it needs root privileges to run, so don’t forget to add sudo in the beginning. Here goes an example:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ext4
|
||||
|
||||
```
|
||||
|
||||
Note that it is not possible to convert a root file system, which is a security measure. Use a test partition or an experimental thumb drive instead. In the meantime, Fstransform will through a lot of auxiliary output in the console. The most useful part is the estimated time of completion, which keep you informed about how long the process will take. Again, few small files on an almost empty drive will make Fstransform do its job in a minute or so, whereas more real-world tasks may involve hours of wait time.
|
||||
|
||||
### More file systems are supported
|
||||
|
||||
As mentioned above, it is possible to try Fstransform with ntfs, btrfs, fat and exfat partitions. These types are very experimental, and nobody can guarantee that the converion will flow perfect. Still, there are many success stories, and you can add your own by testing Fstransform with a sample data set on a test partition. Those additional file systems can be enabled by the use of the –force-untested-file-systems parameter:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ntfs --force-untested-file-systems
|
||||
|
||||
```
|
||||
|
||||
Sometimes the process may iterrupt with an error. Feel free to repeat the command again — it may eventually complete the conversion from second or third attempt.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/transform-file-systems-in-linux/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://github.com/cosmos72/fstransform
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot_20180805_230116.png
|
||||
@ -0,0 +1,142 @@
|
||||
How To Switch Between Different Versions Of Commands In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
A couple days ago, we discussed how to [**switch between multiple PHP versions**][1]. In that method, we used **‘update-alternatives’** command to switch from one PHP version to another. That means, the update-alternatives commands helps you to set which system wide version of PHP you want to use by default. To put this in layman terms, you can change the version of a command system wide using ‘update-alternatives’ command. What if you want to change command versions dynamically depending on what directory you’re in? This is where **‘alt’** utility comes in help. The alt is a command line tool that helps you to switch between different versions of commands in Unix-like systems. It is a simple, free, open source tool written in **Rust** programming language.
|
||||
|
||||
### Installation
|
||||
|
||||
Installing alt utility is trivial.
|
||||
|
||||
To install alt on your Linux machine, just run the following command:
|
||||
```
|
||||
$ curl -sL https://github.com/dotboris/alt/raw/master/install.sh | bash -s
|
||||
|
||||
```
|
||||
|
||||
Next, add the shims directory to your PATH environment variable depending upon the SHELL you are use.
|
||||
|
||||
For BASH:
|
||||
```
|
||||
$ echo 'export PATH="$HOME/.local/alt/shims:$PATH"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
For ZSH:
|
||||
```
|
||||
$ echo 'export PATH="$HOME/.local/alt/shims:$PATH"' >> ~/.zshrc
|
||||
$ source ~/.zshrc
|
||||
|
||||
```
|
||||
|
||||
For FISH:
|
||||
```
|
||||
$ echo 'set -x PATH "$HOME/.local/alt/shims" $PATH' >> ~/.config/fish/config.fish
|
||||
|
||||
```
|
||||
|
||||
Alt is installed!
|
||||
|
||||
### Switch Between Different Versions Of Commands Using Alt Tool In Linux
|
||||
|
||||
Like I mentioned earlier, alt works with the current directory. That means, when you switch from one version to another, you do so for the current working directory only, not system wide.
|
||||
|
||||
Let us see an example. I have installed two PHP versions in my Ubuntu system, PHP 5.6 and PHP 7.2 respectively and I have some PHP applications in a directory called **‘myproject’**.
|
||||
|
||||
First, let us see the globally installed PHP version using command:
|
||||
```
|
||||
$ php -v
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![Find PHP version][3]
|
||||
|
||||
As you see in the above screenshot, my system wide default version is PHP7.2.
|
||||
|
||||
Next, I am gong to “myproject” directory where I have kept my PHP applications.
|
||||
```
|
||||
$ cd myproject
|
||||
|
||||
```
|
||||
|
||||
Scan the available PHP versions using the following command:
|
||||
```
|
||||
$ alt scan php
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![alt scan php][4]
|
||||
|
||||
As you can see, I have two PHP versions, PHP5.6 and PHP7.2. Now press **< SPACEBAR>** key to select all available versions. After selecting all available versions, you will see a cross mark behind each version as shown below picture. Use UP/DOWN arrows to move between the versions. Finally press ENTER to save the changes.
|
||||
|
||||
![Select php version][5]
|
||||
|
||||
Next run the following command to choose which PHP version you want to use inside the ‘myproject’ directory:
|
||||
```
|
||||
$ alt use php
|
||||
|
||||
```
|
||||
|
||||
I am going to use PHP5.6 version, so I selected it(use arrow keys to select) and hit ENTER key.
|
||||
|
||||
![set php version][6]
|
||||
|
||||
You can now use php 5.6 (/usr/bin/php5.6) when in /home/sk/myproject directory.
|
||||
|
||||
Let us check if the PHP5.6 is set as default inside the myproject directory:
|
||||
```
|
||||
$ php -v
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![Check PHP version][7]
|
||||
|
||||
It will stay as 5.6 version until you change to different version. Got it? Good! Please note that we use php5.6 version only inside this directory. On system level, PHP7.2 is still the default version. Have a look at the following image.
|
||||
|
||||
![Check PHP version 1][8]
|
||||
|
||||
As you can see in the above screenshot, I have two different versions of PHP. Inside the ‘myproject’ directory, I got PHP5.6 and outside the myproject, PHP version is 7.2.
|
||||
|
||||
Similarly, you can set any version of your choice in each directory. I used PHP for the demonstration purpose. You can, however, use any software of your choice, for example NodeJS.
|
||||
|
||||
Here is the demonstration video for NodeJS.
|
||||
|
||||
![][9]
|
||||
|
||||
The alt utility can be useful when you wanted to test your applications under different versions of applications.
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-switch-between-different-versions-of-commands-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/how-to-switch-between-multiple-php-versions-in-ubuntu/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/08/Find-PHP-version.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/08/alt-scan-php.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/08/Select-php-version.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/08/set-php-version.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/08/Check-PHP-version.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/08/Check-PHP-version-1.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/08/Alt-NodeJS-demo.gif
|
||||
201
sources/tech/20180813 Tips for using the top command in Linux.md
Normal file
201
sources/tech/20180813 Tips for using the top command in Linux.md
Normal file
@ -0,0 +1,201 @@
|
||||
Tips for using the top command in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Trying to find out what's running on your machine—and which process is using up all your memory and making things slllooowwww—is a task served well by the utility `top`.
|
||||
|
||||
`top` is an extremely useful program that acts similar to Windows Task Manager or MacOS's Activity Monitor. Running `top` on your *nix machine will show you a live, running view of the process running on your system.
|
||||
```
|
||||
$ top
|
||||
|
||||
```
|
||||
|
||||
Depending on which version of `top` you're running, you'll get something that looks like this:
|
||||
```
|
||||
top - 08:31:32 up 1 day, 4:09, 0 users, load average: 0.20, 0.12, 0.10
|
||||
|
||||
Tasks: 3 total, 1 running, 2 sleeping, 0 stopped, 0 zombie
|
||||
|
||||
%Cpu(s): 0.5 us, 0.3 sy, 0.0 ni, 99.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
|
||||
KiB Mem: 4042284 total, 2523744 used, 1518540 free, 263776 buffers
|
||||
|
||||
KiB Swap: 1048572 total, 0 used, 1048572 free. 1804264 cached Mem
|
||||
|
||||
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
|
||||
1 root 20 0 21964 3632 3124 S 0.0 0.1 0:00.23 bash
|
||||
|
||||
193 root 20 0 123520 29636 8640 S 0.0 0.7 0:00.58 flask
|
||||
|
||||
195 root 20 0 23608 2724 2400 R 0.0 0.1 0:00.21 top
|
||||
|
||||
```
|
||||
|
||||
Your version of `top` may look different from this, particularly in the columns that are displayed.
|
||||
|
||||
### How to read the output
|
||||
|
||||
You can tell what you're running based on the output, but trying to interpret the results can be slightly confusing.
|
||||
|
||||
The first few lines contain a bunch of statistics (the details) followed by a table with a list of results (the list). Let's start with the latter.
|
||||
|
||||
#### The list
|
||||
|
||||
These are the processes that are running on the system. By default, they are ordered by CPU usage in descending order. This means the items at the top of the list are using more CPU resources and causing more load on your system. They are literally the "top" processes by resource usage. You have to admit, it's a clever name.
|
||||
|
||||
The `COMMAND` column on the far right reports the name of the process (the command you ran to start them). In this example, they are `bash` (a command interpreter we're running `top` in), `flask` (a web micro-framework written in Python), and `top` itself.
|
||||
|
||||
The other columns provide useful information about the processes:
|
||||
|
||||
* `PID`: the process id, a unique identifier for addressing the processes
|
||||
* `USER`: the user running the process
|
||||
* `PR`: the task's priority
|
||||
* `NI`: a nicer representation of the priority
|
||||
* `VIRT`: virtual memory size in KiB (kibibytes)*
|
||||
* `RES`: resident memory size in KiB* (the "physical memory" and a subset of VIRT)
|
||||
* `SHR`: shared memory size in KiB* (the "shared memory" and a subset of VIRT)
|
||||
* `S`: process state, usually **I** =idle, **R** =running, **S** =sleeping, **Z** =zombie, **T** or **t** =stopped (there are also other, less common options)
|
||||
* `%CPU`: Percentage of CPU usage since the last screen update
|
||||
* `%MEM`: percentage of `RES` memory usage since the last screen update
|
||||
* `TIME+`: total CPU time used since the process started
|
||||
* `COMMAND`: the command, as described above
|
||||
|
||||
|
||||
|
||||
*Knowing exactly what the `VIRT`, `RES`, and `SHR` values represent doesn't really matter in everyday operations. The important thing to know is that the process with the most `VIRT` is the process using the most memory. If you're in `top` because you're debugging why your computer feels like it's in a pool of molasses, the process with the largest `VIRT` number is the culprit. If you want to learn exactly what "shared" and "physical" memory mean, check out "Linux Memory Types" in the [top manual][1].
|
||||
|
||||
And, yes, I did mean to type kibibytes, not kilobytes. The 1,024 value that you normally call a kilobyte is actually a kibibyte. The Greek kilo ("χίλιοι") means thousand and means 1,000 of something (e.g., a kilometer is a thousand meters, a kilogram is a thousand grams). Kibi is a portmanteau of kilo and byte, and it means 1,024 bytes (or 210). But, because words are hard to say, many people say kilobyte when they mean 1,024 bytes. All this means is `top` is trying to use the proper terms here, so just go with it. #themoreyouknow 🌈.
|
||||
|
||||
#### A note on screen updates:
|
||||
|
||||
Live screen updates are one of the objectively **really cool things** Linux programs can do. This means they can update their own display in real time, so they appear animated. Even though they're using text. So cool! In our case, the time between updates is important, because some of our statistics (`%CPU` and `%MEM`) are based on the value since the last screen update.
|
||||
|
||||
And because we're running in a persistent application, we can press key commands to make live changes to settings or configurations (instead of, say, closing the application and running the application again with a different command-line flag).
|
||||
|
||||
Typing `h` invokes the "help" screen, which also shows the default delay (the time between screen updates). By default, this value is (around) three seconds, but you can change it by typing `d` (presumably for "delay") or `s` (probably for "screen" or "seconds").
|
||||
|
||||
#### The details
|
||||
|
||||
Above the list of processes, there's a whole bunch of other useful information. Some of these details may look strange and confusing, but once you take some time to step through each one, you'll see they're very useful stats to pull up in a pinch.
|
||||
|
||||
The first row contains general system information
|
||||
|
||||
* `top`: we're running `top`! Hi `top`!
|
||||
* `XX:YY:XX`: the time, updated every time the screen updates
|
||||
* `up` (then `X day, YY:ZZ`): the system's [uptime][2], or how much time has passed since the system turned on
|
||||
* `load average` (then three numbers): the [system load][3] over the last one, five, and 15 minutes, respectively
|
||||
|
||||
|
||||
|
||||
The second row (`Tasks`) shows information about the running tasks, and it's fairly self-explanatory. It shows the total number of processes and the number of running, sleeping, stopped, and zombie processes. This is literally a sum of the `S` (state) column described above.
|
||||
|
||||
The third row (`%Cpu(s)`) shows the CPU usage separated by types. The data are the values between screen refreshes. The values are:
|
||||
|
||||
* `us`: user processes
|
||||
* `sy`: system processes
|
||||
* `ni`: [nice][4] user processes
|
||||
* `id`: the CPU's idle time; a high idle time means there's not a lot going on otherwise
|
||||
* `wa`: wait time, or time spent waiting for I/O completion
|
||||
* `hi`: time spent waiting for hardware interrupts
|
||||
* `si`: time spent waiting for software interrupts
|
||||
* `st`: "time stolen from this VM by the hypervisor"
|
||||
|
||||
|
||||
|
||||
You can collapse the `Tasks` and `%Cpu(s)` rows by typing `t` (for "toggle").
|
||||
|
||||
The fourth (`KiB Mem`) and fifth rows (`KiB Swap`) provide information for memory and swap. These values are:
|
||||
|
||||
* `total`
|
||||
* `used`
|
||||
* `free`
|
||||
|
||||
|
||||
|
||||
But also:
|
||||
|
||||
* memory `buffers`
|
||||
* swap `cached Mem`
|
||||
|
||||
|
||||
|
||||
By default, they're listed in KiB, but pressing `E` (for "extend memory scaling") cycles through different values: kibibytes, mebibytes, gibibytes, tebibytes, pebibytes, and exbibytes. (That is, kilobytes, megabytes, gigabytes, terabytes, petabytes, and exabytes, but their "real names.")
|
||||
|
||||
The `top` user manual shows even more information about useful flags and configurations. To find the manual on your system, you can run `man top`. There are various websites that show an [HTML rendering of the manual][1], but note that these may be for a different version of top.
|
||||
|
||||
### Two top alternatives
|
||||
|
||||
You don't always have to use `top` to understand what's going on. Depending on your circumstances, other tools might help you diagnose issues, especially when you want a more graphical or specialized interface.
|
||||
|
||||
#### htop
|
||||
|
||||
`htop` is a lot like `top`, but it brings something extremely useful to the table: a graphical representation of CPU and memory use.
|
||||
|
||||
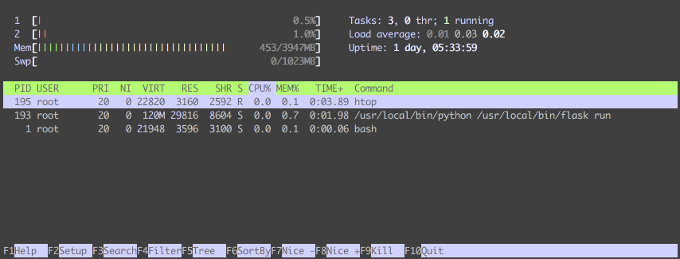
|
||||
|
||||
This is how the environment we examined in `top` looks in `htop`. The display is a lot simpler, but still rich in features.
|
||||
|
||||
Our task counts, load, uptime, and list of processes are still there, but we get a nifty, colorized, animated view of the CPU usage per core and a graph of memory usage.
|
||||
|
||||
Here's what the different colors mean (you can also get this information by pressing `h` for "help").
|
||||
|
||||
CPU task priorities or types:
|
||||
|
||||
* blue: low priority
|
||||
* green: normal priority
|
||||
* red: kernel tasks
|
||||
* blue: virtualized tasks
|
||||
* the value at end of the bar is the percentage of used CPU
|
||||
|
||||
|
||||
|
||||
Memory:
|
||||
|
||||
* green: used memory
|
||||
* blue: buffered memory
|
||||
* yellow: cached memory
|
||||
* the values at the end of the bar show the used and total memory
|
||||
|
||||
|
||||
|
||||
If colors aren't useful for you, you can run `htop -C` to disable them; instead `htop` will use different symbols to separate the CPU and memory types.
|
||||
|
||||
At the bottom, there's a useful display of active function keys that you can use to do things like filter results or change the sort order. Try out some of the commands to see what they do. Just be careful when trying out `F9`. This will bring up a list of signals that will kill (i.e., stop) a process. I would suggest exploring these options outside of a production environment.
|
||||
|
||||
The author of `htop`, Hisham Muhammad (and yes, it's called `htop` after Hisham) presented a [lightning talk][5] about `htop` at [FOSDEM 2018][6] in February. He explained how `htop` not only has neat graphics, but also surfaces more modern statistical information about processes that older monitoring utilities (like `top`) don't.
|
||||
|
||||
You can read more about `htop` on the [manual page][7] or the [htop website][8]. (Warning: the website contains an animated background of `htop`.)
|
||||
|
||||
#### docker stats
|
||||
|
||||
If you're working with Docker, you can run `docker stats` to generate a context-rich representation of what your containers are doing.
|
||||
|
||||
This can be more helpful than `top` because, instead of separating by processes, you are separating by container. This is especially useful when a container is slow, as seeing which container is using the most resources is quicker than running `top` and trying to map the process to the container.
|
||||
|
||||
The above explanations of acronyms and descriptors in `top` and `htop` should make it easy to understand the ones in `docker stats`. However, the [docker stats documentation][9] provides helpful descriptions of each column.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/top-tips-speed-up-computer
|
||||
|
||||
作者:[Katie McLaughlin][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/glasnt
|
||||
[1]:http://man7.org/linux/man-pages/man1/top.1.html
|
||||
[2]:https://en.wikipedia.org/wiki/Uptime
|
||||
[3]:https://en.wikipedia.org/wiki/Load_(computing)
|
||||
[4]:https://en.wikipedia.org/wiki/Nice_(Unix)#Etymology
|
||||
[5]:https://www.youtube.com/watch?v=L25waVhy78o
|
||||
[6]:https://fosdem.org/2018/schedule/event/htop/
|
||||
[7]:https://linux.die.net/man/1/htop
|
||||
[8]:https://hisham.hm/htop/index.php
|
||||
[9]:https://docs.docker.com/engine/reference/commandline/stats/
|
||||
@ -0,0 +1,111 @@
|
||||
5 open source strategy and simulation games for Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games are often not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
|
||||
|
||||
So, can someone who only uses free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website to install and play it.
|
||||
|
||||
This article looks at strategy and simulation games. I have already written about [arcade-style games][1], [board & card games][2], [puzzle games][3], [racing & flying games][4], and [role-playing games][5].
|
||||
|
||||
### Freeciv
|
||||
|
||||
|
||||
|
||||
[Freeciv][6] is an open source version of the [Civilization series][7] of computer games. Gameplay is most similar to the earlier games in the Civilization series, and Freeciv even has options to use Civilization 1 and Civilization 2 rule sets. Freeciv involves building cities, exploring the world map, developing technologies, and competing with other civilizations trying to do the same. Victory conditions include defeating all the other civilizations, developing a space colony, or hitting deadline if neither of the first two conditions are met. The game can be played against AI opponents or other human players. Different tile-sets are available to change the look of the game's map.
|
||||
|
||||
To install Freeciv, run the following command:
|
||||
|
||||
* On Fedora: `dnf install freeciv`
|
||||
* On Debian/Ubuntu: `apt install freeciv`
|
||||
|
||||
|
||||
|
||||
### MegaGlest
|
||||
|
||||
|
||||
|
||||
[MegaGlest][8] is an open source real-time strategy game in the style of Blizzard Entertainment's [Warcraft][9] and [StarCraft][10] games. Players control one of several different factions, building structures and recruiting units to explore the map and battle their opponents. At the beginning of the match, a player can build only the most basic buildings and recruit the weakest units. To build and recruit better things, players must work their way up their factions technology tree by building structures and recruiting units that unlock more advanced options. Combat units will attack when enemy units come into range, but for optimal strategy, it is best to manage the battle directly by controlling the units. Simultaneously managing the construction of new structures, recruiting new units, and managing battles can be a challenge, but that is the point of a real-time strategy game. MegaGlest provides a nice variety of factions, so there are plenty of reasons to try new and different strategies.
|
||||
|
||||
To install MegaGlest, run the following command:
|
||||
|
||||
* On Fedora: `dnf install megaglest`
|
||||
* On Debian/Ubuntu: `apt install megaglest`
|
||||
|
||||
|
||||
|
||||
### OpenTTD
|
||||
|
||||
|
||||
|
||||
[OpenTTD][11] (see also [our review][12]) is an open source implementation of [Transport Tycoon Deluxe][13]. The object of the game is to create a transportation network and earn money, which allows the player to build an even bigger transportation network. The network can include boats, buses, trains, trucks, and planes. By default, gameplay takes place between 1950 and 2050, with players aiming to get the highest performance rating possible before time runs out. The performance rating is based on things like the amount of cargo delivered, the number of vehicles they have, and how much money they earned.
|
||||
|
||||
To install OpenTTD, run the following command:
|
||||
|
||||
* On Fedora: `dnf install openttd`
|
||||
* On Debian/Ubuntu: `apt install openttd`
|
||||
|
||||
|
||||
|
||||
### The Battle for Wesnoth
|
||||
|
||||
|
||||
|
||||
[The Battle for Wesnoth][14] is one of the most polished open source games available. This turn-based strategy game has a fantasy setting. Play takes place on a hexagonal grid, where individual units battle each other for control. Each type of unit has unique strengths and weaknesses, which requires players to plan their attacks accordingly. There are many different campaigns available for The Battle for Wesnoth, each with different objectives and storylines. The Battle for Wesnoth also comes with a map editor for players interested in creating their own maps or campaigns.
|
||||
|
||||
To install The Battle for Wesnoth, run the following command:
|
||||
|
||||
* On Fedora: `dnf install wesnoth`
|
||||
* On Debian/Ubuntu: `apt install wesnoth`
|
||||
|
||||
|
||||
|
||||
### UFO: Alien Invasion
|
||||
|
||||
|
||||
|
||||
[UFO: Alien Invasion][15] is an open source tactical strategy game inspired by the [X-COM series][20]. There are two distinct gameplay modes: geoscape and tactical. In geoscape mode, the player takes control of the big picture and deals with managing their bases, researching new technologies, and controlling overall strategy. In tactical mode, the player controls a squad of soldiers and directly confronts the alien invaders in a turn-based battle. Both modes provide different gameplay styles, but both require complex strategy and tactics.
|
||||
|
||||
To install UFO: Alien Invasion, run the following command:
|
||||
|
||||
* On Debian/Ubuntu: `apt install ufoai`
|
||||
|
||||
|
||||
|
||||
Unfortunately, UFO: Alien Invasion is not packaged for Fedora.
|
||||
|
||||
Did I miss one of your favorite open source strategy or simulation games? Share it in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/strategy-simulation-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://opensource.com/article/18/6/puzzle-games-linux
|
||||
[4]:https://opensource.com/article/18/7/racing-flying-games-linux
|
||||
[5]:https://opensource.com/article/18/8/role-playing-games-linux
|
||||
[6]:http://www.freeciv.org/
|
||||
[7]:https://en.wikipedia.org/wiki/Civilization_(series)
|
||||
[8]:https://megaglest.org/
|
||||
[9]:https://en.wikipedia.org/wiki/Warcraft
|
||||
[10]:https://en.wikipedia.org/wiki/StarCraft
|
||||
[11]:https://www.openttd.org/
|
||||
[12]:https://opensource.com/life/15/7/linux-game-review-openttd
|
||||
[13]:https://en.wikipedia.org/wiki/Transport_Tycoon#Transport_Tycoon_Deluxe
|
||||
[14]:https://www.wesnoth.org/
|
||||
[15]:https://ufoai.org/
|
||||
[16]:https://opensource.com/downloads/cheat-sheets?intcmp=7016000000127cYAAQ
|
||||
[17]:https://opensource.com/alternatives?intcmp=7016000000127cYAAQ
|
||||
[18]:https://opensource.com/tags/linux?intcmp=7016000000127cYAAQ
|
||||
[19]:https://developers.redhat.com/cheat-sheets/advanced-linux-commands/?intcmp=7016000000127cYAAQ
|
||||
[20]:https://en.wikipedia.org/wiki/X-COM
|
||||
@ -0,0 +1,221 @@
|
||||
Automating backups on a Raspberry Pi NAS
|
||||
======
|
||||

|
||||
|
||||
In the [first part][1] of this three-part series using a Raspberry Pi for network-attached storage (NAS), we covered the fundamentals of the NAS setup, attached two 1TB hard drives (one for data and one for backups), and mounted the data drive on a remote device via the network filesystem (NFS). In part two, we will look at automating backups. Automated backups allow you to continually secure your data and recover from a hardware defect or accidental file removal.
|
||||
|
||||
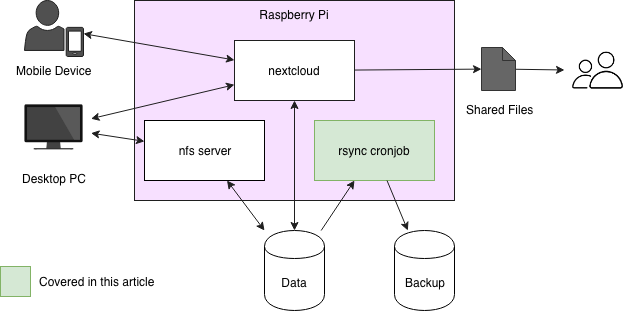
|
||||
|
||||
### Backup strategy
|
||||
|
||||
Let's get started by coming up with with a backup strategy for our small NAS. I recommend creating daily backups of your data and scheduling them for a time they won't interfere with other NAS activities, including when you need to access or store your files. For example, you could trigger the backup activities each day at 2am.
|
||||
|
||||
You also need to decide how long you'll keep each backup, since you would quickly run out of storage if you kept each daily backup indefinitely. Keeping your daily backups for one week allows you to travel back into your recent history if you realize something went wrong over the previous seven days. But what if you need something from further in the past? Keeping each Monday backup for a month and one monthly backup for a longer period of time should be sufficient. Let's keep the monthly backups for a year and one backup every year for long-distance time travels, e.g., for the last five years.
|
||||
|
||||
This results in a bunch of backups on your backup drive over a five-year period:
|
||||
|
||||
* 7 daily backups
|
||||
* 4 (approx.) weekly backups
|
||||
* 12 monthly backups
|
||||
* 5 annual backups
|
||||
|
||||
|
||||
|
||||
You may recall that your backup drive and your data drive are of equal size (1TB each). How will more than 10 backups of 1TB from your data drive fit onto a 1TB backup disk? If you create full backups, they won't. Instead, you will create incremental backups, reusing the data from the last backup if it didn't change and creating replicas of new or changed files. That way, the backup doesn't double every night, but only grows a little bit depending on the changes that happen to your data over a day.
|
||||
|
||||
Here is my situation: My NAS has been running since August 2016, and 20 backups are on the backup drive. Currently, I store 406GB of files on the data drive. The backups take up 726GB on my backup drive. Of course, this depends heavily on your data's change frequency, but as you can see, the incremental backups don't consume as much space as 20 full backups would. Nevertheless, over time the 1TB disk will probably become insufficient for your backups. Once your data grows close to the 1TB limit (or whatever your backup drive capacity), you should choose a bigger backup drive and move your data there.
|
||||
|
||||
### Creating backups with rsync
|
||||
|
||||
To create a full backup, you can use the rsync command line tool. Here is an example command to create the initial full backup.
|
||||
```
|
||||
pi@raspberrypi:~ $ rsync -a /nas/data/ /nas/backup/2018-08-01
|
||||
|
||||
```
|
||||
|
||||
This command creates a full replica of all data stored on the data drive, mounted on `/nas/data`, on the backup drive. There, it will create the folder `2018-08-01` and create the backup inside it. The `-a` flag starts rsync in archive-mode, which means it preserves all kinds of metadata, like modification dates, permissions, and owners, and copies soft links as soft links.
|
||||
|
||||
Now that you have created your full, initial backup as of August 1, on August 2, you will create your first daily incremental backup.
|
||||
```
|
||||
pi@raspberrypi:~ $ rsync -a --link-dest /nas/backup/2018-08-01/ /nas/data/ /nas/backup/2018-08-02
|
||||
|
||||
```
|
||||
|
||||
This command tells rsync to again create a backup of `/nas/data`. The target directory this time is `/nas/backup/2018-08-02`. The script also specified the `--link-dest` option and passed the location of the last backup as an argument. With this option specified, rsync looks at the folder `/nas/backup/2018-08-01` and checks what data files changed compared to that folder's content. Unchanged files will not be copied, rather they will be hard-linked to their counterparts in yesterday's backup folder.
|
||||
|
||||
When using a hard-linked file from a backup, you won't notice any difference between the initial copy and the link. They behave exactly the same, and if you delete either the link or the initial file, the other will still exist. You can imagine them as two equal entry points to the same file. Here is an example:
|
||||
|
||||
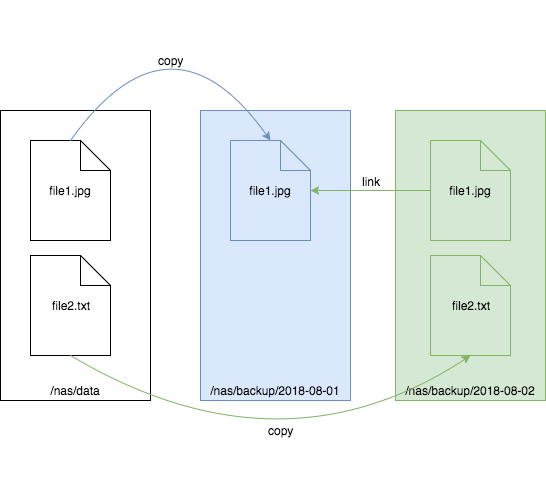
|
||||
|
||||
The left box reflects the state shortly after the second backup. The box in the middle is yesterday's replica. The `file2.txt` didn't exist yesterday, but the image `file1.jpg` did and was copied to the backup drive. The box on the right reflects today's incremental backup. The incremental backup command created `file2.txt`, which didn't exist yesterday. Since `file1.jpg` didn't change since yesterday, today a hard link is created so it doesn't take much additional space on the disk.
|
||||
|
||||
### Automate your backups
|
||||
|
||||
You probably don't want to execute your daily backup command by hand at 2am each day. Instead, you can automate your backup by using a script like the following, which you may want to start with a cron job.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
|
||||
TODAY=$(date +%Y-%m-%d)
|
||||
|
||||
DATADIR=/nas/data/
|
||||
|
||||
BACKUPDIR=/nas/backup/
|
||||
|
||||
SCRIPTDIR=/nas/data/backup_scripts
|
||||
|
||||
LASTDAYPATH=${BACKUPDIR}/$(ls ${BACKUPDIR} | tail -n 1)
|
||||
|
||||
TODAYPATH=${BACKUPDIR}/${TODAY}
|
||||
|
||||
if [[ ! -e ${TODAYPATH} ]]; then
|
||||
|
||||
mkdir -p ${TODAYPATH}
|
||||
|
||||
fi
|
||||
|
||||
|
||||
|
||||
rsync -a --link-dest ${LASTDAYPATH} ${DATADIR} ${TODAYPATH} $@
|
||||
|
||||
|
||||
|
||||
${SCRIPTDIR}/deleteOldBackups.sh
|
||||
|
||||
```
|
||||
|
||||
The first block calculates the last backup's folder name to use for links and the name of today's backup folder. The second block has the rsync command (as described above). The last block executes a `deleteOldBackups.sh` script. It will clean up the old, unnecessary backups based on the backup strategy outlined above. You could also execute the cleanup script independently from the backup script if you want it to run less frequently.
|
||||
|
||||
The following script is an example implementation of the backup strategy in this how-to article.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
BACKUPDIR=/nas/backup/
|
||||
|
||||
|
||||
|
||||
function listYearlyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5
|
||||
|
||||
do ls ${BACKUPDIR} | egrep "$(date +%Y -d "${i} year ago")-[0-9]{2}-[0-9]{2}" | sort -u | head -n 1
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listMonthlyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5 6 7 8 9 10 11 12
|
||||
|
||||
do ls ${BACKUPDIR} | egrep "$(date +%Y-%m -d "${i} month ago")-[0-9]{2}" | sort -u | head -n 1
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listWeeklyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4
|
||||
|
||||
do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "last monday -${i} weeks")"
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listDailyBackups() {
|
||||
|
||||
for i in 0 1 2 3 4 5 6
|
||||
|
||||
do ls ${BACKUPDIR} | grep "$(date +%Y-%m-%d -d "-${i} day")"
|
||||
|
||||
done
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function getAllBackups() {
|
||||
|
||||
listYearlyBackups
|
||||
|
||||
listMonthlyBackups
|
||||
|
||||
listWeeklyBackups
|
||||
|
||||
listDailyBackups
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listUniqueBackups() {
|
||||
|
||||
getAllBackups | sort -u
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
function listBackupsToDelete() {
|
||||
|
||||
ls ${BACKUPDIR} | grep -v -e "$(echo -n $(listUniqueBackups) |sed "s/ /\\\|/g")"
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
cd ${BACKUPDIR}
|
||||
|
||||
listBackupsToDelete | while read file_to_delete; do
|
||||
|
||||
rm -rf ${file_to_delete}
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
This script will first list all the backups to keep (according to our backup strategy), then it will delete all the backup folders that are not necessary anymore.
|
||||
|
||||
To execute the scripts every night to create daily backups, schedule the backup script by running `crontab -e` as the root user. (You need to be in root to make sure it has permission to read all the files on the data drive, no matter who created them.) Add a line like the following, which starts the script every night at 2am.
|
||||
```
|
||||
0 2 * * * /nas/data/backup_scripts/daily.sh
|
||||
|
||||
```
|
||||
|
||||
For more information, read about [scheduling tasks with cron][2].
|
||||
|
||||
* Unmount your backup drive or mount it as read-only when no backups are running
|
||||
* Attach the backup drive to a remote server and sync the files over the internet
|
||||
|
||||
|
||||
|
||||
There are additional things you can do to fortify your backups against accidental removal or damage, including the following:
|
||||
|
||||
This example backup strategy enables you to back up your valuable data to make sure it won't get lost. You can also easily adjust this technique for your personal needs and preferences.
|
||||
|
||||
In part three of this series, we will talk about [Nextcloud][3], a convenient way to store and access data on your NAS system that also provides offline access as it synchronizes your data to the client devices.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/automate-backups-raspberry-pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
[2]:https://opensource.com/article/17/11/how-use-cron-linux
|
||||
[3]:https://nextcloud.com/
|
||||
@ -0,0 +1,139 @@
|
||||
How To Record Terminal Sessions As SVG Animations In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Recording Terminal sessions may help in several cases. You can use those recording sessions to document everything that you did in Terminal and save them for future reference. You can use them to demonstrate different Linux commands and its use cases to your juniors, students and anyone who are willing to Learn Linux. Luckily, we have many tools to record Terminal sessions in Unix-like operating systems. We already have featured some of the tools/commands which helps you to record the Terminal sessions in the past. You can go through them in the links given below.
|
||||
|
||||
|
||||
+ [How To Record Everything You Do In Terminal][3]
|
||||
+ [Asciinema – Record Terminal Sessions And Share Them On The Web][4]
|
||||
|
||||
|
||||
Today, we are going to see yet another tool to record the Terminal activities. Say hello to **“Termtosvg”**. As the name implies, Termtosvg records your Terminal sessions as standalone SVG animations. It is a simple command line utility written in **Python** programming language. It generates lightweight and clean looking animations embeddable on a project page. It supports custom color themes, terminal UI and animation controls via [SVG templates][1]. It is also compatible with asciinema recording format. Termtosvg supports GNU/Linux, Mac OS and BSD OSes.
|
||||
|
||||
|
||||
### Installing Termtosvg
|
||||
|
||||
Termtosvg can be installed using PIP, a python package manager to install applications written using Python language. If you haven’t installed PIP already, refer the following guide.
|
||||
|
||||
After installing PIP, run the following command to install Termtosvg tool:
|
||||
```
|
||||
$ pip3 install --user termtosvg
|
||||
|
||||
```
|
||||
|
||||
And, install the following prerequisites to render the Terminal screen.
|
||||
```
|
||||
$ pip3 install pyte python-xlib svgwrite
|
||||
|
||||
```
|
||||
|
||||
Done. Let us go ahead and generate Terminal sessions in SVG format.
|
||||
|
||||
### Record Terminal Sessions As SVG Animations In Linux
|
||||
|
||||
Recording Terminal sessions using Termtosvg is very simple. Just open your Terminal window and run the following command to start recording it.
|
||||
```
|
||||
$ termtosvg
|
||||
|
||||
```
|
||||
|
||||
**Note:** If you termtosvg command is not available, restart your system once.
|
||||
|
||||
You will see the following output after running ‘termtosvg’ command:
|
||||
```
|
||||
Recording started, enter "exit" command or Control-D to end
|
||||
|
||||
```
|
||||
|
||||
You will now be in a sub-shell where you can execute the Linux commands as usual. Everything you do in the Terminal will be recorded.
|
||||
|
||||
Let me run a random commands.
|
||||
```
|
||||
$ mkdir mydirectory
|
||||
|
||||
$ cd mydirectory/
|
||||
|
||||
$ touch file.txt
|
||||
|
||||
$ cd ..
|
||||
|
||||
$ uname -a
|
||||
|
||||
```
|
||||
|
||||
Once you’re done, press **CTRL+D** or type **exit** to stop recording. The resulting recording will be saved in **/tmp** folder with a unique name.
|
||||
|
||||

|
||||
|
||||
You can then open the SVG file in any web browser of your choice from Terminal like below.
|
||||
```
|
||||
$ firefox /tmp/termtosvg_ddkehjpu.svg
|
||||
|
||||
```
|
||||
|
||||
You can also directly open the SVG file from browser ( **File - > <path-to-svg>**).
|
||||
|
||||
Here is the output of the above recording in my Firefox browser.
|
||||
|
||||

|
||||
|
||||
Here is some more examples on how to use Termtosvg to record Terminal sessions.
|
||||
|
||||
Like I mentioned already, Termtosvg will record a terminal session and save it as an SVG animation file in **/tmp** directory by default.
|
||||
|
||||
However, you can generate an SVG animation with a custom name, for example **animation.svg** , and save it in a custom location, for example **/home/sk/ostechnix/**.
|
||||
```
|
||||
$ termtosvg /home/sk/ostechnix/animation.svg
|
||||
|
||||
```
|
||||
|
||||
Record a terminal session and render it using a specific template:
|
||||
```
|
||||
$ termtosvg -t ~/templates/my_template.svg
|
||||
|
||||
```
|
||||
|
||||
Record a terminal session with a specific screen geometry:
|
||||
```
|
||||
$ termtosvg -g 80x24 animation.svg
|
||||
|
||||
```
|
||||
|
||||
Record a terminal session in asciicast v2 format:
|
||||
```
|
||||
$ termtosvg record recording.cast
|
||||
|
||||
```
|
||||
|
||||
Render an SVG animation from a recording in asciicast format:
|
||||
```
|
||||
$ termtosvg render recording.cast animation.svg
|
||||
|
||||
```
|
||||
|
||||
For more details, refer [**Termtosvg manual**][2].
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-record-terminal-sessions-as-svg-animations-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://nbedos.github.io/termtosvg/pages/templates.html
|
||||
[2]:https://github.com/nbedos/termtosvg/blob/develop/man/termtosvg.md
|
||||
[3]: https://www.ostechnix.com/record-everything-terminal/
|
||||
[4]: https://www.ostechnix.com/asciinema-record-terminal-sessions-share-web/
|
||||
@ -0,0 +1,113 @@
|
||||
How To Enable Hardware Accelerated Video Decoding In Chromium On Ubuntu Or Linux Mint
|
||||
======
|
||||
You may have noticed that watching HD videos from Youtube and other similar websites in Google Chrome or Chromium browsers on Linux considerably increases your CPU usage and, if you use a laptop, it gets quite hot and the battery drains very quickly. That's because Chrome / Chromium (Firefox too but there's no way to force this) doesn't support hardware accelerated video decoding on Linux.
|
||||
|
||||
**This article explains how to install a Chromium development build which includes a patch that enables VA-API on Linux, bringing support for GPU accelerated video decoding, which should significantly decrease the CPU usage when watching HD videos online. The instructions cover only Intel and Nvidia graphics cards, as I don't have an ATI/AMD graphics card to try this, nor do I have experience with such graphics cards.**
|
||||
|
||||
This is Chromium from the Ubuntu (18.04) repositories without GPU accelerated video decoding playing a 1080p YouTube video:
|
||||
|
||||
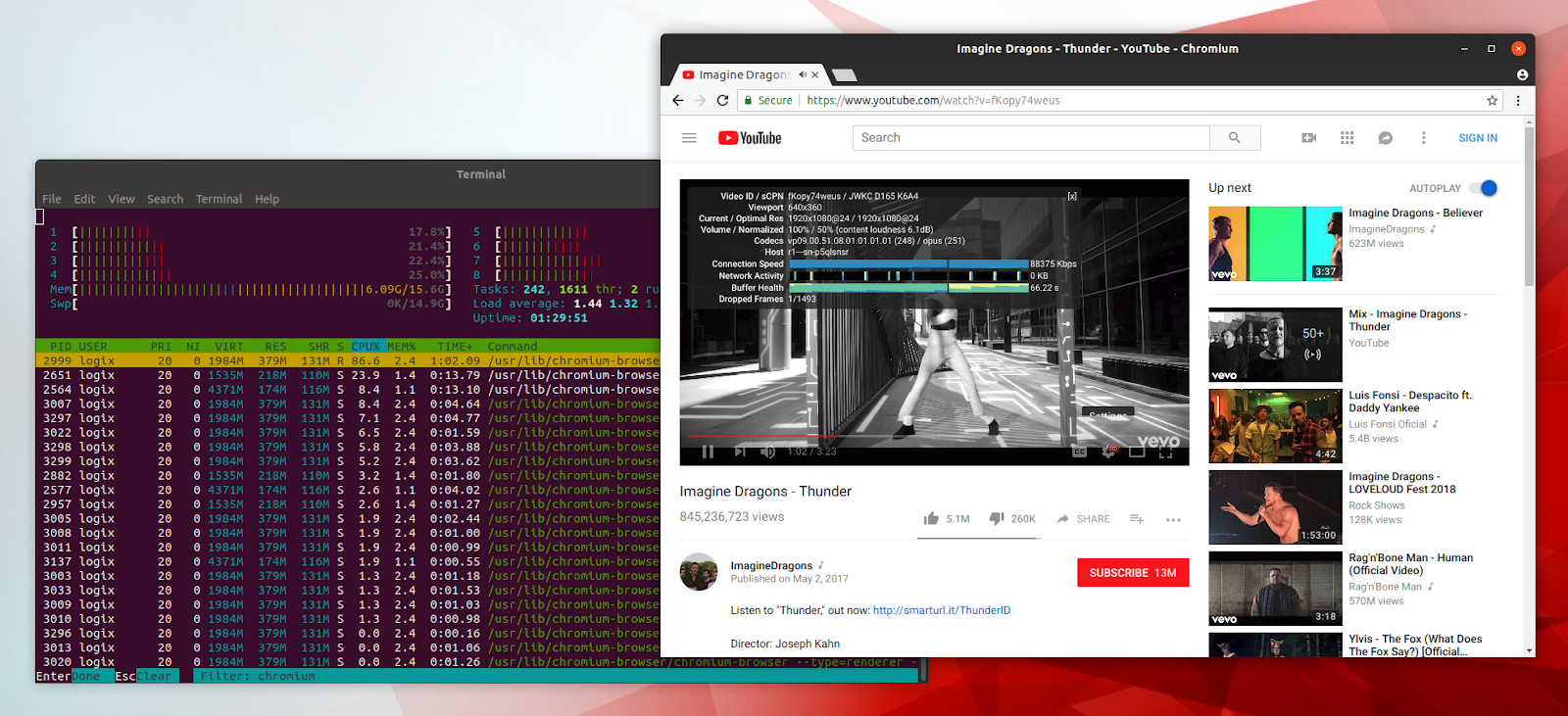
|
||||
|
||||
The same 1080p YouTube video playing in Chromium with the VA-API patch and hardware accelerated video decode enabled on Ubuntu 18.04:
|
||||
|
||||
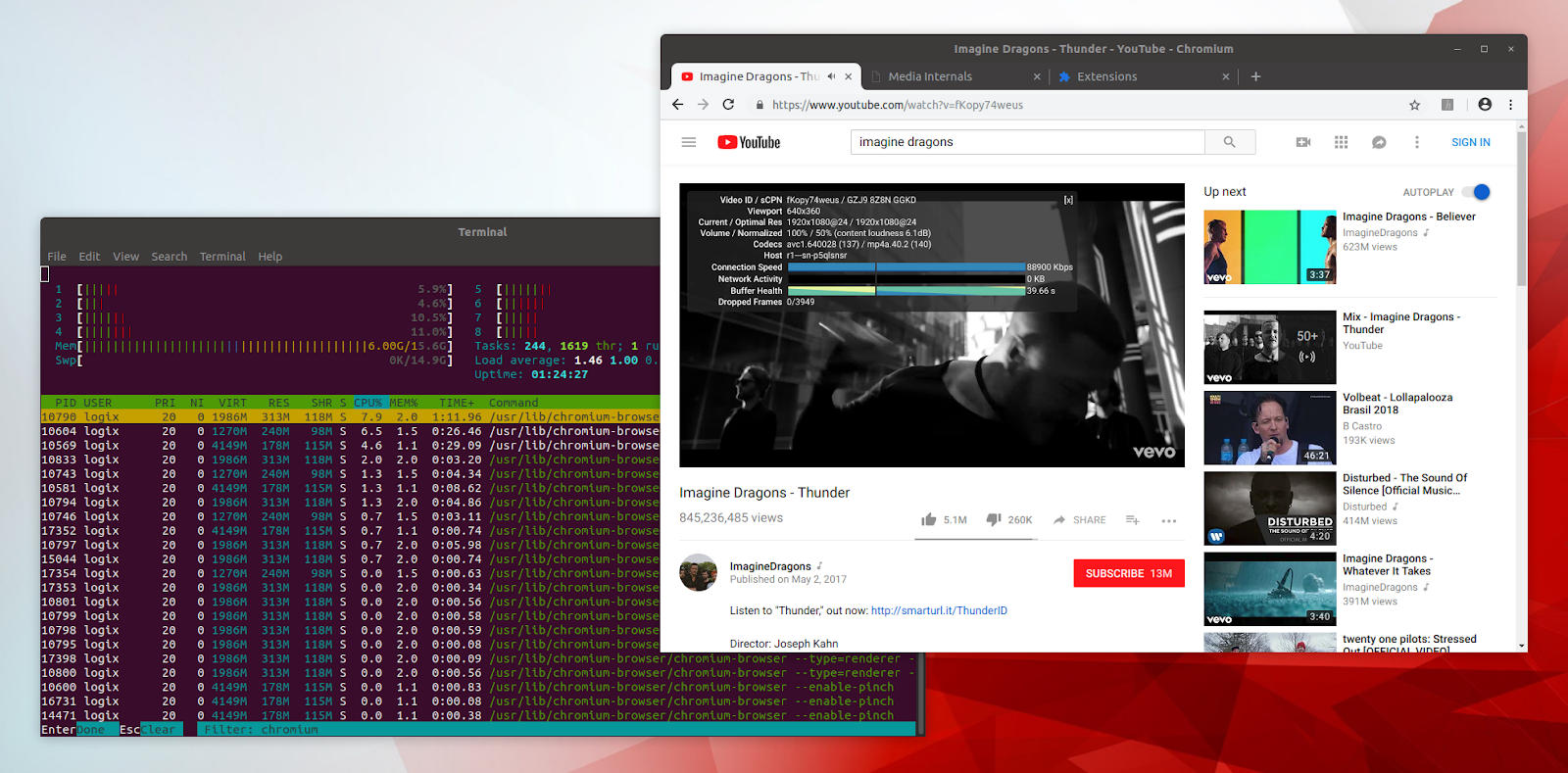
|
||||
|
||||
Notice the CPU usage in the screenshots. Both screenshots were taken on my old, but still quite powerful desktop. On my laptop, the Chromium CPU usage without hardware acceleration goes way higher.
|
||||
|
||||
The _Enable VAVDA, VAVEA and VAJDA on linux with VAAPI only_ " was was initially submitted to Chromium more than a year ago, but it has yet to be merged.
|
||||
|
||||
Chrome has an option to override the software rendering list (
|
||||
|
||||
`#ignore-gpu-blacklist`
|
||||
|
||||
), but this option does not enable hardware accelerated video decoding. After enabling this option, you may find the following when visiting
|
||||
|
||||
`chrome://gpu`
|
||||
|
||||
: " _Video Decode: Hardware accelerated_ ", but this does not mean it actually works. Open a HD video on YouTube and check the CPU usage in a tool such as
|
||||
|
||||
`htop`
|
||||
|
||||
(this is what I'm using in the screenshots above to check the CPU usage) - you should see high CPU usage because GPU video decoding is not actually enabled. There's also a section below for how to check if you're actually using hardware accelerated video decoding.
|
||||
|
||||
**The patches used by the Chromium Ubuntu builds with VA-API enabled used in this article are available[here][1].**
|
||||
|
||||
### Installing and using Chromium browser with VA-API support on Ubuntu or Linux Mint
|
||||
|
||||
**It should be clear to everyone reading this that Chromium Dev Branch is not considered stable. So you might find bugs, it may crash, etc. It works fine right now but who knows what may happen after some update.**
|
||||
|
||||
**What's more, the Chromium Dev Branch PPA requires you to perform some extra steps if you want to enable Widevine support** (so you can play Netflix videos and paid YouTube videos, etc.), **or if you need features like Sync** (which needs registering an API key and setting it up on your system). Instructions for performing these tweaks are explained in the
|
||||
|
||||
Chromium with the VA-API patch is also available for some other Linux distributions, in third-party repositories, like
|
||||
|
||||
**1\. Install Chromium Dev Branch with VA-API support.**
|
||||
|
||||
There's a Chromium Beta PPA with the VA-API patch, but it lacks vdpau-video for Ubuntu 18.04. If you want, you can use the `vdpau-va-driver` from the You can add the Chromium
|
||||
```
|
||||
sudo add-apt-repository ppa:saiarcot895/chromium-dev
|
||||
sudo apt-get update
|
||||
sudo apt install chromium-browser
|
||||
|
||||
```
|
||||
|
||||
**2\. Install the VA-API driver**
|
||||
|
||||
For Intel graphics cards, you'll need to install the `i965-va-driver` package (it may already be installed):
|
||||
```
|
||||
sudo apt install i965-va-driver
|
||||
|
||||
```
|
||||
|
||||
For Nvidia graphics cards (it should work with both the open source Nouveau drivers and the proprietary Nvidia drivers), install `vdpau-va-driver` :
|
||||
```
|
||||
sudo apt install vdpau-va-driver
|
||||
|
||||
```
|
||||
|
||||
**3\. Enable the Hardware-accelerated video option in Chromium.**
|
||||
|
||||
Copy and paste the following in the Chrome URL bar: `chrome://flags/#enable-accelerated-video` (or search for the `Hardware-accelerated video` option in `chrome://flags`) and enable it, then restart Chromium browser.
|
||||
|
||||
On a default Google Chrome / Chromium build, this option shows as unavailable, but you'll be able to enable it now because we've used the VA-API enabled Chromium build.
|
||||
|
||||
**4\. Install[h264ify][2] Chrome extension.**
|
||||
|
||||
YouTube (and probably some other websites as well) uses VP8 or VP9 video codecs by default, and many GPUs don't support hardware decoding for this codec. The h264ify extension will force YouTube to use H.264, which should be supported by most GPUs, instead of VP8/VP9.
|
||||
|
||||
This extension can also block 60fps videos, useful on lower end machines.
|
||||
|
||||
You can check the codec used by a YouTube video by right clicking on the video and selecting `Stats for nerds` . With the h264ify extension enabled, you should see avc / mp4a as the codecs. Without this extension, the codec should be something like vp09 / opus.
|
||||
|
||||
### How to check if Chromium is using GPU video decoding
|
||||
|
||||
Open a video on YouTube. Next, open a new tab in Chromium and enter the following in the URL bar: `chrome://media-internals` .
|
||||
|
||||
On the `chrome://media-internals` tab, click on the video url (in order to expand it), scroll down and look under `Player Properties` , and you should find the `video_decoder` property. If the `video_decoder` value is `GpuVideoDecoder` it means that the video that's currently playing on YouTube in the other tab is using hardware-accelerated video decoding.
|
||||
|
||||
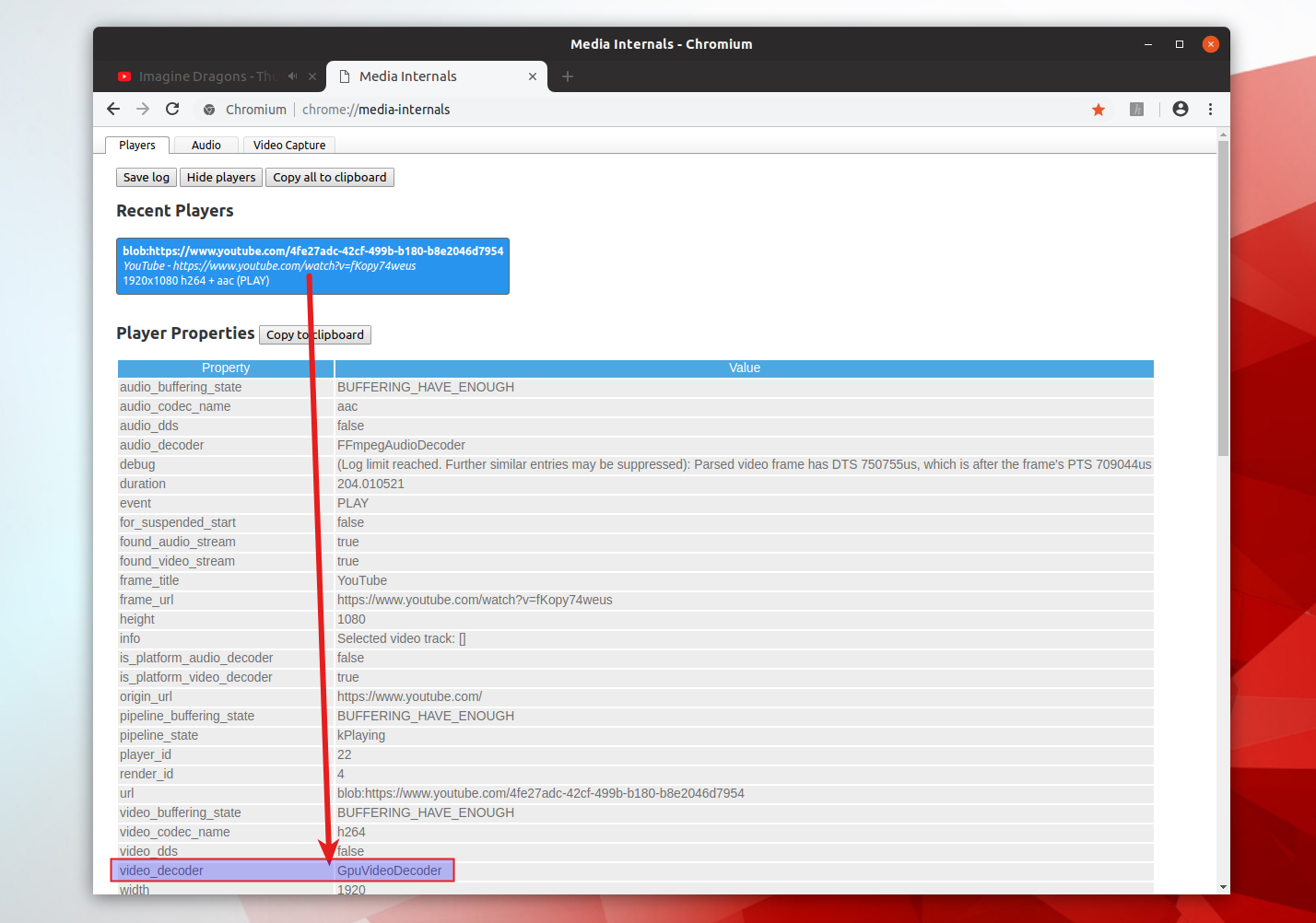
|
||||
|
||||
If it says `FFmpegVideoDecoder` or `VpxVideoDecoder` , accelerated video decoding is not working, or maybe you forgot to install or disabled the h264ify Chrome extension.
|
||||
|
||||
If it's not working, you could try to debug it by running `chromium-browser` from the command line and see if it shows any VA-API related errors. You can also run `vainfo` (install it in Ubuntu or Linux Mint: `sudo apt install vainfo`) and `vdpauinfo` (for Nvidia; install it in Ubuntu or Linux Mint: `sudo apt install vdpauinfo`) and see if it shows an error.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/how-to-enable-hardware-accelerated.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/saiarcot895/chromium-ubuntu-build/tree/master/debian/patches
|
||||
[2]:https://chrome.google.com/webstore/detail/h264ify/aleakchihdccplidncghkekgioiakgal
|
||||
[3]:https://chromium-review.googlesource.com/c/chromium/src/+/532294
|
||||
[4]:https://launchpad.net/~saiarcot895/+archive/ubuntu/chromium-dev
|
||||
[5]:https://aur.archlinux.org/packages/?O=0&SeB=nd&K=chromium+vaapi&outdated=&SB=n&SO=a&PP=50&do_Search=Go
|
||||
[6]:https://aur.archlinux.org/packages/libva-vdpau-driver-chromium/
|
||||
[7]:https://launchpad.net/~saiarcot895/+archive/ubuntu/chromium-beta
|
||||
[8]:https://launchpad.net/~saiarcot895/+archive/ubuntu/chromium-dev/+packages
|
||||
@ -0,0 +1,599 @@
|
||||
献给命令行重度用户的一组实用 BASH 脚本
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我偶然发现了一组用于命令行重度用户的实用 BASH 脚本,这些脚本被称为 **Bash-Snippets**,它们对于那些整天都与终端打交道的人来说可能会很有帮助。想要查看你居住地的天气情况?它为你做了。想知道股票价格?你可以运行显示股票当前详细信息的脚本。觉得无聊?你可以看一些 YouTube 视频。这些全部在命令行中完成,你无需安装任何严重消耗内存的 GUI 应用程序。
|
||||
|
||||
在撰写本文时,Bash-Snippets 提供以下 19 个实用工具:
|
||||
|
||||
1. **Cheat** – Linux 命令备忘单。
|
||||
2. **Cloudup** – 一个将 GitHub 仓库备份到 bitbucket 的工具。
|
||||
3. **Crypt** – 加解密文件。
|
||||
4. **Cryptocurrency** – 前 10 大加密货币的实时汇率转换。
|
||||
5. **Currency** – 货币转换器。
|
||||
6. **Geo** – 提供 wan、lan、router、dns、mac 和 ip 的详细信息。
|
||||
7. **Lyrics** – 从命令行快速获取给定歌曲的歌词。
|
||||
8. **Meme** – 创造命令行表情包。
|
||||
9. **Movies** – 搜索并显示电影详情。
|
||||
10. **Newton** – 执行数值计算一直到符号数学解析。(to 校正:这里不理解)
|
||||
11. **Qrify** – 将给定的字符串转换为二维码。
|
||||
12. **Short** – 缩短 URL
|
||||
13. **Siteciphers** – 检查给定 https 站点启用或禁用的密码。
|
||||
14. **Stocks** – 提供某些股票的详细信息。
|
||||
15. **Taste** – 推荐引擎提供三个类似的项目,如提供物品(如书籍、音乐、艺术家、电影和游戏等。)
|
||||
16. **Todo** – 命令行待办事项管理。
|
||||
17. **Transfer** – 从命令行快速传输文件。
|
||||
18. **Weather** – 显示你所在地的天气详情。
|
||||
19. **Youtube-Viewer** – 从终端观看 YouTube 视频。
|
||||
|
||||
作者可能会在将来添加更多实用程序和/或功能,因此我建议你密切关注该项目的网站或 GitHub 页面以供将来更新。
|
||||
|
||||
### Bash-Snippets – 一组实用 BASH 脚本献给命令行重度用户
|
||||
|
||||
#### 安装
|
||||
|
||||
你可以在任何支持 BASH 的操作系统上安装这些脚本。
|
||||
|
||||
首先,克隆 git 仓库,使用以下命令:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
进入目录:
|
||||
```
|
||||
$ cd Bash-Snippets/
|
||||
|
||||
```
|
||||
|
||||
切换到最新的稳定版本:
|
||||
```
|
||||
$ git checkout v1.22.0
|
||||
|
||||
```
|
||||
|
||||
最后,使用以下命令安装 Bash-Snippets:
|
||||
```
|
||||
$ sudo ./install.sh
|
||||
|
||||
```
|
||||
|
||||
这将询问你要安装哪些脚本。只需输入**Y** 并按 ENTER 键即可安装相应的脚本。如果你不想安装某些特定脚本,输入 **N** 并按 Enter 键。
|
||||
```
|
||||
Do you wish to install currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
要安装所有脚本,运行:
|
||||
```
|
||||
$ sudo ./install.sh all
|
||||
|
||||
```
|
||||
|
||||
要安装特定的脚本,比如 currency,运行:
|
||||
```
|
||||
$ sudo ./install.sh currency
|
||||
|
||||
```
|
||||
|
||||
你也可以使用 [**Linuxbrew**][1] 包管理器来安装它。
|
||||
|
||||
安装所有的工具,运行:
|
||||
```
|
||||
$ brew install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
安装特定的工具:
|
||||
```
|
||||
$ brew install bash-snippets --without-all-tools --with-newton --with-weather
|
||||
|
||||
```
|
||||
|
||||
另外,对于那些基于 Debian 系统的,例如 Ubuntu, Linux Mint,可以添加 PPA 源:
|
||||
```
|
||||
$ sudo add-apt-repository ppa:navanchauhan/bash-snippets
|
||||
$ sudo apt update
|
||||
$ sudo apt install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
#### 用法
|
||||
|
||||
**需要网络连接**才能使用这些工具。用法很简单。让我们来看看如何使用其中的一些脚本,我假设你已经安装了所有脚本。
|
||||
|
||||
**1\. Currency – 货币转换器**
|
||||
|
||||
这个脚本根据实时汇率转换货币。输入当前货币代码和要交换的货币,以及交换的金额,如下所示:
|
||||
```
|
||||
$ currency
|
||||
What is the base currency: INR
|
||||
What currency to exchange to: USD
|
||||
What is the amount being exchanged: 10
|
||||
|
||||
=========================
|
||||
| INR to USD
|
||||
| Rate: 0.015495
|
||||
| INR: 10
|
||||
| USD: .154950
|
||||
=========================
|
||||
|
||||
```
|
||||
|
||||
你也可以在单条命令中传递所有参数,如下所示:
|
||||
```
|
||||
$ currency INR USD 10
|
||||
|
||||
```
|
||||
|
||||
参考以下屏幕截图:
|
||||
|
||||
[![Bash-Snippets][2]][3]
|
||||
|
||||
**2\. Stocks – 显示股票价格详细信息**
|
||||
|
||||
如果你想查看一只股票价格的详细信息,输入股票即可,如下所示:
|
||||
```
|
||||
$ stocks Intel
|
||||
|
||||
INTC stock info
|
||||
=============================================
|
||||
| Exchange Name: NASDAQ
|
||||
| Latest Price: 34.2500
|
||||
| Close (Previous Trading Day): 34.2500
|
||||
| Price Change: 0.0000
|
||||
| Price Change Percentage: 0.00%
|
||||
| Last Updated: Jul 12, 4:00PM EDT
|
||||
=============================================
|
||||
|
||||
```
|
||||
|
||||
上面输出了 **Intel 股票** 的详情。
|
||||
|
||||
**3\. Weather – 显示天气详细信息**
|
||||
|
||||
让我们查看以下天气详细信息,运行以下命令:
|
||||
```
|
||||
$ weather
|
||||
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
![][4]
|
||||
|
||||
正如你在上面屏幕截图中看到的那样,它提供了 3 天的天气预报。不使用任何参数的话,它将根据你的 IP 地址显示天气详细信息。你还可以显示特定城市或国家/地区的天气详情,如下所示:
|
||||
```
|
||||
$ weather Chennai
|
||||
|
||||
```
|
||||
|
||||
同样,你可以查看输入以下命令来从查看月相(月亮的形态):
|
||||
```
|
||||
$ weather moon
|
||||
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][5]
|
||||
|
||||
**4\. Crypt – 加解密文件**
|
||||
|
||||
此脚本对 openssl 做了一层包装,允许你快速轻松地加密和解密文件。
|
||||
|
||||
要加密文件,使用以下命令:
|
||||
```
|
||||
$ crypt -e [original file] [encrypted file]
|
||||
|
||||
```
|
||||
|
||||
例如,以下命令将加密 **ostechnix.txt**,并将其保存在当前工作目录下,名为 **encrypt_ostechnix.txt**。
|
||||
```
|
||||
$ crypt -e ostechnix.txt encrypt_ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
输入两次文件密码:
|
||||
```
|
||||
Encrypting ostechnix.txt...
|
||||
enter aes-256-cbc encryption password:
|
||||
Verifying - enter aes-256-cbc encryption password:
|
||||
Successfully encrypted
|
||||
|
||||
```
|
||||
|
||||
上面命令将使用 **AES 256 位密钥**加密给定文件。密码不会以纯文本格式保存。你可以加密 .pdf, .txt, .docx, .doc, .png, .jpeg 类型的文件。
|
||||
|
||||
要解密文件,使用以下命令:
|
||||
```
|
||||
$ crypt -d [encrypted file] [output file]
|
||||
|
||||
```
|
||||
|
||||
例如:
|
||||
```
|
||||
$ crypt -d encrypt_ostechnix.txt ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
输入密码解密:
|
||||
```
|
||||
Decrypting encrypt_ostechnix.txt...
|
||||
enter aes-256-cbc decryption password:
|
||||
Successfully decrypted
|
||||
|
||||
```
|
||||
|
||||
**5\. Movies – 查看电影详情**
|
||||
|
||||
使用这个脚本,你可以查看电影详情。
|
||||
|
||||
以下命令显示了一部名为 “mother” 的电影的详情:
|
||||
```
|
||||
$ movies mother
|
||||
|
||||
==================================================
|
||||
| Title: Mother
|
||||
| Year: 2009
|
||||
| Tomato: 95%
|
||||
| Rated: R
|
||||
| Genre: Crime, Drama, Mystery
|
||||
| Director: Bong Joon Ho
|
||||
| Actors: Hye-ja Kim, Bin Won, Goo Jin, Je-mun Yun
|
||||
| Plot: A mother desperately searches for the killer who framed her son for a girl's horrific murder.
|
||||
==================================================
|
||||
|
||||
```
|
||||
|
||||
**6\. 显示类似条目**
|
||||
|
||||
要使用这个脚本,你需要从**[这里][6]** 获取 API 密钥。不过不用担心,它完全是免费的。一旦你获得 API 密钥后,将以下行添加到 **~/.bash_profile**:**export TASTE_API_KEY=”你的 API 密钥放在这里”**
|
||||
|
||||
现在你可以查看类似的项目,如提供的项目,如下所示:(to 校正者:不理解这个脚本的意思肿么办)
|
||||
```
|
||||
$ taste -i Red Hot Chilli Peppers
|
||||
|
||||
```
|
||||
|
||||
**7\. Short – 缩短 URL**
|
||||
|
||||
这个脚本会缩短给定的 URL。
|
||||
```
|
||||
$ short <URL>
|
||||
|
||||
```
|
||||
|
||||
**8\. Geo – 显示网络的详情**
|
||||
|
||||
|
||||
这个脚本会帮助你查找网络的详细信息,例如 wan, lan, router, dns, mac 和 ip 地址。
|
||||
|
||||
例如,要查找你的局域网 ip,运行:
|
||||
```
|
||||
$ geo -l
|
||||
|
||||
```
|
||||
|
||||
我系统上的输出:
|
||||
```
|
||||
192.168.43.192
|
||||
|
||||
```
|
||||
|
||||
查看广域网 ip:
|
||||
```
|
||||
$ geo -w
|
||||
|
||||
```
|
||||
|
||||
在终端中输入 `geo` 来查看更多详细信息。
|
||||
```
|
||||
$ geo
|
||||
Geo
|
||||
Description: Provides quick access for wan, lan, router, dns, mac, and ip geolocation data
|
||||
Usage: geo [flag]
|
||||
-w Returns WAN IP
|
||||
-l Returns LAN IP(s)
|
||||
-r Returns Router IP
|
||||
-d Returns DNS Nameserver
|
||||
-m Returns MAC address for interface. Ex. eth0
|
||||
-g Returns Current IP Geodata
|
||||
Examples:
|
||||
geo -g
|
||||
geo -wlrdgm eth0
|
||||
Custom Geo Output =>
|
||||
[all] [query] [city] [region] [country] [zip] [isp]
|
||||
Example: geo -a 8.8.8.8 -o city,zip,isp
|
||||
-o [options] Returns Specific Geodata
|
||||
-a [address] For specific ip in -s
|
||||
-v Returns Version
|
||||
-h Returns Help Screen
|
||||
-u Updates Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
**9\. Cheat – 显示 Linux 命令的备忘单**
|
||||
|
||||
想参考 Linux 命令的备忘单吗?这是可能的。以下命令将显示 **curl** 命令的备忘单:
|
||||
```
|
||||
$ cheat curl
|
||||
|
||||
```
|
||||
|
||||
只需用你选择的命令替换 **curl** 即可显示其备忘单。这对于快速参考你要使用的任何命令非常有用。
|
||||
|
||||
**10\. Youtube-Viewer – 观看 YouTube 视频**
|
||||
|
||||
使用此脚本,你可以直接在终端上搜索或观看 YouTube 视频。
|
||||
|
||||
让我们来看一些有关 **Ed Sheeran** 的视频。
|
||||
```
|
||||
$ ytview Ed Sheeran
|
||||
|
||||
```
|
||||
|
||||
从列表中选择要播放的视频。所选内容将在你的默认媒体播放器中播放。
|
||||
|
||||
![][7]
|
||||
|
||||
要查看艺术家的近期视频,你可以使用:
|
||||
```
|
||||
$ ytview -c [channel name]
|
||||
|
||||
```
|
||||
|
||||
要寻找视频,只需输入:
|
||||
```
|
||||
$ ytview -s [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
或者:
|
||||
```
|
||||
$ ytview [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
**11\. cloudup – 备份p GitHub 仓库到 bitbucket**
|
||||
|
||||
你在 GitHub 上托管过任何项目吗?如果托管过,那么你可以随时间 GitHub 仓库备份到 **bitbucket**,它是一种用于源代码和开发项目的基于 Web 的托管服务。
|
||||
|
||||
你可以使用 **-a** 选项一次性备份指定用户的所有 GitHub 仓库,或者不使用它来备份单个仓库。
|
||||
|
||||
要备份 GitHub 仓库,运行:
|
||||
```
|
||||
$ cloudup
|
||||
|
||||
```
|
||||
|
||||
系统将要求你输入 GitHub 用户名, 要备份的仓库名称以及 bitbucket 用户名和密码等。
|
||||
|
||||
**12\. Qrify – 将字符串转换为二维码**
|
||||
|
||||
这个脚本将任何给定的文本字符串转换为二维码。这对于发送链接或者保存一串命令到手机非常有用。
|
||||
```
|
||||
$ qrify convert this text into qr code
|
||||
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][8]
|
||||
|
||||
很酷,不是吗?
|
||||
|
||||
**13\. Cryptocurrency**
|
||||
|
||||
它将显示十大加密货币实时汇率。
|
||||
|
||||
输入以下命令,然后单击 ENTER 来运行:
|
||||
```
|
||||
$ cryptocurrency
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
|
||||
**14\. Lyrics**
|
||||
|
||||
这个脚本从命令行快速获取一首歌曲的歌词。
|
||||
|
||||
例如,我将获取 **“who is it”** 歌曲的歌词,这是一首由 **Michael Jackson(迈克尔·杰克逊)** 演唱的流行歌曲。
|
||||
```
|
||||
$ lyrics -a michael jackson -s who is it
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
**15\. Meme**
|
||||
这个脚本允许你从命令行创建简单的表情包。它比基于 GUI 的表情包生成器快得多。
|
||||
|
||||
要创建一个表情包,只需输入:
|
||||
```
|
||||
$ meme -f mymeme
|
||||
Enter the name for the meme's background (Ex. buzz, doge, blb ): buzz
|
||||
Enter the text for the first line: THIS IS A
|
||||
Enter the text for the second line: MEME
|
||||
|
||||
```
|
||||
|
||||
这将在你当前的工作目录创建 jpg 文件。
|
||||
|
||||
**16\. Newton**
|
||||
|
||||
厌倦了解决复杂的数学问题?你来对了。Newton 脚本将执行数值计算,直到符号数学解析。(to 校正者:这里不太理解)
|
||||
|
||||
![][11]
|
||||
|
||||
**17\. Siteciphers**
|
||||
|
||||
这个脚本可以帮助你检查在给定的 https 站点上启用/禁用哪些密码。
|
||||
```
|
||||
$ siteciphers google.com
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
**18\. Todo**
|
||||
|
||||
它允许你直接从终端创建日常任务。
|
||||
|
||||
让我们来创建一些任务。
|
||||
```
|
||||
$ todo -a The first task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
要添加其它任务,只需添加任务名称重新运行上述命令即可。
|
||||
```
|
||||
$ todo -a The second task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). The second task Tue Jun 26 14:52:29 IST 2018
|
||||
|
||||
```
|
||||
|
||||
要查看任务列表,运行:
|
||||
```
|
||||
$ todo -g
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). A The second task Tue Jun 26 14:51:46 IST 2018
|
||||
|
||||
```
|
||||
|
||||
一旦你完成了任务,就可以将其从列表中删除,如下所示:
|
||||
```
|
||||
$ todo -r 2
|
||||
Sucessfully removed task number 2
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
要清除所有任务,运行:
|
||||
```
|
||||
$ todo -c
|
||||
Tasks cleared.
|
||||
|
||||
```
|
||||
|
||||
**19\. Transfer**
|
||||
|
||||
Transfer 脚本允许你通过 Internet 快速轻松地传输文件和目录。
|
||||
|
||||
让我们上传一个文件:
|
||||
```
|
||||
$ transfer test.txt
|
||||
Uploading test.txt
|
||||
################################################################################################################################################ 100.0%
|
||||
Success!
|
||||
Transfer Download Command: transfer -d desiredOutputDirectory ivmfj test.txt
|
||||
Transfer File URL: https://transfer.sh/ivmfj/test.txt
|
||||
|
||||
```
|
||||
|
||||
该文件将上传到 transfer.sh 站点。Transfer.sh 允许你一次上传最大 **10 GB** 的文件。所有共享文件在 **14 天**后自动过期。如你所见,任何人都可以通过 Web 浏览器访问 URL 或使用 transfer 目录来下载文件,当然,transfer 必须安装在他/她的系统中。
|
||||
|
||||
现在从你的系统中移除文件。
|
||||
```
|
||||
$ rm -fr test.txt
|
||||
|
||||
```
|
||||
|
||||
现在,你可以随时(14 天内)从 transfer.sh 站点下载该文件,如下所示:
|
||||
```
|
||||
$ transfer -d Downloads ivmfj test.txt
|
||||
|
||||
```
|
||||
|
||||
获取关于此实用脚本的更多详情,参考以下指南。
|
||||
* [从命令行在 Internet 上共享文件的一个简单快捷方法](https://www.ostechnix.com/easy-fast-way-share-files-internet-command-line/)
|
||||
|
||||
##### 获得帮助
|
||||
|
||||
如果你不知道如何使用特定脚本,只需输入该脚本的名称,然后按下 ENTER 键,你将会看到使用细节。以下示例显示 **Qrify** 脚本的帮助信息。
|
||||
```
|
||||
$ qrify
|
||||
Qrify
|
||||
Usage: qrify [stringtoturnintoqrcode]
|
||||
Description: Converts strings or urls into a qr code.
|
||||
-u Update Bash-Snippet Tools
|
||||
-m Enable multiline support (feature not working yet)
|
||||
-h Show the help
|
||||
-v Get the tool version
|
||||
Examples:
|
||||
qrify this is a test string
|
||||
qrify -m two\\nlines
|
||||
qrify github.com # notice no http:// or https:// this will fail
|
||||
|
||||
```
|
||||
|
||||
#### 更新脚本
|
||||
|
||||
你可以随时使用 -u 选项更新已安装的工具。以下命令更新 “weather” 工具。
|
||||
```
|
||||
$ weather -u
|
||||
|
||||
```
|
||||
|
||||
#### 卸载
|
||||
|
||||
你可以使用以下命令来卸载这些工具。
|
||||
|
||||
克隆仓库:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
进入 Bash-Snippets 目录:
|
||||
```
|
||||
$ cd Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
运行以下命令来卸载脚本:
|
||||
```
|
||||
$ sudo ./uninstall.sh
|
||||
|
||||
```
|
||||
|
||||
输入 **y**,并按下 ENTER 键来移除每个脚本。
|
||||
```
|
||||
Do you wish to uninstall currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
**另请阅读:**
|
||||
|
||||
好了,这就是全部了。我必须承认,在测试这些脚本时我印象很深刻。我真的很喜欢将所有有用的脚本组合到一个包中的想法。感谢开发者。试一试,你不会失望的。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/collection-useful-bash-scripts-heavy-commandline-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_001.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_002-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_003.png
|
||||
[6]:https://tastedive.com/account/api_access
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/07/ytview-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_005.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/07/cryptocurrency.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/07/lyrics.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/07/newton.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/07/siteciphers.png
|
||||
@ -0,0 +1,149 @@
|
||||
Arch Linux 应用自动安装脚本
|
||||
======
|
||||
|
||||

|
||||
|
||||
Arch 用户你们好!今天,我偶然发现了一个叫做“**ArchI0**”的实用工具,它是基于命令行菜单的 Arch Linux 应用自动安装脚本。使用此脚本是安装基于 Arch 的发行版所有必要应用最简易的方式。请注意**此脚本仅适用于菜鸟级使用者**。中高级使用者可以轻松掌握[**如何使用 pacman **][1]来完成这件事。如果你想学习如何使用 Arch Linux,我建议你一个个手动安装所有的软件。对那些仍是菜鸟并且希望为自己基于 Arch 的系统快速安装所有必要应用的用户,可以使用此脚本。
|
||||
|
||||
### ArchI0 – Arch Linux 应用自动安装脚本
|
||||
|
||||
此脚本的开发者已经制作了 **ArchI0live** 和 **ArchI0** 两个脚本。你可以通过 ArchI0live 测试,无需安装。这可能有助于在将脚本安装到系统之前了解其实际内容。
|
||||
|
||||
### 安装 ArchI0
|
||||
|
||||
要安装此脚本,使用如下命令通过 Git 克隆 ArchI0 脚本仓库:
|
||||
```
|
||||
$ git clone https://github.com/SifoHamlaoui/ArchI0.git
|
||||
|
||||
```
|
||||
|
||||
上面的命令会克隆 ArchI0 的 Github 仓库内容,在你当前目录的一个名为 ArchI0 的文件夹里。使用如下命令进入此目录:
|
||||
```
|
||||
$ cd ArchI0/
|
||||
|
||||
```
|
||||
|
||||
使用如下命令赋予脚本可执行权限:
|
||||
```
|
||||
$ chmod +x ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
使用如下命令执行脚本:
|
||||
```
|
||||
$ sudo ./ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
此脚本需要以 root 或 sudo 用户身份执行,因为安装应用需要 root 权限。
|
||||
|
||||
> **注意:** 有些人想知道此脚本中所有命令的开头部分,第一个命令是下载 **figlet**,因为此脚本的 logo 是使用 figlet 显示的。第二个命令是安装用来打开并查看许可协议文件的 **Leafpad**。第三个命令是安装从 sourceforge 下载文件的 **wget**。第四和第五个命令是下载许可协议文件并用 leafpad 打开。此外,最后的第6条命令是在阅读许可协议文件之后关闭它。
|
||||
|
||||
输入你的 Arch Linux 系统架构然后按回车键。当其请求安装此脚本时,键入 y 然后按回车键。
|
||||
|
||||
![][3]
|
||||
|
||||
一旦开始安装,将会重定向至主菜单。
|
||||
|
||||
![][4]
|
||||
|
||||
正如前面的截图, ArchI0 有13个目录,包含90个容易安装的程序。这90个程序刚好足够配置一个完整的 Arch Linux 桌面,可执行日常活动。键入 **a** 可查看关于此脚本的信息,键入 **q** 可退出此脚本。
|
||||
|
||||
安装后无需执行 ArchI0live 脚本。可以直接使用如下命令启动:
|
||||
```
|
||||
$ sudo ArchI0
|
||||
|
||||
```
|
||||
|
||||
它会每次询问你选择 Arch Linux 发行版的架构。
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
Preparing To Run Script
|
||||
Checking For ROOT: PASSED
|
||||
What Is Your OS Architecture? {32/64} 64
|
||||
|
||||
```
|
||||
|
||||
从现在开始,你可以从主菜单列出的类别选择要安装的程序。要查看特定类别下的可用程序列表,输入类别号即可。举个例子,要查看**文本编辑器**分类下的可用程序列表,输入 **1** 然后按回车键。
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ R00T MENU ]
|
||||
Make A Choice
|
||||
1) Text Editors
|
||||
2) FTP/Torrent Applications
|
||||
3) Download Managers
|
||||
4) Network managers
|
||||
5) VPN clients
|
||||
6) Chat Applications
|
||||
7) Image Editors
|
||||
8) Video editors/Record
|
||||
9) Archive Handlers
|
||||
10) Audio Applications
|
||||
11) Other Applications
|
||||
12) Development Environments
|
||||
13) Browser/Web Plugins
|
||||
14) Dotfiles
|
||||
15) Usefull Links
|
||||
------------------------
|
||||
a) About ArchI0 Script
|
||||
q) Leave ArchI0 Script
|
||||
|
||||
Choose An Option: 1
|
||||
|
||||
```
|
||||
|
||||
接下来,选择你想安装的程序。要返回至主菜单,输入 **q** 然后按回车键。
|
||||
|
||||
我想安装 Emacs,所以我输入 **3**。
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ TEXT EDITORS ]
|
||||
[ Option ] [ Description ]
|
||||
1) GEdit
|
||||
2) Geany
|
||||
3) Emacs
|
||||
4) VIM
|
||||
5) Kate
|
||||
---------------------------
|
||||
q) Return To Main Menu
|
||||
|
||||
Choose An Option: 3
|
||||
|
||||
```
|
||||
|
||||
现在,Emacs 将会安装至你的 Arch Linux 系统。
|
||||
|
||||
![][5]
|
||||
|
||||
所选择的应用安装完成后,你可以按回车键返回主菜单。
|
||||
|
||||
### 结论
|
||||
|
||||
毫无疑问,此脚本让 Arch Linux 用户使用起来更加容易,特别是刚开始使用的人。如果你正寻找快速简单无需 pacman 的安装应用的方法,此脚本是一个不错的选择。试用一下并在下面的评论区让我们知道你对此脚本的看法。
|
||||
|
||||
就这些。希望这个工具能帮到你。我们每天都会推送实用的指南。如果你觉得我们的指南挺实用,请分享至你的社交网络,专业圈子并支持 OSTechNix。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/archi0-arch-linux-applications-automatic-installation-script/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_003.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_004-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/pacman-as-superuser_005.png
|
||||
@ -1,227 +1,195 @@
|
||||
盘点 Python 的目标受众
|
||||
============================================================
|
||||
|
||||
Python 是为谁设计的?
|
||||
|
||||
* [Python 的参考解析器使用情况][8]
|
||||
* [CPython 主要服务于哪些受众?][9]
|
||||
* [这些相关问题的原因是什么?][10]
|
||||
* [适合进入 PyPI 规划的方面有哪些?][11]
|
||||
* [当添加它们到标准库中时,为什么一些 API 会被改变?][12]
|
||||
* [为什么一些 API 是以<ruby>临时<rt>provisional</rt></ruby>的形式被添加的?][13]
|
||||
* [为什么只有一些标准库 API 被升级?][14]
|
||||
* [标准库任何部分都有独立的版本吗?][15]
|
||||
* [这些注意事项为什么很重要?][16]
|
||||
|
||||
几年前,我在 python-dev 邮件列表中,以及在活跃的 CPython 核心开发人员和认为参与这一过程不是有效利用他们个人时间和精力的人中[强调][38]说,“CPython 的发展太快了也太慢了”是很多冲突的原因之一。
|
||||
|
||||
我一直认为事实确实如此,但这也是一个要点,在这几年中我也花费了一些时间去反思它。在我写那篇文章的时候,我还在<ruby>波音防务澳大利亚公司<rt>Boeing Defence Australia</rt></ruby>工作。下个月,我将离开波音进入<ruby>红帽亚太<rt>Red Hat Asia-Pacific</rt></ruby>,并且开始在大企业的[开源供应链管理][39]上获得<ruby>再分发者<rt>redistributor</rt></ruby>层面的视角。
|
||||
|
||||
### Python 的参考解析器使用情况
|
||||
|
||||
我尝试将 CPython 的使用情况分解如下,它虽然有些过于简化(注意,这些分类的界线并不是很清晰,他们仅关注于思考新软件特性和版本发布后不同因素的影响):
|
||||
|
||||
* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,_不会去_ 写或维护生产级别的软件。例如:
|
||||
* 澳大利亚的 [数字课程][1]
|
||||
* Lorena A. Barba 的 [AeroPython][2]
|
||||
* 个人级的自动化和爱好者的项目:主要的是软件,而且经常是只有软件,用户通常是写它的人。例如:
|
||||
* my Digital Blasphemy [图片下载器][3]
|
||||
* Paul Fenwick 的 (Inter)National [Rick Astley Hotline][4]
|
||||
* <ruby>组织<rt>organisational</rt></ruby>过程自动化:主要是软件,而且经常是只有软件,用户是为了利益而编写它的组织。例如:
|
||||
* CPython 的 [核心工作流工具][5]
|
||||
* Linux 发行版的开发、构建 & 发行管理工具
|
||||
* “<ruby>一劳永逸<rt>Set-and-forget</rt></ruby>” 的基础设施中:这里是软件,(这种说法有时候有些争议),在生命周期中该软件几乎不会升级,但是,在底层平台可能会升级。例如:
|
||||
* 大多数的自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这种情况是让人非常不安的)
|
||||
* 拨款资助的软件(当最初的拨款耗尽时,维护通常会终止)
|
||||
* 有严格认证要求的软件(如果没有绝对必要的话,从经济性考虑,重新认证比常规更新来说要昂贵很多)
|
||||
* 没有自动升级功能的嵌入式软件系统
|
||||
* 持续升级的基础设施:具有健壮支撑的工程学模型的软件,对于依赖和平台升级通常是例行的,而不去关心其它的代码改变。例如:
|
||||
* Facebook 的 Python 服务基础设施
|
||||
* 滚动发布的 Linux 分发版
|
||||
* 大多数的公共 PaaS 无服务器环境(Heroku、OpenShift、AWS Lambda、Google Cloud Functions、Azure Cloud Functions等等)
|
||||
* 间隔性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
|
||||
* [VFX 平台][6]
|
||||
* 长周期支持的 Linux 分发版
|
||||
* CPython 和 Python 标准库
|
||||
* 基础设施管理 & 编排工具(比如 OpenStack、 Ansible)
|
||||
* 硬件控制系统
|
||||
* 短生命周期的软件:软件仅被使用一次,然后就丢弃或忽略,而不是随后接着升级。例如:
|
||||
* <ruby>临时<rt>Ad hoc</rt></ruby>自动脚本
|
||||
* 被确定为 “终止” 的单用户游戏(你玩它们一次后,甚至都忘了去卸载它,或许在一个新的设备上都不打算再去安装它)
|
||||
* 短暂的或非持久状态的单用户游戏(如果你卸载并重安装它们,你的游戏体验也不会有什么大的变化)
|
||||
* 特定事件的应用程序(这些应用程序与特定的物理事件捆绑,一旦事件结束,这些应用程序就不再有用了)
|
||||
* 频繁使用的应用程序:部署后定期升级的软件。例如:
|
||||
* 业务管理软件
|
||||
* 个人 & 专业的生产力应用程序(比如,Blender)
|
||||
* 开发工具 & 服务(比如,Mercurial、 Buildbot、 Roundup)
|
||||
* 多用户游戏,和其它明显的处于持续状态的还没有被定义为 “终止” 的游戏
|
||||
* 有自动升级功能的嵌入式软件系统
|
||||
* 共享的抽象层:在一个特定的问题领域中,设计用于让工作更高效的软件组件。即便是你没有亲自掌握该领域的所有错综复杂的东西。例如:
|
||||
* 大多数的运行时库和归入这一类的框架(比如,Django、Flask、Pyramid、SQL Alchemy、NumPy、SciPy、requests)
|
||||
* 适合归入这一类的许多测试和类型推断工具(比如,pytest、Hypothesis、vcrpy、behave、mypy)
|
||||
* 其它应用程序的插件(比如,Blender plugins、OpenStack hardware adapters)
|
||||
* 本身就代表了 “Python 世界” 基准的标准库(那是一个 [难以置信的复杂][7] 的世界观)
|
||||
|
||||
### CPython 主要服务于哪些受众?
|
||||
|
||||
从根本上说,CPython 和标准库的主要受众是哪些呢,是那些不管出于什么原因,将有限的标准库和从 PyPI 显式声明安装的第三方库组合起来所提供的服务,还不能够满足需求的那些人。
|
||||
|
||||
为了更进一步简化上面回顾的不同用法和部署模型,尽可能的总结,将最大的 Python 用户群体分开来看,一种是,在一些感兴趣的环境中将 Python 作为一种_脚本语言_使用的那些人;另外一种是将它用作一个_应用程序开发语言_的那些人,他们最终发布的是一种产品而不是他们的脚本。
|
||||
|
||||
把 Python 作为一种脚本语言来使用的开发者的典型特性包括:
|
||||
|
||||
* 主要的工作单元是由一个 Python 文件组成的(或 Jupyter notebook !),而不是一个 Python 和元数据文件的目录
|
||||
* 没有任何形式的单独的构建步骤 —— 是_作为_一个脚本分发的,类似于分发一个独立的 shell 脚本的方式
|
||||
* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),除了在目标系统上要求预配置运行时环境外
|
||||
* 没有显式的规定依赖关系,除了最低的 Python 版本,或一个预期的运行环境声明。如果需要一个标准库以外的依赖项,他们会通过一个环境脚本去提供(无论是操作系统、数据分析平台、还是嵌入 Python 运行时的应用程序)
|
||||
* 没有单独的测试套件,使用“通过你给定的输入,这个脚本是否给出了你期望的结果?” 这种方式来进行测试
|
||||
* 如果在执行前需要测试,它将以 “试运行” 和 “预览” 模式来向用户展示软件_将_怎样运行
|
||||
* 如果可以完全使用静态代码分析工具,它是通过集成进用户的软件开发环境的,而不是为个别的脚本单独设置的。
|
||||
|
||||
相比之下,使用 Python 作为一个应用程序开发语言的开发者特征包括:
|
||||
|
||||
* 主要的工作单元是由 Python 和元数据文件组成的目录,而不是单个 Python 文件
|
||||
* 在发布之前有一个单独的构建步骤去预处理应用程序,哪怕是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 文档中
|
||||
* 是否有独立的安装步骤去预处理将要使用的应用程序,取决于应用程序是如何打包的,和支持的目标环境
|
||||
* 外部的依赖明确表示为项目目录中的一个元数据文件中,要么是直接在项目的目录中(比如,`pyproject.toml`、`requirements.txt`、`Pipfile`),要么是作为生成的发行包的一部分(比如,`setup.py`、`flit.ini`)
|
||||
* 存在一个独立的测试套件,或者作为一个 Python API 的一个单元测试,或者作为功能接口的集成测试,或者是两者的一个结合
|
||||
* 静态分析工具的使用是在项目级配置的,并作为测试管理的一部分,而不是取决于环境
|
||||
|
||||
作为以上分类的一个结果,CPython 和标准库的主要用途是,在相应的 CPython 特性发布后,为教育和<ruby>临时<rt>ad hoc</rt></ruby>的 Python 脚本环境,最终提供的是定义重分发者假定功能的独立基准 3- 5 年。
|
||||
|
||||
对于<ruby>临时<rt>ad hoc</rt></ruby>脚本使用的情况,这个 3 - 5 年的延迟是由于重分发者给用户制作新版本的延迟造成的,以及那些重分发版本的用户们花在修改他们的标准操作环境上的时间。
|
||||
|
||||
在教育环境中的情况是,教育工作者需要一些时间去评估新特性,和决定是否将它们包含进提供给他们的学生的课程中。
|
||||
|
||||
### 这些相关问题的原因是什么?
|
||||
|
||||
这篇文章很大程度上是受 Twitter 上对 [我的这个评论][20] 的讨论鼓舞的,它援引了定义在 [PEP 411][21] 中<ruby>临时<rt>Provisional</rt></ruby> API 的情形,作为一个开源项目的例子,对用户发出事实上的邀请,请其作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
|
||||
|
||||
这些回复包括一些在更高级别的库中支持临时 API 的困难程度的一些沮丧性表述、没有这些库做临时状态的传递、以及因此而被限制为只有临时 API 的最新版本才支持这些相关特性,而不是任何早期版本的迭代。
|
||||
|
||||
我的 [主要回应][22] 是,建议开源提供者应该强制实施有限支持,通过这种强制的有限支持可以让个人的维护努力变得可持续。这意味着,如果对临时 API 的老版本提供迭代支持是非常痛苦的,到那时,只有在项目开发人员自己需要、或有人为此支付费用时,他们才会去提供支持。这与我的这个观点是类似的,那就是,志愿者提供的项目是否应该免费支持老的、商业性质的、长周期的 Python 版本,这对他们来说是非常麻烦的事,我[不认为他们应该去做][23],正如我所期望的那样,大多数这样的需求都来自于管理差劲的、习以为常的惯性,而不是真正的需求(真正的需求,应该去支付费用来解决问题)。
|
||||
|
||||
而我的[第二个回应][24]是去实现这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中最早在 2011 年的一篇的文章中,以及在 Python 3 问答的回复中的 [这里][25]、[这里][26]、和[这里][27],以及去年的这篇文章 [Python 包生态系统][28] 中也提到了一些),但我从来没有真实地尝试直接去解释它在标准库设计过程中的影响。
|
||||
|
||||
如果没有这些背景,设计过程中的一部分,比如临时 API 的引入,或者是<ruby>受启发而不同于它<rt>inspired-by-not-the-same-as</rt></ruby>的引入,看起来似乎是完全没有意义的,因为他们看起来似乎是在尝试对 API 进行标准化,而实际上并没有。
|
||||
|
||||
### 适合进入 PyPI 规划的方面有哪些?
|
||||
|
||||
提交给 python-ideas 或 python-dev 的_任何_建议所面临的第一个门槛就是清楚地回答这个问题:“为什么 PyPI 上的一个模块不够好?”。绝大多数的建议都在这一步失败了,为了通过这一步,这里有几个常见的话题:
|
||||
|
||||
* 与其去下载一个合适的第三方库,新手一般可能更倾向于从互联网上 “复制粘贴” 错误的指导。(比如,这就是为什么存在 `secrets` 库的原因:它使得人们很少去使用 `random` 模块,由于安全敏感的原因,它预期用于游戏和统计模拟的)
|
||||
* 这个模块是打算去提供一个实现的参考,并允许与其它的相互竞争的实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(比如,`asyncio`、`wsgiref`、`unittest`、和 `logging` 全部都是这种情况)
|
||||
* 这个模块是预期用于标准库的其它部分(比如,`enum` 就是这种情况,像`unittest`一样)
|
||||
* 这个模块是被设计去支持语言之外的一些语法(比如,`contextlib`、`asyncio` 和 `typing` 模块,就是这种情况)
|
||||
* 这个模块只是普通的临时的脚本用途(比如,`pathlib` 和 `ipaddress` 就是这种情况)
|
||||
* 这个模块被用于一个教育环境(比如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你可能根本就不会用它来做全部的统计分析)
|
||||
|
||||
通过前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被接收到标准库中,但它已经足以转变问题为 “在接下来的几年中,你所推荐的要包含的库能否对一般的入门级 Python 开发人员的经验有所提升?”
|
||||
|
||||
标准库中的 `ensurepip` 和 `venv` 模块的引入也明确地告诉再分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
|
||||
|
||||
### 当添加它们到标准库中时,为什么一些 API 会被改变?
|
||||
|
||||
现在已经存在的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上添加的是吸收了用户对现有 API 体验之后,进行重新设计和重新实现的 API,但是,会根据另外的设计考虑和已经成为其中一部分的语言实现参考来进行一些删除或细节修改。
|
||||
|
||||
例如,不像广受欢迎的第三方库的前身 `path.py`,`pathlib` 并_没有_定义字符串子类,而是以独立的类型替代。作为解决文件互操作性问题的结果,定义了文件系统路径协议,它允许使用文件系统路径的接口去使用更多的对象。
|
||||
|
||||
为了在“IP 地址” 这个概念的教学上提供一个更好的工具,为 `ipaddress` 模块设计的 API,将地址和网络的定义调整为显式的、独立定义的主机接口(IP 地址被关联到特定的 IP 网络),而最原始的 `ipaddr` 模块中,在网络术语的使用方式上不那么严格。
|
||||
|
||||
另外的情况是,标准库将综合多种现有的方法的来构建,以及为早已存在的库定义 API 时,还有可能依靠不存在的语法特性。比如,`asyncio` 和 `typing` 模块就全部考虑了这些因素,虽然在 PEP 557 中正在考虑将后者所考虑的因素应用到 `dataclasses` API 上。(它可以被总结为 “像属性一样,但是使用可变注释作为字段声明”)。
|
||||
|
||||
这类改变的原理是,这类库不会消失,并且它们的维护者对标准库维护相关的那些限制通常并不感兴趣(特别是,相对缓慢的发行节奏)。在这种情况下,在标准库文档的更新版本中,很常见的做法是使用 “See Also” 链接指向原始模块,尤其是在第三方版本提供了额外的特性以及标准库模块中忽略的那些特性时。
|
||||
|
||||
### 为什么一些 API 是以临时的形式被添加的?
|
||||
|
||||
虽然 CPython 维护了 API 的弃用策略,但在没有正当理由的情况下,我们通常不会去使用该策略(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
|
||||
|
||||
然而在实践中,当添加这种受已有的第三方启发而不是直接精确拷贝第三方设计的新 API 时,所承担的风险要高于一些正常设计决定可能出现问题的风险。
|
||||
|
||||
当我们考虑这种改变的风险比平常要高,我们将相关的 API 标记为临时,表示保守的终端用户要避免完全依赖它们,而共享抽象层的开发者可能希望,对他们准备去支持的那个临时 API 的版本,考虑实施比平时更严格的限制。
|
||||
|
||||
### 为什么只有一些标准库 API 被升级?
|
||||
|
||||
这里简短的回答得到升级的主要 API 有哪些?:
|
||||
|
||||
* 不太可能有大量的外部因素干扰的附加更新
|
||||
* 无论是对临时脚本使用案例还是对促进将来多个第三方解决方案之间的互操作性,都有明显好处的
|
||||
* 对这方面感兴趣的人提交了一个可接受的建议
|
||||
|
||||
如果一个用于应用程序开发的模块存在一个非常明显的限制,比如,`datetime`,如果重分发者通过可供替代的第三方选择很容易地实现了改善,比如,`requests`,或者,如果标准库的发布节奏与所需要的包之间真的存在冲突,比如,`certifi`,那么,建议对标准库版本进行改变的因素将显著减少。
|
||||
|
||||
从本质上说,这和上面的关于 PyPI 问题正好相反:因为,从应用程序开发人员体验改善的角度来说,PyPI 分发机制通常_是_足够好的,这种分发方式的改进是有意义的,允许重分发者和平台提供者自行决定将哪些内容作为他们缺省提供的一部分。
|
||||
|
||||
假设在 3-5 年时间内,缺省出现了被认为是改变带来的可感知的价值时,才会将这些改变纳入到 CPython 和标准库中。
|
||||
|
||||
### 标准库任何部分都有独立的版本吗?
|
||||
|
||||
是的,它就像是 `ensurepip` 使用的捆绑模式(CPython 发行了一个 `pip` 的最新捆绑版本,而并没有把它放进标准库中),将来可能被应用到其它模块中。
|
||||
|
||||
最有可能的第一个候选者是 `distutils` 构建系统,因为切换到这种模式将允许构建系统在多个发行版本之间保持一致。
|
||||
|
||||
这种处理方式的其它的可能候选者是 Tcl/Tk 图形捆绑和 IDLE 编辑器,它们已经被拆分,并且通过一些重分发程序转换成可选安装项。
|
||||
|
||||
### 这些注意事项为什么很重要?
|
||||
|
||||
从本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
|
||||
|
||||
那些写一些临时脚本或为学生设计一些教学习题的人,通常不认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、商业分析师、动画师、架构设计师等等。
|
||||
|
||||
对于一种语言,当我们全部的担心都是开发人员的经验时,那么我们就可以根据人们所知道的内容、他们使用的工具种类、他们所遵循的开发流程种类、构建和部署他们软件的方法等假定,来做大量的简化。
|
||||
|
||||
当一个应用程序运行时(runtime),_也_作为一个脚本引擎广为流行时,事情将变的更加复杂。在同一个项目中去平衡两种受众的需求,将就会导致双方的不理解和怀疑,做任何一件事都将变得很困难。
|
||||
|
||||
这篇文章不是为了说,我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是去合理地回应那些对添加到 Python 标准库中的看上去很荒谬的特性的质疑,它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
|
||||
|
||||
作者:[Nick Coghlan][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.curiousefficiency.org/pages/about.html
|
||||
[1]:https://aca.edu.au/#home-unpack
|
||||
[2]:https://github.com/barbagroup/AeroPython
|
||||
[3]:https://nbviewer.jupyter.org/urls/bitbucket.org/ncoghlan/misc/raw/default/notebooks/Digital%20Blasphemy.ipynb
|
||||
[4]:https://github.com/pjf/rickastley
|
||||
[5]:https://github.com/python/core-workflow
|
||||
[6]:http://www.vfxplatform.com/
|
||||
[7]:http://www.curiousefficiency.org/posts/2015/10/languages-to-improve-your-python.html#broadening-our-horizons
|
||||
[8]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#use-cases-for-python-s-reference-interpreter
|
||||
[9]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#which-audience-does-cpython-primarily-serve
|
||||
[10]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-is-this-relevant-to-anything
|
||||
[11]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#where-does-pypi-fit-into-the-picture
|
||||
[12]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-changed-when-adding-them-to-the-standard-library
|
||||
[13]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-added-in-provisional-form
|
||||
[14]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-only-some-standard-library-apis-upgraded
|
||||
[15]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#will-any-parts-of-the-standard-library-ever-be-independently-versioned
|
||||
[16]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-do-these-considerations-matter
|
||||
[17]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id1
|
||||
[18]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id2
|
||||
[19]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id3
|
||||
[20]:https://twitter.com/ncoghlan_dev/status/916994106819088384
|
||||
[21]:https://www.python.org/dev/peps/pep-0411/
|
||||
[22]:https://twitter.com/ncoghlan_dev/status/917092464355241984
|
||||
[23]:http://www.curiousefficiency.org/posts/2015/04/stop-supporting-python26.html
|
||||
[24]:https://twitter.com/ncoghlan_dev/status/917088410162012160
|
||||
[25]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#wouldn-t-a-python-2-8-release-help-ease-the-transition
|
||||
[26]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#doesn-t-this-make-python-look-like-an-immature-and-unstable-platform
|
||||
[27]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#what-about-insert-other-shiny-new-feature-here
|
||||
[28]:http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html
|
||||
[29]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id4
|
||||
[30]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id5
|
||||
[31]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id6
|
||||
[32]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id7
|
||||
[33]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id8
|
||||
[34]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id9
|
||||
[35]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
|
||||
[36]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#disqus_thread
|
||||
[37]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.rst
|
||||
[38]:http://www.curiousefficiency.org/posts/2011/04/musings-on-culture-of-python-dev.html
|
||||
[39]:http://community.redhat.com/blog/2015/02/the-quid-pro-quo-of-open-infrastructure/
|
||||
[40]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
|
||||
盘点 Python 的目标受众
|
||||
======
|
||||
|
||||
Python 是为谁设计的?
|
||||
|
||||
几年前,我在 python-dev 邮件列表中,以及在活跃的 CPython 核心开发人员和认为参与这一过程不是有效利用个人时间和精力的人中[强调][17]说,“CPython 的发展太快了也太慢了” 是很多冲突的原因之一。
|
||||
|
||||
我一直认为事实确实如此,但这也是一个要点,在这几年中我也花费了很多时间去反思它。在我写那篇文章的时候,我还在波音防务澳大利亚公司(Boeing Defence Australia)工作。下个月,我离开了波音进入红帽亚太(Red Hat Asia-Pacific),并且开始在大企业的[开源供应链管理][18]方面收获了<ruby>再分发者<rt>redistributor</rt></ruby>层面的视角。
|
||||
|
||||
### Python 的参考解析器使用情况
|
||||
|
||||
我尝试将 CPython 的使用情况分解如下,尽管看起来有些过于简化(注意,这些分类的界线并不是很清晰,他们仅关注于考虑新软件特性和版本发布后不同因素的影响):
|
||||
|
||||
* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,不会去编写或维护生产级别的软件。例如:
|
||||
* 澳大利亚的[数字课程][1]
|
||||
* Lorena A. Barba 的 [AeroPython][2]
|
||||
* 个人类的自动化和爱好者的项目:主要且经常是一类自写自用的软件。例如:
|
||||
* my Digital Blasphemy [图片下载器][3]
|
||||
* Paul Fenwick 的 (Inter)National [Rick Astley Hotline][4]
|
||||
* <ruby>组织<rt>organisational</rt></ruby>过程自动化:主要且经常是为组织利益而编写的。例如:
|
||||
* CPython 的[核心工作流工具][5]
|
||||
* Linux 发行版的开发、构建和发行管理工具
|
||||
* “<ruby>一劳永逸<rt>Set-and-forget</rt></ruby>” 的基础设施:这类软件在其生命周期中几乎不会升级,但在底层平台可能会升级(这种说法有时候有些争议)。例如:
|
||||
* 大多数自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这种情况是让人非常不安的)
|
||||
* 拨款资助的软件(当最初的拨款耗尽时,维护通常会终止)
|
||||
* 有严格认证要求的软件(如果没有绝对必要的话,从经济性考虑,重新认证比常规升级来说要昂贵很多)
|
||||
* 没有自动升级功能的嵌入式软件系统
|
||||
* 持续升级的基础设施:具有健壮支撑的工程学模型的软件,对于依赖和平台升级通常是例行的,不必关心源码变更。例如:
|
||||
* Facebook 的 Python 服务基础设施
|
||||
* 滚动发布的 Linux 分发版
|
||||
* 大多数的公共 PaaS 无服务器环境(Heroku、OpenShift、AWS Lambda、Google Cloud Functions、Azure Cloud Functions 等等)
|
||||
* 长周期性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
|
||||
* [VFX 平台][6]
|
||||
* <ruby>长期支持<rt>LTS</rt></ruby>的 Linux 分发版
|
||||
* CPython 和 Python 标准库
|
||||
* 基础设施管理和编排工具(如 OpenStack、Ansible)
|
||||
* 硬件控制系统
|
||||
* 短生命周期的软件:软件仅被使用一次,然后就丢弃或忽略,而不是随后接着升级。例如:
|
||||
* <ruby>临时<rt>Ad hoc</rt></ruby>自动化脚本
|
||||
* 被确定为 “终止” 的单用户游戏(你玩了一次后,甚至都忘了去卸载它们,或许在一个新的设备上都不打算再去安装了)
|
||||
* 不具备(或不完整)状态保存的单用户游戏(如果你卸载并重安装它们,游戏体验也不会有什么大的变化)
|
||||
* 特定事件的应用程序(这些应用程序与特定的事件捆绑,一旦事件结束,这些应用程序就不再有用了)
|
||||
* 常规用途的应用程序:部署后定期升级的软件。例如:
|
||||
* 业务管理软件
|
||||
* 个人和专业的生产力应用程序(如 Blender)
|
||||
* 开发工具和服务(如 Mercurial、Buildbot、Roundup)
|
||||
* 多用户游戏,和其它明显处于持续状态还没有被定义为 “终止” 的游戏
|
||||
* 有自动升级功能的嵌入式软件系统
|
||||
* 共享的抽象层:在一个特定的问题领域中,设计用于让工作更高效的软件组件。即便是你没有亲自掌握该领域的所有错综复杂的东西。例如:
|
||||
* 大多数的<ruby>运行时<rt>runtime</rt></ruby>库都归入这一类的框架(如 Django、Flask、Pyramid、SQL Alchemy、NumPy、SciPy、requests)
|
||||
* 适合归入这一类的许多测试和类型接口工具(如 pytest、Hypothesis、vcrpy、behave、mypy)
|
||||
* 其它应用程序的插件(如 Blender plugins、OpenStack hardware adapters)
|
||||
* 本身就代表了 “Python 世界” 基准的标准库(那是一个[难以置信的复杂][7]的世界观)
|
||||
|
||||
### CPython 主要服务于哪些受众?
|
||||
|
||||
从根本上说,CPython 和标准库的主要受众是哪些呢?是那些不管出于什么原因,将有限的标准库和从 PyPI 显式声明安装的第三方库组合起来所提供的服务还不能够满足需求的那些人。
|
||||
|
||||
为了更进一步简化上面回顾的不同用法和部署模型,宏观地将最大的 Python 用户群体分开来看,一类是在一些感兴趣的环境中将 Python 作为一种 _脚本语言_ 使用的人;另外一种是将它用作一个 _应用程序开发语言_ 的人,他们最终发布的是一种产品而不是他们的脚本。
|
||||
|
||||
把 Python 作为一种脚本语言来使用的开发者的典型特性包括:
|
||||
|
||||
* 主要的工作单元是由一个 Python 文件组成的(或 Jupyter notebook),而不是一个 Python 和元数据文件的目录
|
||||
* 没有任何形式的单独的构建步骤 —— 是作为一个脚本分发的,类似于分发一个独立的 shell 脚本的方式
|
||||
* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),因为在目标系统上要求预配置运行时环境
|
||||
* 没有显式的规定依赖关系,除了最低的 Python 版本,或一个预期的运行环境声明。如果需要一个标准库以外的依赖项,他们会通过一个环境脚本去提供(无论是操作系统、数据分析平台、还是嵌入 Python 运行时的应用程序)
|
||||
* 没有单独的测试套件,使用 “通过你给定的输入,这个脚本是否给出了你期望的结果?” 这种方式来进行测试
|
||||
* 如果在执行前需要测试,它将以<ruby>试运行<rt>dry run></rt></ruby>和<ruby>预览<rt>preview</rt></ruby>模式来向用户展示软件将怎样运行
|
||||
* 如果使用静态代码分析工具,则通过集成到用户的软件开发环境中,而不是为每个脚本单独设置
|
||||
|
||||
相比之下,使用 Python 作为一个应用程序开发语言的开发者特征包括:
|
||||
|
||||
* 主要的工作单元是由 Python 和元数据文件组成的目录,而不是单个 Python 文件
|
||||
* 在发布之前有一个单独的构建步骤去预处理应用程序,哪怕是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 中
|
||||
* 应用程序是否有独立的安装步骤做预处理,取决于它是如何打包的,和支持的目标环境
|
||||
* 外部的依赖明确存在于项目目录下的一个元数据文件中,要么是直接在项目目录中(如 `pyproject.toml`、`requirements.txt`、`Pipfile`),要么是作为生成的发行包的一部分(如 `setup.py`、`flit.ini`)
|
||||
* 有独立的测试套件,或者作为一个 Python API 的一个单元测试,或者作为功能接口的集成测试,或者是两者都有
|
||||
* 静态分析工具的使用是在项目级配置的,并作为测试管理的一部分,而不是作为依赖
|
||||
|
||||
作为以上分类的一个结果,CPython 和标准库的主要用途是,在相应的 CPython 特性发布后,为教育和<ruby>临时<rt>ad hoc</rt></ruby>的 Python 脚本环境提供 3-5 年基础维护服务。
|
||||
|
||||
对于临时脚本使用的情况,这个 3-5 年的延迟是由于再分发者给用户开发新版本的延迟造成的,以及那些再分发版本的用户们花在修改他们的标准操作环境上的时间。
|
||||
|
||||
对于教育环境中的情况是,教育工作者需要一些时间去评估新特性,然后决定是否将它们包含进教学的课程中。
|
||||
|
||||
### 这些相关问题的原因是什么?
|
||||
|
||||
这篇文章很大程度上是受 Twitter 上对[我的这个评论][8]的讨论的启发,它援引了定义在 [PEP 411][9] 中<ruby>临时<rt>Provisional</rt></ruby> API 的情形,作为一个开源项目的例子,对用户发出事实上的邀请,请其作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
|
||||
|
||||
这些回复包括一些在更高级别的库中支持临时 API 的困难程度的一些沮丧性表述,没有这些库做临时状态的传递,因此而被限制为只有临时 API 的最新版本才支持这些相关特性,而不是任何早期版本的迭代。
|
||||
|
||||
我的[主要回应][10]是,建议开源提供者应该强制实施有限支持,通过这种强制的有限支持可以让个人的维护努力变得可持续。这意味着,如果对临时 API 的老版本提供迭代支持是非常痛苦的,那么,只有在项目开发人员自己需要、或有人为此支付费用时,他们才会去提供支持。这与我的这个观点是类似的,那就是,志愿者提供的项目是否应该免费支持老的、商业性质的、长周期的 Python 版本,这对他们来说是非常麻烦的事,我[不认为他们应该这样做][11],正如我所期望的那样,大多数这样的需求都来自于管理差劲的惯性,而不是真正的需求(真正的需求,应该去支付费用来解决问题)。
|
||||
|
||||
而我的[第二个回应][12]是去实现这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中最早在 2011 年的一篇的文章中,以及在 Python 3 问答的回复中的[这里][13]、[这里][14]、和[这里][15],以及去年的这篇文章 [Python 包生态系统][16]中也提到了一些),但我从来没有真实地尝试直接去解释它在标准库设计过程中的影响。
|
||||
|
||||
如果没有这些背景,设计过程中的一部分,比如临时 API 的引入,或者是<ruby>受启发而不同于它<rt>inspired-by-not-the-same-as</rt></ruby>的引入,看起来似乎是完全没有意义的,因为他们看起来似乎是在尝试对 API 进行标准化,而实际上并没有。
|
||||
|
||||
### 适合进入 PyPI 规划的方面有哪些?
|
||||
|
||||
任何提交给 python-ideas 或 python-dev 的提案所面临的第一个门槛就是清楚地回答这个问题:“为什么 PyPI 上的模块不够好?”。绝大多数的提案都在这一步失败了,为了通过这一步,这里有几个常见的话题:
|
||||
|
||||
* 比起下载一个合适的第三方库,新手一般可能更倾向于从互联网上 “复制粘贴” 错误的指导。(这就是为什么存在 `secrets` 库的原因:它使得人们很少去使用 `random` 模块,由于安全敏感的原因,它预期用于游戏和模拟统计)
|
||||
* 该模块旨在提供一个参考实现,并允许与其它的竞争实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(如 `asyncio`、`wsgiref`、`unittest`、和 `logging` 都是这种情况)
|
||||
* 该模块是预期用于标准库的其它部分(如 `enum` 就是这种情况,像 `unittest` 一样)
|
||||
* 该模块是被设计用于支持语言之外的一些语法(如 `contextlib`、`asyncio` 和 `typing`)
|
||||
* 该模块只是普通的临时的脚本用途(如 `pathlib` 和 `ipaddress`)
|
||||
* 该模块被用于一个教育环境(例如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你可能根本就不会用它来做完整的统计分析)
|
||||
|
||||
只通过了前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被纳入标准库中,但它已经足以将问题转变为 “在未来几年中,你所推荐的要包含的库能否对一般的入门级 Python 开发人员的经验有所提升?”
|
||||
|
||||
标准库中的 `ensurepip` 和 `venv` 模块的引入也明确地告诉再分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
|
||||
|
||||
### 当添加它们到标准库中时,为什么一些 API 会被修改?
|
||||
|
||||
现有的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上添加的是吸收了用户对现有 API 体验之后进行重新设计和重新实现的 API,但是会根据另外的设计考虑和已经成为其中一部分的语言实现参考来进行一些删除或细节修改。
|
||||
|
||||
例如,与流行的第三方库 `path.py`、`pathlib` 的前身不同,它们并没有定义字符串子类,而是以独立的类型替代。作为解决文件互操作性问题的结果,定义了文件系统路径协议,它允许使用文件系统路径的接口去使用更多的对象。
|
||||
|
||||
为了在 “IP 地址” 这个概念的教学上提供一个更好的工具,`ipaddress` 模块设计调整为明确地将主机接口定义与地址和网络的定义区分开(IP 地址被关联到特定的 IP 网络),而最原始的 `ipaddr` 模块中,在网络术语的使用方式上不那么严格。
|
||||
|
||||
另外的情况是,标准库将综合多种现有的方法的来构建,以及为早已存在的库定义 API 时,还有可能依赖不存在的语法特性。比如,`asyncio` 和 `typing` 模块就全部考虑了这些因素,虽然在 PEP 557 中正在考虑将后者所考虑的因素应用到 `dataclasses` API 上。(它可以被总结为 “像属性一样,但是使用可变注释作为字段声明”)。
|
||||
|
||||
这类修改的原理是,这类库不会消失,并且它们的维护者对标准库维护相关的那些限制通常并不感兴趣(特别是相对缓慢的发布节奏)。在这种情况下,在标准库文档的更新版本中使用 “See Also” 链接指向原始模块的做法非常常见,尤其是在第三方版本额外提供了标准库模块中忽略的那些特性时。
|
||||
|
||||
### 为什么一些 API 是以临时的形式被添加的?
|
||||
|
||||
虽然 CPython 维护了 API 的弃用策略,但在没有正当理由的情况下,我们通常不会去使用该策略(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
|
||||
|
||||
然而在实践中,当添加这种受已有的第三方启发而不是直接精确拷贝第三方设计的新 API 时,所承担的风险要高于一些正常设计决定可能出现问题的风险。
|
||||
|
||||
当我们考虑到这种改变的风险比平常要高,我们将相关的 API 标记为临时,表示保守的终端用户要避免完全依赖它们,而共享抽象层的开发者可能希望对他们准备去支持的那个临时 API 的版本考虑实施比平时更严格的限制。
|
||||
|
||||
### 为什么只有一些标准库 API 被升级?
|
||||
|
||||
这里简短的回答得到升级的主要 API 有哪些:
|
||||
|
||||
* 不太可能有大量的外部因素干扰的附加更新的
|
||||
* 无论是对临时脚本用例还是对促进将来多个第三方解决方案之间的互操作性,都有明显好处的
|
||||
* 对这方面感兴趣的人提交了一个可接受的建议的
|
||||
|
||||
如果在将模块用于应用程序开发目的时(如 `datetime`),现有模块的限制主要是显而易见的,如果再分发者通过第三方方案很容易地实现了改进,(如 `requests`),或者如果标准库的发布节奏与所需要的包之间真的存在冲突,(如 `certifi`),那么,建议对标准库版本进行改变的因素将显著减少。
|
||||
|
||||
从本质上说,这和上面关于 PyPI 问题正好相反:因为从应用程序开发人员体验的角度来说,PyPI 的分发机制通常已经够好了,这种分发方式的改进是有意义的,允许再分发者和平台提供者自行决定将哪些内容作为他们缺省提供的一部分。
|
||||
|
||||
假设在 3-5 年时间内,缺省出现了被认为是改变带来的可感知的价值时,才会将这些改变纳入到 CPython 和标准库中。
|
||||
|
||||
### 标准库任何部分都有独立的版本吗?
|
||||
|
||||
是的,就像是 `ensurepip` 使用的捆绑模式(CPython 发行了一个 `pip` 的最新捆绑版本,而并没有把它放进标准库中),将来可能被应用到其它模块中。
|
||||
|
||||
最有可能的第一个候选者是 `distutils` 构建系统,因为切换到这种模式将允许构建系统在多个发行版本之间保持一致。
|
||||
|
||||
这种处理方式的其它可能候选者是 Tcl/Tk 图形套件和 IDLE 编辑器,它们已经被拆分,并且一些开发者将其改为可选安装项。
|
||||
|
||||
### 这些注意事项为什么很重要?
|
||||
|
||||
从本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
|
||||
|
||||
那些写一些临时脚本或为学生设计一些教学习题的人,通常不认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、市场研究员、动画师、平面设计师等等。
|
||||
|
||||
对于一种语言,当我们全部的担心都是开发人员的经验时,那么我们就可以根据人们所知道的内容、他们使用的工具种类、他们所遵循的开发流程种类、构建和部署他们软件的方法等假定,来做大量的简化。
|
||||
|
||||
当应用程序运行时作为脚本引擎广泛流行时,事情会变得更加复杂。做好任何一项工作已经很困难,并且作为单个项目的一部分来平衡两个受众的需求会导致双方经常不理解和不相信。
|
||||
|
||||
这篇文章不是为了说明我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是去合理地回应那些对添加到 Python 标准库中的看上去很荒谬的特性的质疑,它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
|
||||
|
||||
---
|
||||
|
||||
via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
|
||||
|
||||
作者:[Nick Coghlan][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.curiousefficiency.org/pages/about.html
|
||||
[1]: https://aca.edu.au/#home-unpack
|
||||
[2]: https://github.com/barbagroup/AeroPython
|
||||
[3]: https://nbviewer.jupyter.org/urls/bitbucket.org/ncoghlan/misc/raw/default/notebooks/Digital%20Blasphemy.ipynb
|
||||
[4]: https://github.com/pjf/rickastley
|
||||
[5]: https://github.com/python/core-workflow
|
||||
[6]: http://www.vfxplatform.com/
|
||||
[7]: http://www.curiousefficiency.org/posts/2015/10/languages-to-improve-your-python.html#broadening-our-horizons
|
||||
[8]: https://twitter.com/ncoghlan_dev/status/916994106819088384
|
||||
[9]: https://www.python.org/dev/peps/pep-0411/
|
||||
[10]: https://twitter.com/ncoghlan_dev/status/917092464355241984
|
||||
[11]: http://www.curiousefficiency.org/posts/2015/04/stop-supporting-python26.html
|
||||
[12]: https://twitter.com/ncoghlan_dev/status/917088410162012160
|
||||
[13]: http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#wouldn-t-a-python-2-8-release-help-ease-the-transition
|
||||
[14]: http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#doesn-t-this-make-python-look-like-an-immature-and-unstable-platform
|
||||
[15]: http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#what-about-insert-other-shiny-new-feature-here
|
||||
[16]: http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html
|
||||
[17]: http://www.curiousefficiency.org/posts/2011/04/musings-on-culture-of-python-dev.html
|
||||
[18]: http://community.redhat.com/blog/2015/02/the-quid-pro-quo-of-open-infrastructure/
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
用于与非 Linux 用户合作的 Linux 命令行工具
|
||||
======
|
||||

|
||||
我大部分时间都在使用 Shell(命令行,终端或其他不管在你使用的平台上的名称)上。但是,当我需要与大量其他人合作时,这可能会有点挑战,特别是在大型企业公司中 - 除了 shell 外其他都使用。
|
||||
|
||||
当公司内的其他人使用与你不同的平台时,问题就会变得更加严重。我倾向于使用 Linux。如果我在 Linux 终端上做了很多日常工作,而我的大多数同事都使用 Windows 10(完全使用 GUI 端),那么事情就会变得有问题。
|
||||
|
||||
**Network World 上另外一篇文章:**[**11 个没用但很酷的 Linux 终端技巧**][1]
|
||||
|
||||
幸运的是,在过去的几年里,我已经想出如何处理这些问题。我已经找到了在非 Unix 的企业环境中使用 Linux(或其他类 Unix 系统)Shell 的方法。这些工具/技巧同样适用于在公司服务器上工作的系统管理员s,就像对开发人员或营销人员一样。。
|
||||
|
||||
## 用于与非 Linux 用户合作的 Linux 命令行工具
|
||||
|
||||
让我们首先关注对于大公司中的许多人来说似乎最难解决的两个方面:文档兼容性和企业即时消息。
|
||||
|
||||
### Linux 和非 Linux 系统之间的文档兼容性
|
||||
|
||||
出现的最大问题之一是简单的文字处理文档兼容性。
|
||||
|
||||
假设你的公司已在 Microsoft Office 上进行了标准化。这让你难过。但不要失去希望!有很多方法可以使它(基本)可用 - 甚至在 shell 中。
|
||||
|
||||
两个工具在我的武器库中至关重要:[Pandoc][2] 和 [Wordgrinder][3]。
|
||||
|
||||
Wordgrinder 是一个简单,直观的文字处理器。它可能不像 LibreOffice 那样功能齐全(或者,实际上,任何主要的 GUI 文字处理应用程序),但速度很快。它很稳定。它有足够的功能(和文件格式)来完成工作。事实上,我完全在 Wordgrinder 中写了我的大部分文章和书籍。
|
||||
|
||||
但是有一个问题(你知道肯定会有)。
|
||||
|
||||
Wordgrinder 不支持 .doc(或 .docx)文件。这意味着它无法读取使用 Windows 和 MS Office 的同事发送给你的大多数文件。
|
||||
|
||||
这就是P andoc 的用武之地。它是一个简单的文档转换器,可以将各种文件作为输入(MS Word、LibreOffice、HTML、markdown 等)并将它们转换为其他内容。它支持的格式数量绝对是惊人的 - PDF、ePub、各种幻灯片格式。它确实使格式之间的文档转换变得轻而易举。
|
||||
|
||||
这并不是说我不会偶尔遇到格式或功能问题。转换有大量自定义格式,某些脚本和嵌入式图表的 Word 文档?是的,在这个过程中会丢失很多。
|
||||
|
||||
但实际上,Pandoc(用于转换文件)和 Wordgrinder(用于文档编辑)的组合已经证明非常有用和强大。
|
||||
|
||||
### Linux 和非 Linux 系统之间的企业即时消息传递
|
||||
|
||||
每家公司都喜欢在即时通讯系统上实现标准化 - 所有员工都可以使用它来保持实时联系。
|
||||
|
||||
在命令行中,这可能会变得棘手。如果贵公司使用 Google 环聊怎么办?或者 Novell GroupWise Messenger 怎么样?既没有官方支持,也没有基于终端的客户端。
|
||||
|
||||
谢天谢地,还有[ Finch 和 Hangups][4]。
|
||||
|
||||
Finch 是 Pidgin(开源,多协议消息客户端)的终端版本。它支持各种协议,包括 Novell GroupWise、(很快会死)AOL Instant Messenger 以及其他一些协议。
|
||||
|
||||
而 Hangups 是 Google Hangouts 客户端的开源实现 - 包含消息历史记录和精美的标签界面。
|
||||
|
||||
这些方案都不会为你提供语音或视频聊天功能,但对于基于文本的消息,它们的工作得非常好。它们并不完美(Finch 的用户界面需要时间习惯),但它们肯定足以与你的同事保持联系。
|
||||
|
||||
这些方案能否让你在纯文本 shell 中舒适地过完一个工作日?可能不会。就个人而言,我发现(使用这些工具和其他工具)我可以轻松地将 80% 的时间花在纯文本界面上。
|
||||
|
||||
这感觉很棒。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3235688/linux/linux-command-line-tools-for-working-with-non-linux-users.html
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Bryan-Lunduke/
|
||||
[1]:http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html#tk.nww-fsb
|
||||
[2]:https://www.youtube.com/watch?v=BkTYHChkDoE
|
||||
[3]:https://www.youtube.com/watch?v=WnMyamBgKFE
|
||||
[4]:https://www.youtube.com/watch?v=19lbWnYOsTc
|
||||
119
translated/tech/20171102 Using User Namespaces on Docker.md
Normal file
119
translated/tech/20171102 Using User Namespaces on Docker.md
Normal file
@ -0,0 +1,119 @@
|
||||
使用 Docker 的 User Namespaces 功能
|
||||
======
|
||||
User Namespaces 于 Docker1.10 版正式纳入其中,该功能允许主机系统将自身的 `uid` 和 `gid` 映射为容器进程中的另一个其他 `uid` 和 `gid`。这对 Docker 的安全性来说是一项巨大的改进。下面我会通过一个案例来展示一下 User Namespaces 能够解决的问题,以及如何启用该功能。
|
||||
|
||||
### 创建一个 Docker Machine
|
||||
|
||||
如果你已经创建好了一台用来实验 User Namespaces 的 docker machine,那么可以跳过这一步。我在自己的 Macbook 上安装了 Docker Toolbox,因此我只需要使用 `docker-machine` 命令就很简单地创建一个基于 VirtualBox 的 Docker Machine( 这里假设主机名为 `host1`):
|
||||
```
|
||||
# Create host1
|
||||
$ docker-machine create --driver virtualbox host1
|
||||
|
||||
# Login to host1
|
||||
$ docker-machine ssh host1
|
||||
|
||||
```
|
||||
|
||||
### 理解在 User Napespaces 未启用的情况下,非 root 用户能够做什么
|
||||
|
||||
在启用 User Namespaces 前,我们先来看一下会有什么问题。Docker 到底哪个地方做错了?首先,使用 Docker 的一大优势在于用户在容器中可以拥有 root 权限,因此用户可以很方便地安装软件包。但是该项 Linux 容器技术是一把双刃剑。只要经过少许操作,非 root 用户就能以 root 的权限访问主机系统中的内容,比如 `/etc` . 下面是操作步骤。
|
||||
```
|
||||
# Run a container and mount host1's /etc onto /root/etc
|
||||
$ docker run --rm -v /etc:/root/etc -it ubuntu
|
||||
|
||||
# Make some change on /root/etc/hosts
|
||||
root@34ef23438542:/# vi /root/etc/hosts
|
||||
|
||||
# Exit from the container
|
||||
root@34ef23438542:/# exit
|
||||
|
||||
# Check /etc/hosts
|
||||
$ cat /etc/hosts
|
||||
|
||||
```
|
||||
|
||||
你可以看到,步骤简单到难以置信,很明显 Docker 并不适用于运行在多人共享的电脑上。但是现在,通过 User Namespaces,Docker 可以让你避免这个问题。
|
||||
|
||||
### 启用 User Namespaces
|
||||
```
|
||||
# Create a user called "dockremap"
|
||||
$ sudo adduser dockremap
|
||||
|
||||
# Setup subuid and subgid
|
||||
$ sudo sh -c 'echo dockremap:500000:65536 > /etc/subuid'
|
||||
$ sudo sh -c 'echo dockremap:500000:65536 > /etc/subgid'
|
||||
|
||||
```
|
||||
|
||||
然后,打开 `/etc/init.d/docker`,并在 `/usr/local/bin/docker daemon` 后面加上 `--userns-remap=default`,像这样:
|
||||
```
|
||||
$ sudo vi /etc/init.d/docker
|
||||
:
|
||||
:
|
||||
/usr/local/bin/docker daemon --userns-remap=default -D -g "$DOCKER_DIR" -H unix:// $DOCKER_HOST $EXTRA_ARGS >> "$DOCKER_LOGFILE" 2>&1 &
|
||||
:
|
||||
:
|
||||
|
||||
```
|
||||
|
||||
然后重启 Docker:
|
||||
```
|
||||
$ sudo /etc/init.d/docker restart
|
||||
|
||||
```
|
||||
|
||||
这就完成了!
|
||||
|
||||
**注意:** 若你使用的是 CentOS 7,则你需要了解两件事。
|
||||
|
||||
**1。** 内核默认并没有启用 User Namespaces。运行下面命令并重启系统,可以启用该功能。
|
||||
```
|
||||
sudo grubby --args="user_namespace.enable=1" \
|
||||
--update-kernel=/boot/vmlinuz-3.10.0-XXX.XX.X.el7.x86_64
|
||||
|
||||
```
|
||||
|
||||
**2。** CentOS 7 使用 systemctl 来管理服务,因此你需要编辑的文件是 `/usr/lib/systemd/system/docker.service`。
|
||||
|
||||
### 确认 User Namespaces 是否正常工作
|
||||
|
||||
若一切都配置妥当,则你应该无法再在容器中编辑 host1 上的 `/etc` 了。让我们来试一下。
|
||||
```
|
||||
# Create a container and mount host1's /etc to container's /root/etc
|
||||
$ docker run --rm -v /etc:/root/etc -it ubuntu
|
||||
|
||||
# Check the owner of files in /root/etc, which should be "nobody nogroup".
|
||||
root@d5802c5e670a:/# ls -la /root/etc
|
||||
total 180
|
||||
drwxr-xr-x 11 nobody nogroup 1100 Mar 21 23:31 .
|
||||
drwx------ 3 root root 4096 Mar 21 23:50 ..
|
||||
lrwxrwxrwx 1 nobody nogroup 19 Mar 21 23:07 acpi -> /usr/local/etc/acpi
|
||||
-rw-r--r-- 1 nobody nogroup 48 Mar 10 22:09 boot2docker
|
||||
drwxr-xr-x 2 nobody nogroup 60 Mar 21 23:07 default
|
||||
:
|
||||
:
|
||||
|
||||
# Try creating a file in /root/etc
|
||||
root@d5802c5e670a:/# touch /root/etc/test
|
||||
touch: cannot touch '/root/etc/test': Permission denied
|
||||
|
||||
# Try deleting a file
|
||||
root@d5802c5e670a:/# rm /root/etc/hostname
|
||||
rm: cannot remove '/root/etc/hostname': Permission denied
|
||||
|
||||
```
|
||||
|
||||
好了,太棒了。这就是 User Namespaces 的工作方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://coderwall.com/p/s_ydlq/using-user-namespaces-on-docker
|
||||
|
||||
作者:[Koji Tanaka][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://coderwall.com/kjtanaka
|
||||
@ -0,0 +1,262 @@
|
||||
API Star: Python 3 的 API 框架 – Polyglot.Ninja()
|
||||
======
|
||||
|
||||
为了在 Python 中快速构建 API,我主要依赖于 [Flask][1]。最近我遇到了一个名为 “API Star” 的基于 Python 3 的新 API 框架。由于几个原因,我对它很感兴趣。首先,该框架包含 Python 新特点,如类型提示和 asyncio。接着它再进一步并且为开发人员提供了很棒的开发体验。我们很快就会讲到这些功能,但在我们开始之前,我首先要感谢 Tom Christie,感谢他为 Django REST Framework 和 API Star 所做的所有工作。
|
||||
|
||||
现在说回 API Star -- 我感觉这个框架很有成效。我可以选择基于 asyncio 编写异步代码,或者可以选择传统后端方式就像 WSGI 那样。它配备了一个命令行工具 - `apistar` 来帮助我们更快地完成工作。它支持 Django ORM 和 SQLAlchemy,这是可选的。它有一个出色类型系统,使我们能够定义输入和输出的约束,API Star 可以自动生成 api 模式(包括文档),提供验证和序列化功能等等。虽然 API Star 专注于构建 API,但你也可以非常轻松地在其上构建 Web 应用程序。在我们自己构建一些东西之前,所有这些可能都没有意义的。
|
||||
|
||||
### 开始
|
||||
|
||||
我们将从安装 API Star 开始。为此实验创建一个虚拟环境是一个好主意。如果你不知道如何创建一个虚拟环境,不要担心,继续往下看。
|
||||
```
|
||||
pip install apistar
|
||||
|
||||
```
|
||||
(译注:上面的命令是在 Python 3 虚拟环境下使用的)
|
||||
|
||||
如果你没有使用虚拟环境或者 Python 3 的 `pip`,它被称为 `pip3`,那么使用 `pip3 install apistar` 代替。
|
||||
|
||||
一旦我们安装了这个包,我们就应该可以使用 `apistar` 命令行工具了。我们可以用它创建一个新项目,让我们在当前目录中创建一个新项目。
|
||||
```
|
||||
apistar new .
|
||||
|
||||
```
|
||||
|
||||
现在我们应该创建两个文件:`app.py`,它包含主应用程序,然后是 `test.py`,它用于测试。让我们来看看 `app.py` 文件:
|
||||
```
|
||||
from apistar import Include, Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
from apistar.handlers import docs_urls, static_urls
|
||||
|
||||
|
||||
def welcome(name=None):
|
||||
if name is None:
|
||||
return {'message': 'Welcome to API Star!'}
|
||||
return {'message': 'Welcome to API Star, %s!' % name}
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'GET', welcome),
|
||||
Include('/docs', docs_urls),
|
||||
Include('/static', static_urls)
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
在我们深入研究代码之前,让我们运行应用程序并查看它是否正常工作。我们在浏览器中输入 `http://127.0.0.1:8080/`,我们将得到以下响应:
|
||||
```
|
||||
{"message": "Welcome to API Star!"}
|
||||
|
||||
```
|
||||
|
||||
如果我们输入:`http://127.0.0.1:8080/?name=masnun`
|
||||
```
|
||||
{"message": "Welcome to API Star, masnun!"}
|
||||
|
||||
```
|
||||
|
||||
同样的,输入 `http://127.0.0.1:8080/docs/`,我们将看到自动生成的 API 文档。
|
||||
|
||||
现在让我们来看看代码。我们有一个 `welcome` 函数,它接收一个名为 `name` 的参数,其默认值为 `None`。API Star 是一个智能的 api 框架。它将尝试在 url 路径或者查询字符串中找到 `name` 键并将其传递给我们的函数,它还基于其生成 API 文档。这真是太好了,不是吗?
|
||||
|
||||
然后,我们创建一个 `Route` 和 `Include` 实例列表,并将列表传递给 `App` 实例。`Route` 对象用于定义用户自定义路由。顾名思义,`Include` 包含了在给定的路径下的其它 url 路径。
|
||||
|
||||
### 路由
|
||||
|
||||
路由很简单。当构造 `App` 实例时,我们需要传递一个列表作为 `routes` 参数,这个列表应该有我们刚才看到的 `Route` 或 `Include` 对象组成。对于 `Route`,我们传递一个 url 路径,http 方法和可调用的请求处理程序(函数或者其他)。对于 `Include` 实例,我们传递一个 url 路径和一个 `Routes` 实例列表。
|
||||
|
||||
##### 路径参数
|
||||
|
||||
我们可以在花括号内添加一个名称来声明 url 路径参数。例如 `/user/{user_id}` 定义了一个 url,其中 `user_id` 是路径参数,或者说是一个将被注入到处理函数(实际上是可调用的)中的变量。这有一个简单的例子:
|
||||
```
|
||||
from apistar import Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
|
||||
def user_profile(user_id: int):
|
||||
return {'message': 'Your profile id is: {}'.format(user_id)}
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/user/{user_id}', 'GET', user_profile),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
如果我们访问 `http://127.0.0.1:8080/user/23`,我们将得到以下响应:
|
||||
```
|
||||
{"message": "Your profile id is: 23"}
|
||||
|
||||
```
|
||||
|
||||
但如果我们尝试访问 `http://127.0.0.1:8080/user/some_string`,它将无法匹配。因为我们定义了 `user_profile` 函数,且为 `user_id` 参数添加了一个类型提示。如果它不是整数,则路径不匹配。但是如果我们继续删除类型提示,只使用 `user_profile(user_id)`,它将匹配此 url。这也展示了 API Star 的智能之处和利用类型和好处。
|
||||
|
||||
#### 包含/分组路由
|
||||
|
||||
有时候将某些 url 组合在一起是有意义的。假设我们有一个处理用户相关功能的 `user` 模块,将所有与用户相关的 url 分组在 `/user` 路径下可能会更好。例如 `/user/new`, `/user/1`, `/user/1/update` 等等。我们可以轻松地在单独的模块或包中创建我们的处理程序和路由,然后将它们包含在我们自己的路由中。
|
||||
|
||||
让我们创建一个名为 `user` 的新模块,文件名为 `user.py`。我们将以下代码放入这个文件:
|
||||
```
|
||||
from apistar import Route
|
||||
|
||||
|
||||
def user_new():
|
||||
return {"message": "Create a new user"}
|
||||
|
||||
|
||||
def user_update(user_id: int):
|
||||
return {"message": "Update user #{}".format(user_id)}
|
||||
|
||||
|
||||
def user_profile(user_id: int):
|
||||
return {"message": "User Profile for: {}".format(user_id)}
|
||||
|
||||
|
||||
user_routes = [
|
||||
Route("/new", "GET", user_new),
|
||||
Route("/{user_id}/update", "GET", user_update),
|
||||
Route("/{user_id}/profile", "GET", user_profile),
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
现在我们可以从 app 主文件中导入 `user_routes`,并像这样使用它:
|
||||
```
|
||||
from apistar import Include
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
from user import user_routes
|
||||
|
||||
routes = [
|
||||
Include("/user", user_routes)
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
现在 `/user/new` 将委托给 `user_new` 函数。
|
||||
|
||||
### 访问查询字符串/查询参数
|
||||
|
||||
查询参数中传递的任何参数都可以直接注入到处理函数中。比如 url `/call?phone=1234`,处理函数可以定义一个 `phone` 参数,它将从查询字符串/查询参数中接收值。如果 url 查询字符串不包含 `phone` 的值,那么它将得到 `None`。我们还可以为参数设置一个默认值,如下所示:
|
||||
```
|
||||
def welcome(name=None):
|
||||
if name is None:
|
||||
return {'message': 'Welcome to API Star!'}
|
||||
return {'message': 'Welcome to API Star, %s!' % name}
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中,我们为 `name` 设置了一个默认值 `None`。
|
||||
|
||||
### 注入对象
|
||||
|
||||
通过给一个请求程序添加类型提示,我们可以将不同的对象注入到视图中。注入请求相关对象有助于处理程序直接从内部访问它们。API Star 内置的 `http` 包中有几个内置对象。我们也可以使用它的类型系统来创建我们自己的自定义对象并将它们注入到我们的函数中。API Star 还根据指定的约束进行数据验证。
|
||||
|
||||
让我们定义自己的 `User` 类型,并将其注入到我们的请求处理程序中:
|
||||
```
|
||||
from apistar import Include, Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
from apistar import typesystem
|
||||
|
||||
|
||||
class User(typesystem.Object):
|
||||
properties = {
|
||||
'name': typesystem.string(max_length=100),
|
||||
'email': typesystem.string(max_length=100),
|
||||
'age': typesystem.integer(maximum=100, minimum=18)
|
||||
}
|
||||
|
||||
required = ["name", "age", "email"]
|
||||
|
||||
|
||||
def new_user(user: User):
|
||||
return user
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'POST', new_user),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
现在如果我们发送这样的请求:
|
||||
```
|
||||
curl -X POST \
|
||||
http://127.0.0.1:8080/ \
|
||||
-H 'Cache-Control: no-cache' \
|
||||
-H 'Content-Type: application/json' \
|
||||
-d '{"name": "masnun", "email": "masnun@gmail.com", "age": 12}'
|
||||
```
|
||||
|
||||
猜猜发生了什么?我们得到一个错误,说年龄必须等于或大于 18。类型系允许我们进行智能数据验证。如果我们启用了 `docs` url,我们还将自动记录这些参数。
|
||||
|
||||
### 发送响应
|
||||
|
||||
如果你已经注意到,到目前为止,我们只可以传递一个字典,它将被转换为 JSON 并作为默认返回。但是,我们可以使用 `apistar` 中的 `Response` 类来设置状态码和其它任意响应头。这有一个简单的例子:
|
||||
```
|
||||
from apistar import Route, Response
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
|
||||
def hello():
|
||||
return Response(
|
||||
content="Hello".encode("utf-8"),
|
||||
status=200,
|
||||
headers={"X-API-Framework": "API Star"},
|
||||
content_type="text/plain"
|
||||
)
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'GET', hello),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
它应该返回纯文本响应和一个自定义标响应头。请注意,`content` 应该是字节,而不是字符串。这就是我编码它的原因。
|
||||
|
||||
### 继续
|
||||
|
||||
我刚刚介绍了 API
|
||||
Star 的一些特性,API Star 中还有许多非常酷的东西,我建议通过 [Github Readme][2] 文件来了解这个优秀框架所提供的不同功能的更多信息。我还将尝试在未来几天内介绍关于 API Star 的更多简短的,集中的教程。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://polyglot.ninja/api-star-python-3-api-framework/
|
||||
|
||||
作者:[MASNUN][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://polyglot.ninja/author/masnun/
|
||||
[1]:http://polyglot.ninja/rest-api-best-practices-python-flask-tutorial/
|
||||
[2]:https://github.com/encode/apistar
|
||||
@ -1,516 +0,0 @@
|
||||
如何查看 Linux 中所有正在运行的服务
|
||||
======
|
||||
|
||||
|
||||
有许多方法和工具可以查看 Linux 中所有正在运行的服务。大多数管理员会在 sysVinit 系统中使用 `service service-name status` 或 `/etc/init.d/service-name status`,而在 systemd 系统中使用 `systemctl status service-name`。
|
||||
|
||||
以上命令可以清楚地显示该服务是否在服务器上运行,这也是每个 Linux 管理员都该知道的非常简单和基础的命令。
|
||||
|
||||
如果你对系统环境并不熟悉,也不清楚系统在运行哪些服务,你会如何检查?
|
||||
|
||||
是的,我们的确有必要这样检查一下。这将有助于我们了解系统上运行了什么服务,以及哪些是必要的、哪些需要被禁用。
|
||||
|
||||
### 什么是 SysVinit
|
||||
|
||||
init(初始化 initialization 的简称)是在系统启动期间运行的第一个进程。Init 是一个守护进程,它将持续运行直至关机。
|
||||
|
||||
SysVinit 是早期传统的 init 系统和系统管理器。由于 sysVinit 系统上一些长期悬而未决的问题,大多数最新的发行版都适用于 systemd 系统。
|
||||
|
||||
### 什么是 systemd
|
||||
|
||||
systemd 是一个新的 init 系统以及系统管理器,它已成为大多数 Linux 发行版中非常流行且广泛适应的新的标准 init 系统。Systemctl 是一个 systemd 管理工具,它可以帮助我们管理 systemd 系统。
|
||||
|
||||
### 方法一:如何在 sysVinit 系统中查看运行的服务
|
||||
|
||||
以下命令可以帮助我们列出 sysVinit 系统中所有正在运行的服务。
|
||||
|
||||
如果服务很多,我建议使用文件视图命令,如 less、more 等,以便得到清晰的结果。
|
||||
```
|
||||
# service --status-all
|
||||
or
|
||||
# service --status-all | more
|
||||
or
|
||||
# service --status-all | less
|
||||
|
||||
abrt-ccpp hook is installed
|
||||
abrtd (pid 2131) is running...
|
||||
abrt-dump-oops is stopped
|
||||
acpid (pid 1958) is running...
|
||||
atd (pid 2164) is running...
|
||||
auditd (pid 1731) is running...
|
||||
Frequency scaling enabled using ondemand governor
|
||||
crond (pid 2153) is running...
|
||||
hald (pid 1967) is running...
|
||||
htcacheclean is stopped
|
||||
httpd is stopped
|
||||
Table: filter
|
||||
Chain INPUT (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
1 ACCEPT all ::/0 ::/0 state RELATED,ESTABLISHED
|
||||
2 ACCEPT icmpv6 ::/0 ::/0
|
||||
3 ACCEPT all ::/0 ::/0
|
||||
4 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:80
|
||||
5 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:21
|
||||
6 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:22
|
||||
7 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:25
|
||||
8 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2082
|
||||
9 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2086
|
||||
10 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2083
|
||||
11 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2087
|
||||
12 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:10000
|
||||
13 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
1 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
|
||||
iptables: Firewall is not running.
|
||||
irqbalance (pid 1826) is running...
|
||||
Kdump is operational
|
||||
lvmetad is stopped
|
||||
mdmonitor is stopped
|
||||
messagebus (pid 1929) is running...
|
||||
SUCCESS! MySQL running (24376)
|
||||
rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
|
||||
named is stopped
|
||||
netconsole module not loaded
|
||||
Usage: startup.sh { start | stop }
|
||||
Configured devices:
|
||||
lo eth0 eth1
|
||||
Currently active devices:
|
||||
lo eth0
|
||||
ntpd is stopped
|
||||
portreserve (pid 1749) is running...
|
||||
master (pid 2107) is running...
|
||||
Process accounting is disabled.
|
||||
quota_nld is stopped
|
||||
rdisc is stopped
|
||||
rngd is stopped
|
||||
rpcbind (pid 1840) is running...
|
||||
rsyslogd (pid 1756) is running...
|
||||
sandbox is stopped
|
||||
saslauthd is stopped
|
||||
smartd is stopped
|
||||
openssh-daemon (pid 9859) is running...
|
||||
svnserve is stopped
|
||||
vsftpd (pid 4008) is running...
|
||||
xinetd (pid 2031) is running...
|
||||
zabbix_agentd (pid 2150 2149 2148 2147 2146 2140) is running...
|
||||
|
||||
```
|
||||
|
||||
执行以下命令,可以只查看正在运行的服务。
|
||||
```
|
||||
# service --status-all | grep running
|
||||
|
||||
crond (pid 535) is running...
|
||||
httpd (pid 627) is running...
|
||||
mysqld (pid 911) is running...
|
||||
rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
|
||||
rsyslogd (pid 449) is running...
|
||||
saslauthd (pid 492) is running...
|
||||
sendmail (pid 509) is running...
|
||||
sm-client (pid 519) is running...
|
||||
openssh-daemon (pid 478) is running...
|
||||
xinetd (pid 485) is running...
|
||||
|
||||
```
|
||||
|
||||
运行以下命令以查看指定服务的状态。
|
||||
```
|
||||
# service --status-all | grep httpd
|
||||
httpd (pid 627) is running...
|
||||
|
||||
```
|
||||
|
||||
或者,使用以下命令也可以查看指定服务的状态。
|
||||
```
|
||||
# service httpd status
|
||||
|
||||
httpd (pid 627) is running...
|
||||
|
||||
```
|
||||
|
||||
使用以下命令查看系统启动时哪些服务会被启用。
|
||||
```
|
||||
# chkconfig --list
|
||||
crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
htcacheclean 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
httpd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
|
||||
ip6tables 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
modules_dep 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
named 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
netconsole 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
netfs 0:off 1:off 2:off 3:off 4:on 5:on 6:off
|
||||
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
nmb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
nscd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
portreserve 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
quota_nld 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
rdisc 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
restorecond 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
rpcbind 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
saslauthd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
|
||||
sendmail 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
smb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
snmpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
snmptrapd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
udev-post 0:off 1:on 2:on 3:off 4:on 5:on 6:off
|
||||
winbind 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
xinetd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
||||
|
||||
xinetd based services:
|
||||
chargen-dgram: off
|
||||
chargen-stream: off
|
||||
daytime-dgram: off
|
||||
daytime-stream: off
|
||||
discard-dgram: off
|
||||
discard-stream: off
|
||||
echo-dgram: off
|
||||
echo-stream: off
|
||||
finger: off
|
||||
ntalk: off
|
||||
rsync: off
|
||||
talk: off
|
||||
tcpmux-server: off
|
||||
time-dgram: off
|
||||
time-stream: off
|
||||
|
||||
```
|
||||
|
||||
### 方法二:如何在 systemd 系统中查看运行的服务
|
||||
|
||||
以下命令帮助我们列出 systemd 系统中所有服务。
|
||||
```
|
||||
# systemctl
|
||||
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
sys-devices-virtual-block-loop0.device loaded active plugged /sys/devices/virtual/block/loop0
|
||||
sys-devices-virtual-block-loop1.device loaded active plugged /sys/devices/virtual/block/loop1
|
||||
sys-devices-virtual-block-loop2.device loaded active plugged /sys/devices/virtual/block/loop2
|
||||
sys-devices-virtual-block-loop3.device loaded active plugged /sys/devices/virtual/block/loop3
|
||||
sys-devices-virtual-block-loop4.device loaded active plugged /sys/devices/virtual/block/loop4
|
||||
sys-devices-virtual-misc-rfkill.device loaded active plugged /sys/devices/virtual/misc/rfkill
|
||||
sys-devices-virtual-tty-ttyprintk.device loaded active plugged /sys/devices/virtual/tty/ttyprintk
|
||||
sys-module-fuse.device loaded active plugged /sys/module/fuse
|
||||
sys-subsystem-net-devices-enp0s3.device loaded active plugged 82540EM Gigabit Ethernet Controller (PRO/1000 MT Desktop Adapter)
|
||||
-.mount loaded active mounted Root Mount
|
||||
dev-hugepages.mount loaded active mounted Huge Pages File System
|
||||
dev-mqueue.mount loaded active mounted POSIX Message Queue File System
|
||||
run-user-1000-gvfs.mount loaded active mounted /run/user/1000/gvfs
|
||||
run-user-1000.mount loaded active mounted /run/user/1000
|
||||
snap-core-3887.mount loaded active mounted Mount unit for core
|
||||
snap-core-4017.mount loaded active mounted Mount unit for core
|
||||
snap-core-4110.mount loaded active mounted Mount unit for core
|
||||
snap-gping-13.mount loaded active mounted Mount unit for gping
|
||||
snap-termius\x2dapp-8.mount loaded active mounted Mount unit for termius-app
|
||||
sys-fs-fuse-connections.mount loaded active mounted FUSE Control File System
|
||||
sys-kernel-debug.mount loaded active mounted Debug File System
|
||||
acpid.path loaded active running ACPI Events Check
|
||||
cups.path loaded active running CUPS Scheduler
|
||||
systemd-ask-password-plymouth.path loaded active waiting Forward Password Requests to Plymouth Directory Watch
|
||||
systemd-ask-password-wall.path loaded active waiting Forward Password Requests to Wall Directory Watch
|
||||
init.scope loaded active running System and Service Manager
|
||||
session-c2.scope loaded active running Session c2 of user magi
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
anacron.service loaded active running Run anacron jobs
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
apparmor.service loaded active exited AppArmor initialization
|
||||
apport.service loaded active exited LSB: automatic crash report generation
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
console-setup.service loaded active exited Set console font and keymap
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
postfix.service loaded active exited Postfix Mail Transport Agent
|
||||
|
||||
```
|
||||
|
||||
* **`UNIT`** 相应的 systemd 单元名称
|
||||
* **`LOAD`** 相应的单元是否被加载到内存中
|
||||
* **`ACTIVE`** 该单元是否处于活动状态
|
||||
* **`SUB`** 该单元是否处于运行状态(LCTT 译者注:是较于 ACTIVE 更加详细的状态描述,不同的单元类型有不同的状态。)
|
||||
* **`DESCRIPTION`** 关于该单元的简短描述
|
||||
|
||||
|
||||
以下选项可根据类型列出单元。
|
||||
```
|
||||
# systemctl list-units --type service
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
anacron.service loaded active running Run anacron jobs
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
apparmor.service loaded active exited AppArmor initialization
|
||||
apport.service loaded active exited LSB: automatic crash report generation
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
console-setup.service loaded active exited Set console font and keymap
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
fwupd.service loaded active running Firmware update daemon
|
||||
[email protected] loaded active running Getty on tty1
|
||||
grub-common.service loaded active exited LSB: Record successful boot for GRUB
|
||||
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
|
||||
keyboard-setup.service loaded active exited Set the console keyboard layout
|
||||
kmod-static-nodes.service loaded active exited Create list of required static device nodes for the current kernel
|
||||
|
||||
```
|
||||
|
||||
以下选项可帮助您根据状态列出单位,输出与前例类似但更直截了当。
|
||||
```
|
||||
# systemctl list-unit-files --type service
|
||||
|
||||
UNIT FILE STATE
|
||||
accounts-daemon.service enabled
|
||||
acpid.service disabled
|
||||
alsa-restore.service static
|
||||
alsa-state.service static
|
||||
alsa-utils.service masked
|
||||
anacron-resume.service enabled
|
||||
anacron.service enabled
|
||||
apache-htcacheclean.service disabled
|
||||
[email protected] disabled
|
||||
apache2.service enabled
|
||||
[email protected] disabled
|
||||
apparmor.service enabled
|
||||
[email protected] static
|
||||
apport.service generated
|
||||
apt-daily-upgrade.service static
|
||||
apt-daily.service static
|
||||
aptik-battery-monitor.service generated
|
||||
atop.service enabled
|
||||
atopacct.service enabled
|
||||
[email protected] enabled
|
||||
avahi-daemon.service enabled
|
||||
bluetooth.service enabled
|
||||
|
||||
```
|
||||
|
||||
运行以下命令以查看指定服务的状态。
|
||||
```
|
||||
# systemctl | grep apache2
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
|
||||
```
|
||||
|
||||
或者,使用以下命令也可查看指定服务的状态。
|
||||
```
|
||||
# systemctl status apache2
|
||||
● apache2.service - The Apache HTTP Server
|
||||
Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: enabled)
|
||||
Drop-In: /lib/systemd/system/apache2.service.d
|
||||
└─apache2-systemd.conf
|
||||
Active: active (running) since Tue 2018-03-06 12:34:09 IST; 8min ago
|
||||
Process: 2786 ExecReload=/usr/sbin/apachectl graceful (code=exited, status=0/SUCCESS)
|
||||
Main PID: 1171 (apache2)
|
||||
Tasks: 55 (limit: 4915)
|
||||
CGroup: /system.slice/apache2.service
|
||||
├─1171 /usr/sbin/apache2 -k start
|
||||
├─2790 /usr/sbin/apache2 -k start
|
||||
└─2791 /usr/sbin/apache2 -k start
|
||||
|
||||
Mar 06 12:34:08 magi-VirtualBox systemd[1]: Starting The Apache HTTP Server...
|
||||
Mar 06 12:34:09 magi-VirtualBox apachectl[1089]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.0.2.15. Set the 'ServerName' directive globally to suppre
|
||||
Mar 06 12:34:09 magi-VirtualBox systemd[1]: Started The Apache HTTP Server.
|
||||
Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloading The Apache HTTP Server.
|
||||
Mar 06 12:39:10 magi-VirtualBox apachectl[2786]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using fe80::7929:4ed1:279f:4d65. Set the 'ServerName' directive gl
|
||||
Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloaded The Apache HTTP Server.
|
||||
|
||||
```
|
||||
|
||||
执行以下命令,只查看正在运行的服务。
|
||||
```
|
||||
# systemctl | grep running
|
||||
acpid.path loaded active running ACPI Events Check
|
||||
cups.path loaded active running CUPS Scheduler
|
||||
init.scope loaded active running System and Service Manager
|
||||
session-c2.scope loaded active running Session c2 of user magi
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
fwupd.service loaded active running Firmware update daemon
|
||||
[email protected] loaded active running Getty on tty1
|
||||
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
|
||||
lightdm.service loaded active running Light Display Manager
|
||||
ModemManager.service loaded active running Modem Manager
|
||||
NetworkManager.service loaded active running Network Manager
|
||||
polkit.service loaded active running Authorization Manager
|
||||
|
||||
```
|
||||
|
||||
使用以下命令查看系统启动时会被启用的服务列表。
|
||||
```
|
||||
# systemctl list-unit-files | grep enabled
|
||||
acpid.path enabled
|
||||
cups.path enabled
|
||||
accounts-daemon.service enabled
|
||||
anacron-resume.service enabled
|
||||
anacron.service enabled
|
||||
apache2.service enabled
|
||||
apparmor.service enabled
|
||||
atop.service enabled
|
||||
atopacct.service enabled
|
||||
[email protected] enabled
|
||||
avahi-daemon.service enabled
|
||||
bluetooth.service enabled
|
||||
console-setup.service enabled
|
||||
cron.service enabled
|
||||
cups-browsed.service enabled
|
||||
cups.service enabled
|
||||
display-manager.service enabled
|
||||
dns-clean.service enabled
|
||||
friendly-recovery.service enabled
|
||||
[email protected] enabled
|
||||
gpu-manager.service enabled
|
||||
keyboard-setup.service enabled
|
||||
lightdm.service enabled
|
||||
ModemManager.service enabled
|
||||
network-manager.service enabled
|
||||
networking.service enabled
|
||||
NetworkManager-dispatcher.service enabled
|
||||
NetworkManager-wait-online.service enabled
|
||||
NetworkManager.service enabled
|
||||
|
||||
```
|
||||
|
||||
systemd-cgtop 按资源使用情况(任务、CPU、内存、输入和输出)列出控制组。
|
||||
```
|
||||
# systemd-cgtop
|
||||
|
||||
Control Group Tasks %CPU Memory Input/s Output/s
|
||||
/ - - 1.5G - -
|
||||
/init.scope 1 - - - -
|
||||
/system.slice 153 - - - -
|
||||
/system.slice/ModemManager.service 3 - - - -
|
||||
/system.slice/NetworkManager.service 4 - - - -
|
||||
/system.slice/accounts-daemon.service 3 - - - -
|
||||
/system.slice/acpid.service 1 - - - -
|
||||
/system.slice/apache2.service 55 - - - -
|
||||
/system.slice/aptik-battery-monitor.service 1 - - - -
|
||||
/system.slice/atop.service 1 - - - -
|
||||
/system.slice/atopacct.service 1 - - - -
|
||||
/system.slice/avahi-daemon.service 2 - - - -
|
||||
/system.slice/colord.service 3 - - - -
|
||||
/system.slice/cron.service 1 - - - -
|
||||
/system.slice/cups-browsed.service 3 - - - -
|
||||
/system.slice/cups.service 2 - - - -
|
||||
/system.slice/dbus.service 6 - - - -
|
||||
/system.slice/fwupd.service 5 - - - -
|
||||
/system.slice/irqbalance.service 1 - - - -
|
||||
/system.slice/lightdm.service 7 - - - -
|
||||
/system.slice/polkit.service 3 - - - -
|
||||
/system.slice/repowerd.service 14 - - - -
|
||||
/system.slice/rsyslog.service 4 - - - -
|
||||
/system.slice/rtkit-daemon.service 3 - - - -
|
||||
/system.slice/snapd.service 8 - - - -
|
||||
/system.slice/system-getty.slice 1 - - - -
|
||||
|
||||
```
|
||||
|
||||
同时,我们可以使用 pstree 命令(输出来自 SysVinit 系统)查看正在运行的服务。
|
||||
```
|
||||
# pstree
|
||||
init-|-crond
|
||||
|-httpd---2*[httpd]
|
||||
|-kthreadd/99149---khelper/99149
|
||||
|-2*[mingetty]
|
||||
|-mysqld_safe---mysqld---9*[{mysqld}]
|
||||
|-rsyslogd---3*[{rsyslogd}]
|
||||
|-saslauthd---saslauthd
|
||||
|-2*[sendmail]
|
||||
|-sshd---sshd---bash---pstree
|
||||
|-udevd
|
||||
`-xinetd
|
||||
|
||||
```
|
||||
|
||||
我们还可以使用 pstree 命令(输出来自 systemd 系统)查看正在运行的服务。
|
||||
```
|
||||
# pstree
|
||||
systemd─┬─ModemManager─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─NetworkManager─┬─dhclient
|
||||
│ ├─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─accounts-daemon─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─acpid
|
||||
├─agetty
|
||||
├─anacron
|
||||
├─apache2───2*[apache2───26*[{apache2}]]
|
||||
├─aptd───{gmain}
|
||||
├─aptik-battery-m
|
||||
├─atop
|
||||
├─atopacctd
|
||||
├─avahi-daemon───avahi-daemon
|
||||
├─colord─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─cron
|
||||
├─cups-browsed─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─cupsd
|
||||
├─dbus-daemon
|
||||
├─fwupd─┬─{GUsbEventThread}
|
||||
│ ├─{fwupd}
|
||||
│ ├─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─gnome-keyring-d─┬─{gdbus}
|
||||
│ ├─{gmain}
|
||||
│ └─{timer}
|
||||
|
||||
```
|
||||
|
||||
### 方法三:如何使用 chkservice 在 systemd 系统中查看正在运行的服务
|
||||
|
||||
chkservice 是一个管理系统单元的终端工具,需要超级用户权限。
|
||||
```
|
||||
# chkservice
|
||||
|
||||
```
|
||||
|
||||
![][1]
|
||||
|
||||
要查看帮助页面,请单击 `?` 按钮,它将显示管理 systemd 服务的可用选项。
|
||||
![][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-1.png
|
||||
[2]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-2.png
|
||||
@ -0,0 +1,488 @@
|
||||
# 理解指标和使用 Python 去监视
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
## 获取订阅
|
||||
|
||||
加入我们吧,我们有 85,000 位开源支持者,加入后会定期接收到我们免费提供的提示和文章摘要。
|
||||
|
||||
当我第一次看到术语“计数器”和“计量器”和使用颜色及标记着“意思”和“最大 90”的数字图表时,我的反应之一是逃避。就像我看到它们一样,我并不感兴趣,因为我不理解它们是干什么的或如何去使用。因为我的工作不需要我去注意它们,它们被我完全无视。
|
||||
|
||||
这都是在两年以前的事了。随着我的职业发展,我希望去了解更多关于我们的网络应用程序的知识,而那个时候就是我开始去学习指标的时候。
|
||||
|
||||
我的理解监视的学习之旅共有三个阶段(到目前为止),它们是:
|
||||
|
||||
* 阶段 1:什么?(看别处)
|
||||
* 阶段 2:没有指标,我们真的是瞎撞。
|
||||
* 阶段 3:出现不合理的指标我们该如何做?
|
||||
|
||||
我现在处于阶段 2,我将分享到目前为止我学到了些什么。我正在向阶段 3 进发,在本文结束的位置我提供了一些我正在使用的学习资源。
|
||||
|
||||
我们开始吧!
|
||||
|
||||
## 需要的软件
|
||||
|
||||
更多关于 Python 的资源
|
||||
|
||||
* [Python 是什么?][1]
|
||||
* [Python IDE 排行榜][2]
|
||||
* [Python GUI 框架排行榜][3]
|
||||
* [最新的 Python 主题][4]
|
||||
* [更多开发者资源][5]
|
||||
|
||||
在文章中讨论时用到的 demo 都可以在 [我的 GitHub 仓库][6] 中找到。你需要安装 docker 和 docker-compose 才能使用它们。
|
||||
|
||||
## 为什么要监视?
|
||||
|
||||
关于监视的主要原因是:
|
||||
|
||||
* 理解 _正常的_ 和 _不正常的_ 系统和服务的特征
|
||||
* 做容量规划、弹性伸缩
|
||||
* 有助于排错
|
||||
* 了解软件/硬件改变的效果
|
||||
* 测量响应中的系统行为变化
|
||||
* 当系统出现意外行为时发出警报
|
||||
|
||||
## 指标和指标类型
|
||||
|
||||
从我们的用途来看,一个**指标**就是在一个给定时间点上的某些数量的 _测量_ 值。博客文章的总点击次数、参与讨论的总人数、在缓存系统中数据没有被找到的次数、你的网站上的已登录用户数 —— 这些都是指标的例子。
|
||||
|
||||
它们总体上可以分为三类:
|
||||
|
||||
### 计数器
|
||||
|
||||
以你的个人博客为例。你发布一篇文章后,过一段时间后,你希望去了解有多少点击量,数字只会增加。这就是一个**计数器**指标。在你的博客文章的生命周期中,它的值从 0 开始增加。用图表来表示,一个计数器看起来应该像下面的这样:
|
||||
|
||||

|
||||
|
||||
一个计数器指标总是在增加的。
|
||||
|
||||
### 计量器
|
||||
|
||||
如果你想去跟踪你的博客每天或每周的点击量,而不是基于时间的总点击量。这种指标被称为一个**计量器**,它的值可上可下。用图表来表示,一个计量器看起来应该像下面的样子:
|
||||
|
||||

|
||||
|
||||
一个计量器指标可以增加或减少。
|
||||
|
||||
一个计量器的值在某些时间窗口内通常有一个_最大值_ 和 _最小值_ 。
|
||||
|
||||
### 柱状图和计时器
|
||||
|
||||
一个**柱状图**(在 Prometheus 中这么叫它)或一个**计时器**(在 StatsD 中这么叫它)是跟踪已采样的_观测结果_ 的指标。不像一个计数器类或计量器类指标,柱状图指标的值并不是显示为上或下的样式。我知道这可能并没有太多的意义,并且可能和一个计量器图看上去没有什么不同。它们的这同之处在于,你期望使用柱状图数据来做什么,而不是与一个计量器图做比较。因此,监视系统需要知道那个指标是一个柱状图类型,它允许你去做哪些事情。
|
||||
|
||||

|
||||
|
||||
一个柱状图指标可以增加或减少。
|
||||
|
||||
## Demo 1:计算和报告指标
|
||||
|
||||
[Demo 1][7] 是使用 [Flask][8] 框架写的一个基本的 web 应用程序。它演示了我们如何去 _计算_ 和 _报告_ 指标。
|
||||
|
||||
在 src 目录中有 `app.py` 和 `src/helpers/middleware.py` 应用程序,包含以下内容:
|
||||
|
||||
```
|
||||
from flask import request
|
||||
import csv
|
||||
import time
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([str(int(time.time())), str(resp_time)])
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def setup_metrics(app):
|
||||
app.before_request(start_timer)
|
||||
app.after_request(stop_timer)
|
||||
```
|
||||
|
||||
当在应用程序中调用 `setup_metrics()` 时,它在请求处理之前被配置为调用 `start_timer()` 函数,然后在请求处理之后、响应发送之前调用 `stop_timer()` 函数。在上面的函数中,我们写了时间戳并用它来计算处理请求所花费的时间。
|
||||
|
||||
当我们在 demo1 目录中的 docker-compose 上开始去启动 web 应用程序,然后在一个客户端容器中生成一些对 web 应用程序的请求。你将会看到创建了一个 `src/metrics.csv` 文件,它有两个字段:timestamp 和 request_latency。
|
||||
|
||||
通过查看这个文件,我们可以推断出两件事情:
|
||||
|
||||
* 生成了很多数据
|
||||
* 没有观测到任何与指标相关的特征
|
||||
|
||||
没有观测到与指标相关的特征,我们就不能说这个指标与哪个 HTTP 端点有关联,或这个指标是由哪个应用程序的节点所生成的。因此,我们需要使用合适的元数据去限定每个观测指标。
|
||||
|
||||
## Statistics 101~~(译者注:这是一本统计学入门教材的名字)~~
|
||||
|
||||
假如我们回到高中数学,我们应该回忆起一些统计术语,虽然不太确定,但应该包括平均数、中位数、百分位、和柱状图。我们来简要地回顾一下它们,不用去管他们的用法,就像是在上高中一样。
|
||||
|
||||
### 平均数
|
||||
|
||||
**平均数**,或一系列数字的平均值,是将数字汇总然后除以列表的个数。3、2、和 10 的平均数是 (3+2+10)/3 = 5。
|
||||
|
||||
### 中位数
|
||||
|
||||
**中位数**是另一种类型的平均,但它的计算方式不同;它是列表从小到大排序(反之亦然)后取列表的中间数字。以我们上面的列表中(2、3、10),中位数是 3。计算并不简单,它取决于列表中数字的个数。
|
||||
|
||||
### 百分位
|
||||
|
||||
**百分位**是指那个百(千)分比数字低于我们给定的百分数的程度。在一些场景中,百分位是指这个测量值低于我们数据的百(千)分比数字的程度。比如,上面列表中 95% 是 9.29999。百分位的测量范围是 0 到 100(不包括)。0% 是一组数字的最小分数。你可能会想到它的中位数是 50%,它的结果是 3。
|
||||
|
||||
一些监视系统将百分位称为 `upper_X`,其中 _X_ 就是百分位;`_upper 90_` 指的是值在 90%的位置。
|
||||
|
||||
### 分位数
|
||||
|
||||
**q-Quantile** 是将有 _N_ 个数的集合等分为 q_N_ 个集合。**q** 的取值范围为 0 到 1(全部都包括)。当 **q** 取值为 0.5 时,值就是中位数。分位数和百分位数的关系是,分位数值 **q** 等于 **100_q_** 百分位值。
|
||||
|
||||
### 柱状图
|
||||
|
||||
**柱状图**这个指标,我们早期学习过,它是监视系统中一个_详细的实现_。在统计学中,一个柱状图是一个将数据分组为 _桶_ 的图表。我们来考虑一个人为的、不同的示例:阅读你的博客的人的年龄。如果你有一些这样的数据,并想将它进行大致的分组,绘制成的柱状图将看起来像下面的这样:
|
||||
|
||||

|
||||
|
||||
### 累积柱状图
|
||||
|
||||
一个**累积柱状图**也是一个柱状图,它的每个桶的数包含前一个桶的数,因此命名为_累积_。将上面的数据集做成累积柱状图后,看起来应该是这样的:
|
||||
|
||||

|
||||
|
||||
### 我们为什么需要做统计?
|
||||
|
||||
在上面的 Demo 1 中,我们注意到在我们报告指标时,这里生成了许多数据。当我们将它用于指标时我们需要做统计,因为它们实在是太多了。我们需要的是整体行为,我们没法去处理单个值。我们预期展现出来的值的行为应该是代表我们观察的系统的行为。
|
||||
|
||||
## Demo 2:指标上增加特征
|
||||
|
||||
在我们上面的的 Demo 1 应用程序中,当我们计算和报告一个请求的延迟时,它指向了一个由一些_特征_ 唯一标识的特定请求。下面是其中一些:
|
||||
|
||||
* HTTP 端点
|
||||
* HTTP 方法
|
||||
* 运行它的主机/节点的标识符
|
||||
|
||||
如果我们将这些特征附加到要观察的指标上,每个指标将有更多的内容。我们来解释一下 [Demo 2][9] 中添加到我们的指标上的特征。
|
||||
|
||||
在写入指标时,src/helpers/middleware.py 文件将在 CSV 文件中写入多个列:
|
||||
|
||||
```
|
||||
node_ids = ['10.0.1.1', '10.1.3.4']
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
node_id = node_ids[random.choice(range(len(node_ids)))]
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([
|
||||
str(int(time.time())), 'webapp1', node_id,
|
||||
request.endpoint, request.method, str(response.status_code),
|
||||
str(resp_time)
|
||||
])
|
||||
|
||||
return response
|
||||
```
|
||||
|
||||
因为这只是一个演示,在报告指标时,我们将随意的报告一些随机 IP 作为节点的 ID。当我们在 demo2 目录下运行 docker-compose 时,我们的结果将是一个有多个列的 CSV 文件。
|
||||
|
||||
### 用 pandas 分析指标
|
||||
|
||||
我们将使用 [pandas][10] 去分析这个 CSV 文件。运行中的 docker-compose 将打印出一个 URL,我们将使用它来打开一个 [Jupyter][11] 会话。一旦我们上传 `Analysis.ipynb notebook` 到会话中,我们就可以将 CSV 文件读入到一个 pandas 数据帧中:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
metrics = pd.read_csv('/data/metrics.csv', index_col=0)
|
||||
```
|
||||
|
||||
index_col 指定时间戳作为索引。
|
||||
|
||||
因为每个特征我们都在数据帧中添加一个列,因此我们可以基于这些列进行分组和聚合:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
metrics.groupby(['node_id', 'http_status']).latency.aggregate(np.percentile, 99.999)
|
||||
```
|
||||
|
||||
更多内容请参考 Jupyter notebook 在数据上的分析示例。
|
||||
|
||||
## 我应该监视什么?
|
||||
|
||||
一个软件系统有许多的变量,这些变量的值在它的生命周期中不停地发生变化。软件是运行在某种操作系统上的,而操作系统同时也在不停地变化。在我看来,当某些东西出错时,你所拥有的数据越多越好。
|
||||
|
||||
我建议去监视的关键操作系统指标有:
|
||||
|
||||
* CPU 使用
|
||||
* 系统内存使用
|
||||
* 文件描述符使用
|
||||
* 磁盘使用
|
||||
|
||||
还需要监视的其它关键指标根据你的软件应用程序不同而不同。
|
||||
|
||||
### 网络应用程序
|
||||
|
||||
如果你的软件是一个监听客户端请求和为它提供服务的网络应用程序,需要测量的关键指标还有:
|
||||
|
||||
* 入站请求数(计数器)
|
||||
* 未处理的错误(计数器)
|
||||
* 请求延迟(柱状图/计时器)
|
||||
* 队列时间,如果在你的应用程序中有队列(柱状图/计时器)
|
||||
* 队列大小,如果在你的应用程序中有队列(计量器)
|
||||
* 工作进程/线程使用(计量器)
|
||||
|
||||
如果你的网络应用程序在一个客户端请求的环境中向其它服务发送请求,那么它应该有一个指标去记录它与那个服务之间的通讯行为。需要监视的关键指标包括请求数、请求延迟、和响应状态。
|
||||
|
||||
### HTTP web 应用程序后端
|
||||
|
||||
HTTP 应用程序应该监视上面所列出的全部指标。除此之外,还应该按 HTTP 状态代码分组监视所有非 200 的 HTTP 状态代码的大致数据。如果你的 web 应用程序有用户注册和登录功能,同时也应该为这个功能设置指标。
|
||||
|
||||
### 长周期运行的进程
|
||||
|
||||
长周期运行的进程如 Rabbit MQ 消费者或 task-queue 工作进程,虽然它们不是网络服务,它们以选取一个任务并处理它的工作模型来运行。因此,我们应该监视请求的进程数和这些进程的请求延迟。
|
||||
|
||||
不管是什么类型的应用程序,都有指标与合适的**元数据**相关联。
|
||||
|
||||
## 将监视集成到一个 Python 应用程序中
|
||||
|
||||
将监视集成到 Python 应用程序中需要涉及到两个组件:
|
||||
|
||||
* 更新你的应用程序去计算和报告指标
|
||||
* 配置一个监视基础设施来容纳应用程序的指标,并允许去查询它们
|
||||
|
||||
下面是记录和报告指标的基本思路:
|
||||
|
||||
```
|
||||
def work():
|
||||
requests += 1
|
||||
# report counter
|
||||
start_time = time.time()
|
||||
|
||||
# < do the work >
|
||||
|
||||
# calculate and report latency
|
||||
work_latency = time.time() - start_time
|
||||
...
|
||||
```
|
||||
|
||||
考虑到上面的模式,我们经常使用修饰符、内容管理器、中间件(对于网络应用程序)所带来的好处去计算和报告指标。在 Demo 1 和 Demo 2 中,我们在一个 Flask 应用程序中使用修饰符。
|
||||
|
||||
### 指标报告时的拉取和推送模型
|
||||
|
||||
大体来说,在一个 Python 应用程序中报告指标有两种模式。在 _拉取_ 模型中,监视系统在一个预定义的 HTTP 端点上“刮取”应用程序。在_推送_ 模型中,应用程序发送数据到监视系统。
|
||||
|
||||

|
||||
|
||||
工作在 _拉取_ 模型中的监视系统的一个例子是 [Prometheus][12]。而 [StatsD][13] 是 _推送_ 模型的一个例子。
|
||||
|
||||
### 集成 StatsD
|
||||
|
||||
将 StatsD 集成到一个 Python 应用程序中,我们将使用 [StatsD Python 客户端][14],然后更新我们的指标报告部分的代码,调用合适的库去推送数据到 StatsD 中。
|
||||
|
||||
首先,我们需要去创建一个客户端实例:
|
||||
|
||||
```
|
||||
statsd = statsd.StatsClient(host='statsd', port=8125, prefix='webapp1')
|
||||
```
|
||||
|
||||
`prefix` 关键字参数将为通过这个客户端报告的所有指标添加一个指定的前缀。
|
||||
|
||||
一旦我们有了客户端,我们可以使用如下的代码为一个计时器报告值:
|
||||
|
||||
```
|
||||
statsd.timing(key, resp_time)
|
||||
```
|
||||
|
||||
增加计数器:
|
||||
|
||||
```
|
||||
statsd.incr(key)
|
||||
```
|
||||
|
||||
将指标关联到元数据上,一个键的定义为:metadata1.metadata2.metric,其中每个 metadataX 是一个可以进行聚合和分组的字段。
|
||||
|
||||
这个演示应用程序 [StatsD][15] 是将 statsd 与 Python Flask 应用程序集成的一个完整示例。
|
||||
|
||||
### 集成 Prometheus
|
||||
|
||||
去使用 Prometheus 监视系统,我们使用 [Promethius Python 客户端][16]。我们将首先去创建有关的指标类对象:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY = Histogram('request_latency_seconds', 'Request latency',
|
||||
['app_name', 'endpoint']
|
||||
)
|
||||
```
|
||||
|
||||
在上面的语句中的第三个参数是与这个指标相关的标识符。这些标识符是由与单个指标值相关联的元数据定义的。
|
||||
|
||||
去记录一个特定的观测指标:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY.labels('webapp', request.path).observe(resp_time)
|
||||
```
|
||||
|
||||
下一步是在我们的应用程序中定义一个 Prometheus 能够刮取的 HTTP 端点。这通常是一个被称为 `/metrics` 的端点:
|
||||
|
||||
```
|
||||
@app.route('/metrics')
|
||||
def metrics():
|
||||
return Response(prometheus_client.generate_latest(), mimetype=CONTENT_TYPE_LATEST)
|
||||
```
|
||||
|
||||
这个演示应用程序 [Prometheus][17] 是将 prometheus 与 Python Flask 应用程序集成的一个完整示例。
|
||||
|
||||
### 哪个更好:StatsD 还是 Prometheus?
|
||||
|
||||
本能地想到的下一个问题便是:我应该使用 StatsD 还是 Prometheus?关于这个主题我写了几篇文章,你可能发现它们对你很有帮助:
|
||||
|
||||
* [Your options for monitoring multi-process Python applications with Prometheus][18]
|
||||
* [Monitoring your synchronous Python web applications using Prometheus][19]
|
||||
* [Monitoring your asynchronous Python web applications using Prometheus][20]
|
||||
|
||||
## 指标的使用方式
|
||||
|
||||
我们已经学习了一些关于为什么要在我们的应用程序上配置监视的原因,而现在我们来更深入地研究其中的两个用法:报警和自动扩展。
|
||||
|
||||
### 使用指标进行报警
|
||||
|
||||
指标的一个关键用途是创建警报。例如,假如过去的五分钟,你的 HTTP 500 的数量持续增加,你可能希望给相关的人发送一封电子邮件或页面提示。对于配置警报做什么取决于我们的监视设置。对于 Prometheus 我们可以使用 [Alertmanager][21],而对于 StatsD,我们使用 [Nagios][22]。
|
||||
|
||||
### 使用指标进行自动扩展
|
||||
|
||||
在一个云基础设施中,如果我们当前的基础设施供应过量或供应不足,通过指标不仅可以让我们知道,还可以帮我们实现一个自动伸缩的策略。例如,如果在过去的五分钟里,在我们服务器上的工作进程使用率达到 90%,我们可以水平扩展。我们如何去扩展取决于云基础设施。AWS 的自动扩展,缺省情况下,扩展策略是基于系统的 CPU 使用率、网络流量、以及其它因素。然而,让基础设施伸缩的应用程序指标,我们必须发布 [自定义的 CloudWatch 指标][23]。
|
||||
|
||||
## 在多服务架构中的应用程序监视
|
||||
|
||||
当我们超越一个单应用程序架构时,比如当客户端的请求在响应被发回之前,能够触发调用多个服务,就需要从我们的指标中获取更多的信息。我们需要一个统一的延迟视图指标,这样我们就能够知道响应这个请求时每个服务花费了多少时间。这可以用 [distributed tracing][24] 来实现。
|
||||
|
||||
你可以在我的博客文章 [在你的 Python 应用程序中通过 Zipkin 引入分布式跟踪][25] 中看到在 Python 中进行分布式跟踪的示例。
|
||||
|
||||
## 划重点
|
||||
|
||||
总之,你需要记住以下几点:
|
||||
|
||||
* 理解你的监视系统中指标类型的含义
|
||||
* 知道监视系统需要的你的数据的测量单位
|
||||
* 监视你的应用程序中的大多数关键组件
|
||||
* 监视你的应用程序在它的大多数关键阶段的行为
|
||||
|
||||
以上要点是假设你不去管理你的监视系统。如果管理你的监视系统是你的工作的一部分,那么你还要考虑更多的问题!
|
||||
|
||||
## 其它资源
|
||||
|
||||
以下是我在我的监视学习过程中找到的一些非常有用的资源:
|
||||
|
||||
### 综合的
|
||||
|
||||
* [监视分布式系统][26]
|
||||
* [观测和监视最佳实践][27]
|
||||
* [谁想使用秒?][28]
|
||||
|
||||
### StatsD/Graphite
|
||||
|
||||
* [StatsD 指标类型][29]
|
||||
|
||||
### Prometheus
|
||||
|
||||
* [Prometheus 指标类型][30]
|
||||
* [How does a Prometheus gauge work?][31]
|
||||
* [Why are Prometheus histograms cumulative?][32]
|
||||
* [在 Python 中监视批作业][33]
|
||||
* [Prometheus:监视 SoundCloud][34]
|
||||
|
||||
## 避免犯错(即第 3 阶段的学习)
|
||||
|
||||
在我们学习监视的基本知识时,时刻注意不要犯错误是很重要的。以下是我偶然发现的一些很有见解的资源:
|
||||
|
||||
* [How not to measure latency][35]
|
||||
* [Histograms with Prometheus: A tale of woe][36]
|
||||
* [Why averages suck and percentiles are great][37]
|
||||
* [Everything you know about latency is wrong][38]
|
||||
* [Who moved my 99th percentile latency?][39]
|
||||
* [Logs and metrics and graphs][40]
|
||||
* [HdrHistogram: A better latency capture method][41]
|
||||
|
||||
---
|
||||
|
||||
想学习更多内容,参与到 [PyCon Cleveland 2018][43] 上的 Amit Saha 的讨论,[Counter, gauge, upper 90—Oh my!][42]
|
||||
|
||||
## 关于作者
|
||||
|
||||
[][44]
|
||||
|
||||
Amit Saha — 我是一名对基础设施、监视、和工具感兴趣的软件工程师。我是“用 Python 做数学”的作者和创始人,以及 Fedora Scientific Spin 维护者。
|
||||
|
||||
[关于我的更多信息][45]
|
||||
|
||||
* [Learn how you can contribute][46]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/metrics-monitoring-and-python][47]
|
||||
|
||||
作者: [Amit Saha][48] 选题者: [@lujun9972][49] 译者: [qhwdw][50] 校对: [校对者ID][51]
|
||||
|
||||
本文由 [LCTT][52] 原创编译,[Linux中国][53] 荣誉推出
|
||||
|
||||
[1]: https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]: https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]: https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]: https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]: https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]: https://github.com/amitsaha/python-monitoring-talk
|
||||
[7]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo1
|
||||
[8]: http://flask.pocoo.org/
|
||||
[9]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo2
|
||||
[10]: https://pandas.pydata.org/
|
||||
[11]: http://jupyter.org/
|
||||
[12]: https://prometheus.io/
|
||||
[13]: https://github.com/etsy/statsd
|
||||
[14]: https://pypi.python.org/pypi/statsd
|
||||
[15]: https://github.com/amitsaha/python-monitoring-talk/tree/master/statsd
|
||||
[16]: https://pypi.python.org/pypi/prometheus_client
|
||||
[17]: https://github.com/amitsaha/python-monitoring-talk/tree/master/prometheus
|
||||
[18]: http://echorand.me/your-options-for-monitoring-multi-process-python-applications-with-prometheus.html
|
||||
[19]: https://blog.codeship.com/monitoring-your-synchronous-python-web-applications-using-prometheus/
|
||||
[20]: https://blog.codeship.com/monitoring-your-asynchronous-python-web-applications-using-prometheus/
|
||||
[21]: https://github.com/prometheus/alertmanager
|
||||
[22]: https://www.nagios.org/about/overview/
|
||||
[23]: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
|
||||
[24]: http://opentracing.io/documentation/
|
||||
[25]: http://echorand.me/introducing-distributed-tracing-in-your-python-application-via-zipkin.html
|
||||
[26]: https://landing.google.com/sre/book/chapters/monitoring-distributed-systems.html
|
||||
[27]: http://www.integralist.co.uk/posts/monitoring-best-practices/?imm_mid=0fbebf&cmp=em-webops-na-na-newsltr_20180309
|
||||
[28]: https://www.robustperception.io/who-wants-seconds/
|
||||
[29]: https://github.com/etsy/statsd/blob/master/docs/metric_types.md
|
||||
[30]: https://prometheus.io/docs/concepts/metric_types/
|
||||
[31]: https://www.robustperception.io/how-does-a-prometheus-gauge-work/
|
||||
[32]: https://www.robustperception.io/why-are-prometheus-histograms-cumulative/
|
||||
[33]: https://www.robustperception.io/monitoring-batch-jobs-in-python/
|
||||
[34]: https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud
|
||||
[35]: https://www.youtube.com/watch?v=lJ8ydIuPFeU&feature=youtu.be
|
||||
[36]: http://linuxczar.net/blog/2017/06/15/prometheus-histogram-2/
|
||||
[37]: https://www.dynatrace.com/news/blog/why-averages-suck-and-percentiles-are-great/
|
||||
[38]: https://bravenewgeek.com/everything-you-know-about-latency-is-wrong/
|
||||
[39]: https://engineering.linkedin.com/performance/who-moved-my-99th-percentile-latency
|
||||
[40]: https://grafana.com/blog/2016/01/05/logs-and-metrics-and-graphs-oh-my/
|
||||
[41]: http://psy-lob-saw.blogspot.com.au/2015/02/hdrhistogram-better-latency-capture.html
|
||||
[42]: https://us.pycon.org/2018/schedule/presentation/133/
|
||||
[43]: https://us.pycon.org/2018/
|
||||
[44]: https://opensource.com/users/amitsaha
|
||||
[45]: https://opensource.com/users/amitsaha
|
||||
[46]: https://opensource.com/participate
|
||||
[47]: https://opensource.com/article/18/4/metrics-monitoring-and-python
|
||||
[48]: https://opensource.com/users/amitsaha
|
||||
[49]: https://github.com/lujun9972
|
||||
[50]: https://github.com/qhwdw
|
||||
[51]: https://github.com/校对者ID
|
||||
[52]: https://github.com/LCTT/TranslateProject
|
||||
[53]: https://linux.cn/
|
||||
@ -1,57 +0,0 @@
|
||||
老树发新芽:微服务 – DXC Blogs
|
||||
======
|
||||

|
||||
|
||||
如果我告诉你有这样一种软件架构,一个应用程序的组件通过基于网络的通讯协议为其它组件提供服务,我估计你可能会说它是 …
|
||||
|
||||
是的,确实是。如果你从上世纪九十年代就开始了你的编程生涯,那么你肯定会说它是 [面向服务的架构 (SOA)][1]。但是,如果你是个年青人,并且在云上获得初步的经验,那么,你将会说:“哦,你说的是 [微服务][2]。”
|
||||
|
||||
你们都没错。如果想真正地了解它们的差别,你需要深入地研究这两种架构。
|
||||
|
||||
在 SOA 中,一个服务是一个功能,它是定义好的、自包含的、并且是不依赖上下文和其它服务的状态的功能。总共有两种服务。一种是消费者服务,它从另外类型的服务 —— 提供者服务 —— 中请求一个服务。一个 SOA 服务可以同时扮演这两种角色。
|
||||
|
||||
SOA 服务可以与其它服务交换数据。两个或多个服务也可以彼此之间相互协调。这些服务执行基本的任务,比如创建一个用户帐户、提供登陆功能、或验证支付。
|
||||
|
||||
与其说 SOA 是模块化一个应用程序,还不如说它是把分布式的、独立维护和部署的组件,组合成一个应用程序。然后在服务器上运行这些组件。
|
||||
|
||||
早期版本的 SOA 使用面向对象的协议进行组件间通讯。例如,微软的 [分布式组件对象模型 (DCOM)][3] 和使用 [通用对象请求代理架构 (CORBA)][5] 规范的 [对象请求代理 (ORBs)][4]。
|
||||
|
||||
用于消息服务的最新版本,比如 [Java 消息服务 (JMS)][6] 或者 [高级消息队列协议 (AMQP)][7]。这些服务通过企业服务总线 (ESB) 进行连接。基于这些总线,来传递和接收可扩展标记语言(XML)格式的数据。
|
||||
|
||||
[微服务][2] 是一个架构样式,其中的应用程序以松散耦合的服务或模块组成。它适用于开发大型的、复杂的应用程序的持续集成/持续部署(CI/CD)模型。一个应用程序就是一堆模块的汇总。
|
||||
|
||||
每个微服务提供一个应用程序编程接口(API)端点。它们通过轻量级协议连接,比如,[表述性状态转移 (REST)][8],或 [gRPC][9]。数据倾向于使用 [JavaScript 对象标记 (JSON)][10] 或 [Protobuf][11] 来表示。
|
||||
|
||||
这两种架构都可以用于去替代以前老的整体式架构,整体式架构的应用程序被构建为单个自治的单元。例如,在一个客户机 - 服务器模式中,一个典型的 Linux、Apache、MySQL、PHP/Python/Perl (LAMP) 服务器端应用程序将去处理 HTTP 请求、运行子程序、以及从底层的 MySQL 数据库中检索/更新数据。所有这些应用程序”绑“在一起提供服务。当你改变了任何一个东西,你都必须去构建和部署一个新版本。
|
||||
|
||||
使用 SOA,你可以只改变需要的几个组件,而不是整个应用程序。使用微服务,你可以做到一次只改变一个服务。使用微服务,你才能真正做到一个解耦架构。
|
||||
|
||||
微服务也比 SOA 更轻量级。不过 SOA 服务是部署到服务器和虚拟机上,而微服务是部署在容器中。协议也更轻量级。这使得微服务比 SOA 更灵活。因此,它更适合于要求敏捷性的电商网站。
|
||||
|
||||
说了这么多,到底意味着什么呢?微服务就是 SOA 在容器和云计算上的变种。
|
||||
|
||||
老式的 SOA 并没有离我们远去,但是,因为我们持续将应用程序搬迁到容器中,所以微服务架构将越来越流行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blogs.dxc.technology/2018/05/08/everything-old-is-new-again-microservices/
|
||||
|
||||
作者:[Cloudy Weather][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blogs.dxc.technology/author/steven-vaughan-nichols/
|
||||
[1]:https://www.service-architecture.com/articles/web-services/service-oriented_architecture_soa_definition.html
|
||||
[2]:http://microservices.io/
|
||||
[3]:https://technet.microsoft.com/en-us/library/cc958799.aspx
|
||||
[4]:https://searchmicroservices.techtarget.com/definition/Object-Request-Broker-ORB
|
||||
[5]:http://www.corba.org/
|
||||
[6]:https://docs.oracle.com/javaee/6/tutorial/doc/bncdq.html
|
||||
[7]:https://www.amqp.org/
|
||||
[8]:https://www.service-architecture.com/articles/web-services/representational_state_transfer_rest.html
|
||||
[9]:https://grpc.io/
|
||||
[10]:https://www.json.org/
|
||||
[11]:https://github.com/google/protobuf/
|
||||
@ -0,0 +1,281 @@
|
||||
开始使用Python调试器
|
||||
======
|
||||
|
||||

|
||||
|
||||
Python生态系统包含丰富的工具和库,可以改善开发人员的生活。 例如,杂志之前已经介绍了如何[使用交互式shell增强Python][1]。 本文重点介绍另一种可以节省时间并提高Python技能的工具:Python调试器。
|
||||
|
||||
### Python调试器
|
||||
|
||||
Python标准库提供了一个名为pdb的调试器。 此调试器提供了调试所需的大多数功能,如断点,单行步进,堆栈帧的检查等等。
|
||||
|
||||
pdb的基本知识很有用,因为它是标准库的一部分。 你可以在无法安装其他增强的调试器的环境中使用它。
|
||||
|
||||
#### 运行pdb
|
||||
|
||||
运行pdb的最简单方法是从命令行,将程序作为参数传递给debug。 考虑以下脚本:
|
||||
|
||||
```
|
||||
# pdb_test.py
|
||||
#!/usr/bin/python3
|
||||
|
||||
from time import sleep
|
||||
|
||||
def countdown(number):
|
||||
for i in range(number, 0, -1):
|
||||
print(i)
|
||||
sleep(1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
seconds = 10
|
||||
countdown(seconds)
|
||||
```
|
||||
|
||||
你可以从命令行运行pdb,如下所示:
|
||||
|
||||
```
|
||||
$ python3 -m pdb pdb_test.py
|
||||
> /tmp/pdb_test.py(1)<module>()
|
||||
-> from time import sleep
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
使用pdb的另一种方法是在程序中设置断点。 为此,请导入pdb模块并使用set_trace函数:
|
||||
|
||||
```
|
||||
# pdb_test.py
|
||||
#!/usr/bin/python3
|
||||
|
||||
from time import sleep
|
||||
|
||||
|
||||
def countdown(number):
|
||||
for i in range(number, 0, -1):
|
||||
import pdb; pdb.set_trace()
|
||||
print(i)
|
||||
sleep(1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
seconds = 10
|
||||
countdown(seconds)
|
||||
|
||||
$ python3 pdb_test.py
|
||||
> /tmp/pdb_test.py(6)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
脚本在断点处停止,pdb显示脚本中的下一行。 你也可以在失败后执行调试器。 这称为*事后调试(postmortem debugging)*。
|
||||
|
||||
#### 导航执行堆栈
|
||||
|
||||
调试中的一个常见用例是导航执行堆栈。 Python调试器运行后,以下命令很有用:
|
||||
|
||||
+ w(here) : 显示当前执行的行以及执行堆栈的位置。
|
||||
|
||||
|
||||
```
|
||||
$ python3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) w
|
||||
/tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
+ l(ist) : 显示当前位置周围更多的上下文(代码)。
|
||||
|
||||
|
||||
```
|
||||
$ python3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) l
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 -> print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
```
|
||||
|
||||
+ u(p)/d(own) : 向上或向下导航调用堆栈。
|
||||
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) up
|
||||
> /tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
(Pdb) down
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
#### 单步执行程序
|
||||
|
||||
pdb提供以下命令来执行和单步执行代码:
|
||||
|
||||
+ n(ext): 继续执行,直到达到当前函数中的下一行,否则返回
|
||||
+ s(tep): 执行当前行并在第一个可能的场合停止(在被调用的函数或当前函数中)
|
||||
+ c(ontinue): 继续执行,仅在断点处停止。
|
||||
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) n
|
||||
10
|
||||
> /tmp/test_pdb.py(11)countdown()
|
||||
-> sleep(1)
|
||||
(Pdb) n
|
||||
> /tmp/test_pdb.py(8)countdown()
|
||||
-> for i in range(number, 0, -1):
|
||||
(Pdb) n
|
||||
> /tmp/test_pdb.py(9)countdown()
|
||||
-> import pdb; pdb.set_trace()
|
||||
(Pdb) s
|
||||
--Call--
|
||||
> /usr/lib64/python3.6/pdb.py(1584)set_trace()
|
||||
-> def set_trace():
|
||||
(Pdb) c
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) c
|
||||
9
|
||||
> /tmp/test_pdb.py(9)countdown()
|
||||
-> import pdb; pdb.set_trace()
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
该示例显示了next和step之间的区别。 实际上,当使用step时,调试器会进入pdb模块源代码,而接下来就会执行set_trace函数。
|
||||
|
||||
#### 检查变量内容
|
||||
|
||||
pdb非常有用的地方是检查执行堆栈中存储的变量的内容。 例如,a(rgs)命令打印当前函数的变量,如下所示:
|
||||
|
||||
```
|
||||
py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) where
|
||||
/tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) args
|
||||
number = 10
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
pdb打印变量的值,在本例中是10。
|
||||
|
||||
可用于打印变量值的另一个命令是p(rint)。
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) list
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 -> print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
(Pdb) print(seconds)
|
||||
10
|
||||
(Pdb) p i
|
||||
10
|
||||
(Pdb) p number - i
|
||||
0
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
如示例中最后的命令所示,print可以在显示结果之前计算表达式。
|
||||
|
||||
[Python文档][2]包含每个pdb命令的参考和示例。 对于开始使用Python调试器人来说,这是一个有用的读物。
|
||||
|
||||
### 增强的调试器
|
||||
|
||||
一些增强的调试器提供了更好的用户体验。 大多数为pdb添加了有用的额外功能,例如语法突出高亮,更好的回溯和自我检查。 流行的增强调试器包括[IPython的ipdb][3]和[pdb ++][4]。
|
||||
|
||||
这些示例显示如何在虚拟环境中安装这两个调试器。 这些示例使用新的虚拟环境,但在调试应用程序的情况下,应使用应用程序的虚拟环境。
|
||||
|
||||
#### 安装IPython的ipdb
|
||||
|
||||
要安装IPython ipdb,请在虚拟环境中使用pip:
|
||||
|
||||
```
|
||||
$ python3 -m venv .test_pdb
|
||||
$ source .test_pdb/bin/activate
|
||||
(test_pdb)$ pip install ipdb
|
||||
```
|
||||
|
||||
要在脚本中调用ipdb,必须使用以下命令。 请注意,该模块称为ipdb而不是pdb:
|
||||
|
||||
```
|
||||
import ipdb; ipdb.set_trace()
|
||||
```
|
||||
|
||||
IPython的ipdb也可以在Fedora包中使用,所以你可以使用Fedora的包管理器dnf来安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-ipdb
|
||||
```
|
||||
|
||||
#### 安装pdb++
|
||||
|
||||
你可以类似地安装pdb++:
|
||||
|
||||
```
|
||||
$ python3 -m venv .test_pdb
|
||||
$ source .test_pdb/bin/activate
|
||||
(test_pdb)$ pip install pdbp
|
||||
```
|
||||
|
||||
pdb++重写了pdb模块,因此你可以使用相同的语法在程序中添加断点:
|
||||
|
||||
```
|
||||
import pdb; pdb.set_trace()
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
学习如何使用Python调试器可以节省你在排查应用程序问题时的时间。 对于了解应用程序或某些库的复杂部分如何工作也是有用的,从而提高Python开发人员的技能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/getting-started-python-debugger/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://fedoramagazine.org/enhance-python-interactive-shell
|
||||
[2]:https://docs.python.org/3/library/pdb.html
|
||||
[3]:https://github.com/gotcha/ipdb
|
||||
[4]:https://github.com/antocuni/pdb
|
||||
@ -1,190 +0,0 @@
|
||||
用以检查 Linux 内存使用的 5 个命令
|
||||
======
|
||||
|
||||

|
||||
Linux 操作系统包含大量工具,所有这些工具都可以帮助你管理系统。从简单的文件和目录工具到非常复杂的安全命令,在 Linux 中没有多少是你做不了的。而且,尽管普通桌面用户可能不需要在命令行熟悉这些工具,但对于 Linux 管理员来说,它们是必需的。为什么?首先,你在某些时候不得不使用没有 GUI 的 Linux 服务器。其次,命令行工具通常比 GUI 替代工具提供更多的功能和灵活性。
|
||||
|
||||
确定内存使用情况是你可能需要的技能,尤其是特定应用程序变为流氓和占用系统内存时。当发生这种情况时,知道有多种工具可以帮助你进行故障排除十分方便的。或者,你可能需要收集有关 Linux 交换分区的信息,或者有关安装的 RAM 的详细信息?对于这些也有相应的命令。让我们深入了解各种 Linux 命令行工具,以帮助你检查系统内存使用情况。这些工具并不是非常难以使用,在本文中,我将向你展示五种不同的方法来解决这个问题。
|
||||
|
||||
我将在 [Ubuntu 18.04 服务器平台][1]上进行演示,但是你应该在你选择的发行版中找到对应的所有命令。更妙的是,你不需要安装任何东西(因为大多数这些工具都包含 Linux 系统中)。
|
||||
|
||||
话虽如此,让我们开始工作吧。
|
||||
|
||||
### top
|
||||
|
||||
我想从最明显的工具开始。top 命令提供正在运行的系统的动态实时视图,它检查每个进程的内存使用情况。这非常重要,因为你可以轻松地对同一命令的多次迭代消耗不同的内存量。虽然你无法在没有外设的服务器上找到它,但是你已经注意到打开 Chrome 使你的系统速度变慢了。发出 top 命令以查看 Chrome 有多个进程在运行(每个选项卡一个 - 图 1)。
|
||||
|
||||
![top][3]
|
||||
|
||||
图1:top 命令中出现多个 Chrome 进程。
|
||||
|
||||
(to 校正者:不知道这句话什么意思,难道是是否允许转载的?)
|
||||
[Used with permission][4]
|
||||
|
||||
Chrome 并不是唯一显示多个进程的应用。你看到图 1 中的 Firefox 了吗?那是 Firefox 的主进程,而 Web Content 进程是其打开的选项卡。在输出的顶部,你将看到系统统计信息。在我的机器上([System76 Leopard Extreme][5]),我总共有 16GB 可用 RAM,其中只有超过 10GB 的 RAM 正在使用中。然后,你可以整理列表,查看每个进程使用的内存百分比。
|
||||
|
||||
top 最好的事情之一就是发现可能已经失控的进程 ID(PID)服务数量。有了这些 PID,你可以对有问题的任务进行故障排除(或 kill)。
|
||||
|
||||
如果你想让 top 显示更友好的内存信息,使用命令 top -o%MEM,这会使 top 按进程所用内存对所有进程进行排序(图 2)。
|
||||
|
||||
|
||||
![top][7]
|
||||
|
||||
图 2:在 top 命令中按使用内存对进程排序
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
top 命令还为你提供有关使用了多少交换空间的实时更新。
|
||||
|
||||
### free
|
||||
|
||||
然而有时候,top 命令可能不会满足你的需求。你可能只需要查看系统的可用和已用内存。对此,Linux 还有 free 命令。free 命令显示:
|
||||
(to 校正者:以下这种可能翻译得不太准确,望纠正)
|
||||
* 可用和已使用的物理内存总量
|
||||
|
||||
* 系统中交换内存的总量
|
||||
|
||||
* 内核使用的缓冲区和缓存
|
||||
|
||||
在终端窗口中,输入 free 命令。它的输出不是实时的,相反,你将获得的是当前空闲和已用内存的即时快照(图 3)。
|
||||
|
||||
![free][9]
|
||||
|
||||
图 3 :free 命令的输出简单明了。
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
当然,你可以通过添加 -m 选项来让 free 显示得更友好一点,就像这样:free -m。这将显示内存的使用情况,以 MB 为单位(图 4)。
|
||||
|
||||
![free][11]
|
||||
|
||||
图 4:free 命令以一种更易于阅读的形式输出。
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
当然,如果你的系统是远程的,你将希望使用 -g 选项(以 GB 为单位),比如 free -g。
|
||||
|
||||
如果你需要内存总量,你可以添加 t 选项,比如:free -mt。这将简单地计算每列中的内存总量(图 5)。
|
||||
|
||||
![total][13]
|
||||
|
||||
图 5:为你提供空闲的内存列。
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
### vmstat
|
||||
|
||||
另一个非常方便的工具是 vmstat。这个特殊的命令是一个报告虚拟内存统计信息的小技巧。vmstat 命令将报告关于:
|
||||
|
||||
* 进程
|
||||
|
||||
* 内存
|
||||
|
||||
* 页
|
||||
|
||||
* 阻塞 IO
|
||||
|
||||
* traps
|
||||
|
||||
* 磁盘
|
||||
|
||||
* CPU
|
||||
|
||||
使用 vmstat 的最佳方法是使用 -s 选项,如 vmstat -s。这将在单列中报告统计信息(这比默认报告更容易阅读)。vmstat 命令将提供比你需要的更多的信息(图 6),但更多的总是更好的(在这种情况下)。
|
||||
|
||||
![vmstat][15]
|
||||
|
||||
图 6:使用 vmstat 命令来检查内存使用情况。
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
### dmidecode
|
||||
|
||||
如果你想找到关于已安装的系统 RAM 的详细信息,该怎么办?为此,你可以使用 dmidecode 命令。这个特殊的工具是 DMI 表解码器,它将系统的 DMI 表内容转储成人类可读的格式。如果你不清楚 DMI 表是什么,那么可以这样说,(to 校正者:这句话可以不加)它是可以用来描述系统的构成(以及系统的演变)。
|
||||
|
||||
要运行 dmidecode 命令,你需要 sudo 权限。因此输入命令 sudo dmidecode -t 17。该命令的输出(图 7)可能很长,因为它显示所有内存类型设备的信息。因此,如果你无法上下滚动,则可能需要将该命令的输出发送到一个文件中,比如:sudo dmidecode -t 17> dmi_infoI,或将其传递给 less 命令,如 sudo dmidecode | less。
|
||||
|
||||
![dmidecode][17]
|
||||
|
||||
图 7:dmidecode 命令的输出。
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
### /proc/meminfo
|
||||
|
||||
你可能会问自己:“这些命令从哪里获取这些信息?”在某些情况下,它们从 /proc/meminfo 文件中获取。你猜猜?你可以使用命令 less /proc/meminfo 直接读取该文件。通过使用 less 命令,你可以在长长的输出中向上和向下滚动,以准确找到你需要的内容(图 8)。
|
||||
|
||||
![/proc/meminfo][19]
|
||||
|
||||
图 8:less /proc/meminfo 命令的输出。
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
关于 /proc/meminfo 你应该知道:这不是一个真实的文件。相反 /pro/meminfo 是一个虚拟文件,包含有关系统的实时动态信息。特别是,你需要检查以下值:
|
||||
|
||||
* 全部内存
|
||||
|
||||
* 空闲内存
|
||||
|
||||
* 可用内存
|
||||
|
||||
* 缓冲区
|
||||
|
||||
* 文件缓存
|
||||
|
||||
* 交换缓存
|
||||
|
||||
* 全部交换区
|
||||
|
||||
* 空闲交换区
|
||||
|
||||
如果你想使用 /proc/meminfo,你可以用连词像 egrep 命令一样使用它:egrep --color'Mem | Cache | Swap'/proc/meminfo。这将生成一个易于阅读的列表,其中包含 Mem, Cache 和 Swap 等所有包含颜色的条目(图 9)。
|
||||
|
||||
![/proc/meminfo][21]
|
||||
|
||||
图 9:让 /proc/meminfo 更容易阅读。
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
### 继续学习
|
||||
|
||||
你要做的第一件事就是阅读每个命令的手册页(例如 man top, man free, man vmstat, man dmidecode)。从命令的手册页开始,对于如何在 Linux 上使用一个工具,它总是一个很好的学习方法。
|
||||
|
||||
通过 Linux 基金会和 edX 的免费 [“Linux 简介”][22]课程了解有关 Linux 的更多知识。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/5-commands-checking-memory-usage-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.ubuntu.com/download/server
|
||||
[2]:/files/images/memory1jpg
|
||||
[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_1.jpg?itok=fhhhUL_l (top)
|
||||
[4]:/licenses/category/used-permission
|
||||
[5]:https://system76.com/desktops/leopard
|
||||
[6]:/files/images/memory2jpg
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_2.jpg?itok=zuVkQfvv (top)
|
||||
[8]:/files/images/memory3jpg
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_3.jpg?itok=rvuQp3t0 (free)
|
||||
[10]:/files/images/memory4jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_4.jpg?itok=K_luLLPt (free)
|
||||
[12]:/files/images/memory5jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_5.jpg?itok=q50atcsX (total)
|
||||
[14]:/files/images/memory6jpg
|
||||
[15]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_6.jpg?itok=bwFnUVmy (vmstat)
|
||||
[16]:/files/images/memory7jpg
|
||||
[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_7.jpg?itok=UNHIT_P6 (dmidecode)
|
||||
[18]:/files/images/memory8jpg
|
||||
[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_8.jpg?itok=t87jvmJJ (/proc/meminfo)
|
||||
[20]:/files/images/memory9jpg
|
||||
[21]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_9.jpg?itok=t-iSMEKq (/proc/meminfo)
|
||||
[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,216 @@
|
||||
用 NodeJS 进行 Twitter 情感分析
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
如果你想知道大家对某件事情的看法,Twitter 是最好的地方了。Twitter 是观点持续不断的涌现出来的地方,每秒钟大概有 6000 条新 Twitter 发送出来。因特网上的发展很快,如果你想与时俱进或者跟上潮流,Twitter 就是你要去的地方。
|
||||
|
||||
现在,我们生活在一个数据为王的时代,很多公司都善于运用 Twitter 上的数据。根据测量到的他们新产品的人气,尝试预测之后的市场趋势,分析 Twitter 上的数据有很多用处。通过数据,商人把产品卖给合适的用户,收集关于他们品牌和改进的反馈,或者获取他们产品或促销活动失败的原因。不仅仅是商人,很多政治和经济上的决定是在观察人们意见的基础上所作的。今天,我会试着让你感受下关于 Twitter 的简单 [情感分析][1],判断这个 Twitter 是正能量,负能量还是中性的。这不会像专业人士所用的那么复杂,但至少,它会让你知道挖掘观念的想法。
|
||||
|
||||
我们将使用 NodeJs,因为 JavaScript 太常用了,而且它还是最容易入门的语言。
|
||||
|
||||
### 前置条件:
|
||||
|
||||
* 安装了 NodeJs 和 NPM
|
||||
|
||||
* 有 NodeJs 和 NPM 包的经验
|
||||
|
||||
* 熟悉命令行。
|
||||
|
||||
好了,就是这样。开始吧
|
||||
|
||||
### 开始
|
||||
|
||||
为了你的项目新建一个目录,进入这个目录下面。打开终端(或是命令行)。进入刚创建的目录下面,运行命令 `npm init -y`。这会在这个目录下创建一个 `package.json` 文件。现在我们可以安装需要的 npm 包了。只需要创建一个新文件,命名为 `index.js` 然后我们就完成了初始的编码。
|
||||
|
||||
### 获取 tweets
|
||||
|
||||
好了,我们想要分析 Twitter ,为了实现这个目的,我们需要获取 Twitter 的标题。为此,我们要用到 [twit][2] 包。因此,先用 `npm i wit` 命令安装它。我们还需要在 APP 上注册账户,用来访问 Twitter 的 API。点击这个 [链接][3],填写所有项目,从 “Keys and Access Token” 标签页中复制 “Consumer Key”,“Consumer Secret”,“Access token” 和 “Access Token Secret” 这几项到 `.env` 文件中,就像这样:
|
||||
|
||||
```
|
||||
# .env
|
||||
# replace the stars with values you copied
|
||||
CONSUMER_KEY=************
|
||||
CONSUMER_SECRET=************
|
||||
ACCESS_TOKEN=************
|
||||
ACCESS_TOKEN_SECRET=************
|
||||
|
||||
```
|
||||
|
||||
现在开始。
|
||||
|
||||
用你最喜欢的代码编辑器打开 `index.js`。我们需要用 `npm i dotenv` 命令安装 `dotenv` 包来读取 `.env` 文件。好了,创建一个 API 实例。
|
||||
|
||||
```
|
||||
const Twit = require('twit');
|
||||
const dotenv = require('dotenv');
|
||||
|
||||
dotenv.config();
|
||||
|
||||
const { CONSUMER_KEY
|
||||
, CONSUMER_SECRET
|
||||
, ACCESS_TOKEN
|
||||
, ACCESS_TOKEN_SECRET
|
||||
} = process.env;
|
||||
|
||||
const config_twitter = {
|
||||
consumer_key: CONSUMER_KEY,
|
||||
consumer_secret: CONSUMER_SECRET,
|
||||
access_token: ACCESS_TOKEN,
|
||||
access_token_secret: ACCESS_TOKEN_SECRET,
|
||||
timeout_ms: 60*1000
|
||||
};
|
||||
|
||||
let api = new Twit(config_twitter);
|
||||
|
||||
```
|
||||
|
||||
这里已经用所需的配置文件建立了到 Twitter 上的连接。但我们什么事情都没做。先定义个获取 Twitter 的函数:
|
||||
|
||||
```
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, tweet_mode: 'extended'});
|
||||
return tweets.data.statuses.map(tweet => tweet.full_text);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这是个 async 函数,因为 `api.get` 函数返回一个 promise 对象,而不是 `then` 链,我想通过这种简单的方式获取推文。它接收两个参数 -q 和 count,`q` 是查询或者我们想要搜索的关键字,`count` 是让这个 `api` 返回的 Twitter 数量。
|
||||
|
||||
目前为止我们拥有了一个从 Twitter 上获取完整文本的简单方法,我们要获取的文本中可能包含某些连接或者原推文可能已经被删除了。所以我们会编写另一个函数,获取并返回即便是转发的 Twitter 的文本,,并且删除其中存在的链接。
|
||||
|
||||
```
|
||||
function get_text(tweet) {
|
||||
let txt = tweet.retweeted_status ? tweet.retweeted_status.full_text : tweet.full_text;
|
||||
return txt.split(/ |\n/).filter(v => !v.startsWith('http')).join(' ');
|
||||
}
|
||||
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, 'tweet_mode': 'extended'});
|
||||
return tweets.data.statuses.map(get_text);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
现在我们拿到了文本。下一步是从文本中获取情感。为此我们会使用 `npm` 中的另一个包 —— [`sentiment`][4]。让我们像安装其他包那样安装 `sentiment`,添加到脚本中。
|
||||
|
||||
```
|
||||
const sentiment = require('sentiment')
|
||||
|
||||
```
|
||||
|
||||
`sentiment` 用起来很简单。我们只用把 `sentiment` 函数用在我们想要分析的文本上,它就能返回文本的相对分数。如果分数小于 0,它表达的就是消极情感,大于 0 的分数是积极情感,而 0,如你所料,表示中性的情感。基于此,我们将会把 tweets 打印成不同的颜色 —— 绿色表示积极,红色表示消极,蓝色表示中性。为此,我们会用到 [`colors`][5] 包。先安装这个包,然后添加到脚本中。
|
||||
|
||||
```
|
||||
const colors = require('colors/safe');
|
||||
|
||||
```
|
||||
|
||||
好了,现在把所有东西都整合到 `main` 函数中。
|
||||
|
||||
```
|
||||
async function main() {
|
||||
let keyword = \* define the keyword that you want to search for *\;
|
||||
let count = \* define the count of tweets you want *\;
|
||||
let tweets = await get_tweets(keyword, count);
|
||||
for (tweet of tweets) {
|
||||
let score = sentiment(tweet).comparative;
|
||||
tweet = `${tweet}\n`;
|
||||
if (score > 0) {
|
||||
tweet = colors.green(tweet);
|
||||
} else if (score < 0) {
|
||||
tweet = colors.red(tweet);
|
||||
} else {
|
||||
tweet = colors.blue(tweet);
|
||||
}
|
||||
console.log(tweet);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
最后,执行 `main` 函数。
|
||||
|
||||
```
|
||||
main();
|
||||
|
||||
```
|
||||
|
||||
就是这样,一个简单的分析 tweet 中的基本情感的脚本。
|
||||
|
||||
```
|
||||
\\ full script
|
||||
const Twit = require('twit');
|
||||
const dotenv = require('dotenv');
|
||||
const sentiment = require('sentiment');
|
||||
const colors = require('colors/safe');
|
||||
|
||||
dotenv.config();
|
||||
|
||||
const { CONSUMER_KEY
|
||||
, CONSUMER_SECRET
|
||||
, ACCESS_TOKEN
|
||||
, ACCESS_TOKEN_SECRET
|
||||
} = process.env;
|
||||
|
||||
const config_twitter = {
|
||||
consumer_key: CONSUMER_KEY,
|
||||
consumer_secret: CONSUMER_SECRET,
|
||||
access_token: ACCESS_TOKEN,
|
||||
access_token_secret: ACCESS_TOKEN_SECRET,
|
||||
timeout_ms: 60*1000
|
||||
};
|
||||
|
||||
let api = new Twit(config_twitter);
|
||||
|
||||
function get_text(tweet) {
|
||||
let txt = tweet.retweeted_status ? tweet.retweeted_status.full_text : tweet.full_text;
|
||||
return txt.split(/ |\n/).filter(v => !v.startsWith('http')).join(' ');
|
||||
}
|
||||
|
||||
async function get_tweets(q, count) {
|
||||
let tweets = await api.get('search/tweets', {q, count, 'tweet_mode': 'extended'});
|
||||
return tweets.data.statuses.map(get_text);
|
||||
}
|
||||
|
||||
async function main() {
|
||||
let keyword = 'avengers';
|
||||
let count = 100;
|
||||
let tweets = await get_tweets(keyword, count);
|
||||
for (tweet of tweets) {
|
||||
let score = sentiment(tweet).comparative;
|
||||
tweet = `${tweet}\n`;
|
||||
if (score > 0) {
|
||||
tweet = colors.green(tweet);
|
||||
} else if (score < 0) {
|
||||
tweet = colors.red(tweet);
|
||||
} else {
|
||||
tweet = colors.blue(tweet)
|
||||
}
|
||||
console.log(tweet)
|
||||
}
|
||||
}
|
||||
|
||||
main();
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://boostlog.io/@anshulc95/twitter-sentiment-analysis-using-nodejs-5ad1331247018500491f3b6a
|
||||
|
||||
作者:[Anshul Chauhan][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://boostlog.io/@anshulc95
|
||||
[1]:https://en.wikipedia.org/wiki/Sentiment_analysis
|
||||
[2]:https://github.com/ttezel/twit
|
||||
[3]:https://boostlog.io/@anshulc95/apps.twitter.com
|
||||
[4]:https://www.npmjs.com/package/sentiment
|
||||
[5]:https://www.npmjs.com/package/colors
|
||||
[6]:https://boostlog.io/tags/nodejs
|
||||
[7]:https://boostlog.io/tags/twitter
|
||||
[8]:https://boostlog.io/@anshulc95
|
||||
@ -0,0 +1,199 @@
|
||||
不要安装 Yaourt!在 Arch 上使用以下这些替代品。
|
||||
======
|
||||
**前略:Yaourt 曾是最流行的 AUR 助手,但现已停止开发。在这篇文章中,我们会为 Arch 衍生发行版们列出 Yaourt 最佳的替代品。**
|
||||
|
||||
[Arch User Repository][1] 或者叫 AUR,是一个为 Arch 用户而生的社区驱动软件仓库。Debian/Ubuntu 用户的对应类比是 PPA。
|
||||
|
||||
AUR 包含了不直接被 [Arch Linux][2] 官方所背书的软件。如果有人想在 Arch 上发布软件或者包,他可以通过 AUR 提供给客户。这让末端用户们可以使用到比默认仓库里更多的软件。
|
||||
|
||||
所以你该如何使用 AUR 呢?简单来说,你需要不同的工具以从 AUR 中安装软件。Arch 的包管理器 [pacman][3] 不直接支持 AUR。那些支持 AUR 的特殊工具我们称之为 [AUR Helpers][4]。
|
||||
|
||||
Yaourt (Yet AnOther User Repository Tool) 曾是一个以便于用户从 AUR 下载软件的, pacman 的再包装。他基本上使用和 pacman 一样的语法。Yaourt 对于 AUR 的搜索,安装,乃至冲突解决和包依赖都有着良好的支持。
|
||||
|
||||
然而,Yaourt 的开发进度近来十分缓慢,甚至在 Arch Wiki 上已经被[列为][5]“停止或有问题”。[许多 Arch 用户认为它不安全][6] 进而开始寻找其他的 AUR 助手。
|
||||
|
||||
![Yaourt 以外的 AUR Helpers][7]
|
||||
|
||||
在这篇文章中,我们会介绍 Yaourt 最佳的替代品以便于你从 AUR 下载安装案件。
|
||||
|
||||
### AUR Helper 最好的选择
|
||||
|
||||
我刻意忽略掉了例如 Trizen 和 Packer 这样的选择,因为他们也被列为“停止或有问题”的了。
|
||||
|
||||
#### 1\. aurman
|
||||
|
||||
[aurman][8] 是最好的 AUR 助手之一,也能胜任 Yaourt 替代品。他对所有 pacman 的操作有着一样的语法。你可以搜索 AUR,解决包依赖,安装前检查 PKGBUILD 的内容等等。
|
||||
|
||||
##### aurman 的特性
|
||||
|
||||
* aurman 支持所有 pacman 操作并且引入了可靠的包依赖解决,冲突判定和分包(split package)支持
|
||||
* 分线程的 sudo 循环会在后来运行所以你每次安装只需要输入一次管理员密码
|
||||
* 提供开发者包支持并且可以区分显性安装和隐性安装的包
|
||||
* 支持搜索AUR
|
||||
* 你可以检视并编辑 PKGBUILD 的内容
|
||||
* 可以用作单独的 [包依赖解决][9]
|
||||
|
||||
|
||||
|
||||
##### 安装 aurman
|
||||
```
|
||||
git clone https://aur.archlinux.org/aurman.git
|
||||
cd aurman
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### 使用 aurman
|
||||
|
||||
用名字搜索:
|
||||
```
|
||||
aurman -Ss <package-name>
|
||||
|
||||
```
|
||||
安装:
|
||||
```
|
||||
aurman -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
#### 2\. yay
|
||||
|
||||
[yay][10] 是我们列表上下一个选项。它使用 Go 语言写成,宗旨是提供 pacman 的界面并且让用户输入最少化,yay 自己几乎没有任何依赖软件。
|
||||
|
||||
##### yay 的特性
|
||||
|
||||
* yay 提供 AUR 表格补全并且从 ABS 或 AUR 下载 PKGBUILD
|
||||
* 支持收窄搜索,并且不需要引用 PKGBUILD 源
|
||||
* yay 的二进制文件除了 pacman 以外别无依赖
|
||||
* 提供先进的包依赖解决以及在编译安装之后移除编译时的依赖
|
||||
* 支持日色彩输出,使用 /etc/pacman.conf 文件配置
|
||||
* yay 可被配置成只支持 AUR 或者 repo 里的软件包
|
||||
|
||||
|
||||
|
||||
##### 安装 yay
|
||||
|
||||
你可以从 git 克隆并编译安装
|
||||
```
|
||||
git clone https://aur.archlinux.org/yay.git
|
||||
cd yay
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### 使用 yay
|
||||
|
||||
搜索:
|
||||
```
|
||||
yay -Ss <package-name>
|
||||
|
||||
```
|
||||
|
||||
安装:
|
||||
```
|
||||
yay -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
#### 3\. pakku
|
||||
|
||||
[Pakku][11] 是另一个还在开发早期的 pacman 再包装,虽然它还处于开放早期,但这部说明它逊于其他任何 AUR 助手。Pakku 能良好地支持搜索和安安装,并且也可以在安装后移除不必要的编译依赖。
|
||||
|
||||
##### pakku 的特性
|
||||
|
||||
* 从 AUR 搜索安装软件
|
||||
* 检视不同 build 之间的文件变化
|
||||
* 从官方仓库编译并事后移除编译依赖
|
||||
* 获取 PKGBUILD 以及 pacman 整合
|
||||
* 类 pacman 的用户界面和选项支持
|
||||
* 支持pacman 配置文件以及无需 PKGBUILD soucing
|
||||
|
||||
|
||||
|
||||
##### 安装 pakku
|
||||
```
|
||||
git clone https://aur.archlinux.org/pakku.git
|
||||
cd pakku
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### 使用 pakku
|
||||
|
||||
搜索:
|
||||
```
|
||||
pakku -Ss spotify
|
||||
|
||||
```
|
||||
|
||||
安装:
|
||||
```
|
||||
pakku -S spotify
|
||||
|
||||
```
|
||||
|
||||
#### 4\. aurutils
|
||||
|
||||
[aurutils][12] 本质上是一堆自动化脚本的集合。他可以搜索 AUR,检查更新,并且解决包依赖。
|
||||
|
||||
##### aurutils 的特性
|
||||
|
||||
* 不同的任务可以有多个仓库
|
||||
* aursync -u 一键同步所有本地代码库
|
||||
* aursearch 搜索提供 pkgbase,long format 和 raw 支持
|
||||
* 能忽略指定包
|
||||
|
||||
|
||||
|
||||
##### 安装 aurutils
|
||||
```
|
||||
git clone https://aur.archlinux.org/aurutils.git
|
||||
cd aurutils
|
||||
makepkg -si
|
||||
|
||||
```
|
||||
|
||||
##### 使用 aurutils
|
||||
|
||||
搜索:
|
||||
```
|
||||
aurutils -Ss <package-name>
|
||||
|
||||
```
|
||||
|
||||
安装:
|
||||
```
|
||||
aurutils -S <package-name>
|
||||
|
||||
```
|
||||
|
||||
所有这些包,在有 Yaourt 或者其他 AUR 助手的情况下都可以直接安装。
|
||||
|
||||
#### 写在最后
|
||||
|
||||
Arch Linux 有着[很多 AUR 助手][4] 可以自动完成 AUR 各方面的日常任务。很多用户依然使用 Yaourt 来完成 AUR 相关任务,每个人都有自己不一样的偏好,欢迎留言告诉我们你在 Arch 里使用什么,又有什么心得?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-aur-helpers/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
[2]:https://www.archlinux.org/
|
||||
[3]:https://wiki.archlinux.org/index.php/pacman
|
||||
[4]:https://wiki.archlinux.org/index.php/AUR_helpers
|
||||
[5]:https://wiki.archlinux.org/index.php/AUR_helpers#Comparison_table
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/4azqyb/whats_so_bad_with_yaourt/
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/no-yaourt-arch-800x450.jpeg
|
||||
[8]:https://github.com/polygamma/aurman
|
||||
[9]:https://github.com/polygamma/aurman/wiki/Using-aurman-as-dependency-solver
|
||||
[10]:https://github.com/Jguer/yay
|
||||
[11]:https://github.com/kitsunyan/pakku
|
||||
[12]:https://github.com/AladW/aurutils
|
||||
@ -1,273 +0,0 @@
|
||||
系统管理员的 SELinux 指南:这个大问题的 42 个答案
|
||||
======
|
||||
|
||||

|
||||
|
||||
> "一个重要而普遍的事实是,事情并不总是你看上去的那样 …"
|
||||
> ―Douglas Adams,银河系漫游指南
|
||||
|
||||
安全、坚固、遵从性、策略 —— 系统管理员启示录的四骑士。除了我们的日常任务之外 —— 监视、备份、实施、调优、更新等等 —— 我们还负责我们的系统安全。甚至是那些第三方提供给我们的禁用了安全增强的系统。这看起来像《碟中碟》中 [Ethan Hunt][1] 的工作一样。
|
||||
|
||||
面对这种窘境,一些系统管理员决定去[服用蓝色小药丸][2],因为他们认为他们永远也不会知道如生命、宇宙、以及其它一些大问题的答案。而我们都知道,它的答案就是这 **[42][3]** 个。
|
||||
|
||||
按《银河系漫游指南》的精神,这里是关于在你的系统上管理和使用 [SELinux][4] 这个大问题的 42 个答案。
|
||||
|
||||
1. SELinux 是一个标签系统,这意味着每个进程都有一个标签。每个文件、目录、以及系统对象都有一个标签。策略规则负责控制标签化进程和标签化对象之间的访问。由内核强制执行这些规则。
|
||||
|
||||
|
||||
2. 两个最重要的概念是:标签化(文件、进程、端口等等)和强制类型(它将基于类型对每个进程进行隔离)。
|
||||
|
||||
|
||||
3. 正确的标签格式是 `user:role:type:level`(可选)。
|
||||
|
||||
|
||||
4. 多级别安全(MLS)的目的是基于它们所使用数据的安全级别,对进程(域)强制实施控制。比如,一个秘密级别的进程是不能读取极机密级别的数据。
|
||||
|
||||
|
||||
5. 多类别安全(MCS)从每个其它类(如虚拟机、OpenShift gears、SELinux 沙盒、容器等等)中强制保护类似的进程。
|
||||
|
||||
|
||||
6. 在引导时内核参数可以改变 SELinux 模式:
|
||||
* `autorelabel=1` → 强制给系统标签化
|
||||
* `selinux=0` → 内核不加载 SELinux 基础设施的任何部分
|
||||
* `enforcing=0` → 引导为 permissive 模式
|
||||
|
||||
|
||||
7. 如果给整个系统标签化:
|
||||
`# touch /.autorelabel #reboot`
|
||||
如果系统标签中有大量的错误,为了能够让 autorelabel 成功,你可以用 permissive 模式引导系统。
|
||||
|
||||
|
||||
8. 检查 SELinux 是否启用:`# getenforce`
|
||||
|
||||
|
||||
9. 临时启用/禁用 SELinux:`# setenforce [1|0]`
|
||||
|
||||
|
||||
10. SELinux 状态工具:`# sestatus`
|
||||
|
||||
|
||||
11. 配置文件:`/etc/selinux/config`
|
||||
|
||||
|
||||
12. SELinux 是如何工作的?这是一个为 Apache Web Server 标签化的示例:
|
||||
* 二进制文件:`/usr/sbin/httpd`→`httpd_exec_t`
|
||||
* 配置文件目录:`/etc/httpd`→`httpd_config_t`
|
||||
* 日志文件目录:`/var/log/httpd` → `httpd_log_t`
|
||||
* 内容目录:`/var/www/html` → `httpd_sys_content_t`
|
||||
* 启动脚本:`/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
|
||||
* 进程:`/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
|
||||
* 端口:`80/tcp, 443/tcp` → `httpd_t, http_port_t`
|
||||
|
||||
|
||||
|
||||
在 `httpd_t` 环境中运行的一个进程可以与具有 `httpd_something_t` 标签的对象交互。
|
||||
|
||||
13. 许多命令都可以接收一个 `-Z` 参数去查看、创建、和修改环境:
|
||||
* `ls -Z`
|
||||
* `id -Z`
|
||||
* `ps -Z`
|
||||
* `netstat -Z`
|
||||
* `cp -Z`
|
||||
* `mkdir -Z`
|
||||
|
||||
|
||||
|
||||
当文件基于它们的父级目录的环境(有一些例外)创建后,它的环境就已经被设置。RPM 包可以在安装时设置环境。
|
||||
|
||||
14. 这里有导致 SELinux 出错的四个关键原因,它们将在下面的 15 - 21 号问题中展开描述:
|
||||
* 标签化问题
|
||||
* SELinux 需要知道一些东西
|
||||
* 在一个 SELinux 策略/app 中有 bug
|
||||
* 你的信息可能被损坏
|
||||
|
||||
|
||||
15. 标签化问题:如果在 `/srv/myweb` 中你的文件没有正确的标签,访问可能会被拒绝。这里有一些修复这类问题的方法:
|
||||
* 如果你知道标签:
|
||||
`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
|
||||
* 如果你知道使用等价标签的文件:
|
||||
`# semanage fcontext -a -e /srv/myweb /var/www`
|
||||
* 恢复环境(对于以上两种情况):
|
||||
`# restorecon -vR /srv/myweb`
|
||||
|
||||
|
||||
16. 标签化问题:如果你是移动了一个文件,而不是去复制它,那么这个文件将保持原始的环境。修复这类问题:
|
||||
* 用标签改变环境的命令:
|
||||
`# chcon -t httpd_system_content_t /var/www/html/index.html`
|
||||
|
||||
* 用引用标签改变环境的命令:
|
||||
`# chcon --reference /var/www/html/ /var/www/html/index.html`
|
||||
|
||||
* 恢复环境(对于以上两种情况):
|
||||
|
||||
`# restorecon -vR /var/www/html/`
|
||||
|
||||
|
||||
17. 如果 SELinux 需要知道 HTTPD 是在 8585 端口上监听,告诉 SELinux:
|
||||
`# semanage port -a -t http_port_t -p tcp 8585`
|
||||
|
||||
|
||||
18. SELinux 需要知道是否允许在运行时无需重写 SELinux 策略而改变 SELinux 策略部分的布尔值。例如,如果希望 httpd 去发送邮件,输入:`# setsebool -P httpd_can_sendmail 1`
|
||||
|
||||
|
||||
19. SELinux 需要知道 SELinux 设置的 off/on 的布尔值:
|
||||
* 查看所有的布尔值:`# getsebool -a`
|
||||
* 查看每个布尔值的描述:`# semanage boolean -l`
|
||||
* 设置布尔值:`# setsebool [_boolean_] [1|0]`
|
||||
* 将它配置为永久值,添加 `-P` 标志。例如:
|
||||
`# setsebool httpd_enable_ftp_server 1 -P`
|
||||
|
||||
|
||||
20. SELinux 策略/apps 可能有 bug,包括:
|
||||
* 与众不同的代码路径
|
||||
* 配置
|
||||
* 重定向 `stdout`
|
||||
* 文件描述符漏洞
|
||||
* 可运行内存
|
||||
* 错误构建的库打开了一个 ticket(不要提交 Bugzilla 报告;这里没有使用 Bugzilla 的 SLAs)
|
||||
|
||||
|
||||
21. 如果你定义了域,你的信息可能被损坏:
|
||||
* 加载内核模块
|
||||
* 关闭 SELinux 的强制模式
|
||||
* 写入 `etc_t/shadow_t`
|
||||
* 修改 iptables 规则
|
||||
|
||||
|
||||
22. 开发策略模块的 SELinux 工具:
|
||||
`# yum -y install setroubleshoot setroubleshoot-server`
|
||||
安装完成之后重引导机器或重启 `auditd` 服务。
|
||||
|
||||
|
||||
23. 使用 `journalctl` 去列出所有与 `setroubleshoot` 相关的日志:
|
||||
`# journalctl -t setroubleshoot --since=14:20`
|
||||
|
||||
|
||||
24. 使用 `journalctl` 去列出所有与特定 SELinux 标签相关的日志。例如:
|
||||
`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
|
||||
|
||||
|
||||
25. 当 SELinux 发生错误以及建议一些可能的解决方案时,使用 `setroubleshoot` 日志。例如:从 `journalctl` 中:
|
||||
[code] Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
|
||||
|
||||
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
|
||||
|
||||
|
||||
|
||||
***** Plugin restorecon (99.5 confidence) suggests ************************
|
||||
|
||||
|
||||
|
||||
If you want to fix the label,
|
||||
|
||||
/var/www/html/index.html default label should be httpd_syscontent_t.
|
||||
|
||||
Then you can restorecon.
|
||||
|
||||
Do
|
||||
|
||||
# /sbin/restorecon -v /var/www/html/index.html
|
||||
|
||||
|
||||
|
||||
|
||||
26. 日志:SELinux 记录的信息全部在这些地方:
|
||||
* `/var/log/messages`
|
||||
* `/var/log/audit/audit.log`
|
||||
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
|
||||
|
||||
|
||||
27. 日志:在审计日志中查找 SELinux 错误:
|
||||
`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
|
||||
|
||||
|
||||
28. 为特定的服务去搜索 SELinux 的访问向量缓存(AVC)信息:
|
||||
`# ausearch -m avc -c httpd`
|
||||
|
||||
|
||||
29. `audit2allow` 实用工具从拒绝的操作的日志中采集信息,然后生成 SELinux policy-allow 规则。例如:
|
||||
* 产生一个人类可读的关于为什么拒绝访问的描述:`# audit2allow -w -a`
|
||||
* 查看已允许的拒绝访问的强制类型规则:`# audit2allow -a`
|
||||
* 创建一个自定义模块:`# audit2allow -a -M mypolicy`
|
||||
`-M` 选项使用一个指定的名字去创建一个类型强制文件(.te)并编译这个规则到一个策略包(.pp)中:`mypolicy.pp mypolicy.te`
|
||||
* 安装自定义模块:`# semodule -i mypolicy.pp`
|
||||
|
||||
|
||||
30. 配置单个进程(域)运行在 permissive 模式:`# semanage permissive -a httpd_t`
|
||||
|
||||
|
||||
31. 如果不再希望一个域在 permissive 模式中:`# semanage permissive -d httpd_t`
|
||||
|
||||
|
||||
32. 禁用所有的 permissive 域:`# semodule -d permissivedomains`
|
||||
|
||||
|
||||
33. 启用 SELinux MLS 策略:`# yum install selinux-policy-mls`
|
||||
在 `/etc/selinux/config` 中:
|
||||
`SELINUX=permissive`
|
||||
`SELINUXTYPE=mls`
|
||||
确保 SELinux 运行在 permissive 模式:`# setenforce 0`
|
||||
使用 `fixfiles` 脚本去确保那个文件在下次重引导后重打标签:
|
||||
`# fixfiles -F onboot # reboot`
|
||||
|
||||
|
||||
34. 使用一个特定的 MLS 范围创建用户:`# useradd -Z staff_u john`
|
||||
使用 `useradd` 命令,映射新用户到一个已存在的 SELinux 用户(上面例子中是 `staff_u`)。
|
||||
|
||||
|
||||
35. 查看 SELinux 和 Linux 用户之间的映射:`# semanage login -l`
|
||||
|
||||
|
||||
36. 为用户定义一个指定的范围:`# semanage login --modify --range s2:c100 john`
|
||||
|
||||
|
||||
37. 调整用户 home 目录上的标签(如果需要的话):`# chcon -R -l s2:c100 /home/john`
|
||||
|
||||
|
||||
38. 列出当前分类:`# chcat -L`
|
||||
|
||||
|
||||
39. 修改分类或者开始去创建你自己的分类、修改文件:
|
||||
`/etc/selinux/_<selinuxtype>_/setrans.conf`
|
||||
|
||||
|
||||
40. 在指定的文件、角色、和用户环境中运行一个命令或脚本:
|
||||
`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
|
||||
* `-t` 是文件环境
|
||||
* `-r` 是角色环境
|
||||
* `-u` 是用户环境
|
||||
|
||||
|
||||
41. 在容器中禁用 SELinux:
|
||||
* 使用 Podman:`# podman run --security-opt label=disable` …
|
||||
* 使用 Docker:`# docker run --security-opt label=disable` …
|
||||
|
||||
|
||||
42. 如果需要给容器提供完全访问系统的权限:
|
||||
* 使用 Podman:`# podman run --privileged` …
|
||||
* 使用 Docker:`# docker run --privileged` …
|
||||
|
||||
|
||||
|
||||
就这些了,你已经知道了答案。因此请相信我:**不用恐慌,去打开 SELinux 吧**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
|
||||
作者:[Alex Callejas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/darkaxl
|
||||
[1]:https://en.wikipedia.org/wiki/Ethan_Hunt
|
||||
[2]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
|
||||
[3]:https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29
|
||||
[4]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
@ -1,269 +0,0 @@
|
||||
系统管理员的 SELinux 指南: 42 个重大相关问题的答案
|
||||
============================================================
|
||||
|
||||
> 获取有关生活、宇宙和除了有关 SELinux 的重要问题的答案
|
||||
|
||||

|
||||
Image credits : [JanBaby][13], via Pixabay [CC0][14].
|
||||
|
||||
> ”一个重要并且受欢迎的事实是:事情并不总是它们该有的样子“
|
||||
> ―Douglas Adams,_银河系漫游指南_
|
||||
|
||||
安全、加固、规范化、策略是末世中系统管理员的四骑士。除了我们的日常任务--监控、备份、实现、调优、升级以及类似任务--我们还需要对我们系统的安全负责。即使这些系统是第三方提供商告诉我们该禁用增强安全性的系统。这就像 [Ethan Hunt][15] 面临的 _不可能的任务_。
|
||||
|
||||
面对这些困境,有些系统管理员决定 [拿绿色药丸][16],因为他们认为他们将不会知道诸如生活、宇宙和其他事情等重大问题的答案,并且众所周知的是,那个答案是 42.
|
||||
|
||||
受到_银河系漫游指南_启发,下面有 42 个有关在你系统中管理和使用 [SELinux][17] 这个重大问题的答案。
|
||||
|
||||
1. SELinux 是一个标签系统,这意味着每个进程都有一个标签。每个文件、目录和系统事物都有一个标签。策略规则控制着被标记的进程和被标记的事物之间的获取。内核强制执行这些规则。
|
||||
|
||||
1. 最重要的两个概念是: _标签_(文件、进程、端口等)和 _类型强制_(基于不同的类型隔离不同的进程)。
|
||||
|
||||
1. 正确的标签格式是 `user:role:type:level`(_可选_)。
|
||||
|
||||
1. _多层安全(MLS)强制_ 的目的是基于它们索要使用数据的安全级别来控制进程(_区域_)。例如一个秘密级别的进程不能读取绝密级别的数据。
|
||||
|
||||
1. _多目录安全(MCS)强制_ 相互保护相似的进程(例如虚拟机、OpenShift gears、SELinux 沙盒、容器等等)。
|
||||
|
||||
1. 在启动时改变 SELinux 模式的内核参数有:
|
||||
* `autorelabel=1` → 强制系统重新标签
|
||||
|
||||
* `selinux=0` → 内核并不加载 SELinux 设施的任何部分
|
||||
|
||||
* `enforcing=0` → 以许可模式启动
|
||||
|
||||
1. 假如你需要重新标签整个系统:
|
||||
`# touch /.autorelabel
|
||||
#reboot`
|
||||
假如你的标签中包含大量错误,为了让 autorelabel 能够成功,你需要以许可模式启动
|
||||
|
||||
1. 检查 SELinux 是否启用:`# getenforce`
|
||||
|
||||
1. 临时启用或禁用 SELinux:`# setenforce [1|0]`
|
||||
|
||||
1. SELinux 状态工具:`# sestatus`
|
||||
|
||||
1. 配置文件:`/etc/selinux/config`
|
||||
|
||||
1. SELinux 是如何工作的呢?下面是一个标签一个 Apache Web 服务器的例子:
|
||||
* 二进制:`/usr/sbin/httpd`→`httpd_exec_t`
|
||||
|
||||
* 配置目录:`/etc/httpd`→`httpd_config_t`
|
||||
|
||||
* 日志文件目录:`/var/log/httpd` → `httpd_log_t`
|
||||
|
||||
* 内容目录:`/var/www/html` → `httpd_sys_content_t`
|
||||
|
||||
* 启动脚本:`/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
|
||||
|
||||
* 进程:`/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
|
||||
|
||||
* 端口:`80/tcp, 443/tcp` → `httpd_t, http_port_t`
|
||||
|
||||
一个运行在 `httpd_t` 安全上下文的端口可以和被标记为 `httpd_something_t` 标签的事物交互。
|
||||
|
||||
1. 许多命令接收 `-Z` 参数来查看、创建和修改安全上下文:
|
||||
* `ls -Z`
|
||||
|
||||
* `id -Z`
|
||||
|
||||
* `ps -Z`
|
||||
|
||||
* `netstat -Z`
|
||||
|
||||
* `cp -Z`
|
||||
|
||||
* `mkdir -Z`
|
||||
|
||||
当文件被创建时,它们的安全上下文会根据它们父目录的安全上下文来创建(可能有某些例外)。RPM 可以在安装过程中设定安全上下文。
|
||||
|
||||
1. 导致 SELinux 错误的四个关键的因素如下,它们将在 15-21 条深入解释:
|
||||
* 标签问题
|
||||
|
||||
* SELinux 需要知晓更多信息
|
||||
|
||||
* SELinux 策略或者应用有 bug
|
||||
|
||||
* 你的信息可能被损坏了
|
||||
|
||||
1. _标签问题:_ 假如你的位于 `/srv/myweb` 的文件没有被正确地标志,获取这些资源时可能会被拒绝。下面是一些解决方法:
|
||||
* 假如你知道标签:
|
||||
`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
|
||||
|
||||
* 假如你知道和它有相同标签的文件:
|
||||
`# semanage fcontext -a -e /srv/myweb /var/www`
|
||||
|
||||
* 恢复安全上下文(针对上述两种情形):
|
||||
`# restorecon -vR /srv/myweb`
|
||||
|
||||
1. _标识问题:_ 假如你移动了一个文件而不是复制它,这个文件仍然保留原来的安全上下文。为了修复这些问题,你需要:
|
||||
* 使用标签来改变安全上下文:
|
||||
`# chcon -t httpd_system_content_t /var/www/html/index.html`
|
||||
|
||||
* 使用参考文件的标签来改变安全上下文:
|
||||
`# chcon --reference /var/www/html/ /var/www/html/index.html`
|
||||
|
||||
* 恢复安全上下文(针对上述两种情形): `# restorecon -vR /var/www/html/`
|
||||
|
||||
1. 假如_SELinux 需要知道_ HTTPD 在端口 8585 上监听,使用下面的命令告诉它:
|
||||
`# semanage port -a -t http_port_t -p tcp 8585`
|
||||
|
||||
1. _SELinux 需要知道_ 布尔值来允许在运行时改变 SELinux 的策略,而不需要知道任何关于 SELinux 策略读写的信息。例如,假如你想让 httpd 去发送邮件,键入:`# setsebool -P httpd_can_sendmail 1`
|
||||
|
||||
1. _SELinux 需要知道_ 布尔值来做 SELinux 的开关设定:
|
||||
* 查看所有的布尔值:`# getsebool -a`
|
||||
|
||||
* 查看每一个的描述:`# semanage boolean -l`
|
||||
|
||||
* 设定某个布尔值,执行:`# setsebool [_boolean_] [1|0]`
|
||||
|
||||
* 添加 `-P` 参数来作为永久设置,例如:
|
||||
`# setsebool httpd_enable_ftp_server 1 -P`
|
||||
|
||||
1. SELinux 策略或者应用有 bug,包括:
|
||||
* 不寻常的代码路径
|
||||
|
||||
* 配置
|
||||
|
||||
* `stdout` 的重定向
|
||||
|
||||
* 泄露的文件描述符
|
||||
|
||||
* 可执行内存
|
||||
|
||||
* 损坏的已构建的库
|
||||
打开一个工单(但别书写一个 Bugzilla 报告,使用 Bugzilla 没有对应的服务)。
|
||||
|
||||
1. _你的信息可能被损坏了_ 假如你被限制在某个区域,尝试这样做:
|
||||
* 加载内核模块
|
||||
|
||||
* 关闭 SELinux 的强制模式
|
||||
|
||||
* 向 `etc_t/shadow_t` 写入东西
|
||||
|
||||
* 修改 iptables 规则
|
||||
|
||||
1. 下面是安装针对策略模块的发展的 SELinux 工具:
|
||||
`# yum -y install setroubleshoot setroubleshoot-server`
|
||||
在你安装后重启或重启动 `auditd` 服务
|
||||
|
||||
1. 使用 `journalctl` 来监听所有跟 `setroubleshoot` 有关的日志:
|
||||
`# journalctl -t setroubleshoot --since=14:20`
|
||||
|
||||
1. 使用 `journalctl` 来监听所有跟某个特定 SELinux 标签相关的日志,例如:
|
||||
`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
|
||||
|
||||
1. 当 SELinux 错误发生时,使用`setroubleshoot` 的日志,并尝试找到某些可能的解决方法。例如,从 `journalctl`:
|
||||
```
|
||||
Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
|
||||
|
||||
***** Plugin restorecon (99.5 confidence) suggests ************************
|
||||
|
||||
If you want to fix the label,
|
||||
/var/www/html/index.html default label should be httpd_syscontent_t.
|
||||
Then you can restorecon.
|
||||
Do
|
||||
# /sbin/restorecon -v /var/www/html/index.html
|
||||
```
|
||||
|
||||
1. 带有 SELinux 记录的日志:
|
||||
* `/var/log/messages`
|
||||
|
||||
* `/var/log/audit/audit.log`
|
||||
|
||||
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
|
||||
|
||||
1. 在 audit 日志文件中查找有关 SELinux 的错误:
|
||||
`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
|
||||
|
||||
1. 针对某个特定的服务,搜寻 SELinux 的访问向量缓存(Access Vector Cache,,AVC)信息:
|
||||
`# ausearch -m avc -c httpd`
|
||||
|
||||
1. `audit2allow` 程序可以通过从日志中搜集有关被拒绝的操作,然后生成 SELinux 策略允许的规则,例如:
|
||||
* 生成一个为什么会被拒绝访问的对人友好的描述: `# audit2allow -w -a`
|
||||
|
||||
* 查看允许被拒绝的访问的类型强制规则: `# audit2allow -a`
|
||||
|
||||
* 创建一个自定义模块:`# audit2allow -a -M mypolicy`
|
||||
其中的 `-M` 选项将创建一个特定名称的类型强制文件(.te),(.te) 并且将规则编译进一个策略包(.pp)中:`mypolicy.pp mypolicy.te`
|
||||
|
||||
* 安装自定义模块:`# semodule -i mypolicy.pp`
|
||||
|
||||
1. 为了配置一个单独的进程(区域)来更宽松地运行: `# semanage permissive -a httpd_t`
|
||||
|
||||
1. 假如你不在想某个区域是宽松的:`# semanage permissive -d httpd_t`
|
||||
|
||||
1. 禁用所有的宽松区域: `# semodule -d permissivedomains`
|
||||
|
||||
1. 启用 SELinux MLS 策略:`# yum install selinux-policy-mls`
|
||||
在 `/etc/selinux/config` 文件中配置:
|
||||
`SELINUX=permissive`
|
||||
`SELINUXTYPE=mls`
|
||||
确保 SELinux 正运行在宽松模式下:`# setenforce 0`
|
||||
使用 `fixfiles` 脚本来确保在下一次重启时文件将被重新标识:
|
||||
`# fixfiles -F onboot # reboot`
|
||||
|
||||
1. 创建一个带有特定 MLS 范围的用户:`# useradd -Z staff_u john`
|
||||
使用 `useradd` 命令来将新的用户映射到一个现存的 SELinux 用户(在这个例子中,用户为 `staff_u`)。
|
||||
|
||||
1. 查看 SELinux 和 Linux 用户之间的映射:`# semanage login -l`
|
||||
|
||||
1. 为某个用户定义一个特别的范围:`# semanage login --modify --range s2:c100 john`
|
||||
|
||||
1. 更正用户家目录的标志(假如需要的话):`# chcon -R -l s2:c100 /home/john`
|
||||
|
||||
1. 列出当前的类别:`# chcat -L`
|
||||
|
||||
1. 更改类别或者创建你自己类别,修改如下的文件:
|
||||
`/etc/selinux/_<selinuxtype>_/setrans.conf`
|
||||
|
||||
1. 以某个特定的文件、角色和用户安全上下文来运行一个命令或者脚本:
|
||||
`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
|
||||
* `-t` 是 _文件安全上下文_
|
||||
|
||||
* `-r` 是 _角色安全上下文_
|
||||
|
||||
* `-u` 是 _用户安全上下文_
|
||||
|
||||
1. 禁用 SELinux 来运行容器:
|
||||
* 使用 Podman:`# podman run --security-opt label=disable` …
|
||||
|
||||
* 使用 Docker:`# docker run --security-opt label=disable` …
|
||||
|
||||
1. 假如你需要给一个容器对系统的完整访问权限:
|
||||
* 使用 Podman:`# podman run --privileged` …
|
||||
|
||||
* 使用 Docker:`# docker run --privileged` …
|
||||
|
||||
知道了上面的这些,你就已经知道答案了。所以请 **不要惊慌,打开 SELinux**。
|
||||
|
||||
### 作者简介
|
||||
|
||||
Alex Callejas - Alex Callejas 是位于墨西哥城的红帽公司拉丁美洲区的一名技术客服经理。作为一名系统管理员,他已有超过 10 年的经验。在基础设施强化方面具有很强的专业知识。对开源抱有热情,通过在不同的公共事件和大学中分享他的知识来支持社区。天生的极客,当然他一般选择使用 Fedora Linux 发行版。[这里][11]有更多关于我的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
|
||||
作者:[Alex Callejas][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/darkaxl
|
||||
[11]:https://opensource.com/users/darkaxl
|
||||
[13]:https://pixabay.com/en/security-secure-technology-safety-2168234/
|
||||
[14]:https://creativecommons.org/publicdomain/zero/1.0/deed.en
|
||||
[15]:https://en.wikipedia.org/wiki/Ethan_Hunt
|
||||
[16]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
|
||||
[17]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[18]:https://opensource.com/users/darkaxl
|
||||
[19]:https://opensource.com/users/darkaxl
|
||||
[20]:https://opensource.com/article/18/7/sysadmin-guide-selinux#comments
|
||||
[21]:https://opensource.com/tags/security
|
||||
[22]:https://opensource.com/tags/linux
|
||||
[23]:https://opensource.com/tags/sysadmin
|
||||
Loading…
Reference in New Issue
Block a user