mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
Merge pull request #1909 from KayGuoWhu/master
[Translated]20141017 How to check hard disk health on Linux using smartmontools
This commit is contained in:
commit
a77ee26014
@ -1,3 +1,4 @@
|
||||
[translating by KayGuoWhu]
|
||||
Linux TCP/IP networking: net-tools vs. iproute2
|
||||
================================================================================
|
||||
Many sysadmins still manage and troubleshoot various network configurations by using a combination of ifconfig, route, arp and netstat command-line tools, collectively known as net-tools. Originally rooted in the BSD TCP/IP toolkit, the net-tools was developed to configure network functionality of older Linux kernels. Its development in the Linux community so far has ceased since 2001. Some Linux distros such as Arch Linux and CentOS/RHEL 7 have already deprecated net-tools in favor of iproute2.
|
||||
|
||||
@ -1,147 +0,0 @@
|
||||
[translating by KayGuoWhu]
|
||||
How to check hard disk health on Linux using smartmontools
|
||||
================================================================================
|
||||
If there is something that you never want to happen on your Linux system, that is having hard drives die on you without any warning. [Backups][1] and storage technologies such as [RAID][2] can get you back on your feet in no time, but the cost associated with a sudden loss of a hardware device can take a considerable toll on your budget, especially if you haven't planned ahead of time what to do in such circumstances.
|
||||
|
||||
To avoid running into this kind of setbacks, you can try [smartmontools][3] which is a software package that manages and monitors storage hardware by using Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T. or just SMART). Most modern ATA/SATA, SCSI/SAS, and solid-state hard disks nowadays come with the SMART system built-in. The purpose of SMART is to monitor the reliability of the hard drive, to predict drive failures, and to carry out different types of drive self-tests. The smartmontools consists of two utility programs called smartctl and smartd. Together, they will provide advanced warnings of disk degradation and failure on Linux platforms.
|
||||
|
||||
This tutorial will provide installation and configuration guide for smartmontools on Linux.
|
||||
|
||||
### Installing Smartmontools ###
|
||||
|
||||
Installation of smartmontools is straightforward as it available in base repositories of most Linux distros.
|
||||
|
||||
#### Debian and derivatives: ####
|
||||
|
||||
# aptitude install smartmontools
|
||||
|
||||
#### Red Hat-based distributions: ####
|
||||
|
||||
# yum install smartmontools
|
||||
|
||||
### Checking Hard Drive Health with Smartctl ###
|
||||
|
||||
First off, list the hard drives connected to your system with the following command:
|
||||
|
||||
# ls -l /dev | grep -E 'sd|hd'
|
||||
|
||||
The output should be similar to:
|
||||
|
||||
|
||||
|
||||
where sdx indicate device names assigned to the hard drives installed on your machine.
|
||||
|
||||
To display information about a particular hard disk (e.g., device model, S/N, firmware version, size, ATA version/revision, availability and status of SMART capability), run smartctl with "--info" flag, and specify the hard drive's device name as follows.
|
||||
|
||||
In this example, we will choose /dev/sda.
|
||||
|
||||
# smartctl --info /dev/sda
|
||||
|
||||

|
||||
|
||||
Although the ATA version information may seem to go unnoticed at first, it is one of the most important factors when looking for a replacement part. Each ATA version is backward compatible with the previous versions. For example, older ATA-1 or ATA-2 devices work fine on ATA-6 and ATA-7 interfaces, but unfortunately, that is not true for the other way around. In cases where the device version and interface version don't match, they work together at the capabilities of the lesser of the two. That being said, an ATA-7 hard drive is the safest choice for a replacement part in this case.
|
||||
|
||||
You can examine the health status of a particular hard drive with:
|
||||
|
||||
# smartctl -s on -a /dev/sda
|
||||
|
||||
In this command, "-s on" flag enables SMART on the specified device. You can ommit it if SMART support is already enabled for /dev/sda.
|
||||
|
||||
The SMART information for a disk consists of several sections. Among other things, "READ SMART DATA" section shows the overall health status of the drive.
|
||||
|
||||
=== START OF READ SMART DATA SECTION ===
|
||||
SMART overall-health self-assessment rest result: PASSED
|
||||
|
||||
The result of this test can be either PASSED or FAILED. In the latter case, a hardware failure is imminent, so you may want to start backing up your important data from that drive!
|
||||
|
||||
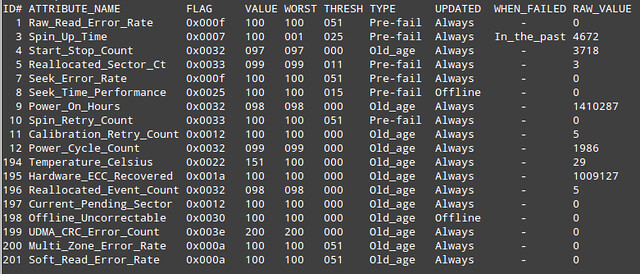
The next thing you will want to look at is the [SMART attribute][4] table, as shown below.
|
||||
|
||||
|
||||
|
||||
Basically, SMART attribute table lists values of a number of attributes defined for a particular drive by its manufacturer, as well as failure threshold for these attributes. This table is automatically populated and updated by drive firmware.
|
||||
|
||||
- **ID#**: attribute ID, usually a decimal (or hex) number between 1 and 255.
|
||||
- **ATTRIBUTE_NAME**: attribute names defined by a drive manufacturer.
|
||||
- **FLAG**: attribute handling flag (we can ignore it).
|
||||
- **VALUE**: this is one of the most important information in the table, indicating a "normalized" value of a given attribute, whose range is between 1 and 253. 253 means the best condition, while 1 means the worse condition. Depending on attributes and manufacturers, an initial VALUE can be set to either 100 or 200.
|
||||
- **WORST**: the lowest VALUE ever recorded.
|
||||
- **THRESH**: the lowest value that WORST should ever be allowed to fall to, before reporting a given hard drive as FAILED.
|
||||
- **TYPE**: the type of attribute (either Pre-fail or Old_age). A Pre-fail attribute is considered a critical attribute; one that participates in the overall SMART health assessment (PASSED/FAILED) of the drive. If any Pre-fail attribute fails, then the drive is considered "about to fail." On the other hand, an Old_age attribute is considered (for SMART purposes) a non-critical attribute (e.g., normal wear and tear); one that does not fail the drive per se.
|
||||
- **UPDATED**: indicates how often an attribute is updated. Offline represents the case when offline tests are being performed on the drive.
|
||||
- **WHEN_FAILED**: this will be set to "FAILING_NOW" (if VALUE is less than or equal to THRESH), or "In_the_past" (if WORST is less than equal to THRESH), or "-" (if none of the above). In case of "FAILING_NOW", back up your important files ASAP, especially if the attribute is of TYPE Pre-fail. "In_the_past" means that the attribute has failed before, but that it's OK at the time of running the test. "-" indicates that this attribute has never failed.
|
||||
- **RAW_VALUE**: a manufacturer-defined raw value, from which VALUE is derived.
|
||||
|
||||
At this point you may be thinking, "Yes, smartctl seems like a nice tool. but I would like to avoid the hassle of having to run it manually." Wouldn't it be nice if it could be run at specified intervals, and at the same time inform me of the testsresults?
|
||||
|
||||
Fortunately, the answer is yes. And that's when smartd comes in.
|
||||
|
||||
### Configuring Smartctl and Smartd for Live Monitoring ###
|
||||
|
||||
First, edit smartctl's configuration file (/etc/default/smartmontools) to tell it to start smartd at system startup, and to specify check intervals in seconds (e.g., 7200 = 2 hours).
|
||||
|
||||
start_smartd=yes
|
||||
smartd_opts="--interval=7200"
|
||||
|
||||
Next, edit smartd's configuration file (/etc/smartd.conf) to add the followign line.
|
||||
|
||||
/dev/sda -m myemail@mydomain.com -M test
|
||||
|
||||
|
||||
- **-m <email-address>**: specifies an email address to send test reports to. This can be a system user such as root, or an email address such as myemail@mydomain.com if the server is configured to relay emails to the outside of your system.
|
||||
- **-M <delivery-type>**: specifies the desired type of delivery for an email report.
|
||||
- **once**: sends only one warning email for each type of disk problem detected.
|
||||
- **daily**: sends additional warning reminder emails, once per day, for each type of disk problem detected.
|
||||
- **diminishing**: sends additional warning reminder emails, after a one-day interval, then a two-day interval, then a four-day interval, and so on for each type of disk problem detected. Each interval is twice as long as the previous interval.
|
||||
- **test**: sends a single test email immediately upon smartd startup.
|
||||
- **exec PATH**: runs the executable PATH instead of the default mail command. PATH must point to an executable binary file or script. This allows to specify a desired action (beep the console, shutdown the system, and so on) when a problem is detected.
|
||||
|
||||
Save the changes and restart smartd.
|
||||
|
||||
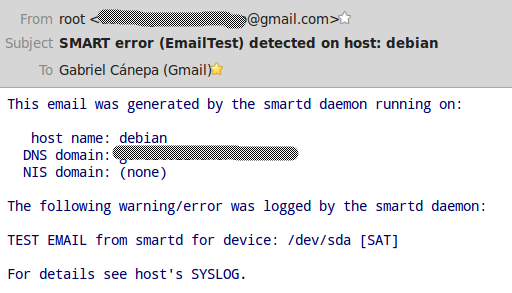
You should expect this kind of email sent by smartd.
|
||||
|
||||
|
||||
|
||||
Luckily for us, no error was detected. Had it not been so, the errors would have appeared below the line "The following warning/error was logged by the smartd daemon."
|
||||
|
||||
Finally, you can schedule tests at your preferred schedule using the "-s" flag and the regular expression in the form of "T/MM/DD/d/HH", where:
|
||||
|
||||
T in the regular expression indicates the kind of test:
|
||||
|
||||
- L: long test
|
||||
- S: short test
|
||||
- C: Conveyance test (ATA only)
|
||||
- O: Offline (ATA only)
|
||||
|
||||
and the remaining characters represent the date and time when the test should be performed:
|
||||
|
||||
- MM is the month of the year.
|
||||
- DD is the day of the month.
|
||||
- HH is the hour of day.
|
||||
- d is the day of the week (ranging from 1=Monday through 7=Sunday).
|
||||
- MM, DD, and HH are expressed with two decimal digits.
|
||||
|
||||
A dot in any of these places indicates all possible values. An expression inside parentheses such as ‘(A|B|C)’ denotes any one of the three possibilities A, B, or C. An expression inside square brackets such as [1-5] denotes a range (1 through 5 inclusive).
|
||||
|
||||
For example, to perform a long test every business day at 1 pm for all disks, add the following line to /etc/smartd.conf. Make sure to restart smartd.
|
||||
|
||||
DEVICESCAN -s (L/../../[1-5]/13)
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Whether you want to quickly check the electrical and mechanical performance of a disk, or perform a longer and more thorough test scans the entire disk surface, do not let yourself get so caught up in your day-to-day responsibilities as to forget to regularly check on the health of your disks. You will thank yourself later!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/check-hard-disk-health-linux-smartmontools.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/how-to-create-secure-incremental-offsite-backup-in-linux.html
|
||||
[2]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[3]:http://www.smartmontools.org/
|
||||
[4]:http://en.wikipedia.org/wiki/S.M.A.R.T.
|
||||
@ -0,0 +1,150 @@
|
||||
在Linux上使用smartmontools查看硬盘的健康状态
|
||||
================================================================================
|
||||
要说Linux用户最不愿意看到的事情,莫过于在毫无警告的情况下发现硬盘崩溃了。诸如[RAID][2]的[备份][1]和存储技术可以在任何时候帮用户恢复数据,但为预防硬件突然崩溃造成数据丢失所花费的代价却是相当可观的,特别是在用户从来没有提前考虑过在这些情况下的应对措施时。
|
||||
|
||||
为了避免遇到这种困境,用户可以试用一款叫做[smartmontools][3]的软件包程序,它通过使用自我监控(Self-Monitoring)、分析(Analysis)和报告(Reporting)三种技术(缩写为S.M.A.R.T或SMART)来管理和监控存储硬件。如今大部分的ATA/SATA、SCSI/SAS和固态硬盘都搭载内置的SMART系统。SMART的目的是监控硬盘的可靠性、预测磁盘故障和执行各种类型的磁盘自检。smartmontools由smartctl和smartd两部分工具程序组成,它们一起为Linux平台提供对磁盘退化和故障的高级警告。
|
||||
|
||||
这篇文章会描述Linux上smartmontools的安装和配置方法。
|
||||
|
||||
### 安装Smartmontools ###
|
||||
|
||||
由于smartmontools在大部分Linux发行版的基本软件库中都可用,所以安装很方便。
|
||||
|
||||
#### Debian和其衍生版:####
|
||||
|
||||
# aptitude install smartmontools
|
||||
|
||||
#### 基于Red Hat的发行版:####
|
||||
|
||||
# yum install smartmontools
|
||||
|
||||
### 使用Smartctl检测硬盘的健康状况 ###
|
||||
|
||||
首先,使用下面的命令列出和系统相连的硬盘:
|
||||
|
||||
# ls -l /dev | grep -E 'sd|hd'
|
||||
|
||||
输出结果和下图类似:
|
||||
|
||||

|
||||
|
||||
其中sdx代表分配给机器上对应硬盘上的设备名。
|
||||
|
||||
如果想要显示出某个指定硬盘的信息(比如设备模式、S/N、固件版本、大小、ATA版本/修订号、SMART功能的可用性和状态),在运行smartctl命令时添加"--info"选项,并按如下所示指定硬盘的设备名。
|
||||
|
||||
在本例中,选择/dev/sda。
|
||||
|
||||
# smartctl --info /dev/sda
|
||||
|
||||

|
||||
|
||||
尽管最开始可能不会注意到ATA(译者注:硬盘接口技术)的版本信息,但当需要替换硬盘时它确实是最重要的因素之一。每一代ATA版本都保持向下兼容。例如,老的ATA-1或ATA-2设备可以正常工作在ATA-6和ATA-7接口上,但反过来就不行了。在设备版本和接口版本两者不匹配的情况下,它们会按照两者中版本较小的规范来运行。也就是说,在这种情况下,需要替换硬盘时,ATA-7硬盘是最安全的选择。
|
||||
|
||||
可以通过这个命令来检测某个硬盘的健康状况:
|
||||
|
||||
# smartctl -s on -a /dev/sda
|
||||
|
||||
在这个命令中,"-s on"标志开启指定设备上的SMART功能。如果/dev/sda上已开启SMART支持,那就省略它。
|
||||
|
||||
硬盘的SMART信息包含很多部分。其中,"READ SMART DATA"部分显示出硬盘的整体健康状况。
|
||||
|
||||
=== START OF READ SMART DATA SECTION ===
|
||||
SMART overall-health self-assessment rest result: PASSED
|
||||
|
||||
这个测试的结果是PASSED或FAILED。后者表示即将出现硬件故障,所以需要开始备份这块磁盘上的重要数据!
|
||||
|
||||
下一个需要关注的地方是[SMART属性][4]表,如下所示。
|
||||
|
||||

|
||||
|
||||
基本上,SMART属性表列出了制造商在硬盘中定义好的属性值,以及这些属性相关的故障阈值。这个表由驱动固件自动生成和更新。
|
||||
|
||||
- **ID**:属性ID,通常是一个1到255之间的十进制或十六进制的数字。
|
||||
- **ATTRIBUTE_NAME**:硬盘制造商定义的属性名。
|
||||
- **FLAG**:属性操作标志(可以忽略)。
|
||||
- **VALUE**:这是表格中最重要的信息之一,代表给定属性的标准化值,在1到253之间。253意味着最好情况,1意味着最坏情况。取决于属性和制造商,初始化VALUE可以被设置成100或200.
|
||||
- **WORST**:所记录的最小VALUE。
|
||||
- **THRESH**:在报告硬盘FAILED状态前,WORST可以允许的最小值。
|
||||
- **TYPE**:属性的类型(Pre-fail或Old_age)。Pre-fail类型的属性可被看成一个关键属性,表示参与磁盘的整体SMART健康评估(PASSED/FAILED)。如果任何Pre-fail类型的属性故障,那么可视为磁盘将要发生故障。另一方面,Old_age类型的属性可被看成一个非关键的属性(如正常的磁盘磨损),表示不会使磁盘本身发生故障。
|
||||
- **UPDATED**:表示属性的更新频率。Offline代表磁盘上执行离线测试的时间。
|
||||
- **WHEN_FAILED**:如果VALUE小于等于THRESH,会被设置成“FAILING_NOW”;如果WORST小于等于THRESH会被设置成“In_the_past”;如果都不是,会被设置成“-”。在“FAILING_NOW”情况下,需要备份重要文件ASAP,特别是属性是Pre-fail类型时。“In_the_past”代表属性已经故障了,但在运行测试的时候没问题。“-”代表这个属性从没故障过。
|
||||
- **RAW_VALUE**:制造商定义的原始值,从VALUE派生。
|
||||
|
||||
这时候你可能会想,“是的,smartctl看起来是个不错的工具,但我更想知道如何避免手动运行的麻烦。”如果能够以指定的间隔运行,同时又能通知我测试结果,那不是更好吗?”
|
||||
|
||||
好消息是,这个功能已经有了。是smartd发挥作用的时候了!
|
||||
|
||||
### 配置Smartctl和Smartd实现实时监控 ###
|
||||
|
||||
首先,编辑smartctl的配置文件(/etc/default/smartmontools)以便在系统启动时启动smartd,并以秒为单位指定间隔时间(如7200 = 2小时)。
|
||||
|
||||
start_smartd=yes
|
||||
smartd_opts="--interval=7200"
|
||||
|
||||
下一步,编辑smartd的配置文件(/etc/smartd.conf),添加以下行内容。
|
||||
|
||||
/dev/sda -m myemail@mydomain.com -M test
|
||||
|
||||
- **-m <email-address>**:指定发送测试报告到某个电子邮件地址。这里可以是系统用户比如root,或者如果服务器已经配置成发送电子邮件到系统外部,则是类似于myemail@mydomain.com的邮件地址。
|
||||
- **-M <delvery-type>**:指定发送邮件报告的期望类型。
|
||||
- **once**:为检测到的每种磁盘问题只发送一封警告邮件。
|
||||
- **daily**:为检测到的每种磁盘问题每隔一天发送一封额外的警告提醒邮件。
|
||||
- **diminishing**:为检测到的每种问题发送一封额外的警告提醒邮件,开始是每隔一天,然后每隔两天,每隔四天,以此类推。每个间隔是前一次间隔的2倍。
|
||||
- **test**:只要smartd一启动,立即发送一封测试邮件。
|
||||
- **exec PATH**:取代默认的邮件命令,运行PATH路径下的可执行文件。PATH必须指向一个可执行的二进制文件或脚本。当检测到一个问题时,可以指定执行一个期望的动作(闪烁控制台、关闭系统等等)。
|
||||
|
||||
保存改动并重启smartd。
|
||||
|
||||
smartd发送的邮件应该是这个样子。
|
||||
|
||||

|
||||
|
||||
在上图中,没有检测到错误。如果实际上检测到了错误,那么错误会出现在“下列警告/错误由smartd守护进程写入日志”这一行的下面。
|
||||
|
||||
最后,可以使用“-s”标志和形如“T/MM/DD/d/HH”的正则表达式按照想要的调度方案执行测试,其中:
|
||||
|
||||
正则表达式中的T代表测试的类型:
|
||||
|
||||
- L:长测试
|
||||
- S:短测试
|
||||
- C:传输测试(仅限ATA)
|
||||
- O:离线测试(仅限ATA)
|
||||
|
||||
其它的字符代表测试执行的日期和时间:
|
||||
|
||||
- MM是一年中的月份。
|
||||
- DD是一月中的天份。
|
||||
- HH是一天中的小时。
|
||||
- d是一个星期中的某天(从1=周一到7=周日)。
|
||||
- MM、DD和HH使用两位十进制数字表示。
|
||||
|
||||
在上述表达中的小圆点表示所有可能的值。形如'(A|B|C)'在圆括号里的表达式表示三个可能值A、B和C中的任意一个。形如[1-5]在方括号中的表达式表示1到5的范围(包含5).
|
||||
|
||||
例如,想要在每个工作日的下午一点为所有的磁盘执行一次长测试,在/etc/smartd.conf中添加如下行内容。确保编辑完重启smartd。
|
||||
|
||||
DEVICESCAN -s (L/../../[1-5]/13)
|
||||
|
||||
### 总结 ###
|
||||
|
||||
无论你想要快速查看磁盘的电子和机械性能,还是对整个磁盘执行一次长时间扫描测试,都不要让自己陷入日复一日地执行命令中而忘记了定期检测磁盘的健康状态。多关注磁盘的健康状况,你会受益的!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/check-hard-disk-health-linux-smartmontools.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/how-to-create-secure-incremental-offsite-backup-in-linux.html
|
||||
[2]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[3]:http://www.smartmontools.org/
|
||||
[4]:http://en.wikipedia.org/wiki/S.M.A.R.T.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user