mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
a730d29640
@ -8,14 +8,13 @@
|
||||
3. CPU 和内存瓶颈
|
||||
4. 网络瓶颈
|
||||
|
||||
|
||||
### 1. top - 进程活动监控命令
|
||||
|
||||
top 命令显示 Linux 的进程。它提供了一个系统的实时动态视图,即实际的进程活动。默认情况下,它显示在服务器上运行的 CPU 占用率最高的任务,并且每五秒更新一次。
|
||||
`top` 命令会显示 Linux 的进程。它提供了一个运行中系统的实时动态视图,即实际的进程活动。默认情况下,它显示在服务器上运行的 CPU 占用率最高的任务,并且每五秒更新一次。
|
||||
|
||||

|
||||
|
||||
图 01:Linux top 命令
|
||||
*图 01:Linux top 命令*
|
||||
|
||||
#### top 的常用快捷键
|
||||
|
||||
@ -23,22 +22,24 @@ top 命令显示 Linux 的进程。它提供了一个系统的实时动态视图
|
||||
|
||||
| 快捷键 | 用法 |
|
||||
| ---- | -------------------------------------- |
|
||||
| t | 是否显示总结信息 |
|
||||
| m | 是否显示内存信息 |
|
||||
| A | 根据各种系统资源的利用率对进程进行排序,有助于快速识别系统中性能不佳的任务。 |
|
||||
| f | 进入 top 的交互式配置屏幕,用于根据特定的需求而设置 top 的显示。 |
|
||||
| o | 交互式地调整 top 每一列的顺序。 |
|
||||
| r | 调整优先级(renice) |
|
||||
| k | 杀掉进程(kill) |
|
||||
| z | 开启或关闭彩色或黑白模式 |
|
||||
| `t` | 是否显示汇总信息 |
|
||||
| `m` | 是否显示内存信息 |
|
||||
| `A` | 根据各种系统资源的利用率对进程进行排序,有助于快速识别系统中性能不佳的任务。 |
|
||||
| `f` | 进入 `top` 的交互式配置屏幕,用于根据特定的需求而设置 `top` 的显示。 |
|
||||
| `o` | 交互式地调整 `top` 每一列的顺序。 |
|
||||
| `r` | 调整优先级(`renice`) |
|
||||
| `k` | 杀掉进程(`kill`) |
|
||||
| `z` | 切换彩色或黑白模式 |
|
||||
|
||||
相关链接:[Linux 如何查看 CPU 利用率?][1]
|
||||
|
||||
### 2. vmstat - 虚拟内存统计
|
||||
|
||||
vmstat 命令报告有关进程、内存、分页、块 IO、陷阱和 cpu 活动等信息。
|
||||
`vmstat` 命令报告有关进程、内存、分页、块 IO、中断和 CPU 活动等信息。
|
||||
|
||||
`# vmstat 3`
|
||||
```
|
||||
# vmstat 3
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -56,11 +57,15 @@ procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
|
||||
|
||||
#### 显示 Slab 缓存的利用率
|
||||
|
||||
`# vmstat -m`
|
||||
```
|
||||
# vmstat -m
|
||||
```
|
||||
|
||||
#### 获取有关活动和非活动内存页面的信息
|
||||
|
||||
`# vmstat -a`
|
||||
```
|
||||
# vmstat -a
|
||||
```
|
||||
|
||||
相关链接:[如何查看 Linux 的资源利用率从而找到系统瓶颈?][2]
|
||||
|
||||
@ -84,9 +89,11 @@ root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
|
||||
|
||||
### 4. uptime - Linux 系统运行了多久
|
||||
|
||||
uptime 命令可以用来查看服务器运行了多长时间:当前时间、已运行的时间、当前登录的用户连接数,以及过去 1 分钟、5 分钟和 15 分钟的系统负载平均值。
|
||||
`uptime` 命令可以用来查看服务器运行了多长时间:当前时间、已运行的时间、当前登录的用户连接数,以及过去 1 分钟、5 分钟和 15 分钟的系统负载平均值。
|
||||
|
||||
`# uptime`
|
||||
```
|
||||
# uptime
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -94,13 +101,15 @@ uptime 命令可以用来查看服务器运行了多长时间:当前时间、
|
||||
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
|
||||
```
|
||||
|
||||
1 可以被认为是最佳负载值。不同的系统会有不同的负载:对于单核 CPU 系统来说,1 到 3 的负载值是可以接受的;而对于 SMP(对称多处理)系统来说,负载可以是 6 到 10。
|
||||
`1` 可以被认为是最佳负载值。不同的系统会有不同的负载:对于单核 CPU 系统来说,`1` 到 `3` 的负载值是可以接受的;而对于 SMP(对称多处理)系统来说,负载可以是 `6` 到 `10`。
|
||||
|
||||
### 5. ps - 显示系统进程
|
||||
|
||||
ps 命令显示当前运行的进程。要显示所有的进程,请使用 -A 或 -e 选项:
|
||||
`ps` 命令显示当前运行的进程。要显示所有的进程,请使用 `-A` 或 `-e` 选项:
|
||||
|
||||
`# ps -A`
|
||||
```
|
||||
# ps -A
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -132,23 +141,31 @@ ps 命令显示当前运行的进程。要显示所有的进程,请使用 -A
|
||||
55704 pts/1 00:00:00 ps
|
||||
```
|
||||
|
||||
ps 与 top 类似,但它提供了更多的信息。
|
||||
`ps` 与 `top` 类似,但它提供了更多的信息。
|
||||
|
||||
#### 显示长输出格式
|
||||
|
||||
`# ps -Al`
|
||||
```
|
||||
# ps -Al
|
||||
```
|
||||
|
||||
显示完整输出格式(它将显示传递给进程的命令行参数):
|
||||
|
||||
`# ps -AlF`
|
||||
```
|
||||
# ps -AlF
|
||||
```
|
||||
|
||||
#### 显示线程(轻量级进程(LWP)和线程的数量(NLWP))
|
||||
|
||||
`# ps -AlFH`
|
||||
```
|
||||
# ps -AlFH
|
||||
```
|
||||
|
||||
#### 在进程后显示线程
|
||||
|
||||
`# ps -AlLm`
|
||||
```
|
||||
# ps -AlLm
|
||||
```
|
||||
|
||||
#### 显示系统上所有的进程
|
||||
|
||||
@ -162,7 +179,7 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
```
|
||||
# ps -ejH
|
||||
# ps axjf
|
||||
# [pstree][4]
|
||||
# pstree
|
||||
```
|
||||
|
||||
#### 显示进程的安全信息
|
||||
@ -192,11 +209,15 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
```
|
||||
# ps -C lighttpd -o pid=
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
# pgrep lighttpd
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
# pgrep -u vivek php-cgi
|
||||
```
|
||||
@ -215,15 +236,19 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
|
||||
#### 找出占用 CPU 资源最多的前 10 个进程
|
||||
|
||||
`# ps -auxf | sort -nr -k 3 | head -10`
|
||||
```
|
||||
# ps -auxf | sort -nr -k 3 | head -10
|
||||
```
|
||||
|
||||
相关链接:[显示 Linux 上所有运行的进程][5]
|
||||
|
||||
### 6. free - 内存使用情况
|
||||
|
||||
free 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。
|
||||
`free` 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。
|
||||
|
||||
`# free `
|
||||
```
|
||||
# free
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -242,9 +267,11 @@ Swap: 1052248 0 1052248
|
||||
|
||||
### 7. iostat - CPU 平均负载和磁盘活动
|
||||
|
||||
iostat 命令用于汇报 CPU 的使用情况,以及设备、分区和网络文件系统(NFS)的 IO 统计信息。
|
||||
`iostat` 命令用于汇报 CPU 的使用情况,以及设备、分区和网络文件系统(NFS)的 IO 统计信息。
|
||||
|
||||
`# iostat `
|
||||
```
|
||||
# iostat
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -265,17 +292,21 @@ sda3 0.00 0.00 0.00 1615 0
|
||||
|
||||
### 8. sar - 监控、收集和汇报系统活动
|
||||
|
||||
sar 命令用于收集、汇报和保存系统活动信息。要查看网络统计,请输入:
|
||||
`sar` 命令用于收集、汇报和保存系统活动信息。要查看网络统计,请输入:
|
||||
|
||||
`# sar -n DEV | more`
|
||||
```
|
||||
# sar -n DEV | more
|
||||
```
|
||||
|
||||
显示 24 日的网络统计:
|
||||
|
||||
`# sar -n DEV -f /var/log/sa/sa24 | more`
|
||||
|
||||
您还可以使用 sar 显示实时使用情况:
|
||||
您还可以使用 `sar` 显示实时使用情况:
|
||||
|
||||
`# sar 4 5`
|
||||
```
|
||||
# sar 4 5
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -295,12 +326,13 @@ Average: all 2.02 0.00 0.27 0.01 0.00 97.70
|
||||
+ [如何将 Linux 系统资源利用率的数据写入文件中][53]
|
||||
+ [如何使用 kSar 创建 sar 性能图以找出系统瓶颈][54]
|
||||
|
||||
|
||||
### 9. mpstat - 监控多处理器的使用情况
|
||||
|
||||
mpstat 命令显示每个可用处理器的使用情况,编号从 0 开始。命令 mpstat -P ALL 显示了每个处理器的平均使用率:
|
||||
`mpstat` 命令显示每个可用处理器的使用情况,编号从 0 开始。命令 `mpstat -P ALL` 显示了每个处理器的平均使用率:
|
||||
|
||||
`# mpstat -P ALL`
|
||||
```
|
||||
# mpstat -P ALL
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -323,13 +355,17 @@ Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
|
||||
|
||||
### 10. pmap - 监控进程的内存使用情况
|
||||
|
||||
pmap 命令用以显示进程的内存映射,使用此命令可以查找内存瓶颈。
|
||||
`pmap` 命令用以显示进程的内存映射,使用此命令可以查找内存瓶颈。
|
||||
|
||||
`# pmap -d PID`
|
||||
```
|
||||
# pmap -d PID
|
||||
```
|
||||
|
||||
显示 PID 为 47394 的进程的内存信息,请输入:
|
||||
|
||||
`# pmap -d 47394`
|
||||
```
|
||||
# pmap -d 47394
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -362,16 +398,15 @@ mapped: 933712K writeable/private: 4304K shared: 768000K
|
||||
|
||||
最后一行非常重要:
|
||||
|
||||
* **mapped: 933712K** 映射到文件的内存量
|
||||
* **writeable/private: 4304K** 私有地址空间
|
||||
* **shared: 768000K** 此进程与其他进程共享的地址空间
|
||||
|
||||
* `mapped: 933712K` 映射到文件的内存量
|
||||
* `writeable/private: 4304K` 私有地址空间
|
||||
* `shared: 768000K` 此进程与其他进程共享的地址空间
|
||||
|
||||
相关链接:[使用 pmap 命令查看 Linux 上单个程序或进程使用的内存][8]
|
||||
|
||||
### 11. netstat - Linux 网络统计监控工具
|
||||
|
||||
netstat 命令显示网络连接、路由表、接口统计、伪装连接和多播连接等信息。
|
||||
`netstat` 命令显示网络连接、路由表、接口统计、伪装连接和多播连接等信息。
|
||||
|
||||
```
|
||||
# netstat -tulpn
|
||||
@ -380,27 +415,32 @@ netstat 命令显示网络连接、路由表、接口统计、伪装连接和多
|
||||
|
||||
### 12. ss - 网络统计
|
||||
|
||||
ss 命令用于获取套接字统计信息。它可以显示类似于 netstat 的信息。不过 netstat 几乎要过时了,ss 命令更具优势。要显示所有 TCP 或 UDP 套接字:
|
||||
`ss` 命令用于获取套接字统计信息。它可以显示类似于 `netstat` 的信息。不过 `netstat` 几乎要过时了,`ss` 命令更具优势。要显示所有 TCP 或 UDP 套接字:
|
||||
|
||||
`# ss -t -a`
|
||||
```
|
||||
# ss -t -a
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
`# ss -u -a `
|
||||
```
|
||||
# ss -u -a
|
||||
```
|
||||
|
||||
显示所有带有 SELinux 安全上下文(Security Context)的 TCP 套接字:
|
||||
显示所有带有 SELinux <ruby>安全上下文<rt>Security Context</rt></ruby>的 TCP 套接字:
|
||||
|
||||
`# ss -t -a -Z `
|
||||
```
|
||||
# ss -t -a -Z
|
||||
```
|
||||
|
||||
请参阅以下关于 ss 和 netstat 命令的资料:
|
||||
请参阅以下关于 `ss` 和 `netstat` 命令的资料:
|
||||
|
||||
+ [ss:显示 Linux TCP / UDP 网络套接字信息][56]
|
||||
+ [使用 netstat 命令获取有关特定 IP 地址连接的详细信息][57]
|
||||
|
||||
|
||||
### 13. iptraf - 获取实时网络统计信息
|
||||
|
||||
iptraf 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可以生成多种网络统计信息,包括 TCP 信息、UDP 计数、ICMP 和 OSPF 信息、以太网负载信息、节点统计信息、IP 校验错误等。它以简单的格式提供了以下信息:
|
||||
`iptraf` 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可以生成多种网络统计信息,包括 TCP 信息、UDP 计数、ICMP 和 OSPF 信息、以太网负载信息、节点统计信息、IP 校验错误等。它以简单的格式提供了以下信息:
|
||||
|
||||
* 基于 TCP 连接的网络流量统计
|
||||
* 基于网络接口的 IP 流量统计
|
||||
@ -410,41 +450,53 @@ iptraf 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可
|
||||
|
||||
![Fig.02: General interface statistics: IP traffic statistics by network interface ][9]
|
||||
|
||||
图 02:常规接口统计:基于网络接口的 IP 流量统计
|
||||
*图 02:常规接口统计:基于网络接口的 IP 流量统计*
|
||||
|
||||
![Fig.03 Network traffic statistics by TCP connection][10]
|
||||
|
||||
图 03:基于 TCP 连接的网络流量统计
|
||||
*图 03:基于 TCP 连接的网络流量统计*
|
||||
|
||||
相关链接:[在 Centos / RHEL / Fedora Linux 上安装 IPTraf 以获取网络统计信息][11]
|
||||
|
||||
### 14. tcpdump - 详细的网络流量分析
|
||||
|
||||
tcpdump 命令是简单的分析网络通信的命令。您需要充分了解 TCP/IP 协议才便于使用此工具。例如,要显示有关 DNS 的流量信息,请输入:
|
||||
`tcpdump` 命令是简单的分析网络通信的命令。您需要充分了解 TCP/IP 协议才便于使用此工具。例如,要显示有关 DNS 的流量信息,请输入:
|
||||
|
||||
`# tcpdump -i eth1 'udp port 53'`
|
||||
```
|
||||
# tcpdump -i eth1 'udp port 53'
|
||||
```
|
||||
|
||||
查看所有去往和来自端口 80 的 IPv4 HTTP 数据包,仅打印真正包含数据的包,而不是像 SYN、FIN 和仅含 ACK 这类的数据包,请输入:
|
||||
|
||||
`# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'`
|
||||
```
|
||||
# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
|
||||
```
|
||||
|
||||
显示所有目标地址为 202.54.1.5 的 FTP 会话,请输入:
|
||||
|
||||
`# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'`
|
||||
```
|
||||
# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'
|
||||
```
|
||||
|
||||
打印所有目标地址为 192.168.1.5 的 HTTP 会话:
|
||||
|
||||
`# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'`
|
||||
```
|
||||
# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'
|
||||
```
|
||||
|
||||
使用 [wireshark][12] 查看文件的详细内容,请输入:
|
||||
|
||||
`# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80`
|
||||
```
|
||||
# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80
|
||||
```
|
||||
|
||||
### 15. iotop - I/O 监控
|
||||
|
||||
iotop 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程的顺序显示 I/O 使用情况。
|
||||
`iotop` 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程的顺序显示 I/O 使用情况。
|
||||
|
||||
`$ sudo iotop`
|
||||
```
|
||||
$ sudo iotop
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -454,9 +506,11 @@ iotop 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程
|
||||
|
||||
### 16. htop - 交互式的进程查看器
|
||||
|
||||
htop 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它比 top 命令更简单易用。您无需使用 PID、无需离开 htop 界面,便可以杀掉进程或调整其调度优先级。
|
||||
`htop` 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它比 `top` 命令更简单易用。您无需使用 PID、无需离开 `htop` 界面,便可以杀掉进程或调整其调度优先级。
|
||||
|
||||
`$ htop`
|
||||
```
|
||||
$ htop
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -464,40 +518,40 @@ htop 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它
|
||||
|
||||
相关链接:[CentOS / RHEL:安装 htop——交互式文本模式进程查看器][58]
|
||||
|
||||
|
||||
### 17. atop - 高级版系统与进程监控工具
|
||||
|
||||
atop 是一个非常强大的交互式 Linux 系统负载监控器,它从性能的角度显示最关键的硬件资源信息。您可以快速查看 CPU、内存、磁盘和网络性能。它还可以从进程的级别显示哪些进程造成了相关 CPU 和内存的负载。
|
||||
`atop` 是一个非常强大的交互式 Linux 系统负载监控器,它从性能的角度显示最关键的硬件资源信息。您可以快速查看 CPU、内存、磁盘和网络性能。它还可以从进程的级别显示哪些进程造成了相关 CPU 和内存的负载。
|
||||
|
||||
`$ atop`
|
||||
```
|
||||
$ atop
|
||||
```
|
||||
|
||||
![atop Command Line Tools to Monitor Linux Performance][16]
|
||||
|
||||
相关链接:[CentOS / RHEL:安装 atop 工具——高级系统和进程监控器][59]
|
||||
|
||||
|
||||
### 18. ac 和 lastcomm
|
||||
|
||||
您一定需要监控 Linux 服务器上的进程和登录活动吧。psacct 或 acct 软件包中包含了多个用于监控进程活动的工具,包括:
|
||||
您一定需要监控 Linux 服务器上的进程和登录活动吧。`psacct` 或 `acct` 软件包中包含了多个用于监控进程活动的工具,包括:
|
||||
|
||||
|
||||
1. ac 命令:显示有关用户连接时间的统计信息
|
||||
1. `ac` 命令:显示有关用户连接时间的统计信息
|
||||
2. [lastcomm 命令][17]:显示已执行过的命令
|
||||
3. accton 命令:打开或关闭进程账号记录功能
|
||||
4. sa 命令:进程账号记录信息的摘要
|
||||
3. `accton` 命令:打开或关闭进程账号记录功能
|
||||
4. `sa` 命令:进程账号记录信息的摘要
|
||||
|
||||
相关链接:[如何对 Linux 系统的活动做详细的跟踪记录][18]
|
||||
|
||||
### 19. monit - 进程监控器
|
||||
|
||||
Monit 是一个免费且开源的进程监控软件,它可以自动重启停掉的服务。您也可以使用 Systemd、daemontools 或其他类似工具来达到同样的目的。[本教程演示如何在 Debian 或 Ubuntu Linux 上安装和配置 monit 作为进程监控器][19]。
|
||||
`monit` 是一个免费且开源的进程监控软件,它可以自动重启停掉的服务。您也可以使用 Systemd、daemontools 或其他类似工具来达到同样的目的。[本教程演示如何在 Debian 或 Ubuntu Linux 上安装和配置 monit 作为进程监控器][19]。
|
||||
|
||||
|
||||
### 20. nethogs - 找出占用带宽的进程
|
||||
### 20. NetHogs - 找出占用带宽的进程
|
||||
|
||||
NetHogs 是一个轻便的网络监控工具,它按照进程名称(如 Firefox、wget 等)对带宽进行分组。如果网络流量突然爆发,启动 NetHogs,您将看到哪个进程(PID)导致了带宽激增。
|
||||
|
||||
`$ sudo nethogs`
|
||||
```
|
||||
$ sudo nethogs
|
||||
```
|
||||
|
||||
![nethogs linux monitoring tools open source][20]
|
||||
|
||||
@ -505,31 +559,37 @@ NetHogs 是一个轻便的网络监控工具,它按照进程名称(如 Firef
|
||||
|
||||
### 21. iftop - 显示主机上网络接口的带宽使用情况
|
||||
|
||||
iftop 命令监听指定接口(如 eth0)上的网络通信情况。[它显示了一对主机的带宽使用情况][22]。
|
||||
`iftop` 命令监听指定接口(如 eth0)上的网络通信情况。[它显示了一对主机的带宽使用情况][22]。
|
||||
|
||||
`$ sudo iftop`
|
||||
```
|
||||
$ sudo iftop
|
||||
```
|
||||
|
||||
![iftop in action][23]
|
||||
|
||||
### 22. vnstat - 基于控制台的网络流量监控工具
|
||||
|
||||
vnstat 是一个简单易用的基于控制台的网络流量监视器,它为指定网络接口保留每小时、每天和每月网络流量日志。
|
||||
`vnstat` 是一个简单易用的基于控制台的网络流量监视器,它为指定网络接口保留每小时、每天和每月网络流量日志。
|
||||
|
||||
`$ vnstat `
|
||||
```
|
||||
$ vnstat
|
||||
```
|
||||
|
||||
![vnstat linux network traffic monitor][25]
|
||||
|
||||
相关链接:
|
||||
|
||||
+ [为 ADSL 或专用远程 Linux 服务器保留日常网络流量日志][60]
|
||||
+ [CentOS / RHEL:安装 vnStat 网络流量监控器以保留日常网络流量日志][61]
|
||||
+ [CentOS / RHEL:使用 PHP 网页前端接口查看 Vnstat 图表][62]
|
||||
|
||||
|
||||
### 23. nmon - Linux 系统管理员的调优和基准测量工具
|
||||
|
||||
nmon 是 Linux 系统管理员用于性能调优的利器,它在命令行显示 CPU、内存、网络、磁盘、文件系统、NFS、消耗资源最多的进程和分区信息。
|
||||
`nmon` 是 Linux 系统管理员用于性能调优的利器,它在命令行显示 CPU、内存、网络、磁盘、文件系统、NFS、消耗资源最多的进程和分区信息。
|
||||
|
||||
`$ nmon`
|
||||
```
|
||||
$ nmon
|
||||
```
|
||||
|
||||
![nmon command][26]
|
||||
|
||||
@ -537,9 +597,11 @@ nmon 是 Linux 系统管理员用于性能调优的利器,它在命令行显
|
||||
|
||||
### 24. glances - 密切关注 Linux 系统
|
||||
|
||||
glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供了大量的信息,还可以用作客户端-服务器架构。
|
||||
`glances` 是一款开源的跨平台监控工具。它在小小的屏幕上提供了大量的信息,还可以工作于客户端-服务器模式下。
|
||||
|
||||
`$ glances`
|
||||
```
|
||||
$ glances
|
||||
```
|
||||
|
||||
![Glances][28]
|
||||
|
||||
@ -547,11 +609,11 @@ glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供
|
||||
|
||||
### 25. strace - 查看系统调用
|
||||
|
||||
想要跟踪 Linux 系统的调用和信号吗?试试 strace 命令吧。它对于调试网页服务器和其他服务器问题很有用。了解如何利用其 [追踪进程][30] 并查看它在做什么。
|
||||
想要跟踪 Linux 系统的调用和信号吗?试试 `strace` 命令吧。它对于调试网页服务器和其他服务器问题很有用。了解如何利用其 [追踪进程][30] 并查看它在做什么。
|
||||
|
||||
### 26. /proc/ 文件系统 - 各种内核信息
|
||||
### 26. /proc 文件系统 - 各种内核信息
|
||||
|
||||
/proc 文件系统提供了不同硬件设备和 Linux 内核的详细信息。更多详细信息,请参阅 [Linux 内核 /proc][31] 文档。常见的 /proc 例子:
|
||||
`/proc` 文件系统提供了不同硬件设备和 Linux 内核的详细信息。更多详细信息,请参阅 [Linux 内核 /proc][31] 文档。常见的 `/proc` 例子:
|
||||
|
||||
```
|
||||
# cat /proc/cpuinfo
|
||||
@ -562,23 +624,23 @@ glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供
|
||||
|
||||
### 27. Nagios - Linux 服务器和网络监控
|
||||
|
||||
[Nagios][32] 是一款普遍使用的开源系统和网络监控软件。您可以轻松地监控所有主机、网络设备和服务,当状态异常和恢复正常时它都会发出警报通知。[FAN][33] 是“全自动 Nagios”的缩写。FAN 的目标是提供包含由 Nagios 社区提供的大多数工具包的 Nagios 安装。FAN 提供了标准 ISO 格式的 CDRom 镜像,使安装变得更加容易。除此之外,为了改善 Nagios 的用户体验,发行版还包含了大量的工具。
|
||||
[Nagios][32] 是一款普遍使用的开源系统和网络监控软件。您可以轻松地监控所有主机、网络设备和服务,当状态异常和恢复正常时它都会发出警报通知。[FAN][33] 是“全自动 Nagios”的缩写。FAN 的目标是提供包含由 Nagios 社区提供的大多数工具包的 Nagios 安装。FAN 提供了标准 ISO 格式的 CD-Rom 镜像,使安装变得更加容易。除此之外,为了改善 Nagios 的用户体验,发行版还包含了大量的工具。
|
||||
|
||||
### 28. Cacti - 基于 Web 的 Linux 监控工具
|
||||
|
||||
Cacti 是一个完整的网络图形化解决方案,旨在充分利用 RRDTool 的数据存储和图形功能。Cacti 提供了快速轮询器、高级图形模板、多种数据采集方法和用户管理功能。这些功能被包装在一个直观易用的界面中,确保可以实现从局域网到拥有数百台设备的复杂网络上的安装。它可以提供有关网络、CPU、内存、登录用户、Apache、DNS 服务器等的数据。了解如何在 CentOS / RHEL 下 [安装和配置 Cacti 网络图形化工具][34]。
|
||||
|
||||
### 29. KDE System Guard - 实时系统报告和图形化显示
|
||||
### 29. KDE 系统监控器 - 实时系统报告和图形化显示
|
||||
|
||||
KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通过 ssh 会话运行。它提供了许多功能,比如监控本地和远程主机的客户端-服务器架构。前端图形界面使用传感器来检索信息。传感器可以返回简单的值或更复杂的信息,如表格。每种类型的信息都有一个或多个显示界面,并被组织成工作表的形式,这些工作表可以分别保存和加载。所以,KSysguard 不仅是一个简单的任务管理器,还是一个控制大型服务器平台的强大工具。
|
||||
KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通过 ssh 会话运行。它提供了许多功能,比如可以监控本地和远程主机的客户端-服务器模式。前端图形界面使用传感器来检索信息。传感器可以返回简单的值或更复杂的信息,如表格。每种类型的信息都有一个或多个显示界面,并被组织成工作表的形式,这些工作表可以分别保存和加载。所以,KSysguard 不仅是一个简单的任务管理器,还是一个控制大型服务器平台的强大工具。
|
||||
|
||||
![Fig.05 KDE System Guard][35]
|
||||
|
||||
图 05:KDE System Guard {图片来源:维基百科}
|
||||
*图 05:KDE System Guard {图片来源:维基百科}*
|
||||
|
||||
详细用法,请参阅 [KSysguard 手册][36]。
|
||||
|
||||
### 30. Gnome 系统监控器
|
||||
### 30. GNOME 系统监控器
|
||||
|
||||
系统监控程序能够显示系统基本信息,并监控系统进程、系统资源使用情况和文件系统。您还可以用其修改系统行为。虽然不如 KDE System Guard 强大,但它提供的基本信息对新用户还是有用的:
|
||||
|
||||
@ -598,7 +660,7 @@ KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通
|
||||
|
||||
![Fig.06 The Gnome System Monitor application][37]
|
||||
|
||||
图 06:Gnome 系统监控程序
|
||||
*图 06:Gnome 系统监控程序*
|
||||
|
||||
### 福利:其他工具
|
||||
|
||||
@ -606,16 +668,15 @@ KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通
|
||||
|
||||
* [nmap][38] - 扫描服务器的开放端口
|
||||
* [lsof][39] - 列出打开的文件和网络连接等
|
||||
* [ntop][40] 网页工具 - ntop 是查看网络使用情况的最佳工具,与 top 命令之于进程的方式类似,即网络流量监控工具。您可以查看网络状态和 UDP、TCP、DNS、HTTP 等协议的流量分发。
|
||||
* [Conky][41] - X Window 系统的另一个很好的监控工具。它具有很高的可配置性,能够监视许多系统变量,包括 CPU 状态、内存、交换空间、磁盘存储、温度、进程、网络接口、电池、系统消息和电子邮件等。
|
||||
* [ntop][40] 基于网页的工具 - `ntop` 是查看网络使用情况的最佳工具,与 `top` 命令之于进程的方式类似,即网络流量监控工具。您可以查看网络状态和 UDP、TCP、DNS、HTTP 等协议的流量分发。
|
||||
* [Conky][41] - X Window 系统下的另一个很好的监控工具。它具有很高的可配置性,能够监视许多系统变量,包括 CPU 状态、内存、交换空间、磁盘存储、温度、进程、网络接口、电池、系统消息和电子邮件等。
|
||||
* [GKrellM][42] - 它可以用来监控 CPU 状态、主内存、硬盘、网络接口、本地和远程邮箱及其他信息。
|
||||
* [mtr][43] - mtr 将 traceroute 和 ping 程序的功能结合在一个网络诊断工具中。
|
||||
* [mtr][43] - `mtr` 将 `traceroute` 和 `ping` 程序的功能结合在一个网络诊断工具中。
|
||||
* [vtop][44] - 图形化活动监控终端
|
||||
|
||||
|
||||
如果您有其他推荐的系统监控工具,欢迎在评论区分享。
|
||||
|
||||
#### 关于作者
|
||||
### 关于作者
|
||||
|
||||
作者 Vivek Gite 是 nixCraft 的创建者,也是经验丰富的系统管理员,以及 Linux 操作系统和 Unix shell 脚本的培训师。他的客户遍布全球,行业涉及 IT、教育、国防航天研究以及非营利部门等。您可以在 [Twitter][45]、[Facebook][46] 和 [Google+][47] 上关注他。
|
||||
|
||||
@ -625,7 +686,7 @@ via: https://www.cyberciti.biz/tips/top-linux-monitoring-tools.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,22 @@
|
||||
Torrent 提速 - 为什么总是无济于事
|
||||
Torrent 提速为什么总是无济于事
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
是不是总是想要 **更快的 torrent 速度**?不管现在的速度有多块,但总是无法对此满足。我们对 torrent 速度的痴迷使我们经常从包括 YouTube 视频在内的许多网站上寻找并应用各种所谓的技巧。但是相信我,从小到大我就没发现哪个技巧有用过。因此本文我们就就来看看,为什么尝试提高 torrent 速度是行不通的。
|
||||
|
||||
## 影响速度的因素
|
||||
### 影响速度的因素
|
||||
|
||||
### 本地因素
|
||||
#### 本地因素
|
||||
|
||||
从下图中可以看到 3 台电脑分别对应的 A,B,C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1,2,3 三个连接点。
|
||||
从下图中可以看到 3 台电脑分别对应的 A、B、C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1、2、3 三个连接点。
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
若用户 A 和用户 B 之间要分享文件,他们之间直接分享就能达到最大速度了而无需使用 torrent。这个速度跟互联网什么的都没有关系。
|
||||
|
||||
+ 网线的性能
|
||||
|
||||
+ 网卡的性能
|
||||
|
||||
+ 路由器的性能
|
||||
|
||||
当谈到 torrent 的时候,人们都是在说一些很复杂的东西,但是却总是不得要点。
|
||||
@ -30,7 +29,7 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
即使你把目标降到 30 Megabytes,然而你连接到路由器的电缆/网线的性能最多只有 100 megabits 也就是 10 MegaBytes。这是一个纯粹的瓶颈问题,由一个薄弱的环节影响到了其他强健部分,也就是说这个传输速率只能达到 10 Megabytes,即电缆的极限速度。现在想象有一个 torrent 即使能够用最大速度进行下载,那也会由于你的硬件不够强大而导致瓶颈。
|
||||
|
||||
### 外部因素
|
||||
#### 外部因素
|
||||
|
||||
现在再来看一下这幅图。用户 C 在很遥远的某个地方。甚至可能在另一个国家。
|
||||
|
||||
@ -40,24 +39,23 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
第二,由于 C 与本地之间多个有连接点,其中一个点就有可能成为瓶颈所在,可能由于繁重的流量和相对薄弱的硬件导致了缓慢的速度。
|
||||
|
||||
### Seeders( 译者注:做种者) 与 Leechers( 译者注:只下载不做种的人)
|
||||
#### 做种者与吸血者
|
||||
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,一个很好的种子提供者但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,有一个很好的种子提供者,但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
|
||||
## 结论
|
||||
### 结论
|
||||
|
||||
我们尝试搞清楚哪些因素影响了 torrent 速度的好坏。不管我们如何用软件进行优化,大多数时候是这是由于物理瓶颈导致的。我从来不关心那些软件,使用默认配置对我来说就够了。
|
||||
|
||||
希望你会喜欢这篇文章,有什么想法敬请留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/increase-torrent-speed-will-never-work
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
如何在 Ubuntu 16.04 上安装和使用 Encryptpad
|
||||
==============
|
||||
|
||||
EncryptPad 是一个自由开源软件,它通过简单方便的图形界面和命令行接口来查看和修改加密的文本,它使用 OpenPGP RFC 4880 文件格式。通过 EncryptPad,你可以很容易的加密或者解密文件。你能够像保存密码、信用卡信息等私人信息,并使用密码或者密钥文件来访问。
|
||||
|
||||
### 特性
|
||||
|
||||
- 支持 windows、Linux 和 Max OS。
|
||||
- 可定制的密码生成器,可生成健壮的密码。
|
||||
- 随机的密钥文件和密码生成器。
|
||||
- 支持 GPG 和 EPD 文件格式。
|
||||
- 能够通过 CURL 自动从远程远程仓库下载密钥。
|
||||
- 密钥文件的路径能够存储在加密的文件中。如果这样做的话,你不需要每次打开文件都指定密钥文件。
|
||||
- 提供只读模式来防止文件被修改。
|
||||
- 可加密二进制文件,例如图片、视频、归档等。
|
||||
|
||||
|
||||
在这份教程中,我们将学习如何在 Ubuntu 16.04 中安装和使用 EncryptPad。
|
||||
|
||||
### 环境要求
|
||||
|
||||
- 在系统上安装了 Ubuntu 16.04 桌面版本。
|
||||
- 在系统上有 `sudo` 的权限的普通用户。
|
||||
|
||||
### 安装 EncryptPad
|
||||
|
||||
在默认情况下,EncryPad 在 Ubuntu 16.04 的默认仓库是不存在的。你需要安装一个额外的仓库。你能够通过下面的命令来添加它 :
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:nilaimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,用下面的命令来更新仓库:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
最后一步,通过下面命令安装 EncryptPad:
|
||||
|
||||
```
|
||||
sudo apt-get install encryptpad encryptcli -y
|
||||
```
|
||||
|
||||
当 EncryptPad 安装完成后,你可以在 Ubuntu 的 Dash 上找到它。
|
||||
|
||||
### 使用 EncryptPad 生成密钥和密码
|
||||
|
||||
现在,在 Ubunntu Dash 上输入 `encryptpad`,你能够在你的屏幕上看到下面的图片 :
|
||||
|
||||
[![Ubuntu DeskTop][1]][2]
|
||||
|
||||
下一步,点击 EncryptPad 的图标。你能够看到 EncryptPad 的界面,它是一个简单的文本编辑器,带有顶部菜单栏。
|
||||
|
||||
[![EncryptPad screen][3]][4]
|
||||
|
||||
首先,你需要生成一个密钥文件和密码用于加密/解密任务。点击顶部菜单栏中的 “Encryption->Generate Key”,你会看见下面的界面:
|
||||
|
||||
[![Generate key][5]][6]
|
||||
|
||||
选择文件保存的路径,点击 “OK” 按钮,你将看到下面的界面:
|
||||
|
||||
[![select path][7]][8]
|
||||
|
||||
输入密钥文件的密码,点击 “OK” 按钮 ,你将看到下面的界面:
|
||||
|
||||
[![last step][9]][10]
|
||||
|
||||
点击 “yes” 按钮来完成该过程。
|
||||
|
||||
### 加密和解密文件
|
||||
|
||||
现在,密钥文件和密码都已经生成了。可以执行加密和解密操作了。在这个文件编辑器中打开一个文件文件,点击 “encryption” 图标 ,你会看见下面的界面:
|
||||
|
||||
[![Encry operation][11]][12]
|
||||
|
||||
提供需要加密的文件和指定输出的文件,提供密码和前面产生的密钥文件。点击 “Start” 按钮来开始加密的进程。当文件被成功的加密,会出现下面的界面:
|
||||
|
||||
[![Success Encrypt][13]][14]
|
||||
|
||||
文件已经被该密码和密钥文件加密了。
|
||||
|
||||
如果你想解密被加密后的文件,打开 EncryptPad ,点击 “File Encryption” ,选择 “Decryption” 操作,提供加密文件的位置和你要保存输出的解密文件的位置,然后提供密钥文件地址,点击 “Start” 按钮,它将要求你输入密码,输入你先前加密使用的密码,点击 “OK” 按钮开始解密过程。当该过程成功完成,你会看到 “File has been decrypted successfully” 的消息 。
|
||||
|
||||
|
||||
[![decrypt ][16]][17]
|
||||
[![][18]][18]
|
||||
[![][13]]
|
||||
|
||||
|
||||
**注意:**
|
||||
|
||||
如果你遗忘了你的密码或者丢失了密钥文件,就没有其他的方法可以打开你的加密信息了。对于 EncrypePad 所支持的格式是没有后门的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-use-encryptpad-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dash.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dash.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dashboard.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-key.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-key.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-use-key-file.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-use-key-file.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-start-encryption.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-start-encryption.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-page.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-page.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
@ -3,68 +3,70 @@
|
||||
|
||||

|
||||
|
||||
当你在 Web 浏览器或任何 GUI 登录中输入密码时,密码会被标记成星号 ******** 或圆形符号 ••••••••••••• 。这是内置的安全机制,以防止你附近的用户看到你的密码。但是当你在终端输入密码来执行任何 **sudo** 或 **su** 的管理任务时,你不会在输入密码的时候看见星号或者圆形符号。它不会有任何输入密码的视觉指示,也不会有任何光标移动,什么也没有。你不知道你是否输入了所有的字符。你只会看到一个空白的屏幕!
|
||||
当你在 Web 浏览器或任何 GUI 登录中输入密码时,密码会被标记成星号 `********` 或圆点符号 `•••••••••••••` 。这是内置的安全机制,以防止你附近的用户看到你的密码。但是当你在终端输入密码来执行任何 `sudo` 或 `su` 的管理任务时,你不会在输入密码的时候看见星号或者圆点符号。它不会有任何输入密码的视觉指示,也不会有任何光标移动,什么也没有。你不知道你是否输入了所有的字符。你只会看到一个空白的屏幕!
|
||||
|
||||
看看下面的截图。
|
||||
|
||||
![][2]
|
||||
|
||||
正如你在上面的图片中看到的,我已经输入了密码,但没有任何指示(星号或圆形符号)。现在,我不确定我是否输入了所有密码。这个安全机制也可以防止你附近的人猜测密码长度。当然,这种行为可以改变。这是本指南要说的。这并不困难。请继续阅读。
|
||||
正如你在上面的图片中看到的,我已经输入了密码,但没有任何指示(星号或圆点符号)。现在,我不确定我是否输入了所有密码。这个安全机制也可以防止你附近的人猜测密码长度。当然,这种行为可以改变。这是本指南要说的。这并不困难。请继续阅读。
|
||||
|
||||
#### 当你在终端输入密码时显示星号
|
||||
|
||||
要在终端输入密码时显示星号,我们需要在 **“/etc/sudoers”** 中做一些小修改。在做任何更改之前,最好备份这个文件。为此,只需运行:
|
||||
要在终端输入密码时显示星号,我们需要在 `/etc/sudoers` 中做一些小修改。在做任何更改之前,最好备份这个文件。为此,只需运行:
|
||||
|
||||
```
|
||||
sudo cp /etc/sudoers{,.bak}
|
||||
```
|
||||
|
||||
上述命令将 /etc/sudoers 备份成名为 /etc/sudoers.bak。你可以恢复它,以防万一在编辑文件后出错。
|
||||
上述命令将 `/etc/sudoers` 备份成名为 `/etc/sudoers.bak`。你可以恢复它,以防万一在编辑文件后出错。
|
||||
|
||||
接下来,使用下面的命令编辑 `/etc/sudoers`:
|
||||
|
||||
接下来,使用下面的命令编辑 **“/etc/sudoers”**:
|
||||
```
|
||||
sudo visudo
|
||||
```
|
||||
|
||||
找到下面这行:
|
||||
|
||||
```
|
||||
Defaults env_reset
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
在该行的末尾添加一个额外的单词 **“,pwfeedback”**,如下所示。
|
||||
在该行的末尾添加一个额外的单词 `,pwfeedback`,如下所示。
|
||||
|
||||
```
|
||||
Defaults env_reset,pwfeedback
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
然后,按下 **“CTRL + x”** 和 **“y”** 保存并关闭文件。重新启动终端以使更改生效。
|
||||
然后,按下 `CTRL + x` 和 `y` 保存并关闭文件。重新启动终端以使更改生效。
|
||||
|
||||
现在,当你在终端输入密码时,你会看到星号。
|
||||
|
||||
![][5]
|
||||
|
||||
如果你对在终端输入密码时看不到密码感到不舒服,那么这个小技巧会有帮助。请注意,当你输入输入密码时其他用户就可以预测你的密码长度。如果你不介意,请按照上述方法进行更改,以使你的密码可见(当然,标记为星号!)。
|
||||
如果你对在终端输入密码时看不到密码感到不舒服,那么这个小技巧会有帮助。请注意,当你输入输入密码时其他用户就可以预测你的密码长度。如果你不介意,请按照上述方法进行更改,以使你的密码可见(当然,显示为星号!)。
|
||||
|
||||
现在就是这样了。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/display-asterisks-type-password-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png
|
||||
@ -3,19 +3,19 @@ Kali Linux 是什么,你需要它吗?
|
||||
|
||||

|
||||
|
||||
如果你听到一个 13 岁的黑客吹嘘它是多么的牛逼,是有可能的,因为有 Kali Linux 的存在。尽管有可能会被称为“脚本小子”,但是事实上,Kali 仍旧是安全专家手头的重要工具(或工具集)。
|
||||
如果你听到一个 13 岁的黑客吹嘘他是多么的牛逼,是有可能的,因为有 Kali Linux 的存在。尽管有可能会被称为“脚本小子”,但是事实上,Kali 仍旧是安全专家手头的重要工具(或工具集)。
|
||||
|
||||
Kali 是一个基于 Debian 的 Linux 发行版。它的目标就是为了简单;在一个实用的工具包里尽可能多的包含渗透和审计工具。Kali 实现了这个目标。大多数做安全测试的开源工具都被囊括在内。
|
||||
Kali 是一个基于 Debian 的 Linux 发行版。它的目标就是为了简单:在一个实用的工具包里尽可能多的包含渗透和审计工具。Kali 实现了这个目标。大多数做安全测试的开源工具都被囊括在内。
|
||||
|
||||
**相关** : [4 个极好的为隐私和案例设计的 Linux 发行版][1]
|
||||
**相关** : [4 个极好的为隐私和安全设计的 Linux 发行版][1]
|
||||
|
||||
### 为什么是 Kali?
|
||||
|
||||
![Kali Linux Desktop][2]
|
||||
|
||||
[Kali][3] 是由 Offensive Security (https://www.offensive-security.com/)公司开发和维护的。它在安全领域是一家知名的、值得信赖的公司,它甚至还有一些受人尊敬的认证,来对安全从业人员做资格认证。
|
||||
[Kali][3] 是由 [Offensive Security](https://www.offensive-security.com/) 公司开发和维护的。它在安全领域是一家知名的、值得信赖的公司,它甚至还有一些受人尊敬的认证,来对安全从业人员做资格认证。
|
||||
|
||||
Kali 也是一个简便的安全解决方案。Kali 并不要求你自己去维护一个 Linux,或者收集你自己的软件和依赖。它是一个“交钥匙工程”。所有这些繁杂的工作都不需要你去考虑,因此,你只需要专注于要审计的真实工作上,而不需要去考虑准备测试系统。
|
||||
Kali 也是一个简便的安全解决方案。Kali 并不要求你自己去维护一个 Linux 系统,或者你自己去收集软件和依赖项。它是一个“交钥匙工程”。所有这些繁杂的工作都不需要你去考虑,因此,你只需要专注于要审计的真实工作上,而不需要去考虑准备测试系统。
|
||||
|
||||
### 如何使用它?
|
||||
|
||||
@ -61,7 +61,7 @@ via: https://www.maketecheasier.com/what-is-kali-linux-and-do-you-need-it/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
yangjiaqiang 翻译中
|
||||
|
||||
How To Set Up PF Firewall on FreeBSD to Protect a Web Server
|
||||
======
|
||||
|
||||
|
||||
@ -1,269 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Mail transfer agent (MTA) basics
|
||||
======
|
||||
|
||||
## Overview
|
||||
|
||||
In this tutorial, learn to:
|
||||
|
||||
* Use the `mail` command.
|
||||
* Create mail aliases.
|
||||
* Configure email forwarding.
|
||||
* Understand common mail transfer agent (MTA) programs such as postfix, sendmail, qmail, and exim.
|
||||
|
||||
|
||||
|
||||
## Controlling where your mail goes
|
||||
|
||||
Email on a Linux system is delivered using MTAs. Your MTA delivers mail to other users on your system and MTAs communicate with each other to deliver mail all over a group of systems or all over the world.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
To get the most from the tutorials in this series, you need a basic knowledge of Linux and a working Linux system on which you can practice the commands covered in this tutorial. You should be familiar with GNU and UNIX commands. Sometimes different versions of a program format output differently, so your results might not always look exactly like the listings shown here.
|
||||
|
||||
In this tutorial, I use Ubuntu 14.04 LTS and sendmail 8.14.4 for the sendmail examples.
|
||||
|
||||
## Mail transfer
|
||||
|
||||
Mail transfer agents such as sendmail deliver mail between users and between systems. Most Internet mail uses the Simple Mail Transfer Protocol (SMTP), but local mail may be transferred through files or sockets among other possibilities. Mail is a store and forward operation, so mail is stored in some kind of file or database until a user collects it or a receiving system or communication link is available. Configuring and securing an MTA is quite a complex task, most of which is beyond the scope of this introductory tutorial.
|
||||
|
||||
## The mail command
|
||||
|
||||
If you use SMTP email, you probably know that there are many, many mail clients that you can use, including `mail`, `mutt`, `alpine`, `notmuch`, and a host of other console and graphical mail clients. The `mail` command is an old standby that can be used to script the sending of mail as well as receive and manage your incoming mail.
|
||||
|
||||
You can use `mail` interactively to send messages by passing a list of addressees, or with no arguments you can use it to look at your incoming mail. Listing 1 shows how to send a message to user steve and user pat on your system with a carbon copy to user bob. When prompted for the cc:user and the subject, enter the body and complete the message by pressing **Ctrl+D** (hold down the Ctrl key and press D).
|
||||
|
||||
##### Listing 1. Using `mail` interactively to send mail
|
||||
```
|
||||
ian@attic4-u14:~$ mail steve,pat
|
||||
Cc: bob
|
||||
Subject: Test message 1
|
||||
This is a test message
|
||||
|
||||
Ian
|
||||
```
|
||||
|
||||
If all is well, your mail is sent. If there is an error, you will see an error message. For example, if you typed an invalid name as a recipient, the mail is not sent. Note that in this example, all users are on your local system and therefore all must be valid users.
|
||||
|
||||
You can also send mail non-interactively using the command line. Listing 2 shows how to send a small message to users steve and pat. This capability is particularly useful in scripts. Different versions of the `mail` command are available in different packages. Some support a `-c` option for cc:, but the version I am using here does not, so I specify only the to: addresses.
|
||||
|
||||
Listing 2. Using `mail` non-interactively
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t steve,pat -s "Test message 2" <<< "Another test.\n\nIan"
|
||||
```
|
||||
|
||||
If you use `mail` with no options you will see a list of your incoming mail as shown in Listing 3. You see that user steve has the two messages I sent above, plus an earlier one from me and a later one from user bob. All the mail is marked as 'N' for new mail.
|
||||
|
||||
Listing 3. Using `mail` for incoming mail
|
||||
```
|
||||
steve@attic4-u14:~$ mail
|
||||
"/var/mail/steve": 4 messages 4 new
|
||||
>N 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
N 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
N 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
The currently selected message is shown with a '>', which is message number 1 in Listing 3. If you press **Enter** , the first page of the next unread message will be displayed. Press the **Space bar** to page through the message. When you finish reading the message and return to the '?' prompt, press **Enter** again to view the next message, and so on. At any '?' prompt you can type 'h' to see the list of message headers again. The ones you have read will now show 'R' in the status as shown in Listing 4.
|
||||
|
||||
Listing 4. Using 'h' to display mail headers
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
Here Steve has read the three messages from Ian but has not read the message from Bob. You can select individual messages by number, and you can also delete messages that you don't want by typing 'd', or '3d' to delete the third message. If you type 'q' you will quit the `mail` command. Messages that you have read will be transferred to the mbox file in your home directory and the unread messages will remain in your inbox, by default in /var/mail/$(id -un). See Listing 5.
|
||||
|
||||
Listing 5. Using 'q' to quit `mail`
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
? q
|
||||
Saved 3 messages in /home/steve/mbox
|
||||
Held 1 message in /var/mail/steve
|
||||
You have mail in /var/mail/steve
|
||||
```
|
||||
|
||||
If you type 'x' to exit instead of 'q' to quit, your mailbox will be left unchanged. Because this is on the /var file system, your system administrator may allow mail to be kept there only for a limited time. To reread or otherwise process mail that has been saved to your local mbox file, use the `-f` option to specify the file you want to read. For example `mail -f mbox`.
|
||||
|
||||
## Mail aliases
|
||||
|
||||
In the previous section you saw how mail can be sent to various users on a system. You can use a fully qualified name, such as ian@myexampledomain.com to send mail to a user on another system.
|
||||
|
||||
Sometimes you might want all the mail for a user to go to some other place. For example, you may have a server farm and want all the root mail to go to a central system administrator. Or you may want to create a mailing list where mail goes to several people. To do this, you use aliases that allow you to define one or more destinations for a given user name. The destinations may be other user mail boxes, files, pipes, or commands that do further processing. You do this by specifying the aliases in /etc/mail/aliases or /etc/aliases. Depending on your system, you may find that one of these is a symbolic link to the other, or you may have only one of them. You need root authority to change the aliases file.
|
||||
|
||||
The general form of an alias is
|
||||
name: addr_1, addr_2, addr_3, ...
|
||||
where the name is a local user name to alias or an alias and the addr_1, addr_2, ... are one or more aliases. Aliases can be a local user, a local file name, another alias, a command, an include file, or an external address.
|
||||
|
||||
So how does sendmail distinguish the aliases (the addr-N values)?
|
||||
|
||||
* A local user name is a text string that matches the name of a user on this system. Technically this means it can be found using the `getpwnam` call .
|
||||
* A local file name is a full path and file name that starts with '/'. It must be writeable by `sendmail`. Messages are appended to the file.
|
||||
* A command starts with the pipe symbol (|). Messages are sent to the command using standard input.
|
||||
* An include file alias starts with :include: and specifies a path and file name. The aliases in file are added to the aliases for this name.
|
||||
* An external address is an email address such as john@somewhere.com.
|
||||
|
||||
|
||||
|
||||
You should find an example file, such as /usr/share/sendmail/examples/db/aliases that was installed with your sendmail package. It contains some recommended aliases for postmaster, MAILER-DAEMON, abuse, and spam. In Listing 6, I have combined entries from the example file on my Ubuntu 14.04 LTS system with some rather artificial examples that illustrate several of the possibilities.
|
||||
|
||||
Listing 6. Somewhat artificial /etc/mail/aliases example
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/mail/aliases
|
||||
# First include some default system aliases from
|
||||
# /usr/share/sendmail/examples/db/aliases
|
||||
|
||||
#
|
||||
# Mail aliases for sendmail
|
||||
#
|
||||
# You must run newaliases(1) after making changes to this file.
|
||||
#
|
||||
|
||||
# Required aliases
|
||||
postmaster: root
|
||||
MAILER-DAEMON: postmaster
|
||||
|
||||
# Common aliases
|
||||
abuse: postmaster
|
||||
spam: postmaster
|
||||
|
||||
# Other aliases
|
||||
|
||||
# Send steve's mail to bob and pat instead
|
||||
steve: bob,pat
|
||||
|
||||
# Send pat's mail to a file in her home directory and also to her inbox.
|
||||
# Finally send it to a command that will make another copy.
|
||||
pat: /home/pat/accumulated-mail,
|
||||
\pat,
|
||||
|/home/pat/makemailcopy.sh
|
||||
|
||||
# Mailing list for system administrators
|
||||
sysadmins: :include: /etc/aliases-sysadmins
|
||||
```
|
||||
|
||||
Note that pat is both an alias and a user of the system. Alias expansion is recursive, so if an alias is also a name, then it will be expanded. Sendmail does not send mail twice to a given user, so if you just put 'pat' as an alias for 'pat', then it would be ignored since sendmail had already found and processed 'pat'. To avoid this problem, you prefix an alias name with a '\' to indicate that it is a name not subject to further aliasing. This way, pat's mail can be sent to her normal inbox as well as the file and command.
|
||||
|
||||
Lines in the aliases that start with '$' are comments and are ignored. Lines that start with blanks are treated as continuation lines.
|
||||
|
||||
The include file /etc/aliases-sysadmins is shown in Listing 7.
|
||||
|
||||
Listing 7. The /etc/aliases-sysadmins include file
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/aliases-sysadmins
|
||||
|
||||
# Mailing list for system administrators
|
||||
bob,pat
|
||||
```
|
||||
|
||||
## The newaliases command
|
||||
|
||||
Most configuration files used by sendmail are compiled into database files. This is also true for mail aliases. You use the `newaliases` command to compile your /etc/mail/aliases and any included files to /etc/mail/aliases.db. Note that `newaliases` is equivalent to `sendmail -bi`. Listing 8 shows an example.
|
||||
|
||||
Listing 8. Rebuild the database for the mail aliases file
|
||||
```
|
||||
ian@attic4-u14:~$ sudo newaliases
|
||||
/etc/mail/aliases: 7 aliases, longest 62 bytes, 184 bytes total
|
||||
ian@attic4-u14:~$ ls -l /etc/mail/aliases*
|
||||
lrwxrwxrwx 1 root smmsp 10 Dec 8 15:48 /etc/mail/aliases -> ../aliases
|
||||
-rw-r----- 1 smmta smmsp 12288 Dec 13 23:18 /etc/mail/aliases.db
|
||||
```
|
||||
|
||||
## Examples of using aliases
|
||||
|
||||
Listing 9 shows a simple shell script that is used as a command in my alias example.
|
||||
|
||||
Listing 9. The makemailcopy.sh script
|
||||
```
|
||||
ian@attic4-u14:~$ cat ~pat/makemailcopy.sh
|
||||
#!/bin/bash
|
||||
|
||||
# Note: Target file ~/mail-copy must be writeable by sendmail!
|
||||
cat >> ~pat/mail-copy
|
||||
```
|
||||
|
||||
Listing 10 shows the files that are updated when you put all this to the test.
|
||||
|
||||
Listing 10. The /etc/aliases-sysadmins include file
|
||||
```
|
||||
ian@attic4-u14:~$ date
|
||||
Wed Dec 13 22:54:22 EST 2017
|
||||
ian@attic4-u14:~$ mail -t sysadmins -s "sysadmin test 1" <<< "Testing mail"
|
||||
ian@attic4-u14:~$ ls -lrt $(find /var/mail ~pat -type f -mmin -3 2>/dev/null )
|
||||
-rw-rw---- 1 pat mail 2046 Dec 13 22:54 /home/pat/mail-copy
|
||||
-rw------- 1 pat mail 13240 Dec 13 22:54 /var/mail/pat
|
||||
-rw-rw---- 1 pat mail 9442 Dec 13 22:54 /home/pat/accumulated-mail
|
||||
-rw-rw---- 1 bob mail 12522 Dec 13 22:54 /var/mail/bob
|
||||
```
|
||||
|
||||
Some points to note:
|
||||
|
||||
* There is a user 'mail' with group name 'mail' that is used by sendmail.
|
||||
* User mail is stored by sendmail in /var/mail which is also the home directory of user 'mail'. The inbox for user 'ian' defaults to /var/mail/ian.
|
||||
* If you want sendmail to write files in a user directory, the file must be writeable by sendmail. Rather than making it world writeable, it is customary to make it group writeable and make the group 'mail'. You may need a system administrator to do this for you.
|
||||
|
||||
|
||||
|
||||
## Using a .forward file to forward mail
|
||||
|
||||
The aliases file must be managed by a system administrator. Individual users can enable forwarding of their own mail using a .forward file in their own home directory. You can put anything in your .forward file that is allowed on the right side of the aliases file. The file contains plain text and does not need to be compiled. When mail is destined for you, sendmail checks for a .forward file in your home directory and processes the entries the same way it processes aliases.
|
||||
|
||||
## Mail queues and the mailq command
|
||||
|
||||
Linux mail handling uses a store-and-forward model. You have already seen that your incoming mail is stored in a file in /var/mail until you read it. Outgoing mail is also stored until a receiving server connection is available. You use the `mailq` command to see what mail is queued. Listing 11 shows an example of mail being sent to an external user, ian@attic4-c6, and the result of running the `mailq` command. In this case, there is currently no active link to attic4-c6, so the mail will remain queued until a link becomes active.
|
||||
|
||||
Listing 11. Using the `mailq` command
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t ian@attic4-c6 -s "External mail" <<< "Testing external mail queues"
|
||||
ian@attic4-u14:~$ mailq
|
||||
MSP Queue status...
|
||||
/var/spool/mqueue-client is empty
|
||||
Total requests: 0
|
||||
MTA Queue status...
|
||||
/var/spool/mqueue (1 request)
|
||||
-----Q-ID----- --Size-- -----Q-Time----- ------------Sender/Recipient-----------
|
||||
vBE4mdE7025908* 29 Wed Dec 13 23:48 <ian@attic4-u14.hopto.org>
|
||||
<ian@attic4-c6.hopto.org>
|
||||
Total requests: 1
|
||||
```
|
||||
|
||||
## Other mail transfer agents
|
||||
|
||||
In response to security issues with sendmail, several other mail transfer agents were developed during the 1990's. Postfix is perhaps the most popular, but qmail and exim are also widely used.
|
||||
|
||||
Postfix started life at IBM research as an alternative to sendmail. It attempts to be fast, easy to administer, and secure. The outside looks somewhat like sendmail, but the inside is completely different.
|
||||
|
||||
Qmail is a secure, reliable, efficient, simple message transfer agent developerd by Dan Bernstein. However, the core qmail package has not been updated for many years. Qmail and several other packages have now been collected into IndiMail.
|
||||
|
||||
Exim is another MTA developed at the University of Cambridge. Originally, the name stood for EXperimental Internet Mailer.
|
||||
|
||||
All of these MTAs were designed as sendmail replacements, so they all have some form of sendmail compatibility. Each can handle aliases and .forward files. Some provide a `sendmail` command as a front end to the particular MTA's own command. Most allow the usual sendmail options, although some options might be ignore silently. The `mailq` command is supported directly or by an alternate command with a similar function. For example, you can use `mailq` or `exim -bp` to display the exim mail queue. Needless to say, output can look different compared to that produced by sendmail's `mailq` command.
|
||||
|
||||
See Related topics where you can find more information on all of these MTAs.
|
||||
|
||||
This concludes your introduction to mail transfer agents on Linux.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-3/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
How To Find (Top-10) Largest Files In Linux
|
||||
======
|
||||
When you are running out of disk space in system, you may prefer to check with df command or du command or ncdu command but all these will tell you only current directory files and doesn't shows the system wide files.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Partclone – A Versatile Free Software for Partition Imaging and Cloning
|
||||
======
|
||||
|
||||
|
||||
@ -1,253 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Analyzing the Linux boot process
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : Penguin, Boot. Modified by Opensource.com. CC BY-SA 4.0.
|
||||
|
||||
The oldest joke in open source software is the statement that "the code is self-documenting." Experience shows that reading the source is akin to listening to the weather forecast: sensible people still go outside and check the sky. What follows are some tips on how to inspect and observe Linux systems at boot by leveraging knowledge of familiar debugging tools. Analyzing the boot processes of systems that are functioning well prepares users and developers to deal with the inevitable failures.
|
||||
|
||||
In some ways, the boot process is surprisingly simple. The kernel starts up single-threaded and synchronous on a single core and seems almost comprehensible to the pitiful human mind. But how does the kernel itself get started? What functions do [initial ramdisk][1] ) and bootloaders perform? And wait, why is the LED on the Ethernet port always on?
|
||||
|
||||
Read on for answers to these and other questions; the [code for the described demos and exercises][2] is also available on GitHub.
|
||||
|
||||
### The beginning of boot: the OFF state
|
||||
|
||||
#### Wake-on-LAN
|
||||
|
||||
The OFF state means that the system has no power, right? The apparent simplicity is deceptive. For example, the Ethernet LED is illuminated because wake-on-LAN (WOL) is enabled on your system. Check whether this is the case by typing:
|
||||
```
|
||||
$# sudo ethtool <interface name>
|
||||
```
|
||||
|
||||
where `<interface name>` might be, for example, `eth0`. (`ethtool` is found in Linux packages of the same name.) If "Wake-on" in the output shows `g`, remote hosts can boot the system by sending a [MagicPacket][3]. If you have no intention of waking up your system remotely and do not wish others to do so, turn WOL off either in the system BIOS menu, or via:
|
||||
```
|
||||
$# sudo ethtool -s <interface name> wol d
|
||||
```
|
||||
|
||||
The processor that responds to the MagicPacket may be part of the network interface or it may be the [Baseboard Management Controller][4] (BMC).
|
||||
|
||||
#### Intel Management Engine, Platform Controller Hub, and Minix
|
||||
|
||||
The BMC is not the only microcontroller (MCU) that may be listening when the system is nominally off. x86_64 systems also include the Intel Management Engine (IME) software suite for remote management of systems. A wide variety of devices, from servers to laptops, includes this technology, [which enables functionality][5] such as KVM Remote Control and Intel Capability Licensing Service. The [IME has unpatched vulnerabilities][6], according to [Intel's own detection tool][7]. The bad news is, it's difficult to disable the IME. Trammell Hudson has created an [me_cleaner project][8] that wipes some of the more egregious IME components, like the embedded web server, but could also brick the system on which it is run.
|
||||
|
||||
The IME firmware and the System Management Mode (SMM) software that follows it at boot are [based on the Minix operating system][9] and run on the separate Platform Controller Hub processor, not the main system CPU. The SMM then launches the Universal Extensible Firmware Interface (UEFI) software, about which much has [already been written][10], on the main processor. The Coreboot group at Google has started a breathtakingly ambitious [Non-Extensible Reduced Firmware][11] (NERF) project that aims to replace not only UEFI but early Linux userspace components such as systemd. While we await the outcome of these new efforts, Linux users may now purchase laptops from Purism, System76, or Dell [with IME disabled][12], plus we can hope for laptops [with ARM 64-bit processors][13].
|
||||
|
||||
#### Bootloaders
|
||||
|
||||
Besides starting buggy spyware, what function does early boot firmware serve? The job of a bootloader is to make available to a newly powered processor the resources it needs to run a general-purpose operating system like Linux. At power-on, there not only is no virtual memory, but no DRAM until its controller is brought up. A bootloader then turns on power supplies and scans buses and interfaces in order to locate the kernel image and the root filesystem. Popular bootloaders like U-Boot and GRUB have support for familiar interfaces like USB, PCI, and NFS, as well as more embedded-specific devices like NOR- and NAND-flash. Bootloaders also interact with hardware security devices like [Trusted Platform Modules][14] (TPMs) to establish a chain of trust from earliest boot.
|
||||
|
||||
![Running the U-boot bootloader][16]
|
||||
|
||||
Running the U-boot bootloader in the sandbox on the build host.
|
||||
|
||||
The open source, widely used [U-Boot ][17]bootloader is supported on systems ranging from Raspberry Pi to Nintendo devices to automotive boards to Chromebooks. There is no syslog, and when things go sideways, often not even any console output. To facilitate debugging, the U-Boot team offers a sandbox in which patches can be tested on the build-host, or even in a nightly Continuous Integration system. Playing with U-Boot's sandbox is relatively simple on a system where common development tools like Git and the GNU Compiler Collection (GCC) are installed:
|
||||
```
|
||||
|
||||
|
||||
$# git clone git://git.denx.de/u-boot; cd u-boot
|
||||
|
||||
$# make ARCH=sandbox defconfig
|
||||
|
||||
$# make; ./u-boot
|
||||
|
||||
=> printenv
|
||||
|
||||
=> help
|
||||
```
|
||||
|
||||
That's it: you're running U-Boot on x86_64 and can test tricky features like [mock storage device][2] repartitioning, TPM-based secret-key manipulation, and hotplug of USB devices. The U-Boot sandbox can even be single-stepped under the GDB debugger. Development using the sandbox is 10x faster than testing by reflashing the bootloader onto a board, and a "bricked" sandbox can be recovered with Ctrl+C.
|
||||
|
||||
### Starting up the kernel
|
||||
|
||||
#### Provisioning a booting kernel
|
||||
|
||||
Upon completion of its tasks, the bootloader will execute a jump to kernel code that it has loaded into main memory and begin execution, passing along any command-line options that the user has specified. What kind of program is the kernel? `file /boot/vmlinuz` indicates that it is a bzImage, meaning a big compressed one. The Linux source tree contains an [extract-vmlinux tool][18] that can be used to uncompress the file:
|
||||
```
|
||||
|
||||
|
||||
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
|
||||
|
||||
$# file vmlinux
|
||||
|
||||
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
|
||||
|
||||
linked, stripped
|
||||
```
|
||||
|
||||
The kernel is an [Executable and Linking Format][19] (ELF) binary, like Linux userspace programs. That means we can use commands from the `binutils` package like `readelf` to inspect it. Compare the output of, for example:
|
||||
```
|
||||
|
||||
|
||||
$# readelf -S /bin/date
|
||||
|
||||
$# readelf -S vmlinux
|
||||
```
|
||||
|
||||
The list of sections in the binaries is largely the same.
|
||||
|
||||
So the kernel must start up something like other Linux ELF binaries ... but how do userspace programs actually start? In the `main()` function, right? Not precisely.
|
||||
|
||||
Before the `main()` function can run, programs need an execution context that includes heap and stack memory plus file descriptors for `stdio`, `stdout`, and `stderr`. Userspace programs obtain these resources from the standard library, which is `glibc` on most Linux systems. Consider the following:
|
||||
```
|
||||
|
||||
|
||||
$# file /bin/date
|
||||
|
||||
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
|
||||
|
||||
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
|
||||
|
||||
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
|
||||
|
||||
stripped
|
||||
```
|
||||
|
||||
ELF binaries have an interpreter, just as Bash and Python scripts do, but the interpreter need not be specified with `#!` as in scripts, as ELF is Linux's native format. The ELF interpreter [provisions a binary][20] with the needed resources by calling `_start()`, a function available from the `glibc` source package that can be [inspected via GDB][21]. The kernel obviously has no interpreter and must provision itself, but how?
|
||||
|
||||
Inspecting the kernel's startup with GDB gives the answer. First install the debug package for the kernel that contains an unstripped version of `vmlinux`, for example `apt-get install linux-image-amd64-dbg`, or compile and install your own kernel from source, for example, by following instructions in the excellent [Debian Kernel Handbook][22]. `gdb vmlinux` followed by `info files` shows the ELF section `init.text`. List the start of program execution in `init.text` with `l *(address)`, where `address` is the hexadecimal start of `init.text`. GDB will indicate that the x86_64 kernel starts up in the kernel's file [arch/x86/kernel/head_64.S][23], where we find the assembly function `start_cpu0()` and code that explicitly creates a stack and decompresses the zImage before calling the `x86_64 start_kernel()` function. ARM 32-bit kernels have the similar [arch/arm/kernel/head.S][24]. `start_kernel()` is not architecture-specific, so the function lives in the kernel's [init/main.c][25]. `start_kernel()` is arguably Linux's true `main()` function.
|
||||
|
||||
### From start_kernel() to PID 1
|
||||
|
||||
#### The kernel's hardware manifest: the device-tree and ACPI tables
|
||||
|
||||
At boot, the kernel needs information about the hardware beyond the processor type for which it has been compiled. The instructions in the code are augmented by configuration data that is stored separately. There are two main methods of storing this data: [device-trees][26] and [ACPI tables][27]. The kernel learns what hardware it must run at each boot by reading these files.
|
||||
|
||||
For embedded devices, the device-tree is a manifest of installed hardware. The device-tree is simply a file that is compiled at the same time as kernel source and is typically located in `/boot` alongside `vmlinux`. To see what's in the binary device-tree on an ARM device, just use the `strings` command from the `binutils` package on a file whose name matches `/boot/*.dtb`, as `dtb` refers to a device-tree binary. Clearly the device-tree can be modified simply by editing the JSON-like files that compose it and rerunning the special `dtc` compiler that is provided with the kernel source. While the device-tree is a static file whose file path is typically passed to the kernel by the bootloader on the command line, a [device-tree overlay][28] facility has been added in recent years, where the kernel can dynamically load additional fragments in response to hotplug events after boot.
|
||||
|
||||
x86-family and many enterprise-grade ARM64 devices make use of the alternative Advanced Configuration and Power Interface ([ACPI][27]) mechanism. In contrast to the device-tree, the ACPI information is stored in the `/sys/firmware/acpi/tables` virtual filesystem that is created by the kernel at boot by accessing onboard ROM. The easy way to read the ACPI tables is with the `acpidump` command from the `acpica-tools` package. Here's an example:
|
||||
|
||||
![ACPI tables on Lenovo laptops][30]
|
||||
|
||||
|
||||
ACPI tables on Lenovo laptops are all set for Windows 2001.
|
||||
|
||||
Yes, your Linux system is ready for Windows 2001, should you care to install it. ACPI has both methods and data, unlike the device-tree, which is more of a hardware-description language. ACPI methods continue to be active post-boot. For example, starting the command `acpi_listen` (from package `apcid`) and opening and closing the laptop lid will show that ACPI functionality is running all the time. While temporarily and dynamically [overwriting the ACPI tables][31] is possible, permanently changing them involves interacting with the BIOS menu at boot or reflashing the ROM. If you're going to that much trouble, perhaps you should just [install coreboot][32], the open source firmware replacement.
|
||||
|
||||
#### From start_kernel() to userspace
|
||||
|
||||
The code in [init/main.c][25] is surprisingly readable and, amusingly, still carries Linus Torvalds' original copyright from 1991-1992. The lines found in `dmesg | head` on a newly booted system originate mostly from this source file. The first CPU is registered with the system, global data structures are initialized, and the scheduler, interrupt handlers (IRQs), timers, and console are brought one-by-one, in strict order, online. Until the function `timekeeping_init()` runs, all timestamps are zero. This part of the kernel initialization is synchronous, meaning that execution occurs in precisely one thread, and no function is executed until the last one completes and returns. As a result, the `dmesg` output will be completely reproducible, even between two systems, as long as they have the same device-tree or ACPI tables. Linux is behaving like one of the RTOS (real-time operating systems) that runs on MCUs, for example QNX or VxWorks. The situation persists into the function `rest_init()`, which is called by `start_kernel()` at its termination.
|
||||
|
||||
![Summary of early kernel boot process.][34]
|
||||
|
||||
Summary of early kernel boot process.
|
||||
|
||||
The rather humbly named `rest_init()` spawns a new thread that runs `kernel_init()`, which invokes `do_initcalls()`. Users can spy on `initcalls` in action by appending `initcall_debug` to the kernel command line, resulting in `dmesg` entries every time an `initcall` function runs. `initcalls` pass through seven sequential levels: early, core, postcore, arch, subsys, fs, device, and late. The most user-visible part of the `initcalls` is the probing and setup of all the processors' peripherals: buses, network, storage, displays, etc., accompanied by the loading of their kernel modules. `rest_init()` also spawns a second thread on the boot processor that begins by running `cpu_idle()` while it waits for the scheduler to assign it work.
|
||||
|
||||
`kernel_init()` also [sets up symmetric multiprocessing][35] (SMP). With more recent kernels, find this point in `dmesg` output by looking for "Bringing up secondary CPUs..." SMP proceeds by "hotplugging" CPUs, meaning that it manages their lifecycle with a state machine that is notionally similar to that of devices like hotplugged USB sticks. The kernel's power-management system frequently takes individual cores offline, then wakes them as needed, so that the same CPU hotplug code is called over and over on a machine that is not busy. Observe the power-management system's invocation of CPU hotplug with the [BCC tool][36] called `offcputime.py`.
|
||||
|
||||
Note that the code in `init/main.c` is nearly finished executing when `smp_init()` runs: The boot processor has completed most of the one-time initialization that the other cores need not repeat. Nonetheless, the per-CPU threads must be spawned for each core to manage interrupts (IRQs), workqueues, timers, and power events on each. For example, see the per-CPU threads that service softirqs and workqueues in action via the `ps -o psr` command.
|
||||
```
|
||||
|
||||
|
||||
$\# ps -o pid,psr,comm $(pgrep ksoftirqd)
|
||||
|
||||
PID PSR COMMAND
|
||||
|
||||
7 0 ksoftirqd/0
|
||||
|
||||
16 1 ksoftirqd/1
|
||||
|
||||
22 2 ksoftirqd/2
|
||||
|
||||
28 3 ksoftirqd/3
|
||||
|
||||
|
||||
|
||||
$\# ps -o pid,psr,comm $(pgrep kworker)
|
||||
|
||||
PID PSR COMMAND
|
||||
|
||||
4 0 kworker/0:0H
|
||||
|
||||
18 1 kworker/1:0H
|
||||
|
||||
24 2 kworker/2:0H
|
||||
|
||||
30 3 kworker/3:0H
|
||||
|
||||
[ . . . ]
|
||||
```
|
||||
|
||||
where the PSR field stands for "processor." Each core must also host its own timers and `cpuhp` hotplug handlers.
|
||||
|
||||
How is it, finally, that userspace starts? Near its end, `kernel_init()` looks for an `initrd` that can execute the `init` process on its behalf. If it finds none, the kernel directly executes `init` itself. Why then might one want an `initrd`?
|
||||
|
||||
#### Early userspace: who ordered the initrd?
|
||||
|
||||
Besides the device-tree, another file path that is optionally provided to the kernel at boot is that of the `initrd`. The `initrd` often lives in `/boot` alongside the bzImage file vmlinuz on x86, or alongside the similar uImage and device-tree for ARM. List the contents of the `initrd` with the `lsinitramfs` tool that is part of the `initramfs-tools-core` package. Distro `initrd` schemes contain minimal `/bin`, `/sbin`, and `/etc` directories along with kernel modules, plus some files in `/scripts`. All of these should look pretty familiar, as the `initrd` for the most part is simply a minimal Linux root filesystem. The apparent similarity is a bit deceptive, as nearly all the executables in `/bin` and `/sbin` inside the ramdisk are symlinks to the [BusyBox binary][37], resulting in `/bin` and `/sbin` directories that are 10x smaller than glibc's.
|
||||
|
||||
Why bother to create an `initrd` if all it does is load some modules and then start `init` on the regular root filesystem? Consider an encrypted root filesystem. The decryption may rely on loading a kernel module that is stored in `/lib/modules` on the root filesystem ... and, unsurprisingly, in the `initrd` as well. The crypto module could be statically compiled into the kernel instead of loaded from a file, but there are various reasons for not wanting to do so. For example, statically compiling the kernel with modules could make it too large to fit on the available storage, or static compilation may violate the terms of a software license. Unsurprisingly, storage, network, and human input device (HID) drivers may also be present in the `initrd`--basically any code that is not part of the kernel proper that is needed to mount the root filesystem. The `initrd` is also a place where users can stash their own [custom ACPI][38] table code.
|
||||
|
||||
![Rescue shell and a custom <code>initrd</code>.][40]
|
||||
|
||||
Having some fun with the rescue shell and a custom `initrd`.
|
||||
|
||||
`initrd`'s are also great for testing filesystems and data-storage devices themselves. Stash these test tools in the `initrd` and run your tests from memory rather than from the object under test.
|
||||
|
||||
At last, when `init` runs, the system is up! Since the secondary processors are now running, the machine has become the asynchronous, preemptible, unpredictable, high-performance creature we know and love. Indeed, `ps -o pid,psr,comm -p 1` is liable to show that userspace's `init` process is no longer running on the boot processor.
|
||||
|
||||
### Summary
|
||||
|
||||
The Linux boot process sounds forbidding, considering the number of different pieces of software that participate even on simple embedded devices. Looked at differently, the boot process is rather simple, since the bewildering complexity caused by features like preemption, RCU, and race conditions are absent in boot. Focusing on just the kernel and PID 1 overlooks the large amount of work that bootloaders and subsidiary processors may do in preparing the platform for the kernel to run. While the kernel is certainly unique among Linux programs, some insight into its structure can be gleaned by applying to it some of the same tools used to inspect other ELF binaries. Studying the boot process while it's working well arms system maintainers for failures when they come.
|
||||
|
||||
To learn more, attend Alison Chaiken's talk, [Linux: The first second][41], at [linux.conf.au][42], which will be held January 22-26 in Sydney.
|
||||
|
||||
Thanks to [Akkana Peck][43] for originally suggesting this topic and for many corrections.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/analyzing-linux-boot-process
|
||||
|
||||
作者:[Alison Chaiken][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[2]:https://github.com/chaiken/LCA2018-Demo-Code
|
||||
[3]:https://en.wikipedia.org/wiki/Wake-on-LAN
|
||||
[4]:https://lwn.net/Articles/630778/
|
||||
[5]:https://www.youtube.com/watch?v=iffTJ1vPCSo&index=65&list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[6]:https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&languageid=en-fr
|
||||
[7]:https://www.intel.com/content/www/us/en/support/articles/000025619/software.html
|
||||
[8]:https://github.com/corna/me_cleaner
|
||||
[9]:https://lwn.net/Articles/738649/
|
||||
[10]:https://lwn.net/Articles/699551/
|
||||
[11]:https://trmm.net/NERF
|
||||
[12]:https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled
|
||||
[13]:https://lwn.net/Articles/733837/
|
||||
[14]:https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639
|
||||
[15]:/file/383501
|
||||
[16]:https://opensource.com/sites/default/files/u128651/linuxboot_1.png (Running the U-boot bootloader)
|
||||
[17]:http://www.denx.de/wiki/DULG/Manual
|
||||
[18]:https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux
|
||||
[19]:http://man7.org/linux/man-pages/man5/elf.5.html
|
||||
[20]:https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html
|
||||
[21]:https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e
|
||||
[22]:http://kernel-handbook.alioth.debian.org/
|
||||
[23]:https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S
|
||||
[24]:https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S
|
||||
[25]:https://github.com/torvalds/linux/blob/master/init/main.c
|
||||
[26]:https://www.youtube.com/watch?v=m_NyYEBxfn8
|
||||
[27]:http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf
|
||||
[28]:http://lwn.net/Articles/616859/
|
||||
[29]:/file/383506
|
||||
[30]:https://opensource.com/sites/default/files/u128651/linuxboot_2.png (ACPI tables on Lenovo laptops)
|
||||
[31]:https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt
|
||||
[32]:https://www.coreboot.org/Supported_Motherboards
|
||||
[33]:/file/383511
|
||||
[34]:https://opensource.com/sites/default/files/u128651/linuxboot_3.png (Summary of early kernel boot process.)
|
||||
[35]:http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc
|
||||
[36]:http://www.brendangregg.com/ebpf.html
|
||||
[37]:https://www.busybox.net/
|
||||
[38]:https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt
|
||||
[39]:/file/383516
|
||||
[40]:https://opensource.com/sites/default/files/u128651/linuxboot_4.png (Rescue shell and a custom <code>initrd</code>.)
|
||||
[41]:https://rego.linux.conf.au/schedule/presentation/16/
|
||||
[42]:https://linux.conf.au/index.html
|
||||
[43]:http://shallowsky.com/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Parsing HTML with Python
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Check Your Linux PC for Meltdown or Spectre Vulnerability
|
||||
======
|
||||
|
||||
|
||||
@ -1,96 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Easily Correct Misspelled Bash Commands In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
I know, I know! You could just hit the UP arrow to bring up the command you just ran, and navigate to the misspelled word using the LEFT/RIGHT keys, and correct the misspelled word(s), finally hit ENTER key to run it again, right? But, wait. There is another easier way to correct misspelled Bash commands in GNU/Linux. This brief tutorial explains how to do it. Read on.
|
||||
|
||||
### Correct Misspelled Bash Commands In Linux
|
||||
|
||||
Have you run a mistyped command something like below?
|
||||
```
|
||||
$ unme -r
|
||||
bash: unme: command not found
|
||||
|
||||
```
|
||||
|
||||
Did you notice? There is a typo in the above command. I missed the letter “a” in the “uname” command.
|
||||
|
||||
I have done this kind of silly mistakes in many occasions. Before I know this trick, I used to hit UP arrow to bring up the command and go to the misspelled word in the command, correct the spelling and typos and hit the ENTER key to run that command again. But believe me. The below trick is super easy to correct any typos and spelling mistakes in a command you just ran.
|
||||
|
||||
To easily correct the above misspelled command, just run:
|
||||
```
|
||||
$ ^nm^nam^
|
||||
|
||||
```
|
||||
|
||||
This will replace the characters “nm” with “nam” in the “uname” command. Cool, yeah? It’s not only corrects the typos, but also runs the command. Check the following screenshot.
|
||||
|
||||
![][2]
|
||||
|
||||
Use this trick when you made a typo in a command. Please note that it works only in Bash shell.
|
||||
|
||||
**Bonus tip:**
|
||||
|
||||
Have you ever wondered how to automatically correct spelling mistakes and typos when using “cd” command? No? It’s alright! The following trick will explain how to do it.
|
||||
|
||||
This trick will only help to correct the spelling mistakes and typos when using “cd” command.
|
||||
|
||||
Let us say, you want to switch to “Downloads” directory using command:
|
||||
```
|
||||
$ cd Donloads
|
||||
bash: cd: Donloads: No such file or directory
|
||||
|
||||
```
|
||||
|
||||
Oops! There is no such file or directory with name “Donloads”. Well, the correct name was “Downloads”. The “w” is missing in the above command.
|
||||
|
||||
To fix this issue and automatically correct the typos while using cd command, edit your **.bashrc** file:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Add the following line at end.
|
||||
```
|
||||
[...]
|
||||
shopt -s cdspell
|
||||
|
||||
```
|
||||
|
||||
Type **:wq** to save and exit the file.
|
||||
|
||||
Finally, run the following command to update the changes.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Now, if there are any typos or spelling mistakes in the path while using cd command, it will automatically corrects and land you in the correct directory.
|
||||
|
||||
![][3]
|
||||
|
||||
As you see in the above command, I intentionally made a typo (“Donloads” instead of “Downloads”), but Bash automatically detected the correct directory name and cd into it.
|
||||
|
||||
[**Fish**][4] and **Zsh** shells have this feature built-in. So, you don’t need this trick if you use them.
|
||||
|
||||
This trick, however, has some limitations. It works only if you use the correct case. In the above example, if you type “cd donloads” instead of “cd Donloads”, it won’t recognize the correct path. Also, if there were more than one letters missing in the path, it won’t work either.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/misspelled-command.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/cd-command.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
@ -1,186 +0,0 @@
|
||||
Python Global Keyword (With Examples)
|
||||
======
|
||||
Before reading this article, make sure you have got some basics of [Python Global, Local and Nonlocal Variables][1].
|
||||
|
||||
### Introduction to global Keyword
|
||||
|
||||
In Python, `global` keyword allows you to modify the variable outside of the current scope. It is used to create a global variable and make changes to the variable in a local context.
|
||||
|
||||
#### Rules of global Keyword
|
||||
|
||||
The basic rules for `global` keyword in Python are:
|
||||
|
||||
* When we create a variable inside a function, it’s local by default.
|
||||
* When we define a variable outside of a function, it’s global by default. You don’t have to use `global` keyword.
|
||||
* We use `global` keyword to read and write a global variable inside a function.
|
||||
* Use of `global` keyword outside a function has no effect
|
||||
|
||||
|
||||
|
||||
#### Use of global Keyword (With Example)
|
||||
|
||||
Let’s take an example.
|
||||
|
||||
##### Example 1: Accessing global Variable From Inside a Function
|
||||
```
|
||||
c = 1 # global variable
|
||||
|
||||
def add():
|
||||
print(c)
|
||||
|
||||
add()
|
||||
|
||||
```
|
||||
|
||||
When we run above program, the output will be:
|
||||
```
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
However, we may have some scenarios where we need to modify the global variable from inside a function.
|
||||
|
||||
##### Example 2: Modifying Global Variable From Inside the Function
|
||||
```
|
||||
c = 1 # global variable
|
||||
|
||||
def add():
|
||||
c = c + 2 # increment c by 2
|
||||
print(c)
|
||||
|
||||
add()
|
||||
|
||||
```
|
||||
|
||||
When we run above program, the output shows an error:
|
||||
```
|
||||
UnboundLocalError: local variable 'c' referenced before assignment
|
||||
|
||||
```
|
||||
|
||||
This is because we can only access the global variable but cannot modify it from inside the function.
|
||||
|
||||
The solution for this is to use the `global` keyword.
|
||||
|
||||
##### Example 3: Changing Global Variable From Inside a Function using global
|
||||
```
|
||||
c = 0 # global variable
|
||||
|
||||
def add():
|
||||
global c
|
||||
c = c + 2 # increment by 2
|
||||
print("Inside add():", c)
|
||||
|
||||
add()
|
||||
print("In main:", c)
|
||||
|
||||
```
|
||||
|
||||
When we run above program, the output will be:
|
||||
```
|
||||
Inside add(): 2
|
||||
In main: 2
|
||||
|
||||
```
|
||||
|
||||
In the above program, we define c as a global keyword inside the `add()` function.
|
||||
|
||||
Then, we increment the variable c by `1`, i.e `c = c + 2`. After that, we call the `add()` function. Finally, we print global variable c.
|
||||
|
||||
As we can see, change also occured on the global variable outside the function, `c = 2`.
|
||||
|
||||
### Global Variables Across Python Modules
|
||||
|
||||
In Python, we create a single module `config.py` to hold global variables and share information across Python modules within the same program.
|
||||
|
||||
Here is how we can share global variable across the python modules.
|
||||
|
||||
##### Example 4 : Share a global Variable Across Python Modules
|
||||
|
||||
Create a `config.py` file, to store global variables
|
||||
```
|
||||
a = 0
|
||||
b = "empty"
|
||||
|
||||
```
|
||||
|
||||
Create a `update.py` file, to change global variables
|
||||
```
|
||||
import config
|
||||
|
||||
config.a = 10
|
||||
config.b = "alphabet"
|
||||
|
||||
```
|
||||
|
||||
Create a `main.py` file, to test changes in value
|
||||
```
|
||||
import config
|
||||
import update
|
||||
|
||||
print(config.a)
|
||||
print(config.b)
|
||||
|
||||
```
|
||||
|
||||
When we run the `main.py` file, the output will be
|
||||
```
|
||||
10
|
||||
alphabet
|
||||
|
||||
```
|
||||
|
||||
In the above, we create three files: `config.py`, `update.py` and `main.py`.
|
||||
|
||||
The module `config.py` stores global variables of a and b. In `update.py` file, we import the `config.py` module and modify the values of a and b. Similarly, in `main.py` file we import both `config.py` and `update.py` module. Finally, we print and test the values of global variables whether they are changed or not.
|
||||
|
||||
### Global in Nested Functions
|
||||
|
||||
Here is how you can use a global variable in nested function.
|
||||
|
||||
##### Example 5: Using a Global Variable in Nested Function
|
||||
```
|
||||
def foo():
|
||||
x = 20
|
||||
|
||||
def bar():
|
||||
global x
|
||||
x = 25
|
||||
|
||||
print("Before calling bar: ", x)
|
||||
print("Calling bar now")
|
||||
bar()
|
||||
print("After calling bar: ", x)
|
||||
|
||||
foo()
|
||||
print("x in main : ", x)
|
||||
|
||||
```
|
||||
|
||||
The output is :
|
||||
```
|
||||
Before calling bar: 20
|
||||
Calling bar now
|
||||
After calling bar: 20
|
||||
x in main : 25
|
||||
|
||||
```
|
||||
|
||||
In the above program, we declare global variable inside the nested function `bar()`. Inside `foo()` function, x has no effect of global keyword.
|
||||
|
||||
Before and after calling `bar()`, the variable x takes the value of local variable i.e `x = 20`. Outside of the `foo()` function, the variable x will take value defined in the `bar()` function i.e `x = 25`. This is because we have used `global` keyword in x to create global variable inside the `bar()` function (local scope).
|
||||
|
||||
If we make any changes inside the `bar()` function, the changes appears outside the local scope, i.e. `foo()`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.programiz.com/python-programming/global-keyword
|
||||
|
||||
作者:[programiz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.programiz.com
|
||||
[1]:https://www.programiz.com/python-programming/global-local-nonlocal-variables
|
||||
@ -1,156 +0,0 @@
|
||||
yixunx translating
|
||||
Advanced Dnsmasq Tips and Tricks
|
||||
======
|
||||
|
||||
!](https://www.linux.com/sites/lcom/files/styles/rendered_file/public/banner_3.25.47_pm.png?itok=2YaDe86d)
|
||||
|
||||
Many people know and love Dnsmasq and rely on it for their local name services. Today we look at advanced configuration file management, how to test your configurations, some basic security, DNS wildcards, speedy DNS configuration, and some other tips and tricks. Next week, we'll continue with a detailed look at how to configure DNS and DHCP.
|
||||
|
||||
### Testing Configurations
|
||||
|
||||
When you're testing new configurations, you should run Dnsmasq from the command line, rather than as a daemon. This example starts it without launching the daemon, prints command output, and logs all activity:
|
||||
```
|
||||
# dnsmasq --no-daemon --log-queries
|
||||
dnsmasq: started, version 2.75 cachesize 150
|
||||
dnsmasq: compile time options: IPv6 GNU-getopt
|
||||
DBus i18n IDN DHCP DHCPv6 no-Lua TFTP conntrack
|
||||
ipset auth DNSSEC loop-detect inotify
|
||||
dnsmasq: reading /etc/resolv.conf
|
||||
dnsmasq: using nameserver 192.168.0.1#53
|
||||
dnsmasq: read /etc/hosts - 9 addresses
|
||||
|
||||
```
|
||||
|
||||
You can see tons of useful information in this small example, including version, compiled options, system name service files, and its listening address. Ctrl+c stops it. By default, Dnsmasq does not have its own log file, so entries are dumped into multiple locations in `/var/log`. You can use good old `grep` to find Dnsmasq log entries. This example searches `/var/log` recursively, prints the line numbers after the filenames, and excludes `/var/log/dist-upgrade`:
|
||||
```
|
||||
# grep -ir --exclude-dir=dist-upgrade dnsmasq /var/log/
|
||||
|
||||
```
|
||||
|
||||
Note the fun grep gotcha with `--exclude-dir=`: Don't specify the full path, but just the directory name.
|
||||
|
||||
You can give Dnsmasq its own logfile with this command-line option, using whatever file you want:
|
||||
```
|
||||
# dnsmasq --no-daemon --log-queries --log-facility=/var/log/dnsmasq.log
|
||||
|
||||
```
|
||||
|
||||
Or enter it in your Dnsmasq configuration file as `log-facility=/var/log/dnsmasq.log`.
|
||||
|
||||
### Configuration Files
|
||||
|
||||
Dnsmasq is configured in `/etc/dnsmasq.conf`. Your Linux distribution may also use `/etc/default/dnsmasq`, `/etc/dnsmasq.d/`, and `/etc/dnsmasq.d-available/`. (No, there cannot be a universal method, as that is against the will of the Linux Cat Herd Ruling Cabal.) You have a fair bit of flexibility to organize your Dnsmasq configuration in a way that pleases you.
|
||||
|
||||
`/etc/dnsmasq.conf` is the grandmother as well as the boss. Dnsmasq reads it first at startup. `/etc/dnsmasq.conf` can call other configuration files with the `conf-file=` option, for example `conf-file=/etc/dnsmasqextrastuff.conf`, and directories with the `conf-dir=` option, e.g. `conf-dir=/etc/dnsmasq.d`.
|
||||
|
||||
Whenever you make a change in a configuration file, you must restart Dnsmasq.
|
||||
|
||||
You may include or exclude configuration files by extension. The asterisk means include, and the absence of the asterisk means exclude:
|
||||
```
|
||||
conf-dir=/etc/dnsmasq.d/,*.conf, *.foo
|
||||
conf-dir=/etc/dnsmasq.d,.old, .bak, .tmp
|
||||
|
||||
```
|
||||
|
||||
You may store your host configurations in multiple files with the `--addn-hosts=` option.
|
||||
|
||||
Dnsmasq includes a syntax checker:
|
||||
```
|
||||
$ dnsmasq --test
|
||||
dnsmasq: syntax check OK.
|
||||
|
||||
```
|
||||
|
||||
### Useful Configurations
|
||||
|
||||
Always include these lines:
|
||||
```
|
||||
domain-needed
|
||||
bogus-priv
|
||||
|
||||
```
|
||||
|
||||
These prevent packets with malformed domain names and packets with private IP addresses from leaving your network.
|
||||
|
||||
This limits your name services exclusively to Dnsmasq, and it will not use `/etc/resolv.conf` or any other system name service files:
|
||||
```
|
||||
no-resolv
|
||||
|
||||
```
|
||||
|
||||
Reference other name servers. The first example is for a local private domain. The second and third examples are OpenDNS public servers:
|
||||
```
|
||||
server=/fooxample.com/192.168.0.1
|
||||
server=208.67.222.222
|
||||
server=208.67.220.220
|
||||
|
||||
```
|
||||
|
||||
Or restrict just local domains while allowing external lookups for other domains. These are answered only from `/etc/hosts` or DHCP:
|
||||
```
|
||||
local=/mehxample.com/
|
||||
local=/fooxample.com/
|
||||
|
||||
```
|
||||
|
||||
Restrict which network interfaces Dnsmasq listens to:
|
||||
```
|
||||
interface=eth0
|
||||
interface=wlan1
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq, by default, reads and uses `/etc/hosts`. This is a fabulously fast way to configure a lot of hosts, and the `/etc/hosts` file only has to exist on the same computer as Dnsmasq. You can make the process even faster by entering only the hostnames in `/etc/hosts`, and use Dnsmasq to add the domain. `/etc/hosts` looks like this:
|
||||
```
|
||||
127.0.0.1 localhost
|
||||
192.168.0.1 host2
|
||||
192.168.0.2 host3
|
||||
192.168.0.3 host4
|
||||
|
||||
```
|
||||
|
||||
Then add these lines to `dnsmasq.conf`, using your own domain, of course:
|
||||
```
|
||||
expand-hosts
|
||||
domain=mehxample.com
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq will automatically expand the hostnames to fully qualified domain names, for example, host2 to host2.mehxample.com.
|
||||
|
||||
### DNS Wildcards
|
||||
|
||||
In general, DNS wildcards are not a good practice because they invite abuse. But there are times when they are useful, such as inside the nice protected confines of your LAN. For example, Kubernetes clusters are considerably easier to manage with wildcard DNS, unless you enjoy making DNS entries for your hundreds or thousands of applications. Suppose your Kubernetes domain is mehxample.com; in Dnsmasq a wildcard that resolves all requests to mehxample.com looks like this:
|
||||
```
|
||||
address=/mehxample.com/192.168.0.5
|
||||
|
||||
```
|
||||
|
||||
The address to use in this case is the public IP address for your cluster. This answers requests for hosts and subdomains in mehxample.com, except for any that are already configured in DHCP or `/etc/hosts`.
|
||||
|
||||
Next week, we'll go into more detail on managing DNS and DHCP, including different options for different subnets, and providing authoritative name services.
|
||||
|
||||
### Additional Resources
|
||||
|
||||
* [DNS Spoofing with Dnsmasq][1]
|
||||
|
||||
* [Dnsmasq For Easy LAN Name Services][2]
|
||||
|
||||
* [Dnsmasq][3]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/advanced-dnsmasq-tips-and-tricks
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/7/dns-spoofing-dnsmasq
|
||||
[2]:https://www.linux.com/learn/dnsmasq-easy-lan-name-services
|
||||
[3]:http://www.thekelleys.org.uk/dnsmasq/doc.html
|
||||
@ -0,0 +1,119 @@
|
||||
How to Get Started Using WSL in Windows 10
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the [previous article][1], we talked about the Windows Subsystem for Linux (WSL) and its target audience. In this article, we will walk through the process of getting started with WSL on your Windows 10 machine.
|
||||
|
||||
### Prepare your system for WSL
|
||||
|
||||
You must be running the latest version of Windows 10 with Fall Creator Update installed. Then, check which version of Windows 10 is installed on your system by searching on “About” in the search box of the Start menu. You should be running version 1709 or the latest to use WSL.
|
||||
|
||||
Here is a screenshot from my system.
|
||||
|
||||
![kHFKOvrbG1gXdB9lsbTqXC4N4w0Lbsz1Bul5ey9m][2]
|
||||
|
||||
If an older version is installed, you need to download and install the Windows 10 Fall Creator Update (FCU) from [this][3] page. Once FCU is installed, go to Update Settings (just search for “updates” in the search box of the Start menu) and install any available updates.
|
||||
|
||||
Go to Turn Windows Features On or Off (you know the drill by now) and scroll to the bottom and tick on the box Windows Subsystem for Linux, as shown in the following figure. Click Ok. It will download and install the needed packages.
|
||||
|
||||
![oV1mDqGe3zwQgL0N3rDasHH6ZwHtxaHlyrLzjw7x][4]
|
||||
|
||||
Upon the completion of the installation, the system will offer to restart. Go ahead and reboot your machine. WSL won’t launch without a system reboot, as shown below:
|
||||
|
||||
![GsNOQLJlHeZbkaCsrDIhfVvEoycu3D0upoTdt6aN][5]
|
||||
|
||||
Once your system starts, go back to the Turn features on or off setting to confirm that the box next to Windows Subsystem for Linux is selected.
|
||||
|
||||
### Install Linux in Windows
|
||||
|
||||
There are many ways to install Linux on Windows, but we will choose the easiest way. Open the Windows Store and search for Linux. You will see the following option:
|
||||
|
||||
![YAR4UgZiFAy2cdkG4U7jQ7_m81lrxR6aHSMOdED7][6]
|
||||
|
||||
Click on Get the apps, and Windows Store will provide you with three options: Ubuntu, openSUSE Leap 42, and SUSE Linux Enterprise Server. You can install all three distributions side by side and run all three distributions simultaneously. To be able to use SLE, you need a subscription.
|
||||
|
||||
In this case, I am installing openSUSE Leap 42 and Ubuntu. Select your desired distro and click on the Get button to install it. Once installed, you can launch openSUSE in Windows. It can be pinned to the Start menu for quick access.
|
||||
|
||||
![4LU6eRrzDgBprDuEbSFizRuP1J_zS3rBnoJbU2OA][7]
|
||||
|
||||
### Using Linux in Windows
|
||||
|
||||
When you launch the distro, it will open the Bash shell and install the distro. Once installed, you can go ahead and start using it. Simple. Just bear in mind that there is no user in openSUSE and it runs as root user, whereas Ubuntu will ask you to create a user. On Ubuntu, you can perform administrative tasks as sudo user.
|
||||
|
||||
You can easily create a user on openSUSE:
|
||||
```
|
||||
# useradd [username]
|
||||
|
||||
# passwd [username]
|
||||
|
||||
```
|
||||
|
||||
Create a new password for the user and you are all set. For example:
|
||||
```
|
||||
# useradd swapnil
|
||||
|
||||
# passwd swapnil
|
||||
|
||||
```
|
||||
|
||||
You can switch from root to this use by running the su command:
|
||||
```
|
||||
su swapnil
|
||||
|
||||
```
|
||||
|
||||
You do need non-root use to perform many tasks, like using commands like rsync to move files on your local machine.
|
||||
|
||||
The first thing you need to do is update the distro. For openSUSE:
|
||||
```
|
||||
zypper up
|
||||
|
||||
```
|
||||
|
||||
For Ubuntu:
|
||||
```
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
```
|
||||
|
||||
![7cRgj1O6J8yfO3L4ol5sP-ZCU7_uwOuEoTzsuVW9][8]
|
||||
|
||||
You now have native Linux Bash shell on Windows. Want to ssh into your server from Windows 10? There’s no need to install puTTY or Cygwin. Just open Bash and then ssh into your server. Easy peasy.
|
||||
|
||||
Want to rsync files to your server? Go ahead and use rsync. It really transforms Windows into a usable machine for those Windows users who want to use native Linux command linux tools on their machines without having to deal with VMs.
|
||||
|
||||
### Where is Fedora?
|
||||
|
||||
You may be wondering about Fedora. Unfortunately, Fedora is not yet available through the store. Matthew Miller, the release manager of Fedora said on Twitter, “We're working on resolving some non-technical issues. I'm afraid I don't have any more than that right now.”
|
||||
|
||||
We don’t know yet what these non-technical issues are. When some users asked why the WSL team could not publish Fedora themselves --- after all it’s an open source project -- Rich Turner, a project manager at Microsoft [responded][9], “We have a policy of not publishing others' IP into the store. We believe that the community would MUCH prefer to see a distro published by the distro owner vs. seeing it published by Microsoft or anyone else that isn't the authoritative source.”
|
||||
|
||||
So, Microsoft can’t just go ahead and publish Debian or Arch Linux on Windows Store. The onus is on the official communities to bring their distros to Windows 10 users.
|
||||
|
||||
### What’s next
|
||||
|
||||
In the next article, we will talk about using Windows 10 as a Linux machine and performing most of the tasks that you would perform on your Linux system using the command-line tools.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/windows-subsystem-linux-bridge-between-two-platforms
|
||||
[2]:https://lh6.googleusercontent.com/kHFKOvrbG1gXdB9lsbTqXC4N4w0Lbsz1Bul5ey9mr_E255GiiBxf8cRlatrte6z23yvo8lHJG8nQ_WeHhUNYqPp7kHuQTTMueqMshCT71JsbMr2Wih9KFHuHgNg1BclWz-iuBt4O
|
||||
[3]:https://www.microsoft.com/en-us/software-download/windows10
|
||||
[4]:https://lh4.googleusercontent.com/oV1mDqGe3zwQgL0N3rDasHH6ZwHtxaHlyrLzjw7xF9M9_AcHPNSxM18KDWK2ZpVcUOfxVVpNH9LwUJT5EtRE7zUrJC_gWV5f345SZRAgXcJzOE-8rM8-RCPTNtns6vVP37V5Eflp
|
||||
[5]:https://lh5.googleusercontent.com/GsNOQLJlHeZbkaCsrDIhfVvEoycu3D0upoTdt6aNEozAcQA59Z3hDu_SxT6I4K4gwxLPX0YnmUsCKjaQaaG2PoAgUYMcN0Zv0tBFaoUL3sZryddM4mdRj1E2tE-IK_GLK4PDa4zf
|
||||
[6]:https://lh3.googleusercontent.com/YAR4UgZiFAy2cdkG4U7jQ7_m81lrxR6aHSMOdED7MKEoYxEsX_yLwyMj9N2edt3GJ2JLx6mUsFEZFILCCSBU2sMOqveFVWZTHcCXhFi5P2Xk-9Ikc3NK9seup5CJObIcYJPORdPW
|
||||
[7]:https://lh6.googleusercontent.com/4LU6eRrzDgBprDuEbSFizRuP1J_zS3rBnoJbU2OAOH3Mx7nfOROfyf81k1s4YQyLBcu0qSXOoaqbYkXL5Wpp9gNCdKH_WsEcqWzjG6uXzYvCYQ42psOz6Iz3NF7ElsPrdiFI0cYv
|
||||
[8]:https://lh6.googleusercontent.com/7cRgj1O6J8yfO3L4ol5sP-ZCU7_uwOuEoTzsuVW9cU5xiBWz_cpZ1IBidNT0C1wg9zROIncViUzXD0vPoH5cggQtuwkanRfRdDVXOI48AcKFLt-Iq2CBF4mGRwqqWvSOhb0HFpjm
|
||||
[9]:https://github.com/Microsoft/WSL/issues/2584
|
||||
434
sources/tech/20180221 12 useful zypper command examples.md
Normal file
434
sources/tech/20180221 12 useful zypper command examples.md
Normal file
@ -0,0 +1,434 @@
|
||||
12 useful zypper command examples
|
||||
======
|
||||
Learn zypper command with 12 useful examples along with sample outputs. zypper is used for package and patch management in Suse Linux systems.
|
||||
|
||||
![zypper command examples][1]
|
||||
|
||||
zypper is package management system powered by [ZYpp package manager engine][2]. Suse Linux uses zypper for package management. In this article we will be sharing 12 useful zypper commands along with examples whcih are helpful for your day today sysadmin tasks.
|
||||
|
||||
Without any argument `zypper` command will list you all available switches which can be used. Its quite handy than referring to man page which is pretty much in detail.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper
|
||||
Usage:
|
||||
zypper [--global-options] <command> [--command-options] [arguments]
|
||||
zypper <subcommand> [--command-options] [arguments]
|
||||
|
||||
Global Options:
|
||||
--help, -h Help.
|
||||
--version, -V Output the version number.
|
||||
--promptids Output a list of zypper's user prompts.
|
||||
--config, -c <file> Use specified config file instead of the default .
|
||||
--userdata <string> User defined transaction id used in history and plugins.
|
||||
--quiet, -q Suppress normal output, print only error
|
||||
messages.
|
||||
--verbose, -v Increase verbosity.
|
||||
--color
|
||||
--no-color Whether to use colors in output if tty supports it.
|
||||
--no-abbrev, -A Do not abbreviate text in tables.
|
||||
--table-style, -s Table style (integer).
|
||||
--non-interactive, -n Do not ask anything, use default answers
|
||||
automatically.
|
||||
--non-interactive-include-reboot-patches
|
||||
Do not treat patches as interactive, which have
|
||||
the rebootSuggested-flag set.
|
||||
--xmlout, -x Switch to XML output.
|
||||
--ignore-unknown, -i Ignore unknown packages.
|
||||
|
||||
--reposd-dir, -D <dir> Use alternative repository definition file
|
||||
directory.
|
||||
--cache-dir, -C <dir> Use alternative directory for all caches.
|
||||
--raw-cache-dir <dir> Use alternative raw meta-data cache directory.
|
||||
--solv-cache-dir <dir> Use alternative solv file cache directory.
|
||||
--pkg-cache-dir <dir> Use alternative package cache directory.
|
||||
|
||||
Repository Options:
|
||||
--no-gpg-checks Ignore GPG check failures and continue.
|
||||
--gpg-auto-import-keys Automatically trust and import new repository
|
||||
signing keys.
|
||||
--plus-repo, -p <URI> Use an additional repository.
|
||||
--plus-content <tag> Additionally use disabled repositories providing a specific keyword.
|
||||
Try '--plus-content debug' to enable repos indic ating to provide debug packages.
|
||||
--disable-repositories Do not read meta-data from repositories.
|
||||
--no-refresh Do not refresh the repositories.
|
||||
--no-cd Ignore CD/DVD repositories.
|
||||
--no-remote Ignore remote repositories.
|
||||
--releasever Set the value of $releasever in all .repo files (default: distribution version)
|
||||
|
||||
Target Options:
|
||||
--root, -R <dir> Operate on a different root directory.
|
||||
--disable-system-resolvables
|
||||
Do not read installed packages.
|
||||
|
||||
Commands:
|
||||
help, ? Print help.
|
||||
shell, sh Accept multiple commands at once.
|
||||
|
||||
Repository Management:
|
||||
repos, lr List all defined repositories.
|
||||
addrepo, ar Add a new repository.
|
||||
removerepo, rr Remove specified repository.
|
||||
renamerepo, nr Rename specified repository.
|
||||
modifyrepo, mr Modify specified repository.
|
||||
refresh, ref Refresh all repositories.
|
||||
clean Clean local caches.
|
||||
|
||||
Service Management:
|
||||
services, ls List all defined services.
|
||||
addservice, as Add a new service.
|
||||
modifyservice, ms Modify specified service.
|
||||
removeservice, rs Remove specified service.
|
||||
refresh-services, refs Refresh all services.
|
||||
|
||||
Software Management:
|
||||
install, in Install packages.
|
||||
remove, rm Remove packages.
|
||||
verify, ve Verify integrity of package dependencies.
|
||||
source-install, si Install source packages and their build
|
||||
dependencies.
|
||||
install-new-recommends, inr
|
||||
Install newly added packages recommended
|
||||
by installed packages.
|
||||
|
||||
Update Management:
|
||||
update, up Update installed packages with newer versions.
|
||||
list-updates, lu List available updates.
|
||||
patch Install needed patches.
|
||||
list-patches, lp List needed patches.
|
||||
dist-upgrade, dup Perform a distribution upgrade.
|
||||
patch-check, pchk Check for patches.
|
||||
|
||||
Querying:
|
||||
search, se Search for packages matching a pattern.
|
||||
info, if Show full information for specified packages.
|
||||
patch-info Show full information for specified patches.
|
||||
pattern-info Show full information for specified patterns.
|
||||
product-info Show full information for specified products.
|
||||
patches, pch List all available patches.
|
||||
packages, pa List all available packages.
|
||||
patterns, pt List all available patterns.
|
||||
products, pd List all available products.
|
||||
what-provides, wp List packages providing specified capability.
|
||||
|
||||
Package Locks:
|
||||
addlock, al Add a package lock.
|
||||
removelock, rl Remove a package lock.
|
||||
locks, ll List current package locks.
|
||||
cleanlocks, cl Remove unused locks.
|
||||
|
||||
Other Commands:
|
||||
versioncmp, vcmp Compare two version strings.
|
||||
targetos, tos Print the target operating system ID string.
|
||||
licenses Print report about licenses and EULAs of
|
||||
installed packages.
|
||||
download Download rpms specified on the commandline to a local directory.
|
||||
source-download Download source rpms for all installed packages
|
||||
to a local directory.
|
||||
|
||||
Subcommands:
|
||||
subcommand Lists available subcommands.
|
||||
|
||||
Type 'zypper help <command>' to get command-specific help.
|
||||
```
|
||||
##### How to install package using zypper
|
||||
|
||||
`zypper` takes `in` or `install` switch to install package on your system. Its same as [yum package installation][3], supplying package name as argument and package manager (zypper here) will resolve all dependencies and install them along with your required package.
|
||||
|
||||
```
|
||||
# zypper install telnet
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
|
||||
The following NEW package is going to be installed:
|
||||
telnet
|
||||
|
||||
1 new package to install.
|
||||
Overall download size: 51.8 KiB. Already cached: 0 B. After the operation, additional 113.3 KiB will be used.
|
||||
Continue? [y/n/...? shows all options] (y): y
|
||||
Retrieving package telnet-1.2-165.63.x86_64 (1/1), 51.8 KiB (113.3 KiB unpacked)
|
||||
Retrieving: telnet-1.2-165.63.x86_64.rpm .........................................................................................................................[done]
|
||||
Checking for file conflicts: .....................................................................................................................................[done]
|
||||
(1/1) Installing: telnet-1.2-165.63.x86_64 .......................................................................................................................[done]
|
||||
```
|
||||
|
||||
Above output for your reference in which we installed `telnet` package.
|
||||
|
||||
Suggested read : [Install packages in YUM and APT systems][3]
|
||||
|
||||
##### How to remove package using zypper
|
||||
|
||||
For erasing or removing packages in Suse Linux, use `zypper` with `remove` or `rm` switch.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper rm telnet
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
|
||||
The following package is going to be REMOVED:
|
||||
telnet
|
||||
|
||||
1 package to remove.
|
||||
After the operation, 113.3 KiB will be freed.
|
||||
Continue? [y/n/...? shows all options] (y): y
|
||||
(1/1) Removing telnet-1.2-165.63.x86_64 ..........................................................................................................................[done]
|
||||
```
|
||||
We removed previously installed telnet package here.
|
||||
|
||||
##### Check dependencies and verify integrity of installed packages using zypper
|
||||
|
||||
There are times when one can install package by force ignoring dependencies. `zypper` gives you power to scan all installed packages and checks for their dependencies too. If any dependency is missing, it offers you to install/rempve it and hence maintain integrity of your installed packages.
|
||||
|
||||
Use `verify` or `ve` switch with `zypper` to check integrity of installed packages.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper ve
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
Dependencies of all installed packages are satisfied.
|
||||
```
|
||||
In above output, you can see last line confirms that all dependencies of installed packages are completed and no action required.
|
||||
|
||||
##### How to download package using zypper in Suse Linux
|
||||
|
||||
`zypper` offers way to download package in local directory without installation. You can use this downloaded package on another system with same configuration. Packages will be downloaded to `/var/cache/zypp/packages/<repo>/<arch>/` directory.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper download telnet
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Retrieving package telnet-1.2-165.63.x86_64 (1/1), 51.8 KiB (113.3 KiB unpacked)
|
||||
(1/1) /var/cache/zypp/packages/SMT-http_smt-ec2_susecloud_net:SLES12-SP3-Pool/x86_64/telnet-1.2-165.63.x86_64.rpm ................................................[done]
|
||||
|
||||
download: Done.
|
||||
|
||||
# ls -lrt /var/cache/zypp/packages/SMT-http_smt-ec2_susecloud_net:SLES12-SP3-Pool/x86_64/
|
||||
total 52
|
||||
-rw-r--r-- 1 root root 53025 Feb 21 03:17 telnet-1.2-165.63.x86_64.rpm
|
||||
|
||||
```
|
||||
You can see we have downloaded telnet package locally using `zypper`
|
||||
|
||||
Suggested read : [Download packages in YUM and APT systems without installing][4]
|
||||
|
||||
##### How to list available package update in zypper
|
||||
|
||||
`zypper` allows you to view all available updates for your installed packages so that you can plan update activity in advance. Use `list-updates` or `lu` switch to show you list of all available updates for installed packages.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lu
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
S | Repository | Name | Current Version | Available Version | Arch
|
||||
--|-----------------------------------|----------------------------|-------------------------------|------------------------------------|-------
|
||||
v | SLES12-SP3-Updates | at-spi2-core | 2.20.2-12.3 | 2.20.2-14.3.1 | x86_64
|
||||
v | SLES12-SP3-Updates | bash | 4.3-82.1 | 4.3-83.5.2 | x86_64
|
||||
v | SLES12-SP3-Updates | ca-certificates-mozilla | 2.7-11.1 | 2.22-12.3.1 | noarch
|
||||
v | SLE-Module-Containers12-Updates | containerd | 0.2.5+gitr639_422e31c-20.2 | 0.2.9+gitr706_06b9cb351610-16.8.1 | x86_64
|
||||
v | SLES12-SP3-Updates | crash | 7.1.8-4.3.1 | 7.1.8-4.6.2 | x86_64
|
||||
v | SLES12-SP3-Updates | rsync | 3.1.0-12.1 | 3.1.0-13.10.1 | x86_64
|
||||
```
|
||||
Output is properly formatted for easy reading. Column wise it shows name of repo where package belongs, package name, installed version, new updated available version & architecture.
|
||||
|
||||
##### List and install patches in Suse linux
|
||||
|
||||
Use `list-patches` or `lp` switch to display all available patches for your Suse Linux system which needs to be applied.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lp
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
Repository | Name | Category | Severity | Interactive | Status | Summary
|
||||
----------------------------------|------------------------------------------|-------------|-----------|-------------|--------|------------------------------------------------------------------------------------
|
||||
SLE-Module-Containers12-Updates | SUSE-SLE-Module-Containers-12-2018-273 | security | important | --- | needed | Version update for docker, docker-runc, containerd, golang-github-docker-libnetwork
|
||||
SLE-Module-Containers12-Updates | SUSE-SLE-Module-Containers-12-2018-62 | recommended | low | --- | needed | Recommended update for sle2docker
|
||||
SLE-Module-Public-Cloud12-Updates | SUSE-SLE-Module-Public-Cloud-12-2018-268 | recommended | low | --- | needed | Recommended update for python-ecdsa
|
||||
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-116 | security | moderate | --- | needed | Security update for rsync
|
||||
---- output clipped ----
|
||||
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-89 | security | moderate | --- | needed | Security update for perl-XML-LibXML
|
||||
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-90 | recommended | low | --- | needed | Recommended update for lvm2
|
||||
|
||||
Found 37 applicable patches:
|
||||
37 patches needed (18 security patches)
|
||||
```
|
||||
|
||||
Output is pretty much nicely organised with respective headers. You can easily figure out and plan your patch update accordingly. We can see out of 37 patches available on our system 18 are security ones and needs to be applied on high priority!
|
||||
|
||||
You can install all needed patches by issuing `zypper patch` command.
|
||||
|
||||
##### How to update package using zypper
|
||||
|
||||
To update package using zypper, use `update` or `up` switch followed by package name. In above list updates command we learned that `rsync` package update is available on our server. Let update it now –
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper update rsync
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
|
||||
The following package is going to be upgraded:
|
||||
rsync
|
||||
|
||||
1 package to upgrade.
|
||||
Overall download size: 325.2 KiB. Already cached: 0 B. After the operation, additional 64.0 B will be used.
|
||||
Continue? [y/n/...? shows all options] (y): y
|
||||
Retrieving package rsync-3.1.0-13.10.1.x86_64 (1/1), 325.2 KiB (625.5 KiB unpacked)
|
||||
Retrieving: rsync-3.1.0-13.10.1.x86_64.rpm .......................................................................................................................[done]
|
||||
Checking for file conflicts: .....................................................................................................................................[done]
|
||||
(1/1) Installing: rsync-3.1.0-13.10.1.x86_64 .....................................................................................................................[done]
|
||||
```
|
||||
|
||||
##### Search package using zypper in Suse Linux
|
||||
|
||||
If you are not sure about full package name, no worries. You can search packages in zypper by supplying search string with `se` or `search` switch
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper se lvm
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
S | Name | Summary | Type
|
||||
---|---------------|------------------------------|-----------
|
||||
| libLLVM | Libraries for LLVM | package
|
||||
| libLLVM-32bit | Libraries for LLVM | package
|
||||
| llvm | Low Level Virtual Machine | package
|
||||
| llvm-devel | Header Files for LLVM | package
|
||||
| lvm2 | Logical Volume Manager Tools | srcpackage
|
||||
i+ | lvm2 | Logical Volume Manager Tools | package
|
||||
| lvm2-devel | Development files for LVM2 | package
|
||||
|
||||
```
|
||||
In above example we searched `lvm` string and came up with the list shown above. You can use `Name` in zypper install/remove/update commands.
|
||||
|
||||
##### Check installed package information using zypper
|
||||
|
||||
You can check installed packages details using zypper. `info` or `if` switch will list out information of installed package. It can also displays package details which is not installed. In that case, `Installed` parameter will reflect `No` value.
|
||||
```
|
||||
root@kerneltalks # zypper info rsync
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
|
||||
Information for package rsync:
|
||||
------------------------------
|
||||
Repository : SLES12-SP3-Updates
|
||||
Name : rsync
|
||||
Version : 3.1.0-13.10.1
|
||||
Arch : x86_64
|
||||
Vendor : SUSE LLC <https://www.suse.com/>
|
||||
Support Level : Level 3
|
||||
Installed Size : 625.5 KiB
|
||||
Installed : Yes
|
||||
Status : up-to-date
|
||||
Source package : rsync-3.1.0-13.10.1.src
|
||||
Summary : Versatile tool for fast incremental file transfer
|
||||
Description :
|
||||
Rsync is a fast and extraordinarily versatile file copying tool. It can copy
|
||||
locally, to/from another host over any remote shell, or to/from a remote rsync
|
||||
daemon. It offers a large number of options that control every aspect of its
|
||||
behavior and permit very flexible specification of the set of files to be
|
||||
copied. It is famous for its delta-transfer algorithm, which reduces the amount
|
||||
of data sent over the network by sending only the differences between the
|
||||
source files and the existing files in the destination. Rsync is widely used
|
||||
for backups and mirroring and as an improved copy command for everyday use.
|
||||
```
|
||||
|
||||
##### List repositories using zypper
|
||||
|
||||
To list repo use `lr` or `repos` switch with zypper command. It will list all available repos which includes enabled and not-enabled both repos.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lr
|
||||
Refreshing service 'cloud_update'.
|
||||
Repository priorities are without effect. All enabled repositories share the same priority.
|
||||
|
||||
# | Alias | Name | Enabled | GPG Check | Refresh
|
||||
---|--------------------------------------------------------------------------------------|-------------------------------------------------------|---------|-----------|--------
|
||||
1 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Debuginfo-Pool | SLE-Module-Adv-Systems-Management12-Debuginfo-Pool | No | ---- | ----
|
||||
2 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Debuginfo-Updates | SLE-Module-Adv-Systems-Management12-Debuginfo-Updates | No | ---- | ----
|
||||
3 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Pool | SLE-Module-Adv-Systems-Management12-Pool | Yes | (r ) Yes | No
|
||||
4 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Updates | SLE-Module-Adv-Systems-Management12-Updates | Yes | (r ) Yes | Yes
|
||||
5 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Containers12-Debuginfo-Pool | SLE-Module-Containers12-Debuginfo-Pool | No | ---- | ----
|
||||
6 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Containers12-Debuginfo-Updates | SLE-Module-Containers12-Debuginfo-Updates | No | ---- | ----
|
||||
```
|
||||
|
||||
here you need to check enabled column to check which repos are enabled and which are not.
|
||||
|
||||
##### Add and remove repo in Suse Linux using zypper
|
||||
|
||||
To add repo you will need URI of repo/.repo file or else you end up in below error.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper addrepo -c SLES12-SP3-Updates
|
||||
If only one argument is used, it must be a URI pointing to a .repo file.
|
||||
```
|
||||
|
||||
|
||||
With URI, you can add repo like below :
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper addrepo -c http://smt-ec2.susecloud.net/repo/SUSE/Products/SLE-SDK/12-SP3/x86_64/product?credentials=SMT-http_smt-ec2_susecloud_net SLE-SDK12-SP3-Pool
|
||||
Adding repository 'SLE-SDK12-SP3-Pool' ...........................................................................................................................[done]
|
||||
Repository 'SLE-SDK12-SP3-Pool' successfully added
|
||||
|
||||
URI : http://smt-ec2.susecloud.net/repo/SUSE/Products/SLE-SDK/12-SP3/x86_64/product?credentials=SMT-http_smt-ec2_susecloud_net
|
||||
Enabled : Yes
|
||||
GPG Check : Yes
|
||||
Autorefresh : No
|
||||
Priority : 99 (default priority)
|
||||
|
||||
Repository priorities are without effect. All enabled repositories share the same priority.
|
||||
```
|
||||
|
||||
Use `addrepo` or `ar` switch with `zypper` to add repo in Suse. Followed by URI and lastly you need to provide alias as well.
|
||||
|
||||
To remove repo in Suse, use `removerepo` or `rr` switch with `zypper`.
|
||||
```
|
||||
root@kerneltalks # zypper removerepo nVidia-Driver-SLE12-SP3
|
||||
Removing repository 'nVidia-Driver-SLE12-SP3' ....................................................................................................................[done]
|
||||
Repository 'nVidia-Driver-SLE12-SP3' has been removed.
|
||||
```
|
||||
|
||||
##### Clean local zypper cache
|
||||
|
||||
Cleaning up local zypper caches with `zypper clean` command –
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper clean
|
||||
All repositories have been cleaned up.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/commands/12-useful-zypper-command-examples/
|
||||
|
||||
作者:[KernelTalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a2.kerneltalks.com/wp-content/uploads/2018/02/zypper-command-examples.png
|
||||
[2]:https://en.wikipedia.org/wiki/ZYpp
|
||||
[3]:https://kerneltalks.com/tools/package-installation-linux-yum-apt/
|
||||
[4]:https://kerneltalks.com/howto/download-package-using-yum-apt/
|
||||
@ -0,0 +1,115 @@
|
||||
Create a wiki on your Linux desktop with Zim
|
||||
======
|
||||
|
||||
|
||||
|
||||
There's no denying the usefulness of a wiki, even to a non-geek. You can do so much with one—write notes and drafts, collaborate on projects, build complete websites. And so much more.
|
||||
|
||||
I've used more than a few wikis over the years, either for my own work or at various contract and full-time gigs I've held. While traditional wikis are fine, I really like the idea of [desktop wikis][1] . They're small, easy to install and maintain, and even easier to use. And, as you've probably guessed, there are a number a desktop wikis available for Linux.
|
||||
|
||||
Let's take a look at one of the better desktop wikis: [Zim][2].
|
||||
|
||||
### Getting going
|
||||
|
||||
You can either [download][3] and install Zim from the software's website, or do it the easy way and install it through your distro's package manager.
|
||||
|
||||
Once Zim's installed, start it up.
|
||||
|
||||
A key concept in Zim is notebooks. They're like a collection of wiki pages on a single subject. When you first start Zim, it asks you to specify a folder for your notebooks and the name of a notebook. Zim suggests "Notes" for the name, and `~/Notebooks/` for the folder. Change that if you want. I did.
|
||||
|
||||
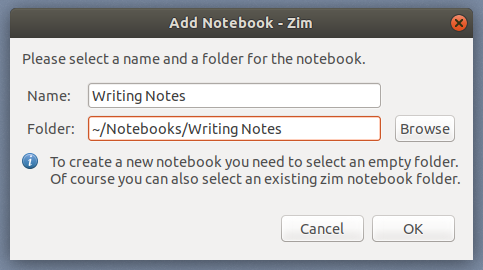
|
||||
|
||||
After you set the name and the folder for your notebook, click **OK**. You get what's essentially a container for your wiki pages.
|
||||
|
||||
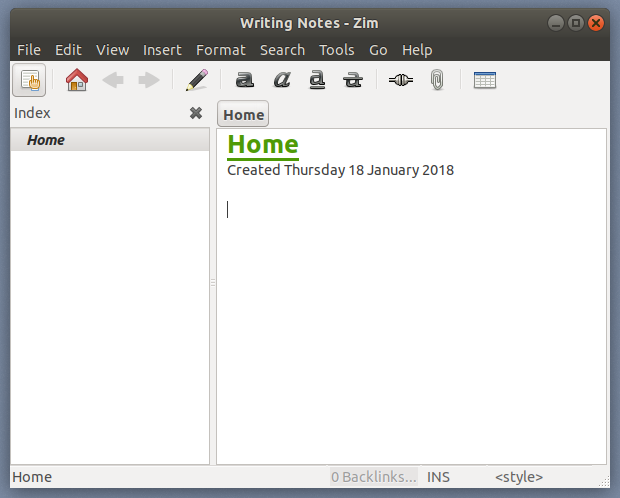
|
||||
|
||||
### Adding pages to a notebook
|
||||
|
||||
So you have a container. Now what? You start adding pages to it, of course. To do that, select **File > New Page**.
|
||||
|
||||
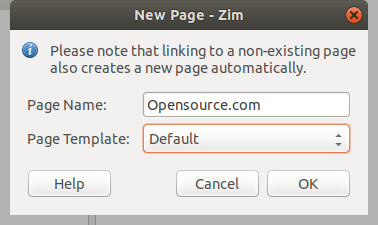
|
||||
|
||||
Enter a name for the page, then click **OK**. From there, you can start typing to add information to that page.
|
||||
|
||||
|
||||
|
||||
That page can be whatever you want it to be: notes for a course you're taking, the outline for a book or article or essay, or an inventory of your books. It's up to you.
|
||||
|
||||
Zim has a number of formatting options, including:
|
||||
|
||||
* Headings
|
||||
* Character formatting
|
||||
* Bullet and numbered lists
|
||||
* Checklists
|
||||
|
||||
|
||||
|
||||
You can also add images and attach files to your wiki pages, and even pull in text from a text file.
|
||||
|
||||
### Zim's wiki syntax
|
||||
|
||||
You can add formatting to a page using the toolbar, but that's not the only way to do the deed. If, like me, you're kind of old school, you can use wiki markup for formatting.
|
||||
|
||||
[Zim's markup][4] is based on the markup that's used with [DokuWiki][5]. It's essentially [WikiText][6] with a few minor variations. To create a bullet list, for example, type an asterisk. Surround a word or a phrase with two asterisks to make it bold.
|
||||
|
||||
### Adding links
|
||||
|
||||
If you have a number of pages in a notebook, it's easy to link them. There are two ways to do that.
|
||||
|
||||
The first way is to use [CamelCase][7] to name the pages. Let's say I have a notebook called "Course Notes." I can rename the notebook for the data analysis course I'm taking by typing "AnalysisCourse." When I want to link to it from another page in the notebook, I just type "AnalysisCourse" and press the space bar. Instant hyperlink.
|
||||
|
||||
The second way is to click the **Insert link** button on the toolbar. Type the name of the page you want to link to in the **Link to** field, select it from the displayed list of options, then click **Link**.
|
||||
|
||||
|
||||
|
||||
I've only been able to link between pages in the same notebook. Whenever I've tried to link to a page in another notebook, the file (which has the extension .txt) always opens in a text editor.
|
||||
|
||||
### Exporting your wiki pages
|
||||
|
||||
There might come a time when you want to use the information in a notebook elsewhere—say, in a document or on a web page. Instead of copying and pasting (and losing formatting), you can export your notebook pages to any of the following formats:
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
|
||||
|
||||
To do that, click on the wiki page you want to export. Then, select **File > Export**. Decide whether to export the whole notebook or just a single page, then click **Forward**.
|
||||
|
||||
|
||||
|
||||
Select the file format you want to use to save the page or notebook. With HTML and LaTeX, you can choose a template. Play around to see what works best for you. For example, if you want to turn your wiki pages into HTML presentation slides, you can choose "SlideShow_s5" from the **Template** list. If you're wondering, that produces slides driven by the [S5 slide framework][8].
|
||||
|
||||
|
||||
|
||||
Click **Forward**. If you're exporting a notebook, you can choose to export the pages as individual files or as one file. You can also point to the folder where you want to save the exported file.
|
||||
|
||||
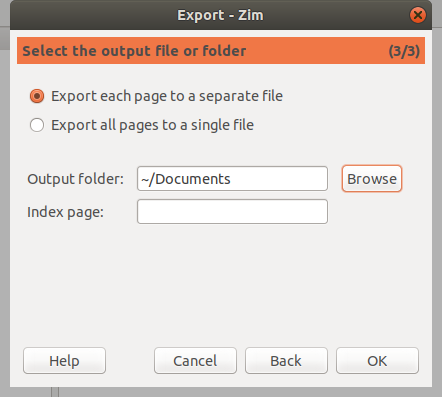
|
||||
|
||||
### Is that all Zim can do?
|
||||
|
||||
Not even close. Zim also has a number of [plugins][9] that expand its capabilities. It even packs a built-in web server that lets you view your notebooks as static HTML files. This is useful for sharing your pages and notebooks on an internal network.
|
||||
|
||||
All in all, Zim is a powerful, yet compact tool for managing your information. It's easily the best desktop wiki I've used, and it's one that I keep going back to.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
250
sources/tech/20180221 Getting started with SQL.md
Normal file
250
sources/tech/20180221 Getting started with SQL.md
Normal file
@ -0,0 +1,250 @@
|
||||
Getting started with SQL
|
||||
======
|
||||
|
||||

|
||||
|
||||
Building a database using SQL is simpler than most people think. In fact, you don't even need to be an experienced programmer to use SQL to create a database. In this article, I'll explain how to create a simple relational database management system (RDMS) using MySQL 5.6. Before I get started, I want to quickly thank [SQL Fiddle][1], which I used to run my script. It provides a useful sandbox for testing simple scripts.
|
||||
|
||||
|
||||
In this tutorial, I'll build a database that uses the simple schema shown in the entity relationship diagram (ERD) below. The database lists students and the course each is studying. I used two entities (i.e., tables) to keep things simple, with only a single relationship and dependency. The entities are called `dbo_students` and `dbo_courses`.
|
||||
|
||||
|
||||
|
||||
The multiplicity of the database is 1-to-many, as each course can contain many students, but each student can study only one course.
|
||||
|
||||
A quick note on terminology:
|
||||
|
||||
1. A table is called an entity.
|
||||
2. A field is called an attribute.
|
||||
3. A record is called a tuple.
|
||||
4. The script used to construct the database is called a schema.
|
||||
|
||||
|
||||
|
||||
### Constructing the schema
|
||||
|
||||
To construct the database, use the `CREATE TABLE <table name>` command, then define each field name and data type. This database uses `VARCHAR(n)` (string) and `INT(n)` (integer), where n refers to the number of values that can be stored. For example `INT(2)` could be 01.
|
||||
|
||||
This is the code used to create the two tables:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
```
|
||||
|
||||
`NOT NULL` means that the field cannot be empty, and `AUTO_INCREMENT` means that when a new tuple is added, the ID number will be auto-generated with 1 added to the previously stored ID number in order to enforce referential integrity across entities. `PRIMARY KEY` is the unique identifier attribute for each table. This means each tuple has its own distinct identity.
|
||||
|
||||
### Relationships as a constraint
|
||||
|
||||
As it stands, the two tables exist on their own with no connections or relationships. To connect them, a foreign key must be identified. In `dbo_students`, the foreign key is `course_studied`, the source of which is within `dbo_courses`, meaning that the field is referenced. The specific command within SQL is called a `CONSTRAINT`, and this relationship will be added using another command called `ALTER TABLE`, which allows tables to be edited even after the schema has been constructed.
|
||||
|
||||
The following code adds the relationship to the database construction script:
|
||||
```
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
```
|
||||
|
||||
Using the `CONSTRAINT` command is not actually necessary, but it's good practice because it means the constraint can be named and it makes maintenance easier. Now that the database is complete, it's time to add some data.
|
||||
|
||||
### Adding data to the database
|
||||
|
||||
`INSERT INTO <table name>` is the command used to directly choose which attributes (i.e., fields) data is added to. The entity name is defined first, then the attributes. Underneath this command is the data that will be added to that entity, creating a tuple. If `NOT NULL` has been specified, it means that the attribute cannot be left blank. The following code shows how to add records to the table:
|
||||
```
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
```
|
||||
|
||||
Now that the database schema is complete and data is added, it's time to run queries on the database.
|
||||
|
||||
### Queries
|
||||
|
||||
Queries follow a set structure using these commands:
|
||||
```
|
||||
SELECT <attributes>
|
||||
|
||||
FROM <entity>
|
||||
|
||||
WHERE <condition>
|
||||
|
||||
```
|
||||
|
||||
To display all records within the `dbo_courses` entity and display the course code and course name, use an asterisk. This is a wildcard that eliminates the need to type all attribute names. (Its use is not recommended in production databases.) The code for this query is:
|
||||
```
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
|
||||
```
|
||||
|
||||
The output of this query shows all tuples in the table, so all available courses can be displayed:
|
||||
```
|
||||
| course_id | course_name |
|
||||
|
||||
|-----------|----------------------|
|
||||
|
||||
| 1 | Software Engineering |
|
||||
|
||||
| 2 | Computer Science |
|
||||
|
||||
| 3 | Computing |
|
||||
|
||||
```
|
||||
|
||||
In a future article, I'll explain more complicated queries using one of the three types of joins: Inner, Outer, or Cross.
|
||||
|
||||
Here is the completed script:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
|
||||
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
|
||||
```
|
||||
|
||||
### Learning more
|
||||
|
||||
SQL isn't difficult; I think it is simpler than programming, and the language is universal to different database systems. Note that `dbo.<entity>` is not a required entity-naming convention; I used it simply because it is the standard in Microsoft SQL Server.
|
||||
|
||||
If you'd like to learn more, the best guide this side of the internet is [W3Schools.com][2]'s comprehensive guide to SQL for all database platforms.
|
||||
|
||||
Please feel free to play around with my database. Also, if you have suggestions or questions, please respond in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/getting-started-sql
|
||||
|
||||
作者:[Aaron Cocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaroncocker
|
||||
[1]:http://sqlfiddle.com
|
||||
[2]:https://www.w3schools.com/sql/default.asp
|
||||
@ -0,0 +1,120 @@
|
||||
cTop - A CLI Tool For Container Monitoring
|
||||
======
|
||||
Recent days Linux containers are famous, even most of us already working on it and few of us start learning about it.
|
||||
|
||||
We have already covered article about the famous GUI (Graphical User Interface) tools such as Portainer & Rancher. This will help us to manage containers through GUI.
|
||||
|
||||
This tutorial will help us to understand and monitor Linux containers through cTop command. It’s a command-line tool like top command.
|
||||
|
||||
### What’s cTop
|
||||
|
||||
[ctop][1] provides a concise and condensed overview of real-time metrics for multiple containers. It’s Top-like interface for container metrics.
|
||||
|
||||
It displays containers metrics such as CPU utilization, Memory utilization, Disk I/O Read & Write, Process ID (PID), and Network Transmit(TX – Transmit FROM this server) and receive(RX – Receive TO this server).
|
||||
|
||||
ctop comes with built-in support for Docker and runC; connectors for other container and cluster systems are planned for future releases.
|
||||
It doesn’t requires any arguments and uses Docker host variables by default.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [Portainer – A Simple Docker Management GUI][2]
|
||||
**(#)** [Rancher – A Complete Container Management Platform For Production Environment][3]
|
||||
|
||||
### How To Install cTop
|
||||
|
||||
Developer offers a simple shell script, which help us to use ctop instantly. What we have to do, just download the ctop shell file at `/bin` directory for global access. Finally assign the execute permission to ctop shell file.
|
||||
|
||||
Download the ctop shell file @ `/usr/local/bin` directory.
|
||||
```
|
||||
$ sudo wget https://github.com/bcicen/ctop/releases/download/v0.7/ctop-0.7-linux-amd64 -O /usr/local/bin/ctop
|
||||
|
||||
```
|
||||
|
||||
Set execute permission to ctop shell file.
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/ctop
|
||||
|
||||
```
|
||||
|
||||
Alternatively you can install and run ctop through docker. Make sure you should have installed docker as a pre-prerequisites for this. To install docker, refer the following link.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How to install Docker in Linux][4]
|
||||
**(#)** [How to play with Docker images on Linux][5]
|
||||
**(#)** [How to play with Docker containers on Linux][6]
|
||||
**(#)** [How to Install, Run Applications inside Docker Containers][7]
|
||||
```
|
||||
$ docker run --rm -ti \
|
||||
--name=ctop \
|
||||
-v /var/run/docker.sock:/var/run/docker.sock \
|
||||
quay.io/vektorlab/ctop:latest
|
||||
|
||||
```
|
||||
|
||||
### How To Use cTop
|
||||
|
||||
Just launch the ctop utility without any arguments. By default it’s bind with `a` key which display of all containers (running and non-running).
|
||||
ctop header shows your system time and total number of containers.
|
||||
```
|
||||
$ ctop
|
||||
|
||||
```
|
||||
|
||||
You might get the output similar to below.
|
||||
![][9]
|
||||
|
||||
### How To Manage Containers
|
||||
|
||||
You can able to administrate the containers using ctop. Select a container that you want to manage then hit `Enter` button and choose required options like start, stop, remove, etc,.
|
||||
![][10]
|
||||
|
||||
### How To Sort Containers
|
||||
|
||||
By default ctop sort the containers using state field. Hit `s` key to sort the containers in the different aspect.
|
||||
![][11]
|
||||
|
||||
### How To View the Containers Metrics
|
||||
|
||||
If you want to view more details & metrics about the container, just select the corresponding which you want to view then hit `o` key.
|
||||
![][12]
|
||||
|
||||
### How To View Container Logs
|
||||
|
||||
Select the corresponding container which you want to view the logs then hit `l` key.
|
||||
![][13]
|
||||
|
||||
### Display Only Active Containers
|
||||
|
||||
Run ctop command with `-a` option to show active containers only.
|
||||
![][14]
|
||||
|
||||
### Open Help Dialog Box
|
||||
|
||||
Run ctop, just hit `h`key to open help section.
|
||||
![][15]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/bcicen/ctop
|
||||
[2]:https://www.2daygeek.com/portainer-a-simple-docker-management-gui/
|
||||
[3]:https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/
|
||||
[4]:https://www.2daygeek.com/install-docker-on-centos-rhel-fedora-ubuntu-debian-oracle-archi-scentific-linux-mint-opensuse/
|
||||
[5]:https://www.2daygeek.com/list-search-pull-download-remove-docker-images-on-linux/
|
||||
[6]:https://www.2daygeek.com/create-run-list-start-stop-attach-delete-interactive-daemonized-docker-containers-on-linux/
|
||||
[7]:https://www.2daygeek.com/install-run-applications-inside-docker-containers/
|
||||
[8]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-1.png
|
||||
[10]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-2.png
|
||||
[11]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-3.png
|
||||
[12]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-4a.png
|
||||
[13]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-7.png
|
||||
[14]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-5.png
|
||||
[15]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-6.png
|
||||
233
sources/tech/20180222 How to configure an Apache web server.md
Normal file
233
sources/tech/20180222 How to configure an Apache web server.md
Normal file
@ -0,0 +1,233 @@
|
||||
How to configure an Apache web server
|
||||
======
|
||||
|
||||

|
||||
|
||||
I have hosted my own websites for many years now. Since switching from OS/2 to Linux more than 20 years ago, I have used [Apache][1] as my server software. Apache is solid, well-known, and quite easy to configure for a basic installation. It is not really that much more difficult to configure for a more complex setup, such as multiple websites.
|
||||
|
||||
Installation and configuration of the Apache web server must be performed as root. Configuring the firewall also needs to be performed as root. Using a browser to view the results of this work should be done as a non-root user. (I use the useron `student` on my virtual host.)
|
||||
|
||||
### Installation
|
||||
|
||||
Note: I use a virtual machine (VM) using Fedora 27 with Apache 2.4.29. If you have a different distribution or a different release of Fedora, your commands and the locations and content of the configuration files may be different. However, the configuration lines you need to modify are the same.
|
||||
|
||||
The Apache web server is easy to install. On my CentOS 6.x server, it just takes a simple `yum` command. It installs all the necessary dependencies if any are missing. I used the `dnf` command below on one of my Fedora virtual machines. The syntax for `dnf` and `yum` are the same except for the name of the command itself.
|
||||
```
|
||||
dnf -y install httpd
|
||||
|
||||
```
|
||||
|
||||
The VM is a very basic desktop installation I am using as a testbed for writing a book. Even on this system, only six dependencies were installed in under a minute.
|
||||
|
||||
All the configuration files for Apache are located in `/etc/httpd/conf` and `/etc/httpd/conf.d`. The data for the websites is located in `/var/www` by default, but you can change that if you want.
|
||||
|
||||
### Configuration
|
||||
|
||||
The primary Apache configuration file is `/etc/httpd/conf/httpd.conf`. It contains a lot of configuration statements that don't need to be changed for a basic installation. In fact, only a few changes must be made to this file to get a basic website up and running. The file is very large so, rather than clutter this article with a lot of unnecessary stuff, I will show only those directives that you need to change.
|
||||
|
||||
First, take a bit of time and browse through the `httpd.conf` file to familiarize yourself with it. One of the things I like about Red Hat versions of most configuration files is the number of comments that describe the various sections and configuration directives in the files. The `httpd.conf` file is no exception, as it is quite well commented. Use these comments to understand what the file is configuring.
|
||||
|
||||
The first item to change is the `Listen` statement, which defines the IP address and port on which Apache is to listen for page requests. Right now, you just need to make this website available to the local machine, so use the `localhost` address. The line should look like this when you finish:
|
||||
```
|
||||
Listen 127.0.0.1:80
|
||||
|
||||
```
|
||||
|
||||
With this directive set to the IP address of the `localhost`, Apache will listen only for connections from the local host. If you want the web server to listen for connections from remote hosts, you would use the host's external IP address.
|
||||
|
||||
The `DocumentRoot` directive specifies the location of the HTML files that make up the pages of the website. That line does not need to be changed because it already points to the standard location. The line should look like this:
|
||||
```
|
||||
DocumentRoot "/var/www/html"
|
||||
|
||||
```
|
||||
|
||||
The Apache installation RPM creates the `/var/www` directory tree. If you wanted to change the location where the website files are stored, this configuration item is used to do that. For example, you might want to use a different name for the `www` subdirectory to make the identification of the website more explicit. That might look like this:
|
||||
```
|
||||
DocumentRoot "/var/mywebsite/html"
|
||||
|
||||
```
|
||||
|
||||
These are the only Apache configuration changes needed to create a simple website. For this little exercise, only one change was made to the `httpd.conf` file—the `Listen` directive. Everything else is already configured to produce a working web server.
|
||||
|
||||
One other change is needed, however: opening port 80 in our firewall. I use [iptables][2] as my firewall, so I change `/etc/sysconfig/iptables` to add a statement that allows HTTP protocol. The entire file looks like this:
|
||||
```
|
||||
# sample configuration for iptables service
|
||||
|
||||
# you can edit this manually or use system-config-firewall
|
||||
|
||||
# please do not ask us to add additional ports/services to this default configuration
|
||||
|
||||
*filter
|
||||
|
||||
:INPUT ACCEPT [0:0]
|
||||
|
||||
:FORWARD ACCEPT [0:0]
|
||||
|
||||
:OUTPUT ACCEPT [0:0]
|
||||
|
||||
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
|
||||
-A INPUT -p icmp -j ACCEPT
|
||||
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
|
||||
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
|
||||
|
||||
-A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
|
||||
|
||||
-A INPUT -j REJECT --reject-with icmp-host-prohibited
|
||||
|
||||
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
|
||||
|
||||
COMMIT
|
||||
|
||||
```
|
||||
|
||||
The line I added is the third from the bottom, which allows incoming traffic on port 80. Now I reload the altered iptables configuration.
|
||||
```
|
||||
[root@testvm1 ~]# cd /etc/sysconfig/ ; iptables-restore iptables
|
||||
|
||||
```
|
||||
|
||||
### Create the index.html file
|
||||
|
||||
The `index.html` file is the default file a web server will serve up when you access the website using just the domain name and not a specific HTML file name. In the `/var/www/html` directory, create a file with the name `index.html`. Add the content `Hello World`. You do not need to add any HTML markup to make this work. The sole job of the web server is to serve up a stream of text data, and the server has no idea what the date is or how to render it. It simply transmits the data stream to the requesting host.
|
||||
|
||||
After saving the file, set the ownership to `apache.apache`.
|
||||
```
|
||||
[root@testvm1 html]# chown apache.apache index.html
|
||||
|
||||
```
|
||||
|
||||
### Start Apache
|
||||
|
||||
Apache is very easy to start. Current versions of Fedora use `systemd`. Run the following commands to start it and then to check the status of the server:
|
||||
```
|
||||
[root@testvm1 ~]# systemctl start httpd
|
||||
|
||||
[root@testvm1 ~]# systemctl status httpd
|
||||
|
||||
● httpd.service - The Apache HTTP Server
|
||||
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; disabled; vendor preset: disabled)
|
||||
|
||||
Active: active (running) since Thu 2018-02-08 13:18:54 EST; 5s ago
|
||||
|
||||
Docs: man:httpd.service(8)
|
||||
|
||||
Main PID: 27107 (httpd)
|
||||
|
||||
Status: "Processing requests..."
|
||||
|
||||
Tasks: 213 (limit: 4915)
|
||||
|
||||
CGroup: /system.slice/httpd.service
|
||||
|
||||
├─27107 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
├─27108 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
├─27109 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
├─27110 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
└─27111 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
|
||||
|
||||
Feb 08 13:18:54 testvm1 systemd[1]: Starting The Apache HTTP Server...
|
||||
|
||||
Feb 08 13:18:54 testvm1 systemd[1]: Started The Apache HTTP Server.
|
||||
|
||||
```
|
||||
|
||||
The commands may be different on your server. On Linux systems that use SystemV start scripts, the commands would be:
|
||||
```
|
||||
[root@testvm1 ~]# service httpd start
|
||||
|
||||
Starting httpd: [Fri Feb 09 08:18:07 2018] [ OK ]
|
||||
|
||||
[root@testvm1 ~]# service httpd status
|
||||
|
||||
httpd (pid 14649) is running...
|
||||
|
||||
```
|
||||
|
||||
If you have a web browser like Firefox or Chrome on your host, you can use the URL `localhost` on the URL line of the browser to display your web page, simple as it is. You could also use a text mode web browser like [Lynx][3] to view the web page. First, install Lynx (if it is not already installed).
|
||||
```
|
||||
[root@testvm1 ~]# dnf -y install lynx
|
||||
|
||||
```
|
||||
|
||||
Then use the following command to display the web page.
|
||||
```
|
||||
[root@testvm1 ~]# lynx localhost
|
||||
|
||||
```
|
||||
|
||||
The result looks like this in my terminal session. I have deleted a lot of the empty space on the page.
|
||||
```
|
||||
Hello World
|
||||
|
||||
|
||||
|
||||
<snip>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||
|
||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||
|
||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||
|
||||
```
|
||||
|
||||
Next, edit your `index.html` file and add a bit of HTML markup so it looks like this:
|
||||
```
|
||||
<h1>Hello World</h1>
|
||||
|
||||
```
|
||||
|
||||
Now refresh the browser. For Lynx, use the key combination Ctrl+R. The results look just a bit different. The text is in color, which is how Lynx displays headings if your terminal supports color, and it is now centered. In a GUI browser the text would be in a large font.
|
||||
```
|
||||
Hello World
|
||||
|
||||
|
||||
|
||||
<snip>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||
|
||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||
|
||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||
|
||||
```
|
||||
|
||||
### Parting thoughts
|
||||
|
||||
As you can see from this little exercise, it is easy to set up an Apache web server. The specifics will vary depending upon your distribution and the version of Apache supplied by that distribution. In my environment, this was a pretty trivial exercise.
|
||||
|
||||
But there is more because Apache is very flexible and powerful. Next month I will discuss hosting multiple websites using a single instance of Apache.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://httpd.apache.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Iptables
|
||||
[3]:http://lynx.browser.org/
|
||||
@ -0,0 +1,324 @@
|
||||
通过ncurses在终端创建一个冒险游戏
|
||||
======
|
||||
怎样使用curses函数读取键盘并操作屏幕。
|
||||
|
||||
我[之前的文章][1]介绍了ncurses库并提供了一个简单的程序展示一些将文本放到屏幕上的一些curses函数。
|
||||
|
||||
### 探险
|
||||
|
||||
当我逐渐长大,家里有了一台苹果2电脑。我和我兄弟正是在这台电脑上自学了如何用AppleSoft BASIC写程序。我在写了一些数学智力游戏之后,继续创造游戏。作为80年代的人,我已经是龙与地下城桌游的粉丝,在游戏中角色扮演一个追求打败怪物并在陌生土地上抢掠的战士或者男巫。所以我创建一个基本的冒险游戏也在情理之中。
|
||||
|
||||
AppleSoft BASIC支持一种简洁的特性:在标准分辨率图形模式(GR模式)下,你可以检测屏幕上特定点的颜色。这为创建一个冒险游戏提供了捷径。比起创建并更新周期性传送到屏幕的内存地图,我现在可以依赖GR模式为我维护地图,我的程序还可以当玩家字符在屏幕四处移动的时候查询屏幕。通过这种方式,我让电脑完成了大部分艰难的工作。因此,我的自顶向下的冒险游戏使用了块状的GR模式图形来展示我的游戏地图。
|
||||
|
||||
我的冒险游戏使用了一张简单的地图,上面有一大片绿地伴着山脉从中间蔓延向下和一个在左上方的大湖。我要粗略地为桌游战役绘制这个地图,其中包含一个允许玩家穿过到远处的狭窄通道。
|
||||
|
||||

|
||||
|
||||
图1.一个有湖和山的简单桌游地图
|
||||
|
||||
你可以用curses绘制这个地图,并用字符代表草地、山脉和水。接下来,我描述怎样使用curses那样做以及如何在Linux终端创建和进行类似的一个冒险游戏?
|
||||
|
||||
### 构建程序
|
||||
|
||||
在我的上一篇文章,我提到了大多数curses程序以相同的一组指令获取终端类型和设置curses环境:
|
||||
|
||||
```
|
||||
initscr();
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
```
|
||||
|
||||
在这个程序,我添加了另外的语句:
|
||||
|
||||
```
|
||||
keypad(stdscr, TRUE);
|
||||
|
||||
```
|
||||
|
||||
这里的TRUE标志允许curses从用户终端读取小键盘和功能键。如果你想要在你的程序中使用上下左右方向键,你需要使用这里的keypad(stdscr, TRUE)。
|
||||
|
||||
这样做了之后,你可以你可以开始在终端屏幕上绘图了。curses函数包括了一系列方法在屏幕上绘制文本。在我之前的文章中,我展示了addch()和addstr()函数以及他们对应的在添加文本之前先移动到指定屏幕位置的副本mvaddch()和mvaddstr()函数。为了创建这个冒险游戏,你可以使用另外一组函数:vline()和hline(),以及它们对应的函数mvvline()和mvhline()。这些mv函数接收屏幕坐标,一个要绘制的字符和要重复此字符的次数。例如,mvhline(1, 2, '-', 20)将会绘制一条开始于第一行第二列并由20个横线组成的线段。
|
||||
|
||||
为了以编程方式绘制地图到终端,让我们先定义这个draw_map()函数:
|
||||
|
||||
```
|
||||
#define GRASS ' '
|
||||
#define EMPTY '.'
|
||||
#define WATER '~'
|
||||
#define MOUNTAIN '^'
|
||||
#define PLAYER '*'
|
||||
|
||||
void draw_map(void)
|
||||
{
|
||||
int y, x;
|
||||
|
||||
/* 绘制探索地图 */
|
||||
|
||||
/* 背景 */
|
||||
|
||||
for (y = 0; y < LINES; y++) {
|
||||
mvhline(y, 0, GRASS, COLS);
|
||||
}
|
||||
|
||||
/* 山和山道 */
|
||||
|
||||
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
|
||||
mvvline(0, x, MOUNTAIN, LINES);
|
||||
}
|
||||
|
||||
mvhline(LINES / 4, 0, GRASS, COLS);
|
||||
|
||||
/* 湖 */
|
||||
|
||||
for (y = 1; y < LINES / 2; y++) {
|
||||
mvhline(y, 1, WATER, COLS / 3);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
在绘制这副地图时,记住填充大块字符到屏幕使用的mvvline()和mvhline()函数。我绘制从0列开始的字符水平线(mvhline)以创建草地区域,直到整个屏幕的高度和宽度。我绘制从0行开始的多条垂直线(mvvline)在此上添加了山脉,绘制单行水平线添加了一条山道(mvhline)。并且,我通过绘制一系列短水平线(mvhline)创建了湖。这种绘制重叠方块的方式看起来似乎并没有效率,但是记住在我们调用refresh()函数之前curses并不会真正更新屏幕。
|
||||
|
||||
绘制完地图,创建游戏就还剩下进入循环让程序等待用户按下上下左右方向键中的一个然后让玩家图标正确移动了。如果玩家想要移动的地方是空的,就应该允许玩家到那里。
|
||||
|
||||
你可以把curses当做捷径使用。比起在程序中实例化一个版本的地图并复制到屏幕(这么复杂),你可以让屏幕为你跟踪所有东西。inch()函数和相关联的mvinch()函数允许你探测屏幕的内容。这让你可以查询curses以了解玩家想要移动到的位置是否被水填满或者被山阻挡。这样做你需要一个之后会用到的一个帮助函数:
|
||||
|
||||
```
|
||||
int is_move_okay(int y, int x)
|
||||
{
|
||||
int testch;
|
||||
|
||||
/* 如果要进入的位置可以进入,返回true */
|
||||
|
||||
testch = mvinch(y, x);
|
||||
return ((testch == GRASS) || (testch == EMPTY));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
如你所见,这个函数探测行x、列y并在空间未被占据的时候返回true,否则返回false。
|
||||
|
||||
这样我们写移动循环就很容易了:从键盘获取一个键值然后根据是上下左右键移动用户字符。这里是一个简单版本的这种循环:
|
||||
|
||||
```
|
||||
|
||||
do {
|
||||
ch = getch();
|
||||
|
||||
/* 测试输入的值并获取方向 */
|
||||
|
||||
switch (ch) {
|
||||
case KEY_UP:
|
||||
if ((y > 0) && is_move_okay(y - 1, x)) {
|
||||
y = y - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_DOWN:
|
||||
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
|
||||
y = y + 1;
|
||||
}
|
||||
break;
|
||||
case KEY_LEFT:
|
||||
if ((x > 0) && is_move_okay(y, x - 1)) {
|
||||
x = x - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_RIGHT
|
||||
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
|
||||
x = x + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
while (1);
|
||||
|
||||
```
|
||||
|
||||
为了在游戏中使用(这个循环),你需要在循环里添加一些代码来启用其它的键(例如传统的移动键WASD)以提供方法供用户退出游戏和在屏幕上四处移动。这里是完整的程序:
|
||||
|
||||
```
|
||||
|
||||
/* quest.c */
|
||||
|
||||
#include
|
||||
#include
|
||||
|
||||
#define GRASS ' '
|
||||
#define EMPTY '.'
|
||||
#define WATER '~'
|
||||
#define MOUNTAIN '^'
|
||||
#define PLAYER '*'
|
||||
|
||||
int is_move_okay(int y, int x);
|
||||
void draw_map(void);
|
||||
|
||||
int main(void)
|
||||
{
|
||||
int y, x;
|
||||
int ch;
|
||||
|
||||
/* 初始化curses */
|
||||
|
||||
initscr();
|
||||
keypad(stdscr, TRUE);
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
clear();
|
||||
|
||||
/* 初始化探索地图 */
|
||||
|
||||
draw_map();
|
||||
|
||||
/* 在左下角初始化玩家 */
|
||||
|
||||
y = LINES - 1;
|
||||
x = 0;
|
||||
|
||||
do {
|
||||
/* 默认获得一个闪烁的光标--表示玩家字符 */
|
||||
|
||||
mvaddch(y, x, PLAYER);
|
||||
move(y, x);
|
||||
refresh();
|
||||
|
||||
ch = getch();
|
||||
|
||||
/* 测试输入的键并获取方向 */
|
||||
|
||||
switch (ch) {
|
||||
case KEY_UP:
|
||||
case 'w':
|
||||
case 'W':
|
||||
if ((y > 0) && is_move_okay(y - 1, x)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
y = y - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_DOWN:
|
||||
case 's':
|
||||
case 'S':
|
||||
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
y = y + 1;
|
||||
}
|
||||
break;
|
||||
case KEY_LEFT:
|
||||
case 'a':
|
||||
case 'A':
|
||||
if ((x > 0) && is_move_okay(y, x - 1)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
x = x - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_RIGHT:
|
||||
case 'd':
|
||||
case 'D':
|
||||
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
x = x + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
while ((ch != 'q') && (ch != 'Q'));
|
||||
|
||||
endwin();
|
||||
|
||||
exit(0);
|
||||
}
|
||||
|
||||
int is_move_okay(int y, int x)
|
||||
{
|
||||
int testch;
|
||||
|
||||
/* 当空间可以进入时返回true */
|
||||
|
||||
testch = mvinch(y, x);
|
||||
return ((testch == GRASS) || (testch == EMPTY));
|
||||
}
|
||||
|
||||
void draw_map(void)
|
||||
{
|
||||
int y, x;
|
||||
|
||||
/* 绘制探索地图 */
|
||||
|
||||
/* 背景 */
|
||||
|
||||
for (y = 0; y < LINES; y++) {
|
||||
mvhline(y, 0, GRASS, COLS);
|
||||
}
|
||||
|
||||
/* 山脉和山道 */
|
||||
|
||||
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
|
||||
mvvline(0, x, MOUNTAIN, LINES);
|
||||
}
|
||||
|
||||
mvhline(LINES / 4, 0, GRASS, COLS);
|
||||
|
||||
/* 湖 */
|
||||
|
||||
for (y = 1; y < LINES / 2; y++) {
|
||||
mvhline(y, 1, WATER, COLS / 3);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
在完整的程序清单中,你可以看见使用curses函数创建游戏的完整布置:
|
||||
|
||||
1) 初始化curses环境。
|
||||
|
||||
2) 绘制地图。
|
||||
|
||||
3) 初始化玩家坐标(左下角)
|
||||
|
||||
4) 循环:
|
||||
|
||||
* 绘制玩家字符。
|
||||
|
||||
* 从键盘获取键值。
|
||||
|
||||
* 对应地上下左右调整玩家坐标。
|
||||
|
||||
* 重复。
|
||||
|
||||
5) 完成时关闭curses环境并退出。
|
||||
|
||||
### 开始玩
|
||||
|
||||
当你运行游戏时,玩家的字符在左下角初始化。当玩家在游戏区域四处移动的时候,程序创建了“一串”点。这样可以展示玩家经过了的点,让玩家避免经过不必要的路径。
|
||||
|
||||

|
||||
|
||||
图2\. 初始化在左下角的玩家
|
||||
|
||||

|
||||
|
||||
图3\. 玩家可以在游戏区域四处移动,例如湖周围和山的通道
|
||||
|
||||
为了创建上面这样的完整冒险游戏,你可能需要在他/她的字符在游戏区域四处移动的时候随机创建不同的怪物。你也可以创建玩家可以发现在打败敌人后可以掠夺的特殊道具,这些道具应能提高玩家的能力。
|
||||
|
||||
但是作为起点,这是一个展示如何使用curses函数读取键盘和操纵屏幕的好程序。
|
||||
|
||||
### 下一步
|
||||
|
||||
这是一个如何使用curses函数更新和读取屏幕和键盘的简单例子。按照你的程序需要做什么,curses可以做得更多。在下一篇文章中,我计划展示如何更新这个简单程序以使用颜色。同时,如果你想要学习更多curses,我鼓励你去读位于Linux文档计划的Pradeep Padala之[如何使用NCURSES编程][2]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/creating-adventure-game-terminal-ncurses
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[Leemeans](https://github.com/leemeans)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/jim-hall
|
||||
[1]:http://www.linuxjournal.com/content/getting-started-ncurses
|
||||
[2]:http://tldp.org/HOWTO/NCURSES-Programming-HOWTO
|
||||
@ -1,108 +0,0 @@
|
||||
# How To Install and Use Encryptpad on Ubuntu 16.04
|
||||
```
|
||||
EncryptPad 是一个免费的开源软件 ,它通过简单的图片转换和命令行接口来查看和修改加密的文件文件 ,它使用 OpenPGP RFC 4880 文件格式 。通过 EncryptPad ,你可以很容易的加密或者解密文件 。你能够像保存密码 ,信用卡信息 ,密码或者密钥文件这类的私人信息 。
|
||||
```
|
||||
## 特性
|
||||
- 支持 windows ,Linux ,和 Max OS 。
|
||||
- 可定制的密码生成器 ,足够健壮的密码 。
|
||||
- 随机密钥文件和密码生成器 。
|
||||
- 至此 GPG 和 EPD 文件格式 。
|
||||
- 通过 CURL 自动从远程远程仓库下载密钥 。
|
||||
- 密钥文件能够存储在加密文件中 。如果生效 ,你不需要每次打开文件都指定密钥文件 。
|
||||
- 提供只读模式来保护文件不被修改 。
|
||||
- 可加密二进制文件 。例如 图片 ,视屏 ,档案 。
|
||||
|
||||
```
|
||||
在这份引导说明中 ,我们将学习如何在 Ubuntu 16.04 中安装和使用 EncryptPad 。
|
||||
```
|
||||
## 环境要求
|
||||
- 在系统上安装了 Ubuntu 16.04 桌面版本 。
|
||||
- 用户在系统上有 sudo 的权限 。
|
||||
|
||||
## 安装 EncryptPad
|
||||
在默认情况下 ,EncryPad 在 Ubuntu 16.04 的默认仓库是不存在的 。你需要安装一个额外的仓库 。你能够通过下面的命令来添加它 :
|
||||
- **sudo apt-add-repository ppa:nilaimogard/webupd8**
|
||||
|
||||
下一步 ,用下面的命令来更新仓库 :
|
||||
- **sudo apt-get update -y**
|
||||
|
||||
最后一步 ,通过下面命令安装 EncryptPAd :
|
||||
- **sudo apt-get install encryptpad encryptcli -y**
|
||||
|
||||
当 EncryptPad 安装完成 ,你需要将它固定到 Ubuntu 的仪表板上 。
|
||||
|
||||
## 使用 EncryptPad 生成密钥和密码
|
||||
```
|
||||
现在 ,去 Ubunntu Dash 上输入 encryptpad ,你能够在你的屏幕上看到下面的图片 :
|
||||
```
|
||||
[![Ubuntu DeskTop][1]][2]
|
||||
|
||||
```
|
||||
下一步 ,点击 EncryptPad 的图标 。你能够看到 EncryptPad 的界面 ,有一个简单的文本编辑器以及顶部菜单栏 。
|
||||
```
|
||||
[![EncryptPad screen][3]][4]
|
||||
|
||||
```
|
||||
首先 ,你需要产生一个密钥和密码来给将来加密/解密任务使用 。点击顶部菜单栏中的 Encryption->Generate Key ,你会看见下面的界面 :
|
||||
```
|
||||
[![Generate key][5]][6]
|
||||
```
|
||||
选择文件保存的路径 ,点击 OK 按钮 ,你将看到下面的界面 。
|
||||
```
|
||||
[![select path][7]][8]
|
||||
```
|
||||
输入密钥文件的密码 ,点击 OK 按钮 ,你将看到下面的界面 :
|
||||
```
|
||||
[![last step][9]][10]
|
||||
```
|
||||
点击 yes 按钮来完成进程 。
|
||||
```
|
||||
## 加密和解密文件
|
||||
```
|
||||
现在 ,密钥文件和密码都已经生成了 。现在可以执行加密和解密操作了 。在这个文件编辑器中打开一个文件文件 ,点击加密图标 ,你会看见下面的界面 :
|
||||
```
|
||||
[![Encry operation][11]][12]
|
||||
```
|
||||
提供需要加密的文件和指定输出的文件 ,提供密码和前面产生的密钥文件 。点击 Start 按钮来开始加密的进程 。当文件被成功的加密 ,会出现下面的界面 :
|
||||
````
|
||||
[![Success Encrypt][13]][14]
|
||||
```
|
||||
文件已经被密码和密钥加密了 。
|
||||
```
|
||||
|
||||
```
|
||||
如果你想解密被加密后的文件 ,打开 EncryptPad ,点击 File Encryption ,选择 Decryptio 操作 ,提供加密文件的地址和输出解密文件的地址 ,提供密钥文件地址 ,点击 Start 按钮 ,如果请求输入密码 ,输入你先前加密使用的密码 ,点击 OK 按钮开始解密过程 。当过程成功完成 ,你会看到 “ File has been decrypted successfully message ” 。
|
||||
```
|
||||
[![decrypt ][16]][17]
|
||||
[![][18]][18]
|
||||
[![][13]]
|
||||
|
||||
|
||||
**注意**
|
||||
```
|
||||
如果你遗忘了你的密码或者丢失了密钥文件 ,没有其他的方法打开你的加密信息 。对于 EncrypePad 支持的格式是没有后门的 。
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dash.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dash.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dashboard.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-key.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-key.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-use-key-file.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-use-key-file.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-start-encryption.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-start-encryption.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-page.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-page.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
267
translated/tech/20171221 Mail transfer agent (MTA) basics.md
Normal file
267
translated/tech/20171221 Mail transfer agent (MTA) basics.md
Normal file
@ -0,0 +1,267 @@
|
||||
邮件传输代理(MTA)基础
|
||||
======
|
||||
|
||||
## 概述
|
||||
|
||||
本教程中,你将学习:
|
||||
|
||||
* 使用 `mail` 命令。
|
||||
* 创建邮件别名。
|
||||
* 配置电子邮件转发。
|
||||
* 了解常见邮件传输代理(MTA),比如,postfix、sendmail、qmail、以及 exim。
|
||||
|
||||
|
||||
|
||||
## 控制邮件去向
|
||||
|
||||
Linux 系统上的电子邮件是使用 MTAs 投递的。你的 MTA 投递邮件到你的系统上的其他用户,以及系统上的其它系统组或者与全世界的其它 MTAs 通讯以投递邮件。
|
||||
|
||||
### 前提条件
|
||||
|
||||
为完成本系列教程的大部分内容,你需要具备 Linux 的基础知识,你需要拥有一个 Linux 系统来实践本教程中的命令。你应该熟悉 GNU 以及 UNIX 命令。有时候不同版本的程序的输出格式可能不同,因此,在你的系统中输出的结果可能与我在下面列出的稍有不同。
|
||||
|
||||
在本教程中,我使用的是 Ubuntu 14.04 LTS 和 sendmail 8.14.4 来做的演示。
|
||||
|
||||
## 邮件传输
|
||||
|
||||
邮件传输代理(比如 sendmail)在用户和系统之间投递邮件。大量的因特网邮件使用简单邮件传输协议(SMTP),但是本地邮件可能是通过文件或者套接字等其它可能的方式来传输的。邮件是一种存储和转发的操作,因此,在用户接收邮件或者接收系统或者通讯联系可用之前,邮件一直是存储在某种文件或者数据库中。配置和确保 MTA 的安全是非常复杂的任务,它们中的大部分内容都已经超出了本教程的范围。
|
||||
|
||||
## mail 命令
|
||||
|
||||
如果你使用 SMTP 协议传输电子邮件,你或许知道你可以使用的许多邮件客户端,包括 `mail`、`mutt`、`alpine`、`notmuch`、以及其它基于主机控制台或者图形界面的邮件客户端。`mail` 命令是最老的、可用于脚本中的、发送和接收以及管理收到的邮件的备用命令。
|
||||
|
||||
你可以使用 `mail` 命令交互式的向列表中的收件人发送信息,或者不使用参数去查看你收到的邮件。Listing 1 展示了如何在你的系统上去发送信息到用户 steve 和 pat,同时抄送拷贝给用户 bob。当提示 cc:和 subject:时,输入相应的抄送用户以及邮件主题,接着输入邮件正文,输入完成后按下 **Ctrl+D** (按下 Ctrl 键并保持再按下 D 之后全部松开)。
|
||||
|
||||
##### Listing 1. 使用 `mail` 交互式发送邮件
|
||||
```
|
||||
ian@attic4-u14:~$ mail steve,pat
|
||||
Cc: bob
|
||||
Subject: Test message 1
|
||||
This is a test message
|
||||
|
||||
Ian
|
||||
```
|
||||
|
||||
如果一切顺利,你的邮件已经发出。如果在这里发生错误,你将看到错误信息。例如,如果你在接收者列表中输入一个无效的用户名,邮件将无法发送。注意在本示例中,所有的用户都在本地系统上存在,因此他们都是有效用户。
|
||||
|
||||
你也可以使用命令行以非交互式发送邮件。Listing 2 展示了如何给用户 steve 和 pat 发送一封邮件。这种方式可以用在脚本中。在不同的包中 `mail` 命令的版本不同。对于抄送(cc:)有些支持一个 `-c` 选项,但是我使用的这个版本不支持这个选项,因此,我仅将邮件发送到收件人。
|
||||
|
||||
Listing 2. 使用 `mail` 命令非交互式发送邮件
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t steve,pat -s "Test message 2" <<< "Another test.\n\nIan"
|
||||
```
|
||||
|
||||
如果你使用没有选项的 `mail` 命令,你将看到一个如 Listing 3 中所展示的那样一个收到的邮件的列表。你将看到用户 steve 有我上面发送的两个信息,再加上我以前发送的一个信息和后来用户 bob 发送的信息。所有的邮件都用 'N' 标记为新邮件。
|
||||
|
||||
Listing 3. 使用 `mail` 查看收到的邮件
|
||||
```
|
||||
steve@attic4-u14:~$ mail
|
||||
"/var/mail/steve": 4 messages 4 new
|
||||
>N 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
N 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
N 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
当前选中的信息使用一个 '>' 来标识,它是 Listing 3 中的第一封邮件。如果你按下 **回车键(Enter)**,将显示下一封未读邮件的第一页。按下 **空格楗(Space bar)** 将显示这个信息的下一页。当你读完这个信息并想返回到 '?' 提示时,按下 **回车键** 再次查看下一封邮件,依次类推。在任何 '?' 提示符下,你可以输入 'h' 再次去查看邮件头。你看过的邮件前面将显示一个 'R' 状态,如 Listing 4 所示。
|
||||
|
||||
Listing 4. 使用 'h' 去显示邮件头
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
在这个图中,Steve 已经读了三个信息,但是没有读来自 bob 的信息。你可以通过数字来选择单个的信息,你也可以通过输入 ‘d' 删除你不想要的信息,或者输入 '3d' 去删除三封信息。如果你输入 'q' 你将退出 `mail` 命令。已读的信息将被转移到你的 home 目录下的 mbox 文件中,而未读的信息仍然保留在你的收件箱中,默认在 /var/mail/$(id -un)。如 Listing 5 所示。
|
||||
|
||||
Listing 5. 使用 'q' 退出 `mail`
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
? q
|
||||
Saved 3 messages in /home/steve/mbox
|
||||
Held 1 message in /var/mail/steve
|
||||
You have mail in /var/mail/steve
|
||||
```
|
||||
|
||||
如果你输入 'x' 而不是使用 'q' 去退出,你的邮箱在退出后将不保留你做的改变。因为这在 /var 文件系统中,你的系统管理员可能仅允许邮件在一个有限的时间范围内去保留三封邮件。去重读或者以其它方式再次处理保存在你的本地邮箱中的邮件,你可以使用 `-f` 选项去指定想要去读的文件。比如,`mail -f mbox`。
|
||||
|
||||
## 邮件别名
|
||||
|
||||
在前面的节中,看了如何在系统上给许多用户发送邮件。你可以使用一个全限定名字(比如 ian@myexampledomain.com)给其它系统上的用户发送邮件。
|
||||
|
||||
有时候你可能希望用户的所有邮件都可以发送到其它地方。比如,你有一个服务器群,你希望所有的 root 用户的邮件都发给核心系统管理员。或者你可能希望去创建一个邮件列表,将邮件发送给一些人。为实现上述目标,你可以使用别名,别名允许你为一个给定的用户名定义一个或者多个目的地。这个目的地或者是其它用户的邮箱、文件、管道、或者是某个进一步处理的命令。你可以在 /etc/mail/aliases 或者 /etc/aliases 中创建别名来实现上述目的。根据你的系统的不同,你可以找到上述其中一个,符号链接到它们、或者其中之一。改变别名文件你需要有 root 权限。
|
||||
|
||||
别名的格式一般是:
|
||||
name: addr_1, addr_2, addr_3, ...
|
||||
name 的位置是一个本地用户名字到别名,或者一个别名和 addr_1,addr_2,... 一个或多个别名。别名可以是一个本地用户,一个本地文件名,另一个别名,一个命令,一个包含文件,或者一个外部地址。
|
||||
|
||||
因此,发送邮件时如何区分别名呢(addr-N 值)?
|
||||
|
||||
* 一个本地用户名是你机器上系统中的一个用户名字。从技术角度来说,它可以通过调用 `getpwnam` 命令找到它。
|
||||
* 一个本地文件名是以 '/' 开始的完全路径和文件名。它必须通过 `sendmail` 来写。信息是追加到这个文件上的。
|
||||
* 一个命令是以一个管道符号开始的(|)。信息是通过标准输入的方式发送到命令的。
|
||||
* 一个包含文件别名是以 `:include:` 和指定的一个路径和文件名开始的。文件中的别名被添加到别名中。
|
||||
* 一个外部地址是一个电子邮件地址,比如 john@somewhere.com。
|
||||
|
||||
|
||||
|
||||
你可以在你的系统中找到一个示例文件,它是与你的 sendmail 包一起安装的,它的位置在 /usr/share/sendmail/examples/db/aliases。它包含一些给 postmaster、MAILER-DAEMON、abuse、和 spam的建议别名。在 Listing 6,我把我的 Ubuntu 14.04 LTS 系统上的一些示例文件,和人为的示例结合起来说明一些可能的情况。
|
||||
|
||||
Listing 6. 人为的 /etc/mail/aliases 示例
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/mail/aliases
|
||||
# First include some default system aliases from
|
||||
# /usr/share/sendmail/examples/db/aliases
|
||||
|
||||
#
|
||||
# Mail aliases for sendmail
|
||||
#
|
||||
# You must run newaliases(1) after making changes to this file.
|
||||
#
|
||||
|
||||
# Required aliases
|
||||
postmaster: root
|
||||
MAILER-DAEMON: postmaster
|
||||
|
||||
# Common aliases
|
||||
abuse: postmaster
|
||||
spam: postmaster
|
||||
|
||||
# Other aliases
|
||||
|
||||
# Send steve's mail to bob and pat instead
|
||||
steve: bob,pat
|
||||
|
||||
# Send pat's mail to a file in her home directory and also to her inbox.
|
||||
# Finally send it to a command that will make another copy.
|
||||
pat: /home/pat/accumulated-mail,
|
||||
\pat,
|
||||
|/home/pat/makemailcopy.sh
|
||||
|
||||
# Mailing list for system administrators
|
||||
sysadmins: :include: /etc/aliases-sysadmins
|
||||
```
|
||||
|
||||
注意那个 pat 既是一个别名也是一个系统中的用户。别名是以递归的方式展开的,因此,如果一个别名也是一个名字,那么它将被展开。Sendmail 并不会给同一个用户发送相同的邮件两遍,因此,如果你正好将 'pat' 作为 'pat' 的别名,那么 sendmail 在已经找到并处理完用户 ’pat‘ 之后,将忽略别名 'pat’。为避免这种问题,你可以在别名前使用一个'\' 做为前缀去指示它是一个不要进一步引起混淆的名字。在这种情况下,pat 的邮件除了文件和命令之外,其余的可能会被发送到他的正常的邮箱中。
|
||||
|
||||
在 aliases 中以 '$' 开始的行是注释,它会被忽略。以空白开始的行会以延续行来处理。
|
||||
|
||||
Listing 7 展示了包含文件 /etc/aliases-sysadmins。
|
||||
|
||||
Listing 7 包含文件 /etc/aliases-sysadmins
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/aliases-sysadmins
|
||||
|
||||
# Mailing list for system administrators
|
||||
bob,pat
|
||||
```
|
||||
|
||||
## newaliases 命令
|
||||
|
||||
sendmail 使用的主要配置文件被编译成数据库文件。邮件别名也是如此。你可以使用 `newaliases` 命令去编译你的 /etc/mail/aliases 和任何包含文件到 /etc/mail/aliases.db 中。注意,那个 `newaliases` 命令等价于 `sendmail -bi`。Listing 8 展示了一个示例。
|
||||
|
||||
Listing 8. 为邮件别名重建数据库
|
||||
```
|
||||
ian@attic4-u14:~$ sudo newaliases
|
||||
/etc/mail/aliases: 7 aliases, longest 62 bytes, 184 bytes total
|
||||
ian@attic4-u14:~$ ls -l /etc/mail/aliases*
|
||||
lrwxrwxrwx 1 root smmsp 10 Dec 8 15:48 /etc/mail/aliases -> ../aliases
|
||||
-rw-r----- 1 smmta smmsp 12288 Dec 13 23:18 /etc/mail/aliases.db
|
||||
```
|
||||
|
||||
## 使用别名的示例
|
||||
|
||||
Listing 9 展示了一个简单的 shell 脚本,它在我的别名示例中以一个命令的方式来使用。
|
||||
|
||||
Listing 9. makemailcopy.sh 脚本
|
||||
```
|
||||
ian@attic4-u14:~$ cat ~pat/makemailcopy.sh
|
||||
#!/bin/bash
|
||||
|
||||
# Note: Target file ~/mail-copy must be writeable by sendmail!
|
||||
cat >> ~pat/mail-copy
|
||||
```
|
||||
|
||||
Listing 10 展示了用于测试时更新的文件。
|
||||
|
||||
Listing 10. /etc/aliases-sysadmins 包含文件
|
||||
```
|
||||
ian@attic4-u14:~$ date
|
||||
Wed Dec 13 22:54:22 EST 2017
|
||||
ian@attic4-u14:~$ mail -t sysadmins -s "sysadmin test 1" <<< "Testing mail"
|
||||
ian@attic4-u14:~$ ls -lrt $(find /var/mail ~pat -type f -mmin -3 2>/dev/null )
|
||||
-rw-rw---- 1 pat mail 2046 Dec 13 22:54 /home/pat/mail-copy
|
||||
-rw------- 1 pat mail 13240 Dec 13 22:54 /var/mail/pat
|
||||
-rw-rw---- 1 pat mail 9442 Dec 13 22:54 /home/pat/accumulated-mail
|
||||
-rw-rw---- 1 bob mail 12522 Dec 13 22:54 /var/mail/bob
|
||||
```
|
||||
|
||||
需要注意的几点:
|
||||
|
||||
* 有一个用户 'mail' 与 sendmail 使用的组名字 'mail' 是一样的。
|
||||
* sendmail 在 /var/mail 保存用户邮件,它也在用户 ‘mail' 的 home 目录下。用户 'ian' 的默认收件箱在 /var/mail/ian 中。
|
||||
* 如果你希望 sendmail 在用户目录下写入文件,这个文件必须允许 sendmail 可写入。与其让任何人都可以写入,还不如定义一个组可写入,组名称为 'mail'。这需要系统管理员来帮你完成。
|
||||
|
||||
|
||||
|
||||
## 使用一个 `.forward` 文件去转发邮件
|
||||
|
||||
别名文件是由系统管理员来管理的。个人用户可以使用它们自己的 home 目录下的 `.forward` 文件去转发他们自己的邮件。你可以在你的 `.forward` 文件中放任何东西,它可以放在别名文件的右侧。这个文件的内容是明文的,不需要编译。当你收到邮件时,sendmail 将检查你的 home 目录中的 `.forward` 文件,然后就像处理别名一样处理它。
|
||||
|
||||
## 邮件队列和 mailq 命令
|
||||
|
||||
Linux 邮件使用存储-转发的处理模式。你已经看到的已接收邮件,在你读它之前一直保存在文件 /var/mail 中。你发出的邮件在接收服务器连接可用之前也会被保存。你可以使用 `mailq` 命令去查看邮件队列。Listing 11 展示了一个发送给外部用户 ian@attic4-c6 的一个邮件示例,以及运行 `mailq` 命令的结果。在这个案例中,当前服务器没有连接到 attic4-c6,因此邮件在与对方服务器连接可用之前一直保存在队列中。
|
||||
|
||||
Listing 11. 使用 `mailq` 命令
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t ian@attic4-c6 -s "External mail" <<< "Testing external mail queues"
|
||||
ian@attic4-u14:~$ mailq
|
||||
MSP Queue status...
|
||||
/var/spool/mqueue-client is empty
|
||||
Total requests: 0
|
||||
MTA Queue status...
|
||||
/var/spool/mqueue (1 request)
|
||||
-----Q-ID----- --Size-- -----Q-Time----- ------------Sender/Recipient-----------
|
||||
vBE4mdE7025908* 29 Wed Dec 13 23:48 <ian@attic4-u14.hopto.org>
|
||||
<ian@attic4-c6.hopto.org>
|
||||
Total requests: 1
|
||||
```
|
||||
|
||||
## 其它邮件传输代理
|
||||
|
||||
为解决使用 sendmail 时安全方面的问题,在 上世纪九十年代开发了几个其它的邮件传输代理。Postfix 或许是最流行的一个,但是 qmail 和 exim 也大量使用。
|
||||
|
||||
Postfix 是 IBM 为代替 sendmail 而研发的。它更快、也易于管理、安全性更好一些。从外表看它非常像 sendmail,但是它的内部完全与 sendmail 不同。
|
||||
|
||||
Qmail 是一个安全、可靠、高效、简单的邮件传输代理,它由 Dan Bernstein 开发。但是,最近几年以来,它的核心包已经不再更新了。Qmail 和几个其它的包已经被吸收到 IndiMail 中了。
|
||||
|
||||
Exim 是另外一个 MTA,它由 University of Cambridge 开发。最初,它的名字是 `EXperimental Internet Mailer`。
|
||||
|
||||
所有的这些 MTAs 都是为代替 sendmail 而设计的,因此,它们它们都兼容 sendmail 的一些格式。它们都能够处理别名和 `.forward` 文件。有些规定了一个 `sendmail` 命令作为一个前端到特定的 MTA 的自有命令。尽管一些选项可能会被静默忽略,但是大多数都允许使用常见的 sendmail 选项。`mailq` 命令是被直接支持的,或者使用一个类似功能的命令来代替。比如,你可以使用 `mailq` 或者 `exim -bp` 去显示 exim 邮件队列。当然,输出可以看到与 sendmail 的 `mailq` 命令的不同之外。
|
||||
|
||||
查看相关的主题,你可以找到更多的关于这些 MTA 的更多信息。
|
||||
|
||||
对 Linux 上的邮件传输代理的介绍到此结束。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-3/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
260
translated/tech/20180116 Analyzing the Linux boot process.md
Normal file
260
translated/tech/20180116 Analyzing the Linux boot process.md
Normal file
@ -0,0 +1,260 @@
|
||||
Linux 启动过程分析
|
||||
======
|
||||
|
||||

|
||||
|
||||
图片由企鹅和靴子“赞助”,由 Opensource.com 修改。CC BY-SA 4.0。
|
||||
|
||||
关于开源软件最古老的笑话是:“代码是自文档化的(self-documenting)”。经验表明,阅读源代码就像听天气预报一样:明智的人依然出门会看看室外的天气。本文讲述了如何运用调试工具来观察和分析 Linux 系统的启动。分析一个正常的系统启动过程,有助于用户和开发人员应对不可避免的故障。
|
||||
|
||||
从某些方面看,启动过程非常简单。内核在单核上启动单线程和同步,似乎可以理解。但内核本身是如何启动的呢?[initrd(initial ramdisk)][1]和引导程序(bootloaders)具有哪些功能?还有,为什么以太网端口上的 LED 灯是常亮的呢?
|
||||
|
||||
请继续阅读寻找答案。GitHub 也提供了 [介绍演示和练习的代码][2]。
|
||||
|
||||
### 启动的开始:OFF 状态
|
||||
|
||||
#### 局域网唤醒(Wake-on-LAN)
|
||||
|
||||
OFF 状态表示系统没有上电,没错吧?表面简单,其实不然。例如,如果系统启用连局域网唤醒机制(WOL),以太网指示灯将亮起。通过以下命令来检查是否是这种情况:
|
||||
|
||||
```
|
||||
$# sudo ethtool <interface name>
|
||||
```
|
||||
|
||||
其中 `<interface name>` 是网络接口的名字,比如 `eth0`。(`ethtool` 可以在同名的 Linux 软件包中找到。)如果输出中的 “Wake-on” 显示 “g”,则远程主机可以通过发送 [魔法数据包(MagicPacket)][3] 来启动系统。如果您无意远程唤醒系统,也不希望其他人这样做,请在系统 BIOS 菜单中将 WOL 关闭,或者用以下方式:
|
||||
|
||||
```
|
||||
$# sudo ethtool -s <interface name> wol d
|
||||
```
|
||||
|
||||
响应魔法数据包的处理器可能是网络接口的一部分,也可能是 [底板管理控制器(Baseboard Management Controller,BMC)][4]。
|
||||
|
||||
#### 英特尔管理引擎、平台路径控制器和 Minix
|
||||
|
||||
BMC 不是唯一的在系统关闭时仍在监听的微控制器(MCU)。x86_64 系统还包含了用于远程管理系统的英特尔管理引擎(IME)软件套件。从服务器到笔记本电脑,各种各样的设备都包含了这项技术,开启了如 KVM 远程控制和英特尔功能许可服务等 [功能][5]。根据 [Intel 自己的检测工具][7],[IME 存在尚未修补的漏洞][6]。坏消息是,要禁用 IME 很难。Trammell Hudson 发起了一个 [me_cleaner 项目][8],它可以清除一些相对恶劣的 IME 组件,比如嵌入式 Web 服务器,但也可能会影响运行它的系统。
|
||||
|
||||
IME 固件和系统管理模式(SMM)软件是 [基于 Minix 操作系统][9] 的,并运行在单独的平台路径控制器上,而不是主 CPU 上。然后,SMM 启动位于主处理器上的通用可扩展固件接口(UEFI)软件,相关内容 [已被提及很多][10]。Google 的 Coreboot 小组已经启动了一个雄心勃勃的 [非扩展性缩减版固件][11](NERF)项目,其目的不仅是要取代 UEFI,还要取代早期的 Linux 用户空间组件,如 systemd。在我们等待这些新成果的同时,Linux 用户现在就可以从 Purism、System76 或 Dell 等处购买 [禁用了 IME][12] 的笔记本电脑,另外 [带有 ARM 64 位处理器笔记本电脑][13] 还是值得期待的。
|
||||
|
||||
####
|
||||
#### 引导程序
|
||||
|
||||
除了启动问题不断的间谍软件外,早期的引导固件还有什么功能呢?引导程序的作用是为新上电的处理器提供运行像 Linux 之类的通用操作系统所需的资源。在开机时,不但没有虚拟内存,在控制器启动之前连 DRAM 也没有。然后,引导程序打开电源,并扫描总线和接口,以定位到内核镜像和根文件系统的位置。U-Boot 和 GRUB 等常见的引导程序支持 USB、PCI 和 NFS 等接口,以及更多的嵌入式专用设备,如 NOR 和 NAND 闪存。引导程序还与 [可信平台模块][14](TPMs)等硬件安全设备进行交互,在启动最开始建立信任链。
|
||||
|
||||
![Running the U-boot bootloader][16]
|
||||
|
||||
在构建主机上的沙盒中运行 U-boot 引导程序。
|
||||
|
||||
包括树莓派、任天堂设备、汽车板和 Chromebook 在内的系统都支持广泛使用的开源引导程序 [U-Boot][17]。它没有系统日志,当发生问题时,甚至没有任何控制台输出。为了便于调试,U-Boot 团队提供了一个沙盒,可以在构建主机甚至是夜间的持续整合(Continuous Integration)系统上测试补丁程序。如果系统上安装了 Git 和 GNU Compiler Collection(GCC)等通用的开发工具,使用 U-Boot 沙盒会相对简单:
|
||||
|
||||
```
|
||||
|
||||
|
||||
$# git clone git://git.denx.de/u-boot; cd u-boot
|
||||
|
||||
$# make ARCH=sandbox defconfig
|
||||
|
||||
$# make; ./u-boot
|
||||
|
||||
=> printenv
|
||||
|
||||
=> help
|
||||
```
|
||||
|
||||
在 x86_64 上运行 U-Boot,可以测试一些棘手的功能,如 [模拟存储设备][2] 重新分区、基于 TPM 的密钥操作以及 USB 设备热插拔等。U-Boot 沙盒甚至可以在 GDB 调试器下单步执行。使用沙盒进行开发的速度比将引导程序刷新到电路板上的测试快 10 倍,并且可以使用 Ctrl + C 恢复一个“变砖”的沙盒。
|
||||
|
||||
### 启动内核
|
||||
|
||||
#### 配置引导内核
|
||||
|
||||
完成任务后,引导程序将跳转到已加载到主内存中的内核代码,并开始执行,传递用户指定的任何命令行选项。内核是什么样的程序呢?用命令 `file /boot/vmlinuz` 可以看到它是一个“bzImage”,意思是一个大的压缩的镜像。Linux 源代码树包含了一个可以解压缩这个文件的工具—— [extract-vmlinux][18]:
|
||||
|
||||
```
|
||||
|
||||
|
||||
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
|
||||
|
||||
$# file vmlinux
|
||||
|
||||
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
|
||||
|
||||
linked, stripped
|
||||
```
|
||||
|
||||
内核是一个 [可执行与可链接格式][19](ELF)的二进制文件,就像 Linux 的用户空间程序一样。这意味着我们可以使用 `binutils` 包中的命令,如 `readelf` 来检查它。比较一下输出,例如:
|
||||
|
||||
```
|
||||
|
||||
|
||||
$# readelf -S /bin/date
|
||||
|
||||
$# readelf -S vmlinux
|
||||
```
|
||||
|
||||
这两个文件中的段内容大致相同。
|
||||
|
||||
所以内核必须像其他的 Linux ELF 文件一样启动,但用户空间程序是如何启动的呢?在 `main()` 函数中?并不确切。
|
||||
|
||||
在 `main()` 函数运行之前,程序需要一个执行上下文,包括堆栈内存以及 `stdio`、`stdout` 和 `stderr` 的文件描述符。用户空间程序从标准库(多数 Linux 系统在用“glibc”)中获取这些资源。参照以下输出:
|
||||
|
||||
```
|
||||
|
||||
|
||||
$# file /bin/date
|
||||
|
||||
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
|
||||
|
||||
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
|
||||
|
||||
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
|
||||
|
||||
stripped
|
||||
```
|
||||
|
||||
ELF 二进制文件有一个解释器,就像 Bash 和 Python 脚本一样,但是解释器不需要像脚本那样用 `#!` 指定,因为 ELF 是 Linux 的原生格式。ELF 解释器通过调用 `_start()` 函数来用所需资源 [配置一个二进制文件][20],这个函数可以从 glibc 源代码包中找到,可以 [用 GDB 查看][21]。内核显然没有解释器,必须自我配置,这是怎么做到的呢?
|
||||
|
||||
用 GDB 检查内核的启动给出了答案。首先安装内核的调试软件包,内核中包含一个未剥离的(unstripped)vmlinux,例如 `apt-get install linux-image-amd64-dbg`,或者从源代码编译和安装你自己的内核,可以参照 [Debian Kernel Handbook][22] 中的指令。`gdb vmlinux` 后加 `info files` 可显示 ELF 段 `init.text`。在 `init.text` 中用 `l *(address)` 列出程序执行的开头,其中 `address` 是 `init.text` 的十六进制开头。用 GDB 可以看到 x86_64 内核从内核文件 [arch/x86/kernel/head_64.S][23] 开始启动,在这个文件中我们找到了汇编函数 `start_cpu0()`,以及一段明确的代码显示在调用 `x86_64 start_kernel()` 函数之前创建了堆栈并解压了 zImage。ARM 32 位内核也有类似的文件 [arch/arm/kernel/head.S][24]。`start_kernel()` 不针对特定的体系结构,所以这个函数驻留在内核的 [init/main.c][25] 中。`start_kernel()` 可以说是 Linux 真正的 `main()` 函数。
|
||||
|
||||
### 从 start_kernel() 到 PID 1
|
||||
|
||||
#### 内核的硬件清单:设备树和 ACPI 表
|
||||
|
||||
在引导时,内核需要硬件信息,不仅仅是已编译过的处理器类型。代码中的指令通过单独存储的配置数据进行扩充。有两种主要的数据存储方法:[设备树][26] 和 [高级配置和电源接口(ACPI)表][27]。内核通过读取这些文件了解每次启动时需要运行的硬件。
|
||||
|
||||
对于嵌入式设备,设备树是已安装硬件的清单。设备树只是一个与内核源代码同时编译的文件,通常与 `vmlinux` 一样位于 `/boot` 目录中。要查看 ARM 设备上的设备树的内容,只需对名称与 `/boot/*.dtb` 匹配的文件执行 `binutils` 包中的 `strings` 命令即可,`dtb` 是指一个设备树二进制文件。显然,只需编辑构成它的类 JSON 文件并重新运行随内核源代码提供的特殊 `dtc` 编译器即可修改设备树。虽然设备树是一个静态文件,其文件路径通常由命令行引导程序传递给内核,但近年来增加了一个 [设备树覆盖][28] 的功能,内核在启动后可以动态加载热插拔的附加设备。
|
||||
|
||||
x86 系列和许多企业级的 ARM64 设备使用 [ACPI][27] 机制。与设备树不同的是,ACPI 信息存储在内核在启动时通过访问板载 ROM 而创建的 `/sys/firmware/acpi/tables` 虚拟文件系统中。读取 ACPI 表的简单方法是使用 `acpica-tools` 包中的 `acpidump` 命令。例如:
|
||||
|
||||
![ACPI tables on Lenovo laptops][30]
|
||||
|
||||
|
||||
联想笔记本电脑的 ACPI 表都是为 Windows 2001 设置的。
|
||||
|
||||
是的,你的 Linux 系统已经准备好用于 Windows 2001 了,你要考虑安装吗?与设备树不同,ACPI 具有方法和数据,而设备树更多地是一种硬件描述语言。ACPI 方法在启动后仍处于活动状态。例如,运行 `acpi_listen` 命令(在 `apcid` 包中),然后打开和关闭笔记本机盖会发现 ACPI 功能一直在运行。暂时地和动态地 [覆盖 ACPI 表][31] 是可能的,而永久地改变它需要在引导时与 BIOS 菜单交互或刷新 ROM。如果你遇到那么多麻烦,也许你应该 [安装 coreboot][32],这是开源固件的替代品。
|
||||
|
||||
#### 从 start_kernel() 到用户空间
|
||||
|
||||
[init/main.c][25] 中的代码竟然是可读的,而且有趣的是,它仍然在使用 1991 - 1992 年的 Linus Torvalds 的原始版权。在一个刚启动的系统上运行 `dmesg | head`,其输出主要来源于此文件。第一个 CPU 注册到系统中,全局数据结构被初始化,并且调度程序、中断处理程序(IRQ)、定时器和控制台按照严格的顺序逐一启动。在 `timekeeping_init()` 函数运行之前,所有的时间戳都是零。内核初始化的这部分是同步的,也就是说执行只发生在一个线程中,在最后一个完成并返回之前,没有任何函数会被执行。因此,即使在两个系统之间,`dmesg` 的输出也是完全可重复的,只要它们具有相同的设备树或 ACPI 表。Linux 的行为就像在 MCU 上运行的 RTOS(实时操作系统)一样,如 QNX 或 VxWorks。这种情况持续存在于函数 `rest_init()` 中,该函数在终止时由 `start_kernel()` 调用。
|
||||
|
||||
![Summary of early kernel boot process.][34]
|
||||
|
||||
早期的内核启动流程
|
||||
|
||||
函数 `rest_init()` 产生了一个新进程以运行 `kernel_init()`,并调用了 `do_initcalls()`。用户可以通过将 `initcall_debug` 附加到内核命令行来监控 `initcalls`,这样每运行一次 `initcall` 函数就会产生 `dmesg` 条目。`initcalls` 会历经七个连续的级别:early、core、postcore、arch、subsys、fs、device 和 late。`initcalls` 最为用户可见的部分是所有处理器外围设备的探测和设置:总线、网络、存储和显示器等等,同时加载其内核模块。`rest_init()` 也会在引导处理器上产生第二个线程,它首先运行 `cpu_idle()`,然后等待调度器分配工作。
|
||||
|
||||
`kernel_init()` 也可以 [设置对称多处理(SMP)结构][35]。在较新的内核中,如果 `dmesg` 的输出中出现“启动第二个 CPU...”等字样,系统便使用了 SMP。SMP 通过“热插拔”CPU 来进行,这意味着它用状态机来管理其生命周期,这种状态机在概念上类似于热插拔的 U 盘一样。内核的电源管理系统经常会使某个核(core)离线,然后根据需要将其唤醒,以便在不忙的机器上反复调用同一段的 CPU 热插拔代码。观察电源管理系统调用 CPU 热插拔代码的 [BCC 工具][36] 称为 `offcputime.py`。
|
||||
|
||||
请注意,`init/main.c` 中的代码在 `smp_init()` 运行时几乎已执行完毕:引导处理器已经完成了大部分其他核无需重复的一次性初始化操作。尽管如此,跨 CPU 的线程仍然要在每个核上生成,以管理每个核的中断(IRQ)、工作队列、定时器和电源事件。例如,通过 `ps -o psr` 命令可以查看服务 softirqs 和 workqueues 在每个 CPU 上的线程。
|
||||
|
||||
```
|
||||
|
||||
|
||||
$\# ps -o pid,psr,comm $(pgrep ksoftirqd)
|
||||
|
||||
PID PSR COMMAND
|
||||
|
||||
7 0 ksoftirqd/0
|
||||
|
||||
16 1 ksoftirqd/1
|
||||
|
||||
22 2 ksoftirqd/2
|
||||
|
||||
28 3 ksoftirqd/3
|
||||
|
||||
|
||||
|
||||
$\# ps -o pid,psr,comm $(pgrep kworker)
|
||||
|
||||
PID PSR COMMAND
|
||||
|
||||
4 0 kworker/0:0H
|
||||
|
||||
18 1 kworker/1:0H
|
||||
|
||||
24 2 kworker/2:0H
|
||||
|
||||
30 3 kworker/3:0H
|
||||
|
||||
[ . . . ]
|
||||
```
|
||||
|
||||
其中,PSR 字段代表“处理器”。每个核还必须拥有自己的定时器和 `cpuhp` 热插拔处理程序。
|
||||
|
||||
那么用户空间是如何启动的呢?在最后,`kernel_init()` 寻找可以代表它执行 `init` 进程的 `initrd`。如果没有找到,内核直接执行 `init` 本身。那么为什么需要 `initrd` 呢?
|
||||
|
||||
#### 早期的用户空间:谁规定要用 initrd?
|
||||
|
||||
除了设备树之外,在启动时可以提供给内核的另一个文件路径是 `initrd` 的路径。`initrd` 通常位于 `/boot` 目录中,与 x86 系统中的 bzImage 文件 vmlinuz 一样,或是与 ARM 系统中的 uImage 和设备树相同。用 `initramfs-tools-core` 软件包中的 `lsinitramfs` 工具可以列出 `initrd` 的内容。发行版的 `initrd` 方案包含了最小化的 `/bin`、`/sbin` 和 `/etc` 目录以及内核模块,还有 `/scripts` 中的一些文件。所有这些看起来都很熟悉,因为 `initrd` 大致上是一个简单的最小化 Linux 根文件系统。看似相似,其实不然,因为位于虚拟内存盘中的 `/bin` 和 `/sbin` 目录下的所有可执行文件几乎都是指向 [BusyBox binary][38] 的符号链接,由此导致 `/bin` 和 `/sbin` 目录比 glibc 的小 10 倍。
|
||||
|
||||
如果要做的只是加载一些模块,然后在普通的根文件系统上启动 `init`,为什么还要创建一个 `initrd` 呢?想想一个加密的根文件系统,解密可能依赖于加载一个位于根文件系统 `/lib/modules` 的内核模块,当然还有 `initrd` 中的。加密模块可能被静态地编译到内核中,而不是从文件加载,但有多种原因不希望这样做。例如,用模块静态编译内核可能会使其太大而不能适应存储空间,或者静态编译可能会违反软件许可条款。不出所料,存储、网络和人类输入设备(HID)驱动程序也可能存在于 `initrd` 中。`initrd` 基本上包含了任何挂载根文件系统所必需的非内核代码。`initrd` 也是用户存放 [自定义ACPI][38] 表代码的地方。
|
||||
|
||||
![Rescue shell and a custom <code>initrd</code>.][40]
|
||||
|
||||
救援模式的 shell 和自定义的 `initrd` 还是很有意思的。
|
||||
|
||||
`initrd` 对测试文件系统和数据存储设备也很有用。将这些测试工具存放在 `initrd` 中,并从内存中运行测试,而不是从被测对象中运行。
|
||||
|
||||
最后,当 `init` 开始运行时,系统就启动啦!由于辅助处理器正在运行,机器已经成为我们所熟知和喜爱的异步、可抢占、不可预测和高性能的生物。的确,`ps -o pid,psr,comm -p 1` 很容易显示已不在引导处理器上运行的用户空间的 `init` 进程。
|
||||
|
||||
### Summary
|
||||
### 总结
|
||||
|
||||
Linux 引导过程听起来或许令人生畏,即使考虑到简单嵌入式设备上的软件数量。换个角度来看,启动过程相当简单,因为启动中没有抢占、RCU 和竞争条件等扑朔迷离的复杂功能。只关注内核和 PID 1 会忽略了引导程序和辅助处理器为运行内核执行的大量准备工作。虽然内核在 Linux 程序中是独一无二的,但通过一些检查 ELF 文件的工具也可以了解其结构。学习一个正常的启动过程,可以帮助运维人员处理启动的故障。
|
||||
|
||||
要了解更多信息,请参阅 Alison Chaiken 的演讲——[Linux: The first second][41],将在 1 月 22 日至 26 日在悉尼举行。参见 [linux.conf.au][42]。
|
||||
|
||||
感谢 [Akkana Peck][43] 的提议和指正。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/analyzing-linux-boot-process
|
||||
|
||||
作者:[Alison Chaiken][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[2]:https://github.com/chaiken/LCA2018-Demo-Code
|
||||
[3]:https://en.wikipedia.org/wiki/Wake-on-LAN
|
||||
[4]:https://lwn.net/Articles/630778/
|
||||
[5]:https://www.youtube.com/watch?v=iffTJ1vPCSo&amp;amp;amp;amp;amp;index=65&amp;amp;amp;amp;amp;list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[6]:https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&amp;amp;amp;amp;amp;languageid=en-fr
|
||||
[7]:https://www.intel.com/content/www/us/en/support/articles/000025619/software.html
|
||||
[8]:https://github.com/corna/me_cleaner
|
||||
[9]:https://lwn.net/Articles/738649/
|
||||
[10]:https://lwn.net/Articles/699551/
|
||||
[11]:https://trmm.net/NERF
|
||||
[12]:https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled
|
||||
[13]:https://lwn.net/Articles/733837/
|
||||
[14]:https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639
|
||||
[15]:/file/383501
|
||||
[16]:https://opensource.com/sites/default/files/u128651/linuxboot_1.png "Running the U-boot bootloader"
|
||||
[17]:http://www.denx.de/wiki/DULG/Manual
|
||||
[18]:https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux
|
||||
[19]:http://man7.org/linux/man-pages/man5/elf.5.html
|
||||
[20]:https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html
|
||||
[21]:https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e
|
||||
[22]:http://kernel-handbook.alioth.debian.org/
|
||||
[23]:https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S
|
||||
[24]:https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S
|
||||
[25]:https://github.com/torvalds/linux/blob/master/init/main.c
|
||||
[26]:https://www.youtube.com/watch?v=m_NyYEBxfn8
|
||||
[27]:http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf
|
||||
[28]:http://lwn.net/Articles/616859/
|
||||
[29]:/file/383506
|
||||
[30]:https://opensource.com/sites/default/files/u128651/linuxboot_2.png "ACPI tables on Lenovo laptops"
|
||||
[31]:https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt
|
||||
[32]:https://www.coreboot.org/Supported_Motherboards
|
||||
[33]:/file/383511
|
||||
[34]:https://opensource.com/sites/default/files/u128651/linuxboot_3.png "Summary of early kernel boot process."
|
||||
[35]:http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc
|
||||
[36]:http://www.brendangregg.com/ebpf.html
|
||||
[37]:https://www.busybox.net/
|
||||
[38]:https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt
|
||||
[39]:/file/383516
|
||||
[40]:https://opensource.com/sites/default/files/u128651/linuxboot_4.png "Rescue shell and a custom <code>initrd</code>."
|
||||
[41]:https://rego.linux.conf.au/schedule/presentation/16/
|
||||
[42]:https://linux.conf.au/index.html
|
||||
[43]:http://shallowsky.com/
|
||||
@ -0,0 +1,132 @@
|
||||
Python 中的 Hello World 和字符串操作
|
||||
======
|
||||
|
||||
|
||||
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 github 上找到。
|
||||
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的[视频][3]。
|
||||
|
||||
[Python 的 Hello World 和字符串操作视频][2]
|
||||
|
||||
#### ** 开始 (先决条件)
|
||||
|
||||
在你的操作系统上安装 Anaconda(Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
|
||||
在 Windows 上安装 Anaconda: [链接[5]
|
||||
|
||||
在 Mac 上安装 Anaconda: [链接][6]
|
||||
|
||||
在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
#### 打开一个 Jupyter Notebook
|
||||
|
||||
打开你的终端(Mac)或命令行,并输入以下内容([请参考视频中的 1:16 处][8])来打开 Jupyter Notebook:
|
||||
```
|
||||
jupyter notebook
|
||||
|
||||
```
|
||||
|
||||
#### 打印语句/Hello World
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 **shift + 回车**来执行代码。
|
||||
```
|
||||
# This is a one line comment
|
||||
print('Hello World!')
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
打印输出 “Hello World!”
|
||||
|
||||
#### 字符串和字符串操作
|
||||
|
||||
字符串是 python 类的一种特殊类型。作为对象,在类中,你可以使用 .methodName() 来调用字符串对象的方法。字符串类在 python 中默认是可用的,所以你不需要 import 语句来使用字符串对象接口。
|
||||
```
|
||||
# Create a variable
|
||||
# Variables are used to store information to be referenced
|
||||
# and manipulated in a computer program.
|
||||
firstVariable = 'Hello World'
|
||||
print(firstVariable)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
输出打印变量 firstVariable
|
||||
```
|
||||
# Explore what various string methods
|
||||
print(firstVariable.lower())
|
||||
print(firstVariable.upper())
|
||||
print(firstVariable.title())
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 .lower()、.upper() 和 title() 方法输出
|
||||
```
|
||||
# Use the split method to convert your string into a list
|
||||
print(firstVariable.split(' '))
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 split 方法输出(此例中以空格分隔)
|
||||
```
|
||||
# You can add strings together.
|
||||
a = "Fizz" + "Buzz"
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
字符串连接
|
||||
|
||||
#### 查询方法的功能
|
||||
|
||||
对于新程序员,他们经常问你如何知道每种方法的功能。Python 提供了两种方法来实现。
|
||||
|
||||
1.(在不在 Jupyter Notebook 中都可用)使用 **help** 查询每个方法的功能。
|
||||
|
||||
|
||||
|
||||
![][9]
|
||||
查询每个方法的功能
|
||||
|
||||
2. (Jupyter Notebook exclusive) You can also look up what a method does by having a question mark after a method.
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
|
||||
```
|
||||
# To look up what each method does in jupyter (doesnt work outside of jupyter)
|
||||
firstVariable.lower?
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
在 Jupyter 中查找每个方法的功能
|
||||
|
||||
#### 结束语
|
||||
|
||||
如果你对本文或在[ YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [github][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulation-gdgwd8ymp
|
||||
|
||||
作者:[Michael][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/mgalarny
|
||||
[1]:https://github.com/mGalarnyk/Python_Tutorials/blob/master/Python_Basics/Intro/Python3Basics_Part1.ipynb
|
||||
[2]:https://www.youtube.com/watch?v=JqGjkNzzU4s
|
||||
[3]:https://www.youtube.com/watch?v=kApPBm1YsqU
|
||||
[4]:https://www.continuum.io/downloads
|
||||
[5]:https://medium.com/@GalarnykMichael/install-python-on-windows-anaconda-c63c7c3d1444
|
||||
[6]:https://medium.com/@GalarnykMichael/install-python-on-mac-anaconda-ccd9f2014072
|
||||
[7]:https://medium.com/@GalarnykMichael/install-python-on-ubuntu-anaconda-65623042cb5a
|
||||
[8]:https://youtu.be/JqGjkNzzU4s?t=1m16s
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==
|
||||
[10]:https://medium.com/@GalarnykMichael/python-basics-2-simple-math-4ac7cc928738
|
||||
@ -0,0 +1,93 @@
|
||||
如何在 Linux 中轻松修正拼写错误的 Bash 命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
我知道你可以按下向上箭头来调出你运行过的命令,然后使用左/右键移动到拼写错误的单词,并更正拼写错误的单词,最后按回车键再次运行它,对吗?可是等等。还有一种更简单的方法可以纠正 GNU/Linux 中拼写错误的 Bash 命令。这个教程解释了如何做到这一点。请继续阅读。
|
||||
|
||||
### 在 Linux 中纠正拼写错误的 Bash 命令
|
||||
|
||||
你有没有运行过类似于下面的错误输入命令?
|
||||
```
|
||||
$ unme -r
|
||||
bash: unme: command not found
|
||||
|
||||
```
|
||||
|
||||
你注意到了吗?上面的命令中有一个错误。我在 “uname” 命令缺少了字母 “a”。
|
||||
|
||||
我在很多时候犯过这种愚蠢的错误。在我知道这个技巧之前,我习惯按下向上箭头来调出命令并转到命令中拼写错误的单词,纠正拼写错误,然后按回车键再次运行该命令。但相信我。下面的技巧非常易于纠正你刚刚运行的命令中的任何拼写错误。
|
||||
|
||||
要轻松更正上述拼写错误的命令,只需运行:
|
||||
```
|
||||
$ ^nm^nam^
|
||||
|
||||
```
|
||||
|
||||
这会将 “uname” 命令中将 “nm” 替换为 “nam”。很酷,是吗?它不仅纠正错别字,而且还能运行命令。查看下面的截图。
|
||||
|
||||
![][2]
|
||||
|
||||
当你在命令中输入错字时使用这个技巧。请注意,它仅适用于 Bash shell。
|
||||
|
||||
**额外提示:**
|
||||
|
||||
你有没有想过在使用 “cd” 命令时如何自动纠正拼写错误?没有么?没关系!下面的技巧将解释如何做到这一点。
|
||||
|
||||
这个技巧只能纠正使用 “cd” 命令时的拼写错误。
|
||||
|
||||
比如说,你想使用命令切换到 “Downloads” 目录:
|
||||
```
|
||||
$ cd Donloads
|
||||
bash: cd: Donloads: No such file or directory
|
||||
|
||||
```
|
||||
|
||||
哎呀!没有名称为 “Donloads” 的文件或目录。是的,正确的名称是 “Downloads”。上面的命令中缺少 “w”。
|
||||
|
||||
要解决此问题并在使用 cd 命令时自动更正错误,请编辑你的 **.bashrc** 文件:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
最后添加以下行。
|
||||
```
|
||||
[...]
|
||||
shopt -s cdspell
|
||||
|
||||
```
|
||||
|
||||
输入 **:wq** 保存并退出文件。
|
||||
|
||||
最后,运行以下命令更新更改。
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
现在,如果在使用 cd 命令时路径中存在任何拼写错误,它将自动更正并进入正确的目录。
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的命令中看到的那样,我故意输错(“Donloads” 而不是 “Downloads”),但 Bash 自动检测到正确的目录名并 cd 进入它。
|
||||
|
||||
[**Fish**][4] 和**Zsh** shell 内置的此功能。所以,如果你使用的是它们,那么你不需要这个技巧。
|
||||
|
||||
然而,这个技巧有一些局限性。它只适用于使用正确的大小写。在上面的例子中,如果你输入的是 “cd donloads” 而不是 “cd Donloads”,它将无法识别正确的路径。另外,如果路径中缺少多个字母,它也不起作用。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/misspelled-command.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/cd-command.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
@ -0,0 +1,159 @@
|
||||
Python Global 关键字(含示例)
|
||||
======
|
||||
在读这篇文章之前,确保你对 [Python Global,Local 和 Nonlocal 变量][1] 有一定的基础。
|
||||
|
||||
### global 关键字简介
|
||||
|
||||
在 Python 中,`global` 关键字允许你修改当前范围之外的变量。它用于创建全局变量并在本地上下文中更改变量。
|
||||
|
||||
### global 关键字的规则
|
||||
在 Python 中,有关 `global` 关键字基本规则如下:
|
||||
|
||||
* 当我们在一个函数中创建一个变量时,默认情况下它是本地变量。
|
||||
* 当我们在一个函数之外定义一个变量时,默认情况下它是全局变量。你不必使用 `global` 关键字。
|
||||
* 我们使用 `global` 关键字在一个函数中来读写全局变量。
|
||||
* 在一个函数外使用 `global` 关键字没有效果。
|
||||
|
||||
#### 使用 global 关键字(含示例)
|
||||
|
||||
我们来举个例子。
|
||||
|
||||
##### 示例 1:从函数内部访问全局变量
|
||||
|
||||
c = 1 # 全局变量
|
||||
|
||||
def add():
|
||||
print(c)
|
||||
|
||||
add()
|
||||
|
||||
运行程序,输出为:
|
||||
|
||||
1
|
||||
|
||||
但是我们可能有一些场景需要从函数内部修改全局变量。
|
||||
|
||||
##### 示例 2:在函数内部修改全局变量
|
||||
|
||||
c = 1 # 全局变量
|
||||
|
||||
def add():
|
||||
c = c + 2 # 将 c 增加 2
|
||||
print(c)
|
||||
|
||||
add()
|
||||
|
||||
运行程序,输出显示错误:
|
||||
|
||||
UnboundLocalError: local variable 'c' referenced before assignment
|
||||
|
||||
这是因为在函数中,我们只能访问全局变量但是不能修改它。
|
||||
|
||||
解决的办法是使用 `global` 关键字。
|
||||
|
||||
##### 示例 3:使用 global 在函数中改变全局变量
|
||||
|
||||
c = 0 # global variable
|
||||
|
||||
def add():
|
||||
global c
|
||||
c = c + 2 # 将 c 增加 2
|
||||
print("Inside add():", c)
|
||||
|
||||
add()
|
||||
print("In main:", c)
|
||||
|
||||
运行程序,输出为:
|
||||
|
||||
Inside add(): 2
|
||||
In main: 2
|
||||
|
||||
在上面的程序中,我们在 `add()` 函数中定义了 c 将其作为 global 关键字。
|
||||
|
||||
然后,我们给变量 c 增加 `1`,(译注:这里应该是给 c 增加 `2` )即 `c = c + 2`。之后,我们调用了 `add()` 函数。最后,打印全局变量 c。
|
||||
|
||||
正如我们所看到的,在函数外的全局变量也发生了变化,`c = 2`。
|
||||
|
||||
### Python 模块中的全局变量
|
||||
|
||||
在 Python 中,我们创建一个单独的模块 `config.py` 来保存全局变量并在同一个程序中的 Python 模块之间共享信息。
|
||||
|
||||
以下是如何通过 Python 模块共享全局变量。
|
||||
|
||||
##### 示例 4:在Python模块中共享全局变量
|
||||
|
||||
创建 `config.py` 文件来存储全局变量
|
||||
|
||||
a = 0
|
||||
b = "empty"
|
||||
|
||||
创建 `update.py` 文件来改变全局变量
|
||||
|
||||
import config
|
||||
|
||||
config.a = 10
|
||||
config.b = "alphabet"
|
||||
|
||||
创建 `main.py` 文件来测试其值的变化
|
||||
|
||||
import config
|
||||
import update
|
||||
|
||||
print(config.a)
|
||||
print(config.b)
|
||||
|
||||
运行 `main.py`,输出为:
|
||||
|
||||
10
|
||||
alphabet
|
||||
|
||||
在上面,我们创建了三个文件: `config.py`, `update.py` 和 `main.py`。
|
||||
|
||||
在 `config.py` 模块中保存了全局变量 a 和 b。在 `update.py` 文件中,我们导入了 `config.py` 模块并改变了 a 和 b 的值。同样,在 `main.py` 文件,我们导入了 `config.py` 和 `update.py` 模块。最后,我们打印并测试全局变量的值,无论它们是否被改变。
|
||||
|
||||
### 在嵌套函数中的全局变量
|
||||
|
||||
以下是如何在嵌套函数中使用全局变量。
|
||||
|
||||
##### 示例 5:在嵌套函数中使用全局变量
|
||||
|
||||
def foo():
|
||||
x = 20
|
||||
|
||||
def bar():
|
||||
global x
|
||||
x = 25
|
||||
|
||||
print("Before calling bar: ", x)
|
||||
print("Calling bar now")
|
||||
bar()
|
||||
print("After calling bar: ", x)
|
||||
|
||||
foo()
|
||||
print("x in main : ", x)
|
||||
|
||||
输出为:
|
||||
|
||||
Before calling bar: 20
|
||||
Calling bar now
|
||||
After calling bar: 20
|
||||
x in main : 25
|
||||
|
||||
在上面的程序中,我们在一个嵌套函数 `bar()` 中声明了全局变量。在 `foo()` 函数中, 变量 x 没有全局关键字的作用。
|
||||
|
||||
调用 `bar()` 之前和之后, 变量 x 取本地变量的值,即 `x = 20`。在 `foo()` 函数之外,变量 x 会取在函数 `bar()` 中的值,即 `x = 25`。这是因为在 `bar()` 中,我们对 x 使用 `global` 关键字创建了一个全局变量(本地范围)。
|
||||
|
||||
如果我们在 `bar()` 函数内进行了任何修改,那么这些修改就会出现在本地范围之外,即 `foo()`。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://www.programiz.com/python-programming/global-keyword](https://www.programiz.com/python-programming/global-keyword)
|
||||
|
||||
作者:[programiz][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.programiz.com
|
||||
[1]:https://www.programiz.com/python-programming/global-local-nonlocal-variables
|
||||
155
translated/tech/20180208 Advanced Dnsmasq Tips and Tricks.md
Normal file
155
translated/tech/20180208 Advanced Dnsmasq Tips and Tricks.md
Normal file
@ -0,0 +1,155 @@
|
||||
Dnsmasq 进阶技巧
|
||||
======
|
||||
|
||||

|
||||
|
||||
许多人熟知和热爱 Dnsmasq,并在他们的本地域名服务上使用它。今天我们将介绍进阶配置文件管理、如何测试你的配置、一些基础的安全知识、DNS 泛域名、快速 DNS 配置,以及其他一些技巧与窍门。下个星期我们将继续详细讲解如何配置 DNS 和 DHCP。
|
||||
|
||||
### 测试配置
|
||||
|
||||
当你测试新的配置的时候,你应该从命令行运行 Dnsmasq,而不是使用守护进程。下面的例子演示了如何不用守护进程运行它,同时显示指令的输出并保留运行日志:
|
||||
```
|
||||
# dnsmasq --no-daemon --log-queries
|
||||
dnsmasq: started, version 2.75 cachesize 150
|
||||
dnsmasq: compile time options: IPv6 GNU-getopt
|
||||
DBus i18n IDN DHCP DHCPv6 no-Lua TFTP conntrack
|
||||
ipset auth DNSSEC loop-detect inotify
|
||||
dnsmasq: reading /etc/resolv.conf
|
||||
dnsmasq: using nameserver 192.168.0.1#53
|
||||
dnsmasq: read /etc/hosts - 9 addresses
|
||||
|
||||
```
|
||||
|
||||
在这个小例子中你能看到许多有用的信息,包括版本、编译参数、系统域名服务文件、以及它的监听地址。可以使用 Ctrl+C 停止进程。在默认情况下,Dnsmasq 没有自己的日志文件,所以日志会被记录到 `/var/log` 目录下的多个地方。你可以使用经典的 `grep` 来找到 Dnsmasq 的日志文件。下面这条指令会递归式地搜索 `/var/log`、在每个匹配的文件名之后显示匹配的行数,并忽略 `/var/log/dist-upgrade` 里的内容:
|
||||
```
|
||||
# grep -ir --exclude-dir=dist-upgrade dnsmasq /var/log/
|
||||
|
||||
```
|
||||
|
||||
使用 `grep --exclude-dir=` 时有一个有趣的小陷阱需要注意:不要使用完整路径,而应该只写目录名称。
|
||||
|
||||
你可以使用如下的命令行参数来让 Dnsmasq 使用你指定的文件作为它专属的日志文件:
|
||||
```
|
||||
# dnsmasq --no-daemon --log-queries --log-facility=/var/log/dnsmasq.log
|
||||
|
||||
```
|
||||
|
||||
或者在你的 Dnsmasq 配置文件中加上 `log-facility=/var/log/dnsmasq.log`。
|
||||
|
||||
### 配置文件
|
||||
|
||||
Dnsmasq 的配置文件位于 `/etc/dnsmasq.conf`。你的 Linux 发行版也可能会使用 `/etc/default/dnsmasq`、`/etc/dnsmasq.d/`,或者 `/etc/dnsmasq.d-available/`(不,我们不能统一标准,因为这违反了 Linux 七嘴八舌秘密议会的旨意)。你有很多自由来随意安置你的配置文件。
|
||||
|
||||
`/etc/dnsmasq.conf` 是德高望重的老大。Dnsmasq 在启动时会最先读取它。`/etc/dnsmasq.conf` 可以使用 `conf-file=` 选项来调用其他的配置文件,例如 `conf-file=/etc/dnsmasqextrastuff.conf`,或使用 `conf-dir=` 选项来调用目录下的所有文件,例如 `conf-dir=/etc/dnsmasq.d`。
|
||||
|
||||
每当你对配置文件进行了修改,你都必须重启 Dnsmasq。
|
||||
|
||||
你可以根据扩展名来包含或忽略配置文件。星号表示包含,不加星号表示忽略:
|
||||
```
|
||||
conf-dir=/etc/dnsmasq.d/,*.conf, *.foo
|
||||
conf-dir=/etc/dnsmasq.d,.old, .bak, .tmp
|
||||
|
||||
```
|
||||
|
||||
你可以用 `--addn-hosts=` 选项来把你的主机配置分布在多个文件中。
|
||||
|
||||
Dnsmasq 包含了一个语法检查器:
|
||||
```
|
||||
$ dnsmasq --test
|
||||
dnsmasq: syntax check OK.
|
||||
|
||||
```
|
||||
|
||||
### 实用配置
|
||||
|
||||
永远加入这几行:
|
||||
```
|
||||
domain-needed
|
||||
bogus-priv
|
||||
|
||||
```
|
||||
|
||||
它们可以避免含有格式出错的域名或私人 IP 地址的数据包离开你的网络。
|
||||
|
||||
让你的域名服务只使用 Dnsmasq,而不去使用 `/etc/resolv.conf` 或任何其他的域名服务文件:
|
||||
```
|
||||
no-resolv
|
||||
|
||||
```
|
||||
|
||||
使用其他的域名服务器。第一个例子是只对于某一个域名使用不同的域名服务器。第二个和第三个例子是 OpenDNS 公用服务器:
|
||||
```
|
||||
server=/fooxample.com/192.168.0.1
|
||||
server=208.67.222.222
|
||||
server=208.67.220.220
|
||||
|
||||
```
|
||||
|
||||
你也可以将某些域名限制为只能本地解析,但不影响其他域名。这些被限制的域名只能从 `/etc/hosts` 或 DHCP 解析:
|
||||
```
|
||||
local=/mehxample.com/
|
||||
local=/fooxample.com/
|
||||
|
||||
```
|
||||
|
||||
限制 Dnsmasq 监听的网络接口:
|
||||
```
|
||||
interface=eth0
|
||||
interface=wlan1
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq 在默认设置下会读取并使用 `/etc/hosts`。这是一个又快又好的配置大量域名的方法,并且 `/etc/hosts` 只需要和 Dnsmasq 在同一台电脑上。你还可以让这个过程再快一些,可以在 `/etc/hosts` 文件中只写主机名,然后用 Dnsmasq 来添加域名。`/etc/hosts` 看上去是这样的:
|
||||
```
|
||||
127.0.0.1 localhost
|
||||
192.168.0.1 host2
|
||||
192.168.0.2 host3
|
||||
192.168.0.3 host4
|
||||
|
||||
```
|
||||
|
||||
然后把这几行写入 `dnsmasq.conf`(当然,要换成你自己的域名):
|
||||
```
|
||||
expand-hosts
|
||||
domain=mehxample.com
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq 会自动把这些主机名扩展为完整的域名,比如 host2 会变为 host2.mehxample.com。
|
||||
|
||||
### DNS 泛域名
|
||||
|
||||
一般来说,使用 DNS 泛域名不是一个好习惯,因为它们太容易被误用了。但它们有时会很有用,比如在你的局域网的严密保护之下的时候。一个例子是使用 DNS 泛域名会让 Kubernetes 集群变得容易管理许多,除非你喜欢给你成百上千的应用写 DNS 记录。假设你的 Kubernetes 域名是 mehxample.com,那么下面这行配置可以让 Dnsmasq 解析所有对 mehxample.com 的请求:
|
||||
```
|
||||
address=/mehxample.com/192.168.0.5
|
||||
|
||||
```
|
||||
|
||||
这里使用的地址是你的集群的公网 IP 地址。这会响应对 mehxample.com 的所有主机名和子域名的请求,除非请求的目标地址已经在 DHCP 或者 `/etc/hosts` 中配置过。
|
||||
|
||||
下星期我们将探索更多的管理 DNS 和 DHCP 的细节,包括对不同的子网络使用不同的设置,以及提供权威域名服务器。
|
||||
|
||||
### 更多参考
|
||||
|
||||
* [使用 Dnsmasq 进行 DNS 欺骗][1]
|
||||
|
||||
* [使用 Dnsmasq 配置简单的局域网域名服务][2]
|
||||
|
||||
* [Dnsmasq][3]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/advanced-dnsmasq-tips-and-tricks
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[yixunx](https://github.com/yixunx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/7/dns-spoofing-dnsmasq
|
||||
[2]:https://www.linux.com/learn/dnsmasq-easy-lan-name-services
|
||||
[3]:http://www.thekelleys.org.uk/dnsmasq/doc.html
|
||||
Loading…
Reference in New Issue
Block a user