mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
a704576480
3
.gitmodules
vendored
3
.gitmodules
vendored
@ -1,3 +0,0 @@
|
|||||||
[submodule "comic"]
|
|
||||||
path = comic
|
|
||||||
url = https://wxy@github.com/LCTT/comic.git
|
|
||||||
1
comic
1
comic
@ -1 +0,0 @@
|
|||||||
Subproject commit e5db5b880dac1302ee0571ecaaa1f8ea7cf61901
|
|
||||||
@ -1,12 +1,13 @@
|
|||||||
如何使用 Apache Web 服务器配置多个站点
|
如何使用 Apache Web 服务器配置多个站点
|
||||||
|
|
||||||
=====
|
=====
|
||||||
|
|
||||||
|
> 如何在流行而强大的 Apache Web 服务器上托管两个或多个站点。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
在我的[上一篇文章][1]中,我解释了如何为单个站点配置 Apache Web 服务器,事实证明这很容易。在这篇文章中,我将向你展示如何使用单个 Apache 实例来服务多个站点。
|
在我的[上一篇文章][1]中,我解释了如何为单个站点配置 Apache Web 服务器,事实证明这很容易。在这篇文章中,我将向你展示如何使用单个 Apache 实例来服务多个站点。
|
||||||
|
|
||||||
注意:我写这篇文章的环境是 Fedora 27 虚拟机,配置了 Apache 2.4.29。如果你有另一个 Fedora 的发行版,那么你使用的命令以及配置文件的位置和内容可能会有所不同。
|
注意:我写这篇文章的环境是 Fedora 27 虚拟机,配置了 Apache 2.4.29。如果你用另一个发行版或不同的 Fedora 版本,那么你使用的命令以及配置文件的位置和内容可能会有所不同。
|
||||||
|
|
||||||
正如我之前的文章中提到的,Apache 的所有配置文件都位于 `/etc/httpd/conf` 和 `/etc/httpd/conf.d`。默认情况下,站点的数据位于 `/var/www` 中。对于多个站点,你需要提供多个位置,每个位置对应托管的站点。
|
正如我之前的文章中提到的,Apache 的所有配置文件都位于 `/etc/httpd/conf` 和 `/etc/httpd/conf.d`。默认情况下,站点的数据位于 `/var/www` 中。对于多个站点,你需要提供多个位置,每个位置对应托管的站点。
|
||||||
|
|
||||||
@ -14,113 +15,93 @@
|
|||||||
|
|
||||||
使用基于名称的虚拟主机,你可以为多个站点使用一个 IP 地址。现代 Web 服务器,包括 Apache,使用指定 URL 的 `hostname` 部分来确定哪个虚拟 Web 主机响应页面请求。这仅仅需要比一个站点更多的配置。
|
使用基于名称的虚拟主机,你可以为多个站点使用一个 IP 地址。现代 Web 服务器,包括 Apache,使用指定 URL 的 `hostname` 部分来确定哪个虚拟 Web 主机响应页面请求。这仅仅需要比一个站点更多的配置。
|
||||||
|
|
||||||
即使你只从单个站点开始,我也建议你将其设置为虚拟主机,这样可以在以后更轻松地添加更多站点。在本文中,我将在上一篇文章中介绍我们停止的位置,因此你需要设置原始站点,即基于名称的虚拟站点。
|
即使你只从单个站点开始,我也建议你将其设置为虚拟主机,这样可以在以后更轻松地添加更多站点。在本文中,我将从上一篇文章中我们停止的地方开始,因此你需要设置原来的站点,即基于名称的虚拟站点。
|
||||||
|
|
||||||
### 准备原始站点
|
### 准备原来的站点
|
||||||
|
|
||||||
在设置第二个站点之前,你需要为现有网站提供基于名称的虚拟主机。如果你现在没有网站,[请返回并立即创建一个][1]。
|
在设置第二个站点之前,你需要为现有网站提供基于名称的虚拟主机。如果你现在没有站点,[请返回并立即创建一个][1]。
|
||||||
|
|
||||||
一旦你有了站点,将以下内容添加到 `/etc/httpd/conf/httpd.conf` 配置文件的底部(添加此内容是你需要对 `httpd.conf` 文件进行的唯一更改):
|
一旦你有了站点,将以下内容添加到 `/etc/httpd/conf/httpd.conf` 配置文件的底部(添加此内容是你需要对 `httpd.conf` 文件进行的唯一更改):
|
||||||
|
|
||||||
```
|
```
|
||||||
<VirtualHost 127.0.0.1:80>
|
<VirtualHost 127.0.0.1:80>
|
||||||
|
|
||||||
DocumentRoot /var/www/html
|
DocumentRoot /var/www/html
|
||||||
|
|
||||||
ServerName www.site1.org
|
ServerName www.site1.org
|
||||||
|
|
||||||
</VirtualHost>
|
</VirtualHost>
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
这将是第一个虚拟主机节(to 校正:这里虚拟主机节不太清除),它应该保持为第一个,以使其成为默认定义。这意味着通过 IP 地址或解析为此 IP 地址但没有特定命名主机配置节的其它名称对服务器的 HTTP 访问将定向到此虚拟主机。所有其它虚拟主机配置节都应遵循此节。
|
这将是第一个虚拟主机配置节,它应该保持为第一个,以使其成为默认定义。这意味着通过 IP 地址或解析为此 IP 地址但没有特定命名主机配置节的其它名称对服务器的 HTTP 访问将定向到此虚拟主机。所有其它虚拟主机配置节都应跟在此节之后。
|
||||||
|
|
||||||
你还需要使用 `/etc/hosts` 中的条目设置你的网站以提供名称解析。上次,我们只使用了 `localhost` 的 IP 地址。通常,这可以使用你使用的任何名称服务来完成,例如 Google 或 Godaddy。对于你的测试网站,通过在 `/etc/hosts` 中的 `localhost` 行添加一个新名称来完成此操作。添加两个网站的条目,方便你以后不需再次编辑此文件。结果如下:
|
你还需要使用 `/etc/hosts` 中的条目设置你的网站以提供名称解析。上次,我们只使用了 `localhost` 的 IP 地址。通常,这可以使用你使用的任何名称服务来完成,例如 Google 或 Godaddy。对于你的测试网站,通过在 `/etc/hosts` 中的 `localhost` 行添加一个新名称来完成此操作。添加两个网站的条目,方便你以后不需再次编辑此文件。结果如下:
|
||||||
|
|
||||||
```
|
```
|
||||||
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 www.site1.org www.site2.org
|
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 www.site1.org www.site2.org
|
||||||
```
|
```
|
||||||
|
|
||||||
让我们将 `/var/www/html/index.html` 文件改变得更加明显一点。它应该看起来像这样(带有一些额外的文本来识别这是站点 1):
|
让我们将 `/var/www/html/index.html` 文件改变得更加明显一点。它应该看起来像这样(带有一些额外的文本来识别这是站点 1):
|
||||||
|
|
||||||
```
|
```
|
||||||
<h1>Hello World</h1>
|
<h1>Hello World</h1>
|
||||||
|
|
||||||
Web site 1.
|
Web site 1.
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
重新启动 HTTPD 服务器,已启用对 `httpd` 配置的更改。然后,你可以从命令行使用 Lynx 文本模式查看网站。
|
重新启动 HTTPD 服务器,已启用对 `httpd` 配置的更改。然后,你可以从命令行使用 Lynx 文本模式查看网站。
|
||||||
|
|
||||||
```
|
```
|
||||||
[root@testvm1 ~]# systemctl restart httpd
|
[root@testvm1 ~]# systemctl restart httpd
|
||||||
|
|
||||||
[root@testvm1 ~]# lynx www.site1.org
|
[root@testvm1 ~]# lynx www.site1.org
|
||||||
|
|
||||||
Hello World
|
Hello World
|
||||||
|
Web site 1.
|
||||||
Web site 1.
|
|
||||||
|
|
||||||
<snip>
|
<snip>
|
||||||
|
|
||||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||||
|
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
|
||||||
|
|
||||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
你可以看到原始网站的修改内容,没有明显的错误,先按下 "Q" 键,然后按 "Y" 退出 Lynx Web 浏览器。
|
你可以看到原始网站的修改内容,没有明显的错误,先按下 `Q` 键,然后按 `Y` 退出 Lynx Web 浏览器。
|
||||||
|
|
||||||
### 配置第二个站点
|
### 配置第二个站点
|
||||||
|
|
||||||
现在你已经准备好建立第二个网站。使用以下命令创建新的网站目录结构:
|
现在你已经准备好建立第二个网站。使用以下命令创建新的网站目录结构:
|
||||||
|
|
||||||
```
|
```
|
||||||
[root@testvm1 html]# mkdir -p /var/www/html2
|
[root@testvm1 html]# mkdir -p /var/www/html2
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
注意,第二个站点只是第二个 `html` 目录,与第一个站点位于同一 `/var/www` 目录下。
|
注意,第二个站点只是第二个 `html` 目录,与第一个站点位于同一 `/var/www` 目录下。
|
||||||
|
|
||||||
现在创建一个新的索引文件 `/var/www/html2/index.html`,其中包含以下内容(此索引文件稍有不同,以区别于原始网站):
|
现在创建一个新的索引文件 `/var/www/html2/index.html`,其中包含以下内容(此索引文件稍有不同,以区别于原来的网站):
|
||||||
|
|
||||||
```
|
```
|
||||||
<h1>Hello World -- Again</h1>
|
<h1>Hello World -- Again</h1>
|
||||||
|
|
||||||
Web site 2.
|
Web site 2.
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
在 `httpd.conf` 中为第二个站点创建一个新的配置节,并将其放在上一个虚拟主机节下面(这两个应该看起来非常相似)。此节告诉 Web 服务器在哪里可以找到第二个站点的 HTML 文件。
|
在 `httpd.conf` 中为第二个站点创建一个新的配置节,并将其放在上一个虚拟主机配置节下面(这两个应该看起来非常相似)。此节告诉 Web 服务器在哪里可以找到第二个站点的 HTML 文件。
|
||||||
|
|
||||||
```
|
```
|
||||||
<VirtualHost 127.0.0.1:80>
|
<VirtualHost 127.0.0.1:80>
|
||||||
|
|
||||||
DocumentRoot /var/www/html2
|
DocumentRoot /var/www/html2
|
||||||
|
|
||||||
ServerName www.site2.org
|
ServerName www.site2.org
|
||||||
|
|
||||||
</VirtualHost>
|
</VirtualHost>
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
重启 HTTPD,并使用 Lynx 来查看结果。
|
重启 HTTPD,并使用 Lynx 来查看结果。
|
||||||
|
|
||||||
```
|
```
|
||||||
[root@testvm1 httpd]# systemctl restart httpd
|
[root@testvm1 httpd]# systemctl restart httpd
|
||||||
|
|
||||||
[root@testvm1 httpd]# lynx www.site2.org
|
[root@testvm1 httpd]# lynx www.site2.org
|
||||||
|
|
||||||
|
Hello World -- Again
|
||||||
|
|
||||||
|
Web site 2.
|
||||||
Hello World -- Again
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Web site 2.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
<snip>
|
<snip>
|
||||||
|
|
||||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||||
|
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
|
||||||
|
|
||||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||||
|
|
||||||
```
|
```
|
||||||
@ -144,10 +125,10 @@ via: https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
|||||||
|
|
||||||
作者:[David Both][a]
|
作者:[David Both][a]
|
||||||
译者:[MjSeven](https://github.com/MjSeven)
|
译者:[MjSeven](https://github.com/MjSeven)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]:https://opensource.com/users/dboth
|
[a]:https://opensource.com/users/dboth
|
||||||
[1]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
[1]:https://linux.cn/article-9506-1.html
|
||||||
[2]:https://httpd.apache.org/docs/2.4/
|
[2]:https://httpd.apache.org/docs/2.4/
|
||||||
@ -1,13 +1,13 @@
|
|||||||
用 GNOME Boxes 下载一个镜像
|
用 GNOME Boxes 下载一个操作系统镜像
|
||||||
======
|
======
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性,使得它在运行不同的 Linux 发行版时更加容易。你现在可以在 Boxes 中自动安装列表中这些发行版。该列表甚至包括红帽企业 Linux。红帽开发人员计划包括[免费订阅红帽企业版 Linux][1]。 使用[红帽开发者][2]帐户,Boxes 可以自动设置一个名为 Developer Suite 订阅的 RHEL 虚拟机。 下面是它的工作原理。
|
Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性,使得它在运行不同的 Linux 发行版时更加容易。你现在可以在 Boxes 中自动安装那些发行版以及像 FreeBSD 和 FreeDOS 这样的操作系统,甚至还包括红帽企业 Linux。红帽开发者计划包括了一个[红帽企业版 Linux 的免费订阅][1]。 使用[红帽开发者][2]帐户,Boxes 可以自动设置一个名为 Developer Suite 订阅的 RHEL 虚拟机。 下面是它的工作原理。
|
||||||
|
|
||||||
### 红帽企业版 Linux
|
### 红帽企业版 Linux
|
||||||
|
|
||||||
要创建一个红帽企业版 Linux 的虚拟机,启动 Boxes,点击新建。从源选择列表中选择下载一个镜像。在顶部,点击红帽企业版 Linux。这将会打开网址为 [developers.redhat.com][2] 的一个网络表单。使用已有的红帽开发者账号登录,或是新建一个。
|
要创建一个红帽企业版 Linux 的虚拟机,启动 Boxes,点击“新建”。从源选择列表中选择“下载一个镜像”。在顶部,点击“红帽企业版 Linux”。这将会打开网址为 [developers.redhat.com][2] 的一个 Web 表单。使用已有的红帽开发者账号登录,或是新建一个。
|
||||||
|
|
||||||
![][3]
|
![][3]
|
||||||
|
|
||||||
@ -15,11 +15,11 @@ Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性
|
|||||||
|
|
||||||
![][5]
|
![][5]
|
||||||
|
|
||||||
点击提交,然后就会开始下载安装磁盘镜像。下载需要的时间取决于你的网络状况。在这期间你可以去喝杯茶或者咖啡歇息一下。
|
点击“提交”,然后就会开始下载安装磁盘镜像。下载需要的时间取决于你的网络状况。在这期间你可以去喝杯茶或者咖啡歇息一下。
|
||||||
|
|
||||||
![][6]
|
![][6]
|
||||||
|
|
||||||
等媒体下载完成(一般位于 ~/Downloads ),Boxes 会有一个快速安装的显示。填入账号和密码然后点击继续,当你确认了虚拟机的信息之后点击创建。快速安装会自动完成接下来的整个安装!(现在你可以去享受你的第二杯茶或者咖啡了)
|
等介质下载完成(一般位于 `~/Downloads` ),Boxes 会有一个“快速安装”的显示。填入账号和密码然后点击“继续”,当你确认了虚拟机的信息之后点击“创建”。“快速安装”会自动完成接下来的整个安装!(现在你可以去享受你的第二杯茶或者咖啡了)
|
||||||
|
|
||||||
![][7]
|
![][7]
|
||||||
|
|
||||||
@ -27,7 +27,7 @@ Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性
|
|||||||
|
|
||||||
![][9]
|
![][9]
|
||||||
|
|
||||||
等到安装结束,虚拟机会直接重启并登录到桌面。在虚拟机里,在应用菜单的系统工具一栏启动红帽订阅管理。这一步需要输入管理员密码。
|
等到安装结束,虚拟机会直接重启并登录到桌面。在虚拟机里,在应用菜单的“系统工具”一栏启动“红帽订阅管理”。这一步需要输入 root 密码。
|
||||||
|
|
||||||
![][10]
|
![][10]
|
||||||
|
|
||||||
@ -37,13 +37,13 @@ Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性
|
|||||||
|
|
||||||
![][12]
|
![][12]
|
||||||
|
|
||||||
现在你可以通过任何一种更新方法,像是 yum 或是 GNOME Software 进行下载和更新了。
|
现在你可以通过任何一种更新方法,像是 `yum` 或是 GNOME Software 进行下载和更新了。
|
||||||
|
|
||||||
![][13]
|
![][13]
|
||||||
|
|
||||||
### FreeDOS 或是其他
|
### FreeDOS 或是其他
|
||||||
|
|
||||||
Boxes 可以安装很多的 Linux 发行版,而不仅仅只是红帽企业版。 作为 KVM 和 qemu 的前端,Boxes 支持各种操作系统。 使用 [libosinfo][14],Boxes 可以自动下载(在某些情况下安装)相当多不同操作系统。
|
Boxes 可以安装很多操作系统,而不仅仅只是红帽企业版。 作为 KVM 和 qemu 的前端,Boxes 支持各种操作系统。使用 [libosinfo][14],Boxes 可以自动下载(在某些情况下安装)相当多不同操作系统。
|
||||||
|
|
||||||
![][15]
|
![][15]
|
||||||
|
|
||||||
@ -53,13 +53,23 @@ Boxes 可以安装很多的 Linux 发行版,而不仅仅只是红帽企业版
|
|||||||
|
|
||||||
![][17]
|
![][17]
|
||||||
|
|
||||||
### 在 Boxes 上受欢迎的操作系统
|
### Boxes 上流行的操作系统
|
||||||
|
|
||||||
这里仅仅是一些目前在它上面比较受欢迎的选择。
|
这里仅仅是一些目前在它上面比较受欢迎的选择。
|
||||||
|
|
||||||
![][18]![][19]![][20]![][21]![][22]![][23]
|
![][18]
|
||||||
|
|
||||||
Fedora 会定期更新它的操作系统信息数据库。确保你会经常检查是否有新的操作系统选项。
|
![][19]
|
||||||
|
|
||||||
|
![][20]
|
||||||
|
|
||||||
|
![][21]
|
||||||
|
|
||||||
|
![][22]
|
||||||
|
|
||||||
|
![][23]
|
||||||
|
|
||||||
|
Fedora 会定期更新它的操作系统信息数据库(osinfo-db)。确保你会经常检查是否有新的操作系统选项。
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
@ -69,7 +79,7 @@ via: https://fedoramagazine.org/download-os-gnome-boxes/
|
|||||||
作者:[Link Dupont][a]
|
作者:[Link Dupont][a]
|
||||||
选题:[lujun9972](https://github.com/lujun9972)
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
59
published/20180830 6 places to host your git repository.md
Normal file
59
published/20180830 6 places to host your git repository.md
Normal file
@ -0,0 +1,59 @@
|
|||||||
|
6 个托管 git 仓库的地方
|
||||||
|
======
|
||||||
|
> GitHub 被收购导致一些用户去寻找这个流行的代码仓库的替代品。这里有一些你可以考虑一下。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
也许你是少数一些没有注意到的人之一,就在之前,[微软收购了 GitHub][1]。两家公司达成了共识。微软在近些年已经变成了开源的有力支持者,而 GitHub 从成立起,就已经成为了大量的开源项目的实际代码库。
|
||||||
|
|
||||||
|
然而,最近发生的这次收购可能会带给你一些苦恼。毕竟公司的收购让你意识到了你的开源代码放在了一个商业平台上。可能你现在还没准备好迁移到其他的平台上去,但是至少这可以给你提供一些可选项。让我们找找网上现在都有哪些可用的平台。
|
||||||
|
|
||||||
|
### 选择之一: GitHub
|
||||||
|
|
||||||
|
严格来说,这是一个合格的选项。[GitHub][2] 历史上没有什么失信的地方,而且微软后来也一直笑对开源。把你的项目继续放在 GitHub 上,保持观望没有什么不可以。它现在依然是最大的软件开发的网络社区,同时还有许多对于问题追踪、代码审查、持续集成、通用的代码管理等很有用的工具。而且它还是基于 Git 的,这是每个人都喜欢的开源版本控制系统。你的代码还是你的代码。如果没有出现什么问题,那保持原状是没错的。
|
||||||
|
|
||||||
|
### 选择之二: GitLab
|
||||||
|
|
||||||
|
[GitLab][3] 是考虑替代代码库平台时的主要竞争者。它是完全开源的。你可以像在 GitHub 一样把你的代码托管在 GitLab,但你也可以选择在你自己的服务器上自行托管自己的 GitLab 实例,并完全控制谁可以访问那里的所有内容以及如何访问和管理。GitLab 与 GitHub 功能几乎相同,有些人甚至可能会说它的持续集成和测试工具更优越。尽管 GitLab 上的开发者社区肯定比 GitHub 上的开发者社区要小,但这并没有什么。你可能会在那里的人群中找到更多志同道合的开发者。
|
||||||
|
|
||||||
|
### 选择之三: Bitbucket
|
||||||
|
|
||||||
|
[Bitbucket][4] 已经存在很多年了。在某些方面,它可以作为 GitHub 未来的一面镜子。Bitbucket 八年前被一家大公司(Atlassian)收购,并且已经经历了一些变化。它仍然是一个像 GitHub 这样的商业平台,但它远不是一个创业公司,而且从组织上说它的基础相当稳定。Bitbucket 具有 GitHub 和 GitLab 上的大部分功能,以及它自己的一些新功能,如对 [Mercurial][5] 仓库的原生支持。
|
||||||
|
|
||||||
|
### 选择之四: SourceForge
|
||||||
|
|
||||||
|
[SourceForge][6] 是开源代码库的鼻祖。如果你曾经有一个开源项目,Sourceforge 就是那个托管你的代码并向其他人分享你的发布版本的地方。它迁移到 Git 版本控制用了一段时间,它有一些商业收购和再次收购的历史,以及一些对某些开源项目糟糕的捆绑决策。也就是说,SourceForge 从那时起似乎已经恢复,该网站仍然是一个有着不少开源项目的地方。然而,很多人仍然感到有点受伤,而且有些人并不是很支持它的平台货币化的各种尝试,所以一定要睁大眼睛。
|
||||||
|
|
||||||
|
### 选择之五: 自己管理
|
||||||
|
|
||||||
|
如果你想自己掌握自己项目的命运(除了你自己没人可以指责你),那么一切都由自己来做可能对你来说是最佳的选择。无论对于大项目还是小项目,都是好的选择。Git 是开源的,所以自己托管也很容易。如果你想要问题追踪和代码审查功能,你可以运行一个 GitLab 或者 [Phabricator][7] 的实例。对于持续集成,你可以设置自己的 [Jenkins][8] 自动化服务实例。是的,你需要对自己的基础架构开销和相关的安全要求负责。但是,这个设置过程并不是很困难。所以如果你不想自己的代码被其他人的平台所吞没,这就是一种很好的方法。
|
||||||
|
|
||||||
|
### 选择之六:以上全部
|
||||||
|
|
||||||
|
以下是所有这些的美妙之处:尽管这些平台上有一些专有的选项,但它们仍然建立在坚实的开源技术之上。而且不仅仅是开源,而是明确设计为分布在大型网络(如互联网)上的多个节点上。你不需要只使用一个。你可以使用一对……或者全部。使用 GitLab 将你自己的设施作为保证的基础,并在 GitHub 和 Bitbucket 上安装克隆存储库,以进行问题跟踪和持续集成。将你的主代码库保留在 GitHub 上,但是出于你自己的考虑,可以在 GitLab 上安装“备份”克隆。
|
||||||
|
|
||||||
|
关键在于你可以选择。我们能有这么多选择,都是得益于那些非常有用而强大的项目之上的开源许可证。未来一片光明。
|
||||||
|
|
||||||
|
当然,在这个列表中我肯定忽略了一些开源平台。方便的话请补充给我们。你是否使用了多个平台?哪个是你最喜欢的?你都可以在这里说出来!
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/8/github-alternatives
|
||||||
|
|
||||||
|
作者:[Jason van Gumster][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/mairin
|
||||||
|
[1]: https://www.theverge.com/2018/6/4/17422788/microsoft-github-acquisition-official-deal
|
||||||
|
[2]: https://github.com/
|
||||||
|
[3]: https://gitlab.com
|
||||||
|
[4]: https://bitbucket.org
|
||||||
|
[5]: https://www.mercurial-scm.org/wiki/Repository
|
||||||
|
[6]: https://sourceforge.net
|
||||||
|
[7]: https://phacility.com/phabricator/
|
||||||
|
[8]: https://jenkins.io
|
||||||
@ -1,110 +0,0 @@
|
|||||||
HankChow translating
|
|
||||||
|
|
||||||
3 areas to drive DevOps change
|
|
||||||
======
|
|
||||||
Driving large-scale organizational change is painful, but when it comes to DevOps, the payoff is worth the pain.
|
|
||||||

|
|
||||||
|
|
||||||
Pain avoidance is a powerful motivator. Some studies hint that even [plants experience a type of pain][1] and take steps to defend themselves. Yet we have plenty of examples of humans enduring pain on purpose—exercise often hurts, but we still do it. When we believe the payoff is worth the pain, we'll endure almost anything.
|
|
||||||
|
|
||||||
The truth is that driving large-scale organizational change is painful. It hurts for those having to change their values and behaviors, it hurts for leadership, and it hurts for the people just trying to do their jobs. In the case of DevOps, though, I can tell you the pain is worth it.
|
|
||||||
|
|
||||||
I've seen firsthand how teams learn they must spend time improving their technical processes, take ownership of their automation pipelines, and become masters of their fate. They gain the tools they need to be successful.
|
|
||||||
|
|
||||||
![Improvements after DevOps transformation][3]
|
|
||||||
|
|
||||||
Image by Lee Eason. CC BY-SA 4.0
|
|
||||||
|
|
||||||
This chart shows the value of that change. In a company where I directed a DevOps transformation, its 60+ teams submitted more than 900 requests per month to release management. If you add up the time those tickets stayed open, it came to more than 350 days per month. What could your company do with an extra 350 person-days per month? In addition to the improvements seen above, they went from 100 to 9,000 deployments per month, a 24% decrease in high-severity bugs, happier engineers, and improved net promoter scores (NPS). The biggest NPS improvements link to the teams furthest along on their DevOps journey, as the [Puppet State of DevOps][4] report predicted. The bottom line is that investments into technical process improvement translate into better business outcomes.
|
|
||||||
|
|
||||||
DevOps leaders must focus on three main areas to drive this change: executives, culture, and team health.
|
|
||||||
|
|
||||||
### Executives
|
|
||||||
|
|
||||||
The bottom line is that investments into technical process improvement translate into better business outcomes.
|
|
||||||
|
|
||||||
The larger your organization, the greater the distance (and opportunities for misunderstanding) between business leadership and the individuals delivering services to your customers. To make things worse, the landscape of tools and practices in technology is changing at an accelerating rate. This makes it practically impossible for business leaders to understand on their own how transformations like DevOps or agile work.
|
|
||||||
|
|
||||||
The larger your organization, the greater the distance (and opportunities for misunderstanding) between business leadership and the individuals delivering services to your customers. To make things worse, the landscape of tools and practices in technology is changing at an accelerating rate. This makes it practically impossible for business leaders to understand on their own how transformations like DevOps or agile work.
|
|
||||||
|
|
||||||
DevOps leaders must help executives come along for the ride. Educating leaders gives them options when they're making decisions and makes it more likely they'll choose paths that help your company.
|
|
||||||
|
|
||||||
For example, let's say your executives believe DevOps is going to improve how you deploy your products into production, but they don't understand how. You've been working with a software team to help automate their deployment. When an executive hears about a deploy failure (and there will be failures), they will want to understand how it occurred. When they learn the software team did the deployment rather than the release management team, they may try to protect the business by decreeing all production releases must go through traditional change controls. You will lose credibility, and teams will be far less likely to trust you and accept further changes.
|
|
||||||
|
|
||||||
It takes longer to rebuild trust with executives and get their support after an incident than it would have taken to educate them in the first place. Put the time in upfront to build alignment, and it will pay off as you implement tactical changes.
|
|
||||||
|
|
||||||
Two pieces of advice when building that alignment:
|
|
||||||
|
|
||||||
* First, **don't ignore any constraints** they raise. If they have worries about contracts or security, make the heads of legal and security your new best friends. By partnering with them, you'll build their trust and avoid making costly mistakes.
|
|
||||||
* Second, **use metrics to build a bridge** between what your delivery teams are doing and your executives' concerns. If the business has a goal to reduce customer churn, and you know from research that many customers leave because of unplanned downtime, reinforce that your teams are committed to tracking and improving Mean Time To Detection and Resolution (MTTD and MTTR). You can use those key metrics to show meaningful progress that teams and executives understand and get behind.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Culture
|
|
||||||
|
|
||||||
DevOps is a culture of continuous improvement focused on code, build, deploy, and operational processes. Culture describes the organization's values and behaviors. Essentially, we're talking about changing how people behave, which is never easy.
|
|
||||||
|
|
||||||
I recommend reading [The Wolf in CIO's Clothing][5]. Spend time thinking about psychology and motivation. Read [Drive][6] or at least watch Daniel Pink's excellent [TED Talk][7]. Read [The Hero with a Thousand Faces][8] and learn to identify the different journeys everyone is on. If none of these things sound interesting, you are not the right person to drive change in your company. Otherwise, read on!
|
|
||||||
|
|
||||||
Essentially, we're talking about changing how people behave, which is never easy.
|
|
||||||
|
|
||||||
Most rational people behave according to their values. Most organizations don't have explicit values everyone understands and lives by. Therefore, you'll need to identify the organization's values that have led to the behaviors that have led to the current state. You also need to make sure you can tell the story about how those values came to be and how they led to where you are. When you tell that story, be careful not to demonize those values—they aren't immoral or evil. People did the best they could at the time, given what they knew and what resources they had.
|
|
||||||
|
|
||||||
Most rational people behave according to their values. Most organizations don't have explicit values everyone understands and lives by. Therefore, you'll need to identify the organization's values that have led to the behaviors that have led to the current state. You also need to make sure you can tell the story about how those values came to be and how they led to where you are. When you tell that story, be careful not to demonize those values—they aren't immoral or evil. People did the best they could at the time, given what they knew and what resources they had.
|
|
||||||
|
|
||||||
Explain that the company and its organizational goals are changing, and the team must alter its values. It's helpful to express this in terms of contrast. For example, your company may have historically valued cost savings above all else. That value is there for a reason—the company was cash-strapped. To get new products out, the infrastructure group had to tightly couple services by sharing database clusters or servers. Over time, those practices created a real mess that became hard to maintain. Simple changes started breaking things in unexpected ways. This led to tight change-control processes that were painful for delivery teams, so they stopped changing things.
|
|
||||||
|
|
||||||
Play that movie for five years, and you end up with little to no innovation, legacy technology, attraction and retention problems, and poor-quality products. You've grown the company, but you've hit a ceiling, and you can't continue to grow with those same values and behaviors. Now you must put engineering efficiency above cost saving. If one option will help teams maintain their service easier, but the other option is cheaper in the short term, you go with the first option.
|
|
||||||
|
|
||||||
You must tell this story again and again. Then you must celebrate any time a team expresses the new value through their behavior—even if they make a mistake. When a team has a deploy failure, congratulate them for taking the risk and encourage them to keep learning. Explain how their behavior is leading to the right outcome and support them. Over time, teams will see the message is real, and they'll feel safe altering their behavior.
|
|
||||||
|
|
||||||
### Team health
|
|
||||||
|
|
||||||
Have you ever been in a planning meeting and heard something like this: "We can't really estimate that story until John gets back from vacation. He's the only one who knows that area of the code well enough." Or: "We can't get this task done because it's got a cross-team dependency on network engineering, and the guy that set up the firewall is out sick." Or: "John knows that system best; if he estimated the story at a 3, then let's just go with that." When the team works on that story, who will most likely do the work? That's right, John will, and the cycle will continue.
|
|
||||||
|
|
||||||
For a long time, we've accepted that this is just the nature of software development. If we don't solve for it, we perpetuate the cycle.
|
|
||||||
|
|
||||||
Entropy will always drive teams naturally towards disorder and bad health. Our job as team members and leaders is to intentionally manage against that entropy and keep our teams healthy. Transformations like DevOps, agile, moving to the cloud, or refactoring a legacy application all amplify and accelerate that entropy. That's because transformations add new skills and expertise needed for the team to take on that new type of work.
|
|
||||||
|
|
||||||
Let's look at an example of a product team refactoring its legacy monolith. As usual, they build those new services in AWS. The legacy monolith was deployed to the data center, monitored, and backed up by IT. IT made sure the application's infosec requirements were met at the infrastructure layer. They conducted disaster recovery tests, patched the servers, and installed and configured required intrusion detection and antivirus agents. And they kept change control records, required for the annual audit process, of everything was done to the application's infrastructure.
|
|
||||||
|
|
||||||
I often see product teams make the fatal mistake of thinking IT is all cost and bottleneck. They're hungry to shed the skin of IT and use the public cloud, but they never stop to appreciate the critical services IT provides. Moving to the cloud means you implement these things differently; they don't go away. AWS is still a data center, and any team utilizing it accepts the related responsibilities.
|
|
||||||
|
|
||||||
In practice, this means product teams must learn how to do those IT services when they move to the cloud. So, when our fictional product team starts refactoring its legacy application and putting new services in in the cloud, it will need a vastly expanded skillset to be successful. Those skills don't magically appear—they're learned or hired—and team leaders and managers must actively manage the process.
|
|
||||||
|
|
||||||
I built [Tekata.io][9] because I couldn't find any tools to support me as I helped my teams evolve. Tekata is free and easy to use, but the tool is not as important as the people and process. Make sure you build continuous learning into your cadence and keep track of your team's weak spots. Those weak spots affect your ability to deliver, and filling them usually involves learning new things, so there's a wonderful synergy here. In fact, 76% of millennials think professional development opportunities are [one of the most important elements][10] of company culture.
|
|
||||||
|
|
||||||
### Proof is in the payoff
|
|
||||||
|
|
||||||
DevOps transformations involve altering the behavior, and therefore the culture, of your teams. That must be done with executive support and understanding. At the same time, those behavior changes mean learning new skills, and that process must also be managed carefully. But the payoff for pulling this off is more productive teams, happier and more engaged team members, higher quality products, and happier customers.
|
|
||||||
|
|
||||||
Lee Eason will present [Tales From A DevOps Transformation][11] at [All Things Open][12], October 21-23 in Raleigh, N.C.
|
|
||||||
|
|
||||||
Disclaimer: All opinions are statements in this article are exclusively those of Lee Eason and are not representative of Ipreo or IHS Markit.
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/18/10/tales-devops-transformation
|
|
||||||
|
|
||||||
作者:[Lee Eason][a]
|
|
||||||
选题:[lujun9972][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/leeeason
|
|
||||||
[b]: https://github.com/lujun9972
|
|
||||||
[1]: https://link.springer.com/article/10.1007%2Fs00442-014-2995-6
|
|
||||||
[2]: /file/411061
|
|
||||||
[3]: https://opensource.com/sites/default/files/uploads/devops-delays.png (Improvements after DevOps transformation)
|
|
||||||
[4]: https://puppet.com/resources/whitepaper/state-of-devops-report
|
|
||||||
[5]: https://www.gartner.com/en/publications/wolf-cio
|
|
||||||
[6]: https://en.wikipedia.org/wiki/Drive:_The_Surprising_Truth_About_What_Motivates_Us
|
|
||||||
[7]: https://www.ted.com/talks/dan_pink_on_motivation?language=en#t-2094
|
|
||||||
[8]: https://en.wikipedia.org/wiki/The_Hero_with_a_Thousand_Faces
|
|
||||||
[9]: https://tekata.io/
|
|
||||||
[10]: https://www.execu-search.com/~/media/Resources/pdf/2017_Hiring_Outlook_eBook
|
|
||||||
[11]: https://allthingsopen.org/talk/tales-from-a-devops-transformation/
|
|
||||||
[12]: https://allthingsopen.org/
|
|
||||||
@ -0,0 +1,60 @@
|
|||||||
|
5 tips for facilitators of agile meetings
|
||||||
|
======
|
||||||
|
Boost your team's productivity and motivation with these agile principles.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
As Agile practitioner, I often hear that the best way to have business meetings is to avoid more meetings, or to cancel them altogether.
|
||||||
|
|
||||||
|
Do your meetings fail to keep attendees engaged or run longer than they should? Perhaps you have mixed feelings about participating in meetings—but don't want to be excluded?
|
||||||
|
|
||||||
|
If all this sounds familiar, read on.
|
||||||
|
|
||||||
|
### How do we fix meetings?
|
||||||
|
|
||||||
|
To succeed in this role, you must understand that agile is not something that you do, but something that you can become.
|
||||||
|
|
||||||
|
Meetings are an integral part of work culture, so improving them can bring important benefits. But improving how meetings are structured requires a change in how the entire organization is led and managed. This is where the agile mindset comes into play.
|
||||||
|
|
||||||
|
An agile mindset is an _attitude that equates failure and problems with opportunities for learning, and a belief that we can all improve over time._ Meetings can bring great value to an organization, as long as they are not pointless. The best way to eliminate pointless meetings is to have a meeting facilitator with an agile mindset. The key attribute of agile-driven facilitation is to focus on problem-solving.
|
||||||
|
|
||||||
|
Agile meeting facilitators confronting a complex problem start by breaking the meeting agenda down into modules. They also place more value on adapting to change than sticking to a plan. They work with meeting attendees to develop a solution based on feedback loops. This assures audience engagement and makes the meetings productive. The result is an integrated, agreed-upon solution that comprises a set of coherent action items aligned on a goal
|
||||||
|
|
||||||
|
### What are the skills of an agile meeting facilitator?
|
||||||
|
|
||||||
|
An agile meeting facilitator is able to quickly adapt to changing circumstances. He or she integrates all stakeholders and encourages them to share knowledge and skills.
|
||||||
|
|
||||||
|
To succeed in this role, you must understand that agile is not something that you do, but something that you can become. As the [Manifesto for Agile Software Development][1] notes, tools and processes are important, but it is more important to have competent people working together effectively.
|
||||||
|
|
||||||
|
### 5 tips for agile meeting facilitation
|
||||||
|
|
||||||
|
1. **Start with the problem in mind.** Identify the purpose of the meeting and narrow the agenda items to those that are most important. Stay tuned in and focused.
|
||||||
|
|
||||||
|
2. **Make sure that a senior leader doesn’t run the meeting.** Many senior leaders tend to create an environment in which the team expects to be told what to do. Instead, create an environment in which diverse ideas are the norm. Encourage open discussion in which leaders share where—but not how—innovation is needed. This reduces the layer of control and approval, increases the time focused on decision-making, and boosts the team’s motivation.
|
||||||
|
|
||||||
|
3. **Identify bottlenecks early.** Bureaucratic procedures or lack of collaboration between team members leads to meeting meltdowns and poor results. Anticipate how things might go wrong and be prepared to offer suggestions, not dictate solutions.
|
||||||
|
|
||||||
|
4. **Show, don’t tell.** Share the meeting goals and create the meeting agenda in advance. Allow time to adjust the agenda items and their order to achieve the best flow. Make sure that the meeting’s agenda is clear and visible to all attendees.
|
||||||
|
|
||||||
|
5. **Know when to wait.** Map out a clear timeline for the meeting and help keep the meeting on track. Understand when you should allow an item to go long versus when you should table a discussion. This will go a long way toward helping you stay on track.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
The ultimate goal is to create a work environment that encourages contribution and empowers the team. Improving how meetings are run will help your organization transition from a traditional hierarchy to a more agile enterprise.
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/agile-culture-5-tips-meeting-facilitators
|
||||||
|
|
||||||
|
作者:[Dominika Bula][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/dominika
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: http://agilemanifesto.org/
|
||||||
@ -0,0 +1,74 @@
|
|||||||
|
Why it matters that Microsoft released old versions of MS-DOS as open source
|
||||||
|
======
|
||||||
|
|
||||||
|
Microsoft's release of MS-DOS 1.25 and 2.0 on GitHub adopts an open source license that's compatible with GNU GPL.
|
||||||
|

|
||||||
|
|
||||||
|
One open source software project I work on is the FreeDOS Project. It's a complete, free, DOS-compatible operating system that you can use to play classic DOS games, run legacy business software, or develop embedded systems. Any program that works on MS-DOS should also run on FreeDOS.
|
||||||
|
|
||||||
|
So I took notice when Microsoft recently released the source code to MS-DOS 1.25 and 2.0 via a [GitHub repository][1]. This is a huge step for Microsoft, and I’d like to briefly explain why it is significant.
|
||||||
|
|
||||||
|
### MS-DOS as open source software
|
||||||
|
|
||||||
|
Some open source fans may recall that this is not the first time Microsoft has officially released the MS-DOS source code. On March 25, 2014, Microsoft posted the source code to MS-DOS 1.1 and 2.0 via the [Computer History Museum][2]. Unfortunately, this source code was released under a “look but do not touch” license that limited what you could do with it. According to the license from the 2014 source code release, users were barred from re-using it in other projects and could use it “[solely for non-commercial research, experimentation, and educational purposes.][3]”
|
||||||
|
|
||||||
|
The museum license wasn’t friendly to open source software, and as a result, the MS-DOS source code was ignored. On the FreeDOS Project, we interpreted the “look but do not touch” license as a potential risk to FreeDOS, so we decided developers who had viewed the MS-DOS source code could not contribute to FreeDOS.
|
||||||
|
|
||||||
|
But Microsoft’s recent MS-DOS source code release represents a significant change. This MS-DOS source code uses the MIT License (also called the Expat License). Quoting Microsoft’s [LICENSE.md][4] file on GitHub:
|
||||||
|
|
||||||
|
> ## MS-DOS v1.25 and v2.0 Source Code
|
||||||
|
>
|
||||||
|
> Copyright © Microsoft Corporation.
|
||||||
|
>
|
||||||
|
> All rights reserved.
|
||||||
|
>
|
||||||
|
> MIT License.
|
||||||
|
>
|
||||||
|
> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the Software), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
||||||
|
>
|
||||||
|
> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||||
|
>
|
||||||
|
> THE SOFTWARE IS PROVIDED AS IS, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NON-INFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,TORT OR OTHERWISE, ARISING FROM OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
||||||
|
|
||||||
|
If that text looks familiar to you, it is because that’s the same text as the MIT License recognized by the [Open Source Initiative][5]. It’s also the same as the Expat License recognized by the [Free Software Foundation][6].
|
||||||
|
|
||||||
|
The Free Software Foundation (via GNU) says the Expat License is compatible with the [GNU General Public License][7]. Specifically, GNU describes the Expat License as “a lax, permissive non-copyleft free software license, compatible with the GNU GPL. It is sometimes ambiguously referred to as the MIT License.” Also according to GNU, when they say a license is [compatible with the GNU GPL][8], “you can combine code released under the other license [MIT/Expat License] with code released under the GNU GPL in one larger program.”
|
||||||
|
|
||||||
|
Microsoft’s use of the MIT/Expat License for the original MS-DOS source code is significant because the license is not only open source software but free software.
|
||||||
|
|
||||||
|
### What does it mean?
|
||||||
|
|
||||||
|
This is great, but there’s a practical side to the source code release. You might think, “If Microsoft has released the MS-DOS source code under a license compatible with the GNU GPL, will that help FreeDOS?”
|
||||||
|
|
||||||
|
Not really. Here's why: FreeDOS started from an original source code base, independent from MS-DOS. Certain functions and behaviors of MS-DOS were identified and documented in the comprehensive [Interrupt List by Ralf Brown][9], and we provided MS-DOS compatibility in FreeDOS by referencing the Interrupt List. But many significant fundamental technical differences remain between FreeDOS and MS-DOS. For example, FreeDOS uses a completely different memory structure and memory layout. You can’t simply forklift MS-DOS source code into FreeDOS and expect it to work. The code assumptions are quite different.
|
||||||
|
|
||||||
|
There’s also the simple matter that these are very old versions of MS-DOS. For example, MS-DOS 2.0 was the first version to support directories and redirection. But these versions of MS-DOS did not yet include more advanced features, including networking, CDROM support, and ’386 support such as EMM386. These features have been standard in FreeDOS for a long time.
|
||||||
|
|
||||||
|
So the MS-DOS source code release is interesting, but FreeDOS would not be able to reuse this code for any modern features anyway. FreeDOS has already surpassed these versions of MS-DOS in functionality and features.
|
||||||
|
|
||||||
|
### Congratulations
|
||||||
|
|
||||||
|
Still, it’s important to recognize the big step that Microsoft has taken in releasing these versions of MS-DOS as open source software. The new MS-DOS source code release on GitHub does away with the restrictive license from 2014 and adopts a recognized open source software license that is compatible with the GNU GPL. Congratulations to Microsoft for releasing MS-DOS 1.25 and 2.0 under an open source license!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/microsoft-open-source-old-versions-ms-dos
|
||||||
|
|
||||||
|
作者:[Jim Hall][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jim-hall
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://github.com/Microsoft/MS-DOS
|
||||||
|
[2]: http://www.computerhistory.org/press/ms-source-code.html
|
||||||
|
[3]: http://www.computerhistory.org/atchm/microsoft-research-license-agreement-msdos-v1-1-v2-0/
|
||||||
|
[4]: https://github.com/Microsoft/MS-DOS/blob/master/LICENSE.md
|
||||||
|
[5]: https://opensource.org/licenses/MIT
|
||||||
|
[6]: https://directory.fsf.org/wiki/License:Expat
|
||||||
|
[7]: https://www.gnu.org/licenses/license-list.en.html#Expat
|
||||||
|
[8]: https://www.gnu.org/licenses/gpl-faq.html#WhatDoesCompatMean
|
||||||
|
[9]: http://www.cs.cmu.edu/~ralf/files.html
|
||||||
@ -0,0 +1,158 @@
|
|||||||
|
The 5 Best Linux Distributions for Development
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
Jack Wallen looks at some of the best LInux distributions for development efforts.[Creative Commons Zero][6]
|
||||||
|
|
||||||
|
When considering Linux, there are so many variables to take into account. What package manager do you wish to use? Do you prefer a modern or old-standard desktop interface? Is ease of use your priority? How flexible do you want your distribution? What task will the distribution serve?
|
||||||
|
|
||||||
|
It is that last question which should often be considered first. Is the distribution going to work as a desktop or a server? Will you be doing network or system audits? Or will you be developing? If you’ve spent much time considering Linux, you know that for every task there are several well-suited distributions. This certainly holds true for developers. Even though Linux, by design, is an ideal platform for developers, there are certain distributions that rise above the rest, to serve as great operating systems to serve developers.
|
||||||
|
|
||||||
|
I want to share what I consider to be some of the best distributions for your development efforts. Although each of these five distributions can be used for general purpose development (with maybe one exception), they each serve a specific purpose. You may or may not be surprised by the selections.
|
||||||
|
|
||||||
|
With that said, let’s get to the choices.
|
||||||
|
|
||||||
|
### Debian
|
||||||
|
|
||||||
|
The [Debian][14] distribution winds up on the top of many a Linux list. With good reason. Debian is that distribution from which so many are based. It is this reason why many developers choose Debian. When you develop a piece of software on Debian, chances are very good that package will also work on [Ubuntu][15], [Linux Mint][16], [Elementary OS][17], and a vast collection of other distributions.
|
||||||
|
|
||||||
|
Beyond that obvious answer, Debian also has a very large amount of applications available, by way of the default repositories (Figure 1).
|
||||||
|
|
||||||
|

|
||||||
|
Figure 1: Available applications from the standard Debian repositories.[Used with permission][1]
|
||||||
|
|
||||||
|
To make matters even programmer-friendly, those applications (and their dependencies) are simple to install. Take, for instance, the build-essential package (which can be installed on any distribution derived from Debian). This package includes the likes of dkpg-dev, g++, gcc, hurd-dev, libc-dev, and make—all tools necessary for the development process. The build-essential package can be installed with the command sudo apt install build-essential.
|
||||||
|
|
||||||
|
There are hundreds of other developer-specific applications available from the standard repositories, tools such as:
|
||||||
|
|
||||||
|
* Autoconf—configure script builder
|
||||||
|
|
||||||
|
* Autoproject—creates a source package for a new program
|
||||||
|
|
||||||
|
* Bison—general purpose parser generator
|
||||||
|
|
||||||
|
* Bluefish—powerful GUI editor, targeted towards programmers
|
||||||
|
|
||||||
|
* Geany—lightweight IDE
|
||||||
|
|
||||||
|
* Kate—powerful text editor
|
||||||
|
|
||||||
|
* Eclipse—helps builders independently develop tools that integrate with other people’s tools
|
||||||
|
|
||||||
|
The list goes on and on.
|
||||||
|
|
||||||
|
Debian is also as rock-solid a distribution as you’ll find, so there’s very little concern you’ll lose precious work, by way of the desktop crashing. As a bonus, all programs included with Debian have met the [Debian Free Software Guidelines][18], which adheres to the following “social contract”:
|
||||||
|
|
||||||
|
* Debian will remain 100% free.
|
||||||
|
|
||||||
|
* We will give back to the free software community.
|
||||||
|
|
||||||
|
* We will not hide problems.
|
||||||
|
|
||||||
|
* Our priorities are our users and free software
|
||||||
|
|
||||||
|
* Works that do not meet our free software standards are included in a non-free archive.
|
||||||
|
|
||||||
|
Also, if you’re new to developing on Linux, Debian has a handy [Programming section in their user manual][19].
|
||||||
|
|
||||||
|
### openSUSE Tumbleweed
|
||||||
|
|
||||||
|
If you’re looking to develop with a cutting-edge, rolling release distribution, [openSUSE][20] offers one of the best in [Tumbleweed][21]. Not only will you be developing with the most up to date software available, you’ll be doing so with the help of openSUSE’s amazing administrator tools … of which includes YaST. If you’re not familiar with YaST (Yet another Setup Tool), it’s an incredibly powerful piece of software that allows you to manage the whole of the platform, from one convenient location. From within YaST, you can also install using RPM Groups. Open YaST, click on RPM Groups (software grouped together by purpose), and scroll down to the Development section to see the large amount of groups available for installation (Figure 2).
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
Figure 2: Installing package groups in openSUSE Tumbleweed.[Creative Commons Zero][2]
|
||||||
|
|
||||||
|
openSUSE also allows you to quickly install all the necessary devtools with the simple click of a weblink. Head over to the [rpmdevtools install site][22] and click the link for Tumbleweed. This will automatically add the necessary repository and install rpmdevtools.
|
||||||
|
|
||||||
|
By developing with a rolling release distribution, you know you’re working with the most recent releases of installed software.
|
||||||
|
|
||||||
|
### CentOS
|
||||||
|
|
||||||
|
Let’s face it, [Red Hat Enterprise Linux][23] (RHEL) is the de facto standard for enterprise businesses. If you’re looking to develop for that particular platform, and you can’t afford a RHEL license, you cannot go wrong with [CentOS][24]—which is, effectively, a community version of RHEL. You will find many of the packages found on CentOS to be the same as in RHEL—so once you’re familiar with developing on one, you’ll be fine on the other.
|
||||||
|
|
||||||
|
If you’re serious about developing on an enterprise-grade platform, you cannot go wrong starting with CentOS. And because CentOS is a server-specific distribution, you can more easily develop for a web-centric platform. Instead of developing your work and then migrating it to a server (hosted on a different machine), you can easily have CentOS setup to serve as an ideal host for both developing and testing.
|
||||||
|
|
||||||
|
Looking for software to meet your development needs? You only need open up the CentOS Application Installer, where you’ll find a Developer section that includes a dedicated sub-section for Integrated Development Environments (IDEs - Figure 3).
|
||||||
|
|
||||||
|

|
||||||
|
Figure 3: Installing a powerful IDE is simple in CentOS.[Used with permission][3]
|
||||||
|
|
||||||
|
CentOS also includes Security Enhanced Linux (SELinux), which makes it easier for you to test your software’s ability to integrate with the same security platform found in RHEL. SELinux can often cause headaches for poorly designed software, so having it at the ready can be a real boon for ensuring your applications work on the likes of RHEL. If you’re not sure where to start with developing on CentOS 7, you can read through the [RHEL 7 Developer Guide][25].
|
||||||
|
|
||||||
|
### Raspbian
|
||||||
|
|
||||||
|
Let’s face it, embedded systems are all the rage. One easy means of working with such systems is via the Raspberry Pi—a tiny footprint computer that has become incredibly powerful and flexible. In fact, the Raspberry Pi has become the hardware used by DIYers all over the planet. Powering those devices is the [Raspbian][26] operating system. Raspbian includes tools like [BlueJ][27], [Geany][28], [Greenfoot][29], [Sense HAT Emulator][30], [Sonic Pi][31], and [Thonny Python IDE][32], [Python][33], and [Scratch][34], so you won’t want for the necessary development software. Raspbian also includes a user-friendly desktop UI (Figure 4), to make things even easier.
|
||||||
|
|
||||||
|

|
||||||
|
Figure 4: The Raspbian main menu, showing pre-installed developer software.[Used with permission][4]
|
||||||
|
|
||||||
|
For anyone looking to develop for the Raspberry Pi platform, Raspbian is a must have. If you’d like to give Raspbian a go, without the Raspberry Pi hardware, you can always install it as a VirtualBox virtual machine, by way of the ISO image found [here][35].
|
||||||
|
|
||||||
|
### Pop!_OS
|
||||||
|
|
||||||
|
Don’t let the name full you, [System76][36]’s [Pop!_OS][37] entry into the world of operating systems is serious. And although what System76 has done to this Ubuntu derivative may not be readily obvious, it is something special.
|
||||||
|
|
||||||
|
The goal of System76 is to create an operating system specific to the developer, maker, and computer science professional. With a newly-designed GNOME theme, Pop!_OS is beautiful (Figure 5) and as highly functional as you would expect from both the hardware maker and desktop designers.
|
||||||
|
|
||||||
|
### [devel_5.jpg][11]
|
||||||
|
|
||||||
|

|
||||||
|
Figure 5: The Pop!_OS Desktop.[Used with permission][5]
|
||||||
|
|
||||||
|
But what makes Pop!_OS special is the fact that it is being developed by a company dedicated to Linux hardware. This means, when you purchase a System76 laptop, desktop, or server, you know the operating system will work seamlessly with the hardware—on a level no other company can offer. I would predict that, with Pop!_OS, System76 will become the Apple of Linux.
|
||||||
|
|
||||||
|
### Time for work
|
||||||
|
|
||||||
|
In their own way, each of these distributions. You have a stable desktop (Debian), a cutting-edge desktop (openSUSE Tumbleweed), a server (CentOS), an embedded platform (Raspbian), and a distribution to seamless meld with hardware (Pop!_OS). With the exception of Raspbian, any one of these distributions would serve as an outstanding development platform. Get one installed and start working on your next project with confidence.
|
||||||
|
|
||||||
|
_Learn more about Linux through the free ["Introduction to Linux" ][13]course from The Linux Foundation and edX._
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/5-best-linux-distributions-development
|
||||||
|
|
||||||
|
作者:[JACK WALLEN ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/jlwallen
|
||||||
|
[1]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||||
|
[3]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[4]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[5]:https://www.linux.com/licenses/category/used-permission
|
||||||
|
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||||
|
[7]:https://www.linux.com/files/images/devel1jpg
|
||||||
|
[8]:https://www.linux.com/files/images/devel2jpg
|
||||||
|
[9]:https://www.linux.com/files/images/devel3jpg
|
||||||
|
[10]:https://www.linux.com/files/images/devel4jpg
|
||||||
|
[11]:https://www.linux.com/files/images/devel5jpg
|
||||||
|
[12]:https://www.linux.com/files/images/king-penguins1920jpg
|
||||||
|
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||||
|
[14]:https://www.debian.org/
|
||||||
|
[15]:https://www.ubuntu.com/
|
||||||
|
[16]:https://linuxmint.com/
|
||||||
|
[17]:https://elementary.io/
|
||||||
|
[18]:https://www.debian.org/social_contract
|
||||||
|
[19]:https://www.debian.org/doc/manuals/debian-reference/ch12.en.html
|
||||||
|
[20]:https://www.opensuse.org/
|
||||||
|
[21]:https://en.opensuse.org/Portal:Tumbleweed
|
||||||
|
[22]:https://software.opensuse.org/download.html?project=devel%3Atools&package=rpmdevtools
|
||||||
|
[23]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||||
|
[24]:https://www.centos.org/
|
||||||
|
[25]:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/pdf/developer_guide/Red_Hat_Enterprise_Linux-7-Developer_Guide-en-US.pdf
|
||||||
|
[26]:https://www.raspberrypi.org/downloads/raspbian/
|
||||||
|
[27]:https://www.bluej.org/
|
||||||
|
[28]:https://www.geany.org/
|
||||||
|
[29]:https://www.greenfoot.org/
|
||||||
|
[30]:https://www.raspberrypi.org/blog/sense-hat-emulator/
|
||||||
|
[31]:http://sonic-pi.net/
|
||||||
|
[32]:http://thonny.org/
|
||||||
|
[33]:https://www.python.org/
|
||||||
|
[34]:https://scratch.mit.edu/
|
||||||
|
[35]:http://rpf.io/x86iso
|
||||||
|
[36]:https://system76.com/
|
||||||
|
[37]:https://system76.com/pop
|
||||||
@ -1,166 +0,0 @@
|
|||||||
LuuMing translating
|
|
||||||
Setting Up a Timer with systemd in Linux
|
|
||||||
======
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Previously, we saw how to enable and disable systemd services [by hand][1], [at boot time and on power down][2], [when a certain device is activated][3], and [when something changes in the filesystem][4].
|
|
||||||
|
|
||||||
Timers add yet another way of starting services, based on... well, time. Although similar to cron jobs, systemd timers are slightly more flexible. Let's see how they work.
|
|
||||||
|
|
||||||
### "Run when"
|
|
||||||
|
|
||||||
Let's expand the [Minetest][5] [service you set up][1] in [the first two articles of this series][2] as our first example on how to use timer units. If you haven't read those articles yet, you may want to go and give them a look now.
|
|
||||||
|
|
||||||
So you will "improve" your Minetest set up by creating a timer that will run the game's server 1 minute after boot up has finished instead of right away. The reason for this could be that, as you want your service to do other stuff, like send emails to the players telling them the game is available, you will want to make sure other services (like the network) are fully up and running before doing anything fancy.
|
|
||||||
|
|
||||||
Jumping in at the deep end, your _minetest.timer_ unit will look like this:
|
|
||||||
```
|
|
||||||
# minetest.timer
|
|
||||||
[Unit]
|
|
||||||
Description=Runs the minetest.service 1 minute after boot up
|
|
||||||
|
|
||||||
[Timer]
|
|
||||||
OnBootSec=1 m
|
|
||||||
Unit=minetest.service
|
|
||||||
|
|
||||||
[Install]
|
|
||||||
WantedBy=basic.target
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
Not hard at all.
|
|
||||||
|
|
||||||
As usual, you have a `[Unit]` section with a description of what the unit does. Nothing new there. The `[Timer]` section is new, but it is pretty self-explanatory: it contains information on when the service will be triggered and the service to trigger. In this case, the `OnBootSec` is the directive you need to tell systemd to run the service after boot has finished.
|
|
||||||
|
|
||||||
Other directives you could use are:
|
|
||||||
|
|
||||||
* `OnActiveSec=`, which tells systemd how long to wait after the timer itself is activated before starting the service.
|
|
||||||
* `OnStartupSec=`, on the other hand, tells systemd how long to wait after systemd was started before starting the service.
|
|
||||||
* `OnUnitActiveSec=` tells systemd how long to wait after the service the timer is activating was last activated.
|
|
||||||
* `OnUnitInactiveSec=` tells systemd how long to wait after the service the timer is activating was last deactivated.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Continuing down the _minetest.timer_ unit, the `basic.target` is usually used as a synchronization point for late boot services. This means it makes _minetest.timer_ wait until local mount points and swap devices are mounted, sockets, timers, path units and other basic initialization processes are running before letting _minetest.timer_ start. As we explained in [the second article on systemd units][2], _targets_ are like the old run levels and can be used to put your machine into one state or another, or, like here, to tell your service to wait until a certain state has been reached.
|
|
||||||
|
|
||||||
The _minetest.service_ you developed in the first two articles [ended up][2] looking like this:
|
|
||||||
```
|
|
||||||
# minetest.service
|
|
||||||
[Unit]
|
|
||||||
Description= Minetest server
|
|
||||||
Documentation= https://wiki.minetest.net/Main_Page
|
|
||||||
|
|
||||||
[Service]
|
|
||||||
Type= simple
|
|
||||||
User=
|
|
||||||
|
|
||||||
ExecStart= /usr/games/minetest --server
|
|
||||||
ExecStartPost= /home//bin/mtsendmail.sh "Ready to rumble?" "Minetest Starting up"
|
|
||||||
|
|
||||||
TimeoutStopSec= 180
|
|
||||||
ExecStop= /home//bin/mtsendmail.sh "Off to bed. Nightie night!" "Minetest Stopping in 2 minutes"
|
|
||||||
ExecStop= /bin/sleep 120
|
|
||||||
ExecStop= /bin/kill -2 $MAINPID
|
|
||||||
|
|
||||||
[Install]
|
|
||||||
WantedBy= multi-user.target
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
There’s nothing you need to change here. But you do have to change _mtsendmail.sh_ (your email sending script) from this:
|
|
||||||
```
|
|
||||||
#!/bin/bash
|
|
||||||
# mtsendmail
|
|
||||||
sleep 20
|
|
||||||
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
|
|
||||||
sleep 10
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
to this:
|
|
||||||
```
|
|
||||||
#!/bin/bash
|
|
||||||
# mtsendmail.sh
|
|
||||||
echo $1 | mutt -F /home/paul/.muttrc -s "$2" pbrown@mykolab.com
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
What you are doing is stripping out those hacky pauses in the Bash script. Systemd does the waiting now.
|
|
||||||
|
|
||||||
### Making it work
|
|
||||||
|
|
||||||
To make sure things work, disable _minetest.service_ :
|
|
||||||
```
|
|
||||||
sudo systemctl disable minetest
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
so it doesn't get started when the system starts; and, instead, enable _minetest.timer_ :
|
|
||||||
```
|
|
||||||
sudo systemctl enable minetest.timer
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
Now you can reboot you server machine and, when you run `sudo journalctl -u minetest.*` you will see how, first the _minetest.timer_ unit gets executed and then the _minetest.service_ starts up after a minute... more or less.
|
|
||||||
|
|
||||||
![minetest timer][7]
|
|
||||||
|
|
||||||
Figure 1: The minetest.service gets started one minute after the minetest.timer... more or less.
|
|
||||||
|
|
||||||
[Used with permission][8]
|
|
||||||
|
|
||||||
### A Matter of Time
|
|
||||||
|
|
||||||
A couple of clarifications about why the _minetest.timer_ entry in the systemd's Journal shows its start time as 09:08:33, while the _minetest.service_ starts at 09:09:18, that is less than a minute later: First, remember we said that the `OnBootSec=` directive calculates when to start a service from when boot is complete. By the time _minetest.timer_ comes along, boot has finished a few seconds ago.
|
|
||||||
|
|
||||||
The other thing is that systemd gives itself a margin of error (by default, 1 minute) to run stuff. This helps distribute the load when several resource-intensive processes are running at the same time: by giving itself a minute, systemd can wait for some processes to power down. This also means that _minetest.service_ will start somewhere between the 1 minute and 2 minute mark after boot is completed, but when exactly within that range is anybody's guess.
|
|
||||||
|
|
||||||
For the record, [you can change the margin of error with `AccuracySec=` directive][9].
|
|
||||||
|
|
||||||
Another thing you can do is check when all the timers on your system are scheduled to run or the last time the ran:
|
|
||||||
```
|
|
||||||
systemctl list-timers --all
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
![check timer][11]
|
|
||||||
|
|
||||||
Figure 2: Check when your timers are scheduled to fire or when they fired last.
|
|
||||||
|
|
||||||
[Used with permission][8]
|
|
||||||
|
|
||||||
The final thing to take into consideration is the format you should use to express the periods of time. Systemd is very flexible in that respect: `2 h`, `2 hours` or `2hr` will all work to express a 2 hour delay. For seconds, you can use `seconds`, `second`, `sec`, and `s`, the same way as for minutes you can use `minutes`, `minute`, `min`, and `m`. You can see a full list of time units systemd understands by checking `man systemd.time`.
|
|
||||||
|
|
||||||
### Next Time
|
|
||||||
|
|
||||||
You'll see how to use calendar dates and times to run services at regular intervals and how to combine timers and device units to run services at defined point in time after you plug in some hardware.
|
|
||||||
|
|
||||||
See you then!
|
|
||||||
|
|
||||||
Learn more about Linux through the free ["Introduction to Linux" ][12]course from The Linux Foundation and edX.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
|
||||||
|
|
||||||
作者:[Paul Brown][a]
|
|
||||||
选题:[lujun9972](https://github.com/lujun9972)
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.linux.com/users/bro66
|
|
||||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
|
|
||||||
[2]:https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping
|
|
||||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
|
||||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
|
||||||
[5]:https://www.minetest.net/
|
|
||||||
[6]:/files/images/minetest-timer-1png
|
|
||||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-1.png?itok=TG0xJvYM (minetest timer)
|
|
||||||
[8]:/licenses/category/used-permission
|
|
||||||
[9]:https://www.freedesktop.org/software/systemd/man/systemd.timer.html#AccuracySec=
|
|
||||||
[10]:/files/images/minetest-timer-2png
|
|
||||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-2.png?itok=pYxyVx8- (check timer)
|
|
||||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
translating by Flowsnow
|
||||||
|
|
||||||
Quiet log noise with Python and machine learning
|
Quiet log noise with Python and machine learning
|
||||||
======
|
======
|
||||||
|
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
(translating by runningwater)
|
||||||
How To Determine Which System Manager Is Running On Linux System
|
How To Determine Which System Manager Is Running On Linux System
|
||||||
======
|
======
|
||||||
We all are heard about this word many times but only few of us know what is this exactly. We will show you how to identify the system manager.
|
We all are heard about this word many times but only few of us know what is this exactly. We will show you how to identify the system manager.
|
||||||
@ -164,7 +165,7 @@ via: https://www.2daygeek.com/how-to-determine-which-init-system-manager-is-runn
|
|||||||
|
|
||||||
作者:[Prakash Subramanian][a]
|
作者:[Prakash Subramanian][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[runningwater](https://github.com/runningwater)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
translating by dianbanjiu
|
||||||
How to use Pandoc to produce a research paper
|
How to use Pandoc to produce a research paper
|
||||||
======
|
======
|
||||||
Learn how to manage section references, figures, tables, and more in Markdown.
|
Learn how to manage section references, figures, tables, and more in Markdown.
|
||||||
|
|||||||
@ -1,79 +0,0 @@
|
|||||||
5 tips for choosing the right open source database
|
|
||||||
======
|
|
||||||
When selecting a mission-critical application, you can't afford to make mistakes.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
So, your company has a directive to adopt more open source database technologies, and they've recruited you to select the right direction. Whether you are an open source technology veteran or a newcomer, this is a daunting and overwhelming task.
|
|
||||||
|
|
||||||
Over the past several years, open source technology adoption has steadily increased in the enterprise space. With its popularity comes a crowded marketplace with open source software companies promising that their solution will solve every problem and fit every workload. Be wary of these promises. Choosing the right open source technology—especially a database—is an important and difficult decision you can't make lightly.
|
|
||||||
|
|
||||||
In my experience as an IT professional at [Percona][1] and other companies, I've been fortunate to work hands-on in adopting open source technologies and guiding others in making the right decisions. There are many important factors to consider; hopefully, this article will shine a light on a few.
|
|
||||||
|
|
||||||
### 1. Have a goal.
|
|
||||||
|
|
||||||
This may seem simple, but based on my many conversations with people exploring MySQL, MongoDB, or PostgreSQL, it is top of the list in importance.
|
|
||||||
|
|
||||||
To avoid getting overwhelmed by the unlimited combinations of open source database software in the market, have a specific goal in mind. Maybe your goal is to provide your internal developers with a standardized, open source database backend that is managed by your internal database team. Perhaps your goal is to rip and replace the entire functionality of a legacy application and database backend with new open source technology.
|
|
||||||
|
|
||||||
Once you have defined a goal, you can focus your efforts. This will lead to better conversations internally as well as externally with open source database software vendors and advocates.
|
|
||||||
|
|
||||||
### 2. Understand your workload.
|
|
||||||
|
|
||||||
Despite the increasing ability of database technologies to wear many hats, each specializes in certain areas, e.g., MongoDB is now transactional, MySQL now has JSON storage. A growing trend in open source databases involves providing check boxes claiming certain features are available. One of the biggest mistakes is not using the right tool for the right job. Something leads a company down the wrong path—perhaps an overzealous developer or a manager with tunnel vision. The unfortunate thing is that the wrong tool can work fine for smaller volumes of transactions and data, but later there will be bottlenecks that can be solved only by using a different tool.
|
|
||||||
|
|
||||||
If you want a data analytics warehouse, an open source relational database is probably not the right choice. If you want a transaction-processing app with rigid data integrity and consistency, NoSQL options may not be the right option.
|
|
||||||
|
|
||||||
### 3. Don't reinvent the wheel.
|
|
||||||
|
|
||||||
Open source database technologies have rapidly grown, expanded, and hardened over the past several decades. We've seen a transformation from new, questionably production-ready databases to proven, enterprise-grade database backends. It's no longer necessary to be a bleeding edge, early adopter to choose open source database technologies. Organizations have grown around these communities to provide production support and tooling in the open source database space for a growing number of startups, midsized businesses, and Fortune 500 companies.
|
|
||||||
|
|
||||||
Battery Ventures, a tech-focused investment firm, recently introduced its [BOSS Index][2] for tracking the most popular open source projects. It's not perfect, but it provides great insight into some of the most widely adopted and active open source projects. Not surprisingly, database technologies dominate the list, comprising five of the top 10 technologies. This is a great starting point for someone new to the open source database space. A lot of times, vendors have already produced suitable architectures for solving specific problems.
|
|
||||||
|
|
||||||
My point is that someone has probably already done what you are trying to do. Learn from their successes and failures. Even if it is not a perfect fit, a solution can likely be modified to suit your needs. For example, Amazon provides a [CloudFormation script][3] for deploying MongoDB in its EC2 environment.
|
|
||||||
|
|
||||||
If you are a bleeding-edge early adopter, that doesn't mean you can't explore. If you have a unique challenge or workload that seems to fit a new open source database technology, go for it. Keep in mind that there are inherent risks (and rewards!) to being an early adopter.
|
|
||||||
|
|
||||||
### 4\. Start simple
|
|
||||||
|
|
||||||
|
|
||||||
How many [nines][4] does your database truly need? "Achieving high availability" is often a nebulous goal for many companies. Of course, the most common answer is "it's mission-critical, and we cannot afford any downtime."
|
|
||||||
|
|
||||||
The more complicated your database environment, the more difficult and costly it is to manage. You can theoretically achieve higher uptime, but the tradeoffs will be the feasibility of management and performance. When in doubt, start simple. There are always options to scale out when the need arises.
|
|
||||||
|
|
||||||
For example, Booking.com is a widely known travel reservation site. It might be less widely known that it uses MySQL as a database backend. Nicolai Plum, a Booking.com senior systems architect, gave [a talk][5] outlining the evolution of the company's MySQL database. One of the takeaways was that the database started simple. It had to evolve over time, but in the beginning, simple master–replica architecture sufficed. As the workload and dataset increased, it introduced load balancers, multiple read replicas, archiving to Hadoop for analytics, etc. However, the early architecture was extremely simple.
|
|
||||||
|
|
||||||
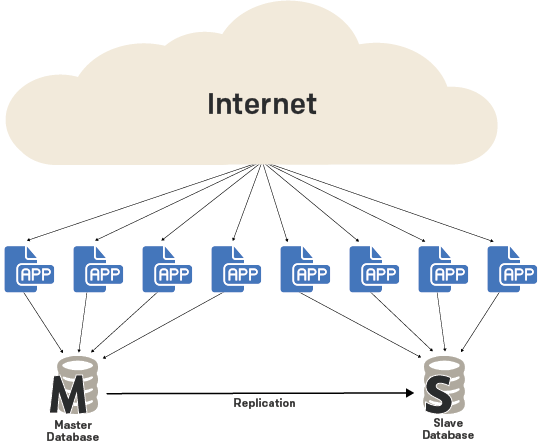
|
|
||||||
|
|
||||||
### 5. When in doubt, ask an expert.
|
|
||||||
|
|
||||||
If you're unsure whether a database would be a good fit, reach out on forums, websites, or to vendors and strike up a conversation. This can be exciting as you research which database technologies meet your requirements and which do not. Often there are suitable alternatives that you haven't considered. The open source community is all about sharing knowledge.
|
|
||||||
|
|
||||||
There is one important thing to be aware of when reaching out to open source software and services vendors. Many have open-core business models that incentivize adopting their database software. Take their advice or guidance with a grain of salt and use your own ability to research, create proofs of concept, and explore alternatives.
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
Choosing the right open source database is an important decision. Start by asking the right questions. All too often, people put the cart before the horse, making decisions before really understanding their needs.
|
|
||||||
|
|
||||||
Barrett Chambers will present [Choosing the Right Open Source Database][6] at [All Things Open][7], October 21-23 in Raleigh, N.C.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/18/10/tips-choosing-right-open-source-database
|
|
||||||
|
|
||||||
作者:[Barrett Chambers][a]
|
|
||||||
选题:[lujun9972][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/barrettc
|
|
||||||
[b]: https://github.com/lujun9972
|
|
||||||
[1]: https://www.percona.com/
|
|
||||||
[2]: https://techcrunch.com/2017/04/07/tracking-the-explosive-growth-of-open-source-software/
|
|
||||||
[3]: https://docs.aws.amazon.com/quickstart/latest/mongodb/welcome.html
|
|
||||||
[4]: https://en.wikipedia.org/wiki/Five_nines
|
|
||||||
[5]: https://www.percona.com/live/mysql-conference-2015/sessions/bookingcom-evolution-mysql-system-design
|
|
||||||
[6]: https://allthingsopen.org/talk/choosing-the-right-open-source-database/
|
|
||||||
[7]: https://allthingsopen.org/
|
|
||||||
@ -0,0 +1,94 @@
|
|||||||
|
translating by Flowsnow
|
||||||
|
|
||||||
|
Getting started with functional programming in Python using the toolz library
|
||||||
|
======
|
||||||
|
|
||||||
|
The toolz library allows you to manipulate functions, making it easier to understand and test code.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
In the second of a two-part series, we continue to explore how we can import ideas from functional programming methodology into Python to have the best of both worlds.
|
||||||
|
|
||||||
|
In the previous post, we covered [immutable data structures][1]. Those allow us to write "pure" functions, or functions that have no side effects, merely accepting some arguments and returning a result while maintaining decent performance.
|
||||||
|
|
||||||
|
In this post, we build on that using the `toolz` library. This library has functions that manipulate such functions, and they work especially well with pure functions. In the functional programming world, these are often referred to as "higher-order functions" since they take functions as arguments and return functions as results.
|
||||||
|
|
||||||
|
Let's start with this:
|
||||||
|
|
||||||
|
```
|
||||||
|
def add_one_word(words, word):
|
||||||
|
return words.set(words.get(word, 0) + 1)
|
||||||
|
```
|
||||||
|
|
||||||
|
This function assumes that its first argument is an immutable dict-like object, and it returns a new dict-like object with the relevant place incremented: It's a simple frequency counter.
|
||||||
|
|
||||||
|
However, it is useful only if we apply it to a stream of words and reduce. We have access to a reducer in the built-in module `functools`. `functools.reduce(function, stream, initializer)`.
|
||||||
|
|
||||||
|
We want a function that, applied to a stream, will return a frequency count.
|
||||||
|
|
||||||
|
We start by using `toolz.curry`:
|
||||||
|
|
||||||
|
```
|
||||||
|
add_all_words = curry(functools.reduce, add_one_word)
|
||||||
|
```
|
||||||
|
|
||||||
|
With this version, we will need to supply the initializer. However, we can't just add `pyrsistent.m` to the `curry`; it is in the wrong order.
|
||||||
|
|
||||||
|
```
|
||||||
|
add_all_words_flipped = flip(add_all_words)
|
||||||
|
```
|
||||||
|
|
||||||
|
The `flip` higher-level function returns a function that calls the original, with arguments flipped.
|
||||||
|
|
||||||
|
```
|
||||||
|
get_all_words = add_all_words_flipped(pyrsistent.m())
|
||||||
|
```
|
||||||
|
|
||||||
|
We take advantage of the fact that `flip` auto-curries its argument to give it a starting value: an empty dictionary.
|
||||||
|
|
||||||
|
Now we can do `get_all_words(word_stream)` and get a frequency dictionary. However, how do we get a word stream? Python files are by line streams.
|
||||||
|
|
||||||
|
```
|
||||||
|
def to_words(lines):
|
||||||
|
for line in lines:
|
||||||
|
yield from line.split()
|
||||||
|
```
|
||||||
|
|
||||||
|
After testing each function by itself, we can combine them:
|
||||||
|
|
||||||
|
```
|
||||||
|
words_from_file = toolz.compose(get_all_words, to_words)
|
||||||
|
```
|
||||||
|
|
||||||
|
In this case, the composition being of just being two functions was straightforward to read: Apply `to_words` first, then apply `get_all_words` to the result. The prose, it seems, is in the inverse of the code.
|
||||||
|
|
||||||
|
This matters when we start taking composability seriously. It is sometimes possible to write the code as a sequence of units, test each individually, and finally, compose them all. If there are several elements, the ordering of compose can get tricky to understand.
|
||||||
|
|
||||||
|
The `toolz` library borrows from the Unix command line and uses `pipe` as a function that does the same, but in the reverse order.
|
||||||
|
|
||||||
|
```
|
||||||
|
words_from_file = toolz.pipe(to_words, get_all_words)
|
||||||
|
```
|
||||||
|
|
||||||
|
Now it reads more intuitively: Pipe the input into `to_words`, and pipe the results into `get_all_words`. On a command line, the equivalent would look like this:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat files | to_words | get_all_words
|
||||||
|
```
|
||||||
|
|
||||||
|
The `toolz` library allows us to manipulate functions, slicing, dicing, and composing them to make our code easier to understand and to test.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/functional-programming-python-toolz
|
||||||
|
|
||||||
|
作者:[Moshe Zadka][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/moshez
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
|
||||||
@ -0,0 +1,85 @@
|
|||||||
|
4 cool new projects to try in COPR for October 2018
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
COPR is a [collection][1] of personal repositories for software that isn’t carried in the standard Fedora repositories. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the standard set of Fedora Fedora packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||||
|
|
||||||
|
Here’s a set of new and interesting projects in COPR.
|
||||||
|
|
||||||
|
### GitKraken
|
||||||
|
|
||||||
|
[GitKraken][2] is a useful git client for people who prefer a graphical interface over command-line, providing all the features you expect. Additionally, GitKraken can create repositories and files, and has a built-in editor. A useful feature of GitKraken is the ability to stage lines or hunks of files, and to switch between branches fast. However, in some cases, you may experience performance issues with larger projects.
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
#### Installation instructions
|
||||||
|
|
||||||
|
The repo currently provides GitKraken for Fedora 27, 28, 29 and Rawhide, and for OpenSUSE Tumbleweed. To install GitKraken, use these commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf copr enable elken/gitkraken
|
||||||
|
sudo dnf install gitkraken
|
||||||
|
```
|
||||||
|
|
||||||
|
### Music On Console
|
||||||
|
|
||||||
|
[Music On Console][4] player, or mocp, is a simple console audio player. It has an interface similar to the Midnight Commander and is easy use. You simply navigate to a directory with music files and select a file or directory to play. In addition, mocp provides a set of commands, allowing it to be controlled directly from command line.
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
#### Installation instructions
|
||||||
|
|
||||||
|
The repo currently provides Music On Console player for Fedora 28 and 29. To install mocp, use these commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf copr enable Krzystof/Moc
|
||||||
|
sudo dnf install moc
|
||||||
|
```
|
||||||
|
|
||||||
|
### cnping
|
||||||
|
|
||||||
|
[Cnping][6] is a small graphical ping tool for IPv4, useful for visualization of changes in round-trip time. It offers an option to control the time period between each packet as well as the size of data sent. In addition to the graph shown, cnping provides basic statistics on round-trip times and packet loss.![][7]
|
||||||
|
|
||||||
|
#### Installation instructions
|
||||||
|
|
||||||
|
The repo currently provides cnping for Fedora 27, 28, 29 and Rawhide. To install cnping, use these commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf copr enable dreua/cnping
|
||||||
|
sudo dnf install cnping
|
||||||
|
```
|
||||||
|
|
||||||
|
### Pdfsandwich
|
||||||
|
|
||||||
|
[Pdfsandwich][8] is a tool for adding text to PDF files which contain text in an image form — such as scanned books. It uses optical character recognition (OCR) to create an additional layer with the recognized text behind the original page. This can be useful for copying and working with the text.
|
||||||
|
|
||||||
|
#### Installation instructions
|
||||||
|
|
||||||
|
The repo currently provides pdfsandwich for Fedora 27, 28, 29 and Rawhide, and for EPEL 7. To install pdfsandwich, use these commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf copr enable merlinm/pdfsandwich
|
||||||
|
sudo dnf install pdfsandwich
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/4-cool-new-projects-try-copr-october-2018/
|
||||||
|
|
||||||
|
作者:[Dominik Turecek][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://copr.fedorainfracloud.org/
|
||||||
|
[2]: https://www.gitkraken.com/git-client
|
||||||
|
[3]: https://fedoramagazine.org/wp-content/uploads/2018/10/copr-gitkraken.png
|
||||||
|
[4]: http://moc.daper.net/
|
||||||
|
[5]: https://fedoramagazine.org/wp-content/uploads/2018/10/copr-mocp.png
|
||||||
|
[6]: https://github.com/cnlohr/cnping
|
||||||
|
[7]: https://fedoramagazine.org/wp-content/uploads/2018/10/copr-cnping.png
|
||||||
|
[8]: http://www.tobias-elze.de/pdfsandwich/
|
||||||
@ -0,0 +1,85 @@
|
|||||||
|
Get organized at the Linux command line with Calcurse
|
||||||
|
======
|
||||||
|
|
||||||
|
Keep up with your calendar and to-do list with Calcurse.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Do you need complex, feature-packed graphical or web applications to get and stay organized? I don't think so. The right command line tool can do the job and do it well.
|
||||||
|
|
||||||
|
Of course, uttering the words command and line together can strike fear into the hearts of some Linux users. The command line, to them, is terra incognita.
|
||||||
|
|
||||||
|
Organizing yourself at the command line is easy with [Calcurse][1]. Calcurse brings a graphical look and feel to a text-based interface. You get the simplicity and focus of the command line married to ease of use and navigation.
|
||||||
|
|
||||||
|
Let's take a closer look at Calcurse, which is open sourced under the BSD License.
|
||||||
|
|
||||||
|
### Getting the software
|
||||||
|
|
||||||
|
If compiling code is your thing (it's not mine, generally), you can grab the source code from the [Calcurse website][1]. Otherwise, get the [binary installer][2] for your Linux distribution. You might even be able to get Calcurse from your Linux distro's package manager. It never hurts to check.
|
||||||
|
|
||||||
|
Compile or install Calcurse (neither takes all that long), and you're ready to go.
|
||||||
|
|
||||||
|
### Using Calcurse
|
||||||
|
|
||||||
|
Crack open a terminal window and type **calcurse**.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Calcurse's interface consists of three panels:
|
||||||
|
|
||||||
|
* Appointments (the left side of the screen)
|
||||||
|
* Calendar (the top right)
|
||||||
|
* To-do list (the bottom right)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Move between the panels by pressing the Tab key on your keyboard. To add a new item to a panel, press **a**. Calcurse walks you through what you need to do to add the item.
|
||||||
|
|
||||||
|
One interesting quirk is that the Appointment and Calendar panels work together. You add an appointment by tabbing to the Calendar panel. There, you choose the date for your appointment. Once you do that, you tab back to the Appointments panel. I know …
|
||||||
|
|
||||||
|
Press **a** to set a start time, a duration (in minutes), and a description of the appointment. The start time and duration are optional. Calcurse displays appointments on the day they're due.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Here's what a day's appointments look like:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
The to-do list works on its own. Tab to the ToDo panel and (again) press **a**. Type a description of the task, then set a priority (1 is the highest and 9 is the lowest). Calcurse lists your uncompleted tasks in the ToDo panel.
|
||||||
|
|
||||||
|
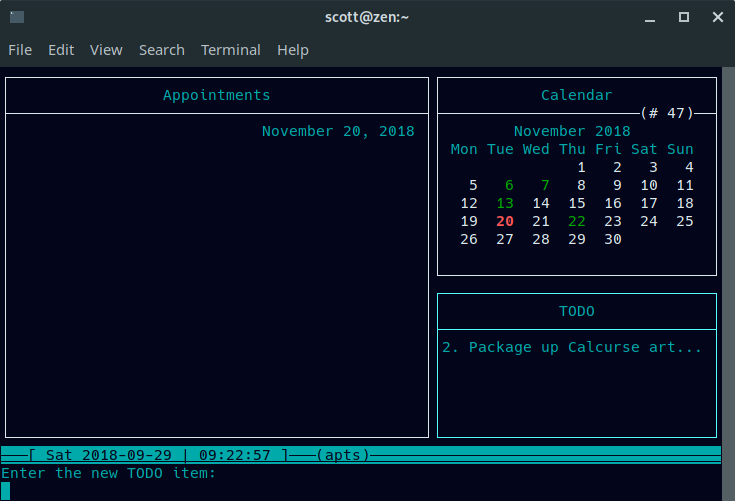
|
||||||
|
|
||||||
|
If your task has a long description, Calcurse truncates it. You can view long descriptions by navigating to the task using the up or down arrow keys on your keyboard, then pressing **v**.
|
||||||
|
|
||||||
|
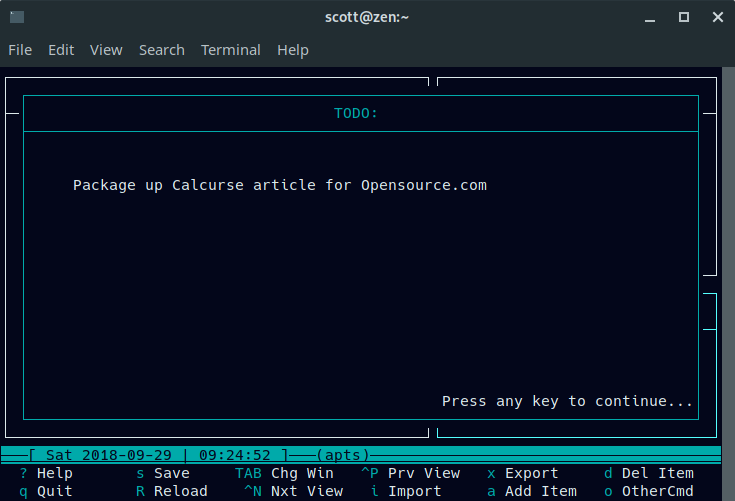
|
||||||
|
|
||||||
|
Calcurse saves its information in text files in a hidden folder called **.calcurse** in your home directory—for example, **/home/scott/.calcurse**. If Calcurse stops working, it's easy to find your information.
|
||||||
|
|
||||||
|
### Other useful features
|
||||||
|
|
||||||
|
Other Calcurse features include the ability to set recurring appointments. To do that, find the appointment you want to repeat and press **r** in the Appointments panel. You'll be asked to set the frequency (for example, daily or weekly) and how long you want the appointment to repeat.
|
||||||
|
|
||||||
|
You can also import calendars in [ICAL][3] format or export your data in either ICAL or [PCAL][4] format. With ICAL, you can share your data with other calendar applications. With PCAL, you can generate a Postscript version of your calendar.
|
||||||
|
|
||||||
|
There are also a number of command line arguments you can pass to Calcurse. You can read about them [in the documentation][5].
|
||||||
|
|
||||||
|
While simple, Calcurse does a solid job of helping you keep organized. You'll need to be a bit more mindful of your tasks and appointments, but you'll be able to focus better on what you need to do and where you need to be.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/calcurse
|
||||||
|
|
||||||
|
作者:[Scott Nesbitt][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/scottnesbitt
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: http://www.calcurse.org/
|
||||||
|
[2]: http://www.calcurse.org/downloads/#packages
|
||||||
|
[3]: https://tools.ietf.org/html/rfc2445
|
||||||
|
[4]: http://pcal.sourceforge.net/
|
||||||
|
[5]: http://www.calcurse.org/files/manual.chunked/ar01s04.html#_invocation
|
||||||
99
translated/talk/20181008 3 areas to drive DevOps change.md
Normal file
99
translated/talk/20181008 3 areas to drive DevOps change.md
Normal file
@ -0,0 +1,99 @@
|
|||||||
|
推动 DevOps 变革的三个方面
|
||||||
|
======
|
||||||
|
推动大规模的组织变革是一个痛苦的过程。对于 DevOps 来说,尽管也有阵痛,但变革带来的价值则相当可观。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
避免痛苦是一种强大的动力。一些研究表明,[植物也会通过遭受疼痛的过程][1]以采取措施来保护自己。我们人类有时也会刻意让自己受苦——在剧烈运动之后,身体可能会发生酸痛,但我们仍然坚持运动。那是因为当人认为整个过程利大于弊时,几乎可以忍受任何事情。
|
||||||
|
|
||||||
|
推动大规模的组织变革得过程确实是痛苦的。有人可能会因难以改变价值观和行为而感到痛苦,有人可能会因难以带领团队而感到痛苦,也有人可能会因难以开展工作而感到痛苦。但就 DevOps 而言,我可以说这些痛苦都是值得的。
|
||||||
|
|
||||||
|
我也曾经关注过一个团队耗费大量时间优化技术流程的过程,在这个过程中,团队逐渐将流程进行自动化改造,并最终获得了成功。
|
||||||
|
|
||||||
|
![Improvements after DevOps transformation][3]
|
||||||
|
|
||||||
|
图片来源:Lee Eason. CC BY-SA 4.0
|
||||||
|
|
||||||
|
这张图表充分表明了变革的价值。一家公司在我主导实行了 DevOps 转型之后,60 多个团队每月提交了超过 900 个发布请求。这些工作量的原耗时高达每个月 350 天,而这么多的工作量对于任何公司来说都是不可忽视的。除此以外,他们每月的部署次数从 100 次增加到了 9000 次,高危 bug 减少了 24%,工程师们更轻松了,<ruby>净推荐值<rt>Net Promoter Score</rt></ruby>(NPS)也提高了,而 NPS 提高反过来也让团队的 DevOps 转型更加顺利。正如 [Puppet 发布的 DevOps 报告][4]所预测的,用在技术流程改进上的投资可以在业务成果上明显地体现出来。
|
||||||
|
|
||||||
|
而 DevOps 主导者在推动变革是必须关注这三个方面:团队管理,团队文化和团队活力。
|
||||||
|
|
||||||
|
### 团队管理
|
||||||
|
|
||||||
|
组织架构越大,业务领导与一线员工之间的距离就会越大,当然发生误解的可能性也会越大。而且各种技术工具和实际应用都在以日新月异的速度变化,这就导致业务领导几乎不可能对 DevOps 或敏捷开发的转型方向有一个亲身的了解。
|
||||||
|
|
||||||
|
DevOps 主导者必须和管理层密切合作,在进行决策的时候给出相关的意见,以帮助他们做出正确的决策。
|
||||||
|
|
||||||
|
公司的管理层只是知道 DevOps 会对产品部署的方式进行改进,而并不了解其中的具体过程。当管理层发现你在和软件团队执行自动化部署失败时,就会想要了解这件事情的细节。如果管理层了解到进行部署的是软件团队而不是专门的发布管理团队,就可能会坚持使用传统的变更流程来保证业务的正常运作。你可能会失去团队的信任,团队也可能不愿意作出进一步的改变。
|
||||||
|
|
||||||
|
如果没有和管理层做好心理上的预期,一旦发生意外的生产事件,都会对你和管理层之间的信任造成难以消除的影响。所以,最好事先和管理层之间在各方面协调好,这会让你在后续的工作中避免很多麻烦。
|
||||||
|
|
||||||
|
对于和管理层之间的协调,这里有两条建议:
|
||||||
|
|
||||||
|
* 一是**重视所有规章制度**。如果管理层对合同、安全等各方面有任何疑问,你都可以向法务或安全负责人咨询,这样做可以避免犯下后果严重的错误。
|
||||||
|
* 二是**将管理层的重点关注的方面输出为量化指标**。举个例子,如果公司的目标是减少客户流失,而你调查得出计划外的停机是造成客户流失的主要原因,那么就可以让团队对故障的<ruby>平均检测时间<rt>Mean Time To Detection</rt></ruby>(MTTD)和<ruby>平均解决时间<rt>Mean Time To Resolution</rt></ruby>(MTTR)实行重点优化。你可以使用这些关键指标来量化团队的工作成果,而管理层对此也可以有一个直观的了解。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 团队文化
|
||||||
|
|
||||||
|
DevOps 是一种专注于持续改进代码、构建、部署和操作流程的文化,而团队文化代表了团队的价值观和行为。从本质上说,团队文化是要塑造团队成员的行为方式,而这并不是一件容易的事。
|
||||||
|
|
||||||
|
我推荐一本叫做《[披着狼皮的 CIO][5]》的书。另外,研究心理学、阅读《[Drive][6]》、观看 Daniel Pink 的 [TED 演讲][7]、阅读《[千面英雄][7]》、了解每个人的心路历程,以上这些都是你推动公司技术变革所应该尝试去做的事情。
|
||||||
|
|
||||||
|
理性的人大多都按照自己的价值观工作,然而团队通常没有让每个人都能达成共识的明确价值观。因此,你需要明确团队目前的价值观,包括价值观的形成过程和价值观的目标导向。也不能将这些价值观强加到团队成员身上,只需要让团队成员在目前的硬件条件下力所能及地做到最好就可以了
|
||||||
|
|
||||||
|
同时需要向团队成员阐明,公司正在发生组织上的变化,团队的价值观也随之改变,最好也厘清整个过程中将会作出什么变化。例如,公司以往或许是由于资金有限,一直将节约成本的原则放在首位,在研发新产品的时候,基础架构团队不得不通过共享数据库集群或服务器,从而导致了服务之间的紧密耦合。然而随着时间的推移,这种做法会产生难以维护的混乱,即使是一个小小的变化也可能造成无法预料的后果。这就导致交付团队难以执行变更控制流程,进而令变更停滞不前。
|
||||||
|
|
||||||
|
如果这种状况持续多年,最终的结果将会是毫无创新、技术老旧、问题繁多以及产品品质低下,公司的发展到达了瓶颈,原本的价值观已经不再适用。所以,工作效率的优先级必须高于节约成本。
|
||||||
|
|
||||||
|
你必须强调团队的价值观。每当团队按照价值观取得了一定的工作进展,都应该对团队作出激励。在团队部署出现失败时,鼓励他们承担风险、继续学习,同时指导团队如何改进他们的工作并表示支持。长此下来,团队成员就会对你产生信任,并逐渐切合团队的价值观。
|
||||||
|
|
||||||
|
### 团队活力
|
||||||
|
|
||||||
|
你有没有在会议上听过类似这样的话?“在张三度假回来之前,我们无法对这件事情做出评估。他是唯一一个了解代码的人”,或者是“我们完成不了这项任务,它在网络上需要跨团队合作,而防火墙管理员刚好请病假了”,又或者是“张三最清楚这个系统最好,他说是怎么样,通常就是怎么样”。那么如果团队在处理工作时,谁才是主力?就是张三。而且也一直会是他。
|
||||||
|
|
||||||
|
我们一直都认为这就是软件开发的本质。但是如果我们不作出改变,这种循环就会一直保持下去。
|
||||||
|
|
||||||
|
熵的存在会让团队自发地变得混乱和缺乏活力,团队的成员和主导者的都有责任控制这个熵并保持团队的活力。DevOps、敏捷开发、上云、代码重构这些行为都会令熵增加速,这是因为转型让团队需要学习更多新技能和专业知识以开展新工作。
|
||||||
|
|
||||||
|
我们来看一个产品团队重构遗留代码的例子。像往常一样,他们在 AWS 上构建新的服务。而传统的系统则在数据中心部署,并由 IT 部门进行监控和备份。IT 部门会确保在基础架构的层面上满足应用的安全需求、进行灾难恢复测试、系统补丁、安装配置了入侵检测和防病毒代理,而且 IT 部门还保留了年度审计流程所需的变更控制记录。
|
||||||
|
|
||||||
|
产品团队经常会犯一个致命的错误,就是认为 IT 部门是需要突破的瓶颈。他们希望脱离已有的 IT 部门并使用公有云,但实际上是他们忽视了 IT 部门提供的关键服务。迁移到云上只是以不同的方式实现这些关键服务,因为 AWS 也是一个数据中心,团队即使使用 AWS 也需要完成 IT 运维任务。
|
||||||
|
|
||||||
|
实际上,产品团队在迁移到云时候也必须学习如何使用这些 IT 服务。因此,当产品团队开始重构遗留的代码并部署到云上时,也需要学习大量的技能才能正常运作。这些技能不会无师自通,必须自行学习或者聘用相关的人员,团队的主导者也必须积极进行管理。
|
||||||
|
|
||||||
|
在带领团队时,我找不到任何适合我的工具,因此我建立了 [Tekita.io][9] 这个项目。Tekata 免费而且容易使用。但相比起来,把注意力集中在人员和流程上更为重要,你需要不断学习,持续关注团队的弱项,因为它们会影响团队的交付能力,而修补这些弱项往往需要学习大量的新知识,这就需要团队成员之间有一个很好的协作。因此 76% 的年轻人都认为个人发展机会是公司文化[最重要的的一环][10]。
|
||||||
|
|
||||||
|
### 效果就是最好的证明
|
||||||
|
|
||||||
|
DevOps 转型会改变团队的工作方式和文化,这需要得到管理层的支持和理解。同时,工作方式的改变意味着新技术的引入,所以在管理上也必须谨慎。但转型的最终结果是团队变得更高效、成员变得更积极、产品变得更优质,客户也变得更快乐。
|
||||||
|
|
||||||
|
免责声明:本文中的内容仅为 Lee Eason 的个人立场,不代表 Ipreo 或 IHS Markit。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/tales-devops-transformation
|
||||||
|
|
||||||
|
作者:[Lee Eason][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[HankChow](https://github.com/HankChow)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/leeeason
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://link.springer.com/article/10.1007%2Fs00442-014-2995-6
|
||||||
|
[2]: /file/411061
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/devops-delays.png "Improvements after DevOps transformation"
|
||||||
|
[4]: https://puppet.com/resources/whitepaper/state-of-devops-report
|
||||||
|
[5]: https://www.gartner.com/en/publications/wolf-cio
|
||||||
|
[6]: https://en.wikipedia.org/wiki/Drive:_The_Surprising_Truth_About_What_Motivates_Us
|
||||||
|
[7]: https://www.ted.com/talks/dan_pink_on_motivation?language=en#t-2094
|
||||||
|
[8]: https://en.wikipedia.org/wiki/The_Hero_with_a_Thousand_Faces
|
||||||
|
[9]: https://tekata.io/
|
||||||
|
[10]: https://www.execu-search.com/~/media/Resources/pdf/2017_Hiring_Outlook_eBook
|
||||||
|
[11]: https://allthingsopen.org/talk/tales-from-a-devops-transformation/
|
||||||
|
[12]: https://allthingsopen.org/
|
||||||
|
|
||||||
@ -12,7 +12,7 @@
|
|||||||
|
|
||||||
在本实验及后面的实验中,你将逐步构建你的内核。我们将会为你提供一些附加的资源。使用 Git 去获取这些资源、提交自实验 1 以来的改变(如有需要的话)、获取课程仓库的最新版本、以及在我们的实验 2 (origin/lab2)的基础上创建一个称为 lab2 的本地分支:
|
在本实验及后面的实验中,你将逐步构建你的内核。我们将会为你提供一些附加的资源。使用 Git 去获取这些资源、提交自实验 1 以来的改变(如有需要的话)、获取课程仓库的最新版本、以及在我们的实验 2 (origin/lab2)的基础上创建一个称为 lab2 的本地分支:
|
||||||
|
|
||||||
```
|
```c
|
||||||
athena% cd ~/6.828/lab
|
athena% cd ~/6.828/lab
|
||||||
athena% add git
|
athena% add git
|
||||||
athena% git pull
|
athena% git pull
|
||||||
@ -23,9 +23,11 @@ Switched to a new branch "lab2"
|
|||||||
athena%
|
athena%
|
||||||
```
|
```
|
||||||
|
|
||||||
|
上面的 `git checkout -b` 命令其实做了两件事情:首先它创建了一个本地分支 `lab2`,它跟踪给我们提供课程内容的远程分支 `origin/lab2` ,第二件事情是,它更改的你的 `lab` 目录的内容反映到 `lab2` 分支上存储的文件中。Git 允许你在已存在的两个分支之间使用 `git checkout *branch-name*` 命令去切换,但是在你切换到另一个分支之前,你应该去提交那个分支上你做的任何出色的变更。
|
||||||
|
|
||||||
现在,你需要将你在 lab1 分支中的改变合并到 lab2 分支中,命令如下:
|
现在,你需要将你在 lab1 分支中的改变合并到 lab2 分支中,命令如下:
|
||||||
|
|
||||||
```
|
```c
|
||||||
athena% git merge lab1
|
athena% git merge lab1
|
||||||
Merge made by recursive.
|
Merge made by recursive.
|
||||||
kern/kdebug.c | 11 +++++++++--
|
kern/kdebug.c | 11 +++++++++--
|
||||||
@ -35,6 +37,8 @@ Merge made by recursive.
|
|||||||
athena%
|
athena%
|
||||||
```
|
```
|
||||||
|
|
||||||
|
在一些案例中,Git 或许并不能找到如何将你的更改与新的实验任务合并(例如,你在第二个实验任务中变更了一些代码的修改)。在那种情况下,你使用 git 命令去合并,它会告诉你哪个文件发生了冲突,你必须首先去解决冲突(通过编辑冲突的文件),然后使用 `git commit -a` 去重新提交文件。
|
||||||
|
|
||||||
实验 2 包含如下的新源代码,后面你将遍历它们:
|
实验 2 包含如下的新源代码,后面你将遍历它们:
|
||||||
|
|
||||||
- inc/memlayout.h
|
- inc/memlayout.h
|
||||||
@ -53,13 +57,15 @@ athena%
|
|||||||
|
|
||||||
在你准备进行实验和写代码之前,先添加你的 `answers-lab2.txt` 文件到 Git 仓库,提交你的改变然后去运行 `make handin`。
|
在你准备进行实验和写代码之前,先添加你的 `answers-lab2.txt` 文件到 Git 仓库,提交你的改变然后去运行 `make handin`。
|
||||||
|
|
||||||
```
|
```c
|
||||||
athena% git add answers-lab2.txt
|
athena% git add answers-lab2.txt
|
||||||
athena% git commit -am "my answer to lab2"
|
athena% git commit -am "my answer to lab2"
|
||||||
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
|
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
|
||||||
athena% make handin
|
athena% make handin
|
||||||
```
|
```
|
||||||
|
|
||||||
|
正如前面所说的,我们将使用一个评级程序来分级你的解决方案,你可以在 `lab` 目录下运行 `make grade`,使用评级程序来测试你的内核。为了完成你的实验,你可以改变任何你需要的内核源代码和头文件。但毫无疑问的是,你不能以任何形式去改变或破坏评级代码。
|
||||||
|
|
||||||
### 第 1 部分:物理页面管理
|
### 第 1 部分:物理页面管理
|
||||||
|
|
||||||
操作系统必须跟踪物理内存页是否使用的状态。JOS 以页为最小粒度来管理 PC 的物理内存,以便于它使用 MMU 去映射和保护每个已分配的内存片段。
|
操作系统必须跟踪物理内存页是否使用的状态。JOS 以页为最小粒度来管理 PC 的物理内存,以便于它使用 MMU 去映射和保护每个已分配的内存片段。
|
||||||
@ -98,6 +104,8 @@ athena% make handin
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
一个 C 指针是虚拟地址的“偏移量”部分。在 `boot/boot.S` 中我们安装了一个全局描述符表(GDT),它通过设置所有的段基址为 0,并且限制为 `0xffffffff` 来有效地禁用段转换。因此“段选择器”并不会生效,而线性地址总是等于虚拟地址的偏移量。在实验 3 中,为了设置权限级别,我们将与段有更多的交互。但是对于内存转换,我们将在整个 JOS 实验中忽略段,只专注于页转换。
|
||||||
|
|
||||||
回顾实验 1 中的第 3 部分,我们安装了一个简单的页表,这样内核就可以在 0xf0100000 链接的地址上运行,尽管它实际上是加载在 0x00100000 处的 ROM BIOS 的物理内存上。这个页表仅映射了 4MB 的内存。在实验中,你将要为 JOS 去设置虚拟内存布局,我们将从虚拟地址 0xf0000000 处开始扩展它,首先将物理内存扩展到 256MB,并映射许多其它区域的虚拟内存。
|
回顾实验 1 中的第 3 部分,我们安装了一个简单的页表,这样内核就可以在 0xf0100000 链接的地址上运行,尽管它实际上是加载在 0x00100000 处的 ROM BIOS 的物理内存上。这个页表仅映射了 4MB 的内存。在实验中,你将要为 JOS 去设置虚拟内存布局,我们将从虚拟地址 0xf0000000 处开始扩展它,首先将物理内存扩展到 256MB,并映射许多其它区域的虚拟内存。
|
||||||
|
|
||||||
> 练习 3
|
> 练习 3
|
||||||
@ -165,9 +173,9 @@ JOS 分割处理器的 32 位线性地址空间为两部分:用户环境(进
|
|||||||
|
|
||||||
你可以在 `inc/memlayout.h` 中找到一个图表,它有助于你去理解 JOS 内存布局,这在本实验和后面的实验中都会用到。
|
你可以在 `inc/memlayout.h` 中找到一个图表,它有助于你去理解 JOS 内存布局,这在本实验和后面的实验中都会用到。
|
||||||
|
|
||||||
### 权限和缺页隔离
|
### 权限和故障隔离
|
||||||
|
|
||||||
由于内核和用户的内存都存在于它们各自环境的地址空间中,因此我们需要在 x86 的页表中使用权限位去允许用户代码只能访问用户所属地址空间的部分。否则的话,用户代码中的 bug 可能会覆写内核数据,导致系统崩溃或者发生各种莫名其妙的的故障;用户代码也可能会偷窥其它环境的私有数据。
|
由于内核和用户的内存都存在于它们各自环境的地址空间中,因此我们需要在 x86 的页表中使用权限位去允许用户代码只能访问用户所属地址空间的部分。否则,用户代码中的 bug 可能会覆写内核数据,导致系统崩溃或者发生各种莫名其妙的的故障;用户代码也可能会偷窥其它环境的私有数据。
|
||||||
|
|
||||||
对于 ULIM 以上部分的内存,用户环境没有任何权限,只有内核才可以读取和写入这部分内存。对于 [UTOP,ULIM] 地址范围,内核和用户都有相同的权限:它们可以读取但不能写入这个地址范围。这个地址范围是用于向用户环境暴露某些只读的内核数据结构。最后,低于 UTOP 的地址空间是为用户环境所使用的;用户环境将为访问这些内核设置权限。
|
对于 ULIM 以上部分的内存,用户环境没有任何权限,只有内核才可以读取和写入这部分内存。对于 [UTOP,ULIM] 地址范围,内核和用户都有相同的权限:它们可以读取但不能写入这个地址范围。这个地址范围是用于向用户环境暴露某些只读的内核数据结构。最后,低于 UTOP 的地址空间是为用户环境所使用的;用户环境将为访问这些内核设置权限。
|
||||||
|
|
||||||
|
|||||||
@ -1,102 +0,0 @@
|
|||||||
对于开发者来说5个最好的Linux发行版
|
|
||||||
============================================================
|
|
||||||

|
|
||||||
Jack Wallen介绍了一些非常适合用来做开发工作的Linux发行版本.[Creative Commons Zero][6]
|
|
||||||
在考虑使用Linux时,需要做很多的考量。你希望使用什么包管理器?你更喜欢现代还是比较旧的桌面界面?易用性是你使用Linux的首选吗?你希望分发的灵活性?发行版的服务性任务是什么?
|
|
||||||
这是你在开始使用Linux之前必须考虑的问题。发行版是作为桌面还是服务器运行?你会做网络或者系统审计吗?或者你会开发?如果你花了很多时间考虑Linux,你知道每个任务都有非常合适的Linux发行版。这当然非常适用于开发人员。尽管Linux在设计上对于开发人员来说是一个理想的平台,但某些发行版高于其他的发行版,可以作为最好的开发人员的操作系统去服务开发人员。
|
|
||||||
我想来分享我自己认为是你在做开发工作当中的最佳Linux发行版。虽然这五个发行版的每一个都可以用来通用开发(可能有一个是例外),但是它们都有各自的特定目的,你看会或不会对这些选择感觉到惊讶
|
|
||||||
话虽如此,让我们做出选择
|
|
||||||
### Debian
|
|
||||||
在[Debian][14]的发行版中许多Linux列表中排名靠前。 有充分的理由。 Debian是许多人所依赖的发行版. 这就是为什么更多的开发人员去选择debian的理由。 当你在Debian上开发一个软件的时候,很有可能该软件包可以适用于[Ubuntu][15], [Linux Mint][16], [Elementary OS][17],以及大量的其他Debian发行版。
|
|
||||||
除了这个非常明显的答案之外,Debian还通过默认存储库提供了大量可用的应用程序(图1)。
|
|
||||||

|
|
||||||
图 1: 标准的Debian存储库里面可用的应用程序。[Used with permission][1]
|
|
||||||
为了让程序员友好,这些应用程序 (以及它们的依赖项) 易于安装.例如,构建必需的包(可以安装在Debian的任何衍生发行版上)。该软件包包括dkpg-dev,g ++,gcc,hurd-dev,libc-dev以及开发过程所需的make-all工具。可以使用命令sudo apt install build-essential安装build-essential软件包。
|
|
||||||
标准存储库当中提供了数百种的特定于开发人员的应用程序,例如:
|
|
||||||
* Autoconf—配置构建脚本的软件
|
|
||||||
* Autoproject—为新程序创建源码包
|
|
||||||
* Bison—通用的解析生成器
|
|
||||||
* Bluefish—面向程序员的强大GUI编辑器
|
|
||||||
* Geany—轻量化的IDE
|
|
||||||
* Kate—强大的文本编辑器
|
|
||||||
* Eclipse—帮助构建者独立开发与其他工具的集成性软件
|
|
||||||
这个清单一直在继续更新.
|
|
||||||
Debian也是你能找到的坚于磐石的发行版,因此很少有人担心因为桌面崩溃而让你失去宝贵的工作。作为奖励,Debian的所有应用程序都必须符合[Debian自由软件指南][18], 该指南遵守以下 “社会契约”:
|
|
||||||
* Debian 保持完全免费.
|
|
||||||
* 我们将无偿回馈自由软件社区.
|
|
||||||
* 我们不会隐藏问题.
|
|
||||||
* 我们的首要任务是我们的用户和自由软件
|
|
||||||
* 不符合我们的免费软件标准的作品在非免费档案中..
|
|
||||||
此外,你不熟悉在Linux上进行开发,Debian在其[用户手册][19]中有一个方便编程的部分。
|
|
||||||
### openSUSE Tumbleweed (滚动更新版)
|
|
||||||
如果你希望开发出最前沿的滚动发行版本, [openSUSE][20] 将提供最好的[Tumbleweed][21]之一。 还可以借助openSUSE当中令人惊叹的管理员工具(其中包括YaST)来实现这一目标。如果你不熟悉YaST(又一个设置工具)的话,它是一个非常强大的软件,允许您从一个方便的位置来管理整个平台。在YaST中,您还可以使用RPM组进行安装。打开YaST,单击RPM Groups(按目的分组的软件),然后向下滚动到Development部分以查看可安装的大量组(图2)
|
|
||||||

|
|
||||||
图 2: 在openSUSE Tumbleweed中安装软件包组.[Creative Commons Zero][2]
|
|
||||||
openSUSE还允许您通过简单的单击链接快速安装所有必需的devtools [rpmdevtools安装页面][22], 然后单击Tumbleweed的链接。这将自动添加必要的存储库并安装rpmdevtools
|
|
||||||
对于开发者来说,通过滚动版本进行开发,你可以知道你已安装的软件是最新版本。
|
|
||||||
### CentOS
|
|
||||||
让我们来看一下, [红帽企业版Linux][23] (RHEL) 是企业事务的事实标准. 如果你正在寻找针对特定平台进行开发,并且你有点担心无法承担RHEL的许可证,那么[CentOS][24]就是你不错的选择— 实际上,它是RHEL的社区版本。你会发现CentOS上的许多软件包与RHEL中的软件包相同 - 所以一旦熟悉了一个软件包,你就可以使用其他的软件包。
|
|
||||||
如果你认真考虑在企业级平台上进行开发,那么CentOS就是不错的选择。而且由于CentOS是特定于服务器的发行版,因此您可以更轻松地以Web为中心的平台进行开发。您可以轻松地将CentOS作为开发和测试的理想主机,而不是开发您的工作然后将其迁移到服务器(托管在不同的计算机上).
|
|
||||||
寻找满足你开发需求的软件? 你只需要打开CentOS软件中心, 其中包含了集成开发环境(IDE - 图3)的专用子部分
|
|
||||||

|
|
||||||
图 3: 在CentOS中安装功能强大的IDE很简单。.[Used with permission][3]
|
|
||||||
Centos还包括安全增强性的Linux(SElinux),它使你可以更加轻松的去测试你的软件与RHEL中的同一安全平台的集成功能,SElinux经常会让设计不佳的软件感到头疼,因此准备了它可以真正有利于确保你的应用程序在RHEL之类的应用程序上面运行。如果你不确定如何在Centos上进行开发工作。你可以阅读[RHEL 7 开发人员指南][25].
|
|
||||||
### Raspbian
|
|
||||||
让我们来看一下, 嵌入式操作系统风靡一时. 使用这种 操作系统最简单的一种方法就是通过Raspberry Pi——一种极小的单片机(也可以称为小型计算机). 事实上,Raspberry Pi 已经成为了全球喜爱DIY用户使用的硬件. 为这些 设备供电的是 [Raspbian][26]操作系统. Raspbian包含[BlueJ][27], [Geany][28], [Greenfoot][29], [Sense HAT Emulator][30], [Sonic Pi][31], 和 [Thonny Python IDE][32], [Python][33], 和 [Scratch][34]等一些工具, 因此你不需要开发软件。Raspbian还包括一个用户友好的桌面UI(图4),使事情变得更加容易。
|
|
||||||

|
|
||||||
图 4: Raspbian主菜单,显示预安装的开发人员软件.[Used with permission][4]
|
|
||||||
对于任何想要对Raspberry Pi平台开发的人来说,Raspbian是必要的。如果你想在不使用Raspberry Pi硬件的情况下使用Raspbian系统,您可以通过下载[此处][35]的ISO映像将其安装在VirtualBox虚拟机中
|
|
||||||
### Pop!_OS
|
|
||||||
不要让这个名字迷惑你,,不要让这个名字迷惑你, 进入[System76][36]的 [Pop!_OS][37]操作系统世界是非常严格的. 虽然System76对这个Ubuntu衍生产品做了很多修改但不是很明显,但这是特别的。
|
|
||||||
System76的目标是创建一个特定于开发人员,制造商和计算机科学专业人员的操作系统。通过新设计的GNOME主题,Pop!_OS非常漂亮(图5),并且功能与硬件制造商使桌面设计人员一样强大。
|
|
||||||
### [devel_5.jpg][11]
|
|
||||||

|
|
||||||
图 5: Pop!_OS 桌面.[Used with permission][5]
|
|
||||||
但是,Pop!_OS的特殊之处在于它是由一家致力于Linux硬件的公司开发的。这意味着,当您购买System76笔记本电脑,台式机或服务器时,您就会知道操作系统将与硬件无缝协作 - 这是其他公司无法提供的。我预测,Pop!_OS将使System76将成为Linux界Apple。
|
|
||||||
### 工作时间
|
|
||||||
以他们自己的方式,每个发行版。你有一个稳定的桌面(Debian),一个尖端的桌面(openSUSE Tumbleweed),一个服务器(CentOS),一个嵌入式平台(Raspbian),以及一个与硬件无缝融合的发行版(Pop!_OS)。除了Raspbian之外,这些发行版中的任何一个都将成为一个出色的开发平台。安装一个并开始自信地开展下一个项目。
|
|
||||||
可以通过Linux Foundation和edX 免费提供的["Linux简介" ][13]来了解更多的有关Linux信息
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/5-best-linux-distributions-development
|
|
||||||
作者:[JACK WALLEN ][a]
|
|
||||||
译者:[geekmar](https://github.com/geekmar)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
[a]:https://www.linux.com/users/jlwallen
|
|
||||||
[1]:https://www.linux.com/licenses/category/used-permission
|
|
||||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
|
||||||
[3]:https://www.linux.com/licenses/category/used-permission
|
|
||||||
[4]:https://www.linux.com/licenses/category/used-permission
|
|
||||||
[5]:https://www.linux.com/licenses/category/used-permission
|
|
||||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
|
||||||
[7]:https://www.linux.com/files/images/devel1jpg
|
|
||||||
[8]:https://www.linux.com/files/images/devel2jpg
|
|
||||||
[9]:https://www.linux.com/files/images/devel3jpg
|
|
||||||
[10]:https://www.linux.com/files/images/devel4jpg
|
|
||||||
[11]:https://www.linux.com/files/images/devel5jpg
|
|
||||||
[12]:https://www.linux.com/files/images/king-penguins1920jpg
|
|
||||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
|
||||||
[14]:https://www.debian.org/
|
|
||||||
[15]:https://www.ubuntu.com/
|
|
||||||
[16]:https://linuxmint.com/
|
|
||||||
[17]:https://elementary.io/
|
|
||||||
[18]:https://www.debian.org/social_contract
|
|
||||||
[19]:https://www.debian.org/doc/manuals/debian-reference/ch12.en.html
|
|
||||||
[20]:https://www.opensuse.org/
|
|
||||||
[21]:https://en.opensuse.org/Portal:Tumbleweed
|
|
||||||
[22]:https://software.opensuse.org/download.html?project=devel%3Atools&package=rpmdevtools
|
|
||||||
[23]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
|
||||||
[24]:https://www.centos.org/
|
|
||||||
[25]:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/pdf/developer_guide/Red_Hat_Enterprise_Linux-7-Developer_Guide-en-US.pdf
|
|
||||||
[26]:https://www.raspberrypi.org/downloads/raspbian/
|
|
||||||
[27]:https://www.bluej.org/
|
|
||||||
[28]:https://www.geany.org/
|
|
||||||
[29]:https://www.greenfoot.org/
|
|
||||||
[30]:https://www.raspberrypi.org/blog/sense-hat-emulator/
|
|
||||||
[31]:http://sonic-pi.net/
|
|
||||||
[32]:http://thonny.org/
|
|
||||||
[33]:https://www.python.org/
|
|
||||||
[34]:https://scratch.mit.edu/
|
|
||||||
[35]:http://rpf.io/x86iso
|
|
||||||
[36]:https://system76.com/
|
|
||||||
[37]:https://system76.com/pop
|
|
||||||
@ -0,0 +1,167 @@
|
|||||||
|
在 Linux 上使用 systemd 设置定时器
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
之前,我们看到了如何[手动的][1]、[在开机与关机时][2]、[在启用某个设备时][3]、[在文件系统发生改变时][4]启用与禁用 systemd 服务。
|
||||||
|
|
||||||
|
定时器增加了另一种启动服务的方式,基于...时间。尽管与定时任务很相似,但 systemd 定时器稍微地灵活一些。让我们看看它是怎么工作的。
|
||||||
|
|
||||||
|
### “定时运行”
|
||||||
|
|
||||||
|
让我们展开[本系列前两篇文章][2]中[你所设置的 ][1] [Minetest][5] 服务器作为如何使用定时器单元的第一个例子。如果你还没有读过那几篇文章,可以现在去看看。
|
||||||
|
|
||||||
|
你将通过创建一个定时器来改进 Minetest 服务器,使得在定时器启动 1 分钟后运行游戏服务器而不是立即运行。这样做的原因可能是,在启动之前可能会用到其他的服务,例如发邮件给其他玩家告诉他们游戏已经准备就绪,你要确保其他的服务(例如网络)在开始前完全启动并运行。
|
||||||
|
|
||||||
|
跳到最底下,你的 `_minetest.timer_` 单元看起来就像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
# minetest.timer
|
||||||
|
[Unit]
|
||||||
|
Description=Runs the minetest.service 1 minute after boot up
|
||||||
|
|
||||||
|
[Timer]
|
||||||
|
OnBootSec=1 m
|
||||||
|
Unit=minetest.service
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=basic.target
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
一点也不难吧。
|
||||||
|
|
||||||
|
通常,开头是 `[Unit]` 和一段描述单元作用的信息,这儿没什么新东西。`[Timer]` 这一节是新出现的,但它的作用不言自明:它包含了何时启动服务,启动哪个服务的信息。在这个例子当中,`OnBootSec` 是告诉 systemd 在系统启动后运行服务的指令。
|
||||||
|
|
||||||
|
其他的指令有:
|
||||||
|
|
||||||
|
* `OnActiveSec=`,告诉 systemd 在定时器启动后多长时间运行服务。
|
||||||
|
* `OnStartupSec=`,同样的,它告诉 systemd 在 systemd 进程启动后多长时间运行服务。
|
||||||
|
* `OnUnitActiveSec=`,告诉 systemd 在上次由定时器激活的服务启动后多长时间运行服务。
|
||||||
|
* `OnUnitInactiveSec=`,告诉 systemd 在上次由定时器激活的服务停用后多长时间运行服务。
|
||||||
|
|
||||||
|
继续 `_minetest.timer_` 单元,`basic.target` 通常用作<ruby>后期引导服务<rt>late boot services</rt></ruby>的<ruby>同步点<rt>synchronization point</rt></ruby>。这就意味着它可以让 `_minetest.timer_` 单元运行在安装完<ruby>本地挂载点<rt>local mount points</rt></ruby>或交换设备,套接字、定时器、路径单元和其他基本的初始化进程之后。就像在[第二篇文章中 systemd 单元][2]里解释的那样,`_targets_` 就像<ruby>旧的运行等级<rt>old run levels</rt></ruby>,可以将你的计算机置于某个状态,或像这样告诉你的服务在达到某个状态后开始运行。
|
||||||
|
|
||||||
|
在前两篇文章中你配置的`_minetest.service_`文件[最终][2]看起来就像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
# minetest.service
|
||||||
|
[Unit]
|
||||||
|
Description= Minetest server
|
||||||
|
Documentation= https://wiki.minetest.net/Main_Page
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
Type= simple
|
||||||
|
User=
|
||||||
|
|
||||||
|
ExecStart= /usr/games/minetest --server
|
||||||
|
ExecStartPost= /home//bin/mtsendmail.sh "Ready to rumble?" "Minetest Starting up"
|
||||||
|
|
||||||
|
TimeoutStopSec= 180
|
||||||
|
ExecStop= /home//bin/mtsendmail.sh "Off to bed. Nightie night!" "Minetest Stopping in 2 minutes"
|
||||||
|
ExecStop= /bin/sleep 120
|
||||||
|
ExecStop= /bin/kill -2 $MAINPID
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy= multi-user.target
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
这儿没什么需要修改的。但是你需要将 `_mtsendmail.sh_`(发送你的 email 的脚本)从:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
# mtsendmail
|
||||||
|
sleep 20
|
||||||
|
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
|
||||||
|
sleep 10
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
改成:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
# mtsendmail.sh
|
||||||
|
echo $1 | mutt -F /home/paul/.muttrc -s "$2" pbrown@mykolab.com
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
你做的事是去除掉 Bash 脚本中那些蹩脚的停顿。Systemd 现在正在等待。
|
||||||
|
|
||||||
|
### 让它运行起来
|
||||||
|
|
||||||
|
确保一切运作正常,禁用 `_minetest.service_`:
|
||||||
|
```
|
||||||
|
sudo systemctl disable minetest
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
这使得系统启动时它不会一同启动;然后,相反地,启用 `_minetest.timer_`:
|
||||||
|
```
|
||||||
|
sudo systemctl enable minetest.timer
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你就可以重启服务器了,当运行`sudo journalctl -u minetest.*`后,你就会看到 `_minetest.timer_` 单元执行后大约一分钟,`_minetest.service_` 单元开始运行。
|
||||||
|
|
||||||
|
![minetest timer][7]
|
||||||
|
|
||||||
|
图 1:minetest.timer 运行大约 1 分钟后 minetest.service 开始运行
|
||||||
|
|
||||||
|
[经许可使用][8]
|
||||||
|
|
||||||
|
### 时间的问题
|
||||||
|
|
||||||
|
`_minetest.timer_` 在 systemd 的日志里显示的启动时间为 09:08:33 而 `_minetest.service` 启动时间是 09:09:18,它们之间少于 1 分钟,关于这件事有几点需要说明一下:首先,请记住我们说过 `OnBootSec=` 指令是从引导完成后开始计算服务启动的时间。当 `_minetest.timer_` 的时间到来时,引导已经在几秒之前完成了。
|
||||||
|
|
||||||
|
另一件事情是 systemd 给自己设置了一个<ruby>误差幅度<rt>margin of error</rt></ruby>(默认是 1 分钟)来运行东西。这有助于在多个<ruby>资源密集型进程<rt>resource-intensive processes</rt></ruby>同时运行时分配负载:通过分配 1 分钟的时间,systemd 可以等待某些进程关闭。这也意味着 `_minetest.service_`会在引导完成后的 1~2 分钟之间启动。但精确的时间谁也不知道。
|
||||||
|
|
||||||
|
作为记录,你可以用 `AccuracySec=` 指令[修改误差幅度][9]。
|
||||||
|
|
||||||
|
你也可以检查系统上所有的定时器何时运行或是上次运行的时间:
|
||||||
|
|
||||||
|
```
|
||||||
|
systemctl list-timers --all
|
||||||
|
```
|
||||||
|
|
||||||
|
![check timer][11]
|
||||||
|
|
||||||
|
图 2:检查定时器何时运行或上次运行的时间
|
||||||
|
|
||||||
|
[经许可使用][8]
|
||||||
|
|
||||||
|
最后一件值得思考的事就是你应该用怎样的格式去表示一段时间。Systemd 在这方面非常灵活:`2 h`,`2 hours` 或 `2hr` 都可以用来表示 2 个小时。对于“秒”,你可以用 `seconds`,`second`,`sec` 和 `s`。“分”也是同样的方式:`minutes`,`minute`,`min` 和 `m`。你可以检查 `man systemd.time` 来查看 systemd 能够理解的所有时间单元。
|
||||||
|
|
||||||
|
### 下一次
|
||||||
|
|
||||||
|
下次你会看到如何使用日历中的日期和时间来定期运行服务,以及如何通过组合定时器与设备单元在插入某些硬件时运行服务。
|
||||||
|
|
||||||
|
回头见!
|
||||||
|
|
||||||
|
在 Linux 基金会和 edx 上通过免费课程 [“Introduction to Linux”][12] 学习更多关于 Linux 的知识。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||||
|
|
||||||
|
作者:[Paul Brown][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[LuuMing](https://github.com/LuuMing)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linux.com/users/bro66
|
||||||
|
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
|
||||||
|
[2]:https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping
|
||||||
|
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||||
|
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||||
|
[5]:https://www.minetest.net/
|
||||||
|
[6]:/files/images/minetest-timer-1png
|
||||||
|
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-1.png?itok=TG0xJvYM (minetest timer)
|
||||||
|
[8]:/licenses/category/used-permission
|
||||||
|
[9]:https://www.freedesktop.org/software/systemd/man/systemd.timer.html#AccuracySec=
|
||||||
|
[10]:/files/images/minetest-timer-2png
|
||||||
|
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-2.png?itok=pYxyVx8- (check timer)
|
||||||
|
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||||
@ -1,59 +0,0 @@
|
|||||||
6 个托管你 git 仓库的地方
|
|
||||||
======
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
也许你是少数一些没有注意到的人之一就在几周前,[微软收购了 GitHub][1]。两家公司达成了共识。微软在近些年已经变成了开源的有力支持者,GitHub 从成立起,就已经成为了许多开源项目的实际代码库。
|
|
||||||
|
|
||||||
然而,最近的购买可能会带给你一些烦躁。毕竟公司的收购让你意识到了你的开源代码放在了一个商业平台上。可能你现在还没准备好迁移到其他的平台上去,但是至少这可以给你提供一些可选项。让我们找找网上现在都有哪些可用的平台。
|
|
||||||
|
|
||||||
### 选择之一: GitHub
|
|
||||||
|
|
||||||
严格来说,这是一个合格的选项。[GitHub][2] 历史上没有什么糟糕的失败,而且微软最近也确实发展了不少开源项目。把你的项目继续放在 GitHub 上,继续保持观望没有什么不可以。它现在依然是最大的软件开发的网络社区,同时还有许多对于问题追踪、代码复查、持续集成、通用的代码管理很有用的工具。而且它还是基于 Git 的,Git 是每个人都喜欢的开源版本控制系统。你的代码还是你的代码。
|
|
||||||
|
|
||||||
### 选择之二: GitLab
|
|
||||||
|
|
||||||
[GitLab][3] 是代码库平台主要的竞争者。它是完全开源的。你可以像在 GitHhub 一样把你的代码托管在 GitLab,但你也可以选择在你自己的服务器上自行托管你自己的 GitLab 实例,并完全控制谁可以访问那里的所有内容以及如何访问、管理。 GitLab 与 GitHub 功能几乎相同,有些人甚至可能会说它的持续集成和测试工具更优越。尽管 GitLab 上的开发者社区肯定比 GitHub 上的开发者社区要小,但它仍然没有什么可以被指责的。你可能会在那里的人群中找到更多志同道合的开发者。
|
|
||||||
|
|
||||||
### 选择之三: Bitbucket
|
|
||||||
|
|
||||||
[Bitbucket][4] 已经存在很多年了。在某些方面,它可以作为 GitHub 未来的一面镜子。 Bitbucket 八年前被一家大公司(Atlassian)收购,并且已经经历了一些转换过程。 它仍然是一个像 GitHub 这样的商业平台,但它远不是一个创业公司,而且从组织上说它的基础相当稳定。 Bitbucket 分享了 GitHub 和 GitLab 上的大部分功能,以及它自己的一些新功能,如对 [Mercurial][5] 存储库的本机支持。
|
|
||||||
|
|
||||||
### 选择之四: SourceForge
|
|
||||||
|
|
||||||
[SourceForge][6] 是开源代码库的鼻祖。如果你曾经有一个开源项目,Sourceforge 是一个托管你的代码和向他人分享你的发行版的地方。迁移到 Git 进行版本控制需要一段时间,它有自己的商业收购和重新组构的事件,以及一些开源项目的一些不幸的捆绑决策。也就是说,SourceForge 从那时起似乎已经恢复,该网站仍然是一个有着不少开源项目的地方。 然而,很多人仍然感到有点受伤,而且有些人并不是各种尝试通过平台货币化的忠实粉丝,所以一定要睁大眼睛。
|
|
||||||
|
|
||||||
### 选择之五: 自己管理
|
|
||||||
|
|
||||||
如果你想自己掌握自己项目的命运(除了你自己没人可以责备你),然后一切都由自己来做对你来说可能是最佳的选择。无论对于大项目还是小项目。Git 是开源的,所以自己托管也很容易。如果你问题追踪和代码审查,你可以运行一个 GitLab 或者 [Phabricator][7] 的实例。对于持续集成,你可以设置自己的 [Jenkins][8] 自动化服务的实例。是的,你需要对自己的基础架构开销和相关的安全要求负责。但是,这个设置过程并不是很困难。所以如果你不想自己的代码被其他人的平台所吞没,这就是一种很好的方法。
|
|
||||||
|
|
||||||
### 选择之六:以上全部
|
|
||||||
|
|
||||||
以下是所有这些的美妙之处:尽管这些平台上有一些专有的选项,但它们仍然建立在坚实的开源技术之上。 而且不仅仅是开源,而是明确设计为分布在大型网络(如互联网)上的多个节点上。 你不需要只使用一个。 你可以使用一对......或者全部。 使用 GitLab 将你自己的设置作为保证的基础,并在 GitHub 和 Bitbucket 上安装克隆存储库,以进行问题跟踪和持续集成。 将你的主代码库保留在 GitHub 上,但是为了你自己的想法,可以在 GitLab 上安装“备份”克隆。
|
|
||||||
|
|
||||||
关键在于你的选择是什么。我们能有这么多选择,都是得益于那些非常有用的项目上的开源协议。未来一片光明。
|
|
||||||
|
|
||||||
当然,在这个列表中我肯定忽略了一些开源平台。你是否使用了很多的平台?哪个是你最喜欢的?你都可以在这里说出来!
|
|
||||||
|
|
||||||
:)
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/18/8/github-alternatives
|
|
||||||
|
|
||||||
作者:[Jason van Gumster][a]
|
|
||||||
选题:[lujun9972](https://github.com/lujun9972)
|
|
||||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/mairin
|
|
||||||
[1]: https://www.theverge.com/2018/6/4/17422788/microsoft-github-acquisition-official-deal
|
|
||||||
[2]: https://github.com/
|
|
||||||
[3]: https://gitlab.com
|
|
||||||
[4]: https://bitbucket.org
|
|
||||||
[5]: https://www.mercurial-scm.org/wiki/Repository
|
|
||||||
[6]: https://sourceforge.net
|
|
||||||
[7]: https://phacility.com/phabricator/
|
|
||||||
[8]: https://jenkins.io
|
|
||||||
@ -0,0 +1,78 @@
|
|||||||
|
正确选择开源数据库的 5 个技巧
|
||||||
|
======
|
||||||
|
> 对关键应用的选择不容许丝毫错误。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
你或许会遇到需要选择适合的开源数据库的情况。但这无论对于开源方面的老手或是新手,都是一项艰巨的任务。
|
||||||
|
|
||||||
|
在过去的几年中,采用开源技术的企业越来越多。面对这样的趋势,众多开源应用公司都纷纷承诺自己提供的解决方案能够各种问题、适应各种负载。但这些承诺不能轻信,在开源应用上的选择是重要而艰难的,尤其是数据库这种关键的应用。
|
||||||
|
|
||||||
|
凭借我在 [Percona][1] 和其它公司担任 IT 专家的经验,我很幸运能够指导其他人在开源技术的选择上做出正确的决策,因为需要考虑的重要因素太多了。希望通过这篇文章能够向大家分享这方面的一些技巧。
|
||||||
|
|
||||||
|
### 有一个明确的目标
|
||||||
|
|
||||||
|
这一点看似简单,但在和很多人聊过 MySQL、MongoDB、PostgreSQL 之后,我觉得这一点才是最重要的。
|
||||||
|
|
||||||
|
面对繁杂的开源数据库,更需要明确自己的目标。无论这个数据库是作为开发用的标准化数据库后端,抑或是用于替换遗留代码中的原有数据库,这都是一个明确的目标。
|
||||||
|
|
||||||
|
目标一旦确定,就可以集中精力与开源软件的提供方商讨更多细节了。
|
||||||
|
|
||||||
|
### 了解你的工作负载
|
||||||
|
|
||||||
|
尽管开源数据库技术的功能越来越丰富,但这些新加入的功能都不太具有普适性。譬如 MongoDB 新增了事务的支持、MySQL 新增了 JSON 存储的功能等等。目前开源数据库的普遍趋势是不断加入新的功能,但很多人的误区却在于没有选择最适合的工具来完成自己的工作——这样的人或许是一个自大的开发者,又或许是一个视野狭窄的主管——最终导致公司业务上的损失。最致命的是,在业务初期,使用了不适合的工具往往也可以顺利地完成任务,但随着业务的增长,很快就会到达瓶颈,尽管这个时候还可以替换更合适的工具,但成本就比较高了。
|
||||||
|
|
||||||
|
例如,如果你需要的是数据分析仓库,关系数据库可能不是一个适合的选择;如果你处理事务的应用要求严格的数据完整性和一致性,就不要考虑 NoSQL 了。
|
||||||
|
|
||||||
|
### 不要重新发明轮子
|
||||||
|
|
||||||
|
在过去的数十年,开源数据库技术迅速发展壮大。开源数据库从新生,到受到质疑,再到受到认可,现在已经成为很多企业生产环境的数据库。企业不再需要担心选择开源数据库技术会产生风险,因为开源数据库通常都有活跃的社区,可以为越来越多的初创公司、中型企业甚至 500 强公司提供开源数据库领域的支持和第三方工具。
|
||||||
|
|
||||||
|
Battery Ventures 是一家专注于技术的投资公司,最近推出了一个用于跟踪最受欢迎开源项目的 [BOSS 指数][2] 。它提供了对一些被广泛采用的开源项目和活跃的开源项目的详细情况。其中,数据库技术毫无悬念地占据了榜单的主导地位,在前十位之中占了一半。这个 BOSS 指数对于刚接触开源数据库领域的人来说,这是一个很好的切入点。当然,开源技术的提供者也会针对很多常见的典型问题给出对应的解决方案。
|
||||||
|
|
||||||
|
我认为,你想要做的事情很可能已经有人解决过了。即使这些先行者的解决方案不一定完全契合你的需求,但也可以从他们成功或失败案例中根据你自己的需求修改得出合适的解决方案。
|
||||||
|
|
||||||
|
如果你采用了一个最前沿的技术,这就是你探索的好机会了。如果你的工作负载刚好适合新的开源数据库技术,放胆去尝试吧。第一个吃螃蟹的人总是会得到意外的挑战和收获。
|
||||||
|
|
||||||
|
### 先从简单开始
|
||||||
|
|
||||||
|
你的数据库实际上需要达到多少个 [9][4] 的可用性?对许多公司来说,“实现高可用性”仅仅只是一个模糊的目标。当然,最常见的答案都会是“它是关键应用,我们无论多短的停机时间都是无法忍受的”。
|
||||||
|
|
||||||
|
数据库环境越复杂,管理的难度就越大,成本也会越高。理论上你总可以将数据库的可用性提得更高,但代价将会是大大增加的管理难度和性能下降。所以,先从简单开始,直到有需要时再逐步扩展。
|
||||||
|
|
||||||
|
例如,Booking.com 是一个有名的旅游预订网站。但少有人知的是,它使用 MySQL 作为数据库后端。 Booking.com 高级系统架构师 Nicolai Plum 曾经发表过一次[演讲][5],讲述了他们公司使用 MySQL 数据库的历程。其中一个重点就是,在初始阶段数据库可以被配置得很简单,然后逐渐变得复杂。对于早期的数据库需求,一个简单的主从架构就足够了,但随着工作负载和数据量的增加,数据库引入了负载均衡、多个读取副本,还使用 Hadoop 进行分析。尽管如此,早期的架构仍然是非常简单的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 有疑问,找专家
|
||||||
|
|
||||||
|
如果你仍然不确定数据库选择得是否合适,可以在论坛、网站或者与软件的提供者处商讨。研究各种开源数据库是否满足自己的需求是一件很有意义的事,因为总会发现你从不知道的技术。而开源社区就是分享这些信息的地方。
|
||||||
|
|
||||||
|
当你接触到开源软件和软件提供者时,有一件重要的事情需要注意。很多公司都有开放的核心业务模式,鼓励采用他们的数据库软件。你可以只接受他们的部分建议和指导,然后用你自己的能力去研究和探索替代方案。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
选择正确的开源数据库是一个重要的过程。很多时候,人们都会在真正理解需求之前就做出决定,这是本末倒置的。
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/tips-choosing-right-open-source-database
|
||||||
|
|
||||||
|
作者:[Barrett Chambers][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[HankChow](https://github.com/HankChow)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/barrettc
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.percona.com/
|
||||||
|
[2]: https://techcrunch.com/2017/04/07/tracking-the-explosive-growth-of-open-source-software/
|
||||||
|
[3]: https://docs.aws.amazon.com/quickstart/latest/mongodb/welcome.html
|
||||||
|
[4]: https://en.wikipedia.org/wiki/Five_nines
|
||||||
|
[5]: https://www.percona.com/live/mysql-conference-2015/sessions/bookingcom-evolution-mysql-system-design
|
||||||
|
[6]: https://allthingsopen.org/talk/choosing-the-right-open-source-database/
|
||||||
|
[7]: https://allthingsopen.org/
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user