mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'refs/remotes/LCTT/master'
This commit is contained in:
commit
a67218133f
@ -0,0 +1,128 @@
|
||||
一位开发者的 Linux 容器之旅
|
||||
================================================================================
|
||||

|
||||
|
||||
我告诉你一个秘密:使得我的应用程序进入到全世界的 DevOps 云计算之类的东西对我来说仍然有一点神秘。但随着时间流逝,我意识到理解大规模的机器增减和应用程序部署的来龙去脉对一个开发者来说是非常重要的知识。这类似于成为一个专业的音乐家,当然你肯定需要知道如何使用你的乐器,但是,如果你不知道一个录音棚是如何工作的,或者如何适应一个交响乐团,那么你在这样的环境中工作会变得非常困难。
|
||||
|
||||
在软件开发的世界里,使你的代码进入我们的更大的世界如同把它编写出来一样重要。DevOps 重要,而且是很重要。
|
||||
|
||||
因此,为了弥合开发(Dev)和部署(Ops)之间的空隙,我会从头开始介绍容器技术。为什么是容器?因为有强力的证据表明,容器是机器抽象的下一步:使计算机成为场所而不再是一个东西。理解容器是我们共同的旅程。
|
||||
|
||||
在这篇文章中,我会介绍容器化(containerization)背后的概念。包括容器和虚拟机的区别,以及容器构建背后的逻辑以及它是如何适应应用程序架构的。我会探讨轻量级的 Linux 操作系统是如何适应容器生态系统。我还会讨论使用镜像创建可重用的容器。最后我会介绍容器集群如何使你的应用程序可以快速扩展。
|
||||
|
||||
在后面的文章中,我会一步一步向你介绍容器化一个示例应用程序的过程,以及如何为你的应用程序容器创建一个托管集群。同时,我会向你展示如何使用 Deis 将你的示例应用程序部署到你本地系统以及多种云供应商的虚拟机上。
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
### 虚拟机的好处 ###
|
||||
|
||||
为了理解容器如何适应事物发展,你首先要了解容器的前任:虚拟机。
|
||||
|
||||
[虚拟机][1] (virtual machine (VM))是运行在物理宿主机上的软件抽象。配置一个虚拟机就像是购买一台计算机:你需要定义你想要的 CPU 数目、RAM 和磁盘存储容量。配置好了机器后,你为它加载操作系统,以及你想让虚拟机支持的任何服务器或者应用程序。
|
||||
|
||||
虚拟机允许你在一台硬件主机上运行多个模拟计算机。这是一个简单的示意图:
|
||||
|
||||

|
||||
|
||||
虚拟机可以让你能充分利用你的硬件资源。你可以购买一台巨大的、轰隆作响的机器,然后在上面运行多个虚拟机。你可以有一个数据库虚拟机以及很多运行相同版本的定制应用程序的虚拟机所构成的集群。你可以在有限的硬件资源获得很多的扩展能力。如果你觉得你需要更多的虚拟机而且你的宿主硬件还有容量,你可以添加任何你需要的虚拟机。或者,如果你不再需要一个虚拟机,你可以关闭该虚拟机并删除虚拟机镜像。
|
||||
|
||||
### 虚拟机的局限 ###
|
||||
|
||||
但是,虚拟机确实有局限。
|
||||
|
||||
如上面所示,假如你在一个主机上创建了三个虚拟机。主机有 12 个 CPU,48 GB 内存和 3TB 的存储空间。每个虚拟机配置为有 4 个 CPU,16 GB 内存和 1TB 存储空间。到现在为止,一切都还好。主机有这个容量。
|
||||
|
||||
但这里有个缺陷。所有分配给一个虚拟机的资源,无论是什么,都是专有的。每台机器都分配了 16 GB 的内存。但是,如果第一个虚拟机永不会使用超过 1GB 分配的内存,剩余的 15 GB 就会被浪费在那里。如果第三个虚拟机只使用分配的 1TB 存储空间中的 100GB,其余的 900GB 就成为浪费空间。
|
||||
|
||||
这里没有资源的流动。每台虚拟机拥有分配给它的所有资源。因此,在某种方式上我们又回到了虚拟机之前,把大部分金钱花费在未使用的资源上。
|
||||
|
||||
虚拟机还有*另一个*缺陷。让它们跑起来需要很长时间。如果你处于基础设施需要快速增长的情形,即使增加虚拟机是自动的,你仍然会发现你的很多时间都浪费在等待机器上线。
|
||||
|
||||
### 来到:容器 ###
|
||||
|
||||
概念上来说,容器是一个 Linux 进程,Linux 认为它只是一个运行中的进程。该进程只知道它被告知的东西。另外,在容器化方面,该容器进程也分配了它自己的 IP 地址。这点很重要,重要的事情讲三遍,这是第二遍。**在容器化方面,容器进程有它自己的 IP 地址。**一旦给予了一个 IP 地址,该进程就是宿主网络中可识别的资源。然后,你可以在容器管理器上运行命令,使容器 IP 映射到主机中能访问公网的 IP 地址。建立了该映射,无论出于什么意图和目的,容器就是网络上一个可访问的独立机器,从概念上类似于虚拟机。
|
||||
|
||||
这是第三遍,容器是拥有不同 IP 地址从而使其成为网络上可识别的独立 Linux 进程。下面是一个示意图:
|
||||
|
||||

|
||||
|
||||
容器/进程以动态、合作的方式共享主机上的资源。如果容器只需要 1GB 内存,它就只会使用 1GB。如果它需要 4GB,就会使用 4GB。CPU 和存储空间利用也是如此。CPU、内存和存储空间的分配是动态的,和典型虚拟机的静态方式不同。所有这些资源的共享都由容器管理器来管理。
|
||||
|
||||
最后,容器能非常快速地启动。
|
||||
|
||||
因此,容器的好处是:**你获得了虚拟机独立和封装的好处,而抛弃了静态资源专有的缺陷**。另外,由于容器能快速加载到内存,在扩展到多个容器时你能获得更好的性能。
|
||||
|
||||
### 容器托管、配置和管理 ###
|
||||
|
||||
托管容器的计算机运行着被剥离的只剩下主要部分的某个 Linux 版本。现在,宿主计算机流行的底层操作系统是之前提到的 [CoreOS][2]。当然还有其它,例如 [Red Hat Atomic Host][3] 和 [Ubuntu Snappy][4]。
|
||||
|
||||
该 Linux 操作系统被所有容器所共享,减少了容器足迹的重复和冗余。每个容器只包括该容器特有的部分。下面是一个示意图:
|
||||
|
||||

|
||||
|
||||
你可以用它所需的组件来配置容器。一个容器组件被称为**层(layer)**。层是一个容器镜像,(你会在后面的部分看到更多关于容器镜像的介绍)。你从一个基本层开始,这通常是你想在容器中使用的操作系统。(容器管理器只提供你所要的操作系统在宿主操作系统中不存在的部分。)当你构建你的容器配置时,你需要添加层,例如你想要添加网络服务器时这个层就是 Apache,如果容器要运行脚本,则需要添加 PHP 或 Python 运行时环境。
|
||||
|
||||
分层非常灵活。如果应用程序或者服务容器需要 PHP 5.2 版本,你相应地配置该容器即可。如果你有另一个应用程序或者服务需要 PHP 5.6 版本,没问题,你可以使用 PHP 5.6 配置该容器。不像虚拟机,更改一个版本的运行时依赖时你需要经过大量的配置和安装过程;对于容器你只需要在容器配置文件中重新定义层。
|
||||
|
||||
所有上面描述的容器的各种功能都由一个称为容器管理器(container manager)的软件控制。现在,最流行的容器管理器是 [Docker][5] 和 [Rocket][6]。上面的示意图展示了容器管理器是 Docker,宿主操作系统是 CentOS 的主机情景。
|
||||
|
||||
### 容器由镜像构成 ###
|
||||
|
||||
当你需要将我们的应用程序构建到容器时,你就要编译镜像。镜像代表了你的容器需要完成其工作的容器模板。(容器里可以在容器里面,如下图)。镜像存储在注册库(registry)中,注册库通过网络访问。
|
||||
|
||||
从概念上讲,注册库类似于一个使用 Java 的人眼中的 [Maven][7] 仓库、使用 .NET 的人眼中的 [NuGet][8] 服务器。你会创建一个列出了你应用程序所需镜像的容器配置文件。然后你使用容器管理器创建一个包括了你的应用程序代码以及从容器注册库中下载的部分资源。例如,如果你的应用程序包括了一些 PHP 文件,你的容器配置文件会声明你会从注册库中获取 PHP 运行时环境。另外,你还要使用容器配置文件声明需要复制到容器文件系统中的 .php 文件。容器管理器会封装你应用程序的所有东西为一个独立容器,该容器将会在容器管理器的管理下运行在宿主计算机上。
|
||||
|
||||
这是一个容器创建背后概念的示意图:
|
||||
|
||||

|
||||
|
||||
让我们仔细看看这个示意图。
|
||||
|
||||
(1)代表一个定义了你容器所需东西以及你容器如何构建的容器配置文件。当你在主机上运行容器时,容器管理器会读取该配置文件,从云上的注册库中获取你需要的容器镜像,(2)将镜像作为层添加到你的容器中。
|
||||
|
||||
另外,如果组成镜像需要其它镜像,容器管理器也会获取这些镜像并把它们作为层添加进来。(3)容器管理器会将需要的文件复制到容器中。
|
||||
|
||||
如果你使用了配置(provisioning)服务,例如 [Deis][9],你刚刚创建的应用程序容器做成镜像,(4)配置服务会将它部署到你选择的云供应商上,比如类似 AWS 和 Rackspace 云供应商。
|
||||
|
||||
### 集群中的容器 ###
|
||||
|
||||
好了。这里有一个很好的例子说明了容器比虚拟机提供了更好的配置灵活性和资源利用率。但是,这并不是全部。
|
||||
|
||||
容器真正的灵活是在集群中。记住,每个容器有一个独立的 IP 地址。因此,能把它放到负载均衡器后面。将容器放到负载均衡器后面,这就上升了一个层面。
|
||||
|
||||
你可以在一个负载均衡容器后运行容器集群以获得更高的性能和高可用计算。这是一个例子:
|
||||
|
||||

|
||||
|
||||
假如你开发了一个资源密集型的应用程序,例如图片处理。使用类似 [Deis][9] 的容器配置技术,你可以创建一个包括了你图片处理程序以及你图片处理程序需要的所有资源的容器镜像。然后,你可以部署一个或多个容器镜像到主机上的负载均衡器下。一旦创建了容器镜像,你可以随时使用它。当系统繁忙时可以添加更多的容器实例来满足手中的工作。
|
||||
|
||||
这里还有更多好消息。每次添加实例到环境中时,你不需要手动配置负载均衡器以便接受你的容器镜像。你可以使用服务发现技术让容器告知均衡器它可用。然后,一旦获知,均衡器就会将流量分发到新的结点。
|
||||
|
||||
### 全部放在一起 ###
|
||||
|
||||
容器技术完善了虚拟机缺失的部分。类似 CoreOS、RHEL Atomic、和 Ubuntu 的 Snappy 宿主操作系统,和类似 Docker 和 Rocket 的容器管理技术结合起来,使得容器变得日益流行。
|
||||
|
||||
尽管容器变得更加越来越普遍,掌握它们还是需要一段时间。但是,一旦你懂得了它们的窍门,你可以使用类似 [Deis][9] 这样的配置技术使容器创建和部署变得更加简单。
|
||||
|
||||
从概念上理解容器和进一步实际使用它们完成工作一样重要。但我认为不实际动手把想法付诸实践,概念也难以理解。因此,我们该系列的下一阶段就是:创建一些容器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://deis.com/blog/2015/developer-journey-linux-containers
|
||||
|
||||
作者:[Bob Reselman][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://deis.com/blog
|
||||
[1]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[2]:https://coreos.com/using-coreos/
|
||||
[3]:http://www.projectatomic.io/
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
[5]:https://www.docker.com/
|
||||
[6]:https://coreos.com/blog/rocket/
|
||||
[7]:https://en.wikipedia.org/wiki/Apache_Maven
|
||||
[8]:https://www.nuget.org/
|
||||
[9]:http://deis.com/learn
|
||||
@ -2,9 +2,9 @@ Linux 下如何安装 Retro Terminal
|
||||
================================================================================
|
||||

|
||||
|
||||
你有怀旧情节?那就试试 **安装 retro terminal 应用** [cool-retro-term][1] 来一瞥过去的时光吧。顾名思义,`cool-retro-term` 是一个兼具酷炫和怀旧的终端。
|
||||
你有怀旧情节?那就试试 **安装复古终端应用** [cool-retro-term][1] 来一瞥过去的时光吧。顾名思义,`cool-retro-term` 是一个兼具酷炫和怀旧的终端。
|
||||
|
||||
你还记得那段遍地都是 CRT 显示器、终端屏幕闪烁不停的时光吗?现在你并不需要穿越到过去来见证那段时光。假如你观看背景设置在上世纪 90 年代的电影,你就可以看到大量带有绿色或黑底白字的显像管显示器。再加上它们通常带有极客光环,这使得它们看起来更酷。
|
||||
你还记得那段遍地都是 CRT 显示器、终端屏幕闪烁不停的时光吗?现在你并不需要穿越到过去来见证那段时光。假如你观看背景设置在上世纪 90 年代的电影,你就可以看到大量带有绿色或黑底白字的显像管显示器。这种极客光环让它们看起来非常酷!
|
||||
|
||||
若你已经厌倦了你机器中终端的外表,正寻找某些炫酷且‘新奇’的东西,则 `cool-retro-term` 将会带给你一个复古的终端外表,使你可以重温过去。你也可以改变它的颜色、动画类型并添加一些额外的特效。
|
||||
|
||||
@ -48,7 +48,7 @@ Linux 下如何安装 Retro Terminal
|
||||
|
||||
./cool-retro-term
|
||||
|
||||
假如你想使得这个应用可在程序菜单中被快速获取到,以便你不用再每次手动地用命令来启动它,则你可以使用下面的命令:
|
||||
假如你想把这个应用放在程序菜单中以便快速找到,这样你就不用再每次手动地用命令来启动它,则你可以使用下面的命令:
|
||||
|
||||
sudo cp cool-retro-term.desktop /usr/share/applications
|
||||
|
||||
@ -60,13 +60,13 @@ Linux 下如何安装 Retro Terminal
|
||||
|
||||
via: http://itsfoss.com/cool-retro-term/
|
||||
|
||||
作者:[Hossein Heydari][a]
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/hossein/
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://github.com/Swordfish90/cool-retro-term
|
||||
[2]:http://itsfoss.com/tag/antergos/
|
||||
[3]:https://manjaro.github.io/
|
||||
@ -1,6 +1,6 @@
|
||||
如何在 Linux 上使用 SSHfs 挂载一个远程文件系统
|
||||
================================================================================
|
||||
你有想通过安全 shell 挂载一个远程文件系统到本地的经历吗?如果有的话,SSHfs 也许就是你所需要的。它通过使用 SSH 和 Fuse(LCTT 译注:Filesystem in Userspace,用户态文件系统,是 Linux 中用于挂载某些网络空间,如 SSH,到本地文件系统的模块) 允许你挂载远程计算机(或者服务器)到本地。
|
||||
你曾经想过用安全 shell 挂载一个远程文件系统到本地吗?如果有的话,SSHfs 也许就是你所需要的。它通过使用 SSH 和 Fuse(LCTT 译注:Filesystem in Userspace,用户态文件系统,是 Linux 中用于挂载某些网络空间,如 SSH,到本地文件系统的模块) 允许你挂载远程计算机(或者服务器)到本地。
|
||||
|
||||
**注意**: 这篇文章假设你明白[SSH 如何工作并在你的系统中配置 SSH][1]。
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
如果你使用的不是 Ubuntu,那就在你的发行版软件包管理器中搜索软件包名称。最好搜索和 fuse 或 SSHfs 相关的关键字,因为取决于你运行的系统,软件包名称可能稍微有些不同。
|
||||
|
||||
在你的系统上安装完软件包之后,就该创建 fuse 组了。在你安装 fuse 的时候,应该会在你的系统上创建一个组。如果没有的话,在终端窗口中输入以下命令以便在你的 Linux 系统中创建组:
|
||||
在你的系统上安装完软件包之后,就该创建好 fuse 组了。在你安装 fuse 的时候,应该会在你的系统上创建一个组。如果没有的话,在终端窗口中输入以下命令以便在你的 Linux 系统中创建组:
|
||||
|
||||
sudo groupadd fuse
|
||||
|
||||
@ -26,7 +26,7 @@
|
||||
|
||||

|
||||
|
||||
别担心上面命令的 `$USER`。shell 会自动用你自己的用户名替换。处理了和组相关的事之后,就是时候创建要挂载远程文件的目录了。
|
||||
别担心上面命令的 `$USER`。shell 会自动用你自己的用户名替换。处理了和组相关的工作之后,就是时候创建要挂载远程文件的目录了。
|
||||
|
||||
mkdir ~/remote_folder
|
||||
|
||||
@ -54,9 +54,9 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在 Linux 上有很多工具可以用于访问远程文件并挂载到本地。如之前所说,如果有的话,也只有很少的工具能充分利用 SSH 的强大功能。我希望在这篇指南的帮助下,也能认识到 SSHfs 是一个多么强大的工具。
|
||||
在 Linux 上有很多工具可以用于访问远程文件并挂载到本地。但是如之前所说,如果有的话,也只有很少的工具能充分利用 SSH 的强大功能。我希望在这篇指南的帮助下,也能认识到 SSHfs 是一个多么强大的工具。
|
||||
|
||||
你觉得 SSHfs 怎么样呢?在线的评论框里告诉我们吧!
|
||||
你觉得 SSHfs 怎么样呢?在下面的评论框里告诉我们吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -64,7 +64,7 @@ via: https://www.maketecheasier.com/sshfs-mount-remote-filesystem-linux/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,13 @@
|
||||
Linux又问必答-- 如何在Linux中改变默认的Java版本
|
||||
Linux 有问必答:如何在 Linux 中改变默认的 Java 版本
|
||||
================================================================================
|
||||
> **提问**:当我尝试在Linux中运行一个Java程序时,我遇到了一个错误。看上去像程序编译所使用的Javab版本与我本地的不同。我该如何在Linux上切换默认的Java版本?
|
||||
> **提问**:当我尝试在Linux中运行一个Java程序时,我遇到了一个错误。看上去像程序编译所使用的Java版本与我本地的不同。我该如何在Linux上切换默认的Java版本?
|
||||
|
||||
>
|
||||
> Exception in thread "main" java.lang.UnsupportedClassVersionError: com/xmodulo/hmon/gui/NetConf : Unsupported major.minor version 51.0
|
||||
|
||||
当Java程序编译时,编译环境会设置一个“target”变量来设置程序可以运行的最低Java版本。如果你Linux系统上运行的程序不满足最低的JRE版本要求,那么你会在运行的时候遇到下面的错误。
|
||||
当Java程序编译时,编译环境会设置一个“target”变量来设置程序可以运行的最低Java版本。如果你Linux系统上运行的程序不能满足最低的JRE版本要求,那么你会在运行的时候遇到下面的错误。
|
||||
|
||||
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/xmodulo/hmon/gui/NetConf : Unsupported major.minor version 51.0
|
||||
|
||||
比如,这种情况下程序在Java JRE 1.7下编译,但是系统只有Java JRE 1.6。
|
||||
比如,程序在Java JRE 1.7下编译,但是系统只有Java JRE 1.6。
|
||||
|
||||
要解决这个问题,你需要改变默认的Java版本到Java JRE 1.7或者更高(假设JRE已经安装了)。
|
||||
|
||||
@ -21,7 +19,7 @@ Linux又问必答-- 如何在Linux中改变默认的Java版本
|
||||
|
||||
本例中,总共安装了4个不同的Java版本:OpenJDK JRE 1.6、Oracle Java JRE 1.6、OpenJDK JRE 1.7 和 Oracle Java JRE 1.7。现在默认的Java版本是OpenJDK JRE 1.6。
|
||||
|
||||
如果没有安装需要的Java JRE,你可以参考[这些指导][1]来完成安装。
|
||||
如果没有安装需要的Java JRE,你可以参考[这些指导][1]来完成安装。
|
||||
|
||||
现在有可用的候选版本,你可以用下面的命令在可用的Java JRE之间**切换默认的Java版本**:
|
||||
|
||||
@ -45,7 +43,7 @@ via: http://ask.xmodulo.com/change-default-java-version-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
LastPass的开源替代品
|
||||
LastPass 的开源替代品
|
||||
================================================================================
|
||||
LastPass是一个跨平台的密码管理程序。在Linux平台中,它可作为Firefox, Chrome和Opera浏览器的插件使用。LastPass Sesame支持Ubuntu/Debian与Fedora系统。此外,LastPass还有安装在Firefox Portable的便携版,可将其安装在USB设备上。再加上适用于Ubuntu/Debian, Fedora和openSUSE的LastPass Pocket, 其具有良好的跨平台覆盖性。虽然LastPass备受好评,但它是一个专有软件。此外,LastPass最近被LogMeIn收购。如果你在找一个开源的替代品,这篇文章可能会对你有所帮助。
|
||||
|
||||
我们正面临着信息大爆炸。无论你是要在线经营生意,找工作,还是只为了休闲来进行阅读,互联网都是一个广大的信息源。在这种情况下,长期保留信息是很困难的。然而,及时地获取某些特定信息非常重要。密码就是这样的一个例子。
|
||||
我们正面临着信息大爆炸。无论你是要在线经营生意,找工作,还是只为了休闲来进行阅读,互联网都是一个海量的信息源。在这种情况下,长期保留信息是很困难的。然而,及时地获取某些特定信息非常重要。密码就是这样的一个例子。
|
||||
|
||||
作为一个电脑用户,你可能会面临在不同服务或网站使用相同或不同密码的困境。这个事情非常复杂,因为有些网站会限制你对密码的选择。比如,一个网站可能会限制密码的最小位数,大写字母,数字或者特殊字符,这使得在所有网站使用统一密码变得不可能。更重要的是,不在不同网站中使用同一密码有安全方面的原因。这样就不可避免地意味着人们经常会有很多密码要记。一个解决方案是将所有的密码写下来。然而,这种做法也极度的不安全。
|
||||
|
||||
为了解决需要记忆无穷多串密码的问题,目前比较流行的解决方案是使用密码管理软件。事实上,这类软件对于活跃的互联网用户来说极为实用。它使得你获取、管理和安全保存所有密码变得极为容易,而大多数密码都是被软件或文件系统加密过的。因此,用户只需要记住一个简单的密码就可以获取到其它所有密码。密码管理软件鼓励用户对于不同服务去采用独一无二的,非直观的强密码。
|
||||
为了解决需要记忆无穷多串密码的问题,目前比较流行的解决方案是使用密码管理软件。事实上,这类软件对于活跃的互联网用户来说极为实用。它使得你获取、管理和安全保存所有密码变得极为容易,而大多数密码都是用软件或文件系统加密过的。因此,用户只需要记住一个简单的密码就可以获取到其它所有密码。密码管理软件鼓励用户对于不同服务去采用独一无二的,非直观的高强度的密码。
|
||||
|
||||
为了让大家更深入地了解Linux软件的质量,我将介绍4款优秀的、可替代LastPass的开源软件。
|
||||
|
||||
@ -14,25 +14,27 @@ LastPass是一个跨平台的密码管理程序。在Linux平台中,它可作
|
||||
|
||||

|
||||
|
||||
KeePassX提供KeePass的多平台接口,是一款开源、跨平台的密码管理软件。这款软件可以帮助你以安全的方式保管密码。你可以将所有密码保存在一个数据库中,而这个数据库被一个主密码或密码盘来保管。
|
||||
KeePassX是KeePass的多平台移植,是一款开源、跨平台的密码管理软件。这款软件可以帮助你以安全的方式保管密码。你可以将所有密码保存在一个数据库中,而这个数据库被一个主密码或密码盘来保管。这使得用户只需要记住一个单一的主密码或插入密码盘即可解锁整个数据库。
|
||||
|
||||
密码数据库使用AES(即Rijndael)或者TwoFish算法进行加密,密钥长度为256位。
|
||||
|
||||
该软件功能包括:
|
||||
|
||||
- 多重管理模式 - 使每条密码更容易被识别
|
||||
- 管理模式丰富
|
||||
- 通过标题使每条密码更容易被识别
|
||||
- 可设置密码过期时间
|
||||
- 可插入附件
|
||||
- 可为不同分组或密码自定义标志
|
||||
- 在分组中对密码排序
|
||||
- 搜索函数:可在特定分组或整个数据库中搜索
|
||||
- Auto-Type: 这个功能允许你在登录网站时只需要按下几个键。KeePassX可以帮助你输入剩下的密码。Auto-Type通过读取当前窗口的标题,对密码数据库进行搜索来获取相应的密码
|
||||
- 数据库安全性强,用户可通过密码或一个密钥文件(可存储在CD或U盘中)访问数据库
|
||||
- 自动生成安全的密码
|
||||
- 具有预防措施,获取选中的密码并检查其安全性
|
||||
- 加密 - 用256位密钥,通过AES(高级加密标准)或TwoFish算法加密数据库
|
||||
- 搜索功能:可在特定分组或整个数据库中搜索
|
||||
- 自动键入: 这个功能允许你在登录网站时只需要按下几个键。KeePassX可以帮助你输入剩下的密码。自动键入通过读取当前窗口的标题,对密码数据库进行搜索来获取相应的密码
|
||||
- 数据库安全性强,用户可通过密码或一个密钥文件(可存储在CD或U盘中)访问数据库(或两者)
|
||||
- 安全密码自动生成
|
||||
- 具有预防措施,获取用星号隐藏的密码并检查其安全性
|
||||
- 加密 - 用256位密钥,通过AES(高级加密标准)或TwoFish算法加密数据库,
|
||||
- 密码可以导入或导出。可从PwManager文件(*.pwm)或KWallet文件(*.xml)中导入密码,可导出为文本(*.txt)格式。
|
||||
|
||||
---
|
||||
- 软件官网:[www.keepassx.org][1]
|
||||
- 开发者:KeepassX Team
|
||||
- 软件许可证:GNU GPL V2
|
||||
@ -42,21 +44,23 @@ KeePassX提供KeePass的多平台接口,是一款开源、跨平台的密码
|
||||
|
||||

|
||||
|
||||
Encryptr是一个开源的、零知晓的、基于云端的密码管理/电子钱包软件,以Crypton为基础开发。Crypton是一个Javascript库,允许开发者利用其开发应用,上传文件至服务器,而服务器无法知道用户所存储的文件内容。
|
||||
Encryptr是一个开源的、零知识(zero-knowledge)的、基于云端的密码管理/电子钱包软件,以Crypton为基础开发。Crypton是一个Javascript库,允许开发者利用其开发应用来上传文件至服务器,而服务器无法知道用户所存储的文件内容。
|
||||
|
||||
Encryptr可将你的敏感信息,比如密码、信用卡数据、PIN码、或认证码存储在云端。然而,由于它基于零知晓的Cypton框架开发,Encryptr可保证只有用户才拥有访问或读取秘密信息的权限。
|
||||
Encryptr可将你的敏感信息,比如密码、信用卡数据、PIN码、或认证码存储在云端。然而,由于它基于零知识的Cypton框架开发,Encryptr可保证只有用户才拥有访问或读取秘密信息的权限。
|
||||
|
||||
由于其跨平台的特性,Encryptr允许用户随时随地、安全地通过一个账户从云端获取机密信息。
|
||||
|
||||
软件特性包括:
|
||||
|
||||
- 使用极安全、零知晓的Crypton框架,软件只在本地加密/解密数据
|
||||
- 使用非常安全的零知识Crypton框架,只在你的本地加密/解密数据
|
||||
- 易于使用
|
||||
- 基于云端
|
||||
- 可存储三种类型的数据:密码、信用卡账号以及通用的键值对
|
||||
- 可对每条密码设置“备注”项
|
||||
- 对本地密码进行缓存加密,以节省上传时间
|
||||
- 过滤和搜索密码
|
||||
- 对密码进行本地加密缓存,以节省载入时间
|
||||
|
||||
---
|
||||
- 软件官网: [encryptr.org][2]
|
||||
- 开发者: Tommy Williams
|
||||
- 软件许可证: GNU GPL v3
|
||||
@ -74,7 +78,9 @@ RatticDB被设计为一个“密码生命周期管理工具”而不是单单一
|
||||
|
||||
- 简洁的ACL设计
|
||||
- 可改变队列功能,可让用户知晓何时需要更改某应用的密码
|
||||
- Ansible配置
|
||||
- 支持Ansible配置
|
||||
|
||||
---
|
||||
|
||||
- 软件官网: [rattic.org][3]
|
||||
- 开发者: Daniel Hall
|
||||
@ -85,9 +91,9 @@ RatticDB被设计为一个“密码生命周期管理工具”而不是单单一
|
||||
|
||||

|
||||
|
||||
Seahorse是一个于Gnome前端运行的GnuPG - GNU隐私保护软件。它的目标是提供一个易于使用密钥管理工具,一并提供一个易于使用的界面来控制加密操作。
|
||||
Seahorse是一个GnuPG(GNU隐私保护软件)的Gnome前端界面。它的目标是提供一个易于使用密钥管理工具,以及一个易于使用的界面来控制加密操作。
|
||||
|
||||
Seahorse是一个工具,用来提供安全沟通和数据存储服务。数据加密和数字密钥生成操作可以轻易通过GUI来演示,密钥管理操作也可以轻易通过直观的界面来进行。
|
||||
Seahorse是一个工具,用来提供安全传输和数据存储服务。数据加密和数字密钥生成操作可以轻易通过GUI来操作,密钥管理操作也可以轻易通过直观的界面来进行。
|
||||
|
||||
此外,Seahorse包含一个Gedit插件,可以使用鹦鹉螺文件管理器管理文件,一个管理剪贴板中事物的小程序,一个存储私密密码的代理,还有一个GnuPG和OpenSSH的密钥管理工具。
|
||||
|
||||
@ -95,7 +101,7 @@ Seahorse是一个工具,用来提供安全沟通和数据存储服务。数据
|
||||
|
||||
- 对文本进行加密/解密/签名
|
||||
- 管理密钥及密钥环
|
||||
- 将密钥及密钥环于密钥服务器同步
|
||||
- 将密钥及密钥环与密钥服务器同步
|
||||
- 密码签名及发布
|
||||
- 将密码缓存起来,无需多次重复键入
|
||||
- 对密钥及密钥环进行备份
|
||||
@ -103,6 +109,8 @@ Seahorse是一个工具,用来提供安全沟通和数据存储服务。数据
|
||||
- 生成SSH密钥,对其进行验证及储存
|
||||
- 多语言支持
|
||||
|
||||
---
|
||||
|
||||
- 软件官网: [www.gnome.org/projects/seahorse][4]
|
||||
- 开发者: Jacob Perkins, Jose Carlos, Garcia Sogo, Jean Schurger, Stef Walter, Adam Schreiber
|
||||
- 软件许可证: GNU GPL v2
|
||||
@ -113,7 +121,7 @@ Seahorse是一个工具,用来提供安全沟通和数据存储服务。数据
|
||||
via: http://www.linuxlinks.com/article/20151108125950773/LastPassAlternatives.html
|
||||
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,48 @@
|
||||
Linux 有问必答:如何在 Linux 上自动设置 JAVA_HOME 环境变量
|
||||
================================================================================
|
||||
> **问题**:我需要在我的 Linux 机器上编译 Java 程序。为此我已经安装了 JDK (Java Development Kit),而现在我正试图设置 JAVA\_HOME 环境变量使其指向安装好的 JDK 。关于在 Linux 上设置 JAVA\_HOME 环境变量,最受推崇的办法是什么?
|
||||
|
||||
许多 Java 程序或基于 Java 的*集成开发环境* (IDE)都需要设置好 JAVA_HOME 环境变量。该变量应指向 *Java 开发工具包* (JDK)或 *Java 运行时环境* (JRE)的安装目录。JDK 不仅包含了 JRE 提供的一切,还带有用于编译 Java 程序的额外的二进制代码和库文件(例如编译器,调试器及 JavaDoc 文档生成器)。JDK 是用来构建 Java 程序的,如果只是运行已经构建好的 Java 程序,单独一份 JRE 就足够了。
|
||||
|
||||
当您正试图设置 JAVA\_HOME 环境变量时,麻烦的事情在于 JAVA\_HOME 变量需要根据以下几点而改变:(1) 您是否安装了 JDK 或 JRE;(2) 您安装了哪个版本;(3) 您安装的是 Oracle JDK 还是 Open JDK。
|
||||
|
||||
因此每当您的开发环境或运行时环境发生改变(例如为 JDK 更新版本)时,您需要根据实际情况调整 JAVA\_HOME 变量,而这种做法是繁重且缺乏效率的。
|
||||
|
||||
以下 export 命令能为您**自动设置** JAVA\_HOME 环境变量,而无须顾及上述的因素。
|
||||
|
||||
若您安装的是 JRE:
|
||||
|
||||
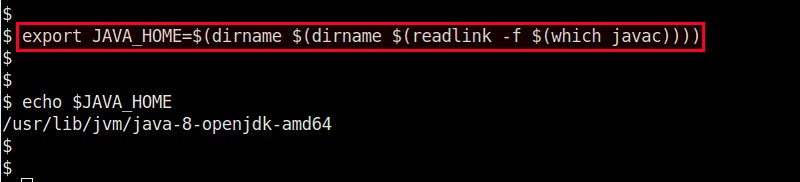
export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))
|
||||
|
||||
若您安装的是 JDK:
|
||||
|
||||
export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which javac))))
|
||||
|
||||
根据您的情况,将上述命令中的一条写入 ~/.bashrc(或 /etc/profile)文件中,它就会永久地设置好 JAVA\_HOME 变量。
|
||||
|
||||
注意,由于 java 或 javac 可以建立起多个层次的符号链接,为此"readlink -f"命令是用来获取它们真正的执行路径的。
|
||||
|
||||
举个例子,假如您安装的是 Oracle JRE 7,那么上述的第一条 export 命令将自动设置 JAVA\_HOME 为:
|
||||
|
||||
/usr/lib/jvm/java-7-oracle/jre
|
||||
|
||||
若您安装的是 Open JDK 第8版,那么第二条 export 命令将设置 JAVA\_HOME 为:
|
||||
|
||||
/usr/lib/jvm/java-8-openjdk-amd64
|
||||
|
||||
|
||||
|
||||
简而言之,这些 export 命令会在您重装/升级您的JDK/JRE,或[更换默认 Java 版本][1]时自动更新 JAVA\_HOME 变量。您不再需要手动调整它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/set-java_home-environment-variable-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Ricky-Gong](https://github.com/Ricky-Gong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/change-default-java-version-linux.html
|
||||
@ -1,11 +1,10 @@
|
||||
第七部分 - 在 Linux 客户端配置基于 Kerberos 身份验证的 NFS 服务器
|
||||
RHCE 系列(七):在 Linux 客户端配置基于 Kerberos 身份验证的 NFS 服务器
|
||||
================================================================================
|
||||
在本系列的前一篇文章,我们回顾了[如何在可能包括多种类型操作系统的网络上配置 Samba 共享][1]。现在,如果你需要为一组类-Unix 客户端配置文件共享,很自然的你会想到网络文件系统,或简称 NFS。
|
||||
|
||||
在本系列的前一篇文章,我们回顾了[如何在可能包括多种类型操作系统的网络上配置 Samba 共享][1]。现在,如果你需要为一组类 Unix 客户端配置文件共享,很自然的你会想到网络文件系统,或简称 NFS。
|
||||
|
||||

|
||||
|
||||
RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服务器
|
||||
*RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服务器*
|
||||
|
||||
在这篇文章中我们会介绍配置基于 Kerberos 身份验证的 NFS 共享的整个流程。假设你已经配置好了一个 NFS 服务器和一个客户端。如果还没有,可以参考 [安装和配置 NFS 服务器][2] - 它列出了需要安装的依赖软件包并解释了在进行下一步之前如何在服务器上进行初始化配置。
|
||||
|
||||
@ -24,28 +23,26 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||
#### 创建 NFS 组并配置 NFS 共享目录 ####
|
||||
|
||||
1. 新建一个名为 nfs 的组并给它添加用户 nfsnobody,然后更改 /nfs 目录的权限为 0770,组属主为 nfs。于是,nfsnobody(对应请求用户)在共享目录有写的权限,你就不需要在 /etc/exports 文件中使用 no_root_squash(译者注:设为 root_squash 意味着在访问 NFS 服务器上的文件时,客户机上的 root 用户不会被当作 root 用户来对待)。
|
||||
1、 新建一个名为 nfs 的组并给它添加用户 nfsnobody,然后更改 /nfs 目录的权限为 0770,组属主为 nfs。于是,nfsnobody(对应请求用户)在共享目录有写的权限,你就不需要在 /etc/exports 文件中使用 no_root_squash(LCTT 译注:设为 root_squash 意味着在访问 NFS 服务器上的文件时,客户机上的 root 用户不会被当作 root 用户来对待)。
|
||||
|
||||
# groupadd nfs
|
||||
# usermod -a -G nfs nfsnobody
|
||||
# chmod 0770 /nfs
|
||||
# chgrp nfs /nfs
|
||||
|
||||
2. 像下面那样更改 export 文件(/etc/exports)只允许从 box1 使用 Kerberos 安全验证的访问(sec=krb5)。
|
||||
2、 像下面那样更改 export 文件(/etc/exports)只允许从 box1 使用 Kerberos 安全验证的访问(sec=krb5)。
|
||||
|
||||
**注意**:anongid 的值设置为之前新建的组 nfs 的 GID:
|
||||
|
||||
**exports – 添加 NFS 共享**
|
||||
|
||||
----------
|
||||
|
||||
/nfs box1(rw,sec=krb5,anongid=1004)
|
||||
|
||||
3. 再次 exprot(-r)所有(-a)NFS 共享。为输出添加详情(-v)是个好主意,因为它提供了发生错误时解决问题的有用信息:
|
||||
3、 再次 exprot(-r)所有(-a)NFS 共享。为输出添加详情(-v)是个好主意,因为它提供了发生错误时解决问题的有用信息:
|
||||
|
||||
# exportfs -arv
|
||||
|
||||
4. 重启并启用 NFS 服务器以及相关服务。注意你不需要启动 nfs-lock 和 nfs-idmapd,因为系统启动时其它服务会自动启动它们:
|
||||
4、 重启并启用 NFS 服务器以及相关服务。注意你不需要启动 nfs-lock 和 nfs-idmapd,因为系统启动时其它服务会自动启动它们:
|
||||
|
||||
# systemctl restart rpcbind nfs-server nfs-lock nfs-idmap
|
||||
# systemctl enable rpcbind nfs-server
|
||||
@ -61,14 +58,12 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||
正如你看到的,为了简便,NFS 服务器和 KDC 在同一台机器上,当然如果你有更多可用机器你也可以把它们安装在不同的机器上。两台机器都在 `mydomain.com` 域。
|
||||
|
||||
最后同样重要的是,Kerberos 要求客户端和服务器中至少有一个域名解析的基本模式和[网络时间协议][5]服务,因为 Kerberos 身份验证的安全一部分基于时间戳。
|
||||
最后同样重要的是,Kerberos 要求客户端和服务器中至少有一个域名解析的基本方式和[网络时间协议][5]服务,因为 Kerberos 身份验证的安全一部分基于时间戳。
|
||||
|
||||
为了配置域名解析,我们在客户端和服务器中编辑 /etc/hosts 文件:
|
||||
|
||||
**host 文件 – 为域添加 DNS**
|
||||
|
||||
----------
|
||||
|
||||
192.168.0.18 box1.mydomain.com box1
|
||||
192.168.0.20 box2.mydomain.com box2
|
||||
|
||||
@ -82,10 +77,9 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||
# chronyc tracking
|
||||
|
||||
|
||||

|
||||
|
||||
用 Chrony 同步服务器时间
|
||||
*用 Chrony 同步服务器时间*
|
||||
|
||||
### 安装和配置 Kerberos ###
|
||||
|
||||
@ -109,7 +103,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||

|
||||
|
||||
创建 Kerberos 数据库
|
||||
*创建 Kerberos 数据库*
|
||||
|
||||
下一步,使用 kadmin.local 工具为 root 创建管理权限:
|
||||
|
||||
@ -129,7 +123,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||

|
||||
|
||||
添加 Kerberos 到 NFS 服务器
|
||||
*添加 Kerberos 到 NFS 服务器*
|
||||
|
||||
为 root/admin 获取和缓存票据授权票据(ticket-granting ticket):
|
||||
|
||||
@ -138,7 +132,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||
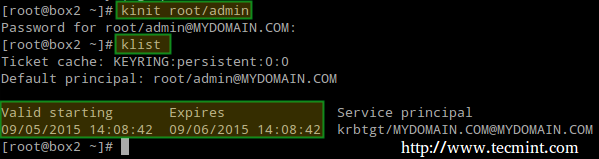
|
||||
|
||||
缓存 Kerberos
|
||||
*缓存 Kerberos*
|
||||
|
||||
真正使用 Kerberos 之前的最后一步是保存被授权使用 Kerberos 身份验证的规则到一个密钥表文件(在服务器中):
|
||||
|
||||
@ -154,7 +148,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||

|
||||
|
||||
挂载 NFS 共享
|
||||
*挂载 NFS 共享*
|
||||
|
||||
现在让我们卸载共享,在客户端中重命名密钥表文件(模拟它不存在)然后试着再次挂载共享目录:
|
||||
|
||||
@ -163,7 +157,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||

|
||||
|
||||
挂载/卸载 Kerberos NFS 共享
|
||||
*挂载/卸载 Kerberos NFS 共享*
|
||||
|
||||
现在你可以使用基于 Kerberos 身份验证的 NFS 共享了。
|
||||
|
||||
@ -177,12 +171,12 @@ via: http://www.tecmint.com/setting-up-nfs-server-with-kerberos-based-authentica
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
[1]:https://linux.cn/article-6550-1.html
|
||||
[2]:http://www.tecmint.com/configure-nfs-server/
|
||||
[3]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[4]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
@ -1,45 +0,0 @@
|
||||
sevenot translating
|
||||
Curious about Linux? Try Linux Desktop on the Cloud
|
||||
================================================================================
|
||||
Linux maintains a very small market share as a desktop operating system. Current surveys estimate its share to be a mere 2%; contrast that with the various strains (no pun intended) of Windows which total nearly 90% of the desktop market. For Linux to challenge Microsoft's monopoly on the desktop, there needs to be a simple way of learning about this different operating system. And it would be naive to believe a typical Windows user is going to buy a second machine, tinker with partitioning a hard disk to set up a multi-boot system, or just jump ship to Linux without an easy way back.
|
||||
|
||||

|
||||
|
||||
We have examined a number of risk-free ways users can experiment with Linux without dabbling with partition management. Various options include Live CD/DVDs, USB keys and desktop virtualization software. For the latter, I can strongly recommend VMWare (VMWare Player) or Oracle VirtualBox, two relatively easy and free ways of installing and running multiple operating systems on a desktop or laptop computer. Each virtual machine has its own share of CPU, memory, network interfaces etc which is isolated from other virtual machines. But virtual machines still require some effort to get Linux up and running, and a reasonably powerful machine. Too much effort for a mere inquisitive mind.
|
||||
|
||||
It can be difficult to break down preconceptions. Many Windows users will have experimented with free software that is available on Linux. But there are many facets to learn on Linux. And it takes time to become accustomed to the way things work in Linux.
|
||||
|
||||
Surely there should be an effortless way for a beginner to experiment with Linux for the first time? Indeed there is; step forward the online cloud lab.
|
||||
|
||||
### LabxNow ###
|
||||
|
||||

|
||||
|
||||
LabxNow provides a free service for general users offering Linux remote desktop over the browser. The developers promote the service as having a personal remote lab (to play around, develop, whatever!) that will be accessible from anywhere, with the internet of course.
|
||||
|
||||
The service currently offers a free virtual private server with 2 cores, 4GB RAM and 10GB SSD space. The service runs on a 4 AMD 6272 CPU with 128GB RAM.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Machine images: Ubuntu 14.04 with Xfce 4.10, RHEL 6.5, CentOS with Gnome, and Oracle
|
||||
- Hardware: CPU - 1 or 2 cores; RAM: 512MB, 1GB, 2GB or 4GB
|
||||
- Fast network for data transfers
|
||||
- Works with all popular browsers
|
||||
- Install anything, run anything - an excellent way to experiment and learn all about Linux without any risk
|
||||
- Easily add, delete, manage and customize VMs
|
||||
- Share VMs, Remote desktop support
|
||||
|
||||
All you need is a reasonable Internet connected device. Forget about high cost VPS, domain space or hardware support. LabxNow offers a great way of experimenting with Ubuntu, RHEL and CentOS. It gives Windows users an excellent environment to dip their toes into the wonderful world of Linux. Further, it allows users to do (programming) work from anywhere in the word without having the stress of installing Linux on each machine. Point your web browser at [www.labxnow.org/labxweb/][1].
|
||||
|
||||
There are other services (mostly paid services) that allow users to experiment with Linux. These include Cloudsigma which offers a free 7 day trial, and Icebergs.io (full root access via HTML5). But for now, LabxNow gets my recommendation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.labxnow.org/labxweb/
|
||||
@ -1,3 +1,4 @@
|
||||
sevenot translating
|
||||
A Linux User Using ‘Windows 10′ After More than 8 Years – See Comparison
|
||||
================================================================================
|
||||
Windows 10 is the newest member of windows NT family of which general availability was made on July 29, 2015. It is the successor of Windows 8.1. Windows 10 is supported on Intel Architecture 32 bit, AMD64 and ARMv7 processors.
|
||||
@ -341,4 +342,4 @@ via: http://www.tecmint.com/a-linux-user-using-windows-10-after-more-than-8-year
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://www.microsoft.com/en-us/software-download/windows10ISO
|
||||
[1]:https://www.microsoft.com/en-us/software-download/windows10ISO
|
||||
|
||||
77
sources/talk/20151117 How bad a boss is Linus Torvalds.md
Normal file
77
sources/talk/20151117 How bad a boss is Linus Torvalds.md
Normal file
@ -0,0 +1,77 @@
|
||||
How bad a boss is Linus Torvalds?
|
||||
================================================================================
|
||||

|
||||
|
||||
*Linus Torvalds addressed a packed auditorium of Linux enthusiasts during his speech at the LinuxWorld show in San Jose, California, on August 10, 1999. Credit: James Niccolai*
|
||||
|
||||
**It depends on context. In the world of software development, he’s what passes for normal. The question is whether that situation should be allowed to continue.**
|
||||
|
||||
I've known Linus Torvalds, Linux's inventor, for over 20 years. We're not chums, but we like each other.
|
||||
|
||||
Lately, Torvalds has been getting a lot of flack for his management style. Linus doesn't suffer fools gladly. He has one way of judging people in his business of developing the Linux kernel: How good is your code?
|
||||
|
||||
Nothing else matters. As Torvalds said earlier this year at the Linux.conf.au Conference, "I'm not a nice person, and I don't care about you. [I care about the technology and the kernel][1] -- that's what's important to me."
|
||||
|
||||
Now, I can deal with that kind of person. If you can't, you should avoid the Linux kernel community, where you'll find a lot of this kind of meritocratic thinking. Which is not to say that I think everything in Linuxland is hunky-dory and should be impervious to calls for change. A meritocracy I can live with; a bastion of male dominance where women are subjected to scorn and disrespect is a problem.
|
||||
|
||||
That's why I see the recent brouhaha about Torvalds' management style -- or more accurately, his total indifference to the personal side of management -- as nothing more than standard operating procedure in the world of software development. And at the same time, I see another instance that has come to light as evidence of a need for things to really change.
|
||||
|
||||
The first situation arose with the [release of Linux 4.3][2], when Torvalds used the Linux Kernel Mailing List to tear into a developer who had inserted some networking code that Torvalds thought was -- well, let's say "crappy." "[[A]nd it generates [crappy] code.][3] It looks bad, and there's no reason for it." He goes on in this vein for quite a while. Besides the word "crap" and its earthier synonym, he uses the word "idiotic" pretty often.
|
||||
|
||||
Here's the thing, though. He's right. I read the code. It's badly written and it does indeed seem to have been designed to use the new "overflow_usub()" function just for the sake of using it.
|
||||
|
||||
Now, some people see this diatribe as evidence that Torvalds is a bad-tempered bully. I see a perfectionist who, within his field, doesn't put up with crap.
|
||||
|
||||
Many people have told me that this is not how professional programmers should act. People, have you ever worked with top developers? That's exactly how they act, at Apple, Microsoft, Oracle and everywhere else I've known them.
|
||||
|
||||
I've heard Steve Jobs rip a developer to pieces. I've cringed while a senior Oracle developer lead tore into a room of new programmers like a piranha through goldfish.
|
||||
|
||||
In Accidental Empires, his classic book on the rise of PCs, Robert X. Cringely described Microsoft's software management style when Bill Gates was in charge as a system where "Each level, from Gates on down, screams at the next, goading and humiliating them." Ah, yes, that's the Microsoft I knew and hated.
|
||||
|
||||
The difference between the leaders at big proprietary software companies and Torvalds is that he says everything in the open for the whole world to see. The others do it in private conference rooms. I've heard people claim that Torvalds would be fired in their company. Nope. He'd be right where he is now: on top of his programming world.
|
||||
|
||||
Oh, and there's another difference. If you get, say, Larry Ellison mad at you, you can kiss your job goodbye. When you get Torvalds angry at your work, you'll get yelled at in an email. That's it.
|
||||
|
||||
You see, Torvalds isn't anyone's boss. He's the guy in charge of a project with about 10,000 contributors, but he has zero hiring and firing authority. He can hurt your feelings, but that's about it.
|
||||
|
||||
That said, there is a serious problem within both open-source and proprietary software development circles. No matter how good a programmer you are, if you're a woman, the cards are stacked against you.
|
||||
|
||||
No case shows this better than that of Sarah Sharp, an Intel developer and formerly a top Linux programmer. [In a post on her blog in October][4], she explained why she had stopped contributing to the Linux kernel more than a year earlier: "I finally realized that I could no longer contribute to a community where I was technically respected, but I could not ask for personal respect.... I did not want to work professionally with people who were allowed to get away with subtle sexist or homophobic jokes."
|
||||
|
||||
Who can blame her? I can't. Torvalds, like almost every software manager I've ever known, I'm sorry to say, has permitted a hostile work environment.
|
||||
|
||||
He would probably say that it's not his job to ensure that Linux contributors behave with professionalism and mutual respect. He's concerned with the code and nothing but the code.
|
||||
|
||||
As Sharp wrote:
|
||||
|
||||
> I have the utmost respect for the technical efforts of the Linux kernel community. They have scaled and grown a project that is focused on maintaining some of the highest coding standards out there. The focus on technical excellence, in combination with overloaded maintainers, and people with different cultural and social norms, means that Linux kernel maintainers are often blunt, rude, or brutal to get their job done. Top Linux kernel developers often yell at each other in order to correct each other's behavior.
|
||||
>
|
||||
> That's not a communication style that works for me. …
|
||||
>
|
||||
> Many senior Linux kernel developers stand by the right of maintainers to be technically and personally brutal. Even if they are very nice people in person, they do not want to see the Linux kernel communication style change.
|
||||
|
||||
She's right.
|
||||
|
||||
Where I differ from other observers is that I don't think that this problem is in any way unique to Linux or open-source communities. With five years of work in the technology business and 25 years as a technology journalist, I've seen this kind of immature boy behavior everywhere.
|
||||
|
||||
It's not Torvalds' fault. He's a technical leader with a vision, not a manager. The real problem is that there seems to be no one in the software development universe who can set a supportive tone for teams and communities.
|
||||
|
||||
Looking ahead, I hope that companies and organizations, such as the Linux Foundation, can find a way to empower community managers or other managers to encourage and enforce civil behavior.
|
||||
|
||||
We won't, unfortunately, find that kind of managerial finesse in our pure technical or business leaders. It's not in their DNA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
@ -1,801 +0,0 @@
|
||||
wyangsun translating
|
||||
Linux workstation security checklist
|
||||
================================================================================
|
||||
This is a set of recommendations used by the Linux Foundation for their systems
|
||||
administrators. All of LF employees are remote workers and we use this set of
|
||||
guidelines to ensure that a sysadmin's system passes core security requirements
|
||||
in order to reduce the risk of it becoming an attack vector against the rest
|
||||
of our infrastructure.
|
||||
|
||||
Even if your systems administrators are not remote workers, chances are that
|
||||
they perform a lot of their work either from a portable laptop in a work
|
||||
environment, or set up their home systems to access the work infrastructure
|
||||
for after-hours/emergency support. In either case, you can adapt this set of
|
||||
recommendations to suit your environment.
|
||||
|
||||
This, by no means, is an exhaustive "workstation hardening" document, but
|
||||
rather an attempt at a set of baseline recommendations to avoid most glaring
|
||||
security errors without introducing too much inconvenience. You may read this
|
||||
document and think it is way too paranoid, while someone else may think this
|
||||
barely scratches the surface. Security is just like driving on the highway --
|
||||
anyone going slower than you is an idiot, while anyone driving faster than you
|
||||
is a crazy person. These guidelines are merely a basic set of core safety
|
||||
rules that is neither exhaustive, nor a replacement for experience, vigilance,
|
||||
and common sense.
|
||||
|
||||
Each section is split into two areas:
|
||||
|
||||
- The checklist that can be adapted to your project's needs
|
||||
- Free-form list of considerations that explain what dictated these decisions
|
||||
|
||||
## Severity levels
|
||||
|
||||
The items in each checklist include the severity level, which we hope will help
|
||||
guide your decision:
|
||||
|
||||
- _(CRITICAL)_ items should definitely be high on the consideration list.
|
||||
If not implemented, they will introduce high risks to your workstation
|
||||
security.
|
||||
- _(MODERATE)_ items will improve your security posture, but are less
|
||||
important, especially if they interfere too much with your workflow.
|
||||
- _(LOW)_ items may improve the overall security, but may not be worth the
|
||||
convenience trade-offs.
|
||||
- _(PARANOID)_ is reserved for items we feel will dramatically improve your
|
||||
workstation security, but will probably require a lot of adjustment to the
|
||||
way you interact with your operating system.
|
||||
|
||||
Remember, these are only guidelines. If you feel these severity levels do not
|
||||
reflect your project's commitment to security, you should adjust them as you
|
||||
see fit.
|
||||
|
||||
## Choosing the right hardware
|
||||
|
||||
We do not mandate that our admins use a specific vendor or a specific model, so
|
||||
this section addresses core considerations when choosing a work system.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] System supports SecureBoot _(CRITICAL)_
|
||||
- [ ] System has no firewire, thunderbolt or ExpressCard ports _(MODERATE)_
|
||||
- [ ] System has a TPM chip _(LOW)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### SecureBoot
|
||||
|
||||
Despite its controversial nature, SecureBoot offers prevention against many
|
||||
attacks targeting workstations (Rootkits, "Evil Maid," etc), without
|
||||
introducing too much extra hassle. It will not stop a truly dedicated attacker,
|
||||
plus there is a pretty high degree of certainty that state security agencies
|
||||
have ways to defeat it (probably by design), but having SecureBoot is better
|
||||
than having nothing at all.
|
||||
|
||||
Alternatively, you may set up [Anti Evil Maid][1] which offers a more
|
||||
wholesome protection against the type of attacks that SecureBoot is supposed
|
||||
to prevent, but it will require more effort to set up and maintain.
|
||||
|
||||
#### Firewire, thunderbolt, and ExpressCard ports
|
||||
|
||||
Firewire is a standard that, by design, allows any connecting device full
|
||||
direct memory access to your system ([see Wikipedia][2]). Thunderbolt and
|
||||
ExpressCard are guilty of the same, though some later implementations of
|
||||
Thunderbolt attempt to limit the scope of memory access. It is best if the
|
||||
system you are getting has none of these ports, but it is not critical, as
|
||||
they usually can be turned off via UEFI or disabled in the kernel itself.
|
||||
|
||||
#### TPM Chip
|
||||
|
||||
Trusted Platform Module (TPM) is a crypto chip bundled with the motherboard
|
||||
separately from the core processor, which can be used for additional platform
|
||||
security (such as to store full-disk encryption keys), but is not normally used
|
||||
for day-to-day workstation operation. At best, this is a nice-to-have, unless
|
||||
you have a specific need to use TPM for your workstation security.
|
||||
|
||||
## Pre-boot environment
|
||||
|
||||
This is a set of recommendations for your workstation before you even start
|
||||
with OS installation.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] UEFI boot mode is used (not legacy BIOS) _(CRITICAL)_
|
||||
- [ ] Password is required to enter UEFI configuration _(CRITICAL)_
|
||||
- [ ] SecureBoot is enabled _(CRITICAL)_
|
||||
- [ ] UEFI-level password is required to boot the system _(LOW)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### UEFI and SecureBoot
|
||||
|
||||
UEFI, with all its warts, offers a lot of goodies that legacy BIOS doesn't,
|
||||
such as SecureBoot. Most modern systems come with UEFI mode on by default.
|
||||
|
||||
Make sure a strong password is required to enter UEFI configuration mode. Pay
|
||||
attention, as many manufacturers quietly limit the length of the password you
|
||||
are allowed to use, so you may need to choose high-entropy short passwords vs.
|
||||
long passphrases (see below for more on passphrases).
|
||||
|
||||
Depending on the Linux distribution you decide to use, you may or may not have
|
||||
to jump through additional hoops in order to import your distribution's
|
||||
SecureBoot key that would allow you to boot the distro. Many distributions have
|
||||
partnered with Microsoft to sign their released kernels with a key that is
|
||||
already recognized by most system manufacturers, therefore saving you the
|
||||
trouble of having to deal with key importing.
|
||||
|
||||
As an extra measure, before someone is allowed to even get to the boot
|
||||
partition and try some badness there, let's make them enter a password. This
|
||||
password should be different from your UEFI management password, in order to
|
||||
prevent shoulder-surfing. If you shut down and start a lot, you may choose to
|
||||
not bother with this, as you will already have to enter a LUKS passphrase and
|
||||
this will save you a few extra keystrokes.
|
||||
|
||||
## Distro choice considerations
|
||||
|
||||
Chances are you'll stick with a fairly widely-used distribution such as Fedora,
|
||||
Ubuntu, Arch, Debian, or one of their close spin-offs. In any case, this is
|
||||
what you should consider when picking a distribution to use.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Has a robust MAC/RBAC implementation (SELinux/AppArmor/Grsecurity) _(CRITICAL)_
|
||||
- [ ] Publishes security bulletins _(CRITICAL)_
|
||||
- [ ] Provides timely security patches _(CRITICAL)_
|
||||
- [ ] Provides cryptographic verification of packages _(CRITICAL)_
|
||||
- [ ] Fully supports UEFI and SecureBoot _(CRITICAL)_
|
||||
- [ ] Has robust native full disk encryption support _(CRITICAL)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### SELinux, AppArmor, and GrSecurity/PaX
|
||||
|
||||
Mandatory Access Controls (MAC) or Role-Based Access Controls (RBAC) are an
|
||||
extension of the basic user/group security mechanism used in legacy POSIX
|
||||
systems. Most distributions these days either already come bundled with a
|
||||
MAC/RBAC implementation (Fedora, Ubuntu), or provide a mechanism to add it via
|
||||
an optional post-installation step (Gentoo, Arch, Debian). Obviously, it is
|
||||
highly advised that you pick a distribution that comes pre-configured with a
|
||||
MAC/RBAC system, but if you have strong feelings about a distribution that
|
||||
doesn't have one enabled by default, do plan to configure it
|
||||
post-installation.
|
||||
|
||||
Distributions that do not provide any MAC/RBAC mechanisms should be strongly
|
||||
avoided, as traditional POSIX user- and group-based security should be
|
||||
considered insufficient in this day and age. If you would like to start out
|
||||
with a MAC/RBAC workstation, AppArmor and PaX are generally considered easier
|
||||
to learn than SELinux. Furthermore, on a workstation, where there are few or
|
||||
no externally listening daemons, and where user-run applications pose the
|
||||
highest risk, GrSecurity/PaX will _probably_ offer more security benefits than
|
||||
SELinux.
|
||||
|
||||
#### Distro security bulletins
|
||||
|
||||
Most of the widely used distributions have a mechanism to deliver security
|
||||
bulletins to their users, but if you are fond of something esoteric, check
|
||||
whether the developers have a documented mechanism of alerting the users about
|
||||
security vulnerabilities and patches. Absence of such mechanism is a major
|
||||
warning sign that the distribution is not mature enough to be considered for a
|
||||
primary admin workstation.
|
||||
|
||||
#### Timely and trusted security updates
|
||||
|
||||
Most of the widely used distributions deliver regular security updates, but is
|
||||
worth checking to ensure that critical package updates are provided in a
|
||||
timely fashion. Avoid using spin-offs and "community rebuilds" for this
|
||||
reason, as they routinely delay security updates due to having to wait for the
|
||||
upstream distribution to release it first.
|
||||
|
||||
You'll be hard-pressed to find a distribution that does not use cryptographic
|
||||
signatures on packages, updates metadata, or both. That being said, fairly
|
||||
widely used distributions have been known to go for years before introducing
|
||||
this basic security measure (Arch, I'm looking at you), so this is a thing
|
||||
worth checking.
|
||||
|
||||
#### Distros supporting UEFI and SecureBoot
|
||||
|
||||
Check that the distribution supports UEFI and SecureBoot. Find out whether it
|
||||
requires importing an extra key or whether it signs its boot kernels with a key
|
||||
already trusted by systems manufacturers (e.g. via an agreement with
|
||||
Microsoft). Some distributions do not support UEFI/SecureBoot but offer
|
||||
alternatives to ensure tamper-proof or tamper-evident boot environments
|
||||
([Qubes-OS][3] uses Anti Evil Maid, mentioned earlier). If a distribution
|
||||
doesn't support SecureBoot and has no mechanisms to prevent boot-level attacks,
|
||||
look elsewhere.
|
||||
|
||||
#### Full disk encryption
|
||||
|
||||
Full disk encryption is a requirement for securing data at rest, and is
|
||||
supported by most distributions. As an alternative, systems with
|
||||
self-encrypting hard drives may be used (normally implemented via the on-board
|
||||
TPM chip) and offer comparable levels of security plus faster operation, but at
|
||||
a considerably higher cost.
|
||||
|
||||
## Distro installation guidelines
|
||||
|
||||
All distributions are different, but here are general guidelines:
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Use full disk encryption (LUKS) with a robust passphrase _(CRITICAL)_
|
||||
- [ ] Make sure swap is also encrypted _(CRITICAL)_
|
||||
- [ ] Require a password to edit bootloader (can be same as LUKS) _(CRITICAL)_
|
||||
- [ ] Set up a robust root password (can be same as LUKS) _(CRITICAL)_
|
||||
- [ ] Use an unprivileged account, part of administrators group _(CRITICAL)_
|
||||
- [ ] Set up a robust user-account password, different from root _(CRITICAL)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Full disk encryption
|
||||
|
||||
Unless you are using self-encrypting hard drives, it is important to configure
|
||||
your installer to fully encrypt all the disks that will be used for storing
|
||||
your data and your system files. It is not sufficient to simply encrypt the
|
||||
user directory via auto-mounting cryptfs loop files (I'm looking at you, older
|
||||
versions of Ubuntu), as this offers no protection for system binaries or swap,
|
||||
which is likely to contain a slew of sensitive data. The recommended
|
||||
encryption strategy is to encrypt the LVM device, so only one passphrase is
|
||||
required during the boot process.
|
||||
|
||||
The `/boot` partition will always remain unencrypted, as the bootloader needs
|
||||
to be able to actually boot the kernel before invoking LUKS/dm-crypt. The
|
||||
kernel image itself should be protected against tampering with a cryptographic
|
||||
signature checked by SecureBoot.
|
||||
|
||||
In other words, `/boot` should always be the only unencrypted partition on your
|
||||
system.
|
||||
|
||||
#### Choosing good passphrases
|
||||
|
||||
Modern Linux systems have no limitation of password/passphrase length, so the
|
||||
only real limitation is your level of paranoia and your stubbornness. If you
|
||||
boot your system a lot, you will probably have to type at least two different
|
||||
passwords: one to unlock LUKS, and another one to log in, so having long
|
||||
passphrases will probably get old really fast. Pick passphrases that are 2-3
|
||||
words long, easy to type, and preferably from rich/mixed vocabularies.
|
||||
|
||||
Examples of good passphrases (yes, you can use spaces):
|
||||
- nature abhors roombas
|
||||
- 12 in-flight Jebediahs
|
||||
- perdon, tengo flatulence
|
||||
|
||||
You can also stick with non-vocabulary passwords that are at least 10-12
|
||||
characters long, if you prefer that to typing passphrases.
|
||||
|
||||
Unless you have concerns about physical security, it is fine to write down your
|
||||
passphrases and keep them in a safe place away from your work desk.
|
||||
|
||||
#### Root, user passwords and the admin group
|
||||
|
||||
We recommend that you use the same passphrase for your root password as you
|
||||
use for your LUKS encryption (unless you share your laptop with other trusted
|
||||
people who should be able to unlock the drives, but shouldn't be able to
|
||||
become root). If you are the sole user of the laptop, then having your root
|
||||
password be different from your LUKS password has no meaningful security
|
||||
advantages. Generally, you can use the same passphrase for your UEFI
|
||||
administration, disk encryption, and root account -- knowing any of these will
|
||||
give an attacker full control of your system anyway, so there is little
|
||||
security benefit to have them be different on a single-user workstation.
|
||||
|
||||
You should have a different, but equally strong password for your regular user
|
||||
account that you will be using for day-to-day tasks. This user should be member
|
||||
of the admin group (e.g. `wheel` or similar, depending on the distribution),
|
||||
allowing you to perform `sudo` to elevate privileges.
|
||||
|
||||
In other words, if you are the sole user on your workstation, you should have 2
|
||||
distinct, robust, equally strong passphrases you will need to remember:
|
||||
|
||||
**Admin-level**, used in the following locations:
|
||||
|
||||
- UEFI administration
|
||||
- Bootloader (GRUB)
|
||||
- Disk encryption (LUKS)
|
||||
- Workstation admin (root user)
|
||||
|
||||
**User-level**, used for the following:
|
||||
|
||||
- User account and sudo
|
||||
- Master password for the password manager
|
||||
|
||||
All of them, obviously, can be different if there is a compelling reason.
|
||||
|
||||
## Post-installation hardening
|
||||
|
||||
Post-installation security hardening will depend greatly on your distribution
|
||||
of choice, so it is futile to provide detailed instructions in a general
|
||||
document such as this one. However, here are some steps you should take:
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Globally disable firewire and thunderbolt modules _(CRITICAL)_
|
||||
- [ ] Check your firewalls to ensure all incoming ports are filtered _(CRITICAL)_
|
||||
- [ ] Make sure root mail is forwarded to an account you check _(CRITICAL)_
|
||||
- [ ] Check to ensure sshd service is disabled by default _(MODERATE)_
|
||||
- [ ] Set up an automatic OS update schedule, or update reminders _(MODERATE)_
|
||||
- [ ] Configure the screensaver to auto-lock after a period of inactivity _(MODERATE)_
|
||||
- [ ] Set up logwatch _(MODERATE)_
|
||||
- [ ] Install and use rkhunter _(LOW)_
|
||||
- [ ] Install an Intrusion Detection System _(PARANOID)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Blacklisting modules
|
||||
|
||||
To blacklist a firewire and thunderbolt modules, add the following lines to a
|
||||
file in `/etc/modprobe.d/blacklist-dma.conf`:
|
||||
|
||||
blacklist firewire-core
|
||||
blacklist thunderbolt
|
||||
|
||||
The modules will be blacklisted upon reboot. It doesn't hurt doing this even if
|
||||
you don't have these ports (but it doesn't do anything either).
|
||||
|
||||
#### Root mail
|
||||
|
||||
By default, root mail is just saved on the system and tends to never be read.
|
||||
Make sure you set your `/etc/aliases` to forward root mail to a mailbox that
|
||||
you actually read, otherwise you may miss important system notifications and
|
||||
reports:
|
||||
|
||||
# Person who should get root's mail
|
||||
root: bob@example.com
|
||||
|
||||
Run `newaliases` after this edit and test it out to make sure that it actually
|
||||
gets delivered, as some email providers will reject email coming in from
|
||||
nonexistent or non-routable domain names. If that is the case, you will need to
|
||||
play with your mail forwarding configuration until this actually works.
|
||||
|
||||
#### Firewalls, sshd, and listening daemons
|
||||
|
||||
The default firewall settings will depend on your distribution, but many of
|
||||
them will allow incoming `sshd` ports. Unless you have a compelling legitimate
|
||||
reason to allow incoming ssh, you should filter that out and disable the `sshd`
|
||||
daemon.
|
||||
|
||||
systemctl disable sshd.service
|
||||
systemctl stop sshd.service
|
||||
|
||||
You can always start it temporarily if you need to use it.
|
||||
|
||||
In general, your system shouldn't have any listening ports apart from
|
||||
responding to ping. This will help safeguard you against network-level 0-day
|
||||
exploits.
|
||||
|
||||
#### Automatic updates or notifications
|
||||
|
||||
It is recommended to turn on automatic updates, unless you have a very good
|
||||
reason not to do so, such as fear that an automatic update would render your
|
||||
system unusable (it's happened in the past, so this fear is not unfounded). At
|
||||
the very least, you should enable automatic notifications of available updates.
|
||||
Most distributions already have this service automatically running for you, so
|
||||
chances are you don't have to do anything. Consult your distribution
|
||||
documentation to find out more.
|
||||
|
||||
You should apply all outstanding errata as soon as possible, even if something
|
||||
isn't specifically labeled as "security update" or has an associated CVE code.
|
||||
All bugs have the potential of being security bugs and erring on the side of
|
||||
newer, unknown bugs is _generally_ a safer strategy than sticking with old,
|
||||
known ones.
|
||||
|
||||
#### Watching logs
|
||||
|
||||
You should have a keen interest in what happens on your system. For this
|
||||
reason, you should install `logwatch` and configure it to send nightly activity
|
||||
reports of everything that happens on your system. This won't prevent a
|
||||
dedicated attacker, but is a good safety-net feature to have in place.
|
||||
|
||||
Note, that many systemd distros will no longer automatically install a syslog
|
||||
server that `logwatch` needs (due to systemd relying on its own journal), so
|
||||
you will need to install and enable `rsyslog` to make sure your `/var/log` is
|
||||
not empty before logwatch will be of any use.
|
||||
|
||||
#### Rkhunter and IDS
|
||||
|
||||
Installing `rkhunter` and an intrusion detection system (IDS) like `aide` or
|
||||
`tripwire` will not be that useful unless you actually understand how they work
|
||||
and take the necessary steps to set them up properly (such as, keeping the
|
||||
databases on external media, running checks from a trusted environment,
|
||||
remembering to refresh the hash databases after performing system updates and
|
||||
configuration changes, etc). If you are not willing to take these steps and
|
||||
adjust how you do things on your own workstation, these tools will introduce
|
||||
hassle without any tangible security benefit.
|
||||
|
||||
We do recommend that you install `rkhunter` and run it nightly. It's fairly
|
||||
easy to learn and use, and though it will not deter a sophisticated attacker,
|
||||
it may help you catch your own mistakes.
|
||||
|
||||
## Personal workstation backups
|
||||
|
||||
Workstation backups tend to be overlooked or done in a haphazard, often unsafe
|
||||
manner.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Set up encrypted workstation backups to external storage _(CRITICAL)_
|
||||
- [ ] Use zero-knowledge backup tools for cloud backups _(MODERATE)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Full encrypted backups to external storage
|
||||
|
||||
It is handy to have an external hard drive where one can dump full backups
|
||||
without having to worry about such things like bandwidth and upstream speeds
|
||||
(in this day and age most providers still offer dramatically asymmetric
|
||||
upload/download speeds). Needless to say, this hard drive needs to be in itself
|
||||
encrypted (again, via LUKS), or you should use a backup tool that creates
|
||||
encrypted backups, such as `duplicity` or its GUI companion, `deja-dup`. I
|
||||
recommend using the latter with a good randomly generated passphrase, stored in
|
||||
your password manager. If you travel with your laptop, leave this drive at home
|
||||
to have something to come back to in case your laptop is lost or stolen.
|
||||
|
||||
In addition to your home directory, you should also back up `/etc` and
|
||||
`/var/log` for various forensic purposes.
|
||||
|
||||
Above all, avoid copying your home directory onto any unencrypted storage, even
|
||||
as a quick way to move your files around between systems, as you will most
|
||||
certainly forget to erase it once you're done, exposing potentially private or
|
||||
otherwise security sensitive data to snooping hands -- especially if you keep
|
||||
that storage media in the same bag with your laptop.
|
||||
|
||||
#### Selective zero-knowledge backups off-site
|
||||
|
||||
Off-site backups are also extremely important and can be done either to your
|
||||
employer, if they offer space for it, or to a cloud provider. You can set up a
|
||||
separate duplicity/deja-dup profile to only include most important files in
|
||||
order to avoid transferring huge amounts of data that you don't really care to
|
||||
back up off-site (internet cache, music, downloads, etc).
|
||||
|
||||
Alternatively, you can use a zero-knowledge backup tool, such as
|
||||
[SpiderOak][5], which offers an excellent Linux GUI tool and has additional
|
||||
useful features such as synchronizing content between multiple systems and
|
||||
platforms.
|
||||
|
||||
## Best practices
|
||||
|
||||
What follows is a curated list of best practices that we think you should
|
||||
adopt. It is most certainly non-exhaustive, but rather attempts to offer
|
||||
practical advice that strikes a workable balance between security and overall
|
||||
usability.
|
||||
|
||||
### Browsing
|
||||
|
||||
There is no question that the web browser will be the piece of software with
|
||||
the largest and the most exposed attack surface on your system. It is a tool
|
||||
written specifically to download and execute untrusted, frequently hostile
|
||||
code. It attempts to shield you from this danger by employing multiple
|
||||
mechanisms such as sandboxes and code sanitization, but they have all been
|
||||
previously defeated on multiple occasions. You should learn to approach
|
||||
browsing websites as the most insecure activity you'll engage in on any given
|
||||
day.
|
||||
|
||||
There are several ways you can reduce the impact of a compromised browser, but
|
||||
the truly effective ways will require significant changes in the way you
|
||||
operate your workstation.
|
||||
|
||||
#### 1: Use two different browsers
|
||||
|
||||
This is the easiest to do, but only offers minor security benefits. Not all
|
||||
browser compromises give an attacker full unfettered access to your system --
|
||||
sometimes they are limited to allowing one to read local browser storage,
|
||||
steal active sessions from other tabs, capture input entered into the browser,
|
||||
etc. Using two different browsers, one for work/high security sites, and
|
||||
another for everything else will help prevent minor compromises from giving
|
||||
attackers access to the whole cookie jar. The main inconvenience will be the
|
||||
amount of memory consumed by two different browser processes.
|
||||
|
||||
Here's what we recommend:
|
||||
|
||||
##### Firefox for work and high security sites
|
||||
|
||||
Use Firefox to access work-related sites, where extra care should be taken to
|
||||
ensure that data like cookies, sessions, login information, keystrokes, etc,
|
||||
should most definitely not fall into attackers' hands. You should NOT use
|
||||
this browser for accessing any other sites except select few.
|
||||
|
||||
You should install the following Firefox add-ons:
|
||||
|
||||
- [ ] NoScript _(CRITICAL)_
|
||||
- NoScript prevents active content from loading, except from user
|
||||
whitelisted domains. It is a great hassle to use with your default browser
|
||||
(though offers really good security benefits), so we recommend only
|
||||
enabling it on the browser you use to access work-related sites.
|
||||
|
||||
- [ ] Privacy Badger _(CRITICAL)_
|
||||
- EFF's Privacy Badger will prevent most external trackers and ad platforms
|
||||
from being loaded, which will help avoid compromises on these tracking
|
||||
sites from affecting your browser (trackers and ad sites are very commonly
|
||||
targeted by attackers, as they allow rapid infection of thousands of
|
||||
systems worldwide).
|
||||
|
||||
- [ ] HTTPS Everywhere _(CRITICAL)_
|
||||
- This EFF-developed Add-on will ensure that most of your sites are accessed
|
||||
over a secure connection, even if a link you click is using http:// (great
|
||||
to avoid a number of attacks, such as [SSL-strip][7]).
|
||||
|
||||
- [ ] Certificate Patrol _(MODERATE)_
|
||||
- This tool will alert you if the site you're accessing has recently changed
|
||||
their TLS certificates -- especially if it wasn't nearing expiration dates
|
||||
or if it is now using a different certification authority. It helps
|
||||
alert you if someone is trying to man-in-the-middle your connection,
|
||||
but generates a lot of benign false-positives.
|
||||
|
||||
You should leave Firefox as your default browser for opening links, as
|
||||
NoScript will prevent most active content from loading or executing.
|
||||
|
||||
##### Chrome/Chromium for everything else
|
||||
|
||||
Chromium developers are ahead of Firefox in adding a lot of nice security
|
||||
features (at least [on Linux][6]), such as seccomp sandboxes, kernel user
|
||||
namespaces, etc, which act as an added layer of isolation between the sites
|
||||
you visit and the rest of your system. Chromium is the upstream open-source
|
||||
project, and Chrome is Google's proprietary binary build based on it (insert
|
||||
the usual paranoid caution about not using it for anything you don't want
|
||||
Google to know about).
|
||||
|
||||
It is recommended that you install **Privacy Badger** and **HTTPS Everywhere**
|
||||
extensions in Chrome as well and give it a distinct theme from Firefox to
|
||||
indicate that this is your "untrusted sites" browser.
|
||||
|
||||
#### 2: Use two different browsers, one inside a dedicated VM
|
||||
|
||||
This is a similar recommendation to the above, except you will add an extra
|
||||
step of running Chrome inside a dedicated VM that you access via a fast
|
||||
protocol, allowing you to share clipboards and forward sound events (e.g.
|
||||
Spice or RDP). This will add an excellent layer of isolation between the
|
||||
untrusted browser and the rest of your work environment, ensuring that
|
||||
attackers who manage to fully compromise your browser will then have to
|
||||
additionally break out of the VM isolation layer in order to get to the rest
|
||||
of your system.
|
||||
|
||||
This is a surprisingly workable configuration, but requires a lot of RAM and
|
||||
fast processors that can handle the increased load. It will also require an
|
||||
important amount of dedication on the part of the admin who will need to
|
||||
adjust their work practices accordingly.
|
||||
|
||||
#### 3: Fully separate your work and play environments via virtualization
|
||||
|
||||
See [Qubes-OS project][3], which strives to provide a high-security
|
||||
workstation environment via compartmentalizing your applications into separate
|
||||
fully isolated VMs.
|
||||
|
||||
### Password managers
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Use a password manager _(CRITICAL_)
|
||||
- [ ] Use unique passwords on unrelated sites _(CRITICAL)_
|
||||
- [ ] Use a password manager that supports team sharing _(MODERATE)_
|
||||
- [ ] Use a separate password manager for non-website accounts _(PARANOID)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
Using good, unique passwords should be a critical requirement for every member
|
||||
of your team. Credential theft is happening all the time -- either via
|
||||
compromised computers, stolen database dumps, remote site exploits, or any
|
||||
number of other means. No credentials should ever be reused across sites,
|
||||
especially for critical applications.
|
||||
|
||||
##### In-browser password manager
|
||||
|
||||
Every browser has a mechanism for saving passwords that is fairly secure and
|
||||
can sync with vendor-maintained cloud storage while keeping the data encrypted
|
||||
with a user-provided passphrase. However, this mechanism has important
|
||||
disadvantages:
|
||||
|
||||
1. It does not work across browsers
|
||||
2. It does not offer any way of sharing credentials with team members
|
||||
|
||||
There are several well-supported, free-or-cheap password managers that are
|
||||
well-integrated into multiple browsers, work across platforms, and offer
|
||||
group sharing (usually as a paid service). Solutions can be easily found via
|
||||
search engines.
|
||||
|
||||
##### Standalone password manager
|
||||
|
||||
One of the major drawbacks of any password manager that comes integrated with
|
||||
the browser is the fact that it's part of the application that is most likely
|
||||
to be attacked by intruders. If this makes you uncomfortable (and it should),
|
||||
you may choose to have two different password managers -- one for websites
|
||||
that is integrated into your browser, and one that runs as a standalone
|
||||
application. The latter can be used to store high-risk credentials such as
|
||||
root passwords, database passwords, other shell account credentials, etc.
|
||||
|
||||
It may be particularly useful to have such tool for sharing superuser account
|
||||
credentials with other members of your team (server root passwords, ILO
|
||||
passwords, database admin passwords, bootloader passwords, etc).
|
||||
|
||||
A few tools can help you:
|
||||
|
||||
- [KeePassX][8], which improves team sharing in version 2
|
||||
- [Pass][9], which uses text files and PGP and integrates with git
|
||||
- [Django-Pstore][10], which uses GPG to share credentials between admins
|
||||
- [Hiera-Eyaml][11], which, if you are already using Puppet for your
|
||||
infrastructure, may be a handy way to track your server/service credentials
|
||||
as part of your encrypted Hiera data store
|
||||
|
||||
### Securing SSH and PGP private keys
|
||||
|
||||
Personal encryption keys, including SSH and PGP private keys, are going to be
|
||||
the most prized items on your workstation -- something the attackers will be
|
||||
most interested in obtaining, as that would allow them to further attack your
|
||||
infrastructure or impersonate you to other admins. You should take extra steps
|
||||
to ensure that your private keys are well protected against theft.
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Strong passphrases are used to protect private keys _(CRITICAL)_
|
||||
- [ ] PGP Master key is stored on removable storage _(MODERATE)_
|
||||
- [ ] Auth, Sign and Encrypt Subkeys are stored on a smartcard device _(MODERATE)_
|
||||
- [ ] SSH is configured to use PGP Auth key as ssh private key _(MODERATE)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
The best way to prevent private key theft is to use a smartcard to store your
|
||||
encryption private keys and never copy them onto the workstation. There are
|
||||
several manufacturers that offer OpenPGP capable devices:
|
||||
|
||||
- [Kernel Concepts][12], where you can purchase both the OpenPGP compatible
|
||||
smartcards and the USB readers, should you need one.
|
||||
- [Yubikey NEO][13], which offers OpenPGP smartcard functionality in addition
|
||||
to many other cool features (U2F, PIV, HOTP, etc).
|
||||
|
||||
It is also important to make sure that the master PGP key is not stored on the
|
||||
main workstation, and only subkeys are used. The master key will only be
|
||||
needed when signing someone else's keys or creating new subkeys -- operations
|
||||
which do not happen very frequently. You may follow [the Debian's subkeys][14]
|
||||
guide to learn how to move your master key to removable storage and how to
|
||||
create subkeys.
|
||||
|
||||
You should then configure your gnupg agent to act as ssh agent and use the
|
||||
smartcard-based PGP Auth key to act as your ssh private key. We publish a
|
||||
[detailed guide][15] on how to do that using either a smartcard reader or a
|
||||
Yubikey NEO.
|
||||
|
||||
If you are not willing to go that far, at least make sure you have a strong
|
||||
passphrase on both your PGP private key and your SSH private key, which will
|
||||
make it harder for attackers to steal and use them.
|
||||
|
||||
### SELinux on the workstation
|
||||
|
||||
If you are using a distribution that comes bundled with SELinux (such as
|
||||
Fedora), here are some recommendation of how to make the best use of it to
|
||||
maximize your workstation security.
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Make sure SELinux is enforcing on your workstation _(CRITICAL)_
|
||||
- [ ] Never blindly run `audit2allow -M`, always check _(CRITICAL)_
|
||||
- [ ] Never `setenforce 0` _(MODERATE)_
|
||||
- [ ] Switch your account to SELinux user `staff_u` _(MODERATE)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
SELinux is a Mandatory Access Controls (MAC) extension to core POSIX
|
||||
permissions functionality. It is mature, robust, and has come a long way since
|
||||
its initial roll-out. Regardless, many sysadmins to this day repeat the
|
||||
outdated mantra of "just turn it off."
|
||||
|
||||
That being said, SELinux will have limited security benefits on the
|
||||
workstation, as most applications you will be running as a user are going to
|
||||
be running unconfined. It does provide enough net benefit to warrant leaving
|
||||
it on, as it will likely help prevent an attacker from escalating privileges
|
||||
to gain root-level access via a vulnerable daemon service.
|
||||
|
||||
Our recommendation is to leave it on and enforcing.
|
||||
|
||||
##### Never `setenforce 0`
|
||||
|
||||
It's tempting to use `setenforce 0` to flip SELinux into permissive mode
|
||||
on a temporary basis, but you should avoid doing that. This essentially turns
|
||||
off SELinux for the entire system, while what you really want is to
|
||||
troubleshoot a particular application or daemon.
|
||||
|
||||
Instead of `setenforce 0` you should be using `semanage permissive -a
|
||||
[somedomain_t]` to put only that domain into permissive mode. First, find out
|
||||
which domain is causing troubles by running `ausearch`:
|
||||
|
||||
ausearch -ts recent -m avc
|
||||
|
||||
and then look for `scontext=` (source SELinux context) line, like so:
|
||||
|
||||
scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
|
||||
^^^^^^^^^^^^^^
|
||||
|
||||
This tells you that the domain being denied is `gpg_pinentry_t`, so if you
|
||||
want to troubleshoot the application, you should add it to permissive domains:
|
||||
|
||||
semange permissive -a gpg_pinentry_t
|
||||
|
||||
This will allow you to use the application and collect the rest of the AVCs,
|
||||
which you can then use in conjunction with `audit2allow` to write a local
|
||||
policy. Once that is done and you see no new AVC denials, you can remove that
|
||||
domain from permissive by running:
|
||||
|
||||
semanage permissive -d gpg_pinentry_t
|
||||
|
||||
##### Use your workstation as SELinux role staff_r
|
||||
|
||||
SELinux comes with a native implementation of roles that prohibit or grant
|
||||
certain privileges based on the role associated with the user account. As an
|
||||
administrator, you should be using the `staff_r` role, which will restrict
|
||||
access to many configuration and other security-sensitive files, unless you
|
||||
first perform `sudo`.
|
||||
|
||||
By default, accounts are created as `unconfined_r` and most applications you
|
||||
execute will run unconfined, without any (or with only very few) SELinux
|
||||
constraints. To switch your account to the `staff_r` role, run the following
|
||||
command:
|
||||
|
||||
usermod -Z staff_u [username]
|
||||
|
||||
You should log out and log back in to enable the new role, at which point if
|
||||
you run `id -Z`, you'll see:
|
||||
|
||||
staff_u:staff_r:staff_t:s0-s0:c0.c1023
|
||||
|
||||
When performing `sudo`, you should remember to add an extra flag to tell
|
||||
SELinux to transition to the "sysadmin" role. The command you want is:
|
||||
|
||||
sudo -i -r sysadm_r
|
||||
|
||||
At which point `id -Z` will show:
|
||||
|
||||
staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
|
||||
|
||||
**WARNING**: you should be comfortable using `ausearch` and `audit2allow`
|
||||
before you make this switch, as it's possible some of your applications will
|
||||
no longer work when you're running as role `staff_r`. At the time of writing,
|
||||
the following popular applications are known to not work under `staff_r`
|
||||
without policy tweaks:
|
||||
|
||||
- Chrome/Chromium
|
||||
- Skype
|
||||
- VirtualBox
|
||||
|
||||
To switch back to `unconfined_r`, run the following command:
|
||||
|
||||
usermod -Z unconfined_u [username]
|
||||
|
||||
and then log out and back in to get back into the comfort zone.
|
||||
|
||||
## Further reading
|
||||
|
||||
The world of IT security is a rabbit hole with no bottom. If you would like to
|
||||
go deeper, or find out more about security features on your particular
|
||||
distribution, please check out the following links:
|
||||
|
||||
- [Fedora Security Guide](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
|
||||
- [CESG Ubuntu Security Guide](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
|
||||
- [Debian Security Manual](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
|
||||
- [Arch Linux Security Wiki](https://wiki.archlinux.org/index.php/Security)
|
||||
- [Mac OSX Security](https://www.apple.com/support/security/guides/)
|
||||
|
||||
## License
|
||||
This work is licensed under a
|
||||
[Creative Commons Attribution-ShareAlike 4.0 International License][0].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/lfit/itpol/blob/master/linux-workstation-security.md#linux-workstation-security-checklist
|
||||
|
||||
作者:[mricon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/mricon
|
||||
[0]: http://creativecommons.org/licenses/by-sa/4.0/
|
||||
[1]: https://github.com/QubesOS/qubes-antievilmaid
|
||||
[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
|
||||
[3]: https://qubes-os.org/
|
||||
[4]: https://xkcd.com/936/
|
||||
[5]: https://spideroak.com/
|
||||
[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
|
||||
[7]: http://www.thoughtcrime.org/software/sslstrip/
|
||||
[8]: https://keepassx.org/
|
||||
[9]: http://www.passwordstore.org/
|
||||
[10]: https://pypi.python.org/pypi/django-pstore
|
||||
[11]: https://github.com/TomPoulton/hiera-eyaml
|
||||
[12]: http://shop.kernelconcepts.de/
|
||||
[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
|
||||
[14]: https://wiki.debian.org/Subkeys
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
@ -1,5 +1,3 @@
|
||||
translating by Ezio
|
||||
|
||||
Remember sed and awk? All Linux admins should
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,236 +0,0 @@
|
||||
How to Install Redis Server on CentOS 7
|
||||
================================================================================
|
||||
Hi everyone, today Redis is the subject of our article, we are going to install it on CentOS 7. Build sources files, install the binaries, create and install files. After installing its components, we will set its configuration as well as some operating system parameters to make it more reliable and faster.
|
||||
|
||||

|
||||
|
||||
Redis server
|
||||
|
||||
Redis is an open source multi-platform data store written in ANSI C, that uses datasets directly from memory achieving extremely high performance. It supports various programming languages, including Lua, C, Java, Python, Perl, PHP and many others. It is based on simplicity, about 30k lines of code that do "few" things, but do them well. Despite you work on memory, persistence may exist and it has a fairly reasonable support for high availability and clustering, which does good in keeping your data safe.
|
||||
|
||||
### Building Redis ###
|
||||
|
||||
There is no official RPM package available, we need to build it from sources, in order to do this you will need install Make and GCC.
|
||||
|
||||
Install GNU Compiler Collection and Make with yum if it is not already installed
|
||||
|
||||
yum install gcc make
|
||||
|
||||
Download the tarball from [redis download page][1].
|
||||
|
||||
curl http://download.redis.io/releases/redis-3.0.4.tar.gz -o redis-3.0.4.tar.gz
|
||||
|
||||
Extract the tarball contents
|
||||
|
||||
tar zxvf redis-3.0.4.tar.gz
|
||||
|
||||
Enter Redis the directory we have extracted
|
||||
|
||||
cd redis-3.0.4
|
||||
|
||||
Use Make to build the source files
|
||||
|
||||
make
|
||||
|
||||
### Install ###
|
||||
|
||||
Enter on the src directory
|
||||
|
||||
cd src
|
||||
|
||||
Copy Redis server and client to /usr/local/bin
|
||||
|
||||
cp redis-server redis-cli /usr/local/bin
|
||||
|
||||
Its good also to copy sentinel, benchmark and check as well.
|
||||
|
||||
cp redis-sentinel redis-benchmark redis-check-aof redis-check-dump /usr/local/bin
|
||||
|
||||
Make Redis config directory
|
||||
|
||||
mkdir /etc/redis
|
||||
|
||||
Create a working and data directory under /var/lib/redis
|
||||
|
||||
mkdir -p /var/lib/redis/6379
|
||||
|
||||
#### System parameters ####
|
||||
|
||||
In order to Redis work correctly you need to set some kernel options
|
||||
|
||||
Set the vm.overcommit_memory to 1, which means always, this will avoid data to be truncated, take a look [here][2] for more.
|
||||
|
||||
sysctl -w vm.overcommit_memory=1
|
||||
|
||||
Change the maximum of backlog connections some value higher than the value on tcp-backlog option of redis.conf, which defaults to 511. You can find more on sysctl based ip networking "tunning" on [kernel.org][3] website.
|
||||
|
||||
sysctl -w net.core.somaxconn=512.
|
||||
|
||||
Disable transparent huge pages support, that is known to cause latency and memory access issues with Redis.
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### redis.conf ###
|
||||
|
||||
Redis.conf is the Redis configuration file, however you will see the file named as 6379.conf here, where the number is the same as the network port is listening to. This name is recommended if you are going to run more than one Redis instance.
|
||||
|
||||
Copy sample redis.conf to **/etc/redis/6379.conf**.
|
||||
|
||||
cp redis.conf /etc/redis/6379.conf
|
||||
|
||||
Now edit the file and set at some of its parameters.
|
||||
|
||||
vi /etc/redis/6379.conf
|
||||
|
||||
#### daemonize ####
|
||||
|
||||
Set daemonize to no, systemd need it to be in foreground, otherwise Redis will suddenly die.
|
||||
|
||||
daemonize no
|
||||
|
||||
#### pidfile ####
|
||||
|
||||
Set the pidfile to redis_6379.pid under /var/run.
|
||||
|
||||
pidfile /var/run/redis_6379.pid
|
||||
|
||||
#### port ####
|
||||
|
||||
Change the network port if you are not going to use the default
|
||||
|
||||
port 6379
|
||||
|
||||
#### loglevel ####
|
||||
|
||||
Set your loglevel.
|
||||
|
||||
loglevel notice
|
||||
|
||||
#### logfile ####
|
||||
|
||||
Set the logfile to /var/log/redis_6379.log
|
||||
|
||||
logfile /var/log/redis_6379.log
|
||||
|
||||
#### dir ####
|
||||
|
||||
Set the directory to /var/lib/redis/6379
|
||||
|
||||
dir /var/lib/redis/6379
|
||||
|
||||
### Security ###
|
||||
|
||||
Here are some actions that you can take to enforce the security.
|
||||
|
||||
#### Unix sockets ####
|
||||
|
||||
In many cases, the client application resides on the same machine as the server, so there is no need to listen do network sockets. If this is the case you may want to use unix sockets instead, for this you need to set the **port** option to 0, and then enable unix sockets with the following options.
|
||||
|
||||
Set the path to the socket file
|
||||
|
||||
unixsocket /tmp/redis.sock
|
||||
|
||||
Set restricted permission to the socket file
|
||||
|
||||
unixsocketperm 700
|
||||
|
||||
Now, to have access with redis-cli you should use the -s flag pointing to the socket file
|
||||
|
||||
redis-cli -s /tmp/redis.sock
|
||||
|
||||
#### requirepass ####
|
||||
|
||||
You may need remote access, if so, you should use a password, that will be required before any operation.
|
||||
|
||||
requirepass "bTFBx1NYYWRMTUEyNHhsCg"
|
||||
|
||||
#### rename-command ####
|
||||
|
||||
Imagine the output of the next command. Yes, it will dump the configuration of the server, so you should deny access to this kind information whenever is possible.
|
||||
|
||||
CONFIG GET *
|
||||
|
||||
To restrict, or even disable this and other commands by using the **rename-command**. You must provide a command name and a replacement. To disable, set the replacement string to "" (blank), this is more secure as it will prevent someone from guessing the command name.
|
||||
|
||||
rename-command FLUSHDB "FLUSHDB_MY_SALT_G0ES_HERE09u09u"
|
||||
rename-command FLUSHALL ""
|
||||
rename-command CONFIG "CONFIG_MY_S4LT_GO3S_HERE09u09u"
|
||||
|
||||

|
||||
|
||||
Access through unix sockets with password and command changes
|
||||
|
||||
#### Snapshots ####
|
||||
|
||||
By default Redis will periodically dump its datasets to **dump.rdb** on the data directory we set. You can configure how often the rdb file will be updated by the save command, the first parameter is a timeframe in seconds and the second is a number of changes performed on the data file.
|
||||
|
||||
Every 15 hours if there was at least 1 key change
|
||||
|
||||
save 900 1
|
||||
|
||||
Every 5 hours if there was at least 10 key changes
|
||||
|
||||
save 300 10
|
||||
|
||||
Every minute if there was at least 10000 key changes
|
||||
|
||||
save 60 10000
|
||||
|
||||
The **/var/lib/redis/6379/dump.rdb** file contains a dump of the dataset on memory since last save. Since it creates a temporary file and then replace the original file, there is no problem of corruption and you can always copy it directly without fear.
|
||||
|
||||
### Starting at boot ###
|
||||
|
||||
You may use systemd to add Redis to the system startup
|
||||
|
||||
Copy sample init_script to /etc/init.d, note also the number of the port on the script name
|
||||
|
||||
cp utils/redis_init_script /etc/init.d/redis_6379
|
||||
|
||||
We are going to use systemd, so create a unit file named redis_6379.service under **/etc/systems/system**
|
||||
|
||||
vi /etc/systemd/system/redis_6379.service
|
||||
|
||||
Put this content, try man systemd.service for details
|
||||
|
||||
[Unit]
|
||||
Description=Redis on port 6379
|
||||
|
||||
[Service]
|
||||
Type=forking
|
||||
ExecStart=/etc/init.d/redis_6379 start
|
||||
ExecStop=/etc/init.d/redis_6379 stop
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
Now add the memory overcommit and maximum backlog options we have set before to the **/etc/sysctl.conf** file.
|
||||
|
||||
vm.overcommit_memory = 1
|
||||
|
||||
net.core.somaxconn=512
|
||||
|
||||
For the transparent huge pages support there is no sysctl directive, so you can put the command at the end of /etc/rc.local
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
That's enough to start, with these settings you will be able to deploy Redis server for many simpler scenarios, however there is many options on redis.conf for more complex environments. On some cases, you may use [replication][4] and [Sentinel][5] to provide high availability, [split the data][6] across servers, create a cluster of servers. Thanks for reading!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/install-redis-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
[1]:http://redis.io/download
|
||||
[2]:https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
|
||||
[3]:https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
|
||||
[4]:http://redis.io/topics/replication
|
||||
[5]:http://redis.io/topics/sentinel
|
||||
[6]:http://redis.io/topics/partitioning
|
||||
@ -1,124 +0,0 @@
|
||||
translating by ezio
|
||||
|
||||
How to Install SQLite 3.9.1 with JSON Support on Ubuntu 15.04
|
||||
================================================================================
|
||||
Hello and welcome to our today's article on SQLite which is the most widely deployed SQL database engine in the world that comes with zero-configuration, that means no setup or administration needed. SQLite is public-domain software package that provides relational database management system, or RDBMS that is used to store user-defined records in large tables. In addition to data storage and management, database engine process complex query commands that combine data from multiple tables to generate reports and data summaries.
|
||||
|
||||
SQLite is very small and light weight that does not require a separate server process or system to operate. It is available on UNIX, Linux, Mac OS-X, Android, iOS and Windows which is being used in various software applications like Opera, Ruby On Rails, Adobe System, Mozilla Firefox, Google Chrome and Skype.
|
||||
|
||||
### 1) Basic Requirements: ###
|
||||
|
||||
There is are no such complex complex requirements for the installation of SQLite as it mostly comes support all major cross platforms.
|
||||
|
||||
So, let's login to your Ubuntu server with sudo or root credentials using your CLI or Secure Shell. Then update your system so that your operating system is upto date with latest packages.
|
||||
|
||||
In ubuntu, the below command is to be used for system update.
|
||||
|
||||
# apt-get update
|
||||
|
||||
If you are starting to deploy SQLite on on a fresh Ubuntu, then make sure that you have installed some basic system management utilities like wget, make, unzip, gcc.
|
||||
|
||||
To install wget, make and gcc packages on ubuntu, you use the below command, then press "Y" to allow and proceed with installation of these packages.
|
||||
|
||||
# apt-get install wget make gcc
|
||||
|
||||
### 2) Download SQLite ###
|
||||
|
||||
To download the latest package of SQLite, you can refer to their official [SQLite Download Page][1] as shown below.
|
||||
|
||||

|
||||
|
||||
You can copy the link of its resource package and download it on ubuntu server using the wget utility command.
|
||||
|
||||
# wget https://www.sqlite.org/2015/sqlite-autoconf-3090100.tar.gz
|
||||
|
||||

|
||||
|
||||
After downloading is complete, extract the package and change your current directory to the extracted SQLite folder by using the below command as shown.
|
||||
|
||||
# tar -zxvf sqlite-autoconf-3090100.tar.gz
|
||||
|
||||
### 3) Installing SQLite ###
|
||||
|
||||
Now we are going to install and configure the SQLite package that we downloaded. So, to compile and install SQLite on ubuntu run the configuration script within the same directory where your have extracted the SQLite package as shown below.
|
||||
|
||||
root@ubuntu-15:~/sqlite-autoconf-3090100# ./configure –prefix=/usr/local
|
||||
|
||||

|
||||
|
||||
Once the package is configuration is done under the mentioned prefix, then run the below command make command to compile the package.
|
||||
|
||||
root@ubuntu-15:~/sqlite-autoconf-3090100# make
|
||||
source='sqlite3.c' object='sqlite3.lo' libtool=yes \
|
||||
DEPDIR=.deps depmode=none /bin/bash ./depcomp \
|
||||
/bin/bash ./libtool --tag=CC --mode=compile gcc -DPACKAGE_NAME=\"sqlite\" -DPACKAGE_TARNAME=\"sqlite\" -DPACKAGE_VERSION=\"3.9.1\" -DPACKAGE_STRING=\"sqlite\ 3.9.1\" -DPACKAGE_BUGREPORT=\"http://www.sqlite.org\" -DPACKAGE_URL=\"\" -DPACKAGE=\"sqlite\" -DVERSION=\"3.9.1\" -DSTDC_HEADERS=1 -DHAVE_SYS_TYPES_H=1 -DHAVE_SYS_STAT_H=1 -DHAVE_STDLIB_H=1 -DHAVE_STRING_H=1 -DHAVE_MEMORY_H=1 -DHAVE_STRINGS_H=1 -DHAVE_INTTYPES_H=1 -DHAVE_STDINT_H=1 -DHAVE_UNISTD_H=1 -DHAVE_DLFCN_H=1 -DLT_OBJDIR=\".libs/\" -DHAVE_FDATASYNC=1 -DHAVE_USLEEP=1 -DHAVE_LOCALTIME_R=1 -DHAVE_GMTIME_R=1 -DHAVE_DECL_STRERROR_R=1 -DHAVE_STRERROR_R=1 -DHAVE_POSIX_FALLOCATE=1 -I. -D_REENTRANT=1 -DSQLITE_THREADSAFE=1 -DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_RTREE -g -O2 -c -o sqlite3.lo sqlite3.c
|
||||
|
||||
After running make command, to complete the installation of SQLite on ubuntu run the 'make install' command as shown below.
|
||||
|
||||
# make install
|
||||
|
||||

|
||||
|
||||
### 4) Testing SQLite Installation ###
|
||||
|
||||
To confirm the successful installation of SQLite 3.9, run the below command in your command line interface.
|
||||
|
||||
# sqlite3
|
||||
|
||||
You will the SQLite verion after running the above command as shown.
|
||||
|
||||

|
||||
|
||||
### 5) Using SQLite ###
|
||||
|
||||
SQLite is very handy to use. To get the detailed information about its usage, simply run the below command in the SQLite console.
|
||||
|
||||
sqlite> .help
|
||||
|
||||
So here is the list of all its available commands, with their description that you can get help to start using SQLite.
|
||||
|
||||

|
||||
|
||||
Now in this last section , we make use of few SQLite commands to create a new database using the SQLite3 command line interface.
|
||||
|
||||
To to create a new database run the below command.
|
||||
|
||||
# sqlite3 test.db
|
||||
|
||||
To create a table within the new database run the below command.
|
||||
|
||||
sqlite> create table memos(text, priority INTEGER);
|
||||
|
||||
After creating the table, insert some data using the following commands.
|
||||
|
||||
sqlite> insert into memos values('deliver project description', 15);
|
||||
sqlite> insert into memos values('writing new artilces', 100);
|
||||
|
||||
To view the inserted data from the table , run the below command.
|
||||
|
||||
sqlite> select * from memos;
|
||||
deliver project description|15
|
||||
writing new artilces|100
|
||||
|
||||
to exit from the sqlite3 type the below command.
|
||||
|
||||
sqlite> .exit
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article you learned the installation of latest version of SQLite 3.9.1 which enables the recently JSON1 support in its 3.9.0 version and so on. Its is an amazing library that gets embedded inside the application that makes use of it to keep the resources much efficient and lighter. We hope you find this article much helpful, feel free to get back to us if you find any difficulty.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-sqlite-json-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://www.sqlite.org/download.html
|
||||
@ -1,84 +0,0 @@
|
||||
How to Manage Your To-Do Lists in Ubuntu Using Go For It Application
|
||||
================================================================================
|
||||

|
||||
|
||||
Task management is arguably one of the most important and challenging part of professional as well as personal life. Professionally, as you assume more and more responsibility, your performance is directly related to or affected with your ability to manage the tasks you’re assigned.
|
||||
|
||||
If your job involves working on a computer, then you’ll be happy to know that there are various applications available that claim to make task management easy for you. While most of them cater to Windows users, there are many options available on Linux, too. In this article we will discuss one such application: Go For It.
|
||||
|
||||
### Go For It ###
|
||||
|
||||
[Go For It][1] (GFI) is developed by Manuel Kehl, who describes it as a “a simple and stylish productivity app, featuring a to-do list, merged with a timer that keeps your focus on the current task.” The timer feature, specifically, is interesting, as it also makes sure that you take a break from your current task and relax for sometime before proceeding further.
|
||||
|
||||
### Download and Installation ###
|
||||
|
||||
Users of Debian-based systems, like Ubuntu, can easily install the app by running the following commands in terminal:
|
||||
|
||||
sudo add-apt-repository ppa:mank319/go-for-it
|
||||
sudo apt-get update
|
||||
sudo apt-get install go-for-it
|
||||
|
||||
Once done, you can execute the application by running the following command:
|
||||
|
||||
go-for-it
|
||||
|
||||
### Usage and Configuration ###
|
||||
|
||||
Here is how the GFI interface looks when you run the app for the very first time:
|
||||
|
||||

|
||||
|
||||
As you can see, the interface consists of three tabs: To-Do, Timer, and Done. While the To-Do tab contains a list of tasks (the 4 tasks shown in the image above are there by default – you can delete them by clicking on the rectangular box in front of them), the Timer tab contains task timer, while Done contains a list of tasks that you’ve finished successfully. Right at the bottom is a text box where you can enter the task text and click “+” to add it to the list above.
|
||||
|
||||
For example, I added a task named “MTE-research-work” to the list and selected it by clicking on it in the list – see the screenshot below:
|
||||
|
||||

|
||||
|
||||
Then I selected the Timer tab. Here I could see a 25-minute timer for the active task which was “MTE-reaserch-work.”
|
||||
|
||||

|
||||
|
||||
Of course, you can change the timer value and set to any time you want. I, however, didn’t change the value and clicked the Start button present below to start the task timer. Once 60 seconds were left, GFI issued a notification indicating the same.
|
||||
|
||||

|
||||
|
||||
And once the time was up, I was asked to take a break of five minutes.
|
||||
|
||||

|
||||
|
||||
Once those five minutes were over, I could again start the task timer for my task.
|
||||
|
||||

|
||||
|
||||
When you’re done with your task, you can click the Done button in the Timer tab. The task is then removed from the To-Do tab and listed in the Done tab.
|
||||
|
||||

|
||||
|
||||
GFI also allows you to tweak some of its settings. For example, the settings window shown below contains options to tweak the default task duration, break duration, and reminder time.
|
||||
|
||||

|
||||
|
||||
It’s worth mentioning that GFI stores the to-do lists in the Todo.txt format which simplifies synchronization with mobile devices and makes it possible for you to edit tasks using other frontends – read more about it [here][2].
|
||||
|
||||
You can also see the GFI app in action in the video below.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe frameborder="0" src="http://www.youtube.com/embed/mnw556C9FZQ?autoplay=1&autohide=2&border=1&wmode=opaque&enablejsapi=1&controls=1&showinfo=0" id="youtube-iframe"></iframe>
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As you have observed, GFI is an easy to understand and simple to use task management application. Although it doesn’t offer a plethora of features, it does what it claims – the timer integration is especially useful. If you’re looking for a basic, open-source task management tool for Linux, Go For It is worth trying.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/to-do-lists-ubuntu-go-for-it/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[2]:http://todotxt.com/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ezio
|
||||
|
||||
How to Monitor the Progress of a Linux Command Line Operation Using PV Command
|
||||
================================================================================
|
||||

|
||||
@ -76,4 +78,4 @@ via: https://www.maketecheasier.com/monitor-progress-linux-command-line-operatio
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:http://linux.die.net/man/1/pv
|
||||
[2]:http://linux.die.net/man/1/dialog
|
||||
[2]:http://linux.die.net/man/1/dialog
|
||||
|
||||
@ -0,0 +1,92 @@
|
||||
translation by strugglingyouth
|
||||
|
||||
Linux FAQs with Answers--How to install Node.js on Linux
|
||||
================================================================================
|
||||
> **Question**: How can I install Node.js on [insert your Linux distro]?
|
||||
|
||||
[Node.js][1] is a server-side software platform built on Google's V8 JavaScript engine. Node.js has become a popular choice for building high-performance server-side applications all in JavaScript. What makes Node.js even more attractive for backend server development is the [huge ecosystem][2] of Node.js libraries and applications. Node.js comes with a command line utility called npm which allows you to easily install, version-control, and manage dependencies of Node.js libraries and applications from the vast npm online repository.
|
||||
|
||||
In this tutorial, I will describe **how to install Node.js on major Linux distros including Debian, Ubuntu, Fedora and CentOS**.
|
||||
|
||||
Node.js is available as a pre-built package on some distros (e.g., Fedora or Ubuntu), while you need to install it from its source on other distros. As Node.js is fast evolving, it is recommended to install the latest Node.js from its source, instead of installing an outdated pre-built package. The lasted Node.js comes with npm (Node.js package manager) bundled, allowing you to install external Node.js modules easily.
|
||||
|
||||
### Install Node.js on Debian ###
|
||||
|
||||
Starting from Debian 8 (Jessie), Node.js is available in the official repositories. Thus you can install it with:
|
||||
|
||||
$ sudo apt-get install npm
|
||||
|
||||
On Debian 7 (Wheezy) or earlier, you can install Node.js from its source as follows.
|
||||
|
||||
$ sudo apt-get install python g++ make
|
||||
$ wget http://nodejs.org/dist/node-latest.tar.gz
|
||||
$ tar xvfvz node-latest.tar.gz
|
||||
$ cd node-v0.10.21 (replace a version with your own)
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### Install Node.js on Ubuntu or Linux Mint ###
|
||||
|
||||
Node.js is included in Ubuntu (13.04 and higher). Thus installation is straightforward. The following will install Node.js and npm.
|
||||
|
||||
$ sudo apt-get install npm
|
||||
$ sudo ln -s /usr/bin/nodejs /usr/bin/node
|
||||
|
||||
While stock Ubuntu ships Node.js, you can install a more recent version from [its PPA][3].
|
||||
|
||||
$ sudo apt-get install python-software-properties python g++ make
|
||||
$ sudo add-apt-repository -y ppa:chris-lea/node.js
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install npm
|
||||
|
||||
### Install Node.js on Fedora ###
|
||||
|
||||
Node.js is included in the base repository of Fedora. Therefore you can use yum to install Node.js on Fedora.
|
||||
|
||||
$ sudo yum install npm
|
||||
|
||||
If you want to install the latest version of Node.js, you can build it from its source as follows.
|
||||
|
||||
$ sudo yum groupinstall 'Development Tools'
|
||||
$ wget http://nodejs.org/dist/node-latest.tar.gz
|
||||
$ tar xvfvz node-latest.tar.gz
|
||||
$ cd node-v0.10.21 (replace a version with your own)
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### Install Node.js on CentOS or RHEL ###
|
||||
|
||||
To install Node.js with yum package manager on CentOS, first enable EPEL repository, and then run:
|
||||
|
||||
$ sudo yum install npm
|
||||
|
||||
If you want to build the latest Node.js on CentOS, follow the same procedure as in Fedora.
|
||||
|
||||
### Install Node.js on Arch Linux ###
|
||||
|
||||
Node.js is available in the Arch Linux community repository. Thus installation is as simple as running:
|
||||
|
||||
$ sudo pacman -S nodejs npm
|
||||
|
||||
### Check the Version of Node.js ###
|
||||
|
||||
Once you have installed Node.js, you can check Node.js version as follows.
|
||||
|
||||
$ node --version
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-node-js-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://nodejs.org/
|
||||
[2]:https://www.npmjs.com/
|
||||
[3]:https://launchpad.net/~chris-lea/+archive/node.js
|
||||
@ -0,0 +1,125 @@
|
||||
Install Android On BQ Aquaris Ubuntu Phone In Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
If you happen to own the first Ubuntu phone and want to **replace Ubuntu with Android on the bq Aquaris e4.5**, this post is going to help you.
|
||||
|
||||
There can be plenty of reasons why you might want to remove Ubuntu and use the mainstream Android OS. One of the foremost reason is that the OS itself is at an early stage and intend to target developers and enthusiasts. Whatever may be your reason, installing Android on bq Aquaris is a piece of cake, thanks to the tools provided by bq.
|
||||
|
||||
Let’s see what to do we need to install Android on bq Aquaris.
|
||||
|
||||
### Prerequisite ###
|
||||
|
||||
- Working Internet connection to download Android factory image and install tools for flashing Android
|
||||
- USB data cable
|
||||
- A system running Linux
|
||||
|
||||
This tutorial is performed using Ubuntu 15.10. But the steps should be applicable to most other Linux distributions.
|
||||
|
||||
### Replace Ubuntu with Android in bq Aquaris e4.5 ###
|
||||
|
||||
#### Step 1: Download Android firmware ####
|
||||
|
||||
First step is to download the Android image for bq Aquaris e4.5. Good thing is that it is available from the bq’s support website. You can download the firmware, around 650 MB in size, from the link below:
|
||||
|
||||
- [Download Android for bq Aquaris e4.5][1]
|
||||
|
||||
Yes, you would get OTA updates with it. At present the firmware version is 2.0.1 which is based on Android Lolipop. Over time, there could be a new firmware based on Marshmallow and then the above link could be outdated.
|
||||
|
||||
I suggest to check the [bq support page][2] and download the latest firmware from there.
|
||||
|
||||
Once downloaded, extract it. In the extracted directory, look for **MT6582_Android_scatter.txt** file. We shall be using it later.
|
||||
|
||||
#### Step 2: Download flash tool ####
|
||||
|
||||
bq has provided its own flash tool, Herramienta MTK Flash Tool, for easier installation of Android or Ubuntu on the device. You can download the tool from the link below:
|
||||
|
||||
- [Download MTK Flash Tool][3]
|
||||
|
||||
Since the flash tool might be upgraded in future, you can always get the latest version of flash tool from the [bq support page][4].
|
||||
|
||||
Once downloaded extract the downloaded file. You should see an executable file named **flash_tool** in it. We shall be using it later.
|
||||
|
||||
#### Step 3: Remove conflicting packages (optional) ####
|
||||
|
||||
If you are using recent version of Ubuntu or Ubuntu based Linux distributions, you may encounter “BROM ERROR : S_UNDEFINED_ERROR (1001)” later in this tutorial.
|
||||
|
||||
To avoid this error, you’ll have to uninstall conflicting package. Use the commands below:
|
||||
|
||||
sudo apt-get remove modemmanager
|
||||
|
||||
Restart udev service with the command below:
|
||||
|
||||
sudo service udev restart
|
||||
|
||||
Just to check for any possible side effects on kernel module cdc_acm, run the command below:
|
||||
|
||||
lsmod | grep cdc_acm
|
||||
|
||||
If the output of the above command is an empty list, you’ll have to reinstall this kernel module:
|
||||
|
||||
sudo modprobe cdc_acm
|
||||
|
||||
#### Step 4: Prepare to flash Android ####
|
||||
|
||||
Go to the downloaded and extracted flash tool directory (in step 2). Use command line for this purpose because you’ll have to use the root privileges here.
|
||||
|
||||
Presuming that you saved it in the Downloads directory, use the command below to go to this directory (in case you do not know how to navigate between directories in command line).
|
||||
|
||||
cd ~/Downloads/SP_Flash*
|
||||
|
||||
After that use the command below to run the flash tool as root:
|
||||
|
||||
sudo ./flash_tool
|
||||
|
||||
You’ll see a window popped as the one below. Don’t bother about Download Agent field, it will be automatically filled. Just focus on Scatter-loading field.
|
||||
|
||||

|
||||
|
||||
Remember we talked about **MT6582_Android_scatter.txt** in step 1? This text file is in the extracted directory of the Andriod firmware you downloaded in step 1. Click on Scatter-loading (in the above picture) and point to MT6582_Android_scatter.txt file.
|
||||
|
||||
When you do that, you’ll see several green lines like the one below:
|
||||
|
||||

|
||||
|
||||
#### Step 5: Flashing Android ####
|
||||
|
||||
We are almost ready. Switch off your phone and connect it to your computer via a USB cable.
|
||||
|
||||
Select Firmware Upgrade from the dropdown and after that click on the big download button.
|
||||
|
||||

|
||||
|
||||
If everything is correct, you should see a flash status in the bottom of the tool:
|
||||
|
||||

|
||||
|
||||
When the procedure is successfully completed, you’ll see a notification like this:
|
||||
|
||||

|
||||
|
||||
Unplug your phone and power it on. You should see a white screen with AQUARIS written in the middle and at bottom, “powered by Android” would be displayed. It might take upto 10 minutes before you could configure and start using Android.
|
||||
|
||||
Note: If something goes wrong in the process, Press power, volume up, volume down button together and boot in to fast boot mode. Turn off again and connect the cable again. Repeat the process of firmware upgrade. It should work.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Thanks to the tools provided, it becomes easier to **flash Android on bq Ubuntu Phone**. Of course, you can use the same steps to replace Android with Ubuntu. All you need is to download Ubuntu firmware instead of Android.
|
||||
|
||||
I hope this tutorial helped you to replace Ubuntu with Android on your bq phone. If you have questions or suggestions, feel free to ask in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-android-ubuntu-phone/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5_L/2.0.1_20150623-1900_bq-FW.zip
|
||||
[2]:http://www.bq.com/gb/support/aquaris-e4-5
|
||||
[3]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5/Ubuntu/Web%20version/Web%20version/SP_Flash_Tool_exe_linux_v5.1424.00.zip
|
||||
[4]:http://www.bq.com/gb/support/aquaris-e4-5-ubuntu-edition
|
||||
@ -0,0 +1,318 @@
|
||||
Install PostgreSQL 9.4 And phpPgAdmin On Ubuntu 15.10
|
||||
================================================================================
|
||||

|
||||
|
||||
### Introduction ###
|
||||
|
||||
[PostgreSQL][1] is a powerful, open-source object-relational database system. It runs under all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS, Solaris, Tru64), and Windows OS.
|
||||
|
||||
Here is what **Mark Shuttleworth**, the founder of **Ubuntu**, says about PostgreSQL.
|
||||
|
||||
> Postgres is a truly awesome database. When we started working on Launchpad I wasn’t sure if it would be up to the job. I was so wrong. It’s been robust, fast, and professional in every regard.
|
||||
>
|
||||
> — Mark Shuttleworth.
|
||||
|
||||
In this handy tutorial, let us see how to install PostgreSQL 9.4 on Ubuntu 15.10 server.
|
||||
|
||||
### Install PostgreSQL ###
|
||||
|
||||
PostgreSQL is available in the default repositories. So enter the following command from the Terminal to install it.
|
||||
|
||||
sudo apt-get install postgresql postgresql-contrib
|
||||
|
||||
If you’re looking for other versions, add the PostgreSQL repository, and install it as shown below.
|
||||
|
||||
The **PostgreSQL apt repository** supports LTS versions of Ubuntu (10.04, 12.04 and 14.04) on amd64 and i386 architectures as well as select non-LTS versions(14.10). While not fully supported, the packages often work on other non-LTS versions as well, by using the closest LTS version available.
|
||||
|
||||
#### On Ubuntu 14.10 systems: ####
|
||||
|
||||
Create the file **/etc/apt/sources.list.d/pgdg.list**;
|
||||
|
||||
sudo vi /etc/apt/sources.list.d/pgdg.list
|
||||
|
||||
Add a line for the repository:
|
||||
|
||||
deb http://apt.postgresql.org/pub/repos/apt/ utopic-pgdg main
|
||||
|
||||
**Note**: The above repository will only work on Ubuntu 14.10. It is not updated yet to Ubuntu 15.04 and 15.10.
|
||||
|
||||
**On Ubuntu 14.04**, add the following line:
|
||||
|
||||
deb http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg main
|
||||
|
||||
**On Ubuntu 12.04**, add the following line:
|
||||
|
||||
deb http://apt.postgresql.org/pub/repos/apt/ precise-pgdg main
|
||||
|
||||
Import the repository signing key:
|
||||
|
||||
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc
|
||||
|
||||
----------
|
||||
|
||||
sudo apt-key add -
|
||||
|
||||
Update the package lists:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
Then install the required version.
|
||||
|
||||
sudo apt-get install postgresql-9.4
|
||||
|
||||
### Accessing PostgreSQL command prompt ###
|
||||
|
||||
The default database name and database user are “**postgres**”. Switch to postgres user to perform postgresql related operations:
|
||||
|
||||
sudo -u postgres psql postgres
|
||||
|
||||
#### Sample Output: ####
|
||||
|
||||
psql (9.4.5)
|
||||
Type "help" for help.
|
||||
postgres=#
|
||||
|
||||
To exit from posgresql prompt, type **\q** in the **psql** prompt return back to the Terminal.
|
||||
|
||||
### Set “postgres” user password ###
|
||||
|
||||
Login to postgresql prompt,
|
||||
|
||||
sudo -u postgres psql postgres
|
||||
|
||||
.. and set postgres password with following command:
|
||||
|
||||
postgres=# \password postgres
|
||||
Enter new password:
|
||||
Enter it again:
|
||||
postgres=# \q
|
||||
|
||||
To install PostgreSQL Adminpack, enter the command in postgresql prompt:
|
||||
|
||||
sudo -u postgres psql postgres
|
||||
|
||||
----------
|
||||
|
||||
postgres=# CREATE EXTENSION adminpack;
|
||||
CREATE EXTENSION
|
||||
|
||||
Type **\q** in the **psql** prompt to exit from posgresql prompt, and return back to the Terminal.
|
||||
|
||||
### Create New User and Database ###
|
||||
|
||||
For example, let us create a new user called “**senthil**” with password “**ubuntu**”, and database called “**mydb**”.
|
||||
|
||||
sudo -u postgres createuser -D -A -P senthil
|
||||
|
||||
----------
|
||||
|
||||
sudo -u postgres createdb -O senthil mydb
|
||||
|
||||
### Delete Users and Databases ###
|
||||
|
||||
To delete the database, switch to postgres user:
|
||||
|
||||
sudo -u postgres psql postgres
|
||||
|
||||
Enter command:
|
||||
|
||||
$ drop database <database-name>
|
||||
|
||||
To delete a user, enter the following command:
|
||||
|
||||
$ drop user <user-name>
|
||||
|
||||
### Configure PostgreSQL-MD5 Authentication ###
|
||||
|
||||
**MD5 authentication** requires the client to supply an MD5-encrypted password for authentication. To do that, edit **/etc/postgresql/9.4/main/pg_hba.conf** file:
|
||||
|
||||
sudo vi /etc/postgresql/9.4/main/pg_hba.conf
|
||||
|
||||
Add or Modify the lines as shown below
|
||||
|
||||
[...]
|
||||
# TYPE DATABASE USER ADDRESS METHOD
|
||||
# "local" is for Unix domain socket connections only
|
||||
local all all md5
|
||||
# IPv4 local connections:
|
||||
host all all 127.0.0.1/32 md5
|
||||
host all all 192.168.1.0/24 md5
|
||||
# IPv6 local connections:
|
||||
host all all ::1/128 md5
|
||||
[...]
|
||||
|
||||
Here, 192.168.1.0/24 is my local network IP address. Replace this value with your own address.
|
||||
|
||||
Restart postgresql service to apply the changes:
|
||||
|
||||
sudo systemctl restart postgresql
|
||||
|
||||
Or,
|
||||
|
||||
sudo service postgresql restart
|
||||
|
||||
### Configure PostgreSQL-Configure TCP/IP ###
|
||||
|
||||
By default, TCP/IP connection is disabled, so that the users from another computers can’t access postgresql. To allow to connect users from another computers, Edit file **/etc/postgresql/9.4/main/postgresql.conf:**
|
||||
|
||||
sudo vi /etc/postgresql/9.4/main/postgresql.conf
|
||||
|
||||
Find the lines:
|
||||
|
||||
[...]
|
||||
#listen_addresses = 'localhost'
|
||||
[...]
|
||||
#port = 5432
|
||||
[...]
|
||||
|
||||
Uncomment both lines, and set the IP address of your postgresql server or set ‘*’ to listen from all clients as shown below. You should be careful to make postgreSQL to be accessible from all remote clients.
|
||||
|
||||
[...]
|
||||
listen_addresses = '*'
|
||||
[...]
|
||||
port = 5432
|
||||
[...]
|
||||
|
||||
Restart postgresql service to save changes:
|
||||
|
||||
sudo systemctl restart postgresql
|
||||
|
||||
Or,
|
||||
|
||||
sudo service postgresql restart
|
||||
|
||||
### Manage PostgreSQL with phpPgAdmin ###
|
||||
|
||||
[**phpPgAdmin**][2] is a web-based administration utility written in PHP for managing PosgreSQL.
|
||||
|
||||
phpPgAdmin is available in default repositories. So, Install phpPgAdmin using command:
|
||||
|
||||
sudo apt-get install phppgadmin
|
||||
|
||||
By default, you can access phppgadmin using **http://localhost/phppgadmin** from your local system’s web browser.
|
||||
|
||||
To access remote systems, do the following.
|
||||
On Ubuntu 15.10 systems:
|
||||
|
||||
Edit file **/etc/apache2/conf-available/phppgadmin.conf**,
|
||||
|
||||
sudo vi /etc/apache2/conf-available/phppgadmin.conf
|
||||
|
||||
Find the line **Require local** and comment it by adding a **#** in front of the line.
|
||||
|
||||
#Require local
|
||||
|
||||
And add the following line:
|
||||
|
||||
allow from all
|
||||
|
||||
Save and exit the file.
|
||||
|
||||
Then, restart apache service.
|
||||
|
||||
sudo systemctl restart apache2
|
||||
|
||||
On Ubuntu 14.10 and previous versions:
|
||||
|
||||
Edit file **/etc/apache2/conf.d/phppgadmin**:
|
||||
|
||||
sudo nano /etc/apache2/conf.d/phppgadmin
|
||||
|
||||
Comment the following line:
|
||||
|
||||
[...]
|
||||
#allow from 127.0.0.0/255.0.0.0 ::1/128
|
||||
|
||||
Uncomment the following line to make phppgadmin from all systems.
|
||||
|
||||
allow from all
|
||||
|
||||
Edit **/etc/apache2/apache2.conf**:
|
||||
|
||||
sudo vi /etc/apache2/apache2.conf
|
||||
|
||||
Add the following line:
|
||||
|
||||
Include /etc/apache2/conf.d/phppgadmin
|
||||
|
||||
Then, restart apache service.
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
### Configure phpPgAdmin ###
|
||||
|
||||
Edit file **/etc/phppgadmin/config.inc.php**, and do the following changes. Most of these options are self-explanatory. Read them carefully to know why do you change these values.
|
||||
|
||||
sudo nano /etc/phppgadmin/config.inc.php
|
||||
|
||||
Find the following line:
|
||||
|
||||
$conf['servers'][0]['host'] = '';
|
||||
|
||||
Change it as shown below:
|
||||
|
||||
$conf['servers'][0]['host'] = 'localhost';
|
||||
|
||||
And find the line:
|
||||
|
||||
$conf['extra_login_security'] = true;
|
||||
|
||||
Change the value to **false**.
|
||||
|
||||
$conf['extra_login_security'] = false;
|
||||
|
||||
Find the line:
|
||||
|
||||
$conf['owned_only'] = false;
|
||||
|
||||
Set the value as **true**.
|
||||
|
||||
$conf['owned_only'] = true;
|
||||
|
||||
Save and close the file. Restart postgresql service and Apache services.
|
||||
|
||||
sudo systemctl restart postgresql
|
||||
|
||||
----------
|
||||
|
||||
sudo systemctl restart apache2
|
||||
|
||||
Or,
|
||||
|
||||
sudo service postgresql restart
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
Now open your browser and navigate to **http://ip-address/phppgadmin**. You will see the following screen.
|
||||
|
||||

|
||||
|
||||
Login with users that you’ve created earlier. I already have created a user called “**senthil**” with password “**ubuntu**” before, so I log in with user “senthil”.
|
||||
|
||||

|
||||
|
||||
Now, you will be able to access the phppgadmin dashboard.
|
||||
|
||||

|
||||
|
||||
Log in with postgres user:
|
||||
|
||||

|
||||
|
||||
That’s it. Now you’ll able to create, delete and alter databases graphically using phppgadmin.
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-postgresql-9-4-and-phppgadmin-on-ubuntu-15-10/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.twitter.com/ostechnix
|
||||
[1]:http://www.postgresql.org/
|
||||
[2]:http://phppgadmin.sourceforge.net/doku.php
|
||||
@ -0,0 +1,328 @@
|
||||
Going Beyond Hello World Containers is Hard Stuff
|
||||
================================================================================
|
||||
In [my previous post][1], I provided the basic concepts behind Linux container technology. I wrote as much for you as I did for me. Containers are new to me. And I figured having the opportunity to blog about the subject would provide the motivation to really learn the stuff.
|
||||
|
||||
I intend to learn by doing. First get the concepts down, then get hands-on and write about it as I go. I assumed there must be a lot of Hello World type stuff out there to give me up to speed with the basics. Then, I could take things a bit further and build a microservice container or something.
|
||||
|
||||
I mean, it can’t be that hard, right?
|
||||
|
||||
Wrong.
|
||||
|
||||
Maybe it’s easy for someone who spends significant amount of their life immersed in operations work. But for me, getting started with this stuff turned out to be hard to the point of posting my frustrations to Facebook...
|
||||
|
||||
But, there is good news: I got it to work! And it’s always nice being able to make lemonade from lemons. So I am going to share the story of how I made my first microservice container with you. Maybe my pain will save you some time.
|
||||
|
||||
If you've ever found yourself in a situation like this, fear not: folks like me are here to deal with the problems so you don't have to!
|
||||
|
||||
Let’s begin.
|
||||
|
||||
### A Thumbnail Micro Service ###
|
||||
|
||||
The microservice I designed was simple in concept. Post a digital image in JPG or PNG format to an HTTP endpoint and get back a a 100px wide thumbnail.
|
||||
|
||||
Here’s what that looks like:
|
||||
|
||||

|
||||
|
||||
I decide to use a NodeJS for my code and version of [ImageMagick][2] to do the thumbnail transformation.
|
||||
|
||||
I did my first version of the service, using the logic shown here:
|
||||
|
||||

|
||||
|
||||
I download the [Docker Toolbox][3] which installs an the Docker Quickstart Terminal. Docker Quickstart Terminal makes creating containers easier. The terminal fires up a Linux virtual machine that has Docker installed, allowing you to run Docker commands from within a terminal.
|
||||
|
||||
In my case, I am running on OS X. But there’s a Windows version too.
|
||||
|
||||
I am going to use Docker Quickstart Terminal to build a container image for my microservice and run a container from that image.
|
||||
|
||||
The Docker Quickstart Terminal runs in your regular terminal, like so:
|
||||
|
||||

|
||||
|
||||
### The First Little Problem and the First Big Problem ###
|
||||
|
||||
So I fiddled around with NodeJS and ImageMagick and I got the service to work on my local machine.
|
||||
|
||||
Then, I created the Dockerfile, which is the configuration script Docker uses to build your container. (I’ll go more into builds and Dockerfile more later on.)
|
||||
|
||||
Here’s the build command I ran on the Docker Quickstart Terminal:
|
||||
|
||||
$ docker build -t thumbnailer:0.1
|
||||
|
||||
I got this response:
|
||||
|
||||
docker: "build" requires 1 argument.
|
||||
|
||||
Huh.
|
||||
|
||||
After 15 minutes I realized: I forgot to put a period . as the last argument!
|
||||
|
||||
It needs to be:
|
||||
|
||||
$ docker build -t thumbnailer:0.1 .
|
||||
|
||||
But this wasn’t the end of my problems.
|
||||
|
||||
I got the image to build and then I typed [the the `run` command][4] on the Docker Quickstart Terminal to fire up a container based on the image, called `thumbnailer:0.1`:
|
||||
|
||||
$ docker run -d -p 3001:3000 thumbnailer:0.1
|
||||
|
||||
The `-p 3001:3000` argument makes it so the NodeJS microservice running on port 3000 within the container binds to port 3001 on the host virtual machine.
|
||||
|
||||
Looks so good so far, right?
|
||||
|
||||
Wrong. Things are about to get pretty bad.
|
||||
|
||||
I determined the IP address of the virtual machine created by Docker Quickstart Terminal by running the `docker-machine` command:
|
||||
|
||||
$ docker-machine ip default
|
||||
|
||||
This returns the IP address of the default virtual machine, the one that is run under the Docker Quickstart Terminal. For me, this IP address was 192.168.99.100.
|
||||
|
||||
I browsed to http://192.168.99.100:3001/ and got the file upload page I built:
|
||||
|
||||

|
||||
|
||||
I selected a file and clicked the Upload Image button.
|
||||
|
||||
But it didn’t work.
|
||||
|
||||
The terminal is telling me it can’t find the `/upload` directory my microservice requires.
|
||||
|
||||
Now, keep in mind, I had been at this for about a day—between the fiddling and research. I’m feeling a little frustrated by this point.
|
||||
|
||||
Then, a brain spark flew. Somewhere along the line remembered reading a microservice should not do any data persistence on its own! Saving data should be the job of another service.
|
||||
|
||||
So what if the container can’t find the `/upload` directory? The real issue is: my microservice has a fundamentally flawed design.
|
||||
|
||||
Let’s take another look:
|
||||
|
||||

|
||||
|
||||
Why am I saving a file to disk? Microservices are supposed to be fast. Why not do all my work in memory? Using memory buffers will make the "I can’t find no stickin’ directory" error go away and will increase the performance of my app dramatically.
|
||||
|
||||
So that’s what I did. And here’s what the plan was:
|
||||
|
||||

|
||||
|
||||
Here’s the NodeJS I wrote to do all the in-memory work for creating a thumbnail:
|
||||
|
||||
// Bind to the packages
|
||||
var express = require('express');
|
||||
var router = express.Router();
|
||||
var path = require('path'); // used for file path
|
||||
var im = require("imagemagick");
|
||||
|
||||
// Simple get that allows you test that you can access the thumbnail process
|
||||
router.get('/', function (req, res, next) {
|
||||
res.status(200).send('Thumbnailer processor is up and running');
|
||||
});
|
||||
|
||||
// This is the POST handler. It will take the uploaded file and make a thumbnail from the
|
||||
// submitted byte array. I know, it's not rocket science, but it serves a purpose
|
||||
router.post('/', function (req, res, next) {
|
||||
req.pipe(req.busboy);
|
||||
req.busboy.on('file', function (fieldname, file, filename) {
|
||||
var ext = path.extname(filename)
|
||||
|
||||
// Make sure that only png and jpg is allowed
|
||||
if(ext.toLowerCase() != '.jpg' && ext.toLowerCase() != '.png'){
|
||||
res.status(406).send("Service accepts only jpg or png files");
|
||||
}
|
||||
|
||||
var bytes = [];
|
||||
|
||||
// put the bytes from the request into a byte array
|
||||
file.on('data', function(data) {
|
||||
for (var i = 0; i < data.length; ++i) {
|
||||
bytes.push(data[i]);
|
||||
}
|
||||
console.log('File [' + fieldname + '] got bytes ' + bytes.length + ' bytes');
|
||||
});
|
||||
|
||||
// Once the request is finished pushing the file bytes into the array, put the bytes in
|
||||
// a buffer and process that buffer with the imagemagick resize function
|
||||
file.on('end', function() {
|
||||
var buffer = new Buffer(bytes,'binary');
|
||||
console.log('Bytes got ' + bytes.length + ' bytes');
|
||||
|
||||
//resize
|
||||
im.resize({
|
||||
srcData: buffer,
|
||||
height: 100
|
||||
}, function(err, stdout, stderr){
|
||||
if (err){
|
||||
throw err;
|
||||
}
|
||||
// get the extension without the period
|
||||
var typ = path.extname(filename).replace('.','');
|
||||
res.setHeader("content-type", "image/" + typ);
|
||||
res.status(200);
|
||||
// send the image back as a response
|
||||
res.send(new Buffer(stdout,'binary'));
|
||||
});
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
module.exports = router;
|
||||
|
||||
Okay, so we’re back on track and everything is hunky dory on my local machine. I go to sleep.
|
||||
|
||||
But, before I do I test the microservice code running as standard Node app on localhost...
|
||||
|
||||

|
||||
|
||||
It works fine. Now all I needed to do was get it working in a container.
|
||||
|
||||
The next day I woke up, grabbed some coffee, and built an image—not forgetting to put in the period!
|
||||
|
||||
$ docker build -t thumbnailer:01 .
|
||||
|
||||
I am building from the root directory of my thumbnailer project. The build command uses the Dockerfile that is in the root directory. That’s how it goes: put the Dockerfile in the same place you want to run build and the Dockerfile will be used by default.
|
||||
|
||||
Here is the text of the Dockerfile I was using:
|
||||
|
||||
FROM ubuntu:latest
|
||||
MAINTAINER bob@CogArtTech.com
|
||||
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y nodejs nodejs-legacy npm
|
||||
RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
|
||||
RUN apt-get clean
|
||||
|
||||
COPY ./package.json src/
|
||||
|
||||
RUN cd src && npm install
|
||||
|
||||
COPY . /src
|
||||
|
||||
WORKDIR src/
|
||||
|
||||
CMD npm start
|
||||
|
||||
What could go wrong?
|
||||
|
||||
### The Second Big Problem ###
|
||||
|
||||
I ran the `build` command and I got this error:
|
||||
|
||||
Do you want to continue? [Y/n] Abort.
|
||||
|
||||
The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
|
||||
|
||||
I figured something was wrong with the microservice. I went back to my machine, fired up the service on localhost, and uploaded a file.
|
||||
|
||||
Then I got this error from NodeJS:
|
||||
|
||||
Error: spawn convert ENOENT
|
||||
|
||||
What’s going on? This worked the other night!
|
||||
|
||||
I searched and searched, for every permutation of the error I could think of. After about four hours of replacing different node modules here and there, I figured: why not restart the machine?
|
||||
|
||||
I did. And guess what? The error went away!
|
||||
|
||||
Go figure.
|
||||
|
||||
### Putting the Genie Back in the Bottle ###
|
||||
|
||||
So, back to the original quest: I needed to get this build working.
|
||||
|
||||
I removed all of the containers running on the VM, using [the `rm` command][5]:
|
||||
|
||||
$ docker rm -f $(docker ps -a -q)
|
||||
|
||||
The `-f` flag here force removes running images.
|
||||
|
||||
Then I removed all of my Docker images, using [the `rmi` command][6]:
|
||||
|
||||
$ docker rmi if $(docker images | tail -n +2 | awk '{print $3}')
|
||||
|
||||
I go through the whole process of rebuilding the image, installing the container and try to get the microservice running. Then after about an hour of self-doubt and accompanying frustration, I thought to myself: maybe this isn’t a problem with the microservice.
|
||||
|
||||
So, I looked that the the error again:
|
||||
|
||||
Do you want to continue? [Y/n] Abort.
|
||||
|
||||
The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
|
||||
|
||||
Then it hit me: the build is looking for a Y input from the keyboard! But, this is a non-interactive Dockerfile script. There is no keyboard.
|
||||
|
||||
I went back to the Dockerfile, and there it was:
|
||||
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y nodejs nodejs-legacy npm
|
||||
RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
|
||||
RUN apt-get clean
|
||||
|
||||
The second `apt-get` command is missing the `-y` flag which causes "yes" to be given automatically where usually it would be prompted for.
|
||||
|
||||
I added the missing `-y` to the command:
|
||||
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y nodejs nodejs-legacy npm
|
||||
RUN apt-get install -y imagemagick libmagickcore-dev libmagickwand-dev
|
||||
RUN apt-get clean
|
||||
|
||||
And guess what: after two days of trial and tribulation, it worked! Two whole days!
|
||||
|
||||
So, I did my build:
|
||||
|
||||
$ docker build -t thumbnailer:0.1 .
|
||||
|
||||
I fired up the container:
|
||||
|
||||
$ docker run -d -p 3001:3000 thumbnailer:0.1
|
||||
|
||||
Got the IP address of the Virtual Machine:
|
||||
|
||||
$ docker-machine ip default
|
||||
|
||||
Went to my browser and entered http://192.168.99.100:3001/ into the address bar.
|
||||
|
||||
The upload page loaded.
|
||||
|
||||
I selected an image, and this is what I got:
|
||||
|
||||

|
||||
|
||||
It worked!
|
||||
|
||||
Inside a container, for the first time!
|
||||
|
||||
### So What Does It All Mean? ###
|
||||
|
||||
A long time ago, I accepted the fact when it comes to tech, sometimes even the easy stuff is hard. Along with that, I abandoned the desire to be the smartest guy in the room. Still, the last few days trying get basic competency with containers has been, at times, a journey of self doubt.
|
||||
|
||||
But, you wanna know something? It’s 2 AM on an early morning as I write this, and every nerve wracking hour has been worth it. Why? Because you gotta put in the time. This stuff is hard and it does not come easy for anyone. And don’t forget: you’re learning tech and tech runs the world!
|
||||
|
||||
P.S. Check out this two part video of Hello World containers, check out [Raziel Tabib’s][7] excellent work in this video...
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/PJ95WY2DqXo" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
And don't miss part two...
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/lss2rZ3Ppuk" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://deis.com/blog/2015/beyond-hello-world-containers-hard-stuff
|
||||
|
||||
作者:[Bob Reselman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://deis.com/blog
|
||||
[1]:http://deis.com/blog/2015/developer-journey-linux-containers
|
||||
[2]:https://github.com/rsms/node-imagemagick
|
||||
[3]:https://www.docker.com/toolbox
|
||||
[4]:https://docs.docker.com/reference/commandline/run/
|
||||
[5]:https://docs.docker.com/reference/commandline/rm/
|
||||
[6]:https://docs.docker.com/reference/commandline/rmi/
|
||||
[7]:http://twitter.com/RazielTabib
|
||||
@ -0,0 +1,43 @@
|
||||
sevenot translated
|
||||
好奇Linux?试试云端的Linux桌面
|
||||
================================================================================
|
||||
Linux在桌面操作系统市场上只占据了非常小的份额,目前调查来看,估计只有2%的市场份额;对比来看丰富多变的Windows系统占据了接近90%的市场份额。对于Linux来说要挑战Windows在桌面操作系统市场的垄断,需要一个简单的方式来让用户学习不同的操作系统。如果你相信传统的Windows用户再买一台机器来使用Linux,你就太天真了。我们只能去试想用户重新分盘,设置引导程序来使用双系统,或者跳过所有步骤回到一个最简单的方法。
|
||||

|
||||
|
||||
我们实验过一系列无风险的使用方法让用户试操作Linux,并且不涉及任何分区管理,包括CD/DVDs光盘、USB钥匙和桌面虚拟化软件。通过实验,我强烈推荐使用VMware的VMware Player或者Oracle VirtualBox虚拟机,对于桌面操作系统或者便携式电脑的用户,这是一种相对简单而且免费的的方法来安装运行多操作系统。每一台虚拟机和其他虚拟机相隔离,但是共享CPU,存贮,网络接口等等。但是虚拟机仍需要一定的资源来安装运行Linux,也需要一台相当强劲的主机。对于一个好奇心不大的人,这样做实在是太麻烦了。
|
||||
|
||||
要打破用户传统的使用观念市非常困难的。很多Windows用户可以尝试使用Linux提供的免费软件,但也有太多要学习的Linux系统知识。这会花掉相当一部分时间来习惯Linux的工作方式。
|
||||
|
||||
当然了,对于一个第一次在Linux上操作的新手,有没有一个更高效的方法呢?答案是肯定的,接着往下看看云实验平台。
|
||||
|
||||
### LabxNow ###
|
||||
|
||||

|
||||
|
||||
LabxNow提供了一个免费服务,方便广大用户通过浏览器来访问远程Liunx桌面。开发者将其加强为一个用户个人远程实验室(用户可以在系统里运行、开发任何程序),用户可以在任何地方通过互联网登入远程实验室。
|
||||
|
||||
这项服务现在可以为个人用户提供2核处理器,4GB RAM和10GB的固态硬盘,运行在128G RAM的4 AMD 6272处理器上。
|
||||
|
||||
#### 配置参数: ####
|
||||
|
||||
- 系统镜像:基于Ubuntu 14.04的Xface 4.10,RHEL 6.5,CentOS(Gnome桌面),Oracle
|
||||
- 硬件: CPU - 1核或者2核; 内存: 512MB, 1GB, 2GB or 4GB
|
||||
- 超快的网络数据传输
|
||||
- 可以运行在所有流行的浏览器上
|
||||
- 可以安装任意程序,可以运行任何程序 – 这是一个非常棒的方法,可以随意做实验学你你想学的所有知识, 没有 一点风险
|
||||
- 添加、删除、管理、制定虚拟机非常方便
|
||||
- 支持虚拟机共享,远程桌面
|
||||
|
||||
你所需要的只是一台有稳定网络的设备。不用担心虚拟专用系统(VPS)、域名、或者硬件带来的高费用。LabxNow提供了一个非常好的方法在Ubuntu、RHEL和CentOS上实验。它给Windows用户一个极好的环境,让他们探索美妙的Linux世界。说得深一点,它可以让用户随时随地在里面工作,而没有了要在每台设备上安装Linux的压力。点击下面这个链接进入[www.labxnow.org/labxweb/][1]。
|
||||
|
||||
这里还有一些其它服务(大部分市收费服务)可以让用户在Linux使用。包括Cloudsigma环境的7天使用权和Icebergs.io(通过HTML5实现root权限)。但是现在,我推荐LabxNow。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
来自: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
|
||||
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.labxnow.org/labxweb/
|
||||
@ -0,0 +1,49 @@
|
||||
N1:下一代开源邮件客户端
|
||||
================================================================================
|
||||

|
||||
|
||||
当我们谈论到Linux中的邮件客户端,通常上 Thunderbird、Geary 和 [Evolution][3] 会出现在我们的脑海。作为对这些大咖们的挑战,一款新的开源邮件客户端正在涌入市场。
|
||||
|
||||
|
||||
### 设计和功能 ###
|
||||
|
||||
[N1][4]是一个同时聚焦设计和功能的下一代开源邮件客户端。作为一个开源软件,N1目前支持 Linux 和 Mac OS X,Windows的版本还在开发中。
|
||||
|
||||
N1宣传它自己为“可扩展的开源邮件客户端”,因为它包含了 Javascript 插件架构,任何人都可以为它创建强大的新功能。可扩展是一个非常流行的功能,它帮助[开源编辑器Atom][5]变得流行。N1同样把重点放在了可扩展上面。
|
||||
|
||||
除了可扩展性,N1同样着重设计了程序的外观。下面N1的截图就是个很好的例子:
|
||||
|
||||

|
||||
|
||||
Mac OS X上的N1客户端。图片来自:N1
|
||||
|
||||
除了这个功能,N1兼容上百的邮件提供商包括Gmail、Yahoo、iCloud、Microsoft Exchange等等,桌面应用提供离线功能。
|
||||
|
||||
### 目前只能邀请使用 ###
|
||||
|
||||
我不知道为什么每个人都选择了 OnePlus 的‘只能邀请使用’的市场策略。目前,N1桌面端只能被邀请才能下载。你可以用下面的链接请求一个邀请。N1团队会在几天内邮件给你下载链接。
|
||||
|
||||
|
||||
- [请求N1邀请][6]
|
||||
|
||||
### 感兴趣了么? ###
|
||||
|
||||
我并不是桌面邮件客户端的粉丝,但是 N1 的确引起了我的兴趣,让我想要试一试。你呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/n1-open-source-email-client/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.mozilla.org/en-US/thunderbird/
|
||||
[2]:https://wiki.gnome.org/Apps/Geary
|
||||
[3]:https://help.gnome.org/users/evolution/stable/
|
||||
[4]:https://nylas.com/N1/
|
||||
[5]:http://itsfoss.com/atom-stable-released/
|
||||
[6]:https://invite.nylas.com/download
|
||||
@ -2,11 +2,11 @@ Aix, HP-UX, Solaris, BSD, 和 LINUX 简史
|
||||
================================================================================
|
||||

|
||||
|
||||
有句话说,当一扇门在你面前关上的时候,另一扇门就会打开。[Ken Thompson][1] 和 [Dennis Richie][2] 两个人就是最好的例子。他们俩是 **20世纪** 最优秀的信息技术专家,因为他们创造了 **UNIX**,最具影响力和创新性的软件之一。
|
||||
要记住,当一扇门在你面前关闭的时候,另一扇门就会打开。[Ken Thompson][1] 和 [Dennis Richie][2] 两个人就是这句名言很好的实例。他们俩是 **20世纪** 最优秀的信息技术专家,因为他们创造了 **UNIX**,最具影响力和创新性的软件之一。
|
||||
|
||||
### UNIX 系统诞生于贝尔实验室 ###
|
||||
|
||||
**UNIX** 最开始的名字是 **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice),它有一个大家庭,并不是从石头里蹦出来的。UNIX的祖父是 **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem),它的父亲是 **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice),这个系统能支持大量用户通过交互式分时使用大型机。
|
||||
**UNIX** 最开始的名字是 **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice),它有一个大家庭,并不是从石头缝里蹦出来的。UNIX的祖父是 **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem),它的父亲是 **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice),这个系统能支持大量用户通过交互式分时使用大型机。
|
||||
|
||||
UNIX 诞生于 **1969** 年,由 **Ken Thompson** 以及后来加入的 **Dennis Richie** 共同完成。这两位优秀的研究员和科学家一起在一个**通用电子**和**麻省理工学院**的合作项目里工作,项目目标是开发一个叫 Multics 的交互式分时系统。
|
||||
|
||||
@ -20,71 +20,71 @@ UNIX 的第一声啼哭是在一台 PDP-7 微型机上,它是 Thompson 测试
|
||||
|
||||
> “我们想要的不仅是一个优秀的编程环境,而是能围绕这个系统形成团体。按我们自己的经验,通过远程访问和分时共享主机实现的公共计算,本质上不只是用终端输入程序代替打孔机而已,而是鼓励密切沟通。”Dennis Richie 说。
|
||||
|
||||
UNIX 是第一个靠近理想的系统,在这里程序员可以坐在机器前自由摆弄程序,探索各种可能性并随手测试。在 UNIX 整个生命周期里,因为大量因为其他操作系统限制而投身过来的高手做出的无私贡献,它的功能模型一直保持上升趋势。
|
||||
UNIX 是第一个靠近理想的系统,在这里程序员可以坐在机器前自由摆弄程序,探索各种可能性并随手测试。在 UNIX 整个生命周期里,它吸引了大量因其他操作系统限制而投身过来的高手做出无私贡献,因此它的功能模型一直保持上升趋势。
|
||||
|
||||
UNIX 在 1970 年因为 PDP-11/20 获得了首次资金注入,之后正式更名为 UNIX 并支持在 PDP-11/20 上运行。UNIX 带来的第一次收获是在 1971 年,贝尔实验室的专利部门配备来做文字处理。
|
||||
|
||||
### UNIX 上的 C 语言革命 ###
|
||||
|
||||
Dennis Richie 在 1972 年发明了一种叫 “**C**” 的高级编程语言,之后他和 Ken Thompson 决定用 “C” 重写 UNIX 系统,来支持更好的移植性。他们在那一年里编写和调试了差不多 100,000 行代码。在使用了 “C” 语言后,系统可移植性非常好,只需要修改一小部分机器相关的代码就可以将 UNIX 移植到其他计算机平台上。
|
||||
Dennis Richie 在 1972 年发明了一种叫 “**C**” 的高级编程语言 ,之后他和 Ken Thompson 决定用 “C” 重写 UNIX 系统,来支持更好的移植性。他们在那一年里编写和调试了差不多 100,000 行代码。在使用了 “C” 语言后,系统可移植性非常好,只需要修改一小部分机器相关的代码就可以将 UNIX 移植到其他计算机平台上。
|
||||
|
||||
UNIX 第一次公开露面是在 1973 年 Dennis Ritchie 和 Ken Thompson 在操作系统原理上发表的一篇论文,然后 AT&T 发布了 UNIX 系统第 5 版,并授权给教育机构使用,然后在 1976 年第一次以 **$20.000** 的价格授权企业使用 UNIX 第 6 版。应用最广泛的是 1980 年发布的 UNIX 第 7 版,任何人都可以购买,只是授权条款非常有限。授权内容包括源代码,以及用 PDP-11 汇编语言写的及其相关内核。各种版本 UNIX 系统完全由它的用户手册确定。
|
||||
UNIX 第一次公开露面是 1973 年 Dennis Ritchie 和 Ken Thompson 在操作系统原理上发表的一篇论文,然后 AT&T 发布了 UNIX 系统第 5 版,并授权给教育机构使用,然后在 1976 年第一次以 **$20.000** 的价格授权企业使用 UNIX 第 6 版。应用最广泛的是 1980 年发布的 UNIX 第 7 版,任何人都可以购买授权,只是授权条款非常有限。授权内容包括源代码,以及用 PDP-11 汇编语言写的及其相关内核。反正,各种版本 UNIX 系统完全由它的用户手册确定。
|
||||
|
||||
### AIX 系统 ###
|
||||
|
||||
在 **1983** 年,**Microsoft** 计划开发 **Xenix** 作为 MS-DOS 的多用户版继任者,他们在那一年花了 $8,000 搭建了一台拥有 **512 KB** 内存以及 **10 MB**硬盘并运行 Xenix 的 Altos 586。而到 1984 年为止,全世界已经安装了超过 100,000 份 UNIX System V 第二版。在 1986 年发布了包含因特网域名服务的 4.3BSD,而且 **IBM** 宣布 **AIX 系统**的安装数已经超过 250,000。AIX 基于 Unix System V 开发,这套系统拥有 BSD 风格的根文件系统,是两者的结合。
|
||||
|
||||
AIX 第一次引入了 **日志文件系统 (JFS)** 以及集成逻辑卷管理器 (LVM)。IBM 在 1989 年将 AIX 移植到自己的 RS/6000 平台。2001 年发布的 5L 版是一个突破性的版本,提供了 Linux 友好性以及支持 Power4 服务器的逻辑分区。
|
||||
|
||||
在 **1983** 年,**Microsoft** 计划开发 **Xenix** 作为 MS-DOS 的多用户版继任者,他们在那一年花了 $8,000 搭建了一台拥有 **512 KB** 内存以及 **10 MB**硬盘并运行 Xenix 的 Altos 586。而到 1984 年为止,全世界 UNIX System V 第二版的安装数量已经超过了 100,000 。在 1986 年发布了包含因特网域名服务的 4.3BSD,而且 **IBM** 宣布 **AIX 系统**的安装数已经超过 250,000。AIX 基于 Unix System V 开发,这套系统拥有 BSD 风格的根文件系统,是两者的结合。
|
||||
|
||||
AIX 第一次引入了 **日志文件系统 (JFS)** 以及集成逻辑卷管理器 (LVM)。IBM 在 1989 年将 AIX 移植到自己的 RS/6000 平台。2001 年发布的 5L 版是一个突破性的版本,提供了 Linux 友好性以及支持 Power4 服务器的逻辑分区。
|
||||
|
||||
在 2004 年发布的 AIX 5.3 引入了支持 Advanced Power Virtualization (APV) 的虚拟化技术,支持对称多线程,微分区,以及可分享的处理器池。
|
||||
|
||||
|
||||
在 2007 年,IBM 同时发布 AIX 6.1 和 Power6 架构,开始加强自己的虚拟化产品。他们还将 Advanced Power Virtualization 重新包装成 PowerVM。
|
||||
|
||||
|
||||
这次改进包括被称为 WPARs 的负载分区形式,类似于 Solaris 的 zones/Containers,但是功能更强。
|
||||
|
||||
### HP-UX 系统 ###
|
||||
|
||||
|
||||
**惠普 UNIX (HP-UX)** 源于 System V 第 3 版。这套系统一开始只支持 PA-RISC HP 9000 平台。HP-UX 第 1 版发布于 1984 年。
|
||||
|
||||
HP-UX 第 9 版引入了 SAM,一个基于角色的图形用户界面 (GUI),用户可以用来管理整个系统。在 1995 年发布的第 10 版,调整了系统文件分布以及目录结构,变得有点类似 AT&T SVR4。
|
||||
|
||||
|
||||
HP-UX 第 9 版引入了 SAM,一个基于字符的图形用户界面 (GUI),用户可以用来管理整个系统。在 1995 年发布的第 10 版,调整了系统文件分布以及目录结构,变得有点类似 AT&T SVR4。
|
||||
|
||||
第 11 版发布于 1997 年。这是 HP 第一个支持 64 位寻址的版本。不过在 2000 年重新发布成 11i,因为 HP 为特定的信息技术目的,引入了操作环境和分级应用的捆绑组。
|
||||
|
||||
|
||||
在 2001 年发布的 11.20 版宣称支持 Itanium 系统。HP-UX 是第一个使用 ACLs(访问控制列表)管理文件权限的 UNIX 系统,也是首先支持内建逻辑卷管理器的系统之一。
|
||||
|
||||
|
||||
如今,HP-UX 因为 HP 和 Veritas 的合作关系使用了 Veritas 作为主文件系统。
|
||||
|
||||
HP-UX 目前最新的版是 11iv3, update 4。
|
||||
|
||||
HP-UX 目前的最新版本是 11iv3, update 4。
|
||||
|
||||
### Solaris 系统 ###
|
||||
|
||||
|
||||
Sun 的 UNIX 版本是 **Solaris**,用来接替 1992 年创建的 **SunOS**。SunOS 一开始基于 BSD(伯克利软件发行版)风格的 UNIX,但是 SunOS 5.0 版以及之后的版本都是基于重新包装成 Solaris 的 Unix System V 第 4 版。
|
||||
|
||||
|
||||
SunOS 1.0 版于 1983 年发布,用于支持 Sun-1 和 Sun-2 平台。随后在 1985 年发布了 2.0 版。在 1987 年,Sun 和 AT&T 宣布合作一个项目以 SVR4 为基础将 System V 和 BSD 合并成一个版本。
|
||||
|
||||
|
||||
Solaris 2.4 是 Sun 发布的第一个 Sparc/x86 版本。1994 年 11 月份发布的 SunOS 4.1.4 版是最后一个版本。Solaris 7 是首个 64 位 Ultra Sparc 版本,加入了对文件系统元数据记录的原生支持。
|
||||
|
||||
|
||||
Solaris 9 发布于 2002 年,支持 Linux 特性以及 Solaris 卷管理器。之后,2005 年发布了 Solaris 10,带来许多创新,比如支持 Solaris Containers,新的 ZFS 文件系统,以及逻辑域。
|
||||
|
||||
|
||||
目前 Solaris 最新的版本是 第 10 版,最后的更新发布于 2008 年。
|
||||
|
||||
### Linux ###
|
||||
|
||||
到了 1991 年,用来替代商业操作系统的免费系统的需求日渐高涨。因此 **Linus Torvalds** 开始构建一个免费操作系统,最终成为 **Linux**。Linux 最开始只有一些 “C” 文件,并且使用了阻止商业发行的授权。Linux 是一个类 UNIX 系统但又不尽相同。
|
||||
|
||||
2015 年 发布了基于 GNU Public License 授权的 3.18 版。IBM 声称有超过 1800 万行开源代码开放给开发者。
|
||||
|
||||
如今 GNU Public License 是应用最广泛的免费软件授权方式。根据开源软件原则,这份授权允许个人和企业自由分发,运行,通过拷贝共享,学习,以及修改软件源码。
|
||||
到了 1991 年,用来替代商业操作系统的免费系统的需求日渐高涨。因此 **Linus Torvalds** 开始构建一个免费的操作系统,最终成为 **Linux**。Linux 最开始只有一些 “C” 文件,并且使用了阻止商业发行的授权。Linux 是一个类 UNIX 系统但又不尽相同。
|
||||
|
||||
2015 年 发布了基于 GNU Public License 授权的 3.18 版。IBM 声称有超过 1800 万行开源代码开放给开发者。
|
||||
|
||||
如今 GNU Public License 是应用最广泛的免费软件授权方式。根据开源软件原则,这份授权允许个人和企业自由分发、运行、通过拷贝共享、学习,以及修改软件源码。
|
||||
|
||||
### UNIX vs. Linux: 技术概要 ###
|
||||
|
||||
- Linux 鼓励多样性,Linux 的开发人员有更宽广的背景,有更多不同经验和意见。
|
||||
- Linux 比 UNIX 支持更多的平台和架构。
|
||||
- UNIX 商业版本的开发人员会为他们的操作系统考虑特定目标平台以及用户。
|
||||
- **Linux 比 UNIX 有更好的安全性**,更少受病毒或恶意软件攻击。Linux 上大约有 60-100 种病毒,但是没有任何一种还在传播。另一方面,UNIX 上大约有 85-120 种病毒,但是其中有一些还在传播中。
|
||||
- 通过 UNIX 命令,系统上的工具和元素很少改变,甚至很多接口和命令行参数在后续 UNIX 版本中一直沿用。
|
||||
- 有些 Linux 开发项目以自愿为基础进行资助,比如 Debian。其他项目会维护一个和商业 Linux 的社区版,比如 SUSE 的 openSUSE 以及红帽的 Fedora。
|
||||
- 传统 UNIX 是扩大规模,而另一方面 Linux 是扩大范围。
|
||||
|
||||
- Linux 鼓励多样性,Linux 的开发人员有更广阔的背景,有更多不同经验和意见。
|
||||
- Linux 比 UNIX 支持更多的平台和架构。
|
||||
- UNIX 商业版本的开发人员会为他们的操作系统考虑特定目标平台以及用户。
|
||||
- **Linux 比 UNIX 有更好的安全性**,更少受病毒或恶意软件攻击。Linux 上大约有 60-100 种病毒,但是没有任何一种还在传播。另一方面,UNIX 上大约有 85-120 种病毒,但是其中有一些还在传播中。
|
||||
- 通过 UNIX 命令,系统上的工具和元素很少改变,甚至很多接口和命令行参数在后续 UNIX 版本中一直沿用。
|
||||
- 有些 Linux 开发项目以自愿为基础进行资助,比如 Debian。其他项目会维护一个和商业 Linux 的社区版,比如 SUSE 的 openSUSE 以及红帽的 Fedora。
|
||||
- 传统 UNIX 是纵向扩展,而另一方面 Linux 是横向扩展。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -92,7 +92,7 @@ via: http://www.unixmen.com/brief-history-aix-hp-ux-solaris-bsd-linux/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,24 +1,24 @@
|
||||
Nautilus的文件搜索将迎来重大提升
|
||||
Nautilus的文件搜索将迎来巨大提升
|
||||
================================================================================
|
||||

|
||||
|
||||
**在Nautilus中搜索位置文件和文件夹将会将会变得很简单。**
|
||||
**在Nautilus中搜索零散文件和文件夹将会将会变得相当简单。**
|
||||
|
||||
一个[GNOME文件管理器][1]中新的**搜索过滤器**正在开发中。它大量使用的GNOME的弹出式菜单来找出搜索结果并精确找到你关心的。
|
||||
[GNOME文件管理器][1]中一个新的**搜索过滤器**正在开发中。它大量使用 GNOME 漂亮的弹出式菜单努力提供一个简单的方法缩小搜索结果并精确找到你需要的。
|
||||
|
||||
开发者Georges Stavracas正致力于新的UI并[描述][2]新的编辑器为“更干净、更理智、更直观”。
|
||||
开发者Georges Stavracas正致力于新的UI并[描述][2]新的编辑器为“更干净、更合理、更直观”。
|
||||
|
||||
根据[上传到Youtube][3]的视频-他还没有嵌入它-他没有错。
|
||||
根据他[上传到Youtube][3]的视频来展示新的方式-他还没有嵌入它-他没有错。
|
||||
|
||||
> 他在他的博客中写到:“Nautilus有非常复杂但是强大的内部,它允许我们做很多事情。事实上这对于很多选项的代码也是这样。那么,为何它曾经看上去这么糟糕?”
|
||||
> 他在他的博客中写到:“ Nautilus 有非常复杂但是强大的内部组成,它允许我们做很多事情。事实上有代码可提供很多选择。那么,为何它曾经看上去这么糟糕?”
|
||||
|
||||
问题有部分修辞;新的搜索过滤器界面对用户展示了“强大的内部”。搜索可以根据类型、名字或者日期范围来进行过滤。
|
||||
问题有部分比较夸张;新的搜索过滤器界面向用户展示了“强大的内部组成”。搜索结果可以根据类型、名字或者日期范围来进行过滤。
|
||||
|
||||
对像Nautilus这种app的任何修改有可能让一些用户不安,因此像这样有帮助、直接的新UI会带来一些争议。
|
||||
对于像 Nautilus 这类 app 的任何修改有可能让一些用户不安,因此像这样帮助性的、直接的新UI会带来一些争议。
|
||||
|
||||
不要担心不满会影响进度(毫无疑问,虽然像[移除类型优先搜索][4]的争议自2014年以来一直在争论)。[上个月发布的][5]GNOME 3.18给Nautilus引入了新的文件进度对话框,以及更好的远程共享,包括Google Drive。
|
||||
虽然对于不满的担心貌似会影响进度(毫无疑问,虽然像[移除类型优先搜索][4]的争议自2014年以来一直在争论)。GNOME 3.18 在[上个月发布了][5],给 Nautilus 引入了新的文件进度对话框,以及远程共享的更好整合,包括 Google Drive。
|
||||
|
||||
Stavracas的搜索过滤还没被合并进Files的trunk,但是重做的UI已经初步计划在明年春天的GNOME 3.20中实现。
|
||||
Stavracas 的搜索过滤器还没被合并进 Files 的 trunk,但是重做的搜索 UI 已经初步计划在明年春天的 GNOME 3.20 中实现。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -26,7 +26,7 @@ via: http://www.omgubuntu.co.uk/2015/10/new-nautilus-search-filter-ui
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
487
translated/tech/20150831 Linux workstation security checklist.md
Normal file
487
translated/tech/20150831 Linux workstation security checklist.md
Normal file
@ -0,0 +1,487 @@
|
||||
Linux平台安全备忘录
|
||||
================================================================================
|
||||
这是一组Linux基金会自己系统管理员的推荐规范。所有Linux基金会的雇员都是远程工作,我们使用这套指导方针确保系统管理员的系统通过核心安全需求,降低我们平台成为攻击目标的风险。
|
||||
|
||||
即使你的系统管理员不用远程工作,很有可能的是,很多人的工作是在一个便携的笔记本上完成的,或者在业余时间或紧急时刻他们在工作平台中部署自己的家用系统。不论发生何种情况,你都能对应这个规范匹配到你的环境中。
|
||||
|
||||
这绝不是一个详细的“工作站加固”文档,可以说这是一个努力避免大多数明显安全错误导致太多不便的一组规范的底线。你可能阅读这个文档会认为它的方法太偏执,同时另一些人也许会认为这仅仅是一些肤浅的研究。安全就像在高速公路上开车 -- 任何比你开的慢的都是一个傻瓜,然而任何比你开的快的人都是疯子。这个指南仅仅是一些列核心安全规则,既不详细又不是替代经验,警惕,和常识。
|
||||
|
||||
每一节都分为两个部分:
|
||||
|
||||
- 核对适合你项目的需求
|
||||
- 随意列出关心的项目,解释为什么这么决定
|
||||
|
||||
## 严重级别
|
||||
|
||||
在清单的每一个项目都包括严重级别,这些是我们希望能帮助指导你的决定:
|
||||
|
||||
- _(关键)_ 项目应该在考虑列表上被明确的重视。如果不采取措施,将会导致你的平台安全出现高风险。
|
||||
- _(中等)_ 项目将改善你的安全形态,但不是很重要,尤其是如果他们太多的干涉你的工作流程。
|
||||
- _(低等)_ 项目也许会改善整体安全性,但是在便利权衡下也许并不值得。
|
||||
- _(可疑)_ 留作感觉会明显完善我们平台安全的项目,但是可能会需要大量的调整与操作系统交互的方式。
|
||||
|
||||
记住,这些只是参考。如果你觉得这些严重级别不能表达你的工程对安全承诺,正如你所见你应该调整他们为你合适的。
|
||||
|
||||
## 选择正确的硬件
|
||||
|
||||
我们禁止管理员使用一个特殊供应商或者一个特殊的型号,所以在选择工作系统时这部分是核心注意事项。
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 系统支持安全启动 _(关键)_
|
||||
- [ ] 系统没有火线,雷电或者扩展卡接口 _(中等)_
|
||||
- [ ] 系统有TPM芯片 _(低)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 安全引导
|
||||
|
||||
尽管它是有争议的性质,安全引导提供了对抗很多针对平台的攻击(Rootkits, "Evil Maid,"等等),没有介绍太多额外的麻烦。它将不会停止真正专用的攻击者,加上有很大程度上,站点安全机构有办法应对它(可能通过设计),但是拥有安全引导总比什么都没有强。
|
||||
|
||||
作为选择,你也许部署了[Anti Evil Maid][1]提供更多健全的保护,对抗安全引导支持的攻击类型,但是它需要更多部署和维护的工作。
|
||||
|
||||
#### 系统没有火线,雷电或者扩展卡接口
|
||||
|
||||
火线是一个标准,故意的,允许任何连接设备完全直接内存访问你的系统([查看维基百科][2])。雷电接口和扩展卡同样有问题,虽然一些后来部署的雷电接口试图限制内存访问的范围。如果你没有这些系统端口,那是最好的,但是它并不严重,他们通常可以通过UEFI或内核本身禁用。
|
||||
|
||||
#### TPM芯片
|
||||
|
||||
可信平台模块(TPM)是主板上的一个与核心处理器单独分开的加密芯片,他可以用来增加平台的安全性(比如存储完整磁盘加密密钥),不过通常不用在日常平台操作。最多,这是个很好的存在,除非你有特殊需要使用TPM增加你平台安全性。
|
||||
|
||||
## 预引导环境
|
||||
|
||||
这是你开始安装系统前的一系列推荐规范。
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 使用UEFI引导模式(不是传统BIOS)_(关键)_
|
||||
- [ ] 进入UEFI配置需要使用密码 _(关键)_
|
||||
- [ ] 使用安全引导 _(关键)_
|
||||
- [ ] 启动系统需要UEFI级别密码 _(低)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### UEFI和安全引导
|
||||
|
||||
UEFI尽管有缺点,还是提供很多传统BIOS没有的好功能,比如安全引导。大多数现代的系统都默认使用UEFI模式。
|
||||
|
||||
UEFI配置模式密码要确保密码强度。注意,很多厂商默默地限制了你使用密码长度,所以对比长口令你也许应该选择高熵短密码(更多地密码短语看下面)。
|
||||
|
||||
基于你选择的Linux分支,你也许会也许不会跳过额外的圈子,以导入你的发行版的安全引导键,才允许你启动发行版。很多分支已经与微软合作大多数厂商给他们已发布的内核签订密钥,这已经是大多数厂商公认的了,因此为了避免问题你必须处理密钥导入。
|
||||
|
||||
作为一个额外的措施,在允许某人得到引导分区然后尝试做一些不好的事之前,让他们输入密码。为了防止肩窥,这个密码应该跟你的UEFI管理密码不同。如果你关闭启动太多,你也许该选择别把心思费在这上面,当你已经进入LUKS密码,这将为您节省一些额外的按键。
|
||||
|
||||
## 发行版选择注意事项
|
||||
|
||||
很有可能你会坚持一个广泛使用的发行版如Fedora,Ubuntu,Arch,Debian,或他们的一个类似分支。无论如何,这是你选择使用发行版应该考虑的。
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 拥有一个强健的MAC/RBAC系统(SELinux/AppArmor/Grsecurity) _(关键)_
|
||||
- [ ] 公开的安全公告 _(关键)_
|
||||
- [ ] 提供及时的安全补丁 _(关键)_
|
||||
- [ ] 提供密码验证的包 _(关键)_
|
||||
- [ ] 完全支持UEFI和安全引导 _(关键)_
|
||||
- [ ] 拥有健壮的原生全磁盘加密支持 _(关键)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### SELinux,AppArmor,和GrSecurity/PaX
|
||||
|
||||
强制访问控制(MAC)或者基于角色的访问控制(RBAC)是一个POSIX系统遗留的基于用户或组的安全机制延伸。这些天大多数发行版已经绑定MAC/RBAC系统(Fedora,Ubuntu),或通过提供一种机制一个可选的安装后的步骤来添加它(Gentoo,Arch,Debian)。很明显,强烈建议您选择一个预装MAC/RBAC系统的分支,但是如果你对一个分支情有独钟,没有默认启用它,装完系统后应计划配置安装它。
|
||||
|
||||
应该坚决避免使用不带任何MAC/RBAC机制的分支,像传统的POSIX基于用户和组的安全在当今时代应该算是考虑不足。如果你想建立一个MAC/RBAC工作站,通常会考虑AppArmor和PaX,他们比SELinux更容易学习。此外,在一个工作站上,有很少或者没有额外的监听用户运行的应用造成的最高风险,GrSecurity/PaX_可能_会比SELinux提供更多的安全效益。
|
||||
|
||||
#### 发行版安全公告
|
||||
|
||||
大多数广泛使用的分支都有一个机制发送安全公告到他们的用户,但是如果你对一些机密感兴趣,查看开发人员是否有记录机制提醒用户安全漏洞和补丁。缺乏这样的机制是一个重要的警告信号,这个分支不够成熟,不能被视为主要管理工作站。
|
||||
|
||||
#### 及时和可靠的安全更新
|
||||
|
||||
多数常用的发行版提供的定期安全更新,但为确保关键包更新及时提供是值得检查的。避免使用分支和"社区重建"的原因是,由于不得不等待上游分支先发布它,他们经常延迟安全更新。
|
||||
|
||||
你如果找到一个在安装包,更新元数据,或两者上不使用加密签名的发行版,将会处于困境。这么说,常用的发行版多年前就已经知道这个基本安全的意义(Arch,我正在看你),所以这也是值得检查的。
|
||||
|
||||
#### 发行版支持UEFI和安全引导
|
||||
|
||||
检查发行版支持UEFI和安全引导。查明它是否需要导入额外的密钥或是否要求启动内核有一个已经被系统厂商信任的密钥签名(例如跟微软达成合作)。一些发行版不支持UEFI或安全启动,但是提供了替代品来确保防篡改或防破坏引导环境([Qubes-OS][3]使用Anti Evil Maid,前面提到的)。如果一个发行版不支持安全引导和没有机制防止引导级别攻击,还是看看别的吧。
|
||||
|
||||
#### 全磁盘加密
|
||||
|
||||
全磁盘加密是保护静止数据要求,大多数发行版都支持。作为一个选择方案,系统自加密硬件驱动也许用来(通常通过主板TPM芯片实现)和提供类似安全级别加更快的选项,但是花费也更高。
|
||||
|
||||
## 发行版安装指南
|
||||
|
||||
所有发行版都是不同的,但是也有一些一般原则:
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 使用健壮的密码全磁盘加密(LUKS) _(关键)_
|
||||
- [ ] 确保交换分区也加密了 _(关键)_
|
||||
- [ ] 确保引导程序设置了密码(可以和LUKS一样) _(关键)_
|
||||
- [ ] 设置健壮的root密码(可以和LUKS一样) _(关键)_
|
||||
- [ ] 使用无特权账户登录,管理员组的一部分 _(关键)_
|
||||
- [ ] 设置强壮的用户登录密码,不同于root密码 _(关键)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 全磁盘加密
|
||||
|
||||
除非你正在使用自加密硬件设备,配置你的安装程序给磁盘完整加密用来存储你的数据与你的系统文件很重要。通过自动安装的cryptfs循环文件加密用户目录还不够简单(我正在看你,老版Ubuntu),这并没有给系统二进制文件或交换分区提供保护,它可能包含大量的敏感数据。推荐的加密策略是加密LVM设备,所以在启动过程中只需要一个密码。
|
||||
|
||||
`/boot`分区将一直保持非加密,当引导程序需要引导内核前,调用LUKS/dm-crypt。内核映像本身应该用安全引导加密签名检查防止被篡改。
|
||||
|
||||
换句话说,`/boot`应该是你系统上唯一没有加密的分区。
|
||||
|
||||
#### 选择好密码
|
||||
|
||||
现代的Linux系统没有限制密码口令长度,所以唯一的限制是你的偏执和倔强。如果你要启动你的系统,你将大概至少要输入两个不同的密码:一个解锁LUKS,另一个登陆,所以长密码将会使你老的很快。最好从丰富或混合的词汇中选择2-3个单词长度,容易输入的密码。
|
||||
|
||||
优秀密码例子(是的,你可以使用空格):
|
||||
- nature abhors roombas
|
||||
- 12 in-flight Jebediahs
|
||||
- perdon, tengo flatulence
|
||||
|
||||
如果你更喜欢输入口令句,你也可以坚持使用无词汇密码但最少要10-12个字符长度。
|
||||
|
||||
除非你有人身安全的担忧,写下你的密码,并保存在一个远离你办公桌的安全的地方才合适。
|
||||
|
||||
#### Root,用户密码和管理组
|
||||
|
||||
我们建议,你的root密码和你的LUKS加密使用同样的密码(除非你共享你的笔记本给可信的人,他应该能解锁设备,但是不应该能成为root用户)。如果你是笔记本电脑的唯一用户,那么你的root密码与你的LUKS密码不同是没有意义的安全优势。通常,你可以使用同样的密码在你的UEFI管理,磁盘加密,和root登陆 -- 知道这些任意一个都会让攻击者完全控制您的系统,在单用户工作站上使这些密码不同,没有任何安全益处。
|
||||
|
||||
你应该有一个不同的,但同样强健的常规用户帐户密码用来每天工作。这个用户应该是管理组用户(例如`wheel`或者类似,根据分支),允许你执行`sudo`来提升权限。
|
||||
|
||||
换句话说,如果在你的工作站只有你一个用户,你应该有两个独特的,强健的,同样的强壮的密码需要记住:
|
||||
|
||||
**管理级别**,用在以下区域:
|
||||
|
||||
- UEFI管理
|
||||
- 引导程序(GRUB)
|
||||
- 磁盘加密(LUKS)
|
||||
- 工作站管理(root用户)
|
||||
|
||||
**User-level**, used for the following:
|
||||
**用户级别**,用在以下:
|
||||
|
||||
- 用户登陆和sudo
|
||||
- 密码管理器的主密码
|
||||
|
||||
很明显,如果有一个令人信服的理由他们所有可以不同。
|
||||
|
||||
## 安装后的加强
|
||||
|
||||
安装后的安全性加强在很大程度上取决于你选择的分支,所以在一个通用的文档中提供详细说明是徒劳的,例如这一个。然而,这里有一些你应该采取的步骤:
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 在全体范围内禁用火线和雷电模块 _(关键)_
|
||||
- [ ] 检查你的防火墙,确保过滤所有传入端口 _(关键)_
|
||||
- [ ] 确保root邮件转发到一个你可以查看到的账户 _(关键)_
|
||||
- [ ] 检查以确保sshd服务默认情况下是禁用的 _(中等)_
|
||||
- [ ] 建立一个系统自动更新任务,或更新提醒 _(中等)_
|
||||
- [ ] 配置屏幕保护程序在一段时间的不活动后自动锁定 _(中等)_
|
||||
- [ ] 建立日志监控 _(中等)_
|
||||
- [ ] 安装使用rkhunter _(低等)_
|
||||
- [ ] 安装一个入侵检测系统 _(偏执)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 黑名单模块
|
||||
|
||||
将火线和雷电模块列入黑名单,增加一行到`/etc/modprobe.d/blacklist-dma.conf`文件:
|
||||
|
||||
blacklist firewire-core
|
||||
blacklist thunderbolt
|
||||
|
||||
重启后的模块将被列入黑名单。这样做是无害的,即使你没有这些端口(但也不做任何事)。
|
||||
|
||||
#### Root邮件
|
||||
|
||||
默认的root邮件只是存储在系统基本上没人读过。确保你设置了你的`/etc/aliases`来转发root邮件到你确实能读取的邮箱,否则你也许错过了重要的系统通知和报告:
|
||||
|
||||
# Person who should get root's mail
|
||||
root: bob@example.com
|
||||
|
||||
编辑后这些后运行`newaliases`,然后测试它确保已投递,像一些邮件供应商将拒绝从没有或者不可达的域名的邮件。如果是这个原因,你需要配置邮件转发直到确实可用。
|
||||
|
||||
#### 防火墙,sshd,和监听进程
|
||||
|
||||
默认的防火墙设置将取决于您的发行版,但是大多数都允许`sshd`端口连入。除非你有一个令人信服的合理理由允许连入ssh,你应该过滤出来,禁用sshd守护进程。
|
||||
|
||||
systemctl disable sshd.service
|
||||
systemctl stop sshd.service
|
||||
|
||||
如果你需要使用它,你也可以临时启动它。
|
||||
|
||||
通常,你的系统不应该有任何侦听端口除了响应ping。这将有助于你对抗网络级别的零日漏洞利用。
|
||||
|
||||
#### 自动更新或通知
|
||||
|
||||
建议打开自动更新,除非你有一个非常好的理由不这么做,如担心自动更新将使您的系统无法使用(这是发生在过去,所以这种恐惧并非杞人忧天)。至少,你应该启用自动通知可用的更新。大多数发行版已经有这个服务自动运行,所以你不需要做任何事。查阅你的发行版文档查看更多。
|
||||
|
||||
你应该尽快应用所有明显的勘误,即使这些不是特别贴上“安全更新”或有关联的CVE代码。所有错误都潜在的安全漏洞和新的错误,比起坚持旧的,已知的错误,未知错误通常是更安全的策略。
|
||||
|
||||
#### 监控日志
|
||||
|
||||
你应该对你的系统上发生了什么很感兴趣。出于这个原因,你应该安装`logwatch`然后配置它每夜发送在你的系统上发生的任何事情的活动报告。这不会预防一个专业的攻击者,但是一个好安全网功能。
|
||||
|
||||
注意,许多systemd发行版将不再自动安装一个“logwatch”需要的syslog服务(由于systemd依靠自己的分类),所以你需要安装和启用“rsyslog”来确保使用logwatch之前你的/var/log不是空。
|
||||
|
||||
#### Rkhunter和IDS
|
||||
|
||||
安装`rkhunter`和一个入侵检测系统(IDS)像`aide`或者`tripwire`将不会有用,除非你确实理解他们如何工作采取必要的步骤来设置正确(例如,保证数据库在额外的媒介,从可信的环境运行检测,记住执行系统更新和配置更改后要刷新数据库散列,等等)。如果你不愿在你的工作站执行这些步骤调整你如何工作,这些工具将带来麻烦没有任何实在的安全益处。
|
||||
|
||||
我们强烈建议你安装`rkhunter`并每晚运行它。它相当易于学习和使用,虽然它不会阻止一个复杂的攻击者,它也能帮助你捕获你自己的错误。
|
||||
|
||||
## 个人工作站备份
|
||||
|
||||
工作站备份往往被忽视,或无计划的做,常常是不安全的方式。
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 设置加密备份工作站到外部存储 _(关键)_
|
||||
- [ ] 使用零认知云备份的备份工具 _(中等)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 全加密备份存到外部存储
|
||||
|
||||
把全部备份放到一个移动磁盘中比较方便,不用担心带宽和流速(在这个时代,大多数供应商仍然提供显著的不对称的上传/下载速度)。不用说,这个移动硬盘本身需要加密(又一次,通过LIKS),或者你应该使用一个备份工具建立加密备份,例如`duplicity`或者它的GUI版本,`deja-dup`。我建议使用后者并使用随机生成的密码,保存到你的密码管理器中。如果你带上笔记本去旅行,把这个磁盘留在家,以防你的笔记本丢失或被窃时可以找回备份。
|
||||
|
||||
除了你的家目录外,你还应该备份`/etc`目录和处于鉴定目的的`/var/log`目录。
|
||||
|
||||
首先是,避免拷贝你的家目录到任何非加密存储上,甚至是快速的在两个系统上移动文件,一旦完成你肯定会忘了清除它,暴露个人隐私或者安全信息到监听者手中 -- 尤其是把这个存储跟你的笔记本防盗同一个包里。
|
||||
|
||||
#### 零认知站外备份选择性
|
||||
|
||||
站外备份也是相当重要的,是否可以做到要么需要你的老板提供空间,要么找一家云服务商。你可以建一个单独的duplicity/deja-dup配置,只包括重要的文件,以免传输大量你不想备份的数据(网络缓存,音乐,下载等等)。
|
||||
|
||||
作为选择,你可以使用零认知备份工具,例如[SpiderOak][5],它提供一个卓越的Linux GUI工具还有实用的特性,例如在多个系统或平台间同步内容。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
下面是我们认为你应该采用的最佳实践列表。它当然不是非常详细的,而是试图提供实用的建议,一个可行的整体安全性和可用性之间的平衡
|
||||
|
||||
### 浏览
|
||||
|
||||
毫无疑问,在你的系统上web浏览器将是最大、最容易暴露的攻击层面的软件。它是专门下载和执行不可信,恶意代码的一个工具。它试图采用沙箱和代码卫生处理等多种机制保护你免受这种危险,但是在之前多个场合他们都被击败了。你应该学到浏览网站是最不安全的活动在你参与的任何一天。
|
||||
|
||||
有几种方法可以减少浏览器的影响,但真正有效的方法需要你操作您的工作站将发生显著的变化。
|
||||
|
||||
#### 1: 实用两个不同的浏览器
|
||||
|
||||
这很容易做到,但是只有很少的安全效益。并不是所有浏览器都妥协给攻击者完全自由访问您的系统 -- 有时他们只能允许一个读取本地浏览器存储,窃取其他标签的活动会话,捕获输入浏览器,例如,实用两个不同的浏览器,一个用在工作/高安全站点,另一个用在其他,有助于防止攻击者请求整个饼干罐的小妥协。主要的不便是两个不同的浏览器消耗内存大量。
|
||||
|
||||
我们建议:
|
||||
|
||||
##### 火狐用来工作和高安全站点
|
||||
|
||||
使用火狐登陆工作有关的站点,应该额外关心的是确保数据如cookies,会话,登陆信息,打键次数等等,明显不应该落入攻击者手中。除了少数的几个网站,你不应该用这个浏览器访问其他网站。
|
||||
|
||||
你应该安装下面的火狐扩展:
|
||||
|
||||
- [ ] NoScript _(关键)_
|
||||
- NoScript阻止活动内容加载,除非在用户白名单里的域名。跟你默认浏览器比它使用起来很麻烦(可是提供了真正好的安全效益),所以我们建议只在开启了它的浏览器上访问与工作相关的网站。
|
||||
|
||||
- [ ] Privacy Badger _(关键)_
|
||||
- EFF的Privacy Badger将在加载时预防大多数外部追踪器和广告平台,在这些追踪站点影响你的浏览器时将有助于避免妥协(追踪着和广告站点通常会成为攻击者的目标,因为他们会迅速影响世界各地成千上万的系统)。
|
||||
|
||||
- [ ] HTTPS Everywhere _(关键)_
|
||||
- 这个EFF开发的扩展将确保你访问的大多数站点都在安全连接上,甚至你点击的连接使用的是http://(有效的避免大多数的攻击,例如[SSL-strip][7])。
|
||||
|
||||
- [ ] Certificate Patrol _(中等)_
|
||||
- 如果你正在访问的站点最近改变了他们的TLS证书 -- 特别是如果不是接近失效期或者现在使用不同的证书颁发机构,这个工具将会警告你。它有助于警告你是否有人正尝试中间人攻击你的连接,但是产生很多无害的假的类似情况。
|
||||
|
||||
你应该让火狐成为你的默认打开连接的浏览器,因为NoScript将在加载或者执行时阻止大多数活动内容。
|
||||
|
||||
##### 其他一切都用Chrome/Chromium
|
||||
|
||||
Chromium开发者在增加很多很好的安全特性方面比火狐强(至少[在Linux上][6])),例如seccomp沙箱,内核用户名空间等等,这担当一个你访问网站和你其他系统间额外的隔离层。Chromium是流开源项目,Chrome是Google所有的基于它构建的包(使用它输入时要非常谨慎任,何你不想让谷歌知道的事情都不要使用它)。
|
||||
|
||||
有人推荐你在Chrome上也安装**Privacy Badger**和**HTTPS Everywhere**扩展,然后给他一个不同的主题,从火狐指出这是你浏览器“不信任的站点”。
|
||||
|
||||
#### 2: 使用两个不同浏览器,一个在专用的虚拟机里
|
||||
|
||||
这有点像上面建议的做法,除了您将添加一个额外的步骤,通过快速访问协议运行专用虚拟机内部Chrome,允许你共享剪贴板和转发声音事件(如,Spice或RDP)。这将在不可信的浏览器和你其他的工作环境之间添加一个优秀的隔离层,确保攻击者完全危害你的浏览器将不得不另外打破VM隔离层,以达到系统的其余部分。
|
||||
|
||||
这是一个出奇可行的结构,但是需要大量的RAM和高速处理器可以处理增加的负载。这还需要一个重要的奉献的管理员需要相应地调整自己的工作实践。
|
||||
|
||||
#### 3: 通过虚拟化完全隔离你的工作和娱乐环境
|
||||
|
||||
看[Qubes-OS项目][3],它致力于通过划分你的应用到完全独立分开的VM中,提供高安全工作环境。
|
||||
|
||||
### 密码管理器
|
||||
|
||||
#### 清单
|
||||
|
||||
- [ ] 使用密码管理器 _(关键)_
|
||||
- [ ] 不相关的站点使用不同的密码 _(关键)_
|
||||
- [ ] 使用支持团队共享的密码管理器 _(中等)_
|
||||
- [ ] 给非网站用户使用一个单独的密码管理器 _(偏执)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
使用好的,唯一的密码对你的团队成员来说应该是非常关键的需求。证书盗取一直在发生 — 要么通过中间计算机,盗取数据库备份,远程站点利用,要么任何其他的打算。证书从不应该通过站点被重用,尤其是关键的应用。
|
||||
|
||||
|
||||
##### 浏览器中的密码管理器
|
||||
|
||||
每个浏览器有一个比较安全的保存密码机制,通过供应商的机制可以同步到云存储同事用户提供密码保证数据加密。无论如何,这个机制有严重的劣势:
|
||||
|
||||
|
||||
1. 不能跨浏览器工作
|
||||
2. 不提供任何与团队成员共享凭证的方法
|
||||
|
||||
也有一些良好的支持,免费或便宜的密码管理器,很好的融合到多个浏览器,跨平台工作,提供小组共享(通常是支付服务)。可以很容易地通过搜索引擎找到解决方案。
|
||||
|
||||
##### 独立的密码管理器
|
||||
|
||||
任何密码管理器都有一个主要的缺点,与浏览器结合,事实上是应用的一部分,这样最有可能被入侵者攻击。如果这让你不舒服(应该这样),你应该选择两个不同的密码管理器 -- 一个集成在浏览器中用来保存网站密码,一个作为独立运行的应用。后者可用于存储高风险凭证如root密码,数据库密码,其他shell账户凭证等。
|
||||
|
||||
有这样的工具可以特别有效的在团腿成员间共享超级用户的凭据(服务器根密码,ILO密码,数据库管理密码,引导装载程序密码等等)。
|
||||
|
||||
这几个工具可以帮助你:
|
||||
|
||||
- [KeePassX][8],2版中改善了团队共享
|
||||
- [Pass][9],它使用了文本文件和PGP并与git结合
|
||||
- [Django-Pstore][10],他是用GPG在管理员之间共享凭据
|
||||
- [Hiera-Eyaml][11],如果你已经在你的平台中使用了Puppet,可以便捷的追踪你的服务器/服务凭证,像你的Hiera加密数据的一部分。
|
||||
|
||||
### 加固SSH和PGP私钥
|
||||
|
||||
个人加密密钥,包括SSH和PGP私钥,都是你工作站中最重要的物品 -- 攻击将在获取到感兴趣的东西,这将允许他们进一步攻击你的平台或冒充你为其他管理员。你应该采取额外的步骤,确保你的私钥免遭盗窃。
|
||||
|
||||
#### 清单
|
||||
|
||||
- [ ] 强壮的密码用来保护私钥 _(关键)_
|
||||
- [ ] PGP的主密码保存在移动存储中 _(中等)_
|
||||
- [ ] 身份验证、签名和加密注册表子项存储在智能卡设备 _(中等)_
|
||||
- [ ] SSH配置为使用PGP认证密钥作为ssh私钥 _(中等)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
防止私钥被偷的最好方式是使用一个智能卡存储你的加密私钥,不要拷贝到工作平台上。有几个厂商提供支持OpenPGP的设备:
|
||||
|
||||
- [Kernel Concepts][12],在这里可以采购支持OpenPGP的智能卡和USB读取器,你应该需要一个。
|
||||
- [Yubikey NEO][13],这里提供OpenPGP功能的智能卡还提供很多很酷的特性(U2F, PIV, HOTP等等)。
|
||||
|
||||
确保PGP主密码没有存储在工作平台也很重要,只有子密码在使用。主密钥只有在登陆其他的密钥和创建子密钥时使用 — 不经常发生这种操作。你可以照着[Debian的子密钥][14]向导来学习如何移动你的主密钥到移动存储和创建子密钥。
|
||||
|
||||
你应该配置你的gnupg代理作为ssh代理然后使用基于智能卡PGP认证密钥作为你的ssh私钥。我们公布了一个细节向导如何使用智能卡读取器或Yubikey NEO。
|
||||
|
||||
如果你不想那么麻烦,最少要确保你的PGP私钥和你的SSH私钥有个强健的密码,这将让攻击者很难盗取使用它们。
|
||||
|
||||
### 工作站上的SELinux
|
||||
|
||||
如果你使用的发行版绑定了SELinux(如Fedora),这有些如何使用它的建议,让你的工作站达到最大限度的安全。
|
||||
|
||||
#### 清单
|
||||
|
||||
- [ ] 确保你的工作站强制使用SELinux _(关键)_
|
||||
- [ ] 不要盲目的执行`audit2allow -M`,经常检查 _(关键)_
|
||||
- [ ] 从不 `setenforce 0` _(中等)_
|
||||
- [ ] 切换你的用户到SELinux用户`staff_u` _(中等)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
SELinux是一个强制访问控制(MAC)为POSIX许可核心功能扩展。它是成熟,强健,自从它推出以来已经有很长的路了。不管怎样,许多系统管理员现在重复过时的口头禅“关掉它就行。”
|
||||
|
||||
话虽如此,在工作站上SELinux还是限制了安全效益,像很多应用都要作为一个用户自由的运行。开启它有益于给网络提供足够的保护,有可能有助于防止攻击者通过脆弱的后台服务提升到root级别的权限用户。
|
||||
|
||||
我们的建议是开启它并强制使用。
|
||||
|
||||
##### 从不`setenforce 0`
|
||||
|
||||
使用`setenforce 0`短时间内把SELinux设置为许可模式,但是你应该避免这样做。其实你是想查找一个特定应用或者程序的问题,实际上这样是把全部系统的SELinux关闭了。
|
||||
|
||||
你应该使用`semanage permissive -a [somedomain_t]`替换`setenforce 0`,只把这个程序放入许可模式。首先运行`ausearch`查看那个程序发生问题:
|
||||
|
||||
ausearch -ts recent -m avc
|
||||
|
||||
然后看下`scontext=`(SELinux的上下文)行,像这样:
|
||||
|
||||
scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
|
||||
^^^^^^^^^^^^^^
|
||||
|
||||
这告诉你程序`gpg_pinentry_t`被拒绝了,所以你想查看应用的故障,应该增加它到许可模式:
|
||||
|
||||
semange permissive -a gpg_pinentry_t
|
||||
|
||||
这将允许你使用应用然后收集AVC的其他部分,你可以连同`audit2allow`写一个本地策略。一旦完成你就不会看到新的AVC的拒绝,你可以从许可中删除程序,运行:
|
||||
|
||||
semanage permissive -d gpg_pinentry_t
|
||||
|
||||
##### 用SELinux的用户staff_r,使用你的工作站
|
||||
|
||||
SELinux附带的本地角色实现基于角色的用户帐户禁止或授予某些特权。作为一个管理员,你应该使用`staff_r`角色,这可以限制访问很多配置和其他安全敏感文件,除非你先执行`sudo`。
|
||||
|
||||
默认,用户作为`unconfined_r`被创建,你可以运行大多数应用,没有任何(或只有一点)SELinux约束。转换你的用户到`staff_r`角色,运行下面的命令:
|
||||
|
||||
usermod -Z staff_u [username]
|
||||
|
||||
你应该退出然后登陆激活新角色,届时如果你运行`id -Z`,你将会看到:
|
||||
|
||||
staff_u:staff_r:staff_t:s0-s0:c0.c1023
|
||||
|
||||
在执行`sudo`时,你应该记住增加一个额外的标准告诉SELinux转换到"sysadmin"角色。你想要的命令是:
|
||||
|
||||
sudo -i -r sysadm_r
|
||||
|
||||
届时`id -Z`将会显示:
|
||||
|
||||
staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
|
||||
|
||||
**警告**:在进行这个切换前你应该舒服的使用`ausearch`和`audit2allow`,当你作为`staff_r`角色运行时你的应用有可能不再工作了。写到这里时,以下流行的应用已知在`staff_r`下没有做策略调整就不会工作:
|
||||
|
||||
- Chrome/Chromium
|
||||
- Skype
|
||||
- VirtualBox
|
||||
|
||||
切换回`unconfined_r`,运行下面的命令:
|
||||
|
||||
usermod -Z unconfined_u [username]
|
||||
|
||||
然后注销再重新回到舒服的区域。
|
||||
|
||||
## 延伸阅读
|
||||
|
||||
IT安全的世界是一个没有底的兔子洞。如果你想深入,或者找到你的具体发行版更多的安全特性,请查看下面这些链接:
|
||||
|
||||
- [Fedora Security Guide](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
|
||||
- [CESG Ubuntu Security Guide](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
|
||||
- [Debian Security Manual](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
|
||||
- [Arch Linux Security Wiki](https://wiki.archlinux.org/index.php/Security)
|
||||
- [Mac OSX Security](https://www.apple.com/support/security/guides/)
|
||||
|
||||
## 许可
|
||||
|
||||
这项工作在[创作共用授权4.0国际许可证][0]许可下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/lfit/itpol/blob/master/linux-workstation-security.md#linux-workstation-security-list
|
||||
|
||||
作者:[mricon][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/mricon
|
||||
[0]: http://creativecommons.org/licenses/by-sa/4.0/
|
||||
[1]: https://github.com/QubesOS/qubes-antievilmaid
|
||||
[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
|
||||
[3]: https://qubes-os.org/
|
||||
[4]: https://xkcd.com/936/
|
||||
[5]: https://spideroak.com/
|
||||
[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
|
||||
[7]: http://www.thoughtcrime.org/software/sslstrip/
|
||||
[8]: https://keepassx.org/
|
||||
[9]: http://www.passwordstore.org/
|
||||
[10]: https://pypi.python.org/pypi/django-pstore
|
||||
[11]: https://github.com/TomPoulton/hiera-eyaml
|
||||
[12]: http://shop.kernelconcepts.de/
|
||||
[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
|
||||
[14]: https://wiki.debian.org/Subkeys
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
@ -1,128 +0,0 @@
|
||||
开发者的 Linux 容器之旅
|
||||
================================================================================
|
||||

|
||||
|
||||
我告诉你一个秘密:使得我的应用程序进入到全世界的所有云计算的东西,对我来说仍然有一点神秘。但随着时间流逝,我意识到理解大规模机器配置和应用程序部署的来龙去脉对一个开发者来说是非常重要的知识。这类似于成为一个专业的音乐家。你当然需要知道如何使用你的乐器。但是,如果你不知道一个录音室是如何工作的,或者你如何适应一个交响乐团,你在这样的环境中工作会变得非常困难。
|
||||
|
||||
在软件开发的世界里,使你的代码进入我们更大的世界正如写出它来一样重要。开发重要,而且是很重要。
|
||||
|
||||
因此,为了弥合开发和部署之间的间隔,我会从头开始介绍容器技术。为什么是容器?因为有强有力的证据表明,容器是机器抽象的下一步:使计算机成为场所而不再是一个东西。理解容器是我们共同的旅程。
|
||||
|
||||
在这篇文章中,我会介绍容器化背后的概念。容器和虚拟机的区别。以及容器构建背后的逻辑以及它是如何适应应用程序架构的。我会探讨轻量级的 Linux 操作系统是如何适应容器生态系统。我还会讨论使用镜像创建可重用的容器。最后我会介绍容器集群如何使你的应用程序可以快速扩展。
|
||||
|
||||
在后面的文章中,我会一步一步向你介绍容器化一个事例应用程序的过程,以及如何为你的应用程序容器创建一个托管集群。同时,我会向你展示如何使用 Deis 将你的事例应用程序部署到你本地系统以及多种云供应商的虚拟机上。
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
### 虚拟机的好处 ###
|
||||
|
||||
为了理解容器如何适应事物发展,你首先要了解容器的前者:虚拟机
|
||||
|
||||
[虚拟机][1] 是运行在物理宿主机上的软件抽象。配置一个虚拟机就像是购买一台计算机:你需要定义你想要的 CPU 数目,RAM 和磁盘存储容量。配置好了机器后,你把它加载到操作系统,然后是你想让虚拟机支持的任何服务器或者应用程序。
|
||||
|
||||
虚拟机允许你在一台硬件主机上运行多个模拟计算机。这是一个简单的示意图:
|
||||
|
||||

|
||||
|
||||
虚拟机使得能充分利用你的硬件资源。你可以购买一台大型机然后在上面运行多个虚拟机。你可以有一个数据库虚拟机以及很多运行相同版本定制应用程序的虚拟机构成的集群。你可以在有限的硬件资源获得很多的扩展能力。如果你觉得你需要更多的虚拟机而且你的宿主硬件还有容量,你可以添加任何你想要的。或者,如果你不再需要一个虚拟机,你可以关闭该虚拟机并删除虚拟机镜像。
|
||||
|
||||
### 虚拟机的局限 ###
|
||||
|
||||
但是,虚拟机确实有局限。
|
||||
|
||||
如上面所示,假如你在一个主机上创建了三个虚拟机。主机有 12 个 CPU,48 GB 内存和 3TB 的存储空间。每个虚拟机配置为有 4 个 CPU,16 GB 内存和 1TB 存储空间。到现在为止,一切都还好。主机有这个容量。
|
||||
|
||||
但这里有个缺陷。所有分配给一个虚拟机的资源,无论是什么,都是专有的。每台机器都分配了 16 GB 的内存。但是,如果第一个虚拟机永不会使用超过 1GB 分配的内存,剩余的 15 GB 就会被浪费在那里。如果第三天虚拟机只使用分配的 1TB 存储空间中的 100GB,其余的 900GB 就成为浪费空间。
|
||||
|
||||
这里没有资源的流动。每台虚拟机拥有分配给它的所有资源。因此,在某种方式上我们又回到了虚拟机之前,把大部分金钱花费在未使用的资源上。
|
||||
|
||||
虚拟机还有*另一个*缺陷。扩展他们需要很长时间。如果你处于基础设施需要快速增长的情形,即使虚拟机配置是自动的,你仍然会发现你的很多时间都浪费在等待机器上线。
|
||||
|
||||
### 来到:容器 ###
|
||||
|
||||
概念上来说,容器是 Linux 中认为只有它自己的一个进程。该进程只知道告诉它的东西。另外,在容器化方面,该容器进程也分配了它自己的 IP 地址。这点很重要,我会再次重复。**在容器化方面,容器进程有它自己的 IP 地址**。一旦给予了一个 IP 地址,该进程就是宿主网络中可识别的资源。然后,你可以在容器管理器上运行命令,使容器 IP 映射到主机中能访问公网的 IP 地址。该映射发生时,对于任何意图和目的,一个容器就是网络上一个可访问的独立机器,概念上类似于虚拟机。
|
||||
|
||||
再次说明,容器是拥有不同 IP 地址从而使其成为网络上可识别的独立 Linux 进程。下面是一个示意图:
|
||||
|
||||

|
||||
|
||||
容器/进程以动态合作的方式共享主机上的资源。如果容器只需要 1GB 内存,它就只会使用 1GB。如果它需要 4GB,就会使用 4GB。CPU 和存储空间利用也是如此。CPU,内存和存储空间的分配是动态的,和典型虚拟机的静态方式不同。所有这些资源的共享都由容器管理器管理。
|
||||
|
||||
最后,容器能快速启动。
|
||||
|
||||
因此,容器的好处是:**你获得了虚拟机独立和封装的好处而抛弃了专有静态资源的缺陷**。另外,由于容器能快速加载到内存,在扩展到多个容器时你能获得更好的性能。
|
||||
|
||||
### 容器托管、配置和管理 ###
|
||||
|
||||
托管容器的计算机运行着被剥离的只剩下主要部分的 Linux 版本。现在,宿主计算机流行的底层操作系统是上面提到的 [CoreOS][2]。当然还有其它,例如 [Red Hat Atomic Host][3] 和 [Ubuntu Snappy][4]。
|
||||
|
||||
所有容器之间共享Linux 操作系统,减少了容器足迹的重复和冗余。每个容器只包括该容器唯一的部分。下面是一个示意图:
|
||||
|
||||

|
||||
|
||||
你用它所需的组件配置容器。一个容器组件被称为**层**。一层是一个容器镜像,(你会在后面的部分看到更多关于容器镜像的介绍)。你从一个基本层开始,这通常是你想在容器中使用的操作系统。(容器管理器只提供你想要的操作系统在宿主操作系统中不存在的部分。)当你构建配置你的容器时,你会添加层,例如你想要添加网络服务器 Apache,如果容器要运行脚本,则需要添加 PHP 或 Python 运行时。
|
||||
|
||||
分层非常灵活。如果应用程序或者服务容器需要 PHP 5.2 版本,你相应地配置该容器即可。如果你有另一个应用程序或者服务需要 PHP 5.6 版本,没问题,你可以使用 PHP 5.6 配置该容器。不像虚拟机,更改一个版本的运行时依赖时你需要经过大量的配置和安装过程;对于容器你只需要在容器配置文件中重新定义层。
|
||||
|
||||
所有上面描述的容器多功能性都由一个称为容器管理器的软件控制。现在,最流行的容器管理器是 [Docker][5] 和 [Rocket][6]。上面的示意图展示了容器管理器是 Docker,宿主操作系统是 CentOS 的主机情景。
|
||||
|
||||
### 容器由镜像构成 ###
|
||||
|
||||
当你需要将我们的应用程序构建到容器时,你就会编译镜像。镜像代表了需要完成容器工作的容器模板。(容器里的容器)。镜像被保存在网络上的注册表里。
|
||||
|
||||
从概念上讲,注册表类似于一个使用 Java 的人眼中的 [Maven][7] 仓库,使用 .NET 的人眼中的 [NuGet][8] 服务器。你会创建一个列出了你应用程序所需镜像的容器配置文件。然后你使用容器管理器创建一个包括了你应用程序代码以及从注册表中下载的构成资源的容器。例如,如果你的应用程序包括了一些 PHP 文件,你的容器配置文件会声明你会从注册表中获取 PHP 运行时。另外,你还要使用容器配置文件声明需要复制到容器文件系统中的 .php 文件。容器管理器会封装你应用程序的所有东西为一个独立容器。该容器将会在容器管理器的管理下运行在宿主计算机上。
|
||||
|
||||
这是一个容器创建背后概念的示意图:
|
||||
|
||||

|
||||
|
||||
让我们仔细看看这个示意图。
|
||||
|
||||
(1)表示一个定义了你容器所需东西以及你容器如何构建的容器配置文件。当你在主机上运行容器时,容器管理器会读取配置文件从云上的注册表中获取你需要的容器镜像,(2)作为层将镜像添加到你的容器。
|
||||
|
||||
另外,如果组成镜像需要其它镜像,容器管理器也会获取这些镜像并把它们作为层添加进来。(3)容器管理器会将需要的文件复制到容器中。
|
||||
|
||||
如果你使用了配置服务,例如 [Deis][9],你刚刚创建的应用程序容器作为镜像存在(4)配置服务会将它部署到你选择的云供应商上。类似 AWS 和 Rackspace 云供应商。
|
||||
|
||||
### 集群中的容器 ###
|
||||
|
||||
好了。这里有一个很好的例子说明了容器比虚拟机提供了更好的配置灵活性和资源利用率。但是,这并不是全部。
|
||||
|
||||
容器真正灵活是在集群中。记住,每个容器有一个独立的 IP 地址。因此,能把它放到负载均衡器后面。将容器放到负载均衡器后面,就上升了一个层次。
|
||||
|
||||
你可以在一个负载均衡容器后运行容器集群以获得更高的性能和高可用计算。这是一个例子:
|
||||
|
||||

|
||||
|
||||
假如你开发了一个进行资源密集型工作的应用程序。例如图片处理。使用类似 [Deis][9] 的容器配置技术,你可以创建一个包括了你图片处理程序以及你图片处理程序需要的所有资源的容器镜像。然后,你可以部署一个或多个容器镜像到主机上的负载均衡器。一旦创建了容器镜像,你可以在系统快要刷爆时把它放到一边,为了满足手中的工作时添加更多的容器实例。
|
||||
|
||||
这里还有更多好消息。你不需要每次添加实例到环境中时手动配置负载均衡器以便接受你的容器镜像。你可以使用服务发现技术告知均衡器你容器的可用性。然后,一旦获知,均衡器就会将流量分发到新的结点。
|
||||
|
||||
### 全部放在一起 ###
|
||||
|
||||
容器技术完善了虚拟机不包括的部分。类似 CoreOS、RHEL Atomic、和 Ubuntu 的 Snappy 宿主操作系统,和类似 Docker 和 Rocket 的容器管理技术结合起来,使得容器变得日益流行。
|
||||
|
||||
尽管容器变得更加越来越普遍,掌握它们还是需要一段时间。但是,一旦你懂得了它们的窍门,你可以使用类似 [Deis][9] 的配置技术使容器创建和部署变得更加简单。
|
||||
|
||||
概念上理解容器和进一步实际使用它们完成工作一样重要。但我认为不实际动手把想法付诸实践,概念也难以理解。因此,我们该系列的下一阶段就是:创建一些容器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://deis.com/blog/2015/developer-journey-linux-containers
|
||||
|
||||
作者:[Bob Reselman][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://deis.com/blog
|
||||
[1]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[2]:https://coreos.com/using-coreos/
|
||||
[3]:http://www.projectatomic.io/
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
[5]:https://www.docker.com/
|
||||
[6]:https://coreos.com/blog/rocket/
|
||||
[7]:https://en.wikipedia.org/wiki/Apache_Maven
|
||||
[8]:https://www.nuget.org/
|
||||
[9]:http://deis.com/learn
|
||||
@ -0,0 +1,236 @@
|
||||
How to Install Redis Server on CentOS 7.md
|
||||
|
||||
如何在CentOS 7上安装Redis 服务
|
||||
================================================================================
|
||||
|
||||
大家好, 本文的主题是Redis,我们将要在CentOS 7 上安装它。编译源代码,安装二进制文件,创建、安装文件。然后安装组建,我们还会配置redis ,就像配置操作系统参数一样,目标就是让redis 运行的更加可靠和快速。
|
||||
|
||||

|
||||
|
||||
Redis 服务器
|
||||
|
||||
Redis 是一个开源的多平台数据存储软件,使用ANSI C 编写,直接在内存使用数据集,这使得它得以实现非常高的效率。Redis 支持多种编程语言,包括Lua, C, Java, Python, Perl, PHP 和其他很多语言。redis 的代码量很小,只有约3万行,它只做很少的事,但是做的很好。尽管你在内存里工作,但是对数据持久化的需求还是存在的,而redis 的可靠性就很高,同时也支持集群,这儿些可以很好的保证你的数据安全。
|
||||
|
||||
### 构建 Redis ###
|
||||
|
||||
redis 目前没有官方RPM 安装包,我们需要从牙UN代码编译,而为了要编译就需要安装Make 和GCC。
|
||||
|
||||
如果没有安装过GCC 和Make,那么就使用yum 安装。
|
||||
|
||||
yum install gcc make
|
||||
|
||||
从[官网][1]下载tar 压缩包。
|
||||
|
||||
curl http://download.redis.io/releases/redis-3.0.4.tar.gz -o redis-3.0.4.tar.gz
|
||||
|
||||
解压缩。
|
||||
|
||||
tar zxvf redis-3.0.4.tar.gz
|
||||
|
||||
进入解压后的目录。
|
||||
|
||||
cd redis-3.0.4
|
||||
|
||||
使用Make 编译源文件。
|
||||
|
||||
make
|
||||
|
||||
### 安装 ###
|
||||
|
||||
进入源文件的目录。
|
||||
|
||||
cd src
|
||||
|
||||
复制 Redis server 和 client 到 /usr/local/bin
|
||||
|
||||
cp redis-server redis-cli /usr/local/bin
|
||||
|
||||
最好也把sentinel,benchmark 和check 复制过去。
|
||||
|
||||
cp redis-sentinel redis-benchmark redis-check-aof redis-check-dump /usr/local/bin
|
||||
|
||||
创建redis 配置文件夹。
|
||||
|
||||
mkdir /etc/redis
|
||||
|
||||
在`/var/lib/redis` 下创建有效的保存数据的目录
|
||||
|
||||
mkdir -p /var/lib/redis/6379
|
||||
|
||||
#### 系统参数 ####
|
||||
|
||||
为了让redis 正常工作需要配置一些内核参数。
|
||||
|
||||
配置vm.overcommit_memory 为1,它的意思是一直避免数据被截断,详情[见此][2].
|
||||
|
||||
sysctl -w vm.overcommit_memory=1
|
||||
|
||||
修改backlog 连接数的最大值超过redis.conf 中的tcp-backlog 值,即默认值511。你可以在[kernel.org][3] 找到更多有关基于sysctl 的ip 网络隧道的信息。
|
||||
|
||||
sysctl -w net.core.somaxconn=512.
|
||||
|
||||
禁止支持透明大页,,因为这会造成redis 使用过程产生延时和内存访问问题。
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### redis.conf ###
|
||||
Redis.conf 是redis 的配置文件,然而你会看到这个文件的名字是6379.conf ,而这个数字就是redis 监听的网络端口。这个名字是告诉你可以运行超过一个redis 实例。
|
||||
|
||||
复制redis.conf 的示例到 **/etc/redis/6379.conf**.
|
||||
|
||||
cp redis.conf /etc/redis/6379.conf
|
||||
|
||||
现在编辑这个文件并且配置参数。
|
||||
|
||||
vi /etc/redis/6379.conf
|
||||
|
||||
#### 守护程序 ####
|
||||
|
||||
设置daemonize 为no,systemd 需要它运行在前台,否则redis 会突然挂掉。
|
||||
|
||||
daemonize no
|
||||
|
||||
#### pidfile ####
|
||||
|
||||
设置pidfile 为/var/run/redis_6379.pid。
|
||||
|
||||
pidfile /var/run/redis_6379.pid
|
||||
|
||||
#### port ####
|
||||
|
||||
如果不准备用默认端口,可以修改。
|
||||
|
||||
port 6379
|
||||
|
||||
#### loglevel ####
|
||||
|
||||
设置日志级别。
|
||||
|
||||
loglevel notice
|
||||
|
||||
#### logfile ####
|
||||
|
||||
修改日志文件路径。
|
||||
|
||||
logfile /var/log/redis_6379.log
|
||||
|
||||
#### dir ####
|
||||
|
||||
设置目录为 /var/lib/redis/6379
|
||||
|
||||
dir /var/lib/redis/6379
|
||||
|
||||
### 安全 ###
|
||||
|
||||
下面有几个操作可以提高安全性。
|
||||
|
||||
#### Unix sockets ####
|
||||
|
||||
在很多情况下,客户端程序和服务器端程序运行在同一个机器上,所以不需要监听网络上的socket。如果这和你的使用情况类似,你就可以使用unix socket 替代网络socket ,为此你需要配置**port** 为0,然后配置下面的选项来使能unix socket。
|
||||
|
||||
设置unix socket 的套接字文件。
|
||||
|
||||
unixsocket /tmp/redis.sock
|
||||
|
||||
限制socket 文件的权限。
|
||||
|
||||
unixsocketperm 700
|
||||
|
||||
现在为了获取redis-cli 的访问权限,应该使用-s 参数指向socket 文件。
|
||||
|
||||
redis-cli -s /tmp/redis.sock
|
||||
|
||||
#### 密码 ####
|
||||
|
||||
你可能需要远程访问,如果是,那么你应该设置密码,这样子每次操作之前要求输入密码。
|
||||
|
||||
requirepass "bTFBx1NYYWRMTUEyNHhsCg"
|
||||
|
||||
#### 重命名命令 ####
|
||||
|
||||
想象一下下面一条条指令的输出。使得,这回输出服务器的配置,所以你应该在任何可能的情况下拒绝这种信息。
|
||||
|
||||
CONFIG GET *
|
||||
|
||||
为了限制甚至禁止这条或者其他指令可以使用**rename-command** 命令。你必须提供一个命令名和替代的名字。要禁止的话需要设置replacement 为空字符串,这样子禁止任何人猜测命令的名字会比较安全。
|
||||
|
||||
rename-command FLUSHDB "FLUSHDB_MY_SALT_G0ES_HERE09u09u"
|
||||
rename-command FLUSHALL ""
|
||||
rename-command CONFIG "CONFIG_MY_S4LT_GO3S_HERE09u09u"
|
||||
|
||||

|
||||
|
||||
通过密码和修改命令来访问unix socket。
|
||||
|
||||
#### 快照 ####
|
||||
|
||||
默认情况下,redis 会周期性的将数据集转储到我们设置的目录下的文件**dump.rdb**。你可以使用save 命令配置转储的频率,他的第一个参数是以秒为单位的时间帧(译注:按照下文的意思单位应该是分钟),第二个参数是在数据文件上进行修改的数量。
|
||||
|
||||
每隔15小时并且最少修改过一次键。
|
||||
save 900 1
|
||||
|
||||
每隔5小时并且最少修改过10次键。
|
||||
|
||||
save 300 10
|
||||
|
||||
每隔1小时并且最少修改过10000次键。
|
||||
|
||||
save 60 10000
|
||||
|
||||
文件**/var/lib/redis/6379/dump.rdb** 包含了内存里经过上次保存命令的转储数据。因为他创建了临时文件并且替换了源文件,这里没有被破坏的问题,而且你不用担心直接复制这个文件。
|
||||
|
||||
### 开机时启动 ###
|
||||
|
||||
You may use systemd to add Redis to the system startup
|
||||
你可以使用systemd 将redis 添加到系统开机启动列表。
|
||||
|
||||
复制init_script 示例文件到/etc/init.d,注意脚本名所代表的端口号。
|
||||
|
||||
cp utils/redis_init_script /etc/init.d/redis_6379
|
||||
|
||||
现在我们来使用systemd,所以在**/etc/systems/system** 下创建一个单位文件名字为redis_6379.service。
|
||||
|
||||
vi /etc/systemd/system/redis_6379.service
|
||||
|
||||
填写下面的内容,详情可见systemd.service。
|
||||
|
||||
[Unit]
|
||||
Description=Redis on port 6379
|
||||
|
||||
[Service]
|
||||
Type=forking
|
||||
ExecStart=/etc/init.d/redis_6379 start
|
||||
ExecStop=/etc/init.d/redis_6379 stop
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
现在添加我之前在**/etc/sysctl.conf** 里面修改多的内存过分提交和backlog 最大值的选项。
|
||||
|
||||
vm.overcommit_memory = 1
|
||||
|
||||
net.core.somaxconn=512
|
||||
|
||||
对于透明大页支持,并没有直接sysctl 命令可以控制,所以需要将下面的命令放到/etc/rc.local 的结尾。
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### 总结 ###
|
||||
|
||||
这些足够启动了,通过设置这些选项你将足够部署redis 服务到很多简单的场景,然而在redis.conf 还有很多为复杂环境准备的redis 的选项。在一些情况下,你可以使用[replication][4] 和 [Sentinel][5] 来提高可用性,或者[将数据分散][6]在多个服务器上,创建服务器集群 。谢谢阅读。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/install-redis-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
[1]:http://redis.io/download
|
||||
[2]:https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
|
||||
[3]:https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
|
||||
[4]:http://redis.io/topics/replication
|
||||
[5]:http://redis.io/topics/sentinel
|
||||
[6]:http://redis.io/topics/partitioning
|
||||
@ -0,0 +1,121 @@
|
||||
如何在Ubuntu 15.04 上安装带JSON 支持的SQLite 3.9.1
|
||||
================================================================================
|
||||
欢迎阅读我们关于SQLite 的文章,SQLite 是当今时间上使用最广泛的SQL 数据库引擎,它他基本不需要配置,不需要安装或者管理就可以运行。SQLite 是一个是开放领域的软件,是关系数据库的管理系统,或者说RDBMS,用来在大表存储用户定义的记录。对于数据存储和管理来说,数据库引擎要处理复杂的查询命令,这些命令可能会从多个表获取数据然后生成报告的数据总结。
|
||||
|
||||
SQLite 是一个非常小、轻量级,不需要分离的服务进程或系统。他可以运行在UNIX,Linux,Mac OS-X,Android,iOS 和Windows 上,已经被大量的软件程序使用,如Opera, Ruby On Rails, Adobe System, Mozilla Firefox, Google Chrome 和 Skype。
|
||||
|
||||
### 1) 基本需求: ###
|
||||
|
||||
在几乎全部支持SQLite 的平台上安装SQLite 基本上没有复杂的要求。
|
||||
|
||||
所以让我们在CLI 或者Secure Shell 上使用sudo 或者root 权限登录Ubuntu 服务器。然后更新系统,这样子就可以让操作系统的软件更新到新版本。
|
||||
|
||||
在Ubuntu 上,下面的命令是用来更新系统的软件源的。
|
||||
|
||||
# apt-get update
|
||||
|
||||
如果你要在新安装的Ubuntu 上部署SQLite,那么你需要安装一些基础的系统管理工具,如wget, make, unzip, gcc。
|
||||
|
||||
要安装wget,可以使用下面的命令,然后输入Y 如果系统提示的话:
|
||||
|
||||
# apt-get install wget make gcc
|
||||
|
||||
### 2) 下载 SQLite ###
|
||||
|
||||
要下载SQLite 最好是在[SQLite 官网][1]下载,如下所示
|
||||
|
||||

|
||||
|
||||
你也可以直接复制资源的连接然后再命令行使用wget 下载,如下所示:
|
||||
|
||||
# wget https://www.sqlite.org/2015/sqlite-autoconf-3090100.tar.gz
|
||||
|
||||

|
||||
|
||||
下载完成之后,解压缩安装包,切换工作目录到解压缩后的SQLite 目录,使用下面的命令。
|
||||
|
||||
# tar -zxvf sqlite-autoconf-3090100.tar.gz
|
||||
|
||||
### 3) 安装 SQLite ###
|
||||
|
||||
现在我们要开始安装、配置刚才下载的SQLite。所以在Ubuntu 上编译、安装SQLite,运行配置脚本。
|
||||
|
||||
root@ubuntu-15:~/sqlite-autoconf-3090100# ./configure –prefix=/usr/local
|
||||
|
||||

|
||||
|
||||
配置要上面的prefix 之后,运行下面的命令编译安装包。
|
||||
|
||||
root@ubuntu-15:~/sqlite-autoconf-3090100# make
|
||||
source='sqlite3.c' object='sqlite3.lo' libtool=yes \
|
||||
DEPDIR=.deps depmode=none /bin/bash ./depcomp \
|
||||
/bin/bash ./libtool --tag=CC --mode=compile gcc -DPACKAGE_NAME=\"sqlite\" -DPACKAGE_TARNAME=\"sqlite\" -DPACKAGE_VERSION=\"3.9.1\" -DPACKAGE_STRING=\"sqlite\ 3.9.1\" -DPACKAGE_BUGREPORT=\"http://www.sqlite.org\" -DPACKAGE_URL=\"\" -DPACKAGE=\"sqlite\" -DVERSION=\"3.9.1\" -DSTDC_HEADERS=1 -DHAVE_SYS_TYPES_H=1 -DHAVE_SYS_STAT_H=1 -DHAVE_STDLIB_H=1 -DHAVE_STRING_H=1 -DHAVE_MEMORY_H=1 -DHAVE_STRINGS_H=1 -DHAVE_INTTYPES_H=1 -DHAVE_STDINT_H=1 -DHAVE_UNISTD_H=1 -DHAVE_DLFCN_H=1 -DLT_OBJDIR=\".libs/\" -DHAVE_FDATASYNC=1 -DHAVE_USLEEP=1 -DHAVE_LOCALTIME_R=1 -DHAVE_GMTIME_R=1 -DHAVE_DECL_STRERROR_R=1 -DHAVE_STRERROR_R=1 -DHAVE_POSIX_FALLOCATE=1 -I. -D_REENTRANT=1 -DSQLITE_THREADSAFE=1 -DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_RTREE -g -O2 -c -o sqlite3.lo sqlite3.c
|
||||
|
||||
运行完上面的命令之后,要在Ubuntu 上完成SQLite 的安装得运行下面的命令。
|
||||
|
||||
# make install
|
||||
|
||||

|
||||
|
||||
### 4) 测试 SQLite 安装 ###
|
||||
|
||||
要保证SQLite 3.9 安装成功了,运行下面的命令。
|
||||
|
||||
# sqlite3
|
||||
|
||||
SQLite 的版本会显示在命令行。
|
||||
|
||||

|
||||
|
||||
### 5) 使用 SQLite ###
|
||||
|
||||
SQLite 很容易上手。要获得详细的使用方法,在SQLite 控制台里输入下面的命令。
|
||||
|
||||
sqlite> .help
|
||||
|
||||
这里会显示全部可用的命令和详细说明。
|
||||
|
||||

|
||||
|
||||
现在开始最后一部分,使用一点SQLite 命令创建数据库。
|
||||
|
||||
要创建一个新的数据库需要运行下面的命令。
|
||||
|
||||
# sqlite3 test.db
|
||||
|
||||
然后创建一张新表。
|
||||
|
||||
sqlite> create table memos(text, priority INTEGER);
|
||||
|
||||
接着使用下面的命令插入数据。
|
||||
|
||||
sqlite> insert into memos values('deliver project description', 15);
|
||||
sqlite> insert into memos values('writing new artilces', 100);
|
||||
|
||||
要查看插入的数据可以运行下面的命令。
|
||||
|
||||
sqlite> select * from memos;
|
||||
deliver project description|15
|
||||
writing new artilces|100
|
||||
|
||||
或者使用下面的命令离开。
|
||||
|
||||
sqlite> .exit
|
||||
|
||||

|
||||
### 结论 ###
|
||||
|
||||
通过本文你可以了解如果安装支持JSON1 的最新版的SQLite,SQLite 从3.9.0 开始支持JSON1。这是一个非常棒的库,可以用来获取内嵌到应用程序,利用它可以很有效而且很轻量的管理资源。我们希望你能觉得本文有所帮助,请自由的像我们反馈你遇到的问题和困难。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-sqlite-json-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://www.sqlite.org/download.html
|
||||
@ -0,0 +1,84 @@
|
||||
如何在 Ubuntu 上用 Go For It 管理您的待办清单 (To-Do Lists)
|
||||
================================================================================
|
||||

|
||||
|
||||
任务管理可以说是工作及日常生活中最重要也最具挑战性的事情之一。当您在工作中承担越来越多的责任时,您的表现将与您管理任务的能力直接挂钩。
|
||||
|
||||
若您的工作有部分需要在电脑上完成,那么您一定很乐意知道,有多款应用软件自称可以为您减轻任务管理的负担。即便这些软件中的大多数都是为 Windows 用户服务的,在 Linux 系统中仍然有不少选择。在本文中,我们就来讨论这样一款软件:Go For It.
|
||||
|
||||
### Go For It ###
|
||||
|
||||
[Go For It][1] (GFI) 由 Manuel Kehl 开发,他声称:“这是款简单易用且时尚优雅的生产力软件,以待办清单(To-Do List)为主打特色,并整合了一个能让你专注于当前事务的定时器。”这款软件的定时器功能尤其有趣,它还可以确保您在继续工作之前暂停下来,放松一段时间。
|
||||
|
||||
### 下载并安装 ###
|
||||
|
||||
使用基于 Debian 系统(如Ubuntu)的用户可以通过运行以下终端命令轻松地安装这款软件:
|
||||
|
||||
sudo add-apt-repository ppa:mank319/go-for-it
|
||||
sudo apt-get update
|
||||
sudo apt-get install go-for-it
|
||||
|
||||
以上命令执行完毕后,您就可以使用这条命令运行这款应用软件了:
|
||||
|
||||
go-for-it
|
||||
|
||||
### 使用及配置###
|
||||
|
||||
当你第一次运行 GFI 时,它的界面是长这样的:
|
||||
|
||||

|
||||
|
||||
可以看到,界面由三个标签页组成,分别是*待办* (To-Do),*定时器* (Timer)和*完成* (Done)。*待办*页是一个任务列表(上图所示的4个任务是默认生成的——您可以点击头部的方框删除它们),*定时器*页内含有任务定时器,而*完成*页则是已完成任务的列表。底部有个文本框,您可以在此输入任务描述,并点击“+”号将任务添加到上面的列表中。
|
||||
|
||||
举个例子,我将一个名为“MTE-research-work”的任务添加到了列表中,并点击选中了它,如下图所示:
|
||||
|
||||

|
||||
|
||||
然后我进入*定时器*页,在这里我可以看到一个为当前“MTE-reaserch-work”任务设定的定时器,定时25分钟。
|
||||
|
||||

|
||||
|
||||
当然,您可以将定时器设定为你喜欢的任何值。然而我并没有修改,而是直接点击下方的“开始 (Start)”按钮启动定时器。一旦剩余时间为60秒,GFI 就会给出一个提示。
|
||||
|
||||

|
||||
|
||||
一旦时间到,它会提醒我休息5分钟。
|
||||
|
||||

|
||||
|
||||
5分钟过后,我可以为我的任务再次开启定时器。
|
||||
|
||||

|
||||
|
||||
任务完成以后,您可以点击*定时器*页中的“完成 (Done)”按钮,然后这个任务就会从*待办*页被转移到*完成*页。
|
||||
|
||||

|
||||
|
||||
GFI 也能让您稍微调整一些它的设置。例如,下图所示的设置窗口就包含了一些选项,让您修改默认的任务时长,休息时长和提示时刻。
|
||||
|
||||

|
||||
|
||||
值得一提的是,GFI 是以 TODO.txt 格式保存待办清单的,这种格式方便了移动设备之间的同步,也让您能使用其他前端程序来编辑任务——更多详情请阅读[这里][2]。
|
||||
|
||||
您还可以通过以下视频观看 GFI 的动态展示。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe frameborder="0" src="http://www.youtube.com/embed/mnw556C9FZQ?autoplay=1&autohide=2&border=1&wmode=opaque&enablejsapi=1&controls=1&showinfo=0" id="youtube-iframe"></iframe>
|
||||
|
||||
### 结论###
|
||||
|
||||
正如您所看到的,GFI 是一款简洁明了且易于使用的任务管理软件。虽然它不提供非常丰富的功能,但它实现了它的承诺,定时器的整合特别有用。如果您正在寻找一款实现了基础功能,并且开源的 Linux 任务管理软件,Go For It 值得您一试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/to-do-lists-ubuntu-go-for-it/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[Ricky-Gong](https://github.com/Ricky-Gong)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[2]:http://todotxt.com/
|
||||
@ -0,0 +1,171 @@
|
||||
Linux 101:最有效地使用 Systemd
|
||||
================================================================================
|
||||
干嘛要这么做?
|
||||
|
||||
- 理解现代 Linux 发行版中的显著变化;
|
||||
- 看看 Systemd 是如何取代 SysVinit 的;
|
||||
- 处理好*单元* (unit)和新的 journal 日志。
|
||||
|
||||
吐槽邮件,人身攻击,死亡威胁——Lennart Poettering,Systemd 的作者,对收到这些东西早就习以为常了。这位 Red Hat 公司的员工最近在 Google+ 上怒斥 FOSS 社区([http://tinyurl.com/poorlennart][1])的本质,悲痛且失望地表示:“那真是个令人恶心的地方”。他着重指出 Linus Torvalds 在邮件列表上言辞刻薄的帖子,并谴责这位内核的领导者为在线讨论定下基调,并使得人身攻击及贬抑之辞成为常态。
|
||||
|
||||
但为何 Poettering 会遭受如此多的憎恨?为何就这么个搞搞开源软件的人要忍受这等愤怒?答案就在于他的软件的重要性。如今大多数发行版中,Systemd 是 Linux 内核发起的第一个程序,并且它还扮演多种角色。它会启动系统服务,处理用户登陆,每隔特定的时间执行一些任务,还有很多很多。它在不断地成长,并逐渐成为 Linux 的某种“基础系统”——提供系统启动和发行版维护所需的所有工具。
|
||||
|
||||
如今,在以下几点上 Systemd 颇具争议:它逃避了一些确立好的 Unix 传统,例如纯文本的日志文件;它被看成是个“大一统”的项目,试图接管一切;它还是我们这个操作系统的支柱的重要革新。然而大多数主流发行版已经接受了(或即将接受)它,因此它就保留了下来。而且它确实是有好处的:更快地启动,更简单地管理那些有依赖的服务程序,提供强大且安全的日志系统等。
|
||||
|
||||
因此在这篇教程中,我们将探索 Systemd 的特性,并向您展示如何最有效地利用这些特性。即便您此刻并不是这款软件的粉丝,读完本文后您至少可以更加了解和适应它。
|
||||
|
||||

|
||||
|
||||
**这部没正经的动画片来自[http://tinyurl.com/m2e7mv8][2],它把 Systemd 塑造成一只狂暴的动物,吞噬它路过的一切。大多数批评者的言辞可不像这只公仔一样柔软。**
|
||||
|
||||
### 启动及服务 ###
|
||||
|
||||
大多数主流发行版要么已经采用 Systemd,要么即将在下个发布中采用(如 Debian 和 Ubuntu)。在本教程中,我们使用 Fedora 21——该发行版已经是 Systemd 的优秀实验场地——的一个预览版进行演示,但不论您用哪个发行版,要用到的命令和注意事项都应该是一样的。这是 Systemd 的一个加分点:它消除了不同发行版之间许多细微且琐碎的区别。
|
||||
|
||||
在终端中输入 **ps ax | grep systemd**,看到第一行,其中的数字 **1** 表示它的进程号是1,也就是说它是 Linux 内核发起的第一个程序。因此,内核一旦检测完硬件并组织好了内存,就会运行 **/usr/lib/systemd/systemd** 可执行程序,这个程序会按顺序依次发起其他程序。(在还没有 Systemd 的日子里,内核会去运行 **/sbin/init**,随后这个程序会在名为 SysVinit 的系统中运行其余的各种启动脚本。)
|
||||
|
||||
Systemd 的核心是一个叫*单元* (unit)的概念,它是一些存有关于服务(在运行在后台的程序),设备,挂载点,和操作系统其他方面信息的配置文件。Systemd 的其中一个目标就是简化这些事物之间的相互作用,因此如果你有程序需要在某个挂载点被创建或某个设备被接入后开始运行,Systemd 可以让这一切正常运作起来变得相当容易。(在没有 Systemd 的日子里,要使用脚本来把这些事情调配好,那可是相当丑陋的。)要列出您 Linux 系统上的所有单元,输入以下命令:
|
||||
|
||||
systemctl list-unit-files
|
||||
|
||||
现在,**systemctl** 是与 Systemd 交互的主要工具,它有不少选项。在单元列表中,您会注意到这儿有一些格式:被使能的单元显示为绿色,被禁用的显示为红色。标记为“static”的单元不能直接启用,它们是其他单元所依赖的对象。若要限制输出列表只包含服务,使用以下命令:
|
||||
|
||||
systemctl list-unit-files --type=service
|
||||
|
||||
注意,一个单元显示为“enabled”,并不等于对应的服务正在运行,而只能说明它可以被开启。要获得某个特定服务的信息,以 GDM (the Gnome Display Manager) 为例,输入以下命令:
|
||||
|
||||
systemctl status gdm.service
|
||||
|
||||
这条命令提供了许多有用的信息:一段人类可读的服务描述,单元配置文件的位置,启动的时间,进程号,以及它所从属的 CGroups (用以限制各组进程的资源开销)。
|
||||
|
||||
如果您去查看位于 **/usr/lib/systemd/system/gdm.service** 的单元配置文件,您可以看到多种选项,包括要被运行的二进制文件(“ExecStart”那一行),相冲突的其他单元(即不能同时进入运行的单元),以及需要在本单元执行前进入运行的单元(“After”那一行)。一些单元有附加的依赖选项,例如“Requires”(必要的依赖)和“Wants”(可选的依赖)。
|
||||
|
||||
此处另一个有趣的选项是:
|
||||
|
||||
Alias=display-manager.service
|
||||
|
||||
当您启动 **gdm.service** 后,您将可以通过 **systemctl status display-manager.service** 来查看它的状态。当您知道有*显示管理程序* (display manager)在运行并想对它做点什么,但您不关心那究竟是 GDM,KDM,XDM 还是什么别的显示管理程序时,这个选项会非常有用。
|
||||
|
||||
|
||||
|
||||
**使用 systemctl status 命令后面跟一个单元名,来查看对应的服务有什么情况。**
|
||||
|
||||
### “目标”锁定 ###
|
||||
|
||||
如果您在 **/usr/lib/systemd/system** 目录中输入 **ls** 命令,您将看到各种以 **.target** 结尾的文件。一个*启动目标* (target)是一种将多个单元聚合在一起以致于将它们同时启动的方式。例如,对大多数类 Unix 操作系统而言有一种“多用户”状态,意思是系统已被成功启动,后台服务正在运行,并且已准备好让一个或多个用户登陆并工作——至少在文本模式下。(其他状态包括用于进行管理工作的单用户状态,以及用于机器关机的重启状态。)
|
||||
|
||||
如果您打开 **multi-user.target** 文件一探究竟,您可能期待看到的是一个要被启动的单元列表。但您会发现这个文件内部几乎空空如也——其实,一个服务会通过 **WantedBy** 选项让自己成为启动目标的依赖。因此如果您去打开 **avahi-daemon.service**, **NetworkManager.service** 及其他 **.service** 文件看看,您将在 Install 段看到这一行:
|
||||
|
||||
WantedBy=multi-user.target
|
||||
|
||||
因此,切换到多用户启动目标会使能那些包含上述语句的单元。还有其他一些启动目标可用(例如 **emergency.target** 用于一个紧急情况使用的 shell,以及 **halt.target** 用于机器关机),您可以用以下方式轻松地在它们之间切换:
|
||||
|
||||
systemctl isolate emergency.target
|
||||
|
||||
在许多方面,这些都很像 SysVinit 中的*运行级* (runlevel),如文本模式的 **multi-user.target** 类似于第3运行级,**graphical.target** 类似于第5运行级,**reboot.target** 类似于第6运行级,诸如此类。
|
||||
|
||||
|
||||
|
||||
**与传统的脚本相比,单元配置文件也许看起来很陌生,但并不难以理解。**
|
||||
|
||||
### 开启与停止 ###
|
||||
|
||||
现在您也许陷入了沉思:我们已经看了这么多,但仍没看到如何停止和开启服务!这其实是有原因的。从外部看,Systemd 也许很复杂,像野兽一般难以驾驭。因此在您开始摆弄它之间,有必要从宏观的角度看看它是如何工作的。实际用来管理服务的命令非常简单:
|
||||
|
||||
systemctl stop cups.service
|
||||
systemctl start cups.service
|
||||
|
||||
(若某个单元被禁用了,您可以先通过 **systemctl enable** 加该单元名的方式将其使能。这种做法会为该单元创建一个符号链接,并将其放置在当前启动目标的 .wants 目录下,这些 .wants 目录在**/etc/systemd/system** 文件夹中。)
|
||||
|
||||
还有两个有用的命令是 **systemctl restart** 和 **systemctl reload**,后面接单元名。后者要求单元重新加载它的配置文件。Systemd 的绝大部分都有良好的文档,因此您可以查看手册 (**man systemctl**) 了解每条命令的细节。
|
||||
|
||||
> ### 定时器单元:取代 Cron ###
|
||||
>
|
||||
> 除了系统初始化和服务管理,Systemd 还染指其他方面。在很大程度上,它能够完成 **cron** 的工作,而且可以说是以更灵活的方式(并带有更易读的语法)。**cron** 是一个以规定时间间隔执行任务的程序——例如清楚临时文件,刷新缓存等。
|
||||
>
|
||||
> 如果您再次进入 **/usr/lib/systemd/system** 目录,您会看到那儿有多个 **.timer** 文件。用 **less** 来查看这些文件,您会发现它们与 **.service** 和 **.target** 文件有着相似的结构,而区别在于 **[Timer]** 段。举个例子:
|
||||
>
|
||||
> [Timer]
|
||||
> OnBootSec=1h
|
||||
> OnUnitActiveSec=1w
|
||||
>
|
||||
> **OnBootSec** 选项告诉 Systemd 在系统启动一小时后启动这个单元。第二个选项的意思是:自那以后每周启动这个单元一次。关于定时器有大量选项您可以设置——输入 **man systemd.time** 查看完整列表。
|
||||
>
|
||||
> Systemd 的时间精度默认为一分钟。也就是说,它会在设定时刻的一分钟内运行单元,但不一定精确到那一秒。这么做是基于电源管理方面的原因,但如果您需要一个没有任何延时且精确到毫秒的定时器,您可以添加以下一行:
|
||||
>
|
||||
> AccuracySec=1us
|
||||
>
|
||||
> 另外, **WakeSystem** 选项(可以被设置为 true 或 false)决定了定时器是否可以唤醒处于休眠状态的机器。
|
||||
|
||||
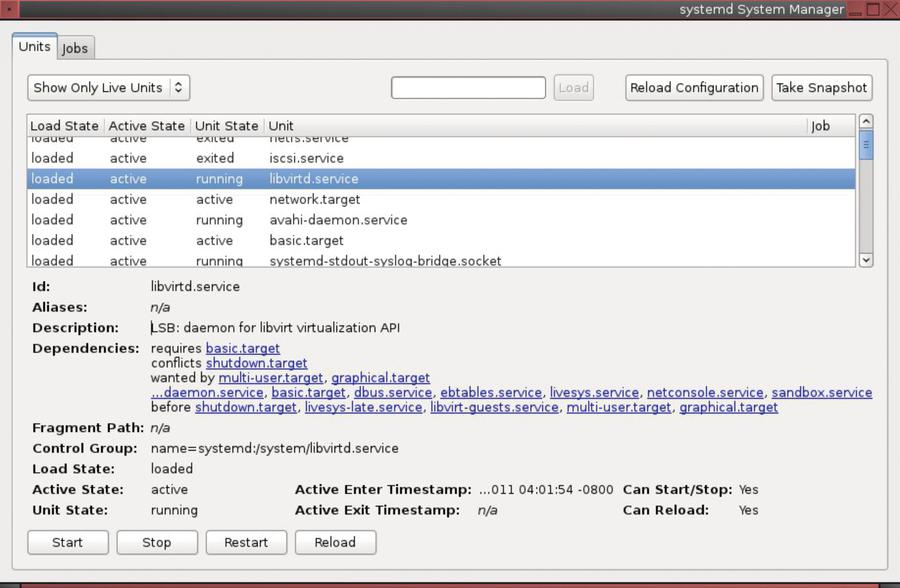
|
||||
|
||||
**存在一个 Systemd 的图形界面程序,即便它已有多年未被积极维护。**
|
||||
|
||||
### 日志文件:向 journald 问声好 ###
|
||||
|
||||
Systemd 的第二个主要部分是 journal 。这是个日志系统,类似于 syslog 但也有些显著区别。如果您是个 Unix 日志管理模式的 粉丝,准备好热血沸腾吧:这是个二进制日志,因此您不能使用常规的命令行文本处理工具来解析它。这个设计决定不出意料地在网上引起了激烈的争论,但它的确有些优点。例如,日志可以被更系统地组织,带有更多元数据,因此可以更容易地根据可执行文件名和进程号等过滤出信息。
|
||||
|
||||
要查看整个 journal,输入以下命令:
|
||||
|
||||
journalctl
|
||||
|
||||
像许多其他的 Systemd 命令一样,该命令将输出通过管道的方式引向 **less** 程序,因此您可以使用空格键向下滚动,“/”(斜杠)键查找,以及其他熟悉的快捷键。您也能在此看到少许颜色,像红色的警告及错误信息。
|
||||
|
||||
以上命令会输出很多信息。为了限制其只输出当前启动的消息,使用如下命令:
|
||||
|
||||
journalctl -b
|
||||
|
||||
这就是 Systemd 大放异彩的地方!您想查看自上次启动以来的全部消息吗?试试 **journalctl -b -1** 吧。再上一次的?用 **-2** 替换 **-1** 吧。那自某个具体时间,例如2014年10月24日16:38以来的呢?
|
||||
|
||||
journalctl -b --since=”2014-10-24 16:38”
|
||||
|
||||
即便您对二进制日志感到遗憾,那依然是个有用的特性,并且对许多系统管理员来说,构建类似的过滤器比起写正则表达式而言容易多了。
|
||||
|
||||
我们已经可以根据特定的时间来准确查找日志了,那可以根据特定程序吗?对单元而言,试试这个:
|
||||
|
||||
journalctl -u gdm.service
|
||||
|
||||
(注意:这是个查看 X server 产生的日志的好办法。)那根据特定的进程号?
|
||||
|
||||
journalctl _PID=890
|
||||
|
||||
您甚至可以请求只看某个可执行文件产生的消息:
|
||||
|
||||
journalctl /usr/bin/pulseaudio
|
||||
|
||||
若您想将输出的消息限制在某个优先级,可以使用 **-p** 选项。该选项参数为 0 的话只会显示紧急消息(也就是说,是时候向 **\$DEITY** 祈求保佑了),为 7 的话会显示所有消息,包括调试消息。请查看手册 (**man journalctl**) 获取更多关于优先级的信息。
|
||||
|
||||
值得指出的是,您也可以将多个选项结合在一起,若想查看在当前启动中由 GDM 服务输出的优先级数小于等于 3 的消息,请使用下述命令:
|
||||
|
||||
journalctl -u gdm.service -p 3 -b
|
||||
|
||||
最后,如果您仅仅想打开一个随 journal 持续更新的终端窗口,就像在没有 Systemd 时使用 tail 命令实现的那样,输入 **journalctl -f** 就好了。
|
||||
|
||||
|
||||
|
||||
**二进制日志并不流行,但 journal 的确有它的优点,如非常方便的信息查找及过滤。**
|
||||
|
||||
> ### 没有 Systemd 的生活?###
|
||||
>
|
||||
> 如果您就是完全不能接收 Systemd,您仍然有一些主流发现版中的选择。尤其是 Slackware,作为历史最为悠久的发行版,目前还没有做出改变,但它的主要开发者并没有将其从未来规划中移除。一些不出名的发行版也在坚持使用 SysVinit 。
|
||||
>
|
||||
> 但这又将持续多久呢?Gnome 正越来越依赖于 Systemd,其他的主流桌面环境也会步其后尘。这也是引起 BSD 社区一阵恐慌的原因:Systemd 与 Linux 内核紧密相连,导致在某种程度上,桌面环境正变得越来越不可移植。一种折中的解决方案也许会以 Uselessd ([http://uselessd.darknedgy.net][3]) 的形式到来:一种裁剪版的 Systemd,纯粹专注于启动和监控进程,而不消耗整个基础系统。
|
||||
>
|
||||
> 
|
||||
>
|
||||
> 若您不喜欢 Systemd,可以尝试一下 Gentoo 发行版,它将 Systemd 作为初始化工具的一种选择,但并不强制用户使用 Systemd。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/linux-101-get-the-most-out-of-systemd/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[Ricky-Gong](https://github.com/Ricky-Gong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
[1]:http://tinyurl.com/poorlennart
|
||||
[2]:http://tinyurl.com/m2e7mv8
|
||||
[3]:http://uselessd.darknedgy.net/
|
||||
Loading…
Reference in New Issue
Block a user