mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
commit
a591462b93
@ -1,52 +0,0 @@
|
||||
Translating by XLCYun.
|
||||
A Week With GNOME As My Linux Desktop: What They Get Right & Wrong - Page 4 - GNOME Settings
|
||||
================================================================================
|
||||
### Settings ###
|
||||
|
||||
There are a few specific KDE Control modules that I am going to pick at, mostly because they are so laughable horrible compared to their gnome counter-part that its honestly pathetic.
|
||||
|
||||
First one up? Printers.
|
||||
|
||||
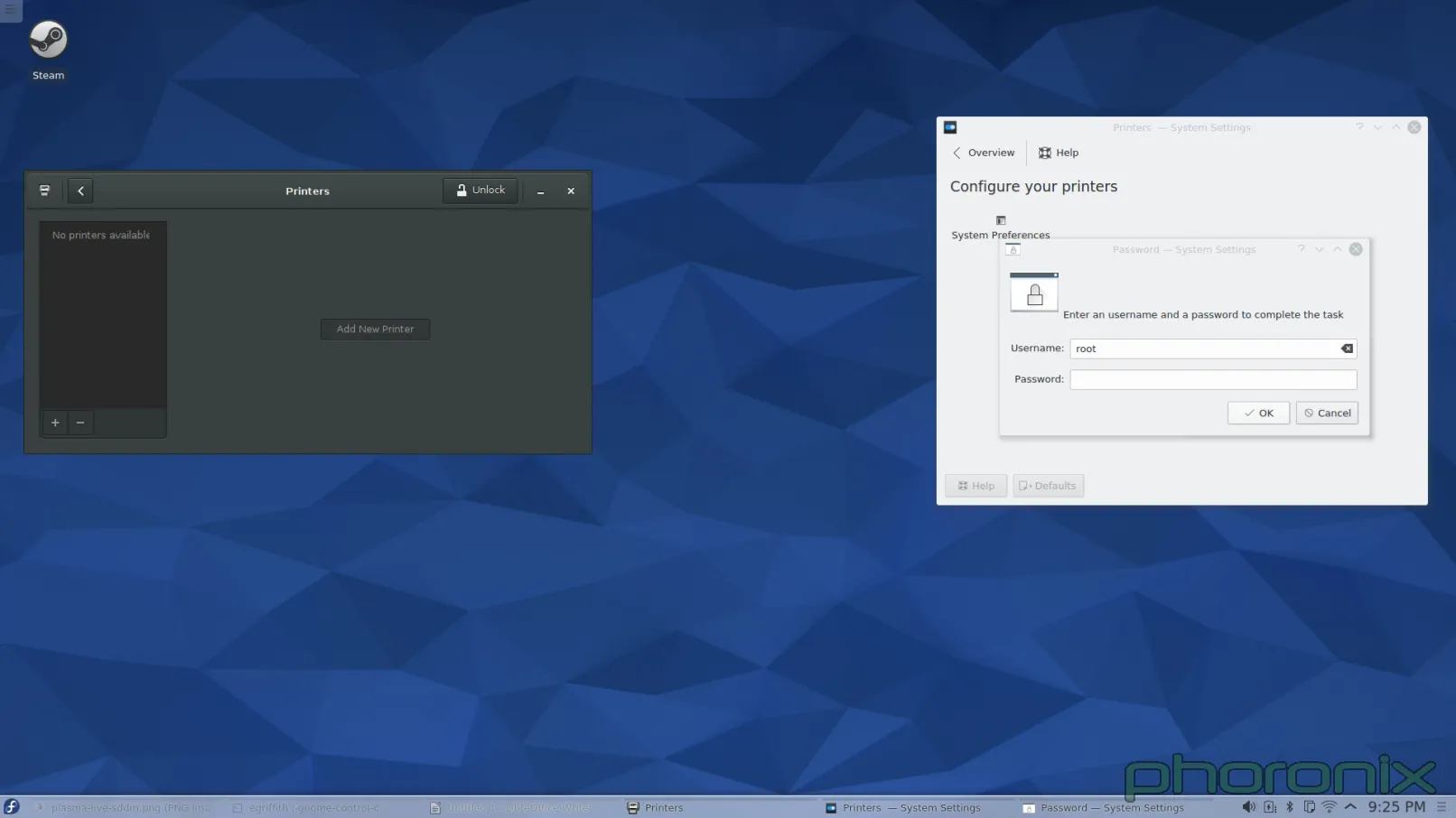
|
||||
|
||||
Gnome is on the left, KDE is on the right. You know what the difference is between the printer applet on the left, and the one on the right? When I opened up Gnome Control Center and hit "Printers" the applet popped up and nothing happened. When I opened up KDE System Settings and hit "Printers" I got a password prompt. Before I was even allowed to LOOK at the printers I had to give up ROOT'S password.
|
||||
|
||||
Let me just re-iterate that. In this, the days of PolicyKit and Logind, I am still being asked for Root's password for what should be a sudo operation. I didn't even SETUP root's password when I installed the system. I had to drop down to Konsole and run 'sudo passwd root' so that I could GIVE root a password so that I could go back into System Setting's printer applet and then give up root's password to even LOOK at what printers were available. Once I did that I got prompted for root's password AGAIN when I hit "Add Printer" then I got prompted for root's password AGAIN after I went through and selected a printer and driver. Three times I got asked for ROOT'S password just to add a printer to the system.
|
||||
|
||||
When I added a printer under Gnome I didn't get prompted for my SUDO password until I hit "Unlock" in the printer applet. I got asked once, then I never got asked again. KDE, I am begging you... Adopt Gnome's "Unlock" methodology. Do not prompt for a password until you really need one. Furthermore, whatever library is out there that allows for KDE applications to bypass PolicyKit / Logind (if its available) and prompt directly for root... Bin that code. If this was a multi-user system I either have to give up root's password, or be there every second of every day in order to put it in any time a user might have to update, change, or add a new printer. Both options are completely unacceptable.
|
||||
|
||||
One more thing...
|
||||
|
||||
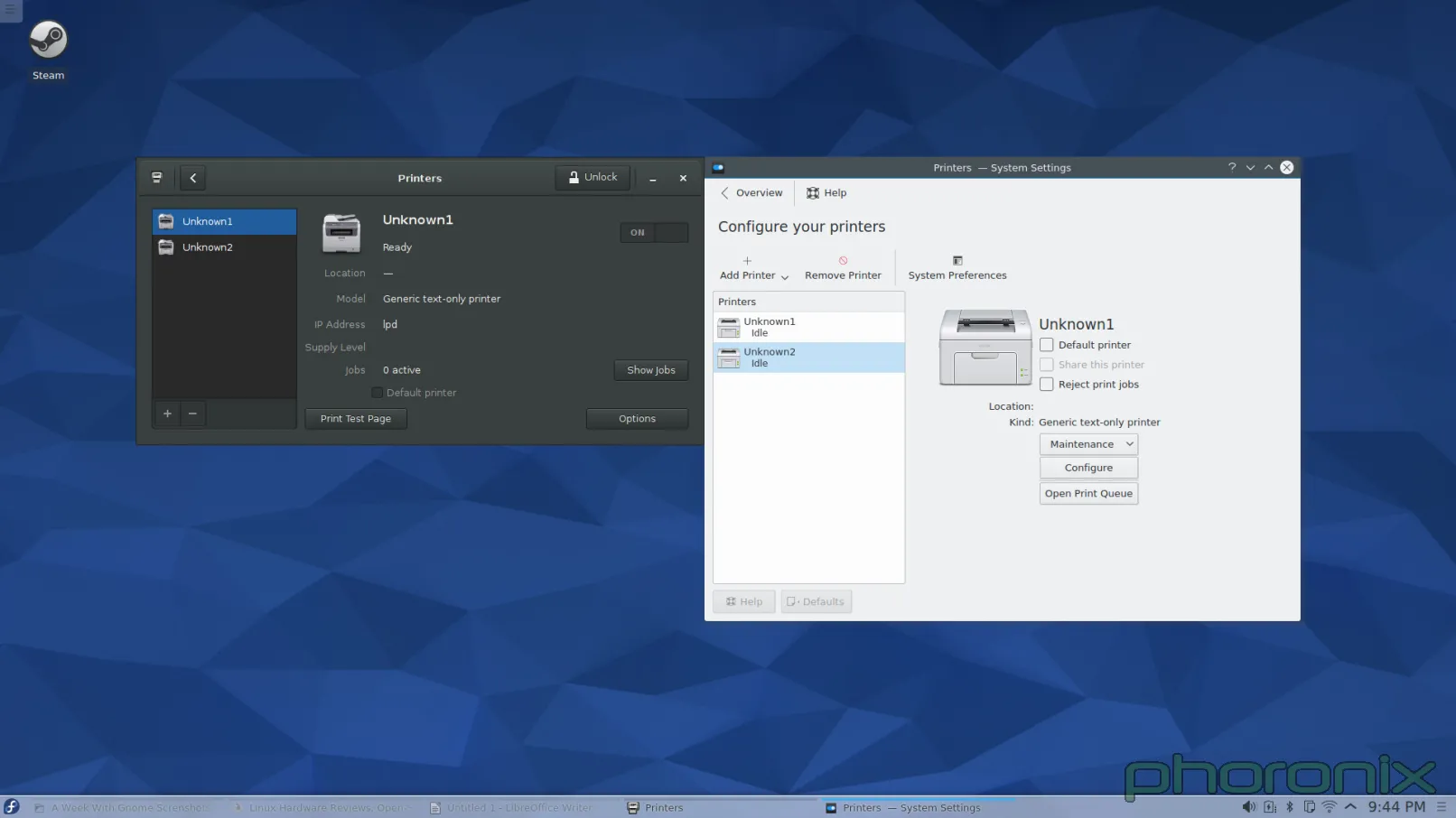
|
||||
|
||||
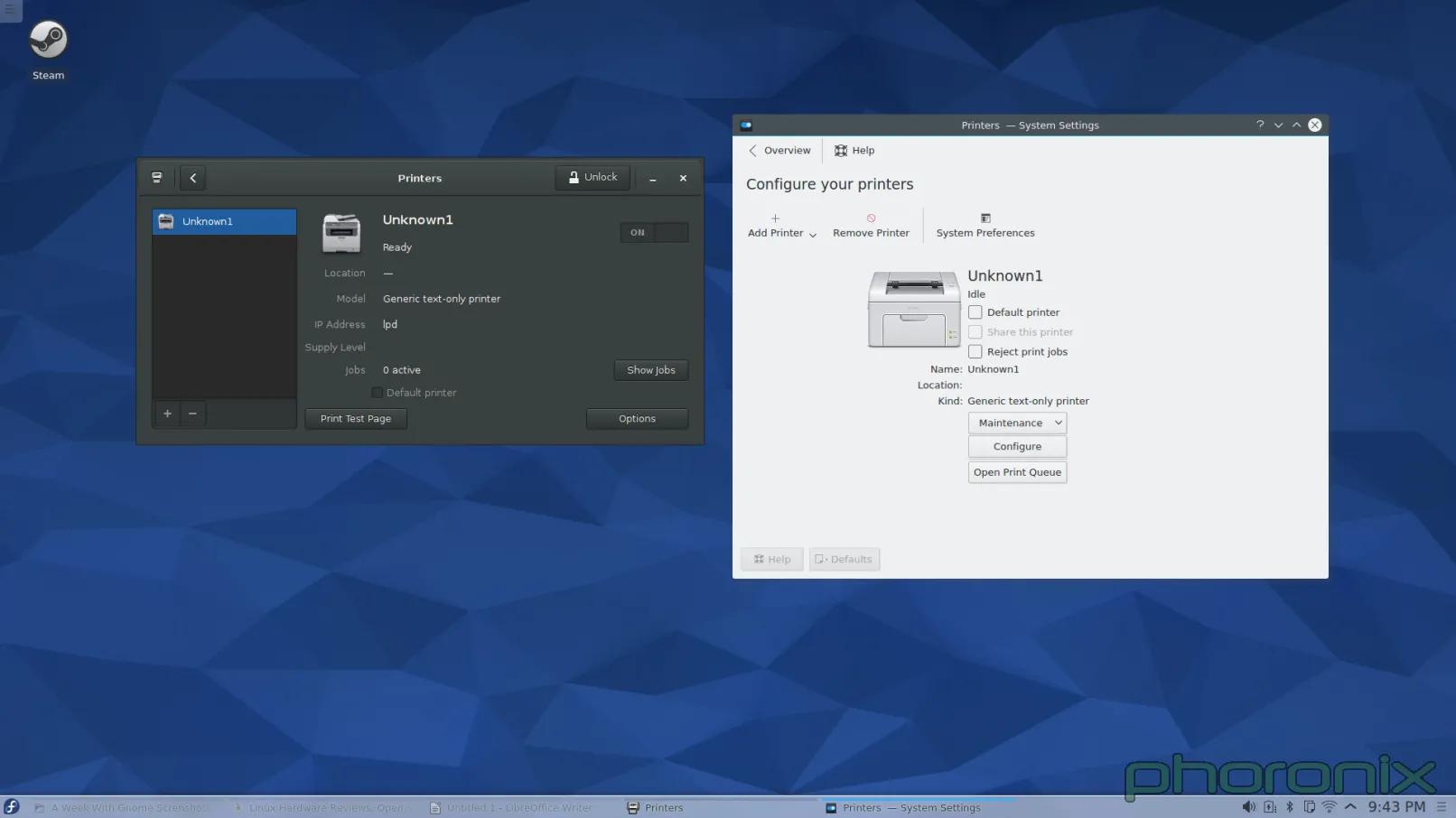
|
||||
|
||||
Question to the forums: What looks cleaner to you? I had this realization when I was writing this article: Gnome's applet makes it very clear where any additional printers are going to go, they set aside a column on the left to list them. Before I added a second printer to KDE, and it suddenly grew a left side column, I had this nightmare-image in my head of the applet just shoving another icon into the screen and them being listed out like preview images in a folder of pictures. I was pleasantly surprised to see that I was wrong but the fact that the applet just 'grew' another column that didn't exist before and drastically altered its presentation is not really 'good' either. It's a design that's confusing, shocking, and non-intuitive.
|
||||
|
||||
Enough about printers though... Next KDE System Setting that is up for my public stoning? Multimedia, Aka Phonon.
|
||||
|
||||
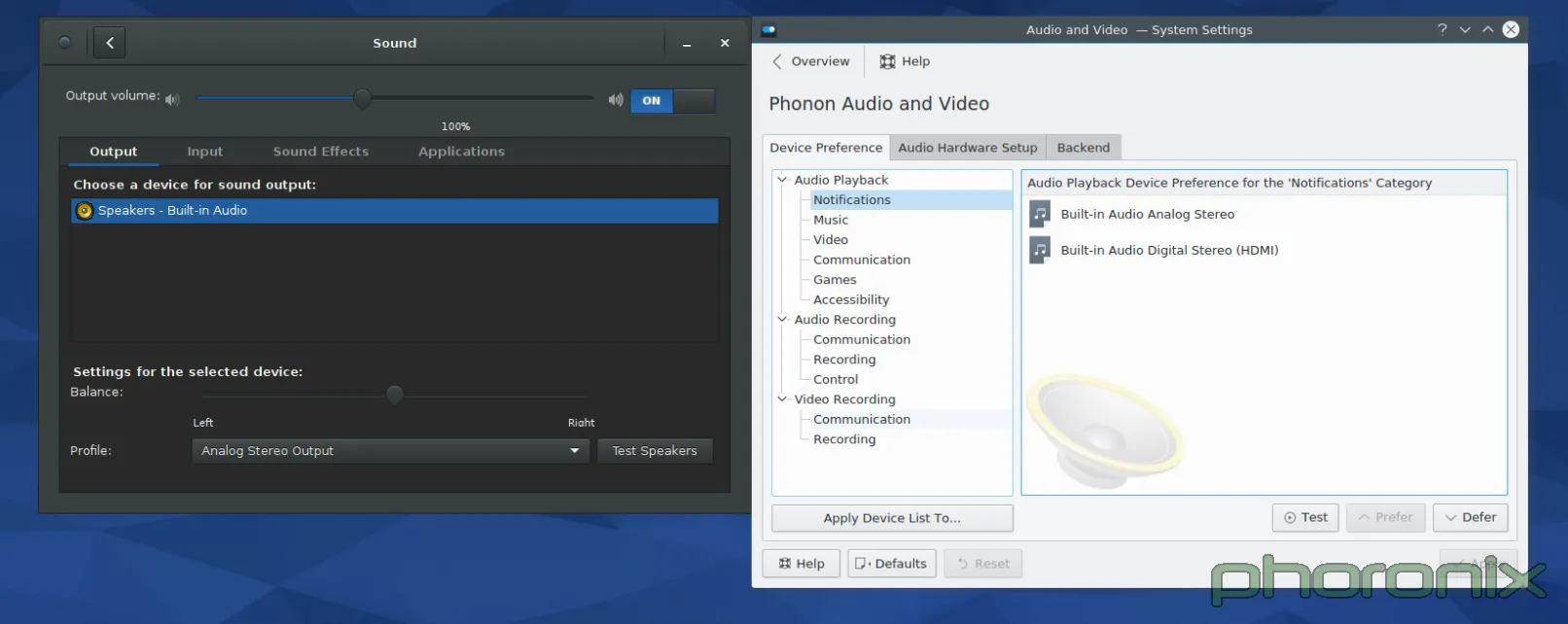
|
||||
|
||||
As always, Gnome's on the left, KDE is on the right. Let's just run through the Gnome setting first... The eyes go left to right, top to bottom, right? So let's do the same. First up: volume control slider. The blue hint against the empty bar with 100% clearly marked removes all confusion about which way is "volume up." Immediately after the slider is an easy On/Off toggle that functions a mute on/off. Points to Gnome for remembering what the volume was set to BEFORE I muted sound, and returning to that same level AFTER I press volume-up to un-mute. Kmixer, you amnesiac piece of crap, I wish I could say as much about you.
|
||||
|
||||
Moving on! Tabbed options for Output, Input and Applications? With per application volume controls within easy reach? Gnome I love you more and more with every passing second. Balance options, sound profiles, and a clearly marked "Test Speakers" option.
|
||||
|
||||
I'm not sure how this could have been implemented in a cleaner, more concise way. Yes, it's just a Gnome-ized Pavucontrol but I think that's the point. Pavucontrol got it mostly right to begin with, the Sound applet in Gnome Control Center just refines it slightly to make it even closer to perfect.
|
||||
|
||||
Phonon, you're up. And let me start by saying: What the fsck am I looking at? -I- get that I am looking at the priority list for the audio devices on the system, but the way it is presented is a bit of a nightmare. Also where are the things the user probably cares about? A priority list is a great thing to have, it SHOULD be available, but it's something the user messes with once or twice and then never touches again. It's not important, or common, enough to warrant being front and center. Where's the volume slider? Where's per application controls? The things that users will be using more frequently? Well.. those are under Kmix, a separate program, with its own settings and configuration... not under the System Settings... which kind of makes System Settings a bit of a misnomer. And in that same vein, Let's hop over to network settings.
|
||||
|
||||
|
||||
|
||||
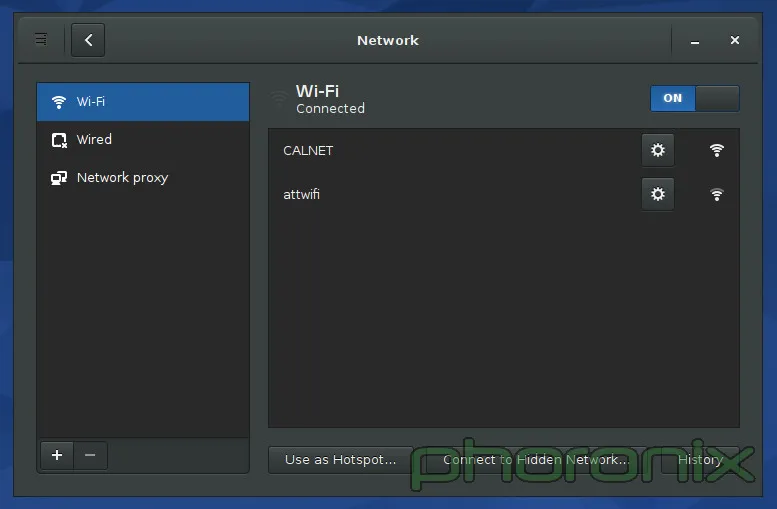
Presented above is the Gnome Network Settings. KDE's isn't included because of the reason I'm about to hit on. If you go to KDE's System Settings and hit any of the three options under the "Network" Section you get tons of options: Bluetooth settings, default username and password for Samba shares (Seriously, "Connectivity" only has 2 options: Username and password for SMB shares. How the fsck does THAT deserve the all-inclusive title "Connectivity"?), controls for Browser Identification (which only work for Konqueror...a dead project), proxy settings, etc... Where's my wifi settings? They aren't there. Where are they? Well, they are in the network applet's private settings... not under Network Settings...
|
||||
|
||||
KDE, you're killing me. You have "System Settings" USE IT!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,409 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
How to monitor NGINX - Part 1
|
||||
================================================================================
|
||||

|
||||
|
||||
### What is NGINX? ###
|
||||
|
||||
[NGINX][1] (pronounced “engine X”) is a popular HTTP server and reverse proxy server. As an HTTP server, NGINX serves static content very efficiently and reliably, using relatively little memory. As a [reverse proxy][2], it can be used as a single, controlled point of access for multiple back-end servers or for additional applications such as caching and load balancing. NGINX is available as a free, open-source product or in a more full-featured, commercially distributed version called NGINX Plus.
|
||||
|
||||
NGINX can also be used as a mail proxy and a generic TCP proxy, but this article does not directly address NGINX monitoring for these use cases.
|
||||
|
||||
### Key NGINX metrics ###
|
||||
|
||||
By monitoring NGINX you can catch two categories of issues: resource issues within NGINX itself, and also problems developing elsewhere in your web infrastructure. Some of the metrics most NGINX users will benefit from monitoring include **requests per second**, which provides a high-level view of combined end-user activity; **server error rate**, which indicates how often your servers are failing to process seemingly valid requests; and **request processing time**, which describes how long your servers are taking to process client requests (and which can point to slowdowns or other problems in your environment).
|
||||
|
||||
More generally, there are at least three key categories of metrics to watch:
|
||||
|
||||
- Basic activity metrics
|
||||
- Error metrics
|
||||
- Performance metrics
|
||||
|
||||
Below we’ll break down a few of the most important NGINX metrics in each category, as well as metrics for a fairly common use case that deserves special mention: using NGINX Plus for reverse proxying. We will also describe how you can monitor all of these metrics with your graphing or monitoring tools of choice.
|
||||
|
||||
This article references metric terminology [introduced in our Monitoring 101 series][3], which provides a framework for metric collection and alerting.
|
||||
|
||||
#### Basic activity metrics ####
|
||||
|
||||
Whatever your NGINX use case, you will no doubt want to monitor how many client requests your servers are receiving and how those requests are being processed.
|
||||
|
||||
NGINX Plus can report basic activity metrics exactly like open-source NGINX, but it also provides a secondary module that reports metrics slightly differently. We discuss open-source NGINX first, then the additional reporting capabilities provided by NGINX Plus.
|
||||
|
||||
**NGINX**
|
||||
|
||||
The diagram below shows the lifecycle of a client connection and how the open-source version of NGINX collects metrics during a connection.
|
||||
|
||||

|
||||
|
||||
Accepts, handled, and requests are ever-increasing counters. Active, waiting, reading, and writing grow and shrink with request volume.
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts</td>
|
||||
<td style="text-align: left;">Count of client connections attempted by NGINX</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">handled</td>
|
||||
<td style="text-align: left;">Count of successful client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped (calculated)</td>
|
||||
<td style="text-align: left;">Count of dropped connections (accepts – handled)</td>
|
||||
<td style="text-align: left;">Work: Errors*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests</td>
|
||||
<td style="text-align: left;">Count of client requests</td>
|
||||
<td style="text-align: left;">Work: Throughput</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan="3" style="text-align: left;">*<em>Strictly speaking, dropped connections is <a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics">a metric of resource saturation</a>, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as <a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics">a work metric</a>.</em></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
The **accepts** counter is incremented when an NGINX worker picks up a request for a connection from the OS, whereas **handled** is incremented when the worker actually gets a connection for the request (by establishing a new connection or reusing an open one). These two counts are usually the same—any divergence indicates that connections are being **dropped**, often because a resource limit, such as NGINX’s [worker_connections][4] limit, has been reached.
|
||||
|
||||
Once NGINX successfully handles a connection, the connection moves to an **active** state, where it remains as client requests are processed:
|
||||
|
||||
Active state
|
||||
|
||||
- **Waiting**: An active connection may also be in a Waiting substate if there is no active request at the moment. New connections can bypass this state and move directly to Reading, most commonly when using “accept filter” or “deferred accept”, in which case NGINX does not receive notice of work until it has enough data to begin working on the response. Connections will also be in the Waiting state after sending a response if the connection is set to keep-alive.
|
||||
- **Reading**: When a request is received, the connection moves out of the waiting state, and the request itself is counted as Reading. In this state NGINX is reading a client request header. Request headers are lightweight, so this is usually a fast operation.
|
||||
- **Writing**: After the request is read, it is counted as Writing, and remains in that state until a response is returned to the client. That means that the request is Writing while NGINX is waiting for results from upstream systems (systems “behind” NGINX), and while NGINX is operating on the response. Requests will often spend the majority of their time in the Writing state.
|
||||
|
||||
Often a connection will only support one request at a time. In this case, the number of Active connections == Waiting connections + Reading requests + Writing requests. However, the newer SPDY and HTTP/2 protocols allow multiple concurrent requests/responses to be multiplexed over a connection, so Active may be less than the sum of Waiting, Reading, and Writing. (As of this writing, NGINX does not support HTTP/2, but expects to add support during 2015.)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
As mentioned above, all of open-source NGINX’s metrics are available within NGINX Plus, but Plus can also report additional metrics. The section covers the metrics that are only available from NGINX Plus.
|
||||
|
||||

|
||||
|
||||
Accepted, dropped, and total are ever-increasing counters. Active, idle, and current track the current number of connections or requests in each of those states, so they grow and shrink with request volume.
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepted</td>
|
||||
<td style="text-align: left;">Count of client connections attempted by NGINX</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped</td>
|
||||
<td style="text-align: left;">Count of dropped connections</td>
|
||||
<td style="text-align: left;">Work: Errors*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">idle</td>
|
||||
<td style="text-align: left;">Client connections with zero current requests</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">total</td>
|
||||
<td style="text-align: left;">Count of client requests</td>
|
||||
<td style="text-align: left;">Work: Throughput</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan="3" style="text-align: left;">*<em>Strictly speaking, dropped connections is a metric of resource saturation, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as a work metric.</em></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
The **accepted** counter is incremented when an NGINX Plus worker picks up a request for a connection from the OS. If the worker fails to get a connection for the request (by establishing a new connection or reusing an open one), then the connection is dropped and **dropped** is incremented. Ordinarily connections are dropped because a resource limit, such as NGINX Plus’s [worker_connections][4] limit, has been reached.
|
||||
|
||||
**Active** and **idle** are the same as “active” and “waiting” states in open-source NGINX as described [above][5], with one key exception: in open-source NGINX, “waiting” falls under the “active” umbrella, whereas in NGINX Plus “idle” connections are excluded from the “active” count. **Current** is the same as the combined “reading + writing” states in open-source NGINX.
|
||||
|
||||
**Total** is a cumulative count of client requests. Note that a single client connection can involve multiple requests, so this number may be significantly larger than the cumulative number of connections. In fact, (total / accepted) yields the average number of requests per connection.
|
||||
|
||||
**Metric differences between Open-Source and Plus**
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;">NGINX (open-source)</th>
|
||||
<th style="text-align: left;">NGINX Plus</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts</td>
|
||||
<td style="text-align: left;">accepted</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped must be calculated</td>
|
||||
<td style="text-align: left;">dropped is reported directly</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">reading + writing</td>
|
||||
<td style="text-align: left;">current</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">waiting</td>
|
||||
<td style="text-align: left;">idle</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active (includes “waiting” states)</td>
|
||||
<td style="text-align: left;">active (excludes “idle” states)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests</td>
|
||||
<td style="text-align: left;">total</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**Metric to alert on: Dropped connections**
|
||||
|
||||
The number of connections that have been dropped is equal to the difference between accepts and handled (NGINX) or is exposed directly as a standard metric (NGINX Plus). Under normal circumstances, dropped connections should be zero. If your rate of dropped connections per unit time starts to rise, look for possible resource saturation.
|
||||
|
||||

|
||||
|
||||
**Metric to alert on: Requests per second**
|
||||
|
||||
Sampling your request data (**requests** in open-source, or **total** in Plus) with a fixed time interval provides you with the number of requests you’re receiving per unit of time—often minutes or seconds. Monitoring this metric can alert you to spikes in incoming web traffic, whether legitimate or nefarious, or sudden drops, which are usually indicative of problems. A drastic change in requests per second can alert you to problems brewing somewhere in your environment, even if it cannot tell you exactly where those problems lie. Note that all requests are counted the same, regardless of their URLs.
|
||||
|
||||

|
||||
|
||||
**Collecting activity metrics**
|
||||
|
||||
Open-source NGINX exposes these basic server metrics on a simple status page. Because the status information is displayed in a standardized form, virtually any graphing or monitoring tool can be configured to parse the relevant data for analysis, visualization, or alerting. NGINX Plus provides a JSON feed with much richer data. Read the companion post on [NGINX metrics collection][6] for instructions on enabling metrics collection.
|
||||
|
||||
#### Error metrics ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">4xx codes</td>
|
||||
<td style="text-align: left;">Count of client errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX logs, NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes</td>
|
||||
<td style="text-align: left;">Count of server errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX logs, NGINX Plus</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
NGINX error metrics tell you how often your servers are returning errors instead of producing useful work. Client errors are represented by 4xx status codes, server errors with 5xx status codes.
|
||||
|
||||
**Metric to alert on: Server error rate**
|
||||
|
||||
Your server error rate is equal to the number of 5xx errors divided by the total number of [status codes][7] (1xx, 2xx, 3xx, 4xx, 5xx), per unit of time (often one to five minutes). If your error rate starts to climb over time, investigation may be in order. If it spikes suddenly, urgent action may be required, as clients are likely to report errors to the end user.
|
||||
|
||||

|
||||
|
||||
A note on client errors: while it is tempting to monitor 4xx, there is limited information you can derive from that metric since it measures client behavior without offering any insight into particular URLs. In other words, a change in 4xx could be noise, e.g. web scanners blindly looking for vulnerabilities.
|
||||
|
||||
**Collecting error metrics**
|
||||
|
||||
Although open-source NGINX does not make error rates immediately available for monitoring, there are at least two ways to capture that information:
|
||||
|
||||
- Use the expanded status module available with commercially supported NGINX Plus
|
||||
- Configure NGINX’s log module to write response codes in access logs
|
||||
|
||||
Read the companion post on NGINX metrics collection for detailed instructions on both approaches.
|
||||
|
||||
#### Performance metrics ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">request time</td>
|
||||
<td style="text-align: left;">Time to process each request, in seconds</td>
|
||||
<td style="text-align: left;">Work: Performance</td>
|
||||
<td style="text-align: left;">NGINX logs</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**Metric to alert on: Request processing time**
|
||||
|
||||
The request time metric logged by NGINX records the processing time for each request, from the reading of the first client bytes to fulfilling the request. Long response times can point to problems upstream.
|
||||
|
||||
**Collecting processing time metrics**
|
||||
|
||||
NGINX and NGINX Plus users can capture data on processing time by adding the $request_time variable to the access log format. More details on configuring logs for monitoring are available in our companion post on [NGINX metrics collection][8].
|
||||
|
||||
#### Reverse proxy metrics ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">Active connections by upstream server</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes by upstream server</td>
|
||||
<td style="text-align: left;">Server errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">Available servers per upstream group</td>
|
||||
<td style="text-align: left;">Servers passing health checks</td>
|
||||
<td style="text-align: left;">Resource: Availability</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
One of the most common ways to use NGINX is as a [reverse proxy][9]. The commercially supported NGINX Plus exposes a large number of metrics about backend (or “upstream”) servers, which are relevant to a reverse proxy setup. This section highlights a few of the key upstream metrics that are available to users of NGINX Plus.
|
||||
|
||||
NGINX Plus segments its upstream metrics first by group, and then by individual server. So if, for example, your reverse proxy is distributing requests to five upstream web servers, you can see at a glance whether any of those individual servers is overburdened, and also whether you have enough healthy servers in the upstream group to ensure good response times.
|
||||
|
||||
**Activity metrics**
|
||||
|
||||
The number of **active connections per upstream server** can help you verify that your reverse proxy is properly distributing work across your server group. If you are using NGINX as a load balancer, significant deviations in the number of connections handled by any one server can indicate that the server is struggling to process requests in a timely manner or that the load-balancing method (e.g., [round-robin or IP hashing][10]) you have configured is not optimal for your traffic patterns
|
||||
|
||||
**Error metrics**
|
||||
|
||||
Recall from the error metric section above that 5xx (server error) codes are a valuable metric to monitor, particularly as a share of total response codes. NGINX Plus allows you to easily extract the number of **5xx codes per upstream server**, as well as the total number of responses, to determine that particular server’s error rate.
|
||||
|
||||
**Availability metrics**
|
||||
|
||||
For another view of the health of your web servers, NGINX also makes it simple to monitor the health of your upstream groups via the total number of **servers currently available within each group**. In a large reverse proxy setup, you may not care very much about the current state of any one server, just as long as your pool of available servers is capable of handling the load. But monitoring the total number of servers that are up within each upstream group can provide a very high-level view of the aggregate health of your web servers.
|
||||
|
||||
**Collecting upstream metrics**
|
||||
|
||||
NGINX Plus upstream metrics are exposed on the internal NGINX Plus monitoring dashboard, and are also available via a JSON interface that can serve up metrics into virtually any external monitoring platform. See examples in our companion post on [collecting NGINX metrics][11].
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this post we’ve touched on some of the most useful metrics you can monitor to keep tabs on your NGINX servers. If you are just getting started with NGINX, monitoring most or all of the metrics in the list below will provide good visibility into the health and activity levels of your web infrastructure:
|
||||
|
||||
- [Dropped connections][12]
|
||||
- [Requests per second][13]
|
||||
- [Server error rate][14]
|
||||
- [Request processing time][15]
|
||||
|
||||
Eventually you will recognize additional, more specialized metrics that are particularly relevant to your own infrastructure and use cases. Of course, what you monitor will depend on the tools you have and the metrics available to you. See the companion post for [step-by-step instructions on metric collection][16], whether you use NGINX or NGINX Plus.
|
||||
|
||||
At Datadog, we have built integrations with both NGINX and NGINX Plus so that you can begin collecting and monitoring metrics from all your web servers with a minimum of setup. Learn how to monitor NGINX with Datadog [in this post][17], and get started right away with [a free trial of Datadog][18].
|
||||
|
||||
### Acknowledgments ###
|
||||
|
||||
Many thanks to the NGINX team for reviewing this article prior to publication and providing important feedback and clarifications.
|
||||
|
||||
----------
|
||||
|
||||
Source Markdown for this post is available [on GitHub][19]. Questions, corrections, additions, etc.? Please [let us know][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -0,0 +1,54 @@
|
||||
将GNOME作为我的Linux桌面的一周: 他们做对的与做错的 - 第四节 - GNOME设置
|
||||
================================================================================
|
||||
### Settings设置 ###
|
||||
|
||||
在这我要挑一挑几个特定KDE控制模块的毛病,大部分原因是因为相比它们的对手GNOME来说,糟糕得太可笑,实话说,真是悲哀。
|
||||
|
||||
第一个接招的?打印机。
|
||||
|
||||

|
||||
|
||||
GNOME在左,KDE在右。你知道左边跟右边的打印程序有什么区别吗?当我在GNOME控制中心打开“打印机”时,程序窗口弹出来了,之后没有也没发生。而当我在KDE系统设置打开“打印机”时,我收到了一条密码提示。甚至我都没能看一眼打印机呢,我就必须先交出ROOT密码。
|
||||
|
||||
让我再重复一遍。在今天,PolicyKit和Logind的日子里,对一个应该是sudo的操作,我依然被询问要求ROOT的密码。我安装系统的时候甚至都没设置root密码。所以我必须跑到Konsole去,然后运行'sudo passwd root'命令,这样我才能给root设一个密码,这样我才能回到系统设置中的打印程序,然后交出root密码,然后仅仅是看一看哪些打印机可用。完成了这些工作后,当我点击“添加打印机”时,我再次收到请求ROOT密码的提示,当我解决了它后再选择一个打印机和驱动时,我再次收到请求ROOT密码的提示。仅仅是为了添加一个打印机到系统我就收到三次密码请求。
|
||||
|
||||
而在GNOME下添加打印机,在点击打印机程序中的”解锁“之前,我没有收到任何请求SUDO密码的提示。整个过程我只被请求过一次,仅此而已。KDE,求你了……采用GNOME的”解锁“模式吧。不到一定需要的时候不要发出提示。还有,不管是哪个库,只要它允许KDE应用程序绕过PolicyKit/Logind(如果有的话)并直接请求ROOT权限……那就把它封进箱里吧。如果这是个多用户系统,那我要么必须交出ROOT密码,要么我必须时时刻刻呆着以免有一个用户需要升级、更改或添加一个新的打印机。而这两种情况都是完全无法接受的。
|
||||
|
||||
有还一件事……
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
给论坛的问题:怎么样看起来更简洁?我在写这篇文章时意识到:当有任何的附加打印机准备好时,Gnome打印机程序会把过程做得非常简洁,它们在左边上放了一个竖直栏来列出这些打印机。而我在KDE添加第二台打印机时,它突然增加出一个左边栏来。而在添加之前,我脑海中已经有了一个恐怖的画面它会像图片文件夹显示预览图一样,直接插入另外一个图标到界面里去。我很高兴也很惊讶的看到我是错的。但是事实是它直接”长出”另外一个从末存在的竖直栏,彻底改变了它的界面布局,而这样也称不上“好”。终究还是一种令人困惑,奇怪而又不直观的设计。
|
||||
|
||||
打印机说得够多了……下一个接受我公开石刑的KDE系统设置是?多媒体,即Phonon。
|
||||
|
||||

|
||||
|
||||
一如既往,GNOME在左边,KDE在右边。让我们先看看GNOME的系统设置先……眼睛从左到右,从上到下,对吧?来吧,就这样做。首先:音量控制滑条。滑条中的蓝色条与空白条百分百清晰地消除了哪边是“音量增加”的困惑。在音量控制条后马上就是一个On/Off开关,用来开关静音功能。Gnome的再次得分在于静音后能记住当前设置的音量,而在点击音量增加按钮取消静音后能回到原来设置的音量中来。Kmixer,你个健忘的垃圾,我真的希望我能多讨论你。
|
||||
|
||||
|
||||
继续!输入输出和应用程序的标签选项?每一个应用程序的音量随时可控?Gnome,每过一秒,我爱你越深。均衡的选项设置,声音配置,和清晰地标上标志的“测试麦克风”选项。
|
||||
|
||||
|
||||
|
||||
我不清楚它能否以一种更干净更简洁的设计实现。是的,它只是一个Gnome化的Pavucontrol,但我想这就是重要的地方。Pavucontrol在这方面几乎完全做对了,Gnome控制中心中的“声音”应用程序的改善使它向完美更进了一步。
|
||||
|
||||
Phonon,该你上了。但开始前我想说:我TM看到的是什么?我知道我看到的是音频设备的权限列表,但是它呈现的方式有点太坑。还有,那些用户可能关心的那些东西哪去了?拥有一个权限列表当然很好,它也应该存在,但问题是权限列表属于那种用户乱搞一两次之后就不会再碰的东西。它还不够重要,或者说常用到可以直接放在正中间位置的程度。音量控制滑块呢?对每个应用程序的音量控制功能呢?那些用户使用最频繁的东西呢?好吧,它们在Kmix中,一个分离的程序,拥有它自己的配置选项……而不是在系统设置下……这样真的让“系统设置”这个词变得有点用词不当。
|
||||
|
||||

|
||||
|
||||
上面展示的Gnome的网络设置。KDE的没有展示,原因就是我接下来要吐槽的内容了。如果你进入KDE的系统设置里,然后点击“网络”区域中三个选项中的任何一个,你会得到一大堆的选项:蓝牙设置,Samba分享的默认用户名和密码(说真的,“连通性(Connectivity)”下面只有两个选项:SMB的用户名和密码。TMD怎么就配得上“连通性”这么大的词?),浏览器身份验证控制(只有Konqueror能用……一个已经倒闭的项目),代理设置,等等……我的wifi设置哪去了?它们没在这。哪去了?好吧,它们在网络应用程序的设置里面……而不是在网络设置里……
|
||||
|
||||
KDE,你这是要杀了我啊,你有“系统设置”当凶器,拿着它动手吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
416
translated/tech/20150717 How to monitor NGINX- Part 1.md
Normal file
416
translated/tech/20150717 How to monitor NGINX- Part 1.md
Normal file
@ -0,0 +1,416 @@
|
||||
如何监控 NGINX - 第1部分
|
||||
================================================================================
|
||||

|
||||
|
||||
### NGINX 是什么? ###
|
||||
|
||||
[NGINX][1] (发音为 “engine X”) 是一种流行的 HTTP 和反向代理服务器。作为一个 HTTP 服务器,NGINX 提供静态内容非常高效可靠,使用较少的内存。作为[反向代理][2],它可以用作一个单一的控制器来为其他应用代理至后端的多个服务器上,如高速缓存和负载平衡。NGINX 是作为一个免费,开源的产品并有更全的功能,商业版的叫 NGINX Plus。
|
||||
|
||||
NGINX 也可以用作邮件代理和通用的 TCP 代理,但本文并不直接说明对 NGINX 的这些用例做监控。
|
||||
|
||||
### NGINX 主要指标 ###
|
||||
|
||||
通过监控 NGINX 可以捕捉两类问题:NGINX 本身的资源问题,也有很多问题会出现在你的基础网络设施处。大多数 NGINX 用户受益于以下指标的监控,包括**requests per second**,它提供了一个所有用户活动的高级视图;**server error rate** ,这表明你的服务器已经多长没有处理看似有效的请求;还有**request processing time**,这说明你的服务器处理客户端请求的总共时长(并且可以看出性能降低时或当前环境的其他问题)。
|
||||
|
||||
更一般地,至少有三个主要的指标类别来监视:
|
||||
|
||||
- 基本活动指标
|
||||
- 错误指标
|
||||
- 性能指标
|
||||
|
||||
下面我们将分析在每个类别中最重要的 NGINX 指标,以及用一个相当普遍的案例来说明,值得特别说明的是:使用 NGINX Plus 作反向代理。我们还将介绍如何使用图形工具或可选择的监控工具来监控所有的指标。
|
||||
|
||||
本文引用指标术语[介绍我们的监控在 101 系列][3],,它提供了指标收集和警告框架。
|
||||
|
||||
#### 基本活动指标 ####
|
||||
|
||||
无论你在怎样的情况下使用 NGINX,毫无疑问你要监视服务器接收多少客户端请求和如何处理这些请求。
|
||||
|
||||
NGINX Plus 上像开源 NGINX 一样可以报告基本活动指标,但它也提供了略有不同的辅助模块。我们首先讨论开源的 NGINX,再来说明 NGINX Plus 提供的其他指标的功能。
|
||||
|
||||
**NGINX**
|
||||
|
||||
下图显示了一个客户端连接,以及如何在连接过程中收集指标的活动周期在开源 NGINX 版本上。
|
||||
|
||||

|
||||
|
||||
接受,处理,增加请求的计数器。主动,等待,读,写增加和减少请求量。
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts</td>
|
||||
<td style="text-align: left;">Count of client connections attempted by NGINX</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">handled</td>
|
||||
<td style="text-align: left;">Count of successful client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped (calculated)</td>
|
||||
<td style="text-align: left;">Count of dropped connections (accepts – handled)</td>
|
||||
<td style="text-align: left;">Work: Errors*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests</td>
|
||||
<td style="text-align: left;">Count of client requests</td>
|
||||
<td style="text-align: left;">Work: Throughput</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan="3" style="text-align: left;">*<em>Strictly speaking, dropped connections is <a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics">a metric of resource saturation</a>, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as <a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics">a work metric</a>.</em></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
NGINX 进程接受 OS 的连接请求时**accepts** 计数器增加,而**handled** 是当实际的请求得到连接时(通过建立一个新的连接或重新使用一个空闲的)。这两个计数器的值通常都是相同的,表明连接正在被**dropped**,往往由于资源限制,如 NGINX 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
一旦 NGINX 成功处理一个连接时,连接会移动到**active**状态,然后保持为客户端请求进行处理:
|
||||
|
||||
Active 状态
|
||||
|
||||
- **Waiting**: 活动的连接也可以是一个 Waiting 子状态,如果有在此刻没有活动请求。新连接绕过这个状态并直接移动到读,最常见的是使用“accept filter” 和 “deferred accept”,在这种情况下,NGINX 不会接收进程的通知,直到它具有足够的数据来开始响应工作。如果连接设置为 keep-alive ,连接在发送响应后将处于等待状态。
|
||||
|
||||
- **Reading**: 当接收到请求时,连接移出等待状态,并且该请求本身也被视为 Reading。在这种状态下NGINX 正在读取客户端请求首部。请求首部是比较少的,因此这通常是一个快速的操作。
|
||||
|
||||
- **Writing**: 请求被读取之后,将其计为 Writing,并保持在该状态,直到响应返回给客户端。这意味着,该请求在 Writing 时, NGINX 同时等待来自负载均衡服务器的结果(系统“背后”的 NGINX),NGINX 也同时响应。请求往往会花费大量的时间在 Writing 状态。
|
||||
|
||||
通常,一个连接在同一时间只接受一个请求。在这种情况下,Active 连接的数目 == Waiting 连接 + Reading 请求 + Writing 请求。然而,较新的 SPDY 和 HTTP/2 协议允许多个并发请求/响应对被复用的连接,所以 Active 可小于 Waiting,Reading,Writing 的总和。 (在撰写本文时,NGINX 不支持 HTTP/2,但预计到2015年期间将会支持。)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
正如上面提到的,所有开源 NGINX 的指标在 NGINX Plus 中是可用的,但另外也提供其他的指标。本节仅说明了 NGINX Plus 可用的指标。
|
||||
|
||||
|
||||

|
||||
|
||||
接受,中断,总数是不断增加的。活动,空闲和已建立连接的,当前状态下每一个连接或请求的数量是随着请求量增加和收缩的。
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepted</td>
|
||||
<td style="text-align: left;">Count of client connections attempted by NGINX</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped</td>
|
||||
<td style="text-align: left;">Count of dropped connections</td>
|
||||
<td style="text-align: left;">Work: Errors*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">idle</td>
|
||||
<td style="text-align: left;">Client connections with zero current requests</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">total</td>
|
||||
<td style="text-align: left;">Count of client requests</td>
|
||||
<td style="text-align: left;">Work: Throughput</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan="3" style="text-align: left;">*<em>Strictly speaking, dropped connections is a metric of resource saturation, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as a work metric.</em></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
当 NGINX Plus 进程接受 OS 的连接请求时 **accepted** 计数器递增。如果进程请求连接失败(通过建立一个新的连接或重新使用一个空闲),则该连接断开 **dropped** 计数增加。通常连接被中断是因为资源限制,如 NGINX Plus 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
**Active** 和 **idle** 和开源 NGINX 的“active” 和 “waiting”状态是相同的,[如上所述][5],有一个不同的地方:在开源 NGINX 上,“waiting”状态包括在“active”中,而在 NGINX Plus 上“idle”的连接被排除在“active” 计数外。**Current** 和开源 NGINX 是一样的也是由“reading + writing” 状态组成。
|
||||
|
||||
|
||||
**Total** 为客户端请求的累积计数。请注意,单个客户端连接可涉及多个请求,所以这个数字可能会比连接的累计次数明显大。事实上,(total / accepted)是每个连接请求的平均数量。
|
||||
|
||||
**开源 和 Plus 之间指标的不同**
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;">NGINX (open-source)</th>
|
||||
<th style="text-align: left;">NGINX Plus</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts</td>
|
||||
<td style="text-align: left;">accepted</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped must be calculated</td>
|
||||
<td style="text-align: left;">dropped is reported directly</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">reading + writing</td>
|
||||
<td style="text-align: left;">current</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">waiting</td>
|
||||
<td style="text-align: left;">idle</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active (includes “waiting” states)</td>
|
||||
<td style="text-align: left;">active (excludes “idle” states)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests</td>
|
||||
<td style="text-align: left;">total</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**提醒指标: 中断连接**
|
||||
|
||||
被中断的连接数目等于接受和处理之差(NGINX),或被公开直接作为指标的标准(NGINX加)。在正常情况下,中断连接数应该是零。如果每秒中中断连接的速度开始上升,寻找资源可能用尽的地方。
|
||||
|
||||

|
||||
|
||||
**提醒指标: 每秒请求数**
|
||||
|
||||
提供你(开源中的**requests**或者 Plus 中**total**)固定时间间隔每秒或每分钟请求的平均数据。监测这个指标可以查看 Web 的输入流量的最大值,无论是合法的还是恶意的,有可能会突然下降,通常可以看出问题。每秒的请求若发生急剧变化可以提醒你出问题了,即使它不能告诉你确切问题的位置所在。请注意,所有的请求都算作是相同的,无论哪个 URLs。
|
||||
|
||||

|
||||
|
||||
**收集活动指标**
|
||||
|
||||
开源的 NGINX 提供了一个简单状态页面来显示基本的服务器指标。该状态信息以标准格式被显示,实际上任何图形或监控工具可以被配置去解析相关的数据为分析,可视化,或提醒而用。NGINX Plus 提供一个 JSON 接口来显示更多的数据。阅读[NGINX 指标收集][6]后来启用指标收集的功能。
|
||||
|
||||
#### 错误指标 ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">4xx codes</td>
|
||||
<td style="text-align: left;">Count of client errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX logs, NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes</td>
|
||||
<td style="text-align: left;">Count of server errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX logs, NGINX Plus</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
NGINX 错误指标告诉你服务器经常返回哪些错误,这也是有用的。客户端错误返回4XX状态码,服务器端错误返回5XX状态码。
|
||||
|
||||
**提醒指标: 服务器错误率**
|
||||
|
||||
服务器错误率等于5xx错误状态代码的总数除以[状态码][7](1XX,2XX,3XX,4XX,5XX)的总数,每单位时间(通常为一到五分钟)的数目。如果你的错误率随着时间的推移开始攀升,调查可能的原因。如果突然增加,可能需要采取紧急行动,因为客户端可能收到错误信息。
|
||||
|
||||

|
||||
|
||||
客户端收到错误时的注意事项:虽然监控4XX是很有用的,但从该指标中你仅可以捕捉有限的信息,因为它只是衡量客户的行为而不捕捉任何特殊的 URLs。换句话说,在4xx出现时只是相当于一点噪音,例如寻找漏洞的网络扫描仪。
|
||||
|
||||
**收集错误度量**
|
||||
|
||||
虽然开源 NGINX 不会监测错误率,但至少有两种方法可以捕获其信息:
|
||||
|
||||
- 使用商业支持的 NGINX Plus 提供的可扩展状态模块
|
||||
- 配置 NGINX 的日志模块将响应码写入访问日志
|
||||
|
||||
阅读关于 NGINX 指标收集的后两个方法的详细说明。
|
||||
|
||||
#### 性能指标 ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">request time</td>
|
||||
<td style="text-align: left;">Time to process each request, in seconds</td>
|
||||
<td style="text-align: left;">Work: Performance</td>
|
||||
<td style="text-align: left;">NGINX logs</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**提醒指标: 请求处理时间**
|
||||
|
||||
请求时间指标记录 NGINX 处理每个请求的时间,从第一个客户端的请求字节读出到完成请求。较长的响应时间可以将问题指向负载均衡服务器。
|
||||
|
||||
**收集处理时间指标**
|
||||
|
||||
NGINX 和 NGINX Plus 用户可以通过添加 $request_time 变量到访问日志格式中来捕捉处理时间数据。关于配置日志监控的更多细节在[NGINX指标收集][8]。
|
||||
|
||||
#### 反向代理指标 ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">Active connections by upstream server</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes by upstream server</td>
|
||||
<td style="text-align: left;">Server errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">Available servers per upstream group</td>
|
||||
<td style="text-align: left;">Servers passing health checks</td>
|
||||
<td style="text-align: left;">Resource: Availability</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
[反向代理][9]是 NGINX 最常见的使用方法之一。商业支持的 NGINX Plus 显示了大量有关后端(或“负载均衡”)的服务器指标,这是反向代理设置的。本节重点介绍了几个关键的负载均衡服务器的指标为 NGINX Plus 用户。
|
||||
|
||||
NGINX Plus 的负载均衡服务器指标首先是组的,然后是单个服务器的。因此,例如,你的反向代理将请求分配到五个 Web 负载均衡服务器上,你可以一眼看出是否有单个服务器压力过大,也可以看出负载均衡服务器组的健康状况,以确保良好的响应时间。
|
||||
|
||||
**活动指标**
|
||||
|
||||
**active connections per upstream server**的数量可以帮助你确认反向代理是否正确的分配工作到负载均衡服务器上。如果你正在使用 NGINX 作为负载均衡器,任何一台服务器处理的连接数有显著的偏差都可能表明服务器正在努力处理请求或你配置处理请求的负载均衡的方法(例如[round-robin or IP hashing][10])不是最适合你流量模式的。
|
||||
|
||||
**错误指标**
|
||||
|
||||
错误指标,上面所说的高于5XX(服务器错误)状态码,是监控指标中有价值的一个,尤其是响应码部分。 NGINX Plus 允许你轻松地提取每个负载均衡服务器 **5xx codes per upstream server**的数量,以及响应的总数量,以此来确定该特定服务器的错误率。
|
||||
|
||||
|
||||
**可用性指标**
|
||||
|
||||
对于 web 服务器的运行状况,另一种观点认为,NGINX 也可以很方便监控你的负载均衡服务器组的健康通过**servers currently available within each group**的总量。在一个大的反向代理上,你可能不会非常关心其中一个服务器的当前状态,就像你只要可用的服务器组能够处理当前的负载就行了。但监视负载均衡服务器组内的所有服务器可以提供一个高水平的图像来判断 Web 服务器的健康状况。
|
||||
|
||||
**收集负载均衡服务器的指标**
|
||||
|
||||
NGINX Plus 负载均衡服务器的指标显示在内部 NGINX Plus 的监控仪表盘上,并且也可通过一个JSON 接口来服务于所有外部的监控平台。在这儿看一个例子[收集 NGINX 指标][11]。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经谈到了一些有用的指标,你可以使用表格来监控 NGINX 服务器。如果你是刚开始使用 NGINX,下面提供了良好的网络基础设施的健康和活动的可视化工具来监控大部分或所有的指标:
|
||||
|
||||
- [Dropped connections][12]
|
||||
- [Requests per second][13]
|
||||
- [Server error rate][14]
|
||||
- [Request processing time][15]
|
||||
|
||||
最终,你会学到更多,更专业的衡量指标,尤其是关于你自己基础设施和使用情况的。当然,监控哪一项指标将取决于你可用的工具。参见[一步一步来说明指标收集][16],不管你使用 NGINX 还是 NGINX Plus。
|
||||
|
||||
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。了解如何用 NGINX Datadog来监控 [在本文中][17],并开始使用 [免费的 Datadog][18]。
|
||||
|
||||
### Acknowledgments ###
|
||||
|
||||
在文章发表之前非常感谢 NGINX 团队审阅这篇,并提供重要的反馈和说明。
|
||||
|
||||
----------
|
||||
|
||||
文章来源在这儿 [on GitHub][19]。问题,更正,补充等?请[告诉我们][20]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
Loading…
Reference in New Issue
Block a user