mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge branch 'master' into master
This commit is contained in:
commit
a58b4778e4
93
published/20171011 Why Linux Works.md
Normal file
93
published/20171011 Why Linux Works.md
Normal file
@ -0,0 +1,93 @@
|
||||
Linux 是如何成功运作的
|
||||
============================================================
|
||||
|
||||
_在大量金钱与围绕 Linux 激烈争夺的公司之间,真正给操作系统带来活力的正是那些开发者。_
|
||||
|
||||
事实证明上,Linux 社区是可行的,因为它本身无需太过担心社区的正常运作。尽管 Linux 已经在超级计算机、移动设备和云计算等多个领域占据了主导的地位,但 Linux 内核开发人员更多的是关注于代码本身,而不是其所在公司的利益。
|
||||
|
||||
这是一个出现在 [Dawn Foster 博士][8]研究 Linux 内核协作开发的博士论文中的重要结论。Foster 是在英特尔公司和<ruby>木偶实验室<rt>Puppet Labs</rt></ruby>的前任社区领导人,他写到,“很多人首先把自己看作是 Linux 内核开发者,其次才是作为一名雇员。”
|
||||
|
||||
随着大量的“<ruby>基金洗劫型<rt>foundation washing</rt></ruby>”公司开始侵蚀各种开源项目,意图在虚构的社区面具之下隐藏企业特权,但 Linux 依然设法保持了自身的纯粹。问题是这是怎么做到的?
|
||||
|
||||
### 跟随金钱的脚步
|
||||
|
||||
毕竟,如果有任何开源项目会进入到企业贪婪的视线中,那它一定是 Linux。早在 2008 年,[Linux 生态系统的估值已经达到了最高 250 亿美元][9]。最近 10 年,伴随着数量众多的云服务、移动端,以及大数据基础设施对于 Linux 的依赖,这一数据一定倍增了。甚至在像 Oracle 这样单独一个公司里,Linux 也能提供数十亿美元的价值。
|
||||
|
||||
那么就难怪有这样一个通过代码来影响 Linux 发展方向的必争之地。
|
||||
|
||||
在 [Linux 基金会的最新报道][10]中,让我们看看在过去一年中那些最活跃的 Linux 贡献者,以及他们所在的企业[像](https://linux.cn/article-8220-1.html)[“海龟”一样](https://en.wikipedia.org/wiki/Turtles_all_the_way_down)高高叠起。
|
||||
|
||||

|
||||
|
||||
这些企业花费大量的资金来雇佣开发者去为自由软件做贡献,并且每个企业都从这些投资中得到了回报。由于存在企业对 Linux 过度影响的潜在可能,导致一些人对引领 Linux 开发的 Linux 基金会[表示不满][11]。在像微软这样曾经的开源界宿敌的企业挥舞着钞票进入 Linux 基金会之后,这些批评言论正变得越来越响亮。
|
||||
|
||||
但这只是一位虚假的敌人,坦率地说,这是一个以前的敌人。
|
||||
|
||||
虽然企业为了利益而给 Linux 基金会投入资金已经是事实,不过这些赞助并不能收买基金会而影响到代码。在这个最伟大的开源社区中,金钱可以帮助招募到开发者,但这些开发者相比关注企业而更专注于代码。就像 Linux 基金会执行董事 [Jim Zemlin 所强调的][12]:
|
||||
|
||||
> “我们的项目中技术角色都是独立于企业的。没有人会在其提交的内容上标记他们的企业身份: 在 Linux 基金会的项目当中有关代码的讨论是最大声的。在我们的项目中,开发者可以从一个公司跳槽到另一个公司而不会改变他们在项目中所扮演的角色。之后企业或政府采用了这些代码而创造的价值,反过来又投资到项目上。这样的良性循环有益于所有人,并且也是我们的项目目标。”
|
||||
|
||||
任何读过 [Linus Torvalds 的][13] 的邮件列表评论的人都不可能认为他是个代表着这个或那个公司的人。这对于其他的杰出贡献者来说也是一样的。虽然他们几乎都是被大公司所雇佣,但是一般情况下,这些公司为这些开发者支付薪水让他们去做想做的开发,而且事实上,他们正在做他们想做的。
|
||||
|
||||
毕竟,很少有公司会有足够的耐心或承受风险来为资助一群新手 Linux 内核开发者,并等上几年,等他们中出现几个人可以贡献出质量足以打动内核团队的代码。所以他们选择雇佣已有的、值得信赖的开发者。正如 [2016 Linux 基金会报告][14]所写的,“无薪开发者的数量正在持续地缓慢下降,同时 Linux 内核开发被证明是一种雇主们所需要的日益有价值的技能,这确保了有经验的内核开发者不会长期停留在无薪阶段。”
|
||||
|
||||
然而,这样的信任是代码所带来的,并不是通过企业的金钱。因此没有一个 Linux 内核开发者会为眼前的金钱而丢掉他们已经积攒的信任,当出现新的利益冲突时妥协代码质量就很快失去信任。因此不存在这种问题。
|
||||
|
||||
### 不是康巴亚,就是权利的游戏,非此即彼
|
||||
|
||||
最终,Linux 内核开发就是一种身份认同, Foster 的研究是这样认为的。
|
||||
|
||||
为 Google 工作也许很棒,而且也许带有一个体面的头衔以及免费的干洗。然而,作为一个关键的 Linux 内核子系统的维护人员,很难得到任意数量的公司承诺高薪酬的雇佣机会。
|
||||
|
||||
Foster 这样写到,“他们甚至享受当前的工作并且觉得他们的雇主不错,许多(Linux 内核开发者)倾向于寻找一些临时的工作关系,那样他们作为内核开发者的身份更被视作固定工作,而且更加重要。”
|
||||
|
||||
由于作为一名 Linux 开发者的身份优先,企业职员的身份次之,Linux 内核开发者甚至可以轻松地与其雇主的竞争对手合作。之所以这样,是因为雇主们最终只能有限制地控制开发者的工作,原因如上所述。Foster 深入研究了这一问题:
|
||||
|
||||
> “尽管企业对其雇员所贡献的领域产生了一些影响,在他们如何去完成工作这点上,雇员还是很自由的。许多人在日常工作中几乎没有接受任何指令,来自雇主的高度信任对工作是非常有帮助的。然而,他们偶尔会被要求做一些特定的零碎工作或者是在一个对公司重要的特定领域投入兴趣。
|
||||
|
||||
> 许多内核开发者也与他们的竞争者展开日常的基础协作,在这里他们仅作为个人相互交流,而不需要关心雇主之间的竞争。这是我在 Intel 工作时经常见到的一幕,因为我们内核开发者几乎都是与我们主要的竞争对手一同工作的。”
|
||||
|
||||
那些公司可能会在运行 Linux 的芯片上、或 Linux 发行版,亦或者是被其他健壮的操作系统支持的软件上产生竞争,但开发者们主要专注于一件事情:使 Linux 越来越好。同样,这是因为他们的身份与 Linux 维系在一起,而不是编码时所在防火墙(指公司)。
|
||||
|
||||
Foster 通过 USB 子系统的邮件列表(在 2013 年到 2015 年之间)说明了这种相互作用,用深色线条描绘了公司之间更多的电子邮件交互:
|
||||
|
||||

|
||||
|
||||
在价格讨论中一些公司明显的来往可能会引起反垄断机构的注意,但在 Linux 大陆中,这只是简单的商业行为。结果导致为所有各方在自由市场相互竞争中得到一个更好的操作系统。
|
||||
|
||||
### 寻找合适的平衡
|
||||
|
||||
这样的“合作”,如 Novell 公司的创始人 Ray Noorda 所说的那样,存在于最佳的开源社区里,但只有在真正的社区里才存在。这很难做到,举个例子,对一个由单一供应商所主导的项目来说,实现正确的合作关系很困难。由 Google 发起的 [Kubernetes][15] 表明这是可能的,但其它像是 Docker 这样的项目却在为同样的目标而挣扎,很大一部分原因是他们一直不愿放弃对自己项目的技术领导。
|
||||
|
||||
也许 Kubernetes 能够工作的很好是因为 Google 并不觉得必须占据重要地位,而且事实上,它_希望_其他公司担负起开发领导的职责。凭借出色的代码解决了一个重要的行业需求,像 Kubernetes 这样的项目就能获得成功,只要 Google 既能帮助它,又为它开辟出一条道路,这就鼓励了 Red Hat 及其它公司做出杰出的贡献。
|
||||
|
||||
不过,Kubernetes 是个例外,就像 Linux 曾经那样。成功是因为企业的贪婪,有许多要考虑的,并且要在之间获取平衡。如果一个项目仅仅被公司自己的利益所控制,常常会在公司的技术管理上体现出来,而且再怎么开源许可也无法对企业产生影响。
|
||||
|
||||
简而言之,Linux 的成功运作是因为众多企业都想要控制它但却难以做到,由于其在工业中的重要性,使得开发者和构建人员更愿意作为一名 _Linux 开发者_ 而不是 Red Hat (或 Intel 亦或 Oracle … )工程师。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/why-linux-works.html
|
||||
|
||||
作者:[Matt Asay][a]
|
||||
译者:[softpaopao](https://github.com/softpaopao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[1]:https://www.datamation.com/feedback/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[2]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[3]:https://www.datamation.com/e-mail/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[4]:https://www.datamation.com/print/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[5]:https://www.datamation.com/open-source/why-linux-works.html#comment_form
|
||||
[6]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[7]:https://www.datamation.com/open-source/
|
||||
[8]:https://opensource.com/article/17/10/collaboration-linux-kernel
|
||||
[9]:http://www.osnews.com/story/20416/Linux_Ecosystem_Worth_25_Billion
|
||||
[10]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
|
||||
[11]:https://www.datamation.com/open-source/the-linux-foundation-and-the-uneasy-alliance.html
|
||||
[12]:https://thenewstack.io/linux-foundation-critics/
|
||||
[13]:https://github.com/torvalds
|
||||
[14]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
|
||||
[15]:https://kubernetes.io/
|
||||
115
published/20171017 A tour of Postgres Index Types.md
Normal file
115
published/20171017 A tour of Postgres Index Types.md
Normal file
@ -0,0 +1,115 @@
|
||||
Postgres 索引类型探索之旅
|
||||
=============
|
||||
|
||||
在 Citus 公司,为让事情做的更好,我们与客户一起在数据建模、优化查询、和增加 [索引][3]上花费了许多时间。我的目标是为客户的需求提供更好的服务,从而创造成功。我们所做的其中一部分工作是[持续][5]为你的 Citus 集群保持良好的优化和 [高性能][4];另外一部分是帮你了解关于 Postgres 和 Citus 你所需要知道的一切。毕竟,一个健康和高性能的数据库意味着 app 执行的更快,并且谁不愿意这样呢? 今天,我们简化一些内容,与客户分享一些关于 Postgres 索引的信息。
|
||||
|
||||
Postgres 有几种索引类型, 并且每个新版本都似乎增加一些新的索引类型。每个索引类型都是有用的,但是具体使用哪种类型取决于(1)数据类型,有时是(2)表中的底层数据和(3)执行的查找类型。接下来的内容我们将介绍在 Postgres 中你可以使用的索引类型,以及你何时该使用何种索引类型。在开始之前,这里有一个我们将带你亲历的索引类型列表:
|
||||
|
||||
* B-Tree
|
||||
* <ruby>倒排索引<rt>Generalized Inverted Index</rt></ruby> (GIN)
|
||||
* <ruby>倒排搜索树<rt>Generalized Inverted Seach Tree</rt></ruby> (GiST)
|
||||
* <ruby>空间分区的<rt>Space partitioned</rt></ruby> GiST (SP-GiST)
|
||||
* <ruby>块范围索引<rt>Block Range Index</rt></ruby> (BRIN)
|
||||
* Hash
|
||||
|
||||
现在开始介绍索引。
|
||||
|
||||
### 在 Postgres 中,B-Tree 索引是你使用的最普遍的索引
|
||||
|
||||
如果你有一个计算机科学的学位,那么 B-Tree 索引可能是你学会的第一个索引。[B-tree 索引][6] 会创建一个始终保持自身平衡的一棵树。当它根据索引去查找某个东西时,它会遍历这棵树去找到键,然后返回你要查找的数据。使用索引是大大快于顺序扫描的,因为相对于顺序扫描成千上万的记录,它可以仅需要读几个 [页][7] (当你仅返回几个记录时)。
|
||||
|
||||
如果你运行一个标准的 `CREATE INDEX` 语句,它将为你创建一个 B-tree 索引。 B-tree 索引在大多数的数据类型上是很有价值的,比如文本、数字和时间戳。如果你刚开始在你的数据库中使用索引,并且不在你的数据库上使用太多的 Postgres 的高级特性,使用标准的 B-Tree 索引可能是你最好的选择。
|
||||
|
||||
### GIN 索引,用于多值列
|
||||
|
||||
<ruby>倒排索引<rt>Generalized Inverted Index</rt></ruby>,一般称为 [GIN][8],大多适用于当单个列中包含多个值的数据类型。
|
||||
|
||||
据 Postgres 文档:
|
||||
|
||||
> “GIN 设计用于处理被索引的条目是复合值的情况,并且由索引处理的查询需要搜索在复合条目中出现的值。例如,这个条目可能是文档,查询可以搜索文档中包含的指定字符。”
|
||||
|
||||
包含在这个范围内的最常见的数据类型有:
|
||||
|
||||
* [hStore][1]
|
||||
* Array
|
||||
* Range
|
||||
* [JSONB][2]
|
||||
|
||||
关于 GIN 索引中最让人满意的一件事是,它们能够理解存储在复合值中的数据。但是,因为一个 GIN 索引需要有每个被添加的单独类型的数据结构的特定知识,因此,GIN 索引并不是支持所有的数据类型。
|
||||
|
||||
### GiST 索引, 用于有重叠值的行
|
||||
|
||||
<ruby>倒排搜索树<rt>Generalized Inverted Seach Tree</rt></ruby>(GiST)索引多适用于当你的数据与同一列的其它行数据重叠时。GiST 索引最好的用处是:如果你声明一个几何数据类型,并且你希望知道两个多边型是否包含一些点时。在一种情况中一个特定的点可能被包含在一个盒子中,而与此同时,其它的点仅存在于一个多边形中。使用 GiST 索引的常见数据类型有:
|
||||
|
||||
* 几何类型
|
||||
* 需要进行全文搜索的文本类型
|
||||
|
||||
GiST 索引在大小上有很多的固定限制,否则,GiST 索引可能会变的特别大。作为其代价,GiST 索引是有损的(不精确的)。
|
||||
|
||||
据官方文档:
|
||||
|
||||
> “GiST 索引是有损的,这意味着索引可能产生虚假匹配,所以需要去检查真实的表行去消除虚假匹配。 (当需要时 PostgreSQL 会自动执行这个动作)”
|
||||
|
||||
这并不意味着你会得到一个错误结果,它只是说明了在 Postgres 给你返回数据之前,会做了一个很小的额外工作来过滤这些虚假结果。
|
||||
|
||||
特别提示:同一个数据类型上 GIN 和 GiST 索引往往都可以使用。通常一个有很好的性能表现,但会占用很大的磁盘空间,反之亦然。说到 GIN 与 GiST 的比较,并没有某个完美的方案可以适用所有情况,但是,以上规则应用于大部分常见情况。
|
||||
|
||||
### SP-GiST 索引,用于更大的数据
|
||||
|
||||
空间分区 GiST (SP-GiST)索引采用来自 [Purdue][9] 研究的空间分区树。 SP-GiST 索引经常用于当你的数据有一个天然的聚集因素,并且不是一个平衡树的时候。 电话号码是一个非常好的例子 (至少 US 的电话号码是)。 它们有如下的格式:
|
||||
|
||||
* 3 位数字的区域号
|
||||
* 3 位数字的前缀号 (与以前的电话交换机有关)
|
||||
* 4 位的线路号
|
||||
|
||||
这意味着第一组前三位处有一个天然的聚集因素,接着是第二组三位,然后的数字才是一个均匀的分布。但是,在电话号码的一些区域号中,存在一个比其它区域号更高的饱合状态。结果可能导致树非常的不平衡。因为前面有一个天然的聚集因素,并且数据不对等分布,像电话号码一样的数据可能会是 SP-GiST 的一个很好的案例。
|
||||
|
||||
### BRIN 索引, 用于更大的数据
|
||||
|
||||
块范围索引(BRIN)专注于一些类似 SP-GiST 的情形,它们最好用在当数据有一些自然排序,并且往往数据量很大时。如果有一个以时间为序的 10 亿条的记录,BRIN 也许就能派上用场。如果你正在查询一组很大的有自然分组的数据,如有几个邮编的数据,BRIN 能帮你确保相近的邮编存储在磁盘上相近的地方。
|
||||
|
||||
当你有一个非常大的比如以日期或邮编排序的数据库, BRIN 索引可以让你非常快的跳过或排除一些不需要的数据。此外,与整体数据量大小相比,BRIN 索引相对较小,因此,当你有一个大的数据集时,BRIN 索引就可以表现出较好的性能。
|
||||
|
||||
### Hash 索引, 总算不怕崩溃了
|
||||
|
||||
Hash 索引在 Postgres 中已经存在多年了,但是,在 Postgres 10 发布之前,对它们的使用一直有个巨大的警告,它不是 WAL-logged 的。这意味着如果你的服务器崩溃,并且你无法使用如 [wal-g][10] 故障转移到备机或从存档中恢复,那么你将丢失那个索引,直到你重建它。 随着 Postgres 10 发布,它们现在是 WAL-logged 的,因此,你可以再次考虑使用它们 ,但是,真正的问题是,你应该这样做吗?
|
||||
|
||||
Hash 索引有时会提供比 B-Tree 索引更快的查找,并且创建也很快。最大的问题是它们被限制仅用于“相等”的比较操作,因此你只能用于精确匹配的查找。这使得 hash 索引的灵活性远不及通常使用的 B-Tree 索引,并且,你不能把它看成是一种替代品,而是一种用于特殊情况的索引。
|
||||
|
||||
### 你该使用哪个?
|
||||
|
||||
我们刚才介绍了很多,如果你有点被吓到,也很正常。 如果在你知道这些之前, `CREATE INDEX` 将始终为你创建使用 B-Tree 的索引,并且有一个好消息是,对于大多数的数据库, Postgres 的性能都很好或非常好。 :) 如果你考虑使用更多的 Postgres 特性,下面是一个当你使用其它 Postgres 索引类型的备忘清单:
|
||||
|
||||
* B-Tree - 适用于大多数的数据类型和查询
|
||||
* GIN - 适用于 JSONB/hstore/arrays
|
||||
* GiST - 适用于全文搜索和几何数据类型
|
||||
* SP-GiST - 适用于有天然的聚集因素但是分布不均匀的大数据集
|
||||
* BRIN - 适用于有顺序排列的真正的大数据集
|
||||
* Hash - 适用于相等操作,而且,通常情况下 B-Tree 索引仍然是你所需要的。
|
||||
|
||||
如果你有关于这篇文章的任何问题或反馈,欢迎加入我们的 [slack channel][11]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
|
||||
作者:[Craig Kerstiens][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
[1]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[2]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[3]:https://www.citusdata.com/blog/2017/10/11/index-all-the-things-in-postgres/
|
||||
[4]:https://www.citusdata.com/blog/2017/09/29/what-performance-can-you-expect-from-postgres/
|
||||
[5]:https://www.citusdata.com/product/cloud
|
||||
[6]:https://en.wikipedia.org/wiki/B-tree
|
||||
[7]:https://www.8kdata.com/blog/postgresql-page-layout/
|
||||
[8]:https://www.postgresql.org/docs/10/static/gin.html
|
||||
[9]:https://www.cs.purdue.edu/spgist/papers/W87R36P214137510.pdf
|
||||
[10]:https://www.citusdata.com/blog/2017/08/18/introducing-wal-g-faster-restores-for-postgres/
|
||||
[11]:https://slack.citusdata.com/
|
||||
[12]:https://twitter.com/share?url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/&text=A%20tour%20of%20Postgres%20Index%20Types&via=citusdata
|
||||
[13]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
@ -0,0 +1,211 @@
|
||||
2017 年哪个公司对开源贡献最多?让我们用 GitHub 的数据分析下
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
在这篇分析报告中,我们将使用 2017 年度截止至当前时间(2017 年 10 月)为止,GitHub 上所有公开的推送事件的数据。对于每个 GitHub 用户,我们将尽可能地猜测其所属的公司。此外,我们仅查看那些今年得到了至少 20 个星标的仓库。
|
||||
|
||||
以下是我的报告结果,你也可以[在我的交互式 Data Studio 报告上进一步加工][1]。
|
||||
|
||||
### 顶级云服务商的比较
|
||||
|
||||
2017 年它们在 GitHub 上的表现:
|
||||
|
||||
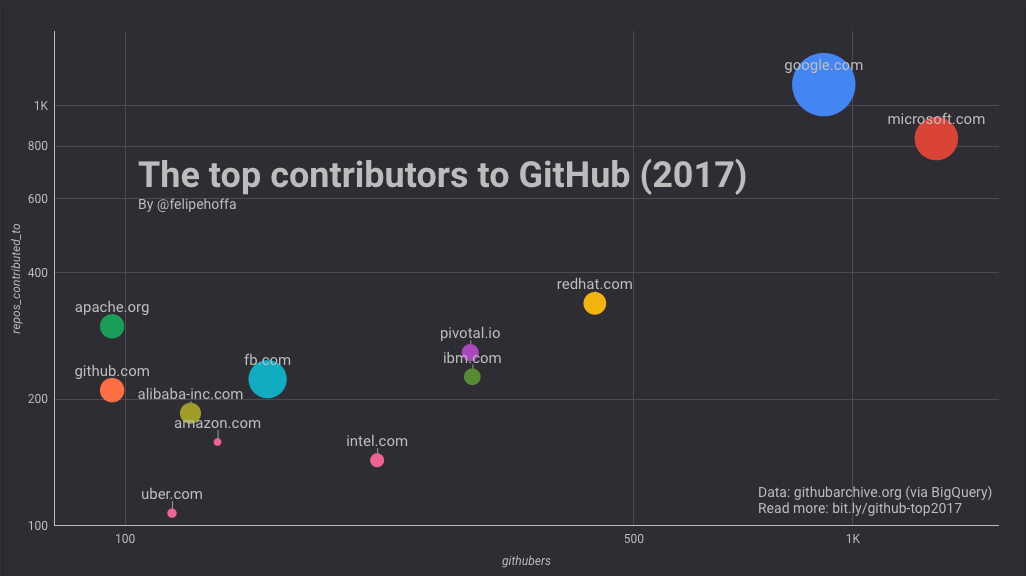
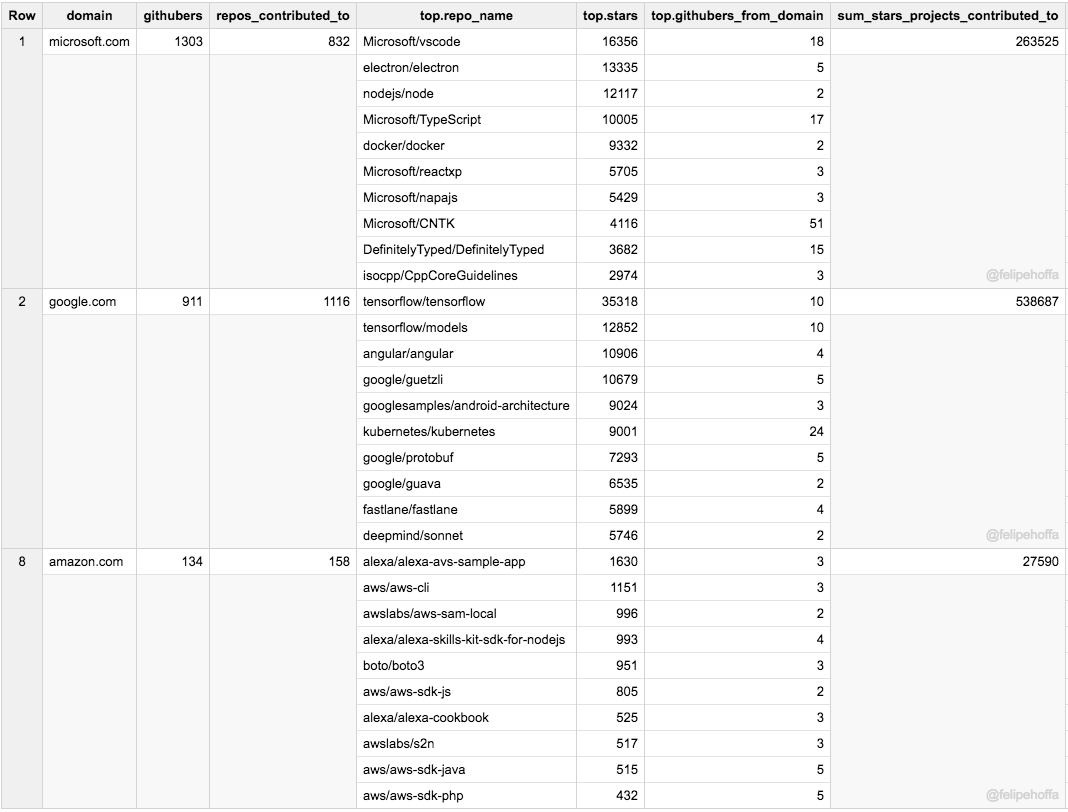
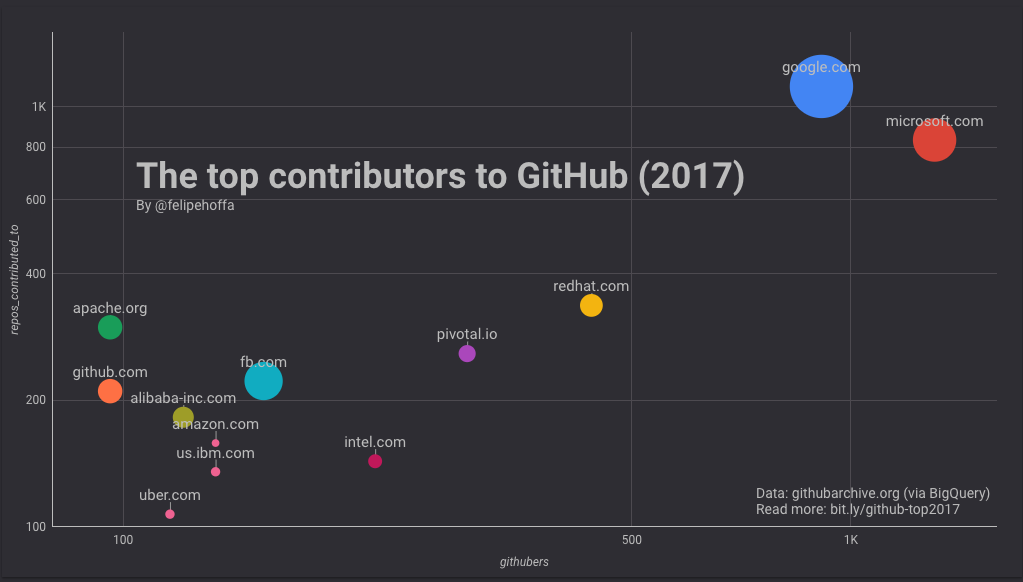
* 微软看起来约有 1300 名员工积极地推送代码到 GitHub 上的 825 个顶级仓库。
|
||||
* 谷歌显示出约有 900 名员工在 GitHub 上活跃,他们推送代码到大约 1100 个顶级仓库。
|
||||
* 亚马逊似乎只有 134 名员工活跃在 GitHub 上,他们推送代码到仅仅 158 个顶级项目上。
|
||||
* 不是所有的项目都一样:在超过 25% 的仓库上谷歌员工要比微软员工贡献的多,而那些仓库得到了更多的星标(53 万对比 26 万)。亚马逊的仓库 2017 年合计才得到了 2.7 万个星标。
|
||||
|
||||
|
||||
|
||||
### 红帽、IBM、Pivotal、英特尔和 Facebook
|
||||
|
||||
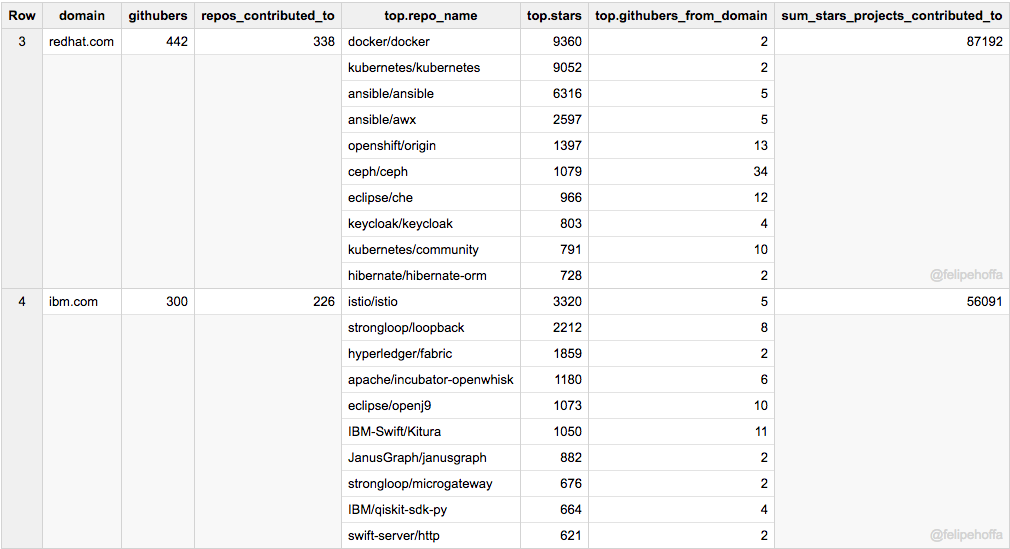
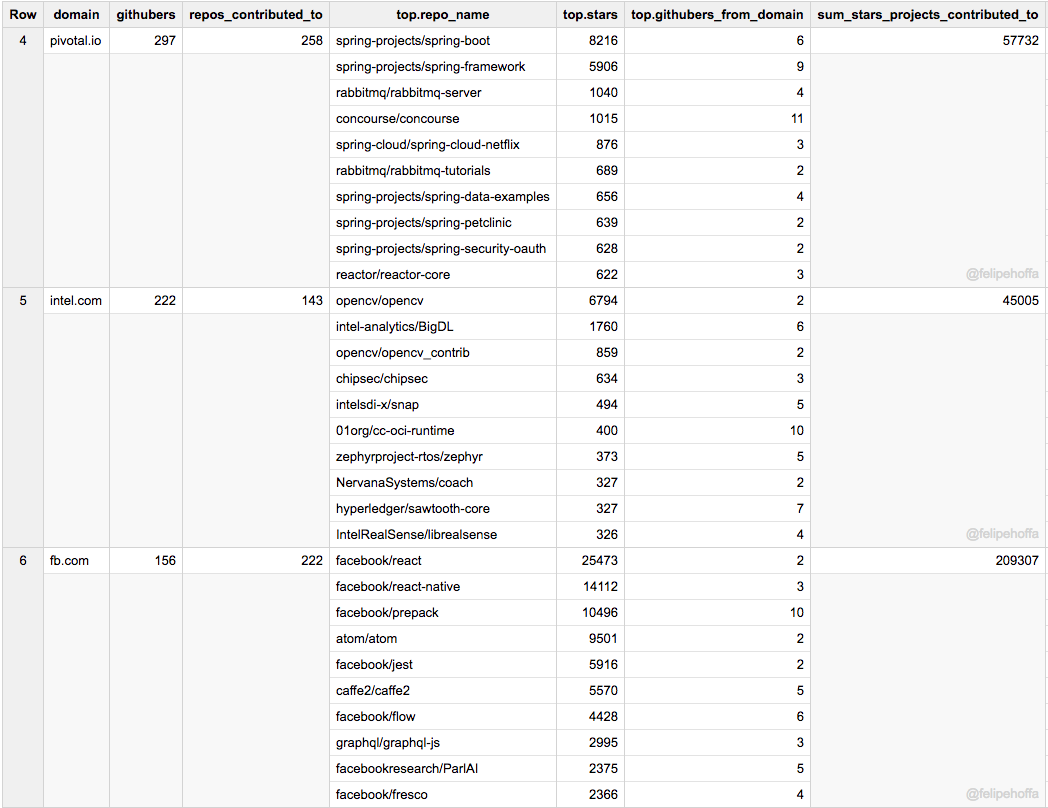
如果说亚马逊看起来被微软和谷歌远远抛在了身后,那么这之间还有哪些公司呢?根据这个排名来看,红帽、Pivotal 和英特尔在 GitHub 上做出了巨大贡献:
|
||||
|
||||
注意,下表中合并了所有的 IBM 地区域名(各个地区会展示在其后的表格中)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
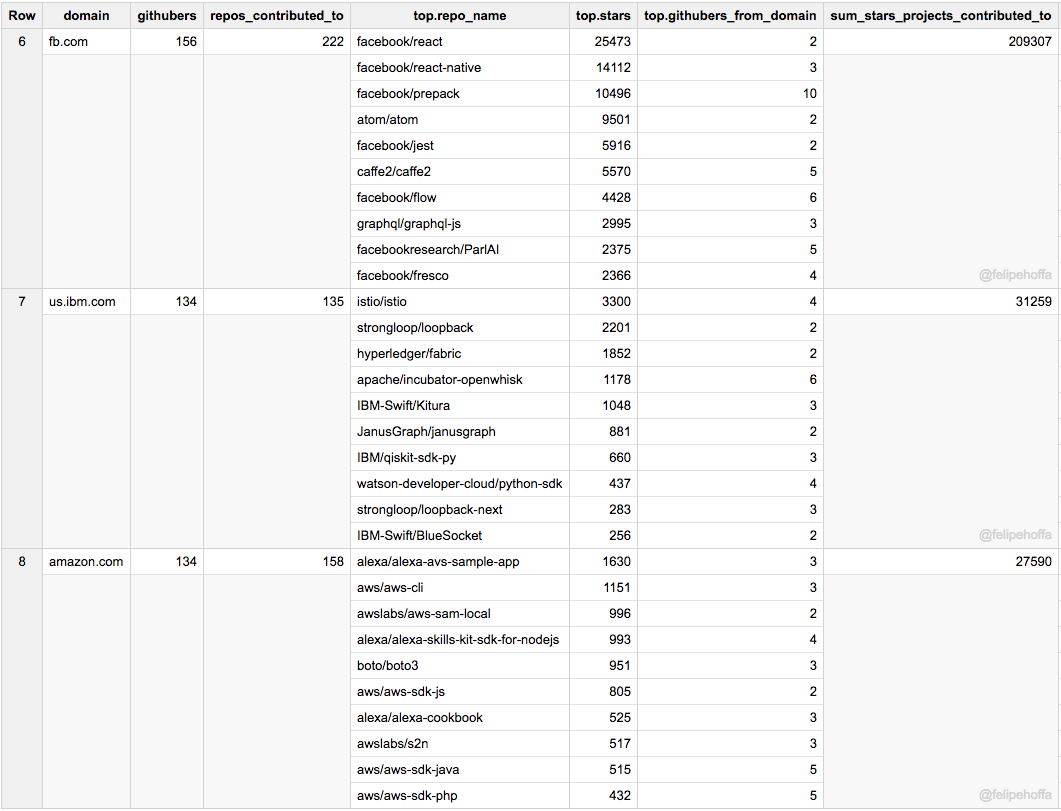
Facebook 和 IBM(美)在 GitHub 上的活跃用户数同亚马逊差不多,但是它们所贡献的项目得到了更多的星标(特别是 Facebook):
|
||||
|
||||
|
||||
|
||||
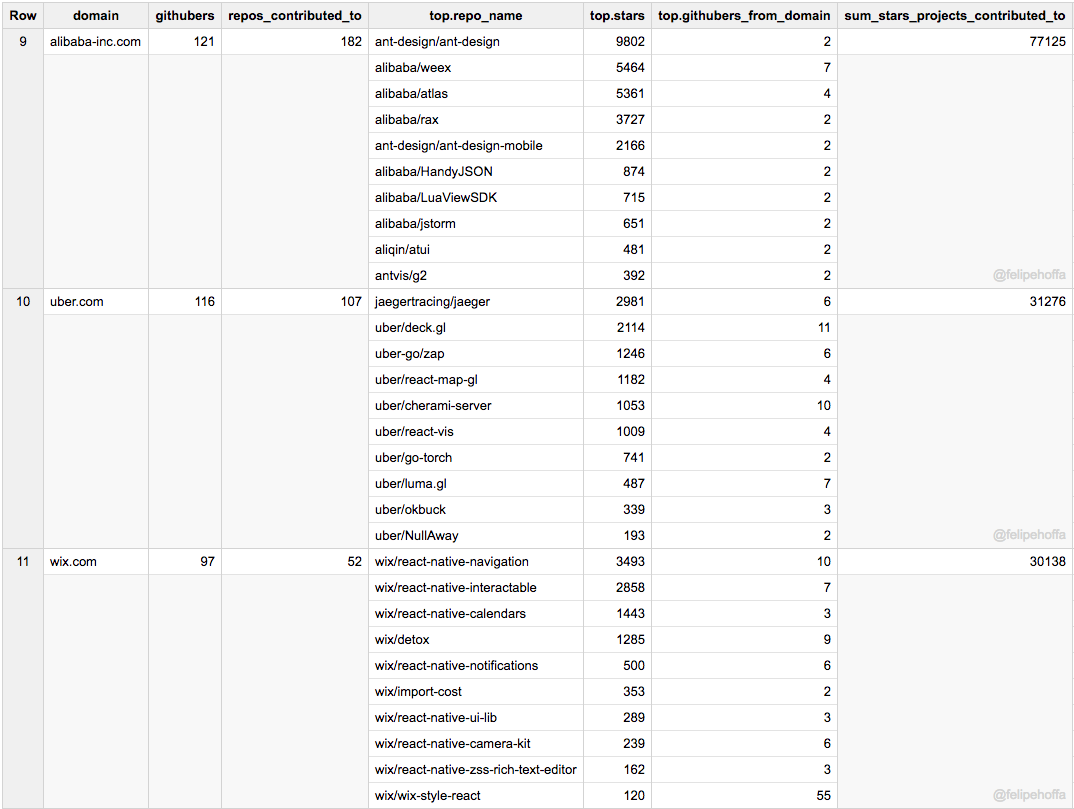
接下来是阿里巴巴、Uber 和 Wix:
|
||||
|
||||
|
||||
|
||||
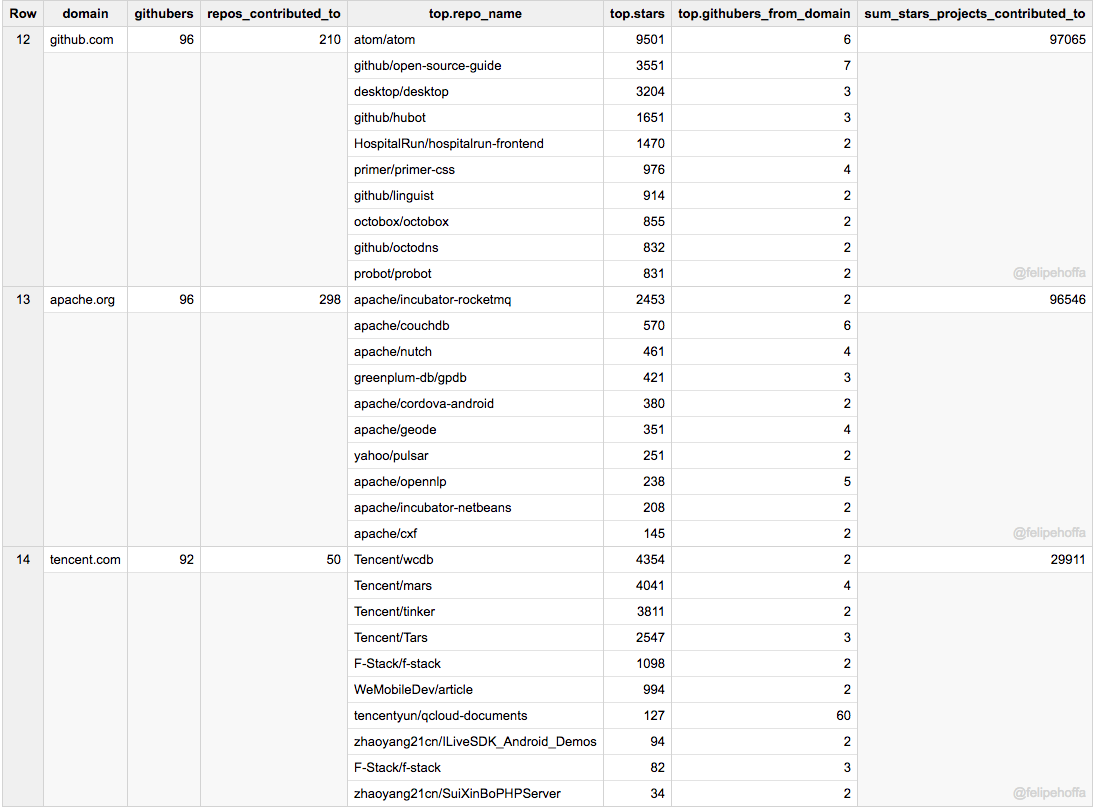
以及 GitHub 自己、Apache 和腾讯:
|
||||
|
||||
|
||||
|
||||
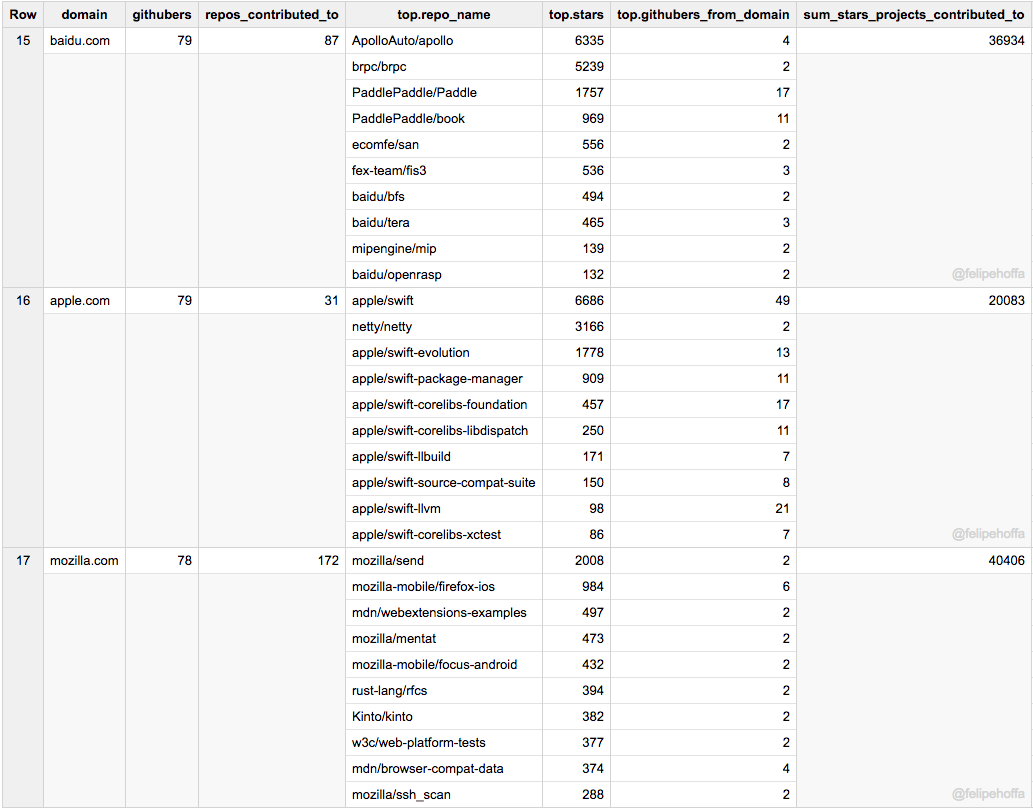
百度、苹果和 Mozilla:
|
||||
|
||||
|
||||
|
||||
(LCTT 译注:很高兴看到国内的顶级互联网公司阿里巴巴、腾讯和百度在这里排名前列!)
|
||||
|
||||
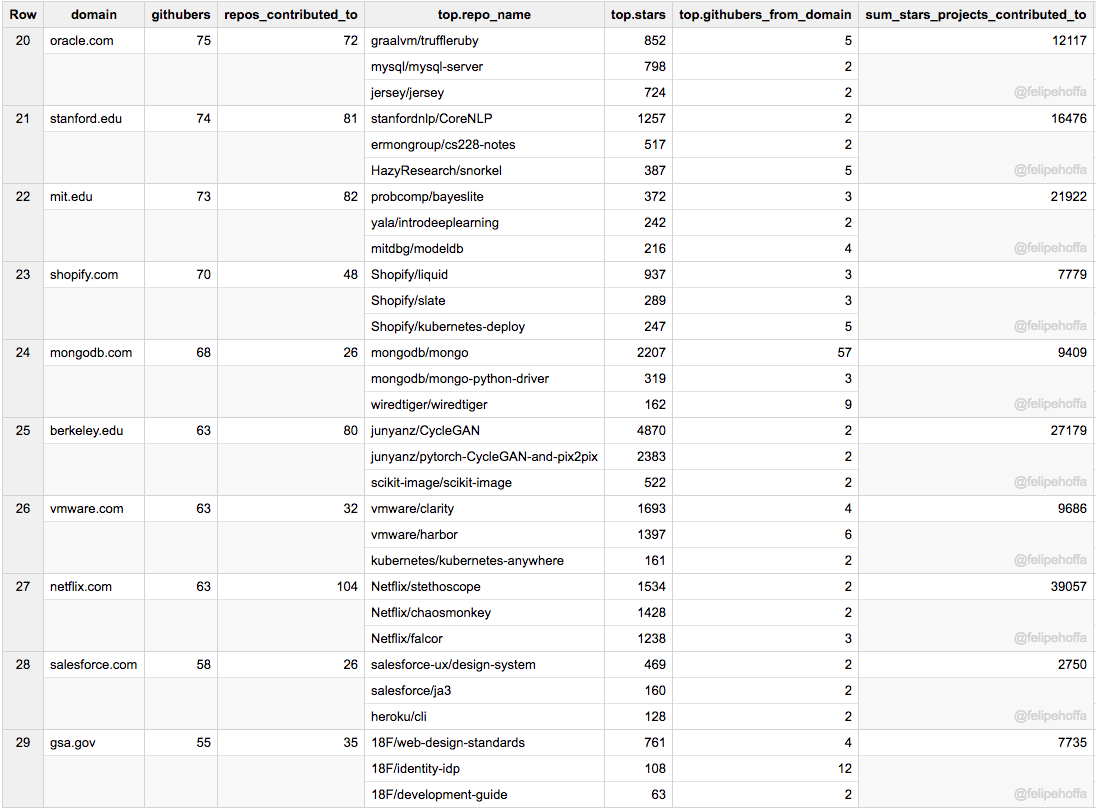
甲骨文、斯坦福大学、麻省理工、Shopify、MongoDb、伯克利大学、VmWare、Netflix、Salesforce 和 Gsa.gov:
|
||||
|
||||
|
||||
|
||||
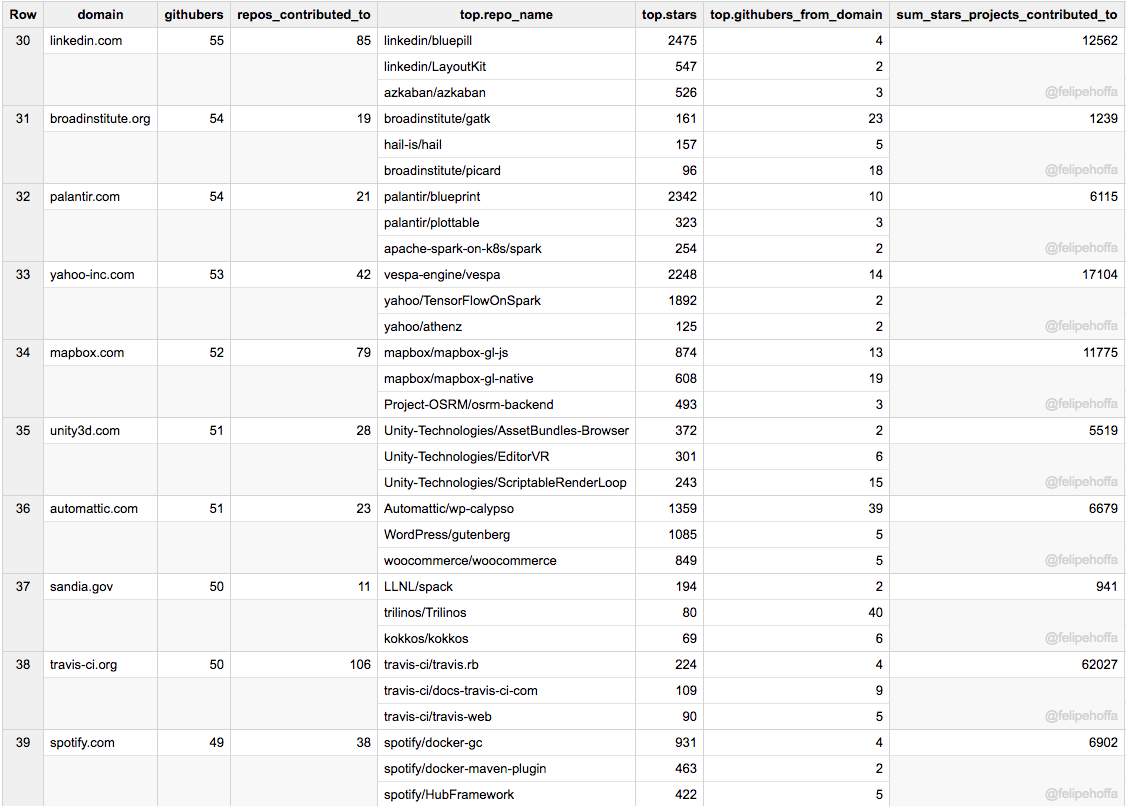
LinkedIn、Broad Institute、Palantir、雅虎、MapBox、Unity3d、Automattic(WordPress 的开发商)、Sandia、Travis-ci 和 Spotify:
|
||||
|
||||
|
||||
|
||||
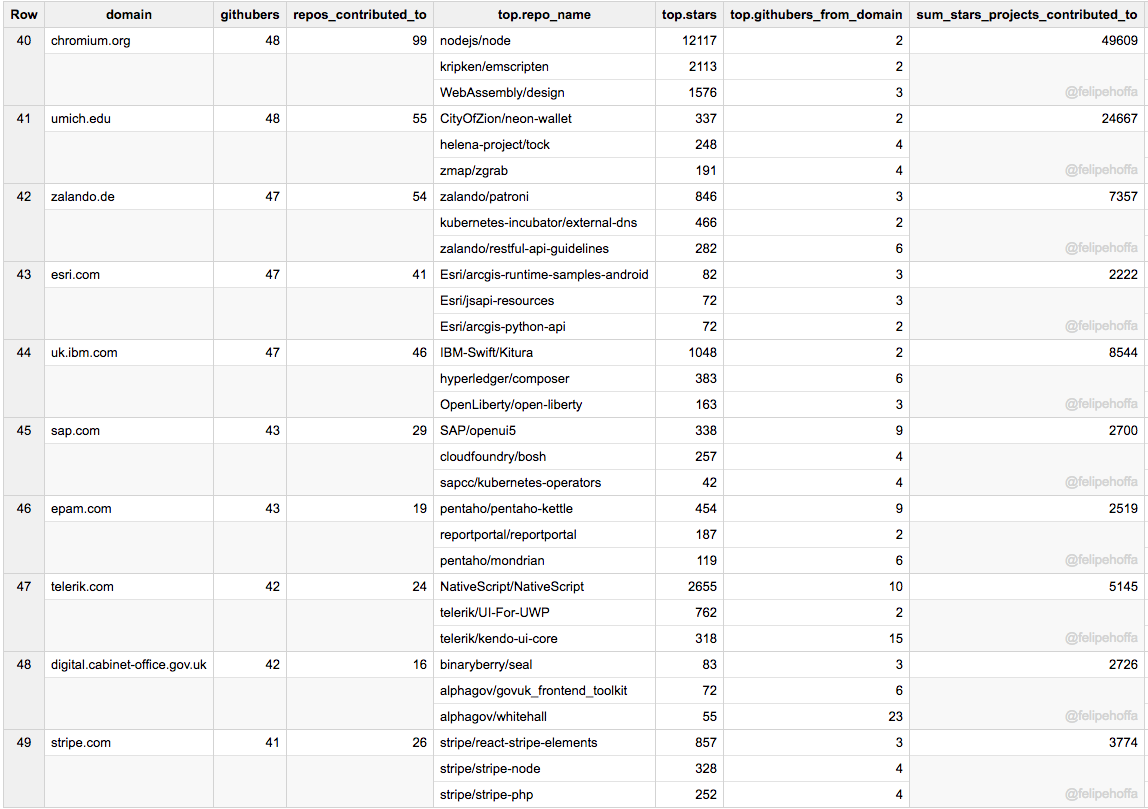
Chromium、UMich、Zalando、Esri、IBM (英)、SAP、EPAM、Telerik、UK Cabinet Office 和 Stripe:
|
||||
|
||||
|
||||
|
||||
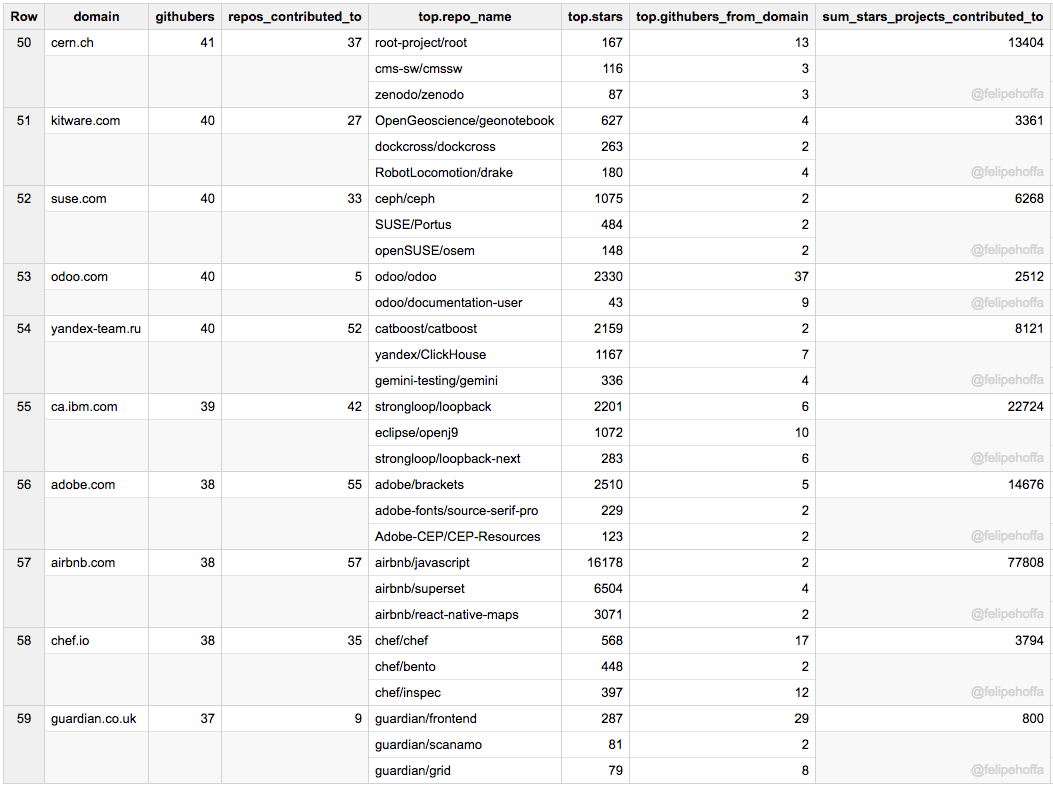
Cern、Odoo、Kitware、Suse、Yandex、IBM (加)、Adobe、AirBnB、Chef 和 The Guardian:
|
||||
|
||||
|
||||
|
||||
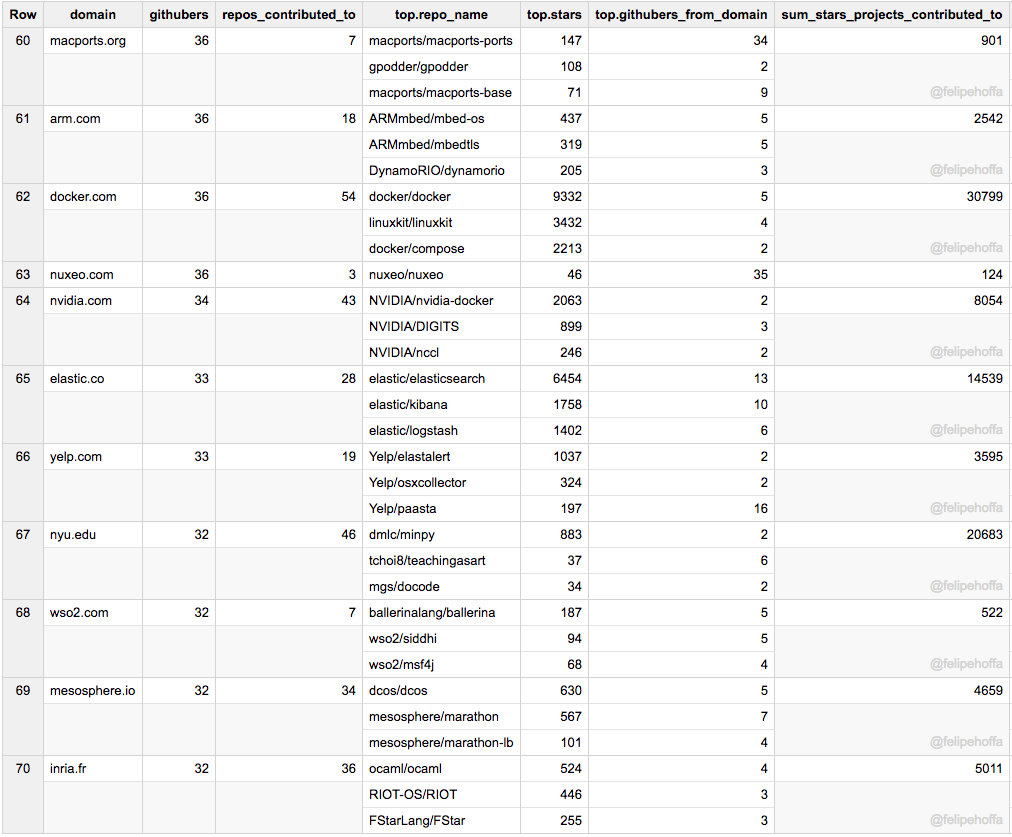
Arm、Macports、Docker、Nuxeo、NVidia、Yelp、Elastic、NYU、WSO2、Mesosphere 和 Inria:
|
||||
|
||||
|
||||
|
||||
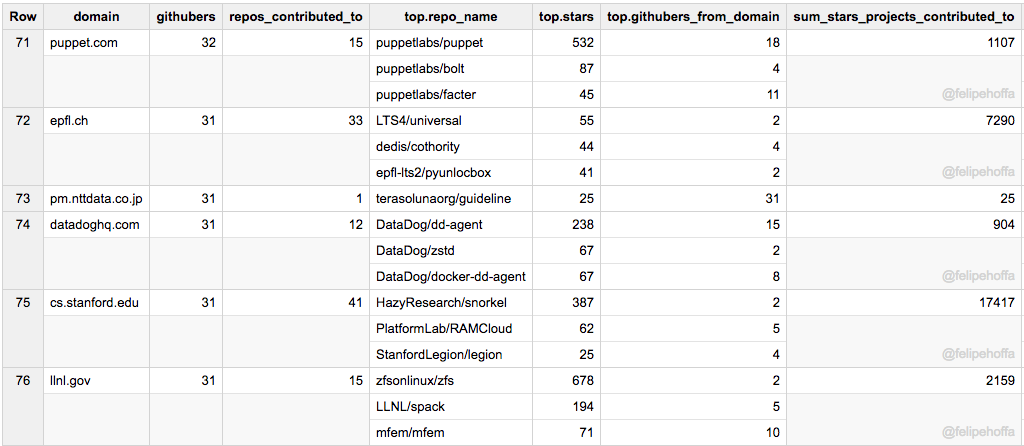
Puppet、斯坦福(计算机科学)、DatadogHQ、Epfl、NTT Data 和 Lawrence Livermore Lab:
|
||||
|
||||
|
||||
|
||||
### 我的分析方法
|
||||
|
||||
#### 我是怎样将 GitHub 用户关联到其公司的
|
||||
|
||||
在 GitHub 上判定每个用户所述的公司并不容易,但是我们可以使用其推送事件的提交消息中展示的邮件地址域名来判断。
|
||||
|
||||
* 同样的邮件地址可以出现在几个用户身上,所以我仅考虑那些对此期间获得了超过 20 个星标的项目进行推送的用户。
|
||||
* 我仅统计了在此期间推送超过 3 次的 GitHub 用户。
|
||||
* 用户推送代码到 GitHub 上可以在其推送中显示许多不同的邮件地址,这部分是由 GIt 工作机制决定的。为了判定每个用户的组织,我会查找那些在推送中出现更频繁的邮件地址。
|
||||
* 不是每个用户都在 GitHub 上使用其组织的邮件。有许多人使用 gmail.com、users.noreply.github.com 和其它邮件托管商的邮件地址。有时候这是为了保持匿名和保护其公司邮箱,但是如果我不能定位其公司域名,这些用户我就不会统计。抱歉。
|
||||
* 有时候员工会更换所任职的公司。我会将他们分配给其推送最多的公司。
|
||||
|
||||
#### 我的查询语句
|
||||
|
||||
```
|
||||
#standardSQL
|
||||
WITH
|
||||
period AS (
|
||||
SELECT *
|
||||
FROM `githubarchive.month.2017*` a
|
||||
),
|
||||
repo_stars AS (
|
||||
SELECT repo.id, COUNT(DISTINCT actor.login) stars, APPROX_TOP_COUNT(repo.name, 1)[OFFSET(0)].value repo_name
|
||||
FROM period
|
||||
WHERE type='WatchEvent'
|
||||
GROUP BY 1
|
||||
HAVING stars>20
|
||||
),
|
||||
pushers_guess_emails_and_top_projects AS (
|
||||
SELECT *
|
||||
# , REGEXP_EXTRACT(email, r'@(.*)') domain
|
||||
, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
|
||||
FROM (
|
||||
SELECT actor.id
|
||||
, APPROX_TOP_COUNT(actor.login,1)[OFFSET(0)].value login
|
||||
, APPROX_TOP_COUNT(JSON_EXTRACT_SCALAR(payload, '$.commits[0].author.email'),1)[OFFSET(0)].value email
|
||||
, COUNT(*) c
|
||||
, ARRAY_AGG(DISTINCT TO_JSON_STRING(STRUCT(b.repo_name,stars))) repos
|
||||
FROM period a
|
||||
JOIN repo_stars b
|
||||
ON a.repo.id=b.id
|
||||
WHERE type='PushEvent'
|
||||
GROUP BY 1
|
||||
HAVING c>3
|
||||
)
|
||||
)
|
||||
SELECT * FROM (
|
||||
SELECT domain
|
||||
, githubers
|
||||
, (SELECT COUNT(DISTINCT repo) FROM UNNEST(repos) repo) repos_contributed_to
|
||||
, ARRAY(
|
||||
SELECT AS STRUCT JSON_EXTRACT_SCALAR(repo, '$.repo_name') repo_name
|
||||
, CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64) stars
|
||||
, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo
|
||||
GROUP BY 1, 2
|
||||
HAVING githubers_from_domain>1
|
||||
ORDER BY stars DESC LIMIT 3
|
||||
) top
|
||||
, (SELECT SUM(CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64)) FROM (SELECT DISTINCT repo FROM UNNEST(repos) repo)) sum_stars_projects_contributed_to
|
||||
FROM (
|
||||
SELECT domain, COUNT(*) githubers, ARRAY_CONCAT_AGG(ARRAY(SELECT * FROM UNNEST(repos) repo)) repos
|
||||
FROM pushers_guess_emails_and_top_projects
|
||||
#WHERE domain IN UNNEST(SPLIT('google.com|microsoft.com|amazon.com', '|'))
|
||||
WHERE domain NOT IN UNNEST(SPLIT('gmail.com|users.noreply.github.com|qq.com|hotmail.com|163.com|me.com|googlemail.com|outlook.com|yahoo.com|web.de|iki.fi|foxmail.com|yandex.ru', '|')) # email hosters
|
||||
GROUP BY 1
|
||||
HAVING githubers > 30
|
||||
)
|
||||
WHERE (SELECT MAX(githubers_from_domain) FROM (SELECT repo, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY repo))>4 # second filter email hosters
|
||||
)
|
||||
ORDER BY githubers DESC
|
||||
```
|
||||
|
||||
### FAQ
|
||||
|
||||
#### 有的公司有 1500 个仓库,为什么只统计了 200 个?有的仓库有 7000 个星标,为什么只显示 1500 个?
|
||||
|
||||
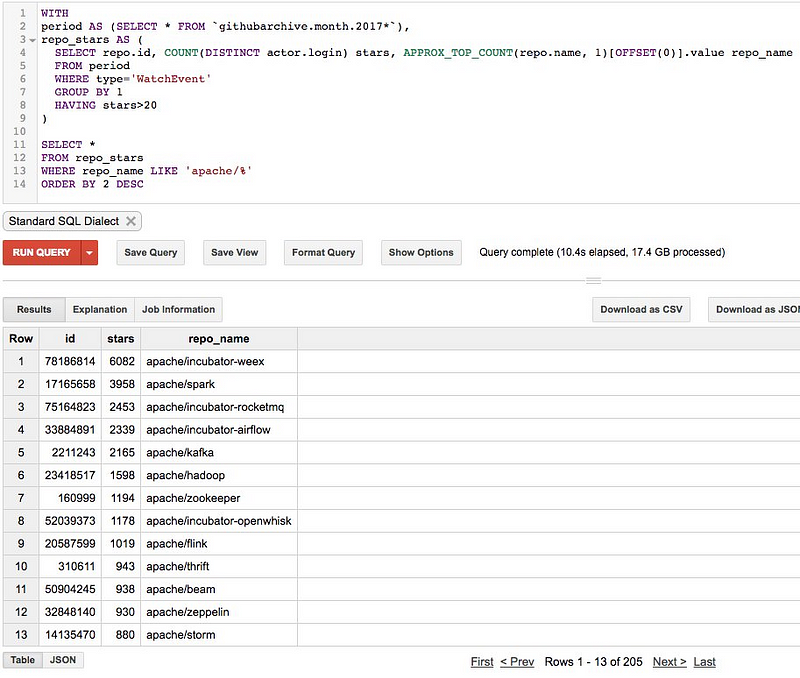
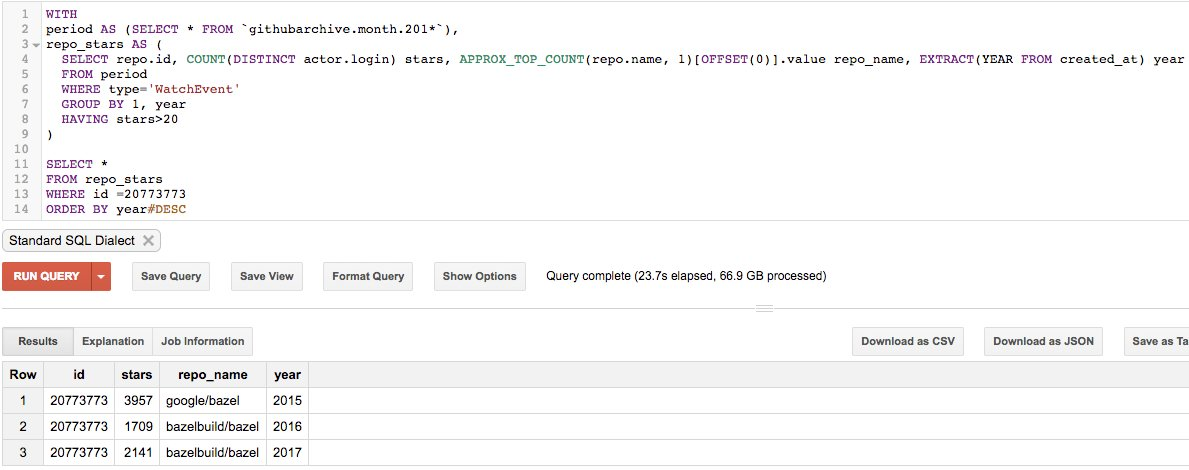
我进行了过滤。我只统计了 2017 年的星标。举个例子说,Apache 在 GitHub 上有超过 1500 个仓库,但是今年只有 205 个项目得到了超过 20 个星标。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 这表明了开源的发展形势么?
|
||||
|
||||
注意,这个对 GitHub 的分析没有包括像 Android、Chromium、GNU、Mozilla 等顶级社区,也没有包括 Apache 基金会或 Eclipse 基金会,还有一些[其它][2]项目选择在 GitHub 之外开展起活动。
|
||||
|
||||
#### 这对于我的组织不公平
|
||||
|
||||
我只能统计我所看到的数据。欢迎对我的统计的前提提出意见,以及对我的统计方法给出改进方法。如果有能用的查询语句就更好了。
|
||||
|
||||
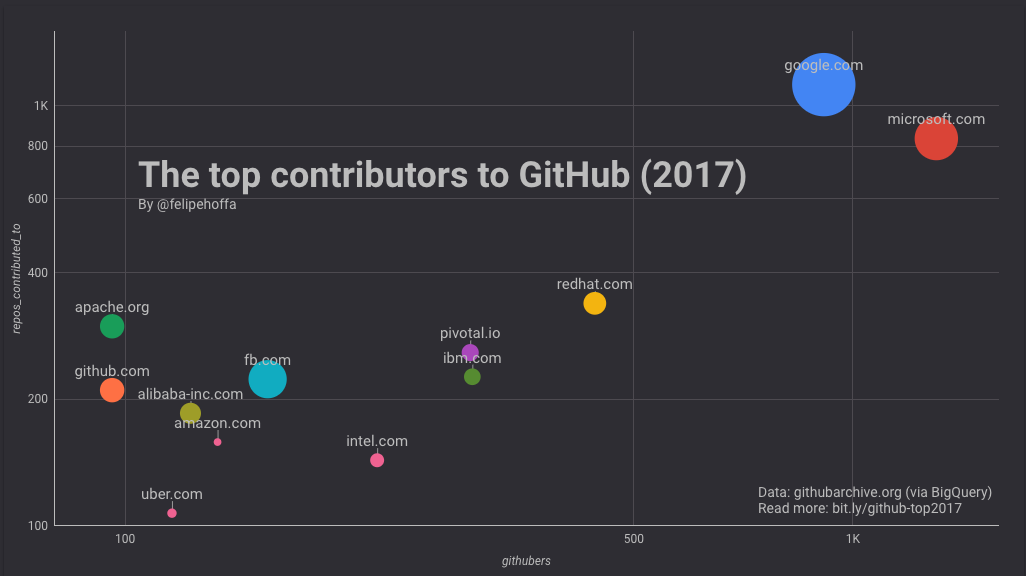
举个例子,要看看当我合并了 IBM 的各个地区域名到其顶级域时排名发生了什么变化,可以用一条 SQL 语句解决:
|
||||
|
||||
```
|
||||
SELECT *, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
当合并了其地区域名后, IBM 的相对位置明显上升了。
|
||||
|
||||
#### 回音
|
||||
|
||||
- [关于“ GitHub 2017 年顶级贡献者”的一些思考][3]
|
||||
|
||||
### 接下来
|
||||
|
||||
我以前犯过错误,而且以后也可能再次出错。请查看所有的原始数据,并质疑我的前提假设——看看你能得到什么结论是很有趣的。
|
||||
|
||||
- [用一下交互式 Data Studio 报告][5]
|
||||
|
||||
感谢 [Ilya Grigorik][6] 保留的 [GitHub Archive][7] 提供了这么多年的 GitHub 数据!
|
||||
|
||||
想要看更多的文章?看看我的 [Medium][8]、[在 twitter 上关注我][9] 并订阅 [reddit.com/r/bigquery][10]。[试试 BigQuery][11],每个月可以[免费][12]分析 1 TB 的数据。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/the-top-contributors-to-github-2017-be98ab854e87
|
||||
|
||||
作者:[Felipe Hoffa][a]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@hoffa?source=post_header_lockup
|
||||
[1]:https://datastudio.google.com/open/0ByGAKP3QmCjLU1JzUGtJdTlNOG8
|
||||
[2]:https://developers.google.com/open-source/organizations
|
||||
[3]:https://redmonk.com/jgovernor/2017/10/25/some-thoughts-on-the-top-contributors-to-github-2017/
|
||||
[4]:https://redmonk.com/jgovernor/2017/10/25/some-thoughts-on-the-top-contributors-to-github-2017/
|
||||
[5]:https://datastudio.google.com/open/0ByGAKP3QmCjLU1JzUGtJdTlNOG8
|
||||
[6]:https://medium.com/@igrigorik
|
||||
[7]:http://githubarchive.org/
|
||||
[8]:http://medium.com/@hoffa/
|
||||
[9]:http://twitter.com/felipehoffa
|
||||
[10]:https://reddit.com/r/bigquery
|
||||
[11]:https://www.reddit.com/r/bigquery/comments/3dg9le/analyzing_50_billion_wikipedia_pageviews_in_5/
|
||||
[12]:https://cloud.google.com/blog/big-data/2017/01/how-to-run-a-terabyte-of-google-bigquery-queries-each-month-without-a-credit-card
|
||||
@ -1,48 +1,39 @@
|
||||
为何 Kubernetes 如此受欢迎?
|
||||
============================================================
|
||||
|
||||
### Google 开发的容器管理系统很快成为开源历史上最大的成功案例之一。
|
||||
> Google 开发的这个容器管理系统很快成为开源历史上最成功的案例之一。
|
||||
|
||||

|
||||
|
||||
图片来源: RIkki Endsley. [CC BY-SA 4.0][7]
|
||||
|
||||
[Kubernetes][8] 是一个在过去几年中不断在普及的开源容器管理系统。它被众多行业中最大的企业用于关键任务,已成为开源最大的成功案例之一。这是怎么发生的?该如何解释 Kubernetes 的广泛应用呢?
|
||||
[Kubernetes][8] 是一个在过去几年中快速蹿升起来的开源的容器管理系统。它被众多行业中最大的企业用于关键任务,已成为开源方面最成功的案例之一。这是怎么发生的?该如何解释 Kubernetes 的广泛应用呢?
|
||||
|
||||
### Kubernetes 的背景:起源于 Google 的 Borg 系统
|
||||
|
||||
随着计算世界变得更加分布式、更多的基于网络的云计算,更多的是我们看到大型单体应用慢慢地转化为多个敏捷的微服务。这些微服务能让用户单独缩放应用程序的关键功能,并处理数百万客户。除此之外,我们还看到 Docker 容器等技术出现在企业中,为用户快速构建这些微服务创造了一致、可移植、便捷的方式。
|
||||
随着计算世界变得更加分布式、更加基于网络、以及更多的云计算,我们看到了大型的<ruby>独石<rt>monolithic</rt></ruby>应用慢慢地转化为多个敏捷微服务。这些微服务能让用户单独缩放应用程序的关键功能,以处理数百万客户。除此之外,我们还看到像 Docker 这样的容器等技术出现在企业中,为用户快速构建这些微服务创造了一致的、可移植的、便捷的方式。
|
||||
|
||||
Linux 容器
|
||||
|
||||
* [什么是 Linux 容器?][1]
|
||||
|
||||
* [什么是 Docker?][2]
|
||||
|
||||
* [什么是 Kubernetes?][3]
|
||||
|
||||
* [容器术语介绍][4]
|
||||
|
||||
随着 Docker 继续蓬勃发展,管理这些微服务器和容器成为最重要的要求。这时已经运行基于容器的基础设施已经多年的 Google 大胆地决定开源一个名为 [Borg][15] 的项目。Borg 系统是运行 Google 服务的关键,如 Google 搜索和 Gmail。谷歌决定开源其基础设施为世界上任何一家公司创造了一种顶尖公司运行其基础架构的方式。
|
||||
随着 Docker 继续蓬勃发展,管理这些微服务器和容器成为最重要的要求。这时已经运行基于容器的基础设施已经多年的 Google 大胆地决定开源一个名为 [Borg][15] 的项目。Borg 系统是运行诸如 Google 搜索和 Gmail 这样的 Google 服务的关键。谷歌决定开源其基础设施为世界上任何一家公司创造了一种像顶尖公司一样运行其基础架构的方式。
|
||||
|
||||
### 最大的开源社区之一
|
||||
|
||||
在开源之后,Kubernetes 发现自己与其他容器管理系统竞争,即 Docker Swarm 和 Apache Mesos。Kubernetes 近几个月来超过这些其他系统的原因之一是社区和系统背后的支持:它是最大的开源社区之一(GitHub 上超过 27,000 多个 star),有来自上千个组织(1,409 个贡献者)的贡献,并且被集中在一个大型、中立的开源基金会:[原生云计算基金会][9](CNCF)。
|
||||
在开源之后,Kubernetes 发现自己在与其他容器管理系统竞争,即 Docker Swarm 和 Apache Mesos。Kubernetes 近几个月来超过这些其他系统的原因之一得益于社区和系统背后的支持:它是最大的开源社区之一(GitHub 上超过 27,000 多个星标),有来自上千个组织(1,409 个贡献者)的贡献,并且被集中在一个大型、中立的开源基金会里,即[原生云计算基金会][9](CNCF)。
|
||||
|
||||
CNCF 也是更大的 Linux 基金会的一部分,拥有一些顶级企业,其中包括微软、谷歌和亚马逊。此外,CNCF 的企业成员队伍持续增长,SAP 和 Oracle 在过去几个月内加入白金会员。这些加入 CNFC 的公司,Kubernetes 项目是前沿和中心的,这证明了这些企业在社区中投入多少来实现云计算战略的一部分。
|
||||
CNCF 也是更大的 Linux 基金会的一部分,拥有一些顶级企业成员,其中包括微软、谷歌和亚马逊。此外,CNCF 的企业成员队伍持续增长,SAP 和 Oracle 在过去几个月内加入白金会员。这些加入 CNCF 的公司,其中 Kubernetes 项目是前沿和中心的,这证明了有多少企业投注于社区来实现云计算战略的一部分。
|
||||
|
||||
Kubernetes 周围的企业社区也在激增,供应商为企业版提供了更多的安全性、可管理性和支持。Red Hat、CoreOS 和 Platform 9 是少数几个使企业 Kubernetes 成为战略前进关键,并投入巨资以确保开源项目继续维护。
|
||||
Kubernetes 外围的企业社区也在激增,供应商提供了带有更多的安全性、可管理性和支持的企业版。Red Hat、CoreOS 和 Platform 9 是少数几个使企业级 Kubernetes 成为战略前进的关键因素,并投入巨资以确保开源项目继续得到维护的公司。
|
||||
|
||||
### 提供混合云的好处
|
||||
### 混合云带来的好处
|
||||
|
||||
企业以这样一个飞速的方式采用 Kubernetes 的另一个原因是 Kubernetes 可以在任何云端工作。大多数企业在现有的内部数据中心和公共云之间共享资产,对混合云技术的需求至关重要。
|
||||
|
||||
Kubernetes 可以部署在公司先前存在的数据中心内、任意一个公共云环境、甚至可以作为服务运行。由于 Kubernetes 抽象底层基础架构层,开发人员可以专注于构建应用程序,然后将它们部署到任何这些环境中。这有助于加速公司的 Kubernetes 采用,因为它可以在内部运行 Kubernetes,同时继续构建云战略。
|
||||
Kubernetes 可以部署在公司先前存在的数据中心内、任意一个公共云环境、甚至可以作为服务运行。由于 Kubernetes 抽象了底层基础架构层,开发人员可以专注于构建应用程序,然后将它们部署到任何这些环境中。这有助于加速公司的 Kubernetes 采用,因为它可以在内部运行 Kubernetes,同时继续构建云战略。
|
||||
|
||||
### 现实世界的案例
|
||||
|
||||
Kubernetes 继续增长的另一个原因是,大型公司正在利用这项技术来解决业界最大的挑战。Capital One、Pearson Education 和 Ancestry.com 只是少数几家公布了 Kubernetes [使用案例][10]的公司。
|
||||
|
||||
[Pokemon Go][11] 是最流行的宣传 Kubernetes 能力的使用案例。在它发布之前,在线多人游戏预计会相当受欢迎。但一旦发布,它就像火箭一样起飞,达到了预期流量的 50 倍。通过使用 Kubernetes 作为 Google Cloud 之上的基础设施覆盖,Pokemon Go 可以大规模扩展以满足意想不到的需求。
|
||||
[Pokemon Go][11] 是最流行的宣传 Kubernetes 能力的使用案例。在它发布之前,人们都觉得在线多人游戏会相当的得到追捧。但当它一旦发布,就像火箭一样起飞,达到了预期流量的 50 倍。通过使用 Kubernetes 作为 Google Cloud 之上的基础设施层,Pokemon Go 可以大规模扩展以满足意想不到的需求。
|
||||
|
||||
最初作为来自 Google 的开源项目,背后有 Google 15 年的服务经验和来自 Borg 的继承- Kubernetes 现在是有许多企业成员的大型基金会(CNCF)的一部分。它继续受到欢迎,并被广泛应用于金融、大型多人在线游戏(如 Pokemon Go)以及教育公司和传统企业 IT 的关键任务中。考虑到所有,所有的迹象表明,Kubernetes 将继续更加流行,并仍然是开源中最大的成功案例之一。
|
||||
|
||||
@ -50,16 +41,15 @@ Kubernetes 继续增长的另一个原因是,大型公司正在利用这项技
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
Anurag Gupta - Anurag Gupta 是推动统一日志层 Fluentd Enterprise 发展的 Treasure Data 的产品经理。 Anurag 致力于大型数据技术,包括 Azure Log Analytics 和企业 IT 服务,如 Microsoft System Center。
|
||||
Anurag Gupta - Anurag Gupta 是推动统一日志层 Fluentd Enterprise 发展的 Treasure Data 的产品经理。 Anurag 致力于大型数据技术,包括 Azure Log Analytics 和如 Microsoft System Center 的企业 IT 服务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/why-kubernetes-so-popular
|
||||
|
||||
作者:[Anurag Gupta ][a]
|
||||
作者:[Anurag Gupta][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,43 @@
|
||||
GitLab:我们正将源码贡献许可证切换到 DCO
|
||||
============================================================
|
||||
|
||||
> 我们希望通过取消“<ruby>贡献者许可协议<rt>Contributor License Agreement</rt></ruby>”(CLA)来支持“<ruby>[开发者原创证书][3]<rt>Developer's Certificate of Origin</rt></ruby>”(DCO),让每个人都能更轻松地做出贡献。
|
||||
|
||||
我们致力于成为[开源的好管家][1],而这一承诺的一部分意味着我们永远不会停止重新评估我们如何做到这一点。承诺“每个人都可以贡献”就是消除贡献的障碍。对于我们的一些社区,“<ruby>贡献者许可协议<rt>Contributor License Agreement</rt></ruby>”(CLA)是对 GitLab 贡献的阻碍,所以我们改为“<ruby>[开发者原创证书][3]<rt>Developer's Certificate of Origin</rt></ruby>”(DCO)。
|
||||
|
||||
许多大型的开源项目都想成为自己命运的主人。拥有基于开源软件运行自己的基础架构的自由,以及修改和审计源代码的能力,而不依赖于供应商,这使开源具有吸引力。我们希望 GitLab 成为每个人的选择。
|
||||
|
||||
### 为什么改变?
|
||||
|
||||
贡献者许可协议(CLA)是对其它项目进行开源贡献的行业标准,但对于不愿意考虑法律条款的开发人员来说,这是不受欢迎的,并且由于需要审查冗长的合同而潜在地放弃他们的一些权利。贡献者发现协议不必要的限制,并且阻止开源项目的开发者使用 GitLab。我们接触过 Debian 开发人员,他们考虑放弃 CLA,而这就是我们正在做的。
|
||||
|
||||
### 改变了什么?
|
||||
|
||||
到今天为止,我们正在推出更改,以便 GitLab 源码的贡献者只需要一个项目许可证(所有仓库都是 MIT,除了 Omnibus 是 Apache 许可证)和一个[开发者原创证书][2] (DCO)即可。DCO 为开发人员提供了更大的灵活性和可移植性,这也是 Debian 和 GNOME 计划将其社区和项目迁移到 GitLab 的原因之一。我们希望这一改变能够鼓励更多的开发者为 GitLab 做出贡献。谢谢 Debian,提醒我们做出这个改变。
|
||||
|
||||
> “我们赞扬 GitLab 放弃他们的 CLA,转而使用对 OSS 更加友好的方式,开源社区诞生于一个汇集在一起并转化为项目的贡献海洋,这一举动肯定了 GitLab 愿意保护个人及其创作过程,最重要的是,把知识产权掌握在创造者手中。”
|
||||
|
||||
> —— GNOME 董事会主席 Carlos Soriano
|
||||
|
||||
|
||||
> “我们很高兴看到 GitLab 通过从 CLA 转换到 DCO 来简化和鼓励社区贡献。我们认识到,做这种本质性的改变并不容易,我们赞扬 GitLab 在这里所展示的时间、耐心和深思熟虑的考虑。”
|
||||
|
||||
> —— Debian 项目负责人 Chris Lamb
|
||||
|
||||
你可以[阅读这篇关于我们做出这个决定的分析][3]。阅读所有关于我们 [GitLab 社区版的管理][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2017/11/01/gitlab-switches-to-dco-license/
|
||||
|
||||
作者:[Jamie Hurewitz][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://about.gitlab.com/team/#hurewitzjamie
|
||||
[1]:https://about.gitlab.com/2016/01/11/being-a-good-open-source-steward/
|
||||
[2]:https://developercertificate.org/
|
||||
[3]:https://docs.google.com/a/gitlab.com/document/d/1zpjDzL7yhGBZz3_7jCjWLfRQ1Jryg1mlIVmG8y6B1_Q/edit?usp=sharing
|
||||
[4]:https://about.gitlab.com/stewardship/
|
||||
@ -1,3 +1,4 @@
|
||||
translating by hkurj
|
||||
What every software engineer should know about search
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,169 +0,0 @@
|
||||
Translating by qhwdw
|
||||
[Streams: a new general purpose data structure in Redis.][1]
|
||||
==================================
|
||||
|
||||
|
||||
Until a few months ago, for me streams were no more than an interesting and relatively straightforward concept in the context of messaging. After Kafka popularized the concept, I mostly investigated their usefulness in the case of Disque, a message queue that is now headed to be translated into a Redis 4.2 module. Later I decided that Disque was all about AP messaging, which is, fault tolerance and guarantees of delivery without much efforts from the client, so I decided that the concept of streams was not a good match in that case.
|
||||
|
||||
However, at the same time, there was a problem in Redis, that was not taking me relaxed about the data structures exported by default. There is some kind of gap between Redis lists, sorted sets, and Pub/Sub capabilities. You can kindly use all these tools in order to model a sequence of messages or events, but with different tradeoffs. Sorted sets are memory hungry, can’t model naturally the same message delivered again and again, clients can’t block for new messages. Because a sorted set is not a sequential data structure, it’s a set where elements can be moved around changing their scores: no wonder if it was not a good match for things like time series. Lists have different problems creating similar applicability issues in certain use cases: you cannot explore what is in the middle of a list because the access time in that case is linear. Moreover no fan-out is possible, blocking operations on list serve a single element to a single client. Nor there was a fixed element identifier in lists, in order to say: given me things starting from that element. For one-to-many workloads there is Pub/Sub, which is great in many cases, but for certain things you do not want fire-and-forget: to retain a history is important, not just to refetch messages after a disconnection, also because certain list of messages, like time series, are very important to explore with range queries: what were my temperature readings in this 10 seconds range?
|
||||
|
||||
The way I tried to address the above problems, was planning a generalization of sorted sets and lists into a unique more flexible data structure, however my design attempts ended almost always in making the resulting data structure ways more artificial than the current ones. One good thing about Redis is that the data structures exported resemble more the natural computer science data structures, than, “this API that Salvatore invented”. So in the end, I stopped my attempts, and said, ok that’s what we can provide so far, maybe I’ll add some history to Pub/Sub, or some more flexibility to lists access patterns in the future. However every time an user approached me during a conference saying “how would you model time series in Redis?” or similar related questions, my face turned green.
|
||||
|
||||
Genesis
|
||||
=======
|
||||
|
||||
After the introduction of modules in Redis 4.0, users started to see how to fix this problem themselves. One of them, Timothy Downs, wrote me the following over IRC:
|
||||
|
||||
<forkfork> the module I'm planning on doing is to add a transaction log style data type - meaning that a very large number of subscribers can do something like pub sub without a lot of redis memory growth
|
||||
<forkfork> subscribers keeping their position in a message queue rather than having redis maintain where each consumer is up to and duplicating messages per subscriber
|
||||
|
||||
This captured my imagination. I thought about it a few days, and realized that this could be the moment when we could solve all the above problems at once. What I needed was to re-imagine the concept of “log”. It is a basic programming element, everybody is used to it, because it’s just as simple as opening a file in append mode and writing data to it in some format. However Redis data structures must be abstract. They are in memory, and we use RAM not just because we are lazy, but because using a few pointers, we can conceptualize data structures and make them abstract, to allow them to break free from the obvious limits. For instance normally a log has several problems: the offset is not logical, but is an actual bytes offset, what if we want logical offsets that are related to the time an entry was inserted? We have range queries for free. Similarly, a log is often hard to garbage collect: how to remove old elements in an append only data structure? Well, in our idealized log, we just say we want at max this number of entries, and the old ones will go away, and so forth.
|
||||
|
||||
While I was trying to write a specification starting from the seed idea of Timothy, I was working to a radix tree implementation that I was using for Redis Cluster, to optimize certain parts of its internals. This provided the ground in order to implement a very space efficient log, that was still accessible in logarithmic time to get ranges. At the same time I started reading about Kafka streams to get other interesting ideas that could fit well into my design, and this resulted into getting the concept of Kafka consumer groups, and idealizing it again for Redis and the in-memory use case. However the specification remained just a specification for months, at the point that after some time I rewrote it almost from scratch in order to upgrade it with many hints that I accumulated talking with people about this upcoming addition to Redis. I wanted Redis streams to be a very good use case for time series especially, not just for other kind of events and messaging applications.
|
||||
|
||||
Let’s write some code
|
||||
=====================
|
||||
|
||||
Back from Redis Conf, during the summertime, I was implementing a library called “listpack”. This library is just the successor of ziplist.c, that is, a data structure that can represent a list of string elements inside a single allocation. It’s just a very specialized serialization format, with the peculiarity of being parsable also in reverse order, from right to left: something needed in order to substitute ziplists in all the use cases.
|
||||
|
||||
Mixing radix trees + listpacks, it is possible to easily build a log that is at the same time very space efficient, and indexed, that means, allowing for random access by IDs and time. Once this was ready, I started to write the code in order to implement the stream data structure. I’m still finishing the implementation, however at this point, inside the Redis “streams” branch at Github, there is enough to start playing and having fun. I don’t claim that the API is 100% final, but there are two interesting facts: one is that at this point, only the consumer groups are missing, plus a number of less important commands to manipulate the stream, but all the big things are implemented already. The second is the decision to backport all the stream work back into the 4.0 branch in about two months, once everything looks stable. It means that Redis users will not have to wait for Redis 4.2 in order to use streams, they will be available ASAP for production usage. This is possible because being a new data structure, almost all the code changes are self-contained into the new code. With the exception of the blocking list operations: the code was refactored so that we share the same code for streams and lists blocking operations, with a great simplification of the Redis internals.
|
||||
|
||||
Tutorial: welcome to Redis Streams
|
||||
==================================
|
||||
|
||||
In some way, you can think at streams as a supercharged version of Redis lists. Streams elements are not just a single string, they are more objects composed of fields and values. Range queries are possible and fast. Each entry in a stream has an ID, which is a logical offset. Different clients can blocking-wait for elements with IDs greater than a specified one. A fundamental command of Redis streams is XADD. Yes, all the Redis stream commands are prefixed by an “X”.
|
||||
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
|
||||
The XADD command will append the specified entry as a new element to the specified stream “mystream”. The entry, in the example above, has two fields: sensor-id and temperature, however each entry in the same stream can have different fields. Using the same field names will just lead to better memory usage. An interesting thing is also that the fields order is guaranteed to be retained. XADD returns the ID of the just inserted entry, because with the asterisk in the third argument, we asked the command to auto-generate the ID. This is almost always what you want, but it is possible also to force a specific ID, for instance in order to replicate the command to slaves and AOF files.
|
||||
|
||||
The ID is composed of two parts: a millisecond time and a sequence number. 1506871964177 is the millisecond time, and is just a Unix time with millisecond resolution. The number after the dot, 0, is the sequence number, and is used in order to distinguish entries added in the same millisecond. Both numbers are 64 bit unsigned integers. This means that we can add all the entries we want in a stream, even in the same millisecond. The millisecond part of the ID is obtained using the maximum between the current local time of the Redis server generating the ID, and the last entry inside the stream. So even if, for instance, the computer clock jumps backward, the IDs will continue to be incremental. In some way you can think stream entry IDs as whole 128 bit numbers. However the fact that they have a correlation with the local time of the instance where they are added, means that we have millisecond precision range queries for free.
|
||||
|
||||
As you can guess, adding two entries in a very fast way, will result in only the sequence number to be incremented. We can simulate the “fast insertion” simply with a MULTI/EXEC block:
|
||||
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
|
||||
The above example also shows how we can use different fields for different entries without having to specifying any schema initially. What happens however is that every first message of every block (that usually contains something in the range of 50-150 messages) is used as reference, and successive entries having the same fields are compressed with a single flag saying “same fields of the first entry in this block”. So indeed using the same fields for successive messages saves a lot of memory, even when the set of fields slowly change over time.
|
||||
|
||||
In order to retrieve data from the stream there are two ways: range queries, that are implemented by the XRANGE command, and streaming, implemented by the XREAD command. XRANGE just fetches a range of items from start to stop, inclusive. So for instance I can fetch a single item, if I know its ID, with:
|
||||
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
|
||||
However you can use the special start symbol of “-“ and the special stop symbol of “+” to signify the minimum and maximum ID possible. It’s also possible to use the COUNT option in order to limit the amount of entries returned. A more complex XRANGE example is the following:
|
||||
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
|
||||
Here we are reasoning in terms of ranges of IDs, however you can use XRANGE in order to get a specific range of elements in a given time range, because you can omit the “sequence” part of the IDs. So what you can do is to just specify times in milliseconds. The following means: “Give me 10 entries starting from the Unix time 1506872463”:
|
||||
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
|
||||
A final important thing to note about XRANGE is that, given that we receive the IDs in the reply, and the immediately successive ID is trivially obtained just incrementing the sequence part of the ID, it is possible to use XRANGE to incrementally iterate the whole stream, receiving for every call the specified number of elements. After the *SCAN family of commands in Redis, that allowed iteration of Redis data structures *despite* the fact they were not designed for being iterated, I avoided to make the same error again.
|
||||
|
||||
Streaming with XREAD: blocking for new data
|
||||
===========================================
|
||||
|
||||
XRANGE is perfect when we want to access our stream to get ranges by ID or time, or single elements by ID. However in the case of streams that different clients must consume as data arrives, this is not good enough and would require some form of pooling (that could be a good idea for *certain* applications that just connect from time to time to get data).
|
||||
|
||||
The XREAD command is designed in order to read, at the same time, from multiple streams just specifying the ID of the last entry in the stream we got. Moreover we can request to block if no data is available, to be unblocked when data arrives. Similarly to what happens with blocking list operations, but here data is not consumed from the stream, and multiple clients can access the same data at the same time.
|
||||
|
||||
This is a canonical example of XREAD call:
|
||||
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
|
||||
And it means: get data from “mystream” and “otherstream”. If no data is available, block the client, with a timeout of 5000 milliseconds. After the STREAMS option we specify the keys we want to listen for, and the last ID we have. However a special ID of “$” means: assume I’ve all the elements that there are in the stream right now, so give me just starting from the next element arriving.
|
||||
|
||||
If, from another client, I send the commnad:
|
||||
|
||||
> XADD otherstream * message “Hi There”
|
||||
|
||||
This is what happens on the XREAD side:
|
||||
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
|
||||
We get the key that received data, together with the data received. In the next call, we’ll likely use the ID of the last message received:
|
||||
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
|
||||
And so forth. However note that with this usage pattern, it is possible that the client will connect again after a very big delay (because it took time to process messages, or for any other reason). In such a case, in the meantime, a lot of messages could pile up, so it is wise to always use the COUNT option with XREAD, in order to make sure the client will not be flooded with messages and the server will not have to lose too much time just serving tons of messages to a single client.
|
||||
|
||||
Capped streams
|
||||
==============
|
||||
|
||||
So far so good… however streams at some point have to remove old messages. Fortunately this is possible with the MAXLEN option of the XADD command:
|
||||
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
|
||||
This basically means, if the stream, after adding the new element is found to have more than 1 million messages, remove old messages so that the length returns back to 1 million elements. It’s just like using RPUSH + LTRIM with lists, but this time we have a built-in mechanism to do so. However note that the above means that every time we add a new message, we have also to incur in the work needed in order to remove a message from the other side of the stream. This takes some CPU, so it is possible to use the “~” symbol before the count in MAXLEN, in order to specify that we are not really demanding *exactly* 1 million messages, but if there are a few more it’s not a big problem:
|
||||
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
|
||||
This way XADD will remove messages only when it can remove a whole node. This will make having the capped stream almost for free compared to vanilla XADD.
|
||||
|
||||
Consumer groups (work in progress)
|
||||
==================================
|
||||
|
||||
This is the first of the features that is not already implemented in Redis, but is a work in progress. It is also the idea more clearly inspired by Kafka, even if implemented here in a pretty different way. The gist is that with XREAD, clients can also add a “GROUP <name>” option. Automatically all the clients in the same group will get *different* messages. Of course there could be multiple groups reading from the same stream, in such cases all groups will receive duplicates of the same messages arriving in the stream, but within each group, messages will not be repeated.
|
||||
|
||||
An extension to groups is that it will be possible to specify a “RETRY <milliseconds>” option when groups are specified: in this case, if messages are not acknowledged for processing with XACK, they will be delivered again after the specified amount of milliseconds. This provides some best effort reliability to the delivering of the messages, in case the client has no private means to mark messages as processed. This part is a work in progress as well.
|
||||
|
||||
Memory usage and saving loading times
|
||||
=====================================
|
||||
|
||||
Because of the design used to model Redis streams, the memory usage is remarkably low. It depends on the number of fields, values, and their lengths, but for simple messages we are at a few millions of messages for every 100 MB of used memory. Moreover, the format is conceived to need very minimal serialization: the listpack blocks that are stored as radix tree nodes, have the same representation on disk and in memory, so they are trivially stored and read. For instance Redis can read 5 million entries from the RDB file in 0.3 seconds.
|
||||
This makes replication and persistence of streams very efficient.
|
||||
|
||||
It is planned to also allow deletion of items in the middle. This is only partially implemented, but the strategy is to mark entries as deleted in the entry flag, and when a given ratio between entries and deleted entires is reached, the block is rewritten to collect the garbage, and if needed it is glued to another adjacent block in order to avoid fragmentation.
|
||||
|
||||
Conclusions end ETA
|
||||
===================
|
||||
|
||||
Redis streams will be part of Redis stable in the 4.0 series before the end of the year. I think that this general purpose data structure is going to put a huge patch in order for Redis to cover a lot of use cases that were hard to cover: that means that you had to be creative in order to abuse the current data structures to fix certain problems. One very important use case is time series, but my feeling is that also streaming of messages for other use cases via TREAD is going to be very interesting both as replacement for Pub/Sub applications that need more reliability than fire-and-forget, and for completely new use cases. For now, if you want to start to evaluate the new capabilities in the context of your problems, just fetch the “streams” branch at Github and start playing. After all bug reports are welcome :-)
|
||||
|
||||
If you like videos, a real-time session showing streams is here: https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://antirez.com/
|
||||
[1]:http://antirez.com/news/114
|
||||
[2]:http://antirez.com/user/antirez
|
||||
[3]:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
@ -0,0 +1,66 @@
|
||||
Translating by qhwdw No, the Linux desktop hasn't jumped in popularity
|
||||
============================================================
|
||||
|
||||
Stories have been circulating that the Linux desktop had jumped in popularity and was used more than macOS. Alas, it's not so.
|
||||
|
||||
There have been numerous stories that the Linux desktop has more than doubled from its usual 1.5 to 3 percent marketshare to 5 percent. These reports have been based on [NetMarketShare][4]'s desktop operating system analysis, which showed Linux leaping from 2.5 percent in July, to almost 5 percent in September. But unfortunately for Linux fans, it's not true.
|
||||
|
||||
Neither does it appear to be Google's Chrome OS, which tends to be under-represented in NetMarketShare and [StatCounter][5]desktop operating system numbers, being counted as Linux. Mind you, that would be fair, since [Chrome OS is based on Linux][6].
|
||||
|
||||
The real explanation is far more mundane. It seems to be merely a mistake. Vince Vizzaccaro, NetMarketShare's executive marketing share of marketing told me, "The Linux share being reported is not correct. We are aware of the issue and are currently looking into it."
|
||||
|
||||
If that sounds odd to you, that's because you probably think that NetMarketShare and StatCounter simply count user numbers. They don't. Instead, each uses its own secret sauce to come up with operating system numbers.
|
||||
|
||||
NetMarketShare's methodology is to "[collect data from the browsers of site visitors][7] to our exclusive on-demand network of HitsLink Analytics and SharePost clients. The network includes over 40,000 websites, and spans the globe. We 'count' unique visitors to our network sites, and only count one unique visit to each network site per day."
|
||||
|
||||
The company then weights the data by country. "We compare our traffic to the CIA Internet Traffic by Country table, and weight our data accordingly. For example, if our global data shows that Brazil represents 2% of our traffic, and the CIA table shows Brazil to represent 4% of global Internet traffic, we will count each unique visitor from Brazil twice."
|
||||
|
||||
How exactly do they "weigh" that single visit per day to a site data? We don't know.
|
||||
|
||||
StatCounter also has its own method. It uses a "[tracking code installed on more than 2 million sites globally][8]. These sites cover various activities and geographic locations. Every month, we record billions of page views to these sites. For each page view, we analyse the browser/operating system/screen resolution used and we establish if the page view is from a mobile device. ... We summarize all this data to get our Global Stats information.
|
||||
|
||||
We provide independent, unbiased stats on internet usage trends. We do not collate our stats with any other information sources. [No artificial weightings are used][9]."
|
||||
|
||||
How do they summarize their data? Guess what? We don't know that either.
|
||||
|
||||
So whenever you see operating system or browser numbers from either of these often-quoted services, take them with a very large grain of salt.
|
||||
|
||||
For the most accurate, albeit US-centric operating system and browser numbers, I prefer to use data from the federal government's [Digital Analytics Program (DAP)][10].
|
||||
|
||||
Unlike the others, DAP's numbers come from billions of visits over the past 90 days to over [400 US executive branch government domains][11]. That's [about 5,000 total websites][12], and includes every cabinet department. DAP gets its raw data from a Google Analytics account. DAP has [open-sourced the code, which displays the data on the web][13] and its [data-collection code][14]. Best of all, unlike the others, you can download its data in [JavaScript Object Notation (JSON)][15] format so you can analyze the raw numbers yourself.
|
||||
|
||||
In the [US Analytics][16] site, which summarizes DAP's data, you will find desktop Linux, as usual, hanging out in "other" at 1.5 percent. Windows, as always, is on top with 45.9 percent, followed by Apple iOS, at 25.5 percent, Android at 18.6 percent, and macOS at 8.5 percent.
|
||||
|
||||
Sorry folks, I wish it were higher too. Indeed, I am sure it is. No one, not even DAP, seems to do a good job of pulling out the Linux-based Chrome OS data. Still, the Linux desktop remains the preserve for Linux experts, software developers, system administrators, and engineers. Linux fans must remain content with the top dog operating system in all other computing devices -- servers, clouds, supercomputers, etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/no-the-linux-desktop-hasnt-jumped-in-popularity/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[2]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[3]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[4]:https://www.netmarketshare.com/
|
||||
[5]:https://statcounter.com/
|
||||
[6]:http://www.zdnet.com/article/the-secret-origins-of-googles-chrome-os/
|
||||
[7]:http://www.netmarketshare.com/faq.aspx#Methodology
|
||||
[8]:http://gs.statcounter.com/faq#methodology
|
||||
[9]:http://gs.statcounter.com/faq#no-weighting
|
||||
[10]:https://www.digitalgov.gov/services/dap/
|
||||
[11]:https://analytics.usa.gov/data/live/second-level-domains.csv
|
||||
[12]:https://analytics.usa.gov/data/live/sites.csv
|
||||
[13]:https://github.com/GSA/analytics.usa.gov
|
||||
[14]:https://github.com/18F/analytics-reporter
|
||||
[15]:http://json.org/
|
||||
[16]:https://analytics.usa.gov/
|
||||
[17]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[18]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[19]:http://www.zdnet.com/blog/open-source/
|
||||
[20]:http://www.zdnet.com/topic/enterprise-software/
|
||||
@ -0,0 +1,177 @@
|
||||
Instant +100% command line productivity boost
|
||||
============================================================
|
||||
|
||||
Being productive is fun.
|
||||
|
||||
There are a lot of fields to improve your productivity. Today I am going to share some command line tips and tricks to make your life easier.
|
||||
|
||||
### TLDR
|
||||
|
||||
My full setup includes all the stuff discussed in this article and even more. Check it out: [https://github.com/sobolevn/dotfiles][9]
|
||||
|
||||
### Shell
|
||||
|
||||
Using a good, helping, and the stable shell is the key to your command line productivity. While there are many choices, I prefer `zsh` coupled with `oh-my-zsh`. It is amazing for several reasons:
|
||||
|
||||
* Autocomplete nearly everything
|
||||
|
||||
* Tons of plugins
|
||||
|
||||
* Really helping and customizable `PROMPT`
|
||||
|
||||
You can follow these steps to install this setup:
|
||||
|
||||
1. Install `zsh`: [https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH][1]
|
||||
|
||||
2. Install `oh-my-zsh`: [http://ohmyz.sh/][2]
|
||||
|
||||
3. Choose plugins that might be useful for you: [https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins][3]
|
||||
|
||||
You may also want to tweak your settings to [turn off case sensitive autocomplete][10]. Or change how your [history works][11].
|
||||
|
||||
That's it. You will gain instant +50% productivity. Now hit tab as much as you can!
|
||||
|
||||
### Theme
|
||||
|
||||
Choosing theme is quite important as well since you see it all the time. It has to be functional and pretty. I also prefer minimalistic themes, since it does not contain a lot of visual noise and unused information.
|
||||
|
||||
Your theme should show you:
|
||||
|
||||
* current folder
|
||||
|
||||
* current branch
|
||||
|
||||
* current repository status: clean or dirty
|
||||
|
||||
* error codes if any
|
||||
|
||||
I also prefer my theme to have new commands on a new line, so there is enough space to read and write it.
|
||||
|
||||
I personally use [`sobole`][12]. It looks pretty awesome. It has two modes.
|
||||
|
||||
Light:
|
||||
|
||||
[][13]
|
||||
|
||||
And dark:
|
||||
|
||||
[][14]
|
||||
|
||||
Get your another +15% boost. And an awesome-looking theme.
|
||||
|
||||
### Syntax highlighting
|
||||
|
||||
For me, it is very important to have enough visual information from my shell to make right decisions. Like "does this command have any typos in its name" or "do I have paired scopes in this command"? And I really make tpyos all the time.
|
||||
|
||||
So, [`zsh-syntax-highlighting`][15] was a big finding for me. It comes with reasonable defaults, but you can [change anything you want][16].
|
||||
|
||||
These steps brings us extra +5%.
|
||||
|
||||
### Working with files
|
||||
|
||||
I travel inside my directories a lot. Like _a lot_ . And I do all the things there:
|
||||
|
||||
* navigating back and forwards
|
||||
|
||||
* listing files and directories
|
||||
|
||||
* printing files' contents
|
||||
|
||||
I prefer to use [`z`][17] to navigate to the folders I have already been to. This tool is awesome. It uses 'frecency' method to turn your `.dot TAB` into `~/dev/shell/config/.dotfiles`. Really nice!
|
||||
|
||||
When printing files you want usually to know several things:
|
||||
|
||||
* file names
|
||||
|
||||
* permissions
|
||||
|
||||
* owner
|
||||
|
||||
* git status of the file
|
||||
|
||||
* modified date
|
||||
|
||||
* size in human readable form
|
||||
|
||||
You also probably what to show hidden files to show up by default as well. So, I use [`exa`][18] as the replacement for standard `ls`. Why? Because it has a lot of stuff enabled by default:
|
||||
|
||||
[][19]
|
||||
|
||||
To print the file contents I use standard `cat` or if I want to see to proper syntax highlighting I use a custom alias:
|
||||
|
||||
```
|
||||
# exa:
|
||||
alias la="exa -abghl --git --color=automatic"
|
||||
|
||||
# `cat` with beautiful colors. requires: pip install -U Pygments
|
||||
alias c='pygmentize -O style=borland -f console256 -g'
|
||||
```
|
||||
|
||||
Now you have mastered the navigation. Get your +15% productivity boost.
|
||||
|
||||
### Searching
|
||||
|
||||
When searching in a source code of your applications you don't want to include folders like `node_modules` or `bower_components` into your results by default. You also want your search to be fast and smooth.
|
||||
|
||||
Here's a good replacement for the built in search methods: [`the_silver_searcher`][20].
|
||||
|
||||
It is written in pure `C` and uses a lot of smart logic to work fast.
|
||||
|
||||
Using `ctrl` + `R` for [reverse search][21] in `history` is very useful. But have you ever found yourself in a situation when I can quite remember a command? What if there were a tool that makes this search even greater enabling fuzzy searching and a nice UI?
|
||||
|
||||
There is such a tool, actually. It is called `fzf`:
|
||||
|
||||
[][22]
|
||||
|
||||
It can be used to fuzzy-find anything, not just history. But it requires [some configuration][23].
|
||||
|
||||
You are now a search ninja with +15% productivity bonus.
|
||||
|
||||
### Further reading
|
||||
|
||||
Using better CLIs: [https://dev.to/sobolevn/using-better-clis-6o8][24]
|
||||
|
||||
### Conclusion
|
||||
|
||||
Following these simple steps, you can dramatically increase your command line productivity, like +100% (numbers are approximate).
|
||||
|
||||
There are other tools and hacks I will cover in the next articles.
|
||||
|
||||
Do you like reading about the latest trends in software development? Subscribe to our blog on Medium: [https://medium.com/wemake-services][25]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dev.to/sobolevn/instant-100-command-line-productivity-boost
|
||||
|
||||
作者:[Nikita Sobolev ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dev.to/sobolevn
|
||||
[1]:https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH
|
||||
[2]:http://ohmyz.sh/
|
||||
[3]:https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins
|
||||
[4]:https://dev.to/sobolevn
|
||||
[5]:http://github.com/sobolevn
|
||||
[6]:https://dev.to/t/commandline
|
||||
[7]:https://dev.to/t/dotfiles
|
||||
[8]:https://dev.to/t/productivity
|
||||
[9]:https://github.com/sobolevn/dotfiles
|
||||
[10]:https://github.com/sobolevn/dotfiles/blob/master/zshrc#L12
|
||||
[11]:https://github.com/sobolevn/dotfiles/blob/master/zshrc#L24
|
||||
[12]:https://github.com/sobolevn/sobole-zsh-theme
|
||||
[13]:https://res.cloudinary.com/practicaldev/image/fetch/s--Lz_uthoR--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/env-and-user.png
|
||||
[14]:https://res.cloudinary.com/practicaldev/image/fetch/s--4o6hZwL9--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/dark-mode.png
|
||||
[15]:https://github.com/zsh-users/zsh-syntax-highlighting
|
||||
[16]:https://github.com/zsh-users/zsh-syntax-highlighting/blob/master/docs/highlighters.md
|
||||
[17]:https://github.com/rupa/z
|
||||
[18]:https://github.com/ogham/exa
|
||||
[19]:https://res.cloudinary.com/practicaldev/image/fetch/s--n_YCO9Hj--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/ogham/exa/master/screenshots.png
|
||||
[20]:https://github.com/ggreer/the_silver_searcher
|
||||
[21]:https://unix.stackexchange.com/questions/73498/how-to-cycle-through-reverse-i-search-in-bash
|
||||
[22]:https://res.cloudinary.com/practicaldev/image/fetch/s--hykHvwjq--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://thepracticaldev.s3.amazonaws.com/i/erts5tffgo5i0rpi8q3r.png
|
||||
[23]:https://github.com/sobolevn/dotfiles/blob/master/shell/.external#L19
|
||||
[24]:https://dev.to/sobolevn/using-better-clis-6o8
|
||||
[25]:https://medium.com/wemake-services
|
||||
@ -1,105 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Tips to Secure Your Network in the Wake of KRACK
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
The recent KRACK vulnerability targets the link between your device and the Wi-Fi access point, which is probably a router either in your home, your office, or your favorite cafe. These tips can help improve the security of your connection.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
The [KRACK attacks vulnerability][4] is now more than 48 hours old and has been discussed in detail on a number of [technology-related sites][5], so I won’t repeat the technical details of the attack here. To summarize:
|
||||
|
||||
* A flaw in the WPA2 wireless handshake protocol allows attackers to sniff or manipulate the traffic between your device and the wi-fi access point.
|
||||
|
||||
* It is particularly bad for Linux and Android devices, due either to ambiguous wording in the WPA2 standard or to misunderstanding during its implementation. Effectively, until the underlying OS is patched, the vulnerability allows attackers to force all wireless traffic to happen without any encryption at all.
|
||||
|
||||
* This vulnerability can be patched on the client, so the sky hasn’t fallen and the WPA2 wireless encryption standard is not obsoleted in the same sense that the WEP standard is (do NOT “fix” this problem by switching to WEP).
|
||||
|
||||
* Most popular Linux distributions are already shipping updates that fix this vulnerability on the client, so apply your updates dutifully.
|
||||
|
||||
* Android will be shipping fixes for this vulnerability Very Soon. If your device is receiving Android security patches, you will receive a fix before long. If your device is no longer receiving such updates, then this particular vulnerability is merely another reason why you should stop using old, unsupported Android devices.
|
||||
|
||||
That said, from my perspective, Wi-Fi is merely another link in the chain of untrusted infrastructure and we should altogether avoid treating it as a trusted communication channel.
|
||||
|
||||
### Wi-Fi as untrusted infrastructure
|
||||
|
||||
If you’re reading this article from your laptop or your mobile device, then your chain of communication probably looks something like this:
|
||||
|
||||

|
||||
|
||||
The KRACK attack targets the link between your device and the Wi-Fi access point, which is probably a router either in your home, your office, your neighborhood library, or your favorite cafe.
|
||||
|
||||

|
||||
|
||||
In reality, this diagram should look something like this:
|
||||
|
||||

|
||||
|
||||
Wi-Fi is merely the first link in a long chain of communication happening over channels that we should not trust. If I were to guess, the Wi-Fi router you’re using has probably not received a security update since the day it got put together. Worse, it probably came with default or easily guessable administrative credentials that were never changed. Unless you set up and configured that router yourself and you can remember the last time you updated its firmware, you should assume that it is now controlled by someone else and cannot be trusted.
|
||||
|
||||
Past the Wi-Fi router, we enter the zone of generally distrusting the infrastructure at large -- depending on your general paranoia levels. Here we have upstream ISPs and providers, many of whom have been caught monitoring, altering, analyzing, and selling our personal traffic in an attempt to make additional money off our browsing habits. Often their own security patching schedules leave a lot to be desired and end up exposing our traffic to malicious eyes.
|
||||
|
||||
On the Internet at large, we have to worry about powerful state-level actors with ability to manipulate [core networking protocols][6] in order to carry out mass surveillance programs or perform state-level traffic filtering.
|
||||
|
||||
### HTTPS Protocol
|
||||
|
||||
Thankfully, we have a solution to the problem of secure communication over untrusted medium, and we use it every day -- the HTTPS protocol encrypts our Internet traffic point-to-point and ensures that we can trust that the sites we communicate with are who they say they are.
|
||||
|
||||
The Linux Foundation initiatives like [Let’s Encrypt][7] make it easy for site owners worldwide to offer end-to-end encryption that helps ensure that any compromised equipment between our personal devices and the websites we are trying to access does not matter.
|
||||
|
||||

|
||||
|
||||
Well... almost does not matter.
|
||||
|
||||
### DNS remains a problem
|
||||
|
||||
Even if we dutifully use HTTPS to create a trusted communication channel, there is still a chance that an attacker with access to our Wi-Fi router or someone who can alter our Wi-Fi traffic -- as is the case with KRACK -- can trick us into communicating with the wrong website. They can do so by taking advantage of the fact that we still greatly rely on DNS -- an unencrypted, easily spoofed [protocol from the 1980s][8].
|
||||
|
||||

|
||||
|
||||
DNS is a system that translates human-friendly domain names like “linux.com” into IP addresses that computers can use to communicate with each other. To translate a domain name into an IP address, the computer would query the resolver software -- usually running on the Wi-Fi router or on the system itself. The resolver would then query a distributed network of “root” nameservers to figure out which system on the Internet has what is called “authoritative” information about what IP address corresponds to the “linux.com” domain name.
|
||||
|
||||
The trouble is, all this communication happens over unauthenticated, [easily spoofable][9], cleartext protocols, and responses can be easily altered by attackers to make the query return incorrect data. If someone manages to spoof a DNS query and return the wrong IP address, they can manipulate where our system ends up sending the HTTP request.
|
||||
|
||||
Fortunately, HTTPS has a lot of built-in protection to make sure that it is not easy for someone to pretend to be another site. The TLS certificate on the malicious server must match the DNS name you are requesting -- and be issued by a reputable [Certificate Authority][10] recognized by your browser. If that is not the case, the browser will show a big warning that the host you are trying to communicate with is not who they say they are. If you see such warning, please be extremely cautious before choosing to override it, as you could be giving away your secrets to people who will use them against you.
|
||||
|
||||
If the attackers have full control of the router, they can prevent your connection from using HTTPS in the first place, by intercepting the response from the server that instructs your browser to set up a secure connection (this is called “[the SSL strip attack][11]”). To help protect you from this attack, sites may add a [special response header][12] telling your browser to always use HTTPS when communicating with them in the future, but this only works after your first visit. For some very popular sites, browsers now include a [hardcoded list of domains][13] that should always be accessed over HTTPS even on the first visit.
|
||||
|
||||
The solution to DNS spoofing exists and is called [DNSSEC][14], but it has seen very slow adoption due to important hurdles -- real and perceived. Until DNSSEC is used universally, we must assume that DNS information we receive cannot be fully trusted.
|
||||
|
||||
### Use VPN to solve the last-mile security problem
|
||||
|
||||
So, if you cannot trust Wi-Fi -- and/or the wireless router in the basement that is probably older than most of your pets -- what can be done to ensure the integrity of the “last-mile” communication, the one that happens between your device and the Internet at large?
|
||||
|
||||
One acceptable solution is to use a reputable VPN provider that will establish a secure communication link between your system and their infrastructure. The hope here is that they pay closer attention to security than your router vendor and your immediate Internet provider, so they are in a better position to assure that your traffic is protected from being sniffed or spoofed by malicious parties. Using VPN on all your workstations and mobile devices ensures that vulnerabilities like KRACK attacks or insecure routers do not affect the integrity of your communication with the outside world.
|
||||
|
||||

|
||||
|
||||
The important caveat here is that when choosing a VPN provider you must be reasonably assured of their trustworthiness; otherwise, you’re simply trading one set of malicious actors for another. Stay far away from anything offering “free VPN,” as they are probably making money by spying on you and selling your traffic to marketing firms. [This site][2] is a good resource that would allow you to compare various VPN providers to see how they stack against each other.
|
||||
|
||||
Not all of your devices need to have VPN installed on them, but the ones that you use daily to access sites with your private personal information -- and especially anything with access to your money and your identity (government, banking sites, social networking, etc.) must be secured. VPN is not a panacea against all network-level vulnerabilities, but it will definitely help protect you when you’re stuck using unsecured Wi-Fi at the airport, or the next time a KRACK-like vulnerability is discovered.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.vpnmentor.com/bestvpns/overall/
|
||||
[3]:https://www.linux.com/files/images/krack-securityjpg
|
||||
[4]:https://www.krackattacks.com/
|
||||
[5]:https://blog.cryptographyengineering.com/2017/10/16/falling-through-the-kracks/
|
||||
[6]:https://en.wikipedia.org/wiki/BGP_hijacking
|
||||
[7]:https://letsencrypt.org/
|
||||
[8]:https://en.wikipedia.org/wiki/Domain_Name_System#History
|
||||
[9]:https://en.wikipedia.org/wiki/DNS_spoofing
|
||||
[10]:https://en.wikipedia.org/wiki/Certificate_authority
|
||||
[11]:https://en.wikipedia.org/wiki/Moxie_Marlinspike#Notable_research
|
||||
[12]:https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
|
||||
[13]:https://hstspreload.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions
|
||||
@ -1,4 +1,4 @@
|
||||
translating---geekpi
|
||||
jrglinux is translating!!!
|
||||
|
||||
But I don't know what a container is
|
||||
============================================================
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
We're switching to a DCO for source code contributions
|
||||
============================================================
|
||||
|
||||
We want to make it even easier for everyone to contribute, by doing away with our Contributor License Agreement in favor of the Developer's Certificate of Origin.
|
||||
|
||||
We're committed to being [good stewards of open source][1], and part of that commitment means we never stop re-evaluating how we do that. Saying "everyone can contribute" is about removing barriers to contribution. For some of our community, the Contributor License Agreement is a deterrent to contributing to GitLab, so we're changing to a Developer's Certificate of Origin instead.
|
||||
|
||||
Many large open source projects want to be masters of their own destiny. Having the freedom to run your own infrastructure based on open source software, together with the ability to modify and audit source code and not be dependent on a vendor, makes open source appealing. We want GitLab to be an option for everyone.
|
||||
|
||||
### Why the change?
|
||||
|
||||
A Contributor License Agreement (CLA) is the industry standard for open source contributions to other projects, but it's unpopular with developers, who don't want to enter into legal terms and are put off by having to review a lengthy contract and potentially give up some of their rights. Contributors find the agreement unnecessarily restrictive, and it's deterring developers of open source projects from using GitLab. We were approached by Debian developers to consider dropping the CLA, and that's what we're doing.
|
||||
|
||||
### What's changing?
|
||||
|
||||
As of today, we're rolling out changes so that contributors to the GitLab source code will only be required to make contributions and bug fixes under a project license (MIT for all repositories with the exception of Omnibus which would be licensed under Apache) and a [Developer's Certificate of Origin][2] (DCO). The DCO gives developers greater flexibility and portability for their contributions, and it's one of the reasons that Debian and GNOME plan to migrate their communities and projects to GitLab. We hope this change encourages more developers to contribute to GitLab. Thank you Debian, for prompting us to make this change.
|
||||
|
||||
> "We applaud GitLab for dropping their CLA in favor of a more OSS-friendly approach. Open source communities are born from a sea of contributions that come together and transform into projects. This gesture affirmed GitLab's willingness to protect the individual, their creative process, and most importantly, keeps intellectual property in the hands of the creator." - Carlos Soriano, Board Director at GNOME
|
||||
|
||||
> "We’re thrilled to see GitLab simplifying and encouraging community contributions by switching from a CLA to the DCO. We recognize that making a change of this nature is not easy and we applaud the time, patience and thoughtful consideration GitLab has shown here." - Chris Lamb, Debian Project Leader
|
||||
|
||||
You can [read the analysis that informed our decision][3]. Read all about our [stewardship of GitLab Community Edition][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2017/11/01/gitlab-switches-to-dco-license/
|
||||
|
||||
作者:[ Jamie Hurewitz ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://about.gitlab.com/team/#hurewitzjamie
|
||||
[1]:https://about.gitlab.com/2016/01/11/being-a-good-open-source-steward/
|
||||
[2]:https://developercertificate.org/
|
||||
[3]:https://docs.google.com/a/gitlab.com/document/d/1zpjDzL7yhGBZz3_7jCjWLfRQ1Jryg1mlIVmG8y6B1_Q/edit?usp=sharing
|
||||
[4]:https://about.gitlab.com/stewardship/
|
||||
@ -0,0 +1,167 @@
|
||||
[Streams:Redis中新的一个通用数据结构][1]
|
||||
==================================
|
||||
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,streams 只是一个有趣且相对简单的概念。在 Kafka 概念普及之后,我主要研究他们在 Disque 实例中的效能。Disque 是一个将被转化到 Redis 4.2 模块中的消息队列。后来我明白 Disque 将是关于 AP 消息的全部,它将在不需要客户端过多参与的情况下实现容错和保证送达,因此,我认为 streams 的概念在那种情况下并不适用。
|
||||
|
||||
但是,在 Redis 中有一个问题,那就是从缺省导出数据结构并不轻松。它在 Redis 列表、排序集和发布/订阅(Pub/Sub)能力上有某些缺陷,你可以权衡差异,友好地使用这些工具去模拟一个消息或事件的序列。排序集是大量耗费内存的,不能用相同的消息模型一次又一次的传递,客户端不能阻塞新消息。因为一个排序集并不是一个序列化的数据结构,它是一个根据他们量的变化而变化的元素集:它不是像时间系列一样很适合的东西。列表有另外的问题,它在某些用户案例中产生适用性问题:你无法浏览列表中是什么,因为在那种情况下,访问时间是线性的。此外,没有任何输出,列表上的阻塞操作仅为单个客户端提供单个元素。比如说:从那个元素开始给我提供内容,列表中也没有固定的元素标识。对于一到多的工作负载,这里有发布/订阅,它在大多数情况下是非常好的,但是,对于某些不想“即发即弃”的东西:去保留一个历史是很重要的,而不是断开之后重新获得消息,也因为某些消息列表,像时间系列,在用范围查询浏览时,是非常重要的:在这 10 秒范围内我的温度读数是多少?
|
||||
|
||||
这有一种方法可以尝试处理上面的问题,计划对排序集进行通用化,并列入一个唯一的更灵活的数据结构,然而,我的设计尝试最终以生成一个相对当前的人造的数据结构的结果结束,一个关于 Redis 数据结构导出的更好的想法是,让它更像天然的计算机科学的数据结构。而不是, “Salvatore 发明的 API”。因此,在最后我停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许,我将为发布/订阅增加一些历史,或者将来对列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说“你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸变绿了。
|
||||
|
||||
起源
|
||||
=======
|
||||
|
||||
在将 Redis 4.0 中的模块介绍完之后,用户开始去看他们自己怎么去修复这些问题。他们之一,Timothy Downs,通过 IRC 写信给我:
|
||||
|
||||
<forkfork> 这个模块,我计划去增加一个事务日志式的数据类型 - 这意味着大量的订阅者可以在没有大量的内存增加的情况下做一些像发布/订阅那样的事情
|
||||
<forkfork> 订阅者保持他在消息队列中的位置,而不是在 Redis 上维护每个客户和复制消息的每个订阅者
|
||||
|
||||
这激发了我的想像力。我想了几天,并且意识到这可能是我们立刻同时解决上面的问题的契机。我需要去重新想像 “日志” 的概念是什么。它是个基本的编程元素,每个人都使用到它,因为它是非常简单地在追加模式中打开一个文件并以一定的格式写入数据,数据结构必须是抽象的。然而 Redis ,它们在内存中,并且我们使用 RAM 并不是因为我们懒,但是,因为使用一些指针,我们可以概念化数据结构并让他们抽象,并允许他们去摆脱明显的限制。对于实例,正常的日志有几个问题:偏移不是逻辑的,但是,它是一个真实的字节偏移,如果你想逻辑偏移是什么,那是与条目插入的时间相关的,我们有范围查询可用。同样的,一个日志通常很难收集:在一个只追加的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只是说,我想要最大的条目数,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法,去尝试着写一个规范的时候,我使用了 radix 树去实现,它是用于 Redis 集群的,去优化它内部的某些部分。这为实现一个有效的空间日志提供了基础。它在对数的时间(logarithmic time)内得到范围是仍然可访问的。同时,我开始去读关于 Kafka 流,去得到另外的创意,它也非常适合我的设计,并且产生了一个 Kafka 客户组的概念,并且,将它理想化用于 Redis 和内存中(in-memory)使用的案例。然而,该规范仅保留了几个月,在一段时间后,我积累了与别人讨论的即将增加到 Redis 中的内容,为了升级它,使用了许多提示(hint)几乎从头到尾重写了一遍。我想 Redis 流尤其对于时间系列是非常有用的,而不仅是用于事件和消息类的应用程序。
|
||||
|
||||
让我们写一些代码
|
||||
=====================
|
||||
|
||||
从 Redis 会议回来后,在整个夏天,我实现了一个称为 “listpack” 的库。这个库是 ziplist.c 的继承者,那是一个表示在单个分配中字符串元素的列表的数据结构。它是一个非常专业的序列化格式,有在相反的顺序中可解析的特性,从右到左: 在所有的用户案例中用于替代 ziplists 中所需的某些东西。
|
||||
|
||||
结合 radix 树 + listpacks,它可以很容易地去构建一个日志,它同时也是非常高效的,并且是索引化的,意味着,允许通过 IDs 和时间进行随机访问。自从实现这个方法后,为了实现流数据结构,我开始去写一些代码。我直到完成实现,不管怎样,在这个时候,在 Github 上的 Redis 内部的 “streams” 分支,去启动共同开发并接受订阅已经足够了。我并没有声称那个 API 是最终版本,但是,这有两个有趣的事实:一是,在那时,仅客户组是缺失的,加上一些不那么重要的命令去操作流,但是,所有的大的方面都已经实现了。二是,一旦各个方面比较稳定了之后 ,决定将所有的流的工作移植到 4.0 分支,它大约两个月后发布。这意味着 Redis 用户为了使用流,不用等待 Redis 4.2,它们将对生产使用的 ASAP 可用。这是可能的,因为有一个新的数据结构,几乎所有的代码改变都是独立于新代码的。除了阻塞列表操作之外 :代码都重构了,因此,我们和流共享了相同的代码,并且,列表阻塞操作在 Redis 内部进行了大量的简化。
|
||||
|
||||
教程:欢迎使用 Redis 流
|
||||
==================================
|
||||
|
||||
在某种程序上,你应该感谢流作为 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,它们更多是一个域(fields)和值(values)组成的对象。范围查询更适用而且更快。流中的每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以阻塞等待(blocking-wait)比指定的 IDs 更大的元素。Redis 流的一个基本的命令是 XADD。是的,所有的 Redis 命令都是以一个“X”为前缀的。
|
||||
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
|
||||
这个 XADD 命令将追加指定的条目作为一个新元素到一个指定的流 “mystream” 中。在上面的示例中的这个条目有两个域:sensor-id 和 temperature,然而,每个条目在同一个流中可以有不同的域。使用相同的域名字将导致更多的内存使用。一个有趣的事情是,域的排序是保证保存的。XADD 仅返回插入的条目的 ID,因为在第三个参数中有星号(*),我们请求命令去自动生成 ID。这几乎总是你想要的,但是,它也可能去强制指定一个 ID,实例为了去复制这个命令到被动服务器和 AOF 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。1506871964177 是毫秒时间,它仅是一个使用毫秒解决方案的 UNIX 时间。圆点(.)后面的数字 0,是一个序列号,它是为了区分相同毫秒数的条目增加上去的。所有的数字都是 64 位的无符号整数。这意味着在流中,我们可以增加所有我们想要的条目,在相同毫秒数中的事件。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目之间的最大值来获取。因此,对实例来说,即使是计算机时间向后跳,这个 IDs 仍然是增加的。在某些情况下,你可能想流条目的 IDs 作为完整的 128 位数字。然而,现实是,它们与被添加的实例的本地时间有关,意味着我们有毫秒级的精确的范围查询。
|
||||
|
||||
如你想像的那样,以一个快速的方式去添加两个条目,结果是仅序列号增加。我可以使用一个 MULTI/EXEC 块去简单模拟“快速插入”,如下:
|
||||
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
|
||||
在上面的示例中,也展示了无需在开始时指定任何模式(schema)的情况下,对不同的条目,使用不同的域。会发生什么呢?每个块(它通常包含 50 - 150 个消息范围的内容)的每一个信息被用作参考。并且,有相同域的连续条目被使用一个标志进行压缩,这个标志表明“这个块中的第一个条目的相同域”。因此,对于连续消息使用相同域可以节省许多内存,即使是域的集合随着时间发生缓慢变化。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 XRANGE 命令实现的,并且对于正在变化的流,通过 XREAD 命令去实现。XRANGE 命令仅取得包括从开始到停止范围内的条目。因此,对于实例,如果我知道它的 ID,我可以取得单个条目,像这样:
|
||||
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
|
||||
然而,你可以使用指定的开始符号 “-” 和停止符号 “+” 去表示可能的最小和最大 ID。为了限制返回条目的数量,它也可以使用 COUNT 选项。下面是一个更复杂的 XRANGE 示例:
|
||||
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
|
||||
这里我们讲的是 IDs 的范围,然后,为了在一个给定时间范围内取得特定元素的范围,你可以使用 XRANGE,因为你可以省略 IDs 的“序列” 部分。因此,你可以做的仅是指定“毫秒”时间,下面的命令的意思是: “从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
|
||||
关于 XRANGE 注意的最重要的事情是,由于我们在回复中收到了 IDs,并且连续 ID 是无法直接获得的,因为 ID 的序列部分是增加的,它可以使用 XRANGE 去遍历整个流,接收每个调用的元素的特定个数。在 Redis 中的*SCAN*系列命令之后,那是允许 Redis 数据结构迭代的,尽管事实上它们不是为迭代设计的,我以免再次产生相同的错误。
|
||||
|
||||
使用 XREAD 处理变化的流:阻塞新的数据
|
||||
===========================================
|
||||
|
||||
XRANGE 用于,当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去得到单个元素时,是非常完美的。然而,在当数据到达时,不同的客户端必须同时使用流的情况下,它就不是一个很好的解决方案,并且它是需要某种形式的“池”的。(对于*某些*应用程序来说,这可能是个好主意,因为它们仅是偶尔连接取数的)。
|
||||
|
||||
XREAD 命令是为读设计的,同时从多个流中仅指定我们得到的流中的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,去解除阻塞。类似于阻塞列表操作产生的效果,但是,这里的数据是从流中得到的。并且多个客户端可以在同时访问相同的数据。
|
||||
|
||||
这里有一个关于 XREAD 调用的规范示例:
|
||||
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
|
||||
它的意思是:从 “mystream” 和 “otherstream” 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。之后我们用关键字 STREAMS 指定我们想要监听的流,和最后的 ID,指定的 ID “$” 意思是:假设我现在已经有了流中的所有元素,因此,从下一个到达的元素开始给我。
|
||||
|
||||
如果,从另外一个客户端,我发出这样的命令:
|
||||
|
||||
> XADD otherstream * message “Hi There”
|
||||
|
||||
在 XREAD 侧会出现什么情况呢?
|
||||
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
|
||||
和到过的数据一起,我们得到了最新到达的数据的 key,在下次的调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
|
||||
依次类推。然而需要注意的是使用方式,有可能客户端在一个非常大的延迟(因为它处理消息需要时间,或者其它什么原因)之后再次连接。在这种情况下,同时会有很多消息堆积,为了确保客户端不被消息淹没,并且服务器不会丢失太多时间的提供给单个客户端的大量消息,所以,总是使用 XREAD 的 COUNT 选项是明智的。
|
||||
|
||||
流封顶
|
||||
==============
|
||||
|
||||
到现在为止,一直还都不错… 然而,有些时候,流需要去删除一些旧的消息。幸运的是,这可以使用 XADD 命令的 MAXLEN 选项去做:
|
||||
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
|
||||
它是基本意思是,如果流添加的新元素被发现超过 1000000 个消息,那么,删除旧的消息,以便于长度回到 1000000 个元素以内。它很像是使用 RPUSH + LTRIM 的列表,但是,这是我们使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将使用一些 CPU 资源,所以,在计算 MAXLEN 的之前,尽可能使用 “~” 符号,为了表明我们不是要求非常*精确*的 1000000 个消息。但是,这里有很多,它还不是一个大的问题:
|
||||
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
|
||||
这种方式的 XADD 删除消息,仅用于当它可以删除整个节点的时候。相比 vanilla XADD,这种方式几乎可以自由地对流进行封顶。
|
||||
|
||||
(进程内工作的)客户组
|
||||
==================================
|
||||
|
||||
这是不在 Redis 中实现的第一个特性,但是,它是在进程内工作的。它也是来自 Kafka 的灵感,尽管在这里以不同的方式去实现的。重点是使用了 XREAD,客户端也可以增加一个 “GROUP <name>” 选项。 在相同组的所有客户端自动调用,以得到*不同的*消息。当然,这里不能从同一个流中被多个组读。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在不同的组,消息是不会重复的。
|
||||
|
||||
当指定组时,尽可能指定一个 “RETRY <milliseconds>” 选项去扩展组:在这种情况下,如果消息没有使用 XACK 去进行确认,它将在指定的毫秒数后进行再次投递。这种情况下,客户端没有私有的方法去标记已处理的消息,这也是一项正在进行中的工作。
|
||||
|
||||
内存使用和节省的加载时间
|
||||
=====================================
|
||||
|
||||
因为被设计用来模拟 Redis 流,所以,根据它们的域的数量、值和长度,内存使用是显著降低的。但对于简单的消息,每 100 MB 内存使用可以有几百万条消息,此外,设想中的格式去需要极少的系列化:是存储为 radix 树节点的 listpack 块,在磁盘上和内存中是用同一个来表示的,因此,它们被琐碎地存储和读取。在一个实例中,Redis 能在 0.3 秒内可以从 RDB 文件中读取 500 万个条目。这使的流的复制和持久存储是非常高效的。
|
||||
|
||||
它也被计划允许从条目中间删除。现在仅部分实现,策略是整个条目标记中删除的条目被标记为已删除条目,并且,当达到设置的已删除条目占全部条目的比例时,这个块将被回收重写,并且,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
最终发布时间的结论
|
||||
===================
|
||||
|
||||
Redis 流将包含在年底前推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,为了用于解决很多现在很难去解决的情况:那意味着你需要创造性地滥用当前提供的数据结构去解决那些问题。一个非常重要的使用情况是时间系列,但是,我的感觉是,对于其它案例来说,通过 TREAD 来传递消息将是非常有趣的,因为它可以替代那些需要更高可靠性的发布/订阅的应用程序,而不是“即用即弃”,以及全新的使用案例。现在,如果你想在你的有问题的环境中,去评估新的数据结构的能力,可以在 GitHub 上去获得 “streams” 分支,开始去玩吧。欢迎向我们报告所有的 bug 。 :-)
|
||||
|
||||
如果你喜欢这个视频,展示这个 streams 的实时会话在这里: https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://antirez.com/
|
||||
[1]:http://antirez.com/news/114
|
||||
[2]:http://antirez.com/user/antirez
|
||||
[3]:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
@ -1,93 +0,0 @@
|
||||
Linux 是如何运作的
|
||||
============================================================
|
||||
|
||||
_在大量金钱与围绕 Linux 激烈争夺的公司之间的,正是那些真正给操作系统带来活力的开发者。_
|
||||
|
||||
实际上,[Linux 社区][7]本身无需太过担心社区的正常运作。Linux 已经尽可能的在多个领域占据着主导的地位 —— 从超级计算机到移动设备再到云计算 —— Linux 内核开发人员更多的是关注于代码本身,而不是其所在公司的利益。
|
||||
|
||||
这是一个出现在[Dawn Foster 博士的成果][8]中关于 Linux 内核的合作审查的著名的结论。Foster 博士是在英特尔公司和木偶实验室的前社区领导人,他写到,“很多人优先把自己看作是 Linux 内核开发者,其次才是作为一名雇员。”
|
||||
|
||||
大量的“基金洗劫型”公司已经强加于各种开源项目上,意图在虚构的社区面具之下隐藏企业特权,但 Linux 一直设法保持自身的纯粹。问题是怎么做到。
|
||||
|
||||
**跟随金钱的脚步**
|
||||
|
||||
毕竟,如果有开源项目需参与到企业的利欲中,那它一定是 Linux。回到 2008 年,[ Linux 生态系统的估值已经达到了最高 250 亿美元][9]。最近10年,伴随着数量众多的云服务,移动端,以及大数据基础设施对于 Linux 的依赖,这一数值一定还在急剧增长。甚至在像 Oracle 这样的单独一个公司,就实现了十亿美元的价值。
|
||||
|
||||
那么有点惊奇,这里有这样一个 landgrab 通过代码来影响 Linux 的方向。
|
||||
|
||||
看看在过去一年中那些对 Linux 最活跃的贡献者以及这些企业像“海龟”背地球一样撑起的版图, 就像[Linux 基金会的最新报道][10]中的截图:
|
||||
|
||||

|
||||
|
||||
这些企业花费大量的资金来雇佣开发者去构建自由软件,并且每个企业都有赖于这些投资所带来的回报。因为借由 Linux 潜在的企业灵活性,导致一些企业对 Linux 基金会的领导人[表示不满][11]。在像 Microsoft 这样曾为开源界宿敌的企业加入 Linux 基金会之后,这些批评言论正变得越来越响亮。
|
||||
|
||||
但老实说,这样一位假想的宿敌已经有点过时了。
|
||||
|
||||
虽然企业排队资金赞助 Linux 基金会已经成为了事实,不过这些赞助并没有收买基金会而影响到代码。在最伟大的开源社区中,金钱可以帮助招募开发者,但这些开发者相比企业更优先专注于代码。就像 Linux 基金会执行董事[ Jim Zemlin 强调的那样][12]:
|
||||
|
||||
“我们的项目中技术角色都是独立于企业的。没有人会在其提交的内容上标记他们的企业身份:在 Linux 基金会的项目中进行密切的代码交流。在我们的项目中,开发者可以从一个公司切换到另一个公司并且不会改变他们在项目中所扮演的角色。之后企业或政府采纳了这些代码所创造的价值,反过来可以使该项目获得投资。这样的良性循环对大家都有好处,并且也是我们项目的目标之一。”
|
||||
|
||||
读过 [Linus Torvalds 的][13] 的邮寄列表批注的人很难相信他就曾是这样的企业的上当者。对其他杰出贡献者保持同样的信任。他们总是普遍被大公司所雇佣,通常这些企业实际上会为开发者已经有意识的去完成并已经在进行的工作支付了一定的费用。
|
||||
|
||||
归根结底,很少有公司会有耐心或者必备的风险预测来为一群 Linux 内核骇客提供资金,并在内核团队有影响力的位置为一些他们 _可能_ 贡献质量足够的代码等上数年时间。所以他们选择雇佣已有的值得信赖的开发者。正如 [2016 Linux 基金会报告][14]所写的,“无薪开发者的数量继续[d]缓慢下降,同时 Linux 内核的开发证明是雇主们对有价值的技能需求日益增长,确保了有经验的 kernel 开发者不会在无薪阶段停留太长时间。”
|
||||
|
||||
这是代码所带来的信任,并不是通过企业的金钱。因此没有一个 Linux 内核开发者会为眼前的金钱而丢掉他们已经积攒的信任,那样会在出现新的利益冲突时妥协代码质量并很快失去信任。
|
||||
|
||||
**不是康巴亚,就是权利的游戏,非此即彼**
|
||||
|
||||
最终,Linux 内核开发是关于认同, Foster 的部分研究是这样认为的。
|
||||
|
||||
在 Google 工作会很棒,而且也许带有一个体面的头衔以及免费的干洗。然而,作为一个重要的 Linux 内核子系统的维护人员,很难承诺并保证,不会被其他提供更高薪水的公司所雇佣。
|
||||
|
||||
Foster 这样写到, “他们甚至享受当前的工作并且觉得他们的雇主不错,许多 [Linux 内核开发者] 倾向于审视一些临时的工作关系,而且他们作为内核开发者的身份被看作更有经验且更加重要。”
|
||||
|
||||
由于作为一名 Linux 开发者的身份优先,企业职员的身份第二,Linux 内核开发者甚至可以轻松地与其雇主的竞争对手合作。因为雇主们无力去引导他们开发者的工作,这也呼应了上边的原因。Foster 深入研究了这一问题:
|
||||
|
||||
“尽管企业对其雇员所贡献的领域产生了一些影响,在他们如何去完成工作这点上,雇员还是很自由的。许多人在日常工作中几乎没有接受任何指导,来自雇主的信任对工作是非常有帮助的。然而,他们偶尔会被要求做一些特定的零碎工作或者是在一个对公司重要的特定领域投入兴趣。
|
||||
|
||||
许多内核开发者同样与他们的竞争者进行日常的基础协作,在这里他们仅作为个人相互交流而不需要关心雇主之间的竞争。这是我在 Intel 工作时经常见到的一幕,因为我们内核开发者几乎都是与我们主要的竞争对手一同工作的。”
|
||||
|
||||
那些企业会在芯片上通过运行 Linux,或 Linux 发行版,亦或者是被其他健壮的操作系统支持的软件来进行竞争,但开发者们主要专注于一件事情:尽可能的使用 Linux 。同样,这是因为他们的身份被捆在 Linux 上,而不是坐在防火墙后面写代码。
|
||||
|
||||
Foster 通过 USB 子系统邮寄列表(在 2013 年到 2015 年之间)说明了这种相互作用,用深色线条着重描绘的公司之间电子邮件交互:
|
||||
|
||||

|
||||
|
||||
在价格讨论中很明显一些公司可能会在反垄断的权利中增加疑虑,但这种简单的商业行为在 Linux 大陆中一如既往。结果导致为各方产生一个操作系统并迫使他们在自由市场相互竞争。
|
||||
|
||||
**寻找合适的平衡**
|
||||
|
||||
Novell 公司的创始人 Ray Noorda 或许就是这样在最佳的开源社区之间的“合作竞争”,但只工作在真正的社区存在的地方。这很难做到,举个例子,为一个由单一供应商所主导的项目实现正确的紧张合作。由 Google 发起的[Kubernetes][15]就表明这是可能的,但其他的像是 Docker 这样的项目却在为同样的目标而挣扎,很大一部分原因是他们一直不愿放弃对自己项目的技术领导。
|
||||
|
||||
也许 Kubernetes 能够很好的工作是因为 Google 并不觉得必须占据重要地位,而且事实上,是 _希望_ 其他公司担负起开发领导的职责。通过一个梦幻般的代码库,如果 Google 帮助培养,就有利于像 Kubernetes 这样的项目获得成功,然后开辟一条道路,这就鼓励了 Red Hat 及其他公司做出杰出的贡献。
|
||||
|
||||
不过,Kubernetes 是个例外,就像 Linux 曾经那样。这里有许多 _因为_ 企业的利欲而获得成功的例子,并且在利益竞争中获取平衡。如果一个项目仅仅被公司自己的利益所控制,常常会在公司的技术管理上体现出来,而且再怎么开源许可也无法对企业产生影响。
|
||||
|
||||
简而言之,Linux 的运作是因为众多企业都想要控制它但却难以做到,由于其在工业中的重要性,使得开发者和构建人员更加灵活的作为一名 _Linux 开发者_ 而不是 Red Hat (或 Intel 亦或 Oracle … )工程师。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/why-linux-works.html
|
||||
|
||||
作者:[Matt Asay][a]
|
||||
译者:[softpaopao](https://github.com/softpaopao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[1]:https://www.datamation.com/feedback/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[2]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[3]:https://www.datamation.com/e-mail/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[4]:https://www.datamation.com/print/https://www.datamation.com/open-source/why-linux-works.html
|
||||
[5]:https://www.datamation.com/open-source/why-linux-works.html#comment_form
|
||||
[6]:https://www.datamation.com/author/Matt-Asay-1133910.html
|
||||
[7]:https://www.datamation.com/open-source/
|
||||
[8]:https://opensource.com/article/17/10/collaboration-linux-kernel
|
||||
[9]:http://www.osnews.com/story/20416/Linux_Ecosystem_Worth_25_Billion
|
||||
[10]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
|
||||
[11]:https://www.datamation.com/open-source/the-linux-foundation-and-the-uneasy-alliance.html
|
||||
[12]:https://thenewstack.io/linux-foundation-critics/
|
||||
[13]:https://github.com/torvalds
|
||||
[14]:https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5
|
||||
[15]:https://kubernetes.io/
|
||||
@ -1,123 +0,0 @@
|
||||
# Postgres 索引类型探索之旅
|
||||
|
||||
在 Citus上,为让事情做的更好,我们与客户一起在数据建模、优化查询、和增加 [索引][3]上花了一些时间。我的目标是为客户需要提供更好的服务,让你更成功。部分原因是[我们持续][5]为你的 Citus 集群保持良好的优化和 [高性能][4]。 另外部分是帮你了解你所需要的关于 Postgres and Citus的一切。毕竟,一个健康和高性能的数据库意味着 app 执行的更快,并且谁不愿意这样呢? 今天,我们简化一些内容,与客户仅分享关于 Postgres 索引的一些信息。
|
||||
|
||||
Postgres 有几种索引类型, 并且每个新版本都似乎增加一些新的索引类型。每个索引类型都是有用的,但是使用那种类型取决于 1\. (有时是)数据类型 2\. 表中的底层数据、和 3\. 执行的查找类型。 接下来的内容我们将介绍在 Postgres 中你可用的索引类型,以及你何时使用何种索引类型。在开始之前,这里有一个我们将带你亲历的索引类型列表:
|
||||
|
||||
* B-Tree
|
||||
|
||||
* Generalized Inverted Index (GIN)
|
||||
|
||||
* Generalized Inverted Seach Tree (GiST)
|
||||
|
||||
* Space partitioned GiST (SP-GiST)
|
||||
|
||||
* Block Range Indexes (BRIN)
|
||||
|
||||
* Hash
|
||||
|
||||
现在开始介绍索引
|
||||
|
||||
### 在 Postgres 中, 一个 B-Tree 索引是你使用的最普遍的索引
|
||||
|
||||
如果你有一个计算机科学的学位,那么 B-Tree 索引可能是你学会的第一个索引。一个 [B-tree 索引][6] 创建一个保持自身平衡的一棵树。当它根据索引去查找某个东西时,它会遍历这棵树去找到键,然后返回你要查找的数据。使用一个索引是大大快于顺序扫描的,因为相对于顺序扫描成千上万的记录,它可以仅需要读几个 [页][7] (当你仅返回几个记录时)。
|
||||
|
||||
如果你运行一个标准的 `CREATE INDEX` ,它将为你创建一个 B-tree 索引。 B-tree 索引在大多数的数据类型上是很有价值的,比如 text、numbers、和 timestamps。如果你正好在你的数据库中使用索引, 并且不在你的数据库上使用太多的 Postgres 的高级特性,使用标准的 B-Tree 索引可能是你最好的选择。
|
||||
|
||||
### GIN 索引,用于多值列
|
||||
|
||||
Generalized Inverted Indexes,一般称为 [GIN][8],大多适用于当单个列中包含多个值的数据类型
|
||||
|
||||
在 Postgres 文档中: _“GIN 是设计用于处理被索引的条目是复合值的情况的, 并且由索引处理的查询需要搜索在复合条目中出现的值。例如,这个条目可能是文档,并且查询可以搜索文档中包含的指定字符。”_
|
||||
|
||||
包含在这个范围内的最常见的数据类型有:
|
||||
|
||||
* [hStore][1]
|
||||
|
||||
* Arrays
|
||||
|
||||
* Range types
|
||||
|
||||
* [JSONB][2]
|
||||
|
||||
关于 GIN 索引中最让人满意的一件事是,它们知道索引的数据在复合值中。但是,因为一个 GIN 索引有一个关于对需要被添加的每个单独的类型支持的数据结构的特定的知识,因此,GIN 索引并不是支持所有的数据类型。
|
||||
|
||||
### GiST 索引, 用于有重叠值的行
|
||||
|
||||
GiST 索引多适用于当你的数据与同一列的其它行数据重叠时。关于 GiST 索引最好的用处是:如果你声明一个几何数据类型,并且你希望去看两个多边型包含的一些点。在一个例子中一个特定的点可能被包含在一个 box 中,而与此同时,其它的点仅存在于一个多边形中。你想去使用 GiST 索引的常见数据类型有:
|
||||
|
||||
* 几何类型
|
||||
|
||||
* 当需要进行全文搜索的文本类型
|
||||
|
||||
GiST 索引在大小上有很多的限制,否则,GiST 索引可能会变的特别大。最后导致 GiST 索引产生损害。从官方文档中: _“一个 GiST 索引是有损害的,意味着索引可能产生虚假的匹配,并且需要去检查真实的表行去消除虚假的匹配。 (当需要时 PostgreSQL 会自动执行这个动作)”_ 这并不意味着你会得到一个错误的结果,它正好说明了在 Postgres 给你返回数据之前,做了一个很小的额外的工作去过滤这些虚假结果。
|
||||
|
||||
_特别提示: GIN 和 GiST 索引可能经常在相同的数据类型上有益处的。其中之一是可能经常有很好的性能表现,但是,使用 GIN 可能占用很大的磁盘空间,并且对于 GiST 反之亦然。说到 GIN vs. GiST 的比较,并没有一个完美的大小去适用所有案例,但是,以上规则应用于大部分常见情况。_
|
||||
|
||||
### SP-GiST 索引,用于大的数据
|
||||
|
||||
空间分区的 GiST 索引利用来自 [Purdue][9] 研究的一些空间分区树。 SP-GiST 索引经常用于,当你的数据有一个天然的聚集因素并且还不是一个平衡树的时候。 电话号码是一个非常好的例子 (至少 US 的电话号码是)。 它们有如下的格式:
|
||||
|
||||
* 3 位数字的区域号
|
||||
|
||||
* 3 位数字的前缀号 (与以前的电话交换机有关)
|
||||
|
||||
* 4 位的线路号
|
||||
|
||||
这意味着第一组前三位处有一个天然的聚集因素, 接着是第二组三位, 然后的数字才是一个均匀的分布。但是,在电话号码的一些区域号中,存在一个比其它区域号更高的饱合状态。结果可能导致树非常的不平衡。因为前面有一个天然的聚集因素,并且像电话号码一样数据到数据的不对等分布,可能会是 SP-GiST 的一个很好的案例。
|
||||
|
||||
### BRIN 索引, 用于大的数据
|
||||
|
||||
BRIN 索引可以专注于一些类似使用 SP-GiST 的案例,当数据有一些自然的排序,并且往往数据量很大时,它们的性能表现是最好的。如果有一个以时间为序的 10 亿条的记录, BRIN 可能对它很有帮助。如果你正在查询一组很大的有自然分组的数据,如有几个 zip 代码的数据,BRIN 能帮你确保类似的 zip 代码在磁盘上位于它们彼此附近。
|
||||
|
||||
当你有一个非常大的比如以日期或 zip 代码排序的数据库, BRIN 索引可以允许你非常快的去跳过或排除一些不需要的数据。此外,与整体数据量大小相比,BRIN 索引相对较小,因此,当你有一个大的数据集时,BRIN 索引就可以表现出较好的性能。
|
||||
|
||||
### Hash 索引, 总算崩溃安全了
|
||||
|
||||
Hash 索引在 Postgres 中已经存在多年了,但是,在 Postgres 10 发布之前,它们一直有一个巨大的警告,不能使用 WAL-logged。这意味着如果你的服务器崩溃,并且你无法使用如 [wal-g][10] 故障转移到备机或从存档中恢复,那么你将丢失那个索引,直到你重建它。 随着 Postgres 10 发布,它们现在可以使用 WAL-logged,因此,你可以再次考虑使用它们 ,但是,真正的问题是,你应该这样做吗?
|
||||
|
||||
Hash 索引有时会提供比 B-Tree 索引更快的查找,并且创建也很快。最大的问题是它们被限制仅用于相等的比较操作,因此你只能用于精确匹配的查找。这使得 hash 索引的灵活性远不及通常使用的 B-Tree 索引,并且,你不能把它看成是一种替代,而是一种使用于特殊情况的索引。
|
||||
|
||||
### 你该使用哪个?
|
||||
|
||||
我们刚才介绍了很多,如果你有点被吓到,也很正常。 如果在你知道这些之前, `CREATE INDEX` ,将始终为你创建使用 B-Tree 索引,并且有一个好消息是,对于大多数的 Postgres 数据库,你做的一直很好或非常好。 :) 从你开始使用更多的 Postgres 特性的角度来说,下面是一个当你使用其它 Postgres 索引类型的备忘清单:
|
||||
|
||||
* B-Tree - 适用于大多数的数据类型和查询
|
||||
|
||||
* GIN - 适用于 JSONB/hstore/arrays
|
||||
|
||||
* GiST - 适用于全文搜索和几何数据类型
|
||||
|
||||
* SP-GiST - 适用于有天然的聚集因素但是分布不均匀的大数据集
|
||||
|
||||
* BRIN - 适用于有顺序排列的真正的大数据集
|
||||
|
||||
* Hash - 适用于等式操作,而且,通常情况下 B-Tree 索引仍然是你所需要的。
|
||||
|
||||
如果你有关于这篇文章的任何问题或反馈,欢迎加入我们的 [slack channel][11]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
|
||||
作者:[Craig Kerstiens ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
[1]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[2]:https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/
|
||||
[3]:https://www.citusdata.com/blog/2017/10/11/index-all-the-things-in-postgres/
|
||||
[4]:https://www.citusdata.com/blog/2017/09/29/what-performance-can-you-expect-from-postgres/
|
||||
[5]:https://www.citusdata.com/product/cloud
|
||||
[6]:https://en.wikipedia.org/wiki/B-tree
|
||||
[7]:https://www.8kdata.com/blog/postgresql-page-layout/
|
||||
[8]:https://www.postgresql.org/docs/10/static/gin.html
|
||||
[9]:https://www.cs.purdue.edu/spgist/papers/W87R36P214137510.pdf
|
||||
[10]:https://www.citusdata.com/blog/2017/08/18/introducing-wal-g-faster-restores-for-postgres/
|
||||
[11]:https://slack.citusdata.com/
|
||||
[12]:https://twitter.com/share?url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/&text=A%20tour%20of%20Postgres%20Index%20Types&via=citusdata
|
||||
[13]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/
|
||||
@ -0,0 +1,104 @@
|
||||
由 KRACK 攻击想到的确保网络安全的小贴士
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
最近的 KRACK (密钥重装攻击,一个安全漏洞名称或该漏洞利用攻击行为的名称)漏洞攻击的目标是,在你的设备和 Wi-Fi 访问点之间的链路,它或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器,这些提示能帮你提升你的连接的安全性。[Creative Commons Zero][1]Pixabay
|
||||
|
||||
[KRACK 漏洞攻击][4] 现在已经超过 48 小时,并且已经在 [相关技术网站][5] 上有很多详细的讨论,因此,我将不在这里重复攻击的技术细节。攻击方式的总结如下:
|
||||
|
||||
* 在 WPA2 无线握手协议中的一个缺陷允许攻击者在你的设备和 wi-fi 访问点之间嗅探或操纵通讯。
|
||||
|
||||
* 它在 Linux 和 Android 设备上尤其严重,由于在 WPA2 标准中的措施含糊不清,也或许是在实现它时的错误理解,事实上,直到操作系统底层打完补丁以前,该漏洞一直可以强制实现无线之间的无加密通讯。
|
||||
|
||||
* 这个漏洞可以在客户端上修补,因此,天并没有塌下来,而且,WPA2 加密标准并没有像 WEP 标准那样被淘汰(不能通过切换到 WEP 加密的方式去“修复”这个问题)。
|
||||
|
||||
* 大多数流行的 Linux 分发版都已经通过升级修复了这个客户端上的漏洞,因此,老老实实地去更新它吧。
|
||||
|
||||
* Android 也很快修复了这个漏洞。如果你的设备接收到了 Android 安全补丁,你将修复这个漏洞。如果你的设备不再接收这些更新,那么,这个特别的漏洞将是你停止使用你的旧设备的一个理由。
|
||||
|
||||
即使如此,从我的观点来看, Wi-Fi 是不受信任的基础设施链中的另一个环节,并且,我们应该完全避免将其视为可信任的通信通道。
|
||||
|
||||
### 作为不受信任的基础设备的 Wi-Fi
|
||||
|
||||
如果从你的笔记本电脑或移动设备中读到这篇文章,那么,你的通信链路看起来应该是这样:
|
||||
|
||||

|
||||
|
||||
KRACK 攻击目标是在你的设备和 Wi-Fi 访问点之间的链接,它或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器。
|
||||
|
||||

|
||||
|
||||
实际上,这个图示应该看起来像这样:
|
||||
|
||||

|
||||
|
||||
Wi-Fi 仅仅是在我们不信任的信道的长通信链的第一个链路。如果我去假设,你使用的 Wi-Fi 路由器没有使用一个安全更新,并且,更严重的是,它或许使用了一个从未被更改过的、缺省的,易猜出的管理凭据(用户名和密码)。除非你自己安装并配置你的路由器,并且你可以记得你上次更新的它的固件,否则,你应该假设现在它已经被一些人控制并不受信任的。
|
||||
|
||||
说完 Wi-Fi 路由器,我们的通讯进入一般意义上的常见不信任区域 -- 根据你的猜疑水平,这里有上游的 ISPs 和提供商,其中的很多已经被监视、更改、分析和销售我们的流量数据,试图从我们的浏览习惯中赠更多的钱。通常他们的安全补丁计划还留下许多期望改进的地方,最终让我们的流量暴露在一些恶意者眼中。
|
||||
|
||||
一般来说,在因特网上,我们必须担心强大的国家级的参与者能够操纵核心网络协议,以执行大规模的网络监视和状态级的流量过滤。
|
||||
|
||||
### HTTPS 协议
|
||||
|
||||
值的庆幸的是,我们有一个基于不信任的介质进行安全通讯的解决方案,并且,我们可以每天都能使用它 -- HTTPS 协议,它加密你的点对点的因特网通讯,并且确信我们可以信任,站点与我们之间的通讯。
|
||||
|
||||
Linux 基金会的一些措施,比如像 [让我们加密吧][7] 使世界各地的网站所有者都可以很容易地提供端到端的加密,这有助于确保我们的个人设备与我们试图访问的网站之间的任何有安全隐患的设备不再重要。
|
||||
|
||||

|
||||
|
||||
是的... 几乎无关紧要。
|
||||
|
||||
### DNS —— 剩下的一个问题
|
||||
|
||||
虽然,我们可以尽职尽责使用 HTTPS 去创建一个可信的通信信道,但是,这里仍然有一个攻击者可以访问我们的路由器或修改我们的 Wi-Fi 流量的机会 -- 在使用 KRACK 的这个案例中 -- 可以欺骗我们的通讯进入一个错误的网站。他们可以利用我们仍然非常依赖 DNS 的这一事实 -- 一个未加密的、易受欺骗的 [诞生自1980年代的协议][8]。
|
||||
|
||||

|
||||
|
||||
DNS 是一个将人类友好的域名像 “linux.com” 这样的,转换成计算机可以用于和其它计算机通讯的 IP 地址的一个系统。去转换一个域名到一个 IP 地址,计算机将查询解析软件 -- 通常运行在 Wi-Fi 路由器或一个系统上。解析软件将查询一个分布式的 “root” 域名服务器网络,去找到在因特网上哪个系统有 “linux.com” 域名所对应的 IP 地址的“权威”信息。、
|
||||
|
||||
麻烦的是,所有发生的这些通讯都是未经认证的、[易于欺骗的][9]、明文协议、并且响应可以很容易地被攻击者修改,去返回一个不正确的数据。如果有人去欺骗一个 DNS 查询并且返回错误的 IP 地址,他们可以操纵我们的系统最终发送 HTTP 请求到那里。
|
||||
|
||||
幸运的是,HTTPS 有一些内置的保护措施去确保它不会很容易地被其它人诱导至其它假冒站点。恶意服务器上的 TLS 凭据必须与你请求的 DNS 名字匹配 -- 并且它必须通过你的浏览器由一个公认的、可信任的 [认证机构][10] 发布。如果不是这种情况,你的浏览器将在你试图去与他们告诉你的地址进行通讯时出现一个很大的警告。如果你看到这样的警告,在选择不理会警告之前,请你格外小心,因为,它有可能会把你的秘密泄露给那些可能会对付你的人。
|
||||
|
||||
如果攻击者完全控制了路由器,他们在一开始时,通过拦截来自服务器的指示你建立一个安全连接的响应,可以阻止你使用 HTTPS 连接(这被称为 “[SSL 脱衣攻击][11]”)。 为帮助你保护这种类型的攻击,站点可以增加一个 [特殊响应头][12] 去告诉你的浏览器以后与它通讯时使用 HTTPS 协议,但是,这仅仅是在你首次访问之后的事。对于一些非常流行的站点,浏览器现在包含一个 [域名硬编码列表][13],即使是首次连接,它也将总是使用 HTTPS 协议访问。
|
||||
|
||||
现在已经有了 DNS 欺骗的解决方案,它被称为 [DNSSEC][14],由于有重大的障碍 -- 真实和可感知的(译者注,指的是要求实名认证),它看起来接受程序很慢。直到 DNSSEC 被普遍使用之前,我们必须假设,我们接收到的 DNS 信息是不能完全信任的。
|
||||
|
||||
### 使用 VPN 去解决“最后一公里”的安全问题
|
||||
|
||||
因此,如果你不能信任固件太旧的 Wi-Fi -- 和/或无线路由器 -- 我们能做些什么来确保,发生在你的设备与一般说的因特网之间的“最后一公里”通讯的完整性呢?
|
||||
|
||||
一个可接受的解决方案是去使用信誉好的 VPN 供应商的 VPN 服务,它将在你的系统和他们的基础设施之间建立一条安全的通讯链路。这里有一个期望,就是它比你的路由器提供者和你的当前因特网供应商更注重安全,因为,他们处于一个更好的位置去确保你的流量不会受到恶意的攻击或欺骗。在你的工作站和移动设备之间使用 VPN,可以确保免受像 KRACK 这样的漏洞攻击,或不安全的路由器不会影响你与外界通讯的完整性。
|
||||
|
||||

|
||||
|
||||
这有一个很重要的警告是,当你选择一个 VPN 供应商时,你必须确信他们的信用;否则,你将被另外的一拨恶意的“演员”交易。远离任何人提供的所谓“免费 VPN”,因为,它们可以通过监视你和向市场营销公司销售你的流量来赚钱。 [这个网站][2] 是一个很好的资源,你可以去比较他们提供的各种 VPN,去看他们是怎么互相竞争的。
|
||||
|
||||
注意,你所有的设备都应该在它上面安装 VPN,那些你每天使用的网站,你的私人信息,尤其是任何与你的钱和你的身份(政府、银行网站、社交网络、等等)有关的东西都必须得到保护。VPN 并不是对付所有网络级漏洞的万能药,但是,当你在机场使用无法保证的 Wi-Fi 时,或者下次发现类似 KRACK 的漏洞时,它肯定会保护你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.vpnmentor.com/bestvpns/overall/
|
||||
[3]:https://www.linux.com/files/images/krack-securityjpg
|
||||
[4]:https://www.krackattacks.com/
|
||||
[5]:https://blog.cryptographyengineering.com/2017/10/16/falling-through-the-kracks/
|
||||
[6]:https://en.wikipedia.org/wiki/BGP_hijacking
|
||||
[7]:https://letsencrypt.org/
|
||||
[8]:https://en.wikipedia.org/wiki/Domain_Name_System#History
|
||||
[9]:https://en.wikipedia.org/wiki/DNS_spoofing
|
||||
[10]:https://en.wikipedia.org/wiki/Certificate_authority
|
||||
[11]:https://en.wikipedia.org/wiki/Moxie_Marlinspike#Notable_research
|
||||
[12]:https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
|
||||
[13]:https://hstspreload.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions
|
||||
@ -1,38 +0,0 @@
|
||||
我们正将源码贡献切换到 DCO
|
||||
============================================================
|
||||
|
||||
我们希望通过取消“贡献者许可协议”来支持开发者原始证书,让每个人都能更轻松地做出贡献。
|
||||
|
||||
我们致力于成为[开源的好管家][1],而这一承诺的一部分意味着我们永远不会停止重新评估我们如何做到这一点。承诺“每个人都可以贡献”就是消除贡献的障碍。对于我们的一些社区,贡献者许可协议是对 GitLab 贡献的阻碍,所以我们改为开发者原始证书。
|
||||
|
||||
许多大型的开源项目都想成为自己命运的主人。拥有基于开源软件运行自己的基础架构的自由,以及修改和审计源代码的能力,而不依赖于供应商,这使开源具有吸引力。我们希望 GitLab 成为每个人的选择。
|
||||
|
||||
### 为什么改变?
|
||||
|
||||
贡献者许可协议 (CLA) 是其他项目的开源贡献的行业标准,但对于不愿意参与法律条款的开发人员来说,这是不受欢迎的,并且由于需要审查冗长的合同而可能放弃他们的一些权利。贡献者发现协议不必要的限制,并且阻止开源项目的开发者使用 GitLab。我们接触到 Debian 开发人员,他们考虑放弃 CLA, 这就是我们正在做的。
|
||||
|
||||
### 改变什么?
|
||||
|
||||
到今天为止,我们正在推出更改,以便 GitLab 源码的贡献者只需要一个项目许可证(所有仓库都是 MIT,除了 Omnibus 是 Apache)和一个[开发者原始证书][2] (DCO)。DCO 为开发人员提供了更大的灵活性和可移植性,这也是 Debian 和 GNOME 计划将其社区和项目迁移到 GitLab 的原因之一。我们希望这一改变能够鼓励更多的开发者为 GitLab 做出贡献。谢谢 Debian,提醒我们做出这个改变。
|
||||
|
||||
>“我们赞扬 GitLab 放弃他们的 CLA,转而使用更加 OSS 友好的方式,开源社区诞生于一个汇集在一起并转化为项目的贡献的海洋,这一举动肯定了 GitLab 愿意保护个人及其创作过程最重要的是把知识产权掌握在创造者手中。” - GNOME 董事会主席 Carlos Soriano
|
||||
|
||||
>“我们很高兴看到 GitLab 通过从 CLA 转换到 DCO 来简化和鼓励社区贡献。我们认识到,改变这种性质并不容易,我们赞扬 GitLab 在这里所展示的时间、耐心和深思熟虑的考虑。” - Debian 项目负责人 Chris Lamb
|
||||
|
||||
你可以[阅读告知我们决定的分析][3]。阅读所有关于我们[ GitLab 社区版的管理][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2017/11/01/gitlab-switches-to-dco-license/
|
||||
|
||||
作者:[ Jamie Hurewitz ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://about.gitlab.com/team/#hurewitzjamie
|
||||
[1]:https://about.gitlab.com/2016/01/11/being-a-good-open-source-steward/
|
||||
[2]:https://developercertificate.org/
|
||||
[3]:https://docs.google.com/a/gitlab.com/document/d/1zpjDzL7yhGBZz3_7jCjWLfRQ1Jryg1mlIVmG8y6B1_Q/edit?usp=sharing
|
||||
[4]:https://about.gitlab.com/stewardship/
|
||||
Loading…
Reference in New Issue
Block a user