mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
commit
a491e7d767
@ -1,222 +0,0 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 1 - LFCS: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
================================================================================
|
||||
The Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, a new program that aims at helping individuals all over the world to get certified in basic to intermediate system administration tasks for Linux systems. This includes supporting running systems and services, along with first-hand troubleshooting and analysis, and smart decision-making to escalate issues to engineering teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 1
|
||||
|
||||
Please watch the following video that demonstrates about The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
The series will be titled Preparation for the LFCS (Linux Foundation Certified Sysadmin) Parts 1 through 10 and cover the following topics for Ubuntu, CentOS, and openSUSE:
|
||||
|
||||
- Part 1: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
- Part 2: How to Install and Use vi/m as a full Text Editor
|
||||
- Part 3: Archiving Files/Directories and Finding Files on the Filesystem
|
||||
- Part 4: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
|
||||
- Part 5: Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
|
||||
- Part 6: Assembling Partitions as RAID Devices – Creating & Managing System Backups
|
||||
- Part 7: Managing System Startup Process and Services (SysVinit, Systemd and Upstart
|
||||
- Part 8: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
|
||||
- Part 9: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
|
||||
- Part 10: Learning Basic Shell Scripting and Filesystem Troubleshooting
|
||||
|
||||
|
||||
This post is Part 1 of a 10-tutorial series, which will cover the necessary domains and competencies that are required for the LFCS certification exam. That being said, fire up your terminal, and let’s start.
|
||||
|
||||
### Processing Text Streams in Linux ###
|
||||
|
||||
Linux treats the input to and the output from programs as streams (or sequences) of characters. To begin understanding redirection and pipes, we must first understand the three most important types of I/O (Input and Output) streams, which are in fact special files (by convention in UNIX and Linux, data streams and peripherals, or device files, are also treated as ordinary files).
|
||||
|
||||
The difference between > (redirection operator) and | (pipeline operator) is that while the first connects a command with a file, the latter connects the output of a command with another command.
|
||||
|
||||
# command > file
|
||||
# command1 | command2
|
||||
|
||||
Since the redirection operator creates or overwrites files silently, we must use it with extreme caution, and never mistake it with a pipeline. One advantage of pipes on Linux and UNIX systems is that there is no intermediate file involved with a pipe – the stdout of the first command is not written to a file and then read by the second command.
|
||||
|
||||
For the following practice exercises we will use the poem “A happy child” (anonymous author).
|
||||
|
||||
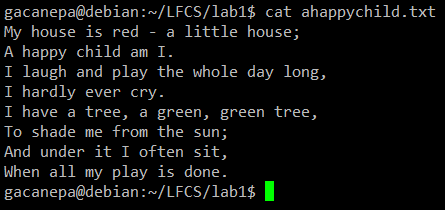
|
||||
|
||||
cat command example
|
||||
|
||||
#### Using sed ####
|
||||
|
||||
The name sed is short for stream editor. For those unfamiliar with the term, a stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
|
||||
|
||||
The most basic (and popular) usage of sed is the substitution of characters. We will begin by changing every occurrence of the lowercase y to UPPERCASE Y and redirecting the output to ahappychild2.txt. The g flag indicates that sed should perform the substitution for all instances of term on every line of file. If this flag is omitted, sed will replace only the first occurrence of term on each line.
|
||||
|
||||
**Basic syntax:**
|
||||
|
||||
# sed ‘s/term/replacement/flag’ file
|
||||
|
||||
**Our example:**
|
||||
|
||||
# sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt
|
||||
|
||||

|
||||
|
||||
sed command example
|
||||
|
||||
Should you want to search for or replace a special character (such as /, \, &) you need to escape it, in the term or replacement strings, with a backward slash.
|
||||
|
||||
For example, we will substitute the word and for an ampersand. At the same time, we will replace the word I with You when the first one is found at the beginning of a line.
|
||||
|
||||
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
|
||||
|
||||

|
||||
|
||||
sed replace string
|
||||
|
||||
In the above command, a ^ (caret sign) is a well-known regular expression that is used to represent the beginning of a line.
|
||||
|
||||
As you can see, we can combine two or more substitution commands (and use regular expressions inside them) by separating them with a semicolon and enclosing the set inside single quotes.
|
||||
|
||||
Another use of sed is showing (or deleting) a chosen portion of a file. In the following example, we will display the first 5 lines of /var/log/messages from Jun 8.
|
||||
|
||||
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
|
||||
|
||||
Note that by default, sed prints every line. We can override this behaviour with the -n option and then tell sed to print (indicated by p) only the part of the file (or the pipe) that matches the pattern (Jun 8 at the beginning of line in the first case and lines 1 through 5 inclusive in the second case).
|
||||
|
||||
Finally, it can be useful while inspecting scripts or configuration files to inspect the code itself and leave out comments. The following sed one-liner deletes (d) blank lines or those starting with # (the | character indicates a boolean OR between the two regular expressions).
|
||||
|
||||
# sed '/^#\|^$/d' apache2.conf
|
||||
|
||||

|
||||
|
||||
sed match string
|
||||
|
||||
#### uniq Command ####
|
||||
|
||||
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent. Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files). By default, sort takes the first field (separated by spaces) as key field. To specify a different key field, we need to use the -k option.
|
||||
|
||||
**Examples**
|
||||
|
||||
The du –sch /path/to/directory/* command returns the disk space usage per subdirectories and files within the specified directory in human-readable format (also shows a total per directory), and does not order the output by size, but by subdirectory and file name. We can use the following command to sort by size.
|
||||
|
||||
# du -sch /var/* | sort –h
|
||||
|
||||
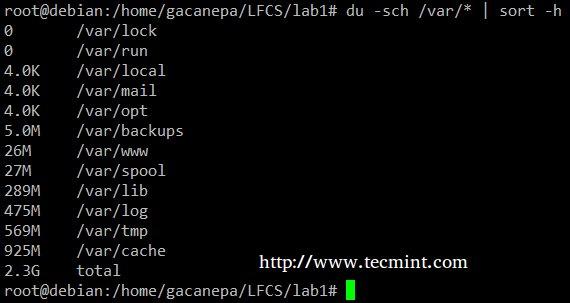
|
||||
|
||||
sort command example
|
||||
|
||||
You can count the number of events in a log by date by telling uniq to perform the comparison using the first 6 characters (-w 6) of each line (where the date is specified), and prefixing each output line by the number of occurrences (-c) with the following command.
|
||||
|
||||
# cat /var/log/mail.log | uniq -c -w 6
|
||||
|
||||

|
||||
|
||||
Count Numbers in File
|
||||
|
||||
Finally, you can combine sort and uniq (as they usually are). Consider the following file with a list of donors, donation date, and amount. Suppose we want to know how many unique donors there are. We will use the following command to cut the first field (fields are delimited by a colon), sort by name, and remove duplicate lines.
|
||||
|
||||
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
|
||||
|
||||

|
||||
|
||||
Find Unique Records in File
|
||||
|
||||
- Read Also: [13 “cat” Command Examples][1]
|
||||
|
||||
#### grep Command ####
|
||||
|
||||
grep searches text files or (command output) for the occurrence of a specified regular expression and outputs any line containing a match to standard output.
|
||||
|
||||
**Examples**
|
||||
|
||||
Display the information from /etc/passwd for user gacanepa, ignoring case.
|
||||
|
||||
# grep -i gacanepa /etc/passwd
|
||||
|
||||

|
||||
|
||||
grep command example
|
||||
|
||||
Show all the contents of /etc whose name begins with rc followed by any single number.
|
||||
|
||||
# ls -l /etc | grep rc[0-9]
|
||||
|
||||

|
||||
|
||||
List Content Using grep
|
||||
|
||||
- Read Also: [12 “grep” Command Examples][2]
|
||||
|
||||
#### tr Command Usage ####
|
||||
|
||||
The tr command can be used to translate (change) or delete characters from stdin, and write the result to stdout.
|
||||
|
||||
**Examples**
|
||||
|
||||
Change all lowercase to uppercase in sortuniq.txt file.
|
||||
|
||||
# cat sortuniq.txt | tr [:lower:] [:upper:]
|
||||
|
||||

|
||||
|
||||
Sort Strings in File
|
||||
|
||||
Squeeze the delimiter in the output of ls –l to only one space.
|
||||
|
||||
# ls -l | tr -s ' '
|
||||
|
||||

|
||||
|
||||
Squeeze Delimiter
|
||||
|
||||
#### cut Command Usage ####
|
||||
|
||||
The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on number of bytes (-b option), characters (-c), or fields (-f). In this last case (based on fields), the default field separator is a tab, but a different delimiter can be specified by using the -d option.
|
||||
|
||||
**Examples**
|
||||
|
||||
Extract the user accounts and the default shells assigned to them from /etc/passwd (the –d option allows us to specify the field delimiter, and the –f switch indicates which field(s) will be extracted.
|
||||
|
||||
# cat /etc/passwd | cut -d: -f1,7
|
||||
|
||||

|
||||
|
||||
Extract User Accounts
|
||||
|
||||
Summing up, we will create a text stream consisting of the first and third non-blank files of the output of the last command. We will use grep as a first filter to check for sessions of user gacanepa, then squeeze delimiters to only one space (tr -s ‘ ‘). Next, we’ll extract the first and third fields with cut, and finally sort by the second field (IP addresses in this case) showing unique.
|
||||
|
||||
# last | grep gacanepa | tr -s ‘ ‘ | cut -d’ ‘ -f1,3 | sort -k2 | uniq
|
||||
|
||||

|
||||
|
||||
last command example
|
||||
|
||||
The above command shows how multiple commands and pipes can be combined so as to obtain filtered data according to our desires. Feel free to also run it by parts, to help you see the output that is pipelined from one command to the next (this can be a great learning experience, by the way!).
|
||||
|
||||
### Summary ###
|
||||
|
||||
Although this example (along with the rest of the examples in the current tutorial) may not seem very useful at first sight, they are a nice starting point to begin experimenting with commands that are used to create, edit, and manipulate files from the Linux command line. Feel free to leave your questions and comments below – they will be much appreciated!
|
||||
|
||||
#### Reference Links ####
|
||||
|
||||
- [About the LFCS][3]
|
||||
- [Why get a Linux Foundation Certification?][4]
|
||||
- [Register for the LFCS exam][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -0,0 +1,220 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 1 - LFCS系列第一讲:如何在Linux上使用GNU'sed'命令来创建、编辑和操作文件
|
||||
================================================================================
|
||||
Linux基金会宣布了一个全新的LFCS(Linux Foundation Certified Sysadmin,Linux基金会认证系统管理员)认证计划。这一计划旨在帮助遍布全世界的人们获得其在处理Linux系统管理任务上能力的认证。这些能力包括支持运行的系统服务,以及第一手的故障诊断和分析和为工程师团队在升级时提供智能决策。
|
||||
|
||||

|
||||
|
||||
Linux基金会认证系统管理员——第一讲
|
||||
|
||||
请观看下面关于Linux基金会认证计划的演示:
|
||||
|
||||
<embed src="http://static.video.qq.com/TPout.swf?vid=l0163eohhs9&auto=0" allowFullScreen="true" quality="high" width="480" height="400" align="middle" allowScriptAccess="always" type="application/x-shockwave-flash"></embed>
|
||||
|
||||
该系列将命名为《LFCS预备第一讲》至《LFCS预备第十讲》并覆盖关于Ubuntu,CentOS以及openSUSE的下列话题。
|
||||
|
||||
- 第一讲:如何在Linux上使用GNU'sed'命令来创建、编辑和操作文件
|
||||
- 第二讲:如何安装和使用vi/m全功能文字编辑器
|
||||
- 第三讲:归档文件/目录和在文件系统中寻找文件
|
||||
- 第四讲:为存储设备分区,格式化文件系统和配置交换分区
|
||||
- 第五讲:在Linux中挂载/卸载本地和网络(Samba & NFS)文件系统
|
||||
- 第六讲:组合分区作为RAID设备——创建&管理系统备份
|
||||
- 第七讲:管理系统启动进程和服务(使用SysVinit, Systemd 和 Upstart)
|
||||
- 第八讲:管理用户和组,文件权限和属性以及启用账户的sudo权限
|
||||
- 第九讲:Linux包管理与Yum,RPM,Apt,Dpkg,Aptitude,Zypper
|
||||
- 第十讲:学习简单的Shell脚本和文件系统故障排除
|
||||
|
||||
本文是覆盖这个参加LFCS认证考试的所必需的范围和能力的十个教程的第一讲。话虽如此,快打开你的终端,让我们开始吧!
|
||||
|
||||
### 处理Linux中的文本流 ###
|
||||
|
||||
Linux将程序中的输入和输出当成字符流或者字符序列。在开始理解重定向和管道之前,我们必须先了解三种最重要的I/O(Input and Output,输入和输出)流,事实上,它们都是特殊的文件(根据UNIX和Linux中的约定,数据流和外围设备或者设备文件也被视为普通文件)。
|
||||
|
||||
> (重定向操作符) 和 | (管道操作符)之间的区别是:前者将命令与文件相连接,而后者将命令的输出和另一个命令相连接。
|
||||
|
||||
# command > file
|
||||
# command1 | command2
|
||||
|
||||
由于重定向操作符静默创建或覆盖文件,我们必须特别小心谨慎地使用它,并且永远不要把它和管道混淆起来。在Linux和UNIX系统上管道的优势是:第一个命令的输出不会写入一个文件而是直接被第二个命令读取。
|
||||
|
||||
在下面的操作练习中,我们将会使用这首诗——《A happy child》(匿名作者)
|
||||
|
||||

|
||||
|
||||
cat command example
|
||||
|
||||
#### 使用 sed ####
|
||||
|
||||
sed是流编辑器(stream editor)的缩写。为那些不懂术语的人额外解释一下,流编辑器是用来在一个输入流(文件或者管道中的输入)执行基本的文本转换的工具。
|
||||
|
||||
sed最基本的用法是字符替换。我们将通过把每个出现的小写y改写为大写Y并且将输出重定向到ahappychild2.txt开始。g标志表示sed应该替换文件每一行中所有应当替换的实例。如果这个标志省略了,sed将会只替换每一行中第一次出现的实例。
|
||||
|
||||
**基本语法:**
|
||||
|
||||
# sed ‘s/term/replacement/flag’ file
|
||||
|
||||
**我们的样例:**
|
||||
|
||||
# sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt
|
||||
|
||||

|
||||
|
||||
sed command example
|
||||
|
||||
如果你要在替换文本中搜索或者替换特殊字符(如/,\,&),你需要使用反斜杠对它进行转义。
|
||||
|
||||
例如,我们将会用一个符号来替换一个文字。与此同时,我们将把一行最开始出现的第一个I替换为You。
|
||||
|
||||
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
|
||||
|
||||

|
||||
|
||||
sed replace string
|
||||
|
||||
在上面的命令中,^(插入符号)是众所周知用来表示一行开头的正则表达式。
|
||||
|
||||
正如你所看到的,我们可以通过使用分号分隔以及用括号包裹来把两个或者更多的替换命令(并在他们中使用正则表达式)链接起来。
|
||||
|
||||
另一种sed的用法是显示或者删除文件中选中的一部分。在下面的样例中,将会显示/var/log/messages中从6月8日开始的头五行。
|
||||
|
||||
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
|
||||
|
||||
请注意,在默认的情况下,sed会打印每一行。我们可以使用-n选项来覆盖这一行为并且告诉sed只需要打印(用p来表示)文件(或管道)中匹配的部分(第一种情况下行开头的第一个6月8日以及第二种情况下的一到五行*此处翻译欠妥,需要修正*)。
|
||||
|
||||
最后,可能有用的技巧是当检查脚本或者配置文件的时候可以保留文件本身并且删除注释。下面的单行sed命令删除(d)空行或者是开头为`#`的行(|字符返回两个正则表达式之间的布尔值)。
|
||||
|
||||
# sed '/^#\|^$/d' apache2.conf
|
||||
|
||||

|
||||
|
||||
sed match string
|
||||
|
||||
#### uniq C命令 ####
|
||||
|
||||
uniq命令允许我们返回或者删除文件中重复的行,默认写入标准输出。我们必须注意到,除非两个重复的行相邻,否则uniq命令不会删除他们。因此,uniq经常和前序排序(此处翻译欠妥)(一种用来对文本行进行排序的算法)搭配使用。默认情况下,排序使用第一个字段(用空格分隔)作为关键字段。要指定一个不同的关键字段,我们需要使用-k选项。
|
||||
|
||||
**样例**
|
||||
|
||||
du –sch /path/to/directory/* 命令将会以人类可读的格式返回在指定目录下每一个子文件夹和文件的磁盘空间使用情况(也会显示每个目录总体的情况),而且不是按照大小输出,而是按照子文件夹和文件的名称。我们可以使用下面的命令来让它通过大小排序。
|
||||
|
||||
# du -sch /var/* | sort –h
|
||||
|
||||

|
||||
|
||||
sort command example
|
||||
|
||||
你可以通过使用下面的命令告诉uniq比较每一行的前6个字符(-w 6)(指定了不同的日期)来统计日志事件的个数,而且在每一行的开头输出出现的次数(-c)。
|
||||
|
||||
|
||||
# cat /var/log/mail.log | uniq -c -w 6
|
||||
|
||||

|
||||
|
||||
Count Numbers in File
|
||||
|
||||
最后,你可以组合使用sort和uniq命令(通常如此)。考虑下面文件中捐助者,捐助日期和金额的列表。假设我们想知道有多少个捐助者。我们可以使用下面的命令来分隔第一字段(字段由冒号分隔),按名称排序并且删除重复的行。
|
||||
|
||||
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
|
||||
|
||||

|
||||
|
||||
Find Unique Records in File
|
||||
|
||||
- 也可阅读: [13个“cat”命令样例][1]
|
||||
|
||||
#### grep 命令 ####
|
||||
|
||||
grep在文件(或命令输出)中搜索指定正则表达式并且在标准输出中输出匹配的行。
|
||||
|
||||
**样例**
|
||||
|
||||
显示文件/etc/passwd中用户gacanepa的信息,忽略大小写。
|
||||
|
||||
# grep -i gacanepa /etc/passwd
|
||||
|
||||

|
||||
|
||||
grep command example
|
||||
|
||||
显示/etc文件夹下所有rc开头并跟随任意数字的内容。
|
||||
|
||||
# ls -l /etc | grep rc[0-9]
|
||||
|
||||

|
||||
|
||||
List Content Using grep
|
||||
|
||||
- 也可阅读: [12个“grep”命令样例][2]
|
||||
|
||||
#### tr Command Usage ####
|
||||
|
||||
tr命令可以用来从标准输入中翻译(改变)或者删除字符并将结果写入到标准输出中。
|
||||
|
||||
**样例**
|
||||
|
||||
把sortuniq.txt文件中所有的小写改为大写。
|
||||
|
||||
# cat sortuniq.txt | tr [:lower:] [:upper:]
|
||||
|
||||

|
||||
|
||||
Sort Strings in File
|
||||
|
||||
压缩`ls –l`输出中的定界符至一个空格。
|
||||
# ls -l | tr -s ' '
|
||||
|
||||

|
||||
|
||||
Squeeze Delimiter
|
||||
|
||||
#### cut 命令使用方法 ####
|
||||
|
||||
cut命令可以基于字节数(-b选项),字符(-c)或者字段(-f)提取部分输入(从标准输入或者文件中)并且将结果输出到标准输出。在最后一种情况下(基于字段),默认的字段分隔符是一个tab,但不同的分隔符可以由-d选项来指定。
|
||||
|
||||
**样例**
|
||||
|
||||
从/etc/passwd中提取用户账户和他们被分配的默认shell(-d选项允许我们指定分界符,-f选项指定那些字段将被提取)。
|
||||
|
||||
# cat /etc/passwd | cut -d: -f1,7
|
||||
|
||||

|
||||
|
||||
Extract User Accounts
|
||||
|
||||
总结一下,我们将使用最后一个命令的输出中第一和第三个非空文件创建一个文本流。我们将使用grep作为第一过滤器来检查用户gacanepa的会话,然后将分隔符压缩至一个空格(tr -s ' ')。下一步,我们将使用cut来提取第一和第三个字段,最后使用第二个字段(本样例中,指的是IP地址)来排序之后再用uniq去重。
|
||||
|
||||
# last | grep gacanepa | tr -s ‘ ‘ | cut -d’ ‘ -f1,3 | sort -k2 | uniq
|
||||
|
||||

|
||||
|
||||
last command example
|
||||
|
||||
上面的命令显示了如何将多个命令和管道结合起来以便根据我们的愿望得到过滤后的数据。你也可以逐步地使用它以帮助你理解输出是如何从一个命令传输到下一个命令的(顺便说一句,这是一个非常好的学习经验!)
|
||||
|
||||
### 总结 ###
|
||||
|
||||
尽管这个例子(以及在当前教程中的其他实例)第一眼看上去可能不是非常有用,但是他们是体验在Linux命令行中创建,编辑和操作文件的一个非常好的开始。请随时留下你的问题和意见——不胜感激!
|
||||
|
||||
#### 参考链接 ####
|
||||
|
||||
- [关于LFCS][3]
|
||||
- [为什么需要Linux基金会认证?][4]
|
||||
- [注册LFCS考试][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[Xuanwo](https://github.com/Xuanwo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
Loading…
Reference in New Issue
Block a user