mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
a3939ac90a
@ -1,3 +1,4 @@
|
||||
|
||||
// Copyright 2018 The Go Authors. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
How To Force User To Change Password On Next Login In Linux
|
||||
======
|
||||
When you created the users account with a default password, you have to force the users to change their password on next login.
|
||||
|
||||
@ -1,64 +0,0 @@
|
||||
How to check free disk space in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Keeping track of disk utilization information is on system administrators' (and others') daily to-do list. Linux has a few built-in utilities that help provide that information.
|
||||
|
||||
### df
|
||||
|
||||
The `df` command stands for "disk-free," and shows available and used disk space on the Linux system.
|
||||
|
||||
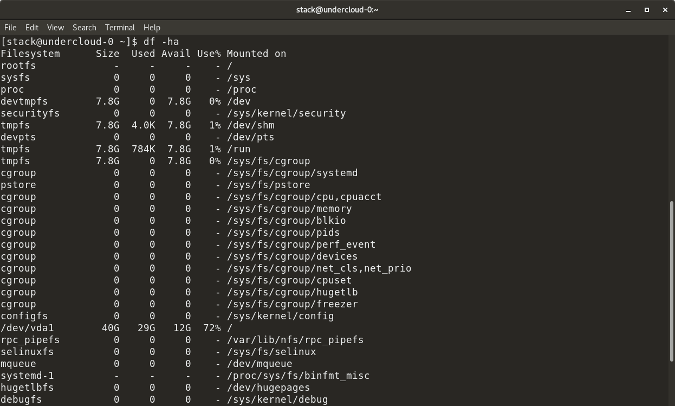
`df -h` shows disk space in human-readable format
|
||||
|
||||
`df -a` shows the file system's complete disk usage even if the Available field is 0
|
||||
|
||||
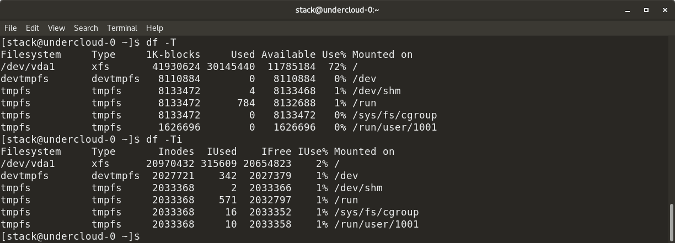
`df -T` shows the disk usage along with each block's filesystem type (e.g., xfs, ext2, ext3, btrfs, etc.)
|
||||
|
||||
`df -i` shows used and free inodes
|
||||
|
||||
|
||||
### du
|
||||
|
||||
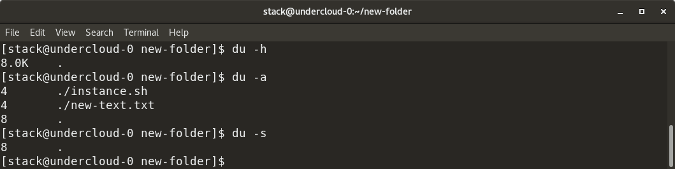
`du` shows the disk usage of files, folders, etc. in the default kilobyte size
|
||||
|
||||
`du -h` shows disk usage in human-readable format for all directories and subdirectories
|
||||
|
||||
`du -a` shows disk usage for all files
|
||||
|
||||
`du -s` provides total disk space used by a particular file or directory
|
||||
|
||||
|
||||
The following commands will check your total space and your utilized space.
|
||||
|
||||
### ls -al
|
||||
|
||||
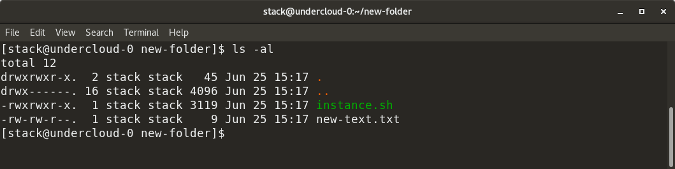
`ls -al` lists the entire contents, along with their size, of a particular directory
|
||||
|
||||
|
||||
### stat
|
||||
|
||||
`stat <file/directory> `displays the size and other stats of a file/directory or a filesystem.
|
||||
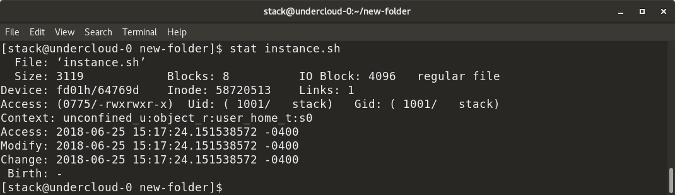
|
||||
|
||||
### fdisk -l
|
||||
|
||||
`fdisk -l` shows disk size along with disk partitioning information
|
||||
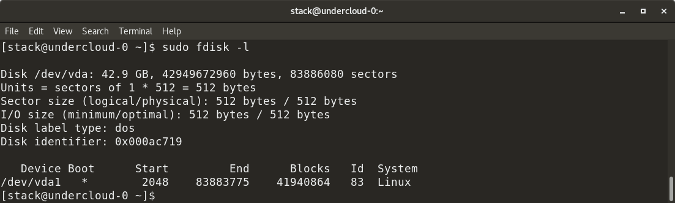
|
||||
|
||||
These are most of the built-in utilities for checking file space in Linux. There are many similar tools, like [Disks][1] (GUI), [Ncdu][2], etc., that also show disk space utilization. Do you have a favorite tool that's not on this list? Please share in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-check-free-disk-space-linux
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://wiki.gnome.org/Apps/Disks
|
||||
[2]:https://dev.yorhel.nl/ncdu
|
||||
@ -1,67 +1,78 @@
|
||||
streams:一个新的 Redis 通用数据结构
|
||||
==================================
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,streams 只是一个有趣且相对简单的概念。在 Kafka 流行这个概念之后,我主要研究它们在 Disque 实例中的用途。Disque 是一个将会转化为 Redis 4.2 的模块的消息队列。后来我发现 Disque 全都是 AP 消息,它将在不需要客户端过多参与的情况下实现容错和保证送达,因此,我认为 streams 的概念在那种情况下并不适用。
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,streams 只是一个有趣且相对简单的概念。在 Kafka 流行这个概念之后,我主要研究它们在 Disque 实例中的用途。Disque 是一个将会转变为 Redis 4.2 模块的消息队列。后来我发现 Disque 全都是 AP 消息,它将在不需要客户端过多参与的情况下实现容错和保证送达,因此,我认为 streams 的概念在那种情况下并不适用。
|
||||
|
||||
但是,在 Redis 中有一个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis 列表、排序集和发布/订阅(Pub/Sub)能力上有某些缺陷。你可以合适地使用这些工具去模拟一个消息或事件的序列,而有所权衡。排序集是大量耗费内存的,不能自然的模拟一次又一次的相同消息的传递,客户端不能阻塞新消息。因为一个排序集并不是一个序列化的数据结构,它是一个根据它们量的变化而移动的元素集:它不是很像时间系列一样的东西。列表有另外的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中部是什么,因为在那种情况下,访问时间是线性的。此外,没有任何的指定输出功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。对于一到多的工作负载,这里有发布/订阅,它在大多数情况下是非常好的,但是,对于某些不想“即发即弃”的东西:保留一个历史是很重要的,而不是断开之后重新获得消息,也因为某些消息列表,像时间系列,在用范围查询浏览时,是非常重要的:在这 10 秒范围内我的温度读数是多少?
|
||||
然而同时,在 Redis 中有一个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis 列表、排序集和发布/订阅(Pub/Sub)能力之间有某些缺陷。你可以权衡使用这些工具去模拟一个消息或事件的序列。
|
||||
|
||||
排序集是大量耗费内存的,不能自然的模拟一次又一次的相同消息的传递,客户端不能阻塞新消息。因为一个排序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:它不是很像时间系列一样的东西。
|
||||
|
||||
列表有另外的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中部是什么,因为在那种情况下,访问时间是线性的。此外,没有任何的指定输出功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
|
||||
对于一到多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想“即发即弃”的东西:保留一个历史是很重要的,而不是断开之后重新获得消息,也因为某些消息列表,像时间系列,用范围查询浏览是非常重要的:在这 10 秒范围内我的温度读数是多少?
|
||||
|
||||
这有一种方法可以尝试处理上面的问题,我计划对排序集进行通用化,并列入一个唯一的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而结束。一个关于 Redis 数据结构导出的更好的想法是,让它更像天然的计算机科学的数据结构,而不是,“Salvatore 发明的 API”。因此,在最后我停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许,我将为发布/订阅增加一些历史信息,或者将来对列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说“你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
|
||||
|
||||
### 起源
|
||||
|
||||
在将 Redis 4.0 中的模块介绍完之后,用户开始去看他们自己怎么去修复这些问题。他们之一,Timothy Downs,通过 IRC 写信给我:
|
||||
在 Redis 4.0 中引入模块之后,用户开始去看他们自己怎么去修复这些问题。他们中的一个,Timothy Downs,通过 IRC 写信给我:
|
||||
|
||||
<forkfork> 这个模块,我计划去增加一个事务日志式的数据类型 - 这意味着大量的订阅者可以在没有大量的内存增加的情况下做一些像发布/订阅那样的事情
|
||||
<forkfork> 订阅者保持他在消息队列中的位置,而不是在 Redis 上维护每个客户和复制消息的每个订阅者
|
||||
\<forkfork> 这个模块,我计划去增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在没有大量增加 redis 内存使用的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 订阅者保持它在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
|
||||
|
||||
这激发了我的想像力。我想了几天,并且意识到这可能是我们立刻同时解决上面的问题的契机。我需要去重新想像 “日志” 的概念是什么。它是个基本的编程元素,每个人都使用到它,因为它是非常简单地在追加模式中打开一个文件并以一定的格式写入数据,数据结构必须是抽象的。然而 Redis ,它们在内存中,并且我们使用 RAM 并不是因为我们懒,但是,因为使用一些指针,我们可以概念化数据结构并让他们抽象,并允许他们去摆脱明显的限制。对于实例,正常的日志有几个问题:偏移不是逻辑的,但是,它是一个真实的字节偏移,如果你想逻辑偏移是什么,那是与条目插入的时间相关的,我们有范围查询可用。同样的,一个日志通常很难收集:在一个只追加的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只是说,我想要最大的条目数,而旧的元素一个也不要,等等。
|
||||
这激发了我的想像力。我想了几天,并且意识到这可能是我们立刻同时解决上面所有问题的契机。我需要去重新构想 “日志” 的概念是什么。它是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以允许它们摆脱明显的限制。对于正常的例子来说,日志有几个问题:偏移不是逻辑的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移,我们有范围查询可用。同样的,日志通常很难进行垃圾收集:在一个只追加的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只是说,我想要编号最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法,去尝试着写一个规范的时候,我使用了 radix 树去实现,它是用于 Redis 集群的,去优化它内部的某些部分。这为实现一个有效的空间日志提供了基础。它在对数的时间(logarithmic time)内得到范围是仍然可访问的。同时,我开始去读关于 Kafka 流,去得到另外的创意,它也非常适合我的设计,并且产生了一个 Kafka 客户组的概念,并且,将它理想化用于 Redis 和内存中(in-memory)使用的案例。然而,该规范仅保留了几个月,在一段时间后,我积累了与别人讨论的即将增加到 Redis 中的内容,为了升级它,使用了许多提示(hint)几乎从头到尾重写了一遍。我想 Redis 流尤其对于时间系列是非常有用的,而不仅是用于事件和消息类的应用程序。
|
||||
当我从 Timothy 的想法萌芽,去尝试着写一个规范的时候,我使用了我用于 Redis 集群中的 radix 树实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而仍然可以用对数时间来访问范围。同时,我开始去读关于 Kafka 流以获得另外的灵感,它也非常适合我的设计,并且产生了一个 Kafka 消费组的概念,并且,理想化的话,它可以用于 Redis 和内存用例。然而,该规范仅维持了几个月,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的即将增加到 Redis 中的内容所得到的许多建议一起升级。我希望 Redis 流是非常有用的,尤其对于时间序列,而不仅是用于事件和消息类的应用程序。
|
||||
|
||||
让我们写一些代码
|
||||
=====================
|
||||
### 让我们写一些代码
|
||||
|
||||
从 Redis 会议回来后,在整个夏天,我实现了一个称为 “listpack” 的库。这个库是 ziplist.c 的继承者,那是一个表示在单个分配中字符串元素的列表的数据结构。它是一个非常专业的序列化格式,有在相反的顺序中可解析的特性,从右到左: 在所有的用户案例中用于替代 ziplists 中所需的某些东西。
|
||||
从 Redis 大会回来后,在整个夏天,我实现了一个称为 “listpack” 的库。这个库是 ziplist.c 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:需要它以便在各种用例中替代 ziplists。
|
||||
|
||||
结合 radix 树 + listpacks,它可以很容易地去构建一个日志,它同时也是非常高效的,并且是索引化的,意味着,允许通过 IDs 和时间进行随机访问。自从实现这个方法后,为了实现流数据结构,我开始去写一些代码。我直到完成实现,不管怎样,在这个时候,在 Github 上的 Redis 内部的 “streams” 分支,去启动共同开发并接受订阅已经足够了。我并没有声称那个 API 是最终版本,但是,这有两个有趣的事实:一是,在那时,仅客户组是缺失的,加上一些不那么重要的命令去操作流,但是,所有的大的方面都已经实现了。二是,一旦各个方面比较稳定了之后 ,决定将所有的流的工作移植到 4.0 分支,它大约两个月后发布。这意味着 Redis 用户为了使用流,不用等待 Redis 4.2,它们将对生产使用的 ASAP 可用。这是可能的,因为有一个新的数据结构,几乎所有的代码改变都是独立于新代码的。除了阻塞列表操作之外 :代码都重构了,因此,我们和流共享了相同的代码,并且,列表阻塞操作在 Redis 内部进行了大量的简化。
|
||||
结合 radix 树和 listpacks,它可以很容易地去构建一个日志,它同时也是非常空间高效的,并且是索引化的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我最终完成了该实现,不管怎样,现在,在 Github 上的 Redis 的 “streams” 分支里面,它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有趣的事实:一是,在那时,只有消费组是缺失的,加上一些不那么重要的命令去操作流,但是,所有的大的方面都已经实现了。二是,一旦各个方面比较稳定了之后 ,决定大概用两个月的时间将所有的流的工作向后移植到 4.0 分支。这意味着 Redis 用户为了使用流,不用等待 Redis 4.2,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部。
|
||||
|
||||
教程:欢迎使用 Redis 流
|
||||
==================================
|
||||
### 教程:欢迎使用 Redis 流
|
||||
|
||||
在某种程序上,你应该感谢流作为 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,它们更多是一个域(fields)和值(values)组成的对象。范围查询更适用而且更快。流中的每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以阻塞等待(blocking-wait)比指定的 IDs 更大的元素。Redis 流的一个基本的命令是 XADD。是的,所有的 Redis 命令都是以一个“X”为前缀的。
|
||||
在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,它们更多是一个<ruby>域<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询更适用而且更快。流中的每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 流的一个基本的命令是 XADD。是的,所有的 Redis 流命令都是以一个“X”为前缀的。
|
||||
|
||||
```
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
```
|
||||
|
||||
这个 XADD 命令将追加指定的条目作为一个新元素到一个指定的流 “mystream” 中。在上面的示例中的这个条目有两个域:sensor-id 和 temperature,然而,每个条目在同一个流中可以有不同的域。使用相同的域名字将导致更多的内存使用。一个有趣的事情是,域的排序是保证保存的。XADD 仅返回插入的条目的 ID,因为在第三个参数中有星号(*),我们请求命令去自动生成 ID。这几乎总是你想要的,但是,它也可能去强制指定一个 ID,实例为了去复制这个命令到被动服务器和 AOF 文件。
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 “mystream” 的新元素。在上面的示例中的这个条目有两个域:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的域。使用相同的域名字可以更好地利用内存。一个有趣的事情是,域的排序是可以保证顺序的。XADD 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示我们邀请命令自动生成 ID。一般情况下需求如此,但是,也可以去强制指定一个 ID,这种情况用于复制这个命令到被动服务器和 AOF 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。1506871964177 是毫秒时间,它仅是一个使用毫秒解决方案的 UNIX 时间。圆点(.)后面的数字 0,是一个序列号,它是为了区分相同毫秒数的条目增加上去的。所有的数字都是 64 位的无符号整数。这意味着在流中,我们可以增加所有我们想要的条目,在相同毫秒数中的事件。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目之间的最大值来获取。因此,对实例来说,即使是计算机时间向后跳,这个 IDs 仍然是增加的。在某些情况下,你可能想流条目的 IDs 作为完整的 128 位数字。然而,现实是,它们与被添加的实例的本地时间有关,意味着我们有毫秒级的精确的范围查询。
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它仅是一个毫秒级的 UNIX 时间。圆点(`.`)后面的数字 `0`,是一个序列号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着在流中,我们可以增加所有我们想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,对实例来说,即使是计算机时间向后跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,现实是,它们与被添加的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
|
||||
|
||||
如你想像的那样,以一个快速的方式去添加两个条目,结果是仅序列号增加。我可以使用一个 MULTI/EXEC 块去简单模拟“快速插入”,如下:
|
||||
如你想像的那样,以一个非常快速的方式去添加两个条目,结果是仅序列号增加。我可以使用一个 `MULTI`/`EXEC` 块去简单模拟“快速插入”,如下:
|
||||
|
||||
> MULTI
|
||||
```
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
```
|
||||
|
||||
在上面的示例中,也展示了无需在开始时指定任何模式(schema)的情况下,对不同的条目,使用不同的域。会发生什么呢?每个块(它通常包含 50 - 150 个消息范围的内容)的每一个信息被用作参考。并且,有相同域的连续条目被使用一个标志进行压缩,这个标志表明“这个块中的第一个条目的相同域”。因此,对于连续消息使用相同域可以节省许多内存,即使是域的集合随着时间发生缓慢变化。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 XRANGE 命令实现的,并且对于正在变化的流,通过 XREAD 命令去实现。XRANGE 命令仅取得包括从开始到停止范围内的条目。因此,对于实例,如果我知道它的 ID,我可以取得单个条目,像这样:
|
||||
在上面的示例中,也展示了无需在开始时指定任何<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的域。会发生什么呢?每个块(它通常包含 50 - 150 个消息内容)的每一个信息被用作参考。并且,有相同域的连续条目被使用一个标志进行压缩,这个标志表明与“这个块中的第一个条目的相同域”。因此,对于连续消息使用相同域可以节省许多内存,即使是域的集合随着时间发生缓慢变化。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;以及流式,它是通过 XREAD 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的条目。因此,对于实例,如果我知道它的 ID,我可以取得单个条目,像这样:
|
||||
|
||||
```
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
```
|
||||
|
||||
然而,你可以使用指定的开始符号 “-” 和停止符号 “+” 去表示可能的最小和最大 ID。为了限制返回条目的数量,它也可以使用 COUNT 选项。下面是一个更复杂的 XRANGE 示例:
|
||||
|
||||
然而,你可以使用指定的开始符号 `-` 和停止符号 `+` 去表示最小和最大的 ID。为了限制返回条目的数量,它也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
|
||||
```
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
@ -71,9 +82,11 @@ QUEUED
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
```
|
||||
|
||||
这里我们讲的是 IDs 的范围,然后,为了在一个给定时间范围内取得特定元素的范围,你可以使用 XRANGE,因为你可以省略 IDs 的“序列” 部分。因此,你可以做的仅是指定“毫秒”时间,下面的命令的意思是: “从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为你可以省略 ID 的“序列” 部分。因此,你可以做的仅是指定“毫秒”时间,下面的命令的意思是: “从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
@ -81,24 +94,27 @@ QUEUED
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
```
|
||||
|
||||
关于 XRANGE 注意的最重要的事情是,由于我们在回复中收到了 IDs,并且连续 ID 是无法直接获得的,因为 ID 的序列部分是增加的,它可以使用 XRANGE 去遍历整个流,接收每个调用的元素的特定个数。在 Redis 中的*SCAN*系列命令之后,那是允许 Redis 数据结构迭代的,尽管事实上它们不是为迭代设计的,我以免再次产生相同的错误。
|
||||
关于 `XRANGE` 最后一个重要的事情是,考虑到我们在回复中收到 ID,并且随后连续的 ID 只是增加了 ID 的序列部分,所以可以使用 `XRANGE` 去遍历整个流,接收每个调用的指定个数的元素。在 Redis 中的`*SCAN` 系列命令之后,它允许 Redis 数据结构迭代,尽管事实上它们不是为迭代设计的,但我避免再犯相同的错误。
|
||||
|
||||
使用 XREAD 处理变化的流:阻塞新的数据
|
||||
===========================================
|
||||
### 使用 XREAD 处理变化的流:阻塞新的数据
|
||||
|
||||
XRANGE 用于,当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去得到单个元素时,是非常完美的。然而,在当数据到达时,不同的客户端必须同时使用流的情况下,它就不是一个很好的解决方案,并且它是需要某种形式的“池”的。(对于*某些*应用程序来说,这可能是个好主意,因为它们仅是偶尔连接取数的)。
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去得到单个元素时,使用 XRANGE 是非常完美的。然而,在当数据到达时,流必须由不同的客户端处理时,它就不是一个很好的解决方案,它是需要某种形式的“池”。(对于*某些*应用程序来说,这可能是个好主意,因为它们仅是偶尔连接取数的)
|
||||
|
||||
XREAD 命令是为读设计的,同时从多个流中仅指定我们得到的流中的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,去解除阻塞。类似于阻塞列表操作产生的效果,但是,这里的数据是从流中得到的。并且多个客户端可以在同时访问相同的数据。
|
||||
|
||||
这里有一个关于 XREAD 调用的规范示例:
|
||||
`XREAD` 命令是为读设计的,同时从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,去解除阻塞。类似于阻塞列表操作产生的效果,但是,这里的数据是从流中得到的。并且多个客户端可以在同时访问相同的数据。
|
||||
|
||||
这里有一个关于 `XREAD` 调用的规范示例:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
```
|
||||
|
||||
它的意思是:从 “mystream” 和 “otherstream” 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。之后我们用关键字 STREAMS 指定我们想要监听的流,和最后的 ID,指定的 ID “$” 意思是:假设我现在已经有了流中的所有元素,因此,从下一个到达的元素开始给我。
|
||||
|
||||
如果,从另外一个客户端,我发出这样的命令:
|
||||
它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。之后我们用关键字 `STREAMS` 指定我们想要监听的流,和我们的最后 ID,指定的 ID `$` 意思是:假设我现在已经有了流中的所有元素,因此,从下一个到达的元素开始给我。
|
||||
|
||||
如果,从另外一个客户端,我发出这样的命令:
|
||||
|
||||
```
|
||||
> XADD otherstream * message “Hi There”
|
||||
|
||||
在 XREAD 侧会出现什么情况呢?
|
||||
@ -107,44 +123,47 @@ XREAD 命令是为读设计的,同时从多个流中仅指定我们得到的
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
```
|
||||
|
||||
和到过的数据一起,我们得到了最新到达的数据的 key,在下次的调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
和收到的数据一起,我们得到了最新收到的数据的 key,在下次的调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
```
|
||||
|
||||
依次类推。然而需要注意的是使用方式,有可能客户端在一个非常大的延迟(因为它处理消息需要时间,或者其它什么原因)之后再次连接。在这种情况下,同时会有很多消息堆积,为了确保客户端不被消息淹没,并且服务器不会丢失太多时间的提供给单个客户端的大量消息,所以,总是使用 XREAD 的 COUNT 选项是明智的。
|
||||
依次类推。然而需要注意的是使用方式,有可能客户端在一个非常大的延迟(因为它处理消息需要时间,或者其它什么原因)之后再次连接。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,并且服务器不会花费太多时间提供给单个客户端的大量消息,所以,总是使用 `XREAD` 的 `COUNT` 选项是明智的。
|
||||
|
||||
流封顶
|
||||
==============
|
||||
|
||||
到现在为止,一直还都不错… 然而,有些时候,流需要去删除一些旧的消息。幸运的是,这可以使用 XADD 命令的 MAXLEN 选项去做:
|
||||
### 流封顶
|
||||
|
||||
到现在为止,一直还都不错…… 然而,有些时候,流需要去删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
```
|
||||
|
||||
它是基本意思是,如果流添加的新元素被发现超过 1000000 个消息,那么,删除旧的消息,以便于长度回到 1000000 个元素以内。它很像是使用 RPUSH + LTRIM 的列表,但是,这是我们使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将使用一些 CPU 资源,所以,在计算 MAXLEN 的之前,尽可能使用 “~” 符号,为了表明我们不是要求非常*精确*的 1000000 个消息。但是,这里有很多,它还不是一个大的问题:
|
||||
|
||||
它是基本意思是,如果流添加的新元素被发现超过 `1000000` 个消息,那么,删除旧的消息,以便于长度回到 `1000000` 个元素以内。它很像是使用 `RPUSH` + `LTRIM` 的列表,但是,这是我们使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将使用一些 CPU 资源,所以,在计算 MAXLEN 的之前,尽可能使用 `~` 符号,为了表明我们不是要求非常*精确*的 1000000 个消息,而是稍微多一些也不是一个大的问题:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
```
|
||||
|
||||
这种方式的 XADD 删除消息,仅用于当它可以删除整个节点的时候。相比 vanilla XADD,这种方式几乎可以自由地对流进行封顶。
|
||||
这种方式 XADD 仅当它可以删除整个节点的时候才会删除元素。相比普通的 `XADD`,这种方式几乎可以自由地对流进行封顶。
|
||||
|
||||
(进程内工作的)客户组
|
||||
==================================
|
||||
### 消费组(开发中)
|
||||
|
||||
这是不在 Redis 中实现的第一个特性,但是,它是在进程内工作的。它也是来自 Kafka 的灵感,尽管在这里以不同的方式去实现的。重点是使用了 XREAD,客户端也可以增加一个 “GROUP <name>” 选项。 在相同组的所有客户端自动调用,以得到*不同的*消息。当然,这里不能从同一个流中被多个组读。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在不同的组,消息是不会重复的。
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。它也是来自 Kafka 的灵感,尽管在这里以不同的方式去实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。 在相同组的所有客户端自动调用,以得到*不同的*消息。当然,不能从同一个流中被多个组读。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
|
||||
当指定组时,尽可能指定一个 “RETRY <milliseconds>” 选项去扩展组:在这种情况下,如果消息没有使用 XACK 去进行确认,它将在指定的毫秒数后进行再次投递。这种情况下,客户端没有私有的方法去标记已处理的消息,这也是一项正在进行中的工作。
|
||||
当指定组时,能够指定一个 “RETRY <milliseconds>” 选项去扩展组:在这种情况下,如果消息没有使用 XACK 去进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法去标记已处理的消息。这也是一项正在进行中的工作。
|
||||
|
||||
内存使用和节省的加载时间
|
||||
=====================================
|
||||
### 内存使用和节省的加载时间
|
||||
|
||||
因为被设计用来模拟 Redis 流,所以,根据它们的域的数量、值和长度,内存使用是显著降低的。但对于简单的消息,每 100 MB 内存使用可以有几百万条消息,此外,设想中的格式去需要极少的系列化:是存储为 radix 树节点的 listpack 块,在磁盘上和内存中是用同一个来表示的,因此,它们被琐碎地存储和读取。在一个实例中,Redis 能在 0.3 秒内可以从 RDB 文件中读取 500 万个条目。这使的流的复制和持久存储是非常高效的。
|
||||
因为被设计用来模拟 Redis 流,内存使用是显著降低的。这依赖于它们的域的数量、值和长度,但对于简单的消息,每 100 MB 内存使用可以有几百万条消息,此外,设想中的格式去需要极少的系列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中是以相同方式表示的,因此,它们可以被轻松地存储和读取。在一个实例中,Redis 能在 0.3 秒内可以从 RDB 文件中读取 500 万个条目。这使的流的复制和持久存储是非常高效的。
|
||||
|
||||
它也被计划允许从条目中间删除。现在仅部分实现,策略是整个条目标记中删除的条目被标记为已删除条目,并且,当达到设置的已删除条目占全部条目的比例时,这个块将被回收重写,并且,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
也计划允许从条目中间删除。现在仅部分实现,策略是删除的条目在标记中标识为已删除条目,并且,当达到已删除条目占全部条目的给定比例时,这个块将被回收重写,并且,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
最终发布时间的结论
|
||||
===================
|
||||
### 最终发布时间的结论
|
||||
|
||||
Redis 流将包含在年底前推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,为了用于解决很多现在很难去解决的情况:那意味着你需要创造性地滥用当前提供的数据结构去解决那些问题。一个非常重要的使用情况是时间系列,但是,我的感觉是,对于其它案例来说,通过 TREAD 来传递消息将是非常有趣的,因为它可以替代那些需要更高可靠性的发布/订阅的应用程序,而不是“即用即弃”,以及全新的使用案例。现在,如果你想在你的有问题的环境中,去评估新的数据结构的能力,可以在 GitHub 上去获得 “streams” 分支,开始去玩吧。欢迎向我们报告所有的 bug 。 :-)
|
||||
Redis 流将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难去解决的情况:那意味着你(之前)需要创造性地滥用当前提供的数据结构去解决那些问题。一个非常重要的使用情况是时间系列,但是,我的感觉是,对于其它用例来说,通过 `TREAD` 来传递消息将是非常有趣的,因为它可以替代那些需要更高可靠性的发布/订阅的应用程序,而不是“即用即弃”,以及全新的用例。现在,如果你想在你需要的环境中评估新的数据结构的能力,可以在 GitHub 上去获得 “streams” 分支,开始去玩吧。欢迎向我们报告所有的 bug 。 :-)
|
||||
|
||||
如果你喜欢这个视频,展示这个 streams 的实时会话在这里: https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
@ -153,9 +172,9 @@ Redis 流将包含在年底前推出的 Redis 4.0 系列的稳定版中。我认
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez ][a]
|
||||
作者:[antirez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
如何检查 Linux 中的可用磁盘空间
|
||||
======
|
||||
|
||||

|
||||
|
||||
跟踪磁盘利用率信息是系统管理员(和其他人)的日常待办事项列表之一。Linux 有一些内置的使用程序来帮助提供这些信息。
|
||||
|
||||
### df
|
||||
|
||||
`df` 命令意思是 “disk-free”,显示 Linux 系统上可用和已使用的磁盘空间。
|
||||
|
||||
`df -h` 以人类可读的格式显示磁盘空间。
|
||||
|
||||
`df -a` 显示文件系统的完整磁盘使用情况,即使 Available(可用) 字段为 0
|
||||

|
||||
|
||||
`df -T` 显示磁盘使用情况以及每个块的文件系统类型(例如,xfs, ext2, ext3, btrfs 等)
|
||||
|
||||
`df -i` 显示已使用和未使用的 inodes
|
||||

|
||||
|
||||
### du
|
||||
|
||||
`du` 显示文件,目录等的磁盘使用情况,默认情况下以 kb 为单位显示
|
||||
|
||||
`du -h` 以人类可读的方式显示所有目录和子目录的磁盘使用情况
|
||||
|
||||
`du -a` 显示所有文件的磁盘使用情况
|
||||
|
||||
`du -s` 提供特定文件或目录使用的总磁盘空间
|
||||

|
||||
|
||||
以下命令将检查 Linux 系统的总空间和使用空间。
|
||||
|
||||
### ls -al
|
||||
|
||||
`ls -al` 列出了特定目录的全部内容及大小。
|
||||

|
||||
|
||||
### stat
|
||||
|
||||
`stat <文件/目录> `显示文件/目录或文件系统的大小和其他统计信息。
|
||||

|
||||
|
||||
### fdisk -l
|
||||
|
||||
`fdisk -l` 显示磁盘大小以及磁盘分区信息。
|
||||

|
||||
|
||||
这些是用于检查 Linux 文件空间的大多数内置实用程序。有许多类似的工具,如 [Disks][1](GUI 工具),[Ncdu][2] 等,它们也显示磁盘空间的利用率。你有你最喜欢的工具而它不在这个列表上吗?请在评论中分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-check-free-disk-space-linux
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://wiki.gnome.org/Apps/Disks
|
||||
[2]:https://dev.yorhel.nl/ncdu
|
||||
Loading…
Reference in New Issue
Block a user