mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
a36ca49109
@ -4,7 +4,7 @@
|
||||
|
||||
### Puppet 是什么? ###
|
||||
|
||||
Puppet 是一款为 IT 系统管理员和顾问设计的自动化软件,你可以用它自动化地完成诸如安装应用程序和服务、补丁管理和部署等工作。所有资源的相关配置都以“manifests”的方式保存,单台机器或者多台机器都可以使用。如果你想了解更多内容,Puppet 实验室的网站上有关于 [Puppet 及其工作原理][1]的更详细的介绍。
|
||||
Puppet 是一款为 IT 系统管理员和顾问们设计的自动化软件,你可以用它自动化地完成诸如安装应用程序和服务、补丁管理和部署等工作。所有资源的相关配置都以“manifests”的方式保存,单台机器或者多台机器都可以使用。如果你想了解更多内容,Puppet 实验室的网站上有关于 [Puppet 及其工作原理][1]的更详细的介绍。
|
||||
|
||||
### 本教程要做些什么? ###
|
||||
|
||||
@ -58,7 +58,7 @@ Puppet 是一款为 IT 系统管理员和顾问设计的自动化软件,你可
|
||||
|
||||
# chkconfig puppet on
|
||||
|
||||
Puppet 客户端需要知道 Puppet master 服务器的地址。最佳方案是使用 DNS 服务器解析 Puppet master 服务器地址。如果你没有 DNS 服务器,在 `/etc/hosts` 里添加下面这几行也可以:
|
||||
Puppet 客户端需要知道 Puppet master 服务器的地址。最佳方案是使用 DNS 服务器解析 Puppet master 服务器地址。如果你没有 DNS 服务器,在 `/etc/hosts` 里添加类似下面这几行也可以:
|
||||
|
||||
> 1.2.3.4 server.your.domain
|
||||
|
||||
@ -125,7 +125,7 @@ master 服务器名也要在 `/etc/puppet/puppet.conf` 文件的“[agent]”小
|
||||
|
||||
> runinterval = <yourtime>
|
||||
|
||||
这个选项的值可以是秒(格式比如 30 或者 30s),分钟(30m),小时(6h),天(2d)以及年(5y)。值得注意的是,0 意味着“立即执行”而不是“从不执行”。
|
||||
这个选项的值可以是秒(格式比如 30 或者 30s),分钟(30m),小时(6h),天(2d)以及年(5y)。值得注意的是,**0 意味着“立即执行”而不是“从不执行”**。
|
||||
|
||||
### 提示和技巧 ###
|
||||
|
||||
@ -139,7 +139,7 @@ master 服务器名也要在 `/etc/puppet/puppet.conf` 文件的“[agent]”小
|
||||
|
||||
# puppet agent -t --debug
|
||||
|
||||
Debug 选项会显示 Puppet 本次运行时的差不多每一个步骤,这在调试非常复杂的问题时很有用。另一个很有用的选项是:
|
||||
debug 选项会显示 Puppet 本次运行时的差不多每一个步骤,这在调试非常复杂的问题时很有用。另一个很有用的选项是:
|
||||
|
||||
# puppet agent -t --noop
|
||||
|
||||
@ -187,7 +187,7 @@ via: http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[sailing](https://github.com/sailing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,15 @@
|
||||
移除Linux系统上的文件元数据
|
||||
如何在Linux上移除文件内的隐私数据
|
||||
================================================================================
|
||||
|
||||
典型的数据文件通常关联着“元数据”,其包含这个文件的描述信息,表现为一系列属性-值的集合。元数据一般包括创建者名称、生成文件的工具、文件创建/修改时期、创建位置和编辑历史等等。EXIF(镜像标准)、RDF(web资源)和DOI(数字文档)是几种流行的元数据标准。
|
||||
|
||||
典型的数据文件通常关联着“元数据”,其包含这个文件的描述信息,表现为一系列属性-值的集合。元数据一般包括创建者名称、生成文件的工具、文件创建/修改时期、创建位置和编辑历史等等。几种流行的元数据标准有 EXIF(图片)、RDF(web资源)和DOI(数字文档)等。
|
||||
|
||||
虽然元数据在数据管理领域有它的优点,但事实上它会[危害][1]你的隐私。相机图片中的EXIF格式数据会泄露出可识别的个人信息,比如相机型号、拍摄相关的GPS坐标和用户偏爱的照片编辑软件等。在文档和电子表格中的元数据包含作者/所属单位信息和相关的编辑历史。不一定这么绝对,但诸如[metagoofil][2]一类的元数据收集工具在信息收集的过程中常最作为入侵测试的一部分被利用。
|
||||
|
||||
对那些想要从共享数据中擦除一切个人元数据的用户来说,有一些方法从数据文件中移除元数据。你可以使用已有的文档或图片编辑软件,通常有自带的元数据编辑功能。在这个教程里,我会介绍一种不错的、单独的**元数据清理工具**,其目标只有一个:**匿名一切私有元数据**。
|
||||
|
||||
[MAT][3](元数据匿名工具箱)是一款专业的元数据清理器,使用Python编写。它在Tor工程旗下开发而成,在[Trails][4]上衍生出标准,后者是一种私人增强的live操作系统。【翻译得别扭,麻烦修正:)】
|
||||
[MAT][3](元数据匿名工具箱)是一款专业的元数据清理器,使用Python编写。它属于Tor旗下的项目,而且是Live 版的隐私增强操作系统 [Trails][4] 的标配应用。
|
||||
|
||||
与诸如[exiftool][5]等只能对有限数量的文件类型进行写入的工具相比,MAT支持从各种各样的文件中消除元数据:图片(png、jpg)、文档(odt、docx、pptx、xlsx和pdf)、归档文件(tar、tar.bz2)和音频(mp3、ogg、flac)等。
|
||||
与诸如[exiftool][5]等只能对有限种类的文件类型进行写入的工具相比,MAT支持从各种各样的文件中消除元数据:图片(png、jpg)、文档(odt、docx、pptx、xlsx和pdf)、归档文件(tar、tar.bz2)和音频(mp3、ogg、flac)等。
|
||||
|
||||
### 在Linux上安装MAT ###
|
||||
|
||||
@ -18,7 +17,7 @@
|
||||
|
||||
$ sudo apt-get install mat
|
||||
|
||||
在Fedora上,并没有预先生成的MAT包,所以你需要从源码生成。这是我在Fedora上生成MAT的步骤(不成功的话,请查看教程底部):
|
||||
在Fedora上,并没有预先生成的MAT软件包,所以你需要从源码生成。这是我在Fedora上生成MAT的步骤(不成功的话,请查看教程底部):
|
||||
|
||||
$ sudo yum install python-devel intltool python-pdfrw perl-Image-ExifTool python-mutagen
|
||||
$ sudo pip install hachoir-core hachoir-parser
|
||||
@ -95,7 +94,7 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
MAT是一款简单但非常好用的工具,用来预防从元数据中无意泄露私人数据。请注意如果有必要,还是需要你去隐藏文件内容。MAT能做的是消除与文件相关的元数据,但并不会对文件本身进行任何操作。简而言之,MAT是一名救生员,因为它可以处理大多数常见的元数据移除,但不应该只指望它来保证你的隐私。[译者注:养成良好的隐私保护意识和习惯才是最好的方法]
|
||||
MAT是一款简单但非常好用的工具,用来预防从元数据中无意泄露私人数据。请注意如果有必要,文件内容也需要保护。MAT能做的是消除与文件相关的元数据,但并不会对文件本身进行任何操作。简而言之,MAT是一名救生员,因为它可以处理大多数常见的元数据移除,但不应该只指望它来保证你的隐私。[译者注:养成良好的隐私保护意识和习惯才是最好的方法]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -103,7 +102,7 @@ via: http://xmodulo.com/2014/08/remove-file-metadata-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
在Linux中使用逻辑卷管理器构建灵活的磁盘存储——第一部分
|
||||
在Linux中使用LVM构建灵活的磁盘存储(第一部分)
|
||||
================================================================================
|
||||
**逻辑卷管理器(LVM)**让磁盘空间管理更为便捷。如果一个文件系统需要更多的空间,它可以在它的卷组中将空闲空间添加到它的逻辑卷中,而文件系统可以根据你的意愿调整大小。如果某个磁盘启动失败,替换磁盘可以使用卷组注册成一个物理卷,而逻辑卷扩展可以将数据迁移到新磁盘而不会丢失数据。
|
||||
**逻辑卷管理器(LVM)**让磁盘空间管理更为便捷。如果一个文件系统需要更多的空间,可以在它的卷组中将空闲空间添加到其逻辑卷中,而文件系统可以根据你的意愿调整大小。如果某个磁盘启动失败,用于替换的磁盘可以使用卷组注册成一个物理卷,而逻辑卷扩展可以将数据迁移到新磁盘而不会丢失数据。
|
||||
|
||||
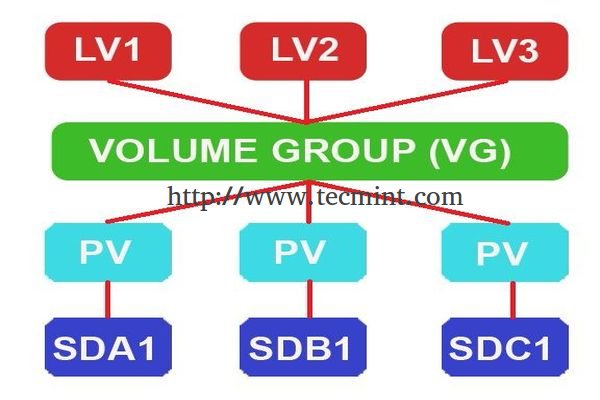
|
||||
在Linux中创建LVM存储
|
||||
<center></center>
|
||||
|
||||
在现代世界中,每台服务器空间都会因为我们的需求增长而不断扩展。逻辑卷可以用于RAID,SAN。单个物理卷将会被加入组以创建卷组,在卷组中,我们需要切割空间以创建逻辑卷。在使用逻辑卷时,我们可以使用某些命令来跨磁盘、跨逻辑卷扩展,或者减少逻辑卷大小,而不用重新格式化和重新对当前磁盘分区。卷可以跨磁盘抽取数据,这会增加I/O数据量。
|
||||
<center>*在Linux中创建LVM存储*</center>
|
||||
|
||||
在如今,每台服务器空间都会因为我们的需求增长而不断扩展。逻辑卷可以用于RAID,SAN。单个物理卷将会被加入组以创建卷组,在卷组中,我们需要切割空间以创建逻辑卷。在使用逻辑卷时,我们可以使用某些命令来跨磁盘、跨逻辑卷扩展,或者减少逻辑卷大小,而不用重新格式化和重新对当前磁盘分区。卷可以跨磁盘抽取数据,这会增加I/O数据量。
|
||||
|
||||
### LVM特性 ###
|
||||
|
||||
@ -27,8 +28,8 @@
|
||||
# vgs
|
||||
# lvs
|
||||
|
||||

|
||||
检查物理卷
|
||||
<center></center>
|
||||
<center>*检查物理卷*</center>
|
||||
|
||||
下面是上面截图中各个参数的说明。
|
||||
|
||||
@ -52,8 +53,8 @@
|
||||
|
||||
# fdisk -l
|
||||
|
||||

|
||||
验证添加的磁盘
|
||||
<center></center>
|
||||
<center>*验证添加的磁盘*</center>
|
||||
|
||||
- 用于操作系统(CentOS 6.5)的默认磁盘。
|
||||
- 默认磁盘上定义的分区(vda1 = swap),(vda2 = /)。
|
||||
@ -61,8 +62,8 @@
|
||||
|
||||
各个磁盘大小都是20GB,默认的卷组的PE大小为4MB,我们在该服务器上配置的卷组使用默认PE。
|
||||
|
||||

|
||||
卷组显示
|
||||
<center></center>
|
||||
<center>*卷组显示*</center>
|
||||
|
||||
- **VG Name** – 卷组名称。
|
||||
- **Format** – LVM架构使用LVM2。
|
||||
@ -82,8 +83,8 @@
|
||||
|
||||
# df -TH
|
||||
|
||||
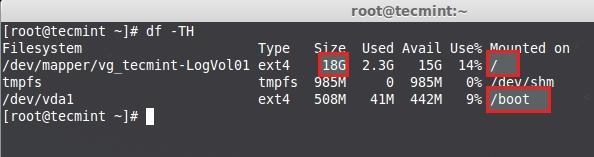
|
||||
检查磁盘空间
|
||||
<center></center>
|
||||
<center>*检查磁盘空间*</center>
|
||||
|
||||
上面的图片中显示了用于根的挂载点已使用了**18GB**,因此没有空闲空间可用了。
|
||||
|
||||
@ -91,15 +92,15 @@
|
||||
|
||||
我们可以扩展当前使用的卷组以获得更多空间。但在这里,我们将要做的是,创建新的卷组,然后在里面肆意妄为吧。过会儿,我们可以看到怎样来扩展使用中的卷组的文件系统。
|
||||
|
||||
在使用新磁盘钱,我们需要使用fdisk来对磁盘分区。
|
||||
在使用新磁盘前,我们需要使用fdisk来对磁盘分区。
|
||||
|
||||
# fdisk -cu /dev/sda
|
||||
|
||||
- **c** – 关闭DOS兼容模式,推荐使用该选项。
|
||||
- **u** – 当列出分区表时,会以扇区而不是柱面显示。
|
||||
|
||||

|
||||
创建新的物理分区
|
||||
<center></center>
|
||||
<center>*创建新的物理分区*</center>
|
||||
|
||||
接下来,请遵循以下步骤来创建新分区。
|
||||
|
||||
@ -118,8 +119,8 @@
|
||||
|
||||
# fdisk -l
|
||||
|
||||

|
||||
验证分区表
|
||||
<center></center>
|
||||
<center>*验证分区表*</center>
|
||||
|
||||
### 创建物理卷 ###
|
||||
|
||||
@ -135,8 +136,8 @@
|
||||
|
||||
# pvs
|
||||
|
||||

|
||||
创建物理卷
|
||||
<center></center>
|
||||
<center>*创建物理卷*</center>
|
||||
|
||||
### 创建卷组 ###
|
||||
|
||||
@ -152,11 +153,11 @@
|
||||
|
||||
# vgs
|
||||
|
||||

|
||||
创建卷组
|
||||
<center></center>
|
||||
<center>*创建卷组*</center>
|
||||
|
||||

|
||||
验证卷组
|
||||
<center></center>
|
||||
<center>*验证卷组*</center>
|
||||
|
||||
理解vgs命令输出:
|
||||
|
||||
@ -173,15 +174,15 @@
|
||||
|
||||
# vgs -v
|
||||
|
||||

|
||||
检查卷组信息
|
||||
<center></center>
|
||||
<center>*检查卷组信息*</center>
|
||||
|
||||
**8.** 要获取更多关于新创建的卷组信息,运行以下命令。
|
||||
|
||||
# vgdisplay tecmint_add_vg
|
||||
|
||||
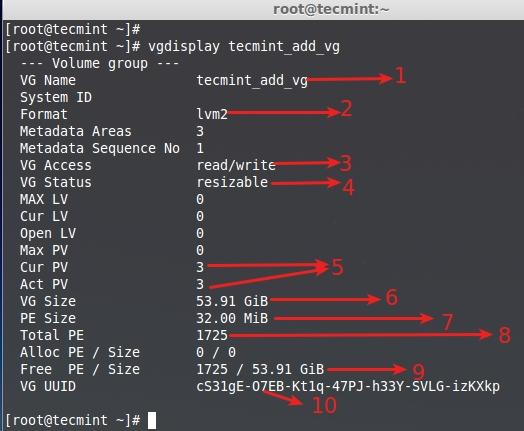
|
||||
列出新卷组
|
||||
<center></center>
|
||||
<center>*列出新卷组*</center>
|
||||
|
||||
- 卷组名称
|
||||
- 使用的LVM架构。
|
||||
@ -200,15 +201,15 @@
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
列出当前卷组
|
||||
<center></center>
|
||||
<center>*列出当前卷组*</center>
|
||||
|
||||
**10.** 这些逻辑卷处于**vg_tecmint**卷组中使用**pvs**命令来列出并查看有多少空闲空间可以创建逻辑卷。
|
||||
|
||||
# pvs
|
||||
|
||||
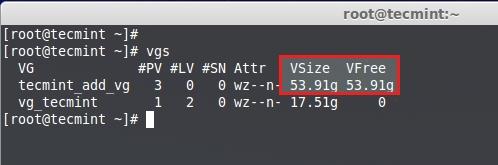
|
||||
检查空闲空间
|
||||
<center></center>
|
||||
<center>*检查空闲空间*</center>
|
||||
|
||||
**11.** 卷组大小为**54GB**,而且未被使用,所以我们可以在该组内创建LV。让我们将卷组平均划分大小来创建3个逻辑卷,就是说**54GB**/3 = **18GB**,创建出来的单个逻辑卷应该会是18GB。
|
||||
|
||||
@ -218,8 +219,8 @@
|
||||
|
||||
# vgdisplay tecmint_add_vg
|
||||
|
||||
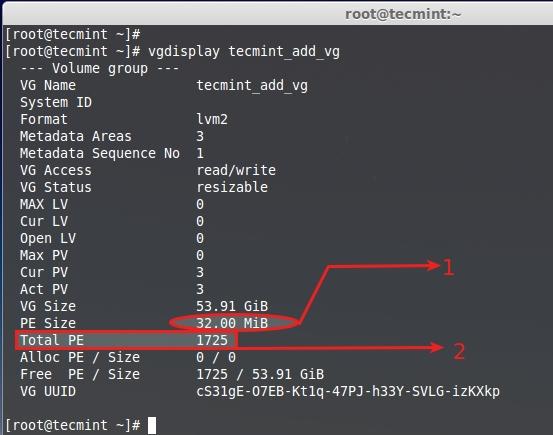
|
||||
创建新逻辑卷
|
||||
<center></center>
|
||||
<center>*创建新逻辑卷*</center>
|
||||
|
||||
- 默认分配给该卷组的PE为32MB,这里单个的PE大小为32MB。
|
||||
- 总可用PE是1725。
|
||||
@ -233,8 +234,8 @@
|
||||
1725PE/3 = 575 PE.
|
||||
575 PE x 32MB = 18400 --> 18GB
|
||||
|
||||
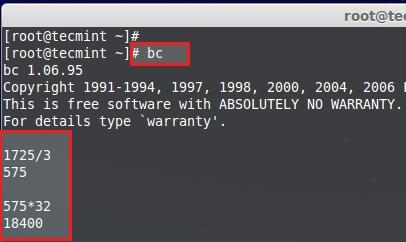
|
||||
计算磁盘空间
|
||||
<center></center>
|
||||
<center>*计算磁盘空间*</center>
|
||||
|
||||
按**CRTL+D**退出**bc**。现在让我们使用575个PE来创建3个逻辑卷。
|
||||
|
||||
@ -253,8 +254,8 @@
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
列出创建的逻辑卷
|
||||
<center></center>
|
||||
<center>*列出创建的逻辑卷*</center>
|
||||
|
||||
#### 方法2: 使用GB大小创建逻辑卷 ####
|
||||
|
||||
@ -272,8 +273,8 @@
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
验证创建的逻辑卷
|
||||
<center></center>
|
||||
<center>*验证创建的逻辑卷*</center>
|
||||
|
||||
这里,我们可以看到,当创建第三个LV的时候,我们不能收集到18GB空间。这是因为尺寸有小小的改变,但在使用或者尺寸来创建LV时,这个问题会被忽略。
|
||||
|
||||
@ -287,8 +288,8 @@
|
||||
|
||||
# mkfs.ext4 /dev/tecmint_add_vg/tecmint_manager
|
||||
|
||||

|
||||
创建Ext4文件系统
|
||||
<center></center>
|
||||
<center>*创建Ext4文件系统*</center>
|
||||
|
||||
**13.** 让我们在**/mnt**下创建目录,并将已创建好文件系统的逻辑卷挂载上去。
|
||||
|
||||
@ -302,8 +303,8 @@
|
||||
|
||||
# df -h
|
||||
|
||||

|
||||
挂载逻辑卷
|
||||
<center></center>
|
||||
<center>*挂载逻辑卷*</center>
|
||||
|
||||
#### 永久挂载 ####
|
||||
|
||||
@ -321,32 +322,31 @@
|
||||
/dev/mapper/tecmint_add_vg-tecmint_public /mnt/tecmint_public ext4 defaults 0 0
|
||||
/dev/mapper/tecmint_add_vg-tecmint_manager /mnt/tecmint_manager ext4 defaults 0 0
|
||||
|
||||

|
||||
获取mtab挂载条目
|
||||
<center>*</center>
|
||||
<center>*获取mtab挂载条目*</center>
|
||||
|
||||
|
||||
打开fstab文件
|
||||
<center></center>
|
||||
<center>*打开fstab文件*</center>
|
||||
|
||||

|
||||
添加自动挂载条目
|
||||
<center></center>
|
||||
<center>*添加自动挂载条目*</center>
|
||||
|
||||
重启前,执行mount -a命令来检查fstab条目。
|
||||
|
||||
# mount -av
|
||||
|
||||

|
||||
验证fstab条目
|
||||
<center></center>
|
||||
<center>*验证fstab条目*</center>
|
||||
|
||||
这里,我们已经了解了怎样来使用逻辑卷构建灵活的存储,从使用物理磁盘到物理卷,物理卷到卷组,卷组再到逻辑卷。
|
||||
|
||||
在我即将奉献的文章中,我将介绍如何扩展卷组、逻辑卷,减少逻辑卷,拍快照以及从快照中恢复。到那时,保持TecMint更新到这些精彩文章中的内容。
|
||||
--------------------------------------------------------------------------------
|
||||
在我即将奉献的文章中,我将介绍如何扩展卷组、逻辑卷,减少逻辑卷,拍快照以及从快照中恢复。 --------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
配置Linux访问控制列表(ACL)
|
||||
配置 Linux 的访问控制列表(ACL)
|
||||
================================================================================
|
||||
使用拥有权限控制的Liunx,工作是一件轻松的任务。它可以定义任何user,group和other的权限。无论是在桌面电脑或者不会有很多用户的虚拟Linux实例,或者当用户不愿意分享他们之间的文件时,这样的工作是很棒的。然而,如果你是在一个大型组织,你运行了NFS或者Samba服务给不同的用户。然后你将会需要灵活的挑选并设置很多复杂的配置和权限去满足你的组织不同的需求。
|
||||
使用拥有权限控制的Liunx,工作是一件轻松的任务。它可以定义任何user,group和other的权限。无论是在桌面电脑或者不会有很多用户的虚拟Linux实例,或者当用户不愿意分享他们之间的文件时,这样的工作是很棒的。然而,如果你是在一个大型组织,你运行了NFS或者Samba服务给不同的用户,然后你将会需要灵活的挑选并设置很多复杂的配置和权限去满足你的组织不同的需求。
|
||||
|
||||
Linux(和其他Unix,兼容POSIX的)所以拥有访问控制列表(ACL),它是一种分配权限之外的普遍范式。例如,默认情况下你需要确认3个权限组:owner,group和other。使用ACL,你可以增加权限给其他用户或组别,而不单只是简单的"other"或者是拥有者不存在的组别。可以允许指定的用户A、B、C拥有写权限而不再是让他们整个组拥有写权限。
|
||||
Linux(和其他Unix等POSIX兼容的操作系统)有一种被称为访问控制列表(ACL)的权限控制方法,它是一种权限分配之外的普遍范式。例如,默认情况下你需要确认3个权限组:owner、group和other。而使用ACL,你可以增加权限给其他用户或组别,而不单只是简单的"other"或者是拥有者不存在的组别。可以允许指定的用户A、B、C拥有写权限而不再是让他们整个组拥有写权限。
|
||||
|
||||
ACL支持多种Linux文件系统,包括ext2, ext3, ext4, XFS, Btfrs, 等。如果你不确定你的文件系统是否支持ACL,请参考文档。
|
||||
|
||||
@ -32,15 +32,15 @@ Archlinux 中:
|
||||
|
||||
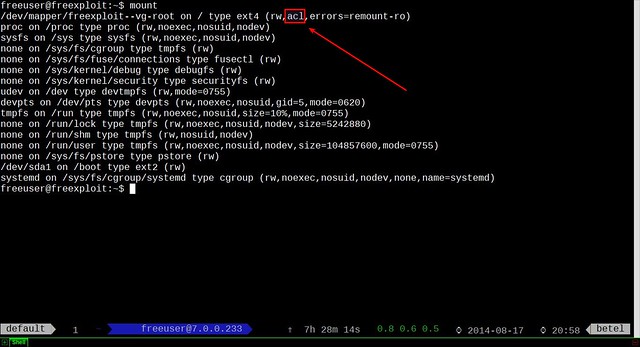
|
||||
|
||||
你可以注意到,我的root分区中ACL属性已经开启。万一你没有开启,你需要编辑/etc/fstab文件。增加acl标记,在你需要开启ACL的分区之前。
|
||||
你可以注意到,我的root分区中ACL属性已经开启。万一你没有开启,你需要编辑/etc/fstab文件,在你需要开启ACL的分区的选项前增加acl标记。
|
||||
|
||||
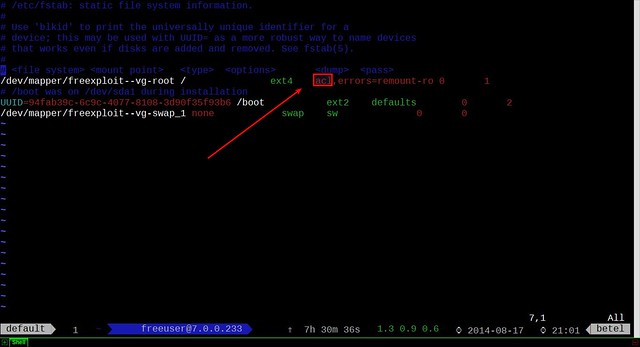
|
||||
|
||||
现在我们需要重新挂载分区(我喜欢完全重启,因为我不想丢掉数据),如果你对任何分区开启ACL,你必须也重新挂载它。
|
||||
现在我们需要重新挂载分区(我喜欢完全重启,因为我不想丢失数据),如果你对其它分区开启ACL,你必须也重新挂载它。
|
||||
|
||||
$ sudo mount / -o remount
|
||||
|
||||
令人敬佩!现在我们已经在我们的系统中开启ACL,让我们开始和它一起工作。
|
||||
干的不错!现在我们已经在我们的系统中开启ACL,让我们开始和它一起工作。
|
||||
|
||||
### ACL 范例 ###
|
||||
|
||||
@ -54,7 +54,6 @@ Archlinux 中:
|
||||
|
||||
我想要分享这个目录给其他两个用户test和test2,一个拥有完整权限,另一个只有读权限。
|
||||
|
||||
First, to set ACLs for user test:
|
||||
首先,为用户test设置ACL:
|
||||
|
||||
$ sudo setfacl -m u:test:rwx /shared
|
||||
@ -84,7 +83,7 @@ First, to set ACLs for user test:
|
||||
|
||||

|
||||
|
||||
你可以注意到,正常权限后多一个+标记。这表示ACL已经设置成功。为了真正读取ACL,我们需要运行:
|
||||
你可以注意到,正常权限后多一个+标记。这表示ACL已经设置成功。要具体看一下ACL,我们需要运行:
|
||||
|
||||
$ sudo getfacl /shared
|
||||
|
||||
@ -102,11 +101,11 @@ First, to set ACLs for user test:
|
||||
|
||||

|
||||
|
||||
最后一件事。在设置了ACL文件或目录工作时,cp和mv命令会改变这些设置。在cp的情况下,需要添加“p”参数来复制ACL设置。如果这不可行,它将会展示一个警告。mv默认移动ACL设置,如果这也不可行,它也会向您展示一个警告。
|
||||
最后,在设置了ACL文件或目录工作时,cp和mv命令会改变这些设置。在cp的情况下,需要添加“p”参数来复制ACL设置。如果这不可行,它将会展示一个警告。mv默认移动ACL设置,如果这也不可行,它也会向您展示一个警告。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
使用ACL给了在你想要分享的文件上巨大的权利和控制,特别是在NFS/Samba服务。此外,如果你的主管共享主机,这个工具是必备的。
|
||||
使用ACL让在你想要分享的文件上拥有更多的能力和控制,特别是在NFS/Samba服务。此外,如果你的主管共享主机,这个工具是必备的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -114,7 +113,7 @@ via: http://xmodulo.com/2014/08/configure-access-control-lists-acls-linux.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[VicYu](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
Google drive和Ubuntu 14.04 LTS的胶合
|
||||
墙外香花:Google drive和Ubuntu 14.04 LTS的胶合
|
||||
================================================================================
|
||||
Google尚未发布其**官方Linux客户端**,以用于从Ubuntu访问其drive。然开源社区却业已开发完毕非官方之软件包‘**grive-tools**’。
|
||||
Google尚未发布用于从Ubuntu访问其drive的**官方Linux客户端**。然开源社区却业已开发完毕非官方之软件包‘**grive-tools**’。
|
||||
|
||||
Grive乃是Google Drive(**在线存储服务**)的GNU/Linux系统客户端,允许你**同步**所选目录到云端,以及上传新文件到Google Drive。
|
||||
|
||||
@ -22,7 +22,7 @@ Grive乃是Google Drive(**在线存储服务**)的GNU/Linux系统客户端
|
||||
|
||||
**步骤:1** 安装完了,通过输入**Grive**在**Unity Dash**搜索应用,并打开之。
|
||||
|
||||

|
||||

|
||||
|
||||
**步骤:2** 登入google drive,你将被问及访问google drive的权限。
|
||||
|
||||
@ -36,25 +36,25 @@ Grive乃是Google Drive(**在线存储服务**)的GNU/Linux系统客户端
|
||||
|
||||
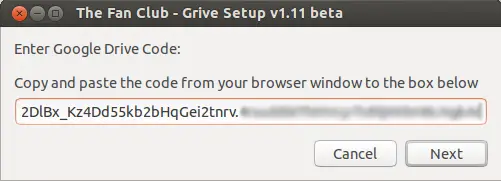
**步骤:3** 下面将提供给你一个 **google代码**,复制并粘贴到**Grive设置框**内。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
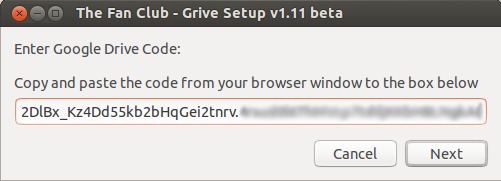
|
||||
|
||||
点击下一步后,将会开始同步google drive到你**家目录**下的‘**Google Drive**’文件夹。完成后,将出现如下窗口。
|
||||
|
||||
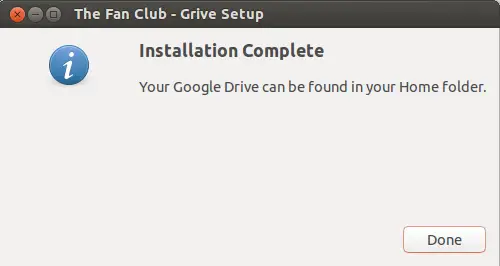
|
||||
|
||||
Google Drive folder created under **user's home directory**
|
||||
Google Drive 文件夹会创建在**用户的主目录**下。
|
||||
|
||||

|
||||
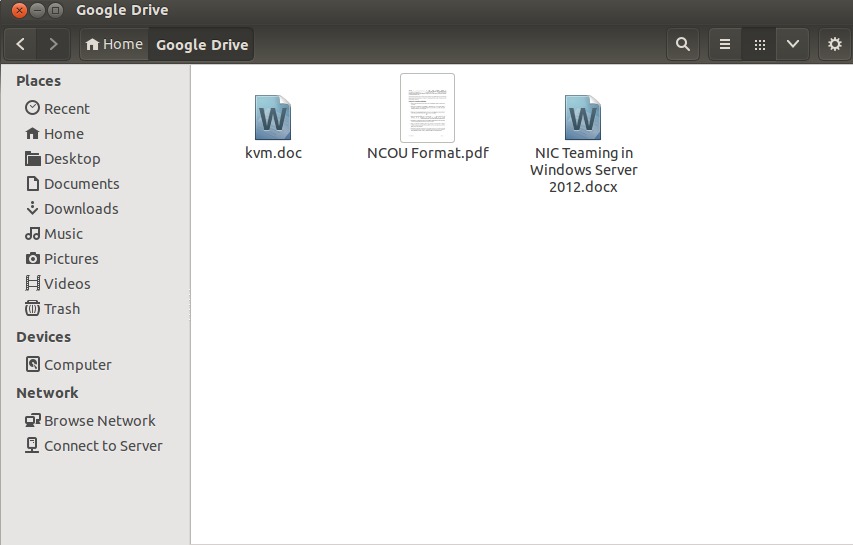
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/mount-google-drive-in-ubuntu/
|
||||
|
||||
作者:[Pradeep Kumar ][a]
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答——如何使用tcpdump来捕获TCP SYN,ACK和FIN包
|
||||
Linux有问必答:如何使用tcpdump来捕获TCP SYN,ACK和FIN包
|
||||
================================================================================
|
||||
> **问题**:我想要监控TCP连接活动(如,建立连接的三次握手,以及断开连接的四次握手)。要完成此事,我只需要捕获TCP控制包,如SYN,ACK或FIN标记相关的包。我怎样使用tcpdump来仅仅捕获TCP SYN,ACK和/或FYN包?
|
||||
|
||||
作为事实上的捕获工具,tcpdump提供了强大而又灵活的包过滤功能。作为tcpdump基础的libpcap包捕获引擎支持标准的包过滤规则,如基于5重包头的过滤(如基于源/目的IP地址/端口和IP协议类型)。
|
||||
作为业界标准的捕获工具,tcpdump提供了强大而又灵活的包过滤功能。作为tcpdump基础的libpcap包捕获引擎支持标准的包过滤规则,如基于5重包头的过滤(如基于源/目的IP地址/端口和IP协议类型)。
|
||||
|
||||
tcpdump/libpcap的包过滤规则也支持更多通用分组表达式,在这些表达式中,包中的任意字节范围都可以使用关系或二进制操作符进行检查。对于字节范围表达,你可以使用以下格式:
|
||||
|
||||
@ -34,8 +34,8 @@ tcpdump/libpcap的包过滤规则也支持更多通用分组表达式,在这
|
||||
|
||||
via: http://ask.xmodulo.com/capture-tcp-syn-ack-fin-packets-tcpdump.html
|
||||
|
||||
作者:[作者名][a]
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,15 +1,14 @@
|
||||
Linux FAQ - Ubuntu如何使用命令行移除PPA仓库
|
||||
Linux有问必答:Ubuntu如何使用命令行移除PPA仓库
|
||||
================================================================================
|
||||
> **问题**: 前段时间,我的Ubuntu增加了一个第三方的PPA仓库,如何才能移除这个PPA仓库呢?
|
||||
|
||||
个人软件包档案(PPA)是Ubuntu独有的解决方案,允许独立开发者和贡献者构建、贡献任何定制的软件包来作为通过启动面板的第三方APT仓库。如果你是Ubuntu用户,有可能你已经增加一些流行的第三方PPA仓库到你的Ubuntu系统。如果你需要删除掉已经预先配置好的PPA仓库,下面将教你怎么做。
|
||||
|
||||
|
||||
假如你有一个第三方PPA仓库叫“ppa:webapps/preview”增加到了你的系统中,如下。
|
||||
假如你想增加一个叫“ppa:webapps/preview”第三方PPA仓库到你的系统中,如下:
|
||||
|
||||
$ sudo add-apt-repository ppa:webapps/preview
|
||||
|
||||
如果你想要 **单独地删除一个PPA仓库**,运行下面的命令。
|
||||
如果你想要 **单独地删除某个PPA仓库**,运行下面的命令:
|
||||
|
||||
$ sudo add-apt-repository --remove ppa:someppa/ppa
|
||||
|
||||
@ -17,22 +16,22 @@ Linux FAQ - Ubuntu如何使用命令行移除PPA仓库
|
||||
|
||||
如果你想要 **完整的删除一个PPA仓库并包括来自这个PPA安装或更新过的软件包**,你需要ppa-purge命令。
|
||||
|
||||
安装ppa-purge软件包:
|
||||
首先要安装ppa-purge软件包:
|
||||
|
||||
$ sudo apt-get install ppa-purge
|
||||
|
||||
删除PPA仓库和与之相关的软件包,运行下列命令:
|
||||
然后使用如下命令删除PPA仓库和与之相关的软件包:
|
||||
|
||||
$ sudo ppa-purge ppa:webapps/preview
|
||||
|
||||
特别滴,在发行版更新后,你需要[分辨和清除已损坏的PPA仓库][1],这个方法特别有用!
|
||||
特别滴,在发行版更新后,当你[分辨和清除已损坏的PPA仓库][1]时这个方法特别有用!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/how-to-remove-ppa-repository-from-command-line-on-ubuntu.html
|
||||
|
||||
译者:[Vic___](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答-- 如何用Perl检测Linux的发行版本
|
||||
Linux有问必答:如何用Perl检测Linux的发行版本
|
||||
================================================================================
|
||||
> **提问**:我需要写一个Perl程序,它会包含Linux发行版相关的代码。为此,Perl程序需要能够自动检测运行中的Linux的发行版(如Ubuntu、CentOS、Debian、Fedora等等),以及它是什么版本号。如何用Perl检测Linux的发行版本?
|
||||
|
||||
如果要用Perl脚本检测Linux的发行版,你可以使用一个名为[Linux::Distribution][1]的Perl模块。该模块通过检查/etc/lsb-release以及其他特定的/etc下的发行版特定的目录来猜测底层Linux操作系统。它支持检测所有主要的Linux发行版,包括Fedora、CentOS、Arch Linux、Debian、Ubuntu、SUSE、Red Hat、Gentoo、Slackware、Knoppix和Mandrake。
|
||||
如果要用Perl脚本检测Linux的发行版,你可以使用一个名为[Linux::Distribution][1]的Perl模块。该模块通过检查/etc/lsb-release以及其他在/etc下的发行版特定的目录来猜测底层Linux操作系统。它支持检测所有主要的Linux发行版,包括Fedora、CentOS、Arch Linux、Debian、Ubuntu、SUSE、Red Hat、Gentoo、Slackware、Knoppix和Mandrake。
|
||||
|
||||
要在Perl中使用这个模块,你首先需要安装它。
|
||||
|
||||
@ -20,7 +20,7 @@ Linux有问必答-- 如何用Perl检测Linux的发行版本
|
||||
|
||||
$ sudo yum -y install perl-CPAN
|
||||
|
||||
使用这条命令来构建并安装模块:
|
||||
然后,使用这条命令来构建并安装模块:
|
||||
|
||||
$ sudo perl -MCPAN -e 'install Linux::Distribution'
|
||||
|
||||
@ -46,7 +46,7 @@ Linux::Distribution模块安装完成之后,你可以使用下面的代码片
|
||||
via: http://ask.xmodulo.com/detect-linux-distribution-in-perl.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -47,6 +47,6 @@ via: http://www.unixmen.com/reset-root-password-centos-7/
|
||||
|
||||
作者:M.el Khamlichi
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
快速地向你展示**如何检查你的系统是否受到Shellshock的影响**如果有,**怎样修复你的系统免于被Bash漏洞利用**。
|
||||
快速地向你展示**如何检查你的系统是否受到Shellshock的影响**,如果有,**怎样修复你的系统免于被Bash漏洞利用**。
|
||||
|
||||
如果你正跟踪新闻,你可能已经听说过在[Bash][1]中发现了一个漏洞,这被称为**Bash Bug**或者** Shellshock**。 [红帽][2]是第一个发现这个漏洞的机构。Shellshock错误允许攻击者注入自己的代码,从而使系统开放各给种恶意软件和远程攻击。事实上,[黑客已经利用它来启动DDoS攻击][3]。
|
||||
|
||||
@ -55,7 +55,7 @@ via: http://itsfoss.com/linux-shellshock-check-fix/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by ZTinoZ
|
||||
7 Improvements The Linux Desktop Needs
|
||||
======================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
shaohaolin translating
|
||||
Can Ubuntu Do This? — Answers to The 4 Questions New Users Ask Most
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
Upstream and Downstream: why packaging takes time
|
||||
================================================================================
|
||||
Here in the KDE office in Barcelona some people spend their time on purely upstream KDE projects and some of us are primarily interested in making distros work which mean our users can get all the stuff we make. I've been asked why we don't just automate the packaging and go and do more productive things. One view of making on a distro like Kubuntu is that its just a way to package up the hard work done by others to take all the credit. I don't deny that, but there's quite a lot to the packaging of all that hard work, for a start there's a lot of it these days.
|
||||
|
||||
@ -1,41 +0,0 @@
|
||||
Linus Torvalds Started a Revolution on August 25, 1991. Happy Birthday, Linux!
|
||||
================================================================================
|
||||

|
||||
Linus Torvalds
|
||||
|
||||
**The Linux project has just turned 23 and it's now the biggest collaborative endeavor in the world, with thousands of people working on it.**
|
||||
|
||||
Back in 1991, a young programmer called Linus Torvalds wanted to make a free operating system that wasn't going to be as big as the GNU project and that was just a hobby. He started something that would turn out to be the most successful operating system on the planet, but no one would have been able to guess it back then.
|
||||
|
||||
Linus Torvalds sent an email on August 25, 1991, asking for help in testing his new operating system. Things haven't changed all that much in the meantime and he still sends emails about new Linux releases, although back then it wasn't called like that.
|
||||
|
||||
"I'm doing a (free) operating system (just a hobby, won't be big and professional like gnu) for 386(486) AT clones. This has been brewing since april, and is starting to get ready. I'd like any feedback on things people like/dislike in minix, as my OS resembles it somewhat (same physical layout of the file-system (due to practical reasons) among other things). I've currently ported bash(1.08) and gcc(1.40), and things seem to work."
|
||||
|
||||
"This implies that I'll get something practical within a few months, and I'd like to know what features most people would want. Any suggestions are welcome, but I won't promise I'll implement them :-) PS. Yes - it's free of any minix code, and it has a multi-threaded fs. It is NOT protable (uses 386 task switching etc), and it probably never will support anything other than AT-harddisks, as that's all I have :-(. " [wrote][1] Linus Torvalds.
|
||||
|
||||
This is the entire mails that started it all, although it's interesting to see how things have evolved since then. The Linux operating system caught on, especially on the server market, but the power of Linux also extended in other areas.
|
||||
|
||||
In fact, it's hard to find any technology that hasn't been influenced by a Linus OS. Phones, TVs, fridges, minicomputers, consoles, tablets, and basically everything that has a chip in it is capable of running Linux or it already has some sort of Linux-based OS installed on it.
|
||||
|
||||
Linux is omnipresent on billions of devices and its influence is growing each year on an exponential basis. You might think that Linus is also the wealthiest man on the planet, but remember, Linux is free software and anyone can use it, modify it, and make money of it. He didn't do it for the money.
|
||||
|
||||
Linus Torvalds started a revolution in 1991, but it hasn't ended. In fact, you could say that it's just getting started.
|
||||
|
||||
> Happy Anniversary, Linux! Please join us in celebrating 23 years of the free OS that has changed the world. [pic.twitter.com/mTVApV85gD][2]
|
||||
>
|
||||
> — The Linux Foundation (@linuxfoundation) [August 25, 2014][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Started-a-Revolution-on-August-25-1991-Happy-Birthday-Linux-456212.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[2]:http://t.co/mTVApV85gD
|
||||
[3]:https://twitter.com/linuxfoundation/statuses/503799441900314624
|
||||
@ -1,86 +0,0 @@
|
||||
(translating by runningwater)
|
||||
Why Do Some Old Programming Languages Never Die?
|
||||
================================================================================
|
||||
> We like what we already know.
|
||||
|
||||

|
||||
|
||||
Many of today’s most well-known programming languages are old enough to vote. PHP is 20. Python is 23. HTML is 21. Ruby and JavaScript are 19. C is a whopping 42 years old.
|
||||
|
||||
Nobody could have predicted this. Not even computer scientist [Brian Kernighan][1], co-author of the very first book on C, which is still being printed today. (The language itself was the work of Kernighan's [co-author Dennis Ritchie][2], who passed away in 2011.)
|
||||
|
||||
“I dimly recall a conversation early on with the editors, telling them that we’d sell something like 5,000 copies of the book,” Kernighan told me in a recent interview. “We managed to do better than that. I didn’t think students would still be using a version of it as a textbook in 2014.”
|
||||
|
||||
What’s especially remarkable about C's persistence is that Google developed a new language, Go, specifically to more efficiently solve the problems C solves now. Still, it’s hard for Kernighan to imagine something like Go outright killing C no matter how good it is.
|
||||
|
||||
“Most languages don’t die—or at least once they get to a certain level of acceptance they don’t die," he said. "C still solves certain problems better than anything else, so it sticks around.”
|
||||
|
||||
### Write What You Know ###
|
||||
|
||||
Why do some computer languages become more successful than others? Because developers choose to use them. That’s logical enough, but it gets tricky when you want to figure out why developers choose to use the languages they do.
|
||||
|
||||
Ari Rabkin and Leo Meyerovich are researchers from, respectively, Princeton and the University of California at Berkeley who devoted two years to answering just that question. Their resulting paper, [Empirical Analysis of Programming Language Adoption][3], describes their analysis of more than 200,000 Sourceforge projects and polling of more than 13,000 programmers.
|
||||
|
||||
Their main finding? Most of the time programmers choose programming languages they know.
|
||||
|
||||
“There are languages we use because we’ve always used them,” Rabkin told me. “For example, astronomers historically use IDL [Interactive Data Language] for their computer programs, not because it has special features for stars or anything, but because it has tremendous inertia. They have good programs they’ve built with it that they want to keep.”
|
||||
|
||||
In other words, it’s partly thanks to name recognition that established languages retain monumental staying power. Of course, that doesn’t mean popular languages don’t change. Rabkin noted that the C we use today is nothing like the language Kernighan first wrote about, which probably wouldn’t be fully compatible with a modern C compiler.
|
||||
|
||||
“There’s an old, relevant joke in which an engineer is asked which language he thinks people will be using in 30 years and he says, ‘I don’t know, but it’ll be called Fortran’,” Rabkin said. “Long-lived languages are not the same as how they were when they were designed in the '70s and '80s. People have mostly added things instead of removed because that doesn’t break backwards compatibility, but many features have been fixed.”
|
||||
|
||||
This backwards compatibility means that not only can programmers continue to use languages as they update programs, they also don’t need to go back and rewrite the oldest sections. That older ‘legacy code’ keeps languages around forever, but at a cost. As long as it’s there, people’s beliefs about a language will stick around, too.
|
||||
|
||||
### PHP: A Case Study Of A Long-Lived Language ###
|
||||
|
||||
Legacy code refers to programs—or portions of programs—written in outdated source code. Think, for instance, of key programming functions for a business or engineering project that are written in a language that no one supports. They still carry out their original purpose and are too difficult or expensive to rewrite in modern code, so they stick around, forcing programmers to turn handsprings to ensure they keep working even as other code changes around them.
|
||||
|
||||
Any language that's been around more than a few years has a legacy-code problem of some sort, and PHP is no exception. PHP is an interesting example because its legacy code is distinctly different from its modern code, in what proponents say—and critics admit—is a huge improvement.
|
||||
|
||||
Andi Gutmans is a co-inventor of the Zend Engine, the compiler that became standard by the time PHP4 came around. Gutmans said he and his partner originally wanted to improve PHP3, and were so successful that the original PHP inventor, Rasmus Lerdorf, joined their project. The result was a compiler for PHP4 and its successor, PHP5.
|
||||
|
||||
As a consequence, the PHP of today is quite different from its progenitor, the original PHP. Yet in Gutmans' view, the base of legacy code written in older PHP versions keeps alive old prejudices against the language—such as the notion that PHP is riddled with security holes, or that it can't "scale" to handle large computing tasks.
|
||||
|
||||
"People who criticize PHP are usually criticizing where it was in 1998,” he says. “These people are not up-to-date with where it is today. PHP today is a very mature ecosystem.”
|
||||
|
||||
Today, Gutmans says, the most important thing for him as a steward is to encouraging people to keep updating to the latest versions. “PHP is a big enough community now that you have big legacy code bases," he says. "But generally speaking, most of our communities are on PHP5.3 at minimum.”
|
||||
|
||||
The issue is that users never fully upgrade to the latest version of any language. It’s why many Python users are still using Python 2, released in 2000, instead of Python 3, released in 2008. Even after six years major users like Google still aren’t upgrading. There are a variety of reasons for this, but it made many developers wary about taking the plunge.
|
||||
|
||||
“Nothing ever dies," Rabkin says. "Any language with legacy code will last forever. Rewrites are expensive and if it’s not broke don’t fix it.”
|
||||
|
||||
### Developer Brains As Scarce Resources ###
|
||||
|
||||
Of course, developers aren’t choosing these languages merely to maintain pesky legacy code. Rabkin and Meyerovich found that when it comes to language preference, age is just a number. As Rabkin told me:
|
||||
|
||||
> A thing that really shocked us and that I think is important is that we grouped people by age and asked them how many languages they know. Our intuition was that it would gradually rise over time; it doesn’t. Twenty-five-year-olds and 45-year-olds all know about the same number of languages. This was constant through several rewordings of the question. Your chance of knowing a given language does not vary with your age.
|
||||
|
||||
In other words, it’s not just old developers who cling to the classics; young programmers are also discovering and adopting old languages for the first time. That could be because the languages have interesting libraries and features, or because the communities these developers are a part of have adopted the language as a group.
|
||||
|
||||
“There’s a fixed amount of programmer attention in the world,” said Rabkin. “If a language delivers enough distinctive value, people will learn it and use it. If the people you exchange code and knowledge with you share a language, you’ll want to learn it. So for example, as long as those libraries are Python libraries and community expertise is Python experience, Python will do well.”
|
||||
|
||||
Communities are a huge factor in how languages do, the researchers discovered. While there's not much difference between high level languages like Python and Ruby, for example, programmers are prone to develop strong feelings about the superiority of one over the other.
|
||||
|
||||
“Rails didn’t have to be written in Ruby, but since it was, it proves there were social factors at work,” Rabkin says. “For example, the thing that resurrected Objective-C is that the Apple engineering team said, ‘Let’s use this.’ They didn’t have to pick it.”
|
||||
|
||||
Through social influence and legacy code, our oldest and most popular computer languages have powerful inertia. How could Go surpass C? If the right people and companies say it ought to.
|
||||
|
||||
“It comes down to who is better at evangelizing a language,” says Rabkin.
|
||||
|
||||
Lead image by [Blake Patterson][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://readwrite.com/2014/09/02/programming-language-coding-lifetime
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://readwrite.com/author/lauren-orsini
|
||||
[1]:http://en.wikipedia.org/wiki/Brian_Kernighan
|
||||
[2]:http://en.wikipedia.org/wiki/Dennis_Ritchie
|
||||
[3]:http://asrabkin.bitbucket.org/papers/oopsla13.pdf
|
||||
[4]:https://www.flickr.com/photos/blakespot/2444037775/
|
||||
@ -1,3 +1,5 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
10 Open Source Cloning Software For Linux Users
|
||||
================================================================================
|
||||
> These cloning software take all disk data, convert them into a single .img file and you can copy it to another hard drive.
|
||||
@ -84,4 +86,4 @@ via: http://www.efytimes.com/e1/fullnews.asp?edid=148039
|
||||
[7]:http://doclone.nongnu.org/
|
||||
[8]:http://www.macrium.com/reflectfree.aspx
|
||||
[9]:http://www.runtime.org/driveimage-xml.htm
|
||||
[10]:http://www.paragon-software.com/home/br-free/
|
||||
[10]:http://www.paragon-software.com/home/br-free/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
(翻译中 by runningwater)
|
||||
Camicri Cube: An Offline And Portable Package Management System
|
||||
================================================================================
|
||||

|
||||
@ -158,7 +159,7 @@ via: http://www.unixmen.com/camicri-cube-offline-portable-package-management-sys
|
||||
|
||||
[SK][a](Senthilkumar, aka SK, is a Linux enthusiast, FOSS Supporter & Linux Consultant from Tamilnadu, India. A passionate and dynamic person, aims to deliver quality content to IT professionals and loves very much to write and explore new things about Linux, Open Source, Computers and Internet.)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[runningwater](https://github.com/runningwater) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[bazz2 bazz2 bazz2]
|
||||
20 Postfix Interview Questions & Answers
|
||||
================================================================================
|
||||
### Q:1 What is postfix and default port used for postfix ? ###
|
||||
@ -119,4 +120,4 @@ via: http://www.linuxtechi.com/postfix-interview-questions-answers/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
|
||||
@ -1,158 +0,0 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
How to create a cloud-based encrypted file system on Linux
|
||||
================================================================================
|
||||
Commercial cloud storage services such as [Amazon S3][1] and [Google Cloud Storage][2] offer highly available, scalable, infinite-capacity object store at affordable costs. To accelerate wide adoption of their cloud offerings, these providers are fostering rich developer ecosystems around their products based on well-defined APIs and SDKs. Cloud-backed file systems are one popular by-product of such active developer communities, for which several open-source implementations exist.
|
||||
|
||||
[S3QL][3] is one of the most popular open-source cloud-based file systems. It is a FUSE-based file system backed by several commercial or open-source cloud storages, such as Amazon S3, Google Cloud Storage, Rackspace CloudFiles, or OpenStack. As a full featured file system, S3QL boasts of a number of powerful capabilities, such as unlimited capacity, up to 2TB file sizes, compression, UNIX attributes, encryption, snapshots with copy-on-write, immutable trees, de-duplication, hardlink/symlink support, etc. Any bytes written to an S3QL file system are compressed/encrypted locally before being transmitted to cloud backend. When you attempt to read contents stored in an S3QL file system, the corresponding objects are downloaded from cloud (if not in the local cache), and decrypted/uncompressed on the fly.
|
||||
|
||||
To be clear, S3QL does have limitations. For example, you cannot mount the same S3FS file system on several computers simultaneously, but only once at a time. Also, no ACL (access control list) support is available.
|
||||
|
||||
In this tutorial, I am going to describe **how to set up an encrypted file system on top of Amazon S3, using S3QL**. As an example use case, I will also demonstrate how to run rsync backup tool on top of a mounted S3QL file system.
|
||||
|
||||
### Preparation ###
|
||||
|
||||
To use this tutorial, you will need to create an [Amazon AWS account][4] (sign up is free, but requires a valid credit card).
|
||||
|
||||
If you haven't done so, first [create an AWS access key][4] (access key ID and secret access key) which is needed to authorize S3QL to access your AWS account.
|
||||
|
||||
Now, go to AWS S3 via AWS management console, and create a new empty bucket for S3QL.
|
||||
|
||||
|
||||
|
||||
For best performance, choose a region which is geographically closest to you.
|
||||
|
||||
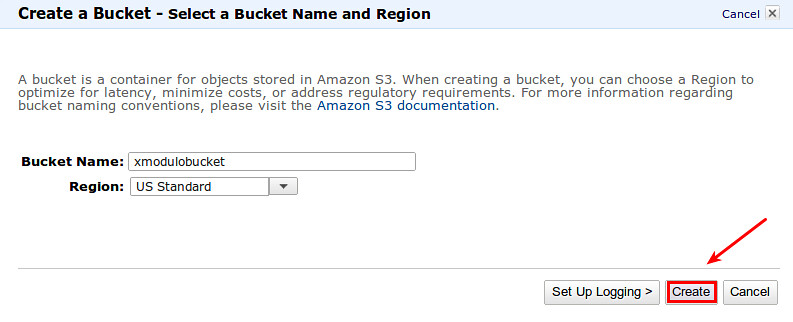
|
||||
|
||||
### Install S3QL on Linux ###
|
||||
|
||||
S3QL is available as a pre-built package on most Linux distros.
|
||||
|
||||
#### On Debian, Ubuntu or Linux Mint: ####
|
||||
|
||||
$ sudo apt-get install s3ql
|
||||
|
||||
#### On Fedora: ####
|
||||
|
||||
$ sudo yum install s3ql
|
||||
|
||||
On Arch Linux, use [AUR][6].
|
||||
|
||||
### Configure S3QL for the First Time ###
|
||||
|
||||
Create authinfo2 file in ~/.s3ql directory, which is a default S3QL configuration file. This file contains information about a required AWS access key, S3 bucket name and encryption passphrase. The encryption passphrase is used to encrypt the randomly-generated master encryption key. This master key is then used to encrypt actual S3QL file system data.
|
||||
|
||||
$ mkdir ~/.s3ql
|
||||
$ vi ~/.s3ql/authinfo2
|
||||
|
||||
----------
|
||||
|
||||
[s3]
|
||||
storage-url: s3://[bucket-name]
|
||||
backend-login: [your-access-key-id]
|
||||
backend-password: [your-secret-access-key]
|
||||
fs-passphrase: [your-encryption-passphrase]
|
||||
|
||||
The AWS S3 bucket that you specify should be created via AWS management console beforehand.
|
||||
|
||||
Make the authinfo2 file readable to you only for security.
|
||||
|
||||
$ chmod 600 ~/.s3ql/authinfo2
|
||||
|
||||
### Create an S3QL File System ###
|
||||
|
||||
You are now ready to create an S3QL file system on top of AWS S3.
|
||||
|
||||
Use mkfs.s3ql command to create a new S3QL file system. The bucket name you supply with the command should be matched with the one in authinfo2 file. The "--ssl" option forces you to use SSL to connect to backend storage servers. By default, the mkfs.s3ql command will enable compression and encryption in the S3QL file system.
|
||||
|
||||
$ mkfs.s3ql s3://[bucket-name] --ssl
|
||||
|
||||
You will be asked to enter an encryption passphrase. Type the same passphrase as you defined in ~/.s3ql/autoinfo2 (under "fs-passphrase").
|
||||
|
||||
If a new file system was created successfully, you will see the following output.
|
||||
|
||||
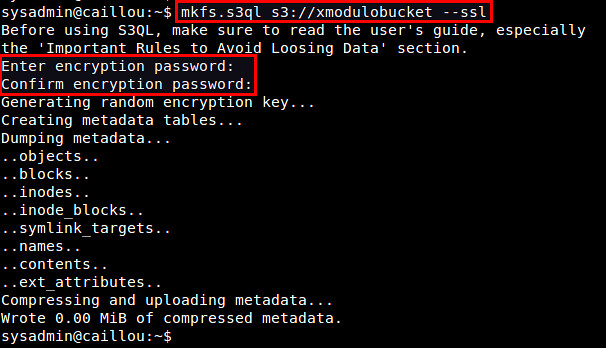
|
||||
|
||||
### Mount an S3QL File System ###
|
||||
|
||||
Once you created an S3QL file system, the next step is to mount it.
|
||||
|
||||
First, create a local mount point, and then use mount.s3ql command to mount an S3QL file system.
|
||||
|
||||
$ mkdir ~/mnt_s3ql
|
||||
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
You do not need privileged access to mount an S3QL file system. Just make sure that you have write access to the local mount point.
|
||||
|
||||
Optionally, you can specify a compression algorithm to use (e.g., lzma, bzip2, zlib) with "--compress" option. Without it, lzma algorithm is used by default. Note that when you specify a custom compression algorithm, it will apply to newly created data objects, not existing ones.
|
||||
|
||||
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
For performance reason, an S3QL file system maintains a local file cache, which stores recently accessed (partial or full) files. You can customize the file cache size using "--cachesize" and "--max-cache-entries" options.
|
||||
|
||||
To allow other users than you to access a mounted S3QL file system, use "--allow-other" option.
|
||||
|
||||
If you want to export a mounted S3QL file system to other machines over NFS, use "--nfs" option.
|
||||
|
||||
After running mount.s3ql, check if the S3QL file system is successfully mounted:
|
||||
|
||||
$ df ~/mnt_s3ql
|
||||
$ mount | grep s3ql
|
||||
|
||||
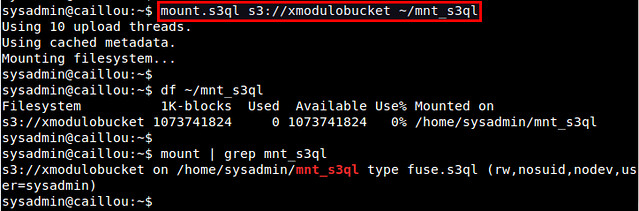
|
||||
|
||||
### Unmount an S3QL File System ###
|
||||
|
||||
To unmount an S3QL file system (with potentially uncommitted data) safely, use umount.s3ql command. It will wait until all data (including the one in local file system cache) has been successfully transferred and written to backend servers. Depending on the amount of write-pending data, this process can take some time.
|
||||
|
||||
$ umount.s3ql ~/mnt_s3ql
|
||||
|
||||
View S3QL File System Statistics and Repair an S3QL File System
|
||||
|
||||
To view S3QL file system statistics, you can use s3qlstat command, which shows information such as total data/metadata size, de-duplication and compression ratio.
|
||||
|
||||
$ s3qlstat ~/mnt_s3ql
|
||||
|
||||
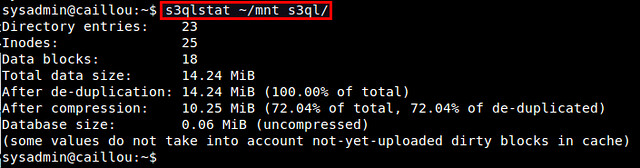
|
||||
|
||||
You can check and repair an S3QL file system with fsck.s3ql command. Similar to fsck command, the file system being checked needs to be unmounted first.
|
||||
|
||||
$ fsck.s3ql s3://[bucket-name]
|
||||
|
||||
### S3QL Use Case: Rsync Backup ###
|
||||
|
||||
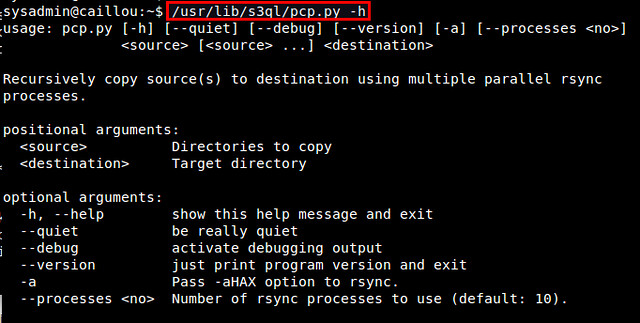
Let me conclude this tutorial with one popular use case of S3QL: local file system backup. For this, I recommend using rsync incremental backup tool especially because S3QL comes with a rsync wrapper script (/usr/lib/s3ql/pcp.py). This script allows you to recursively copy a source tree to a S3QL destination using multiple rsync processes.
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -h
|
||||
|
||||
|
||||
|
||||
The following command will back up everything in ~/Documents to an S3QL file system via four concurrent rsync connections.
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
|
||||
|
||||
The files will first be copied to the local file cache, and then gradually flushed to the backend servers over time in the background.
|
||||
|
||||
For more information about S3QL such as automatic mounting, snapshotting, immuntable trees, I strongly recommend checking out the [official user's guide][7]. Let me know what you think of S3QL. Share your experience with any other tools.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-cloud-based-encrypted-file-system-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://aws.amazon.com/s3
|
||||
[2]:http://code.google.com/apis/storage/
|
||||
[3]:https://bitbucket.org/nikratio/s3ql/
|
||||
[4]:http://aws.amazon.com/
|
||||
[5]:http://ask.xmodulo.com/create-amazon-aws-access-key.html
|
||||
[6]:https://aur.archlinux.org/packages/s3ql/
|
||||
[7]:http://www.rath.org/s3ql-docs/
|
||||
@ -1,155 +0,0 @@
|
||||
How to monitor server memory usage with Nagios Remote Plugin Executor (NRPE)
|
||||
================================================================================
|
||||
In a [previous tutorial][1]注:此篇文章在同一个更新中,如果也翻译了,发布的时候可修改相应的链接, we have seen how we can set up Nagios Remote Plugin Executor (NRPE) in an existing Nagios setup. However, the scripts and plugins needed to monitor memory usage do not come with stock Nagios. In this tutorial, we will see how we can configure NRPE to monitor RAM usage of a remote server.
|
||||
|
||||
The script that we will use for monitoring RAM is available at [Nagios Exchange][2], as well as the creators' [Github repository][3].
|
||||
|
||||
Assuming that NRPE has already been set up, we start the process by downloading the script in the server that we want to monitor.
|
||||
|
||||
### Preparing Remote Servers ###
|
||||
|
||||
#### On Debain/Ubuntu: ####
|
||||
|
||||
# cd /usr/lib/nagios/plugins/
|
||||
# wget https://raw.githubusercontent.com/justintime/nagios-plugins/master/check_mem/check_mem.pl
|
||||
# mv check_mem.pl check_mem
|
||||
# chmod +x check_mem
|
||||
|
||||
#### On RHEL/CentOS: ####
|
||||
|
||||
# cd /usr/lib64/nagios/plugins/ (or /usr/lib/nagios/plugins/ for 32-bit)
|
||||
# wget https://raw.githubusercontent.com/justintime/nagios-plugins/master/check_mem/check_mem.pl
|
||||
# mv check_mem.pl check_mem
|
||||
# chmod +x check_mem
|
||||
|
||||
You can check whether the script generates output properly by manually running the following command on localhost. When used with NRPE, this command is supposed to check free memory, warn when free memory is less than 20%, and generate critical alarm when free memory is less than 10%.
|
||||
|
||||
# ./check_mem -f -w 20 -c 10
|
||||
|
||||
----------
|
||||
|
||||
OK - 34.0% (2735744 kB) free.|TOTAL=8035340KB;;;; USED=5299596KB;6428272;7231806;; FREE=2735744KB;;;; CACHES=2703504KB;;;;
|
||||
|
||||
If you see something like the above as an output, that means the command is working okay.
|
||||
|
||||
Now that the script is ready, we define the command to check RAM usage for NRPE. As mentioned before, the command will check free memory, warn when free memory is less than 20%, and generate critical alarm when free memory is less than 10%.
|
||||
|
||||
# vim /etc/nagios/nrpe.cfg
|
||||
|
||||
#### For Debian/Ubuntu: ####
|
||||
|
||||
command[check_mem]=/usr/lib/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
#### For RHEL/CentOS 32 bit: ####
|
||||
|
||||
command[check_mem]=/usr/lib/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
#### For RHEL/CentOS 64 bit: ####
|
||||
|
||||
command[check_mem]=/usr/lib64/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
### Preparing Nagios Server ###
|
||||
|
||||
In the Nagios server, we define a custom command for NRPE. The command can be stored in any directory within Nagios. To keep the tutorial simple, we will put the command definition in /etc/nagios directory.
|
||||
|
||||
#### For Debian/Ubuntu: ####
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H '$HOSTADDRESS$' -c '$ARG1$'
|
||||
}
|
||||
|
||||
#### For RHEL/CentOS 32 bit: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
|
||||
}
|
||||
|
||||
#### For RHEL/CentOS 64 bit: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib64/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
|
||||
}
|
||||
|
||||
Now we define the service check in Nagios.
|
||||
|
||||
#### On Debian/Ubuntu: ####
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe_service_check.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use local-service
|
||||
host_name remote-server
|
||||
service_description Check RAM
|
||||
check_command check_nrpe!check_mem
|
||||
}
|
||||
|
||||
#### On RHEL/CentOS: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_service_check.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use local-service
|
||||
host_name remote-server
|
||||
service_description Check RAM
|
||||
check_command check_nrpe!check_mem
|
||||
}
|
||||
|
||||
Finally, we restart the Nagios service.
|
||||
|
||||
#### On Debian/Ubuntu: ####
|
||||
|
||||
# service nagios3 restart
|
||||
|
||||
#### On RHEL/CentOS 6: ####
|
||||
|
||||
# service nagios restart
|
||||
|
||||
#### On RHEL/CentOS 7: ####
|
||||
|
||||
# systemctl restart nagios.service
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
Nagios should start checking RAM usage of a remote-server using NRPE. If you are having any problem, you could check the following.
|
||||
|
||||
|
||||
- Make sure that NRPE port is allowed all the way to the remote host. Default NRPE port is TCP 5666.
|
||||
- You could try manually checking NRPE operation by executing the check_nrpe command: /usr/lib/nagios/plugins/check_nrpe -H remote-server
|
||||
- You could also try to run the check_mem command manually: /usr/lib/nagios/plugins/check_nrpe -H remote-server –c check_mem
|
||||
- In the remote server, set debug=1 in /etc/nagios/nrpe.cfg. Restart the NRPE service and check the log file /var/log/messages (RHEL/CentOS) or /var/log/syslog (Debain/Ubuntu). The log files should contain relevant information if there is any configuration or permission errors. If there are not hits in the log, it is very likely that the requests are not reaching the remote server due to port filtering at some point.
|
||||
|
||||
To sum up, this tutorial demonstrated how we can easily tune NRPE to monitor RAM usage of remote servers. The process is as simple as downloading the script, defining the commands, and restarting the services. Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/monitor-server-memory-usage-nagios-remote-plugin-executor.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/2014/03/nagios-remote-plugin-executor-nrpe-linux.html
|
||||
[2]:http://exchange.nagios.org/directory/Plugins/Operating-Systems/Solaris/check_mem-2Epl/details
|
||||
[3]:https://github.com/justintime/nagios-plugins/blob/master/check_mem/check_mem.pl
|
||||
@ -0,0 +1,43 @@
|
||||
|
||||
生日快乐,Linux! 1991年8月25日,Linus Torvalds 开启新的篇章。
|
||||
================================================================================
|
||||

|
||||
Linus Torvalds
|
||||
|
||||
**Linux工程刚刚进入第23个年头。有着成千上万的人一起开源的努力,Linux 现在是全世界最大的合作结晶。**
|
||||
|
||||
时光倒流到1991年,一个名字叫Linus Torvalds的程序员想开发一个免费的操作系统。当时他并没有打算把这个软件做得像GNU工程那么大,他做这个工程仅仅是因为他的爱好。他开始研发的东西变成了全世界最成功的操作系统,但是在当时没有人可以想像这个东西是什么样子的。
|
||||
|
||||
Linus Torvalds 在1991年8月25日发了一封邮件。邮件内容是请求帮助测试他新开发的操作系统。尽管那时候他的软件还没改变太多,但是他仍然坚持发送Linux更新发布的邮件。那个时候他的软件还没有被命名为Linux。
|
||||
|
||||
“我正在做一个(免费的)386(486)先进技术处理器操作系统(仅仅是为了个人喜好,不会像GNU那样大和专业)。” 自从4月份,我已经酝酿这个想法,并且已经开始准备好了。我很乐意听见各种关于喜欢与不喜欢minix的反馈,因为我的操作系统(在文件管理系统的物理层面(由于实际的原因)或者在其他方面)于它(minix)相似。最近,我发布了bash(1.08)版本和gcc(1.40)版本,暂时来说它们运行正常。
|
||||
|
||||
“这意味着在未来几个月内,我会得到一些实际的东西。与此同时,我很乐意
|
||||
知道用户希望添加哪些功能。任何建议都是可以,但是我不保证都会去开发它们 :-) 附言:嗯-它是不受限于任何minix代码,并且它有多线程的文件系统。 它不是很轻便(使用386任务交互等), 它可能永远都不会支持任何设备,除了先进的硬盘。 这就是目前为止我所知道的。 :-(. " [发信人][1] Linus Torvalds.
|
||||
|
||||
一切都是由这封邮件开始的,很有趣的是从那时候起已经可以感受到东西是怎么养逐步形成的。Linux操作系统不仅赶上了时代的步伐,尤其是在服务器市场上,而且强大的Linux覆盖了其他领域。
|
||||
|
||||
事实上,现在已经很难去寻找一个技术还没有被Linus操作系统影响的。手机,电视,冰箱,微型电脑,操纵台,平板电脑,基本每一个带有电子芯片都是可以运行Linux或者它已经安装了一些以Linux为基础研发的操作系统。
|
||||
|
||||
Linux无处不在,它已经覆盖了无数的设备,并且它的影响力以每年幂指数的数率增长。你可能认为Linus(先生)是世界上最有财富的人,但是不要忘记了,Linux是一个免费的软件。每个人都可以使用它,修改它,甚至以它为赚钱的工具。他(Linus)做这个不是为了金钱。
|
||||
|
||||
Linus Torvalds 在1991年开启的时代的改革,但是这个改革还没有结束。 实际上,你可以认为这仅仅是个开始。
|
||||
|
||||
> 生日快乐,Linux!请加入我们庆祝一个已经改变世界的免费操作系统的23岁生日。[pic.twitter.com/mTVApV85gD][2]
|
||||
>
|
||||
> — The Linux Foundation (@linuxfoundation) [August 25, 2014][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Started-a-Revolution-on-August-25-1991-Happy-Birthday-Linux-456212.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[Shaohao Lin](https://github.com/shaohaolin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[2]:http://t.co/mTVApV85gD
|
||||
[3]:https://twitter.com/linuxfoundation/statuses/503799441900314624
|
||||
@ -0,0 +1,85 @@
|
||||
为什么一些古老的编程语言不会消亡?
|
||||
================================================================================
|
||||
> 我们中意于我们所知道的。
|
||||
|
||||

|
||||
|
||||
当今许多知名的编程语言已经都非常古老了。PHP 语言20年、Python 语言23年、HTML 语言21年、Ruby 语言和 JavaScript 语言已经19年,C 语言更是高达42年之久。
|
||||
|
||||
这是没人能预料得到的,即使是计算机科学家 [Brian Kernighan][1] 也一样。他是写著第一本关于 C 语言的作者之一,只到今天这本书还在印刷着。(C 语言本身的发明者 [Dennis Ritchie][2] 是 Kernighan 的合著者,他于 2011 年已辞世。)
|
||||
|
||||
“我依稀记得早期跟编辑们的谈话,告诉他们我们已经卖出了5000册左右的量,”最近采访 Kernighan 时他告诉我说。“我们设法做的更好。我没有想到的是在2014年的教科书里学生仍然在使用第一个版本的书。”
|
||||
|
||||
关于 C 语言的持久性特别显著的就是 Google 开发出了新的语言 Go,解决同一问题比用 C 语言更有效率。
|
||||
|
||||
“大多数语言并不会消失或者至少很大一部分用户承认它们不会消失,”他说。“C 语言仍然在一定的领域独领风骚,所以它很接地气。”
|
||||
|
||||
### 编写所熟悉的 ###
|
||||
|
||||
为什么某些计算机编程语言要比其它的更流行?因为开发者都选择使用它们。逻辑上来说,这解释已经足够,但还想深入了解为什么开发人员会选择使用它们呢,这就有点棘手了。
|
||||
|
||||
分别来自普林斯顿大学和加州大学伯克利分校的研究者 Ari Rabkin 和 Leo Meyerovich 花费了两年时间来研究解决上面的问题。他们的研究报告,[《编程语言使用情况实例分析》][3],记录了对超过 200,000 个 Sourceforge 项目和超过 13,000 个程序员投票结果的分析。
|
||||
|
||||
他们主要的发现呢?大多数时候程序员选择的编程语言都是他们所熟悉的。
|
||||
|
||||
“存在着我们使用的语言是因为我们经常使用他们,” Rabkin 告诉我。“例如:天文学家就经常使用 IDL [交互式数据语言]来开发他们的计算机程序,并不是因为它具有什么特殊的星级功能或其它特点,而是因为用它形成习惯了。他们已经用些语言构建出很优秀的程序了,并且想保持原状。”
|
||||
|
||||
换句话说,它部分要归功于创建其的语言的的知名度仍保留较大劲头。当然,这并不意味着流行的语言不会变化。Rabkin 指出我们今天在使用的 C 语言就跟 Kernighan 第一次创建时的一点都不同,那时的 C 编译器跟现代的也不是完全兼容。
|
||||
|
||||
“有一个古老的,关于工程师的笑话。工程师被问到哪一种编程语言人们会使用30年,他说,‘我不知道,但它总会被叫做 Fortran’,” Rabkin 说到。“长期存活的语言跟他们在70年代和80年代刚设计出来的时候不一样了。人们通常都是在上面增加功能,而不会删除功能,因为要保持向后兼容,但有些功能会被修正。”
|
||||
|
||||
向后兼容意思就是当语言升级后,程序员不仅可以使用升级语言的新特性,也不用回去重写已经实现的老代码块。老的“遗留代码”的语法规则已经不用了,但舍弃是要花成本的。只要它们存在,我们就有理由相信相关的语言也会存在。
|
||||
|
||||
### PHP: 存活长久语言的一个案例学习 ###
|
||||
|
||||
遗留代码指的是用过时的源代码编写的程序或部分程序。想想看,一个企业或工程项目的关键程序功能部分是用没人维护的编程语言写出来的。因为它们仍起着作用,用现代的源代码重写非常困难或着代价太高,所以它们不得不保留下来,即使其它部分的代码都变动了,程序员也必须不断折腾以保证它们能正常工作。
|
||||
|
||||
任何的编程语言,存在了超过几十年时间都具有某种形式的遗留代码问题, PHP 也不加例外。PHP 是一个很有趣的例子,因为它的遗留代码跟现在的代码明显不同,支持者或评论家都承认这是一个巨大的进步。
|
||||
|
||||
Andi Gutmans 是 已经成为 PHP4 的标准编译器的 Zend Engine 的发明者之一。Gutmans 说他和搭档本来是想改进完善 PHP3 的,他们的工作如此成功,以至于 PHP 的原发明者 Rasmus Lerdorf 也加入他们的项目。结果就成为了 PHP4 和他的后续者 PHP5 的编译器。
|
||||
|
||||
因此,当今的 PHP 与它的祖先即最开始的 PHP 是完全不同的。然而,在 Gutmans 看来,在用古老的 PHP 语言版本写的遗留代码的地方一直存在着偏见以至于上升到整个语言的高度。比如 PHP 充满着安全漏洞或没有“集群”功能来支持大规模的计算任务等概念。
|
||||
|
||||
“批评 PHP 的人们通常批评的是在 1998 年时候的 PHP 版本,”他说。“这些人都没有与时俱进。当今的 PHP 已经有了很成熟的生态系统了。”
|
||||
|
||||
如今,Gutmans 说,他作为一个管理者最重要的事情就是鼓励人们升级到最新版本。“PHP有个很大的社区,足以支持您的遗留代码的问题,”他说。“但总的来说,我们的社区大部分都在 PHP5.3 及以上的。”
|
||||
|
||||
问题是,任何语言用户都不会全部升级到最新版本。这就是为什么 Python 用户仍在使用 2000 年发布的 Python 2,而不是使用 2008 年发布的 Python 3 的原因。甚至是已经六年了喜欢 Google 的大多数用户仍没有升级。这种情况是多种原因造成的,但它使得很多开发者在承担风险。
|
||||
|
||||
“任何东西都不会消亡的,”Rabkin 说。“任何语言的遗留代码都会一直存在。重写的代价是非常高昂的,如果它们不出问题就不要去改动。”
|
||||
|
||||
### 开发者是稀缺的资源 ###
|
||||
|
||||
当然,开发者是不会选择那些仅仅只是为了维护老旧代码的的程序语言的。当谈论到对语言选择的偏好时,Rabkin 和 Meyerovich 发现年龄仅仅只代表个数字。Rabkin 告诉我说:
|
||||
|
||||
> 有一件事使我们被深深震撼到了。这事最重要的就是我们给人们按年龄分组,然后询问他们知道多少编程语言。我们主观的认为随着年龄的增长知道的会越来越多,但实际上却不是,25岁年龄组和45岁年龄组知道的语言数目是一样的。几个反复询问的问题这里持续不变的。您知道一种语言的几率并不与您的年龄挂钩。
|
||||
|
||||
换句话说,不仅仅里年长的开发者坚持传统,年轻的程序员会承认并采用古老的编程语言作为他们的第一们语言。这可能是因为这些语言具有很有趣的开发库及功能特点,也可能是因为在社区里开发者都是一个组的都喜爱这种开发语言。
|
||||
|
||||
“在全球程序员关注的语言的数量是有定数的,” Rabkin 说。“如果一们语言表现出足够独特的价值,人们将会学习和使用它。如果是和您交流代码和知识的的某个人分享一门编程语言,您将会学习它。因此,例如,只要那些开发库是 Python 库和社区特长是 Python 语言的经验,那么 Python 将会大行其道。”
|
||||
|
||||
研究人员发现关于语言实现的功能,社区是一个巨大的因素。虽然像 Python 和 Ruby 这样的高级语言并没有太大的差别,但,例如程序员就更容易觉得一种比另一种优越。
|
||||
|
||||
“Rails 不一定要用 Ruby 语言编写,但它用了,这就是社会因素在起作用,” Rabkin 说。“例如,复活 Objective-C 语言这件事就是苹果的工程师团队说‘让我们使用它吧,’ 他们就没得选择了。”
|
||||
|
||||
通观社会的影响及老旧代码这些问题,我们发现最古老的和最新的计算机语言都有巨大的惰性。Go 语言怎么样能超越 C 语言呢?如果有合适的人或公司说它超越它就超越。
|
||||
|
||||
“它归结为谁传播的更好谁就好,” Rabkin 说。
|
||||
|
||||
开始的图片来自 [Blake Patterson][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://readwrite.com/2014/09/02/programming-language-coding-lifetime
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://readwrite.com/author/lauren-orsini
|
||||
[1]:http://en.wikipedia.org/wiki/Brian_Kernighan
|
||||
[2]:http://en.wikipedia.org/wiki/Dennis_Ritchie
|
||||
[3]:http://asrabkin.bitbucket.org/papers/oopsla13.pdf
|
||||
[4]:https://www.flickr.com/photos/blakespot/2444037775/
|
||||
@ -0,0 +1,156 @@
|
||||
如何在 Linux 系统中创建一个云端的加密文件系统
|
||||
================================================================================
|
||||
[Amazon S3][1] 和 [Google Cloud Storage][2] 之类的商业云存储服务以能承受的价格提供了高可用性、可扩展、无限容量的对象存储服务。为了加速这些云产品的广泛采用,这些提供商为他们的产品基于明确的 API 和 SDK 培养了一个良好的开发者生态系统。而基于云的文件系统便是这些活跃的开发者社区中的典型产品,已经有了好几个开源的实现。
|
||||
|
||||
[S3QL][3] 便是最流行的开源云端文件系统之一。它是一个基于 FUSE 的文件系统,提供了好几个商业或开源的云存储后端,比如 Amazon S3、Google Cloud Storage、Rackspace CloudFiles,还有 OpenStack。作为一个功能完整的文件系统,S3QL 拥有不少强大的功能:最大 2T 的文件大小、压缩、UNIX 属性、加密、基于写入时复制的快照、不可变树、重复数据删除,以及软、硬链接支持等等。写入 S3QL 文件系统任何数据都将首先被本地压缩、加密,之后才会传输到云后端。当你试图从 S3QL 文件系统中取出内容的时候,如果它们不在本地缓存中,相应的对象会从云端下载回来,然后再即时地解密、解压缩。
|
||||
|
||||
需要明确的是,S3QL 的确也有它的限制。比如,你不能把同一个 S3FS 文件系统在几个不同的电脑上同时挂载,只能有一台电脑同时访问它。另外,ACL(访问控制列表)也并没有被支持。
|
||||
|
||||
在这篇教程中,我将会描述“如何基于 Amazon S3 用 S3QL 配置一个加密文件系统”。作为一个使用范例,我还会说明如何在挂载的 S3QL 文件系统上运行 rsync 备份工具。
|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
本教程首先需要你创建一个 [Amazon AWS 帐号][4](注册是免费的,但是需要一张有效的信用卡)。
|
||||
|
||||
然后 [创建一个 AWS access key][4](access key ID 和 secret access key),S3QL 使用这些信息来访问你的 AWS 帐号。
|
||||
|
||||
之后通过 AWS 管理面板访问 AWS S3,并为 S3QL 创建一个新的空 bucket。
|
||||
|
||||

|
||||
|
||||
为最佳性能考虑,请选择一个地理上距离你最近的区域。
|
||||
|
||||

|
||||
|
||||
### 在 Linux 上安装 S3QL ###
|
||||
|
||||
在大多数 Linux 发行版中都有预先编译好的 S3QL 软件包。
|
||||
|
||||
#### 对于 Debian、Ubuntu 或 Linux Mint:####
|
||||
|
||||
$ sudo apt-get install s3ql
|
||||
|
||||
#### 对于 Fedora:####
|
||||
|
||||
$ sudo yum install s3ql
|
||||
|
||||
对于 Arch Linux,使用 [AUR][6]。
|
||||
|
||||
### 首次配置 S3QL ###
|
||||
|
||||
在 ~/.s3ql 目录中创建 autoinfo2 文件,它是 S3QL 的一个默认的配置文件。这个文件里的信息包括必须的 AWS access key,S3 bucket 名,以及加密口令。这个加密口令将被用来加密一个随机生成的主密钥,而主密钥将被用来实际地加密 S3QL 文件系统数据。
|
||||
|
||||
$ mkdir ~/.s3ql
|
||||
$ vi ~/.s3ql/authinfo2
|
||||
|
||||
----------
|
||||
|
||||
[s3]
|
||||
storage-url: s3://[bucket-name]
|
||||
backend-login: [your-access-key-id]
|
||||
backend-password: [your-secret-access-key]
|
||||
fs-passphrase: [your-encryption-passphrase]
|
||||
|
||||
指定的 AWS S3 bucket 需要预先通过 AWS 管理面板来创建。
|
||||
|
||||
为了安全起见,让 authinfo2 文件仅对你可访问。
|
||||
|
||||
$ chmod 600 ~/.s3ql/authinfo2
|
||||
|
||||
### 创建 S3QL 文件系统 ###
|
||||
|
||||
现在你已经准备好可以在 AWS S3 上创建一个 S3QL 文件系统了。
|
||||
|
||||
使用 mkfs.s3ql 工具来创建一个新的 S3QL 文件系统。这个命令中的 bucket 名应该与 authinfo2 文件中所指定的相符。使用“--ssl”参数将强制使用 SSL 连接到后端存储服务器。默认情况下,mkfs.s3ql 命令会在 S3QL 文件系统中启用压缩和加密。
|
||||
|
||||
$ mkfs.s3ql s3://[bucket-name] --ssl
|
||||
|
||||
你会被要求输入一个加密口令。请输入你在 ~/.s3ql/autoinfo2 中通过“fs-passphrase”指定的那个口令。
|
||||
|
||||
如果一个新文件系统被成功创建,你将会看到这样的输出:
|
||||
|
||||

|
||||
|
||||
### 挂载 S3QL 文件系统 ###
|
||||
|
||||
当你创建了一个 S3QL 文件系统之后,下一步便是要挂载它。
|
||||
|
||||
首先创建一个本地的挂载点,然后使用 mount.s3ql 命令来挂载 S3QL 文件系统。
|
||||
|
||||
$ mkdir ~/mnt_s3ql
|
||||
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
挂载一个 S3QL 文件系统不需要特权用户,只要确定你对该挂载点有写权限即可。
|
||||
|
||||
视情况,你可以使用“--compress”参数来指定一个压缩算法(如 lzma、bzip2、zlib)。在不指定的情况下,lzma 将被默认使用。注意如果你指定了一个自定义的压缩算法,它将只会应用到新创建的数据对象上,并不会影响已经存在的数据对象。
|
||||
|
||||
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
因为性能原因,S3QL 文件系统维护了一份本地文件缓存,里面包括了最近访问的(部分或全部的)文件。你可以通过“--cachesize”和“--max-cache-entries”选项来自定义文件缓存的大小。
|
||||
|
||||
如果想要除你以外的用户访问一个已挂载的 S3QL 文件系统,请使用“--allow-other”选项。
|
||||
|
||||
如果你想通过 NFS 导出已挂载的 S3QL 文件系统到其他机器,请使用“--nfs”选项。
|
||||
|
||||
运行 mount.s3ql 之后,检查 S3QL 文件系统是否被成功挂载了:
|
||||
|
||||
$ df ~/mnt_s3ql
|
||||
$ mount | grep s3ql
|
||||
|
||||

|
||||
|
||||
### 卸载 S3QL 文件系统 ###
|
||||
|
||||
想要安全地卸载一个(可能含有未提交数据的)S3QL 文件系统,请使用 umount.s3ql 命令。它将会等待所有数据(包括本地文件系统缓存中的部分)成功传输到后端服务器。取决于等待写的数据的多少,这个过程可能需要一些时间。
|
||||
|
||||
$ umount.s3ql ~/mnt_s3ql
|
||||
|
||||
### 查看 S3QL 文件系统统计信息及修复 S3QL 文件系统 ###
|
||||
|
||||
若要查看 S3QL 文件系统统计信息,你可以使用 s3qlstat 命令,它将会显示诸如总的数据、元数据大小、重复文件删除率和压缩率等信息。
|
||||
|
||||
$ s3qlstat ~/mnt_s3ql
|
||||
|
||||

|
||||
|
||||
你可以使用 fsck.s3ql 命令来检查和修复 S3QL 文件系统。与 fsck 命令类似,待检查的文件系统必须首先被卸载。
|
||||
|
||||
$ fsck.s3ql s3://[bucket-name]
|
||||
|
||||
### S3QL 使用案例:Rsync 备份 ###
|
||||
|
||||
让我用一个流行的使用案例来结束这篇教程:本地文件系统备份。为此,我推荐使用 rsync 增量备份工具,特别是因为 S3QL 提供了一个 rsync 的封装脚本(/usr/lib/s3ql/pcp.py)。这个脚本允许你使用多个 rsync 进程递归地复制目录树到 S3QL 目标。
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -h
|
||||
|
||||

|
||||
|
||||
下面这个命令将会使用 4 个并发的 rsync 连接来备份 ~/Documents 里的所有内容到一个 S3QL 文件系统。
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
|
||||
|
||||
这些文件将首先被复制到本地文件缓存中,然后在后台再逐步地同步到后端服务器。
|
||||
|
||||
若想了解与 S3QL 有关的更多信息,如自动挂载、快照、不可变树,我强烈推荐阅读 [官方用户指南][7]。欢迎告诉我你对 S3QL 怎么看,以及你对任何其他工具的使用经验。
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-cloud-based-encrypted-file-system-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://aws.amazon.com/s3
|
||||
[2]:http://code.google.com/apis/storage/
|
||||
[3]:https://bitbucket.org/nikratio/s3ql/
|
||||
[4]:http://aws.amazon.com/
|
||||
[5]:http://ask.xmodulo.com/create-amazon-aws-access-key.html
|
||||
[6]:https://aur.archlinux.org/packages/s3ql/
|
||||
[7]:http://www.rath.org/s3ql-docs/
|
||||
@ -0,0 +1,155 @@
|
||||
如何用Nagios远程执行插件(NRPE)来检测服务器内存使用率
|
||||
================================================================================
|
||||
在[先前的教程中][1]注:此篇文章在同一个更新中,如果也翻译了,发布的时候可修改相应的链接,我们已经见到了如何在Nagios设置中设置Nagios远程执行插件(NRPE)。然而,监控内存使用率的脚本和插件并没有在原生的Nagios中。本篇中,我们会看到如何配置NRPE来监控远程服务器上的内存使用率。
|
||||
|
||||
我们要用的监控内存的脚本在[Nagios 市场][2]上,也在创建者的[Github仓库][3]中。
|
||||
|
||||
假设我们已经安装了NRPE,我们首先在我们想要监控的服务器上下载脚本。
|
||||
|
||||
### 准备远程服务器 ###
|
||||
|
||||
#### 在 Debain/Ubuntu 中: ####
|
||||
|
||||
# cd /usr/lib/nagios/plugins/
|
||||
# wget https://raw.githubusercontent.com/justintime/nagios-plugins/master/check_mem/check_mem.pl
|
||||
# mv check_mem.pl check_mem
|
||||
# chmod +x check_mem
|
||||
|
||||
#### 在 RHEL/CentOS 中: ####
|
||||
|
||||
# cd /usr/lib64/nagios/plugins/ (or /usr/lib/nagios/plugins/ for 32-bit)
|
||||
# wget https://raw.githubusercontent.com/justintime/nagios-plugins/master/check_mem/check_mem.pl
|
||||
# mv check_mem.pl check_mem
|
||||
# chmod +x check_mem
|
||||
|
||||
你可以通过手工在本地运行下面的命令来检查脚本的输出是否正常。当使用NRPE时,这条命令应该会检测空闲的内存,当可用内存小于20%时会发出警告,并且在可用内存小于10%时会生成一个严重警告。
|
||||
|
||||
# ./check_mem -f -w 20 -c 10
|
||||
|
||||
----------
|
||||
|
||||
OK - 34.0% (2735744 kB) free.|TOTAL=8035340KB;;;; USED=5299596KB;6428272;7231806;; FREE=2735744KB;;;; CACHES=2703504KB;;;;
|
||||
|
||||
如果你看到像上面那样的输出,那就意味这命令正常工作着。
|
||||
|
||||
现在脚本已经准备好了,我们要定义NRPE检查内存使用率的命令了。如上所述,命令会检查可用内存,在可用率小于20%时发出警报,小于10%时发出严重警告。
|
||||
|
||||
# vim /etc/nagios/nrpe.cfg
|
||||
|
||||
#### 对于 Debian/Ubuntu: ####
|
||||
|
||||
command[check_mem]=/usr/lib/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
#### 对于 RHEL/CentOS 32 bit: ####
|
||||
|
||||
command[check_mem]=/usr/lib/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
#### 对于 RHEL/CentOS 64 bit: ####
|
||||
|
||||
command[check_mem]=/usr/lib64/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
### 准备 Nagios 服务器 ###
|
||||
|
||||
在Nagios服务器中,我们为NRPE定义了一条自定义命令。该命令可存储在Nagios内的任何目录中。为了让本教程简单,我们会将命令定义放在/etc/nagios目录中。
|
||||
|
||||
#### 对于 Debian/Ubuntu: ####
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H '$HOSTADDRESS$' -c '$ARG1$'
|
||||
}
|
||||
|
||||
#### 对于 RHEL/CentOS 32 bit: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
|
||||
}
|
||||
|
||||
#### 对于 RHEL/CentOS 64 bit: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib64/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
|
||||
}
|
||||
|
||||
现在我们定义Nagios的服务检查
|
||||
|
||||
#### 在 Debian/Ubuntu 上: ####
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe_service_check.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use local-service
|
||||
host_name remote-server
|
||||
service_description Check RAM
|
||||
check_command check_nrpe!check_mem
|
||||
}
|
||||
|
||||
#### 在 RHEL/CentOS 上: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_service_check.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use local-service
|
||||
host_name remote-server
|
||||
service_description Check RAM
|
||||
check_command check_nrpe!check_mem
|
||||
}
|
||||
|
||||
最后我们重启Nagios服务
|
||||
|
||||
#### 在 Debian/Ubuntu 上: ####
|
||||
|
||||
# service nagios3 restart
|
||||
|
||||
#### 在 RHEL/CentOS 6 上: ####
|
||||
|
||||
# service nagios restart
|
||||
|
||||
#### 在 RHEL/CentOS 7 上: ####
|
||||
|
||||
# systemctl restart nagios.service
|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
Nagios应该开始在使用NRPE的远程服务器上检查内存使用率了。如果你有任何问题,你可以检查下面这些情况。
|
||||
|
||||
|
||||
- 确保NRPE的端口在远程主机上是总是允许的。默认NRPE的端口是TCP 5666。
|
||||
- 你可以尝试通过执行check_nrpe 命令: /usr/lib/nagios/plugins/check_nrpe -H remote-server 手工检查NRPE操作。
|
||||
- 你同样可以尝试运行check_mem 命令:/usr/lib/nagios/plugins/check_nrpe -H remote-server –c check_mem
|
||||
- 在远程服务器上,在/etc/nagios/nrpe.cfg中设置debug=1。重启NRPE服务并检查这些日志文件,/var/log/messages (RHEL/CentOS)或者/var/log/syslog (Debain/Ubuntu)。如果有任何的配置或者权限错误,日志中应该包含了相关的信息。如果日志中没有反映出什么,很有可能是由于请求在某些端口上有过滤而没有到达远程服务器上。
|
||||
|
||||
总结一下,这边教程描述了我们该如何调试NRPE来监控远程服务器的内存使用率。过程只需要下载脚本、定义命令和重启服务就行了。希望这对你们有帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/monitor-server-memory-usage-nagios-remote-plugin-executor.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/2014/03/nagios-remote-plugin-executor-nrpe-linux.html
|
||||
[2]:http://exchange.nagios.org/directory/Plugins/Operating-Systems/Solaris/check_mem-2Epl/details
|
||||
[3]:https://github.com/justintime/nagios-plugins/blob/master/check_mem/check_mem.pl
|
||||
Loading…
Reference in New Issue
Block a user