mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
a2f225c240
@ -1,257 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Scaling the GitLab database
|
||||
============================================================
|
||||
|
||||
An in-depth look at the challenges faced when scaling the GitLab database and the solutions we applied to help solve the problems with our database setup.
|
||||
|
||||
For a long time GitLab.com used a single PostgreSQL database server and a single replica for disaster recovery purposes. This worked reasonably well for the first few years of GitLab.com's existence, but over time we began seeing more and more problems with this setup. In this article we'll take a look at what we did to help solve these problems for both GitLab.com and self-hosted GitLab instances.
|
||||
|
||||
For example, the database was under constant pressure, with CPU utilization hovering around 70 percent almost all the time. Not because we used all available resources in the best way possible, but because we were bombarding the server with too many (badly optimized) queries. We realized we needed a better setup that would allow us to balance the load and make GitLab.com more resilient to any problems that may occur on the primary database server.
|
||||
|
||||
When tackling these problems using PostgreSQL there are essentially four techniques you can apply:
|
||||
|
||||
1. Optimize your application code so the queries are more efficient (and ideally use fewer resources).
|
||||
|
||||
2. Use a connection pooler to reduce the number of database connections (and associated resources) necessary.
|
||||
|
||||
3. Balance the load across multiple database servers.
|
||||
|
||||
4. Shard your database.
|
||||
|
||||
Optimizing the application code is something we have been working on actively for the past two years, but it's not a final solution. Even if you improve performance, when traffic also increases you may still need to apply the other two techniques. For the sake of this article we'll skip over this particular subject and instead focus on the other techniques.
|
||||
|
||||
### Connection pooling
|
||||
|
||||
In PostgreSQL a connection is handled by starting an OS process which in turn needs a number of resources. The more connections (and thus processes), the more resources your database will use. PostgreSQL also enforces a maximum number of connections as defined in the [max_connections][5] setting. Once you hit this limit PostgreSQL will reject new connections. Such a setup can be illustrated using the following diagram:
|
||||
|
||||

|
||||
|
||||
Here our clients connect directly to PostgreSQL, thus requiring one connection per client.
|
||||
|
||||
By pooling connections we can have multiple client-side connections reuse PostgreSQL connections. For example, without pooling we'd need 100 PostgreSQL connections to handle 100 client connections; with connection pooling we may only need 10 or so PostgreSQL connections depending on our configuration. This means our connection diagram will instead look something like the following:
|
||||
|
||||

|
||||
|
||||
Here we show an example where four clients connect to pgbouncer but instead of using four PostgreSQL connections we only need two of them.
|
||||
|
||||
For PostgreSQL there are two connection poolers that are most commonly used:
|
||||
|
||||
* [pgbouncer][1]
|
||||
|
||||
* [pgpool-II][2]
|
||||
|
||||
pgpool is a bit special because it does much more than just connection pooling: it has a built-in query caching mechanism, can balance load across multiple databases, manage replication, and more.
|
||||
|
||||
On the other hand pgbouncer is much simpler: all it does is connection pooling.
|
||||
|
||||
### Database load balancing
|
||||
|
||||
Load balancing on the database level is typically done by making use of PostgreSQL's "[hot standby][6]" feature. A hot-standby is a PostgreSQL replica that allows you to run read-only SQL queries, contrary to a regular standby that does not allow any SQL queries to be executed. To balance load you'd set up one or more hot-standby servers and somehow balance read-only queries across these hosts while sending all other operations to the primary. Scaling such a setup is fairly easy: simply add more hot-standby servers (if necessary) as your read-only traffic increases.
|
||||
|
||||
Another benefit of this approach is having a more resilient database cluster. Web requests that only use a secondary can continue to operate even if the primary server is experiencing issues; though of course you may still run into errors should those requests end up using the primary.
|
||||
|
||||
This approach however can be quite difficult to implement. For example, explicit transactions must be executed on the primary since they may contain writes. Furthermore, after a write we want to continue using the primary for a little while because the changes may not yet be available on the hot-standby servers when using asynchronous replication.
|
||||
|
||||
### Sharding
|
||||
|
||||
Sharding is the act of horizontally partitioning your data. This means that data resides on specific servers and is retrieved using a shard key. For example, you may partition data per project and use the project ID as the shard key. Sharding a database is interesting when you have a very high write load (as there's no other easy way of balancing writes other than perhaps a multi-master setup), or when you have _a lot_ of data and you can no longer store it in a conventional manner (e.g. you simply can't fit it all on a single disk).
|
||||
|
||||
Unfortunately the process of setting up a sharded database is a massive undertaking, even when using software such as [Citus][7]. Not only do you need to set up the infrastructure (which varies in complexity depending on whether you run it yourself or use a hosted solution), but you also need to adjust large portions of your application to support sharding.
|
||||
|
||||
### Cases against sharding
|
||||
|
||||
On GitLab.com the write load is typically very low, with most of the database queries being read-only queries. In very exceptional cases we may spike to 1500 tuple writes per second, but most of the time we barely make it past 200 tuple writes per second. On the other hand we can easily read up to 10 million tuples per second on any given secondary.
|
||||
|
||||
Storage-wise, we also don't use that much data: only about 800 GB. A large portion of this data is data that is being migrated in the background. Once those migrations are done we expect our database to shrink in size quite a bit.
|
||||
|
||||
Then there's the amount of work required to adjust the application so all queries use the right shard keys. While quite a few of our queries usually include a project ID which we could use as a shard key, there are also many queries where this isn't the case. Sharding would also affect the process of contributing changes to GitLab as every contributor would now have to make sure a shard key is present in their queries.
|
||||
|
||||
Finally, there is the infrastructure that's necessary to make all of this work. Servers have to be set up, monitoring has to be added, engineers have to be trained so they are familiar with this new setup, the list goes on. While hosted solutions may remove the need for managing your own servers it doesn't solve all problems. Engineers still have to be trained and (most likely very expensive) bills have to be paid. At GitLab we also highly prefer to ship the tools we need so the community can make use of them. This means that if we were going to shard the database we'd have to ship it (or at least parts of it) in our Omnibus packages. The only way you can make sure something you ship works is by running it yourself, meaning we wouldn't be able to use a hosted solution.
|
||||
|
||||
Ultimately we decided against sharding the database because we felt it was an expensive, time-consuming, and complex solution to a problem we do not have.
|
||||
|
||||
### Connection pooling for GitLab
|
||||
|
||||
For connection pooling we had two main requirements:
|
||||
|
||||
1. It has to work well (obviously).
|
||||
|
||||
2. It has to be easy to ship in our Omnibus packages so our users can also take advantage of the connection pooler.
|
||||
|
||||
Reviewing the two solutions (pgpool and pgbouncer) was done in two steps:
|
||||
|
||||
1. Perform various technical tests (does it work, how easy is it to configure, etc).
|
||||
|
||||
2. Find out what the experiences are of other users of the solution, what problems they ran into and how they dealt with them, etc.
|
||||
|
||||
pgpool was the first solution we looked into, mostly because it seemed quite attractive based on all the features it offered. Some of the data from our tests can be found in [this][8] comment.
|
||||
|
||||
Ultimately we decided against using pgpool based on a number of factors. For example, pgpool does not support sticky connections. This is problematic when performing a write and (trying to) display the results right away. Imagine creating an issue and being redirected to the page, only to run into an HTTP 404 error because the server used for any read-only queries did not yet have the data. One way to work around this would be to use synchronous replication, but this brings many other problems to the table; problems we prefer to avoid.
|
||||
|
||||
Another problem is that pgpool's load balancing logic is decoupled from your application and operates by parsing SQL queries and sending them to the right server. Because this happens outside of your application you have very little control over which query runs where. This may actually be beneficial to some because you don't need additional application logic, but it also prevents you from adjusting the routing logic if necessary.
|
||||
|
||||
Configuring pgpool also proved quite difficult due to the sheer number of configuration options. Perhaps the final nail in the coffin was the feedback we got on pgpool from those having used it in the past. The feedback we received regarding pgpool was usually negative, though not very detailed in most cases. While most of the complaints appeared to be related to earlier versions of pgpool it still made us doubt if using it was the right choice.
|
||||
|
||||
The feedback combined with the issues described above ultimately led to us deciding against using pgpool and using pgbouncer instead. We performed a similar set of tests with pgbouncer and were very satisfied with it. It's fairly easy to configure (and doesn't have that much that needs configuring in the first place), relatively easy to ship, focuses only on connection pooling (and does it really well), and had very little (if any) noticeable overhead. Perhaps my only complaint would be that the pgbouncer website can be a little bit hard to navigate.
|
||||
|
||||
Using pgbouncer we were able to drop the number of active PostgreSQL connections from a few hundred to only 10-20 by using transaction pooling. We opted for using transaction pooling since Rails database connections are persistent. In such a setup, using session pooling would prevent us from being able to reduce the number of PostgreSQL connections, thus brining few (if any) benefits. By using transaction pooling we were able to drop PostgreSQL's `max_connections` setting from 3000 (the reason for this particular value was never really clear) to 300\. pgbouncer is configured in such a way that even at peak capacity we will only need 200 connections; giving us some room for additional connections such as `psql` consoles and maintenance tasks.
|
||||
|
||||
A side effect of using transaction pooling is that you cannot use prepared statements, as the `PREPARE` and `EXECUTE` commands may end up running in different connections; producing errors as a result. Fortunately we did not measure any increase in response timings when disabling prepared statements, but we _did_ measure a reduction of roughly 20 GB in memory usage on our database servers.
|
||||
|
||||
To ensure both web requests and background jobs have connections available we set up two separate pools: one pool of 150 connections for background processing, and a pool of 50 connections for web requests. For web requests we rarely need more than 20 connections, but for background processing we can easily spike to a 100 connections simply due to the large number of background processes running on GitLab.com.
|
||||
|
||||
Today we ship pgbouncer as part of GitLab EE's High Availability package. For more information you can refer to ["Omnibus GitLab PostgreSQL High Availability."][9]
|
||||
|
||||
### Database load balancing for GitLab
|
||||
|
||||
With pgpool and its load balancing feature out of the picture we needed something else to spread load across multiple hot-standby servers.
|
||||
|
||||
For (but not limited to) Rails applications there is a library called [Makara][10] which implements load balancing logic and includes a default implementation for ActiveRecord. Makara however has some problems that were a deal-breaker for us. For example, its support for sticky connections is very limited: when you perform a write the connection will stick to the primary using a cookie, with a fixed TTL. This means that if replication lag is greater than the TTL you may still end up running a query on a host that doesn't have the data you need.
|
||||
|
||||
Makara also requires you to configure quite a lot, such as all the database hosts and their roles, with no service discovery mechanism (our current solution does not yet support this either, though it's planned for the near future). Makara also [does not appear to be thread-safe][11], which is problematic since Sidekiq (the background processing system we use) is multi-threaded. Finally, we wanted to have control over the load balancing logic as much as possible.
|
||||
|
||||
Besides Makara there's also [Octopus][12] which has some load balancing mechanisms built in. Octopus however is geared towards database sharding and not just balancing of read-only queries. As a result we did not consider using Octopus.
|
||||
|
||||
Ultimately this led to us building our own solution directly into GitLab EE. The merge request adding the initial implementation can be found [here][13], though some changes, improvements, and fixes were applied later on.
|
||||
|
||||
Our solution essentially works by replacing `ActiveRecord::Base.connection` with a proxy object that handles routing of queries. This ensures we can load balance as many queries as possible, even queries that don't originate directly from our own code. This proxy object in turn determines what host a query is sent to based on the methods called, removing the need for parsing SQL queries.
|
||||
|
||||
### Sticky connections
|
||||
|
||||
Sticky connections are supported by storing a pointer to the current PostgreSQL WAL position the moment a write is performed. This pointer is then stored in Redis for a short duration at the end of a request. Each user is given their own key so that the actions of one user won't lead to all other users being affected. In the next request we get the pointer and compare this with all the secondaries. If all secondaries have a WAL pointer that exceeds our pointer we know they are in sync and we can safely use a secondary for our read-only queries. If one or more secondaries are not yet in sync we will continue using the primary until they are in sync. If no write is performed for 30 seconds and all the secondaries are still not in sync we'll revert to using the secondaries in order to prevent somebody from ending up running queries on the primary forever.
|
||||
|
||||
Checking if a secondary has caught up is quite simple and is implemented in `Gitlab::Database::LoadBalancing::Host#caught_up?` as follows:
|
||||
|
||||
```
|
||||
def caught_up?(location)
|
||||
string = connection.quote(location)
|
||||
|
||||
query = "SELECT NOT pg_is_in_recovery() OR " \
|
||||
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
|
||||
|
||||
row = connection.select_all(query).first
|
||||
|
||||
row && row['result'] == 't'
|
||||
ensure
|
||||
release_connection
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
Most of the code here is standard Rails code to run raw queries and grab the results. The most interesting part is the query itself, which is as follows:
|
||||
|
||||
```
|
||||
SELECT NOT pg_is_in_recovery()
|
||||
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
|
||||
|
||||
```
|
||||
|
||||
Here `WAL-POINTER` is the WAL pointer as returned by the PostgreSQL function `pg_current_xlog_insert_location()`, which is executed on the primary. In the above code snippet the pointer is passed as an argument, which is then quoted/escaped and passed to the query.
|
||||
|
||||
Using the function `pg_last_xlog_replay_location()` we can get the WAL pointer of a secondary, which we can then compare to our primary pointer using `pg_xlog_location_diff()`. If the result is greater than 0 we know the secondary is in sync.
|
||||
|
||||
The check `NOT pg_is_in_recovery()` is added to ensure the query won't fail when a secondary that we're checking was _just_ promoted to a primary and our GitLab process is not yet aware of this. In such a case we simply return `true` since the primary is always in sync with itself.
|
||||
|
||||
### Background processing
|
||||
|
||||
Our background processing code _always_ uses the primary since most of the work performed in the background consists of writes. Furthermore we can't reliably use a hot-standby as we have no way of knowing whether a job should use the primary or not as many jobs are not directly tied into a user.
|
||||
|
||||
### Connection errors
|
||||
|
||||
To deal with connection errors our load balancer will not use a secondary if it is deemed to be offline, plus connection errors on any host (including the primary) will result in the load balancer retrying the operation a few times. This ensures that we don't immediately display an error page in the event of a hiccup or a database failover. While we also deal with [hot standby conflicts][14] on the load balancer level we ended up enabling `hot_standby_feedback` on our secondaries as doing so solved all hot-standby conflicts without having any negative impact on table bloat.
|
||||
|
||||
The procedure we use is quite simple: for a secondary we'll retry a few times with no delay in between. For a primary we'll retry the operation a few times using an exponential backoff.
|
||||
|
||||
For more information you can refer to the source code in GitLab EE:
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb][3]
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing][4]
|
||||
|
||||
Database load balancing was first introduced in GitLab 9.0 and _only_ supports PostgreSQL. More information can be found in the [9.0 release post][15] and the [documentation][16].
|
||||
|
||||
### Crunchy Data
|
||||
|
||||
In parallel to working on implementing connection pooling and load balancing we were working with [Crunchy Data][17]. Until very recently I was the only [database specialist][18] which meant I had a lot of work on my plate. Furthermore my knowledge of PostgreSQL internals and its wide range of settings is limited (or at least was at the time), meaning there's only so much I could do. Because of this we hired Crunchy to help us out with identifying problems, investigating slow queries, proposing schema optimisations, optimising PostgreSQL settings, and much more.
|
||||
|
||||
For the duration of this cooperation most work was performed in confidential issues so we could share private data such as log files. With the cooperation coming to an end we have removed sensitive information from some of these issues and opened them up to the public. The primary issue was [gitlab-com/infrastructure#1448][19], which in turn led to many separate issues being created and resolved.
|
||||
|
||||
The benefit of this cooperation was immense as it helped us identify and solve many problems, something that would have taken me months to identify and solve if I had to do this all by myself.
|
||||
|
||||
Fortunately we recently managed to hire our [second database specialist][20] and we hope to grow the team more in the coming months.
|
||||
|
||||
### Combining connection pooling and database load balancing
|
||||
|
||||
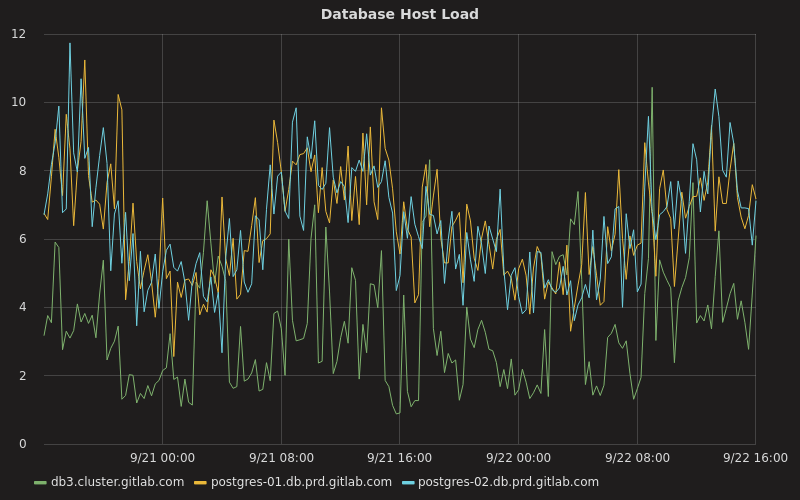
Combining connection pooling and database load balancing allowed us to drastically reduce the number of resources necessary to run our database cluster as well as spread load across our hot-standby servers. For example, instead of our primary having a near constant CPU utilisation of 70 percent today it usually hovers between 10 percent and 20 percent, while our two hot-standby servers hover around 20 percent most of the time:
|
||||
|
||||

|
||||
|
||||
Here `db3.cluster.gitlab.com` is our primary while the other two hosts are our secondaries.
|
||||
|
||||
Other load-related factors such as load averages, disk usage, and memory usage were also drastically improved. For example, instead of the primary having a load average of around 20 it barely goes above an average of 10:
|
||||
|
||||
|
||||
|
||||
During the busiest hours our secondaries serve around 12 000 transactions per second (roughly 740 000 per minute), while the primary serves around 6 000 transactions per second (roughly 340 000 per minute):
|
||||
|
||||

|
||||
|
||||
Unfortunately we don't have any data on the transaction rates prior to deploying pgbouncer and our database load balancer.
|
||||
|
||||
An up-to-date overview of our PostgreSQL statistics can be found at our [public Grafana dashboard][21].
|
||||
|
||||
Some of the settings we have set for pgbouncer are as follows:
|
||||
|
||||
| Setting | Value |
|
||||
| --- | --- |
|
||||
| default_pool_size | 100 |
|
||||
| reserve_pool_size | 5 |
|
||||
| reserve_pool_timeout | 3 |
|
||||
| max_client_conn | 2048 |
|
||||
| pool_mode | transaction |
|
||||
| server_idle_timeout | 30 |
|
||||
|
||||
With that all said there is still some work left to be done such as: implementing service discovery ([#2042][22]), improving how we check if a secondary is available ([#2866][23]), and ignoring secondaries that are too far behind the primary ([#2197][24]).
|
||||
|
||||
It's worth mentioning that we currently do not have any plans of turning our load balancing solution into a standalone library that you can use outside of GitLab, instead our focus is on providing a solid load balancing solution for GitLab EE.
|
||||
|
||||
If this has gotten you interested and you enjoy working with databases, improving application performance, and adding database-related features to GitLab (such as [service discovery][25]) you should definitely check out the [job opening][26] and the [database specialist handbook entry][27] for more information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/
|
||||
|
||||
作者:[Yorick Peterse ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://about.gitlab.com/team/#yorickpeterse
|
||||
[1]:https://pgbouncer.github.io/
|
||||
[2]:http://pgpool.net/mediawiki/index.php/Main_Page
|
||||
[3]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb
|
||||
[4]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing
|
||||
[5]:https://www.postgresql.org/docs/9.6/static/runtime-config-connection.html#GUC-MAX-CONNECTIONS
|
||||
[6]:https://www.postgresql.org/docs/9.6/static/hot-standby.html
|
||||
[7]:https://www.citusdata.com/
|
||||
[8]:https://gitlab.com/gitlab-com/infrastructure/issues/259#note_23464570
|
||||
[9]:https://docs.gitlab.com/ee/administration/high_availability/alpha_database.html
|
||||
[10]:https://github.com/taskrabbit/makara
|
||||
[11]:https://github.com/taskrabbit/makara/issues/151
|
||||
[12]:https://github.com/thiagopradi/octopus
|
||||
[13]:https://gitlab.com/gitlab-org/gitlab-ee/merge_requests/1283
|
||||
[14]:https://www.postgresql.org/docs/current/static/hot-standby.html#HOT-STANDBY-CONFLICT
|
||||
[15]:https://about.gitlab.com/2017/03/22/gitlab-9-0-released/
|
||||
[16]:https://docs.gitlab.com/ee/administration/database_load_balancing.html
|
||||
[17]:https://www.crunchydata.com/
|
||||
[18]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
[19]:https://gitlab.com/gitlab-com/infrastructure/issues/1448
|
||||
[20]:https://gitlab.com/_stark
|
||||
[21]:http://monitor.gitlab.net/dashboard/db/postgres-stats?refresh=5m&orgId=1
|
||||
[22]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[23]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2866
|
||||
[24]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2197
|
||||
[25]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[26]:https://about.gitlab.com/jobs/specialist/database/
|
||||
[27]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
255
translated/tech/20171002 Scaling the GitLab database.md
Normal file
255
translated/tech/20171002 Scaling the GitLab database.md
Normal file
@ -0,0 +1,255 @@
|
||||
扩展 GitLab 数据库
|
||||
============================================================
|
||||
|
||||
在扩展 GitLab 数据库和我们应用的解决方案,去帮助解决我们的数据库设置中的问题时,我们深入分析了所面临的挑战。
|
||||
|
||||
很长时间以来 GitLab.com 使用了一个单个的 PostgreSQL 数据库服务器和一个用于灾难恢复的单个复制。在 GitLab.com 最初的几年,它工作的还是很好的,但是,随着时间的推移,我们看到这种设置的很多问题,在这篇文章中,我们将带你了解我们在帮助解决 GitLab.com 和 GitLab 实例所在的主机时都做了些什么。
|
||||
|
||||
例如,数据库在正常负载下, CPU 使用率几乎所有时间都处于 70% 左右。并不是因为我们以最好的方式使用了全部的可用资源,而是因为我们使用了太多的(未经优化的)查询去“冲击”服务器。我们意识到需要去优化设置,这样我们就可以平衡负载,使 GitLab.com 能够更灵活地应对可能出现在主数据库服务器上的任何问题。
|
||||
|
||||
在我们使用 PostgreSQL 去跟踪这些问题时,使用了以下的四种技术:
|
||||
|
||||
1. 优化你的应用程序代码,以使查询更加高效(并且理论上使用了很少的资源)。
|
||||
|
||||
2. 使用一个连接池去减少必需的数据库连接数量(和相关的资源)。
|
||||
|
||||
3. 跨多个服务器去平衡负载。
|
||||
|
||||
4. 分片你的数据库
|
||||
|
||||
在过去的两年里,我们一直在积极地优化应用程序代码,但它不是一个完美的解决方案,甚至,如果你改善了性能,当流量也增加时,你还需要去应用其它的两种技术。为了这篇文章,我们将跳过特定主题,而专注于其它技术。
|
||||
|
||||
### 连接池
|
||||
|
||||
在 PostgreSQL 中一个连接是通过启动一个操作系统进程来处理的,这反过来又需要大量的资源,更多的连接(和这些进程),将使用你的数据库上的更多的资源。 PostgreSQL 也在 [max_connections][5] 设置中定义了一个强制执行的最大连接数量。一旦达到这个限制,PostgreSQL 将拒绝新的连接, 比如,下面的图表示的设置:
|
||||
|
||||

|
||||
|
||||
这里我们的客户端直接连接到 PostgreSQL,这样每个客户端请求一个连接。
|
||||
|
||||
通过连接池,我们可以有多个客户端侧连接重复使用一个 PostgreSQL 连接。例如,没有连接池时,我们需要 100 个 PostgreSQL 连接去处理 100 个客户端连接;使用连接池后,我们仅需要 10 个,或者依据我们配置的 PostgreSQL 连接。这意味着我们的连接图表将变成下面看到的那样:
|
||||
|
||||

|
||||
|
||||
这里我们展示了一个示例,四个客户端连接到 pgbouncer,但不是使用了四个 PostgreSQL 连接,而是仅需要两个。
|
||||
|
||||
对于 PostgreSQL 这里我们使用了两个最常用的连接池:
|
||||
|
||||
* [pgbouncer][1]
|
||||
|
||||
* [pgpool-II][2]
|
||||
|
||||
pgpool 有一点特殊,因为它不仅仅是连接池:它有一个内置的查询缓存机制,可以跨多个数据库负载均衡、管理复制等等。
|
||||
|
||||
另一个 pgbouncer 是很简单的:它就是一个连接池。
|
||||
|
||||
### 数据库负载均衡
|
||||
|
||||
数据库级的负载均衡一般是使用 PostgreSQL 的 "[热备机][6]" 特性来实现的。 一个热备机是允许你去运行只读 SQL 查询的 PostgreSQL 复制,与不允许运行任何 SQL 查询的普通备用机相反。去使用负载均衡,你需要设置一个或多个热备服务器,并且以某些方式去平衡这些跨主机的只读查询,同时将其它操作发送到主服务器上。扩展这样一个设置是很容易的:简单地增加多个热备机(如果需要的话)以增加只读流量。
|
||||
|
||||
这种方法的另一个好处是拥有一个更具弹性的数据库集群。即使主服务器出现问题,仅使用次级服务器也可以继续处理 Web 请求;当然,如果这些请求最终使用主服务器,你可能仍然会遇到错误。
|
||||
|
||||
然而,这种方法很难实现。例如,一旦它们包含写操作,事务显然需要在主服务器上运行。此外,在写操作完成之后,我们希望继续使用主服务器,因为在使用异步复制的时候,热备机服务器上可能还没有这些更改。
|
||||
|
||||
### 分片
|
||||
|
||||
分片是水平分割你的数据的行为。这意味着数据保存在特定的服务器上并且使用一个分片键检索。例如,你可以按项目分片数据并且使用项目 ID 做为分片键。当你有一个很高的写负载时(除了一个多主设置外,没有一个其它的简单方法来平衡写操作),分片数据库是很有用的。或者当你有_大量_的数据并且不你再使用传统方式保存它。(比如,你可以简单地把它放进一个单个磁盘中)。
|
||||
|
||||
不幸的是,设置分片数据库是一个任务量很大的过程,甚至,在我们使用软件如 [Citus][7] 时。你不仅需要设置基础设施 (不同的复杂程序取决于是你运行在你自己的数据中心还是托管主机的解决方案),你还得需要调整你的应用程序中很大的一部分去支持分片。
|
||||
|
||||
### 反对分片的案例
|
||||
|
||||
在 GitLab.com 上一般情况下写负载是非常低的,同时大多数的查询都是只读查询。在极端情况下,尖峰值达到每秒 1500 元组写入,但是,在大多数情况下不超过每秒 200 元组写入。另一方面,我们可以在任何给定的次级服务器上轻松达到每秒 1000 万元组读取。
|
||||
|
||||
明智的存储,我们也不使用太多的数据:大约 800 GB。这些数据中的很大一部分是被迁移到后台的,这些数据一经迁移后,我们的数据库收缩的相当多。
|
||||
|
||||
接下来的工作量就是调整应用程序,以便于所有查询都可以正确地使用分片键。 直到大量的查询都包含了一个项目 ID,它是我们使用的分片键,也有许多的查询不是这种情况。分片也会影响贡献者的改变过程,作为每个贡献者,现在必须确保它们的查询中包含分片键。
|
||||
|
||||
最后,是完成这些工作所需要的基础设施。服务器已经完成设置,并添加监视、完成对工程师们的培训,以便于他们熟悉上面列出的这些新的设置。虽然托管解决方案可能不需要你自己管理服务器,但它不能解决所有问题。工程师们仍然需要去培训(很可能非常昂贵)并需要为此支付账单。在 GitLab 上,我们也非常乐意提供我们需要的这些工具,这样社区就可以使用它们。这意味着如果我们去分片数据库, 我们将在我们的 Omnibus 包中提供它(或至少是其中的一部分)。确保你提供的服务的唯一方法就是你自己去管理它,这意味着我们不能使用主机托管的解决方案。
|
||||
|
||||
最终,我们决定不使用数据库分片,因为它是昂贵的、费时的、复杂的解决方案。
|
||||
|
||||
### GitLab 的连接池
|
||||
|
||||
对于连接池我们有两个主要的诉求:
|
||||
|
||||
1. 它必须工作的很好(很显然这是必需的)。
|
||||
|
||||
2. 它必须易于在我们的 Omnibus 包中运用,以便于我们的用户也可以从连接池中得到好处。
|
||||
|
||||
用下面两步去评估这两个解决方案(pgpool 和 pgbouncer):
|
||||
|
||||
1. 执行各种技术测试(是否有效,配置是否容易,等等)。
|
||||
|
||||
2. 找出使用这个解决方案的其它用户的经验,他们遇到了什么问题?怎么去解决的?等等。
|
||||
|
||||
pgpool 是我们考察的第一个解决方案,主要是因为它提供的很多特性看起来很有吸引力。我们的其中一些测试数据可以在 [这里][8] 找到。
|
||||
|
||||
最终,基于多个因素,我们决定不使用 pgpool 。例如, pgpool 不支持粘连接。 当执行一个写入并(尝试)立即显示结果时,它会出现问题。想像一下,创建一个资料(issue)并立即重定向到这个页面, 没有想到会出现 HTTP 404,这是因为任何用于只读查询的服务器还没有收到数据。针对这种情况的一种解决办法是使用同步复制,但这会给表带来更多的其它问题,而我们希望去避免问题。
|
||||
|
||||
另一个问题是, pgpool 的负载均衡逻辑与你的应用程序是不相干的,是通过解析 SQL 查询并将它们发送到正确的服务器。因为这发生在你的应用程序之外,你几乎无法控制查询运行在哪里。这实际上对某些人也可能是有好处的, 因为你不需要额外的应用程序逻辑。但是,它也妨碍了你在需要的情况下调整路由逻辑。
|
||||
|
||||
由于配置选项非常多,配置 pgpool 也是很困难的。从过去使用过它的那些人中得到的反馈,可能促使我们最终决定不使用它了。即使是大多数的案例都不是很详细的情况下,我们收到的反馈对 pgpool 通常都持有负面的观点。虽然出现的报怨大多数都与早期版本的 pgpool 有关,但仍然让我们怀疑使用它是否是个正确的选择。
|
||||
|
||||
结合上面描述的问题和反馈,最终我们决定不使用 pgpool 而是使用 pgbouncer 。我们用 pgbouncer 执行了一个类似的测试,并且对它的结果是非常满意的。它非常容易配置(而且一开始不需要很多的配置),运用相对容易,仅专注于连接池(而且它真的很好), 而且没有明显的开销(如果有的话)。也许我唯一的报怨是,pgbouncer 的网站有点难以导航。
|
||||
|
||||
使用 pgbouncer 后,通过使用事务池我们可以将活动的 PostgreSQL 连接数从几百降到仅 10 - 20 个。我们选择事务池是因为 Rails 数据库连接是持久的。这个设置中,使用会话池可以防止我们降低 PostgreSQL 连接数,这样会有一些好处(如果有的话)。通过使用事务池,我们可以去降低 PostgreSQL 的 `max_connections` 的设置值,从 3000 (这个特定值的原因我们也不清楚) 到 300 。这样配置的 pgbouncer ,即使在尖峰时,我们也仅需要 200 个连接,这为我们提供了一些额外连接的空间,如 `psql` 控制台和维护任务。
|
||||
|
||||
对于使用事务池的影响方面,你不能使用预处理语句,因为 `PREPARE` 和 `EXECUTE` 命令可以在不同的连接中运行,产生错误的结果。 幸运的是,当我们禁用了预处理语句时,并没有测量到任何响应时间的增加,但是我们 _确定_ 测量到在我们的服务器上内存使用减少了大约 20 GB。
|
||||
|
||||
为确保我们的 web 请求和后台作业都有可用连接,我们设置了两个独立的池: 一个有 150 个连接的后台进程连接池,和一个有 50 个连接的 web 请求连接池。对于 web 连接需要的请求,我们很少超过 20 个,但是,对于后台进程,由于在 GitLab.com 上后台运行着大量的进程,我们的尖峰值可以很容易达到 100 个连接。
|
||||
|
||||
今天,我们提供 pgbouncer 作为 GitLab EE 高可用包的一部分。对于更多的信息,你可以参考 ["Omnibus GitLab PostgreSQL High Availability."][9]。
|
||||
|
||||
### GitLab 上的数据库负载均衡
|
||||
|
||||
使用 pgpool 和它的负载均衡特性,我们需要一些其它的东西去分发负载到多个热备服务器上。
|
||||
|
||||
对于(但不限于) Rails 应用程序,它有一个叫 [Makara][10] 的库,它实现了负载均衡的逻辑并包含缺省实现的活动记录。然而,Makara 也有一些我们认为是有些遗憾的问题。例如,它支持的粘连接是非常有限的:当你使用一个 cookie 和一个固定的 TTL 去执行一个写操作时,连接将粘到主服务器。这意味着,如果复制极大地滞后于 TTL,最终你可能会发现,你的查询运行在一个没有你需要的数据的主机上。
|
||||
|
||||
Makara 也需要你做很多配置,如所有的数据库主机和它们的规则,没有服务发现机制(我们当前的解决方案也不支持它们,即使它是将来计划的)。 Makara 也 [似乎不是线程安全的][11],这是有问题的,因为 Sidekiq (我们使用的后台进程)是多线程的。 最终,我们希望尽可能地去控制负载均衡的逻辑。
|
||||
|
||||
除了 Makara 之外 ,这也有 [Octopus][12] ,它也是内置的负载均衡机制。但是 Octopus 是面向分片数据库的,而不仅是均衡只读查询的。因此,最终我们不考虑使用 Octopus。
|
||||
|
||||
最终,我们构建了自己的解决方案,直接进入 GitLab EE。 合并需求并增加到初始实现,可以在 [这里][13]找到,尽管一些更改、提升在以后去应用。
|
||||
|
||||
我们的解决方案本质上是通过用一个处理查询路由的代理对象替换 `ActiveRecord::Base.connection` 。它可以让我们尽可能去均衡负载,甚至,不是直接从我们所有的代码中来的查询。这个代理对象基于调用方式去决定将查询转发到哪个主机, 消除了解析 SQL 查询的需要。
|
||||
|
||||
### 粘连接
|
||||
|
||||
粘连接是通过在执行写入时,将当前 PostgreSQL WAL 位置存储到一个指针中实现支持的。对于一个短的请求,在请求即将结束时,指针是保存在 Redis 中,每个用户提供他自己的 key,因此,一个用户的动作不会导致其他的用户受到影响。下次请求时,我们取得指针,并且与所有的次级服务器进行比较。如果所有的次级服务器都有一个数量超过我们的指针的 WAL 指针,因为我们知道它们是同步的,我们可以为我们的只读查询安全地使用次级服务器。如果一个或多个次级服务器没有同步,我们将继续使用主服务器直到它们同步。如果执行的写入操作在 30 秒内没有完成,并且所有的次级服务器还没有同步,我们将恢复使用次级服务器,这是为了防止有些人的查询永远运行在主服务器上。
|
||||
|
||||
检查一个次级服务器是否在 `Gitlab::Database::LoadBalancing::Host#caught_up?` 中被捕获是很简单的, 如下:
|
||||
|
||||
```
|
||||
def caught_up?(location)
|
||||
string = connection.quote(location)
|
||||
|
||||
query = "SELECT NOT pg_is_in_recovery() OR " \
|
||||
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
|
||||
|
||||
row = connection.select_all(query).first
|
||||
|
||||
row && row['result'] == 't'
|
||||
ensure
|
||||
release_connection
|
||||
end
|
||||
|
||||
```
|
||||
这里的大部分代码是标准的 Rails 代码,去运行原生查询(raw queries)和获取结果,查询的最有趣的部分如下:
|
||||
|
||||
```
|
||||
SELECT NOT pg_is_in_recovery()
|
||||
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
|
||||
|
||||
```
|
||||
|
||||
这里 `WAL-POINTER` 是 WAL 指针,通过 PostgreSQL 函数 `pg_current_xlog_insert_location()`返回的,它是在主服务器上执行的。在上面的代码片断中,指针是传递给一个数组的,然后它被引入或传出给查询。
|
||||
|
||||
使用函数 `pg_last_xlog_replay_location()` 我们可以取得次级服务器的 WAL 指针,然后,我们可以通过函数 `pg_xlog_location_diff()` 与我们的主服务器上的指针进行比较。如果结果大于 0 ,我们就可以知道次级服务器是同步的。
|
||||
|
||||
当一个次级服务器被提升为主服务器,并且我们的 GitLab 进程还不知道这一点的时候,检查 `NOT pg_is_in_recovery()` 是添加的,以确保查询不会失败。在这个案例中,主服务器与它自己是同步的,所以它简单返回一个 `true`.
|
||||
|
||||
### 后台进程
|
||||
|
||||
我们的后台进程代码 _总是_ 使用主服务器,因为在后台执行的大部分工作都是写入。此外,我们不能可靠地使用一个热备机,因为我们无法知道作业是否在主服务器执行,因为许多作业并没有直接绑定到用户上。
|
||||
|
||||
### 连接错误
|
||||
|
||||
去解决负载均衡器不使用一个如果被认为是离线的次级服务器的连接错误,加上,任何主机上(包括主服务器)的连接错误将导致负载均衡器多次重试,这是确保,在遇到偶发的小问题或数据库失败事件时,不会立即显示一个错误页面。当我们在负载均衡器级别上处理 [热备机冲突][14] 的问题时,我们最终在次级服务器上启用了 `hot_standby_feedback` ,这样就解决了热备机冲突的所有问题,而不会对表膨胀造成任何负面影响。
|
||||
|
||||
我们使用的过程很简单:对于次级服务器,我们在它们之间用无延迟试了几次。对于主服务器,我们通过使用指数回退来尝试几次。
|
||||
|
||||
更多信息你可以查看 GitLab EE 上的源代码:
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb][3]
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing][4]
|
||||
|
||||
数据库负载均衡第一次介绍在 GitLab 9.0 中并且 _仅_ 支持 PostgreSQL。更多信息可以在 [9.0 release post][15] 和 [documentation][16] 中找到。
|
||||
|
||||
### Crunchy Data
|
||||
|
||||
在部署连接池和负载均衡的同时,我们与 [Crunchy Data][17] 一起工作。直到最近我还是唯一的 [数据库专家][18],它意味着我有很多工作要做。此外,我知道的 PostgreSQL 的内部的和它大量的设置是有限的 (或者至少现在是),这意味着我能做的有限。因为这些原因,我们雇用了 Crunchy 去帮我们找出问题、研究慢查询、建议模式优化、优化 PostgreSQL 设置等等。
|
||||
|
||||
在合作期间,大部分工作都是在相互信任的基础上完成的,因此,我们共享私人数据,比如日志。在合作结束时,我们从一些资料和公开的内容中删除了敏感数据,主要的资料在 [gitlab-com/infrastructure#1448][19], 这又反过来导致许多问题被产生和解决。
|
||||
|
||||
这次合作的好处是巨大的,他帮助我们发现并解决了许多的问题,如果必须我们自己来做的话,我们可能需要花上几个月的时间来识别和解决它。
|
||||
|
||||
幸运的是,最近我们成功地雇佣了我们的 [第二个数据库专家][20] 并且我们希望以后我们的团队能够发展壮大。
|
||||
|
||||
### 整合连接池和数据库负载均衡
|
||||
|
||||
整合连接池和数据库负载均衡允许我们去大幅减少运行数据库集群所需要的资源和在热备机上分发的负载。例如,以前我们的主服务器 CPU 使用率一直徘徊在 70%,现在它一般在 10% 到 20% 之间,而我们的两台热备机服务器则大部分时间在 20% 左右:
|
||||
|
||||

|
||||
|
||||
在这里, `db3.cluster.gitlab.com` 是我们的主服务器,而其它的两台是我们的次级服务器。
|
||||
|
||||
其它的负载相关的因素,如平均负载、磁盘使用、内存使用也大为改善。例如,主服务器现在的平均负载几乎不会超过 10,而不像以前它一直徘徊在 20 左右:
|
||||
|
||||

|
||||
|
||||
在业务繁忙期间,我们的次级服务器每秒事务数在 12000 左右(大约为每分钟 740000),而主服务器每秒事务数在 6000 左右(大约每分钟 340000):
|
||||
|
||||

|
||||
|
||||
可惜的是,在部署 pgbouncer 和我们的数据库负载均衡器之前,我们没有关于事务速率的任何数据。
|
||||
|
||||
我们的 PostgreSQL 的最新统计数据的摘要可以在我们的 [public Grafana dashboard][21] 上找到。
|
||||
|
||||
我们的其中一些 pgbouncer 的设置如下:
|
||||
|
||||
| Setting | Value |
|
||||
| --- | --- |
|
||||
| default_pool_size | 100 |
|
||||
| reserve_pool_size | 5 |
|
||||
| reserve_pool_timeout | 3 |
|
||||
| max_client_conn | 2048 |
|
||||
| pool_mode | transaction |
|
||||
| server_idle_timeout | 30 |
|
||||
|
||||
除了前面所说的这些外,还有一些工作要作,比如: 部署服务发现([#2042][22]), 持续改善如何检查次级服务器是否可用([#2866][23]),和忽略落后于主服务器太多的次级服务器 ([#2197][24])。
|
||||
|
||||
值得一提的是,到目前为止,我们还没有任何计划将我们的负载均衡解决方案,独立打包成一个你可以在 GitLab 之外使用的库,相反,我们的重点是为 GitLab EE 提供一个可靠的负载均衡解决方案。
|
||||
|
||||
如果你对它感兴趣,并喜欢使用数据库,改善应用程序性能,给 GitLab上增加数据库相关的特性(比如: [服务发现][25]),你一定要去查看一下 [招聘职位][26] 和 [数据库专家手册][27] 去获取更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/
|
||||
|
||||
作者:[Yorick Peterse ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://about.gitlab.com/team/#yorickpeterse
|
||||
[1]:https://pgbouncer.github.io/
|
||||
[2]:http://pgpool.net/mediawiki/index.php/Main_Page
|
||||
[3]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb
|
||||
[4]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing
|
||||
[5]:https://www.postgresql.org/docs/9.6/static/runtime-config-connection.html#GUC-MAX-CONNECTIONS
|
||||
[6]:https://www.postgresql.org/docs/9.6/static/hot-standby.html
|
||||
[7]:https://www.citusdata.com/
|
||||
[8]:https://gitlab.com/gitlab-com/infrastructure/issues/259#note_23464570
|
||||
[9]:https://docs.gitlab.com/ee/administration/high_availability/alpha_database.html
|
||||
[10]:https://github.com/taskrabbit/makara
|
||||
[11]:https://github.com/taskrabbit/makara/issues/151
|
||||
[12]:https://github.com/thiagopradi/octopus
|
||||
[13]:https://gitlab.com/gitlab-org/gitlab-ee/merge_requests/1283
|
||||
[14]:https://www.postgresql.org/docs/current/static/hot-standby.html#HOT-STANDBY-CONFLICT
|
||||
[15]:https://about.gitlab.com/2017/03/22/gitlab-9-0-released/
|
||||
[16]:https://docs.gitlab.com/ee/administration/database_load_balancing.html
|
||||
[17]:https://www.crunchydata.com/
|
||||
[18]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
[19]:https://gitlab.com/gitlab-com/infrastructure/issues/1448
|
||||
[20]:https://gitlab.com/_stark
|
||||
[21]:http://monitor.gitlab.net/dashboard/db/postgres-stats?refresh=5m&orgId=1
|
||||
[22]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[23]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2866
|
||||
[24]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2197
|
||||
[25]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[26]:https://about.gitlab.com/jobs/specialist/database/
|
||||
[27]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
Loading…
Reference in New Issue
Block a user