mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
a2a262a0af
@ -7,7 +7,7 @@
|
||||
|
||||

|
||||
|
||||
使用这种方式的明显好处就是你可以通过使用他们各自的官方应用访问你的各种云存储。目前,提供官方Linux客户端的服务提供商有[SpiderOak](1), [Dropbox](2), [Ubuntu One](3),[Copy](5)。[Ubuntu One](3)虽不出名但的确是[一个不错的云存储竞争着](4)。[Copy][5]则提供比Dropbox更多的空间,是[Dropbox的替代选择之一](6)。使用这些官方Linux客户端可以保持你的电脑与他们的服务器之间的通信,还可以让你进行属性设置,如选择性同步。
|
||||
使用这种方式的明显好处就是你可以通过使用他们各自的官方应用访问你的各种云存储。目前,提供官方Linux客户端的服务提供商有[SpiderOak][1], [Dropbox][2], [Ubuntu One][3],[Copy][5]。[Ubuntu One][3]虽不出名但的确是[一个不错的云存储竞争着][4]。[Copy][5]则提供比Dropbox更多的空间,是[Dropbox的替代选择之一][6]。使用这些官方Linux客户端可以保持你的电脑与他们的服务器之间的通信,还可以让你进行属性设置,如选择性同步。
|
||||
|
||||
对于普通桌面用户,使用官方客户端是最好的选择,因为官方客户端可以提供最多的功能和最好的兼容性。使用它们也很简单,只需要下载他们对应你的发行版的软件包,然后安装安装完后在运行一下就Ok了。安装客户端时,它一般会指导你完成这些简单的过程。
|
||||
|
||||
@ -25,9 +25,9 @@
|
||||
|
||||
当你运行最后一条命令后,脚本会提醒你这是你第一次运行这个脚本。它将告诉你去浏览一个Dropbox的特定网页以便访问你的账户。它还会告诉你所有你需要放入网站的信息,这是为了让Dropbox给你App Key和App Secret以及赋予这个脚本你给予的访问权限。现在脚本就拥有了访问你账户的合法授权了。
|
||||
|
||||
这些一旦完成,你就可以这个脚本执行各种任务了,例如上传、下载、删除、移动、复制、创建文件夹、查看文件、共享文件、查看文件信息和取消共享。对于全部的语法解释,你可以查看一下[这个页面](9)。
|
||||
这些一旦完成,你就可以这个脚本执行各种任务了,例如上传、下载、删除、移动、复制、创建文件夹、查看文件、共享文件、查看文件信息和取消共享。对于全部的语法解释,你可以查看一下[这个页面][9]。
|
||||
|
||||
###通过[Storage Made Easy](7)将SkyDrive带到Linux上
|
||||
###通过[Storage Made Easy][7]将SkyDrive带到Linux上
|
||||
|
||||
微软并没有提供SkyDrive的官方Linux客户端,这一点也不令人惊讶。但是你并不意味着你不能在Linux上访问SkyDrive,记住:SkyDrive的web版本是可用的。
|
||||
|
||||
@ -41,7 +41,7 @@
|
||||
|
||||
第一次启动时。它会要求你登录,还有询问你要把云存储挂载到什么地方。在你做完了这些后,你就可以浏览你选择的文件夹,你还可以访问你的Storage Made Easy空间以及你的SkyDrive空间了!这种方法对于那些想在Linux上使用SkyDrive的人来说非常好,对于想把他们的多个云存储服务整合到一个地方的人来说也很不错。这种方法的缺点是你无法使用他们各自官方客户端中可以使用的特殊功能。
|
||||
|
||||
因为现在在你的Linux桌面上也可以使用SkyDrive,接下来你可能需要阅读一下我写的[SkyDrive与Google Drive的比较](8)以便于知道究竟哪种更适合于你。
|
||||
因为现在在你的Linux桌面上也可以使用SkyDrive,接下来你可能需要阅读一下我写的[SkyDrive与Google Drive的比较][8]以便于知道究竟哪种更适合于你。
|
||||
|
||||
###结论
|
||||
|
||||
|
||||
@ -1,44 +1,45 @@
|
||||
修复安装完 Ubuntu 后无可引导设备错误
|
||||
修复安装完 Ubuntu 后无可引导设备的错误
|
||||
================================================================================
|
||||
通常情况下,我启动 Ubuntu 和 Windows 双系统,但是这次我决定完全消除 Windows 纯净安装 Ubuntu。纯净安装 Ubuntu 完成后,结束时屏幕输出 **no bootable device found** 而不是进入 GRUB 界面。显然,安装搞砸了 UEFI 引导设置。
|
||||
|
||||
通常情况下,我会安装启动 Ubuntu 和 Windows 的双系统,但是这次我决定完全消除 Windows 纯净安装 Ubuntu。纯净安装 Ubuntu 完成后,结束时屏幕输出 **无可引导设备(no bootable device found)** 而不是进入 GRUB 界面。显然,安装搞砸了 UEFI 引导设置。
|
||||
|
||||

|
||||
|
||||
我会告诉你我是如何修复**在宏碁笔记本上安装 Ubuntu 后出现无可引导设备错误**。我声明了我使用的是宏碁灵越 R13,这很重要,因为我们需要更改固件设置,而这些设置可能因制造商和设备有所不同。
|
||||
我会告诉你我是如何修复**在宏碁笔记本上安装 Ubuntu 后出现无可引导设备错误**的。我声明了我使用的是宏碁灵越 R13,这很重要,因为我们需要更改固件设置,而这些设置可能因制造商和设备有所不同。
|
||||
|
||||
因此在你开始这里介绍的步骤之前,先看一下发生这个错误时我计算机的状态:
|
||||
|
||||
- 我的宏碁灵越 R13 预装了 Windows8.1 和 UEFI 引导管理器
|
||||
- 关闭了 Secure boot(我的笔记本刚维修过,维修人员又启用了它,直到出现了问题我才发现)。你可以阅读这篇博文了解[如何在宏碁笔记本中关闭 secure boot][1]
|
||||
- 我通过选择清除所有东西安装 Ubuntu,例如现有的 Windows 8.1,各种分区等。
|
||||
- 我的宏碁灵越 R13 预装了 Windows 8.1 和 UEFI 引导管理器
|
||||
- 安全引导( Secure boot)没有关闭,(我的笔记本刚维修过,维修人员又启用了它,直到出现了问题我才发现)。你可以阅读这篇博文了解[如何在宏碁笔记本中关闭安全引导(secure boot)][1]
|
||||
- 我选择了清除所有东西安装 Ubuntu,例如现有的 Windows 8.1,各种分区等
|
||||
- 安装完 Ubuntu 之后,从硬盘启动时我看到无可引导设备错误。但能从 USB 设备正常启动
|
||||
|
||||
在我看来,没有禁用 secure boot 可能是这个错误的原因。但是,我没有数据支撑我的观点。这仅仅是预感。有趣的是,双系统启动 Windows 和 Linux 经常会出现这两个 Grub 问题:
|
||||
在我看来,没有禁用安全引导(secure boot)可能是这个错误的原因。但是,我没有数据支撑我的观点。这仅仅是预感。有趣的是,双系统启动 Windows 和 Linux 经常会出现这两个 Grub 问题:
|
||||
|
||||
- [error: no such partition grub rescue][2]
|
||||
- [Minimal BASH like line editing is supported][3]
|
||||
- [错误:没有 grub 救援分区][2]
|
||||
- [支持最小化 BASH 式的行编辑][3]
|
||||
|
||||
如果你遇到类似的情况,你可以试试我的修复方法。
|
||||
|
||||
### 修复安装完 Ubuntu 后无可引导设备错误 ###
|
||||
|
||||
请原谅我没有丰富的图片。我的一加相机不能很好地拍摄笔记本屏幕。
|
||||
请原谅我的图片质量很差。我的一加相机不能很好地拍摄笔记本屏幕。
|
||||
|
||||
#### 第一步 ####
|
||||
|
||||
关闭电源并进入 boot 设置。我需要在宏碁灵越 R13 上快速地按 Fn+F2。如果你使用固态硬盘的话要按的非常快,因为固态硬盘启动速度很快。取决于你的制造商,你可能要用 Del 或 F10 或者 F12。
|
||||
关闭电源并进入引导设置。我需要在宏碁灵越 R13 上快速地按下 Fn+F2。如果你使用固态硬盘的话要按的非常快,因为固态硬盘启动速度很快。这取决于你的制造商,你可能要用 Del 或 F10 或者 F12。
|
||||
|
||||
#### 第二步 ####
|
||||
|
||||
在 boot 设置中,确保启用了 Secure Boot。它在 Boot 标签里。
|
||||
在引导设置中,确保启用了 Secure Boot。它在 Boot 标签里。
|
||||
|
||||
#### 第三步 ####
|
||||
|
||||
进入到 Security 标签,查找 “Select an UEFI file as trusted for executing” 并敲击回车。
|
||||
进入到 Security 标签,找到 “选择一个用于执行的可信任 UEFI 文件(Select an UEFI file as trusted for executing)” 并敲击回车。
|
||||
|
||||

|
||||
|
||||
特意说明,我们这一步是要在你的设备中添加 UEFI 设置文件(安装 Ubuntu 的时候生成)到可信 UEFI 启动。如果你记得的话,UEFI 启动的主要目的是提供安全性,由于(可能)没有禁用 Secure Boot,设备不会试图从新安装的操作系统中启动。添加它到类似白名单的可信列表,会使设备从 Ubuntu UEFI 文件启动。
|
||||
特意说明,我们这一步是要在你的设备中添加 UEFI 设置文件(安装 Ubuntu 的时候生成)到可信 UEFI 启动中。如果你记得的话,UEFI 启动的主要目的是提供安全性,由于(可能)没有禁用安全引导(Secure Boot),设备不会试图从新安装的操作系统中启动。添加它到类似白名单的可信列表,会使设备从 Ubuntu UEFI 文件启动。
|
||||
|
||||
#### 第四步 ####
|
||||
|
||||
@ -48,13 +49,13 @@
|
||||
|
||||
#### 第五步 ####
|
||||
|
||||
你应该可以看到 <EFI>,敲击回车。
|
||||
你应该可以看到 \<EFI> 了,敲击回车。
|
||||
|
||||

|
||||
|
||||
#### 第六步 ####
|
||||
|
||||
在下一个屏幕中你会看到 <Ubuntu>。耐心点,马上就好了。
|
||||
在下一个屏幕中你会看到 \<Ubuntu>。耐心点,马上就好了。
|
||||
|
||||

|
||||
|
||||
@ -71,7 +72,7 @@
|
||||
|
||||
#### 第八步 ####
|
||||
|
||||
当我们添加它到可信 EFI 文件并执行时,按 F10 保存并退出。
|
||||
当我们添加它到可信 EFI 文件并执行后,按 F10 保存并退出。
|
||||
|
||||

|
||||
|
||||
@ -87,7 +88,7 @@ via: http://itsfoss.com/no-bootable-device-found-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,22 @@
|
||||
使用脚本便捷地在Ubuntu系统中安装最新的Linux内核
|
||||
使用脚本便捷地在 Ubuntu 中安装最新 Linux 内核
|
||||
================================================================================
|
||||

|
||||
|
||||
想要安装最新的Linux内核吗?一个简单的脚本就可以在Ubuntu系统中方便的完成这项工作。
|
||||
|
||||
Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或者低延时版内核安装到 Ubuntu 系统中。这个脚本会在询问一些问题后从 [Ubuntu kernel mainline page][1] 下载安装最新的 Linux 内核包。
|
||||
Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或者低延时版的内核安装到 Ubuntu 系统中。这个脚本会在询问一些问题后从 [Ubuntu 内核主线页面][1] 下载安装最新的 Linux 内核包。
|
||||
|
||||
### 通过脚本来安装、升级Linux内核: ###
|
||||
|
||||
1. 点击 [github page][2] 右上角的 “Download Zip” 来下载脚本。
|
||||
1. 点击这个 [github 页面][2] 右上角的 “Download Zip” 来下载该脚本。
|
||||
|
||||
2. 鼠标右键单击用户下载目录下的 Zip 文件,选择 “Extract Here” 将其解压到此处。
|
||||
2. 鼠标右键单击用户下载目录下的 Zip 文件,选择 “在此展开” 将其解压。
|
||||
|
||||
3. 右键点击解压后的文件夹,选择 “Open in Terminal” 在终端中导航到此文件夹下。
|
||||
3. 右键点击解压后的文件夹,选择 “在终端中打开” 到此文件夹下。
|
||||
|
||||
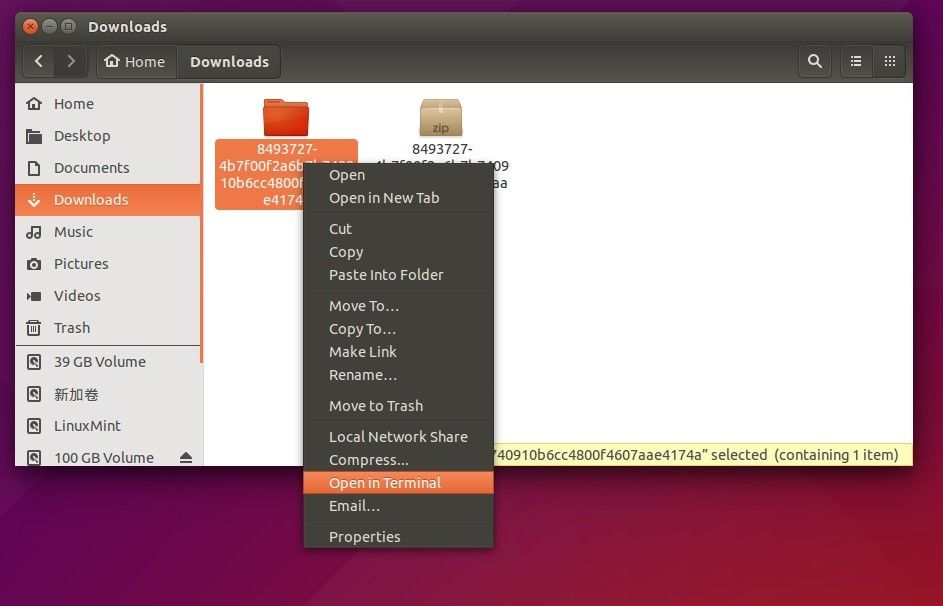
|
||||
|
||||
此时将会打开一个终端,并且自动导航到结果文件夹下。如果你找不到 “Open in Terminal” 选项的话,在 Ubuntu 软件中心搜索安装 `nautilus-open-terminal` ,然后重新登录系统即可(也可以再终端中运行 `nautilus -q` 来取代重新登录系统的操作)。
|
||||
此时将会打开一个终端,并且自动导航到目标文件夹下。如果你找不到 “在终端中打开” 选项的话,在 Ubuntu 软件中心搜索安装 `nautilus-open-terminal` ,然后重新登录系统即可(也可以再终端中运行 `nautilus -q` 来取代重新登录系统的操作)。
|
||||
4. 当进入终端后,运行以下命令来赋予脚本执行本次操作的权限。
|
||||
|
||||
chmod +x *
|
||||
@ -39,7 +39,7 @@ Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或
|
||||
|
||||
### 如何移除旧的(或新的)内核: ###
|
||||
|
||||
1. 从Ubuntu软件中心安装 Synaptic Package Manager。
|
||||
1. 从 Ubuntu 软件中心安装 Synaptic Package Manager。
|
||||
|
||||
2. 打开 Synaptic Package Manager 然后如下操作:
|
||||
|
||||
@ -68,8 +68,8 @@ Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,40 +1,33 @@
|
||||
在 Ubuntu 上安装 Qmmp 0.9.0 类似 Winamp 的音频播放器
|
||||
在 Ubuntu 上安装类 Winamp 的音频播放器 Qmmp 0.9.0
|
||||
================================================================================
|
||||

|
||||
|
||||
Qmmp,基于 Qt 的音频播放器,与 Winamp 或 xmms 的用户界面类似,现在最新版本是0.9.0。PPA 已经在 Ubuntu 15.10,Ubuntu 15.04,Ubuntu 14.04,Ubuntu 12.04 和其衍生物中已经更新了。
|
||||
Qmmp,一个基于 Qt 的音频播放器,与 Winamp 或 xmms 的用户界面类似,现在最新版本是0.9.0。PPA 已经在 Ubuntu 15.10,Ubuntu 15.04,Ubuntu 14.04,Ubuntu 12.04 和其衍生版本中已经更新了。
|
||||
|
||||
Qmmp 0.9.0 是一个较大的版本,有许多新的功能,有许多改进和新的转变。它添加了如下功能:
|
||||
|
||||
- 音频-信道序列转换器;
|
||||
- 9通道支持均衡器;
|
||||
- 艺术家专辑标签支持;
|
||||
- 支持艺术家专辑标签;
|
||||
- 异步排序;
|
||||
- 通过文件的修改日期排序;
|
||||
- 按艺术家专辑排序;
|
||||
- 支持多专栏;
|
||||
- 有隐藏踪迹长度功能;
|
||||
- 不用修改 qmmp.pri 来禁用插件(仅在 qmake 中)功能
|
||||
- 记住播放列表滚动位置功能;
|
||||
- 排除提示数据文件功能;
|
||||
- 排除 cue 数据文件功能;
|
||||
- 更改用户代理功能;
|
||||
- 改变窗口标题功能;
|
||||
- 复位字体功能;
|
||||
- 恢复默认快捷键功能;
|
||||
- 默认热键为“Rename List”功能;
|
||||
- 功能禁用弹出的 GME 插件;
|
||||
- 简单的用户界面(QSUI)有以下变化:
|
||||
- 增加了多列表的支持;
|
||||
- 禁用 gme 插件淡出的功能;
|
||||
- 简单用户界面(QSUI)有以下变化:
|
||||
- 增加了多列的支持;
|
||||
- 增加了按艺术家专辑排序;
|
||||
- 增加了按文件的修改日期进行排序;
|
||||
- 增加了隐藏歌曲长度功能;
|
||||
- 增加了默认热键为“Rename List”;
|
||||
- 增加了“Rename List”的默认热键;
|
||||
- 增加了“Save List”功能到标签菜单;
|
||||
- 增加了复位字体功能;
|
||||
- 增加了复位快捷键功能;
|
||||
- 改进了状态栏;
|
||||
|
||||
它还改进了播放列表的通知,播放列表容器,采样率转换器,cmake 构建脚本,标题格式,在 mpeg 插件中支持 ape 标签,fileops 插件,降低了 cpu 占用率,改变默认的皮肤(炫光)和分离播放列表。
|
||||
它还改进了播放列表的改变通知,播放列表容器,采样率转换器,cmake 构建脚本,标题格式化,在 mpeg 插件中支持 ape 标签,fileops 插件,降低了 cpu 占用率,改变默认的皮肤(炫光)和分离的播放列表。
|
||||
|
||||
|
||||
|
||||
@ -42,7 +35,7 @@ Qmmp 0.9.0 是一个较大的版本,有许多新的功能,有许多改进和
|
||||
|
||||
新版本已经制做了 PPA,适用于目前所有 Ubuntu 发行版和衍生版。
|
||||
|
||||
1. 添加 [Qmmp PPA][1].
|
||||
1、 添加 [Qmmp PPA][1].
|
||||
|
||||
从 Dash 中打开终端并启动应用,通过按 Ctrl+Alt+T 快捷键。当它打开时,运行命令:
|
||||
|
||||
@ -50,7 +43,7 @@ Qmmp 0.9.0 是一个较大的版本,有许多新的功能,有许多改进和
|
||||
|
||||

|
||||
|
||||
2. 在添加 PPA 后,通过更新软件来升级 Qmmp 播放器。刷新系统缓存,并通过以下命令安装软件:
|
||||
2、 在添加 PPA 后,通过更新软件来升级 Qmmp 播放器。刷新系统缓存,并通过以下命令安装软件:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -63,8 +56,8 @@ Qmmp 0.9.0 是一个较大的版本,有许多新的功能,有许多改进和
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/qmmp-0-9-0-in-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,209 @@
|
||||
RHCSA 系列(四): 编辑文本文件及分析文本
|
||||
================================================================================
|
||||
|
||||
作为系统管理员的日常职责的一部分,每个系统管理员都必须处理文本文件,这包括编辑已有文件(大多可能是配置文件),或创建新的文件。有这样一个说法,假如你想在 Linux 世界中挑起一场圣战,你可以询问系统管理员们,什么是他们最喜爱的编辑器以及为什么。在这篇文章中,我们并不打算那样做,但我们将向你呈现一些技巧,这些技巧对使用两款在 RHEL 7 中最为常用的文本编辑器: nano(由于其简单和易用,特别是对于新手来说)和 vi/m(由于其自身的几个特色使得它不仅仅是一个简单的编辑器)来说都大有裨益。我确信你可以找到更多的理由来使用其中的一个或另一个,或许其他的一些编辑器如 emacs 或 pico。这完全取决于你自己。
|
||||
|
||||

|
||||
|
||||
*RHCSA: 使用 Nano 和 Vim 编辑文本文件 – Part 4*
|
||||
|
||||
### 使用 Nano 编辑器来编辑文件 ###
|
||||
|
||||
要启动 nano,你可以在命令提示符下输入 `nano`,或可选地跟上一个文件名(在这种情况下,若文件存在,它将在编辑模式中被打开)。若文件不存在,或我们省略了文件名, nano 也将在编辑模式下开启,但将为我们开启一个空白屏以便开始输入:
|
||||
|
||||

|
||||
|
||||
*Nano 编辑器*
|
||||
|
||||
正如你在上一张图片中所见的那样, nano 在屏幕的底部呈现出一些可以通过指定的快捷键来触发的功能(\^,即插入记号,代指 Ctrl 键)。它们中的一些是:
|
||||
|
||||
- Ctrl + G: 触发一个帮助菜单,带有一个关于功能和相应的描述的完整列表;
|
||||
|
||||
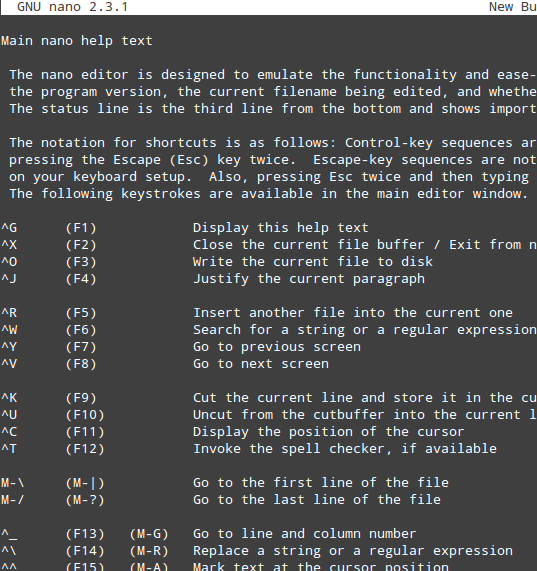
|
||||
|
||||
*Nano 编辑器帮助菜单*
|
||||
|
||||
- Ctrl + O: 保存更改到一个文件。它可以让你用一个与源文件相同或不同的名称来保存该文件,然后按 Enter 键来确认。
|
||||
|
||||

|
||||
|
||||
*Nano 编辑器的保存更改模式*
|
||||
|
||||
- Ctrl + X: 离开当前文件,假如更改没有被保存,则它们将被丢弃;
|
||||
- Ctrl + R: 通过指定一个完整的文件路径,让你选择一个文件来将该文件的内容插入到当前文件中;
|
||||
|
||||
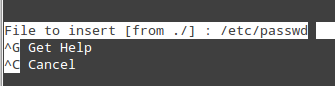
|
||||
|
||||
*Nano: 插入文件内容到主文件中*
|
||||
|
||||
上图的操作将把 `/etc/passwd` 的内容插入到当前文件中。
|
||||
|
||||
- Ctrl + K: 剪切当前行;
|
||||
- Ctrl + U: 粘贴;
|
||||
- Ctrl + C: 取消当前的操作并返回先前的屏幕;
|
||||
|
||||
为了轻松地在打开的文件中浏览, nano 提供了下面的功能:
|
||||
|
||||
- Ctrl + F 和 Ctrl + B 分别先前或向后移动光标;而 Ctrl + P 和 Ctrl + N 则分别向上或向下移动一行,功能与箭头键相同;
|
||||
- Ctrl + space 和 Alt + space 分别向前或向后移动一个单词;
|
||||
|
||||
最后,
|
||||
|
||||
- 假如你想将光标移动到文档中的特定位置,使用 Ctrl + _ (下划线) 并接着输入 X,Y 将准确地带你到 第 X 行,第 Y 列。
|
||||
|
||||

|
||||
|
||||
*在 nano 中定位到具体的行和列*
|
||||
|
||||
上面的例子将带你到当前文档的第 15 行,第 14 列。
|
||||
|
||||
假如你可以回忆起你早期的 Linux 岁月,特别是当你刚从 Windows 迁移到 Linux 中,你就可能会同意:对于一个新手来说,使用 nano 来开始学习是最好的方式。
|
||||
|
||||
### 使用 Vim 编辑器来编辑文件 ###
|
||||
|
||||
Vim 是 vi 的加强版本,它是 Linux 中一个著名的文本编辑器,可在所有兼容 POSIX 的 *nix 系统中获取到,例如在 RHEL 7 中。假如你有机会并可以安装 Vim,请继续;假如不能,这篇文章中的大多数(若不是全部)的提示也应该可以正常工作。
|
||||
|
||||
Vim 的一个出众的特点是可以在多个不同的模式中进行操作:
|
||||
|
||||
- 命令模式(Command Mode)将允许你在文件中跳转和输入命令,这些命令是由一个或多个字母组成的简洁且大小写敏感的组合。假如你想重复执行某个命令特定次数,你可以在这个命令前加上需要重复的次数(这个规则只有极少数例外)。例如, `yy`(或 `Y`,yank 的缩写)可以复制整个当前行,而 `4yy`(或 `4Y`)则复制整个从当前行到接下来的 3 行(总共 4 行)。
|
||||
- 我们总是可以通过敲击 `Esc` 键来进入命令模式(无论我们正工作在哪个模式下)。
|
||||
- 在末行模式(Ex Mode)中,你可以操作文件(包括保存当前文件和运行外部的程序或命令)。要进入末行模式,你必须从命令模式中(换言之,输入 `Esc` + `:`)输入一个冒号(`:`),再直接跟上你想使用的末行模式命令的名称。
|
||||
- 对于插入模式(Insert Mode),可以输入字母 `i` 进入,然后只需要输入文字即可。大多数的击键结果都将出现在屏幕中的文本中。
|
||||
|
||||
现在,让我们看看如何在 vim 中执行在上一节列举的针对 nano 的相同的操作。不要忘记敲击 Enter 键来确认 vim 命令。
|
||||
|
||||
为了从命令行中获取 vim 的完整手册,在命令模式下键入 `:help` 并敲击 Enter 键:
|
||||
|
||||
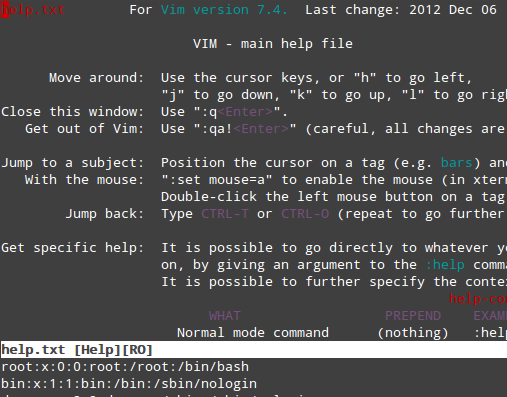
|
||||
|
||||
*vim 编辑器帮助菜单*
|
||||
|
||||
上面的部分呈现出一个内容列表,这些定义的小节则描述了 Vim 的特定话题。要浏览某一个小节,可以将光标放到它的上面,然后按 `Ctrl + ]` (闭方括号)。注意,底部的小节展示的是当前文件的内容。
|
||||
|
||||
1、 要保存更改到文件,在命令模式中运行下面命令中的任意一个,就可以达到这个目的:
|
||||
|
||||
```
|
||||
:wq!
|
||||
:x!
|
||||
ZZ (是的,两个 ZZ,前面无需添加冒号)
|
||||
```
|
||||
|
||||
2、 要离开并丢弃更改,使用 `:q!`。这个命令也将允许你离开上面描述过的帮助菜单,并返回到命令模式中的当前文件。
|
||||
|
||||
3、 剪切 N 行:在命令模式中键入 `Ndd`。
|
||||
|
||||
4、 复制 M 行:在命令模式中键入 `Myy`。
|
||||
|
||||
5、 粘贴先前剪贴或复制过的行:在命令模式中按 `P`键。
|
||||
|
||||
6、 要插入另一个文件的内容到当前文件:
|
||||
|
||||
:r filename
|
||||
|
||||
例如,插入 `/etc/fstab` 的内容,可以这样做:
|
||||
|
||||
[在 vi 编辑器中插入文件的内容](http://www.tecmint.com/wp-content/uploads/2015/03/Insert-Content-vi-Editor.png)
|
||||
|
||||
*在 vi 编辑器中插入文件的内容*
|
||||
|
||||
7、 插入一个命令的输出到当前文档:
|
||||
|
||||
:r! command
|
||||
|
||||
例如,要在光标所在的当前位置后面插入日期和时间:
|
||||
|
||||
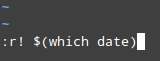
|
||||
|
||||
*在 vi 编辑器中插入时间和日期*
|
||||
|
||||
在另一篇我写的文章中,([LFCS 系列(二)][1]),我更加详细地解释了在 vim 中可用的键盘快捷键和功能。或许你可以参考那个教程来查看如何使用这个强大的文本编辑器的更深入的例子。
|
||||
|
||||
### 使用 grep 和正则表达式来分析文本 ###
|
||||
|
||||
到现在为止,你已经学习了如何使用 nano 或 vim 创建和编辑文件。打个比方说,假如你成为了一个文本编辑器忍者 – 那又怎样呢? 在其他事情上,你也需要知道如何在文本中搜索正则表达式。
|
||||
|
||||
正则表达式(也称为 "regex" 或 "regexp") 是一种识别一个特定文本字符串或模式的方式,使得一个程序可以将这个模式和任意的文本字符串相比较。尽管利用 grep 来使用正则表达式值得用一整篇文章来描述,这里就让我们复习一些基本的知识:
|
||||
|
||||
**1、 最简单的正则表达式是一个由数字和字母构成的字符串(例如,单词 "svm") ,或者两个(在使用两个字符串时,你可以使用 `|`(或) 操作符):**
|
||||
|
||||
# grep -Ei 'svm|vmx' /proc/cpuinfo
|
||||
|
||||
上面命令的输出结果中若有这两个字符串之一的出现,则标志着你的处理器支持虚拟化:
|
||||
|
||||

|
||||
|
||||
*正则表达式示例*
|
||||
|
||||
**2、 第二种正则表达式是一个范围列表,由方括号包裹。**
|
||||
|
||||
例如, `c[aeiou]t` 匹配字符串 cat、cet、cit、cot 和 cut,而 `[a-z]` 和 `[0-9]` 则相应地匹配小写字母或十进制数字。假如你想重复正则表达式 X 次,在正则表达式的后面立即输入 `{X}`即可。
|
||||
|
||||
例如,让我们从 `/etc/fstab` 中析出存储设备的 UUID:
|
||||
|
||||
# grep -Ei '[0-9a-f]{8}-([0-9a-f]{4}-){3}[0-9a-f]{12}' -o /etc/fstab
|
||||
|
||||

|
||||
|
||||
*从一个文件中析出字符串*
|
||||
|
||||
方括号中的第一个表达式 `[0-9a-f]` 被用来表示小写的十六进制字符,`{8}`是一个量词,暗示前面匹配的字符串应该重复的次数(在一个 UUID 中的开头序列是一个 8 个字符长的十六进制字符串)。
|
||||
|
||||
在圆括号中,量词 `{4}`和连字符暗示下一个序列是一个 4 个字符长的十六进制字符串,接着的量词 `({3})`表示前面的表达式要重复 3 次。
|
||||
|
||||
最后,在 UUID 中的最后一个 12 个字符长的十六进制字符串可以由 `[0-9a-f]{12}` 取得, `-o` 选项表示只打印出在 `/etc/fstab`中匹配行中的匹配的(非空)部分。
|
||||
|
||||
**3、 POSIX 字符类**
|
||||
|
||||
|字符类|匹配 …|
|
||||
|-----|-----|
|
||||
| `[:alnum:]` | 任意字母或数字 [a-zA-Z0-9] |
|
||||
| `[:alpha:]` |任意字母 [a-zA-Z] |
|
||||
| `[:blank:]` |空格或制表符 |
|
||||
| `[:cntrl:]` |任意控制字符 (ASCII 码的 0 至 32) |
|
||||
| `[:digit:]` |任意数字 [0-9] |
|
||||
| `[:graph:]` |任意可见字符 |
|
||||
| `[:lower:]` |任意小写字母 [a-z] |
|
||||
| `[:print:]` |任意非控制字符 |
|
||||
| `[:space:]` |任意空格 |
|
||||
| `[:punct:]` |任意标点字符 |
|
||||
| `[:upper:]` |任意大写字母 [A-Z] |
|
||||
| `[:xdigit:]` |任意十六进制数字 [0-9a-fA-F] |
|
||||
| `[:word:]` |任意字母,数字和下划线 [a-zA-Z0-9_] |
|
||||
|
||||
例如,我们可能会对查找已添加到我们系统中给真实用户的 UID 和 GID(参考“[RHCSA 系列(二): 如何进行文件和目录管理][2]”来回忆起这些知识)感兴趣。那么,我们将在 `/etc/passwd` 文件中查找 4 个字符长的序列:
|
||||
|
||||
# grep -Ei [[:digit:]]{4} /etc/passwd
|
||||
|
||||

|
||||
|
||||
*在文件中查找一个字符串*
|
||||
|
||||
上面的示例可能不是真实世界中使用正则表达式的最好案例,但它清晰地启发了我们如何使用 POSIX 字符类来使用 grep 分析文本。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
|
||||
在这篇文章中,我们已经提供了一些技巧来最大地利用针对命令行用户的两个文本编辑器 nano 和 vim,这两个工具都有相关的扩展文档可供阅读,你可以分别查询它们的官方网站(链接在下面给出)以及使用“[RHCSA 系列(一): 回顾基础命令及系统文档][3]”中给出的建议。
|
||||
|
||||
#### 参考文件链接 ####
|
||||
|
||||
- [http://www.nano-editor.org/][4]
|
||||
- [http://www.vim.org/][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-how-to-use-nano-vi-editors/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/vi-editor-usage/
|
||||
[2]:https://linux.cn/article-6155-1.html
|
||||
[3]:https://linux.cn/article-6133-1-rel.html
|
||||
[4]:http://www.nano-editor.org/
|
||||
[5]:http://www.vim.org/
|
||||
[6]:http://www.tecmint.com/vi-editor-usage/
|
||||
@ -0,0 +1,41 @@
|
||||
Ubuntu Linux-Based Open Source OS Runs 42 Percent of Dell PCs in China
|
||||
================================================================================
|
||||
> Dell says that 42 percent of the PCs it sells in the Chinese market run Kylin, an open source operating system based on Ubuntu Linux that Canonical helped to create.
|
||||
|
||||
Open source fans, rejoice: The Year of the Linux Desktop has arrived. Or something close to it is on the horizon in China, at least, where [Dell][1] has reported that more than 40 percent of the PCs it sells run a variant of [Ubuntu Linux][2] that [Canonical][3] helped develop.
|
||||
|
||||
Specifically, Dell said that 42 percent of computers in China run NeoKylin, an operating system that originated as an effort in China to build a home-grown alternative to [Microsoft][4] (MSFT) Windows. Also known simply Kylin, the OS has been based on Ubuntu since 2013, when Canonical began collaborating with the Chinese government to create an Ubuntu variant tailored for the Chinese market.
|
||||
|
||||
Earlier versions of Kylin, which has been around since 2001, were based on other operating systems, including FreeBSD, an open source Unix-like operating system that is distinct from Linux.
|
||||
|
||||
Ubuntu Kylin looks and feels a lot like modern versions of Ubuntu proper. It sports the [Unity][5] interface and runs the standard suite of open source apps, as well as specialized ones such as Youker Assistant, a graphical front end that helps users manage basic computing tasks. Kylin's default theme makes it look just a little more like Windows than stock Ubuntu, however.
|
||||
|
||||
Given the relative stagnation of the market for desktop Linux PCs in most of the world, Dell's announcement is striking. And in light of China's [hostility][6] toward modern editions of Windows, the news does not bode well for Microsoft's prospects in the Chinese market.
|
||||
|
||||
Dell's comment on Linux PC sales in China—which appeared in the form of a statement by an executive to the Wall Street Journal—comes on the heels of the company's [announcement][7] of $125 million of new investment in China.
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/091515/ubuntu-linux-based-open-source-os-runs-42-percent-dell-pc
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://dell.com/
|
||||
[2]:http://ubuntu.com/
|
||||
[3]:http://canonical.com/
|
||||
[4]:http://microsoft.com/
|
||||
[5]:http://unity.ubuntu.com/
|
||||
[6]:http://www.wsj.com/articles/windows-8-faces-new-criticism-in-china-1401882772
|
||||
[7]:http://thevarguy.com/business-technology-solution-sales/091415/dell-125-million-directed-china-jobs-new-business-and-innovation
|
||||
@ -0,0 +1,83 @@
|
||||
Best command line tools for linux performance monitoring
|
||||
================================================================================
|
||||
Sometimes a system can be slow and many reasons can be the root cause. To identify the process that is consuming memory, disk I/O or processor capacity you need to use tools to see what is happening in an operation system.
|
||||
|
||||
There are many tools to monitor a GNU/Linux server. In this article, I am providing 7 monitoring tools and i hope it will help you.
|
||||
|
||||
###Htop
|
||||
Htop is an alternative of top command but it provides interactive system-monitor process-viewer and more user friendly output than top.
|
||||
|
||||
htop also provides a better way to navigate to any process using keyboard Up/Down keys as well as we can also operate it using mouse.
|
||||
|
||||
For Check our previous post:[How to install and use htop on RHEL/Centos and Fedora linux][1]
|
||||
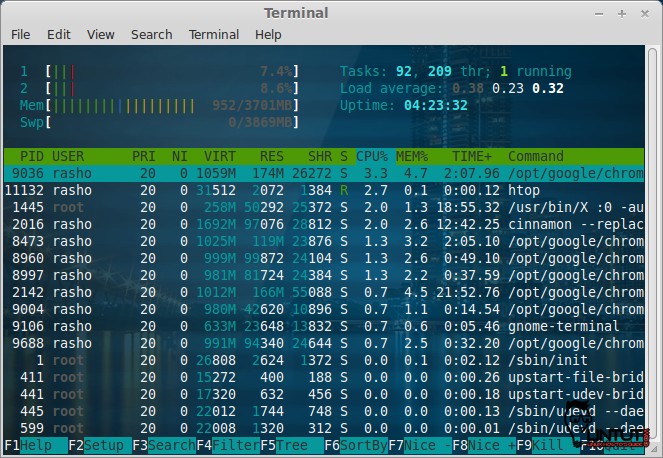
|
||||
###dstat
|
||||
Dstat is a versatile replacement for vmstat, iostat, netstat and ifstat. Dstat overcomes some of their limitations and adds some extra features, more counters and flexibility. Dstat is handy for monitoring systems during performance tuning tests, benchmarks or troubleshooting.
|
||||
|
||||
Dstat allows you to view all of your system resources in real-time, you can eg. compare disk utilization in combination with interrupts from your IDE controller, or compare the network bandwidth numbers directly with the disk throughput (in the same interval).
|
||||
Dstat gives you detailed selective information in columns and clearly indicates in what magnitude and unit the output is displayed. Less confusion, less mistakes. And most importantly, it makes it very easy to write plugins to collect your own counters and extend in ways you never expected.
|
||||
|
||||
Dstat’s output by default is designed for being interpreted by humans in real-time, however you can export details to CSV output to a file to be imported later into Gnumeric or Excel to generate graphs.
|
||||
Check our previous post:[How to install and use dstat on RHEL/CentOS,Fedora and Debian/Ubuntu based distribution][2]
|
||||
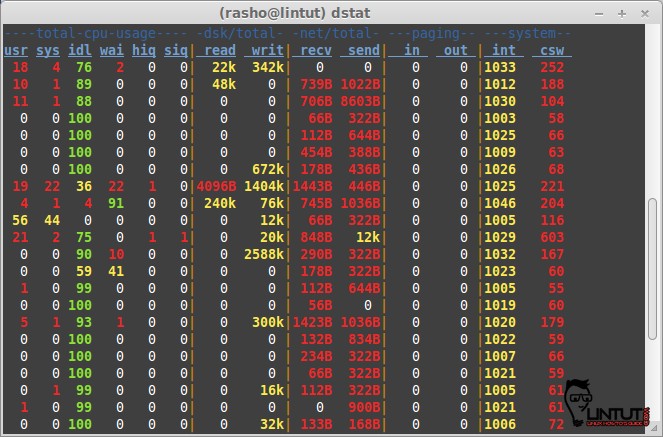
|
||||
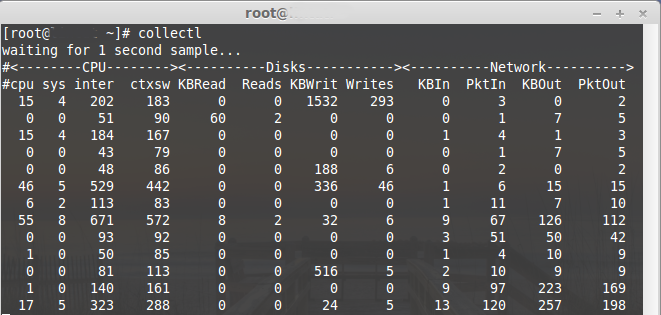
###Collectl
|
||||
Collectl is a light-weight performance monitoring tool capable of reporting interactively as well as logging to disk. It reports statistics on cpu, disk, infiniband, lustre, memory, network, nfs, process, quadrics, slabs and more in easy to read format.
|
||||
In this article i will show you how to install and sample usage Collectl on Debian/Ubuntu and RHEL/Centos and Fedora linux.
|
||||
|
||||
Check our previous post:[Collectl-Monitoring system resources][3]
|
||||
|
||||
|
||||
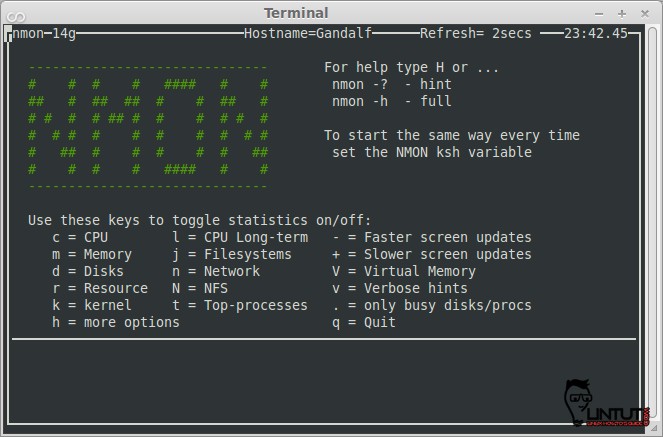
###Nmon
|
||||
nmon is a beutiful tool to monitor linux system performance. It works on Linux, IBM AIX Unix, Power,x86, amd64 and ARM based system such as Raspberry Pi. The nmon command displays and recordslocal system information. The command can run either in interactive or recording mode.
|
||||
|
||||
Check our previous post: [Nmon – linux monitoring tools][4]
|
||||
|
||||
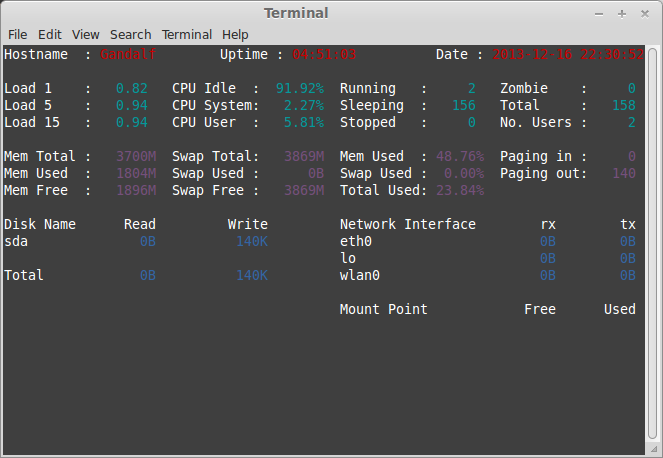
###Saidar
|
||||
Saidar is a curses-based application to display system statistics. It use the libstatgrab library, which provides cross platform access to statistics about the system on which it’s run. Reported statistics includeCPU, load, processes, memory, swap, network input and output and disks activities along with their free space.
|
||||
|
||||
Check our previous post:[Saidar – system monitoring tool][5]
|
||||
|
||||
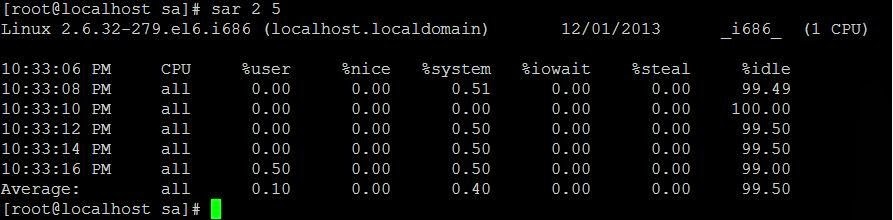
###Sar
|
||||
The sar utility, which is part of the systat package, can be used to review history performance data on your server. System resource utilization can be seen for given time frames to help troubleshoot performance issues, or to optimize performance.
|
||||
|
||||
Check our previous post:[Using Sar To Monitor System Performance][6]
|
||||
|
||||
|
||||
###Glances
|
||||
Glances is a cross-platform curses-based command line monitoring tool writen in Python which use the psutil library to grab informations from the system. Glance monitoring CPU, Load Average, Memory, Network Interfaces, Disk I/O, Processesand File System spaces utilization.
|
||||
|
||||
Glances can adapt dynamically the displayed information depending on the terminal siwrize. It can also work in a client/server mode for remote monitoring.
|
||||
|
||||
Check our previous post: [Glances – Real Time System Monitoring Tool for Linux][7]
|
||||
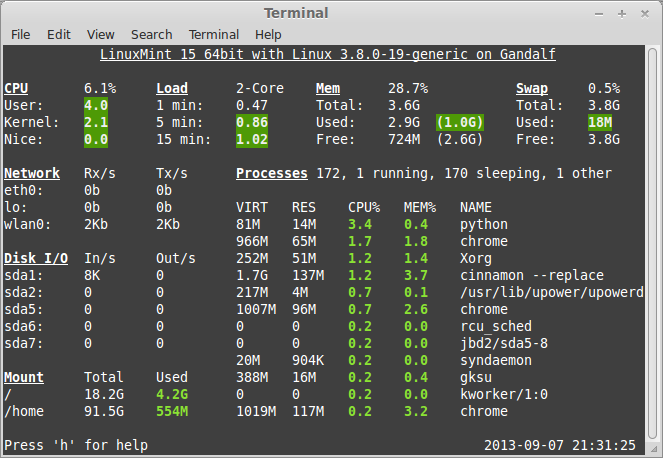
|
||||
|
||||
###Atop
|
||||
[Atop](http://www.atoptool.nl/) is an interactive monitor to view the load on a Linux system. It shows the occupation of the most critical hardware resources on system level, i.e. cpu, memory, disk and network. It also shows which processes are responsible for the indicated load with respect to cpu- and memory load on process level. Disk load is shown if per process “storage accounting” is active in the kernel or if the kernel patch ‘cnt’ has been installed. Network load is only shown per process if the kernel patch ‘cnt’ has been installed.
|
||||
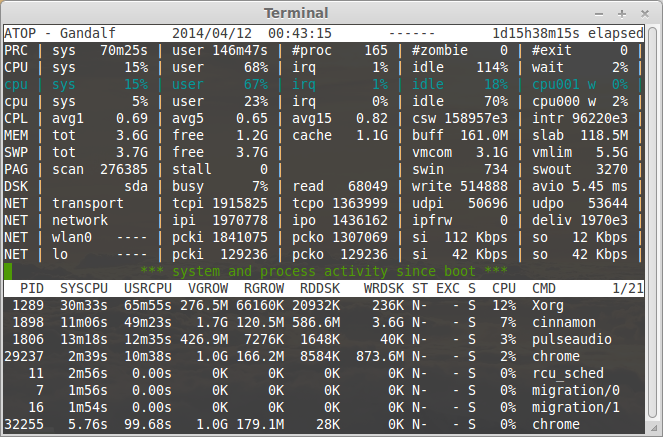
|
||||
For more about Atop check next post:[Atop - monitor system resources in linux][8]
|
||||
So, if you come across any other similar tool then let us know in the comment box below.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://lintut.com/best-command-line-tools-for-linux-performance-monitring/
|
||||
|
||||
作者:[rasho][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:http://lintut.com/install-htop-in-rhel-centos-fedora-linux/
|
||||
[2]:http://lintut.com/dstat-linux-monitoring-tools/
|
||||
[3]:http://lintut.com/collectl-monitoring-system-resources/
|
||||
[4]:http://lintut.com/nmon-linux-monitoring-tools/
|
||||
[5]:http://lintut.com/saidar-system-monitoring-tool/
|
||||
[6]:http://lintut.com/using-sar-to-monitor-system-performance/
|
||||
[7]:http://lintut.com/glances-an-eye-on-your-system/
|
||||
[8]:http://lintut.com/atop-linux-system-resource-monitor/
|
||||
@ -0,0 +1,227 @@
|
||||
Display Awesome Linux Logo With Basic Hardware Info Using screenfetch and linux_logo Tools
|
||||
================================================================================
|
||||
Do you want to display a super cool logo of your Linux distribution along with basic hardware information? Look no further try awesome screenfetch and linux_logo utilities.
|
||||
|
||||
### Say hello to screenfetch ###
|
||||
|
||||
screenFetch is a CLI bash script to show system/theme info in screenshots. It runs on a Linux, OS X, FreeBSD and many other Unix-like system. From the man page:
|
||||
|
||||
> This handy Bash script can be used to generate one of those nifty terminal theme information + ASCII distribution logos you see in everyone's screenshots nowadays. It will auto-detect your distribution and display an ASCII version of that distribution's logo and some valuable information to the right.
|
||||
|
||||
#### Installing screenfetch on Linux ####
|
||||
|
||||
Open the Terminal application. Simply type the following [apt-get command][1] on a Debian or Ubuntu or Mint Linux based system:
|
||||
|
||||
$ sudo apt-get install screenfetch
|
||||
|
||||
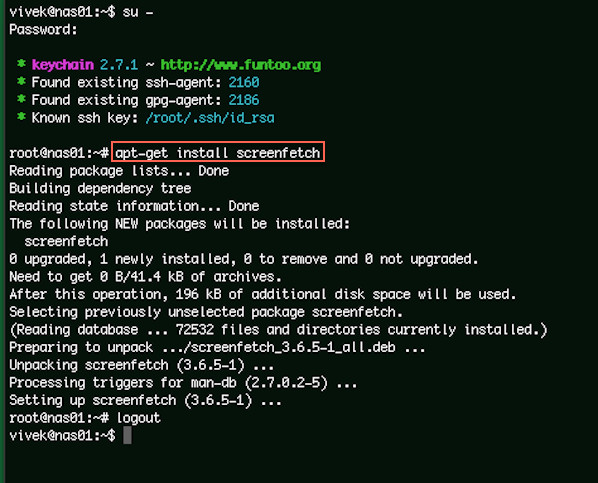
|
||||
|
||||
Fig.01: Installing screenfetch using apt-get
|
||||
|
||||
#### Installing screenfetch Mac OS X ####
|
||||
|
||||
Type the following command:
|
||||
|
||||
$ brew install screenfetch
|
||||
|
||||

|
||||
|
||||
Fig.02: Installing screenfetch using brew command
|
||||
|
||||
#### Installing screenfetch on FreeBSD ####
|
||||
|
||||
Type the following pkg command:
|
||||
|
||||
$ sudo pkg install sysutils/screenfetch
|
||||
|
||||
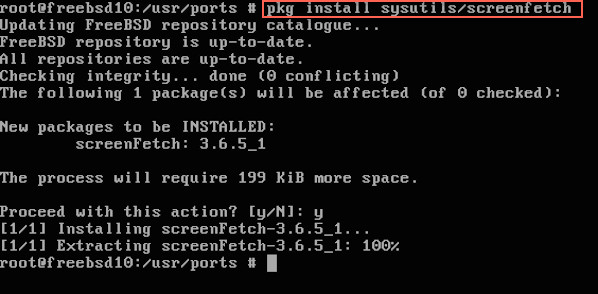
|
||||
|
||||
Fig.03: FreeBSD install screenfetch using pkg
|
||||
|
||||
#### Installing screenfetch on Fedora Linux ####
|
||||
|
||||
Type the following dnf command:
|
||||
|
||||
$ sudo dnf install screenfetch
|
||||
|
||||
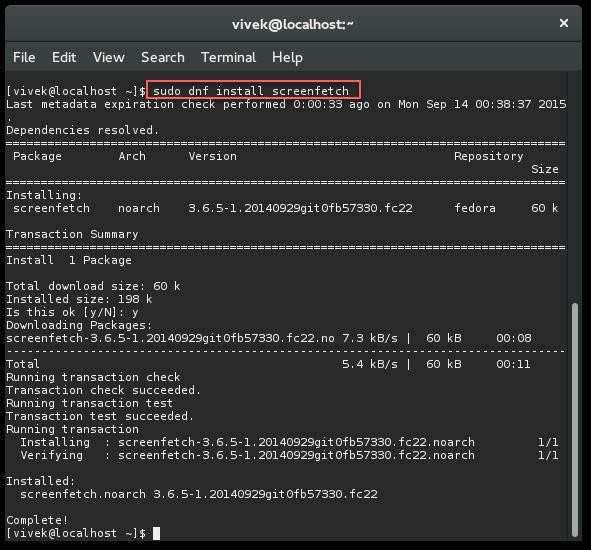
|
||||
|
||||
Fig.04: Fedora Linux 22 install screenfetch using dnf
|
||||
|
||||
#### How do I use screefetch utility? ####
|
||||
|
||||
Simply type the following command:
|
||||
|
||||
$ screenfetch
|
||||
|
||||
Here is the output from various operating system:
|
||||
|
||||
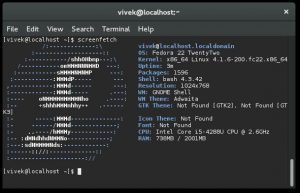
|
||||
|
||||
Screenfetch on Fedora
|
||||
|
||||
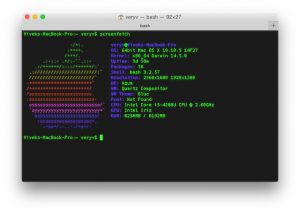
|
||||
|
||||
Screenfetch on OS X
|
||||
|
||||
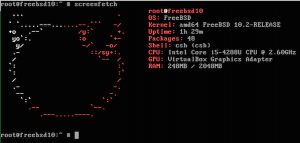
|
||||
|
||||
Screenfetch on FreeBSD
|
||||
|
||||
|
||||
|
||||
Screenfetch on Debian Linux
|
||||
|
||||
#### Take screenshot ####
|
||||
|
||||
To take a screenshot and to save a file, enter:
|
||||
|
||||
$ screenfetch -s
|
||||
|
||||
You will see a screenshot file at ~/Desktop/screenFetch-*.jpg. To take a screenshot and upload to imgur directly, enter:
|
||||
|
||||
$ screenfetch -su imgur
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
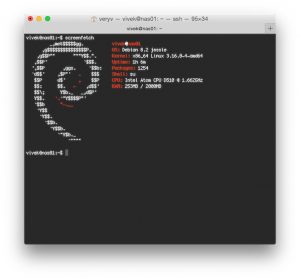
-/+:. veryv@Viveks-MacBook-Pro
|
||||
:++++. OS: 64bit Mac OS X 10.10.5 14F27
|
||||
/+++/. Kernel: x86_64 Darwin 14.5.0
|
||||
.:-::- .+/:-``.::- Uptime: 3d 1h 36m
|
||||
.:/++++++/::::/++++++/:` Packages: 56
|
||||
.:///////////////////////:` Shell: bash 3.2.57
|
||||
////////////////////////` Resolution: 2560x1600 1920x1200
|
||||
-+++++++++++++++++++++++` DE: Aqua
|
||||
/++++++++++++++++++++++/ WM: Quartz Compositor
|
||||
/sssssssssssssssssssssss. WM Theme: Blue
|
||||
:ssssssssssssssssssssssss- Font: Not Found
|
||||
osssssssssssssssssssssssso/` CPU: Intel Core i5-4288U CPU @ 2.60GHz
|
||||
`syyyyyyyyyyyyyyyyyyyyyyyy+` GPU: Intel Iris
|
||||
`ossssssssssssssssssssss/ RAM: 6405MB / 8192MB
|
||||
:ooooooooooooooooooo+.
|
||||
`:+oo+/:-..-:/+o+/-
|
||||
|
||||
Taking shot in 3.. 2.. 1.. 0.
|
||||
==> Uploading your screenshot now...your screenshot can be viewed at http://imgur.com/HKIUznn
|
||||
|
||||
You can visit [http://imgur.com/HKIUznn][2] to see uploaded screenshot.
|
||||
|
||||
### Say hello to linux_logo ###
|
||||
|
||||
The linux_logo program generates a color ANSI picture of a penguin which includes some system information obtained from the /proc filesystem.
|
||||
|
||||
#### Installation ####
|
||||
|
||||
Simply type the following command as per your Linux distro.
|
||||
|
||||
#### Debian/Ubutnu/Mint ####
|
||||
|
||||
# apt-get install linux_logo
|
||||
|
||||
#### CentOS/RHEL/Older Fedora ####
|
||||
|
||||
# yum install linux_logo
|
||||
|
||||
#### Fedora Linux v22+ or newer ####
|
||||
|
||||
# dnf install linux_logo
|
||||
|
||||
#### Run it ####
|
||||
|
||||
Simply type the following command:
|
||||
|
||||
$ linux_logo
|
||||
|
||||
|
||||
|
||||
linux_logo in action
|
||||
|
||||
#### But wait, there's more! ####
|
||||
|
||||
You can see a list of compiled in logos using:
|
||||
|
||||
$ linux_logo -f -L list
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
Available Built-in Logos:
|
||||
Num Type Ascii Name Description
|
||||
1 Classic Yes aix AIX Logo
|
||||
2 Banner Yes bsd_banner FreeBSD Logo
|
||||
3 Classic Yes bsd FreeBSD Logo
|
||||
4 Classic Yes irix Irix Logo
|
||||
5 Banner Yes openbsd_banner OpenBSD Logo
|
||||
6 Classic Yes openbsd OpenBSD Logo
|
||||
7 Banner Yes solaris The Default Banner Logos
|
||||
8 Banner Yes banner The Default Banner Logo
|
||||
9 Banner Yes banner-simp Simplified Banner Logo
|
||||
10 Classic Yes classic The Default Classic Logo
|
||||
11 Classic Yes classic-nodots The Classic Logo, No Periods
|
||||
12 Classic Yes classic-simp Classic No Dots Or Letters
|
||||
13 Classic Yes core Core Linux Logo
|
||||
14 Banner Yes debian_banner_2 Debian Banner 2
|
||||
15 Banner Yes debian_banner Debian Banner (white)
|
||||
16 Classic Yes debian Debian Swirl Logos
|
||||
17 Classic Yes debian_old Debian Old Penguin Logos
|
||||
18 Classic Yes gnu_linux Classic GNU/Linux
|
||||
19 Banner Yes mandrake Mandrakelinux(TM) Banner
|
||||
20 Banner Yes mandrake_banner Mandrake(TM) Linux Banner
|
||||
21 Banner Yes mandriva Mandriva(TM) Linux Banner
|
||||
22 Banner Yes pld PLD Linux banner
|
||||
23 Classic Yes raspi An ASCII Raspberry Pi logo
|
||||
24 Banner Yes redhat RedHat Banner (white)
|
||||
25 Banner Yes slackware Slackware Logo
|
||||
26 Banner Yes sme SME Server Banner Logo
|
||||
27 Banner Yes sourcemage_ban Source Mage GNU/Linux banner
|
||||
28 Banner Yes sourcemage Source Mage GNU/Linux large
|
||||
29 Banner Yes suse SUSE Logo
|
||||
30 Banner Yes ubuntu Ubuntu Logo
|
||||
|
||||
Do "linux_logo -L num" where num is from above to get the appropriate logo.
|
||||
Remember to also use -a to get ascii version.
|
||||
|
||||
To see aix logo, enter:
|
||||
|
||||
$ linux_logo -f -L aix
|
||||
|
||||
To see openbsd logo:
|
||||
|
||||
$ linux_logo -f -L openbsd
|
||||
|
||||
Or just see some random Linux logo:
|
||||
|
||||
$ linux_logo -f -L random_xy
|
||||
|
||||
You [can combine bash for loop as follows to display various logos][3], enter:
|
||||
|
||||

|
||||
|
||||
Gif 01: linux_logo and bash for loop for fun and profie
|
||||
|
||||
### Getting help ###
|
||||
|
||||
Simply type the following command:
|
||||
|
||||
$ screefetch -h
|
||||
$ linux_logo -h
|
||||
|
||||
**References**
|
||||
|
||||
- [screenFetch home page][4]
|
||||
- [linux_logo home page][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/hardware/howto-display-linux-logo-in-bash-terminal-using-screenfetch-linux_logo/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[2]:http://imgur.com/HKIUznn
|
||||
[3]:http://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[4]:https://github.com/KittyKatt/screenFetch
|
||||
[5]:https://github.com/deater/linux_logo
|
||||
@ -0,0 +1,105 @@
|
||||
|
||||
translating by ezio
|
||||
|
||||
How to Setup Node JS v4.0.0 on Ubuntu 14.04 / 15.04
|
||||
================================================================================
|
||||
Hi everyone, Node.JS Version 4.0.0 has been out, the popular server-side JavaScript platform has combines the Node.js and io.js code bases. This release represents the combined efforts encapsulated in both the Node.js project and the io.js project that are now combined in a single codebase. The most important change is this Node.js is ships with version 4.5 of Google's V8 JavaScript engine, which is the same version that ships with the current Chrome browser. So, being able to more closely track V8’s releases means Node.js runs JavaScript faster, more securely, and with the ability to use many desirable ES6 language features.
|
||||
|
||||

|
||||
|
||||
Node.js 4.0.0 aims to provide an easy update path for current users of io.js and node as there are no major API changes. Let’s see how you can easily get it installed and setup on Ubuntu server by following this simple article.
|
||||
|
||||
### Basic System Setup ###
|
||||
|
||||
Node works perfectly on Linux, Macintosh, and Solaris operating systems and among the Linux operating systems it has the best results using Ubuntu OS. That's why we are to setup it Ubuntu 15.04 while the same steps can be followed using Ubuntu 14.04.
|
||||
|
||||
#### 1) System Resources ####
|
||||
|
||||
The basic system resources for Node depend upon the size of your infrastructure requirements. So, here in this tutorial we will setup Node with 1 GB RAM, 1 GHz Processor and 10 GB of available disk space with minimal installation packages installed on the server that is no web or database server packages are installed.
|
||||
|
||||
#### 2) System Update ####
|
||||
|
||||
It always been recommended to keep your system upto date with latest patches and updates, so before we move to the installation on Node, let's login to your server with super user privileges and run update command.
|
||||
|
||||
# apt-get update
|
||||
|
||||
#### 3) Installing Dependencies ####
|
||||
|
||||
Node JS only requires some basic system and software utilities to be present on your server, for its successful installation like 'make' 'gcc' and 'wget'. Let's run the below command to get them installed if they are not already present.
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### Download Latest Node JS v4.0.0 ###
|
||||
|
||||
Let's download the latest Node JS version 4.0.0 by following this link of [Node JS Download Page][1].
|
||||
|
||||

|
||||
|
||||
We will copy the link location of its latest package and download it using 'wget' command as shown.
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
Once download completes, unpack using 'tar' command as shown.
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### Installing Node JS v4.0.0 ###
|
||||
|
||||
Now we have to start the installation of Node JS from its downloaded source code. So, change your directory and configure the source code by running its configuration script before compiling it on your ubuntu server.
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
Now run the 'make install' command to compile the Node JS installation package as shown.
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
The make command will take a couple of minutes while compiling its binaries so after executinf above command, wait for a while and keep calm.
|
||||
|
||||
### Testing Node JS Installation ###
|
||||
|
||||
Once the compilation process is complete, we will test it if every thing went fine. Let's run the following command to confirm the installed version of Node JS.
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
By executing 'node' without any arguments from the command-line you will be dropped into the REPL (Read-Eval-Print-Loop) that has simplistic emacs line-editing where you can interactively run JavaScript and see the results.
|
||||
|
||||

|
||||
|
||||
### Writing Test Program ###
|
||||
|
||||
We can also try out a very simple console program to test the successful installation and proper working of Node JS. To do so we will create a file named "test.js" and write the following code into it and save the changes made in the file as shown.
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
Now in order to run the above program, from the command prompt run the below command.
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
So, upon successful installation we will get the output as shown in the screen, where as in the above program it loads the "util" class into a variable "util" and then uses the "util" object to perform the console tasks. While the console.log is a command similar to the cout in C++.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
That’s it. Hope this gives you a good idea of Node.js going with Node.js on Ubuntu. If you are new to developing applications with Node.js. After all we can say that we can expect significant performance gains with Node JS Version 4.0.0.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -0,0 +1,78 @@
|
||||
translating by ezio
|
||||
|
||||
Linux FAQs with Answers--How to check weather forecasts from the command line on Linux
|
||||
================================================================================
|
||||
> **Question**: I often check local weather forecasts on the Linux desktop. However, is there an easy way to access weather forecast information in the terminal environment, where I don't have access to desktop widgets or web browser?
|
||||
|
||||
For Linux desktop users, there are many ways to access weather forecasts, e.g., using standalone weather apps, desktop widgets, or panel applets. If your work environment is terminal-based, there are also several ways to access weather forecasts from the command line.
|
||||
|
||||
Among them is [wego][1], **a cute little weather app for the terminal**. Using an ncurses-based fancy interface, this command-line app allows you to see current weather conditions and forecasts at a glance. It retrieves the weather forecasts for the next 5 days via a weather forecast API.
|
||||
|
||||
### Install Wego on Linux ###
|
||||
|
||||
Installation of wego is pretty simple. wego is written in Go language, thus the first step is to [install Go language][2]. After installing Go, proceed to install wego as follows.
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
The wego tool will be installed under $GOPATH/bin. So add $GOPATH/bin to your $PATH variable.
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
Now go ahead and invoke wego from the command line.
|
||||
|
||||
$ wego
|
||||
|
||||
The first time you run wego, it will generate a config file (~/.wegorc), where you need to specify a weather API key.
|
||||
|
||||
You can obtain a free API key from [worldweatheronline.com][3]. Free sign-up is quick and easy. You only need a valid email address.
|
||||
|
||||

|
||||
|
||||
Your .wegorc will look like the following.
|
||||
|
||||

|
||||
|
||||
Other than API key, you can specify in ~/.wegorc your preferred location, use of metric/imperial units, and language.
|
||||
|
||||
Note that the weather API is rate-limited; 5 queries per second, and 250 queries per day.
|
||||
|
||||
When you invoke wego command again, you will see the latest weather forecast (of your preferred location), shown as follows.
|
||||
|
||||

|
||||
|
||||
The displayed weather information includes: (1) temperature, (2) wind direction and speed, (3) viewing distance, and (4) precipitation amount and probability.
|
||||
|
||||
By default, it will show 3-day weather forecast. To change this behavior, you can supply the number of days (upto five) as an argument. For example, to see 5-day forecast:
|
||||
|
||||
$ wego 5
|
||||
|
||||
If you want to check the weather of any other location, you can specify the city name.
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
1. You encounter the following error while running wego.
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
This error can happen when you run wego on a platform which is not supported by the native Go compiler gc (e.g., Fedora). In that case, you can compile the program using gccgo, a compiler-frontend for Go language. This can be done as follows.
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -0,0 +1,48 @@
|
||||
Enable Automatic System Updates In Ubuntu
|
||||
================================================================================
|
||||
Before seeing **how to enable automatic system updates in Ubuntu**, first let’s see why should we do it in the first place.
|
||||
|
||||
By default Ubuntu checks for updates daily. When there are security updates, it shows immediately but for other updates (i.e. regular software updates) it pop ups once a week. So, if you have been using Ubuntu for a while, this may be a familiar sight for you:
|
||||
|
||||

|
||||
|
||||
Now if you are a normal desktop user, you don’t really care about what kind of updates are these. And this is not entirely a bad thing. You trust Ubuntu to provide you good updates, right? So, you just select ‘Install Now’ most of the time, don’t you?
|
||||
|
||||
And all you do is to click on Install Now, why not enable the automatic system updates? Enabling automatic system updates means all the latest updates will be automatically downloaded and installed without requiring any actions from you. Isn’t it convenient?
|
||||
|
||||
### Enable automatic updates in Ubuntu ###
|
||||
|
||||
I am using Ubuntu 15.04 in this tutorial but the steps are the same for Ubuntu 14.04 as well.
|
||||
|
||||
Go to Unity Dash and look for Software & Updates:
|
||||
|
||||

|
||||
|
||||
This will open the Software sources settings for you. Click on Updates tab here:
|
||||
|
||||

|
||||
|
||||
In here, you’ll see the default settings which is daily check for updates and immediate notification for security updates.
|
||||
|
||||

|
||||
|
||||
All you need to do is to change the action which reads “When there are” to “Download and install automatically”. This will download all the available updates and install them automatically.
|
||||
|
||||

|
||||
|
||||
That’s it. Close it and you have automatic updates enabled in Ubuntu. In fact this tutorial is pretty similar to [changing update notification frequency in Ubuntu][1].
|
||||
|
||||
Do you use automatic updates installation or you prefer to install them manually?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/automatic-system-updates-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/ubuntu-notify-updates-frequently/
|
||||
@ -0,0 +1,81 @@
|
||||
Linux FAQs with Answers--How to find out which CPU core a process is running on
|
||||
================================================================================
|
||||
> Question: I have a Linux process running on my multi-core processor system. How can I find out which CPU core the process is running on?
|
||||
|
||||
When you run performance-critical HPC applications or network-heavy workload on [multi-core NUMA processors][1], CPU/memory affinity is one important factor to consider to maximize their performance. Scheduling closely related processes on the same NUMA node can reduce slow remote memory access. On processors like Intel's Sandy Bridge processor which has an integrated PCIe controller, you want to schedule network I/O workload on the same NUMA node as the NIC card to exploit PCI-to-CPU affinity.
|
||||
|
||||
As part of performance tuning or troubleshooting, you may want to know on which CPU core (or NUMA node) a particular process is currently scheduled.
|
||||
|
||||
Here are several ways to **find out which CPU core is a given Linux process or a thread is scheduled on**.
|
||||
|
||||
### Method One ###
|
||||
|
||||
If a process is explicitly pinned to a particular CPU core using commands like [taskset][2], you can find out the pinned CPU using the following taskset command:
|
||||
|
||||
$ taskset -c -p <pid>
|
||||
|
||||
For example, if the process you are interested in has PID 5357:
|
||||
|
||||
$ taskset -c -p 5357
|
||||
|
||||
----------
|
||||
|
||||
pid 5357's current affinity list: 5
|
||||
|
||||
The output says the process is pinned to CPU core 5.
|
||||
|
||||
However, if you haven't explicitly pinned the process to any CPU core, you will get something like the following as the affinity list.
|
||||
|
||||
pid 5357's current affinity list: 0-11
|
||||
|
||||
The output indicates that the process can potentially be scheduled on any CPU core from 0 to 11. So in this case, taskset is not useful in identifying which CPU core the process is currently assigned to, and you should use other methods as described below.
|
||||
|
||||
### Method Two ###
|
||||
|
||||
The ps command can tell you the CPU ID each process/thread is currently assigned to (under "PSR" column).
|
||||
|
||||
$ ps -o pid,psr,comm -p <pid>
|
||||
|
||||
----------
|
||||
|
||||
PID PSR COMMAND
|
||||
5357 10 prog
|
||||
|
||||
The output says the process with PID 5357 (named "prog") is currently running on CPU core 10. If the process is not pinned, the PSR column can keep changing over time depending on where the kernel scheduler assigns the process.
|
||||
|
||||
### Method Three ###
|
||||
|
||||
The top command can also show the CPU assigned to a given process. First, launch top command with "p" option. Then press 'f' key, and add "Last used CPU" column to the display. The currently used CPU core will appear under "P" (or "PSR") column.
|
||||
|
||||
$ top -p 5357
|
||||
|
||||

|
||||
|
||||
Compared to ps command, the advantage of using top command is that you can continuously monitor how the assigned CPU changes over time.
|
||||
|
||||
### Method Four ###
|
||||
|
||||
Yet another method to check the currently used CPU of a process/thread is to use [htop command][3].
|
||||
|
||||
Launch htop from the command line. Press <F2> key, go to "Columns", and add PROCESSOR under "Available Columns".
|
||||
|
||||
The currently used CPU ID of each process will appear under "CPU" column.
|
||||
|
||||

|
||||
|
||||
Note that all previous commands taskset, ps and top assign CPU core IDs 0, 1, 2, ..., N-1. However, htop assigns CPU core IDs starting from 1 (upto N).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/cpu-core-process-is-running.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[2]:http://xmodulo.com/run-program-process-specific-cpu-cores-linux.html
|
||||
[3]:http://ask.xmodulo.com/install-htop-centos-rhel.html
|
||||
@ -0,0 +1,211 @@
|
||||
RHCE Series: Implementing HTTPS through TLS using Network Security Service (NSS) for Apache
|
||||
================================================================================
|
||||
If you are a system administrator who is in charge of maintaining and securing a web server, you can’t afford to not devote your very best efforts to ensure that data served by or going through your server is protected at all times.
|
||||
|
||||

|
||||
|
||||
RHCE Series: Implementing HTTPS through TLS using Network Security Service (NSS) for Apache – Part 8
|
||||
|
||||
In order to provide more secure communications between web clients and servers, the HTTPS protocol was born as a combination of HTTP and SSL (Secure Sockets Layer) or more recently, TLS (Transport Layer Security).
|
||||
|
||||
Due to some serious security breaches, SSL has been deprecated in favor of the more robust TLS. For that reason, in this article we will explain how to secure connections between your web server and clients using TLS.
|
||||
|
||||
This tutorial assumes that you have already installed and configured your Apache web server. If not, please refer to following article in this site before proceeding further.
|
||||
|
||||
- [Install LAMP (Linux, MySQL/MariaDB, Apache and PHP) on RHEL/CentOS 7][1]
|
||||
|
||||
### Installation of OpenSSL and Utilities ###
|
||||
|
||||
First off, make sure that Apache is running and that both http and https are allowed through the firewall:
|
||||
|
||||
# systemctl start http
|
||||
# systemctl enable http
|
||||
# firewall-cmd --permanent –-add-service=http
|
||||
# firewall-cmd --permanent –-add-service=https
|
||||
|
||||
Then install the necessary packages:
|
||||
|
||||
# yum update && yum install openssl mod_nss crypto-utils
|
||||
|
||||
**Important**: Please note that you can replace mod_nss with mod_ssl in the command above if you want to use OpenSSL libraries instead of NSS (Network Security Service) to implement TLS (which one to use is left entirely up to you, but we will use NSS in this article as it is more robust; for example, it supports recent cryptography standards such as PKCS #11).
|
||||
|
||||
Finally, uninstall mod_ssl if you chose to use mod_nss, or viceversa.
|
||||
|
||||
# yum remove mod_ssl
|
||||
|
||||
### Configuring NSS (Network Security Service) ###
|
||||
|
||||
After mod_nss is installed, its default configuration file is created as /etc/httpd/conf.d/nss.conf. You should then make sure that all of the Listen and VirtualHost directives point to port 443 (default port for HTTPS):
|
||||
|
||||
nss.conf – Configuration File
|
||||
|
||||
----------
|
||||
|
||||
Listen 443
|
||||
VirtualHost _default_:443
|
||||
|
||||
Then restart Apache and check whether the mod_nss module has been loaded:
|
||||
|
||||
# apachectl restart
|
||||
# httpd -M | grep nss
|
||||
|
||||

|
||||
|
||||
Check Mod_NSS Module Loaded in Apache
|
||||
|
||||
Next, the following edits should be made in `/etc/httpd/conf.d/nss.conf` configuration file:
|
||||
|
||||
1. Indicate NSS database directory. You can use the default directory or create a new one. In this tutorial we will use the default:
|
||||
|
||||
NSSCertificateDatabase /etc/httpd/alias
|
||||
|
||||
2. Avoid manual passphrase entry on each system start by saving the password to the database directory in /etc/httpd/nss-db-password.conf:
|
||||
|
||||
NSSPassPhraseDialog file:/etc/httpd/nss-db-password.conf
|
||||
|
||||
Where /etc/httpd/nss-db-password.conf contains ONLY the following line and mypassword is the password that you will set later for the NSS database:
|
||||
|
||||
internal:mypassword
|
||||
|
||||
In addition, its permissions and ownership should be set to 0640 and root:apache, respectively:
|
||||
|
||||
# chmod 640 /etc/httpd/nss-db-password.conf
|
||||
# chgrp apache /etc/httpd/nss-db-password.conf
|
||||
|
||||
3. Red Hat recommends disabling SSL and all versions of TLS previous to TLSv1.0 due to the POODLE SSLv3 vulnerability (more information [here][2]).
|
||||
|
||||
Make sure that every instance of the NSSProtocol directive reads as follows (you are likely to find only one if you are not hosting other virtual hosts):
|
||||
|
||||
NSSProtocol TLSv1.0,TLSv1.1
|
||||
|
||||
4. Apache will refuse to restart as this is a self-signed certificate and will not recognize the issuer as valid. For this reason, in this particular case you will have to add:
|
||||
|
||||
NSSEnforceValidCerts off
|
||||
|
||||
5. Though not strictly required, it is important to set a password for the NSS database:
|
||||
|
||||
# certutil -W -d /etc/httpd/alias
|
||||
|
||||
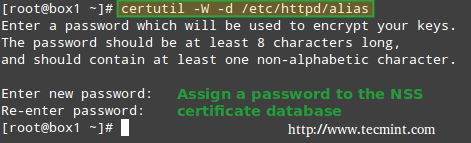
|
||||
|
||||
Set Password for NSS Database
|
||||
|
||||
### Creating a Apache SSL Self-Signed Certificate ###
|
||||
|
||||
Next, we will create a self-signed certificate that will identify the server to our clients (please note that this method is not the best option for production environments; for such use you may want to consider buying a certificate verified by a 3rd trusted certificate authority, such as DigiCert).
|
||||
|
||||
To create a new NSS-compliant certificate for box1 which will be valid for 365 days, we will use the genkey command. When this process completes:
|
||||
|
||||
# genkey --nss --days 365 box1
|
||||
|
||||
Choose Next:
|
||||
|
||||

|
||||
|
||||
Create Apache SSL Key
|
||||
|
||||
You can leave the default choice for the key size (2048), then choose Next again:
|
||||
|
||||

|
||||
|
||||
Select Apache SSL Key Size
|
||||
|
||||
Wait while the system generates random bits:
|
||||
|
||||

|
||||
|
||||
Generating Random Key Bits
|
||||
|
||||
To speed up the process, you will be prompted to enter random text in your console, as shown in the following screencast. Please note how the progress bar stops when no input from the keyboard is received. Then, you will be asked to:
|
||||
|
||||
1. Whether to send the Certificate Sign Request (CSR) to a Certificate Authority (CA): Choose No, as this is a self-signed certificate.
|
||||
|
||||
2. to enter the information for the certificate.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" src="//www.youtube.com/embed/mgsfeNfuurA" allowfullscreen="allowfullscreen"></iframe>
|
||||
|
||||
Finally, you will be prompted to enter the password to the NSS certificate that you set earlier:
|
||||
|
||||
# genkey --nss --days 365 box1
|
||||
|
||||

|
||||
|
||||
Apache NSS Certificate Password
|
||||
|
||||
At anytime, you can list the existing certificates with:
|
||||
|
||||
# certutil –L –d /etc/httpd/alias
|
||||
|
||||

|
||||
|
||||
List Apache NSS Certificates
|
||||
|
||||
And delete them by name (only if strictly required, replacing box1 by your own certificate name) with:
|
||||
|
||||
# certutil -d /etc/httpd/alias -D -n "box1"
|
||||
|
||||
if you need to.c
|
||||
|
||||
### Testing Apache SSL HTTPS Connections ###
|
||||
|
||||
Finally, it’s time to test the secure connection to our web server. When you point your browser to https://<web server IP or hostname>, you will get the well-known message “This connection is untrusted“:
|
||||
|
||||

|
||||
|
||||
Check Apache SSL Connection
|
||||
|
||||
In the above situation, you can click on Add Exception and then Confirm Security Exception – but don’t do it yet. Let’s first examine the certificate to see if its details match the information that we entered earlier (as shown in the screencast).
|
||||
|
||||
To do so, click on View… –> Details tab above and you should see this when you select Issuer from the list:
|
||||
|
||||

|
||||
|
||||
Confirm Apache SSL Certificate Details
|
||||
|
||||
Now you can go ahead, confirm the exception (either for this time or permanently) and you will be taken to your web server’s DocumentRoot directory via https, where you can inspect the connection details using your browser’s builtin developer tools:
|
||||
|
||||
In Firefox you can launch it by right clicking on the screen, and choosing Inspect Element from the context menu, specifically through the Network tab:
|
||||
|
||||

|
||||
|
||||
Inspect Apache HTTPS Connection
|
||||
|
||||
Please note that this is the same information as displayed before, which was entered during the certificate previously. There’s also a way to test the connection using command line tools:
|
||||
|
||||
On the left (testing SSLv3):
|
||||
|
||||
# openssl s_client -connect localhost:443 -ssl3
|
||||
|
||||
On the right (testing TLS):
|
||||
|
||||
# openssl s_client -connect localhost:443 -tls1
|
||||
|
||||

|
||||
|
||||
Testing Apache SSL and TLS Connections
|
||||
|
||||
Refer to the screenshot above for more details.
|
||||
|
||||
### Summary ###
|
||||
|
||||
As I’m sure you already know, the presence of HTTPS inspires trust in visitors who may have to enter personal information in your site (from user names and passwords all the way to financial / bank account information).
|
||||
|
||||
In that case, you will want to get a certificate signed by a trusted Certificate Authority as we explained earlier (the steps to set it up are identical with the exception that you will need to send the CSR to a CA, and you will get the signed certificate back); otherwise, a self-signed certificate as the one used in this tutorial will do.
|
||||
|
||||
For more details on the use of NSS, please refer to the online help about [mod-nss][3]. And don’t hesitate to let us know if you have any questions or comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-apache-https-self-signed-certificate-using-nss/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[1]:http://www.tecmint.com/author/gacanepa/
|
||||
[2]:https://access.redhat.com/articles/1232123
|
||||
[3]:https://git.fedorahosted.org/cgit/mod_nss.git/plain/docs/mod_nss.html
|
||||
@ -0,0 +1,69 @@
|
||||
Linux有问必答--如何删除Ubuntu上不再使用的老内核
|
||||
================================================================================
|
||||
> **提问**:过去我已经在我的Ubuntu上升级了几次内核。现在我想要删除这些旧的内核镜像来节省我的磁盘空间。如何用最简单的方法删除Ubuntu上先前版本的内核?
|
||||
|
||||
在Ubuntu上,有几个方法来升级内核。在Ubuntu桌面中,软件更新允许你每天检查并更新到最新的内核上。在Ubuntu服务器上,一个无人值守的包会自动更新内核最为一项最要的安全更新。然而,你可以手动用apt-get或者aptitude命令来更新。
|
||||
|
||||
随着时间的流逝,持续的内核更新会在系统中积聚大量的不再使用的内核,浪费你的磁盘空间。每个内核镜像和其相关联的模块/头文件会占用200-400MB的磁盘空间,因此由不再使用的内核而浪费的磁盘空间会快速地增加。
|
||||
|
||||
|
||||
|
||||
GRUB管理器为每个旧内核都维护了一个GRUB入口,防止你想要进入它们。
|
||||
|
||||
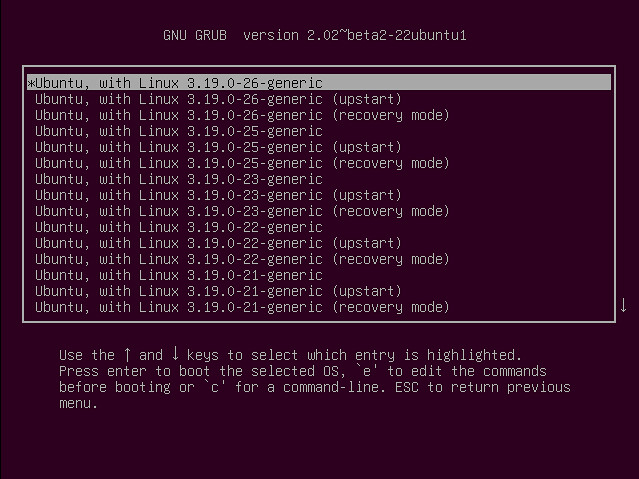
|
||||
|
||||
作为磁盘清理的一部分,如果你不再使用这些,你可以考虑清理掉这些镜像。
|
||||
|
||||
### 如何清理旧内核镜像 ###
|
||||
|
||||
在删除旧内核之前,记住最好留有2个最近的内核(最新的和上一个版本),以防主要的版本出错。现在就让我们看看如何在Ubuntu上清理旧内核。
|
||||
|
||||
在Ubuntu内核镜像包哈了以下的包。
|
||||
|
||||
- **linux-image-<VERSION-NUMBER>**: 内核镜像
|
||||
- **linux-image-extra-<VERSION-NUMBER>**: 额外的内核模块
|
||||
- **linux-headers-<VERSION-NUMBER>**: 内核头文件
|
||||
|
||||
首先检查系统中安装的内核镜像。
|
||||
|
||||
$ dpkg --list | grep linux-image
|
||||
$ dpkg --list | grep linux-headers
|
||||
|
||||
在列出的内核镜像中,你可以移除一个特定的版本(比如3.19.0-15)。
|
||||
|
||||
$ sudo apt-get purge linux-image-3.19.0-15
|
||||
$ sudo apt-get purge linux-headers-3.19.0-15
|
||||
|
||||
上面的命令会删除内核镜像和它相关联的内核模块和头文件。
|
||||
|
||||
updated to remove the corresponding GRUB entry from GRUB menu.
|
||||
注意如果你还没有升级内核那么删除旧内核会自动触发安装新内核。这样在删除旧内核之后,GRUB配置会自动升级来移除GRUB菜单中相关GRUB入口。
|
||||
|
||||
如果你有很多没用的内核,你可以用shell表达式来一次性地删除多个内核。注意这个括号表达式只在bash或者兼容的shell中才有效。
|
||||
|
||||
$ sudo apt-get purge linux-image-3.19.0-{18,20,21,25}
|
||||
$ sudo apt-get purge linux-headers-3.19.0-{18,20,21,25}
|
||||
|
||||

|
||||
|
||||
上面的命令会删除4个内核镜像:3.19.0-18、3.19.0-20、3.19.0-21 和 3.19.0-25。
|
||||
|
||||
如果GRUB配置由于任何原因在删除旧内核后没有正确升级,你可以尝试手动用update-grub2命令来更新配置。
|
||||
|
||||
$ sudo update-grub2
|
||||
|
||||
现在就重启来验证GRUB菜单已经正确清理了。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/remove-kernel-images-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -1,258 +0,0 @@
|
||||
RHCSA 系列:使用 Nano 和 Vim 编辑文本文件/使用 grep 和 regexps 分析文本 – Part 4
|
||||
================================================================================
|
||||
作为系统管理员的日常职责的一部分,每个系统管理员都必须处理文本文件,这包括编辑现存文件(大多可能是配置文件),或创建新的文件。有这样一个说法,假如你想在 Linux 世界中挑起一场圣战,你可以询问系统管理员们,什么是他们最喜爱的编辑器以及为什么。在这篇文章中,我们并不打算那样做,但我们将向你呈现一些技巧,这些技巧对使用两款在 RHEL 7 中最为常用的文本编辑器: nano(由于其简单和易用,特别是对于新手来说) 和 vi/m(由于其自身的几个特色使得它不仅仅是一个简单的编辑器)来说都大有裨益。我确信你可以找到更多的理由来使用其中的一个或另一个,或许其他的一些编辑器如 emacs 或 pico。这完全取决于你。
|
||||
|
||||

|
||||
|
||||
RHCSA: 使用 Nano 和 Vim 编辑文本文件 – Part 4
|
||||
|
||||
### 使用 Nano 编辑器来编辑文件 ###
|
||||
|
||||
要启动 nano,你可以在命令提示符下输入 `nano`,或选择性地跟上一个文件名(在这种情况下,若文件存在,它将在编辑模式中被打开)。若文件不存在,或我们省略了文件名, nano 也将在 编辑模式下开启,但将为我们开启一个空白屏以便开始输入:
|
||||
|
||||

|
||||
|
||||
Nano 编辑器
|
||||
|
||||
正如你在上一张图片中所见的那样, nano 在屏幕的底部呈现出一些功能,它们可以通过暗指的快捷键来触发(^,即插入记号,代指 Ctrl 键)。它们中的一些是:
|
||||
|
||||
- Ctrl + G: 触发一个帮助菜单,带有一个关于功能和相应的描述的完整列表;
|
||||
- Ctrl + X: 离开当前文件,假如更改没有被保存,则它们将被丢弃;
|
||||
- Ctrl + R: 通过指定一个完整的文件路径,让你选择一个文件来将该文件的内容插入到当前文件中;
|
||||
|
||||

|
||||
|
||||
Nano 编辑器帮助菜单
|
||||
|
||||
- Ctrl + O: 保存更改到一个文件。它将让你用一个与源文件相同或不同的名称来保存该文件,然后按 Enter 键来确认。
|
||||
|
||||

|
||||
|
||||
Nano 编辑器的保存更改模式
|
||||
|
||||
- Ctrl + X: 离开当前文件,假如更改没有被保存,则它们将被丢弃;
|
||||
- Ctrl + R: 通过指定一个完整的文件路径,让你选择一个文件来将该文件的内容插入到当前文件中;
|
||||
|
||||

|
||||
|
||||
Nano: 插入文件内容到主文件中
|
||||
|
||||
上图的操作将把 `/etc/passwd` 的内容插入到当前文件中。
|
||||
|
||||
- Ctrl + K: 剪切当前行;
|
||||
- Ctrl + U: 粘贴;
|
||||
- Ctrl + C: 取消当前的操作并返回先前的屏幕;
|
||||
|
||||
为了轻松地在打开的文件中浏览, nano 提供了下面的功能:
|
||||
|
||||
- Ctrl + F 和 Ctrl + B 分别先前或向后移动光标;而 Ctrl + P 和 Ctrl + N 则分别向上或向下移动一行,功能与箭头键相同;
|
||||
- Ctrl + space 和 Alt + space 分别向前或向后移动一个单词;
|
||||
|
||||
最后,
|
||||
|
||||
- 假如你想将光标移动到文档中的特定位置,使用 Ctrl + _ (下划线) 并接着输入 X,Y 将准确地带你到 第 X 行,第 Y 列。
|
||||
|
||||

|
||||
|
||||
在 nano 中定位到具体的行和列
|
||||
|
||||
上面的例子将带你到当前文档的第 15 行,第 14 列。
|
||||
|
||||
假如你可以回忆起你早期的 Linux 岁月,特别是当你刚从 Windows 迁移到 Linux 中,你就可能会同意:对于一个新手来说,使用 nano 来开始学习是最好的方式。
|
||||
|
||||
### 使用 Vim 编辑器来编辑文件 ###
|
||||
|
||||
|
||||
Vim 是 vi 的加强版本,它是 Linux 中一个著名的文本编辑器,可在所有兼容 POSIX 的 *nix 系统中获取到,例如在 RHEL 7 中。假如你有机会并可以安装 Vim,请继续;假如不能,这篇文章中的大多数(若不是全部)的提示也应该可以正常工作。
|
||||
|
||||
Vim 的一个出众的特点是可以在多个不同的模式中进行操作:
|
||||
|
||||
- 命令模式将允许你在文件中跳转和输入命令,这些命令是由一个或多个字母组成的简洁且对大小写敏感的组合。假如你想重复执行某个命令特定次,你可以在这个命令前加上需要重复的次数(这个规则只有极少数例外)。例如, yy(或 Y,yank 的缩写)可以复制整个当前行,而 4yy(或 4Y)则复制整个当前行到接着的 3 行(总共 4 行)。
|
||||
- 在 ex 模式中,你可以操作文件(包括保存当前文件和运行外部的程序或命令)。要进入 ex 模式,你必须在命令模式前(或其他词前,Esc + :)输入一个冒号(:),再直接跟上你想使用的 ex 模式命令的名称。
|
||||
- 对于插入模式,可以输入字母 i 进入,我们只需要输入文字即可。大多数的键击结果都将出现在屏幕中的文本中。
|
||||
- 我们总是可以通过敲击 Esc 键来进入命令模式(无论我们正工作在哪个模式下)。
|
||||
|
||||
现在,让我们看看如何在 vim 中执行在上一节列举的针对 nano 的相同的操作。不要忘记敲击 Enter 键来确认 vim 命令。
|
||||
|
||||
为了从命令行中获取 vim 的完整手册,在命令模式下键入 `:help` 并敲击 Enter 键:
|
||||
|
||||

|
||||
|
||||
vim 编辑器帮助菜单
|
||||
|
||||
上面的小节呈现出一个目录列表,而定义过的小节则主要关注 Vim 的特定话题。要浏览某一个小节,可以将光标放到它的上面,然后按 Ctrl + ] (闭方括号)。注意,底部的小节展示的是当前文件的内容。
|
||||
|
||||
1. 要保存更改到文件,在命令模式中运行下面命令中的任意一个,就可以达到这个目的:
|
||||
|
||||
```
|
||||
:wq!
|
||||
:x!
|
||||
ZZ (是的,两个 ZZ,前面无需添加冒号)
|
||||
```
|
||||
|
||||
2. 要离开并丢弃更改,使用 `:q!`。这个命令也将允许你离开上面描述过的帮助菜单,并返回到命令模式中的当前文件。
|
||||
|
||||
3. 剪切 N 行:在命令模式中键入 `Ndd`。
|
||||
|
||||
4. 复制 M 行:在命令模式中键入 `Myy`。
|
||||
|
||||
5. 粘贴先前剪贴或复制过的行:在命令模式中按 `P`键。
|
||||
|
||||
6. 要插入另一个文件的内容到当前文件:
|
||||
|
||||
:r filename
|
||||
|
||||
例如,插入 `/etc/fstab` 的内容,可以这样做:
|
||||
|
||||
[在 vi 编辑器中插入文件的内容](http://www.tecmint.com/wp-content/uploads/2015/03/Insert-Content-vi-Editor.png)
|
||||
|
||||
在 vi 编辑器中插入文件的内容
|
||||
|
||||
7. 插入一个命名的输出到当前文档:
|
||||
|
||||
:r! command
|
||||
|
||||
例如,要在光标所在的当前位置后面插入日期和时间:
|
||||
|
||||

|
||||
|
||||
在 vi 编辑器中插入时间和日期
|
||||
|
||||
在另一篇我写的文章中,([LFCS 系列的 Part 2][1]),我更加详细地解释了在 vim 中可用的键盘快捷键和功能。或许你可以参考那个教程来查看如何使用这个强大的文本编辑器的更深入的例子。
|
||||
|
||||
### 使用 Grep 和正则表达式来分析文本 ###
|
||||
|
||||
到现在为止,你已经学习了如何使用 nano 或 vim 创建和编辑文件。打个比方说,假如你成为了一个文本编辑器忍者 – 那又怎样呢? 在其他事情上,你也需要知道如何在文本中搜索正则表达式。
|
||||
|
||||
正则表达式(也称为 "regex" 或 "regexp") 是一种识别一个特定文本字符串或模式的方式,使得一个程序可以将这个模式和任意的文本字符串相比较。尽管利用 grep 来使用正则表达式值得用一整篇文章来描述,这里就让我们复习一些基本的知识:
|
||||
|
||||
**1. 最简单的正则表达式是一个由数字和字母构成的字符串(即,单词 "svm") 或两个(在使用两个字符串时,你可以使用 `|`(或) 操作符):**
|
||||
|
||||
# grep -Ei 'svm|vmx' /proc/cpuinfo
|
||||
|
||||
上面命令的输出结果中若有这两个字符串之一的出现,则标志着你的处理器支持虚拟化:
|
||||
|
||||

|
||||
|
||||
正则表达式示例
|
||||
|
||||
**2. 第二种正则表达式是一个范围列表,由方括号包裹。**
|
||||
|
||||
例如, `c[aeiou]t` 匹配字符串 cat,cet,cit,cot 和 cut,而 `[a-z]` 和 `[0-9]` 则相应地匹配小写字母或十进制数字。假如你想重复正则表达式 X 次,在正则表达式的后面立即输入 `{X}`即可。
|
||||
|
||||
例如,让我们从 `/etc/fstab` 中析出存储设备的 UUID:
|
||||
|
||||
# grep -Ei '[0-9a-f]{8}-([0-9a-f]{4}-){3}[0-9a-f]{12}' -o /etc/fstab
|
||||
|
||||

|
||||
|
||||
从一个文件中析出字符串
|
||||
|
||||
方括号中的第一个表达式 `[0-9a-f]` 被用来表示小写的十六进制字符,`{8}`是一个量词,暗示前面匹配的字符串应该重复的次数(在一个 UUID 中的开头序列是一个 8 个字符长的十六进制字符串)。
|
||||
|
||||
在圆括号中,量词 `{4}`和连字符暗示下一个序列是一个 4 个字符长的十六进制字符串,接着的量词 `({3})`表示前面的表达式要重复 3 次。
|
||||
|
||||
最后,在 UUID 中的最后一个 12 个字符长的十六进制字符串可以由 `[0-9a-f]{12}` 取得, `-o` 选项表示只打印出在 `/etc/fstab`中匹配行中的匹配的(非空)部分。
|
||||
|
||||
**3. POSIX 字符类 **
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="201"></colgroup>
|
||||
<colgroup width="440"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center" height="25" bgcolor="#999999" style="border: 1px solid #000000;"><b>字符类</b></td>
|
||||
<td align="center" bgcolor="#999999" style="border: 1px solid #000000;"><b>匹配 …</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:alnum:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意字母或数字 [a-zA-Z0-9] </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:alpha:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意字母 [a-zA-Z] </td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:blank:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 空格或制表符</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:cntrl:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意控制字符 (ASCII 码的 0 至 32)</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:digit:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意数字 [0-9]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:graph:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意可见字符</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:lower:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意小写字母 [a-z] </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:print:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意非控制字符 <td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:space:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意空格</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:punct:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意标点字符</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:upper:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意大写字母 [A-Z] </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:xdigit:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意十六进制数字 [0-9a-fA-F]</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [:word:]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意字母,数字和下划线 [a-zA-Z0-9_]</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
例如,我们可能会对查找已添加到我们系统中给真实用户的 UID 和 GID(参考这个系列的 [Part 2][2]来回忆起这些知识)感兴趣。那么,我们将在 `/etc/passwd` 文件中查找 4 个字符长的序列:
|
||||
|
||||
# grep -Ei [[:digit:]]{4} /etc/passwd
|
||||
|
||||

|
||||
|
||||
在文件中查找一个字符串
|
||||
|
||||
上面的示例可能不是真实世界中使用正则表达式的最好案例,但它清晰地启发了我们如何使用 POSIX 字符类来使用 grep 分析文本。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
|
||||
在这篇文章中,我们已经提供了一些技巧来最大地利用针对命令行用户的两个文本编辑器 nano 和 vim,这两个工具都有相关的扩展文档可供阅读,你可以分别查询它们的官方网站(链接在下面给出)以及使用这个系列中的 [Part 1][3] 给出的建议。
|
||||
|
||||
#### 参考文件链接 ####
|
||||
|
||||
- [http://www.nano-editor.org/][4]
|
||||
- [http://www.vim.org/][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-how-to-use-nano-vi-editors/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/vi-editor-usage/
|
||||
[2]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[3]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[4]:http://www.nano-editor.org/
|
||||
[5]:http://www.vim.org/
|
||||
Loading…
Reference in New Issue
Block a user