mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
a part of translation
This commit is contained in:
commit
a25ca0a9d2
@ -1,14 +1,15 @@
|
||||
First 5 Commands When I Connect on a Linux Server
|
||||
连接到 Linux 服务器时首先要运行的 5 个命令
|
||||
============================================================
|
||||
|
||||

|
||||
[Creative Commons Attribution][1][Sylvain Kalache][2][First 5 shell commands I type when I connect to a linux server][3]
|
||||

|
||||
|
||||
After half a decade working as a system administrator/SRE, I know where to start when I am connecting to a Linux server. There is a set of information that you must know about the server in order to properly, well most of the time, debug it.
|
||||
[Creative Commons Attribution][1][Sylvain Kalache][2][当我连接到 Linux 服务器时运行的前 5 个命令][3]
|
||||
|
||||
### First 60 seconds on a Linux server
|
||||
作为一个系统管理员/SRE 工作 5 年后,我知道当我连接到一台 Linux 服务器时我首先应该做什么。这里有一系列关于服务器你必须了解的信息,以便你可以(在大部分时间里)更好的调试该服务器。
|
||||
|
||||
These commands are well known for experienced software engineers but I realized that for a beginner who is getting started with Linux systems, such as my students at [Holberton School][5], it is not obvious. That’s why I decided to share the list of the first 5 commands I type when I connect on a Linux server.
|
||||
### 连上 Linux 服务器的第一分钟
|
||||
|
||||
这些命令对于有经验的软件工程师来说都非常熟悉,但我意识到对于一个刚开始接触 Linux 系统的初学者来说,例如我在 [Holberton 学校][5]任教的学生,却并非如此。这也是我为什么决定分享当我连上 Linux 服务器首先要运行的前 5 个命令的原因。
|
||||
|
||||
```
|
||||
w
|
||||
@ -18,7 +19,7 @@ df
|
||||
netstat
|
||||
```
|
||||
|
||||
These 5 commands are shipped with any Linux distribution so you can use them everywhere without extra installation needed.
|
||||
这 5 个命令在任何一个 Linux 发行版中都有,因此不需要额外的安装步骤你就可以直接使用它们。
|
||||
|
||||
### w:
|
||||
|
||||
@ -31,9 +32,9 @@ root pts/1 104-7-14-91.ligh 23:40 5.00s 0.01s 0.03s sshd: root [priv]
|
||||
[ubuntu@ip-172-31-48-251 ~]$
|
||||
```
|
||||
|
||||
A lot of great information in there. First, you can see the server [uptime][6] which is the time during which the server has been continuously running. You can then see what users are connected on the server, quite useful when you want to make sure that you are not impacting a colleague’s work. Finally the [load average][7] will give you a good sense of the server health.
|
||||
这里列出了很多有用的信息。首先,你可以看到服务器运行时间 [uptime][6],也就是服务器持续运行的时间。然后你可以看到有哪些用户连接到了服务器,当你要确认你没有影响你同事工作的时候这非常有用。最后 [load average][7] 能很好的向你展示服务器的健康状态。
|
||||
|
||||
### history:
|
||||
### history
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ~]$ history
|
||||
@ -44,9 +45,9 @@ A lot of great information in there. First, you can see the server [uptime][6]
|
||||
5 cat ../../app/services/discourse_service.rb
|
||||
```
|
||||
|
||||
`History` will tell you what was previously run by the user you are currently connected to. You will learn a lot about what type work was previously performed on the machine, what could have gone wrong with it, and where you might want to start your debugging work.
|
||||
`history` 能告诉你当前连接的用户之前运行了什么命令。你可以看到很多关于这台机器之前在执行什么类型的任务、可能出现了什么错误、可以从哪里开始调试工作等信息。
|
||||
|
||||
### top:
|
||||
### top
|
||||
|
||||
```
|
||||
top - 23:47:54 up 273 days, 21:00, 2 users, load average: 0.02, 0.07, 0.10
|
||||
@ -68,9 +69,9 @@ Swap: 0k total, 0k used, 0k free, 1052320k cached
|
||||
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
|
||||
```
|
||||
|
||||
The next information you want to know: what is currently running on this server. With `top` you can see all running processes, then order them by CPU, memory utilization and catch the ones that are resource intensive.
|
||||
你想知道的下一个信息:服务器当前在执行什么工作。使用 `top` 命令你可以看到所有正在执行的进程,然后可以按照 CPU、内存使用进行排序,并找到占用资源的进程。
|
||||
|
||||
### df:
|
||||
### df
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ~]$ df -h
|
||||
@ -80,9 +81,9 @@ devtmpfs 1.9G 12K 1.9G 1% /dev
|
||||
tmpfs 1.9G 0 1.9G 0% /dev/shm
|
||||
```
|
||||
|
||||
The next important resource that your server needs to have to be working properly is disk space. Running out of it is a very classic issue.
|
||||
你服务器正常工作需要的下一个重要资源就是磁盘空间。磁盘空间消耗完是非常典型的问题。
|
||||
|
||||
### netstat:
|
||||
### netstat
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ec2-user]# netstat -lp
|
||||
@ -97,17 +98,17 @@ tcp 0 0 *:4242 *:* LIST
|
||||
tcp 0 0 *:ssh *:* LISTEN 1209/sshd
|
||||
```
|
||||
|
||||
Computers are a big part of our world now because they have the ability to communicate between each other via sockets. It is critical for you to know on what port and IP your server is listening on and what processes are using those.
|
||||
计算机已成为我们世界的重要一部分,因为它们有通过网络进行相互交流的能力。知道你的服务器正在监听什么端口、IP地址是什么、以及哪些进程在使用它们,这对于你来说都非常重要。
|
||||
|
||||
Obviously this list might change depending on your goal and the amount of existing information you have. For example, when you want to debug specifically for performance, [Netflix came up with a customized list][8]. Do you have a useful command that is not in my top 5? Please share it in the comments section!
|
||||
显然这个列表会随着你的目的和你已有的信息而变化。例如,当你需要调试性能的时候,[Netflix 就有一个自定义的列表][8]。你有任何不在我 Top 5 中的有用命令吗?在评论部分和我们一起分享吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/first-5-commands-when-i-connect-linux-server
|
||||
|
||||
作者:[SYLVAIN KALACHE ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[SYLVAIN KALACHE][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
79
published/20161028 Configuring WINE with Winetricks.md
Normal file
79
published/20161028 Configuring WINE with Winetricks.md
Normal file
@ -0,0 +1,79 @@
|
||||
用 Winetricks 配置 WINE
|
||||
============================================================
|
||||
|
||||
### 简介
|
||||
|
||||
如果 `winecfg` (WINE 的配置工具)是一把螺丝刀,那么 `winetricks` 就是一个钻床。它们各有特长,但是 `winetricks` 真的是一个强大的多的工具。实际上,它甚至可以启动 `winecfg`。
|
||||
|
||||
`winecfg` 让你可以改变 WINE 本身的设置,而 `winetricks` 则可以让你改造实际的 Windows 层,它可以让你安装 Windows 重要的系统组件,比如 .dll 文件和系统字体,还可以允许你修改 Windows 注册表的信息。它还有任务管理器、卸载工具和文件浏览器。
|
||||
|
||||
尽管 `winetricks` 可以做以上这些工作,但是大部分时间我们用到的功能也就是管理 `dll` 文件和 Windows 组件。
|
||||
|
||||
### 安装
|
||||
|
||||
和 `winecfg` 不同,`winetricks` 不是集成在 WINE 中的。这样也没什么问题,由于它实际上只是个脚本文件,你可以在各种发行版上很轻松地下载和使用它。现在,许多发行版把 `winetricks` 打包。只要你喜欢,你也可以下载打包后的版本。不过,有些包可能会比较老旧,所以本指南将使用脚本,毕竟脚本通用且更新及时。默认情况下,它的图形界面有些丑,所以你要是想个性化界面,最好通过你的发行版的包管理器安装一个 `zenity`。
|
||||
|
||||
现在假定你想在你的 `/home` 目录下配置 `winetricks`。 `cd` 到此,然后 `wget` 这个脚本。
|
||||
|
||||
```
|
||||
$ cd ~
|
||||
|
||||
$ wget https://raw.githubusercontent.com/Winetricks/winetricks/master/src/winetricks
|
||||
```
|
||||
|
||||
然后,给这个脚本可执行权限。
|
||||
|
||||
```
|
||||
$ chmod+x winetricks
|
||||
```
|
||||
|
||||
`winetricks` 可以通过命令行运行,在行末指定要安装的东西。但是大部分情况下,你都不知道 .dll 文件或者是你想安装字体确切的名字,那么,这时候最好利用图形界面程序。启动这个程序和其他程序没什么不同,就是在末尾什么都别输入就行了。
|
||||
|
||||
```
|
||||
$ ~/winetricks
|
||||
```
|
||||
|
||||

|
||||
|
||||
当窗口第一次打开时候,将会给你一个有 <ruby>“查看帮助”<rt>View help</rt></ruby> 和 <ruby>“安装应用”<rt>Install an application</rt></ruby> 选项的菜单。一般情况下,我们选择 <ruby>“选择默认的 wineprefix”<rt>Select the default wineprefix</rt></ruby>,这将是你主要使用的选项。其他的也能用,但是不推荐使用。接下来,单击 “OK”,你就会进入到 WINE prefix 的配置菜单,你可以在这完成所有你要使用 `winetricks` 完成的事情。
|
||||
|
||||

|
||||
|
||||
### 字体
|
||||
|
||||

|
||||
|
||||
字体一直很重要,一些应用程序没有字体就没法正常的加载。`winetricks` 可以轻松地安装许多常用 Windows 字体.在配置菜单中,选中 <ruby>“安装字体”<rt>Install a font</rt></ruby> 单选按钮,然后点击 “OK” 即可。
|
||||
|
||||
然后你就会得到一列字体清单,它们都有着相对应的复选框。你很难确切知道你到底需要什么字体,所以一般按每个应用决定使用什么字体,我们可以先安装一款插件 `corefonts`,它包含了大多数 Windows 系统中应用程序所设定的字体。安装它也十分简单,所以可以试试。
|
||||
|
||||
要安装 `corefonts` ,请选择相应的复选框,然后点击 “OK”,你就会看到和在 Windows 下差不多的提示,字体就会被安装了。完成了这个插件的安装,你就会回到先前的菜单界面。接下来就是安装你需要的别的插件,步骤相同。
|
||||
|
||||
### .dll 文件和组件
|
||||
|
||||

|
||||
|
||||
`winetricks` 安装 Windows 下的 .dll 文件和别的组件也十分简单。如果你需要安装的话,在菜单页选择 <ruby>“安装 Windows DLL 或组件”<rt>Install a Windows DLL or component</rt></ruby>,然后点击 “OK”。
|
||||
|
||||
窗口就会进入到另一个菜单界面,其中包含可用的 dll 和其他 Windows 组件。在相应的复选框进行选择,点击 “OK”。脚本就会下载你选择的组件,接着通过 Windows 一般的安装进程进行安装。像 Windows 机器上安装那样跟着提示往下走。可能会有报错信息。很多时候,Windows 安装程序会报错,但是你接着会收到来自 `winetricks` 窗口的消息,说明它正在绕过此问题。这很正常。由于组件之间的相互依赖关系,你可能会也可能不会看到成功安装的信息。只要确保安装完成时候,菜单页中你的选项仍旧处于被选中状态就行了。
|
||||
|
||||
### 注册表
|
||||
|
||||

|
||||
|
||||
你不需要常常编辑注册表中 WINE 对应的值,但是对于有些程序确实需要。技术层面来讲,`winetricks` 不向用户提供注册表编辑器,但是要访问编辑器也很容易。在菜单页选中<ruby>“运行注册表编辑”<rt>Run regedit</rt></ruby>,点击 “OK”,你就可以打开一个简单的注册表编辑器。事实上,写入注册表的值有点超出本篇引导文章的范围了,但是我还要多说一句,如果你已经知道你在干什么,增加一个注册表条目不是很难。注册表有点像电子表格,你可以将正确的值填入右面的格子中。这个说的有点过于简单,但是就是这样的。你可以在以下地址精准地找到你需要在 WINE Appdp 所要填入或编辑的东西。 https://appdb.winehq.org。
|
||||
|
||||
### 结束语
|
||||
|
||||
很明显 `winetricks` 还有许多许多强大的功能,但是本篇指南的目的只是给你一点基础知识,以使用这个强大的工具,使你的程序通过 WINE 运行。WINE Appdb 对每个程序都有相应的设置,将来会越来越丰富。
|
||||
|
||||
------------------
|
||||
via: https://linuxconfig.org/configuring-wine-with-winetricks
|
||||
|
||||
作者:Nick Congleton
|
||||
译者:[Taylor1024](https://github.com/Taylor1024)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -2,114 +2,114 @@
|
||||
============================================================
|
||||

|
||||
|
||||
>来源 : 图片来自 Jen Wike Huger
|
||||
*来源 : 图片来自 Jen Wike Huger*
|
||||
|
||||
JavaScript 即未来趋势所在。
|
||||
|
||||
Javascript 拥有众多的技术领导者的拥护和支持,其中一位就是 WordPress 的作者 Matt Mullenweg , 他表示 [WordPress 开发者][18] 应该学习 JavaScript , 这也清晰地向 WordPress 社区传达了 JavaScript 在未来的重要性。 同时,这一观点也被普遍接受。向着更先进的技术靠拢与过渡也同时保证了 WordPress 在未来的挑战中不会落于人后。
|
||||
Javascript 得到了众多的技术领导者的拥护和支持,其中一位就是 WordPress 的作者 Matt Mullenweg , 他表示 [WordPress 开发者][18] 应该学习 JavaScript , 这也清晰地向 WordPress 社区传达了 JavaScript 在未来的重要性。 同时,这一观点也被普遍接受。向着更先进的技术靠拢与过渡也同时保证了 WordPress 在未来的挑战中不会落于人后。
|
||||
|
||||
JavaScript 同时也是众多站在开源立场的技术中的佼佼者。与现在所流行的观点相反,JavaScript 不是一个工程,而是一个由其核心团队共同制定和维护的开放标准。[ECMAScript][19] , 另一个和 JavaScript 相关的名字, 它虽然不是开源的,但它也有一个开放的标准。
|
||||
JavaScript 同时也是众多站在开源立场的技术中的佼佼者。与现在所流行的观点相反,JavaScript 不是一个工程,而是一个由其核心团队共同制定和维护的开放标准。[ECMAScript][19] , 这是另一个和 JavaScript 相关的名字, 它虽然不是开源的,但它也有一个开放的标准。
|
||||
|
||||
当你在浏览 GitHub 的时候你就可以发现 JavaScript 在当今有多么流行了。而且就 [repository 的数量][20] 而言,JavaScript 绝对位于所有的编程语言当中最顶尖的那一层次。 同时,在 Livecoding.tv 上你也能看出 JavaScript 有多么突出,这里的用户发布的关于 JavaScript 的视频的数量比其他的话题多得多。在写这篇文章的时候(原作者写下这篇文章的日期,非译者翻译日期),Livecoding.tv 上已经有 [45,919 个 用户原创的 JavaScript 视频教程][21] 。
|
||||
当你在浏览 GitHub 的时候你就可以发现 JavaScript 在当今有多么流行了。而且就[仓库的数量][20] 而言,JavaScript 绝对位于所有的编程语言当中最顶尖的那一层次。 同时,在 Livecoding.tv 上你也能看出 JavaScript 有多么突出,这里的用户发布的关于 JavaScript 的视频的数量比其他的话题多得多。在写这篇文章的时候(2016 年底),Livecoding.tv 上已经有 [45,919 个 用户原创的 JavaScript 视频教程][21] 。
|
||||
|
||||
### 热门的开源 JavaScript 框架和库
|
||||
|
||||
回归到主题, 庞大的社区是 JavaScript 的一个得天独厚的优势,同时这也驱动了 JavaScript 的蓬勃发展。这里有数以百千计的成熟的 JavaScript 框架和库供开发者使用,同时这些最优秀的框架和库都是开源的。对当前的 JavaScript 开发者来说,能够使用这些优秀的框架和库来进行快速开发已经是必须技能了。当今的市场需要快速开发,但是,重复造轮子是没有必要的。不论你是一个 JavaScript 新手还是一个资深的 JavaScript 开发者,使用框架和库都能极大提高你的工作效率。
|
||||
回归到主题, 庞大的社区是 JavaScript 的一个得天独厚的优势,同时这也推动了 JavaScript 的蓬勃发展。这里有数以百千计的成熟的 JavaScript 框架和库供开发者使用,同时这些最优秀的框架和库都是开源的。对当前的 JavaScript 开发者来说,能够使用这些优秀的框架和库来进行快速开发已经是必须技能了。当今的市场需要快速开发,但是,重复造轮子是没有必要的。不论你是一个 JavaScript 新手还是一个资深的 JavaScript 开发者,使用框架和库都能极大提高你的工作效率。
|
||||
|
||||
好了,让我们开始吧!
|
||||
|
||||
### 1\. Angular.js
|
||||
#### 1\. Angular.js
|
||||
|
||||
[Angular.js][1] 是目前最热门的 JavaScript 框架之一。它用于开发者构建复杂的 web 应用。Angular.js 背后的思想是它的单页应用 model。同时它 也支持 MVC 架构。在 Angular.js 中 ,开发者可以在前端中使用 JavaScript 代码,并从字面上扩展 HTML词汇。
|
||||
[Angular.js][1] 是目前最热门的 JavaScript 框架之一。它用于开发者构建复杂的 web 应用。Angular.js 背后的思想是它的单页应用 model。同时它 也支持 MVC 架构。在 Angular.js 中 ,开发者可以在前端中使用 JavaScript 代码,并从字面上扩展 HTML 词汇。
|
||||
|
||||
Angular.js 自 2009 年出现以来已经有了很大的改进。Angular 1 当前的稳定版本是 1.5.8/1.2.30 。你也可以试一试 Angular 2 ,相对于 Angular 1 来说它有了重大的改进,但这个新版本仍未在全球范围内被普遍使用。
|
||||
|
||||
在 Angular.js 中,数据绑定是完成作业的一个重要概念。在用户与接口的交互中,当交互完成 view 就会自动更新新值,随即新值与 model 交互以确保一切都是同步的。在底层的逻辑在 model 中执行完成后,DOM 也会随即更新。
|
||||
在 Angular.js 中,数据绑定是完成工作的一个重要概念。在用户与接口的交互中,当交互完成,view 就会自动更新,随即新值与 model 交互以确保一切都是同步的。底层的逻辑在 model 中执行完成后,DOM 也会随即更新。
|
||||
|
||||
### 2\. Backbone.js
|
||||
#### 2\. Backbone.js
|
||||
|
||||
复杂 web 应用并不适用于所有场景。一些较简单的 web 应用框架例如 [Backbone.js][2] 就非常适合学习 web app 开发。Backbone.js 是一个简单的框架,可以快速方便地构建简单的 web 应用。和 Angular.js 一样,Backbone.js 也支持 MVC 。Backbone.js 还有一些其它关键特性如路由,RESTful API 支持,适当的状态管理等等。你甚至还可以用 Backbone.js 来构建单页应用。
|
||||
|
||||
当前的稳定版本是 1.3.3,可以在 [GitHub][22] 中找到。
|
||||
|
||||
### 3\. D3.js
|
||||
#### 3\. D3.js
|
||||
|
||||
[D3.js][3] 是一个优秀的 JavaScript 库,它允许开发者创建具有数据处理功能的富 web 页面。D3.js 使用 SVG, HTML 和 CSS 来实现这一切功能。使用 D3.js ,你可以更轻松地将数据绑定到 DOM 及启用数据驱动事件。使用 D3.js ,你还可以创建高质量的数据驱动的 web 页面来提供一个更易于理解的视觉效果来呈现数据。查看示例 : [LCF 符号哈密顿图][23] ,由 D3.js 强力驱动。
|
||||
[D3.js][3] 是一个优秀的 JavaScript 库,它允许开发者创建具有数据处理功能的富 web 页面。D3.js 使用 SVG、HTML 和 CSS 来实现这一切功能。使用 D3.js ,你可以更轻松地将数据绑定到 DOM 及启用数据驱动事件。使用 D3.js ,你还可以创建高质量的数据驱动的 web 页面来提供一个更易于理解的视觉效果来呈现数据。查看示例 : [LCF 符号哈密顿图][23] ,由 D3.js 强力驱动。
|
||||
|
||||
### 4\. React.js
|
||||
#### 4\. React.js
|
||||
|
||||
[React.js][4] 是一个使用起来很有趣的 JavaScript 框架。和其它的 JavaScript 框架不同,React.js 志在构建一个高可扩展的前端用户界面。React.js 出现于 2013 年,它采用了 BSD 开源协议。它以其能够开发复杂且漂亮的用户界面所带来的优势而迅速发展壮大。
|
||||
[React.js][4] 是一个使用起来很有趣的 JavaScript 框架。和其它的 JavaScript 框架不同,React.js 志在构建一个高可扩展的前端用户界面。React.js 出现于 2013 年,它采用了 BSD 开源协议。它因其能够开发复杂且漂亮的用户界面所带来的优势而迅速发展壮大。
|
||||
|
||||
React.js 背后的核心思想是虚拟 DOM 。虚拟 DOM 在客户端和服务端之间扮演着一个中间人的角色并带来了显著的性能提升。虚拟 DOM 的改变和 server DOM 一样,只需要更新所需的元素,相对于传统的 UI 渲染来说极大提升了渲染速度。
|
||||
React.js 背后的核心思想是虚拟 DOM 。虚拟 DOM 在客户端和服务端之间扮演着一个中间人的角色并带来了显著的性能提升。虚拟 DOM 的改变和服务器端 DOM 一样,只需要更新所需的元素,相对于传统的 UI 渲染来说极大提升了渲染速度。
|
||||
|
||||
你还可以使用 Recat 来实现 meterial 风格的设计,使你能够开发具有无与伦比的性能的 web 应用。
|
||||
|
||||
### 5\. jQuery
|
||||
#### 5\. jQuery
|
||||
|
||||
[jQuery][5] 是一个非常流行的 JavaScript 库,它拥有众多特性例如事件处理,动画等。当你在做一个 web 项目的时候,你不会想要把时间浪费在为一些简单的功能写代码上。jQuery 为减少你的工作量提供了一些易于使用的 API 。这些 API 在所有的常见的浏览器中都能够使用。使用 jQuery, 你可以无缝地控制 DOM 以及 Ajax 这样在近几年来拥有高需求的作业。使用 jQuery, 开发者不必担心一些低级的交互,同时可以使他们的 web 应用的开发更加容易与迅速。
|
||||
[jQuery][5] 是一个非常流行的 JavaScript 库,它拥有众多特性例如事件处理、动画等。当你在做一个 web 项目的时候,你不会想要把时间浪费在为一些简单的功能写代码上。jQuery 为减少你的工作量提供了一些易于使用的 API 。这些 API 在所有的常见的浏览器中都能够使用。使用 jQuery, 你可以无缝地控制 DOM 以及 Ajax 这样在近几年来拥有大量需求的任务。使用 jQuery,开发者不必担心一些低级的交互,同时可以使他们的 web 应用的开发更加容易与迅速。
|
||||
|
||||
jQuery 同时便于分离 HTML 和 JavaScript 代码,使开发者能够编写简洁同时跨浏览器兼容的代码。并且使用 jQuery 创建的 web 应用在将来也易于改善和扩展。
|
||||
jQuery 同时便于分离 HTML 和 JavaScript 代码,使开发者能够编写简洁而跨浏览器兼容的代码。并且使用 jQuery 创建的 web 应用在将来也易于改善和扩展。
|
||||
|
||||
### 6\. Ember.js
|
||||
#### 6\. Ember.js
|
||||
|
||||
[Ember.js][6] 是一个 Angular.js 和 React.js 的功能的混合体。当你在浏览社区的时候你能明显地感受到 Ember.js 的热门程度。Ember.js 的新特性也不断地在添加。它在数据同步方面与 Angular.js 很像。 双向的数据交换可以确保应用的快速性和可扩展性。同时,它还能够帮助开发者创建一些前端元素。
|
||||
[Ember.js][6] 是一个 Angular.js 和 React.js 的功能混合体。当你在浏览社区的时候你能明显地感受到 Ember.js 的热门程度。Ember.js 的新特性也不断地在添加。它在数据同步方面与 Angular.js 很像。 双向的数据交换可以确保应用的快速性和可扩展性。同时,它还能够帮助开发者创建一些前端元素。
|
||||
|
||||
和 React.js 的相似之处在于,Ember.js 提供了同样的服务端虚拟 DOM 以确保高性能和高可扩展。同时, Ember.js 提倡简化代码,提供了丰富的 API。Ember.js 还有非常优秀的社区。
|
||||
和 React.js 的相似之处在于,Ember.js 提供了同样的服务器端虚拟 DOM 以确保高性能和高可扩展。同时, Ember.js 提倡简化代码,提供了丰富的 API。Ember.js 还有非常优秀的社区。
|
||||
|
||||
### 7\. Polymer.js
|
||||
#### 7\. Polymer.js
|
||||
|
||||
如果你曾想过创建你自己的 HTML5 元素,那么你可以使用[Polymer.js][7] 来做这些事。 Polymer 主要集中于通过给 web 开发者提供创建自己的标签的功能来提供扩展功能。例如,你可以创建一个和 HTML5 中的 \<video> 类似的具有自己的功能的 <my_video> 元素。
|
||||
如果你曾想过创建你自己的 HTML5 元素,那么你可以使用 [Polymer.js][7] 来做这些事。 Polymer 主要集中于通过给 web 开发者提供创建自己的标签的功能来提供扩展功能。例如,你可以创建一个和 HTML5 中的 \<video> 类似的具有自己的功能的 \<my_video> 元素。
|
||||
|
||||
Polymer 在 2013 年被 Google 引入并处于 [3-Clause BSD][24] 协议之下。
|
||||
Polymer 在 2013 年被 Google 引入并以 [三句版 BSD][24] 协议发布。
|
||||
|
||||
### 8\. Three.js
|
||||
#### 8\. Three.js
|
||||
|
||||
[Three.js][8] 又是另一个 JavaScript 库is yet another JavaScript library,主要用于 3D 效果开发。如果你在做游戏开发的动画效果,那么你可以利用 Three.js 的优势。Three.js 在底层中使用 WebGL 使 Three.js 可以轻松地被用于在屏幕上渲染 3D 物体。举一个比较知名的使用 Three.js 的例子就是 HexGLA,一个未来派赛车游戏。
|
||||
[Three.js][8] 又是另一个 JavaScript 库,主要用于 3D 效果开发。如果你在做游戏开发的动画效果,那么你可以利用 Three.js 的优势。Three.js 在底层中使用 WebGL 使 Three.js 可以轻松地被用于在屏幕上渲染 3D 物体。举一个比较知名的使用 Three.js 的例子就是 HexGLA,这是一个未来派赛车游戏。
|
||||
|
||||
### 9\. PhantomJS
|
||||
#### 9\. PhantomJS
|
||||
|
||||
使用 JavaScript 工作就意味着和不同的浏览器打交道,同时,当提及浏览器的时候,就不得不讨论资源管理。在 [PhantomJS][25] 中,由于有 headless WebKit 的支持,所以你可以随时监测你的 web 应用。Headless WebKit 是 Chrome 和 Safari 使用的渲染引擎中的一部分。
|
||||
使用 JavaScript 工作就意味着和不同的浏览器打交道,同时,当提及浏览器的时候,就不得不讨论资源管理。在 [PhantomJS][25] 中,由于有 Headless WebKit 的支持,所以你可以随时监测你的 web 应用。Headless WebKit 是 Chrome 和 Safari 使用的渲染引擎中的一部分。
|
||||
|
||||
这整个过程是自动化的,你所需要做的只是使用这个 API 来构建你的 web 应用。
|
||||
|
||||
### 10\. BabylonJS
|
||||
#### 10\. BabylonJS
|
||||
|
||||
[BabylonJS][9] 与 Three.js 不相伯仲, 提供了 JavaScript API 来创建无缝且强有力的 3D web 应用。它是开源的,且基于 JavaScript 和 WebGL 。创建一个简单的 3D 物体比如一个球体是非常简单的,你只需要写短短几行代码。通过这个库提供的 [文档][10],你可以很好地掌握它的内容。 同时 BabylonJS 的主页上也提供了一些优秀的 demo 来当作参考。在其官网上你可以找到这些 Demo。
|
||||
[BabylonJS][9] 与 Three.js 不相伯仲, 提供了创建平滑而强大的 3D web 应用的 JavaScript API。它是开源的,且基于 JavaScript 和 WebGL 。创建一个简单的 3D 物体,比如一个球体是非常简单的,你只需要写短短几行代码。通过这个库提供的 [文档][10],你可以很好地掌握它的内容。 同时 BabylonJS 的主页上也提供了一些优秀的 demo 来当作参考。在其官网上你可以找到这些 Demo。
|
||||
|
||||
### 11\. Boba.js
|
||||
#### 11\. Boba.js
|
||||
|
||||
Web 应用总是有一个共通的需求,那就是分析。如果你还在苦于将数据的分析与统计插入到 JavaScript 的 web 应用中,那么你可以试一下 [Boba.js][11]。Boba.js 可以帮助你将分析的数据插入到你的 web 应用中并且支持旧的 ga.js 。你甚至可以把 metrics 和 Boba.js 集成在一起,只需要依赖 jQuery 即可。
|
||||
Web 应用总是有一个共通的需求,那就是分析。如果你还在苦于将数据的分析与统计插入到 JavaScript 的 web 应用中,那么你可以试一下 [Boba.js][11]。Boba.js 可以帮助你将分析的数据插入到你的 web 应用中并且支持旧的 ga.js 。你甚至可以把数据指标和 Boba.js 集成在一起,只需要依赖 jQuery 即可。
|
||||
|
||||
### 12\. Underscore.js
|
||||
#### 12\. Underscore.js
|
||||
|
||||
[Underscore.js][12] 解决了 “当我面对一个空白 HTML 页面并希望即刻开始工作,我需要什么” 这个问题。当你刚开始一个项目, 你可能会感到失落或者重复一系列你在之前项目中常做的步骤。 为了简化开启一个项目的过程和给你起个头,Underscore.js 这个 JavaScript 库给你提供了一系列的方法。例如,你可以使用你在之前项目中常用的 Backbone.js 中的 suspender 或者 jQuery 的一些方法。
|
||||
[Underscore.js][12] 解决了 “当我面对一个空白 HTML 页面并希望即刻开始工作,我需要什么” 这个问题。当你刚开始一个项目,你可能会感到失落或者重复一系列你在之前项目中常做的步骤。 为了简化开启一个项目的过程和给你起个头,Underscore.js 这个 JavaScript 库给你提供了一系列的方法。例如,你可以使用你在之前项目中常用的 Backbone.js 中的 suspender 或者 jQuery 的一些方法。
|
||||
|
||||
一些实用的帮助例如 "filter" 和 "invoke the map" 给你起了个好头,以助于你尽可能快的投入到工作中。 Underscore.js 同时还自带了一个套件来简化你的测试工作。
|
||||
一些实用的帮助例如 “filter” 和 “invoke the map” 可以给你起个好头,以助于你尽可能快的投入到工作中。 Underscore.js 同时还自带了一个套件来简化你的测试工作。
|
||||
|
||||
### 13\. Meteor.js
|
||||
#### 13\. Meteor.js
|
||||
|
||||
[Meteor.js][13] 是一个快速构建 JavaScript 应用的框架。它是开源的且它能够用于构建桌面应用,移动应用和 web 应用。Meteor.js 是一个全栈的框架同时允许多平台的端到端开发。 你可以使用 Meteor.js 来实现前端和后端功能,同时它也能密切监视应用的性能。Meteor.js 的社区非常庞大,所以它会有不断的新特性更新或者是 bug 修复。Meteor.js 也是模块化的,同时它能配合一些其它的优秀的 API 使用。
|
||||
[Meteor.js][13] 是一个快速构建 JavaScript 应用的框架。它是开源的且它能够用于构建桌面应用、移动应用和 web 应用。Meteor.js 是一个全栈的框架同时允许多平台的端到端开发。 你可以使用 Meteor.js 来实现前端和后端功能,同时它也能密切监视应用的性能。Meteor.js 的社区非常庞大,所以它会有不断的新特性更新或者是 bug 修复。Meteor.js 也是模块化的,同时它能配合一些其它的优秀的 API 使用。
|
||||
|
||||
### 14\. Knockout.js
|
||||
#### 14\. Knockout.js
|
||||
|
||||
[Knockout.js][14] 在这些库中可能是最被低估的一个。它是一个基于 MIT 开源协议的开源 JavaScript 框架。作者是 [Steve Sanderson][15]。它基于 MVVM 模式。
|
||||
|
||||
### 值得注意的是: Node.js
|
||||
#### 值得注意的是: Node.js
|
||||
|
||||
[Node.js][16] 是一个强有力的 JavaScript 运行时环境。它可以被用于使用真实世界书局来构建快速且可扩展的应用。它既不是一个框架也不是一个库,而是一个基于 Google Chrome 的 V8 引擎的运行时环境。你可以用 Node.js 来创建多元化的 JavaScript 应用,包括单页应用,即时 web 应用等等。从技术层面上来讲,由于它的事件驱动式架构,所以 Node.js 支持异步 I/O 。这种做法使得它成为开发高可扩展应用的一个极好的解决方案的选择。查看 [Node.js][17]在 livecoding.tv 上的视频。
|
||||
[Node.js][16] 是一个强有力的 JavaScript 运行时环境。它可以被用于使用真实世界数据来构建快速且可扩展的应用。它既不是一个框架也不是一个库,而是一个基于 Google Chrome 的 V8 引擎的运行时环境。你可以用 Node.js 来创建多元化的 JavaScript 应用,包括单页应用、即时 web 应用等等。从技术层面上来讲,由于它的事件驱动式架构,所以 Node.js 支持异步 I/O 。这种做法使得它成为开发高可扩展应用的一个极好的解决方案的选择。查看 [Node.js][17]在 livecoding.tv 上的视频。
|
||||
|
||||
### 总结
|
||||
|
||||
JavaScript 是 web 开发中的通用语言。它之所以快速发展不仅仅是因为它所提供的内容,更多的是因为它的庞大的开源社区的支持。以上提到的框架和库对任何一个 JavaScript 开发者来说都是必须知道的。它们都提供了一些途径来探索 JavaScript 和前端开发。上面提及的大部分框架和库频繁地在 Livecoding.tv 上出现,大部分来自对 JavaScript 及其相关技术感兴趣的软件工程师。
|
||||
JavaScript 是 web 开发中的通用语言。它之所以快速发展不仅仅是因为它所提供的内容,更多的是因为它的庞大的开源社区的支持。以上提到的框架和库对任何一个 JavaScript 开发者来说都是必须知道的。它们都提供了一些途径来探索 JavaScript 和前端开发。上面提及的大部分框架和库频繁地在 Livecoding.tv 上出现,其大部分来自对 JavaScript 及其相关技术感兴趣的软件工程师。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/16/11/15-javascript-frameworks-libraries
|
||||
|
||||
作者:[Dr. Michael J. Garbade ][a]
|
||||
作者:[Dr. Michael J. Garbade][a]
|
||||
译者:[chenxinlong](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
如何挑选你的第一门编程语言
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
opensource.com 供图
|
||||
|
||||
想学编程的原因有很多,你也许是想要做一个程序,又或者你只是想投身于这个行业,所以,在选择你的第一门编程语言之前,问问你自己:你想要在哪里运行程序?你想要程序来完成什么工作?
|
||||
|
||||
你学习编程的原因将会决定你的第一门编程语言的选择。
|
||||
|
||||
_在这篇文章里,我会交替使用“编码”(code)、“编程”(program)、“开发”(develop) 等动词,“代码”(code)、“程序”(program)、“应用程序”(application)、“应用”(app)等名词。这是考虑到了你可能听过的语言用法。_
|
||||
|
||||
### 了解你的设备
|
||||
|
||||
在你编程语言的选择上,你的程序将运行在何处是个决定性因素。
|
||||
|
||||
桌面应用是运行在台式机或者笔记本电脑上的传统软件程序。这样你编写的代码在同一时间内只能在一台电脑上运行。移动应用,也就是我们所熟知的“app”,运行在使用 IOS 、Android 或者其他操作系统的移动设备上。网页应用是功能像应用的网页。
|
||||
|
||||
按互联网的 客户-服务器(C/S)架构分,网页开发者经常被分为两类:
|
||||
|
||||
* 前端开发,就是编写运行在浏览器里面的代码。这是个面对用户的部分,或者说是程序的前脸。有时候被称为“客户端编程”,因为浏览器是网站的客户-服务器架构的客户端部分。浏览器会运行在你本地的电脑或者设备上。
|
||||
* 后台开发,也就是大家所熟知的“服务器端开发”,编写的代码运行在你无法实际接触的服务器上。
|
||||
|
||||
### 创造什么
|
||||
|
||||
编程是一门广泛的学科,能应用在不同的领域。常见的应用有:
|
||||
|
||||
* 数据科学
|
||||
* 网页开发
|
||||
* 游戏开发,以及
|
||||
* 不同类型的工作自动化
|
||||
|
||||
现在我们已经讨论了为什么你要编程,你要程序运行在哪里,让我们看一下两门对于新手来说不错的编程语言吧。
|
||||
|
||||
### Python
|
||||
|
||||
[Python][2] 是对于第一次编程的人来说是最为流行的编程语言之一,而且这不是巧合。Python 是一门通用的编程语言。这意味着它能应用在广泛的编程任务上。几乎**没有**你不能用 Python 完成的工作。这一点使得很多新手能在实际中应用这门编程语言。另外, Python 有两个重要的设计特征,使得其对于新手更友好:清晰、类似于英语的[语法][3],和强调代码的[可读性][4]。
|
||||
|
||||
从本质上讲,一门编程语言的语法就是你所输入的能让这编程语言执行的内容。这包括单词,特殊字符(例如 `;`、`$`、`%` 或者 `{}`),空格或者以上任意的组合。Python 尽可能地使用英语,不像其他编程语言那样经常使用标点符号或者特殊的字符。所以,Python 阅读起来更自然、更像是人类语言。这一点帮助新的编程人员可以聚焦于解决问题,而能花费更少的时间纠结于语言自身的特性上。
|
||||
|
||||
清晰语法的同时注重于可读性。在编写代码的时候,你所创造的代码的逻辑“块”,就是一些为了相关联目标而共同工作的代码。在许多编程语言里,这些块用特殊字符所标记(或限定)。它们或许被 `{}` 或者其他字符所包住。块分割字符和你写代码的能力,这两者不管怎么结合起来都会降低可读性。让我们来看一个例子。
|
||||
|
||||
这有个被称为 `fun` 的简短函数。它要求输入一个数字,`x` 就是它的输入。如果 `x` 等于 `0`,它将会运行另一个被称为`no_fun` 的函数(这函数做了些很无趣的事情)。新函数不需要输入。反之,简短函数将会运行一个使用输入 `x` 的名为 `big_fun` 的函数。
|
||||
|
||||
这个函数用 [C 语言 ][5]将会是这样写的:
|
||||
|
||||
```
|
||||
void fun(int x)
|
||||
{
|
||||
if (x == 0) {
|
||||
no_fun();
|
||||
} else {
|
||||
big_fun(x);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
或者,像是这样:
|
||||
|
||||
```
|
||||
void fun(int x) { if (x == 0) {no_fun(); } else {big_fun(x); }}
|
||||
```
|
||||
|
||||
功能上两者等价,而且都能运行。`{}` 和 `;` 告诉我们哪里是代码块的不同部分。然而,第一个对于人们来说_明显_更容易阅读。相比之下完成相同功能的 Python 是这样的:
|
||||
|
||||
```
|
||||
def fun(x):
|
||||
if x == 0:
|
||||
no_fun()
|
||||
else:
|
||||
big_fun(x)
|
||||
```
|
||||
|
||||
在这里,只有一个选择。如果代码不是这样排列的,它将无法工作。如果你编写了可以工作的代码,你就有了可阅读的代码。同样也留意一下两者在语法上的差异。不同的是 `def` ,在 Python 代码中这个词是英语单词,大家都很熟悉这单词的含义(LCTT 译注:def 是 definition 的缩写,定义的意思)。在 C 语言的例子中 `void` 和 `int` 就没有那么直观。
|
||||
|
||||
Python 也有个优秀的生态系统。这有两层意思,第一,你有一个使用该语言的庞大、活跃的社区,当你需要帮助指导的时候,你能向他们求助。第二,它有大量早已存在的库,库是指完成特定功能的代码集合。从高级数学运算、图形到计算机视觉,甚至是你能想象到的任何事情。
|
||||
|
||||
Python 作为你第一门编程语言有两个缺点。第一是它有时候安装起来很复杂,特别是在运行着 Windows 的电脑上。(如果你有一台 Mac 或者 Linux 的电脑,Python 默认已经安装好了。)虽然这问题不是不能克服,而且情况总在改善,但是这对于一些人来说还是个阻碍。第二个缺点是,对于那些明确想要建设网站的人来讲,虽然有很多用 Python 写的项目(例如 [Django][6] 和[Flask][7] ),但是编写运行在浏览器上的 Python 代码却没有什么好的选择。它主要是后台或者服务器端语言。
|
||||
|
||||
### JavaScript
|
||||
|
||||
如果你知道你学习编程的主要原因是建设网站的话,[JavaScript][8] 或许是你的最佳选择。 JavaScript 是关于网页的编程语言。除了是网页的默认编程语言之外, JavaScript 作为初学的语言有几点优点。
|
||||
|
||||
第一,无须安装任何东西。你可以打开文本编辑器(例如 Windows 上的记事本,但不是一个文字处理软件,例如 Microsoft Word)然后开始输入 JavaScript 。代码将在你的浏览器中运行。最顶尖的浏览器内置了JavaScript 引擎,所以你的代码将可以运行在几乎所有的电脑和很多的移动设备上。事实上,能马上在浏览器中运行代码为编程人员提供了一个非常_快_的反馈,这对于新手来说是很好的。你能尝试一些事情然后很快地看到结果。
|
||||
|
||||
开始 JavaScript 是作为前端语言的,不过一个名为 [Node.js][9] 的环境能让你编写运行在浏览器或者服务器上的代码。现在 JavaScript 能当作前端或者后台语言使用。这增加了它的使用人数。JavaScript 也有大量能提供除核心功能外的额外功能的包,这使得它能当作一门通用语言来使用。JavaScript 不只是网页开发语言,就像 Python 那样,它也有个充满生气的、活跃的生态系统。
|
||||
|
||||
尽管有这些优点,但是 JavaScript 对于新手来说并非十全十美。[JavaScript 的语法](https://en.wikipedia.org/wiki/JavaScript_syntax#Basics)并不像 Python 那样清晰,也不怎么像英语。更像是之前例子里提到的 C 语言。它并不是把可读性当作主要的设计特性。
|
||||
|
||||
### 做出选择
|
||||
|
||||
选 Python 或者 JavaScript 作为入门语言都没有问题。关键是你打算做什么。为什么你要学习编程?你的回答很大程度上影响你的决定。如果你是想为开源做贡献,你将会找到_大量_用这两门语言编写的项目。另外,许多主要不是用 JavaScript 写的项目仍使用 JavaScript 用作前端组件。当你做决定时,别忘了你本地的社区。你有在使用其中一门语言的朋友或者同事吗?对于一个新手来说,有实时的帮助是非常重要的。
|
||||
|
||||
祝好运,开心编程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Kojo Idrissa - 我是一个新晋的软件开发者(1 年),从会计和大学教学转型而来。自从有开源软件以来,我就是它的一个粉丝。但是在我之前的事业中并不需要做很多的编程工作。技术上,我专注于 Python ,自动化测试和学习 Django 。我希望我能尽快地学更多的 JavaScript 。话题上,我专注于帮助刚开始学习编程或想参与为开源项目做贡献的人们。我也关注在技术领域的包容文化。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/choosing-your-first-programming-language
|
||||
|
||||
作者:[Kojo Idrissa][a]
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[bestony](https://github.com/bestony)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/transitionkojo
|
||||
[1]: https://opensource.com/article/17/1/choosing-your-first-programming-language?rate=fWoYXudAZ59IkAKZ8n5lQpsa4bErlSzDEo512Al6Onk
|
||||
[2]: https://www.python.org/about/
|
||||
[3]: https://en.wikipedia.org/wiki/Python_syntax_and_semantics
|
||||
[4]: https://en.wikipedia.org/wiki/Python_syntax_and_semantics#Indentation
|
||||
[5]: https://en.wikipedia.org/wiki/C_(programming_language
|
||||
[6]: https://www.djangoproject.com/
|
||||
[7]: http://flask.pocoo.org/
|
||||
[8]: https://en.wikipedia.org/wiki/JavaScript
|
||||
[9]: https://nodejs.org/en/
|
||||
[10]: https://en.wikipedia.org/wiki/JavaScript_syntax#Basics5
|
||||
@ -3,7 +3,7 @@ Samba 系列(六):使用 Rsync 命令同步两个 Samba4 AD DC 之间的 S
|
||||
|
||||
这篇文章讲的是在两个 **Samba4 活动目录域控制器**之间,通过一些强大的 Linux 工具来完成 SysVol 的复制操作,比如 [Rsync 数据同步工具][2],[Cron 任务调度进程][3]和 [SSH 协议][4]。
|
||||
|
||||
#### 要求:
|
||||
### 需求:
|
||||
|
||||
- [Samba 系列(五):将另一台 Ubuntu DC 服务器加入到 Samba4 AD DC 实现双域控主机模][1]
|
||||
|
||||
@ -25,7 +25,7 @@ Samba 系列(六):使用 Rsync 命令同步两个 Samba4 AD DC 之间的 S
|
||||
# nano /etc/ntp.conf
|
||||
```
|
||||
|
||||
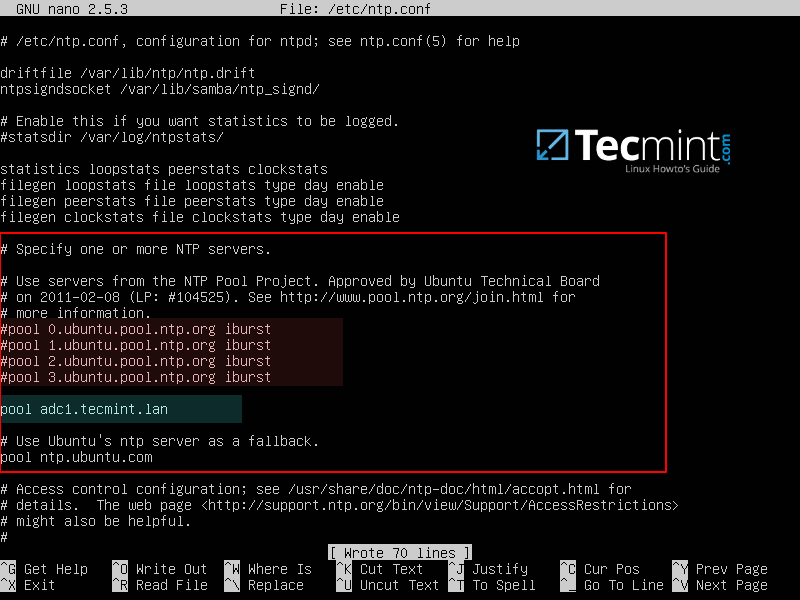
把下面几行添加到 **ntp.conf** 配置文件。
|
||||
把下面几行添加到 `ntp.conf` 配置文件。
|
||||
|
||||
```
|
||||
pool 0.ubuntu.pool.ntp.org iburst
|
||||
@ -35,7 +35,8 @@ pool 0.ubuntu.pool.ntp.org iburst
|
||||
pool adc1.tecmint.lan
|
||||
# Use Ubuntu's ntp server as a fallback.
|
||||
pool ntp.ubuntu.com
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
@ -49,12 +50,13 @@ restrict source notrap nomodify noquery mssntp
|
||||
ntpsigndsocket /var/lib/samba/ntp_signd/
|
||||
```
|
||||
|
||||
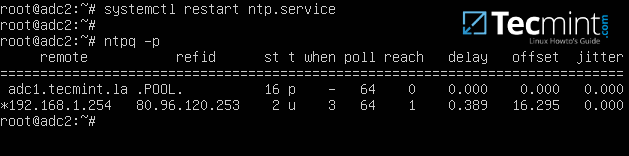
4、最后,关闭并保存该配置文件,然后重启 NTP 服务以应用更改。等待几分钟后时间同步完成,执行 **ntpq** 命令打印出 **adc1** 时间同步情况。
|
||||
4、最后,关闭并保存该配置文件,然后重启 NTP 服务以应用更改。等待几分钟后时间同步完成,执行 `ntpq` 命令打印出 **adc1** 时间同步情况。
|
||||
|
||||
```
|
||||
# systemctl restart ntp
|
||||
# ntpq -p
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
@ -65,7 +67,7 @@ ntpsigndsocket /var/lib/samba/ntp_signd/
|
||||
|
||||
默认情况下,**Samba4 AD DC** 不会通过 **DFS-R**(<ruby>分布式文件系统复制<rt>Distributed File System Replication</rt></ruby>)或者 **FRS**(<ruby>文件复制服务<rt>File Replication Service</rt></ruby>)来复制 SysVol 目录。
|
||||
|
||||
这意味着只有在第一个域控制器联机时,<ruby>**组策略对象**<rt>Group Policy objects </rt></ruby>才可用。否则组策略设置和登录脚本不会应用到已加入域的 Windosws 机器上。
|
||||
这意味着只有在第一个域控制器联机时,<ruby>**组策略对象**<rt>Group Policy objects</rt></ruby>才可用。否则组策略设置和登录脚本不会应用到已加入域的 Windosws 机器上。
|
||||
|
||||
为了克服这个障碍,以及基本实现 SysVol 目录复制的目的,我们通过执行一个[基于 SSH 的身份认证][10]并使用 SSH 加密通道的[Linux 同步命令][9]来从第一个域控制器安全地传输 **GPO** 对象到第二个域控制器。
|
||||
|
||||
@ -75,31 +77,33 @@ ntpsigndsocket /var/lib/samba/ntp_signd/
|
||||
|
||||
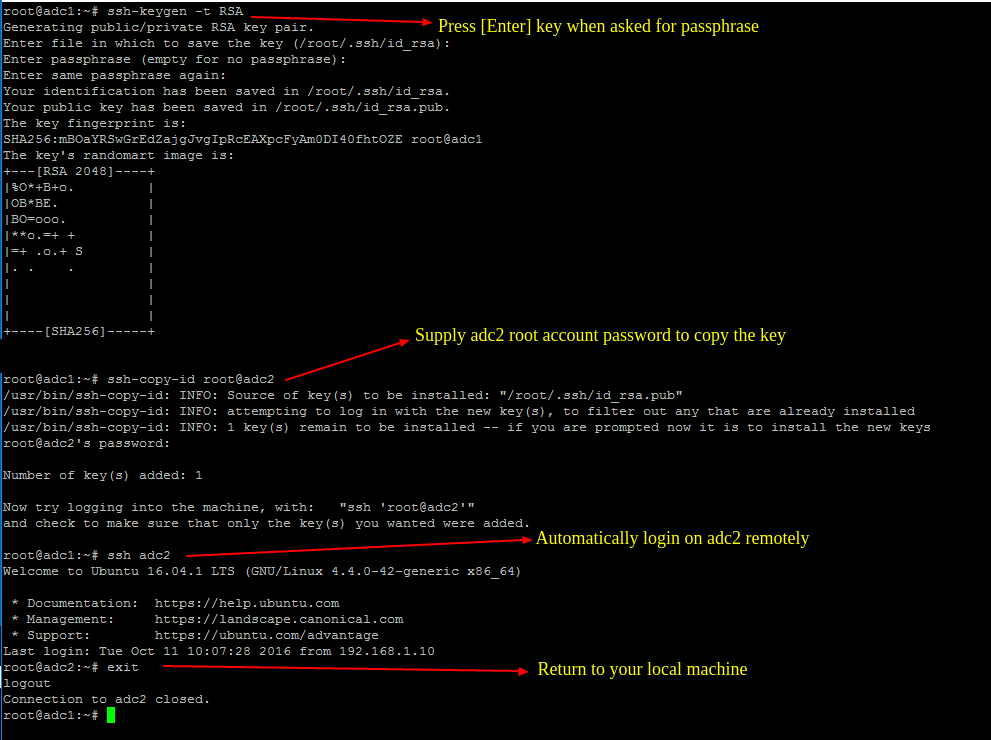
5、要进行 **SysVol** 复制,先到[第一个 AD DC 服务器上生成 SSH 密钥][11],然后使用下面的命令把该密钥传输到第二个 DC 服务器。
|
||||
|
||||
在生成密钥的过程中不要设置密码 **passphrase**,以便在无用户干预的情况下进行传输。
|
||||
在生成密钥的过程中不要设置密码,以便在无用户干预的情况下进行传输。
|
||||
|
||||
```
|
||||
# ssh-keygen -t RSA
|
||||
# ssh-copy-id root@adc2
|
||||
# ssh adc2
|
||||
# exit
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
*在 Samba4 DC 服务器上生成 SSH 密钥*
|
||||
|
||||
6、 当你确认 root 用户可以从第一个 **DC** 服务器以免密码方式登录到第二个 **DC** 服务器时,执行下面的 **Rsync** 命令,加上 `--dry-run` 参数来模拟 SysVol 复制过程。注意把对应的参数值替换成你自己的数据。
|
||||
6、 当你确认 root 用户可以从第一个 **DC** 服务器以免密码方式登录到第二个 **DC** 服务器时,执行下面的 `rsync` 命令,加上 `--dry-run` 参数来模拟 SysVol 复制过程。注意把对应的参数值替换成你自己的数据。
|
||||
|
||||
```
|
||||
# rsync --dry-run -XAavz --chmod=775 --delete-after --progress --stats /var/lib/samba/sysvol/ root@adc2:/var/lib/samba/sysvol/
|
||||
```
|
||||
|
||||
7、如果模拟复制过程正常,那么再次执行去掉 `--dry-run` 参数的 rsync 命令,来真实的在域控制器之间复制 GPO 对象。
|
||||
7、如果模拟复制过程正常,那么再次执行去掉 `--dry-run` 参数的 `rsync` 命令,来真实的在域控制器之间复制 GPO 对象。
|
||||
|
||||
```
|
||||
# rsync -XAavz --chmod=775 --delete-after --progress --stats /var/lib/samba/sysvol/ root@adc2:/var/lib/samba/sysvol/
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
@ -113,6 +117,7 @@ ntpsigndsocket /var/lib/samba/ntp_signd/
|
||||
```
|
||||
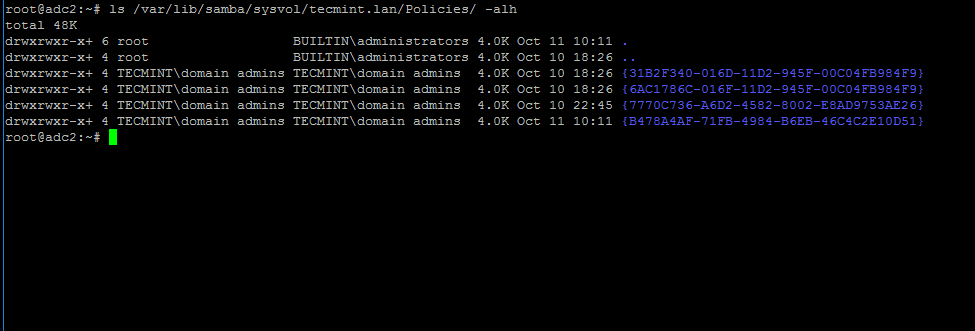
# ls -alh /var/lib/samba/sysvol/your_domain/Policiers/
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
@ -125,7 +130,7 @@ ntpsigndsocket /var/lib/samba/ntp_signd/
|
||||
# crontab -e
|
||||
```
|
||||
|
||||
添加一条每隔 5 分钟运行的同步命令,并把执行结果以及错误信息输出到日志文件 /var/log/sysvol-replication.log 。如果执行命令异常,你可以查看该文件来定位问题。
|
||||
添加一条每隔 5 分钟运行的同步命令,并把执行结果以及错误信息输出到日志文件 `/var/log/sysvol-replication.log` 。如果执行命令异常,你可以查看该文件来定位问题。
|
||||
|
||||
```
|
||||
*/5 * * * * rsync -XAavz --chmod=775 --delete-after --progress --stats /var/lib/samba/sysvol/ root@adc2:/var/lib/samba/sysvol/ > /var/log/sysvol-replication.log 2>&1
|
||||
@ -1,27 +1,29 @@
|
||||
# Arch Linux on a Lenovo Yoga 900
|
||||
联想 Yoga 900 笔记本安装 Arch Linux 系统后的感悟
|
||||
深入点评联想 Yoga 900 笔记本安装 Arch Linux 系统
|
||||
==============
|
||||
|
||||
_注意:这篇文章比较长,有将近 5500 多个单词,而且还有很多非常有意思的链接,因此,你最好还是先给自己准备点喝的吧,然后再花时间来阅读。_
|
||||
|
||||

|
||||
在 [联想 Yoga 2 笔记本电脑][2] 上使用了 3 年多的 Arch Linux 系统后,我决定换个新的 Yoga 900 笔记本电脑来安装 Arch Linux 系统:
|
||||
|
||||

|
||||
|
||||
_联想 Yoga 900 笔记本电脑在[亚马逊网站上的特价][1] 为 925 美元 —— 8GB 内存, 256 GB 固态硬盘, 3200×1800 的分辨率,处理器为 Skylake 3.2GHz , Iris Graphics 显卡。_
|
||||
|
||||
同等配置的戴尔笔记本电脑 [XPS 13][3] 搭载新一代 Inter 处理器,售价 1650 美元。 Yoga 910 为当前最新款,价格为 1300 美元。但是,我压根就不会考虑这一款,因为它的键盘设计得太狗屎了。很多评论都从其外观颜色及材质方面大作文章,但是我偏偏从它的键盘设计上来挑刺。
|
||||
|
||||
### 键盘
|
||||
|
||||
|
||||
Yoga 2 Pro 和 Yoga 900 这两款笔记本电脑从外观上看没啥区别。它的键盘设计跟曾经光鲜亮丽的 IBM Thinkpad 的键盘比起来可真是差远了,但是这还不算是最狗屎的键盘,好歹我还用了三年多的 Yoga 2 ,而且早已经习惯了。不幸的是,新款 Yoga 910 的键盘设计更是糟糕透了。
|
||||
|
||||

|
||||
|
||||
_Yoga 2 和 Yoga 900 的键盘布局_
|
||||
|
||||

|
||||
|
||||
_Yoga 910 的键盘_
|
||||
|
||||
Yoga 910 键盘的问题是它的 右-shift 按键位置不合理,你不挪动手根本就按不到那个键。这个键的位置非常特殊,可以说是跟我上 9 年级打字课时所用的 IBM 打字机键盘到目前为止用过的所有键盘都不一样。我更愿意看到这个失误出现在华硕或是戴尔公司的电脑上,而不是来自于曾经让一代代美国人学习和工作并且创造了打印机传奇历史的 IBM 公司。
|
||||
Yoga 910 键盘的问题是它的 右-shift 按键位置不合理,你不挪动手根本就按不到那个键。这个键的位置非常特殊,可以说是跟我上 9 年级打字课时所用的 IBM 打字机键盘到目前为止用过的所有键盘都不一样。我宁愿看到这个失误出现在华硕或是戴尔公司的电脑上,而不是来自于曾经让一代代美国人学习和工作并且创造了打印机传奇历史的 IBM 公司。(LCTT 译注:联想的 Yoga 还和 IBM 有什么关系么?)
|
||||
|
||||
Yoga 团队每一年都会更改键盘布局。想象一下,如果 IBM 公司在 20 世纪的时候也不断改变他们的打印机键盘布局,而且还吹嘘这是为了提高"[工作效率]"[4]。那么这个公司可能早就倒闭了!
|
||||
|
||||
@ -31,17 +33,17 @@ Yoga 团队每一年都会更改键盘布局。想象一下,如果 IBM 公司
|
||||
|
||||
Yoga 910 的键盘布局改变得太多了,也许再也回不到曾经的老式键盘了。我希望 Yoga 的键盘不要再随便改了。我更愿意拥有一个比电脑更高效 10 倍的键盘。
|
||||
|
||||
我在联想官网的评论中看到有些用户由于对 Yoga 910 的键使用不习惯的原因而申请退货。我觉得联想公司应该制定这样一条规定:如果革个工程师想更改键盘布局,他们必须给出一个***非常充分***的理由,如果这种设计给用户在使用方面造成了巨大的不便,那么将以剁其一根手指的代价来让他也体会下这种痛苦。如果真有这样一条规则,那么将会大大减少那些毫无意义的更改键盘的行为。 Yoga 910 笔记本电脑可以说是联想公司呕心沥血之杰作了,但是其输入系统却是一大败笔。
|
||||
我在联想官网的评论中看到有些用户由于对 Yoga 910 的键使用不习惯的原因而申请退货。我觉得联想公司应该制定这样一条规定:如果某个工程师想更改键盘布局,他们必须给出一个**非常充分**的理由,如果这种设计给用户在使用方面造成了巨大的不便,那么将以剁其一根手指的代价来让他也体会下这种痛苦。如果真有这样一条规则,那么将会大大减少那些毫无意义的更改键盘的行为。 Yoga 910 笔记本电脑可以说是联想公司呕心沥血之杰作了,但是其输入系统却是一大败笔。
|
||||
|
||||
### 总体评价
|
||||
|
||||
Yoga 2 对于我的任何操作,其反应速度都非常快。它的固态硬盘也非常给力,但是用在 Arch Linux 系统下就有些大材小用了。那些只使用 Windows 系统的用户就不会体会到他们的系统有多么的庞大臃肿:
|
||||
|
||||

|
||||

|
||||
|
||||
在 90 年代时期,由于处理器的性能每隔 18 个月翻一倍,并且软件的大小也经常成倍的增长,因此,一款新的电脑每隔几年就会发布出来。现在早已发生了翻天覆地的变化。新款的 Yoga 900 笔记本电脑在运行性能测试的过程中,速度比我的 Yoga 2 还要快 30% 。 Yoga 900 的 CPU 主频为 3.2 GHz ,老款的 Yoga 2 主频为 2.6 GHz ,因此, Yoga 900 最大的亮点是更快的 CPU 处理频率。
|
||||
|
||||
Haswell 处理器架构于 2013 年发布了,而 Skylake 处理器架构在 2015 年才发布,因此,经过两年的发展,处理器性能有了很大的改善。新一代的处理器最大的改进是采用 14 纳米工艺制造技术来代替原先的 22 纳米工艺技术,这意味着新款笔记本电脑散热更小,电池使用时间更长。我的老款的 Yoga 2 笔记本在中等亮度的情况下,电池使用时长只有 3 个半小时左右,但是新款 Yoga 900 的电池使用时长高达 7 小时。
|
||||
Haswell 处理器架构发布于 2013 年,而 Skylake 处理器架构在 2015 年才发布,因此,经过两年的发展,处理器性能有了很大的改善。新一代的处理器最大的改进是采用 14 纳米工艺制造技术来代替原先的 22 纳米工艺技术,这意味着新款笔记本电脑散热更小,电池使用时间更长。我的老款的 Yoga 2 笔记本在中等亮度的情况下,电池使用时长只有 3 个半小时左右,但是新款 Yoga 900 的电池使用时长高达 7 小时。
|
||||
|
||||
Yoga 2 的转轴已经开始松动和裂开了,我也没有一个好的办法来拧紧,只能从网上找新的配件来更换或者发给联想售后进行维修了。
|
||||
|
||||
@ -59,114 +61,116 @@ Yoga 2 总的来说是一款设计精良的产品,但是如果我将显示器
|
||||
|
||||
### 触摸板
|
||||
|
||||
Yoga 2 最严重的问题出现在触摸板上。这不是硬件导致的,而是驱动程序自身的问题,由于触摸板驱动程序本身没人在维护,因此存在很多缺陷。很遗憾, Synaptics 公司本来可以很轻易地安排一个工程师来维护这几千行的代码,但是联想重新写了另外一个版本的与系统内核集成在一起的驱动程序,而且还没有公开发布出来。
|
||||
Yoga 2 最严重的问题出现在触摸板上。这不是硬件导致的,而是驱动程序自身的问题,由于触摸板驱动程序本身没人在维护,因此存在一些缺陷。很遗憾, Synaptics 公司本来可以很轻易地安排一个工程师来维护这几千行的代码,但是联想重新写了另外一个版本的驱动程序,但是还没有开源发布出来,以便可以包括到系统内核中。
|
||||
|
||||
然而,为了让触摸板设备和其它输入设备的管理和使用更加方便简捷,一个叫做 [Libinput][5] 的新软件库被建立起来。 Libinput 最好的一点就是,维护人员会修复各种缺陷。还有一个很适用的功能就是如果你左指尖触摸鼠标单击区域,它现在会通过你的右指尖记录指针移动轨迹。但是,让人难以接受的事情是, Synaptics 的这个基本的功能在 Linux 系统中很多年前就无法使用了。
|
||||
因此,为了让触摸板设备和其它输入设备的管理和使用更加方便简捷,建立了一个叫做 [Libinput][5] 的新软件库。 Libinput 最好的一点就是,维护人员会修复各种缺陷。还有一个很实用的功能就是如果你左指尖触摸鼠标单击区域,它现在会通过你的右指尖记录指针移动轨迹。但是,让人难以接受的事情是, Synaptics 的这个基本的功能在 Linux 系统中很多年前就无法使用了。
|
||||
|
||||
触摸板设备一直运行正常,但是它不再像以前那样发出敲击声了。实际上这也不是什么问题,但是这会让我担心我在触摸板上的操作是否正确。老款的 Thinkpad 笔记本电脑有好几个左右按键,因此,如果其中一个损坏了,你可以使用另外一个,但是 Yoga 笔记本只有一个鼠标左右按键,如果损坏了就只能插入鼠标来代替使用了。(联想还巴不得你的电脑赶紧坏了好换新的。)
|
||||
|
||||
### 内核支持
|
||||
|
||||
当年我购买 Haswell 处理器的笔记本电脑时,硬件都是最新的,因此,我折腾了好几个月才把 Linux 驱动程序相关的问题解决了。而现在我使用的新一代的 Skylake 处理器的笔记本电脑,在[处理器发布 8 个多月后][6],其内核崩溃的问题才被修复了。以前老款笔记本电脑的 [电源管理][7] 一直运行不正常,但是从新款笔记本电脑使用来看,以前的问题大都不存在了,而且有了很大的改善。如果用户不进行任何操作,这个笔记本电脑会自动进入到低功耗 C6-C10 状态。(这个功能是由 Linux 系统中的 **powertop 省电工具** 进行控制的。)
|
||||
当年我购买 Haswell 处理器的笔记本电脑时,硬件都是最新的,因此,我折腾了好几个月才把 Linux 驱动程序相关的问题解决了。而现在我使用的新一代的 Skylake 处理器的笔记本电脑,在[处理器发布 8 个多月后][6],其内核崩溃的问题才被修复了。以前老款笔记本电脑的 [电源管理][7] 一直运行不正常,但是从新款笔记本电脑使用来看,以前的问题大都不存在了,而且有了很大的改善。如果用户不进行任何操作,这个笔记本电脑会自动进入到低功耗的 C6 - C10 状态。(这个功能是由 Linux 系统中的 **powertop 省电工具** 进行控制的。)
|
||||
|
||||
电源管理这个功能非常重要,它不仅会影响到电池的使用寿命,而且由于[电解迁移][8]的原因,那些非常小的电路板会逐渐耗尽。英特尔公司甚至发出公告:”电池使用的长期可靠性是无法保障的,除非所有程序都运行在低功耗的空闲状态。“通过让程序运行在低功耗模式下,以使用更小的电源回路,从而让电池使用寿命更长。
|
||||
电源管理这个功能非常重要,它不仅会影响到电池的使用寿命,而且由于[电解迁移][8]的原因,那些微小电路会逐渐耗尽。英特尔公司甚至发出公告:”电池使用的长期可靠性是无法保障的,除非所有程序都运行在低功耗的空闲状态。“通过让程序运行在低功耗模式下,以使用更小的电路,从而让电池使用寿命更长。
|
||||
|
||||
现在 Haswell 处理器架构对 Linux 系统的支持性已经非常好了,但是之前的很长一段时间,它的支持性都很差。刚开始那一年,我提出了很多 Haswell 处理器相关的问题,但是现在可以看出这两款处理器在对 Linux 系统的支持上都有了很大的改善。
|
||||
|
||||
### 联想笔记本的 BIOS 不兼容 Linux 系统
|
||||
|
||||
在 Yoga 900 电脑上安装 Arch Linux 系统之前,我得在 Windows 系统中再格式化出一个新的 BIOS 分区来。实际上,我的电脑中得有 2 个 BIOS 系统。最新版本的 Yoga 900 BIOS [不包括][9]我需要的必备修补程序,犹豫了一会之后,我恍然大悟,然后我 [安装][10]了一个单独的 "仅 Linux 系统" 的 BIOS 更新,这样我的联想电脑就不再支持 Windows 系统了:"你不可怜下我吗?“
|
||||
在 Yoga 900 电脑上安装 Arch Linux 系统之前,我得在 Windows 系统中再刷一个新的 BIOS 。实际上,我的电脑中得有 2 个 BIOS。最新版本的 Yoga 900 BIOS [不包括][9]我需要的必备修补程序,所以在挠头了一会之后,我恍然大悟,然后我 [安装][10]了一个单独的“仅 Linux 系统”的 BIOS 更新,这样我的联想电脑就不再支持 Windows 系统了:“你不[可怜][11]下我吗?”
|
||||
|
||||
那些经常关注 Linux 系统的用户就很清楚, Yoga 900 和其它最新款的联想笔记本电脑无法安装 Linux 系统,因为它不会[检测硬件驱动程序][12]。联想回复其笔记本电脑已不再支持 Linux 系统了,因为它使用的是[新型的 RAID 控制器模式][13] 。然而,实现 RAID 机制就意味着需要更多的磁盘,而笔记本电脑只有一个硬盘,并且也没有多余的空间来安装另外一块磁盘了。
|
||||
那些经常关注 Linux 系统的用户就很清楚, Yoga 900 和其它最新款的联想笔记本电脑无法安装 Linux 系统,因为它甚至不能[检测到硬盘][12]。联想最初回复其笔记本电脑已不再支持 Linux 系统了,因为它使用的是[新型的 RAID 控制器模式][13] 。然而,实现 RAID 机制就意味着更多的磁盘,而笔记本电脑实际上只有一个硬盘,并且也没有多余的空间来安装另外一块磁盘了。
|
||||
|
||||
下面是联想给出的[官方解释][14]:
|
||||
|
||||
>“为了更好地支持 Yoga 系列产品以及整个行业领先的 360 度铰链转轴设计技术的发展,我们采用了一种存储控制器模式,很遗憾,这种模式不支持 Linux 系统,也不允许安装 Linux 系统。”
|
||||
> “为了更好地支持 Yoga 系列产品以及行业领先的 360 度铰链转轴设计技术的发展,我们采用了一种存储控制器模式,很遗憾,这种模式不支持 Linux 系统,不能够安装 Linux 系统。”
|
||||
|
||||
我觉得很搞笑,为了转轴而采用特殊的存储控制器!这就好比一个汽车制造公司宣称由于新型的广播设备,他们必须改变汽车的轮胎一样。
|
||||
|
||||
这引发了巨大的争议,感谢 Reddit 网站的 [Baron][15][H][16][K][17] 的努力,他为媒体提供了大量的信息,并联系了伊利诺斯州检查院。搜索 "[联想 Yoga][18][L][19][inux 兼容性][20]" 出现 300,000 条结果。联想或许会因为销售不允许用户安装自己的操作系统的”通用“ PC 而触犯法律。对于我来说,为电脑设置默认的操作系统是毫无意义的。
|
||||
这引发了巨大的争议,感谢 Reddit 网站的 [BaronHK][15] 的努力,他为媒体提供了大量的信息,并联系了伊利诺斯州检查院。搜索 "[联想 Yoga 的 Linux 兼容性][20]" 出现 300,000 条结果。联想或许会因为销售不允许用户安装自己的操作系统的“通用”PC 而触犯法律。对于我来说,为电脑设置默认的操作系统是毫无意义的。
|
||||
|
||||
黑客也被卷入到这场”战争“中进来,他们最终发现通过设置 UEFI ,这款笔记本也能够支持 AHCI 控制器模式,只是默认被禁用了。简单来说,联想故意取消对 Linux 系统的支持没啥好处。因为大家都已经明白事实真相了,如果这件事闹到法庭上,联想也只能自取其辱。
|
||||
技术高手们也被卷入到这场“战争”中进来,他们最终发现通过设置 UEFI ,这款笔记本也能够支持 AHCI 控制器模式,只是默认被禁用了。简单来说,联想故意取消对 Linux 系统的支持没啥好处。因为大家都已经明白事实真相了,如果这件事闹到法庭上,联想也只能自取其辱。
|
||||
|
||||
幸运的是,这些新闻引起了他们的关注,并且他们也逐渐地更新了 BIOS 。这篇文章就是在运行着 Linux 系统的 Yoga 900 笔记本电脑上写的,因此,我们应该庆祝下这个伟大的胜利。大家都希望联想从中受到教训,但是我并不看好。他们本来就应该为你的电脑提供一个选择操作系统的机会。他们应该在用户之前就发现了这个缺陷了。我将等待一个周左右的时间才能拿到定制化的电脑。他们应该把分区设置好,并且让用户定制很多东西,安装最新版的软件,而不是使用一个需要很多更新的老镜像文件。
|
||||
幸运的是,这些新闻引起了他们的关注,并且他们最终更新了 BIOS 。这篇文章就是在运行着 Linux 系统的 Yoga 900 笔记本电脑上写的,因此,我们应该庆祝下这个伟大的胜利。大家都希望联想从中受到教训,但是我并不看好。他们本来就应该为你的电脑提供一个选择操作系统的机会。他们应该在用户之前就发现了这个缺陷了。我将等待一周左右的时间才能拿到定制化的电脑。他们应该把分区设置好,并且让用户定制很多东西,安装最新版的软件,而不是使用一个需要很多更新的老镜像文件。
|
||||
|
||||
一些钟爱联想电脑的用户认为这是 Linux 系统自己的问题,是 Linux 系统本身就不支持最新的 RAID 驱动模式导致的问题。然而, AHCI 控制器模式本来是一个非常流行的标准,但是由于英特尔公司为这种硬件写的代码"[太糟糕][21]"而被 Linux 系统内核开发团队拒绝了。该团队要求英特尔公司提供这种硬件的详细设计说明,但是他们一直没有给出任何答复。
|
||||
一些钟爱联想电脑的用户认为这是 Linux 系统自己的问题,是 Linux 系统本身就不支持最新的 RAID 驱动模式导致的问题。然而, AHCI 控制器模式本来是一个非常流行的标准,而由于英特尔公司为这种新的 RAID 硬件写的代码“[太糟糕][21]”而被 Linux 系统内核开发团队拒绝了。该团队要求英特尔公司提供这种硬件的详细设计说明,但是他们一直没有给出任何答复。
|
||||
|
||||
### 散热
|
||||
|
||||
当 CPU 占用很高时, Yoga 2 笔记本会变得很烫。有一次我把笔记本放到毯子上编译 LibreOffice 软件时就把底部的塑料壳烧焦了,这实在是太丑陋了,这让我看上去像是一个很穷酸的程序员。我试着用铁刷子和松脂油来擦除烧售的部分,但是也没什么鸟用。
|
||||
当 CPU 占用很高时, Yoga 2 笔记本会变得很烫。有一次我把笔记本放到毯子上编译 LibreOffice 软件时就把底部的塑料壳烧焦了,这实在是太丑陋了,这让我看上去像是一个很穷酸的程序员。我试着用铁刷子和松脂油来擦除烧焦的部分,但是也没什么鸟用。
|
||||
|
||||

|
||||
|
||||
新款的笔记本电脑使用金属外壳,不容易褪色,并且 Skylake 处理器架构比 Haswell 的要强劲得多。把散热口设计了跟转轴融合在一起,这是一个非常明智及巧妙的做法,如果散热口在其它位置则可能被堵塞住。
|
||||
新款的笔记本电脑使用金属外壳,不容易褪色,并且 Skylake 处理器架构比 Haswell 的要强劲得多。把散热口设计了跟转轴融合在一起,这是一个非常明智及巧妙的做法,如果散热口在下方则可能被堵塞住。
|
||||
|
||||
用了很多年的 Yoga 2 ,我觉得最烦人的一件事就是它的风扇里累积了厚厚的尘埃,运行时听上去就像是沙子摩擦的声音!这些尘埃分布得很广,使用时产生的声音也大,让人容易分心。我把笔记本电脑拆开来清除里面的尘埃,但是风扇的叶片是隐藏的,无法进行清除。我只能把整个风扇替换掉了。在 Yoga2 上完成简单的工作,比如文字处理和浏览器上网时,风扇不会旋转,但是当它旋转时,如果不带耳机会感到很烦人。
|
||||
|
||||
Yoga 900 的风扇叶片密度很高,而且运行的很平稳,也不会让人分心。 Yoga 900 的风扇好像一直都在旋转,但是速度非常慢,而且声音很小也很安静。我家里电冰箱和空气净化器的声音都要比它大得多,除了笔记本电脑在负载的情况下声音有点大,不过那也不影响我工作。
|
||||
Yoga 900 的风扇叶片密度很高,而且运行的很平稳,也不会让人分心。 Yoga 900 的风扇好像一直都在旋转,但是速度非常慢,而且声音很小也很安静。我家里电冰箱和空气净化器的声音都要比它大得多,除了笔记本电脑在高负载的情况下声音有点大,不过那也不影响我工作。
|
||||
|
||||
### 显示器
|
||||
|
||||
Yoga 2 的显示屏很大气,但是也同样存在大家所熟知的问题,比如屏幕上的黄色看上去更像是橙色。然而,整体画质看起来还算细腻,其它颜色方面也不错。 Yoga 900 的屏幕已经修复了那个黄颜色的问题。它不是一个真正的 4K 屏,实际上仅有 3200×1800 的分辨率,但是从 15.6 寸的显示屏上看,它的像素要比真正的 4K 屏要细腻得多,所以显示效果超级锐利。
|
||||
Yoga 2 的显示屏很大气,但是也同样存在大家所熟知的问题,比如屏幕上的黄色看上去更像是橙色。然而,整体画质看起来还算细腻,其它颜色方面也不错。 Yoga 900 的屏幕已经修复了那个黄颜色的问题。它不是一个真正的 4K 屏,实际上仅有 3200×1800 的分辨率,但是从 15.6 寸的显示屏上看,它的像素要比真正的 4K 屏要细腻得多,所以显示效果超级锐利。有些人说这屏幕分辨率是假的,因为它使用了“[RG/BW Pentile 矩阵](http://i.imgur.com/8pYBfcU.png)”,但是对我来说,高分辨率的图片看起来就很棒,何况文本。
|
||||
|
||||
当年我购买 Yoga 2 笔记本电脑时,由于其使用的是当时最新的 Haswell 处理器架构,所以我遇到很多英特尔显卡显示异常的问题,这些问题过了几个月后才被解决。之后,我还发现了一个会导致 Linux 系统崩溃的内存泄漏问题,并且这个缺陷好多年都没被处理。
|
||||
当年我购买 Yoga 2 笔记本电脑时,由于其使用的是当时最新的 Haswell 处理器架构,所以我遇到了各种英特尔显卡显示异常的问题,这些问题过了几个月后才被解决。之后,我还发现了一个会导致 Linux 系统崩溃的内存泄漏问题,并且这个缺陷好多年都没被处理。
|
||||
|
||||
我在 VLC 播放器中使用( shift + 箭头键)快进视频时,遇到了好几次内存耗尽的问题。系统也没显示 VLC 播放器占用了多少的内存,但是电脑内存却耗尽了。很明显这是内核导致的内存泄漏问题。我创建了一个 swap 文件作为虚拟内存使用,以减少内存耗尽的时间,但是有好几次我没注意时,这个文件又被占满了。几年后,这个问题逐渐消失了,而且现在 Linux 系统也运行得很稳定。
|
||||
我在 VLC 播放器中使用 shift + 箭头键快进视频时,遇到了好几次内存耗尽的问题。系统也没显示 VLC 播放器占用了多少的内存,但是电脑内存却耗尽了。很明显这是内核导致的内存泄漏问题。我创建了一个 swap 文件作为虚拟内存使用,以减少内存耗尽的时间,但是有好几次我没注意时,这个文件又被占满了。几年后,这个问题逐渐消失了,而且现在 Linux 系统也运行得很稳定。
|
||||
|
||||
大家都认为英特尔公司为 Linux 系统开发的驱动程序是最好的,但是他们更像是微软内部的一个实验项目。英特尔 公司的驱动程序开发人员都很专业,只是 Linux 系统的驱动开发人员都不够多。在发布硬件之前,他们都竭力让驱动程序做得更完美。 英特尔公司生产的 [1][22][13][23] [这些处理器][24] 都是基于 Skylake 处理器架构的,只是在特性上有细微的区别。听起来你会觉得有很多类型的处理器,但是在 [Haswell 处理器][25] 时期,英特尔公司生产出高度集成的 256 核芯片处理器。10 年前我听一个 Inter 公司的员工说过,相对于 Windows 来说,他们仅投入了 1% 到 Linux 系统上,从现在的情形来看,确实是那样的。
|
||||
大家都认为英特尔公司为 Linux 系统开发的驱动程序是最好的,但是他们更像是微软内部的一个秘密的臭鼬工厂项目。英特尔公司的驱动程序开发人员都很专业,就是人员不够多。在发布硬件之前,他们都竭力让驱动程序做得更完美。 英特尔公司生产的 [113 款处理器][24] 都是基于 Skylake 处理器架构的,只是在特性上有细微的区别。听起来你会觉得有很多类型的处理器,但是在 [Haswell 处理器][25] 时期,英特尔公司生产了 256 款芯片。10 年前我听一个英特尔公司的员工说过,相对于 Windows 来说,他们仅投入了 1% 到 Linux 系统上,从现在的情形来看,确实是那样的。
|
||||
|
||||
在我使用 Yoga 2 的过程中唯一遇到的性能问题是无法正常播放 4K 视频。屏幕经常出现卡顿,或是出现每秒跳跃 5 帧的现象:
|
||||
在我使用 Yoga 2 的过程中唯一遇到的性能问题是无法正常播放 4K 视频,屏幕经常出现卡顿,或是出现每秒才播放 5 帧的现象:
|
||||
|
||||

|
||||
|
||||
Yoga 2 甚至是在播放 1920×1080 分辨率的视频时有时候也显得很吃力,看样子它最多只能以 60fps 的速度来播放视频。出现这样的情况也可能是因为我一直在运行着其它的应用程序,比如 Firefox 浏览器和 LibreOffice 办公软件。
|
||||
|
||||
Skylake 处理器主要用于在 60 fps 的速度下使用 H.264 、 VP9 以及其它解码方式来播放 4K 视频。实际上这款处理器中有很多硬件专门用于加速[多媒体][26][特性][27]。我尝试使用 **ffmpeg 软件** 来处理 H264 格式的硬件编码,我发现即使只使用一个 CPU 的情况下,其处理速度也比原来的处理器快 4 倍。这种性能太棒了。不爽的是,在设置的过程中有点麻烦,因为你必须使用很多命令行参数:
|
||||
Skylake 处理器主要用于在 60fps 的速度下使用 H.264 、 VP9 以及其它编解码方式来播放 4K 视频。实际上这款处理器中有很多硬件专门用于加速[多媒体特性][27]。我尝试使用 **ffmpeg 软件** 来处理 H264 格式的硬件编码,我发现即使只使用一个 CPU 的情况下,其处理速度也比原来的处理器快 4 倍。这种性能太棒了。不爽的是,在设置的过程中有点麻烦,因为你必须使用很多命令行参数:
|
||||
|
||||
```
|
||||
-threads 1 -vaapi_device /dev/dri/renderD128 -vcodec h264_vaapi -vf format='nv12|vaapi,hwupload'
|
||||
```
|
||||
|
||||
“**-threads 1 -vaapi_device /dev/dri/renderD128 -vcodec h264_vaapi -vf format=’nv12|vaapi,hwupload’**”
|
||||
我尝试找到一种方法让 **ffmpeg 软件** 保存这些命令,这样我就不用每次都手动输入这么多参数了,但是最后发现根本行不通。而且无论怎样,在整个过程中也不能自动传递这些参数。我还发现在使用这个硬件的的过程中不能缩放视频尺寸,它会忽略该操作,因此,我很少会用这个工具。如果 **ffmpeg 软件** 可以实现这一点就完美了。由于很多用户都不了解,或者是不想太麻烦,所以还有很多未使用的硬件资源。这个软件有很多跟 Linux 系统和 Windows 系统相关的应用接口,如果要进行视频编码和解码,将会是[一件麻烦事][28]。
|
||||
|
||||
我尝试找到一种方法让 **ffmpeg 软件** 保存这些命令,这样我就不用每次都手动输入这么多参数了,但是最后发现根本行不通。而且无论怎样,在整个过程中也不能自动传递这些参数。我还发现在使用这个硬件的的过程中不能重置视频大小,只能忽略或接受,因此,我很少会用这个工具。如果 **ffmpeg 软件** 可以实现这一点就完美了。由于很多用户都不了解,或者是不想太麻烦,所以还有很多未使用的硬件资源。这个软件有很多跟 Linux 系统和 Windows 系统相关的应用接口,如果要进行视频编码和解码,将会是[一件麻烦事][28]。
|
||||
Skylake 处理器架构在播放 4K 视频方面表现得更出色,但是有时候它也会出现卡顿现象,然后瞬间降到 10fps 的播放速度。我想起其中一部分卡顿现象就是在播放《X 战警》的过程中。我尝试在 Wayland 下播放 4K 视频时却很流畅,这让我非常满意。很高兴看到 OpenGL 给予的大力支持。在硬件方面, 英特尔公司 2014 年以来支持的最新版本是 4.5 。
|
||||
|
||||
Skylake 处理器架构在播放 4K 视频方面表现得更出色,但是有时候它也会出现卡顿现象,然后瞬间降到 10 fps 的播放速度。我想起其中一部分卡顿现象就是在播放《X 战警》的过程中。我尝试在 Wayland 下播放 4K 视频时却很流畅,这让我非常满意。很高兴看到 OpenGL 给予的大力支持。在硬件方面, Inter 公司 2014 年以来支持的最新版本是 4.5 。
|
||||
|
||||
我的 Yoga 900 (-13ISK2) 笔记本电脑实际上是一个升级版,使用比 520 [更快][29] 的 Iris 540 图像协同处理器,而且它的流处理器多达 24 个。然而,它只能用来玩 SuperTuxKart 游戏,而且还得将游戏显示效果设置为中等,分辨率调整为 1600×900 ,速度为 20 fps ,我也不想在这里吹什么牛。说真的,这款游戏比前几年改善了很多,而且游戏界面也漂亮得多。
|
||||
我的 Yoga 900 (-13ISK2)笔记本电脑实际上是一个升级版,使用比 520 [更快][29] 的 Iris 540 图像协同处理器,而且它的流处理器多达 24 个。然而,它只能用来玩 SuperTuxKart 游戏,而且还得将游戏显示效果设置为中等,分辨率调整为 1600×900 ,速度为 20fps ,我也不想在这里吹什么牛。说真的,这款游戏比前几年改善了很多,而且游戏界面也漂亮得多。
|
||||
|
||||

|
||||
|
||||
英特尔公司在中国有一个从事[使能][30]的团队,专门支持 OpenCL 对显卡的使用。但是,我从未看到 Blender 的任何用户使用它,因此我怀疑这个团队是不是作摆设用的。英特尔公司已经很长时间都没有支持 OpenCL 了,那些使用 Blender 软件处理重要工作的用户早已换成 Nvidia 或者 AMD 显卡,即使英特尔公司后来重新写了代码,大家也没太多的兴趣做测试。
|
||||
英特尔公司在中国有一个团队致力于[使][30] 该显卡支持 OpenCL。但是,我从未看到 Blender 的任何用户使用它,因此我怀疑这个团队是不是作摆设用的。英特尔公司已经很长时间都没有支持 OpenCL 了,那些使用 Blender 软件处理重要工作的用户早已换成 Nvidia 或者 AMD 显卡,即使英特尔公司后来重新写了代码,大家也没太多的兴趣做测试。
|
||||
|
||||
有一件事让我感到非常意外,我在另外一台机器上做光线追踪测试时发现,一个四核的处理器比使用循环引擎的 NVidia 960M 的处理器要快得多。很明显,在处理那个任务时, 640 CUDA 多核心处理器也比不上 4 个英特尔公司的 CPU 。更高级的英特尔处理器有 2000 多个核心,性能更强悍。
|
||||
|
||||
### HiDPI
|
||||
### HiDPI 高分辨率支持
|
||||
|
||||
最近这几年, Linux 系统在高分辨率屏幕方面已经做得越来越好了,但是仍然有很长的路要走。还好目前的 Gnome 版本对 HiDPI 的支持也算完美。如果你把火狐浏览器的 **layout.css.devPixelsPerPx** 这个参数值设置为 2\ ,其显示效果更美观。然而这个 13.3 寸的屏幕分辨率还是显得略小了些,我还安装了一个无斜视加强版插件,这让屏幕在 120 度范围内看起来更方便。
|
||||
最近这三年来, Linux 系统在高分辨率屏幕方面已经做得越来越好了,但是仍然有很长的路要走。还好目前的 Gnome 版本对 HiDPI 的支持也算完美。如果你把火狐浏览器的 **layout.css.devPixelsPerPx** 这个参数值设置为 2 ,其显示效果更美观。然而这个 13.3 寸的屏幕分辨率还是显得略小了些,我还安装了一个无斜视加强版(No-Squint Plus)插件,这让屏幕在 120 度范围内看起来更方便。
|
||||
|
||||
很高兴地看到 LibreOffice 办公软件的界面在当前设置的屏幕下变得更加美观,因为我安装了 2014 年 4 月份发布的[一些补丁][31],而且这些功能还一直在不断的完善中。最大的问题是 LibreOffice 软件界面的工具图标重叠起来了。有很多主题都包括 SVG 图标,但是这些图标不会跟产品一起发布出来。跟 PNG 类型的图标相比, SVG 图标加载更慢,而且还要占用缓存。[Tomaž Vajngerl 在这方面投入很多的精力][32],但是还未发布出来。尽管这样, LibreOffice 比那些没有易识别图标的 Linux 系统应用程序要漂亮得多。
|
||||
很高兴地看到 LibreOffice 办公软件的界面在当前设置的屏幕下变得更加美观,因为我安装了 2014 年 4 月份发布的[一些补丁][31],而且这些功能还一直在不断的完善中。最大的问题是 LibreOffice 软件界面的工具图标重叠起来了。有很多主题都包括 SVG 图标,但是这些图标不会跟产品一起发布出来。跟 PNG 类型的图标相比, SVG 图标加载更慢,而且还要缓存才行。[Tomaž Vajngerl 在这方面投入很多的精力][32],但是还未发布出来。尽管这样, LibreOffice 比那些没有易识别图标的 Linux 系统应用程序要漂亮得多。
|
||||
|
||||
应用程序在高分辨率屏幕中的检测与应用方面正在不断的完善,但是还有其它一些很流行的小程序,比如 Gimp ,Audacity 和 Inkscape 仍然不能使用。我为 Gimp 软件安装了一个很强大的定制化主题,但是所有的图标都变得大不一样,尽管这些图标已经显示得够大了,但是也很难识别出来。
|
||||
应用程序在高分辨率屏幕中的检测与应用方面正在不断的完善,但是还有其它一些很流行的程序,比如 Gimp ,Audacity 和 Inkscape 仍然不能使用高分辨率屏幕。我为 Gimp 软件安装了一个很强大的定制化主题,但是所有的图标都变得大不一样,尽管这些图标已经显示得够大了,但是也很难识别出来。
|
||||
|
||||
Linux 系统仅占了 1.5% 的市场份额,然而,遗憾的是其相关负责人也没有对这些问题给予更多的重视。虽然很多应用软件逐步使用 GTK 3 工具来开发它们的图形界面,但是 Audacity 这款音频处理软件好像是已经[终止][33]开发了。在第一次调查中我发现,那些提供长期支持的应用程序仍然有很多地方需要改进,但是 3 年多过去了,即使是那些很出名的软件也没做到位。
|
||||
Linux 系统占有了 1.5% 的市场份额,遗憾的是这些问题并没有得到更多的重视。虽然很多应用软件逐步使用 GTK 3 来开发它们的图形界面,但是比如说 Audacity 这款音频处理软件好像是已经[终止][33]开发了。在我的第一篇评论中我发现,那些提供长期支持的应用程序仍然有很多地方需要改进,但是 3 年多过去了,即使是那些很出名的软件也没做到位。
|
||||
|
||||
### SSD 固态硬盘
|
||||
|
||||
由于我平时对系统做了各种各样的优化,尤其是对火狐浏览器做的优化,因此我的老款电脑的硬盘仍然可以正常工作。还记得我的 **/tmp** 目录被我设置成自动作为 RAM 设备,因此,我经常把文件默认下载到那里。有时候我会在 /tmp 目录下把一个 500 MB 的视频剪辑成 20 MB 的小视频,或者是转换成另外的格式,因此我对硬盘的写操作做得比较频繁。这样做的工作量很大,也可能没必要,但是在 RAM 存储中运行速度更快。
|
||||
由于我平时对系统做了各种各样的优化,尤其是对火狐浏览器做的优化,因此我的老款电脑的硬盘仍然可以正常工作。还记得我的 **/tmp** 目录被我自动设置为 RAM 设备,因此,我经常把文件默认下载到那里。有时候我要把一个 500 MB 的视频剪辑成 20 MB 的小视频,或者是转换成另外的格式,因此我在 /tmp 目录下做这些工作节约了大量的写入操作。这样做需要更多的工作量,也可能没必要,但是在 RAM 存储中运行速度更快。
|
||||
|
||||
在这三年里,我几乎对每个硬盘的存储单元做了 25 次写入,这意味着这块硬盘可以使用 350 年左右。极大部分的写操作都用于 Arch Linux 系统的更新。我每个月都会构建新的 LibreOffice 软件,每周都会更新“稳定”版系统内核。实时把系统升级到最新棒真的让人很爽,但是与 Debian 的稳定版系统相比起来,这将会进行 100 多次写入操作。然后,能够让每一个系统组件都升级到最新版,这也是值得的。
|
||||
在这三年里,我几乎对每个硬盘的存储单元做了 25 次写入,这意味着这块硬盘可以使用 350 年左右。绝大部分的写操作都用于 Arch Linux 系统的更新。我每个月都会构建新的 LibreOffice 软件,每周都会更新“稳定”版系统内核。实时把系统升级到最新棒真的让人很爽,但是与 Debian 的稳定版系统相比起来,这将会进行 100 多次写入操作。然而,能够让每一个系统组件都升级到最新版,这也是值得的。
|
||||
|
||||
新的三星硬盘诊断工具也无法检测出每个硬盘存储单元的写次数。事实上,我也不能确定这个硬盘的存储单元类型是什么以及在处理任务的过程中写了多少次。我相信从“占用率“这个数据可以看到硬盘的使用时长,但是也许这只跟空闲的存储单元有关。我没有找到任何相关文档,因此我只能猜测到大致跟下面的数据差不多了:
|
||||
|
||||
|||
|
||||
|--|--|
|
||||
| **型号:** | **SAMSUNG MZVLV256HCHP-000L2** |
|
||||
新的三星硬盘诊断工具无法检测出每个硬盘存储单元的写次数。事实上,我也不能确定这个硬盘的存储单元类型是什么以及在处理任务的过程中写了多少次。我相信从“已用百分比“这个数据可以看到硬盘的使用时长,但是也许这只跟空闲的存储单元有关。我没有找到任何相关文档,因此我只能猜测到大致跟下面的数据差不多了:
|
||||
|
||||
|
||||
| **型号:** | **SAMSUNG MZVLV256HCHP-000L2** |
|
||||
| --- | --- |
|
||||
| **固件版本(0x06):** | **3 Slots** |
|
||||
| **可用空间:** | **100%** |
|
||||
| **可用的空闲阈值:** | **10%** |
|
||||
| **已用百分比:** | **0%** |
|
||||
| ****存储单元写数据:**** | **198,997 [101 GB]** |
|
||||
| **存储单元写数据:** | **305,302 [156 GB]** |
|
||||
| **读取的数据单元:** | **198,997 [101 GB]** |
|
||||
| **写入的数据单元:** | **305,302 [156 GB]** |
|
||||
| **主机读命令:** | **3,480,816** |
|
||||
| **主机写命令:** | **10,176,457** |
|
||||
| **错误日志条目信息:** | **5** |
|
||||
| **错误日志条目:** | **5** |
|
||||
|
||||
### 损坏的左 Ctrl 键
|
||||
|
||||
@ -184,13 +188,13 @@ Yoga 900 键盘布局跟 Yoga 2 Pro 版一致,但是内部结构不同。 Yoga
|
||||
|
||||
我用了好几个小时后才注意到了这个问题,我确信那是生产笔记本电脑过程中的疏忽导致的。这是一块非常小的塑料块,在装配的过程中就早已变形或损坏了。
|
||||
|
||||
尽管这个电脑还在保修期,可以免费进行维修,我可不想为这些小事情耽搁太多时间,因此我在网上找到一个叫做 laptopkey.com 的网站,然后订购了一个换键和转轴。真是太诡异了,竟然有三种类型的转轴!我花了好一会才搞明白我的电脑适合哪一种类型,因为这三种类型太难区分了:
|
||||
尽管这个电脑还在保修期,可以免费进行维修,我可不想为这些小事情耽搁太多时间,因此我在网上找到一个叫做 laptopkey.com 的网站,然后订购了一个换键和支架。真是太诡异了,竟然有三种类型的支架!我花了好一会才搞明白我的电脑适合哪一种类型,因为这三种类型太难区分了:
|
||||
|
||||

|
||||
|
||||
因此我预定了这个配件,但是还得花费至少一个星期的时间才到收到。这真是太让我抓狂了,因为我每次使用复制粘贴、视频跳跃或者是在编辑器里按单词移动及其它相关操作时,只能使用右 Ctrl 键。我觉得我可以把右边的 Ctrl 键更换到左边来,但是我从未这么弄过。
|
||||
|
||||
因此,我尝试跟着网上找到的视频步骤把这个键弄下来:我先用指甲扣起左上角到一定高度。然后用同样的方式操作右上角,但是另外一个小塑料片被折断了,因此我弄坏了两个键轴。如果不损坏这些非常细小的塑料夹片,根本不可能把按键撬下来。这种类型的键盘只不是理论上可以进行更换吧。
|
||||
因此,我尝试跟着网上找到的视频步骤把这个键弄下来:我先用指甲扣起左上角到一定高度。然后用同样的方式操作右上角,但是另外一个小塑料片被折断了,因此我弄坏了两个键轴。如果不损坏这些非常细小的塑料夹片,根本不可能把按键撬下来。这种类型的键盘只不过是理论上可以进行更换吧。
|
||||
|
||||
因此,我决定采用笨办法,使用强力胶。我情愿让这个该死的按键就这样固定死了,我暂时没有一个紧急的方法来替换它们。这真是太折腾了,因为我只需要大概直径 1mm 的胶水:如果弄太多的胶水可能会让情况变得更糟糕。
|
||||
|
||||
@ -200,42 +204,41 @@ Yoga 900 键盘布局跟 Yoga 2 Pro 版一致,但是内部结构不同。 Yoga
|
||||
|
||||
在我使用了 3 年多的 Arch Linux 系统之后,我再也没兴趣去尝试其它操作系统了。虽然英特尔公司更新驱动程序的步伐有些落后,但是无论怎样,在日常工作中使用 Arch Linux 系统还是挺让人愉快的,而且每一个星期都有所进步。实时更新任何程序真的让人很爽。我经常使用比 Ubuntu 系统发布时间还要新的软件包。虽然 Ubuntu 用户可以在自定义的 PPA 中找到更新的软件包,但是这种软件包都没有经过任何测试或修复,因此用户在使用过程中会遇到各种各样的问题。
|
||||
|
||||
也有用户抱怨 Ubuntu 系统升级时会导致机器自动重启或者强制用户重新安装软件,因此,即使安装的过程很快,之后却需要很长的时间来维护。我每次听到有人抱怨 Arch 系统的安装过程时,最终的原因还不是他们自己操作不当或是文件系统损坏的问题。
|
||||
也有用户抱怨 Ubuntu 系统升级时会导致机器自动重启或者强制用户重新安装软件,因此,即使安装的过程很快,之后却需要很长的时间来维护。我每次听到有人抱怨 Arch 系统的安装过程时,最终的原因总是归结为他们自己操作不当或是类似 btrfs 文件系统损坏的问题。
|
||||
|
||||
我曾经想尝试安装 [Antergos 系统][34],那是一款基于 Arch Linux 并搭载了桌面环境的 Linux 发行版。然而,安装过程中的设置界面在显示器上看不清楚,而且最小化安装后也识别不到触摸板,那是我仅有的 1 GB 存储空间了。因此,我决定还是重新安装原来的 Arch Linux 系统。还好 Yoga 笔记本仍然支持传统的 BIOS 启动方式,这样我就不用再去折腾 [UEFI][35] 了。
|
||||
我曾经想尝试安装 [Antergos 系统][34],那是一款基于 Arch Linux 并搭载了桌面环境的 Linux 发行版。然而,安装过程中的设置界面在显示器上看不清楚,而且最小化安装后也识别不到触摸板,那是由于我仅有一个有可用空间的老式 1 GB U 盘了。因此,我决定还是重新安装原来的 Arch Linux 系统。还好 Yoga 笔记本仍然支持传统的 BIOS 启动方式,这样我就不用再去折腾 [UEFI][35] 了。
|
||||
|
||||
很遗憾我没能试用 Antergos 系统,因为我觉得对于那些技术水平一般的用户或是想快速入门 Arch Linux 系统的用户来说, Antergos 算是一个非常强大的 Linux 发行版了。 Arch 在维基上有丰富的文档新资料教你如何完美地使用这个 Linux 系统。我喜欢每周定时对固态硬盘做优化,包括调试[用户配置文件-同步-进程][36]脚本、对安卓系统的支持以及在视频播放中使用硬件加速等等。在 Linux 系统中有很多大家都需要去折腾的功能特性,只需要输入几行命令就可以搞定了。
|
||||
很遗憾我没能试用 Antergos 系统,因为我觉得对于那些技术水平一般的用户或是想快速入门 Arch Linux 系统的用户来说, Antergos 算是一个非常强大的 Linux 发行版了。 Arch 在维基上有丰富的文档新资料教你如何完美地使用这个 Linux 系统。我喜欢优化,比如每周定时对固态硬盘做优化、[用户配置文件-同步-进程][36]脚本、对安卓系统的支持以及在视频播放中使用硬件加速等等。在 Linux 系统中有很多大家都需要去折腾的功能特性,只需要输入几行命令就可以搞定了。
|
||||
|
||||
Manjaro 也是一款非常流行的基于 Arch Linux 并搭载了桌面环境的 Linux 发行版,但是用了 3 年多的 Arch Linux 系统后,我更信任使用 Arch 系统中的软件包来解决组件之间的问题。我在 Reddit 网站看到一些评论,有用户反映说 Manjaro 系统升级后就崩溃了。
|
||||
Manjaro 也是一款非常流行的基于 Arch Linux 并搭载了桌面环境的 Linux 发行版,但是用了 3 年多的 Arch Linux 系统后,我更信任 Arch 的封包人会解决组件之间的问题。我在 Reddit 网站看到一些评论,有用户反映说 Manjaro 系统升级后就崩溃了。
|
||||
|
||||
我对 Arch Linux 系统唯一不爽的一点就是它又难看又不可读的引导加载界面。还好我只需要使用老电脑中的 **grub.cfg** 配置文件来替换掉就可以了。
|
||||
我对 Arch Linux 系统唯一不爽的一点就是它丑陋而看不懂的引导加载界面。还好我只需要使用老电脑中的 **grub.cfg** 配置文件来替换掉就可以了。
|
||||
|
||||
### 安装 Arch Linux 系统
|
||||
|
||||
起初我只想简单地把硬盘从老的笔记本电脑移植到新的笔记本电脑上,这样我就不用安装任何东西了,但是拆开电脑后,我发现 M.2 接口的固态硬盘形状很特殊。本来我也可以使用一个简单的块复制方法来完成移植,但是这一次是一个很好的回顾安装过程的机会,所以我决定从头再来一遍。 3 年多的时间里,我安装了很多没用的应用程序,即使有些被我卸载了,系统中还存在很多的遗留文件。
|
||||
起初我只想简单地把硬盘从老的笔记本电脑移植到新的笔记本电脑上,这样我就不用安装任何东西了,但是拆开电脑后,我发现 M.2 接口的固态硬盘形状很特殊。本来我也可以使用一个低级块复制方法来完成移植,但是这一次是一个很好的回顾安装过程的机会,所以我决定从头再来一遍。 3 年多的时间里,我安装了很多没用的应用程序,即使有些被我卸载了,系统中还存在很多的遗留文件。
|
||||
|
||||
由于 Arch 900 笔记本电脑已经发布出来一段时间了,其硬件也不是最新的,所以安装 Arch Linux 系统的过程进行得很顺利。我还要使用 **rfkill 工具来开启无线上网** 功能,除此之外,系统都正常运行了。显然, Linux 系统下还不能正常使用 rfkill 工具。幸运的是在启动 rfkill 工具时, **systemd** 会自动恢复rfkill 的数据。
|
||||
由于 Arch 900 笔记本电脑已经发布出来一段时间了,其硬件也不是最新的,所以安装 Arch Linux 系统的过程进行得很顺利。我仍然需要使用 **rfkill 工具来开启无线上网** 功能,除此之外,系统都正常运行了。显然, Linux 系统下还不能正确读取该型号的 rfkill 信息。幸运的是在启动 rfkill 工具时, **systemd** 会自动恢复 rfkill 的数据。
|
||||
|
||||
### Kernel Buglist内核故障列表
|
||||
### 内核故障列表
|
||||
|
||||
有一件事让我非常惊讶, Linux 操作系统的缺陷列表太混乱了。我知道有很多的用户参与其中,其变化频率也很高,但是,一成不变的最糟糕的事情却是系统缺陷报告。我搞不懂为什么有些系统缺陷已经存在好多年了,但是却丝毫没有修复的迹象。
|
||||
有一件事让我非常惊讶, Linux 操作系统的缺陷列表太混乱了。我知道有很多的用户参与其中,其变化频率也很高,但是,最糟糕的事情却是系统缺陷报告依然如故。我搞不懂为什么有些系统缺陷已经存在好多年了,但是却丝毫没有修复的迹象。
|
||||
|
||||
我在上次的审查中打过一个很好的比方。假设航空公司花了一两年的时间才把你丢失的行李找回来了。还你会信任那家公司吗?实际上,如果你还有几千个已知的系统缺陷和上百次系统回归,那么你发布新的发行版有什么意义呢?如果波音公司的每一架飞机都有 1% 的坠机概率,那他们会这么多年都置之不理吗?
|
||||
我在上次的评论中打过一个很好的比方。假设航空公司花了一两年的时间才把你丢失的行李找回来了。还你会信任那家公司吗?实际上,如果你还有几千个已知的系统缺陷和上百次系统性能回退,那么你发布新的发行版有什么意义呢?如果波音公司的每一架飞机都有 1% 的坠机概率,那他们会这么多年都置之不理吗?
|
||||
|
||||
也许 Linux 系统基金会应该雇佣一些专职的工程师来修复那些看似被遗忘的系统缺陷问题。有很多人从事 Linux 系统工作,大家都清楚该系统有很多历史缺陷未修复——通常情况下,这些问题都是普通用户自己处理的。我觉得目前的 Linux 系统就不要发布任何更新了,先花几个月的时间去修复那些系统缺陷,直到缺陷数量小于 50\ 个时,再发布新版本,这样的系统内核会更稳定。现在还有 4672 个系统缺陷问题未解决。这将会是一个非常好的改变发行版主版本号的理由。
|
||||
也许 Linux 系统基金会应该雇佣一些专职的工程师来修复那些看似被遗忘的系统缺陷问题。有很多人从事 Linux 系统工作,大家都清楚该系统有很多历史缺陷未修复——通常情况下,这些问题都是由普通用户自己处理的。我觉得目前的 Linux 系统就不要发布任何更新了,先花几个月的时间去修复那些系统缺陷,直到缺陷数量小于 50 个时,再发布新版本,这样的系统内核会更稳定。现在还有 [4672 个](http://bit.ly/LinuxBugs)系统缺陷问题未解决,这才是一个非常好的改变发行版主版本号的理由。
|
||||
|
||||
有些东西跟每周发布一个新的稳定发行版是相悖的,但是这种方式还持续了这么多年了,而且他们每次都发布一些重要补丁,因此他们也算是做了一些非常有意义的工作。内核的开发速度很快,也变得越来越好,因此早已超出我吐槽的范围了,但是我还是觉得他们应该尝试一些新的东西。
|
||||
有些东西跟每周发布一个新的稳定版本是相悖的,但是这种方式还持续了这么多年了,而且他们每次都发布一些重要补丁,因此他们也算是做了一些非常有意义的工作。内核的开发速度很快,也变得越来越好,因此早已超出我吐槽的范围了,但是我还是觉得他们应该尝试换个思路。
|
||||
|
||||
至少,系统缺陷问题应该在规定的时间内处理。如果超出指定时间,这个系统缺陷应该提交给到维护工程师并逐渐发送给 Linux 本人。如果某个领域内存在很多的历史缺陷也没人去修复,那么 Linus 应该公开并严厉批评相关组织机构。他们更应该像波音公司那样去思考解决问题。
|
||||
至少,系统缺陷问题应该在规定的时间内处理。如果超出指定时间,这个系统缺陷应该提交给到维护者并逐渐发送给 Linus 本人。如果某个领域内存在很多的历史缺陷也没人去修复,那么 Linus 应该公开并严厉批评相关组织机构。他们更应该像波音公司那样去思考解决问题。
|
||||
|
||||
### Lenovo
|
||||
### 联想公司
|
||||
|
||||
很多 Linux 用户都痛击联想公司对定制化的笔记本缺少支持,好在他们创造了性价比较高的硬件。正如我多年前写的一样,很明显,联想公司在发布 Yoga 2 之前就没人安装过 Linux 系统来进行测试, Yoga 900 笔记本也是如此,因为这是根本不可能的事情。
|
||||
|
||||
我觉得他们公司的每个员工都应该安装双系统。这在设置上并不难,用户也更希望他们这样做。联想有 60000 多员工。至少他们应该在公司内部成立一个 Yoga 团队,然后招一些人来着手处理 **Linux 系统** 问题。
|
||||
Windows 系统在很多方面比 Linux 系统更难用。Windows 系统虽然能够运行更多的应用程序,但是我觉得也许他们公司的大部分员工还是更乐于使用自定义的 Linux 系统吧。
|
||||
我觉得他们公司的每个员工都应该安装双系统。这在设置上并不难,用户也更希望他们这样做。联想有 60000 多员工。至少他们应该在公司内部成立一个 Yoga 团队,然后招一些人来着手处理 **Linux 系统** 问题。Windows 系统在很多方面比 Linux 系统更难用。Windows 系统虽然能够运行更多的应用程序,但是我觉得也许他们一半的用户还是更乐于使用合理配置的 Linux 系统吧。
|
||||
|
||||
尽管现在联想对 Linux 系统很不屑,他们制造的麻烦比软件方面还多。在很多型号的笔记本电脑中, RAM 芯片被焊接固定了。他们只允许白名单设备和预授权的插件安装到联想笔记本电脑中。 Yoga 笔记本也没有独立显卡,而且联想公司本来也不支持更新主板上的插件。我想有人会把这些矛头指向联想公司的 CEO 。
|
||||
尽管现在联想对 Linux 系统很不屑,他们制造的麻烦比软件方面还多。在很多型号的笔记本电脑中, RAM 芯片被焊接固定了。他们只允许白名单设备和预授权的卡可以安装到联想笔记本电脑中。 Yoga 笔记本也没有独立显卡,而且联想公司本来也不支持更新主板上的卡。我想有人会把这些矛头指向联想公司的 CEO 。
|
||||
|
||||
### 总结
|
||||
|
||||
@ -249,11 +252,11 @@ Windows 系统从 Linux 系统中汲取了很多特性,但是 Windows 系统
|
||||
|
||||
至少对于我来说,我不需要使用任何 Windows 的应用程序,也不需要浪费额外的时间去维护了。在 Windows 系统中修复问题时,你可以到很多不同的地方查询解决问题的方法。 Linux 系统有很多的地方要进行配置,但是总的来说,这已经很简单了。
|
||||
|
||||
我有个朋友为了更新驱动程序,需要在 Windows 下安装第三方软件,因为更新这种操作需要从微软网站以及其它更多的网站来抓取源代码。 Windows 系统已经比前几年做得更好了,有更多的游戏和桌面应用程序,但是它仍然是一个封闭式老系统。
|
||||
我有个朋友为了更新驱动程序,需要在 Windows 下安装第三方软件,因为更新这种操作需要从微软网站以及其它更多的网站来抓取代码。 Windows 系统已经比前几年做得更好了,有更多的游戏和桌面应用程序,但是它仍然是一个封闭式老系统。
|
||||
|
||||
我发现 Gnome Classic 桌面给人一种简洁性的体验。我希望它不是使用很繁杂的[流行 Javascript 脚本][42]语言编写的,他们还要重新建立一个关于定制化主题和颜色主题的社区。 Gnome 2 和 Windows 10 系统中的有些非常有用的功能也消失了,而且也没有老版本的稳定。 2011 年发布的 Gnome 3.0 完全就是走回头路,但是 6 年后的 Gnome 3.22 终于再续辉煌。
|
||||
我发现 Gnome 经典桌面给人一种简洁性的体验。我希望它不是使用很繁杂的[流行 Javascript 脚本][42]语言编写的,他们还要重新建立一个关于定制化主题和颜色主题的社区。 Gnome 2 和 Windows 10 系统中的有些非常有用的功能也消失了,而且也没有老版本的稳定。 2011 年发布的 Gnome 3.0 完全就是走回头路,但是 6 年后的 Gnome 3.22 终于再续辉煌。
|
||||
|
||||
Gnome Classic 桌面环境是最优秀的图形化界面之一,[很多优秀的特性][43]都变得越来越好了。已安装完成 Arch Linux 系统的 Yoga 900 笔记本电脑现在都运行正常了,我期待着 Linux 系统对 HiDPI 模式和其它方面的改进!我迫不及待地想深入学习 LibreOffice 办公软件里的语法检查特性。
|
||||
Gnome 经典桌面环境是最优秀的图形化界面之一,[很多优秀的特性][43]都变得越来越好了。已安装完成 Arch Linux 系统的 Yoga 900 笔记本电脑现在都运行正常了,我期待着 Linux 系统对 HiDPI 模式和其它方面的改进!我迫不及待地想深入学习 LibreOffice 办公软件里的语法检查特性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -261,7 +264,7 @@ via: http://keithcu.com/wordpress/?p=3739
|
||||
|
||||
作者:[keithccurtis][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
如何在 Linux 中列出通过 RPM 或者 DEB 包安装的文件
|
||||
============================================================
|
||||
|
||||
你是否想要了解安装包中各个文件在 Linux 系统中安装(位于)的位置?我们将在本文介绍如何列出文件的来源,或存在于某个特定包或者一组软件包中的文件。
|
||||
|
||||
这篇文章可以帮你轻松地找到重要的软件包文件,如配置文件、帮助文档等。我们来看看找出文件在哪个包中或者从哪个包中安装的几个方法:
|
||||
|
||||
### 如何列出 Linux 中全部已安装软件包的文件
|
||||
|
||||
你可以使用 [repoquery 命令][6],它是 [yum-utils][7] 的一部分,用来列出给定的软件包在 CentOS/RHEL 系统上安装的文件。
|
||||
|
||||
要安装并使用 yum-utils,运行下面的命令:
|
||||
|
||||
```
|
||||
# yum update
|
||||
# yum install yum-utils
|
||||
```
|
||||
|
||||
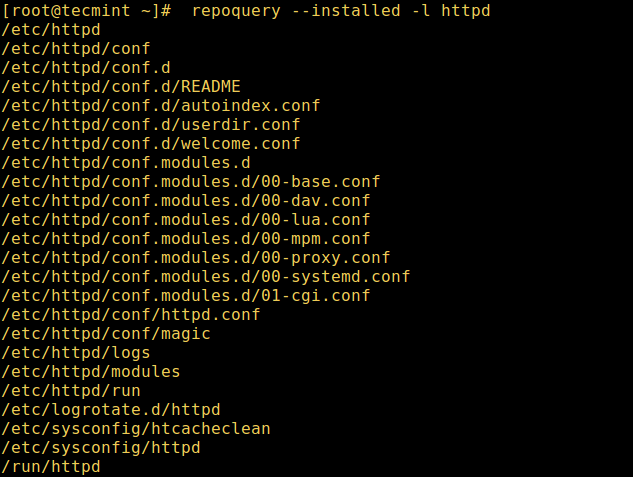
现在你可以列出一个已安装包的文件了,比如 httpd 服务器 (注意包名是大小写敏感的)。`--installed` 表示已经安装的包,`-l` 列出所有的文件:
|
||||
|
||||
```
|
||||
# repoquery --installed -l httpd
|
||||
# dnf repoquery --installed -l httpd [On Fedora 22+ versions]
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
*repoquery 列出 httpd 安装的文件*
|
||||
|
||||
重要:在 Fedora 22 以上的版本中,`repoquery` 命令在基于 RPM 的发行版中已经与 [dnf 包管理器][9]整合,可以用上面的方法列出安装的文件。
|
||||
|
||||
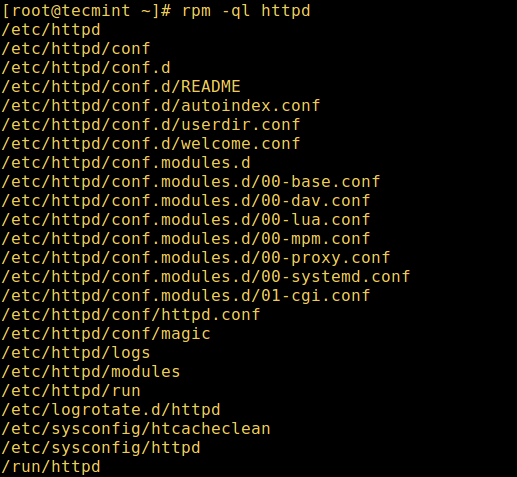
除此之外,你也可以使用下面的 [rpm 命令][10]列出 .rpm 包中或已经安装的 .rpm 包的文件,下面的 `-q` 和 `-l` 表示列出其后跟着的包中的文件:
|
||||
|
||||
```
|
||||
# rpm -ql httpd
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
*rpm 查询已安装程序的安装包*
|
||||
|
||||
另外一个有用的建议是使用 `-p` 在安装之前列出 `.rpm` 中的文件。
|
||||
|
||||
```
|
||||
# rpm -qlp telnet-server-1.2-137.1.i586.rpm
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu 发行版中,你可以使用 [dpkg 命令][12]带上 `-L` 标志在 Debian 系统或其衍生版本中列出给定 .deb 包的安装的文件。
|
||||
|
||||
在这个例子中,我们会列出 apache2 Web 服务器安装的文件:
|
||||
|
||||
```
|
||||
$ dpkg -L apache2
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
*dpkg 列出安装的包*
|
||||
|
||||
不要忘记查看其它有关在 Linux 中软件包管理的文章。
|
||||
|
||||
1. [20 个有用的 yum 包管理命令][1]
|
||||
2. [20 个有用的 rpm 包管理命令] [2]
|
||||
3. [15 个 Ubuntu 中有用的 apt 包管理命令] [3]
|
||||
4. [15 个 Ubuntu 中有用的 dpkg命令][4]
|
||||
5. [5 个最佳的对 Linux 新手的包管理器][5]
|
||||
|
||||
就是这样了!在本文中,我们向你展示了如何在 Linux 中列出/找到给定的软件包或软件包组安装的所有文件。在下面的评论栏中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 的爱好者,目前任 TecMint 的作者,志向是一名 Linux 系统管理员、web 开发者。他喜欢用电脑工作,并热衷于分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/list-files-installed-from-rpm-deb-package-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[3]:http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[4]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[5]:http://www.tecmint.com/linux-package-managers/
|
||||
[6]:http://www.tecmint.com/list-installed-packages-in-rhel-centos-fedora/
|
||||
[7]:http://www.tecmint.com/linux-yum-package-management-with-yum-utils/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Repoquery-List-Installed-Files-of-Httpd.png
|
||||
[9]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[10]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/rpm-ql-httpd.png
|
||||
[12]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/dpkg-List-Installed-Packages.png
|
||||
[14]:http://www.tecmint.com/author/aaronkili/
|
||||
[15]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[16]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,5 +1,3 @@
|
||||
GHLandy Translating
|
||||
|
||||
Why we need open leaders more than ever
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by Bestony
|
||||
How to use pull requests to improve your code reviews
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by YYforymj
|
||||
|
||||
|
||||
[How debuggers work: Part 1 - Basics][21]
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,144 +0,0 @@
|
||||
Translating by sanfusu
|
||||
|
||||
[Data-Oriented Hash Table][1]
|
||||
============================================================
|
||||
|
||||
In recent years, there’s been a lot of discussion and interest in “data-oriented design”—a programming style that emphasizes thinking about how your data is laid out in memory, how you access it and how many cache misses it’s going to incur. With memory reads taking orders of magnitude longer for cache misses than hits, the number of misses is often the key metric to optimize. It’s not just about performance-sensitive code—data structures designed without sufficient attention to memory effects may be a big contributor to the general slowness and bloatiness of software.
|
||||
|
||||
The central tenet of cache-efficient data structures is to keep things flat and linear. For example, under most circumstances, to store a sequence of items you should prefer a flat array over a linked list—every pointer you have to chase to find your data adds a likely cache miss, while flat arrays can be prefetched and enable the memory system to operate at peak efficiency.
|
||||
|
||||
This is pretty obvious if you know a little about how the memory hierarchy works—but it’s still a good idea to test things sometimes, even if they’re “obvious”! [Baptiste Wicht tested `std::vector` vs `std::list` vs `std::deque`][4] (the latter of which is commonly implemented as a chunked array, i.e. an array of arrays) a couple of years ago. The results are mostly in line with what you’d expect, but there are a few counterintuitive findings. For instance, inserting or removing values in the middle of the sequence—something lists are supposed to be good at—is actually faster with an array, if the elements are a POD type and no bigger than 64 bytes (i.e. one cache line) or so! It turns out to actually be faster to shift around the array elements on insertion/removal than to first traverse the list to find the right position and then patch a few pointers to insert/remove one element. That’s because of the many cache misses in the list traversal, compared to relatively few for the array shift. (For larger element sizes, non-POD types, or if you already have a pointer into the list, the list wins, as you’d expect.)
|
||||
|
||||
Thanks to data like Baptiste’s, we know a good deal about how memory layout affects sequence containers. But what about associative containers, i.e. hash tables? There have been some expert recommendations: [Chandler Carruth tells us to use open addressing with local probing][5] so that we don’t have to chase pointers, and [Mike Acton suggests segregating keys from values][6] in memory so that we get more keys per cache line, improving locality when we have to look at multiple keys. These ideas make good sense, but again, it’s a good idea to test things, and I couldn’t find any data. So I had to collect some of my own!
|
||||
|
||||
### [][7]The Tests
|
||||
|
||||
I tested four different quick-and-dirty hash table implementations, as well as `std::unordered_map`. All five used the same hash function, Bob Jenkins’ [SpookyHash][8] with 64-bit hash values. (I didn’t test different hash functions, as that wasn’t the point here; I’m also not looking at total memory consumption in my analysis.) The implementations are identified by short codes in the results tables:
|
||||
|
||||
* **UM**: `std::unordered_map`. In both VS2012 and libstdc++-v3 (used by both gcc and clang), UM is implemented as a linked list containing all the elements, and an array of buckets that store iterators into the list. In VS2012, it’s a doubly-linked list and each bucket stores both begin and end iterators; in libstdc++, it’s a singly-linked list and each bucket stores just a begin iterator. In both cases, the list nodes are individually allocated and freed. Max load factor is 1.
|
||||
* **Ch**: separate chaining—each bucket points to a singly-linked list of element nodes. The element nodes are stored in a flat array pool, to avoid allocating each node individually. Unused nodes are kept on a free list. Max load factor is 1.
|
||||
* **OL**: open addressing with linear probing—each bucket stores a 62-bit hash, a 2-bit state (empty, filled, or removed), key, and value. Max load factor is 2/3.
|
||||
* **DO1**: “data-oriented 1”—like OL, but the hashes and states are segregated from the keys and values, in two separate flat arrays.
|
||||
* **DO2**: “data-oriented 2”—like OL, but the hashes/states, keys, and values are segregated in three separate flat arrays.
|
||||
|
||||
All my implementations, as well as VS2012’s UM, use power-of-2 sizes by default, growing by 2x upon exceeding their max load factor. In libstdc++, UM uses prime-number sizes by default and grows to the next prime upon exceeding its max load factor. However, I don’t think these details are very important for performance. The prime-number thing is a hedge against poor hash functions that don’t have enough entropy in their lower bits, but we’re using a good hash function.
|
||||
|
||||
The OL, DO1 and DO2 implementations will collectively be referred to as OA (open addressing), since we’ll find later that their performance characteristics are often pretty similar.
|
||||
|
||||
For each of these implementations, I timed several different operations, at element counts from 100K to 1M and for payload sizes (i.e. total key+value size) from 8 to 4K bytes. For my purposes, keys and values were always POD types and keys were always 8 bytes (except for the 8-byte payload, in which key and value were 4 bytes each). I kept the keys to a consistent size because my purpose here was to test memory effects, not hash function performance. Each test was repeated 5 times and the minimum timing was taken.
|
||||
|
||||
The operations tested were:
|
||||
|
||||
* **Fill**: insert a randomly shuffled sequence of unique keys into the table.
|
||||
* **Presized fill**: like Fill, but first reserve enough memory for all the keys we’ll insert, to prevent rehashing and reallocing during the fill process.
|
||||
* **Lookup**: perform 100K lookups of random keys, all of which are in the table.
|
||||
* **Failed lookup**: perform 100K lookups of random keys, none of which are in the table.
|
||||
* **Remove**: remove a randomly chosen half of the elements from a table.
|
||||
* **Destruct**: destroy a table and free its memory.
|
||||
|
||||
You can [download my test code here][9]. It builds for Windows or Linux, in 64-bit only. There are some flags near the top of `main()` that you can toggle to turn on or off different tests—with all of them on, it will likely take an hour or two to run. The results I gathered are also included, in an Excel spreadsheet in that archive. (Beware that the Windows and Linux results are run on different CPUs, so timings aren’t directly comparable.) The code also runs unit tests to verify that all the hash table implementations are behaving correctly.
|
||||
|
||||
Incidentally, I also tried two additional implementations: separate chaining with the first node stored in the bucket instead of the pool, and open addressing with quadratic probing. Neither of these was good enough to include in the final data, but the code for them is still there.
|
||||
|
||||
### [][10]The Results
|
||||
|
||||
There’s a ton of data here. In this section I’ll discuss the results in some detail, but if your eyes are glazing over in this part, feel free to skip down to the conclusions in the next section.
|
||||
|
||||
### [][11]Windows
|
||||
|
||||
Here are the graphed results of all the tests, compiled with Visual Studio 2012, and run on Windows 8.1 on a Core i7-4710HQ machine. (Click to zoom.)
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
From left to right are different payload sizes, from top to bottom are the various operations, and each graph plots time in milliseconds versus hash table element count for each of the five implementations. (Note that not all the Y-axes have the same scale!) I’ll summarize the main trends for each operation.
|
||||
|
||||
**Fill**: Among my hash tables, chaining is a bit better than any of the OA variants, with the gap widening at larger payloads and table sizes. I guess this is because chaining only has to pull an element off the free list and stick it on the front of its bucket, while OA may have to search a few buckets to find an empty one. The OA variants perform very similarly to each other, but DO1 appears to have a slight advantage.
|
||||
|
||||
All of my hash tables beat UM by quite a bit at small payloads, where UM pays a heavy price for doing a memory allocation on every insert. But they’re about equal at 128 bytes, and UM wins by quite a bit at large payloads: there, all of my implementations are hamstrung by the need to resize their element pool and spend a lot of time moving the large elements into the new pool, while UM never needs to move elements once they’re allocated. Notice the extreme “steppy” look of the graphs for my implementations at large payloads, which confirms that the problem comes when resizing. In contrast, UM is quite linear—it only has to resize its bucket array, which is cheap enough not to make much of a bump.
|
||||
|
||||
**Presized fill**: Generally similar to Fill, but the graphs are more linear, not steppy (since there’s no rehashing), and there’s less difference between all the implementations. UM is still slightly faster than chaining at large payloads, but only slightly—again confirming that the problem with Fill was the resizing. Chaining is still consistently faster than the OA variants, but DO1 has a slight advantage over the other OAs.
|
||||
|
||||
**Lookup**: All the implementations are closely clustered, with UM and DO2 the front-runners, except at the smallest payload, where it seems like DO1 and OL may be faster. It’s impressive how well UM is doing here, actually; it’s holding its own against the data-oriented variants despite needing to traverse a linked list.
|
||||
|
||||
Incidentally, it’s interesting to see that the lookup time weakly depends on table size. Hash table lookup is expected constant-time, so from the asymptotic view it shouldn’t depend on table size at all. But that’s ignoring cache effects! When we do 100K lookups on a 10K-entry table, for instance, we’ll get a speedup because most of the table will be in L3 after the first 10K–20K lookups.
|
||||
|
||||
**Failed lookup**: There’s a bit more spread here than the successful lookups. DO1 and DO2 are the front-runners, with UM not far behind, and OL a good deal worse than the rest. My guess is this is probably a case of OL having longer searches on average, especially in the case of a failed lookup; with the hash values spaced out in memory between keys and values, that hurts. DO1 and DO2 have equally-long searches, but they have all the hash values packed together in memory, and that turns things around.
|
||||
|
||||
**Remove**: DO2 is the clear winner, with DO1 not far behind, chaining further behind, and UM in a distant last place due to the need to free memory on every remove; the gap widens at larger payloads. The remove operation is the only one that doesn’t touch the value data, only the hashes and keys, which explains why DO1 and DO2 are differentiated from each other here but pretty much equal in all the other tests. (If your value type was non-POD and needed to run a destructor, that difference would presumably disappear.)
|
||||
|
||||
**Destruct**: Chaining is the fastest except at the smallest payload, where it’s about equal to the OA variants. All the OA variants are essentially equal. Note that for my hash tables, all they’re doing on destruction is freeing a handful of memory buffers, but [on Windows, freeing memory has a cost proportional to the amount allocated][13]. (And it’s a significant cost—an allocation of ~1 GB is taking ~100 ms to free!)
|
||||
|
||||
UM is the slowest to destruct—by an order of magnitude at small payloads, and only slightly slower at large payloads. The need to free each individual element instead of just freeing a couple of arrays really hurts here.
|
||||
|
||||
### [][14]Linux
|
||||
|
||||
I also ran tests with gcc 4.8 and clang 3.5, on Linux Mint 17.1 on a Core i5-4570S machine. The gcc and clang results were very similar, so I’ll only show the gcc ones; the full set of results are in the code download archive, linked above. (Click to zoom.)
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Most of the results are quite similar to those in Windows, so I’ll just highlight a few interesting differences.
|
||||
|
||||
**Lookup**: Here, DO1 is the front-runner, where DO2 was a bit faster on Windows. Also, UM and chaining are way behind all the other implementations, which is actually what I expected to see in Windows as well, given that they have to do a lot of pointer chasing while the OA variants just stride linearly through memory. It’s not clear to me why the Windows and Linux results are so different here. UM is also a good deal slower than chaining, especially at large payloads, which is odd; I’d expect the two of them to be about equal.
|
||||
|
||||
**Failed lookup**: Again, UM is way behind all the others, even slower than OL. Again, it’s puzzling to me why this is so much slower than chaining, and why the results differ so much between Linux and Windows.
|
||||
|
||||
**Destruct**: For my implementations, the destruct cost was too small to measure at small payloads; at large payloads, it grows quite linearly with table size—perhaps proportional to the number of virtual memory pages touched, rather than the number allocated? It’s also orders of magnitude faster than the destruct cost on Windows. However, this isn’t anything to do with hash tables, really; we’re seeing the behavior of the respective OSes’ and runtimes’ memory systems here. It seems that Linux frees large blocks memory a lot faster than Windows (or it hides the cost better, perhaps deferring work to process exit, or pushing things off to another thread or process).
|
||||
|
||||
UM with its per-element frees is now orders of magnitude slower than all the others, across all payload sizes. In fact, I cut it from the graphs because it was screwing up the Y-axis scale for all the others.
|
||||
|
||||
### [][16]Conclusions
|
||||
|
||||
Well, after staring at all that data and the conflicting results for all the different cases, what can we conclude? I’d love to be able to tell you unequivocally that one of these hash table variants beats out the others, but of course it’s not that simple. Still, there is some wisdom we can take away.
|
||||
|
||||
First, in many cases it’s _easy_ to do better than `std::unordered_map`. All of the implementations I built for these tests (and they’re not sophisticated; it only took me a couple hours to write all of them) either matched or improved upon `unordered_map`, except for insertion performance at large payload sizes (over 128 bytes), where `unordered_map`‘s separately-allocated per-node storage becomes advantageous. (Though I didn’t test it, I also expect `unordered_map` to win with non-POD payloads that are expensive to move.) The moral here is that if you care about performance at all, don’t assume the data structures in your standard library are highly optimized. They may be optimized for C++ standard conformance, not performance. :P
|
||||
|
||||
Second, you could do a lot worse than to just use DO1 (open addressing, linear probing, with the hashes/states segregated from keys/values in separate flat arrays) whenever you have small, inexpensive payloads. It’s not the fastest for insertion, but it’s not bad either (still way better than `unordered_map`), and it’s very fast for lookup, removal, and destruction. What do you know—“data-oriented design” works!
|
||||
|
||||
Note that my test code for these hash tables is far from production-ready—they only support POD types, don’t have copy constructors and such, don’t check for duplicate keys, etc. I’ll probably build some more realistic hash tables for my utility library soon, though. To cover the bases, I think I’ll want two variants: one based on DO1, for small, cheap-to-move payloads, and another that uses chaining and avoids ever reallocating and moving elements (like `unordered_map`) for large or expensive-to-move payloads. That should give me the best of both worlds.
|
||||
|
||||
In the meantime, I hope this has been illuminating. And remember, if Chandler Carruth and Mike Acton give you advice about data structures, listen to them. 😉
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
I’m a graphics programmer, currently freelancing in Seattle. Previously I worked at NVIDIA on the DevTech software team, and at Sucker Punch Productions developing rendering technology for the Infamous series of games for PS3 and PS4.
|
||||
|
||||
I’ve been interested in graphics since about 2002 and have worked on a variety of assignments, including fog, atmospheric haze, volumetric lighting, water, visual effects, particle systems, skin and hair shading, postprocessing, specular models, linear-space rendering, and GPU performance measurement and optimization.
|
||||
|
||||
You can read about what I’m up to on my blog. In addition to graphics, I’m interested in theoretical physics, and in programming language design.
|
||||
|
||||
You can contact me at nathaniel dot reed at gmail dot com, or follow me on Twitter (@Reedbeta) or Google+. I can also often be found answering questions at Computer Graphics StackExchange.
|
||||
|
||||
--------------
|
||||
|
||||
via: http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
|
||||
作者:[Nathan Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
[2]:http://reedbeta.com/blog/category/coding/
|
||||
[3]:http://reedbeta.com/blog/data-oriented-hash-table/#comments
|
||||
[4]:http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
|
||||
[5]:https://www.youtube.com/watch?v=fHNmRkzxHWs
|
||||
[6]:https://www.youtube.com/watch?v=rX0ItVEVjHc
|
||||
[7]:http://reedbeta.com/blog/data-oriented-hash-table/#the-tests
|
||||
[8]:http://burtleburtle.net/bob/hash/spooky.html
|
||||
[9]:http://reedbeta.com/blog/data-oriented-hash-table/hash-table-tests.zip
|
||||
[10]:http://reedbeta.com/blog/data-oriented-hash-table/#the-results
|
||||
[11]:http://reedbeta.com/blog/data-oriented-hash-table/#windows
|
||||
[12]:http://reedbeta.com/blog/data-oriented-hash-table/results-vs2012.png
|
||||
[13]:https://randomascii.wordpress.com/2014/12/10/hidden-costs-of-memory-allocation/
|
||||
[14]:http://reedbeta.com/blog/data-oriented-hash-table/#linux
|
||||
[15]:http://reedbeta.com/blog/data-oriented-hash-table/results-g++4.8.png
|
||||
[16]:http://reedbeta.com/blog/data-oriented-hash-table/#conclusions
|
||||
@ -1,3 +1,5 @@
|
||||
fuowang 翻译中
|
||||
|
||||
Linux on UEFI:A Quick Installation Guide
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,247 +0,0 @@
|
||||
申请翻译
|
||||
|
||||
A Raspberry Pi Hadoop Cluster with Apache Spark on YARN: Big Data 101
|
||||
======
|
||||
|
||||
Sometimes on DQYDJ we like to reveal a little bit of the process behind the data. In that past, that has meant articles on how we ingest fixed width data with R and how we model the cost of a Negative Income Tax in America, amongst many other fine examples.
|
||||
|
||||
Today I’ll be sharing some explorations with Big Data. For a change of pace I’ll be doing it with the world’s most famous Little Computer – the Raspberry Pi. If that’s not your thing, we’ll see you in the next piece (probably with some already finished data). For the rest of you, read on… today we’re going to build a Raspberry Pi Hadoop Cluster!
|
||||
|
||||
### I. Why Even Build a Raspberry Pi Hadoop Cluster?
|
||||
|
||||

|
||||
>3/4 Angle of my Three Node Raspberry Pi Hadoop Cluster
|
||||
|
||||
We do a lot of work with data here on DQYDJ, but nothing we have done qualifies as Big Data.
|
||||
|
||||
Like so many controversial topics, the difference between “Big” Data and lower-case data might be best explained with a joke:
|
||||
|
||||
>“If it fits in RAM, it’s not Big Data.” – Unknown (If you know, pass it along!)
|
||||
|
||||
It seems like there are two solutions to the problem here:
|
||||
|
||||
1. We can find a dataset big enough to overwhelm any actual physical or virtual RAM on our home computers.
|
||||
2. Or, we can buy some computers where the data we have now would overwhelm the machine without special treatment.
|
||||
|
||||
Enter the Raspberry Pi 2 Model B!
|
||||
|
||||
These impressive little works of art and engineering have 1 GB of RAM and your choice of MicroSD card for a hard drive. Furthermore, you can get them for under $50 each, so you can build out a Hadoop cluster for under $250.
|
||||
|
||||
There might be no cheaper ticket into the Big Data world!
|
||||
|
||||
|
||||
### II. Building The Raspberry Pi Hadoop Cluster
|
||||
|
||||

|
||||
>My favorite part of the build – the raw materials!
|
||||
|
||||
Now I’ll link you to what I used to build the cluster itself. Note that if you do buy on Amazon using these links you’ll be supporting the site. (Thank you for the support!)
|
||||
|
||||
- Raspberry Pi 2 Model B (x3)
|
||||
- Pictures of ingredients for a Raspberry Pi Hadoop Cluster
|
||||
- 4 Layer Acrylic Case/Stand
|
||||
- 6 Post USB Charger (I picked the White RAVPower 50W 10A 6-Port USB Charger)
|
||||
- 5 Port Ethernet Switch (Fast is fine, the ethernet ports on the Pi are only 100 Mbit)
|
||||
- MicroSD Cards (This 5 pack of 32 GB cards was perfectly fine)
|
||||
- Short MicroUSB Cables (to power the Pis)
|
||||
- Short Ethernet Patch Cables
|
||||
- Two sided foam tape (I had some 3M brand, it worked wonderfully)
|
||||
|
||||
#### Now Bake the Pis!
|
||||
|
||||
1. First, mount the three Raspberry Pis, one each to an acrylic panel (see the below image).
|
||||
2. Next, mount the ethernet switch to a fourth acrylic panel with 2 sided foam tape.
|
||||
3. Mount the USB charger on the acrylic panel which will become the ‘top’ (again with 2 sided foam tape)
|
||||
4. Follow the instructions for the acrylic case and build the levels – I chose to put the Pis below the switch and charger (see the two completed build shots).
|
||||
|
||||
Figure out a way to get the wires where you need them – if you bought the same USB cables and Ethernet cables as me, I was able to wrap them around the mounting posts between levels.
|
||||
|
||||
Leave the Pis unplugged for now – you will burn the Raspbian OS on the MicroSDs before continuing.
|
||||
|
||||

|
||||
>Raspberry Pis Mounted on Acrylic
|
||||
|
||||
#### Burn Raspbian to the MicroSDs!
|
||||
|
||||
Put Raspbian on 3 MicroSDs – follow the instructions on the [Raspberry Pi Raspbian page][1]. I use my Windows 7 PC for this, and [Win32DiskImager][2].
|
||||
|
||||
Pop one of the cards into whatever Pi you want to be the master node, then start it up by plugging in USB!
|
||||
|
||||
#### Setup the Master
|
||||
|
||||
There is no need for me to repeat an excellent guide here – you should [follow the instructions in Because We Can Geek’s guide][3] and install Hadoop 2.7.1.
|
||||
|
||||
There were a few caveats with my setup – I’ll walk you through what I ended up using to get a working setup. Note that I am using the IP addresses 192.168.1.50 – 192.168.1.52, with the two slaves on .51 and .52 and the master on .50. Your network will vary, you will have to look around or discuss this step in the comments if you need help setting up static addresses on your network.
|
||||
|
||||
Once you are done with the guide, you should enable a swapfile. Spark on YARN will be cutting it very close on RAM, so faking it with a swapfile is what you’ll need as you approach memory limits.
|
||||
|
||||
(If you haven’t done this before, [this tutorial will get you there][4]. Keep swappiness at a low level – MicroSD cards don’t handle it well).
|
||||
|
||||
Now I’m ready to share some subtle differences between my setup and Because We Can Geek’s.
|
||||
|
||||
For starters, make sure you pick uniform names for all of your Pi nodes – in /etc/hostname, I used ‘RaspberryPiHadoopMaster’ for the master, and ‘RaspberryPiHadoopSlave#’ for the slaves.
|
||||
|
||||
Here is my /etc/hosts on the Master:
|
||||
|
||||
You will also need to edit a few configuration files in order to get Hadoop, YARN, and Spark playing nicely. (You may as well make these edits now.)
|
||||
|
||||
Here is hdfs-site.xml:
|
||||
|
||||
```
|
||||
yarn-site.xml (Note the changes in memory!):
|
||||
|
||||
slaves:
|
||||
|
||||
core-site.xml:
|
||||
```
|
||||
|
||||
#### Setup the 2 Slaves:
|
||||
|
||||
Again, [just follow the instructions on Because We Can Geek][5]. You will need to make minor edits to the files above – note that the master doesn’t change in yarn-site.xml, and you do not need to have a slaves file on the slaves themselves.
|
||||
|
||||
|
||||
|
||||
|
||||
### III. Test YARN on Our Raspberry Pi Hadoop Cluster!
|
||||
|
||||

|
||||
>The Raspberry Pi Hadoop Cluster Straight On!
|
||||
|
||||
If everything is working, on the master you should be able to do a:
|
||||
|
||||
>\> start-dfs.sh
|
||||
|
||||
>\> start-yarn.sh
|
||||
|
||||
And see everything come up! Do this from the Hadoop user, which will be ‘hduser’ if you obey the tutorials.
|
||||
|
||||
Next, run ‘hdfs dfsadmin -report’ to see if all three datanodes have come up. Verify you have the bolded line in your report, ‘Live datanodes (3)’:
|
||||
|
||||
```
|
||||
Configured Capacity: 93855559680 (87.41 GB)
|
||||
Raspberry Pi Hadoop Cluster picture Straight On
|
||||
Present Capacity: 65321992192 (60.84 GB)
|
||||
DFS Remaining: 62206627840 (57.93 GB)
|
||||
DFS Used: 3115364352 (2.90 GB)
|
||||
DFS Used%: 4.77%
|
||||
Under replicated blocks: 0
|
||||
Blocks with corrupt replicas: 0
|
||||
Missing blocks: 0
|
||||
Missing blocks (with replication factor 1): 0
|
||||
————————————————-
|
||||
Live datanodes (3):
|
||||
Name: 192.168.1.51:50010 (RaspberryPiHadoopSlave1)
|
||||
Hostname: RaspberryPiHadoopSlave1
|
||||
Decommission Status : Normal
|
||||
|
||||
…
|
||||
|
||||
…
|
||||
|
||||
…
|
||||
```
|
||||
|
||||
You may now run through some ‘Hello, World!’ type exercises, or feel free to move to the next step!
|
||||
|
||||
|
||||
|
||||
### IV. Installing Spark on YARN on Pi!
|
||||
|
||||
YARN stands for Yet Another Resource Negotiator, and is included in the base Hadoop install as an easy to use resource manager.
|
||||
|
||||
[Apache Spark][6] is another package in the Hadoop ecosystem – it’s an execution engine, much like the (in)famous and [bundled MapReduce][7]. At a general level, Spark benefits from in-memory storage over the disk-based storage of MapReduce. Some workloads will run at 10-100x the speed of a comparable MapReduce workload – after you’ve got your cluster built, read a bit on the difference between Spark and MapReduce.
|
||||
|
||||
On a personal level, I was particularly impressed with the Spark offering because of the easy integration of two languages used quite often by Data Engineers and Scientists – Python and R.
|
||||
|
||||
Installation of Apache Spark is very easy – in your home directory, ‘wget <path to a Apache Spark built for Hadoop 2.7>’ ([from this page][8]). Then, ‘tar -xzf <that tgz file>’. Finally, copy the resulting directory to /opt and clean up any of the files you downloaded – that’s all there is to it!
|
||||
|
||||
I also have a two line ‘spark-env.sh’ file, which is inside the ‘conf’ directory of Spark:
|
||||
|
||||
>SPARK_MASTER_IP=192.168.1.50
|
||||
|
||||
>SPARK_WORKER_MEMORY=512m
|
||||
|
||||
(I’m not even sure this is necessary, since we will be running on YARN)
|
||||
|
||||
|
||||
### V. Hello, World! Finding an Interesting Data-set for Apache Spark!
|
||||
|
||||
|
||||
The canonical ‘Hello, World!’ in the Hadoop world is to do some sort of word counting.
|
||||
|
||||
I decided that I wanted my introduction to do something introspective… why not count my most commonly used words on this site? Perhaps some big data about myself would be useful…maybe?
|
||||
|
||||
It’s a simple two step process to dump and sanitize your blog data, if you’re running on WordPress like we are.
|
||||
|
||||
1. I used ‘[Export to Text][9]‘ to dump all of my content into a text file.
|
||||
2. I wrote some quick Python to strip all the HTML using [the library bleach][10]:
|
||||
|
||||
Now you’ll have a smaller file suitable for copying to HDFS on your Pi cluster!
|
||||
|
||||
If you didn’t do this work on the master Pi, find a way to transfer it over (scp, rsync, etc.), and copy it to HDFS with a command like this:
|
||||
|
||||
>hdfs dfs -copyFromLocal dqydj_stripped.txt /dqydj_stripped.txt
|
||||
|
||||
You’re now ready for the final step – writing some code for Apache Spark!
|
||||
|
||||
|
||||
|
||||
### VI: Lighting Apache Spark
|
||||
|
||||
Cloudera had an excellent program to use as a base for our super-wordcount program, which you can find here. We’re going to modify it for our introspective Word Counting program.
|
||||
|
||||
Install the package ‘stop-words’ for Python on your master Pi. Although interesting (I’ve used the word ‘the’ on DQYDJ 23,295 times!), you probably don’t want to see your stop words dominating the top of your data. Additionally, replace any references to my dqydj files in the following code with the path to your own special dataset:
|
||||
|
||||
Save wordCount.py and make sure all of your paths are correct.
|
||||
|
||||
Now you’re ready for the incantation that got Spark running on YARN for me, and (drumroll, please) revealed which words I use the most on DQYDJ:
|
||||
|
||||
>/opt/spark-2.0.0-bin-hadoop2.7/bin/spark-submit –master yarn –executor-memory 512m –name wordcount –executor-cores 8 wordCount.py /dqydj_stripped.txt
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### VII. The Conclusion: Which Words Do I Use the Most on DQYDJ?
|
||||
|
||||
|
||||
he top ten “non-stop words” on DQYDJ? “can, will, it’s, one, even, like, people, money, don’t, also“.
|
||||
|
||||
Hey, not bad – money snuck into the top ten. That seems like a good thing to talk about on a website dedicated to finance, investing and economics – right?
|
||||
|
||||
Here’s the rest of the top 50 most frequently used words by yours truly. Please use them to draw wild conclusions about the quality of the rest of my posts!
|
||||
|
||||
|
||||
|
||||
I hope you enjoyed this introduction to Hadoop, YARN, and Apache Spark – you’re now set to go off and write other applications on top of Spark.
|
||||
|
||||
Your next step is to start to read through the documentation of Pyspark (and the libraries for other languages too, if you’re so inclined) to learn some of the functionality available to you. Depending on your interests and how your data is actually stored, you’ll have a number of paths to explore further – there are packages for streaming data, SQL, and even machine learning!
|
||||
|
||||
What do you think? Are you going to build a Raspberry Pi Hadoop Cluster? Want to rent some time on mine? What’s the most surprising word you see up there, and why is it ‘S&P’?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dqydj.com/raspberry-pi-hadoop-cluster-apache-spark-yarn/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[PK][a]
|
||||
译者:[popy32](https://github.com/sfantree)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://dqydj.com/about/#contact_us
|
||||
[1]: https://www.raspberrypi.org/downloads/raspbian/
|
||||
[2]: https://sourceforge.net/projects/win32diskimager/
|
||||
[3]: http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-1/
|
||||
[4]: https://www.digitalocean.com/community/tutorials/how-to-add-swap-on-ubuntu-14-04
|
||||
[5]: http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-2/
|
||||
[6]: https://spark.apache.org/
|
||||
[7]: https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
|
||||
[8]: https://spark.apache.org/downloads.html
|
||||
[9]: https://wordpress.org/support/plugin/export-to-text
|
||||
[10]: https://pypi.python.org/pypi/bleach
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
Translated by chunyang-wen
|
||||
svtter 翻译中
|
||||
|
||||
GitLab Workflow: An Overview
|
||||
======
|
||||
|
||||
|
||||
@ -1,98 +0,0 @@
|
||||
++翻译中
|
||||
+
|
||||
+
|
||||
### Configuring WINE with Winetricks
|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Introduction][1]
|
||||
* [2. Installing][2]
|
||||
* [3. Fonts][3]
|
||||
* [4. .dlls and Components][4]
|
||||
* [5. Registry][5]
|
||||
* [6. Closing][6]
|
||||
* [7. Table of Contents][7]
|
||||
|
||||
### Introduction
|
||||
|
||||
If `winecfg` is a screwdriver, `winetricks` is a power drill. They both have their place, but `winetricks` is just a much more powerful tool. Actually, it even has the ability to launch `winecfg`.
|
||||
|
||||
While `winecfg` gives you the ability to change the settings of WINE itself, `winetricks` gives you the ability to modify the actual Windows layer. It allows you to install important components like `.dlls` and system fonts as well as giving you the capability to edit the Windows registry. It also has a task manager, an uninstall utility, and file browser.
|
||||
|
||||
Even though `winetricks` can do all of this, the majority of the time, you're going to be using it to manage `dlls` and Windows components.
|
||||
|
||||
### Installing
|
||||
|
||||
Unlike `winecfg`, `winetricks` doesn't come with WINE. That's fine, though, since it's actually just a script, so it's very easy to download and use on any distribution. Now, many distributions do package `winetricks`. You can definitely use the packaged version if you'd like. Sometimes, those packages fall out-of-date, so this guide is going to use the script, since it's both current and universal. By default, the graphical window is fairly ugly, so if you'd prefer a stylized window, install `zenity` through your distribution's package manager.
|
||||
|
||||
Assuming that you want `winetricks` in your `/home` directory, `cd` there and `wget` the script.
|
||||
```
|
||||
$ cd ~
|
||||
$ wget https://raw.githubusercontent.com/Winetricks/winetricks/master/src/winetricks
|
||||
```
|
||||
Then, make the script executable.
|
||||
```
|
||||
$ chmod+x winetricks
|
||||
```
|
||||
`winetricks` can be run in the command line, specifying what needs to be installed at the end of the command, but in most cases, you won't know the exact names of the `.dlls` or fonts that you're trying to install. For that reason, the graphical utility is best. Launching it really isn't any different. Just don't specify anything on the end.
|
||||
```
|
||||
$ ~/winetricks
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
When the window first opens, it will display a menu with options including "View help" and "Install an application." By default, "Select the default wineprefix" will be selected. That's the primary option that you will use. The others may work, but aren't really recommended. To proceed, click "OK," and you will be brought to the menu for that WINE prefix.Everything that you will need to do through `winetricks` can be done through this prefix menu.
|
||||
|
||||

|
||||
|
||||
|
||||
### Fonts
|
||||
|
||||

|
||||
|
||||
|
||||
Fonts are surprisingly important. Some applications won't load or won't load properly without them.`winetricks` makes installing many common Windows fonts very easy. From the prefix menu, select the "Install a font" radio button and press "OK."
|
||||
|
||||
You will be presented with a new list of fonts and corresponding checkboxes. It's hard to say exactly which fonts you will need, so most of this should be decided on a per-application basis, but it's usually a good idea to install `corefonts`. It contains the major Windows system fonts that many applications would be expecting to be present on a Windows machine. Installing them can't really hurt anything, so just having them is usually best.
|
||||
|
||||
To install `corefonts`, check the corresponding checkbox and press "OK." You will be given roughly the same install prompts as you would on Windows, and the fonts will be installed. When it's done, you will be taken back to the prefix menu. Follow that same process for each additional font that you need.
|
||||
|
||||
### .dlls and Components
|
||||
|
||||

|
||||
|
||||
|
||||
`winetricks` tries to make installing Windows `.dll` files and other components as simple as possible. If you need to install them, select "Install a Windows DLL or component" on the prefix menu and click "OK."
|
||||
|
||||
The window will switch over to a menu of available `dlls` and other Windows components. Using the corresponding checkboxes, check off any that you need, and click "OK." The script will download each selected component and begin installing them via the usual Windows install process. Follow the prompts like you would on a Windows machine. Expect error messages. Many times, the Windows installers will present errors, but you will then receive windows from `winetricks` stating that it is following a workaround. That is perfectly normal. Depending on the component, you may or may not receive a success message. Just ensure that the box is still checked in the menu when the install is complete.
|
||||
|
||||
### Registry
|
||||
|
||||

|
||||
|
||||
|
||||
It's not all that often that you have to edit registry values in WINE, but with some programs, you may. Technically, `winetricks` doesn't provide the registry editor, but it makes accessing it easier. Select "Run regedit" from the prefix menu and press "OK." A basic Windows registry editor will open up. Actually creating registry values is a bit out of the scope of this guide, but adding entries isn't too hard if you already know what you're entering. The registry acts sort of like a spreadsheet, so you can just plug in the right values into the right cells. That's somewhat of an oversimplification, but it works. You can usually find exactly what needs to be added or edited on the WINE Appdb `https://appdb.winehq.org`.
|
||||
|
||||
### Closing
|
||||
|
||||
There's obviously much more that can be done with `winetricks`, but the purpose of this guide is to give you the basic knowledge that you'll need to use this powerful tool to get your programs up and running through WINE. The WINE Appdb is a wealth of knowledge on a per-program basis, and will be an invaluable resource going forward.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/configuring-wine-with-winetricks
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/configuring-wine-with-winetricks
|
||||
[1]:https://linuxconfig.org/configuring-wine-with-winetricks#h1-introduction
|
||||
[2]:https://linuxconfig.org/configuring-wine-with-winetricks#h2-installing
|
||||
[3]:https://linuxconfig.org/configuring-wine-with-winetricks#h3-fonts
|
||||
[4]:https://linuxconfig.org/configuring-wine-with-winetricks#h4-dlls-and-components
|
||||
[5]:https://linuxconfig.org/configuring-wine-with-winetricks#h5-registry
|
||||
[6]:https://linuxconfig.org/configuring-wine-with-winetricks#h6-closing
|
||||
[7]:https://linuxconfig.org/configuring-wine-with-winetricks#h7-table-of-contents
|
||||
@ -1,6 +1,5 @@
|
||||
# Kprobes Event Tracing on ARMv8
|
||||
|
||||
Timeszoro Translating
|
||||
|
||||

|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by StdioA
|
||||
|
||||
Top open source creative tools in 2016
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,146 +0,0 @@
|
||||
Partition Backup
|
||||
============
|
||||
|
||||
Many times you may have data on a partition, especially on a Universal Serial Bus (USB) drive. It may be necessary at times to make a copy of a drive or a single partition on it. Raspberry Pi users definitely have this need for the bootable SD Cards. Owners of other small form computers can also find this useful. Sometimes it is best to make a backup quickly if a device seems to be failing.
|
||||
|
||||
To perform the examples in this article you will need a utility called 'dcfldd'.
|
||||
|
||||
**The dcfldd Utility**
|
||||
|
||||
The utility is an enhancement of the 'dd' utility from the 'coreutils' package. The 'dcfldd' was made by Nicholas Harbour while he worked at the Department of Defense Computer Forensics Lab (DCFL). The name is then based off where he worked – 'dcfldd'.
|
||||
|
||||
For systems still using the CoreUtils 8.23 or less there isn't an option to easily see the progress of the copy being performed. Sometimes it seems as if nothing is happening and you are tempted to stop the copy.
|
||||
|
||||
**NOTE:** If you have the ‘dd’ version 8.24 or later then you need not use ‘dcfldd’ and simply replace any ‘dcfldd’ with ‘dd’. All other parameters will work.
|
||||
|
||||
On a Debian system simply use your Package Manager and search for 'dcfldd'. You can also open a Terminal and use the command:
|
||||
|
||||
_sudo apt-get install dcfldd_
|
||||
|
||||
For a Red Hat system try the following:
|
||||
|
||||
_cd /tmp
|
||||
wget dl.fedoraproject.org/pub/epel/6/i386/dcfldd-1.3.4.1-4.el6.i686.rpm
|
||||
sudo yum install dcfldd-1.3.4.1-4.el6.i686.rpm
|
||||
dcfldd --version_
|
||||
|
||||
**NOTE:** The above installs the 32-bit version. For the 64-bit version use the following commands:
|
||||
|
||||
_cd /tmp
|
||||
wget dl.fedoraproject.org/pub/epel/6/x86_64/dcfldd-1.3.4.1-4.el6.x86_64.rpm
|
||||
sudo yum install dcfldd-1.3.4.1-4.el6.x86_64.rpm
|
||||
dcfldd --version_
|
||||
|
||||
The last statement of each set of commands will list the version of the 'dcfldd' and show you that the command file has been downloaded.
|
||||
|
||||
**NOTE: **Be sure you execute the ‘dd’ or ‘dcfldd’ as root.
|
||||
|
||||
Now that you have the command installed you can continue on with using it to backup and restore partitions.
|
||||
|
||||
**Backup Partitions**
|
||||
|
||||
When backing up a drive it is possible to back up the whole drive or a single partition. If the drive has multiple partitions then each can be backed up separately.
|
||||
|
||||
Before we get too far in performing a backup let's look at the difference of a drive and partition. Let's assume we have an SD Card which is formatted as one large drive. The SD Card contains only one partition. If the space is split to allow the SD Card to be seen as two drives, then it has two partitions. If a program like GParted were opened for an SD Card, as shown in Figure 1, you can see it has two partitions.
|
||||
|
||||
**FIGURE 1**
|
||||
|
||||
The drive is /dev/sdc and contains both partitions /dev/sdc1 and /dev/sdc2.
|
||||
|
||||
Let's take, for instance, an SD Card from a Raspberry Pi. The SD Card is 8 GB in size and has two partitions (as shown in Figure 1). The first partition contains BerryBoot which is a boot loader. The second partition contains Kali. There is no space available to install a second Operating System (OS). A second SD Card is to be used which is 16 GB in size, but to copy it to the second SD Card the first one must be backed up.
|
||||
|
||||
To back up the first SD Card we will back up the drive which is /dev/sdc. The command to perform the backup is as follows:
|
||||
|
||||
_dcfldd if=/dev/sdc of=/tmp/SD-Card-Backup.img_
|
||||
|
||||
The backup is made of the Input File (if) and the output file (of) is set to the folder '/tmp' and a file called 'SD-Card-Backup.img'.
|
||||
|
||||
The 'dd' and 'dcfldd' both read and write the files one byte at a time. Technically with the above command it reads and writes a default of 512 bytes at a time. Keep in mind that the copy is an exact copy – bit for bit and byte for byte.
|
||||
|
||||
The default of 512 bytes can be changed with the parameter for Block Size - 'bs='. For instance, to read/write 1 megabyte at a time the parameter 'bs=1M'. There can be some discrepancy in the abbreviations used as follows:
|
||||
|
||||
* b – 512 bytes
|
||||
* KB – 1000 bytes
|
||||
* K – 1024 bytes
|
||||
* MB – 1000x1000 bytes
|
||||
* M – 1024x1024 bytes
|
||||
* GB – 1000x1000x1000 bytes
|
||||
* G – 1024x1024x1024 bytes
|
||||
|
||||
You can specify the read blocks and write blocks separately. To specify the read amount use ‘ibs=’. To specify the write amount then use ‘obs=’.
|
||||
|
||||
I performed a test to backup a 120 MB partition using three different Block Sizes. The first was the default of 512 bytes and it took 7 seconds. The second was a Block Size of 1024 K and took 2 seconds. The third had a Block Size of 2048 K and took 3 seconds. The times will vary depending on the system, various other hardware implementations, but in general larger block sizes than the defaults can be a little faster.
|
||||
|
||||
Once you have a backup made you will need to know how to restore the data to a drive.
|
||||
|
||||
**Restore Partitions**
|
||||
|
||||
Now that we have a backup at some point we can assume the data may become corrupted or need to be restored for some reason.
|
||||
|
||||
The command is the same as the backup except that the source and target are reversed. In the above example the command would be changed to:
|
||||
|
||||
_dcfldd of=/dev/sdc if=/tmp/SD-Card-Backup.img_
|
||||
|
||||
Here, the image file is being used as the input file (if) and the drive (sdc) is used as the output file (of).
|
||||
|
||||
**NOTE:** Do remember that the output device will be overwritten and all data on it will be lost. It is usually best to remove all partitions from the SD Card with GParted before restoring data.
|
||||
|
||||
If you have a use for multiple SD Cards, such as having multiple Raspberry Pi boards, you can write to multiple cards at once. To do this you need to know the card’s ID on the system. For example, let’s say we want to copy the image ‘BerryBoot.img’ to two SD Cards. The SD Cards are at /dev/sdc and /dev/sdd. The command will be set to read/write in 1 MB Blocks while showing the progress. The command would be:
|
||||
|
||||
_dcfldd if=BerryBoot.img bs=1M status=progress | tee >(dcfldd of=/dev/sdc) | dcfldd of=/dev/sdd_
|
||||
|
||||
In this command the first dcfldd uses the input file and sets the Block Size to 1 MB. The status is set to show the progress. The input is then piped (|) to the command ‘tee’. The ‘tee’ is used to split the input to multiple places. The first output is to the command ‘(dcfldd of=/dev/sdc)’. The command is in parenthesis and will be performed as a command. The last pipe (|) is needed, otherwise the ‘tee’ command will send the information to the ‘stdout’ (screen) as well. So the final output is to the command ‘_dcfldd of=/dev/sdd’_. If you had a third card, or even more, simply add another redirector and command such as ‘_>(dcfldd of=/dev/sde_’.
|
||||
|
||||
**NOTE:** Do remember that the final command must be after a pipe (|).
|
||||
|
||||
Data being written must be verified at times to be sure the data is correct.
|
||||
|
||||
**Verify Data**
|
||||
|
||||
Once an image is made or a backup restored you can verify the data being written. To verify data you will use a different program called ‘_diff_’.
|
||||
|
||||
To use ‘diff’ you will need to designate the location of the image file and the physical media where it was copied from or written to on the system. The ‘_diff_’ command can be used after the backup was made or after the image was restored.
|
||||
|
||||
The command has two parameters. The first is the physical media and the second is the image file name.
|
||||
|
||||
From the example of ‘_dcfldd of=/dev/sdc if=/tmp/SD-Card-Backup.img’_ the ‘_diff_’ command would be:
|
||||
|
||||
_diff /dev/sdc /tmp/SD-Card-Backup.img_
|
||||
|
||||
If any differences are found between the image and the physical device you will be alerted. If no messages are given then the data has been verified as identical.
|
||||
|
||||
Making sure the data is identical is key to verifying the integrity of the backup or restore. One main problem to watch for when performing a Backup is image size.
|
||||
|
||||
**Splitting The Image**
|
||||
|
||||
Let’s assume you want to back up a 16GB SD Card. The image will then be approximately the same size. What if you can only back it up to a FAT32 partition? The maximum file size limit is 4 GB on FAT32.
|
||||
|
||||
What must be done is that the file will have to be split into 4 GB pieces. The splitting of the image file can be done while it is being written by piping (|) the data to the ‘_split_’ command.
|
||||
|
||||
The backup is performed in the same way, but the command will include the pipe and split command. The example backup command is ‘_dcfldd if=/dev/sdc of=/tmp/SD-Card-Backup.img_’ and the new command for splitting the file is as follows:
|
||||
|
||||
_dcfldd if=/dev/sdc | split -b 4000MB - /tmp/SD-Card-Backup.img_
|
||||
|
||||
**NOTE:** The size suffix means the same as for the ‘_dd_’ and ‘_dcfldd_’ command. The dash by itself in the ‘_split_’ command is used to fill the input file which is being piped from the the ‘_dcfldd_’ command.
|
||||
|
||||
The files will be saved as ‘_SD-Card-Backup.imgaa_’ and ‘_SD-Card-Backup.imgab_’ and so on. If you are worried about the file size being too close to the 4 GB limit, then try 3500MB.
|
||||
|
||||
Restoring the files back to the drive is simple. You use the command ‘_ca_’ to join them and then write the output using ‘_dcfldd_’ as follows:
|
||||
|
||||
_cat /tmp/SD-Card-Backup.img* | dcfldd of=/dev/sdc_
|
||||
|
||||
You can include any desired parameters to the command for the ‘_dcfldd_’ portion.
|
||||
|
||||
I hope you understand and can perform any needed backup and restoration of data as you need for SD Cards and the like.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxforum.com/threads/partition-backup.3638/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||
@ -1,3 +1,6 @@
|
||||
+++
|
||||
++翻译中
|
||||
+++++
|
||||
The 6 unwritten rules of open source development
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,138 +0,0 @@
|
||||
Command line aliases in the Linux Shell
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Command line aliases in Linux][1]
|
||||
2. [Related details][2]
|
||||
3. [Conclusion][3]
|
||||
|
||||
So far, in this tutorial series, we have discussed the basic usage as well as related details of the [cd -][5] and **pushd**/**popd** commands, as well as the **CDPATH** environment variable. In this fourth and the final installment, we will discuss the concept of aliases as well how you can use them to make your command line navigation easier and smoother.
|
||||
|
||||
As always, before jumping on to the heart of the tutorial, it's worth sharing that all the instructions as well examples presented in this article have been tested on Ubuntu 14.04LTS. The command line shell we've used is bash (version 4.3.11).
|
||||
|
||||
### Command line aliases in Linux
|
||||
|
||||
In layman's terms, aliases can be thought of as short names or abbreviations to a complex command or a group of commands, including their arguments or options. So basically, with aliases, you create easy to remember names for not-so-easy-to-type/remember commands.
|
||||
|
||||
For example, the following command creates an alias 'home' for the 'cd ~' command:
|
||||
|
||||
alias home="cd ~"
|
||||
|
||||
This means that now you can quickly type 'home' and press enter whenever you want to come back to your home directory from anywhere on your system.
|
||||
|
||||
Here's what the alias command man page says about this utility:
|
||||
|
||||
```
|
||||
The alias utility shall create or redefine alias definitions or write the values of existing alias definitions to standard output. An alias definition provides a string value that shall replace a command name when it is encountered
|
||||
|
||||
An alias definition shall affect the current shell execution environment and the execution environments of the subshells of the current shell. When used as specified by this volume of IEEE Std 1003.1-2001, the alias definition shall not affect the parent process of the current shell nor any utility environment invoked by the shell.
|
||||
```
|
||||
|
||||
So, how exactly aliases help in command line navigation? Well, here's a simple example:
|
||||
|
||||
Suppose you are working in the _/home/himanshu/projects/howtoforge_ directory, which further contains many subdirectories, and sub-subdirectories. For example, following is one complete directory branch:
|
||||
|
||||
```
|
||||
/home/himanshu/projects/howtoforge/command-line/navigation/tips-tricks/part4/final
|
||||
```
|
||||
|
||||
Now imagine, you are in the 'final' directory, and then you want to get back to the 'tips-tricks' directory, and from there, you need to get back to the 'howtoforge' directory. What would you do?
|
||||
|
||||
Well, normally, you'd run the following set of commands:
|
||||
|
||||
cd ../..
|
||||
|
||||
cd ../../..
|
||||
|
||||
While this approach isn't wrong per se, it's definitely not convenient, especially when you've to go back, say 5 directories in a very long path. So, what's the solution? The answer is: aliases.
|
||||
|
||||
What you can do is, you can create easy to remember (and type) aliases for each of the _cd .._ commands. For example:
|
||||
|
||||
alias bk1="cd .."
|
||||
alias bk2="cd ../.."
|
||||
alias bk3="cd ../../.."
|
||||
alias bk4="cd ../../../.."
|
||||
alias bk5="cd ../../../../.."
|
||||
|
||||
So now whenever you want to go back, say 5 places, from your current working directory, you can just run the following command:
|
||||
|
||||
bk5
|
||||
|
||||
Isn't that easy now?
|
||||
|
||||
### Related details
|
||||
|
||||
While the technique we've used to define aliases so far (using the alias command) on the shell prompt does the trick, the aliases exist only for the current terminal session. There are good chances that you may want aliases defined by you to persist so that they can be used in any new command line terminal window/tab you launch thereafter.
|
||||
|
||||
For this, you need to define your aliases in the _~/.bash_aliases_ file, which is loaded by your _~/.bashrc_ file by default (please verify this if you are using an older Ubuntu version).
|
||||
|
||||
Following is the excerpt from my .bashrc file that talks about the .bash_aliases file:
|
||||
|
||||
```
|
||||
# Alias definitions.
|
||||
# You may want to put all your additions into a separate file like
|
||||
# ~/.bash_aliases, instead of adding them here directly.
|
||||
# See /usr/share/doc/bash-doc/examples in the bash-doc package.
|
||||
|
||||
if [ -f ~/.bash_aliases ]; then
|
||||
. ~/.bash_aliases
|
||||
fi
|
||||
```
|
||||
|
||||
Once you've added an alias definition to your .bash_aliases file, that alias will be available on any and every new terminal. However, you'll not be able to use it in any other terminal which was already open when you defined that alias - the way out is to source .bashrc from those terminals. Following is the exact command that you'll have to run:
|
||||
|
||||
source ~/.bashrc
|
||||
|
||||
If that sounds a little too much of work (yes, I am looking at you LAZY ONES), then here's a shortcut to do all this:
|
||||
|
||||
"alias [the-alias]" >> ~/.bash_aliases && source ~/.bash_aliases
|
||||
|
||||
Needless to say, you'll have to replace [the-alias] with the actual command. For example:
|
||||
|
||||
"alias bk5='cd ../../../../..'" >> ~/.bash_aliases && source ~/.bash_aliases
|
||||
|
||||
Moving on, now suppose you've created some aliases, and have been using them on and off for a few months. Suddenly, one day, you doubt that one of them isn't working as expected. So you feel the need to look at the exact command that was assigned to that alias. What would you do?
|
||||
|
||||
Of course, you can open your .bash_aliases file and take a look there, but this process can be a bit time consuming, especially when the file contains a lot of aliases. So, if you're looking for an easy way out, here's one: all you have to do is to run the _alias_ command with the alias-name as argument.
|
||||
|
||||
Here's an example:
|
||||
|
||||
$ alias bk6
|
||||
alias bk6='cd ../../../../../..'
|
||||
|
||||
As you can see, the aforementioned command displayed the actual command assigned to the bk6 alias. There's one more way: to use the _type_ command. Following is an example:
|
||||
|
||||
$ type bk6
|
||||
bk6 is aliased to `cd ../../../../../..'
|
||||
|
||||
So the type command produces a more human-understandable output.
|
||||
|
||||
Another thing worth sharing here is that you can use aliases for the common typos you make. For example:
|
||||
|
||||
alias mroe='more'
|
||||
|
||||
_Finally, it's also worth mentioning that not everybody is in favor of using aliases. Most of them argue that once you get used to the aliases you define for your ease, it gets really difficult for you to work on some other system where those aliases don't exist (and you're not allowed to create any as well). For more (as well as precise reasons) why some experts don't recommend using aliases, you can head[here][4]. _
|
||||
|
||||
### Conclusion
|
||||
|
||||
Like the CDPATH environment variable we discussed in the previous part, alias is also a double edged sword that one should use very cautiously. Don't get discouraged though, as everything has its own advantages and disadvantages. Just that practice and complete knowledge is the key when you're dealing with concepts like aliases.
|
||||
|
||||
So this marks the end of this tutorial series. Hope you enjoyed it as well learned some new things/concepts from it. In case you have any doubts or queries, please share them with us (and the rest of the world) in comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/
|
||||
[1]:https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/#command-line-aliases-in-linux
|
||||
[2]:https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/#related-details
|
||||
[3]:https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/#conclusion
|
||||
[4]:http://unix.stackexchange.com/questions/66934/why-is-aliasing-over-standard-commands-not-recommended
|
||||
[5]:https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/
|
||||
@ -1,146 +0,0 @@
|
||||
vim-kakali translating
|
||||
|
||||
How to compare directories with Meld on Linux
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Compare directories using Meld][1]
|
||||
2. [Conclusion][2]
|
||||
|
||||
We've [already covered][4] Meld from a beginner's point of view (including the tool's installation part), and we've also covered some tips/tricks that are primarily aimed at intermediate Meld users. If you remember, in the beginner's tutorial, we mentioned that Meld can be used to compare both files as well as directories. Now that we've already covered file comparison, it's time to discuss the tool's directory comparison feature.
|
||||
|
||||
_But before we do that it'd be worth sharing that all the instructions and examples presented in this tutorial have been tested on Ubuntu 14.04 and the Meld version we've used is 3.14.2._
|
||||
|
||||
### Compare directories using Meld
|
||||
|
||||
To compare two directories using Meld, launch the tool and select the _Directory comparison_ option.
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
Then select the directories that you want to compare:
|
||||
|
||||
[
|
||||
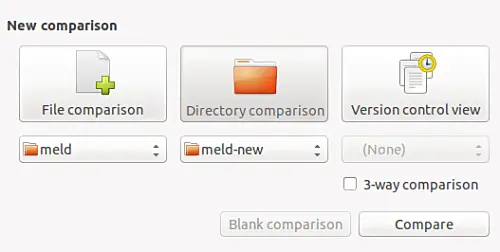
|
||||
][6]
|
||||
|
||||
Once that is done, click the _Compare_ button, and you'll see that Meld will compare both directories side by side, like the tool does in case of files:
|
||||
|
||||
[
|
||||
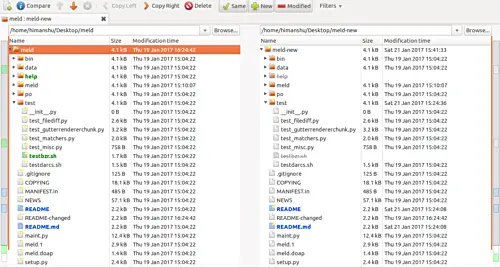
|
||||
][7]
|
||||
|
||||
Of course, these being directories, they are displayed as side-by-side trees. And as you can see in the screenshot above, the differences - whether it's a new file or a changed file - are highlighted in different colors.
|
||||
|
||||
According to Meld's official documentation, each file or folder that you see in the comparison area of the window has a state of its own. A state basically reveals how a particular file/folder is different from the corresponding entry in the other directory.
|
||||
|
||||
The following table - taken from the tool's website - explains in details the folder comparison states in Meld.
|
||||
|
||||
|**State** | **Appearance** | **Meaning** |
|
||||
| --- | --- | --- |
|
||||
| Same | Normal font | The file/folder is the same across all compared folders. |
|
||||
| Same when filtered | Italics | These files are different across folders, but once text filters are applied, these files become identical. |
|
||||
| Modified | Blue and bold | These files differ between the folders being compared. |
|
||||
| New | Green and bold | This file/folder exists in this folder, but not in the others. |
|
||||
| Missing | Greyed out text with a line through the middle | This file/folder doesn't exist in this folder, but does in one of the others. |
|
||||
| Error | Bright red with a yellow background and bold | When comparing this file, an error occurred. The most common error causes are file permissions (i.e., Meld was not allowed to open the file) and filename encoding errors. |
|
||||
|
||||
By default, Meld shows all the contents of the folders being compared, even if they are same (meaning there's no difference between them). However, you can ask the tool to not display these files/directories by clicking the _Same_ button in the toolbar - the click should disable this button.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
For example, here's our directory comparison when I clicked and disabled the _Same_ button:
|
||||
|
||||
[
|
||||
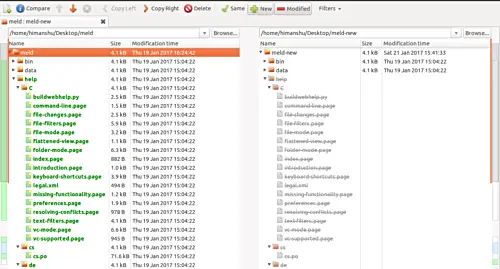
|
||||
][9]
|
||||
|
||||
So you can see that only the differences between the two directories (new and modified files) are shown now. Similarly, if you disable the _New_ button, only the modified files will be displayed. So basically, you can use these buttons to customize what kind of changes are displayed by Meld while comparing two directories.
|
||||
|
||||
Coming to the changes, you can hop from one change to another using the up and down arrow keys that sit above the display area in the tool's window, and to open two files for side-by-side comparison, you can either double click the name of any of the files, or click the _Compare_ button that sits beside the arrows.
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
**Note 1**: If you observe closely, there are bars on the left and right-hand sides of the display area in Meld window. These bars basically provide "a simple coloured summary of the comparison results." For each differing file or folder, there's a small colored section in these bars. You can click any such section to directly jump to that place in the comparison area.
|
||||
|
||||
**Note 2**: While you can always open files side by side and merge changes the way you want, in case you want all the changes to be merged to the corresponding file/folder (meaning you want to make the corresponding file/folder exactly same) then you can use the _Copy Left_ and _Copy Right_ buttons:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
For example, select a file or folder in the left pane and click the _Copy Right_ button to make the corresponding entry in the right pane exactly same.
|
||||
|
||||
Moving on, there's a _Filters_ drop-down menu that sits just next to the _Same_, _New_, and _Modified_ trio of buttons. Here you can select/deselect file types to tell Meld whether or not to show these kind of files/folders in the display area during a directory comparison. The official documentation explains the entries in this menu as "patterns of filenames that will not be looked at when performing a folder comparison."
|
||||
|
||||
The entries in the list include backups, OS-specific metadata, version control, binaries, and media.
|
||||
|
||||
[
|
||||
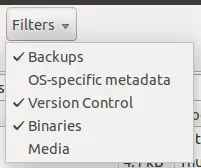
|
||||
][12]
|
||||
|
||||
The aforementioned menu is also accessible by heading to _View->File Filters_. You can add new elements to this menu (as well as remove existing ones if you want) by going to _Edit->Preferences->File Filters_.
|
||||
|
||||
[
|
||||
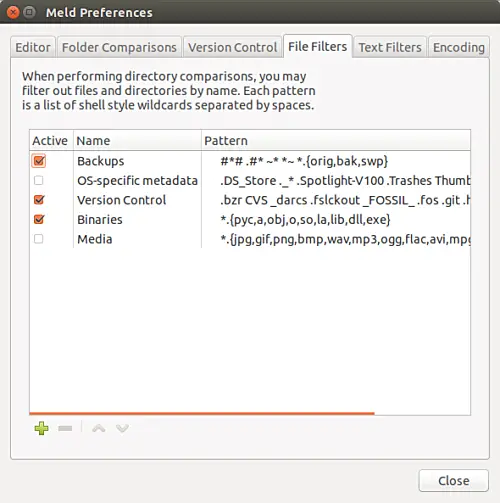
|
||||
][13]
|
||||
|
||||
To create a new filter, you need to use shell glob patterns. Following is the list of shell glob characters that Meld recognises:
|
||||
|
||||
| **Wildcard** | **Matches** |
|
||||
| --- | --- |
|
||||
| * | anything (i.e., zero or more characters) |
|
||||
| ? | exactly one character |
|
||||
| [abc] | any one of the listed characters |
|
||||
| [!abc] | anything except one of the listed characters |
|
||||
| {cat,dog} | either "cat" or "dog" |
|
||||
|
||||
Finally, an important point worth knowing about Meld is that the case of a file's name plays an important part as comparison is case sensitive by default. This means that, for example, the files README, readme and ReadMe would all be treated by the tool as different files.
|
||||
|
||||
Thankfully, however, Meld also provides you a way to turn off this feature. All you have to do is to head to the _View_ menu and then select the _Ignore Filename Case_ option.
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
### Conclusion
|
||||
|
||||
As you'd agree, directory comparison using Meld isn't difficult - in fact I'd say it's pretty easy. The only area that might require time to learn is creating file filters, but that's not to say you should never learn it. Obviously, it all depends on what your requirement is.
|
||||
|
||||
Oh, and yes, you can even compare three directories using Meld, a feature that you can access by _clicking the 3-way comparison_ box when you choose the directories that you want to compare. We didn't discuss the feature in this article, but definitely will in one of our future articles.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/#compare-directories-using-meld
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/#conclusion
|
||||
[3]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-same-button.png
|
||||
[4]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux/
|
||||
[5]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-dir-comp-1.png
|
||||
[6]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-sel-dir-2.png
|
||||
[7]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-dircomp-begins-3.png
|
||||
[8]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-same-disabled.png
|
||||
[9]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-only-diff.png
|
||||
[10]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-compare-arrows.png
|
||||
[11]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-copy-right-left.png
|
||||
[12]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-filters.png
|
||||
[13]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-edit-filters-menu.png
|
||||
[14]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-ignore-case.png
|
||||
@ -1,197 +0,0 @@
|
||||
bmon – A Powerful Network Bandwidth Monitoring and Debugging Tool for Linux
|
||||
============================================================
|
||||
|
||||
bmon is a simple yet powerful, text-based [network monitoring and debugging tool][1] for Unix-like systems, which captures networking related statistics and displays them visually in a human friendly format. It is a reliable and effective real-time bandwidth monitor and rate estimator.
|
||||
|
||||
It can read input using an assortment of input modules and presents output in various output modes, including an interactive curses user interface as well as a programmable text output for scripting purposes.
|
||||
|
||||
**Suggested Read:** [20 Command Line Tools to Monitor Linux Performance][2]
|
||||
|
||||
### Install bmon Bandwidth Monitoring Tool in Linux
|
||||
|
||||
Almost all Linux distributions has bmon package in the default repositories and can be easily install from default package manger, but the available version might be little older.
|
||||
|
||||
```
|
||||
$ sudo yum install bmon [On RHEL/CentOS/Fedora]
|
||||
$ sudo dnf install bmon [On Fedora 22+]
|
||||
$ sudo apt-get install bmon [On Debian/Ubuntu/Mint]
|
||||
```
|
||||
|
||||
Alternatively, you can get `.rpm` and `.deb` packages for your Linux distribution from [https://pkgs.org/download/bmon][3].
|
||||
|
||||
If you wanted to have a most recent version of bmon (i.e version 4.0), you need to build it from source using following commands.
|
||||
|
||||
#### On CentOS, RHEL and Fedora
|
||||
|
||||
```
|
||||
$ git clone https://github.com/tgraf/bmon.git
|
||||
$ cd bmon
|
||||
$ sudo yum install make libconfuse-devel libnl3-devel libnl-route3-devel ncurses-devel
|
||||
$ sudo ./autogen.sh
|
||||
$ sudo./configure
|
||||
$ sudo make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
#### On Debian, Ubuntu and Linux Mint
|
||||
|
||||
```
|
||||
$ git clone https://github.com/tgraf/bmon.git
|
||||
$ cd bmon
|
||||
$ sudo apt-get install build-essential make libconfuse-dev libnl-3-dev libnl-route-3-dev libncurses-dev pkg-config dh-autoreconf
|
||||
$ sudo ./autogen.sh
|
||||
$ sudo ./configure
|
||||
$ sudo make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
### How to Use bmon Bandwidth Monitoring Tool in Linux
|
||||
|
||||
Run it as below (for starters: RX means received bytes per second and TX refers to transmitted bytes per second):
|
||||
|
||||
```
|
||||
$ bmon
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
To view more detailed graphical statistics/information of bandwidth usage, press `d` key and refer screnshot below.
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
Press `[Shift + ?]` to view the quick reference below. To exit the interface, press [Shift + ?] again.
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
bmon – Quick Reference
|
||||
|
||||
To view statistics of a given interface, select it using the `Up` and `Down` arrows. However, to monitor a specific interface only, specify it as an argument on the command line as follows.
|
||||
|
||||
**Suggested Read:** [13 Tools to Monitor Linux Performance][7]
|
||||
|
||||
The flag `-p` sets a policy defining which network interfaces to display, in the example below, we will be monitoring the `enp1s0` network interface:
|
||||
|
||||
```
|
||||
$ bmon -p enp1s0
|
||||
```
|
||||
[
|
||||
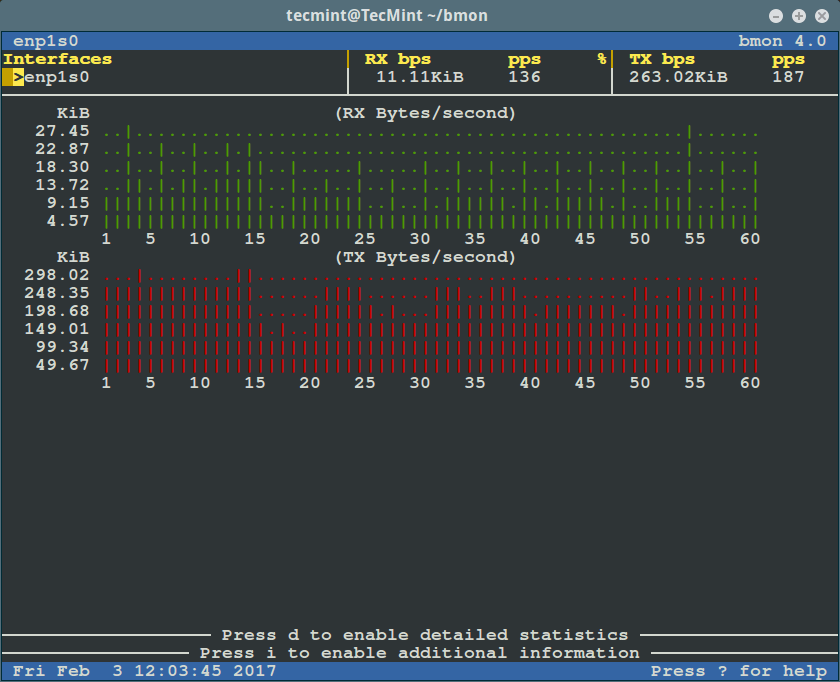
|
||||
][8]
|
||||
|
||||
bmon – Monitor Ethernet Bandwidth
|
||||
|
||||
To use bit per second instead of bytes per second, use the `-b` flag like so:
|
||||
|
||||
```
|
||||
$ bmon -bp enp1s0
|
||||
```
|
||||
|
||||
We can also define the intervals per second with the `-r` flag as follows:
|
||||
|
||||
```
|
||||
$ bmon -r 5 -p enp1s0
|
||||
```
|
||||
|
||||
### How to Use bmon Input Modules
|
||||
|
||||
bmon has a number of input modules that offer statistical data about interfaces, which includes:
|
||||
|
||||
1. netlink – employs the Netlink protocol to collect interface and traffic control statistics from the kernel. This is the default input module.
|
||||
2. proc — reads interface statistics from the /proc/net/dev file. It is considered a legacy interface and offered for backwards compatibly. It is a fallback module in case the Netlink interface is not available.
|
||||
3. dummy – this is a programmable input module for debugging and testing purposes.
|
||||
4. null – disables data collection.
|
||||
|
||||
To find additional info about a module, invoke the it with the “help” option set as follows:
|
||||
|
||||
```
|
||||
$ bmon -i netlink:help
|
||||
```
|
||||
|
||||
The next command will invoke bmon with the proc input module enabled:
|
||||
|
||||
```
|
||||
$ bmon -i proc -p enp1s0
|
||||
```
|
||||
|
||||
### How to Use bmon Output Modules
|
||||
|
||||
bmon also uses output modules to display or export the statistical data collected by the input modules above, which includes:
|
||||
|
||||
1. curses – this is an interactive curses based text user interface, it offers real time rate estimations and a graphical representation of each attribute. It is the default output mode.
|
||||
2. ascii – is a straightforward programmable text output meant for human consumption. It can display list of interfaces, detailed counters and graphs to the console. It is the default fallback output mode when curses is not available.
|
||||
3. format – is a fully scriptable output mode, it’s meant for consumption by other programs-meaning we can use its output values at a later time in scripts or programs for analysis and more.
|
||||
4. null – this disables output.
|
||||
|
||||
To get more info concerning a module, run the it with the “help” flag set like so:
|
||||
|
||||
```
|
||||
$ bmon -o curses:help
|
||||
```
|
||||
|
||||
The command that follows will invoke bmon in ascii output mode:
|
||||
|
||||
```
|
||||
$ bmon -p enp1s0 -o ascii
|
||||
```
|
||||
[
|
||||
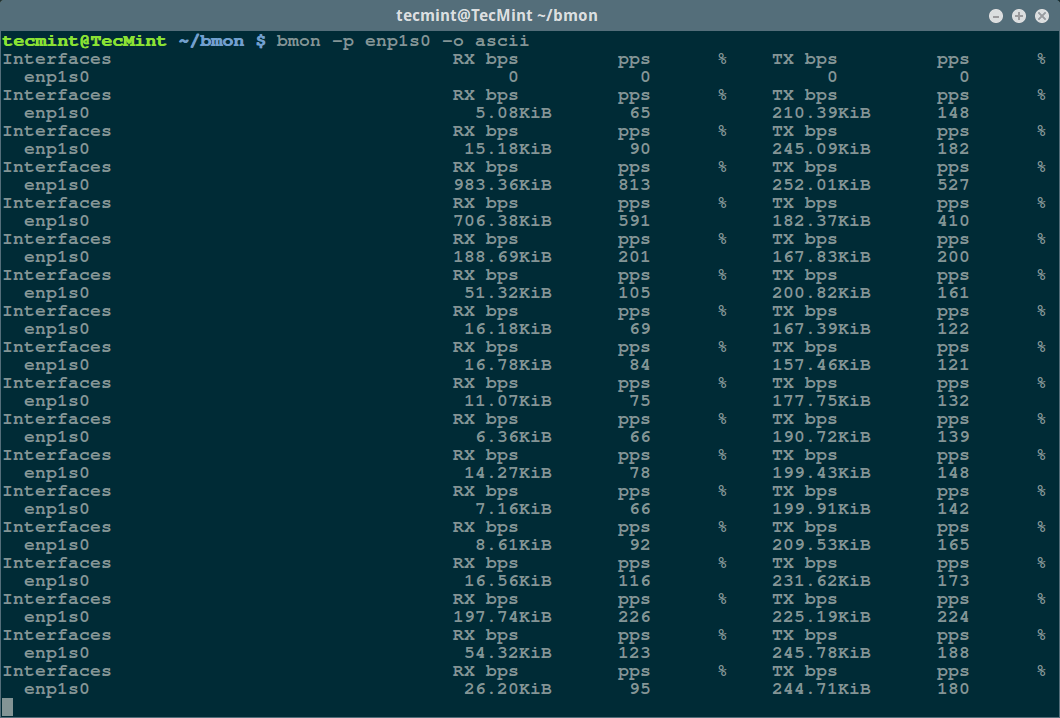
|
||||
][9]
|
||||
|
||||
bmon – Ascii Output Mode
|
||||
|
||||
We can run the format output module as well, then use the values obtained for scripting or in another program:
|
||||
|
||||
```
|
||||
$ bmon -p enp1s0 -o format
|
||||
```
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
bmon – Format Output Mode
|
||||
|
||||
For additional usage info, options and examples, read the bmon man page:
|
||||
|
||||
```
|
||||
$ man bmon
|
||||
```
|
||||
|
||||
Visit the bmon Github repository: [https://github.com/tgraf/bmon][11].
|
||||
|
||||
That’s all for now, test the various features of bmon in different scenarios and share your thoughts about it with us via the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/bmon-network-bandwidth-monitoring-debugging-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/bcc-best-linux-performance-monitoring-tools/
|
||||
[2]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[3]:https://pkgs.org/download/bmon
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Linux-Bandwidth-Monitoring.gif
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Detailed-Bandwidth-Statistics.gif
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Quick-Reference.png
|
||||
[7]:http://www.tecmint.com/linux-performance-monitoring-tools/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Monitor-Ethernet-Bandwidth.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Ascii-Output-Mode.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-format-output-mode.png
|
||||
[11]:https://github.com/tgraf/bmon
|
||||
@ -1,131 +0,0 @@
|
||||
translating by mudongliang
|
||||
# OpenSUSE Leap 42.2 Gnome - Better but not really
|
||||
|
||||
Updated: February 6, 2017
|
||||
|
||||
It is time to give Leap a second chance. Let me be extra corny. Give leap a chance. Yes. Well, several weeks ago, I reviewed the Plasma edition of the latest [openSUSE][1] release, and while it was busy firing all cannon, like a typical Stormtrooper, most of the beams did not hit the target. It was a fairly mediocre distro, delivering everything but then stopping just short of the goodness mark.
|
||||
|
||||
I will now conduct a Gnome experiment. Load the distro with a fresh new desktop environment, and see how it behaves. We did something rather similar with CentOS recently, with some rather surprising results. Hint. Maybe we will get lucky. Let's do it.
|
||||
|
||||

|
||||
|
||||
### Gnome it up
|
||||
|
||||
You can install new desktop environments by checking the Patterns tab in YaST > Software Management. Specifically, you can install Gnome, Xfce, LXQt, MATE, and others. A very simple procedure worth some 900 MB of disk data. No errors, no woes.
|
||||
|
||||

|
||||
|
||||
### Pretty Gnome stuff
|
||||
|
||||
I spent a short period of time taming openSUSE. Having had a lot of experience with [Fedora 24][2] doing this exact same stuff, i.e. [pimping][3], the procedure was rather fast and simple. Get some Gnome [extensions][4] first. Keep on low fire for 20 minutes. Stir and serve in clay bowls.
|
||||
|
||||
For dessert, launch Gnome Tweak Tool and add the window buttons. Most importantly, install the abso-serious-lutely needed, life-saving [Dash to Dock][5] extension, because then you can finally work like a human being without that maddening lack of efficiency called Activities. Digest, toss in some fresh [icons][6], and Bob's our uncle. All in all, it took me exactly 42 minutes and 12 seconds to get this completed. Get it? 42.2 minutes. OMGZ!
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Other customization and tweaks
|
||||
|
||||
I actually used Breeze window decorations in Gnome, and this seems to work very well. So much better than trying to customize Plasma. Behold and weep, for the looks were dire and pure!
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Smartphone support
|
||||
|
||||
So much better than Plasma - both [iPhone][7] and [Ubuntu Phone][8] were correctly identified and mounted. This reminds me of all the discrepancies and inconsistencies in the behavior of the [KDE][9] and [Gnome][10] editions of CentOS 7.2\. So this definitely crosses the boundaries of specific platforms. It has everything to do with the desktop environment.
|
||||
|
||||

|
||||
|
||||
The one outstanding bug is, you need to purge icon cache sometimes, or you will end up with old icons in file
|
||||
managers. There will be a whole article on this coming soon.
|
||||
|
||||
### Multimedia
|
||||
|
||||
No luck. Same problems like the Plasma edition. Missing dependencies. Can't have H.264 codecs, meaning you cannot really watch 99% of all the things that you need. That's like saying, no Internet for a month.
|
||||
|
||||

|
||||
|
||||
### Resource utilization
|
||||
|
||||
The Gnome edition is faster than the Plasma one, even with the Compositor turned off, and ignoring the KWin crashes and freezes. The CPU ticks at about 2-3%, and memory hovers around the 900MB mark. Middle of the road results, I say.
|
||||
|
||||

|
||||
|
||||
### Battery usage
|
||||
|
||||
Worse than Plasma actually. Not sure why. But even with the brightness adjusted to about 50%, Leap Gnome gave my G50 only about 2.5 hours of electronic love. I did not explore as to where it all gets wasted, but it sure does.
|
||||
|
||||

|
||||
|
||||
### Weird issues
|
||||
|
||||
There were also some glitches and errors. For instance, the desktop keeps on asking me for the Wireless password, maybe because Gnome does not handle KWallet very well or something. Also, KWin was left running after I logged out of a Plasma session, eating a good solid 100% CPU until I killed it. Such a disgrace.
|
||||
|
||||

|
||||
|
||||
### Hardware support
|
||||
|
||||
Suspend & resume, alles gut. I did not experience network drops in the Gnome version yet. The webcam works, too. In general, hardware support seems quite decent. Bluetooth works, though. Yay! Maybe we should label this under networking? To wit.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Networking
|
||||
|
||||
Samba printing? You get that same, lame applet like in [Yakkety Yak][11], which all gets messed up visually. But then it says no print shares, check firewall. Ah whatever. It's no longer 1999\. Being able to print is not a privilege, it's a basic human right. People have staged revolutions over far less. And I cannot take a screenshot of this. That bad.
|
||||
|
||||
### The rest of it?
|
||||
|
||||
All in all, it was a standard Gnome desktop, with its slightly mentally challenged approach to computing and ergonomics, tamed through the rigorous use of extensions. It is a little friendlier than the Plasma version, and you get better overall results with most of the normal, everyday stuff. Then you get stumped by a silly lack of options that Plasma has in overwhelming abundance. But then you remember your desktop isn't freezing every minute or so, and that's a definite bonus.
|
||||
|
||||
### Conclusion
|
||||
|
||||
OpenSUSE Leap 42.2 Gnome is a better product than its Plasma counterpart, and no mistake. It is more stable, it is faster, more elegant, more easily customizable, and most of the critical everyday functions actually work. For example, you can print to Samba, if you are inclined to fight the firewall, copy files to Samba without losing timestamps, use Bluetooth, use your Ubuntu Phone, and all this without the crippling effects of constant crashes. The entire stack is just more fully featured and better supported.
|
||||
|
||||
However, Leap is still only a reasonable release and nothing more. It struggles in many core areas that other distros do with more panache and elegance, and there are some big, glaring problems in the overall product that are a direct result of bad QA. At the very least, this lack of quality has been an almost consistent element with openSUSE these past few years. Now and then, you get a decent hatchling, but most of them are just average. That's probably the word that best defines openSUSE Leap. Average. You should try and see for yourself. You will most likely not be amazed. Such a shame, because for me, SUSE has a sweet spot, and yet, it stubbornly refuses to rekindle the love. 6/10\. Have a go, play with your emotions.
|
||||
|
||||
Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
My name is Igor Ljubuncic. I'm more or less 38 of age, married with no known offspring. I am currently working as a Principal Engineer with a cloud technology company, a bold new frontier. Until roughly early 2015, I worked as the OS Architect with an engineering computing team in one of the largest IT companies in the world, developing new Linux-based solutions, optimizing the kernel and hacking the living daylights out of Linux. Before that, I was a tech lead of a team designing new, innovative solutions for high-performance computing environments. Some other fancy titles include Systems Expert and System Programmer and such. All of this used to be my hobby, but since 2008, it's a paying job. What can be more satisfying than that?
|
||||
|
||||
From 2004 until 2008, I used to earn my bread by working as a physicist in the medical imaging industry. My work expertise focused on problem solving and algorithm development. To this end, I used Matlab extensively, mainly for signal and image processing. Furthermore, I'm certified in several major engineering methodologies, including MEDIC Six Sigma Green Belt, Design of Experiment, and Statistical Engineering.
|
||||
|
||||
I also happen to write books, including high fantasy and technical work on Linux; mutually inclusive.
|
||||
|
||||
Please see my full list of open-source projects, publications and patents, just scroll down.
|
||||
|
||||
For a complete list of my awards, nominations and IT-related certifications, hop yonder and yonder please.
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/opensuse-42-2-gnome.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.dedoimedo.com/computers/opensuse-42-2.html
|
||||
[2]:http://www.dedoimedo.com/computers/fedora-24-gnome.html
|
||||
[3]:http://www.dedoimedo.com/computers/fedora-24-pimp.html
|
||||
[4]:http://www.dedoimedo.com/computers/fedora-23-extensions.html
|
||||
[5]:http://www.dedoimedo.com/computers/gnome-3-dash.html
|
||||
[6]:http://www.dedoimedo.com/computers/fedora-24-pimp-more.html
|
||||
[7]:http://www.dedoimedo.com/computers/iphone-6-after-six-months.html
|
||||
[8]:http://www.dedoimedo.com/computers/ubuntu-phone-sep-2016.html
|
||||
[9]:http://www.dedoimedo.com/computers/lenovo-g50-centos-kde.html
|
||||
[10]:http://www.dedoimedo.com/computers/lenovo-g50-centos-gnome.html
|
||||
[11]:http://www.dedoimedo.com/computers/ubuntu-yakkety-yak.html
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
How to Make ‘Vim Editor’ as Bash-IDE Using ‘bash-support’ Plugin in Linux
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,141 +0,0 @@
|
||||
# Microsoft Office Online gets better - on Linux, too
|
||||
|
||||
One of the core things that will make or break your Linux experience is the lack of the Microsoft Office suite, well, for Linux. If you are forced to use Office products to make a living, and this applies to a very large number of people, you might not be able to afford open-source alternatives. Get the paradox?
|
||||
|
||||
Indeed, LibreOffice a [great][1] free program, but what if your client, customer or boss demands Word and Excel files? Can you, indeed, [afford any mistakes][2] or errors or glitches in converting these files from ODT or whatnot into DOCX and such, and vice versa? This is a very tricky set of questions. Unfortunately, for most people, technically, this means Linux is out of limits. Well, not quite.
|
||||
|
||||

|
||||
|
||||
### Enter Microsoft Office Online, Enter Linux
|
||||
|
||||
For a number of years, Microsoft has had its cloud office offering. No news there. What makes this cool and relevant is, it's available through any modern browser interface, and this means Linux, too! I have also tested this [solution][3] a while back, and it worked great. I was able to use the product just fine, save files in their native format, or even export my documents in the ODF format, which is really nice.
|
||||
|
||||
I decided to revisit this suite and see how it's evolved in the past few years, and see whether it still likes Linux. My scapegoat for this experience was a [Fedora 25][4] instance, and I had the Microsoft Office Online running open in several tabs. I did this in parallel to testing [SoftMaker Office 2016][5]. Sounds like a lot of fun, and it was.
|
||||
|
||||
### First impressions
|
||||
|
||||
I have to say, I was pleased. The Office does not require any special plugins. No Silverlight or Flash or anything like that. Pure HTML and Javascript, and lots of it. Still, the interface is fairly responsive. The only thing I did not like was the gray background in Word documents, which can be exhausting after a while. Other than that, the suite was working fine, there were no delays, lags or weird, unexpected errors. But let us proceed slowly then, shall we.
|
||||
|
||||
The suite does require that you log in with an online account or a phone number - it does not have to be a Live or Hotmail email. Any one will do. If you also have a Microsoft [phone][6], then you can use the same account, and you will be able to sync your data. The account grants you 5 GB of OneDrive storage for free, as well. This is quite neat. Not stellar or super exciting, but rather decent.
|
||||
|
||||

|
||||
|
||||
You have access to a whole range of programs, including the mandatory trio - Word, Excel and Powerpoint, but then, the rest of the stuff is also available, including some new fancy stuff. Documents are auto-saved, but you can also download copies and convert to other formats, like PDF and ODF.
|
||||
|
||||
For me, this is excellent. And let me share a short personal story. I write my [fantasy][7] books using LibreOffice. But then, when I need to send them to a publisher for editing or proofreading, I need to convert them to DOCX. Alas, this requires Microsoft Office. With my [Linux problem solving book][8], I had to use Word from the start, because there was a lot of collaboration work required with my editor, which mandated the use of the proprietary solution. There are no emotions here. Only cold monetary and business considerations. Mistakes are not acceptable.
|
||||
|
||||

|
||||
|
||||
Having access to Office Online can give a lot of people the leeway they need for occasional, recreational use of Word and Excel and alike without having to buy the whole, expensive suite. If you are a daytime LibreOffice fan, you can be a nighttime party animal at the Microsoft Office Heartbreakers Club without a guilty conscience. When someone ships you a Word or Powerpoint file, you can upload and manipulate them online, then export as needed. Likewise, you can create your work online, send it to people with strict requirements, then grab yourself a copy in ODF, and work with LibreOffice if needed. The flexibility is quite useful, but that should not be your main driver. Still, for Linux people, this gives them a lot of freedom they do not normally have. Because even if they do want to use Microsoft Office, it simply isn't available as a native install.
|
||||
|
||||

|
||||
|
||||
### Features, options, tools
|
||||
|
||||
I started hammering out a document - with all the fine trimming of a true jousting rouncer. I wrote some text, applied a style or three, hyperlinked some text, embedded an image, added a footnote, and then commented on my writing and even replied to myself in the best fashion of a poly-personality geek.
|
||||
|
||||
Apart from the gray background - and we will learn how to work around this in a nice yet nerdy way skunkworks style, because there isn't an option to tweak the background color in the browser interface - things were looking fine.
|
||||
|
||||
You even have Skype integrated into the suite, so you can chat and collaborate. Or rather collaborate and listen. Hue hue. Quite neat. The right-click button lets you select a few quick actions, including links, comments and translations. The last piece still needs a lot of work, because it did not quite give me what I expected. The translations are wonky.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
You can also add images - including embedded Bing search, which will also, by default, filter images based on their licensing and re-distribution rights. This is neat, especially if you need to create a document and must avoid any copyright claims and such.
|
||||
|
||||

|
||||
|
||||
### More on comments, tracking
|
||||
|
||||
Quite useful. For realz. The online nature of this product also means changes and edits to the documents will be tracked by default, so you also have a basic level of versioning available. However, session edits are lost once you close the document.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
The one error that will visibly come up - if you try to edit the document in Word or Excel on Linux, you will get prompted that you're being naughty, because this is not a supported action, for obvious reasons.
|
||||
|
||||

|
||||
|
||||
### Excel and friends
|
||||
|
||||
The practical workflows extends beyond Word. I also tried Excel, and it did as advertised, including having some neat and useful templates and such. Worked just fine, and there's no lag updating cells and formulas. You get most of the functionality you need and expect.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### OneDrive
|
||||
|
||||
This is where you can create and organize folders and files, move documents about, and share them with your friends (if you have any) and colleagues. 5 GB for free, upgradeable for a fee, of course. Worked fine, overall. It does take a few moments to refresh and display contents. Open documents will not be deleted, so this may look like a bug, but it makes perfect sense from the computational perspective.
|
||||
|
||||

|
||||
|
||||
### Help
|
||||
|
||||
If you get confused - or feel like being dominatrixed by AI, you can ask the cloud collective intelligence of the Redmond Borg ship for assistance. This is quite useful, if not as straightforward or laser-sharp as it can be. But the effort is benevolent.
|
||||
|
||||

|
||||
|
||||
### Problems
|
||||
|
||||
During my three-hour adventure, I only encountered two glitches. One, during a document edit, the browser had a warning (yellow triangle) about an insecure element loaded and used in an otherwise secure HTTPS session. Two, I hit a snag of failing to create a new Excel document. A one-time issue, and it hasn't happened since.
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
Microsoft Office Online is a great product, and better than it was when I tested it some two years ago. It's fairly snappy, it looks nice, it behaves well, the errors are far and few in between, and it offers genuine Microsoft Office compatibility even to Linux users, which can be of significant personal and business importance to some. I won't say this is the best thing that happened to humanity since VHS was invented, but it's a nice addition, and it bridges a big gap that Linux folks have faced since day one. Quite handy, and the ODF support is another neat touch.
|
||||
|
||||
Now, to make things even spicier, if you like this whole cloud concept thingie, you might also be interested in [Open365][9], a LibreOffice-based office productivity platform, with an added bonus of a mail client and image processing software, plus 20 GB free storage. Best of all, you can have both of these running in your browser, in parallel. All it takes is another tab or two.
|
||||
|
||||
Back to Microsoft, if you a Linuxperson, you may actually require Microsoft office products now and then. The easier way to enjoy them - or at the very least, use them when needed without having to commit to a full operating system stack - is through the online office suite. Free, elegant, and largely transparent. Worth checking out, provided you can put the ideological game aside. There you go. Enjoy thy clouden. Or something.
|
||||
|
||||
Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
My name is Igor Ljubuncic. I'm more or less 38 of age, married with no known offspring. I am currently working as a Principal Engineer with a cloud technology company, a bold new frontier. Until roughly early 2015, I worked as the OS Architect with an engineering computing team in one of the largest IT companies in the world, developing new Linux-based solutions, optimizing the kernel and hacking the living daylights out of Linux. Before that, I was a tech lead of a team designing new, innovative solutions for high-performance computing environments. Some other fancy titles include Systems Expert and System Programmer and such. All of this used to be my hobby, but since 2008, it's a paying job. What can be more satisfying than that?
|
||||
|
||||
From 2004 until 2008, I used to earn my bread by working as a physicist in the medical imaging industry. My work expertise focused on problem solving and algorithm development. To this end, I used Matlab extensively, mainly for signal and image processing. Furthermore, I'm certified in several major engineering methodologies, including MEDIC Six Sigma Green Belt, Design of Experiment, and Statistical Engineering.
|
||||
|
||||
I also happen to write books, including high fantasy and technical work on Linux; mutually inclusive.
|
||||
|
||||
Please see my full list of open-source projects, publications and patents, just scroll down.
|
||||
|
||||
For a complete list of my awards, nominations and IT-related certifications, hop yonder and yonder please.
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/office-online-linux-better.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.ocsmag.com/2015/02/16/libreoffice-4-4-review-finally-it-rocks/
|
||||
[2]:http://www.ocsmag.com/2014/03/14/libreoffice-vs-microsoft-office-part-deux/
|
||||
[3]:http://www.dedoimedo.com/computers/office-online-linux.html
|
||||
[4]:http://www.dedoimedo.com/computers/fedora-25-gnome.html
|
||||
[5]:http://www.ocsmag.com/2017/01/18/softmaker-office-2016-your-alternative-to-libreoffice/
|
||||
[6]:http://www.dedoimedo.com/computers/microsoft-lumia-640.html
|
||||
[7]:http://www.thelostwordsbooks.com/
|
||||
[8]:http://www.dedoimedo.com/computers/linux-problem-solving-book.html
|
||||
[9]:http://www.ocsmag.com/2016/08/17/open365/
|
||||
@ -1,267 +0,0 @@
|
||||
ucasFL translating
|
||||
Installation of Devuan Linux (Fork of Debian)
|
||||
============================================================
|
||||
|
||||
|
||||
Devuan Linux, the most recent fork of Debian, is a version of Debian that is designed to be completely free of systemd.
|
||||
|
||||
Devuan was announced towards the end of 2014 and has been actively developed over that time. The most recently release is the beta2 release of codenamed: Jessie (Yes the same name as the current stable version of Debian).
|
||||
|
||||
The final release for the current stable release is said to be ready in early 2017\. To read more about the project please visit the community’s home page: [https://devuan.org/][1].
|
||||
|
||||
This article will walk through the installation of Devuan’s current release. Most of the packages available in Debian are available in Devuan allowing for a fairly seamless transition for Debian users to Devuan should they prefer the freedom to choose their initialization system.
|
||||
|
||||
#### System Requirements
|
||||
|
||||
Devuan, like Debian. Is very light on system requirements. The biggest determining factor is the desktop environment the user wishes to use. This guide will assume that the user would like a ‘flashier’ desktop environment and will suggest the following minimums:
|
||||
|
||||
1. At least 15GB of disk space; strongly encouraged to have more
|
||||
2. At least 2GB of ram; more is encouraged
|
||||
3. USB or CD/DVD boot support
|
||||
4. Internet connection; installer will download files from the Internet
|
||||
|
||||
### Devuan Linux Installation
|
||||
|
||||
As with all of the author’s guides, this guide will be assuming that a USB drive is available to use as the installation media. Take note that the USB drive should be as close to 4/8GB as possible and ALL DATA WILL BE REMOVED!
|
||||
|
||||
The author has had issues with larger USB drives but some may still work. Regardless, following the next few steps WILL RESULT IN DATA LOSS ON THE USB DRIVE.
|
||||
|
||||
Please be sure to backup all data before proceeding. This bootable Kali Linux USB drive is going to be created from another Linux machine.
|
||||
|
||||
1. First obtain the latest release of Devuan installation ISO from [https://devuan.org/][2] or you can obtain from a Linux station, type the following commands:
|
||||
|
||||
```
|
||||
$ cd ~/Downloads
|
||||
$ wget -c https://files.devuan.org/devuan_jessie_beta/devuan_jessie_1.0.0-beta2_amd64_CD.iso
|
||||
```
|
||||
|
||||
2. The commands above will download the installer ISO file to the user’s ‘Downloads’ folder. The next process is to write the ISO to a USB drive to boot the installer.
|
||||
|
||||
To accomplish this we can use the `'dd'` tool within Linux. First, the disk name needs to be located with [lsblk command][3] though.
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Find Device Name in Linux
|
||||
|
||||
With the name of the USB drive determined as `/dev/sdc`, the Devuan ISO can be written to the drive with the `dd` tool.
|
||||
|
||||
```
|
||||
$ sudo dd if=~/Downloads/devuan_jessie_1.0.0-beta2_amd64_CD.iso of=/dev/sdc
|
||||
```
|
||||
|
||||
Important: The above command requires root privileges so utilize ‘sudo’ or login as the root user to run the command. Also this command will REMOVE EVERYTHING on the USB drive. Be sure to backup needed data.
|
||||
|
||||
3. Once the ISO is copied over to the USB drive, plug the USB drive into the respective computer that Devuan should be installed upon and proceed to boot to the USB drive.
|
||||
|
||||
Upon successful booting to the USB drive, the user will be presented with the following screen and should proceed with the ‘Install’ or ‘Graphical Install’ options.
|
||||
|
||||
This guide will be using the ‘Graphical Install’ method.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Devuan Graphic Installation
|
||||
|
||||
4. Allow the installer to boot to the localization menus. Once here the user will be prompted with a string of windows asking about the user’s keyboard layout and language. Simply select the desired options to continue.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Devuan Language Selection
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Devuan Location Selection
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Devuan Keyboard Configuration
|
||||
|
||||
5. The next step is to provide the installer with the hostname and domain name that this machine will be a member.
|
||||
|
||||
The hostname should be something unique but the domain can be left blank if the computer won’t be part of a domain.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Set Devuan Linux Hostname
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Set Devuan Linux Domain Name
|
||||
|
||||
6. Once the hostname and domain name information have been provided the installer will want the user to provide a ‘root’ user password.
|
||||
|
||||
Take note to remember this password as it will be required to do administrative tasks on this Devuan machine! Devuan doesn’t install the sudo package by default so the admin user will be ‘root’ when this installation finishes.
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Setup Devuan Linux Root User
|
||||
|
||||
7. The next series of questions will be for the creation of a non-root user. It is always a good to avoid using your system as the root user whenever possible. The installer will prompt for the creation of a non-root user at this point.
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Setup Devuan Linux User Account
|
||||
|
||||
8. Once the root user password and user creation prompts have completed, the installer will request that the clock be [set up with NTP][13].
|
||||
|
||||
Again a connection to the internet will be required in order for this to work for most systems!
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Devuan Linux Timezone Setup
|
||||
|
||||
9. The next step will be the act of partitioning the system. For most user’s ‘Guided – use entire disk’ is typically sufficient. However, if advanced partitioning is desired, this would be the time to set them up.
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Devuan Linux Partitioning
|
||||
|
||||
Be sure to confirm the partition changes after clicking continue above in order to write the partitions to the disk!
|
||||
|
||||
10. Once the partitioning is completed, the installer will begin to install the base files for Devuan. This process will take a few minutes but will stop when the system is ready to configure a network mirror (software repository). Most users will want to click ‘yes’ when prompted to use a network mirror.
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Devuan Linux Configure Package Manager
|
||||
|
||||
Clicking `yes` here will present the user with a list of network mirrors by country. It is typically best to pick the mirror that is geographically closest to the machines location.
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
Devuan Linux Mirror Selection
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
Devuan Linux Mirrors
|
||||
|
||||
11. The next screen is the traditional Debian ‘popularity contest’ all this does is track what packages are downloaded for statistics on package usage.
|
||||
|
||||
This can be enabled or disabled to the administrator’s preference during the installation process.
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
Configure Devuan Linux Popularity Contest
|
||||
|
||||
12. After a brief scan of the repositories and a couple of package updates, the installer will present the user with a list of software packages that can be installed to provide a Desktop Environment, SSH access, and other system tools.
|
||||
|
||||
While Devuan has some of the major Desktop Environments listed, it should be noted that not all of them are ready for use in Devuan yet. The author has had good luck with Xfce, LXDE, and Mate in Devuan (Future articles will walk the user through how to install Enlightenment from source in Devuan as well).
|
||||
|
||||
If interested in installing a different Desktop Environment, un-check the ‘Devuan Desktop Environment’ check box.
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
Devuan Linux Software Selection
|
||||
|
||||
Depending on the number of items selected in the above installer screen, there may be a couple of minutes of downloads and installations taking place.
|
||||
|
||||
When all the software installation is completed, the installer will prompt the user for the location to install ‘grub’. This is typically done on ‘/dev/sda’ as well.
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
Devuan Linux Grub Install
|
||||
|
||||
[
|
||||

|
||||
][22]
|
||||
|
||||
Devuan Linux Grub Install Disk
|
||||
|
||||
13. After GRUB successfully installs to the boot drive, the installer will alert the user that the installation is complete and to reboot the system.
|
||||
|
||||
[
|
||||

|
||||
][23]
|
||||
|
||||
Devuan Linux Installation Completes
|
||||
|
||||
14. Assuming that the installation was indeed successful, the system should either boot into the chosen Desktop Environment or if no Desktop Environment was selected, the machine will boot to a text based console.
|
||||
|
||||
[
|
||||

|
||||
][24]
|
||||
|
||||
Devuan Linux Console
|
||||
|
||||
This concludes the installation of the latest version of Devuan Linux. The next article in this short series will cover the [installation of the Enlightenment Desktop Environment][25] from source code on a Devuan system. Please let Tecmint know if you have any issues or questions and thanks for reading!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
He is an Instructor of Computer Technology with Ball State University where he currently teaches all of the departments Linux courses and co-teaches Cisco networking courses. He is an avid Debian user as well as many of the derivatives of Debian such as Mint, Ubuntu, and Kali. Rob holds a Masters in Information and Communication Sciences as well as several industry certifications from Cisco, EC-Council, and Linux Foundation.
|
||||
|
||||
-----------------------------
|
||||
|
||||
via: http://www.tecmint.com/installation-of-devuan-linux/
|
||||
|
||||
作者:[Rob Turner ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/robturner/
|
||||
[1]:https://devuan.org/
|
||||
[2]:https://devuan.org/
|
||||
[3]:http://www.tecmint.com/find-usb-device-name-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Device-Name-in-Linux.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Graphic-Installation.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Language-Selection.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Location-Selection.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Keyboard-Configuration.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-Devuan-Linux-Hostname.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-Devuan-Linux-Domain-Name.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Setup-Devuan-Linux-Root-User.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Setup-Devuan-Linux-User-Account.png
|
||||
[13]:http://www.tecmint.com/install-and-configure-ntp-server-client-in-debian/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Clock-on-Devuan-Linux.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Partitioning.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Configure-Package-Manager.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Mirror-Selection.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Mirrors.png
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Devuan-Linux-Popularity-Contest.png
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Software-Selection.png
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Grub-Install.png
|
||||
[22]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Grub-Install-Disk.png
|
||||
[23]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Installation-Completes.png
|
||||
[24]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Console.png
|
||||
[25]:http://www.tecmint.com/install-enlightenment-on-devuan-linux/
|
||||
[26]:http://www.tecmint.com/author/robturner/
|
||||
[27]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[28]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,308 +0,0 @@
|
||||
translating by chenxinlong
|
||||
How to set up a personal web server with a Raspberry Pi
|
||||
============================================================
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
A personal web server is "the cloud," except you own and control it as opposed to a large corporation.
|
||||
|
||||
Owning a little cloud has a lot of benefits, including customization, free storage, free Internet services, a path into open source software, high-quality security, full control over your content, the ability to make quick changes, a place to experiment with code, and much more. Most of these benefits are immeasurable, but financially these benefits can save you over $100 per month.
|
||||
|
||||

|
||||
|
||||
Image by Mitchell McLaughlin, CC BY-SA 4.0
|
||||
|
||||
I could have used AWS, but I prefer complete freedom, full control over security, and learning how things are built.
|
||||
|
||||
* Self web-hosting: No BlueHost or DreamHost
|
||||
* Cloud storage: No Dropbox, Box, Google Drive, Microsoft Azure, iCloud, or AWS
|
||||
* On-premise security
|
||||
* HTTPS: Let’s Encrypt
|
||||
* Analytics: Google
|
||||
* OpenVPN: Do not need private Internet access (at an estimated $7 per month)
|
||||
|
||||
Things I used:
|
||||
|
||||
* Raspberry Pi 3 Model B
|
||||
* MicroSD Card (32GB recommended, [Raspberry Pi Compatible SD Cards][1])
|
||||
* USB microSD card reader
|
||||
* Ethernet cable
|
||||
* Router connected to Wi-Fi
|
||||
* Raspberry Pi case
|
||||
* Amazon Basics MicroUSB cable
|
||||
* Apple wall charger
|
||||
* USB mouse
|
||||
* USB keyboard
|
||||
* HDMI cable
|
||||
* Monitor (with HDMI input)
|
||||
* MacBook Pro
|
||||
|
||||
### Step 1: Setting up the Raspberry Pi
|
||||
|
||||
Download the most recent release of Raspbian (the Raspberry Pi operating system). [Raspbian Jessie][6] ZIP version is ideal [1]. Unzip or extract the downloaded file. Copy it onto the SD card. [Pi Filler][7] makes this process easy. [Download Pi Filer 1.3][8] or the most recent version. Unzip or extract the downloaded file and open it. You should be greeted with this prompt:
|
||||
|
||||

|
||||
|
||||
Make sure the USB card reader has NOT been inserted yet. If it has, eject it. Proceed by clicking Continue. A file explorer should appear. Locate the uncompressed Raspberry Pi OS file from your Mac or PC and select it. You should see another prompt like the one pictured below:
|
||||
|
||||

|
||||
|
||||
Insert the MicroSD card (32GB recommended, 16GB minimum) into the USB MicroSD Card Reader. Then insert the USB reader into the Mac or PC. You can rename the SD card to "Raspberry" to distinguish it from others. Click Continue. Make sure the SD card is empty. Pi Filler will _erase_ all previous storage at runtime. If you need to back up the card, do so now. When you are ready to continue, the Raspbian OS will be written to the SD card. It should take between one to three minutes. Once the write is completed, eject the USB reader, remove the SD card, and insert it into the Raspberry Pi SD card slot. Give the Raspberry Pi power by plugging the power cord into the wall. It should start booting up. The Raspberry Pi default login is:
|
||||
|
||||
**username: pi
|
||||
password: raspberry**
|
||||
|
||||
When the Raspberry Pi has completed booting for the first time, a configuration screen titled "Setup Options" should appear like the image below [2]:
|
||||
|
||||

|
||||
|
||||
Select the "Expand Filesystem" option and hit the Enter key [3]. Also, I recommend selecting the second option, "Change User Password." It is important for security. It also personalizes your Raspberry Pi.
|
||||
|
||||
Select the third option in the setup options list, "Enable Boot To Desktop/Scratch" and hit the Enter key. It will take you to another window titled "Choose boot option" as shown in the image below.
|
||||
|
||||

|
||||
|
||||
In the "Choose boot option" window, select the second option, "Desktop log in as user 'pi' at the graphical desktop" and hit the Enter button [4]. Once this is done you will be taken back to the "Setup Options" page. If not, select the "OK" button at the bottom of this window and you will be taken back to the previous window.
|
||||
|
||||
Once both these steps are done, select the "Finish" button at the bottom of the page and it should reboot automatically. If it does not, then use the following command in the terminal to reboot.
|
||||
|
||||
**$ sudo reboot**
|
||||
|
||||
After the reboot from the previous step, if everything went well, you will end up on the desktop similar to the image below.
|
||||
|
||||

|
||||
|
||||
Once you are on the desktop, open a terminal and enter the following commands to update the firmware of the Raspberry Pi.
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get upgrade-y
|
||||
|
||||
$ sudo apt-get dist-upgrade -y
|
||||
|
||||
$ sudo rpi-update
|
||||
```
|
||||
|
||||
This may take a few minutes. Now the Raspberry Pi is up-to-date and running.
|
||||
|
||||
### Step 2: Configuring the Raspberry Pi
|
||||
|
||||
SSH, which stands for Secure Shell, is a cryptographic network protocol that lets you securely transfer data between your computer and your Raspberry Pi. You can control your Raspberry Pi from your Mac's command line without a monitor or keyboard.
|
||||
|
||||
To use SSH, first, you need your Pi's IP address. Open the terminal and type:
|
||||
|
||||
```
|
||||
$ sudo ifconfig
|
||||
```
|
||||
|
||||
If you are using Ethernet, look at the "eth0" section. If you are using Wi-Fi, look at the "wlan0" section.
|
||||
|
||||
Find "inet addr" followed by an IP address—something like 192.168.1.115, a common default IP I will use for the duration of this article.
|
||||
|
||||
With this address, open terminal and type:
|
||||
|
||||
```
|
||||
$ ssh pi@192.168.1.115
|
||||
```
|
||||
|
||||
For SSH on PC, see footnote [5].
|
||||
|
||||
Enter the default password "raspberry" when prompted, unless you changed it.
|
||||
|
||||
You are now logged in via SSH.
|
||||
|
||||
### Remote desktop
|
||||
|
||||
Using a GUI (graphical user interface) is sometimes easier than a command line. On the Raspberry Pi's command line (using SSH) type:
|
||||
|
||||
```
|
||||
$ sudo apt-get install xrdp
|
||||
```
|
||||
|
||||
Xrdp supports the Microsoft Remote Desktop Client for Mac and PC.
|
||||
|
||||
On Mac, navigate to the app store and search for "Microsoft Remote Desktop." Download it. (For a PC, see footnote [6].)
|
||||
|
||||
After installation, search your Mac for a program called "Microsoft Remote Desktop." Open it. You should see this:
|
||||
|
||||

|
||||
|
||||
Image by Mitchell McLaughlin, CC BY-SA 4.0
|
||||
|
||||
Click "New" to set up a remote connection. Fill in the blanks as shown below.
|
||||
|
||||

|
||||
|
||||
Image by Mitchell McLaughlin, CC BY-SA 4.0
|
||||
|
||||
Save it by exiting out of the "New" window.
|
||||
|
||||
You should now see the remote connection listed under "My Desktops." Double click it.
|
||||
|
||||
After briefly loading, you should see your Raspberry Pi desktop in a window on your screen, which looks like this:
|
||||
|
||||

|
||||
|
||||
Perfect. Now, you don't need a separate mouse, keyboard, or monitor to control the Pi. This is a much more lightweight setup.
|
||||
|
||||
### Static local IP address
|
||||
|
||||
Sometimes the local IP address 192.168.1.115 will change. We need to make it static. Type:
|
||||
|
||||
```
|
||||
$ sudo ifconfig
|
||||
```
|
||||
|
||||
Write down from the "eth0" section or the "wlan0" section, the "inet addr" (Pi's current IP), the "bcast" (the broadcast IP range), and the "mask" (subnet mask address). Then, type:
|
||||
|
||||
```
|
||||
$ netstat -nr
|
||||
```
|
||||
|
||||
Write down the "destination" and the "gateway/network."
|
||||
|
||||

|
||||
|
||||
The cumulative records should look something like this:
|
||||
|
||||
```
|
||||
net address 192.168.1.115
|
||||
bcast 192.168.1.255
|
||||
mask 255.255.255.0
|
||||
gateway 192.168.1.1
|
||||
network 192.168.1.1
|
||||
destination 192.168.1.0
|
||||
```
|
||||
|
||||
With this information, you can set a static internal IP easily. Type:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/dhcpcd.conf
|
||||
```
|
||||
|
||||
Do not use **/etc/network/interfaces**.
|
||||
|
||||
Then all you need to do is append this to the bottom of the file, substituting the correct IP address you want.
|
||||
|
||||
```
|
||||
interface eth0
|
||||
static ip_address=192.168.1.115
|
||||
static routers=192.168.1.1
|
||||
static domain_name_servers=192.168.1.1
|
||||
```
|
||||
|
||||
Once you have set the static internal IP address, reboot the Raspberry Pi with:
|
||||
|
||||
```
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
After rebooting, from terminal type:
|
||||
|
||||
```
|
||||
$ sudo ifconfig
|
||||
```
|
||||
|
||||
Your new static settings should appear for your Raspberry Pi.
|
||||
|
||||
### Static global IP address
|
||||
|
||||
If your ISP (internet service provider) has already given you a static external IP address, you can skip ahead to the port forwarding section. If not, continue reading.
|
||||
|
||||
You have set up SSH, a remote desktop, and a static internal IP address, so now computers inside the local network will know where to find the Pi. But you still can't access your Raspberry Pi from outside the local Wi-Fi network. You need your Raspberry Pi to be accessible publicly from anywhere on the Internet. This requires a static external IP address [7].
|
||||
|
||||
It can be a sensitive process initially. Call your ISP and request a static external (sometimes referred to as static global) IP address. The ISP holds the decision-making power, so I would be extremely careful dealing with them. They may refuse your static external IP address request. If they do, you can't fault the ISP because there is a legal and operational risk with this type of request. They particularly do not want customers running medium- or large-scale Internet services. They might explicitly ask why you need a static external IP address. It is probably best to be honest and tell them you plan on hosting a low-traffic personal website or a similar small not-for-profit internet service. If all goes well, they should open a ticket and call you in a week or two with an address.
|
||||
|
||||
### Port forwarding
|
||||
|
||||
This newly obtained static global IP address your ISP assigned is for accessing the router. The Raspberry Pi is still unreachable. You need to set up port forwarding to access the Raspberry Pi specifically.
|
||||
|
||||
Ports are virtual pathways where information travels on the Internet. You sometimes need to forward a port in order to make a computer, like the Raspberry Pi, accessible to the Internet because it is behind a network router. A YouTube video titled [What is TCP/IP, port, routing, intranet, firewall, Internet][9] by VollmilchTV helped me visually understand ports.
|
||||
|
||||
Port forwarding can be used for projects like a Raspberry Pi web server, or applications like VoIP or peer-to-peer downloading. There are [65,000+ ports][10] to choose from, so you can assign a different port for every Internet application you build.
|
||||
|
||||
The way to set up port forwarding can depend on your router. If you have a Linksys, a YouTube video titled _[How to go online with your Apache Ubuntu server][2]_ by Gabriel Ramirez explains how to set it up. If you don't have a Linksys, read the documentation that comes with your router in order to customize and define ports to forward.
|
||||
|
||||
You will need to port forward for SSH as well as the remote desktop.
|
||||
|
||||
Once you believe you have port forwarding configured, check to see if it is working via SSH by typing:
|
||||
|
||||
```
|
||||
$ ssh pi@your_global_ip_address
|
||||
```
|
||||
|
||||
It should prompt you for the password.
|
||||
|
||||
Check to see if port forwarding is working for the remote desktop as well. Open Microsoft Remote Desktop. Your previous remote connection settings should be saved, but you need to update the "PC name" field with the static external IP address (for example, 195.198.227.116) instead of the static internal address (for example, 192.168.1.115).
|
||||
|
||||
Now, try connecting via remote desktop. It should briefly load and arrive at the Pi's desktop.
|
||||
|
||||

|
||||
|
||||
Good job. The Raspberry Pi is now accessible from the Internet and ready for advanced projects.
|
||||
|
||||
As a bonus option, you can maintain two remote connections to your Pi. One via the Internet and the other via the LAN (local area network). It's easy to set up. In Microsoft Remote Desktop, keep one remote connection called "Pi Internet" and another called "Pi Local." Configure Pi Internet's "PC name" to the static external IP address—for example, 195.198.227.116\. Configure Pi Local's "PC name" to the static internal IP address—for example, 192.168.1.115\. Now, you have the option to connect globally or locally.
|
||||
|
||||
If you have not seen it already, watch _[How to go online with your Apache Ubuntu server][3]_ by Gabriel Ramirez as a transition into Project 2\. It will show you the technical architecture behind your project. In our case, you are using a Raspberry Pi instead of an Ubuntu server. The dynamic DNS sits between the domain company and your router, which Ramirez omits. Beside this subtlety, the video is spot on when explaining visually how the system works. You might notice this tutorial covers the Raspberry Pi setup and port forwarding, which is the server-side or back end. See the original source for more advanced projects covering the domain name, dynamic DNS, Jekyll (static HTML generator), and Apache (web hosting), which is the client-side or front end.
|
||||
|
||||
### Footnotes
|
||||
|
||||
[1] I do not recommend starting with the NOOBS operating system. I prefer starting with the fully functional Raspbian Jessie operating system.
|
||||
|
||||
[2] If "Setup Options" does not pop up, you can always find it by opening Terminal and executing this command:
|
||||
|
||||
```
|
||||
$ sudo-rasps-config
|
||||
```
|
||||
|
||||
[3] We do this to make use of all the space present on the SD card as a full partition. All this does is expand the operating system to fit the entire space on the SD card, which can then be used as storage memory for the Raspberry Pi.
|
||||
|
||||
[4] We do this because we want to boot into a familiar desktop environment. If we do not do this step, the Raspberry Pi boots into a terminal each time with no GUI.
|
||||
|
||||
[5]
|
||||
|
||||

|
||||
|
||||
[Download and run PuTTY][11] or another SSH client for Windows. Enter your IP address in the field, as shown in the above screenshot. Keep the default port at 22\. Hit Enter, and PuTTY will open a terminal window, which will prompt you for your username and password. Fill those in, and begin working remotely on your Pi.
|
||||
|
||||
[6] If it is not already installed, download [Microsoft Remote Desktop][12]. Search your computer for Microsoft Remote Desktop. Run it. Input the IP address when prompted. Next, an xrdp window will pop up, prompting you for your username and password.
|
||||
|
||||
[7] The router has a dynamically assigned external IP address, so in theory, it can be reached from the Internet momentarily, but you'll need the help of your ISP to make it permanently accessible. If this was not the case, you would need to reconfigure the remote connection on each use.
|
||||
|
||||
_For the original source, visit [Mitchell McLaughlin's Full-Stack Computer Projects][4]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Mitchell McLaughlin - I'm an open-web contributor and developer. My areas of interest are broad, but specifically I enjoy open source software/hardware, bitcoin, and programming in general. I reside in San Francisco. My work experience in the past has included brief stints at GoPro and Oracle.
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/3/building-personal-web-server-raspberry-pi-3
|
||||
|
||||
作者:[Mitchell McLaughlin ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mitchm
|
||||
[1]:http://elinux.org/RPi_SD_cards
|
||||
[2]:https://www.youtube.com/watch?v=i1vB7JnPvuE#t=07m08s
|
||||
[3]:https://www.youtube.com/watch?v=i1vB7JnPvuE#t=07m08s
|
||||
[4]:https://mitchellmclaughlin.com/server.html
|
||||
[5]:https://opensource.com/article/17/3/building-personal-web-server-raspberry-pi-3?rate=Zdmkgx8mzy9tFYdVcQZSWDMSy4uDugnbCKG4mFsVyaI
|
||||
[6]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[7]:http://ivanx.com/raspberrypi/
|
||||
[8]:http://ivanx.com/raspberrypi/files/PiFiller.zip
|
||||
[9]:https://www.youtube.com/watch?v=iskxw6T1Wb8
|
||||
[10]:https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers
|
||||
[11]:http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
|
||||
[12]:https://www.microsoft.com/en-us/store/apps/microsoft-remote-desktop/9wzdncrfj3ps
|
||||
[13]:https://opensource.com/user/41906/feed
|
||||
[14]:https://opensource.com/article/17/3/building-personal-web-server-raspberry-pi-3#comments
|
||||
[15]:https://opensource.com/users/mitchm
|
||||
@ -1,5 +1,3 @@
|
||||
申请翻译
|
||||
|
||||
Many SQL Performance Problems Stem from “Unnecessary, Mandatory Work”
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,174 +0,0 @@
|
||||
Make Container Management Easy With Cockpit
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
If you’re looking for an easy way to manage a Linux server that includes containers, you should check out Cockpit.[Creative Commons Zero][6]
|
||||
|
||||
If you administer a Linux server, you’ve probably been in search of a solid administration tool. That quest has probably taken you to such software as [Webmin][14] and [cPanel][15]. But if you’re looking for an easy way to manage a Linux server that also includes Docker, one tool stands above the rest for that particular purpose: [Cockpit][16].
|
||||
|
||||
Why Cockpit? Because it includes the ability to handle administrative tasks such as:
|
||||
|
||||
* Connect and Manage multiple machines
|
||||
|
||||
* Manage containers via Docker
|
||||
|
||||
* Interact with a Kubernetes or Openshift clusters
|
||||
|
||||
* Modify network settings
|
||||
|
||||
* Manage user accounts
|
||||
|
||||
* Access a web-based shell
|
||||
|
||||
* View system performance information by way of helpful graphs
|
||||
|
||||
* View system services and log files
|
||||
|
||||
Cockpit can be installed on [Debian][17], [Red Hat][18], [CentOS][19], [Arch Linux][20], and [Ubuntu][21]. Here, I will focus on installing the system on a Ubuntu 16.04 server that already includes Docker.
|
||||
|
||||
Out of the list of features, the one that stands out is the container management. Why? Because it make installing and managing containers incredibly simple. In fact, you might be hard-pressed to find a better container management solution.
|
||||
With that said, let’s install this solution and see just how easy it is to use.
|
||||
|
||||
### Installation
|
||||
|
||||
As I mentioned earlier, I will be installing Cockpit on an instance of Ubuntu 16.04, with Docker already running. The steps for installation are quite simple. The first thing you must do is log into your Ubuntu server. Next you must add the necessary repository with the command:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:cockpit-project/cockpit
|
||||
```
|
||||
|
||||
When prompted, hit the Enter key on your keyboard and wait for the prompt to return. Once you are back at your bash prompt, update apt with the command:
|
||||
|
||||
```
|
||||
sudo apt-get get update
|
||||
```
|
||||
|
||||
Install Cockpit by issuing the command:
|
||||
|
||||
```
|
||||
sudo apt-get -y install cockpit cockpit-docker
|
||||
```
|
||||
|
||||
After the installation completes, it is necessary to start the Cockpit service and then enable it so it auto-starts at boot. To do this, issue the following two commands:
|
||||
|
||||
```
|
||||
sudo systemctl start cockpit
|
||||
sudo systemctl enable cockpit
|
||||
```
|
||||
|
||||
That’s all there is to the installation.
|
||||
|
||||
### Logging into Cockpit
|
||||
|
||||
To gain access to the Cockpit web interface, point a browser (that happens to be on the same network as the Cockpit server) to http://IP_OF_SERVER:9090, and you will be presented with a login screen (Figure 1).
|
||||
|
||||

|
||||
|
||||
Figure 1: The Cockpit login screen.[Used with permission][1]
|
||||
|
||||
A word of warning with using Cockpit and Ubuntu. Many of the tasks that can be undertaken with Cockpit require administrative access. If you log in with a standard user, you won’t be able to work with some of the tools like Docker. To get around that, you can enable the root user on Ubuntu. This isn’t always a good idea. By enabling the root account, you are bypassing the security system that has been in place for years. However, for the purpose of this article, I will enable the root user with the following two commands:
|
||||
|
||||
```
|
||||
sudo passwd root
|
||||
|
||||
sudo passwd -u root
|
||||
```
|
||||
|
||||
NOTE: Make sure you give the root account a very challenging password.
|
||||
|
||||
Should you want to revert this change, you only need issue the command:
|
||||
|
||||
```
|
||||
sudo passwd -l root
|
||||
```
|
||||
|
||||
With other distributions, such as CentOS and Red Hat, you will be able to log into Cockpit with the username _root_ and the root password, without having to go through the extra hopes as described above.
|
||||
If you’re hesitant to enable the root user, you can always pull down the images, from the server terminal (using the command _docker pull IMAGE_NAME w_ here _IMAGE_NAME_ is the image you want to pull). That would add the image to your docker server, which can then be managed via a regular user. The only caveat to this is that the regular user must be added to the Docker group with the command:
|
||||
|
||||
```
|
||||
sudo usermod -aG docker USER
|
||||
```
|
||||
|
||||
Where USER is the actual username to be added to the group. Once you’ve done that, log out, log back in, and then restart Docker with the command:
|
||||
|
||||
```
|
||||
sudo service docker restart
|
||||
```
|
||||
|
||||
Now the regular user can start and stop the added Docker images/containers without having to enable the root user. The only caveat is that user will not be able to add new images via the Cockpit interface.
|
||||
|
||||
Using Cockpit
|
||||
|
||||
Once you’ve logged in, you will be treated to the Cockpit main window (Figure 2).
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 2: The Cockpit main window.[Used with permission][2]
|
||||
|
||||
You can go through each of the sections to check on the status of the server, work with users, etc., but we want to go right to the containers. Click on the Containers section to display the current running contains as well as the available images (Figure 3).
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 3: Managing containers is incredibly simple with Cockpit.[Used with permission][3]
|
||||
|
||||
To start an image, simply locate the image and click the associated start button. From the resulting popup window (Figure 4), you can check all the information about the image (and adjust as needed), before clicking the Run button.
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 4: Running a Docker image with the help of Cockpit.[Used with permission][4]
|
||||
|
||||
Once the image is running, you can check its status by clicking on the entry under the Containers section and then Stop, Restart, or Delete the instance. You can also click Change resource limits and then adjust either the Memory limit and/or CPU priority.
|
||||
|
||||
### Adding new images
|
||||
|
||||
Say you have logged on as the root user. If so, you can add new images with the help of the Cockpit GUI. From the Containers section, click the Get new image button and then, in the resulting window, search for the image you want to add. Say you want to add the latest official build of Centos. Type centos in the search field and then, once the search results populate, select the official listing and click Download (Figure 5).
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 5: Adding the latest build of the official Centos images to Docker, via Cockpit.[Used with permission][5]
|
||||
|
||||
Once the image has downloaded, it will be available to Docker and can be run via Cockpit.
|
||||
|
||||
### As simple as it gets
|
||||
|
||||
Managing Docker doesn’t get any easier. Yes, there is a caveat when working with Cockpit on Ubuntu, but if it’s your only option, there are ways to make it work. With the help of Cockpit, you can not only easily manage Docker images, you can do so from any web browser that has access to your Linux server. Enjoy your newfound Docker ease.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][13]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/3/make-container-management-easy-cockpit
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[7]:https://www.linux.com/files/images/cockpitajpg
|
||||
[8]:https://www.linux.com/files/images/cockpitbjpg
|
||||
[9]:https://www.linux.com/files/images/cockpitcjpg
|
||||
[10]:https://www.linux.com/files/images/cockpitdjpg
|
||||
[11]:https://www.linux.com/files/images/cockpitfjpg
|
||||
[12]:https://www.linux.com/files/images/cockpit-containersjpg
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[14]:http://www.webmin.com/
|
||||
[15]:http://cpanel.com/
|
||||
[16]:http://cockpit-project.org/
|
||||
[17]:https://www.debian.org/
|
||||
[18]:https://www.redhat.com/en
|
||||
[19]:https://www.centos.org/
|
||||
[20]:https://www.archlinux.org/
|
||||
[21]:https://www.ubuntu.com/
|
||||
@ -1,205 +0,0 @@
|
||||
How to Install a DHCP Server in CentOS, RHEL and Fedora
|
||||
============================================================
|
||||
|
||||
|
||||
DHCP (Dynamic Host Configuration Protocol) is a network protocol that enables a server to automatically assign an IP address and provide other related network configuration parameters to a client on a network, from a pre-defined IP pool.
|
||||
|
||||
This means that each time a client (connected to the network) boots up, it gets a “dynamic” IP address, as opposed to “static” IP address that never changes. The IP address assigned by a DHCP server to DHCP client is on a “lease”, the lease time can vary depending on how long a client is likely to require the connection or DHCP configuration.
|
||||
|
||||
In this tutorial, we will cover how to install and configure a DHCP server in CentOS/RHEL and Fedora distributions.
|
||||
|
||||
#### Testing Environment Setup
|
||||
|
||||
We are going to use following testing environment for this setup.
|
||||
|
||||
```
|
||||
DHCP Server - CentOS 7
|
||||
DHCP Clients - Fedora 25 and Ubuntu 16.04
|
||||
```
|
||||
|
||||
#### How Does DHCP Work?
|
||||
|
||||
Before we move any further, let’s briefly explain how DHCP works:
|
||||
|
||||
* When a client computer (configured to use DHCP) and connected to a network is powered on, it forwards a DHCPDISCOVER message to the DHCP server.
|
||||
* And after the DHCP server receives the DHCPDISCOVER request message, it replies with a DHCPOFFER message.
|
||||
* Then the client receives the DHCPOFFER message, and it sends a DHCPREQUEST message to the server indicating, it is prepared to get the network configuration offered in the DHCPOFFERmessage.
|
||||
* Last but not least, the DHCP server receives the DHCPREQUEST message from the client, and sends the DHCPACK message showing that the client is now permitted to use the IP address assigned to it.
|
||||
|
||||
### Step 1: Installing DHCP Server in CentOS
|
||||
|
||||
1. Installing DCHP is quite straight forward, simply run the command below.
|
||||
|
||||
```
|
||||
# yum -y install dhcp
|
||||
```
|
||||
|
||||
Important: Assuming there is more than one network interface attached to the system, but you want the DHCP server to only be started on one of the interfaces, set the DHCP server to start only on that interface as follows.
|
||||
|
||||
2. Open the file /etc/sysconfig/dhcpd, add the name of the specific interface to the list of DHCPDARGS, for example if the interface is `eth0`, then add:
|
||||
|
||||
```
|
||||
DHCPDARGS=eth0
|
||||
```
|
||||
|
||||
Save the file and exit.
|
||||
|
||||
### Step 2: Configuring DHCP Server in CentOS
|
||||
|
||||
3. For starters, to setup a DHCP server, the first step is to create the `dhcpd.conf` configuration file, and the main DHCP configuration file is normally /etc/dhcp/dhcpd.conf (which is empty by default), it keeps all network information sent to clients.
|
||||
|
||||
However, there is a sample configuration file /usr/share/doc/dhcp*/dhcpd.conf.sample, which is a good starting point for configuring a DHCP server.
|
||||
|
||||
And, there are two types of statements defined in the DHCP configuration file, these are:
|
||||
|
||||
* parameters – state how to carry out a task, whether to perform a task, or what network configuration options to send to the DHCP client.
|
||||
* declarations – specify the network topology, define the clients, offer addresses for the clients, or apply a group of parameters to a group of declarations.
|
||||
|
||||
Therefore, start by copying the sample configuration file as the main configuration file like so:
|
||||
|
||||
```
|
||||
# cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
4. Now, open the main configuration file and define your DHCP server options:
|
||||
|
||||
```
|
||||
# vi /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
Start by setting the following global parameters which will apply to all the subnetworks (do specify values that apply to your scenario) at the top of the file:
|
||||
|
||||
```
|
||||
option domain-name "tecmint.lan";
|
||||
option domain-name-servers ns1.tecmint.lan, ns2.tecmint.lan;
|
||||
default-lease-time 3600;
|
||||
max-lease-time 7200;
|
||||
authoritative;
|
||||
```
|
||||
|
||||
5. Now, define a subnetwork; in this example, we will configure DHCP for 192.168.56.0/24 LAN network (remember to use parameters that apply to your scenario):
|
||||
|
||||
```
|
||||
subnet 192.168.56.0 netmask 255.255.255.0 {
|
||||
option routers 192.168.56.1;
|
||||
option subnet-mask 255.255.255.0;
|
||||
option domain-search "tecmint.lan";
|
||||
option domain-name-servers 192.168.56.1;
|
||||
range 192.168.56.10 192.168.56.100;
|
||||
range 192.168.56.120 192.168.56.200;
|
||||
}
|
||||
```
|
||||
|
||||
### Step 3: Assign Static IP to DHCP Client
|
||||
|
||||
You can assign a static IP address to a specific client computer on the network, simply define the section below in /etc/dhcp/dhcpd.conf file, where you must explicitly specify it’s MAC addresses and the fixed IP to be assigned:
|
||||
|
||||
```
|
||||
host ubuntu-node {
|
||||
hardware ethernet 00:f0:m4:6y:89:0g;
|
||||
fixed-address 192.168.56.105;
|
||||
}
|
||||
host fedora-node {
|
||||
hardware ethernet 00:4g:8h:13:8h:3a;
|
||||
fixed-address 192.168.56.110;
|
||||
}
|
||||
```
|
||||
|
||||
Save the file and close it.
|
||||
|
||||
Note: You can find out or display the Linux MAC address using following command.
|
||||
|
||||
```
|
||||
# ifconfig -a eth0 | grep HWaddr
|
||||
```
|
||||
|
||||
6. Now start the DHCP service for the mean time and enable it to start automatically from the next system boot, using following commands:
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
# systemctl start dhcpd
|
||||
# systemctl enable dhcpd
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
# service dhcpd start
|
||||
# chkconfig dhcpd on
|
||||
```
|
||||
|
||||
7. Next, do not forget to permit DHCP service (DHCPD daemon listens on port 67/UDP) as below:
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
# firewall-cmd --add-service=dhcp --permanent
|
||||
# firewall-cmd --reload
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
# iptables -A INPUT -p tcp -m state --state NEW --dport 67 -j ACCEPT
|
||||
# service iptables save
|
||||
```
|
||||
|
||||
### Step 4: Configuring DHCP Clients
|
||||
|
||||
8. Now, you can configure your clients on the network to automatically receive IP addresses from the DHCP server. Login to the client machine and modify the Ethernet interface configuration file as follows (take not of the interface name/number):
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
|
||||
```
|
||||
|
||||
Add the options below:
|
||||
|
||||
```
|
||||
DEVICE=eth0
|
||||
BOOTPROTO=dhcp
|
||||
TYPE=Ethernet
|
||||
ONBOOT=yes
|
||||
```
|
||||
|
||||
Save the file and exit.
|
||||
|
||||
9. You can also perform the settings using the GUI on a desktop computer, set the Method to Automatic (DHCP) as shown in the screenshot below (Ubuntu 16.04 desktop).
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
Set DHCP in Client Network
|
||||
|
||||
10. Then restart network services as follows (you can possibly reboot the system):
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
# systemctl restart network
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
# service network restart
|
||||
```
|
||||
|
||||
At this point, if all settings were correct, your clients should be receiving IP addresses automatically from the DHCP server.
|
||||
|
||||
You may also read:
|
||||
|
||||
1. [How to Install and Configure Multihomed ISC DHCP Server on Debian Linux][1]
|
||||
2. [10 Useful “IP” Commands to Configure Network Interfaces][2]
|
||||
|
||||
In this tutorial, we showed you how to setup a DHCP server in RHEL/CentOS. Use the comment form below to write back top us. In an upcoming article, we will show you how to setup a DHCP server in Debian/Ubuntu. Until then, always stay connected to TecMint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-dhcp-server-in-centos-rhel-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/install-and-configure-multihomed-isc-dhcp-server-on-debian-linux/
|
||||
[2]:http://www.tecmint.com/ip-command-examples/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-DHCP-in-Client-Network.png
|
||||
[4]:http://www.tecmint.com/author/aaronkili/
|
||||
[5]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[6]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,105 +0,0 @@
|
||||
How to List Files Installed From a RPM or DEB Package in Linux
|
||||
============================================================
|
||||
|
||||
Have you ever wondered where the various files contained inside a package are installed (located) in the Linux file system? In this article, we’ll show how to list all files installed from or present in a certain package or group of packages in Linux.
|
||||
|
||||
This can help you to easily locate important package files like configurations files, documentation and more. Let’s look at the different methods of listing files in or installed from a package:
|
||||
|
||||
### How to List All Files of Installed Package in Linux
|
||||
|
||||
You can use the [repoquery command][6] which is part of the [yum-utils to list files installed][7] on a CentOS/RHEL system from a given package.
|
||||
|
||||
To install and use yum-utils, run the commands below:
|
||||
|
||||
```
|
||||
# yum update
|
||||
# yum install yum-utils
|
||||
```
|
||||
|
||||
Now you can list files of an installed RPM package, for example httpd web server (note that the package name is case-sensitive). The `--installed` flag means installed packages and `-l` flags enables listing of files:
|
||||
|
||||
```
|
||||
# repoquery --installed -l httpd
|
||||
# dnf repoquery --installed -l httpd [On Fedora 22+ versions]
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Repoquery List Installed Files of Httpd
|
||||
|
||||
Important: In Fedora 22+ version, the repoquery command is integrated with [dnf package manager][9] for RPM based distribution to list files installed from a package as shown above.
|
||||
|
||||
Alternatively, you can as well use the [rpm command][10] below to list the files inside or installed on the system from a `.rpm` package as follows, where the `-g` and `-l` means to list files in package receptively:
|
||||
|
||||
```
|
||||
# rpm -ql httpd
|
||||
```
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
RPM Query Package for Installed Files
|
||||
|
||||
Another useful option is used to use `-p` to list `.rpm` package files before installing it.
|
||||
|
||||
```
|
||||
# rpm -qlp telnet-server-1.2-137.1.i586.rpm
|
||||
```
|
||||
|
||||
On Debian/Ubuntu distributions, you can use the [dpkg command][12] with the `-L` flag to list files installed to your Debian system or its derivatives, from a given `.deb` package.
|
||||
|
||||
In this example, we will list files installed from apache2 web server:
|
||||
|
||||
```
|
||||
$ dpkg -L apache2
|
||||
```
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
dpkg List Installed Packages
|
||||
|
||||
Don’t forget to check out following useful articles for package management in Linux.
|
||||
|
||||
1. [20 Useful ‘Yum’ Commands for Package Management][1]
|
||||
2. [20 Useful RPM Commands for Package Management][2]
|
||||
3. [15 Useful APT Commands for Package Management in Ubuntu][3]
|
||||
4. [15 Useful Dpkg Commands for Ubuntu Linux][4]
|
||||
5. [5 Best Linux Package Managers for Linux Newbies][5]
|
||||
|
||||
That’s all! In this article, we showed you how to list/locate all files installed from a given package or group of packages in Linux. Share your thoughts with us using the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/list-files-installed-from-rpm-deb-package-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[3]:http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[4]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[5]:http://www.tecmint.com/linux-package-managers/
|
||||
[6]:http://www.tecmint.com/list-installed-packages-in-rhel-centos-fedora/
|
||||
[7]:http://www.tecmint.com/linux-yum-package-management-with-yum-utils/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Repoquery-List-Installed-Files-of-Httpd.png
|
||||
[9]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[10]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/rpm-ql-httpd.png
|
||||
[12]:http://www.tecmint.com/dpkg-command-examples/
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/dpkg-List-Installed-Packages.png
|
||||
[14]:http://www.tecmint.com/author/aaronkili/
|
||||
[15]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[16]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,3 +1,4 @@
|
||||
trnhoe translating~
|
||||
Introduction to functional programming
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,199 +0,0 @@
|
||||
Remmina – A Feature Rich Remote Desktop Sharing Tool for Linux
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
Remmina is a is free and open-source, feature-rich and powerful remote desktop client for Linux and other Unix-like systems, written in GTK+3\. It’s intended for system administrators and travelers, who need to remotely access and work with many computers.
|
||||
|
||||
It supports several network protocols in a simple, unified, homogeneous and easy-to-use user interface.
|
||||
|
||||
#### Remmina Features
|
||||
|
||||
* Supports RDP, VNC, NX, XDMCP and SSH.
|
||||
* Enables users to maintain a list of connection profiles, organized by groups.
|
||||
* Supports quick connections by users directly putting in the server address.
|
||||
* Remote desktops with higher resolutions are scrollable/scalable in both window and fullscreen mode.
|
||||
* Supports viewport fullscreen mode; here the remote desktop automatically scrolls when the mouse moves over the screen edge.
|
||||
* Also supports floating toolbar in fullscreen mode; enables you to switch between modes, toggle keyboard grabbing, minimize and beyond.
|
||||
* Offers tabbed interface, optionally managed by groups.
|
||||
* Also offers tray icon, allows you to quickly access configured connection profiles.
|
||||
|
||||
In this article, we will show you how to install and use Remmina with a few supported protocols in Linux for desktop sharing.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
* Allow desktop sharing in remote machines (enable remote machines to permit remote connections).
|
||||
* Setup SSH services on the remote machines.
|
||||
|
||||
### How to Install Remmina Desktop Sharing Tool in Linux
|
||||
|
||||
Remmina and its plugin packages are already provided in the official repositories of the all if not most of the mainstream Linux distributions. Run the commands below to install it with all supported plugins:
|
||||
|
||||
```
|
||||
------------ On Debian/Ubuntu ------------
|
||||
$ sudo apt-get install remmina remmina-plugin-*
|
||||
```
|
||||
|
||||
```
|
||||
------------ On CentOS/RHEL ------------
|
||||
# yum install remmina remmina-plugin-*
|
||||
```
|
||||
|
||||
```
|
||||
------------ On Fedora 22+ ------------
|
||||
$ sudo dnf copr enable hubbitus/remmina-next
|
||||
$ sudo dnf upgrade --refresh 'remmina*' 'freerdp*'
|
||||
```
|
||||
|
||||
Once you have installed it, search for remmina in the Ubuntu Dash or Linux Mint Menu, then launch it:
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
Remmina Desktop Sharing Client
|
||||
|
||||
You can perform any configurations via the graphical interface or by editing the files under `$HOME/.remmina` or `$HOME/.config/remmina`.
|
||||
|
||||
To setup a new connection to a remote server press `[Ctrl+N]` or go to Connection -> New, configure the remote connection profile as shown in the screenshot below. This is the basic settings interface.
|
||||
|
||||
[
|
||||
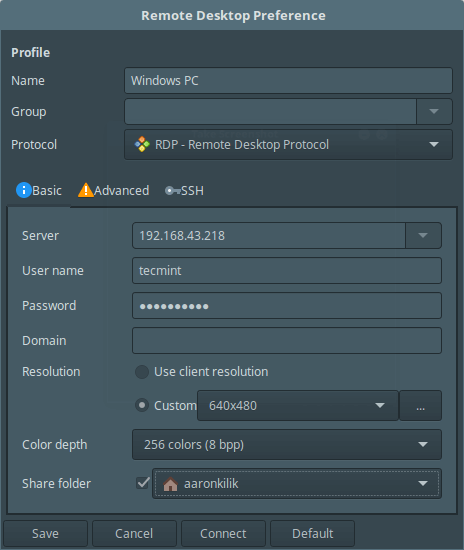
|
||||
][2]
|
||||
|
||||
Remmina Basic Desktop Preferences
|
||||
|
||||
Click on Advanced from the interface above to configure advanced connection settings.
|
||||
|
||||
[
|
||||
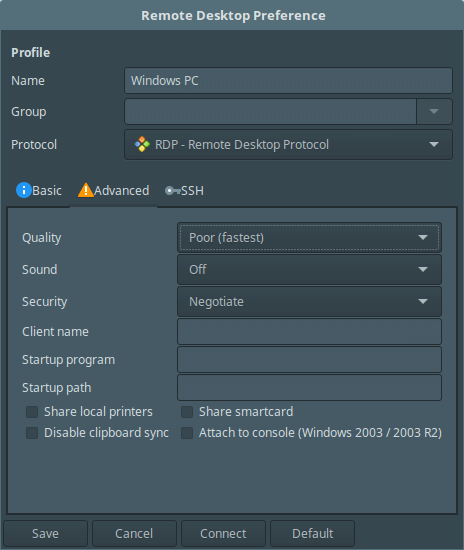
|
||||
][3]
|
||||
|
||||
Remmina Advance Desktop Settings
|
||||
|
||||
To configure SSH settings, click on the SSH from the profile interface above.
|
||||
|
||||
[
|
||||
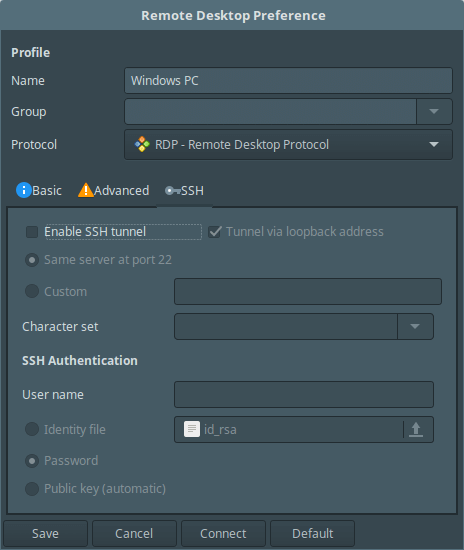
|
||||
][4]
|
||||
|
||||
Remmina SSH Settings
|
||||
|
||||
Once you have configured all the necessary settings, save the settings by clicking on Save button and from the main interface, you’ll be able to view all your configured remote connection profiles as shown below.
|
||||
|
||||
[
|
||||
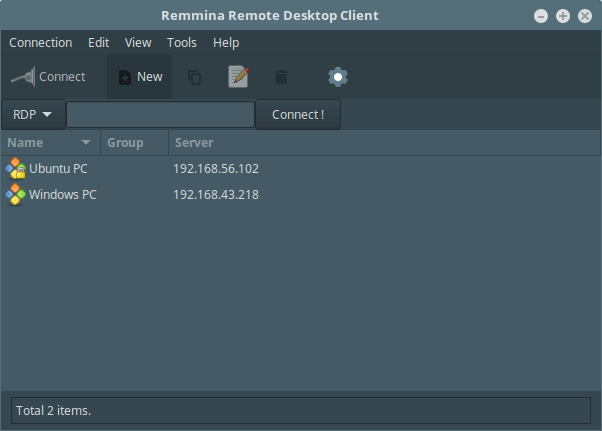
|
||||
][5]
|
||||
|
||||
Remmina Configured Servers
|
||||
|
||||
#### Connecting to Remote Machine Using sFTP
|
||||
|
||||
Choose the connection profile and edit the settings, choose SFTP – Secure File Transfer from the Protocols down menu. Then set a startup path (optional) and specify the SSH authentication details. Lastly, click Connect.
|
||||
|
||||
[
|
||||
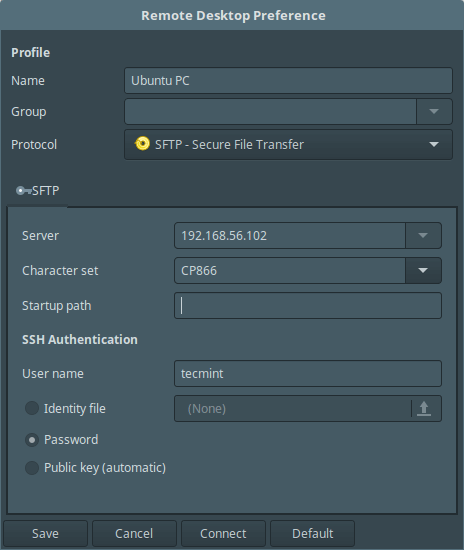
|
||||
][6]
|
||||
|
||||
Remmina sftp Connection
|
||||
|
||||
Enter your SSH user password here.
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
Enter SSH Password
|
||||
|
||||
If you see the interface below, then the SFTP connection is successful, you can now [transfer files between your machines][8].
|
||||
|
||||
[
|
||||
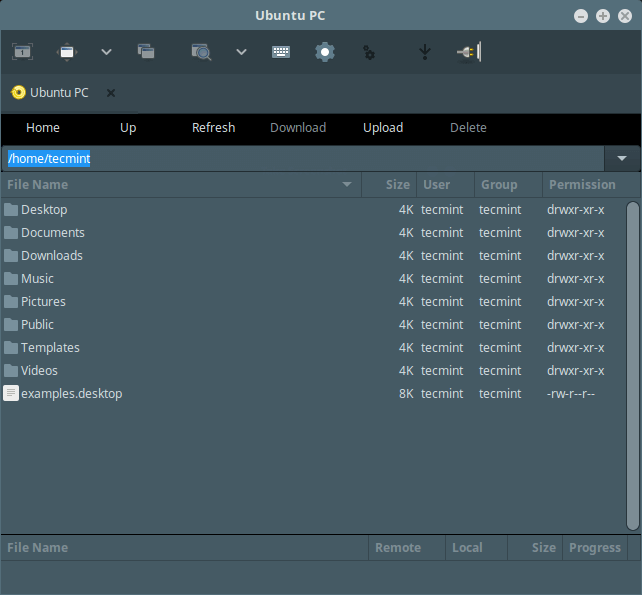
|
||||
][9]
|
||||
|
||||
Remmina Remote sFTP Filesystem
|
||||
|
||||
#### Connect to Remote Machine Using SSH
|
||||
|
||||
Select the connection profile and edit the settings, then choose SSH – Secure Shell from the Protocolsdown menu and optionally set a startup program and SSH authentication details. Lastly, click Connect, and enter the user SSH password.
|
||||
|
||||
[
|
||||
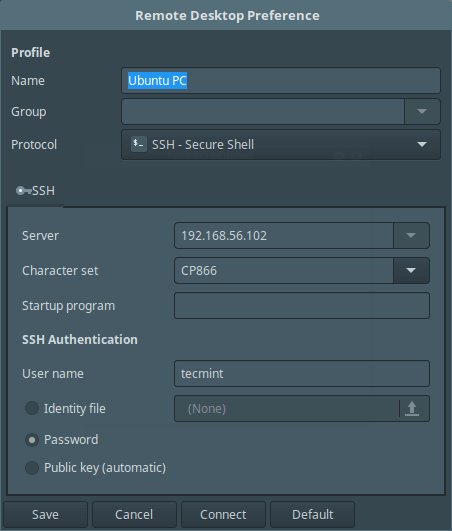
|
||||
][10]
|
||||
|
||||
Remmina SSH Connection
|
||||
|
||||
When you see the interface below, it means your connection is successful, you can now control the remote machine using SSH.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
Remmina Remote SSH Connection
|
||||
|
||||
#### Connect to Remote Machine Using VNC
|
||||
|
||||
Choose the connection profile from the list and edit the settings, then select VNC – Virtual Network Computing from the Protocols down menu. Configure basic, advanced and ssh settings for the connection and click Connect, then enter the user SSH password.
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Remmina VNC Connection
|
||||
|
||||
Once you see the following interface, it implies that you have successfully connected to the remote machine using VNC protocol.
|
||||
|
||||
Enter the user login password from the desktop login interface as shown in the screenshot below.
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
Remmina Remote Desktop Login
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
Remmina Remote Desktop Sharing
|
||||
|
||||
Simply follow the steps above to use the other remaining protocols to access remote machines, it’s that simple.
|
||||
|
||||
Remmina Homepage: [https://www.remmina.org/wp/][15]
|
||||
|
||||
That’s all! In this article, we showed you how to install and use Remmina remote connection client with a few supported protocols in Linux. You can share any thoughts in the comments via the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Desktop-Sharing-Client.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Basic-Desktop-Preferences.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Advance-Desktop-Settings.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/ssh-remote-desktop-preferences.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Configured-Servers.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-sftp-connection.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/enter-userpasswd.png
|
||||
[8]:http://www.tecmint.com/sftp-upload-download-directory-in-linux/
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-sFTP-Filesystem.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-SSH-Connection.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-SSH-Connection.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-VNC-Connection.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-Desktop-Login.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-Desktop-Sharing.png
|
||||
[15]:https://www.remmina.org/wp/
|
||||
[16]:http://www.tecmint.com/author/aaronkili/
|
||||
[17]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[18]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,139 @@
|
||||
XYenChi is translating
|
||||
# 微软 Office 在线版变得更好 - linux上亦然
|
||||
|
||||
对于 linux 用户,影响 linux 使用体验的主要因素之一便是缺少微软 office 套装。如果你非得靠office 谋生,而它被绝大多数人使用,你可能不能承受使用开源产品的代价。理解矛盾之所在了吗?
|
||||
|
||||
的确, LibreOffice 是一个 [很棒的][1] 免费程序,但如果你的客户, 顾客或老板需要 Word 和 Excel 文件呢? 你确定能 [承担任何失误][2] 在转换这些文件从ODT或别的格式到DOCX之类时的错误或小问题 , 反之亦然。这是一系列难办的问题。 不幸的是,在技术在层面上对大多数人linux超出了能力范围。当然,不是绝对 。
|
||||
|
||||

|
||||
|
||||
### 加入微软 Office 在线, 加入 Linux
|
||||
|
||||
众所周知,微软拥有自己的云 office 服务多年。通过当今任何浏览器都可以使用使得它很棒且具有意义,这意味着 linux 也能使用!我前阵子刚测试了这个[方法][3]并且它表现出色。我能够轻松使用这个产品,以原本的格式保存文件或是转换我 ODF 格式的文件,这真的很棒。
|
||||
|
||||
我决定再次使用这个套装看看它在过去几年的进步以及是否依旧对 Linux 友好。我使用 [Fedora 25][4](一种操作系统)作为例子。我同时做这些去测试 [SoftMaker Office 2016][5]. 听起来有趣,也确实如此
|
||||
|
||||
### 第一印象
|
||||
|
||||
我得说我很高兴。office 不需要任何特别的插件。没有Silverlight 或 Flash 之类的东西。 单纯而大量的 HTML 和 Javascript 。 同时,交互界面反映及其迅速。唯一我不喜欢的就是 Word 文档的灰色背景,它让人很快感到疲劳。除了这个,整个套装工作流畅,没有延迟、奇怪之处及意料之外的错误。接下来让我们放慢脚步。
|
||||
|
||||
这个套装倒是需要你登录在线账户或者手机号——不必是 Live 或 Hotmail 邮箱。任何邮箱都可以。如果你有微软 [手机][6], 那么你可以用相同的账户并且可以同步你的数据。账户也会免费分配 5GB OneDrive 的储存空间。这很有条理,不是优秀或令人超级兴奋而是非常得当
|
||||
|
||||

|
||||
|
||||
你可以使用各种各样的程序, 包括必需的三件套 - Word, Excel 和 Powerpoint, bu并且其他的东西也供使用, 包括一些新奇事物.文档自动保存, 但你也可以下载备份和转换成其他格式,像PDF和ODF。
|
||||
|
||||
对我来说这简直完美。分享一个自己的小故事。我用 LibreOffice 写一本 [新奇的][7]书,之后当我需要将它们送去出版社编辑或者校对,我需要把它们转换成 DOCX 格式。唉,这需要微软 office。从我的 [Linux 问题解决大全][8]得知,我得一开始就使用Word,因为有一堆工作要与授权使用专有解决方案的编辑合作完成。没有任何情面可讲,只有出于对冷酷的金钱和商业的考量。错误是不容许接受的。
|
||||
|
||||

|
||||
|
||||
使用 office 在线版在特殊场合能给很多人自由空间。 偶尔使用Word、Excel等,不需要购买整个完整的套装。如果你是 LibreOffice 的忠实粉丝,也可以暗地里将微软 Office 当作消遣而不必感到愧疚。有人传给你一个 Word 或 PPT 文件,你可以上传然后在线操作它们,然后转换成所需要的。这样的话你就可以在线生成你的工作,发送给要求严格的人,同时自己留一个 ODF 格式的备份,有需要的话就用 LibreOffice 操作。虽然这种方法的灵活性很是实用,但这不应该成为你的主要手段。对于 Linux 用户,这给予了很多他们平时所没有的自由,毕竟即使你想用微软 Office 也不好安装。
|
||||
|
||||

|
||||
|
||||
### 特性, 选项, 工具
|
||||
|
||||
我开始琢磨一个文档——考虑到这其中各种细枝末节。用一种或三种风格写作,链接文本,嵌入图片,加上脚注,评论自己的文章甚至作为一个多重人格的极客巧妙地回复自己的评论。
|
||||
|
||||
除了灰色背景——我们得学会很好地完成一项无趣工作,即便是像臭鼬工厂那样的工作方式,因为浏览器里没有选项调整背景颜色——其实也还好。
|
||||
|
||||
Skype 也整合到了其中,你可以沟通合作。色相,非常整洁。鼠标右键可以选择一些快捷操作,包括链接、评论和翻译。改进的地方还有不少,它没有给我想要的,翻译有差错。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
你也可以加入图片——包括默认嵌入必应搜索筛选图片基于他们的监听和再分配权。这很棒,特别是当你想要创作而又想避免版权纷争时。
|
||||
|
||||

|
||||
|
||||
### 更多评论、追踪
|
||||
|
||||
说老实话,很实用,在线使用使得更改和编辑被默认追踪,所以你就有基本的版本控制功能。不过如果直接关闭不保存的话,阶段性的编辑会遗失。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
看到一个错误——如果你试着在 Linux 上编辑 Word 或 Excel 文件,会被提示你很调皮,因为这明显是个不支持的操作。
|
||||
|
||||

|
||||
|
||||
### Excel and friends
|
||||
|
||||
实际工作流程不止使用 Word。我也使用 Excel,众所周知,它包含了很多整齐有效的模板之类的。好用而且在更新单元格和公式时没有任何延迟,涵盖了你所需要的大多数功能。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### OneDrive
|
||||
|
||||
在这里你可以新建文件夹和文件、移动文件、给你的朋友(如果你有的话)和同事们分享文件。5 GB 免费,当然,收费增容。总的来说,做的不错。在更新和展示内容上会花费一定时间。打开了的文档不能被删除,这可能看起来像一个漏洞,但从计算机角度来看是完美的体验。
|
||||
|
||||

|
||||
|
||||
### 帮助
|
||||
|
||||
如果你感到疑惑——比如被人工智能戏耍,可以向 Redmond Borg ship 的云智囊团寻求帮助。 虽然这种方式不那么直接,但至少好用,结果往往也能令人满意T。
|
||||
|
||||

|
||||
|
||||
### 问题
|
||||
|
||||
在我三个小时的摸索中,我只遇到了两个小问题。一是文件编辑的时候浏览器会有警告(黄色三角),提醒我不安全的因素加载了建议使用 HTTPS 会话。二是创建 Excel 文件失败,只出现过一次。
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
微软 Office 在线版是一个优秀的产品,与我两年前测试相比较,它变得更好了。外观出色,表现良好,使用期间错误很少,完美兼容,甚至对于 Linux 用户,使之具有个人意义和商业价值。我不能说它是自 VHS (Video Home System,家用录像系统)最好的,但一定是很棒的,它架起了 Linux 用户与微软 Office 之间的桥梁,解决了 Linux 用户长期以来的问题,方便且很好的支持 ODF 。
|
||||
|
||||
现在我们来让事情变得更有趣些,如果你喜欢云概念的事物,那你可能对[Open365][9]感兴趣, 一个基于 LibreOfiice 的办公软件, 加上额外的邮件客户端和图像处理软件,还有 20 GB 的免费存储空间。最重要的是,你可以用浏览器同时完成这一切,只需要多开几个窗口。
|
||||
回到微软,如果你是 Linux 用户,如今可能确实需要微软 Office 产品。在线 Office 套装无疑是更方便的使用方法——或者至少不需要更改操作系统。它免费、优雅、透明度高。值得一提的是,你可以把思维游戏放在一边,享受你的云端生活。
|
||||
|
||||
干杯
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我的名字是 Igor Ljubuncic. 38 岁左右, 已婚已育.现在是一家云技术公司的首席工程师,一个新的领域。直到 2015 年初,我作为团队中的一名操作系统工程师就职于世界上最大的信息技术公司之一 。开发新的 Linux 解决方案、完善内核、入侵 linux 进程。在这之前,我是创新设计团队的技术指导,致力于高性能计算环境的创新解决方案。还有一些像系统专家、系统程序员之类的新奇的名字。这些全是我的爱好,直到2008年,变成了工作,还有什么能比这更令人满意呢?
|
||||
从 2004 到 2008,我作为物理学家在医学影像行业谋生。我专攻解决问题和发展算法,后来大量使用 Matlab 处理信号和图像。另外我认证了很多工程计算方法,包括 MEDIC Six Sigma Green Belt, 实验设计 和数据化工程。
|
||||
|
||||
我也开始写作,包括 Linux 上新鲜的技术性的工作。彼此包括。
|
||||
|
||||
请看我完整的开源项目清单、出版物、专利,下拉。
|
||||
|
||||
完整的奖励和提名请看那边。
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/office-online-linux-better.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.ocsmag.com/2015/02/16/libreoffice-4-4-review-finally-it-rocks/
|
||||
[2]:http://www.ocsmag.com/2014/03/14/libreoffice-vs-microsoft-office-part-deux/
|
||||
[3]:http://www.dedoimedo.com/computers/office-online-linux.html
|
||||
[4]:http://www.dedoimedo.com/computers/fedora-25-gnome.html
|
||||
[5]:http://www.ocsmag.com/2017/01/18/softmaker-office-2016-your-alternative-to-libreoffice/
|
||||
[6]:http://www.dedoimedo.com/computers/microsoft-lumia-640.html
|
||||
[7]:http://www.thelostwordsbooks.com/
|
||||
[8]:http://www.dedoimedo.com/computers/linux-problem-solving-book.html
|
||||
[9]:http://www.ocsmag.com/2016/08/17/open365/
|
||||
@ -1,127 +0,0 @@
|
||||
如何挑选你的第一门编程语言
|
||||
============================================================
|
||||
[][1]
|
||||

|
||||
|
||||
|
||||
opensource.com 供图
|
||||
|
||||
人们有着各种各样的原因想学编程。你也许是想要做一个程序,又或者你只是想投入其中。所以,在选择你的第一门编程语言之前,问问你自己:你想要程序运行在哪里?你想要程序做什么?
|
||||
|
||||
你选择编程的原因将会决定第一门编程语言的选择。
|
||||
|
||||
_在这篇文章里,我会交替使用“编程”(code , program)、“开发”(develop) 等动词,“代码”(code)、“程序”(program)、“应用”(application/app)等名词。这考虑到你可能听过的语言用法_
|
||||
|
||||
### 了解你的设备
|
||||
|
||||
在你编程语言的选择上,你的程序将运行在何处是个决定性因素。
|
||||
|
||||
桌面应用是运行在台式机或者笔记本电脑上的传统软件程序。这样你编写的代码在同一时间内只能在一台电脑上运行。移动应用,也就是我们所熟知的“ APP ”,运行在使用 IOS 、Android 或者其他操作系统的移动设备上。网页应用是功能像应用的网页。
|
||||
|
||||
按互联网的 客户-服务器 架构分,网页开发者经常被分为两类:
|
||||
|
||||
* 前端开发,就是编写运行在浏览器自身的代码。这是个面对用户的部分,或者说是程序的前端。有时候被称为客户端编程,因为浏览器是互联网的客户-服务器架构的半壁江山。浏览器会运行在你本地的电脑或者设备上。
|
||||
|
||||
* 后台开发,也就是大家所熟知的服务器端开发,编写的代码运行在你无法实际接触的服务器上。
|
||||
|
||||
### 创造什么
|
||||
|
||||
编程是一门广泛的学科,能应用在不同的领域。常见的应用有:
|
||||
|
||||
* 数据科学
|
||||
* 网页开发
|
||||
* 游戏开发
|
||||
* 不同类型的工作自动化
|
||||
|
||||
现在我们已经讨论了为什么你要编程,你要为运行在哪里而编程,让我们看一下两门对于新手来说不错的编程语言吧。
|
||||
|
||||
### Python
|
||||
|
||||
[Python][2] 是对于第一次编程的人来说是最为流行的编程语言之一,而且这不是巧合。Python 是一门通用的编程语言。这意味着它能应用在广泛的编程任务上。你能用 Python 完成几乎_所有_事情。这一点使得很多新手能在实际中应用这门编程语言。另外, Python 有两个重要的设计特征,使得其对于新手更友好:清晰、类似于英语的[语法][3]和强调代码的[可读性][4]。
|
||||
|
||||
从本质上讲,一门编程语言的语法就是你所输入的能让这编程语言生效的内容。这包括单词,特殊字符(例如“ ; ”、“ $ ”、“ % ” 或者 “ {} ”),空格或者以上任意的组合。Python 尽可能地使用英语,不像其他编程语言那样经常使用标点符号或者特殊的字符。所以,Python 阅读起来更自然、更像是人类语言。这一点帮助新的编程人员聚焦于解决问题,而且他们能花费更少的时间挣扎在语言自身的特性上。
|
||||
|
||||
清晰语法的同时注重于可读性。在编写代码的时候,你将会创造代码的逻辑“块”,就是一些为了相关联目标而共同工作的代码。在许多编程语言里,这些块用特殊字符所标记(或限定)。他们或许被“ {} ”或者其他字符所包住。块分割字符和你写代码的能力,这两者的任意组合都能增加可读性。让我们来看一个例子。
|
||||
|
||||
这有个被称为 “ fun ”的简短函数。它要求输入一个数字,“ x ”就是它的输入。如果“ x ” 等于 ** 0 **,它将会运行另一个被称为“ no_fun ”的函数(这功能做了些很无趣的事情)。新函数不需要输入。反之,简短函数将会运行一个使用输入 “ x ” 的名为 “ big_fun ”的函数。
|
||||
|
||||
这个函数用[ C 语言 ][5]将会是这样写的:
|
||||
|
||||
```
|
||||
void fun(int x)
|
||||
{
|
||||
if (x == 0) {
|
||||
no_fun();
|
||||
} else {
|
||||
big_fun(x);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
或者,像是这样:
|
||||
|
||||
```
|
||||
void fun(int x) { if (x == 0) {no_fun(); } else {big_fun(x); }}
|
||||
```
|
||||
|
||||
功能上两者等价,而且都能运行。" {} " 和 “ ;” 告诉我们哪里是代码块的不同部分。然而,第一个对于人们来说_明显_更容易阅读。相比之下完成相同功能的 Python 是这样的:
|
||||
|
||||
```
|
||||
def fun(x):
|
||||
if x == 0:
|
||||
no_fun()
|
||||
else:
|
||||
big_fun(x)
|
||||
```
|
||||
|
||||
在这里,只有一个选择。如果代码不是这样排列的,它将无法工作。如果你编写了可以工作的代码,你就有了可阅读的代码。同样也留意一下两者在语法上的差异。不同的是“ def ” ,在 Python 代码中这个词是英语单词,大家都很熟悉这单词的含义(译者注:def 是 definition 的缩写,定义的意思)。在 C 语言的例子中 “ void ” 和 “ int ” 就没有那么直接。
|
||||
|
||||
Python 也有个优秀的生态系统。这有两层意思,第一,你有一个使用该语言的庞大、活跃的社区,当你需要帮助指导的时候,你能向他们求助。第二,它有大量早已存在的库,库是指完成特定功能的代码集合。从高级数学运算、图形到计算机视觉,甚至是你能想象到的任何事情。
|
||||
|
||||
Python 作为你第一门编程语言有两个缺点。第一是它有时候安装起来很复杂,特别是在运行着 Windows 的电脑上。(如果你有一台 Mac 或者 Linux 的电脑,Python 默认已经安装好了。)虽然这问题不是不能克服,而且情况总在改善,但是这对于一些人来说还是个阻碍。第二个缺点是,对于那些明确想要建设网站的人来讲,虽然有很多用 Python 写的项目(例如 [Django][6] 和[Flask][7] ),但是编写运行在浏览器上的 Python 代码却没有多少选择。它主要是后台或者服务器端语言。
|
||||
|
||||
### JavaScript
|
||||
|
||||
如果你知道你学习编程的主要原因是建设网站的话,[JavaScript][8]或许是你的最佳选择。 JavaScript 是关于网页的编程语言。除了是网页的默认编程语言之外, JavaScript 作为初学的语言有几点优点。
|
||||
|
||||
第一,无须安装任何东西。你可以打开文本编辑器(例如 Windows 上的记事本,但不是一个文字处理软件例如 Microsoft Word)然后开始输入 JavaScript 。代码将在你的浏览器中运行。最顶尖的浏览器内置了JavaScript 引擎,所以你的代码将会运行在几乎所有的电脑和很多的移动设备上。事实是,能马上在浏览器中运行代码提供了一个非常_快_的反馈,这对于新手来说是很好的。你能尝试一些事情然后很快地看到结果。
|
||||
|
||||
当 JavaScript 开始作为前端语言时,一个名为[Node.js][9] 的环境能让你编写运行在浏览器或者服务器上的代码。现在 JavaScript 能当作前端或者后台语言使用。这增加了它的使用人数。JavaScript 也有很多能提供除核心功能外的额外功能的包,这使得它能当作一门通用语言来使用。JavaScript 不只是网页开发语言,就像 Python 那样,它也有个充满生气的、活跃的生态系统。
|
||||
|
||||
尽管有这些优点,但是 JavaScript 对于新手来说并非十全十美。JavaScript 的语法并不像 Python 那样清晰,也不怎么像英语。更像是之前例子里提到的 C 语言。它并不是把可读性当作主要的设计特性。
|
||||
|
||||
### 做出选择
|
||||
|
||||
选 Python 或者 JavaScript 作为入门语言都很难出错。关键是你打算做什么。为什么你要学习编程?你的回答很大程度上影响你的决定。如果你是想为开源做贡献,你将会找到_大量_用这两门语言编写的项目。另外,许多原本不是用 JavaScript 写的项目仍能被用作前端部件。当你做决定时,别忘了你本地的社区。你有在使用其中一门语言的朋友或者同事吗?对于一个新手来说,有实时的帮助是非常重要的。
|
||||
|
||||
祝好运,开心编程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Kojo Idrissa - 我是一个新晋的软件开发者(1 年),从会计和大学教学转型而来。自从有开源软件以来,我就是它的一个粉丝。但是在我之前的事业中并不需要做很多的编程工作。技术上,我专注于 Python ,自动化测试和学习 Django 。我希望我能尽快地学更多的 JavaScript 。话题上,我专注于帮助刚开始学习编程或想参与为开源项目做贡献的人们。我也关注在技术领域的包容文化。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/choosing-your-first-programming-language
|
||||
|
||||
作者:[Kojo Idrissa][a]
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[bestony](https://github.com/bestony)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/transitionkojo
|
||||
[1]: https://opensource.com/article/17/1/choosing-your-first-programming-language?rate=fWoYXudAZ59IkAKZ8n5lQpsa4bErlSzDEo512Al6Onk
|
||||
[2]: https://www.python.org/about/
|
||||
[3]: https://en.wikipedia.org/wiki/Python_syntax_and_semantics
|
||||
[4]: https://en.wikipedia.org/wiki/Python_syntax_and_semantics#Indentation
|
||||
[5]: https://en.wikipedia.org/wiki/C_(programming_language
|
||||
[6]: https://www.djangoproject.com/
|
||||
[7]: http://flask.pocoo.org/
|
||||
[8]: https://en.wikipedia.org/wiki/JavaScript
|
||||
[9]: https://nodejs.org/en/
|
||||
[10]: https://en.wikipedia.org/wiki/JavaScript_syntax#Basics5
|
||||
@ -0,0 +1,208 @@
|
||||
|
||||
在树莓派上通过Apache Spark on YARN搭建Hadoop集群
|
||||
===
|
||||
有些时候我们想从DQYDJ网站的数据中分析点有用的东西出来,在过去,我们要用R语言提取固定宽度的数据,然后通过数学建模分析美国的最低收入补贴,当然也包括其他优秀的方法。
|
||||
|
||||
今天我将向你展示对大数据的一点探索,不过有点变化,使用的是全世界最流行的微型电脑————树莓派,如果手头没有,那就看下一篇吧(可能是已经处理好的数据)对于其他用户,请继续阅读吧,今天我们要建立一个树莓派 Hadoop集群!
|
||||
|
||||
|
||||
为什么要建立一个Raspberry Pi的Hadoop集群?
|
||||
|
||||

|
||||
>由三个树莓派节点组成的Hadoop集群
|
||||
|
||||
对DQYDJ这句谚语我们做了大量的数据处理工作,但这些还不能称得上是大数据。
|
||||
|
||||
和许许多多有争议的话题一样,数据的大小之别被解释成这样一个笑话:
|
||||
|
||||
如果能被RAM所存储,那么它就不是大数据。 ————佚名
|
||||
|
||||
似乎这儿有两种解决问题的方法:
|
||||
|
||||
1.我们可以找到一个足够大的数据集合,任何家用电脑的内存都存不下。
|
||||
2.我们可以
|
||||
|
||||
上手树莓派2B
|
||||
|
||||
这个由设计师和工程师制作出来的精致小玩意儿拥有1GB的RAM,扩展SD卡充当它的硬盘,此外,每一台的价格都低于50刀,这意味着你可以花不到250刀的价格搭建一个集群。
|
||||
|
||||
或许天下没有比这更便宜的入场券来带你进入大数据的大门。
|
||||
|
||||
### 制作一个树莓派集群
|
||||
|
||||
我最喜欢制作的原材料。
|
||||
|
||||
这里我将给出我原来为了制作树莓派集群购买原材料的链接,如果以后要在亚马逊购买的话你可先这些链接收藏起来,也是对本站的一点支持。(谢谢)
|
||||
|
||||
- 树莓派2B x3
|
||||
- 集群原理图
|
||||
- 4层亚克力支架
|
||||
- 6口USB转接器
|
||||
- 内存卡
|
||||
- MicroUSB数据线
|
||||
- 短网线
|
||||
- 双面胶
|
||||
|
||||
开始制作
|
||||
|
||||
1.首先,装好三个树莓派,每一个用螺丝钉固定在亚克力面板上。(看下图)
|
||||
2.接下来,安装以太网交换机,用双面胶贴在其中一个在亚克力面板上。
|
||||
3.用双面胶贴将USB转接器贴在一个在亚克力面板使之成为最顶层。
|
||||
4.接着就是一层一层都拼好——这里我选择将树莓派放在交换机和USB转接器的底下(可以看看完整安装好的两张截图)
|
||||
|
||||
如果你需要电线的话我想出了一个好方法-如果你和我一样购买力USB线和网线,我可以将它们卷起来放在亚克力板子的每一层
|
||||
|
||||
现在不要急着上电,需要将系统烧录到SD卡上才能继续。
|
||||
|
||||
烧录
|
||||
|
||||
按照这个教程将Raspbian烧录到三张SD卡上,我使用的是Win7下的[Win32DiskImager][2]。
|
||||
|
||||
将其中一张烧录好的SD卡插在你想作为主节点的树莓派上,连接USB线并启动它。
|
||||
|
||||
启动主节点
|
||||
|
||||
这里有一篇非常棒的教程,讲如何安装Hadoop 2.7.1,此处就不再熬述。
|
||||
|
||||
在启动过程中有一些要注意的地方,我将和你一起设置直到最后一步,记住我现在使用的IP段为192.168.1.50 – 192.168.1.52,主节点是.50,从节点是.51和.52,你的网络可能会有所不同,如果你想设置静态IP的话可以在评论区看看或讨论。
|
||||
|
||||
一旦你完成了这些步骤,接下来要做的就是启用交换文件,Spark on YARN将分割出一块很接近内存空间的交换文件,当你内存快用完时便会使用这个交换分区。
|
||||
|
||||
(如果你以前没有做过有关交换分区的操作的话,可以看看这篇教程,记住交换分区不要太多,因为内存卡的性能扛不住)
|
||||
|
||||
现在我准备介绍有关我和其他Geek关于启动设置一些微妙的区别
|
||||
|
||||
对于初学者,确保你给你的树莓派起了一个名字——在/etc/hostname设置,我的主节点设置为‘RaspberryPiHadoopMaster’ ,从节点设置为 ‘RaspberryPiHadoopSlave#’
|
||||
|
||||
主节点的/etc/hosts配置如下:
|
||||
|
||||
如果你想让 Hadoop, YARN, and Spark运行正常的话,你也需要修改这些配置文件。
|
||||
|
||||
hdfs-site.xml:
|
||||
|
||||
```
|
||||
yarn-site.xml (Note the changes in memory!):
|
||||
|
||||
slaves:
|
||||
|
||||
core-site.xml:
|
||||
```
|
||||
|
||||
设置从节点:
|
||||
|
||||
接下来按照Because We Can Geek上的教程,你需要对上面的文件作出小小的改动。主节点没有改变其中的yarn-site.xml,所以从节点中不必含有这个文件。
|
||||
|
||||
III.在我们的树莓派集群中测试YARN!
|
||||
|
||||
如果所有设备都正常工作,在主节点上你应该执行如下命令:
|
||||
|
||||
> start-dfs.sh
|
||||
|
||||
> start-yarn.sh
|
||||
|
||||
当设备启动后,遵循教程以Hadoop用户方式执行。
|
||||
|
||||
接下来执行`hdfs dfsadmin -report`查看三个节点是否都正确启动,确认你看到一行粗体文字‘Live datanodes (3)’:
|
||||
|
||||
Configured Capacity: 93855559680 (87.41 GB)
|
||||
Raspberry Pi Hadoop Cluster picture Straight On
|
||||
Present Capacity: 65321992192 (60.84 GB)
|
||||
DFS Remaining: 62206627840 (57.93 GB)
|
||||
DFS Used: 3115364352 (2.90 GB)
|
||||
DFS Used%: 4.77%
|
||||
Under replicated blocks: 0
|
||||
Blocks with corrupt replicas: 0
|
||||
Missing blocks: 0
|
||||
Missing blocks (with replication factor 1): 0
|
||||
————————————————-
|
||||
Live datanodes (3):
|
||||
Name: 192.168.1.51:50010 (RaspberryPiHadoopSlave1)
|
||||
Hostname: RaspberryPiHadoopSlave1
|
||||
Decommission Status : Normal
|
||||
|
||||
你现在可以做一些简单的诸如‘Hello, World!’的测试,或者直接进行下一步。
|
||||
|
||||
IV.安装SPARK ON YARN
|
||||
|
||||
YARN是另一种非常好用的资源调度器,已经集成在Hadoop安装包中。
|
||||
|
||||
Apache Spark 是 Hadoop 生态圈中的一款软件包,它是一个可执行的引擎。就像著名的预装软件MapReduce一样。在一般情况下,Spark得益于存储在基于磁盘的MapReduce。运行负载堪比10-100倍的MapReduce-安装完成后你可以试试Spark 和 MapReduce的有什么不同。
|
||||
|
||||
我个人对Spark还是留下非常深刻的印象,因为它提供了两种数据工程师和科学家都比较擅长的语言– Python 和 R。
|
||||
|
||||
安装Apache Spark非常简单,在你家目录下,wget这个地址,然后‘tar -xzf ’,最后把解压出来的文件移动至 /opt 并清除刚才下载的文件,以上这些就是安装步骤。
|
||||
|
||||
我又创建了只有两行的文件spark-env.sh,其中包含Spark的配置文件目录。
|
||||
|
||||
SPARK_MASTER_IP=192.168.1.50
|
||||
|
||||
SPARK_WORKER_MEMORY=512m
|
||||
|
||||
(在YARN跑起来之前我不确定这些是否有必要。)
|
||||
|
||||
V. 你好,世界! 为Apache Spark发现一个有趣的数据集!
|
||||
|
||||
在Hadoop进行对‘Hello, World!’的单词计数。
|
||||
|
||||
我决定改进一下`hello world`的例子,这个例子在平常也用不上,也许统计一些关于我自己的大数据会更有用…
|
||||
|
||||
如果你有一个正在运行的`WordPress`博客,可以通过简单的两步来导出和
|
||||
|
||||
我使用`Export to Text‘导出文章的内容到纯文本文件中,我使用一些压缩库编写了一个`Python`来压缩了`HTML文件`,现在你可以将一个更小的文件复制到pi搭建的HDFS集群。
|
||||
|
||||
如果你没有进行上面的操作,还有一种方法将文件转移到pi上
|
||||
|
||||
>hdfs dfs -copyFromLocal dqydj_stripped.txt /dqydj_stripped.txt
|
||||
|
||||
现在准备进行最后一步 - 向Apache Spark写入相同的代码。
|
||||
|
||||
### VI: 点燃 Apache Spark
|
||||
|
||||
我们的单词计数程序基于Cloudera进行修改,你可以在这里找到。我们要修改我们的自己的单词计数程序。
|
||||
|
||||
在主节点上安装‘stop-words’这个`python`第三方包,有趣的是我在DQYDJ上使用了23,295次the这个单词,你可能不想看到这些语法单词占据着单词计数的前列,另外,用下列代码替换所有有关dqydj的参考文件,注意你自己的数据库路径。
|
||||
|
||||
保存好wordCount.py确保上面的路径都是正确无误的。
|
||||
|
||||
现在,通过运行在YARN上的Spark,你可以看到我在DQYDJ使用最多的单词是哪一个。
|
||||
|
||||
>/opt/spark-2.0.0-bin-hadoop2.7/bin/spark-submit –master yarn –executor-memory 512m –name wordcount –executor-cores 8 wordCount.py /dqydj_stripped.txt
|
||||
|
||||
### 我在DQYDJ使用最多的单词
|
||||
|
||||
可能入列的单词有哪一些呢?can, will, it’s, one, even, like, people, money, don’t, also“.
|
||||
|
||||
嘿,不差钱–悄悄进入前十。在一个致力于金融、投资和经济的网站上谈论这似乎是件好事,对吧?
|
||||
|
||||
这是余下的50个最常用的词汇,请用他们得出有关我余下文章的结论。
|
||||
|
||||

|
||||
|
||||
我希望你能喜欢这篇关于Hadoop, YARN, 和 Apache Spark的教程,现在你可以在Spark运行其他的任务。
|
||||
|
||||
你的下一步是任务是开始读pyspark文档(库或其他语言)去学习一些可用的功能。根据你的兴趣和你实际存储的数据,你将会深入学习到有流数据包的SQL,甚至机器学习!
|
||||
|
||||
你要建立一个树莓派集群吗?看看你使用最频繁的单词是什么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
原文: https://dqydj.com/raspberry-pi-hadoop-cluster-apache-spark-yarn/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[PK][a]
|
||||
译者:[popy32](https://github.com/sfantree)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://dqydj.com/about/#contact_us
|
||||
[1]: https://www.raspberrypi.org/downloads/raspbian/
|
||||
[2]: https://sourceforge.net/projects/win32diskimager/
|
||||
[3]: http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-1/
|
||||
[4]: https://www.digitalocean.com/community/tutorials/how-to-add-swap-on-ubuntu-14-04
|
||||
[5]: http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-2/
|
||||
[6]: https://spark.apache.org/
|
||||
[7]: https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
|
||||
[8]: https://spark.apache.org/downloads.html
|
||||
[9]: https://wordpress.org/support/plugin/export-to-text
|
||||
[10]: https://pypi.python.org/pypi/bleach
|
||||
|
||||
@ -1,43 +1,43 @@
|
||||
探索传统 JavaScript 基准测试
|
||||
============================================================
|
||||
|
||||
可以很公平地说,[JavaScript][22] 是当下软件工程最为重要的技术。由于在语言设计者看来,JavaScript 不是十分优雅;在编译器工程师看来,它的性能没有多卓越;并且它还没有一个足够庞大的标准库,所以对于深入接触过编程语言、编译器和虚拟机的人来说,这依然是一个惊喜。取决于你和谁吐槽,JavaScript 的缺点花上数周都列举不完,不过你总会找到一些你从所未知的神奇的东西。尽管这看起来明显困难重重,不过 JavaScript 今天还是成为了 web 的核心,并且还成为服务器/云端的主要技术(通过 [Node.js][23]),甚至还开辟了进入物联网领域的道路。
|
||||
可以很公平地说,[JavaScript][22] 是当下软件工程最重要的技术。对于那些深入接触过编程语言、编译器和虚拟机的人来说,这仍然有点令人惊讶,因为在语言设计者看来,`JavaScript` 不是十分优雅;在编译器工程师看来,它没有多少可优化的地方;而且还没有一个伟大的标准库。取决于你和谁吐槽,`JavaScript` 的缺点你花上数周都枚举不完,不过你总会找到一些你从所未知的神奇的东西。尽管这看起来明显困难重重,不过 `JavaScript` 还是成为当今 web 的核心,并且还成为服务器端/云端的主导技术(通过 [Node.js][23]),甚至还开辟了进军物联网空间的道路。
|
||||
|
||||
问题来了,为什么 JavaScript 如此受欢迎/成功?我从未得到一个很好的答案。如今我们有很多理由使用 JavaScript,或许最重要的是围绕其构建的庞大的生态系统以及今天大量可用的资源。但所有这一切实际上是发展到一定程度的结果。为什么 JavaScript 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 JavaScript。回顾过去,似乎第一次 JavaScript 浪潮爆发在上个年代的后半段。不出所料,那个时候 JavaScript 引擎在不同的负载下实现了巨大的加速,这可能刷新了很多人对 JavaScript 的看法。
|
||||
问题来了,为什么 `JavaScript` 如此受欢迎/成功?我知道没有一个很好的答案。如今我们有许多使用 `JavaScript` 的好理由,或许最重要的是围绕其构建的庞大的生态系统,以及今天大量可用的资源。但所有这一切实际上是发展到一定程度的后果。为什么 `JavaScript` 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 `JavaScript`。回顾过去,似乎第一波 `JavaScript` 浪潮爆发在上个年代的后半段。不出所料,那个时候 `JavaScript` 引擎在不同的负载下实现了巨大的加速,这可能让很多人对 `JavaScript` 刮目相看。
|
||||
|
||||
回到过去那些日子,这些加速测试使用了今天所谓的传统 JavaScript 基准,从苹果的 [SunSpider 基准][24](所有 JavaScript 微基准之母)到 Mozilla 的 [Kraken 基准][25] 和谷歌的 V8 基准。后来,V8 基准被 [Octane 基准][26] 取代,而苹果发布了自家新的 [JetStream 基准][27]。这些传统的 JavaScript 基准测试驱动了令人惊叹的努力,使 JavaScript 的性能达到一个在本世纪初没人能预料到的水平。据报道加速达到了 1000 倍,一夜之间在网站使用 `<script>` 标签不再是魔鬼的舞蹈,做客户端不仅仅是可能的,甚至是被鼓励的。
|
||||
回到过去那些日子,这些加速测试使用了现在所谓的传统 `JavaScript` 基准——从苹果的 [SunSpider 基准][24](JavaScript 微基准之母)到 Mozilla 的 [Kraken 基准][25] 和谷歌的 `V8` 基准。后来,`V8` 基准被 [Octane 基准][26] 取代,而苹果发布了新的 [JetStream 基准][27]。这些传统的 `JavaScript` 基准测试驱动了无数人的努力,使 `JavaScript` 的性能达到了本世纪初没人能预料到的水平。据报道加速达到了 1000 倍,一夜之间在网站使用 `<script>` 标签不再是魔鬼的舞蹈,做客户端不再仅仅是可能的了,甚至是被鼓励的。
|
||||
|
||||
[][28]
|
||||
|
||||
在 2016 年,所有(相关的)JavaScript 引擎达到了一个令人难以置信的水平,web 应用可以像端应用一样快。引擎配有复杂的优化编译器,通过根据收集的关于类型/形状的反馈来推测某些操作(即属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数这些优化是由 SunSpider 或 Kraken 等微基准以及 Octane 和 JetStream 等静态测试套件驱动的。由于有基于像 [asm.js][29] 和 [Emscripten][30] 这样的 JavaScript 技术,我们甚至可以将大型 C++ 应用编译成 JavaScript,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 [AngryBots][31],无需沙盒,而过去的 web 游戏需要安装一堆诸如 Adobe Flash 或 Chrome PNaCl 的插件。
|
||||
现在是 2016 年,所有(相关的)`JavaScript` 引擎的性能都达到了一个令人难以置信的水平,web 应用可以像端应用(或者本地的应用)一样快。引擎配有复杂的优化编译器,通过收集过去关于类型/形状的反馈来推测某些操作(即属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数优化是由 `SunSpider` 或 `Kraken` 等微基准以及 `Octane` 和 `JetStream` 等静态测试套件驱动的。由于有像 [asm.js][29] 和 [Emscripten][30] 这样的 `JavaScript` 技术,我们甚至可以将大型 `C++` 应用程序编译成 `JavaScript`,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 [AngryBots][31],无需沙盒,而过去的 web 游戏需要安装一堆诸如 `Adobe Flash` 或 `Chrome PNaCl` 的插件。
|
||||
|
||||
这些成就绝大多数都要归功于这些微基准和静态性能测试套件,以及这些传统 JavaScript 基准间至关重要的竞争。你可以说你可以用 SunSpider 来干什么,但很显然,没有 SunSpider,JavaScript 的性能可能达不到今天的高度。好的,赞美到此为止。现在看看另一面,所有的静态性能测试——无论是微基准还是大型应用的宏基准,都注定要随着时间的推移变得不相关!为什么?因为在开始游戏前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般实用性将呈指数下降。例如,我们将 Octane 作为现实世界中 web 应用性能的代理,并且在相当长一段时间里,它可能做得相当不错,但是现在,Octane 与现实世界中的时间分布是截然不同的,因此当前优化 Octane 以超越自身可能在现实中得不到任何显著的改进(无论是通用 web 还是 Node.js 的工作负载)。
|
||||
这些成就绝大多数都要归功于这些微基准和静态性能测试套件,以及这些传统 `JavaScript` 基准间至关重要的竞争。你可以对 `SunSpider` 表示不满,但很显然,没有 `SunSpider`,`JavaScript` 的性能可能达不到今天的高度。好吧,赞美到此为止。现在看看另一方面,所有静态性能测试——无论是微基准还是大型应用的宏基准,都注定要随着时间的推移变得不相关!为什么?因为在开始游戏前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般适用性将呈指数下降。例如,我们将 `Octane` 作为现实世界中 web 应用性能的代理,并且在相当长的一段时间里,它可能做得很不错,但是现在,`Octane` 与现实场景中的时间分布是截然不同的,因此即使眼下再优化 `Octane` 至超越自身,可能在现实世界中还是得不到任何显著的改进(无论是通用 web 还是 `Node.js` 的工作负载)。
|
||||
|
||||
[][32]
|
||||
|
||||
由于传统 JavaScript 基准(包括最新版的 JetStream 和 Octane)可能已经超越其有用性变得越来越明显,我们开始调查新的方法来测量年初(2016 年)真实世界的性能,为 V8 和 Chrome 添加了大量新的性能追踪钩子。我们特意添加了一些机制来查看我们在浏览 web 时花费的时间,即是否是脚本执行、垃圾回收、编译等,并且这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 Octane 花费超过 70% 的时间执行 JavaScript 和回收垃圾,而浏览 web 的时候,通常执行 JavaScript 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。而花费大量时间来解析和编译,这不像 Octane 的作风。因此,将更多的时间用在优化 JavaScript 执行上将提高你的 Octane 跑分,但不会对加载 [youtube.com][33] 有任何积极的影响。事实上,花费更多的时间来优化 JavaScript 执行甚至可能会损伤你的真实性能,因为编译器需要更多的时间,或者你需要跟踪额外的反馈,从而最终为编译、IC 和运行时桶开销更多的时间。
|
||||
由于传统 `JavaScript` 基准(包括最新版的 `JetStream` 和 `Octane`)可能已经超越其有用性变得越来越明显,我们开始调查新的方法来测量年初现实场景的性能,为 `V8` 和 `Chrome` 添加了大量新的性能追踪钩子。我们还特意添加一些机制来查看我们在浏览 web 时的时间开销,即是否是脚本执行、垃圾回收、编译等,并且这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 `Octane` 花费超过 70% 的时间执行 `JavaScript` 和回收垃圾,而浏览 web 的时候,通常执行 `JavaScript` 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。反而花费大量时间来解析和编译,这不像 `Octane` 的作风。因此,将更多的时间用在优化 `JavaScript` 执行上将提高你的 `Octane` 跑分,但不会对加载 [youtube.com][33] 有任何积极的影响。事实上,花费更多的时间来优化 `JavaScript` 执行甚至可能有损你现实场景的性能,因为编译器需要更多的时间,或者你需要跟踪更多的反馈,最终为编译、IC 和运行时桶开销更多的时间。
|
||||
|
||||
[][34]
|
||||
|
||||
还有另外一组基准测试用于测试浏览器整体性能(包括 JavaScript 和 DOM 性能),最新推出的是 [Speedometer 基准][35]。基准试图通过运行一个用不同的主流 web 框架实现的简单的 [TodoMVC][36] 应用(现在看来有点过时了,不过新版本正在研发中)以捕获真实性能。各种在 Octane 下的测试(angular、ember、react、vanilla、flight 和 bbackbone)都囊括在幻灯片中,你可以看到这些测试似乎更好地代表了现在的性能指标。但是请注意,这些数据收集与本文撰写将近 6 个月以前,而且我们优化了更多的现实世界模式(例如我们正在重构 IC 系统以显著地减小开销,并且 [解析器也正在重新设计][37])。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不是现实世界 Node.js 应用性能的一个好代表。
|
||||
还有另外一组基准测试用于测量浏览器整体性能(包括 `JavaScript` 和 `DOM` 性能),最新推出的是 [Speedometer 基准][35]。基准试图通过运行一个用不同的主流 web 框架实现的简单的 [TodoMVC][36] 应用(现在看来有点过时了,不过新版本正在研发中)以捕获真实性能。各种在 Octane 下的测试(Angular、Ember、React、Vanilla、Flight 和 Backbone)都罗列在幻灯片中,你可以看到这些测试似乎更好地代表了现在的性能指标。但是请注意,这些数据收集在本文撰写将近 6 个月以前,而且我们优化了更多的现实场景模式(例如我们正在重构 IC 系统以显著地降低开销,并且 [解析器也正在重新设计][37])。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不是现实场景中 `Node.js` 应用性能的一个好代理。
|
||||
|
||||
[][38]
|
||||
|
||||
这些可能已经为大多数人所知了,因此我将用本文剩下的部分强调一些关于我为什么认为这不仅有用,而且对于 JavaScript 社区停止关注某一阔值的静态峰值性能基准测试的健康很关键的具体案例。让我通过一些例子说明 JavaScript 引擎如何做游戏基准。
|
||||
所有这一切可能已经路人皆知了,因此我将用本文剩下的部分强调一些关于我为什么认为这不仅有用,而且对于 `JavaScript` 社区的健康(必须停止关注某一阔值的静态峰值性能基准测试)很关键的具体案例。让我通过一些例子说明 `JavaScript` 引擎怎样来玩弄基准。
|
||||
|
||||
### 臭名昭著的 SunSpider 案例
|
||||
|
||||
一篇关于传统 JavaScript 基准测试的博客文章如果没有指出 SunSpider 的问题是不完整的。让我们从性能测试的最佳例子开始,它在现实世界中不是很使用:[`bitops-bitwise-and.js` 性能测试][39]
|
||||
一篇关于传统 `JavaScript` 基准测试的博客如果没有指出 `SunSpider` 明显的问题是不完整的。让我们从性能测试的最佳实践开始,它在现实场景中不是很适用:[`bitops-bitwise-and.js` 性能测试][39]
|
||||
|
||||
[][40]
|
||||
|
||||
有一些算法需要快速的位运算,特别是从 C/C++ 转译成 JavaScript 的地方,所以它确实有一些意义,能够快速执行此操作.然而,现实世界的网页可能不关心引擎是否可以执行位运算,并且在循环中比另一个引擎快两倍.但是再盯着这段代码几秒钟,你可能会注意到在第一次循环迭代之后 `bitwiseAndValue` 将变成 `0`,并且在接下来的 599999 次迭代中将保持为 `0`。所以一旦你在此获得好的性能,即在体面的硬件上所有测试均低于 5ms,在经过尝试认识到只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 [loop peeling][41] 后面的死代码),你就可以用这个基准来测试游戏了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 `bitwiseAndValue` 是全局对象的常规属性还是在执行脚本之前不存在,全局对象必须没有拦截器,或者它的原型等等,但如果你真的想要赢得这个基准,并且你愿意全身心投入,那么你可以在不到 1ms 的时间内执行这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
|
||||
有一些算法需要进行快速的位运算,特别是从 `C/C++` 转译成 `JavaScript` 的地方,所以快速执行按位操作确实有点意义。然而,现实场景中的网页可能不关心引擎是否可以执行位运算,并且能否在循环中比另一个引擎快两倍。但是再盯着这段代码几秒钟,你可能会注意到,在第一次循环迭代之后 `bitwiseAndValue` 将变成 `0`,并且在接下来的 599999 次迭代中将保持为 `0`。所以一旦你在此获得好性能,即在体面的硬件上所有测试均低于 5ms,在经过尝试之后意识到,只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 [loop peeling][41] 后面的死代码),现在你可以开始玩弄这个基准了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 `bitwiseAndValue` 是全局对象的常规属性还是在执行脚本之前不存在,全局对象或者它的原型上必须没有拦截器。但如果你真的想要赢得这个基准测试,并且你愿意全力以赴,那么你可以在不到 1ms 的时间内完成这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
|
||||
|
||||
好的,那么 [`bitops-bitwise-and.js`][42] 测试彻底肯定是微基准最失败的案例。让我们继续转移到 SunSpider 中更真实的世界——[`string-tagcloud.js`][43] 测试,它基本上运行着一个较早版本的 `json.js` polyfill。该测试可以说看起来更合理,但是查看基准的配置之后立刻显示:大量的时间浪费在一条 `eval` 表达式(高达 20% 的总执行时间被用于解析和编译,再加上实际执行编译后代码的 10% 的时间)。
|
||||
好吧,那么 [`bitops-bitwise-and.js`][42] 测试彻底肯定是微基准最失败的案例。让我们继续转移到 SunSpider 中更逼真的场景——[`string-tagcloud.js`][43] 测试,它的底层运行着一个较早版本的 `json.js polyfill`。该测试可以说看起来比位运算测试更合理,但是查看基准的配置之后立刻显示:大量的时间浪费在一条 `eval` 表达式(高达 20% 的总执行时间被用于解析和编译,再加上实际执行编译后代码的 10% 的时间)。
|
||||
|
||||
[][44]
|
||||
|
||||
仔细看看,这个 `eval` 只执行了一次,并传递一个 JSON 格式的字符串,它包含一个由 2501 个含有 `tag` 和 `popularity` 字段的对象组成的数组:
|
||||
仔细看看,这个 `eval` 只执行了一次,并传递一个 `JSON` 格式的字符串,它包含一个由 2501 个含有 `tag` 和 `popularity` 属性的对象组成的数组:
|
||||
|
||||
```
|
||||
([
|
||||
@ -55,7 +55,7 @@
|
||||
},
|
||||
{
|
||||
"tag": "multangularness",
|
||||
"popularity": 368304452
|
||||
"popularity": 368304452任何
|
||||
},
|
||||
{
|
||||
"tag": "Fesapo unventurous",
|
||||
@ -77,7 +77,7 @@
|
||||
])
|
||||
```
|
||||
|
||||
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 JSON 并生成适当的对象图的开销将更加低。所以,加快这个基准的一个窍门是模拟 `eval`,并尝试总是将数据首先作为 JSON 解析,然后再回溯到真实的解析、编译、执行,直到尝试读取 JSON 失败(尽管需要一些额外的魔法来跳过括号)。回到 2007 年,这甚至不算是一个坏的手段,因为没有 [`JSON.parse`][45],不过在 2017 年这只是 JavaScript 引擎的技术债,可能会放慢 `eval` 的合法使用。
|
||||
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 `JSON` 并生成适当的对象图的开销将更加低廉。所以,加快这个基准测试的一个小把戏就是模拟 `eval`,并尝试总是将数据首先作为 `JSON` 解析,然后再回溯到真实的解析、编译、执行,直到尝试读取 `JSON` 失败(尽管需要一些额外的黑魔法来跳过括号)。早在 2007 年,这甚至不算是一个坏点子,因为没有 [`JSON.parse`][45],不过在 2017 年这只是 `JavaScript` 引擎的技术债,可能会让 `eval` 的合法使用遥遥无期。
|
||||
|
||||
```
|
||||
--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
|
||||
@ -93,7 +93,7 @@
|
||||
}
|
||||
```
|
||||
|
||||
事实上,将基准测试更新到现代 JavaScript 会立刻提升性能,正如今天的 V8 LKGR 从 36ms 降到了 26ms,性能足足提升了 30%!
|
||||
事实上,将基准测试更新到现代 `JavaScript` 会立刻提升性能,正如今天的 `V8 LKGR` 从 36ms 降到了 26ms,性能足足提升了 30%!
|
||||
|
||||
```
|
||||
$ node string-tagcloud.js.ORIG
|
||||
@ -105,65 +105,65 @@ v8.0.0-pre
|
||||
$
|
||||
```
|
||||
|
||||
这是静态基准测试和性能测试套件常见的一个问题。今天,没人会认真地使用 `eval` 来解析 JSON 数据(不仅是因为性能问题,还出于显著的安全性考虑),而是坚持为过去五年写的所有代码使用 [`JSON.parse`][46]。事实上,使用 `eval` 来解析 JSON 可能会被视作生产代码中的一个漏洞!所以引擎作者致力于关注新代码的性能没有反映在旧基准中,相反,使得 `eval` 在 `string-tagcloud.js` 中赢得不必要的复杂性是有益的。
|
||||
这是静态基准和性能测试套件常见的一个问题。今天,没有人会正儿八经地用 `eval` 解析 `JSON` 数据(不仅是因为性能问题,还出于严重的安全性考虑),而是坚持为所有代码使用诞生于五年前的 [`JSON.parse`][46]。事实上,使用 `eval` 解析 `JSON` 可能会被视作生产环境的一个漏洞!所以引擎作者致力于新代码的性能所作的努力并没有反映在这个古老的基准中,相反地,使用 `eval` 来赢得 `string-tagcloud.js` 测试是没有必要的。
|
||||
|
||||
好吧,让我们看看另一个例子:[`3d-cube.js`][47]。这个基准做了很多矩阵运算,即使最聪明的编译器都做不了很多,但只是必须要执行它。基本上,基准花了很多时间执行 `loop` 函数以及其调用的函数。
|
||||
好吧,让我们看看另一个例子:[`3d-cube.js`][47]。这个基准测试做了很多矩阵运算,即便是最聪明的编译器仅仅执行这个运算都做不了这么多。基本上,基准测试花了大量的时间执行 `Loop` 函数及其调用的函数。
|
||||
|
||||
[][48]
|
||||
|
||||
一个有趣的发现是:`RotateX`、`RotateY` 和 `RotateZ` 函数总是使用相同的常量参数 `Phi`。
|
||||
一个有趣的发现是:`RotateX`、`RotateY` 和 `RotateZ` 函数总是调用相同的常量参数 `Phi`。
|
||||
|
||||
[][49]
|
||||
|
||||
这意味着我们基本上总是计算 [`Math.sin`][50] 和 [`Math.cos`][51] 的相同值,每次执行都要计算 204 次。只有 3 个不同的输入值:
|
||||
这意味着我们基本上总是为 [`Math.sin`][50] 和 [`Math.cos`][51] 计算相同的值,每次执行都要计算 204 次。只有 3 个不同的输入值:
|
||||
|
||||
* 0.017453292519943295,
|
||||
* 0.05235987755982989,
|
||||
* 以及 0.08726646259971647
|
||||
* 0.08726646259971647
|
||||
|
||||
显然,这里你可以做的一件事就是通过缓存先前的计算值来避免重复计算相同的正弦值和余弦值。事实上,这是 V8 以前的做法,而其它引擎例如 SpiderMonkey 仍然这样做。我们从 V8 中删除了所谓的超载缓存,因为缓存的开销在实际工作负载中是不可忽视的,你不总是在一行中计算相同的值,这在其它地方倒不稀奇。当我们在 2013 和 2014 年移除这个基准特定的优化时,我们对 SunSpider 基准产生了强烈的冲击,但我们完全相信,优化基准并没有意义,同时以这种方式批判真实使用案例。
|
||||
显然,你可以在这里做的一件事情就是通过缓存以前的计算值来避免重复计算相同的正弦值和余弦值。事实上,这是 `V8` 以前的做法,而其它引擎例如 `SpiderMonkey` 仍然这样做。我们从 `V8` 中删除了所谓的超载缓存,因为缓存的开销在现实中的工作负载是不可忽视的,你不可能总是在一行代码中计算相同的值,这在其它地方倒不稀奇。当我们在 2013 和 2014 年移除这个特定的基准优化时,我们对 `SunSpider` 基准产生了强烈的冲击,但我们完全相信,优化基准并没有任何意义,同时以这种方式批判现实场景中的使用案例。
|
||||
|
||||
[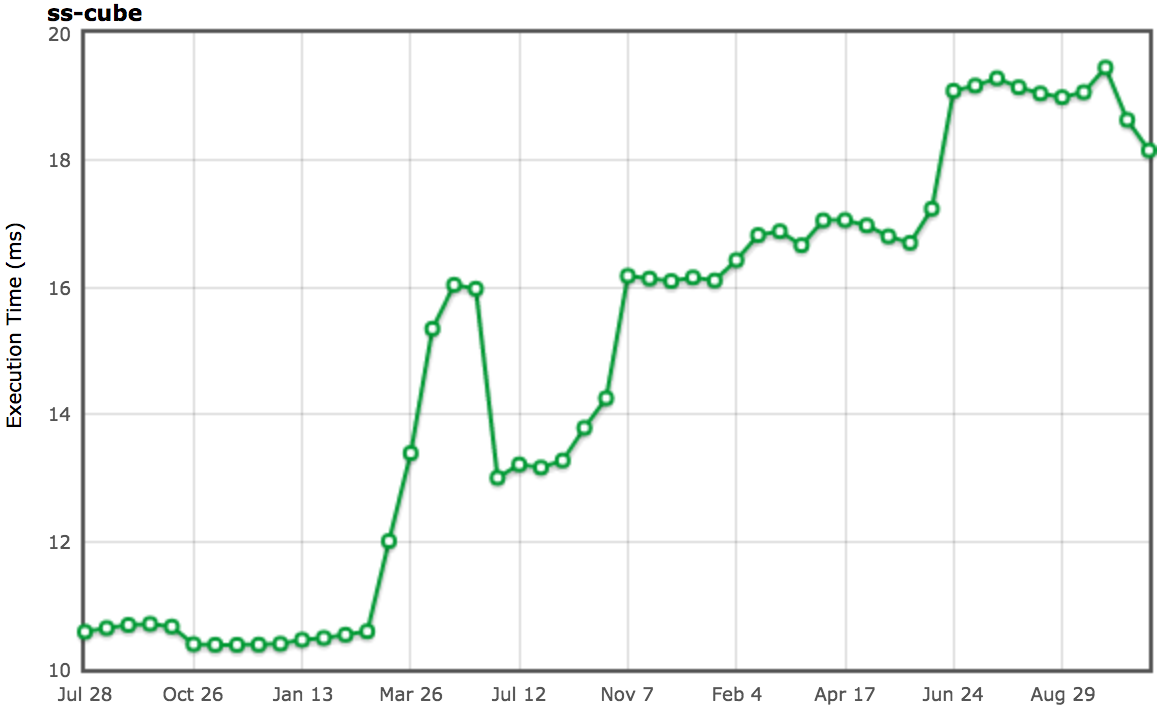][52]
|
||||
|
||||
显然,处理恒定正弦/余弦输入的更好方法是一个内联的启发式计算,它试图平衡内联因素并考虑到其它不同因素,例如在调用位置处优先选择内联,其中恒定折叠可能是有益的,例如在 `RotateX`、`RotateY` 和 `RotateZ` 调用网站。但是出于各种原因这对于 Crankshaft 编译器并不真的是可行的。使用 Ignition 和 TurboFan 将是一个明智的选择,我们已经在做更好的 [内联启发式计算][53]。
|
||||
显然,处理恒定正弦/余弦输入的更好的方法是一个内联的启发式算法,它试图平衡内联因素与其它不同的因素,例如在调用位置优先选择内联,其中恒定折叠可以是有益的,例如在 `RotateX`、`RotateY` 和 `RotateZ` 中调用边界值的案例。但是出于各种原因,这对于 `Crankshaft` 编译器并不可行。使用 `Ignition` 和 `TurboFan` 倒是一个明智的选择,我们已经在开发更好的[内联启发式算法][53]。
|
||||
|
||||
### 垃圾回收是有害的
|
||||
|
||||
除了这些非常特定的测试问题,SunSpider 还有另一个根本的问题:总体执行时间。V8 在体面的英特尔硬件上运行整个基准测试目前大概只需要 200ms(使用默认配置)。次要的 GC 在 1ms 到 25ms 之间(取决于新空间中的活对象和旧空间的碎片),而主 GC 暂停可以浪费 30ms(甚至不考虑增量标记的开销),这超过了 SunSpider 总体运行时间的 10%!因此,任何不想承受由于 GC 循环而造成 10-20% 的减速的引擎,必须以某种方式确保它在运行 SunSpider 时不会触发 GC。
|
||||
除了这些非常具体的测试问题,`SunSpider` 还有一个根本的问题:总体执行时间。目前 `V8` 在体面的英特尔硬件上运行整个基准测试大概只需要 200ms(使用默认配置)。次要的 `GC` 在 1ms 到 25ms 之间(取决于新空间中的活对象和旧空间的碎片),而主 `GC` 暂停可以浪费掉 30ms(甚至不考虑增量标记的开销),这超过了 `SunSpider` 套件总体执行时间的 10%!因此,任何不想因 `GC` 循环而造成减速 10-20% 的引擎,必须用某种方式确保它在运行 `SunSpider` 时不会触发 `GC`。
|
||||
|
||||
[][54]
|
||||
|
||||
有不同的技巧来实现这个想法,不过就我所知,没有一个在现实世界中有任何积极的影响。V8 使用了一个相当简单的技巧:由于每个 SunSpider 测试运行在一个新的 `<iframe>` 中,这对应于 V8 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 SunSpider 测试花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们不会触发 GC,而实际运行测试。这个技巧很好,99.9% 的情况下不会与真正的用途冲突;除了每一个非常时刻,它可以给你强烈冲击,如果无论什么原因,你做的东西,让你看起来像是 V8 的 SunSpider 测试驱动者,然后你就可以得到强制 GC 的强烈冲击,这对你的应用可能会有负面影响。所以紧记一点:**不要让你的应用看起来像 SunSpider!**
|
||||
就实现而言,有不同的方案,不过就我所知,没有一个在现实场景中产生了任何积极的影响。`V8` 使用了一个相当简单的技巧:由于每个 `SunSpider` 套件都运行在一个新的 `<iframe>` 中,这对应于 `V8` 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 `SunSpider` 测试花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们在实际运行测试的时候不会触发 `GC`。这个技巧很好,99.9% 的案例没有与实际用途冲突;除了每时每刻,无论你在做什么,都让你看起来像是 `V8` 的 `SunSpider` 测试驱动程序,那么你可能会遇到困难,或许你可以通过强制 `GC` 来解决,不过这对你的应用可能会有负面影响。所以紧记一点:**不要让你的应用看起来像 SunSpider!**
|
||||
|
||||
我可以继续展示更多的 SunSpider 示例,但我不认为这非常有用。到目前为止,应该清楚的是,对于 SunSpider 的进一步优化,超过良好性能的阔值将不会反映真实世界的任何好处。事实上,世界可能会从 SunSpider 消失中受益,因为引擎可以放弃只是用于 SunSpider 的奇淫技巧,甚至可以伤害到真实用例。不幸的是,SunSpider 仍然被(科技)媒体大量使用来比较他们所认为的浏览器性能,或者甚至用来比较收集!所以手机制造商和安卓制造商对于让 SunSpider(以及其它现在毫无意义的基准 FWIW) 上的 Chrome 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 SunSpider 中得分较高的旧版 V8,向他们的用户展示各种未修复的安全漏洞(在新版中早已被修复),并保护用户免受最新版本的 V8 的任何真实世界的性能优势!
|
||||
我可以继续展示更多 `SunSpider` 示例,但我不认为这非常有用。到目前为止,应该清楚的是,`SunSpider` 为刷新业绩而做的进一步优化在现实场景中没有带来任何好处。事实上,世界可能会因为没有 `SunSpider` 而更美好,因为引擎可以放弃只是用于 `SunSpider` 的奇淫技巧,甚至可以伤害到现实中的用例。不幸的是,SunSpider 仍然被(科技)媒体大量地用来比较他们眼中的浏览器性能,或者甚至用来比较手机!所以手机制造商和安卓制造商对于让 `SunSpider`(以及其它现在毫无意义的基准 `FWIW`) 上的 `Chrome` 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 `SunSpider` 中得分较高的旧版 `V8`,向他们的用户展示各种未修复的安全漏洞(在新版中早已被修复),并保护用户免受最新版本的 `V8` 的任何现实场景的性能优势!
|
||||
|
||||
[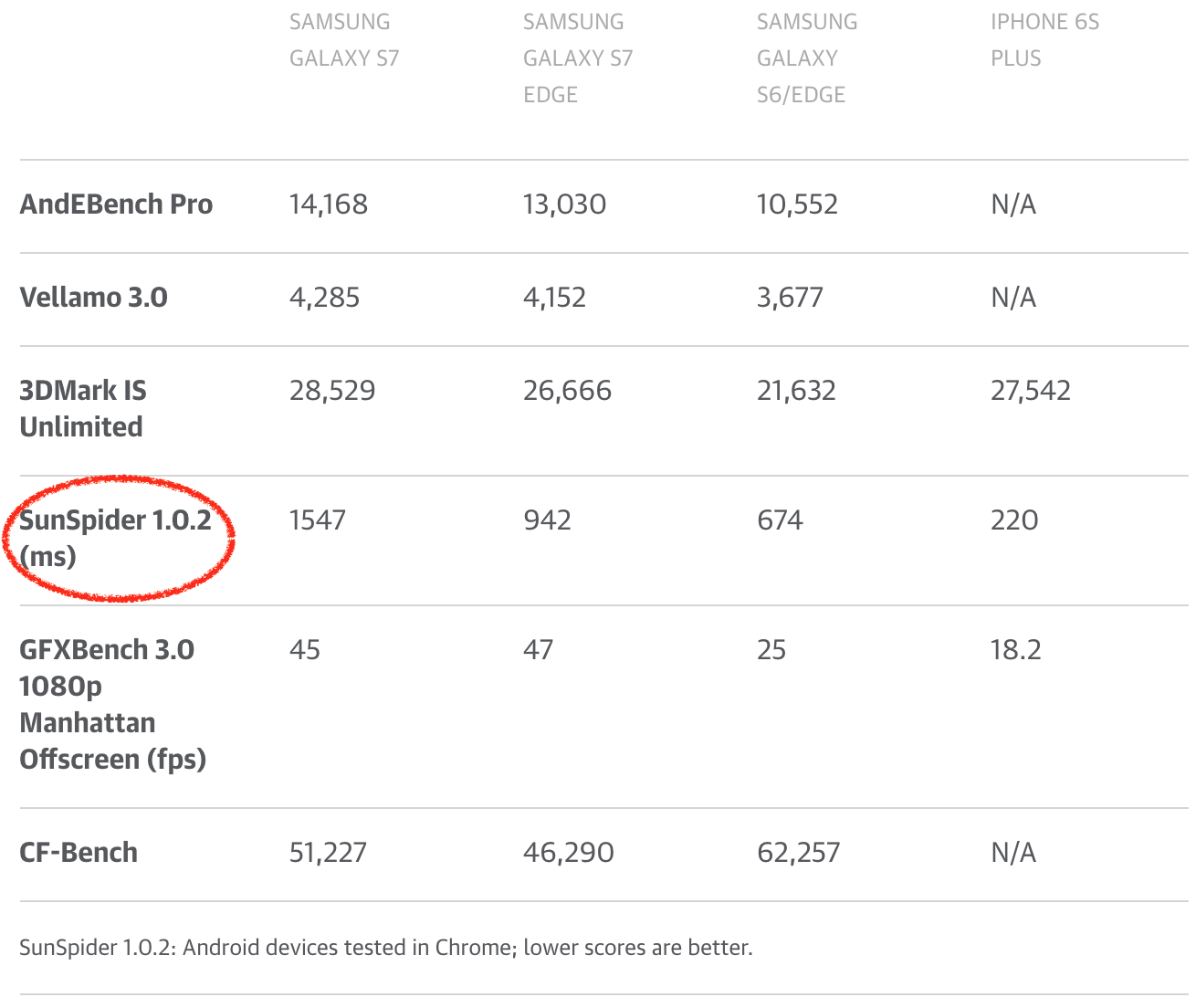][55]
|
||||
|
||||
作为 JavaScript 社区的一员,如果我们真的想认真对待 JavaScript 领域的真实世界性能,我们需要使技术新闻停止使用传统的 JavaScript 基准来比较浏览器或手机。我看到有一个好处是能够在每个浏览器中运行一个基准,并比较它的数量,但是请使用一个基准与今天的事物是相关的,例如真实的 web 页面;如果你觉得需要通过浏览器基准来比较两部手机,请至少考虑使用 [Speedometer][56]。
|
||||
作为 `JavaScript` 社区的一员,如果我们真的想认真对待 `JavaScript` 领域现实场景的性能,我们需要让各大技术媒体停止使用传统的 `JavaScript` 基准来比较浏览器或手机。我看到的一个好处是能够在每个浏览器中运行一个基准测试,并比较它的得分,但是请使用一个与当今世界相关的基准,例如真实的 `web` 页面;如果你觉得需要通过浏览器基准来比较两部手机,请至少考虑使用 [Speedometer][56]。
|
||||
|
||||
### 轻松一刻
|
||||
|
||||

|
||||
|
||||
我总是喜欢这个在 [Myles Borins][57] 的谈话,所以我不得不无情地偷取了他的想法。所以现在我们从 SunSpider 的咆哮中回过头来,让我们继续检查其它经典基准。
|
||||
我一直很喜欢这个 [Myles Borins][57] 谈话,所以我不得不无耻地向他偷师。现在我们从 `SunSpider` 的谴责中回过头来,让我们继续检查其它经典基准。
|
||||
|
||||
### 不是那么明显的 Kraken 案例
|
||||
### 不是那么详细的 Kraken 案例
|
||||
|
||||
Kraken 基准是 [Mozilla 于 2010 年 9 月 发布的][58],据说它包含了真实世界应用的片段/内核,并且与 SunSpider 相比少了一个微基准。我不想花太多时间在 Kraken 上,因为我认为它不像 SunSpider 和 Octane 一样对 JavaScript 性能有着深远的影响,所以我将强调一个特别的案例——[`audio-oscillator.js`][59] 测试。
|
||||
`Kraken` 基准是 [Mozilla 于 2010 年 9 月 发布的][58],据说它包含了现实场景应用的片段/内核,并且与 `SunSpider` 相比少了一个微基准。我不想花太多时间在 `Kraken` 上,因为我认为它不像 `SunSpider` 和 `Octane` 一样对 `JavaScript` 性能有着深远的影响,所以我将强调一个特别的案例——[`audio-oscillator.js`][59] 测试。
|
||||
|
||||
[][60]
|
||||
|
||||
正如你所见,测试调用 `calcOsc` 函数 500 次。`calcOsc` 首先在全局的正弦 `Oscillator` 上调用 `generate`,然后创建一个新的 `Oscillator`,调用 `generate` 并将其添加到全局正弦的振荡器。没有详细说明测试为什么是这样做的,让我们看看 `Oscillator` 原型上的 `generate` 方法。
|
||||
正如你所见,测试调用了 `calcOsc` 函数 500 次。`calcOsc` 首先在全局的正弦 `Oscillator` 上调用 `generate`,然后创建一个新的 `Oscillator`,调用 `generate` 并将其添加到全局正弦的 `oscillator`。没有详细说明测试为什么是这样做的,让我们看看 `Oscillator` 原型上的 `generate` 方法。
|
||||
|
||||
[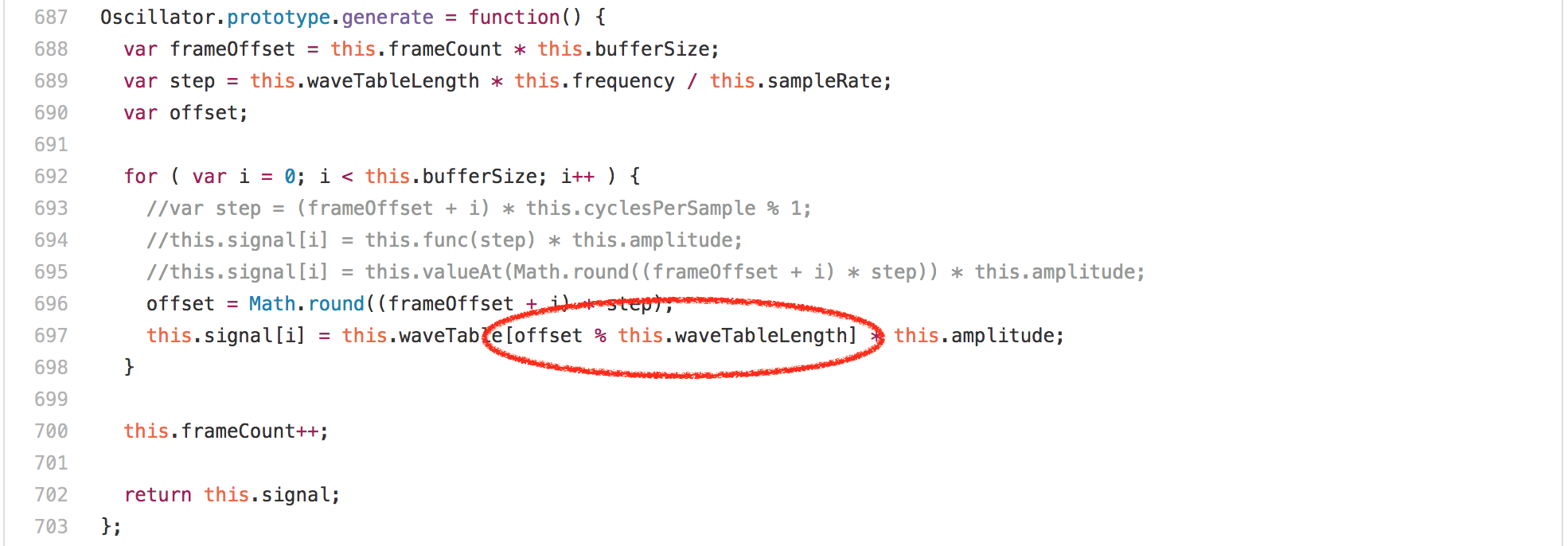][61]
|
||||
|
||||
看看代码,你会期望这被数组访问或乘法循环中的 [`Math.round`][62] 调用所主导,但令人惊讶的是 `offset % this.waveTableLength` 表达式完全支配了 `Oscillator.prototype.generate` 的运行时。在任何的英特尔机器上的分析器中运行此基准测试显示,超过 20% 的通过都归功于我们为模数生成的 `idiv` 指令。然而一个有趣的发现是,`Oscillator` 实例的 `waveTableLength` 字段总是包含相同的值——2048,因为它在 `Oscillator` 构造器中只分配一次。
|
||||
看看代码,你会期望这是被循环中的数组访问或者乘法或者 [`Math.round`][62] 调用所主导的,但令人惊讶的是 `offset % this.waveTableLength` 表达式完全支配了 `Oscillator.prototype.generate` 的运行。在任何的英特尔机器上的分析器中运行此基准测试显示,超过 20% 的通过数据都归功于我们为模数生成的 `idiv` 指令。然而一个有趣的发现是,`Oscillator` 实例的 `waveTableLength` 字段总是包含相同的值——2048,因为它在 `Oscillator` 构造器中只分配一次。
|
||||
|
||||
[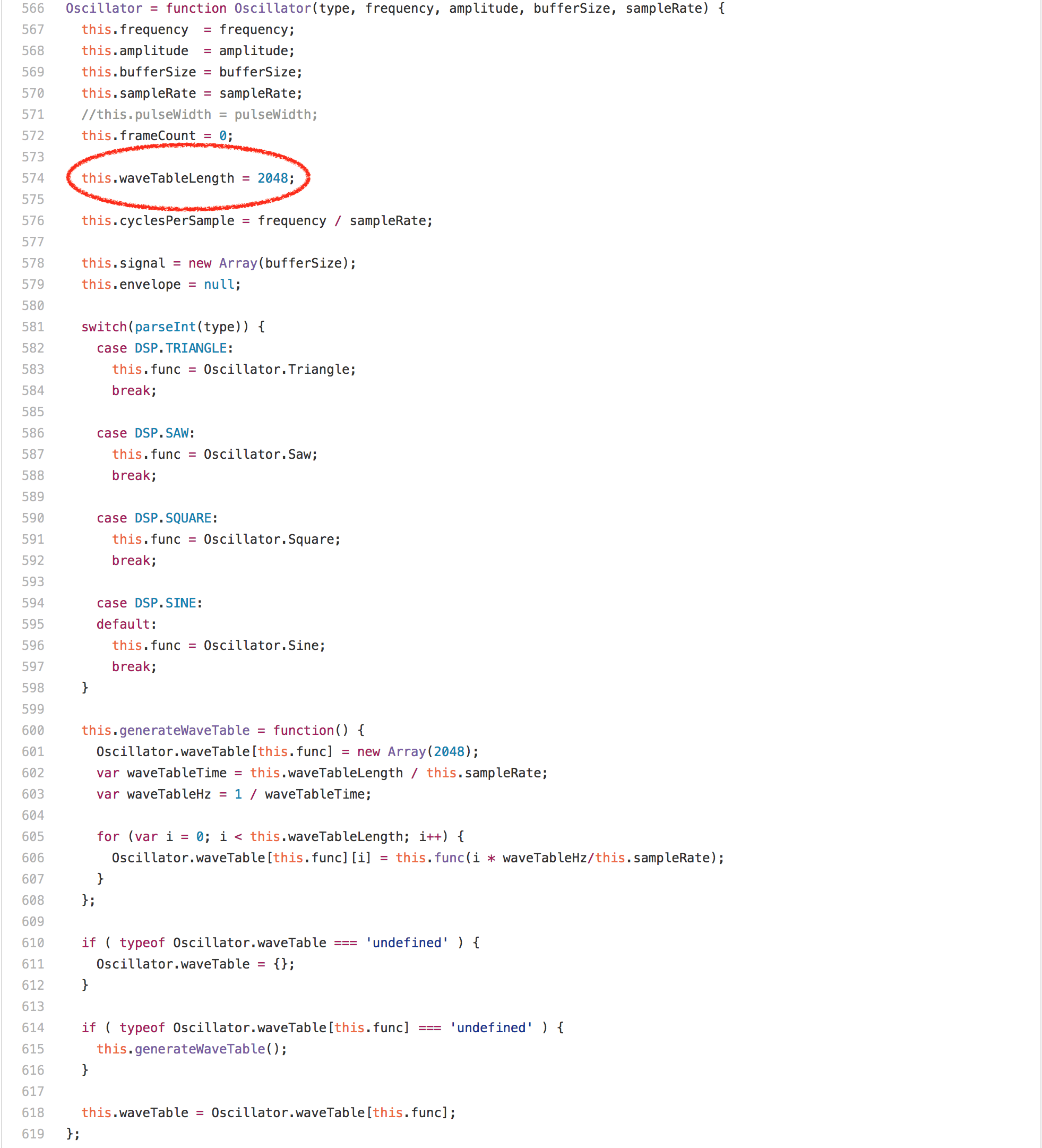][63]
|
||||
|
||||
如果我们知道整数模数运算的右边是 2 的幂,我们可以生成[更好的代码][64],显然完全避免了英特尔上的 `idiv` 指令。所以我们需要的是一个方法来获取信息,从 `Oscillator` 构造器到 `Oscillator.prototype.generate` 中的模运算,`this.waveTableLength` 的值总是 2048。一个显而易见的方法是尝试依赖内联的一切进入 `calcOsc` 函数,并让 load/store 消除为我们的常数传播,但这不会为正弦振荡器工作,这只是分配在 `calcOsc` 函数。
|
||||
如果我们知道整数模数运算的右边是 2 的幂,我们可以生成[更好的代码][64],显然完全避免了英特尔上的 `idiv` 指令。所以我们需要获取一种信息使 `this.waveTableLength` 从 `Oscillator` 构造器到 `Oscillator.prototype.generate` 中的模运算都是 2048。一个显而易见的方法是尝试依赖于将所有内容内嵌到 `calcOsc` 函数,并让 `load/store` 消除为我们进行的常量传播,但这对于在 `calcOsc` 函数之外分配的正弦振荡器无效。
|
||||
|
||||
因此,我们做的是添加支持跟踪某些常数值作为模运算符的右侧反馈。这在 V8 中是有意义的,因为我们为诸如 `+`、`*` 和 `%` 的二进制操作跟踪类型反馈,这意味着操作者跟踪输入的类型和产生的输出类型(参见最近圆桌讨论关于 [动态语言的快速运算][65] 的幻灯片)。当然,用 fullcodegen 和 Crankshaft 挂接起来也是相当容易的,`MOD` 的 `BinaryOpIC` 也可以跟踪两个右边的已知权。
|
||||
因此,我们所做的就是添加支持跟踪某些常数值作为模运算符的右侧反馈。这在 `V8` 中是有意义的,因为我们为诸如 `+`、`*` 和 `%` 的二进制操作跟踪类型反馈,这意味着操作者跟踪输入的类型和产生的输出类型(参见最近圆桌讨论关于[动态语言的快速运算][65]的幻灯片)。当然,用 `fullcodegen` 和 `Crankshaft` 挂接起来也是相当容易的,`MOD` 的 `BinaryOpIC` 也可以跟踪两个右边的已知权。
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
@ -173,7 +173,7 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
$
|
||||
```
|
||||
|
||||
实际上运行默认配置的 V8(的 Crankshaft 和 fullcodegen)显示 `BinaryOpIC` 正在为模数的右侧拾取恰当的恒定反馈,并且正确地跟踪左手边总是一个小整数(V8 中的 `Smi`),我们也总是生成一个小的整数结果。查看生成的代码使用 `--print-opt-code --code-comments` 快速显示,Crankshaft 利用反馈在 `Oscillator.prototype.generate` 中生成一个高效的代码序列的整数模数:
|
||||
显示表明 `BinaryOpIC` 正在为模数的右侧拾取适当的恒定反馈,并正确跟踪左侧始终是一个小整数(`V8` 的 `Smi` 说),我们也总是产生一个小的整数结果 。 使用 `--print-opt-code -code-comments` 查看生成的代码,很快就显示出,`Crankshaft` 利用反馈在 `Oscillator.prototype.generate` 中为整数模数生成一个有效的代码序列:
|
||||
|
||||
```
|
||||
[...SNIP...]
|
||||
@ -197,11 +197,11 @@ $
|
||||
[...SNIP...]
|
||||
```
|
||||
|
||||
所以你看到我们加载 `this.waveTableLength`(`rbx` 持有 `this` 的引用)的值,检查它仍然是 2048(十六进制的 0x800),如果是这样,只是执行一个位和适当的掩码 0x7ff(`r11` 包含循环感应变量 `i` 的值),而不是使用 `idiv` 指令(注意保留左侧的符号)。
|
||||
所以你看到我们加载 `this.waveTableLength`(`rbx` 持有 `this` 的引用)的值,检查它仍然是 2048(十六进制的 0x800),如果是这样,只是执行一个按位操作和适当的掩码 0x7ff(`r11` 包含循环感应变量 `i` 的值),而不是使用 `idiv` 指令(注意保留左侧的符号)。
|
||||
|
||||
### 过度专业化的问题
|
||||
|
||||
所以这个技巧酷毙了,但正如许多基准关注的技巧都有一个主要的缺点:太过于专业了!一旦右手侧发生变化,所有优化过的代码需要重新优化(假设右手始终是两个不再拥有的权),任何进一步的优化尝试都必须再次使用 `idiv`,因为 `BinaryOpIC` 很可能以 `Smi * Smi -> Smi` 的形式报告反馈。例如,假设我们实例化另一个 `Oscillator`,在其上设置不同的 `waveTableLength`,并为振荡器调用 `generate`,那么即使实际上有趣的 `Oscillator` 不受影响,我们也会损失 20% 的性能(例如,引擎在这里实行非局部惩罚)。
|
||||
所以这个技巧酷毙了,但正如许多基准关注的技巧都有一个主要的缺点:太过于专业了!一旦右侧发生变化,所有优化过的代码需要重构(假设右手始终是两个不再拥有的权),任何进一步的优化尝试都必须再次使用 `idiv`,因为 `BinaryOpIC` 很可能以 `Smi * Smi -> Smi` 的形式报告反馈。例如,假设我们实例化另一个 `Oscillator`,在其上设置不同的 `waveTableLength`,并为振荡器调用 `generate`,那么即使实际上有趣的 `Oscillator` 不受影响,我们也会损失 20% 的性能(例如,引擎在这里实行非局部惩罚)。
|
||||
|
||||
```
|
||||
--- audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
|
||||
@ -218,7 +218,7 @@ $
|
||||
sine.generate();
|
||||
```
|
||||
|
||||
将原始的 `audio-oscillator.js` 的执行时间与包含额外未使用的 `Oscillator` 实例与修改的 `waveTableLength` 的版本进行比较,可以显示预期的结果:
|
||||
将原始的 `audio-oscillator.js` 执行时间与包含额外未使用的 `Oscillator` 实例与修改的 `waveTableLength` 的版本进行比较,可以显示预期的结果:
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
|
||||
@ -228,9 +228,9 @@ Time (audio-oscillator-once): 81 ms.
|
||||
$
|
||||
```
|
||||
|
||||
这是一个非常可怕的性能悬崖的例子:让我们说开发人员为库编写代码,并使用某些样本输入值进行仔细的调整和优化,性能是体面的。现在,用户开始使用该库读取性能笔记,但不知何故从性能悬崖下降,因为她/他正在以一种稍微不同的方式使用库,即以某种方式污染某个 `BinaryOpIC` 的类型反馈,并且受到减速 20% 的打击(与该库作者的测量相比),该库的作者和用户都无法解释,这似乎是任意的。
|
||||
这是一个非常可怕的性能悬崖的例子:假设开发人员为库编写代码,并使用某些样本输入值进行仔细的调整和优化,性能是体面的。现在,用户开始使用该库读取性能日志,但不知何故从性能悬崖下降,因为她/他正在以一种稍微不同的方式使用库,即以某种方式污染某种 `BinaryOpIC` 的类型反馈,并且遭受 20% 的减速(与该库作者的测量相比),该库的作者和用户都无法解释,这似乎是随机的。
|
||||
|
||||
现在这在 JavaScript 的领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 JavaScript 的性能是基于乐观的假设和猜测的事实。我们已经花了 **很多** 时间和精力来试图找到避免这些性能悬崖的方法,并且仍然提供(几乎)相同的性能。事实证明,尽可能避免 `idiv`,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 TurboFan 的做法有异于 Crankshaft 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化两个右手侧的(未知)权看起来像这样(在伪代码中):
|
||||
现在这在 `JavaScript` 领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 `JavaScript` 的性能是基于乐观的假设和猜测的事实。我们已经花了 **大量** 时间和精力来试图找到避免这些性能悬崖的方法,不过依旧提供(几乎)相同的性能。事实证明,尽可能避免 `idiv` 是很有意义的,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 `TurboFan` 的做法有异于 `Crankshaft` 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化两个右手侧的(未知)权看起来像这样(在伪代码中):
|
||||
|
||||
```
|
||||
if 0 < rhs then
|
||||
@ -249,7 +249,7 @@ else
|
||||
zero
|
||||
```
|
||||
|
||||
这导致更加一致的和可预测的性能(与 TurboFan):
|
||||
这产生更加一致和可预测的性能(使用 `TurboFan`):
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
|
||||
@ -259,21 +259,21 @@ Time (audio-oscillator-once): 69 ms.
|
||||
$
|
||||
```
|
||||
|
||||
基准和过度专业化的问题是,基准可以给你提示在哪里看和做什么,但它不告诉你你要走多元,不能正确保护优化。例如,所有 JavaScript 引擎都使用基准来防止性能下降,但是运行 Kraken 不能保护我们在 TurboFan 中的一般方法,即我们可以将 TurboFan 中的模优化降级到过度专业版本的 Crankshaft,而基准不会告诉我们却在倒退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们做的相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不会任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度专业化将支配一切,你会有一个真正的、可接受的、巨大的性能悬崖线。
|
||||
基准和过度专业化的问题在于基准可以给你提示在哪里可以看看以及该怎么做,但它不告诉你你应该走多远,不能保护优化。例如,所有 `JavaScript` 引擎都使用基准来防止性能下降,但是运行 `Kraken` 不能保护我们在 `TurboFan` 中的一般方法,即我们可以将 `TurboFan` 中的模优化降级到过度专业版本的 `Crankshaft`,而基准不会告诉我们却在倒退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们做的相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不会任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度专业化将支配一切,你会有一个真正的、可接受的、巨大的性能悬崖线。
|
||||
|
||||
Kraken 测试还有许多其它的问题,不过现在让我们继续讨论过去五年中最有影响力的 JavaScript 基准测试—— Octane 测试。
|
||||
`Kraken` 测试还有许多其它的问题,不过现在让我们继续讨论过去五年中最有影响力的 `JavaScript` 基准测试—— `Octane` 测试。
|
||||
|
||||
### 仔细看看 Octane
|
||||
### 深入接触 Octane
|
||||
|
||||
[Octane][66] 基准是 V8 基准的继承者,最初[由谷歌于 2012 年中期发布][67],目前的版本 Octane 2.0 [与 2013 年年底发布][68]。这个版本包含 15 个独立测试,其中对于 Splay 和 Mandreel,我们用来测试吞吐量和延迟。这些测试范围从 [微软 TypeScript 编译器][69] 编译自身到 zlib 测试测量原生的 [asm.js][70] 性能,再到 RegExp 引擎的性能测试、光线追踪器、2D 物理引擎等。有关各个基准测试项的详细概述,请参阅[说明书][71]。所有这些测试项目都经过仔细的筛选,以反映 JavaScript 性能的方方面面,我们认为这在 2012 年非常重要,或许预计在不久的将来会变得更加重要。
|
||||
[Octane][66] 基准是 `V8` 基准的继承者,最初由[谷歌于 2012 年中期发布][67],目前的版本 `Octane` 2.0 [于 2013 年年底发布][68]。这个版本包含 15 个独立测试,其中对于 `Splay` 和 `Mandreel`,我们用来测试吞吐量和延迟。这些测试范围从 [微软 TypeScript 编译器][69] 编译自身到 `zlib` 测试测量原生的 [asm.js][70] 性能,再到 `RegExp` 引擎的性能测试、光线追踪器、2D 物理引擎等。有关各个基准测试项的详细概述,请参阅[说明书][71]。所有这些测试项目都经过仔细的筛选,以反映 `JavaScript` 性能的方方面面,我们认为这在 2012 年非常重要,或许预计在不久的将来会变得更加重要。
|
||||
|
||||
在很大程度上 Octane 在实现其将 JavaScript 性能提高到更高水平的目标方面无比成功,它在 2012 年和 2013 年引导了良性的竞争,Octane 带来了巨大的业绩的成就。但是现在几乎是 2017 年,世界看起来与 2012 年真的迥然不同了。除了通常的和经常引用的批评,Octane 中的大多数项目基本上已经过时(例如,老版本的 TypeScript,zlib 通过老版本的 [Emscripten][72] 编译而成,Mandreel 甚至不再可用等等),某种更重要的方式影响了 Octane 的用途:
|
||||
在很大程度上 `Octane` 在实现其将 `JavaScript` 性能提高到更高水平的目标方面无比的成功,它在 2012 年和 2013 年引导了良性的竞争,`Octane` 创造了巨大的业绩和成就。但是现在将近 2017 年了,世界看起来与 2012 年真的迥然不同了。除了通常和经常被引用的批评,`Octane` 中的大多数项目基本上已经过时(例如,老版本的 `TypeScript`,`zlib` 通过老版本的 [Emscripten][72] 编译而成,`Mandreel` 甚至不再可用等等),某种更重要的方式影响了 `Octane` 的用途:
|
||||
|
||||
我们看到大型 web 框架赢得了 web 种族之争,尤其是像 [Ember][73] 和 [AngularJS][74] 这样的重型框架,它们使用了 JavaScript 执行模式,不过根本没有被 Octane 所反映,并且经常受到(我们)Octane 具体优化的损害。我们还看到 JavaScript 在服务器和工具前端获胜,这意味着有大规模的 JavaScript 应用现在通常运行上数星期,如果不是运行上数年都不会被 Octane 捕获。正如开篇所述,我们有硬数据表明 Octane 的执行和内存配置文件与我们每天在 web 上看到的截然不同。
|
||||
我们看到大型 web 框架赢得了 web 种族之争,尤其是像 [Ember][73] 和 [AngularJS][74] 这样的重型框架,它们使用了 `JavaScript` 执行模式,不过根本没有被 `Octane` 所反映,并且经常受到(我们)`Octane` 具体优化的损害。我们还看到 `JavaScript` 在服务器和工具前端获胜,这意味着有大规模的 `JavaScript` 应用现在通常运行上数星期,如果不是运行上数年都不会被 `Octane` 捕获。正如开篇所述,我们有硬数据表明 `Octane` 的执行和内存配置文件与我们每天在 web 上看到的截然不同。
|
||||
|
||||
让我们来看看今天 Octane 一些基准游戏的具体例子,其中优化不再反映在现实世界。请注意,即使这可能听起来有点负面回顾,它绝对不意味着这样!正如我已经说过好几遍,Octane 是 JavaScript 性能故事中的重要一章,它发挥了非常重要的作用。在过去由 Octane 驱动的 JavaScript 引擎中的所有优化都是善意地添加的,因为 Octane 是真实世界性能的好代理!每个年代都有它的基准,而对于每一个基准都有一段时间你必须要放手!
|
||||
让我们来看看今天一些玩弄 `Octane` 基准的具体例子,其中优化不再反映在现实场景。请注意,即使这可能听起来有点负面回顾,它绝对不意味着这样!正如我已经说过好几遍,`Octane` 是 `JavaScript` 性能故事中的重要一章,它发挥了至关重要的作用。在过去由 `Octane` 驱动的 `JavaScript` 引擎中的所有优化都是善意地添加的,因为 `Octane` 是现实场景性能的好代理!每个年代都有它的基准,而对于每一个基准都有一段时间你必须要放手!
|
||||
|
||||
话虽这么说,让我们在路上看这个节目,首先看看 Box2D 测试,它是基于 [Box2DWeb][75] (一个最初由 Erin Catto 写的移植到 JavaScript 的流行的 2D 物理引擎)的。总的来说,很多浮点数学驱动了很多 JavaScript 引擎下很好的优化,但是,事实证明它包含一个可以肆意玩弄基准的漏洞(怪我,我发现了漏洞,并添加在这种情况下的漏洞)。在基准中有一个函数 `D.prototype.UpdatePairs`,看起来像这样:
|
||||
话虽如此,让我们在路上看这个节目,首先看看 `Box2D` 测试,它是基于 [Box2DWeb][75] (一个最初由 Erin Catto 编写的移植到 `JavaScript` 的流行的 2D 物理引擎)的。总的来说,很多浮点数学驱动了很多 `JavaScript` 引擎下很好的优化,但是,事实证明它包含一个可以肆意玩弄基准的漏洞(怪我,我发现了漏洞,并添加在这种情况下的漏洞)。在基准中有一个函数 `D.prototype.UpdatePairs`,看起来像这样:
|
||||
|
||||
```
|
||||
D.prototype.UpdatePairs = function(b) {
|
||||
@ -308,7 +308,7 @@ D.prototype.UpdatePairs = function(b) {
|
||||
};
|
||||
```
|
||||
|
||||
一些分析显示,在第一个循环中传递给 `e.m_tree.Query` 的无害的内部函数花费了大量的时间:
|
||||
一些分析显示,在第一个循环中传递给 `e.m_tree.Query` 的无辜的内部函数花费了大量的时间:
|
||||
|
||||
```
|
||||
function(t) {
|
||||
@ -333,7 +333,7 @@ x.proxyA = t < m ? t : m;
|
||||
x.proxyB = t >= m ? t : m;
|
||||
```
|
||||
|
||||
所以这两行无辜的代码要负起 99% 的时间开销的责任!这怎么来的?好吧,与 JavaScript 中的许多东西一样,[抽象关系比较][79] 的直观用法不一定是正确的。在这个函数中,`t` 和 `m` 都是 `L` 的实例,它是这个应用的一个中心类,但不会覆盖 `Symbol.toPrimitive`、`“toString”`、`“valueOf”` 或 `Symbol.toStringTag` 属性,它们与抽象关系比较相关。所以如果你写 `t < m` 会发生什么呢?
|
||||
所以这两行无辜的代码要负起 99% 的时间开销的责任!这怎么来的?好吧,与 `JavaScript` 中的许多东西一样,[抽象关系比较][79] 的直观用法不一定是正确的。在这个函数中,`t` 和 `m` 都是 `L` 的实例,它是这个应用的一个中心类,但不会覆盖 `Symbol.toPrimitive`、`“toString”`、`“valueOf”` 或 `Symbol.toStringTag` 属性,它们与抽象关系比较相关。所以如果你写 `t < m` 会发生什么呢?
|
||||
|
||||
1. 调用 [ToPrimitive][12](`t`, `hint Number`)。
|
||||
2. 运行 [OrdinaryToPrimitive][13](`t`, `"number"`),因为这里没有 `Symbol.toPrimitive`。
|
||||
@ -363,7 +363,7 @@ x.proxyB = t >= m ? t : m;
|
||||
},
|
||||
```
|
||||
|
||||
由于这样做会跳过比较来达到 13% 的惊人加速,并且所有的属性查找和内置函数的调用都会被触发。
|
||||
因为这样做会跳过比较以达到 13% 的惊人的性能提升,并且所有的属性查找和内置函数的调用都会被它触发。
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
|
||||
@ -373,7 +373,7 @@ Score (Box2D): 55359
|
||||
$
|
||||
```
|
||||
|
||||
那么我们是怎么做的呢?事实证明,我们已经有一种用于跟踪比较对象的形状的机制,比较发生于 `CompareIC`,即所谓的已知接收器映射跟踪(其中的映射是 V8 的对象形状+原型),不过这是有限的抽象和严格相等比较。但是我可以很容易地扩展跟踪,并且收集反馈进行抽象的关系比较:
|
||||
那么我们是怎么做呢?事实证明,我们已经有一种用于跟踪比较对象的形状的机制,比较发生于 `CompareIC`,即所谓的已知接收器映射跟踪(其中的映射是 `V8` 的对象形状+原型),不过这是有限的抽象和严格相等比较。但是我可以很容易地扩展跟踪,并且收集反馈进行抽象的关系比较:
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
@ -384,7 +384,7 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
$
|
||||
```
|
||||
|
||||
这里基准代码中使用的 `CompareIC` 告诉我们,对于我们正在查看的函数中的 LT(小于)和 GTE(大于或等于)比较,到目前为止这只能看到`接收器`(V8 的 JavaScript 对象),并且所有这些接收器具有相同的映射 `0x1d5a860493a1`,其对应于 `L` 实例的映射。因此,在优化的代码中,只要我们知道比较的两侧映射的结果都为 `0x1d5a860493a1`,并且没人混淆 `L` 的原型链(即 `Symbol.toPrimitive`、`"valueOf"` 和 `"toString"` 这些方法都是默认的,并且没人赋予过 `Symbol.toStringTag` 的访问权限),我们可以将这些操作分别常量折叠为 `false` 和 `true`。剩下的故事都是关于 Crankshaft 的黑魔法,有很多一部分都是由于初始化的时候忘记正确地检查 `Symbol.toStringTag` 属性:
|
||||
这里基准代码中使用的 `CompareIC` 告诉我们,对于我们正在查看的函数中的 `LT`(小于)和 `GTE`(大于或等于)比较,到目前为止这只能看到 `RECEIVERs`(接收器,`V8` 的 `JavaScript` 对象),并且所有这些接收器具有相同的映射 `0x1d5a860493a1`,其对应于 `L` 实例的映射。因此,在优化的代码中,只要我们知道比较的两侧映射的结果都为 `0x1d5a860493a1`,并且没人混淆 `L` 的原型链(即 `Symbol.toPrimitive`、`"valueOf"` 和 `"toString"` 这些方法都是默认的,并且没人赋予过 `Symbol.toStringTag` 的访问权限),我们可以将这些操作分别常量折叠为 `false` 和 `true`。剩下的故事都是关于 `Crankshaft` 的黑魔法,有很多一部分都是由于初始化的时候忘记正确地检查 `Symbol.toStringTag` 属性:
|
||||
|
||||
[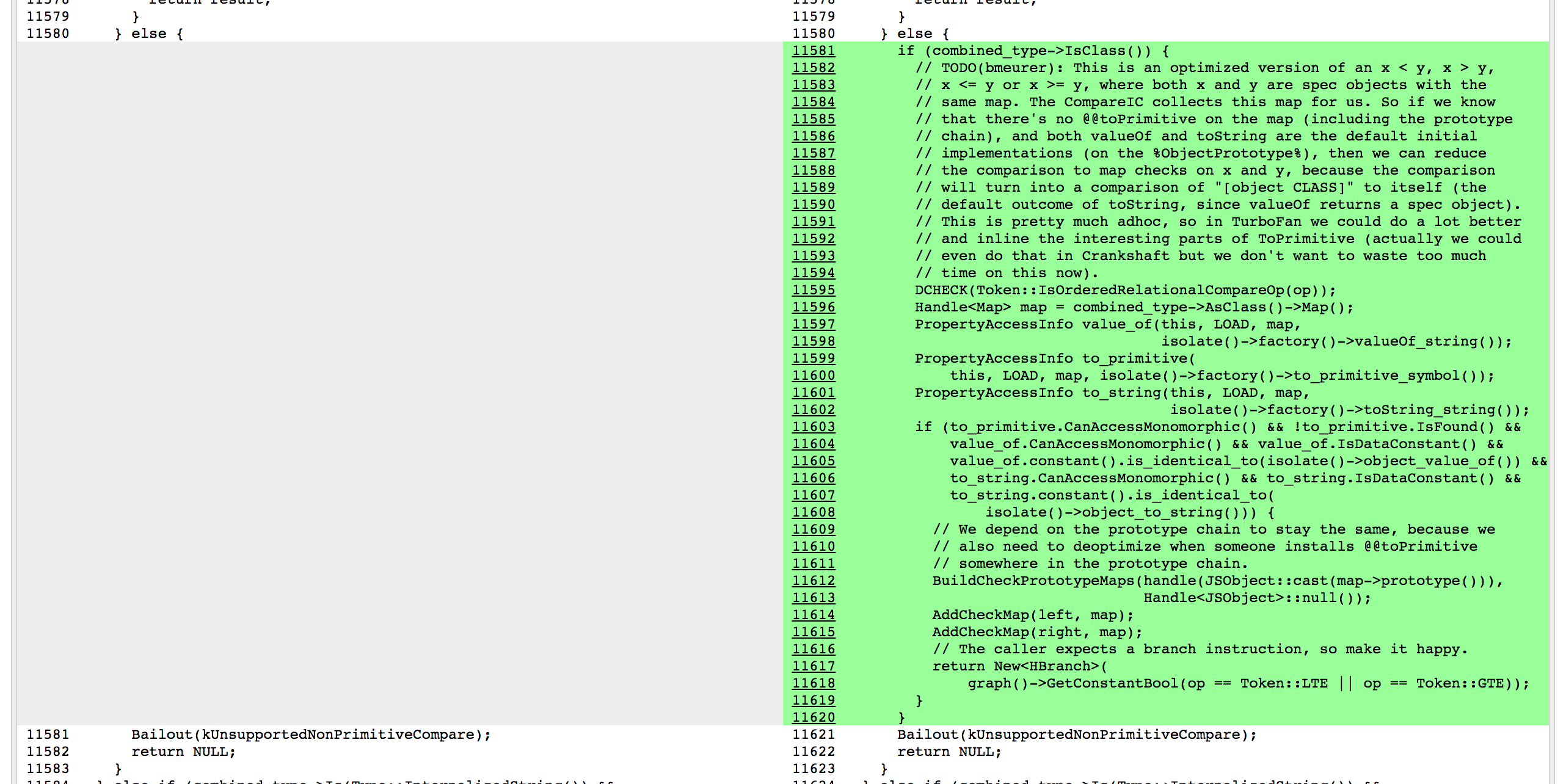][80]
|
||||
|
||||
@ -392,23 +392,23 @@ $
|
||||
|
||||
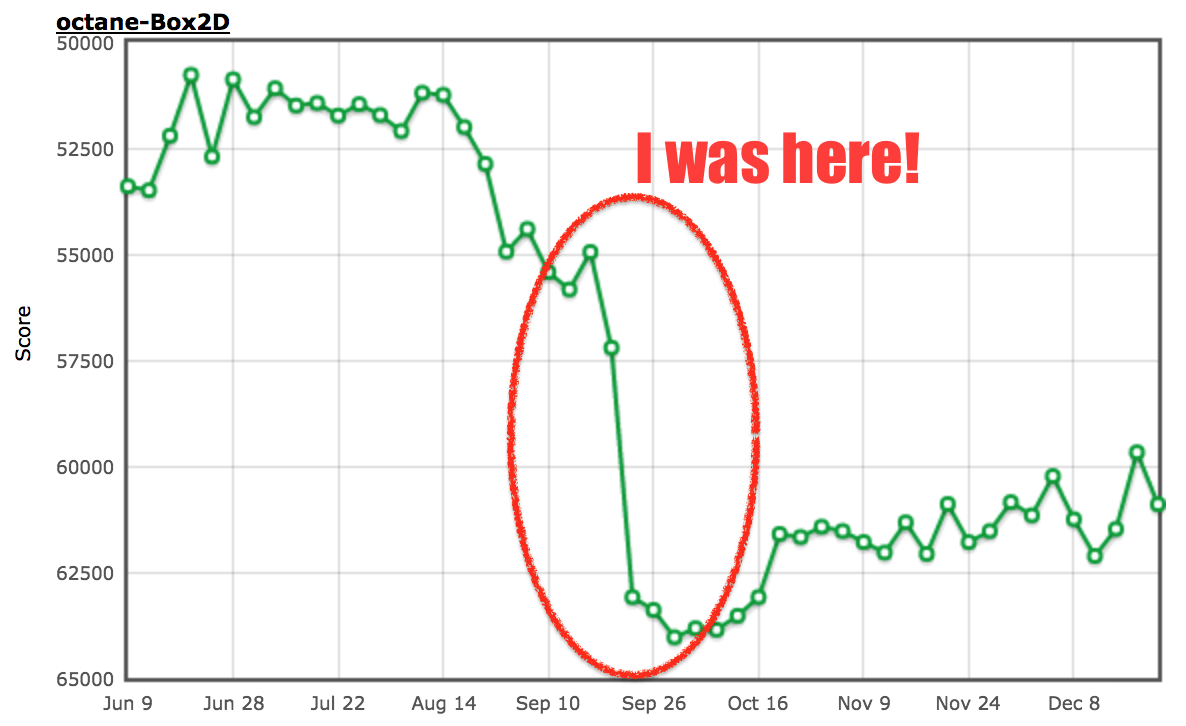
|
||||
|
||||
我要声明一下,当时我并不相信这个特定的行为总是指向源代码中的漏洞,所以我甚至期望外部代码经常会遇到这种情况,同时也因为我假设 JavaScript 开发人员不会总是关心这些种类的潜在错误。但是,我大错特错了,在此我马上悔改!我不得不承认,这个特殊的优化纯粹是一个基准测试的东西,并不会有助于任何真实代码(除非代码是为了从这个优化中获益而写,不过以后你可以在代码中直接写入 `true` 或 `false`,而不用再总是使用常量关系比较)。你可能想知道我们为什么在打补丁后又马上回滚了一下。这是我们整个团队投入到 ES2015 实施的非常时期,这才是真正的恶魔之舞,我们需要在没有严格的回归测试的情况下将所有新特性(ES2015 就是个怪兽)纳入传统基准。
|
||||
我要声明一下,当时我并不相信这个特定的行为总是指向源代码中的漏洞,所以我甚至期望外部代码经常会遇到这种情况,同时也因为我假设 `JavaScript` 开发人员不会总是关心这些种类的潜在错误。但是,我大错特错了,在此我马上悔改!我不得不承认,这个特殊的优化纯粹是一个基准测试的东西,并不会有助于任何真实代码(除非代码是为了从这个优化中获益而写,不过以后你可以在代码中直接写入 `true` 或 `false`,而不用再总是使用常量关系比较)。你可能想知道我们为什么在打补丁后又马上回滚了一下。这是我们整个团队投入到 `ES2015` 实施的非常时期,这才是真正的恶魔之舞,我们需要在没有严格的回归测试的情况下将所有新特性(`ES2015` 就是个怪兽)纳入传统基准。
|
||||
|
||||
关于 Box2D 点到为止了,让我们看看 Mandreel 基准。Mandreel 是一个用来将 C/C++ 代码编译成 JavaScript 的编译器,它并没有用上新一代的 [Emscripten][82] 编译器所使用,并且已经被弃用(或多或少已经从互联网消失了)大约三年的 JavaScript 子集 [asm.js][81]。然而,Octane 仍然有一个通过 [Mandreel][84] 编译的[子弹物理引擎][83]。MandreelLatency 测试十分有趣,它测试 Mandreel 基准与频繁的时间测量检测点。有一种说法是,由于 Mandreel 强制使用虚拟机编译器,此测试提供了由编译器引入的延迟的指示,并且测量检测点之间的长时间停顿降低了最终得分。这听起来似乎合情合理,确实有一定的意义。然而,像往常一样,供应商找到了在这个基准上作弊的方法。
|
||||
关于 `Box2D` 点到为止了,让我们看看 `Mandreel` 基准。`Mandreel` 是一个用来将 `C/C++` 代码编译成 `JavaScript` 的编译器,它并没有用上新一代的 [Emscripten][82] 编译器所使用,并且已经被弃用(或多或少已经从互联网消失了)大约三年的 `JavaScript` 子集 [asm.js][81]。然而,`Octane` 仍然有一个通过 [Mandreel][84] 编译的[子弹物理引擎][83]。`MandreelLatency` 测试十分有趣,它测试 `Mandreel` 基准与频繁的时间测量检测点。有一种说法是,由于 `Mandreel` 强制使用虚拟机编译器,此测试提供了由编译器引入的延迟的指示,并且测量检测点之间的长时间停顿降低了最终得分。这听起来似乎合情合理,确实有一定的意义。然而,像往常一样,供应商找到了在这个基准上作弊的方法。
|
||||
|
||||
[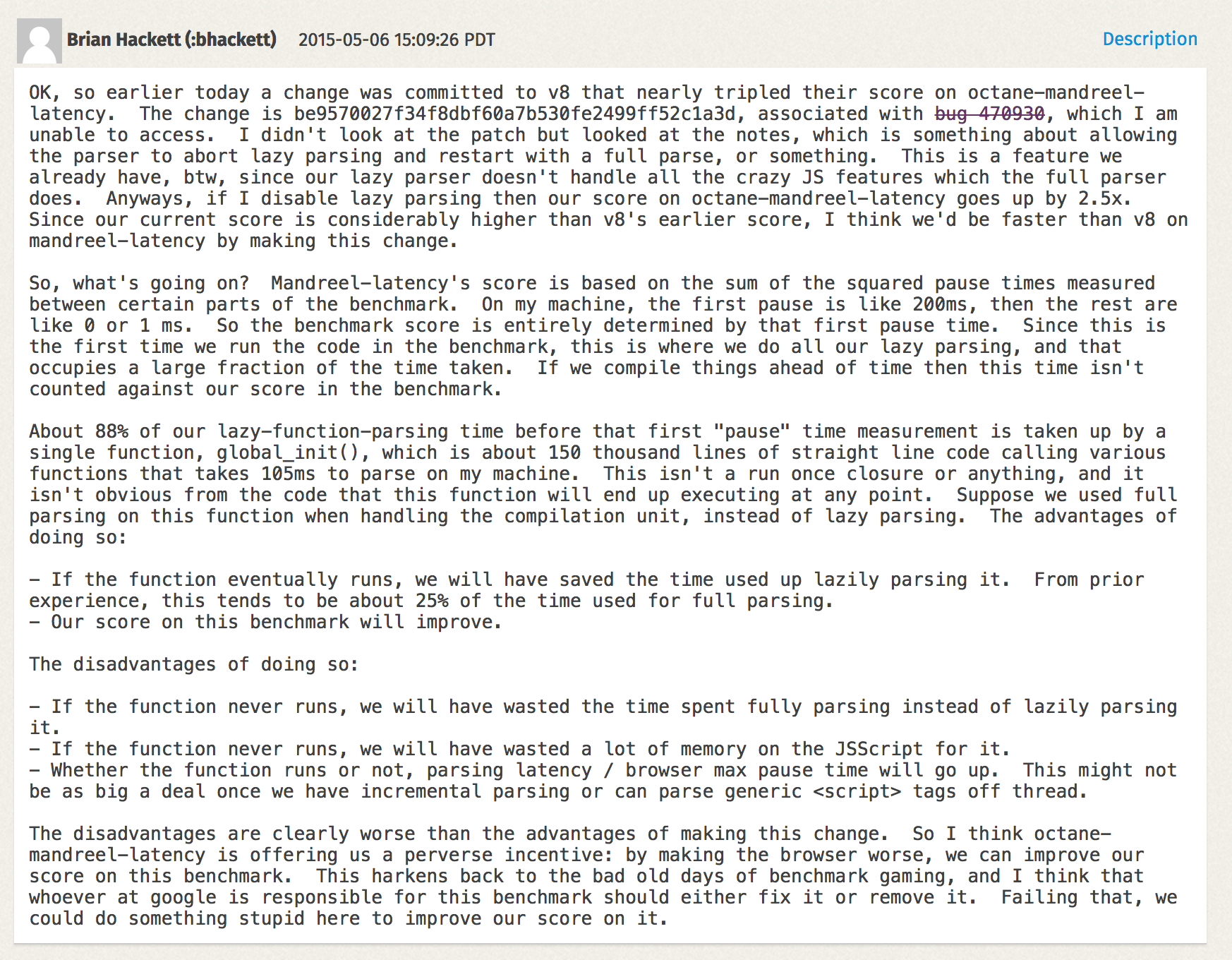][85]
|
||||
|
||||
Mandreel 自带一个重型初始化函数 `global_init`,光是解析这个函数并为其生成基线代码就花费了不可思议的时间。因为引擎通常在脚本中多次解析各种函数,一个所谓的预解析步骤用来发现脚本内的函数。然后作为函数第一次被调用完整的解析步骤以生成基线代码(或者说字节码)。这在 V8 中被称为[懒解析][86]。V8 有一些启发式检测函数,当预解析浪费时间的时候可以立刻调用,不过对于 Mandreel 基准的 `global_init` 函数就不太清楚了,于是我们将经历这个大家伙“预解析+解析+编译”的长时间停顿。所以我们[添加了一个额外的启发式函数][87]以避免 `global_init` 函数的预解析。
|
||||
`Mandreel` 自带一个重型初始化函数 `global_init`,光是解析这个函数并为其生成基线代码就花费了不可思议的时间。因为引擎通常在脚本中多次解析各种函数,一个所谓的预解析步骤用来发现脚本内的函数。然后作为函数第一次被调用完整的解析步骤以生成基线代码(或者说字节码)。这在 `V8` 中被称为[懒解析][86]。`V8` 有一些启发式检测函数,当预解析浪费时间的时候可以立刻调用,不过对于 `Mandreel` 基准的 `global_init` 函数就不太清楚了,于是我们将经历这个大家伙“预解析+解析+编译”的长时间停顿。所以我们[添加了一个额外的启发式函数][87]以避免 `global_init` 函数的预解析。
|
||||
|
||||
[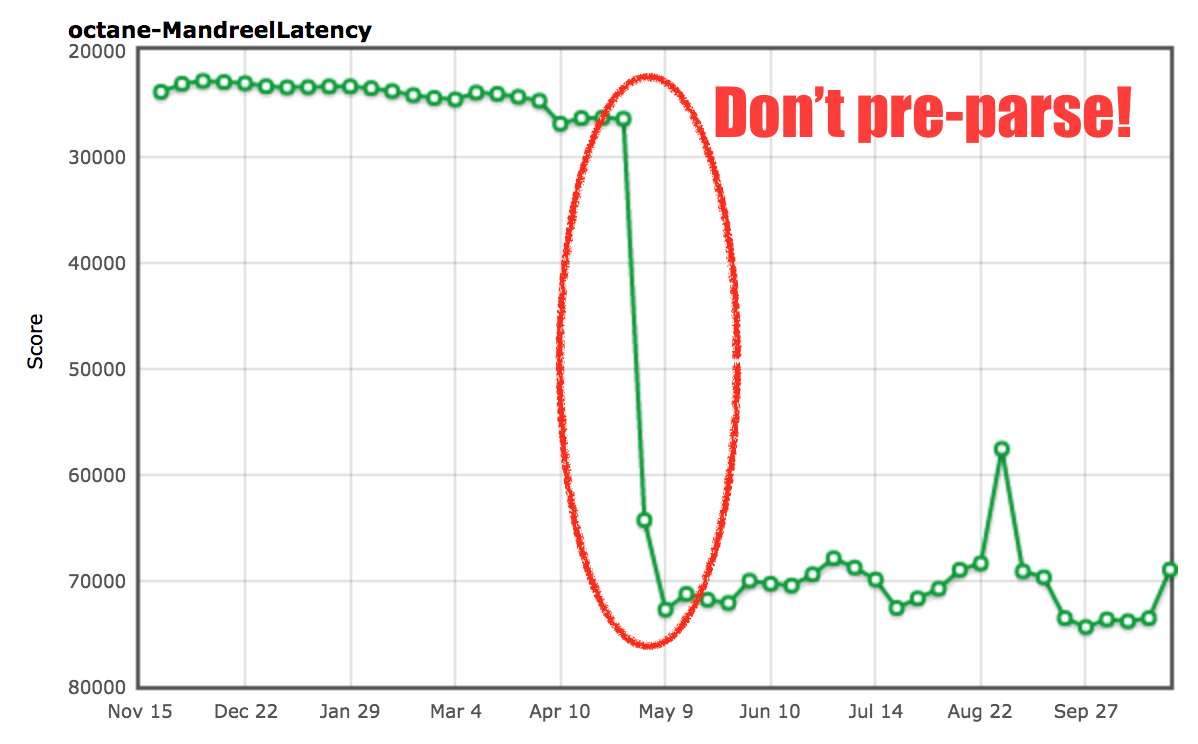][88]
|
||||
|
||||
由此可见,在检测 `global_init` 和避免昂贵的预解析步骤我们几乎提升了 2 倍。我们不太确定这是否会对真实用例产生负面影响,不过保证你在预解析大函数的时候将会受益匪浅(因为它们不会立即执行)。
|
||||
|
||||
让我们来看看另一个稍有争议的基准测试:[`splay.js`][89] 测试,一个用于处理伸展树(二叉查找树的一种)和练习自动内存管理子系统(也被成为垃圾回收器)的数据操作基准。它自带一个延迟测试,这会引导 Splay 代码通过频繁的测量检测点,检测点之间的长时间停顿表明垃圾回收器的延迟很高。此测试测量延迟暂停的频率,将它们分类到桶中,并以较低的分数惩罚频繁的长暂停。这听起来很棒!没有 GC 停顿,没有垃圾。纸上谈兵到此为止。让我们看看这个基准,以下是整个伸展树业务的核心:
|
||||
让我们来看看另一个稍有争议的基准测试:[`splay.js`][89] 测试,一个用于处理伸展树(二叉查找树的一种)和练习自动内存管理子系统(也被成为垃圾回收器)的数据操作基准。它自带一个延迟测试,这会引导 `Splay` 代码通过频繁的测量检测点,检测点之间的长时间停顿表明垃圾回收器的延迟很高。此测试测量延迟暂停的频率,将它们分类到桶中,并以较低的分数惩罚频繁的长暂停。这听起来很棒!没有 `GC` 停顿,没有垃圾。纸上谈兵到此为止。让我们看看这个基准,以下是整个伸展树业务的核心:
|
||||
|
||||
[][90]
|
||||
|
||||
这是伸展树结构的核心,尽管你可能想看完整的基准,不过这或多或少是 SplayLatency 得分的重要来源。怎么回事?实际上,基准测试是建立巨大的伸展树,尽可能保留所有节点,从而还原它原本的空间。使用像 V8 这样的代数垃圾回收器,如果程序违反了[代数假设][91],导致极端的时间停顿,从本质上看,将所有东西从新空间撤回到旧空间的开销是非常昂贵的。在旧配置中运行 V8 可以清楚地展示这个问题:
|
||||
这是伸展树结构的核心,尽管你可能想看完整的基准,不过这或多或少是 `SplayLatency` 得分的重要来源。怎么回事?实际上,基准测试是建立巨大的伸展树,尽可能保留所有节点,从而还原它原本的空间。使用像 `V8` 这样的代数垃圾回收器,如果程序违反了[代数假设][91],导致极端的时间停顿,从本质上看,将所有东西从新空间撤回到旧空间的开销是非常昂贵的。在旧配置中运行 `V8` 可以清楚地展示这个问题:
|
||||
|
||||
```
|
||||
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||
@ -491,7 +491,7 @@ $ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||
$
|
||||
```
|
||||
|
||||
因此这里关键的发现是直接在旧空间中分配伸展树节点可基本避免在周围复制对象的所有开销,并且将次要 GC 周期的数量减少到最小(从而减少 GC 引起的停顿时间)。我们想出了一种称为[分配站点预占][92]的机制,当运行到基线代码时,将尝试动态收集分配站点的反馈,以决定在此分配的对象的部分是否确切存在,如果是,则优化代码以直接在旧空间分配对象——即预占对象。
|
||||
因此这里关键的发现是直接在旧空间中分配伸展树节点可基本避免在周围复制对象的所有开销,并且将次要 `GC` 周期的数量减少到最小(从而减少 `GC` 引起的停顿时间)。我们想出了一种称为[分配站点预占][92]的机制,当运行到基线代码时,将尝试动态收集分配站点的反馈,以决定在此分配的对象的部分是否确切存在,如果是,则优化代码以直接在旧空间分配对象——即预占对象。
|
||||
|
||||
```
|
||||
$ out/Release/d8 --trace-gc octane-splay.js
|
||||
@ -518,15 +518,15 @@ $ out/Release/d8 --trace-gc octane-splay.js
|
||||
$
|
||||
```
|
||||
|
||||
事实上,这完全解决了 SplayLatency 基准的问题,并将我们的得分超过 250%!
|
||||
事实上,这完全解决了 `SplayLatency` 基准的问题,并提高我们的得分至超过 250%!
|
||||
|
||||
[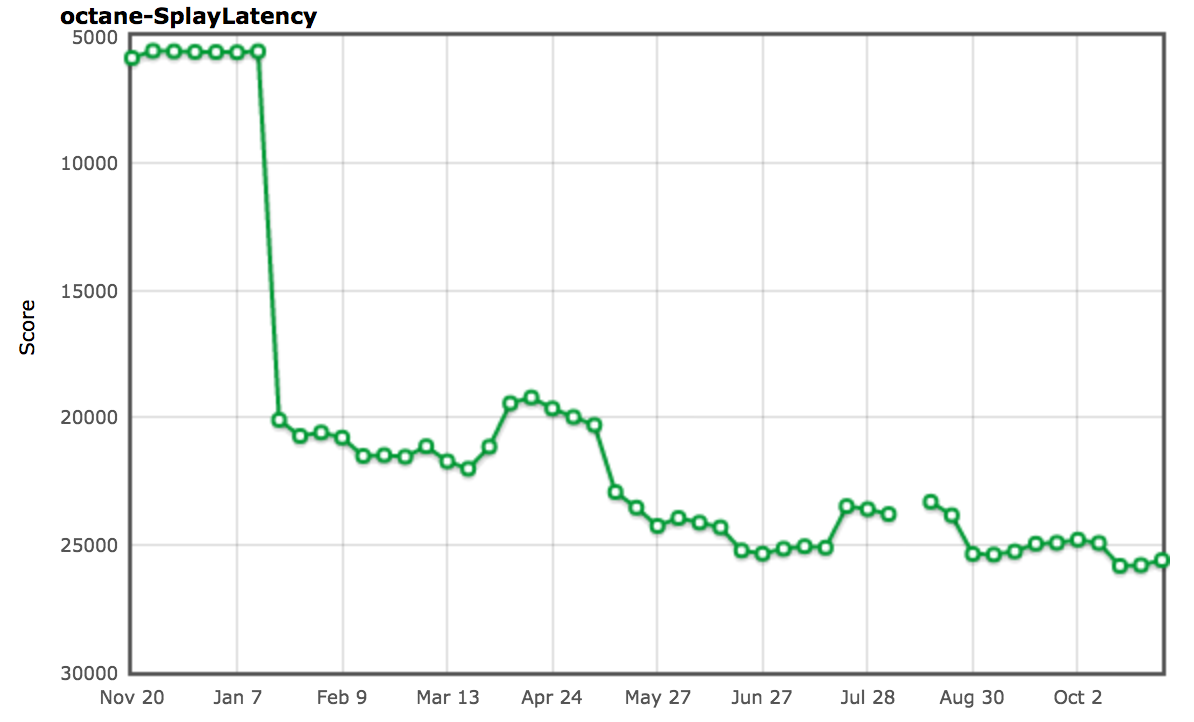][93]
|
||||
|
||||
正如 [SIGPLAN 论文][94] 中所提及的,我们有充分的理由相信,分配站点预占机制可能真的赢得了真实世界应用的欢心,并真正期待看到改进和扩展后的机制,那时将不仅仅是对象和数组字面量。但是不久后我们意识到[分配站点预占机制对真实世界引用产生了相当严重的负面影响][97]。我们实际上得到很多负面新闻,包括 Ember.js 开发者和用户的唇枪舌战,不仅是因为分配站点预占机制,不过它是事故的罪魁祸首。
|
||||
正如 [SIGPLAN 论文][94] 中所提及的,我们有充分的理由相信,分配站点预占机制可能真的赢得了真实世界应用的欢心,并真正期待看到改进和扩展后的机制,那时将不仅仅是对象和数组字面量。但是不久后我们意识到[分配站点预占机制对真实世界引用产生了相当严重的负面影响][97]。我们实际上得到很多负面新闻,包括 `Ember.js` 开发者和用户的唇枪舌战,不仅是因为分配站点预占机制,不过它是事故的罪魁祸首。
|
||||
|
||||
分配站点预占机制的基本问题数之不尽,这在今天的应用中非常常见(主要是由于框架,同时还有其它原因),假设你的对象工厂最初是用于创建构成你的对象模型和视图的长周期对象的,它将你的工厂方法中的分配站点转换为永久状态,并且从工厂分配的所有内容都立即转到旧空间。现在初始设置完成后,你的应用开始工作,作为其中的一部分,从工厂分配临时对象会污染旧空间,最终导致开销昂贵的垃圾回收周期以及其它负面的副作用,例如过早触发增量标记。
|
||||
|
||||
我们开始重新考虑基准驱动的努力,并开始寻找驱动真实世界的替代方案,这导致了 [Orinoco][98] 的诞生,它的目标是逐步改进垃圾回收器;这个努力的一部分是一个称为“统一堆”的项目,如果页面中的所有内容都存在,它将尝试避免复制对象。也就是说站在更高的层面看:如果新空间充满活动对象,只需将所有新空间页面标记为属于旧空间,然后从空白页面创建一个新空间。这可能不会在 SplayLatency 基准测试中得到相同的分数,但是这对于真实世界的用例更友好,它可以自动适配具体的用例。我们还考虑并发标记,将标记工作卸载到单独的线程,从而进一步减少增量标记对延迟和吞吐量的负面影响。
|
||||
我们开始重新考虑基准驱动的工作,并开始寻找驱动现实场景的替代方案,这导致了 [Orinoco][98] 的诞生,它的目标是逐步改进垃圾回收器;这个努力的一部分是一个称为“统一堆”的项目,如果页面中的所有内容都存在,它将尝试避免复制对象。也就是说站在更高的层面看:如果新空间充满活动对象,只需将所有新空间页面标记为属于旧空间,然后从空白页面创建一个新空间。这可能不会在 `SplayLatency` 基准测试中得到相同的分数,但是这对于真实用例更友好,它可以自动适配具体的用例。我们还考虑并发标记,将标记工作卸载到单独的线程,从而进一步减少增量标记对延迟和吞吐量的负面影响。
|
||||
|
||||
### 轻松一刻
|
||||
|
||||
@ -534,7 +534,7 @@ $
|
||||
|
||||
喘口气。
|
||||
|
||||
好吧,我想这对于我的观点的强调应该足够了。我可以继续指出更多的例子,其中 Octane 驱动的改进后来变成了一个坏主意,也许改天我会接着写下去。但是今天就到此为止了吧。
|
||||
好吧,我想这足以强调我的观点了。我可以继续指出更多的例子,其中 `Octane` 驱动的改进后来变成了一个坏主意,也许改天我会接着写下去。但是今天就到此为止了吧。
|
||||
|
||||
### 结论
|
||||
|
||||
@ -542,11 +542,11 @@ $
|
||||
|
||||
[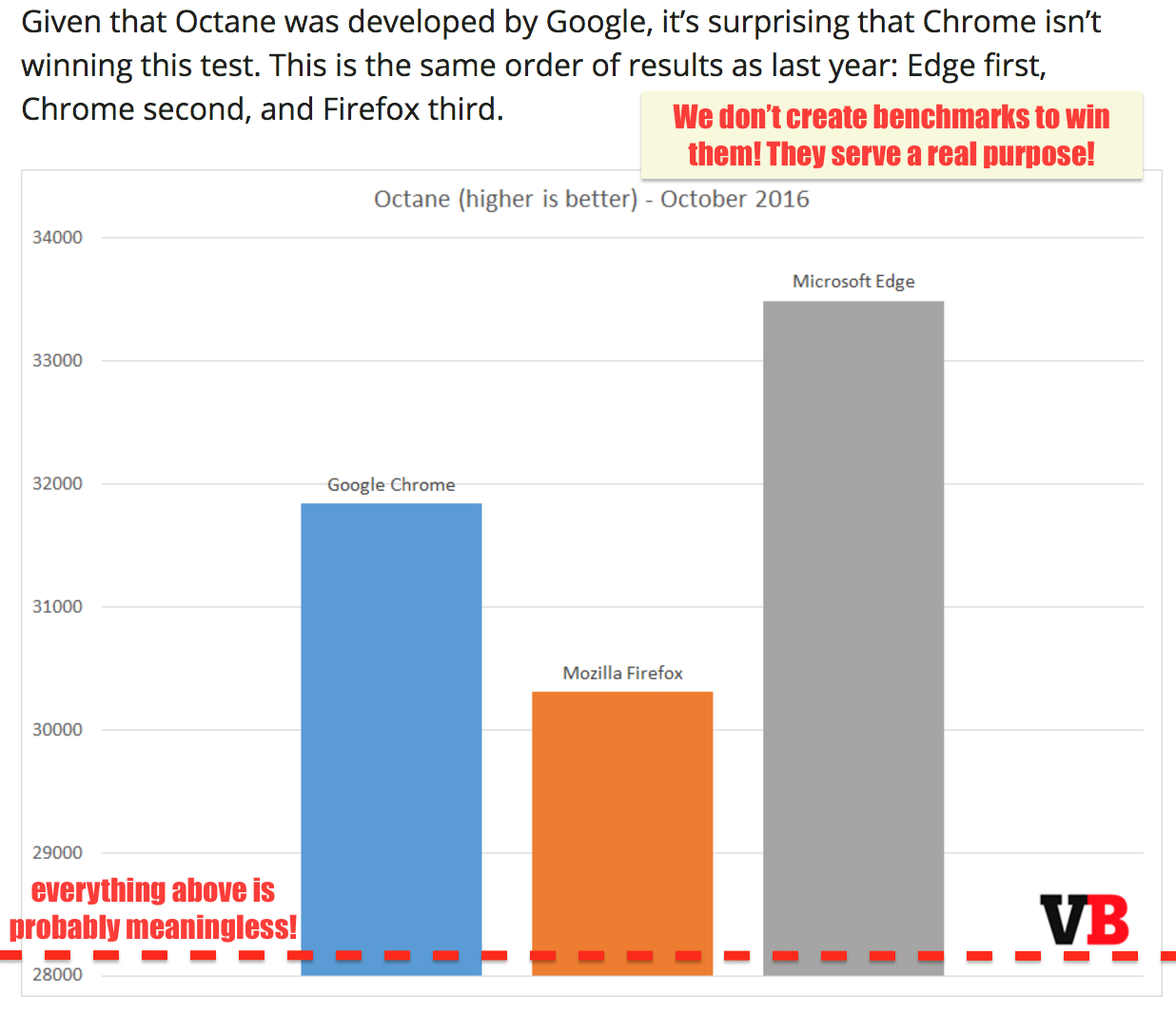][99]
|
||||
|
||||
没人害怕竞争,但是玩弄可能已经坏掉的基准不像是在合理使用工程时间。我们可以尽更大的努力,并把 JavaScript 提高到更高的水平。让我们开展有意义的性能测试,以便为最终用户和开发者带来有意思的领域竞争。此外,让我们再对服务器和运行在 Node.js(还有 V8 和 ChakraCore)中的工具代码做一些有意义的改进!
|
||||
没人害怕竞争,但是玩弄可能已经坏掉的基准不像是在合理使用工程时间。我们可以尽更大的努力,并把 JavaScript 提高到更高的水平。让我们开展有意义的性能测试,以便为最终用户和开发者带来有意思的领域竞争。此外,让我们再对服务器和运行在 `Node.js`(还有 `V8` 和 `ChakraCore`)中的工具代码做一些有意义的改进!
|
||||
|
||||

|
||||
|
||||
结束语:不要用传统的 JavaScript 基准来比较手机。这是真正最没用的事情,因为 JavaScript 的性能通常取决于软件,而不一定是硬件,并且 Chrome 每 6 周发布一个新版本,所以你在三月的测试结果到了四月就已经毫不相关了。如果在浏览器中发送一个数字都一部手机不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 [Speedometer 基准][100]。
|
||||
结束语:不要用传统的 `JavaScript` 基准来比较手机。这是真正最没用的事情,因为 `JavaScript` 的性能通常取决于软件,而不一定是硬件,并且 `Chrome` 每 6 周发布一个新版本,所以你在三月的测试结果到了四月就已经毫不相关了。如果在浏览器中发送一个数字都一部手机不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 [Speedometer 基准][100]。
|
||||
|
||||
感谢你花时间阅读!
|
||||
|
||||
@ -563,8 +563,8 @@ $
|
||||
via: http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks
|
||||
|
||||
作者:[Benedikt Meurer][a]
|
||||
译者:[译者ID](https://github.com/OneNewLife)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
校对:[OneNewLife](https://github.com/OneNewLife)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
146
translated/tech/20170112 Partition Backup.md
Normal file
146
translated/tech/20170112 Partition Backup.md
Normal file
@ -0,0 +1,146 @@
|
||||
分区备份
|
||||
============
|
||||
|
||||
通常你可能会把数据放在一个分区上,尤其是通用串行总线(USB)设备。有时候可能需要对该设备或者上面的一个分区进行备份。树莓派用户为了可引导 SD 卡当然有这个需求。其它小型机的用户也会发现这非常有用。有时候设备看起来要出现故障时最好快速做个备份。
|
||||
|
||||
进行本文中的实验你需要一个叫 ‘dcfldd’ 的工具。
|
||||
|
||||
**dcfldd 工具**
|
||||
|
||||
该工具是 'coreutils' 软件包中 ‘dd’ 工具的增强版。‘dcfldd’ 是 Nicholas Harbour 在国防部计算机取证实验室(DCFL)工作期间研发的。该工具的名字也基于他工作的地方 - ‘dcfldd’。
|
||||
|
||||
对于仍然在使用 CoreUtils 8.23 或更低版本的系统,无法轻松查看正在创建副本的进度。有时候看起来就像什么都没有发生然后你就想取消掉备份。
|
||||
|
||||
**注意:**如果你使用 8.24 或更新版本的 ‘dd’ 工具,你就不需要使用 ‘dcfldd’,只需要用 ‘dd’ 替换 ‘dcfldd’ 即可。所有其它参数仍然适用。
|
||||
|
||||
在 Debian 系统上你只需要在 Package Manager 中搜索 ‘dcfldd’。你也可以打开一个终端然后输入下面的命令:
|
||||
|
||||
_sudo apt-get install dcfldd_
|
||||
|
||||
对于 Red Hat 系统,可以用下面的命令:
|
||||
|
||||
_cd /tmp
|
||||
wget dl.fedoraproject.org/pub/epel/6/i386/dcfldd-1.3.4.1-4.el6.i686.rpm
|
||||
sudo yum install dcfldd-1.3.4.1-4.el6.i686.rpm
|
||||
dcfldd --version_
|
||||
|
||||
**注意:** 上面的命令安装的是 32 位版本。对于 64 位版本,使用下面的命令:
|
||||
|
||||
_cd /tmp
|
||||
wget dl.fedoraproject.org/pub/epel/6/x86_64/dcfldd-1.3.4.1-4.el6.x86_64.rpm
|
||||
sudo yum install dcfldd-1.3.4.1-4.el6.x86_64.rpm
|
||||
dcfldd --version_
|
||||
|
||||
每组命令中的最后一个语句会列出 ‘dcfldd’ 的版本并显示该命令文件已经被加载。
|
||||
|
||||
**注意:**确保你以 root 用户执行 ‘dd’ 或者 ‘dcfldd’ 命令。
|
||||
|
||||
安装完该工具后你就可以继续使用它备份和恢复分区。
|
||||
|
||||
**备份分区**
|
||||
|
||||
备份设备的时候可以备份整个设备也可以只是其中的一个分区。如果设备有多个分区,我们可以分别备份每个分区。
|
||||
|
||||
在进行备份之前,先让我们来看一下设备和分区的区别。假设我们有一个已经被格式化为一大块设备 SD 卡。SD 卡只有一个分区。如果空间被切分使得 SD 卡看起来是两个设备,那么它就有两个分区。如果用类似 GParted 的程序打开 SD 卡,如图 1 所示,你可以看到它有两个分区。
|
||||
|
||||
**图 1**
|
||||
|
||||
设备 /dev/sdc 有 /dev/sdc1 和 /dev/sdc2 两个分区。
|
||||
|
||||
假设我们有一个树莓派中的 SD 卡。SD 卡容量为 8 GB,有两个分区(如图 1 所示)。第一个分区存放 BerryBoot 启动引导器。第二个分区存放 Kali(译者注:Kali Linux 是一个 Debian 派生的 Linux 发行版)。现在已经没有可用的空间用来安装第二个操作系统。我们使用大小为 16 GB 的第二个 SD 卡,但拷贝到第二个 SD 卡之前第一个 SD 卡必须先备份。
|
||||
|
||||
要备份第一个 SD 卡我们需要备份设备 /dev/sdc。进行备份的命令如下所示:
|
||||
|
||||
_dcfldd if=/dev/sdc of=/tmp/SD-Card-Backup.img_
|
||||
|
||||
备份包括输入文件(if)以及被设置为 '/tmp' 目录下名为 'SD-Card-Backup.img' 的输出文件(of)。
|
||||
|
||||
‘dd’ 和 ‘dcfldd’ 都是每次读写文件中的一个字节。通过上述命令,它一次读写的默认值为 512 个字节。记住,该复制是一个精准的拷贝 - 逐位逐字节。
|
||||
|
||||
默认的 512 个字节可以通过块大小参数 - ‘bs=’ 更改。例如,要每次读写 1 兆字节,参数为 ‘bs=1M’。以下所用的缩写有一些差异:
|
||||
|
||||
* b – 512 字节
|
||||
* KB – 1000 字节
|
||||
* K – 1024 字节
|
||||
* MB – 1000x1000 字节
|
||||
* M – 1024x1024 字节
|
||||
* GB – 1000x1000x1000 字节
|
||||
* G – 1024x1024x1024 字节
|
||||
|
||||
你也可以单独指定读和写的块大小。要指定读块的大小使用 ‘ibs=’。要指定写块的大小使用 ‘obs=’。
|
||||
|
||||
我使用三个不同的块大小做了一个 120 MB 分区的备份测试。第一个时候默认的 512 字节,它用了 7 秒钟。第二个块大小为 1024 K,它用时 2 秒。第三个块大小是 2048 K,它用时 3 秒。用时会随系统以及其它硬件实现的不同而变化,但通常来说更大的块大小会比默认的稍微快一点。
|
||||
|
||||
一旦你完成了一次备份,你还需要知道如何把数据恢复到设备中。
|
||||
|
||||
**恢复分区**
|
||||
|
||||
现在我们已经有了一个备份点,假设数据可能被损毁了或者由于某些原因需要进行恢复。
|
||||
|
||||
命令和备份时相同,只是源和目标相反。对于上面的例子,命令会变为:
|
||||
|
||||
_dcfldd of=/dev/sdc if=/tmp/SD-Card-Backup.img_
|
||||
|
||||
这里,镜像文件被用作输入文件(if)而设备(sdc)被用作输出文件(of)。
|
||||
|
||||
**注意:** 要记住输出设备会被重写,它上面的所有数据都会丢失。通常来说在恢复数据之前最好用 GParted 删除 SD 卡上的所有分区。
|
||||
|
||||
假如你在使用多个 SD 卡,例如多个树莓派主板,你可以一次性写多块 SD 卡。为了做到这点你需要知道系统中卡的 ID。例如,假设我们想把镜像 ‘BerryBoot.img’ 拷贝到两个 SD 卡。SD 卡分别是 /dev/sdc 和 /dev/sdd。下面的命令在显示进度时每次读写 1 MB 的块。命令如下:
|
||||
|
||||
_dcfldd if=BerryBoot.img bs=1M status=progress | tee >(dcfldd of=/dev/sdc) | dcfldd of=/dev/sdd_
|
||||
|
||||
在这个命令中,第一个 dcfldd 指定输入文件并把块大小设置为 1 MB。status 被设置为显示进度。然后输入通过管道(|)传输给命令 ‘tee’。‘tee’ 用于将输入分发到多个地方。第一个输出是到命令 ‘(dcfldd of=/dev/sdc)’。命令被放到小括号内被作为一个命令执行。我们还需要最后一个管道(|),否则命令 ‘tee’ 会把信息发送到 ‘stdout’ (屏幕)。因此,最后的输出是被发送到命令 ‘_dcfldd of=/dev/sdd’_。如果你有第三个 SD 卡,甚至更多,只需要添加另外的重定向和命令,类似 ‘_>(dcfldd of=/dev/sde_’。
|
||||
|
||||
**注意:**记住最后一个命令必须在管道(|)后面。
|
||||
|
||||
必须验证写的数据确保数据是正确的。
|
||||
|
||||
**验证数据**
|
||||
|
||||
一旦创建了一个镜像或者恢复了一个备份,你可以验证这些写的数据。要验证数据你会使用名为 ‘_diff_’ 的领一个不同程序。
|
||||
|
||||
使用 ‘diff’ 你需要指定镜像文件的位置以及系统中拷贝自或写入的物理媒介。你可以在创建备份或者恢复了一个镜像之后使用 ‘_diff_’ 命令。
|
||||
|
||||
该命令有两个参数。第一个是物理媒介,第二个是镜像文件名称。
|
||||
|
||||
对于例子 ‘_dcfldd of=/dev/sdc if=/tmp/SD-Card-Backup.img’_,对应的 ‘_diff_’ 命令是:
|
||||
|
||||
_diff /dev/sdc /tmp/SD-Card-Backup.img_
|
||||
|
||||
如果镜像和物理设备有任何的不同,你会被告知。如果没有显示任何信息,那么数据就验证为完全相同。
|
||||
|
||||
确保数据完全一致是验证备份和恢复完整性的关键。进行备份时需要注意的一个主要问题是镜像大小。
|
||||
|
||||
**分割镜像**
|
||||
|
||||
假设你想要备份一个 16GB 的 SD 卡。镜像文件大小会大概相同。如果你只能把它备份到 FAT32 分区会怎样呢?FAT32 最大文件大小限制是 4 GB。
|
||||
|
||||
必须做的是文件必须被切分为 4 GB 的分片。通过管道(|)将数据传输给 ‘_split_’ 命令可以切分正在被写的镜像文件。
|
||||
|
||||
创建备份的方法相同,但命令会包括管道和切分命令。对于命令为 ‘_dcfldd if=/dev/sdc of=/tmp/SD-Card-Backup.img_’ 的事例备份,切分文件的新命令如下:
|
||||
|
||||
_dcfldd if=/dev/sdc | split -b 4000MB - /tmp/SD-Card-Backup.img_
|
||||
|
||||
**注意:** 大小后缀和 ‘_dd_’ 及 ‘_dcfldd_’ 命令的意义相同。 ‘_split_’ 命令中的破折号用于将通过管道从 ‘_dcfldd_’ 命令传输过来的数据填充到输入文件。
|
||||
|
||||
文件会被保存为 ‘_SD-Card-Backup.imgaa_’ 和 ‘_SD-Card-Backup.imgab_’,如此类推。如果你担心文件大小太接近 4 GB 的限制,可以试着用 3500MB。
|
||||
|
||||
将文件恢复到设备也很简单。你使用 ‘_cat_’ 命令将它们连接起来然后像下面这样用 ‘_dcfldd_’ 写输出:
|
||||
|
||||
_cat /tmp/SD-Card-Backup.img* | dcfldd of=/dev/sdc_
|
||||
|
||||
你可以在 “_dcfldd_” 命令中包含任何需要的参数。
|
||||
|
||||
我希望你了解并能执行任何需要的数据备份和恢复,正如 SD 卡和类似设备所需的那样。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxforum.com/threads/partition-backup.3638/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||
@ -0,0 +1,138 @@
|
||||
Linux Shell 中的命令行别名
|
||||
============================================================
|
||||
|
||||
### 本文包括
|
||||
|
||||
1. [Linux 中的命令行别名][1]
|
||||
2. [相关细节][2]
|
||||
3. [总结][3]
|
||||
|
||||
到目前为止,在该系列指南中,我们已经讨论了 [cd -][5] 和 **pushd**/**popd** 命令的基本使用方法和相关细节,以及 **CDPATH** 环境变量。在这第四期、也是最后一期文章中,我们会讨论别名的概念以及你可以如何使用它们使你的命令行导航更加轻松和平稳。
|
||||
|
||||
一如往常,在进入该指南的核心之前,值得指出本文中的所有命令以及展示的例子都在 Ubuntu 14.04LTS 中进行了测试。我们使用的命令行 shell 是 bash(4.3.11 版本)。
|
||||
|
||||
### Linux 中的命令行别名
|
||||
|
||||
按照外行人的定义,别名可以被认为是一个复杂命令或者一组命令(包括它们的参数和选项)的简称或缩写。所以基本上,使用别名,你可以为那些不那么容易书写/记忆的命令创建易于记忆的名称。
|
||||
|
||||
例如,下面的命令为 'cd ~' 命令创建别名 ‘home’:
|
||||
|
||||
alias home="cd ~"
|
||||
|
||||
这意味着现在在你的系统中无论何地,无论何时你想要回到你的主目录时,你可以很快地输入 ‘home’ 然后按回车键实现。
|
||||
|
||||
关于 alias 命令,man 手册是这么描述的:
|
||||
|
||||
```
|
||||
alias 工具可以创建或者重定义别名定义,或者把现有别名定义输出到标准输出。别名定义提供了输入一个命令时应该被替换的字符串值
|
||||
|
||||
一个别名定义会影响当前 shell 的执行环境以及当前 shell 所有子 shell 的执行环境。按照 IEEE Std 1003.1-2001 规定,别名定义不应该影响当前 shell 的父进程以及任何 shell 调用的程序环境。
|
||||
```
|
||||
|
||||
那么,别名到底如何帮助命令行导航呢?这是一个简单的例子:
|
||||
|
||||
假设你正在 _/home/himanshu/projects/howtoforge_ 目录工作,它包括很多子目录以及子子目录。例如下面就是一个完整的目录分支:
|
||||
|
||||
```
|
||||
/home/himanshu/projects/howtoforge/command-line/navigation/tips-tricks/part4/final
|
||||
```
|
||||
|
||||
现在想象你在 ‘final’ 目录,然后你想回到 ‘tips-tricks’ 目录,然后再从那里,回到 ‘howtoforge’ 目录。你会怎么做呢?
|
||||
|
||||
是的,一般情况下,你会运行下面的一组命令:
|
||||
|
||||
cd ../..
|
||||
|
||||
cd ../../..
|
||||
|
||||
虽然这种方法并没有错误,但它绝对不方便,尤其是当你在一个很长的路径中想往回走例如说 5 个目录时。那么,有什么解决办法吗?答案就是:别名。
|
||||
|
||||
你可以做的是,为每个 _cd .._ 命令创建容易记忆(和书写)的别名。例如:
|
||||
|
||||
alias bk1="cd .."
|
||||
alias bk2="cd ../.."
|
||||
alias bk3="cd ../../.."
|
||||
alias bk4="cd ../../../.."
|
||||
alias bk5="cd ../../../../.."
|
||||
|
||||
现在无论你什么时候想从当前工作目录往回走,例如说 5 个目录,你只需要运行下面的命令:
|
||||
|
||||
bk5
|
||||
|
||||
现在这不是很简单吗?
|
||||
|
||||
### 相关细节
|
||||
|
||||
尽管当前我们在 shell 中用于定义别名的技术(通过使用 alias 命令)实现了效果,别名只存在于当前终端会话。很有可能你会希望你定义的别名能保存下来,使得此后你可以在任何新启动的命令行窗口/标签页中使用它们。
|
||||
|
||||
为此,你需要在 _~/.bash\_aliases_ 文件中定义你的别名,你的 _~/.bashrc_ 文件默认会加载该文件(如果你使用更早版本的 Ubuntu,请验证这点)。
|
||||
|
||||
下面是我的 .bashrc 文件中关于 .bash\_aliases 文件的部分:
|
||||
|
||||
```
|
||||
# Alias definitions.
|
||||
# You may want to put all your additions into a separate file like
|
||||
# ~/.bash_aliases, instead of adding them here directly.
|
||||
# See /usr/share/doc/bash-doc/examples in the bash-doc package.
|
||||
|
||||
if [ -f ~/.bash_aliases ]; then
|
||||
. ~/.bash_aliases
|
||||
fi
|
||||
```
|
||||
|
||||
一旦你把别名定义添加到你的 .bash\_aliases 文件,该别名在任何新终端中都可用。但是,在任何其它你定义别名时已经启动的终端中,你还不能使用它们 - 解决办法是在这些终端中重新加载 .bashrc。下面就是你需要执行的具体命令:
|
||||
|
||||
source ~/.bashrc
|
||||
|
||||
如果你觉得这要做的也太多了(是的,我期待你更懒惰的办法),那么这里有一个快捷方式来做到这一切:
|
||||
|
||||
"alias [the-alias]" >> ~/.bash\_aliases && source ~/.bash\_aliases
|
||||
|
||||
毫无疑问,你需要用实际的命令替换 [the-alias]。例如:
|
||||
|
||||
"alias bk5='cd ../../../../..'" >> ~/.bash\_aliases && source ~/.bash\_aliases
|
||||
|
||||
接下来,假设你已经创建了一些别名,并时不时使用它们有一段时间了。突然有一天,你发现它们其中的一个并不像期望的那样。因此你觉得需要查看被赋予该别名的真正命令。你会怎么做呢?
|
||||
|
||||
当然,你可以打开你的 .bash\_aliases 文件在那里看看,但这种方式可能有点费时,尤其是当文件中包括很多别名的时候。因此,如果你正在查找一种更简单的方式,这就有一个:你需要做的只是运行 _alias_ 命令并把别名名称作为参数。
|
||||
|
||||
这里有个例子:
|
||||
|
||||
$ alias bk6
|
||||
alias bk6='cd ../../../../../..'
|
||||
|
||||
你可以看到,上面提到的命令显示了被赋值给别名 bk6 的实际命令。这里还有另一种办法:使用 _type_ 命令。下面是一个例子:
|
||||
|
||||
$ type bk6
|
||||
bk6 is aliased to `cd ../../../../../..'
|
||||
|
||||
type 命令产生了一个易于人类理解的输出。
|
||||
|
||||
另一个值得分享的是你可以将别名用于常见的输入错误。例如:
|
||||
|
||||
alias mroe='more'
|
||||
|
||||
_最后,还值得注意的是并非每个人都喜欢使用别名。他们中的大部分人认为一旦你习惯了你为了简便而定义的别名,当你在其它相同而不存在别名(而且不允许你创建)的系统中工作时就会变得非常困难。更多(也是更准确的)为什么一些专家不推荐使用别名的原因,你到[这里][4]查看。_
|
||||
|
||||
### 总结
|
||||
|
||||
就像我们之前文章讨论过的 CDPATH 环境变量,别名也是一把应该谨慎使用的双刃剑。尽管如此也别太丧气,因为每个东西都有它自己的好处和劣势。遇到类似别名的概念时,更多的练习和完备的知识才是重点。
|
||||
|
||||
那么这就是该系列指南的最后章节。希望你喜欢它并能从中学到新的东西/概念。如果你有任何疑问或者问题,请在下面的评论框中和我们(以及其他人)分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/
|
||||
[1]:https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/#command-line-aliases-in-linux
|
||||
[2]:https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/#related-details
|
||||
[3]:https://www.howtoforge.com/tutorial/command-line-aliases-in-linux/#conclusion
|
||||
[4]:http://unix.stackexchange.com/questions/66934/why-is-aliasing-over-standard-commands-not-recommended
|
||||
[5]:https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/
|
||||
@ -0,0 +1,131 @@
|
||||
在 Linux 上使用 Meld 比较文件夹
|
||||
============================================================
|
||||
|
||||
### 本文导航
|
||||
1. [用 Meld 比较文件夹][1]
|
||||
2. [总结][2]
|
||||
|
||||
我们已经从一个新手的角度了解了 Meld (包括 Meld 的安装),我们也提及了一些 Meld 中级用户常用的小技巧。如果你有印象,在新手教程中,我们说过 Meld 可以比较文件和文件夹。已经讨论过怎么讨论文件,今天,我们来看看 Meld 怎么比较文件夹。
|
||||
|
||||
本教程中的所有命令和例子都是在 Ubuntu 14.04 上测试的,使用的 Meld 版本基于 3.14.2 版。
|
||||
|
||||
|
||||
### 用 Meld 比较文件夹
|
||||
打开 Meld 工具,然后选择_比较文件夹_选项来比较两个文件夹。
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
选择你要比较的文件夹:
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
然后单击_比较_按钮,你会看到 Meld 像图中这样分成两栏显示。
|
||||
[
|
||||

|
||||
][7]
|
||||
分栏会树形显示这些文件/文件夹。你可以在上图中看到明显的区别——不论文件是新建的还是被修改过的——都会以不同的颜色高亮显示。
|
||||
|
||||
根据 Meld 的官方文档可以知道在窗口中看到的每个不同的文件或文件夹都会被突出显示。这样就很容易看出这个文件/文件夹与另一个分栏中对应位置的文件/文件夹的区别。
|
||||
|
||||
下表是 Meld 网站上列出的在比较文件夹时突出显示的不同字体大小/颜色/背景等代表的含义。
|
||||
|
||||
|
||||
|**State** | **Appearance** | **Meaning** |
|
||||
| --- | --- | --- |
|
||||
| Same | Normal font | The file/folder is the same across all compared folders. |
|
||||
| Same when filtered | Italics | These files are different across folders, but once text filters are applied, these files become identical. |
|
||||
| Modified | Blue and bold | These files differ between the folders being compared. |
|
||||
| New | Green and bold | This file/folder exists in this folder, but not in the others. |
|
||||
| Missing | Greyed out text with a line through the middle | This file/folder doesn't exist in this folder, but does in one of the others. |
|
||||
| Error | Bright red with a yellow background and bold | When comparing this file, an error occurred. The most common error causes are file permissions (i.e., Meld was not allowed to open the file) and filename encoding errors. |
|
||||
Meld 默认会列出文件夹中的所有内容,即使这些内容没有任何不同。当然,你也可以在工具栏中单击_同样的_按钮设置 Meld 不显示这些相同的文件/文件夹——单击这个按钮使其不可用。
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
下面是单击_同样的_按钮使其不可用的截图:
|
||||
[
|
||||

|
||||
][9]
|
||||
这样你会看到只显示了两个文件夹中不同的文件(新建的和修改过的)。同样,如果你单击_新建的_按钮使其不可用,那么 Meld 就只会列出修改过的文件。所以,在比较文件夹时可以通过这些按钮自定义要显示的内容。
|
||||
|
||||
你可以使用上下箭头来切换选择是显示新建的文件还是修改过的文件,然后打开两个文件进行分栏比较。双击文件或者单击箭头旁边的_比较_按钮都可以进行分栏比较。。
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
**提示 1**:如果你仔细观察,就会看到 Meld 窗口的左边和右边有一些小进度块。这些进度块就像是“用颜色区分的包含不同文件/文件夹的数个区段”。每个区段都由很多的小进度块组成,而一个个小小的有颜色的进度块就表示此处有不同的文件/文件夹。你可以单击每一个这样的小小进度块跳到它对应的文件/文件夹。
|
||||
|
||||
|
||||
**提示 2**:尽管你经常分栏比较文件然后以你的方式合并不同的文件,假如你想要合并所有不同的文件/文件夹(就是说你想要把一个文件夹中特有的文件/文件夹添加到另一个文件夹中),那么你可以用_复制到左边_和_复制到右边_按钮:
|
||||
[
|
||||

|
||||
][11]
|
||||
比如,你可以在左边的分栏中选择一个文件或文件夹,然后单击_复制到右边_按钮在右边的文件夹中对应的位置新建完全一样的文件或文件夹。
|
||||
|
||||
现在,在窗口的下栏菜单中找到_过滤_按钮,它就在_同样的_、_新建的_和_修改过的_ 这三个按钮下面。这里你可以选择或取消文件的类型来让 Meld 在比较文件夹时决定是否显示这种类型的文件/文件夹。官方文档解释说菜单中的这个条目表示“被匹配到的文件不会显示。”
|
||||
|
||||
这个条目包括备份文件,操作系统元数据,版本控制文件、二进制文件和多媒体文件。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
前面提到的条目也可以通过这样的方式找到:_浏览->文件过滤_。你可以同过 _编辑->首选项->文件过滤_ 为这个条目增加新元素(也可以删除已经存在的元素)。
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
要新建一个过滤条件,你需要使用一组 shell 符号,下表列出了 Meld 支持的 shell 符号:
|
||||
|
||||
|
||||
| **Wildcard** | **Matches** |
|
||||
| --- | --- |
|
||||
| * | anything (i.e., zero or more characters) |
|
||||
| ? | exactly one character |
|
||||
| [abc] | any one of the listed characters |
|
||||
| [!abc] | anything except one of the listed characters |
|
||||
| {cat,dog} | either "cat" or "dog" |
|
||||
最重要的一点是 Meld 的文件名默认大小写敏感。也就是说,Meld 认为 readme 和 ReadMe 与 README 是不一样的文件。
|
||||
|
||||
幸运的是,你可以关掉 Meld 的大小写敏感。只需要打开_浏览_菜单然后选择_忽略文件名大小写_选项。
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
### 结论
|
||||
你是否觉得使用 Meld 比较文件夹很容易呢——事实上,我认为它相当容易。只有新建一个过滤器会花点时间,但是这不意味着你没必要学习创建过滤器。显然,这取决于你要过滤的内容。
|
||||
|
||||
真的很棒,你甚至可以用 Meld 比较三个文件夹。想要比较三个文件夹时你可以通过_单击 3 个比较_ 复选框。今天,我们不介绍怎么比较三个文件夹,但它肯定会出现在后续的教程中。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/#compare-directories-using-meld
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/#conclusion
|
||||
[3]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-same-button.png
|
||||
[4]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux/
|
||||
[5]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-dir-comp-1.png
|
||||
[6]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-sel-dir-2.png
|
||||
[7]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-dircomp-begins-3.png
|
||||
[8]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-same-disabled.png
|
||||
[9]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-only-diff.png
|
||||
[10]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-compare-arrows.png
|
||||
[11]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-copy-right-left.png
|
||||
[12]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-filters.png
|
||||
[13]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-edit-filters-menu.png
|
||||
[14]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-ignore-case.png
|
||||
@ -0,0 +1,198 @@
|
||||
bmon - Linux 下一个强大的网络带宽监视和调试工具
|
||||
============================================================
|
||||
|
||||
bmon 是类 Unix 系统中一个基于文本,简单但非常强大的 [网络监视和调试工具][1],它能抓取网络相关统计信息并把它们以用户友好的格式展现出来。它是一个可靠高效的带宽监视和网速预估器。
|
||||
|
||||
它能使用各种输入模块读取输入,并以各种输出模式显示输出,包括交互式用户界面和用于脚本编写的可编程文本输出。
|
||||
|
||||
**推荐阅读:** [监控 Linux 性能的20个命令行工具][2]
|
||||
|
||||
### 在 Linux 上安装 bmon 带宽监视工具
|
||||
|
||||
几乎所有 Linux 发行版的默认仓库中都有 bmon 软件包,可以从默认包管理器中轻松安装,但可用的版本可能比较旧。
|
||||
|
||||
```
|
||||
$ sudo yum install bmon [On RHEL/CentOS/Fedora]
|
||||
$ sudo dnf install bmon [On Fedora 22+]
|
||||
$ sudo apt-get install bmon [On Debian/Ubuntu/Mint]
|
||||
```
|
||||
|
||||
另外,你也可以从 [https://pkgs.org/download/bmon][3] 获取对应你 Linux 发行版的 `.rpm` 和 `.deb` 软件包。
|
||||
|
||||
如果你想要最新版本(例如版本4.0)的 bmon,你需要通过下面的命令从源码构建。
|
||||
|
||||
#### 在 CentOS、RHEL 和 Fedora 中
|
||||
|
||||
```
|
||||
$ git clone https://github.com/tgraf/bmon.git
|
||||
$ cd bmon
|
||||
$ sudo yum install make libconfuse-devel libnl3-devel libnl-route3-devel ncurses-devel
|
||||
$ sudo ./autogen.sh
|
||||
$ sudo./configure
|
||||
$ sudo make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
#### 在 Debian、Ubuntu 和 Linux Mint 中
|
||||
|
||||
```
|
||||
$ git clone https://github.com/tgraf/bmon.git
|
||||
$ cd bmon
|
||||
$ sudo apt-get install build-essential make libconfuse-dev libnl-3-dev libnl-route-3-dev libncurses-dev pkg-config dh-autoreconf
|
||||
$ sudo ./autogen.sh
|
||||
$ sudo ./configure
|
||||
$ sudo make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
### 如何在 Linux 中使用 bmon 带宽监视工具
|
||||
|
||||
通过以下命令运行它(给初学者:RX 表示每秒接收数据,TX 表示每秒发送数据):
|
||||
|
||||
```
|
||||
$ bmon
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
按 `d` 键可以查看更详细的带宽使用情况的图形化统计信息,参考下面的截图。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
按 `[Shift + ?]` 可以查看快速指南。再次按 `[Shift + ?]` 可以退出(指南)界面。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
bmon – 快速指南
|
||||
|
||||
通过 `Up` 和 `Down` 箭头键可以查看特定网卡的统计信息。但是,要监视一个特定的网卡,你也可以像下面这样作为命令行参数指定。
|
||||
|
||||
**推荐阅读:** [监控 Linux 性能的13个工具][7]
|
||||
|
||||
标签 `-p` 指定了要显示的网卡,在下面的例子中,我们会监视网卡 `enp1s0`:
|
||||
|
||||
```
|
||||
$ bmon -p enp1s0
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
bmon – 监控以太网带宽
|
||||
|
||||
要查看每秒位数而不是字节数,可以像下面这样使用 `-b` 标签:
|
||||
|
||||
```
|
||||
$ bmon -bp enp1s0
|
||||
```
|
||||
|
||||
我们也可以像下面这样指定每秒的间隔数:
|
||||
|
||||
```
|
||||
$ bmon -r 5 -p enp1s0
|
||||
```
|
||||
|
||||
### 如何使用 bmon 的输入模块
|
||||
### How to Use bmon Input Modules
|
||||
|
||||
bmon 有很多能提供网卡统计数据的输入模块,其中包括:
|
||||
|
||||
1. netlink - 使用 Netlink 协议从内核中收集网卡和流量控制统计信息。这是默认的输入模块。
|
||||
2. proc - 从 /proc/net/dev 文件读取网卡统计信息。它被认为是传统界面,且提供了向后兼容性。它是 Netlink 接口不可用时的备用模块。
|
||||
3. dummy - 这是用于调试和测试的可编程输入模块。
|
||||
4. null - 停用数据收集。
|
||||
|
||||
要查看关于某个模块的其余信息,可以像下面这样使用 “help” 选项调用它:
|
||||
|
||||
```
|
||||
$ bmon -i netlink:help
|
||||
```
|
||||
|
||||
下面的命令将启用 proc 输入模块运行 bmon:
|
||||
|
||||
```
|
||||
$ bmon -i proc -p enp1s0
|
||||
```
|
||||
|
||||
### 如何使用 bmon 输出模块
|
||||
|
||||
bmon 也使用输出模块显示或者导出上面输入模块收集的统计数据,输出模块包括:
|
||||
|
||||
1. curses - 这是一个交互式的文本用户界面,它提供实时的网上估计以及每个属性的图形化表示。这是默认的输出模块。
|
||||
2. ascii - 这是用于用户查看的简单可编程文本输出。它能显示网卡列表、详细计数以及图形到控制台。当 curses 不可用时这是默认的备选输出模块。
|
||||
3. format - 这是完全脚本化的输出模式,供其它程序使用 - 意味着我们可以在后面的脚本和程序中使用它的输出值进行分析。
|
||||
4. null - 停用输出。
|
||||
|
||||
像下面这样通过 “help” 标签获取更多的模块信息。
|
||||
To get more info concerning a module, run the it with the “help” flag set like so:
|
||||
|
||||
```
|
||||
$ bmon -o curses:help
|
||||
```
|
||||
|
||||
下面的命令会用 ascii 输出模式运行 bmon:
|
||||
```
|
||||
$ bmon -p enp1s0 -o ascii
|
||||
```
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
bmon – Ascii 输出模式
|
||||
|
||||
我们也可以用 format 输出模式,然后在脚本或者其它程序中使用获取的值:
|
||||
|
||||
```
|
||||
$ bmon -p enp1s0 -o format
|
||||
```
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
bmon – Format 输出模式
|
||||
|
||||
想要其它的使用信息、选项和事例,可以阅读 bmon 的 man 手册:
|
||||
|
||||
```
|
||||
$ man bmon
|
||||
```
|
||||
|
||||
访问 bmon 的Github 仓库:[https://github.com/tgraf/bmon][11].
|
||||
|
||||
就是这些,在不同场景下尝试 bmon 的多个功能吧,别忘了在下面的评论部分和我们分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者、Linux 系统管理员、网络开发人员,现在也是 TecMint 的内容创作者,她喜欢和电脑一起工作,坚信共享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/bmon-network-bandwidth-monitoring-debugging-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/bcc-best-linux-performance-monitoring-tools/
|
||||
[2]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[3]:https://pkgs.org/download/bmon
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Linux-Bandwidth-Monitoring.gif
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Detailed-Bandwidth-Statistics.gif
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Quick-Reference.png
|
||||
[7]:http://www.tecmint.com/linux-performance-monitoring-tools/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Monitor-Ethernet-Bandwidth.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-Ascii-Output-Mode.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/02/bmon-format-output-mode.png
|
||||
[11]:https://github.com/tgraf/bmon
|
||||
@ -0,0 +1,128 @@
|
||||
# OpenSUSE Leap 42.2 Gnome - 好些了但是还不是那么好
|
||||
|
||||
更新: 2017 年二月六号
|
||||
|
||||
是时候再给 Leap 一个机会了。让我再罗嗦一下。给 Leap 一次机会吧。是的。几周之前,我回顾了最新的 [openSUSE][1] 发行版的 Plasma 版本,虽然它火力全开,就像经典的帝国冲锋队(注:帝国冲锋队是科幻电影《星球大战》系列中,隶属反派政权银河帝国下的军事部队),但是多部分攻击没有命中要害。这是一个相对普通的,传递一切,但是缺少精华的发行版。
|
||||
|
||||
我现在将做一个 Gnome 的实验。为这个发行版搭载一个全新的桌面环境,同时观察它的表现。我们最近在 CentOS 上做了一些类似的事情,但是得到了相当惊讶的结果。我们可能受幸运之神祝福。现在开始动手。
|
||||
|
||||

|
||||
|
||||
### 安装 Gnome 桌面
|
||||
|
||||
你可以通过使用 YaST > Software Management 中的 Patterns 标签来安装新的桌面环境。特别的,你可以安装 Gnome, Xfce, LXQt, MATE 以及其他桌面环境。一个非常简单的过程需要大概 900M 的磁盘空间。没有错误,没有警告。
|
||||
|
||||

|
||||
|
||||
### Gnome 的美化工作
|
||||
|
||||
我花费了较短时间来征服 openSUSE。鉴于我拥有大量的在 [Fedora 24][2] 上做相同工作,如[拉皮条(原文:pimping)][3],的经验,所以这个过程是相当快和简单的。首先,获得一些 Gnome [扩展][4]。静待 20 分钟,搅拌并服务于粘土碗(原文:Stir and serve in clay bowls)。
|
||||
|
||||
对于餐后甜点,开启 Gnome Tweak Tool ,然后添加一些窗口按钮。最重要的,安装最最重要的,救命的插件 - [Dash to Dock][5]。因为之后你终于可以想人类一样工作,而没有使人恼火的的低效率活动。消化,调整一些新的图标。这个工作最终耗时 42 分 12 秒。明白了吗?42.2 分钟。天啊。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 别的定制和增强
|
||||
|
||||
我实际上在 Gnome 中使用 Breeze 窗口装饰,而且工作地挺好。这比你尝试去个性化 Plasma 要好的多。看了一眼后流泪了,因为这个界面看起来太可怕了。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 智能手机支持
|
||||
|
||||
比 Plasma 好太多了 - [iPhone][7] 和 [Ubuntu Phone][8] 都可以正常的识别和挂载。这个提醒了所有 CentOS 7.2 的 [KDE][9] 和 [Gnome][10] 行为的差异和不一致。所以这个肯定跨越了特殊平台的界限。桌面环境有这个通病。
|
||||
|
||||

|
||||
|
||||
一个显著的 bug 是你需要时常清理图标的缓存,否则你会在文件管理器里面看到老的图标。关于这个问题,我很快会有一整个文章来说明。
|
||||
|
||||
### 多媒体
|
||||
|
||||
不幸的是,Gnome 出现了和 Plasma 相同的问题。缺少依赖。没有 H.264 编码,意味着你不可以看99%你需要的东西。这就像是,一个月没有网。
|
||||
|
||||

|
||||
|
||||
### 资源利用
|
||||
|
||||
Gnome 版本比 Plasma 更快,即使合成器(原文:Compositor)关掉,可以忽略 KWin 崩溃以及反应迟缓。CPU 的利用率在 2-3%,内存使用率徘徊在 900M。我觉得应该处于中游。
|
||||
|
||||

|
||||
|
||||
### 电池消耗
|
||||
|
||||
实际上 Gnome 的电池损耗比 Plasma 严重。不确定为什么。但是即使屏幕亮度调到 50%,Leap Gnome 只能给我的 G50 续航大约 2.5 小时。我没有深究电池消耗在什么地方,但是它却确实消耗很快。
|
||||
|
||||

|
||||
|
||||
### 奇怪的问题
|
||||
|
||||
Gnome 也有一些小毛病和错误。比如说,桌面不停地请求无线网络的密码,可能是我的 Gnome 没有很好地处理 KWallet 或者别的什么。同时,在我注销 Plasma 会话之后,KWi仍然在运行,消耗了100% 的 CPU 直到我杀死这个进行。真是一件丢人的事。
|
||||
|
||||

|
||||
|
||||
### 硬件支持
|
||||
|
||||
暂停并恢复,一切顺利。我至今没有在 Gnome 版本中体验断网。webcam 同样工作。总之,硬件支持貌似相当好。蓝牙也正常工作。哇!可能是我们在网络下标注它。(原文:To wit)
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 网络
|
||||
|
||||
利用 Samba 打印?你有相同的,差劲的小应用程序,就像在 [Yakkety Yak][11],它把视野全弄乱了。但是之后,它说没有打印共享,请检查防火墙。无论如何,这部在是 1999 年了。能够打印不再是一项特权,而是一个基本人的权利。人类在这上面已经举行变革。但是,我没有在这个上面进行截图。太糟了。
|
||||
|
||||
### 剩下的呢?
|
||||
|
||||
总而言之,这是一个标准的 Gnome 桌面,带有它的一点点智力上的挑战的方式去计算和人类工程学,也可以通过扩展的严密使用来驯服。它比 Plasma 更友好一些,你可以在大多数日常的工作中,得到更好的结果。之后,你就会被选项的缺少困住,但是这些选项在 Plasma 中压倒性地多。但是你要记住,你的桌面不再每分钟都反应迟缓,这确实是个奖励。
|
||||
|
||||
### 结论
|
||||
|
||||
OpenSUSE Leap 42.2 Gnome 是一个比 Plasma 部分更好的产品,而且没有错误。它更稳定,更快,更加优雅,更加容易定制,而且那些关键的日常功能都确定工作。例如,如果你倾向于不用防火墙,你可以打印到 Samba,在不失去时间戳的情况下拷贝文件到 Samba 服务器,使用蓝牙,使用你的 Ubuntu 手机,而且这些都不会出现很严重结果的崩溃。整个栈是非常有特色,并且更好地被支持。
|
||||
|
||||
然而,Leap 仍然是一个合理的发行版。它在一些其他发行版处理地优秀和高雅的核心地域挣扎,而且比较差的 QA,直接导致了许多大而显著的问题。至少,质量的缺失已经成为过去这些年 openSUSE 几乎不变的元素。现在或者将来,你会得到一个相当好的幼体。但是它们中大多很普通。这就是大概最能定义 openSUSE Leap 的词,普通。你应该自己去尝试和观察。你很有可能不会惊讶。这个羞愧的事情,因为对我来说,SUSE 有一个充满乐趣的地方,并且现在它倔强地拒绝重新点燃爱火。
|
||||
|
||||
干杯。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是 Igor Ljubuncic。现在大约 38 岁,已婚但还没有孩子。我现在在一个大胆创新的云科技公司做首席工程师。直到大约 2015 年初,我还在一个全世界最大的 IT 公司之一中做系统架构工程师,和一个工程计算团队开发新的基于 Linux 的解决方案,优化内核以及攻克 Linux 的问题。在那之前,我是一个为高性能计算环境设计创新解决方案的团队的技术领导。还有一些其他花哨的头衔,包括系统专家、系统程序员等等。所有这些都曾是我的爱好,但从 2008 年开始成为了我的有偿的工作。还有什么比这更令人满意的呢?
|
||||
|
||||
从 2004 年到 2008 年间,我曾通过作为医学影像行业的物理学家来糊口。我的工作专长集中在解决问题和算法开发。为此,我广泛地使用了Matlab,主要用于信号和图像处理。另外,我得到了几个主要的工程方法学的认证,包括 MEDIC 六西格玛绿带、试验设计以及统计工程学。
|
||||
|
||||
我也写过书,包括《Linux 上的高幻想和技术工作》和《相互包容》。
|
||||
|
||||
请参阅我的完整开源项目,出版物和专利列表,只需向下滚动。
|
||||
|
||||
有关我的奖项、提名和 IT 相关认证的完整列表,请进行跳转。
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/opensuse-42-2-gnome.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.dedoimedo.com/computers/opensuse-42-2.html
|
||||
[2]:http://www.dedoimedo.com/computers/fedora-24-gnome.html
|
||||
[3]:http://www.dedoimedo.com/computers/fedora-24-pimp.html
|
||||
[4]:http://www.dedoimedo.com/computers/fedora-23-extensions.html
|
||||
[5]:http://www.dedoimedo.com/computers/gnome-3-dash.html
|
||||
[6]:http://www.dedoimedo.com/computers/fedora-24-pimp-more.html
|
||||
[7]:http://www.dedoimedo.com/computers/iphone-6-after-six-months.html
|
||||
[8]:http://www.dedoimedo.com/computers/ubuntu-phone-sep-2016.html
|
||||
[9]:http://www.dedoimedo.com/computers/lenovo-g50-centos-kde.html
|
||||
[10]:http://www.dedoimedo.com/computers/lenovo-g50-centos-gnome.html
|
||||
[11]:http://www.dedoimedo.com/computers/ubuntu-yakkety-yak.html
|
||||
@ -0,0 +1,266 @@
|
||||
如何安装 Devuan Linux (Debian 的复刻)
|
||||
============================================================
|
||||
|
||||
|
||||
Devuan Linux 是 Debian 最新的复刻,是基于 Debian 的一个被设计为完全自由的系统版本。
|
||||
|
||||
据宣布,在 2014 年年底那段时间已经开发出 Devuan 。最新的发行版本是 beta2,发行代号为: Jessie (和当前 Debian 的稳定版同名)。
|
||||
|
||||
当前稳定版的最后发行据说会在 2017 年初。如果想了解关于该项目的更多信息,请访问社区官网:[https://devuan.org/][1] 。
|
||||
|
||||
本文将阐述 Devuan 当前发行版的安装。在 Debian 上可用的大多数包在 Devuan 上也是可用的,这有利于用户从 Debian 到 Devuan 的无缝过渡,他们应该更喜欢自由选择自己的初始化系统。
|
||||
|
||||
#### 系统要求
|
||||
|
||||
Devuan 和 Debian 类似,对系统的要求非常低。最大的决定性因素是,用户希望使用什么样的桌面环境。这篇指南假设用户将使用一个“虚拟”桌面环境,建议至少满足下面所示的最低系统要求:
|
||||
|
||||
1. 至少 15GB 的硬盘空间;强烈鼓励有更大空间
|
||||
2. 至少 2GB 的内存空间;鼓励更多
|
||||
3. 支持 USB 或 CD/DVD 启动
|
||||
4. 网络连接;安装过程中将会从网上下载文件
|
||||
|
||||
### Devuan Linux 安装
|
||||
|
||||
正如所有的指南一样,这篇指南假设有一个 USB 驱动器,可作为安装媒介。注意,USB 驱动器应该有大约 4/8GB 大,并且需要删除所有数据。
|
||||
|
||||
我警告不要使用太大的 USB 驱动器,但还是有人会使用。无论如何,在接下来的一些步骤中,将导致 USB 驱动上的数据全部丢失。
|
||||
|
||||
在开始准备安装之前,请先备份 USB 驱动器上的所有数据。这个可启动的 Kali Linux USB 启动器将在另一个 Linux 系统上创建。
|
||||
|
||||
1、首先,从 [https://devuan.org/][2] 获取最新发行版的 Devuan 安装镜像,或者,你也可以在 Linux 终端上输入下面的命令来获取安装镜像:
|
||||
|
||||
```
|
||||
$ cd ~/Downloads
|
||||
$ wget -c https://files.devuan.org/devuan_jessie_beta/devuan_jessie_1.0.0-beta2_amd64_CD.iso
|
||||
```
|
||||
|
||||
2、上面的命令将会把安装镜像文件下载到用户的 ‘Downloads’ 目录。下一步是把安装镜像写入 USB 驱动器中,从而启动安装程序。
|
||||
|
||||
为了写入镜像,需要使用一个在 Linux 中叫做 `dd` 的工具。首先,需要使用 [lsblk 命令][3]来定位硬盘名字:
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*找到 Linux 中的设备名字*
|
||||
|
||||
USB 驱动器的名字为 `/dev/sdc`,现在,可以使用 `dd` 工具把 Devuan 镜像写入驱动器中:
|
||||
|
||||
```
|
||||
$ sudo dd if=~/Downloads/devuan_jessie_1.0.0-beta2_amd64_CD.iso of=/dev/sdc
|
||||
```
|
||||
|
||||
重点:上面的命令需要有 root 权限,你可以使用 ‘sudo’ 或者以 root 用户登录来运行命令。同时,这个命令将会删除 USB 驱动器上的所有数据,所以请确保备份了需要的数据。
|
||||
|
||||
3、当镜像写入 USB 驱动以后,把 USB 驱动插入要安装 Devuan 的电脑上,然后从 USB 驱动器启动电脑。
|
||||
|
||||
从 USB 驱动器成功启动以后,将会出现下面所示的屏幕,你需要在 ‘Install’ 和 ‘Graphical Install’ 这两个选项间选择一个继续安装进程。
|
||||
|
||||
在这篇指南中,我将使用 ‘Graphical Install’ 方式。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*Devuan Graphic 安装*
|
||||
|
||||
4、当安装程序启动到定位菜单以后,将会提示用户选择键盘布局和语言。只需选择你想要的选项,然后继续安装
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
*Devuan 语言选择*
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*Devuan 定位选择*
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*Devuan 键盘配置*
|
||||
|
||||
5、下一步是向安装程序提供主机名和电脑所属的域名
|
||||
|
||||
需要填写一个独一无二的主机名,但如果电脑不属于任何域,那么域名可以不填。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*设置 Devuan Linux 的主机名*
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
*设置 Devuan Linux 的域名*
|
||||
|
||||
6、填好主机名和域名信息以后,需要提供一个 ‘root’ 用户密码。
|
||||
|
||||
请务必记住这个密码,因为当你在这台 Devuan 机器上执行管理任务时需要提供这个密码。默认情况下, Devuan 不会安装 ‘sudo’ 包,所以当安装完成以后,管理用户就是 root 用户。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
*设置 Devuan Linux Root 用户*
|
||||
|
||||
7、下一步需要做的事情是创建一个非 root 用户。在任何可能的情况下,避免以 root 用户使用系统总是更好的。此时,安装程序将会提示你创建一个非 root 用户。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
*创建 Devuan Linux 用户账户*
|
||||
|
||||
8、一旦输入 root 用户密码,提示非 root 用户已经创建好以后,安装程序将会请求[通过 NTP 设置时钟][13]
|
||||
|
||||
这时需要再次连接网络,大多数系统都需要这样。
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
*设置 Devuan Linux 的时区*
|
||||
|
||||
9、下一步需要做的是系统分区。对于绝大多数用户来说,通常是使用整个硬盘,这是典型、高效的。然而,如果需要进行高级分区,现在是时候来进行分区了。
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
*Devuan Linux 分区*
|
||||
|
||||
在上面点击 ‘continue’ 以后,请确保确认分区更改,从而把分区写入硬盘。
|
||||
|
||||
10、分区完成以后,安装程序为 Devuan 安装一些基础文件。这个过程将会花费几分钟时间,直到系统开始配置网络镜像(软件库)才会停下来。当提示使用网络镜像时,通常点击 ‘yes’。
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
*Devuan Linux 配置包管理器*
|
||||
|
||||
点击 'yes' 以后将会给用户呈现一系列以国家分类的网络镜像。通常最好选择地理位置上离电脑最近的镜像。
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
*Devuan Linux 镜像选择*
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
*Devuan Linux 镜像*
|
||||
|
||||
11、下一步是设置 Debian 传统的 ‘popularity contest’ ,它能够追踪已下载包的使用统计。
|
||||
|
||||
在安装过程中,可以在管理员首选项中启用或禁用该功能。
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
*配置 Devuan Linux 的 Popularity Contest*
|
||||
|
||||
12、在简单浏览仓库和一些包的更新以后,安装程序会给用户展示一系列软件包,安装这些包可以提供一个桌面环境、SSH 访问和其他系统工具。
|
||||
|
||||
Devuan 会列举出一些主流桌面环境,但应该指出的是,并不是所有的桌面在 Devuan 上均可用。幸运的是,作者在 Devuan 上使用过 Xfce 、LXDE 和 Mate ,这几个均可用(未来的文章将会探究如何从源代码安装这些桌面环境)。
|
||||
|
||||
如果对安装一个不同的桌面环境感兴趣,不要点击 ‘Devuan Desktop Environment’ 复选框。
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
*Devuan Linux 软件选择*
|
||||
|
||||
根据在上面的安装屏幕中选择的项目数,可能需要几分钟的时间来下载和安装软件。
|
||||
|
||||
当所有的软件都安装好以后,安装程序将会提示用户选择 ‘grub’ 的安装位置。典型情况是选择安装在 ‘/dev/sda’ 目录下。
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
*Devuan Linux 安装 grub 引导程序*
|
||||
|
||||
[
|
||||

|
||||
][22]
|
||||
|
||||
*Devuan Linux Grub 程序的安装硬盘*
|
||||
|
||||
13、当 GRUB 程序成功安装到 boot 驱动器以后,安装程序将会提示用户安装已经完成,请重启系统。
|
||||
|
||||
[
|
||||

|
||||
][23]
|
||||
|
||||
*Devuan Linux 安装完成*
|
||||
|
||||
14、假设安装确实完成了,那么系统要么启动到选择桌面环境,或者如果没有桌面环境可选择的话,启动到一个基于文本的控制台。
|
||||
|
||||
[
|
||||

|
||||
][24]
|
||||
|
||||
Devuan Linux 控制台。
|
||||
|
||||
这篇文章总结了最新版本的 Devuan Linux 的安装。在这个系列的下一篇文章将会阐述[如何从源代码为 Devuan Linux 安装桌面环境][25]。如果你有任何问题或疑问,请记得让 Tecmint 知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
作者是 Ball 州立大学的计算机系讲师,目前教授计算机系的所有 Linux 课程,同时也教授 Cisco 网络课程。他是 Debian 以及其他 Debian 的衍生版比如 Mint、Ubuntu 和 Kali 的狂热用户。他拥有信息学和通信科学的硕士学位,同时获得了 Cisco、EC 理事会和 Linux 基金会的行业认证。
|
||||
|
||||
-----------------------------
|
||||
|
||||
via: http://www.tecmint.com/installation-of-devuan-linux/
|
||||
|
||||
作者:[Rob Turner ][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/robturner/
|
||||
[1]:https://devuan.org/
|
||||
[2]:https://devuan.org/
|
||||
[3]:http://www.tecmint.com/find-usb-device-name-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Device-Name-in-Linux.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Graphic-Installation.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Language-Selection.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Location-Selection.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Keyboard-Configuration.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-Devuan-Linux-Hostname.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-Devuan-Linux-Domain-Name.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Setup-Devuan-Linux-Root-User.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Setup-Devuan-Linux-User-Account.png
|
||||
[13]:http://www.tecmint.com/install-and-configure-ntp-server-client-in-debian/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Clock-on-Devuan-Linux.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Partitioning.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Configure-Package-Manager.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Mirror-Selection.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Mirrors.png
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Devuan-Linux-Popularity-Contest.png
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Software-Selection.png
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Grub-Install.png
|
||||
[22]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Grub-Install-Disk.png
|
||||
[23]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Installation-Completes.png
|
||||
[24]:http://www.tecmint.com/wp-content/uploads/2017/03/Devuan-Linux-Console.png
|
||||
[25]:http://www.tecmint.com/install-enlightenment-on-devuan-linux/
|
||||
[26]:http://www.tecmint.com/author/robturner/
|
||||
[27]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[28]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,309 @@
|
||||
如何用树莓派搭建一个自己的 web 服务器
|
||||
============================================================
|
||||
|
||||

|
||||
>图片来源 : opensource.com
|
||||
|
||||
个人网络服务器即 “云”,只是是你去拥有和控制它,而不是托管在一个大型的公司上。
|
||||
|
||||
|
||||
拥有一个自己的云有很多好处,包括定制,免费存储,免费的互联网服务,开源软件的路径,高品质的安全性,完全控制您的内容,快速更改的能力,一个实验的地方 代码等等。 这些好处大部分是无法估量的,但在财务上,这些好处可以节省您每个月超过 100 美元。
|
||||
|
||||

|
||||
|
||||
图片来自 Mitchell McLaughlin, CC BY-SA 4.0
|
||||
|
||||
我本可以选择 AWS ,但我更喜欢完全自由且安全性可控,并且我可以学一下这些东西是如何搭建的。
|
||||
|
||||
* 私有主机: 不使用 BlueHost 或 DreamHost
|
||||
* 云存储:不使用 Dropbox, Box, Google Drive, Microsoft Azure, iCloud, 或是 AWS
|
||||
* 确保内部安全
|
||||
* HTTPS:Let’s Encrypt
|
||||
* 分析: Google
|
||||
* OpenVPN:Do not need private Internet access (预计每个月花费 $7)
|
||||
|
||||
我所使用的物品清单:
|
||||
|
||||
* 树莓派 3 代 Model B
|
||||
* MicroSD 卡 (推荐使用 32GB, [兼容树莓派的 SD 卡][1])
|
||||
* USB microSD 卡读卡器
|
||||
* 以太网络线
|
||||
* 连接上 Wi-Fi 的路由器
|
||||
* 树莓派盒子
|
||||
* 亚马逊倍思的 MicroUSB 数据线
|
||||
* 苹果的充电器
|
||||
* USB 鼠标
|
||||
* USB 键盘
|
||||
* HDMI 线材
|
||||
* 显示器 (支持接入 HDMI)
|
||||
* MacBook Pro
|
||||
|
||||
### 步骤 1: 启动树莓派
|
||||
|
||||
下载最新发布的 Raspbian (树莓派的操作系统). [Raspbian Jessie][6] 的 ZIP 包就可以用。解压缩或提取下载的文件然后把它拷贝到 SD 卡里。使用 [Pi Filler][7] 可以让这些过程变得更简单。[下载 Pi Filer 1.3][8] 或最新的版本。解压或提取下载文件之后打开它,你应该会看到这样的提示:
|
||||
|
||||

|
||||
|
||||
确保 USB 读卡器这时还没有插上。如果已经插上了那就先推出。点 Continue 继续下一步。你会看到一个让你选择文件的界面,选择你之前解压缩后的树莓派系统文件。然后你会看到另一个提示如图所示:
|
||||
|
||||

|
||||
|
||||
把 MicroSD 卡 (推荐 32GB ,至少 16GB) 插入到 USB MicroSD 卡读卡器里。然后把 USB 读卡器接入到你的电脑里。你可以把你的 SD 卡重命名为 "Raspberry" 以区别其他设备。然后点 continue。请先确保你的 SD 卡是空的,因为 Pi Filler 也会在运行时 _擦除_ 所有事先存在 SD 卡里的内容。如果你要备份卡里的内容,那你最好就马上备份。当你点 continue 的时候,Raspbian OS 就会被写入到 SD 卡里。这个过程大概会花费一到三分钟左右。当写入完成后,推出 USB 读卡器,把 SD 卡拔出来插入到树莓派的 SD 卡槽里。把电源线接上,给树莓派提供电源。这时树莓派就会自己启动。树莓派的默认登录账户信息是:
|
||||
|
||||
**用户名: pi
|
||||
密码: raspberry**
|
||||
|
||||
当树莓派首次启动完成时,会跳出一个标题为 "Setup Options" 的配置界面,就像下面的图片一样 [2]:
|
||||
|
||||

|
||||
|
||||
选择 "Expand Filesystem" 这一选项并回车 [3]. 同时,我还推荐选择第二个选项 "Change User Password" 。这对保证安全性来说尤为重要。它还能个性化你的树莓派.
|
||||
|
||||
在选项列表中选择第三项 "Enable Boot To Desktop/Scratch" 并回车。这时会跳到另一个标题为 "Choose boot option" 的界面,就像下面这张图这样。
|
||||
|
||||

|
||||
|
||||
在 "Choose boot option" 这个界面选择第二个选项 "Desktop log in as user 'pi' at the graphical desktop" 并回车 [4]。完成这个操作之后会回到之前的 "Setup Options" 界面。如果没有回到之前的界面的话就选择当前界面底部的 "OK" 按钮并回车。
|
||||
|
||||
当这些操作都完成之后,选择当前界面底部的 "Finish" 按钮并回车,这时它就会自动重启。如果没有自动重启的话,就在终端里使用如下命令来重启。
|
||||
|
||||
**$ sudo reboot**
|
||||
|
||||
接上一步的重启,如果所有步骤都顺利进行的话,你会进入到类似下面这样桌面环境中。
|
||||
|
||||

|
||||
|
||||
当你进入了桌面之后,在终端中执行如下命令来更新树莓派的固件。
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get upgrade-y
|
||||
|
||||
$ sudo apt-get dist-upgrade -y
|
||||
|
||||
$ sudo rpi-update
|
||||
```
|
||||
|
||||
这些操作可能会花费几分钟时间。完成之后,现在运行着的树莓派就时最新的了。
|
||||
|
||||
### 步骤 2: 配置树莓派
|
||||
|
||||
SSH 指的是 Secure Shell,是一种加密网络协议,可让你在计算机和树莓派之间安全地传输数据。 你可以从 Mac 的命令行控制你的树莓派,而无需显示器或键盘。
|
||||
|
||||
要使用 SSH,首先需要你的树莓派的 IP 地址。 打开终端并输入:
|
||||
|
||||
```
|
||||
$ sudo ifconfig
|
||||
```
|
||||
|
||||
如果你在使用以太网,看 "eth0" 这一块。如果你在使用 Wi-Fi, 看 "wlan0" 这一块。
|
||||
|
||||
查找“inet addr”,后跟一个IP地址,如192.168.1.115,这是本篇文章中使用的默认IP
|
||||
|
||||
有了这个地址,在终端中输入 :
|
||||
|
||||
```
|
||||
$ ssh pi@192.168.1.115
|
||||
```
|
||||
|
||||
对于PC上的SSH,请参见脚注[5]。
|
||||
|
||||
出现提示时输入默认密码“raspberry”,除非你之前更改过密码。
|
||||
|
||||
现在你已经通过 SSH 登录成功。
|
||||
|
||||
### 远程桌面
|
||||
|
||||
使用GUI(图形用户界面)有时比命令行更容易。 在树莓派的命令行(使用SSH)上键入:
|
||||
|
||||
```
|
||||
$ sudo apt-get install xrdp
|
||||
```
|
||||
|
||||
Xrdp 支持 Mac 和 PC 的 Microsoft Remote Desktop 客户端。
|
||||
|
||||
在 Mac 上,在 App store 中搜索 “Microsoft Remote Desktop”。 下载它。 (对于PC,请参见脚注[6]。)
|
||||
|
||||
安装完成之后,在你的 Mac 中搜索一个叫 "Microsoft Remote Desktop" 的应用并打开它,你会看到 :
|
||||
|
||||

|
||||
|
||||
图片来自 Mitchell McLaughlin, CC BY-SA 4.0
|
||||
|
||||
点击 "New" 新建一个远程连接,在空白处填写如下配置。
|
||||
|
||||

|
||||
|
||||
图片来自 Mitchell McLaughlin, CC BY-SA 4.0
|
||||
|
||||
关闭 “New” 窗口就会自动保存。
|
||||
|
||||
你现在应该看到 “My Desktop” 下列出的远程连接。 双击它。
|
||||
|
||||
简单加载后,你应该在屏幕上的窗口中看到你的树莓派桌面,如下所示:
|
||||
|
||||

|
||||
|
||||
好了,现在你不需要额外的鼠标、键盘或显示器就能控制你的树莓派。这是一个更为轻量级的配置。
|
||||
|
||||
### 静态本地 ip 地址
|
||||
|
||||
有时候你的本地 IP 地址 192.168.1.115 会发生改变。我们需要让这个 IP 地址静态化。输入:
|
||||
|
||||
```
|
||||
$ sudo ifconfig
|
||||
```
|
||||
|
||||
从 “eth0” 部分或 “wlan0” 部分,“inet addr”(树莓派当前 IP),“bcast”(广播 IP 范围)和 “mask”(子网掩码地址))中删除。 然后输入:
|
||||
|
||||
```
|
||||
$ netstat -nr
|
||||
```
|
||||
|
||||
记下 "destination" 和 "gateway/network."
|
||||
|
||||

|
||||
|
||||
cumulative records 应该大概是这样子的:
|
||||
|
||||
```
|
||||
net address 192.168.1.115
|
||||
bcast 192.168.1.255
|
||||
mask 255.255.255.0
|
||||
gateway 192.168.1.1
|
||||
network 192.168.1.1
|
||||
destination 192.168.1.0
|
||||
```
|
||||
|
||||
有了这些信息,你可以很简单地设置一个静态 IP。输入:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/dhcpcd.conf
|
||||
```
|
||||
|
||||
不要设置 **/etc/network/interfaces**
|
||||
|
||||
剩下要做的就是把这些内容追加到这个文件的底部,把 IP 换成你想要的 IP 地址。
|
||||
|
||||
```
|
||||
interface eth0
|
||||
static ip_address=192.168.1.115
|
||||
static routers=192.168.1.1
|
||||
static domain_name_servers=192.168.1.1
|
||||
```
|
||||
|
||||
一旦你设置了静态内部 IP 地址,这时需要通过如下命令重启你的树莓派 :
|
||||
|
||||
```
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启完成之后,在终端中输入 :
|
||||
|
||||
```
|
||||
$ sudo ifconfig
|
||||
```
|
||||
|
||||
这时你就可以看到你的树莓派上的新的静态配置了。
|
||||
|
||||
### 静态全局 IP address
|
||||
|
||||
如果您的 ISP(互联网服务提供商)已经给您一个静态外部 IP 地址,您可以跳过端口转发部分。 如果没有,请继续阅读。
|
||||
|
||||
你已经设置了SSH,远程桌面和静态内部 IP 地址,因此现在本地网络中的计算机将会知道在哪里可以找到你的树莓派。 但是你仍然无法从本地 Wi-Fi 网络外部访问你的树莓派。 你需要树莓派可以从互联网上的任何地方公开访问。 这需要静态外部IP地址[7]。
|
||||
|
||||
调用您的 ISP 并请求静态外部(有时称为静态全局)IP 地址可能会是一个非常敏感的过程。 ISP 拥有决策权,所以我会非常小心处理。 他们可能拒绝你的的静态外部 IP 地址请求。 如果他们拒绝了你的请求,你不要怪罪于他们,因为这种类型的请求有法律和操作风险。 他们特别不希望客户运行中型或大型互联网服务。 他们可能会明确地询问为什么需要一个静态的外部 IP 地址。 最好说实话,告诉他们你打算主办一个低流量的个人网站或类似的小型非营利互联网服务。 如果一切顺利,他们应该打开一张票,并在一两个月内给你打电话。
|
||||
|
||||
### 端口转发
|
||||
|
||||
这个新获得的 ISP 分配的静态全局 IP 地址是用于访问路由器。 树莓派现在仍然无法访问。 你需要设置端口转发才能访问树莓派。
|
||||
|
||||
端口是信息在互联网上传播的虚拟途径。 你有时需要转发端口,以使计算机像树莓派一样可以访问 Internet,因为它位于网络路由器后面。 VollmilchTV 专栏在 YouTube 上的一个视频 [什么是TCP / IP,端口,路由,Intranet,防火墙,互联网] [9]帮助我更好地了解端口。
|
||||
|
||||
端口转发可用于像 树莓派 Web服务器或 VoIP 或点对点下载的应用程序。 有[65,000+个端口] [10]可供选择,因此你可以为你构建的每个 Internet 应用程序分配一个不同的端口。
|
||||
|
||||
设置端口转发的方式取决于你的路由器。 如果你有 Linksys 的话,Gabriel Ramirez 在 YouTbue 上有一个标题叫 [How to go online with your Apache Ubuntu server] [2] 的视频解释了如何设置。 如果您没有 Linksys,请阅读路由器附带的文档,以便自定义和定义要转发的端口。
|
||||
|
||||
你将需要转发 SSH 以及远程桌面端口。
|
||||
|
||||
如果你认为你已经过配置端口转发了,输入下面的命令以查看它是否正在通过 SSH 工作:
|
||||
|
||||
```
|
||||
$ ssh pi@your_global_ip_address
|
||||
```
|
||||
|
||||
它应该会提示你输入密码。
|
||||
|
||||
检查端口转发是否适用于远程桌面。 打开 Microsoft Remote Desktop。 你之前的的远程连接设置应该已经保存了,但需要使用静态外部IP地址(例如195.198.227.116)来更新“PC名称”字段,而不是静态内部地址(例如192.168.1.115)。
|
||||
|
||||
现在,尝试通过远程桌面连接。 它应该简单地加载并到达树莓派的桌面。
|
||||
|
||||

|
||||
|
||||
好了, 树莓派现在可以从互联网上访问了,并且已经准备好进行高级项目了。
|
||||
|
||||
作为一个奖励选项,您可以保持两个远程连接到您的Pi。 一个通过互联网,另一个通过LAN(局域网)。 很容易设置。 在 Microsoft Remote Desktop 中,保留一个称为 “Pi Internet” 的远程连接,另一个称为 “Pi Local”。 将 Pi Internet的 “PC name” 配置为静态外部IP地址,例如195.198.227.116 \。 将 Pi Local 的 “PC name” 配置为静态内部IP地址,例如192.168.1.115 \。 现在,您可以选择在全球或本地连接。
|
||||
|
||||
如果你还没有看过由 Gabriel Ramirez 发布的 [如何使用您的Apache Ubuntu服务器上线] [3],那么你可以去看一下作为过渡到第二个项目的教程。 它将向您展示项目背后的技术架构。 在我们的例子中,你使用的是树莓派而不是 Ubuntu 服务器。 动态DNS位于域公司和您的路由器之间,这是 Ramirez 省略的部分。 除了这个微妙之处外,视频是在整体上解释系统的工作原理。 您可能会注意到本教程涵盖了树莓派设置和端口转发,这是服务器端或后端。 查看原始来源,涵盖域名,动态DNS,Jekyll(静态HTML生成器)和Apache(网络托管)的更高级项目,这是客户端或前端。
|
||||
|
||||
### 脚注
|
||||
|
||||
[1] 我不建议从 NOOBS 操作系统开始。 我更喜欢从功能齐全的 Raspbian Jessie 操作系统开始。
|
||||
|
||||
[2] 如果没有弹出 “Setup Options”,可以通过打开终端并执行该命令来始终找到它:
|
||||
|
||||
```
|
||||
$ sudo-rasps-config
|
||||
```
|
||||
|
||||
[3] 我们这样做是为了将 SD 卡上存在的所有空间用作一个完整的分区。 所有这一切都是扩大操作系统以适应 SD 卡上的整个空间,然后可以将其用作树莓派的存储内存。
|
||||
|
||||
[4] 我们这样做是因为我们想启动进入熟悉的桌面环境。 如果我们不做这个步骤,树莓派每次会进入到终端而不是 GUI 中。
|
||||
|
||||
[5]
|
||||
|
||||

|
||||
|
||||
[下载并运行 PuTTY] [11] 或 Windows 的另一个 SSH 客户端。 在该字段中输入你的IP地址,如上图所示。 将默认端口保留在22 \。 回车,PuTTY 将打开一个终端窗口,提示你输入用户名和密码。 填写然后开始在树莓派上进行你的远程工作。
|
||||
|
||||
[6]如果尚未安装,请下载 [Microsoft Remote Desktop] [12]。 搜索您的计算机上的的 Microsoft Remote Desktop。 运行。 提示时输入IP地址。 接下来,会弹出一个xrdp窗口,提示你输入用户名和密码。
|
||||
|
||||
[7]路由器具有动态分配的外部 IP 地址,所以在理论上,它可以从互联网上暂时访问,但是您需要ISP的帮助才能使其永久访问。 如果不是这样,你需要在每次使用时重新配置远程连接。
|
||||
|
||||
_原文出自 [Mitchell McLaughlin's Full-Stack Computer Projects][4]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Mitchell McLaughlin - 我是一名开放网络的贡献者和开发者。 我感兴趣的领域很广泛,但我特别喜欢开源软件/硬件,比特币和编程。 我住在旧金山 我有过一些简短的 GoPro 和 Oracle 工作经验。
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/3/building-personal-web-server-raspberry-pi-3
|
||||
|
||||
作者:[Mitchell McLaughlin ][a]
|
||||
译者:[chenxinlong](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mitchm
|
||||
[1]:http://elinux.org/RPi_SD_cards
|
||||
[2]:https://www.youtube.com/watch?v=i1vB7JnPvuE#t=07m08s
|
||||
[3]:https://www.youtube.com/watch?v=i1vB7JnPvuE#t=07m08s
|
||||
[4]:https://mitchellmclaughlin.com/server.html
|
||||
[5]:https://opensource.com/article/17/3/building-personal-web-server-raspberry-pi-3?rate=Zdmkgx8mzy9tFYdVcQZSWDMSy4uDugnbCKG4mFsVyaI
|
||||
[6]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[7]:http://ivanx.com/raspberrypi/
|
||||
[8]:http://ivanx.com/raspberrypi/files/PiFiller.zip
|
||||
[9]:https://www.youtube.com/watch?v=iskxw6T1Wb8
|
||||
[10]:https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers
|
||||
[11]:http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
|
||||
[12]:https://www.microsoft.com/en-us/store/apps/microsoft-remote-desktop/9wzdncrfj3ps
|
||||
[13]:https://opensource.com/user/41906/feed
|
||||
[14]:https://opensource.com/article/17/3/building-personal-web-server-raspberry-pi-3#comments
|
||||
[15]:https://opensource.com/users/mitchm
|
||||
@ -0,0 +1,173 @@
|
||||
使用 Cockpit 方便地管理容器
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
如果你正在寻找一种简单的方法来管理包含容器的 Linux 服务器,那么你应该看看 Cockpit。[Creative Commons Zero][6]
|
||||
|
||||
如果你管理着一台 Linux 服务器,那么你可能正在寻找一个可靠的管理工具。为了这个你可能已经看了 [Webmin][14] 和 [cPanel][15] 这类软件。但是,如果你正在寻找一种简单的方法来管理还包括 Docker 的 Linux 服务器,那么有一个工具可以用于这个需求:[Cockpit][16]。
|
||||
|
||||
为什么使用 Cockpit?因为它可以处理管理任务,例如:
|
||||
|
||||
* 连接并管理多台机器
|
||||
|
||||
* 通过 Docker 管理容器
|
||||
|
||||
* 与 Kubernetes 或 Openshift 集群进行交互
|
||||
|
||||
* 修改网络设置
|
||||
|
||||
* 管理用户帐号
|
||||
|
||||
* 访问基于 Web 的 shell
|
||||
|
||||
* 通过图表查看系统性能信息
|
||||
|
||||
* 查看系统服务和日志文件
|
||||
|
||||
Cockpit 可以安装在 [Debian][17]、[Red Hat][18]、[CentOS] [19]、[Arch Linux][20] 和 [Ubuntu][21] 之上。在这里,我将使用一台已经安装了 Docker 的 Ubuntu 16.04 服务器来安装系统。
|
||||
|
||||
在上面的功能列表中,其中最突出的是容器管理。为什么?因为它使安装和管理容器变得非常简单。事实上,你可能很难找到更好的容器管理解决方案。
|
||||
因此,让我们来安装这个方案并看看它的使用是多么简单。
|
||||
|
||||
### 安装
|
||||
|
||||
正如我前面提到的,我将在一台运行着 Docker 的 Ubuntu 16.04 实例上安装 Cockpit。安装步骤很简单。你要做的第一件事是登录你的 Ubuntu 服务器。接下来,你必须使用下面的命令添加必要的仓库:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:cockpit-project/cockpit
|
||||
```
|
||||
|
||||
出现提示时,按下键盘上的 Enter 键,等待提示返回。一旦返回到 bash 提示符,使用下面的命令来更新 apt:
|
||||
|
||||
```
|
||||
sudo apt-get get update
|
||||
```
|
||||
|
||||
使用下面的命令安装 Cockpit:
|
||||
|
||||
```
|
||||
sudo apt-get -y install cockpit cockpit-docker
|
||||
```
|
||||
|
||||
安装完成后,需要启动 Cockpit 服务并使它开机自动启动。要做到这个,使用下面的两个命令:
|
||||
|
||||
```
|
||||
sudo systemctl start cockpit
|
||||
sudo systemctl enable cockpit
|
||||
```
|
||||
|
||||
安装就到这里了。
|
||||
|
||||
### 登录到 Cockpit
|
||||
|
||||
要访问 Cockpit 的 web 界面,打开浏览器(与 Cockpit 服务器在同一个网络内),输入 http://IP_OF_SERVER:9090,你就会看到登录页面(图 1)。
|
||||
|
||||

|
||||
|
||||
图 1:Cockpit 登录页面。[授权使用][1]
|
||||
|
||||
在 Ubuntu 中使用 Cockpit 有个警告。Cockpit 中的很多任务需要管理员权限。如果你使用标准用户登录,则无法使用 Docker 等一些工具。 要解决这个问题,你可以在 Ubuntu 上启用 root 用户。但这并不总是一个好主意。通过启用 root 帐户,你将绕过多年来一直存在的安全系统。但是,为了本文,我将使用以下两个命令启用 root 用户:
|
||||
|
||||
```
|
||||
sudo passwd root
|
||||
|
||||
sudo passwd -u root
|
||||
```
|
||||
|
||||
注意,请确保你给 root 帐户一个强壮的密码。
|
||||
|
||||
你想恢复这个修改的话,你只需输入下面的命令:
|
||||
|
||||
```
|
||||
sudo passwd -l root
|
||||
```
|
||||
|
||||
在其他发行版(如 CentOS 和 Red Hat)中,你可以使用用户名 _root_ 和 root 密码登录 Cockpit,而无需像上面那样需要额外的步骤。
|
||||
|
||||
如果你还在犹豫启用 root 用户,则可以始终在服务终端拉取镜像(使用命令 _docker pull IMAGE_NAME _, 这里的 _IMAGE_NAME_ 是你要拉取的镜像)。这会将镜像添加到你的 docker 服务器中,然后可以通过普通用户进行管理。唯一需要注意的是,普通用户必须使用以下命令将自己添加到 Docker 组:
|
||||
|
||||
```
|
||||
sudo usermod -aG docker USER
|
||||
```
|
||||
|
||||
USER 是实际添加到组的用户名。在你完成后,重新登出并登入,接着使用下面的命令重启 Docker:
|
||||
|
||||
```
|
||||
sudo service docker restart
|
||||
```
|
||||
|
||||
现在常规用户可以启动并停止 Docker 镜像/容器而无需启用 root 用户了。唯一一点是用户不能通过 Cockpit 界面添加新的镜像。
|
||||
|
||||
使用 Cockpit
|
||||
|
||||
一旦你登录后,你可以看到 Cockpit 的主界面(图 2)。
|
||||
|
||||
|
||||

|
||||
|
||||
图 2:Cockpit 主界面。[授权使用][2]
|
||||
|
||||
你可以通过每个栏目来检查服务器的状态,与用户合作等,但是我们想要直接进入容器。单击 “Containers” 那栏以显示当前运行的以及可用的镜像(图3)。
|
||||
|
||||

|
||||
|
||||
图 3:使用 Cockpit 管理容器难以置信地简单。[授权使用][3]
|
||||
|
||||
要启动一个镜像,只要找到镜像并点击关联的启动按钮。在弹出的窗口中(图 4),你可以在点击运行之前查看所有镜像的信息(并根据需要调整)。
|
||||
|
||||
|
||||

|
||||
|
||||
图 4: 使用 Cockpit 运行 Docker 镜像。[授权使用][4]
|
||||
|
||||
镜像运行后,你可以点击它查看状态,并可以停止、重启、删除示例。你也可以点击修改资源限制并接着调整内存限制还有(或者)CPU 优先级。
|
||||
|
||||
### 添加新的镜像
|
||||
|
||||
假设你以 root 用户身份登录。如果是这样,那么你可以在 Cockpit GUI 的帮助下添加新的镜像。在“ Container” 栏目下,点击获取新的镜像按钮,然后在新的窗口中搜索要添加的镜像。假设你要添加 CentOS 的最新官方版本。在搜索栏中输入 centos,在得到搜索结果后,选择官方列表,然后单击下载(图5)。
|
||||
|
||||

|
||||
|
||||
图 5:使用 Cockpit 添加最新的官方构建 CentOS 镜像到 Docker 中。[Used with permission][5]
|
||||
|
||||
镜像下载完后,那它就在 Docker 中可用了,并可以通过 Cockpit 运行。
|
||||
|
||||
### 如它获取那样简单
|
||||
|
||||
管理 Docker 并不容易。是的,在 Ubuntu 上运行 Cockpit 会有一个警告,但如果这是你唯一的选择,那么还有办法让它工作。在 Cockpit 的帮助下,你不仅可以轻松管理 Docker 镜像,也可以在任何可以访问 Linux 服务器的 web 浏览器上进行。请享受这个新发现的容易使用 Docker 的方法。
|
||||
|
||||
_在 Linux Foundation 以及 edX 中通过免费的 ["Introduction to Linux"][13] 课程学习 Linux。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/3/make-container-management-easy-cockpit
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[7]:https://www.linux.com/files/images/cockpitajpg
|
||||
[8]:https://www.linux.com/files/images/cockpitbjpg
|
||||
[9]:https://www.linux.com/files/images/cockpitcjpg
|
||||
[10]:https://www.linux.com/files/images/cockpitdjpg
|
||||
[11]:https://www.linux.com/files/images/cockpitfjpg
|
||||
[12]:https://www.linux.com/files/images/cockpit-containersjpg
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[14]:http://www.webmin.com/
|
||||
[15]:http://cpanel.com/
|
||||
[16]:http://cockpit-project.org/
|
||||
[17]:https://www.debian.org/
|
||||
[18]:https://www.redhat.com/en
|
||||
[19]:https://www.centos.org/
|
||||
[20]:https://www.archlinux.org/
|
||||
[21]:https://www.ubuntu.com/
|
||||
@ -0,0 +1,203 @@
|
||||
如何在 CentOS、RHEL 和 Fedora 上安装 DHCP 服务
|
||||
============================================================
|
||||
|
||||
DHCP(Dynamic Host Configuration Protocol)是一个网络协议,它使得服务器能从预定义的 IP 池中为网络中的客户端节点自动分配 IP 地址并提供其它相关的网络配置参数。
|
||||
|
||||
这意味着每次客户端节点启动(连接到网络)的时候,它都会获得一个和从不改变的“静态” IP 地址相反的“动态” IP 地址。DHCP 服务器给 DHCP 客户端分配 IP 地址称为“租约”,租约时间随客户端需要的连接时间或 DHCP 的配置而异。
|
||||
|
||||
在这篇指南中,我们会介绍如何在 CentOS/RHEL 和 Fedora 发行版中安装和配置 DHCP 服务。
|
||||
|
||||
#### 设置测试环境
|
||||
|
||||
本次安装中我们使用如下的测试环境。
|
||||
|
||||
```
|
||||
DHCP 服务器 - CentOS 7
|
||||
DHCP 客户端 - Fedora 25 和 Ubuntu 16.04
|
||||
```
|
||||
|
||||
#### DHCP 如何工作?
|
||||
|
||||
在进入下一步之前,让我们首先了解一下 DHCP 的工作流程:
|
||||
|
||||
* 当已连接到网络的客户端计算机(配置为使用 DHCP)启动时,它会发送一个 DHCPDISCOVER 消息到 DHCP 服务器。
|
||||
* 当 DHCP 服务器接收到 DHCPDISCOVER 请求消息时,它会回复一个 DHCPOFFER 消息。
|
||||
* 客户端收到 DHCPOFFER 消息后,它再发送给服务器一个 DHCPREQUEST 消息,表示客户端已准备好获取 DHCPOFFER 消息中提供的网络配置。
|
||||
* 最后,DHCP 服务器收到客户端的 DHCPREQUEST 消息,并回复 DHCPACK 消息,表示允许客户端使用分配给它的 IP 地址。
|
||||
|
||||
### 第一步:在 CentOS 上安装 DHCP 服务
|
||||
|
||||
1. 安装 DHCP 服务非常简单,只需要运行下面的命令即可。
|
||||
|
||||
```
|
||||
$ yum -y install dhcp
|
||||
```
|
||||
|
||||
重要:假如系统中有多个网卡,但你想只在其中一个网卡上启用 DHCP 服务,可以按照下面的步骤在该网卡上启用 DHCP 服务。
|
||||
|
||||
2. 打开文件 /etc/sysconfig/dhcpd,将指定网卡的名称添加到 DHCPDARGS 列表,假如网卡名称为 `eth0`,则添加:
|
||||
|
||||
```
|
||||
DHCPDARGS=eth0
|
||||
```
|
||||
|
||||
保存文件并退出 。
|
||||
|
||||
### 第二步:在 CentOS 上配置 DHCP 服务
|
||||
|
||||
3. 对于初学者来说,配置 DHCP 服务的第一步是创建 `dhcpd.conf` 配置文件,DHCP 主要配置文件一般是 /etc/dhcp/dhcpd.conf(默认情况下该文件为空),该文件保存了发送给客户端的所有网络信息。
|
||||
|
||||
但是,有一个样例配置文件 /usr/share/doc/dhcp*/dhcpd.conf.sample,这是配置 DHCP 服务的良好开始。
|
||||
|
||||
DHCP 配置文件中定义了两种类型的语句:
|
||||
|
||||
* 参数 - 说明如何执行任务、是否执行任务、或者给 DHCP 客户端发送什么网络配置选项。
|
||||
* 声明 - 指定网络拓扑、定义客户端、提供客户端地址、或将一组参数应用于一组声明。
|
||||
|
||||
因此,首先复制示例配置文件为主配置文件:
|
||||
|
||||
```
|
||||
$ cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
4. 然后,打开主配置文件并定义你的 DHCP 服务选项:
|
||||
|
||||
```
|
||||
$ vi /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
首先在文件开头设置以下应用于全部子网的全局参数(注意要使用你实际场景中的值):
|
||||
|
||||
```
|
||||
option domain-name "tecmint.lan";
|
||||
option domain-name-servers ns1.tecmint.lan, ns2.tecmint.lan;
|
||||
default-lease-time 3600;
|
||||
max-lease-time 7200;
|
||||
authoritative;
|
||||
```
|
||||
|
||||
5. 然后,定义一个子网;在这个事例中,我们会为 192.168.56.0/24 局域网配置 DHCP(注意使用你实际场景中的值):
|
||||
|
||||
```
|
||||
subnet 192.168.56.0 netmask 255.255.255.0 {
|
||||
option routers 192.168.56.1;
|
||||
option subnet-mask 255.255.255.0;
|
||||
option domain-search "tecmint.lan";
|
||||
option domain-name-servers 192.168.56.1;
|
||||
range 192.168.56.10 192.168.56.100;
|
||||
range 192.168.56.120 192.168.56.200;
|
||||
}
|
||||
```
|
||||
|
||||
### 第三步:为 DHCP 客户端分配静态 IP
|
||||
|
||||
只需要在 /etc/dhcp/dhcpd.conf 文件中定义下面的部分,其中你必须显式指定它的 MAC 地址和打算分配的 IP,你就可以为网络中指定的客户端计算机分配一个静态 IP 地址:
|
||||
|
||||
```
|
||||
host ubuntu-node {
|
||||
hardware ethernet 00:f0:m4:6y:89:0g;
|
||||
fixed-address 192.168.56.105;
|
||||
}
|
||||
host fedora-node {
|
||||
hardware ethernet 00:4g:8h:13:8h:3a;
|
||||
fixed-address 192.168.56.110;
|
||||
}
|
||||
```
|
||||
|
||||
保存文件并关闭。
|
||||
|
||||
注意:你可以使用下面的命令找到 Linux 的 MAC 地址。
|
||||
|
||||
```
|
||||
$ ifconfig -a eth0 | grep HWaddr
|
||||
```
|
||||
|
||||
6. 现在,使用下面的命令启动 DHCP 服务,并使在下次系统启动时自动启动:
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
$ systemctl start dhcpd
|
||||
$ systemctl enable dhcpd
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
$ service dhcpd start
|
||||
$ chkconfig dhcpd on```
|
||||
|
||||
7. 另外,别忘了使用下面的命令允许 DHCP 服务通过防火墙(DHCPD 守护进程通过 UDP 监听67号端口):
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
$ firewall-cmd --add-service=dhcp --permanent
|
||||
$ firewall-cmd --reload
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
$ iptables -A INPUT -p tcp -m state --state NEW --dport 67 -j ACCEPT
|
||||
$ service iptables save
|
||||
```
|
||||
|
||||
### 第四步:配置 DHCP 客户端
|
||||
|
||||
8. 现在,你可以为网络中的客户端配置自动从 DHCP 服务器中获取 IP 地址。登录到客户端机器并按照下面的方式修改以太网接口的配置文件(注意网卡的名称和编号):
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
|
||||
```
|
||||
|
||||
添加下面的选项:
|
||||
|
||||
```
|
||||
DEVICE=eth0
|
||||
BOOTPROTO=dhcp
|
||||
TYPE=Ethernet
|
||||
ONBOOT=yes
|
||||
```
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
9. 你也可以在桌面服务器中按照下面的截图(Ubuntu 16.04桌面版)通过 GUI 设置 Method 为 Automatic (DHCP)。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
在客户端网络中设置 DHCP
|
||||
|
||||
10. 按照下面的命令重启网络服务(你也可以通过重启系统):
|
||||
|
||||
```
|
||||
---------- On CentOS/RHEL 7 ----------
|
||||
$ systemctl restart network
|
||||
---------- On CentOS/RHEL 6 ----------
|
||||
$ service network restart
|
||||
```
|
||||
|
||||
到了这里,如果所有设置都是正确的,你的客户端就应该能自动从 DHCP 服务器中获取 IP 地址。
|
||||
|
||||
你也可以阅读:
|
||||
|
||||
1. [如何在 Debian Linux 中安装和配置 Multihomed ISC DHCP 服务][1]
|
||||
2. [配置网络的10个有用的 “IP” 命令][2]
|
||||
|
||||
在这篇文章中我们为你展示了如何在 RHEL/CentOS 中安装 DHCP 服务。在下面的评论框中给我们反馈吧。在接下来的文章中,我们还会为你展示如何在 Debian/Ubuntu 中安装 DHCP 服务。和 TecMint 保持联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 的爱好者,即将推出的 Linux SysAdmin 网络开发人员,目前也是 TecMint 的内容创作者,他喜欢和电脑一起工作,并且坚信共享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-dhcp-server-in-centos-rhel-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/install-and-configure-multihomed-isc-dhcp-server-on-debian-linux/
|
||||
[2]:http://www.tecmint.com/ip-command-examples/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-DHCP-in-Client-Network.png
|
||||
[4]:http://www.tecmint.com/author/aaronkili/
|
||||
[5]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[6]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,62 +1,62 @@
|
||||
[GitHub 风味的 Markdown 的正式规范][8]
|
||||
[GitHub 风格的 Markdown 的正式规范][8]
|
||||
====================
|
||||
|
||||
很庆幸,我们当初选择 Markdown 作为用户在 GitHub 上托管内容的标记语言,它为用户提供了强大且直接的方式 (不管是技术的还是非技术的) 来编写可以很好的渲染成 HTML 的纯文本文档。
|
||||
|
||||
其最主要的限制,就是缺乏在最模糊的语言细节上的标准。比如,使用多少个空格来进行行缩进、两个不同元素之间需要使用多少空行区分、大量繁琐细节往往造成不同实现之间的改变:相似的 Markdown 文档会因为你选用的语法解析器而渲染成大量不同的呈现效果。
|
||||
其最主要的限制,就是缺乏在最模糊的语言细节上的标准。比如,使用多少个空格来进行行缩进、两个不同元素之间需要使用多少空行区分、大量繁琐细节往往造成不同的实现:相似的 Markdown 文档会因为选用的不同的语法解析器而渲染成大量不同的呈现效果。
|
||||
|
||||
五年前,我们在 [Sundown][13] 的基础之上开始构建 GitHub 自定义版本的 Markdown —— GFM (GitHub 风味的 Markdown),这是我们特地为解决当时已有的 Markdown 解析器的不足而开发的一款解析器。
|
||||
五年前,我们在 [Sundown][13] 的基础之上开始构建 GitHub 自定义版本的 Markdown —— GFM (<ruby>GitHub 风格的 Markdown<rt>GitHub Flavored Markdown</rt></ruby>),这是我们特地为解决当时已有的 Markdown 解析器的不足而开发的一款解析器。
|
||||
|
||||
今天,我们希望通过发布 GitHub 风味的 Markdown 的正式语法规范及其相应的参考实现能够改善现状。
|
||||
今天,我们希望通过发布 GitHub 风格的 Markdown 的正式语法规范及其相应的参考实现来改善现状。
|
||||
|
||||
该正式规范基于 [CommonMark][14],这是一个有野心的项目,旨在通过一个反应现实世界用法的方式来规范目前互联网上绝大多数网站使用的 Markdown 语法。CommonMark 运行人们以他们原有的习惯来使用 Markdown,同时为开发者提供一个综合规范和参考实例,从而实现跨平台的 Markdown 互操作和显示。
|
||||
该正式规范基于 [CommonMark][14],这是一个雄心勃勃的项目,旨在通过一个反映现实世界用法的方式来规范目前互联网上绝大多数网站使用的 Markdown 语法。CommonMark 允许人们以他们原有的习惯来使用 Markdown,同时为开发者提供一个综合规范和参考实例,从而实现跨平台的 Markdown 互操作和显示。
|
||||
|
||||
#### 规范
|
||||
|
||||
使用 CommonMark 规范并围绕它来重设我们当前用户内容堆栈并非微不足道。目前,我们纠结的主要问题是该规范 (及其参考实现) 过多关注有原生 Perl 实现支持的 Markdown 通用子集。这还不包括那些 GitHub 上已经在用的扩展特性。最明显的就是缺少 _表格 (tables)、删除线 (strikethrough)、自动链接 (autolinks)_ 和 _任务列表 (task lists)_ 的支持。
|
||||
使用 CommonMark 规范并围绕它来重设我们当前用户内容堆栈需要不少努力。我们纠结的主要问题是该规范 (及其参考实现) 过多关注由原生 Perl 实现支持的 Markdown 通用子集。这还不包括那些 GitHub 上已经在用的扩展特性。最明显的就是缺少 _表格 (tables)、删除线 (strikethrough)、自动链接 (autolinks)_ 和 _任务列表 (task lists)_ 的支持。
|
||||
|
||||
为完全指定 GitHub 的 Markdown 版本 (也成为 GFM),我必须要要正式定义这些特性的的语法和语意。我们是在现存的 CommonMark 规范中来完成这一项工作的,同时还特意关注以确保我们的扩展处于一个严格模式并且是原有规范的一个超集。
|
||||
为完全指定 GitHub 的 Markdown 版本 (也称为 GFM),我们必须要要正式定义这些特性的的语法和语意,这在以前从未做过。我们是在现存的 CommonMark 规范中来完成这一项工作的,同时还特意关注以确保我们的扩展是原有规范的一个严格且可选的超集。
|
||||
|
||||
当评估 [GFM 规范][15] 的时候,你可以清楚的了解那些是 GFM 规范的扩展功能,因为它们都是高亮显示了。并且你也会看到原有规范的所有部分都保存原样,因此,GFM 规范能够与其他任何实现兼容。
|
||||
当评估 [GFM 规范][15] 的时候,你可以清楚的知道哪些是 GFM 特定规范的补充内容,因为它们都高亮显示了。并且你也会看到原有规范的所有部分都保存原样,因此,GFM 规范能够与其他任何实现兼容。
|
||||
|
||||
#### 实现
|
||||
|
||||
为确保我们网站中的 Markdown 渲染能够完美兼容 CommonMark 规范,GitHub 的 GFM 解析器的后端实现基于 `cmark`来开发,这是 CommonMark 规范的一个参考实现,由 [John MacFarlane][16] 和 许多其他的 [出色的贡献者][17] 开发完成的。
|
||||
为确保我们网站中的 Markdown 渲染能够完美兼容 CommonMark 规范,GitHub 的 GFM 解析器的后端实现基于 `cmark` 来开发,这是 CommonMark 规范的一个参考实现,由 [John MacFarlane][16] 和 许多其他的 [出色的贡献者][17] 开发完成。
|
||||
|
||||
就像规范本身那样,`cmark` 是 Markdown 的严格子集解析器,所以我们还必须在现存解析器的基础上完成 GitHub 自定义扩展的解析功能。你可以通过 [`cmark` 的分支][18] 来查看变更记录;为了与跟踪上游项目,我们定义将我们的 patches 变基到上游主线上去。我们希望,这些扩展的正式规范一旦确定,这些 patch 集同样可以应用到原始项目的上游变更中去。
|
||||
就像规范本身那样,`cmark` 是 Markdown 的严格子集解析器,所以我们还必须在现存解析器的基础上完成 GitHub 自定义扩展的解析功能。你可以通过 [`cmark` 的分支][18] 来查看变更记录;为了跟踪不断改进的上游项目,我们持续将我们的补丁变基到上游主线上去。我们希望,这些扩展的正式规范一旦确定,这些 patch 集同样可以应用到原始项目的上游变更中去。
|
||||
|
||||
除了在 `cmark` 分支中实现 GFM 规范特性,我们也同时将许多目标相似的变更贡献到上游。绝大多数的贡献都主要围绕性能和安全。我们的后端每天都需要渲染大量的 Markdown 文档,所以我们主要关注这些操作可以尽可能的高效率完成,同时还要确保那些滥用的恶意 Markdown 文档无法攻击到我们的服务器。
|
||||
|
||||
第一版使用 C 语言编写的解析器存在严重的安全隐患:通过足够深度的特殊 Markdown 元素的嵌套,它可能造成堆栈溢出 (甚至有时候可以运行任意代码)。而 `cmark` 实现就行我们之前设计的解析器 Sundown,为抵御这些攻击而专门进行从零开始设计。其解析算法和基于 AST 的输出主要用以优雅的解决深层递归以及其他的恶意文档格式。
|
||||
第一版使用 C 语言编写的解析器存在严重的安全隐患:通过足够深度的特殊 Markdown 元素的嵌套,它可能造成堆栈溢出 (甚至有时候可以运行任意代码)。而 `cmark` 实现,就像我们之前设计的解析器 Sundown,从一开始设计就考虑到要抵御这些攻击。其解析算法和基于 AST 的输出可以优雅的解决深层递归以及其他的恶意文档格式。
|
||||
|
||||
`cmark` 在性能方面则是有点粗糙:根绝当时构建 Sundown 所了解到的性能技巧,我们向上游贡献了许多最优方案,但除去所有这些变更之外,当前版本的 `cmark` 仍然无法与 Sundown 匹敌:我们的基准测试表明,`cmark` 在绝大多数文档渲染的性能上要比 Sundown 低 20% 到 30%。
|
||||
`cmark` 在性能方面则是有点粗糙:基于实现 Sundown 时我们所学到的性能技巧,我们向上游贡献了许多优化方案,但除去所有这些变更之外,当前版本的 `cmark` 仍然无法与 Sundown 本身匹敌:我们的基准测试表明,`cmark` 在绝大多数文档渲染的性能上要比 Sundown 低 20% 到 30%。
|
||||
|
||||
那句古老的优化谚语 _最快的代码就是不需要运行的代码 (the fastest code is the code that doesn’t run)_ 在此处同样适用:实际上,`cmark` 比 Sundown 要进行 _多一些操作_。在其他的功能上,`cmark` 支持 UTF8 字符集,对参考的支持、扩展的接口清理的效果更佳。最重要的是它如同 Sundown 那样,并不会将 Markdown _翻译成_ HTML。它实际上从 Markdown 源码中生成一个 AST (抽象语法树,Abstract Syntax Tree),然后我们就看将之转换和逐渐渲染成 HTML。
|
||||
|
||||
如果你有想过我们处理 Sundown 的原型实现 (特别是文档中关于查询用户的 mention 和 issue 参考、插入任务列表等) 时的 HTML 语法剖析,你会发现 `cmark` 基于 AST 的方法可以节约大量时间 _和_ 降低我们用户内容堆栈的复杂度。Markdown AST 是一个非常强大的工具,并且值得 `cmark` 生成它所付出的性能成本。
|
||||
如果考虑下我们在 Sundown 的最初实现 (特别是文档中关于查询用户的 mention 和 issue 参考、插入任务列表等) 时的 HTML 语法剖析工作量,你会发现 `cmark` 基于 AST 的方法可以节约大量时间 _和_ 降低我们用户内容堆栈的复杂度。Markdown AST 是一个非常强大的工具,并且值得 `cmark` 生成它所付出的性能成本。
|
||||
|
||||
### 迁移
|
||||
|
||||
变更我们用户的内容堆栈以兼容 CommonMark 规范,并不同于转换我们曾用于解析 Markdown 的库那样容易:目前我们在遇到最根本的障碍就是由于一些不常用语法 (LCTT 译注:原文是 the Corner,作为名词的原意为角落、偏僻处、窘境,这应该是指那些不常用语法),CommonMark 规范 (以及有歧义的 Markdown 原文) 可能会以一种意想不到的凡是来渲染一些老旧的 Markdown 内容。
|
||||
变更我们用户的内容堆栈以兼容 CommonMark 规范,并不同于转换我们用来解析 Markdown 的库那样容易:目前我们在遇到最根本的障碍就是由于一些不常用语法 (LCTT 译注:原文是 the Corner,作为名词的原意为角落、偏僻处、窘境,这应该是指那些不常用语法),CommonMark 规范 (以及有歧义的 Markdown 原文) 可能会以一种意想不到的方式来渲染一些老旧的 Markdown 内容。
|
||||
the fundamental roadblock we encountered here is that the corner cases that CommonMark specifies (and that the original Markdown documentation left ambiguous) could cause some old Markdown content to render in unexpected ways.
|
||||
|
||||
通过综合分析 GitHub 中大量的 Markdown 语料库,我们断定现存的用户内容只有不到 1% 会受到新版本实现的影响:我们是通过同时使用新 (`cmark`,兼容 CommonMark 规范) 旧 (Sundown) 版本的库来渲染大量的 Markdown 文档、标准化 HTML 结果、分析它们的不同点,最后才得到这一个数据的。
|
||||
|
||||
|
||||
只有 1% 的文档存在少量的渲染问题,使得换用新实现并获取其更多出看起来是非常合理的权衡,但是是根据当前 GitHub 的规模,这个 1% 是非常多的内容以及很多的受影响用户。我们真的不想导致任何用户需要重新校对一个老旧的问题、看到先前可以渲染成 HTML 的内容又呈现为 ASCII 码 —— 尽管这明显不会导致任何原始内容的丢失,却是糟糕的用户体验。
|
||||
|
||||
因此,我们相处相应的方法来缓和迁移过程。首先,第一件我们做的事就是收集用户托管在我们网站上的两种不同类型 Markdown 的数据:用户的评论 (比如Gists、issues、PR 等)以及在 git 仓库中的 Markdown 文档。
|
||||
因此,我们想出相应的方法来缓和迁移过程。首先,第一件我们做的事就是收集用户托管在我们网站上的两种不同类型 Markdown 的数据:用户的评论 (比如 Gists、issues、PR 等)以及在 git 仓库中的 Markdown 文档。
|
||||
|
||||
这两种内容有着本质上的区别:用户文档存储在我们的数据库中,这意味着他们的 Markdown 语法可以标准化 (比如添加或移除空格、修正缩进或则插入缺失的 Markdown 说明符,直到它们可正常渲染为止)。然而,那些存储在 Git 仓库中的 Markdown 文档则是 _根本_ 无法触及,因为这些内容已经散列成为 Git 存储模型的一部分。
|
||||
这两种内容有着本质上的区别:用户评论存储在我们的数据库中,这意味着他们的 Markdown 语法可以标准化 (比如添加或移除空格、修正缩进或则插入缺失的 Markdown 说明符,直到它们可正常渲染为止)。然而,那些存储在 Git 仓库中的 Markdown 文档则是 _根本_ 无法触及,因为这些内容已经散列成为 Git 存储模型的一部分。
|
||||
|
||||
幸运的是,我们发现绝大多数使用了复杂的 Markdown 特性的用户内容都是用户评论 (特别是 issue 主体和 PR 主体),而存储于仓库中的文档则大多数情况下都可以使用新旧渲染器下正常进行渲染。
|
||||
幸运的是,我们发现绝大多数使用了复杂的 Markdown 特性的用户内容都是用户评论 (特别是 issue 主体和 PR 主体),而存储于仓库中的文档则大多数情况下都可以使用新旧渲染器正常进行渲染。
|
||||
|
||||
因此,我们加快了标准化现存用户内容的语法的进程,以便是她们在新旧实现下渲染效果一致。
|
||||
因此,我们加快了标准化现存用户内容的语法的进程,以便使它们在新旧实现下渲染效果一致。
|
||||
|
||||
我们用以文档转换的方法相当实用:我们那个旧的 Markdown 解析器 Sundown 更多的是扮演着翻译器而非解析器的角色。输入 Markdown 内容之后,一系列的语意回调就会把原始的 Markdown 内容转换为目标语言 (在我们的实际适用中则是 HTML5) 的对应标记。基于这一设计方法,我们决定适用语意回调让 Sumdown 将原始 Markdown 转换为兼容 CommonMark 的 Markdown,而非 HTML。
|
||||
我们用以文档转换的方法相当实用:我们那个旧的 Markdown 解析器, Sundown,更多的是扮演着翻译器而非解析器的角色。输入 Markdown 内容之后,一系列的语意回调就会把原始的 Markdown 内容转换为目标语言 (在我们的实际使用中是 HTML5) 的对应标记。基于这一设计方法,我们决定使用语意回调让 Sumdown 将原始 Markdown 转换为兼容 CommonMark 的 Markdown,而非 HTML。
|
||||
|
||||
除了转换之外,这还是一个高效的标准化过程,并且我们对此信心满满,毕竟完成这一任务的是我们在 5 五年前就使用过的解析器。因此,所有的现存文档在保留其原始语意的情况下都能够进行明确的解析。
|
||||
除了转换之外,这还是一个高效的标准化过程,并且我们对此信心满满,毕竟完成这一任务的是我们在五年前就使用过的解析器。因此,所有的现存文档在保留其原始语意的情况下都能够进行明确的解析。
|
||||
|
||||
一旦升级 Sundown 来标准化输入文档并充分测试之后,我们就会做好了开启转换进程的准备。最开始的一步,就是在新的 `cmark` 实现上为所有的用户内容进行反置转换,以便确保我们能有一个有限的分界点来进行过渡。我们将为网站上这几个月内所有 **新的** 用户评论启用 CommonMark,这一过程不会引起任何人注意的 —— 他们这是一个关于 CommonMark 团队出色工作的圣约,通过一个最具现实世界用法的方式来正式规范 Markdown 语言.
|
||||
一旦升级 Sundown 来标准化输入文档并充分测试之后,我们就会做好开启转换进程的准备。最开始的一步,就是在新的 `cmark` 实现上为所有的用户内容进行反置转换,以便确保我们能有一个有限的分界点来进行过渡。我们将为网站上这几个月内所有 **新的** 用户评论启用 CommonMark,这一过程不会引起任何人注意的 —— 他们这是一个关于 CommonMark 团队出色工作的圣约,通过一个最具现实世界用法的方式来正式规范 Markdown 语言。
|
||||
|
||||
在后端,我们开启 MySQL 转换来升级替代用户的 Markdown 内容。在所有的评论进行标准化之后,在将其写回到数据库之前,我们将使用新实现来进行渲染并与旧实现的渲染结果进行对比,以确保 HTML 输出结果视觉可鉴以及用户数据在任何情况下都不被破坏。总而言之,只有不到 1% 的输入文档会受到表彰进程的修改,这符合我们的的期望,同时再次证明 CommonMark 规范能够呈现语言的真实用法。
|
||||
|
||||
@ -92,7 +92,7 @@ via: https://githubengineering.com/a-formal-spec-for-github-markdown/
|
||||
|
||||
作者:[Yuki Izumi][a][Vicent Martí][b]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,197 @@
|
||||
Remmina - 一个 Linux 下功能丰富的远程桌面共享工具
|
||||
============================================================
|
||||
|
||||
**Remmina** 是一款在 Linux 和其他类 Unix 系统下的免费开源、功能丰富、强大的远程桌面客户端,它用 GTK+ 3 编写而成。它适用于那些需要远程访问及使用许多计算机的系统管理员和在外出行人员。
|
||||
|
||||
它以简单、统一、同一性、易于使用的用户界面支持多种网络协议。
|
||||
|
||||
#### Remmina 功能
|
||||
|
||||
* 支持 RDP、VNC、NX、XDMCP 和 SSH。
|
||||
* 用户能够以组的形式维护一份连接配置列表。
|
||||
* 支持用户直接输入服务器地址的快速连接。
|
||||
* 具有更高分辨率的远程桌面,可以在窗口和全屏模式下滚动/缩放。
|
||||
* 支持窗口全屏模式;当鼠标移动到屏幕边缘时,远程桌面会自动滚动。
|
||||
* 还支持全屏模式浮动工具栏;使你能够在不同模式间切换、触发键盘获取、最小化等。
|
||||
* 提供选项卡式界面,可选择由组管理。
|
||||
* 还提供托盘图标,允许你快速访问已配置的连接文件。
|
||||
|
||||
在本文中,我们将向你展示如何在 Linux 中安装 Remmina,以及使用它通过支持的不同协议实现桌面共享。
|
||||
|
||||
#### 先决条件
|
||||
|
||||
* 在远程机器上允许桌面共享(让远程机器允许远程连接)。
|
||||
* 在远程机器上设置 SSH 服务。
|
||||
|
||||
### 如何在 Linux 中安装 Remmina 远程共享工具
|
||||
|
||||
Remmina 及其插件包已经在所有主流的 Linux 发行版的大多数官方仓库中提供。运行下面的命令以安装它和所有支持的插件:
|
||||
|
||||
```
|
||||
------------ 在 Debian/Ubuntu 中 ------------
|
||||
$ sudo apt-get install remmina remmina-plugin-*
|
||||
```
|
||||
|
||||
```
|
||||
------------ 在 CentOS/RHEL 中 ------------
|
||||
# yum install remmina remmina-plugin-*
|
||||
```
|
||||
|
||||
```
|
||||
------------ 在 Fedora 22+ 中 ------------
|
||||
$ sudo dnf copr enable hubbitus/remmina-next
|
||||
$ sudo dnf upgrade --refresh 'remmina*' 'freerdp*'
|
||||
```
|
||||
|
||||
一旦安装完成后,在 Ubuntu 或 Linux Mint 菜单中搜索 **remmina**,接着运行它:
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
*Remmina 桌面共享客户端*
|
||||
|
||||
你可以通过图形界面或者编辑 `$HOME/.remmina` 或者 `$HOME/.config/remmina` 下的文件来进行配置。
|
||||
|
||||
要设置到一个新的远程服务器的连接,按下 `[Ctrl+N]` 并点击 **Connection -> New**,如下截图中配置远程连接。这是基本的设置界面。
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
*Remmina 基础桌面配置*
|
||||
|
||||
点击界面上的 “**Advanced**”,配置高级连接设置。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*Remmina 高级桌面设置*
|
||||
|
||||
要配置 **SSH**,点击界面中的 SSH。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*Remmina SSH 设置*
|
||||
|
||||
在完成所有的必要配置后,点击 “**Save**” 保存设置,在主界面中你会如下看到所有已配置远程连接。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*Remmina 配置的服务器*
|
||||
|
||||
#### 使用 sFTP 连接到远程机器
|
||||
|
||||
选择连接配置并编辑设置,在 “**Protocols**” 下拉菜单中选择 **sFTP - 安全文件传输**。接着设置启动路径(可选),并指定 SSH 验证细节。最后点击**连接**。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
*Remmina sftp 连接*
|
||||
|
||||
这里输入你的 SSH 用户密码。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*输入 SSH 密码*
|
||||
|
||||
如果你看到下面的界面,那么代表 SFTP 连接成功了,你现在可以[在两台机器键传输文件了][8]。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*Remmina 远程 sFTP 文件系统*
|
||||
|
||||
#### 使用 SSH 连接到远程机器
|
||||
|
||||
选择连接配置并编辑设置,在 “**Protocols**” 下拉菜单中选择 **SSH - Secure Shell**,并可选设置启动程序以及 SSH 验证细节。最后点击**连接**并输入 SSH 密码。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
*Remmina SSH 连接*
|
||||
|
||||
当你看到下面的界面,这意味着你的连接成功了,你现在可以使用 SSH 控制远程机器了。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
*Remmina 远程 SSH 连接*
|
||||
|
||||
#### 使用 VNC 连接到远程机器
|
||||
|
||||
选择连接配置并编辑设置,在 “**Protocols**” 下拉菜单中选择 **VNC - 虚拟网络计算**。为连接配置基础、高级以及 ssh 设置,点击**连接**,接着输入用户 SSH 密码。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
*Remmina VNC 连接*
|
||||
|
||||
一旦你看到下面的界面时,这意味着你已经成功使用 VNC 协议连接到远程机器上了。
|
||||
|
||||
如下截图所示,在桌面登录界面输入用户登录密码。
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
*Remmina 远程桌面登录*
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
*Remmina 远程桌面共享*
|
||||
|
||||
使用上面的步骤可以很简单地使用其他的协议访问远程机器。
|
||||
|
||||
Remmina 主页: [https://www.remmina.org/wp/][15]
|
||||
|
||||
就是这样了!在本文中,我们向你展示了如何在 Linux 中安装与使用 Remmina 远程连接客户端中的几种支持的协议。你可以在下面的评论栏中分享你的任何想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux 系统管理员和网络开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Desktop-Sharing-Client.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Basic-Desktop-Preferences.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Advance-Desktop-Settings.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/ssh-remote-desktop-preferences.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Configured-Servers.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-sftp-connection.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/enter-userpasswd.png
|
||||
[8]:http://www.tecmint.com/sftp-upload-download-directory-in-linux/
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-sFTP-Filesystem.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-SSH-Connection.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-SSH-Connection.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-VNC-Connection.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-Desktop-Login.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Remote-Desktop-Sharing.png
|
||||
[15]:https://www.remmina.org/wp/
|
||||
[16]:http://www.tecmint.com/author/aaronkili/
|
||||
[17]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[18]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,380 @@
|
||||
Translating by sanfusu
|
||||
<!--[Data-Oriented Hash Table][1]-->
|
||||
[面向数据的哈希表][1]
|
||||
============================================================
|
||||
|
||||
<!--In recent years, there’s been a lot of discussion and interest in “data-oriented design”—a programming style that emphasizes thinking about how your data is laid out in memory, how you access it and how many cache misses it’s going to incur. -->
|
||||
最近几年中,面向数据的设计已经受到了很多的关注 —— 一种强调内存中数据布局的编程风格,包括如何访问以及将会引发多少的 cache 缺失。
|
||||
<!--With memory reads taking orders of magnitude longer for cache misses than hits, the number of misses is often the key metric to optimize.-->
|
||||
由于在内存读取操作中缺失所占的数量级要大于命中的数量级,所以缺失的数量通常是优化的关键标准。
|
||||
<!--It’s not just about performance-sensitive code—data structures designed without sufficient attention to memory effects may be a big contributor to the general slowness and bloatiness of software.
|
||||
-->
|
||||
这不仅仅关乎那些对性能有要求的 code-data 结构设计的软件,由于缺乏对内存效益的重视而成为软件运行缓慢、膨胀的一个很大因素。
|
||||
|
||||
<!--The central tenet of cache-efficient data structures is to keep things flat and linear. For example, under most circumstances, to store a sequence of items you should prefer a flat array over a linked list—every pointer you have to chase to find your data adds a likely cache miss, while flat arrays can be prefetched and enable the memory system to operate at peak efficiency.
|
||||
-->
|
||||
|
||||
高效缓存数据结构的中心原则是将事情变得平滑和线性。
|
||||
比如,在大部分情况下,存储一个序列元素更倾向于使用平滑的数组而不是链表 —— 每一次通过指针来查找数据都会为 cache 缺失增加一份风险;而平滑的数组可以预先获取,并使得内存系统以最大的效率运行
|
||||
|
||||
<!--This is pretty obvious if you know a little about how the memory hierarchy works—but it’s still a good idea to test things sometimes, even if they’re “obvious”! [Baptiste Wicht tested `std::vector` vs `std::list` vs `std::deque`][4] (the latter of which is commonly implemented as a chunked array, i.e. an array of arrays) a couple of years ago. The results are mostly in line with what you’d expect, but there are a few counterintuitive findings. For instance, inserting or removing values in the middle of the sequence—something lists are supposed to be good at—is actually faster with an array, if the elements are a POD type and no bigger than 64 bytes (i.e. one cache line) or so! It turns out to actually be faster to shift around the array elements on insertion/removal than to first traverse the list to find the right position and then patch a few pointers to insert/remove one element. That’s because of the many cache misses in the list traversal, compared to relatively few for the array shift. (For larger element sizes, non-POD types, or if you already have a pointer into the list, the list wins, as you’d expect.)
|
||||
-->
|
||||
|
||||
如果你知道一点内存层级如何运作的知识,下面的内容会是想当然的结果——但是有时候即便他们相当明显,测试一下任不失为一个好主意。
|
||||
[Baptiste Wicht 测试过了 `std::vector` vs `std::list` vs `std::deque`][4]
|
||||
(几年前,后者通常使用分块数组来实现,比如:一个数组的数组)
|
||||
结果大部分会和你预期的保持一致,但是会存在一些违反直觉的东西。
|
||||
作为实例:在序列链表的中间位置做插入或者移除操作被认为会比数组快
|
||||
但如果该元素是一个 POD 类型,并且不大于 64 字节或者在 64 字节左右(在一个 cache 流水线内),
|
||||
通过对要操作的元素周围的数组元素进行移位操作要比从头遍历链表来的快。
|
||||
这是由于在遍历链表以及通过指针插入/删除元素的时候可能会导致不少的 cache 缺失,相对而言,数组移位则很少会发生。
|
||||
(对于更大的元素,非 POD 类型,或者你你已经有了指向链表元素的指针,此时和预期的一样,链表胜出)
|
||||
|
||||
|
||||
|
||||
<!--Thanks to data like Baptiste’s, we know a good deal about how memory layout affects sequence containers.-->
|
||||
多亏了 Baptiste 的数据,我们知道了内存布局如何影响序列容器。
|
||||
<!--But what about associative containers, i.e. hash tables?-->
|
||||
但是关联容器,比如 hash 表会怎么样呢?
|
||||
<!--There have been some expert recommendations: -->
|
||||
已经有了些权威推荐:
|
||||
<!--[Chandler Carruth tells us to use open addressing with local probing][5] -->
|
||||
[Chandler Carruth 推荐的带局部探测的开放寻址][5]
|
||||
<!--so that we don’t have to chase pointers,-->
|
||||
(此时,我们没必要追踪指针)
|
||||
<!--and [Mike Acton suggests segregating keys from values][6]
|
||||
in memory so that we get more keys per cache line,
|
||||
improving locality when we have to look at multiple keys. -->
|
||||
以及[Mike Acton 推荐的在内存中将 value 和 key 隔离][6](这种情况下,我们可以在每一个 cache 流水线中得到更多的 key), 这可以在我们不得查找多个 key 时提高局部性能。
|
||||
<!-- These ideas make good sense, but again, it’s a good idea to test things, -->
|
||||
<!-- and I couldn’t find any data. So I had to collect some of my own! -->
|
||||
这些想法很有意义,但再一次的说明:测试永远是好习惯,但由于我找不到任何数据,所以只好自己收集了。
|
||||
|
||||
<!--### [][7]The Tests-->
|
||||
### [][7]测试
|
||||
|
||||
<!--
|
||||
I tested four different quick-and-dirty hash table implementations, as well as `std::unordered_map`. All five used the same hash function, Bob Jenkins’ [SpookyHash][8] with 64-bit hash values. (I didn’t test different hash functions, as that wasn’t the point here; I’m also not looking at total memory consumption in my analysis.) The implementations are identified by short codes in the results tables:
|
||||
-->
|
||||
我测试了四个不同的 quick-and-dirty 哈希表实现,另外还包括 `std::unordered_map` 。
|
||||
这五个哈希表都使用了同一个哈希函数 —— Bob Jenkins' [SpookyHash][8](64 位哈希值)。
|
||||
(由于哈希函数在这里不是重点,所以我没有测试不同的哈希函数;我同样也没有检测我的分析中的总内存消耗。)
|
||||
实现会通过短代码在测试结果表中标注出来。
|
||||
|
||||
* **UM**: `std::unordered_map` 。<!--In both VS2012 and libstdc++-v3 (used by both gcc and clang), UM is implemented as a linked list containing all the elements, and an array of buckets that store iterators into the list. In VS2012, it’s a doubly-linked list and each bucket stores both begin and end iterators; in libstdc++, it’s a singly-linked list and each bucket stores just a begin iterator. In both cases, the list nodes are individually allocated and freed. Max load factor is 1.-->
|
||||
在 VS2012 和 libstdc++-v3 (libstdc++-v3: gcc 和 clang 都会用到这东西)中,
|
||||
UM 是以链接表的形式实现,所有的元素都在链表中,buckets 数组中存储了链表的迭代器。
|
||||
VS2012 中,则是一个双链表,每一个 bucket 存储了起始迭代器和结束迭代器;
|
||||
libstdc++ 中,是一个单链表,每一个 bucket 只存储了一个起始迭代器。
|
||||
这两种情况里,链表节点是独立申请和释放的。最大负载因子是 1 。
|
||||
|
||||
* **Ch**: <!--separate chaining—each bucket points to a singly-linked list of element nodes. The element nodes are stored in a flat array pool, to avoid allocating each node individually. Unused nodes are kept on a free list. Max load factor is 1.-->
|
||||
分离的、链状 buket 指向一个元素节点的单链表。
|
||||
为了避免分开申请每一个节点,元素节点存储在平滑的数组池中。
|
||||
未使用的节点保存在一个空闲链表中。
|
||||
最大负载因子是 1。
|
||||
|
||||
* **OL**:<!--open addressing with linear probing—each bucket stores a 62-bit hash,
|
||||
a 2-bit state (empty, filled, or removed), key, and value. Max load factor is 2/3.-->
|
||||
开地址线性探测 —— 每一个 bucket 存储一个 62 bit 的 hash 值,一个 2 bit 的状态值(包括 empty,filled,removed 三个状态),key 和 vale 。最大负载因子是 2/3。
|
||||
* **DO1**:<!--“data-oriented 1”—like OL, but the hashes and states are segregated from the keys and values, in two separate flat arrays.-->
|
||||
data-oriented 1 —— 和 OL 相似,但是哈希值、状态值和 key、values 分离在两个隔离的平滑数组中。
|
||||
|
||||
* **DO2**:<!--“data-oriented 2”—like OL, but the hashes/states, keys, and values are segregated in three separate flat arrays.-->
|
||||
"data-oriented 2" —— 与 OL 类似,但是哈希/状态,keys 和 values 被分离在 3 个相隔离的平滑数组中。
|
||||
|
||||
<!--All my implementations, as well as VS2012’s UM, use power-of-2 sizes by default, growing by 2x upon exceeding their max load factor. -->
|
||||
在我的所有实现中,包括 VS2012 的 UM 实现,默认使用尺寸为 2 的 n 次方。如果超出了最大负载因子,则扩展两倍。
|
||||
<!--In libstdc++, UM uses prime-number sizes by default and grows to the next prime upon exceeding its max load factor.-->
|
||||
在 libstdc++ 中,UM 默认尺寸是一个素数。如果超出了最大负载因子,则扩展为下一个素数大小。
|
||||
<!--However, I don’t think these details are very important for performance.-->
|
||||
但是我不认为这些细节对性能很重要。
|
||||
<!--The prime-number thing is a hedge against poor hash functions that don’t have enough entropy in their lower bits, but we’re using a good hash function.-->
|
||||
素数是一种对低 bit 位上没有足够熵的低劣 hash 函数的挽救手段,但是我们正在用的是一个很好的 hash 函数。
|
||||
|
||||
<!--The OL, DO1 and DO2 implementations will collectively be referred to as OA (open addressing), since we’ll find later that their performance characteristics are often pretty similar.-->
|
||||
OL,DO1 和 DO2 的实现将共同的被称为 OA(open addressing)——稍后我们将发现他们在性能特性上非常相似。
|
||||
<!--For each of these implementations, I timed several different operations, at element counts from 100K to 1M and for payload sizes (i.e. total key+value size) from 8 to 4K bytes.-->
|
||||
在每一个实现中,单元数从 100 K 到 1 M,有效负载(比如:总的 key + value 大小)从 8 到 4 k 字节
|
||||
我为几个不同的操作记了时间。
|
||||
<!--For my purposes, keys and values were always POD types and keys were always 8 bytes (except for the 8-byte payload, in which key and value were 4 bytes each).-->
|
||||
keys 和 values 永远是 POD 类型,keys 永远是 8 个字节(除了 8 字节的有效负载,此时 key 和 value 都是 4 字节)
|
||||
<!-- I kept the keys to a consistent size because my purpose here was to test memory effects, not hash function performance. Each test was repeated 5 times and the minimum timing was taken. -->
|
||||
因为我的目的是为了测试内存影响而不是哈希函数性能,所以我将 key 放在连续的尺寸空间中。
|
||||
每一个测试都会重复 5 遍,然后记录最小的耗时。
|
||||
|
||||
<!-- The operations tested were: -->
|
||||
测试的操作在这里:
|
||||
|
||||
* **Fill**:<!-- insert a randomly shuffled sequence of unique keys into the table. -->
|
||||
将一个随机的 key 序列插入到表中(key 在序列中是唯一的)。
|
||||
* **Presized fill**:<!-- like Fill, but first reserve enough memory for all the keys we’ll insert, to prevent rehashing and reallocing during the fill process. -->
|
||||
和 Fill 相似,但是在插入之间我们先为所有的 key 保留足够的内存空间,以防止在 fill 过程中 rehash 或者重申请。
|
||||
* **Lookup**: <!-- perform 100K lookups of random keys, all of which are in the table. -->
|
||||
执行 100 k 随机 key 查找,所有的 key 都在 table 中。
|
||||
* **Failed lookup**: <!-- perform 100K lookups of random keys, none of which are in the table. -->
|
||||
执行 100 k 随机 key 查找,所有的 key 都不在 table 中。
|
||||
* **Remove**:<!-- remove a randomly chosen half of the elements from a table. -->
|
||||
从 table 中移除随机选择的半数元素。
|
||||
* **Destruct**:<!-- destroy a table and free its memory. -->
|
||||
销毁 table 并释放内存.
|
||||
|
||||
<!-- You can [download my test code here][9]. -->
|
||||
你可以[在这里下载我的测试代码][9]。
|
||||
<!-- It builds for Windows or Linux, in 64-bit only. -->
|
||||
这些代码只能在 64 机器上编译(包括Windows和Linux)。
|
||||
<!-- There are some flags near the top of `main()` that you can toggle to turn on or off different tests—with all of them on, it will likely take an hour or two to run. -->
|
||||
在 `main()` 函数附件有一些标记,你可把他们打开或者关掉——如果全开,可能会需要一两个小时才能结束运行。
|
||||
<!-- The results I gathered are also included, in an Excel spreadsheet in that archive. -->
|
||||
我搜集的结果也放在了那个打包文件里的 Excel 表中。
|
||||
<!-- (Beware that the Windows and Linux results are run on different CPUs, so timings aren’t directly comparable.) -->
|
||||
(注意: Windows 和 Linux 在不同的 CPU 上跑的,所以时间不具备可比较性)
|
||||
<!-- The code also runs unit tests to verify that all the hash table implementations are behaving correctly. -->
|
||||
代码也跑了一些单元测试,用来验证所有的 hash 表实现都能运行正确。
|
||||
|
||||
<!-- Incidentally, I also tried two additional implementations: -->
|
||||
我还顺带尝试了附加的两个实现:
|
||||
<!-- separate chaining with the first node stored in the bucket instead of the pool, and open addressing with quadratic probing. -->
|
||||
Ch 中第一个节点存放在 bucket 中而不是 pool 里,二次探测的开放寻址。
|
||||
<!-- Neither of these was good enough to include in the final data, but the code for them is still there. -->
|
||||
这两个都不足以好到可以放在最终的数据里,但是他们的代码仍放在了打包文件里面。
|
||||
<!-- ### [][10]The Results -->
|
||||
### [][10]结果
|
||||
|
||||
<!-- There’s a ton of data here. -->
|
||||
这里有成吨的数据!!
|
||||
<!-- In this section I’ll discuss the results in some detail, but if your eyes are glazing over in this part, feel free to skip down to the conclusions in the next section. -->
|
||||
这一节我将详细的讨论一下结果,但是如果你对此不感兴趣,可以直接跳到下一节的总结。
|
||||
|
||||
### [][11]Windows
|
||||
|
||||
<!-- Here are the graphed results of all the tests, compiled with Visual Studio 2012, and run on Windows 8.1 on a Core i7-4710HQ machine. (Click to zoom.) -->
|
||||
这是所有的测试的图表结果,使用 Visual Studio 2012 编译,运行于 Windows8.1 和 Core i7-4710HQ 机器上。(点击可以放大。)
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
<!-- From left to right are different payload sizes, from top to bottom are the various operations, and each graph plots time in milliseconds versus hash table element count for each of the five implementations. -->
|
||||
从左至右是不同的有效负载大小,从上往下是不同的操作
|
||||
<!-- (Note that not all the Y-axes have the same scale!) I’ll summarize the main trends for each operation. -->
|
||||
(注意:不是所有的Y轴都是相同的比例!)我将为每一个操作总结一下主要趋向。
|
||||
|
||||
**Fill**:
|
||||
<!-- Among my hash tables, chaining is a bit better than any of the OA variants, with the gap widening at larger payloads and table sizes. -->
|
||||
在我的 hash 表中,Ch 稍比任何的 OA 变种要好。随着哈希表大小和有效负载的加大,差距也随之变大。
|
||||
<!-- I guess this is because chaining only has to pull an element off the free list and stick it on the front of its bucket, while OA may have to search a few buckets to find an empty one. -->
|
||||
我猜测这是由于 Ch 只需要从一个空闲链表中拉取一个元素,然后把他放在 bucket 前面,而 OA 不得不搜索一部分 buckets 来找到一个空位置。
|
||||
<!-- The OA variants perform very similarly to each other, but DO1 appears to have a slight advantage. -->
|
||||
所有的 OA 变种的性能表现基本都很相似,当然 DO1 稍微有点优势。
|
||||
|
||||
<!-- All of my hash tables beat UM by quite a bit at small payloads, where UM pays a heavy price for doing a memory allocation on every insert. -->
|
||||
在小负载的情况,UM 几乎是所有 hash 表中表现最差的 —— 因为 UM 为每一次的插入申请(内存)付出了沉重的代价。
|
||||
<!-- But they’re about equal at 128 bytes, and UM wins by quite a bit at large payloads: -->
|
||||
但是在 128 字节的时候,这些 hash 表基本相当,大负载的时候 UM 还赢了点。
|
||||
<!-- there, all of my implementations are hamstrung by the need to resize their element pool and spend a lot of time moving the large elements into the new pool, while UM never needs to move elements once they’re allocated. -->
|
||||
因为,我所有的实现都需要重新调整元素池的大小,并需要移动大量的元素到新池里面,这一点我几乎无能为力;而 UM 一旦为元素申请了内存后便不需要移动了。
|
||||
<!-- Notice the extreme “steppy” look of the graphs for my implementations at large payloads, -->
|
||||
注意大负载中图表上夸张的跳步!
|
||||
<!-- which confirms that the problem comes when resizing. -->
|
||||
这更确认了重新调整大小带来的问题。
|
||||
<!-- In contrast, UM is quite linear—it only has to resize its bucket array, which is cheap enough not to make much of a bump. -->
|
||||
相反,UM 只是线性上升 —— 只需要重新调整 bucket 数组大小。由于没有太多隆起的地方,所以相对有效率。
|
||||
|
||||
**Presized fill**:
|
||||
<!-- Generally similar to Fill, but the graphs are more linear, not steppy (since there’s no rehashing), and there’s less difference between all the implementations. -->
|
||||
大致和 Fill 相似,但是图示结果更加的线性光滑,没有太大的跳步(因为不需要 rehash ),所有的实现差距在这一测试中要缩小了些。
|
||||
<!-- UM is still slightly faster than chaining at large payloads, but only slightly—again confirming that the problem with Fill was the resizing. -->
|
||||
大负载时 UM 依然稍快于 Ch,问题还是在于重新调整大小上。
|
||||
<!-- Chaining is still consistently faster than the OA variants, but DO1 has a slight advantage over the other OAs. -->
|
||||
Ch 仍是稳步少快于 OA 变种,但是 DO1 比其他的 OA 稍有优势。
|
||||
|
||||
**Lookup**:
|
||||
<!-- All the implementations are closely clustered, with UM and DO2 the front-runners, except at the smallest payload, where it seems like DO1 and OL may be faster. -->
|
||||
所有的实现都相当的集中。除了最小负载时,DO1 和 OL 稍快,其余情况下 UM 和 DO2 都跑在了前面。<!--Note: 你确定?-->
|
||||
<!-- It’s impressive how well UM is doing here, actually; -->
|
||||
真的,我无法描述 UM 在这一步做的多么好。
|
||||
<!-- it’s holding its own against the data-oriented variants despite needing to traverse a linked list. -->
|
||||
尽管需要遍历链表,但是 UM 还是坚守了面向数据的本性。
|
||||
|
||||
<!-- Incidentally, it’s interesting to see that the lookup time weakly depends on table size. -->
|
||||
顺带一提,查找时间和 hash 表的大小有着很弱的关联,这真的很有意思。
|
||||
<!-- Hash table lookup is expected constant-time, so from the asymptotic view it shouldn’t depend on table size at all. But that’s ignoring cache effects! -->
|
||||
哈希表查找时间期望上是一个常量时间,所以在的渐进视图中,性能不应该依赖于表的大小。但是那是在忽视了 cache 影响的情况下!
|
||||
<!-- When we do 100K lookups on a 10K-entry table, for instance, we’ll get a speedup because most of the table will be in L3 after the first 10K–20K lookups. -->
|
||||
作为具体的例子,当我们在具有 10 k 条目的表中做 100 k 查找时,速度会便变快,因为在第一次 10 k - 20 k 查找后,大部分的表会处在 L3 中。
|
||||
|
||||
**Failed lookup**:
|
||||
<!-- There’s a bit more spread here than the successful lookups. -->
|
||||
相对于成功查找,这里就有点更分散一些。
|
||||
<!-- DO1 and DO2 are the front-runners, with UM not far behind, and OL a good deal worse than the rest. -->
|
||||
DO1 和 DO2 跑在了前面,但 UM 并没有落下,OL 则是捉襟见肘啊。
|
||||
<!-- My guess is this is probably a case of OL having longer searches on average, especially in the case of a failed lookup; -->
|
||||
我猜测,这可能是因为 OL 整体上具有更长的搜索路径,尤其是在失败查询时;
|
||||
<!-- with the hash values spaced out in memory between keys and values, that hurts. -->
|
||||
内存中,hash 值在 key 和 value 之飘来荡去的找不着出路,我也很受伤啊。
|
||||
<!-- DO1 and DO2 have equally-long searches, but they have all the hash values packed together in memory, and that turns things around. -->
|
||||
DO1 和 DO2 具有相同的搜索长度,但是他们将所有的 hash 值打包在内存中,这使得问题有所缓解。
|
||||
|
||||
**Remove**:
|
||||
<!-- DO2 is the clear winner, with DO1 not far behind, chaining further behind, and UM in a distant last place due to the need to free memory on every remove; -->
|
||||
DO2 很显然是赢家,但 DO1 也未落下。Ch 则落后,UM 则是差的不是一丁半点(主要是因为每次移除都要释放内存);
|
||||
<!-- the gap widens at larger payloads. -->
|
||||
差距随着负载的增加而拉大。
|
||||
<!-- The remove operation is the only one that doesn’t touch the value data, only the hashes and keys, which explains why DO1 and DO2 are differentiated from each other here but pretty much equal in all the other tests. -->
|
||||
移除操作是唯一不需要接触数据的操作,只需要 hash 值和 key 的帮助,这也是为什么 DO1 和 DO2 在移除操作中的表现大相径庭,而其他测试中却保持一致。
|
||||
<!-- (If your value type was non-POD and needed to run a destructor, that difference would presumably disappear.) -->
|
||||
(如果你的值不是 POD 类型的,并需要析构,这种差异应该是会消失的。)
|
||||
|
||||
**Destruct**:
|
||||
<!-- Chaining is the fastest except at the smallest payload, where it’s about equal to the OA variants. -->
|
||||
Ch 除了最小负载,其他的情况都是最快的(最小负载时,约等于 OA 变种)。
|
||||
<!-- All the OA variants are essentially equal. -->
|
||||
所有的 OA 变种基本都是相等的。
|
||||
<!-- Note that for my hash tables, all they’re doing on destruction is freeing a handful of memory buffers, -->
|
||||
注意,在我的 hash 表中所做的所有析构操作都是释放少量的内存 buffer 。
|
||||
<!-- but [on Windows, freeing memory has a cost proportional to the amount allocated][13]. -->
|
||||
但是 [在Windows中,释放内存的消耗和大小成比例关系][13]。
|
||||
<!-- (And it’s a significant cost—an allocation of ~1 GB is taking ~100 ms to free!) -->
|
||||
(而且,这是一个很显著的开支 —— 申请 ~1 GB 的内存需要 ~100 ms 的时间去释放!)
|
||||
|
||||
<!-- UM is the slowest to destruct—by an order of magnitude at small payloads, and only slightly slower at large payloads. -->
|
||||
UM 在析构时是最慢的一个(小负载时,慢的程度可以用数量级来衡量),大负载时依旧是稍慢些。
|
||||
<!-- The need to free each individual element instead of just freeing a couple of arrays really hurts here. -->
|
||||
对于 UM 来讲,释放每一个元素而不是释放一组数组真的是一个硬伤。
|
||||
|
||||
### [][14]Linux
|
||||
|
||||
<!-- I also ran tests with gcc 4.8 and clang 3.5, on Linux Mint 17.1 on a Core i5-4570S machine. The gcc and clang results were very similar, so I’ll only show the gcc ones; the full set of results are in the code download archive, linked above. (Click to zoom.) -->
|
||||
我还在装有 Linux Mint 17.1 的 Core i5-4570S 机器上使用 gcc 4.8 和 clang 3.5 来运行了测试。gcc 和 clang 的结果很相像,因此我只展示了 gcc 的;完整的结果集合包含在了代码下载打包文件中,链接在上面。(点击来缩放)
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
<!-- Most of the results are quite similar to those in Windows, so I’ll just highlight a few interesting differences. -->
|
||||
大部分结果和 Windows 很相似,因此我只高亮了一些有趣的不同点。
|
||||
|
||||
**Lookup**:
|
||||
<!-- Here, DO1 is the front-runner, where DO2 was a bit faster on Windows. -->
|
||||
这里 DO1 跑在前头,而在 Windows 中 DO2 更快些。
|
||||
<!-- Also, UM and chaining are way behind all the other implementations, which is actually what I expected to see in Windows as well, given that they have to do a lot of pointer chasing while the OA variants just stride linearly through memory. --><!-- @error这里原文写错了吧-->
|
||||
同样,UM 和 Ch 落后于其他所有的实现——过多的指针追踪,然而 OA 只需要在内存中线性的移动即可。
|
||||
<!-- It’s not clear to me why the Windows and Linux results are so different here. UM is also a good deal slower than chaining, especially at large payloads, which is odd; I’d expect the two of them to be about equal. -->
|
||||
至于 Windows 和 Linux 结果为何不同,则不是很清楚。UM 同样比 Ch 慢了不少,特别是大负载时,这很奇怪;我期望的是他们可以基本相同。
|
||||
|
||||
**Failed lookup**:
|
||||
<!-- Again, UM is way behind all the others, even slower than OL. -->
|
||||
UM 再一次落后于其他实现,甚至比 OL 还要慢。
|
||||
<!-- Again, it’s puzzling to me why this is so much slower than chaining, and why the results differ so much between Linux and Windows. -->
|
||||
我再一次无法理解为何 UM 比 Ch 慢这么多,Linux 和 Windows 的结果为何有着如此大的差距。
|
||||
|
||||
|
||||
**Destruct**:
|
||||
<!-- For my implementations, the destruct cost was too small to measure at small payloads; -->
|
||||
在我的实现中,小负载的时候,析构的消耗太少了,以至于无法测量;
|
||||
<!-- at large payloads, it grows quite linearly with table size—perhaps proportional to the number of virtual memory pages touched, rather than the number allocated? -->
|
||||
在大负载中,线性增加的比例和创建的虚拟内存页数量相关,而不是申请到的数量?
|
||||
<!-- It’s also orders of magnitude faster than the destruct cost on Windows. -->
|
||||
同样,要比 Windows 中的析构快上几个数量级。
|
||||
<!-- However, this isn’t anything to do with hash tables, really; -->
|
||||
但是并不是所有的都和 hash 表有关;
|
||||
<!-- we’re seeing the behavior of the respective OSes’ and runtimes’ memory systems here. -->
|
||||
我们在这里可以看出不同系统和运行时内存系统的表现。
|
||||
<!-- It seems that Linux frees large blocks memory a lot faster than Windows (or it hides the cost better, perhaps deferring work to process exit, or pushing things off to another thread or process). -->
|
||||
貌似,Linux 释放大内存块是要比 Windows 快上不少(或者 Linux 很好的隐藏了开支,或许将释放工作推迟到了进程退出,又或者将工作推给了其他线程或者进程)。
|
||||
|
||||
<!-- UM with its per-element frees is now orders of magnitude slower than all the others, across all payload sizes. -->
|
||||
UM 由于要释放每一个元素,所以在所有的负载中都比其他慢上几个数量级。
|
||||
<!-- In fact, I cut it from the graphs because it was screwing up the Y-axis scale for all the others. -->
|
||||
事实上,我将图片做了剪裁,因为 UM 太慢了,以至于破坏了 Y 轴的比例。
|
||||
|
||||
<!-- ### [][16]Conclusions -->
|
||||
### [][16]总结
|
||||
|
||||
<!-- Well, after staring at all that data and the conflicting results for all the different cases, what can we conclude? -->
|
||||
好,当我们凝视各种情况下的数据和矛盾的结果时,我们可以得出什么结果呢?
|
||||
<!-- I’d love to be able to tell you unequivocally that one of these hash table variants beats out the others, but of course it’s not that simple. -->
|
||||
我想直接了当的告诉你这些 hash 表变种中有一个打败了其他所有的 hash 表,但是这显然不那么简单。
|
||||
<!-- Still, there is some wisdom we can take away. -->
|
||||
不过我们仍然可以学到一些东西。
|
||||
|
||||
<!-- First, in many cases it’s _easy_ to do better than `std::unordered_map`. -->
|
||||
首先,在大多数情况下我们“很容易”做的比 `std::unordered_map` 还要好。
|
||||
<!-- All of the implementations I built for these tests (and they’re not sophisticated; it only took me a couple hours to write all of them) either matched or improved upon `unordered_map`, -->
|
||||
我为这些测试所写的所有实现(他们并不复杂;我只花了一两个小时就写完了)要么是符合 `unordered_map` 要么是在其基础上做的提高,
|
||||
<!-- except for insertion performance at large payload sizes (over 128 bytes), where `unordered_map`‘s separately-allocated per-node storage becomes advantageous. -->
|
||||
除了大负载(超过128字节)中的插入性能, `unordered_map` 为每一个节点独立申请存储占了优势。
|
||||
<!-- (Though I didn’t test it, I also expect `unordered_map` to win with non-POD payloads that are expensive to move.) -->
|
||||
(尽管我没有测试,我同样期望 `unordered_map` 能在非 POD 类型的负载上取得胜利。)
|
||||
<!-- The moral here is that if you care about performance at all, don’t assume the data structures in your standard library are highly optimized. -->
|
||||
具有指导意义的是,如果你非常关心性能,不要假设你的标准库中的数据结构是高度优化的。
|
||||
<!-- They may be optimized for C++ standard conformance, not performance. :P -->
|
||||
他们可能只是在 C++ 标准的一致性上做了优化,但不是性能。:P
|
||||
|
||||
<!-- Second, you could do a lot worse than to just use DO1 (open addressing, linear probing, with the hashes/states segregated from keys/values in separate flat arrays) whenever you have small, inexpensive payloads. -->
|
||||
其次,如果不管在小负载还是超负载中,若都只用 DO1 (开放寻址,线性探测,hashes/states 和 key/vaules分别处在隔离的平滑数组中),那可能不会有啥好表现。
|
||||
<!-- It’s not the fastest for insertion, but it’s not bad either (still way better than `unordered_map`), and it’s very fast for lookup, removal, and destruction. -->
|
||||
这不是最快的插入,但也不坏(还比 `unordered_map` 快),并且在查找,移除,析构中也很快。
|
||||
<!-- What do you know—“data-oriented design” works! -->
|
||||
你所知道的 —— “面向数据设计”完成了!
|
||||
|
||||
<!-- Note that my test code for these hash tables is far from production-ready—they only support POD types, -->
|
||||
注意,我的为这些哈希表做的测试代码远未能用于生产环境——他们只支持 POD 类型,
|
||||
<!-- don’t have copy constructors and such, don’t check for duplicate keys, etc. -->
|
||||
没有拷贝构造函数以及类似的东西,也未检测重复的 key,等等。
|
||||
<!-- I’ll probably build some more realistic hash tables for my utility library soon, though. -->
|
||||
我将可能尽快的构建一些实际的 hash 表,用于我的实用库中。
|
||||
<!-- To cover the bases, I think I’ll want two variants: one based on DO1, for small, cheap-to-move payloads, and another that uses chaining and avoids ever reallocating and moving elements (like `unordered_map`) for large or expensive-to-move payloads. -->
|
||||
为了覆盖基础部分,我想我将有两个变种:一个基于 DO1,用于小的,移动时不需要太大开支的负载;另一个用于链接并且避免重新申请和移动元素(就像 `unordered_map` ),用于大负载或者移动起来需要大开支的负载情况。
|
||||
<!-- That should give me the best of both worlds. -->
|
||||
这应该会给我带来最好的两个世界。
|
||||
|
||||
<!-- In the meantime, I hope this has been illuminating. -->
|
||||
与此同时,我希望你们会有所启迪。
|
||||
<!-- And remember, if Chandler Carruth and Mike Acton give you advice about data structures, listen to them. 😉 -->
|
||||
最后记住,如果 Chandler Carruth 和 Mike Acton 在数据结构上给你提出些建议,你一定要听 😉
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
<!-- I’m a graphics programmer, currently freelancing in Seattle. Previously I worked at NVIDIA on the DevTech software team, and at Sucker Punch Productions developing rendering technology for the Infamous series of games for PS3 and PS4. -->
|
||||
我是一名图形程序员,目前在西雅图做自由职业者。之前我在 NVIDIA 的 DevTech 软件团队中工作,并在美少女特工队工作室中为 PS3 和 PS4 的 Infamous 系列游戏开发渲染技术。
|
||||
|
||||
<!-- I’ve been interested in graphics since about 2002 and have worked on a variety of assignments, including fog, atmospheric haze, volumetric lighting, water, visual effects, particle systems, skin and hair shading, postprocessing, specular models, linear-space rendering, and GPU performance measurement and optimization. -->
|
||||
自 2002 年起,我对图形非常感兴趣,并且已经完成了一系列的工作,包括:雾、大气雾霾、体积照明、水、视觉效果、粒子系统、皮肤和头发阴影、后处理、镜面模型、线性空间渲染、和 GPU 性能测量和优化。
|
||||
|
||||
<!-- You can read about what I’m up to on my blog. In addition to graphics, I’m interested in theoretical physics, and in programming language design. -->
|
||||
你可以在我的博客了解更多和我有关的事,处理图形,我还对理论物理和程序设计感兴趣。
|
||||
|
||||
<!-- You can contact me at nathaniel dot reed at gmail dot com, or follow me on Twitter (@Reedbeta) or Google+. I can also often be found answering questions at Computer Graphics StackExchange. -->
|
||||
你可以在 nathaniel.reed@gmail.com 或者在 Twitter(@Reedbeta)/Google+ 上关注我。我也会经常在 StackExchange 上回答计算机图形的问题。
|
||||
|
||||
--------------
|
||||
|
||||
via: http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
|
||||
作者:[Nathan Reed][a]
|
||||
译者:[sanfusu](https://github.com/sanfusu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
[2]:http://reedbeta.com/blog/category/coding/
|
||||
[3]:http://reedbeta.com/blog/data-oriented-hash-table/#comments
|
||||
[4]:http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
|
||||
[5]:https://www.youtube.com/watch?v=fHNmRkzxHWs
|
||||
[6]:https://www.youtube.com/watch?v=rX0ItVEVjHc
|
||||
[7]:http://reedbeta.com/blog/data-oriented-hash-table/#the-tests
|
||||
[8]:http://burtleburtle.net/bob/hash/spooky.html
|
||||
[9]:http://reedbeta.com/blog/data-oriented-hash-table/hash-table-tests.zip
|
||||
[10]:http://reedbeta.com/blog/data-oriented-hash-table/#the-results
|
||||
[11]:http://reedbeta.com/blog/data-oriented-hash-table/#windows
|
||||
[12]:http://reedbeta.com/blog/data-oriented-hash-table/results-vs2012.png
|
||||
[13]:https://randomascii.wordpress.com/2014/12/10/hidden-costs-of-memory-allocation/
|
||||
[14]:http://reedbeta.com/blog/data-oriented-hash-table/#linux
|
||||
[15]:http://reedbeta.com/blog/data-oriented-hash-table/results-g++4.8.png
|
||||
[16]:http://reedbeta.com/blog/data-oriented-hash-table/#conclusions
|
||||
Loading…
Reference in New Issue
Block a user