")
+def show_sample_files(filepath):
+ return static_file(filepath, root="files")
+```
+
+### 2、查看文档
+
+所有组件准备就绪后,让我们添加函数以使编辑者可以利用应用接口操作。
+
+第一个选项使用户可以打开和查看文档。连接模板中的文档编辑器 API :
+
+```
+
+```
+
+`editor_url` 是文档编辑器的链接接口。
+
+打开每个文件以供查看的按钮:
+
+```
+
+```
+
+现在我们需要添加带有 `id` 的 `div` 标签,打开文档编辑器:
+
+```
+
+```
+
+要打开编辑器,必须调用调用一个函数:
+
+```
+
+```
+
+DocEditor 函数有两个参数:将在其中打开编辑器的元素 `id` 和带有编辑器设置的 `JSON`。
+在此示例中,使用了以下必需参数:
+
+ * `documentType` 由其格式标识(`.docx`、`.xlsx`、`.pptx` 用于相应的文本、电子表格和演示文稿)
+ * `document.url` 是你要打开的文件链接。
+ * `editorConfig.mode`。
+
+我们还可以添加将在编辑器中显示的 `title`。
+
+接下来,我们可以在 Python 应用程序中查看文档。
+
+### 3、编辑文档
+
+首先,添加 “Edit”(编辑)按钮:
+
+```
+
+```
+
+然后创建一个新功能,打开文件进行编辑。类似于查看功能。
+
+现在创建 3 个函数:
+
+```
+
+```
+
+`destroyEditor` 被调用以关闭一个打开的编辑器。
+
+你可能会注意到,`edit()` 函数中缺少 `editorConfig` 参数,因为默认情况下它的值是:`{"mode":"edit"}`。
+
+现在,我们拥有了打开文档以在 Python 应用程序中进行协同编辑的所有功能。
+
+### 4、如何在 Python 应用中利用 ONLYOFFICE 协同编辑文档
+
+通过在编辑器中设置对同一文档使用相同的 `document.key` 来实现协同编辑。 如果没有此键值,则每次打开文件时,编辑器都会创建编辑会话。
+
+为每个文档设置唯一键,以使用户连接到同一编辑会话时进行协同编辑。 密钥格式应为以下格式:`filename +"_key"`。下一步是将其添加到当前文档的所有配置中。
+
+```
+document: {
+ url: "host_url" + '/' + filepath,
+ title: filename,
+ key: filename + '_key'
+},
+```
+
+### 5、如何在 Python 应用中利用 ONLYOFFICE 保存文档
+
+每次我们更改并保存文件时,ONLYOFFICE 都会存储其所有版本。 让我们仔细看看它是如何工作的。 关闭编辑器后,文档服务器将构建要保存的文件版本并将请求发送到 `callbackUrl` 地址。 该请求包含 `document.key`和指向刚刚构建的文件的链接。
+
+`document.key` 用于查找文件的旧版本并将其替换为新版本。 由于这里没有任何数据库,因此仅使用 `callbackUrl` 发送文件名。
+
+在 `editorConfig.callbackUrl` 的设置中指定 `callbackUrl` 参数并将其添加到 `edit()` 方法中:
+
+```
+ function edit(filename) {
+ const filepath = 'files/' + filename;
+ if (editor) {
+ editor.destroyEditor()
+ }
+ editor = new DocsAPI.DocEditor("editor",
+ {
+ documentType: get_file_type(filepath),
+ document: {
+ url: "host_url" + '/' + filepath,
+ title: filename,
+ key: filename + '_key'
+ }
+ ,
+ editorConfig: {
+ mode: 'edit',
+ callbackUrl: "host_url" + '/callback' + '&filename=' + filename // add file name as a request parameter
+ }
+ });
+ }
+```
+
+编写一种方法,在获取到 POST 请求发送到 `/callback` 地址后将保存文件:
+
+```
+@post("/callback") # processing post requests for /callback
+def callback():
+ if request.json['status'] == 2:
+ file = requests.get(request.json['url']).content
+ with open('files/' + request.query['filename'], 'wb') as f:
+ f.write(file)
+ return "{\"error\":0}"
+
+```
+
+`# status 2` 是已生成的文件,当我们关闭编辑器时,新版本的文件将保存到存储器中。
+
+### 6、管理用户
+
+如果应用中有用户,并且你需要查看谁在编辑文档,请在编辑器的配置中输入其标识符(`id`和`name`)。
+
+在界面中添加选择用户的功能:
+
+```
+
+```
+
+如果在标记 `
+
+
+
+
+```
+
+要在浏览器中运行此文件,请双击文件或打开你喜欢的浏览器,点击菜单,然后选择**文件->打开文件**。(如果使用 Brackets 软件,也可以使用角落处的闪电图标在浏览器中打开文件)。
+
+### 生成伪随机数
+
+猜谜游戏的第一步是为玩家生成一个数字供玩家猜测。JavaScript 包含几个内置的全局对象,可帮助你编写代码。要生成随机数,请使用 `Math` 对象。
+
+JavaScript中的 [Math][17] 具有处理和数学相关的属性和功能。你将使用两个数学函数来生成随机数,供你的玩家猜测。
+
+[Math.random()][18],会将生成一个介于 0 和 1 之间的伪随机数。(`Math.random` 包含 0 但不包含 1。这意味着该函数可以生成 0 ,永远不会产生 1)
+
+对于此游戏,请将随机数设置在 1 到 100 之间以缩小玩家的选择范围。取刚刚生成的小数,然后乘以 100,以产生一个介于 0 到……甚至不是 100 之间的小数。至此,你将需要其他步骤来解决这个问题。
+
+现在,你的数字仍然是小数,但你希望它是一个整数。为此,你可以使用属于 `Math` 对象的另一个函数 [Math.floor()][19]。`Math.floor()` 的目的是返回小于或等于你作为参数指定的数字的最大整数,这意味着它会四舍五入为最接近的整数:
+
+```
+Math.floor(Math.random() * 100)
+```
+
+这样你将得到 0 到 99 之间的整数,这不是你想要的范围。你可以在最后一步修复该问题,即在结果中加 1。瞧!现在,你有一个(有点)随机生成的数字,介于 1 到 100 之间:
+
+```
+Math.floor(Math.random() * 100) + 1
+```
+
+### 变量
+
+现在,你需要存储随机生成的数字,以便可以将其与玩家的猜测进行比较。为此,你可以将其存储到一个 **变量**。
+
+JavaScript 具有不同类型的变量,你可以选择这些类型,具体取决于你要如何使用该变量。对于此游戏,请使用 `const` 和 `let`。
+
+ * `let` 用于指示变量在整个程序中可以改变。
+ * `const` 用于指示变量不应该被修改。
+
+`const` 和 `let` 还有很多要说的,但现在知道这些就足够了。
+
+随机数在游戏中仅生成一次,因此你将使用 `const` 变量来保存该值。你想给变量起一个清楚地表明要存储什么值的名称,因此将其命名为 `randomNumber`:
+
+```
+const randomNumber
+```
+
+有关命名的注意事项:JavaScript 中的变量和函数名称以驼峰形式编写。如果只有一个单词,则全部以小写形式书写。如果有多个单词,则第一个单词均为小写,其他任何单词均以大写字母开头,且单词之间没有空格。
+
+### 打印到控制台
+
+通常,你不想向任何人显示随机数,但是开发人员可能想知道生成的数字以使用它来帮助调试代码。 使用 JavaScript,你可以使用另一个内置函数 [console.log()][20] 将数字输出到浏览器的控制台。
+
+大多数浏览器都包含开发人员工具,你可以通过按键盘上的 `F12` 键来打开它们。从那里,你应该看到一个 **控制台** 标签。打印到控制台的所有信息都将显示在此处。由于到目前为止编写的代码将在浏览器加载后立即运行,因此,如果你查看控制台,你应该会看到刚刚生成的随机数!
+
+![Javascript game with console][21]
+
+### 函数
+
+接下来,你需要一种方法来从数字输入字段中获得玩家的猜测,将其与你刚刚生成的随机数进行比较,并向玩家提供反馈,让他们知道他们是否正确猜到了。为此,编写一个函数。 **函数** 是执行一定任务的代码块。函数是可以重用的,这意味着如果你需要多次运行相同的代码,则可以调用函数,而不必重写执行任务所需的所有步骤。
+
+根据你使用的 JavaScript 版本,有许多不同的方法来编写或声明函数。由于这是该语言的基础入门,因此请使用基本函数语法声明函数。
+
+以关键字 `function` 开头,然后起一个函数名。好的做法是使用一个描述该函数的功能的名称。在这个例子中,你正在检查玩家的猜测的数,因此此函数的名字可以是 `checkGuess`。在函数名称之后,写上一组小括号,然后写上一组花括号。 你将在以下花括号之间编写函数的主体:
+
+```
+function checkGuess() {}
+```
+
+### 使用 DOM
+
+JavaScript 的目的之一是与网页上的 HTML 交互。它通过文档对象模型(DOM)进行此操作,DOM 是 JavaScript 用于访问和更改网页信息的对象。现在,你需要从 HTML 中获取数字输入字段中玩家的猜测。你可以使用分配给 HTML 元素的 `id` 属性(在这种情况下为 `guess`)来做到这一点:
+
+```
+
+```
+
+JavaScript 可以通过访问玩家输入到数字输入字段中的数来获取其值。你可以通过引用元素的 ID 并在末尾添加 `.value` 来实现。这次,使用 `let` 定义的变量来保存用户的猜测值:
+
+```
+let myGuess = guess.value
+```
+
+玩家在数字输入字段中输入的任何数字都将被分配给 `checkGuess` 函数中的 `myGuess` 变量。
+
+### 条件语句
+
+下一步是将玩家的猜测与游戏产生的随机数进行比较。你还想给玩家反馈,让他们知道他们的猜测是太高,太低还是正确。
+
+你可以使用一系列条件语句来决定玩家将收到的反馈。**条件语句** 在运行代码块之前检查是否满足条件。如果不满足条件,则代码停止,继续检查下一个条件,或者继续执行其余代码,而无需执行条件块中的代码:
+
+```
+if (myGuess === randomNumber){
+ feedback.textContent = "You got it right!"
+}
+else if(myGuess > randomNumber) {
+ feedback.textContent = "Your guess was " + myGuess + ". That's too high. Try Again!"
+}
+else if(myGuess < randomNumber) {
+ feedback.textContent = "Your guess was " + myGuess + ". That's too low. Try Again!"
+}
+```
+
+第一个条件块使用比较运算符 `===` 将玩家的猜测与游戏生成的随机数进行比较。比较运算符检查右侧的值,将其与左侧的值进行比较,如果匹配则返回布尔值 `true`,否则返回布尔值 `false`。
+
+如果数字匹配(猜对了!),为了让玩家知道。通过将文本添加到具有 `id` 属性 `feedback` 的 `` 标记中来操作 DOM。就像上面的 `guess.value` 一样,除了不是从 DOM 获取信息,而是更改其中的信息。`
` 元素没有像 `` 元素那样的值,而是具有文本,因此请使用 `.textContent` 访问元素并设置要显示的文本:
+
+```
+feedback.textContent = "You got it right!"
+```
+
+当然,玩家很有可能在第一次尝试时就猜错了,因此,如果 `myGuess` 和 `randomNumber` 不匹配,请给玩家一个线索,以帮助他们缩小猜测范围。如果第一个条件失败,则代码将跳过该 `if` 语句中的代码块,并检查下一个条件是否为 `true`。 这使你进入 `else if` 块:
+
+```
+else if(myGuess > randomNumber) {
+ feedback.textContent = "Your guess was " + myGuess + ". That's too high. Try Again!"
+}
+```
+
+如果你将其作为句子阅读,则可能是这样的:“如果玩家的猜测等于随机数,请让他们知道他们猜对了。否则,请检查玩家的猜测是否大于 `randomNumber`,如果是,则显示玩家的猜测并告诉他们太高了。”
+
+最后一种可能性是玩家的猜测低于随机数。 要检查这一点,再添加一个 `else if` 块:
+
+```
+else if(myGuess < randomNumber) {
+ feedback.textContent = "Your guess was " + myGuess + ". That's too low. Try Again!"
+}
+```
+
+### 用户事件和事件监听器
+
+如果你看上面的代码,则会看到某些代码在页面加载时自动运行,但有些则不会。你想在玩游戏之前生成随机数,但是你不想在玩家将数字输入到数字输入字段并准备检查它之前检查其猜测。
+
+生成随机数并将其打印到控制台的代码不在函数的范围内,因此它将在浏览器加载脚本时自动运行。 但是,要使函数内部的代码运行,你必须对其进行调用。
+
+调用函数有几种方法。在此,你希望该函数在用户单击 “Check My Guess” 按钮时运行。单击按钮将创建一个用户事件,然后 JavaScript 可以 “监听” 这个事件,以便知道何时需要运行函数。
+
+代码的最后一行将事件侦听器添加到按钮上,以在单击按钮时调用函数。当它“听到”该事件时,它将运行分配给事件侦听器的函数:
+
+```
+submitGuess.addEventListener('click', checkGuess)
+```
+
+就像访问 DOM 元素的其他实例一样,你可以使用按钮的 ID 告诉 JavaScript 与哪个元素进行交互。 然后,你可以使用内置的 `addEventListener` 函数来告诉 JavaScript 要监听的事件。
+
+你已经看到了带有参数的函数,但花点时间看一下它是如何工作的。参数是函数执行其任务所需的信息。并非所有函数都需要参数,但是 `addEventListener` 函数需要两个参数。它采用的第一个参数是将为其监听的用户事件的名称。用户可以通过多种方式与 DOM 交互,例如键入、移动鼠标,键盘上的 `TAB` 键和粘贴文本。在这种情况下,你正在监听的用户事件是单击按钮,因此第一个参数将是 `click`。
+
+`addEventListener`的第二个所需的信息是用户单击按钮时要运行的函数的名称。 这里我们需要 `checkGuess` 函数。
+
+现在,当玩家按下 “Check My Guess” 按钮时,`checkGuess` 函数将获得他们在数字输入字段中输入的值,将其与随机数进行比较,并在浏览器中显示反馈,以使玩家知道他们猜的怎么样。 太棒了!你的游戏已准备就绪。
+
+### 学习 JavaScript 以获取乐趣和收益
+
+这一点点的平凡无奇的 JavaScript 只是这个庞大的生态系统所提供功能的一小部分。这是一种值得花时间投入学习的语言,我鼓励你继续挖掘并学习更多。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/learn-javascript
+
+作者:[Mandy Kendall][a]
+选题:[lujun9972][b]
+译者:[amwps290](https://github.com/amwps290)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mkendall
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_javascript.jpg?itok=60evKmGl "Javascript code close-up with neon graphic overlay"
+[2]: https://opensource.com/tags/javascript
+[3]: https://opensource.com/article/20/11/reactjs-tutorial
+[4]: https://opensource.com/article/18/9/open-source-javascript-chart-libraries
+[5]: https://opensource.com/article/20/12/brackets
+[6]: http://december.com/html/4/element/html.html
+[7]: http://december.com/html/4/element/head.html
+[8]: http://december.com/html/4/element/meta.html
+[9]: http://december.com/html/4/element/title.html
+[10]: http://december.com/html/4/element/body.html
+[11]: http://december.com/html/4/element/h1.html
+[12]: http://december.com/html/4/element/p.html
+[13]: http://december.com/html/4/element/label.html
+[14]: http://december.com/html/4/element/input.html
+[15]: http://december.com/html/4/element/form.html
+[16]: http://december.com/html/4/element/script.html
+[17]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math
+[18]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math/random
+[19]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math/floor
+[20]: https://developer.mozilla.org/en-US/docs/Web/API/Console/log
+[21]: https://opensource.com/sites/default/files/javascript-game-with-console.png "Javascript game with console"
diff --git a/published/202102/20210121 How Nextcloud is the ultimate open source productivity suite.md b/published/202102/20210121 How Nextcloud is the ultimate open source productivity suite.md
new file mode 100644
index 0000000000..397dfea81f
--- /dev/null
+++ b/published/202102/20210121 How Nextcloud is the ultimate open source productivity suite.md
@@ -0,0 +1,70 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13077-1.html)
+[#]: subject: (How Nextcloud is the ultimate open source productivity suite)
+[#]: via: (https://opensource.com/article/21/1/nextcloud-productivity)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+Nextcloud 是如何成为终极开源生产力套件的
+======
+
+> Nextcloud 可以取代你用于协作、组织和任务管理的许多在线应用。
+
+
+
+在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的第十一天。
+
+基于 Web 的服务几乎可以在任何地方访问你的数据,它们每小时可以支持数百万用户。不过对于我们中的一些人来说,由于各种原因,运行自己的服务比使用大公司的服务更可取。也许我们的工作是受监管的或有明确安全要求。也许我们有隐私方面的考虑,或者只是喜欢能够自己构建、运行和修复事物。不管是什么情况,[Nextcloud][2] 都可以提供你所需要的大部分服务,但是是在你自己的硬件上。
+
+![NextCloud Dashboard displaying service options][3]
+
+*Nextcloud 控制面板(Kevin Sonney, [CC BY-SA 4.0][4])*
+
+大多数时候,当我们想到 Nextcloud 时,我们会想到文件共享和同步,类似于 Dropbox、OneDrive 和 Google Drive 等商业产品。然而,如今,它是一个完整的生产力套件,拥有电子邮件客户端、日历、任务和笔记本。
+
+有几种方法可以安装和运行 Nextcloud。你可以把它安装到裸机服务器上、在 Docker 容器中运行,或者作为虚拟机运行。如果可以考虑,还有一些托管服务将为你运行 Nextcloud。最后,有适用于所有主流操作系统的应用,包括移动应用,以便随时访问。
+
+![Nextcloud virtual machine][5]
+
+*Nextcloud 虚拟机(Kevin Sonney, [CC BY-SA 4.0][4])*
+
+默认情况下,Nextcloud 会安装文件共享和其他一些相关应用(或附加组件)。你可以在管理界面中找到“应用”页面,这里允许你安装单个附加组件和一些预定义的相关应用捆绑。对我而言,我选择了 “Groupware Bundle”,其中包括“邮件”、“日历”、“联系人”和 “Deck”。“Deck” 是一个轻量级的看板,用于处理任务。我也安装了“记事本”和“任务”应用。
+
+Nextcloud “邮件” 是一个非常直白的 IMAP 邮件客户端。虽然 Nextcloud 没有将 IMAP 或 SMTP 服务器作为软件包的一部分,但你可以很容易地在操作系统中添加一个或使用远程服务。“日历”应用是相当标准的,也允许你订阅远程日历。有一个缺点是,远程日历(例如,来自大型云提供商)是只读的,所以你可以查看但不能修改它们。
+
+![NextCoud App Interface][6]
+
+*Nextcloud 应用界面 (Kevin Sonney, [CC BY-SA 4.0][4])*
+
+“记事本” 是一个简单的文本记事本,允许你创建和更新简短的笔记、日记和相关的东西。“任务” 是一款待办事项应用,支持多个列表、任务优先级、完成百分比以及其他一些用户期待的标准功能。如果你安装了 “Deck”,它的任务卡也会被列出来。每个看板都会显示自己的列表,所以你可以使用 “Deck” 或 “任务” 来跟踪完成的内容。
+
+“Deck” 本身就是一个看板应用,将任务以卡片的形式呈现在流程中。如果你喜欢看板流程,它是一个追踪进度的优秀应用。
+
+![Taking notes][7]
+
+*做笔记 (Kevin Sonney, [CC BY-SA 4.0][4])*
+
+Nextcloud 中所有的应用都原生支持通过标准协议进行共享。与一些类似的解决方案不同,它的分享并不是为了完成功能列表中的一项而加上去的。分享是 Nextcloud 存在的主要原因之一,所以使用起来非常简单。你还可以将链接分享到社交媒体、通过电子邮件分享等。你可以用一个 Nextcloud 取代多个在线服务,它在任何地方都可以访问,以协作为先。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/nextcloud-productivity
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/team_dev_email_chat_video_work_wfm_desk_520.png?itok=6YtME4Hj (Working on a team, busy worklife)
+[2]: https://nextcloud.com/
+[3]: https://opensource.com/sites/default/files/day11-image1_0.png
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://opensource.com/sites/default/files/pictures/nextcloud-vm.png (Nextcloud virtual machine)
+[6]: https://opensource.com/sites/default/files/pictures/nextcloud-app-interface.png (NextCoud App Interface)
+[7]: https://opensource.com/sites/default/files/day11-image3.png (Taking notes in Nextcloud)
diff --git a/published/202102/20210122 3 tips for automating your email filters.md b/published/202102/20210122 3 tips for automating your email filters.md
new file mode 100644
index 0000000000..f3644bb0e5
--- /dev/null
+++ b/published/202102/20210122 3 tips for automating your email filters.md
@@ -0,0 +1,60 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13073-1.html)
+[#]: subject: (3 tips for automating your email filters)
+[#]: via: (https://opensource.com/article/21/1/email-filter)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+3 个自动化电子邮件过滤器的技巧
+======
+
+> 通过这些简单的建议,减少你的电子邮件并让你的生活更轻松。
+
+
+
+在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的第十二天。
+
+如果有一件事是我喜欢的,那就是自动化。只要有机会,我就会把小任务进行自动化。早起打开鸡舍的门?我买了一扇门,可以在日出和日落时开门和关门。每天从早到晚实时监控鸡群?用 Node-RED 和 [OBS-Websockets][2] 稍微花点时间,就能搞定。
+
+我们还有电子邮件。几天前,我写过关于处理邮件的文章,也写过关于标签和文件夹的文章。只要做一点前期的工作,你就可以在邮件进来的时候,你就可以自动摆脱掉大量管理邮件的开销。
+
+![Author has 480 filters][3]
+
+*是的,我有很多过滤器。(Kevin Sonney, [CC BY-SA 4.0][4])*
+
+有两种主要方式来过滤你的电子邮件:在服务端或者客户端上。我更喜欢在服务端上做,因为我不断地在尝试新的和不同的电子邮件客户端。(不,真的,我光这个星期就已经使用了五个不同的客户端。我可能有问题。)
+
+无论哪种方式,我都喜欢用电子邮件过滤规则做几件事,以使我的电子邮件更容易浏览,并保持我的收件箱不混乱。
+
+ 1. 将不紧急的邮件移到“稍后阅读”文件夹中。对我而言,这包括来自社交网络、新闻简报和邮件列表的通知。
+ 2. 按列表或主题给消息贴上标签。我属于几个组织,虽然它们经常会被放在“稍后阅读”文件夹中,但我会添加第二个或第三个标签,以说明该来源或项目的内容,以帮助搜索时找到相关的东西。
+ 3. 不要把规则搞得太复杂。这个想法让我困难了一段时间。我想把邮件发送到某个文件夹的所有可能情况都加到一个规则里。如果有什么问题或需要添加或删除的东西,有一个大规则只是让它更难修复。
+
+![Unsubscribe from email][5]
+
+*点击它,点击它就行!(Kevin Sonney, [CC BY-SA 4.0][4])*
+
+说了这么多,还有一件事我一直在做,它有助于减少我花在电子邮件上的时间:退订邮件。两年前我感兴趣的那个邮件列表已经不感兴趣了,所以就不订阅了。产品更新通讯是我去年停止使用的商品?退订!这一直在积极解放我。我每年都会试着评估几次列表中的邮件信息是否(仍然)有用。
+
+过滤器和规则可以是非常强大的工具,让你的电子邮件保持集中,减少花在它们身上的时间。而点击取消订阅按钮是一种解放。试试就知道了!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/email-filter
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/innovation_lightbulb_gears_devops_ansible.png?itok=TSbmp3_M (gears and lightbulb to represent innovation)
+[2]: https://opensource.com/article/20/6/obs-websockets-streaming
+[3]: https://opensource.com/sites/default/files/day12-image1_0.png
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://opensource.com/sites/default/files/day12-image2_0.png
diff --git a/published/202102/20210125 Explore binaries using this full-featured Linux tool.md b/published/202102/20210125 Explore binaries using this full-featured Linux tool.md
new file mode 100644
index 0000000000..ffa4c8554b
--- /dev/null
+++ b/published/202102/20210125 Explore binaries using this full-featured Linux tool.md
@@ -0,0 +1,635 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13074-1.html)
+[#]: subject: (Explore binaries using this full-featured Linux tool)
+[#]: via: (https://opensource.com/article/21/1/linux-radare2)
+[#]: author: (Gaurav Kamathe https://opensource.com/users/gkamathe)
+
+全功能的二进制文件分析工具 Radare2 指南
+======
+
+> Radare2 是一个为二进制分析定制的开源工具。
+
+
+
+在《[Linux 上分析二进制文件的 10 种方法][2]》中,我解释了如何使用 Linux 上丰富的原生工具集来分析二进制文件。但如果你想进一步探索你的二进制文件,你需要一个为二进制分析定制的工具。如果你是二进制分析的新手,并且大多使用的是脚本语言,这篇文章《[GNU binutils 里的九种武器][3]》可以帮助你开始学习编译过程和什么是二进制。
+
+### 为什么我需要另一个工具?
+
+如果现有的 Linux 原生工具也能做类似的事情,你自然会问为什么需要另一个工具。嗯,这和你用手机做闹钟、做笔记、做相机、听音乐、上网、偶尔打电话和接电话的原因是一样的。以前,使用单独的设备和工具处理这些功能 —— 比如拍照的实体相机,记笔记的小记事本,起床的床头闹钟等等。对用户来说,有一个设备来做多件(但相关的)事情是*方便的*。另外,杀手锏就是独立功能之间的*互操作性*。
+
+同样,即使许多 Linux 工具都有特定的用途,但在一个工具中捆绑类似(和更好)的功能是非常有用的。这就是为什么我认为 [Radare2][4] 应该是你需要处理二进制文件时的首选工具。
+
+根据其 [GitHub 简介][5],Radare2(也称为 r2)是一个“类 Unix 系统上的逆向工程框架和命令行工具集”。它名字中的 “2” 是因为这个版本从头开始重写的,使其更加模块化。
+
+### 为什么选择 Radare2?
+
+有大量(非原生的)Linux 工具可用于二进制分析,为什么要选择 Radare2 呢?我的理由很简单。
+
+首先,它是一个开源项目,有一个活跃而健康的社区。如果你正在寻找新颖的功能或提供着 bug 修复的工具,这很重要。
+
+其次,Radare2 可以在命令行上使用,而且它有一个功能丰富的图形用户界面(GUI)环境,叫做 Cutter,适合那些对 GUI 比较熟悉的人。作为一个长期使用 Linux 的用户,我对习惯于在 shell 上输入。虽然熟悉 Radare2 的命令稍微有一点学习曲线,但我会把它比作 [学习 Vim][6]。你可以先学习基本的东西,一旦你掌握了它们,你就可以继续学习更高级的东西。很快,它就变成了肌肉记忆。
+
+第三,Radare2 通过插件可以很好的支持外部工具。例如,最近开源的 [Ghidra][7] 二进制分析和逆向工具很受欢迎,因为它的反编译器功能是逆向软件的关键要素。你可以直接从 Radare2 控制台安装 Ghidra 反编译器并使用,这很神奇,让你两全其美。
+
+### 开始使用 Radare2
+
+要安装 Radare2,只需克隆其存储库并运行 `user.sh` 脚本。如果你的系统上还没有一些预备软件包,你可能需要安装它们。一旦安装完成,运行 `r2 -v` 命令来查看 Radare2 是否被正确安装:
+
+```
+$ git clone https://github.com/radareorg/radare2.git
+$ cd radare2
+$ ./sys/user.sh
+
+# version
+
+$ r2 -v
+radare2 4.6.0-git 25266 @ linux-x86-64 git.4.4.0-930-g48047b317
+commit: 48047b3171e6ed0480a71a04c3693a0650d03543 build: 2020-11-17__09:31:03
+$
+```
+
+#### 获取二进制测试样本
+
+现在 `r2` 已经安装好了,你需要一个样本二进制程序来试用它。你可以使用任何系统二进制文件(`ls`、`bash` 等),但为了使本教程的内容简单,请编译以下 C 程序:
+
+```
+$ cat adder.c
+```
+
+```
+#include
+
+int adder(int num) {
+ return num + 1;
+}
+
+int main() {
+ int res, num1 = 100;
+ res = adder(num1);
+ printf("Number now is : %d\n", res);
+ return 0;
+}
+```
+
+```
+$ gcc adder.c -o adder
+$ file adder
+adder: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=9d4366f7160e1ffb46b14466e8e0d70f10de2240, not stripped
+$ ./adder
+Number now is : 101
+```
+
+#### 加载二进制文件
+
+要分析二进制文件,你必须在 Radare2 中加载它。通过提供文件名作为 `r2` 命令的一个命令行参数来加载它。你会进入一个独立的 Radare2 控制台,这与你的 shell 不同。要退出控制台,你可以输入 `Quit` 或 `Exit` 或按 `Ctrl+D`:
+
+```
+$ r2 ./adder
+ -- Learn pancake as if you were radare!
+[0x004004b0]> quit
+$
+```
+
+#### 分析二进制
+
+在你探索二进制之前,你必须让 `r2` 为你分析它。你可以通过在 `r2` 控制台中运行 `aaa` 命令来实现:
+
+```
+$ r2 ./adder
+ -- Sorry, radare2 has experienced an internal error.
+[0x004004b0]>
+[0x004004b0]>
+[0x004004b0]> aaa
+[x] Analyze all flags starting with sym. and entry0 (aa)
+[x] Analyze function calls (aac)
+[x] Analyze len bytes of instructions for references (aar)
+[x] Check for vtables
+[x] Type matching analysis for all functions (aaft)
+[x] Propagate noreturn information
+[x] Use -AA or aaaa to perform additional experimental analysis.
+[0x004004b0]>
+```
+
+这意味着每次你选择一个二进制文件进行分析时,你必须在加载二进制文件后输入一个额外的命令 `aaa`。你可以绕过这一点,在命令后面跟上 `-A` 来调用 `r2`;这将告诉 `r2` 为你自动分析二进制:
+
+```
+$ r2 -A ./adder
+[x] Analyze all flags starting with sym. and entry0 (aa)
+[x] Analyze function calls (aac)
+[x] Analyze len bytes of instructions for references (aar)
+[x] Check for vtables
+[x] Type matching analysis for all functions (aaft)
+[x] Propagate noreturn information
+[x] Use -AA or aaaa to perform additional experimental analysis.
+ -- Already up-to-date.
+[0x004004b0]>
+```
+
+#### 获取一些关于二进制的基本信息
+
+在开始分析一个二进制文件之前,你需要一些背景信息。在许多情况下,这可以是二进制文件的格式(ELF、PE 等)、二进制的架构(x86、AMD、ARM 等),以及二进制是 32 位还是 64 位。方便的 `r2` 的 `iI` 命令可以提供所需的信息:
+
+```
+[0x004004b0]> iI
+arch x86
+baddr 0x400000
+binsz 14724
+bintype elf
+bits 64
+canary false
+class ELF64
+compiler GCC: (GNU) 8.3.1 20190507 (Red Hat 8.3.1-4)
+crypto false
+endian little
+havecode true
+intrp /lib64/ld-linux-x86-64.so.2
+laddr 0x0
+lang c
+linenum true
+lsyms true
+machine AMD x86-64 architecture
+maxopsz 16
+minopsz 1
+nx true
+os linux
+pcalign 0
+pic false
+relocs true
+relro partial
+rpath NONE
+sanitiz false
+static false
+stripped false
+subsys linux
+va true
+
+[0x004004b0]>
+[0x004004b0]>
+```
+
+### 导入和导出
+
+通常情况下,当你知道你要处理的是什么样的文件后,你就想知道二进制程序使用了什么样的标准库函数,或者了解程序的潜在功能。在本教程中的示例 C 程序中,唯一的库函数是 `printf`,用来打印信息。你可以通过运行 `ii` 命令看到这一点,它显示了该二进制所有导入的库:
+
+```
+[0x004004b0]> ii
+[Imports]
+nth vaddr bind type lib name
+―――――――――――――――――――――――――――――――――――――
+1 0x00000000 WEAK NOTYPE _ITM_deregisterTMCloneTable
+2 0x004004a0 GLOBAL FUNC printf
+3 0x00000000 GLOBAL FUNC __libc_start_main
+4 0x00000000 WEAK NOTYPE __gmon_start__
+5 0x00000000 WEAK NOTYPE _ITM_registerTMCloneTable
+```
+
+该二进制也可以有自己的符号、函数或数据。这些函数通常显示在 `Exports` 下。这个测试的二进制导出了两个函数:`main` 和 `adder`。其余的函数是在编译阶段,当二进制文件被构建时添加的。加载器需要这些函数来加载二进制文件(现在不用太关心它们):
+
+```
+[0x004004b0]>
+[0x004004b0]> iE
+[Exports]
+
+nth paddr vaddr bind type size lib name
+――――――――――――――――――――――――――――――――――――――――――――――――――――――
+82 0x00000650 0x00400650 GLOBAL FUNC 5 __libc_csu_fini
+85 ---------- 0x00601024 GLOBAL NOTYPE 0 _edata
+86 0x00000658 0x00400658 GLOBAL FUNC 0 _fini
+89 0x00001020 0x00601020 GLOBAL NOTYPE 0 __data_start
+90 0x00000596 0x00400596 GLOBAL FUNC 15 adder
+92 0x00000670 0x00400670 GLOBAL OBJ 0 __dso_handle
+93 0x00000668 0x00400668 GLOBAL OBJ 4 _IO_stdin_used
+94 0x000005e0 0x004005e0 GLOBAL FUNC 101 __libc_csu_init
+95 ---------- 0x00601028 GLOBAL NOTYPE 0 _end
+96 0x000004e0 0x004004e0 GLOBAL FUNC 5 _dl_relocate_static_pie
+97 0x000004b0 0x004004b0 GLOBAL FUNC 47 _start
+98 ---------- 0x00601024 GLOBAL NOTYPE 0 __bss_start
+99 0x000005a5 0x004005a5 GLOBAL FUNC 55 main
+100 ---------- 0x00601028 GLOBAL OBJ 0 __TMC_END__
+102 0x00000468 0x00400468 GLOBAL FUNC 0 _init
+
+[0x004004b0]>
+```
+
+### 哈希信息
+
+如何知道两个二进制文件是否相似?你不能只是打开一个二进制文件并查看里面的源代码。在大多数情况下,二进制文件的哈希值(md5sum、sha1、sha256)是用来唯一识别它的。你可以使用 `it` 命令找到二进制的哈希值:
+
+```
+[0x004004b0]> it
+md5 7e6732f2b11dec4a0c7612852cede670
+sha1 d5fa848c4b53021f6570dd9b18d115595a2290ae
+sha256 13dd5a492219dac1443a816ef5f91db8d149e8edbf26f24539c220861769e1c2
+[0x004004b0]>
+```
+
+### 函数
+
+代码按函数分组;要列出二进制中存在的函数,请运行 `afl` 命令。下面的列表显示了 `main` 函数和 `adder` 函数。通常,以 `sym.imp` 开头的函数是从标准库(这里是 glibc)中导入的:
+
+```
+[0x004004b0]> afl
+0x004004b0 1 46 entry0
+0x004004f0 4 41 -> 34 sym.deregister_tm_clones
+0x00400520 4 57 -> 51 sym.register_tm_clones
+0x00400560 3 33 -> 32 sym.__do_global_dtors_aux
+0x00400590 1 6 entry.init0
+0x00400650 1 5 sym.__libc_csu_fini
+0x00400658 1 13 sym._fini
+0x00400596 1 15 sym.adder
+0x004005e0 4 101 loc..annobin_elf_init.c
+0x004004e0 1 5 loc..annobin_static_reloc.c
+0x004005a5 1 55 main
+0x004004a0 1 6 sym.imp.printf
+0x00400468 3 27 sym._init
+[0x004004b0]>
+```
+
+### 交叉引用
+
+在 C 语言中,`main` 函数是一个程序开始执行的地方。理想情况下,其他函数都是从 `main` 函数调用的,在退出程序时,`main` 函数会向操作系统返回一个退出状态。这在源代码中是很明显的,然而,二进制程序呢?如何判断 `adder` 函数的调用位置呢?
+
+你可以使用 `axt` 命令,后面加上函数名,看看 `adder` 函数是在哪里调用的;如下图所示,它是从 `main` 函数中调用的。这就是所谓的交叉引用。但什么调用 `main` 函数本身呢?从下面的 `axt main` 可以看出,它是由 `entry0` 调用的(关于 `entry0` 的学习我就不说了,留待读者练习)。
+
+```
+[0x004004b0]> axt sym.adder
+main 0x4005b9 [CALL] call sym.adder
+[0x004004b0]>
+[0x004004b0]> axt main
+entry0 0x4004d1 [DATA] mov rdi, main
+[0x004004b0]>
+```
+
+### 寻找定位
+
+在处理文本文件时,你经常通过引用行号和行或列号在文件内移动;在二进制文件中,你需要使用地址。这些是以 `0x` 开头的十六进制数字,后面跟着一个地址。要找到你在二进制中的位置,运行 `s` 命令。要移动到不同的位置,使用 `s` 命令,后面跟上地址。
+
+函数名就像标签一样,内部用地址表示。如果函数名在二进制中(未剥离的),可以使用函数名后面的 `s` 命令跳转到一个特定的函数地址。同样,如果你想跳转到二进制的开始,输入 `s 0`:
+
+```
+[0x004004b0]> s
+0x4004b0
+[0x004004b0]>
+[0x004004b0]> s main
+[0x004005a5]>
+[0x004005a5]> s
+0x4005a5
+[0x004005a5]>
+[0x004005a5]> s sym.adder
+[0x00400596]>
+[0x00400596]> s
+0x400596
+[0x00400596]>
+[0x00400596]> s 0
+[0x00000000]>
+[0x00000000]> s
+0x0
+[0x00000000]>
+```
+
+### 十六进制视图
+
+通常情况下,原始二进制没有意义。在十六进制模式下查看二进制及其等效的 ASCII 表示法会有帮助:
+
+```
+[0x004004b0]> s main
+[0x004005a5]>
+[0x004005a5]> px
+- offset - 0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
+0x004005a5 5548 89e5 4883 ec10 c745 fc64 0000 008b UH..H....E.d....
+0x004005b5 45fc 89c7 e8d8 ffff ff89 45f8 8b45 f889 E.........E..E..
+0x004005c5 c6bf 7806 4000 b800 0000 00e8 cbfe ffff ..x.@...........
+0x004005d5 b800 0000 00c9 c30f 1f40 00f3 0f1e fa41 .........@.....A
+0x004005e5 5749 89d7 4156 4989 f641 5541 89fd 4154 WI..AVI..AUA..AT
+0x004005f5 4c8d 2504 0820 0055 488d 2d04 0820 0053 L.%.. .UH.-.. .S
+0x00400605 4c29 e548 83ec 08e8 57fe ffff 48c1 fd03 L).H....W...H...
+0x00400615 741f 31db 0f1f 8000 0000 004c 89fa 4c89 t.1........L..L.
+0x00400625 f644 89ef 41ff 14dc 4883 c301 4839 dd75 .D..A...H...H9.u
+0x00400635 ea48 83c4 085b 5d41 5c41 5d41 5e41 5fc3 .H...[]A\A]A^A_.
+0x00400645 9066 2e0f 1f84 0000 0000 00f3 0f1e fac3 .f..............
+0x00400655 0000 00f3 0f1e fa48 83ec 0848 83c4 08c3 .......H...H....
+0x00400665 0000 0001 0002 0000 0000 0000 0000 0000 ................
+0x00400675 0000 004e 756d 6265 7220 6e6f 7720 6973 ...Number now is
+0x00400685 2020 3a20 2564 0a00 0000 0001 1b03 3b44 : %d........;D
+0x00400695 0000 0007 0000 0000 feff ff88 0000 0020 ...............
+[0x004005a5]>
+```
+
+### 反汇编
+
+如果你使用的是编译后的二进制文件,则无法查看源代码。编译器将源代码转译成 CPU 可以理解和执行的机器语言指令;其结果就是二进制或可执行文件。然而,你可以查看汇编指令(的助记词)来理解程序正在做什么。例如,如果你想查看 `main` 函数在做什么,你可以使用 `s main` 寻找 `main` 函数的地址,然后运行 `pdf` 命令来查看反汇编的指令。
+
+要理解汇编指令,你需要参考体系结构手册(这里是 x86),它的应用二进制接口(ABI,或调用惯例),并对堆栈的工作原理有基本的了解:
+
+```
+[0x004004b0]> s main
+[0x004005a5]>
+[0x004005a5]> s
+0x4005a5
+[0x004005a5]>
+[0x004005a5]> pdf
+ ; DATA XREF from entry0 @ 0x4004d1
+┌ 55: int main (int argc, char **argv, char **envp);
+│ ; var int64_t var_8h @ rbp-0x8
+│ ; var int64_t var_4h @ rbp-0x4
+│ 0x004005a5 55 push rbp
+│ 0x004005a6 4889e5 mov rbp, rsp
+│ 0x004005a9 4883ec10 sub rsp, 0x10
+│ 0x004005ad c745fc640000. mov dword [var_4h], 0x64 ; 'd' ; 100
+│ 0x004005b4 8b45fc mov eax, dword [var_4h]
+│ 0x004005b7 89c7 mov edi, eax
+│ 0x004005b9 e8d8ffffff call sym.adder
+│ 0x004005be 8945f8 mov dword [var_8h], eax
+│ 0x004005c1 8b45f8 mov eax, dword [var_8h]
+│ 0x004005c4 89c6 mov esi, eax
+│ 0x004005c6 bf78064000 mov edi, str.Number_now_is__:__d ; 0x400678 ; "Number now is : %d\n" ; const char *format
+│ 0x004005cb b800000000 mov eax, 0
+│ 0x004005d0 e8cbfeffff call sym.imp.printf ; int printf(const char *format)
+│ 0x004005d5 b800000000 mov eax, 0
+│ 0x004005da c9 leave
+└ 0x004005db c3 ret
+[0x004005a5]>
+```
+
+这是 `adder` 函数的反汇编结果:
+
+```
+[0x004005a5]> s sym.adder
+[0x00400596]>
+[0x00400596]> s
+0x400596
+[0x00400596]>
+[0x00400596]> pdf
+ ; CALL XREF from main @ 0x4005b9
+┌ 15: sym.adder (int64_t arg1);
+│ ; var int64_t var_4h @ rbp-0x4
+│ ; arg int64_t arg1 @ rdi
+│ 0x00400596 55 push rbp
+│ 0x00400597 4889e5 mov rbp, rsp
+│ 0x0040059a 897dfc mov dword [var_4h], edi ; arg1
+│ 0x0040059d 8b45fc mov eax, dword [var_4h]
+│ 0x004005a0 83c001 add eax, 1
+│ 0x004005a3 5d pop rbp
+└ 0x004005a4 c3 ret
+[0x00400596]>
+```
+
+### 字符串
+
+查看二进制中存在哪些字符串可以作为二进制分析的起点。字符串是硬编码到二进制中的,通常会提供重要的提示,可以让你将重点转移到分析某些区域。在二进制中运行 `iz` 命令来列出所有的字符串。这个测试二进制中只有一个硬编码的字符串:
+
+```
+[0x004004b0]> iz
+[Strings]
+nth paddr vaddr len size section type string
+―――――――――――――――――――――――――――――――――――――――――――――――――――――――
+0 0x00000678 0x00400678 20 21 .rodata ascii Number now is : %d\n
+
+[0x004004b0]>
+```
+
+### 交叉引用字符串
+
+和函数一样,你可以交叉引用字符串,看看它们是从哪里被打印出来的,并理解它们周围的代码:
+
+```
+[0x004004b0]> ps @ 0x400678
+Number now is : %d
+
+[0x004004b0]>
+[0x004004b0]> axt 0x400678
+main 0x4005c6 [DATA] mov edi, str.Number_now_is__:__d
+[0x004004b0]>
+```
+
+### 可视模式
+
+当你的代码很复杂,有多个函数被调用时,很容易迷失方向。如果能以图形或可视化的方式查看哪些函数被调用,根据某些条件采取了哪些路径等,会很有帮助。在移动到感兴趣的函数后,可以通过 `VV` 命令来探索 `r2` 的可视化模式。例如,对于 `adder` 函数:
+
+```
+[0x004004b0]> s sym.adder
+[0x00400596]>
+[0x00400596]> VV
+```
+
+![Radare2 Visual mode][8]
+
+*(Gaurav Kamathe, [CC BY-SA 4.0][9])*
+
+### 调试器
+
+到目前为止,你一直在做的是静态分析 —— 你只是在看二进制文件中的东西,而没有运行它,有时你需要执行二进制文件,并在运行时分析内存中的各种信息。`r2` 的内部调试器允许你运行二进制文件、设置断点、分析变量的值、或者转储寄存器的内容。
+
+用 `-d` 标志启动调试器,并在加载二进制时添加 `-A` 标志进行分析。你可以通过使用 `db ` 命令在不同的地方设置断点,比如函数或内存地址。要查看现有的断点,使用 `dbi` 命令。一旦你放置了断点,使用 `dc` 命令开始运行二进制文件。你可以使用 `dbt` 命令查看堆栈,它可以显示函数调用。最后,你可以使用 `drr` 命令转储寄存器的内容:
+
+```
+$ r2 -d -A ./adder
+Process with PID 17453 started...
+= attach 17453 17453
+bin.baddr 0x00400000
+Using 0x400000
+asm.bits 64
+[x] Analyze all flags starting with sym. and entry0 (aa)
+[x] Analyze function calls (aac)
+[x] Analyze len bytes of instructions for references (aar)
+[x] Check for vtables
+[x] Type matching analysis for all functions (aaft)
+[x] Propagate noreturn information
+[x] Use -AA or aaaa to perform additional experimental analysis.
+ -- git checkout hamster
+[0x7f77b0a28030]>
+[0x7f77b0a28030]> db main
+[0x7f77b0a28030]>
+[0x7f77b0a28030]> db sym.adder
+[0x7f77b0a28030]>
+[0x7f77b0a28030]> dbi
+0 0x004005a5 E:1 T:0
+1 0x00400596 E:1 T:0
+[0x7f77b0a28030]>
+[0x7f77b0a28030]> afl | grep main
+0x004005a5 1 55 main
+[0x7f77b0a28030]>
+[0x7f77b0a28030]> afl | grep sym.adder
+0x00400596 1 15 sym.adder
+[0x7f77b0a28030]>
+[0x7f77b0a28030]> dc
+hit breakpoint at: 0x4005a5
+[0x004005a5]>
+[0x004005a5]> dbt
+0 0x4005a5 sp: 0x0 0 [main] main sym.adder+15
+1 0x7f77b0687873 sp: 0x7ffe35ff6858 0 [??] section..gnu.build.attributes-1345820597
+2 0x7f77b0a36e0a sp: 0x7ffe35ff68e8 144 [??] map.usr_lib64_ld_2.28.so.r_x+65034
+[0x004005a5]> dc
+hit breakpoint at: 0x400596
+[0x00400596]> dbt
+0 0x400596 sp: 0x0 0 [sym.adder] rip entry.init0+6
+1 0x4005be sp: 0x7ffe35ff6838 0 [main] main+25
+2 0x7f77b0687873 sp: 0x7ffe35ff6858 32 [??] section..gnu.build.attributes-1345820597
+3 0x7f77b0a36e0a sp: 0x7ffe35ff68e8 144 [??] map.usr_lib64_ld_2.28.so.r_x+65034
+[0x00400596]>
+[0x00400596]>
+[0x00400596]> dr
+rax = 0x00000064
+rbx = 0x00000000
+rcx = 0x7f77b0a21738
+rdx = 0x7ffe35ff6948
+r8 = 0x7f77b0a22da0
+r9 = 0x7f77b0a22da0
+r10 = 0x0000000f
+r11 = 0x00000002
+r12 = 0x004004b0
+r13 = 0x7ffe35ff6930
+r14 = 0x00000000
+r15 = 0x00000000
+rsi = 0x7ffe35ff6938
+rdi = 0x00000064
+rsp = 0x7ffe35ff6838
+rbp = 0x7ffe35ff6850
+rip = 0x00400596
+rflags = 0x00000202
+orax = 0xffffffffffffffff
+[0x00400596]>
+```
+
+### 反编译器
+
+能够理解汇编是二进制分析的前提。汇编语言总是与二进制建立和预期运行的架构相关。一行源代码和汇编代码之间从来没有 1:1 的映射。通常,一行 C 源代码会产生多行汇编代码。所以,逐行读取汇编代码并不是最佳的选择。
+
+这就是反编译器的作用。它们试图根据汇编指令重建可能的源代码。这与用于创建二进制的源代码绝不完全相同,它是基于汇编的源代码的近似表示。另外,要考虑到编译器进行的优化,它会生成不同的汇编代码以加快速度,减小二进制的大小等,会使反编译器的工作更加困难。另外,恶意软件作者经常故意混淆代码,让恶意软件的分析人员望而却步。
+
+Radare2 通过插件提供反编译器。你可以安装任何 Radare2 支持的反编译器。使用 `r2pm -l` 命令可以查看当前插件。使用 `r2pm install` 命令来安装一个示例的反编译器 `r2dec`:
+
+```
+$ r2pm -l
+$
+$ r2pm install r2dec
+Cloning into 'r2dec'...
+remote: Enumerating objects: 100, done.
+remote: Counting objects: 100% (100/100), done.
+remote: Compressing objects: 100% (97/97), done.
+remote: Total 100 (delta 18), reused 27 (delta 1), pack-reused 0
+Receiving objects: 100% (100/100), 1.01 MiB | 1.31 MiB/s, done.
+Resolving deltas: 100% (18/18), done.
+Install Done For r2dec
+gmake: Entering directory '/root/.local/share/radare2/r2pm/git/r2dec/p'
+[CC] duktape/duktape.o
+[CC] duktape/duk_console.o
+[CC] core_pdd.o
+[CC] core_pdd.so
+gmake: Leaving directory '/root/.local/share/radare2/r2pm/git/r2dec/p'
+$
+$ r2pm -l
+r2dec
+$
+```
+
+### 反编译器视图
+
+要反编译一个二进制文件,在 `r2` 中加载二进制文件并自动分析它。在本例中,使用 `s sym.adder` 命令移动到感兴趣的 `adder` 函数,然后使用 `pdda` 命令并排查看汇编和反编译后的源代码。阅读这个反编译后的源代码往往比逐行阅读汇编更容易:
+
+```
+$ r2 -A ./adder
+[x] Analyze all flags starting with sym. and entry0 (aa)
+[x] Analyze function calls (aac)
+[x] Analyze len bytes of instructions for references (aar)
+[x] Check for vtables
+[x] Type matching analysis for all functions (aaft)
+[x] Propagate noreturn information
+[x] Use -AA or aaaa to perform additional experimental analysis.
+ -- What do you want to debug today?
+[0x004004b0]>
+[0x004004b0]> s sym.adder
+[0x00400596]>
+[0x00400596]> s
+0x400596
+[0x00400596]>
+[0x00400596]> pdda
+ ; assembly | /* r2dec pseudo code output */
+ | /* ./adder @ 0x400596 */
+ | #include <stdint.h>
+ |
+ ; (fcn) sym.adder () | int32_t adder (int64_t arg1) {
+ | int64_t var_4h;
+ | rdi = arg1;
+ 0x00400596 push rbp |
+ 0x00400597 mov rbp, rsp |
+ 0x0040059a mov dword [rbp - 4], edi | *((rbp - 4)) = edi;
+ 0x0040059d mov eax, dword [rbp - 4] | eax = *((rbp - 4));
+ 0x004005a0 add eax, 1 | eax++;
+ 0x004005a3 pop rbp |
+ 0x004005a4 ret | return eax;
+ | }
+[0x00400596]>
+```
+
+### 配置设置
+
+随着你对 Radare2 的使用越来越熟悉,你会想改变它的配置,以适应你的工作方式。你可以使用 `e` 命令查看 `r2` 的默认配置。要设置一个特定的配置,在 `e` 命令后面添加 `config = value`:
+
+```
+[0x004005a5]> e | wc -l
+593
+[0x004005a5]> e | grep syntax
+asm.syntax = intel
+[0x004005a5]>
+[0x004005a5]> e asm.syntax = att
+[0x004005a5]>
+[0x004005a5]> e | grep syntax
+asm.syntax = att
+[0x004005a5]>
+```
+
+要使配置更改永久化,请将它们放在 `r2` 启动时读取的名为 `.radare2rc` 的启动文件中。这个文件通常在你的主目录下,如果没有,你可以创建一个。一些示例配置选项包括:
+
+```
+$ cat ~/.radare2rc
+e asm.syntax = att
+e scr.utf8 = true
+eco solarized
+e cmd.stack = true
+e stack.size = 256
+$
+```
+
+### 探索更多
+
+你已经看到了足够多的 Radare2 功能,对这个工具有了一定的了解。因为 Radare2 遵循 Unix 哲学,即使你可以从它的主控台做各种事情,它也会在下面使用一套独立的二进制来完成它的任务。
+
+探索下面列出的独立二进制文件,看看它们是如何工作的。例如,用 `iI` 命令在控制台看到的二进制信息也可以用 `rabin2 ` 命令找到:
+
+```
+$ cd bin/
+$
+$ ls
+prefix r2agent r2pm rabin2 radiff2 ragg2 rarun2 rasm2
+r2 r2-indent r2r radare2 rafind2 rahash2 rasign2 rax2
+$
+```
+
+你觉得 Radare2 怎么样?请在评论中分享你的反馈。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/linux-radare2
+
+作者:[Gaurav Kamathe][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gkamathe
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/binary_code_computer_screen.png?itok=7IzHK1nn (Binary code on a computer screen)
+[2]: https://linux.cn/article-12187-1.html
+[3]: https://linux.cn/article-11441-1.html
+[4]: https://rada.re/n/
+[5]: https://github.com/radareorg/radare2
+[6]: https://opensource.com/article/19/3/getting-started-vim
+[7]: https://ghidra-sre.org/
+[8]: https://opensource.com/sites/default/files/uploads/radare2_visual-mode_0.png (Radare2 Visual mode)
+[9]: https://creativecommons.org/licenses/by-sa/4.0/
diff --git a/published/202102/20210125 Use Joplin to find your notes faster.md b/published/202102/20210125 Use Joplin to find your notes faster.md
new file mode 100644
index 0000000000..13e6be8bdf
--- /dev/null
+++ b/published/202102/20210125 Use Joplin to find your notes faster.md
@@ -0,0 +1,63 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13080-1.html)
+[#]: subject: (Use Joplin to find your notes faster)
+[#]: via: (https://opensource.com/article/21/1/notes-joplin)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+使用 Joplin 更快地找到你的笔记
+======
+
+> 在多个手写和数字平台上整理笔记是一个严峻的挑战。这里有一个小技巧,可以更好地组织你的笔记,并快速找到你需要的东西。
+
+
+
+在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的第十五天。
+
+保持生产力也意味着(在某种程度上)要有足够的组织能力,以便找到笔记并在需要时参考它们。这不仅是对我自己的挑战,也是与我交谈的很多人的挑战。
+
+多年来,我在应用中单独或使用数字笔记、纸质笔记、便签、数字便签、Word 文档、纯文本文件以及一堆我忘记的其他格式的组合。这不仅让寻找笔记变得困难,而且知道把它们放在哪里是一个更大的挑战。
+
+![Stacks of paper notes on a desk][2]
+
+*一堆笔记 (Jessica Cherry, [CC BY-SA 4.0][3])*
+
+还有就是做笔记最重要的一点:如果你以后找不到它,笔记就没有任何价值。知道含有你所需信息的笔记存在于你保存笔记的*某处*,根本没有任何帮助。
+
+我是如何为自己解决这个问题的呢?正如他们所说,这是一个过程,我希望这也是一个对其他人有效的过程。
+
+我首先看了看自己所做的笔记种类。不同的主题需要用不同的方式保存吗?由于我为我的播客手写笔记,而几乎所有其他的东西都使用纯文本笔记,我需要两种不同的方式来维护它们。对于手写的笔记,我把它们都放在一个文件夹里,方便我参考。
+
+![Man holding a binder full of notes][4]
+
+*三年多的笔记 (Kevin Sonney, [CC BY-SA 4.0][3])*
+
+为了保存我的数字笔记,我需要将它们全部集中到一个地方。这个工具需要能够从多种设备上访问,具有有用的搜索功能,并且能够导出或共享我的笔记。在尝试了很多很多不同的选项之后,我选择了 [Joplin][5]。Joplin 可以让我用 Markdown 写笔记,有一个相当不错的搜索功能,有适用于所有操作系统(包括手机)的应用,并支持几种不同的设备同步方式。另外,它还有文件夹*和*标签,因此我可以按照对我有意义的方式将笔记分组。
+
+![Organized Joplin notes management page][6]
+
+*我的 Joplin*
+
+我花了一些时间才把所有的东西都放在我想要的地方,但最后,这真的是值得的。现在,我可以找到我所做的笔记,而不是让它们散落在我的办公室、不同的机器和各种服务中。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/notes-joplin
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/wfh_work_home_laptop_work.png?itok=VFwToeMy (Working from home at a laptop)
+[2]: https://opensource.com/sites/default/files/day15-image1.jpg
+[3]: https://creativecommons.org/licenses/by-sa/4.0/
+[4]: https://opensource.com/sites/default/files/day15-image2.png
+[5]: https://joplinapp.org/
+[6]: https://opensource.com/sites/default/files/day15-image3.png
diff --git a/published/202102/20210125 Why you need to drop ifconfig for ip.md b/published/202102/20210125 Why you need to drop ifconfig for ip.md
new file mode 100644
index 0000000000..c4370c6f6d
--- /dev/null
+++ b/published/202102/20210125 Why you need to drop ifconfig for ip.md
@@ -0,0 +1,201 @@
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13089-1.html"
+[#]: subject: "Why you need to drop ifconfig for ip"
+[#]: via: "https://opensource.com/article/21/1/ifconfig-ip-linux"
+[#]: author: "Rajan Bhardwaj https://opensource.com/users/rajabhar"
+
+放弃 ifconfig,拥抱 ip 命令
+======
+
+> 开始使用现代方法配置 Linux 网络接口。
+
+
+
+在很长一段时间内,`ifconfig` 命令是配置网络接口的默认方法。它为 Linux 用户提供了很好的服务,但是网络很复杂,所以配置网络的命令必须健壮。`ip` 命令是现代系统中新的默认网络命令,在本文中,我将向你展示如何使用它。
+
+`ip` 命令工作在 [OSI 网络栈][2] 的两个层上:第二层(数据链路层)和第三层(网络 或 IP)层。它做了之前 `net-tools` 包的所有工作。
+
+### 安装 ip
+
+`ip` 命令包含在 `iproute2util` 包中,它可能已经在你的 Linux 发行版中安装了。如果没有,你可以从发行版的仓库中进行安装。
+
+### ifconfig 和 ip 使用对比
+
+`ip` 和 `ifconfig` 命令都可以用来配置网络接口,但它们做事方法不同。接下来,作为对比,我将用它们来执行一些常见的任务。
+
+#### 查看网口和 IP 地址
+
+如果你想查看主机的 IP 地址或网络接口信息,`ifconfig` (不带任何参数)命令提供了一个很好的总结。
+
+```
+$ ifconfig
+
+eth0: flags=4099 mtu 1500
+ ether bc:ee:7b:5e:7d:d8 txqueuelen 1000 (Ethernet)
+ RX packets 0 bytes 0 (0.0 B)
+ RX errors 0 dropped 0 overruns 0 frame 0
+ TX packets 0 bytes 0 (0.0 B)
+ TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
+
+lo: flags=73 mtu 65536
+ inet 127.0.0.1 netmask 255.0.0.0
+ inet6 ::1 prefixlen 128 scopeid 0x10
+ loop txqueuelen 1000 (Local Loopback)
+ RX packets 41 bytes 5551 (5.4 KiB)
+ RX errors 0 dropped 0 overruns 0 frame 0
+ TX packets 41 bytes 5551 (5.4 KiB)
+ TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
+
+wlan0: flags=4163 mtu 1500
+ inet 10.1.1.6 netmask 255.255.255.224 broadcast 10.1.1.31
+ inet6 fdb4:f58e:49f:4900:d46d:146b:b16:7212 prefixlen 64 scopeid 0x0
+ inet6 fe80::8eb3:4bc0:7cbb:59e8 prefixlen 64 scopeid 0x20
+ ether 08:71:90:81:1e:b5 txqueuelen 1000 (Ethernet)
+ RX packets 569459 bytes 779147444 (743.0 MiB)
+ RX errors 0 dropped 0 overruns 0 frame 0
+ TX packets 302882 bytes 38131213 (36.3 MiB)
+ TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
+```
+
+新的 `ip` 命令提供了类似的结果,但命令是 `ip address show`,或者简写为 `ip a`:
+
+```
+$ ip a
+
+1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
+ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
+ inet 127.0.0.1/8 scope host lo
+ valid_lft forever preferred_lft forever
+ inet6 ::1/128 scope host
+ valid_lft forever preferred_lft forever
+2: eth0: mtu 1500 qdisc pfifo_fast state DOWN group default qlen 1000
+ link/ether bc:ee:7b:5e:7d:d8 brd ff:ff:ff:ff:ff:ff
+3: wlan0: mtu 1500 qdisc noqueue state UP group default qlen 1000
+ link/ether 08:71:90:81:1e:b5 brd ff:ff:ff:ff:ff:ff
+ inet 10.1.1.6/27 brd 10.1.1.31 scope global dynamic wlan0
+ valid_lft 83490sec preferred_lft 83490sec
+ inet6 fdb4:f58e:49f:4900:d46d:146b:b16:7212/64 scope global noprefixroute dynamic
+ valid_lft 6909sec preferred_lft 3309sec
+ inet6 fe80::8eb3:4bc0:7cbb:59e8/64 scope link
+ valid_lft forever preferred_lft forever
+```
+
+#### 添加 IP 地址
+
+使用 `ifconfig` 命令添加 IP 地址命令为:
+
+```
+$ ifconfig eth0 add 192.9.203.21
+```
+
+`ip` 类似:
+
+```
+$ ip address add 192.9.203.21 dev eth0
+```
+
+`ip` 中的子命令可以缩短,所以下面这个命令同样有效:
+
+```
+$ ip addr add 192.9.203.21 dev eth0
+```
+
+你甚至可以更短些:
+
+```
+$ ip a add 192.9.203.21 dev eth0
+```
+
+#### 移除一个 IP 地址
+
+添加 IP 地址与删除 IP 地址正好相反。
+
+使用 `ifconfig`,命令是:
+
+```
+$ ifconfig eth0 del 192.9.203.21
+```
+
+`ip` 命令的语法是:
+
+```
+$ ip a del 192.9.203.21 dev eth0
+```
+
+#### 启用或禁用组播
+
+使用 `ifconfig` 接口来启用或禁用 [组播][3]:
+
+```
+# ifconfig eth0 multicast
+```
+
+对于 `ip`,使用 `set` 子命令与设备(`dev`)以及一个布尔值和 `multicast` 选项:
+
+```
+# ip link set dev eth0 multicast on
+```
+
+#### 启用或禁用网络
+
+每个系统管理员都熟悉“先关闭,然后打开”这个技巧来解决问题。对于网络接口来说,即打开或关闭网络。
+
+`ifconfig` 命令使用 `up` 或 `down` 关键字来实现:
+
+```
+# ifconfig eth0 up
+```
+
+或者你可以使用一个专用命令:
+
+```
+# ifup eth0
+```
+
+`ip` 命令使用 `set` 子命令将网络设置为 `up` 或 `down` 状态:
+
+```
+# ip link set eth0 up
+```
+
+#### 开启或关闭地址解析功能(ARP)
+
+使用 `ifconfig`,你可以通过声明它来启用:
+
+```
+# ifconfig eth0 arp
+```
+
+使用 `ip`,你可以将 `arp` 属性设置为 `on` 或 `off`:
+
+```
+# ip link set dev eth0 arp on
+```
+
+### ip 和 ipconfig 的优缺点
+
+`ip` 命令比 `ifconfig` 更通用,技术上也更有效,因为它使用的是 `Netlink` 套接字,而不是 `ioctl` 系统调用。
+
+`ip` 命令可能看起来比 `ifconfig` 更详细、更复杂,但这是它拥有更多功能的一个原因。一旦你开始使用它,你会了解它的内部逻辑(例如,使用 `set` 而不是看起来随意混合的声明或设置)。
+
+最后,`ifconfig` 已经过时了(例如,它缺乏对网络命名空间的支持),而 `ip` 是为现代网络而生的。尝试并学习它,使用它,你会由衷高兴的!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/ifconfig-ip-linux
+
+作者:[Rajan Bhardwaj][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rajabhar
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/gears_devops_learn_troubleshooting_lightbulb_tips_520.png?itok=HcN38NOk "Tips and gears turning"
+[2]: https://en.wikipedia.org/wiki/OSI_model
+[3]: https://en.wikipedia.org/wiki/Multicast
diff --git a/published/202102/20210126 Use your Raspberry Pi as a productivity powerhouse.md b/published/202102/20210126 Use your Raspberry Pi as a productivity powerhouse.md
new file mode 100644
index 0000000000..d7deca1036
--- /dev/null
+++ b/published/202102/20210126 Use your Raspberry Pi as a productivity powerhouse.md
@@ -0,0 +1,75 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13084-1.html)
+[#]: subject: (Use your Raspberry Pi as a productivity powerhouse)
+[#]: via: (https://opensource.com/article/21/1/raspberry-pi-productivity)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+将你的树莓派用作生产力源泉
+======
+
+> 树莓派已经从主要为黑客和业余爱好者服务,成为了小型生产力工作站的可靠选择。
+
+
+
+在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的第十六天。
+
+[树莓派][2]是一台相当棒的小电脑。它体积小,功能却出奇的强大,而且非常容易设置和使用。我曾将它们用于家庭自动化项目、面板和专用媒体播放器。但它也能成为生产力的动力源泉么?
+
+答案相当简单:是的。
+
+![Geary and Calendar apps on the Raspberry Pi][3]
+
+*Geary 和 Calendar 应用 (Kevin Sonney, [CC BY-SA 4.0][4])*
+
+基本的 [Raspbian][5] 安装包括 [Claw Mail][6],这是一个轻量级的邮件客户端。它的用户界面有点过时了,而且非常的简陋。如果你是一个 [Mutt 用户][7],它可能会满足你的需求。
+
+我更喜欢安装 [Geary][8],因为它也是轻量级的,而且有一个现代化的界面。另外,与 Claws 不同的是,Geary 默认支持富文本 (HTML) 邮件。我不喜欢富文本电子邮件,但它已经成为必要的,所以对它有良好的支持是至关重要的。
+
+默认的 Raspbian 安装不包含日历,所以我添加了 [GNOME 日历][9] ,因为它可以与远程服务通信(因为我的几乎所有日历都在云提供商那里)。
+
+![GTG and GNote open on Raspberry Pi][10]
+
+*GTG 和 GNote(Kevin Sonney, [CC BY-SA 4.0][4])*
+
+那笔记和待办事项清单呢?有很多选择,但我喜欢用 [GNote][11] 来做笔记,用 [Getting-Things-GNOME!][12] 来做待办事项。两者都相当轻量级,并且可以相互同步,也可以同步到其他服务。
+
+你会注意到,我在这里使用了不少 GNOME 应用。为什么不直接安装完整的 GNOME 桌面呢?在内存为 4Gb(或 8Gb)的树莓派 4 上,GNOME 工作得很好。你需要采取一些额外的步骤来禁用 Raspbian 上的默认 wifi 设置,并用 Network Manager 来代替它,但这个在网上有很好的文档,而且真的很简单。
+
+GNOME 中包含了 [Evolution][13],它将邮件、日历、笔记、待办事项和联系人管理整合到一个应用中。与 Geary 和 GNOME Calendar 相比,它有点重,但在树莓派 4 上却很稳定。这让我很惊讶,因为我习惯了 Evolution 有点消耗资源,但树莓派 4 却和我的品牌笔记本一样运行良好,而且资源充足。
+
+![Evolution on Raspbian][14]
+
+*Raspbian 上的 Evolution (Kevin Sonney, [CC BY-SA 4.0][4])*
+
+树莓派在过去的几年里进步很快,已经从主要为黑客和业余爱好者服务,成为了小型生产力工作站的可靠选择。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/raspberry-pi-productivity
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/todo_checklist_team_metrics_report.png?itok=oB5uQbzf (Team checklist and to dos)
+[2]: https://www.raspberrypi.org/
+[3]: https://opensource.com/sites/default/files/day16-image1.png
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://www.raspbian.org/
+[6]: https://www.claws-mail.org/
+[7]: http://www.mutt.org/
+[8]: https://wiki.gnome.org/Apps/Geary
+[9]: https://wiki.gnome.org/Apps/Calendar
+[10]: https://opensource.com/sites/default/files/day16-image2.png
+[11]: https://wiki.gnome.org/Apps/Gnote
+[12]: https://wiki.gnome.org/Apps/GTG
+[13]: https://opensource.com/business/18/1/desktop-email-clients
+[14]: https://opensource.com/sites/default/files/day16-image3.png
diff --git a/published/202102/20210126 Write GIMP scripts to make image processing faster.md b/published/202102/20210126 Write GIMP scripts to make image processing faster.md
new file mode 100644
index 0000000000..4caa8357ff
--- /dev/null
+++ b/published/202102/20210126 Write GIMP scripts to make image processing faster.md
@@ -0,0 +1,234 @@
+[#]: collector: (lujun9972)
+[#]: translator: (amwps290)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13093-1.html)
+[#]: subject: (Write GIMP scripts to make image processing faster)
+[#]: via: (https://opensource.com/article/21/1/gimp-scripting)
+[#]: author: (Cristiano L. Fontana https://opensource.com/users/cristianofontana)
+
+编写 GIMP 脚本使图像处理更快
+======
+
+> 通过向一批图像添加效果来学习 GIMP 的脚本语言 Script-Fu。
+
+
+
+前一段时间,我想给方程图片加一个黑板式的外观。我开始是使用 [GIMP][2] 来处理的,我对结果很满意。问题是我必须对图像执行几个操作,当我想再次使用此样式,不想对所有图像重复这些步骤。此外,我确信我会很快忘记这些步骤。
+
+![Fourier transform equations][3]
+
+*傅立叶变换方程式(Cristiano Fontana,[CC BY-SA 4.0] [4])*
+
+GIMP 是一个很棒的开源图像编辑器。尽管我已经使用了多年,但从未研究过其批处理功能或 [Script-Fu][5] 菜单。这是探索它们的绝好机会。
+
+### 什么是 Script-Fu?
+
+[Script-Fu][6] 是 GIMP 内置的脚本语言。是一种基于 [Scheme][7] 的编程语言。如果你从未使用过 Scheme,请尝试一下,因为它可能非常有用。我认为 Script-Fu 是一个很好的入门方法,因为它对图像处理具有立竿见影的效果,所以你可以很快感觉到自己的工作效率的提高。你也可以使用 [Python][8] 编写脚本,但是 Script-Fu 是默认选项。
+
+为了帮助你熟悉 Scheme,GIMP 的文档提供了深入的 [教程][9]。Scheme 是一种类似于 [Lisp][10] 的语言,因此它的主要特征是使用 [前缀][11] 表示法和 [许多括号][12]。函数和运算符通过前缀应用到操作数列表中:
+
+```
+(函数名 操作数 操作数 ...)
+
+(+ 2 3)
+↳ 返回 5
+
+(list 1 2 3 5)
+↳ 返回一个列表,包含 1、 2、 3 和 5
+```
+
+我花了一些时间才找到完整的 GIMP 函数列表文档,但实际上很简单。在 **Help** 菜单中,有一个 **Procedure Browser**,其中包含所有可用的函数的丰富详尽文档。
+
+![GIMP Procedure Browser][13]
+
+### 使用 GIMP 的批处理模式
+
+你可以使用 `-b` 选项以批处理的方式启动 GIMP。`-b` 选项的参数可以是你想要运行的脚本,或者用一个 `-` 来让 GIMP 进入交互模式而不是命令行模式。正常情况下,当你启动 GIMP 的时候,它会启动图形界面,但是你可以使用 `-i` 选项来禁用它。
+
+### 开始编写你的第一个脚本
+
+创建一个名为 `chalk.scm` 的文件,并把它保存在 **Preferences** 窗口中 **Folders** 选项下的 **Script** 中指定的 `script` 文件夹下。就我而言,是在 `$HOME/.config/GIMP/2.10/scripts`。
+
+在 `chalk.scm` 文件中,写入下面的内容:
+
+```
+(define (chalk filename grow-pixels spread-amount percentage)
+ (let* ((image (car (gimp-file-load RUN-NONINTERACTIVE filename filename)))
+ (drawable (car (gimp-image-get-active-layer image)))
+ (new-filename (string-append "modified_" filename)))
+ (gimp-image-select-color image CHANNEL-OP-REPLACE drawable '(0 0 0))
+ (gimp-selection-grow image grow-pixels)
+ (gimp-context-set-foreground '(0 0 0))
+ (gimp-edit-bucket-fill drawable BUCKET-FILL-FG LAYER-MODE-NORMAL 100 255 TRUE 0 0)
+ (gimp-selection-none image)
+ (plug-in-spread RUN-NONINTERACTIVE image drawable spread-amount spread-amount)
+ (gimp-drawable-invert drawable TRUE)
+ (plug-in-randomize-hurl RUN-NONINTERACTIVE image drawable percentage 1 TRUE 0)
+ (gimp-file-save RUN-NONINTERACTIVE image drawable new-filename new-filename)
+ (gimp-image-delete image)))
+```
+
+### 定义脚本变量
+
+在脚本中, `(define (chalk filename grow-pixels spread-amound percentage) ...)` 函数定义了一个名叫 `chalk` 的新函数。它的函数参数是 `filename`、`grow-pixels`、`spread-amound` 和 `percentage`。在 `define` 中的所有内容都是 `chalk` 函数的主体。你可能已经注意到,那些名字比较长的变量中间都有一个破折号来分割。这是类 Lisp 语言的惯用风格。
+
+`(let* ...)` 函数是一个特殊过程,可以让你定义一些只有在这个函数体中才有效的临时变量。临时变量有 `image`、`drawable` 以及 `new-filename`。它使用 `gimp-file-load` 来载入图片,这会返回它所包含的图片的一个列表。并通过 `car` 函数来选取第一项。然后,它选择第一个活动层并将其引用存储在 `drawable` 变量中。最后,它定义了包含图像新文件名的字符串。
+
+为了帮助你更好地了解该过程,我将对其进行分解。首先,启动带 GUI 的 GIMP,然后你可以通过依次点击 **Filters → Script-Fu → Console** 来打开 Script-Fu 控制台。 在这种情况下,不能使用 `let *`,因为变量必须是持久的。使用 `define` 函数定义 `image` 变量,并为其提供查找图像的正确路径:
+
+```
+(define image (car (gimp-file-load RUN-NONINTERACTIVE "Fourier.png" "Fourier.png")))
+```
+
+似乎在 GUI 中什么也没有发生,但是图像已加载。 你需要通过以下方式来让图像显示:
+
+```
+(gimp-display-new image)
+```
+
+![GUI with the displayed image][14]
+
+现在,获取活动层并将其存储在 `drawable` 变量中:
+
+```
+(define drawable (car (gimp-image-get-active-layer image)))
+```
+
+最后,定义图像的新文件名:
+
+```
+(define new-filename "modified_Fourier.png")
+```
+
+运行命令后,你将在 Script-Fu 控制台中看到以下内容:
+
+![Script-Fu console][15]
+
+在对图像执行操作之前,需要定义将在脚本中作为函数参数的变量:
+
+```
+(define grow-pixels 2)
+(define spread-amount 4)
+(define percentage 3)
+```
+
+### 处理图片
+
+现在,所有相关变量都已定义,你可以对图像进行操作了。 脚本的操作可以直接在控制台上执行。第一步是在活动层上选择黑色。颜色被写成一个由三个数字组成的列表,即 `(list 0 0 0)` 或者是 `'(0 0 0)`:
+
+```
+(gimp-image-select-color image CHANNEL-OP-REPLACE drawable '(0 0 0))
+```
+
+![Image with the selected color][16]
+
+扩大选取两个像素:
+
+```
+(gimp-selection-grow image grow-pixels)
+```
+
+![Image with the selected color][17]
+
+将前景色设置为黑色,并用它填充选区:
+
+```
+(gimp-context-set-foreground '(0 0 0))
+(gimp-edit-bucket-fill drawable BUCKET-FILL-FG LAYER-MODE-NORMAL 100 255 TRUE 0 0)
+```
+
+![Image with the selection filled with black][18]
+
+删除选区:
+
+```
+(gimp-selection-none image)
+```
+
+![Image with no selection][19]
+
+随机移动像素:
+
+```
+(plug-in-spread RUN-NONINTERACTIVE image drawable spread-amount spread-amount)
+```
+
+![Image with pixels moved around][20]
+
+反转图像颜色:
+
+```
+(gimp-drawable-invert drawable TRUE)
+```
+
+![Image with pixels moved around][21]
+
+随机化像素:
+
+```
+(plug-in-randomize-hurl RUN-NONINTERACTIVE image drawable percentage 1 TRUE 0)
+```
+
+![Image with pixels moved around][22]
+
+将图像保存到新文件:
+
+```
+(gimp-file-save RUN-NONINTERACTIVE image drawable new-filename new-filename)
+```
+
+![Equations of the Fourier transform and its inverse][23]
+
+*傅立叶变换方程 (Cristiano Fontana, [CC BY-SA 4.0][4])*
+
+### 以批处理模式运行脚本
+
+现在你知道了脚本的功能,可以在批处理模式下运行它:
+
+```
+gimp -i -b '(chalk "Fourier.png" 2 4 3)' -b '(gimp-quit 0)'
+```
+
+在运行 `chalk` 函数之后,它将使用 `-b` 选项调用第二个函数 `gimp-quit` 来告诉 GIMP 退出。
+
+### 了解更多
+
+本教程向你展示了如何开始使用 GIMP 的内置脚本功能,并介绍了 GIMP 的 Scheme 实现:Script-Fu。如果你想继续前进,建议你查看官方文档及其[入门教程][9]。如果你不熟悉 Scheme 或 Lisp,那么一开始的语法可能有点吓人,但我还是建议你尝试一下。这可能是一个不错的惊喜。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/gimp-scripting
+
+作者:[Cristiano L. Fontana][a]
+选题:[lujun9972][b]
+译者:[amwps290](https://github.com/amwps290)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/cristianofontana
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/painting_computer_screen_art_design_creative.png?itok=LVAeQx3_ (Painting art on a computer screen)
+[2]: https://www.gimp.org/
+[3]: https://opensource.com/sites/default/files/uploads/fourier.png (Fourier transform equations)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://docs.gimp.org/en/gimp-filters-script-fu.html
+[6]: https://docs.gimp.org/en/gimp-concepts-script-fu.html
+[7]: https://en.wikipedia.org/wiki/Scheme_(programming_language)
+[8]: https://docs.gimp.org/en/gimp-filters-python-fu.html
+[9]: https://docs.gimp.org/en/gimp-using-script-fu-tutorial.html
+[10]: https://en.wikipedia.org/wiki/Lisp_%28programming_language%29
+[11]: https://en.wikipedia.org/wiki/Polish_notation
+[12]: https://xkcd.com/297/
+[13]: https://opensource.com/sites/default/files/uploads/procedure_browser.png (GIMP Procedure Browser)
+[14]: https://opensource.com/sites/default/files/uploads/gui01_image.png (GUI with the displayed image)
+[15]: https://opensource.com/sites/default/files/uploads/console01_variables.png (Script-Fu console)
+[16]: https://opensource.com/sites/default/files/uploads/gui02_selected.png (Image with the selected color)
+[17]: https://opensource.com/sites/default/files/uploads/gui03_grow.png (Image with the selected color)
+[18]: https://opensource.com/sites/default/files/uploads/gui04_fill.png (Image with the selection filled with black)
+[19]: https://opensource.com/sites/default/files/uploads/gui05_no_selection.png (Image with no selection)
+[20]: https://opensource.com/sites/default/files/uploads/gui06_spread.png (Image with pixels moved around)
+[21]: https://opensource.com/sites/default/files/uploads/gui07_invert.png (Image with pixels moved around)
+[22]: https://opensource.com/sites/default/files/uploads/gui08_hurl.png (Image with pixels moved around)
+[23]: https://opensource.com/sites/default/files/uploads/modified_fourier.png (Equations of the Fourier transform and its inverse)
diff --git a/published/202102/20210127 3 email mistakes and how to avoid them.md b/published/202102/20210127 3 email mistakes and how to avoid them.md
new file mode 100644
index 0000000000..4e0b3c8cc9
--- /dev/null
+++ b/published/202102/20210127 3 email mistakes and how to avoid them.md
@@ -0,0 +1,77 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13086-1.html)
+[#]: subject: (3 email mistakes and how to avoid them)
+[#]: via: (https://opensource.com/article/21/1/email-mistakes)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+3 个电子邮件错误以及如何避免它们
+======
+
+> 自动化是美好的,但也不总是那样。确保你的电子邮件自动回复和抄送配置正确,这样你就不会浪费大家的时间。
+
+
+
+在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的第十七天。
+
+好了,我们已经谈到了一些我们应该对电子邮件做的事情:[不要再把它当作即时通讯工具][2]、[优先处理事情][3]、[努力达到收件箱 0 新邮件][4],以及[有效过滤][5]。但哪些事情是我们不应该做的呢?
+
+![Automated email reply][6]
+
+*你真幸运 (Kevin Sonney, [CC BY-SA 4.0][7])*
+
+### 1、请不要对所有事情自动回复
+
+邮件列表中总有些人,他们去度假了,并设置了一个“我在度假”的自动回复信息。然而,他们没有正确地设置,所以它对列表上的每一封邮件都会回复“我在度假”,直到管理员将其屏蔽或取消订阅。
+
+我们都感受到了这种痛苦,我承认过去至少有一次,我就是那个人。
+
+从我的错误中吸取教训,并确保你的自动回复器或假期信息对它们将回复谁和多久回复一次有限制。
+
+![An actual email with lots of CC'd recipients][8]
+
+*这是一封真实的电子邮件 (Kevin Sonney, [CC BY-SA 4.0][7])*
+
+### 2、请不要抄送给所有人
+
+我们都至少做过一次。我们需要发送邮件的人员众多,因此我们只需抄送他们*所有人*。有时这是有必要的,但大多数时候,它并不是。当然,你邀请每个人在庭院吃生日蛋糕,或者你的表姐要结婚了,或者公司刚拿到一个大客户,这都是好事。如果你有邮件列表的话,请用邮件列表,如果没有的话,请给每个人密送。说真的,密送是你的朋友。
+
+### 3、回复所有人不是你的朋友
+
+![Reply options in Kmail][9]
+
+这一条与上一条是相辅相成的。我不知道有多少次看到有人向一个名单(或者是一个大群的人)发送信息,而这个信息本来是要发给一个人的。我见过这样发送的相对好的邮件,以及随之而来的纪律处分邮件。
+
+认真地说,除非必须,不要使用“回复全部”按钮。即使是这样,也要确保你*真的*需要这样做。
+
+有些电子邮件应用比其他应用管理得更好。Kmail,[KDE Kontact][10] 的电子邮件组件,在**回复**工具栏按钮的子菜单中,有几个不同的回复选项。你可以选择只回复给**发件人**字段中的任何实体(通常是一个人,但有时是一个邮件列表),或者回复给作者(在抄送或密送中去除每一个人),或者只回复给一个邮件列表,或者回复*所有人*(不要这样做)。看到明确列出的选项,的确可以帮助你了解谁会收到你要发送的邮件副本,这有时比你想象的更发人深省。我曾经发现,当我意识到一个评论并不一定会对一个复杂的讨论的最终目标有所帮助时,我就会把邮件的收件人改为只是作者,而不是整个列表。
+
+(另外,如果你写的邮件可能会给你的 HR 或公司带来麻烦,请在点击发送之前多考虑下。——
+
+希望你已经*不再*在电子邮件中这么做了。如果你认识的人是这样的呢?欢迎与他们分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/email-mistakes
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_screen_windows_files.png?itok=kLTeQUbY (Computer screen with files or windows open)
+[2]: https://opensource.com/article/21/1/email-rules
+[3]: https://opensource.com/article/21/1/prioritize-tasks
+[4]: https://opensource.com/article/21/1/inbox-zero
+[5]: https://opensource.com/article/21/1/email-filter
+[6]: https://opensource.com/sites/default/files/day17-image1.png
+[7]: https://creativecommons.org/licenses/by-sa/4.0/
+[8]: https://opensource.com/sites/default/files/day17-image2.png
+[9]: https://opensource.com/sites/default/files/kmail-replies.jpg (Reply options in Kmail)
+[10]: https://opensource.com/article/21/1/kde-kontact
diff --git a/published/202102/20210127 Why I use the D programming language for scripting.md b/published/202102/20210127 Why I use the D programming language for scripting.md
new file mode 100644
index 0000000000..63618522ea
--- /dev/null
+++ b/published/202102/20210127 Why I use the D programming language for scripting.md
@@ -0,0 +1,176 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13100-1.html)
+[#]: subject: (Why I use the D programming language for scripting)
+[#]: via: (https://opensource.com/article/21/1/d-scripting)
+[#]: author: (Lawrence Aberba https://opensource.com/users/aberba)
+
+我为什么要用 D 语言写脚本?
+======
+
+> D 语言以系统编程语言而闻名,但它也是编写脚本的一个很好的选择。
+
+
+
+D 语言由于其静态类型和元编程能力,经常被宣传为系统编程语言。然而,它也是一种非常高效的脚本语言。
+
+由于 Python 在自动化任务和快速实现原型想法方面的灵活性,它通常被选为脚本语言。这使得 Python 对系统管理员、[管理者][2]和一般的开发人员非常有吸引力,因为它可以自动完成他们可能需要手动完成的重复性任务。
+
+我们自然也可以期待任何其他的脚本编写语言具有 Python 的这些特性和能力。以下是我认为 D 是一个不错的选择的两个原因。
+
+### 1、D 很容易读和写
+
+作为一种类似于 C 的语言,D 应该是大多数程序员所熟悉的。任何使用 JavaScript、Java、PHP 或 Python 的人对 D 语言都很容易上手。
+
+如果你还没有安装 D,请[安装 D 编译器][3],这样你就可以[运行本文中的 D 代码][4]。你也可以使用[在线 D 编辑器][5]。
+
+下面是一个 D 代码的例子,它从一个名为 `words.txt` 的文件中读取单词,并在命令行中打印出来:
+
+```
+open
+source
+is
+cool
+```
+
+用 D 语言写脚本:
+
+```
+#!/usr/bin/env rdmd
+// file print_words.d
+
+// import the D standard library
+import std;
+
+void main(){
+ // open the file
+ File("./words.txt")
+
+ //iterate by line
+ .byLine
+
+ // print each number
+ .each!writeln;
+}
+```
+
+这段代码以 [释伴][6] 开头,它将使用 [rdmd][7] 来运行这段代码,`rdmd` 是 D 编译器自带的编译和运行代码的工具。假设你运行的是 Unix 或 Linux,在运行这个脚本之前,你必须使用` chmod` 命令使其可执行:
+
+```
+chmod u+x print_words.d
+```
+
+现在脚本是可执行的,你可以运行它:
+
+```
+./print_words.d
+```
+
+这将在你的命令行中打印以下内容:
+
+```
+open
+source
+is
+cool
+```
+
+恭喜你,你写了第一个 D 语言脚本。你可以看到 D 是如何让你按顺序链式调用函数,这让阅读代码的感觉很自然,类似于你在头脑中思考问题的方式。这个[功能让 D 成为我最喜欢的编程语言][8]。
+
+试着再写一个脚本:一个非营利组织的管理员有一个捐款的文本文件,每笔金额都是单独的一行。管理员想把前 10 笔捐款相加,然后打印出金额:
+
+```
+#!/usr/bin/env rdmd
+// file sum_donations.d
+
+import std;
+
+void main()
+{
+ double total = 0;
+
+ // open the file
+ File("monies.txt")
+
+ // iterate by line
+ .byLine
+
+ // pick first 10 lines
+ .take(10)
+
+ // remove new line characters (\n)
+ .map!(strip)
+
+ // convert each to double
+ .map!(to!double)
+
+ // add element to total
+ .tee!((x) { total += x; })
+
+ // print each number
+ .each!writeln;
+
+ // print total
+ writeln("total: ", total);
+}
+```
+
+与 `each` 一起使用的 `!` 操作符是[模板参数][9]的语法。
+
+### 2、D 是快速原型设计的好帮手
+
+D 是灵活的,它可以快速地将代码敲打在一起,并使其发挥作用。它的标准库中包含了丰富的实用函数,用于执行常见的任务,如操作数据(JSON、CSV、文本等)。它还带有一套丰富的通用算法,用于迭代、搜索、比较和 mutate 数据。这些巧妙的算法通过定义通用的 [基于范围的接口][10] 而按照序列进行处理。
+
+上面的脚本显示了 D 中的链式调用函数如何提供顺序处理和操作数据的要领。D 的另一个吸引人的地方是它不断增长的用于执行普通任务的第三方包的生态系统。一个例子是,使用 [Vibe.d][11] web 框架构建一个简单的 web 服务器很容易。下面是一个例子:
+
+```
+#!/usr/bin/env dub
+/+ dub.sdl:
+dependency "vibe-d" version="~>0.8.0"
++/
+void main()
+{
+ import vibe.d;
+ listenHTTP(":8080", (req, res) {
+ res.writeBody("Hello, World: " ~ req.path);
+ });
+ runApplication();
+}
+```
+
+它使用官方的 D 软件包管理器 [Dub][12],从 [D 软件包仓库][13]中获取 vibe.d Web 框架。Dub 负责下载 Vibe.d 包,然后在本地主机 8080 端口上编译并启动一个 web 服务器。
+
+### 尝试一下 D 语言
+
+这些只是你可能想用 D 来写脚本的几个原因。
+
+D 是一种非常适合开发的语言。你可以很容易从 D 下载页面安装,因此下载编译器,看看例子,并亲自体验 D 语言。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/d-scripting
+
+作者:[Lawrence Aberba][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/aberba
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-concentration-focus-windows-office.png?itok=-8E2ihcF (Woman using laptop concentrating)
+[2]: https://opensource.com/article/20/3/automating-community-management-python
+[3]: https://tour.dlang.org/tour/en/welcome/install-d-locally
+[4]: https://tour.dlang.org/tour/en/welcome/run-d-program-locally
+[5]: https://run.dlang.io/
+[6]: https://en.wikipedia.org/wiki/Shebang_(Unix)
+[7]: https://dlang.org/rdmd.html
+[8]: https://opensource.com/article/20/7/d-programming
+[9]: http://ddili.org/ders/d.en/templates.html
+[10]: http://ddili.org/ders/d.en/ranges.html
+[11]: https://vibed.org
+[12]: https://dub.pm/getting_started
+[13]: https://code.dlang.org
diff --git a/published/202102/20210128 4 tips for preventing notification fatigue.md b/published/202102/20210128 4 tips for preventing notification fatigue.md
new file mode 100644
index 0000000000..843364bb91
--- /dev/null
+++ b/published/202102/20210128 4 tips for preventing notification fatigue.md
@@ -0,0 +1,75 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13094-1.html)
+[#]: subject: (4 tips for preventing notification fatigue)
+[#]: via: (https://opensource.com/article/21/1/alert-fatigue)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+防止通知疲劳的 4 个技巧
+======
+
+> 不要让提醒淹没自己:设置重要的提醒,让其它提醒消失。你会感觉更好,工作效率更高。
+
+![W】(https://img.linux.net.cn/data/attachment/album/202102/06/234924mo3okotjlv7lo3yo.jpg)
+
+在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的第十八天。
+
+当我和人们谈论生产力时,我注意到一件事,那就是几乎每个人都是为了保持更清晰的头脑。我们不是把所有的约会都记在脑子里,而是把它们放在一个数字日历上,在事件发生前提醒我们。我们有数字或实体笔记,这样我们就不必记住某件事的每一个小细节。我们有待办事项清单,提醒我们去做该做的事情。
+
+![Text box offering to send notifications][2]
+
+*NOPE(Kevin Sonney, [CC BY-SA 4.0][3])*
+
+如此多的应用、网站和服务想要提醒我们每一件小事,我们很容易就把它们全部调出来。而且,如果我们不这样做,我们将开始遭受**提醒疲劳**的困扰 —— 这时我们处于边缘的状态,只是等待下一个提醒,并生活在恐惧之中。
+
+提醒疲劳在那些因工作而被随叫随到的人中非常常见。它也发生在那些 **FOMO** (错失恐惧症)的人身上,从而对每一个关键词、标签或在社交媒体上提到他们感兴趣的事情都会设置提醒。
+
+此时,设置能引起我们的注意,但不会被忽略的提醒是件棘手的事情。不过,我确实有一些有用的提示,这样重要的提醒可能会在这个忙碌的世界中越过我们自己的心理过滤器。
+
+![Alert for a task][4]
+
+*我可以忽略这个,对吧?(Kevin Sonney, [CC BY-SA 4.0][3])*
+
+ 1. 弄清楚什么更适合你:视觉提醒或声音提醒。我使用视觉弹出和声音的组合,但这对我是有效的。有些人需要触觉提醒。比如手机或手表的震动。找到适合你的那一种。
+ 2. 为重要的提醒指定独特的音调或视觉效果。我有一个朋友,他的工作页面的铃声最响亮、最讨厌。这旨在吸引他的注意力,让他看到提醒。我的显示器上有一盏灯,当我在待命时收到工作提醒时,它就会闪烁红灯,以及发送通知到我手机上。
+ 3. 关掉那些实际上无关紧要的警报。社交网络、网站和应用都希望得到你的关注。它们不会在意你是否错过会议、约会迟到,或者熬夜到凌晨 4 点。关掉那些不重要的,让那些重要的可以被看到。
+ 4. 每隔一段时间就改变一下。上个月有效的东西,下个月可能就不行了。我们会适应、习惯一些东西,然后我们会忽略。如果有些东西不奏效,就换个东西试试吧!它不会伤害你,即使无法解决问题,也许你也会学到一些新知识。
+
+![Blue alert indicators light][5]
+
+*蓝色是没问题。红色是有问题。(Kevin Sonney, [CC BY-SA 4.0][3])*
+
+### 开源和选择
+
+一个好的应用可以通知提供很多选择。我最喜欢的一个是 Android 的 Etar 日历应用。[Etar 可以从开源 F-droid 仓库中获得][6]。
+
+Etar 和许多开源应用一样,为你提供了很多选项,尤其是通知设置。
+
+![Etar][7]
+
+通过 Etar,你可以激活或停用弹出式通知,设置打盹时间、打盹延迟、是否提醒你已拒绝的事件等。结合有计划的日程安排策略,你可以通过控制数字助手对你需要做的事情进行提示的频率来改变你一天的进程。
+
+提醒和警报真的很有用,只要我们收到重要的提醒并予以注意即可。这可能需要做一些实验,但最终,少一些噪音是好事,而且更容易注意到真正需要我们注意的提醒。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/alert-fatigue
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/team_dev_email_chat_video_work_wfm_desk_520.png?itok=6YtME4Hj (Working on a team, busy worklife)
+[2]: https://opensource.com/sites/default/files/day18-image1.png
+[3]: https://creativecommons.org/licenses/by-sa/4.0/
+[4]: https://opensource.com/sites/default/files/day18-image2.png
+[5]: https://opensource.com/sites/default/files/day18-image3.png
+[6]: https://f-droid.org/en/packages/ws.xsoh.etar/
+[7]: https://opensource.com/sites/default/files/etar.jpg (Etar)
diff --git a/published/202102/20210128 How to Run a Shell Script in Linux -Essentials Explained for Beginners.md b/published/202102/20210128 How to Run a Shell Script in Linux -Essentials Explained for Beginners.md
new file mode 100644
index 0000000000..f2c5fd298c
--- /dev/null
+++ b/published/202102/20210128 How to Run a Shell Script in Linux -Essentials Explained for Beginners.md
@@ -0,0 +1,168 @@
+[#]: collector: (lujun9972)
+[#]: translator: (robsean)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13106-1.html)
+[#]: subject: (How to Run a Shell Script in Linux [Essentials Explained for Beginners])
+[#]: via: (https://itsfoss.com/run-shell-script-linux/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+基础:如何在 Linux 中运行一个 Shell 脚本
+======
+
+
+
+在 Linux 中有两种运行 shell 脚本的方法。你可以使用:
+
+```
+bash script.sh
+```
+
+或者,你可以像这样执行 shell 脚本:
+
+```
+./script.sh
+```
+
+这可能很简单,但没太多解释。不要担心,我将使用示例来进行必要的解释,以便你能理解为什么在运行一个 shell 脚本时要使用给定的特定语法格式。
+
+我将使用这一行 shell 脚本来使需要解释的事情变地尽可能简单:
+
+```
+abhishek@itsfoss:~/Scripts$ cat hello.sh
+
+echo "Hello World!"
+```
+
+### 方法 1:通过将文件作为参数传递给 shell 以运行 shell 脚本
+
+第一种方法涉及将脚本文件的名称作为参数传递给 shell 。
+
+考虑到 bash 是默认 shell,你可以像这样运行一个脚本:
+
+```
+bash hello.sh
+```
+
+你知道这种方法的优点吗?**你的脚本不需要执行权限**。对于简单的任务非常方便快速。
+
+![在 Linux 中运行一个 Shell 脚本][1]
+
+如果你还不熟悉,我建议你 [阅读我的 Linux 文件权限详细指南][2] 。
+
+记住,将其作为参数传递的需要是一个 shell 脚本。一个 shell 脚本是由命令组成的。如果你使用一个普通的文本文件,它将会抱怨错误的命令。
+
+![运行一个文本文件为脚本][3]
+
+在这种方法中,**你要明确地具体指定你想使用 bash 作为脚本的解释器** 。
+
+shell 只是一个程序,并且 bash 只是 Shell 的一种实现。还有其它的 shell 程序,像 ksh 、[zsh][4] 等等。如果你安装有其它的 shell ,你也可以使用它们来代替 bash 。
+
+例如,我已安装了 zsh ,并使用它来运行相同的脚本:
+
+![使用 Zsh 来执行 Shell 脚本][5]
+
+### 方法 2:通过具体指定 shell 脚本的路径来执行脚本
+
+另外一种运行一个 shell 脚本的方法是通过提供它的路径。但是要这样做之前,你的文件必须是可执行的。否则,当你尝试执行脚本时,你将会得到 “权限被拒绝” 的错误。
+
+因此,你首先需要确保你的脚本有可执行权限。你可以 [使用 chmod 命令][8] 来给予你自己脚本的这种权限,像这样:
+
+```
+chmod u+x script.sh
+```
+
+使你的脚本是可执行之后,你只需输入文件的名称及其绝对路径或相对路径。大多数情况下,你都在同一个目录中,因此你可以像这样使用它:
+
+```
+./script.sh
+```
+
+如果你与你的脚本不在同一个目录中,你可以具体指定脚本的绝对路径或相对路径:
+
+![在其它的目录中运行 Shell 脚本][9]
+
+在脚本前的这个 `./` 是非常重要的(当你与脚本在同一个目录中)。
+
+![][10]
+
+为什么当你在同一个目录下,却不能使用脚本名称?这是因为你的 Linux 系统会在 `PATH` 环境变量中指定的几个目录中查找可执行的文件来运行。
+
+这里是我的系统的 `PATH` 环境变量的值:
+
+```
+abhishek@itsfoss:~$ echo $PATH
+/home/abhishek/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
+```
+
+这意味着在下面目录中具有可执行权限的任意文件都可以在系统的任何位置运行:
+
+ * `/home/abhishek/.local/bin`
+ * `/usr/local/sbin`
+ * `/usr/local/bin`
+ * `/usr/sbin`
+ * `/usr/bin`
+ * `/sbin`
+ * `/bin`
+ * `/usr/games`
+ * `/usr/local/games`
+ * `/snap/bin`
+
+Linux 命令(像 `ls`、`cat` 等)的二进制文件或可执行文件都位于这些目录中的其中一个。这就是为什么你可以在你系统的任何位置通过使用命令的名称来运作这些命令的原因。看看,`ls` 命令就是位于 `/usr/bin` 目录中。
+
+![][11]
+
+当你使用脚本而不具体指定其绝对路径或相对路径时,系统将不能在 `PATH` 环境变量中找到提及的脚本。
+
+> 为什么大多数 shell 脚本在其头部包含 #! /bin/bash ?
+>
+> 记得我提过 shell 只是一个程序,并且有 shell 程序的不同实现。
+>
+> 当你使用 `#! /bin/bash` 时,你是具体指定 bash 作为解释器来运行脚本。如果你不这样做,并且以 `./script.sh` 的方式运行一个脚本,它通常会在你正在运行的 shell 中运行。
+>
+> 有问题吗?可能会有。看看,大多数的 shell 语法是大多数种类的 shell 中通用的,但是有一些语法可能会有所不同。
+>
+> 例如,在 bash 和 zsh 中数组的行为是不同的。在 zsh 中,数组索引是从 1 开始的,而不是从 0 开始。
+>
+>![Bash Vs Zsh][12]
+>
+> 使用 `#! /bin/bash` 来标识该脚本是 bash 脚本,并且应该使用 bash 作为脚本的解释器来运行,而不受在系统上正在使用的 shell 的影响。如果你使用 zsh 的特殊语法,你可以通过在脚本的第一行添加 `#! /bin/zsh` 的方式来标识其是 zsh 脚本。
+>
+> 在 `#!` 和 `/bin/bash` 之间的空格是没有影响的。你也可以使用 `#!/bin/bash` 。
+
+### 它有帮助吗?
+
+我希望这篇文章能够增加你的 Linux 知识。如果你还有问题或建议,请留下评论。
+
+专家用户可能依然会挑出我遗漏的东西。但这种初级题材的问题是,要找到信息的平衡点,避免细节过多或过少,并不容易。
+
+如果你对学习 bash 脚本感兴趣,在我们专注于系统管理的网站 [Linux Handbook][14] 上,我们有一个 [完整的 Bash 初学者系列][13] 。如果你想要,你也可以 [购买带有附加练习的电子书][15] ,以支持 Linux Handbook。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/run-shell-script-linux/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[robsean](https://github.com/robsean)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/run-a-shell-script-linux.png?resize=741%2C329&ssl=1
+[2]: https://linuxhandbook.com/linux-file-permissions/
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/running-text-file-as-script.png?resize=741%2C329&ssl=1
+[4]: https://www.zsh.org
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/execute-shell-script-with-zsh.png?resize=741%2C253&ssl=1
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/run-multiple-commands-in-linux.png?fit=800%2C450&ssl=1
+[7]: https://itsfoss.com/run-multiple-commands-linux/
+[8]: https://linuxhandbook.com/chmod-command/
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/running-shell-script-in-other-directory.png?resize=795%2C272&ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/executing-shell-scripts-linux.png?resize=800%2C450&ssl=1
+[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/locating-command-linux.png?resize=795%2C272&ssl=1
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/bash-vs-zsh.png?resize=795%2C386&ssl=1
+[13]: https://linuxhandbook.com/tag/bash-beginner/
+[14]: https://linuxhandbook.com
+[15]: https://www.buymeacoffee.com/linuxhandbook
diff --git a/published/202102/20210129 Manage containers with Podman Compose.md b/published/202102/20210129 Manage containers with Podman Compose.md
new file mode 100644
index 0000000000..d1d3ce6286
--- /dev/null
+++ b/published/202102/20210129 Manage containers with Podman Compose.md
@@ -0,0 +1,174 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13125-1.html)
+[#]: subject: (Manage containers with Podman Compose)
+[#]: via: (https://fedoramagazine.org/manage-containers-with-podman-compose/)
+[#]: author: (Mehdi Haghgoo https://fedoramagazine.org/author/powergame/)
+
+用 Podman Compose 管理容器
+======
+
+![][1]
+
+容器很棒,让你可以将你的应用连同其依赖项一起打包,并在任何地方运行。从 2013 年的 Docker 开始,容器已经让软件开发者的生活变得更加轻松。
+
+Docker 的一个缺点是它有一个中央守护进程,它以 root 用户的身份运行,这对安全有影响。但这正是 Podman 的用武之地。Podman 是一个 [无守护进程容器引擎][2],用于开发、管理和在你的 Linux 系统上以 root 或无 root 模式运行 OCI 容器。
+
+下面这些文章可以用来了解更多关于 Podman 的信息:
+
+ * [使用 Podman 以非 root 用户身份运行 Linux 容器][11]
+ * [在 Fedora 上使用 Podman 的 Pod][3]
+ * [在 Fedora 中结合权能使用 Podman][4]
+
+如果你使用过 Docker,你很可能也知道 Docker Compose,它是一个用于编排多个可能相互依赖的容器的工具。要了解更多关于 Docker Compose 的信息,请看它的[文档][5]。
+
+### 什么是 Podman Compose?
+
+[Podman Compose][6] 项目的目标是作为 Docker Compose 的替代品,而不需要对 docker-compose.yaml 文件进行任何修改。由于 Podman Compose 使用吊舱 工作,所以最好看下“吊舱”的最新定义。
+
+> 一个“吊舱 ”(如一群鲸鱼或豌豆荚)是由一个或多个[容器][7]组成的组,具有共享的存储/网络资源,以及如何运行容器的规范。
+>
+> [Pods - Kubernetes 文档][8]
+
+(LCTT 译注:容器技术领域大量使用了航海比喻,pod 一词,意为“豆荚”,在航海领域指“吊舱” —— 均指盛装多个物品的容器。常不翻译,考虑前后文,可译做“吊舱”。)
+
+Podman Compose 的基本思想是,它选中 `docker-compose.yaml` 文件里面定义的服务,为每个服务创建一个容器。Docker Compose 和 Podman Compose 的一个主要区别是,Podman Compose 将整个项目的容器添加到一个单一的吊舱中,而且所有的容器共享同一个网络。如你在例子中看到的,在创建容器时使用 `--add-host` 标志,它甚至用和 Docker Compose 一样的方式命名容器。
+
+### 安装
+
+Podman Compose 的完整安装说明可以在[项目页面][6]上找到,它有几种方法。要安装最新的开发版本,使用以下命令:
+
+```
+pip3 install https://github.com/containers/podman-compose/archive/devel.tar.gz
+```
+
+确保你也安装了 [Podman][9],因为你也需要它。在 Fedora 上,使用下面的命令来安装Podman:
+
+```
+sudo dnf install podman
+```
+
+### 例子:用 Podman Compose 启动一个 WordPress 网站
+
+想象一下,你的 `docker-compose.yaml` 文件在一个叫 `wpsite` 的文件夹里。一个典型的 WordPress 网站的 `docker-compose.yaml` (或 `docker-compose.yml`) 文件是这样的:
+
+```
+version: "3.8"
+services:
+ web:
+ image: wordpress
+ restart: always
+ volumes:
+ - wordpress:/var/www/html
+ ports:
+ - 8080:80
+ environment:
+ WORDPRESS_DB_HOST: db
+ WORDPRESS_DB_USER: magazine
+ WORDPRESS_DB_NAME: magazine
+ WORDPRESS_DB_PASSWORD: 1maGazine!
+ WORDPRESS_TABLE_PREFIX: cz
+ WORDPRESS_DEBUG: 0
+ depends_on:
+ - db
+ networks:
+ - wpnet
+ db:
+ image: mariadb:10.5
+ restart: always
+ ports:
+ - 6603:3306
+
+ volumes:
+ - wpdbvol:/var/lib/mysql
+
+ environment:
+ MYSQL_DATABASE: magazine
+ MYSQL_USER: magazine
+ MYSQL_PASSWORD: 1maGazine!
+ MYSQL_ROOT_PASSWORD: 1maGazine!
+ networks:
+ - wpnet
+volumes:
+ wordpress: {}
+ wpdbvol: {}
+
+networks:
+ wpnet: {}
+```
+
+如果你用过 Docker,你就会知道你可运行 `docker-compose up` 来启动这些服务。Docker Compose 会创建两个名为 `wpsite_web_1` 和 `wpsite_db_1` 的容器,并将它们连接到一个名为 `wpsite_wpnet` 的网络。
+
+现在,看看当你在项目目录下运行 `podman-compose up` 时会发生什么。首先,一个以执行命令的目录命名的吊舱被创建。接下来,它寻找 YAML 文件中定义的任何名称的卷,如果它们不存在,就创建卷。然后,在 YAML 文件的 `services` 部分列出的每个服务都会创建一个容器,并添加到吊舱中。
+
+容器的命名与 Docker Compose 类似。例如,为你的 web 服务创建一个名为 `wpsite_web_1` 的容器。Podman Compose 还为每个命名的容器添加了 `localhost` 别名。之后,容器仍然可以通过名字互相解析,尽管它们并不像 Docker 那样在一个桥接网络上。要做到这一点,使用选项 `-add-host`。例如,`-add-host web:localhost`。
+
+请注意,`docker-compose.yaml` 包含了一个从主机 8080 端口到容器 80 端口的 Web 服务的端口转发。现在你应该可以通过浏览器访问新 WordPress 实例,地址为 `http://localhost:8080`。
+
+![WordPress Dashboard][10]
+
+### 控制 pod 和容器
+
+要查看正在运行的容器,使用 `podman ps`,它可以显示 web 和数据库容器以及吊舱中的基础设施容器。
+
+```
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+a364a8d7cec7 docker.io/library/wordpress:latest apache2-foregroun... 2 hours ago Up 2 hours ago 0.0.0.0:8080->80/tcp, 0.0.0.0:6603->3306/tcp wpsite_web_1
+c447024aa104 docker.io/library/mariadb:10.5 mysqld 2 hours ago Up 2 hours ago 0.0.0.0:8080->80/tcp, 0.0.0.0:6603->3306/tcp wpsite_db_1
+12b1e3418e3e k8s.gcr.io/pause:3.2
+```
+
+你也可以验证 Podman 已经为这个项目创建了一个吊舱,以你执行命令的文件夹命名。
+
+```
+POD ID NAME STATUS CREATED INFRA ID # OF CONTAINERS
+8a08a3a7773e wpsite Degraded 2 hours ago 12b1e3418e3e 3
+```
+
+要停止容器,在另一个命令窗口中输入以下命令:
+
+```
+podman-compose down
+```
+
+你也可以通过停止和删除吊舱来实现。这实质上是停止并移除所有的容器,然后再删除包含的吊舱。所以,同样的事情也可以通过这些命令来实现:
+
+```
+podman pod stop podname
+podman pod rm podname
+```
+
+请注意,这不会删除你在 `docker-compose.yaml` 中定义的卷。所以,你的 WordPress 网站的状态被保存下来了,你可以通过运行这个命令来恢复它。
+
+```
+podman-compose up
+```
+
+总之,如果你是一个 Podman 粉丝,并且用 Podman 做容器工作,你可以使用 Podman Compose 来管理你的开发和生产中的容器。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/manage-containers-with-podman-compose/
+
+作者:[Mehdi Haghgoo][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/powergame/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/01/podman-compose-1-816x345.jpg
+[2]: https://podman.io
+[3]: https://fedoramagazine.org/podman-pods-fedora-containers/
+[4]: https://linux.cn/article-12859-1.html
+[5]: https://docs.docker.com/compose/
+[6]: https://github.com/containers/podman-compose
+[7]: https://kubernetes.io/docs/concepts/containers/
+[8]: https://kubernetes.io/docs/concepts/workloads/pods/
+[9]: https://podman.io/getting-started/installation
+[10]: https://fedoramagazine.org/wp-content/uploads/2021/01/Screenshot-from-2021-01-08-06-27-29-1024x767.png
+[11]: https://linux.cn/article-10156-1.html
\ No newline at end of file
diff --git a/published/202102/20210131 3 wishes for open source productivity in 2021.md b/published/202102/20210131 3 wishes for open source productivity in 2021.md
new file mode 100644
index 0000000000..4517bae151
--- /dev/null
+++ b/published/202102/20210131 3 wishes for open source productivity in 2021.md
@@ -0,0 +1,64 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13113-1.html)
+[#]: subject: (3 wishes for open source productivity in 2021)
+[#]: via: (https://opensource.com/article/21/1/productivity-wishlist)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+2021 年开源生产力的 3 个愿望
+======
+
+> 2021年,开源世界可以拓展的有很多。这是我特别感兴趣的三个领域。
+
+![Looking at a map for career journey][1]
+
+在前几年,这个年度系列涵盖了单个的应用。今年,我们除了关注 2021 年的策略外,还将关注一体化解决方案。欢迎来到 2021 年 21 天生产力的最后一天。
+
+我们已经到了又一个系列的结尾处。因此,让我们谈谈我希望在 2021 年看到的更多事情。
+
+### 断网
+
+![Large Lego set built by the author][2]
+
+*我在假期期间制作的(Kevin Sonney, [CC BY-SA 4.0][3])*
+
+对*许多、许多的*人来说,2020 年是非常困难的一年。疫情大流行、各种政治事件、24 小时的新闻轰炸等等,都对我们的精神健康造成了伤害。虽然我确实谈到了 [抽出时间进行自我护理][4],但我只是想断网:也就是关闭提醒、手机、平板等,暂时无视这个世界。我公司的一位经理实际上告诉我们,如果放假或休息一天,就把所有与工作有关的东西都关掉(除非我们在值班)。我最喜欢的“断网”活动之一就是听音乐和搭建大而复杂的乐高。
+
+### 可访问性
+
+尽管我谈论的许多技术都是任何人都可以做的,但是软件方面的可访问性都有一定难度。相对于自由软件运动之初,Linux 和开源世界在辅助技术方面已经有了长足发展。但是,仍然有太多的应用和系统不会考虑有些用户没有与设计者相同的能力。我一直在关注这一领域的发展,因为每个人都应该能够访问事物。
+
+### 更多的一体化选择
+
+![JPilot all in one organizer software interface][5]
+
+*JPilot(Kevin Sonney, [CC BY-SA 4.0][3])*
+
+在 FOSS 世界中,一体化的个人信息管理解决方案远没有商业软件世界中那么多。总体趋势是使用单独的应用,它们必须通过配置来相互通信或通过中介服务(如 CalDAV 服务器)。移动市场在很大程度上推动了这一趋势,但我仍然向往像 [JPilot][6] 这样无需额外插件或服务就能完成几乎所有我需要的事情的日子。
+
+非常感谢大家阅读这个年度系列。如果你认为我错过了什么,或者明年需要注意什么,请在下方评论。
+
+就像我在 [生产力炼金术][7] 上说的那样,尽最大努力保持生产力!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/productivity-wishlist
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/career_journey_road_gps_path_map_520.png?itok=PpL6jJgY (Looking at a map for career journey)
+[2]: https://opensource.com/sites/default/files/day21-image1.png
+[3]: https://creativecommons.org/licenses/by-sa/4.0/
+[4]: https://opensource.com/article/21/1/self-care
+[5]: https://opensource.com/sites/default/files/day21-image2.png
+[6]: http://www.jpilot.org/
+[7]: https://productivityalchemy.com
diff --git a/published/202102/20210201 Generate QR codes with this open source tool.md b/published/202102/20210201 Generate QR codes with this open source tool.md
new file mode 100644
index 0000000000..bc554bf5cb
--- /dev/null
+++ b/published/202102/20210201 Generate QR codes with this open source tool.md
@@ -0,0 +1,81 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13097-1.html)
+[#]: subject: (Generate QR codes with this open source tool)
+[#]: via: (https://opensource.com/article/21/2/zint-barcode-generator)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+
+Zint:用这个开源工具生成二维码
+======
+
+> Zint 可以轻松生成 50 多种类型的自定义条码。
+
+
+
+二维码是一种很好的可以向人们提供信息的方式,且没有打印的麻烦和费用。大多数人的智能手机都支持二维码扫描,无论其操作系统是什么。
+
+你可能想使用二维码的原因有很多。也许你是一名教师,希望通过补充材料来测试你的学生,以增强学习效果,或者是一家餐厅,需要在遵守社交距离准则的同时提供菜单。我经常行走于自然小径,那里贴有树木和其他植物的标签。用二维码来补充这些小标签是一种很好的方式,它可以提供关于公园展品的额外信息,而无需花费和维护标识牌。在这些和其他情况下,二维码是非常有用的。
+
+在互联网上搜索一个简单的、开源的方法来创建二维码时,我发现了 [Zint][2]。Zint 是一个优秀的开源 (GPLv3.0) 生成条码的解决方案。根据该项目的 [GitHub 仓库][3]:“Zint 是一套可以方便地对任何一种公共领域条形码标准的数据进行编码的程序,并允许你将这种功能集成到你自己的程序中。”
+
+Zint 支持 50 多种类型的条形码,包括二维码(ISO 18004),你可以轻松地创建这些条形码,然后复制和粘贴到 word 文档、博客、维基和其他数字媒体中。人们可以用智能手机扫描这些二维码,快速链接到信息。
+
+### 安装 Zint
+
+Zint 适用于 Linux、macOS 和 Windows。
+
+你可以在基于 Ubuntu 的 Linux 发行版上使用 `apt` 安装 Zint 命令:
+
+```
+$ sudo apt install zint
+```
+
+我还想要一个图形用户界面(GUI),所以我安装了 Zint-QT:
+
+```
+$ sudo apt install zint-qt
+```
+
+请参考手册的[安装部分][4],了解 macOS 和 Windows 的说明。
+
+### 用 Zint 生成二维码
+
+安装好后,我启动了它,并创建了我的第一个二维码,这是一个指向 Opensource.com 的链接。
+
+![Generating QR code with Zint][5]
+
+Zint 的 50 多个其他条码选项包括许多国家的邮政编码、DotCode、EAN、EAN-14 和通用产品代码 (UPC)。[项目文档][2]中包含了它可以渲染的所有代码的完整列表。
+
+你可以将任何条形码复制为 BMP 或 SVG,或者将输出保存为你应用中所需要的任何尺寸的图像文件。这是我的 77x77 像素的二维码。
+
+![QR code][7]
+
+该项目维护了一份出色的用户手册,其中包含了在[命令行][8]和 [GUI][9] 中使用 Zint 的说明。你甚至可以[在线][10]试用 Zint。对于功能请求或错误报告,请[访问网站][11]或[发送电子邮件][12]。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/zint-barcode-generator
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/wfh_work_home_laptop_work.png?itok=VFwToeMy (Working from home at a laptop)
+[2]: http://www.zint.org.uk/
+[3]: https://github.com/zint/zint
+[4]: http://www.zint.org.uk/Manual.aspx?type=p&page=2
+[5]: https://opensource.com/sites/default/files/uploads/zintqrcode_generation.png (Generating QR code with Zint)
+[6]: https://creativecommons.org/licenses/by-sa/4.0/
+[7]: https://opensource.com/sites/default/files/uploads/zintqrcode_77px.png (QR code)
+[8]: http://zint.org.uk/Manual.aspx?type=p&page=4
+[9]: http://zint.org.uk/Manual.aspx?type=p&page=3
+[10]: http://www.barcode-generator.org/
+[11]: https://lists.sourceforge.net/lists/listinfo/zint-barcode
+[12]: mailto:zint-barcode@lists.sourceforge.net
diff --git a/published/202102/20210202 Filmulator is a Simple, Open Source, Raw Image Editor for Linux Desktop.md b/published/202102/20210202 Filmulator is a Simple, Open Source, Raw Image Editor for Linux Desktop.md
new file mode 100644
index 0000000000..12f6aa8801
--- /dev/null
+++ b/published/202102/20210202 Filmulator is a Simple, Open Source, Raw Image Editor for Linux Desktop.md
@@ -0,0 +1,86 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13119-1.html)
+[#]: subject: (Filmulator is a Simple, Open Source, Raw Image Editor for Linux Desktop)
+[#]: via: (https://itsfoss.com/filmulator/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Filmulator:一个简单的、开源的 Raw 图像编辑器
+======
+
+
+
+> Filmulator 是一个开源的具有库管理功能的 raw 照片编辑应用,侧重于简单、易用和简化的工作流程。
+
+### Filmulator:适用于 Linux(和 Windows)的 raw 图像编辑器
+
+[Linux 中有一堆 raw 照片编辑器][1],[Filmulator][2] 就是其中之一。Filmulator 的目标是仅提供基本要素,从而使 raw 图像编辑变得简单。它还增加了库处理的功能,如果你正在为你的相机图像寻找一个不错的应用,这是一个加分项。
+
+对于那些不知道 raw 的人来说,[raw 图像文件][3]是一个最低限度处理、未压缩的文件。换句话说,它是未经压缩的数字文件,并且只经过了最低限度的处理。专业摄影师更喜欢用 raw 文件拍摄照片,并自行处理。普通人从智能手机拍摄照片,它通常被压缩为 JPEG 格式或被过滤。
+
+让我们来看看在 Filmulator 编辑器中会有什么功能。
+
+### Filmulator 的功能
+
+![Filmulator interface][4]
+
+Filmulator 宣称,它不是典型的“胶片效果滤镜” —— 这只是复制了胶片的外在特征。相反,Filmulator 从根本上解决了胶片的魅力所在:显影过程。
+
+它模拟了胶片的显影过程:从胶片的“曝光”,到每个像素内“银晶”的生长,再到“显影剂”在相邻像素之间与储槽中大量显影剂的扩散。
+
+Fimulator 开发者表示,这种模拟带来了以下好处:
+
+ * 大的明亮区域变得更暗,压缩了输出动态范围。
+ * 小的明亮区域使周围环境变暗,增强局部对比度。
+ * 在明亮区域,饱和度得到增强,有助于保留蓝天、明亮肤色和日落的色彩。
+ * 在极度饱和的区域,亮度会被减弱,有助于保留细节,例如花朵。
+
+以下是经 Filmulator 处理后的 raw 图像的对比,以自然的方式增强色彩,而不会引起色彩剪切。
+
+![原图][5]
+
+![处理后][10]
+
+### 在 Ubuntu/Linux 上安装 Filmulator
+
+Filmulator 有一个 AppImage 可用,这样你就可以在 Linux 上轻松使用它。使用 [AppImage 文件][6]真的很简单。下载后,使它可执行,然后双击运行。
+
+- [下载 Filmulator for Linux][7]
+
+对 Windows 用户也有一个 Windows 版本。除此之外,你还可以随时前往[它的 GitHub 仓库][8]查看它的源代码。
+
+有一份[小文档][9]来帮助你开始使用 Fimulator。
+
+### 总结
+
+Fimulator 的设计理念是为任何工作提供最好的工具,而且只有这一个工具。这意味着牺牲了灵活性,但获得了一个大大简化和精简的用户界面。
+
+我连业余摄影师都不是,更别说是专业摄影师了。我没有单反或其他高端摄影设备。因此,我无法测试和分享我对 Filmulator 的实用性的经验。
+
+如果你有更多处理 raw 图像的经验,请尝试下 Filmulator,并分享你的意见。有一个 AppImage 可以让你快速测试它,看看它是否适合你的需求。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/filmulator/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/raw-image-tools-linux/
+[2]: https://filmulator.org/
+[3]: https://www.findingtheuniverse.com/what-is-raw-in-photography/
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/Filmulate.jpg?resize=799%2C463&ssl=1
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/image-without-filmulator.jpeg?ssl=1
+[6]: https://itsfoss.com/use-appimage-linux/
+[7]: https://filmulator.org/download/
+[8]: https://github.com/CarVac/filmulator-gui
+[9]: https://github.com/CarVac/filmulator-gui/wiki
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/image-with-filmulator.jpeg?ssl=1
\ No newline at end of file
diff --git a/published/202102/20210203 Paru - A New AUR Helper and Pacman Wrapper Based on Yay.md b/published/202102/20210203 Paru - A New AUR Helper and Pacman Wrapper Based on Yay.md
new file mode 100644
index 0000000000..c30c45aaab
--- /dev/null
+++ b/published/202102/20210203 Paru - A New AUR Helper and Pacman Wrapper Based on Yay.md
@@ -0,0 +1,153 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13122-1.html)
+[#]: subject: (Paru – A New AUR Helper and Pacman Wrapper Based on Yay)
+[#]: via: (https://itsfoss.com/paru-aur-helper/)
+[#]: author: (Dimitrios Savvopoulos https://itsfoss.com/author/dimitrios/)
+
+Paru:基于 Yay 的新 AUR 助手
+======
+
+
+
+[用户选择 Arch Linux][1] 或 [基于 Arch 的 Linux 发行版][2]的主要原因之一就是 [Arch 用户仓库(AUR)][3]。
+
+遗憾的是,[pacman][4],也就是 Arch 的包管理器,不能以类似官方仓库的方式访问 AUR。AUR 中的包是以 [PKGBUILD][5] 的形式存在的,需要手动过程来构建。
+
+AUR 助手可以自动完成这个过程。毫无疑问,[yay][6] 是最受欢迎和备受青睐的 AUR 助手之一。
+
+最近,`yay` 的两位开发者之一的 [Morganamilo][7][宣布][8]将退出 `yay` 的维护工作,以开始自己的 AUR 助手 [paru][9]。`paru` 是用 [Rust][10] 编写的,而 `yay` 是用 [Go][11] 编写的,它的设计是基于 yay 的。
+
+请注意,`yay` 还没有结束支持,它仍然由 [Jguer][12] 积极维护。他还[评论][13]说,`paru` 可能适合那些寻找丰富功能的 AUR 助手的用户。因此我推荐大家尝试一下。
+
+### 安装 Paru AUR 助手
+
+要安装 `paru`,打开你的终端,逐一输入以下命令:
+
+```
+sudo pacman -S --needed base-devel
+git clone https://aur.archlinux.org/paru.git
+cd paru
+makepkg -si
+```
+
+现在已经安装好了,让我们来看看如何使用它。
+
+### 使用 Paru AUR 助手的基本命令
+
+在我看来,这些都是 `paru` 最基本的命令。你可以在 [GitHub][9] 的官方仓库中探索更多。
+
+ * `paru <用户输入>`:搜索并安装“用户输入”
+ * `paru -`:`paru -Syu` 的别名
+ * `paru -Sua`:仅升级 AUR 包。
+ * `paru -Qua`:打印可用的 AUR 更新
+ * `paru -Gc <用户输入>`:显示“用户输入”的 AUR 评论
+
+### 充分使用 Paru AUR 助手
+
+你可以在 GitHub 上访问 `paru` 的[更新日志][14]来查看完整的变更日志历史,或者你可以在[首次发布][15]中查看对 `yay` 的变化。
+
+#### 在 Paru 中启用颜色
+
+要在 `paru` 中启用颜色,你必须先在 `pacman` 中启用它。所有的[配置文件][16]都在 `/etc` 目录下。在此例中,我[使用 Nano 文本编辑器][17],但是,你可以选择使用任何[基于终端的文本编辑器][18]。
+
+```
+sudo nano /etc/pacman.conf
+```
+
+打开 `pacman` 配置文件后,取消 `Color` 的注释,即可启用此功能。
+
+![][19]
+
+#### 反转搜索顺序
+
+根据你的搜索条件,最相关的包通常会显示在搜索结果的顶部。在 `paru` 中,你可以反转搜索顺序,使你的搜索更容易。
+
+与前面的例子类似,打开 `paru` 配置文件:
+
+```
+sudo nano /etc/paru.conf
+```
+
+取消注释 `BottomUp` 项,然后保存文件。
+
+![][20]
+
+如你所见,顺序是反转的,第一个包出现在了底部。
+
+![][21]
+
+#### 编辑 PKGBUILD (对于高级用户)
+
+如果你是一个有经验的 Linux 用户,你可以通过 `paru` 编辑 AUR 包。要做到这一点,你需要在 `paru` 配置文件中启用该功能,并设置你所选择的文件管理器。
+
+在此例中,我将使用配置文件中的默认值,即 vifm 文件管理器。如果你还没有使用过它,你可能需要安装它。
+
+```
+sudo pacman -S vifm
+sudo nano /etc/paru.conf
+```
+
+打开配置文件,如下所示取消注释。
+
+![][22]
+
+让我们回到 [Google Calendar][23] 的 AUR 包,并尝试安装它。系统会提示你审查该软件包。输入 `Y` 并按下回车。
+
+![][24]
+
+从文件管理器中选择 PKGBUILD,然后按下回车查看软件包。
+
+![][25]
+
+你所做的任何改变都将是永久性的,下次升级软件包时,你的改变将与上游软件包合并。
+
+![][26]
+
+### 总结
+
+`paru` 是 [AUR 助手家族][27]的又一个有趣的新成员,前途光明。此时,我不建议更换 `yay`,因为它还在维护,但一定要试试 `paru`。你可以把它们两个都安装到你的系统中,然后得出自己的结论。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/paru-aur-helper/
+
+作者:[Dimitrios Savvopoulos][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/dimitrios/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/why-arch-linux/
+[2]: https://itsfoss.com/arch-based-linux-distros/
+[3]: https://itsfoss.com/aur-arch-linux/
+[4]: https://itsfoss.com/pacman-command/
+[5]: https://wiki.archlinux.org/index.php/PKGBUILD
+[6]: https://news.itsfoss.com/qt-6-released/
+[7]: https://github.com/Morganamilo
+[8]: https://www.reddit.com/r/archlinux/comments/jjn1c1/paru_v100_and_stepping_away_from_yay/
+[9]: https://github.com/Morganamilo/paru
+[10]: https://www.rust-lang.org/
+[11]: https://golang.org/
+[12]: https://github.com/Jguer
+[13]: https://aur.archlinux.org/packages/yay/#pinned-788241
+[14]: https://github.com/Morganamilo/paru/releases
+[15]: https://github.com/Morganamilo/paru/releases/tag/v1.0.0
+[16]: https://linuxhandbook.com/linux-directory-structure/#-etc-configuration-files
+[17]: https://itsfoss.com/nano-editor-guide/
+[18]: https://itsfoss.com/command-line-text-editors-linux/
+[19]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/pacman.conf-color.png?resize=800%2C480&ssl=1
+[20]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/paru.conf-bottomup.png?resize=800%2C480&ssl=1
+[21]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/paru.conf-bottomup-2.png?resize=800%2C480&ssl=1
+[22]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/paru.conf-vifm.png?resize=732%2C439&ssl=1
+[23]: https://aur.archlinux.org/packages/gcalcli/
+[24]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/paru-proceed-for-review.png?resize=800%2C480&ssl=1
+[25]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/paru-proceed-for-review-2.png?resize=800%2C480&ssl=1
+[26]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/paru-proceed-for-review-3.png?resize=800%2C480&ssl=1
+[27]: https://itsfoss.com/best-aur-helpers/
+[28]: https://news.itsfoss.com/
\ No newline at end of file
diff --git a/published/202102/20210204 A hands-on tutorial of SQLite3.md b/published/202102/20210204 A hands-on tutorial of SQLite3.md
new file mode 100644
index 0000000000..057e0ce98e
--- /dev/null
+++ b/published/202102/20210204 A hands-on tutorial of SQLite3.md
@@ -0,0 +1,255 @@
+[#]: collector: "lujun9972"
+[#]: translator: "amwps290"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13117-1.html"
+[#]: subject: "A hands-on tutorial of SQLite3"
+[#]: via: "https://opensource.com/article/21/2/sqlite3-cheat-sheet"
+[#]: author: "Klaatu https://opensource.com/users/klaatu"
+
+SQLite3 实践教程
+======
+
+> 开始使用这个功能强大且通用的数据库吧。
+
+
+
+应用程序经常需要保存数据。无论你的用户是创建简单的文本文档、复杂的图形布局、游戏进度还是错综复杂的客户和订单号列表,软件通常都意味着生成数据。有很多方法可以存储数据以供重复使用。你可以将文本转储为 INI、[YAML][2]、XML 或 JSON 等配置格式,可以输出原始的二进制数据,也可以将数据存储在结构化数据库中。SQLite 是一个自包含的、轻量级数据库,可轻松创建、解析、查询、修改和传输数据。
+
+- 下载 [SQLite3 备忘录][3]
+
+SQLite 专用于 [公共领域][4],[从技术上讲,这意味着它没有版权,因此不需要许可证][5]。如果你需要许可证,则可以 [购买所有权担保][6]。SQLite 非常常见,大约有 1 万亿个 SQLite 数据库正在使用中。在每个基于 Webkit 的 Web 浏览器,现代电视机,汽车多媒体系统以及无数其他软件应用程序中,Android 和 iOS 设备, macOS 和 Windows 10 计算机,大多数 Linux 系统上都包含多个这种数据库。
+
+总而言之,它是用于存储和组织数据的一个可靠而简单的系统。
+
+### 安装
+
+你的系统上可能已经有 SQLite 库,但是你需要安装其命令行工具才能直接使用它。在 Linux上,你可能已经安装了这些工具。该工具提供的命令是 `sqlite3` (而不仅仅是 sqlite)。
+
+如果没有在你的 Linux 或 BSD 上安装 SQLite,你则可以从软件仓库中或 ports 树中安装 SQLite,也可以从源代码或已编译的二进制文件进行[下载并安装][7]。
+
+在 macOS 或 Windows 上,你可以从 [sqlite.org][7] 下载并安装 SQLite 工具。
+
+### 使用 SQLite
+
+通过编程语言与数据库进行交互是很常见的。因此,像 Java、Python、Lua、PHP、Ruby、C++ 以及其他编程语言都提供了 SQLite 的接口(或“绑定”)。但是,在使用这些库之前,了解数据库引擎的实际情况以及为什么你对数据库的选择很重要是有帮助的。本文向你介绍 SQLite 和 `sqlite3` 命令,以便你熟悉该数据库如何处理数据的基础知识。
+
+### 与 SQLite 交互
+
+你可以使用 `sqlite3` 命令与 SQLite 进行交互。 该命令提供了一个交互式的 shell 程序,以便你可以查看和更新数据库。
+
+```
+$ sqlite3
+SQLite version 3.34.0 2020-12-01 16:14:00
+Enter ".help" for usage hints.
+Connected to a transient in-memory database.
+Use ".open FILENAME" to reopen on a persistent database.
+sqlite>
+```
+
+该命令将使你处于 SQLite 的子 shell 中,因此现在的提示符是 SQLite 的提示符。你以前使用的 Bash 命令在这里将不再适用。你必须使用 SQLite 命令。要查看 SQLite 命令列表,请输入 `.help`:
+
+```
+sqlite> .help
+.archive ... Manage SQL archives
+.auth ON|OFF SHOW authorizer callbacks
+.backup ?DB? FILE Backup DB (DEFAULT "main") TO FILE
+.bail ON|off Stop after hitting an error. DEFAULT OFF
+.binary ON|off Turn BINARY output ON OR off. DEFAULT OFF
+.cd DIRECTORY CHANGE the working directory TO DIRECTORY
+[...]
+```
+
+这些命令中的其中一些是二进制的,而其他一些则需要唯一的参数(如文件名、路径等)。这些是 SQLite Shell 的管理命令,不是用于数据库查询。数据库以结构化查询语言(SQL)进行查询,许多 SQLite 查询与你从 [MySQL][8] 和 [MariaDB][9] 数据库中已经知道的查询相同。但是,数据类型和函数有所不同,因此,如果你熟悉另一个数据库,请特别注意细微的差异。
+
+### 创建数据库
+
+启动 SQLite 时,可以打开内存数据库,也可以选择要打开的数据库:
+
+```
+$ sqlite3 mydatabase.db
+```
+
+如果还没有数据库,则可以在 SQLite 提示符下创建一个数据库:
+
+```
+sqlite> .open mydatabase.db
+```
+
+现在,你的硬盘驱动器上有一个空文件,可以用作 SQLite 数据库。 文件扩展名 `.db` 是任意的。你也可以使用 `.sqlite` 或任何你想要的后缀。
+
+### 创建一个表
+
+数据库包含一些表,可以将其可视化为电子表格。有许多的行(在数据库中称为记录)和列。行和列的交集称为字段。
+
+结构化查询语言(SQL)以其提供的内容而命名:一种以可预测且一致的语法查询数据库内容以接收有用的结果的方法。SQL 读起来很像普通的英语句子,即使有点机械化。当前,你的数据库是一个没有任何表的空数据库。
+
+你可以使用 `CREATE` 来创建一个新表,你可以和 `IF NOT EXISTS` 结合使用。以便不会破坏现在已有的同名的表。
+
+你无法在 SQLite 中创建一个没有任何字段的空表,因此在尝试 `CREATE` 语句之前,必须考虑预期表将存储的数据类型。在此示例中,我将使用以下列创建一个名为 `member` 的表:
+
+ * 唯一标识符
+ * 人名
+ * 记录创建的时间和日期
+
+#### 唯一标识符
+
+最好用唯一的编号来引用记录,幸运的是,SQLite 认识到这一点,创建一个名叫 `rowid` 的列来为你自动实现这一点。
+
+无需 SQL 语句即可创建此字段。
+
+#### 数据类型
+
+对于我的示例表中,我正在创建一个 `name` 列来保存 `TEXT` 类型的数据。为了防止在没有指定字段数据的情况下创建记录,可以添加 `NOT NULL` 指令。
+
+用 `name TEXT NOT NULL` 语句来创建。
+
+SQLite 中有五种数据类型(实际上是 _储存类别_):
+
+ * `TEXT`:文本字符串
+ * `INTEGER`:一个数字
+ * `REAL`:一个浮点数(小数位数无限制)
+ * `BLOB`:二进制数据(例如,.jpeg 或 .webp 图像)
+ * `NULL`:空值
+
+#### 日期和时间戳
+
+SQLite 有一个方便的日期和时间戳功能。它本身不是数据类型,而是 SQLite 中的一个函数,它根据所需的格式生成字符串或整数。 在此示例中,我将其保留为默认值。
+
+创建此字段的 SQL 语句是:`datestamp DATETIME DEFAULT CURRENT_TIMESTAMP`。
+
+### 创建表的语句
+
+在 SQLite 中创建此示例表的完整 SQL:
+
+```
+sqlite> CREATE TABLE
+...> IF NOT EXISTS
+...> member (name TEXT NOT NULL,
+...> datestamp DATETIME DEFAULT CURRENT_TIMESTAMP);
+```
+
+在此代码示例中,我在语句的分句后按了回车键。以使其更易于阅读。除非以分号(`;`)终止,否则 SQLite 不会运行你的 SQL 语句。
+
+你可以使用 SQLite 命令 `.tables` 验证表是否已创建:
+
+```
+sqlite> .tables
+member
+```
+
+### 查看表中的所有列
+
+你可以使用 `PRAGMA` 语句验证表包含哪些列和行:
+
+```
+sqlite> PRAGMA table_info(member);
+0|name|TEXT|1||0
+1|datestamp|DATETIME|0|CURRENT_TIMESTAMP|0
+```
+
+### 数据输入
+
+你可以使用 `INSERT` 语句将一些示例数据填充到表中:
+
+```
+> INSERT INTO member (name) VALUES ('Alice');
+> INSERT INTO member (name) VALUES ('Bob');
+> INSERT INTO member (name) VALUES ('Carol');
+> INSERT INTO member (name) VALUES ('David');
+```
+
+查看表中的数据:
+
+```
+> SELECT * FROM member;
+Alice|2020-12-15 22:39:00
+Bob|2020-12-15 22:39:02
+Carol|2020-12-15 22:39:05
+David|2020-12-15 22:39:07
+```
+
+#### 添加多行数据
+
+现在创建第二个表:
+
+```
+> CREATE TABLE IF NOT EXISTS linux (
+...> distro TEXT NOT NULL);
+```
+
+填充一些示例数据,这一次使用小的 `VALUES` 快捷方式,因此你可以在一个命令中添加多行。关键字 `VALUES` 期望以括号形式列出列表,而用多个逗号分隔多个列表:
+
+```
+> INSERT INTO linux (distro)
+...> VALUES ('Slackware'), ('RHEL'),
+...> ('Fedora'),('Debian');
+```
+
+### 修改表结构
+
+你现在有两个表,但是到目前为止,两者之间没有任何关系。它们每个都包含独立的数据,但是可能你可能需要将第一个表的成员与第二个表中列出的特定项相关联。
+
+为此,你可以为第一个表创建一个新列,该列对应于第二个表。由于两个表都设计有唯一标识符(这要归功于 SQLite 的自动创建),所以连接它们的最简单方法是将其中一个的 `rowid` 字段用作另一个的选择器。
+
+在第一个表中创建一个新列,以存储第二个表中的值:
+
+```
+> ALTER TABLE member ADD os INT;
+```
+
+使用 `linux` 表中的唯一标识符作为 `member` 表中每一条记录中 `os` 字段的值。因为记录已经存在。因此你可以使用 `UPDATE` 语句而不是使用 `INSERT` 语句来更新数据。需要特别注意的是,你首先需要选中特定的一行来然后才能更新其中的某个字段。从句法上讲,这有点相反,更新首先发生,选择匹配最后发生:
+
+```
+> UPDATE member SET os=1 WHERE name='Alice';
+```
+
+对 `member` 表中的其他行重复相同的过程。更新 `os` 字段,为了数据多样性,在四行记录上分配三种不同的发行版(其中一种加倍)。
+
+### 联接表
+
+现在,这两个表相互关联,你可以使用 SQL 显示关联的数据。数据库中有多种 _联接方式_,但是一旦掌握了基础知识,就可以尝试所有的联接形式。这是一个基本联接,用于将 `member` 表的 `os` 字段中的值与 linux 表的 `rowid` 字段相关联:
+
+```
+> SELECT * FROM member INNER JOIN linux ON member.os=linux.rowid;
+Alice|2020-12-15 22:39:00|1|Slackware
+Bob|2020-12-15 22:39:02|3|Fedora
+Carol|2020-12-15 22:39:05|3|Fedora
+David|2020-12-15 22:39:07|4|Debian
+```
+
+`os` 和 `rowid` 字段形成了关联。
+
+在一个图形应用程序中,你可以想象 `os` 字段是一个下拉选项菜单,其中的值是 `linux` 表中 `distro` 字段中的数据。将相关的数据集通过唯一的字段相关联,可以确保数据的一致性和有效性,并且借助 SQL,你可以在以后动态地关联它们。
+
+### 了解更多
+
+SQLite 是一个非常有用的自包含的、可移植的开源数据库。学习以交互方式使用它是迈向针对 Web 应用程序进行管理或通过编程语言库使用它的重要的第一步。
+
+如果你喜欢 SQLite,也可以尝试由同一位作者 Richard Hipp 博士的 [Fossil][10]。
+
+在学习和使用 SQLite 时,有一些常用命令可能会有所帮助,所以请立即下载我们的 [SQLite3 备忘单][3]!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/sqlite3-cheat-sheet
+
+作者:[Klaatu][a]
+选题:[lujun9972][b]
+译者:[amwps290](https://github.com/amwps290)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/klaatu
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coverimage_cheat_sheet.png?itok=lYkNKieP "Cheat Sheet cover image"
+[2]: https://www.redhat.com/sysadmin/yaml-beginners
+[3]: https://opensource.com/downloads/sqlite-cheat-sheet
+[4]: https://sqlite.org/copyright.html
+[5]: https://directory.fsf.org/wiki/License:PublicDomain
+[6]: https://www.sqlite.org/purchase/license?
+[7]: https://www.sqlite.org/download.html
+[8]: https://www.mysql.com/
+[9]: https://mariadb.org/
+[10]: https://opensource.com/article/20/11/fossil
diff --git a/published/202102/20210207 Why the success of open source depends on empathy.md b/published/202102/20210207 Why the success of open source depends on empathy.md
new file mode 100644
index 0000000000..6905d890a1
--- /dev/null
+++ b/published/202102/20210207 Why the success of open source depends on empathy.md
@@ -0,0 +1,58 @@
+[#]: collector: (lujun9972)
+[#]: translator: (scvoet)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13120-1.html)
+[#]: subject: (Why the success of open source depends on empathy)
+[#]: via: (https://opensource.com/article/21/2/open-source-empathy)
+[#]: author: (Bronagh Sorota https://opensource.com/users/bsorota)
+
+为何开源的成功取决于同理心?
+======
+
+> 随着对同理心认识的提高和传播同理心的激励,开源生产力将得到提升,协作者将会聚拢,可以充分激发开源软件开发的活力。
+
+
+
+开源开发的协调创新精神和社区精神改变了世界。Jim Whitehurst 在[《开放式组织》][2]中解释说,开源的成功源于“将人们视为社区的一份子,从交易思维转变为基于承诺基础的思维方式”。 但是,开源开发模型的核心仍然存在障碍:它经常性地缺乏人类的同理心。
+
+同理心是理解或感受他人感受的能力。在开源社区中,面对面的人际互动和协作是很少的。任何经历过 GitHub 拉取请求或议题的开发者都曾收到过来自他们可能从未见过的人的评论,这些人往往身处地球的另一端,而他们的交流也可能同样遥远。现代开源开发就是建立在这种异步、事务性的沟通基础之上。因此,人们在社交媒体平台上所经历的同类型的网络欺凌和其他虐待行为,在开源社区中也不足为奇。
+
+当然,并非所有开源交流都会事与愿违。许多人在工作中发展出了尊重并秉持着良好的行为标准。但是很多时候,人们的沟通也常常缺乏常识性的礼仪,他们将人们像机器而非人类一般对待。这种行为是激发开源创新模型全部潜力的障碍,因为它让许多潜在的贡献者望而却步,并扼杀了灵感。
+
+### 恶意交流的历史
+
+代码审查中存在的敌意言论对开源社区来说并不新鲜,它多年来一直被社区所容忍。开源教父莱纳斯·托瓦尔兹经常在代码不符合他的标准时[抨击][3] Linux 社区,并将贡献者赶走。埃隆大学计算机科学教授 Megan Squire 借助[机器学习][4]分析了托瓦尔兹的侮辱行为,发现它们在四年内的数量高达数千次。2018 年,莱纳斯因自己的不良行为而自我放逐,责成自己学习同理心,道歉并为 Linux 社区制定了行为准则。
+
+2015 年,[Sage Sharp][5] 虽然在技术上受人尊重,但因其缺乏对个人的尊重,被辞去了 FOSS 女性外展计划中的 Linux 内核协调员一职。
+
+PR 审核中存在的贬低性评论对开发者会造成深远的影响。它导致开发者在提交 PR 时产生畏惧感,让他们对预期中的反馈感到恐惧。这吞噬了开发者对自己能力的信心。它逼迫工程师每次都只能追求完美,从而减缓了开发速度,这与许多社区采用的敏捷方法论背道而驰。
+
+### 如何缩小开源中的同理心差距?
+
+通常情况下,冒犯的评论常是无意间的,而通过一些指导,作者则可以学会如何在不带负面情绪的情况下表达意见。GitHub 不会监控议题和 PR 的评论是否有滥用内容,相反,它提供了一些工具,使得社区能够对其内容进行审查。仓库的所有者可以删除评论和锁定对话,所有贡献者可以报告滥用和阻止用户。
+
+制定社区行为准则可为所有级别的贡献者提供一个安全且包容的环境,并且能让所有级别的贡献者参与并定义降低协作者之间冲突的过程。
+
+我们能够克服开源中存在的同理心问题。面对面的辩论比文字更有利于产生共鸣,所以尽可能选择视频通话。以同理心的方式分享反馈,树立榜样。如果你目睹了一个尖锐的评论,请做一个指导者而非旁观者。如果你是受害者,请大声说出来。在面试候选人时,评估同理心能力,并将同理心能力与绩效评估和奖励挂钩。界定并执行社区行为准则,并管理好你的社区。
+
+随着对同理心认识的提高和传播同理心的激励,开源生产力将得到提升,协作者将会聚拢,可以充分激发开源软件开发的活力。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/open-source-empathy
+
+作者:[Bronagh Sorota][a]
+选题:[lujun9972][b]
+译者:[scvoet](https://github.com/scvoet)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/bsorota
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/practicing-empathy.jpg?itok=-A7fj6NF (Practicing empathy)
+[2]: https://www.redhat.com/en/explore/the-open-organization-book
+[3]: https://arstechnica.com/information-technology/2013/07/linus-torvalds-defends-his-right-to-shame-linux-kernel-developers/
+[4]: http://flossdata.syr.edu/data/insults/hicssInsultsv2.pdf
+[5]: https://en.wikipedia.org/wiki/Sage_Sharp
diff --git a/published/202102/20210208 3 open source tools that make Linux the ideal workstation.md b/published/202102/20210208 3 open source tools that make Linux the ideal workstation.md
new file mode 100644
index 0000000000..82a71b31f7
--- /dev/null
+++ b/published/202102/20210208 3 open source tools that make Linux the ideal workstation.md
@@ -0,0 +1,76 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13133-1.html)
+[#]: subject: (3 open source tools that make Linux the ideal workstation)
+[#]: via: (https://opensource.com/article/21/2/linux-workday)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+让 Linux 成为理想的工作站的 3 个开源工具
+======
+
+> Linux 不但拥有你认为所需的一切,还有更多可以让你高效工作的工具。
+
+
+
+在 2021 年,有更多让人们喜欢 Linux 的理由。在这个系列中,我将分享 21 种使用 Linux 的不同理由。今天,我将与你分享为什么 Linux 是你工作的最佳选择。
+
+每个人都希望在工作期间提高工作效率。如果你的工作通常涉及到文档、演示文稿和电子表格的工作,那么你可能已经习惯了特定的例行工作。问题在于,这个*惯常的例行工作*通常是由一两个特定的应用程序决定的,无论是某个办公套件还是桌面操作系统。当然,习惯并不意味着它是理想的,但是它往往会毫无疑义地持续存在,甚至影响到企业的运作架构。
+
+### 更聪明地工作
+
+如今,许多办公应用程序都在云端运行,因此如果你愿意的话,你可以在 Linux 上使用相同的方式。然而,由于许多典型的知名办公应用程序并不符合 Linux 上的文化预期,因此你可能会发现自己受到启发,想去探索其他的选择。正如任何渴望走出“舒适区”的人所知道的那样,这种微妙的打破可能会出奇的有用。很多时候,你不知道自己效率低下,因为你实际上并没有尝试过以不同的方式做事。强迫自己去探索其他方式,你永远不知道会发现什么。你甚至不必完全知道要寻找的内容。
+
+### LibreOffice
+
+Linux(或任何其他平台)上显而易见的开源办公主力之一是 [LibreOffice][2]。它具有多个组件,包括文字处理器、演示软件、电子表格、关系型数据库界面、矢量绘图等。它可以从其他流行的办公应用程序中导入许多文档格式,因此从其他工具过渡到 LibreOffice 通常很容易。
+
+然而,LibreOffice 不仅仅是一个出色的办公套件。LibreOffice 支持宏,所以机智的用户可以自动完成重复性任务。它还具有终端命令的功能,因此你可以在不启动 LibreOffice 界面的情况下执行许多任务。
+
+想象一下,比如要打开 21 个文档,导航到**文件**菜单,到**导出**或**打印**菜单项,并将文件导出为 PDF 或 EPUB。这至少需要 84 次以上的点击,可能要花费一个小时的时间。相比之下,打开一个文档文件夹,并转换所有文件为 PDF 或 EPUB,只需要执行一个迅速的命令或菜单操作。转换将在后台运行,而你可以处理其他事情。只需要四分之一的时间,可能更少。
+
+```
+$ libreoffice --headless --convert-to epub *.docx
+```
+
+这是一个小改进,是由 Linux 工具集和你可以自定义环境和工作流程的便利性所潜在带来的鼓励。
+
+### Abiword 和 Gnumeric
+
+有时,你并不需要一个大而全的办公套件。如果你喜欢简化你的办公室工作,那么使用一个轻量级和针对特定任务的应用程序可能更好。例如,我大部分时间都是用文本编辑器写文章,因为我知道在转换为 HTML 的过程中,所有的样式都会被丢弃。但有些时候,文字处理器是很有用的,无论是打开别人发给我的文档,还是因为我想用一种快速简单的方法来生成一些样式漂亮的文本。
+
+[Abiword][3] 是一款简单的文字处理器,它基本支持流行的文档格式,并具备你所期望的文字处理器的所有基本功能。它并不意味着是一个完整的办公套件,这是它最大的特点。虽然没有太多的选择,但我们仍然处于信息过载的时代,这正是一个完整的办公套件或文字处理器有时会犯的错误。如果你想避免这种情况,那就用一些简单的东西来代替。
+
+同样,[Gnumeric][4] 项目提供了一个简单的电子表格应用程序。Gnumeric 避免了任何严格意义上的电子表格所不需要的功能,所以你仍然可以获得强大的公式语法、大量的函数,以及样式和操作单元格的所有选项。我不怎么使用电子表格,所以我发现自己在极少数需要查看或处理分类账中的数据时,对 Gnumeric 相当满意。
+
+### Pandoc
+
+通过专门的命令和文件处理程序,可以最小化。`pandoc` 命令专门用于文件转换。它就像 `libreoffice --headless` 命令一样,只是要处理的文档格式数量是它的十倍。你甚至可以用它来生成演示文稿! 如果你的工作之一是从一个文档中提取源文本,并以多种格式交付它,那么 Pandoc 是必要的,所以你应该[下载我们的攻略][5]看看。
+
+广义上讲,Pandoc 代表的是一种完全不同的工作方式。它让你脱离了办公应用的束缚。它将你从试图将你的想法写成文字,并同时决定这些文字应该使用什么字体的工作中分离出来。在纯文本中工作,然后转换为各种交付格式,让你可以使用任何你想要的应用程序,无论是移动设备上的记事本,还是你碰巧坐在电脑前的简单文本编辑器,或者是云端的文本编辑器。
+
+### 寻找替代品
+
+Linux 有很多意想不到的替代品。你可以从你正在做的事情中退后一步,分析你的工作流程,评估你所需的结果,并调查那些声称可以完全你的需求的新应用程序来找到它们。
+
+改变你所使用的工具、工作流程和日常工作可能会让你迷失方向,特别是当你不知道你要找的到底是什么的时候。但 Linux 的优势在于,你有机会重新评估你在多年的计算机使用过程中潜意识里形成的假设。如果你足够努力地寻找答案,你最终会意识到问题所在。通常,你最终会欣赏你学到的东西。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-workday
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/laptop_screen_desk_work_chat_text.png?itok=UXqIDRDD (Person using a laptop)
+[2]: http://libreoffice.org
+[3]: https://www.abisource.com
+[4]: http://www.gnumeric.org
+[5]: https://opensource.com/article/20/5/pandoc-cheat-sheet
diff --git a/published/202102/20210208 Why choose Plausible for an open source alternative to Google Analytics.md b/published/202102/20210208 Why choose Plausible for an open source alternative to Google Analytics.md
new file mode 100644
index 0000000000..ed909d31a1
--- /dev/null
+++ b/published/202102/20210208 Why choose Plausible for an open source alternative to Google Analytics.md
@@ -0,0 +1,80 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13135-1.html)
+[#]: subject: (Why choose Plausible for an open source alternative to Google Analytics)
+[#]: via: (https://opensource.com/article/21/2/plausible)
+[#]: author: (Ben Rometsch https://opensource.com/users/flagsmith)
+
+为什么选择 Plausible 作为 Google Analytics 的开源替代品?
+======
+
+> Plausible 作为 Google Analytics 的可行、有效的替代方案正在引起用户的关注。
+
+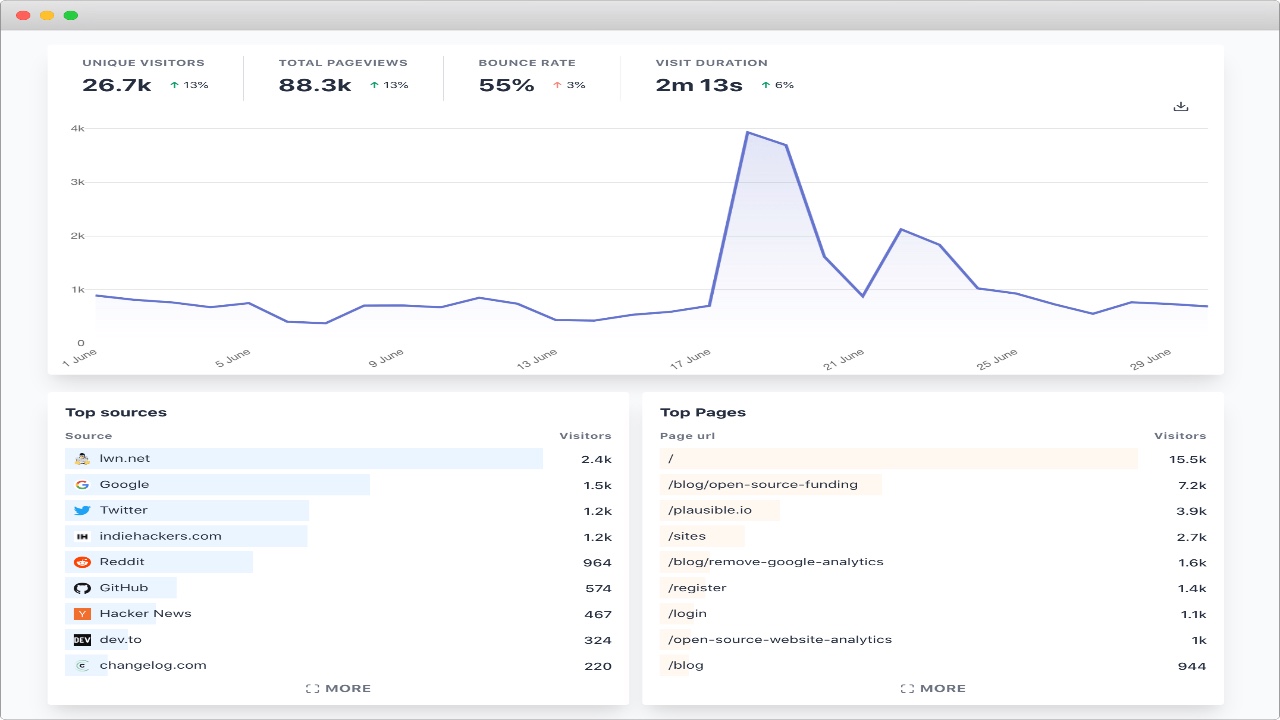
+
+替代 Google Analytics 似乎是一个巨大的挑战。实际上,你可以说这听起来似乎不合理(LCTT 译注:Plausible 意即“貌似合理”)。但这正是 [Plausible.io][2] 取得巨大成功的原因,自 2018 年以来已注册了数千名新用户。
+
+Plausible 的联合创始人 Uku Taht 和 Marko Saric 最近出现在 [The Craft of Open Source][3] 播客上,谈论了这个项目以及他们是如何:
+
+* 创建了一个可行的替代 Google Analytics 的方案
+* 在不到两年的时间里获得了如此大的发展势头
+* 通过开源他们的项目实现其目标
+
+请继续阅读他们与播客主持人和 Flagsmith 创始人 Ben Rometsch 的对话摘要。
+
+### Plausible 是如何开始的
+
+2018 年冬天,Uku 开始编写一个他认为急需的项目:一个可行的、有效的 Google Analytics 替代方案。因为他对 Google 产品的发展方向感到失望,而且所有其他数据解决方案似乎都把 Google 当作“数据处理中间人”。
+
+Uku 的第一直觉是利用现有的数据库解决方案专注于分析方面的工作。马上,他就遇到了一些挑战。开始尝试使用了 PostgreSQL,这在技术上很幼稚,因为它很快就变得不堪重负,效率低下。因此,他的目标蜕变成了做一个分析产品,可以处理大量的数据点,而且性能不会有明显的下降。简而言之,Uku 成功了,Plausible 现在每月可以收取超过 8000 万条记录。
+
+Plausible 的第一个版本于 2019 年夏天发布。2020 年 3 月,Marko 加入,负责项目的传播和营销方面的工作。从那时起,它它的受欢迎程度有了很大的增长。
+
+### 为什么要开源?
+
+Uku 热衷于遵循“独立黑客”的软件开发路线:创建一个产品,把它投放出去,然后看看它如何成长。开源在这方面是有意义的,因为你可以迅速发展一个社区并获得人气。
+
+但 Plausible 一开始并不是开源的。Uku 最初担心软件的敏感代码,比如计费代码,但他很快就发布了,因为这对没有 API 令牌的人来说是没有用的。
+
+现在,Plausible 是在 [AGPL][4] 下完全开源的,他们选择了 AGPL 而不是 MIT 许可。Uku 解释说,在 MIT 许可下,任何人都可以不受限制地对代码做任何事情。在 AGPL 下,如果有人修改代码,他们必须将他们的修改开源,并将代码回馈给社区。这意味着,大公司不能拿着原始代码在此基础上进行构建,然后获得所有的回报。他们必须共享,使得竞争环境更加公平。例如,如果一家公司想插入他们的计费或登录系统,他们有法律义务发布代码。
+
+在播客中,Uku 向我询问了关于 Flagsmith 的授权,目前 Flagsmith 的授权采用 BSD 三句版许可,该许可证是高度开放的,但我即将把一些功能移到更严格的许可后面。到目前为止,Flagsmith 社区已经理解了这一变化,因为他们意识到这将带来更多更好的功能。
+
+### Plausible vs. Google Analytics
+
+Uku 说,在他看来,开源的精神是,代码应该是开放的,任何人都可以进行商业使用,并与社区共享,但你可以把一个闭源的 API 模块作为专有附加组件保留下来。这样一来,Plausible 和其他公司就可以通过创建和销售定制的 API 附加许可来满足不同的使用场景。
+
+Marko 职位上是一名开发者,但从营销方面来说,他努力让这个项目在 Hacker News 和 Lobster 等网站上得到报道,并建立了 Twitter 帐户以帮助产生动力。这种宣传带来的热潮也意味着该项目在 GitHub 上起飞,从 500 颗星到 4300 颗星。随着流量的增长,Plausible 出现在 GitHub 的趋势列表中,这让其受欢迎程度像滚雪球一样。
+
+Marko 还非常注重发布和推广博客文章。这一策略得到了回报,在最初的 6 个月里,有四五篇文章进入了病毒式传播,他利用这些峰值来放大营销信息,加速了增长。
+
+Plausible 成长过程中最大的挑战是让人们从 Google Analytics 上转换过来。这个项目的主要目标是创建一个有用、高效、准确的网络分析产品。它还需要符合法规,并为企业和网站访问者提供高度的隐私。
+
+Plausible 现在已经在 8000 多个网站上运行。通过与客户的交谈,Uku 估计其中约 90% 的客户运行过 Google Analytics。
+
+Plausible 以标准的软件即服务 (SaaS) 订阅模式运行。为了让事情更公平,它按月页面浏览量收费,而不是按网站收费。对于季节性网站来说,这可能会有麻烦,比如说电子商务网站在节假日会激增,或者美国大选网站每四年激增一次。这些可能会导致月度订阅模式下的定价问题,但它通常对大多数网站很好。
+
+### 查看播客
+
+想要了解更多关于 Uku 和 Marko 如何以惊人的速度发展开源 Plausible 项目,并使其获得商业上的成功,请[收听播客][3],并查看[其他剧集][5],了解更多关于“开源软件社区的来龙去脉”。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/plausible
+
+作者:[Ben Rometsch][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/flagsmith
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/analytics-graphs-charts.png?itok=sersoqbV (Analytics: Charts and Graphs)
+[2]: https://plausible.io/
+[3]: https://www.flagsmith.com/podcast/02-plausible
+[4]: https://www.gnu.org/licenses/agpl-3.0.en.html
+[5]: https://www.flagsmith.com/podcast
\ No newline at end of file
diff --git a/published/202102/20210209 Viper Browser- A Lightweight Qt5-based Web Browser With A Focus on Privacy and Minimalism.md b/published/202102/20210209 Viper Browser- A Lightweight Qt5-based Web Browser With A Focus on Privacy and Minimalism.md
new file mode 100644
index 0000000000..78f9f8bc07
--- /dev/null
+++ b/published/202102/20210209 Viper Browser- A Lightweight Qt5-based Web Browser With A Focus on Privacy and Minimalism.md
@@ -0,0 +1,106 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13139-1.html)
+[#]: subject: (Viper Browser: A Lightweight Qt5-based Web Browser With A Focus on Privacy and Minimalism)
+[#]: via: (https://itsfoss.com/viper-browser/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Viper 浏览器:一款注重隐私和简约的轻量级 Qt5 浏览器
+======
+
+
+
+> Viper 浏览器是一个基于 Qt 的浏览器,它提供了简单易用的用户体验,同时考虑到隐私问题。
+
+虽然大多数流行的浏览器都运行在 Chromium 之上,但像 [Firefox][1]、[Beaker 浏览器][2]以及其他一些 [chrome 替代品][3]这样独特的替代品不应该停止存在。
+
+尤其是考虑到谷歌最近可能想到从 Chromium 中剥离[谷歌浏览器特有的功能][4],并给出了滥用的借口。
+
+在寻找更多的 Chrome 替代品时,我在 [Mastodon][6] 上看到了一个有趣的项目 “[Viper 浏览器][5]”。
+
+### Viper 浏览器:一个基于 Qt5 的开源浏览器
+
+**注意**:Viper 浏览器是一个只有几个贡献者的相当新的项目。它缺乏某些功能,我将在下文提及。
+
+Viper 是一款有趣的 Web 浏览器,在利用 [QtWebEngine][8] 的同时,它专注于成为一个强大而又轻巧的选择。
+
+QtWebEngine 借用了 Chromium 的代码,但它不包括连接到 Google 平台的二进制文件和服务。
+
+我花了一些时间使用它并进行一些日常浏览活动,我必须说,我对它相当感兴趣。不仅仅是因为它是一个简单易用的东西(浏览器可以那么复杂),而且它还专注于增强你的隐私,为你提供添加不同的广告阻止选项以及一些有用的选项。
+
+![][9]
+
+虽然我认为它并不是为所有人准备的,但还是值得一看的。在你继续尝试之前,让我简单介绍一下它的功能。
+
+### Viper 浏览器的功能
+
+![][10]
+
+我将列出一些你会发现有用的关键功能:
+
+* 管理 cookies 的能力
+* 多个预设选项以选择不同的广告屏蔽器网络。
+* 简单且易于使用
+* 隐私友好的默认搜索引擎 - [Startpage][11] (你可以更改)
+* 能够添加用户脚本
+* 能够添加新的 user-agent
+* 禁用 JavaScript 的选项
+* 能够阻止图像加载
+
+除了这些亮点之外,你还可以轻松地调整隐私设置,以删除你的历史记录、清理已有 cookies,以及一些更多的选项。
+
+![][12]
+
+### 在 Linux 上安装 Viper 浏览器
+
+它只是在[发布页][13]提供了一个 AppImage 文件,你可以利用它在任何 Linux 发行版上进行测试。
+
+如果你需要帮助,你也可以参考我们的[在 Linux 上使用 AppImage 文件][14]指南。如果你好奇,你可以在 [GitHub][5] 上探索更多关于它的内容。
+
+- [Viper 浏览器][5]
+
+### 我对使用 Viper 浏览器的看法
+
+我不认为这是一个可以立即取代你当前浏览器的东西,但如果你有兴趣测试尝试提供 Chrome 替代品的新项目,这肯定是其中之一。
+
+当我试图登录我的谷歌账户时,它阻止了我,说它可能是一个不安全的浏览器或不支持的浏览器。因此,如果你依赖你的谷歌帐户,这是一个令人失望的消息。
+
+但是,其他社交媒体平台也可以与 YouTube 一起正常运行(无需登录)。不支持 Netflix,但总体上浏览体验是相当快速和可用的。
+
+你可以安装用户脚本,但 Chrome 扩展还不支持。当然,这要么是有意为之,要么是在开发过程中特别考虑到它是一款隐私友好型的网络浏览器。
+
+### 总结
+
+考虑到这是一个鲜为人知但对某些人来说很有趣的东西,你对我们有什么建议吗? 是一个值得关注的开源项目么?
+
+请在下面的评论中告诉我。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/viper-browser/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://www.mozilla.org/en-US/firefox/new/
+[2]: https://itsfoss.com/beaker-browser-1-release/
+[3]: https://itsfoss.com/open-source-browsers-linux/
+[4]: https://www.bleepingcomputer.com/news/google/google-to-kill-chrome-sync-feature-in-third-party-browsers/
+[5]: https://github.com/LeFroid/Viper-Browser
+[6]: https://mastodon.social/web/accounts/199851
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/viper-browser.png?resize=800%2C583&ssl=1
+[8]: https://wiki.qt.io/QtWebEngine
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/viper-browser-setup.jpg?resize=793%2C600&ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/viper-preferences.jpg?resize=800%2C660&ssl=1
+[11]: https://www.startpage.com
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/viper-browser-tools.jpg?resize=800%2C262&ssl=1
+[13]: https://github.com/LeFroid/Viper-Browser/releases
+[14]: https://itsfoss.com/use-appimage-linux/
diff --git a/published/202102/20210212 4 reasons to choose Linux for art and design.md b/published/202102/20210212 4 reasons to choose Linux for art and design.md
new file mode 100644
index 0000000000..fbb040cf2e
--- /dev/null
+++ b/published/202102/20210212 4 reasons to choose Linux for art and design.md
@@ -0,0 +1,95 @@
+[#]: collector: (lujun9972)
+[#]: translator: (amorsu)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13157-1.html)
+[#]: subject: (4 reasons to choose Linux for art and design)
+[#]: via: (https://opensource.com/article/21/2/linux-art-design)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+选择 Linux 来做艺术设计的 4 个理由
+======
+
+> 开源会强化你的创造力。因为它把你带出专有的思维定势,开阔你的视野,从而带来更多的可能性。让我们探索一些开源的创意项目。
+
+
+
+2021 年,人们比以前的任何时候都更有理由来爱上 Linux。在这个系列,我会分享 21 个选择 Linux 的原因。今天,让我来解释一下,为什么 Linux 是艺术设计的绝佳选择。
+
+Linux 在服务器和云计算方面获得很多的赞誉。让不少人感到惊讶的是,Linux 刚好也有一系列的很棒的创意设计工具,并且这些工具在用户体验和质量方面可以媲美那些流行的创意设计工具。我第一次使用开源的设计工具时,并不是因为我没有其他工具可以选择。相反的,我是在接触了大量的这些领先的公司提供的专有设计工具后,才开始使用开源设计工具。我之所以最后选择开源设计工具是因为开源更有意义,而且我能获得更好的产出。这些都是一些笼统的说法,所以请允许我解释一下。
+
+### 高可用性意味着高生产力
+
+“生产力”这一次对于不同的人来说含义不一样。当我想到生产力,就是当你坐下来做事情,并能够完成你给自己设定的所有任务的时候,这时就很有成就感。但是当你总是被一些你无法掌控的事情打断,那你的生产力就下降了。
+
+计算机看起来是不可预测的,诚然有很多事情会出错。电脑是由很多的硬件组成的,它们任何一个都有可能在任何时间出问题。软件会有 bug,也有修复这些 bug 的更新,而更新后又会带来新的 bug。如果你对电脑不了解,它可能就像一个定时炸弹,等着爆发。带着数字世界里的这么多的潜在问题,去接受一个当某些条件不满足(比如许可证,或者订阅费)就会不工作的软件,对我来说就显得很不理智。
+
+![Inkscape 应用][2]
+
+开源的创意设计应用不需要订阅费,也不需要许可证。在你需要的时候,它们都能获取得到,并且通常都是跨平台的。这就意味着,当你坐在工作的电脑面前,你就能确定你能用到那些必需的软件。而如果某天你很忙碌,却发现你面前的电脑不工作了,解决办法就是找到一个能工作的,安装你的创意设计软件,然后开始工作。
+
+例如,要找到一台无法运行 Inkscape 的电脑,比找到一台可以运行那些专有软件的电脑要难得多。这就叫做高可用。这是游戏规则的改变者。我从来不曾遇到因为软件用不了而不得不干等,浪费我数小时时间的事情。
+
+### 开放访问更有利于多样性
+
+我在设计行业工作的时候,我的很多同事都是通过自学的方式来学习艺术和技术方面的知识,这让我感到惊讶。有的通过使用那些最新的昂贵的“专业”软件来自学,但总有一大群人是通过使用自由和开源的软件来完善他们的数字化的职业技能。因为,对于孩子,或者没钱的大学生来说,这才是他们能负担的起,而且很容易就能获得的。
+
+这是一种不同的高可用性,但这对我和许多其他用户来说很重要,如果不是因为开源,他们就不会从事创意行业。即使那些有提供付费订阅的开源项目,比如 Ardour,都能确保他的用户在不需要支付任何费用的时候也能使用软件。
+
+![Ardour 界面][4]
+
+当你不限制别人用你的软件的时候,你其实拥有了更多的潜在用户。如果你这样做了,那么你就开放了一个接收多样的创意声音的窗口。艺术钟爱影响力,你可以借鉴的经验和想法越多就越好。这就是开源设计软件所带来的可能性。
+
+### 文件格式支持更具包容性
+
+我们都知道在几乎所有行业里面包容性的价值。在各种意义上,邀请更多的人到派对可以造就更壮观的场面。知道这一点,当看到有的项目或者创新公司只邀请某些人去合作,只接受某些文件格式,就让我感到很痛苦。这看起来很陈旧,就像某个远古时代的精英主义的遗迹,而这是即使在今天都在发生的真实问题。
+
+令人惊讶和不幸的是,这不是因为技术上的限制。专有软件可以访问开源的文件格式,因为这些格式是开源的,而且可以自由地集成到各种应用里面。集成这些格式不需要任何回报。而相比之下,专有的文件格式被笼罩在秘密之中,只被限制于提供给几个愿意付钱的人使用。这很糟糕,而且常常,你无法在没有这些专有软件的情况下打开一些文件来获取你的数据。令人惊喜的是,开源的设计软件却是尽力的支持更多的专有文件格式。以下是一些 Inkscape 所支持的令人难以置信的列表样本:
+
+![可用的 Inkscape 文件格式][5]
+
+而这大部分都是在没有这些专有格式厂商的支持下开发出来的。
+
+支持开放的文件格式可以更包容,对所有人都更好。
+
+### 对新的创意没有限制
+
+我之所以爱上开源的其中一个原因是,解决一个指定任务时,有彻底的多样性。当你在专有软件周围时,你所看到的世界是基于你所能够获取得到的东西。比如说,你过你打算处理一些照片,你通常会把你的意图局限在你所知道的可能性上面。你从你的架子上的 4 款或 10 款应用中,挑选出 3 款,因为它们是目前你唯一能够获取得到的选项。
+
+在开源领域,你通常会有好几个“显而易见的”必备解决方案,但同时你还有一打的角逐者在边缘转悠,供你选择。这些选项有时只是半成品,或者它们超级专注于某项任务,又或者它们学起来有点挑战性,但最主要的是,它们是独特的,而且充满创新的。有时候,它们是被某些不按“套路”出牌的人所开发的,因此处理的方法和市场上现有的产品截然不同。其他时候,它们是被那些熟悉做事情的“正确”方式,但还是在尝试不同策略的人所开发的。这就像是一个充满可能性的巨大的动态的头脑风暴。
+
+这种类型的日常创新能够引领出闪现的灵感、光辉时刻,或者影响广泛的通用性改进。比如说,著名的 GIMP 滤镜,(用于从图像中移除项目并自动替换背景)是如此的受欢迎以至于后来被专有图片编辑软件商拿去“借鉴”。这是成功的一步,但是对于一个艺术家而言,个人的影响才是最关键的。我常感叹于新的 Linux 用户的创意,而我只是在技术展会上展示给他们一个简单的音频,或者视频滤镜,或者绘图应用。没有任何的指导,或者应用场景,从简单的交互中喷发出来的关于新的工具的主意,是令人兴奋和充满启发的,通过实验中一些简单的工具,一个全新的艺术系列可以轻而易举的浮现出来。
+
+只要在适当的工具集都有的情况下,有很多方式来更有效的工作。虽然私有软件通常也不会反对更聪明的工作习惯的点子,专注于实现自动化任务让用户可以更轻松的工作,对他们也没有直接的收益。Linux 和开源软件就是很大程度专为 [自动化和编排][6] 而建的,而不只是服务器。像 [ImageMagick][7] 和 [GIMP 脚本][8] 这样的工具改变了我的处理图片的方式,包括批量处理方面和纯粹实验方面。
+
+你永远不知道你可以创造什么,如果你有一个你从来想象不到会存在的工具的话。
+
+### Linux 艺术家
+
+这里有 [使用开源的艺术家社区][9],从 [photography][10] 到 [makers][11] 到 [musicians][12],还有更多更多。如果你想要创新,试试 Linux 吧。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-art-design
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[amorsu](https://github.com/amorsu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/painting_computer_screen_art_design_creative.png?itok=LVAeQx3_ (Painting art on a computer screen)
+[2]: https://opensource.com/sites/default/files/inkscape_0.jpg
+[3]: https://community.ardour.org/subscribe
+[4]: https://opensource.com/sites/default/files/ardour.jpg
+[5]: https://opensource.com/sites/default/files/formats.jpg
+[6]: https://opensource.com/article/20/11/orchestration-vs-automation
+[7]: https://opensource.com/life/16/6/fun-and-semi-useless-toys-linux#imagemagick
+[8]: https://opensource.com/article/21/1/gimp-scripting
+[9]: https://librearts.org
+[10]: https://pixls.us
+[11]: https://www.redhat.com/en/blog/channel/red-hat-open-studio
+[12]: https://linuxmusicians.com
diff --git a/published/202102/20210215 A practical guide to JavaScript closures.md b/published/202102/20210215 A practical guide to JavaScript closures.md
new file mode 100644
index 0000000000..cebf757a5a
--- /dev/null
+++ b/published/202102/20210215 A practical guide to JavaScript closures.md
@@ -0,0 +1,136 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13140-1.html)
+[#]: subject: (A practical guide to JavaScript closures)
+[#]: via: (https://opensource.com/article/21/2/javascript-closures)
+[#]: author: (Nimisha Mukherjee https://opensource.com/users/nimisha)
+
+JavaScript 闭包实践
+======
+
+> 通过深入了解 JavaScript 的高级概念之一:闭包,更好地理解 JavaScript 代码的工作和执行方式。
+
+
+
+在《[JavaScript 如此受欢迎的 4 个原因][2]》中,我提到了一些高级 JavaScript 概念。在本文中,我将深入探讨其中的一个概念:闭包。
+
+根据 [Mozilla 开发者网络][3](MDN),“闭包是将一个函数和对其周围的状态(词法环境)的引用捆绑在一起(封闭)的组合。”简而言之,这意味着在一个函数内部的函数可以访问其外部(父)函数的变量。
+
+为了更好地理解闭包,可以看看作用域及其执行上下文。
+
+下面是一个简单的代码片段:
+
+```
+var hello = "Hello";
+
+function sayHelloWorld() {
+ var world = "World";
+ function wish() {
+ var year = "2021";
+ console.log(hello + " " + world + " "+ year);
+ }
+ wish();
+}
+sayHelloWorld();
+```
+
+下面是这段代码的执行上下文:
+
+![JS 代码的执行上下文][4]
+
+每次创建函数时(在函数创建阶段)都会创建闭包。每个闭包有三个作用域。
+
+ * 本地作用域(自己的作用域)
+ * 外部函数范围
+ * 全局范围
+
+我稍微修改一下上面的代码来演示一下闭包:
+
+```
+var hello = "Hello";
+
+var sayHelloWorld = function() {
+ var world = "World";
+ function wish() {
+ var year = "2021";
+ console.log(hello + " " + world + " "+ year);
+ }
+ return wish;
+}
+var callFunc = sayHelloWorld();
+callFunc();
+```
+
+内部函数 `wish()` 在执行之前就从外部函数返回。这是因为 JavaScript 中的函数形成了**闭包**。
+
+ * 当 `sayHelloWorld` 运行时,`callFunc` 持有对函数 `wish` 的引用。
+ * `wish` 保持对其周围(词法)环境的引用,其中存在变量 `world`。
+
+### 私有变量和方法
+
+本身,JavaScript 不支持创建私有变量和方法。闭包的一个常见和实用的用途是模拟私有变量和方法,并允许数据隐私。在闭包范围内定义的方法是有特权的。
+
+这个代码片段捕捉了 JavaScript 中闭包的常用编写和使用方式:
+
+```
+var resourceRecord = function(myName, myAddress) {
+ var resourceName = myName;
+ var resourceAddress = myAddress;
+ var accessRight = "HR";
+ return {
+ changeName: function(updateName, privilege) {
+ // only HR can change the name
+ if (privilege === accessRight ) {
+ resourceName = updateName;
+ return true;
+ } else {
+ return false;
+ }
+ },
+ changeAddress: function(newAddress) {
+ // any associate can change the address
+ resourceAddress = newAddress;
+ },
+ showResourceDetail: function() {
+ console.log ("Name:" + resourceName + " ; Address:" + resourceAddress);
+ }
+ }
+}
+// Create first record
+var resourceRecord1 = resourceRecord("Perry","Office");
+// Create second record
+var resourceRecord2 = resourceRecord("Emma","Office");
+// Change the address on the first record
+resourceRecord1.changeAddress("Home");
+resourceRecord1.changeName("Perry Berry", "Associate"); // Output is false as only an HR can change the name
+resourceRecord2.changeName("Emma Freeman", "HR"); // Output is true as HR changes the name
+resourceRecord1.showResourceDetail(); // Output - Name:Perry ; Address:Home
+resourceRecord2.showResourceDetail(); // Output - Name:Emma Freeman ; Address:Office
+```
+
+资源记录(`resourceRecord1` 和 `resourceRecord2`)相互独立。每个闭包通过自己的闭包引用不同版本的 `resourceName` 和 `resourceAddress` 变量。你也可以应用特定的规则来处理私有变量,我添加了一个谁可以修改 `resourceName` 的检查。
+
+### 使用闭包
+
+理解闭包是很重要的,因为它可以更深入地了解变量和函数之间的关系,以及 JavaScript 代码如何工作和执行。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/javascript-closures
+
+作者:[Nimisha Mukherjee][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/nimisha
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop-music-headphones.png?itok=EQZ2WKzy (Woman programming)
+[2]: https://linux.cn/article-12830-1.html
+[3]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Closures
+[4]: https://opensource.com/sites/default/files/uploads/execution-context.png (Execution context for JS code)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
diff --git a/published/202102/20210216 Meet Plots- A Mathematical Graph Plotting App for Linux Desktop.md b/published/202102/20210216 Meet Plots- A Mathematical Graph Plotting App for Linux Desktop.md
new file mode 100644
index 0000000000..1232812fab
--- /dev/null
+++ b/published/202102/20210216 Meet Plots- A Mathematical Graph Plotting App for Linux Desktop.md
@@ -0,0 +1,98 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13151-1.html)
+[#]: subject: (Meet Plots: A Mathematical Graph Plotting App for Linux Desktop)
+[#]: via: (https://itsfoss.com/plots-graph-app/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+认识 Plots:一款适用于 Linux 桌面的数学图形绘图应用
+======
+
+
+
+Plots 是一款图形绘图应用,它可以轻松实现数学公式的可视化。你可以用它来绘制任意三角函数、双曲函数、指数函数和对数函数的和与积。
+
+### 在 Linux 上使用 Plots 绘制数学图形
+
+[Plots][1] 是一款简单的应用,它的灵感来自于像 [Desmos][2] 这样的 Web 图形绘图应用。它能让你绘制不同数学函数的图形,你可以交互式地输入这些函数,还可以自定义绘图的颜色。
+
+Plots 是用 Python 编写的,它使用 [OpenGL][3] 来利用现代硬件。它使用 GTK 3,因此可以很好地与 GNOME 桌面集成。
+
+![][4]
+
+使用 Plots 非常直白。要添加一个新的方程,点击加号。点击垃圾箱图标可以删除方程。还可以选择撤销和重做。你也可以放大和缩小。
+
+![][5]
+
+你输入方程的文本框是友好的。菜单中有一个“帮助”选项可以访问文档。你可以在这里找到关于如何编写各种数学符号的有用提示。你也可以复制粘贴方程。
+
+![][6]
+
+在深色模式下,侧栏公式区域变成了深色,但主绘图区域仍然是白色。我相信这也许是这样设计的。
+
+你可以使用多个函数,并将它们全部绘制在一张图中:
+
+![][7]
+
+我发现它在尝试粘贴一些它无法理解的方程时崩溃了。如果你写了一些它不能理解的东西,或者与现有的方程冲突,所有图形都会消失,去掉不正确的方程就会恢复图形。
+
+不幸的是,没有导出绘图或复制到剪贴板的选项。你可以随时 [在 Linux 中截图][8],并在你要添加图像的文档中使用它。
+
+### 在 Linux 上安装 Plots
+
+Plots 为各种发行版提供了不同的安装方式。
+
+Ubuntu 20.04 和 20.10 用户可以[使用 PPA][11]:
+
+```
+sudo add-apt-repository ppa:apandada1/plots
+sudo apt update
+sudo apt install plots
+```
+
+对于其他基于 Debian 的发行版,你可以使用 [这里][13] 的 [deb 文件安装][12]。
+
+我没有在 AUR 软件包列表中找到它,但是作为 Arch Linux 用户,你可以使用 Flatpak 软件包或者使用 Python 安装它。
+
+- [Plots Flatpak 软件包][14]
+
+如果你感兴趣,可以在它的 GitHub 仓库中查看源代码。如果你喜欢这款应用,请考虑在 GitHub 上给它 star。
+
+- [GitHub 上的 Plots 源码][1]
+
+### 结论
+
+Plots 主要用于帮助学生学习数学或相关科目,但它在很多其他场景下也能发挥作用。我知道不是每个人都需要,但肯定会对学术界和学校的人有帮助。
+
+不过我倒是希望能有导出图片的功能。也许开发者可以在未来的版本中加入这个功能。
+
+你知道有什么类似的绘图应用吗?Plots 与它们相比如何?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/plots-graph-app/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://github.com/alexhuntley/Plots/
+[2]: https://www.desmos.com/
+[3]: https://www.opengl.org/
+[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/fourier-graph-plots.png?resize=800%2C492&ssl=1
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/plots-app-linux-1.png?resize=800%2C518&ssl=1
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/plots-app-linux.png?resize=800%2C527&ssl=1
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/multiple-equations-plots.png?resize=800%2C492&ssl=1
+[8]: https://itsfoss.com/take-screenshot-linux/
+[10]: https://itsfoss.com/keenwrite/
+[11]: https://itsfoss.com/ppa-guide/
+[12]: https://itsfoss.com/install-deb-files-ubuntu/
+[13]: https://launchpad.net/~apandada1/+archive/ubuntu/plots/+packages
+[14]: https://flathub.org/apps/details/com.github.alexhuntley.Plots
diff --git a/published/202102/20210217 5 reasons to use Linux package managers.md b/published/202102/20210217 5 reasons to use Linux package managers.md
new file mode 100644
index 0000000000..76842524a3
--- /dev/null
+++ b/published/202102/20210217 5 reasons to use Linux package managers.md
@@ -0,0 +1,75 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13160-1.html)
+[#]: subject: (5 reasons to use Linux package managers)
+[#]: via: (https://opensource.com/article/21/2/linux-package-management)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+使用 Linux 软件包管理器的 5 个理由
+======
+
+> 包管理器可以跟踪你安装的软件的所有组件,使得更新、重装和故障排除更加容易。
+
+
+
+在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。今天,我将谈谈软件仓库。
+
+在我使用 Linux 之前,我认为在计算机上安装的应用是理所当然的。我会根据需要安装应用,如果我最后没有使用它们,我就会把它们忘掉,让它们占用我的硬盘空间。终于有一天,我的硬盘空间会变得稀缺,我就会疯狂地删除应用,为更重要的数据腾出空间。但不可避免的是,应用只能释放出有限的空间,所以我将注意力转移到与这些应用一起安装的所有其他零碎内容上,无论是媒体内容还是配置文件和文档。这不是一个管理电脑的好方法。我知道这一点,但我并没有想过要有其他的选择,因为正如人们所说,你不知道自己不知道什么。
+
+当我改用 Linux 时,我发现安装应用的方式有些不同。在 Linux 上,会建议你不要去网站上找应用的安装程序。取而代之的是,运行一个命令,应用就会被安装到系统上,并记录每个单独的文件、库、配置文件、文档和媒体资产。
+
+### 什么是软件仓库?
+
+在 Linux 上安装应用的默认方法是从发行版软件仓库中安装。这可能听起来像应用商店,那是因为现代应用商店借鉴了很多软件仓库的概念。[Linux 也有应用商店][2],但软件仓库是独一无二的。你通过一个*包管理器*从软件仓库中获得一个应用,它使你的 Linux 系统能够记录和跟踪你所安装的每一个组件。
+
+这里有五个原因可以让你确切地知道你的系统上有什么东西,可以说是非常有用。
+
+#### 1、移除旧应用
+
+当你的计算机知道应用安装的每一个文件时,卸载你不再需要的文件真的很容易。在 Linux 上,安装 [31 个不同的文本编辑器][3],然后卸载 30 个你不喜欢的文本编辑器是没有问题的。当你在 Linux 上卸载的时候,你就真的卸载了。
+
+#### 2、按你的意思重新安装
+
+不仅卸载要彻底,*重装*也很有意义。在许多平台上,如果一个应用出了问题,有时会建议你重新安装它。通常情况下,谁也说不清为什么要重装一个应用。不过,人们还是经常会隐隐约约地怀疑某个地方的文件已经损坏了(换句话说,数据写入错误),所以希望重装可以覆盖坏的文件以让软件重新工作。这是个不错的建议,但对于任何技术人员来说,不知道是什么地方出了问题都是令人沮丧的。更糟糕的是,如果不仔细跟踪,就不能保证所有的文件都会在重装过程中被刷新,因为通常没有办法知道与应用程序一起安装的所有文件在第一时间就删除了。有了软件包管理器,你可以强制彻底删除旧文件,以确保新文件的全新安装。同样重要的是,你可以研究每个文件并可能找出导致问题的文件,但这是开源和 Linux 的一个特点,而不是包管理。
+
+#### 3、保持你应用的更新
+
+不要听别人告诉你的 Linux 比其他操作系统“更安全”。计算机是由代码组成的,而我们人类每天都会以新的、有趣的方式找到利用这些代码的方法。因为 Linux 上的绝大多数应用都是开源的,所以许多漏洞都会以“常见漏洞和暴露”(CVE)的形式公开。大量涌入的安全漏洞报告似乎是一件坏事,但这绝对是一个*知道*远比*不知道*好的案例。毕竟,没有人告诉你有问题,并不意味着没有问题。漏洞报告是好的。它们对每个人都有好处。而且,当开发人员修复安全漏洞时,对你而言,及时获得这些修复程序很重要,最好不用自己记着动手修复。
+
+包管理器正是为了实现这一点而设计的。当应用收到更新时,无论是修补潜在的安全问题还是引入令人兴奋的新功能,你的包管理器应用都会提醒你可用的更新。
+
+#### 4、保持轻便
+
+假设你有应用 A 和应用 B,这两个应用都需要库 C。在某些操作系统上,通过得到 A 和 B,就会得到了两个 C 的副本。这显然是多余的,所以想象一下,每个应用都会发生几次。冗余的库很快就会增加,而且由于对一个给定的库没有单一的“正确”来源,所以几乎不可能确保你使用的是最新的甚至是一致的版本。
+
+我承认我不会整天坐在这里琢磨软件库,但我确实记得我琢磨的日子,尽管我不知道这就是困扰我的原因。在我还没有改用 Linux 之前,我在处理工作用的媒体文件时遇到错误,或者在玩不同的游戏时出现故障,或者在阅读 PDF 时出现怪异的现象,等等,这些都不是什么稀奇的事情。当时我花了很多时间去调查这些错误。我仍然记得,我的系统上有两个主要的应用分别捆绑了相同(但有区别)的图形后端技术。当一个程序的输出导入到另一个程序时,这种不匹配会导致错误。它本来是可以工作的,但是由于同一个库文件集合的旧版本中的一个错误,一个应用的热修复程序并没有给另一个应用带来好处。
+
+包管理器知道每个应用需要哪些后端(被称为*依赖关系*),并且避免重新安装已经在你系统上的软件。
+
+#### 5、保持简单
+
+作为一个 Linux 用户,我要感谢包管理器,因为它帮助我的生活变得简单。我不必考虑我安装的软件,我需要更新的东西,也不必考虑完成后是否真的将其卸载了。我毫不犹豫地试用软件。而当我在安装一台新电脑时,我运行 [一个简单的 Ansible 脚本][4] 来自动安装我所依赖的所有软件的最新版本。这很简单,很智能,也是一种独特的解放。
+
+### 更好的包管理
+
+Linux 从整体看待应用和操作系统。毕竟,开源是建立在其他开源工作基础上的,所以发行版维护者理解依赖*栈*的概念。Linux 上的包管理了解你的整个系统、系统上的库和支持文件以及你安装的应用。这些不同的部分协调工作,为你提供了一套高效、优化和强大的应用。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-package-management
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_gift_giveaway_box_520x292.png?itok=w1YQhNH1 (Gift box opens with colors coming out)
+[2]: http://flathub.org
+[3]: https://opensource.com/article/21/1/text-editor-roundup
+[4]: https://opensource.com/article/20/9/install-packages-ansible
diff --git a/published/202102/20210217 Use this bootable USB drive on Linux to rescue Windows users.md b/published/202102/20210217 Use this bootable USB drive on Linux to rescue Windows users.md
new file mode 100644
index 0000000000..73d93d1246
--- /dev/null
+++ b/published/202102/20210217 Use this bootable USB drive on Linux to rescue Windows users.md
@@ -0,0 +1,82 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13143-1.html)
+[#]: subject: (Use this bootable USB drive on Linux to rescue Windows users)
+[#]: via: (https://opensource.com/article/21/2/linux-woeusb)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+
+如何在 Linux 中创建 USB 启动盘来拯救 Windows 用户
+======
+
+> WoeUSB 可以在 Linux 中制作 Windows 启动盘,并帮助你的朋友解锁他们罢工的机器。
+
+
+
+人们经常要求我帮助他们恢复被锁死或损坏的 Windows 电脑。有时,我可以使用 Linux USB 启动盘来挂载 Windows 分区,然后从损坏的系统中传输和备份文件。
+
+有的时候,客户丢失了他们的密码或以其他方式锁死了他们的登录账户凭证。解锁账户的一种方法是创建一个 Windows 启动盘来修复计算机。微软允许你从网站下载 Windows 的副本,并提供创建 USB 启动盘的工具。但要使用它们,你需要一台 Windows 电脑,这意味着,作为一个 Linux 用户,我需要其他方法来创建一个 DVD 或 USB 启动盘。我发现在 Linux 上创建 Windows USB 很困难。我的可靠工具,如 [Etcher.io][2]、[Popsicle][3](适用于 Pop!_OS)和 [UNetbootin][4],或者从命令行使用 `dd` 来创建可启动媒体,都不是很成功。
+
+直到我发现了 [WoeUSB-ng][5],一个 [GPL 3.0][6] 许可的 Linux 工具,它可以为 Windows Vista、7、8 和 10 创建一个 USB 启动盘。这个开源软件有两个程序:一个命令行工具和一个图形用户界面 (GUI) 版本。
+
+### 安装 WoeUSB-ng
+
+GitHub 仓库包含了在 Arch、Ubuntu、Fedora 或使用 pip3 [安装][7] WoeUSB-ng 的说明。
+
+如果你是受支持的 Linux 发行版,你可以使用你的包管理器安装 WoeUSB-ng。或者,你可以使用 Python 的包管理器 [pip][8] 来安装应用程序。这在任何 Linux 发行版中都是通用的。这些方法在功能上没有区别,所以使用你熟悉的任何一种。
+
+我运行的是 Pop!_OS,它是 Ubuntu 的衍生版本,但由于对 Python 很熟悉,我选择了 pip3 安装:
+
+```
+$ sudo pip3 install WoeUSB-ng
+```
+
+### 创建一个启动盘
+
+你可以从命令行或 GUI 版本使用 WoeUSB-ng。
+
+要从命令行创建一个启动盘,语法要求命令包含 Windows ISO 文件的路径和一个设备。(本例中是 `/dev/sdX`。使用 `lsblk` 命令来确定你的驱动器)
+
+```
+$ sudo woeusb --device Windows.iso /dev/sdX
+```
+
+你也可以启动该程序,以获得简单易用的界面。在 WoeUSB-ng 应用程序窗口中,找到 `Windows.iso` 文件并选择它。选择你的 USB 目标设备(你想变成 Windows 启动盘的驱动器)。这将会删除这个驱动器上的所有信息,所以要谨慎选择,然后仔细检查(再三检查)你的选择!
+
+当你确认正确选择目标驱动器后,点击 **Install** 按钮。
+
+![WoeUSB-ng UI][9]
+
+创建该介质需要 5 到 10 分钟,这取决于你的 Linux 电脑的处理器、内存、USB 端口速度等。请耐心等待。
+
+当这个过程完成并验证后,你将有可用的 Windows USB 启动盘,以帮助其他人修复 Windows 计算机。
+
+### 帮助他人
+
+开源就是为了帮助他人。很多时候,你可以通过使用基于 Linux 的[系统救援 CD][11] 来帮助 Windows 用户。但有时,唯一的帮助方式是直接从 Windows 中获取,而 WoeUSB-ng 是一个很好的开源工具,它可以让这成为可能。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-woeusb
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
+[2]: https://etcher.io/
+[3]: https://github.com/pop-os/popsicle
+[4]: https://github.com/unetbootin/unetbootin
+[5]: https://github.com/WoeUSB/WoeUSB-ng
+[6]: https://github.com/WoeUSB/WoeUSB-ng/blob/master/COPYING
+[7]: https://github.com/WoeUSB/WoeUSB-ng#installation
+[8]: https://opensource.com/downloads/pip-cheat-sheet
+[9]: https://opensource.com/sites/default/files/uploads/woeusb-ng-gui.png (WoeUSB-ng UI)
+[10]: https://creativecommons.org/licenses/by-sa/4.0/
+[11]: https://www.system-rescue.org/
diff --git a/published/202102/20210218 5 must-have Linux media players.md b/published/202102/20210218 5 must-have Linux media players.md
new file mode 100644
index 0000000000..1125465ae2
--- /dev/null
+++ b/published/202102/20210218 5 must-have Linux media players.md
@@ -0,0 +1,90 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13148-1.html)
+[#]: subject: (5 must-have Linux media players)
+[#]: via: (https://opensource.com/article/21/2/linux-media-players)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+5 款值得拥有的 Linux 媒体播放器
+======
+
+> 无论是电影还是音乐,Linux 都能为你提供一些优秀的媒体播放器。
+
+
+
+在 2021 年,人们有更多的理由喜欢 Linux。在这个系列中,我将分享 21 个使用 Linux 的不同理由。媒体播放是我最喜欢使用 Linux 的理由之一。
+
+你可能更喜欢黑胶唱片和卡带,或者录像带和激光影碟,但你很有可能还是在数字设备上播放你喜欢的大部分媒体。电脑上的媒体有一种无法比拟的便利性,这主要是因为我们大多数人一天中的大部分时间都在电脑附近。许多现代电脑用户并没有过多考虑有哪些应用可以用来听音乐和看电影,因为大多数操作系统都默认提供了媒体播放器,或者因为他们订阅了流媒体服务,因此并没有把媒体文件放在自己身边。但如果你的口味超出了通常的热门音乐和节目列表,或者你以媒体工作为乐趣或利润,那么你就会有你想要播放的本地文件。你可能还对现有用户界面有意见。在 Linux 上,*选择*是一种权利,因此你可以选择无数种播放媒体的方式。
+
+以下是我在 Linux 上必备的五个媒体播放器。
+
+### 1、mpv
+
+![mpv interface][2]
+
+一个现代、干净、简约的媒体播放器。得益于它的 Mplayer、[ffmpeg][3] 和 `libmpv` 后端,它可以播放你可能会扔给它的任何类型媒体。我说“扔给它”,是因为播放一个文件的最快捷、最简单的方法就是把文件拖到 mpv 窗口中。如果你拖动多个文件,mpv 会为你创建一个播放列表。
+
+当你把鼠标放在上面时,它提供了直观的覆盖控件,但最好还是通过键盘操作界面。例如,`Alt+1` 会使 mpv 窗口变成全尺寸,而 `Alt+0` 会使其缩小到一半大小。你可以使用 `,` 和 `.` 键逐帧浏览视频,`[` 和 `]` 键调整播放速度,`/` 和 `*` 调整音量,`m` 静音等等。这些主控功能可以让你快速调整,一旦你学会了这些功能,你几乎可以在想到要调整播放的时候快速调整。无论是工作还是娱乐,mpv 都是我播放媒体的首选。
+
+### 2、Kaffeine 和 Rhythmbox
+
+![Kaffeine interface][4]
+
+KDE Plasma 和 GNOME 桌面都提供了音乐应用([Kaffeine][5] 和 [Rhythmbox][]),可以作为你个人音乐库的前端。它们会让你为你的音乐文件提供一个标准的位置,然后扫描你的音乐收藏,这样你就可以根据专辑、艺术家等来浏览。这两款软件都很适合那些你无法完全决定你想听什么,而又想用一种简单的方式来浏览现有音乐的时候。
+
+[Kaffeine][5] 其实不仅仅是一个音乐播放器。它可以播放视频文件、DVD、CD,甚至数字电视(假设你有输入信号)。我已经整整几天没有关闭 Kaffeine 了,因为不管我是想听音乐还是看电影,Kaffeine 都能让我轻松地开始播放。
+
+### 3、Audacious
+
+![Audacious interface][6]
+
+[Audacious][7] 媒体播放器是一个轻量级的应用,它可以播放你的音乐文件(甚至是 MIDI 文件)或来自互联网的流媒体音乐。对我来说,它的主要吸引力在于它的模块化架构,它鼓励开发插件。这些插件可以播放几乎所有你能想到的音频媒体格式,用图形均衡器调整声音,应用效果,甚至可以重塑整个应用,改变其界面。
+
+很难把 Audacious 仅仅看作是一个应用,因为它很容易让它变成你想要的应用。无论你是 Linux 上的 XMMS、Windows 上的 WinAmp,还是任何其他替代品,你大概都可以用 Audacious 来近似它们。Audacious 还提供了一个终端命令,`audtool`,所以你可以从命令行控制一个正在运行的 Audacious 实例,所以它甚至可以近似于一个终端媒体播放器!
+
+### 4、VLC
+
+![vlc interface][8]
+
+[VLC][9] 播放器可能是向用户介绍开源的应用之首。作为一款久经考验的多媒体播放器,VLC 可以播放音乐、视频、光盘。它还可以通过网络摄像头或麦克风进行流式传输和录制,从而使其成为捕获快速视频或语音消息的简便方法。像 mpv 一样,大多数情况下都可以通过按单个字母的键盘操作来控制它,但它也有一个有用的右键菜单。它可以将媒体从一种格式转换为另一种格式、创建播放列表、跟踪你的媒体库等。VLC 是最好的,大多数播放器甚至无法在功能上与之匹敌。无论你在什么平台上,它都是一款必备的应用。
+
+### 5、Music player daemon
+
+![mpd with the ncmpc interface][10]
+
+[music player daemon(mpd)][11] 是一个特别有用的播放器,因为它在服务器上运行。这意味着你可以在 [树莓派][12] 上启动它,然后让它处于空闲状态,这样你就可以在任何时候播放一首曲子。mpd 的客户端有很多,但我用的是 [ncmpc][13]。有了 ncmpc 或像 [netjukebox][14] 这样的 Web 客户端,我可以从本地主机或远程机器上连接 mpd,选择一张专辑,然后从任何地方播放它。
+
+### Linux 上的媒体播放
+
+在 Linux 上播放媒体是很容易的,这要归功于它出色的编解码器支持和惊人的播放器选择。我只提到了我最喜欢的五个播放器,但还有更多的播放器供你探索。试试它们,找到最好的,然后坐下来放松一下。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-media-players
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LIFE_film.png?itok=aElrLLrw (An old-fashioned video camera)
+[2]: https://opensource.com/sites/default/files/mpv_0.png
+[3]: https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats
+[4]: https://opensource.com/sites/default/files/kaffeine.png
+[5]: https://apps.kde.org/en/kaffeine
+[6]: https://opensource.com/sites/default/files/audacious.png
+[7]: https://audacious-media-player.org/
+[8]: https://opensource.com/sites/default/files/vlc_0.png
+[9]: http://videolan.org
+[10]: https://opensource.com/sites/default/files/mpd-ncmpc.png
+[11]: https://www.musicpd.org/
+[12]: https://opensource.com/article/21/1/raspberry-pi-hifi
+[13]: https://www.musicpd.org/clients/ncmpc/
+[14]: http://www.netjukebox.nl/
+[15]: https://wiki.gnome.org/Apps/Rhythmbox
\ No newline at end of file
diff --git a/published/202102/20210219 7 Ways to Customize Cinnamon Desktop in Linux -Beginner-s Guide.md b/published/202102/20210219 7 Ways to Customize Cinnamon Desktop in Linux -Beginner-s Guide.md
new file mode 100644
index 0000000000..5fd5bdcd1a
--- /dev/null
+++ b/published/202102/20210219 7 Ways to Customize Cinnamon Desktop in Linux -Beginner-s Guide.md
@@ -0,0 +1,132 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13145-1.html)
+[#]: subject: (7 Ways to Customize Cinnamon Desktop in Linux [Beginner’s Guide])
+[#]: via: (https://itsfoss.com/customize-cinnamon-desktop/)
+[#]: author: (Dimitrios https://itsfoss.com/author/dimitrios/)
+
+初级:在 Linux 中自定义 Cinnamon 桌面的 7 种方法
+======
+
+
+
+Linux Mint 是最好的 [适合初学者的 Linux 发行版][1] 之一。尤其是想 [转战 Linux][2] 的 Windows 用户,会发现它的 Cinnamon 桌面环境非常熟悉。
+
+Cinnamon 给人一种传统的桌面体验,很多用户喜欢它的样子。这并不意味着你必须满足于它提供的东西。Cinnamon 提供了几种自定义桌面的方式。
+
+在阅读了 [MATE][3] 和 [KDE 自定义][4] 指南后,很多读者要求为 Linux Mint Cinnamon 也提供类似的教程。因此,我创建了这个关于调整 Cinnamon 桌面的外观和感觉的基本指南。
+
+### 7 种自定义 Cinnamon 桌面的不同方法
+
+在本教程中,我使用的是 [Linux Mint Debian Edition][5](LMDE 4)。你可以在任何运行 Cinnamon 的 Linux 发行版上使用这篇文章的方法。如果你不确定,这里有 [如何检查你使用的桌面环境][6]。
+
+当需要改变 Cinnamon 桌面外观时,我发现非常简单,因为只需点击两下即可。如下图所示,点击菜单图标,然后点击“设置”。
+
+![][7]
+
+所有的外观设置都放在该窗口的顶部。在“系统设置”窗口上的一切都显得整齐划一。
+
+![][8]
+
+#### 1、效果
+
+效果选项简单,不言自明,一目了然。你可以开启或关闭桌面不同元素的特效,或者通过改变特效风格来改变窗口过渡。如果你想改变效果的速度,可以通过自定义标签来实现。
+
+![][9]
+
+#### 2、字体选择
+
+在这个部分,你可以区分整个系统中使用的字体大小和类型,通过字体设置,你可以对外观进行微调。
+
+![][10]
+
+#### 3、主题和图标
+
+我曾经做了几年的 Linux Mint 用户,一个原因是你不需要到处去改变你想要的东西。窗口管理器、图标和面板定制都在一个地方!
+
+你可以将面板改成深色或浅色,窗口边框也可以根据你要的而改变。默认的 Cinnamon 外观设置在我眼里是最好的,我甚至在测试 [Ubuntu Cinnamon Remix][11] 时也应用了一模一样的设置,不过是橙色的。
+
+![][12]
+
+#### 4、Cinnamon 小程序
+
+Cinnamon 小程序是所有包含在底部面板的元素,如日历或键盘布局切换器。在管理选项卡中,你可以添加/删除已经安装的小程序。
+
+你一定要探索一下可以下载的小程序,如天气和 [CPU 温度][13]指示小程序是我额外选择的。
+
+![][14]
+
+#### 5、Cinnamon Desklets
+
+Cinnamon Desklets 是可以直接放置在桌面上的应用。和其他所有的自定义选项一样,Desklets 可以从设置菜单中访问,各种各样的选择可以吸引任何人的兴趣。谷歌日历是一个方便的应用,可以直接在桌面上跟踪你的日程安排。
+
+![][15]
+
+#### 6、桌面壁纸
+
+要改变 Cinnamon 桌面的背景,只需在桌面上点击右键,选择“改变桌面背景”。它将打开一个简单易用的窗口,在左侧列出了可用的背景系统文件夹,右侧有每个文件夹内的图片预览。
+
+![][16]
+
+你可以通过点击加号(`+`)并选择路径来添加自己的文件夹。在“设置”选项卡中,你可以选择你的背景是静态还是幻灯片,以及背景在屏幕上的位置。
+
+![][17]
+
+#### 7、自定义桌面屏幕上的内容
+
+背景并不是你唯一可以改变的桌面元素。如果你在桌面上点击右键,然后点击“自定义”,你可以找到更多的选项。
+
+![][18]
+
+你可以改变图标的大小,将摆放方式从垂直改为水平,并改变它们在两个轴上的间距。如果你不喜欢你所做的,点击重置网格间距回到默认值。
+
+![][19]
+
+此外,如果你点击“桌面设置”,将显示更多的选项。你可以禁用桌面上的图标,将它们放在主显示器或副显示器上,甚至两个都可以。如你所见,你可以选择一些图标出现在桌面上。
+
+![][20]
+
+### 总结
+
+Cinnamon 桌面是最好的选择之一,尤其是当你正在 [从 windows 切换到 Linux][21] 的时候,同时对一个简单而优雅的桌面追求者也是如此。
+
+Cinnamon 桌面非常稳定,在我手上从来没有崩溃过,这也是在各种 Linux 发行版之间,我使用它这么久的主要原因之一。
+
+我没有讲得太详细,但给了你足够的指导,让你自己去探索设置。欢迎反馈你对 Cinnamon 的定制。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/customize-cinnamon-desktop/
+
+作者:[Dimitrios][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/dimitrios/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/best-linux-beginners/
+[2]: https://itsfoss.com/reasons-switch-linux-windows-xp/
+[3]: https://itsfoss.com/ubuntu-mate-customization/
+[4]: https://itsfoss.com/kde-customization/
+[5]: https://itsfoss.com/lmde-4-release/
+[6]: https://itsfoss.com/find-desktop-environment/
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/6-Cinnamon-settings.png?resize=800%2C680&ssl=1
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/7-Cinnamon-Settings.png?resize=800%2C630&ssl=1
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/8-cinnamon-effects.png?resize=800%2C630&ssl=1
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/11-font-selection.png?resize=800%2C650&ssl=1
+[11]: https://itsfoss.com/ubuntu-cinnamon-remix-review/
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/10-cinnamon-themes-and-icons.png?resize=800%2C630&ssl=1
+[13]: https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/
+[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/12-cinnamon-applets.png?resize=800%2C630&ssl=1
+[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/13-cinnamon-desklets.png?resize=800%2C630&ssl=1
+[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/1.-Cinnamon-change-desktop-background.png?resize=800%2C400&ssl=1
+[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/2-Cinnamon-change-desktop-background.png?resize=800%2C630&ssl=1
+[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/1.-desktop-additional-customization.png?resize=800%2C400&ssl=1
+[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/4-desktop-additional-customization.png?resize=800%2C480&ssl=1
+[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/5-desktop-additional-customization.png?resize=800%2C630&ssl=1
+[21]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
diff --git a/published/202102/20210219 Unlock your Chromebook-s hidden potential with Linux.md b/published/202102/20210219 Unlock your Chromebook-s hidden potential with Linux.md
new file mode 100644
index 0000000000..7612fa716f
--- /dev/null
+++ b/published/202102/20210219 Unlock your Chromebook-s hidden potential with Linux.md
@@ -0,0 +1,127 @@
+[#]: collector: (lujun9972)
+[#]: translator: (max27149)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13149-1.html)
+[#]: subject: (Unlock your Chromebook's hidden potential with Linux)
+[#]: via: (https://opensource.com/article/21/2/chromebook-linux)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+用 Linux 释放你 Chromebook 的隐藏潜能
+======
+
+> Chromebook 是令人惊叹的工具,但通过解锁它内部的 Linux 系统,你可以让它变得更加不同凡响。
+
+
+
+Google Chromebook 运行在 Linux 系统之上,但通常它运行的 Linux 系统对普通用户而言,并不是十分容易就能访问得到。Linux 被用作基于开源的 [Chromium OS][2] 运行时环境的后端技术,然后 Google 将其转换为 Chrome OS。大多数用户体验到的界面是一个电脑桌面,可以用来运行 Chrome 浏览器及其应用程序。然而,在这一切的背后,有一个 Linux 系统等待被你发现。如果你知道怎么做,你可以在 Chromebook 上启用 Linux,把一台可能价格相对便宜、功能相对基础的电脑变成一个严谨的笔记本,获取数百个应用和你需要的所有能力,使它成为一个通用计算机。
+
+### 什么是 Chromebook?
+
+Chromebook 是专为 Chrome OS 创造的笔记本电脑,它本身专为特定的笔记本电脑型号而设计。Chrome OS 不是像 Linux 或 Windows 这样的通用操作系统,而是与 Android 或 iOS 有更多的共同点。如果你决定购买 Chromebook,你会发现有许多不同制造商的型号,包括惠普、华硕和联想等等。有些是为学生而设计,而另一些是为家庭或商业用户而设计的。主要的区别通常分别集中在电池功率或处理能力上。
+
+无论你决定买哪一款,Chromebook 都会运行 Chrome OS,并为你提供现代计算机所期望的基本功能。有连接到互联网的网络管理器、蓝牙、音量控制、文件管理器、桌面等等。
+
+![Chrome OS desktop][3]
+
+*Chrome OS 桌面截图*
+
+不过,想从这个简单易用的操作系统中获得更多,你只需要激活 Linux。
+
+### 启用 Chromebook 的开发者模式
+
+如果我让你觉得启用 Linux 看似简单,那是因为它确实简单但又有欺骗性。之所以说有欺骗性,是因为在启用 Linux 之前,你*必须*备份数据。
+
+这个过程虽然简单,但它确实会将你的计算机重置回出厂默认状态。你必须重新登录到你的笔记本电脑中,如果你有数据存储在 Google 云盘帐户上,你必须得把它重新同步回计算机中。启用 Linux 还需要为 Linux 预留硬盘空间,因此无论你的 Chromebook 硬盘容量是多少,都将减少一半或四分之一(自主选择)。
+
+在 Chromebook 上接入 Linux 仍被 Google 视为测试版功能,因此你必须选择使用开发者模式。开发者模式的目的是允许软件开发者测试新功能,安装新版本的操作系统等等,但它可以为你解锁仍在开发中的特殊功能。
+
+要启用开发者模式,请首先关闭你的 Chromebook。假定你已经备份了设备上的所有重要信息。
+
+接下来,按下键盘上的 `ESC` 和 `⟳`,再按 **电源键** 启动 Chromebook。
+
+![ESC and refresh buttons][4]
+
+*ESC 键和 ⟳ 键*
+
+当提示开始恢复时,按键盘上的 `Ctrl+D`。
+
+恢复结束后,你的 Chromebook 已重置为出厂设置,且没有默认的使用限制。
+
+### 开机启动进入开发者模式
+
+在开发者模式下运行意味着每次启动 Chromebook 时,都会提醒你处于开发者模式。你可以按 `Ctrl+D` 跳过启动延迟。有些 Chromebook 会在几秒钟后发出蜂鸣声来提醒你处于开发者模式,使得 `Ctrl+D` 操作几乎是强制的。从理论上讲,这个操作很烦人,但在实践中,我不经常启动我的 Chromebook,因为我只是唤醒它,所以当我需要这样做的时候,`Ctrl+D` 只不过是整个启动过程中小小的一步。
+
+启用开发者模式后的第一次启动时,你必须重新设置你的设备,就好像它是全新的一样。你只需要这样做一次(除非你在未来某个时刻停用开发者模式)。
+
+### 启用 Chromebook 上的 Linux
+
+现在,你已经运行在开发者模式下,你可以激活 Chrome OS 中的 **Linux Beta** 功能。要做到这一点,请打开 **设置**,然后单击左侧列表中的 **Linux Beta**。
+
+激活 **Linux Beta**,并为你的 Linux 系统和应用程序分配一些硬盘空间。在最糟糕的时候,Linux 是相当轻量级的,所以你真的不需要分配太多硬盘空间,但它显然取决于你打算用 Linux 来做多少事。4 GB 的空间对于 Linux 以及几百个终端命令还有二十多个图形应用程序是足够的。我的 Chromebook 有一个 64 GB 的存储卡,我给了 Linux 系统 30 GB,那是因为我在 Chromebook 上所做的大部分事情都是在 Linux 内完成的。
+
+一旦你的 **Linux Beta** 环境准备就绪,你可以通过按键盘上的**搜索**按钮和输入 `terminal` 来启动终端。如果你还是 Linux 新手,你可能不知道当前进入的终端能用来安装什么。当然,这取决于你想用 Linux 来做什么。如果你对 Linux 编程感兴趣,那么你可能会从 Bash(它已经在终端中安装和运行了)和 Python 开始。如果你对 Linux 中的那些迷人的开源应用程序感兴趣,你可以试试 GIMP、MyPaint、LibreOffice 或 Inkscape 等等应用程序。
+
+Chrome OS 的 **Linux Beta** 模式不包含图形化的软件安装程序,但 [应用程序可以从终端安装][5]。可以使用 `sudo apt install` 命令安装应用程序。
+
+ * `sudo` 命令可以允许你使用超级管理员权限来执行某些命令(即 Linux 中的 `root`)。
+ * `apt` 命令是一个应用程序的安装工具。
+ * `install` 是命令选项,即告诉 `apt` 命令要做什么。
+
+你还必须把想要安装的软件包的名字和 `apt` 命令写在一起。以安装 LibreOffice 举例:
+
+```
+sudo apt install libreoffice
+```
+当有提示是否继续时,输入 `y`(代表“确认”),然后按 **回车键**。
+
+一旦应用程序安装完毕,你可以像在 Chrome OS 上启动任何应用程序一样启动它:只需要在应用程序启动器输入它的名字。
+
+了解 Linux 应用程序的名字和它的包名需要花一些时间,但你也可以用 `apt search` 命令来搜索。例如,可以用以下的方法是找到关于照片的应用程序:
+
+```
+apt search photo
+```
+
+因为 Linux 中有很多的应用程序,所以你可以找一些感兴趣的东西,然后尝试一下!
+
+### 与 Linux 共享文件和设备
+
+ **Linux Beta** 环境运行在 [容器][7] 中,因此 Chrome OS 需要获得访问 Linux 文件的权限。要授予 Chrome OS 与你在 Linux 上创建的文件的交互权限,请右击要共享的文件夹并选择 **管理 Linux 共享**。
+
+![Chrome OS Manage Linux sharing interface][8]
+
+*Chrome OS 的 Linux 管理共享界面*
+
+你可以通过 Chrome OS 的 **设置** 程序来管理共享设置以及其他设置。
+
+![Chrome OS Settings menu][9]
+
+*Chrome OS 设置菜单*
+
+### 学习 Linux
+
+如果你肯花时间学习 Linux,你不仅能够解锁你 Chromebook 中隐藏的潜力,还能最终学到很多关于计算机的知识。Linux 是一个有价值的工具,一个非常有趣的玩具,一个通往比常规计算更令人兴奋的事物的大门。去了解它吧,你可能会惊讶于你自己和你 Chromebook 的无限潜能。
+
+---
+
+源自: https://opensource.com/article/21/2/chromebook-linux
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[max27149](https://github.com/max27149)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/wfh_work_home_laptop_work.png?itok=VFwToeMy (Working from home at a laptop)
+[2]: https://www.chromium.org/chromium-os
+[3]: https://opensource.com/sites/default/files/chromeos.png
+[4]: https://opensource.com/sites/default/files/esc-refresh.png
+[5]: https://opensource.com/article/18/1/how-install-apps-linux
+[6]: https://opensource.com/tags/linux
+[7]: https://opensource.com/resources/what-are-linux-containers
+[8]: https://opensource.com/sites/default/files/chromeos-manage-linux-sharing.png
+[9]: https://opensource.com/sites/default/files/chromeos-beta-linux.png
diff --git a/published/202102/20210220 Starship- Open-Source Customizable Prompt for Any Shell.md b/published/202102/20210220 Starship- Open-Source Customizable Prompt for Any Shell.md
new file mode 100644
index 0000000000..0f04781757
--- /dev/null
+++ b/published/202102/20210220 Starship- Open-Source Customizable Prompt for Any Shell.md
@@ -0,0 +1,180 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13152-1.html)
+[#]: subject: (Starship: Open-Source Customizable Prompt for Any Shell)
+[#]: via: (https://itsfoss.com/starship/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Starship:跨 shell 的可定制的提示符
+======
+
+
+
+> 如果你很在意你的终端的外观的话,一个跨 shell 的提示符可以让你轻松地定制和配置 Linux 终端提示符。
+
+虽然我已经介绍了一些帮助你 [自定义终端外观][1] 的技巧,但我也发现了一些有趣的跨 shell 提示符的建议。
+
+### Starship:轻松地调整你的 Linux Shell 提示符
+
+![][2]
+
+[Starship][3] 是一个用 [Rust][4] 编写的开源项目,它可以帮助你建立一个精简、快速、可定制的 shell 提示符。
+
+无论你是使用 bash、fish、还是 Windows 上的 PowerShell,抑或其他 shell,你都可以利用Starship 来定制外观。
+
+请注意,你必须了解它的 [官方文档][5] 才能对所有你喜欢的东西进行高级配置,但在这里,我将包括一个简单的示例配置,以有一个良好的开端,以及一些关于 Startship 的关键信息。
+
+Startship 专注于为你提供一个精简的、快速的、有用的默认 shell 提示符。它甚至会记录并显示执行一个命令所需的时间。例如,这里有一张截图:
+
+![][6]
+
+不仅如此,根据自己的喜好定制提示符也相当简单。下面是一张官方 GIF,展示了它的操作:
+
+![][7]
+
+让我帮你设置一下。我是在 Ubuntu 上使用 bash shell 来测试的。你可以参考我提到的步骤,或者你可以看看 [官方安装说明][8],以获得在你的系统上安装它的更多选择。
+
+### Starship 的亮点
+
+ * 跨平台
+ * 跨 shell 支持
+ * 能够添加自定义命令
+ * 定制 git 体验
+ * 定制使用特定编程语言时的体验
+ * 轻松定制提示符的每一个方面,而不会对性能造成实质影响
+
+### 在 Linux 上安装 Starship
+
+> 安装 Starship 需要下载一个 bash 脚本,然后用 root 权限运行该脚本。
+>
+> 如果你不习惯这样做,你可以使用 snap。
+>
+> ```
+> sudo snap install starship
+> ```
+
+**注意**:你需要安装 [Nerd 字体][9] 才能获得完整的体验。
+
+要开始使用,请确保你安装了 [curl][10]。你可以通过键入如下命令来轻松安装它:
+
+```
+sudo apt install curl
+```
+
+完成后,输入以下内容安装 Starship:
+
+```
+curl -fsSL https://starship.rs/install.sh | bash
+```
+
+这应该会以 root 身份将 Starship 安装到 `usr/local/bin`。你可能会被提示输入密码。看起来如下:
+
+![][11]
+
+### 在 bash 中添加 Starship
+
+如截图所示,你会在终端本身得到设置的指令。在这里,我们需要在 `.bashrc` 用户文件的末尾添加以下一行:
+
+```
+eval "$(starship init bash)"
+```
+
+要想轻松添加,只需键入:
+
+```
+nano .bashrc
+```
+
+然后,通过向下滚动导航到文件的末尾,并在文件末尾添加如下图所示的行:
+
+![][12]
+
+完成后,只需重启终端或重启会话即可看到一个精简的提示符。对于你的 shell 来说,它可能看起来有点不同,但默认情况下应该是一样的。
+
+![][13]
+
+设置好后,你就可以继续自定义和配置提示符了。让我给你看一个我做的配置示例:
+
+### 配置 Starship 提示符:基础
+
+开始你只需要在 `.config` 目录下制作一个配置文件([TOML文件][14])。如果你已经有了这个目录,直接导航到该目录并创建配置文件。
+
+下面是创建目录和配置文件时需要输入的内容:
+
+```
+mkdir -p ~/.config && touch ~/.config/starship.toml
+```
+
+请注意,这是一个隐藏目录。所以,当你试图使用文件管理器从主目录访问它时,请确保在继续之前 [启用查看隐藏文件][15]。
+
+接下来如果你想探索一些你喜欢的东西,你应该参考配置文档。
+
+举个例子,我配置了一个简单的自定义提示,看起来像这样:
+
+![][16]
+
+为了实现这个目标,我的配置文件是这样的:
+
+![][17]
+
+根据他们的官方文档,这是一个基本的自定义格式。但是,如果你不想要自定义格式,只是想用一种颜色或不同的符号来自定义默认的提示,那就会像这样:
+
+![][18]
+
+上述定制的配置文件是这样的:
+
+![][19]
+
+当然,这不是我能做出的最好看的提示符,但我希望你能理解其配置方式。
+
+你可以通过包括图标或表情符来定制目录的外观,你可以调整变量、格式化字符串、显示 git 提交,或者根据使用特定编程语言而调整。
+
+不仅如此,你还可以创建在你的 shell 中使用的自定义命令,让事情变得更简单或舒适。
+
+你可以在他们的 [官方网站][3] 和它的 [GitHub 页面][20] 中探索更多的信息。
+
+- [Starship.rs][3]
+
+### 结论
+
+如果你只是想做一些小的调整,这文档可能会太复杂了。但是,即使如此,它也可以让你用很少的努力实现一个自定义的提示符或精简的提示符,你可以应用于任何普通的 shell 和你正在使用的系统。
+
+总的来说,我不认为它非常有用,但有几个读者建议使用它,看来人们确实喜欢它。我很想看看你是如何 [自定义 Linux 终端][1] 以适应不同的使用方式。
+
+欢迎在下面的评论中分享你的看法,如果你喜欢的话。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/starship/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/customize-linux-terminal/
+[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-screenshot.png?resize=800%2C577&ssl=1
+[3]: https://starship.rs/
+[4]: https://www.rust-lang.org/
+[5]: https://starship.rs/config/
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-time.jpg?resize=800%2C281&ssl=1
+[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-demo.gif?resize=800%2C501&ssl=1
+[8]: https://starship.rs/guide/#%F0%9F%9A%80-installation
+[9]: https://www.nerdfonts.com
+[10]: https://curl.se/
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/install-starship.png?resize=800%2C534&ssl=1
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/startship-bashrc-file.png?resize=800%2C545&ssl=1
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-prompt.png?resize=800%2C552&ssl=1
+[14]: https://en.wikipedia.org/wiki/TOML
+[15]: https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
+[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-custom.png?resize=800%2C289&ssl=1
+[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-custom-config.png?resize=800%2C320&ssl=1
+[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-different-symbol.png?resize=800%2C224&ssl=1
+[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-symbol-change.jpg?resize=800%2C167&ssl=1
+[20]: https://github.com/starship/starship
diff --git a/published/202102/20210221 Not Comfortable Using youtube-dl in Terminal- Use These GUI Apps.md b/published/202102/20210221 Not Comfortable Using youtube-dl in Terminal- Use These GUI Apps.md
new file mode 100644
index 0000000000..e41e61a54c
--- /dev/null
+++ b/published/202102/20210221 Not Comfortable Using youtube-dl in Terminal- Use These GUI Apps.md
@@ -0,0 +1,161 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13158-1.html)
+[#]: subject: (Not Comfortable Using youtube-dl in Terminal? Use These GUI Apps)
+[#]: via: (https://itsfoss.com/youtube-dl-gui-apps/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+不习惯在终端使用 youtube-dl?可以使用这些 GUI 应用
+======
+
+
+
+如果你一直在关注我们,可能已经知道 [youtube-dl 项目曾被 GitHub 暂时下架][1] 以合规。但它现在已经恢复并完全可以访问,可以说它并不是一个非法的工具。
+
+它是一个非常有用的命令行工具,可以让你 [从 YouTube][2] 和其他一些网站下载视频。使用 [youtube-dl][3] 并不复杂,但我明白使用命令来完成这种任务并不是每个人都喜欢的方式。
+
+好在有一些应用为 `youtube-dl` 工具提供了 GUI 前端。
+
+### 使用 youtube-dl GUI 应用的先决条件
+
+在你尝试下面提到的一些选择之前,你可能需要在你的系统上安装 `youtube-dl` 和 [FFmpeg][4],才能够下载/选择不同的格式进行下载。
+
+你可以按照我们的 [ffmpeg 使用完整指南][5] 进行设置,并探索更多关于它的内容。
+
+要安装 [youtube-dl][6],你可以在 Linux 终端输入以下命令:
+
+```
+sudo curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dl
+```
+
+下载最新版本后,你只需要输入以下内容使其可执行就可使用:
+
+```
+sudo chmod a+rx /usr/local/bin/youtube-dl
+```
+
+如果你需要其他方法安装它,也可以按照[官方安装说明][7]进行安装。
+
+### Youtube-dl GUI 应用
+
+大多数 Linux 上的下载管理器也允许你从 YouTube 和其他网站下载视频。然而,youtube-dl GUI 应用可能有额外的选项,如只提取音频或下载特定分辨率和视频格式。
+
+请注意,下面的列表没有特别的排名顺序。你可以根据你的要求选择。
+
+#### 1、AllTube Download
+
+![][8]
+
+**主要特点:**
+
+ * Web GUI
+ * 开源
+ * 可以自托管
+
+AllTube 是一个开源的 web GUI,你可以通过 来访问。
+
+如果你选择使用这款软件,你不需要在系统上安装 youtube-dl 或 ffmpeg。它提供了一个简单的用户界面,你只需要粘贴视频的 URL,然后继续选择你喜欢的文件格式下载。你也可以选择将其部署在你的服务器上。
+
+请注意,你不能使用这个工具提取视频的 MP3 文件,它只适用于视频。你可以通过他们的 [GitHub 页面][9]探索更多关于它的信息。
+
+- [AllTube Download Web GUI][10]
+
+#### 2、youtube-dl GUI
+
+![][11]
+
+**主要特点:**
+
+ * 跨平台
+ * 显示预计下载大小
+ * 有音频和视频下载选择
+
+一个使用 electron 和 node.js 制作的有用的跨平台 GUI 应用。你可以很容易地下载音频和视频,以及选择各种可用的文件格式的选项。
+
+如果你愿意的话,你还可以下载一个频道或播放列表的部分内容。特别是当你下载高质量的视频文件时,预计的下载大小绝对是非常方便的。
+
+如上所述,它也适用于 Windows 和 MacOS。而且,你会在它的 [GitHub 发布][12]中得到一个适用于 Linux 的 AppImage 文件。
+
+- [Youtube-dl GUI][13]
+
+#### 3、Videomass
+
+![][14]
+
+**主要特点:**
+
+ * 跨平台
+ * 转换音频/视频格式
+ * 支持多个 URL
+ * 适用于也想使用 FFmpeg 的用户
+
+如果你想从 YouTube 下载视频或音频,并将它们转换为你喜欢的格式,Videomass 可以是一个不错的选择。
+
+要做到这点,你需要在你的系统上同时安装 youtube-dl 和 ffmpeg。你可以轻松的添加多个 URL 来下载,还可以根据自己的喜好设置输出目录。
+
+![][15]
+
+你还可以获得一些高级设置来禁用 youtube-dl,改变文件首选项,以及随着你的探索,还有一些更方便的选项。
+
+它为 Ubuntu 用户提供了一个 PPA,为任何其他 Linux 发行版提供了一个 AppImage 文件。在它的 [Github 页面][16]探索更多信息。
+
+- [Videomass][17]
+
+#### 附送:Haruna Video Player
+
+![][18]
+
+**主要特点:**
+
+ * 播放/流式传输 YouTube 视频
+
+Haruna Video Player 原本是 [MPV][19] 的前端。虽然使用它不能下载 YouTube 视频,但可以通过 youtube-dl 观看/流式传输 YouTube 视频。
+
+你可以在我们的[文章][20]中探索更多关于视频播放器的内容。
+
+### 总结
+
+尽管你可能会在 GitHub 和其他平台上找到更多的 youtube-dl GUI,但它们中的大多数都不能很好地运行,最终会显示出多个错误,或者不再积极开发。
+
+[Tartube][21] 就是这样的一个选择,你可以尝试一下,但可能无法达到预期的效果。我用 Pop!_OS 和 Ubuntu MATE 20.04(全新安装)进行了测试。每次我尝试下载一些东西时,无论我怎么做都会失败(即使系统中安装了 youtube-dl 和 ffmpeg)。
+
+所以,我个人最喜欢的似乎是 Web GUI([AllTube Download][9]),它不依赖于安装在你系统上的任何东西,也可以自托管。
+
+如果我错过了你最喜欢的选择,请在评论中告诉我什么是最适合你的。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/youtube-dl-gui-apps/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/youtube-dl-github-takedown/
+[2]: https://itsfoss.com/download-youtube-videos-ubuntu/
+[3]: https://itsfoss.com/download-youtube-linux/
+[4]: https://ffmpeg.org/
+[5]: https://itsfoss.com/ffmpeg/#install
+[6]: https://youtube-dl.org/
+[7]: https://ytdl-org.github.io/youtube-dl/download.html
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/alltube-download.jpg?resize=772%2C593&ssl=1
+[9]: https://github.com/Rudloff/alltube
+[10]: https://alltubedownload.net/
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/youtube-dl-gui.jpg?resize=800%2C548&ssl=1
+[12]: https://github.com/jely2002/youtube-dl-gui/releases/tag/v1.8.7
+[13]: https://github.com/jely2002/youtube-dl-gui
+[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/videomass.jpg?resize=800%2C537&ssl=1
+[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/videomass-1.jpg?resize=800%2C542&ssl=1
+[16]: https://github.com/jeanslack/Videomass
+[17]: https://jeanslack.github.io/Videomass/
+[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/haruna-video-player-dark.jpg?resize=800%2C512&ssl=1
+[19]: https://mpv.io/
+[20]: https://itsfoss.com/haruna-video-player/
+[21]: https://github.com/axcore/tartube
diff --git a/published/202103/20160921 lawyer The MIT License, Line by Line.md b/published/202103/20160921 lawyer The MIT License, Line by Line.md
new file mode 100644
index 0000000000..8679330528
--- /dev/null
+++ b/published/202103/20160921 lawyer The MIT License, Line by Line.md
@@ -0,0 +1,296 @@
+[#]: collector: (lujun9972)
+[#]: translator: (bestony)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13180-1.html)
+[#]: subject: (lawyer The MIT License, Line by Line)
+[#]: via: (https://writing.kemitchell.com/2016/09/21/MIT-License-Line-by-Line.html)
+[#]: author: (Kyle E. Mitchell https://kemitchell.com/)
+
+逐行解读 MIT 许可证
+======
+
+
+
+> 每个程序员都应该明白的 171 个字。
+
+[MIT 许可证][1] 是世界上最流行的开源软件许可证。以下是它的逐行解读。
+
+### 阅读许可证
+
+如果你参与了开源软件,但还没有花时间从头到尾的阅读过这个许可证(它只有 171 个单词),你需要现在就去读一下。尤其是如果许可证不是你日常每天都会接触的,把任何看起来不对劲或不清楚的地方记下来,然后继续阅读。我会分段、按顺序、加入上下文和注释,把每一个词再重复一遍。但最重要的还是要有个整体概念。
+
+> The MIT License (MIT)
+>
+> Copyright (c) \ \
+>
+> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
+>
+> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
+>
+> *The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the Software.*
+
+(LCTT 译注:MIT 许可证并无官方的中文文本,我们也没找到任何可靠的、精确的非官方中文文本。在本文中,我们仅作为参考目的提供一份逐字逐行而没有经过润色的中文翻译文本,但该文本及对其的理解**不能**作为 MIT 许可证使用,我们也不为此中文翻译文本的使用承担任何责任,这份中文文本,我们贡献给公共领域。)
+
+> MIT 许可证(MIT)
+>
+> 版权 (c) <年份> <版权人>
+>
+> 特此免费授予任何获得本软件副本和相关文档文件(下称“软件”)的人不受限制地处置该软件的权利,包括不受限制地使用、复制、修改、合并、发布、分发、转授许可和/或出售该软件副本,以及再授权被配发了本软件的人如上的权利,须在下列条件下:
+>
+> 上述版权声明和本许可声明应包含在该软件的所有副本或实质成分中。
+>
+> 本软件是“如此”提供的,没有任何形式的明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和不侵权的保证。在任何情况下,作者或版权持有人都不对任何索赔、损害或其他责任负责,无论这些追责来自合同、侵权或其它行为中,还是产生于、源于或有关于本软件以及本软件的使用或其它处置。
+
+该许可证分为五段,按照逻辑划分如下:
+
+ * **头部**
+ * **许可证名称**:“MIT 许可证”
+ * **版权说明**:“版权 (c) …”
+ * **许可证授予**:“特此授予 …”
+ * **授予范围**:“… 处置软件 …”
+ * **条件**:“… 须在 …”
+ * **归因和声明**:“上述 … 应包含在 …”
+ * **免责声明**:“本软件是‘如此’提供的 …”
+ * **责任限制**:“在任何情况下 …”
+
+接下来详细看看。
+
+### 头部
+
+#### 许可证名称
+
+> The MIT License (MIT)
+
+> MIT 许可证(MIT)
+
+“MIT 许可证”不是一个单一的许可证,而是根据麻省理工学院(MIT)为发行版本准备的语言衍生出来一系列许可证形式。多年来,无论是对于使用它的原始项目,还是作为其他项目的范本,它经历了许多变化。Fedora 项目一直保持着 [收藏 MIT 许可证的好奇心][2],以纯文本的方式记录了那些平淡的变化,如同泡在甲醛中的解剖标本一般,追溯了它的各种演变。
+
+幸运的是,[开放源码倡议组织][3](OSI) 和 [软件数据包交换][4]组织(SPDX)已经将一种通用的 MIT 式的许可证形式标准化为“MIT 许可证”。OSI 反过来又采用了 SPDX 通用开源许可证的标准化 [字符串标志符][5],并将其中的 “MIT” 明确指向了标准化形式的“MIT 许可证”。如果你想为一个新项目使用 MIT 式的条款,请使用其 [标准化的形式][1]。
+
+即使你在 `LICENSE` 文件中包含 “The MIT License” 或 “SPDX:MIT”,任何负责的审查者仍会将文本与标准格式进行比较,以确保安全。尽管自称为“MIT 许可证”的各种许可证形式只在细微的细节上有所不同,但所谓的“MIT 许可证”的松散性已经诱使了一些作者加入麻烦的“自定义”。典型的糟糕、不好的、非常坏的例子是 [JSON 许可证][6],一个 MIT 家族的许可证被加上了“本软件应用于善,而非恶”。这件事情可能是“非常克罗克福特”的(LCTT 译者注,Crockford 是 JSON 格式和 JSON.org 的作者)。这绝对是一件麻烦事,也许这个玩笑本来是开在律师身上的,但他们却笑得前仰后合。
+
+这个故事的寓意是:“MIT 许可证”本身就是模棱两可的。大家可能很清楚你的意思,但你只需要把标准的 MIT 许可证文本复制到你的项目中,就可以节省每个人的时间。如果使用元数据(如包管理器中的元数据文件)来指定 “MIT 许可证”,请确保 `LICENSE` 文件和任何头部的注释都使用标准的许可证文本。所有的这些都可以 [自动化完成][7]。
+
+#### 版权声明
+
+> Copyright (c)
+
+> 版权 (c) <年份> <版权持有人>
+
+在 1976 年(美国)《版权法》颁布之前,美国的版权法规要求采取具体的行动,即所谓的“手续”来确保创意作品的版权。如果你不遵守这些手续,你起诉他人未经授权使用你的作品的权力就会受到限制,往往会完全丧失权力,其中一项手续就是“声明”。在你的作品上打上记号,以其他方式让市场知道你拥有版权。“©” 是一个标准符号,用于标记受版权保护的作品,以发出版权声明。ASCII 字符集没有 © 符号,但 `Copyright (c)` 可以表达同样的意思。
+
+1976 年的《版权法》“落实”了国际《伯尔尼公约》的许多要求,取消了确保版权的手续。至少在美国,著作权人在起诉侵权之前,仍然需要对自己的版权作品进行登记,如果在侵权行为开始之前进行登记,可能会获得更高的赔偿。但在实践中,很多人在对某个人提起诉讼之前,都会先注册版权。你并不会因为没有在上面贴上声明、注册它、向国会图书馆寄送副本等而失去版权。
+
+即使版权声明不像过去那样绝对必要,但它们仍然有很多用处。说明作品的创作年份和版权属于谁,可以让人知道作品的版权何时到期,从而使作品纳入公共领域。作者或作者们的身份也很有用。美国法律对个人作者和“公司”作者的版权条款的计算方式不同。特别是在商业用途中,公司在使用已知竞争对手的软件时,可能也要三思而行,即使许可条款给予了非常慷慨的许可。如果你希望别人看到你的作品并想从你这里获得许可,版权声明可以很好地起到归属作用。
+
+至于“版权持有人”。并非所有标准形式的许可证都有写明这一点的空间。最新的许可证形式,如 [Apache 2.0][8] 和 [GPL 3.0][9],发布的许可证文本是要逐字复制的,并在其他地方加上标题注释和单独文件,以表明谁拥有版权并提供许可证。这些办法巧妙地阻止了对“标准”文本的意外或故意的修改。这还使自动许可证识别更加可靠。
+
+MIT 许可证是从为机构发布的代码而写的语言演变而来。对于机构发布的代码,只有一个明确的“版权持有人”,即发布代码的机构。其他机构抄袭了这些许可证,用他们自己的名字代替了 “MIT”,最终形成了我们现在拥有的通用形式。这一过程同样适用于该时代的其他简短的机构许可证,特别是加州大学伯克利分校的最初的 [四条款 BSD 许可证][10] 成为了现在使用的 [三条款][11] 和 [两条款][12] 变体,以及 MIT 许可证的变体互联网系统联盟的 [ISC 许可证][13]。
+
+在每一种情况下,该机构都根据版权所有权规则将自己列为版权持有人,这些规则称为“[雇佣作品][14]”规则,这些规则赋予雇主和客户在其雇员和承包商代表其从事的某些工作中的版权所有权。这些规则通常不适用于自愿提交代码的分布式协作者。这给项目监管型基金会(如 Apache 基金会和 Eclipse 基金会)带来了一个问题,因为它们接受来自更多不同的贡献者的贡献。到目前为止,通常的基础方法是使用一个单一的许可证,它规定了一个版权持有者,如 [Apache 2.0][8] 和 [EPL 1.0][15],并由贡献者许可协议 [Apache CLA][16] 以及 [Eclipse CLA][17] 为后盾,以从贡献者中收集权利。在像 GPL 这样的左版许可证下,将版权所有权收集在一个地方就更加重要了,因为 GPL 依靠版权所有者来执行许可证条件,以促进软件自由的价值。
+
+如今,大量没有机构或商业管理人的项目都在使用 MIT 风格的许可条款。SPDX 和 OSI 通过标准化不涉及特定实体或机构版权持有人的 MIT 和 ISC 之类的许可证形式,为这些用例提供了帮助。有了这些许可证形式,项目作者的普遍做法是在许可证的版权声明中尽早填上自己的名字...也许还会在这里或那里填上年份。至少根据美国的版权法,由此产生的版权声明并不能说明全部情况。
+
+软件的原始所有者保留其工作的所有权。但是,尽管 MIT 风格的许可条款赋予了他人开发和更改软件的权利,创造了法律上所谓的“衍生作品”,但它们并没有赋予原始作者对他人的贡献的所有权。相反,每个贡献者在以现有代码为起点所做的任何作品都拥有版权,[即使是稍做了一点创意][18]。
+
+这些项目大多数也对接受贡献者许可协议(CLA)的想法嗤之以鼻,更不用说签署版权转让协议了。这既幼稚又可以理解。尽管一些较新的开源开发人员认为,在 GitHub 上发送拉取请求,就会“自动”根据项目现有的许可证条款授权分发贡献,但美国法律不承认任何此类规则。强有力的版权保护是默认的,而不是宽松许可。
+
+> 更新:GitHub 后来修改了全站的服务条款,包括试图至少在 GitHub.com 上改变这一默认值。我在 [另一篇文章][19] 中写了一些对这一发展的想法,并非所有想法都是积极的。
+
+为了填补法律上有效的、有据可查的贡献权利授予与完全没有纸质痕迹之间的差距,一些项目采用了 [开发者原创证书][20],这是贡献者在 Git 提交中使用 `Signed-Off-By` 元数据标签暗示的标准声明。开发者原创证书是在臭名昭著的 SCO 诉讼之后为 Linux 内核开发而开发的,该诉讼称 Linux 的大部分代码源自 SCO 拥有的 Unix 源代码。作为创建显示 Linux 的每一行都来自贡献者的书面记录的一种方法,开发者原创证书的功能良好。尽管开发者原创证书不是许可证,但它确实提供了大量证据,证明提交代码的人希望项目分发其代码,并让其他人根据内核现有的许可证条款使用该代码。内核还维护着一个机器可读的 `CREDITS` 文件,其中列出了贡献者的名字、所属机构、贡献领域和其他元数据。我做了 [一些][21] [实验][22],把这种方法改编成适用于不使用内核开发流程的项目。
+
+### 许可证授权
+
+> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”),
+
+> 特此免费授予任何获得本软件副本和相关文档文件(下称“软件”)的人
+
+MIT 许可证的实质是许可证(你猜对了)。一般来说,许可证是一个人或法律实体(“许可人”)给予另一个人(“被许可人”)做一些法律允许他们起诉的事情的许可。MIT 许可证是一种不起诉的承诺。
+
+法律有时将许可证与给予许可证的承诺区分开来。如果有人违背了提供许可证的承诺,你可以起诉他们违背了承诺,但你最终可能得不到许可证。“特此”是律师们永远摆脱不了的一个矫揉造作、老生常谈的词。这里使用它来表明,许可证文本本身提供了许可证,而不仅仅是许可证的承诺。这是一个合法的 [即调函数表达式(IIFE)][23]。
+
+尽管许多许可证都是授予特定的、指定的被许可人的,但 MIT 许可证是一个“公共许可证”。公共许可证授予所有人(整个公众)许可。这是开源许可中的三大理念之一。MIT 许可证通过“向任何获得……软件副本的人”授予许可证来体现这一思想。稍后我们将看到,获得此许可证还有一个条件,以确保其他人也可以了解他们的许可。
+
+在美国式法律文件中,括号中带引号的首字母大写词汇是赋予术语特定含义的标准方式(“定义”)。当法庭看到文件中其他地方使用了一个已定义的大写术语时,法庭会可靠地回顾定义中的术语。
+
+#### 授权范围
+
+> to deal in the Software without restriction,
+
+> 不受限制地处置该软件的权利,
+
+从被许可人的角度来看,这是 MIT 许可证中最重要的七个字。主要的法律问题就是因侵犯版权而被起诉,和因侵犯专利而被起诉。无论是版权法还是专利法都没有将 “处置” 作为一个术语,它在法庭上没有特定的含义。因此,任何法庭在裁决许可人和被许可人之间的纠纷时,都会询问当事人对这一措辞的含义和理解。法庭将看到的是,该措辞有意宽泛和开放。它为被许可人提供了一个强有力的论据,反对许可人提出的任何主张 —— 即他们不允许被许可人使用该软件做那件特定的事情,即使在授予许可证时双方都没有明显想到。
+
+> including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,
+
+> 包括不受限制地使用、复制、修改、合并、发布、分发、转授许可和/或出售该软件副本,以及再授权被配发了本软件的人如上的权利,
+
+没有一篇法律是完美的、“意义上完全确定”、或明确无误的。小心那些假装不然的人。这是 MIT 许可证中最不完美的部分。主要有三个问题:
+
+首先,“包括不受限制地”是一种法律反模式。它有多种衍生:
+
+ * 包括,但不受限制
+ * 包括,但不限于前述的一般性
+ * 包括,但不限于
+ * 很多、很多毫无意义的变化
+
+所有这些都有一个共同的目标,但都未能可靠地实现。从根本上说,使用它们的起草者也会尽量试探着去做。在 MIT 许可证中,这意味着引入“处置软件”的具体例子 — “使用、复制、修改”等等,但不意味着被许可方的行为必须与给出的例子类似,才能算作“处置”。问题是,如果你最终需要法庭来审查和解释许可证的条款,法庭将把它的工作看作是找出这些语言的含义。如果法庭需要决定“处置”的含义,它不能“无视”这些例子,即使你告诉它。我认为,“不受限制地处置本软件”本身对被许可人更好,也更短。
+
+其次,作为“处置”的例子的那些动词是一个大杂烩。有些在版权法或专利法下有特定的含义,有些稍微有或根本没有含义:
+
+ * “使用”出现在 [《美国法典》第 35 篇,第 271(a)节][24],这是专利法中专利权人可以起诉他人未经许可的行为的清单。
+ * “复制”出现在 [《美国法典》第 17 篇,第 106 节][25],即版权法列出的版权所有人可以起诉他人未经许可的行为。
+ * “修改”既不出现在版权法中,也不出现在专利法中。它可能最接近版权法下的“准备衍生作品”,但也可能涉及改进或其他衍生发明。
+ * 无论是在版权法还是专利法中,“合并”都没有出现。“合并”在版权方面有特定的含义,但这显然不是这里的意图。相反,法庭可能会根据其在行业中的含义来解读“合并”,如“合并代码”。
+ * 无论是在版权法还是专利法中,都没有“发布”。由于“软件”是被发布的内容,根据《[版权法][25]》,它可能最接近于“分发”。该法令还包括“公开”表演和展示作品的权利,但这些权利只适用于特定类型的受版权保护的作品,如戏剧、录音和电影。
+ * “分发”出现在《[版权法][25]》中。
+ * “转授许可”是知识产权法中的一个总称。转授许可的权利是指把自己的许可证授予他人,有权进行你所许可的部分或全部活动。实际上,MIT 许可证的转授许可的权利在开源代码许可证中并不常见。通常的做法是 Heather Meeker 所说的“直接许可”方式,在这种方法中,每个获得该软件及其许可证条款副本的人都直接从所有者那里获得授权。任何可能根据 MIT 许可证获得转授许可的人都可能会得到一份许可证副本,告诉他们其也有直接许可证。
+ * “出售副本”是个混杂品。它接近于《[专利法][24]》中的“要约出售”和“出售”,但指的是“副本”,这是一种版权概念。在版权方面,它似乎接近于“分发”,但《[版权法][25]》没有提到销售。
+ * “允许被配发了本软件的人这样做”似乎是多余的“转授许可”。这也是不必要的,因为获得副本的人也可以直接获得许可证。
+
+最后,由于这种法律、行业、一般知识产权和一般使用条款的混杂,并不清楚 MIT 许可证是否包括专利许可。一般性语言“处置”和一些例子动词,尤其是“使用”,指向了一个专利许可,尽管是一个非常不明确的许可。许可证来自于版权持有人,而版权持有人可能对软件中的发明拥有或不拥有专利权,以及大多数的例子动词和“软件”本身的定义,都强烈地指向版权许可证。诸如 [Apache 2.0][8] 之类的较新的宽容开源许可分别具体地处理了版权、专利甚至商标问题。
+
+#### 三个许可条件
+
+> subject to the following conditions:
+
+> 须在下列条件下:
+
+总有一个陷阱!MIT 许可证有三个!
+
+如果你不遵守 MIT 许可证的条件,你就得不到许可证提供的许可。因此,如果不能履行条件,至少从理论上说,会让你面临一场诉讼,很可能是一场版权诉讼。
+
+开源软件的第二个伟大思想是,利用软件对被许可人的价值来激励被许可人遵守条件,即使被许可人没有支付任何许可费用。最后一个伟大思想,在 MIT 许可证中没有,它构建了许可证条件:像 [GNU 通用公共许可证][9](GPL)这样的左版许可证,使用许可证条件来控制如何对修改后的版本进行许可和发布。
+
+#### 声明条件
+
+> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
+
+> 上述版权声明和本许可声明应包含在该软件的所有副本或实质成分中。
+
+如果你给别人一份软件的副本,你需要包括许可证文本和任何版权声明。这有几个关键目的:
+
+ 1. 给别人一个声明,说明他们有权使用该公共许可证下的软件。这是直接授权模式的一个关键部分,在这种模式下,每个用户直接从版权持有人那里获得许可证。
+ 2. 让人们知道谁是软件的幕后人物,这样他们就可以得到赞美、荣耀和冷冰冰的现金捐赠。
+ 3. 确保保修免责声明和责任限制(在后面)伴随该软件。每个得到该副本的人也应该得到一份这些许可人保护的副本。
+
+没有什么可以阻止你对提供一个副本、甚至是一个没有源代码的编译形式的副本而收费。但是当你这么做的时候,你不能假装 MIT 代码是你自己的专有代码,也不能在其他许可证下提供。接受的人要知道自己在“公共许可证”下的权利。
+
+坦率地说,遵守这个条件正在崩溃。几乎所有的开源许可证都有这样的“归因”条件。系统和装机软件的制作者往往明白,他们需要为自己的每一个发行版本编制一个声明文件或“许可证信息”屏,并附上库和组件的许可证文本副本。项目监管型基金会在教授这些做法方面起到了重要作用。但是整个 Web 开发者群体还没有取得这种经验。这不能用缺乏工具来解释,工具有很多,也不能用 npm 和其他资源库中的包的高度模块化来解释,它们统一了许可证信息的元数据格式。所有好的 JavaScript 压缩器都有保存许可证标题注释的命令行标志。其他工具可以从包树中串联 `LICENSE` 文件。这实在是没有借口。
+
+#### 免责声明
+
+> The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement.
+
+> 本软件是“如此”提供的,没有任何形式的明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和不侵权的保证。
+
+美国几乎每个州都颁布了一个版本的《统一商业法典》(UCC),这是一部规范商业交易的示范性法律。UCC 的第 2 条(加利福尼亚州的“第 2 部分”)规定了商品销售合同,包括了从二手汽车的购买到向制造厂运送大量工业化学品。
+
+UCC 关于销售合同的某些规则是强制性的。这些规则始终适用,无论买卖双方是否喜欢。其他只是“默认”。除非买卖双方以书面形式选择不适用这些默认,否则 UCC 潜在视作他们希望在 UCC 文本中找到交易的基准规则。默认规则中包括隐含的“免责”,或卖方对买方关于所售商品的质量和可用性的承诺。
+
+关于诸如 MIT 许可证之类的公共许可证是合同(许可方和被许可方之间的可执行协议)还是仅仅是许可证(单向的,但可能有附加条件),这在理论上存在很大争议。关于软件是否被视为“商品”,从而触发 UCC 规则的争论较少。许可人之间没有就赔偿责任进行辩论:如果他们免费提供的软件出现故障、导致问题、无法正常工作或以其他方式引起麻烦,他们不想被起诉和被要求巨额赔偿。这与“默示保证”的三个默认规则完全相反:
+
+ 1. 据 [UCC 第 2-314 节][26],“适销性”的默示保证是一种承诺:“商品”(即软件)的质量至少为平均水平,并经过适当包装和标记,并适用于其常规用途。仅当提供该软件的人是该软件的“商人”时,此保证才适用,这意味着他们从事软件交易,并表现出对软件的熟练程度。
+ 2. 据 [UCC 第 2-315 节][27],当卖方知道买方依靠他们提供用于特定目的的货物时,“适用于某一特定目的”的默示保证就会生效。商品实际上需要“适用”这一目的。
+ 3. “非侵权”的默示保证不是 UCC 的一部分,而是一般合同法的共同特征。如果事实证明买方收到的商品侵犯了他人的知识产权,则这种默示的承诺将保护买方。如果根据 MIT 许可证获得的软件实际上并不属于尝试许可该软件的许可人,或者属于他人拥有的专利,那就属于这种情况。
+
+UCC 的 [第2-316(3)节][28] 要求,选择不适用或“排除”适销性和适用于某一特定目的的默示保证措辞必须醒目。“醒目”意味着书面化或格式化,以引起人们的注意,这与旨在从不小心的消费者身边溜走的细小字体相反。各州法律可以对不侵权的免责声明提出类似的引人注目的要求。
+
+长期以来,律师们都有一种错觉,认为用“全大写”写任何东西都符合明显的要求。这是不正确的。法庭曾批评律师协会自以为是,而且大多数人都认为,全大写更多的是阻止阅读,而不是强制阅读。同样的,大多数开源许可证的形式都将其免责声明设置为全大写,部分原因是这是在纯文本的 `LICENSE` 文件中唯一明显的方式。我更喜欢使用星号或其他 ASCII 艺术,但那是很久很久以前的事了。
+
+#### 责任限制
+
+> In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the Software or the use or other dealings in the Software.
+
+> 在任何情况下,作者或版权持有人都不对任何索赔、损害或其他责任负责,无论这些追责来自合同、侵权或其它行为中,还是产生于、源于或有关于本软件以及本软件的使用或其它处置。
+
+MIT 许可证授予软件“免费”许可,但法律并不认为接受免费许可证的人在出错时放弃了起诉的权利,而许可人应该受到责备。“责任限制”,通常与“损害赔偿排除”条款搭配使用,其作用与许可证很像,是不起诉的承诺。但这些都是保护许可人免受被许可人起诉的保护措施。
+
+一般来说,法庭对责任限制和损害赔偿排除条款的解读非常谨慎,因为这些条款可以将大量的风险从一方转移到另一方。为了保护社会的切身利益,让民众有办法纠正在法庭上所犯的错误,他们“严格地”用措辞限制责任,尽可能地对受其保护的一方进行解读。责任限制必须具体才能成立。特别是在“消费者”合同和其他放弃起诉权的人缺乏成熟度或讨价还价能力的情况下,法庭有时会拒绝尊重那些似乎被埋没在视线之外的措辞。部分是出于这个原因,部分是出于习惯,律师们往往也会给责任限制以全大写处理。
+
+再往下看,“责任限制”部分是对被许可人可以起诉的金额上限。在开源许可证中,这个上限总是没有钱,0 元,“不承担责任”。相比之下,在商业许可证中,它通常是过去 12 个月内支付的许可证费用的倍数,尽管它通常是经过谈判的。
+
+“排除”部分具体列出了各种法律主张,即请求赔偿的理由,许可人不能使用。像许多其他法律形式一样,MIT 许可证 提到了“违约”行为(即违反合同)和“侵权”行为。侵权规则是防止粗心或恶意伤害他人的一般规则。如果你在发短信时在路上撞倒了人,你就犯了侵权行为。如果你的公司销售的有问题的耳机会烧伤人们的耳朵,则说明贵公司已经侵权。如果合同没有明确排除侵权索赔,那么法庭有时会在合同中使用排除措辞以防止合同索赔。出于很好的考虑,MIT 许可证抛出“或其它”字样,只是为了截住奇怪的海事法或其它异国情调的法律主张。
+
+“产生于、源于或有关于”这句话是法律起草人固有的、焦虑的不安全感反复出现的症状。关键是,任何与软件有关的诉讼都被这些限制和排除范围所覆盖。万一某些事情可以“产生于”,但不能“源于”或“有关于”,那就最好把这三者都写在里面,所以要把它们打包在一起。更不用说,任何被迫在这部分内容中斤斤计较的法庭将不得不为每个词提出不同的含义,前提是专业的起草者不会在一行中使用不同的词来表示同一件事。更不用说,在实践中,如果法庭对一开始就不利的限制感觉不好,那么他们会更愿意狭隘地解读范围触发器。但我离题了,同样的语言出现在数以百万计的合同中。
+
+### 总结
+
+所有这些诡辩都有点像在进教堂的路上吐口香糖。MIT 许可证是一个法律经典,且有效。它绝不是解决所有软件知识产权弊病的灵丹妙药,尤其是它比已经出现的软件专利灾难还要早几十年。但 MIT 风格的许可证发挥了令人钦佩的作用,实现了一个狭隘的目的,用最少的、谨慎的法律工具组合扭转了版权、销售和合同法等棘手的默认规则。在计算机技术的大背景下,它的寿命是惊人的。MIT 许可证已经超过、并将要超过绝大多数软件许可证。我们只能猜测,当它最终失去青睐时,它能提供多少年的忠实法律服务。对于那些无法提供自己的律师的人来说,这尤其慷慨。
+
+我们已经看到,我们今天所知道的 MIT 许可证是如何成为一套具体的、标准化的条款,使机构特有的、杂乱无章的变化终于有了秩序。
+
+我们已经看到了它对归因和版权声明的处理方法如何为学术、标准、商业和基金会机构的知识产权管理实践提供信息。
+
+我们已经看到了 MIT 许可证是如何运行所有人免费试用软件的,但前提是要保护许可人不受担保和责任的影响。
+
+我们已经看到,尽管有一些生硬的措辞和律师的矫揉造作,但一百七十一个小词可以完成大量的法律工作,为开源软件在知识产权和合同的密集丛林中开辟一条道路。
+
+我非常感谢所有花时间阅读这篇相当长的文章的人,让我知道他们发现它很有用,并帮助改进它。一如既往,我欢迎你通过 [e-mail][29]、[Twitter][30] 和 [GitHub][31] 发表评论。
+
+---
+
+有很多人问,他们在哪里可以读到更多的东西,或者找到其他许可证,比如 GNU 通用公共许可证或 Apache 2.0 许可证。无论你的兴趣是什么,我都会向你推荐以下书籍:
+
+ * Andrew M. St. Laurent 的 [Understanding Open Source & Free Software Licensing][32],来自 O’Reilly。
+ > 我先说这本,因为虽然它有些过时,但它的方法也最接近上面使用的逐行方法。O'Reilly 已经把它[放在网上][33]。
+ * Heather Meeker 的 [Open (Source) for Business][34]
+ > 在我看来,这是迄今为止关于 GNU 通用公共许可证和更广泛的左版的最佳著作。这本书涵盖了历史、许可证、它们的发展,以及兼容性和合规性。这本书是我给那些考虑或处理 GPL 的客户的书。
+ * Larry Rosen 的 [Open Source Licensing][35],来自 Prentice Hall。
+ > 一本很棒的入门书,也可以免费 [在线阅读][36]。对于从零开始的程序员来说,这是开源许可和相关法律的最好介绍。这本在一些具体细节上也有点过时了,但 Larry 的许可证分类法和对开源商业模式的简洁总结经得起时间的考验。
+
+所有这些都对我作为一个开源许可律师的教育至关重要。它们的作者都是我的职业英雄。请读一读吧 — K.E.M
+
+我将此文章基于 [Creative Commons Attribution-ShareAlike 4.0 license][37] 授权
+
+--------------------------------------------------------------------------------
+
+via: https://writing.kemitchell.com/2016/09/21/MIT-License-Line-by-Line.html
+
+作者:[Kyle E. Mitchell][a]
+选题:[lujun9972][b]
+译者:[bestony](https://github.com/bestony)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://kemitchell.com/
+[b]: https://github.com/lujun9972
+[1]: http://spdx.org/licenses/MIT
+[2]: https://fedoraproject.org/wiki/Licensing:MIT?rd=Licensing/MIT
+[3]: https://opensource.org
+[4]: https://spdx.org
+[5]: http://spdx.org/licenses/
+[6]: https://spdx.org/licenses/JSON
+[7]: https://www.npmjs.com/package/licensor
+[8]: https://www.apache.org/licenses/LICENSE-2.0
+[9]: https://www.gnu.org/licenses/gpl-3.0.en.html
+[10]: http://spdx.org/licenses/BSD-4-Clause
+[11]: https://spdx.org/licenses/BSD-3-Clause
+[12]: https://spdx.org/licenses/BSD-2-Clause
+[13]: http://www.isc.org/downloads/software-support-policy/isc-license/
+[14]: http://worksmadeforhire.com/
+[15]: https://www.eclipse.org/legal/epl-v10.html
+[16]: https://www.apache.org/licenses/#clas
+[17]: https://wiki.eclipse.org/ECA
+[18]: https://en.wikipedia.org/wiki/Feist_Publications,_Inc.,_v._Rural_Telephone_Service_Co.
+[19]: https://writing.kemitchell.com/2017/02/16/Against-Legislating-the-Nonobvious.html
+[20]: http://developercertificate.org/
+[21]: https://github.com/berneout/berneout-pledge
+[22]: https://github.com/berneout/authors-certificate
+[23]: https://en.wikipedia.org/wiki/Immediately-invoked_function_expression
+[24]: https://www.govinfo.gov/app/details/USCODE-2017-title35/USCODE-2017-title35-partIII-chap28-sec271
+[25]: https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106
+[26]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2314.&lawCode=COM
+[27]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2315.&lawCode=COM
+[28]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2316.&lawCode=COM
+[29]: mailto:kyle@kemitchell.com
+[30]: https://twitter.com/kemitchell
+[31]: https://github.com/kemitchell/writing/tree/master/_posts/2016-09-21-MIT-License-Line-by-Line.md
+[32]: https://lccn.loc.gov/2006281092
+[33]: http://www.oreilly.com/openbook/osfreesoft/book/
+[34]: https://www.amazon.com/dp/1511617772
+[35]: https://lccn.loc.gov/2004050558
+[36]: http://www.rosenlaw.com/oslbook.htm
+[37]: https://creativecommons.org/licenses/by-sa/4.0/legalcode
\ No newline at end of file
diff --git a/published/202103/20190221 Testing Bash with BATS.md b/published/202103/20190221 Testing Bash with BATS.md
new file mode 100644
index 0000000000..f41ea939b7
--- /dev/null
+++ b/published/202103/20190221 Testing Bash with BATS.md
@@ -0,0 +1,262 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13194-1.html)
+[#]: subject: (Testing Bash with BATS)
+[#]: via: (https://opensource.com/article/19/2/testing-bash-bats)
+[#]: author: (Darin London https://opensource.com/users/dmlond)
+
+利用 BATS 测试 Bash 脚本和库
+======
+
+> Bash 自动测试系统可以使 Bash 代码也通过 Java、Ruby 和 Python 开发人员所使用的同类测试过程。
+
+
+
+用 Java、Ruby 和 Python 等语言编写应用程序的软件开发人员拥有复杂的库,可以帮助他们随着时间的推移保持软件的完整性。他们可以创建测试,以在结构化环境中通过执行一系列动作来运行应用程序,以确保其软件所有的方面均按预期工作。
+
+当这些测试在持续集成(CI)系统中自动进行时,它们的功能就更加强大了,每次推送到源代码库都会触发测试,并且在测试失败时会立即通知开发人员。这种快速反馈提高了开发人员对其应用程序功能完整性的信心。
+
+Bash 自动测试系统([BATS][1])使编写 Bash 脚本和库的开发人员能够将 Java、Ruby、Python 和其他开发人员所使用的相同惯例应用于其 Bash 代码中。
+
+### 安装 BATS
+
+BATS GitHub 页面包含了安装指令。有两个 BATS 辅助库提供更强大的断言或允许覆写 BATS 使用的 Test Anything Protocol([TAP][2])输出格式。这些库可以安装在一个标准位置,并被所有的脚本引用。更方便的做法是,将 BATS 及其辅助库的完整版本包含在 Git 仓库中,用于要测试的每组脚本或库。这可以通过 [git 子模块][3] 系统来完成。
+
+以下命令会将 BATS 及其辅助库安装到 Git 知识库中的 `test` 目录中。
+
+```
+git submodule init
+git submodule add https://github.com/sstephenson/bats test/libs/bats
+git submodule add https://github.com/ztombol/bats-assert test/libs/bats-assert
+git submodule add https://github.com/ztombol/bats-support test/libs/bats-support
+git add .
+git commit -m 'installed bats'
+```
+
+要克隆 Git 仓库并同时安装其子模块,请在 `git clone` 时使用
+`--recurse-submodules` 标记。
+
+每个 BATS 测试脚本必须由 `bats` 可执行文件执行。如果你将 BATS 安装到源代码仓库的 `test/libs` 目录中,则可以使用以下命令调用测试:
+
+```
+./test/libs/bats/bin/bats <测试脚本的路径>
+```
+
+或者,将以下内容添加到每个 BATS 测试脚本的开头:
+
+```
+#!/usr/bin/env ./test/libs/bats/bin/bats
+load 'libs/bats-support/load'
+load 'libs/bats-assert/load'
+```
+
+并且执行命令 `chmod +x <测试脚本的路径>`。 这将 a、使它们可与安装在 `./test/libs/bats` 中的 BATS 一同执行,并且 b、包含这些辅助库。BATS 测试脚本通常存储在 `test` 目录中,并以要测试的脚本命名,扩展名为 `.bats`。例如,一个测试 `bin/build` 的 BATS 脚本应称为 `test/build.bats`。
+
+你还可以通过向 BATS 传递正则表达式来运行一整套 BATS 测试文件,例如 `./test/lib/bats/bin/bats test/*.bats`。
+
+### 为 BATS 覆盖率而组织库和脚本
+
+Bash 脚本和库必须以一种有效地方式将其内部工作原理暴露给 BATS 进行组织。通常,在调用或执行时库函数和运行诸多命令的 Shell 脚本不适合进行有效的 BATS 测试。
+
+例如,[build.sh][4] 是许多人都会编写的典型脚本。本质上是一大堆代码。有些人甚至可能将这堆代码放入库中的函数中。但是,在 BATS 测试中运行一大堆代码,并在单独的测试用例中覆盖它可能遇到的所有故障类型是不可能的。测试这堆代码并有足够的覆盖率的唯一方法就是把它分解成许多小的、可重用的、最重要的是可独立测试的函数。
+
+向库添加更多的函数很简单。额外的好处是其中一些函数本身可以变得出奇的有用。将库函数分解为许多较小的函数后,你可以在 BATS 测试中援引这些库,并像测试任何其他命令一样运行这些函数。
+
+Bash 脚本也必须分解为多个函数,执行脚本时,脚本的主要部分应调用这些函数。此外,还有一个非常有用的技巧,可以让你更容易地用 BATS 测试 Bash 脚本:将脚本主要部分中执行的所有代码都移到一个函数中,称为 `run_main`。然后,将以下内容添加到脚本的末尾:
+
+```
+if [[ "${BASH_SOURCE[0]}" == "${0}" ]]
+then
+ run_main
+fi
+```
+
+这段额外的代码做了一些特别的事情。它使脚本在作为脚本执行时与使用援引进入环境时的行为有所不同。通过援引并测试单个函数,这个技巧使得脚本的测试方式和库的测试方式变得一样。例如,[这是重构的 build.sh,以获得更好的 BATS 可测试性][5]。
+
+### 编写和运行测试
+
+如上所述,BATS 是一个 TAP 兼容的测试框架,其语法和输出对于使用过其他 TAP 兼容测试套件(例如 JUnit、RSpec 或 Jest)的用户来说将是熟悉的。它的测试被组织成单个测试脚本。测试脚本被组织成一个或多个描述性 `@test` 块中,它们描述了被测试应用程序的单元。每个 `@test` 块将运行一系列命令,这些命令准备测试环境、运行要测试的命令,并对被测试命令的退出和输出进行断言。许多断言函数是通过 `bats`、`bats-assert` 和 `bats-support` 库导入的,这些库在 BATS 测试脚本的开头加载到环境中。下面是一个典型的 BATS 测试块:
+
+```
+@test "requires CI_COMMIT_REF_SLUG environment variable" {
+ unset CI_COMMIT_REF_SLUG
+ assert_empty "${CI_COMMIT_REF_SLUG}"
+ run some_command
+ assert_failure
+ assert_output --partial "CI_COMMIT_REF_SLUG"
+}
+```
+
+如果 BATS 脚本包含 `setup`(安装)和/或 `teardown`(拆卸) 函数,则 BATS 将在每个测试块运行之前和之后自动执行它们。这样就可以创建环境变量、测试文件以及执行一个或所有测试所需的其他操作,然后在每次测试运行后将其拆卸。[Build.bats][6] 是对我们新格式化的 `build.sh` 脚本的完整 BATS 测试。(此测试中的 `mock_docker` 命令将在以下关于模拟/打标的部分中进行说明。)
+
+当测试脚本运行时,BATS 使用 `exec`(执行)来将每个 `@test` 块作为单独的子进程运行。这样就可以在一个 `@test` 中导出环境变量甚至函数,而不会影响其他 `@test` 或污染你当前的 Shell 会话。测试运行的输出是一种标准格式,可以被人理解,并且可以由 TAP 使用端以编程方式进行解析或操作。下面是 `CI_COMMIT_REF_SLUG` 测试块失败时的输出示例:
+
+```
+ ✗ requires CI_COMMIT_REF_SLUG environment variable
+ (from function `assert_output' in file test/libs/bats-assert/src/assert.bash, line 231,
+ in test file test/ci_deploy.bats, line 26)
+ `assert_output --partial "CI_COMMIT_REF_SLUG"' failed
+
+ -- output does not contain substring --
+ substring (1 lines):
+ CI_COMMIT_REF_SLUG
+ output (3 lines):
+ ./bin/deploy.sh: join_string_by: command not found
+ oc error
+ Could not login
+ --
+
+ ** Did not delete , as test failed **
+
+1 test, 1 failure
+```
+
+下面是成功测试的输出:
+
+```
+✓ requires CI_COMMIT_REF_SLUG environment variable
+```
+
+### 辅助库
+
+像任何 Shell 脚本或库一样,BATS 测试脚本可以包括辅助库,以在测试之间共享通用代码或增强其性能。这些辅助库,例如 `bats-assert` 和 `bats-support` 甚至可以使用 BATS 进行测试。
+
+库可以和 BATS 脚本放在同一个测试目录下,如果测试目录下的文件数量过多,也可以放在 `test/libs` 目录下。BATS 提供了 `load` 函数,该函数接受一个相对于要测试的脚本的 Bash 文件的路径(例如,在我们的示例中的 `test`),并援引该文件。文件必须以后缀 `.bash` 结尾,但是传递给 `load` 函数的文件路径不能包含后缀。`build.bats` 加载 `bats-assert` 和 `bats-support` 库、一个小型 [helpers.bash][7] 库以及 `docker_mock.bash` 库(如下所述),以下代码位于测试脚本的开头,解释器魔力行下方:
+
+```
+load 'libs/bats-support/load'
+load 'libs/bats-assert/load'
+load 'helpers'
+load 'docker_mock'
+```
+
+### 打标测试输入和模拟外部调用
+
+大多数 Bash 脚本和库运行时都会执行函数和/或可执行文件。通常,它们被编程为基于这些函数或可执行文件的输出状态或输出(`stdout`、`stderr`)以特定方式运行。为了正确地测试这些脚本,通常需要制作这些命令的伪版本,这些命令被设计成在特定测试过程中以特定方式运行,称为“打标”。可能还需要监视正在测试的程序,以确保其调用了特定命令,或者使用特定参数调用了特定命令,此过程称为“模拟”。有关更多信息,请查看在 Ruby RSpec 中 [有关模拟和打标的讨论][8],它适用于任何测试系统。
+
+Bash shell 提供了一些技巧,可以在你的 BATS 测试脚本中使用这些技巧进行模拟和打标。所有这些都需要使用带有 `-f` 标志的 Bash `export` 命令来导出一个覆盖了原始函数或可执行文件的函数。必须在测试程序执行之前完成此操作。下面是重写可执行命令 `cat` 的简单示例:
+
+```
+function cat() { echo "THIS WOULD CAT ${*}" }
+export -f cat
+```
+
+此方法以相同的方式覆盖了函数。如果一个测试需要覆盖要测试的脚本或库中的函数,则在对函数进行打标或模拟之前,必须先声明已测试脚本或库,这一点很重要。否则,在声明脚本时,打标/模拟将被原函数替代。另外,在运行即将进行的测试命令之前确认打标/模拟。下面是`build.bats` 的示例,该示例模拟 `build.sh` 中描述的`raise` 函数,以确保登录函数会引发特定的错误消息:
+
+```
+@test ".login raises on oc error" {
+ source ${profile_script}
+ function raise() { echo "${1} raised"; }
+ export -f raise
+ run login
+ assert_failure
+ assert_output -p "Could not login raised"
+}
+```
+
+一般情况下,没有必要在测试后复原打标/模拟的函数,因为 `export`(输出)仅在当前 `@test` 块的 `exec`(执行)期间影响当前子进程。但是,可以模拟/打标 BATS `assert` 函数在内部使用的命令(例如 `cat`、`sed` 等)是可能的。在运行这些断言命令之前,必须对这些模拟/打标函数进行 `unset`(复原),否则它们将无法正常工作。下面是 `build.bats` 中的一个示例,该示例模拟 `sed`,运行 `build_deployable` 函数并在运行任何断言之前复原 `sed`:
+
+```
+@test ".build_deployable prints information, runs docker build on a modified Dockerfile.production and publish_image when its not a dry_run" {
+ local expected_dockerfile='Dockerfile.production'
+ local application='application'
+ local environment='environment'
+ local expected_original_base_image="${application}"
+ local expected_candidate_image="${application}-candidate:${environment}"
+ local expected_deployable_image="${application}:${environment}"
+ source ${profile_script}
+ mock_docker build --build-arg OAUTH_CLIENT_ID --build-arg OAUTH_REDIRECT --build-arg DDS_API_BASE_URL -t "${expected_deployable_image}" -
+ function publish_image() { echo "publish_image ${*}"; }
+ export -f publish_image
+ function sed() {
+ echo "sed ${*}" >&2;
+ echo "FROM application-candidate:environment";
+ }
+ export -f sed
+ run build_deployable "${application}" "${environment}"
+ assert_success
+ unset sed
+ assert_output --regexp "sed.*${expected_dockerfile}"
+ assert_output -p "Building ${expected_original_base_image} deployable ${expected_deployable_image} FROM ${expected_candidate_image}"
+ assert_output -p "FROM ${expected_candidate_image} piped"
+ assert_output -p "build --build-arg OAUTH_CLIENT_ID --build-arg OAUTH_REDIRECT --build-arg DDS_API_BASE_URL -t ${expected_deployable_image} -"
+ assert_output -p "publish_image ${expected_deployable_image}"
+}
+```
+
+有的时候相同的命令,例如 `foo`,将在被测试的同一函数中使用不同的参数多次调用。这些情况需要创建一组函数:
+
+ * `mock_foo`:将期望的参数作为输入,并将其持久化到 TMP 文件中
+ * `foo`:命令的模拟版本,该命令使用持久化的预期参数列表处理每个调用。必须使用 `export -f` 将其导出。
+ * `cleanup_foo`:删除 TMP 文件,用于拆卸函数。这可以进行测试以确保在删除之前成功完成 `@test` 块。
+
+由于此功能通常在不同的测试中重复使用,因此创建一个可以像其他库一样加载的辅助库会变得有意义。
+
+[docker_mock.bash][9] 是一个很棒的例子。它被加载到 `build.bats` 中,并在任何测试调用 Docker 可执行文件的函数的测试块中使用。使用 `docker_mock` 典型的测试块如下所示:
+
+```
+@test ".publish_image fails if docker push fails" {
+ setup_publish
+ local expected_image="image"
+ local expected_publishable_image="${CI_REGISTRY_IMAGE}/${expected_image}"
+ source ${profile_script}
+ mock_docker tag "${expected_image}" "${expected_publishable_image}"
+ mock_docker push "${expected_publishable_image}" and_fail
+ run publish_image "${expected_image}"
+ assert_failure
+ assert_output -p "tagging ${expected_image} as ${expected_publishable_image}"
+ assert_output -p "tag ${expected_image} ${expected_publishable_image}"
+ assert_output -p "pushing image to gitlab registry"
+ assert_output -p "push ${expected_publishable_image}"
+}
+```
+
+该测试建立了一个使用不同的参数两次调用 Docker 的预期。在对Docker 的第二次调用失败时,它会运行测试命令,然后测试退出状态和对 Docker 调用的预期。
+
+一方面 BATS 利用 `mock_docker.bash` 引入 `${BATS_TMPDIR}` 环境变量,BATS 在测试开始的位置对其进行了设置,以允许测试和辅助程序在标准位置创建和销毁 TMP 文件。如果测试失败,`mock_docker.bash` 库不会删除其持久化的模拟文件,但会打印出其所在位置,以便可以查看和删除它。你可能需要定期从该目录中清除旧的模拟文件。
+
+关于模拟/打标的一个注意事项:`build.bats` 测试有意识地违反了关于测试声明的规定:[不要模拟没有拥有的!][10] 该规定要求调用开发人员没有编写代码的测试命令,例如 `docker`、`cat`、`sed` 等,应封装在自己的库中,应在使用它们脚本的测试中对其进行模拟。然后应该在不模拟外部命令的情况下测试封装库。
+
+这是一个很好的建议,而忽略它是有代价的。如果 Docker CLI API 发生变化,则测试脚本不会检测到此变化,从而导致错误内容直到经过测试的 `build.sh` 脚本在使用新版本 Docker 的生产环境中运行后才显示出来。测试开发人员必须确定要严格遵守此标准的程度,但是他们应该了解其所涉及的权衡。
+
+### 总结
+
+在任何软件开发项目中引入测试制度,都会在以下两方面产生权衡: a、增加开发和维护代码及测试所需的时间和组织,b、增加开发人员在对应用程序整个生命周期中完整性的信心。测试制度可能不适用于所有脚本和库。
+
+通常,满足以下一个或多个条件的脚本和库才可以使用 BATS 测试:
+
+ * 值得存储在源代码管理中
+ * 用于关键流程中,并依靠它们长期稳定运行
+ * 需要定期对其进行修改以添加/删除/修改其功能
+ * 可以被其他人使用
+
+一旦决定将测试规则应用于一个或多个 Bash 脚本或库,BATS 就提供其他软件开发环境中可用的全面测试功能。
+
+致谢:感谢 [Darrin Mann][11] 向我引荐了 BATS 测试。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/testing-bash-bats
+
+作者:[Darin London][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dmlond
+[b]: https://github.com/lujun9972
+[1]: https://github.com/sstephenson/bats
+[2]: http://testanything.org/
+[3]: https://git-scm.com/book/en/v2/Git-Tools-Submodules
+[4]: https://github.com/dmlond/how_to_bats/blob/preBats/build.sh
+[5]: https://github.com/dmlond/how_to_bats/blob/master/bin/build.sh
+[6]: https://github.com/dmlond/how_to_bats/blob/master/test/build.bats
+[7]: https://github.com/dmlond/how_to_bats/blob/master/test/helpers.bash
+[8]: https://www.codewithjason.com/rspec-mocks-stubs-plain-english/
+[9]: https://github.com/dmlond/how_to_bats/blob/master/test/docker_mock.bash
+[10]: https://github.com/testdouble/contributing-tests/wiki/Don't-mock-what-you-don't-own
+[11]: https://github.com/dmann
diff --git a/published/202103/20190730 Using Python to explore Google-s Natural Language API.md b/published/202103/20190730 Using Python to explore Google-s Natural Language API.md
new file mode 100644
index 0000000000..5141eae275
--- /dev/null
+++ b/published/202103/20190730 Using Python to explore Google-s Natural Language API.md
@@ -0,0 +1,299 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13233-1.html)
+[#]: subject: (Using Python to explore Google's Natural Language API)
+[#]: via: (https://opensource.com/article/19/7/python-google-natural-language-api)
+[#]: author: (JR Oakes https://opensource.com/users/jroakes)
+
+利用 Python 探究 Google 的自然语言 API
+======
+
+> Google API 可以凸显出有关 Google 如何对网站进行分类的线索,以及如何调整内容以改进搜索结果的方法。
+
+
+
+作为一名技术性的搜索引擎优化人员,我一直在寻找以新颖的方式使用数据的方法,以更好地了解 Google 如何对网站进行排名。我最近研究了 Google 的 [自然语言 API][2] 能否更好地揭示 Google 是如何分类网站内容的。
+
+尽管有 [开源 NLP 工具][3],但我想探索谷歌的工具,前提是它可能在其他产品中使用同样的技术,比如搜索。本文介绍了 Google 的自然语言 API,并探究了常见的自然语言处理(NLP)任务,以及如何使用它们来为网站内容创建提供信息。
+
+### 了解数据类型
+
+首先,了解 Google 自然语言 API 返回的数据类型非常重要。
+
+#### 实体
+
+实体是可以与物理世界中的某些事物联系在一起的文本短语。命名实体识别(NER)是 NLP 的难点,因为工具通常需要查看关键字的完整上下文才能理解其用法。例如,同形异义字拼写相同,但是具有多种含义。句子中的 “lead” 是指一种金属:“铅”(名词),使某人移动:“牵领”(动词),还可能是剧本中的主要角色(也是名词)?Google 有 12 种不同类型的实体,还有第 13 个名为 “UNKNOWN”(未知)的统称类别。一些实体与维基百科的文章相关,这表明 [知识图谱][4] 对数据的影响。每个实体都会返回一个显著性分数,即其与所提供文本的整体相关性。
+
+![实体][5]
+
+#### 情感
+
+情感,即对某事的看法或态度,是在文件和句子层面以及文件中发现的单个实体上进行衡量。情感的得分范围从 -1.0(消极)到 1.0(积极)。幅度代表情感的非归一化强度;它的范围是 0.0 到无穷大。
+
+![情感][6]
+
+#### 语法
+
+语法解析包含了大多数在较好的库中常见的 NLP 活动,例如 [词形演变][7]、[词性标记][8] 和 [依赖树解析][9]。NLP 主要处理帮助机器理解文本和关键字之间的关系。语法解析是大多数语言处理或理解任务的基础部分。
+
+![语法][10]
+
+#### 分类
+
+分类是将整个给定内容分配给特定行业或主题类别,其置信度得分从 0.0 到 1.0。这些分类似乎与其他 Google 工具使用的受众群体和网站类别相同,如 AdWords。
+
+![分类][11]
+
+### 提取数据
+
+现在,我将提取一些示例数据进行处理。我使用 Google 的 [搜索控制台 API][12] 收集了一些搜索查询及其相应的网址。Google 搜索控制台是一个报告人们使用 Google Search 查找网站页面的术语的工具。这个 [开源的 Jupyter 笔记本][13] 可以让你提取有关网站的类似数据。在此示例中,我在 2019 年 1 月 1 日至 6 月 1 日期间生成的一个网站(我没有提及名字)上提取了 Google 搜索控制台数据,并将其限制为至少获得一次点击(而不只是曝光)的查询。
+
+该数据集包含 2969 个页面和在 Google Search 的结果中显示了该网站网页的 7144 条查询的信息。下表显示,绝大多数页面获得的点击很少,因为该网站侧重于所谓的长尾(越特殊通常就更长尾)而不是短尾(非常笼统,搜索量更大)搜索查询。
+
+![所有页面的点击次数柱状图][14]
+
+为了减少数据集的大小并仅获得效果最好的页面,我将数据集限制为在此期间至少获得 20 次曝光的页面。这是精炼数据集的按页点击的柱状图,其中包括 723 个页面:
+
+![部分网页的点击次数柱状图][15]
+
+### 在 Python 中使用 Google 自然语言 API 库
+
+要测试 API,在 Python 中创建一个利用 [google-cloud-language][16] 库的小脚本。以下代码基于 Python 3.5+。
+
+首先,激活一个新的虚拟环境并安装库。用环境的唯一名称替换 `` 。
+
+```
+virtualenv
+source /bin/activate
+pip install --upgrade google-cloud-language
+pip install --upgrade requests
+```
+
+该脚本从 URL 提取 HTML,并将 HTML 提供给自然语言 API。返回一个包含 `sentiment`、 `entities` 和 `categories` 的字典,其中这些键的值都是列表。我使用 Jupyter 笔记本运行此代码,因为使用同一内核注释和重试代码更加容易。
+
+```
+# Import needed libraries
+import requests
+import json
+
+from google.cloud import language
+from google.oauth2 import service_account
+from google.cloud.language import enums
+from google.cloud.language import types
+
+# Build language API client (requires service account key)
+client = language.LanguageServiceClient.from_service_account_json('services.json')
+
+# Define functions
+def pull_googlenlp(client, url, invalid_types = ['OTHER'], **data):
+
+ html = load_text_from_url(url, **data)
+
+ if not html:
+ return None
+
+ document = types.Document(
+ content=html,
+ type=language.enums.Document.Type.HTML )
+
+ features = {'extract_syntax': True,
+ 'extract_entities': True,
+ 'extract_document_sentiment': True,
+ 'extract_entity_sentiment': True,
+ 'classify_text': False
+ }
+
+ response = client.annotate_text(document=document, features=features)
+ sentiment = response.document_sentiment
+ entities = response.entities
+
+ response = client.classify_text(document)
+ categories = response.categories
+
+ def get_type(type):
+ return client.enums.Entity.Type(entity.type).name
+
+ result = {}
+
+ result['sentiment'] = []
+ result['entities'] = []
+ result['categories'] = []
+
+ if sentiment:
+ result['sentiment'] = [{ 'magnitude': sentiment.magnitude, 'score':sentiment.score }]
+
+ for entity in entities:
+ if get_type(entity.type) not in invalid_types:
+ result['entities'].append({'name': entity.name, 'type': get_type(entity.type), 'salience': entity.salience, 'wikipedia_url': entity.metadata.get('wikipedia_url', '-') })
+
+ for category in categories:
+ result['categories'].append({'name':category.name, 'confidence': category.confidence})
+
+
+ return result
+
+
+def load_text_from_url(url, **data):
+
+ timeout = data.get('timeout', 20)
+
+ results = []
+
+ try:
+
+ print("Extracting text from: {}".format(url))
+ response = requests.get(url, timeout=timeout)
+
+ text = response.text
+ status = response.status_code
+
+ if status == 200 and len(text) > 0:
+ return text
+
+ return None
+
+
+ except Exception as e:
+ print('Problem with url: {0}.'.format(url))
+ return None
+```
+
+要访问该 API,请按照 Google 的 [快速入门说明][17] 在 Google 云主控台中创建一个项目,启用该 API 并下载服务帐户密钥。之后,你应该拥有一个类似于以下内容的 JSON 文件:
+
+![services.json 文件][18]
+
+命名为 `services.json`,并上传到项目文件夹。
+
+然后,你可以通过运行以下程序来提取任何 URL(例如 Opensource.com)的 API 数据:
+
+```
+url = "https://opensource.com/article/19/6/how-ssh-running-container"
+pull_googlenlp(client,url)
+```
+
+如果设置正确,你将看到以下输出:
+
+![拉取 API 数据的输出][19]
+
+为了使入门更加容易,我创建了一个 [Jupyter 笔记本][20],你可以下载并使用它来测试提取网页的实体、类别和情感。我更喜欢使用 [JupyterLab][21],它是 Jupyter 笔记本的扩展,其中包括文件查看器和其他增强的用户体验功能。如果你不熟悉这些工具,我认为利用 [Anaconda][22] 是开始使用 Python 和 Jupyter 的最简单途径。它使安装和设置 Python 以及常用库变得非常容易,尤其是在 Windows 上。
+
+### 处理数据
+
+使用这些函数,可抓取给定页面的 HTML 并将其传递给自然语言 API,我可以对 723 个 URL 进行一些分析。首先,我将通过查看所有页面中返回的顶级分类的数量来查看与网站相关的分类。
+
+#### 分类
+
+![来自示例站点的分类数据][23]
+
+这似乎是该特定站点的关键主题的相当准确的代表。通过查看一个效果最好的页面进行排名的单个查询,我可以比较同一查询在 Google 搜索结果中的其他排名页面。
+
+ * URL 1 |顶级类别:/法律和政府/与法律相关的(0.5099999904632568)共 1 个类别。
+ * 未返回任何类别。
+ * URL 3 |顶级类别:/互联网与电信/移动与无线(0.6100000143051147)共 1 个类别。
+ * URL 4 |顶级类别:/计算机与电子产品/软件(0.5799999833106995)共有 2 个类别。
+ * URL 5 |顶级类别:/互联网与电信/移动与无线/移动应用程序和附件(0.75)共有 1 个类别。
+ * 未返回任何类别。
+ * URL 7 |顶级类别:/计算机与电子/软件/商业与生产力软件(0.7099999785423279)共 2 个类别。
+ * URL 8 |顶级类别:/法律和政府/与法律相关的(0.8999999761581421)共 3 个类别。
+ * URL 9 |顶级类别:/参考/一般参考/类型指南和模板(0.6399999856948853)共有 1 个类别。
+ * 未返回任何类别。
+
+上方括号中的数字表示 Google 对页面内容与该分类相关的置信度。对于相同分类,第八个结果比第一个结果具有更高的置信度,因此,这似乎不是定义排名相关性的灵丹妙药。此外,分类太宽泛导致无法满足特定搜索主题的需要。
+
+通过排名查看平均置信度,这两个指标之间似乎没有相关性,至少对于此数据集而言如此:
+
+![平均置信度排名分布图][24]
+
+这两种方法对网站进行规模审查是有意义的,以确保内容类别易于理解,并且样板或销售内容不会使你的页面与你的主要专业知识领域无关。想一想,如果你出售工业用品,但是你的页面返回 “Marketing(销售)” 作为主要分类。似乎没有一个强烈的迹象表明,分类相关性与你的排名有什么关系,至少在页面级别如此。
+
+#### 情感
+
+我不会在情感上花很多时间。在所有从 API 返回情感的页面中,它们分为两个区间:0.1 和 0.2,这几乎是中立的情感。根据直方图,很容易看出情感没有太大价值。对于新闻或舆论网站而言,测量特定页面的情感到中位数排名之间的相关性将是一个更加有趣的指标。
+
+![独特页面的情感柱状图][25]
+
+#### 实体
+
+在我看来,实体是 API 中最有趣的部分。这是在所有页面中按显著性(或与页面的相关性)选择的顶级实体。请注意,对于相同的术语(销售清单),Google 会推断出不同的类型,可能是错误的。这是由于这些术语出现在内容中的不同上下文中引起的。
+
+![示例网站的顶级实体][26]
+
+然后,我分别查看了每个实体类型,并一起查看了该实体的显著性与页面的最佳排名位置之间是否存在任何关联。对于每种类型,我匹配了与该类型匹配的顶级实体的显著性(与页面的整体相关性),按显著性排序(降序)。
+
+有些实体类型在所有示例中返回的显著性为零,因此我从下面的图表中省略了这些结果。
+
+![显著性与最佳排名位置的相关性][27]
+
+“Consumer Good(消费性商品)” 实体类型具有最高的正相关性,皮尔森相关度为 0.15854,尽管由于较低编号的排名更好,所以 “Person” 实体的结果最好,相关度为 -0.15483。这是一个非常小的样本集,尤其是对于单个实体类型,我不能对数据做太多的判断。我没有发现任何具有强相关性的值,但是 “Person” 实体最有意义。网站通常都有关于其首席执行官和其他主要雇员的页面,这些页面很可能在这些查询的搜索结果方面做得好。
+
+继续,当从整体上看站点,根据实体名称和实体类型,出现了以下主题。
+
+![基于实体名称和实体类型的主题][28]
+
+我模糊了几个看起来过于具体的结果,以掩盖网站的身份。从主题上讲,名称信息是在你(或竞争对手)的网站上局部查看其核心主题的一种好方法。这样做仅基于示例网站的排名网址,而不是基于所有网站的可能网址(因为 Search Console 数据仅记录 Google 中展示的页面),但是结果会很有趣,尤其是当你使用像 [Ahrefs][29] 之类的工具提取一个网站的主要排名 URL,该工具会跟踪许多查询以及这些查询的 Google 搜索结果。
+
+实体数据中另一个有趣的部分是标记为 “CONSUMER_GOOD” 的实体倾向于 “看起来” 像我在看到 “知识结果”的结果,即页面右侧的 Google 搜索结果。
+
+![Google 搜索结果][30]
+
+在我们的数据集中具有三个或三个以上关键字的 “Consumer Good(消费性商品)” 实体名称中,有 5.8% 的知识结果与 Google 对该实体命名的结果相同。这意味着,如果你在 Google 中搜索术语或短语,则右侧的框(例如,上面显示 Linux 的知识结果)将显示在搜索结果页面中。由于 Google 会 “挑选” 代表实体的示例网页,因此这是一个很好的机会,可以在搜索结果中识别出具有唯一特征的机会。同样有趣的是,5.8% 的在 Google 中显示这些知识结果名称中,没有一个实体的维基百科 URL 从自然语言 API 中返回。这很有趣,值得进行额外的分析。这将是非常有用的,特别是对于传统的全球排名跟踪工具(如 Ahrefs)数据库中没有的更深奥的主题。
+
+如前所述,知识结果对于那些希望自己的内容在 Google 中被收录的网站所有者来说是非常重要的,因为它们在桌面搜索中加强高亮显示。假设,它们也很可能与 Google [Discover][31] 的知识库主题保持一致,这是一款适用于 Android 和 iOS 的产品,它试图根据用户感兴趣但没有明确搜索的主题为用户浮现内容。
+
+### 总结
+
+本文介绍了 Google 的自然语言 API,分享了一些代码,并研究了此 API 对网站所有者可能有用的方式。关键要点是:
+
+ * 学习使用 Python 和 Jupyter 笔记本可以为你的数据收集任务打开到一个由令人难以置信的聪明和有才华的人建立的不可思议的 API 和开源项目(如 Pandas 和 NumPy)的世界。
+ * Python 允许我为了一个特定目的快速提取和测试有关 API 值的假设。
+ * 通过 Google 的分类 API 传递网站页面可能是一项很好的检查,以确保其内容分解成正确的主题分类。对于竞争对手的网站执行此操作还可以提供有关在何处进行调整或创建内容的指导。
+ * 对于示例网站,Google 的情感评分似乎并不是一个有趣的指标,但是对于新闻或基于意见的网站,它可能是一个有趣的指标。
+ * Google 发现的实体从整体上提供了更细化的网站的主题级别视图,并且像分类一样,在竞争性内容分析中使用将非常有趣。
+ * 实体可以帮助定义机会,使你的内容可以与搜索结果或 Google Discover 结果中的 Google 知识块保持一致。我们将 5.8% 的结果设置为更长的(字计数)“Consumer Goods(消费商品)” 实体,显示这些结果,对于某些网站来说,可能有机会更好地优化这些实体的页面显著性分数,从而有更好的机会在 Google 搜索结果或 Google Discovers 建议中抓住这个重要作用的位置。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/python-google-natural-language-api
+
+作者:[JR Oakes][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jroakes
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_issue_bug_programming.png?itok=XPrh7fa0 (magnifying glass on computer screen)
+[2]: https://cloud.google.com/natural-language/#natural-language-api-demo
+[3]: https://opensource.com/article/19/3/natural-language-processing-tools
+[4]: https://en.wikipedia.org/wiki/Knowledge_Graph
+[5]: https://opensource.com/sites/default/files/uploads/entities.png (Entities)
+[6]: https://opensource.com/sites/default/files/uploads/sentiment.png (Sentiment)
+[7]: https://en.wikipedia.org/wiki/Lemmatisation
+[8]: https://en.wikipedia.org/wiki/Part-of-speech_tagging
+[9]: https://en.wikipedia.org/wiki/Parse_tree#Dependency-based_parse_trees
+[10]: https://opensource.com/sites/default/files/uploads/syntax.png (Syntax)
+[11]: https://opensource.com/sites/default/files/uploads/categories.png (Categories)
+[12]: https://developers.google.com/webmaster-tools/
+[13]: https://github.com/MLTSEO/MLTS/blob/master/Demos.ipynb
+[14]: https://opensource.com/sites/default/files/uploads/histogram_1.png (Histogram of clicks for all pages)
+[15]: https://opensource.com/sites/default/files/uploads/histogram_2.png (Histogram of clicks for subset of pages)
+[16]: https://pypi.org/project/google-cloud-language/
+[17]: https://cloud.google.com/natural-language/docs/quickstart
+[18]: https://opensource.com/sites/default/files/uploads/json_file.png (services.json file)
+[19]: https://opensource.com/sites/default/files/uploads/output.png (Output from pulling API data)
+[20]: https://github.com/MLTSEO/MLTS/blob/master/Tutorials/Google_Language_API_Intro.ipynb
+[21]: https://github.com/jupyterlab/jupyterlab
+[22]: https://www.anaconda.com/distribution/
+[23]: https://opensource.com/sites/default/files/uploads/categories_2.png (Categories data from example site)
+[24]: https://opensource.com/sites/default/files/uploads/plot.png (Plot of average confidence by ranking position )
+[25]: https://opensource.com/sites/default/files/uploads/histogram_3.png (Histogram of sentiment for unique pages)
+[26]: https://opensource.com/sites/default/files/uploads/entities_2.png (Top entities for example site)
+[27]: https://opensource.com/sites/default/files/uploads/salience_plots.png (Correlation between salience and best ranking position)
+[28]: https://opensource.com/sites/default/files/uploads/themes.png (Themes based on entity name and entity type)
+[29]: https://ahrefs.com/
+[30]: https://opensource.com/sites/default/files/uploads/googleresults.png (Google search results)
+[31]: https://www.blog.google/products/search/introducing-google-discover/
diff --git a/published/202103/20200122 9 favorite open source tools for Node.js developers.md b/published/202103/20200122 9 favorite open source tools for Node.js developers.md
new file mode 100644
index 0000000000..361c8a87d4
--- /dev/null
+++ b/published/202103/20200122 9 favorite open source tools for Node.js developers.md
@@ -0,0 +1,232 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13206-1.html)
+[#]: subject: (9 favorite open source tools for Node.js developers)
+[#]: via: (https://opensource.com/article/20/1/open-source-tools-nodejs)
+[#]: author: (Hiren Dhadhuk https://opensource.com/users/hirendhadhuk)
+
+9 个 Node.js 开发人员最喜欢的开源工具
+======
+
+> 在众多可用于简化 Node.js 开发的工具中,以下 9 种是最佳选择。
+
+
+
+我最近在 [StackOverflow][2] 上读到了一项调查,该调查称超过 49% 的开发人员在其项目中使用了 Node.js。这结果对我来说并不意外。
+
+作为一个狂热的技术使用者,我可以肯定地说 Node.js 的引入引领了软件开发的新时代。现在,它是软件开发最受欢迎的技术之一,仅次于JavaScript。
+
+### Node.js 是什么,为什么如此受欢迎?
+
+Node.js 是一个跨平台的开源运行环境,用于在浏览器之外执行 JavaScript 代码。它也是建立在 Chrome 的 JavaScript 运行时之上的首选运行时环境,主要用于构建快速、可扩展和高效的网络应用程序。
+
+我记得当时我们要花费几个小时来协调前端和后端开发人员,他们分别编写不同脚本。当 Node.js 出现后,所有这些都改变了。我相信,促使开发人员采用这项技术是因为它的双向效率。
+
+使用 Node.js,你可以让你的代码同时运行在客户端和服务器端,从而加快了整个开发过程。Node.js 弥合了前端和后端开发之间的差距,并使开发过程更加高效。
+
+### Node.js 工具浪潮
+
+对于 49% 的开发人员(包括我)来说,Node.js 处于在前端和后端开发的金字塔顶端。有大量的 [Node.js 用例][3] 帮助我和我的团队在截止日期之内交付复杂的项目。幸运的是,Node.js 的日益普及也产生了一系列开源项目和工具,以帮助开发人员使用该环境。
+
+近来,对使用 Node.js 构建的项目的需求突然增加。有时,我发现管理这些项目,并同时保持交付高质量项目的步伐非常具有挑战性。因此,我决定使用为 Node.js 开发人员提供的许多开源工具中一些最高效的,使某些方面的开发自动化。
+
+根据我在 Node.js 方面的丰富经验,我使用了许多的工具,这些工具对整个开发过程都非常有帮助:从简化编码过程,到监测再到内容管理。
+
+为了帮助我的 Node.js 开发同道,我整理了这个列表,其中包括我最喜欢的 9 个简化 Node.js 开发的开源工具。
+
+### Webpack
+
+[Webpack][4] 是一个容易使用的 JavaScript 模块捆绑程序,用于简化前端开发。它会检测具有依赖的模块,并将其转换为描述模块的静态素材。
+
+可以通过软件包管理器 npm 或 Yarn 安装该工具。
+
+利用 npm 命令安装如下:
+
+```
+npm install --save-dev webpack
+```
+
+利用 Yarn 命令安装如下:
+
+```
+yarn add webpack --dev
+```
+
+Webpack 可以创建在运行时异步加载的单个捆绑包或多个素材链。不必单独加载。使用 Webpack 工具可以快速高效地打包这些素材并提供服务,从而改善用户整体体验,并减少开发人员在管理加载时间方面的困难。
+
+### Strapi
+
+[Strapi][5] 是一个开源的无界面内容管理系统(CMS)。无界面 CMS 是一种基础软件,可以管理内容而无需预先构建好的前端。它是一个使用 RESTful API 函数的只有后端的系统。
+
+可以通过软件包管理器 Yarn 或 npx 安装 Strapi。
+
+利用 Yarn 命令安装如下:
+
+```
+yarn create strapi-app my-project --quickstart
+```
+
+利用 npx 命令安装如下:
+
+```
+npx create-strapi-app my-project --quickstart
+```
+
+Strapi 的目标是在任何设备上以结构化的方式获取和交付内容。CMS 可以使你轻松管理应用程序的内容,并确保它们是动态的,可以在任何设备上访问。
+
+它提供了许多功能,包括文件上传、内置的电子邮件系统、JSON Web Token(JWT)验证和自动生成文档。我发现它非常方便,因为它简化了整个 CMS,并为我提供了编辑、创建或删除所有类型内容的完全自主权。
+
+另外,通过 Strapi 构建的内容结构非常灵活,因为你可以创建和重用内容组和可定制的 API。
+
+### Broccoli
+
+[Broccoli][6] 是一个功能强大的构建工具,运行在 [ES6][7] 模块上。构建工具是一种软件,可让你将应用程序或网站中的所有各种素材(例如图像、CSS、JavaScript 等)组合成一种可分发的格式。Broccoli 将自己称为 “雄心勃勃的应用程序的素材管道”。
+
+使用 Broccoli 你需要一个项目目录。有了项目目录后,可以使用以下命令通过 npm 安装 Broccoli:
+
+```
+npm install --save-dev broccoli
+npm install --global broccoli-cli
+```
+
+你也可以使用 Yarn 进行安装。
+
+当前版本的 Node.js 就是使用该工具的最佳版本,因为它提供了长期支持。它可以帮助你避免进行更新和重新安装过程中的麻烦。安装过程完成后,可以在 `Brocfile.js` 文件中包含构建规范。
+
+在 Broccoli 中,抽象单位是“树”,该树将文件和子目录存储在特定子目录中。因此,在构建之前,你必须有一个具体的想法,你希望你的构建是什么样子的。
+
+最好的是,Broccoli 带有用于开发的内置服务器,可让你将素材托管在本地 HTTP 服务器上。Broccoli 非常适合流线型重建,因为其简洁的架构和灵活的生态系统可提高重建和编译速度。Broccoli 可让你井井有条,以节省时间并在开发过程中最大限度地提高生产力。
+
+### Danger
+
+[Danger][8] 是一个非常方便的开源工具,用于简化你的拉取请求(PR)检查。正如 Danger 库描述所说,该工具可通过管理 PR 检查来帮助 “正规化” 你的代码审查系统。Danger 可以与你的 CI 集成在一起,帮助你加快审核过程。
+
+将 Danger 与你的项目集成是一个简单的逐步过程:你只需要包括 Danger 模块,并为每个项目创建一个 Danger 文件。然而,创建一个 Danger 帐户(通过 GitHub 或 Bitbucket 很容易做到),并且为开源软件项目设置访问令牌更加方便。
+
+可以通过 NPM 或 Yarn 安装 Danger。要使用 Yarn,请添加 `danger -D` 到 `package.JSON` 中。
+
+将 Danger 添加到 CI 后,你可以:
+
+ * 高亮显示重要的创建工件
+ * 通过强制链接到 Trello 和 Jira 之类的工具来管理 sprint
+ * 强制生成更新日志
+ * 使用描述性标签
+ * 以及更多
+
+例如,你可以设计一个定义团队文化并为代码审查和 PR 检查设定特定规则的系统。根据 Danger 提供的元数据及其广泛的插件生态系统,可以解决常见的议题。
+
+### Snyk
+
+网络安全是开发人员的主要关注点。[Snyk][9] 是修复开源组件中漏洞的最著名工具之一。它最初是一个用于修复 Node.js 项目漏洞的项目,并且已经演变为可以检测并修复 Ruby、Java、Python 和 Scala 应用程序中的漏洞。Snyk 主要分四个阶段运行:
+
+ * 查找漏洞依赖性
+ * 修复特定漏洞
+ * 通过 PR 检查预防安全风险
+ * 持续监控应用程序
+
+Snyk 可以集成在项目的任何阶段,包括编码、CI/CD 和报告。我发现这对于测试 Node.js 项目非常有帮助,可以测试或构建 npm 软件包时检查是否存在安全风险。你还可以在 GitHub 中为你的应用程序运行 PR 检查,以使你的项目更安全。Synx 还提供了一系列集成,可用于监控依赖关系并解决特定问题。
+
+要在本地计算机上运行 Snyk,可以通过 NPM 安装它:
+
+```
+npm install -g snyk
+```
+
+### Migrat
+
+[Migrat][10] 是一款使用纯文本的数据迁移工具,非常易于使用。 它可在各种软件堆栈和进程中工作,从而使其更加实用。你可以使用简单的代码行安装 Migrat:
+
+```
+$ npm install -g migrat
+```
+
+Migrat 并不需要特别的数据库引擎。它支持多节点环境,因为迁移可以在一个全局节点上运行,也可以在每个服务器上运行一次。Migrat 之所以方便,是因为它便于向每个迁移传递上下文。
+
+你可以定义每个迁移的用途(例如,数据库集、连接、日志接口等)。此外,为了避免随意迁移,即多个服务器在全局范围内进行迁移,Migrat 可以在进程运行时进行全局锁定,从而使其只能在全局范围内运行一次。它还附带了一系列用于 SQL 数据库、Slack、HipChat 和 Datadog 仪表盘的插件。你可以将实时迁移状况发送到这些平台中的任何一个。
+
+### Clinic.js
+
+[Clinic.js][11] 是一个用于 Node.js 项目的开源监视工具。它结合了三种不同的工具 Doctor、Bubbleprof 和 Flame,帮助你监控、检测和解决 Node.js 的性能问题。
+
+你可以通过运行以下命令从 npm 安装 Clinic.js:
+
+```
+$ npm install clinic
+```
+
+你可以根据要监视项目的某个方面以及要生成的报告,选择要使用的 Clinic.js 包含的三个工具中的一个:
+
+ * Doctor 通过注入探针来提供详细的指标,并就项目的总体运行状况提供建议。
+ * Bubbleprof 非常适合分析,并使用 `async_hooks` 生成指标。
+ * Flame 非常适合发现代码中的热路径和瓶颈。
+
+### PM2
+
+监视是后端开发过程中最重要的方面之一。[PM2][12] 是一款 Node.js 的进程管理工具,可帮助开发人员监视项目的多个方面,例如日志、延迟和速度。该工具与 Linux、MacOS 和 Windows 兼容,并支持从 Node.js 8.X 开始的所有 Node.js 版本。
+
+你可以使用以下命令通过 npm 安装 PM2:
+
+```
+$ npm install pm2 --g
+```
+
+如果尚未安装 Node.js,则可以使用以下命令安装:
+
+```
+wget -qO- https://getpm2.com/install.sh | bash
+```
+
+安装完成后,使用以下命令启动应用程序:
+
+```
+$ pm2 start app.js
+```
+
+关于 PM2 最好的地方是可以在集群模式下运行应用程序。可以同时为多个 CPU 内核生成一个进程。这样可以轻松增强应用程序性能并最大程度地提高可靠性。PM2 也非常适合更新工作,因为你可以使用 “热重载” 选项更新应用程序并以零停机时间重新加载应用程序。总体而言,它是为 Node.js 应用程序简化进程管理的好工具。
+
+### Electrode
+
+[Electrode][13] 是 Walmart Labs 的一个开源应用程序平台。该平台可帮助你以结构化方式构建大规模通用的 React/Node.js 应用程序。
+
+Electrode 应用程序生成器使你可以构建专注于代码的灵活内核,提供一些出色的模块以向应用程序添加复杂功能,并附带了广泛的工具来优化应用程序的 Node.js 包。
+
+可以使用 npm 安装 Electrode。安装完成后,你可以使用 Ignite 启动应用程序,并深入研究 Electrode 应用程序生成器。
+
+你可以使用 NPM 安装 Electrode:
+
+```
+npm install -g electrode-ignite xclap-cli
+```
+
+### 你最喜欢哪一个?
+
+这些只是不断增长的开源工具列表中的一小部分,在使用 Node.js 时,这些工具可以在不同阶段派上用场。你最喜欢使用哪些开源 Node.js 工具?请在评论中分享你的建议。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/1/open-source-tools-nodejs
+
+作者:[Hiren Dhadhuk][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/hirendhadhuk
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tools_hardware_purple.png?itok=3NdVoYhl (Tools illustration)
+[2]: https://insights.stackoverflow.com/survey/2019#technology-_-other-frameworks-libraries-and-tools
+[3]: https://www.simform.com/nodejs-use-case/
+[4]: https://webpack.js.org/
+[5]: https://strapi.io/
+[6]: https://broccoli.build/
+[7]: https://en.wikipedia.org/wiki/ECMAScript#6th_Edition_-_ECMAScript_2015
+[8]: https://danger.systems/
+[9]: https://snyk.io/
+[10]: https://github.com/naturalatlas/migrat
+[11]: https://clinicjs.org/
+[12]: https://pm2.keymetrics.io/
+[13]: https://www.electrode.io/
diff --git a/published/202103/20200127 Managing processes on Linux with kill and killall.md b/published/202103/20200127 Managing processes on Linux with kill and killall.md
new file mode 100644
index 0000000000..1d5e76b80e
--- /dev/null
+++ b/published/202103/20200127 Managing processes on Linux with kill and killall.md
@@ -0,0 +1,152 @@
+[#]: collector: "lujun9972"
+[#]: translator: "wyxplus"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13215-1.html"
+[#]: subject: "Managing processes on Linux with kill and killall"
+[#]: via: "https://opensource.com/article/20/1/linux-kill-killall"
+[#]: author: "Jim Hall https://opensource.com/users/jim-hall"
+
+在 Linux 上使用 kill 和 killall 命令来管理进程
+======
+
+> 了解如何使用 ps、kill 和 killall 命令来终止进程并回收系统资源。
+
+
+
+在 Linux 中,每个程序和守护程序都是一个“进程”。 大多数进程代表一个正在运行的程序。而另外一些程序可以派生出其他进程,比如说它会侦听某些事件的发生,然后对其做出响应。并且每个进程都需要一定的内存和处理能力。你运行的进程越多,所需的内存和 CPU 使用周期就越多。在老式电脑(例如我使用了 7 年的笔记本电脑)或轻量级计算机(例如树莓派)上,如果你关注过后台运行的进程,就能充分利用你的系统。
+
+你可以使用 `ps` 命令来查看正在运行的进程。你通常会使用 `ps` 命令的参数来显示出更多的输出信息。我喜欢使用 `-e` 参数来查看每个正在运行的进程,以及 `-f` 参数来获得每个进程的全部细节。以下是一些例子:
+
+```
+$ ps
+ PID TTY TIME CMD
+ 88000 pts/0 00:00:00 bash
+ 88052 pts/0 00:00:00 ps
+ 88053 pts/0 00:00:00 head
+```
+```
+$ ps -e | head
+ PID TTY TIME CMD
+ 1 ? 00:00:50 systemd
+ 2 ? 00:00:00 kthreadd
+ 3 ? 00:00:00 rcu_gp
+ 4 ? 00:00:00 rcu_par_gp
+ 6 ? 00:00:02 kworker/0:0H-events_highpri
+ 9 ? 00:00:00 mm_percpu_wq
+ 10 ? 00:00:01 ksoftirqd/0
+ 11 ? 00:00:12 rcu_sched
+ 12 ? 00:00:00 migration/0
+```
+```
+$ ps -ef | head
+UID PID PPID C STIME TTY TIME CMD
+root 1 0 0 13:51 ? 00:00:50 /usr/lib/systemd/systemd --switched-root --system --deserialize 36
+root 2 0 0 13:51 ? 00:00:00 [kthreadd]
+root 3 2 0 13:51 ? 00:00:00 [rcu_gp]
+root 4 2 0 13:51 ? 00:00:00 [rcu_par_gp]
+root 6 2 0 13:51 ? 00:00:02 [kworker/0:0H-kblockd]
+root 9 2 0 13:51 ? 00:00:00 [mm_percpu_wq]
+root 10 2 0 13:51 ? 00:00:01 [ksoftirqd/0]
+root 11 2 0 13:51 ? 00:00:12 [rcu_sched]
+root 12 2 0 13:51 ? 00:00:00 [migration/0]
+```
+
+最后的例子显示最多的细节。在每一行,`UID`(用户 ID)显示了该进程的所有者。`PID`(进程 ID)代表每个进程的数字 ID,而 `PPID`(父进程 ID)表示其父进程的数字 ID。在任何 Unix 系统中,进程是从 1 开始编号,是内核启动后运行的第一个进程。在这里,`systemd` 是第一个进程,它催生了 `kthreadd`,而 `kthreadd` 还创建了其他进程,包括 `rcu_gp`、`rcu_par_gp` 等一系列进程。
+
+### 使用 kill 命令来管理进程
+
+系统会处理大多数后台进程,所以你不需要操心这些进程。你只需要关注那些你所运行的应用创建的进程。虽然许多应用一次只运行一个进程(如音乐播放器、终端模拟器或游戏等),但其他应用则可能创建后台进程。其中一些应用可能当你退出后还在后台运行,以便下次你使用的时候能快速启动。
+
+当我运行 Chromium(作为谷歌 Chrome 浏览器所基于的开源项目)时,进程管理便成了问题。 Chromium 在我的笔记本电脑上运行非常吃力,并产生了许多额外的进程。现在我仅打开五个选项卡,就能看到这些 Chromium 进程:
+
+```
+$ ps -ef | fgrep chromium
+jhall 66221 [...] /usr/lib64/chromium-browser/chromium-browser [...]
+jhall 66230 [...] /usr/lib64/chromium-browser/chromium-browser [...]
+[...]
+jhall 66861 [...] /usr/lib64/chromium-browser/chromium-browser [...]
+jhall 67329 65132 0 15:45 pts/0 00:00:00 grep -F chromium
+```
+
+我已经省略一些行,其中有 20 个 Chromium 进程和一个正在搜索 “chromium" 字符的 `grep` 进程。
+
+```
+$ ps -ef | fgrep chromium | wc -l
+21
+```
+
+但是在我退出 Chromium 之后,这些进程仍旧运行。如何关闭它们并回收这些进程占用的内存和 CPU 呢?
+
+`kill` 命令能让你终止一个进程。在最简单的情况下,你告诉 `kill` 命令终止你想终止的进程的 PID。例如,要终止这些进程,我需要对 20 个 Chromium 进程 ID 都执行 `kill` 命令。一种方法是使用命令行获取 Chromium 的 PID,而另一种方法针对该列表运行 `kill`:
+
+
+```
+$ ps -ef | fgrep /usr/lib64/chromium-browser/chromium-browser | awk '{print $2}'
+66221
+66230
+66239
+66257
+66262
+66283
+66284
+66285
+66324
+66337
+66360
+66370
+66386
+66402
+66503
+66539
+66595
+66734
+66848
+66861
+69702
+
+$ ps -ef | fgrep /usr/lib64/chromium-browser/chromium-browser | awk '{print $2}' > /tmp/pids
+$ kill $(cat /tmp/pids)
+```
+
+最后两行是关键。第一个命令行为 Chromium 浏览器生成一个进程 ID 列表。第二个命令行针对该进程 ID 列表运行 `kill` 命令。
+
+### 介绍 killall 命令
+
+一次终止多个进程有个更简单方法,使用 `killall` 命令。你或许可以根据名称猜测出,`killall` 会终止所有与该名字匹配的进程。这意味着我们可以使用此命令来停止所有流氓 Chromium 进程。这很简单:
+
+```
+$ killall /usr/lib64/chromium-browser/chromium-browser
+```
+
+但是要小心使用 `killall`。该命令能够终止与你所给出名称相匹配的所有进程。这就是为什么我喜欢先使用 `ps -ef` 命令来检查我正在运行的进程,然后针对要停止的命令的准确路径运行 `killall`。
+
+你也可以使用 `-i` 或 `--interactive` 参数,来让 `killkill` 在停止每个进程之前提示你。
+
+`killall` 还支持使用 `-o` 或 `--older-than` 参数来查找比特定时间更早的进程。例如,如果你发现了一组已经运行了好几天的恶意进程,这将会很有帮助。又或是,你可以查找比特定时间更晚的进程,例如你最近启动的失控进程。使用 `-y` 或 `--young-than` 参数来查找这些进程。
+
+### 其他管理进程的方式
+
+进程管理是系统维护重要的一部分。在我作为 Unix 和 Linux 系统管理员的早期职业生涯中,杀死非法作业的能力是保持系统正常运行的关键。在如今,你可能不需要亲手在 Linux 上的终止流氓进程,但是知道 `kill` 和 `killall` 能够在最终出现问题时为你提供帮助。
+
+你也能寻找其他方式来管理进程。在我这个案例中,我并不需要在我退出浏览器后,使用 `kill` 或 `killall` 来终止后台 Chromium 进程。在 Chromium 中有个简单设置就可以进行控制:
+
+![Chromium background processes setting][2]
+
+不过,始终关注系统上正在运行哪些进程,并且在需要的时候进行干预是一个明智之举。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/1/linux-kill-killall
+
+作者:[Jim Hall][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jim-hall
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 "Penguin with green background"
+[2]: https://opensource.com/sites/default/files/uploads/chromium-settings-continue-running.png "Chromium background processes setting"
diff --git a/published/202103/20200129 Ansible Playbooks Quick Start Guide with Examples.md b/published/202103/20200129 Ansible Playbooks Quick Start Guide with Examples.md
new file mode 100644
index 0000000000..bf14ca23c7
--- /dev/null
+++ b/published/202103/20200129 Ansible Playbooks Quick Start Guide with Examples.md
@@ -0,0 +1,341 @@
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13167-1.html"
+[#]: subject: "Ansible Playbooks Quick Start Guide with Examples"
+[#]: via: "https://www.2daygeek.com/ansible-playbooks-quick-start-guide-with-examples/"
+[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
+
+Ansible 剧本快速入门指南
+======
+
+我们已经写了两篇关于 Ansible 的文章,这是第三篇。
+
+如果你是 Ansible 新手,我建议你阅读下面这两篇文章,它会教你一些 Ansible 的基础以及它是什么。
+
+ * 第一篇: [Ansible 自动化工具安装、配置和快速入门指南][1]
+ * 第二篇: [Ansible 点对点命令快速入门指南示例][2]
+
+如果你已经阅读过了,那么在阅读本文时你才不会感到突兀。
+
+### 什么是 Ansible 剧本?
+
+剧本比点对点命令模式更强大,而且完全不同。
+
+它使用了 `/usr/bin/ansible-playbook` 二进制文件,并且提供丰富的特性使得复杂的任务变得更容易。
+
+如果你想经常运行一个任务,剧本是非常有用的。此外,如果你想在服务器组上执行多个任务,它也是非常有用的。
+
+剧本是由 YAML 语言编写。YAML 代表一种标记语言,它比其它常见的数据格式(如 XML 或 JSON)更容易读写。
+
+下面这张 Ansible 剧本流程图将告诉你它的详细结构。
+
+![][3]
+
+### 理解 Ansible 剧本的术语
+
+ * 控制节点:Ansible 安装的机器,它负责管理客户端节点。
+ * 受控节点:控制节点管理的主机列表。
+ * 剧本:一个剧本文件包含一组自动化任务。
+ * 主机清单:这个文件包含有关管理的服务器的信息。
+ * 任务:每个剧本都有大量的任务。任务在指定机器上依次执行(一个主机或多个主机)。
+ * 模块: 模块是一个代码单元,用于从客户端节点收集信息。
+ * 角色:角色是根据已知文件结构自动加载一些变量文件、任务和处理程序的方法。
+ * 动作:每个剧本含有大量的动作,一个动作从头到尾执行一个特定的自动化。
+ * 处理程序: 它可以帮助你减少在剧本中的重启任务。处理程序任务列表实际上与常规任务没有什么不同,更改由通知程序通知。如果处理程序没有收到任何通知,它将不起作用。
+
+### 基本的剧本是怎样的?
+
+下面是一个剧本的模板:
+
+```
+--- [YAML 文件应该以三个破折号开头]
+- name: [脚本描述]
+ hosts: group [添加主机或主机组]
+ become: true [如果你想以 root 身份运行任务,则标记它]
+ tasks: [你想在任务下执行什么动作]
+ - name: [输入模块选项]
+ module: [输入要执行的模块]
+ module_options-1: value [输入模块选项]
+ module_options-2: value
+ .
+ module_options-N: value
+```
+
+### 如何理解 Ansible 的输出
+
+Ansible 剧本的输出有四种颜色,下面是具体含义:
+
+ * **绿色**:`ok` 代表成功,关联的任务数据已经存在,并且已经根据需要进行了配置。
+ * **黄色**:`changed` 指定的数据已经根据任务的需要更新或修改。
+ * **红色**:`FAILED` 如果在执行任务时出现任何问题,它将返回一个失败消息,它可能是任何东西,你需要相应地修复它。
+ * **白色**:表示有多个参数。
+
+为此,创建一个剧本目录,将它们都放在同一个地方。
+
+```
+$ sudo mkdir /etc/ansible/playbooks
+```
+
+### 剧本-1:在 RHEL 系统上安装 Apache Web 服务器
+
+这个示例剧本允许你在指定的目标机器上安装 Apache Web 服务器:
+
+```
+$ sudo nano /etc/ansible/playbooks/apache.yml
+
+---
+- hosts: web
+ become: yes
+ name: "Install and Configure Apache Web server"
+ tasks:
+ - name: "Install Apache Web Server"
+ yum:
+ name: httpd
+ state: latest
+ - name: "Ensure Apache Web Server is Running"
+ service:
+ name: httpd
+ state: started
+```
+
+```
+$ ansible-playbook apache1.yml
+```
+
+![][3]
+
+### 如何理解 Ansible 中剧本的执行
+
+使用以下命令来查看语法错误。如果没有发现错误,它只显示剧本文件名。如果它检测到任何错误,你将得到一个如下所示的错误,但内容可能根据你的输入文件而有所不同。
+
+```
+$ ansible-playbook apache1.yml --syntax-check
+
+ERROR! Syntax Error while loading YAML.
+ found a tab character that violate indentation
+The error appears to be in '/etc/ansible/playbooks/apache1.yml': line 10, column 1, but may
+be elsewhere in the file depending on the exact syntax problem.
+The offending line appears to be:
+ state: latest
+^ here
+There appears to be a tab character at the start of the line.
+
+YAML does not use tabs for formatting. Tabs should be replaced with spaces.
+For example:
+ - name: update tooling
+ vars:
+ version: 1.2.3
+# ^--- there is a tab there.
+Should be written as:
+ - name: update tooling
+ vars:
+ version: 1.2.3
+# ^--- all spaces here.
+```
+
+或者,你可以使用这个 URL [YAML Lint][4] 在线检查 Ansible 剧本内容。
+
+执行以下命令进行“演练”。当你运行带有 `--check` 选项的剧本时,它不会对远程机器进行任何修改。相反,它会告诉你它将要做什么改变但不是真的执行。
+
+```
+$ ansible-playbook apache.yml --check
+
+PLAY [Install and Configure Apache Webserver] ********************************************************************
+
+TASK [Gathering Facts] *******************************************************************************************
+ok: [node2.2g.lab]
+ok: [node1.2g.lab]
+
+TASK [Install Apache Web Server] *********************************************************************************
+changed: [node2.2g.lab]
+changed: [node1.2g.lab]
+
+TASK [Ensure Apache Web Server is Running] ***********************************************************************
+changed: [node1.2g.lab]
+changed: [node2.2g.lab]
+
+PLAY RECAP *******************************************************************************************************
+node1.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+node2.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+```
+
+如果你想要知道 ansible 剧本实现的详细信息,使用 `-vv` 选项,它会展示如何收集这些信息。
+
+```
+$ ansible-playbook apache.yml --check -vv
+
+ansible-playbook 2.9.2
+ config file = /etc/ansible/ansible.cfg
+ configured module search path = ['/home/daygeek/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
+ ansible python module location = /usr/lib/python3.8/site-packages/ansible
+ executable location = /usr/bin/ansible-playbook
+ python version = 3.8.1 (default, Jan 8 2020, 23:09:20) [GCC 9.2.0]
+Using /etc/ansible/ansible.cfg as config file
+
+PLAYBOOK: apache.yml *****************************************************************************************************
+1 plays in apache.yml
+
+PLAY [Install and Configure Apache Webserver] ****************************************************************************
+
+TASK [Gathering Facts] ***************************************************************************************************
+task path: /etc/ansible/playbooks/apache.yml:2
+ok: [node2.2g.lab]
+ok: [node1.2g.lab]
+META: ran handlers
+
+TASK [Install Apache Web Server] *****************************************************************************************
+task path: /etc/ansible/playbooks/apache.yml:6
+changed: [node2.2g.lab] => {"changed": true, "msg": "Check mode: No changes made, but would have if not in check mod
+e", "rc": 0, "results": ["Installed: httpd"]}
+changed: [node1.2g.lab] => {"changed": true, "changes": {"installed": ["httpd"], "updated": []}, "msg": "", "obsolet
+es": {"urw-fonts": {"dist": "noarch", "repo": "@anaconda", "version": "2.4-16.el7"}}, "rc": 0, "results": []}
+
+TASK [Ensure Apache Web Server is Running] *******************************************************************************
+task path: /etc/ansible/playbooks/apache.yml:10
+changed: [node1.2g.lab] => {"changed": true, "msg": "Service httpd not found on host, assuming it will exist on full run"}
+changed: [node2.2g.lab] => {"changed": true, "msg": "Service httpd not found on host, assuming it will exist on full run"}
+META: ran handlers
+META: ran handlers
+
+PLAY RECAP ***************************************************************************************************************
+node1.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+node2.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+```
+
+### 剧本-2:在 Ubuntu 系统上安装 Apache Web 服务器
+
+这个示例剧本允许你在指定的目标节点上安装 Apache Web 服务器。
+
+```
+$ sudo nano /etc/ansible/playbooks/apache-ubuntu.yml
+
+---
+- hosts: web
+ become: yes
+ name: "Install and Configure Apache Web Server"
+ tasks:
+ - name: "Install Apache Web Server"
+ yum:
+ name: apache2
+ state: latest
+
+ - name: "Start the Apache Web Server"
+ service:
+ name: apaceh2
+ state: started
+
+ - name: "Enable mod_rewrite module"
+ apache2_module:
+ name: rewrite
+ state: present
+
+ notify:
+ - start apache
+
+ handlers:
+ - name: "Ensure Apache Web Server is Running"
+ service:
+ name: apache2
+ state: restarted
+ enabled: yes
+```
+
+### 剧本-3:在 Red Hat 系统上安装软件包列表
+
+这个示例剧本允许你在指定的目标节点上安装软件包。
+
+**方法-1:**
+
+```
+$ sudo nano /etc/ansible/playbooks/packages-redhat.yml
+
+---
+- hosts: web
+ become: yes
+ name: "Install a List of Packages on Red Hat Based System"
+ tasks:
+ - name: "Installing a list of packages"
+ yum:
+ name:
+ - curl
+ - httpd
+ - nano
+ - htop
+```
+
+**方法-2:**
+
+```
+$ sudo nano /etc/ansible/playbooks/packages-redhat-1.yml
+
+---
+- hosts: web
+ become: yes
+ name: "Install a List of Packages on Red Hat Based System"
+ tasks:
+ - name: "Installing a list of packages"
+ yum: name={{ item }} state=latest
+ with_items:
+ - curl
+ - httpd
+ - nano
+ - htop
+```
+
+**方法-3:使用数组变量**
+
+```
+$ sudo nano /etc/ansible/playbooks/packages-redhat-2.yml
+
+---
+- hosts: web
+ become: yes
+ name: "Install a List of Packages on Red Hat Based System"
+ vars:
+ packages: [ 'curl', 'git', 'htop' ]
+ tasks:
+ - name: Install a list of packages
+ yum: name={{ item }} state=latest
+ with_items: "{{ packages }}"
+```
+
+### 剧本-4:在 Linux 系统上安装更新
+
+这个示例剧本允许你在基于 Red Hat 或 Debian 的 Linux 系统上安装更新。
+
+```
+$ sudo nano /etc/ansible/playbooks/security-update.yml
+
+---
+- hosts: web
+ become: yes
+ name: "Install Security Update"
+ tasks:
+ - name: "Installing Security Update on Red Hat Based System"
+ yum: name=* update_cache=yes security=yes state=latest
+ when: ansible_facts['distribution'] == "CentOS"
+
+ - name: "Installing Security Update on Ubuntu Based System"
+ apt: upgrade=dist update_cache=yes
+ when: ansible_facts['distribution'] == "Ubuntu"
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/ansible-playbooks-quick-start-guide-with-examples/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-13142-1.html
+[2]: https://linux.cn/article-13163-1.html
+[3]: https://www.2daygeek.com/wp-content/uploads/2020/01/ansible-playbook-structure-flow-chart-explained.png
+[4]: http://www.yamllint.com/
diff --git a/published/202103/20200219 Multicloud, security integration drive massive SD-WAN adoption.md b/published/202103/20200219 Multicloud, security integration drive massive SD-WAN adoption.md
new file mode 100644
index 0000000000..42239ba15a
--- /dev/null
+++ b/published/202103/20200219 Multicloud, security integration drive massive SD-WAN adoption.md
@@ -0,0 +1,74 @@
+[#]: collector: (lujun9972)
+[#]: translator: (cooljelly)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13239-1.html)
+[#]: subject: (Multicloud, security integration drive massive SD-WAN adoption)
+[#]: via: (https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+多云融合和安全集成推动 SD-WAN 的大规模应用
+======
+
+> 2022 年 SD-WAN 市场 40% 的同比增长主要来自于包括 Cisco、VMWare、Juniper 和 Arista 在内的网络供应商和包括 AWS、Microsoft Azure,Google Anthos 和 IBM RedHat 在内的服务提供商之间的紧密联系。
+
+
+
+越来越多的云应用,以及越来越完善的网络安全性、可视化特性和可管理性,正以惊人的速度推动企业软件定义广域网([SD-WAN][3])的部署。
+
+IDC(LCTT 译注:International Data Corporation)公司的网络基础架构副总裁 Rohit Mehra 表示,根据 IDC 的研究,过去一年中,特别是软件和基础设施即服务(SaaS 和 IaaS)产品推动了 SD-WAN 的实施。
+
+例如,IDC 表示,根据其最近的客户调查结果,有 95% 的客户将在两年内使用 [SD-WAN][7] 技术,而 42% 的客户已经部署了它。IDC 还表示,到 2022 年,SD-WAN 基础设施市场将达到 45 亿美元,此后每年将以每年 40% 的速度增长。
+
+“SD-WAN 的增长是一个广泛的趋势,很大程度上是由企业希望优化远程站点的云连接性的需求推动的。” Mehra 说。
+
+思科最近撰文称,多云网络的发展正在促使许多企业改组其网络,以更好地使用 SD-WAN 技术。SD-WAN 对于采用云服务的企业至关重要,它是园区网、分支机构、[物联网][8]、[数据中心][9] 和云之间的连接中间件。思科公司表示,根据调查,平均每个思科的企业客户有 30 个付费的 SaaS 应用程序,而他们实际使用的 SaaS 应用会更多——在某些情况下甚至超过 100 种。
+
+这种趋势的部分原因是由网络供应商(例如 Cisco、VMware、Juniper、Arista 等)(LCTT 译注:这里的网络供应商指的是提供硬件或软件并可按需组网的厂商)与服务提供商(例如 Amazon AWS、Microsoft Azure、Google Anthos 和 IBM RedHat 等)建立的关系推动的。
+
+去年 12 月,AWS 为其云产品发布了关键服务,其中包括诸如 [AWS Transit Gateway][10] 等新集成技术的关键服务,这标志着 SD-WAN 与多云场景关系的日益重要。使用 AWS Transit Gateway 技术,客户可以将 AWS 中的 VPC(虚拟私有云)和其自有网络均连接到相同的网关。Aruba、Aviatrix Cisco、Citrix Systems、Silver Peak 和 Versa 已经宣布支持该技术,这将简化和增强这些公司的 SD-WAN 产品与 AWS 云服务的集成服务的性能和表现。
+
+Mehra 说,展望未来,对云应用的友好兼容和完善的性能监控等增值功能将是 SD-WAN 部署的关键部分。
+
+随着 SD-WAN 与云的关系不断发展,SD-WAN 对集成安全功能的需求也在不断增长。
+
+Mehra 说,SD-WAN 产品集成安全性的方式比以往单独打包的广域网安全软件或服务要好得多。SD-WAN 是一个更加敏捷的安全环境。SD-WAN 公认的主要组成部分包括安全功能,数据分析功能和广域网优化功能等,其中安全功能则是下一代 SD-WAN 解决方案的首要需求。
+
+Mehra 说,企业将越来越少地关注仅解决某个具体问题的 SD-WAN 解决方案,而将青睐于能够解决更广泛的网络管理和安全需求的 SD-WAN 平台。他们将寻找可以与他们的 IT 基础设施(包括企业数据中心网络、企业园区局域网、[公有云][12] 资源等)集成更紧密的 SD-WAN 平台。他说,企业将寻求无缝融合的安全服务,并希望有其他各种功能的支持,例如可视化、数据分析和统一通信功能。
+
+“随着客户不断将其基础设施与软件集成在一起,他们可以做更多的事情,例如根据其局域网和广域网上的用户、设备或应用程序的需求,实现一致的管理和安全策略,并最终获得更好的整体使用体验。” Mehra 说。
+
+一个新兴趋势是 SD-WAN 产品包需要支持 [SD-branch][13] 技术。 Mehra 说,超过 70% 的 IDC 受调查客户希望在明年使用 SD-Branch。在最近几周,[Juniper][14] 和 [Aruba][15] 公司已经优化了 SD-branch 产品,这一趋势预计将在今年持续下去。
+
+SD-Branch 技术建立在 SD-WAN 的概念和支持的基础上,但更专注于满足分支机构中局域网的组网和管理需求。展望未来,SD-Branch 如何与其他技术集成,例如数据分析、音视频、统一通信等,将成为该技术的主要驱动力。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[cooljelly](https://github.com/cooljelly)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/07/branches_branching_trees_bare_black_and_white_by_gratisography_cc0_via_pexels_1200x800-100763250-large.jpg
+[2]: https://creativecommons.org/publicdomain/zero/1.0/
+[3]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
+[4]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
+[5]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
+[6]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
+[7]: https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html
+[8]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
+[9]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
+[10]: https://aws.amazon.com/transit-gateway/
+[11]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[12]: https://www.networkworld.com/article/2159885/cloud-computing-gartner-5-things-a-private-cloud-is-not.html
+[13]: https://www.networkworld.com/article/3250664/sd-branch-what-it-is-and-why-youll-need-it.html
+[14]: https://www.networkworld.com/article/3487801/juniper-broadens-sd-branch-management-switch-options.html
+[15]: https://www.networkworld.com/article/3513357/aruba-reinforces-sd-branch-with-security-management-upgrades.html
+[16]: https://www.facebook.com/NetworkWorld/
+[17]: https://www.linkedin.com/company/network-world
diff --git a/published/202103/20200410 Get started with Bash programming.md b/published/202103/20200410 Get started with Bash programming.md
new file mode 100644
index 0000000000..84b9aeca70
--- /dev/null
+++ b/published/202103/20200410 Get started with Bash programming.md
@@ -0,0 +1,148 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13210-1.html)
+[#]: subject: (Get started with Bash programming)
+[#]: via: (https://opensource.com/article/20/4/bash-programming-guide)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+如何入门 Bash 编程
+======
+
+> 了解如何在 Bash 中编写定制程序以自动执行重复性操作任务。
+
+
+
+Unix 最初的希望之一是,让计算机的日常用户能够微调其计算机,以适应其独特的工作风格。几十年来,人们对计算机定制的期望已经降低,许多用户认为他们的应用程序和网站的集合就是他们的 “定制环境”。原因之一是许多操作系统的组件未不开源,普通用户无法使用其源代码。
+
+但是对于 Linux 用户而言,定制程序是可以实现的,因为整个系统都围绕着可通过终端使用的命令啦进行的。终端不仅是用于快速命令或深入排除故障的界面;也是一个脚本环境,可以通过为你处理日常任务来减少你的工作量。
+
+### 如何学习编程
+
+如果你以前从未进行过任何编程,可能面临考虑两个不同的挑战:一个是了解怎样编写代码,另一个是了解要编写什么代码。你可以学习 _语法_,但是如果你不知道 _语言_ 中有哪些可用的关键字,你将无法继续。在实践中,要同时开始学习这两个概念,是因为如果没有关键字的堆砌就无法学习语法,因此,最初你要使用基本命令和基本编程结构来编写简单的任务。一旦熟悉了基础知识,就可以探索更多编程语言的内容,从而使你的程序能够做越来越重要的事情。
+
+在 [Bash][2] 中,你使用的大多数 _关键字_ 是 Linux 命令。 _语法_ 就是 Bash。如果你已经频繁地使用过了 Bash,则向 Bash 编程的过渡相对容易。但是,如果你不曾使用过 Bash,你会很高兴地了解到它是一种为清晰和简单而构建的简单语言。
+
+### 交互设计
+
+有时,学习编程时最难搞清楚的事情就是计算机可以为你做些什么。显然,如果一台计算机可以自己完成你要做的所有操作,那么你就不必再碰计算机了。但是现实是,人类很重要。找到你的计算机可以帮助你的事情的关键是注意到你一周内需要重复执行的任务。计算机特别擅长于重复的任务。
+
+但是,为了能告知计算机为你做某事,你必须知道怎么做。这就是 Bash 擅长的领域:交互式编程。在终端中执行一个动作时,你也在学习如何编写脚本。
+
+例如,我曾经负责将大量 PDF 书籍转换为低墨和友好打印的版本。一种方法是在 PDF 编辑器中打开 PDF,从数百张图像(页面背景和纹理都算作图像)中选择每张图像,删除它们,然后将其保存到新的 PDF中。仅仅是一本书,这样就需要半天时间。
+
+我的第一个想法是学习如何编写 PDF 编辑器脚本,但是经过数天的研究,我找不到可以编写编辑 PDF 应用程序的脚本(除了非常丑陋的鼠标自动化技巧)。因此,我将注意力转向了从终端内找出完成任务的方法。这让我有了几个新发现,包括 GhostScript,它是 PostScript 的开源版本(PDF 基于的打印机语言)。通过使用 GhostScript 处理了几天的任务,我确认这是解决我的问题的方法。
+
+编写基本的脚本来运行命令,只不过是复制我用来从 PDF 中删除图像的命令和选项,并将其粘贴到文本文件中而已。将这个文件作为脚本运行,大概也会产生同样的结果。
+
+### 向 Bash 脚本传参数
+
+在终端中运行命令与在 Shell 脚本中运行命令之间的区别在于前者是交互式的。在终端中,你可以随时进行调整。例如,如果我刚刚处理 `example_1.pdf` 并准备处理下一个文档,以适应我的命令,则只需要更改文件名即可。
+
+Shell 脚本不是交互式的。实际上,Shell _脚本_ 存在的唯一原因是让你不必亲自参与。这就是为什么命令(以及运行它们的 Shell 脚本)会接受参数的原因。
+
+在 Shell 脚本中,有一些预定义的可以反映脚本启动方式的变量。初始变量是 `$0`,它代表了启动脚本的命令。下一个变量是 `$1` ,它表示传递给 Shell 脚本的第一个 “参数”。例如,在命令 `echo hello` 中,命令 `echo` 为 `$0,`,关键字 `hello` 为 `$1`,而 `world` 是 `$2`。
+
+在 Shell 中交互如下所示:
+
+```
+$ echo hello world
+hello world
+```
+
+在非交互式 Shell 脚本中,你 _可以_ 以非常直观的方式执行相同的操作。将此文本输入文本文件并将其另存为 `hello.sh`:
+
+```
+echo hello world
+```
+
+执行这个脚本:
+
+```
+$ bash hello.sh
+hello world
+```
+
+同样可以,但是并没有利用脚本可以接受输入这一优势。将 `hello.sh` 更改为:
+
+```
+echo $1
+```
+
+用引号将两个参数组合在一起来运行脚本:
+
+```
+$ bash hello.sh "hello bash"
+hello bash
+```
+
+对于我的 PDF 瘦身项目,我真的需要这种非交互性,因为每个 PDF 都花了几分钟来压缩。但是通过创建一个接受我的输入的脚本,我可以一次将几个 PDF 文件全部提交给脚本。该脚本按顺序处理了每个文件,这可能需要半小时或稍长一点时间,但是我可以用半小时来完成其他任务。
+
+### 流程控制
+
+创建 Bash 脚本是完全可以接受的,从本质上讲,这些脚本是你开始实现需要重复执行任务的准确过程的副本。但是,可以通过控制信息流的方式来使脚本更强大。管理脚本对数据响应的常用方法是:
+
+ * `if`/`then` 选择结构语句
+ * `for` 循环结构语句
+ * `while` 循环结构语句
+ * `case` 语句
+
+计算机不是智能的,但是它们擅长比较和分析数据。如果你在脚本中构建一些数据分析,则脚本会变得更加智能。例如,基本的 `hello.sh` 脚本运行后不管有没有内容都会显示:
+
+```
+$ bash hello.sh foo
+foo
+$ bash hello.sh
+
+$
+```
+
+如果在没有接收输入的情况下提供帮助消息,将会更加容易使用。如下是一个 `if`/`then` 语句,如果你以一种基本的方式使用 Bash,则你可能不知道 Bash 中存在这样的语句。但是编程的一部分是学习语言,通过一些研究,你将了解 `if/then` 语句:
+
+```
+if [ "$1" = "" ]; then
+ echo "syntax: $0 WORD"
+ echo "If you provide more than one word, enclose them in quotes."
+else
+ echo "$1"
+fi
+```
+
+运行新版本的 `hello.sh` 输出如下:
+
+```
+$ bash hello.sh
+syntax: hello.sh WORD
+If you provide more than one word, enclose them in quotes.
+$ bash hello.sh "hello world"
+hello world
+```
+
+### 利用脚本工作
+
+无论你是从 PDF 文件中查找要删除的图像,还是要管理混乱的下载文件夹,抑或要创建和提供 Kubernetes 镜像,学习编写 Bash 脚本都需要先使用 Bash,然后学习如何将这些脚本从仅仅是一个命令列表变成响应输入的东西。通常这是一个发现的过程:你一定会找到新的 Linux 命令来执行你从未想象过可以通过文本命令执行的任务,你会发现 Bash 的新功能,使你的脚本可以适应所有你希望它们运行的不同方式。
+
+学习这些技巧的一种方法是阅读其他人的脚本。了解人们如何在其系统上自动化死板的命令。看看你熟悉的,并寻找那些陌生事物的更多信息。
+
+另一种方法是下载我们的 [Bash 编程入门][3] 电子书。它向你介绍了特定于 Bash 的编程概念,并且通过学习的构造,你可以开始构建自己的命令。当然,它是免费的,并根据 [创作共用许可证][4] 进行下载和分发授权,所以今天就来获取它吧。
+
+- [下载我们介绍用 Bash 编程的电子书!][3]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/4/bash-programming-guide
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command_line_prompt.png?itok=wbGiJ_yg (Command line prompt)
+[2]: https://opensource.com/resources/what-bash
+[3]: https://opensource.com/downloads/bash-programming-guide
+[4]: https://opensource.com/article/20/1/what-creative-commons
diff --git a/published/202103/20200415 How to automate your cryptocurrency trades with Python.md b/published/202103/20200415 How to automate your cryptocurrency trades with Python.md
new file mode 100644
index 0000000000..f310476575
--- /dev/null
+++ b/published/202103/20200415 How to automate your cryptocurrency trades with Python.md
@@ -0,0 +1,414 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wyxplus)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13242-1.html)
+[#]: subject: (How to automate your cryptocurrency trades with Python)
+[#]: via: (https://opensource.com/article/20/4/python-crypto-trading-bot)
+[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
+
+
+如何使用 Python 来自动交易加密货币
+======
+
+> 在本教程中,教你如何设置和使用 Pythonic 来编程。它是一个图形化编程工具,用户可以很容易地使用现成的函数模块创建 Python 程序。
+
+
+
+然而,不像纽约证券交易所这样的传统证券交易所一样,有一段固定的交易时间。对于加密货币而言,则是 7×24 小时交易,这使得任何人都无法独自盯着市场。
+
+在以前,我经常思考与加密货币交易相关的问题:
+
+- 一夜之间发生了什么?
+- 为什么没有日志记录?
+- 为什么下单?
+- 为什么不下单?
+
+通常的解决手段是使用加密交易机器人,当在你做其他事情时,例如睡觉、与家人在一起或享受空闲时光,代替你下单。虽然有很多商业解决方案可用,但是我选择开源的解决方案,因此我编写了加密交易机器人 [Pythonic][2]。 正如去年 [我写过的文章][3] 一样,“Pythonic 是一种图形化编程工具,它让用户可以轻松使用现成的函数模块来创建 Python 应用程序。” 最初它是作为加密货币机器人使用,并具有可扩展的日志记录引擎以及经过精心测试的可重用部件,例如调度器和计时器。
+
+### 开始
+
+本教程将教你如何开始使用 Pythonic 进行自动交易。我选择 [币安][6] 交易所的 [波场][4] 与 [比特币][3] 交易对为例。我之所以选择这个加密货币对,是因为它们彼此之间的波动性大,而不是出于个人喜好。
+
+机器人将根据 [指数移动平均][7] (EMA)来做出决策。
+
+![TRX/BTC 1-hour candle chart][8]
+
+*TRX/BTC 1 小时 K 线图*
+
+EMA 指标通常是一个加权的移动平均线,可以对近期价格数据赋予更多权重。尽管移动平均线可能只是一个简单的指标,但我对它很有经验。
+
+上图中的紫色线显示了 EMA-25 指标(这表示要考虑最近的 25 个值)。
+
+机器人监视当前的 EMA-25 值(t0)和前一个 EMA-25 值(t-1)之间的差距。如果差值超过某个值,则表示价格上涨,机器人将下达购买订单。如果差值低于某个值,则机器人将下达卖单。
+
+差值将是做出交易决策的主要指标。在本教程中,它称为交易参数。
+
+### 工具链
+
+将在本教程使用如下工具:
+
+- 币安专业交易视图(已经有其他人做了数据可视化,所以不需要重复造轮子)
+- Jupyter 笔记本:用于数据科学任务
+- Pythonic:作为整体框架
+- PythonicDaemon :作为终端运行(仅适用于控制台和 Linux)
+
+### 数据挖掘
+
+为了使加密货币交易机器人尽可能做出正确的决定,以可靠的方式获取资产的美国线([OHLC][9])数据是至关重要。你可以使用 Pythonic 的内置元素,还可以根据自己逻辑来对其进行扩展。
+
+一般的工作流程:
+
+1. 与币安时间同步
+2. 下载 OHLC 数据
+3. 从文件中把 OHLC 数据加载到内存
+4. 比较数据集并扩展更新数据集
+
+这个工作流程可能有点夸张,但是它能使得程序更加健壮,甚至在停机和断开连接时,也能平稳运行。
+
+一开始,你需要 **币安 OHLC 查询** 元素和一个 **基础操作** 元素来执行你的代码。
+
+![Data-mining workflow][10]
+
+*数据挖掘工作流程*
+
+OHLC 查询设置为每隔一小时查询一次 **TRXBTC** 资产对(波场/比特币)。
+
+![Configuration of the OHLC query element][11]
+
+*配置 OHLC 查询元素*
+
+其中输出的元素是 [Pandas DataFrame][12]。你可以在 **基础操作** 元素中使用 **输入** 变量来访问 DataFrame。其中,将 Vim 设置为 **基础操作** 元素的默认代码编辑器。
+
+![Basic Operation element set up to use Vim][13]
+
+*使用 Vim 编辑基础操作元素*
+
+具体代码如下:
+
+```
+import pickle, pathlib, os
+import pandas as pd
+
+outout = None
+
+if isinstance(input, pd.DataFrame):
+ file_name = 'TRXBTC_1h.bin'
+ home_path = str(pathlib.Path.home())
+ data_path = os.path.join(home_path, file_name)
+
+ try:
+ df = pickle.load(open(data_path, 'rb'))
+ n_row_cnt = df.shape[0]
+ df = pd.concat([df,input], ignore_index=True).drop_duplicates(['close_time'])
+ df.reset_index(drop=True, inplace=True)
+ n_new_rows = df.shape[0] - n_row_cnt
+ log_txt = '{}: {} new rows written'.format(file_name, n_new_rows)
+ except:
+ log_txt = 'File error - writing new one: {}'.format(e)
+ df = input
+
+ pickle.dump(df, open(data_path, "wb" ))
+ output = df
+```
+
+首先,检查输入是否为 DataFrame 元素。然后在用户的家目录(`~/`)中查找名为 `TRXBTC_1h.bin` 的文件。如果存在,则将其打开,执行新代码段(`try` 部分中的代码),并删除重复项。如果文件不存在,则触发异常并执行 `except` 部分中的代码,创建一个新文件。
+
+只要启用了复选框 **日志输出**,你就可以使用命令行工具 `tail` 查看日志记录:
+
+
+```
+$ tail -f ~/Pythonic_2020/Feb/log_2020_02_19.txt
+```
+
+出于开发目的,现在跳过与币安时间的同步和计划执行,这将在下面实现。
+
+### 准备数据
+
+下一步是在单独的 网格 中处理评估逻辑。因此,你必须借助**返回元素** 将 DataFrame 从网格 1 传递到网格 2 的第一个元素。
+
+在网格 2 中,通过使 DataFrame 通过 **基础技术分析** 元素,将 DataFrame 扩展包含 EMA 值的一列。
+
+![Technical analysis workflow in Grid 2][14]
+
+*在网格 2 中技术分析工作流程*
+
+配置技术分析元素以计算 25 个值的 EMA。
+
+![Configuration of the technical analysis element][15]
+
+*配置技术分析元素*
+
+当你运行整个程序并开启 **技术分析** 元素的调试输出时,你将发现 EMA-25 列的值似乎都相同。
+
+![Missing decimal places in output][16]
+
+*输出中精度不够*
+
+这是因为调试输出中的 EMA-25 值仅包含六位小数,即使输出保留了 8 个字节完整精度的浮点值。
+
+为了能进行进一步处理,请添加 **基础操作** 元素:
+
+![Workflow in Grid 2][17]
+
+*网格 2 中的工作流程*
+
+使用 **基础操作** 元素,将 DataFrame 与添加的 EMA-25 列一起转储,以便可以将其加载到 Jupyter 笔记本中;
+
+![Dump extended DataFrame to file][18]
+
+*将扩展后的 DataFrame 存储到文件中*
+
+### 评估策略
+
+在 Juypter 笔记本中开发评估策略,让你可以更直接地访问代码。要加载 DataFrame,你需要使用如下代码:
+
+![Representation with all decimal places][19]
+
+*用全部小数位表示*
+
+你可以使用 [iloc][20] 和列名来访问最新的 EMA-25 值,并且会保留所有小数位。
+
+你已经知道如何来获得最新的数据。上面示例的最后一行仅显示该值。为了能将该值拷贝到不同的变量中,你必须使用如下图所示的 `.at` 方法方能成功。
+
+你也可以直接计算出你下一步所需的交易参数。
+
+![Buy/sell decision][21]
+
+*买卖决策*
+
+### 确定交易参数
+
+如上面代码所示,我选择 0.009 作为交易参数。但是我怎么知道 0.009 是决定交易的一个好参数呢? 实际上,这个参数确实很糟糕,因此,你可以直接计算出表现最佳的交易参数。
+
+假设你将根据收盘价进行买卖。
+
+![Validation function][22]
+
+*回测功能*
+
+在此示例中,`buy_factor` 和 `sell_factor` 是预先定义好的。因此,发散思维用直接计算出表现最佳的参数。
+
+![Nested for loops for determining the buy and sell factor][23]
+
+*嵌套的 for 循环,用于确定购买和出售的参数*
+
+这要跑 81 个循环(9x9),在我的机器(Core i7 267QM)上花费了几分钟。
+
+![System utilization while brute forcing][24]
+
+*在暴力运算时系统的利用率*
+
+在每个循环之后,它将 `buy_factor`、`sell_factor` 元组和生成的 `profit` 元组追加到 `trading_factors` 列表中。按利润降序对列表进行排序。
+
+![Sort profit with related trading factors in descending order][25]
+
+*将利润与相关的交易参数按降序排序*
+
+当你打印出列表时,你会看到 0.002 是最好的参数。
+
+![Sorted list of trading factors and profit][26]
+
+*交易要素和收益的有序列表*
+
+当我在 2020 年 3 月写下这篇文章时,价格的波动还不足以呈现出更理想的结果。我在 2 月份得到了更好的结果,但即使在那个时候,表现最好的交易参数也在 0.002 左右。
+
+### 分割执行路径
+
+现在开始新建一个网格以保持逻辑清晰。使用 **返回** 元素将带有 EMA-25 列的 DataFrame 从网格 2 传递到网格 3 的 0A 元素。
+
+在网格 3 中,添加 **基础操作** 元素以执行评估逻辑。这是该元素中的代码:
+
+![Implemented evaluation logic][27]
+
+*实现评估策略*
+
+如果输出 `1` 表示你应该购买,如果输出 `2` 则表示你应该卖出。 输出 `0` 表示现在无需操作。使用 **分支** 元素来控制执行路径。
+
+![Branch element: Grid 3 Position 2A][28]
+
+*分支元素:网格 3,2A 位置*
+
+因为 `0` 和 `-1` 的处理流程一样,所以你需要在最右边添加一个分支元素来判断你是否应该卖出。
+
+![Branch element: Grid 3 Position 3B][29]
+
+*分支元素:网格 3,3B 位置*
+
+网格 3 应该现在如下图所示:
+
+![Workflow on Grid 3][30]
+
+*网格 3 的工作流程*
+
+### 下单
+
+由于无需在一个周期中购买两次,因此必须在周期之间保留一个持久变量,以指示你是否已经购买。
+
+你可以利用 **栈** 元素来实现。顾名思义,栈元素表示可以用任何 Python 数据类型来放入的基于文件的栈。
+
+你需要定义栈仅包含一个布尔类型,该布尔类型决定是否购买了(`True`)或(`False`)。因此,你必须使用 `False` 来初始化栈。例如,你可以在网格 4 中简单地通过将 `False` 传递给栈来进行设置。
+
+![Forward a False-variable to the subsequent Stack element][31]
+
+*将 False 变量传输到后续的栈元素中*
+
+在分支树后的栈实例可以进行如下配置:
+
+![Configuration of the Stack element][32]
+
+*设置栈元素*
+
+在栈元素设置中,将 对输入的操作 设置成 无。否则,布尔值将被 `1` 或 `0` 覆盖。
+
+该设置确保仅将一个值保存于栈中(`True` 或 `False`),并且只能读取一个值(为了清楚起见)。
+
+在栈元素之后,你需要另外一个 **分支** 元素来判断栈的值,然后再放置 币安订单 元素。
+
+![Evaluate the variable from the stack][33]
+
+*判断栈中的变量*
+
+将币安订单元素添加到分支元素的 `True` 路径。网格 3 上的工作流现在应如下所示:
+
+![Workflow on Grid 3][34]
+
+*网格 3 的工作流程*
+
+币安订单元素应如下配置:
+
+![Configuration of the Binance Order element][35]
+
+*编辑币安订单元素*
+
+你可以在币安网站上的帐户设置中生成 API 和密钥。
+
+![Creating an API key in Binance][36]
+
+*在币安账户设置中创建一个 API 密钥*
+
+在本文中,每笔交易都是作为市价交易执行的,交易量为 10,000 TRX(2020 年 3 月约为 150 美元)(出于教学的目的,我通过使用市价下单来演示整个过程。因此,我建议至少使用限价下单。)
+
+如果未正确执行下单(例如,网络问题、资金不足或货币对不正确),则不会触发后续元素。因此,你可以假定如果触发了后续元素,则表示该订单已下达。
+
+这是一个成功的 XMRBTC 卖单的输出示例:
+
+![Output of a successfully placed sell order][37]
+
+*成功卖单的输出*
+
+该行为使后续步骤更加简单:你可以始终假设只要成功输出,就表示订单成功。因此,你可以添加一个 **基础操作** 元素,该元素将简单地输出 **True** 并将此值放入栈中以表示是否下单。
+
+如果出现错误的话,你可以在日志信息中查看具体细节(如果启用日志功能)。
+
+![Logging output of Binance Order element][38]
+
+*币安订单元素中的输出日志信息*
+
+### 调度和同步
+
+对于日程调度和同步,请在网格 1 中将整个工作流程置于 币安调度器 元素的前面。
+
+![Binance Scheduler at Grid 1, Position 1A][39]
+
+*在网格 1,1A 位置的币安调度器*
+
+由于币安调度器元素只执行一次,因此请在网格 1 的末尾拆分执行路径,并通过将输出传递回币安调度器来强制让其重新同步。
+
+![Grid 1: Split execution path][40]
+
+*网格 1:拆分执行路径*
+
+5A 元素指向 网格 2 的 1A 元素,并且 5B 元素指向网格 1 的 1A 元素(币安调度器)。
+
+### 部署
+
+你可以在本地计算机上全天候 7×24 小时运行整个程序,也可以将其完全托管在廉价的云系统上。例如,你可以使用 Linux/FreeBSD 云系统,每月约 5 美元,但通常不提供图形化界面。如果你想利用这些低成本的云,可以使用 PythonicDaemon,它能在终端中完全运行。
+
+![PythonicDaemon console interface][41]
+
+*PythonicDaemon 控制台*
+
+PythonicDaemon 是基础程序的一部分。要使用它,请保存完整的工作流程,将其传输到远程运行的系统中(例如,通过安全拷贝协议 SCP),然后把工作流程文件作为参数来启动 PythonicDaemon:
+
+```
+$ PythonicDaemon trading_bot_one
+```
+
+为了能在系统启动时自启 PythonicDaemon,可以将一个条目添加到 crontab 中:
+
+```
+# crontab -e
+```
+
+![Crontab on Ubuntu Server][42]
+
+*在 Ubuntu 服务器上的 Crontab*
+
+### 下一步
+
+正如我在一开始时所说的,本教程只是自动交易的入门。对交易机器人进行编程大约需要 10% 的编程和 90% 的测试。当涉及到让你的机器人用金钱交易时,你肯定会对编写的代码再三思考。因此,我建议你编码时要尽可能简单和易于理解。
+
+如果你想自己继续开发交易机器人,接下来所需要做的事:
+
+- 收益自动计算(希望你有正收益!)
+- 计算你想买的价格
+- 比较你的预订单(例如,订单是否填写完整?)
+
+你可以从 [GitHub][2] 上获取完整代码。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/4/python-crypto-trading-bot
+
+作者:[Stephan Avenwedde][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/hansic99
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calculator_money_currency_financial_tool.jpg?itok=2QMa1y8c "scientific calculator"
+[2]: https://github.com/hANSIc99/Pythonic
+[3]: https://opensource.com/article/19/5/graphically-programming-pythonic
+[4]: https://tron.network/
+[5]: https://bitcoin.org/en/
+[6]: https://www.binance.com/
+[7]: https://www.investopedia.com/terms/e/ema.asp
+[8]: https://opensource.com/sites/default/files/uploads/1_ema-25.png "TRX/BTC 1-hour candle chart"
+[9]: https://en.wikipedia.org/wiki/Open-high-low-close_chart
+[10]: https://opensource.com/sites/default/files/uploads/2_data-mining-workflow.png "Data-mining workflow"
+[11]: https://opensource.com/sites/default/files/uploads/3_ohlc-query.png "Configuration of the OHLC query element"
+[12]: https://pandas.pydata.org/pandas-docs/stable/getting_started/dsintro.html#dataframe
+[13]: https://opensource.com/sites/default/files/uploads/4_edit-basic-operation.png "Basic Operation element set up to use Vim"
+[14]: https://opensource.com/sites/default/files/uploads/6_grid2-workflow.png "Technical analysis workflow in Grid 2"
+[15]: https://opensource.com/sites/default/files/uploads/7_technical-analysis-config.png "Configuration of the technical analysis element"
+[16]: https://opensource.com/sites/default/files/uploads/8_missing-decimals.png "Missing decimal places in output"
+[17]: https://opensource.com/sites/default/files/uploads/9_basic-operation-element.png "Workflow in Grid 2"
+[18]: https://opensource.com/sites/default/files/uploads/10_dump-extended-dataframe.png "Dump extended DataFrame to file"
+[19]: https://opensource.com/sites/default/files/uploads/11_load-dataframe-decimals.png "Representation with all decimal places"
+[20]: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html
+[21]: https://opensource.com/sites/default/files/uploads/12_trade-factor-decision.png "Buy/sell decision"
+[22]: https://opensource.com/sites/default/files/uploads/13_validation-function.png "Validation function"
+[23]: https://opensource.com/sites/default/files/uploads/14_brute-force-tf.png "Nested for loops for determining the buy and sell factor"
+[24]: https://opensource.com/sites/default/files/uploads/15_system-utilization.png "System utilization while brute forcing"
+[25]: https://opensource.com/sites/default/files/uploads/16_sort-profit.png "Sort profit with related trading factors in descending order"
+[26]: https://opensource.com/sites/default/files/uploads/17_sorted-trading-factors.png "Sorted list of trading factors and profit"
+[27]: https://opensource.com/sites/default/files/uploads/18_implemented-evaluation-logic.png "Implemented evaluation logic"
+[28]: https://opensource.com/sites/default/files/uploads/19_output.png "Branch element: Grid 3 Position 2A"
+[29]: https://opensource.com/sites/default/files/uploads/20_editbranch.png "Branch element: Grid 3 Position 3B"
+[30]: https://opensource.com/sites/default/files/uploads/21_grid3-workflow.png "Workflow on Grid 3"
+[31]: https://opensource.com/sites/default/files/uploads/22_pass-false-to-stack.png "Forward a False-variable to the subsequent Stack element"
+[32]: https://opensource.com/sites/default/files/uploads/23_stack-config.png "Configuration of the Stack element"
+[33]: https://opensource.com/sites/default/files/uploads/24_evaluate-stack-value.png "Evaluate the variable from the stack"
+[34]: https://opensource.com/sites/default/files/uploads/25_grid3-workflow.png "Workflow on Grid 3"
+[35]: https://opensource.com/sites/default/files/uploads/26_binance-order.png "Configuration of the Binance Order element"
+[36]: https://opensource.com/sites/default/files/uploads/27_api-key-binance.png "Creating an API key in Binance"
+[37]: https://opensource.com/sites/default/files/uploads/28_sell-order.png "Output of a successfully placed sell order"
+[38]: https://opensource.com/sites/default/files/uploads/29_binance-order-output.png "Logging output of Binance Order element"
+[39]: https://opensource.com/sites/default/files/uploads/30_binance-scheduler.png "Binance Scheduler at Grid 1, Position 1A"
+[40]: https://opensource.com/sites/default/files/uploads/31_split-execution-path.png "Grid 1: Split execution path"
+[41]: https://opensource.com/sites/default/files/uploads/32_pythonic-daemon.png "PythonicDaemon console interface"
+[42]: https://opensource.com/sites/default/files/uploads/33_crontab.png "Crontab on Ubuntu Server"
diff --git a/published/202103/20200702 6 best practices for managing Git repos.md b/published/202103/20200702 6 best practices for managing Git repos.md
new file mode 100644
index 0000000000..81fb81347e
--- /dev/null
+++ b/published/202103/20200702 6 best practices for managing Git repos.md
@@ -0,0 +1,136 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13200-1.html)
+[#]: subject: (6 best practices for managing Git repos)
+[#]: via: (https://opensource.com/article/20/7/git-repos-best-practices)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+6 个最佳的 Git 仓库管理实践
+======
+
+> 抵制在 Git 中添加一些会增加管理难度的东西的冲动;这里有替代方法。
+
+
+
+有权访问源代码使对安全性的分析以及应用程序的安全成为可能。但是,如果没有人真正看过代码,问题就不会被发现,即使人们主动地看代码,通常也要看很多东西。幸运的是,GitHub 拥有一个活跃的安全团队,最近,他们 [发现了已提交到多个 Git 仓库中的特洛伊木马病毒][2],甚至仓库的所有者也偷偷溜走了。尽管我们无法控制其他人如何管理自己的仓库,但我们可以从他们的错误中吸取教训。为此,本文回顾了将文件添加到自己的仓库中的一些最佳实践。
+
+### 了解你的仓库
+
+![Git 仓库终端][3]
+
+这对于安全的 Git 仓库来可以说是头号规则。作为项目维护者,无论是你自己创建的还是采用别人的,你的工作是了解自己仓库中的内容。你可能无法记住代码库中每一个文件,但是你需要了解你所管理的内容的基本组成部分。如果在几十个合并后出现一个游离的文件,你会很容易地发现它,因为你不知道它的用途,你需要检查它来刷新你的记忆。发生这种情况时,请查看该文件,并确保准确了解为什么它是必要的。
+
+### 禁止二进制大文件
+
+![终端中 Git 的二进制检查命令][4]
+
+Git 是为文本而生的,无论是用纯文本编写的 C 或 Python 还是 Java 文本,亦或是 JSON、YAML、XML、Markdown、HTML 或类似的文本。Git 对于二进制文件不是很理想。
+
+两者之间的区别是:
+
+```
+$ cat hello.txt
+This is plain text.
+It's readable by humans and machines alike.
+Git knows how to version this.
+
+$ git diff hello.txt
+diff --git a/hello.txt b/hello.txt
+index f227cc3..0d85b44 100644
+--- a/hello.txt
++++ b/hello.txt
+@@ -1,2 +1,3 @@
+ This is plain text.
++It's readable by humans and machines alike.
+ Git knows how to version this.
+```
+
+和
+
+```
+$ git diff pixel.png
+diff --git a/pixel.png b/pixel.png
+index 563235a..7aab7bc 100644
+Binary files a/pixel.png and b/pixel.png differ
+
+$ cat pixel.png
+�PNG
+▒
+IHDR7n�$gAMA��
+ �abKGD݊�tIME�
+
+ -2R��
+IDA�c`�!�3%tEXtdate:create2020-06-11T11:45:04+12:00��r.%tEXtdate:modify2020-06-11T11:45:04+12:00��ʒIEND�B`�
+```
+
+二进制文件中的数据不能像纯文本一样被解析,因此,如果二进制文件发生任何更改,则必须重写整个内容。一个版本与另一个版本之间唯一的区别就是全部不同,这会快速增加仓库大小。
+
+更糟糕的是,Git 仓库维护者无法合理地审计二进制数据。这违反了头号规则:应该对仓库的内容了如指掌。
+
+除了常用的 [POSIX][5] 工具之外,你还可以使用 `git diff` 检测二进制文件。当你尝试使用 `--numstat` 选项来比较二进制文件时,Git 返回空结果:
+
+```
+$ git diff --numstat /dev/null pixel.png | tee
+- - /dev/null => pixel.png
+$ git diff --numstat /dev/null file.txt | tee
+5788 0 /dev/null => list.txt
+```
+
+如果你正在考虑将二进制大文件(BLOB)提交到仓库,请停下来先思考一下。如果它是二进制文件,那它是由什么生成的。是否有充分的理由不在构建时生成它们,而是将它们提交到仓库?如果你认为提交二进制数据是有意义的,请确保在 `README` 文件或类似文件中指明二进制文件的位置、为什么是二进制文件的原因以及更新它们的协议是什么。必须谨慎对其更新,因为你每提交一个二进制大文件的变化,它的存储空间实际上都会加倍。
+
+### 让第三方库留在第三方
+
+第三方库也不例外。尽管它是开源的众多优点之一,你可以不受限制地重用和重新分发不是你编写的代码,但是有很多充分的理由不把第三方库存储在你自己的仓库中。首先,除非你自己检查了所有代码(以及将来的合并),否则你不能为第三方完全担保。其次,当你将第三方库复制到你的 Git 仓库中时,会将焦点从真正的上游源代码中分离出来。从技术上讲,对库有信心的人只对该库的主副本有把握,而不是对随机仓库的副本有把握。如果你需要锁定特定版本的库,请给开发者提供一个合理的项目所需的发布 URL,或者使用 [Git 子模块][6]。
+
+### 抵制盲目的 git add
+
+![Git 手动添加命令终端中][7]
+
+如果你的项目已编译,请抵制住使用 `git add .` 的冲动(其中 `.` 是当前目录或特定文件夹的路径),因为这是一种添加任何新东西的简单方法。如果你不是手动编译项目,而是使用 IDE 为你管理项目,这一点尤其重要。用 IDE 管理项目时,跟踪添加到仓库中的内容会非常困难,因此仅添加你实际编写的内容非常重要,而不是添加项目文件夹中出现的任何新对象。
+
+如果你使用了 `git add .`,请在推送之前检查暂存区里的内容。如果在运行 `make clean` 或等效命令后,执行 `git status` 时在项目文件夹中看到一个陌生的对象,请找出它的来源,以及为什么仍然在项目的目录中。这是一种罕见的构建工件,不会在编译期间重新生成,因此在提交前请三思。
+
+### 使用 Git ignore
+
+![终端中的 `Git ignore` 命令][8]
+
+许多为程序员打造的便利也非常杂乱。任何项目的典型项目目录,无论是编程的,还是艺术的或其他的,到处都是隐藏的文件、元数据和遗留的工件。你可以尝试忽略这些对象,但是 `git status` 中的提示越多,你错过某件事的可能性就越大。
+
+你可以通过维护一个良好的 `gitignore` 文件来为你过滤掉这种噪音。因为这是使用 Git 的用户的共同要求,所以有一些入门级的 `gitignore` 文件。[Github.com/github/gitignore][9] 提供了几个专门创建的 `gitignore` 文件,你可以下载这些文件并将其放置到自己的项目中,[Gitlab.com][10] 在几年前就将`gitignore` 模板集成到了仓库创建工作流程中。使用这些模板来帮助你为项目创建适合的 `gitignore` 策略并遵守它。
+
+### 查看合并请求
+
+![Git 合并请求][11]
+
+当你通过电子邮件收到一个合并/拉取请求或补丁文件时,不要只是为了确保它能正常工作而进行测试。你的工作是阅读进入代码库的新代码,并了解其是如何产生结果的。如果你不同意这个实现,或者更糟的是,你不理解这个实现,请向提交该实现的人发送消息,并要求其进行说明。质疑那些希望成为版本库永久成员的代码并不是一种社交失误,但如果你不知道你把什么合并到用户使用的代码中,那就是违反了你和用户之间的社交契约。
+
+### Git 责任
+
+社区致力于开源软件良好的安全性。不要鼓励你的仓库中不良的 Git 实践,也不要忽视你克隆的仓库中的安全威胁。Git 功能强大,但它仍然只是一个计算机程序,因此要以人为本,确保每个人的安全。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/7/git-repos-best-practices
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/wfh_work_home_laptop_work.png?itok=VFwToeMy (Working from home at a laptop)
+[2]: https://securitylab.github.com/research/octopus-scanner-malware-open-source-supply-chain/
+[3]: https://opensource.com/sites/default/files/uploads/git_repo.png (Git repository )
+[4]: https://opensource.com/sites/default/files/uploads/git-binary-check.jpg (Git binary check)
+[5]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[6]: https://git-scm.com/book/en/v2/Git-Tools-Submodules
+[7]: https://opensource.com/sites/default/files/uploads/git-cola-manual-add.jpg (Git manual add)
+[8]: https://opensource.com/sites/default/files/uploads/git-ignore.jpg (Git ignore)
+[9]: https://github.com/github/gitignore
+[10]: https://about.gitlab.com/releases/2016/05/22/gitlab-8-8-released
+[11]: https://opensource.com/sites/default/files/uploads/git_merge_request.png (Git merge request)
diff --git a/published/202103/20200915 Improve your time management with Jupyter.md b/published/202103/20200915 Improve your time management with Jupyter.md
new file mode 100644
index 0000000000..3a1cd3d81d
--- /dev/null
+++ b/published/202103/20200915 Improve your time management with Jupyter.md
@@ -0,0 +1,315 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13212-1.html)
+[#]: subject: (Improve your time management with Jupyter)
+[#]: via: (https://opensource.com/article/20/9/calendar-jupyter)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+使用 Jupyter 改善你的时间管理
+======
+
+> 在 Jupyter 里使用 Python 来分析日历,以了解你是如何使用时间的。
+
+
+
+[Python][2] 在探索数据方面具有令人难以置信的可扩展性。利用 [Pandas][3] 或 [Dask][4],你可以将 [Jupyter][5] 扩展到大数据领域。但是小数据、个人资料、私人数据呢?
+
+JupyterLab 和 Jupyter Notebook 为我提供了一个绝佳的环境,可以让我审视我的笔记本电脑生活。
+
+我的探索是基于以下事实:我使用的几乎每个服务都有一个 Web API。我使用了诸多此类服务:待办事项列表、时间跟踪器、习惯跟踪器等。还有一个几乎每个人都会使用到:_日历_。相同的思路也可以应用于其他服务,但是日历具有一个很酷的功能:几乎所有 Web 日历都支持的开放标准 —— CalDAV。
+
+### 在 Jupyter 中使用 Python 解析日历
+
+大多数日历提供了导出为 CalDAV 格式的方法。你可能需要某种身份验证才能访问这些私有数据。按照你的服务说明进行操作即可。如何获得凭据取决于你的服务,但是最终,你应该能够将这些凭据存储在文件中。我将我的凭据存储在根目录下的一个名为 `.caldav` 的文件中:
+
+```
+import os
+with open(os.path.expanduser("~/.caldav")) as fpin:
+ username, password = fpin.read().split()
+```
+
+切勿将用户名和密码直接放在 Jupyter Notebook 的笔记本中!它们可能会很容易因 `git push` 的错误而导致泄漏。
+
+下一步是使用方便的 PyPI [caldav][6] 库。我找到了我的电子邮件服务的 CalDAV 服务器(你可能有所不同):
+
+```
+import caldav
+client = caldav.DAVClient(url="https://caldav.fastmail.com/dav/", username=username, password=password)
+```
+
+CalDAV 有一个称为 `principal`(主键)的概念。它是什么并不重要,只要知道它是你用来访问日历的东西就行了:
+
+```
+principal = client.principal()
+calendars = principal.calendars()
+```
+
+从字面上讲,日历就是关于时间的。访问事件之前,你需要确定一个时间范围。默认一星期就好:
+
+```
+from dateutil import tz
+import datetime
+now = datetime.datetime.now(tz.tzutc())
+since = now - datetime.timedelta(days=7)
+```
+
+大多数人使用的日历不止一个,并且希望所有事件都在一起出现。`itertools.chain.from_iterable` 方法使这一过程变得简单:
+
+```
+import itertools
+
+raw_events = list(
+ itertools.chain.from_iterable(
+ calendar.date_search(start=since, end=now, expand=True)
+ for calendar in calendars
+ )
+)
+```
+
+将所有事件读入内存很重要,以 API 原始的本地格式进行操作是重要的实践。这意味着在调整解析、分析和显示代码时,无需返回到 API 服务刷新数据。
+
+但 “原始” 真的是原始,事件是以特定格式的字符串出现的:
+
+```
+print(raw_events[12].data)
+```
+
+```
+ BEGIN:VCALENDAR
+ VERSION:2.0
+ PRODID:-//CyrusIMAP.org/Cyrus
+ 3.3.0-232-g4bdb081-fm-20200825.002-g4bdb081a//EN
+ BEGIN:VEVENT
+ DTEND:20200825T230000Z
+ DTSTAMP:20200825T181915Z
+ DTSTART:20200825T220000Z
+ SUMMARY:Busy
+ UID:
+ 1302728i-040000008200E00074C5B7101A82E00800000000D939773EA578D601000000000
+ 000000010000000CD71CC3393651B419E9458134FE840F5
+ END:VEVENT
+ END:VCALENDAR
+```
+
+幸运的是,PyPI 可以再次使用另一个辅助库 [vobject][7] 解围:
+
+```
+import io
+import vobject
+
+def parse_event(raw_event):
+ data = raw_event.data
+ parsed = vobject.readOne(io.StringIO(data))
+ contents = parsed.vevent.contents
+ return contents
+```
+
+```
+parse_event(raw_events[12])
+```
+
+```
+ {'dtend': [],
+ 'dtstamp': [],
+ 'dtstart': [],
+ 'summary': [],
+ 'uid': []}
+```
+
+好吧,至少好一点了。
+
+仍有一些工作要做,将其转换为合理的 Python 对象。第一步是 _拥有_ 一个合理的 Python 对象。[attrs][8] 库提供了一个不错的开始:
+
+```
+import attr
+from __future__ import annotations
+@attr.s(auto_attribs=True, frozen=True)
+class Event:
+ start: datetime.datetime
+ end: datetime.datetime
+ timezone: Any
+ summary: str
+```
+
+是时候编写转换代码了!
+
+第一个抽象从解析后的字典中获取值,不需要所有的装饰:
+
+```
+def get_piece(contents, name):
+ return contents[name][0].value
+get_piece(_, "dtstart")
+ datetime.datetime(2020, 8, 25, 22, 0, tzinfo=tzutc())
+```
+
+日历事件总有一个“开始”、有一个“结束”、有一个 “持续时间”。一些谨慎的解析逻辑可以将两者协调为同一个 Python 对象:
+
+```
+def from_calendar_event_and_timezone(event, timezone):
+ contents = parse_event(event)
+ start = get_piece(contents, "dtstart")
+ summary = get_piece(contents, "summary")
+ try:
+ end = get_piece(contents, "dtend")
+ except KeyError:
+ end = start + get_piece(contents, "duration")
+ return Event(start=start, end=end, summary=summary, timezone=timezone)
+```
+
+将事件放在 _本地_ 时区而不是 UTC 中很有用,因此使用本地时区:
+
+```
+my_timezone = tz.gettz()
+from_calendar_event_and_timezone(raw_events[12], my_timezone)
+ Event(start=datetime.datetime(2020, 8, 25, 22, 0, tzinfo=tzutc()), end=datetime.datetime(2020, 8, 25, 23, 0, tzinfo=tzutc()), timezone=tzfile('/etc/localtime'), summary='Busy')
+```
+
+既然事件是真实的 Python 对象,那么它们实际上应该具有附加信息。幸运的是,可以将方法添加到类中。
+
+但是要弄清楚哪个事件发生在哪一天不是很直接。你需要在 _本地_ 时区中选择一天:
+
+```
+def day(self):
+ offset = self.timezone.utcoffset(self.start)
+ fixed = self.start + offset
+ return fixed.date()
+Event.day = property(day)
+```
+
+```
+print(_.day)
+ 2020-08-25
+```
+
+事件在内部始终是以“开始”/“结束”的方式表示的,但是持续时间是有用的属性。持续时间也可以添加到现有类中:
+
+```
+def duration(self):
+ return self.end - self.start
+Event.duration = property(duration)
+```
+
+```
+print(_.duration)
+ 1:00:00
+```
+
+现在到了将所有事件转换为有用的 Python 对象了:
+
+```
+all_events = [from_calendar_event_and_timezone(raw_event, my_timezone)
+ for raw_event in raw_events]
+```
+
+全天事件是一种特例,可能对分析生活没有多大用处。现在,你可以忽略它们:
+
+```
+# ignore all-day events
+all_events = [event for event in all_events if not type(event.start) == datetime.date]
+```
+
+事件具有自然顺序 —— 知道哪个事件最先发生可能有助于分析:
+
+```
+all_events.sort(key=lambda ev: ev.start)
+```
+
+现在,事件已排序,可以将它们加载到每天:
+
+```
+import collections
+events_by_day = collections.defaultdict(list)
+for event in all_events:
+ events_by_day[event.day].append(event)
+```
+
+有了这些,你就有了作为 Python 对象的带有日期、持续时间和序列的日历事件。
+
+### 用 Python 报到你的生活
+
+现在是时候编写报告代码了!带有适当的标题、列表、重要内容以粗体显示等等,有醒目的格式是很意义。
+
+这就是一些 HTML 和 HTML 模板。我喜欢使用 [Chameleon][9]:
+
+```
+template_content = """
+
+
+"""
+```
+
+Chameleon 的一个很酷的功能是使用它的 `html` 方法渲染对象。我将以两种方式使用它:
+
+ * 摘要将以粗体显示
+ * 对于大多数活动,我都会删除摘要(因为这是我的个人信息)
+
+```
+def __html__(self):
+ offset = my_timezone.utcoffset(self.start)
+ fixed = self.start + offset
+ start_str = str(fixed).split("+")[0]
+ summary = self.summary
+ if summary != "Busy":
+ summary = "<REDACTED>"
+ return f"{summary[:30]} -- {start_str} ({self.duration})"
+Event.__html__ = __html__
+```
+
+为了简洁起见,将该报告切成每天的:
+
+```
+import chameleon
+from IPython.display import HTML
+template = chameleon.PageTemplate(template_content)
+html = template(items=itertools.islice(events_by_day.items(), 3, 4))
+HTML(html)
+```
+
+渲染后,它将看起来像这样:
+
+**2020-08-25**
+
+- **\** -- 2020-08-25 08:30:00 (0:45:00)
+- **\** -- 2020-08-25 10:00:00 (1:00:00)
+- **\** -- 2020-08-25 11:30:00 (0:30:00)
+- **\** -- 2020-08-25 13:00:00 (0:25:00)
+- Busy -- 2020-08-25 15:00:00 (1:00:00)
+- **\** -- 2020-08-25 15:00:00 (1:00:00)
+- **\** -- 2020-08-25 19:00:00 (1:00:00)
+- **\** -- 2020-08-25 19:00:12 (1:00:00)
+
+### Python 和 Jupyter 的无穷选择
+
+通过解析、分析和报告各种 Web 服务所拥有的数据,这只是你可以做的事情的表面。
+
+为什么不对你最喜欢的服务试试呢?
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/9/calendar-jupyter
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calendar.jpg?itok=jEKbhvDT (Calendar close up snapshot)
+[2]: https://opensource.com/resources/python
+[3]: https://pandas.pydata.org/
+[4]: https://dask.org/
+[5]: https://jupyter.org/
+[6]: https://pypi.org/project/caldav/
+[7]: https://pypi.org/project/vobject/
+[8]: https://opensource.com/article/19/5/python-attrs
+[9]: https://chameleon.readthedocs.io/en/latest/
diff --git a/published/202103/20201014 Teach a virtual class with Moodle on Linux.md b/published/202103/20201014 Teach a virtual class with Moodle on Linux.md
new file mode 100644
index 0000000000..b41b64f498
--- /dev/null
+++ b/published/202103/20201014 Teach a virtual class with Moodle on Linux.md
@@ -0,0 +1,181 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13190-1.htmlhttps://linux.cn/article-13190-1.html)
+[#]: subject: (Teach a virtual class with Moodle on Linux)
+[#]: via: (https://opensource.com/article/20/10/moodle)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+
+基于 Linux 的 Moodle 虚拟课堂教学
+======
+
+> 基于 Linux 的 Moodle 学习管理系统进行远程教学。
+
+
+
+这次大流行对远程教育的需求比以往任何时候都更大。使得像 [Moodle][2] 这样的学习管理系统(LMS)比以往任何时候都重要,因为越来越多的学校教育是借助虚拟现实技术的提供。
+
+Moodle 是用 PHP 编写的免费 LMS,并以开源 [GNU 公共许可证][3](GPL)分发。它是由 [Martin Dougiamas][4] 开发的,自 2002 年发布以来一直在不断发展。Moodle 可用于混合学习、远程学习、翻转课堂和其他形式的在线学习。目前,全球有超过 [1.9 亿用户][5] 和 145,000 个注册的 Moodle 网站。
+
+我曾作为 Moodle 管理员、教师和学生等角色使用过 Moodle,在本文中,我将向你展示如何设置并开始使用它。
+
+### 在 Linux 系统上安装 Moodle
+
+Moodle 对 [系统要求][6] 适中,并且有大量文档可为你提供帮助。我最喜欢的安装方法是从 [Turnkey Linux][7] 下载并制作 ISO,然后在 VirtualBox 中安装 Moodle 网站。
+
+首先,下载 [Moodle ISO][8] 保存到电脑中。
+
+下一步,安装 VirtualBox 的 Linux 命令行如下:
+
+```
+$ sudo apt install virtualbox
+```
+
+或,
+
+```
+$ sudo dnf install virtualbox
+```
+
+当下载完成后,启动 VirtualBox 并在控制台中选择“新建”按钮。
+
+![创建一个新的 VirtualBox 虚拟机][9]
+
+选择使用的虚拟机的名称、操作系统(Linux)和 Linux 类型(例如 Debian 64 位)。
+
+![命名 VirtualBox 虚拟机][11]
+
+下一步,配置虚拟机内存大小,使用默认值 1024 MB。接下来选择 “动态分配”虚拟磁盘并在虚拟机中添加 `Moodle.iso` 镜像。
+
+![添加 Moodle.iso 到虚拟机][12]
+
+将你的网络设置从 NAT 更改为 “桥接模式”。然后启动虚拟机并安装 ISO 以创建 Moodle 虚拟机。在安装过程中,系统将提示为 root 帐户、MySQL 和Moodle 创建密码。Moodle 密码必须至少包含八个字符,至少一个大写字母和至少一个特殊字符。
+
+重启虚拟机。安装完成后,请确保将 Moodle 应用配置内容记录在安全的地方。(安装后,可以根据需要删除 ISO 文件。)
+
+![Moodle 应用配置][13]
+
+重要提示,在互联网上的任何人还看不到你的 Moodle 实例。它仅存在于你的本地网络中:现在只有建筑物中与你连接到相同的路由器或 wifi 接入点的人可以访问你的站点。全世界的互联网无法连接到它,因为你位于防火墙(可能嵌入在路由器中,还可能嵌入在计算机中)的后面。有关网络配置的更多信息,请阅读 Seth Kenlon 关于 [打开端口和通过防火墙进行流量路由][14] 的文章。
+
+### 开始使用 Moodle
+
+现在你可以登录到 Moodle 机器并熟悉该软件了。使用默认的用户名 `admin` 和创建 Moodle VM 时设置的密码登录 Moodle。
+
+![Moodle 登录界面][15]
+
+首次登录后,你将看到初始的 Moodle 网站的主仪表盘。
+
+![Moodle 管理员仪表盘][16]
+
+默认的应用名称是 “Turnkey Moodle”,但是可以很容易地对其进行更改以适合你的学校、课堂或其他需要和选择。要使你的 Moodle 网站个性化,请在用户界面左侧的菜单中,选择“站点首页”。然后,点击屏幕右侧的 “设置” 图标,然后选择 “编辑设置”。
+
+![Moodle 设置][17]
+
+你可以根据需要更改站点名称,并添加简短名称和站点描述。
+
+![Moodle 网站名][18]
+
+确保滚动到底部并保存更改。现在,你的网站已定制好。
+
+![Moodle 保存更改][19]
+
+默认类别为其他,这不会帮助人们识别你网站的目的。要添加类别,请返回主仪表盘,然后从左侧菜单中选择 “站点管理”。 在 “课程”下,选择 “添加类别”并输入有关你的网站的详细信息。
+
+![在 Moodle 中添加类别选项][20]
+
+要添加课程,请返回 “站点管理”,然后单击 “添加新课程”。你将看到一系列选项,例如为课程命名、提供简短名称、设定类别以及设置课程的开始和结束日期。你还可以为课程形式设置选项,例如社交、每周式课程、主题,以及其外观、文件上传大小、完成情况跟踪等等。
+
+![在 Moodle 中添加课程选项][21]
+
+### 添加和管理用户
+
+现在,你已经设置了课程,你可以添加用户。有多种方法可以做到这一点。如果你是家庭教师,则手动输入是一个不错的开始。Moodle 支持基于电子邮件的注册、[LDAP][22]、[Shibboleth(口令或暗语)][23] 和许多其他方式等。校区和其他较大的机构可以用逗号分隔的文件上传用户。也可以批量添加密码,并在首次登录时强制更改密码。有关更多信息,一定要查阅 Moodle [文档][24]。
+
+Moodle 是一个非常细化的、面向许可的环境。使用 Moodle 的菜单将策略和角色分配给用户并执行这些分配很容易。
+
+Moodle 中有许多角色,每个角色都有特定的特权和许可。默认角色有管理员、课程创建者、教师、非编辑教师、学生、来宾和经过身份验证的用户,但你可以添加其他角色。
+
+### 为课程添加内容
+
+一旦搭建了 Moodle 网站并设置了课程,就可以向课程中添加内容。Moodle 拥有创建出色内容所需要的所有工具,并且它建立在强调 [社会建构主义][25] 观点的坚实教学法之上。
+
+我创建了一个名为 “Code with [Mu][26]” 的示例课程。它在 “编程” 类别和 “Python” 子类别中。
+
+![Moodle 课程列表][27]
+
+我为课程选择了每周式课程,默认为四个星期。使用编辑工具,我隐藏了除课程第一周以外的所有内容。这样可以确保我的学生始终专注于材料。
+
+作为教师或 Moodle 管理员,我可以通过单击 “添加活动或资源” 来将活动添加到每周的教学中。
+
+![在 Moodle 中添加活动][28]
+
+我会看到一个弹出窗口,其中包含可以分配给我的学生的各种活动。
+
+![Moodle 活动菜单][29]
+
+Moodle 的工具和活动使我可以轻松地创建学习材料,并以一个简短的测验来结束一周的学习。
+
+![Moodle 活动清单][30]
+
+你可以使用 1600 多个插件来扩展 Moodle,包括新的活动、问题类型,与其他系统的集成等等。例如,[BigBlueButton][31] 插件支持幻灯片共享、白板、音频和视频聊天以及分组讨论。其他值得考虑的包括用于视频会议的 [Jitsi][32] 插件、[抄袭检查器][33] 和用于颁发徽章的 [开放徽章工厂][34]。
+
+### 继续探索 Moodle
+
+Moodle 是一个功能强大的 LMS,我希望此介绍能引起你的兴趣,以了解更多信息。有很多出色的 [指南][35] 可以帮助你提高技能,如果想要查看 Moodle 的内容,可以在其 [演示站点][36] 上查看运行中的 Moodle;如果你想了解 Moodle 的底层结构或为开发做出 [贡献][38],也可以访问 [Moodle 的源代码][37]。如果你喜欢在旅途中工作,Moodle 也有一款出色的 [移动应用][39],适用于 iOS 和 Android。在 [Twitter][40]、[Facebook][41] 和 [LinkedIn][42] 上关注 Moodle,以了解最新消息。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/10/moodle
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_desk_home_laptop_browser.png?itok=Y3UVpY0l (Digital images of a computer desktop)
+[2]: https://moodle.org/
+[3]: https://docs.moodle.org/19/en/GNU_General_Public_License
+[4]: https://dougiamas.com/about/
+[5]: https://docs.moodle.org/39/en/History
+[6]: https://docs.moodle.org/39/en/Installation_quick_guide#Basic_Requirements
+[7]: https://www.turnkeylinux.org/
+[8]: https://www.turnkeylinux.org/download?file=turnkey-moodle-16.0-buster-amd64.iso
+[9]: https://opensource.com/sites/default/files/uploads/virtualbox_new.png (Create a new VirtualBox)
+[10]: https://creativecommons.org/licenses/by-sa/4.0/
+[11]: https://opensource.com/sites/default/files/uploads/virtualbox_namevm.png (Naming the VirtualBox VM)
+[12]: https://opensource.com/sites/default/files/uploads/virtualbox_attach-iso.png (Attaching Moodle.iso to VM)
+[13]: https://opensource.com/sites/default/files/uploads/moodle_appliance.png (Moodle appliance settings)
+[14]: https://opensource.com/article/20/9/firewall
+[15]: https://opensource.com/sites/default/files/uploads/moodle_login.png (Moodle login screen)
+[16]: https://opensource.com/sites/default/files/uploads/moodle_dashboard.png (Moodle admin dashboard)
+[17]: https://opensource.com/sites/default/files/uploads/moodle_settings.png (Moodle settings)
+[18]: https://opensource.com/sites/default/files/uploads/moodle_name-site.png (Name Moodle site)
+[19]: https://opensource.com/sites/default/files/uploads/moodle_saved.png (Moodle changes saved)
+[20]: https://opensource.com/sites/default/files/uploads/moodle_addcategory.png (Add category option in Moodle)
+[21]: https://opensource.com/sites/default/files/uploads/moodle_addcourse.png (Add course option in Moodle)
+[22]: https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol
+[23]: https://www.shibboleth.net/
+[24]: https://docs.moodle.org/39/en/Main_page
+[25]: https://docs.moodle.org/39/en/Pedagogy#How_Moodle_tries_to_support_a_Social_Constructionist_view
+[26]: https://opensource.com/article/20/9/teach-python-mu
+[27]: https://opensource.com/sites/default/files/uploads/moodle_choosecourse.png (Moodle course list)
+[28]: https://opensource.com/sites/default/files/uploads/moodle_addactivity_0.png (Add activity in Moodle)
+[29]: https://opensource.com/sites/default/files/uploads/moodle_activitiesmenu.png (Moodle activities menu)
+[30]: https://opensource.com/sites/default/files/uploads/moodle_activitieschecklist.png (Moodle activities checklist)
+[31]: https://moodle.org/plugins/mod_bigbluebuttonbn
+[32]: https://moodle.org/plugins/mod_jitsi
+[33]: https://moodle.org/plugins/plagiarism_unicheck
+[34]: https://moodle.org/plugins/local_obf
+[35]: https://learn.moodle.org/
+[36]: https://school.moodledemo.net/
+[37]: https://git.in.moodle.com/moodle/moodle
+[38]: https://git.in.moodle.com/moodle/moodle/-/blob/master/CONTRIBUTING.txt
+[39]: https://download.moodle.org/mobile/
+[40]: https://twitter.com/moodle
+[41]: https://www.facebook.com/moodle
+[42]: https://www.linkedin.com/company/moodle/
diff --git a/published/202103/20201215 6 container concepts you need to understand.md b/published/202103/20201215 6 container concepts you need to understand.md
new file mode 100644
index 0000000000..30d8ba7631
--- /dev/null
+++ b/published/202103/20201215 6 container concepts you need to understand.md
@@ -0,0 +1,104 @@
+[#]: collector: (lujun9972)
+[#]: translator: (AmorSu)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13170-1.html)
+[#]: subject: (6 container concepts you need to understand)
+[#]: via: (https://opensource.com/article/20/12/containers-101)
+[#]: author: (Mike Calizo https://opensource.com/users/mcalizo)
+
+6 个必知必会的关于容器的概念
+======
+
+> 容器现在是无所不在,它们已经快速的改变了 IT 格局。关于容器你需要知道一些什么呢?
+
+
+
+因为容器给企业所带来的巨大的价值和大量的好处,它快速的改变了 IT 格局。几乎所有最新的业务创新,都有容器化贡献的一部分因素,甚至是主要因素。
+
+在现代化应用架构中,能够快速的把变更交付到生产环境的能力,让你比你的竞争对手更胜一筹。容器通过使用微服务架构,帮助开发团队开发功能、更小的失败、更快的恢复,从而加快交付速度。容器化还让应用软件能够快速启动、按需自动扩展云资源。还有,[DevOps][2] 通过灵活性、移动性、和有效性让产品可以尽快进入市场,从而将容器化的所能带来的好处最大化。
+
+在 DevOps 中,虽然速度、敏捷、灵活是容器化的主要保障,但安全则是一个重要的因素。这就导致了 DevSecOps 的出现。它从一开始,到贯穿容器化应用的整个生命周期,都始终将安全融合到应用的开发中。默认情况下,容器化大大地增强了安全性,因为它将应用和宿主机以及其他的容器化应用相互隔离开来。
+
+### 什么是容器?
+
+容器是单体式应用程序所遗留的问题的解决方案。虽然单体式有它的优点,但是它阻碍了组织以敏捷的方式快速前进。而容器则让你能够将单体式分解成 [微服务][3]。
+
+本质上来说,容器只是一些轻量化组件的应用集,比如软件依赖、库、配置文件等等,然后运行在一个隔离的环境之中,这个隔离的环境又是运行在传统操作系统之上的,或者为了可移植性和灵活性而运行在虚拟化环境之上。
+
+![容器的架构][4]
+
+总而言之,容器通过利用像 cgroup、 [内核命名空间][6] 和 [SELinux][7] 这样的内核技术来实现隔离。容器跟宿主机共用一个内核,因此比虚拟机占用更少的资源。
+
+### 容器的优势
+
+这种架构所带来的敏捷性是虚拟机所不可能做到的。此外,在计算和内存资源方面,容器支持一种更灵活的模型,而且它支持突发资源模式,因此应用程序可以在需要的时候,在限定的范围内,使用更多的资源。用另一句话来说,容器提供的扩展性和灵活性,是你在虚拟机上运行的应用程序中所无法实现的。
+
+容器让在公有云或者私有云上部署和分享应用变得非常容易。更重要的是,它所提供的连贯性,帮助运维和开发团队降低了在跨平台部署的过程中的复杂度。
+
+容器还可以实现一套通用的构建组件,可以在开发的任何阶段拿来复用,从而可以重建出一样的环境供开发、测试、预备、生产使用,将“一次编写、到处执行”的概念加以扩展。
+
+和虚拟化相比,容器使实现灵活性、连贯性和快速部署应用的能力变得更加简单 —— 这是 DevOps 的主要原则。
+
+### Docker 因素
+
+[Docker][8] 已经变成了容器的代名词。Docker 让容器技术发生彻底变革并得以推广普及,虽然早在 Docker 之前容器技术就已经存在。这些容器技术包括 AIX 工作负载分区、 Solaris 容器、以及 Linux 容器([LXC][9]),后者被用来 [在一台 Linux 宿主机上运行多个 Linux 环境][10]。
+
+### Kubernetes 效应
+
+Kubernetes 如今已被广泛认为是 [编排引擎][11] 中的领导者。在过去的几年里,[Kubernetes 的普及][12] 加上容器技术的应用日趋成熟,为运维、开发、以及安全团队可以拥抱日益变革的行业,创造了一个理想的环境。
+
+Kubernetes 为容器的管理提供了完整全面的解决方案。它可以在一个集群中运行容器,从而实现类似自动扩展云资源这样的功能,这些云资源包括:自动的、分布式的事件驱动的应用需求。这就保证了“免费的”高可用性。(比如,开发和运维都不需要花太大的劲就可以实现)
+
+此外,在 OpenShift 和 类似 Kubernetes 这样的企业的帮助下,容器的应用变得更加的容易。
+
+![Kubernetes 集群][13]
+
+### 容器会替代虚拟机吗?
+
+[KubeVirt][14] 和类似的 [开源][15] 项目很大程度上表明,容器将会取代虚拟机。KubeVirt 通过将虚拟机转化成容器,把虚拟机带入到容器化的工作流中,因此它们就可以利用容器化应用的优势。
+
+现在,容器和虚拟机更多的是互补的关系,而不是相互竞争的。容器在虚拟机上面运行,因此增加可用性,特别是对于那些要求有持久性的应用。同时容器可以利用虚拟化技术的优势,让硬件的基础设施(如:内存和网络)的管理更加便捷。
+
+### 那么 Windows 容器呢?
+
+微软和开源社区方面都对 Windows 容器的成功实现做了大量的推动。Kubernetes 操作器 加速了 Windows 容器的应用进程。还有像 OpenShift 这样的产品现在可以启用 [Windows 工作节点][16] 来运行 Windows 容器。
+
+Windows 的容器化创造出巨大的诱人的可能性。特别是对于使用混合环境的企业。在 Kubernetes 集群上运行你最关键的应用程序,是你成功实现混合云/多种云环境的目标迈出的一大步。
+
+### 容器的未来
+
+容器在 IT 行业日新月异的变革中扮演着重要的角色,因为企业在向着快速、敏捷的交付软件及解决方案的方向前进,以此来 [超越竞争对手][17]。
+
+容器会继续存在下去。在不久的将来,其他的使用场景,比如边缘计算中的无服务器,将会浮现出来,并且更深地影响我们对从数字设备来回传输数据的速度的认知。唯一在这种变化中存活下来的方式,就是去应用它们。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/12/containers-101
+
+作者:[Mike Calizo][a]
+选题:[lujun9972][b]
+译者:[AmorSu](https://github.com/amorsu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mcalizo
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/kubernetes_containers_ship_lead.png?itok=9EUnSwci (Ships at sea on the web)
+[2]: https://opensource.com/resources/devops
+[3]: https://opensource.com/resources/what-are-microservices
+[4]: https://opensource.com/sites/default/files/uploads/container_architecture.png (Container architecture)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://opensource.com/article/19/10/namespaces-and-containers-linux
+[7]: https://opensource.com/article/20/11/selinux-containers
+[8]: https://opensource.com/resources/what-docker
+[9]: https://linuxcontainers.org/
+[10]: https://opensource.com/article/18/11/behind-scenes-linux-containers
+[11]: https://opensource.com/article/20/11/orchestration-vs-automation
+[12]: https://enterprisersproject.com/article/2020/6/kubernetes-statistics-2020
+[13]: https://opensource.com/sites/default/files/uploads/kubernetes_cluster.png (Kubernetes cluster)
+[14]: https://kubevirt.io/
+[15]: https://opensource.com/resources/what-open-source
+[16]: https://www.openshift.com/blog/announcing-the-community-windows-machine-config-operator-on-openshift-4.6
+[17]: https://www.imd.org/research-knowledge/articles/the-battle-for-digital-disruption-startups-vs-incumbents/
diff --git a/published/202103/20210113 Turn your Raspberry Pi into a HiFi music system.md b/published/202103/20210113 Turn your Raspberry Pi into a HiFi music system.md
new file mode 100644
index 0000000000..4f25621cf2
--- /dev/null
+++ b/published/202103/20210113 Turn your Raspberry Pi into a HiFi music system.md
@@ -0,0 +1,83 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13209-1.html)
+[#]: subject: (Turn your Raspberry Pi into a HiFi music system)
+[#]: via: (https://opensource.com/article/21/1/raspberry-pi-hifi)
+[#]: author: (Peter Czanik https://opensource.com/users/czanik)
+
+把你的树莓派变成一个 HiFi 音乐系统
+======
+
+> 为你的朋友、家人、同事或其他任何拥有廉价发烧设备的人播放音乐。
+
+
+
+在过去的 10 年里,我大部分时间都是远程工作,但当我走进办公室时,我坐在一个充满内向的同伴的房间里,他们很容易被环境噪音和谈话所干扰。我们发现,听音乐可以抑制办公室的噪音,让声音不那么扰人,用愉快的音乐提供一个愉快的工作环境。
+
+起初,我们的一位同事带来了一些老式的有源电脑音箱,把它们连接到他的桌面电脑上,然后问我们想听什么。它可以工作,但音质不是很好,而且只有当他在办公室的时候才可以使用。接下来,我们又买了一对 Altec Lansing 音箱。音质有所改善,但没有什么灵活性。
+
+不久之后,我们得到了一台通用 ARM 单板计算机(SBC),这意味着任何人都可以通过 Web 界面控制播放列表和音箱。但一块普通的 ARM 开发板意味着我们不能使用流行的音乐设备软件。由于非标准的内核,更新操作系统是一件很痛苦的事情,而且 Web 界面也经常出现故障。
+
+当团队壮大并搬进更大的房间后,我们开始梦想着有更好音箱和更容易处理软件和硬件组合的方法。
+
+为了用一种相对便宜、灵活、音质好的方式解决我们的问题,我们用树莓派、音箱和开源软件开发了一个办公室 HiFi。
+
+### HiFi 硬件
+
+用一个专门的 PC 来播放背景音乐就有点过分了。它昂贵、嘈杂(除非是静音的,但那就更贵了),而且不环保。即使是最便宜的 ARM 板也能胜任这个工作,但从软件的角度来看,它们往往存在问题。树莓派还是比较便宜的,虽然不是标准的计算机,但在硬件和软件方面都有很好的支持。
+
+接下来的问题是:用什么音箱。质量好的、有源的音箱很贵。无源音箱的成本较低,但需要一个功放,这需要为这套设备增加另一个盒子。它们还必须使用树莓派的音频输出;虽然可以工作,但并不是最好的,特别是当你已经在高质量的音箱和功放上投入资金的时候。
+
+幸运的是,在数以千计的树莓派硬件扩展中,有内置数字模拟转换器(DAC)的功放。我们选择了 [HiFiBerry 的 Amp][2]。它在我们买来后不久就停产了(被采样率更好的 Amp+ 型号取代),但对于我们的目的来说,它已经足够好了。在开着空调的情况下,我想无论如何你也听不出 48kHz 或 192kHz 的 DAC 有什么不同。
+
+音箱方面,我们选择了 [Audioengine P4][3],是在某店家清仓大甩卖的时候买的,价格超低。它很容易让我们的办公室房间充满了声音而不失真(并且还能传到我们的房间之外,有一些失真,隔壁的工程师往往不喜欢)。
+
+### HiFi 软件
+
+在我们旧的通用 ARM SBC 上我们需要维护一个 Ubuntu,使用一个固定的、古老的、在软件包仓库外的系统内核,这是有问题的。树莓派操作系统包括一个维护良好的内核包,使其成为一个稳定且易于更新的基础系统,但它仍然需要我们定期更新 Python 脚本来访问 Spotify 和 YouTube。对于我们的目的来说,这有点过于高维护。
+
+幸运的是,使用树莓派作为基础意味着有许多现成的软件设备可用。
+
+我们选择了 [Volumio][4],这是一个将树莓派变成音乐播放设备的开源项目。安装是一个简单的*一步步完成*的过程。安装和升级是完全无痛的,而不用辛辛苦苦地安装和维护一个操作系统,并定期调试破损的 Python 代码。配置 HiFiBerry 功放不需要编辑任何配置文件,你只需要从列表中选择即可。当然,习惯新的用户界面需要一定的时间,但稳定性和维护的便捷性让这个改变是值得的。
+
+![Volumio interface][5]
+
+### 播放音乐并体验
+
+虽然大流行期间我们都在家里办公,不过我把办公室的 HiFi 安装在我的家庭办公室里,这意味着我可以自由支配它的运行。一个不断变化的用户界面对于一个团队来说会很痛苦,但对于一个有研发背景的人来说,自己玩一个设备,变化是很有趣的。
+
+我不是一个程序员,但我有很强的 Linux 和 Unix 系统管理背景。这意味着,虽然我觉得修复坏掉的 Python 代码很烦人,但 Volumio 对我来说却足够完美,足够无聊(这是一个很好的“问题”)。幸运的是,在树莓派上播放音乐还有很多其他的可能性。
+
+作为一个终端狂人(我甚至从终端窗口启动 LibreOffice),我主要使用 Music on Console([MOC][6])来播放我的网络存储(NAS)中的音乐。我有几百张 CD,都转换成了 [FLAC][7] 文件。而且我还从 [BandCamp][8] 或 [Society of Sound][9] 等渠道购买了许多数字专辑。
+
+另一个选择是 [音乐播放器守护进程(MPD)][10]。把它运行在树莓派上,我可以通过网络使用 Linux 和 Android 的众多客户端之一与我的音乐进行远程交互。
+
+### 音乐不停歇
+
+正如你所看到的,创建一个廉价的 HiFi 系统在软件和硬件方面几乎是无限可能的。我们的解决方案只是众多解决方案中的一个,我希望它能启发你建立适合你环境的东西。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/raspberry-pi-hifi
+
+作者:[Peter Czanik][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/czanik
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hi-fi-stereo-vintage.png?itok=KYY3YQwE (HiFi vintage stereo)
+[2]: https://www.hifiberry.com/products/amp/
+[3]: https://audioengineusa.com/shop/passivespeakers/p4-passive-speakers/
+[4]: https://volumio.org/
+[5]: https://opensource.com/sites/default/files/uploads/volumeio.png (Volumio interface)
+[6]: https://en.wikipedia.org/wiki/Music_on_Console
+[7]: https://xiph.org/flac/
+[8]: https://bandcamp.com/
+[9]: https://realworldrecords.com/news/society-of-sound-statement/
+[10]: https://www.musicpd.org/
diff --git a/published/202103/20210118 KDE Customization Guide- Here are 11 Ways You Can Change the Look and Feel of Your KDE-Powered Linux Desktop.md b/published/202103/20210118 KDE Customization Guide- Here are 11 Ways You Can Change the Look and Feel of Your KDE-Powered Linux Desktop.md
new file mode 100644
index 0000000000..5f5ced02d5
--- /dev/null
+++ b/published/202103/20210118 KDE Customization Guide- Here are 11 Ways You Can Change the Look and Feel of Your KDE-Powered Linux Desktop.md
@@ -0,0 +1,171 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13172-1.html)
+[#]: subject: (KDE Customization Guide: Here are 11 Ways You Can Change the Look and Feel of Your KDE-Powered Linux Desktop)
+[#]: via: (https://itsfoss.com/kde-customization/)
+[#]: author: (Dimitrios Savvopoulos https://itsfoss.com/author/dimitrios/)
+
+KDE 桌面环境定制指南
+======
+
+
+
+[KDE Plasma 桌面][1] 无疑是定制化的巅峰,因为你几乎可以改变任何你想要的东西。你甚至可以让它充当 [平铺窗口管理器][2]。
+
+KDE Plasma 提供的定制化程度会让初学者感到困惑。用户会迷失在层层深入的选项之中。
+
+为了解决这个问题,我将向你展示你应该注意的 KDE Plasma 定制的关键点。这里有 11 种方法可以改变你的 KDE 桌面的外观和感觉。
+
+![][3]
+
+### 定制 KDE Plasma
+
+我在本教程中使用了 [KDE Neon][4],但你可以在任何使用 KDE Plasma 桌面的发行版中遵循这些方法。
+
+#### 1、Plasma 桌面小工具
+
+桌面小工具可以增加用户体验的便利性,因为你可以立即访问桌面上的重要项目。
+
+现在学生和专业人士使用电脑的时候越来越多,其中一个有用的小部件是便签。
+
+右键点击桌面,选择“添加小工具”。
+
+![][5]
+
+选择你喜欢的小部件,然后简单地将其拖放到桌面上。
+
+![][6]
+
+#### 2、桌面壁纸
+
+不用说,更换壁纸可以改变桌面的外观。
+
+![][7]
+
+在“壁纸”选项卡中,你可以改变的不仅仅是壁纸。从“布局”下拉菜单中,你还可以选择桌面是否放置图标。
+
+“文件夹视图”布局的命名来自于主目录中的传统桌面文件夹,你可以在那里访问你的桌面文件。因此,“文件夹视图”选项将保留桌面上的图标。
+
+如果你选择“桌面”布局,它会使你的桌面图标保持自由而普通。当然,你仍然可以访问主目录下的桌面文件夹。
+
+![][8]
+
+在“壁纸类型”中,你可以选择是否要壁纸,是静止的还是变化的,最后在“位置”中,选择它在屏幕上的样子。
+
+#### 3、鼠标动作
+
+每一个鼠标按键都可以配置为以下动作之一:
+
+ * 切换窗口
+ * 切换桌面
+ * 粘贴
+ * 标准菜单
+ * 应用程序启动器
+ * 切换活动区
+
+右键默认设置为标准菜单,也就是在桌面上点击右键时的菜单。点击旁边的设置图标可以更改动作。
+
+![][9]
+
+#### 4、桌面内容的位置
+
+只有在壁纸选项卡中选择“文件夹视图”时,该选项才可用。默认情况下,桌面上显示的内容是你在主目录下的“桌面”文件夹中的内容。这个位置选项卡让你可以选择不同的文件夹来改变桌面上的内容。
+
+![][10]
+
+#### 5、桌面图标
+
+在这里,你可以选择图标的排列方式(水平或垂直)、左右对齐、排序标准及其大小。如果这些还不够,你还可以探索其他的美学功能。
+
+![][11]
+
+#### 6、桌面过滤器
+
+让我们坦然面对自己吧! 相信每个用户最后都会在某些时候出现桌面凌乱的情况。如果你的桌面变得乱七八糟,找不到文件,你可以按名称或类型应用过滤器,找到你需要的文件。虽然,最好是养成一个良好的文件管理习惯!
+
+![][12]
+
+#### 7、应用仪表盘
+
+如果你喜欢 GNOME 3 的应用程序启动器,那么你可以试试 KDE 应用程序仪表板。你所要做的就是右击菜单图标 > “显示替代品”。
+
+![][13]
+
+点击“应用仪表盘”。
+
+![][14]
+
+#### 8、窗口管理器主题
+
+就像你在 [Xfce 自定义教程][15] 中看到的那样,你也可以在 KDE 中独立改变窗口管理器的主题。这样你就可以为面板选择一种主题,为窗口管理器选择另外一种主题。如果预装的主题不够用,你可以下载更多的主题。
+
+不过受 [MX Linux][16] Xfce 版的启发,我还是忍不住选择了我最喜欢的 “Arc Dark”。
+
+导航到“设置” > “应用风格” > “窗口装饰” > “主题”。
+
+![][17]
+
+#### 9、全局主题
+
+如上所述,KDE Plasma 面板的外观和感觉可以从“设置” > “全局主题”选项卡中进行配置。预装的主题数量并不多,但你可以下载一个适合自己口味的主题。不过默认的 “Breeze Dark” 是一款养眼的主题。
+
+![][18]
+
+#### 10、系统图标
+
+系统图标样式对桌面的外观有很大的影响。无论你选择哪一种,如果你的全局主题是深色的,你应该选择深色图标版本。唯一的区别在于图标文字对比度上,图标文字对比度应该与面板颜色反色,使其具有可读性。你可以在系统设置中轻松访问“图标”标签。
+
+![][19]
+
+#### 11、系统字体
+
+系统字体并不是定制的重点,但如果你每天有一半的时间都在屏幕前,它可能是眼睛疲劳的因素之一。有阅读障碍的用户会喜欢 [OpenDyslexic][20] 字体。我个人选择的是 Ubuntu 字体,不仅我觉得美观,而且是在屏幕前度过一天的好字体。
+
+当然,你也可以通过下载外部资源来 [在 Linux 系统上安装更多的字体][21]。
+
+![][22]
+
+### 总结
+
+KDE Plasma 是 Linux 社区最灵活和可定制的桌面之一。无论你是否是一个修理工,KDE Plasma 都是一个不断发展的桌面环境,具有惊人的现代功能。更好的是,它也可以在性能中等的系统配置上进行管理。
+
+现在,我试图让本指南对初学者友好。当然,可以有更多的高级定制,比如那个 [窗口切换动画][23]。如果你知道一些别的技巧,为什么不在评论区与我们分享呢?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/kde-customization/
+
+作者:[Dimitrios Savvopoulos][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/dimitrios/
+[b]: https://github.com/lujun9972
+[1]: https://kde.org/plasma-desktop/
+[2]: https://github.com/kwin-scripts/kwin-tiling
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/kde-neon-neofetch.png?resize=800%2C600&ssl=1
+[4]: https://itsfoss.com/kde-neon-review/
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/16-kde-neon-add-widgets.png?resize=800%2C500&ssl=1
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/17-kde-neon-widgets.png?resize=800%2C768&ssl=1
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/1-kde-neon-configure-desktop.png?resize=800%2C500&ssl=1
+[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/2-kde-neon-wallpaper.png?resize=800%2C600&ssl=1
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/3-kde-neon-mouse-actions.png?resize=800%2C600&ssl=1
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/10-kde-neon-location.png?resize=800%2C650&ssl=1
+[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/4-kde-neon-desktop-icons.png?resize=798%2C635&ssl=1
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/11-kde-neon-desktop-icons-filter.png?resize=800%2C650&ssl=1
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/5-kde-neon-show-alternatives.png?resize=800%2C500&ssl=1
+[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/6-kde-neon-application-dashboard.png?resize=800%2C450&ssl=1
+[15]: https://itsfoss.com/customize-xfce/
+[16]: https://itsfoss.com/mx-linux-kde-edition/
+[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/12-kde-neon-window-manager.png?resize=800%2C512&ssl=1
+[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/15-kde-neon-global-theme.png?resize=800%2C524&ssl=1
+[19]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/13-kde-neon-system-icons.png?resize=800%2C524&ssl=1
+[20]: https://www.opendyslexic.org/about
+[21]: https://itsfoss.com/install-fonts-ubuntu/
+[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/14-kde-neon-fonts.png?resize=800%2C524&ssl=1
+[23]: https://itsfoss.com/customize-task-switcher-kde/
diff --git a/published/202103/20210121 Convert your Windows install into a VM on Linux.md b/published/202103/20210121 Convert your Windows install into a VM on Linux.md
new file mode 100644
index 0000000000..5262d6d8b6
--- /dev/null
+++ b/published/202103/20210121 Convert your Windows install into a VM on Linux.md
@@ -0,0 +1,244 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13240-1.html)
+[#]: subject: (Convert your Windows install into a VM on Linux)
+[#]: via: (https://opensource.com/article/21/1/virtualbox-windows-linux)
+[#]: author: (David Both https://opensource.com/users/dboth)
+
+在 Linux 上将你的 Windows 系统转换为虚拟机
+======
+
+> 下面是我如何配置 VirtualBox 虚拟机以在我的 Linux 工作站上使用物理的 Windows 操作系统。
+
+
+
+我经常使用 VirtualBox 来创建虚拟机来测试新版本的 Fedora、新的应用程序和很多管理工具,比如 Ansible。我甚至使用 VirtualBox 来测试创建一个 Windows 访客主机。
+
+我从来没有在我的任何一台个人电脑上使用 Windows 作为我的主要操作系统,甚至也没在虚拟机中执行过一些用 Linux 无法完成的冷门任务。不过,我确实为一个需要使用 Windows 下的财务程序的组织做志愿者。这个程序运行在办公室经理的电脑上,使用的是预装的 Windows 10 Pro。
+
+这个财务应用程序并不特别,[一个更好的 Linux 程序][2] 可以很容易地取代它,但我发现许多会计和财务主管极不愿意做出改变,所以我还没能说服我们组织中的人迁移。
+
+这一系列的情况,加上最近的安全恐慌,使得我非常希望将运行 Windows 的主机转换为 Fedora,并在该主机上的虚拟机中运行 Windows 和会计程序。
+
+重要的是要明白,我出于多种原因极度不喜欢 Windows。主要原因是,我不愿意为了在新的虚拟机上安装它而再花钱购买一个 Windows 许可证(Windows 10 Pro 大约需要 200 美元)。此外,Windows 10 在新系统上设置时或安装后需要足够的信息,如果微软的数据库被攻破,破解者就可以窃取一个人的身份。任何人都不应该为了注册软件而需要提供自己的姓名、电话号码和出生日期。
+
+### 开始
+
+这台实体电脑已经在主板上唯一可用的 m.2 插槽中安装了一个 240GB 的 NVMe m.2 的 SSD 存储设备。我决定在主机上安装一个新的 SATA SSD,并将现有的带有 Windows 的 SSD 作为 Windows 虚拟机的存储设备。金士顿在其网站上对各种 SSD 设备、外形尺寸和接口做了很好的概述。
+
+这种方法意味着我不需要重新安装 Windows 或任何现有的应用软件。这也意味着,在这台电脑上工作的办公室经理将使用 Linux 进行所有正常的活动,如电子邮件、访问 Web、使用 LibreOffice 创建文档和电子表格。这种方法增加了主机的安全性。唯一会使用 Windows 虚拟机的时间是运行会计程序。
+
+### 先备份
+
+在做其他事情之前,我创建了整个 NVMe 存储设备的备份 ISO 镜像。我在 500GB 外置 USB 存储盘上创建了一个分区,在其上创建了一个 ext4 文件系统,然后将该分区挂载到 `/mnt`。我使用 `dd` 命令来创建镜像。
+
+我在主机中安装了新的 500GB SATA SSD,并从临场 USB 上安装了 Fedora 32 Xfce 偏好版。在安装后的初次重启时,在 GRUB2 引导菜单上,Linux 和 Windows 操作系统都是可用的。此时,主机可以在 Linux 和 Windows 之间进行双启动。
+
+### 在网上寻找帮助
+
+现在我需要一些关于创建一个使用物理硬盘或 SSD 作为其存储设备的虚拟机的信息。我很快就在 VirtualBox 文档和互联网上发现了很多关于如何做到这一点的信息。虽然 VirtualBox 文档初步帮助了我,但它并不完整,遗漏了一些关键信息。我在互联网上找到的大多数其他信息也很不完整。
+
+在我们的记者 Joshua Holm 的帮助下,我得以突破这些残缺的信息,并以一个可重复的流程来完成这项工作。
+
+### 让它发挥作用
+
+这个过程其实相当简单,虽然需要一个玄妙的技巧才能实现。当我准备好这一步的时候,Windows 和 Linux 操作系统已经到位了。
+
+首先,我在 Linux 主机上安装了最新版本的 VirtualBox。VirtualBox 可以从许多发行版的软件仓库中安装,也可以直接从 Oracle VirtualBox 仓库中安装,或者从 VirtualBox 网站上下载所需的包文件并在本地安装。我选择下载 AMD64 版本,它实际上是一个安装程序而不是一个软件包。我使用这个版本来规避一个与这个特定项目无关的问题。
+
+安装过程总是在 `/etc/group` 中创建一个 `vboxusers` 组。我把打算运行这个虚拟机的用户添加到 `/etc/group` 中的 `vboxusers` 和 `disk` 组。将相同的用户添加到 `disk` 组是很重要的,因为 VirtualBox 是以启动它的用户身份运行的,而且还需要直接访问 `/dev/sdx` 特殊设备文件才能在这种情况下工作。将用户添加到 `disk` 组可以提供这种级别的访问权限,否则他们就不会有这种权限。
+
+然后,我创建了一个目录来存储虚拟机,并赋予它 `root.vboxusers` 的所有权和 `775` 的权限。我使用 `/vms` 用作该目录,但可以是任何你想要的目录。默认情况下,VirtualBox 会在创建虚拟机的用户的子目录中创建新的虚拟机。这将使多个用户之间无法共享对虚拟机的访问,从而不会产生巨大的安全漏洞。将虚拟机目录放置在一个可访问的位置,可以共享虚拟机。
+
+我以非 root 用户的身份启动 VirtualBox 管理器。然后,我使用 VirtualBox 的“偏好 => 一般”菜单将“默认机器文件夹”设置为 `/vms` 目录。
+
+我创建的虚拟机没有虚拟磁盘。“类型” 应该是 `Windows`,“版本”应该设置为 `Windows 10 64-bit`。为虚拟机设置一个合理的内存量,但只要虚拟机处于关闭状态,以后可以更改。在安装的“硬盘”页面,我选择了 “不要添加虚拟硬盘”,点击“创建”。新的虚拟机出现在VirtualBox 管理器窗口中。这个过程也创建了 `/vms/Test1` 目录。
+
+我使用“高级”菜单在一个页面上设置了所有的配置,如图 1 所示。“向导模式”可以获得相同的信息,但需要更多的点击,以通过一个窗口来进行每个配置项目。它确实提供了更多的帮助内容,但我并不需要。
+
+![VirtualBox 对话框:创建新的虚拟机,但不添加硬盘][3]
+
+*图 1:创建一个新的虚拟机,但不要添加硬盘。*
+
+然后,我需要知道 Linux 给原始 Windows 硬盘分配了哪个设备。在终端会话中以 root 身份使用 `lshw` 命令来发现 Windows 磁盘的设备分配情况。在本例中,代表整个存储设备的设备是 `/dev/sdb`。
+
+```
+# lshw -short -class disk,volume
+H/W path Device Class Description
+=========================================================
+/0/100/17/0 /dev/sda disk 500GB CT500MX500SSD1
+/0/100/17/0/1 volume 2047MiB Windows FAT volume
+/0/100/17/0/2 /dev/sda2 volume 4GiB EXT4 volume
+/0/100/17/0/3 /dev/sda3 volume 459GiB LVM Physical Volume
+/0/100/17/1 /dev/cdrom disk DVD+-RW DU-8A5LH
+/0/100/17/0.0.0 /dev/sdb disk 256GB TOSHIBA KSG60ZMV
+/0/100/17/0.0.0/1 /dev/sdb1 volume 649MiB Windows FAT volume
+/0/100/17/0.0.0/2 /dev/sdb2 volume 127MiB reserved partition
+/0/100/17/0.0.0/3 /dev/sdb3 volume 236GiB Windows NTFS volume
+/0/100/17/0.0.0/4 /dev/sdb4 volume 989MiB Windows NTFS volume
+[root@office1 etc]#
+```
+
+VirtualBox 不需要把虚拟存储设备放在 `/vms/Test1` 目录中,而是需要有一种方法来识别要从其启动的物理硬盘。这种识别是通过创建一个 `*.vmdk` 文件来实现的,该文件指向将作为虚拟机存储设备的原始物理磁盘。作为非 root 用户,我创建了一个 vmdk 文件,指向整个 Windows 设备 `/dev/sdb`。
+
+```
+$ VBoxManage internalcommands createrawvmdk -filename /vms/Test1/Test1.vmdk -rawdisk /dev/sdb
+RAW host disk access VMDK file /vms/Test1/Test1.vmdk created successfully.
+```
+
+然后,我使用 VirtualBox 管理器 “文件 => 虚拟介质管理器” 对话框将 vmdk 磁盘添加到可用硬盘中。我点击了“添加”,文件管理对话框中显示了默认的 `/vms` 位置。我选择了 `Test1` 目录,然后选择了 `Test1.vmdk` 文件。然后我点击“打开”,`Test1.vmdk` 文件就显示在可用硬盘列表中。我选择了它,然后点击“关闭”。
+
+下一步就是将这个 vmdk 磁盘添加到我们的虚拟机的存储设备中。在 “Test1 VM” 的设置菜单中,我选择了 “存储”,并点击了添加硬盘的图标。这时打开了一个对话框,在一个名为“未连接”的列表中显示了 `Test1vmdk` 虚拟磁盘文件。我选择了这个文件,并点击了“选择”按钮。这个设备现在显示在连接到 “Test1 VM” 的存储设备列表中。这个虚拟机上唯一的其他存储设备是一个空的 CD/DVD-ROM 驱动器。
+
+我点击了“确定”,完成了将此设备添加到虚拟机中。
+
+在新的虚拟机工作之前,还有一个项目需要配置。使用 VirtualBox 管理器设置对话框中的 “Test1 VM”,我导航到 “系统 => 主板”页面,并在 “启用 EFI”的方框中打上勾。如果你不这样做,当你试图启动这个虚拟机时,VirtualBox 会产生一个错误,说明它无法找到一个可启动的介质。
+
+现在,虚拟机从原始的 Windows 10 硬盘驱动器启动。然而,我无法登录,因为我在这个系统上没有一个常规账户,而且我也无法获得 Windows 管理员账户的密码。
+
+### 解锁驱动器
+
+不,本节并不是要破解硬盘的加密,而是要绕过众多 Windows 管理员账户之一的密码,而这些账户是不属于组织中某个人的。
+
+尽管我可以启动 Windows 虚拟机,但我无法登录,因为我在该主机上没有账户,而向人们索要密码是一种可怕的安全漏洞。尽管如此,我还是需要登录这个虚拟机来安装 “VirtualBox Guest Additions”,它可以提供鼠标指针的无缝捕捉和释放,允许我将虚拟机调整到大于 1024x768 的大小,并在未来进行正常的维护。
+
+这是一个完美的用例,Linux 的功能就是更改用户密码。尽管我是访问之前的管理员的账户来启动,但在这种情况下,他不再支持这个系统,我也无法辨别他的密码或他用来生成密码的模式。我就直接清除了上一个系统管理员的密码。
+
+有一个非常不错的开源软件工具,专门用于这个任务。在 Linux 主机上,我安装了 `chntpw`,它的意思大概是:“更改 NT 的密码”。
+
+```
+# dnf -y install chntpw
+```
+
+我关闭了虚拟机的电源,然后将 `/dev/sdb3` 分区挂载到 `/mnt` 上。我确定 `/dev/sdb3` 是正确的分区,因为它是我在之前执行 `lshw` 命令的输出中看到的第一个大的 NTFS 分区。一定不要在虚拟机运行时挂载该分区,那样会导致虚拟机存储设备上的数据严重损坏。请注意,在其他主机上分区可能有所不同。
+
+导航到 `/mnt/Windows/System32/config` 目录。如果当前工作目录(PWD)不在这里,`chntpw` 实用程序就无法工作。请启动该程序。
+
+```
+# chntpw -i SAM
+chntpw version 1.00 140201, (c) Petter N Hagen
+Hive name (from header): <\SystemRoot\System32\Config\SAM>
+ROOT KEY at offset: 0x001020 * Subkey indexing type is: 686c
+File size 131072 [20000] bytes, containing 11 pages (+ 1 headerpage)
+Used for data: 367/44720 blocks/bytes, unused: 14/24560 blocks/bytes.
+
+<>========<> chntpw Main Interactive Menu <>========<>
+
+Loaded hives:
+
+ 1 - Edit user data and passwords
+ 2 - List groups
+ - - -
+ 9 - Registry editor, now with full write support!
+ q - Quit (you will be asked if there is something to save)
+
+
+What to do? [1] ->
+```
+
+`chntpw` 命令使用 TUI(文本用户界面),它提供了一套菜单选项。当选择其中一个主要菜单项时,通常会显示一个次要菜单。按照明确的菜单名称,我首先选择了菜单项 `1`。
+
+```
+What to do? [1] -> 1
+
+===== chntpw Edit User Info & Passwords ====
+
+| RID -|---------- Username ------------| Admin? |- Lock? --|
+| 01f4 | Administrator | ADMIN | dis/lock |
+| 03eb | john | ADMIN | dis/lock |
+| 01f7 | DefaultAccount | | dis/lock |
+| 01f5 | Guest | | dis/lock |
+| 01f8 | WDAGUtilityAccount | | dis/lock |
+
+Please enter user number (RID) or 0 to exit: [3e9]
+```
+
+接下来,我选择了我们的管理账户 `john`,在提示下输入 RID。这将显示用户的信息,并提供额外的菜单项来管理账户。
+
+```
+Please enter user number (RID) or 0 to exit: [3e9] 03eb
+================= USER EDIT ====================
+
+RID : 1003 [03eb]
+Username: john
+fullname:
+comment :
+homedir :
+
+00000221 = Users (which has 4 members)
+00000220 = Administrators (which has 5 members)
+
+Account bits: 0x0214 =
+[ ] Disabled | [ ] Homedir req. | [ ] Passwd not req. |
+[ ] Temp. duplicate | [X] Normal account | [ ] NMS account |
+[ ] Domain trust ac | [ ] Wks trust act. | [ ] Srv trust act |
+[X] Pwd don't expir | [ ] Auto lockout | [ ] (unknown 0x08) |
+[ ] (unknown 0x10) | [ ] (unknown 0x20) | [ ] (unknown 0x40) |
+
+Failed login count: 0, while max tries is: 0
+Total login count: 47
+
+- - - - User Edit Menu:
+ 1 - Clear (blank) user password
+ 2 - Unlock and enable user account [probably locked now]
+ 3 - Promote user (make user an administrator)
+ 4 - Add user to a group
+ 5 - Remove user from a group
+ q - Quit editing user, back to user select
+Select: [q] > 2
+```
+
+这时,我选择了菜单项 `2`,“解锁并启用用户账户”,这样就可以删除密码,使我可以不用密码登录。顺便说一下 —— 这就是自动登录。然后我退出了该程序。在继续之前,一定要先卸载 `/mnt`。
+
+我知道,我知道,但为什么不呢! 我已经绕过了这个硬盘和主机的安全问题,所以一点也不重要。这时,我确实登录了旧的管理账户,并为自己创建了一个新的账户,并设置了安全密码。然后,我以自己的身份登录,并删除了旧的管理账户,这样别人就无法使用了。
+
+网上也有 Windows Administrator 账号的使用说明(上面列表中的 `01f4`)。如果它不是作为组织管理账户,我可以删除或更改该账户的密码。还要注意的是,这个过程也可以从目标主机上运行临场 USB 来执行。
+
+### 重新激活 Windows
+
+因此,我现在让 Windows SSD 作为虚拟机在我的 Fedora 主机上运行了。然而,令人沮丧的是,在运行了几个小时后,Windows 显示了一条警告信息,表明我需要“激活 Windows”。
+
+在看了许许多多的死胡同网页之后,我终于放弃了使用现有激活码重新激活的尝试,因为它似乎已经以某种方式被破坏了。最后,当我试图进入其中一个在线虚拟支持聊天会话时,虚拟的“获取帮助”应用程序显示我的 Windows 10 Pro 实例已经被激活。这怎么可能呢?它一直希望我激活它,然而当我尝试时,它说它已经被激活了。
+
+### 或者不
+
+当我在三天内花了好几个小时做研究和实验时,我决定回到原来的 SSD 启动到 Windows 中,以后再来处理这个问题。但后来 Windows —— 即使从原存储设备启动,也要求重新激活。
+
+在微软支持网站上搜索也无济于事。在不得不与之前一样的自动支持大费周章之后,我拨打了提供的电话号码,却被自动响应系统告知,所有对 Windows 10 Pro 的支持都只能通过互联网提供。到现在,我已经晚了将近一天才让电脑运行起来并安装回办公室。
+
+### 回到未来
+
+我终于吸了一口气,购买了一份 Windows 10 Home,大约 120 美元,并创建了一个带有虚拟存储设备的虚拟机,将其安装在上面。
+
+我将大量的文档和电子表格文件复制到办公室经理的主目录中。我重新安装了一个我们需要的 Windows 程序,并与办公室经理验证了它可以工作,数据都在那里。
+
+### 总结
+
+因此,我的目标达到了,实际上晚了一天,花了 120 美元,但使用了一种更标准的方法。我仍在对权限进行一些调整,并恢复 Thunderbird 通讯录;我有一些 CSV 备份,但 `*.mab` 文件在 Windows 驱动器上包含的信息很少。我甚至用 Linux 的 `find` 命令来定位原始存储设备上的所有。
+
+我走了很多弯路,每次都要自己重新开始。我遇到了一些与这个项目没有直接关系的问题,但却影响了我的工作。这些问题包括一些有趣的事情,比如把 Windows 分区挂载到我的 Linux 机器的 `/mnt` 上,得到的信息是该分区已经被 Windows 不正确地关闭(是的,在我的 Linux 主机上),并且它已经修复了不一致的地方。即使是 Windows 通过其所谓的“恢复”模式多次重启后也做不到这一点。
+
+也许你从 `chntpw` 工具的输出数据中发现了一些线索。出于安全考虑,我删掉了主机上显示的其他一些用户账号,但我从这些信息中看到,所有的用户都是管理员。不用说,我也改了。我仍然对我遇到的糟糕的管理方式感到惊讶,但我想我不应该这样。
+
+最后,我被迫购买了一个许可证,但这个许可证至少比原来的要便宜一些。我知道的一点是,一旦我找到了所有必要的信息,Linux 这一块就能完美地工作。问题是处理 Windows 激活的问题。你们中的一些人可能已经成功地让 Windows 重新激活了。如果是这样,我还是想知道你们是怎么做到的,所以请把你们的经验添加到评论中。
+
+这是我不喜欢 Windows,只在自己的系统上使用 Linux 的又一个原因。这也是我将组织中所有的计算机都转换为 Linux 的原因之一。只是需要时间和说服力。我们只剩下这一个会计程序了,我需要和财务主管一起找到一个适合她的程序。我明白这一点 —— 我喜欢自己的工具,我需要它们以一种最适合我的方式工作。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/virtualbox-windows-linux
+
+作者:[David Both][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
+[2]: https://opensource.com/article/20/7/godbledger
+[3]: https://opensource.com/sites/default/files/virtualbox.png
diff --git a/published/202103/20210204 5 Tweaks to Customize the Look of Your Linux Terminal.md b/published/202103/20210204 5 Tweaks to Customize the Look of Your Linux Terminal.md
new file mode 100644
index 0000000000..6170252cc3
--- /dev/null
+++ b/published/202103/20210204 5 Tweaks to Customize the Look of Your Linux Terminal.md
@@ -0,0 +1,243 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13181-1.html)
+[#]: subject: (5 Tweaks to Customize the Look of Your Linux Terminal)
+[#]: via: (https://itsfoss.com/customize-linux-terminal/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+定制你的 Linux 终端外观的 5 项调整
+======
+
+
+
+终端仿真器(或简称终端)是任何 Linux 发行版中不可或缺的一部分。
+
+当你改变发行版的主题时,往往终端也会自动得到改造。但这并不意味着你不能进一步定制终端。
+
+事实上,很多读者都问过我们,为什么我们截图或视频中的终端看起来那么酷,我们用的是什么字体等等。
+
+为了回答这个经常被问到的问题,我将向你展示一些简单或复杂的调整来改变终端的外观。你可以在下图中对比一下视觉上的差异:
+
+![][1]
+
+### 自定义 Linux 终端
+
+本教程利用 Pop!_OS 上的 GNOME 终端来定制和调整终端的外观。但是,大多数建议也应该适用于其他终端。
+
+对于大多数元素,如颜色、透明度和字体,你可以利用 GUI 来调整它,而不需要输入任何特殊的命令。
+
+打开你的终端。在右上角寻找汉堡菜单。在这里,点击 “偏好设置”,如下图所示:
+
+![][2]
+
+在这里你可以找到改变终端外观的所有设置。
+
+#### 技巧 0:使用独立的终端配置文件进行定制
+
+我建议你建立一个新的配置文件用于你的定制。为什么要这样做?因为这样一来,你的改变就不会影响到终端的主配置文件。假设你做了一些奇怪的改变,却想不起默认值?配置文件有助于分离你的定制。
+
+如你所见,我有个单独的配置文件,用于截图和制作视频。
+
+![终端配置文件][3]
+
+你可以轻松地更改终端配置文件,并使用新的配置文件打开一个新的终端窗口。
+
+![更改终端配置文件][4]
+
+这就是我想首先提出的建议。现在,让我们看看这些调整。
+
+#### 技巧 1:使用深色/浅色终端主题
+
+你可以改变系统主题,终端主题也会随之改变。除此之外,如果你不想改变系统主题。你也可以切换终端的深色主题或浅色主题,
+
+一旦你进入“偏好设置”,你会注意到在“常规”选项中可以改变主题和其他设置。
+
+![][5]
+
+#### 技巧 2:改变字体和大小
+
+选择你要自定义的配置文件。现在你可以选择自定义文本外观、字体大小、字体样式、间距、光标形状,还可以切换终端铃声。
+
+对于字体,你只能改成你系统上可用的字体。如果你想要不同的字体,请先在你的 Linux 系统上下载并安装字体。
+
+还有一点! 要使用等宽字体,否则字体可能会重叠,文字可能无法清晰阅读。如果你想要一些建议,可以选择 [Share Tech Mono][6](开源)或 [Larabiefont][7](不开源)。
+
+在“文本”选项卡下,选择“自定义字体”,然后更改字体及其大小(如果需要)。
+
+![][8]
+
+#### 技巧 3:改变调色板和透明度
+
+除了文字和间距,你还可以进入“颜色”选项,改变终端的文字和背景的颜色。你还可以调整透明度,让它看起来更酷。
+
+正如你所注意到的那样,你可以从一组预先配置的选项中选择调色板,也可以自己调整。
+
+![][9]
+
+如果你想和我一样启用透明,点击“使用透明背景”选项。
+
+如果你想要和你的系统主题类似的颜色设置,你也可以选择使用系统主题的颜色。
+
+![][10]
+
+#### 技巧 4:调整 bash 提示符变量
+
+通常当你启动终端时,无需任何修改你就会看到你的用户名和主机名(你的发行版名称)作为 bash 提示符。
+
+例如,在我的例子中,它会是 “ankushdas@pop-os:~$”。然而,我把 [主机名永久地改成了][11] “itsfoss”,所以现在看起来像这样:
+
+![][12]
+
+要改变主机名,你可以键入:
+
+```
+hostname 定制名称
+```
+
+然而,这只适用于当前会话。因此,当你重新启动时,它将恢复到默认值。要永久地更改主机名,你需要输入:
+
+```
+sudo hostnamectl set-hostname 定制名称
+```
+
+同样,你也可以改变你的用户名,但它需要一些额外的配置,包括杀死所有与活动用户名相关联的当前进程,所以我们会跳过用它来改变终端的外观/感觉。
+
+#### 技巧 5:不推荐:改变 bash 提示符的字体和颜色(面向高级用户)
+
+然而,你可以使用命令调整 bash 提示符的字体和颜色。
+
+你需要利用 `PS1` 环境变量来控制提示符的显示内容。你可以在 [手册页][14] 中了解更多关于它的信息。
+
+例如,当你键入:
+
+```
+echo $PS1
+```
+
+在我这里输出:
+
+```
+\[\e]0;\u@\h: \w\a\]${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$
+```
+
+我们需要关注的是该输出的第一部分:
+
+```
+\[\e]0;\u@\h: \w\a\]$
+```
+
+在这里,你需要知道以下几点:
+
+ * `\e` 是一个特殊的字符,表示一个颜色序列的开始。
+ * `\u` 表示用户名,后面可以跟着 `@` 符号。
+ * `\h` 表示系统的主机名。
+ * `\w` 表示基本目录。
+ * `\a` 表示活动目录。
+ * `$` 表示非 root 用户。
+
+在你的情况下输出可能不一样,但变量是一样的,所以你需要根据你的输出来试验下面提到的命令。
+
+在你这样做之前,请记住这些:
+
+ * 文本格式代码:`0` 代表正常文本,`1` 代表粗体,`3` 代表斜体,`4` 代表下划线文本。
+ * 背景色的颜色范围:`40` - `47`。
+ * 文本颜色的颜色范围:`30` - `37`。
+
+你只需要键入以下内容来改变颜色和字体:
+
+```
+PS1="\e[41;3;32m[\u@\h:\w\a\$]"
+```
+
+这是输入该命令后 bash 提示符的样子:
+
+![][15]
+
+如果你注意到这个命令,就像上面提到的,`\e` 可以帮助我们分配一个颜色序列。
+
+在上面的命令中,我先分配了一个**背景色**,然后是**文字样式**,接着是**字体颜色**,然后是 `m`。这里,`m` 表示颜色序列的结束。
+
+所以,你要做的就是,调整这部分:
+
+```
+41;3;32
+```
+
+命令其余部分应该是不变的,你只需要分配不同的数字来改变背景色、文字样式和文字颜色。
+
+要注意的是,这并没有特定的顺序,你可以先指定文字样式,再指定背景色,最后指定文字颜色,如 `3;41;32`,这里的命令就变成了:
+
+```
+PS1="\e[3;41;32m[\u@\h:\w\a\$]"
+```
+
+![][16]
+
+正如你所注意到的,无论顺序如何,颜色的定制都是一样的。所以,只要记住自定义的代码,并在你确定你想把它作为一个永久的变化之前,试试它。
+
+上面我提到的命令会临时定制当前会话的 bash 提示符。如果你关闭了会话,你将失去这个自定义设置。
+
+所以,要想把它变成一个永久的改变,你需要把它添加到 `.bashrc` 文件中(这是一个配置文件,每次加载会话时都会加载)。
+
+![][17]
+
+简单键入如下命令来访问该文件:
+
+```
+nano ~/.bashrc
+```
+
+除非你明确知道你在做什么,否则不要改变任何东西。而且,为了可以恢复设置,你应该把 `PS1` 环境变量的备份(默认情况下复制粘贴其中的内容)保存到一个文本文件中。
+
+所以,即使你需要默认的字体和颜色,你也可以再次编辑 `.bashrc` 文件并粘贴 `PS1` 环境变量。
+
+#### 附赠技巧:根据你的墙纸改变终端的调色板
+
+如果你想改变终端的背景和文字颜色,但又不知道该选哪种颜色,你可以使用一个基于 Python 的工具 Pywal,它可以 [根据你的壁纸][18] 或你提供的图片自动改变终端的颜色。
+
+![][19]
+
+如果你有兴趣使用这个工具,我之前已经详细[介绍][18]过了。
+
+### 总结
+
+当然,使用 GUI 定制很容易,同时也可以更好地控制你可以改变的东西。但是,需要知道命令也是必要的,万一你开始 [使用 WSL][21] 或者使用 SSH 访问远程服务器,无论如何都可以定制你的体验。
+
+你是如何定制 Linux 终端的?在评论中与我们分享你的秘方。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/customize-linux-terminal/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/default-terminal.jpg?resize=773%2C493&ssl=1
+[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/linux-terminal-preferences.jpg?resize=800%2C350&ssl=1
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/terminal-profiles.jpg?resize=800%2C619&ssl=1
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/change-terminal-profile.jpg?resize=796%2C347&ssl=1
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/terminal-theme.jpg?resize=800%2C363&ssl=1
+[6]: https://fonts.google.com/specimen/Share+Tech+Mono
+[7]: https://www.dafont.com/larabie-font.font
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/terminal-customization-1.jpg?resize=800%2C500&ssl=1
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/terminal-color-customization.jpg?resize=759%2C607&ssl=1
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/linux-terminal.jpg?resize=800%2C571&ssl=1
+[11]: https://itsfoss.com/change-hostname-ubuntu/
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/itsfoss-hostname.jpg?resize=800%2C188&ssl=1
+[13]: https://itsfoss.com/cdn-cgi/l/email-protection
+[14]: https://linux.die.net/man/1/bash
+[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/terminal-bash-prompt-customization.jpg?resize=800%2C190&ssl=1
+[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/linux-terminal-customization-1s.jpg?resize=800%2C158&ssl=1
+[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/bashrch-customization-terminal.png?resize=800%2C615&ssl=1
+[18]: https://itsfoss.com/pywal/
+[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/08/wallpy-2.jpg?resize=800%2C442&ssl=1
+[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/08/pywal-linux.jpg?fit=800%2C450&ssl=1
+[21]: https://itsfoss.com/install-bash-on-windows/
diff --git a/published/202103/20210204 Get started with distributed tracing using Grafana Tempo.md b/published/202103/20210204 Get started with distributed tracing using Grafana Tempo.md
new file mode 100644
index 0000000000..5326ff3421
--- /dev/null
+++ b/published/202103/20210204 Get started with distributed tracing using Grafana Tempo.md
@@ -0,0 +1,103 @@
+[#]: collector: (lujun9972)
+[#]: translator: (ShuyRoy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13229-1.html)
+[#]: subject: (Get started with distributed tracing using Grafana Tempo)
+[#]: via: (https://opensource.com/article/21/2/tempo-distributed-tracing)
+[#]: author: (Annanay Agarwal https://opensource.com/users/annanayagarwal)
+
+使用 Grafana Tempo 进行分布式跟踪
+======
+
+> Grafana Tempo 是一个新的开源、大容量分布式跟踪后端。
+
+
+
+Grafana 的 [Tempo][2] 是出自 Grafana 实验室的一个简单易用、大规模的、分布式的跟踪后端。Tempo 集成了 [Grafana][3]、[Prometheus][4] 以及 [Loki][5],并且它只需要对象存储进行操作,因此成本低廉,操作简单。
+
+我从一开始就参与了这个开源项目,所以我将介绍一些关于 Tempo 的基础知识,并说明为什么云原生社区会注意到它。
+
+### 分布式跟踪
+
+想要收集对应用程序请求的遥测数据是很常见的。但是在现在的服务器中,单个应用通常被分割为多个微服务,可能运行在几个不同的节点上。
+
+分布式跟踪是一种获得关于应用的性能细粒度信息的方式,该应用程序可能由离散的服务组成。当请求到达一个应用时,它提供了该请求的生命周期的统一视图。Tempo 的分布式跟踪可以用于单体应用或微服务应用,它提供 [请求范围的信息][6],使其成为可观察性的第三个支柱(另外两个是度量和日志)。
+
+接下来是一个分布式跟踪系统生成应用程序甘特图的示例。它使用 Jaeger [HotROD][7] 的演示应用生成跟踪,并把它们存到 Grafana 云托管的 Tempo 上。这个图展示了按照服务和功能划分的请求处理时间。
+
+![Gantt chart from Grafana Tempo][8]
+
+### 减少索引的大小
+
+在丰富且定义良好的数据模型中,跟踪包含大量信息。通常,跟踪后端有两种交互:使用元数据选择器(如服务名或者持续时间)筛选跟踪,以及筛选后的可视化跟踪。
+
+为了加强搜索,大多数的开源分布式跟踪框架会对跟踪中的许多字段进行索引,包括服务名称、操作名称、标记和持续时间。这会导致索引很大,并迫使你使用 Elasticsearch 或者 [Cassandra][10] 这样的数据库。但是,这些很难管理,而且大规模运营成本很高,所以我在 Grafana 实验室的团队开始提出一个更好的解决方案。
+
+在 Grafana 中,我们的待命调试工作流从使用指标报表开始(我们使用 [Cortex][11] 来存储我们应用中的指标,它是一个云原生基金会孵化的项目,用于扩展 Prometheus),深入研究这个问题,筛选有问题服务的日志(我们将日志存储在 Loki 中,它就像 Prometheus 一样,只不过 Loki 是存日志的),然后查看跟踪给定的请求。我们意识到,我们过滤时所需的所有索引信息都可以在 Cortex 和 Loki 中找到。但是,我们需要一个强大的集成,以通过这些工具实现跟踪的可发现性,并需要一个很赞的存储,以根据跟踪 ID 进行键值查找。
+
+这就是 [Grafana Tempo][12] 项目的开始。通过专注于给定检索跟踪 ID 的跟踪,我们将 Tempo 设计为最小依赖性、大容量、低成本的分布式跟踪后端。
+
+### 操作简单,性价比高
+
+Tempo 使用对象存储后端,这是它唯一的依赖。它既可以被用于单一的二进制下,也可以用于微服务模式(请参考仓库中的 [例子][13],了解如何轻松上手)。使用对象存储还意味着你可以存储大量的应用程序的痕迹,而无需任何采样。这可以确保你永远不会丢弃那百万分之一的出错或具有较高延迟的请求的跟踪。
+
+### 与开源工具的强大集成
+
+[Grafana 7.3 包括了 Tempo 数据源][14],这意味着你可以在 Grafana UI 中可视化来自Tempo 的跟踪。而且,[Loki 2.0 的新查询特性][15] 使得 Tempo 中的跟踪更简单。为了与 Prometheus 集成,该团队正在添加对范例的支持,范例是可以添加到时间序列数据中的高基数元数据信息。度量存储后端不会对它们建立索引,但是你可以在 Grafana UI 中检索和显示度量值。尽管范例可以存储各种元数据,但是在这个用例中,存储跟踪 ID 是为了与 Tempo 紧密集成。
+
+这个例子展示了使用带有请求延迟直方图的范例,其中每个范例数据点都链接到 Tempo 中的一个跟踪。
+
+![Using exemplars in Tempo][16]
+
+### 元数据一致性
+
+作为容器化应用程序运行的应用发出的遥测数据通常具有一些相关的元数据。这可以包括集群 ID、命名空间、吊舱 IP 等。这对于提供基于需求的信息是好的,但如果你能将元数据中包含的信息用于生产性的东西,那就更好了。
+
+例如,你可以使用 [Grafana 云代理将跟踪信息导入 Tempo 中][17],代理利用 Prometheus 服务发现机制轮询 Kubernetes API 以获取元数据信息,并且将这些标记添加到应用程序发出的跨域数据中。由于这些元数据也在 Loki 中也建立了索引,所以通过元数据转换为 Loki 标签选择器,可以很容易地从跟踪跳转到查看给定服务的日志。
+
+下面是一个一致元数据的示例,它可用于Tempo跟踪中查看给定范围的日志。
+
+![][18]
+
+### 云原生
+
+Grafana Tempo 可以作为容器化应用,你可以在如 Kubernetes、Mesos 等编排引擎上运行它。根据获取/查询路径上的工作负载,各种服务可以水平伸缩。你还可以使用云原生的对象存储,如谷歌云存储、Amazon S3 或者 Tempo Azure 博客存储。更多的信息,请阅读 Tempo 文档中的 [架构部分][19]。
+
+### 试一试 Tempo
+
+如果这对你和我们一样有用,可以 [克隆 Tempo 仓库][20]试一试。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/tempo-distributed-tracing
+
+作者:[Annanay Agarwal][a]
+选题:[lujun9972][b]
+译者:[RiaXu](https://github.com/ShuyRoy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/annanayagarwal
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_space_graphic_cosmic.png?itok=wu493YbB (Computer laptop in space)
+[2]: https://grafana.com/oss/tempo/
+[3]: http://grafana.com/oss/grafana
+[4]: https://prometheus.io/
+[5]: https://grafana.com/oss/loki/
+[6]: https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
+[7]: https://github.com/jaegertracing/jaeger/tree/master/examples/hotrod
+[8]: https://opensource.com/sites/default/files/uploads/tempo_gantt.png (Gantt chart from Grafana Tempo)
+[9]: https://creativecommons.org/licenses/by-sa/4.0/
+[10]: https://opensource.com/article/19/8/how-set-apache-cassandra-cluster
+[11]: https://cortexmetrics.io/
+[12]: http://github.com/grafana/tempo
+[13]: https://grafana.com/docs/tempo/latest/getting-started/example-demo-app/
+[14]: https://grafana.com/blog/2020/10/29/grafana-7.3-released-support-for-the-grafana-tempo-tracing-system-new-color-palettes-live-updates-for-dashboard-viewers-and-more/
+[15]: https://grafana.com/blog/2020/11/09/trace-discovery-in-grafana-tempo-using-prometheus-exemplars-loki-2.0-queries-and-more/
+[16]: https://opensource.com/sites/default/files/uploads/tempo_exemplar.png (Using exemplars in Tempo)
+[17]: https://grafana.com/blog/2020/11/17/tracing-with-the-grafana-cloud-agent-and-grafana-tempo/
+[18]: https://lh5.googleusercontent.com/vNqk-ygBOLjKJnCbTbf2P5iyU5Wjv2joR7W-oD7myaP73Mx0KArBI2CTrEDVi04GQHXAXecTUXdkMqKRq8icnXFJ7yWUEpaswB1AOU4wfUuADpRV8pttVtXvTpVVv8_OfnDINgfN
+[19]: https://grafana.com/docs/tempo/latest/architecture/architecture/
+[20]: https://github.com/grafana/tempo
diff --git a/published/202103/20210216 How to install Linux in 3 steps.md b/published/202103/20210216 How to install Linux in 3 steps.md
new file mode 100644
index 0000000000..15f9d474fc
--- /dev/null
+++ b/published/202103/20210216 How to install Linux in 3 steps.md
@@ -0,0 +1,144 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13164-1.html)
+[#]: subject: (How to install Linux in 3 steps)
+[#]: via: (https://opensource.com/article/21/2/linux-installation)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+安装 Linux,只需三步
+======
+
+> 操作系统的安装看似神秘,但其实很简单。以下是成功安装 Linux 的步骤。
+
+
+
+在 2021 年,有更多让人们喜欢 Linux 的理由。在这个系列中,我将分享 21 种使用 Linux 的不同理由。下面是如何安装 Linux。
+
+安装一个操作系统(OS)总是令人生畏。对大多数人来说,这是一个难题。安装操作系统不能从操作系统内部进行,因为它要么没有被安装,要么即将被另一个操作系统取代,那么它是如何发生的呢?更糟糕的是,它通常会涉及到硬盘格式、安装位置、时区、用户名、密码等一系列你通常不会想到的混乱问题。Linux 发行版知道这一点,所以它们多年来一直在努力将你在操作系统安装程序中花费的时间减少到最低限度。
+
+### 安装时发生了什么
+
+无论你安装的是一个应用程序还是整个操作系统,*安装*的过程只是将文件从一种媒介复制到另一种媒介的一种花哨方式。不管是什么用户界面,还是用动画将安装过程伪装成多么高度专业化的东西,最终都是一回事:曾经存储在光盘或驱动器上的文件被复制到硬盘上的特定位置。
+
+当安装的是一个应用程序时,放置这些文件的有效位置被高度限制在你的*文件系统*或你的操作系统知道它可以使用的硬盘驱动器的部分。这一点很重要,因为它可以将硬盘分割成不同的空间(苹果公司在本世纪初的 Bootcamp 中使用了这一技巧,允许用户将 macOS 和 Windows 安装到一个硬盘上,但作为单独的实体)。当你安装一个操作系统时,一些特殊的文件会被安装到硬盘上通常是禁区的地方。更重要的是,至少在默认情况下,你的硬盘上的所有现有数据都会被擦除,以便为新系统腾出空间,所以创建一个备份是*必要的*。
+
+### 安装程序
+
+从技术上讲,你实际上不需要用安装程序来安装应用程序甚至操作系统。不管你信不信,有些人通过挂载一块空白硬盘、编译代码并复制文件来手动安装 Linux。这是在一个名为 [Linux From Scratch(LFS)][2] 的项目的帮助下完成的。这个项目旨在帮助爱好者、学生和未来的操作系统设计者更多地了解计算机的工作原理以及每个组件执行的功能。这并不是安装 Linux 的推荐方法,但你会发现,在开源中,通常是这样的:*如果*有些事情可以做,那么就有人在做。而这也是一件好事,因为这些小众的兴趣往往会带来令人惊讶的有用的创新。
+
+假设你不是想对 Linux 进行逆向工程,那么正常的安装方式是使用安装光盘或镜像。
+
+### 3 个简单的步骤来安装 Linux
+
+当你从一个 Linux 安装 DVD 或 U 盘启动时,你会置身于一个最小化的操作环境中,这个环境是为了运行一个或多个有用的应用程序。安装程序是最主要的应用程序,但由于 Linux 是一个如此灵活的系统,你通常也可以运行标准的桌面应用程序,以在你决定安装它之前感受一下这个操作系统是什么样子的。
+
+不同的 Linux 发行版有不同的安装程序界面。下面是两个例子。
+
+Fedora Linux 有一个灵活的安装程序(称为 Anaconda),能够进行复杂的系统配置:
+
+![Fedora 上的 Anaconda 安装界面][3]
+
+*Fedora 上的 Anaconda 安装程序*
+
+Elementary OS 有一个简单的安装程序,主要是为了在个人电脑上安装而设计的:
+
+![Elementary OS 安装程序][4]
+
+*Elementary OS 安装程序*
+
+#### 1、获取安装程序
+
+安装 Linux 的第一步是下载一个安装程序。你可以从你选择尝试的发行版中获得一个 Linux 安装镜像。
+
+ * [Fedora][5] 以率先更新软件而闻名。
+ * [Linux Mint][6] 提供了安装缺失驱动程序的简易选项。
+ * [Elementary][7] 提供了一个美丽的桌面体验和几个特殊的、定制的应用程序。
+
+Linux 安装程序是 `.iso` 文件,是 DVD 介质的“蓝图”。如果你还在使用光学介质,你可以把 `.iso` 文件刻录到 DVD-R 上,或者你可以把它烧录到 U 盘上(确保它是一个空的 U 盘,因为当镜像被烧录到它上时,它的所有内容都会被删除)。要将镜像烧录到 U 盘上,你可以 [使用开源的 Etcher 应用程序][8]。
+
+![Etcher 用于烧录 U 盘][9]
+
+*Etcher 应用程序可以烧录 U 盘。*
+
+现在你可以安装 Linux 了。
+
+#### 2、引导顺序
+
+要在电脑上安装操作系统,你必须引导到操作系统安装程序。这对于一台电脑来说并不是常见的行为,因为很少有人这样做。理论上,你只需要安装一次操作系统,然后你就会不断更新它。当你选择在电脑上安装不同的操作系统时,你就中断了这个正常的生命周期。这不是一件坏事。这是你的电脑,所以你有权力对它进行重新规划。然而,这与电脑的默认行为不同,它的默认行为是开机后立即启动到硬盘上找到的任何操作系统。
+
+在安装 Linux 之前,你必须备份你在目标计算机上的任何数据,因为这些数据在安装时都会被清除。
+
+假设你已经将数据保存到了一个外部硬盘上,然后你将它秘密地存放在安全的地方(而不是连接到你的电脑上),那么你就可以继续了。
+
+首先,将装有 Linux 安装程序的 U 盘连接到电脑上。打开电脑电源,观察屏幕上是否有一些如何中断其默认启动序列的指示。这通常是像 `F2`、`F8`、`Esc` 甚至 `Del` 这样的键,但根据你的主板制造商不同而不同。如果你错过了这个时间窗口,只需等待默认操作系统加载,然后重新启动并再次尝试。
+
+当你中断启动序列时,电脑会提示你引导指令。具体来说,嵌入主板的固件需要知道该到哪个驱动器寻找可以加载的操作系统。在这种情况下,你希望计算机从包含 Linux 镜像的 U 盘启动。如何提示你这些信息取决于主板制造商。有时,它会直接问你,并配有一个菜单:
+
+![引导设备菜单][10]
+
+*启动设备选择菜单*
+
+其他时候,你会被带入一个简陋的界面,你可以用来设置启动顺序。计算机通常默认设置为先查看内部硬盘。如果引导失败,它就会移动到 U 盘、网络驱动器或光驱。你需要告诉你的计算机先寻找一个 U 盘,这样它就会绕过自己的内部硬盘驱动器,而引导 U 盘上的 Linux 镜像。
+
+![BIOS 选择屏幕][11]
+
+*BIOS 选择屏幕*
+
+起初,这可能会让人望而生畏,但一旦你熟悉了界面,这就是一个快速而简单的任务。一旦安装了Linux,你就不必这样做了,因为,在这之后,你会希望你的电脑再次从内部硬盘启动。这是一个很好的技巧,因为在 U 盘上使用 Linux 的关键原因,是在安装前测试计算机的 Linux 兼容性,以及无论涉及什么操作系统的一般性故障排除。
+
+一旦你选择了你的 U 盘作为引导设备,保存你的设置,让电脑复位,然后启动到 Linux 镜像。
+
+#### 3、安装 Linux
+
+一旦你启动进入 Linux 安装程序,就只需通过提示进行操作。
+
+Fedora 安装程序 Anaconda 为你提供了一个“菜单”,上面有你在安装前可以自定义的所有事项。大多数设置为合理的默认值,可能不需要你的互动,但有些则用警示符号标记,表示不能安全地猜测出你的配置,因此需要设置。这些配置包括你想安装操作系统的硬盘位置,以及你想为账户使用的用户名。在你解决这些问题之前,你不能继续进行安装。
+
+对于硬盘的位置,你必须知道你要擦除哪个硬盘,然后用你选择的 Linux 发行版重新写入。对于只有一个硬盘的笔记本来说,这可能是一个显而易见的选择。
+
+![选择安装驱动器的屏幕][12]
+
+*选择要安装操作系统的硬盘(本例中只有一个硬盘)。*
+
+如果你的电脑里有不止一个硬盘,而你只想在其中一个硬盘上安装 Linux,或者你想把两个硬盘当作一个硬盘,那么你必须帮助安装程序了解你的目标。最简单的方法是只给 Linux 分配一个硬盘,让安装程序执行自动分区和格式化,但对于高级用户来说,还有很多其他的选择。
+
+你的电脑必须至少有一个用户,所以要为自己创建一个用户账户。完成后,你可以最后点击 **Done** 按钮,安装 Linux。
+
+![Anaconda 选项完成并准备安装][13]
+
+*Anaconda 选项已经完成,可以安装了*
+
+其他的安装程序可能会更简单,所以你看到的可能与本文中的图片不同。无论怎样,除了预装的操作系统之外,这个安装过程都是最简单的操作系统安装过程之一,所以不要让安装操作系统的想法吓到你。这是你的电脑。你可以、也应该安装一个你拥有所有权的操作系统。
+
+### 拥有你的电脑
+
+最终,Linux 成为了你的操作系统。它是一个由来自世界各地的人们开发的操作系统,其核心是一个:创造一种参与、共同拥有、合作管理的计算文化。如果你有兴趣更好地了解开源,那么就请你迈出一步,了解它的一个光辉典范 Linux,并安装它。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-installation
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
+[2]: http://www.linuxfromscratch.org
+[3]: https://opensource.com/sites/default/files/anaconda-installer.png
+[4]: https://opensource.com/sites/default/files/elementary-installer.png
+[5]: http://getfedora.org
+[6]: http://linuxmint.com
+[7]: http://elementary.io
+[8]: https://opensource.com/article/18/7/getting-started-etcherio
+[9]: https://opensource.com/sites/default/files/etcher_0.png
+[10]: https://opensource.com/sites/default/files/boot-menu.jpg
+[11]: https://opensource.com/sites/default/files/bios_1.jpg
+[12]: https://opensource.com/sites/default/files/install-harddrive-chooser.png
+[13]: https://opensource.com/sites/default/files/anaconda-done.png
diff --git a/published/202103/20210216 What does being -technical- mean.md b/published/202103/20210216 What does being -technical- mean.md
new file mode 100644
index 0000000000..896988d23d
--- /dev/null
+++ b/published/202103/20210216 What does being -technical- mean.md
@@ -0,0 +1,166 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13168-1.html)
+[#]: subject: (What does being 'technical' mean?)
+[#]: via: (https://opensource.com/article/21/2/what-technical)
+[#]: author: (Dawn Parzych https://opensource.com/users/dawnparzych)
+
+“技术”是什么意思?
+======
+
+> 用“技术”和“非技术”的标签对人们进行分类,会伤害个人和组织。本文作为本系列的第 1 篇,将阐述这个问题。
+
+
+
+“技术”一词描述了许多项目和学科:**技术**淘汰赛、**技术性**犯规、攀岩比赛的**技术**课程和花样滑冰运动的**技术**得分。广受欢迎的烹饪节目 “_The Great British Bake-Off_” 包括一个“烘焙**技术**挑战”。任何参加过剧院演出的人都可能熟悉**技术**周,即戏剧或音乐剧首演前的一周。
+
+如你所见,**技术**一词并不严格适用于软件工程和软件操作,所以当我们称一个人或一个角色为“技术”时,我们的意思是什么,为什么使用这个术语?
+
+在我 20 年的技术生涯中,这些问题引起了我的兴趣,所以我决定通过一系列的采访来探讨这个问题。我不是工程师,也不写代码,但这并不意味着我是**非技术型**的。但我经常被贴上这样的标签。我认为自己是**技术型**的,通过这个系列,我希望你会明白为什么。
+
+我知道我不是孤独一个人。群众讨论是很重要的,因为如何定义和看待一个人或一个角色会影响他们做好工作的信心和能力。如果他们感到被压垮或不受尊重,就会降低他们的工作质量,挤压创新和新思想。你看,这一切都是循序渐进的,那么我们怎样才能改善这种状况呢?
+
+我首先采访了 7 个不同角色的人。
+
+在本系列中,我将探讨“技术”一词背后的含义、技术的连续性、将人分类为技术型或非技术型的意外副作用,以及通常被认为是非技术性的技术角色。
+
+### 定义技术和非技术
+
+首先,我们需要做个名词解释。根据字典网,“技术/技术性的”是一个具有多重含义的形容词,包括:
+
+ * 属于或与艺术、科学等学科有关的
+ * 精通或熟悉某一特定的艺术或行业的实际操作
+ * 技术要求高或困难(通常用于体育或艺术)
+
+而“非技术性”一词在科技公司中经常被用来描述非工程人员。但是“非技术性”的定义是“不涉及、不具有某个特定活动领域及其术语的特点,或不熟练”。
+
+作为一个写作和谈论技术的人,我认为自己是技术型的。如果你不熟悉这个领域和术语,就不可能书写或谈论一个技术主题。有了这种理解,每个从事技术工作的人都是技术人员。
+
+### 为什么要分配标签?
+
+那么,为什么划分技术与非技术?这在技术领域有什么意义呢?我们试图通过分配这些标签来实现什么?有没有一个好的理由?而我们有没有重新评估这些理由?让我们讨论一下。
+
+当我听到人们谈论技术人员和非技术人员时,我不禁想起 Seuss 教授写的童话故事 《[The Sneetches][2]》。Sneetches 有没有星星被演化为一种渴望。Sneetches 们进入了一个无限循环,试图达到正确的状态。
+
+标签可以起到一定的作用,但当它们迫使一个群体的等级被视为比另一个更好时,它们就会变得危险。想想你的组织或部门:销售、资源、营销、质控、工程等,哪一组的在重要性上高于或低于另一组?
+
+即使它不是直接说的或写在什么地方,也可能是被人们默认的。这些等级划分通常也存在于规章制度中。技术内容经理 Liz Harris 表示,“在技术写作界存在着一个技术含量的评级,你越是偏技术的文章,你得到的报酬就越高,而且往往在技术写作社区里你得到的关注就越多。”
+
+术语“技术”通常用于指一个人在某一主题上的深度或专业知识水平。销售人员也有可能会要求需要懂技术以更好的帮助客户。从事技术工作的人,他们是技术型的,但是也许更专业的技术人员才能胜任这个项目。因此,请求技术支援可能是含糊不清的表述。你需要一个对产品有深入了解的人吗?你需要一位了解基础设施堆栈的人员吗?还是需要一个能写下如何配置 API 的步骤的人?
+
+我们应该要把技术能力看作是一个连续体,而不是把人简单的看作技术型的或非技术型的。这是什么意思?开发人员关系主管 Mary thengwall 描述了她如何对特定角色所需的不同深度的技术知识进行分类。例如,项目可能需要一个开发人员、一个具有开发人员背景的人员,或一个精通技术的人员。就是那些被归类为精通技术的人也经常被贴上非技术的标签。
+
+根据 Mary 的说法,如果“你能解释(一个技术性的)话题,你知道你的产品工作方式,你知道该说什么和不该说什么的基本知识,那么你就是技术高手。你不必有技术背景,但你需要知道高层次的技术信息,然后还要知道向谁提供更多信息。”
+
+### 标签带来的问题
+
+当我们使用标签来具体说明我们需要完成一项工作时,它们可能会很有帮助,比如“开发人员”、“有开发人员背景”和“技术达人”。但是当我们使用标签的范围太广时,将人们分为两组中的一组可能会产生“弱于”和“优于”的感觉
+
+当一个标签成为现实时,无论是有意还是无意,我们都必须审视自己,重新评估自己的措辞、标签和意图。
+
+高级产品经理 Leon Stigter 提出了他的观点:“作为一个集体行业,我们正在构建更多的技术,让每个人都更容易参与。如果我们对每个人说:‘你不是技术型的’,或者说:‘你是技术型的’,然后把他们分成几个小组,那些被贴上非技术型标签的人可能永远不会去想:‘其实我自己就能完成这个项目’,实际上,我们需要所有这些人真正思考我们行业和社区的发展方向,我认为每一个人都应该有这个主观能动性。”
+
+#### 身份
+
+如果我们把我们的身份贴在一个标签上,当我们认为这个标签不再适用时会发生什么?当 Adam Gordon Bell 从一个开发人员转变为一个管理人员时,他很纠结,因为他总是认为自己是技术人员,而作为一个管理人员,这些技术技能没有被使用。他觉得自己不再有价值了。编写代码并不能提供比帮助团队成员发展事业或确保项目按时交付更大的价值。所有角色都有价值,因为它们都是确保商品和服务的创建、执行和交付所必需的。
+
+“我想我成为一名经理的原因是,我们有一支非常聪明的团队和很多非常有技能的人,但是我们并不总是能完成最出色的工作。所以技术不是限制因素,对吧?”Adam 说:“我想通常不是技术限制了团队的发挥”。
+
+Leon Stigter 说,让人们一起合作并完成令人惊叹的工作的能力是一项很有价值的技能,不应低于技术角色的价值。
+
+#### 自信
+
+[冒充者综合症][3] 是指无法认识到自己的能力和知识,从而导致信心下降,以及完成工作和做好工作的能力下降。当你申请在会议上发言,向科技刊物提交文章,或申请工作时,冒充者综合症就会发作。冒充者综合症是一种微小的声音,它说:
+
+ * “我技术不够胜任这个角色。”
+ * “我认识更多的技术人员,他们在演讲中会做得更好。”
+ * “我在市场部工作,所以我无法为这样的技术网站写文章。”
+
+当你把某人或你自己贴上非技术型标签的时候,这些声音就会变得更响亮。这很容易导致在会议上听不到新的声音或失去团队中的人才。
+
+#### 刻板印象
+
+当你认为某人是技术人员时,你会看到什么样的印象?他们穿什么?他们还有什么特点?他们是外向健谈,还是害羞安静?
+
+Shailvi Wakhlu 是一位高级数据总监,她的职业生涯始于软件工程师,并过渡到数据和分析领域。“当我是一名软件工程师的时候,很多人都认为我不太懂技术,因为我很健谈,很明显这就意味着你不懂技术。他们认为你不孤独的待在角落就是不懂技术。”她说。
+
+我们对谁是技术型与非技术型的刻板印象会影响招聘决策或我们的社区是否具有包容性。你也可能冒犯别人,甚至是能够帮助你的人。几年前,我在某个展台工作,问别人我能不能帮他们。“我要找最专业的人帮忙”他回答说。然后他就出发去寻找他的问题的答案。几分钟后,摊位上的销售代表和那位先生走到我跟前说:“Dawn,你是回答这个人问题的最佳人选。”
+
+#### 污名化
+
+随着时间的推移,我们夸大了“技术”技能的重要性,这导致了“非技术”的标签被贬义地使用。随着技术的蓬勃发展,编程人员的价值也随之增加,因为这种技能为市场带来了新产品和新的商业方式,并直接帮助了盈利。然而,现在我们看到人们故意将技术角色凌驾于非技术角色之上,阻碍了公司的发展和成功。
+
+人际交往技能通常被称为非技术技能。然而,它们有着高度的技术性,比如提供如何完成一项任务的分步指导,或者确定最合适的词语来传达信息或观点。这些技能往往也是决定你能否在工作中取得成功的更重要因素。
+
+通读“城市词典”上的文章和定义,难怪人们会觉得自己的标签有道理,而其他人会患上冒充者综合症,或者觉得自己失去了身份。在线搜索时,“城市词典”定义通常出现在搜索结果的顶部。这个网站大约 20 年前开始是一个定义俚语、文化表达和其他术语的众包词典,现在变成了一个充满敌意和负面定义的网站。
+
+这里有几个例子:“城市词典”将非技术经理定义为“不知道他们管理的人应该做什么的人”
+
+提供如何与“非技术”人员交谈技巧的文章包括以下短语:
+
+ * “如果我抗争,非技术人员究竟是如何应对的?”
+ * “在当今的职业专业人士中,开发人员和工程师拥有一些最令人印象深刻的技能,这些技能是由多年的技术培训和实际经验磨练而成的。”
+
+这些句子意味着非工程师是低人一等的,他们多年的训练和现实世界的经验在某种程度上没有那么令人印象深刻。对于这样的说辞,我可以举一个反例:Therese Eberhard,她的工作被许多人认为是非技术性的。她是个风景画家。她为电影和戏剧画道具和风景。她的工作是确保像甘道夫的手杖这样的道具看起来栩栩如生,而不是像塑料玩具。要想在这个角色上取得成功,需要有很多解决问题和实验化学反应的方法。Therese 在多年的实战经验中磨练了这些技能,对我来说,这相当令人印象深刻。
+
+#### 守门人行为
+
+使用标签会设置障碍,并导致守门人行为,这决定谁可以进入我们的组织,我们的团队,我们的社区。
+
+据一位开源开发者 Eddie Jaoude 所说,“`技术’、`开发人员‘或`测试人员’的头衔在不应该出现的地方制造了障碍或权威。我们应该将重点放在谁能为团队或项目增加价值,而头衔是无关紧要的。”
+
+如果我们把每个人看作一个团队成员,他们应该以这样或那样的方式贡献价值,而不是看他们是否编写文档、测试用例或代码,那么我们将根据真正重要的东西来重视他们,并创建一个能完成惊人工作的团队。如果测试工程师想学习编写代码,或者程序员想学习如何在活动中与人交谈,为什么要设置障碍来阻止这种成长呢?拥抱团队成员学习、改变和向任何方向发展的渴望,为团队和公司的使命服务。
+
+如果有人在某个角色上失败了,与其把他们说成“技术不够”,不如去看看问题到底是什么。你是否需要一个精通 JavaScript 的人,而这个人又是另一种编程语言的专家?并不是说他们不专业,是技能和知识不匹配。你需要合适的人来扮演合适的角色。如果你强迫一个精通业务分析和编写验收标准的人去编写自动化测试用例,他们就会失败。
+
+### 如何取消标签
+
+如果你已经准备好改变你对技术性和非技术性标签的看法,这里有帮助你改变的提示。
+
+#### 寻找替代词
+
+我问我采访过的每个人,我们可以用什么词来代替技术和非技术。没有人能回答!我认为这里的挑战是我们不能把它归结为一个词。要替换术语,你需要使用更多的词。正如我之前写的,我们需要做的是变得更加具体。
+
+你说过或听到过多少次这样的话:
+
+ * “我正在为这个项目寻找技术资源。”
+ * “那个候选人技术不够。”
+ * “我们的软件是为非技术用户设计的。”
+
+技术和非技术词语的这些用法是模糊的,不能表达它们的全部含义。更真实、更详细地了解你的需求那么你应该说:
+
+ * “我想找一个对如何配置 Kubernetes 有深入了解的人。”
+ * “那个候选人对 Go 的了解不够深入。”
+ * “我们的软件是为销售和营销团队设计的。”
+
+#### 拥抱成长心态
+
+知识和技能不是天生的。它们是经过数小时或数年的实践和经验形成的。认为“我只是技术不够”或“我不能学习如何做营销”反映了一种固定的心态。你可以向任何你想发展的方向学习技能。列一张清单,列出你认为哪些是技术技能,或非技术技能,但要具体(如上面的清单)。
+
+#### 认可每个人的贡献
+
+如果你在科技行业工作,你就是技术人员。在一个项目或公司的成功中,每个人都有自己的作用。与所有做出贡献的人分享荣誉,而不仅仅是少数人。认可提出新功能的产品经理,而不仅仅是开发新功能的工程师。认可一个作家,他的文章在你的公司迅速传播并产生了新的线索。认可在数据中发现新模式的数据分析师。
+
+### 下一步
+
+在本系列的下一篇文章中,我将探讨技术中经常被标记为“非技术”的非工程角色。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/what-technical
+
+作者:[Dawn Parzych][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dawnparzych
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/question-mark_chalkboard.jpg?itok=DaG4tje9 (question mark in chalk)
+[2]: https://en.wikipedia.org/wiki/The_Sneetches_and_Other_Stories
+[3]: https://opensource.com/business/15/9/tips-avoiding-impostor-syndrome
+[4]: https://enterprisersproject.com/article/2019/8/why-soft-skills-core-to-IT
diff --git a/published/202103/20210217 4 tech jobs for people who don-t code.md b/published/202103/20210217 4 tech jobs for people who don-t code.md
new file mode 100644
index 0000000000..4252efa8a5
--- /dev/null
+++ b/published/202103/20210217 4 tech jobs for people who don-t code.md
@@ -0,0 +1,127 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13178-1.html)
+[#]: subject: (4 tech jobs for people who don't code)
+[#]: via: (https://opensource.com/article/21/2/non-engineering-jobs-tech)
+[#]: author: (Dawn Parzych https://opensource.com/users/dawnparzych)
+
+不懂代码的人也可以干的 4 种技术工作
+======
+
+> 对于不是工程师的人来说也有很多技术工作可以做。本文作为本系列的第二篇,就具体阐述这些工作。
+
+
+
+在 [本系列的第一篇文章][2] 中,我解释了技术行业如何将人员和角色划分为“技术”或“非技术”类别,以及与此相关的问题。科技行业使得那些对科技感兴趣但不懂编程的人很难找到适合自己的角色。
+
+如果你对技术或开源感兴趣,但对编程不感兴趣,这也有一些工作适合你。科技公司的任何一个职位都可能需要一个精通科技但不一定会写代码的人。但是,你确实需要了解术语并理解产品。
+
+我最近注意到,在诸如技术客户经理、技术产品经理、技术社区经理等职位头衔上增加了“技术”一词。这反映了几年前的趋势,即在头衔上加上“工程师”一词,以表示该职位的技术需要。过了一段时间,每个人的头衔中都有“工程师”这个词,这样的分类就失去了一些吸引力。
+
+当我坐下来写这些文章时,Tim Banks 的这条推特出现在我的通知栏上:
+
+> 已经将职业生涯规划为技术行业的非开发人员(除了信息安全、数据科学/分析师、基础设施工程师等以外的人员)的女性,你希望知道的事情有哪些,有价值的资源有哪些,或者对希望做出类似改变的人有哪些建议?
+>
+> —— Tim Banks is a buttery biscuit (@elchefe) [December 15,2020][3]
+
+这遵循了我第一篇文章中的建议:Tim 并不是简单地询问“非技术角色”;他提供了更重要的详细描述。在 Twitter 这样的媒体上,每一个字符都很重要,这些额外的字符会产生不同的效果。这些是技术角色。如果为了节约笔墨,而简单的称呼他们为“非技术人员”,会改变你的原意,产生不好的影响。
+
+以下是需要技术知识的非工程类角色的示例。
+
+### 技术作者
+
+[技术作者的工作][4] 是在两方或多方之间传递事实信息。传统上,技术作者提供有关如何使用技术产品的说明或文档。最近,我看到术语“技术作者”指的是写其他形式内容的人。科技公司希望一个人为他们的开发者读者写博客文章,而这种技巧不同于文案或内容营销。
+
+**需要的技术技能:**
+
+ * 写作
+ * 特定技术或产品的用户知识或经验
+ * 快速跟上新产品或新特性的速度的能力
+ * 在各种环境中创作的技能
+
+**适合人群:**
+
+ * 可以清楚地提供分步说明
+ * 享受合作
+ * 对活跃的声音和音乐有热情
+ * 喜欢描述事物和解释原理
+
+### 产品经理
+
+[产品经理][5] 负责领导产品战略。职责可能包括收集客户需求并确定其优先级,撰写业务案例,以及培训销售人员。产品经理跨职能工作,利用创造性和技术技能的结合,成功地推出产品。产品经理需要深厚的产品专业知识。
+
+**所需技术技能:**
+
+ * 掌握产品知识,并且会配置或运行演示模型
+ * 与产品相关的技术生态系统知识
+ * 分析和研究技能
+
+**适合以下人群:**
+
+ * 享受制定战略和规划下一步的工作
+ * 在不同的人的需求中可以看到一条共同的线索
+ * 能够清楚地表达业务需求和要求
+ * 喜欢描述原因
+
+### 数据分析师
+
+数据分析师负责收集和解释数据,以帮助推动业务决策,如是否进入新市场、瞄准哪些客户或在何处投资。这个角色需要知道如何使用所有可用的潜在数据来做出决策。我们常常希望把事情简单化,而数据分析往往过于简单化。获取正确的信息并不像编写查询 `select all limit 10` 来获取前 10 行那么简单。你需要知道要加入哪些表。你需要知道如何分类。你需要知道是否需要在运行查询之前或之后以某种方式清理数据。
+
+**所需技术技能:**
+
+ * 了解 SQL、Python 和 R
+ * 能够看到和提取数据中的样本
+ * 了解事物如何端到端运行
+ * 批判性思维
+ * 机器学习
+
+**适合以下人群:**
+
+ * 享受解决问题的乐趣
+ * 渴望学习和提出问题
+
+### 开发者关系
+
+[开发者关系][6] 是一门相对较新的技术学科。它包括 [开发者代言人][7]、开发者传道者和开发者营销等角色。这些角色要求你与开发人员沟通,与他们建立关系,并帮助他们提高工作效率。你向公司倡导开发者的需求,并向开发者代表公司。开发者关系可以包括撰写文章、创建教程、录制播客、在会议上发言以及创建集成和演示。有人说你需要做过开发才能进入开发者关系。我没有走那条路,我知道很多人没有。
+
+**所需技术技能:**
+
+这些将高度依赖于公司和具体角色。你需要部分技能(不是全部)取决于你自己。
+
+ * 了解与产品相关的技术概念
+ * 写作
+ * 教程和播客的视频和音频编辑
+ * 说话
+
+**适合以下人群:**
+
+ * 有同情心,想要教导和授权他人
+ * 可以为他人辩护
+ * 你很有创意
+
+### 无限的可能性
+
+这并不是一个完整的清单,并没有列出技术领域中所有的非工程类角色,而是一些不喜欢每天编写代码的人可以尝试的工作。如果你对科技职业感兴趣,看看你的技能和什么角色最适合。可能性是无穷的。为了帮助你完成旅程,在本系列的最后一篇文章中,我将与这些角色的人分享一些建议。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/non-engineering-jobs-tech
+
+作者:[Dawn Parzych][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dawnparzych
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tips_map_guide_ebook_help_troubleshooting_lightbulb_520.png?itok=L0BQHgjr (Looking at a map)
+[2]: https://linux.cn/article-13168-1.html
+[3]: https://twitter.com/elchefe/status/1338933320147750915?ref_src=twsrc%5Etfw
+[4]: https://opensource.com/article/17/5/technical-writing-job-interview-tips
+[5]: https://opensource.com/article/20/2/product-management-open-source-company
+[6]: https://www.marythengvall.com/blog/2019/5/22/what-is-developer-relations-and-why-should-you-care
+[7]: https://opensource.com/article/20/10/open-source-developer-advocates
diff --git a/published/202103/20210220 Run your favorite Windows applications on Linux.md b/published/202103/20210220 Run your favorite Windows applications on Linux.md
new file mode 100644
index 0000000000..4ecc4a59e2
--- /dev/null
+++ b/published/202103/20210220 Run your favorite Windows applications on Linux.md
@@ -0,0 +1,98 @@
+[#]: collector: (lujun9972)
+[#]: translator: (robsean)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13184-1.html)
+[#]: subject: (Run your favorite Windows applications on Linux)
+[#]: via: (https://opensource.com/article/21/2/linux-wine)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+在 Linux 上运行你最喜欢的 Windows 应用程序
+======
+
+> WINE 是一个开源项目,它可以协助很多 Windows 应用程序在 Linux 上运行,就好像它们是原生程序一样。
+
+
+
+在 2021 年,有很多比以往更喜欢 Linux 的原因。在这系列中,我将分享使用 Linux 的 21 种原因。这里是如何使用 WINE 来实现从 Windows 到 Linux 的无缝切换。
+
+你有只能在 Windows 上运行的应用程序吗?那一个应用程序阻碍你切换到 Linux 的唯一因素吗?如果是这样的话,你将会很高兴知道 WINE,这是一个开源项目,它几乎重新发明了关键的 Windows 库,使为 Windows 编译的应用程序可以在 Linux 上运行。
+
+WINE 代表着“Wine Is Not an Emulator” ,它指的是驱动这项技术的代码。开源开发者从 1993 年就开始致力将应用程序的任何传入 Windows API 调用翻译为 [POSIX][2] 调用。
+
+这是一个令人十分惊讶的编程壮举,尤其是考虑到这个项目是独立运行的,没有来自微软的帮助(至少可以这样说),但是也有局限性。一个应用程序偏离 Windows API 的 “内核” 越远,WINE 就越不能预期应用程序的请求。有一些供应商可以弥补这一点,尤其是 [Codeweavers][3] 和 [Valve Software][4]。在需要翻译应用程序的制作者和翻译的人们及公司之间没有协调配合,因此,比如说一个更新的软件作品和从 [WINE 总部][5] 获得完美适配状态之间可能会有一些时间上的滞后。
+
+然而,如果你想在 Linux 上运行一个著名的 Windows 应用程序,WINE 可能已经为它准备好了可能性。
+
+### 安装 WINE
+
+你可以从你的 Linux 发行版的软件包存储库中安装 WINE 。在 Fedora、CentOS Stream 或 RHEL 系统上:
+
+```
+$ sudo dnf install wine
+```
+
+在 Debian、Linux Mint、Elementary 及相似的系统上:
+
+```
+$ sudo apt install wine
+```
+
+WINE 不是一个你自己启动的应用程序。当启动一个 Windows 应用程序时,它是一个被调用的后端。你与 WINE 的第一次交互很可能就发生在你启动一个 Windows 应用程序的安装程序时。
+
+### 安装一个应用程序
+
+[TinyCAD][6] 是一个极好的用于设计电路的开源应用程序,但是它仅在 Windows 上可用。虽然它是一个小型的应用程序,但是它确实包含一些 .NET 组件,因此应该能对 WINE 进行一些压力测试。
+
+首先,下载 TinyCAD 的安装程序。Windows 安装程序通常都是这样,它是一个 `.exe` 文件。在下载后,双击文件来启动它。
+
+![WINE TinyCAD 安装向导][7]
+
+*TinyCAD 的 WINE 安装向导*
+
+像你在 Windows 上一样逐步完成安装程序。通常最好接受默认选项,尤其是与 WINE 有关的地方。WINE 环境基本上是独立的,隐藏在你的硬盘驱动器上的一个 `drive_c` 目录中,作为 Windows 应用程序使用的一个文件系统的仿真根目录。
+
+![WINE TinyCAD 安装和目标驱动器][8]
+
+*WINE TinyCAD 目标驱动器*
+
+安装完成后,应用程序通常会为你提供启动机会。如果你正准备测试一下它的话,启动应用程序。
+
+### 启动 Windows 应用程序
+
+除了在安装后的第一次启动外,在正常情况下,你启动一个 WINE 应用程序的方式与你启动一个本地 Linux 应用程序相同。不管你使用应用程序菜单、活动屏幕或者只是在运行器中输入应用程序的名称,在 WINE 中运行的桌面 Windows 应用程序都会被视为在 Linux 上的本地应用程序。
+
+![TinyCAD 使用 WINE 运行][9]
+
+*通过 WINE 的支持来运行 TinyCAD*
+
+### 当 WINE 失败时
+
+我在 WINE 中的大多数应用程序,包括 TinyCAD ,都能如期运行。不过,也会有例外。在这些情况下,你可以等几个月来查看 WINE 开发者 (或者,如果是一款游戏,就等候 Valve Software)是否进行追加修补,或者你可以联系一个像 Codeweavers 这样的供应商来查看他们是否出售对你所需要的应用程序的服务支持。
+
+### WINE 是种欺骗,但它用于正道
+
+一些 Linux 用户觉得:如果你使用 WINE 的话,你就是在“欺骗” Linux。它可能会让人有这种感觉,但是 WINE 是一个开源项目,它使用户能够切换到 Linux ,并且仍然能够运行工作或爱好所需的应用程序。如果 WINE 解决了你的问题,让你使用 Linux,那就使用它,并拥抱 Linux 的灵活性。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-wine
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[robsean](https://github.com/robsean)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_screen_windows_files.png?itok=kLTeQUbY (Computer screen with files or windows open)
+[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[3]: https://www.codeweavers.com/crossover
+[4]: https://github.com/ValveSoftware/Proton
+[5]: http://winehq.org
+[6]: https://sourceforge.net/projects/tinycad/
+[7]: https://opensource.com/sites/default/files/wine-tinycad-install.jpg
+[8]: https://opensource.com/sites/default/files/wine-tinycad-drive_0.jpg
+[9]: https://opensource.com/sites/default/files/wine-tinycad-running.jpg
diff --git a/published/202103/20210223 A guide to Python virtual environments with virtualenvwrapper.md b/published/202103/20210223 A guide to Python virtual environments with virtualenvwrapper.md
new file mode 100644
index 0000000000..35b591cf1b
--- /dev/null
+++ b/published/202103/20210223 A guide to Python virtual environments with virtualenvwrapper.md
@@ -0,0 +1,126 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13174-1.html)
+[#]: subject: (A guide to Python virtual environments with virtualenvwrapper)
+[#]: via: (https://opensource.com/article/21/2/python-virtualenvwrapper)
+[#]: author: (Ben Nuttall https://opensource.com/users/bennuttall)
+
+使用 virtualenvwrapper 构建 Python 虚拟环境
+======
+
+> 虚拟环境是安全地使用不同版本的 Python 和软件包组合的关键。
+
+
+
+Python 对管理虚拟环境的支持,已经提供了一段时间了。Python 3.3 甚至增加了内置的 `venv` 模块,用于创建没有第三方库的环境。Python 程序员可以使用几种不同的工具来管理他们的环境,我使用的工具叫做 [virtualenvwrapper][2]。
+
+虚拟环境是将你的 Python 项目及其依赖关系与你的系统安装的 Python 分离的一种方式。如果你使用的是基于 macOS 或 Linux 的操作系统,它很可能在安装中附带了一个 Python 版本,事实上,它很可能依赖于那个特定版本的 Python 才能正常运行。但这是你的计算机,你可能想用它来达到自己的目的。你可能需要安装另一个版本的 Python,而不是操作系统提供的版本。你可能还需要安装一些额外的库。尽管你可以升级你的系统 Python,但不推荐这样做。你也可以安装其他库,但你必须注意不要干扰系统所依赖的任何东西。
+
+虚拟环境是创建隔离的关键,你需要安全地修改不同版本的 Python 和不同组合的包。它们还允许你为不同的项目安装同一库的不同版本,这解决了在相同环境满足所有项目需求这个不可能的问题。
+
+为什么选择 `virtualenvwrapper` 而不是其他工具?简而言之:
+
+ * 与 `venv` 需要在项目目录内或旁边有一个 `venv` 目录不同,`virtualenvwrapper` 将所有环境保存在一个地方:默认在 `~/.virtualenvs` 中。
+ * 它提供了用于创建和激活环境的命令,而且激活环境不依赖于找到正确的 `activate` 脚本。它只需要(从任何地方)`workon projectname`而不需要 `source ~/Projects/flashylights-env/bin/activate`。
+
+### 开始使用
+
+首先,花点时间了解一下你的系统 Python 是如何配置的,以及 `pip` 工具是如何工作的。
+
+以树莓派系统为例,该系统同时安装了 Python 2.7 和 3.7。它还提供了单独的 `pip` 实例,每个版本一个:
+
+ * 命令 `python` 运行 Python 2.7,位于 `/usr/bin/python`。
+ * 命令 `python3` 运行 Python 3.7,位于 `/usr/bin/python3`。
+ * 命令 `pip` 安装 Python 2.7 的软件包,位于 `/usr/bin/pip`。
+ * 命令 `pip3` 安装 Python 3.7 的包,位于 `/usr/bin/pip3`。
+
+![Python commands on Raspberry Pi][3]
+
+在开始使用虚拟环境之前,验证一下使用 `python` 和 `pip` 命令的状态是很有用的。关于你的 `pip` 实例的更多信息可以通过运行 `pip debug` 或 `pip3 debug` 命令找到。
+
+在我运行 Ubuntu Linux 的电脑上几乎是相同的信息(除了它是 Python 3.8)。在我的 Macbook 上也很相似,除了唯一的系统 Python 是 2.6,而我用 `brew` 安装 Python 3.8,所以它位于 `/usr/local/bin/python3`(和 `pip3` 一起)。
+
+### 安装 virtualenvwrapper
+
+你需要使用系统 Python 3 的 `pip` 安装 `virtualenvwrapper`:
+
+
+```
+sudo pip3 install virtualenvwrapper
+```
+
+下一步是配置你的 shell 来加载 `virtualenvwrapper` 命令。你可以通过编辑 shell 的 RC 文件(例如 `.bashrc`、`.bash_profile` 或 `.zshrc`)并添加以下几行:
+
+```
+export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
+export VIRTUALENVWRAPPER_VIRTUALENV=/usr/local/bin/virtualenv
+source /usr/local/bin/virtualenvwrapper.sh
+```
+
+![bashrc][5]
+
+如果你的 Python 3 位于其他地方,请根据你的设置修改第一行。
+
+关闭你的终端,然后重新打开它,这样才能生效。第一次打开终端时,你应该看到 `virtualenvwrapper` 的一些输出。这只会发生一次,因为一些目录是作为设置的一部分被创建的。
+
+现在你应该可以输入 `mkvirtualenv --version` 命令来验证 `virtualenvwrapper` 是否已经安装。
+
+### 创建一个新的虚拟环境
+
+假设你正在进行一个名为 `flashylights` 的项目。要用这个名字创建一个虚拟环境,请运行该命令:
+
+```
+mkvirtualenv flashylights
+```
+
+环境已经创建并激活,所以你会看到 `(flashlylights)` 出现在你的提示前:
+
+![Flashylights prompt][6]
+
+现在环境被激活了,事情发生了变化。`python` 现在指向一个与你之前在系统中识别的 Python 实例完全不同的 Python 实例。它为你的环境创建了一个目录,并在其中放置了 Python 3 二进制文件、pip 命令等的副本。输入 `which python` 和 `which pip` 来查看它们的位置。
+
+![Flashylights command][7]
+
+如果你现在运行一个 Python 程序,你可以用 `python` 代替 `python3` 来运行,你可以用 `pip` 代替 `pip3`。你使用 `pip`安装的任何包都将只安装在这个环境中,它们不会干扰你的其他项目、其他环境或系统安装。
+
+要停用这个环境,运行 `deactivate` 命令。要重新启用它,运行 `workon flashylights`。
+
+你可以用 `workon` 或使用 `lsvirtualenv` 列出所有可用的环境。你可以用 `rmvirtualenv flashylights` 删除一个环境。
+
+在你的开发流程中添加虚拟环境是一件明智的事情。根据我的经验,它可以防止我在系统范围内安装我正在试验的库,这可能会导致问题。我发现 `virtualenvwrapper` 是最简单的可以让我进入流程的方法,并无忧无虑地管理我的项目环境,而不需要考虑太多,也不需要记住太多命令。
+
+### 高级特性
+
+ * 你可以在你的系统上安装多个 Python 版本(例如,在 Ubuntu 上使用 [deadsnakes PPA][8]),并使用该版本创建一个虚拟环境,例如,`mkvirtualenv -p /usr/bin/python3.9 myproject`。
+ * 可以在进入和离开目录时自动激活、停用。
+ * 你可以使用 `postmkvirtualenv` 钩子在每次创建新环境时安装常用工具。
+
+更多提示请参见[文档][9]。
+
+_本文基于 Ben Nuttall 在 [Tooling Tuesday 上关于 virtualenvwrapper 的帖子][10],经许可后重用。_
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/python-virtualenvwrapper
+
+作者:[Ben Nuttall][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/bennuttall
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_python.jpg?itok=G04cSvp_ (Python in a coffee cup.)
+[2]: https://virtualenvwrapper.readthedocs.io/en/latest/index.html
+[3]: https://opensource.com/sites/default/files/uploads/pi-python-cmds.png (Python commands on Raspberry Pi)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://opensource.com/sites/default/files/uploads/bashrc.png (bashrc)
+[6]: https://opensource.com/sites/default/files/uploads/flashylights-activated-prompt.png (Flashylights prompt)
+[7]: https://opensource.com/sites/default/files/uploads/flashylights-activated-cmds.png (Flashylights command)
+[8]: https://tooling.bennuttall.com/deadsnakes/
+[9]: https://virtualenvwrapper.readthedocs.io/en/latest/tips.html
+[10]: https://tooling.bennuttall.com/virtualenvwrapper/
diff --git a/published/202103/20210224 Check Your Disk Usage Using ‘duf- Terminal Tool -Friendly Alternative to du and df commands.md b/published/202103/20210224 Check Your Disk Usage Using ‘duf- Terminal Tool -Friendly Alternative to du and df commands.md
new file mode 100644
index 0000000000..4a72a2ac46
--- /dev/null
+++ b/published/202103/20210224 Check Your Disk Usage Using ‘duf- Terminal Tool -Friendly Alternative to du and df commands.md
@@ -0,0 +1,117 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13165-1.html)
+[#]: subject: (Check Your Disk Usage Using ‘duf’ Terminal Tool [Friendly Alternative to du and df commands])
+[#]: via: (https://itsfoss.com/duf-disk-usage/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+使用 duf 终端工具检查你的磁盘使用情况
+======
+
+
+
+> `duf` 是一个终端工具,旨在增强传统的 Linux 命令 `df` 和 `du`。它可以让你轻松地检查可用磁盘空间,对输出进行分类,并以用户友好的方式呈现。
+
+### duf:一个用 Golang 编写的跨平台磁盘使用情况工具
+
+![][1]
+
+在我知道这个工具之前,我更喜欢使用像 [Stacer][2] 这样的 GUI 程序或者预装的 GNOME 磁盘使用情况程序来 [检查可用的磁盘空间][3] 和系统的磁盘使用量。
+
+不过,[duf][4] 似乎是一个有用的终端工具,可以检查磁盘使用情况和可用空间,它是用 [Golang][5] 编写的。Abhishek 建议我试一试它,但我对它很感兴趣,尤其是考虑到我目前正在学习 Golang,真是太巧了!
+
+无论你是终端大师还是只是一个对终端不适应的初学者,它都相当容易使用。当然,它比 [检查磁盘空间利用率命令 df][6] 更容易理解。
+
+在你把它安装到你的系统上之前,让我重点介绍一下它的一些主要功能和用法。
+
+### duf 的特点
+
+![][7]
+
+ * 提供所有挂载设备的概览且易于理解。
+ * 能够指定目录/文件名并检查该挂载点的可用空间。
+ * 更改/删除输出中的列。
+ * 列出 [inode][8] 信息。
+ * 输出排序。
+ * 支持 JSON 输出。
+ * 如果不能自动检测终端的主题,可以指定主题。
+
+### 在 Linux 上安装和使用 duf
+
+你可以在 [AUR][9] 中找到一个 Arch Linux 的软件包。如果你使用的是 [Nix 包管理器][10],也可以找到一个包。
+
+对于基于 Debian 的发行版和 RPM 包,你可以去它的 [GitHub 发布区][11] 中获取适合你系统的包。
+
+它也适用于 Windows、Android、macOS 和 FreeBSD。
+
+在我这里,我需要 [安装 DEB 包][12],然后就可以使用了。安装好后,使用起来很简单,你只要输入:
+
+```
+duf
+```
+
+这应该会给你提供所有本地设备、已挂载的任何云存储设备以及任何其他特殊设备(包括临时存储位置等)的详细信息。
+
+如果你想一目了然地查看所有 `duf` 的可用命令,你可以输入:
+
+```
+duf --help
+```
+
+![][13]
+
+例如,如果你只想查看本地连接设备的详细信息,而不是其他的,你只需要输入:
+
+```
+duf --only local
+```
+
+另一个例子是根据大小按特定顺序对输出进行排序,下面是你需要输入的内容:
+
+```
+duf --sort size
+```
+
+输出应该是像这样的:
+
+![][14]
+
+你可以探索它的 [GitHub 页面][4],以获得更多关于额外命令和安装说明的信息。
+
+- [下载 duf][4]
+
+### 结束语
+
+我发现终端工具 `duf` 相当方便,可以在不需要使用 GUI 程序的情况下,随时查看可用磁盘空间或使用情况。
+
+你知道有什么类似的工具吗?欢迎在下面的评论中告诉我你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/duf-disk-usage/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/duf-screenshot.jpg?resize=800%2C481&ssl=1
+[2]: https://itsfoss.com/optimize-ubuntu-stacer/
+[3]: https://itsfoss.com/check-free-disk-space-linux/
+[4]: https://github.com/muesli/duf
+[5]: https://golang.org/
+[6]: https://linuxhandbook.com/df-command/
+[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/duf-local.jpg?resize=800%2C195&ssl=1
+[8]: https://linuxhandbook.com/inode-linux/
+[9]: https://itsfoss.com/aur-arch-linux/
+[10]: https://github.com/NixOS/nixpkgs
+[11]: https://github.com/muesli/duf/releases
+[12]: https://itsfoss.com/install-deb-files-ubuntu/
+[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/duf-commands.jpg?resize=800%2C443&ssl=1
+[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/duf-sort-example.jpg?resize=800%2C365&ssl=1
diff --git a/published/202103/20210224 Set your path in FreeDOS.md b/published/202103/20210224 Set your path in FreeDOS.md
new file mode 100644
index 0000000000..00ab8c9daf
--- /dev/null
+++ b/published/202103/20210224 Set your path in FreeDOS.md
@@ -0,0 +1,161 @@
+[#]: subject: (Set your path in FreeDOS)
+[#]: via: (https://opensource.com/article/21/2/path-freedos)
+[#]: author: (Kevin O'Brien https://opensource.com/users/ahuka)
+[#]: collector: (lujun9972)
+[#]: translator: (robsean)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13218-1.html)
+
+在 FreeDOS 中设置你的路径
+======
+
+> 学习 FreeDOS 路径的知识,如何设置它,并且如何使用它。
+
+![查看职业生涯地图][1]
+
+你在开源 [FreeDOS][2] 操作系统中所做的一切工作都是通过命令行完成的。命令行以一个 _提示符_ 开始,这是计算机说法的方式,“我准备好了。请给我一些事情来做。”你可以配置你的提示符的外观,但是默认情况下,它是:
+
+```
+C:\>
+```
+
+从命令行中,你可以做两件事:运行一个内部命令或运行一个程序。外部命令是在你的 `FDOS` 目录中可找到的以单独文件形式存在的程序,以便运行程序包括运行外部命令。它也意味着你可以使用你的计算机运行应用程序软件来做一些东西。你也可以运行一个批处理文件,但是在这种情况下,你所做的全部工作就变成了运行批处理文件中所列出的一系列命令或程序。
+
+### 可执行应用程序文件
+
+FreeDOS 可以运行三种类型的应用程序文件:
+
+ 1. **COM** 是一个用机器语言写的,且小于 64 KB 的文件。
+ 2. **EXE** 也是一个用机器语言写的文件,但是它可以大于 64 KB 。此外,在 EXE 文件的开头部分有信息,用于告诉 DOS 系统该文件是什么类型的以及如何加载和运行。
+ 3. **BAT** 是一个使用文本编辑器以 ASCII 文本格式编写的 _批处理文件_ ,其中包含以批处理模式执行的 FreeDOS 命令。这意味着每个命令都会按顺序执行到文件的结尾。
+
+如果你所输入的一个文件名称不能被 FreeDOS 识别为一个内部命令或一个程序,你将收到一个错误消息 “Bad command or filename” 。如果你看到这个错误,它意味着会是下面三种情况中的其中一种:
+
+ 1. 由于某些原因,你所给予的名称是错误的。你可能拼错了文件名称,或者你可能正在使用错误的命令名称。检查名称和拼写,并再次尝试。
+ 2. 可能你正在尝试运行的程序并没有安装在计算机上。请确认它已经安装了。
+ 3. 文件确实存在,但是 FreeDOS 不知道在哪里可以找到它。
+
+在清单上的最后一项就是这篇文章的主题,它被称为路径。如果你已经习惯于使用 Linux 或 Unix ,你可能已经理解 [PATH 变量][3] 的概念。如果你是命令行的新手,那么路径是一个非常重要的足以让你舒适的东西。
+
+### 路径
+
+当你输入一个可执行应用程序文件的名称时,FreeDOS 必须能找到它。FreeDOS 会在一个具体指定的位置层次结构中查找文件:
+
+ 1. 首先,它查找当前驱动器的活动目录(称为 _工作目录_)。如果你正在目录 `C:\FDOS` 中,接着,你输入名称 `FOOBAR.EXE`,FreeDOS 将在 `C:\FDOS` 中查找带有这个名称的文件。你甚至不需要输入完整的名称。如果你输入 `FOOBAR` ,FreeDOS 将查找任何带有这个名称的可执行文件,不管它是 `FOOBAR.EXE`,`FOOBAR.COM`,或 `FOOBAR.BAT`。只要 FreeDOS 能找到一个匹配该名称的文件,它就会运行该可执行文件。
+ 2. 如果 FreeDOS 不能找到你所输入名称的文件,它将查询被称为 `PATH` 的一些东西。每当 DOS 不能在当前活动命令中找到文件时,会指示 DOS 检查这个列表中目录。
+
+你可以随时使用 `path` 命令来查看你的计算机的路径。只需要在 FreeDOS 提示符中输入 `path` ,FreeDOS 就会返回你的路径设置:
+
+```
+C:\>path
+PATH=C:\FDOS\BIN
+```
+
+第一行是提示符和命令,第二行是计算机返回的东西。你可以看到 DOS 第一个查看的位置就是位于 `C` 驱动器上的 `FDOS\BIN`。如果你想更改你的路径,你可以输入一个 `path` 命令以及你想使用的新路径:
+
+```
+C:\>path=C:\HOME\BIN;C:\FDOS\BIN
+```
+
+在这个示例中,我设置我的路径到我个人的 `BIN` 文件夹,我把它放在一个叫 `HOME` 的自定义目录中,然后再设置为 `FDOS/BIN`。现在,当你检查你的路径时:
+
+```
+C:\>path
+PATH=C:\HOME\BIN;C:\FDOS\BIN
+```
+
+路径设置是按所列目录的顺序处理的。
+
+你可能会注意到有一些字符是小写的,有一些字符是大写的。你使用哪一种都真的不重要。FreeDOS 是不区分大小写的,并且把所有的东西都作为大写字母对待。在内部,FreeDOS 使用的全是大写字母,这就是为什么你看到来自你命令的输出都是大写字母的原因。如果你以小写字母的形式输入命令和文件名称,在一个转换器将自动转换它们为大写字母后,它们将被执行。
+
+输入一个新的路径来替换先前设置的路径。
+
+### autoexec.bat 文件
+
+你可能遇到的下一个问题的是 FreeDOS 默认使用的第一个路径来自何处。这与其它一些重要的设置一起定义在你的 `C` 驱动器的根目录下的 `AUTOEXEC.BAT` 文件中。这是一个批处理文件,它在你启动 FreeDOS 时会自动执行(由此得名)。你可以使用 FreeDOS 程序 `EDIT` 来编辑这个文件。为查看或编辑这个文件的内容,输入下面的命令:
+
+```
+C:\>edit autoexec.bat
+```
+
+这一行出现在顶部附近:
+
+```
+SET PATH=%dosdir%\BIN
+```
+
+这一行定义默认路径的值。
+
+在你查看 `AUTOEXEC.BAT` 后,你可以通过依次按下面的按键来退出 EDIT 应用程序:
+
+ 1. `Alt`
+ 2. `f`
+ 3. `x`
+
+你也可以使用键盘快捷键 `Alt+X`。
+
+### 使用完整的路径
+
+如果你在你的路径中忘记包含 `C:\FDOS\BIN` ,那么你将不能快速访问存储在这里的任何应用程序,因为 FreeDOS 不知道从哪里找到它们。例如,假设我设置我的路径到我个人应用程序集合:
+
+```
+C:\>path=C:\HOME\BIN
+```
+
+内置在命令行中应用程序仍然能正常工作:
+
+```
+C:\cd HOME
+C:\HOME>dir
+ARTICLES
+BIN
+CHEATSHEETS
+GAMES
+DND
+```
+
+不过,外部的命令将不能运行:
+
+```
+C:HOME\ARTICLES>BZIP2 -c example.txt
+Bad command or filename - "BZIP2"
+```
+
+通过提供命令的一个 _完整路径_ ,你可以总是执行一个在你的系统上且不在你的路径中的命令:
+
+```
+C:HOME\ARTICLES>C:\FDOS\BIN\BZIP2 -c example.txt
+C:HOME\ARTICLES>DIR
+example.txb
+```
+
+你可以使用同样的方法从外部介质或其它目录执行应用程序。
+
+### FreeDOS 路径
+
+通常情况下,你很可能希望在路径中保留 `C:\PDOS\BIN` ,因为它包含所有使用 FreeDOS 分发的默认应用程序。
+
+除非你更改 `AUTOEXEC.BAT` 中的路径,否则将在重新启动后恢复默认路径。
+
+现在,你知道如何在 FreeDOS 中管理你的路径,你能够以最适合你的方式了执行命令和维护你的工作环境。
+
+_致谢 [DOS 课程 5: 路径][4] (在 CC BY-SA 4.0 协议下发布) 为本文提供的一些信息。_
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/path-freedos
+
+作者:[Kevin O'Brien][a]
+选题:[lujun9972][b]
+译者:[robsean](https://github.com/robsean)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ahuka
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/career_journey_road_gps_path_map_520.png?itok=PpL6jJgY (Looking at a map for career journey)
+[2]: https://www.freedos.org/
+[3]: https://opensource.com/article/17/6/set-path-linux
+[4]: https://www.ahuka.com/dos-lessons-for-self-study-purposes/dos-lesson-5-the-path/
diff --git a/published/202103/20210225 4 new open source licenses.md b/published/202103/20210225 4 new open source licenses.md
new file mode 100644
index 0000000000..56cdc56402
--- /dev/null
+++ b/published/202103/20210225 4 new open source licenses.md
@@ -0,0 +1,59 @@
+[#]: subject: (4 new open source licenses)
+[#]: via: (https://opensource.com/article/21/2/osi-licenses-cal-cern-ohl)
+[#]: author: (Pam Chestek https://opensource.com/users/pchestek)
+[#]: collector: (lujun9972)
+[#]: translator: (wyxplus)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13224-1.html)
+
+四个新式开源许可证
+======
+
+> 让我们来看看 OSI 最新批准的加密自治许可证和 CERN 开源硬件许可协议。
+
+
+
+作为 [开源定义][2](OSD)的管理者,[开源促进会][3](OSI)20 年来一直在批准“开源”许可证。这些许可证是开源软件生态系统的基础,可确保每个人都可以使用、改进和共享软件。当一个许可证获批为“开源”时,是因为 OSI 认为该许可证可以促进相互的协作和共享,从而使得每个参与开源生态的人获益。
+
+在过去的 20 年里,世界发生了翻天覆地的变化。现如今,软件以新的甚至是无法想象的方式在被使用。OSI 已经预料到,曾经被人们所熟知的开源许可证现已无法满足如今的要求。因此,许可证管理者已经加强了工作,为更广泛的用途提交了几个新的许可证。OSI 所面临的挑战是在评估这些新的许可证概念是否会继续推动共享和合作,是否被值得称为“开源”许可证,最终 OSI 批准了一些用于特殊领域的新式许可证。
+
+### 四个新式许可证
+
+第一个是 [加密自治许可证][4](CAL)。该许可证是为分布式密码应用程序而设计的。此许可证所解决的问题是,现有的开源许可证无法保证开放性,因为如果没有义务也与其他对等体共享数据,那么一个对等体就有可能损害网络的运行。因此,除了是一个强有力的版权保护许可外,CAL 还包括向第三方提供独立使用和修改软件所需的权限和资料的义务,而不会让第三方有数据或功能的损失。
+
+随着越来越多的人使用加密结构进行点对点共享,那么更多的开发人员发现自己需要诸如 CAL 之类的法律工具也就不足为奇了。 OSI 的两个邮件列表 License-Discuss 和 License-Review 上的社区,讨论了拟议的新开源许可证,并询问了有关此许可证的诸多问题。我们希望由此产生的许可证清晰易懂,并希望对其他开源从业者有所裨益。
+
+接下来是,欧洲核研究组织(CERN)提交的 CERN 开放硬件许可证(OHL)系列许可证以供审议。它包括三个许可证,其主要用于开放硬件,这是一个与开源软件相似的开源访问领域,但有其自身的挑战和细微差别。硬件和软件之间的界线现已变得相当模糊,因此应用单独的硬件和软件许可证变得越来越困难。欧洲核子研究组织(CERN)制定了一个可以确保硬件和软件自由的许可证。
+
+OSI 可能在开始时就没考虑将开源硬件许可证添加到其开源许可证列表中,但是世界早已发生变革。因此,尽管 CERN 许可证中的措词涵盖了硬件术语,但它也符合 OSI 认可的所有开源软件许可证的条件。
+
+CERN 开源硬件许可证包括一个 [宽松许可证][5]、一个 [弱互惠许可证][6] 和一个 [强互惠许可证][7]。最近,该许可证已被一个国际研究项目采用,该项目正在制造可用于 COVID-19 患者的简单、易于生产的呼吸机。
+
+### 了解更多
+
+CAL 和 CERN OHL 许可证是针对特殊用途的,并且 OSI 不建议把它们用于其它领域。但是 OSI 想知道这些许可证是否会按预期发展,从而有助于在较新的计算机领域中培育出健壮的开源生态。
+
+可以从 OSI 获得关于 [许可证批准过程][8] 的更多信息。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/osi-licenses-cal-cern-ohl
+
+作者:[Pam Chestek][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/pchestek
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LAW_lawdotgov3.png?itok=e4eFKe0l "Law books in a library"
+[2]: https://opensource.org/osd
+[3]: https://opensource.org/
+[4]: https://opensource.org/licenses/CAL-1.0
+[5]: https://opensource.org/CERN-OHL-P
+[6]: https://opensource.org/CERN-OHL-W
+[7]: https://opensource.org/CERN-OHL-S
+[8]: https://opensource.org/approval
diff --git a/published/202103/20210226 3 Linux terminals you need to try.md b/published/202103/20210226 3 Linux terminals you need to try.md
new file mode 100644
index 0000000000..8a70f27572
--- /dev/null
+++ b/published/202103/20210226 3 Linux terminals you need to try.md
@@ -0,0 +1,81 @@
+[#]: subject: (3 Linux terminals you need to try)
+[#]: via: (https://opensource.com/article/21/2/linux-terminals)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13186-1.html)
+
+值得尝试的 3 个 Linux 终端
+======
+
+> Linux 让你能够选择你喜欢的终端界面,而不是它强加的界面。
+
+
+
+在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。能够选择自己的终端是使用 Linux 的一个重要原因。
+
+很多人认为一旦你用过一个终端界面,你就已经用过所有的终端了。但喜欢终端的用户都知道,它们之间有一些细微但重要的区别。本文将介绍我最喜欢的三种。
+
+不过在深入研究它们之前,先要了解 shell 和终端之间的区别。终端(技术上说是终端模拟器,因为终端曾经是物理硬件设备)是一个在桌面上的窗口中运行的应用。shell 是在终端窗口中对你可见的引擎。流行的 shell 有 [Bash][2]、[tcsh][3] 和 [zsh][4],它们都在终端中运行。
+
+在现代 Linux 上几乎不用说,至少本文中所有的终端都有标签界面。
+
+### Xfce 终端
+
+![Xfce ][5]
+
+[轻量级 Xfce 桌面][7] 提供了一个轻量级的终端,很好地平衡了功能和简单性。它提供了对 shell 的访问(如预期的那样),并且它可以轻松访问几个重要的配置选项。你可以设置当你双击文本时哪些字符会断字、选择你的默认字符编码,并禁用终端窗口的 Alt 快捷方式,这样你最喜欢的 Bash 快捷方式就会传递到 shell。你还可以设置字体和新的颜色主题,或者从常用预设列表中加载颜色主题。它甚至在顶部有一个可选的工具栏,方便你访问你最喜欢的功能。
+
+对我来说,Xfce 的亮点功能是可以非常容易地为你打开的每一个标签页改变背景颜色。当在服务器上运行远程 shell 时,这是非常有价值的。它让我知道自己在哪个标签页中,从而避免了我犯愚蠢的错误。
+
+### rxvt-unicode
+
+![rxvt][8]
+
+[rxvt 终端][9] 是我最喜欢的轻量级控制台。它有许多老式 [xterm][10] 终端仿真器的功能,但它的扩展性更强。它的配置是在 `~/.Xdefaults` 中定义的,所以没有偏好面板或设置菜单,但这使得它很容易管理和备份你的设置。通过使用一些 Perl 库,rxvt 可以有标签,并且通过 xrdb,它可以访问字体和任何你能想到的颜色主题。你可以设置像 `URxvt.urlLancher: firefox` 这样的属性来设置当你打开 URL 时启动的网页浏览器,改变滚动条的外观,修改键盘快捷键等等。
+
+最初的 rxvt 不支持 Unicode(因为当时 Unicode 还不存在),但 `rxvt-unicode`(有时也叫 `urxvt`)包提供了一个完全支持 Unicode 的补丁版本。
+
+我在每台电脑上都有 rxvt,因为对我来说它是最好的通用终端。它不一定是所有用户的最佳终端(例如,它没有拖放界面)。不过,对于寻找快速和灵活终端的中高级用户来说,rxvt 是一个简单的选择。
+
+### Konsole
+
+![Konsole][11]
+
+Konsole 是 KDE Plasma 桌面的终端,是我转到 Linux 后使用的第一个终端,所以它是我对所有其他终端的标准。它确实设定了一个很高的标准。Konsole 有所有通常的不错的功能(还有些其他的),比如简单的颜色主题加上配置文件支持、字体选择、编码、可分离标签、可重命名标签等等。但这在现代桌面上是可以预期的(至少,如果你的桌面运行的是 Plasma 的话)。
+
+Konsole 比其他终端领先许多年(或者几个月)。它可以垂直或水平地分割窗口。你可以把输入复制到所有的标签页上(就像 [tmux][12] 一样)。你可以将其设置为监视自身是否静音或活动并配置通知。如果你在 Android 手机上使用 KDE Connect,这意味着当一个任务完成时,你可以在手机上收到通知。你可以将 Konsole 的输出保存到文本或 HTML 文件中,为打开的标签页添加书签,克隆标签页,调整搜索设置等等。
+
+Konsole 是一个真正的高级用户终端,但它也非常适合新用户。你可以将文件拖放到 Konsole 中,将目录改为硬盘上的特定位置,也可以将路径粘贴进去,甚至可以将文件复制到 Konsole 的当前工作目录中。这让使用终端变得很简单,这也是所有用户都能理解的。
+
+### 尝试一个终端
+
+你的审美观念是黑暗的办公室和黑色背景下绿色文字的温暖光芒吗?还是喜欢阳光明媚的休息室和屏幕上舒缓的墨黑色字体?无论你对完美电脑设置的愿景是什么,如果你喜欢通过输入命令高效地与操作系统交流,那么 Linux 已经为你提供了一个接口。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-terminals
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/freedos.png?itok=aOBLy7Ky (4 different color terminal windows with code)
+[2]: https://opensource.com/resources/what-bash
+[3]: https://opensource.com/article/20/8/tcsh
+[4]: https://opensource.com/article/19/9/getting-started-zsh
+[5]: https://opensource.com/sites/default/files/uploads/terminal-xfce.jpg (Xfce )
+[6]: https://creativecommons.org/licenses/by-sa/4.0/
+[7]: https://opensource.com/article/19/12/xfce-linux-desktop
+[8]: https://opensource.com/sites/default/files/uploads/terminal-rxvt.jpg (rxvt)
+[9]: https://opensource.com/article/19/10/why-use-rxvt-terminal
+[10]: https://opensource.com/article/20/7/xterm
+[11]: https://opensource.com/sites/default/files/uploads/terminal-konsole.jpg (Konsole)
+[12]: https://opensource.com/article/20/1/tmux-console
diff --git a/published/202103/20210228 How to Install the Latest Erlang on Ubuntu Linux.md b/published/202103/20210228 How to Install the Latest Erlang on Ubuntu Linux.md
new file mode 100644
index 0000000000..57d06c19bb
--- /dev/null
+++ b/published/202103/20210228 How to Install the Latest Erlang on Ubuntu Linux.md
@@ -0,0 +1,120 @@
+[#]: subject: (How to Install the Latest Erlang on Ubuntu Linux)
+[#]: via: (https://itsfoss.com/install-erlang-ubuntu/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13182-1.html)
+
+如何在 Ubuntu Linux 上安装最新的 Erlang
+======
+
+
+
+[Erlang][1] 是一种用于构建大规模可扩展实时系统的函数式编程语言。Erlang 最初是由 [爱立信][2] 创建的专有软件,后来被开源。
+
+Erlang 在 [Ubuntu 的 Universe 仓库][3] 中可用。启用该仓库后,你可以使用下面的命令轻松安装它:
+
+```
+sudo apt install erlang
+```
+
+![][4]
+
+但是,*Ubuntu 仓库提供的 Erlang 版本可能不是最新的*。
+
+如果你想要 Ubuntu 上最新的 Erlang 版本,你可以添加 [Erlang Solutions 提供的][5]仓库。它们为各种 Linux 发行版、Windows 和 macOS 提供了预编译的二进制文件。
+
+如果你之前安装了一个名为 `erlang` 的包,那么它将会被升级到由添加的仓库提供的较新版本。
+
+### 在 Ubuntu 上安装最新版本的 Erlang
+
+你需要[在 Linux 终端下载密钥文件][6]。你可以使用 `wget` 工具,所以请确保你已经安装了它:
+
+```
+sudo apt install wget
+```
+
+接下来,使用 `wget` 下载 Erlang Solution 仓库的 GPG 密钥,并将其添加到你的 apt 打包系统中。添加了密钥后,你的系统就会信任来自该仓库的包。
+
+```
+wget -O- https://packages.erlang-solutions.com/ubuntu/erlang_solutions.asc | sudo apt-key add -
+```
+
+现在,你应该在你的 APT `sources.list.d` 目录下为 Erlang 添加一个文件,这个文件将包含有关仓库的信息,APT 包管理器将使用它来获取包和未来的更新。
+
+对于 Ubuntu 20.04(和 Ubuntu 20.10),使用以下命令:
+
+```
+echo "deb https://packages.erlang-solutions.com/ubuntu focal contrib" | sudo tee /etc/apt/sources.list.d/erlang-solution.list
+```
+
+我知道上面的命令提到了 Ubuntu 20.04 focal,但它也适用于 Ubuntu 20.10 groovy。
+
+对于 **Ubuntu 18.04**,使用以下命令:
+
+```
+echo "deb https://packages.erlang-solutions.com/ubuntu bionic contrib" | sudo tee /etc/apt/sources.list.d/erlang-solution.list
+```
+
+你必须更新本地的包缓存,以通知它关于新添加的仓库的包。
+
+```
+sudo apt update
+```
+
+你会注意到,它建议你进行一些升级。如果你列出了可用的升级,你会在那里找到 erlang 包。要更新现有的 erlang 版本或重新安装,使用这个命令:
+
+```
+sudo apt install erlang
+```
+
+安装好后,你可以测试一下。
+
+![][7]
+
+要退出 Erlang shell,使用 `Ctrl+g`,然后输入 `q`,由于我从来没有用过 Erlang,所以我只好尝试了一些按键,然后发现了操作方法。
+
+#### 删除 erlang
+
+要删除该程序,请使用以下命令:
+
+```
+sudo apt remove erlang
+```
+
+还会有一些依赖关系。你可以用下面的命令删除它们:
+
+```
+sudo apt autoremove
+```
+
+如果你愿意,你也可以删除添加的仓库文件。
+
+```
+sudo rm /etc/apt/sources.list.d/erlang-solution.list
+```
+
+就是这样。享受在 Ubuntu Linux 上使用 Erlang 学习和编码的乐趣。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-erlang-ubuntu/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.erlang.org/
+[2]: https://www.ericsson.com/en
+[3]: https://itsfoss.com/ubuntu-repositories/
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/install-erlang-ubuntu.png?resize=800%2C445&ssl=1
+[5]: https://www.erlang-solutions.com/downloads/
+[6]: https://itsfoss.com/download-files-from-linux-terminal/
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/erlang-shell.png?resize=800%2C274&ssl=1
diff --git a/published/202103/20210301 4 open source tools for running a Linux server.md b/published/202103/20210301 4 open source tools for running a Linux server.md
new file mode 100644
index 0000000000..9e19ca6352
--- /dev/null
+++ b/published/202103/20210301 4 open source tools for running a Linux server.md
@@ -0,0 +1,95 @@
+[#]: subject: (4 open source tools for running a Linux server)
+[#]: via: (https://opensource.com/article/21/3/linux-server)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13192-1.html)
+
+4 个打造多媒体和共享服务器的开源工具
+======
+
+> 通过 Linux,你可以将任何设备变成服务器,以共享数据、媒体文件,以及其他资源。
+
+
+
+在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。这里有四个开源工具,可以将任何设备变成 Linux 服务器。
+
+有时,我会发现有关服务器概念的某种神秘色彩。许多人,如果他们在脑海中有一个形象的话,他们认为服务器一定是又大又重的机架式机器,由一个谨慎的系统管理员和一群神奇的修理工精心维护。另一些人则把服务器设想成虚无缥缈的云朵,以某种方式为互联网提供动力。
+
+虽然这种敬畏对 IT 工作的安全性是有好处的,但事实上,在开源计算中,没有人认为服务器是或应该是专家的专属领域。文件和资源共享是开源不可或缺的,而开源让它变得比以往任何时候都更容易,正如这四个开源服务器项目所展示的那样。
+
+### Samba
+
+[Samba 项目][2] 是 Linux 和 Unix 的 Windows 互操作程序套件。尽管它是大多数用户从未与之交互的底层代码,但它的重要性却不容小觑。从历史上看,早在微软争相消灭 Linux 和开源的时候,它就是最大最重要的目标。时代变了,微软已经与 Samba 团队会面以提供支持(至少目前是这样),在这一切中,该项目继续确保 Linux 和 Windows 计算机可以轻松地在同一网络上共存。换句话说,无论你使用什么平台,Samba 都可以让你可以轻松地在本地网络上共享文件。
+
+在 [KDE Plasma][3] 桌面上,你可以右键点击自己的任何目录,选择**属性**。在**属性**对话框中,点击**共享**选项卡,并启用**与 Samba 共享(Microsoft Windows)**。
+
+![Samba][4]
+
+就这样,你已经为本地网络上的用户打开了一个只读访问的目录。也就是说,当你在家的时候,你家同一个 WiFi 网络上的任何人都可以访问该文件夹,如果你在工作,工作场所网络上的任何人都可以访问该文件夹。当然,要访问它,其他用户需要知道在哪里可以找到它。通往计算机的路径可以用 [IP 地址][6] 表示,也可以根据你的网络配置,用主机名表示。
+
+### Snapdrop
+
+如果通过 IP 地址和主机名来打开网络是令人困惑的,或者如果你不喜欢打开一个文件夹进行共享而忘记它是开放的,那么你可能更喜欢 [Snapdrop][7]。这是一个开源项目,你可以自己运行,也可以使用互联网上的演示实例通过 WebRTC 连接计算机。WebRTC 可以通过 Web 浏览器实现点对点的连接,也就是说同一网络上的两个用户可以通过 Snapdrop 找到对方,然后直接进行通信,而不需要通过外部服务器。
+
+![Snapdrop][8]
+
+一旦两个或更多的客户端连接了同一个 Snapdrop 服务,用户就可以通过本地网络来回交换文件和聊天信息。传输的速度很快,而且你的数据也保持在本地。
+
+### VLC
+
+流媒体服务比以往任何时候都更常见,但我在音乐和电影方面有非常规的口味,所以典型的服务似乎很少有我想要的东西。幸运的是,通过连接到媒体驱动器,我可以很容易地将自己的内容从我的电脑上传送到我的房子各个角落。例如,当我想在电脑显示器以外的屏幕上观看一部电影时,我可以在我的网络上串流电影文件,并通过任何可以接收 HTTP 的应用来播放它,无论该应用是在我的电视、游戏机还是手机上。
+
+[VLC][9] 可以轻松设置流媒体。事实上,它是**媒体**菜单中的一个选项,或者你可以按下键盘 `Ctrl+S`。将一个文件或一组文件添加到你的流媒体队列中,然后点击 **Stream** 按钮。
+
+![VLC][10]
+
+VLC 通过配置向导来帮助你决定流媒体数据时使用什么协议。我倾向于使用 HTTP,因为它通常在任何设备上可用。当 VLC 开始播放文件时,请进入播放文件计算机的 IP 或主机名以及给它分配的端口 (当使用 HTTP 时,默认是 8080), 然后坐下来享受。
+
+### PulseAudio
+
+我最喜欢的现代 Linux 功能之一是 [PulseAudio][11]。Pulse 为 Linux 上的音频实现了惊人的灵活性,包括可自动发现的本地网络流媒体。这个功能对我来说的好处是,我可以在办公室的工作站上播放播客和技术会议视频,并通过手机串流音频。无论我走进厨房、休息室还是后院最远的地方,我都能获得完美的音频。此功能在 PulseAudio 之前很久就存在,但是 Pulse 使它像单击按钮一样容易。
+
+需要进行一些设置。首先,你必须确保安装 PulseAudio 设置包(**paprefs**),以便在 PulseAudio 配置中启用网络音频。
+
+![PulseAudio][12]
+
+在 **paprefs** 中,启用网络访问你的本地声音设备,可能不需要认证(假设你信任本地网络上的其他人),并启用你的计算机作为 **Multicast/RTP 发送者**。我通常只选择串流通过我的扬声器播放的任何音频,但你可以在 Pulse 输出选项卡中创建一个单独的音频设备,这样你就可以准确地选择串流的内容。你在这里有三个选项:
+
+ * 串流任何在扬声器上播放的音频
+ * 串流所有输出的声音
+ * 只将音频直接串流到多播设备(按需)。
+
+一旦启用,你的声音就会串流到网络中,并可被其他本地 Linux 设备接收。这是简单和动态的音频共享。
+
+### 分享的不仅仅是代码
+
+Linux 是共享的。它在服务器领域很有名,因为它很擅长*服务*。无论是提供音频流、视频流、文件,还是出色的用户体验,每一台 Linux 电脑都是一台出色的 Linux 服务器。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/linux-server
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rack_server_sysadmin_cloud_520.png?itok=fGmwhf8I (A rack of servers, blue background)
+[2]: http://samba.org
+[3]: https://opensource.com/article/19/12/linux-kde-plasma
+[4]: https://opensource.com/sites/default/files/uploads/samba_0.jpg (Samba)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://opensource.com/article/18/5/how-find-ip-address-linux
+[7]: https://github.com/RobinLinus/snapdrop
+[8]: https://opensource.com/sites/default/files/uploads/snapdrop.jpg (Snapdrop)
+[9]: https://www.videolan.org/index.html
+[10]: https://opensource.com/sites/default/files/uploads/vlc-stream.jpg (VLC)
+[11]: https://www.freedesktop.org/wiki/Software/PulseAudio/
+[12]: https://opensource.com/sites/default/files/uploads/pulse.jpg (PulseAudio)
diff --git a/published/202103/20210302 Meet SysMonTask- A Windows Task Manager Lookalike for Linux.md b/published/202103/20210302 Meet SysMonTask- A Windows Task Manager Lookalike for Linux.md
new file mode 100644
index 0000000000..f26fb208ae
--- /dev/null
+++ b/published/202103/20210302 Meet SysMonTask- A Windows Task Manager Lookalike for Linux.md
@@ -0,0 +1,130 @@
+[#]: subject: (Meet SysMonTask: A Windows Task Manager Lookalike for Linux)
+[#]: via: (https://itsfoss.com/sysmontask/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13189-1.html)
+
+SysMonTask:一个类似于 Windows 任务管理器的 Linux 系统监控器
+======
+
+
+
+得益于桌面环境,几乎所有的 [Linux 发行版都带有任务管理器应用程序][1]。除此之外,还有 [一些其他的 Linux 的系统监控应用程序][2],它们具有更多的功能。
+
+但最近我遇到了一个为 Linux 创建的任务管理器,它看起来像……嗯……Windows 的任务管理器。
+
+你自己看看就知道了。
+
+![][3]
+
+就我个人而言,我不确定用户界面的相似性是否有意义,但开发者和其他一些 Linux 用户可能不同意我的观点。
+
+### SysMonTask: 一个具有 Windows 任务管理器外观的系统监控器
+
+![][4]
+
+开源软件 [SysMonTask][5] 将自己描述为“具有 Windows 任务管理器的紧凑性和实用性的 Linux 系统监控器,以实现更高的控制和监控”。
+
+SysMonTask 以 Python 编写,拥有以下功能:
+
+ * 系统监控图。
+ * 显示 CPU、内存、磁盘、网络适配器、单个 Nvidia GPU 的统计数据。
+ * 在最近的版本中增加了对挂载磁盘列表的支持。
+ * 用户进程选项卡可以进行进程过滤,显示递归-CPU、递归-内存和列头的汇总值。
+ * 当然,你可以在进程选项卡中杀死一个进程。
+ * 还支持系统主题(深色和浅色)。
+
+### 体验 SysMonTask
+
+SysMonTask 需要提升权限。当你启动它时,你会被要求提供你的管理员密码。我不喜欢一个任务管理器一直用 `sudo` 运行,但这只是我的喜好。
+
+我玩了一下,探索它的功能。磁盘的使用量基本稳定不变,所以我把一个 10GB 的文件从外部 SSD 复制到笔记本的磁盘上几次。你可以看到文件传输时对应的峰值。
+
+![][6]
+
+进程标签也很方便。它在列的顶部显示了累积的资源利用率。
+
+杀死按钮被添加在底部,所以你要做的就是选择一个进程,然后点击“Killer” 按钮。它在 [杀死进程][7] 之前会询问你的确认。
+
+![][8]
+
+### 在 Linux 发行版上安装 SysMonTask
+
+对于一个简单的应用程序,它需要下载 50 MB 的存档文件,并占用了大约 200 MB 的磁盘。我想这是因为 Python 的依赖性。
+
+还有就是它读取的是 env。
+
+在写这篇文章的时候,SysMonTask 可以通过 [PPA][9] 在基于 Ubuntu 的发行版上使用。
+
+在基于 Ubuntu 的发行版上,打开一个终端,使用以下命令添加 PPA 仓库:
+
+```
+sudo add-apt-repository ppa:camel-neeraj/sysmontask
+```
+
+当然,你会被要求输入密码。在新版本中,仓库列表会自动更新。所以,你可以直接安装应用程序:
+
+```
+sudo apt install sysmontask
+```
+
+基于 Debian 的发行版也可以尝试从 deb 文件中安装它。它可以在发布页面找到。
+
+对于其他发行版,没有现成的软件包。令我惊讶的是,它基本上是一个 Python 应用程序,所以可以为其他发行版添加一个 PIP 安装程序。也许开发者会在未来的版本中添加它。
+
+由于它是开源软件,你可以随时得到源代码。
+
+- [SysMonTask Deb 文件和源代码][10]
+
+安装完毕后,在菜单中寻找 SysMonTask,并从那里启动它。
+
+#### 删除 SysMonTask
+
+如果你想删除它,使用以下命令:
+
+```
+sudo apt remove sysmontask
+```
+
+最好也 [删除 PPA][11]:
+
+```
+sudo add-apt-repository -r ppa:camel-neeraj/sysmontask
+```
+
+你也可以在这里 [使用 PPA 清除][12] 工具,这是一个处理 PPA 应用程序删除的方便工具。
+
+### 你会尝试吗?
+
+对我来说,功能比外观更重要。SysMonTask 确实有额外的功能,监测磁盘性能和检查 GPU 统计数据,这是其他系统监视器通常不包括的东西。
+
+如果你尝试并喜欢它,也许你会喜欢添加 `Ctrl+Alt+Del` 快捷键来启动 SysMonTask,以获得完整的感觉 :)
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/sysmontask/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/task-manager-linux/
+[2]: https://itsfoss.com/linux-system-monitoring-tools/
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/sysmontask-1.png?resize=800%2C559&ssl=1
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/SysMonTask-CPU.png?resize=800%2C537&ssl=1
+[5]: https://github.com/KrispyCamel4u/SysMonTask
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/sysmontask-disk-usage.png?resize=800%2C498&ssl=1
+[7]: https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/kill-process-sysmontask.png?resize=800%2C500&ssl=1
+[9]: https://itsfoss.com/ppa-guide/
+[10]: https://github.com/KrispyCamel4u/SysMonTask/releases
+[11]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
+[12]: https://itsfoss.com/ppa-purge/
diff --git a/published/202103/20210303 Guake Terminal- A Customizable Linux Terminal for Power Users -Inspired by an FPS Game.md b/published/202103/20210303 Guake Terminal- A Customizable Linux Terminal for Power Users -Inspired by an FPS Game.md
new file mode 100644
index 0000000000..14688c7cde
--- /dev/null
+++ b/published/202103/20210303 Guake Terminal- A Customizable Linux Terminal for Power Users -Inspired by an FPS Game.md
@@ -0,0 +1,102 @@
+[#]: subject: (Guake Terminal: A Customizable Linux Terminal for Power Users [Inspired by an FPS Game])
+[#]: via: (https://itsfoss.com/guake-terminal/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13187-1.html)
+
+Guake 终端:一个灵感来自于 FPS 游戏的 Linux 终端
+======
+
+> 使用 Guake 终端这个可自定义且强大的适合各种用户的工具快速访问你的终端。
+
+### Guake 终端:GNOME 桌面中自上而下终端
+
+
+
+[Guake][2] 是一款为 GNOME 桌面量身定做的终端模拟器,采用下拉式设计。
+
+它最初的灵感来自于一款 FPS 游戏([Quake][3])中的终端。尽管它最初是作为一个快速和易于使用的终端而设计的,但它的功能远不止于此。
+
+Guake 终端提供了大量的功能,以及可定制的选项。在这里,我将重点介绍终端的主要功能,以及如何将它安装到你的任何 Linux 发行版上。
+
+### Guake 终端的特点
+
+![][4]
+
+ * 按下键盘快捷键(`F12`)以覆盖方式在任何地方启动终端
+ * Guake 终端在后台运行,以便持久访问
+ * 能够横向和纵向分割标签页
+ * 从可用的 shell 中(如果有的话)更改默认的 shell
+ * 重新对齐
+ * 从多种调色板中选择改变终端的外观
+ * 能够使用 GUI 方式将终端内容保存到文件中
+ * 需要时切换全屏
+ * 你可以轻松地保存标签,或在需要时打开新的标签
+ * 恢复标签的能力
+ * 可选择配置和学习新的键盘快捷键,以快速访问终端和执行任务
+ * 改变特定选项卡的颜色
+ * 轻松重命名标签,快速访问你需要的内容
+ * 快速打开功能,只需点击一下,就可直接在终端中用你最喜欢的编辑器打开文件
+ * 能够在启动或显示 Guake 终端时添加自己的命令或脚本。
+ * 支持多显示器
+
+![][5]
+
+只是出于乐趣,你可以做很多事情。但是,我也相信,高级用户可以利用这些功能使他们的终端体验更轻松,更高效。
+
+就我用它来测试一些东西和写这篇文章的时候,说实话,我觉得我是在召唤终端。所以,我绝对觉得它很酷!
+
+### 在 Linux 上安装 Guake
+
+![][6]
+
+在 Ubuntu、Fedora 和 Arch 的默认仓库中都有 Guake 终端。
+
+你可以按照它的官方说明来了解你可以使用的命令,如果你使用的是基于 Ubuntu 的发行版,只需输入:
+
+```
+sudo apt install guake
+```
+
+请注意,使用这种方法可能无法获得最新版本。所以,如果你想获得最新的版本,你可以选择使用 [Linux Uprising][7] 的 PPA 来获得最新版本:
+
+```
+sudo add-apt-repository ppa:linuxuprising/guake
+sudo apt update
+sudo apt install guake
+```
+
+无论是哪种情况,你也可以使用 [Pypi][8] 或者参考[官方文档][9]或从 [GitHub 页面][10]获取源码。
+
+- [Guake Terminal][10]
+
+你觉得 Guake 终端怎么样?你认为它是一个有用的终端仿真器吗?你知道有什么类似的软件吗?
+
+欢迎在下面的评论中告诉我你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/guake-terminal/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-terminal-1.png?resize=800%2C363&ssl=1
+[2]: http://guake-project.org/
+[3]: https://quake.bethesda.net/en
+[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-terminal.jpg?resize=800%2C245&ssl=1
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-preferences.jpg?resize=800%2C559&ssl=1
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-terminal-2.png?resize=800%2C432&ssl=1
+[7]: https://www.linuxuprising.com/
+[8]: https://pypi.org/
+[9]: https://guake.readthedocs.io/en/latest/user/installing.html
+[10]: https://github.com/Guake/guake
diff --git a/published/202103/20210304 An Introduction to WebAssembly.md b/published/202103/20210304 An Introduction to WebAssembly.md
new file mode 100644
index 0000000000..a949407612
--- /dev/null
+++ b/published/202103/20210304 An Introduction to WebAssembly.md
@@ -0,0 +1,84 @@
+[#]: subject: (An Introduction to WebAssembly)
+[#]: via: (https://www.linux.com/news/an-introduction-to-webassembly/)
+[#]: author: (Marco Fioretti https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13197-1.html)
+
+WebAssembly 介绍
+======
+
+
+
+### 到底什么是 WebAssembly?
+
+[WebAssembly][1],也叫 Wasm,是一种为 Web 优化的代码格式和 API(应用编程接口),它可以大大提高网站的性能和能力。WebAssembly 的 1.0 版本于 2017 年发布,并于 2019 年成为 W3C 官方标准。
+
+该标准得到了所有主流浏览器供应商的积极支持,原因显而易见:官方列出的 [“浏览器内部”用例][2] 中提到了,其中包括视频编辑、3D 游戏、虚拟和增强现实、p2p 服务和科学模拟。除了让浏览器的功能比JavaScript 强大得多,该标准甚至可以延长网站的寿命:例如,正是 WebAssembly 为 [互联网档案馆的 Flash 动画和游戏][3] 提供了持续的支持。
+
+不过,WebAssembly 并不只用于浏览器,目前它还被用于移动和基于边缘环境的 Cloudflare Workers 等产品中。
+
+### WebAssembly 如何工作?
+
+.wasm 格式的文件包含低级二进制指令(字节码),可由使用通用栈的虚拟机以“接近 CPU 原生速度”执行。这些代码被打包成模块(可以被浏览器直接执行的对象),每个模块可以被一个网页多次实例化。模块内部定义的函数被列在一个专用数组中,或称为表,相应的数据被包含在另一个结构中,称为 缓存数组。开发者可以通过 Javascript `WebAssembly.memory()` 的调用,为 .wasm 代码显式分配内存。
+
+.wasm 格式也有纯文本版本,它可以大大简化学习和调试。然而,WebAssembly 并不是真的要供人直接使用。从技术上讲,.wasm 只是一个与浏览器兼容的**编译目标**:一种用高级编程语言编写的软件编译器可以自动翻译的代码格式。
+
+这种选择正是使开发人员能够使用数十亿人熟悉的语言(C/C++、Python、Go、Rust 等)直接为用户界面进行编程的方式,但以前浏览器无法对其进行有效利用。更妙的是,至少在理论上程序员可以利用它们,无需直接查看 WebAssembly 代码,也无需担心物理 CPU 实际运行他们的代码(因为目标是一个**虚拟**机)。
+
+### 但是我们已经有了 JavaScript,我们真的需要 WebAssembly 吗?
+
+是的,有几个原因。首先,作为二进制指令,.wasm 文件比同等功能的 JavaScript 文件小得多,下载速度也快得多。最重要的是,Javascript 文件必须在浏览器将其转换为其内部虚拟机可用的字节码之前进行完全解析和验证。
+
+而 .wasm 文件则可以一次性验证和编译,从而使“流式编译”成为可能:浏览器在开始**下载它们**的那一刻就可以开始编译和执行它们,就像串流电影一样。
+
+这就是说,并不是所有可以想到的 WebAssembly 应用都肯定会比由专业程序员手动优化的等效 JavaScript 应用更快或更小。例如,如果一些 .wasm 需要包含 JavaScript 不需要的库,这种情况可能会发生。
+
+### WebAssembly 是否会让 JavaScript 过时?
+
+一句话:不会。暂时不会,至少在浏览器内不会。WebAssembly 模块仍然需要 JavaScript,因为在设计上它们不能访问文档对象模型 (DOM)—— [主要用于修改网页的 API][4]。此外,.wasm 代码不能进行系统调用或读取浏览器的内存。WebAssembly 只能在沙箱中运行,一般来说,它能与外界的交互甚至比 JavaScript 更少,而且只能通过 JavaScript 接口进行。
+
+因此,至少在不久的将来 .wasm 模块将只是通过 JavaScript 提供那些如果用 JavaScript 语言编写会消耗更多带宽、内存或 CPU 时间的部分。
+
+### Web 浏览器如何运行 WebAssembly?
+
+一般来说,浏览器至少需要两块来处理动态应用:运行应用代码的虚拟机(VM),以及可以同时修改浏览器行为和网页显示的 API。
+
+现代浏览器内部的虚拟机通过以下方式同时支持 JavaScript 和 WebAssembly:
+
+ 1. 浏览器下载一个用 HTML 标记语言编写的网页,然后进行渲染
+ 2. 如果该 HTML 调用 JavaScript 代码,浏览器的虚拟机就会执行该代码。但是...
+ 3. 如果 JavaScript 代码中包含了 WebAssembly 模块的实例,那么就按照上面的描述获取该实例,然后根据需要通过 JavaScript 的 WebAssembly API 来使用该实例
+ 4. 当 WebAssembly 代码产生的东西将修改 DOM(即“宿主”网页)的结构,JavaScript 代码就会接收到,并继续进行实际的修改。
+
+### 我如何才能创建可用的 WebAssembly 代码?
+
+越来越多的编程语言社区支持直接编译到 Wasm,我们建议从 webassembly.org 的 [入门指南][5] 开始,这取决于你使用什么语言。请注意,并不是所有的编程语言都有相同水平的 Wasm 支持,因此你的工作量可能会有所不同。
+
+我们计划在未来几个月内发布一系列文章,提供更多关于 WebAssembly 的信息。要自己开始使用它,你可以报名参加 Linux 基金会的免费 [WebAssembly 介绍][6]在线培训课程。
+
+这篇[WebAssembly 介绍][7]首次发布在 [Linux Foundation – Training][8]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/news/an-introduction-to-webassembly/
+
+作者:[Dan Brown][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/
+[b]: https://github.com/lujun9972
+[1]: https://webassembly.org/
+[2]: https://webassembly.org/docs/use-cases/
+[3]: https://blog.archive.org/2020/11/19/flash-animations-live-forever-at-the-internet-archive/
+[4]: https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction
+[5]: https://webassembly.org/getting-started/developers-guide/
+[6]: https://training.linuxfoundation.org/training/introduction-to-webassembly-lfd133/
+[7]: https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/
+[8]: https://training.linuxfoundation.org/
diff --git a/published/202103/20210304 Learn to debug code with the GNU Debugger.md b/published/202103/20210304 Learn to debug code with the GNU Debugger.md
new file mode 100644
index 0000000000..0aa5d13cda
--- /dev/null
+++ b/published/202103/20210304 Learn to debug code with the GNU Debugger.md
@@ -0,0 +1,301 @@
+[#]: subject: (Learn to debug code with the GNU Debugger)
+[#]: via: (https://opensource.com/article/21/3/debug-code-gdb)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13203-1.html)
+
+学习使用 GDB 调试代码
+======
+
+> 使用 GNU 调试器来解决你的代码问题。
+
+
+
+GNU 调试器常以它的命令 `gdb` 称呼它,它是一个交互式的控制台,可以帮助你浏览源代码、分析执行的内容,其本质上是对错误的应用程序中出现的问题进行逆向工程。
+
+故障排除的麻烦在于它很复杂。[GNU 调试器][2] 并不是一个特别复杂的应用程序,但如果你不知道从哪里开始,甚至不知道何时和为何你可能需要求助于 GDB 来进行故障排除,那么它可能会让人不知所措。如果你一直使用 `print`、`echo` 或 [printf 语句][3]来调试你的代码,当你开始思考是不是还有更强大的东西时,那么本教程就是为你准备的。
+
+### 有错误的代码
+
+要开始使用 GDB,你需要一些代码。这里有一个用 C++ 写的示例应用程序(如果你一般不使用 C++ 编写程序也没关系,在所有语言中原理都是一样的),其来源于 [猜谜游戏系列][4] 中的一个例子。
+
+```
+#include
+#include //srand
+#include //printf
+
+using namespace std;
+
+int main () {
+
+srand (time(NULL));
+int alpha = rand() % 8;
+cout << "Hello world." << endl;
+int beta = 2;
+
+printf("alpha is set to is %s\n", alpha);
+printf("kiwi is set to is %s\n", beta);
+
+ return 0;
+} // main
+```
+
+这个代码示例中有一个 bug,但它确实可以编译(至少在 GCC 5 的时候)。如果你熟悉 C++,你可能已经看到了,但这是一个简单的问题,可以帮助新的 GDB 用户了解调试过程。编译并运行它就可以看到错误:
+
+```
+$ g++ -o buggy example.cpp
+$ ./buggy
+Hello world.
+Segmentation fault
+```
+
+### 排除段故障
+
+从这个输出中,你可以推测变量 `alpha` 的设置是正确的,因为否则的话,你就不会看到它*后面*的那行代码执行。当然,这并不总是正确的,但这是一个很好的工作理论,如果你使用 `printf` 作为日志和调试器,基本上也会得出同样的结论。从这里,你可以假设 bug 在于成功打印的那一行之后的*某行*。然而,不清楚错误是在下一行还是在几行之后。
+
+GNU 调试器是一个交互式的故障排除工具,所以你可以使用 `gdb` 命令来运行错误的代码。为了得到更好的结果,你应该从包含有*调试符号*的源代码中重新编译你的错误应用程序。首先,看看 GDB 在不重新编译的情况下能提供哪些信息:
+
+```
+$ gdb ./buggy
+Reading symbols from ./buggy...done.
+(gdb) start
+Temporary breakpoint 1 at 0x400a44
+Starting program: /home/seth/demo/buggy
+
+Temporary breakpoint 1, 0x0000000000400a44 in main ()
+(gdb)
+```
+
+当你以一个二进制可执行文件作为参数启动 GDB 时,GDB 会加载该应用程序,然后等待你的指令。因为这是你第一次在这个可执行文件上运行 GDB,所以尝试重复这个错误是有意义的,希望 GDB 能够提供进一步的见解。很直观,GDB 用来启动它所加载的应用程序的命令就是 `start`。默认情况下,GDB 内置了一个*断点*,所以当它遇到你的应用程序的 `main` 函数时,它会暂停执行。要让 GDB 继续执行,使用命令 `continue`:
+
+```
+(gdb) continue
+Continuing.
+Hello world.
+
+Program received signal SIGSEGV, Segmentation fault.
+0x00007ffff71c0c0b in vfprintf () from /lib64/libc.so.6
+(gdb)
+```
+
+毫不意外:应用程序在打印 “Hello world” 后不久就崩溃了,但 GDB 可以提供崩溃发生时正在发生的函数调用。这有可能就足够你找到导致崩溃的 bug,但为了更好地了解 GDB 的功能和一般的调试过程,想象一下,如果问题还没有变得清晰,你想更深入地挖掘这段代码发生了什么。
+
+### 用调试符号编译代码
+
+要充分利用 GDB,你需要将调试符号编译到你的可执行文件中。你可以用 GCC 中的 `-g` 选项来生成这个符号:
+
+```
+$ g++ -g -o debuggy example.cpp
+$ ./debuggy
+Hello world.
+Segmentation fault
+```
+
+将调试符号编译到可执行文件中的结果是得到一个大得多的文件,所以通常不会分发它们,以增加便利性。然而,如果你正在调试开源代码,那么用调试符号重新编译测试是有意义的:
+
+```
+$ ls -l *buggy* *cpp
+-rw-r--r-- 310 Feb 19 08:30 debug.cpp
+-rwxr-xr-x 11624 Feb 19 10:27 buggy*
+-rwxr-xr-x 22952 Feb 19 10:53 debuggy*
+```
+
+### 用 GDB 调试
+
+加载新的可执行文件(本例中为 `debuggy`)以启动 GDB:
+
+```
+$ gdb ./debuggy
+Reading symbols from ./debuggy...done.
+(gdb) start
+Temporary breakpoint 1 at 0x400a44
+Starting program: /home/seth/demo/debuggy
+
+Temporary breakpoint 1, 0x0000000000400a44 in main ()
+(gdb)
+```
+
+如前所述,使用 `start` 命令进行:
+
+```
+(gdb) start
+Temporary breakpoint 1 at 0x400a48: file debug.cpp, line 9.
+Starting program: /home/sek/demo/debuggy
+
+Temporary breakpoint 1, main () at debug.cpp:9
+9 srand (time(NULL));
+(gdb)
+```
+
+这一次,自动的 `main` 断点可以指明 GDB 暂停的行号和该行包含的代码。你可以用 `continue` 恢复正常操作,但你已经知道应用程序在完成之前就会崩溃,因此,你可以使用 `next` 关键字逐行步进检查你的代码:
+
+```
+(gdb) next
+10 int alpha = rand() % 8;
+(gdb) next
+11 cout << "Hello world." << endl;
+(gdb) next
+Hello world.
+12 int beta = 2;
+(gdb) next
+14 printf("alpha is set to is %s\n", alpha);
+(gdb) next
+
+Program received signal SIGSEGV, Segmentation fault.
+0x00007ffff71c0c0b in vfprintf () from /lib64/libc.so.6
+(gdb)
+```
+
+从这个过程可以确认,崩溃不是发生在设置 `beta` 变量的时候,而是执行 `printf` 行的时候。这个 bug 在本文中已经暴露了好几次(破坏者:向 `printf` 提供了错误的数据类型),但暂时假设解决方案仍然不明确,需要进一步调查。
+
+### 设置断点
+
+一旦你的代码被加载到 GDB 中,你就可以向 GDB 询问到目前为止代码所产生的数据。要尝试数据自省,通过再次发出 `start` 命令来重新启动你的应用程序,然后进行到第 11 行。一个快速到达 11 行的简单方法是设置一个寻找特定行号的断点:
+
+```
+(gdb) start
+The program being debugged has been started already.
+Start it from the beginning? (y or n) y
+Temporary breakpoint 2 at 0x400a48: file debug.cpp, line 9.
+Starting program: /home/sek/demo/debuggy
+
+Temporary breakpoint 2, main () at debug.cpp:9
+9 srand (time(NULL));
+(gdb) break 11
+Breakpoint 3 at 0x400a74: file debug.cpp, line 11.
+```
+
+建立断点后,用 `continue` 继续执行:
+
+```
+(gdb) continue
+Continuing.
+
+Breakpoint 3, main () at debug.cpp:11
+11 cout << "Hello world." << endl;
+(gdb)
+```
+
+现在暂停在第 11 行,就在 `alpha` 变量被设置之后,以及 `beta` 被设置之前。
+
+### 用 GDB 进行变量自省
+
+要查看一个变量的值,使用 `print` 命令。在这个示例代码中,`alpha` 的值是随机的,所以你的实际结果可能与我的不同:
+
+```
+(gdb) print alpha
+$1 = 3
+(gdb)
+```
+
+当然,你无法看到一个尚未建立的变量的值:
+
+```
+(gdb) print beta
+$2 = 0
+```
+
+
+### 使用流程控制
+
+要继续进行,你可以步进代码行来到达将 `beta` 设置为一个值的位置:
+
+```
+(gdb) next
+Hello world.
+12 int beta = 2;
+(gdb) next
+14 printf("alpha is set to is %s\n", alpha);
+(gdb) print beta
+$3 = 2
+```
+
+另外,你也可以设置一个观察点,它就像断点一样,是一种控制 GDB 执行代码流程的方法。在这种情况下,你知道 `beta` 变量应该设置为 `2`,所以你可以设置一个观察点,当 `beta` 的值发生变化时提醒你:
+
+```
+(gdb) watch beta > 0
+Hardware watchpoint 5: beta > 0
+(gdb) continue
+Continuing.
+
+Breakpoint 3, main () at debug.cpp:11
+11 cout << "Hello world." << endl;
+(gdb) continue
+Continuing.
+Hello world.
+
+Hardware watchpoint 5: beta > 0
+
+Old value = false
+New value = true
+main () at debug.cpp:14
+14 printf("alpha is set to is %s\n", alpha);
+(gdb)
+```
+
+你可以用 `next` 手动步进完成代码的执行,或者你可以用断点、观察点和捕捉点来控制代码的执行。
+
+### 用 GDB 分析数据
+
+你可以以不同格式查看数据。例如,以八进制值查看 `beta` 的值:
+
+```
+(gdb) print /o beta
+$4 = 02
+```
+
+要查看其在内存中的地址:
+
+```
+(gdb) print /o &beta
+$5 = 0x2
+```
+
+你也可以看到一个变量的数据类型:
+
+```
+(gdb) whatis beta
+type = int
+```
+
+### 用 GDB 解决错误
+
+这种自省不仅能让你更好地了解什么代码正在执行,还能让你了解它是如何执行的。在这个例子中,对变量运行的 `whatis` 命令给了你一个线索,即你的 `alpha` 和 `beta` 变量是整数,这可能会唤起你对 `printf` 语法的记忆,使你意识到在你的 `printf` 语句中,你必须使用 `%d` 来代替 `%s`。做了这个改变,就可以让应用程序按预期运行,没有更明显的错误存在。
+
+当代码编译后发现有 bug 存在时,特别令人沮丧,但最棘手的 bug 就是这样,如果它们很容易被发现,那它们就不是 bug 了。使用 GDB 是猎取并消除它们的一种方法。
+
+### 下载我们的速查表
+
+生活的真相就是这样,即使是最基本的编程,代码也会有 bug。并不是所有的错误都会导致应用程序无法运行(甚至无法编译),也不是所有的错误都是由错误的代码引起的。有时,bug 是基于一个特别有创意的用户所做的意外的选择组合而间歇性发生的。有时,程序员从他们自己的代码中使用的库中继承了 bug。无论原因是什么,bug 基本上无处不在,程序员的工作就是发现并消除它们。
+
+GNU 调试器是一个寻找 bug 的有用工具。你可以用它做的事情比我在本文中演示的要多得多。你可以通过 GNU Info 阅读器来了解它的许多功能:
+
+```
+$ info gdb
+```
+
+无论你是刚开始学习 GDB 还是专业人员的,提醒一下你有哪些命令是可用的,以及这些命令的语法是什么,都是很有帮助的。
+
+- [下载 GDB 速查表][5]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/debug-code-gdb
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/mistake_bug_fix_find_error.png?itok=PZaz3dga (magnifying glass on computer screen, finding a bug in the code)
+[2]: https://www.gnu.org/software/gdb/
+[3]: https://opensource.com/article/20/8/printf
+[4]: https://linux.cn/article-12985-1.html
+[5]: https://opensource.com/downloads/gnu-debugger-cheat-sheet
diff --git a/published/202103/20210304 You Can Now Install Official Evernote Client on Ubuntu and Debian-based Linux Distributions.md b/published/202103/20210304 You Can Now Install Official Evernote Client on Ubuntu and Debian-based Linux Distributions.md
new file mode 100644
index 0000000000..c6eb182519
--- /dev/null
+++ b/published/202103/20210304 You Can Now Install Official Evernote Client on Ubuntu and Debian-based Linux Distributions.md
@@ -0,0 +1,104 @@
+[#]: subject: (You Can Now Install Official Evernote Client on Ubuntu and Debian-based Linux Distributions)
+[#]: via: (https://itsfoss.com/install-evernote-ubuntu/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13195-1.html)
+
+在 Linux 上安装官方 Evernote 客户端
+======
+
+
+
+[Evernote][1] 是一款流行的笔记应用。它在推出时是一个革命性的产品。从那时起,已经有好几个这样的应用,可以将网络剪报、笔记等保存为笔记本格式。
+
+多年来,Evernote 一直没有在 Linux 上使用的桌面客户端。前段时间 Evernote 承诺推出 Linux 应用,其测试版终于可以在基于 Ubuntu 的发行版上使用了。
+
+> 非 FOSS 警报!
+>
+> Evernote Linux 客户端不是开源的。之所以在这里介绍它,是因为该应用是在 Linux 上提供的,我们也会不定期地介绍 Linux 用户常用的非 FOSS 应用。这对普通桌面 Linux 用户有帮助。
+
+### 在 Ubuntu 和基于 Debian 的 Linux 发行版上安装 Evernote
+
+进入这个 Evernote 的[网站页面][2]。
+
+向下滚动一点,接受“早期测试计划”的条款和条件。你会看到一个“立即安装”的按钮出现在屏幕上。点击它来下载 DEB 文件。
+
+![][3]
+
+要 [从 DEB 文件安装应用][4],请双击它。它应该会打开软件中心,并给你选择安装它。
+
+![][5]
+
+安装完成后,在系统菜单中搜索 Evernote 并启动它。
+
+![][6]
+
+当你第一次启动应用时,你需要登录到你的 Evernote 账户。
+
+![][7]
+
+第一次运行会带你进入“主页面”,在这里你可以整理你的笔记本,以便更快速地访问。
+
+![][8]
+
+你现在可以享受在 Linux 上使用 Evernote 了。
+
+### 体验 Evernote 的 Linux 测试版客户端
+
+由于软件处于测试版,因此这里或那里会有些问题。
+
+如上图所示,Evernote Linux 客户端检测到 [Ubuntu 中的深色模式][9] 并自动切换到深色主题。然而,当我把系统主题改为浅色或标准主题时,它并没有立即改变应用主题。这些变化是在我重启 Evernote 应用后才生效的。
+
+另一个问题是关于关闭应用。如果你点击 “X” 按钮关闭 Evernote,程序会进入后台而不是退出。
+
+有一个似乎可以启动最小化的 Evernote 的应用指示器,就像 [Linux 上的 Skype][10]。不幸的是,事实并非如此。它打开了便笺,让你快速输入笔记。
+
+这为你提供了另一个 [Linux 上的笔记应用][11],但它也带来了一个问题。这里没有退出 Evernote 的选项。它只用于打开快速记事应用。
+
+![][12]
+
+那么,如何退出 Evernote 应用呢?为此,再次打开 Evernote 应用。如果它在后台运行,在菜单中搜索它,并启动它,就像你重新打开它一样。
+
+当 Evernote 应用在前台运行时,点击 “文件->退出” 来退出 Evernote。
+
+![][13]
+
+这一点开发者应该在未来的版本中寻求改进。
+
+我也不能说测试版的程序将来会如何更新。它没有添加任何仓库。我只是希望程序本身能够通知用户有新的版本,这样用户就可以下载新的 DEB 文件。
+
+我并没有订阅 Evernote Premium,但我仍然可以在没有网络连接的情况下访问保存的网络文章和笔记。很奇怪,对吧?
+
+总的来说,我很高兴看到 Evernote 终于努力把这个应用带到了 Linux 上。现在,你不必再尝试第三方应用来在 Linux 上使用 Evernote 了,至少在 Ubuntu 和基于 Debian 的发行版上是这样。当然,你可以使用 [Evernote 替代品][14],比如 [Joplin][15],它们都是开源的。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-evernote-ubuntu/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://evernote.com/
+[2]: https://evernote.com/intl/en/b1433t1422
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-early-access-linux.png?resize=799%2C495&ssl=1
+[4]: https://itsfoss.com/install-deb-files-ubuntu/
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/install-evernote-linux.png?resize=800%2C539&ssl=1
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-ubuntu.jpg?resize=800%2C230&ssl=1
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-running-ubuntu.png?resize=800%2C505&ssl=1
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-on-ubuntu.png?resize=800%2C537&ssl=1
+[9]: https://itsfoss.com/dark-mode-ubuntu/
+[10]: https://itsfoss.com/install-skype-ubuntu-1404/
+[11]: https://itsfoss.com/note-taking-apps-linux/
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-app-indicator.png?resize=800%2C480&ssl=1
+[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/quit-evernote-linux.png?resize=799%2C448&ssl=1
+[14]: https://itsfoss.com/5-evernote-alternatives-linux/
+[15]: https://itsfoss.com/joplin/
diff --git a/published/202103/20210305 5 surprising things you can do with LibreOffice from the command line.md b/published/202103/20210305 5 surprising things you can do with LibreOffice from the command line.md
new file mode 100644
index 0000000000..35a3f2fc9f
--- /dev/null
+++ b/published/202103/20210305 5 surprising things you can do with LibreOffice from the command line.md
@@ -0,0 +1,171 @@
+[#]: subject: (5 surprising things you can do with LibreOffice from the command line)
+[#]: via: (https://opensource.com/article/21/3/libreoffice-command-line)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13219-1.html)
+
+5 个用命令行操作 LibreOffice 的技巧
+======
+
+> 直接在命令行中对文件进行转换、打印、保护等操作。
+
+
+
+LibreOffice 拥有所有你想要的办公软件套件的生产力功能,使其成为微软 Office 或谷歌套件的流行的开源替代品。LibreOffice 的能力之一是可以从命令行操作。例如,Seth Kenlon 最近解释了如何使用 LibreOffice 用全局 [命令行选项将多个文件][2] 从 DOCX 转换为 EPUB。他的文章启发我分享一些其他 LibreOffice 命令行技巧和窍门。
+
+在查看 LibreOffice 命令的一些隐藏功能之前,你需要了解如何使用应用选项。并不是所有的应用都接受选项(除了像 `--help` 选项这样的基本选项,它在大多数 Linux 应用中都可以使用)。
+
+```
+$ libreoffice --help
+```
+
+这将返回 LibreOffice 接受的其他选项的描述。有些应用没有太多选项,但 LibreOffice 好几页有用的选项,所以有很多东西可以玩。
+
+就是说,你可以在终端上使用 LibreOffice 进行以下五项有用的操作,来让使软件更加有用。
+
+### 1、自定义你的启动选项
+
+你可以修改你启动 LibreOffice 的方式。例如,如果你想只打开 LibreOffice 的文字处理器组件:
+
+```
+$ libreoffice --writer # 启动文字处理器
+```
+
+你可以类似地打开它的其他组件:
+
+
+```
+$ libreoffice --calc # 启动一个空的电子表格
+$ libreoffice --draw # 启动一个空的绘图文档
+$ libreoffice --web # 启动一个空的 HTML 文档
+```
+
+你也可以从命令行访问特定的帮助文件:
+
+```
+$ libreoffice --helpwriter
+```
+
+![LibreOffice Writer help][3]
+
+或者如果你需要电子表格应用方面的帮助:
+
+```
+$ libreoffice --helpcalc
+```
+
+你可以在不显示启动屏幕的情况下启动 LibreOffice:
+
+```
+$ libreoffice --writer --nologo
+```
+
+你甚至可以在你完成当前窗口的工作时,让它在后台最小化启动:
+
+```
+$ libreoffice --writer --minimized
+```
+
+### 2、以只读模式打开一个文件
+
+你可以使用 `--view` 以只读模式打开文件,以防止意外地对重要文件进行修改和保存:
+
+```
+$ libreoffice --view example.odt
+```
+
+### 3、打开一个模板文档
+
+你是否曾经创建过用作信头或发票表格的文档?LibreOffice 具有丰富的内置模板系统,但是你可以使用 `-n` 选项将任何文档作为模板:
+
+```
+$ libreoffice --writer -n example.odt
+```
+
+你的文档将在 LibreOffice 中打开,你可以对其进行修改,但保存时不会覆盖原始文件。
+
+### 4、转换文档
+
+当你需要做一个小任务,比如将一个文件转换为新的格式时,应用启动的时间可能与完成任务的时间一样长。解决办法是 `--headless` 选项,它可以在不启动图形用户界面的情况下执行 LibreOffice 进程。
+
+例如,在 LibreOffic 中,将一个文档转换为 EPUB 是一个非常简单的任务,但使用 `libreoffice` 命令就更容易:
+
+```
+$ libreoffice --headless --convert-to epub example.odt
+```
+
+使用通配符意味着你可以一次转换几十个文档:
+
+```
+$ libreoffice --headless --convert-to epub *.odt
+```
+
+你可以将文件转换为多种格式,包括 PDF、HTML、DOC、DOCX、EPUB、纯文本等。
+
+### 5、从终端打印
+
+你可以从命令行打印 LibreOffice 文档,而无需打开应用:
+
+```
+$ libreoffice --headless -p example.odt
+```
+
+这个选项不需要打开 LibreOffice 就可以使用默认打印机打印,它只是将文档发送到你的打印机。
+
+要打印一个目录中的所有文件:
+
+```
+$ libreoffice -p *.odt
+```
+
+(我不止一次执行了这个命令,然后用完了纸,所以在你开始之前,确保你的打印机里有足够的纸张。)
+
+你也可以把文件输出成 PDF。通常这和使用 `--convert-to-pdf` 选项没有什么区别,但是很容易记住:
+
+
+```
+$ libreoffice --print-to-file example.odt --headless
+```
+
+### 额外技巧:Flatpak 和命令选项
+
+如果你是使用 [Flatpak][5] 安装的 LibreOffice,所有这些命令选项都可以使用,但你必须通过 Flatpak 传递。下面是一个例子:
+
+```
+$ flatpak run org.libreoffice.LibreOffice --writer
+```
+
+它比本地安装要麻烦得多,所以你可能会受到启发 [写一个 Bash 别名][6] 来使它更容易直接与 LibreOffice 交互。
+
+### 令人惊讶的终端选项
+
+通过查阅手册页面,了解如何从命令行扩展 LibreOffice 的功能:
+
+```
+$ man libreoffice
+```
+
+你是否知道 LibreOffice 具有如此丰富的命令行选项? 你是否发现了其他人似乎都不了解的其他选项? 请在评论中分享它们!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/libreoffice-command-line
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/shortcut_command_function_editing_key.png?itok=a0sEc5vo (hot keys for shortcuts or features on computer keyboard)
+[2]: https://opensource.com/article/21/2/linux-workday
+[3]: https://opensource.com/sites/default/files/uploads/libreoffice-help.png (LibreOffice Writer help)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://www.libreoffice.org/download/flatpak/
+[6]: https://opensource.com/article/19/7/bash-aliases
diff --git a/published/202103/20210307 Track your family calendar with a Raspberry Pi and a low-power display.md b/published/202103/20210307 Track your family calendar with a Raspberry Pi and a low-power display.md
new file mode 100644
index 0000000000..165ca68e13
--- /dev/null
+++ b/published/202103/20210307 Track your family calendar with a Raspberry Pi and a low-power display.md
@@ -0,0 +1,81 @@
+[#]: subject: (Track your family calendar with a Raspberry Pi and a low-power display)
+[#]: via: (https://opensource.com/article/21/3/family-calendar-raspberry-pi)
+[#]: author: (Javier Pena https://opensource.com/users/jpena)
+[#]: collector: (lujun9972)
+[#]: translator: (wyxplus)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13222-1.html)
+
+利用树莓派和低功耗显示器来跟踪你的家庭日程表
+======
+
+> 通过利用开源工具和电子墨水屏,让每个人都清楚家庭的日程安排。
+
+
+
+有些家庭的日程安排很复杂:孩子们有上学活动和放学后的活动,你想要记住的重要事情,每个人都有多个约会等等。虽然你可以使用手机和应用程序来关注所有事情,但在家中放置一个大型低功耗显示器以显示家人的日程不是更好吗?电子墨水日程表刚好满足!
+
+![E Ink calendar][2]
+
+### 硬件
+
+这个项目是作为假日项目开始,因此我试着尽可能多的旧物利用。其中包括一台已经闲置了太长时间树莓派 2。由于我没有电子墨水屏,因此我需要购买一个。幸运的是,我找到了一家供应商,该供应商为支持树莓派的屏幕提供了 [开源驱动程序和示例][4],该屏幕使用 [GPIO][5] 端口连接。
+
+我的家人还想在不同的日程表之间切换,因此需要某种形式的输入。我没有添加 USB 键盘,而是选择了一种更简单的解决方案,并购买了一个类似于在 [这篇文章][6] 中所描述 1x4 大小的键盘。这使我可以将键盘连接到树莓派中的某些 GPIO 端口。
+
+最后,我需要一个相框来容纳整个设置。虽然背面看起来有些凌乱,但它能完成工作。
+
+![Calendar internals][7]
+
+### 软件
+
+我从 [一个类似的项目][8] 中获得了灵感,并开始为我的项目编写 Python 代码。我需要从两个地方获取数据:
+
+ * 天气信息:从 [OpenWeather API][9] 获取
+ * 时间信息:我打算使用 [CalDav 标准][10] 连接到一个在我家服务器上运行的日程表
+
+由于必须等待一些零件的送达,因此我使用了模块化的方法来进行输入和显示,这样我可以在没有硬件的情况下调试大多数代码。日程表应用程序需要驱动程序,于是我编写了一个 [Pygame][11] 驱动程序以便能在台式机上运行它。
+
+编写代码最好的部分是能够重用现有的开源项目,所以访问不同的 API 很容易。我可以专注于设计用户界面,其中包括每个人的周历和每个人的日历,以及允许使用小键盘来选择日程。并且我花时间又添加了一些额外的功能,例如特殊日子的自定义屏幕保护程序。
+
+![E Ink calendar screensaver][12]
+
+最后的集成步骤将确保我的日程表应用程序将在启动时运行,并且能够容错。我使用了一个基本的 [树莓派系统][13] 镜像,并将该应用程序配置到 systemd 服务,以便它可以在出现故障和系统重新启动依旧运行。
+
+做完所有工作,我把代码上传到了 [GitHub][14]。因此,如果你要创建类似的日历,可以随时查看并重构它!
+
+### 结论
+
+日程表已成为我们厨房中的日常工具。它可以帮助我们记住我们的日常活动,甚至我们的孩子在上学前,都可以使用它来查看日程的安排。
+
+对我而言,这个项目让我感受到开源的力量。如果没有开源的驱动程序、库以及开放 API,我们依旧还在用纸和笔来安排日程。很疯狂,不是吗?
+
+需要确保你的日程不冲突吗?学习如何使用这些免费的开源项目来做到这点。
+
+------
+via: https://opensource.com/article/21/3/family-calendar-raspberry-pi
+
+作者:[Javier Pena][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jpena
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calendar-coffee.jpg?itok=9idm1917 "Calendar with coffee and breakfast"
+[2]: https://opensource.com/sites/default/files/uploads/calendar.jpg "E Ink calendar"
+[3]: https://creativecommons.org/licenses/by-sa/4.0/
+[4]: https://github.com/waveshare/e-Paper
+[5]: https://opensource.com/article/19/3/gpio-pins-raspberry-pi
+[6]: https://www.instructables.com/1x4-Membrane-Keypad-w-Arduino/
+[7]: https://opensource.com/sites/default/files/uploads/calendar_internals.jpg "Calendar internals"
+[8]: https://github.com/zli117/EInk-Calendar
+[9]: https://openweathermap.org
+[10]: https://en.wikipedia.org/wiki/CalDAV
+[11]: https://github.com/pygame/pygame
+[12]: https://opensource.com/sites/default/files/uploads/calendar_screensaver.jpg "E Ink calendar screensaver"
+[13]: https://www.raspberrypi.org/software/
+[14]: https://github.com/javierpena/eink-calendar
diff --git a/published/202103/20210308 How to use Poetry to manage your Python projects on Fedora.md b/published/202103/20210308 How to use Poetry to manage your Python projects on Fedora.md
new file mode 100644
index 0000000000..6692e699d1
--- /dev/null
+++ b/published/202103/20210308 How to use Poetry to manage your Python projects on Fedora.md
@@ -0,0 +1,200 @@
+[#]: subject: (How to use Poetry to manage your Python projects on Fedora)
+[#]: via: (https://fedoramagazine.org/how-to-use-poetry-to-manage-your-python-projects-on-fedora/)
+[#]: author: (Kader Miyanyedi https://fedoramagazine.org/author/moonkat/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13202-1.html)
+
+如何在 Fedora 上使用 Poetry 来管理你的 Python 项目?
+======
+
+![Python & Poetry on Fedora][1]
+
+Python 开发人员经常创建一个新的虚拟环境来分离项目依赖,然后用 `pip`、`pipenv` 等工具来管理它们。Poetry 是一个简化 Python 中依赖管理和打包的工具。这篇文章将向你展示如何在 Fedora 上使用 Poetry 来管理你的 Python 项目。
+
+与其他工具不同,Poetry 只使用一个配置文件来进行依赖管理、打包和发布。这消除了对不同文件的需求,如 `Pipfile`、`MANIFEST.in`、`setup.py` 等。这也比使用多个工具更快。
+
+下面详细介绍一下开始使用 Poetry 时使用的命令。
+
+### 在 Fedora 上安装 Poetry
+
+如果你已经使用 Fedora 32 或以上版本,你可以使用这个命令直接从命令行安装 Poetry:
+
+```
+$ sudo dnf install poetry
+```
+
+编者注:在 Fedora Silverblue 或 CoreOs上,Python 3.9.2 是核心提交的一部分,你可以用下面的命令安装 Poetry:
+
+```
+rpm-ostree install poetry
+```
+
+### 初始化一个项目
+
+使用 `new` 命令创建一个新项目:
+
+```
+$ poetry new poetry-project
+```
+
+用 Poetry 创建的项目结构是这样的:
+
+```
+├── poetry_project
+│ └── init.py
+├── pyproject.toml
+├── README.rst
+└── tests
+ ├── init.py
+ └── test_poetry_project.py
+```
+
+Poetry 使用 `pyproject.toml` 来管理项目的依赖。最初,这个文件看起来类似于这样:
+
+```
+[tool.poetry]
+name = "poetry-project"
+version = "0.1.0"
+description = ""
+authors = ["Kadermiyanyedi "]
+
+[tool.poetry.dependencies]
+python = "^3.9"
+
+[tool.poetry.dev-dependencies]
+pytest = "^5.2"
+
+[build-system]
+requires = ["poetry>=0.12"]
+build-backend = "poetry.masonry.api"
+```
+
+这个文件包含 4 个部分:
+
+ * 第一部分包含描述项目的信息,如项目名称、项目版本等。
+ * 第二部分包含项目的依赖。这些依赖是构建项目所必需的。
+ * 第三部分包含开发依赖。
+ * 第四部分描述的是符合 [PEP 517][2] 的构建系统。
+
+如果你已经有一个项目,或者创建了自己的项目文件夹,并且你想使用 Poetry,请在你的项目中运行 `init` 命令。
+
+```
+$ poetry init
+```
+
+在这个命令之后,你会看到一个交互式的 shell 来配置你的项目。
+
+### 创建一个虚拟环境
+
+如果你想创建一个虚拟环境或激活一个现有的虚拟环境,请使用以下命令:
+
+```
+$ poetry shell
+```
+
+Poetry 默认在 `/home/username/.cache/pypoetry` 项目中创建虚拟环境。你可以通过编辑 Poetry 配置来更改默认路径。使用下面的命令查看配置列表:
+
+```
+$ poetry config --list
+
+cache-dir = "/home/username/.cache/pypoetry"
+virtualenvs.create = true
+virtualenvs.in-project = true
+virtualenvs.path = "{cache-dir}/virtualenvs"
+```
+
+修改 `virtualenvs.in-project` 配置变量,在项目目录下创建一个虚拟环境。Poetry 命令是:
+
+```
+$ poetry config virtualenv.in-project true
+```
+
+### 添加依赖
+
+使用 `poetry add` 命令为项目安装一个依赖:
+
+```
+$ poetry add django
+```
+
+你可以使用带有 `--dev` 选项的 `add` 命令来识别任何只用于开发环境的依赖:
+
+```
+$ poetry add black --dev
+```
+
+`add` 命令会创建一个 `poetry.lock` 文件,用来跟踪软件包的版本。如果 `poetry.lock` 文件不存在,那么会安装 `pyproject.toml` 中所有依赖项的最新版本。如果 `poetry.lock` 存在,Poetry 会使用文件中列出的确切版本,以确保每个使用这个项目的人的软件包版本是一致的。
+
+使用 `poetry install` 命令来安装当前项目中的所有依赖:
+
+```
+$ poetry install
+```
+
+通过使用 `--no-dev` 选项防止安装开发依赖:
+
+```
+$ poetry install --no-dev
+```
+
+### 列出软件包
+
+`show` 命令会列出所有可用的软件包。`--tree` 选项将以树状列出软件包:
+
+```
+$ poetry show --tree
+
+django 3.1.7 A high-level Python Web framework that encourages rapid development and clean, pragmatic design.
+├── asgiref >=3.2.10,<4
+├── pytz *
+└── sqlparse >=0.2.2
+```
+
+包含软件包名称,以列出特定软件包的详细信息:
+
+```
+$ poetry show requests
+
+name : requests
+version : 2.25.1
+description : Python HTTP for Humans.
+
+dependencies
+ - certifi >=2017.4.17
+ - chardet >=3.0.2,<5
+ - idna >=2.5,<3
+ - urllib3 >=1.21.1,<1.27
+```
+
+最后,如果你想知道软件包的最新版本,你可以通过 `--latest` 选项:
+
+```
+$ poetry show --latest
+
+idna 2.10 3.1 Internationalized Domain Names in Applications
+asgiref 3.3.1 3.3.1 ASGI specs, helper code, and adapters
+```
+
+### 更多信息
+
+Poetry 的更多详情可在[文档][3]中获取。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/how-to-use-poetry-to-manage-your-python-projects-on-fedora/
+
+作者:[Kader Miyanyedi][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/moonkat/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/03/Poetry_Python-816x345.jpg
+[2]: https://www.python.org/dev/peps/pep-0517/
+[3]: https://python-poetry.org/docs/
diff --git a/published/202103/20210309 Learn Python dictionary values with Jupyter.md b/published/202103/20210309 Learn Python dictionary values with Jupyter.md
new file mode 100644
index 0000000000..2087eb3da6
--- /dev/null
+++ b/published/202103/20210309 Learn Python dictionary values with Jupyter.md
@@ -0,0 +1,150 @@
+[#]: subject: (Learn Python dictionary values with Jupyter)
+[#]: via: (https://opensource.com/article/21/3/dictionary-values-python)
+[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeo)
+[#]: collector: (lujun9972)
+[#]: translator: (DCOLIVERSUN)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13236-1.html)
+
+用 Jupyter 学习 Python 字典
+======
+
+> 字典数据结构可以帮助你快速访问信息。
+
+
+
+字典是 Python 编程语言使用的数据结构。一个 Python 字典由多个键值对组成;每个键值对将键映射到其关联的值上。
+
+例如你是一名老师,想把学生姓名与成绩对应起来。你可以使用 Python 字典,将学生姓名映射到他们关联的成绩上。此时,键值对中键是姓名,值是对应的成绩。
+
+如果你想知道某个学生的考试成绩,你可以从字典中访问。这种快捷查询方式可以为你节省解析整个列表找到学生成绩的时间。
+
+本文介绍了如何通过键访问对应的字典值。学习前,请确保你已经安装了 [Anaconda 包管理器][2]和 [Jupyter 笔记本][3]。
+
+### 1、在 Jupyter 中打开一个新的笔记本
+
+首先在 Web 浏览器中打开并运行 Jupyter。然后,
+
+ 1. 转到左上角的 “File”。
+ 2. 选择 “New Notebook”,点击 “Python 3”。
+
+![新建 Jupyter 笔记本][4]
+
+开始时,新建的笔记本是无标题的,你可以将其重命名为任何名称。我为我的笔记本取名为 “OpenSource.com Data Dictionary Tutorial”。
+
+笔记本中标有行号的位置就是你写代码的区域,也是你输入的位置。
+
+在 macOS 上,可以同时按 `Shift + Return` 键得到输出。在创建新的代码区域前,请确保完成上述动作;否则,你写的任何附加代码可能无法运行。
+
+### 2、新建一个键值对
+
+在字典中输入你希望访问的键与值。输入前,你需要在字典上下文中定义它们的含义:
+
+```
+empty_dictionary = {}
+grades = {
+ "Kelsey": 87,
+ "Finley": 92
+}
+
+one_line = {a: 1, b: 2}
+```
+
+![定义字典键值对的代码][6]
+
+这段代码让字典将特定键与其各自的值关联起来。字典按名称存储数据,从而可以更快地查询。
+
+### 3、通过键访问字典值
+
+现在你想查询指定的字典值;在上述例子中,字典值指特定学生的成绩。首先,点击 “Insert” 后选择 “Insert Cell Below”。
+
+![在 Jupyter 插入新建单元格][7]
+
+在新单元格中,定义字典中的键与值。
+
+然后,告诉字典打印该值的键,找到需要的值。例如,查询名为 Kelsey 的学生的成绩:
+
+```
+# 访问字典中的数据
+grades = {
+ "Kelsey": 87,
+ "Finley": 92
+}
+
+print(grades["Kelsey"])
+87
+```
+
+![查询特定值的代码][8]
+
+当你查询 Kelsey 的成绩(也就是你想要查询的值)时,如果你用的是 macOS,只需要同时按 `Shift+Return` 键。
+
+你会在单元格下方看到 Kelsey 的成绩。
+
+### 4、更新已有的键
+
+当把一位学生的错误成绩添加到字典时,你会怎么办?可以通过更新字典、存储新值来修正这类错误。
+
+首先,选择你想更新的那个键。在上述例子中,假设你错误地输入了 Finley 的成绩,那么 Finley 就是你需要更新的键。
+
+为了更新 Finley 的成绩,你需要在下方插入新的单元格,然后创建一个新的键值对。同时按 `Shift+Return` 键打印字典全部信息:
+
+```
+grades["Finley"] = 90
+print(grades)
+
+{'Kelsey': 87; "Finley": 90}
+```
+
+![更新键的代码][9]
+
+单元格下方输出带有 Finley 更新成绩的字典。
+
+### 5、添加新键
+
+假设你得到一位新学生的考试成绩。你可以用新键值对将那名学生的姓名与成绩补充到字典中。
+
+插入新的单元格,以键值对形式添加新学生的姓名与成绩。当你完成这些后,同时按 `Shift+Return` 键打印字典全部信息:
+
+```
+grades["Alex"] = 88
+print(grades)
+
+{'Kelsey': 87, 'Finley': 90, 'Alex': 88}
+```
+
+![添加新键][10]
+
+所有的键值对输出在单元格下方。
+
+### 使用字典
+
+请记住,键与值可以是任意数据类型,但它们很少是[扩展数据类型][11]。此外,字典不能以指定的顺序存储、组织里面的数据。如果你想要数据有序,最好使用 Python 列表,而非字典。
+
+如果你考虑使用字典,首先要确认你的数据结构是否是合适的,例如像电话簿的结构。如果不是,列表、元组、树或者其他数据结构可能是更好的选择。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/dictionary-values-python
+
+作者:[Lauren Maffeo][a]
+选题:[lujun9972][b]
+译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/lmaffeo
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python-programming-code-keyboard.png?itok=fxiSpmnd (Hands on a keyboard with a Python book )
+[2]: https://docs.anaconda.com/anaconda/
+[3]: https://opensource.com/article/18/3/getting-started-jupyter-notebooks
+[4]: https://opensource.com/sites/default/files/uploads/new-jupyter-notebook.png (Create Jupyter notebook)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://opensource.com/sites/default/files/uploads/define-keys-values.png (Code for defining key-value pairs in the dictionary)
+[7]: https://opensource.com/sites/default/files/uploads/jupyter_insertcell.png (Inserting a new cell in Jupyter)
+[8]: https://opensource.com/sites/default/files/uploads/lookforvalue.png (Code to look for a specific value)
+[9]: https://opensource.com/sites/default/files/uploads/jupyter_updatekey.png (Code for updating a key)
+[10]: https://opensource.com/sites/default/files/uploads/jupyter_addnewkey.png (Add a new key)
+[11]: https://www.datacamp.com/community/tutorials/data-structures-python
diff --git a/published/202103/20210309 Use gImageReader to Extract Text From Images and PDFs on Linux.md b/published/202103/20210309 Use gImageReader to Extract Text From Images and PDFs on Linux.md
new file mode 100644
index 0000000000..af9f99d71a
--- /dev/null
+++ b/published/202103/20210309 Use gImageReader to Extract Text From Images and PDFs on Linux.md
@@ -0,0 +1,101 @@
+[#]: subject: (Use gImageReader to Extract Text From Images and PDFs on Linux)
+[#]: via: (https://itsfoss.com/gimagereader-ocr/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13205-1.html)
+
+在 Linux 上使用 gImageReader 从图像和 PDF 中提取文本
+======
+
+> gImageReader 是一个 GUI 工具,用于在 Linux 中利用 Tesseract OCR 引擎从图像和 PDF 文件中提取文本。
+
+[gImageReader][1] 是 [Tesseract 开源 OCR 引擎][2]的一个前端。Tesseract 最初是由 HP 公司开发的,然后在 2006 年开源。
+
+基本上,OCR(光学字符识别)引擎可以让你从图片或文件(PDF)中扫描文本。默认情况下,它可以检测几种语言,还支持通过 Unicode 字符扫描。
+
+然而,Tesseract 本身是一个没有任何 GUI 的命令行工具。因此,gImageReader 就来解决这点,它可以让任何用户使用它从图像和文件中提取文本。
+
+让我重点介绍一些有关它的内容,同时说下我在测试期间的使用经验。
+
+### gImageReader:一个跨平台的 Tesseract OCR 前端
+
+![][3]
+
+为了简化事情,gImageReader 在从 PDF 文件或包含任何类型文本的图像中提取文本时非常方便。
+
+无论你是需要它来进行拼写检查还是翻译,它都应该对特定的用户群体有用。
+
+以列表总结下功能,这里是你可以用它做的事情:
+
+ * 从磁盘、扫描设备、剪贴板和截图中添加 PDF 文档和图像
+ * 能够旋转图像
+ * 常用的图像控制,用于调整亮度、对比度和分辨率。
+ * 直接通过应用扫描图像
+ * 能够一次性处理多个图像或文件
+ * 手动或自动识别区域定义
+ * 识别纯文本或 [hOCR][4] 文档
+ * 编辑器显示识别的文本
+ * 可对对提取的文本进行拼写检查
+ * 从 hOCR 文件转换/导出为 PDF 文件
+ * 将提取的文本导出为 .txt 文件
+ * 跨平台(Windows)
+
+### 在 Linux 上安装 gImageReader
+
+**注意**:你需要安装 Tesseract 语言包,才能从软件管理器中的图像/文件中进行检测。
+
+![][5]
+
+你可以在一些 Linux 发行版如 Fedora 和 Debian 的默认仓库中找到 gImageReader。
+
+对于 Ubuntu,你需要添加一个 PPA,然后安装它。要做到这点,下面是你需要在终端中输入的内容:
+
+```
+sudo add-apt-repository ppa:sandromani/gimagereader
+sudo apt update
+sudo apt install gimagereader
+```
+
+你也可以从 openSUSE 的构建服务中找到它,Arch Linux 用户可在 [AUR][6] 中找到。
+
+所有的仓库和包的链接都可以在他们的 [GitHub 页面][1]中找到。
+
+### gImageReader 使用经验
+
+当你需要从图像中提取文本时,gImageReader 是一个相当有用的工具。当你尝试从 PDF 文件中提取文本时,它的效果非常好。
+
+对于从智能手机拍摄的图片中提取,检测很接近,但有点不准确。也许当你进行扫描时,从文件中识别字符可能会更好。
+
+所以,你需要亲自尝试一下,看看它是否对你而言工作良好。我在 Linux Mint 20.1(基于 Ubuntu 20.04)上试过。
+
+我只遇到了一个从设置中管理语言的问题,我没有得到一个快速的解决方案。如果你遇到此问题,那么可能需要对其进行故障排除,并进一步了解如何解决该问题。
+
+![][7]
+
+除此之外,它工作良好。
+
+试试吧,让我知道它是如何为你服务的!如果你知道类似的东西(和更好的),请在下面的评论中告诉我。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/gimagereader-ocr/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://github.com/manisandro/gImageReader
+[2]: https://tesseract-ocr.github.io/
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/gImageReader.png?resize=800%2C456&ssl=1
+[4]: https://en.wikipedia.org/wiki/HOCR
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/tesseract-language-pack.jpg?resize=800%2C620&ssl=1
+[6]: https://itsfoss.com/aur-arch-linux/
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/gImageReader-1.jpg?resize=800%2C460&ssl=1
diff --git a/published/202103/20210310 How to Update openSUSE Linux System.md b/published/202103/20210310 How to Update openSUSE Linux System.md
new file mode 100644
index 0000000000..9ff041647e
--- /dev/null
+++ b/published/202103/20210310 How to Update openSUSE Linux System.md
@@ -0,0 +1,107 @@
+[#]: subject: (How to Update openSUSE Linux System)
+[#]: via: (https://itsfoss.com/update-opensuse/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13199-1.html)
+
+如何更新 openSUSE Linux 系统
+======
+
+
+
+就我记忆所及,我一直是 Ubuntu 的用户。我曾经转向过其他发行版,但最终还是一次次回到 Ubuntu。但最近,我开始使用 openSUSE 来尝试一些非 Debian 的东西。
+
+随着我对 [openSUSE][1] 的不断探索,我不断发现 SUSE 中略有不同的东西,并打算在教程中介绍它们。
+
+第一篇我写的是更新 openSUSE 系统。有两种方法可以做到:
+
+ * 使用终端(适用于 openSUSE 桌面和服务器)
+ * 使用图形工具(适用于 openSUSE 桌面)
+
+### 通过命令行更新 openSUSE
+
+更新 openSUSE 的最简单方法是使用 `zypper` 命令。它提供了补丁和更新管理的全部功能。它可以解决文件冲突和依赖性问题。更新也包括 Linux 内核。
+
+如果你正在使用 openSUSE Leap,请使用这个命令:
+
+```
+sudo zypper update
+```
+
+你也可以用 `up` 代替 `update`,但我觉得 `update` 更容易记住。
+
+如果你正在使用 openSUSE Tumbleweed,请使用 `dist-upgrade` 或者 `dup`(简称)。Tumbleweed 是[滚动发行版][2],因此建议使用 `dist-upgrade` 选项。
+
+```
+sudo zypper dist-upgrade
+```
+
+它将显示要升级、删除或安装的软件包列表。
+
+![][3]
+
+如果你的系统需要重启,你会得到通知。
+
+如果你只是想刷新仓库(像 `sudo apt update` 一样),你可以使用这个命令:
+
+```
+sudo zypper refresh
+```
+
+如果你想列出可用的更新,也可以这样做:
+
+```
+sudo zypper list-updates
+```
+
+### 以图形方式更新 openSUSE
+
+如果你使用 openSUSE 作为桌面,你可以选择使用 GUI 工具来安装更新。这个工具可能会根据 [你使用的桌面环境][4] 而改变。
+
+例如,KDE 有自己的软件中心,叫做 “Discover”。你可以用它来搜索和安装新的应用。你也可以用它来安装系统更新。
+
+![][5]
+
+事实上,KDE 会在通知区通知你可用的系统更新。你必须打开 Discover,因为点击通知不会自动进入 Discover。
+
+![][6]
+
+如果你觉得这很烦人,你可以使用这些命令禁用它:
+
+```
+sudo zypper remove plasma5-pk-updates
+sudo zypper addlock plasma5-pk-updates
+```
+
+不过我不推荐。最好是获取可用的更新通知。
+
+还有一个 YAST 软件管理 [GUI 工具][7],你可以用它来对软件包管理进行更精细的控制。
+
+![][8]
+
+就是这些了。这是一篇简短的文章。在下一篇 SUSE 教程中,我将通过实例向大家展示一些常用的 `zypper` 命令。敬请期待。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/update-opensuse/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.opensuse.org/
+[2]: https://itsfoss.com/rolling-release/
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/update-opensuse-with-zypper.png?resize=800%2C406&ssl=1
+[4]: https://itsfoss.com/find-desktop-environment/
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/opensuse-update-gui.png?resize=800%2C500&ssl=1
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/update-notification-opensuse.png?resize=800%2C259&ssl=1
+[7]: https://itsfoss.com/gui-cli-tui/
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/yast-software-management-suse.png?resize=800%2C448&ssl=1
diff --git a/published/202103/20210310 Understanding file names and directories in FreeDOS.md b/published/202103/20210310 Understanding file names and directories in FreeDOS.md
new file mode 100644
index 0000000000..41fa649a93
--- /dev/null
+++ b/published/202103/20210310 Understanding file names and directories in FreeDOS.md
@@ -0,0 +1,110 @@
+[#]: subject: (Understanding file names and directories in FreeDOS)
+[#]: via: (https://opensource.com/article/21/3/files-freedos)
+[#]: author: (Kevin O'Brien https://opensource.com/users/ahuka)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13208-1.html)
+
+了解 FreeDOS 中的文件名和目录
+======
+
+> 了解如何在 FreeDOS 中创建,编辑和命名文件。
+
+
+
+开源操作系统 [FreeDOS][2] 是一个久经考验的项目,可帮助用户玩复古游戏、更新固件、运行过时但受欢迎的应用以及研究操作系统设计。FreeDOS 提供了有关个人计算历史的见解(因为它实现了 80 年代初的事实上的操作系统),但是它是在现代环境中进行的。在本文中,我将使用 FreeDOS 来解释文件名和扩展名是如何发展的。
+
+### 了解文件名和 ASCII 文本
+
+FreeDOS 文件名遵循所谓的 *8.3 惯例*。这意味着所有的 FreeDOS 文件名都有两个部分,分别包含最多八个和三个字符。第一部分通常被称为*文件名*(这可能会让人有点困惑,因为文件名和文件扩展名的组合也被称为文件名)。这一部分可以有一个到八个字符。之后是*扩展名*,可以有零到三个字符。这两部分之间用一个点隔开。
+
+文件名可以使用任何字母或数字。键盘上的许多其他字符也是允许的,但不是所有的字符。这是因为许多其他字符在 FreeDOS 中被指定了特殊用途。一些可以出现在 FreeDOS 文件名中的字符有:
+
+
+```
+~ ! @ # $ % ^ & ( ) _ - { } `
+```
+
+扩展 [ASCII][3] 字符集中也有一些字符可以使用,例如 `�`。
+
+在 FreeDOS 中具有特殊意义的字符,因此不能用于文件名中,包括:
+
+```
+* / + | \ = ? [ ] ; : " . < > ,
+```
+
+另外,你不能在 FreeDOS 文件名中使用空格。FreeDOS 控制台[使用空格将命令的与选项和参数分隔][4]。
+
+FreeDOS 是*不区分大小写*的,所以不管你是使用大写字母还是小写字母都无所谓。所有的字母都会被转换为大写字母,所以无论你做什么,你的文件最终都会在名称中使用大写字母。
+
+#### 文件扩展名
+
+FreeDOS 中的文件不需要有扩展名,但文件扩展名确实有一些用途。某些文件扩展名在 FreeDOS 中有内置的含义,例如:
+
+ * **EXE**:可执行文件
+ * **COM**:命令文件
+ * **SYS**:系统文件
+ * **BAT**:批处理文件
+
+特定的软件程序使用其他扩展名,或者你可以在创建文件时使用它们。这些扩展名没有绝对的文件关联,因此如果你使用 FreeDOS 的文字处理器,你的文件使用什么扩展名并不重要。如果你愿意,你可以发挥创意,将扩展名作为你的文件系统的一部分。例如,你可以用 `*.JAN`、`*.FEB`、`*.MAR`、`*.APR` 等等来命名你的备忘录。
+
+### 编辑文件
+
+FreeDOS 自带的 Edit 应用可以快速方便地进行文本编辑。它是一个简单的编辑器,沿屏幕顶部有一个菜单栏,可以方便地访问所有常用的功能(如复制、粘贴、保存等)。
+
+![Editing in FreeDOS][5]
+
+正如你所期望的那样,还有很多其他的文本编辑器可以使用,包括小巧但用途广泛的 [e3 编辑器][7]。你可以在 GitLab 上找到各种各样的 [FreeDOS 应用][8] 。
+
+### 创建文件
+
+你可以在 FreeDOS 中使用 `touch` 命令创建空文件。这个简单的工具可以更新文件的修改时间或创建一个新文件。
+
+```
+C:\>touch foo.txt
+C:\>dir
+FOO TXT 0 01-12-2021 10:00a
+```
+
+你也可以直接从 FreeDOS 控制台创建文件,而不需要使用 Edit 文本编辑器。首先,使用 `copy` 命令将控制台中的输入(简称 `con`)复制到一个新的文件对象中。用 `Ctrl+Z` 终止输入,然后按**回车**键:
+
+```
+C:\>copy con test.txt
+con => test.txt
+This is a test file.
+^Z
+```
+
+`Ctrl+Z` 字符在控制台中显示为 `^Z`。它并没有被复制到文件中,而是作为文件结束(EOF)的分隔符。换句话说,它告诉 FreeDOS 何时停止复制。这是一个很好的技巧,可以用来做快速的笔记或开始一个简单的文档,以便以后工作。
+
+### 文件和 FreeDOS
+
+FreeDOS 是开源的、免费的且 [易于安装][9]。探究 FreeDOS 如何处理文件,可以帮助你了解多年来计算的发展,不管你平时使用的是什么操作系统。启动 FreeDOS,开始探索现代复古计算吧!
+
+_本文中的部分信息曾发表在 [DOS 课程 7:DOS 文件名;ASCII][10] 中(CC BY-SA 4.0)。_
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/files-freedos
+
+作者:[Kevin O'Brien][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ahuka
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_paper_folder.png?itok=eIJWac15 (Files in a folder)
+[2]: https://www.freedos.org/
+[3]: tmp.2sISc4Tp3G#ASCII
+[4]: https://opensource.com/article/21/2/set-your-path-freedos
+[5]: https://opensource.com/sites/default/files/uploads/freedos_2_files-edit.jpg (Editing in FreeDOS)
+[6]: https://creativecommons.org/licenses/by-sa/4.0/
+[7]: https://opensource.com/article/20/12/e3-linux
+[8]: https://gitlab.com/FDOS/
+[9]: https://opensource.com/article/18/4/gentle-introduction-freedos
+[10]: https://www.ahuka.com/dos-lessons-for-self-study-purposes/dos-lesson-7-dos-filenames-ascii/
diff --git a/published/202103/20210311 Linux Mint Cinnamon vs MATE vs Xfce- Which One Should You Use.md b/published/202103/20210311 Linux Mint Cinnamon vs MATE vs Xfce- Which One Should You Use.md
new file mode 100644
index 0000000000..001e18125d
--- /dev/null
+++ b/published/202103/20210311 Linux Mint Cinnamon vs MATE vs Xfce- Which One Should You Use.md
@@ -0,0 +1,175 @@
+[#]: subject: (Linux Mint Cinnamon vs MATE vs Xfce: Which One Should You Use?)
+[#]: via: (https://itsfoss.com/linux-mint-cinnamon-mate-xfce/)
+[#]: author: (Dimitrios https://itsfoss.com/author/dimitrios/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13213-1.html)
+
+Cinnamon vs MATE vs Xfce:你应该选择那一个 Linux Mint 口味?
+======
+
+
+
+Linux Mint 无疑是 [最适合初学者的 Linux 发行版之一][1]。尤其是对于刚刚迈向 Linux 世界的 Windows 用户来说,更是如此。
+
+2006 年以来(也就是 Linux Mint 首次发布的那一年),他们开发了一系列的提高用户的体验的 [工具][2]。此外,Linux Mint 是基于 Ubuntu 的,所以你有一个可以寻求帮助的庞大的用户社区。
+
+我不打算讨论 Linux Mint 有多好。如果你已经下定决心 [安装Linux Mint][3],你可能会对它网站上的 [下载部分][4] 感到有些困惑。
+
+它给了你三个选择:Cinnamon、MATE 和 Xfce。不知道该如何选择吗?我将在本文中帮你解决这个问题。
+
+![][5]
+
+如果你是个 Linux 的绝对新手,对上面的东西一无所知,我建议你了解一下 [什么是 Linux 桌面环境][6]。如果你能再多花点时间,请阅读这篇关于 [什么是 Linux,以及为什么有这么多看起来相似的 Linux 操作系统][7] 的优秀解释。
+
+有了这些信息,你就可以了解各种 Linux Mint 版本之间的区别了。如果你不知道该选择哪一个,通过这篇文章,我将帮助你做出一个有意识的选择。
+
+### 你应该选择哪个 Linux Mint 版本?
+
+![][8]
+
+简单来说,可供选择的有以下几种:
+
+ * **Cinnamon 桌面**:具有现代感的传统桌面。
+ * **MATE 桌面**:类似 GNOME 2 时代的传统外观桌面。
+ * **Xfce 桌面**:一个流行的轻量级桌面环境。
+
+我们来逐一看看 Mint 的各个变种。
+
+#### Linux Mint Cinnamon 版
+
+Cinnamon 桌面是由 Linux Mint 团队开发的,显然它是 Linux Mint 的主力版本。
+
+早在近十年前,当 GNOME 桌面选择了非常规的 GNOME 3 用户界面时,人们就开始了 Cinnamon 的开发,通过复刻 GNOME 2 的一些组件来保持桌面的传统外观。
+
+很多 Linux 用户喜欢 Cinnamon,就是因为它有像 Windows 7 一样的界面。
+
+![Linux Mint Cinnamon desktop][9]
+
+##### 性能和相应能力
+
+Cinnamon 桌面的性能比过去的版本有所提高,但如果没有固态硬盘,你会觉得有点迟钝。上一次我使用 Cinnamon 桌面是在 4.4.8 版,开机后的内存消耗在 750MB 左右。现在的 4.8.6 版有了很大的改进,开机后减少了 100MB 内存消耗。
+
+为了获得最佳的用户体验,应该考虑双核 CPU,最低 4GB 内存。
+
+![Linux Mint 20 Cinnamon idle system stats][10]
+
+##### 优势
+
+ * 从 Windows 无缝切换
+ * 赏心悦目
+ * 高度 [可定制][11]
+
+##### 劣势
+
+ * 如果你的系统只有 2GB 内存,可能还是不够理想
+
+**附加建议**:如果你喜欢 Debian 而不是 Ubuntu,你可以选择 [Linux Mint Debian 版][12](LMDE)。LMDE 和带有 Cinnamon 桌面的 Debian 主要区别在于 LMDE 向其仓库提供最新的桌面环境。
+
+#### Linux Mint Mate 版
+
+[MATE 桌面环境][13] 也有类似的故事,它的目的是维护和支持 GNOME 2 的代码库和应用程序。它的外观和感觉与 GNOME 2 非常相似。
+
+在我看来,到目前为止,MATE 桌面的最佳实现是 [Ubuntu MATE][14]。在 Linux Mint 中,你会得到一个定制版的 MATE 桌面,它符合 Cinnamon 美学,而不是传统的 GNOME 2 设定。
+
+![Screenshot of Linux Mint MATE desktop][15]
+
+##### 性能和响应能力
+
+MATE 桌面以轻薄著称,这一点毋庸置疑。与 Cinnamon 桌面相比,其 CPU 的使用率始终保持在较低的水平,换言之,在笔记本电脑上会有更好的电池续航时间。
+
+虽然感觉没有 Xfce 那么敏捷(在我看来),但不至于影响用户体验。内存消耗在 500MB 以下起步,这对于功能丰富的桌面环境来说是令人印象深刻的。
+
+![Linux Mint 20 MATE idle system stats][16]
+
+##### 优势
+
+ * 不影响 [功能][17] 的轻量级桌面
+ * 足够的 [定制化][18] 可能性
+
+##### 劣势
+
+ * 传统的外观可能会给你一种过时的感觉
+
+#### Linux Mint Xfce 版
+
+Xfce 项目始于 1996 年,受到了 UNIX 的 [通用桌面环境(CDE)][19] 的启发。Xfce 是 “[XForms][20] Common Environment” 的缩写,但由于它不再使用 XForms 工具箱,所以名字拼写为 “Xfce”。
+
+它的目标是快速、轻量级和易于使用。Xfce 是许多流行的 Linux 发行版的主要桌面,如 [Manjaro][21] 和 [MX Linux][22]。
+
+Linux Mint 提供了一个精致的 Xfce 桌面,但即使是黑暗主题也无法与 Cinnamon 桌面的美感相比。
+
+![Linux Mint 20 Xfce desktop][23]
+
+##### 性能和响应能力
+
+Xfce 是 Linux Mint 提供的最精简的桌面环境。通过点击开始菜单、设置控制面板或探索底部面板,你会发现这是一个简单而又灵活的桌面环境。
+
+尽管我觉得极简主义是一个积极的属性,但 Xfce 并不是一个养眼的产品,反而留下的是比较传统的味道。但对于一些用户来说,经典的桌面环境才是他们的首选。
+
+在第一次开机时,内存的使用情况与 MATE 桌面类似,但并不尽如人意。如果你的电脑没有配备 SSD,Xfce 桌面环境可以让你的系统复活。
+
+![Linux Mint 20 Xfce idle system stats][24]
+
+##### 优势
+
+ * 使用简单
+ * 非常轻巧,适合老式硬件
+ * 坚如磐石的稳定
+
+##### 劣势
+
+ * 过时的外观
+ * 与 Cinnamon 相比,可能没有那么多的定制化服务
+
+### 总结
+
+由于这三款桌面环境都是基于 GTK 工具包的,所以选择哪个纯属个人喜好。它们都很节约系统资源,对于 4GB 内存的适度系统来说,表现良好。Xfce 和 MATE 可以更低一些,支持低至 2GB 内存的系统。
+
+Linux Mint 并不是唯一提供多种选择的发行版。Manjaro、Fedora和 [Ubuntu 等发行版也有各种口味][25] 可供选择。
+
+如果你还是无法下定决心,我建议先选择默认的 Cinnamon 版,并尝试 [在虚拟机中使用 Linux Mint][26]。看看你是否喜欢这个外观和感觉。如果不喜欢,你可以用同样的方式测试其他变体。如果你决定了这个版本,你可以继续 [在你的主系统上安装它][3]。
+
+希望我的这篇文章能够帮助到你。如果你对这个话题还有疑问或建议,请在下方留言。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/linux-mint-cinnamon-mate-xfce/
+
+作者:[Dimitrios][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/dimitrios/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/best-linux-beginners/
+[2]: https://linuxmint-developer-guide.readthedocs.io/en/latest/mint-tools.html#
+[3]: https://itsfoss.com/install-linux-mint/
+[4]: https://linuxmint.com/download.php
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/linux-mint-version-options.png?resize=789%2C277&ssl=1
+[6]: https://itsfoss.com/what-is-desktop-environment/
+[7]: https://itsfoss.com/what-is-linux/
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/Linux-Mint-variants.jpg?resize=800%2C450&ssl=1
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/linux-mint-20.1-cinnamon.jpg?resize=800%2C500&ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/Linux-Mint-20-Cinnamon-ram-usage.png?resize=800%2C600&ssl=1
+[11]: https://itsfoss.com/customize-cinnamon-desktop/
+[12]: https://itsfoss.com/lmde-4-release/
+[13]: https://mate-desktop.org/
+[14]: https://itsfoss.com/ubuntu-mate-20-04-review/
+[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/07/linux-mint-mate.jpg?resize=800%2C500&ssl=1
+[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/Linux-Mint-20-MATE-ram-usage.png?resize=800%2C600&ssl=1
+[17]: https://mate-desktop.org/blog/2020-02-10-mate-1-24-released/
+[18]: https://itsfoss.com/ubuntu-mate-customization/
+[19]: https://en.wikipedia.org/wiki/Common_Desktop_Environment
+[20]: https://en.wikipedia.org/wiki/XForms_(toolkit)
+[21]: https://itsfoss.com/manjaro-linux-review/
+[22]: https://itsfoss.com/mx-linux-19/
+[23]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/07/linux-mint-xfce.jpg?resize=800%2C500&ssl=1
+[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/Linux-Mint-20-Xfce-ram-usage.png?resize=800%2C600&ssl=1
+[25]: https://itsfoss.com/which-ubuntu-install/
+[26]: https://itsfoss.com/install-linux-mint-in-virtualbox/
diff --git a/published/202103/20210311 Set up network parental controls on a Raspberry Pi.md b/published/202103/20210311 Set up network parental controls on a Raspberry Pi.md
new file mode 100644
index 0000000000..79b2b0aa0a
--- /dev/null
+++ b/published/202103/20210311 Set up network parental controls on a Raspberry Pi.md
@@ -0,0 +1,84 @@
+[#]: subject: (Set up network parental controls on a Raspberry Pi)
+[#]: via: (https://opensource.com/article/21/3/raspberry-pi-parental-control)
+[#]: author: (Daniel Oh https://opensource.com/users/daniel-oh)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13216-1.html)
+
+在树莓派上设置家庭网络的家长控制
+======
+
+> 用最少的时间和金钱投入,就能保证孩子上网安全。
+
+![Family learning and reading together at night in a room][1]
+
+家长们一直在寻找保护孩子们上网的方法,从防止恶意软件、横幅广告、弹出窗口、活动跟踪脚本和其他问题,到防止他们在应该做功课的时候玩游戏和看 YouTube。许多企业使用工具来规范员工的网络安全和活动,但问题是如何在家里实现这一点?
+
+简短的答案是一台小巧、廉价的树莓派电脑,它可以让你为孩子和你在家的工作设置家长控制。本文将引导你了解使用树莓派构建自己的启用了家长控制功能的家庭网络有多么容易。
+
+### 安装硬件和软件
+
+对于这个项目,你需要一个树莓派和一个家庭网络路由器。如果你在线购物网站花上 5 分钟浏览,就可以发现很多选择。[树莓派 4][2] 和 [TP-Link 路由器][3] 是初学者的好选择。
+
+有了网络设备和树莓派后,你需要在 Linux 容器或者受支持的操作系统中安装 [Pi-hole][4]。有几种 [安装方法][5],但一个简单的方法是在你的树莓派上执行以下命令:
+
+```
+curl -sSL https://install.pi-hole.net | bash
+```
+
+### 配置 Pi-hole 作为你的 DNS 服务器
+
+接下来,你需要在路由器和 Pi-hole 中配置 DHCP 设置:
+
+ 1. 禁用路由器中的 DHCP 服务器设置
+ 2. 在 Pi-hole 中启用 DHCP 服务器
+
+每台设备都不一样,所以我没有办法告诉你具体需要点击什么来调整设置。一般来说,你可以通过浏览器访问你家的路由器。你的路由器的地址有时会印在路由器的底部,它以 192.168 或 10 开头。
+
+在浏览器中,打开你的路由器的地址,并用你的凭证登录。它通常是简单的 `admin` 和一个数字密码(有时这个密码也打印在路由器上)。如果你不知道登录名,请打电话给你的供应商并询问详情。
+
+在图形界面中,寻找你的局域网内关于 DHCP 的部分,并停用 DHCP 服务器。 你的路由器界面几乎肯定会与我的不同,但这是一个我设置的例子。取消勾选 **DHCP 服务器**:
+
+![Disable DHCP][6]
+
+接下来,你必须在 Pi-hole 上激活 DHCP 服务器。如果你不这样做,除非你手动分配 IP 地址,否则你的设备将无法上网!
+
+### 让你的网络适合家庭
+
+设置完成了。现在,你的网络设备(如手机、平板电脑、笔记本电脑等)将自动找到树莓派上的 DHCP 服务器。然后,每个设备将被分配一个动态 IP 地址来访问互联网。
+
+注意:如果你的路由器设备支持设置 DNS 服务器,你也可以在路由器中配置 DNS 客户端。客户端将把 Pi-hole 作为你的 DNS 服务器。
+
+要设置你的孩子可以访问哪些网站和活动的规则,打开浏览器进入 Pi-hole 管理页面,`http://pi.hole/admin/`。在仪表板上,点击“Whitelist”来添加你的孩子可以访问的网页。你也可以将不允许孩子访问的网站(如游戏、成人、广告、购物等)添加到“Blocklist”。
+
+![Pi-hole admin dashboard][8]
+
+### 接下来是什么?
+
+现在,你已经在树莓派上设置了家长控制,你可以让你的孩子更安全地上网,同时让他们访问经批准的娱乐选项。这也可以通过减少你的家庭串流来降低你的家庭网络使用量。更多高级使用方法,请访问 Pi-hole 的[文档][9]和[博客][10]。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/raspberry-pi-parental-control
+
+作者:[Daniel Oh][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/daniel-oh
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/family_learning_kids_night_reading.png?itok=6K7sJVb1 (Family learning and reading together at night in a room)
+[2]: https://www.raspberrypi.org/products/
+[3]: https://www.amazon.com/s?k=tp-link+router&crid=3QRLN3XRWHFTC&sprefix=TP-Link%2Caps%2C186&ref=nb_sb_ss_ts-doa-p_3_7
+[4]: https://pi-hole.net/
+[5]: https://github.com/pi-hole/pi-hole/#one-step-automated-install
+[6]: https://opensource.com/sites/default/files/uploads/disabledhcp.jpg (Disable DHCP)
+[7]: https://creativecommons.org/licenses/by-sa/4.0/
+[8]: https://opensource.com/sites/default/files/uploads/blocklist.png (Pi-hole admin dashboard)
+[9]: https://docs.pi-hole.net/
+[10]: https://pi-hole.net/blog/#page-content
diff --git a/published/202103/20210312 Visualize multi-threaded Python programs with an open source tool.md b/published/202103/20210312 Visualize multi-threaded Python programs with an open source tool.md
new file mode 100644
index 0000000000..2a389f5245
--- /dev/null
+++ b/published/202103/20210312 Visualize multi-threaded Python programs with an open source tool.md
@@ -0,0 +1,256 @@
+[#]: subject: (Visualize multi-threaded Python programs with an open source tool)
+[#]: via: (https://opensource.com/article/21/3/python-viztracer)
+[#]: author: (Tian Gao https://opensource.com/users/gaogaotiantian)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13253-1.html)
+
+用一个开源工具实现多线程 Python 程序的可视化
+======
+
+> VizTracer 可以跟踪并发的 Python 程序,以帮助记录、调试和剖析。
+
+
+
+并发是现代编程中必不可少的一部分,因为我们有多个核心,有许多需要协作的任务。然而,当并发程序不按顺序运行时,就很难理解它们。对于工程师来说,在这些程序中发现 bug 和性能问题不像在单线程、单任务程序中那么容易。
+
+在 Python 中,你有多种并发的选择。最常见的可能是用 `threading` 模块的多线程,用`subprocess` 和 `multiprocessing` 模块的多进程,以及最近用 `asyncio` 模块提供的 `async` 语法。在 [VizTracer][2] 之前,缺乏分析使用了这些技术程序的工具。
+
+VizTracer 是一个追踪和可视化 Python 程序的工具,对日志、调试和剖析很有帮助。尽管它对单线程、单任务程序很好用,但它在并发程序中的实用性是它的独特之处。
+
+### 尝试一个简单的任务
+
+从一个简单的练习任务开始:计算出一个数组中的整数是否是质数并返回一个布尔数组。下面是一个简单的解决方案:
+
+```
+def is_prime(n):
+ for i in range(2, n):
+ if n % i == 0:
+ return False
+ return True
+
+def get_prime_arr(arr):
+ return [is_prime(elem) for elem in arr]
+```
+
+试着用 VizTracer 以单线程方式正常运行它:
+
+```
+if __name__ == "__main__":
+ num_arr = [random.randint(100, 10000) for _ in range(6000)]
+ get_prime_arr(num_arr)
+```
+
+```
+viztracer my_program.py
+```
+
+![Running code in a single thread][3]
+
+调用堆栈报告显示,耗时约 140ms,大部分时间花在 `get_prime_arr` 上。
+
+![call-stack report][5]
+
+这只是在数组中的元素上一遍又一遍地执行 `is_prime` 函数。
+
+这是你所期望的,而且它并不有趣(如果你了解 VizTracer 的话)。
+
+### 试试多线程程序
+
+试着用多线程程序来做:
+
+```
+if __name__ == "__main__":
+ num_arr = [random.randint(100, 10000) for i in range(2000)]
+ thread1 = Thread(target=get_prime_arr, args=(num_arr,))
+ thread2 = Thread(target=get_prime_arr, args=(num_arr,))
+ thread3 = Thread(target=get_prime_arr, args=(num_arr,))
+
+ thread1.start()
+ thread2.start()
+ thread3.start()
+
+ thread1.join()
+ thread2.join()
+ thread3.join()
+```
+
+为了配合单线程程序的工作负载,这就为三个线程使用了一个 2000 元素的数组,模拟了三个线程共享任务的情况。
+
+![Multi-thread program][6]
+
+如果你熟悉 Python 的全局解释器锁(GIL),就会想到,它不会再快了。由于开销太大,花了 140ms 多一点的时间。不过,你可以观察到多线程的并发性:
+
+![Concurrency of multiple threads][7]
+
+当一个线程在工作(执行多个 `is_prime` 函数)时,另一个线程被冻结了(一个 `is_prime` 函数);后来,它们进行了切换。这是由于 GIL 的原因,这也是 Python 没有真正的多线程的原因。它可以实现并发,但不能实现并行。
+
+### 用多进程试试
+
+要想实现并行,办法就是 `multiprocessing` 库。下面是另一个使用 `multiprocessing` 的版本:
+
+```
+if __name__ == "__main__":
+ num_arr = [random.randint(100, 10000) for _ in range(2000)]
+
+ p1 = Process(target=get_prime_arr, args=(num_arr,))
+ p2 = Process(target=get_prime_arr, args=(num_arr,))
+ p3 = Process(target=get_prime_arr, args=(num_arr,))
+
+ p1.start()
+ p2.start()
+ p3.start()
+
+ p1.join()
+ p2.join()
+ p3.join()
+```
+
+要使用 VizTracer 运行它,你需要一个额外的参数:
+
+```
+viztracer --log_multiprocess my_program.py
+```
+
+![Running with extra argument][8]
+
+整个程序在 50ms 多一点的时间内完成,实际任务在 50ms 之前完成。程序的速度大概提高了三倍。
+
+为了和多线程版本进行比较,这里是多进程版本:
+
+![Multi-process version][9]
+
+在没有 GIL 的情况下,多个进程可以实现并行,也就是多个 `is_prime` 函数可以并行执行。
+
+不过,Python 的多线程也不是一无是处。例如,对于计算密集型和 I/O 密集型程序,你可以用睡眠来伪造一个 I/O 绑定的任务:
+
+```
+def io_task():
+ time.sleep(0.01)
+```
+
+在单线程、单任务程序中试试:
+
+```
+if __name__ == "__main__":
+ for _ in range(3):
+ io_task()
+```
+
+![I/O-bound single-thread, single-task program][10]
+
+整个程序用了 30ms 左右,没什么特别的。
+
+现在使用多线程:
+
+```
+if __name__ == "__main__":
+ thread1 = Thread(target=io_task)
+ thread2 = Thread(target=io_task)
+ thread3 = Thread(target=io_task)
+
+ thread1.start()
+ thread2.start()
+ thread3.start()
+
+ thread1.join()
+ thread2.join()
+ thread3.join()
+```
+
+![I/O-bound multi-thread program][11]
+
+程序耗时 10ms,很明显三个线程是并发工作的,这提高了整体性能。
+
+### 用 asyncio 试试
+
+Python 正在尝试引入另一个有趣的功能,叫做异步编程。你可以制作一个异步版的任务:
+
+```
+import asyncio
+
+async def io_task():
+ await asyncio.sleep(0.01)
+
+async def main():
+ t1 = asyncio.create_task(io_task())
+ t2 = asyncio.create_task(io_task())
+ t3 = asyncio.create_task(io_task())
+
+ await t1
+ await t2
+ await t3
+
+if __name__ == "__main__":
+ asyncio.run(main())
+```
+
+由于 `asyncio` 从字面上看是一个带有任务的单线程调度器,你可以直接在它上使用 VizTracer:
+
+![VizTracer with asyncio][12]
+
+依然花了 10ms,但显示的大部分函数都是底层结构,这可能不是用户感兴趣的。为了解决这个问题,可以使用 `--log_async` 来分离真正的任务:
+
+```
+viztracer --log_async my_program.py
+```
+
+![Using --log_async to separate tasks][13]
+
+现在,用户任务更加清晰了。在大部分时间里,没有任务在运行(因为它唯一做的事情就是睡觉)。有趣的部分是这里:
+
+![Graph of task creation and execution][14]
+
+这显示了任务的创建和执行时间。Task-1 是 `main()` 协程,创建了其他任务。Task-2、Task-3、Task-4 执行 `io_task` 和 `sleep` 然后等待唤醒。如图所示,因为是单线程程序,所以任务之间没有重叠,VizTracer 这样可视化是为了让它更容易理解。
+
+为了让它更有趣,可以在任务中添加一个 `time.sleep` 的调用来阻止异步循环:
+
+```
+async def io_task():
+ time.sleep(0.01)
+ await asyncio.sleep(0.01)
+```
+
+![time.sleep call][15]
+
+程序耗时更长(40ms),任务填补了异步调度器中的空白。
+
+这个功能对于诊断异步程序的行为和性能问题非常有帮助。
+
+### 看看 VizTracer 发生了什么?
+
+通过 VizTracer,你可以在时间轴上查看程序的进展情况,而不是从复杂的日志中想象。这有助于你更好地理解你的并发程序。
+
+VizTracer 是开源的,在 Apache 2.0 许可证下发布,支持所有常见的操作系统(Linux、macOS 和 Windows)。你可以在 [VizTracer 的 GitHub 仓库][16]中了解更多关于它的功能和访问它的源代码。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/python-viztracer
+
+作者:[Tian Gao][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gaogaotiantian
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/colorful_sound_wave.png?itok=jlUJG0bM (Colorful sound wave graph)
+[2]: https://readthedocs.org/projects/viztracer/
+[3]: https://opensource.com/sites/default/files/uploads/viztracer_singlethreadtask.png (Running code in a single thread)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://opensource.com/sites/default/files/uploads/viztracer_callstackreport.png (call-stack report)
+[6]: https://opensource.com/sites/default/files/uploads/viztracer_multithread.png (Multi-thread program)
+[7]: https://opensource.com/sites/default/files/uploads/viztracer_concurrency.png (Concurrency of multiple threads)
+[8]: https://opensource.com/sites/default/files/uploads/viztracer_multithreadrun.png (Running with extra argument)
+[9]: https://opensource.com/sites/default/files/uploads/viztracer_comparewithmultiprocess.png (Multi-process version)
+[10]: https://opensource.com/sites/default/files/uploads/io-bound_singlethread.png (I/O-bound single-thread, single-task program)
+[11]: https://opensource.com/sites/default/files/uploads/io-bound_multithread.png (I/O-bound multi-thread program)
+[12]: https://opensource.com/sites/default/files/uploads/viztracer_asyncio.png (VizTracer with asyncio)
+[13]: https://opensource.com/sites/default/files/uploads/log_async.png (Using --log_async to separate tasks)
+[14]: https://opensource.com/sites/default/files/uploads/taskcreation.png (Graph of task creation and execution)
+[15]: https://opensource.com/sites/default/files/uploads/time.sleep_call.png (time.sleep call)
+[16]: https://github.com/gaogaotiantian/viztracer
diff --git a/published/202103/20210315 6 things to know about using WebAssembly on Firefox.md b/published/202103/20210315 6 things to know about using WebAssembly on Firefox.md
new file mode 100644
index 0000000000..86b133d783
--- /dev/null
+++ b/published/202103/20210315 6 things to know about using WebAssembly on Firefox.md
@@ -0,0 +1,94 @@
+[#]: subject: (6 things to know about using WebAssembly on Firefox)
+[#]: via: (https://opensource.com/article/21/3/webassembly-firefox)
+[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13230-1.html)
+
+在 Firefox 上使用 WebAssembly 要了解的 6 件事
+======
+
+> 了解在 Firefox 上运行 WebAssembly 的机会和局限性。
+
+
+
+WebAssembly 是一种可移植的执行格式,由于它能够以近乎原生的速度在浏览器中执行应用而引起了人们的极大兴趣。WebAssembly 本质上有一些特殊的属性和局限性。但是,通过将其与其他技术结合,将出现全新的可能性,尤其是与浏览器中的游戏有关的可能性。
+
+本文介绍了在 Firefox 上运行 WebAssembly 的概念、可能性和局限性。
+
+### 沙盒
+
+WebAssembly 有 [严格的安全策略][2]。 WebAssembly 中的程序或功能单元称为*模块*。每个模块实例都运行在自己的隔离内存空间中。因此,即使同一个网页加载了多个模块,它们也无法访问另一个模块的虚拟地址空间。设计上,WebAssembly 还考虑了内存安全性和控制流完整性,这使得(几乎)确定性的执行成为可能。
+
+### Web API
+
+通过 JavaScript [Web API][3] 可以访问多种输入和输出设备。根据这个 [提案][4],将来可以不用绕道到 JavaScript 来访问 Web API。C++ 程序员可以在 [Emscripten.org][5] 上找到有关访问 Web API 的信息。Rust 程序员可以使用 [rustwasm.github.io][7] 中写的 [wasm-bindgen][6] 库。
+
+### 文件输入/输出
+
+因为 WebAssembly 是在沙盒环境中执行的,所以当它在浏览器中执行时,它无法访问主机的文件系统。但是,Emscripten 提供了虚拟文件系统形式的解决方案。
+
+Emscripten 使在编译时将文件预加载到内存文件系统成为可能。然后可以像在普通文件系统上一样从 WebAssembly 应用中读取这些文件。这个 [教程][8] 提供了更多信息。
+
+### 持久化数据
+
+如果你需要在客户端存储持久化数据,那么必须通过 JavaScript Web API 来完成。请参考 Mozilla 开发者网络(MDN)关于 [浏览器存储限制和过期标准][9] 的文档,了解不同方法的详细信息。
+
+### 内存管理
+
+WebAssembly 模块作为 [堆栈机][10] 在线性内存上运行。这意味着堆内存分配等概念是没有的。然而,如果你在 C++ 中使用 `new` 或者在 Rust 中使用 `Box::new`,你会期望它会进行堆内存分配。将堆内存分配请求转换成 WebAssembly 的方式在很大程度上依赖于工具链。你可以在 Frank Rehberger 关于 [WebAssembly 和动态内存][11] 的文章中找到关于不同工具链如何处理堆内存分配的详细分析。
+
+### 游戏!
+
+与 [WebGL][12] 结合使用时,WebAssembly 的执行速度很高,因此可以在浏览器中运行原生游戏。大型专有游戏引擎 [Unity][13] 和[虚幻 4][14] 展示了 WebGL 可以实现的功能。也有使用 WebAssembly 和 WebGL 接口的开源游戏引擎。这里有些例子:
+
+ * 自 2011 年 11 月起,[id Tech 4][15] 引擎(更常称之为 Doom 3 引擎)可在 [GitHub][16] 上以 GPL 许可的形式获得。此外,还有一个 [Doom 3 的 WebAssembly 移植版][17]。
+ * Urho3D 引擎提供了一些 [令人印象深刻的例子][18],它们可以在浏览器中运行。
+ * 如果你喜欢复古游戏,可以试试这个 [Game Boy 模拟器][19]。
+ * [Godot 引擎也能生成 WebAssembly][20]。我找不到演示,但 [Godot 编辑器][21] 已经被移植到 WebAssembly 上。
+
+### 有关 WebAssembly 的更多信息
+
+WebAssembly 是一项很有前途的技术,我相信我们将来会越来越多地看到它。除了在浏览器中执行之外,WebAssembly 还可以用作可移植的执行格式。[Wasmer][22] 容器主机使你可以在各种平台上执行 WebAssembly 代码。
+
+如果你需要更多的演示、示例和教程,请看一下这个 [WebAssembly 主题集合][23]。Mozilla 的 [游戏和示例合集][24] 并非全是 WebAssembly,但仍然值得一看。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/webassembly-firefox
+
+作者:[Stephan Avenwedde][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/hansic99
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-concentration-focus-windows-office.png?itok=-8E2ihcF (Woman using laptop concentrating)
+[2]: https://webassembly.org/docs/security/
+[3]: https://developer.mozilla.org/en-US/docs/Web/API
+[4]: https://github.com/WebAssembly/gc/blob/master/README.md
+[5]: https://emscripten.org/docs/porting/connecting_cpp_and_javascript/Interacting-with-code.html
+[6]: https://github.com/rustwasm/wasm-bindgen
+[7]: https://rustwasm.github.io/wasm-bindgen/
+[8]: https://emscripten.org/docs/api_reference/Filesystem-API.html
+[9]: https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API/Browser_storage_limits_and_eviction_criteria
+[10]: https://en.wikipedia.org/wiki/Stack_machine
+[11]: https://frehberg.wordpress.com/webassembly-and-dynamic-memory/
+[12]: https://en.wikipedia.org/wiki/WebGL
+[13]: https://beta.unity3d.com/jonas/AngryBots/
+[14]: https://www.youtube.com/watch?v=TwuIRcpeUWE
+[15]: https://en.wikipedia.org/wiki/Id_Tech_4
+[16]: https://github.com/id-Software/DOOM-3
+[17]: https://wasm.continuation-labs.com/d3demo/
+[18]: https://urho3d.github.io/samples/
+[19]: https://vaporboy.net/
+[20]: https://docs.godotengine.org/en/stable/development/compiling/compiling_for_web.html
+[21]: https://godotengine.org/editor/latest/godot.tools.html
+[22]: https://github.com/wasmerio/wasmer
+[23]: https://github.com/mbasso/awesome-wasm
+[24]: https://developer.mozilla.org/en-US/docs/Games/Examples
diff --git a/published/202103/20210315 Learn how file input and output works in C.md b/published/202103/20210315 Learn how file input and output works in C.md
new file mode 100644
index 0000000000..39915a214f
--- /dev/null
+++ b/published/202103/20210315 Learn how file input and output works in C.md
@@ -0,0 +1,274 @@
+[#]: subject: (Learn how file input and output works in C)
+[#]: via: (https://opensource.com/article/21/3/file-io-c)
+[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
+[#]: collector: (lujun9972)
+[#]: translator: (wyxplus)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13252-1.html)
+
+学习如何用 C 语言来进行文件输入输出操作
+======
+
+> 理解 I/O 有助于提升你的效率。
+
+
+
+如果你打算学习 C 语言的输入、输出,可以从 `stdio.h` 包含文件开始。正如你从其名字中猜到的,该文件定义了所有的标准(“std”)的输入和输出(“io”)函数。
+
+大多数人学习的第一个 `stdio.h` 的函数是打印格式化输出的 `printf` 函数。或者是用来打印一个字符串的 `puts` 函数。这些函数非常有用,可以将信息打印给用户,但是如果你想做更多的事情,则需要了解其他函数。
+
+你可以通过编写一个常见 Linux 命令的副本来了解其中一些功能和方法。`cp` 命令主要用于复制文件。如果你查看 `cp` 的帮助手册,可以看到 `cp` 命令支持非常多的参数和选项。但最简单的功能,就是复制文件:
+
+```
+cp infile outfile
+```
+
+你只需使用一些读写文件的基本函数,就可以用 C 语言来自己实现 `cp` 命令。
+
+### 一次读写一个字符
+
+你可以使用 `fgetc` 和 `fputc` 函数轻松地进行输入输出。这些函数一次只读写一个字符。该用法被定义在 `stdio.h`,并且这也很浅显易懂:`fgetc` 是从文件中读取一个字符,`fputc` 是将一个字符保存到文件中。
+
+```
+int fgetc(FILE *stream);
+int fputc(int c, FILE *stream);
+```
+
+编写 `cp` 命令需要访问文件。在 C 语言中,你使用 `fopen` 函数打开一个文件,该函数需要两个参数:文件名和打开文件的模式。模式通常是从文件读取(`r`)或向文件写入(`w`)。打开文件的方式也有其他选项,但是对于本教程而言,仅关注于读写操作。
+
+因此,将一个文件复制到另一个文件就变成了打开源文件和目标文件,接着,不断从第一个文件读取字符,然后将该字符写入第二个文件。`fgetc` 函数返回从输入文件中读取的单个字符,或者当文件完成后返回文件结束标记(`EOF`)。一旦读取到 `EOF`,你就完成了复制操作,就可以关闭两个文件。该代码如下所示:
+
+```
+ do {
+ ch = fgetc(infile);
+ if (ch != EOF) {
+ fputc(ch, outfile);
+ }
+ } while (ch != EOF);
+```
+
+你可以使用此循环编写自己的 `cp` 程序,以使用 `fgetc` 和 `fputc` 函数一次读写一个字符。`cp.c` 源代码如下所示:
+
+```
+#include
+
+int
+main(int argc, char **argv)
+{
+ FILE *infile;
+ FILE *outfile;
+ int ch;
+
+ /* parse the command line */
+
+ /* usage: cp infile outfile */
+
+ if (argc != 3) {
+ fprintf(stderr, "Incorrect usage\n");
+ fprintf(stderr, "Usage: cp infile outfile\n");
+ return 1;
+ }
+
+ /* open the input file */
+
+ infile = fopen(argv[1], "r");
+ if (infile == NULL) {
+ fprintf(stderr, "Cannot open file for reading: %s\n", argv[1]);
+ return 2;
+ }
+
+ /* open the output file */
+
+ outfile = fopen(argv[2], "w");
+ if (outfile == NULL) {
+ fprintf(stderr, "Cannot open file for writing: %s\n", argv[2]);
+ fclose(infile);
+ return 3;
+ }
+
+ /* copy one file to the other */
+
+ /* use fgetc and fputc */
+
+ do {
+ ch = fgetc(infile);
+ if (ch != EOF) {
+ fputc(ch, outfile);
+ }
+ } while (ch != EOF);
+
+ /* done */
+
+ fclose(infile);
+ fclose(outfile);
+
+ return 0;
+}
+```
+
+你可以使用 `gcc` 来将 `cp.c` 文件编译成一个可执行文件:
+
+```
+$ gcc -Wall -o cp cp.c
+```
+
+`-o cp` 选项告诉编译器将编译后的程序保存到 `cp` 文件中。`-Wall` 选项告诉编译器提示所有可能的警告,如果你没有看到任何警告,则表示一切正常。
+
+### 读写数据块
+
+通过每次读写一个字符来实现自己的 `cp` 命令可以完成这项工作,但这并不是很快。在复制“日常”文件(例如文档和文本文件)时,你可能不会注意到,但是在复制大型文件或通过网络复制文件时,你才会注意到差异。每次处理一个字符需要大量的开销。
+
+实现此 `cp` 命令的一种更好的方法是,读取一块的输入数据到内存中(称为缓存),然后将该数据集合写入到第二个文件。这样做的速度要快得多,因为程序可以一次读取更多的数据,这就就减少了从文件中“读取”的次数。
+
+你可以使用 `fread` 函数将文件读入一个变量中。这个函数有几个参数:将数据读入的数组或内存缓冲区的指针(`ptr`),要读取的最小对象的大小(`size`),要读取对象的个数(`nmemb`),以及要读取的文件(`stream`):
+
+```
+size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
+```
+
+不同的选项为更高级的文件输入和输出(例如,读取和写入具有特定数据结构的文件)提供了很大的灵活性。但是,在从一个文件读取数据并将数据写入另一个文件的简单情况下,可以使用一个由字符数组组成的缓冲区。
+
+你可以使用 `fwrite` 函数将缓冲区中的数据写入到另一个文件。这使用了与 `fread` 函数有相似的一组选项:要从中读取数据的数组或内存缓冲区的指针,要读取的最小对象的大小,要读取对象的个数以及要写入的文件。
+
+```
+size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
+```
+
+如果程序将文件读入缓冲区,然后将该缓冲区写入另一个文件,则数组(`ptr`)可以是固定大小的数组。例如,你可以使用长度为 200 个字符的字符数组作为缓冲区。
+
+在该假设下,你需要更改 `cp` 程序中的循环,以将数据从文件读取到缓冲区中,然后将该缓冲区写入另一个文件中:
+
+```
+ while (!feof(infile)) {
+ buffer_length = fread(buffer, sizeof(char), 200, infile);
+ fwrite(buffer, sizeof(char), buffer_length, outfile);
+ }
+```
+
+这是更新后的 `cp` 程序的完整源代码,该程序现在使用缓冲区读取和写入数据:
+
+```
+#include
+
+int
+main(int argc, char **argv)
+{
+ FILE *infile;
+ FILE *outfile;
+ char buffer[200];
+ size_t buffer_length;
+
+ /* parse the command line */
+
+ /* usage: cp infile outfile */
+
+ if (argc != 3) {
+ fprintf(stderr, "Incorrect usage\n");
+ fprintf(stderr, "Usage: cp infile outfile\n");
+ return 1;
+ }
+
+ /* open the input file */
+
+ infile = fopen(argv[1], "r");
+ if (infile == NULL) {
+ fprintf(stderr, "Cannot open file for reading: %s\n", argv[1]);
+ return 2;
+ }
+
+ /* open the output file */
+
+ outfile = fopen(argv[2], "w");
+ if (outfile == NULL) {
+ fprintf(stderr, "Cannot open file for writing: %s\n", argv[2]);
+ fclose(infile);
+ return 3;
+ }
+
+ /* copy one file to the other */
+
+ /* use fread and fwrite */
+
+ while (!feof(infile)) {
+ buffer_length = fread(buffer, sizeof(char), 200, infile);
+ fwrite(buffer, sizeof(char), buffer_length, outfile);
+ }
+
+ /* done */
+
+ fclose(infile);
+ fclose(outfile);
+
+ return 0;
+}
+```
+
+由于你想将此程序与其他程序进行比较,因此请将此源代码另存为 `cp2.c`。你可以使用 `gcc` 编译程序:
+
+```
+$ gcc -Wall -o cp2 cp2.c
+```
+
+和之前一样,`-o cp2` 选项告诉编译器将编译后的程序保存到 `cp2` 程序文件中。`-Wall` 选项告诉编译器打开所有警告。如果你没有看到任何警告,则表示一切正常。
+
+### 是的,这真的更快了
+
+使用缓冲区读取和写入数据是实现此版本 `cp` 程序更好的方法。由于它可以一次将文件的多个数据读取到内存中,因此该程序不需要频繁读取数据。在小文件中,你可能没有注意到使用这两种方案的区别,但是如果你需要复制大文件,或者在较慢的介质(例如通过网络连接)上复制数据时,会发现明显的差距。
+
+我使用 Linux `time` 命令进行了比较。此命令可以运行另一个程序,然后告诉你该程序花费了多长时间。对于我的测试,我希望了解所花费时间的差距,因此我复制了系统上的 628 MB CD-ROM 镜像文件。
+
+我首先使用标准的 Linux 的 `cp` 命令复制了映像文件,以查看所需多长时间。一开始通过运行 Linux 的 `cp` 命令,同时我还避免使用 Linux 内置的文件缓存系统,使其不会给程序带来误导性能提升的可能性。使用 Linux `cp` 进行的测试,总计花费不到一秒钟的时间:
+
+```
+$ time cp FD13LIVE.iso tmpfile
+
+real 0m0.040s
+user 0m0.001s
+sys 0m0.003s
+```
+
+运行我自己实现的 `cp` 命令版本,复制同一文件要花费更长的时间。每次读写一个字符则花了将近五秒钟来复制文件:
+
+```
+$ time ./cp FD13LIVE.iso tmpfile
+
+real 0m4.823s
+user 0m4.100s
+sys 0m0.571s
+```
+
+从输入读取数据到缓冲区,然后将该缓冲区写入输出文件则要快得多。使用此方法复制文件花不到一秒钟:
+
+```
+$ time ./cp2 FD13LIVE.iso tmpfile
+
+real 0m0.944s
+user 0m0.224s
+sys 0m0.608s
+```
+
+我演示的 `cp` 程序使用了 200 个字符大小的缓冲区。我确信如果一次将更多文件数据读入内存,该程序将运行得更快。但是,通过这种比较,即使只有 200 个字符的缓冲区,你也已经看到了性能上的巨大差异。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/file-io-c
+
+作者:[Jim Hall][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jim-hall
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/file_system.jpg?itok=pzCrX1Kc "4 manilla folders, yellow, green, purple, blue"
+[2]: http://www.opengroup.org/onlinepubs/009695399/functions/fgetc.html
+[3]: http://www.opengroup.org/onlinepubs/009695399/functions/fputc.html
+[4]: http://www.opengroup.org/onlinepubs/009695399/functions/fprintf.html
+[5]: http://www.opengroup.org/onlinepubs/009695399/functions/fopen.html
+[6]: http://www.opengroup.org/onlinepubs/009695399/functions/fclose.html
+[7]: http://www.opengroup.org/onlinepubs/009695399/functions/feof.html
+[8]: http://www.opengroup.org/onlinepubs/009695399/functions/fread.html
+[9]: http://www.opengroup.org/onlinepubs/009695399/functions/fwrite.html
diff --git a/published/202103/20210316 How to write -Hello World- in WebAssembly.md b/published/202103/20210316 How to write -Hello World- in WebAssembly.md
new file mode 100644
index 0000000000..b2e423aeb9
--- /dev/null
+++ b/published/202103/20210316 How to write -Hello World- in WebAssembly.md
@@ -0,0 +1,155 @@
+[#]: subject: (How to write 'Hello World' in WebAssembly)
+[#]: via: (https://opensource.com/article/21/3/hello-world-webassembly)
+[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13250-1.html)
+
+如何在 WebAssembly 中写 “Hello World”?
+======
+> 通过这个分步教程,开始用人类可读的文本编写 WebAssembly。
+
+
+
+WebAssembly 是一种字节码格式,[几乎所有的浏览器][2] 都可以将它编译成其宿主操作系统的机器代码。除了 JavaScript 和 WebGL 之外,WebAssembly 还满足了将应用移植到浏览器中以实现平台独立的需求。作为 C++ 和 Rust 的编译目标,WebAssembly 使 Web 浏览器能够以接近原生的速度执行代码。
+
+当谈论 WebAssembly 应用时,你必须区分三种状态:
+
+ 1. **源码(如 C++ 或 Rust):** 你有一个用兼容语言编写的应用,你想把它在浏览器中执行。
+ 2. **WebAssembly 字节码:** 你选择 WebAssembly 字节码作为编译目标。最后,你得到一个 `.wasm` 文件。
+ 3. **机器码(opcode):** 浏览器加载 `.wasm` 文件,并将其编译成主机系统的相应机器码。
+
+WebAssembly 还有一种文本格式,用人类可读的文本表示二进制格式。为了简单起见,我将其称为 **WASM-text**。WASM-text 可以比作高级汇编语言。当然,你不会基于 WASM-text 来编写一个完整的应用,但了解它的底层工作原理是很好的(特别是对于调试和性能优化)。
+
+本文将指导你在 WASM-text 中创建经典的 “Hello World” 程序。
+
+### 创建 .wat 文件
+
+WASM-text 文件通常以 `.wat` 结尾。第一步创建一个名为 `helloworld.wat` 的空文本文件,用你最喜欢的文本编辑器打开它,然后粘贴进去:
+
+```
+(module
+ ;; 从 JavaScript 命名空间导入
+ (import "console" "log" (func $log (param i32 i32))) ;; 导入 log 函数
+ (import "js" "mem" (memory 1)) ;; 导入 1 页 内存(64kb)
+
+ ;; 我们的模块的数据段
+ (data (i32.const 0) "Hello World from WebAssembly!")
+
+ ;; 函数声明:导出 helloWorld(),无参数
+ (func (export "helloWorld")
+ i32.const 0 ;; 传递偏移 0 到 log
+ i32.const 29 ;; 传递长度 29 到 log(示例文本的字符串长度)
+ call $log
+ )
+)
+```
+
+WASM-text 格式是基于 S 表达式的。为了实现交互,JavaScript 函数用 `import` 语句导入,WebAssembly 函数用 `export` 语句导出。在这个例子中,从 `console` 模块中导入 `log` 函数,它需要两个类型为 `i32` 的参数作为输入,以及一页内存(64KB)来存储字符串。
+
+字符串将被写入偏移量 为 `0` 的数据段。数据段是你的内存的叠加投影,内存是在 JavaScript 部分分配的。
+
+函数用关键字 `func` 标记。当进入函数时,栈是空的。在调用另一个函数之前,函数参数会被压入栈中(这里是偏移量和长度)(见 `call $log`)。当一个函数返回一个 `f32` 类型时(例如),当离开函数时,一个 `f32` 变量必须保留在栈中(但在本例中不是这样)。
+
+### 创建 .wasm 文件
+
+WASM-text 和 WebAssembly 字节码是 1:1 对应的,这意味着你可以将 WASM-text 转换成字节码(反之亦然)。你已经有了 WASM-text,现在将创建字节码。
+
+转换可以通过 [WebAssembly Binary Toolkit][3](WABT)来完成。从该链接克隆仓库,并按照安装说明进行安装。
+
+建立工具链后,打开控制台并输入以下内容,将 WASM-text 转换为字节码:
+
+```
+wat2wasm helloworld.wat -o helloworld.wasm
+```
+
+你也可以用以下方法将字节码转换为 WASM-text:
+
+```
+wasm2wat helloworld.wasm -o helloworld_reverse.wat
+```
+
+一个从 `.wasm` 文件创建的 `.wat` 文件不包括任何函数或参数名称。默认情况下,WebAssembly 用它们的索引来识别函数和参数。
+
+### 编译 .wasm 文件
+
+目前,WebAssembly 只与 JavaScript 共存,所以你必须编写一个简短的脚本来加载和编译 `.wasm` 文件并进行函数调用。你还需要在 WebAssembly 模块中定义你要导入的函数。
+
+创建一个空的文本文件,并将其命名为 `helloworld.html`,然后打开你喜欢的文本编辑器并粘贴进去:
+
+```
+
+
+
+
+ Simple template
+
+
+
+
+
+```
+
+`WebAssembly.Memory(...)` 方法返回一个大小为 64KB 的内存页。函数 `consoleLogString` 根据长度和偏移量从该内存页读取一个字符串。这两个对象作为 `importObject` 的一部分传递给你的 WebAssembly 模块。
+
+在你运行这个例子之前,你可能必须允许 Firefox 从这个目录中访问文件,在地址栏输入 `about:config`,并将 `privacy.file_unique_origin` 设置为 `true`:
+
+![Firefox setting][4]
+
+> **注意:** 这样做会使你容易受到 [CVE-2019-11730][6] 安全问题的影响。
+
+现在,在 Firefox 中打开 `helloworld.html`,按下 `Ctrl+K` 打开开发者控制台。
+
+![Debugger output][7]
+
+### 了解更多
+
+这个 Hello World 的例子只是 MDN 的 [了解 WebAssembly 文本格式][8] 文档中的教程之一。如果你想了解更多关于 WebAssembly 的知识以及它的工作原理,可以看看这些文档。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/hello-world-webassembly
+
+作者:[Stephan Avenwedde][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/hansic99
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/helloworld_bread_lead.jpeg?itok=1r8Uu7gk (Hello World inked on bread)
+[2]: https://developer.mozilla.org/en-US/docs/WebAssembly#browser_compatibility
+[3]: https://github.com/webassembly/wabt
+[4]: https://opensource.com/sites/default/files/uploads/firefox_setting.png (Firefox setting)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://www.mozilla.org/en-US/security/advisories/mfsa2019-21/#CVE-2019-11730
+[7]: https://opensource.com/sites/default/files/uploads/debugger_output.png (Debugger output)
+[8]: https://developer.mozilla.org/en-US/docs/WebAssembly/Understanding_the_text_format
diff --git a/published/202103/20210316 Kooha is a Nascent Screen Recorder for GNOME With Wayland Support.md b/published/202103/20210316 Kooha is a Nascent Screen Recorder for GNOME With Wayland Support.md
new file mode 100644
index 0000000000..20cd761dd8
--- /dev/null
+++ b/published/202103/20210316 Kooha is a Nascent Screen Recorder for GNOME With Wayland Support.md
@@ -0,0 +1,106 @@
+[#]: subject: (Kooha is a Nascent Screen Recorder for GNOME With Wayland Support)
+[#]: via: (https://itsfoss.com/kooha-screen-recorder/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13227-1.html)
+
+Kooha:一款支持 Wayland 的新生 GNOME 屏幕录像机
+======
+
+Linux 中没有一个 [像样的支持 Wayland 显示服务器的屏幕录制软件][1]。
+
+如果你使用 Wayland 的话,[GNOME 内置的屏幕录像机][1] 可能是少有的(也是唯一的)支持的软件。但是那个屏幕录像机没有可视界面和你所期望的标准屏幕录像软件的功能。
+
+值得庆幸的是,有一个新的应用正在开发中,它提供了比 GNOME 屏幕录像机更多一点的功能,并且在 Wayland 上也能正常工作。
+
+### 遇见 Kooha:一个新的 GNOME 桌面屏幕录像机
+
+![][2]
+
+[Kooha][3] 是一个处于开发初期阶段的应用,它可以在 GNOME 中使用,是用 GTK 和 PyGObject 构建的。事实上,它利用了与 GNOME 内置屏幕录像机相同的后端。
+
+以下是 Kooha 的功能:
+
+ * 录制整个屏幕或选定区域
+ * 在 Wayland 和 Xorg 显示服务器上均可使用
+ * 在视频里用麦克风记录音频
+ * 包含或忽略鼠标指针的选项
+ * 可以在开始录制前增加 5 秒或 10 秒的延迟
+ * 支持 WebM 和 MKV 格式的录制
+ * 允许更改默认保存位置
+ * 支持一些键盘快捷键
+
+### 我的 Kooha 体验
+
+![][4]
+
+它的开发者 Dave Patrick 联系了我,由于我急需一款好用的屏幕录像机,所以我马上就去试用了。
+
+目前,[Kooha 只能通过 Flatpak 安装][5]。我安装了 Flatpak,当我试着使用时,它什么都没有记录。我和 Dave 进行了快速的邮件讨论,他告诉我这是由于 [Ubuntu 20.10 中 GNOME 屏幕录像机的 bug][6]。
+
+你可以想象我对支持 Wayland 的屏幕录像机的绝望,我 [将我的 Ubuntu 升级到 21.04 测试版][7]。
+
+在 21.04 中,可以屏幕录像,但仍然无法录制麦克风的音频。
+
+我注意到了另外几件无法按照我的喜好顺利进行的事情。
+
+例如,在录制时,计时器在屏幕上仍然可见,并且包含在录像中。我不会希望在视频教程中出现这种情况。我想你也不会喜欢看到这些吧。
+
+![][8]
+
+另外就是关于多显示器的支持。没有专门选择某一个屏幕的选项。我连接了两个外部显示器,默认情况下,它录制所有三个显示器。可以使用设置捕捉区域,但精确拖动屏幕区域是一项耗时的任务。
+
+它也没有 [Kazam][9] 或其他传统屏幕录像机中有的设置帧率或者编码的选项。
+
+### 在 Linux 上安装 Kooha(如果你使用 GNOME)
+
+请确保在你的 Linux 发行版上启用 Flatpak 支持。目前它只适用于 GNOME,所以请检查你使用的桌面环境。
+
+使用此命令将 Flathub 添加到你的 Flatpak 仓库列表中:
+
+```
+flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
+```
+
+然后用这个命令来安装:
+
+```
+flatpak install flathub io.github.seadve.Kooha
+```
+
+你可以通过菜单或使用这个命令来运行它:
+
+```
+flatpak run io.github.seadve.Kooha
+```
+
+### 总结
+
+Kooha 并不完美,但考虑到 Wayland 领域的巨大空白,我希望开发者努力修复这些问题并增加更多的功能。考虑到 [Ubuntu 21.04 将默认切换到 Wayland][10],以及其他一些流行的发行版如 Fedora 和 openSUSE 已经默认使用 Wayland,这一点很重要。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/kooha-screen-recorder/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/gnome-screen-recorder/
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/kooha-screen-recorder.png?resize=800%2C450&ssl=1
+[3]: https://github.com/SeaDve/Kooha
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/kooha.png?resize=797%2C364&ssl=1
+[5]: https://flathub.org/apps/details/io.github.seadve.Kooha
+[6]: https://bugs.launchpad.net/ubuntu/+source/gnome-shell/+bug/1901391
+[7]: https://itsfoss.com/upgrade-ubuntu-beta/
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/kooha-recording.jpg?resize=800%2C636&ssl=1
+[9]: https://itsfoss.com/kazam-screen-recorder/
+[10]: https://news.itsfoss.com/ubuntu-21-04-wayland/
diff --git a/published/202103/20210317 Use gdu for a Faster Disk Usage Checking in Linux Terminal.md b/published/202103/20210317 Use gdu for a Faster Disk Usage Checking in Linux Terminal.md
new file mode 100644
index 0000000000..81b216a7ab
--- /dev/null
+++ b/published/202103/20210317 Use gdu for a Faster Disk Usage Checking in Linux Terminal.md
@@ -0,0 +1,105 @@
+[#]: subject: (Use gdu for a Faster Disk Usage Checking in Linux Terminal)
+[#]: via: (https://itsfoss.com/gdu/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13234-1.html)
+
+使用 gdu 进行更快的磁盘使用情况检查
+======
+
+
+
+在 Linux 终端中有两种常用的 [检查磁盘使用情况的方法][1]:`du` 命令和 `df` 命令。[du 命令更多的是用来检查目录的使用空间][2],`df` 命令则是提供文件系统级别的磁盘使用情况。
+
+还有更友好的 [用 GNOME “磁盘” 等图形工具在 Linux 中查看磁盘使用情况的方法][3]。如果局限于终端,你可以使用像 [ncdu][5] 这样的 [TUI][4] 工具,以一种图形化的方式获取磁盘使用信息。
+
+### gdu: 在 Linux 终端中检查磁盘使用情况
+
+[gdu][6] 就是这样一个用 Go 编写的工具(因此是 gdu 中的 “g”)。gdu 开发者的 [基准测试][7] 表明,它的磁盘使用情况检查速度相当快,特别是在 SSD 上。事实上,gdu 主要是针对 SSD 的,尽管它也可以在 HDD 上工作。
+
+如果你在使用 `gdu` 命令时没有使用任何选项,它就会显示你当前所在目录的磁盘使用情况。
+
+![][8]
+
+由于它具有文本用户界面(TUI),你可以使用箭头浏览目录和磁盘。你也可以按文件名或大小对结果进行排序。
+
+你可以用它做到:
+
+ * 向上箭头或 `k` 键将光标向上移动
+ * 向下箭头或 `j` 键将光标向下移动
+ * 回车选择目录/设备
+ * 左箭头或 `h` 键转到上级目录
+ * 使用 `d` 键删除所选文件或目录
+ * 使用 `n` 键按名称排序
+ * 使用 `s` 键按大小排序
+ * 使用 `c` 键按项目排序
+
+你会注意到一些条目前的一些符号。这些符号有特定的意义。
+
+![][9]
+
+ * `!` 表示读取目录时发生错误。
+ * `.` 表示在读取子目录时发生错误,大小可能不正确。
+ * `@` 表示文件是一个符号链接或套接字。
+ * `H` 表示文件已经被计数(硬链接)。
+ * `e` 表示目录为空。
+
+要查看所有挂载磁盘的磁盘利用率和可用空间,使用选项 `d`:
+
+```
+gdu -d
+```
+
+它在一屏中显示所有的细节:
+
+![][10]
+
+看起来是个方便的工具,对吧?让我们看看如何在你的 Linux 系统上安装它。
+
+### 在 Linux 上安装 gdu
+
+gdu 是通过 [AUR][11] 提供给 Arch 和 Manjaro 用户的。我想,作为一个 Arch 用户,你应该知道如何使用 AUR。
+
+它包含在即将到来的 Ubuntu 21.04 的 universe 仓库中,但有可能你现在还没有使用它。这种情况下,你可以使用 Snap 安装它,这可能看起来有很多条 `snap` 命令:
+
+```
+snap install gdu-disk-usage-analyzer
+snap connect gdu-disk-usage-analyzer:mount-observe :mount-observe
+snap connect gdu-disk-usage-analyzer:system-backup :system-backup
+snap alias gdu-disk-usage-analyzer.gdu gdu
+```
+
+你也可以在其发布页面找到源代码:
+
+- [下载 gdu 的源代码][12]
+
+我更习惯于使用 `du` 和 `df` 命令,但我觉得一些 Linux 用户可能会喜欢 gdu。你是其中之一吗?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/gdu/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://linuxhandbook.com/df-command/
+[2]: https://linuxhandbook.com/find-directory-size-du-command/
+[3]: https://itsfoss.com/check-free-disk-space-linux/
+[4]: https://itsfoss.com/gui-cli-tui/
+[5]: https://dev.yorhel.nl/ncdu
+[6]: https://github.com/dundee/gdu
+[7]: https://github.com/dundee/gdu#benchmarks
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/gdu-disk-utilization.png?resize=800%2C471&ssl=1
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/gdu-entry-symbols.png?resize=800%2C302&ssl=1
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/gdu-disk-utilization-for-all-drives.png?resize=800%2C471&ssl=1
+[11]: https://itsfoss.com/aur-arch-linux/
+[12]: https://github.com/dundee/gdu/releases
diff --git a/published/202103/20210318 Practice using the Linux grep command.md b/published/202103/20210318 Practice using the Linux grep command.md
new file mode 100644
index 0000000000..5fc2936d2e
--- /dev/null
+++ b/published/202103/20210318 Practice using the Linux grep command.md
@@ -0,0 +1,193 @@
+[#]: subject: "Practice using the Linux grep command"
+[#]: via: "https://opensource.com/article/21/3/grep-cheat-sheet"
+[#]: author: "Seth Kenlon https://opensource.com/users/seth"
+[#]: collector: "lujun9972"
+[#]: translator: "lxbwolf"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13247-1.html"
+
+练习使用 Linux 的 grep 命令
+======
+
+> 来学习下搜索文件中内容的基本操作,然后下载我们的备忘录作为 grep 和正则表达式的快速参考指南。
+
+
+
+`grep`(全局正则表达式打印)是由 Ken Thompson 早在 1974 年开发的基本 Unix 命令之一。在计算领域,它无处不在,通常被用作为动词(“搜索一个文件中的内容”)。如果你的谈话对象有极客精神,那么它也能在真实生活场景中使用。(例如,“我会 `grep` 我的内存条来回想起那些信息。”)简而言之,`grep` 是一种用特定的字符模式来搜索文件中内容的方式。如果你感觉这听起来像是文字处理器或文本编辑器的现代 Find 功能,那么你就已经在计算行业感受到了 `grep` 的影响。
+
+`grep` 绝不是被现代技术抛弃的远古命令,它的强大体现在两个方面:
+
+ * `grep` 可以在终端操作数据流,因此你可以把它嵌入到复杂的处理中。你不仅可以在一个文本文件中*查找*文字,还可以提取文字后把它发给另一个命令。
+ * `grep` 使用正则表达式来提供灵活的搜索能力。
+
+虽然需要一些练习,但学习 `grep` 命令还是很容易的。本文会介绍一些我认为 `grep` 最有用的功能。
+
+- 下载我们免费的 [grep 备忘录][2]
+
+### 安装 grep
+
+Linux 默认安装了 `grep`。
+
+MacOS 默认安装了 BSD 版的 `grep`。BSD 版的 `grep` 跟 GNU 版有一点不一样,因此如果你想完全参照本文,那么请使用 [Homebrew][3] 或 [MacPorts][4] 安装 GNU 版的 `grep`。
+
+### 基础的 grep
+
+所有版本的 `grep` 基础语法都一样。入参是匹配模式和你需要搜索的文件。它会把匹配到的每一行输出到你的终端。
+
+```
+$ grep gnu gpl-3.0.txt
+ along with this program. If not, see .
+.
+.
+```
+
+`grep` 命令默认大小写敏感,因此 “gnu”、“GNU”、“Gnu” 是三个不同的值。你可以使用 `--ignore-case` 选项来忽略大小写。
+
+```
+$ grep --ignore-case gnu gpl-3.0.txt
+ GNU GENERAL PUBLIC LICENSE
+ The GNU General Public License is a free, copyleft license for
+the GNU General Public License is intended to guarantee your freedom to
+GNU General Public License for most of our software; it applies also to
+[...16 more results...]
+.
+.
+```
+
+你也可以通过 `--invert-match` 选项来输出所有没有匹配到的行:
+
+```
+$ grep --invert-match \
+--ignore-case gnu gpl-3.0.txt
+ Version 3, 29 June 2007
+
+ Copyright (C) 2007 Free Software Foundation, Inc.
+[...648 lines...]
+Public License instead of this License. But first, please read
+```
+
+### 管道
+
+能搜索文件中的文本内容是很有用的,但是 [POSIX][8] 的真正强大之处是可以通过“管道”来连接多条命令。我发现我使用 `grep` 最好的方式是把它与其他工具如 `cut`、`tr` 或 [curl][9] 联合使用。
+
+假如现在有一个文件,文件中每一行是我想要下载的技术论文。我可以打开文件手动点击每一个链接,然后点击火狐浏览器的选项把每一个文件保存到我的硬盘,但是需要点击多次且耗费很长时间。而我还可以搜索文件中的链接,用 `--only-matching` 选项*只*打印出匹配到的字符串。
+
+```
+$ grep --only-matching http\:\/\/.*pdf example.html
+http://example.com/linux_whitepaper.pdf
+http://example.com/bsd_whitepaper.pdf
+http://example.com/important_security_topic.pdf
+```
+
+输出是一系列的 URL,每行一个。而这与 Bash 处理数据的方式完美契合,因此我不再把 URL 打印到终端,而是把它们通过管道传给 `curl`:
+
+```
+$ grep --only-matching http\:\/\/.*pdf \
+example.html | curl --remote-name
+```
+
+这条命令可以下载每一个文件,然后以各自的远程文件名命名保存在我的硬盘上。
+
+这个例子中我的搜索模式可能很晦涩。那是因为它用的是正则表达式,一种在大量文本中进行模糊搜索时非常有用的”通配符“语言。
+
+### 正则表达式
+
+没有人会觉得正则表达式(简称 “regex”)很简单。然而,我发现它的名声往往比它应得的要差。诚然,很多人在使用正则表达式时“过于炫耀聪明”,直到它变得难以阅读,大而全,以至于复杂得换行才好理解,但是你不必过度使用正则。这里简单介绍一下我使用正则表达式的方式。
+
+首先,创建一个名为 `example.txt` 的文件,输入以下内容:
+
+```
+Albania
+Algeria
+Canada
+0
+1
+3
+11
+```
+
+最基础的元素是不起眼的 `.` 字符。它表示一个字符。
+
+```
+$ grep Can.da example.txt
+Canada
+```
+
+模式 `Can.da` 能成功匹配到 `Canada` 是因为 `.` 字符表示任意*一个*字符。
+
+可以使用下面这些符号来使 `.` 通配符表示多个字符:
+
+ * `?` 匹配前面的模式零次或一次
+ * `*` 匹配前面的模式零次或多次
+ * `+` 匹配前面的模式一次或多次
+ * `{4}` 匹配前面的模式 4 次(或是你在括号中写的其他次数)
+
+了解了这些知识后,你可以用你认为有意思的所有模式来在 `example.txt` 中做练习。可能有些会成功,有些不会成功。重要的是你要去分析结果,这样你才会知道原因。
+
+例如,下面的命令匹配不到任何国家:
+
+```
+$ grep A.a example.txt
+```
+
+因为 `.` 字符只能匹配一个字符,除非你增加匹配次数。使用 `*` 字符,告诉 `grep` 匹配一个字符零次或者必要的任意多次直到单词末尾。因为你知道你要处理的内容,因此在本例中*零次*是没有必要的。在这个列表中一定没有单个字母的国家。因此,你可以用 `+` 来匹配一个字符至少一次且任意多次直到单词末尾:
+
+```
+$ grep A.+a example.txt
+Albania
+Algeria
+```
+
+你可以使用方括号来提供一系列的字母:
+
+```
+$ grep [A,C].+a example.txt
+Albania
+Algeria
+Canada
+```
+
+也可以用来匹配数字。结果可能会震惊你:
+
+```
+$ grep [1-9] example.txt
+1
+3
+11
+```
+
+看到 11 出现在搜索数字 1 到 9 的结果中,你惊讶吗?
+
+如果把 13 加到搜索列表中,会出现什么结果呢?
+
+这些数字之所以会被匹配到,是因为它们包含 1,而 1 在要匹配的数字中。
+
+你可以发现,正则表达式有时会令人费解,但是通过体验和练习,你可以熟练掌握它,用它来提高你搜索数据的能力。
+
+### 下载备忘录
+
+`grep` 命令还有很多文章中没有列出的选项。有用来更好地展示匹配结果、列出文件、列出匹配到的行号、通过打印匹配到的行周围的内容来显示上下文的选项,等等。如果你在学习 `grep`,或者你经常使用它并且通过查阅它的`帮助`页面来查看选项,那么你可以下载我们的备忘录。这个备忘录使用短选项(例如,使用 `-v`,而不是 `--invert-matching`)来帮助你更好地熟悉 `grep`。它还有一部分正则表达式可以帮你记住用途最广的正则表达式代码。 [现在就下载 grep 备忘录!][2]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/grep-cheat-sheet
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[lxbwolf](https://github.com/lxbwolf)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC "Hand putting a Linux file folder into a drawer"
+[2]: https://opensource.com/downloads/grep-cheat-sheet
+[3]: https://opensource.com/article/20/6/homebrew-mac
+[4]: https://opensource.com/article/20/11/macports
+[5]: http://www.gnu.org/licenses/\>
+[6]: http://www.gnu.org/philosophy/why-not-lgpl.html\>
+[7]: http://fsf.org/\>
+[8]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[9]: https://opensource.com/downloads/curl-command-cheat-sheet
diff --git a/published/202103/20210319 4 cool new projects to try in Copr for March 2021.md b/published/202103/20210319 4 cool new projects to try in Copr for March 2021.md
new file mode 100644
index 0000000000..90754cca83
--- /dev/null
+++ b/published/202103/20210319 4 cool new projects to try in Copr for March 2021.md
@@ -0,0 +1,143 @@
+[#]: subject: (4 cool new projects to try in Copr for March 2021)
+[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-march-2021/)
+[#]: author: (Jakub Kadlčík https://fedoramagazine.org/author/frostyx/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13243-1.html)
+
+COPR 仓库中 4 个很酷的新项目(2021.03)
+======
+
+![][1]
+
+> COPR 是个人软件仓库 [集合][2],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准;或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
+
+本文介绍了 COPR 中一些有趣的新项目。如果你第一次使用 COPR,请参阅 [COPR 用户文档][3]。
+
+### Ytfzf
+
+[Ytfzf][5] 是一个简单的命令行工具,用于搜索和观看 YouTube 视频。它提供了围绕模糊查找程序 [fzf][6] 构建的快速直观的界面。它使用 [youtube-dl][7] 来下载选定的视频,并打开外部视频播放器来观看。由于这种方式,`ytfzf` 比使用浏览器观看 YouTube 资源占用要少得多。它支持缩略图(通过 [ueberzug][8])、历史记录保存、多个视频排队或下载它们以供以后使用、频道订阅以及其他方便的功能。多亏了像 [dmenu][9] 或 [rofi][10] 这样的工具,它甚至可以在终端之外使用。
+
+![][11]
+
+#### 安装说明
+
+目前[仓库][13]为 Fedora 33 和 34 提供 Ytfzf。要安装它,请使用以下命令:
+
+```
+sudo dnf copr enable bhoman/ytfzf
+sudo dnf install ytfzf
+```
+
+### Gemini 客户端
+
+你有没有想过,如果万维网走的是一条完全不同的路线,不采用 CSS 和客户端脚本,你的互联网浏览体验会如何?[Gemini][15] 是 HTTPS 协议的现代替代品,尽管它并不打算取代 HTTPS 协议。[stenstorp/gemini][16] COPR 项目提供了各种客户端来浏览 Gemini _网站_,有 [Castor][17]、[Dragonstone][18]、[Kristall][19] 和 [Lagrange][20]。
+
+[Gemini][21] 站点提供了一些使用该协议的主机列表。以下显示了使用 Castor 访问这个站点的情况:
+
+![][22]
+
+#### 安装说明
+
+该 [仓库][16] 目前为 Fedora 32、33、34 和 Fedora Rawhide 提供 Gemini 客户端。EPEL 7 和 8,以及 CentOS Stream 也可使用。要安装浏览器,请从这里显示的安装命令中选择:
+
+```
+sudo dnf copr enable stenstorp/gemini
+
+sudo dnf install castor
+sudo dnf install dragonstone
+sudo dnf install kristall
+sudo dnf install lagrange
+```
+
+### Ly
+
+[Ly][25] 是一个 Linux 和 BSD 的轻量级登录管理器。它有一个类似于 ncurses 的基于文本的用户界面。理论上,它应该支持所有的 X 桌面环境和窗口管理器(其中很多都 [经过测试][26])。Ly 还提供了基本的 Wayland 支持(Sway 也工作良好)。在配置的某个地方,有一个复活节彩蛋选项,可以在背景中启用著名的 [PSX DOOM fire][27] 动画,就其本身而言,值得一试。
+
+![][28]
+
+#### 安装说明
+
+该 [仓库][30] 目前为 Fedora 32、33 和 Fedora Rawhide 提供 Ly。要安装它,请使用以下命令:
+
+```
+sudo dnf copr enable dhalucario/ly
+sudo dnf install ly
+```
+
+在将 Ly 设置为系统登录界面之前,请在终端中运行 `ly` 命令以确保其正常工作。然后关闭当前的登录管理器,启用 Ly。
+
+```
+sudo systemctl disable gdm
+sudo systemctl enable ly
+```
+
+最后,重启计算机,使其更改生效。
+
+### AWS CLI v2
+
+[AWS CLI v2][32] 带来基于社区反馈进行的稳健而有条理的演变,而不是对原有客户端的大规模重新设计。它引入了配置凭证的新机制,现在允许用户从 AWS 控制台中生成的 `.csv` 文件导入凭证。它还提供了对 AWS SSO 的支持。其他主要改进是服务端自动补全,以及交互式参数生成。一个新功能是交互式向导,它提供了更高层次的抽象,并结合多个 AWS API 调用来创建、更新或删除 AWS 资源。
+
+![][33]
+
+#### 安装说明
+
+该 [仓库][35] 目前为 Fedora Linux 32、33、34 和 Fedora Rawhide 提供 AWS CLI v2。要安装它,请使用以下命令:
+
+```
+sudo dnf copr enable spot/aws-cli-2
+sudo dnf install aws-cli-2
+```
+
+自然地,访问 AWS 账户凭证是必要的。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-march-2021/
+
+作者:[Jakub Kadlčík][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/frostyx/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2020/10/4-copr-945x400-1-816x345.jpg
+[2]: https://copr.fedorainfracloud.org/
+[3]: https://docs.pagure.org/copr.copr/user_documentation.html
+[4]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-march.md#droidcam
+[5]: https://github.com/pystardust/ytfzf
+[6]: https://github.com/junegunn/fzf
+[7]: http://ytdl-org.github.io/youtube-dl/
+[8]: https://github.com/seebye/ueberzug
+[9]: https://tools.suckless.org/dmenu/
+[10]: https://github.com/davatorium/rofi
+[11]: https://fedoramagazine.org/wp-content/uploads/2021/03/ytfzf.png
+[12]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-march.md#installation-instructions
+[13]: https://copr.fedorainfracloud.org/coprs/bhoman/ytfzf/
+[14]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-march.md#gemini-clients
+[15]: https://gemini.circumlunar.space/
+[16]: https://copr.fedorainfracloud.org/coprs/stenstorp/gemini/
+[17]: https://git.sr.ht/~julienxx/castor
+[18]: https://gitlab.com/baschdel/dragonstone
+[19]: https://kristall.random-projects.net/
+[20]: https://github.com/skyjake/lagrange
+[21]: https://gemini.circumlunar.space/servers/
+[22]: https://fedoramagazine.org/wp-content/uploads/2021/03/gemini.png
+[23]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-march.md#installation-instructions-1
+[24]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-march.md#ly
+[25]: https://github.com/nullgemm/ly
+[26]: https://github.com/nullgemm/ly#support
+[27]: https://fabiensanglard.net/doom_fire_psx/index.html
+[28]: https://fedoramagazine.org/wp-content/uploads/2021/03/ly.png
+[29]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-march.md#installation-instructions-2
+[30]: https://copr.fedorainfracloud.org/coprs/dhalucario/ly/
+[31]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-march.md#aws-cli-v2
+[32]: https://aws.amazon.com/blogs/developer/aws-cli-v2-is-now-generally-available/
+[33]: https://fedoramagazine.org/wp-content/uploads/2021/03/aws-cli-2.png
+[34]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-march.md#installation-instructions-3
+[35]: https://copr.fedorainfracloud.org/coprs/spot/aws-cli-2/
diff --git a/published/202103/20210319 Top 10 Terminal Emulators for Linux (With Extra Features or Amazing Looks).md b/published/202103/20210319 Top 10 Terminal Emulators for Linux (With Extra Features or Amazing Looks).md
new file mode 100644
index 0000000000..eaeeccfab7
--- /dev/null
+++ b/published/202103/20210319 Top 10 Terminal Emulators for Linux (With Extra Features or Amazing Looks).md
@@ -0,0 +1,308 @@
+[#]: subject: (Top 10 Terminal Emulators for Linux \(With Extra Features or Amazing Looks\))
+[#]: via: (https://itsfoss.com/linux-terminal-emulators/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13221-1.html)
+
+10 个常见的 Linux 终端仿真器
+======
+
+
+
+默认情况下,所有的 Linux 发行版都已经预装了“终端”应用程序或“终端仿真器”(这才是正确的技术术语)。当然,根据桌面环境的不同,它的外观和感觉会有所不同。
+
+Linux 的特点是,你可以不用局限于你的发行版所提供的东西,你可以用你所选择的替代应用程序。终端也不例外。有几个提供了独特功能的终端仿真器令人印象深刻,可以获得更好的用户体验或更好的外观。
+
+在这里,我将整理一个有趣的终端应用程序的列表,你可以在你的 Linux 发行版上尝试它们。
+
+### 值得赞叹的 Linux 终端仿真器
+
+此列表没有特别的排名顺序,我会先列出一些有趣的,然后是一些最流行的终端仿真器。此外,我还强调了每个提到的终端仿真器的主要功能,你可以选择你喜欢的终端仿真器。
+
+#### 1、Terminator
+
+![][1]
+
+主要亮点:
+
+* 可以在一个窗口中使用多个 GNOME 终端
+
+[Terminator][2] 是一款非常流行的终端仿真器,目前仍在维护中(从 Launchpad 移到了 GitHub)。
+
+它基本上是在一个窗口中为你提供了多个 GNOME 终端。在它的帮助下,你可以轻松地对终端窗口进行分组和重组。你可能会觉得这像是在使用平铺窗口管理器,不过有一些限制。
+
+##### 如何安装 Terminator?
+
+对于基于 Ubuntu 的发行版,你只需在终端输入以下命令:
+
+```
+sudo apt install terminator
+```
+
+你应该可以在大多数 Linux 发行版的默认仓库中找到它。但是,如果你需要安装帮助,请访问它的 [GitHub 页面][3]。
+
+#### 2、Guake 终端
+
+![][4]
+
+主要亮点:
+
+ * 专为在 GNOME 上快速访问终端而设计
+ * 工作速度快,不需要大量的系统资源
+ * 访问的快捷键
+
+[Guake][6] 终端最初的灵感来自于一款 FPS 游戏 Quake。与其他一些终端仿真器不同的是,它的工作方式是覆盖在其他的活动窗口上。
+
+你所要做的就是使用快捷键(`F12`)召唤该仿真器,它就会从顶部出现。你可以自定义该仿真器的宽度或位置,但大多数用户使用默认设置就可以了。
+
+它不仅仅是一个方便的终端仿真器,还提供了大量的功能,比如能够恢复标签、拥有多个标签、对每个标签进行颜色编码等等。你可以查看我关于 [Guake 的单独文章][5] 来了解更多。
+
+##### 如何安装 Guake 终端?
+
+Guake 在大多数 Linux 发行版的默认仓库中都可以找到,你可以参考它的 [官方安装说明][7]。
+
+如果你使用的是基于 Debian 的发行版,只需输入以下命令:
+
+```
+sudo apt install guake
+```
+
+#### 3、Tilix 终端
+
+![][8]
+
+主要亮点:
+
+ * 平铺功能
+ * 支持拖放
+ * 下拉式 Quake 模式
+
+[Tilix][10] 终端提供了与 Guake 类似的下拉式体验 —— 但它允许你在平铺模式下拥有多个终端窗口。
+
+如果你的 Linux 发行版中默认没有平铺窗口,而且你有一个大屏幕,那么这个功能就特别有用,你可以在多个终端窗口上工作,而不需要在不同的工作空间之间切换。
+
+如果你想了解更多关于它的信息,我们之前已经 [单独介绍][9] 过了。
+
+##### 如何安装 Tilix?
+
+Tilix 在大多数发行版的默认仓库中都有。如果你使用的是基于 Ubuntu 的发行版,只需输入:
+
+```
+sudo apt install tilix
+```
+
+#### 4、Hyper
+
+![][13]
+
+主要亮点:
+
+ * 基于 HTML/CSS/JS 的终端
+ * 基于 Electron
+ * 跨平台
+ * 丰富的配置选项
+
+[Hyper][15] 是另一个有趣的终端仿真器,它建立在 Web 技术之上。它并没有提供独特的用户体验,但看起来很不一样,并提供了大量的自定义选项。
+
+它还支持安装主题和插件来轻松定制终端的外观。你可以在他们的 [GitHub 页面][14] 中探索更多关于它的内容。
+
+##### 如何安装 Hyper?
+
+Hyper 在默认的资源库中是不可用的。然而,你可以通过他们的 [官方网站][16] 找到 .deb 和 .rpm 包来安装。
+
+如果你是新手,请阅读文章以获得 [使用 deb 文件][17] 和 [使用 rpm 文件][18] 的帮助。
+
+#### 5、Tilda
+
+![][19]
+
+主要亮点:
+
+ * 下拉式终端
+ * 搜索栏整合
+
+[Tilda][20] 是另一款基于 GTK 的下拉式终端仿真器。与其他一些不同的是,它提供了一个你可以切换的集成搜索栏,还可以让你自定义很多东西。
+
+你还可以设置热键来快速访问或执行某个动作。从功能上来说,它是相当令人印象深刻的。然而,在视觉上,我不喜欢覆盖的行为,而且它也不支持拖放。不过你可以试一试。
+
+##### 如何安装 Tilda?
+
+对于基于 Ubuntu 的发行版,你可以简单地键入:
+
+```
+sudo apt install tilda
+```
+
+你可以参考它的 [GitHub 页面][20],以了解其他发行版的安装说明。
+
+#### 6、eDEX-UI
+
+![][21]
+
+主要亮点:
+
+ * 科幻感的外观
+ * 跨平台
+ * 自定义主题选项
+ * 支持多个终端标签
+
+如果你不是特别想找一款可以帮助你更快的完成工作的终端仿真器,那么 [eDEX-UI][23] 绝对是你应该尝试的。
+
+对于科幻迷和只想让自己的终端看起来独特的用户来说,这绝对是一款漂亮的终端仿真器。如果你不知道,它的灵感很大程度上来自于电影《创:战纪》。
+
+不仅仅是设计或界面,总的来说,它为你提供了独特的用户体验,你会喜欢的。它还可以让你 [自定义终端][12]。如果你打算尝试的话,它确实需要大量的系统资源。
+
+你不妨看看我们 [专门介绍 eDEX-UI][22] 的文章,了解更多关于它的信息和安装步骤。
+
+##### 如何安装 eDEX-UI?
+
+你可以在一些包含 [AUR][24] 的仓库中找到它。无论是哪种情况,你都可以从它的 [GitHub 发布部分][25] 中抓取一个适用于你的 Linux 发行版的软件包(或 AppImage 文件)。
+
+#### 7、Cool Retro Terminal
+
+![][26]
+
+主要亮点:
+
+ * 复古主题
+ * 动画/效果调整
+
+[Cool Retro Terminal][27] 是一款独特的终端仿真器,它为你提供了一个复古的阴极射线管显示器的外观。
+
+如果你正在寻找一些额外功能的终端仿真器,这可能会让你失望。然而,令人印象深刻的是,它在资源上相当轻盈,并允许你自定义颜色、效果和字体。
+
+##### 如何安装 Cool Retro Terminal?
+
+你可以在其 [GitHub 页面][27] 中找到所有主流 Linux 发行版的安装说明。对于基于 Ubuntu 的发行版,你可以在终端中输入以下内容:
+
+```
+sudo apt install cool-retro-term
+```
+
+#### 8、Alacritty
+
+![][28]
+
+主要亮点:
+
+ * 跨平台
+ * 选项丰富,重点是整合。
+
+[Alacritty][29] 是一款有趣的开源跨平台终端仿真器。尽管它被认为是处于“测试”阶段的东西,但它仍然可以工作。
+
+它的目标是为你提供广泛的配置选项,同时考虑到性能。例如,使用键盘点击 URL、将文本复制到剪贴板、使用 “Vi” 模式进行搜索等功能可能会吸引你去尝试。
+
+你可以探索它的 [GitHub 页面][29] 了解更多信息。
+
+##### 如何安装 Alacritty?
+
+官方 GitHub 页面上说可以使用包管理器安装 Alacritty,但我在 Linux Mint 20.1 的默认仓库或 [synaptic 包管理器][30] 中找不到它。
+
+如果你想尝试的话,可以按照 [安装说明][31] 来手动设置。
+
+#### 9、Konsole
+
+![][32]
+
+主要亮点:
+
+ * KDE 的终端
+ * 轻巧且可定制
+
+如果你不是新手,这个可能不用介绍了。[Konsole][33] 是 KDE 桌面环境的默认终端仿真器。
+
+不仅如此,它还集成了很多 KDE 应用。即使你使用的是其他的桌面环境,你也可以试试 Konsole。它是一个轻量级的终端仿真器,拥有众多的功能。
+
+你可以拥有多个标签和多个分组窗口。以及改变终端仿真器的外观和感觉的大量的自定义选项。
+
+##### 如何安装 Konsole?
+
+对于基于 Ubuntu 的发行版和大多数其他发行版,你可以使用默认的版本库来安装它。对于基于 Debian 的发行版,你只需要在终端中输入以下内容:
+
+```
+sudo apt install konsole
+```
+
+#### 10、GNOME 终端
+
+![][34]
+
+主要亮点:
+
+ * GNOME 的终端
+ * 简单但可定制
+
+如果你使用的是任何基于 Ubuntu 的 GNOME 发行版,它已经是天生的了,它可能不像 Konsole 那样可以自定义,但它可以让你轻松地配置终端的大部分重要方面。它可能不像 Konsole 那样可以自定义(取决于你在做什么),但它可以让你轻松配置终端的大部分重要方面。
+
+总的来说,它提供了良好的用户体验和易于使用的界面,并提供了必要的功能。
+
+如果你好奇的话,我还有一篇 [自定义你的 GNOME 终端][12] 的教程。
+
+##### 如何安装 GNOME 终端?
+
+如果你没有使用 GNOME 桌面,但又想尝试一下,你可以通过默认的软件仓库轻松安装它。
+
+对于基于 Debian 的发行版,以下是你需要在终端中输入的内容:
+
+```
+sudo apt install gnome-terminal
+```
+
+### 总结
+
+有好几个终端仿真器。如果你正在寻找不同的用户体验,你可以尝试任何你喜欢的东西。然而,如果你的目标是一个稳定的和富有成效的体验,你需要测试一下,然后才能依靠它们。
+
+对于大多数用户来说,默认的终端仿真器应该足够好用了。但是,如果你正在寻找快速访问(Quake 模式)、平铺功能或在一个终端中的多个窗口,请试试上述选择。
+
+你最喜欢的 Linux 终端仿真器是什么?我有没有错过列出你最喜欢的?欢迎在下面的评论中告诉我你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/linux-terminal-emulators/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/terminator-terminal.jpg?resize=800%2C436&ssl=1
+[2]: https://gnome-terminator.org
+[3]: https://github.com/gnome-terminator/terminator
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-terminal-2.png?resize=800%2C432&ssl=1
+[5]: https://itsfoss.com/guake-terminal/
+[6]: https://github.com/Guake/guake
+[7]: https://guake.readthedocs.io/en/latest/user/installing.html#system-wide-installation
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/tilix-screenshot.png?resize=800%2C460&ssl=1
+[9]: https://itsfoss.com/tilix-terminal-emulator/
+[10]: https://gnunn1.github.io/tilix-web/
+[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/linux-terminal-customization.jpg?fit=800%2C450&ssl=1
+[12]: https://itsfoss.com/customize-linux-terminal/
+[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/hyper-screenshot.png?resize=800%2C527&ssl=1
+[14]: https://github.com/vercel/hyper
+[15]: https://hyper.is/
+[16]: https://hyper.is/#installation
+[17]: https://itsfoss.com/install-deb-files-ubuntu/
+[18]: https://itsfoss.com/install-rpm-files-fedora/
+[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/tilda-terminal.jpg?resize=800%2C427&ssl=1
+[20]: https://github.com/lanoxx/tilda
+[21]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/edex-ui-screenshot.png?resize=800%2C450&ssl=1
+[22]: https://itsfoss.com/edex-ui-sci-fi-terminal/
+[23]: https://github.com/GitSquared/edex-ui
+[24]: https://itsfoss.com/aur-arch-linux/
+[25]: https://github.com/GitSquared/edex-ui/releases
+[26]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2015/10/cool-retro-term-1.jpg?resize=799%2C450&ssl=1
+[27]: https://github.com/Swordfish90/cool-retro-term
+[28]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/alacritty-screenshot.png?resize=800%2C496&ssl=1
+[29]: https://github.com/alacritty/alacritty
+[30]: https://itsfoss.com/synaptic-package-manager/
+[31]: https://github.com/alacritty/alacritty/blob/master/INSTALL.md#debianubuntu
+[32]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/konsole-screenshot.png?resize=800%2C512&ssl=1
+[33]: https://konsole.kde.org/
+[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/default-terminal.jpg?resize=773%2C493&ssl=1
diff --git a/published/202103/20210322 5 everyday sysadmin tasks to automate with Ansible.md b/published/202103/20210322 5 everyday sysadmin tasks to automate with Ansible.md
new file mode 100644
index 0000000000..6f12202b57
--- /dev/null
+++ b/published/202103/20210322 5 everyday sysadmin tasks to automate with Ansible.md
@@ -0,0 +1,300 @@
+[#]: subject: (5 everyday sysadmin tasks to automate with Ansible)
+[#]: via: (https://opensource.com/article/21/3/ansible-sysadmin)
+[#]: author: (Mike Calizo https://opensource.com/users/mcalizo)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13256-1.html)
+
+用 Ansible 自动化系统管理员的 5 个日常任务
+======
+
+> 通过使用 Ansible 自动执行可重复的日常任务,提高工作效率并避免错误。
+
+
+
+如果你讨厌执行重复性的任务,那么我有一个提议给你,去学习 [Ansible][2]!
+
+Ansible 是一个工具,它可以帮助你更轻松、更快速地完成日常任务,这样你就可以更有效地利用时间,比如学习重要的新技术。对于系统管理员来说,它是一个很好的工具,因为它可以帮助你实现标准化,并在日常活动中进行协作,包括:
+
+ 1. 安装、配置和调配服务器和应用程序;
+ 2. 定期更新和升级系统;
+ 3. 监测、减轻和排除问题。
+
+通常,许多这些基本的日常任务都需要手动步骤,而根据个人的技能的不同,可能会造成不一致并导致配置发生漂移。这在小规模的实施中可能是可以接受的,因为你管理一台服务器,并且知道自己在做什么。但当你管理数百或数千台服务器时会发生什么?
+
+如果不小心,这些手动的、可重复的任务可能会因为人为的错误而造成延误和问题,而这些错误可能会影响你及你的组织的声誉。
+
+这就是自动化的价值所在。而 [Ansible][3] 是自动化这些可重复的日常任务的完美工具。
+
+自动化的一些原因是:
+
+ 1. 你想要一个一致和稳定的环境。
+ 2. 你想要促进标准化。
+ 3. 你希望减少停机时间,减少严重事故案例,以便可以享受生活。
+ 4. 你想喝杯啤酒,而不是排除故障问题!
+
+本文提供了一些系统管理员可以使用 Ansible 自动化的日常任务的例子。我把本文中的剧本和角色放到了 GitHub 上的 [系统管理员任务仓库][4] 中,以方便你使用它们。
+
+这些剧本的结构是这样的(我的注释前面有 `==>`)。
+
+```
+[root@homebase 6_sysadmin_tasks]# tree -L 2
+.
+├── ansible.cfg ==> 负责控制 Ansible 行为的配置文件
+├── ansible.log
+├── inventory
+│ ├── group_vars
+│ ├── hosts ==> 包含我的目标服务器列表的清单文件
+│ └── host_vars
+├── LICENSE
+├── playbooks ==> 包含我们将在本文中使用的剧本的目录
+│ ├── c_logs.yml
+│ ├── c_stats.yml
+│ ├── c_uptime.yml
+│ ├── inventory
+│ ├── r_cron.yml
+│ ├── r_install.yml
+│ └── r_script.yml
+├── README.md
+├── roles ==> 包含我们将在本文中使用的角色的目录
+│ ├── check_logs
+│ ├── check_stats
+│ ├── check_uptime
+│ ├── install_cron
+│ ├── install_tool
+│ └── run_scr
+└── templates ==> 包含 jinja 模板的目录
+ ├── cron_output.txt.j2
+ ├── sar.txt.j2
+ └── scr_output.txt.j2
+```
+
+清单类似这样的:
+
+```
+[root@homebase 6_sysadmin_tasks]# cat inventory/hosts
+[rhel8]
+master ansible_ssh_host=192.168.1.12
+workernode1 ansible_ssh_host=192.168.1.15
+
+[rhel8:vars]
+ansible_user=ansible ==> 请用你的 ansible 用户名更新它
+```
+
+这里有五个你可以用 Ansible 自动完成的日常系统管理任务。
+
+### 1、检查服务器的正常运行时间
+
+你需要确保你的服务器一直处于正常运行状态。机构会拥有企业监控工具来监控服务器和应用程序的正常运行时间,但自动监控工具时常会出现故障,你需要登录进去验证一台服务器的状态。手动验证每台服务器的正常运行时间需要花费大量的时间。你的服务器越多,你需要花费的时间就越长。但如果有了自动化,这种验证可以在几分钟内完成。
+
+使用 [check_uptime][5] 角色和 `c_uptime.yml` 剧本:
+
+```
+[root@homebase 6_sysadmin_tasks]# ansible-playbook -i inventory/hosts playbooks/c_uptime.yml -k
+SSH password:
+PLAY [Check Uptime for Servers] ****************************************************************************************************************************************
+TASK [check_uptime : Capture timestamp] *************************************************************************************************
+.
+截断...
+.
+PLAY RECAP *************************************************************************************************************************************************************
+master : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+workernode1 : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+[root@homebase 6_sysadmin_tasks]#
+```
+
+剧本的输出是这样的:
+
+```
+[root@homebase 6_sysadmin_tasks]# cat /var/tmp/uptime-master-20210221004417.txt
+-----------------------------------------------------
+ Uptime for master
+-----------------------------------------------------
+ 00:44:17 up 44 min, 2 users, load average: 0.01, 0.09, 0.09
+-----------------------------------------------------
+[root@homebase 6_sysadmin_tasks]# cat /var/tmp/uptime-workernode1-20210221184525.txt
+-----------------------------------------------------
+ Uptime for workernode1
+-----------------------------------------------------
+ 18:45:26 up 44 min, 2 users, load average: 0.01, 0.01, 0.00
+-----------------------------------------------------
+```
+
+使用 Ansible,你可以用较少的努力以人类可读的格式获得多个服务器的状态,[Jinja 模板][6] 允许你根据自己的需要调整输出。通过更多的自动化,你可以按计划运行,并通过电子邮件发送输出,以达到报告的目的。
+
+### 2、配置额外的 cron 作业
+
+你需要根据基础设施和应用需求定期更新服务器的计划作业。这似乎是一项微不足道的工作,但必须正确且持续地完成。想象一下,如果你对数百台生产服务器进行手动操作,这需要花费多少时间。如果做错了,就会影响生产应用程序,如果计划的作业重叠,就会导致应用程序停机或影响服务器性能。
+
+使用 [install_cron][7] 角色和 `r_cron.yml` 剧本:
+
+```
+[root@homebase 6_sysadmin_tasks]# ansible-playbook -i inventory/hosts playbooks/r_cron.yml -k
+SSH password:
+PLAY [Install additional cron jobs for root] ***************************************************************************************************************************
+.
+截断...
+.
+PLAY RECAP *************************************************************************************************************************************************************
+master : ok=10 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+workernode1 : ok=10 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+```
+
+验证剧本的结果:
+
+```
+[root@homebase 6_sysadmin_tasks]# ansible -i inventory/hosts all -m shell -a "crontab -l" -k
+SSH password:
+master | CHANGED | rc=0 >>
+1 2 3 4 5 /usr/bin/ls /tmp
+#Ansible: Iotop Monitoring
+0 5,2 * * * /usr/sbin/iotop -b -n 1 >> /var/tmp/iotop.log 2>> /var/tmp/iotop.err
+workernode1 | CHANGED | rc=0 >>
+1 2 3 4 5 /usr/bin/ls /tmp
+#Ansible: Iotop Monitoring
+0 5,2 * * * /usr/sbin/iotop -b -n 1 >> /var/tmp/iotop.log 2>> /var/tmp/iotop.err
+```
+
+使用 Ansible,你可以以快速和一致的方式更新所有服务器上的 crontab 条目。你还可以使用一个简单的点对点 Ansible 命令来报告更新后的 crontab 的状态,以验证最近应用的变化。
+
+### 3、收集服务器统计和 sars
+
+在常规的故障排除过程中,为了诊断服务器性能或应用程序问题,你需要收集系统活动报告(sars)和服务器统计。在大多数情况下,服务器日志包含非常重要的信息,开发人员或运维团队需要这些信息来帮助解决影响整个环境的具体问题。
+
+安全团队在进行调查时非常特别,大多数时候,他们希望查看多个服务器的日志。你需要找到一种简单的方法来收集这些文档。如果你能把收集任务委托给他们就更好了。
+
+通过 [check_stats][8] 角色和 `c_stats.yml` 剧本来完成这个任务:
+
+```
+$ ansible-playbook -i inventory/hosts playbooks/c_stats.yml
+
+PLAY [Check Stats/sar for Servers] ***********************************************************************************************************************************
+
+TASK [check_stats : Get current date time] ***************************************************************************************************************************
+changed: [master]
+changed: [workernode1]
+.
+截断...
+.
+PLAY RECAP ***********************************************************************************************************************************************************
+master : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+workernode1 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+```
+
+输出看起来像这样:
+
+```
+$ cat /tmp/sar-workernode1-20210221214056.txt
+-----------------------------------------------------
+ sar output for workernode1
+-----------------------------------------------------
+Linux 4.18.0-193.el8.x86_64 (node1) 21/02/21 _x86_64_ (2 CPU)
+21:39:30 LINUX RESTART (2 CPU)
+-----------------------------------------------------
+```
+
+### 4、收集服务器日志
+
+除了收集服务器统计和 sars 信息,你还需要不时地收集日志,尤其是当你需要帮助调查问题时。
+
+通过 [check_logs][9] 角色和 `r_cron.yml` 剧本来实现:
+
+```
+$ ansible-playbook -i inventory/hosts playbooks/c_logs.yml -k
+SSH password:
+
+PLAY [Check Logs for Servers] ****************************************************************************************************************************************
+.
+截断...
+.
+TASK [check_logs : Capture Timestamp] ********************************************************************************************************************************
+changed: [master]
+changed: [workernode1]
+PLAY RECAP ***********************************************************************************************************************************************************
+master : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+workernode1 : ok=6 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+```
+
+为了确认输出,打开转储位置生成的文件。日志应该是这样的:
+
+```
+$ cat /tmp/logs-workernode1-20210221214758.txt | more
+-----------------------------------------------------
+ Logs gathered: /var/log/messages for workernode1
+-----------------------------------------------------
+
+Feb 21 18:00:27 node1 kernel: Command line: BOOT_IMAGE=(hd0,gpt2)/vmlinuz-4.18.0-193.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel
+-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet
+Feb 21 18:00:27 node1 kernel: Disabled fast string operations
+Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'
+Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers'
+Feb 21 18:00:27 node1 kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers'
+Feb 21 18:00:27 node1 kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
+Feb 21 18:00:27 node1 kernel: x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'compacted' format.
+```
+
+### 5、安装或删除软件包和软件
+
+你需要能够持续快速地在系统上安装和更新软件和软件包。缩短安装或更新软件包和软件所需的时间,可以避免服务器和应用程序不必要的停机时间。
+
+通过 [install_tool][10] 角色和 `r_install.yml` 剧本来实现这一点:
+
+```
+$ ansible-playbook -i inventory/hosts playbooks/r_install.yml -k
+SSH password:
+PLAY [Install additional tools/packages] ***********************************************************************************
+
+TASK [install_tool : Install specified tools in the role vars] *************************************************************
+ok: [master] => (item=iotop)
+ok: [workernode1] => (item=iotop)
+ok: [workernode1] => (item=traceroute)
+ok: [master] => (item=traceroute)
+
+PLAY RECAP *****************************************************************************************************************
+master : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+workernode1 : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
+```
+
+这个例子安装了在 vars 文件中定义的两个特定包和版本。使用 Ansible 自动化,你可以比手动安装更快地安装多个软件包或软件。你也可以使用 vars 文件来定义你要安装的软件包的版本。
+
+```
+$ cat roles/install_tool/vars/main.yml
+---
+# vars file for install_tool
+ins_action: absent
+package_list:
+ - iotop-0.6-16.el8.noarch
+ - traceroute
+```
+
+### 拥抱自动化
+
+要成为一名有效率的系统管理员,你需要接受自动化来鼓励团队内部的标准化和协作。Ansible 使你能够在更少的时间内做更多的事情,这样你就可以将时间花在更令人兴奋的项目上,而不是做重复的任务,如管理你的事件和问题管理流程。
+
+有了更多的空闲时间,你可以学习更多的知识,让自己可以迎接下一个职业机会的到来。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/ansible-sysadmin
+
+作者:[Mike Calizo][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mcalizo
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/gears_devops_learn_troubleshooting_lightbulb_tips_520.png?itok=HcN38NOk (Tips and gears turning)
+[2]: https://www.ansible.com/
+[3]: https://opensource.com/tags/ansible
+[4]: https://github.com/mikecali/6_sysadmin_tasks
+[5]: https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_uptime
+[6]: https://docs.ansible.com/ansible/latest/user_guide/playbooks_templating.html
+[7]: https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/install_cron
+[8]: https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_stats
+[9]: https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/check_logs
+[10]: https://github.com/mikecali/6_sysadmin_tasks/tree/main/roles/install_tool
diff --git a/published/202103/20210322 Why I use exa instead of ls on Linux.md b/published/202103/20210322 Why I use exa instead of ls on Linux.md
new file mode 100644
index 0000000000..1015284fcc
--- /dev/null
+++ b/published/202103/20210322 Why I use exa instead of ls on Linux.md
@@ -0,0 +1,100 @@
+[#]: subject: (Why I use exa instead of ls on Linux)
+[#]: via: (https://opensource.com/article/21/3/replace-ls-exa)
+[#]: author: (Sudeshna Sur https://opensource.com/users/sudeshna-sur)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13237-1.html)
+
+为什么我在 Linux 上使用 exa 而不是 ls?
+======
+
+> exa 是一个 Linux ls 命令的现代替代品。
+
+
+
+我们生活在一个繁忙的世界里,当我们需要查找文件和数据时,使用 `ls` 命令可以节省时间和精力。但如果不经过大量调整,默认的 `ls` 输出并不十分舒心。当有一个 exa 替代方案时,为什么要花时间眯着眼睛看黑白文字呢?
+
+[exa][2] 是一个常规 `ls` 命令的现代替代品,它让生活变得更轻松。这个工具是用 [Rust][3] 编写的,该语言以并行性和安全性而闻名。
+
+### 安装 exa
+
+要安装 `exa`,请运行:
+
+```
+$ dnf install exa
+```
+
+### 探索 exa 的功能
+
+`exa` 改进了 `ls` 文件列表,它提供了更多的功能和更好的默认值。它使用颜色来区分文件类型和元数据。它能识别符号链接、扩展属性和 Git。而且它体积小、速度快,只有一个二进制文件。
+
+#### 跟踪文件
+
+你可以使用 `exa` 来跟踪某个 Git 仓库中新增的文件。
+
+![Tracking Git files with exa][4]
+
+#### 树形结构
+
+这是 `exa` 的基本树形结构。`--level` 的值决定了列表的深度,这里设置为 2。如果你想列出更多的子目录和文件,请增加 `--level` 的值。
+
+![exa's default tree structure][6]
+
+这个树包含了每个文件的很多元数据。
+
+![Metadata in exa's tree structure][7]
+
+#### 配色方案
+
+默认情况下,`exa` 根据 [内置的配色方案][8] 来标识不同的文件类型。它不仅对文件和目录进行颜色编码,还对 `Cargo.toml`、`CMakeLists.txt`、`Gruntfile.coffee`、`Gruntfile.js`、`Makefile` 等多种文件类型进行颜色编码。
+
+#### 扩展文件属性
+
+当你使用 `exa` 探索 xattrs(扩展的文件属性)时,`--extended` 会显示所有的 xattrs。
+
+![xattrs in exa][9]
+
+#### 符号链接
+
+`exa` 能识别符号链接,也能指出实际的文件。
+
+![symlinks in exa][10]
+
+#### 递归
+
+当你想递归当前目录下所有目录的列表时,`exa` 能进行递归。
+
+![recurse in exa][11]
+
+### 总结
+
+我相信 `exa 是最简单、最容易适应的工具之一。它帮助我跟踪了很多 Git 和 Maven 文件。它的颜色编码让我更容易在多个子目录中进行搜索,它还能帮助我了解当前的 xattrs。
+
+你是否已经用 `exa` 替换了 `ls`?请在评论中分享你的反馈。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/replace-ls-exa
+
+作者:[Sudeshna Sur][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sudeshna-sur
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
+[2]: https://the.exa.website/docs
+[3]: https://opensource.com/tags/rust
+[4]: https://opensource.com/sites/default/files/uploads/exa_trackingfiles.png (Tracking Git files with exa)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://opensource.com/sites/default/files/uploads/exa_treestructure.png (exa's default tree structure)
+[7]: https://opensource.com/sites/default/files/uploads/exa_metadata.png (Metadata in exa's tree structure)
+[8]: https://the.exa.website/features/colours
+[9]: https://opensource.com/sites/default/files/uploads/exa_xattrs.png (xattrs in exa)
+[10]: https://opensource.com/sites/default/files/uploads/exa_symlinks.png (symlinks in exa)
+[11]: https://opensource.com/sites/default/files/uploads/exa_recurse.png (recurse in exa)
diff --git a/published/202103/20210323 3 new Java tools to try in 2021.md b/published/202103/20210323 3 new Java tools to try in 2021.md
new file mode 100644
index 0000000000..9dc03f05b4
--- /dev/null
+++ b/published/202103/20210323 3 new Java tools to try in 2021.md
@@ -0,0 +1,75 @@
+[#]: subject: (3 new Java tools to try in 2021)
+[#]: via: (https://opensource.com/article/21/3/enterprise-java-tools)
+[#]: author: (Daniel Oh https://opensource.com/users/daniel-oh)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13249-1.html)
+
+2021 年要尝试的 3 个新的 Java 工具
+======
+
+> 通过这三个工具和框架,为你的企业级 Java 应用和你的职业生涯提供助力。
+
+
+
+尽管在 Kubernetes 上广泛使用 [Python][2]、[Go][3] 和 [Node.js][4] 实现 [人工智能][5] 和机器学习应用以及 [无服务函数][6],但 Java 技术仍然在开发企业应用中发挥着关键作用。根据 [开发者经济学][7] 的数据,在 2020 年第三季度,全球有 800 万名企业 Java 开发者。
+
+虽然这门语言已经存在了超过 25 年,但 Java 世界中总是有新的趋势、工具和框架,可以为你的应用和你的职业生涯赋能。
+
+绝大多数 Java 框架都是为具有动态行为的长时间运行的进程而设计的,这些动态行为用于运行可变的应用服务器,例如物理服务器和虚拟机。自从 Kubernetes 容器在 2014 年发布以来,情况已经发生了变化。在 Kubernetes 上使用 Java 应用的最大问题是通过减少内存占用、加快启动和响应时间以及减少文件大小来优化应用性能。
+
+### 3 个值得考虑的新 Java 框架和工具
+
+Java 开发人员也一直在寻找更简便的方法,将闪亮的新开源工具和项目集成到他们的 Java 应用和日常工作中。这极大地提高了开发效率,并激励更多的企业和个人开发者继续使用 Java 栈。
+
+当试图满足上述企业 Java 生态系统的期望时,这三个新的 Java 框架和工具值得你关注。
+
+#### 1、Quarkus
+
+[Quarkus][8] 旨在以惊人的快速启动时间、超低的常驻内存集(RSS)和高密度内存利用率,在 Kubernetes 等容器编排平台中开发云原生的微服务和无服务。根据 JRebel 的 [第九届全球 Java 开发者生产力年度报告][9],Java 开发者对 Quarkus 的使用率从不到 1% 上升到 6%,[Micronaut][10] 和 [Vert.x][11] 均从去年的 1% 左右分别增长到 4% 和 2%。
+
+#### 2、Eclipse JKube
+
+[Eclipse JKube][12] 使 Java 开发者能够使用 [Docker][13]、[Jib][14] 或 [Source-To-Image][15] 构建策略,基于云原生 Java 应用构建容器镜像。它还能在编译时生成 Kubernetes 和 OpenShift 清单,并改善开发人员对调试、观察和日志工具的体验。
+
+#### 3、MicroProfile
+
+[MicroProfile][16] 解决了与优化企业 Java 的微服务架构有关的最大问题,而无需采用新的框架或重构整个应用。此外,MicroProfile [规范][17](即 Health、Open Tracing、Open API、Fault Tolerance、Metrics、Config)继续与 [Jakarta EE][18] 的实现保持一致。
+
+### 总结
+
+很难说哪个 Java 框架或工具是企业 Java 开发人员实现的最佳选择。只要 Java 栈还有改进的空间,并能加速企业业务的发展,我们就可以期待新的框架、工具和平台的出现,比如上面的三个。花点时间看看它们是否能在 2021 年改善你的企业 Java 应用。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/enterprise-java-tools
+
+作者:[Daniel Oh][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/daniel-oh
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_tea_laptop_computer_work_desk.png?itok=D5yMx_Dr (Person drinking a hot drink at the computer)
+[2]: https://opensource.com/resources/python
+[3]: https://opensource.com/article/18/11/learning-golang
+[4]: https://opensource.com/article/18/7/node-js-interactive-cli
+[5]: https://opensource.com/article/18/12/how-get-started-ai
+[6]: https://opensource.com/article/19/4/enabling-serverless-kubernetes
+[7]: https://developereconomics.com/
+[8]: https://quarkus.io/
+[9]: https://www.jrebel.com/resources/java-developer-productivity-report-2021
+[10]: https://micronaut.io/
+[11]: https://vertx.io/
+[12]: https://www.eclipse.org/jkube/
+[13]: https://opensource.com/resources/what-docker
+[14]: https://github.com/GoogleContainerTools/jib
+[15]: https://www.openshift.com/blog/create-s2i-builder-image
+[16]: https://opensource.com/article/18/1/eclipse-microprofile
+[17]: https://microprofile.io/
+[18]: https://opensource.com/article/18/5/jakarta-ee
diff --git a/published/202103/20210323 Affordable high-temperature 3D printers at home.md b/published/202103/20210323 Affordable high-temperature 3D printers at home.md
new file mode 100644
index 0000000000..fa2b49ee63
--- /dev/null
+++ b/published/202103/20210323 Affordable high-temperature 3D printers at home.md
@@ -0,0 +1,73 @@
+[#]: subject: (Affordable high-temperature 3D printers at home)
+[#]: via: (https://opensource.com/article/21/3/desktop-3d-printer)
+[#]: author: (Joshua Pearce https://opensource.com/users/jmpearce)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13255-1.html)
+
+在家就能用得起的高温 3D 打印机
+======
+
+> 有多实惠?低于 1000 美元。
+
+![High-temperature 3D-printed mask][1]
+
+3D 打印机从 20 世纪 80 年代就已经出现了,但是由于 [RepRap][2] 项目的出现,它们直到获得开源才受到人们的关注。RepRap 意即自我复制快速原型机,它是一种基本上可以自己打印的 3D 打印机。它的开源计划[2004 年][3] 发布之后,导致 3D 打印机的成本从几十万美金降到了几百美金。
+
+这些开源的桌面工具一直局限于 ABS 等低性能、低温热塑性塑料(如乐高积木)。市场上有几款高温打印机,但其高昂的成本(几万到几十万美元)使大多数人无法获得。直到最近,它们才参与了很多竞争,因为它们被一项专利 (US6722872B1) 锁定,该专利于 2021 年 2 月 27 日[到期][4]。
+
+随着这个路障的消除,我们即将看到高温、低成本、熔融纤维 3D 打印机的爆发。
+
+价格低到什么程度?低于 1000 美元如何。
+
+在疫情最严重的时候,我的团队赶紧发布了一个 [开源高温 3D 打印机][5] 的设计,用于制造可高温消毒的个人防护装备(PPE)。该项目的想法是让人们能够 [用高温材料打印 PPE][6](如口罩),并将它放入家用烤箱进行消毒。我们称我们的设备为 Cerberus,它具有以下特点:
+
+ 1. 可达到 200℃ 的加热床
+ 2. 可达到 500℃ 的热源
+ 3. 带有 1kW 加热器核心的隔离式加热室。
+ 4. 主电源(交流电源)电压室和床身加热,以便快速启动。
+
+你可以用现成的零件来构建这个项目,其中一些零件你可以打印,价格不到 1000 美元。它可以成功打印聚醚酮酮 (PEKK) 和聚醚酰亚胺(PEI,以商品名 Ultem 出售)。这两种材料都比现在低成本打印机能打印的任何材料强得多。
+
+![PPE printer][7]
+
+这款高温 3D 打印机的设计是有三个头,但我们发布的时候只有一个头。Cerberus 是以希腊神话中的三头冥界看门狗命名的。通常情况下,我们不会发布只有一个头的打印机,但疫情改变了我们的优先级。[开源社区团结起来][9],帮助解决早期的供应不足,许多桌面 3D 打印机都在产出有用的产品,以帮助保护人们免受 COVID 的侵害。
+
+那另外两个头呢?
+
+其他两个头是为了高温熔融颗粒制造(例如,这个开源的 [3D打印机][10] 的高温版本)并铺设金属线(像在 [这个设计][11] 中),以建立一个开源的热交换器。Cerberus 打印机的其他功能可能是一个自动喷嘴清洁器和在高温下打印连续纤维的方法。另外,你还可以在转台上安装任何你喜欢的东西来制造高端产品。
+
+把一个盒子放在 3D 打印机周围,而把电子元件留在外面的 [专利][12] 到期,为高温家用 3D 打印机铺平了道路,这将使这些设备以合理的成本从单纯的玩具变为工业工具。
+
+已经有公司在 RepRap 传统的基础上,将这些低成本系统推向市场(例如,1250 美元的 [Creality3D CR-5 Pro][13] 3D 打印机可以达到 300℃)。Creality 销售最受欢迎的桌面 3D 打印机,并开源了部分设计。
+
+然而,要打印超高端工程聚合物,这些打印机需要达到 350℃ 以上。开源计划已经可以帮助桌面 3D 打印机制造商开始与垄断公司竞争,这些公司由于躲在专利背后,已经阻碍了 3D 打印 20 年。期待低成本、高温桌面 3D 打印机的竞争将真正升温!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/desktop-3d-printer
+
+作者:[Joshua Pearce][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jmpearce
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/3d_printer_mask.jpg?itok=5ePZghTW (High-temperature 3D-printed mask)
+[2]: https://reprap.org/wiki/RepRap
+[3]: https://reprap.org/wiki/Wealth_Without_Money
+[4]: https://3dprintingindustry.com/news/stratasys-heated-build-chamber-for-3d-printer-patent-us6722872b1-set-to-expire-this-week-185012/
+[5]: https://doi.org/10.1016/j.ohx.2020.e00130
+[6]: https://www.appropedia.org/Open_Source_High-Temperature_Reprap_for_3-D_Printing_Heat-Sterilizable_PPE_and_Other_Applications
+[7]: https://opensource.com/sites/default/files/uploads/ppe-hight3dp.png (PPE printer)
+[8]: https://www.gnu.org/licenses/fdl-1.3.html
+[9]: https://opensource.com/article/20/3/volunteer-covid19
+[10]: https://www.liebertpub.com/doi/10.1089/3dp.2019.0195
+[11]: https://www.appropedia.org/Open_Source_Multi-Head_3D_Printer_for_Polymer-Metal_Composite_Component_Manufacturing
+[12]: https://www.academia.edu/17609790/A_Novel_Approach_to_Obviousness_An_Algorithm_for_Identifying_Prior_Art_Concerning_3-D_Printing_Materials
+[13]: https://creality3d.shop/collections/cr-series/products/cr-5-pro-h-3d-printer
diff --git a/published/20210325 Identify Linux performance bottlenecks using open source tools.md b/published/20210325 Identify Linux performance bottlenecks using open source tools.md
new file mode 100644
index 0000000000..55b95a5034
--- /dev/null
+++ b/published/20210325 Identify Linux performance bottlenecks using open source tools.md
@@ -0,0 +1,265 @@
+[#]: subject: (Identify Linux performance bottlenecks using open source tools)
+[#]: via: (https://opensource.com/article/21/3/linux-performance-bottlenecks)
+[#]: author: (Howard Fosdick https://opensource.com/users/howtech)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13462-1.html)
+
+使用开源工具识别 Linux 的性能瓶颈
+======
+
+> 不久前,识别硬件瓶颈还需要深厚的专业知识。今天的开源 GUI 性能监视器使它变得相当简单。
+
+
+
+计算机是一个集成的系统,它的性能取决于最慢的硬件组件。如果一个组件的能力比其他组件差,性能落后而不能跟上,它就会拖累你的整个系统。这就是一个 _性能瓶颈_。消除一个严重的瓶颈可以使你的系统飞起来。
+
+本文解释了如何识别 Linux 系统中的硬件瓶颈。这些技术同时适用于个人的电脑和服务器。我强调的是个人电脑 —— 我不会涉及局域网管理或数据库系统等领域的服务器特定的瓶颈。这些通常涉及专门的工具。
+
+我也不会多谈解决方案。这对本文来说是个太大的话题。相反,我将写一篇关于性能调整的后续文章。
+
+我将只使用开源的图形用户界面(GUI)工具来完成这项工作。大多数关于 Linux 瓶颈的文章都相当复杂。它们使用专门的命令,并深入研究神秘的细节。
+
+开源提供的 GUI 工具使得识别许多瓶颈变得简单。我的目标是给你一个快速、简单的方法,你可以在任何地方使用。
+
+### 从哪里开始
+
+一台计算机由六个关键的硬件资源组成。
+
+ * 处理器
+ * 内存
+ * 存储器
+ * USB 端口
+ * 互联网连接
+ * 图形处理器
+
+如果任何一个资源表现不佳,就会产生一个性能瓶颈。为了识别瓶颈,你必须监测这六种资源。
+
+开源提供了大量的工具来完成这项工作。我会使用 [GNOME 系统监视器][2]。它的输出很容易理解,而且你可以在大多数软件库中找到它。
+
+启动它并点击“资源”标签。你可以马上发现许多性能问题。
+
+![系统监控-资源面板][3]
+
+*图 1. 系统监控器发现问题。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+在“资源”面板上显示三个部分:CPU 历史、内存和交换历史,以及网络历史。一眼就能看出你的处理器是否不堪负荷了,还是你的电脑没有内存了,抑或你的网络带宽被用光了。
+
+我将在下面探讨这些问题。现在,当你的电脑速度变慢时,首先检查系统监视器。它可以立即为你提供最常见的性能问题的线索。
+
+现在让我们来探讨一下如何识别特定方面的瓶颈。
+
+### 如何识别处理器的瓶颈
+
+要发现瓶颈,你必须首先知道你有什么硬件。开源为这个目的提供了几个工具。我喜欢 [HardInfo][5],因为它的屏幕显示很容易阅读,而且广泛流行。
+
+启动 HardInfo。它的“计算机->摘要”面板可以识别你的 CPU 并告诉你它的核心数、线程数和速度。它还能识别你的主板和其他计算机部件。
+
+![HardInfo Summary Panel][6]
+
+*图 2. HardInfo 显示了硬件细节。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+HardInfo 显示,这台计算机有一个物理 CPU 芯片。该芯片包含两个处理器(或称为核心)。每个核心支持两个线程(或称为逻辑处理器)。这就是总共四个逻辑处理器 —— 正是图 1 中系统监控器的 CPU 历史部分所显示的。
+
+当处理器不能在其时间内对请求做出反应时,就会出现 _处理器瓶颈_,说明它们已经很忙了。
+
+当系统监控器显示逻辑处理器的利用率持续在 80% 或 90% 以上时,你就可以确定这一点。这里有一个例子,四个逻辑处理器中有三个被淹没在 100% 的利用率中。这是一个瓶颈,因为它没有留下多少 CPU 用于其他工作。
+
+![系统监视器的处理器瓶颈][7]
+
+*图 3. 一个处理器的瓶颈。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+#### 哪个程序导致了这个问题?
+
+你需要找出是哪个程序在消耗所有的 CPU。点击系统监视器的“进程”标签。然后点击“CPU 百分比”标头,根据它们消耗的 CPU 的多少对进程进行排序。你将看到哪些应用程序正在扼杀你的系统。
+
+![系统监控进程面板][8]
+
+*图 4. 识别违规的进程。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+前三个进程各消耗了 _总 CPU 资源的 24%_。由于有四个逻辑处理器,这意味着每个进程消耗了一整个处理器。这就像图 3 所示。
+
+在“进程”面板上,一个名为“analytical_AI”的程序被确定为罪魁祸首。你可以在面板上右键单击它,以查看其资源消耗的更多细节,包括内存使用、它所打开的文件、其输入/输出细节,等等。
+
+如果你的登录会话有管理员权限,你可以管理这个进程。你可以改变它的优先级,并停止、继续、结束或杀死它。因此,你可以在这里立即解决你的瓶颈问题。
+
+![系统监视器管理一个进程][9]
+
+*图 5. 右键点击一个进程来管理它。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+如何解决处理瓶颈问题?除了实时管理违规的进程外,你也可以防止瓶颈的发生。例如,你可以用另一个应用程序来代替违规进程,绕过它,改变你使用该应用程序的行为,将该应用程序安排在非工作时间,解决潜在的内存问题,对该应用程序或你的系统软件进行性能调整,或升级你的硬件。这里涉及的内容太多,所以我将在下一篇文章中探讨这些方式。
+
+#### 常见的处理器瓶颈
+
+在用系统监控器监控你的 CPU 时,你会遇到几种常见的瓶颈问题。
+
+有时一个逻辑处理器出现瓶颈,而其他所有的处理器都处于低利用率。这意味着你有一个应用程序,它的代码不够智能,无法利用一个以上的逻辑处理器,而且它已经把正在使用的那个处理器耗尽了。这个应用程序完成的时间将比使用更多的处理器要长。但另一方面,至少它能让你的其他处理器腾出手来做别的工作,而不会接管你的电脑。
+
+你也可能看到一个逻辑处理器永远停留在 100% 的利用率。要么它非常忙,要么是一个进程被挂起了。判断它是否被挂起的方法是,是看该进程是否从不进行任何磁盘活动(正如系统监视器“进程”面板所显示的那样)。
+
+最后,你可能会注意到,当你所有的处理器都陷入瓶颈时,你的内存也被完全利用了。内存不足的情况有时会导致处理器瓶颈。在这种情况下,你要解决的是根本的内存问题,而不是体现出症状的 CPU 问题。
+
+### 如何识别内存瓶颈
+
+鉴于现代 PC 中有大量的内存,内存瓶颈比以前要少得多。然而,如果你运行内存密集型程序,特别是当你的计算机没有很多的随机存取内存(RAM)时,你仍然可能遇到这些问题。
+
+Linux [使用内存][10] 既用于程序,也用于缓存磁盘数据。后者加快了磁盘数据的访问速度。Linux 可以在它需要的任何时候回收这些内存供程序使用。
+
+系统监视器的“资源”面板显示了你的总内存和它被使用的程度。在“进程”面板上,你可以看到单个进程的内存使用情况。
+
+下面是系统监控器“资源”面板中跟踪总内存使用的部分。
+
+![系统监控器的内存瓶颈][11]
+
+*图 6. 一个内存瓶颈。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+在“内存”的右边,你会注意到 [交换空间][12]。这是 Linux 在内存不足时使用的磁盘空间。它将内存写入磁盘以继续操作,有效地将交换空间作为你的内存的一个较慢的扩展。
+
+你要注意的两个内存性能问题是:
+
+1. 内存被大量使用,而且你看到交换空间的活动频繁或不断增加。
+2. 内存和交换空间都被大量使用。
+
+情况一意味着更慢的性能,因为交换空间总是比内存更慢。你是否认为这是一个性能问题,取决于许多因素(例如,你的交换空间有多活跃、它的速度、你的预期,等等)。我的看法是,对于现代个人电脑来说,交换空间任何超过象征性的使用都是不可接受的。
+
+情况二是指内存和交换空间都被大量使用。这是一个 _内存瓶颈_。计算机变得反应迟钝。它甚至可能陷入一种“咆哮”的状态,在这种状态下,除了内存管理之外,它几乎不能完成其他任务。
+
+上面的图 6 显示了一台只有 2GB 内存的旧电脑。当内存使用量超过 80% 时,系统开始向交换空间写入,响应速度下降了。这张截图显示了内存使用量超过了 90%,而且这台电脑已经无法使用。
+
+解决内存问题的最终答案是要么少用内存,要么多买内存。我将在后续文章中讨论解决方案。
+
+### 如何识别存储瓶颈
+
+如今的存储有固态和机械硬盘等多个品种。设备接口包括 PCIe、SATA、雷电和 USB。无论有哪种类型的存储,你都要使用相同的程序来识别磁盘瓶颈。
+
+从系统监视器开始。它的“进程”面板显示各个进程的输入/输出率。因此,你可以快速识别哪些进程做了最多的磁盘 I/O。
+
+但该工具并不显示每个磁盘的总数据传输率。你需要查看特定磁盘上的总负载,以确定该磁盘是否是一个存储瓶颈。
+
+要做到这一点,使用 [atop][13] 命令。它在大多数 Linux 软件库中都有。
+
+只要在命令行提示符下输入 `atop` 即可。下面的输出显示,设备 `sdb` 达到 `busy 101%`。很明显,它已经达到了性能极限,限制了你的系统完成工作的速度。
+
+![atop 磁盘瓶颈][14]
+
+*图 7. atop 命令识别了一个磁盘瓶颈。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+注意到其中一个 CPU 有 85% 的时间在等待磁盘完成它的工作(`cpu001 w 85%`)。这是典型的存储设备成为瓶颈的情况。事实上,许多人首先看 CPU 的 I/O 等待时间来发现存储瓶颈。
+
+因此,要想轻松识别存储瓶颈,请使用 `atop` 命令。然后使用系统监视器上的“进程”面板来识别导致瓶颈的各个进程。
+
+### 如何识别 USB 端口的瓶颈
+
+有些人整天都在使用他们的 USB 端口。然而,他们从不检查这些端口是否被最佳地使用。无论你是插入外部磁盘、U 盘,还是其他东西,你都要确认你是否从 USB 连接的设备中获得了最大性能。
+
+这个图表显示了原因。潜在的 USB 数据传输率差异 _很大_。
+
+![USB 标准][15]
+
+*图 8. USB 速度变化很大。(Howard Fosdick,根据 [Tripplite][16] 和 [Wikipedia][17] 提供的数字,[CC BY-SA 4.0][4])*
+
+HardInfo 的“USB 设备”标签显示了你的计算机支持的 USB 标准。大多数计算机提供不止一种速度。你怎么知道一个特定端口的速度呢?供应商对它们进行颜色编码,如图表中所示。或者你可以在你的计算机的文档中查找。
+
+要看到你得到的实际速度,可以使用开源的 [GNOME 磁盘][18] 程序进行测试。只要启动 GNOME 磁盘,选择它的“磁盘基准”功能,然后运行一个基准测试。这将告诉你在一个端口插入特定设备时,你将得到的最大实际速度。
+
+你可能会得到不同的端口传输速度,这取决于你将哪个设备插入它。数据速率取决于端口和设备的特定组合。
+
+例如,一个可以以 3.1 速度运行的设备如果使用 2.0 端口就会以 2.0 的速度运行。(而且它不会告诉你它是以较慢的速度运行的!)相反,如果你把一个 USB 2.0 设备插入 3.1 端口,它能工作,但速度是 2.0 的速度。所以要获得快速的 USB,你必须确保端口和设备都支持它。GNOME 磁盘为你提供了验证这一点的方法。
+
+要确定 USB 的处理瓶颈,使用你对固态和硬盘所做的同样程序。运行 `atop` 命令来发现 USB 存储瓶颈。然后,使用系统监视器来获取违规进程的详细信息。
+
+### 如何识别互联网带宽瓶颈
+
+系统监控器的“资源”面板会实时告诉你互联网连接速度(见图 1)。
+
+有 [很好的 Python 工具][19] 可以测试你的最大网速,但你也可以在 [Speedtest][20]、[Fast.com][21] 和 [Speakeasy][22] 等网站进行测试。为了获得最佳结果,关闭所有东西,只运行 _速度测试_;关闭你的虚拟私有网络;在一天中的不同时间运行测试;并比较几个测试网站的结果。
+
+然后将你的结果与你的供应商声称的下载和上传速度进行比较。这样,你就可以确认你得到的是你所付费的速度。
+
+如果你有一个单独的路由器,在有和没有它的情况下进行测试。这可以告诉你,你的路由器是否是一个瓶颈。如果你使用 WiFi,在有 WiFi 和没有 WiFi 的情况下进行测试(通过将你的笔记本电脑直接与调制解调器连接)。我经常看到人们抱怨他们的互联网供应商,而实际上他们只是有一个 WiFi 瓶颈,可以自己解决。
+
+如果某些程序正在消耗你的整个互联网连接,你想知道是哪一个。通过使用 `nethogs` 命令找到它。它在大多数软件库中都有。
+
+有一天,我的系统监视器突然显示我的互联网访问量激增。我只是在命令行中输入了 `nethogs`,它立即确定带宽消耗者是 Clamav 防病毒更新。
+
+![Nethogs][23]
+
+*图 9. Nethogs 识别带宽用户。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+### 如何识别图形处理瓶颈
+
+如果你把显示器插在台式电脑后面的主板上,你就在使用 _板载显卡_。如果你把它插在后面的卡上,你就有一个专门的图形子系统。大多数人称它为 _视频卡_ 或 _显卡_。对于台式电脑来说,附加显卡通常比主板上的显卡更强大、更昂贵。笔记本电脑总是使用板载显卡。
+
+HardInfo 的“PCI 设备”面板告诉你关于你的图形处理单元(GPU)。它还显示你的专用视频内存的数量(寻找标有“可预取”的内存)。
+
+![视频芯片组信息][24]
+
+*图 10. HardInfo提供图形处理信息。(Howard Fosdick, [CC BY-SA 4.0][4])*
+
+CPU 和 GPU [非常密切地][25] 一起工作。简而言之,CPU 为 GPU 准备渲染的帧,然后 GPU 渲染这些帧。
+
+当你的 CPU 在等待 100% 繁忙的 GPU 时,就会出现 _GPU 瓶颈_。
+
+为了确定这一点,你需要监控 CPU 和 GPU 的利用率。像 [Conky][26] 和 [Glances][27] 这样的开源监控器,如果它们的扩展插件支持你的图形芯片组,就可以做到这一点。
+
+看一下 Conky 的这个例子。你可以看到,这个系统有很多可用的 CPU。GPU 只有 25% 的使用率。想象一下,如果这个 GPU 的数量接近 100%。那么你就会知道 CPU 在等待 GPU,你就会有一个 GPU 的瓶颈。
+
+![Conky CPU 和 GPU 监控][28]
+
+*图 11. Conky 显示 CPU 和 GPU 的利用率。 (图片来源:[AskUbuntu论坛][29])*
+
+在某些系统上,你需要一个供应商专属的工具来监控你的 GPU。它们可以从 GitHub 上下载,并在 [GPU 监控和诊断命令行工具][30] 这篇文章中有所描述。
+
+### 总结
+
+计算机由一系列集成的硬件资源组成。如果它们中的任何一个在工作量上远远落后于其他资源,就会产生性能瓶颈。这可能会拖累你的整个系统。你需要能够识别和纠正瓶颈,以实现最佳性能。
+
+不久前,识别瓶颈需要深厚的专业知识。今天的开源 GUI 性能监控器使它变得相当简单。
+
+在我的下一篇文章中,我将讨论改善你的 Linux 电脑性能的具体方法。同时,请在评论中分享你自己的经验。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/linux-performance-bottlenecks
+
+作者:[Howard Fosdick][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/howtech
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_lightning.png?itok=wRzjWIlm (Lightning in a bottle)
+[2]: https://wiki.gnome.org/Apps/SystemMonitor
+[3]: https://opensource.com/sites/default/files/uploads/1_system_monitor_resources_panel.jpg (System Monitor - Resources Panel )
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://itsfoss.com/hardinfo/
+[6]: https://opensource.com/sites/default/files/uploads/2_hardinfo_summary_panel.jpg (HardInfo Summary Panel)
+[7]: https://opensource.com/sites/default/files/uploads/3_system_monitor_100_processor_utilization.jpg (System Monitor processor bottleneck)
+[8]: https://opensource.com/sites/default/files/uploads/4_system_monitor_processes_panel.jpg (System Monitor Processes panel)
+[9]: https://opensource.com/sites/default/files/uploads/5_system_monitor_manage_a_process.jpg (System Monitor managing a process)
+[10]: https://www.networkworld.com/article/3394603/when-to-be-concerned-about-memory-levels-on-linux.html
+[11]: https://opensource.com/sites/default/files/uploads/6_system_monitor_out_of_memory.jpg (System Monitor memory bottleneck)
+[12]: https://opensource.com/article/18/9/swap-space-linux-systems
+[13]: https://opensource.com/life/16/2/open-source-tools-system-monitoring
+[14]: https://opensource.com/sites/default/files/uploads/7_atop_storage_bottleneck.jpg (atop disk bottleneck)
+[15]: https://opensource.com/sites/default/files/uploads/8_usb_standards_speeds.jpg (USB standards)
+[16]: https://www.samsung.com/us/computing/memory-storage/solid-state-drives/
+[17]: https://en.wikipedia.org/wiki/USB
+[18]: https://wiki.gnome.org/Apps/Disks
+[19]: https://opensource.com/article/20/1/internet-speed-tests
+[20]: https://www.speedtest.net/
+[21]: https://fast.com/
+[22]: https://www.speakeasy.net/speedtest/
+[23]: https://opensource.com/sites/default/files/uploads/9_nethogs_bandwidth_consumers.jpg (Nethogs)
+[24]: https://opensource.com/sites/default/files/uploads/10_hardinfo_video_card_information.jpg (Video Chipset Information)
+[25]: https://www.wepc.com/tips/cpu-gpu-bottleneck/
+[26]: https://itsfoss.com/conky-gui-ubuntu-1304/
+[27]: https://opensource.com/article/19/11/monitoring-linux-glances
+[28]: https://opensource.com/sites/default/files/uploads/11_conky_cpu_and_gup_monitoring.jpg (Conky CPU and GPU monitoring)
+[29]: https://askubuntu.com/questions/387594/how-to-measure-gpu-usage
+[30]: https://www.cyberciti.biz/open-source/command-line-hacks/linux-gpu-monitoring-and-diagnostic-commands/
diff --git a/published/202104/20190319 How to set up a homelab from hardware to firewall.md b/published/202104/20190319 How to set up a homelab from hardware to firewall.md
new file mode 100644
index 0000000000..54c24e7a14
--- /dev/null
+++ b/published/202104/20190319 How to set up a homelab from hardware to firewall.md
@@ -0,0 +1,107 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wyxplus)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13262-1.html)
+[#]: subject: (How to set up a homelab from hardware to firewall)
+[#]: via: (https://opensource.com/article/19/3/home-lab)
+[#]: author: (Michael Zamot https://opensource.com/users/mzamot)
+
+如何从硬件到防火墙建立一个家庭实验室
+======
+
+> 了解一下用于构建自己的家庭实验室的硬件和软件方案。
+
+
+
+你有想过创建一个家庭实验室吗?或许你想尝试不同的技术,构建开发环境、亦或是建立自己的私有云。拥有一个家庭实验室的理由很多,本教程旨在使入门变得更容易。
+
+规划家庭实验室时,需要考虑三方面:硬件、软件和维护。我们将在这里查看前两方面,并在以后的文章中讲述如何节省维护计算机实验室的时间。
+
+### 硬件
+
+在考虑硬件需求时,首先要考虑如何使用实验室以及你的预算、噪声、空间和电力使用情况。
+
+如果购买新硬件过于昂贵,请搜索当地的大学、广告以及诸如 eBay 或 Craigslist 之类的网站,能获取二手服务器的地方。它们通常很便宜,并且服务器级的硬件可以使用很多年。你将需要三类硬件:虚拟化服务器、存储设备和路由器/防火墙。
+
+#### 虚拟化服务器
+
+一个虚拟化服务器允许你去运行多个共享物理机资源的虚拟机,同时最大化利用和隔离资源。如果你弄坏了一台虚拟机,无需重建整个服务器,只需虚拟一个好了。如果你想进行测试或尝试某些操作而不损坏整个系统,仅需要新建一个虚拟机来运行即可。
+
+在虚拟服务器中,需考虑两个最重要的因素是 CPU 的核心数及其运行速度以及内存容量。如果没有足够的资源够全部虚拟机共享,那么它们将被过度分配并试着获取其他虚拟机的 CPU 的周期和内存。
+
+因此,考虑一个多核 CPU 的平台。你要确保 CPU 支持虚拟化指令(因特尔的 VT-x 指令集和 AMD 的 AMD-V 指令集)。能够处理虚拟化的优质的消费级处理器有因特尔的 i5 或 i7 和 AMD 的 Ryzen 处理器。如果你考虑服务器级的硬件,那么因特尔的志强系列和 AMD 的 EPYC 都是不错的选择。内存可能很昂贵,尤其是最近的 DDR4 内存。当我们估计所需多少内存时,请为主机操作系统的内存至少分配 2 GB 的空间。
+
+如果你担心电费或噪声,则诸如因特尔 NUC 设备之类的解决方案虽然外形小巧、功耗低、噪音低,但是却以牺牲可扩展性为代价。
+
+#### NAS
+
+如果希望装有硬盘驱动器的计算机存储你的所有个人数据,电影,图片等,并为虚拟化服务器提供存储,则需要网络附加存储(NAS)。
+
+在大多数情况下,你不太可能需要一颗强力的 CPU。实际上,许多商业 NAS 的解决方案使用低功耗的 ARM CPU。支持多个 SATA 硬盘的主板是必须的。如果你的主板没有足够的端口,请使用主机总线适配器(HBA)SAS 控制器添加额外的端口。
+
+网络性能对于 NAS 来说是至关重要的,因此最好选择千兆网络(或更快网络)。
+
+内存需求根据你的文件系统而有所不同。ZFS 是 NAS 上最受欢迎的文件系统之一,你需要更多内存才能使用诸如缓存或重复数据删除之类的功能。纠错码(ECC)的内存是防止数据损坏的最佳选择(但在购买前请确保你的主板支持)。最后但同样重要的,不要忘记使用不间断电源(UPS),因为断电可能会使得数据出错。
+
+#### 防火墙和路由器
+
+你是否曾意识到,廉价的路由器/防火墙通常是保护你的家庭网络不受外部环境影响的主要部分?这些路由器很少及时收到安全更新(如果有的话)。现在害怕了吗?好吧,[确实][2]!
+
+通常,你不需要一颗强大的 CPU 或是大量内存来构建你自己的路由器/防火墙,除非你需要高吞吐率或是执行 CPU 密集型任务,像是虚拟私有网络服务器或是流量过滤。在这种情况下,你将需要一个支持 AES-NI 的多核 CPU。
+
+你可能想要至少 2 个千兆或更快的以太网卡(NIC),这不是必需的,但我推荐使用一个管理型交换机来连接你自己的装配的路由器,以创建 VLAN 来进一步隔离和保护你的网络。
+
+![Home computer lab PfSense][4]
+
+### 软件
+
+在选择完你的虚拟化服务器、NAS 和防火墙/路由器后,下一步是探索不同的操作系统和软件,以最大程度地发挥其作用。尽管你可以使用 CentOS、Debian或 Ubuntu 之类的常规 Linux 发行版,但是与以下软件相比,它们通常花费更多的时间进行配置和管理。
+
+#### 虚拟化软件
+
+[KVM][5](基于内核的虚拟机)使你可以将 Linux 变成虚拟机监控程序,以便可以在同一台机器中运行多个虚拟机。最好的是,KVM 作为 Linux 的一部分,它是许多企业和家庭用户的首选。如果你愿意,可以安装 [libvirt][6] 和 [virt-manager][7] 来管理你的虚拟化平台。
+
+[Proxmox VE][8] 是一个强大的企业级解决方案,并且是一个完全开源的虚拟化和容器平台。它基于 Debian,使用 KVM 作为其虚拟机管理程序,并使用 LXC 作为容器。Proxmox 提供了强大的网页界面、API,并且可以扩展到许多群集节点,这很有用,因为你永远不知道何时实验室容量不足。
+
+[oVirt][9](RHV)是另一种使用 KVM 作为虚拟机管理程序的企业级解决方案。不要因为它是企业级的,就意味着你不能在家中使用它。oVirt 提供了强大的网页界面和 API,并且可以处理数百个节点(如果你运行那么多服务器,我可不想成为你的邻居!)。oVirt 用于家庭实验室的潜在问题是它需要一套最低限度的节点:你将需要一个外部存储(例如 NAS)和至少两个其他虚拟化节点(你可以只在一个节点上运行,但你会遇到环境维护方面的问题)。
+
+#### 网络附加存储软件
+
+[FreeNAS][10] 是最受欢迎的开源 NAS 发行版,它基于稳定的 FreeBSD 操作系统。它最强大的功能之一是支持 ZFS 文件系统,该文件系统提供了数据完整性检查、快照、复制和多个级别的冗余(镜像、条带化镜像和条带化)。最重要的是,所有功能都通过功能强大且易于使用的网页界面进行管理。在安装 FreeNAS 之前,请检查硬件是否支持,因为它不如基于 Linux 的发行版那么广泛。
+
+另一个流行的替代方法是基于 Linux 的 [OpenMediaVault][11]。它的主要功能之一是模块化,带有可扩展和添加特性的插件。它包括的功能包括基于网页管理界面,CIFS、SFTP、NFS、iSCSI 等协议,以及卷管理,包括软件 RAID、资源配额,访问控制列表(ACL)和共享管理。由于它是基于 Linux 的,因此其具有广泛的硬件支持。
+
+#### 防火墙/路由器软件
+
+[pfSense][12] 是基于 FreeBSD 的开源企业级路由器和防火墙发行版。它可以直接安装在服务器上,甚至可以安装在虚拟机中(以管理虚拟或物理网络并节省空间)。它有许多功能,可以使用软件包进行扩展。尽管它也有命令行访问权限,但也可以完全使用网页界面对其进行管理。它具有你所希望路由器和防火墙提供的所有功能,例如 DHCP 和 DNS,以及更高级的功能,例如入侵检测(IDS)和入侵防御(IPS)系统。你可以侦听多个不同接口或使用 VLAN 的网络,并且只需鼠标点击几下即可创建安全的 VPN 服务器。pfSense 使用 pf,这是一种有状态的数据包筛选器,它是为 OpenBSD 操作系统开发的,使用类似 IPFilter 的语法。许多公司和组织都有使用 pfSense。
+
+* * *
+
+考虑到所有的信息,是时候动手开始建立你的实验室了。在之后的文章中,我将介绍运行家庭实验室的第三方面:自动化进行部署和维护。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/home-lab
+
+作者:[Michael Zamot (Red Hat)][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mzamot
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb
+[2]: https://opensource.com/article/18/5/how-insecure-your-router
+[3]: /file/427426
+[4]: https://opensource.com/sites/default/files/uploads/pfsense2.png (Home computer lab PfSense)
+[5]: https://www.linux-kvm.org/page/Main_Page
+[6]: https://libvirt.org/
+[7]: https://virt-manager.org/
+[8]: https://www.proxmox.com/en/proxmox-ve
+[9]: https://ovirt.org/
+[10]: https://freenas.org/
+[11]: https://www.openmediavault.org/
+[12]: https://www.pfsense.org/
diff --git a/published/202104/20200106 Open Source Supply Chain- A Matter of Trust.md b/published/202104/20200106 Open Source Supply Chain- A Matter of Trust.md
new file mode 100644
index 0000000000..60aa20fb4c
--- /dev/null
+++ b/published/202104/20200106 Open Source Supply Chain- A Matter of Trust.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Kevin3599)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13321-1.html)
+[#]: subject: (Open Source Supply Chain: A Matter of Trust)
+[#]: via: (https://www.linux.com/articles/open-source-supply-chain-a-matter-of-trust/)
+[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
+
+开源供应链:一个有关信任的问题
+======
+
+[![][1]][2]
+
+共同作者:Curtis Franklin, Jr
+
+开源软件通常被认为比专有软件更安全、更有保障,因为如果用户愿意,他们可以从源代码编译软件。他们知道在他们环境中运行的代码的来源。在他们的环境中运行的代码每个部分都可以被审查,也可以追溯每段代码的开发者。
+
+然而,用户和提供者们正在逐渐远离完全控制软件所带来的复杂性,而在转而追求软件的便捷和易用。
+
+VMware 副总裁兼首席开源官 Dirk Hohndel 说:“当我看到在一个有关网络安全和隐私的讲座中,演讲者运行 `docker run` 命令来安装和运行一些从互联网上下载的随机二进制文件时,我经常会大吃一惊。这两件事似乎有点相左。”
+
+软件供应链,即将应用程序从编码、打包、分发到最终用户的过程是相当复杂的。如果其中有一环出现错误,可能会导致软件存在潜在的风险,特别是对于开源软件。一个恶意行为者可以访问后端,并在用户不知情或不受控的情况下向其插入任何可能的恶意代码。
+
+这样的问题不单单存在于云原生领域,在现代应用开发中很常见,这包括 JavaScript、NPM、PyPI、RubyGems 等等。甚至连 Mac 上的 Homebrew 过去也是通过源代码提供,由用户自己编译。
+
+“如今,你只需要下载二进制文件并安装它,并期望其源代码并没有被恶意修改过。”Hohndel 说,“作为一个行业,我们需要更加关注我们的开源代码供应。这对我来说是非常重要的事,我正努力让更多的人意识到其重要性。”
+
+然而,这不仅仅是一个二进制与源代码的关系。只运行一个二进制文件,而不必从源代码构建所有东西有着巨大的优势。当软件开发需求发生转变时候,这种运行方式允许开发人员在过程中更加灵活和响应更快。通过重用一些二进制文件,他们可以在新的开发和部署中快速地循环。
+
+Hohndel 说:“如果有办法向这些软件添加签名,并建立一个‘即时’验证机制,让用户知道他们可以信任此软件,那就更好了。”
+
+Linux 发行版解决了这个问题,因为发行版充当了看门人的角色,负责检查进入受支持的软件存储库的软件包的完整性。
+
+“像通过 Debian 等发行版提供的软件包都使用了密钥签名。要确保它确实是发行版中应包含的软件,需要进行大量工作。开发者们通过这种方式解决了开源供应链问题。”Hohndel 说。
+
+但是,即使在 Linux 发行版上,人们也希望简化事情,并以正确性和安全性换取速度。现在,诸如 AppImage、Snap 和 Flatpack 之类的项目已经采用了二进制方式,从而将开源供应链信任问题带入了 Linux 发行版。这和 Docker 容器的问题如出一辙。
+
+“理想的解决方案是为开源社区找到一种设计信任系统的方法,该系统可以确保如果二进制文件是用受信任网络中的密钥签名的,那么它就可以被信任,并允许我们可靠地返回源头并进行审核,” Hohndel 建议。
+
+但是,所有这些额外的步骤都会产生成本,大多数项目开发者要么不愿意,或无力承担。一些项目正在尝试寻找解决该问题的方法。例如,NPM 已开始鼓励提交软件包的用户正确认证和保护其账户安全,以提高平台的可信度。
+
+### 开源社区善于解决问题
+
+Hohndel 致力于解决开源供应链问题,并正试图让更多开发者意识到其重要性。去年,VMware 收购了 Bitnami,这为管理由 VMware 所签名的开源软件提供了一个良机。
+
+“我们正在与各种上游开源社区进行交流,以提高对此的认识。我们还在讨论技术解决方案,这些方案将使这些社区更容易解决潜在的开源供应链问题。” Hohndel 说。
+
+开源社区历来致力于确保软件质量,这其中也包括安全性和隐私性。不过,Hohndel 说:“我最担心的是,在对下一个新事物感到兴奋时,我们经常忽略了需要的基础工程原则。”
+
+最终,Hohndel 认为答案将来自开源社区本身。 “开源是一种工程方法论,是一种社会实验。开源就是人们之间相互信任、相互合作、跨国界和公司之间以及竞争对手之间的合作,以我们以前从未有过的方式。”他解释说。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/articles/open-source-supply-chain-a-matter-of-trust/
+
+作者:[Swapnil Bhartiya][a]
+选题:[lujun9972][b]
+译者:[Kevin3599](https://github.com/kevin3599)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/author/swapnil/
+[b]: https://github.com/lujun9972
+[1]: https://www.linux.com/wp-content/uploads/2020/01/hand-1137978_1920-1068x801.jpg (hand-1137978_1920)
+[2]: https://www.linux.com/wp-content/uploads/2020/01/hand-1137978_1920.jpg
+[3]: https://www.swapnilbhartiya.com/open-source-leaders-dirk-hohndel-brings-open-source-to-vmware/
+[4]: https://techcrunch.com/2019/05/15/vmware-acquires-bitnami-to-deliver-packaged-applications-anywhere/
diff --git a/published/202104/20200423 4 open source chat applications you should use right now.md b/published/202104/20200423 4 open source chat applications you should use right now.md
new file mode 100644
index 0000000000..5c445b9586
--- /dev/null
+++ b/published/202104/20200423 4 open source chat applications you should use right now.md
@@ -0,0 +1,138 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wyxplus)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13271-1.html)
+[#]: subject: (4 open source chat applications you should use right now)
+[#]: via: (https://opensource.com/article/20/4/open-source-chat)
+[#]: author: (Sudeshna Sur https://opensource.com/users/sudeshna-sur)
+
+值得现在就去尝试的四款开源聊天应用软件
+======
+
+> 现在,远程协作已作为一项必不可少的能力,让开源实时聊天成为你工具箱中必不可少的一部分吧。
+
+
+
+清晨起床后,我们通常要做的第一件事是检查手机,看看是否有同事和朋友发来的重要信息。无论这是否是一个好习惯,但这种行为早已成为我们日常生活的一部分。
+
+> 人是理性动物。他可以为任何他想相信的事情想出一个理由。
+> – 阿纳托尔·法朗士
+
+无论理由是否合理,我们每天都在使用的一系列的通讯工具,例如电子邮件、电话、网络会议工具或社交网络。甚至在 COVID-19 之前,居家办公就已经使这些通信工具成为我们生活中的重要部分。随着疫情出现,居家办公成为新常态,我们交流方式的方方面面正面临着前所未有的改变,这让这些工具变得不可或缺。
+
+### 为什么需要聊天?
+
+作为全球团队的一部分进行远程工作时,我们必须要有一个相互协作的环境。聊天应用软件在帮助我们保持相互联系中起着至关重要的作用。与电子邮件相比,聊天应用软件可提供与全球各地的同事快速、实时的通信。
+
+选择一款聊天应用软件需要考虑很多因素。为了帮助你选择最适合你的应用软件,在本文中,我将探讨四款开源聊天应用软件,和一个当你需要与同事“面对面”时的开源视频通信工具,然后概述在高效的通讯应用软件中,你应当考虑的一些功能。
+
+### 四款开源聊天软件
+
+#### Rocket.Chat
+
+![Rocket.Chat][2]
+
+[Rocket.Chat][3] 是一个综合性的通讯平台,其将频道分为公开房间(任何人都可以加入)和私有房间(仅受邀请)。你还可以直接将消息发送给已登录的人员。其能共享文档、链接、照片、视频和动态图,以及进行视频通话,并可以在平台中发送语音信息。
+
+Rocket.Chat 是自由开源软件,但是其独特之处在于其可自托管的聊天系统。你可以将其下载到你的服务器上,无论它是本地服务器或是在公有云上的虚拟专用服务器。
+
+Rocket.Chat 是完全免费,其 [源码][4] 可在 Github 获得。许多开源项目都使用 Rocket.Chat 作为他们官方交流平台。该软件在持续不断的发展且不断更新和改进新功能。
+
+我最喜欢 Rocket.Chat 的地方是其能够根据用户需求来进行自定义操作,并且它使用机器学习在用户通讯间进行自动的、实时消息翻译。你也可以下载适用于你移动设备的 Rocket.Chat,以便能随时随地使用。
+
+#### IRC
+
+![IRC on WeeChat 0.3.5][5]
+
+IRC([互联网中继聊天][6])是一款实时、基于文本格式的通信软件。尽管其是最古老的电子通讯形式之一,但在许多知名的软件项目中仍受欢迎。
+
+IRC 频道是单独的聊天室。它可以让你在一个开放的频道中与多人进行聊天或与某人私下一对一聊天。如果频道名称以 `#` 开头,则可以假定它是官方的聊天室,而以 `##` 开头的聊天室通常是非官方的聊天室。
+
+[上手 IRC][7] 很容易。你的 IRC 昵称可以让人们找到你,因此它必须是唯一的。但是,你可以完全自主地选择 IRC 客户端。如果你需要比标准 IRC 客户端更多功能的应用程序,则可以使用 [Riot.im][8] 连接到 IRC。
+
+考虑到它悠久的历史,你为什么还要继续使用 IRC?出于一个原因是,其仍是我们所依赖的许多自由及开源项目的家园。如果你想参于开源软件开发和社区,可以选择用 IRC。
+
+#### Zulip
+
+![Zulip][9]
+
+[Zulip][10] 是十分流行的群聊应用程序,它遵循基于话题线索的模式。在 Zulip 中,你可以订阅流,就像在 IRC 频道或 Rocket.Chat 中一样。但是,每个 Zulip 流都会拥有一个唯一的话题,该话题可帮助你以后查找对话,因此其更有条理。
+
+与其他平台一样,它支持表情符号、内嵌图片、视频和推特预览。它还支持 LaTeX 来分享数学公式或方程式、支持 Markdown 和语法高亮来分享代码。
+
+Zulip 是跨平台的,并提供 API 用于编写你自己的程序。我特别喜欢 Zulip 的一点是它与 GitHub 的集成整合功能:如果我正在处理某个议题,则可以使用 Zulip 的标记回链某个拉取请求 ID。
+
+Zulip 是开源的(你可以在 GitHub 上访问其 [源码][11])并且免费使用,但它有提供预置支持、[LDAP][12] 集成和更多存储类型的付费产品。
+
+#### Let's Chat
+
+![Let's Chat][13]
+
+[Let's Chat][14] 是一个面向小型团队的自托管的聊天解决方案。它使用 Node.js 和 MongoDB 编写运行,只需鼠标点击几下即可将其部署到本地服务器或云服务器。它是自由开源软件,可以在 GitHub 上查看其 [源码][15]。
+
+Let's Chat 与其他开源聊天工具的不同之处在于其企业功能:它支持 LDAP 和 [Kerberos][16] 身份验证。它还具有新用户想要的所有功能:你可以在历史记录中搜索过往消息,并使用 @username 之类的标签来标记人员。
+
+我喜欢 Let's Chat 的地方是它拥有私人的受密码保护的聊天室、发送图片、支持 GIPHY 和代码粘贴。它不断更新,不断增加新功能。
+
+### 附加:开源视频聊天软件 Jitsi
+
+![Jitsi][17]
+
+有时,文字聊天还不够,你还可能需要与某人面谈。在这种情况下,如果不能选择面对面开会交流,那么视频聊天是最好的选择。[Jitsi][18] 是一个完全开源的、支持多平台且兼容 WebRTC 的视频会议工具。
+
+Jitsi 从 Jitsi Desktop 开始,已经发展成为许多 [项目][19],包括 Jitsi Meet、Jitsi Videobridge、jibri 和 libjitsi,并且每个项目都在 GitHub 上开放了 [源码][20]。
+
+Jitsi 是安全且可扩展的,并支持诸如联播和带宽预估之类的高级视频路由的概念,还包括音频、录制、屏幕共享和拨入功能等经典功能。你可以来为你的视频聊天室设置密码以保护其不受干扰,并且它还支持通过 YouTube 进行直播。你还可以搭建自己的 Jitsi 服务器,并将其托管在本地或虚拟专用服务器(例如 Digital Ocean Droplet)上。
+
+我最喜欢 Jitsi 的是它是免费且低门槛的。任何人都可以通过访问 [meet.jit.si][21] 来立即召开会议,并且用户无需注册或安装即可轻松参加会议。(但是,注册的话能拥有日程安排功能。)这种入门级低门槛的视频会议服务让 Jitsi 迅速普及。
+
+### 选择一个聊天应用软件的建议
+
+各种各样的开源聊天应用软件可能让你很难抉择。以下是一些选择一款聊天应用软件的一般准则。
+
+ * 最好具有交互式的界面和简单的导航工具。
+ * 最好寻找一种功能强大且能让人们以各种方式使用它的工具。
+ * 如果与你所使用的工具有进行集成整合的话,可以重点考虑。一些工具与 GitHub 或 GitLab 以及某些应用程序具有良好的无缝衔接,这将是一个非常有用的功能。
+ * 有能托管到云主机的工具将十分方便。
+ * 应考虑到聊天服务的安全性。在私人服务器上托管服务的能力对许多组织和个人来说是必要的。
+ * 最好选择那些具有丰富的隐私设置,并拥有私人聊天室和公共聊天室的通讯工具。
+
+由于人们比以往任何时候都更加依赖在线服务,因此拥有备用的通讯平台是明智之举。例如,如果一个项目正在使用 Rocket.Chat,则必要之时,它还应具有跳转到 IRC 的能力。由于这些软件在不断更新,你可能会发现自己已经连接到多个渠道,因此集成整合其他应用将变得非常有价值。
+
+在各种可用的开源聊天服务中,你喜欢和使用哪些?这些工具又是如何帮助你进行远程办公?请在评论中分享你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/4/open-source-chat
+
+作者:[Sudeshna Sur][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sudeshna-sur
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_communication_team.png?itok=CYfZ_gE7 (Chat bubbles)
+[2]: https://opensource.com/sites/default/files/uploads/rocketchat.png (Rocket.Chat)
+[3]: https://rocket.chat/
+[4]: https://github.com/RocketChat/Rocket.Chat
+[5]: https://opensource.com/sites/default/files/uploads/irc.png (IRC on WeeChat 0.3.5)
+[6]: https://en.wikipedia.org/wiki/Internet_Relay_Chat
+[7]: https://opensource.com/article/16/6/getting-started-irc
+[8]: https://opensource.com/article/17/5/introducing-riot-IRC
+[9]: https://opensource.com/sites/default/files/uploads/zulip.png (Zulip)
+[10]: https://zulipchat.com/
+[11]: https://github.com/zulip/zulip
+[12]: https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol
+[13]: https://opensource.com/sites/default/files/uploads/lets-chat.png (Let's Chat)
+[14]: https://sdelements.github.io/lets-chat/
+[15]: https://github.com/sdelements/lets-chat
+[16]: https://en.wikipedia.org/wiki/Kerberos_(protocol)
+[17]: https://opensource.com/sites/default/files/uploads/jitsi_0_0.jpg (Jitsi)
+[18]: https://jitsi.org/
+[19]: https://jitsi.org/projects/
+[20]: https://github.com/jitsi
+[21]: http://meet.jit.si
diff --git a/published/202104/20200617 How to handle dynamic and static libraries in Linux.md b/published/202104/20200617 How to handle dynamic and static libraries in Linux.md
new file mode 100644
index 0000000000..d74b9a4b50
--- /dev/null
+++ b/published/202104/20200617 How to handle dynamic and static libraries in Linux.md
@@ -0,0 +1,271 @@
+[#]: collector: (lujun9972)
+[#]: translator: (tt67wq)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13318-1.html)
+[#]: subject: (How to handle dynamic and static libraries in Linux)
+[#]: via: (https://opensource.com/article/20/6/linux-libraries)
+[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
+
+怎样在 Linux 中使用动态和静态库
+======
+
+> 了解 Linux 如何使用库,包括静态库和动态库的差别,有助于你解决依赖问题。
+
+
+
+Linux 从某种意义上来说就是一堆相互依赖的静态和动态库。对于 Linux 系统新手来说,库的整个处理过程简直是个迷。但对有经验的人来说,被构建进操作系统的大量共享代码对于编写新应用来说却是个优点。
+
+为了让你熟悉这个话题,我准备了一个小巧的 [应用例子][2] 来展示在普通的 Linux 发行版(在其他操作系统上未验证)上是经常是如何处理库的。为了用这个例子来跟上这个需要动手的教程,请打开命令行输入:
+
+```
+$ git clone https://github.com/hANSIc99/library_sample
+$ cd library_sample/
+$ make
+cc -c main.c -Wall -Werror
+cc -c libmy_static_a.c -o libmy_static_a.o -Wall -Werror
+cc -c libmy_static_b.c -o libmy_static_b.o -Wall -Werror
+ar -rsv libmy_static.a libmy_static_a.o libmy_static_b.o
+ar: creating libmy_static.a
+a - libmy_static_a.o
+a - libmy_static_b.o
+cc -c -fPIC libmy_shared.c -o libmy_shared.o
+cc -shared -o libmy_shared.so libmy_shared.o
+$ make clean
+rm *.o
+```
+
+当执行完这些命令,这些文件应当被添加进目录下(执行 `ls` 来查看):
+
+```
+my_app
+libmy_static.a
+libmy_shared.so
+```
+
+### 关于静态链接
+
+当你的应用链接了一个静态库,这个库的代码就变成了可执行文件的一部分。这个动作只在链接过程中执行一次,这些静态库通常以 `.a` 扩展符结尾。
+
+静态库是多个目标文件的归档([ar][3])。这些目标文件通常是 ELF 格式的。ELF 是 [可执行可链接格式][4] 的简写,它与多个操作系统兼容。
+
+`file` 命令的输出可以告诉你静态库 `libmy_static.a` 是 `ar` 格式的归档文件类型。
+
+```
+$ file libmy_static.a
+libmy_static.a: current ar archive
+```
+
+使用 `ar -t`,你可以看到归档文件的内部。它展示了两个目标文件:
+
+```
+$ ar -t libmy_static.a
+libmy_static_a.o
+libmy_static_b.o
+```
+
+你可以用 `ax -x ` 命令来提取归档文件的文件。被提出的都是 ELF 格式的目标文件:
+
+```
+$ ar -x libmy_static.a
+$ file libmy_static_a.o
+libmy_static_a.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
+```
+
+### 关于动态链接
+
+动态链接指的是使用共享库。共享库通常以 `.so` 的扩展名结尾(“共享对象” 的简写)。
+
+共享库是 Linux 系统中依赖管理的最常用方法。这些共享库在应用启动前被载入内存,当多个应用都需要同一个库时,这个库在系统中只会被加载一次。这个特性减少了应用的内存占用。
+
+另外一个值得注意的地方是,当一个共享库的 bug 被修复后,所有引用了这个库的应用都会受益。但这也意味着,如果一个 bug 还没被发现,那所有相关的应用都会遭受这个 bug 影响(如果这个应用使用了受影响的部分)。
+
+当一个应用需要某个特定版本的库,但是链接器只知道某个不兼容版本的位置,对于初学者来说这个问题非常棘手。在这个场景下,你必须帮助链接器找到正确版本的路径。
+
+尽管这不是一个每天都会遇到的问题,但是理解动态链接的原理总是有助于你修复类似的问题。
+
+幸运的是,动态链接的机制其实非常简洁明了。
+
+为了检查一个应用在启动时需要哪些库,你可以使用 `ldd` 命令,它会打印出给定文件所需的动态库:
+
+```
+$ ldd my_app
+ linux-vdso.so.1 (0x00007ffd1299c000)
+ libmy_shared.so => not found
+ libc.so.6 => /lib64/libc.so.6 (0x00007f56b869b000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007f56b8881000)
+```
+
+可以注意到 `libmy_shared.so` 库是代码仓库的一部分,但是没有被找到。这是因为负责在应用启动之前将所有依赖加载进内存的动态链接器没有在它搜索的标准路径下找到这个库。
+
+对新手来说,与常用库(例如 `bizp2`)版本不兼容相关的问题往往十分令人困惑。一种方法是把该仓库的路径加入到环境变量 `LD_LIBRARY_PATH` 中来告诉链接器去哪里找到正确的版本。在本例中,正确的版本就在这个目录下,所以你可以导出它至环境变量:
+
+```
+$ LD_LIBRARY_PATH=$(pwd):$LD_LIBRARY_PATH
+$ export LD_LIBRARY_PATH
+```
+
+现在动态链接器知道去哪找库了,应用也可以执行了。你可以再次执行 `ldd` 去调用动态链接器,它会检查应用的依赖然后加载进内存。内存地址会在对象路径后展示:
+
+```
+$ ldd my_app
+ linux-vdso.so.1 (0x00007ffd385f7000)
+ libmy_shared.so => /home/stephan/library_sample/libmy_shared.so (0x00007f3fad401000)
+ libc.so.6 => /lib64/libc.so.6 (0x00007f3fad21d000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007f3fad408000)
+```
+
+想知道哪个链接器被调用了,你可以用 `file` 命令:
+
+```
+$ file my_app
+my_app: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=26c677b771122b4c99f0fd9ee001e6c743550fa6, for GNU/Linux 3.2.0, not stripped
+```
+
+链接器 `/lib64/ld-linux-x86–64.so.2` 是一个指向 `ld-2.30.so` 的软链接,它也是我的 Linux 发行版的默认链接器:
+
+```
+$ file /lib64/ld-linux-x86-64.so.2
+/lib64/ld-linux-x86-64.so.2: symbolic link to ld-2.31.so
+```
+
+回头看看 `ldd` 命令的输出,你还可以看到(在 `libmy_shared.so` 边上)每个依赖都以一个数字结尾(例如 `/lib64/libc.so.6`)。共享对象的常见命名格式为:
+
+```
+libXYZ.so..
+```
+
+在我的系统中,`libc.so.6` 也是指向同一目录下的共享对象 `libc-2.31.so` 的软链接。
+
+```
+$ file /lib64/libc.so.6
+/lib64/libc.so.6: symbolic link to libc-2.31.so
+```
+
+如果你正在面对一个应用因为加载库的版本不对导致无法启动的问题,有很大可能你可以通过检查整理这些软链接或者确定正确的搜索路径(查看下方“动态加载器:ld.so”一节)来解决这个问题。
+
+更为详细的信息请查看 [ldd 手册页][5]。
+
+#### 动态加载
+
+动态加载的意思是一个库(例如一个 `.so` 文件)在程序的运行时被加载。这是使用某种特定的编程方法实现的。
+
+当一个应用使用可以在运行时改变的插件时,就会使用动态加载。
+
+查看 [dlopen 手册页][6] 获取更多信息。
+
+#### 动态加载器:ld.so
+
+在 Linux 系统中,你几乎总是正在跟共享库打交道,所以必须有个机制来检测一个应用的依赖并将其加载进内存中。
+
+`ld.so` 按以下顺序在这些地方寻找共享对象:
+
+ 1. 应用的绝对路径或相对路径下(用 GCC 编译器的 `-rpath` 选项硬编码的)
+ 2. 环境变量 `LD_LIBRARY_PATH`
+ 3. `/etc/ld.so.cache` 文件
+
+需要记住的是,将一个库加到系统库归档 `/usr/lib64` 中需要管理员权限。你可以手动拷贝 `libmy_shared.so` 至库归档中来让应用可以运行,而避免设置 `LD_LIBRARY_PATH`。
+
+```
+unset LD_LIBRARY_PATH
+sudo cp libmy_shared.so /usr/lib64/
+```
+
+当你运行 `ldd` 时,你现在可以看到归档库的路径被展示出来:
+
+```
+$ ldd my_app
+ linux-vdso.so.1 (0x00007ffe82fab000)
+ libmy_shared.so => /lib64/libmy_shared.so (0x00007f0a963e0000)
+ libc.so.6 => /lib64/libc.so.6 (0x00007f0a96216000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007f0a96401000)
+```
+
+### 在编译时定制共享库
+
+如果你想你的应用使用你的共享库,你可以在编译时指定一个绝对或相对路径。
+
+编辑 `makefile`(第 10 行)然后通过 `make -B` 来重新编译程序。然后 `ldd` 输出显示 `libmy_shared.so` 和它的绝对路径一起被列出来了。
+
+把这个:
+
+```
+CFLAGS =-Wall -Werror -Wl,-rpath,$(shell pwd)
+```
+
+改成这个(记得修改用户名):
+
+```
+CFLAGS =/home/stephan/library_sample/libmy_shared.so
+```
+
+然后重新编译:
+
+```
+$ make
+```
+
+确认下它正在使用你设定的绝对路径,你可以在输出的第二行看到:
+
+```
+$ ldd my_app
+ linux-vdso.so.1 (0x00007ffe143ed000)
+ libmy_shared.so => /lib64/libmy_shared.so (0x00007fe50926d000)
+ /home/stephan/library_sample/libmy_shared.so (0x00007fe509268000)
+ libc.so.6 => /lib64/libc.so.6 (0x00007fe50909e000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007fe50928e000)
+```
+
+这是个不错的例子,但是如果你在编写给其他人用的库,它是怎样工作的呢?新库的路径可以通过写入 `/etc/ld.so.conf` 或是在 `/etc/ld.so.conf.d/` 目录下创建一个包含路径的 `.conf` 文件来注册至系统。之后,你必须执行 `ldconfig` 命令来覆写 `ld.so.cache` 文件。这一步有时候在你装了携带特殊的共享库的程序来说是不可省略的。
+
+查看 [ld.so 的手册页][7] 获取更多详细信息。
+
+### 怎样处理多种架构
+
+通常来说,32 位和 64 位版本的应用有不同的库。下面列表展示了不同 Linux 发行版库的标准路径:
+
+**红帽家族**
+
+ * 32 位:`/usr/lib`
+ * 64 位:`/usr/lib64`
+
+**Debian 家族**
+
+ * 32 位:`/usr/lib/i386-linux-gnu`
+ * 64 位:`/usr/lib/x86_64-linux-gnu`
+
+**Arch Linux 家族**
+
+ * 32 位:`/usr/lib32`
+ * 64 位:`/usr/lib64`
+
+[FreeBSD][8](技术上来说不算 Linux 发行版)
+
+ * 32 位:`/usr/lib32`
+ * 64 位:`/usr/lib`
+
+知道去哪找这些关键库可以让库链接失效的问题成为历史。
+
+虽然刚开始会有点困惑,但是理解 Linux 库的依赖管理是一种对操作系统掌控感的表现。在其他应用程序中运行这些步骤,以熟悉常见的库,然后继续学习怎样解决任何你可能遇到的库的挑战。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/6/linux-libraries
+
+作者:[Stephan Avenwedde][a]
+选题:[lujun9972][b]
+译者:[tt67wq](https://github.com/tt67wq)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/hansic99
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
+[2]: https://github.com/hANSIc99/library_sample
+[3]: https://en.wikipedia.org/wiki/Ar_%28Unix%29
+[4]: https://linuxhint.com/understanding_elf_file_format/
+[5]: https://www.man7.org/linux/man-pages/man1/ldd.1.html
+[6]: https://www.man7.org/linux/man-pages/man3/dlopen.3.html
+[7]: https://www.man7.org/linux/man-pages/man8/ld.so.8.html
+[8]: https://opensource.com/article/20/5/furybsd-linux
diff --git a/published/202104/20200707 Use systemd timers instead of cronjobs.md b/published/202104/20200707 Use systemd timers instead of cronjobs.md
new file mode 100644
index 0000000000..81e4553369
--- /dev/null
+++ b/published/202104/20200707 Use systemd timers instead of cronjobs.md
@@ -0,0 +1,529 @@
+[#]: collector: (lujun9972)
+[#]: translator: (tt67wq)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13307-1.html)
+[#]: subject: (Use systemd timers instead of cronjobs)
+[#]: via: (https://opensource.com/article/20/7/systemd-timers)
+[#]: author: (David Both https://opensource.com/users/dboth)
+
+使用 systemd 定时器代替 cron 作业
+======
+
+> 定时器提供了比 cron 作业更为细粒度的事件控制。
+
+
+
+我正在致力于将我的 [cron][2] 作业迁移到 systemd 定时器上。我已经使用定时器多年了,但通常来说,我的学识只足以支撑我当前的工作。但在我研究 [systemd 系列][3] 的过程中,我发现 systemd 定时器有一些非常有意思的能力。
+
+与 cron 作业类似,systemd 定时器可以在特定的时间间隔触发事件(shell 脚本和程序),例如每天一次或在一个月中的特定某一天(或许只有在周一生效),或在从上午 8 点到下午 6 点的工作时间内每隔 15 分钟一次。定时器也可以做到 cron 作业无法做到的一些事情。举个例子,定时器可以在特定事件发生后的一段时间后触发一段脚本或者程序去执行,例如开机、启动、上个任务完成,甚至于定时器调用的上个服务单元的完成的时刻。
+
+### 操作系统维护的计时器
+
+当在一个新系统上安装 Fedora 或者是任意一个基于 systemd 的发行版时,作为系统维护过程的一部分,它会在 Linux 宿主机的后台中创建多个定时器。这些定时器会触发事件来执行必要的日常维护任务,比如更新系统数据库、清理临时目录、轮换日志文件,以及更多其他事件。
+
+作为示例,我会查看一些我的主要工作站上的定时器,通过执行 `systemctl status *timer` 命令来展示主机上的所有定时器。星号的作用与文件通配相同,所以这个命令会列出所有的 systemd 定时器单元。
+
+```
+[root@testvm1 ~]# systemctl status *timer
+● mlocate-updatedb.timer - Updates mlocate database every day
+ Loaded: loaded (/usr/lib/systemd/system/mlocate-updatedb.timer; enabled; vendor preset: enabled)
+ Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
+ Trigger: Fri 2020-06-05 00:00:00 EDT; 15h left
+ Triggers: ● mlocate-updatedb.service
+
+Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Updates mlocate database every day.
+
+● logrotate.timer - Daily rotation of log files
+ Loaded: loaded (/usr/lib/systemd/system/logrotate.timer; enabled; vendor preset: enabled)
+ Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
+ Trigger: Fri 2020-06-05 00:00:00 EDT; 15h left
+ Triggers: ● logrotate.service
+ Docs: man:logrotate(8)
+ man:logrotate.conf(5)
+
+Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Daily rotation of log files.
+
+● sysstat-summary.timer - Generate summary of yesterday's process accounting
+ Loaded: loaded (/usr/lib/systemd/system/sysstat-summary.timer; enabled; vendor preset: enabled)
+ Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
+ Trigger: Fri 2020-06-05 00:07:00 EDT; 15h left
+ Triggers: ● sysstat-summary.service
+
+Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Generate summary of yesterday's process accounting.
+
+● fstrim.timer - Discard unused blocks once a week
+ Loaded: loaded (/usr/lib/systemd/system/fstrim.timer; enabled; vendor preset: enabled)
+ Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
+ Trigger: Mon 2020-06-08 00:00:00 EDT; 3 days left
+ Triggers: ● fstrim.service
+ Docs: man:fstrim
+
+Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Discard unused blocks once a week.
+
+● sysstat-collect.timer - Run system activity accounting tool every 10 minutes
+ Loaded: loaded (/usr/lib/systemd/system/sysstat-collect.timer; enabled; vendor preset: enabled)
+ Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
+ Trigger: Thu 2020-06-04 08:50:00 EDT; 41s left
+ Triggers: ● sysstat-collect.service
+
+Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Run system activity accounting tool every 10 minutes.
+
+● dnf-makecache.timer - dnf makecache --timer
+ Loaded: loaded (/usr/lib/systemd/system/dnf-makecache.timer; enabled; vendor preset: enabled)
+ Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
+ Trigger: Thu 2020-06-04 08:51:00 EDT; 1min 41s left
+ Triggers: ● dnf-makecache.service
+
+Jun 02 08:02:33 testvm1.both.org systemd[1]: Started dnf makecache –timer.
+
+● systemd-tmpfiles-clean.timer - Daily Cleanup of Temporary Directories
+ Loaded: loaded (/usr/lib/systemd/system/systemd-tmpfiles-clean.timer; static; vendor preset: disabled)
+ Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
+ Trigger: Fri 2020-06-05 08:19:00 EDT; 23h left
+ Triggers: ● systemd-tmpfiles-clean.service
+ Docs: man:tmpfiles.d(5)
+ man:systemd-tmpfiles(8)
+
+Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Daily Cleanup of Temporary Directories.
+```
+
+每个定时器至少有六行相关信息:
+
+ * 定时器的第一行有定时器名字和定时器目的的简短介绍
+ * 第二行展示了定时器的状态,是否已加载,定时器单元文件的完整路径以及预设信息。
+ * 第三行指明了其活动状态,包括该定时器激活的日期和时间。
+ * 第四行包括了该定时器下次被触发的日期和时间和距离触发的大概时间。
+ * 第五行展示了被定时器触发的事件或服务名称。
+ * 部分(不是全部)systemd 单元文件有相关文档的指引。我虚拟机上输出中有三个定时器有文档指引。这是一个很好(但非必要)的信息。
+ * 最后一行是计时器最近触发的服务实例的日志条目。
+
+你也许有一些不一样的定时器,取决于你的主机。
+
+### 创建一个定时器
+
+尽管我们可以解构一个或多个现有的计时器来了解其工作原理,但让我们创建我们自己的 [服务单元][4] 和一个定时器去触发它。为了保持简单,我们将使用一个相当简单的例子。当我们完成这个实验之后,就能更容易理解其他定时器的工作原理以及发现它们正在做什么。
+
+首先,创建一个运行基础东西的简单的服务,例如 `free` 命令。举个例子,你可能想定时监控空余内存。在 `/etc/systemd/system` 目录下创建如下的 `myMonitor.server` 单元文件。它不需要是可执行文件:
+
+```
+# This service unit is for testing timer units
+# By David Both
+# Licensed under GPL V2
+#
+
+[Unit]
+Description=Logs system statistics to the systemd journal
+Wants=myMonitor.timer
+
+[Service]
+Type=oneshot
+ExecStart=/usr/bin/free
+
+[Install]
+WantedBy=multi-user.target
+```
+
+这大概是你能创建的最简单的服务单元了。现在我们查看一下服务状态同时测试一下服务单元确保它和我们预期一样可用。
+
+
+```
+[root@testvm1 system]# systemctl status myMonitor.service
+● myMonitor.service - Logs system statistics to the systemd journal
+ Loaded: loaded (/etc/systemd/system/myMonitor.service; disabled; vendor preset: disabled)
+ Active: inactive (dead)
+[root@testvm1 system]# systemctl start myMonitor.service
+[root@testvm1 system]#
+```
+
+输出在哪里呢?默认情况下,systemd 服务单元执行程序的标准输出(`STDOUT`)会被发送到系统日志中,它保留了记录供现在或者之后(直到某个时间点)查看。(在本系列的后续文章中,我将介绍系统日志的记录和保留策略)。专门查看你的服务单元的日志,而且只针对今天。`-S` 选项,即 `--since` 的缩写,允许你指定 `journalctl` 工具搜索条目的时间段。这并不代表你不关心过往结果 —— 在这个案例中,不会有过往记录 —— 如果你的机器以及运行了很长时间且堆积了大量的日志,它可以缩短搜索时间。
+
+```
+[root@testvm1 system]# journalctl -S today -u myMonitor.service
+-- Logs begin at Mon 2020-06-08 07:47:20 EDT, end at Thu 2020-06-11 09:40:47 EDT. --
+Jun 11 09:12:09 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
+Jun 11 09:12:09 testvm1.both.org free[377966]: total used free shared buff/cache available
+Jun 11 09:12:09 testvm1.both.org free[377966]: Mem: 12635740 522868 11032860 8016 1080012 11821508
+Jun 11 09:12:09 testvm1.both.org free[377966]: Swap: 8388604 0 8388604
+Jun 11 09:12:09 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
+[root@testvm1 system]#
+```
+
+由服务触发的任务可以是单个程序、一组程序或者是一个脚本语言写的脚本。通过在 `myMonitor.service` 单元文件里的 `[Service]` 块末尾中添加如下行可以为服务添加另一个任务:
+
+```
+ExecStart=/usr/bin/lsblk
+```
+
+再次启动服务,查看日志检查结果,结果应该看上去像这样。你应该在日志中看到两条命令的结果输出:
+
+```
+Jun 11 15:42:18 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
+Jun 11 15:42:18 testvm1.both.org free[379961]: total used free shared buff/cache available
+Jun 11 15:42:18 testvm1.both.org free[379961]: Mem: 12635740 531788 11019540 8024 1084412 11812272
+Jun 11 15:42:18 testvm1.both.org free[379961]: Swap: 8388604 0 8388604
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: sda 8:0 0 120G 0 disk
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─sda1 8:1 0 4G 0 part /boot
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: └─sda2 8:2 0 116G 0 part
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-root 253:0 0 5G 0 lvm /
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-var 253:4 0 20G 0 lvm /var
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: └─VG01-home 253:5 0 10G 0 lvm /home
+Jun 11 15:42:18 testvm1.both.org lsblk[379962]: sr0 11:0 1 1024M 0 rom
+Jun 11 15:42:18 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
+Jun 11 15:42:18 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
+```
+
+现在你知道了你的服务可以按预期工作了,在 `/etc/systemd/system` 目录下创建 `myMonitor.timer` 定时器单元文件,添加如下代码:
+
+```
+# This timer unit is for testing
+# By David Both
+# Licensed under GPL V2
+#
+
+[Unit]
+Description=Logs some system statistics to the systemd journal
+Requires=myMonitor.service
+
+[Timer]
+Unit=myMonitor.service
+OnCalendar=*-*-* *:*:00
+
+[Install]
+WantedBy=timers.target
+```
+
+在 `myMonitor.timer` 文件中的 `OnCalendar` 时间格式,`*-*-* *:*:00`,应该会每分钟触发一次定时器去执行 `myMonitor.service` 单元。我会在文章的后面进一步探索 `OnCalendar` 设置。
+
+到目前为止,在服务被计时器触发运行时观察与之有关的日志记录。你也可以跟踪计时器,跟踪服务可以让你接近实时的看到结果。执行 `journalctl` 时带上 `-f` 选项:
+
+```
+[root@testvm1 system]# journalctl -S today -f -u myMonitor.service
+-- Logs begin at Mon 2020-06-08 07:47:20 EDT. --
+```
+
+执行但是不启用该定时器,看看它运行一段时间后发生了什么:
+
+```
+[root@testvm1 ~]# systemctl start myMonitor.service
+[root@testvm1 ~]#
+```
+
+一条结果立即就显示出来了,下一条大概在一分钟后出来。观察几分钟日志,看看你有没有跟我发现同样的事情:
+
+```
+[root@testvm1 system]# journalctl -S today -f -u myMonitor.service
+-- Logs begin at Mon 2020-06-08 07:47:20 EDT. --
+Jun 13 08:39:18 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
+Jun 13 08:39:18 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
+Jun 13 08:39:19 testvm1.both.org free[630566]: total used free shared buff/cache available
+Jun 13 08:39:19 testvm1.both.org free[630566]: Mem: 12635740 556604 10965516 8036 1113620 11785628
+Jun 13 08:39:19 testvm1.both.org free[630566]: Swap: 8388604 0 8388604
+Jun 13 08:39:18 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: sda 8:0 0 120G 0 disk
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─sda1 8:1 0 4G 0 part /boot
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: └─sda2 8:2 0 116G 0 part
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-root 253:0 0 5G 0 lvm /
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-var 253:4 0 20G 0 lvm /var
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: └─VG01-home 253:5 0 10G 0 lvm /home
+Jun 13 08:39:19 testvm1.both.org lsblk[630567]: sr0 11:0 1 1024M 0 rom
+Jun 13 08:40:46 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
+Jun 13 08:40:46 testvm1.both.org free[630572]: total used free shared buff/cache available
+Jun 13 08:40:46 testvm1.both.org free[630572]: Mem: 12635740 555228 10966836 8036 1113676 11786996
+Jun 13 08:40:46 testvm1.both.org free[630572]: Swap: 8388604 0 8388604
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: sda 8:0 0 120G 0 disk
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─sda1 8:1 0 4G 0 part /boot
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: └─sda2 8:2 0 116G 0 part
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-root 253:0 0 5G 0 lvm /
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-var 253:4 0 20G 0 lvm /var
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: └─VG01-home 253:5 0 10G 0 lvm /home
+Jun 13 08:40:46 testvm1.both.org lsblk[630574]: sr0 11:0 1 1024M 0 rom
+Jun 13 08:40:46 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
+Jun 13 08:40:46 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
+Jun 13 08:41:46 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
+Jun 13 08:41:46 testvm1.both.org free[630580]: total used free shared buff/cache available
+Jun 13 08:41:46 testvm1.both.org free[630580]: Mem: 12635740 553488 10968564 8036 1113688 11788744
+Jun 13 08:41:46 testvm1.both.org free[630580]: Swap: 8388604 0 8388604
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: sda 8:0 0 120G 0 disk
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─sda1 8:1 0 4G 0 part /boot
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: └─sda2 8:2 0 116G 0 part
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-root 253:0 0 5G 0 lvm /
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-var 253:4 0 20G 0 lvm /var
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: └─VG01-home 253:5 0 10G 0 lvm /home
+Jun 13 08:41:47 testvm1.both.org lsblk[630581]: sr0 11:0 1 1024M 0 rom
+Jun 13 08:41:47 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
+Jun 13 08:41:47 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
+```
+
+别忘了检查下计时器和服务的状态。
+
+你在日志里大概至少注意到两件事。第一,你不需要特地做什么来让 `myMonitor.service` 单元中 `ExecStart` 触发器产生的 `STDOUT` 存储到日志里。这都是用 systemd 来运行服务的一部分功能。然而,它确实意味着你需要小心对待服务单元里面执行的脚本和它们能产生多少 `STDOUT`。
+
+第二,定时器并不是精确在每分钟的 :00 秒执行的,甚至每次执行的时间间隔都不是刚好一分钟。这是特意的设计,但是有必要的话可以改变这种行为(如果只是它挑战了你的系统管理员的敏感神经)。
+
+这样设计的初衷是为了防止多个服务在完全相同的时刻被触发。举个例子,你可以用例如 Weekly,Daily 等时间格式。这些快捷写法都被定义为在某一天的 00:00:00 执行。当多个定时器都这样定义的话,有很大可能它们会同时执行。
+
+systemd 定时器被故意设计成在规定时间附近随机波动的时间点触发,以避免同一时间触发。它们在一个时间窗口内半随机触发,时间窗口开始于预设的触发时间,结束于预设时间后一分钟。根据 `systemd.timer` 的手册页,这个触发时间相对于其他已经定义的定时器单元保持在稳定的位置。你可以在日志条目中看到,定时器在启动后立即触发,然后在每分钟后的 46 或 47 秒触发。
+
+大部分情况下,这种概率抖动的定时器是没事的。当调度类似执行备份的任务,只需要它们在下班时间运行,这样是没问题的。系统管理员可以选择确定的开始时间来确保不和其他任务冲突,例如 01:05:00 这样典型的 cron 作业时间,但是有很大范围的时间值可以满足这一点。在开始时间上的一个分钟级别的随机往往是无关紧要的。
+
+然而,对某些任务来说,精确的触发时间是个硬性要求。对于这类任务,你可以向单元文件的 `Timer` 块中添加如下声明来指定更高的触发时间跨度精确度(精确到微秒以内):
+
+```
+AccuracySec=1us
+```
+
+时间跨度可用于指定所需的精度,以及定义重复事件或一次性事件的时间跨度。它能识别以下单位:
+
+ * `usec`、`us`、`µs`
+ * `msec`、`ms`
+ * `seconds`、`second`、`sec`、`s`
+ * `minutes`、`minute`、`min`、`m`
+ * `hours`、`hour`、`hr`、`h`
+ * `days`、`day`、`d`
+ * `weeks`、`week`、`w`
+ * `months`、`month`、`M`(定义为 30.44 天)
+ * `years`、`year`、`y`(定义为 365.25 天)
+
+所有 `/usr/lib/systemd/system` 中的定时器都指定了一个更宽松的时间精度,因为精准时间没那么重要。看看这些系统创建的定时器的时间格式:
+
+```
+[root@testvm1 system]# grep Accur /usr/lib/systemd/system/*timer
+/usr/lib/systemd/system/fstrim.timer:AccuracySec=1h
+/usr/lib/systemd/system/logrotate.timer:AccuracySec=1h
+/usr/lib/systemd/system/logwatch.timer:AccuracySec=12h
+/usr/lib/systemd/system/mlocate-updatedb.timer:AccuracySec=24h
+/usr/lib/systemd/system/raid-check.timer:AccuracySec=24h
+/usr/lib/systemd/system/unbound-anchor.timer:AccuracySec=24h
+[root@testvm1 system]#
+```
+
+看下 `/usr/lib/systemd/system` 目录下部分定时器单元文件的完整内容,看看它们是如何构建的。
+
+在本实验中不必让这个定时器在启动时激活,但下面这个命令可以设置开机自启:
+
+```
+[root@testvm1 system]# systemctl enable myMonitor.timer
+```
+
+你创建的单元文件不需要是可执行的。你同样不需要启用服务,因为它是被定时器触发的。如果你需要的话,你仍然可以在命令行里手动触发该服务单元。尝试一下,然后观察日志。
+
+关于定时器精度、事件时间规格和触发事件的详细信息,请参见 systemd.timer 和 systemd.time 的手册页。
+
+### 定时器类型
+
+systemd 定时器还有一些在 cron 中找不到的功能,cron 只在确定的、重复的、具体的日期和时间触发。systemd 定时器可以被配置成根据其他 systemd 单元状态发生改变时触发。举个例子,定时器可以配置成在系统开机、启动后,或是某个确定的服务单元激活之后的一段时间被触发。这些被称为单调计时器。“单调”指的是一个持续增长的计数器或序列。这些定时器不是持久的,因为它们在每次启动后都会重置。
+
+表格 1 列出了一些单调定时器以及每个定时器的简短定义,同时有 `OnCalendar` 定时器,这些不是单调的,它们被用于指定未来有可能重复的某个确定时间。这个信息来自于 `systemd.timer` 的手册页,有一些不重要的修改。
+
+定时器 | 单调性 | 定义
+---|---|---
+`OnActiveSec=` | X | 定义了一个与定时器被激活的那一刻相关的定时器。
+`OnBootSec=` | X | 定义了一个与机器启动时间相关的计时器。
+`OnStartupSec=` | X | 定义了一个与服务管理器首次启动相关的计时器。对于系统定时器来说,这个定时器与 `OnBootSec=` 类似,因为系统服务管理器在机器启动后很短的时间后就会启动。当以在每个用户服务管理器中运行的单元进行配置时,它尤其有用,因为用户的服务管理器通常在首次登录后启动,而不是机器启动后。
+`OnUnitActiveSec=` | X | 定义了一个与将要激活的定时器上次激活时间相关的定时器。
+`OnUnitInactiveSec=` | X | 定义了一个与将要激活的定时器上次停用时间相关的定时器。
+`OnCalendar=` | | 定义了一个有日期事件表达式语法的实时(即时钟)定时器。查看 `systemd.time(7)` 的手册页获取更多与日历事件表达式相关的语法信息。除此以外,它的语义和 `OnActiveSec=` 类似。
+
+_Table 1: systemd 定时器定义_
+
+单调计时器可使用同样的简写名作为它们的时间跨度,即我们之前提到的 `AccuracySec` 表达式,但是 systemd 将这些名字统一转换成了秒。举个例子,比如你想规定某个定时器在系统启动后五天触发一次事件;它可能看起来像 `OnBootSec=5d`。如果机器启动于 `2020-06-15 09:45:27`,这个定时器会在 `2020-06-20 09:45:27` 或在这之后的一分钟内触发。
+
+### 日历事件格式
+
+日历事件格式是定时器在所需的重复时间触发的关键。我们开始看下一些 `OnCalendar` 设置一起使用的格式。
+
+与 crontab 中的格式相比,systemd 及其计时器使用的时间和日历格式风格不同。它比 crontab 更为灵活,而且可以使用类似 `at` 命令的方式允许模糊的日期和时间。它还应该足够熟悉使其易于理解。
+
+systemd 定时器使用 `OnCalendar=` 的基础格式是 `DOW YYYY-MM-DD HH:MM:SS`。DOW(星期几)是选填的,其他字段可以用一个星号(`*`)来匹配此位置的任意值。所有的日历时间格式会被转换成标准格式。如果时间没有指定,它会被设置为 `00:00:00`。如果日期没有指定但是时间指定了,那么下次匹配的时间可能是今天或者明天,取决于当前的时间。月份和星期可以使用名称或数字。每个单元都可以使用逗号分隔的列表。单元范围可以在开始值和结束值之间用 `..` 指定。
+
+指定日期有一些有趣的选项,波浪号(`~`)可以指定月份的最后一天或者最后一天之前的某几天。`/` 可以用来指定星期几作为修饰符。
+
+这里有几个在 `OnCalendar` 表达式中使用的典型时间格式例子。
+
+日期事件格式 | 描述
+---|---
+`DOW YYYY-MM-DD HH:MM:SS` |
+`*-*-* 00:15:30` | 每年每月每天的 0 点 15 分 30 秒
+`Weekly` | 每个周一的 00:00:00
+`Mon *-*-* 00:00:00` | 同上
+`Mon` | 同上
+`Wed 2020-*-*` | 2020 年每个周三的 00:00:00
+`Mon..Fri 2021-*-*` | 2021 年的每个工作日(周一到周五)的 00:00:00
+`2022-6,7,8-1,15 01:15:00` | 2022 年 6、7、8 月的 1 到 15 号的 01:15:00
+`Mon *-05~03` | 每年五月份的下个周一同时也是月末的倒数第三天
+`Mon..Fri *-08~04` | 任何年份 8 月末的倒数第四天,同时也须是工作日
+`*-05~03/2` | 五月末的倒数第三天,然后 2 天后再来一次。每年重复一次。注意这个表达式使用了波浪号(`~`)。
+`*-05-03/2` | 五月的第三天,然后每两天重复一次直到 5 月底。注意这个表达式使用了破折号(`-`)。
+
+_Table 2: `OnCalendar` 事件时间格式例子_
+
+
+### 测试日历格式
+
+systemd 提供了一个绝佳的工具用于检测和测试定时器中日历时间事件的格式。`systemd-analyze calendar` 工具解析一个时间事件格式,提供标准格式和其他有趣的信息,例如下次“经过”(即匹配)的日期和时间,以及距离下次触发之前大概时间。
+
+首先,看看未来没有时间的日(注意 `Next elapse` 和 `UTC` 的时间会根据你当地时区改变):
+
+```
+[student@studentvm1 ~]$ systemd-analyze calendar 2030-06-17
+ Original form: 2030-06-17
+Normalized form: 2030-06-17 00:00:00
+ Next elapse: Mon 2030-06-17 00:00:00 EDT
+ (in UTC): Mon 2030-06-17 04:00:00 UTC
+ From now: 10 years 0 months left
+[root@testvm1 system]#
+```
+
+现在添加一个时间,在这个例子中,日期和时间是当作无关的部分分开解析的:
+
+```
+[root@testvm1 system]# systemd-analyze calendar 2030-06-17 15:21:16
+ Original form: 2030-06-17
+Normalized form: 2030-06-17 00:00:00
+ Next elapse: Mon 2030-06-17 00:00:00 EDT
+ (in UTC): Mon 2030-06-17 04:00:00 UTC
+ From now: 10 years 0 months left
+
+ Original form: 15:21:16
+Normalized form: *-*-* 15:21:16
+ Next elapse: Mon 2020-06-15 15:21:16 EDT
+ (in UTC): Mon 2020-06-15 19:21:16 UTC
+ From now: 3h 55min left
+[root@testvm1 system]#
+```
+
+为了把日期和时间当作一个单元来分析,可以把它们包在引号里。你在定时器单元里 `OnCalendar=` 时间格式中使用的时候记得把引号去掉,否则会报错:
+
+```
+[root@testvm1 system]# systemd-analyze calendar "2030-06-17 15:21:16"
+Normalized form: 2030-06-17 15:21:16
+ Next elapse: Mon 2030-06-17 15:21:16 EDT
+ (in UTC): Mon 2030-06-17 19:21:16 UTC
+ From now: 10 years 0 months left
+[root@testvm1 system]#
+```
+
+现在我们测试下 Table2 里的例子。我尤其喜欢最后一个:
+
+```
+[root@testvm1 system]# systemd-analyze calendar "2022-6,7,8-1,15 01:15:00"
+ Original form: 2022-6,7,8-1,15 01:15:00
+Normalized form: 2022-06,07,08-01,15 01:15:00
+ Next elapse: Wed 2022-06-01 01:15:00 EDT
+ (in UTC): Wed 2022-06-01 05:15:00 UTC
+ From now: 1 years 11 months left
+[root@testvm1 system]#
+```
+
+让我们看一个例子,这个例子里我们列出了时间表达式的五个经过时间。
+
+```
+[root@testvm1 ~]# systemd-analyze calendar --iterations=5 "Mon *-05~3"
+ Original form: Mon *-05~3
+Normalized form: Mon *-05~03 00:00:00
+ Next elapse: Mon 2023-05-29 00:00:00 EDT
+ (in UTC): Mon 2023-05-29 04:00:00 UTC
+ From now: 2 years 11 months left
+ Iter. #2: Mon 2028-05-29 00:00:00 EDT
+ (in UTC): Mon 2028-05-29 04:00:00 UTC
+ From now: 7 years 11 months left
+ Iter. #3: Mon 2034-05-29 00:00:00 EDT
+ (in UTC): Mon 2034-05-29 04:00:00 UTC
+ From now: 13 years 11 months left
+ Iter. #4: Mon 2045-05-29 00:00:00 EDT
+ (in UTC): Mon 2045-05-29 04:00:00 UTC
+ From now: 24 years 11 months left
+ Iter. #5: Mon 2051-05-29 00:00:00 EDT
+ (in UTC): Mon 2051-05-29 04:00:00 UTC
+ From now: 30 years 11 months left
+[root@testvm1 ~]#
+```
+
+这些应该为你提供了足够的信息去开始测试你的 `OnCalendar` 时间格式。`systemd-analyze` 工具可用于其他有趣的分析,我会在这个系列的下一篇文章来探索这些。
+
+### 总结
+
+systemd 定时器可以用于执行和 cron 工具相同的任务,但是通过按照日历和单调时间格式去触发事件的方法提供了更多的灵活性。
+
+虽然你为此次实验创建的服务单元通常是由定时器调用的,你也可以随时使用 `systemctl start myMonitor.service` 命令去触发它。可以在一个定时器中编写多个维护任务的脚本;它们可以是 Bash 脚本或者其他 Linux 程序。你可以通过触发定时器来运行所有的脚本来运行服务,也可以按照需要执行单独的脚本。
+
+我会在下篇文章中更加深入的探索 systemd 时间格式的用处。
+
+我还没有看到任何迹象表明 cron 和 at 将被废弃。我希望这种情况不会发生,因为至少 `at` 在执行一次性调度任务的时候要比 systemd 定时器容易的多。
+
+### 参考资料
+
+网上有大量的关于 systemd 的参考资料,但是大部分都有点简略、晦涩甚至有误导性。除了本文中提到的资料,下列的网页提供了跟多可靠且详细的 systemd 入门信息。
+
+ * Fedora 项目有一篇切实好用的 [systemd 入门][5],它囊括了几乎所有你需要知道的关于如何使用 systemd 配置、管理和维护 Fedora 计算机的信息。
+ * Fedora 项目也有一个不错的 [备忘录][6],交叉引用了过去 SystemV 命令和 systemd 命令做对比。
+ * 关于 systemd 的技术细节和创建这个项目的原因,请查看 [Freedesktop.org][7] 上的 [systemd 描述][8]。
+ * [Linux.com][9] 的“更多 systemd 的乐趣”栏目提供了更多高级的 systemd [信息和技巧][10]。
+
+此外,还有一系列深度的技术文章,是由 systemd 的设计者和主要实现者 Lennart Poettering 为 Linux 系统管理员撰写的。这些文章写于 2010 年 4 月至 2011 年 9 月间,但它们现在和当时一样具有现实意义。关于 systemd 及其生态的许多其他好文章都是基于这些文章:
+
+ * [Rethinking PID 1][11]
+ * [systemd for Administrators,Part I][12]
+ * [systemd for Administrators,Part II][13]
+ * [systemd for Administrators,Part III][14]
+ * [systemd for Administrators,Part IV][15]
+ * [systemd for Administrators,Part V][16]
+ * [systemd for Administrators,Part VI][17]
+ * [systemd for Administrators,Part VII][18]
+ * [systemd for Administrators,Part VIII][19]
+ * [systemd for Administrators,Part IX][20]
+ * [systemd for Administrators,Part X][21]
+ * [systemd for Administrators,Part XI][22]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/7/systemd-timers
+
+作者:[David Both][a]
+选题:[lujun9972][b]
+译者:[tt67wq](https://github.com/tt67wq)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_todo_clock_time_team.png?itok=1z528Q0y (Team checklist)
+[2]: https://opensource.com/article/17/11/how-use-cron-linux
+[3]: https://opensource.com/users/dboth
+[4]: https://opensource.com/article/20/5/manage-startup-systemd
+[5]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
+[6]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
+[7]: http://Freedesktop.org
+[8]: http://www.freedesktop.org/wiki/Software/systemd
+[9]: http://Linux.com
+[10]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
+[11]: http://0pointer.de/blog/projects/systemd.html
+[12]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
+[13]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
+[14]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
+[15]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
+[16]: http://0pointer.de/blog/projects/three-levels-of-off.html
+[17]: http://0pointer.de/blog/projects/changing-roots
+[18]: http://0pointer.de/blog/projects/blame-game.html
+[19]: http://0pointer.de/blog/projects/the-new-configuration-files.html
+[20]: http://0pointer.de/blog/projects/on-etc-sysinit.html
+[21]: http://0pointer.de/blog/projects/instances.html
+[22]: http://0pointer.de/blog/projects/inetd.html
diff --git a/published/202104/20201106 11 Linux Distributions You Can Rely on for Your Ancient 32-bit Computer.md b/published/202104/20201106 11 Linux Distributions You Can Rely on for Your Ancient 32-bit Computer.md
new file mode 100644
index 0000000000..6ab0eb1e6f
--- /dev/null
+++ b/published/202104/20201106 11 Linux Distributions You Can Rely on for Your Ancient 32-bit Computer.md
@@ -0,0 +1,317 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13326-1.html)
+[#]: subject: (11 Linux Distributions You Can Rely on for Your Ancient 32-bit Computer)
+[#]: via: (https://itsfoss.com/32-bit-linux-distributions/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+14 种可以在古老的 32 位计算机上使用的 Linux 发行版
+======
+
+如果你一直关注最新的 [Linux 发行版][1],那么你一定已经注意到,[大多数流行的 Linux 发行版][2] 已经终止了 32 位支持。Arch Linux、Ubuntu、Fedora,每一个都已经放弃了对这种较旧架构的支持。
+
+但是,如果你拥有仍然需要再利用的老式硬件,或者想将其用于某些用途,该怎么办?不用担心,你的 32 位系统还有一些选择。
+
+在本文中,我试图汇编一些最好的 Linux 发行版,这些发行版将在未来几年继续支持 32 位平台。
+
+### 仍提供 32 位支持的最佳 Linux 发行版
+
+![][3]
+
+此列表与 [我们之前的支持旧笔记本电脑的 Linux 发行版列表][4] 略有不同。即使是 64 位计算机,如果是在 2010 年之前发布的,那么也可以认为它们是旧的。这就是为什么其中列出的一些建议包括现在仅支持 64 位版本的发行版的原因。
+
+根据我的知识和认知,此处提供的信息是正确的,但是如果你发现有误,请在评论部分让我知道。
+
+在继续之前,我认为你知道 [如何检查你拥有的是否是 32 位或 64 位计算机][5]。
+
+#### 1、Debian
+
+![图片来源: mrneilypops / Deviantart][6]
+
+对于 32 位系统,[Debian][11] 是一个绝佳的选择,因为他们的最新的稳定版本仍然支持它。在撰写本文时,最新的稳定发行版 **Debian 10 “buster”** 提供了 32 位版本,并一直支持到 2024 年。
+
+如果你是 Debian 的新手,值得一提的是,你可以在 [官方 Wiki][7] 上获得有关其所有内容的可靠文档。因此,上手应该不是问题。
+
+你可以浏览 [可用的安装程序][8] 进行安装。但是,在开始之前,除了 [安装手册][10] 外,我建议你参考 [安装 Debian 之前要记住的事情][9] 列表。
+
+最低系统要求:
+
+- 512 MB 内存
+- 10 GB 磁盘空间
+- 1 GHz 处理器(奔腾 4 或同等水平)
+
+#### 2、Slax
+
+![][12]
+
+如果你只是想快速启动设备以进行一些临时工作,[Slax][13] 是一个令人印象深刻的选择。
+
+它基于 Debian,但它通过 USB 设备或 DVD 运行旨在成为一种便携且快速的选项。你可以从他们的网站免费下载 32 位 ISO 文件,或购买预装有 Slax 的可擦写 DVD 或加密的闪存盘。
+
+当然,这并不是要取代传统的桌面操作系统。但是,是的,你确实获得了以 Debian 为基础的 32 位支持。
+
+最低系统要求:
+
+- 内存:128MB(离线使用)/ 512MB(用于网页浏览器使用)
+- CPU: i686 或更新版本
+
+#### 3、AntiX
+
+![图片来源: Opensourcefeed][14]
+
+[AntiX][15] 是另一个令人印象深刻的基于 Debian 的发行版。AntiX 是众所周知的无 systemd 发行版,该发行版侧重于性能,是一个轻量级的系统。
+
+它完全适合于所有老式的 32 位系统。它只需要低至 256 MB 内存和 2.7 GB 存储空间。不仅易于安装,而且用户体验也是针对新手和有经验的用户的。
+
+你应该可以得到基于 Debian 的最新稳定分支的最新版本。
+
+最低系统要求:
+
+- 内存:256 MB 的内存
+- CPU:奔腾 3 系统
+- 磁盘空间:5GB 的驱动器空间
+
+#### 4、openSUSE
+
+![][16]
+
+[openSUSE][18] 是一个独立的 Linux 发行版,也支持 32 位系统。实际上最新的常规版本(Leap)不提供 32 位镜像,但滚动发行版本(Tumbleweed)确实提供了 32 位镜像。
+
+如果你是新手,那将是完全不同的体验。但是,我建议你仔细阅读 [为什么要使用 openSUSE 的原因][17]。
+
+它主要面向开发人员和系统管理员,但也可以将其用作普通桌面用户。值得注意的是,openSUSE 不意味在老式硬件上运行,因此必须确保至少有 2 GB 内存、40+ GB 存储空间和双核处理器。
+
+最低系统要求:
+- 奔腾 4 1.6 GHz 或更高的处理器
+- 1GB 物理内存
+- 5 GB 硬盘
+
+#### 5、Emmabuntüs
+
+![][19]
+
+[Emmanbuntus][20] 是一个有趣的发行版,旨在通过 32 位支持来延长硬件的使用寿命,以减少原材料的浪费。作为一个团体,他们还参与向学校提供计算机和数字技术的工作。
+
+它提供了两个不同的版本,一个基于 Ubuntu,另一个基于 Debian。如果你需要更长久的 32 位支持,则可能要使用 Debian 版本。它可能不是最好的选择,但是它具有许多预配置的软件来简化 Linux 学习体验,并提供 32 位支持,如果你希望在此过程中支持他们的事业,那么这是一个相当不错的选择。
+
+最低系统要求:
+
+- 512MB 内存
+- 硬盘驱动器:2GB
+- 奔腾处理器或同等配置
+
+#### 6、NixOS
+
+![Nixos KDE Edition \(图片来源: Distrowatch\)][21]
+
+[NixOS][23] 是另一个支持 32 位系统的独立 Linux 发行版。它着重于提供一个可靠的系统,其中程序包彼此隔离。
+
+这可能不是直接面向普通用户,但它是一个 KDE 支持的可用发行版,具有独特的软件包管理方式。你可以从其官方网站上了解有关其 [功能][22] 的更多信息。
+
+最低系统要求:
+
+- 内存:768 MB
+- 8GB 磁盘空间
+- 奔腾 4 或同等水平
+
+#### 7、Gentoo Linux
+
+![][24]
+
+如果你是经验丰富的 Linux 用户,并且正在寻找 32 位 Linux 发行版,那么 [Gentoo Linux][26] 应该是一个不错的选择。
+
+如果需要,你可以使用 Gentoo Linux 的软件包管理器轻松配置、编译和安装内核。不仅限于众所周知的可配置性,你还可以在较旧的硬件上运行而不会出现任何问题。
+
+即使你不是经验丰富的用户,也想尝试一下,只需阅读 [安装说明][25],就可以大胆尝试了。
+
+最低系统要求:
+
+- 256MB 内存
+- 奔腾 4 或 AMD 的同类产品
+- 2.5 GB 磁盘空间
+
+#### 8、Devuan
+
+![][27]
+
+[Devuan][30] 是另一种无 systemd 的发行版。从技术上讲,它是 Debian 的一个分支,只是没有 systemd ,并鼓励 [初始化系统自由][29]。
+
+对于普通用户来说,它可能不是一个非常流行的 Linux 发行版,但是如果你想要一个无 systemd 的发行版和 32 位支持,Devuan 应该是一个不错的选择。
+
+最低系统要求:
+
+- 内存:1GB
+- CPU:奔腾 1.0GHz
+
+#### 9、Void Linux
+
+![][31]
+
+[Void Linux][33] 是由志愿者独立开发的有趣发行版。它旨在成为一个通用的操作系统,同时提供稳定的滚动发布周期。它以 runit 作为初始化系统替代 systemd,并为你提供了多个 [桌面环境][32] 选择。
+
+它具有非常令人印象深刻的最低需求规格,只需 96 MB 的内存配以奔腾 4 或等同的芯片。试试看吧!
+
+最低系统要求:
+
+- 96MB 内存
+- 奔腾 4 或相当的 AMD 处理器
+
+#### 10、Q4OS
+
+![][34]
+
+[Q4OS][37] 是另一个基于 Debian 的发行版,致力于提供极简和快速的桌面用户体验。它也恰好是我们的 [最佳轻量级 Linux 发行版][4] 列表中的一个。它的 32 位版本具有 [Trinity 桌面][35],你可以在 64 位版本上找到 KDE Plasma 支持。
+
+与 Void Linux 类似,Q4OS 可以运行在至低 128 MB 的内存和 300 MHz 的 CPU 上,需要 3 GB 的存储空间。对于任何老式硬件来说,它应该绰绰有余。因此,我想说,你绝对应该尝试一下!
+
+要了解更多信息,你还可以查看 [我们对 Q4OS 的点评][36]。
+
+Q4OS 的最低要求:
+
+- 内存:128MB(Trinity 桌面)/ 1GB(Plasma 桌面)
+- CPU:300 MHz(Trinity 桌面)/ 1 GHz(Plasma 桌面)
+- 存储空间:5GB(Trinity 桌面)/3GB(Plasma 桌面)
+
+#### 11、MX Linux
+
+![][38]
+
+如果有一个稍微不错的配置(不完全是老式的,而是旧的),对于 32 位系统,我个人推荐 [MX Linux][39]。它也恰好是适合各种类型用户的 [最佳 Linux 发行版][2] 之一。
+
+通常,MX Linux 是基于 Debian 的出色的轻量级和可定制的发行版。你可以选择 KDE、XFce 或 Fluxbox(这是他们自己为旧硬件设计的桌面环境)。你可以在他们的官方网站上找到更多关于它的信息,并尝试一下。
+
+最低系统要求:
+
+- 1GB 内存(建议使用 2GB,以便舒适地使用)
+- 15GB 的磁盘空间(建议 20GB)
+
+
+#### 12、Linux Mint Debian Edtion
+
+![][44]
+
+[基于 Debian 的 Linux Mint][45]?为什么不可以呢?
+
+你可以得到同样的 Cinnamon 桌面体验,只是不基于 Ubuntu。它和基于 Ubuntu 的 Linux Mint 一样容易使用,一样可靠。
+
+不仅仅是基于 Debian,你还可以得到对 64 位和 32 位系统的支持。如果你不想在 32 位系统上使用一个你从未听说过的 Linux 发行版,这应该是一个不错的选择。
+
+最低系统要求:
+
+- 1GB 内存(建议使用 2GB,以便舒适地使用)
+- 15GB 的磁盘空间(建议 20GB)
+
+#### 13、Sparky Linux
+
+![][46]
+
+[Sparky Linux][47] 是 [为初学者定制的最好的轻量级 Linux 发行版][4] 之一。它很容易定制,而且资源占用很少。
+
+它可以根据你的要求提供不同的版本,但它确实支持 32 位版本。考虑到你想为你的旧电脑买点东西,我建议你看看它的 MinimalGUI 版本,除非你真的需要像 Xfce 或 LXQt 这样成熟的桌面环境。
+
+最低系统要求:
+
+- 内存:512 MB
+- CPU:奔腾 4,或 AMD Athlon
+- 磁盘空间:2GB(命令行版),10GB(家庭版),20GB(游戏版)
+
+#### 14、Mageia
+
+![][48]
+
+作为 [Mandriva Linux][49] 的分支,[Mageia Linux][50] 是一个由社区推动的 Linux 发行版,支持 32 位系统。
+
+通常情况下,你会注意到每年都有一个重大版本。他们的目的是贡献他们的工作,以提供一个自由的操作系统,这也是潜在的安全。对于 32 位系统来说,它可能不是一个流行的选择,但它支持很多桌面环境(如 KDE Plasma、GNOME),如果你需要,你只需要从它的软件库中安装它。
+
+你应该可以从他们的官方网站上得到下载桌面环境特定镜像的选项。
+
+最低系统要求:
+
+- 512MB 内存(推荐 2GB)
+- 最小安装需 5GB 存储空间(常规安装 20GB)
+- CPU:奔腾4,或 AMD Athlon
+
+### 荣誉提名:Funtoo & Puppy Linux
+
+[Funtoo][40] 是基于 Gentoo 的由社区开发的 Linux 发行版。它着重于为你提供 Gentoo Linux 的最佳性能以及一些额外的软件包,以使用户获得完整的体验。有趣的是,该开发实际上是由 Gentoo Linux 的创建者 Daniel Robbins 领导的。
+
+[Puppy Linux][51] 是一个很小的 Linux 发行版,除了基本的工具,几乎没有捆绑的软件应用。如果其他选择都不行,而你又想要最轻量级的发行版,Puppy Linux 可能是一个选择。
+
+当然,如果你不熟悉 Linux,这两个可能都不能提供最好的体验。但是,它们确实支持 32 位系统,并且可以在许多较旧的 Intel/AMD 芯片组上很好地工作。可以在它们的官方网站上探索更多的信息。
+
+### 总结
+
+我将列表重点放在基于 Debian 的发行版和一些独立发行版上。但是,如果你不介意长期支持条款,而只想获得一个支持 32 位的镜像,也可以尝试使用任何基于 Ubuntu 18.04 的发行版(或任何官方版本)。
+
+在撰写本文时,它们只剩下几个月的软件支持。因此,我避免将其作为主要选项提及。但是,如果你喜欢基于 Ubuntu 18.04 的发行版或其它任何版本,可以选择 [LXLE][41]、[Linux Lite][42]、[Zorin Lite 15][43] 及其他官方版本。
+
+即使大多数基于 Ubuntu 的现代桌面操作系统都放弃了对 32 位的支持。你仍然有很多选项可以选择。
+
+在 32 位系统中更喜欢哪一个?在下面的评论中让我知道你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/32-bit-linux-distributions/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/what-is-linux-distribution/
+[2]: https://itsfoss.com/best-linux-distributions/
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/11/32-bit-linux.png?resize=800%2C450&ssl=1
+[4]: https://itsfoss.com/lightweight-linux-beginners/
+[5]: https://itsfoss.com/32-bit-64-bit-ubuntu/
+[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/debian-screenshot.png?resize=800%2C450&ssl=1
+[7]: https://wiki.debian.org/FrontPage
+[8]: https://www.debian.org/releases/buster/debian-installer/
+[9]: https://itsfoss.com/before-installing-debian/
+[10]: https://www.debian.org/releases/buster/installmanual
+[11]: https://www.debian.org/
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/04/slax-screenshot.jpg?resize=800%2C600&ssl=1
+[13]: https://www.slax.org
+[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/antiX-19-1.jpg?resize=800%2C500&ssl=1
+[15]: https://antixlinux.com
+[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/01/opensuse-15-1.png?resize=800%2C500&ssl=1
+[17]: https://itsfoss.com/why-use-opensuse/
+[18]: https://www.opensuse.org/
+[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/Emmabuntus-xfce.png?resize=800%2C500&ssl=1
+[20]: https://emmabuntus.org/
+[21]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/nixos-kde.jpg?resize=800%2C500&ssl=1
+[22]: https://nixos.org/features.html
+[23]: https://nixos.org/
+[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/gentoo-linux.png?resize=800%2C450&ssl=1
+[25]: https://www.gentoo.org/get-started/
+[26]: https://www.gentoo.org
+[27]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/06/devuan-beowulf.jpg?resize=800%2C600&ssl=1
+[28]: https://itsfoss.com/devuan-3-release/
+[29]: https://www.devuan.org/os/init-freedom
+[30]: https://www.devuan.org
+[31]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/void-linux.jpg?resize=800%2C450&ssl=1
+[32]: https://itsfoss.com/best-linux-desktop-environments/
+[33]: https://voidlinux.org/
+[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/q4os8Debonaire.jpg?resize=800%2C500&ssl=1
+[35]: https://en.wikipedia.org/wiki/Trinity_Desktop_Environment
+[36]: https://itsfoss.com/q4os-linux-review/
+[37]: https://q4os.org/index.html
+[38]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/08/mx-linux-19-2-kde.jpg?resize=800%2C452&ssl=1
+[39]: https://mxlinux.org/
+[40]: https://www.funtoo.org/Welcome
+[41]: https://www.lxle.net/
+[42]: https://www.linuxliteos.com
+[43]: https://zorinos.com/download/15/lite/32/
+[44]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/11/cinnamon-debian-edition.jpg?w=800&ssl=1
+[45]: https://www.linuxmint.com/download_lmde.php
+[46]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/sparky-linux.jpg?w=800&ssl=1
+[47]: https://sparkylinux.org/download/stable/
+[48]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/11/mageia.jpg?w=800&ssl=1
+[49]: https://en.wikipedia.org/wiki/Mandriva_Linux
+[50]: https://www.mageia.org/en/
+[51]: http://puppylinux.com/
\ No newline at end of file
diff --git a/published/202104/20201109 Getting started with Stratis encryption.md b/published/202104/20201109 Getting started with Stratis encryption.md
new file mode 100644
index 0000000000..6708bdaea5
--- /dev/null
+++ b/published/202104/20201109 Getting started with Stratis encryption.md
@@ -0,0 +1,201 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13311-1.html)
+[#]: subject: (Getting started with Stratis encryption)
+[#]: via: (https://fedoramagazine.org/getting-started-with-stratis-encryption/)
+[#]: author: (briansmith https://fedoramagazine.org/author/briansmith/)
+
+Stratis 加密入门
+======
+
+
+
+Stratis 在其 [官方网站][2] 上被描述为“_易于使用的 Linux 本地存储管理_”。请看这个 [短视频][3],快速演示基础知识。该视频是在 Red Hat Enterprise Linux 8 系统上录制的。视频中显示的概念也适用于 Fedora 中的 Stratis。
+
+Stratis 2.1 版本引入了对加密的支持。继续阅读以了解如何在 Stratis 中开始加密。
+
+### 先决条件
+
+加密需要 Stratis 2.1 或更高版本。这篇文章中的例子使用的是 Fedora 33 的预发布版本。Stratis 2.1 将用在 Fedora 33 的最终版本中。
+
+你还需要至少一个可用的块设备来创建一个加密池。下面的例子是在 KVM 虚拟机上完成的,虚拟磁盘驱动器为 5GB(`/dev/vdb`)。
+
+### 在内核密钥环中创建一个密钥
+
+Linux 内核密钥环用于存储加密密钥。关于内核密钥环的更多信息,请参考 `keyrings` 手册页(`man keyrings`)。
+
+使用 `stratis key set` 命令在内核钥匙圈中设置密钥。你必须指定从哪里读取密钥。要从标准输入中读取密钥,使用 `-capture-key` 选项。要从文件中读取密钥,使用 `-keyfile-path ` 选项。最后一个参数是一个密钥描述。它将稍后你创建加密的 Stratis 池时使用。
+
+例如,要创建一个描述为 `pool1key` 的密钥,并从标准输入中读取密钥,可以输入:
+
+```
+# stratis key set --capture-key pool1key
+Enter desired key data followed by the return key:
+```
+
+该命令提示我们输入密钥数据/密码,然后密钥就创建在内核密钥环中了。
+
+要验证密钥是否已被创建,运行 `stratis key list`:
+
+```
+# stratis key list
+Key Description
+pool1key
+```
+
+这将验证是否创建了 `pool1key`。请注意,这些密钥不是持久的。如果主机重启,在访问加密的 Stratis 池之前,需要再次提供密钥(此过程将在后面介绍)。
+
+如果你有多个加密池,它们可以有一个单独的密钥,也可以共享同一个密钥。
+
+也可以使用以下 `keyctl` 命令查看密钥:
+
+```
+# keyctl get_persistent @s
+318044983
+# keyctl show
+Session Keyring
+ 701701270 --alswrv 0 0 keyring: _ses
+ 649111286 --alswrv 0 65534 \_ keyring: _uid.0
+ 318044983 ---lswrv 0 65534 \_ keyring: _persistent.0
+1051260141 --alswrv 0 0 \_ user: stratis-1-key-pool1key
+```
+
+### 创建加密的 Stratis 池
+
+现在已经为 Stratis 创建了一个密钥,下一步是创建加密的 Stratis 池。加密池只能在创建池时进行。目前不可能对现有的池进行加密。
+
+使用 `stratis pool create` 命令创建一个池。添加 `-key-desc` 和你在上一步提供的密钥描述(`pool1key`)。这将向 Stratis 发出信号,池应该使用提供的密钥进行加密。下面的例子是在 `/dev/vdb` 上创建 Stratis 池,并将其命名为 `pool1`。确保在你的系统中指定一个空的/可用的设备。
+
+```
+# stratis pool create --key-desc pool1key pool1 /dev/vdb
+```
+
+你可以使用 `stratis pool list` 命令验证该池是否已经创建:
+
+```
+# stratis pool list
+Name Total Physical Properties
+pool1 4.98 GiB / 37.63 MiB / 4.95 GiB ~Ca, Cr
+```
+
+在上面显示的示例输出中,`~Ca` 表示禁用了缓存(`~` 否定了该属性)。`Cr` 表示启用了加密。请注意,缓存和加密是相互排斥的。这两个功能不能同时启用。
+
+接下来,创建一个文件系统。下面的例子演示了创建一个名为 `filesystem1` 的文件系统,将其挂载在 `/filesystem1` 挂载点上,并在新文件系统中创建一个测试文件:
+
+```
+# stratis filesystem create pool1 filesystem1
+# mkdir /filesystem1
+# mount /stratis/pool1/filesystem1 /filesystem1
+# cd /filesystem1
+# echo "this is a test file" > testfile
+```
+
+### 重启后访问加密池
+
+当重新启动时,你会发现 Stratis 不再显示你的加密池或它的块设备:
+
+```
+# stratis pool list
+Name Total Physical Properties
+```
+
+```
+# stratis blockdev list
+Pool Name Device Node Physical Size Tier
+```
+
+要访问加密池,首先要用之前使用的相同的密钥描述和密钥数据/口令重新创建密钥:
+
+```
+# stratis key set --capture-key pool1key
+Enter desired key data followed by the return key:
+```
+
+接下来,运行 `stratis pool unlock` 命令,并验证现在可以看到池和它的块设备:
+
+```
+# stratis pool unlock
+# stratis pool list
+Name Total Physical Properties
+pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr
+# stratis blockdev list
+Pool Name Device Node Physical Size Tier
+pool1 /dev/dm-2 4.98 GiB Data
+```
+
+接下来,挂载文件系统并验证是否可以访问之前创建的测试文件:
+
+```
+# mount /stratis/pool1/filesystem1 /filesystem1/
+# cat /filesystem1/testfile
+this is a test file
+```
+
+### 使用 systemd 单元文件在启动时自动解锁 Stratis 池
+
+可以在启动时自动解锁 Stratis 池,无需手动干预。但是,必须有一个包含密钥的文件。在某些环境下,将密钥存储在文件中可能会有安全问题。
+
+下图所示的 systemd 单元文件提供了一个简单的方法来在启动时解锁 Stratis 池并挂载文件系统。欢迎提供更好的/替代方法的反馈。你可以在文章末尾的评论区提供建议。
+
+首先用下面的命令创建你的密钥文件。确保用之前输入的相同的密钥数据/密码来代替`passphrase`。
+
+```
+# echo -n passphrase > /root/pool1key
+```
+
+确保该文件只能由 root 读取:
+
+```
+# chmod 400 /root/pool1key
+# chown root:root /root/pool1key
+```
+
+在 `/etc/systemd/system/stratis-filesystem1.service` 创建包含以下内容的 systemd 单元文件:
+
+```
+[Unit]
+Description = stratis mount pool1 filesystem1 file system
+After = stratisd.service
+
+[Service]
+ExecStartPre=sleep 2
+ExecStartPre=stratis key set --keyfile-path /root/pool1key pool1key
+ExecStartPre=stratis pool unlock
+ExecStartPre=sleep 3
+ExecStart=mount /stratis/pool1/filesystem1 /filesystem1
+RemainAfterExit=yes
+
+[Install]
+WantedBy = multi-user.target
+```
+
+接下来,启用服务,使其在启动时运行:
+
+```
+# systemctl enable stratis-filesystem1.service
+```
+
+现在重新启动并验证 Stratis 池是否已自动解锁,其文件系统是否已挂载。
+
+### 结语
+
+在今天的环境中,加密是很多人和组织的必修课。本篇文章演示了如何在 Stratis 2.1 中启用加密功能。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/getting-started-with-stratis-encryption/
+
+作者:[briansmith][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/briansmith/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2020/11/stratis-encryption-2-816x345.jpg
+[2]: https://stratis-storage.github.io/
+[3]: https://www.youtube.com/watch?v=CJu3kmY-f5o
diff --git a/published/202104/20201204 9 Open Source Forum Software That You Can Deploy on Your Linux Servers.md b/published/202104/20201204 9 Open Source Forum Software That You Can Deploy on Your Linux Servers.md
new file mode 100644
index 0000000000..74d7263544
--- /dev/null
+++ b/published/202104/20201204 9 Open Source Forum Software That You Can Deploy on Your Linux Servers.md
@@ -0,0 +1,213 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13329-1.html)
+[#]: subject: (9 Open Source Forum Software That You Can Deploy on Your Linux Servers)
+[#]: via: (https://itsfoss.com/open-source-forum-software/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+11 个可以部署在 Linux 服务器上的开源论坛软件
+======
+
+> 是否想要建立社区论坛或客户支持门户站点?以下是一些可以在服务器上部署的最佳开源论坛软件。
+
+就像我们的论坛一样,重要的是建立一个让志趣相投的人可以讨论,互动和寻求支持的平台。
+
+论坛为用户(或客户)提供了一个空间,让他们可以接触到在互联网上大多数情况下不容易找到的东西。
+
+如果你是一家企业,则可以聘请开发人员团队并按照自己的方式建立自己的论坛,但这会增加大量预算。
+
+幸运的是,有几个令人印象深刻的开源论坛软件,你只需要将其部署在你的服务器上就万事大吉了!在此过程中,你将节省很多钱,但仍能获得所需的东西。
+
+在这里,我列出了可以在 Linux 服务器上安装的最佳开源论坛软件列表。
+
+### 建立社区门户的最佳开源论坛软件
+
+![][2]
+
+如果你尚未建立过网站,则在部署论坛之前,可能需要看一下 [某些开源网站创建工具][3]。
+
+**注意:** 此列表没有特定的排名顺序。
+
+#### 1、Discourse(现代、流行)
+
+![][4]
+
+[Discourse][7] 是人们用来部署配置讨论平台的最流行的现代论坛软件。实际上,[It's FOSS 社区][1] 论坛使用了 Discourse 平台。
+
+它提供了我所知道的大多数基本功能,包括电子邮件通知、审核工具、样式自定义选项,Slack/WordPress 等第三方集成等等。
+
+它的自托管是完全免费的,你也可以在 [GitHub][5] 上找到该项目。如果你要减少将其部署在自托管服务器上的麻烦,可以选择 [Discourse 提供的托管服务][6](肯定会很昂贵)。
+
+#### 2、Talkyard(受 Discourse 和 StackOverflow 启发)
+
+![][8]
+
+[Talkyard][10] 是完全免费使用的,是一个开源项目。它看起来很像 Discourse,但是如果你深入了解一下,还是有区别的。
+
+你可以在这里获得 StackOverflow 的大多数关键功能,以及在论坛平台上期望得到的所有基本功能。它可能不是一个流行的论坛解决方案,但是如果你想要类似于 Discourse 的功能以及一些有趣的功能,那么值得尝试一下。
+
+你可以在他们的 [GitHub 页面][9] 中进一步了解它。
+
+#### 3、Forem (一种独特的社区平台,正在测试中)
+
+
+
+你可能以前没有听说过 [Forem](https://www.forem.com/),但它支持了 [dev.to](https://dev.to/)(这是一个越来越受欢迎的开发者社区网站)。
+
+它仍然处于测试阶段,所以你或许不会选择在生产服务器上实验。但是,你可以通过在他们的官方网站上填写一个表格并与他们取得联系,让他们为你托管。
+
+尽管没有官方的功能列表来强调所有的东西,但如果我们以 [dev.to](https://dev.to/) 为例,你会得到许多基本的特性和功能,如社区列表、商店、帖子格式化等。你可以在他们的 [公告帖子](https://dev.to/devteam/for-empowering-community-2k6h) 中阅读更多关于它提供的内容,并在 [GitHub](https://github.com/forem/forem) 上探索该项目。
+
+#### 4、NodeBB(现代化、功能齐全)
+
+![][11]
+
+[NodeBB][14] 是一个基于 [Node.js][12] 的开源论坛软件。它的目标是简单、优雅和快速。首先,它面向有托管计划的组织和企业。但是,你也可以选择自己托管它。
+
+你还可以获得实时本地分析功能,以及聊天和通知支持。它还提供一个 API,可以将其与你的现有产品集成。它还支持审核工具和打击垃圾邮件的工具。
+
+你可以获得一些开箱即用的第三方集成支持,例如 WordPress、Mailchimp 等。
+
+请在他们的 [GitHub 页面][13] 或官方网站上可以进一步了解它。
+
+#### 5、Vanilla 论坛(面向企业)
+
+![][15]
+
+[Vanilla 论坛][17] 主要是一款以企业为中心的论坛软件,它的基本功能是为你的平台打造品牌,为客户提供问答,还可以对帖子进行投票。
+
+用户体验具有现代的外观,并且已被像 EA、Adobe 和其他一些大公司使用。
+
+当然,如果你想尝试基于云的 Vanilla 论坛(由专业团队管理)以及对某些高级功能的访问权,可以随时申请演示。无论哪种情况,你都可以选择社区版,该社区版可以免费使用大多数最新功能,但需要自己托管和管理。
+
+你可以在他们的官方网站和 [GitHub 页面][16] 上进一步了解它。
+
+#### 6、bbPress (来自 WordPress)
+
+![][20]
+
+[bbPress][22] 是一个可靠的论坛软件,由 WordPress 的创建者建立。旨在提供一个简单而迅速的论坛体验。
+
+用户界面看起来很老旧,但易于使用,它提供了你通常在论坛软件中需要的基本功能。审核工具很好用,易于设置。你可以使用现有的插件扩展功能,并从几个可用的主题中进行选择以调整论坛的外观。
+
+如果你只想要一个没有花哨功能的简单论坛平台,bbPress 应该是完美的。你也可以查看他们的 [GitHub 页面][21] 了解更多信息。
+
+#### 7、phpBB(经典论坛软件)
+
+![][23]
+
+如果你想要传统的论坛设计,只想要基本功能,则 [phpBB][25] 软件是一个不错的选择。当然,你可能无法获得最佳的用户体验或功能,但是作为按传统设计的论坛平台,它是实用的并且非常有效。
+
+尤其是,对于习惯使用传统方式的用户而言,这将是一种简单而有效的解决方案。
+
+不仅仅是简单,而且在一般的托管供应商那里,它的设置也是非常容易的。在任何共享主机平台上,你都能获得一键式安装功能,因此也不需要太多的技术知识来进行设置。
+
+你可以在他们的官方网站或 [GitHub 页面][24] 上找到更多有关它的信息。
+
+#### 8、Simple Machines 论坛(另一个经典)
+
+![][26]
+
+与 phpBB 类似,[Simple Machines 论坛][27] 是另一种基本(或简单)的论坛。很大程度上你可能无法自定义外观(至少不容易),但是默认外观是干净整洁的,提供了良好的用户体验。
+
+就个人而言,相比 php BB 我更喜欢它,但是你可以前往他们的 [官方网站][27] 进行进一步的探索。同样,你可以使用一键安装方法在任何共享托管服务上轻松安装 Simple Machines 论坛。
+
+#### 9、FluxBB(古典)
+
+![][28]
+
+[FluxBB][30] 是另一个简单、轻量级的开源论坛。与其他的相比,它可能维护的不是非常积极,但是如果你只想部署一个只有很少几个用户的基本论坛,则可以轻松尝试一下。
+
+你可以在他们的官方网站和 [GitHub 页面][29] 上找到更多有关它的信息。
+
+#### 10、MyBB(不太流行,但值得看看)
+
+![][31]
+
+[MyBB][33] 是一款独特的开源论坛软件,它提供多种样式,并包含你需要的基本功能。
+
+从插件支持和审核工具开始,你将获得管理大型社区所需的一切。它还支持类似于 Discourse 和同类论坛软件面向个人用户的私人消息传递。
+
+它可能不是一个流行的选项,但是它可以满足大多数用例,并且完全免费。你可以在 [GitHub][32] 上得到支持和探索这个项目。
+
+#### 11、Flarum(测试版)
+
+![][34]
+
+如果你想要更简单和独特的论坛,请看一下 [Flarum][37]。它是一款轻量级的论坛软件,旨在以移动为先,同时提供快速的体验。
+
+它支持某些第三方集成,也可以使用扩展来扩展功能。就我个人而言,它看起来很漂亮。我没有机会尝试它,你可以看一下它的 [文档][35],可以肯定它具有论坛所需的所有必要功能的特征。
+
+值得注意的是 Flarum 是相当新的,因此仍处于测试阶段。你可能需要先将其部署在测试服务器上测试后,再应用到生产环境。请查看其 [GitHub 页面][36] 了解更多详细信息。
+
+#### 补充:Lemmy(更像是 Reddit 的替代品,但也是一个不错的选择)
+
+
+
+一个用 [Rust](https://www.rust-lang.org/) 构建的 Reddit 的联盟式论坛的替代品。它的用户界面很简单,有些人可能觉得它不够直观,无法获得有吸引力的论坛体验。
+
+其联盟网络仍在构建中,但如果你想要一个类似 Reddit 的社区平台,你可以很容易地将它部署在你的 Linux 服务器上,并制定好管理规则、版主,然后就可以开始了。它支持跨版发帖(参见 Reddit),以及其他基本功能,如标签、投票、用户头像等。
+
+你可以通过其 [官方文档](https://lemmy.ml/docs/about.html) 和 [GitHub 页面](https://github.com/LemmyNet/lemmy) 探索更多信息。
+
+### 总结
+
+大多数开源论坛软件都为基本用例提供了几乎相同的功能。如果你正在寻找特定的功能,则可能需要浏览其文档。
+
+就个人而言,我推荐 Discourse。它很流行,外观现代,拥有大量的用户基础。
+
+你认为最好的开源论坛软件是什么?我是否错过了你的偏爱?在下面的评论中让我知道。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/open-source-forum-software/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.community/
+[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/12/open-source-forum-software.png?resize=800%2C450&ssl=1
+[3]: https://itsfoss.com/open-source-cms/
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/11/itsfoss-community-discourse.jpg?resize=800%2C561&ssl=1
+[5]: https://github.com/discourse/discourse
+[6]: https://discourse.org/buy
+[7]: https://www.discourse.org/
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/11/talkyard-forum.jpg?resize=800%2C598&ssl=1
+[9]: https://github.com/debiki/talkyard
+[10]: https://www.talkyard.io/
+[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/11/nodebb.jpg?resize=800%2C369&ssl=1
+[12]: https://nodejs.org/en/
+[13]: https://github.com/NodeBB/NodeBB
+[14]: https://nodebb.org/
+[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/11/vanilla-forums.png?resize=800%2C433&ssl=1
+[16]: https://github.com/Vanilla
+[17]: https://vanillaforums.com/en/
+[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/open-source-eCommerce.png?fit=800%2C450&ssl=1
+[19]: https://itsfoss.com/open-source-ecommerce/
+[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/11/bbpress.jpg?resize=800%2C552&ssl=1
+[21]: https://github.com/bbpress
+[22]: https://bbpress.org/
+[23]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/11/phpBB.png?resize=798%2C600&ssl=1
+[24]: https://github.com/phpbb/phpbb
+[25]: https://www.phpbb.com/
+[26]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/11/simplemachines.jpg?resize=800%2C343&ssl=1
+[27]: https://www.simplemachines.org/
+[28]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/11/FluxBB.jpg?resize=800%2C542&ssl=1
+[29]: https://github.com/fluxbb/fluxbb/
+[30]: https://fluxbb.org/
+[31]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/11/mybb-example.png?resize=800%2C461&ssl=1
+[32]: https://github.com/mybb/mybb
+[33]: https://mybb.com/
+[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/11/flarum-screenshot.png?resize=800%2C503&ssl=1
+[35]: https://docs.flarum.org/
+[36]: https://github.com/flarum
+[37]: https://flarum.org/
+[38]: https://highoncloud.com/
diff --git a/published/202104/20201209 Program a simple game with Elixir.md b/published/202104/20201209 Program a simple game with Elixir.md
new file mode 100644
index 0000000000..4d7f6e6211
--- /dev/null
+++ b/published/202104/20201209 Program a simple game with Elixir.md
@@ -0,0 +1,134 @@
+[#]: collector: (lujun9972)
+[#]: translator: (tt67wq)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13292-1.html)
+[#]: subject: (Program a simple game with Elixir)
+[#]: via: (https://opensource.com/article/20/12/elixir)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+使用 Elixir 语言编写一个小游戏
+======
+
+> 通过编写“猜数字”游戏来学习 Elixir 编程语言,并将它与一个你熟知的语言做对比。
+
+
+
+为了更好的学习一门新的编程语言,最好的方法是去关注主流语言的一些共有特征:
+
+ * 变量
+ * 表达式
+ * 语句
+
+这些概念是大多数编程语言的基础。因为这些相似性,只要你通晓了一门编程语言,你可以通过对比差异来熟知另一门编程语言。
+
+另外一个学习新编程语言的好方法是开始编写一个简单标准的程序。它可以让你集中精力在语言上而非程序的逻辑本身。在这个系列的文章中,我们使用“猜数字”程序来实现,在这个程序中,计算机会选择一个介于 1 到 100 之间的数字,并要求你来猜测它。程序会循环执行,直到你正确猜出该数字为止。
+
+“猜数字”这个程序使用了编程语言的以下概念:
+
+ * 变量
+ * 输入
+ * 输出
+ * 条件判断
+ * 循环
+
+这是一个学习新编程语言的绝佳实践。
+
+### 猜数字的 Elixir 实现
+
+[Elixir][2] 是一门被设计用于构建稳定可维护应用的动态类型的函数式编程语言。它与 [Erlang][3] 运行于同一虚拟机之上,吸纳了 Erlang 的众多长处的同时拥有更加简单的语法。
+
+你可以编写一个 Elixir 版本的“猜数字”游戏来体验这门语言。
+
+这是我的实现方法:
+
+```
+defmodule Guess do
+ def guess() do
+ random = Enum.random(1..100)
+ IO.puts "Guess a number between 1 and 100"
+ Guess.guess_loop(random)
+ end
+ def guess_loop(num) do
+ data = IO.read(:stdio, :line)
+ {guess, _rest} = Integer.parse(data)
+ cond do
+ guess < num ->
+ IO.puts "Too low!"
+ guess_loop(num)
+ guess > num ->
+ IO.puts "Too high!"
+ guess_loop(num)
+ true ->
+ IO.puts "That's right!"
+ end
+ end
+end
+
+Guess.guess()
+```
+
+Elixir 通过列出变量的名称后面跟一个 `=` 号来为了给变量分配一个值。举个例子,表达式 `random = 0` 给 `random` 变量分配一个数值 0。
+
+代码以定义一个模块开始。在 Elixir 语言中,只有模块可以包含命名函数。
+
+紧随其后的这行代码定义了入口函数 `guess()`,这个函数:
+
+ * 调用 `Enum.random()` 函数来获取一个随机整数
+ * 打印游戏提示
+ * 调用循环执行的函数
+
+剩余的游戏逻辑实现在 `guess_loop()` 函数中。
+
+`guess_loop()` 函数利用 [尾递归][4] 来实现循环。Elixir 中有好几种实现循环的方法,尾递归是比较常用的一种方式。`guess_loop()` 函数做的最后一件事就是调用自身。
+
+`guess_loop()` 函数的第一行读取用户输入。下一行调用 `parse()` 函数将输入转换成一个整数。
+
+`cond` 表达式是 Elixir 版本的多重分支表达式。与其他语言中的 `if/elif` 或者 `if/elsif` 表达式不同,Elixir 对于的首个分支或者最后一个没有分支并没有区别对待。
+
+这个 `cond` 表达式有三路分支:猜测的结果可以比随机数大、小或者相等。前两个选项先输出不等式的方向然后递归调用 `guess_loop()`,循环返回至函数开始。最后一个选项输出 `That's right`,然后这个函数就完成了。
+
+### 输出例子
+
+现在你已经编写了你的 Elixir 代码,你可以运行它来玩“猜数字”的游戏。每次你执行这个程序,Elixir 会选择一个不同的随机数,你可以一直猜下去直到你找到正确的答案:
+
+```
+$ elixir guess.exs
+Guess a number between 1 and 100
+50
+Too high
+30
+Too high
+20
+Too high
+10
+Too low
+15
+Too high
+13
+Too low
+14
+That's right!
+```
+
+“猜数字”游戏是一个学习一门新编程语言的绝佳入门程序,因为它用了非常直接的方法实践了常用的几个编程概念。通过用不同语言实现这个简单的小游戏,你可以实践各个语言的核心概念并且比较它们的细节。
+
+你是否有你最喜爱的编程语言?你将怎样用它来编写“猜数字”这个游戏?关注这个系列的文章来看看其他你可能感兴趣的语言实现。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/12/elixir
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[tt67wq](https://github.com/tt67wq)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/dice_tabletop_board_gaming_game.jpg?itok=y93eW7HN (A die with rainbow color background)
+[2]: https://elixir-lang.org/
+[3]: https://www.erlang.org/
+[4]: https://en.wikipedia.org/wiki/Tail_call
diff --git a/published/202104/20210203 Improve your productivity with this Linux automation tool.md b/published/202104/20210203 Improve your productivity with this Linux automation tool.md
new file mode 100644
index 0000000000..6ef7efff89
--- /dev/null
+++ b/published/202104/20210203 Improve your productivity with this Linux automation tool.md
@@ -0,0 +1,177 @@
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13347-1.html)
+[#]: subject: (Improve your productivity with this Linux automation tool)
+[#]: via: (https://opensource.com/article/21/2/linux-autokey)
+[#]: author: (Matt Bargenquast https://opensource.com/users/mbargenquast)
+
+使用 Linux 自动化工具提高生产率
+======
+
+> 用 AutoKey 配置你的键盘,纠正常见的错别字,输入常用的短语等等。
+
+
+
+[AutoKey][2] 是一个开源的 Linux 桌面自动化工具,一旦它成为你工作流程的一部分,你就会想,如何没有它,那该怎么办。它可以成为一种提高生产率的变革性工具,或者仅仅是减少与打字有关的身体压力的一种方式。
+
+本文将研究如何安装和开始使用 AutoKey ,介绍一些可以立即在工作流程中使用的简单方法,并探讨 AutoKey 高级用户可能会感兴趣的一些高级功能。
+
+### 安装并设置 AutoKey
+
+AutoKey 在许多 Linux 发行版中都是现成的软件包。该项目的 [安装指南][3] 包含许多平台的说明,也包括了从源代码进行构建的指导。本文使用 Fedora 作为操作平台。
+
+AutoKey 有两个变体:为像 GNOME 等基于 [GTK][4] 环境而设计的 autokey-gtk 和基于 [QT][5] 的 autokey-qt。
+
+你可以从命令行安装任一变体:
+
+```
+sudo dnf install autokey-gtk
+```
+
+安装完成后,使用 `autokey-gtk`(或 `autokey-qt`)运行它。
+
+### 探究界面
+
+在将 AutoKey 设置为在后台运行并自动执行操作之前,你首先需要对其进行配置。调出用户界面(UI)配置:
+
+```
+autokey-gtk -c
+```
+
+AutoKey 提供了一些预设配置的示例。你可能希望在熟悉 UI 时将他们留作备用,但是可以根据需要删除它们。
+
+![AutoKey 用户界面][6]
+
+左侧窗格包含一个文件夹式的短语和脚本的层次结构。“短语” 代表要让 AutoKey 输入的文本。“脚本” 是动态的、程序化的等效项,可以使用 Python 编写,并且获得与键盘击键发送到活动窗口基本相同的结果。
+
+右侧窗格构建和配置短语和脚本。
+
+对配置满意后,你可能希望在登录时自动运行 AutoKey,这样就不必每次都启动它。你可以通过在 “首选项”菜单(“编辑 -> 首选项”)中勾选 “登录时自动启动 AutoKey”进行配置。
+
+![登录时自动启动 AutoKey][8]
+
+### 使用 AutoKey 纠正常见的打字排版错误
+
+修复常见的打字排版错误对于 AutoKey 来说是一个容易解决的问题。例如,我始终键入 “gerp” 来代替 “grep”。这里是如何配置 AutoKey 为你解决这些类型问题。
+
+创建一个新的子文件夹,可以在其中将所有“打字排版错误校正”配置分组。在左侧窗格中选择 “My Phrases” ,然后选择 “文件 -> 新建 -> 子文件夹”。将子文件夹命名为 “Typos”。
+
+在 “文件 -> 新建 -> 短语” 中创建一个新短语。并将其称为 “grep”。
+
+通过高亮选择短语 “grep”,然后在 输入短语内容部分(替换默认的 “Enter phrase contents” 文本)中输入 “grep” ,配置 AutoKey 插入正确的关键词。
+
+接下来,通过定义缩写来设置 AutoKey 如何触发此短语。点击用户界面底部紧邻 “缩写” 的 “设置”按钮。
+
+在弹出的对话框中,单击 “添加” 按钮,然后将 “gerp” 添加为新的缩写。勾选 “删除键入的缩写”;此选项让 AutoKey 将任何键入 “gerp” 一词的替换为 “grep”。请不要勾选“在键入单词的一部分时触发”,这样,如果你键入包含 “grep”的单词(例如 “fingerprint”),就不会尝试将其转换为 “fingreprint”。仅当将 “grep” 作为独立的单词键入时,此功能才有效。
+
+![在 AutoKey 中设置缩写][9]
+
+### 限制对特定应用程序的更正
+
+你可能希望仅在某些应用程序(例如终端窗口)中打字排版错误时才应用校正。你可以通过设置 窗口过滤器进行配置。单击 “设置” 按钮来定义。
+
+设置窗口过滤器的最简单方法是让 AutoKey 为你检测窗口类型:
+
+ 1. 启动一个新的终端窗口。
+ 2. 返回 AutoKey,单击 “检测窗口属性”按钮。
+ 3. 单击终端窗口。
+
+这将自动填充窗口过滤器,可能的窗口类值为 `gnome-terminal-server.Gnome-terminal`。这足够了,因此单击 “OK”。
+
+![AutoKey 窗口过滤器][10]
+
+### 保存并测试
+
+对新配置满意后,请确保将其保存。 单击 “文件” ,然后选择 “保存” 以使更改生效。
+
+现在进行重要的测试!在你的终端窗口中,键入 “gerp” 紧跟一个空格,它将自动更正为 “grep”。要验证窗口过滤器是否正在运行,请尝试在浏览器 URL 栏或其他应用程序中键入单词 “gerp”。它并没有变化。
+
+你可能会认为,使用 [shell 别名][11] 可以轻松解决此问题,我完全赞成!与别名不同,只要是面向命令行,无论你使用什么应用程序,AutoKey 都可以按规则纠正错误。
+
+例如,我在浏览器,集成开发环境和终端中输入的另一个常见打字错误 “openshfit” 替代为 “openshift”。别名不能完全解决此问题,而 AutoKey 可以在任何情况下纠正它。
+
+### 键入常用短语
+
+你可以通过许多其他方法来调用 AutoKey 的短语来帮助你。例如,作为从事 OpenShift 的站点可靠性工程师(SRE),我经常在命令行上输入 Kubernetes 命名空间名称:
+
+```
+oc get pods -n openshift-managed-upgrade-operator
+```
+
+这些名称空间是静态的,因此它们是键入特定命令时 AutoKey 可以为我插入的理想短语。
+
+为此,我创建了一个名为 “Namespaces” 的短语子文件夹,并为我经常键入的每个命名空间添加了一个短语条目。
+
+### 分配热键
+
+接下来,也是最关键的一点,我为子文件夹分配了一个 “热键”。每当我按下该热键时,它都会打开一个菜单,我可以在其中选择(要么使用 “方向键”+回车键要么使用数字)要插入的短语。这减少了我仅需几次击键就可以输入这些命令的击键次数。
+
+“My Phrases” 文件夹中 AutoKey 的预配置示例使用 `Ctrl+F7` 热键进行配置。如果你将示例保留在 AutoKey 的默认配置中,请尝试一下。你应该在此处看到所有可用短语的菜单。使用数字或箭头键选择所需的项目。
+
+### 高级自动键入
+
+AutoKey 的 [脚本引擎][12] 允许用户运行可以通过相同的缩写和热键系统调用的 Python 脚本。这些脚本可以通过支持的 API 的函数来完成诸如切换窗口、发送按键或执行鼠标单击之类的操作。
+
+AutoKey 用户非常欢迎这项功能,发布了自定义脚本供其他用户采用。例如,[NumpadIME 脚本][13] 将数字键盘转换为旧的手机样式的文本输入方法,[Emojis-AutoKey][14] 可以通过将诸如: `:smile:` 之类的短语转换为它们等价的表情符号来轻松插入。
+
+这是我设置的一个小脚本,该脚本进入 Tmux 的复制模式,以将前一行中的第一个单词复制到粘贴缓冲区中:
+
+```
+from time import sleep
+
+# 发送 Tmux 命令前缀(b 更改为 s)
+keyboard.send_keys("+s")
+# Enter copy mode
+keyboard.send_key("[")
+sleep(0.01)
+# Move cursor up one line
+keyboard.send_keys("k")
+sleep(0.01)
+# Move cursor to start of line
+keyboard.send_keys("0")
+sleep(0.01)
+# Start mark
+keyboard.send_keys(" ")
+sleep(0.01)
+# Move cursor to end of word
+keyboard.send_keys("e")
+sleep(0.01)
+# Add to copy buffer
+keyboard.send_keys("+m")
+```
+
+之所以有 `sleep` 函数,是因为 Tmux 有时无法跟上 AutoKey 发送击键的速度,并且它们对整体执行时间的影响可忽略不计。
+
+### 使用 AutoKey 自动化
+
+我希望你喜欢这篇使用 AutoKey 进行键盘自动化的探索,它为你提供了有关如何改善工作流程的一些好主意。如果你在使用 AutoKey 时有什么有用的或新颖的方法,一定要在下面的评论中分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-autokey
+
+作者:[Matt Bargenquast][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mbargenquast
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
+[2]: https://github.com/autokey/autokey
+[3]: https://github.com/autokey/autokey/wiki/Installing
+[4]: https://www.gtk.org/
+[5]: https://www.qt.io/
+[6]: https://opensource.com/sites/default/files/uploads/autokey-defaults.png (AutoKey UI)
+[7]: https://creativecommons.org/licenses/by-sa/4.0/
+[8]: https://opensource.com/sites/default/files/uploads/startautokey.png (Automatically start AutoKey at login)
+[9]: https://opensource.com/sites/default/files/uploads/autokey-set_abbreviation.png (Set abbreviation in AutoKey)
+[10]: https://opensource.com/sites/default/files/uploads/autokey-window_filter.png (AutoKey Window Filter)
+[11]: https://opensource.com/article/19/7/bash-aliases
+[12]: https://autokey.github.io/index.html
+[13]: https://github.com/luziferius/autokey_scripts
+[14]: https://github.com/AlienKevin/Emojis-AutoKey
diff --git a/published/202104/20210210 How to Add Fingerprint Login in Ubuntu and Other Linux Distributions.md b/published/202104/20210210 How to Add Fingerprint Login in Ubuntu and Other Linux Distributions.md
new file mode 100644
index 0000000000..19bf109db5
--- /dev/null
+++ b/published/202104/20210210 How to Add Fingerprint Login in Ubuntu and Other Linux Distributions.md
@@ -0,0 +1,103 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13337-1.html)
+[#]: subject: (How to Add Fingerprint Login in Ubuntu and Other Linux Distributions)
+[#]: via: (https://itsfoss.com/fingerprint-login-ubuntu/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+如何在 Ubuntu 中添加指纹登录
+======
+
+
+
+现在很多高端笔记本都配备了指纹识别器。Windows 和 macOS 支持指纹登录已经有一段时间了。在桌面 Linux 中,对指纹登录的支持更多需要极客的调整,但 [GNOME][1] 和 [KDE][2] 已经开始通过系统设置来支持它。
+
+这意味着在新的 Linux 发行版上,你可以轻松使用指纹识别。在这里我将在 Ubuntu 中启用指纹登录,但你也可以在其他运行 GNOME 3.38 的发行版上使用这些步骤。
+
+> **前提条件**
+>
+> 当然,这是显而易见的。你的电脑必须有一个指纹识别器。
+>
+> 这个方法适用于任何运行 GNOME 3.38 或更高版本的 Linux 发行版。如果你不确定,你可以[检查你使用的桌面环境版本][3]。
+>
+> KDE 5.21 也有一个指纹管理器。当然,截图看起来会有所不同。
+
+### 在 Ubuntu 和其他 Linux 发行版中添加指纹登录功能
+
+进入 “设置”,然后点击左边栏的 “用户”。你应该可以看到系统中所有的用户账号。你会看到几个选项,包括 “指纹登录”。
+
+点击启用这里的指纹登录选项。
+
+![Enable fingerprint login in Ubuntu][4]
+
+它将立即要求你扫描一个新的指纹。当你点击 “+” 号来添加指纹时,它会提供一些预定义的选项,这样你就可以很容易地识别出它是哪根手指或拇指。
+
+当然,你可以点击右手食指但扫描左手拇指,不过我看不出你有什么好的理由要这么做。
+
+![Adding fingerprint][5]
+
+在添加指纹时,请按照指示旋转你的手指或拇指。
+
+![Rotate your finger][6]
+
+系统登记了整个手指后,就会给你一个绿色的信号,表示已经添加了指纹。
+
+![Fingerprint successfully added][7]
+
+如果你想马上测试一下,在 Ubuntu 中按 `Super+L` 快捷键锁定屏幕,然后使用指纹进行登录。
+
+![Login With Fingerprint in Ubuntu][8]
+
+#### 在 Ubuntu 上使用指纹登录的经验
+
+指纹登录顾名思义就是使用你的指纹来登录系统。就是这样。当要求对需要 `sudo` 访问的程序进行认证时,你不能使用手指。它不能代替你的密码。
+
+还有一件事。指纹登录可以让你登录,但当系统要求输入 `sudo` 密码时,你不能用手指。Ubuntu 中的 [钥匙环][9] 也仍然是锁定的。
+
+另一件烦人的事情是因为 GNOME 的 GDM 登录界面。当你登录时,你必须先点击你的账户才能进入密码界面。你在这可以使用手指。如果能省去先点击用户帐户 ID 的麻烦就更好了。
+
+我还注意到,指纹识别没有 Windows 中那么流畅和快速。不过,它可以使用。
+
+如果你对 Linux 上的指纹登录有些失望,你可以禁用它。让我在下一节告诉你步骤。
+
+### 禁用指纹登录
+
+禁用指纹登录和最初启用指纹登录差不多。
+
+进入 “设置→用户”,然后点击指纹登录选项。它会显示一个有添加更多指纹或删除现有指纹的页面。你需要删除现有的指纹。
+
+![Disable Fingerprint Login][10]
+
+指纹登录确实有一些好处,特别是对于我这种懒人来说。我不用每次锁屏时输入密码,我也对这种有限的使用感到满意。
+
+用 [PAM][11] 启用指纹解锁 `sudo` 应该不是完全不可能。我记得我 [在 Ubuntu 中设置脸部解锁][12]时,也可以用于 `sudo`。看看以后的版本是否会增加这个功能吧。
+
+你有带指纹识别器的笔记本吗?你是否经常使用它,或者它只是你不关心的东西之一?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/fingerprint-login-ubuntu/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.gnome.org/
+[2]: https://kde.org/
+[3]: https://itsfoss.com/find-desktop-environment/
+[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/enable-fingerprint-ubuntu.png?resize=800%2C607&ssl=1
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/adding-fingerprint-login-ubuntu.png?resize=800%2C496&ssl=1
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/adding-fingerprint-ubuntu-linux.png?resize=800%2C603&ssl=1
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/fingerprint-added-ubuntu.png?resize=797%2C510&ssl=1
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/login-with-fingerprint-ubuntu.jpg?resize=800%2C320&ssl=1
+[9]: https://itsfoss.com/ubuntu-keyring/
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/disable-fingerprint-login.png?resize=798%2C524&ssl=1
+[11]: https://tldp.org/HOWTO/User-Authentication-HOWTO/x115.html
+[12]: https://itsfoss.com/face-unlock-ubuntu/
diff --git a/published/202104/20210222 5 benefits of choosing Linux.md b/published/202104/20210222 5 benefits of choosing Linux.md
new file mode 100644
index 0000000000..df05f65e43
--- /dev/null
+++ b/published/202104/20210222 5 benefits of choosing Linux.md
@@ -0,0 +1,68 @@
+[#]: collector: (lujun9972)
+[#]: translator: (max27149)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13284-1.html)
+[#]: subject: (5 benefits of choosing Linux)
+[#]: via: (https://opensource.com/article/21/2/linux-choice)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+选择 Linux 的五大好处
+======
+
+> Linux 的一大优点是多样化选择,选择激发了用户之间自由分享想法和解决方案。Linux 将如何激发你为这个社区做出贡献呢?
+
+
+
+到了 2021 年,人们比以往任何时候都更有理由喜欢 Linux。在本系列中,我将分享 21 个使用 Linux 的理由。本文讨论选择 Linux 带来的好处。
+
+_选择_ 是 Linux 中被误解最深的特性之一。这种误解从可被选择的 Linux 发行版数量就开始了。Distrowatch.org 报告了数百种可用的和活跃的 Linux 发行版。当然,在这些发行版当中,许多都是业余爱好项目或者针对某些晦涩需求的特别版。因为是开源的,所以实际上,任何人都可以“重新设计”或“重新混搭”现有的 Linux 发行版,赋予一个新名称,提供一个新的默认墙纸,然后称其为自己的作品。尽管这些修改似乎微不足道,但我认为这显示了 Linux 的一些特别之处。
+
+### 灵感
+
+Linux 似乎一直在启迪着人们,从了解它的那一刻起,到创造出自己的版本。
+
+有数十家公司花费数百万美元来从他们自己的产品中获取灵感。商业技术广告试着强硬地说服你,只要你购买某种产品,你就会与所关心的人建立更多的联系,更具创造力、更加充满活力。这些广告用 4k 视频拍摄,焦点柔和,并在欢快振奋的音乐节奏下播放,试图说服人们不仅购买而且还要支持和宣传该公司的产品。
+
+当然,Linux 基本没有营销预算,因为 Linux 是个形形色色的大集合,*没有固定实体*。然而,当人们发现它的存在时候,他们似乎就被启发着去构建属于自己的版本。
+
+灵感的数量很难量化,但是它显然很有价值,要不然那些公司不会花钱来尝试创造灵感。
+
+### 革新
+
+灵感,无论给它标价有多难,它都因它的生产创造而有价值。许多 Linux 用户受启发来为各种奇怪问题定制解决方案。我们解决的大多数问题,对于其他大部分人而言,似乎微不足道:也许你使用 [Seeed 微控制器][2] 来监控番茄植株土壤的水分含量;或者你使用脚本来搜索 Python 软件包的索引,因为你总是会忘记每天导入的库的名称;或者设置了自动清理下载文件夹,因为将文件图标拖进回收站这个活儿干太多了。不管你在使用 Linux 的过程中,为自己解决过什么问题,都是这个平台包含的特性之一,你被这个正在运行中的开放的技术所启发,使其更好地服务于你自己。
+
+### 开放策略
+
+诚然,不论是灵感,还是创新,都不能算 Linux 独有的属性。其他平台也确实让我们激发灵感,我们也以或大或小的方式进行创新。运算能力已在很大程度上拉平了操作系统的竞争领域,你在一个操作系统上可以完成的任何事,在另一个操作系统上或许都能找到对应的方法来完成。
+
+但是,许多用户发现,Linux 操作系统保留了坚定的开放策略,当你尝试可能无人想到过的尝试时,Linux 不会阻挡你。这种情况不会也不可能发生在专有的操作系统上,因为无法进入系统层级的某些区域,因为它们本身就是被设计为不开放源码的。有各种独断的封锁。当你完全按照操作系统的期望进行操作时,你不会碰到那些看不见的墙,但是当你心里想着要做一些只对你有意义的事情的时候,你的系统环境可能变得无从适应。
+
+### 小小的选择,大大的意义
+
+并非所有创新都是大的或重要的,但总的来说,它们带来的变化并不小。如今,数百万用户的那些疯狂想法在 Linux 的各个部分中愈发显现。它们存在于 KDE 或 GNOME 桌面的工作方式中,存在于 [31 种不同的文本编辑器][3] 中 —— 每一种都有人喜爱,存在于不计其数的浏览器插件和多媒体应用程序中,存在于文件系统和扩展属性中,以及数以百万行计的 Linux 内核代码中。而且,如果上述功能中的哪怕仅其中一项,能让你每天额外节省下一小时时间,陪家人、朋友或用在自己的业余爱好上,那么按照定义,套用一句老话就是,“改变生活”。
+
+### 在社区中交流
+
+开源的重要组成部分之一是共享工作。共享代码是开源软件中显而易见的、普遍流行的事务,但我认为,分享,可不仅仅是在 Gitlab 做一次提交那么简单。当人们彼此分享着自己的奇思妙想,除了获得有用的代码贡献作为回报外,再无其他动机,我们都认为这是一种馈赠。这与你花钱从某公司购买软件时的感觉非常不同,甚至与得到某公司对外分享他们自己生产的开源代码时的感觉也有很大不同。开源的实质是,由全人类创造,服务于全人类。当知识和灵感可以被自由地分享时,人与人之间就建立了连接,这是市场营销活动无法复制的东西,我认为我们都认同这一点。
+
+### 选择
+
+Linux 并不是唯一拥有很多选择的平台。无论使用哪种操作系统,你都可以找到针对同一问题的多种解决方案,尤其是在深入研究开源软件的时候。但是,Linux 明显的选择水准指示了推动 Linux 前进的因素:诚邀协作。在 Linux 上,有些创造会很快消失,有些会在你家用电脑中保留数年 —— 即便只是执行一些不起眼的自动化任务,然而有一些则非常成功,以至于被其他系统平台借鉴并变得司空见惯。没关系,无论你在 Linux 上创作出什么,都请毫不犹豫地把它加入千奇百怪的选择之中,你永远都不知道它可能会激发到谁的灵感。
+
+---
+
+via: https://opensource.com/article/21/2/linux-choice
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[max27149](https://github.com/max27149)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
+[2]: https://opensource.com/article/19/12/seeeduino-nano-review
+[3]: https://opensource.com/article/21/1/text-editor-roundup
diff --git a/published/202104/20210225 How to use the Linux anacron command.md b/published/202104/20210225 How to use the Linux anacron command.md
new file mode 100644
index 0000000000..ea7e31d4fe
--- /dev/null
+++ b/published/202104/20210225 How to use the Linux anacron command.md
@@ -0,0 +1,160 @@
+[#]: subject: (How to use the Linux anacron command)
+[#]: via: (https://opensource.com/article/21/2/linux-automation)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13270-1.html)
+
+如何使用 Linux anacron 命令
+======
+
+> 与其手动执行重复性的任务,不如让 Linux 为你做。
+
+
+
+在 2021 年,人们有更多的理由喜欢 Linux。在这个系列中,我将分享使用 Linux 的 21 个不同理由。自动化是使用 Linux 的最佳理由之一。
+
+我最喜欢 Linux 的一个原因是它愿意为我做工作。我不想执行重复性的任务,这些任务会占用我的时间,或者容易出错,或者我可能会忘记,我安排 Linux 为我做这些工作。
+
+### 为自动化做准备
+
+“自动化”这个词既让人望而生畏,又让人心动。我发现用模块化的方式来处理它是有帮助的。
+
+#### 1、你想实现什么?
+
+首先,要知道你想产生什么结果。你是要给图片加水印吗?从杂乱的目录中删除文件?执行重要数据的备份?为自己明确定义任务,这样你就知道自己的目标是什么。如果有什么任务是你发现自己每天都在做的,甚至一天一次以上,那么它可能是自动化的候选者。
+
+#### 2、学习你需要的应用
+
+将大的任务分解成小的组件,并学习如何手动但以可重复和可预测的方式产生每个结果。在 Linux 上可以做的很多事情都可以用脚本来完成,但重要的是要认识到你当前的局限性。学习如何自动调整几张图片的大小,以便可以方便地通过电子邮件发送,与使用机器学习为你的每周通讯生成精心制作的艺术品之间有天壤之别。有的事你可以在一个下午学会,而另一件事可能要花上几年时间。然而,我们都必须从某个地方开始,所以只要从小做起,并时刻注意改进的方法。
+
+#### 3、自动化
+
+在 Linux 上使用一个自动化工具来定期实现它。这就是本文介绍的步骤!
+
+要想自动化一些东西,你需要一个脚本来自动化一个任务。在测试时,最好保持简单,所以本文自动化的任务是在 `/tmp` 目录下创建一个名为 `hello` 的文件。
+
+```
+#!/bin/sh
+
+touch /tmp/hello
+```
+
+将这个简单的脚本复制并粘贴到一个文本文件中,并将其命名为 `example`。
+
+### Cron
+
+每个安装好的 Linux 系统都会有的内置自动化解决方案就是 cron 系统。Linux 用户往往把 cron 笼统地称为你用来安排任务的方法(通常称为 “cron 作业”),但有多个应用程序可以提供 cron 的功能。最通用的是 [cronie][2];它的优点是,它不会像历史上为系统管理员设计的 cron 应用程序那样,假设你的计算机总是开着。
+
+验证你的 Linux 发行版提供的是哪个 cron 系统。如果不是 cronie,你可以从发行版的软件仓库中安装 cronie。如果你的发行版没有 cronie 的软件包,你可以使用旧的 anacron 软件包来代替。`anacron` 命令是包含在 cronie 中的,所以不管你是如何获得它的,你都要确保在你的系统上有 `anacron` 命令,然后再继续。anacron 可能需要管理员 root 权限,这取决于你的设置。
+
+```
+$ which anacron
+/usr/sbin/anacron
+```
+
+anacron 的工作是确保你的自动化作业定期执行。为了做到这一点,anacron 会检查找出最后一次运行作业的时间,然后检查你告诉它运行作业的频率。
+
+假设你将 anacron 设置为每五天运行一次脚本。每次你打开电脑或从睡眠中唤醒电脑时,anacron都会扫描其日志以确定是否需要运行作业。如果一个作业在五天或更久之前运行,那么 anacron 就会运行该作业。
+
+### Cron 作业
+
+许多 Linux 系统都捆绑了一些维护工作,让 cron 来执行。我喜欢把我的工作与系统工作分开,所以我在我的主目录中创建了一个目录。具体来说,有一个叫做 `~/.local` 的隐藏文件夹(“local” 的意思是它是为你的用户账户定制的,而不是为你的“全局”计算机系统定制的),所以我创建了子目录 `etc/cron.daily` 来作为 cron 在我的系统上的家目录。你还必须创建一个 spool 目录来跟踪上次运行作业的时间。
+
+```
+$ mkdir -p ~/.local/etc/cron.daily ~/.var/spool/anacron
+```
+
+你可以把任何你想定期运行的脚本放到 `~/.local/etc/cron.daily` 目录中。现在把 `example` 脚本复制到目录中,然后 [用 chmod 命令使其可执行][3]。
+
+```
+$ cp example ~/.local/etc/cron.daily
+# chmod +x ~/.local/etc/cron.daily/example
+```
+
+接下来,设置 anacron 来运行位于 `~/.local/etc/cron.daily` 目录下的任何脚本。
+
+### anacron
+
+默认情况下,cron 系统的大部分内容都被认为是系统管理员的领域,因为它通常用于重要的底层任务,如轮换日志文件和更新证书。本文演示的配置是为普通用户设置个人自动化任务而设计的。
+
+要配置 anacron 来运行你的 cron 作业,请在 `/.local/etc/anacrontab` 创建一个配置文件:
+
+```
+SHELL=/bin/sh
+PATH=/sbin:/bin:/usr/sbin:/usr/bin
+1 0 cron.mine run-parts /home/tux/.local/etc/cron.daily/
+```
+
+这个文件告诉 anacron 每到新的一天(也就是每日),延迟 0 分钟后,就运行(`run-parts`)所有在 `~/.local/etc/cron.daily` 中找到的可执行脚本。有时,会使用几分钟的延迟,这样你的计算机就不会在你登录后就被所有可能的任务冲击。不过这个设置适合测试。
+
+`cron.mine` 值是进程的一个任意名称。我称它为 `cron.mine`,但你也可以称它为 `cron.personal` 或 `penguin` 或任何你想要的名字。
+
+验证你的 `anacrontab` 文件的语法:
+
+```
+$ anacron -T -t ~/.local/etc/anacrontab \
+ -S /home/tux/.var/spool/anacron
+```
+
+沉默意味着成功。
+
+### 在 .profile 中添加 anacron
+
+最后,你必须确保 anacron 以你的本地配置运行。因为你是以普通用户而不是 root 用户的身份运行 anacron,所以你必须将它引导到你的本地配置:告诉 anacron 要做什么的 `anacrontab` 文件,以及帮助 anacron 跟踪每一个作业最后一次执行是多少天的 spool 目录:
+
+```
+anacron -fn -t /home/tux/.local/etc/anacrontab \
+ -S /home/tux/.var/spool/anacron
+```
+
+`-fn` 选项告诉 anacron *忽略* 时间戳,这意味着你强迫它无论如何都要运行你的 cron 作业。这完全是为了测试的目的。
+
+### 测试你的 cron 作业
+
+现在一切都设置好了,你可以测试作业了。从技术上讲,你可以在不重启的情况下进行测试,但重启是最有意义的,因为这就是设计用来处理中断和不规则的登录会话的。花点时间重启电脑、登录,然后寻找测试文件:
+
+```
+$ ls /tmp/hello
+/tmp/hello
+```
+
+假设文件存在,那么你的示例脚本已经成功执行。现在你可以从 `~/.profile` 中删除测试选项,留下这个作为你的最终配置。
+
+```
+anacron -t /home/tux/.local/etc/anacrontab \
+ -S /home/tux/.var/spool/anacron
+```
+
+### 使用 anacron
+
+你已经配置好了你的个人自动化基础设施,所以你可以把任何你想让你的计算机替你管理的脚本放到 `~/.local/etc/cron.daily` 目录下,它就会按计划运行。
+
+这取决于你希望作业运行的频率。示例脚本是每天执行一次。很明显,这取决于你的计算机在任何一天是否开机和醒着。如果你在周五使用电脑,但把它设置在周末,脚本就不会在周六和周日运行。然而,在周一,脚本会执行,因为 anacron 会知道至少有一天已经过去了。你可以在 `~/.local/etc` 中添加每周、每两周、甚至每月的目录,以安排各种各样的间隔。
+
+要添加一个新的时间间隔:
+
+ 1. 在 `~/.local/etc` 中添加一个目录(例如 `cron.weekly`)。
+ 2. 在 `~/.local/etc/anacrontab` 中添加一行,以便在新目录下运行脚本。对于每周一次的间隔,其配置如下。`7 0 cron.mine run-parts /home/tux/.local/etc/cron.weekly/`(`0` 的值可以选择一些分钟数,以适当地延迟脚本的启动)。
+ 3. 把你的脚本放在 `cron.weekly` 目录下。
+
+欢迎来到自动化的生活方式。它不会让人感觉到,但你将会变得更有效率。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-automation
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command_line_prompt.png?itok=wbGiJ_yg (Command line prompt)
+[2]: https://github.com/cronie-crond/cronie
+[3]: https://opensource.com/article/19/8/linux-chmod-command
diff --git a/published/202104/20210303 5 signs you might be a Rust programmer.md b/published/202104/20210303 5 signs you might be a Rust programmer.md
new file mode 100644
index 0000000000..a2e2de6079
--- /dev/null
+++ b/published/202104/20210303 5 signs you might be a Rust programmer.md
@@ -0,0 +1,73 @@
+[#]: subject: (5 signs you might be a Rust programmer)
+[#]: via: (https://opensource.com/article/21/3/rust-programmer)
+[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13280-1.html)
+
+你可能是 Rust 程序员的五个迹象
+======
+
+> 在我学习 Rust 的过程中,我注意到了 Rust 一族的一些常见行为。
+
+
+
+我是最近才 [皈依 Rust][2] 的,我大约在是 2020 年 4 月底开始学习的。但是,像许多皈依者一样,我还是一个热情的布道者。说实话,我也不是一个很好的 Rust 人,因为我的编码风格不是很好,我写的也不是特别符合 Rust 习惯。我猜想这一方面是因为我在写大量代码之前还没有没有真正学完 Rust(其中一些代码又困扰了我),另一方面是因为我并不是那么优秀的程序员。
+
+但我喜欢 Rust,你也应该喜欢吧。它很友好,比 C 或 C++ 更友好;它为低级系统任务做好了准备,这比 Python 做的更好;而且结构良好,这要超过 Perl;而且,最重要的是,从设计层面开始,它就是完全开源的,这要比 Java 那些语言好得多。
+
+尽管我缺乏专业知识,但我注意到了一些我认为是许多 Rust 爱好者和程序员的共同点。如果你对以下五个迹象点头(其中第一个迹象是由最近的一些令人兴奋的新闻引发的),那么你也可能是一个 Rust 程序员。
+
+### 1、“基金会”一词会使你兴奋
+
+对于 Rust 程序员来说,“基金会”一词将不再与艾萨克·阿西莫夫关联在一起,而是与新成立的 [Rust 基金会][3] 关联。微软、华为、谷歌、AWS 和Mozilla 为该基金会提供了董事(大概也提供了大部分初始资金),该基金会将负责该语言的各个方面,“预示着 Rust 成为企业生产级技术的到来”,[根据临时执行董事][4] Ashley Williams 说。(顺便说一句,很高兴看到一位女士领导这样一项重大的行业计划。)
+
+该基金会似乎致力于维护 Rust 的理念,并确保每个人都有参与的机会。在许多方面,Rust 都是开源项目的典型示例。并不是说它是完美的(无论是语言还是社区),而是因为似乎有足够的爱好者致力于维护高参与度、低门槛的社区方式,我认为这是许多开源项目的核心。我强烈欢迎此举,我认为这只会帮助促进 Rust 在未来数年和数月内的采用和成熟。
+
+### 2、你会因为新闻源中提到 Rust 游戏而感到沮丧
+
+还有一款和电脑有关的东西,也叫做“Rust”,它是一款“只限多玩家生存类的电子游戏”。它比 Rust 这个语言更新一些(2013 年宣布,2018 年发布),但我曾经在搜索 Rust 相关的内容时,犯了一个错误,用这个名字搜索了游戏。互联网络就是这样的,这意味着我的新闻源现在被这个另类的 Rust 野兽感染了,我现在会从它的影迷和公关人员那里随机得到一些更新消息。这是个低调的烦恼,但我很确定在 Rust(语言)社区中并不是就我一个人这样。我强烈建议,如果你确实想了解更多关于这个计算世界的后起之秀的信息,你可以使用一个提高隐私(我拒绝说 "保护隐私")的 [开源浏览器][5] 来进行研究。
+
+### 3、“不安全”这个词会让你感到恐惧。
+
+Rust(语言,再次强调)在帮助你做**正确的事情**™方面做得非常好,当然,在内存安全方面,这是 C 和 C++ 内部的主要关注点(不是因为不可能做到,而是因为真的很难持续正确)。Dave Herman 在 2016 年写了一篇文章《[Safety is Rust's fireflower][6]》,讲述了为什么安全是 Rust 语言的一个积极属性。安全性(内存、类型安全)可能并不赏心悦目,但随着你写的 Rust 越多,你就会习惯并感激它,尤其是当你参与任何系统编程时,这也是 Rust 经常擅长的地方。
+
+现在,Rust 并不能阻止你做**错误的事情**™,但它确实通过让你使用 `unsafe` 关键字,让你在希望超出安全边界的时候做出一个明智的决定。这不仅对你有好处,因为它(希望)会让你非常、非常仔细地思考你在任何使用它的代码块中放入了什么;它对任何阅读你的代码的人也有好处,这是一个触发词,它能让任何不太清醒的 Rust 人至少可以稍微打起精神,在椅子上坐直,然后想:“嗯,这里发生了什么?我需要特别注意。”如果幸运的话,读你代码的人也许能想到重写它的方法,使它利用到 Rust 的安全特性,或者至少减少提交和发布的不安全代码的数量。
+
+### 4、你想知道为什么没有 `?;`、`{:?}` 、`::<>` 这样的表情符号
+
+人们喜欢(或讨厌)涡轮鱼(`::<>`),但在 Rust 代码中你经常还会看到其他的语义结构。特别是 `{:?}` (用于字符串格式化)和 `?;`(`?` 是向调用栈传播错误的一种方式,`;` 则是行/块的结束符,所以你经常会看到它们在一起)。它们在 Rust 代码中很常见,你只需边走边学,边走边解析,而且它们也很有用,我有时会想,为什么它们没有被纳入到正常对话中,至少可以作为表情符号。可能还有其他的。你有什么建议?
+
+### 5、Clippy 是你的朋友(而不是一个动画回形针)
+
+微软的动画回形针 Clippy 可能是 Office 用户很快就觉得讨厌的“功能”,并成为许多 [模因][7] 的起点。另一方面,`cargo clippy` 是那些 [很棒的 Cargo 命令][8] 之一,应该成为每个 Rust 程序员工具箱的一部分。Clippy 是一个语言整洁器,它可以帮助改进你的代码,使它更干净、更整洁、更易读、更惯用,让你与同事或其他人分享 Rust 代码时,不会感到尴尬。Cargo 可以说是让 “Clippy” 这个名字恢复了声誉,虽然我不会选择给我的孩子起这个名字,但现在每当我在网络上遇到这个词的时候,我不会再有一种不安的感觉。
+
+* * *
+
+这篇文章最初发表在 [Alice, Eve, and Bob] [9]上,经作者许可转载。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/rust-programmer
+
+作者:[Mike Bursell][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mikecamel
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/EDU_OSDC_IntroOS_520x292_FINAL.png?itok=woiZamgj (name tag that says hello my name is open source)
+[2]: https://opensource.com/article/20/6/why-rust
+[3]: https://foundation.rust-lang.org/
+[4]: https://foundation.rust-lang.org/posts/2021-02-08-hello-world/
+[5]: https://opensource.com/article/19/7/open-source-browsers
+[6]: https://www.thefeedbackloop.xyz/safety-is-rusts-fireflower/
+[7]: https://knowyourmeme.com/memes/clippy
+[8]: https://opensource.com/article/20/11/commands-rusts-cargo
+[9]: https://aliceevebob.com/2021/02/09/5-signs-that-you-may-be-a-rust-programmer/
diff --git a/published/202104/20210308 Cast your Android device with a Raspberry Pi.md b/published/202104/20210308 Cast your Android device with a Raspberry Pi.md
new file mode 100644
index 0000000000..b41dd7f427
--- /dev/null
+++ b/published/202104/20210308 Cast your Android device with a Raspberry Pi.md
@@ -0,0 +1,141 @@
+[#]: subject: (Cast your Android device with a Raspberry Pi)
+[#]: via: (https://opensource.com/article/21/3/android-raspberry-pi)
+[#]: author: (Sudeshna Sur https://opensource.com/users/sudeshna-sur)
+[#]: collector: (lujun9972)
+[#]: translator: (ShuyRoy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13314-1.html)
+
+将你的安卓手机屏幕投射到 Linux
+======
+
+> 使用 Scrcpy 可以把你的手机屏幕变成一个“应用”,与在树莓派或任何其他基于 Linux 的设备上的应用一起运行。
+
+
+
+要远离我们日常使用的电子产品是很难的。在熙熙攘攘的现代生活中,我想确保我不会错过手机屏幕上弹出的来自朋友和家人的重要信息。我也很忙,不希望迷失在令人分心的事情中,但是拿起手机并且回复信息往往会使我分心。
+
+更糟糕的是,有很多的设备。幸运地是,大多数的设备(从功能强大的笔记本电脑到甚至不起眼的树莓派)都可以运行 Linux。因为它们运行的是 Linux,所以我为一种设置找到的解决方案几乎都适用于其他设备。
+
+### 普遍适用
+
+我想要一种无论我使用什么屏幕,都能统一我生活中不同来源的数据的方法。
+
+我决定通过把手机屏幕复制到电脑上来解决这个问题。本质上,我把手机变成了一个“应用”,可以和我所有的其他程序运行在一起。这有助于我将注意力集中在桌面上,防止我走神,并使我更容易回复紧急通知。
+
+听起来有吸引力吗?你也可以这样做。
+
+### 设置 Scrcpy
+
+[Scrcpy][2] 俗称屏幕复制(Screen Copy),是一个开源的屏幕镜像工具,它可以在 Linux、Windows 或者 macOS 上显示和控制安卓设备。安卓设备和计算机之间的通信主要是通过 USB 连接和安卓调试桥(ADB)。它使用 TCP/IP,且不需要 root 权限访问。
+
+Scrcpy 的设置和配置非常简单。如果你正在运行 Fedora,你可以从 COPR 仓库安装它:
+
+```
+$ sudo dnf copr enable zeno/scrcpy
+$ sudo dnf install scrcpy -y
+```
+
+在 Debian 或者 Ubuntu 上:
+
+```
+$ sudo apt install scrcpy
+```
+
+你也可以自己编译 Scrcpy。即使是在树莓派上,按照 [Scrcpy 的 GitHub 主页][3] 上的说明来构建也不需要很长时间。
+
+### 设置手机
+
+Scrcpy 安装好后,你必须启用 USB 调试并授权每个设备(你的树莓派、笔记本电脑或者工作站)为受信任的控制器。
+
+打开安卓上的“设置”应用程序。如果“开发者选项”没有被激活,按照安卓的 [说明来解锁它][4]。
+
+接下来,启用“USB 调试”。
+
+![Enable USB Debugging option][5]
+
+然后通过 USB 将手机连接到你的树莓派或者笔记本电脑(或者你正在使用的任何设备),如果可以选择的话,将模式设置为 [PTP][7]。如果你的手机不能使用 PTP,将你的手机设置为用于传输文件的模式(而不是,作为一个叠接或者 MIDI 设备)。
+
+你的手机可能会提示你授权你的电脑,这是通过它的 RSA 指纹进行识别的。你只需要在你第一次连接的时候操作即可,在之后你的手机会识别并信任你的计算机。
+
+使用 `lsusb` 命令确认设置:
+
+```
+$ lsusb
+Bus 007 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
+Bus 011 Device 004: ID 046d:c21d Logitech, Inc. F310 Gamepad
+Bus 005 Device 005: ID 0951:1666 Kingston Technology DataTraveler G4
+Bus 005 Device 004: ID 05e3:0608 Genesys Logic, Inc. Hub
+Bus 004 Device 001: ID 18d1:4ee6 Google Inc. Nexus/Pixel Device (PTP + debug)
+Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
+Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
+Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
+```
+
+然后执行 `scrcpy` 以默认设置运行。
+
+![Scrcpy running on a Raspberry Pi][8]
+
+性能和响应能力取决于你使用什么设备来控制你的手机。在树莓派派上,一些动画可能会变慢,甚至有时候会响应滞后。Scrcpy 提供了一个简单的解决办法:降低 Scrcpy 显示图像的位速率和分辨率使得你的计算机能够容易显示动画。使用以下命令来实现:
+
+```
+$ scrcpy --bit-rate 1M --max-size 800
+```
+
+尝试不同的值来找到一个适合你的值。为了使键入更方便,在选定一个命令之后,可以考虑 [创建自己的 Bash 别名][9]。
+
+### 剪断连线
+
+Scrcpy 开始运行后,你甚至可以通过 WiFi 连接你的手机和计算机。Scrcpy 安装过程也会安装 `adb`,它是一个与安卓设备通信的命令。Scrcpy 也可以使用这个命令与你的设备通信,`adb` 可以通过 TCP/IP 连接。
+
+![Scrcpy running on a computer][10]
+
+要尝试的话,请确保你的手机通过 WiFi 连在与你的计算机所使用的相同的无线网络上。依然不要断开你的手机与 USB 的连接!
+
+接下来,通过手机中的“设置”,选择“关于手机”来获取你手机的 IP 地址。查看“状态”选项来获得你的地址。它通常是 192.168 或者 10 开头。
+
+或者,你也可以使用 `adb` 来获得你手机的IP地址:
+
+```
+$ adb shell ip route | awk '{print $9}'
+
+To connect to your device over WiFi, you must enable TCP/IP connections. This, you must do through the adb command:
+$ adb tcpip 5555
+Now you can disconnect your mobile from USB.
+Whenever you want to connect over WiFi, first connect to the mobile with the command adb connect. For instance, assuming my mobile's IP address is 10.1.1.22, the command is:
+$ adb connect 10.1.1.22:5555
+```
+
+连接好之后,你就可以像往常一样运行 Scrcpy 了。
+
+### 远程控制
+
+Scrcpy 很容易使用。你可以在终端或者 [一个图形界面应用][11] 中尝试它。
+
+你是否在使用其它的屏幕镜像工具?如果有的话,请在评论中告诉我们吧。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/android-raspberry-pi
+
+作者:[Sudeshna Sur][a]
+选题:[lujun9972][b]
+译者:[ShuyRoy](https://github.com/ShuyRoy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sudeshna-sur
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/idea_innovation_mobile_phone.png?itok=RqVtvxkd (A person looking at a phone)
+[2]: https://github.com/Genymobile/scrcpy
+[3]: https://github.com/Genymobile/scrcpy/blob/master/BUILD.md
+[4]: https://developer.android.com/studio/debug/dev-options
+[5]: https://opensource.com/sites/default/files/uploads/usb-debugging.jpg (Enable USB Debugging option)
+[6]: https://creativecommons.org/licenses/by-sa/4.0/
+[7]: https://en.wikipedia.org/wiki/Picture_Transfer_Protocol
+[8]: https://opensource.com/sites/default/files/uploads/scrcpy-pi.jpg (Scrcpy running on a Raspberry Pi)
+[9]: https://opensource.com/article/19/7/bash-aliases
+[10]: https://opensource.com/sites/default/files/uploads/ssur-desktop.png (Scrcpy running on a computer)
+[11]: https://opensource.com/article/19/9/mirror-android-screen-guiscrcpy
diff --git a/published/202104/20210317 My favorite open source project management tools.md b/published/202104/20210317 My favorite open source project management tools.md
new file mode 100644
index 0000000000..e52c2a9a92
--- /dev/null
+++ b/published/202104/20210317 My favorite open source project management tools.md
@@ -0,0 +1,167 @@
+[#]: subject: (My favorite open source project management tools)
+[#]: via: (https://opensource.com/article/21/3/open-source-project-management)
+[#]: author: (Frank Bergmann https://opensource.com/users/fraber)
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13344-1.html)
+
+我最喜欢的开源项目管理工具
+======
+
+> 如果你要管理大型复杂的项目,请尝试利用开源选择替换 MS-Project。
+
+
+
+诸如建造卫星、开发机器人或推出新产品之类的项目都是昂贵的,涉及不同的提供商,并且包含必须跟踪的硬依赖性。
+
+大型项目领域中的项目管理方法非常简单(至少在理论上如此)。你可以创建项目计划并将其拆分为较小的部分,直到你可以合理地将成本、持续时间、资源和依赖性分配给各种活动。一旦项目计划获得负责人的批准,你就可以使用它来跟踪项目的执行情况。在时间轴上绘制项目的所有活动将产生一个称为[甘特图][2]的条形图。
+
+甘特图一直被用于 [瀑布项目方法][3],也可以用于敏捷方法。例如,大型项目可能将甘特图用于 Scrum 冲刺,而忽略其他像用户需求这样的细节,从而嵌入敏捷阶段。其他大型项目可能包括多个产品版本(例如,最低可行产品 [MVP]、第二版本、第三版本等)。在这种情况下,上层结构是一种敏捷方法,而每个阶段都计划为甘特图,以处理预算和复杂的依赖关系。
+
+### 项目管理工具
+
+不夸张地说,有数百种现成的工具使用甘特图管理大型项目,而 MS-Project 可能是最受欢迎的工具。它是微软办公软件家族的一部分,可支持到成千上万的活动,并且有大量的功能,支持几乎所有可以想象到的管理项目进度的方式。对于 MS-Project,有时候你并不知道什么更昂贵:是软件许可证还是该工具的培训课程。
+
+另一个缺点是 MS-Project 是一个独立的桌面应用程序,只有一个人可以更新进度表。如果要多个用户进行协作,则需要购买微软 Project 服务器、Web 版的 Project 或 Planner 的许可证。
+
+幸运的是,专有工具还有开源的替代品,包括本文中提及的应用程序。所有这些都是开源的,并且包括基于资源和依赖项的分层活动调度的甘特图。ProjectLibre、GanttProject 和 TaskJuggler 都针对单个项目经理的桌面应用程序。ProjeQtOr 和 Redmine 是用于项目团队的 Web 应用程序,而 ]project-open[ 是用于管理整个组织的 Web 应用程序。
+
+我根据一个单用户计划和对一个大型项目的跟踪评估了这些工具。我的评估标准包括甘特图编辑器功能、Windows/Linux/macOS 上的可用性、可扩展性、导入/导出和报告。(背景披露:我是 ]project-open[ 的创始人,我在多个开源社区中活跃了很多年。此列表包括我们的产品,因此我的观点可能有偏见,但我尝试着眼于每个产品的最佳功能。)
+
+### Redmine 4.1.0
+
+![Redmine][4]
+
+[Redmine][6] 是一个基于 Web 的专注于敏捷方法论的项目管理工具。
+
+其标准安装包括一个甘特图时间轴视图,但缺少诸如调度、拖放、缩进(缩排和凸排)以及资源分配之类的基本功能。你必须单独编辑任务属性才能更改任务树的结构。
+
+Redmine 具有甘特图编辑器插件,但是它们要么已经过时(例如 [Plus Gantt][7]),要么是专有的(例如 [ANKO 甘特图][8])。如果你知道其他开源的甘特图编辑器插件,请在评论中分享它们。
+
+Redmine 用 Ruby on Rails 框架编写,可用于 Windows、Linux 和 macOS。其核心部分采用 GPLv2 许可证。
+
+ * **适合于:** 使用敏捷方法的 IT 团队。
+ * **独特卖点:** 这是 OpenProject 和 EasyRedmine 的原始“上游”父项目。
+
+### ]project-open[ 5.1
+
+![\]project-open\[][9]
+
+[\]project-open\[][10] 是一个基于 Web 的项目管理系统,从整个组织的角度看类似于企业资源计划(ERP)系统。它还可以管理项目档案、预算、发票、销售、人力资源和其他功能领域。有一些不同的变体,如用于管理项目公司的专业服务自动化(PSA)、用于管理企业战略项目的项目管理办公室(PMO)和用于管理部门项目的企业项目管理(EPM)。
+
+]project-open[ 甘特图编辑器包括按等级划分的任务、依赖关系和基于计划工作和分配资源的调度。它不支持资源日历和非人力资源。]project-open[ 系统非常复杂,其 GUI 可能需要刷新。
+
+]project-open[ 是用 TCL 和 JavaScript 编写的,可用于 Windows 和 Linux。 ]project-open[ 核心采用 GPLv2 许可证,并具有适用于大公司的专有扩展。
+
+ * **适合于:** 需要大量财务项目报告的大中型项目组织。
+ * **独特卖点:** ]project-open[ 是一个综合系统,可以运行整个项目公司或部门。
+
+### ProjectLibre 1.9.3
+
+![ProjectLibre][11]
+
+在开源世界中,[ProjectLibre][12] 可能是最接近 MS-Project 的产品。它是一个桌面应用程序,支持所有重要的项目计划功能,包括资源日历、基线和成本管理。它还允许你使用 MS-Project 的文件格式导入和导出计划。
+
+ProjectLibre 非常适合计划和执行中小型项目。然而,它缺少 MS-Project 中的一些高级功能,并且它的 GUI 并不是最漂亮的。
+
+ProjectLibre 用 Java 编写,可用于 Windows、Linux 和macOS,并在开源的通用公共署名许可证(CPAL)下授权。ProjectLibre 团队目前正在开发一个名为 ProjectLibre Cloud 的 Web 产品,并采用专有许可证。
+
+ * **适合于:** 负责中小型项目的个人项目管理者,或者作为没有完整的 MS-Project 许可证的项目成员的查看器。
+ * **独特卖点:** 这是最接近 MS-Project 的开源软件。
+
+### GanttProject 2.8.11
+
+![GanttProject][13]
+
+[GanttProject][14] 与 ProjectLibre 类似,它是一个桌面甘特图编辑器,但功能集更为有限。它不支持基线,也不支持非人力资源,并且报告功能比较有限。
+
+GanttProject 是一个用 Java 编写的桌面应用程序,可在 GPLv3 许可下用于 Windows、Linux 和 macOS。
+
+ * **适合于:** 简单的甘特图或学习基于甘特图的项目管理技术。
+ * **独特卖点:** 它支持流程评估和审阅技术([PERT][15])图表,并使用 WebDAV 的协作。
+
+### TaskJuggler 3.7.1
+
+![TaskJuggler][16]
+
+[TaskJuggler][17] 用于在大型组织中安排多个并行项目,重点是自动解决资源分配冲突(即资源均衡)。
+
+它不是交互式的甘特图编辑器,而是一个命令行工具,其工作方式类似于一个编译器:它从文本文件中读取任务列表,并生成一系列报告,这些报告根据分配的资源、依赖项、优先级和许多其他参数为每个任务提供最佳的开始和结束时间。它支持多个项目、基线、资源日历、班次和时区,并且被设计为可扩展到具有许多项目和资源的企业场景。
+
+使用特定语法编写 TaskJuggler 输入文件可能超出了普通项目经理的能力。但是,你可以使用 ]project-open[ 作为 TaskJuggler 的图形前端来生成输入,包括缺勤、任务进度和记录的工作时间。当以这种方式使用时,TaskJuggler 就成为了功能强大的假设情景规划器。
+
+TaskJuggler 用 Ruby 编写,并且在 GPLv2 许可证下可用于 Windows、Linux 和 macOS。
+
+ * **适合于:** 由真正的技术极客管理的中大型部门。
+ * **独特卖点:** 它在自动资源均衡方面表现出色。
+
+### ProjeQtOr 9.0.4
+
+![ProjeQtOr][18]
+
+[ProjeQtOr][19] 是适用于 IT 项目的、基于 Web 的项目管理应用程序。除了项目、工单和活动外,它还支持风险、预算、可交付成果和财务文件,以将项目管理的许多方面集成到单个系统中。
+
+ProjeQtOr 提供了一个甘特图编辑器,与 ProjectLibre 功能类似,包括按等级划分的任务、依赖关系以及基于计划工作和分配资源。但是,它不支持取值的就地编辑(例如,任务名称、估计时间等);用户必须在甘特图视图下方的输入表单中更改取值,然后保存。
+
+ProjeQtOr 用 PHP 编写,并且在 Affero GPL3 许可下可用于 Windows、Linux 和 macOS。
+
+ * **适合于:** 跟踪项目列表的 IT 部门。
+ * **独特卖点:** 让你为存储每个项目的大量信息,将所有信息保存在一个地方。
+
+### 其他工具
+
+对于特定的用例,以下系统可能是有效的选择,但由于各种原因,它们被排除在主列表之外。
+
+![LIbrePlan][20]
+
+ * [LibrePlan][21] 是一个基于 Web 的项目管理应用程序,专注于甘特图。由于其功能集,它本来会在上面的列表中会占主导地位,但是没有可用于最新 Linux 版本(CentOS 7 或 8)的安装。作者说,更新的说明将很快推出。
+ * [dotProject][22] 是一个用 PHP 编写的基于 Web 的项目管理系统,可在 GPLv2.x 许可证下使用。它包含一个甘特图时间轴报告,但是没有编辑它的选项,并且依赖项还不起作用(它们“仅部分起作用”)。
+ * [Leantime][23] 是一个基于 Web 的项目管理系统,具有漂亮的用 PHP 编写的 GUI,并且可以在 GPLv2 许可证下使用。它包括一个里程碑的甘特时间线,但没有依赖性。
+ * [Orangescrum][24] 是基于 Web 的项目管理工具。甘特图图可以作为付费附件或付费订阅使用。
+ * [Talaia/OpenPPM][25] 是一个基于 Web 的项目组合管理系统。但是,版本 4.6.1 仍显示“即将推出:交互式甘特图”。
+ * [Odoo][26] 和 [OpenProject][27] 都将某些重要功能限制在付费企业版中。
+
+在这篇评论中,目的是包括所有带有甘特图编辑器和依赖调度的开源项目管理系统。如果我错过了一个项目或误导了什么,请在评论中让我知道。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/open-source-project-management
+
+作者:[Frank Bergmann][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/fraber
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/kanban_trello_organize_teams_520.png?itok=ObNjCpxt (Kanban-style organization action)
+[2]: https://en.wikipedia.org/wiki/Gantt_chart
+[3]: https://opensource.com/article/20/3/agiles-vs-waterfall
+[4]: https://opensource.com/sites/default/files/uploads/redmine.png (Redmine)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://www.redmine.org/
+[7]: https://redmine.org/plugins/plus_gantt
+[8]: https://www.redmine.org/plugins/anko_gantt_chart
+[9]: https://opensource.com/sites/default/files/uploads/project-open.png (]project-open[)
+[10]: https://www.project-open.com
+[11]: https://opensource.com/sites/default/files/uploads/projectlibre.png (ProjectLibre)
+[12]: http://www.projectlibre.org
+[13]: https://opensource.com/sites/default/files/uploads/ganttproject.png (GanttProject)
+[14]: https://www.ganttproject.biz
+[15]: https://en.wikipedia.org/wiki/Program_evaluation_and_review_technique
+[16]: https://opensource.com/sites/default/files/uploads/taskjuggler.png (TaskJuggler)
+[17]: https://taskjuggler.org/
+[18]: https://opensource.com/sites/default/files/uploads/projeqtor.png (ProjeQtOr)
+[19]: https://www.projeqtor.org
+[20]: https://opensource.com/sites/default/files/uploads/libreplan.png (LIbrePlan)
+[21]: https://www.libreplan.dev/
+[22]: https://dotproject.net/
+[23]: https://leantime.io
+[24]: https://orangescrum.org/
+[25]: http://en.talaia-openppm.com/
+[26]: https://odoo.com
+[27]: http://openproject.org
diff --git a/published/202104/20210318 Reverse Engineering a Docker Image.md b/published/202104/20210318 Reverse Engineering a Docker Image.md
new file mode 100644
index 0000000000..0afe15981d
--- /dev/null
+++ b/published/202104/20210318 Reverse Engineering a Docker Image.md
@@ -0,0 +1,287 @@
+[#]: subject: (Reverse Engineering a Docker Image)
+[#]: via: (https://theartofmachinery.com/2021/03/18/reverse_engineering_a_docker_image.html)
+[#]: author: (Simon Arneaud https://theartofmachinery.com)
+[#]: collector: (lujun9972)
+[#]: translator: (DCOLIVERSUN)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13258-1.html)
+
+一次 Docker 镜像的逆向工程
+======
+
+
+
+这要从一次咨询的失误说起:政府组织 A 让政府组织 B 开发一个 Web 应用程序。政府机构 B 把部分工作外包给某个人。后来,项目的托管和维护被外包给一家私人公司 C。C 公司发现,之前外包的人(已经离开很久了)构建了一个自定义的 Docker 镜像,并将其成为系统构建的依赖项,但这个人没有提交原始的 Dockerfile。C 公司有合同义务管理这个 Docker 镜像,可是他们他们没有源代码。C 公司偶尔叫我进去做各种工作,所以处理一些关于这个神秘 Docker 镜像的事情就成了我的工作。
+
+幸运的是,Docker 镜像的格式比想象的透明多了。虽然还需要做一些侦查工作,但只要解剖一个镜像文件,就能发现很多东西。例如,这里有一个 [Prettier 代码格式化][1] 的镜像可供快速浏览。
+
+首先,让 Docker 守护进程拉取镜像,然后将镜像提取到文件中:
+
+```
+docker pull tmknom/prettier:2.0.5
+docker save tmknom/prettier:2.0.5 > prettier.tar
+```
+
+是的,该文件只是一个典型 tarball 格式的归档文件:
+
+```
+$ tar xvf prettier.tar
+6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/
+6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/VERSION
+6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/json
+6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar
+88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json
+a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/
+a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/VERSION
+a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/json
+a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar
+d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/
+d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/VERSION
+d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/json
+d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/layer.tar
+manifest.json
+repositories
+```
+
+如你所见,Docker 在命名时经常使用哈希。我们看看 `manifest.json`。它是以难以阅读的压缩 JSON 写的,不过 [JSON 瑞士军刀 jq][2] 可以很好地打印 JSON:
+
+```
+$ jq . manifest.json
+[
+ {
+ "Config": "88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json",
+ "RepoTags": [
+ "tmknom/prettier:2.0.5"
+ ],
+ "Layers": [
+ "a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar",
+ "d4f612de5397f1fc91272cfbad245b89eac8fa4ad9f0fc10a40ffbb54a356cb4/layer.tar",
+ "6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar"
+ ]
+ }
+]
+```
+
+请注意,这三个层对应三个以哈希命名的目录。我们以后再看。现在,让我们看看 `Config` 键指向的 JSON 文件。它有点长,所以我只在这里转储第一部分:
+
+```
+$ jq . 88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json | head -n 20
+{
+ "architecture": "amd64",
+ "config": {
+ "Hostname": "",
+ "Domainname": "",
+ "User": "",
+ "AttachStdin": false,
+ "AttachStdout": false,
+ "AttachStderr": false,
+ "Tty": false,
+ "OpenStdin": false,
+ "StdinOnce": false,
+ "Env": [
+ "PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
+ ],
+ "Cmd": [
+ "--help"
+ ],
+ "ArgsEscaped": true,
+ "Image": "sha256:93e72874b338c1e0734025e1d8ebe259d4f16265dc2840f88c4c754e1c01ba0a",
+```
+
+最重要的是 `history` 列表,它列出了镜像中的每一层。Docker 镜像由这些层堆叠而成。Dockerfile 中几乎每条命令都会变成一个层,描述该命令对镜像所做的更改。如果你执行 `RUN script.sh` 命令创建了 `really_big_file`,然后用 `RUN rm really_big_file` 命令删除文件,Docker 镜像实际生成两层:一个包含 `really_big_file`,一个包含 `.wh.really_big_file` 记录来删除它。整个镜像文件大小不变。这就是为什么你会经常看到像 `RUN script.sh && rm really_big_file` 这样的 Dockerfile 命令链接在一起——它保障所有更改都合并到一层中。
+
+以下是该 Docker 镜像中记录的所有层。注意,大多数层不改变文件系统镜像,并且 `empty_layer` 标记为 `true`。以下只有三个层是非空的,与我们之前描述的相符。
+
+```
+$ jq .history 88f38be28f05f38dba94ce0c1328ebe2b963b65848ab96594f8172a9c3b0f25b.json
+[
+ {
+ "created": "2020-04-24T01:05:03.608058404Z",
+ "created_by": "/bin/sh -c #(nop) ADD file:b91adb67b670d3a6ff9463e48b7def903ed516be66fc4282d22c53e41512be49 in / "
+ },
+ {
+ "created": "2020-04-24T01:05:03.92860976Z",
+ "created_by": "/bin/sh -c #(nop) CMD [\"/bin/sh\"]",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:06.617130538Z",
+ "created_by": "/bin/sh -c #(nop) ARG BUILD_DATE",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:07.020521808Z",
+ "created_by": "/bin/sh -c #(nop) ARG VCS_REF",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:07.36915054Z",
+ "created_by": "/bin/sh -c #(nop) ARG VERSION",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:07.708820086Z",
+ "created_by": "/bin/sh -c #(nop) ARG REPO_NAME",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:08.06429638Z",
+ "created_by": "/bin/sh -c #(nop) LABEL org.label-schema.vendor=tmknom org.label-schema.name=tmknom/prettier org.label-schema.description=Prettier is an opinionated code formatter. org.label-schema.build-date=2020-04-29T06:34:01Z org
+.label-schema.version=2.0.5 org.label-schema.vcs-ref=35d2587 org.label-schema.vcs-url=https://github.com/tmknom/prettier org.label-schema.usage=https://github.com/tmknom/prettier/blob/master/README.md#usage org.label-schema.docker.cmd=do
+cker run --rm -v $PWD:/work tmknom/prettier --parser=markdown --write '**/*.md' org.label-schema.schema-version=1.0",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:08.511269907Z",
+ "created_by": "/bin/sh -c #(nop) ARG NODEJS_VERSION=12.15.0-r1",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:08.775876657Z",
+ "created_by": "/bin/sh -c #(nop) ARG PRETTIER_VERSION",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:26.399622951Z",
+ "created_by": "|6 BUILD_DATE=2020-04-29T06:34:01Z NODEJS_VERSION=12.15.0-r1 PRETTIER_VERSION=2.0.5 REPO_NAME=tmknom/prettier VCS_REF=35d2587 VERSION=2.0.5 /bin/sh -c set -x && apk add --no-cache nodejs=${NODEJS_VERSION} nodejs-np
+m=${NODEJS_VERSION} && npm install -g prettier@${PRETTIER_VERSION} && npm cache clean --force && apk del nodejs-npm"
+ },
+ {
+ "created": "2020-04-29T06:34:26.764034848Z",
+ "created_by": "/bin/sh -c #(nop) WORKDIR /work"
+ },
+ {
+ "created": "2020-04-29T06:34:27.092671047Z",
+ "created_by": "/bin/sh -c #(nop) ENTRYPOINT [\"/usr/bin/prettier\"]",
+ "empty_layer": true
+ },
+ {
+ "created": "2020-04-29T06:34:27.406606712Z",
+ "created_by": "/bin/sh -c #(nop) CMD [\"--help\"]",
+ "empty_layer": true
+ }
+]
+```
+
+太棒了!所有的命令都在 `created_by` 字段中,我们几乎可以用这些命令重建 Dockerfile。但不是完全可以。最上面的 `ADD` 命令实际上没有给我们需要添加的文件。`COPY` 命令也没有全部信息。我们还失去了 `FROM` 语句,因为它们扩展成了从基础 Docker 镜像继承的所有层。
+
+我们可以通过查看时间戳,按 Dockerfile 对层进行分组。大多数层的时间戳相差不到一分钟,代表每一层构建所需的时间。但是前两层是 `2020-04-24`,其余的是 `2020-04-29`。这是因为前两层来自一个基础 Docker 镜像。理想情况下,我们可以找出一个 `FROM` 命令来获得这个镜像,这样我们就有了一个可维护的 Dockerfile。
+
+`manifest.json` 展示第一个非空层是 `a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/layer.tar`。让我们看看它:
+
+```
+$ cd a9cc4ace48cd792ef888ade20810f82f6c24aaf2436f30337a2a712cd054dc97/
+$ tar tf layer.tf | head
+bin/
+bin/arch
+bin/ash
+bin/base64
+bin/bbconfig
+bin/busybox
+bin/cat
+bin/chgrp
+bin/chmod
+bin/chown
+```
+
+看起来它可能是一个操作系统基础镜像,这也是你期望从典型 Dockerfile 中看到的。Tarball 中有 488 个条目,如果你浏览一下,就会发现一些有趣的条目:
+
+```
+...
+dev/
+etc/
+etc/alpine-release
+etc/apk/
+etc/apk/arch
+etc/apk/keys/
+etc/apk/keys/alpine-devel@lists.alpinelinux.org-4a6a0840.rsa.pub
+etc/apk/keys/alpine-devel@lists.alpinelinux.org-5243ef4b.rsa.pub
+etc/apk/keys/alpine-devel@lists.alpinelinux.org-5261cecb.rsa.pub
+etc/apk/protected_paths.d/
+etc/apk/repositories
+etc/apk/world
+etc/conf.d/
+...
+```
+
+果不其然,这是一个 [Alpine][3] 镜像,如果你注意到其他层使用 `apk` 命令安装软件包,你可能已经猜到了。让我们解压 tarball 看看:
+
+```
+$ mkdir files
+$ cd files
+$ tar xf ../layer.tar
+$ ls
+bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
+$ cat etc/alpine-release
+3.11.6
+```
+
+如果你拉取、解压 `alpine:3.11.6`,你会发现里面有一个非空层,`layer.tar` 与 Prettier 镜像基础层中的 `layer.tar` 是一样的。
+
+出于兴趣,另外两个非空层是什么?第二层是包含 Prettier 安装包的主层。它有 528 个条目,包含 Prettier、一堆依赖项和证书更新:
+
+```
+...
+usr/lib/libuv.so.1
+usr/lib/libuv.so.1.0.0
+usr/lib/node_modules/
+usr/lib/node_modules/prettier/
+usr/lib/node_modules/prettier/LICENSE
+usr/lib/node_modules/prettier/README.md
+usr/lib/node_modules/prettier/bin-prettier.js
+usr/lib/node_modules/prettier/doc.js
+usr/lib/node_modules/prettier/index.js
+usr/lib/node_modules/prettier/package.json
+usr/lib/node_modules/prettier/parser-angular.js
+usr/lib/node_modules/prettier/parser-babel.js
+usr/lib/node_modules/prettier/parser-flow.js
+usr/lib/node_modules/prettier/parser-glimmer.js
+usr/lib/node_modules/prettier/parser-graphql.js
+usr/lib/node_modules/prettier/parser-html.js
+usr/lib/node_modules/prettier/parser-markdown.js
+usr/lib/node_modules/prettier/parser-postcss.js
+usr/lib/node_modules/prettier/parser-typescript.js
+usr/lib/node_modules/prettier/parser-yaml.js
+usr/lib/node_modules/prettier/standalone.js
+usr/lib/node_modules/prettier/third-party.js
+usr/local/
+usr/local/share/
+usr/local/share/ca-certificates/
+usr/sbin/
+usr/sbin/update-ca-certificates
+usr/share/
+usr/share/ca-certificates/
+usr/share/ca-certificates/mozilla/
+usr/share/ca-certificates/mozilla/ACCVRAIZ1.crt
+usr/share/ca-certificates/mozilla/AC_RAIZ_FNMT-RCM.crt
+usr/share/ca-certificates/mozilla/Actalis_Authentication_Root_CA.crt
+...
+```
+
+第三层由 `WORKDIR /work` 命令创建,它只包含一个条目:
+
+```
+$ tar tf 6c37da2ee7de579a0bf5495df32ba3e7807b0a42e2a02779206d165f55f1ba70/layer.tar
+work/
+```
+
+[原始 Dockerfile 在 Prettier 的 git 仓库中][4]。
+
+--------------------------------------------------------------------------------
+
+via: https://theartofmachinery.com/2021/03/18/reverse_engineering_a_docker_image.html
+
+作者:[Simon Arneaud][a]
+选题:[lujun9972][b]
+译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://theartofmachinery.com
+[b]: https://github.com/lujun9972
+[1]: https://github.com/tmknom/prettier
+[2]: https://stedolan.github.io/jq/
+[3]: https://www.alpinelinux.org/
+[4]: https://github.com/tmknom/prettier/blob/35d2587ec052e880d73f73547f1ffc2b11e29597/Dockerfile
diff --git a/published/202104/20210324 Read and write files with Bash.md b/published/202104/20210324 Read and write files with Bash.md
new file mode 100644
index 0000000000..d4e0e2b79e
--- /dev/null
+++ b/published/202104/20210324 Read and write files with Bash.md
@@ -0,0 +1,192 @@
+[#]: subject: (Read and write files with Bash)
+[#]: via: (https://opensource.com/article/21/3/input-output-bash)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13259-1.html)
+
+用 Bash 读写文件
+======
+
+> 学习 Bash 读取和写入数据的不同方式,以及何时使用每种方法。
+
+
+
+当你使用 Bash 编写脚本时,有时你需要从一个文件中读取数据或向一个文件写入数据。有时文件可能包含配置选项,而另一些时候这个文件是你的用户用你的应用创建的数据。每种语言处理这个任务的方式都有些不同,本文将演示如何使用 Bash 和其他 [POSIX][2] shell 处理数据文件。
+
+### 安装 Bash
+
+如果你在使用 Linux,你可能已经有了 Bash。如果没有,你可以在你的软件仓库里找到它。
+
+在 macOS 上,你可以使用默认终端,Bash 或 [Zsh][3],这取决于你运行的 macOS 版本。
+
+在 Windows 上,有几种方法可以体验 Bash,包括微软官方支持的 [Windows Subsystem for Linux][4](WSL)。
+
+安装 Bash 后,打开你最喜欢的文本编辑器并准备开始。
+
+### 使用 Bash 读取文件
+
+除了是 [shell][5] 之外,Bash 还是一种脚本语言。有几种方法可以从 Bash 中读取数据。你可以创建一种数据流并解析输出, 或者你可以将数据加载到内存中。这两种方法都是有效的获取信息的方法,但每种方法都有相当具体的用例。
+
+#### 在 Bash 中援引文件
+
+当你在 Bash 中 “援引” 一个文件时,你会让 Bash 读取文件的内容,期望它包含有效的数据,Bash 可以将这些数据放入它建立的数据模型中。你不会想要从旧文件中援引数据,但你可以使用这种方法来读取配置文件和函数。
+
+(LCTT 译注:在 Bash 中,可以通过 `source` 或 `.` 命令来将一个文件读入,这个行为称为 “sourcing”,英文原意为“一次性(试)采购”、“寻找供应商”、“获得”等,考虑到 Bash 的语境和发音,我建议可以翻译为“援引”,或有不当,供大家讨论参考 —— wxy)
+
+例如,创建一个名为 `example.sh` 的文件,并输入以下内容:
+
+```
+#!/bin/sh
+
+greet opensource.com
+
+echo "The meaning of life is $var"
+```
+
+运行这段代码,看见失败了:
+
+```
+$ bash ./example.sh
+./example.sh: line 3: greet: command not found
+The meaning of life is
+```
+
+Bash 没有一个叫 `greet` 的命令,所以无法执行那一行,也没有一个叫 `var` 的变量记录,所以文件没有意义。为了解决这个问题,建立一个名为 `include.sh` 的文件:
+
+```
+greet() {
+ echo "Hello ${1}"
+}
+
+var=42
+```
+
+修改你的 `example.sh` 脚本,加入一个 `source` 命令:
+
+```
+#!/bin/sh
+
+source include.sh
+
+greet opensource.com
+
+echo "The meaning of life is $var"
+```
+
+运行脚本,可以看到工作了:
+
+```
+$ bash ./example.sh
+Hello opensource.com
+The meaning of life is 42
+```
+
+`greet` 命令被带入你的 shell 环境,因为它被定义在 `include.sh` 文件中,它甚至可以识别参数(本例中的 `opensource.com`)。变量 `var` 也被设置和导入。
+
+#### 在 Bash 中解析文件
+
+另一种让数据“进入” Bash 的方法是将其解析为数据流。有很多方法可以做到这一点. 你可以使用 `grep` 或 `cat` 或任何可以获取数据并管道输出到标准输出的命令。另外,你可以使用 Bash 内置的东西:重定向。重定向本身并不是很有用,所以在这个例子中,我也使用内置的 `echo` 命令来打印重定向的结果:
+
+```
+#!/bin/sh
+
+echo $( < include.sh )
+```
+
+将其保存为 `stream.sh` 并运行它来查看结果:
+
+```
+$ bash ./stream.sh
+greet() { echo "Hello ${1}" } var=42
+$
+```
+
+对于 `include.sh` 文件中的每一行,Bash 都会将该行打印(或 `echo`)到你的终端。先用管道把它传送到一个合适的解析器是用 Bash 读取数据的常用方法。例如, 假设 `include.sh` 是一个配置文件, 它的键和值对用一个等号(`=`)分开. 你可以用 `awk` 甚至 `cut` 来获取值:
+
+```
+#!/bin/sh
+
+myVar=`grep var include.sh | cut -d'=' -f2`
+
+echo $myVar
+```
+
+试着运行这个脚本:
+
+```
+$ bash ./stream.sh
+42
+```
+
+### 用 Bash 将数据写入文件
+
+无论你是要存储用户用你的应用创建的数据,还是仅仅是关于用户在应用中做了什么的元数据(例如,游戏保存或最近播放的歌曲),都有很多很好的理由来存储数据供以后使用。在 Bash 中,你可以使用常见的 shell 重定向将数据保存到文件中。
+
+例如, 要创建一个包含输出的新文件, 使用一个重定向符号:
+
+```
+#!/bin/sh
+
+TZ=UTC
+date > date.txt
+```
+
+运行脚本几次:
+
+```
+$ bash ./date.sh
+$ cat date.txt
+Tue Feb 23 22:25:06 UTC 2021
+$ bash ./date.sh
+$ cat date.txt
+Tue Feb 23 22:25:12 UTC 2021
+```
+
+要追加数据,使用两个重定向符号:
+
+```
+#!/bin/sh
+
+TZ=UTC
+date >> date.txt
+```
+
+运行脚本几次:
+
+```
+$ bash ./date.sh
+$ bash ./date.sh
+$ bash ./date.sh
+$ cat date.txt
+Tue Feb 23 22:25:12 UTC 2021
+Tue Feb 23 22:25:17 UTC 2021
+Tue Feb 23 22:25:19 UTC 2021
+Tue Feb 23 22:25:22 UTC 2021
+```
+
+### Bash 轻松编程
+
+Bash 的优势在于简单易学,因为只需要一些基本的概念,你就可以构建复杂的程序。完整的文档请参考 GNU.org 上的 [优秀的 Bash 文档][6]。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/input-output-bash
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
+[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[3]: https://opensource.com/article/19/9/getting-started-zsh
+[4]: https://opensource.com/article/19/7/ways-get-started-linux#wsl
+[5]: https://www.redhat.com/sysadmin/terminals-shells-consoles
+[6]: http://gnu.org/software/bash
diff --git a/published/202104/20210325 Plausible- Privacy-Focused Google Analytics Alternative.md b/published/202104/20210325 Plausible- Privacy-Focused Google Analytics Alternative.md
new file mode 100644
index 0000000000..7b97f5144e
--- /dev/null
+++ b/published/202104/20210325 Plausible- Privacy-Focused Google Analytics Alternative.md
@@ -0,0 +1,94 @@
+[#]: subject: (Plausible: Privacy-Focused Google Analytics Alternative)
+[#]: via: (https://itsfoss.com/plausible/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13283-1.html)
+
+Plausible:注重隐私的 Google Analytics 替代方案
+======
+
+
+
+[Plausible][1]是一款简单的、对隐私友好的分析工具。它可以帮助你分析独立访客数量、页面浏览量、跳出率和访问时间。
+
+如果你有一个网站,你可能会理解这些术语。作为一个网站所有者,它可以帮助你了解你的网站是否随着时间的推移获得更多的访问者,流量来自哪里,如果你对这些事情有一定的了解,你可以努力改进你的网站,以获得更多的访问量。
+
+说到网站分析,统治这个领域的一个服务就是谷歌的免费工具 Google Analytics。就像 Google 是事实上的搜索引擎一样,Google Analytics 是事实上的分析工具。但你不必再忍受它,尤其是当你无法信任大科技公司使用你和你的网站访问者的数据的时候。
+
+Plausible 让你摆脱 Google Analytics 的束缚,我将在本文中讨论这个开源项目。
+
+请注意,如果你从来没有管理过网站或对分析感兴趣,文章中的一些技术术语可能对你来说是陌生的。
+
+### Plausible 是隐私友好的网站分析工具
+
+Plausible 使用的分析脚本是非常轻量级的,大小不到 1KB。
+
+其重点在于保护隐私,因此你可以在不影响访客隐私的情况下获得有价值且可操作的统计数据。Plausible 是为数不多的不需要 cookie 横幅或 GDP 同意的分析工具之一,因为它在隐私方面已经符合 [GDPR 标准][2]。这是超级酷的。
+
+在功能上,它没有 Google Analytics 那样的粒度和细节。Plausible 靠的是简单。它显示的是你过去 30 天的流量统计图。你也可以切换到实时视图。
+
+![][3]
+
+你还可以看到你的流量来自哪里,以及你网站上的哪些页面访问量最大。来源也可以显示 UTM 活动。
+
+![][4]
+
+你还可以选择启用 GeoIP 来了解网站访问者的地理位置。你还可以检查有多少访问者使用桌面或移动设备访问你的网站。还有一个操作系统的选项,正如你所看到的,[Linux Handbook][5] 有 48% 的访问者来自 Windows 设备。很奇怪,对吧?
+
+![][6]
+
+显然,提供的数据与 Google Analytics 的数据相差甚远,但这是有意为之。Plausible 意图是为你提供简单的模式。
+
+### 使用 Plausible:选择付费托管或在你的服务器上自行托管
+
+使用 Plausible 有两种方式:注册他们的官方托管服务。你必须为这项服务付费,这最终会帮助 Plausible 项目的发展。它们有 30 天的试用期,甚至不需要你这边提供任何支付信息。
+
+定价从每月 1 万页浏览量 6 美元开始。价格会随着页面浏览量的增加而增加。你可以在 Plausible 网站上计算价格。
+
+- [Plausible 价格][7]
+
+你可以试用 30 天,看看你是否愿意向 Plausible 开发者支付服务费用,并拥有你的数据。
+
+如果你觉得定价不合理,你可以利用 Plausible 是开源的优势,自己部署。如果你有兴趣,请阅读我们的 [使用 Docker 自助托管 Plausible 实例的深度指南][8]。
+
+我们自行托管 Plausible。我们的 Plausible 实例添加了我们的三个网站。
+
+![Plausble dashboard for It’s FOSS websites][9]
+
+如果你维护一个开源项目的网站,并且想使用 Plausible,你可以通过我们的 [High on Cloud 项目][10] 联系我们。通过 High on Cloud,我们帮助小企业在其服务器上托管和使用开源软件。
+
+### 总结
+
+如果你不是超级痴迷于数据,只是想快速了解网站的表现,Plausible 是一个不错的选择。我喜欢它,因为它是轻量级的,而且遵守隐私。这也是我在 Linux Handbook,我们 [教授 Linux 服务器相关的门户网站][11] 上使用它的主要原因。
+
+总的来说,我对 Plausible 相当满意,并向其他网站所有者推荐它。
+
+你也经营或管理一个网站吗?你是用什么工具来做分析,还是根本不关心这个?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/plausible/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://plausible.io/
+[2]: https://gdpr.eu/compliance/
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/plausible-graph-lhb.png?resize=800%2C395&ssl=1
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/03/plausible-stats-lhb-2.png?resize=800%2C333&ssl=1
+[5]: https://linuxhandbook.com/
+[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/plausible-geo-ip-stats.png?resize=800%2C331&ssl=1
+[7]: https://plausible.io/#pricing
+[8]: https://linuxhandbook.com/plausible-deployment-guide/
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/plausible-analytics-for-itsfoss.png?resize=800%2C231&ssl=1
+[10]: https://highoncloud.com/
+[11]: https://linuxhandbook.com/about/#ethical-web-portal
diff --git a/published/202104/20210326 How to read and write files in C.md b/published/202104/20210326 How to read and write files in C.md
new file mode 100644
index 0000000000..721eda3db0
--- /dev/null
+++ b/published/202104/20210326 How to read and write files in C.md
@@ -0,0 +1,140 @@
+[#]: subject: (How to read and write files in C++)
+[#]: via: (https://opensource.com/article/21/3/ccc-input-output)
+[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
+[#]: collector: (lujun9972)
+[#]: translator: (wyxplus)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13263-1.html)
+
+如何用 C++ 读写文件
+======
+
+> 如果你知道如何在 C++ 中使用输入输出(I/O)流,那么(原则上)你便能够处理任何类型的输入输出设备。
+
+
+
+在 C++ 中,对文件的读写可以通过使用输入输出流与流运算符 `>>` 和 `<<` 来进行。当读写文件的时候,这些运算符被应用于代表硬盘驱动器上文件类的实例上。这种基于流的方法有个巨大的优势:从 C++ 的角度,无论你要读取或写入的内容是文件、数据库、控制台,亦或是你通过网络连接的另外一台电脑,这都无关紧要。因此,知道如何使用流运算符来写入文件能够被转用到其他领域。
+
+### 输入输出流类
+
+C++ 标准库提供了 [ios_base][2] 类。该类作为所有 I/O 流的基类,例如 [basic_ofstream][3] 和 [basic_ifstream][4]。本例将使用读/写字符的专用类型 `ifstream` 和 `ofstream`。
+
+- `ofstream`:输出文件流,并且其能通过插入运算符 `<<` 来实现。
+- `ifstream`:输入文件流,并且其能通过提取运算符 `>>` 来实现。
+
+该两种类型都是在头文件 `` 中所定义。
+
+从 `ios_base` 继承的类在写入时可被视为数据接收器,在从其读取时可被视为数据源,与数据本身完全分离。这种面向对象的方法使 [关注点分离][5] 和 [依赖注入][6] 等概念易于实现。
+
+### 一个简单的例子
+
+本例程是非常简单:实例化了一个 `ofstream` 来写入,和实例化一个 `ifstream` 来读取。
+
+```
+#include // cout, cin, cerr etc...
+#include // ifstream, ofstream
+#include
+
+
+int main()
+{
+ std::string sFilename = "MyFile.txt";
+
+ /******************************************
+ * *
+ * WRITING *
+ * *
+ ******************************************/
+
+ std::ofstream fileSink(sFilename); // Creates an output file stream
+
+ if (!fileSink) {
+ std::cerr << "Canot open " << sFilename << std::endl;
+ exit(-1);
+ }
+
+ /* std::endl will automatically append the correct EOL */
+ fileSink << "Hello Open Source World!" << std::endl;
+
+
+ /******************************************
+ * *
+ * READING *
+ * *
+ ******************************************/
+
+ std::ifstream fileSource(sFilename); // Creates an input file stream
+
+ if (!fileSource) {
+ std::cerr << "Canot open " << sFilename << std::endl;
+ exit(-1);
+ }
+ else {
+ // Intermediate buffer
+ std::string buffer;
+
+ // By default, the >> operator reads word by workd (till whitespace)
+ while (fileSource >> buffer)
+ {
+ std::cout << buffer << std::endl;
+ }
+ }
+
+ exit(0);
+}
+```
+
+该代码可以在 [GitHub][7] 上查看。当你编译并且执行它时,你应该能获得以下输出:
+
+![Console screenshot][8]
+
+这是个简化的、适合初学者的例子。如果你想去使用该代码在你自己的应用中,请注意以下几点:
+
+ * 文件流在程序结束的时候自动关闭。如果你想继续执行,那么应该通过调用 `close()` 方法手动关闭。
+ * 这些文件流类继承自 [basic_ios][10](在多个层次上),并且重载了 `!` 运算符。这使你可以进行简单的检查是否可以访问该流。在 [cppreference.com][11] 上,你可以找到该检查何时会(或不会)成功的概述,并且可以进一步实现错误处理。
+ * 默认情况下,`ifstream` 停在空白处并跳过它。要逐行读取直到到达 [EOF][13] ,请使用 `getline(...)` 方法。
+ * 为了读写二进制文件,请将 `std::ios::binary` 标志传递给构造函数:这样可以防止 [EOL][13] 字符附加到每一行。
+
+### 从系统角度进行写入
+
+写入文件时,数据将写入系统的内存写入缓冲区中。当系统收到系统调用 [sync][14] 时,此缓冲区的内容将被写入硬盘。这也是你在不告知系统的情况下,不要卸下 U 盘的原因。通常,守护进程会定期调用 `sync`。为了安全起见,也可以手动调用 `sync()`:
+
+
+```
+#include // needs to be included
+
+sync();
+```
+
+### 总结
+
+在 C++ 中读写文件并不那么复杂。更何况,如果你知道如何处理输入输出流,(原则上)那么你也知道如何处理任何类型的输入输出设备。对于各种输入输出设备的库能让你更容易地使用流运算符。这就是为什么知道输入输出流的流程会对你有所助益的原因。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/ccc-input-output
+
+作者:[Stephan Avenwedde][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/hansic99
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_screen_windows_files.png?itok=kLTeQUbY "Computer screen with files or windows open"
+[2]: https://en.cppreference.com/w/cpp/io/ios_base
+[3]: https://en.cppreference.com/w/cpp/io/basic_ofstream
+[4]: https://en.cppreference.com/w/cpp/io/basic_ifstream
+[5]: https://en.wikipedia.org/wiki/Separation_of_concerns
+[6]: https://en.wikipedia.org/wiki/Dependency_injection
+[7]: https://github.com/hANSIc99/cpp_input_output
+[8]: https://opensource.com/sites/default/files/uploads/c_console_screenshot.png "Console screenshot"
+[9]: https://creativecommons.org/licenses/by-sa/4.0/
+[10]: https://en.cppreference.com/w/cpp/io/basic_ios
+[11]: https://en.cppreference.com/w/cpp/io/basic_ios/operator!
+[12]: https://en.wikipedia.org/wiki/End-of-file
+[13]: https://en.wikipedia.org/wiki/Newline
+[14]: https://en.wikipedia.org/wiki/Sync_%28Unix%29
diff --git a/published/202104/20210326 Why you should care about service mesh.md b/published/202104/20210326 Why you should care about service mesh.md
new file mode 100644
index 0000000000..9e387a2342
--- /dev/null
+++ b/published/202104/20210326 Why you should care about service mesh.md
@@ -0,0 +1,67 @@
+[#]: subject: (Why you should care about service mesh)
+[#]: via: (https://opensource.com/article/21/3/service-mesh)
+[#]: author: (Daniel Oh https://opensource.com/users/daniel-oh)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13261-1.html)
+
+为什么需要关心服务网格
+======
+
+> 在微服务环境中,服务网格为开发和运营提供了好处。
+
+
+
+很多开发者不知道为什么要关心[服务网格][2]。这是我在开发者见面会、会议和实践研讨会上关于云原生架构的微服务开发的演讲中经常被问到的问题。我的回答总是一样的:“只要你想简化你的微服务架构,它就应该运行在 Kubernetes 上。”
+
+关于简化,你可能也想知道,为什么分布式微服务必须设计得如此复杂才能在 Kubernetes 集群上运行。正如本文所解释的那样,许多开发人员通过服务网格解决了微服务架构的复杂性,并通过在生产中采用服务网格获得了额外的好处。
+
+### 什么是服务网格?
+
+服务网格是一个专门的基础设施层,用于提供一个透明的、独立于代码的 (polyglot) 方式,以消除应用代码中的非功能性微服务能力。
+
+![Before and After Service Mesh][3]
+
+### 为什么服务网格对开发者很重要
+
+当开发人员将微服务部署到云时,无论业务功能如何,他们都必须解决非功能性微服务功能,以避免级联故障。这些功能通常可以体现在服务发现、日志、监控、韧性、认证、弹性和跟踪等方面。开发人员必须花费更多的时间将它们添加到每个微服务中,而不是开发实际的业务逻辑,这使得微服务变得沉重而复杂。
+
+随着企业加速向云计算转移,服务网格 可以提高开发人员的生产力。Kubernetes 加服务网格平台不需要让服务负责处理这些复杂的问题,也不需要在每个服务中添加更多的代码来处理云原生的问题,而是负责向运行在该平台上的任何应用(现有的或新的,用任何编程语言或框架)提供这些服务。那么微服务就可以轻量级,专注于其业务逻辑,而不是云原生的复杂性。
+
+### 为什么服务网格对运维很重要
+
+这并没有回答为什么运维团队需要关心在 Kubernetes 上运行云原生微服务的服务网格。因为运维团队必须确保在 Kubernetes 环境上的大型混合云和多云上部署新的云原生应用的强大安全性、合规性和可观察性。
+
+服务网格由一个用于管理代理路由流量的控制平面和一个用于注入边车的数据平面组成。边车允许运维团队做一些比如添加第三方安全工具和追踪所有服务通信中的流量,以避免安全漏洞或合规问题。服务网格还可以通过在图形面板上可视化地跟踪指标来提高观察能力。
+
+### 如何开始使用服务网格
+
+对于开发者和运维人员,以及从应用开发到平台运维来说,服务网格可以更有效地管理云原生功能。
+
+你可能想知道从哪里开始采用服务网格来配合你的微服务应用和架构。幸运的是,有许多开源的服务网格项目。许多云服务提供商也在他们的 Kubernetes 平台中提供 服务网格。
+
+![CNCF Service Mesh Landscape][5]
+
+你可以在 [CNCF Service Mesh Landscape][6] 页面中找到最受欢迎的服务网格项目和服务的链接。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/service-mesh
+
+作者:[Daniel Oh][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/daniel-oh
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_analytics_cloud.png?itok=eE4uIoaB (Net catching 1s and 0s or data in the clouds)
+[2]: https://www.redhat.com/en/topics/microservices/what-is-a-service-mesh
+[3]: https://opensource.com/sites/default/files/uploads/vm-vs-service-mesh.png (Before and After Service Mesh)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://opensource.com/sites/default/files/uploads/service-mesh-providers.png (CNCF Service Mesh Landscape)
+[6]: https://landscape.cncf.io/card-mode?category=service-mesh&grouping=category
diff --git a/published/202104/20210329 Manipulate data in files with Lua.md b/published/202104/20210329 Manipulate data in files with Lua.md
new file mode 100644
index 0000000000..eb0bf8808b
--- /dev/null
+++ b/published/202104/20210329 Manipulate data in files with Lua.md
@@ -0,0 +1,95 @@
+[#]: subject: (Manipulate data in files with Lua)
+[#]: via: (https://opensource.com/article/21/3/lua-files)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13268-1.html)
+
+用 Lua 操作文件中的数据
+======
+
+> 了解 Lua 如何处理数据的读写。
+
+
+
+有些数据是临时的,存储在 RAM 中,只有在应用运行时才有意义。但有些数据是要持久的,存储在硬盘上供以后使用。当你编程时,无论是简单的脚本还是复杂的工具套件,通常都需要读取和写入文件。有时文件可能包含配置选项,而另一些时候这个文件是你的用户用你的应用创建的数据。每种语言都会以不同的方式处理这项任务,本文将演示如何使用 Lua 处理文件数据。
+
+### 安装 Lua
+
+如果你使用的是 Linux,你可以从你的发行版软件库中安装 Lua。在 macOS 上,你可以从 [MacPorts][2] 或 [Homebrew][3] 安装 Lua。在 Windows 上,你可以从 [Chocolatey][4] 安装 Lua。
+
+安装 Lua 后,打开你最喜欢的文本编辑器并准备开始。
+
+### 用 Lua 读取文件
+
+Lua 使用 `io` 库进行数据输入和输出。下面的例子创建了一个名为 `ingest` 的函数来从文件中读取数据,然后用 `:read` 函数进行解析。在 Lua 中打开一个文件时,有几种模式可以启用。因为我只需要从这个文件中读取数据,所以我使用 `r`(代表“读”)模式:
+
+```
+function ingest(file)
+ local f = io.open(file, "r")
+ local lines = f:read("*all")
+ f:close()
+ return(lines)
+end
+
+myfile=ingest("example.txt")
+print(myfile)
+```
+
+在这段代码中,注意到变量 `myfile` 是为了触发 `ingest` 函数而创建的,因此,它接收该函数返回的任何内容。`ingest` 函数返回文件的行数(从一个称为 `lines` 的变量中0。当最后一步打印 `myfile` 变量的内容时,文件的行数就会出现在终端中。
+
+如果文件 `example.txt` 中包含了配置选项,那么我会写一些额外的代码来解析这些数据,可能会使用另一个 Lua 库,这取决于配置是以 INI 文件还是 YAML 文件或其他格式存储。如果数据是 SVG 图形,我会写额外的代码来解析 XML,可能会使用 Lua 的 SVG 库。换句话说,你的代码读取的数据一旦加载到内存中,就可以进行操作,但是它们都需要加载 `io` 库。
+
+### 用 Lua 将数据写入文件
+
+无论你是要存储用户用你的应用创建的数据,还是仅仅是关于用户在应用中做了什么的元数据(例如,游戏保存或最近播放的歌曲),都有很多很好的理由来存储数据供以后使用。在 Lua 中,这是通过 `io` 库实现的,打开一个文件,将数据写入其中,然后关闭文件:
+
+```
+function exgest(file)
+ local f = io.open(file, "a")
+ io.output(f)
+ io.write("hello world\n")
+ io.close(f)
+end
+
+exgest("example.txt")
+```
+
+为了从文件中读取数据,我以 `r` 模式打开文件,但这次我使用 `a` (用于”追加“)将数据写到文件的末尾。因为我是将纯文本写入文件,所以我添加了自己的换行符(`/n`)。通常情况下,你并不是将原始文本写入文件,你可能会使用一个额外的库来代替写入一个特定的格式。例如,你可能会使用 INI 或 YAML 库来帮助编写配置文件,使用 XML 库来编写 XML,等等。
+
+### 文件模式
+
+在 Lua 中打开文件时,有一些保护措施和参数来定义如何处理文件。默认值是 `r`,允许你只读数据:
+
+ * `r` 只读
+ * `w` 如果文件不存在,覆盖或创建一个新文件。
+ * `r+` 读取和覆盖。
+ * `a` 追加数据到文件中,或在文件不存在的情况下创建一个新文件。
+ * `a+` 读取数据,将数据追加到文件中,或文件不存在的话,创建一个新文件。
+
+还有一些其他的(例如,`b` 代表二进制格式),但这些是最常见的。关于完整的文档,请参考 [Lua.org/manual][5] 上的优秀 Lua 文档。
+
+### Lua 和文件
+
+和其他编程语言一样,Lua 有大量的库支持来访问文件系统来读写数据。因为 Lua 有一个一致且简单语法,所以很容易对任何格式的文件数据进行复杂的处理。试着在你的下一个软件项目中使用 Lua,或者作为 C 或 C++ 项目的 API。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/lua-files
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
+[2]: https://opensource.com/article/20/11/macports
+[3]: https://opensource.com/article/20/6/homebrew-mac
+[4]: https://opensource.com/article/20/3/chocolatey
+[5]: http://lua.org/manual
diff --git a/published/202104/20210329 Why I love using the IPython shell and Jupyter notebooks.md b/published/202104/20210329 Why I love using the IPython shell and Jupyter notebooks.md
new file mode 100644
index 0000000000..269735322f
--- /dev/null
+++ b/published/202104/20210329 Why I love using the IPython shell and Jupyter notebooks.md
@@ -0,0 +1,157 @@
+[#]: subject: (Why I love using the IPython shell and Jupyter notebooks)
+[#]: via: (https://opensource.com/article/21/3/ipython-shell-jupyter-notebooks)
+[#]: author: (Ben Nuttall https://opensource.com/users/bennuttall)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13277-1.html)
+
+为什么我喜欢使用 IPython shell 和 Jupyter 笔记本
+======
+
+> Jupyter 笔记本将 IPython shell 提升到一个新的高度。
+
+
+
+Jupyter 项目最初是以 IPython 和 IPython 笔记本的形式出现的。它最初是一个专门针对 Python 的交互式 shell 和笔记本环境,后来扩展为不分语言的环境,支持 Julia、Python 和 R 以及其他任何语言。
+
+![Jupyter][2]
+
+IPython 是一个 Python shell,类似于你在命令行输入 `python` 或者 `python3` 时看到的,但它更聪明、更有用。如果你曾经在 Python shell 中输入过多行命令,并且想重复它,你就会理解每次都要一行一行地滚动浏览历史记录的挫败感。有了 IPython,你可以一次滚动浏览整个块,同时还可以逐行浏览和编辑这些块的部分内容。
+
+![iPython][4]
+
+它具有自动补全,并提供上下文感知的建议:
+
+![iPython offers suggestions][5]
+
+它默认会整理输出:
+
+![iPython pretty prints][6]
+
+它甚至允许你运行 shell 命令:
+
+![IPython shell commands][7]
+
+它还提供了一些有用的功能,比如将 `?` 添加到对象中,作为运行 `help()` 的快捷方式,而不会破坏你的流程:
+
+![IPython help][8]
+
+如果你使用的是虚拟环境(参见我关于 [virtualenvwrapper][9] 的帖子),可以在环境中用 `pip` 安装:
+
+```
+pip install ipython
+```
+
+要在全系统范围内安装,你可以在 Debian、Ubuntu 或树莓派上使用 `apt`:
+
+```
+sudo apt install ipython3
+```
+
+或使用 `pip`:
+
+```
+sudo pip3 install ipython
+```
+
+### Jupyter 笔记本
+
+Jupyter 笔记本将 IPython shell 提升到了一个新的高度。首先,它们是基于浏览器的,而不是基于终端的。要开始使用,请安装 `jupyter`。
+
+如果你使用的是虚拟环境,请在环境中使用 `pip` 进行安装:
+
+```
+pip install jupyter
+```
+
+要在全系统范围内安装,你可以在 Debian、Ubuntu 或树莓派上使用 `apt`:
+
+```
+sudo apt install jupyter-notebook
+```
+
+或使用 `pip`:
+
+```
+sudo pip3 install jupyter
+```
+
+启动笔记本:
+
+```
+jupyter notebook
+```
+
+这将在你的浏览器中打开:
+
+![Jupyter Notebook][10]
+
+你可以使用 “New” 下拉菜单创建一个新的 Python 3 笔记本:
+
+![Python 3 in Jupyter Notebook][11]
+
+现在你可以在 `In[ ]` 字段中编写和执行命令。使用 `Enter` 在代码块中换行,使用 `Shift+Enter` 来执行:
+
+![Executing commands in Jupyter][12]
+
+你可以编辑和重新运行代码块,你可以重新排序、删除,复制/粘贴,等等。你可以以任何顺序运行代码块,但是要注意的是,任何创建的变量的作用域都将根据执行的时间而不是它们在笔记本中出现的顺序。你可以在 “Kernel” 菜单中重启并清除输出或重启并运行所有的代码块。
+
+使用 `print` 函数每次都会输出。但是如果你有一条没有分配的语句,或者最后一条语句没有分配,那么它总是会输出:
+
+![Jupyter output][13]
+
+你甚至可以把 `In` 和 `Out` 作为可索引对象:
+
+![Jupyter output][14]
+
+所有的 IPython 功能都可以使用,而且通常也会表现得更漂亮一些:
+
+![Jupyter supports IPython features][15]
+
+你甚至可以使用 [Matplotlib][16] 进行内联绘图:
+
+![Graphing in Jupyter Notebook][17]
+
+最后,你可以保存你的笔记本,并将其包含在 Git 仓库中,如果你将其推送到 GitHub,它们将作为已完成的笔记本被渲染:输出、图形和所有一切(如 [本例][18]):
+
+![Saving Notebook to GitHub][19]
+
+* * *
+
+本文原载于 Ben Nuttall 的 [Tooling Tuesday 博客][20],经许可后重用。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/ipython-shell-jupyter-notebooks
+
+作者:[Ben Nuttall][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/bennuttall
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_space_graphic_cosmic.png?itok=wu493YbB (Computer laptop in space)
+[2]: https://opensource.com/sites/default/files/uploads/jupyterpreview.png (Jupyter)
+[3]: https://creativecommons.org/licenses/by-sa/4.0/
+[4]: https://opensource.com/sites/default/files/uploads/ipython-loop.png (iPython)
+[5]: https://opensource.com/sites/default/files/uploads/ipython-suggest.png (iPython offers suggestions)
+[6]: https://opensource.com/sites/default/files/uploads/ipython-pprint.png (iPython pretty prints)
+[7]: https://opensource.com/sites/default/files/uploads/ipython-ls.png (IPython shell commands)
+[8]: https://opensource.com/sites/default/files/uploads/ipython-help.png (IPython help)
+[9]: https://opensource.com/article/21/2/python-virtualenvwrapper
+[10]: https://opensource.com/sites/default/files/uploads/jupyter-notebook-1.png (Jupyter Notebook)
+[11]: https://opensource.com/sites/default/files/uploads/jupyter-python-notebook.png (Python 3 in Jupyter Notebook)
+[12]: https://opensource.com/sites/default/files/uploads/jupyter-loop.png (Executing commands in Jupyter)
+[13]: https://opensource.com/sites/default/files/uploads/jupyter-cells.png (Jupyter output)
+[14]: https://opensource.com/sites/default/files/uploads/jupyter-cells-2.png (Jupyter output)
+[15]: https://opensource.com/sites/default/files/uploads/jupyter-help.png (Jupyter supports IPython features)
+[16]: https://matplotlib.org/
+[17]: https://opensource.com/sites/default/files/uploads/jupyter-graph.png (Graphing in Jupyter Notebook)
+[18]: https://github.com/piwheels/stats/blob/master/2020.ipynb
+[19]: https://opensource.com/sites/default/files/uploads/savenotebooks.png (Saving Notebook to GitHub)
+[20]: https://tooling.bennuttall.com/the-ipython-shell-and-jupyter-notebooks/
diff --git a/published/202104/20210330 NewsFlash- A Modern Open-Source Feed Reader With Feedly Support.md b/published/202104/20210330 NewsFlash- A Modern Open-Source Feed Reader With Feedly Support.md
new file mode 100644
index 0000000000..11f3c7231c
--- /dev/null
+++ b/published/202104/20210330 NewsFlash- A Modern Open-Source Feed Reader With Feedly Support.md
@@ -0,0 +1,98 @@
+[#]: subject: (NewsFlash: A Modern Open-Source Feed Reader With Feedly Support)
+[#]: via: (https://itsfoss.com/newsflash-feedreader/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+[#]: collector: (lujun9972)
+[#]: translator: (DCOLIVERSUN)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13264-1.html)
+
+NewsFlash: 一款支持 Feedly 的现代开源 Feed 阅读器
+======
+
+
+
+有些人可能认为 RSS 阅读器已经不再,但它们仍然坚持在这里,特别是当你不想让大科技算法来决定你应该阅读什么的时候。Feed 阅读器可以帮你自助选择阅读来源。
+
+我最近遇到一个很棒的 RSS 阅读器 NewsFlash。它支持通过基于网页的 Feed 阅读器增加 feed,例如 [Feedly][1] 和 NewsBlur。这是一个很大的安慰,因为如果你已经使用这种服务,就不必人工导入 feed,这节省了你的工作。
+
+NewsFlash 恰好是 [FeedReadeer][2] 的精神继承者,原来的 FeedReader 开发人员也参与其中。
+
+如果你正在找适用的 RSS 阅读器,我们整理了 [Linux Feed 阅读器][3] 列表供您参考。
+
+### NewsFlash: 一款补充网页 RSS 阅读器账户的 Feed 阅读器
+
+![][4]
+
+请注意,NewsFlash 并不只是针对基于网页的 RSS feed 账户量身定做的,你也可以选择使用本地 RSS feed,而不必在多设备间同步。
+
+不过,如果你在用是任何一款支持的基于网页的 feed 阅读器,那么 NewsFlash 特别有用。
+
+这里,我将重点介绍 NewsFlash 提供的一些功能。
+
+### NewsFlash 功能
+
+![][5]
+
+ * 支持桌面通知
+ * 快速搜索、过滤
+ * 支持标签
+ * 便捷、可重定义的键盘快捷键
+ * 本地 feed
+ * OPML 文件导入/导出
+ * 无需注册即可在 Feedly 库中轻松找到不同 RSS Feed
+ * 支持自定义字体
+ * 支持多主题(包括深色主题)
+ * 启动/禁止缩略图
+ * 细粒度调整定期同步间隔时间
+ * 支持基于网页的 Feed 账户,例如 Feedly、Fever、NewsBlur、feedbin、Miniflux
+
+除上述功能外,当你调整窗口大小时,还可以打开阅读器视图,这是一个细腻的补充功能。
+
+![newsflash 截图1][6]
+
+账户重新设置也很容易,这将删除所有本地数据。是的,你可以手动清除缓存并设置到期时间,并为你关注的所有 feed 设置一个用户数据存在本地的到期时间。
+
+### 在 Linux 上安装 NewsFlash
+
+你无法找到适用于各种 Linux 发行版的官方软件包,只有 [Flatpak][8]。
+
+对于 Arch 用户,可以从 [AUR][9] 下载。
+
+幸运的是,[Flatpak][10] 软件包可以让你轻松在 Linux 发行版上安装 NewsFlash。具体请参阅我们的 [Flatpak 指南][11]。
+
+你可以参考 NewsFlash 的 [GitLab 页面][12] 去解决大部分问题。
+
+### 结束语
+
+我现在用 NewsFlash 作为桌面本地解决方案,不用基于网页的服务。你可以通过直接导出 OPML 文件在移动 feed 应用上得到相同的 feed。这已经被我验证过了。
+
+用户界面易于使用,也提供了数一数二的新版 UX。虽然这个 RSS 阅读器看似简单,但提供了你可以找到的所有重要功能。
+
+你怎么看 NewsFlash?你喜欢用其他类似产品吗?欢迎在评论区中分享你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/newsflash-feedreader/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://feedly.com/
+[2]: https://jangernert.github.io/FeedReader/
+[3]: https://itsfoss.com/feed-reader-apps-linux/
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/newsflash.jpg?resize=945%2C648&ssl=1
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/newsflash-screenshot.jpg?resize=800%2C533&ssl=1
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/newsflash-screenshot-1.jpg?resize=800%2C532&ssl=1
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/04/best-feed-reader-apps-linux.jpg?fit=800%2C450&ssl=1
+[8]: https://flathub.org/apps/details/com.gitlab.newsflash
+[9]: https://itsfoss.com/aur-arch-linux/
+[10]: https://itsfoss.com/what-is-flatpak/
+[11]: https://itsfoss.com/flatpak-guide/
+[12]: https://gitlab.com/news-flash/news_flash_gtk
diff --git a/published/202104/20210331 3 reasons I use the Git cherry-pick command.md b/published/202104/20210331 3 reasons I use the Git cherry-pick command.md
new file mode 100644
index 0000000000..5f87ecc61e
--- /dev/null
+++ b/published/202104/20210331 3 reasons I use the Git cherry-pick command.md
@@ -0,0 +1,181 @@
+[#]: subject: (3 reasons I use the Git cherry-pick command)
+[#]: via: (https://opensource.com/article/21/3/git-cherry-pick)
+[#]: author: (Manaswini Das https://opensource.com/users/manaswinidas)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13305-1.html)
+
+我使用 Git cherry-pick 命令的 3 个理由
+======
+
+> “遴选”可以解决 Git 仓库中的很多问题。以下是用 `git cherry-pick` 修复错误的三种方法。
+
+
+
+在版本控制系统中摸索前进是一件很棘手的事情。对于一个新手来说,这可能是非常难以应付的,但熟悉版本控制系统(如 Git)的术语和基础知识是开始为开源贡献的第一步。
+
+熟悉 Git 也能帮助你在开源之路上走出困境。Git 功能强大,让你感觉自己在掌控之中 —— 没有哪一种方法会让你无法恢复到工作版本。
+
+这里有一个例子可以帮助你理解“遴选”的重要性。假设你已经在一个分支上做了好几个提交,但你意识到这是个错误的分支!你现在该怎么办?你现在要做什么?要么在正确的分支上重复所有的变更,然后重新提交,要么把这个分支合并到正确的分支上。等一下,前者太过繁琐,而你可能不想做后者。那么,还有没有办法呢?有的,Git 已经为你准备好了。这就是“遴选”的作用。顾名思义,你可以用它从一个分支中手工遴选一个提交,然后转移到另一个分支。
+
+使用遴选的原因有很多。以下是其中的三个原因。
+
+### 避免重复性工作
+
+如果你可以直接将相同的提交复制到另一个分支,就没有必要在不同的分支中重做相同的变更。请注意,遴选出来的提交会在另一个分支中创建带有新哈希的新提交,所以如果你看到不同的提交哈希,请不要感到困惑。
+
+如果您想知道什么是提交的哈希,以及它是如何生成的,这里有一个说明可以帮助你。提交哈希是用 [SHA-1][2] 算法生成的字符串。SHA-1 算法接收一个输入,然后输出一个唯一的 40 个字符的哈希值。如果你使用的是 [POSIX][3] 系统,请尝试在您的终端上运行这个命令:
+
+```
+$ echo -n "commit" | openssl sha1
+```
+
+这将输出一个唯一的 40 个字符的哈希值 `4015b57a143aec5156fd1444a017a32137a3fd0f`。这个哈希代表了字符串 `commit`。
+
+Git 在提交时生成的 SHA-1 哈希值不仅仅代表一个字符串。它代表的是:
+
+```
+sha1(
+ meta data
+ commit message
+ committer
+ commit date
+ author
+ authoring date
+ Hash of the entire tree object
+)
+```
+
+这就解释了为什么你对代码所做的任何细微改动都会得到一个独特的提交哈希值。哪怕是一个微小的改动都会被发现。这是因为 Git 具有完整性。
+
+### 撤销/恢复丢失的更改
+
+当你想恢复到工作版本时,遴选就很方便。当多个开发人员在同一个代码库上工作时,很可能会丢失更改,最新的版本会被转移到一个陈旧的或非工作版本上。这时,遴选提交到工作版本就可以成为救星。
+
+#### 它是如何工作的?
+
+假设有两个分支:`feature1` 和 `feature2`,你想把 `feature1` 中的提交应用到 `feature2`。
+
+在 `feature1` 分支上,运行 `git log` 命令,复制你想遴选的提交哈希值。你可以看到一系列类似于下面代码示例的提交。`commit` 后面的字母数字代码就是你需要复制的提交哈希。为了方便起见,您可以选择复制前六个字符(本例中为 `966cf3`)。
+
+```
+commit 966cf3d08b09a2da3f2f58c0818baa37184c9778 (HEAD -> master)
+Author: manaswinidas
+Date: Mon Mar 8 09:20:21 2021 +1300
+
+ add instructions
+```
+
+然后切换到 `feature2` 分支,在刚刚从日志中得到的哈希值上运行 `git cherry-pick`:
+
+```
+$ git checkout feature2
+$ git cherry-pick 966cf3.
+```
+
+如果该分支不存在,使用 `git checkout -b feature2` 来创建它。
+
+这里有一个问题。你可能会遇到下面这种情况:
+
+```
+$ git cherry-pick 966cf3
+On branch feature2
+You are currently cherry-picking commit 966cf3d.
+
+nothing to commit, working tree clean
+The previous cherry-pick is now empty, possibly due to conflict resolution.
+If you wish to commit it anyway, use:
+
+ git commit --allow-empty
+
+Otherwise, please use 'git reset'
+```
+
+不要惊慌。只要按照建议运行 `git commit --allow-empty`:
+
+```
+$ git commit --allow-empty
+[feature2 afb6fcb] add instructions
+Date: Mon Mar 8 09:20:21 2021 +1300
+```
+
+这将打开你的默认编辑器,允许你编辑提交信息。如果你没有什么要补充的,可以保存现有的信息。
+
+就这样,你完成了你的第一次遴选。如上所述,如果你在分支 `feature2` 上运行 `git log`,你会看到一个不同的提交哈希。下面是一个例子:
+
+```
+commit afb6fcb87083c8f41089cad58deb97a5380cb2c2 (HEAD -> feature2)
+Author: manaswinidas <[me@example.com][4]>
+Date: Mon Mar 8 09:20:21 2021 +1300
+ add instructions
+```
+
+不要对不同的提交哈希感到困惑。这只是区分 `feature1` 和 `feature2` 的提交。
+
+### 遴选多个提交
+
+但如果你想遴选多个提交的内容呢?你可以使用:
+
+```
+git cherry-pick ...
+```
+
+请注意,你不必使用整个提交的哈希值,你可以使用前五到六个字符。
+
+同样,这也是很繁琐的。如果你想遴选的提交是一系列的连续提交呢?这种方法太费劲了。别担心,有一个更简单的方法。
+
+假设你有两个分支:
+
+ * `feature1` 包括你想复制的提交(从更早的 `commitA` 到 `commitB`)。
+ * `feature2` 是你想把提交从 `feature1` 转移到的分支。
+
+然后:
+
+ 1. 输入 `git checkout `。
+ 2. 获取 `commitA` 和 `commitB` 的哈希值。
+ 3. 输入 `git checkout `。
+ 4. 输入 `git cherry-pick ^..` (请注意,这包括 `commitA` 和 `commitB`)。
+ 5. 如果遇到合并冲突,[像往常一样解决][5],然后输入 `git cherry-pick --continue` 恢复遴选过程。
+
+### 重要的遴选选项
+
+以下是 [Git 文档][6] 中的一些有用的选项,你可以在 `cherry-pick` 命令中使用。
+
+ * `-e`、`--edit`:用这个选项,`git cherry-pick` 可以让你在提交前编辑提交信息。
+ * `-s`、`--signoff`:在提交信息的结尾添加 `Signed-off by` 行。更多信息请参见 `git-commit(1)` 中的 signoff 选项。
+ * `-S[]`、`--pgg-sign[=]`:这些是 GPG 签名的提交。`keyid` 参数是可选的,默认为提交者身份;如果指定了,则必须嵌在选项中,不加空格。
+ * `--ff`:如果当前 HEAD 与遴选的提交的父级提交相同,则会对该提交进行快进操作。
+
+下面是除了 `--continue` 外的一些其他的后继操作子命令:
+
+ * `--quit`:你可以忘记当前正在进行的操作。这可以用来清除遴选或撤销失败后的后继操作状态。
+ * `--abort`:取消操作并返回到操作序列前状态。
+
+下面是一些关于遴选的例子:
+
+ * `git cherry-pick master`:应用 `master` 分支顶端的提交所引入的变更,并创建一个包含该变更的新提交。
+ * `git cherry-pick master~4 master~2':应用 `master` 指向的第五个和第三个最新提交所带来的变化,并根据这些变化创建两个新的提交。
+
+感到不知所措?你不需要记住所有的命令。你可以随时在你的终端输入 `git cherry-pick --help` 查看更多选项或帮助。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/git-cherry-pick
+
+作者:[Manaswini Das][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/manaswinidas
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/pictures/cherry-picking-recipe-baking-cooking.jpg?itok=XVwse6hw (Measuring and baking a cherry pie recipe)
+[2]: https://en.wikipedia.org/wiki/SHA-1
+[3]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[4]: mailto:me@example.com
+[5]: https://opensource.com/article/20/4/git-merge-conflict
+[6]: https://git-scm.com/docs/git-cherry-pick
diff --git a/published/202104/20210331 Use this open source tool to monitor variables in Python.md b/published/202104/20210331 Use this open source tool to monitor variables in Python.md
new file mode 100644
index 0000000000..6349b1fe3c
--- /dev/null
+++ b/published/202104/20210331 Use this open source tool to monitor variables in Python.md
@@ -0,0 +1,169 @@
+[#]: subject: (Use this open source tool to monitor variables in Python)
+[#]: via: (https://opensource.com/article/21/4/monitor-debug-python)
+[#]: author: (Tian Gao https://opensource.com/users/gaogaotiantian)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13279-1.html)
+
+使用这个开源工具来监控 Python 中的变量
+======
+
+> Watchpoints 是一个简单但功能强大的工具,可以帮助你在调试 Python 时监控变量。
+
+
+
+在调试代码时,你经常面临着要弄清楚一个变量何时发生变化。如果没有任何高级工具,那么可以选择使用打印语句在期望它们更改时输出变量。然而,这是一种非常低效的方法,因为变量可能在很多地方发生变化,并且不断地将其打印到终端上会产生很大的干扰,而将它们打印到日志文件中则变得很麻烦。
+
+这是一个常见的问题,但现在有一个简单而强大的工具可以帮助你监控变量:[watchpoints][2]。
+
+[“监视点”的概念在 C 和 C++ 调试器中很常见][3],用于监控内存,但在 Python 中缺乏相应的工具。`watchpoints` 填补了这个空白。
+
+### 安装
+
+要使用它,你必须先用 `pip` 安装它:
+
+```
+$ python3 -m pip install watchpoints
+```
+
+### 在Python中使用 watchpoints
+
+对于任何一个你想监控的变量,使用 `watch` 函数对其进行监控。
+
+```
+from watchpoints import watch
+
+a = 0
+watch(a)
+a = 1
+```
+
+当变量发生变化时,它的值就会被打印到**标准输出**:
+
+```
+====== Watchpoints Triggered ======
+
+Call Stack (most recent call last):
+ (my_script.py:5):
+> a = 1
+a:
+0
+->
+1
+```
+
+信息包括:
+
+ * 变量被改变的行。
+ * 调用栈。
+ * 变量的先前值/当前值。
+
+它不仅适用于变量本身,也适用于对象的变化:
+
+```
+from watchpoints import watch
+
+a = []
+watch(a)
+a = {} # 触发
+a["a"] = 2 # 触发
+```
+
+当变量 `a` 被重新分配时,回调会被触发,同时当分配给 `a` 的对象发生变化时也会被触发。
+
+更有趣的是,监控不受作用域的限制。你可以在任何地方观察变量/对象,而且无论程序在执行什么函数,回调都会被触发。
+
+```
+from watchpoints import watch
+
+def func(var):
+ var["a"] = 1
+
+a = {}
+watch(a)
+func(a)
+```
+
+例如,这段代码打印出:
+
+```
+====== Watchpoints Triggered ======
+
+Call Stack (most recent call last):
+
+ (my_script.py:8):
+> func(a)
+ func (my_script.py:4):
+> var["a"] = 1
+a:
+{}
+->
+{'a': 1}
+```
+
+`watch` 函数不仅可以监视一个变量,它也可以监视一个字典或列表的属性和元素。
+
+```
+from watchpoints import watch
+
+class MyObj:
+ def __init__(self):
+ self.a = 0
+
+obj = MyObj()
+d = {"a": 0}
+watch(obj.a, d["a"]) # 是的,你可以这样做
+obj.a = 1 # 触发
+d["a"] = 1 # 触发
+```
+
+这可以帮助你缩小到一些你感兴趣的特定对象。
+
+如果你对输出格式不满意,你可以自定义它。只需定义你自己的回调函数:
+
+```
+watch(a, callback=my_callback)
+
+# 或者全局设置
+
+watch.config(callback=my_callback)
+```
+
+当触发时,你甚至可以使用 `pdb`:
+
+```
+watch.config(pdb=True)
+```
+
+这与 `breakpoint()` 的行为类似,会给你带来类似调试器的体验。
+
+如果你不想在每个文件中都导入这个函数,你可以通过 `install` 函数使其成为全局:
+
+```
+watch.install() # 或 watch.install("func_name") ,然后以 func_name() 方式使用
+```
+
+我个人认为,`watchpoints` 最酷的地方就是使用直观。你对一些数据感兴趣吗?只要“观察”它,你就会知道你的变量何时发生变化。
+
+### 尝试 watchpoints
+
+我在 [GitHub][2] 上开发维护了 `watchpoints`,并在 Apache 2.0 许可下发布了它。安装并使用它,当然也欢迎大家做出贡献。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/monitor-debug-python
+
+作者:[Tian Gao][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gaogaotiantian
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/look-binoculars-sight-see-review.png?itok=NOw2cm39 (Looking back with binoculars)
+[2]: https://github.com/gaogaotiantian/watchpoints
+[3]: https://opensource.com/article/21/3/debug-code-gdb
diff --git a/published/202104/20210401 Find what changed in a Git commit.md b/published/202104/20210401 Find what changed in a Git commit.md
new file mode 100644
index 0000000000..47202013ef
--- /dev/null
+++ b/published/202104/20210401 Find what changed in a Git commit.md
@@ -0,0 +1,134 @@
+[#]: subject: (Find what changed in a Git commit)
+[#]: via: (https://opensource.com/article/21/4/git-whatchanged)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (DCOLIVERSUN)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13286-1.html)
+
+查看 Git 提交中发生了什么变化
+======
+
+> Git 提供了几种方式可以帮你快速查看提交中哪些文件被改变。
+
+
+
+如果你每天使用 Git,应该会提交不少改动。如果你每天和其他人在一个项目中使用 Git,假设 _每个人_ 每天的提交都是安全的,你会意识到 Git 日志会变得多么混乱,似乎永恒地滚动着变化,却没有任何迹象表明修改了什么。
+
+那么,你该怎样查看指定提交中文件发生哪些变化?这比你想的容易。
+
+### 查看提交中文件发生的变化
+
+要想知道指定提交中哪些文件发生变化,可以使用 `git log --raw` 命令。这是发现一个提交影响了哪些文件的最快速、最方便的方法。`git log` 命令一般都没有被充分利用,主要是因为它有太多的格式化选项,许多用户在面对很多选择以及在一些情况下不明所以的文档时,会望而却步。
+
+然而,Git 的日志机制非常灵活,`--raw` 选项提供了当前分支中的提交日志,以及更改的文件列表。
+
+以下是标准的 `git log` 输出:
+
+```
+$ git log
+commit fbbbe083aed75b24f2c77b1825ecab10def0953c (HEAD -> dev, origin/dev)
+Author: tux
+Date: Sun Nov 5 21:40:37 2020 +1300
+
+ exit immediately from failed download
+
+commit 094f9948cd995acfc331a6965032ea0d38e01f03 (origin/master, master)
+Author: Tux
+Date: Fri Aug 5 02:05:19 2020 +1200
+
+ export makeopts from etc/example.conf
+
+commit 76b7b46dc53ec13316abb49cc7b37914215acd47
+Author: Tux
+Date: Sun Jul 31 21:45:24 2020 +1200
+
+ fix typo in help message
+```
+
+即使作者在提交消息中指定了哪些文件发生变化,日志也相当简洁。
+
+以下是 `git log --raw` 输出:
+
+```
+$ git log --raw
+commit fbbbe083aed75b24f2c77b1825ecab10def0953c (HEAD -> dev, origin/dev)
+Author: tux
+Date: Sun Nov 5 21:40:37 2020 +1300
+
+ exit immediately from failed download
+
+:100755 100755 cbcf1f3 4cac92f M src/example.lua
+
+commit 094f9948cd995acfc331a6965032ea0d38e01f03 (origin/master, master)
+Author: Tux
+Date: Fri Aug 5 02:05:19 2020 +1200
+
+ export makeopts from etc/example.conf
+
+:100755 100755 4c815c0 cbcf1f3 M src/example.lua
+:100755 100755 71653e1 8f5d5a6 M src/example.spec
+:100644 100644 9d21a6f e33caba R100 etc/example.conf etc/example.conf-default
+
+commit 76b7b46dc53ec13316abb49cc7b37914215acd47
+Author: Tux
+Date: Sun Jul 31 21:45:24 2020 +1200
+
+ fix typo in help message
+
+:100755 100755 e253aaf 4c815c0 M src/example.lua
+```
+
+这会准确告诉你哪个文件被添加到提交中,哪些文件发生改变(`A` 是添加,`M` 是修改,`R` 是重命名,`D` 是删除)。
+
+### Git whatchanged
+
+`git whatchanged` 命令是一个遗留命令,它的前身是日志功能。文档说用户不应该用该命令替代 `git log --raw`,并且暗示它实质上已经被废弃了。不过,我还是觉得它是一个很有用的捷径,可以得到同样的输出结果(尽管合并提交的内容不包括在内),如果它被删除的话,我打算为它创建一个别名。如果你只想查看已更改的文件,不想在日志中看到合并提交,可以尝试 `git whatchanged` 作为简单的助记符。
+
+### 查看变化
+
+你不仅可以看到哪些文件发生更改,还可以使用 `git log` 显示文件中发生了哪些变化。你的 Git 日志可以生成一个内联差异,用 `--patch` 选项可以逐行显示每个文件的所有更改:
+
+```
+commit 62a2daf8411eccbec0af69e4736a0fcf0a469ab1 (HEAD -> master)
+Author: Tux
+Date: Wed Mar 10 06:46:58 2021 +1300
+
+ commit
+
+diff --git a/hello.txt b/hello.txt
+index 65a56c3..36a0a7d 100644
+--- a/hello.txt
++++ b/hello.txt
+@@ -1,2 +1,2 @@
+ Hello
+-world
++opensource.com
+```
+
+在这个例子中,“world” 这行字从 `hello.txt` 中删掉,“opensource.com” 这行字则添加进去。
+
+如果你需要在其他地方手动进行相同的修改,这些补丁可以与常见的 Unix 命令一起使用,例如 [diff 与 patch][4]。补丁也是一个好方法,可以总结指定提交中引入新信息的重要部分内容。当你在冲刺阶段引入一个 bug 时,你会发现这里的内容就是非常有价值的概述。为了更快地找到错误的原因,你可以忽略文件中没有更改的部分,只检查新代码。
+
+### 用简单命令得到复杂的结果
+
+你不必理解引用、分支和提交哈希,就可以查看提交中更改了哪些文件。你的 Git 日志旨在向你报告 Git 的活动,如果你想以特定方式格式化它或者提取特定的信息,通常需要费力地浏览许多文档来组合出正确的命令。幸运的是,关于 Git 历史记录最常用的请求之一只需要一两个选项:`--raw` 与 `--patch`。如果你不记得 `--raw`,就想想“Git,什么改变了?”,然后输入 `git whatchanged`。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/git-whatchanged
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_development_programming.png?itok=4OM29-82 (Code going into a computer.)
+[2]: mailto:tux@example.com
+[3]: mailto:Tux@example.com
+[4]: https://opensource.com/article/18/8/diffs-patches
diff --git a/published/202104/20210401 Wrong Time Displayed in Windows-Linux Dual Boot Setup- Here-s How to Fix it.md b/published/202104/20210401 Wrong Time Displayed in Windows-Linux Dual Boot Setup- Here-s How to Fix it.md
new file mode 100644
index 0000000000..625e7d9362
--- /dev/null
+++ b/published/202104/20210401 Wrong Time Displayed in Windows-Linux Dual Boot Setup- Here-s How to Fix it.md
@@ -0,0 +1,104 @@
+[#]: subject: (Wrong Time Displayed in Windows-Linux Dual Boot Setup? Here’s How to Fix it)
+[#]: via: (https://itsfoss.com/wrong-time-dual-boot/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13276-1.html)
+
+如何解决 Windows-Linux 双启动设置中显示时间错误的问题
+======
+
+
+
+如果你 [双启动 Windows 和 Ubuntu][1] 或任何其他 Linux 发行版,你可能会注意到两个操作系统之间的时间差异。
+
+当你 [使用 Linux][2] 时,它会显示正确的时间。但当你进入 Windows 时,它显示的时间是错误的。有时,情况正好相反,Linux 显示的是错误的时间,而 Windows 的时间是正确的。
+
+特别奇怪的是,因为你已连接到互联网,并且已将日期和时间设置为自动使用。
+
+别担心!你并不是唯一一个遇到这种问题的人。你可以在 Linux 终端上使用以下命令来解决这个问题:
+
+```
+timedatectl set-local-rtc 1
+```
+
+同样,不要担心。我会解释为什么你在双启动设置中会遇到时间差。我会向你展示上面的命令是如何修复 Windows 双启动后的时间错误问题的。
+
+### 为什么 Windows 和 Linux 在双启动时显示不同的时间?
+
+一台电脑有两个主要时钟:系统时钟和硬件时钟。
+
+硬件时钟也叫 RTC([实时时钟][3])或 CMOS/BIOS 时钟。这个时钟在操作系统之外,在电脑的主板上。即使在你的系统关机后,它也会继续运行。
+
+系统时钟是你在操作系统内看到的。
+
+当计算机开机时,硬件时钟被读取并用于设置系统时钟。之后,系统时钟被用于跟踪时间。如果你的操作系统对系统时钟做了任何改变,比如改变时区等,它就会尝试将这些信息同步到硬件时钟上。
+
+默认情况下,Linux 认为硬件时钟中存储的时间是 UTC,而不是本地时间。另一方面,Windows 认为硬件时钟上存储的时间是本地时间。这就是问题的开始。
+
+让我用例子来解释一下。
+
+你看我在加尔各答 UTC+5:30 时区。安装后,当我把 [Ubuntu 中的时区][4] 设置为加尔各答时区时,Ubuntu 会把这个时间信息同步到硬件时钟上,但会有 5:30 的偏移,因为对于 Linux 来说它必须是 UTC。
+
+假设加尔各答时区的当前时间是 15:00,这意味着 UTC 时间是 09:30。
+
+现在当我关闭系统并启动到 Windows 时,硬件时钟有 UTC 时间(本例中为 09:30)。但是 Windows 认为硬件时钟已经存储了本地时间。因此,它改变了系统时钟(应该显示为 15:00),而使用 UTC 时间(09:30)作为本地时间。因此,Windows 显示时间为 09:30,这比实际时间(我们的例子中为 15:00)早了 5:30。
+
+![][5]
+
+同样,如果我在 Windows 中通过自动时区和时间按钮来设置正确的时间,你知道会发生什么吗?现在它将在系统上显示正确的时间(15:00),并将此信息(注意图片中的“同步你的时钟”选项)同步到硬件时钟。
+
+如果你启动到 Linux,它会从硬件时钟读取时间,而硬件时钟是当地时间(15:00),但由于 Linux 认为它是 UTC 时间,所以它在系统时钟上增加了 5:30 的偏移。现在 Linux 显示的时间是 20:30,比实际时间超出晚了 5:30。
+
+现在你了解了双启动中时差问题的根本原因,是时候看看如何解决这个问题了。
+
+### 修复 Windows 在 Linux 双启动设置中显示错误时间的问题
+
+有两种方法可以处理这个问题:
+
+ * 让 Windows 将硬件时钟作为 UTC 时间
+ * 让 Linux 将硬件时钟作为本地时间
+
+在 Linux 中进行修改是比较容易的,因此我推荐使用第二种方法。
+
+现在 Ubuntu 和大多数其他 Linux 发行版都使用 systemd,因此你可以使用 `timedatectl` 命令来更改设置。
+
+你要做的是告诉你的 Linux 系统将硬件时钟(RTC)作为本地时间。你可以通过 `set-local-rtc` (为 RTC 设置本地时间)选项来实现:
+
+```
+timedatectl set-local-rtc 1
+```
+
+如下图所示,RTC 现在使用本地时间。
+
+![][6]
+
+现在如果你启动 Windows,它把硬件时钟当作本地时间,而这个时间实际上是正确的。当你在 Linux 中启动时,你的 Linux 系统知道硬件时钟使用的是本地时间,而不是 UTC。因此,它不会尝试添加这个时间的偏移。
+
+这就解决了 Linux 和 Windows 双启动时的时差问题。
+
+你会看到一个关于 RTC 不使用本地时间的警告。对于桌面设置,它不应该引起任何问题。至少,我想不出有什么问题。
+
+希望我把事情给你讲清楚了。如果你还有问题,请在下面留言。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/wrong-time-dual-boot/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
+[2]: https://itsfoss.com/why-use-linux/
+[3]: https://www.computerhope.com/jargon/r/rtc.htm
+[4]: https://itsfoss.com/change-timezone-ubuntu/
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/set-time-windows.jpg?resize=800%2C491&ssl=1
+[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/set-local-time-for-rtc-ubuntu.png?resize=800%2C490&ssl=1
diff --git a/published/202104/20210402 A practical guide to using the git stash command.md b/published/202104/20210402 A practical guide to using the git stash command.md
new file mode 100644
index 0000000000..51917981dd
--- /dev/null
+++ b/published/202104/20210402 A practical guide to using the git stash command.md
@@ -0,0 +1,223 @@
+[#]: subject: (A practical guide to using the git stash command)
+[#]: via: (https://opensource.com/article/21/4/git-stash)
+[#]: author: (Ramakrishna Pattnaik https://opensource.com/users/rkpattnaik780)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13293-1.html)
+
+git stash 命令实用指南
+======
+
+> 学习如何使用 `git stash` 命令,以及何时应该使用它。
+
+
+
+版本控制是软件开发人员日常生活中不可分割的一部分。很难想象有哪个团队在开发软件时不使用版本控制工具。同样也很难想象有哪个开发者没有使用过(或没有听说过)Git。在 2018 年 Stackoverflow 开发者调查中,74298 名参与者中有 87.2% 的人 [使用 Git][2] 进行版本控制。
+
+Linus Torvalds 在 2005 年创建了 Git 用于开发 Linux 内核。本文将介绍 `git stash` 命令,并探讨一些有用的暂存变更的选项。本文假定你对 [Git 概念][3] 有基本的了解,并对工作树、暂存区和相关命令有良好的理解。
+
+### 为什么 git stash 很重要?
+
+首先要明白为什么在 Git 中暂存变更很重要。假设 Git 没有暂存变更的命令。当你正在一个有两个分支(A 和 B)的仓库上工作时,这两个分支已经分叉了一段时间,并且有不同的头。当你正在处理 A 分支的一些文件时,你的团队要求你修复 B 分支的一个错误。你迅速将你的修改保存到 A 分支(但没有提交),并尝试用 `git checkout B` 来签出 B 分支。Git 会立即中止了这个操作,并抛出错误:“你对以下文件的本地修改会被该签出覆盖……请在切换分支之前提交你的修改或将它们暂存起来。”
+
+在这种情况下,有几种方法可以启用分支切换:
+
+ * 在分支 A 中创建一个提交,提交并推送你的修改,以修复 B 中的错误,然后再次签出 A,并运行 `git reset HEAD^` 来恢复你的修改。
+ * 手动保留不被 Git 跟踪的文件中的改动。
+
+第二种方法是个馊主意。第一种方法虽然看起来很传统,但却不太灵活,因为保存未完成工作的修改会被当作一个检查点,而不是一个仍在进行中的补丁。这正是设计 `git stash` 的场景。
+
+`git stash` 将未提交的改动保存在本地,让你可以进行修改、切换分支以及其他 Git 操作。然后,当你需要的时候,你可以重新应用这些存储的改动。暂存是本地范围的,不会被 `git push` 推送到远程。
+
+### 如何使用 git stash
+
+下面是使用 `git stash` 时要遵循的顺序:
+
+ 1. 将修改保存到分支 A。
+ 2. 运行 `git stash`。
+ 3. 签出分支 B。
+ 4. 修正 B 分支的错误。
+ 5. 提交并(可选)推送到远程。
+ 6. 查看分支 A
+ 7. 运行 `git stash pop` 来取回你的暂存的改动。
+
+`git stash` 将你对工作目录的修改存储在本地(在你的项目的 `.git` 目录内,准确的说是 `/.git/refs/stash`),并允许你在需要时检索这些修改。当你需要在不同的上下文之间切换时,它很方便。它允许你保存以后可能需要的更改,是让你的工作目录干净同时保持更改完整的最快方法。
+
+### 如何创建一个暂存
+
+暂存你的变化的最简单的命令是 `git stash`:
+
+```
+$ git stash
+Saved working directory and index state WIP on master; d7435644 Feat: configure graphql endpoint
+```
+
+默认情况下,`git stash` 存储(或称之为“暂存”)未提交的更改(已暂存和未暂存的文件),并忽略未跟踪和忽略的文件。通常情况下,你不需要暂存未跟踪和忽略的文件,但有时它们可能会干扰你在代码库中要做的其他事情。
+
+你可以使用附加选项让 `git stash` 来处理未跟踪和忽略的文件:
+
+ * `git stash -u` 或 `git stash --includ-untracked` 储存未追踪的文件。
+ * `git stash -a` 或 `git stash --all` 储存未跟踪的文件和忽略的文件。
+
+要存储特定的文件,你可以使用 `git stash -p` 或 `git stash -patch` 命令:
+
+```
+$ git stash --patch
+diff --git a/.gitignore b/.gitignore
+index 32174593..8d81be6e 100644
+--- a/.gitignore
++++ b/.gitignore
+@@ -3,6 +3,7 @@
+ # dependencies
+ node_modules/
+ /.pnp
++f,fmfm
+ .pnp.js
+
+ # testing
+(1/1) Stash this hunk [y,n,q,a,d,e,?]?
+```
+
+### 列出你的暂存
+
+你可以用 `git stash list` 命令查看你的暂存。暂存是后进先出(LIFO)方式保存的:
+
+```
+$ git stash list
+stash@{0}: WIP on master: d7435644 Feat: configure graphql endpoint
+```
+
+默认情况下,暂存会显示在你创建它的分支和提交的顶部,被标记为 `WIP`。然而,当你有多个暂存时,这种有限的信息量并没有帮助,因为很难记住或单独检查它们的内容。要为暂存添加描述,可以使用命令 `git stash save `:
+
+```
+$ git stash save "remove semi-colon from schema"
+Saved working directory and index state On master: remove semi-colon from schema
+
+$ git stash list
+stash@{0}: On master: remove semi-colon from schema
+stash@{1}: WIP on master: d7435644 Feat: configure graphql endpoint
+```
+
+### 检索暂存起来的变化
+
+你可以用 `git stash apply` 和 `git stash pop` 这两个命令来重新应用暂存的变更。这两个命令都会重新应用最新的暂存(即 `stash@{0}`)中的改动。`apply` 会重新应用变更;而 `pop` 则会将暂存的变更重新应用到工作副本中,并从暂存中删除。如果你不需要再次重新应用被暂存的更改,则首选 `pop`。
+
+你可以通过传递标识符作为最后一个参数来选择你想要弹出或应用的储藏:
+
+```
+$ git stash pop stash@{1}
+```
+
+或
+
+```
+$ git stash apply stash@{1}
+```
+
+### 清理暂存
+
+删除不再需要的暂存是好的习惯。你必须用以下命令手动完成:
+
+ * `git stash clear` 通过删除所有的暂存库来清空该列表。
+ * `git stash drop ` 从暂存列表中删除一个特定的暂存。
+
+### 检查暂存的差异
+
+命令 `git stash show ` 允许你查看一个暂存的差异:
+
+```
+$ git stash show stash@{1}
+console/console-init/ui/.graphqlrc.yml | 4 +-
+console/console-init/ui/generated-frontend.ts | 742 +++++++++---------
+console/console-init/ui/package.json | 2 +-
+```
+
+要获得更详细的差异,需要传递 `--patch` 或 `-p` 标志:
+
+```
+$ git stash show stash@{0} --patch
+diff --git a/console/console-init/ui/package.json b/console/console-init/ui/package.json
+index 755912b97..5b5af1bd6 100644
+--- a/console/console-init/ui/package.json
++++ b/console/console-init/ui/package.json
+@@ -1,5 +1,5 @@
+ {
+- "name": "my-usepatternfly",
++ "name": "my-usepatternfly-2",
+ "version": "0.1.0",
+ "private": true,
+ "proxy": "http://localhost:4000"
+diff --git a/console/console-init/ui/src/AppNavHeader.tsx b/console/console-init/ui/src/AppNavHeader.tsx
+index a4764d2f3..da72b7e2b 100644
+--- a/console/console-init/ui/src/AppNavHeader.tsx
++++ b/console/console-init/ui/src/AppNavHeader.tsx
+@@ -9,8 +9,8 @@ import { css } from "@patternfly/react-styles";
+
+interface IAppNavHeaderProps extends PageHeaderProps {
+- toolbar?: React.ReactNode;
+- avatar?: React.ReactNode;
++ toolbar?: React.ReactNode;
++ avatar?: React.ReactNode;
+}
+
+export class AppNavHeader extends React.Component<IAppNavHeaderProps>{
+ render()
+```
+
+### 签出到新的分支
+
+你可能会遇到这样的情况:一个分支和你的暂存中的变更有分歧,当你试图重新应用暂存时,会造成冲突。一个简单的解决方法是使用 `git stash branch ` 命令,它将根据创建暂存时的提交创建一个新分支,并将暂存中的修改弹出:
+
+```
+$ git stash branch test_2 stash@{0}
+Switched to a new branch 'test_2'
+On branch test_2
+Changes not staged for commit:
+(use "git add ..." to update what will be committed)
+(use "git restore ..." to discard changes in working directory)
+modified: .graphqlrc.yml
+modified: generated-frontend.ts
+modified: package.json
+no changes added to commit (use "git add" and/or "git commit -a")
+Dropped stash@{0} (fe4bf8f79175b8fbd3df3c4558249834ecb75cd1)
+```
+
+### 在不打扰暂存参考日志的情况下进行暂存
+
+在极少数情况下,你可能需要创建一个暂存,同时保持暂存参考日志(`reflog`)的完整性。这些情况可能出现在你需要一个脚本作为一个实现细节来暂存的时候。这可以通过 `git stash create` 命令来实现;它创建了一个暂存条目,并返回它的对象名,而不将其推送到暂存参考日志中:
+
+```
+$ git stash create "sample stash"
+63a711cd3c7f8047662007490723e26ae9d4acf9
+```
+
+有时,你可能会决定将通过 `git stash create` 创建的暂存条目推送到暂存参考日志:
+
+```
+$ git stash store -m "sample stash testing.." "63a711cd3c7f8047662007490723e26ae9d4acf9"
+$ git stash list
+stash @{0}: sample stash testing..
+```
+
+### 结论
+
+我希望你觉得这篇文章很有用,并学到了新的东西。如果我遗漏了任何有用的使用暂存的选项,请在评论中告诉我。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/git-stash
+
+作者:[Ramakrishna Pattnaik][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rkpattnaik780
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-window-focus.png?itok=g0xPm2kD (young woman working on a laptop)
+[2]: https://insights.stackoverflow.com/survey/2018#work-_-version-control
+[3]: https://opensource.com/downloads/cheat-sheet-git
diff --git a/published/202104/20210403 What problems do people solve with strace.md b/published/202104/20210403 What problems do people solve with strace.md
new file mode 100644
index 0000000000..3160de5910
--- /dev/null
+++ b/published/202104/20210403 What problems do people solve with strace.md
@@ -0,0 +1,136 @@
+[#]: subject: (What problems do people solve with strace?)
+[#]: via: (https://jvns.ca/blog/2021/04/03/what-problems-do-people-solve-with-strace/)
+[#]: author: (Julia Evans https://jvns.ca/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13267-1.html)
+
+strace 可以解决什么问题?
+======
+
+
+
+昨天我 [在 Twitter 上询问大家用 strace 解决了什么问题?][1],和往常一样,大家真的是给出了自己的答案! 我收到了大约 200 个答案,然后花了很多时间手动将它们归为 9 类。
+
+这些解决的问题都是关于寻找程序依赖的文件、找出程序卡住或慢的原因、或者找出程序失败的原因。这些总体上与我自己使用 `strace` 的内容相吻合,但也有一些我没有想到的东西!
+
+我不打算在这篇文章里解释什么是 `strace`,但我有一本 [关于它的免费杂志][2] 和 [一个讲座][3] 以及 [很多博文][4]。
+
+### 问题 1:配置文件在哪里?
+
+最受欢迎的问题是“这个程序有一个配置文件,但我不知道它在哪里”。这可能也是我最常使用 `strace` 解决的问题,因为这是个很简单的问题。
+
+这很好,因为一个程序有一百万种方法来记录它的配置文件在哪里(在手册页、网站上、`--help`等),但只有一种方法可以让它真正打开它(用系统调用!)。
+
+### 问题 2:这个程序还依赖什么文件?
+
+你也可以使用 `strace` 来查找程序依赖的其他类型的文件,比如:
+
+ * 动态链接库(“为什么我的程序加载了这个错误版本的 `.so` 文件?"),比如 [我在 2014 年调试的这个 ruby 问题][5]
+ * 它在哪里寻找它的 Ruby gem(Ruby 出现了几次这种情况!)
+ * SSL 根证书
+ * 游戏的存档文件
+ * 一个闭源程序的数据文件
+ * [哪些 node_modules 文件没有被使用][6]
+
+### 问题 3:为什么这个程序会挂掉?
+
+你有一个程序,它只是坐在那里什么都不做,这是怎么回事?这个问题特别容易回答,因为很多时候你只需要运行 `strace -p PID`,看看当前运行的是什么系统调用。你甚至不需要看几百行的输出。
+
+答案通常是“正在等待某种 I/O”。“为什么会卡住”的一些可能的答案(虽然还有很多!):
+
+ * 它一直在轮询 `select()`
+ * 正在 `wait()` 等待一个子进程完成
+ * 它在向某个没有响应的东西发出网络请求
+ * 正在进行 `write()`,但由于缓冲区已满而被阻止。
+ * 它在 stdin 上做 `read()`,等待输入。
+
+有人还举了一个很好的例子,用 `strace` 调试一个卡住的 `df` 命令:“用 `strace df -h` 你可以找到卡住的挂载,然后卸载它”。
+
+### 问题 4:这个程序卡住了吗?
+
+这是上一个问题的变种:有时一个程序运行的时间比你预期的要长,你只是想知道它是否卡住了,或者它是否还在继续进行。
+
+只要程序在运行过程中进行系统调用,用 `strace` 就可以超简单地回答这个问题:只需 `strace` 它,看看它是否在进行新的系统调用!
+
+### 问题 5:为什么这个程序很慢?
+
+你可以使用 `strace` 作为一种粗略的剖析工具:`strace -t` 会显示每次系统调用的时间戳,这样你就可以寻找大的漏洞,找到罪魁祸首。
+
+以下是 Twitter 上 9 个人使用 `strace` 调试“为什么这个程序很慢?”的小故事。
+
+ * 早在 2000 年,我帮助支持的一个基于 Java 的网站在适度的负载下奄奄一息:页面加载缓慢,甚至完全加载不出来。我们对 J2EE 应用服务器进行了测试,发现它每次只读取一个类文件。开发人员没有使用 BufferedReader,这是典型的 Java 错误。
+ * 优化应用程序的启动时间……运行 `strace` 可以让人大开眼界,因为有大量不必要的文件系统交互在进行(例如,在同一个配置文件上反复打开/读取/关闭;在一个缓慢的 NFS 挂载上加载大量的字体文件,等等)。
+ * 问自己为什么在 PHP 中从会话文件中读取(通常是小于 100 字节)非常慢。结果发现一些 `flock` 系统调用花了大约 60 秒。
+ * 一个程序表现得异常缓慢。使用 `strace` 找出它在每次请求时,通过从 `/dev/random` 读取数据并耗尽熵来重新初始化其内部伪随机数发生器。
+ * 我记得最近一件事是连接到一个任务处理程序,看到它有多少网络调用(这是意想不到的)。
+ * `strace` 显示它打开/读取同一个配置文件数千次。
+ * 服务器随机使用 100% 的 CPU 时间,实际流量很低。原来是碰到打开文件数限制,接受一个套接字时,得到 EMFILE 错误而没有报告,然后一直重试。
+ * 一个工作流运行超慢,但是没有日志,结果它做一个 POST 请求花了 30 秒而超时,然后重试了 5 次……结果后台服务不堪重负,但是也没有可视性。
+ * 使用 `strace` 注意到 `gethostbyname()` 需要很长时间才能返回(你不能直接看到 `gethostbyname`,但你可以看到 `strace` 中的 DNS 数据包)
+
+### 问题 6:隐藏的权限错误
+
+有时候程序因为一个神秘的原因而失败,但问题只是有一些它没有权限打开的文件。在理想的世界里,程序会报告这些错误(“Error opening file /dev/whatever: permission denied”),当然这个世界并不完美,所以 `strace` 真的可以帮助解决这个问题!
+
+这其实是我最近使用 `strace` 做的事情。我使用了一台 AxiDraw 绘图仪,当我试图启动它时,它打印出了一个难以理解的错误信息。我 `strace` 它,结果发现我的用户没有权限打开 USB 设备。
+
+### 问题 7:正在使用什么命令行参数?
+
+有时候,一个脚本正在运行另一个程序,你想知道它传递的是什么命令行标志!
+
+几个来自 Twitter 的例子。
+
+ * 找出实际上是用来编译代码的编译器标志
+ * 由于命令行太长,命令失败了
+
+### 问题 8:为什么这个网络连接失败?
+
+基本上,这里的目标是找到网络连接的域名 / IP 地址。你可以通过 DNS 请求来查找域名,或者通过 `connect` 系统调用来查找 IP。
+
+一般来说,当 `tcpdump` 因为某些原因不能使用或者只是因为比较熟悉 `strace` 时,就经常会使用 `strace` 调试网络问题。
+
+### 问题 9:为什么这个程序以一种方式运行时成功,以另一种方式运行时失败?
+
+例如:
+
+ * 同样的二进制程序在一台机器上可以运行,在另一台机器上却失败了
+ * 可以运行,但被 systemd 单元文件生成时失败
+ * 可以运行,但以 `su - user /some/script` 的方式运行时失败
+ * 可以运行,作为 cron 作业运行时失败
+
+能够比较两种情况下的 `strace` 输出是非常有用的。虽然我在调试“以我的用户身份工作,而在同一台计算机上以不同方式运行时却失败了”时,第一步是“看看我的环境变量”。
+
+### 我在做什么:慢慢地建立一些挑战
+
+我之所以会想到这个问题,是因为我一直在慢慢地进行一些挑战,以帮助人们练习使用 `strace` 和其他命令行工具。我的想法是,给你一个问题,一个终端,你可以自由地以任何方式解决它。
+
+所以我的目标是用它来建立一些你可以用 `strace` 解决的练习题,这些练习题反映了人们在现实生活中实际使用它解决的问题。
+
+### 就是这样!
+
+可能还有更多的问题可以用 `strace` 解决,我在这里还没有讲到,我很乐意听到我错过了什么!
+
+我真的很喜欢看到很多相同的用法一次又一次地出现:至少有 20 个不同的人回答说他们使用 `strace` 来查找配置文件。而且和以往一样,我觉得这样一个简单的工具(“跟踪系统调用!”)可以用来解决这么多不同类型的问题,真的很令人高兴。
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2021/04/03/what-problems-do-people-solve-with-strace/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://twitter.com/b0rk/status/1378014888405168132
+[2]: https://wizardzines.com/zines/strace
+[3]: https://www.youtube.com/watch?v=4pEHfGKB-OE
+[4]: https://jvns.ca/categories/strace
+[5]: https://jvns.ca/blog/2014/03/10/debugging-shared-library-problems-with-strace/
+[6]: https://indexandmain.com/post/shrink-node-modules-with-refining
diff --git a/published/202104/20210404 Converting Multiple Markdown Files into HTML or Other Formats in Linux.md b/published/202104/20210404 Converting Multiple Markdown Files into HTML or Other Formats in Linux.md
new file mode 100644
index 0000000000..fea402d238
--- /dev/null
+++ b/published/202104/20210404 Converting Multiple Markdown Files into HTML or Other Formats in Linux.md
@@ -0,0 +1,146 @@
+[#]: subject: "Converting Multiple Markdown Files into HTML or Other Formats in Linux"
+[#]: via: "https://itsfoss.com/convert-markdown-files/"
+[#]: author: "Bill Dyer https://itsfoss.com/author/bill/"
+[#]: collector: "lujun9972"
+[#]: translator: "lxbwolf"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13274-1.html"
+
+在 Linux 中把多个 Markdown 文件转换成 HTML 或其他格式
+======
+
+
+
+很多时候我与 Markdown 打交道的方式是,先写完一个文件,然后把它转换成 HTML 或其他格式。也有些时候,需要创建一些新的文件。当我要写多个 Markdown 文件时,通常要把他们全部写完之后才转换它们。
+
+我用 `pandoc` 来转换文件,它可以一次性地转换所有 Markdown 文件。
+
+Markdown 格式的文件可以转换成 .html 文件,有时候我需要把它转换成其他格式,如 epub,这个时候 [pandoc][1] 就派上了用场。我更喜欢用命令行,因此本文我会首先介绍它,然而你还可以使用 [VSCodium][2] 在非命令行下完成转换。后面我也会介绍它。
+
+### 使用 pandoc 把多个 Markdown 文件转换成其他格式(命令行方式)
+
+你可以在 Ubuntu 及其他 Debian 系发行版本终端输入下面的命令来快速开始:
+
+```
+sudo apt-get install pandoc
+```
+
+本例中,在名为 `md_test` 目录下我有四个 Markdown 文件需要转换。
+
+```
+[email protected]:~/Documents/md_test$ ls -l *.md
+-rw-r--r-- 1 bdyer bdyer 3374 Apr 7 2020 file01.md
+-rw-r--r-- 1 bdyer bdyer 782 Apr 2 05:23 file02.md
+-rw-r--r-- 1 bdyer bdyer 9257 Apr 2 05:21 file03.md
+-rw-r--r-- 1 bdyer bdyer 9442 Apr 2 05:21 file04.md
+[email protected]:~/Documents/md_test$
+```
+
+现在还没有 HTML 文件。现在我要对这些文件使用 `pandoc`。我会运行一行命令来实现:
+
+ * 调用 `pandoc`
+ * 读取 .md 文件并导出为 .html
+
+下面是我要运行的命令:
+
+```
+for i in *.md ; do echo "$i" && pandoc -s $i -o $i.html ; done
+```
+
+如果你不太理解上面的命令中的 `;`,可以参考 [在 Linux 中一次执行多个命令][3]。
+
+我执行命令后,运行结果如下:
+
+```
+[email protected]:~/Documents/md_test$ for i in *.md ; do echo "$i" && pandoc -s $i -o $i.html ; done
+file01.md
+file02.md
+file03.md
+file04.md
+[email protected]:~/Documents/md_test$
+```
+
+让我再使用一次 `ls` 命令来看看是否已经生成了 HTML 文件:
+
+```
+[email protected]:~/Documents/md_test$ ls -l *.html
+-rw-r--r-- 1 bdyer bdyer 4291 Apr 2 06:08 file01.md.html
+-rw-r--r-- 1 bdyer bdyer 1781 Apr 2 06:08 file02.md.html
+-rw-r--r-- 1 bdyer bdyer 10272 Apr 2 06:08 file03.md.html
+-rw-r--r-- 1 bdyer bdyer 10502 Apr 2 06:08 file04.md.html
+[email protected]:~/Documents/md_test$
+```
+
+转换很成功,现在你已经有了四个 HTML 文件,它们可以用在 Web 服务器上。
+
+pandoc 功能相当多,你可以通过指定输出文件的扩展名来把 Markdown 文件转换成其他支持的格式。不难理解它为什么会被认为是[最好的写作开源工具][4]。
+
+### 使用 VSCodium 把 Markdown 文件转换成 HTML(GUI 方式)
+
+就像我们前面说的那样,我通常使用命令行,但是对于批量转换,我不会使用命令行,你也不必。VSCode 或 [VSCodium][7] 可以完成批量操作。你只需要安装一个 Markdown-All-in-One 扩展,就可以在一次运行中转换多个 Markdown 文件。
+
+有两种方式安装这个扩展:
+
+ * VSCodium 的终端
+ * VSCodium 的插件管理器
+
+通过 VSCodium 的终端安装该扩展:
+
+ 1. 点击菜单栏的 `终端`。会打开终端面板
+ 2. 输入,或[复制下面的命令并粘贴到终端][8]:
+
+```
+codium --install-extension yzhang.markdown-all-in-one
+```
+
+**注意**:如果你使用的 VSCode 而不是 VSCodium,那么请把上面命令中的 `codium` 替换为 `code`
+
+![][9]
+
+第二种安装方式是通过 VSCodium 的插件/扩展管理器:
+
+ 1. 点击 VSCodium 窗口左侧的块区域。会出现一个扩展列表,列表最上面有一个搜索框。
+ 2. 在搜索框中输入 “Markdown All in One”。在列表最上面会出现该扩展。点击 “安装” 按钮来安装它。如果你已经安装过,在安装按钮的位置会出现一个齿轮图标。
+
+![][10]
+
+安装完成后,你可以打开含有需要转换的 Markdown 文件的文件夹。
+
+点击 VSCodium 窗口左侧的纸张图标。你可以选择文件夹。打开文件夹后,你需要打开至少一个文件。你也可以打开多个文件,但是最少打开一个。
+
+当打开文件后,按下 `CTRL+SHIFT+P` 唤起命令面板。然后,在出现的搜索框中输入 `Markdown`。当你输入时,会出现一列 Markdown 相关的命令。其中有一个是 `Markdown All in One: Print documents to HTML` 命令。点击它:
+
+![][11]
+
+你需要选择一个文件夹来存放这些文件。它会自动创建一个 `out` 目录,转换后的 HTML 文件会存放在 `out` 目录下。从下面的图中可以看到,Markdown 文档被转换成了 HTML 文件。在这里,你可以打开、查看、编辑这些 HTML 文件。
+
+![][12]
+
+在等待转换 Markdown 文件时,你可以更多地集中精力在写作上。当你准备好时,你就可以把它们转换成 HTML —— 你可以通过两种方式转换它们。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/convert-markdown-files/
+
+作者:[Bill Dyer][a]
+选题:[lujun9972][b]
+译者:[lxbwolf](https://github.com/lxbwolf)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/bill/
+[b]: https://github.com/lujun9972
+[1]: https://pandoc.org/
+[2]: https://vscodium.com/
+[3]: https://itsfoss.com/run-multiple-commands-linux/
+[4]: https://itsfoss.com/open-source-tools-writers/
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2016/10/Best-Markdown-Editors-for-Linux.jpg?fit=800%2C450&ssl=1
+[6]: https://itsfoss.com/best-markdown-editors-linux/
+[7]: https://itsfoss.com/vscodium/
+[8]: https://itsfoss.com/copy-paste-linux-terminal/
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/vscodium_terminal.jpg?resize=800%2C564&ssl=1
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/vscodium_extension_select.jpg?resize=800%2C564&ssl=1
+[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/vscodium_markdown_function_options.jpg?resize=800%2C564&ssl=1
+[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/vscodium_html_filelist_shown.jpg?resize=800%2C564&ssl=1
diff --git a/published/202104/20210405 7 Git tips for managing your home directory.md b/published/202104/20210405 7 Git tips for managing your home directory.md
new file mode 100644
index 0000000000..67d8a3ceea
--- /dev/null
+++ b/published/202104/20210405 7 Git tips for managing your home directory.md
@@ -0,0 +1,135 @@
+[#]: subject: (7 Git tips for managing your home directory)
+[#]: via: (https://opensource.com/article/21/4/git-home)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (stevenzdg988)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13313-1.html)
+
+7个管理家目录的 Git 技巧
+======
+
+> 这是我怎样设置 Git 来管理我的家目录的方法。
+
+
+
+我有好几台电脑。一台笔记本电脑用于工作,一台工作站放在家里,一台树莓派(或四台),一台 [Pocket CHIP][2],一台 [运行各种不同的 Linux 的 Chromebook][3],等等。我曾经在每台计算机上或多或少地按照相同的步骤设置我的用户环境,也经常告诉自己让每台计算机都略有不同。例如,我在工作中比在家里更经常使用 [Bash 别名][4],并且我在家里使用的辅助脚本可能对工作没有用。
+
+这些年来,我对各种设备的期望开始相融,我会忘记我在家用计算机上建立的功能没有移植到我的工作计算机上,诸如此类。我需要一种标准化我的自定义工具包的方法。使我感到意外的答案是 Git。
+
+Git 是版本跟踪软件。它以既可以用在非常大的开源项目也可以用在极小的开源项目而闻名,甚至最大的专有软件公司也在用它。但是它是为源代码设计的,而不是用在一个装满音乐和视频文件、游戏、照片等的家目录。我听说过有人使用 Git 管理其家目录,但我认为这是程序员们进行的一项附带实验,而不是像我这样的现实生活中的用户。
+
+用 Git 管理我的家目录是一个不断发展的过程。随着时间的推移我一直在学习和适应。如果你决定使用 Git 管理家目录,则可能需要记住以下几点。
+
+### 1、文本和二进制位置
+
+![家目录][5]
+
+当由 Git 管理时,除了配置文件之外,你的家目录对于所有内容而言都是“无人之地”。这意味着当你打开主目录时,除了可预见的目录的列表之外,你什么都看不到。不应有任何杂乱无章的照片或 LibreOffice 文档,也不应有 “我就在这里放一分钟” 的临时文件。
+
+原因很简单:使用 Git 管理家目录时,家目录中所有 _未_ 提交的内容都会变成噪音。每次执行 `git status` 时,你都必须翻过去之前 Git 未跟踪的任何文件,因此将这些文件保存在子目录(添加到 `.gitignore` 文件中)至关重要。
+
+许多 Linux 发行版提供了一组默认目录:
+
+ * `Documents`
+ * `Downloads`
+ * `Music`
+ * `Photos`
+ * `Templates`
+ * `Videos`
+
+如果需要,你可以创建更多。例如,我把创作的音乐(`Music`)和购买来聆听的音乐(`Albums`)区分开来。同样,我的电影(`Cinema`)目录包含了其他人的电影,而视频(`Videos`)目录包含我需要编辑的视频文件。换句话说,我的默认目录结构比大多数 Linux 发行版提供的默认设置更详细,但是我认为这样做有好处。如果没有适合你的目录结构,你更会将其存放在家目录中,因为没有更好的存放位置,因此请提前考虑并规划好适合你的工作目录。你以后总是可以添加更多,但是最好先开始擅长的。
+
+### 2、、设置最优的 `.gitignore`
+
+清理家目录后,你可以像往常一样将其作为 Git 存储库实例化:
+
+```
+$ cd
+$ git init .
+```
+
+你的 Git 仓库中还没有任何内容,你的家目录中的所有内容均未被跟踪。你的第一项工作是筛选未跟踪文件的列表,并确定要保持未跟踪状态的文件。要查看未跟踪的文件:
+
+```
+$ git status
+ .AndroidStudio3.2/
+ .FBReader/
+ .ICEauthority
+ .Xauthority
+ .Xdefaults
+ .android/
+ .arduino15/
+ .ash_history
+[...]
+```
+
+根据你使用家目录的时间长短,此列表可能很长。简单的是你在上一步中确定的目录。通过将它们添加到名为 `.gitignore` 的隐藏文件中,你告诉 Git 停止将它们列为未跟踪文件,并且永远不对其进行跟踪:
+
+```
+$ \ls -lg | grep ^d | awk '{print $8}' >> ~/.gitignore
+```
+
+完成后,浏览 `git status` 所示的其余未跟踪文件,并确定是否有其他文件需要排除。这个过程帮助我发现了几个陈旧的配置文件和目录,这些文件和目录最终被我全部丢弃了,而且还发现了一些特定于一台计算机的文件和目录。我在这里非常严格,因为许多配置文件在自动生成时会表现得更好。例如,我从不提交我的 KDE 配置文件,因为许多文件包含了诸如最新文档之类的信息以及其他机器上不存在的其他元素。
+
+我会跟踪我的个性化配置文件、脚本和实用程序、配置文件和 Bash 配置,以及速查表和我经常引用的其他文本片段。如果有软件主要负责维护的文件,则将其忽略。当对一个文件不确定时,我将其忽略。你以后总是可以取消忽略它(通过从 `.gitignore` 文件中删除它)。
+
+### 3、了解你的数据
+
+我使用的是 KDE,因此我使用开源扫描程序 [Filelight][7] 来了解我的数据概况。Filelight 为你提供了一个图表,可让你查看每个目录的大小。你可以浏览每个目录以查看占用了空间的内容,然后回溯调查其他地方。这是一个令人着迷的系统视图,它使你可以以全新的方式看待你的文件。
+
+![Filelight][8]
+
+使用 Filelight 或类似的实用程序查找不需要提交的意外数据缓存。例如,KDE 文件索引器(Baloo)生成了大量特定于其主机的数据,我绝对不希望将其传输到另一台计算机。
+
+### 4、不要忽略你的 `.gitignore` 文件
+
+在某些项目中,我告诉 Git 忽略我的 `.gitignore` 文件,因为有时我要忽略的内容特定于我的工作目录,并且我不认为同一项目中的其他开发人员需要我告诉他们 `.gitignore` 文件应该是什么样子。因为我的家目录仅供我使用,所以我 _不_ 会忽略我的家目录的 `.gitignore` 文件。我将其与其他重要文件一起提交,因此它已在我的所有系统中被继承。当然,从家目录的角度来看,我所有的系统都是相同的:它们具有一组相同的默认文件夹和许多相同的隐藏配置文件。
+
+### 5、不要担心二进制文件
+
+我对我的系统进行了数周的严格测试,确信将二进制文件提交到 Git 绝对不是明智之举。我试过 GPG 加密的密码文件、试过 LibreOffice 文档、JPEG、PNG 等等。我甚至有一个脚本,可以在将 LibreOffice 文件添加到 Git 之前先解压缩,提取其中的 XML,以便仅提交 XML,然后重新构建 LibreOffice 文件,以便可以在 LibreOffice 中继续工作。我的理论是,提交 XML 会比使用 ZIP 文件(LibreOffice 文档实际上就是一个 ZIP 文件)会让 Git 存储库更小一些。
+
+令我惊讶的是,我发现偶尔提交一些二进制文件并没有大幅增加我的 Git 存储库的大小。我使用 Git 已经很长时间了,我知道如果我要提交几千兆的二进制数据,我的存储库将会受到影响,但是偶尔提交几个二进制文件也不是不惜一切代价要避免的紧急情况。
+
+有了这种信心,我将字体 OTF 和 TTF 文件添加到我的标准主存储库,以及 GDM 的 `.face` 文件以及其他偶尔小型二进制 Blob 文件。不要想太多,不要浪费时间去避免它。只需提交即可。
+
+### 6、使用私有存储库
+
+即使托管方提供了私人帐户,也不要将你的主目录提交到公共 Git 存储库。如果你像我一样,拥有 SSH 密钥、GPG 密钥链和 GPG 加密的文件,这些文件不应该出现在任何人的服务器上,而应该出现在我自己的服务器上。
+
+我在树莓派上 [运行本地 Git 服务器][9](这比你想象的要容易),因此我可以在家里时随时更新任何一台计算机。我是一名远程工作者,所以通常情况下就足够了,但是我也可以在旅行时通过 [虚拟私人网络][10] 访问我的计算机。
+
+### 7、要记得推送
+
+Git 的特点是,只有当你告诉它要推送改动时,它才会把改动推送到你的服务器上。如果你是 Git 的老用户,则此过程可能对你很自然。对于可能习惯于 Nextcloud 或 Syncthing 自动同步的新用户,这可能需要一些时间来适应。
+
+### Git 家目录
+
+使用 Git 管理我的常用文件,不仅使我在不同设备上的生活更加便利。我知道我拥有所有配置和实用程序脚本的完整历史记录,这会鼓励我尝试新的想法,因为如果结果变得 _很糟糕_,则很容易回滚我的更改。Git 曾将我从在 `.bashrc` 文件中一个欠考虑的 `umask` 设置中解救出来、从深夜对包管理脚本的拙劣添加中解救出来、从当时看似很酷的 [rxvt][11] 配色方案的修改中解救出来,也许还有其他一些错误。在家目录中尝试 Git 吧,因为这些提交会让家目录融合在一起。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/git-home
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[stevenzdg988](https://github.com/stevenzdg988)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/house_home_colors_live_building.jpg?itok=HLpsIfIL (Houses in a row)
+[2]: https://opensource.com/article/17/2/pocketchip-or-pi
+[3]: https://opensource.com/article/21/2/chromebook-linux
+[4]: https://opensource.com/article/17/5/introduction-alias-command-line-tool
+[5]: https://opensource.com/sites/default/files/uploads/home-git.jpg (home directory)
+[6]: https://creativecommons.org/licenses/by-sa/4.0/
+[7]: https://utils.kde.org/projects/filelight
+[8]: https://opensource.com/sites/default/files/uploads/filelight.jpg (Filelight)
+[9]: https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6
+[10]: https://www.redhat.com/sysadmin/run-your-own-vpn-libreswan
+[11]: https://opensource.com/article/19/10/why-use-rxvt-terminal
diff --git a/published/202104/20210406 Experiment on your code freely with Git worktree.md b/published/202104/20210406 Experiment on your code freely with Git worktree.md
new file mode 100644
index 0000000000..b684e0e46f
--- /dev/null
+++ b/published/202104/20210406 Experiment on your code freely with Git worktree.md
@@ -0,0 +1,135 @@
+[#]: subject: (Experiment on your code freely with Git worktree)
+[#]: via: (https://opensource.com/article/21/4/git-worktree)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13301-1.html)
+
+使用 Git 工作树对你的代码进行自由实验
+======
+
+> 获得自由尝试的权利,同时在你的实验出错时可以安全地拥有一个新的、链接的克隆存储库。
+
+
+
+Git 的设计部分是为了进行实验。如果你知道你的工作会被安全地跟踪,并且在出现严重错误时有安全状态存在,你就不会害怕尝试新的想法。不过,创新的部分代价是,你很可能会在这个过程中弄得一团糟。文件会被重新命名、移动、删除、更改、切割成碎片;新的文件被引入;你不打算跟踪的临时文件会在你的工作目录中占据一席之地等等。
+
+简而言之,你的工作空间变成了纸牌屋,在“快好了!”和“哦,不,我做了什么?”之间岌岌可危地平衡着。那么,当你需要把仓库恢复到下午的一个已知状态,以便完成一些真正的工作时,该怎么办?我立刻想到了 `git branch` 和 [git stash][2] 这两个经典命令,但这两个命令都不是用来处理未被跟踪的文件的,而且文件路径的改变和其他重大的转变也会让人困惑,它们只能把工作暂存(`stash`)起来以备后用。解决这个需求的答案是 Git 工作树。
+
+### 什么是 Git 工作树
+
+Git 工作树是 Git 仓库的一个链接副本,允许你同时签出多个分支。工作树与主工作副本的路径是分开的,它可以处于不同的状态和不同的分支上。在 Git 中新建工作树的好处是,你可以在不干扰当前工作环境的情况下,做出与当前任务无关的修改、提交修改,然后在以后合并。
+
+直接从 `git-worktree` 手册中找到了一个典型的例子:当你正在为一个项目做一个令人兴奋的新功能时,你的项目经理告诉你有一个紧急的修复工作。问题是你的工作仓库(你的“工作树”)处于混乱状态,因为你正在开发一个重要的新功能。你不想在当前的冲刺中“偷偷地”进行修复,而且你也不愿意把变更暂存起来,为修复创建一个新的分支。相反,你决定创建一个新的工作树,这样你就可以在那里进行修复:
+
+```
+$ git branch | tee
+* dev
+trunk
+$ git worktree add -b hotfix ~/code/hotfix trunk
+Preparing ../hotfix (identifier hotfix)
+HEAD is now at 62a2daf commit
+```
+
+在你的 `code` 目录中,你现在有一个新的目录叫做 `hotfix`,它是一个与你的主项目仓库相连的 Git 工作树,它的 `HEAD` 停在叫做 `trunk` 的分支上。现在你可以把这个工作树当作你的主工作区来对待。你可以把目录切换到它里面,进行紧急修复、提交、并最终删除这个工作树:
+
+```
+$ cd ~/code/hotfix
+$ sed -i 's/teh/the/' hello.txt
+$ git commit --all --message 'urgent hot fix'
+```
+
+一旦你完成了你的紧急工作,你就可以回到你之前的任务。你可以控制你的热修复何时被集成到主项目中。例如,你可以直接将变更从其工作树推送到项目的远程存储库中:
+
+```
+$ git push origin HEAD
+$ cd ~/code/myproject
+```
+
+或者你可以将工作树存档为 TAR 或 ZIP 文件:
+
+```
+$ cd ~/code/myproject
+$ git archive --format tar --output hotfix.tar master
+```
+
+或者你可以从单独的工作树中获取本地的变化:
+
+```
+$ git worktree list
+/home/seth/code/myproject 15fca84 [dev]
+/home/seth/code/hotfix 09e585d [master]
+```
+
+从那里,你可以使用任何最适合你和你的团队的策略合并你的变化。
+
+### 列出活动工作树
+
+你可以使用 `git worktree list` 命令获得工作树的列表,并查看每个工作树签出的分支:
+
+```
+$ git worktree list
+/home/seth/code/myproject 15fca84 [dev]
+/home/seth/code/hotfix 09e585d [master]
+```
+
+你可以在任何一个工作树中使用这个功能。工作树始终是连接的(除非你手动移动它们,破坏 Git 定位工作树的能力,从而切断连接)。
+
+### 移动工作树
+
+Git 会跟踪项目 `.git` 目录下工作树的位置和状态:
+
+```
+$ cat ~/code/myproject/.git/worktrees/hotfix/gitdir
+/home/seth/code/hotfix/.git
+```
+
+如果你需要重定位一个工作树,必须使用 `git worktree move`;否则,当 Git 试图更新工作树的状态时,就会失败:
+
+```
+$ mkdir ~/Temp
+$ git worktree move hotfix ~/Temp
+$ git worktree list
+/home/seth/code/myproject 15fca84 [dev]
+/home/seth/Temp/hotfix 09e585d [master]
+```
+
+### 移除工作树
+
+当你完成你的工作时,你可以用 `remove` 子命令删除它:
+
+```
+$ git worktree remove hotfix
+$ git worktree list
+/home/seth/code/myproject 15fca84 [dev]
+```
+
+为了确保你的 `.git` 目录是干净的,在删除工作树后使用 `prune` 子命令:
+
+```
+$ git worktree remove prune
+```
+
+### 何时使用工作树
+
+与许多选项一样,无论是标签还是书签还是自动备份,都要靠你来跟踪你产生的数据,否则可能会变得不堪重负。不要经常使用工作树,要不你最终会有 20 份存储库的副本,每份副本的状态都略有不同。我发现最好是创建一个工作树,做需要它的任务,提交工作,然后删除树。保持简单和专注。
+
+重要的是,工作树为你管理 Git 存储库的方式提供了更好的灵活性。在需要的时候使用它们,再也不用为了检查另一个分支上的内容而争先恐后地保存工作状态了。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/git-worktree
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/science_experiment_beaker_lab.png?itok=plKWRhlU (Science lab with beakers)
+[2]: https://linux.cn/article-13293-1.html
diff --git a/published/202104/20210406 Teach anyone how to code with Hedy.md b/published/202104/20210406 Teach anyone how to code with Hedy.md
new file mode 100644
index 0000000000..68b0c45815
--- /dev/null
+++ b/published/202104/20210406 Teach anyone how to code with Hedy.md
@@ -0,0 +1,80 @@
+[#]: subject: (Teach anyone how to code with Hedy)
+[#]: via: (https://opensource.com/article/21/4/hedy-teach-code)
+[#]: author: (Joshua Allen Holm https://opensource.com/users/holmja)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13290-1.html)
+
+用 Hedy 教人编程
+======
+
+> Hedy 是一种专门为教人编程而设计的新型编程语言。
+
+
+
+学习编程既要学习编程逻辑,又要学习特定编程语言的语法。我在大学上第一堂编程课的时候,教的语言是 C++。第一个代码例子是基本的 “Hello World” 程序,就像下面的例子。
+
+```
+#include
+
+int main() {
+ std::cout << "Hello World!";
+ return 0;
+}
+```
+
+老师直到几节课后才会解释大部分的代码。我们的期望是,我们只需输入代码,并最终了解为什么需要这些东西以及它们如何工作。
+
+C++(以及其他类似的语言)的复杂语法是为什么 Python 经常被建议作为一种更容易的编程教学语言。下面是 Python 中的同一个例子:
+
+```
+print("Hello World!")
+```
+
+虽然 Python 中的 “Hello World” 基础例子要简单得多,但它仍然有复杂而精确的语法规则。`print` 函数需要在字符串周围加括号和引号。这对于没有编程经验的人来说,还是会感到困惑。Python 比 C++ 少了 “我以后再解释” 的语法问题,但还是有一些。
+
+[Hedy][2] 是一种专门为编码教学而设计的新语言,它通过在语言中将复杂性分成多个关卡来解决语法复杂性的问题。Hedy 没有马上提供语言的全部功能,而是采取循序渐进的方式,随着学生在 Hedy 的学习的通关,慢慢变得更加复杂。随着关卡的进展,该语言获得了新的功能,最终变得更像 Python。目前有七个关卡,但更多的关卡正在计划中。
+
+在第 1 关,Hedy 程序除了打印(`print`)一条语句(不需要引号或括号),提出(`ask`)一个问题,并回传(`echo`)一个答案外,不能做任何事情。第 1 关没有变量,没有循环,结构极精简。回传的工作原理几乎和变量一样,但只针对用户的最后一个输入。这可以让学生对基本概念感到舒适,而不必一下子学习所有的东西。
+
+这是一个第 1 关的 Hedy “Hello World” 程序:
+
+```
+print Hello World
+```
+
+第 2 关引入了变量,但由于 `print` 函数没有使用引号,可能会出现一些有趣的结果。如果用来存储一个人的名字的变量是 `name`,那么就不可能打印输出 `Your name is [name]`,因为 `name` 的第一次使用(本意是字符串)和第二次使用(是变量)都被解释为变量。如果将 `name` 设置为(`is`) `John Doe`,那么 `print Your name is name.` 的输出就会是 `Your John Doe is John Doe`。虽然这听起来很奇怪,但这是一个引入变量概念的好方法,这恰好是第 3 关中增加的一个功能。
+
+第 3 关要求在字符串周围加引号,这使得变量的功能就像在 Python 中一样。现在可以输出与变量相结合的字符串,做出复杂的语句,而不用担心变量名和字符串中的单词之间的冲突。这个级别取消了 “回传”(`echo`)函数,这看起来确实是一个可能会让一些学习者感到沮丧的东西。他们应该使用变量,这是更好的代码,但如果一个 `ask`/`echo` 代码块变成无效语法,可能会让人感到困惑。
+
+第 4 关增加了基本的 `if`/`else` 功能。学生可以从简单的问/答代码转向复杂的交互。例如,一个问“你最喜欢的颜色是什么?”的提示可以根据用户输入的内容接受不同的回复。如果他们输入绿色,回答可以是“绿色!这也是我最喜欢的颜色。”如果他们输入其他的东西,回复可以是不同的。`if`/`else` 块是一个基本的编程概念,Hedy 引入了这个概念,而不必担心复杂的语法或过于精确的格式。
+
+第 5 关有一个 `repeat` 函数,在现有的功能上增加了一个基本的循环。这个循环只能多次重复同一个命令,所以它没有 Python 中的循环那么强大,但它让学生习惯了重复命令的一般概念。这是多介绍了一个编程概念,而不会用无谓的复杂来拖累。学生们可以先掌握概念的基础知识,然后再继续学习同一事物的更强大、更复杂的版本。
+
+在第 6 关,Hedy 现在可以进行基本的数学计算。加法、减法、乘法和除法都支持,但更高级的数学功能不支持。不能使用指数、模数或其他任何 Python 和其他语言能处理的东西。目前,Hedy 还没有更高关卡的产品增加更复杂的数学功能。
+
+第 7 关引入了 Python 风格的缩进,这意味着 `repeat` 可以处理多行代码。学生在这之前都是逐行处理代码,但现在他们可以处理代码块。这个 Hedy 关卡与非教学型编程语言能做的事情相比还是有很大的差距,但它可以教会学生很多东西。
+
+开始学习 Hedy 最简单的方法是访问 Hedy 网站上的 [课程][3],目前有荷兰语、英语、法语、德语、葡萄牙语和西班牙语。这样一来,任何有网页浏览器的人都可以进入学习过程。也可以从 [GitHub][4] 下载 Hedy,并从命令行运行解释器,或者运行 Hedy 网站的本地副本及其交互式课程。基于网页的版本更容易使用,但网页版本和命令行版本都支持运行针对不同复杂程度的 Hedy 程序。
+
+Hedy 永远不会与 Python、C++ 或其他语言竞争,成为现实世界项目编码的首选语言,但它是编码教学的绝佳方式。作为学习过程的一部分,学生编写的程序是真实的,甚至可能是复杂的。Hedy 可以促进学生的学习和创造力,而不会让学生在学习过程中过早地被过多的信息所迷惑。就像数学课一样,在进入微积分之前很久要从学习计数、相加等开始(这个过程需要数年时间),编程也不必一开始就对编程语言的语法问题“我稍后再解释”、精确地遵循这些语法问题,才能产生哪怕是最基本的语言程序。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/hedy-teach-code
+
+作者:[Joshua Allen Holm][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/holmja
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/5538035618_4e19c9787c_o.png?itok=naiD1z1S (Teacher or learner?)
+[2]: https://www.hedycode.com/
+[3]: https://www.hedycode.com/hedy?lang=en
+[4]: https://github.com/felienne/hedy
diff --git a/published/202104/20210407 Show CPU Details Beautifully in Linux Terminal With CPUFetch.md b/published/202104/20210407 Show CPU Details Beautifully in Linux Terminal With CPUFetch.md
new file mode 100644
index 0000000000..e366481a6f
--- /dev/null
+++ b/published/202104/20210407 Show CPU Details Beautifully in Linux Terminal With CPUFetch.md
@@ -0,0 +1,107 @@
+[#]: subject: (Show CPU Details Beautifully in Linux Terminal With CPUFetch)
+[#]: via: (https://itsfoss.com/cpufetch/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13289-1.html)
+
+使用 CPUFetch 在 Linux 终端中漂亮地显示 CPU 细节
+======
+
+
+
+Linux 上有 [检查 CPU 信息的方法][1]。最常见的可能是 `lscpu` 命令,它可以提供大量的系统上所有 CPU 核心的信息。
+
+![lscpu command output][2]
+
+你可以在那里找到 CPU 信息,而无需安装任何额外的包。当然这是可行的。然而,我最近偶然发现了一个新的工具,它以一种漂亮的方式显示 Linux 中的 CPU 细节。
+
+处理器制造商的 ASCII 艺术使它看起来很酷。
+
+![][3]
+
+这看起来很美,不是吗?这类似于 [Neoftech 或者 Screenfetch,在 Linux 中用漂亮的 ASCII 艺术来展示系统信息][4]。与这些工具类似,如果你要展示你的桌面截图,可以使用 CPUFetch。
+
+该工具可以输出处理器制造商的 ASCII 艺术,它的名称、微架构、频率、核心、线程、峰值性能、缓存大小、[高级向量扩展][5] 等等。
+
+除了它提供的一些主题外,你还可以使用自定义颜色。当你在整理桌面,并希望对 Linux 环境中的所有元素进行颜色匹配时,这给了你更多的自由度。
+
+### 在 Linux 上安装 CPUFetch
+
+不幸的是,CPUFetch 是一个相当新的软件,而且它并不包含在你的发行版的软件库中,甚至没有提供现成的 DEB/RPM 二进制文件、PPA、Snap 或 Flatpak 包。
+
+Arch Linux 用户可以在 [AUR][7] 中 [找到][6] 它,但对于其他人来说,唯一的出路是 [从源代码构建][8]。
+
+不要担心。安装以及删除并不是那么复杂。让我来告诉你步骤。
+
+我使用的是 Ubuntu,你会 [需要先在 Ubuntu 上安装 Git][9]。一些发行版会预装 Git,如果没有,请使用你的发行版的包管理器来安装。
+
+现在,把 Git 仓库克隆到你想要的地方。家目录也可以。
+
+```
+git clone https://github.com/Dr-Noob/cpufetch
+```
+
+切换到你刚才克隆的目录:
+
+```
+cd cpufetch
+```
+
+你会在这里看到一个 Makefile 文件。用它来编译代码。
+
+```
+make
+```
+
+![CPUFetch Installation][10]
+
+现在你会看到一个新的可执行文件,名为 `cpufetch`。你运行这个可执行文件来显示终端的 CPU 信息。
+
+```
+./cpufetch
+```
+
+这是我系统的显示。AMD 的徽标用 ASCII 码看起来更酷,你不觉得吗?
+
+![][11]
+
+如何删除 CPUFetch?这很简单。当你编译代码时,它只产生了一个文件,而且也和其他代码在同一个目录下。
+
+所以,要想从系统中删除 CPUFetch,只需删除它的整个文件夹即可。你知道 [在 Linux 终端中删除一个目录][12] 的方法吧?从 `cpufetch` 目录中出来,然后使用 `rm` 命令。
+
+```
+rm -rf cpufetch
+```
+
+这很简单,值得庆幸的是,因为从源代码中删除安装的软件有时真的很棘手。
+
+说回 CPUFetch。我想这是一个实用工具,适合那些喜欢在各种 Linux 群里炫耀自己桌面截图的人。既然发行版有了 Neofetch,CPU 有了 CPUFetch,不知道能不能也来个 Nvidia ASCII 艺术的 GPUfetch?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/cpufetch/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://linuxhandbook.com/check-cpu-info-linux/
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/lscpu-command-output.png?resize=800%2C415&ssl=1
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/cpufetch-1.png?resize=800%2C307&ssl=1
+[4]: https://itsfoss.com/display-linux-logo-in-ascii/
+[5]: https://software.intel.com/content/www/us/en/develop/articles/introduction-to-intel-advanced-vector-extensions.html
+[6]: https://aur.archlinux.org/packages/cpufetch-git
+[7]: https://itsfoss.com/aur-arch-linux/
+[8]: https://itsfoss.com/install-software-from-source-code/
+[9]: https://itsfoss.com/install-git-ubuntu/
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/cpufetch-installation.png?resize=800%2C410&ssl=1
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/cpufetch-for-itsfoss.png?resize=800%2C335&ssl=1
+[12]: https://linuxhandbook.com/remove-files-directories/
diff --git a/published/202104/20210407 Using network bound disk encryption with Stratis.md b/published/202104/20210407 Using network bound disk encryption with Stratis.md
new file mode 100644
index 0000000000..4c1440fd56
--- /dev/null
+++ b/published/202104/20210407 Using network bound disk encryption with Stratis.md
@@ -0,0 +1,284 @@
+[#]: subject: (Using network bound disk encryption with Stratis)
+[#]: via: (https://fedoramagazine.org/network-bound-disk-encryption-with-stratis/)
+[#]: author: (briansmith https://fedoramagazine.org/author/briansmith/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13340-1.html)
+
+使用 Stratis 的网络绑定磁盘加密
+======
+
+
+
+在一个有许多加密磁盘的环境中,解锁所有的磁盘是一项困难的任务。网络绑定磁盘加密(NBDE)有助于自动解锁 Stratis 卷的过程。这是在大型环境中的一个关键要求。Stratis 2.1 版本增加了对加密的支持,这在《[Stratis 加密入门][4]》一文中介绍过。Stratis 2.3 版本最近在使用加密的 Stratis 池时引入了对网络绑定磁盘加密(NBDE)的支持,这是本文的主题。
+
+[Stratis 网站][5] 将 Stratis 描述为一个“_易于使用的 Linux 本地存储管理_”。短视频《[使用 Stratis 管理存储][6]》对基础知识进行了快速演示。该视频是在 Red Hat Enterprise Linux 8 系统上录制的,然而,视频中显示的概念也适用于 Fedora Linux 中的 Stratis。
+
+### 先决条件
+
+本文假设你熟悉 Stratis,也熟悉 Stratis 池加密。如果你不熟悉这些主题,请参考这篇 [文章][4] 和前面提到的 [Stratis 概述视频][6]。
+
+NBDE 需要 Stratis 2.3 或更高版本。本文中的例子使用的是 Fedora Linux 34 的预发布版本。Fedora Linux 34 的最终版本将包含 Stratis 2.3。
+
+### 网络绑定磁盘加密(NBDE)概述
+
+加密存储的主要挑战之一是有一个安全的方法在系统重启后再次解锁存储。在大型环境中,手动输入加密口令并不能很好地扩展。NBDE 解决了这一问题,允许以自动方式解锁加密存储。
+
+在更高层次上,NBDE 需要环境中的 Tang 服务器。客户端系统(使用 Clevis Pin)只要能与 Tang 服务器建立网络连接,就可以自动解密存储。如果网络没有连接到 Tang 服务器,则必须手动解密存储。
+
+这背后的想法是,Tang 服务器只能在内部网络上使用,因此,如果加密设备丢失或被盗,它将不再能够访问内部网络连接到 Tang 服务器,因此不会被自动解密。
+
+关于 Tang 和 Clevis 的更多信息,请参见手册页(`man tang`、`man clevis`)、[Tang 的 GitHub 页面][7] 和 [Clevis 的 GitHub 页面][8]。
+
+### 设置 Tang 服务器
+
+本例使用另一个 Fedora Linux 系统作为 Tang 服务器,主机名为 `tang-server`。首先安装 `tang` 包。
+
+```
+dnf install tang
+```
+
+然后用 `systemctl` 启用并启动 `tangd.socket`。
+
+```
+systemctl enable tangd.socket --now
+```
+
+Tang 使用的是 TCP 80 端口,所以你也需要在防火墙中打开该端口。
+
+```
+firewall-cmd --add-port=80/tcp --permanent
+firewall-cmd --add-port=80/tcp
+```
+
+最后,运行 `tang-show-keys` 来显示输出签名密钥指纹。你以后会需要这个。
+
+```
+# tang-show-keys
+l3fZGUCmnvKQF_OA6VZF9jf8z2s
+```
+
+### 创建加密的 Stratis 池
+
+上一篇关于 Stratis 加密的文章详细介绍了如何设置加密的 Stratis 池,所以本文不会深入介绍。
+
+第一步是捕获一个将用于解密 Stratis 池的密钥。即使使用 NBDE,也需要设置这个,因为在 NBDE 服务器无法到达的情况下,可以用它来手动解锁池。使用以下命令捕获 `pool1` 密钥。
+
+```
+# stratis key set --capture-key pool1key
+Enter key data followed by the return key:
+```
+
+然后我将使用 `/dev/vdb` 设备创建一个加密的 Stratis 池(使用刚才创建的 `pool1key`),命名为 `pool1`。
+
+```
+# stratis pool create --key-desc pool1key pool1 /dev/vdb。
+```
+
+接下来,在这个 Stratis 池中创建一个名为 `filesystem1` 的文件系统,创建一个挂载点,挂载文件系统,并在其中创建一个测试文件:
+
+```
+# stratis filesystem create pool1 filesystem1
+# mkdir /filesystem1
+# mount /dev/stratis/pool1/filesystem1 /filesystem1
+# cd /filesystem1
+# echo "this is a test file" > testfile
+```
+
+### 将 Stratis 池绑定到 Tang 服务器上
+
+此时,我们已经创建了加密的 Stratis 池,并在池中创建了一个文件系统。下一步是将你的 Stratis 池绑定到刚刚设置的 Tang 服务器上。使用 `stratis pool bind nbde` 命令进行。
+
+当你进行 Tang 绑定时,需要向该命令传递几个参数:
+
+ * 池名(在本例中,`pool1`)
+ * 钥匙描述符名称(本例中为 `pool1key`)
+ * Tang 服务器名称(在本例中,`http://tang-server`)
+
+记得之前在 Tang 服务器上,运行了 `tang-show-keys`,显示 Tang 输出的签名密钥指纹是 `l3fZGUCmnvKQF_OA6VZF9jf8z2s`。除了前面的参数外,还需要用参数 `-thumbprint l3fZGUCmnvKQF_OA6VZF9jf8z2s` 传递这个指纹,或者用 `-trust-url` 参数跳过对指纹的验证。
+
+使用 `-thumbprint` 参数更安全。例如:
+
+```
+# stratis pool bind nbde pool1 pool1key http://tang-server --thumbprint l3fZGUCmnvKQF_OA6VZF9jf8z2s
+```
+
+### 用 NBDE 解锁 Stratis 池
+
+接下来重启主机,并验证你可以用 NBDE 解锁 Stratis 池,而不需要使用密钥口令。重启主机后,该池不再可用:
+
+```
+# stratis pool list
+Name Total Physical Properties
+```
+
+要使用 NBDE 解锁池,请运行以下命令:
+
+```
+# stratis pool unlock clevis
+```
+
+注意,你不需要使用密钥口令。这个命令可以在系统启动时自动运行。
+
+此时,Stratis 池已经可以使用了:
+
+```
+# stratis pool list
+Name Total Physical Properties
+pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr
+```
+
+你可以挂载文件系统,访问之前创建的文件:
+
+```
+# mount /dev/stratis/pool1/filesystem1 /filesystem1/
+# cat /filesystem1/testfile
+this is a test file
+```
+
+### 轮换 Tang 服务器密钥
+
+最好定期轮换 Tang 服务器密钥,并更新 Stratis 客户服务器以使用新的 Tang 密钥。
+
+要生成新的 Tang 密钥,首先登录到 Tang 服务器,查看 `/var/db/tang` 目录的当前状态。然后,运行 `tang-show-keys` 命令:
+
+```
+# ls -al /var/db/tang
+total 8
+drwx------. 1 tang tang 124 Mar 15 15:51 .
+drwxr-xr-x. 1 root root 16 Mar 15 15:48 ..
+-rw-r--r--. 1 tang tang 361 Mar 15 15:51 hbjJEDXy8G8wynMPqiq8F47nJwo.jwk
+-rw-r--r--. 1 tang tang 367 Mar 15 15:51 l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk
+# tang-show-keys
+l3fZGUCmnvKQF_OA6VZF9jf8z2s
+```
+
+要生成新的密钥,运行 `tangd-keygen` 并将其指向 `/var/db/tang` 目录:
+
+```
+# /usr/libexec/tangd-keygen /var/db/tang
+```
+
+如果你再看看 `/var/db/tang` 目录,你会看到两个新文件:
+
+```
+# ls -al /var/db/tang
+total 16
+drwx------. 1 tang tang 248 Mar 22 10:41 .
+drwxr-xr-x. 1 root root 16 Mar 15 15:48 ..
+-rw-r--r--. 1 tang tang 361 Mar 15 15:51 hbjJEDXy8G8wynMPqiq8F47nJwo.jwk
+-rw-r--r--. 1 root root 354 Mar 22 10:41 iyG5HcF01zaPjaGY6L_3WaslJ_E.jwk
+-rw-r--r--. 1 root root 349 Mar 22 10:41 jHxerkqARY1Ww_H_8YjQVZ5OHao.jwk
+-rw-r--r--. 1 tang tang 367 Mar 15 15:51 l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk
+```
+
+如果你运行 `tang-show-keys`,就会显示出 Tang 所公布的密钥:
+
+```
+# tang-show-keys
+l3fZGUCmnvKQF_OA6VZF9jf8z2s
+iyG5HcF01zaPjaGY6L_3WaslJ_E
+```
+
+你可以通过将两个原始文件改名为以句号开头的隐藏文件,来防止旧的密钥(以 `l3fZ` 开头)被公布。通过这种方法,旧的密钥将不再被公布,但是它仍然可以被任何没有更新为使用新密钥的现有客户端使用。一旦所有的客户端都更新使用了新密钥,这些旧密钥文件就可以删除了。
+
+```
+# cd /var/db/tang
+# mv hbjJEDXy8G8wynMPqiq8F47nJwo.jwk .hbjJEDXy8G8wynMPqiq8F47nJwo.jwk
+# mv l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk .l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk
+```
+
+此时,如果再运行 `tang-show-keys`,Tang 只公布新钥匙:
+
+```
+# tang-show-keys
+iyG5HcF01zaPjaGY6L_3WaslJ_E
+```
+
+下一步,切换到你的 Stratis 系统并更新它以使用新的 Tang 密钥。当文件系统在线时, Stratis 支持这样做。
+
+首先,解除对池的绑定:
+
+```
+# stratis pool unbind pool1
+```
+
+接下来,用创建加密池时使用的原始口令设置密钥:
+
+```
+# stratis key set --capture-key pool1key
+Enter key data followed by the return key:
+```
+
+最后,用更新后的密钥指纹将 Stratis 池绑定到 Tang 服务器上:
+
+```
+# stratis pool bind nbde pool1 pool1key http://tang-server --thumbprint iyG5HcF01zaPjaGY6L_3WaslJ_E
+```
+
+Stratis 系统现在配置为使用更新的 Tang 密钥。一旦使用旧的 Tang 密钥的任何其他客户系统被更新,在 Tang 服务器上的 `/var/db/tang` 目录中被重命名为隐藏文件的两个原始密钥文件就可以被备份和删除了。
+
+### 如果 Tang 服务器不可用怎么办?
+
+接下来,关闭 Tang 服务器,模拟它不可用,然后重启 Stratis 系统。
+
+重启后,Stratis 池又不可用了:
+
+```
+# stratis pool list
+Name Total Physical Properties
+```
+
+如果你试图用 NBDE 解锁,会因为 Tang 服务器不可用而失败:
+
+```
+# stratis pool unlock clevis
+Execution failed:
+An iterative command generated one or more errors: The operation 'unlock' on a resource of type pool failed. The following errors occurred:
+Partial action "unlock" failed for pool with UUID 4d62f840f2bb4ec9ab53a44b49da3f48: Cryptsetup error: Failed with error: Error: Command failed: cmd: "clevis" "luks" "unlock" "-d" "/dev/vdb" "-n" "stratis-1-private-42142fedcb4c47cea2e2b873c08fcf63-crypt", exit reason: 1 stdout: stderr: /dev/vdb could not be opened.
+```
+
+此时,在 Tang 服务器无法到达的情况下,解锁池的唯一选择就是使用原密钥口令:
+
+```
+# stratis key set --capture-key pool1key
+Enter key data followed by the return key:
+```
+
+然后你可以使用钥匙解锁池:
+
+```
+# stratis pool unlock keyring
+```
+
+接下来,验证池是否成功解锁:
+
+```
+# stratis pool list
+Name Total Physical Properties
+pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr
+```
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/network-bound-disk-encryption-with-stratis/
+
+作者:[briansmith][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/briansmith/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/03/stratis-nbde-816x345.jpg
+[2]: https://unsplash.com/@imattsmart?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[3]: https://unsplash.com/s/photos/lock?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[4]: https://linux.cn/article-13311-1.html
+[5]: https://stratis-storage.github.io/
+[6]: https://www.youtube.com/watch?v=CJu3kmY-f5o
+[7]: https://github.com/latchset/tang
+[8]: https://github.com/latchset/clevis
diff --git a/published/202104/20210407 What is Git cherry-picking.md b/published/202104/20210407 What is Git cherry-picking.md
new file mode 100644
index 0000000000..ba25e9572c
--- /dev/null
+++ b/published/202104/20210407 What is Git cherry-picking.md
@@ -0,0 +1,187 @@
+[#]: subject: (What is Git cherry-picking?)
+[#]: via: (https://opensource.com/article/21/4/cherry-picking-git)
+[#]: author: (Rajeev Bera https://opensource.com/users/acompiler)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13295-1.html)
+
+什么是 Git 遴选(cherry-pick)?
+======
+
+> 了解 `git cherry-pick` 命令是什么,为什么用以及如何使用。
+
+
+
+当你和一群程序员一起工作时,无论项目大小,处理多个 Git 分支之间的变更都会变得很困难。有时,你不想将整个 Git 分支合并到另一个分支,而是想选择并移动几个特定的提交。这个过程被称为 “遴选”。
+
+本文将介绍“遴选”是什么、为何使用以及如何使用。
+
+那么让我们开始吧。
+
+### 什么是遴选?
+
+使用遴选(`cherry-pick`)命令,Git 可以让你将任何分支中的个别提交合并到你当前的 [Git HEAD][2] 分支中。
+
+当执行 `git merge` 或者 `git rebase` 时,一个分支的所有提交都会被合并。`cherry-pick` 命令允许你选择单个提交进行整合。
+
+### 遴选的好处
+
+下面的情况可能会让你更容易理解遴选功能。
+
+想象一下,你正在为即将到来的每周冲刺实现新功能。当你的代码准备好了,你会把它推送到远程分支,准备进行测试。
+
+然而,客户并不是对所有修改都满意,要求你只呈现某些修改。因为客户还没有批准下次发布的所有修改,所以 `git rebase` 不会有预期的结果。为什么会这样?因为 `git rebase` 或者 `git merge` 会把上一个冲刺的每一个调整都纳入其中。
+
+遴选就是答案!因为它只关注在提交中添加的变更,所以遴选只会带入批准的变更,而不添加其他的提交。
+
+还有其他几个原因可以使用遴选:
+
+ * 这对于 bug 修复是必不可少的,因为 bug 是出现在开发分支中对应的提交的。
+ * 你可以通过使用 `git cherry-pick` 来避免不必要的工作,而不用使用其他选项例如 `git diff` 来应用特定变更。
+ * 如果因为不同 Git 分支的版本不兼容而无法将整个分支联合起来,那么它是一个很有用的工具。
+
+### 使用 cherry-pick 命令
+
+在 `cherry-pick` 命令的最简单形式中,你只需使用 [SHA][3] 标识符来表示你想整合到当前 HEAD 分支的提交。
+
+要获得提交的哈希值,可以使用 `git log` 命令:
+
+```
+$ git log --oneline
+```
+
+当你知道了提交的哈希值后,你就可以使用 `cherry-pick` 命令。
+
+语法是:
+
+```
+$ git cherry-pick
+```
+
+例如:
+
+```
+$ git cherry-pick 65be1e5
+```
+
+这将会把指定的修改合并到当前已签出的分支上。
+
+如果你想做进一步的修改,也可以让 Git 将提交的变更内容添加到你的工作副本中。
+
+语法是:
+
+```
+$ git cherry-pick --no-commit
+```
+
+例如:
+
+```
+$ git cherry-pick 65be1e5 --no-commit
+```
+
+如果你想同时选择多个提交,请将它们的提交哈希值用空格隔开:
+
+```
+$ git cherry-pick hash1 hash3
+```
+
+当遴选提交时,你不能使用 `git pull` 命令,因为它能获取一个仓库的提交**并**自动合并到另一个仓库。`cherry-pick` 是一个专门不这么做的工具;另一方面,你可以使用 `git fetch`,它可以获取提交,但不应用它们。毫无疑问,`git pull` 很方便,但它不精确。
+
+### 自己尝试
+
+要尝试这个过程,启动终端并生成一个示例项目:
+
+```
+$ mkdir fruit.git
+$ cd fruit.git
+$ git init .
+```
+
+创建一些数据并提交:
+
+```
+$ echo "Kiwifruit" > fruit.txt
+$ git add fruit.txt
+$ git commit -m 'First commit'
+```
+
+现在,通过创建一个项目的复刻来代表一个远程开发者:
+
+```
+$ mkdir ~/fruit.fork
+$ cd !$
+$ echo "Strawberry" >> fruit.txt
+$ git add fruit.txt
+$ git commit -m 'Added a fruit"
+```
+
+这是一个有效的提交。现在,创建一个不好的提交,代表你不想合并到你的项目中的东西:
+
+```
+$ echo "Rhubarb" >> fruit.txt
+$ git add fruit.txt
+$ git commit -m 'Added a vegetable that tastes like a fruit"
+```
+
+返回你的仓库,从你的假想的开发者那里获取提交的内容:
+
+```
+$ cd ~/fruit.git
+$ git remote add dev ~/fruit.fork
+$ git fetch dev
+remote: Counting objects: 6, done.
+remote: Compressing objects: 100% (2/2), done.
+remote: Total 6 (delta 0), reused 0 (delta 0)
+Unpacking objects: 100% (6/6), done...
+```
+
+```
+$ git log –oneline dev/master
+e858ab2 Added a vegetable that tastes like a fruit
+0664292 Added a fruit
+b56e0f8 First commit
+```
+
+你已经从你想象中的开发者那里获取了提交的内容,但你还没有将它们合并到你的版本库中。你想接受第二个提交,但不想接受第三个提交,所以使用 `cherry-pick`。
+
+```
+$ git cherry-pick 0664292
+```
+
+第二次提交现在在你的仓库里了:
+
+```
+$ cat fruit.txt
+Kiwifruit
+Strawberry
+```
+
+将你的更改推送到远程服务器上,这就完成了!
+
+### 避免使用遴选的原因
+
+在开发者社区中,通常不鼓励所以遴选。主要原因是它会造成重复提交,而你也失去了跟踪你的提交历史的能力。
+
+如果你不按顺序地遴选了大量的提交,这些提交会被记录在你的分支中,这可能会在 Git 分支中导致不理想的结果。
+
+遴选是一个强大的命令,如果没有正确理解可能发生的情况,它可能会导致问题。不过,当你搞砸了,提交到错误的分支时,它可能会救你一命(至少是你当天的工作)。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/cherry-picking-git
+
+作者:[Rajeev Bera][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/acompiler
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/pictures/cherry-picking-recipe-baking-cooking.jpg?itok=XVwse6hw (Measuring and baking a cherry pie recipe)
+[2]: https://acompiler.com/git-head/
+[3]: https://en.wikipedia.org/wiki/Secure_Hash_Algorithms
diff --git a/published/202104/20210407 Why I love using bspwm for my Linux window manager.md b/published/202104/20210407 Why I love using bspwm for my Linux window manager.md
new file mode 100644
index 0000000000..8050039891
--- /dev/null
+++ b/published/202104/20210407 Why I love using bspwm for my Linux window manager.md
@@ -0,0 +1,107 @@
+[#]: subject: (Why I love using bspwm for my Linux window manager)
+[#]: via: (https://opensource.com/article/21/4/bspwm-linux)
+[#]: author: (Stephen Adams https://opensource.com/users/stevehnh)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13308-1.html)
+
+为什么我喜欢用 bspwm 来做我的 Linux 窗口管理器
+======
+
+> 在 Fedora Linux 上安装、配置并开始使用 bspwm 窗口管理器。
+
+
+
+有些人喜欢重新布置家具。还有的人喜欢尝试新鞋或定期重新装修他们的卧室。我呢,则是尝试 Linux 桌面。
+
+在对网上看到的一些不可思议的桌面环境流口水之后,我对一个窗口管理器特别好奇:[bspwm][2]。
+
+![bspwm desktop][3]
+
+我喜欢 [i3][5] 窗口管理器已经有一段时间了,我很喜欢它的布局方式和上手的便捷性。但 bspwm 的某些特性吸引了我。有几个原因让我决定尝试一下:
+
+ * 它_只是_一个窗口管理器(WM)。
+ * 它由几个易于配置的脚本管理。
+ * 它默认支持窗口之间的间隙。
+
+可能是最需要指出的第一个原因是它只是一个窗口管理器。和 i3 一样,默认情况下没有任何图形化的那些花哨东西。你当然可以随心所欲地定制它,但_你_需要付出努力来使它看起来像你想要的。这也是它吸引我的部分原因。
+
+虽然它可以在许多发行版上使用,但在我这个例子中使用的是 Fedora Linux。
+
+### 安装 bspwm
+
+bspwm 在大多数常见的发行版中都有打包,所以你可以用系统的包管理器安装它。下面这个命令还会安装 [sxkhd][6],这是一个 X 窗口系统的守护程序,它“通过执行命令对输入事件做出反应”;还有 [dmenu][7],这是一个通用的 X 窗口菜单:
+
+```
+dnf install bspwm sxkhd dmenu
+```
+
+因为 bspwm 只是一个窗口管理器,所以没有任何内置的快捷键或键盘命令。这也是它与 i3 等软件的不同之处。所以,在你第一次启动窗口管理器之前,请先配置一下 `sxkhd`:
+
+```
+systemctl start sxkhd
+systemctl enable sxkhd
+```
+
+这样就可以在登录时启用 `sxkhd`,但你还需要一些基本功能的配置:
+
+```
+curl https://raw.githubusercontent.com/baskerville/bspwm/master/examples/sxhkdrc --output ~/.config/sxkhd/sxkhdrc
+```
+
+在你深入了解之前,不妨先看看这个文件,因为有些脚本调用的命令可能在你的系统中并不存在。一个很好的例子是调用 `urxvt` 的 `super + Return` 快捷键。把它改成你喜欢的终端,尤其是当你没有安装 `urxvt` 的时候:
+
+```
+#
+# wm independent hotkeys
+#
+
+# terminal emulator
+super + Return
+ urxvt
+
+# program launcher
+super + @space
+ dmenu_run
+```
+
+如果你使用的是 GDM、LightDM 或其他显示管理器(DM),只要在登录前选择 `bspwm` 即可。
+
+### 配置 bspwm
+
+当你登录后,你会看到屏幕上什么都没有。这不是你感觉到的空虚感。而是无限可能性!你现在可以开始摆弄桌面环境的所有部分了。你现在可以开始摆弄这些年你认为理所当然的桌面环境的所有部分了。从头开始构建并不容易,但一旦你掌握了诀窍,就会非常有收获。
+
+任何窗口管理器最困难的是掌握快捷键。你开始会很慢,但在很短的时间内,你就可以只使用键盘在系统中到处操作,在你的朋友和家人面前看起来像一个终极黑客。
+
+你可以通过编辑 `~/.config/bspwm/bspwmrc`,在启动时添加应用,设置桌面和显示器,并为你的窗口应该如何表现设置规则,随心所欲地定制系统。有一些默认设置的例子可以让你开始使用。键盘快捷键都是由 `sxkhdrc` 文件管理的。
+
+还有更多的开源项目可以安装,让你的电脑看起来更漂亮,比如用于桌面背景的 [Feh][8]、状态栏的 [Polybar][9]、应用启动器的 [Rofi][10],还有 [Compton][11] 可以给你提供阴影和透明度,可以让你的电脑看起来焕然一新。
+
+玩得愉快!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/bspwm-linux
+
+作者:[Stephen Adams][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/stevehnh
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/windows_building_sky_scale.jpg?itok=mH6CAX29 (Tall building with windows)
+[2]: https://github.com/baskerville/bspwm
+[3]: https://opensource.com/sites/default/files/uploads/bspwm-desktop.png (bspwm desktop)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://i3wm.org/
+[6]: https://github.com/baskerville/sxhkd
+[7]: https://linux.die.net/man/1/dmenu
+[8]: https://github.com/derf/feh
+[9]: https://github.com/polybar/polybar
+[10]: https://github.com/davatorium/rofi
+[11]: https://github.com/chjj/compton
diff --git a/published/202104/20210409 4 ways open source gives you a competitive edge.md b/published/202104/20210409 4 ways open source gives you a competitive edge.md
new file mode 100644
index 0000000000..4a9603b1ba
--- /dev/null
+++ b/published/202104/20210409 4 ways open source gives you a competitive edge.md
@@ -0,0 +1,84 @@
+[#]: subject: (4 ways open source gives you a competitive edge)
+[#]: via: (https://opensource.com/article/21/4/open-source-competitive-advantage)
+[#]: author: (Jason Blais https://opensource.com/users/jasonblais)
+[#]: collector: (lujun9972)
+[#]: translator: (DCOLIVERSUN)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13299-1.html)
+
+开源为你带来竞争优势的 4 种方式
+======
+
+> 使用开源技术可以帮助组织获得更好的业务结果。
+
+
+
+构建技术栈是每个组织的主要决策。选择合适的工具将让团队获得成功,选择错误的解决方案或平台会对生产率和利润率产生毁灭性影响。为了在当今快节奏的世界中脱颖而出,组织必须明智地选择数字解决方案,好的数字解决方案可以提升团队行动力与运营敏捷性。
+
+这就是为什么越来越多的组织都采用开源解决方案的原因,这些组织来自各行各业,规模有大有小。根据 [麦肯锡][2] 最近的报告,高绩效组织的最大区别是采用不同的开源方案。
+
+采用开源技术可以帮助组织提高竞争优势、获得更好业务成果的原因有以下四点。
+
+### 1、可拓展性和灵活性
+
+可以说,技术世界发展很快。例如,在 2014 年之前,Kubernetes 并不存在,但今天,它却令人印象深刻,无处不在。根据 CNCF [2020 云原生调查][3],91% 的团队正在以某种形式使用 Kubernetes。
+
+组织投资开源的一个主要原因是因为开源赋予组织行动敏捷性,组织可以迅速地将新技术集成到技术栈中。这与传统方法不同,在传统方法中,团队需要几个季度甚至几年来审查、实施、采用软件,这导致团队不可能实现火速转变。
+
+开源解决方案完整地提供源代码,团队可以轻松将软件与他们每天使用的工具连接起来。
+
+简而言之,开源让开发团队能够为手头的东西构建完美的工具,而不是被迫改变工作方式来适应不灵活的专有工具。
+
+### 2、安全性和高可信的协作
+
+在数据泄露备受瞩目的时代,组织需要高度安全的工具来保护敏感数据的安全。
+
+专有解决方案中的漏洞不易被发现,被发现时为时已晚。不幸的是,使用这些平台的团队无法看到源代码,本质上是他们将安全性外包给特定供应商,并希望得到最好的结果。
+
+采用开源的另一个主要原因是开源工具使组织能够自己把控安全。例如,开源项目——尤其是拥有大型开源社区的项目——往往会收到更负责任的漏洞披露,因为每个人在使用过程中都可以彻底检查源代码。
+
+由于源代码是免费提供的,因此披露通常伴随着修复缺陷的详细建议解决方案。这些方案使得开发团队能够快速解决问题,不断增强软件。
+
+在远程办公时代,对于分布式团队来说,在知道敏感数据受到保护的情况下进行协作比以往任何时候都更重要。开源解决方案允许组织审核安全性、完全掌控自己数据,因此开源方案可以促进远程环境下高可信协作方式的成长。
+
+### 3、不受供应商限制
+
+根据 [最近的一项研究][4],68% 的 CIO 担心受供应商限制。当你受限于一项技术中,你会被迫接受别人的结论,而不是自己做结论。
+
+当组织更换供应商时,专有解决方案通常会 [给你带走数据带来挑战][5]。另一方面,开源工具提供了组织需要的自由度和灵活性,以避免受供应商限制,开源工具可以让组织把数据带去任意地方。
+
+### 4、顶尖人才和社区
+
+随着越来越多的公司 [接受远程办公][6],人才争夺战变得愈发激烈。
+
+在软件开发领域,获得顶尖人才始于赋予工程师先进工具,让工程师在工作中充分发挥潜力。开发人员 [越来越喜欢开源解决方案][7] 而不是专有解决方案,组织应该强烈考虑用开源替代商业解决方案,以吸引市场上最好的开发人员。
+
+除了雇佣、留住顶尖人才更容易,公司能够通过开源平台利用贡献者社区,得到解决问题的建议,从平台中得到最大收益。此外,社区成员还可以 [直接为开源项目做贡献][8]。
+
+### 开源带来自由
+
+开源软件在企业团队中越来越受到欢迎——[这是有原因的][8]。它帮助团队灵活地构建完美的工作工具,同时使团队可以维护高度安全的环境。同时,开源允许团队掌控未来方向,而不是局限于供应商的路线图。开源还帮助公司接触才华横溢的工程师和开源社区成员。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/open-source-competitive-advantage
+
+作者:[Jason Blais][a]
+选题:[lujun9972][b]
+译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jasonblais
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/openwires_fromRHT_520_0612LL.png?itok=PqZi55Ab (Open ethernet cords.)
+[2]: https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/developer-velocity-how-software-excellence-fuels-business-performance#
+[3]: https://www.cncf.io/blog/2020/11/17/cloud-native-survey-2020-containers-in-production-jump-300-from-our-first-survey/
+[4]: https://solutionsreview.com/cloud-platforms/flexera-68-percent-of-cios-worry-about-vendor-lock-in-with-public-cloud/
+[5]: https://www.computerworld.com/article/3428679/mattermost-makes-case-for-open-source-as-team-messaging-market-booms.html
+[6]: https://mattermost.com/blog/tips-for-working-remotely/
+[7]: https://opensource.com/article/20/6/open-source-developers-survey
+[8]: https://mattermost.com/blog/100-most-popular-mattermost-features-invented-and-contributed-by-our-amazing-open-source-community/
+[9]: https://mattermost.com/open-source-advantage/
diff --git a/published/202104/20210410 5 signs you-re a groff programmer.md b/published/202104/20210410 5 signs you-re a groff programmer.md
new file mode 100644
index 0000000000..53e41c98fd
--- /dev/null
+++ b/published/202104/20210410 5 signs you-re a groff programmer.md
@@ -0,0 +1,80 @@
+[#]: subject: (5 signs you're a groff programmer)
+[#]: via: (https://opensource.com/article/21/4/groff-programmer)
+[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
+[#]: collector: (lujun9972)
+[#]: translator: (liweitianux)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13316-1.html)
+
+groff 程序员的 5 个标志
+======
+
+> 学习一款老派的文本处理软件 groff,就像是学习骑自行车。
+
+
+
+我第一次发现 Unix 系统是在 20 世纪 90 年代早期,当时我还在大学读本科。我太喜欢这个系统了,所以我将家里电脑上的 MS-DOS 也换成了 Linux 系统。
+
+在 90 年代早期至中期,Linux 所缺失的一个东西是字处理软件。作为其他桌面操作系统的标准办公程序,字处理软件能让你轻松地编辑文本。我经常在 DOS 上使用字处理软件来撰写课程论文。直到 90 年代末,我都没能找到一款 Linux 原生的字处理软件。直到那时,文字处理是我在第一台电脑上保留双启动的少有的原因之一,那样我可以偶尔切换到 DOS 系统写论文。
+
+后来,我发现 Linux 提供了一款文字处理软件:GNU troff,它一般称为 [groff][2],是经典的文本处理系统 troff 的一个现代实现。troff 是 “排版工快印” 的简称,是 nroff 系统的改进版本,而 nroff 又是最初的 roff 系统的新实现。roff 表示快速印出,比如“快速印出”一份文档。
+
+利用文本处理系统,你在纯文本编辑器里编辑内容,通过宏或其他处理命令来添加格式。然后将文件输入文本处理系统,比如 groff,来生成适合打印的格式化输出。另一个知名的文本处理系统是 LaTeX,但是 groff 已经满足我的需求,而且足够简单。
+
+经过一点实践,我发现在 Linux 上使用 groff 来撰写课程论文与使用字处理软件一样容易。尽管我现在不再使用 groff 来写文档了,我依然记得它的那些宏和命令。如果你也是这样并且在那么多年之前学会了使用 groff 写作,你可能会认出这 5 个 groff 程序员的标志。
+
+### 1、你有一个喜欢的宏集
+
+输入由宏点缀的纯文本,你便能在 groff 里对文档进行格式化。groff 里的宏是行首为单个句点(`.`)的短命令。例如:如果你想在输出里插入几行,宏命令 `.sp 2` 会添加两个空行。groff 还具有其他一些基本的宏,支持各种各样的格式化。
+
+为了能让作者更容易地格式化文档,groff 还提供了不同的 宏集,即一组能够让你以自己的方式格式化文档的宏的集合。我学会的第一个宏集是 `-me` 宏集。这个宏集的名称其实是 `e`,你在处理文件时使用 `-me` 选项来指定这个 `e` 宏集。
+
+groff 还包含其他宏集。例如,`-man` 宏集以前是用于格式化 Unix 系统内置的 手册页 的标准宏集,`-ms` 宏集经常用于格式化其他一些技术文档。如果你学会了使用 groff 写作,你可能有一个喜欢的宏集。
+
+### 2、你想专注于内容而非格式
+
+使用 groff 写作的一个很好的特点是,你能专注于你的 _内容_,而不用太担心它看起来会怎么样。对于技术作者而言这是一个很实用的特点。对专业作家来说,groff 是一个很好的、“不会分心”的写作环境。至少,使用 groff `-T` 选项所支持的任何格式来交付内容时你不用担心,这包括 PDF、PostScript、HTML、以及纯文本。不过,你无法直接从 groff 生成 LibreOffice ODT 文件或者 Word DOC 文件。
+
+一旦你使用 groff 写作变得有信心之后,宏便开始 _消失_。用于格式化的宏变成了背景的一部分,而你纯粹地专注于眼前的文本内容。我已经使用 groff 写了足够多内容,以至于我甚至不再看见那些宏。也许,这就像写代码,而你的大脑随意换档,于是你就像计算机一样思考,看到的代码就是一组指令。对我而言,使用 groff 写作就像那样:我仅仅看到文本,而我的大脑将宏自动地翻译成格式。
+
+### 3、你喜欢怀旧复古的感觉
+
+当然,使用一个更典型的字处理软件来写你的文档可能更 _简单_,比如 LibreOffice Writer、甚至 Google Docs 或 Microsoft Word。而且对于某些种类的文档,桌面型字处理软件才是正确的选择。但是,如果你想要这种怀旧复古的感觉,使用 groff 写作很难被打败。
+
+我承认,我的大部分写作是用 LibreOffice Writer 完成的,它的表现很出色。但是当我渴望以一种怀旧复古的方式去做时,我会打开编辑器用 groff 来写文档。
+
+### 4、你希望能到处使用它
+
+groff 及其同类软件在几乎所有的 Unix 系统上都是标准软件包。此外,groff 宏不会随系统而变化。比如,`-me` 宏集在不同系统上都应该相同。因此,一旦你在一个系统上学会使用宏,你能在下一个系统上同样地使用它们。
+
+另外,因为 groff 文档就是纯文本文档,所以你能使用任何你喜欢的编辑器来编辑文档。我喜欢使用 GNU Emacs 来编辑我的 groff 文档,但是你可能使用 GNOME Gedit、Vim、其他你 [最喜欢的文本编辑器][3]。大部分编辑器会支持这样一种模式,其中 groff 宏会以不同的颜色高亮显示,帮助你在处理文件之前便能发现错误。
+
+### 5、你使用 -me 写了这篇文章
+
+当我决定要写这篇文章时,我认为最佳的方式便是直接使用 groff。我想要演示 groff 在编写文档方面是多么的灵活。所以,虽然你正在网上读这篇文章,但是它最初是用 groff 写的。
+
+我希望这激发了你学习如何使用 groff 撰写文档的兴趣。如果你想学习 `-me` 宏集里更高级的函数,参考 Eric Allman 的《Writing papers with groff using -me》,你应该能在系统的 groff 文档找到这本书,文件名为 `meintro.me`。这是一份很好的参考资料,还解释了使用 `-me` 宏集格式化论文的其他方式。
+
+我还提供了这篇文章的原始草稿,其中使用了 `-me` 宏集。下载这个文件并保存为 `five-signs-groff.me`,然后运行 groff 处理来查看它。`-T` 选项设置输出类型,比如 `-Tps` 用于生成 PostScript 输出,`-Thtml` 用于生成 HTML 文件。比如:
+
+```
+groff -me -Thtml five-signs-groff.me > five-signs-groff.html
+```
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/groff-programmer
+
+作者:[Jim Hall][a]
+选题:[lujun9972][b]
+译者:[liweitianux](https://github.com/liweitianux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jim-hall
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/doc-dish-lead.png?itok=h3fCkVmU (Typewriter in the grass)
+[2]: https://en.wikipedia.org/wiki/Groff_(software)
+[3]: https://opensource.com/article/21/2/open-source-text-editors
diff --git a/published/202104/20210410 How to Install Steam on Fedora -Beginner-s Tip.md b/published/202104/20210410 How to Install Steam on Fedora -Beginner-s Tip.md
new file mode 100644
index 0000000000..9aa71925fa
--- /dev/null
+++ b/published/202104/20210410 How to Install Steam on Fedora -Beginner-s Tip.md
@@ -0,0 +1,119 @@
+[#]: subject: (How to Install Steam on Fedora [Beginner’s Tip])
+[#]: via: (https://itsfoss.com/install-steam-fedora/)
+[#]: author: (John Paul https://itsfoss.com/author/john/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13302-1.html)
+
+如何在 Fedora 上安装 Steam
+======
+
+
+
+Steam 对 Linux 游戏玩家来说是最好的东西了。由于 Steam,你可以在 Linux 上玩成百上千的游戏。
+
+如果你还不知道,Steam 是最流行的 PC 游戏平台。2013 年,它开始可以在 Linux 使用。[Steam 最新的 Proton 项目][1] 允许你在 Linux 上玩为 Windows 平台创建的游戏。这让 Linux 游戏库增强了许多倍。
+
+![][2]
+
+Steam 提供了一个桌面客户端,你可以用它从 Steam 商店下载或购买游戏,然后安装并玩它。
+
+过去我们曾讨论过 [在 Ubuntu 上安装 Steam][3]。在这个初学者教程中,我将向你展示在 Fedora Linux 上安装 Steam 的步骤。
+
+### 在 Fedora 上安装 Steam
+
+要在 Fedora 上使用 Steam,你必须使用 RMPFusion 软件库。[RPMFusion][4] 是一套第三方软件库,其中包含了 Fedora 选择不与它们的操作系统一起发布的软件。它们提供自由(开源)和非自由(闭源)的软件库。由于 Steam 在非自由软件库中,你将只安装那一个。
+
+我将同时介绍终端和图形安装方法。
+
+#### 方法 1:通过终端安装 Steam
+
+这是最简单的方法,因为它需要的步骤最少。只需输入以下命令即可启用仓库:
+
+```
+sudo dnf install https://mirrors.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm
+```
+
+你会被要求输入密码。然后你会被要求验证是否要安装这些仓库。你同意后,仓库安装就会完成。
+
+要安装 Steam,只需输入以下命令:
+
+```
+sudo dnf install steam
+```
+
+![Install Steam via command line][5]
+
+输入密码后按 `Y` 接受。安装完毕后,打开 Steam,玩一些游戏。
+
+#### 方法 2:通过 GUI 安装 Steam
+
+你可以从软件中心 [启用 Fedora 上的第三方仓库][6]。打开软件中心并点击菜单。
+
+![][7]
+
+在 “软件仓库” 窗口中,你会看到顶部有一个 “第三方软件仓库”。点击 “安装” 按钮。当提示你输入密码时,就完成了。
+
+![][8]
+
+安装了 Steam 的 RPM Fusion 仓库后,更新你系统的软件缓存(如果需要),并在软件中心搜索 Steam。
+
+![Steam in GNOME Software Center][9]
+
+安装完成后,打开 GNOME 软件中心,搜索 Steam。找到 Steam 页面后,点击安装。当被问及密码时,输入你的密码就可以了。
+
+安装完 Steam 后,启动应用,输入你的 Steam 帐户详情或注册它,然后享受你的游戏。
+
+### 将 Steam 作为 Flatpak 使用
+
+Steam 也可以作为 Flatpak 使用。Fedora 上默认安装 Flatpak。在使用该方法安装 Steam 之前,我们必须安装 Flathub 仓库。
+
+![Install Flathub][10]
+
+首先,在浏览器中打开 [Flatpak 网站][11]。现在,点击标有 “Flathub repository file” 的蓝色按钮。浏览器会询问你是否要在 GNOME 软件中心打开该文件。点击确定。在 GNOME 软件中心打开后,点击安装按钮。系统会提示你输入密码。
+
+如果你在尝试安装 Flathub 仓库时出现错误,请在终端运行以下命令:
+
+```
+flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
+```
+
+安装好 Flathub 仓库后,你需要做的就是在 GNOME 软件中心搜索 Steam。找到后,安装它,你就可以开始玩了。
+
+![Fedora Repo Select][12]
+
+Flathub 版本的 Steam 也有几个附加组件可以安装。其中包括一个 DOS 兼容工具和几个 [Vulkan][13] 和 Proton 工具。
+
+![][14]
+
+我想这应该可以帮助你在 Fedora 上使用 Steam。享受你的游戏 :)
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-steam-fedora/
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/steam-play-proton/
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/05/Steam-Store.jpg?resize=800%2C382&ssl=1
+[3]: https://itsfoss.com/install-steam-ubuntu-linux/
+[4]: https://rpmfusion.org/
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/install-steam-fedora.png?resize=800%2C588&ssl=1
+[6]: https://itsfoss.com/fedora-third-party-repos/
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/11/software-meni.png?resize=800%2C672&ssl=1
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/11/fedora-third-party-repo-gui.png?resize=746%2C800&ssl=1
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/gnome-store-steam.jpg?resize=800%2C434&ssl=1
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/flatpak-install-button.jpg?resize=800%2C434&ssl=1
+[11]: https://www.flatpak.org/setup/Fedora/
+[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/fedora-repo-select.jpg?resize=800%2C434&ssl=1
+[13]: https://developer.nvidia.com/vulkan
+[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/steam-flatpak-addons.jpg?resize=800%2C434&ssl=1
diff --git a/published/202104/20210411 GNOME-s Very Own -GNOME OS- is Not a Linux Distro for Everyone -Review.md b/published/202104/20210411 GNOME-s Very Own -GNOME OS- is Not a Linux Distro for Everyone -Review.md
new file mode 100644
index 0000000000..0e251d8829
--- /dev/null
+++ b/published/202104/20210411 GNOME-s Very Own -GNOME OS- is Not a Linux Distro for Everyone -Review.md
@@ -0,0 +1,135 @@
+[#]: subject: (GNOME’s Very Own “GNOME OS” is Not a Linux Distro for Everyone [Review])
+[#]: via: (https://itsfoss.com/gnome-os/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13287-1.html)
+
+GNOME OS:一个并不是适合所有人的 Linux 发行版
+======
+
+
+
+每当 GNOME 的一个重要版本到来时,总是很想尽快试用它。但是,要想第一时间进行测试,主要还是得依靠 [Fedora Rawhide][1] 开发分支。
+
+然而,开发分支并不总是让人放心的,所以,用来尝试最新的 GNOME 并不是最方便的解决方案。这里,我所说的测试,并不仅仅是指用户的测试,同时也能够用于开发者对设计变更进行测试。
+
+所以,最近来了个大救星 GNOME OS,让测试的过程变得轻松起来。但是,它到底是什么,怎么安装呢?让我们一起来看看吧。
+
+### 什么是 GNOME OS?
+
+GNOME OS 并不是一个独立完整的 Linux 发行版。事实上,它根本不基于任何东西。它是一个不完整的参考系统,只是为了让 GNOME 桌面工作。它仅仅是一个可启动的虚拟机镜像,在 GNOME 进入任何发行版的仓库之前,为调试和测试功能而量身定做的。
+
+在 GNOME 的博客中,有一篇提到了它:
+
+> GNOME OS 旨在通过提供一个用于开发、设计和用户测试的工作系统,来更好地促进 GNOME 的开发。
+
+如果你好奇的话,你可以看看 GNOME 星球上的一篇 [博客文章][2] 来了解关于 GNOME OS 的更多信息。
+
+### 如果它不是一个成熟的 Linux 发行版,那么它是用来干什么的?
+
+![][3]
+
+值得注意的是,每一次新的提交都可以创建一个新的 GNOME OS 镜像,所以它应该会使测试过程变得高效,并帮助你在开发周期的早期测试并发现问题。
+
+不要忘了,设计者不再需要自己构建软件来测试 GNOME Shell 或任何其他核心模块。这为他们节省了时间和整个 GNOME 开发周期。
+
+当然,不仅限于开发者和技术测试人员,它还可以让记者们拿到最新的和最棒的东西,来报道 GNOME 下一个版本或它是如何成型的。
+
+媒体和 GNOME 团队也得到了一个很好的机会,借助于 GNOME OS,他们可以准备视频、图片两种形式的视觉资料来宣传此次发布。
+
+### 如何安装 GNOME OS?
+
+要轻松安装 GNOME OS,你需要先安装 GNOME Boxes 应用程序。
+
+#### 安装 GNOME Boxes
+
+Boxes 是一款简单的虚拟化软件,它不提供任何高级选项,但可以让你轻松安装操作系统镜像来快速测试。它是专门针对桌面终端用户的,所以使用起来也很方便。
+
+要在任何 Linux 发行版上安装它,你可以利用 [Flathub][5] 的 [Flatpak][4] 包。如果你不知道 Flatpak,你可能需要阅读我们的《[在 Linux 中安装和使用 Flatpak][6]》指南。
+
+你也可以在任何基于 Ubuntu 的发行版上直接在终端上输入以下内容进行安装:
+
+```
+sudo apt install gnome-boxes
+```
+
+一旦你安装了 Boxes,从这里安装 GNOME OS 就相当容易了。
+
+#### 安装 GNOME OS
+
+安装好 Boxes 后,你需要启动程序。接下来,点击窗口左上角的 “+” 标志,然后点击 “操作系统下载”,如下图所示。
+
+![][7]
+
+这个选项可以让你直接下载镜像文件,然后就可以继续安装它。
+
+你所需要做的就是搜索 “GNOME”,然后你应该会找到可用的每夜构建版。这可以确保你正在尝试最新和最优秀的 GNOME 开发版本。
+
+另外,你也可以前往 [GNOME OS 每夜构建网站][8] 下载系统镜像,然后在 Boxes 应用中选择 “运行系统镜像文件” 选择该 ISO,如上图截图所示,继续安装。
+
+![][9]
+
+考虑到你没有单独下载镜像。当你点击后,应该会开始下载,并且会出现一个进度条。
+
+![][10]
+
+完成后,如果需要,它会要求你自定义配置,让你创建虚拟机,如下图所示。
+
+![][11]
+
+你可以根据你可用的系统资源来定制资源分配,但应该可以使用默认设置。
+
+点击 “创建”,就会直接开始 GNOME OS 的安装。
+
+![][12]
+
+选择“使用现有的版本”,然后继续。接下来,你必须选择磁盘(保持原样),然后同意擦除你所有的文件和应用程序(它不会删除本地计算机上的任何东西)。
+
+![][13]
+
+现在,它将简单地重新格式化并安装它。然后就完成了。它会提示你重启,重启后,你会发现 GNOME OS 已经安装好了。
+
+它会像其他 Linux 发行版一样简单地启动,并要求你设置一些东西,包括用户名和密码。然后,你就可以开始探索了。
+
+如果你想知道它的样子,它基本上就是最新的 GNOME 桌面环境。在 GNOME 40 正式发布之前,我用 GNOME OS 做了一个 GNOME 40 的概述视频。
+
+### 结束语
+
+GNOME OS 绝对是对开发者、设计师和媒体有用的东西。它可以让你轻松地测试最新的 GNOME 开发版本,而无需投入大量的时间。
+
+我可以很快地测试 [GNOME 40][14],就是因为这个。当然,你要记住,这并不是一个可以在物理设备上安装的完整功能的操作系统。他们有计划让它可以在物理机器上运行,但就目前而言,它只是为虚拟机量身定做的,尤其是使用 GNOME Boxes。
+
+GNOME Boxes 并没有提供任何高级选项,所以设置和使用它变得相当容易。如果体验太慢的话,你可能要调整一下资源,但在我的情况下,总体来说是一个不错的体验。
+
+你试过 GNOME OS 了吗?欢迎在下面的评论中告诉我你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/gnome-os/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://fedoraproject.org/wiki/Releases/Rawhide
+[2]: https://blogs.gnome.org/alatiera/2020/10/07/what-is-gnome-os/
+[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/GNOME-OS-distro-review.png?resize=800%2C450&ssl=1
+[4]: https://itsfoss.com/what-is-flatpak/
+[5]: https://flathub.org/apps/details/org.gnome.Boxes
+[6]: https://itsfoss.com/flatpak-guide/
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/gnome-os-search.jpg?resize=800%2C729&ssl=1
+[8]: https://os.gnome.org/
+[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/gnome-os-boxes.jpg?resize=800%2C694&ssl=1
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/gnome-os-download.jpg?resize=798%2C360&ssl=1
+[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/gnome-boxes-vm-setup.png?resize=800%2C301&ssl=1
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/gnome-nightly-install.jpg?resize=800%2C636&ssl=1
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/gnome-os-installation.jpg?resize=800%2C619&ssl=1
+[14]: https://news.itsfoss.com/gnome-40-release/
diff --git a/published/202104/20210412 6 open source tools and tips to securing a Linux server for beginners.md b/published/202104/20210412 6 open source tools and tips to securing a Linux server for beginners.md
new file mode 100644
index 0000000000..ebc367d9ff
--- /dev/null
+++ b/published/202104/20210412 6 open source tools and tips to securing a Linux server for beginners.md
@@ -0,0 +1,191 @@
+[#]: subject: (6 open source tools and tips to securing a Linux server for beginners)
+[#]: via: (https://opensource.com/article/21/4/securing-linux-servers)
+[#]: author: (Sahana Sreeram https://opensource.com/users/sahanasreeram01gmailcom)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13298-1.html)
+
+6 个提升 Linux 服务器安全的开源工具和技巧
+======
+
+> 使用开源工具来保护你的 Linux 环境不被入侵。
+
+
+
+如今我们的许多个人和专业数据都可以在网上获得,因此无论是专业人士还是普通互联网用户,学习安全和隐私的基本知识是非常重要的。作为一名学生,我通过学校的 CyberPatriot 活动获得了这方面的经验,在那里我有机会与行业专家交流,了解网络漏洞和建立系统安全的基本步骤。
+
+本文基于我作为初学者迄今所学的知识,详细介绍了六个简单的步骤,以提高个人使用的 Linux 环境的安全性。在我的整个旅程中,我利用开源工具来加速我的学习过程,并熟悉了与提升 Linux 服务器安全有关的更高层次的概念。
+
+我使用我最熟悉的 Ubuntu 18.04 版本测试了这些步骤,但这些步骤也适用于其他 Linux 发行版。
+
+### 1、运行更新
+
+开发者们不断地寻找方法,通过修补已知的漏洞,使服务器更加稳定、快速、安全。定期运行更新是一个好习惯,可以最大限度地提高安全性。运行它们:
+
+```
+sudo apt-get update && apt-get upgrade
+```
+
+### 2、启用防火墙保护
+
+[启用防火墙][2] 可以更容易地控制服务器上的进站和出站流量。在 Linux 上有许多防火墙应用程序可以使用,包括 [firewall-cmd][3] 和 简单防火墙([UFW][4])。我使用 UFW,所以我的例子是专门针对它的,但这些原则适用于你选择的任何防火墙。
+
+安装 UFW:
+
+```
+sudo apt-get install ufw
+```
+
+如果你想进一步保护你的服务器,你可以拒绝传入和传出的连接。请注意,这将切断你的服务器与世界的联系,所以一旦你封锁了所有的流量,你必须指定哪些出站连接是允许从你的系统中发出的:
+
+```
+sudo ufw default deny incoming
+sudo ufw default allow outgoing
+```
+
+你也可以编写规则来允许你个人使用所需要的传入连接:
+
+```
+ufw allow
+```
+
+例如,允许 SSH 连接:
+
+```
+ufw allow ssh
+```
+
+最后,启用你的防火墙:
+
+```
+sudo ufw enable
+```
+
+### 3、加强密码保护
+
+实施强有力的密码政策是保持服务器安全、防止网络攻击和数据泄露的一个重要方面。密码策略的一些最佳实践包括强制要求最小长度和指定密码年龄。我使用 libpam-cracklib 软件包来完成这些任务。
+
+安装 libpam-cracklib 软件包:
+
+```
+sudo apt-get install libpam-cracklib
+```
+
+强制要求密码的长度:
+
+ * 打开 `/etc/pam.d/common-password` 文件。
+ * 将 `minlen=12` 行改为你需要的任意字符数,从而改变所有密码的最小字符长度要求。
+
+为防止密码重复使用:
+
+ * 在同一个文件(`/etc/pam.d/common-password`)中,添加 `remember=x` 行。
+ * 例如,如果你想防止用户重复使用他们最后 5 个密码中的一个,使用 `remember=5`。
+
+要强制要求密码年龄:
+
+ * 在 `/etc/login.defs` 文件中找到以下几行,并用你喜欢的时间(天数)替换。例如:
+
+```
+PASS_MIN_AGE: 3
+PASS_MAX_AGE: 90
+PASS_WARN_AGE: 14
+```
+
+强制要求字符规格:
+
+ * 在密码中强制要求字符规格的四个参数是 `lcredit`(小写)、`ucredit`(大写)、`dcredit`(数字)和 `ocredit`(其他字符)。
+ * 在同一个文件(`/etc/pam.d/common-password`)中,找到包含 `pam_cracklib.so` 的行。
+ * 在该行末尾添加以下内容:`lcredit=-a ucredit=-b dcredit=-c ocredit=-d`。
+ * 例如,下面这行要求密码必须至少包含一个每种字符。你可以根据你喜欢的密码安全级别来改变数字。`lcredit=-1 ucredit=-1 dcredit=-1 ocredit=-1`。
+
+### 4、停用容易被利用的非必要服务。
+
+停用不必要的服务是一种最好的做法。这样可以减少开放的端口,以便被利用。
+
+安装 systemd 软件包:
+
+```
+sudo apt-get install systemd
+```
+
+查看哪些服务正在运行:
+
+```
+systemctl list-units
+```
+
+[识别][5] 哪些服务可能会导致你的系统出现潜在的漏洞。对于每个服务可以:
+
+ * 停止当前正在运行的服务:`systemctl stop `。
+ * 禁止服务在系统启动时启动:`systemctl disable `。
+ * 运行这些命令后,检查服务的状态:`systemctl status `。
+
+### 5、检查监听端口
+
+开放的端口可能会带来安全风险,所以检查服务器上的监听端口很重要。我使用 [netstat][6] 命令来显示所有的网络连接:
+
+```
+netstat -tulpn
+```
+
+查看 “address” 列,确定 [端口号][7]。一旦你找到了开放的端口,检查它们是否都是必要的。如果不是,[调整你正在运行的服务][8],或者调整你的防火墙设置。
+
+### 6、扫描恶意软件
+
+杀毒扫描软件可以有用的防止病毒进入你的系统。使用它们是一种简单的方法,可以让你的服务器免受恶意软件的侵害。我首选的工具是开源软件 [ClamAV][9]。
+
+安装 ClamAV:
+
+```
+sudo apt-get install clamav
+```
+
+更新病毒签名:
+
+```
+sudo freshclam
+```
+
+扫描所有文件,并打印出被感染的文件,发现一个就会响铃:
+
+```
+sudo clamscan -r --bell -i /
+```
+
+你可以而且应该设置为自动扫描,这样你就不必记住或花时间手动进行扫描。对于这样简单的自动化,你可以使用 [systemd 定时器][10] 或者你的 [喜欢的 cron][11] 来做到。
+
+### 保证你的服务器安全
+
+我们不能把保护服务器安全的责任只交给一个人或一个组织。随着威胁环境的不断迅速扩大,我们每个人都应该意识到服务器安全的重要性,并采用一些简单、有效的安全最佳实践。
+
+这些只是你提升 Linux 服务器的安全可以采取的众多步骤中的一部分。当然,预防只是解决方案的一部分。这些策略应该与严格监控拒绝服务攻击、用 [Lynis][12] 做系统分析以及创建频繁的备份相结合。
+
+你使用哪些开源工具来保证服务器的安全?在评论中告诉我们它们的情况。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/securing-linux-servers
+
+作者:[Sahana Sreeram][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sahanasreeram01gmailcom
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux11x_cc.png?itok=XMDOouJR (People work on a computer server with devices)
+[2]: https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd
+[3]: https://opensource.com/article/20/2/firewall-cheat-sheet
+[4]: https://wiki.ubuntu.com/UncomplicatedFirewall
+[5]: http://www.yorku.ca/infosec/Administrators/UNIX_disable.html
+[6]: https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/netstat
+[7]: https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers
+[8]: https://opensource.com/article/20/5/systemd-units
+[9]: https://www.clamav.net/
+[10]: https://opensource.com/article/20/7/systemd-timers
+[11]: https://opensource.com/article/21/2/linux-automation
+[12]: https://opensource.com/article/20/5/linux-security-lynis
diff --git a/published/202104/20210412 Encrypt your files with this open source software.md b/published/202104/20210412 Encrypt your files with this open source software.md
new file mode 100644
index 0000000000..bf2e9d9fd2
--- /dev/null
+++ b/published/202104/20210412 Encrypt your files with this open source software.md
@@ -0,0 +1,87 @@
+[#]: subject: (Encrypt your files with this open source software)
+[#]: via: (https://opensource.com/article/21/4/open-source-encryption)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13304-1.html)
+
+用开源的 VeraCrypt 加密你的文件
+======
+
+> VeraCrypt 提供跨平台的开源文件加密功能。
+
+
+
+许多年前,有一个名为 [TrueCrypt][2] 的加密软件。它的源码是可以得到的,尽管没有任何人声称曾对它进行过审计或贡献过。它的作者是(至今仍是)匿名的。不过,它是跨平台的,易于使用,而且真的非常有用。
+
+TrueCrypt 允许你创建一个加密的文件“保险库”,在那里你可以存储任何类型的敏感信息(文本、音频、视频、图像、PDF 等)。只要你有正确的口令,TrueCrypt 就可以解密保险库,并在任何运行 TrueCrypt 的电脑上提供读写权限。这是一项有用的技术,它基本上提供了一个虚拟的、可移动的、完全加密的驱动器(除了文件以外),你可以在其中安全地存储你的数据。
+
+TrueCrypt 最终关闭了,但一个名为 VeraCrypt 的替代项目迅速兴起,填补了这一空白。[VeraCrypt][3] 基于 TrueCrypt 7.1a,比原来的版本有许多改进(包括标准加密卷和引导卷的算法的重大变化)。在 VeraCrypt 1.12 及以后的版本中,你可以使用自定义迭代来提高加密安全性。更好的是,VeraCrypt 可以加载旧的 TrueCrypt 卷,所以如果你是 TrueCrypt 用户,可以很容易地将它们转移到 VeraCrypt 上。
+
+### 安装 VeraCrypt
+
+你可以从 [VeraCrypt 下载页面][4] 下载相应的安装文件,之后在所有主流平台上安装 VeraCrypt。
+
+另外,你也可以自己从源码构建它。在 Linux 上,它需要 wxGTK3、makeself 和通常的开发栈(Binutils、GCC 等)。
+
+当你安装后,从你的应用菜单中启动 VeraCrypt。
+
+### 创建一个 VeraCrypt 卷
+
+如果你刚接触 VeraCrypt,你必须先创建一个 VeraCrypt 加密卷(否则,你没有任何东西可以解密)。在 VeraCrypt 窗口中,点击左侧的 “Create Volume” 按钮。
+
+![Creating a volume with VeraCrypt][5]
+
+在出现的 VeraCrypt 的卷创建向导窗口中,选择要创建一个加密文件容器还是要加密整个驱动器或分区。向导将为你的数据创建一个保险库,所以请按照提示进行操作。
+
+在本文中,我创建了一个文件容器。VeraCrypt 容器和其他文件很像:它保存在硬盘、外置硬盘、云存储或其他任何你能想到的存储数据的地方。与其他文件一样,它可以被移动、复制和删除。与大多数其他文件不同的是,它可以_容纳_更多的文件,这就是为什么我认为它是一个“保险库”,而 VeraCrypt 开发者将其称为“容器”。它的开发者将 VeraCrypt 文件称为“容器”,是因为它可以包含其他数据对象;它与 LXC、Kubernetes 和其他现代 IT 机制所流行的容器技术无关。
+
+#### 选择一个文件系统
+
+在创建卷的过程中,你会被要求选择一个文件系统来决定你放在保险库中的文件的存储方式。微软 FAT 格式是过时的、非日志型,并且限制了卷和文件的大小,但它是所有平台都能读写的一种格式。如果你打算让你的 VeraCrypt 保险库跨平台,FAT 是你最好的选择。
+
+除此之外,NTFS 适用于 Windows 和 Linux。开源的 EXT 系列适用于 Linux。
+
+### 挂载 VeraCrypt 加密卷
+
+当你创建了 VeraCrypt 卷,你就可以在 VeraCrypt 窗口中加载它。要挂载一个加密库,点击右侧的 “Select File” 按钮。选择你的加密文件,选择 VeraCrypt 窗口上半部分的一个编号栏,然后点击位于 VeraCrypt 窗口左下角的 “Mount” 按钮。
+
+你挂载的卷在 VeraCrypt 窗口的可用卷列表中,你可以通过文件管理器访问该卷,就像访问一个外部驱动器一样。例如,在 KDE 上,我打开 [Dolphin][7],进入 `/media/veracrypt1`,然后我就可以把文件复制到我的保险库里。
+
+只要你的设备上有 VeraCrypt,你就可以随时访问你的保险库。在你手动在 VeraCrypt 中挂载之前,文件都是加密的,在那里,文件会保持解密,直到你再次关闭卷。
+
+### 关闭 VeraCrypt 卷
+
+为了保证你的数据安全,当你不需要打开 VeraCrypt 卷时,关闭它是很重要的。这样可以保证数据的安全,不被人窥视,且不被人趁机犯罪。
+
+![Mounting a VeraCrypt volume][8]
+
+关闭 VeraCrypt 容器和打开容器一样简单。在 VeraCrypt 窗口中选择列出的卷,然后点击 “Dismount”。你就不能访问保险库中的文件了,其他人也不会再有访问权。
+
+### VeraCrypt 轻松实现跨平台加密
+
+有很多方法可以保证你的数据安全,VeraCrypt 试图为你提供方便,而无论你需要在什么平台上使用这些数据。如果你想体验简单、开源的文件加密,请尝试 VeraCrypt。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/open-source-encryption
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security-lock-password.jpg?itok=KJMdkKum (Lock)
+[2]: https://en.wikipedia.org/wiki/TrueCrypt
+[3]: https://www.veracrypt.fr/en/Home.html
+[4]: https://www.veracrypt.fr/en/Downloads.html
+[5]: https://opensource.com/sites/default/files/uploads/veracrypt-create.jpg (Creating a volume with VeraCrypt)
+[6]: https://creativecommons.org/licenses/by-sa/4.0/
+[7]: https://en.wikipedia.org/wiki/Dolphin_%28file_manager%29
+[8]: https://opensource.com/sites/default/files/uploads/veracrypt-volume.jpg (Mounting a VeraCrypt volume)
diff --git a/published/202104/20210413 Create an encrypted file vault on Linux.md b/published/202104/20210413 Create an encrypted file vault on Linux.md
new file mode 100644
index 0000000000..94dde76530
--- /dev/null
+++ b/published/202104/20210413 Create an encrypted file vault on Linux.md
@@ -0,0 +1,113 @@
+[#]: subject: (Create an encrypted file vault on Linux)
+[#]: via: (https://opensource.com/article/21/4/linux-encryption)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13296-1.html)
+
+在 Linux 上创建一个加密文件保险库
+======
+
+> 使用 Linux 统一密钥设置(LUKS)为物理驱动器或云存储上的敏感文件创建一个加密保险库。
+
+
+
+最近,我演示了如何在 Linux 上使用统一密钥设置([LUKS][3])和 `cryptsetup` 命令 [实现全盘加密][2]。虽然加密整个硬盘在很多情况下是有用的,但也有一些原因让你不想对整个硬盘进行加密。例如,你可能需要让一个硬盘在多个平台上工作,其中一些平台可能没有集成 [LUKS][3]。此外,现在是 21 世纪,由于云的存在,你可能不会使用物理硬盘来处理所有的数据。
+
+几年前,有一个名为 [TrueCrypt][4] 的系统,允许用户创建加密的文件保险库,可以通过 TrueCrypt 解密来提供读/写访问。这是一项有用的技术,基本上提供了一个虚拟的便携式、完全加密的驱动器,你可以在那里存储重要数据。TrueCrypt 项目关闭了,但它可以作为一个有趣的模型。
+
+幸运的是,LUKS 是一个灵活的系统,你可以使用它和 `cryptsetup` 在一个独立的文件中创建一个加密保险库,你可以将其保存在物理驱动器或云存储中。
+
+下面就来介绍一下怎么做。
+
+### 1、建立一个空文件
+
+首先,你必须创建一个预定大小的空文件。就像是一种保险库或保险箱,你可以在其中存储其他文件。你使用的命令是 `util-linux` 软件包中的 `fallocate`:
+
+```
+$ fallocate --length 512M vaultfile.img
+```
+
+这个例子创建了一个 512MB 的文件,但你可以把你的文件做成任何你想要的大小。
+
+### 2、创建一个 LUKS 卷
+
+接下来,在空文件中创建一个 LUKS 卷:
+
+```
+$ cryptsetup --verify-passphrase \
+ luksFormat vaultfile.img
+```
+
+### 3、打开 LUKS 卷
+
+要想创建一个可以存储文件的文件系统,必须先打开 LUKS 卷,并将其挂载到电脑上:
+
+```
+$ sudo cryptsetup open \
+ --type luks vaultfile.img myvault
+$ ls /dev/mapper
+myvault
+```
+
+### 4、建立一个文件系统
+
+在你打开的保险库中建立一个文件系统:
+
+```
+$ sudo mkfs.ext4 -L myvault /dev/mapper/myvault
+```
+
+如果你现在不需要它做什么,你可以关闭它:
+
+```
+$ sudo cryptsetup close myvault
+```
+
+### 5、开始使用你的加密保险库
+
+现在一切都设置好了,你可以在任何需要存储或访问私人数据的时候使用你的加密文件库。要访问你的保险库,必须将其挂载为一个可用的文件系统:
+
+```
+$ sudo cryptsetup open \
+ --type luks vaultfile.img myvault
+$ ls /dev/mapper
+myvault
+$ sudo mkdir /myvault
+$ sudo mount /dev/mapper/myvault /myvault
+```
+
+这个例子用 `cryptsetup` 打开保险库,然后把保险库从 `/dev/mapper` 下挂载到一个叫 `/myvault` 的新目录。和 Linux 上的任何卷一样,你可以把 LUKS 卷挂载到任何你想挂载的地方,所以除了 `/myvault`,你可以用 `/mnt` 或 `~/myvault` 或任何你喜欢的位置。
+
+当它被挂载后,你的 LUKS 卷就会被解密。你可以像读取和写入文件一样读取和写入它,就像它是一个物理驱动器一样。
+
+当使用完你的加密保险库时,请卸载并关闭它:
+
+```
+$ sudo umount /myvault
+$ sudo cryptsetup close myvault
+```
+
+### 加密的文件保险库
+
+你用 LUKS 加密的镜像文件和其他文件一样,都是可移动的,因此你可以将你的保险库存储在硬盘、外置硬盘,甚至是互联网上。只要你可以使用 LUKS,就可以解密、挂载和使用它来保证你的数据安全。轻松加密,提高数据安全性,不妨一试。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/linux-encryption
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life_bank_vault_secure_safe.png?itok=YoW93h7C (Secure safe)
+[2]: https://opensource.com/article/21/3/encryption-luks
+[3]: https://gitlab.com/cryptsetup/cryptsetup/blob/master/README.md
+[4]: https://en.wikipedia.org/wiki/TrueCrypt
diff --git a/published/202104/20210413 Create and Edit EPUB Files on Linux With Sigil.md b/published/202104/20210413 Create and Edit EPUB Files on Linux With Sigil.md
new file mode 100644
index 0000000000..9a1a3e0397
--- /dev/null
+++ b/published/202104/20210413 Create and Edit EPUB Files on Linux With Sigil.md
@@ -0,0 +1,101 @@
+[#]: subject: (Create and Edit EPUB Files on Linux With Sigil)
+[#]: via: (https://itsfoss.com/sigile-epub-editor/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13325-1.html)
+
+用 Sigil 在 Linux 上创建和编辑 EPUB 文件
+======
+
+
+
+Sigil 是一个开源的 Linux、Windows 和 MacOS 上的 EPUB 编辑器。你可以使用 Sigil 创建一个新的 EPUB 格式的电子书,或编辑现有的 EPUB 电子书(以 `.epub` 扩展结尾的文件)。
+
+如果你感到好奇,EPUB 是一个标准的电子书格式,并被几个数字出版集团认可。它被许多设备和电子阅读器支持,除了亚马逊的 Kindle。
+
+### Sigil 让你创建或编辑 EPUB 文件
+
+[Sigil][1] 是一个允许你编辑 EPUB 文件的开源软件。当然,你可以从头开始创建一个新的 EPUB 文件。
+
+![][2]
+
+很多人在 [创建或编辑电子书时非常相信 Calibre][3]。它确实是一个完整的工具,它有很多的功能,支持的格式不只是 EPUB 格式。然而,Calibre 有时可能需要过多的资源。
+
+Sigil 只专注于 EPUB 书籍,它有以下功能:
+
+ * 支持 EPUB 2 和 EPUB 3(有一定的限制)
+ * 提供代码视图预览
+ * 编辑 EPUB 语法
+ * 带有多级标题的目录生成器
+ * 编辑元数据
+ * 拼写检查
+ * 支持正则查找和替换
+ * 支持导入 EPUB、HTML 文件、图像和样式表
+ * 额外插件
+ * 多语言支持的接口
+ * 支持 Linux、Windows 和 MacOS
+
+Sigil 不是你可以直接输入新书章节的 [所见即所得][4] 类型的编辑器。由于 EPUB 依赖于 XML,因此它专注于代码。可以将其视为用于 EPUB 文件的 [类似于 VS Code 的代码编辑器][5]。出于这个原因,你应该使用一些其他 [开源写作工具][6],以 epub 格式导出你的文件(如果可能的话),然后在 Sigil 中编辑它。
+
+![][7]
+
+Sigil 有一个 [Wiki][8] 来提供一些安装和使用 Sigil 的文档。
+
+### 在 Linux 上安装 Sigil
+
+Sigil 是一款跨平台应用,支持 Windows 和 macOS 以及 Linux。它是一个流行的软件,有超过十年的历史。这就是为什么你应该会在你的 Linux 发行版仓库中找到它。只要在你的发行版的软件中心应用中寻找它就可以了。
+
+![Sigil in Ubuntu Software Center][9]
+
+你可能需要事先启用 universe 仓库。你也可以在 Ubuntu发行版中使用 `apt` 命令:
+
+```
+sudo apt install sigil
+```
+
+Sigil 有很多对 Python 库和模块的依赖,因此它下载和安装了大量的包。
+
+![][10]
+
+我不会列出 Fedora、SUSE、Arch 和其他发行版的命令。你可能已经知道如何使用你的发行版的软件包管理器,对吧?
+
+你的发行版提供的版本不一定是最新的。如果你想要 Sigil 的最新版本,你可以查看它的 GitHub 仓库。
+
+- [Sigil 的 GitHub 仓库][11]
+
+### 并不适合所有人,当然也不适合用于阅读 ePUB 电子书
+
+我不建议使用 Sigil 阅读电子书。Linux 上有 [其他专门的应用来阅读 .epub 文件][12]。
+
+如果你是一个必须处理 EPUB 书籍的作家,或者如果你在数字化旧书,并在各种格式间转换,Sigil 可能是值得一试。
+
+我还没有大量使用 过 Sigil,所以我不提供对它的评论。我让你去探索它,并在这里与我们分享你的经验。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/sigile-epub-editor/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://sigil-ebook.com/
+[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/open-epub-sigil.png?resize=800%2C621&ssl=1
+[3]: https://itsfoss.com/create-ebook-calibre-linux/
+[4]: https://www.computerhope.com/jargon/w/wysiwyg.htm
+[5]: https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
+[6]: https://itsfoss.com/open-source-tools-writers/
+[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/sigil-epub-editor-800x621.png?resize=800%2C621&ssl=1
+[8]: https://github.com/Sigil-Ebook/Sigil/wiki
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/sigil-software-center-ubuntu.png?resize=800%2C424&ssl=1
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/installing-sigil-ubuntu.png?resize=800%2C547&ssl=1
+[11]: https://github.com/Sigil-Ebook/Sigil
+[12]: https://itsfoss.com/open-epub-books-ubuntu-linux/
diff --git a/published/202104/20210414 Make your data boss-friendly with this open source tool.md b/published/202104/20210414 Make your data boss-friendly with this open source tool.md
new file mode 100644
index 0000000000..5104978e55
--- /dev/null
+++ b/published/202104/20210414 Make your data boss-friendly with this open source tool.md
@@ -0,0 +1,108 @@
+[#]: subject: (Make your data boss-friendly with this open source tool)
+[#]: via: (https://opensource.com/article/21/4/visualize-data-eda)
+[#]: author: (Juanjo Ortilles https://opensource.com/users/jortilles)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13310-1.html)
+
+用这个开源工具让你的数据对老板友好起来
+======
+
+> 企业数据分析旨在将数据可视化带给日常商务用户。
+
+
+
+企业数据分析([EDA][2]) 是一个网页应用,它可以通过一个简单、清晰的界面来获取信息。
+
+在巴塞罗那开源分析公司 [Jortilles][3] 工作几年后,我们意识到,现代世界强制性地收集数据,但普通人没有简单的方法来查看或解释这些数据。有一些强大的开源工具可用于此目的,但它们非常复杂。我们找不到一个工具设计成能让没有什么技术能力的普通人轻松使用。
+
+我们之所以开发 EDA,是因为我们认为获取信息是现代组织的要求和义务,并希望为每个人提供获取信息的机会。
+
+![EDA interface][4]
+
+### 可视化你的数据
+
+EDA 使用人们已经理解的商业术语提供了一个数据模型。你可以选择你想要的信息,并可以以你想要的方式查看它。它的目标是对用户友好,同时又功能强大。
+
+EDA 通过元数据模型将数据库中的信息可视化和丰富化。它可以从 BigQuery、Postgres、[MariaDB、MySQL][6] 和其他一些数据库中读取数据。这就把技术性的数据库模型转化为熟悉的商业概念。
+
+它还设计为加快信息传播的速度,因为它可以利用已经存储在数据库中的数据。EDA 可以发现数据库的拓扑结构,并提出业务模型。如果你设计了一个好的数据库模型,你就有了一个好的业务模型。EDA 还可以连接到生产服务器,提供实时分析。
+
+这种数据和数据模型的结合意味着你和你组织中的任何人都可以分析其数据。然而,为了保护数据,你可以定义数据安全,可以精确到行,以授予正当的人访问正当的数据。
+
+EDA 的一些功能包括:
+
+ * 自动生成数据模型
+ * 一致的数据模型,防止出现不一致的查询
+ * 高级用户的 SQL 模式
+ * 数据可视化:
+ * 标准图表(如柱状图、饼状图、线状图、树状图)
+ * 地图整合(如 geoJSON shapefile、纬度、经度)
+ * 电子邮件提醒,可通过关键绩效指标 (KPI) 来定义
+ * 私人和公共信息控制,以启用私人和公共仪表板,你可以通过链接分享它。
+ * 数据缓存和程序刷新。
+
+### 如何使用 EDA
+
+用 EDA 实现数据可视化的第一步是创建数据模型。
+
+#### 创建数据模型
+
+首先,在左侧菜单中选择 “New Datasource”。
+
+接下来,选择你的数据存储的数据库系统(如 Postgres、MariaDB、MySQL、Vertica、SqlServer、Oracle、Big Query),并提供连接参数。
+
+EDA 将自动为你生成数据模型。它读取表和列,并为它们定义名称以及表之间的关系。你还可以通过添加虚拟视图或 geoJSON 图来丰富你的数据模型。
+
+#### 制作仪表板
+
+现在你已经准备好制作第一个仪表板了。在 EDA 界面的主页面上,你应该会看到一个 “New dashboard” 按钮。点击它,命名你的仪表板,并选择你创建的数据模型。新的仪表板将出现一个面板供你配置。
+
+要配置面板,请单击右上角的 “Configuration” 按钮,并选择你要做的事情。在 “Edit query” 中,选择你要显示的数据。这将出现一个新的窗口,你的数据模型由实体和实体的属性表示。选择你要查看的实体和你要使用的属性。例如,对于名为 “Customers” 的实体,你可能会显示 “Customer Name”,对于 “Sales” 实体,你可能希望显示 “Total Sales”。
+
+接下来,运行一个查询,并选择你想要的可视化。
+
+![EDA interface][7]
+
+你可以添加任意数量的面板、过滤器和文本字段,所有这些都有说明。当你保存仪表板后,你可以查看它,与同事分享,甚至发布到互联网上。
+
+### 获取 EDA
+
+最快的方法是用 [公开演示][8] 来查看 EDA。但如果你想自己试一试,可以用 Docker 获取最新的 EDA 版本:
+
+```
+$ docker run -p 80:80 jortilles / eda: latest
+```
+
+我们还有一个 SaaS 选项,适用于任何想要使用 EDA 而无需进行安装、配置和持续更新的用户。你可以在我们的网站上查看 [云选项][9]。
+
+如果你想看看它的实际运行情况,你可以在 YouTube 上观看一些 [演示][10]。
+
+EDA 正在持续开发中,你可以在 GitHub 上找到它的 [源代码][11]。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/visualize-data-eda
+
+作者:[Juanjo Ortilles][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jortilles
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
+[2]: https://eda.jortilles.com/en/jortilles-english/
+[3]: https://www.jortilles.com/
+[4]: https://opensource.com/sites/default/files/uploads/eda-display.jpeg (EDA interface)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://opensource.com/article/20/10/mariadb-mysql-cheat-sheet
+[7]: https://opensource.com/sites/default/files/uploads/eda-chart.jpeg (EDA interface)
+[8]: https://demoeda.jortilles.com/
+[9]: https://eda.jortilles.com
+[10]: https://youtu.be/cBAAJbohHXQ
+[11]: https://github.com/jortilles/EDA
diff --git a/published/202104/20210419 4 steps to customizing your Mac terminal theme with open source tools.md b/published/202104/20210419 4 steps to customizing your Mac terminal theme with open source tools.md
new file mode 100644
index 0000000000..19237b5d7c
--- /dev/null
+++ b/published/202104/20210419 4 steps to customizing your Mac terminal theme with open source tools.md
@@ -0,0 +1,88 @@
+[#]: subject: (4 steps to customizing your Mac terminal theme with open source tools)
+[#]: via: (https://opensource.com/article/21/4/zsh-mac)
+[#]: author: (Bryant Son https://opensource.com/users/brson)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13323-1.html)
+
+用开源工具定制 Mac 终端主题的 4 个步骤
+======
+
+> 用开源工具让你的终端窗口在 Mac 上漂亮起来。
+
+
+
+你是否曾经厌倦了在你的 macOS 电脑上看到同样老式的终端窗口?如果是这样,使用开源的 Oh My Zsh 框架和 Powerlevel10k 主题为你的视图添加一些点缀。
+
+这个基本的逐步教程将让你开始定制你的 macOS 终端。如果你是一个 Linux 用户,请查看 Seth Kenlon 的指南 [为 Zsh 添加主题和插件][2] 以获得深入指导。
+
+### 步骤 1:安装 Oh My Zsh
+
+[Oh My Zsh][3] 是一个开源的、社区驱动的框架,用于管理你的 Z shell (Zsh) 配置。
+
+![Oh My Zsh][4]
+
+Oh My Zsh 是在 MIT 许可下发布的。使用以下命令安装:
+
+```
+$ sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
+```
+
+### 步骤 2:安装 Powerlevel10k 字体
+
+![Powerlevel10k][6]
+
+Powerlevel10k 是一个 MIT 许可的 Zsh 主题。在安装 Powerlevel10k 之前,你需要为你的终端安装自定义字体。
+
+到 [Powerlevel10 GitHub][7] 页面,在 `README` 中 搜索 “fonts”。安装自定义字体的步骤会根据你的操作系统而有所不同。这只需要简单地点击-下载-安装的系列操作。
+
+![Powerlevel10k fonts][8]
+
+### 步骤 3:安装 Powerlevel10k 主题
+
+接下来,运行以下命令安装 Powerlevel10k:
+
+```
+git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k
+```
+
+完成后,用文本编辑器,比如 [Vim][9],打开 `~/.zshrc` 配置文件,设置行 `ZSH_THEME="powerlevel10k/powerlevel10k`,然后保存文件。
+
+### 步骤 4:完成 Powerlevel10 的设置
+
+打开一个新的终端,你应该看到 Powerlevel10k 配置向导。如果没有,运行 `p10k configure` 来调出配置向导。如果你在步骤 2 中安装了自定义字体,那么图标和符号应该正确显示。将默认字体更改为 `MeslowLG NF`。
+
+![Powerlevel10k configuration][10]
+
+当你完成配置后,你应该会看到一个漂亮的终端。
+
+![Oh My Zsh/Powerlevel10k theme][11]
+
+就是这些了!你应该可以享受你美丽的新终端了。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/zsh-mac
+
+作者:[Bryant Son][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/brson
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/freedos.png?itok=aOBLy7Ky (4 different color terminal windows with code)
+[2]: https://opensource.com/article/19/9/adding-plugins-zsh
+[3]: https://ohmyz.sh/
+[4]: https://opensource.com/sites/default/files/uploads/1_ohmyzsh.jpg (Oh My Zsh)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://opensource.com/sites/default/files/uploads/2_powerlevel10k.jpg (Powerlevel10k)
+[7]: https://github.com/romkatv/powerlevel10k
+[8]: https://opensource.com/sites/default/files/uploads/3_downloadfonts.jpg (Powerlevel10k fonts)
+[9]: https://opensource.com/resources/what-vim
+[10]: https://opensource.com/sites/default/files/uploads/4_p10kconfiguration.jpg (Powerlevel10k configuration)
+[11]: https://opensource.com/sites/default/files/uploads/5_finalresult.jpg (Oh My Zsh/Powerlevel10k theme)
diff --git a/published/202104/20210419 Something bugging you in Fedora Linux- Let-s get it fixed.md b/published/202104/20210419 Something bugging you in Fedora Linux- Let-s get it fixed.md
new file mode 100644
index 0000000000..c379370092
--- /dev/null
+++ b/published/202104/20210419 Something bugging you in Fedora Linux- Let-s get it fixed.md
@@ -0,0 +1,70 @@
+[#]: subject: (Something bugging you in Fedora Linux? Let’s get it fixed!)
+[#]: via: (https://fedoramagazine.org/something-bugging-you-in-fedora-linux-lets-get-it-fixed/)
+[#]: author: (Matthew Miller https://fedoramagazine.org/author/mattdm/)
+[#]: collector: (lujun9972)
+[#]: translator: (DCOLIVERSUN)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13333-1.html)
+
+Fedora Linux 中有 Bug 吗?一起来修复它!
+======
+
+![][1]
+
+软件有 bug。任何复杂系统都无法保证每个部分都能按计划工作。Fedora Linux 是一个 _非常_ 复杂的系统,包含几千个包,这些包由全球无数个独立的上游项目创建。每周还有数百个更新。因此,问题是不可避免的。本文介绍了 bug 修复过程以及如何确定 bug 优先级。
+
+### 发布开发过程
+
+作为一个 Linux 发行项目,我们希望为用户提供完善的、一切正常的体验。我们的发布起始于 “Rawhide”。我们在 Rawhide 中集成了所有更新的自由及开源软件的新版本。我们一直在不断改进正在进行的测试和持续集成过程,为了让即使是 Rawhide 也能被冒险者安全使用。可是,从本质来讲,Rawhide 始终有点粗糙。
+
+每年两次,我们把这个粗糙的操作系统先后分支到测试版本、最终版本。当我们这么做时,我们齐心协力地寻找问题。我们在测试日检查特定的区域和功能。制作“候选版本”,并根据我们的 [发布验证测试计划][2] 进行检测。然后我们进入冻结状态,只有批准的更改可以并入候选版本。这就把候选版本从持续的开发隔离开来,持续的开发不断并入 Rawhide 中。所以,不会引入新的问题。
+
+在发布过程中许多 bug 被粉碎去除,这些 bug 有大有小。当一切按计划进行时,我们为所有用户提供了按计划发布的崭新的 Fedora Linux 版本。(在过去几年里,我们已经可靠地重复这一动作——感谢每一个为之努力工作的人!)如果确实有问题,我们可以将其标记为发布阻碍。这就意味着我们要等到修复后才能发布。发布阻碍通常代表重大问题,该表达一定会引发对 bug 的关注。
+
+有时,我们遇到的一些问题是持续存在的。可能一些问题已经持续了一两个版本,或者我们还没有达成共识的解决方案。有些问题确实困扰着许多用户,但个别问题并没有达到阻碍发布的程度。我们可以将这些东西标记为阻碍。但这会像锤子一样砸下来。阻碍可能导致最终粉碎该 bug,但也可能导致破坏了周围。如果进度落后,所有其它的 bug 修复、改进以及人们一直在努力的功能,都不能到达用户手中。
+
+### 按优先顺序排列 bug 流程
+
+所以,我们有另一种方法来解决烦人的 bug。[按优先顺序排列 bug 流程][3],与其他方式不同,可以标出导致大量用户不满意的问题。这里没有锤子,更像是聚光灯。与发布阻碍不同,按优先顺序排列 bug 流程没有一套严格定义的标准。每个 bug 都是根据影响范围和严重性来评估的。
+
+一个由感兴趣的贡献者组成的团队帮助策划一个简短列表,上面罗列着需要注意的问题。然后,我们的工作是将问题匹配到能够解决它们的人。这有助于减轻发布过程中的压力,因为它没有给问题指定任何特定的截止时间。理想情况下,我们能在进入测试阶段之前就发现并解决问题。我们尽量保持列表简短,不会超过几个,这样才会真正有重点。这种做法有助于团队和个人解决问题,因为他们知道我们尊重他们捉襟见肘的时间与精力。
+
+通过这个过程,Fedora 解决了几十个严重而恼人的问题,包括从键盘输入故障到 SELinux 错误,再到数千兆字节大小的旧包更新会逐渐填满你的磁盘。但是我们可以做得更多——我们实际上收到的提案没有达到我们的处理能力上限。因此,如果你知道有什么事情导致了长期挫折或影响了很多人,至今没有达成解决方案,请遵循 [按优先顺序排列 bug 流程][3],提交给我们。
+
+### 你可以帮助我们
+
+邀请所有 Fedora 贡献者参与按优化顺序排列 bug 的流程。评估会议每两周在 IRC 上举办一次。欢迎任何人加入并帮助我们评估提名的 bug。会议时间和地点参见 [日历][4]。Fedora 项目经理在会议开始的前一天将议程发送到 [triage][5] 和 [devel][6] 邮件列表。
+
+### 欢迎报告 bug
+
+当你发现 bug 时,无论大小,我们很感激你能报告 bug。在很多情况下,解决 bug 最好的方式是交给创建该软件的项目。例如,假设渲染数据相机照片的 Darktable 摄影软件出了问题,最好把它带给 Darktable 摄影软件的开发人员。再举个例子,假设 GNOME 或 KDE 桌面环境或组成部分软件出了问题,将这些问题交给这些项目中通常会得到最好的结果。
+
+然而, 如果这是一个特定的 Fedora 问题,比如我们的软件构建或配置或者它的集成方式的问题,请毫不犹豫地 [向我们提交 bug][7]。当你知道有一个问题是我们还没有解决的,也要提交给我们。
+
+我知道这很复杂……最好有一个一站式的地方来处理所有 bug。但是请记住,Fedora 打包者大部分是志愿者,他们负责获取上游软件并将其配置到我们系统中。他们并不总是对他们正在使用的软件的代码有深入研究的专家。有疑问的时候,你可以随时提交一个 [Fedora bug][7]。Fedora 中负责相应软件包的人可以通过他们与上游软件项目的联系提供帮助。
+
+请记住,当你发现一个已通过诊断但尚未得到良好修复的 bug 时,当你看到影响很多人的问题时,或者当有一个长期存在的问题没有得到关注时,请将其提名为高优先级 bug。我们会看以看能做些什么。
+
+_附言:标题中的著名图片当然是来自哈佛大学马克 2 号计算机的日志,这里曾是格蕾丝·赫柏少将工作的地方。但是与这个故事的普遍看法相背,这并不是 “bug” 一词第一次用于表示系统问题——它在工程中已经很常见了,这就是为什么发现一个字面上的 “bug” 作为问题的原因是很有趣的。 #nowyouknow #jokeexplainer_
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/something-bugging-you-in-fedora-linux-lets-get-it-fixed/
+
+作者:[Matthew Miller][a]
+选题:[lujun9972][b]
+译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/mattdm/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/04/bugging_you-816x345.jpg
+[2]: https://fedoraproject.org/wiki/QA:Release_validation_test_plan
+[3]: https://docs.fedoraproject.org/en-US/program_management/prioritized_bugs/
+[4]: https://calendar.fedoraproject.org/base/
+[5]: https://lists.fedoraproject.org/archives/list/triage%40lists.fedoraproject.org/
+[6]: https://lists.fedoraproject.org/archives/list/devel%40lists.fedoraproject.org/
+[7]: https://docs.fedoraproject.org/en-US/quick-docs/howto-file-a-bug/
diff --git a/published/202104/20210420 Blanket- Ambient Noise App With Variety of Sounds to Stay Focused.md b/published/202104/20210420 Blanket- Ambient Noise App With Variety of Sounds to Stay Focused.md
new file mode 100644
index 0000000000..5c9c76d025
--- /dev/null
+++ b/published/202104/20210420 Blanket- Ambient Noise App With Variety of Sounds to Stay Focused.md
@@ -0,0 +1,80 @@
+[#]: subject: (Blanket: Ambient Noise App With Variety of Sounds to Stay Focused)
+[#]: via: (https://itsfoss.com/blanket-ambient-noise-app/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13343-1.html)
+
+Blanket:拥有各种环境噪音的应用,帮助保持注意力集中
+======
+
+> 一个开源的环境噪音播放器,提供各种声音,帮助你集中注意力或入睡。
+
+
+
+随着你周围活动的增加,要保持冷静和专注往往是很困难的。
+
+有时,音乐会有所帮助,但在某些情况下也会分散注意力。但是,环境噪音如何?这总是让人听起来很舒心。谁不想在餐厅里听到鸟叫声、雨滴声和人群的交谈声?好吧,可能不是最后一个,但听自然的声音可以帮助放松和集中注意力。这间接地提高了你的工作效率。
+
+最近,我发现了一个专门的播放器,其中包含了不同的声音,可以帮助任何人集中注意力。
+
+### 使用 Blanket 播放不同的环境声音
+
+Blanket 是一个令人印象深刻的环境噪音播放器,它具有不同的声音,可以帮助你入睡或只是通过帮助你忘记周围的干扰来重获注意力。
+
+它包括自然界的声音,像雨声、海浪声、鸟鸣声、风暴声、风声、水流声、夏夜声。
+
+![][1]
+
+此外,如果你是一个通勤者或在轻微繁忙的环境中感到舒适的人,你可以找到火车、船、城市、咖啡馆或壁炉的声音。
+
+如果你喜欢白噪声或粉红噪声,它结合了人类能听到的所有声音频率,这里也可以找到。
+
+它还可以让你在每次开机时自动启动,如果你喜欢这样的话。
+
+![][2]
+
+### 在 Linux 上安装 Blanket
+
+安装 Blanket 的最好方法是来自 [Flathub][3]。考虑到你已经启用了 [Flatpak][4],你只需在终端键入以下命令就可以安装它:
+
+```
+flatpak install flathub com.rafaelmardojai.Blanket
+```
+
+如果你是 Flatpak 的新手,你可能想通过我们的 [Flatpak 指南][5]了解。
+
+如果你不喜欢使用 Flatpak,你可以使用该项目中的贡献者维护的 PPA 来安装它。对于 Arch Linux 用户,你可以在 [AUR][6] 中找到它,以方便安装。
+
+此外,你还可以找到 Fedora 和 openSUSE 的软件包。要探索所有现成的软件包,你可以前往其 [GitHub 页面][7]。
+
+### 结束语
+
+对于一个简单的环境噪音播放器来说,用户体验是相当好的。我有一副 HyperX Alpha S 耳机,我必须要说,声音的质量很好。
+
+换句话说,它听起来很舒缓,如果你想体验环境声音来集中注意力,摆脱焦虑或只是睡着,我建议你试试。
+
+你试过它了吗?欢迎在下面分享你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/blanket-ambient-noise-app/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/blanket-screenshot.png?resize=614%2C726&ssl=1
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/blanket-autostart-1.png?resize=514%2C214&ssl=1
+[3]: https://flathub.org/apps/details/com.rafaelmardojai.Blanket
+[4]: https://itsfoss.com/what-is-flatpak/
+[5]: https://itsfoss.com/flatpak-guide/
+[6]: https://itsfoss.com/aur-arch-linux/
+[7]: https://github.com/rafaelmardojai/blanket
diff --git a/published/202104/20210420 The Guided Installer in Arch is a Step in the Right Direction.md b/published/202104/20210420 The Guided Installer in Arch is a Step in the Right Direction.md
new file mode 100644
index 0000000000..3a6cc82345
--- /dev/null
+++ b/published/202104/20210420 The Guided Installer in Arch is a Step in the Right Direction.md
@@ -0,0 +1,78 @@
+[#]: subject: (The Guided Installer in Arch is a Step in the Right Direction)
+[#]: via: (https://news.itsfoss.com/arch-new-guided-installer/)
+[#]: author: (Jacob Crume https://news.itsfoss.com/author/jacob/)
+[#]: collector: (lujun9972)
+[#]: translator: (Kevin3599)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13328-1.html)
+
+Arch Linux 中的引导式安装程序是迈向正确的一步
+======
+
+> 在 Arch ISO 中加入一个可选的引导式安装程序,对新手和高级用户都有好处。
+
+
+
+20 年来,Arch Linux 为用户提供了一个完全定制、独特的系统。这些年来,它以牺牲用户友好性为代价,赢得了在定制方面独有的声誉。
+
+作为滚动发行版本,Arch Linux 不提供任何固定发行版本,而是每月更新一次。但是,如果你在最近几周下载了 Arch Linux,那么你很可能已经注意到了一个新的附加功能:archinstall。它使 Arch Linux 更加易于安装。
+
+![][3]
+
+今天,我将探讨 archinstall 的发布对未来的 Arch Linux 项目和发行版意味着什么。
+
+### Arch Linux 新的发展方向?
+
+![][4]
+
+尽管很多人对此感到惊讶,但默认情况下包含官方安装程序实际上是非常明智的举动。这意味着 Arch Linux 的发展方向发生变化,即在保留使其知名的定制性同时更加侧重用户的易用性。
+
+在该安装程序的 GitHub 页面上有这样的描述:
+
+> “引导性安装程序会给用户提供一个友好的逐步安装方式,但是关键在于这个安装程序是个选项,它是可选的,绝不会强迫用户使用其进行安装。”
+
+这意味着新的安装程序不会影响高级用户,同时也使得其可以向更广泛的受众开放,在这一改动所带来的许多优点之中,一个显著的优点即是:更广泛的用户。
+
+更多的用户意味着对项目的更多支持,不管其是通过网络捐赠或参与 Arch Linux 的开发,随着这些项目贡献的增加,不管是新用户还是有经验的用户的使用体验都会得到提升。
+
+### 这必然要发生
+
+回顾过去,我们可以看到安装介质增加了许多对新用户有所帮助的功能。这些示例包括 pacstrap(一个安装基本系统的工具)和 reflector(查找最佳 pacman 镜像的工具)。
+
+另外,多年来,用户一直在追求使用脚本安装的方法,新安装程序允许了用户使用安装脚本。它能够使用 Python 编写脚本,这使得管理员的部署更加容易,成为一个非常有吸引力的选择。
+
+### 更多可定制性(以某种方式?)
+
+尽管这看上去可能有些反直觉,但是这个安装程序实际上能够增进 Arch Linux 的可定制性。当前,Arch Linux 定制性的最大瓶颈是用户的技术水平,而这一问题能够通过 archinstall 解决。
+
+有了新的安装程序,用户不需要掌握创建完美开发环境的技巧,安装程序可以帮助用户完成这些工作,这提供了广泛的自定义选项,是普通用户难以实现的。
+
+### 总结
+
+有了这一新功能,Arch Linux 似乎正在向着“用户友好”这一软件设计哲学靠近,新安装程序为新手和高级用户提供了广泛的好处。其中包括更广泛的定制性和更大的用户社区。
+
+总而言之,这个新变动对整个 Arch Linux 社区都会产生积极的影响。
+
+你对这个 Arch Linux 安装程序怎么看?是否已经尝试过它了呢?
+
+--------------------------------------------------------------------------------
+
+via: https://news.itsfoss.com/arch-new-guided-installer/
+
+作者:[Jacob Crume][a]
+选题:[lujun9972][b]
+译者:[Kevin3599](https://github.com/Kevin3599)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://news.itsfoss.com/author/jacob/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/rolling-release/
+[2]: https://news.itsfoss.com/arch-linux-easy-install/
+[3]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/arch-install-tool.png?resize=780%2C411&ssl=1
+[4]: https://i0.wp.com/github.com/archlinux/archinstall/raw/master/docs/logo.png?resize=371%2C371&ssl=1
+[5]: https://man.archlinux.org/man/pacstrap.8
+[6]: https://wiki.archlinux.org/index.php/Reflector
+
diff --git a/published/202104/20210421 How to Delete Partitions in Linux -Beginner-s Guide.md b/published/202104/20210421 How to Delete Partitions in Linux -Beginner-s Guide.md
new file mode 100644
index 0000000000..e04bca1d9d
--- /dev/null
+++ b/published/202104/20210421 How to Delete Partitions in Linux -Beginner-s Guide.md
@@ -0,0 +1,131 @@
+[#]: subject: (How to Delete Partitions in Linux [Beginner’s Guide])
+[#]: via: (https://itsfoss.com/delete-partition-linux/)
+[#]: author: (Chris Patrick Carias Stas https://itsfoss.com/author/chris/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13346-1.html)
+
+如何在 Linux 中删除分区
+======
+
+
+
+管理分区是一件严肃的事情,尤其是当你不得不删除它们时。我发现自己经常这样做,特别是在使用 U 盘作为实时磁盘和 Linux 安装程序之后,因为它们创建了几个我以后不需要的分区。
+
+在本教程中,我将告诉你如何使用命令行和 GUI 工具在 Linux 中删除分区。
+
+> 警告!
+>
+> 删除了分区,就会失去你的数据。无论何时,当你在操作分区时,一定要备份你的数据。一个轻微的打字错误或手滑都可能是昂贵的。不要说我们没有警告你!
+
+### 使用 GParted 删除磁盘分区 (GUI 方法)
+
+作为一个桌面 Linux 用户,你可能会对基于 GUI 的工具感到更舒服,也许更安全。
+
+有 [几个让你在 Linux 上管理分区的工具][3]。根据你的发行版,你的系统上已经安装了一个甚至多个这样的工具。
+
+在本教程中,我将使用 [GParted][4]。它是一个流行的开源工具,使用起来非常简单和直观。
+
+第一步是 [安装 GParted][5],如果它还没有在你的系统中。你应该能够在你的发行版的软件中心找到它。
+
+![][6]
+
+或者,你也可以使用你的发行版的软件包管理器来安装它。在基于 Debian 和 Ubuntu 的 Linux 发行版中,你可以 [使用 apt install 命令][7]:
+
+```
+sudo apt install gparted
+```
+
+安装完毕后,让我们打开 **GParted**。由于你正在处理磁盘分区,你需要有 root 权限。它将要求进行认证,打开后,你应该看到一个类似这样的窗口:
+
+![][8]
+
+在右上角,你可以选择磁盘,在下面选择你想删除的分区。
+
+接下来,从分区菜单中选择 “删除” 选项:
+
+![][9]
+
+这个过程是没有完整完成的,直到你重写分区表。这是一项安全措施,它让你在确认之前可以选择审查更改。
+
+要完成它,只需点击位于工具栏中的 “应用所有操作” 按钮,然后在要求确认时点击 “应用”。
+
+![][10]
+
+点击 “应用” 后,你会看到一个进度条和一个结果消息说所有的操作都成功了。你可以关闭该信息和主窗口,并认为你的分区已从磁盘中完全删除。
+
+现在你已经知道了 GUI 的方法,让我们继续使用命令行。
+
+### 使用 fdisk 命令删除分区(CLI 方法)
+
+几乎每个 Linux 发行版都默认带有 [fdisk][11],我们今天就来使用这个工具。你需要知道的第一件事是,你想删除的分区被分配到哪个设备上了。为此,在终端输入以下内容:
+
+```
+sudo fdisk --list
+```
+
+这将打印出我们系统中所有的驱动器和分区,以及分配的设备。你 [需要有 root 权限][12],以便让它发挥作用。
+
+在本例中,我将使用一个包含两个分区的 USB 驱动器,如下图所示:
+
+![][13]
+
+系统中分配的设备是 `/sdb`,它有两个分区:`sdb1` 和 `sdb2`。现在你已经确定了哪个设备包含这些分区,你可以通过使用 `fdisk` 和设备的路径开始操作:
+
+```
+sudo fdisk /dev/sdb
+```
+
+这将在命令模式下启动 `fdisk`。你可以随时按 `m` 来查看选项列表。
+
+接下来,输入 `p`,然后按回车查看分区信息,并确认你正在使用正确的设备。如果使用了错误的设备,你可以使用 `q` 命令退出 `fdisk` 并重新开始。
+
+现在输入 `d` 来删除一个分区,它将立即询问分区编号,这与 “Device” 列中列出的编号相对应,在这个例子中是 1 和 2(在下面的截图中可以看到),但是可以也会根据当前的分区表而有所不同。
+
+![][14]
+
+让我们通过输入 `2` 并按下回车来删除第二个分区。你应该看到一条信息:**“Partition 2 has been deleted”**,但实际上,它还没有被删除。`fdisk` 还需要一个步骤来重写分区表并应用这些变化。你看,这就是完全网。
+
+你需要输入 `w`,然后按回车来使这些改变成为永久性的。没有再要求确认。
+
+在这之后,你应该看到下面这样的反馈:
+
+![][15]
+
+现在,使用 `sudo fdisk --list /dev/sdb` 查看该设备的当前分区表,你可以看到第二个分区已经完全消失。你已经完成了使用终端和 `fdisk` 命令来删除你的分区。成功了!
+
+#### 总结
+
+这样,这个关于如何使用终端和 GUI 工具在 Linux 中删除分区的教程就结束了。记住,要始终保持安全,在操作分区之前备份你的文件,并仔细检查你是否使用了正确的设备。删除一个分区将删除其中的所有内容,而几乎没有 [恢复][16] 的机会。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/delete-partition-linux/
+
+作者:[Chris Patrick Carias Stas][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/chris/
+[b]: https://github.com/lujun9972
+[1]: tmp.Q615QYIwTl#gparted
+[2]: tmp.Q615QYIwTl#fdisk
+[3]: https://itsfoss.com/partition-managers-linux/
+[4]: https://gparted.org/index.php
+[5]: https://itsfoss.com/gparted/
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/gparted-ubuntu-software-center.png?resize=800%2C348&ssl=1
+[7]: https://itsfoss.com/apt-command-guide/
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/removing-partitions-linux-004.png?resize=800%2C542&ssl=1
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/removing-partitions-linux-005.png?resize=800%2C540&ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/removing-partitions-linux-006.png?resize=800%2C543&ssl=1
+[11]: https://man7.org/linux/man-pages/man8/fdisk.8.html
+[12]: https://itsfoss.com/root-user-ubuntu/
+[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/removing-partitions-linux-001.png?resize=800%2C255&ssl=1
+[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/removing-partitions-linux-002.png?resize=800%2C362&ssl=1
+[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/removing-partitions-linux-003.png?resize=800%2C153&ssl=1
+[16]: https://itsfoss.com/recover-deleted-files-linux/
diff --git a/published/202104/20210421 Optimize your Python code with C.md b/published/202104/20210421 Optimize your Python code with C.md
new file mode 100644
index 0000000000..0384f49be6
--- /dev/null
+++ b/published/202104/20210421 Optimize your Python code with C.md
@@ -0,0 +1,196 @@
+[#]: subject: (Optimize your Python code with C)
+[#]: via: (https://opensource.com/article/21/4/cython)
+[#]: author: (Alan Smithee https://opensource.com/users/alansmithee)
+[#]: collector: (lujun9972)
+[#]: translator: (ShuyRoy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13338-1.html)
+
+使用 C 优化你的 Python 代码
+======
+
+> Cython 创建的 C 模块可以加速 Python 代码的执行,这对使用效率不高的解释型语言编写的复杂应用是很重要的。
+
+
+
+Cython 是 Python 编程语言的编译器,旨在优化性能并形成一个扩展的 Cython 编程语言。作为 Python 的扩展,[Cython][2] 也是 Python 语言的超集,它支持调用 C 函数和在变量和类属性上声明 C 类型。这使得包装外部 C 库、将 C 嵌入现有应用程序或者为 Python 编写像 Python 一样简单的 C 语言扩展语法变得容易。
+
+Cython 一般用于创建 C 模块来加速 Python 代码的执行。这在使用解释型语言编写的效率不高的复杂应用中非常重要。
+
+### 安装 Cython
+
+你可以在 Linux、BSD、Windows 或 macOS 上安装 Cython 来使用 Python:
+
+```
+$ python -m pip install Cython
+```
+
+安装好后,就可以使用它了。
+
+### 将 Python 转换成 C
+
+使用 Cython 的一个好的方式是从一个简单的 “hello world” 开始。这虽然不是展示 Cython 优点的最好方式,但是它展示了使用 Cython 时发生的情况。
+
+首先,创建一个简单的 Python 脚本,文件命名为 `hello.pyx`(`.pyx` 扩展名并不神奇,从技术上它可以是任何东西,但它是 Cython 的默认扩展名):
+
+```
+print("hello world")
+```
+
+接下来,创建一个 Python 设置脚本。一个像 Python 的 makefile 一样的 `setup.py`,Cython 可以使用它来处理你的 Python 代码:
+
+```
+from setuptools import setup
+from Cython.Build import cythonize
+
+setup(
+ ext_modules = cythonize("hello.pyx")
+)
+```
+
+最后,使用 Cython 将你的 Python 脚本转换为 C 代码:
+
+```
+$ python setup.py build_ext --inplace
+```
+
+你可以在你的工程目录中看到结果。Cython 的 `cythonize` 模块将 `hello.pyx` 转换成一个 `hello.c` 文件和一个 `.so` 库。这些 C 代码有 2648 行,所以它比一个一行的 `hello.pyx` 源码的文本要多很多。`.so` 库也比它的源码大 2000 倍(即 54000 字节和 20 字节相比)。然后,Python 需要运行单个 Python 脚本,所以有很多代码支持这个只有一行的 `hello.pyx` 文件。
+
+要使用 Python 的 “hello world” 脚本的 C 代码版本,请打开一个 Python 提示符并导入你创建的新 `hello` 模块:
+
+
+```
+>>> import hello
+hello world
+```
+
+### 将 C 代码集成到 Python 中
+
+测试计算能力的一个很好的通用测试是计算质数。质数是一个比 1 大的正数,且它只有被 1 或它自己除后才会产生正整数。虽然理论很简单,但是随着数的变大,计算需求也会增加。在纯 Python 中,可以用 10 行以内的代码完成质数的计算。
+
+```
+import sys
+
+number = int(sys.argv[1])
+if not number <= 1:
+ for i in range(2, number):
+ if (number % i) == 0:
+ print("Not prime")
+ break
+else:
+ print("Integer must be greater than 1")
+```
+
+这个脚本在成功的时候是不会提醒的,如果这个数不是质数,则返回一条信息:
+
+```
+$ ./prime.py 3
+$ ./prime.py 4
+Not prime.
+```
+
+将这些转换为 Cython 需要一些工作,一部分是为了使代码适合用作库,另一部分是为了提高性能。
+
+#### 脚本和库
+
+许多用户将 Python 当作一种脚本语言来学习:你告诉 Python 想让它执行的步骤,然后它来做。随着你对 Python(以及一般的开源编程)的了解越多,你可以了解到许多强大的代码都存在于其他应用程序可以利用的库中。你的代码越 _不具有针对性_,程序员(包括你)就越可能将其重用于其他的应用程序。将计算和工作流解耦可能需要更多的工作,但最终这通常是值得的。
+
+在这个简单的质数计算的例子中,将其转换成 Cython,首先是一个设置脚本:
+
+```
+from setuptools import setup
+from Cython.Build import cythonize
+
+setup(
+ ext_modules = cythonize("prime.py")
+)
+```
+
+将你的脚本转换成 C:
+
+```
+$ python setup.py build_ext --inplace
+```
+
+到目前为止,一切似乎都工作的很好,但是当你试图导入并使用新模块时,你会看到一个错误:
+
+```
+>>> import prime
+Traceback (most recent call last):
+ File "", line 1, in
+ File "prime.py", line 2, in init prime
+ number = sys.argv[1]
+IndexError: list index out of range
+```
+
+这个问题是 Python 脚本希望从一个终端运行,其中参数(在这个例子中是要测试是否为质数的整数)是一样的。你需要修改你的脚本,使它可以作为一个库来使用。
+
+#### 写一个库
+
+库不使用系统参数,而是接受其他代码的参数。对于用户输入,与其使用 `sys.argv`,不如将你的代码封装成一个函数来接收一个叫 `number`(或者 `num`,或者任何你喜欢的变量名)的参数:
+
+```
+def calculate(number):
+ if not number <= 1:
+ for i in range(2, number):
+ if (number % i) == 0:
+ print("Not prime")
+ break
+ else:
+ print("Integer must be greater than 1")
+```
+
+这确实使你的脚本有些难以测试,因为当你在 Python 中运行代码时,`calculate` 函数永远不会被执行。但是,Python 编程人员已经为这个问题设计了一个通用、还算直观的解决方案。当 Python 解释器执行一个 Python 脚本时,有一个叫 `__name__` 的特殊变量,这个变量被设置为 `__main__`,但是当它被作为模块导入的时候,`__name__` 被设置为模块的名字。利用这点,你可以写一个既是 Python 模块又是有效 Python 脚本的库:
+
+```
+import sys
+
+def calculate(number):
+ if not number <= 1:
+ for i in range(2, number):
+ if (number % i) == 0:
+ print("Not prime")
+ break
+ else:
+ print("Integer must be greater than 1")
+
+if __name__ == "__main__":
+ number = sys.argv[1]
+ calculate( int(number) )
+```
+
+现在你可以用一个命令来运行代码了:
+
+```
+$ python ./prime.py 4
+Not a prime
+```
+
+你可以将它转换为 Cython 来用作一个模块:
+
+```
+>>> import prime
+>>> prime.calculate(4)
+Not prime
+```
+
+### C Python
+
+用 Cython 将纯 Python 的代码转换为 C 代码是有用的。这篇文章描述了如何做,然而,Cython 还有功能可以帮助你在转换之前优化你的代码,分析你的代码来找到 Cython 什么时候与 C 进行交互,以及更多。如果你正在用 Python,但是你希望用 C 代码改进你的代码,或者进一步理解库是如何提供比脚本更好的扩展性的,或者你只是好奇 Python 和 C 是如何协作的,那么就开始使用 Cython 吧。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/cython
+
+作者:[Alan Smithee][a]
+选题:[lujun9972][b]
+译者:[ShuyRoy](https://github.com/ShuyRoy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/alansmithee
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python-programming-code-keyboard.png?itok=fxiSpmnd (Hands on a keyboard with a Python book )
+[2]: https://cython.org/
diff --git a/published/202104/20210422 Restore an old MacBook with Linux.md b/published/202104/20210422 Restore an old MacBook with Linux.md
new file mode 100644
index 0000000000..6e28e972f5
--- /dev/null
+++ b/published/202104/20210422 Restore an old MacBook with Linux.md
@@ -0,0 +1,94 @@
+[#]: subject: (Restore an old MacBook with Linux)
+[#]: via: (https://opensource.com/article/21/4/restore-macbook-linux)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13341-1.html)
+
+用 Linux 翻新旧的 MacBook
+======
+
+> 不要把你又旧又慢的 MacBook 扔进垃圾桶。用 Linux Mint 延长它的寿命。
+
+
+
+去年,我写了篇关于如何用 Linux 赋予[旧 MacBook 的新生命][2]的文章,在例子中提到了 Elementary OS。最近,我用回那台 2015 年左右的 MacBook Air,发现遗失了我的登录密码。我下载了最新的 Elementary OS 5.1.7 Hera,但无法让实时启动识别我的 Broadcom 4360 无线芯片组。
+
+最近,我一直在使用 [Linux Mint][3] 来翻新旧的笔记本电脑,我想在这台 MacBook Air 上试一下。我下载了 Linux Mint 20.1 ISO,并在我的 Linux 台式电脑上使用 [Popsicle][4] 创建了一个 USB 启动器。
+
+![Popsicle ISO burner][5]
+
+接下来,我将 Thunderbolt 以太网适配器连接到 MacBook,并插入 USB 启动器。我打开系统电源,按下 MacBook 上的 Option 键,指示它从 USB 驱动器启动系统。
+
+Linux Mint 在实时启动模式下启动没问题,但操作系统没有识别出无线连接。
+
+### 我的无线网络在哪里?
+
+这是因为为苹果设备制造 WiFi 卡的公司 Broadcom 没有发布开源驱动程序。这与英特尔、Atheros 和许多其他芯片制造商形成鲜明对比,但它是苹果公司使用的芯片组,所以这是 MacBook 上的一个常见问题。
+
+我通过我的 Thunderbolt 适配器有线连接到以太网,因此我 _是_ 在线的。通过之前的研究,我知道要让无线适配器在这台 MacBook 上工作,我需要在 Bash 终端执行三条独立的命令。然而,在安装过程中,我了解到 Linux Mint 有一个很好的内置驱动管理器,它提供了一个简单的图形用户界面来协助安装软件。
+
+![Linux Mint Driver Manager][7]
+
+该操作完成后,我重启了安装了 Linux Mint 20.1 的新近翻新的 MacBook Air。Broadcom 无线适配器工作正常,使我能够轻松地连接到我的无线网络。
+
+### 手动安装无线
+
+你可以从终端完成同样的任务。首先,清除 Broadcom 内核源码的残余。
+
+```
+$ sudo apt-get purge bcmwl-kernel-source
+```
+
+然后添加一个固件安装程序:
+
+```
+$ sudo apt install firmware-b43-installer
+```
+
+最后,为系统安装新固件:
+
+```
+$ sudo apt install linux-firmware
+```
+
+### 将 Linux 作为你的 Mac 使用
+
+我安装了 [Phoronix 测试套件][8] 以获得 MacBook Air 的系统信息。
+
+![MacBook Phoronix Test Suite output][9]
+
+系统工作良好。对内核 5.4.0-64-generic 的最新更新显示,无线连接仍然存在,并且我与家庭网络之间的连接为 866Mbps。Broadcom 的 FaceTime 摄像头不能工作,但其他东西都能正常工作。
+
+我非常喜欢这台 MacBook 上的 [Linux Mint Cinnamon 20.1][10] 桌面。
+
+![Linux Mint Cinnamon][11]
+
+如果你有一台因 macOS 更新而变得缓慢且无法使用的旧 MacBook,我建议你试一下 Linux Mint。我对这个发行版印象非常深刻,尤其是它在我的 MacBook Air 上的工作情况。它无疑延长了这个强大的小笔记本电脑的寿命。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/restore-macbook-linux
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/write-hand_0.jpg?itok=Uw5RJD03 (Writing Hand)
+[2]: https://opensource.com/article/20/2/macbook-linux-elementary
+[3]: https://linuxmint.com/
+[4]: https://github.com/pop-os/popsicle
+[5]: https://opensource.com/sites/default/files/uploads/popsicle.png (Popsicle ISO burner)
+[6]: https://creativecommons.org/licenses/by-sa/4.0/
+[7]: https://opensource.com/sites/default/files/uploads/mint_drivermanager.png (Linux Mint Driver Manager)
+[8]: https://www.phoronix-test-suite.com/
+[9]: https://opensource.com/sites/default/files/uploads/macbook_specs.png (MacBook Phoronix Test Suite output)
+[10]: https://www.linuxmint.com/edition.php?id=284
+[11]: https://opensource.com/sites/default/files/uploads/mintcinnamon.png (Linux Mint Cinnamon)
diff --git a/published/20210427 Upgrade your Linux PC hardware-using open source tools.md b/published/20210427 Upgrade your Linux PC hardware-using open source tools.md
new file mode 100644
index 0000000000..7ddd890346
--- /dev/null
+++ b/published/20210427 Upgrade your Linux PC hardware-using open source tools.md
@@ -0,0 +1,251 @@
+[#]: subject: (Upgrade your Linux PC hardware using open source tools)
+[#]: via: (https://opensource.com/article/21/4/upgrade-linux-hardware)
+[#]: author: (Howard Fosdick https://opensource.com/users/howtech)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13472-1.html)
+
+使用开源工具升级你的 Linux PC 硬件
+======
+
+> 升级你的电脑硬件来提升性能,以获得最大的回报。
+
+
+
+在我的文章《[使用开源工具识别 Linux 性能瓶颈][2]》中,我解释了一些使用开源的图形用户界面(GUI)工具监测 Linux 性能的简单方法。我的重点是识别 _性能瓶颈_,即硬件资源达到极限并阻碍你的 PC 性能的情况。
+
+你会如何解决性能瓶颈问题呢?你可以调整应用程序或系统软件。或者你可以运行更高效的应用程序。你甚至可以改变你使用电脑的行为,例如,将后台程序安排在非工作时间。
+
+你也可以通过硬件升级来提高电脑的性能。本文重点介绍可以给你带来最大回报的升级。
+
+开源工具是关键。GUI 工具可以帮助你监控你的系统,预测哪些硬件改进会有效。否则,你可能买了硬件后发现它并没有提高性能。在升级之后,这些工具也有助于验证升级是否产生了你预期的好处。
+
+这篇文章概述了一种简单的 PC 硬件升级的方法,其“秘诀”是开源的 GUI 工具。
+
+### 如何升级内存
+
+几年前,升级内存是不用多想的。增加内存几乎总是能提高性能。
+
+今天,情况不再是这样了。个人电脑配备了更多的内存,而且 Linux 能非常有效地使用它。如果你购买了系统用不完的内存,就浪费了钱。
+
+因此,你要花一些时间来监测你的电脑,看看内存升级是否会有助于提升它的性能。例如,在你进行典型的一天工作时观察内存的使用情况。而且一定要检查在内存密集型工作负载中发生了什么。
+
+各种各样的开源工具可以帮助你进行这种监测,不过我用的是 [GNOME 系统监视器][3]。它在大多数 Linux 软件库中都有。
+
+当你启动系统监视器时,它的“资源”面板会显示这样的输出:
+
+![用 GNOME 系统监控器监控内存][4]
+
+*图 1. 用 GNOME 系统监视器监控内存 (Howard Fosdick, [CC BY-SA 4.0][5])*
+
+屏幕中间显示了内存的使用情况。[交换空间][6] 是 Linux 在内存不足时使用的磁盘空间。Linux 通过使用交换空间作为内存的一个较慢的扩展来有效地增加内存。
+
+由于交换空间比内存慢,如果内存交换活动变得显著,增加内存将改善你的计算机的性能。你会得到多大的改善取决于交换活动的数量和交换空间所在的设备的速度。
+
+如果使用了大量的交换空间,你通过增加内存会得到比只使用了少量交换空间更多的性能改善。
+
+如果交换空间位于慢速的机械硬盘上,你会发现增加内存比将交换空间放在最快的固态硬盘上改善更多。
+
+下面是一个关于何时增加内存的例子。这台电脑在内存利用率达到 80% 后显示交换活动在增加。当内存利用率超过 90% 时,它就变得失去反应了。
+
+![系统监控 - 内存不足的情况][7]
+
+*图 2. 内存升级会有帮助(Howard Fosdick, [CC BY-SA 4.0][5])*
+
+#### 如何进行内存升级
+
+在升级之前,你需要确定你有多少个内存插槽,有多少个是空的,它们需要什么样的内存条,以及你的主板所允许的最大内存。
+
+你可以阅读你的计算机的文档来获得这些答案。或者,你可以直接输入这些 Linux 命令行:
+
+问题 | 命令
+---|---
+已安装的内存条有什么特点? | `sudo lshw -short -C memory`
+这台计算机允许的最大内存是多少? | `sudo dmidecode -t memory | grep -i max`
+有多少个内存插槽是空的?(没有输出意味着没有可用的) | `sudo lshw -short -C memory | grep -i empty`
+
+与所有的硬件升级一样,事先拔掉计算机的电源插头。在你接触硬件之前,将自己接地 —— 即使是最微小的电涌也会损坏电路。将内存条完全插入主板的插槽中。
+
+升级后,启动系统监视器。运行之前使你的内存超载的相同程序。
+
+系统监控器应该显示出你扩充的内存,而且你应该发现性能更好了。
+
+### 如何升级存储
+
+我们正处在一个存储快速改进的时代。即使是只用了几年的计算机也可以从磁盘升级中受益。但首先,你要确保升级对你的计算机和工作负载是有意义的。
+
+首先,要找出你有什么磁盘。许多开源工具会告诉你。[Hardinfo][8] 或 [GNOME 磁盘][9] 是不错的选择,因为它们都是广泛可用的,而且它们的输出很容易理解。这些应用程序会告诉你磁盘的品牌、型号和其他细节。
+
+接下来,通过基准测试来确定你的磁盘性能。GNOME 磁盘让这一切变得简单。只要启动该工具并点击它的“磁盘基准测试”选项。这会给出你磁盘的读写率和平均磁盘访问时间。
+
+![GNOME 磁盘基准测试][10]
+
+*图 3. GNOME 磁盘基准输出(Howard Fosdick, [CC BY-SA 4.0][5])*
+
+有了这些信息,你可以在 [PassMark Software][11] 和 [UserBenchmark][12] 等基准测试网站上将你的磁盘与其他人进行比较。这些网站提供性能统计、速度排名,甚至价格和性能数字。你可以了解到你的磁盘与可能的替代品相比的情况。
+
+下面是你可以在 UserBenchmark 找到的一些详细磁盘信息的例子。
+
+![UserBenchmark 的磁盘比较][13]
+
+*图 4. 在 [UserBenchmark][14] 进行的磁盘比较*
+
+#### 监测磁盘利用率
+
+就像你对内存所做的那样,实时监控你的磁盘,看看更换磁盘是否会提高性能。[atop 命令行][15] 会告诉你一个磁盘的繁忙程度。
+
+在它下面的输出中,你可以看到设备 `sdb` 是 `busy 101%`。其中一个处理器有 85% 的时间在等待该磁盘进行工作(`cpu001 w 85%`)。
+
+![atop 命令显示磁盘利用率][16]
+
+*图 5. atop 命令显示磁盘利用率(Howard Fosdick, [CC BY-SA 4.0][5])*
+
+很明显,你可以用一个更快的磁盘来提高性能。
+
+你也会想知道是哪个程序使用了磁盘。只要启动系统监视器并点击其“进程”标签。
+
+现在你知道了你的磁盘有多忙,以及哪些程序在使用它,所以你可以做出一个有根据的判断,是否值得花钱买一个更快的磁盘。
+
+#### 购买磁盘
+
+购买新的内置磁盘时,你会遇到三种主流技术:
+
+ * 机械硬盘(HDD)
+ * SATA 接口的固态硬盘(SSD)
+ * PCIe 接口的 NVMe 固态磁盘(NVMe SSD)
+
+它们的速度差异是什么?你会在网上看到各种不同的数字。这里有一个典型的例子。
+
+![相对磁盘速度][17]
+
+*图 6. 内部磁盘技术的相对速度([Unihost][18])*
+
+ * **红色柱形图:** 机械硬盘提供最便宜的大容量存储。但就性能而言,它们是迄今为止最慢的。
+ * **绿色柱形图:** 固态硬盘比机械硬盘快。但如果固态硬盘使用 SATA 接口,就会限制其性能。这是因为 SATA 接口是十多年前为机械硬盘设计的。
+ * **蓝色柱形图:** 最快的内置磁盘技术是新的 [PCIe 接口的 NVMe 固态盘][19]。这些可以比 SATA 连接的固态硬盘大约快 5 倍,比机械硬盘快 20 倍。
+
+对于外置 SSD,你会发现 [最新的雷电接口和 USB 接口][20] 是最快的。
+
+#### 如何安装一个内置磁盘
+
+在购买任何磁盘之前,请确认你的计算机支持必要的物理接口。
+
+例如,许多 NVMe 固态硬盘使用流行的新 M.2(2280)外形尺寸。这需要一个量身定做的主板插槽、一个 PCIe 适配器卡,或一个外部 USB 适配器。你的选择可能会影响你的新磁盘的性能。
+
+在安装新磁盘之前,一定要备份你的数据和操作系统。然后把它们复制到新磁盘上。像 Clonezilla、Mondo Rescue 或 GParted 这样的开源 [工具][21] 可以完成这项工作。或者你可以使用 Linux 命令行,如 `dd` 或 `cp`。
+
+请确保在最有影响的情况下使用你的快速新磁盘。把它用作启动盘、存储操作系统和应用程序、交换空间,以及最常处理的数据。
+
+升级之后,运行 GNOME 磁盘来测试你的新磁盘。这可以帮助你验证你是否得到了预期的性能提升。你可以用 `atop` 命令来验证实时运行。
+
+### 如何升级 USB 端口
+
+与磁盘存储一样,USB 的性能在过去几年中也有了长足的进步。许多只用了几年的计算机只需增加一个廉价的 USB 端口卡就能获得很大的性能提升。
+
+这种升级是否值得,取决于你使用端口的频率。很少使用它们,如果它们很慢也没有关系。经常使用它们,升级可能真的会影响你的工作。
+
+下面是不同端口标准的最大 USB 数据速率的巨大差异。
+
+![USB 速度][22]
+
+*图 7. USB 速度差别很大(Howard Fosdick,[CC BY-SA 4.0][5],基于 [Tripplite][23] 和 [维基][24] 的数据*
+
+要查看你得到的实际 USB 速度,请启动 GNOME 磁盘。GNOME 磁盘可以对 USB 连接的设备进行基准测试,就像对内部磁盘一样。选择其“磁盘基准测试”选项。
+
+你插入的设备和 USB 端口共同决定了你将得到的速度。如果端口和设备不匹配,你将体验到两者中较慢的速度。
+
+例如,将一个支持 USB 3.1 速度的设备连接到一个 2.0 端口,你将得到 2.0 的数据速率。你的系统不会告诉你这一点,除非你用 GNOME 磁盘这样的工具来检查)。反之,将 2.0 设备连接到 3.1 端口,你也会得到 2.0 的速度。因此,为了获得最好的结果,总是要匹配你的端口和设备的速度。
+
+要实时监控 USB 连接的设备,请使用 `atop` 命令和系统监控器,就像你监控内部磁盘一样。这可以帮助你看到是否碰到了当前设置的限制,并可以通过升级而受益。
+
+升级你的端口很容易。只要购买一个适合你的空闲的 PCIe 插槽的 USB 卡。
+
+USB 3.0 卡的价格只有 25 美元左右。较新、较贵的卡提供 USB 3.1 和 3.2 端口。几乎所有的 USB 卡都是即插即用的,所以 Linux 会自动识别它们。但在购买前一定要核实。
+
+请确保在升级后运行 GNOME 磁盘以验证新的速度。
+
+### 如何升级你的互联网连接
+
+升级你的互联网带宽很容易。只要给你的 ISP 写一张支票即可。
+
+问题是,应该升级吗?
+
+系统监控器显示了你的带宽使用情况(见图 1)。如果你经常遇到你从 ISP 购买的带宽限额,你会从购买更高的限额中受益。
+
+但首先,要确认你是否有一个可以自己解决的问题。我见过很多案例,有人认为他们需要从 ISP 那里购买更多的带宽,而实际上他们只是有一个可以自己解决的连接问题。
+
+首先在 [Speedtest][25] 或 [Fast.com][26] 等网站测试你的最大网速。为了获得准确的结果,关闭所有程序,只运行速度测试;关闭你的虚拟私有网络;在一天中的不同时间运行测试;并比较几个测试网站的结果。如果你使用 WiFi,在有 WiFi 和没有 WiFi 的情况下进行测试(将你的笔记本电脑直接与调制解调器连接)。
+
+如果你有一个单独的路由器,在有它和没有它的情况下进行测试。这将告诉你路由器是否是瓶颈。有时,只是重新定位你家里的路由器或更新其固件就能提高连接速度。
+
+这些测试将验证你是否得到了你从 ISP 购买的带宽速度。它们也会暴露出任何你可以自己解决的本地 WiFi 或路由器问题。
+
+只有在你做了这些测试之后,你才应该得出结论,你需要购买更多的网络带宽。
+
+### 你应该升级你的 CPU 还是 GPU?
+
+升级你的 CPU(中央处理单元)或 GPU(图形处理单元)呢?
+
+笔记本电脑用户通常不能升级这两个单元,因为它们被焊接在主板上。
+
+大多数台式机主板支持一系列的 CPU,并且是可以升级的 —— 假设你还没有使用该系列中最顶级的处理器。
+
+使用系统监视器观察你的 CPU,并确定升级是否有帮助。它的“资源”面板将显示你的 CPU 负载。如果你的所有逻辑处理器始终保持在 80% 或 90% 以上,你可以从更多的 CPU 功率中受益。
+
+这是一个升级 CPU 的有趣项目。只要小心谨慎,任何人都可以做到这一点。
+
+不幸的是,这几乎没有成本效益。大多数卖家对单个 CPU 芯片收取溢价,比他们卖给你的新系统要高。因此,对许多人来说,升级 CPU 并不具有经济意义。
+
+如果你将显示器直接插入台式机的主板,你可能会通过升级图形处理器而受益。只需添加一块显卡。
+
+诀窍是在新显卡和你的 CPU 之间实现平衡的工作负荷。这个 [在线工具][27] 能准确识别哪些显卡能与你的 CPU 最好地配合。[这篇文章][28] 详细解释了如何去升级你的图形处理。
+
+### 在升级前收集数据
+
+个人电脑用户有时会根据直觉来升级他们的 Linux 硬件。一个更好的方法是先监控性能并收集一些数据。开源的 GUI 工具使之变得简单。它们有助于预测硬件升级是否值得你花时间和金钱。然后,在你升级之后,你可以用它们来验证你的改变是否达到了预期效果。
+
+这些是最常见的硬件升级。只要稍加努力并使用正确的开源工具,任何 Linux 用户都可以经济有效地升级一台 PC。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/upgrade-linux-hardware
+
+作者:[Howard Fosdick][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/howtech
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-concentration-focus-windows-office.png?itok=-8E2ihcF (Woman using laptop concentrating)
+[2]: https://linux.cn/article-13462-1.html
+[3]: https://vitux.com/how-to-install-and-use-task-manager-system-monitor-in-ubuntu/
+[4]: https://opensource.com/sites/default/files/uploads/system_monitor_-_resources_panel_0.jpg (Monitoring memory with GNOME System Monitor)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://opensource.com/article/18/9/swap-space-linux-systems
+[7]: https://opensource.com/sites/default/files/uploads/system_monitor_-_out_of_memory_0.jpg (System Monitor - Out Of Memory Condition)
+[8]: https://itsfoss.com/hardinfo/
+[9]: https://en.wikipedia.org/wiki/GNOME_Disks
+[10]: https://opensource.com/sites/default/files/uploads/gnome_disks_-_benchmark_0.jpg (GNOME Disks benchmark)
+[11]: https://www.harddrivebenchmark.net/
+[12]: https://www.userbenchmark.com/
+[13]: https://opensource.com/sites/default/files/uploads/userbenchmark_disk_comparisons_0.jpg (Disk comparisons at UserBenchmark)
+[14]: https://ssd.userbenchmark.com/
+[15]: https://opensource.com/life/16/2/open-source-tools-system-monitoring
+[16]: https://opensource.com/sites/default/files/uploads/atop_-_storage_bottleneck_0.jpg (atop command shows disk utilization)
+[17]: https://opensource.com/sites/default/files/uploads/hdd_vs_ssd_vs_nvme_speeds_0.jpg (Relative disk speeds)
+[18]: https://unihost.com/help/nvme-vs-ssd-vs-hdd-overview-and-comparison/
+[19]: https://www.trentonsystems.com/blog/pcie-gen4-vs-gen3-slots-speeds
+[20]: https://www.howtogeek.com/449991/thunderbolt-3-vs.-usb-c-whats-the-difference/
+[21]: https://www.linuxlinks.com/diskcloning/
+[22]: https://opensource.com/sites/default/files/uploads/usb_standards_-_speeds_0.jpg (USB speeds)
+[23]: https://www.tripplite.com/products/usb-connectivity-types-standards
+[24]: https://en.wikipedia.org/wiki/USB
+[25]: https://www.speedtest.net/
+[26]: https://fast.com/
+[27]: https://www.gpucheck.com/gpu-benchmark-comparison
+[28]: https://helpdeskgeek.com/how-to/see-how-much-your-cpu-bottlenecks-your-gpu-before-you-buy-it/
diff --git a/published/202105/20200316 OpenStreetMap- A Community-Driven Google Maps Alternative.md b/published/202105/20200316 OpenStreetMap- A Community-Driven Google Maps Alternative.md
new file mode 100644
index 0000000000..c2f2d0dc45
--- /dev/null
+++ b/published/202105/20200316 OpenStreetMap- A Community-Driven Google Maps Alternative.md
@@ -0,0 +1,91 @@
+[#]: collector: "lujun9972"
+[#]: translator: "rakino"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13399-1.html"
+[#]: subject: "OpenStreetMap: A Community-Driven Google Maps Alternative"
+[#]: via: "https://itsfoss.com/openstreetmap/"
+[#]: author: "Ankush Das https://itsfoss.com/author/ankush/"
+
+OpenStreetMap:社区驱动的谷歌地图替代品
+======
+
+> 作为谷歌地图的潜在替代品,OpenStreetMap 是一个由社区驱动的地图项目,在本文中我们将了解更多关于这个开源项目的信息。
+
+[OpenStreetMap][1](OSM)是一个可自由编辑的世界地图,任何人都可以对 OpenStreetMap 贡献、编辑和修改,以对其进行改进。
+
+![][2]
+
+查看地图并不需要帐号,但如果你想要编辑或增加地图信息,就得先注册一个帐号了。
+
+尽管 OpenStreetMap 以 [开放数据库许可证][3] 授权,可以自由使用,但也有所限制 —— 你不能使用地图 API 在 OpenStreetMap 之上建立另一个服务来达到商业目的。
+
+因此,你可以下载地图数据来使用,以及在标示版权信息的前提下自己托管这些数据。可以在 OpenStreetMap 的官方网站上了解更多关于其 [API 使用政策][4] 和 [版权][5] 的信息。
+
+在这篇文章中,我们将简单看看 OpenStreetMap 是如何工作的,以及什么样的项目使用 OpenStreetMaps 作为其地图数据的来源。
+
+### OpenStreetMap:概述
+
+![][6]
+
+OpenStreetMap 是很好的谷歌地图替代品,虽然你无法得到和谷歌地图一样的信息水平,但对于基本的导航和旅行来说,OpenStreetMap 已经足够了。
+
+就像其他地图一样,你能够在地图的多个图层间切换,了解自己的位置,并轻松地查找地点。
+
+你可能找不到关于附近企业、商店和餐馆的所有最新信息。但对于基本的导航来说,OpenStreetMap 已经足够了。
+
+通常可以通过网页浏览器在桌面和手机上访问 [OpenStreetMap 的网站][7] 来使用 OpenStreetMap,它还没有一个官方的安卓/iOS 应用程序。
+
+然而,也有各种各样的应用程序在其核心中使用了 OpenStreetMap。因此,如果你想在智能手机上使用 OpenStreetMap,你可以看看一些流行的谷歌地图开源替代:
+
+ * [OsmAnd][8]
+ * [MAPS.ME][9]
+
+**MAPS.ME** 和 **OsmAnd** 是两个适用于安卓和 iOS 的开源应用程序,它们利用 OpenStreetMap 的数据提供丰富的用户体验,并在应用中添加了一堆有用的信息和功能。
+
+如果你愿意,也可以选择其他专有选项,比如 [Magic Earth][10]。
+
+无论是哪种情况,你都可以在 OpenStreetMap 的官方维基页面上看一下适用于 [安卓][11] 和 [iOS][12] 的大量应用程序列表。
+
+### 在 Linux 上使用 OpenStreetMap
+
+![][13]
+
+在 Linux 上使用 OpenStreetMap 最简单的方法就是在网页浏览器中使用它。如果你使用 GNOME 桌面环境,可以安装 GNOME 地图,它是建立在 OpenStreetMap 之上的。
+
+还有几个软件(大多已经过时了)在 Linux 上使用 OpenStreetMap 来达到特定目的,你可以在 OpenStreetMap 的 [官方维基列表][14] 中查看可用软件包的列表。
+
+### 总结
+
+对于最终用户来说,OpenStreetMap 可能不是最好的导航源,但是它的开源模式允许它被自由使用,这意味着可以用 OpenStreetMap 来构建许多服务。例如,[ÖPNVKarte][15] 使用 OpenStreetMap 在一张统一的地图上显示全世界的公共交通设施,这样你就不必再浏览各个运营商的网站了。
+
+你对 OpenStreetMap 有什么看法?你能用它作为谷歌地图的替代品吗?欢迎在下面的评论中分享你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/openstreetmap/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[rakino](https://github.com/rakino)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://www.openstreetmap.org/
+[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/openstreetmap.jpg?ssl=1
+[3]: https://opendatacommons.org/licenses/odbl/
+[4]: https://operations.osmfoundation.org/policies/api/
+[5]: https://www.openstreetmap.org/copyright
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/open-street-map-2.jpg?ssl=1
+[7]: https://www.openstreetmap.org
+[8]: https://play.google.com/store/apps/details?id=net.osmand
+[9]: https://play.google.com/store/apps/details?id=com.mapswithme.maps.pro
+[10]: https://www.magicearth.com/
+[11]: https://wiki.openstreetmap.org/wiki/Android#OpenStreetMap_applications
+[12]: https://wiki.openstreetmap.org/wiki/Apple_iOS
+[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/open-street-map-1.jpg?ssl=1
+[14]: https://wiki.openstreetmap.org/wiki/Linux
+[15]: http://xn--pnvkarte-m4a.de/
\ No newline at end of file
diff --git a/published/202105/20200527 Manage startup using systemd.md b/published/202105/20200527 Manage startup using systemd.md
new file mode 100644
index 0000000000..e5a5d31013
--- /dev/null
+++ b/published/202105/20200527 Manage startup using systemd.md
@@ -0,0 +1,545 @@
+[#]: collector: (lujun9972)
+[#]: translator: (tt67wq)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13402-1.html)
+[#]: subject: (Manage startup using systemd)
+[#]: via: (https://opensource.com/article/20/5/manage-startup-systemd)
+[#]: author: (David Both https://opensource.com/users/dboth)
+
+使用 systemd 来管理启动项
+======
+
+> 了解 systemd 是怎样决定服务启动顺序,即使它本质上是个并行系统。
+
+
+
+最近在设置 Linux 系统时,我想知道如何确保服务和其他单元的依赖关系在这些依赖于它们的服务和单元启动之前就已经启动并运行了。我需要更多 systemd 如何管理启动程序的相关知识,特别是在本质上是一个并行的系统中如何是决定服务启动顺序的。
+
+你可能知道 SystemV(systemd 的前身,我在这个系列的 [第一篇文章][2] 中解释过)通过 Sxx 前缀命名启动脚本来决定启动顺序,xx 是一个 00-99 的数字。然后 SystemV 利用文件名来排序,然后按照所需的运行级别执行队列中每个启动脚本。
+
+但是 systemd 使用单元文件来定义子程序,单元文件可由系统管理员创建或编辑,这些文件不仅可以用于初始化时也可以用于常规操作。在这个系列的 [第三篇文章][3] 中,我解释了如何创建一个挂载单元文件。在第五篇文章中,我解释了如何创建一种不同的单元文件 —— 在启动时执行一个程序的服务单元文件。你也可以修改单元文件中某些配置,然后通过 systemd 日志去查看你的修改在启动序列中的位置。
+
+### 准备工作
+
+先确认你已经在 `/etc/default/grub` 文件中的 `GRUB_CMDLINE_LINUX=` 这行移除了 `rhgb` 和 `quiet`,如同我在这个系列的 [第二篇文章][4] 中展示的那样。这让你能够查看 Linux 启动信息流,你在这篇文章中部分实验中需要用到。
+
+### 程序
+
+在本教程中,你会创建一个简单的程序让你能够在主控台和后续的 systemd 日志中查看启动时的信息。
+
+创建一个 shell 程序 `/usr/local/bin/hello.sh` 然后添加下述内容。你要确保执行结果在启动时是可见的,可以轻松的在 systemd 日志中找到它。你会使用一版携带一些方格的 “Hello world” 程序,这样它会非常显眼。为了确保这个文件是可执行的,且为了安全起见,它需要 root 的用户和组所有权和 [700 权限][5]。
+
+
+```
+#!/usr/bin/bash
+# Simple program to use for testing startup configurations
+# with systemd.
+# By David Both
+# Licensed under GPL V2
+#
+echo "###############################"
+echo "######### Hello World! ########"
+echo "###############################"
+```
+
+在命令行中执行这个程序来检查它能否正常运行。
+
+```
+[root@testvm1 ~]# hello.sh
+###############################
+######### Hello World! ########
+###############################
+[root@testvm1 ~]#
+```
+
+这个程序可以用任意脚本或编译语言实现。`hello.sh` 程序可以被放在 [Linux 文件系统层级结构][6](FHS)上的任意位置。我把它放在 `/usr/local/bin` 目录下,这样它可以直接在命令行中执行而不必在打命令的时候前面带上路径。我发现我创建的很多 shell 程序需要从命令行和其他工具(如 systemd)运行。
+
+### 服务单元文件
+
+创建服务单元文件 `/etc/systemd/system/hello.service`,写入下述内容。这个文件不一定是要可执行的,但是为了安全起见,它需要 root 的用户和组所有权和 [644][7] 或 [640][8] 权限。
+
+```
+# Simple service unit file to use for testing
+# startup configurations with systemd.
+# By David Both
+# Licensed under GPL V2
+#
+
+[Unit]
+Description=My hello shell script
+
+[Service]
+Type=oneshot
+ExecStart=/usr/local/bin/hello.sh
+
+[Install]
+WantedBy=multi-user.target
+```
+
+通过查看服务状态来确认服务单元文件能如期运行。如有任何语法问题,这里会显示错误。
+
+```
+[root@testvm1 ~]# systemctl status hello.service
+● hello.service - My hello shell script
+ Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
+ Active: inactive (dead)
+[root@testvm1 ~]#
+```
+
+你可以运行这类 “oneshot”(单发)类型的服务多次而不会有问题。此类服务适用于服务单元文件启动的程序是主进程,必须在 systemd 启动任何依赖进程之前完成的服务。
+
+共有 7 种服务类型,你可以在 [systemd.service(5)][9] 的手册页上找到每一种(以及服务单元文件的其他部分)的详细解释。(你也可以在文章末尾的 [资料][10] 中找到更多信息。)
+
+出于好奇,我想看看错误是什么样子的。所以我从 `Type=oneshot` 这行删了字母 “o”,现在它看起来是这样 `Type=neshot`,现在再次执行命令:
+
+```
+[root@testvm1 ~]# systemctl status hello.service
+● hello.service - My hello shell script
+ Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
+ Active: inactive (dead)
+
+May 06 08:50:09 testvm1.both.org systemd[1]: /etc/systemd/system/hello.service:12: Failed to parse service type, ignoring: neshot
+[root@testvm1 ~]#
+```
+
+执行结果明确地告诉我错误在哪,这样解决错误变得十分容易。
+
+需要注意的是即使在你将 `hello.service` 文件保存为它原来的形式之后,错误依然存在。虽然重启机器能消除这个错误,但你不必这么做,所以我去找了一个清理这类持久性错误的方法。我曾遇到有些错误需要 `systemctl daemon-reload` 命令来重置错误状态,但是在这个例子里不起作用。可以用这个命令修复的错误似乎总是有一个这样的声明,所以你知道要运行它。
+
+然而,每次修改或新建一个单元文件之后执行 `systemctl daemon-reload` 确实是值得推荐的做法。它提醒 systemd 有修改发生,而且它可以防止某些与管理服务或单元相关的问题。所以继续去执行这条命令吧。
+
+在修改完服务单元文件中的拼写错误后,一个简单的 `systemctl restart hello.service` 命令就可以清除错误。实验一下,通过添加一些其他的错误至 `hello.service` 文件来看看会得到怎样的结果。
+
+### 启动服务
+
+现在你已经准备好启动这个新服务,通过检查状态来查看结果。尽管你可能之前已经重启过,你仍然可以启动或重启这个单发服务任意次,因为它只运行一次就退出了。
+
+继续启动这个服务(如下所示),然后检查状态。你的结果可能和我的有区别,取决于你做了多少试错实验。
+
+```
+[root@testvm1 ~]# systemctl start hello.service
+[root@testvm1 ~]# systemctl status hello.service
+● hello.service - My hello shell script
+ Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
+ Active: inactive (dead)
+
+May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
+May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
+May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
+May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
+May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
+May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
+[root@testvm1 ~]#
+```
+
+从状态检查命令的输出中我们可以看到,systemd 日志表明 `hello.sh` 启动然后服务结束了。你也可以看到脚本的输出。该输出是根据服务的最近调用的日志记录生成的,试试看多启动几次这个服务,然后再看状态命令的输出就能理解我所说的。
+
+你也应该直接查看日志内容,有很多种方法可以实现。一种办法是指定记录类型标识符,在这个例子中就是 shell 脚本的名字。它会展示前几次重启和当前会话的日志记录。如你所见,我已经为这篇文章做了挺长一段时间的研究测试了。
+
+```
+[root@testvm1 ~]# journalctl -t hello.sh
+<剪去>
+-- Reboot --
+May 08 15:55:47 testvm1.both.org hello.sh[840]: ###############################
+May 08 15:55:47 testvm1.both.org hello.sh[840]: ######### Hello World! ########
+May 08 15:55:47 testvm1.both.org hello.sh[840]: ###############################
+-- Reboot --
+May 08 16:01:51 testvm1.both.org hello.sh[840]: ###############################
+May 08 16:01:51 testvm1.both.org hello.sh[840]: ######### Hello World! ########
+May 08 16:01:51 testvm1.both.org hello.sh[840]: ###############################
+-- Reboot --
+May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
+May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
+May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+[root@testvm1 ~]#
+```
+
+为了定位 `hello.service` 单元的 systemd 记录,你可以在 systemd 中搜索。你可以使用 `G+Enter` 来翻页到日志记录
+记录的末尾,然后用回滚来找到你感兴趣的日志。使用 `-b` 选项仅展示最近启动的记录。
+
+```
+[root@testvm1 ~]# journalctl -b -t systemd
+<剪去>
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting SYSV: Late init script for live image....
+May 10 10:37:49 testvm1.both.org systemd[1]: Started SYSV: Late init script for live image..
+May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
+May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
+May 10 10:37:50 testvm1.both.org systemd[1]: Starting D-Bus System Message Bus...
+May 10 10:37:50 testvm1.both.org systemd[1]: Started D-Bus System Message Bus.
+```
+
+我拷贝了一些其他的日志记录,让你对你可能找到的东西有所了解。这条命令喷出了所有属于 systemd 的日志内容 —— 当我写这篇时是 109183 行。这是一个需要整理的大量数据。你可以使用页面的搜索功能,通常是 `less` 或者你可以使用内置的 `grep` 特性。`-g`( 或 `--grep=`)选项可以使用兼容 Perl 的正则表达式。
+```
+[root@testvm1 ~]# journalctl -b -t systemd -g "hello"
+[root@testvm1 ~]# journalctl -b -t systemd -g "hello"
+-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:01:01 EDT. --
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting My hello shell script...
+May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
+May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
+May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
+May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
+May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
+[root@testvm1 ~]#
+```
+
+你可以使用标准的 GNU `grep` 命令,但是这不会展示日志首行的元数据。
+
+如果你只想看包含你的 `hello` 服务的日志记录,你可以指定时间来缩小范围。举个例子,我将在我的测试虚拟机上以 `10:54:00` 为开始时间,这是上述的日志记录开始的分钟数。注意 `--since=` 的选项必须加引号,这个选项也可以写成 `-S "某个时间"`。
+
+日期和时间可能在你的机器上有所不同,所以确保使用能匹配你日志中的时间的时间戳。
+
+```
+[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:00"
+May 10 10:54:35 testvm1.both.org audit: BPF prog-id=54 op=LOAD
+May 10 10:54:35 testvm1.both.org audit: BPF prog-id=55 op=LOAD
+May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
+May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
+May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd"'
+May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/"'
+May 10 10:56:00 testvm1.both.org NetworkManager[840]: [1589122560.0633] dhcp4 (enp0s3): error -113 dispatching events
+May 10 10:56:00 testvm1.both.org NetworkManager[840]: [1589122560.0634] dhcp4 (enp0s3): state changed bound -> fail
+<剪去>
+```
+
+`since` 选项跳过了指定时间点的所有记录,但在此时间点之后仍有大量你不需要的记录。你也可以使用 `until` 选项来裁剪掉你感兴趣的时间之后的记录。我想要事件发生时附近的一分钟,其他的都不用:
+
+```
+[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:35" --until="2020-05-10 10:55:00"
+-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:04:59 EDT. --
+May 10 10:54:35 testvm1.both.org systemd[1]: Reloading.
+May 10 10:54:35 testvm1.both.org audit: BPF prog-id=27 op=UNLOAD
+May 10 10:54:35 testvm1.both.org audit: BPF prog-id=26 op=UNLOAD
+<剪去>
+ay 10 10:54:35 testvm1.both.org audit: BPF prog-id=55 op=LOAD
+May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
+May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
+May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd>
+May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/>
+lines 1-46/46 (END)
+```
+
+如果在这个时间段中仍然有大量的活动的话,你可以使用这些选项组合来进一步缩小结果数据流:
+
+```
+[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:35" --until="2020-05-10 10:55:00" -t "hello.sh"
+-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:10:41 EDT. --
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
+May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
+[root@testvm1 ~]#
+```
+
+你的结果应该与我的相似。你可以从这一系列的实验中看出,这个服务运行的很正常。
+
+### 重启 —— 还是走到这一步
+
+到目前为止,你还没有重启过安装了服务的机器。所以现在重启吧,因为毕竟这个教程是关于启动阶段程序运行的情况。首先,你需要在启动序列中启用这个服务。
+
+```
+[root@testvm1 ~]# systemctl enable hello.service
+Created symlink /etc/systemd/system/multi-user.target.wants/hello.service → /etc/systemd/system/hello.service.
+[root@testvm1 ~]#
+```
+
+注意到这个软链接是被创建在 `/etc/systemd/system/multi-user.target.wants` 目录下的。这是因为服务单元文件指定了服务是被 `multi-user.target` 所“需要”的。
+
+重启机器,确保能在启动阶段观察数据流,这样你能看到 “Hello world” 信息。等等……你看见了么?嗯,我看见了。尽管它很快被刷过去了,但是我确实看到 systemd 的信息显示它启动了 `hello.service` 服务。
+
+看看上次系统启动后的日志。你可以使用页面搜索工具 `less` 来找到 “Hello” 或 “hello”。我裁剪了很多数据,但是留下了附近的日志记录,这样你就能感受到和你服务有关的日志记录在本地是什么样子的:
+
+```
+[root@testvm1 ~]# journalctl -b
+<剪去>
+May 10 10:37:49 testvm1.both.org systemd[1]: Listening on SSSD Kerberos Cache Manager responder socket.
+May 10 10:37:49 testvm1.both.org systemd[1]: Reached target Sockets.
+May 10 10:37:49 testvm1.both.org systemd[1]: Reached target Basic System.
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting Modem Manager...
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting Network Manager...
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting Avahi mDNS/DNS-SD Stack...
+May 10 10:37:49 testvm1.both.org systemd[1]: Condition check resulted in Secure Boot DBX (blacklist) updater being skipped.
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting My hello shell script...
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
+May 10 10:37:49 testvm1.both.org systemd[1]: Started irqbalance daemon.
+May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=irqbalance comm="systemd" exe="/usr/lib/sy>"'
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting LSB: Init script for live image....
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting Hardware Monitoring Sensors...
+<剪去>
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting NTP client/server...
+May 10 10:37:49 testvm1.both.org systemd[1]: Starting SYSV: Late init script for live image....
+May 10 10:37:49 testvm1.both.org systemd[1]: Started SYSV: Late init script for live image..
+May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=livesys-late comm="systemd" exe="/usr/lib/>"'
+May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
+May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
+May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
+May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
+May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
+May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd>"'
+May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/>
+May 10 10:37:50 testvm1.both.org audit: BPF prog-id=28 op=LOAD
+<剪去>
+```
+
+你可以看到 systemd 启动了 `hello.service` 单元,它执行了 `hello.sh` 脚本并将输出记录在日志中。如果你能在启动阶段抓到它,你也应该能看见,systemd 信息表明了它正在启动这个脚本,另外一条信息表明了服务成功。通过观察上面数据流中第一条 systemd 消息,你会发现 systemd 在到达基本的系统目标后很快就启动了你的服务。
+
+但是我想看见信息在启动阶段也被打印出来。有一种方法可以做到:在 `hello.service` 文件的 `[Service]` 段中加入下述行:
+
+```
+StandardOutput=journal+console
+```
+
+现在 `hello.service` 文件看起来像这样:
+
+```
+# Simple service unit file to use for testing
+# startup configurations with systemd.
+# By David Both
+# Licensed under GPL V2
+#
+
+[Unit]
+Description=My hello shell script
+
+[Service]
+Type=oneshot
+ExecStart=/usr/local/bin/hello.sh
+StandardOutput=journal+console
+
+[Install]
+WantedBy=multi-user.target
+```
+
+加上这一行后,重启系统,并在启动过程中观察显示屏上滚动的数据流。你应该在它的小方框中看到信息。在启动序列完成后,你可以查看最近的启动日志,然后定位到你新服务的日志记录。
+
+### 修改次序
+
+现在你的服务已经可用了,你可以看看它在启动序列中哪个位置启动的,尝试下修改它。需要牢记的是 systemd 倾向于在每个主要目标(`basic.target`、`multi-user.target` 和 `graphical.**target`)中并行启动尽可能多的服务和其他的单元类型。你应该刚刚看过最近一次开机的日志记录,它应该和上面我的日志看上去类似。
+
+注意,systemd 在它到达到基本系统目标(`basic.target`)后不久就启动了你的测试服务。这正是你在在服务单元文件的 `WantedBy` 行中指定的,所以它是对的。在你做出修改之前,列出 `/etc/systemd/system/multi-user.target.wants` 目录下的内容,你会看到一个指向服务单元文件的软链接。服务单元文件的 `[Install]` 段指定了哪一个目标会启动这个服务,执行 `systemctl enable hello.service` 命令会在适当的 `targets.wants` 路径下创建软链接。
+
+```
+hello.service -> /etc/systemd/system/hello.service
+```
+
+某些服务需要在 `basic.target` 阶段启动,其他则没这个必要,除非系统正在启动 `graphical.target`。这个实验中的服务不会在 `basic.target` 期间启动 —— 假设你直到 `graphical.target` 阶段才需要它启动。那么修改 `WantedBy` 这一行:
+
+```
+WantedBy=graphical.target
+```
+
+一定要先禁用 `hello.service` 再重新启用它,这样可以删除旧链接并且在 `graphical.targets.wants` 目录下创建一个新的链接。我注意到如果我在修改服务需要的目标之前忘记禁用该服务,我可以运行 `systemctl disable` 命令,链接将从两个 `targets.wants` 目录中删除。之后我只需要重新启用这个服务然后重启电脑。
+
+启动 `graphical.target` 下的服务有个需要注意的地方,如果电脑启动到 `multi-user.target` 阶段,这个服务不会自动启动。如果这个服务需要 GUI 桌面接口,这或许是你想要的,但是它同样可能不是你想要的。
+
+用 `-o short-monotonic` 选项来查看 `graphical.target` 和 `multi-user.target` 的日志,展示内核启动几秒后的日志,精度为微秒级别:
+
+```
+[root@testvm1 ~]# journalctl -b -o short-monotonic
+```
+
+`multi-user.target` 的部分日志:
+
+```
+[ 17.264730] testvm1.both.org systemd[1]: Starting My hello shell script...
+[ 17.265561] testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
+<剪去>
+[ 19.478468] testvm1.both.org systemd[1]: Starting LSB: Init script for live image....
+[ 19.507359] testvm1.both.org iptables.init[844]: iptables: Applying firewall rules: [ OK ]
+[ 19.507835] testvm1.both.org hello.sh[843]: ###############################
+[ 19.507835] testvm1.both.org hello.sh[843]: ######### Hello World! ########
+[ 19.507835] testvm1.both.org hello.sh[843]: ###############################
+<剪去>
+[ 21.482481] testvm1.both.org systemd[1]: hello.service: Succeeded.
+[ 21.482550] testvm1.both.org smartd[856]: Opened configuration file /etc/smartmontools/smartd.conf
+[ 21.482605] testvm1.both.org systemd[1]: Finished My hello shell script.
+```
+
+还有部分 `graphical.target` 的日志:
+
+```
+[ 19.436815] testvm1.both.org systemd[1]: Starting My hello shell script...
+[ 19.437070] testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
+<剪去>
+[ 19.612614] testvm1.both.org hello.sh[841]: ###############################
+[ 19.612614] testvm1.both.org hello.sh[841]: ######### Hello World! ########
+[ 19.612614] testvm1.both.org hello.sh[841]: ###############################
+[ 19.629455] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
+[ 19.629569] testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
+[ 19.629682] testvm1.both.org systemd[1]: hello.service: Succeeded.
+[ 19.629782] testvm1.both.org systemd[1]: Finished My hello shell script.
+```
+
+尽管单元文件的 `WantedBy` 部分包含了 `graphical.target`,`hello.service` 单元在启动后大约 19.5 或 19.6 秒后运行。但是 `hello.service` 在 `multi-user.target` 中开始于 17.24 秒,在 `graphical target` 中开始于 19.43 秒。
+
+这意味着什么呢?看看 `/etc/systemd/system/default.target` 这个链接。文件内容显示 systemd 先启动了默认目标 `graphical.target`,然后 `graphical.target` 触发了 `multi-user.target`。
+
+```
+[root@testvm1 system]# cat default.target
+# SPDX-License-Identifier: LGPL-2.1+
+#
+# This file is part of systemd.
+#
+# systemd is free software; you can redistribute it and/or modify it
+# under the terms of the GNU Lesser General Public License as published by
+# the Free Software Foundation; either version 2.1 of the License, or
+# (at your option) any later version.
+
+[Unit]
+Description=Graphical Interface
+Documentation=man:systemd.special(7)
+Requires=multi-user.target
+Wants=display-manager.service
+Conflicts=rescue.service rescue.target
+After=multi-user.target rescue.service rescue.target display-manager.service
+AllowIsolate=yes
+[root@testvm1 system]#
+```
+
+不管是用 `graphical.target` 还是 `multi-user.target` 启动服务,`hello.service` 单元都在启动后的 19.5 或 19.6 秒后启动。基于这个事实和日志结果(特别是使用单调输出的日志),你就知道这些目标是在并行启动。再看看日志中另外一件事:
+
+
+```
+[ 28.397330] testvm1.both.org systemd[1]: Reached target Multi-User System.
+[ 28.397431] testvm1.both.org systemd[1]: Reached target Graphical Interface.
+```
+
+两个目标几乎是同时完成的。这是和理论一致的,因为 `graphical.target` 触发了 `multi-user.target`,在 `multi-user.target` 到达(即完成)之前它是不会完成的。但是 `hello.service` 比这个完成的早的多。
+
+这一切表明,这两个目标几乎是并行启动的。如果你查看日志,你会发现各种目标和来自这类主要目标的服务大多是平行启动的。很明显,`multi-user.target` 没有必要在 `graphical.target` 启动前完成。所以,简单的使用这些主要目标来并不能很好地排序启动序列,尽管它在保证单元只在它们被 `graphical.target` 需要时启动这方面很有用。
+
+在继续之前,把 `hello.service` 单元文件回滚至 `WantedBy=multi-user.target`(如果还没做的话)。
+
+### 确保一个服务在网络运行后启动
+
+一个常见的启动问题是保证一个单元在网络启动运行后再启动。Freedesktop.org 的文章《[在网络启动后运行服务][11]》中提到,目前没有一个真正的关于网络何时算作“启动”的共识。然而,这篇文章提供了三个选项,满足完全可用网络需求的是 `network-online.target`。需要注意的是 `network.target` 是在关机阶段使用的而不是启动阶段,所以它对你做有序启动方面没什么帮助。
+
+在做出任何改变之前,一定要检查下日志,确认 `hello.service` 单元在网络可用之前可以正确启动。你可以在日志中查找 `network-online.target` 来确认。
+
+你的服务并不真的需要网络服务,但是你可以把它当作是需要网络的。
+
+因为设置 `WantedBy=graphical.target` 并不能保证服务会在网络启动可用后启动,所以你需要其他的方法来做到这一点。幸运的是,有个简单的方法可以做到。将下面两行代码加入 `hello.service` 单元文件的 `[Unit]` 段:
+
+```
+After=network-online.target
+Wants=network-online.target
+```
+
+两个字段都需要才能生效。重启机器,在日志中找到服务的记录:
+
+```
+[ 26.083121] testvm1.both.org NetworkManager[842]: [1589227764.0293] device (enp0s3): Activation: successful, device activated.
+[ 26.083349] testvm1.both.org NetworkManager[842]: [1589227764.0301] manager: NetworkManager state is now CONNECTED_GLOBAL
+[ 26.085818] testvm1.both.org NetworkManager[842]: [1589227764.0331] manager: startup complete
+[ 26.089911] testvm1.both.org systemd[1]: Finished Network Manager Wait Online.
+[ 26.090254] testvm1.both.org systemd[1]: Reached target Network is Online.
+[ 26.090399] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=NetworkManager-wait-online comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? termina>"'
+[ 26.091991] testvm1.both.org systemd[1]: Starting My hello shell script...
+[ 26.095864] testvm1.both.org sssd[be[implicit_files]][1007]: Starting up
+[ 26.290539] testvm1.both.org systemd[1]: Condition check resulted in Login and scanning of iSCSI devices being skipped.
+[ 26.291075] testvm1.both.org systemd[1]: Reached target Remote File Systems (Pre).
+[ 26.291154] testvm1.both.org systemd[1]: Reached target Remote File Systems.
+[ 26.292671] testvm1.both.org systemd[1]: Starting Notify NFS peers of a restart...
+[ 26.294897] testvm1.both.org systemd[1]: iscsi.service: Unit cannot be reloaded because it is inactive.
+[ 26.304682] testvm1.both.org hello.sh[1010]: ###############################
+[ 26.304682] testvm1.both.org hello.sh[1010]: ######### Hello World! ########
+[ 26.304682] testvm1.both.org hello.sh[1010]: ###############################
+[ 26.306569] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
+[ 26.306669] testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
+[ 26.306772] testvm1.both.org systemd[1]: hello.service: Succeeded.
+[ 26.306862] testvm1.both.org systemd[1]: Finished My hello shell script.
+[ 26.584966] testvm1.both.org sm-notify[1011]: Version 2.4.3 starting
+```
+
+这样证实了 `hello.service` 单元会在 `network-online.target` 之后启动。这正是你想要的。你可能也看见了 “Hello World” 消息在启动阶段出现。还需要注意的是,在启动时记录出现的时间戳比之前要晚了大约 6 秒。
+
+### 定义启动序列的最好方法
+
+本文章详细地探讨了 Linux 启动时 systemd 和单元文件以及日志的细节,并且发现了当错误被引入单元文件时候会发生什么。作为系统管理员,我发现这类实验有助于我理解程序或者服务出故障时的行为,并且在安全环境中有意破坏是一种学习的好方法。
+
+文章中实验结果证明,仅将服务单元添加至 `multi-user.target` 或者 `graphical.target` 并不能确定它在启动序列中的位置。它仅仅决定了一个单元是否作为图形环境一部分启动。事实上,启动目标 `multi-user.target` 和 `graphical.target` 和所有它们的 `Wants` 以及 `Required` 几乎是并行启动的。确保单元在特定位置启动的最好方法是确定它所依赖的单元,并将新单元配置成 `Want` 和 `After` 它的依赖。
+
+
+### 资源
+
+网上有大量的关于 systemd 的参考资料,但是大部分都有点简略、晦涩甚至有误导性。除了本文中提到的资料,下列的网页提供了跟多可靠且详细的 systemd 入门信息。
+
+Fedora 项目有一篇切实好用的 systemd 入门,它囊括了几乎所有你需要知道的关于如何使用 systemd 配置、管理和维护 Fedora 计算机的信息。
+
+Fedora 项目也有一个不错的 备忘录,交叉引用了过去 SystemV 命令和 systemd 命令做对比。
+
+关于 systemd 的技术细节和创建这个项目的原因,请查看 Freedesktop.org 上的 systemd 描述。
+
+Linux.com 的“更多 systemd 的乐趣”栏目提供了更多高级的 systemd 信息和技巧。
+
+此外,还有一系列深度的技术文章,是由 systemd 的设计者和主要开发者 Lennart Poettering 为 Linux 系统管理员撰写的。这些文章写于 2010 年 4 月至 2011 年 9 月间,但它们现在和当时一样具有现实意义。关于 systemd 及其生态的许多其他好文章都是基于这些文章:
+
+ * [Rethinking PID 1][18]
+ * [systemd for Administrators,Part I][19]
+ * [systemd for Administrators,Part II][20]
+ * [systemd for Administrators,Part III][21]
+ * [systemd for Administrators,Part IV][22]
+ * [systemd for Administrators,Part V][23]
+ * [systemd for Administrators,Part VI][24]
+ * [systemd for Administrators,Part VII][25]
+ * [systemd for Administrators,Part VIII][26]
+ * [systemd for Administrators,Part IX][27]
+ * [systemd for Administrators,Part X][28]
+ * [systemd for Administrators,Part XI][29]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/5/manage-startup-systemd
+
+作者:[David Both][a]
+选题:[lujun9972][b]
+译者:[tt67wq](https://github.com/tt67wq)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
+[2]: https://linux.cn/article-12214-1.html
+[3]: https://opensource.com/article/20/5/systemd-units
+[4]: https://opensource.com/article/20/5/systemd-startup
+[5]: https://chmodcommand.com/chmod-700/
+[6]: https://opensource.com/life/16/10/introduction-linux-filesystems
+[7]: https://chmodcommand.com/chmod-644/
+[8]: https://chmodcommand.com/chmod-640/
+[9]: http://man7.org/linux/man-pages/man5/systemd.service.5.html
+[10]: tmp.bYMHU00BHs#resources
+[11]: https://www.freedesktop.org/wiki/Software/systemd/NetworkTarget/
+[12]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
+[13]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
+[14]: http://Freedesktop.org
+[15]: http://www.freedesktop.org/wiki/Software/systemd
+[16]: http://Linux.com
+[17]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
+[18]: http://0pointer.de/blog/projects/systemd.html
+[19]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
+[20]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
+[21]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
+[22]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
+[23]: http://0pointer.de/blog/projects/three-levels-of-off.html
+[24]: http://0pointer.de/blog/projects/changing-roots
+[25]: http://0pointer.de/blog/projects/blame-game.html
+[26]: http://0pointer.de/blog/projects/the-new-configuration-files.html
+[27]: http://0pointer.de/blog/projects/on-etc-sysinit.html
+[28]: http://0pointer.de/blog/projects/instances.html
+[29]: http://0pointer.de/blog/projects/inetd.html
diff --git a/published/202105/20201103 Create a list in a Flutter mobile app.md b/published/202105/20201103 Create a list in a Flutter mobile app.md
new file mode 100644
index 0000000000..a27893ee35
--- /dev/null
+++ b/published/202105/20201103 Create a list in a Flutter mobile app.md
@@ -0,0 +1,346 @@
+[#]: collector: (lujun9972)
+[#]: translator: (ywxgod)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13446-1.html)
+[#]: subject: (Create a list in a Flutter mobile app)
+[#]: via: (https://opensource.com/article/20/11/flutter-lists-mobile-app)
+[#]: author: (Vitaly Kuprenko https://opensource.com/users/kooper)
+
+在 Flutter 移动应用程序中创建一个列表
+======
+
+> 了解如何创建 Flutter 应用的界面以及如何在它们之间进行数据传递。
+
+
+
+Flutter 是一个流行的开源工具包,它可用于构建跨平台的应用。在文章《[用 Flutter 创建移动应用][2]》中,我已经向大家展示了如何在 Linux 中安装 [Flutter][3] 并创建你的第一个应用。而这篇文章,我将向你展示如何在你的应用中添加一个列表,点击每一个列表项可以打开一个新的界面。这是移动应用的一种常见设计方法,你可能以前见过的,下面有一个截图,能帮助你对它有一个更直观的了解:
+
+![测试 Flutter 应用][4]
+
+Flutter 使用 [Dart][6] 语言。在下面的一些代码片段中,你会看到以斜杠开头的语句。两个斜杠(`//`)是指代码注释,用于解释某些代码片段。三个斜杠(`///`)则表示的是 Dart 的文档注释,用于解释 Dart 类和类的属性,以及其他的一些有用的信息。
+
+### 查看Flutter应用的主要部分
+
+Flutter 应用的典型入口点是 `main()` 函数,我们通常可以在文件 `lib/main.dart` 中找到它:
+
+```
+void main() {
+ runApp(MyApp());
+}
+```
+
+应用启动时,`main()` 会被调用,然后执行 `MyApp()`。 `MyApp` 是一个无状态微件(`StatelessWidget`),它包含了`MaterialApp()` 微件中所有必要的应用设置(应用的主题、要打开的初始页面等):
+
+```
+class MyApp extends StatelessWidget {
+ @override
+ Widget build(BuildContext context) {
+ return MaterialApp(
+ title: 'Flutter Demo',
+ theme: ThemeData(
+ primarySwatch: Colors.blue,
+ visualDensity: VisualDensity.adaptivePlatformDensity,
+ ),
+ home: MyHomePage(title: 'Flutter Demo Home Page'),
+ );
+ }
+}
+```
+
+生成的 `MyHomePage()` 是应用的初始页面,是一个有状态的微件,它包含包含可以传递给微件构造函数参数的变量(从上面的代码看,我们传了一个 `title` 变量给初始页面的构造函数):
+
+```
+class MyHomePage extends StatefulWidget {
+ MyHomePage({Key key, this.title}) : super(key: key);
+
+ final String title;
+
+ @override
+ _MyHomePageState createState() => _MyHomePageState();
+}
+```
+
+有状态微件(`StatefulWidget`)表示这个微件可以拥有自己的状态:`_MyHomePageState`。调用 `_MyHomePageState` 中的 `setState()` 方法,可以重新构建用户界面:
+
+```
+class _MyHomePageState extends State {
+ int _counter = 0; // Number of taps on + button.
+
+ void _incrementCounter() { // Increase number of taps and update UI by calling setState().
+ setState(() {
+ _counter++;
+ });
+ }
+ ...
+}
+```
+
+不管是有状态的,还是无状态的微件,它们都有一个 `build()` 方法,该方法负责微件的 UI 外观。
+
+```
+@override
+Widget build(BuildContext context) {
+ return Scaffold( // Page widget.
+ appBar: AppBar( // Page app bar with title and back button if user can return to previous screen.
+ title: Text(widget.title), // Text to display page title.
+ ),
+ body: Center( // Widget to center child widget.
+ child: Column( // Display children widgets in column.
+ mainAxisAlignment: MainAxisAlignment.center,
+ children: [
+ Text( // Static text.
+ 'You have pushed the button this many times:',
+ ),
+ Text( // Text with our taps number.
+ '$_counter', // $ sign allows us to use variables inside a string.
+ style: Theme.of(context).textTheme.headline4,// Style of the text, “Theme.of(context)” takes our context and allows us to access our global app theme.
+ ),
+ ],
+ ),
+ ),
+ // Floating action button to increment _counter number.
+ floatingActionButton: FloatingActionButton(
+ onPressed: _incrementCounter,
+ tooltip: 'Increment',
+ child: Icon(Icons.add),
+ ),
+ );
+}
+```
+
+### 修改你的应用
+
+一个好的做法是,把 `main()` 方法和其他页面的代码分开放到不同的文件中。要想将它们分开,你需要右击 `lib` 目录,然后选择 “New > Dart File” 来创建一个 .dart 文件:
+
+![创建一个新的 Dart 文件][10]
+
+将新建的文件命名为 `items_list_page`。
+
+切换回到 `main.dart` 文件,将 `MyHomePage` 和 `_MyHomePageState` 中的代码,剪切并粘贴到我们新建的文件。然后将光标放到 `StatefulWidget` 上(下面红色的下划线处), 按 `Alt+Enter` 后出现下拉列表,然后选择 `package:flutter/material.dart`:
+
+![导入 Flutter 包][11]
+
+经过上面的操作我们将 `flutter/material.dart` 包添加到了 `main.dart` 文件中,这样我们就可以使用 Flutter 提供的默认的 material 主题微件。
+
+然后, 在类名 `MyHomePage` 右击,“Refactor > Rename...”将其重命名为 `ItemsListPage`:
+
+![重命名 StatefulWidget 类][12]
+
+Flutter 识别到你重命名了 `StatefulWidget` 类,它会自动将它的 `State` 类也跟着重命名:
+
+![State 类被自动重命名][13]
+
+回到 `main.dart` 文件,将文件名 `MyHomePage` 改为 `ItemsListPage`。 一旦你开始输入, 你的 Flutter 集成开发环境(可能是 IntelliJ IDEA 社区版、Android Studio 和 VS Code 或 [VSCodium][14]),会给出自动代码补完的建议。
+
+![IDE 建议自动补完的代码][15]
+
+按回车键即可完成输入,缺失的导入语句会被自动添加到文件的顶部。
+
+![添加缺失的导入语句][16]
+
+到此,你已经完成了初始设置。现在你需要在 `lib` 目录创建一个新的 .dart 文件,命名为 `item_model`。(注意,类命是大写驼峰命名,一般的文件名是下划线分割的命名。)然后粘贴下面的代码到新的文件中:
+
+```
+/// Class that stores list item info:
+/// [id] - unique identifier, number.
+/// [icon] - icon to display in UI.
+/// [title] - text title of the item.
+/// [description] - text description of the item.
+class ItemModel {
+ // class constructor
+ ItemModel(this.id, this.icon, this.title, this.description);
+
+ // class fields
+ final int id;
+ final IconData icon;
+ final String title;
+ final String description;
+}
+```
+
+回到 `items_list_page.dart` 文件,将已有的 `_ItemsListPageState` 代码替换为下面的代码:
+
+```
+class _ItemsListPageState extends State {
+
+// Hard-coded list of [ItemModel] to be displayed on our page.
+ final List _items = [
+ ItemModel(0, Icons.account_balance, 'Balance', 'Some info'),
+ ItemModel(1, Icons.account_balance_wallet, 'Balance wallet', 'Some info'),
+ ItemModel(2, Icons.alarm, 'Alarm', 'Some info'),
+ ItemModel(3, Icons.my_location, 'My location', 'Some info'),
+ ItemModel(4, Icons.laptop, 'Laptop', 'Some info'),
+ ItemModel(5, Icons.backup, 'Backup', 'Some info'),
+ ItemModel(6, Icons.settings, 'Settings', 'Some info'),
+ ItemModel(7, Icons.call, 'Call', 'Some info'),
+ ItemModel(8, Icons.restore, 'Restore', 'Some info'),
+ ItemModel(9, Icons.camera_alt, 'Camera', 'Some info'),
+ ];
+
+ @override
+ Widget build(BuildContext context) {
+ return Scaffold(
+ appBar: AppBar(
+ title: Text(widget.title),
+ ),
+ body: ListView.builder( // Widget which creates [ItemWidget] in scrollable list.
+ itemCount: _items.length, // Number of widget to be created.
+ itemBuilder: (context, itemIndex) => // Builder function for every item with index.
+ ItemWidget(_items[itemIndex], () {
+ _onItemTap(context, itemIndex);
+ }),
+ ));
+ }
+
+ // Method which uses BuildContext to push (open) new MaterialPageRoute (representation of the screen in Flutter navigation model) with ItemDetailsPage (StateFullWidget with UI for page) in builder.
+ _onItemTap(BuildContext context, int itemIndex) {
+ Navigator.of(context).push(MaterialPageRoute(
+ builder: (context) => ItemDetailsPage(_items[itemIndex])));
+ }
+}
+
+
+// StatelessWidget with UI for our ItemModel-s in ListView.
+class ItemWidget extends StatelessWidget {
+ const ItemWidget(this.model, this.onItemTap, {Key key}) : super(key: key);
+
+ final ItemModel model;
+ final Function onItemTap;
+
+ @override
+ Widget build(BuildContext context) {
+ return InkWell( // Enables taps for child and add ripple effect when child widget is long pressed.
+ onTap: onItemTap,
+ child: ListTile( // Useful standard widget for displaying something in ListView.
+ leading: Icon(model.icon),
+ title: Text(model.title),
+ ),
+ );
+ }
+}
+```
+
+为了提高代码的可读性,可以考虑将 `ItemWidget` 作为一个单独的文件放到 `lib` 目录中。
+
+现在唯一缺少的是 `ItemDetailsPage` 类。在 `lib` 目录中我们创建一个新文件并命名为 `item_details_page`。然后将下面的代码拷贝进去:
+
+```
+import 'package:flutter/material.dart';
+
+import 'item_model.dart';
+
+/// Widget for displaying detailed info of [ItemModel]
+class ItemDetailsPage extends StatefulWidget {
+ final ItemModel model;
+
+ const ItemDetailsPage(this.model, {Key key}) : super(key: key);
+
+ @override
+ _ItemDetailsPageState createState() => _ItemDetailsPageState();
+}
+
+class _ItemDetailsPageState extends State {
+ @override
+ Widget build(BuildContext context) {
+ return Scaffold(
+ appBar: AppBar(
+ title: Text(widget.model.title),
+ ),
+ body: Center(
+ child: Column(
+ children: [
+ const SizedBox(height: 16),
+ Icon(
+ widget.model.icon,
+ size: 100,
+ ),
+ const SizedBox(height: 16),
+ Text(
+ 'Item description: ${widget.model.description}',
+ style: TextStyle(fontSize: 18),
+ )
+ ],
+ ),
+ ),
+ );
+ }
+}
+```
+
+上面的代码几乎没什么新东西,不过要注意的是 `_ItemDetailsPageState` 里使用了 `widget.item.title` 这样的语句,它让我们可以从有状态类中引用到其对应的微件(`StatefulWidget`)。
+
+### 添加一些动画
+
+现在让我们来添加一些基础的动画:
+
+ 1. 找到 `ItemWidget` 代码块(或者文件)
+ 2. 将光标放到 `build()` 方法中的 `Icon()` 微件上
+ 3. 按 `Alt+Enter`,然后选择“Wrap with widget...”
+
+![查看微件选项][18]
+
+输入 `Hero`,然后从建议的下拉列表中选择 `Hero((Key key, @required this, tag, this.create))`:
+
+![查找 Hero 微件][19]
+
+下一步, 给 Hero 微件添加 `tag` 属性 `tag: model.id`:
+
+![在 Hero 微件上添加 tag 属性为 model.id][20]
+
+最后我们在 `item_details_page.dart` 文件中做相同的修改:
+
+![修改item_details_page.dart文件][21]
+
+前面的步骤,其实我们是用 `Hero()` 微件对 `Icon()` 微件进行了封装。还记得吗?前面我们定义 `ItemModel` 类时,定义了一个 `id field`,但没有在任何地方使用到。因为 Hero 微件会为其每个子微件添加一个唯一的标签。当 Hero 检测到不同页面(`MaterialPageRoute`)中存在相同标签的 Hero 时,它会自动在这些不同的页面中应用过渡动画。
+
+可以在安卓模拟器或物理设备上运行我们的应用来测试这个动画。当你打开或者关闭列表项的详情页时,你会看到一个漂亮的图标动画:
+
+![测试 Flutter 应用][4]
+
+### 收尾
+
+这篇教程,让你学到了:
+
+ * 一些符合标准的,且能用于自动创建应用的组件。
+ * 如何添加多个页面以及在页面间传递数据。
+ * 如何给多个页面添加简单的动画。
+
+如果你想了解更多,查看 Flutter 的 [文档][22](有一些视频和样例项目的链接,还有一些创建 Flutter 应用的“秘方”)与 [源码][23],源码的开源许可证是 BSD 3。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/11/flutter-lists-mobile-app
+
+作者:[Vitaly Kuprenko][a]
+选题:[lujun9972][b]
+译者:[ywxgod](https://github.com/ywxgod)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/kooper
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/team-phone-collaboration-mobile-device.png?itok=v3EjbRK6 (Mobile devices and collaboration leads to staring at our phones)
+[2]: https://linux.cn/article-12693-1.html
+[3]: https://flutter.dev/
+[4]: https://opensource.com/sites/default/files/uploads/flutter_test.gif (Testing the Flutter app)
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://dart.dev/
+[7]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+key
+[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
+[9]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+icon
+[10]: https://opensource.com/sites/default/files/uploads/flutter_new-dart-file_0.png (Create a new Dart file)
+[11]: https://opensource.com/sites/default/files/uploads/flutter_import-package.png (Importing Flutter package)
+[12]: https://opensource.com/sites/default/files/uploads/flutter_rename-class.png (Renaming StatefulWidget class)
+[13]: https://opensource.com/sites/default/files/uploads/flutter_stateclassrenamed.png (State class renamed automatically)
+[14]: https://opensource.com/article/20/6/open-source-alternatives-vs-code
+[15]: https://opensource.com/sites/default/files/uploads/flutter_autocomplete.png (IDE suggests autocompleting code)
+[16]: https://opensource.com/sites/default/files/uploads/flutter_import-input.png (Adding missing import )
+[17]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+listview
+[18]: https://opensource.com/sites/default/files/uploads/flutter_wrapwithwidget.png (Wrap with widget option)
+[19]: https://opensource.com/sites/default/files/uploads/flutter_hero.png (Finding the Hero widget)
+[20]: https://opensource.com/sites/default/files/uploads/flutter_hero-tag.png (Adding the tag property model.id to the Hero widget)
+[21]: https://opensource.com/sites/default/files/uploads/flutter_details-tag.png (Changing item_details_page.dart file)
+[22]: https://flutter.dev/docs
+[23]: https://github.com/flutter
diff --git a/published/202105/20201117 Getting started with btrfs for Linux.md b/published/202105/20201117 Getting started with btrfs for Linux.md
new file mode 100644
index 0000000000..a47f573e08
--- /dev/null
+++ b/published/202105/20201117 Getting started with btrfs for Linux.md
@@ -0,0 +1,232 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13440-1.html)
+[#]: subject: (Getting started with btrfs for Linux)
+[#]: via: (https://opensource.com/article/20/11/btrfs-linux)
+[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
+
+Btrfs 文件系统入门
+======
+
+> B-tree 文件系统(Btrfs)融合了文件系统和卷管理器。它为 Linux 操作系统提供了高级文件系统应当拥有的诸多不错的功能特性。
+
+
+
+好几年前 Btrfs 就已经可以在 Linux 中使用了,所以你可能已经熟悉它了。如果没有,你可能对它尚有疑虑,尤其是如果你使用的是 Fedora 工作站 (Btrfs 现在是它的默认文件系统)。本文旨在帮助你熟悉它及其高级功能,例如 [写时复制][2] 和 [校验和][3]。
+
+Btrfs 是 “B-Tree Filesystem” 的缩写,实际上是文件系统和卷管理器的结合体。它通常被视为对 ZFS 的回应,ZFS 早在 2005 年就被引入 Sun 微系统的 Solaris 操作系统中,现在基本上被一个名为 OpenZFS 的开源实现所取代。Ubuntu 和 FreeBSD 常常使用 OpenZFS。其他具有类似特性的示例有红帽的 Stratis 和 Linux 逻辑卷管理器(LVM)。
+
+### 安装
+
+为了尝试 Btrfs,我下载了 Fedora 33 工作站 [ISO 文件][4] 并将其安装到一个新的虚拟机(VM)中。安装过程与以前的版本没有变化。我没有自定义任何设置,包括驱动器分区和格式化,以保持本教程的准确“开箱即用”设置。当虚拟机启动并运行后,我安装并运行了 GNOME 分区编辑器([GParted][5]),以获得一个良好的、工厂级的驱动器布局视图。
+
+![GParted's view of Btrfs on Fedora 33 Workstation using GParted][6]
+
+从安装这一点来说,与你以前所习惯的情况没什么不同;事实上,你可以正常使用该系统,甚至可能没有注意到文件系统是 Btrfs。然而,拥有这个新的默认文件系统使你能够利用几个很酷的特性。
+
+### 检查 Btrfs 文件系统
+
+我暂时没有找到特定于 Btrfs 的图形工具,尽管它的一些功能已经被合并到现有的磁盘管理工具中。
+
+在命令行中,你可以更仔细地查看 Btrfs 格式:
+
+```
+# btrfs filesystem show
+Label: 'fedora_localhost-live' uuid: f2bb02f9-5c41-4c91-8eae-827a801ee58a
+ Total devices 1 FS bytes used 6.36GiB
+ devid 1 size 10.41GiB used 8.02GiB path /dev/vda3
+```
+
+### 修改 Btrfs 标签
+
+我首先注意到的是安装程序设置的文件系统标签:`fedora_localhost-live`。这是不准确的,因为它现在是一个已安装的系统,不再是 [livecd][8]。所以我使用 `btrfs filesystem label` 命令对其进行了更改。
+
+修改 Btrfs 标签非常的简单:
+
+```
+# btrfs filesystem label /
+fedora_localhost-live
+# btrfs filesystem label / fedora33workstation
+# btrfs filesystem label /
+fedora33workstation
+```
+
+### 管理 Btrfs 子卷
+
+子卷看起来像是可以由 Btrfs 管理的标准目录。我的新 Fedora 33 工作站上有几个子卷:
+
+```
+# btrfs subvolume list /
+ID 256 gen 2458 top level 5 path home
+ID 258 gen 2461 top level 5 path root
+ID 265 gen 1593 top level 258 path var/lib/machines
+```
+
+使用 `btrfs subvolume Create` 命令创建新的子卷,或使用 `btrfs subvolume delete` 删除子卷:
+
+```
+# btrfs subvolume create /opt/foo
+Create subvolume '/opt/foo'
+# btrfs subvolume list /
+ID 256 gen 2884 top level 5 path home
+ID 258 gen 2888 top level 5 path root
+ID 265 gen 1593 top level 258 path var/lib/machines
+ID 276 gen 2888 top level 258 path opt/foo
+# btrfs subvolume delete /opt/foo
+Delete subvolume (no-commit): '/opt/foo'
+```
+
+子卷允许设置配额、拍摄快照以及复制到其他位置和其他主机等操作。那么系统管理员如何利用这些功能?用户主目录又是如何操作的呢?
+
+#### 添加用户
+
+就像从前一样,添加一个新的用户帐户会创建一个主目录供该帐户使用:
+
+```
+# useradd student1
+# getent passwd student1
+student1:x:1006:1006::/home/student1:/bin/bash
+# ls -l /home
+drwx------. 1 student1 student1 80 Oct 29 00:21 student1
+```
+
+传统上,用户的主目录是 `/home` 的子目录。所有权和操作权是为所有者量身定制的,但是特殊功能来没有管理它们。而企业服务器环境是另外一种情况。通常,目录是为特定的应用程序及其用户保留的。你可以利用 Btrfs 来管理和应用对这些目录的约束。
+
+为了将 Btrfs 子卷作为用户主页,在 `useradd` 命令中有一个新选项:`--Btrfs-subvolume-home`。尽管手册页尚未更新(截至本文撰写之时),但你可以通过运行 `useradd --help` 来查看该选项。通过在添加新用户时传递此选项,将创建一个新的 Btrfs 子卷。它的功能与创建常规目录时的 `-d` 选项类似:
+
+```
+# useradd --btrfs-subvolume-home student2
+Create subvolume '/home/student2'
+```
+
+使用 `getent passwd student2` 验证用户,它将显示为正常。但是,运行 `btrfs subvolume` 命令列出子卷,你将看到一些有趣的内容:新用户的主目录!
+
+```
+# btrfs subvolume list /
+ID 256 gen 2458 top level 5 path home
+ID 258 gen 2461 top level 5 path root
+ID 265 gen 1593 top level 258 path var/lib/machines
+ID 272 gen 2459 top level 256 path home/student2
+```
+
+探索企业服务器环境的第二个场景。假设你需要在 `/opt` 中安装一个 [WildFly][9] 服务器并部署一个 Java web 应用程序。通常,你的第一步是创建一个 `wildfly` 用户。使用新的 `--btrfs-subvolume-home` 选项和 `-b` 选项来指定 `/opt` 作为基本目录:
+
+```
+# useradd -b /opt --btrfs-subvolume-home wildfly
+Create subvolume '/opt/wildfly'
+```
+
+于是,`wildfly` 用户可以使用了,并且主目录设置在了 `/opt/wildfly`。
+
+#### 删除用户
+
+删除用户时,有时需要同时删除该用户的文件和主目录。`userdel` 命令有 `-r` 选项,它可以同时删除 Btrfs 子卷:
+
+```
+# userdel -r student2
+Delete subvolume (commit): '/home/student2'
+```
+
+#### 设置磁盘使用配额
+
+在我的一节计算机科学课上,一个学生运行了一个失控的 C 程序,然后写进了磁盘,将我们院的 Unix 系统上整个 `/home` 目录都填满了!在管理员终止失控进程并清除一些空间之前,服务器将无法使用。上述情况也是如此;那个 Wildfly 企业应用程序将为其用户提供越来越多的日志文件和内容存储。如何防止服务器因磁盘已满而死机?设置磁盘使用限制是个好主意。幸运的是,Btrfs 通过设置配额的方式支持这一点。
+
+配置配额需要几个步骤。第一步是在 Btrfs 文件系统上启用配额:
+
+```
+# btrfs quota enable /
+```
+
+确保你知道每个子卷的配额组(qgroup)ID 号,该编号由 `btrfs subvolume list` 命令显示。每个子卷都需要基于 ID 号码来关联配额组。这可以通过 `btrfs qgroup create` 单独完成,但是,btrfs 维基提供了以下命令来加快为文件系统上的子卷创建配额组:
+
+```
+> btrfs subvolume list \ | cut -d' ' -f2 | xargs -I{} -n1 btrfs qgroup destroy 0/{} \
+```
+
+在新安装的 Fedora 33 工作站系统中,你在根文件系统路径上操作,`/`。用根路径替换 `\`:
+
+```
+# btrfs subvolume list / | cut -d' ' -f2 | xargs -I{} -n1 btrfs qgroup create 0/{} /
+```
+
+然后运行 `btrfs quota rescan`,查看新的配额组:
+
+```
+# btrfs quota rescan /
+quota rescan started
+# btrfs qgroup show /
+qgroupid rfer excl
+-------- ---- ----
+0/5 16.00KiB 16.00KiB
+0/256 272.04MiB 272.04MiB
+0/258 6.08GiB 6.08GiB
+0/265 16.00KiB 16.00KiB
+0/271 16.00KiB 16.00KiB
+0/273 16.00KiB 16.00KiB
+```
+
+于是现在,你可以将配额分配给其中一个配额组,然后将配额应用于其关联的子卷。因此,如果要将 `student3` 的主目录使用限制为 1 GB,请使用 `btrfs qgroup limit` 命令:
+
+```
+# btrfs qgroup limit 1G /home/student3
+```
+
+查看特定子卷的配额:
+
+```
+# btrfs qgroup show -reF /home/student3
+qgroupid rfer excl max_rfer max_excl
+-------- ---- ---- -------- --------
+0/271 16.00KiB 16.00KiB 1.00GiB none
+```
+
+稍有不同的选项参数将显示所有配额组和设置的所有配额:
+
+```
+# btrfs qgroup show -re /
+qgroupid rfer excl max_rfer max_excl
+-------- ---- ---- -------- --------
+0/5 16.00KiB 16.00KiB none none
+0/256 272.04MiB 272.04MiB none none
+0/258 6.08GiB 6.08GiB none none
+0/265 16.00KiB 16.00KiB none none
+0/271 16.00KiB 16.00KiB 1.00GiB none
+0/273 16.00KiB 16.00KiB none none
+```
+
+### 其他特性
+
+这些例子提供了 Btrfs 特性的一些思考。运行 `btrfs --help` 查看命令的完整列表。还有许多其他值得注意的功能;例如,快照和发送/接收是两个值得学习的功能。
+
+### 总结讨论
+
+Btrfs 为向 Linux 提供高级文件系统特性集贡献了很多特性。这不是第一次;我知道 ZFS 在大约 15 年前引入了这种类型的文件系统,但是 Btrfs 是完全开源的,不受专利的限制。
+
+如果你想探索这个文件系统,我建议从虚拟机或备用系统开始。
+
+我想能够出现一些图形化的管理工具,为那些喜欢用图形工具的系统管理员提供便利。幸运的是,Btrfs 具有强大的开发活动,Fedora 33 项目决定将其设置为工作站上的默认值就证明了这一点。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/11/btrfs-linux
+
+作者:[Alan Formy-Duval][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/alanfdoss
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_organize_letter.png?itok=GTtiiabr (Filing cabinet for organization)
+[2]: https://en.wikipedia.org/wiki/Copy-on-write
+[3]: https://en.wikipedia.org/wiki/Checksum
+[4]: https://getfedora.org/en/workstation/download/
+[5]: https://gparted.org/
+[6]: https://opensource.com/sites/default/files/uploads/gparted_btrfs.png (GParted's view of Btrfs on Fedora 33 Workstation using GParted)
+[7]: https://creativecommons.org/licenses/by-sa/4.0/
+[8]: https://en.wikipedia.org/wiki/Live_CD
+[9]: https://www.wildfly.org/
diff --git a/published/202105/20201123 6 predictions for JavaScript build tools.md b/published/202105/20201123 6 predictions for JavaScript build tools.md
new file mode 100644
index 0000000000..fcb3f0f83e
--- /dev/null
+++ b/published/202105/20201123 6 predictions for JavaScript build tools.md
@@ -0,0 +1,145 @@
+[#]: collector: (lujun9972)
+[#]: translator: (ywxgod)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13423-1.html)
+[#]: subject: (6 predictions for JavaScript build tools)
+[#]: via: (https://opensource.com/article/20/11/javascript-build-tools)
+[#]: author: (Shedrack Akintayo https://opensource.com/users/shedrack-akintayo)
+
+对 JavaScript 构建工具的 6 个预测
+======
+
+> JavaScript 前端工具的生态系统充满着变数和竞争,且只有最好的工具才会存活下来。
+
+
+
+生产中使用的代码与开发中的有所不同. 在生产中,我们需要构建一些能运行得够快、能管理各种依赖关系、能自动执行任务、能加载外部模块等功能的包。而那些将开发中的代码转为生产代码的 [JavaScript][2] 工具我们就称之为 _构建工具。_
+
+我们可以通过各个构建步骤以及其重要性来解释前端代码需要被“构建”的原因。
+
+### 前端代码构建步骤
+
+前端代码的构建涉及下面的四个步骤:
+
+#### 1、转译
+
+通过转译,开发者可以使用到语言最新、最热门的更新和扩展,并保持浏览器的兼容性等。下面是使用 [Babel][3] 的一个例子:
+
+```
+// 数组映射中的箭头函数语法
+const double = [1, 2, 3].map((num) => num * 2);
+// 转译后
+const double = [1, 2, 3].map(function(num) {
+ return num * 2;
+});
+```
+
+#### 2、分包
+
+分包是处理所有 `import` 与`require` 语句的过程;找到相匹配的 JavaScript 代码片段、包和库;将它们添加到适当的域中;然后将它们打包到一个大的 JavaScript 文件中。常用的分包器包括 Browserify、Webpack 与 Parcel。
+
+#### 3、压缩
+
+压缩是通过删除空白和代码注释来减少最终的文件大小。在压缩过程中,我们还可以更进一步添加代码混淆步骤,混淆会更改变量名和方法名,使代码变得晦涩难懂,因此一旦代码交付到客户端,它就不是那么容易能让人读懂。下面是一个使用 Grunt 的例子:
+
+```
+// 压缩前
+const double = [1, 2, 3].map(function(num) {
+ return num * 2;
+});
+// 压缩后
+const double=[1,2,3].map(function(num){return num*2;});
+```
+
+#### 4、打包
+
+完成上面的所有步骤之后, 我们需要将这些具有兼容性、且经过分包、压缩/混淆过的文件放置到某个地方。打包正是这样一个过程,它将上述步骤所产生的结果放置到开发者指定的某个位置上,这通常是通过打包器完成的。
+
+### 前端构建工具
+
+前端工具及构建工具可以分为以下几类:
+
+ * 包管理: NPM、Yarn
+ * 转译器: Babel 等
+ * 打包器: Webpack、Parcel、Browserify
+ * 压缩混淆: UglifyJS、Packer、Minify 等
+
+JavaScript 生态系统中有各种各样的构建工具可以使用,包括下面的这些:
+
+#### Grunt 和 Bower
+
+[Grunt][4] 是作为命令行工具引入的,它仅提供一个脚本来指定和配置相关构建任务。[Bower][5] 作为包管理器,提供了一种客户端包的管理方法而紧追其后。这两者,再加上 NPM,它们经常在一起使用,它们看上去似乎可以满足大多数的自动化需求,但 Grunt 的问题在于它无法提供给开发者配置更复杂任务的自由,而 Bower 使开发者管理的程序包是平常的两倍,因为它将前端包、后台包分开了(例如,Bower 组件与 Node 模块)。
+
+**Grunt 与 Bower 的未来:** Grunt 与 Bower 正在退出 JavaScript 工具生态,但是还有一些替代品。
+
+#### Gulp 和 Browserify
+
+[Gulp][6] 是在 Grunt 发布一年半之后才发布的。但 Gulp 却让大家感到很自然、舒服。用 JavaScript 来写构建脚本与用 JSON 来写相比更自由。你可以在 Gulp 的构建脚本中编写函数、即时创建变量、在任何地方使用条件语句 —— 但就这些,并不能说让我们的感觉变得特别自然和舒适,只能说这只是其中的一个可能的原因。[Browserify][7] 和 Gulp 可以配合使用,Browserify 允许 NPM 包(用于后端 Node 服务器)被直接带入到前端,就这一点已经直接让 Bower 废了。而正是这种用一个包管理器来处理前后端包的方式让人感到更自然和更好。
+
+**Gulp 的未来:** Gulp 可能会被改进,以便匹配当前流行的构建工具,但这完全取决于创造者的意愿。Gulp 仍在使用中,只是不再像以前那么流行了。
+
+#### Webpack 和 NPM/Yarn 脚本
+
+[Webpack][8] 是现代前端开发工具中最热门的宠儿,它是一个开源的 JavaScript 模块打包器。Webpack 主要是为处理 JavaScript 而创造的,但如果包含相应的加载器,它也可以转换 HTML、CSS 和图片等前端资源。通过 Webpack,你也可以像 Gulp 一样编写构建脚本,并通过 [NPM/Yarn][9] 来执行它们。
+
+**Webpack 的未来:** Webpack 是目前 JavaScript 工具生态系统中最热门的工具,最近几乎所有的 JavaScript 库都在使用 React 和 Webpack。Webpack 目前处于第四个版本,不会很快消失。(LCTT 译注:Webpack 目前已经发布了第五个版本了,且还在火热更新中)
+
+#### Parcel
+
+[Parcel][10] 是一个 Web 应用打包器,于 2018 年推出,因其开发者体验而与众不同。Parcel 能利用处理器多核功能提供极快的打包性能,且还零配置。但 Parcel 还是一个新星,对于一些大型应用,其采用率并不高。相比之下,开发人员更喜欢使用 Webpack,因为 Webpack 有更广泛的支持和可定制性。
+
+**Parcel 的未来:** Parcel 非常容易使用,如果你统计打包和构建时间,它会比 Webpack 更快,而且它还提供了更好的开发者体验。Parcel 没有被大量采用的原因可能是它仍然比较新。在前端构建工具的生态系统中,Parcel 的前景会非常光明,它将会存在一段时间。
+
+#### Rollup
+
+[Rollup][11] 是 JavaScript 的一个模块分包器,它可将一小段代码编译为更大更复杂的库或应用。Rollup 一般建议用来构建 JavaScript 库,特别是那种导入和依赖的第三方库较少的那种库。
+
+**Rollup 的未来:** Rollup 很酷,且正在被迅速采用。它有很多强大的功能,将在很长一段时间内作为前端工具生态系统的一个组成部分而存在。
+
+### 了解更多
+
+JavaScript 前端工具的生态系统充满着变数和竞争,且只有最好的工具才能存活下来。在不久的将来,我们的构建工具将具有更少(或没有)的配置,更方便的定制化,更好的扩展性的和更好的构建速度。
+
+该用什么样的构建工具用于你的前端项目,你需要根据具体的项目需求来做出决定。至于选择什么样的工具,才是最合适自己的,大多数时候,需要我们自己作出取舍。
+
+更多信息, 请看:
+
+ * [JavaScript tooling: The evolution and future of JS/frontend build tools][12]
+ * [Tools and modern workflow for frontend developers][13]
+ * [Modern frontend: The tools and build process explained][14]
+ * [Best build tools in frontend development][15]
+
+* * *
+
+_这篇文章最初发表在 [Shedrack Akintayo 的博客][16] 上,经许可后重新发表。_
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/20/11/javascript-build-tools
+
+作者:[Shedrack Akintayo][a]
+选题:[lujun9972][b]
+译者:[ywxgod](https://github.com/ywxgod)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/shedrack-akintayo
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
+[2]: https://www.javascript.com/
+[3]: https://babeljs.io/
+[4]: https://gruntjs.com/
+[5]: https://bower.io/
+[6]: https://gulpjs.com/
+[7]: http://browserify.org/
+[8]: https://webpack.js.org/
+[9]: https://github.com/yarnpkg/yarn
+[10]: https://parceljs.org/
+[11]: https://rollupjs.org/guide/en/
+[12]: https://qmo.io/blog/javascript-tooling-the-evolution-and-future-of-js-front-end-build-tools/
+[13]: https://blog.logrocket.com/tools-and-modern-workflow-for-front-end-developers-505c7227e917/
+[14]: https://medium.com/@trevorpoppen/modern-front-end-the-tools-and-build-process-explained-36641b5c1a53
+[15]: https://www.developerdrive.com/best-build-tools-frontend-development/
+[16]: https://www.sheddy.xyz/posts/javascript-build-tools-past-and-beyond
diff --git a/published/202105/20210104 Network address translation part 1 - packet tracing.md b/published/202105/20210104 Network address translation part 1 - packet tracing.md
new file mode 100644
index 0000000000..b1b8c31243
--- /dev/null
+++ b/published/202105/20210104 Network address translation part 1 - packet tracing.md
@@ -0,0 +1,226 @@
+[#]: collector: (lujun9972)
+[#]: translator: (cooljelly)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13364-1.html)
+[#]: subject: (Network address translation part 1 – packet tracing)
+[#]: via: (https://fedoramagazine.org/network-address-translation-part-1-packet-tracing/)
+[#]: author: (Florian Westphal https://fedoramagazine.org/author/strlen/)
+
+网络地址转换(NAT)之报文跟踪
+======
+
+
+
+这是有关网络地址转换(NAT)的系列文章中的第一篇。这一部分将展示如何使用 iptables/nftables 报文跟踪功能来定位 NAT 相关的连接问题。
+
+### 引言
+
+网络地址转换(NAT)是一种将容器或虚拟机暴露在互联网中的一种方式。传入的连接请求将其目标地址改写为另一个地址,随后被路由到容器或虚拟机。相同的技术也可用于负载均衡,即传入的连接被分散到不同的服务器上去。
+
+当网络地址转换没有按预期工作时,连接请求将失败,会暴露错误的服务,连接最终出现在错误的容器中,或者请求超时,等等。调试此类问题的一种方法是检查传入请求是否与预期或已配置的转换相匹配。
+
+### 连接跟踪
+
+NAT 不仅仅是修改 IP 地址或端口号。例如,在将地址 X 映射到 Y 时,无需添加新规则来执行反向转换。一个被称为 “conntrack” 的 netfilter 系统可以识别已有连接的回复报文。每个连接都在 conntrack 系统中有自己的 NAT 状态。反向转换是自动完成的。
+
+### 规则匹配跟踪
+
+nftables 工具(以及在较小的程度上,iptables)允许针对某个报文检查其处理方式以及该报文匹配规则集合中的哪条规则。为了使用这项特殊的功能,可在合适的位置插入“跟踪规则”。这些规则会选择被跟踪的报文。假设一个来自 IP 地址 C 的主机正在访问一个 IP 地址是 S 以及端口是 P 的服务。我们想知道报文匹配了哪条 NAT 转换规则,系统检查了哪些规则,以及报文是否在哪里被丢弃了。
+
+由于我们要处理的是传入连接,所以我们将规则添加到 prerouting 钩子上。prerouting 意味着内核尚未决定将报文发往何处。修改目标地址通常会使报文被系统转发,而不是由主机自身处理。
+
+### 初始配置
+
+```
+# nft 'add table inet trace_debug'
+# nft 'add chain inet trace_debug trace_pre { type filter hook prerouting priority -200000; }'
+# nft "insert rule inet trace_debug trace_pre ip saddr $C ip daddr $S tcp dport $P tcp flags syn limit rate 1/second meta nftrace set 1"
+```
+
+第一条规则添加了一张新的规则表,这使得将来删除和调试规则可以更轻松。一句 `nft delete table inet trace_debug` 命令就可以删除调试期间临时加入表中的所有规则和链。
+
+第二条规则在系统进行路由选择之前(`prerouting` 钩子)创建了一个基本钩子,并将其优先级设置为负数,以保证它在连接跟踪流程和 NAT 规则匹配之前被执行。
+
+然而,唯一最重要的部分是第三条规则的最后一段:`meta nftrace set 1`。这条规则会使系统记录所有匹配这条规则的报文所关联的事件。为了尽可能高效地查看跟踪信息(提高信噪比),考虑对跟踪的事件增加一个速率限制,以保证其数量处于可管理的范围。一个好的选择是限制每秒钟最多一个报文或一分钟最多一个报文。上述案例记录了所有来自终端 `$C` 且去往终端 `$S` 的端口 `$P` 的所有 SYN 报文和 SYN/ACK 报文。限制速率的配置语句可以防范事件过多导致的洪泛风险。事实上,大多数情况下只记录一个报文就足够了。
+
+对于 iptables 用户来讲,配置流程是类似的。等价的配置规则类似于:
+
+```
+# iptables -t raw -I PREROUTING -s $C -d $S -p tcp --tcp-flags SYN SYN --dport $P -m limit --limit 1/s -j TRACE
+```
+
+### 获取跟踪事件
+
+原生 nft 工具的用户可以直接运行 `nft` 进入 nft 跟踪模式:
+
+```
+# nft monitor trace
+```
+
+这条命令会将收到的报文以及所有匹配该报文的规则打印出来(用 `CTRL-C` 来停止输出):
+
+```
+trace id f0f627 ip raw prerouting packet: iif "veth0" ether saddr ..
+```
+
+我们将在下一章详细分析该结果。如果你用的是 iptables,首先通过 `iptables –version` 命令检查一下已安装的版本。例如:
+
+```
+
+# iptables --version
+iptables v1.8.5 (legacy)
+```
+
+`(legacy)` 意味着被跟踪的事件会被记录到内核的环形缓冲区中。你可以用 `dmesg` 或 `journalctl` 命令来查看这些事件。这些调试输出缺少一些信息,但和新工具提供的输出从概念上来讲很类似。你将需要首先查看规则被记录下来的行号,并与活跃的 iptables 规则集合手动关联。如果输出显示 `(nf_tables)`,你可以使用 `xtables-monitor` 工具:
+
+```
+# xtables-monitor --trace
+```
+
+如果上述命令仅显示版本号,你仍然需要查看 `dmesg`/`journalctl` 的输出。`xtables-monitor` 工具和 `nft` 监控跟踪工具使用相同的内核接口。它们之间唯一的不同点就是,`xtables-monitor` 工具会用 `iptables` 的语法打印事件,且如果你同时使用了 `iptables-nft` 和 `nft`,它将不能打印那些使用了 maps/sets 或其他只有 nftables 才支持的功能的规则。
+
+### 示例
+
+我们假设需要调试一个到虚拟机/容器的端口不通的问题。`ssh -p 1222 10.1.2.3` 命令应该可以远程连接那台服务器上的某个容器,但连接请求超时了。
+
+你拥有运行那台容器的主机的登录权限。现在登录该机器并增加一条跟踪规则。可通过前述案例查看如何增加一个临时的调试规则表。跟踪规则类似于这样:
+
+```
+nft "insert rule inet trace_debug trace_pre ip daddr 10.1.2.3 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1"
+```
+
+在添加完上述规则后,运行 `nft monitor trace`,在跟踪模式下启动 nft,然后重试刚才失败的 `ssh` 命令。如果规则集较大,会出现大量的输出。不用担心这些输出,下一节我们会做逐行分析。
+
+```
+trace id 9c01f8 inet trace_debug trace_pre packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
+trace id 9c01f8 inet trace_debug trace_pre rule ip daddr 10.2.1.2 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1 (verdict continue)
+trace id 9c01f8 inet trace_debug trace_pre verdict continue
+trace id 9c01f8 inet trace_debug trace_pre policy accept
+trace id 9c01f8 inet nat prerouting packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
+trace id 9c01f8 inet nat prerouting rule ip daddr 10.1.2.3 tcp dport 1222 dnat ip to 192.168.70.10:22 (verdict accept)
+trace id 9c01f8 inet filter forward packet: iif "enp0" oif "veth21" ether saddr .. ip daddr 192.168.70.10 .. tcp dport 22 tcp flags == syn tcp window 29200
+trace id 9c01f8 inet filter forward rule ct status dnat jump allowed_dnats (verdict jump allowed_dnats)
+trace id 9c01f8 inet filter allowed_dnats rule drop (verdict drop)
+trace id 20a4ef inet trace_debug trace_pre packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
+```
+
+### 对跟踪结果作逐行分析
+
+输出结果的第一行是触发后续输出的报文编号。这一行的语法与 nft 规则语法相同,同时还包括了接收报文的首部字段信息。你也可以在这一行找到接收报文的接口名称(此处为 `enp0`)、报文的源和目的 MAC 地址、报文的源 IP 地址(可能很重要 - 报告问题的人可能选择了一个错误的或非预期的主机),以及 TCP 的源和目的端口。同时你也可以在这一行的开头看到一个“跟踪编号”。该编号标识了匹配跟踪规则的特定报文。第二行包括了该报文匹配的第一条跟踪规则:
+
+```
+trace id 9c01f8 inet trace_debug trace_pre rule ip daddr 10.2.1.2 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1 (verdict continue)
+```
+
+这就是刚添加的跟踪规则。这里显示的第一条规则总是激活报文跟踪的规则。如果在这之前还有其他规则,它们将不会在这里显示。如果没有任何跟踪输出结果,说明没有抵达这条跟踪规则,或者没有匹配成功。下面的两行表明没有后续的匹配规则,且 `trace_pre` 钩子允许报文继续传输(判定为接受)。
+
+下一条匹配规则是:
+
+```
+trace id 9c01f8 inet nat prerouting rule ip daddr 10.1.2.3 tcp dport 1222 dnat ip to 192.168.70.10:22 (verdict accept)
+```
+
+这条 DNAT 规则设置了一个到其他地址和端口的映射。规则中的参数 `192.168.70.10` 是需要收包的虚拟机的地址,目前为止没有问题。如果它不是正确的虚拟机地址,说明地址输入错误,或者匹配了错误的 NAT 规则。
+
+### IP 转发
+
+通过下面的输出我们可以看到,IP 路由引擎告诉 IP 协议栈,该报文需要被转发到另一个主机:
+
+```
+trace id 9c01f8 inet filter forward packet: iif "enp0" oif "veth21" ether saddr .. ip daddr 192.168.70.10 .. tcp dport 22 tcp flags == syn tcp window 29200
+```
+
+这是接收到的报文的另一种呈现形式,但和之前相比有一些有趣的不同。现在的结果有了一个输出接口集合。这在之前不存在的,因为之前的规则是在路由决策之前(`prerouting` 钩子)。跟踪编号和之前一样,因此仍然是相同的报文,但目标地址和端口已经被修改。假设现在还有匹配 `tcp dport 1222` 的规则,它们将不会对现阶段的报文产生任何影响了。
+
+如果该行不包含输出接口(`oif`),说明路由决策将报文路由到了本机。对路由过程的调试属于另外一个主题,本文不再涉及。
+
+```
+trace id 9c01f8 inet filter forward rule ct status dnat jump allowed_dnats (verdict jump allowed_dnats)
+```
+
+这条输出表明,报文匹配到了一个跳转到 `allowed_dnats` 链的规则。下一行则说明了连接失败的根本原因:
+
+```
+trace id 9c01f8 inet filter allowed_dnats rule drop (verdict drop)
+```
+
+这条规则无条件地将报文丢弃,因此后续没有关于该报文的日志输出。下一行则是另一个报文的输出结果了:
+
+```
+trace id 20a4ef inet trace_debug trace_pre packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
+```
+
+跟踪编号已经和之前不一样,然后报文的内容却和之前是一样的。这是一个重传尝试:第一个报文被丢弃了,因此 TCP 尝试了重传。可以忽略掉剩余的输出结果了,因为它并没有提供新的信息。现在是时候检查那条链了。
+
+### 规则集合分析
+
+上一节我们发现报文在 inet filter 表中的一个名叫 `allowed_dnats` 的链中被丢弃。现在我们来查看它:
+
+```
+# nft list chain inet filter allowed_dnats
+table inet filter {
+ chain allowed_dnats {
+ meta nfproto ipv4 ip daddr . tcp dport @allow_in accept
+ drop
+ }
+}
+```
+
+接受 `@allow_in` 集的数据包的规则没有显示在跟踪日志中。我们通过列出元素的方式,再次检查上述报文的目标地址是否在 `@allow_in` 集中:
+
+```
+# nft "get element inet filter allow_in { 192.168.70.10 . 22 }"
+Error: Could not process rule: No such file or directory
+```
+
+不出所料,地址-服务对并没有出现在集合中。我们将其添加到集合中。
+
+```
+# nft "add element inet filter allow_in { 192.168.70.10 . 22 }"
+```
+
+现在运行查询命令,它将返回新添加的元素。
+
+```
+# nft "get element inet filter allow_in { 192.168.70.10 . 22 }"
+table inet filter {
+ set allow_in {
+ type ipv4_addr . inet_service
+ elements = { 192.168.70.10 . 22 }
+ }
+}
+```
+
+`ssh` 命令现在应该可以工作,且跟踪结果可以反映出该变化:
+
+```
+trace id 497abf58 inet filter forward rule ct status dnat jump allowed_dnats (verdict jump allowed_dnats)
+
+trace id 497abf58 inet filter allowed_dnats rule meta nfproto ipv4 ip daddr . tcp dport @allow_in accept (verdict accept)
+
+trace id 497abf58 ip postrouting packet: iif "enp0" oif "veth21" ether .. trace id 497abf58 ip postrouting policy accept
+```
+
+这表明报文通过了转发路径中的最后一个钩子 - `postrouting`。
+
+如果现在仍然无法连接,问题可能处在报文流程的后续阶段,有可能并不在 nftables 的规则集合范围之内。
+
+### 总结
+
+本文介绍了如何通过 nftables 的跟踪机制检查丢包或其他类型的连接问题。本系列的下一篇文章将展示如何检查连接跟踪系统和可能与连接跟踪流相关的 NAT 信息。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/network-address-translation-part-1-packet-tracing/
+
+作者:[Florian Westphal][a]
+选题:[lujun9972][b]
+译者:[cooljelly](https://github.com/cooljelly)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/strlen/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2020/12/network-address-translation-part-1-816x346.png
diff --git a/published/202105/20210114 Cross-compiling made easy with Golang.md b/published/202105/20210114 Cross-compiling made easy with Golang.md
new file mode 100644
index 0000000000..72a662d890
--- /dev/null
+++ b/published/202105/20210114 Cross-compiling made easy with Golang.md
@@ -0,0 +1,217 @@
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13385-1.html"
+[#]: subject: "Cross-compiling made easy with Golang"
+[#]: via: "https://opensource.com/article/21/1/go-cross-compiling"
+[#]: author: "Gaurav Kamathe https://opensource.com/users/gkamathe"
+
+使用 Golang 的交叉编译
+======
+
+> 走出舒适区,我了解了 Go 的交叉编译功能。
+
+
+
+在 Linux 上测试软件时,我使用各种架构的服务器,例如 Intel、AMD、Arm 等。当我 [分配了一台满足我的测试需求的 Linux 机器][2],我仍然需要执行许多步骤:
+
+ 1. 下载并安装必备软件
+ 2. 验证构建服务器上是否有新的测试软件包
+ 3. 获取并设置依赖软件包所需的 yum 仓库
+ 4. 下载并安装新的测试软件包(基于步骤 2)
+ 5. 获取并设置必需的 SSL 证书
+ 6. 设置测试环境,获取所需的 Git 仓库,更改配置,重新启动守护进程等
+ 7. 做其他需要做的事情
+
+### 用脚本自动化
+
+这些步骤非常常规,以至于有必要对其进行自动化并将脚本保存到中央位置(例如文件服务器),在需要时可以在此处下载脚本。为此,我编写了 100-120 行的 Bash shell 脚本,它为我完成了所有配置(包括错误检查)。这个脚本通过以下方式简化了我的工作流程:
+
+ 1. 配置新的 Linux 系统(支持测试的架构)
+ 2. 登录系统并从中央位置下载自动化 shell 脚本
+ 3. 运行它来配置系统
+ 4. 开始测试
+
+### 学习 Go 语言
+
+我想学习 [Go 语言][3] 有一段时间了,将我心爱的 Shell 脚本转换为 Go 程序似乎是一个很好的项目,可以帮助我入门。它的语法看起来很简单,在尝试了一些测试程序后,我开始着手提高自己的知识并熟悉 Go 标准库。
+
+我花了一个星期的时间在笔记本电脑上编写 Go 程序。我经常在我的 x86 服务器上测试程序,清除错误并使程序健壮起来,一切都很顺利。
+
+直到完全转换到 Go 程序前,我继续依赖自己的 shell 脚本。然后,我将二进制文件推送到中央文件服务器上,以便每次配置新服务器时,我要做的就是获取二进制文件,将可执行标志打开,然后运行二进制文件。我对早期的结果很满意:
+
+```
+$ wget http://file.example.com//bins/prepnode
+$ chmod +x ./prepnode
+$ ./prepnode
+```
+
+### 然后,出现了一个问题
+
+第二周,我从资源池中分配了一台新的服务器,像往常一样,我下载了二进制文件,设置了可执行标志,然后运行二进制文件。但这次它出错了,是一个奇怪的错误:
+
+```
+$ ./prepnode
+bash: ./prepnode: cannot execute binary file: Exec format error
+$
+```
+
+起初,我以为可能没有成功设置可执行标志。但是,它已按预期设置:
+
+```
+$ ls -l prepnode
+-rwxr-xr-x. 1 root root 2640529 Dec 16 05:43 prepnode
+```
+
+发生了什么事?我没有对源代码进行任何更改,编译没有引发任何错误或警告,而且上次运行时效果很好,因此我仔细查看了错误消息 `format error`。
+
+我检查了二进制文件的格式,一切看起来都没问题:
+
+```
+$ file prepnode
+prepnode: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped
+```
+
+我迅速运行了以下命令,识别所配置的测试服务器的架构以及二进制试图运行的平台。它是 Arm64 架构,但是我编译的二进制文件(在我的 x86 笔记本电脑上)生成的是 x86-64 格式的二进制文件:
+
+```
+$ uname -m
+aarch64
+```
+
+### 脚本编写人员的编译第一课
+
+在那之前,我从未考虑过这种情况(尽管我知道这一点)。我主要研究脚本语言(通常是 Python)以及 Shell 脚本。在任何架构的大多数 Linux 服务器上都可以使用 Bash Shell 和 Python 解释器。总之,之前一切都很顺利。
+
+但是,现在我正在处理 Go 这种编译语言,它生成可执行的二进制文件。编译后的二进制文件由特定架构的 [指令码][4] 或汇编指令组成,这就是为什么我收到格式错误的原因。由于 Arm64 CPU(运行二进制文件的地方)无法解释二进制文件的 x86-64 指令,因此它抛出错误。以前,shell 和 Python 解释器为我处理了底层指令码或特定架构的指令。
+
+### Go 的交叉编译
+
+我检查了 Golang 的文档,发现要生成 Arm64 二进制文件,我要做的就是在运行 `go build` 命令编译 Go 程序之前设置两个环境变量。
+
+`GOOS` 指的是操作系统,例如 Linux、Windows、BSD 等,而 `GOARCH` 指的是要在哪种架构上构建程序。
+
+```
+$ env GOOS=linux GOARCH=arm64 go build -o prepnode_arm64
+```
+
+构建程序后,我重新运行 `file` 命令,这一次它显示的是 ARM AArch64,而不是之前显示的 x86。因此,我在我的笔记本上能为不同的架构构建二进制文件。
+
+```
+$ file prepnode_arm64
+prepnode_arm64: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), statically linked, not stripped
+```
+
+我将二进制文件从笔记本电脑复制到 ARM 服务器上。现在运行二进制文件(将可执行标志打开)不会产生任何错误:
+
+```
+$ ./prepnode_arm64 -h
+Usage of ./prepnode_arm64:
+ -c Clean existing installation
+ -n Do not start test run (default true)
+ -s Use stage environment, default is qa
+ -v Enable verbose output
+```
+
+### 其他架构呢?
+
+x86 和 Arm 是我测试软件所支持的 5 种架构中的两种,我担心 Go 可能不会支持其它架构,但事实并非如此。你可以查看 Go 支持的架构:
+
+```
+$ go tool dist list
+```
+
+Go 支持多种平台和操作系统,包括:
+
+ * AIX
+ * Android
+ * Darwin
+ * Dragonfly
+ * FreeBSD
+ * Illumos
+ * JavaScript
+ * Linux
+ * NetBSD
+ * OpenBSD
+ * Plan 9
+ * Solaris
+ * Windows
+
+要查找其支持的特定 Linux 架构,运行:
+
+```
+$ go tool dist list | grep linux
+```
+
+如下面的输出所示,Go 支持我使用的所有体系结构。尽管 x86_64 不在列表中,但 AMD64 兼容 x86-64,所以你可以生成 AMD64 二进制文件,它可以在 x86 架构上正常运行:
+
+```
+$ go tool dist list | grep linux
+linux/386
+linux/amd64
+linux/arm
+linux/arm64
+linux/mips
+linux/mips64
+linux/mips64le
+linux/mipsle
+linux/ppc64
+linux/ppc64le
+linux/riscv64
+linux/s390x
+```
+
+### 处理所有架构
+
+为我测试的所有体系结构生成二进制文件,就像从我的 x86 笔记本电脑编写一个微小的 shell 脚本一样简单:
+
+```
+#!/usr/bin/bash
+archs=(amd64 arm64 ppc64le ppc64 s390x)
+
+for arch in ${archs[@]}
+do
+ env GOOS=linux GOARCH=${arch} go build -o prepnode_${arch}
+done
+
+```
+
+```
+$ file prepnode_*
+prepnode_amd64: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, Go BuildID=y03MzCXoZERH-0EwAAYI/p909FDnk7xEUo2LdHIyo/V2ABa7X_rLkPNHaFqUQ6/5p_q8MZiR2WYkA5CzJiF, not stripped
+prepnode_arm64: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), statically linked, Go BuildID=q-H-CCtLv__jVOcdcOpA/CywRwDz9LN2Wk_fWeJHt/K4-3P5tU2mzlWJa0noGN/SEev9TJFyvHdKZnPaZgb, not stripped
+prepnode_ppc64: ELF 64-bit MSB executable, 64-bit PowerPC or cisco 7500, version 1 (SYSV), statically linked, Go BuildID=DMWfc1QwOGIq2hxEzL_u/UE-9CIvkIMeNC_ocW4ry/r-7NcMATXatoXJQz3yUO/xzfiDIBuUxbuiyaw5Goq, not stripped
+prepnode_ppc64le: ELF 64-bit LSB executable, 64-bit PowerPC or cisco 7500, version 1 (SYSV), statically linked, Go BuildID=C6qCjxwO9s63FJKDrv3f/xCJa4E6LPVpEZqmbF6B4/Mu6T_OR-dx-vLavn1Gyq/AWR1pK1cLz9YzLSFt5eU, not stripped
+prepnode_s390x: ELF 64-bit MSB executable, IBM S/390, version 1 (SYSV), statically linked, Go BuildID=faC_HDe1_iVq2XhpPD3d/7TIv0rulE4RZybgJVmPz/o_SZW_0iS0EkJJZHANxx/zuZgo79Je7zAs3v6Lxuz, not stripped
+```
+
+现在,每当配置一台新机器时,我就运行以下 `wget` 命令下载特定体系结构的二进制文件,将可执行标志打开,然后运行:
+
+```
+$ wget http://file.domain.com//bins/prepnode_
+$ chmod +x ./prepnode_
+$ ./prepnode_
+```
+
+### 为什么?
+
+你可能想知道,为什么我没有坚持使用 shell 脚本或将程序移植到 Python 而不是编译语言上来避免这些麻烦。所以有舍有得,那样的话我不会了解 Go 的交叉编译功能,以及程序在 CPU 上执行时的底层工作原理。在计算机中,总要考虑取舍,但绝不要让它们阻碍你的学习。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/1/go-cross-compiling
+
+作者:[Gaurav Kamathe][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gkamathe
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/laptop_screen_desk_work_chat_text.png?itok=UXqIDRDD "Person using a laptop"
+[2]: https://opensource.com/article/20/12/linux-server
+[3]: https://golang.org/
+[4]: https://en.wikipedia.org/wiki/Opcode
\ No newline at end of file
diff --git a/published/202105/20210204 A guide to understanding Linux software libraries in C.md b/published/202105/20210204 A guide to understanding Linux software libraries in C.md
new file mode 100644
index 0000000000..66d2e89b71
--- /dev/null
+++ b/published/202105/20210204 A guide to understanding Linux software libraries in C.md
@@ -0,0 +1,481 @@
+[#]: collector: (lujun9972)
+[#]: translator: (mengxinayan)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13413-1.html)
+[#]: subject: (A guide to understanding Linux software libraries in C)
+[#]: via: (https://opensource.com/article/21/2/linux-software-libraries)
+[#]: author: (Marty Kalin https://opensource.com/users/mkalindepauledu)
+
+用 C 语言理解 Linux 软件库
+======
+
+> 软件库是重复使用代码的一种简单而合理的方式。
+
+
+
+软件库是一种是一直以来长期存在的、简单合理的复用代码的方式。这篇文章解释了如何从头开始构建库并使得其可用。尽管这两个示例库都以 Linux 为例,但创建、发布和使用这些库的步骤也可以应用于其它类 Unix 系统。
+
+这些示例库使用 C 语言编写,非常适合该任务。Linux 内核大部分由 C 语言和少量汇编语言编写(Windows 和 Linux 的表亲如 macOS 也是如此)。用于输入/输出、网络、字符串处理、数学、安全、数据编码等的标准系统库等主要由 C 语言编写。所以使用 C 语言编写库就是使用 Linux 的原生语言来编写。除此之外,C 语言的性能也在一众高级语言中鹤立鸡群。
+
+还有两个来访问这些库的示例客户程序(一个使用 C,另一个使用 Python)。毫无疑问可以使用 C 语言客户程序来访问 C 语言编写的库,但是 Python 客户程序示例说明了一个由 C 语言编写的库也可以服务于其他编程语言。
+
+### 静态库和动态库对比
+
+Linux 系统存在两种类型库:
+
+ * **静态库(也被称为归档库)**:在编译过程中的链接阶段,静态库会被编译进程序(例如 C 或 Rust)中。每个客户程序都有属于自己的一份库的拷贝。静态库有一个显而易见的缺点 —— 当库需要进行一定改动时(例如修复一个 bug),静态库必须重新链接一次。接下来要介绍的动态库避免了这一缺点。
+ * **动态库(也被称为共享库)**:动态库首先会在程序编译中的链接阶段被标记,但是客户程序和库代码在运行之前仍然没有联系,且库代码不会进入到客户程序中。系统的动态加载器会把一个共享库和正在运行的客户程序进行连接,无论该客户程序是由静态编译语言(如 C)编写,还是由动态解释语言(如 Python)编写。因此,动态库不需要麻烦客户程序便可以进行更新。最后,多个客户程序可以共享同一个动态库的单一副本。
+
+通常来说,动态库优于静态库,尽管其复杂性较高而性能较低。下面是两种类型的库如何创建和发布:
+
+ 1. 库的源代码会被编译成一个或多个目标模块,目标模块是二进制文件,可以被包含在库中并且链接到可执行的二进制中。
+ 2. 目标模块会会被打包成一个文件。对于静态库,标准的文件拓展名是 `.a` 意为“归档”;对于动态库,标准的文件拓展名是 `.so` 意为“共享目标”。对于这两个相同功能的示例库,分别发布为 `libprimes.a` (静态库)和 `libshprimes.so` (动态库)。两种库的文件名都使用前缀 `lib` 进行标识。
+ 3. 库文件被复制到标准目录下,使得客户程序可以轻松地访问到库。无论是静态库还是动态库,典型的位置是 `/usr/lib` 或者 `/usr/local/lib`,当然其他位置也是可以的。
+
+构建和发布每种库的具体步骤会在下面详细介绍。首先我将介绍两种库里涉及到的 C 函数。
+
+### 示例库函数
+
+这两个示例库都是由五个相同的 C 函数构建而成的,其中四个函数可供客户程序使用。第五个函数是其他四个函数的一个工具函数,它显示了 C 语言怎么隐藏信息。每个函数的源代码都很短,可以将这些函数放在单个源文件中,尽管也可以放在多个源文件中(如四个公布的函数都有一个文件)。
+
+这些库函数是基本的处理函数,以多种方式来处理质数。所有的函数接收无符号(即非负)整数值作为参数:
+
+- `is_prime` 函数测试其单个参数是否为质数。
+- `are_coprimes` 函数检查了其两个参数的最大公约数(gcd)是否为 1,即是否为互质数。
+- `prime_factors`:函数列出其参数的质因数。
+- `glodbach`:函数接收一个大于等于 4 的偶数,列出其可以分解为两个质数的和。它也许存在多个符合条件的数对。该函数是以 18 世纪数学家 [克里斯蒂安·哥德巴赫][2] 命名的,他的猜想是任意一个大于 2 的偶数可以分解为两个质数之和,这依旧是数论里最古老的未被解决的问题。
+
+工具函数 `gcd` 留在已部署的库文件中,但是在没有包含这个函数的文件无法访问此函数。因此,一个使用库的客户程序无法调用 `gcd` 函数。仔细观察 C 函数可以明白这一点。
+
+### 更多关于 C 函数的内容
+
+每个在 C 语言中的函数都有一个存储类,它决定了函数的范围。对于函数,有两种选择。
+
+- 函数默认的存储类是 `extern`,它给了函数一个全局域。一个客户程序可以调用在示例库中用 `extern` 修饰的任意函数。下面是一个带有显式 `extern` 声明的 `are_coprimes` 函数定义:
+
+ ```
+ extern unsigned are_coprimes(unsigned n1, unsigned n2) {
+ ...
+ }
+ ```
+- 存储类 `static` 将一个函数的的范围限制到函数被定义的文件中。在示例库中,工具函数 `gcd` 是静态的(`static`):
+
+ ```
+ static unsigned gcd(unsigned n1, unsigned n2) {
+ ...
+ }
+ ```
+
+只有在 `primes.c` 文件中的函数可以调用 `gcd`,而只有 `are_coprimes` 函数会调用它。当静态库和动态库被构建和发布后,其他的程序可以调用外部的(`extern`)函数,如 `are_coprimes` ,但是不可以调用静态(`static`)函数 `gcd`。静态(`static`)存储类通过将函数范围限制在其他库函数内,进而实现了对库的客户程序隐藏 `gcd` 函数。
+
+在 `primes.c` 文件中除了 `gcd` 函数外,其他函数并没有指明存储类,默认将会设置为外部的(`extern`)。然而,在库中显式注明 `extern` 更加常见。
+
+C 语言区分了函数的定义和声明,这对库来说很重要。接下来让我们开始了解定义。C 语言仅允许命名函数不允许匿名函数,并且每个函数需要定义以下内容:
+
+- 一个唯一的名字。一个程序不允许存在两个同名的函数。
+- 一个可以为空的参数列表。参数需要指明类型。
+- 一个返回值类型(例如:`int` 代表 32 位有符号整数),当没有返回值时设置为空类型(`void`)。
+- 用一对花括号包围起来的函数主体部分。在一个特制的示例中,函数主体部分可以为空。
+
+程序中的每个函数必须要被定义一次。
+
+下面是库函数 `are_coprimes` 的完整定义:
+
+```
+extern unsigned are_coprimes(unsigned n1, unsigned n2) { /* 定义 */
+ return 1 == gcd(n1, n2); /* 最大公约数是否为 1? */
+}
+```
+
+函数返回一个布尔值(`0` 代表假,`1` 代表真),取决于两个整数参数值的最大公约数是否为 1。工具函数 `gcd` 计算两个整数参数 `n1` 和 `n2` 的最大公约数。
+
+函数声明不同于定义,其不需要主体部分:
+
+```
+extern unsigned are_coprimes(unsigned n1, unsigned n2); /* 声明 */
+```
+
+声明在参数列表后用一个分号代表结束,它没有被花括号包围起来的主体部分。程序中的函数可以被多次声明。
+
+为什么需要声明?在 C 语言中,一个被调用的函数必须对其调用者可见。有多种方式可以提供这样的可见性,具体依赖于编译器如何实现。一个必然可行的方式就是当它们二者位于同一个文件中时,将被调用的函数定义在在它的调用者之前。
+
+```
+void f() {...} /* f 定义在其被调用前 */
+void g() { f(); } /* ok */
+```
+
+当函数 `f` 被在调用前声明,此时函数 `f` 的定义可以移动到函数 `g` 的下方。
+
+```
+void f(); /* 声明使得函数 f 对调用者可见 */
+void g() { f(); } /* ok */
+void f() {...} /* 相较于前一种方式,此方式显得更简洁 */
+```
+
+但是当如果一个被调用的函数和调用它的函数不在同一个文件中时呢?因为前文提到一个函数在一个程序中需要被定义一次,那么如何使得让一个文件中被定义的函数在另一个文件中可见?
+
+这个问题会影响库,无论是静态库还是动态库。例如在这两个质数库中函数被定义在源文件 `primes.c` 中,每个库中都有该函数的二进制副本,但是这些定义的函数必须要对使用库的 C 程序可见,该 C 程序有其自身的源文件。
+
+函数声明可以帮助提供跨文件的可见性。对于上述的“质数”例子,它有一个名为 `primes.h` 的头文件,其声明了四个函数使得它们对使用库的 C 程序可见。
+
+```
+/** 头文件 primes.h:函数声明 **/
+extern unsigned is_prime(unsigned);
+extern void prime_factors(unsigned);
+extern unsigned are_coprimes(unsigned, unsigned);
+extern void goldbach(unsigned);
+```
+
+这些声明通过为每个函数指定其调用语法来作为接口。
+
+为了客户程序的便利性,头文件 `primes.h` 应该存储在 C 编译器查找路径下的目录中。典型的位置有 `/usr/include` 和 `/usr/local/include`。一个 C 语言客户程序应使用 `#include` 包含这个头文件,并尽可能将这条语句其程序源代码的首部(头文件将会被导入另一个源文件的“头”部)。C 语言头文件可以被导入其他语言(如 Rust 语言)中的 `bindgen`,使其它语言的客户程序可以访问 C 语言的库。
+
+总之,一个库函数只可以被定义一次,但可以在任何需要它的地方进行声明,任一使用 C 语言库的程序都需要该声明。头文件可以包含函数声明,但不能包含函数定义。如果头文件包含了函数定义,那么该文件可能会在一个 C 语言程序中被多次包含,从而破坏了一个函数在 C 语言程序中必须被精确定义一次的规则。
+
+### 库的源代码
+
+下面是两个库的源代码。这部分代码、头文件、以及两个示例客户程序都可以在 [我的网页][3] 上找到。
+
+```
+#include
+#include
+
+extern unsigned is_prime(unsigned n) {
+ if (n <= 3) return n > 1; /* 2 和 3 是质数 */
+ if (0 == (n % 2) || 0 == (n % 3)) return 0; /* 2 和 3 的倍数不会是质数 */
+
+ /* 检查 n 是否是其他 < n 的值的倍数 */
+ unsigned i;
+ for (i = 5; (i * i) <= n; i += 6)
+ if (0 == (n % i) || 0 == (n % (i + 2))) return 0; /* 不是质数 */
+
+ return 1; /* 一个不是 2 和 3 的质数 */
+}
+
+extern void prime_factors(unsigned n) {
+ /* 在数字 n 的质因数分解中列出所有 2 */
+ while (0 == (n % 2)) {
+ printf("%i ", 2);
+ n /= 2;
+ }
+
+ /* 数字 2 已经处理完成,下面处理奇数 */
+ unsigned i;
+ for (i = 3; i <= sqrt(n); i += 2) {
+ while (0 == (n % i)) {
+ printf("%i ", i);
+ n /= i;
+ }
+ }
+
+ /* 还有其他质因数?*/
+ if (n > 2) printf("%i", n);
+}
+
+/* 工具函数:计算最大公约数 */
+static unsigned gcd(unsigned n1, unsigned n2) {
+ while (n1 != 0) {
+ unsigned n3 = n1;
+ n1 = n2 % n1;
+ n2 = n3;
+ }
+ return n2;
+}
+
+extern unsigned are_coprimes(unsigned n1, unsigned n2) {
+ return 1 == gcd(n1, n2);
+}
+
+extern void goldbach(unsigned n) {
+ /* 输入错误 */
+ if ((n <= 2) || ((n & 0x01) > 0)) {
+ printf("Number must be > 2 and even: %i is not.\n", n);
+ return;
+ }
+
+ /* 两个简单的例子:4 和 6 */
+ if ((4 == n) || (6 == n)) {
+ printf("%i = %i + %i\n", n, n / 2, n / 2);
+ return;
+ }
+
+ /* 当 n > 8 时,存在多种可能性 */
+ unsigned i;
+ for (i = 3; i < (n / 2); i++) {
+ if (is_prime(i) && is_prime(n - i)) {
+ printf("%i = %i + %i\n", n, i, n - i);
+ /* 如果只需要一对,那么用 break 语句替换这句 */
+ }
+ }
+}
+```
+
+*库函数*
+
+这些函数可以被库利用。两个库可以从相同的源代码中获得,同时头文件 `primes.h` 是两个库的 C 语言接口。
+
+### 构建库
+
+静态库和动态库在构建和发布的步骤上有一些细节的不同。静态库需要三个步骤,而动态库需要增加两个步骤即一共五个步骤。额外的步骤表明了动态库的动态方法具有更多的灵活性。让我们先从静态库开始。
+
+库的源文件 `primes.c` 被编译成一个目标模块。下面是命令,百分号 `%` 代表系统提示符,两个井字符 `#` 是我的注释。
+
+```
+% gcc -c primes.c ## 步骤1(静态)
+```
+
+这一步生成目标模块是二进制文件 `primes.o`。`-c` 标志意味着只编译。
+
+下一步是使用 Linux 的 `ar` 命令将目标对象归档。
+
+```
+% ar -cvq libprimes.a primes.o ## 步骤2(静态)
+```
+
+`-cvq` 三个标识分别是“创建”、“详细的”、“快速添加”(以防新文件没有添加到归档中)的简称。回忆一下,前文提到过前缀 `lib` 是必须的,而库名是任意的。当然,库的文件名必须是唯一的,以避免冲突。
+
+归档已经准备好要被发布:
+
+```
+% sudo cp libprimes.a /usr/local/lib ## 步骤3(静态)
+```
+
+现在静态库对接下来的客户程序是可见的,示例在后面。(包含 `sudo` 可以确保有访问权限将文件复制进 `/usr/local/lib` 目录中)
+
+动态库还需要一个或多个对象模块进行打包:
+
+```
+% gcc primes.c -c -fpic ## 步骤1(动态)
+```
+
+增加的选项 `-fpic` 指示编译器生成与位置无关的代码,这意味着不需要将该二进制模块加载到一个固定的内存位置。在一个拥有多个动态库的系统中这种灵活性是至关重要的。生成的对象模块会略大于静态库生成的对象模块。
+
+下面是从对象模块创建单个库文件的命令:
+
+```
+% gcc -shared -Wl,-soname,libshprimes.so -o libshprimes.so.1 primes.o ## 步骤2(动态)
+```
+
+选项 `-shared` 表明了该库是一个共享的(动态的)而不是静态的。`-Wl` 选项引入了一系列编译器选项,第一个便是设置动态库的 `-soname`,这是必须设置的。`soname` 首先指定了库的逻辑名字(`libshprimes.so`),接下来的 `-o` 选项指明了库的物理文件名字(`libshprimes.so.1`)。这样做的目的是为了保持逻辑名不变的同时允许物理名随着新版本而发生变化。在本例中,在物理文件名 `libshprimes.so.1` 中最后的 1 代表是第一个库的版本。尽管逻辑文件名和物理文件名可以是相同的,但是最佳做法是将它们命名为不同的名字。一个客户程序将会通过逻辑名(本例中为 `libshprimes.so`)来访问库,稍后我会进一步解释。
+
+接下来的一步是通过复制共享库到合适的目录下使得客户程序容易访问,例如 `/usr/local/lib` 目录:
+
+```
+% sudo cp libshprimes.so.1 /usr/local/lib ## 步骤3(动态)
+```
+
+现在在共享库的逻辑名(`libshprimes.so`)和它的物理文件名(`/usr/local/lib/libshprimes.so.1`)之间设置一个符号链接。最简单的方式是将 `/usr/local/lib` 作为工作目录,在该目录下输入命令:
+
+```
+% sudo ln --symbolic libshprimes.so.1 libshprimes.so ## 步骤4(动态)
+```
+
+逻辑名 `libshprimes.so` 不应该改变,但是符号链接的目标(`libshrimes.so.1`)可以根据需要进行更新,新的库实现可以是修复了 bug,提高性能等。
+
+最后一步(一个预防措施)是调用 `ldconfig` 工具来配置系统的动态加载器。这个配置保证了加载器能够找到新发布的库。
+
+```
+% sudo ldconfig ## 步骤5(动态)
+```
+
+到现在,动态库已为包括下面的两个在内的示例客户程序准备就绪了。
+
+### 一个使用库的 C 程序
+
+这个示例 C 程序是一个测试程序,它的源代码以两条 `#include` 指令开始:
+
+```
+#include /* 标准输入/输出函数 */
+#include /* 我的库函数 */
+```
+
+文件名两边的尖括号表示可以在编译器的搜索路径中找到这些头文件(对于 `primes.h` 文件来说在 `/usr/local/inlcude` 目录下)。如果不包含 `#include`,编译器会抱怨缺少 `is_prime` 和 `prime_factors` 等函数的声明,它们在两个库中都有发布。顺便提一句,测试程序的源代码不需要更改即可测试两个库中的每一个库。
+
+相比之下,库的源文件(`primes.c`)使用 `#include` 指令打开以下头文件:
+
+```
+#include
+#include
+```
+
+`math.h` 头文件是必须的,因为库函数 `prime_factors` 会调用数学函数 `sqrt`,其在标准库 `libm.so` 中。
+
+作为参考,这是测试库程序的源代码:
+
+```
+#include
+#include
+
+int main() {
+ /* 是质数 */
+ printf("\nis_prime\n");
+ unsigned i, count = 0, n = 1000;
+ for (i = 1; i <= n; i++) {
+ if (is_prime(i)) {
+ count++;
+ if (1 == (i % 100)) printf("Sample prime ending in 1: %i\n", i);
+ }
+ }
+ printf("%i primes in range of 1 to a thousand.\n", count);
+
+ /* prime_factors */
+ printf("\nprime_factors\n");
+ printf("prime factors of 12: ");
+ prime_factors(12);
+ printf("\n");
+
+ printf("prime factors of 13: ");
+ prime_factors(13);
+ printf("\n");
+
+ printf("prime factors of 876,512,779: ");
+ prime_factors(876512779);
+ printf("\n");
+
+ /* 是合数 */
+ printf("\nare_coprime\n");
+ printf("Are %i and %i coprime? %s\n",
+ 21, 22, are_coprimes(21, 22) ? "yes" : "no");
+ printf("Are %i and %i coprime? %s\n",
+ 21, 24, are_coprimes(21, 24) ? "yes" : "no");
+
+ /* 哥德巴赫 */
+ printf("\ngoldbach\n");
+ goldbach(11); /* error */
+ goldbach(4); /* small one */
+ goldbach(6); /* another */
+ for (i = 100; i <= 150; i += 2) goldbach(i);
+
+ return 0;
+}
+```
+
+*测试程序*
+
+在编译 `tester.c` 文件到可执行文件时,难处理的部分时链接选项的顺序。回想前文中提到两个示例库都是用 `lib` 作为前缀开始,并且每一个都有一个常规的拓展后缀:`.a` 代表静态库 `libprimes.a`,`.so` 代表动态库 `libshprimes.so`。在链接规范中,前缀 `lib` 和拓展名被忽略了。链接标志以 `-l` (小写 L)开始,并且一条编译命令可能包含多个链接标志。下面是一个完整的测试程序的编译指令,使用动态库作为示例:
+
+```
+% gcc -o tester tester.c -lshprimes -lm
+```
+
+第一个链接标志指定了库 `libshprimes.so`,第二个链接标志指定了标准数学库 `libm.so`。
+
+链接器是懒惰的,这意味着链接标志的顺序是需要考虑的。例如,调整上述实例中的链接顺序将会产生一个编译时错误:
+
+```
+% gcc -o tester tester.c -lm -lshprimes ## 危险!
+```
+
+链接 `libm.so` 库的标志先出现,但是这个库中没有函数被测试程序显式调用;因此,链接器不会链接到 `math.so` 库。调用 `sqrt` 库函数仅发生在 `libshprimes.so` 库中包含的 `prime_factors` 函数。编译测试程序返回的错误是:
+
+```
+primes.c: undefined reference to 'sqrt'
+```
+
+因此,链接标志的顺序应该是通知链接器需要 `sqrt` 函数:
+
+```
+% gcc -o tester tester.c -lshprimes -lm ## 首先链接 -lshprimes
+```
+
+链接器在 `libshprimes.so` 库中发现了对库函数 `sqrt` 的调用,所以接下来对数学库 `libm.so`做了合适的链接。链接还有一个更复杂的选项,它支持链接的标志顺序。然而在本例中,最简单的方式就是恰当地排列链接标志。
+
+下面是运行测试程序的部分输出结果:
+
+```
+is_prime
+Sample prime ending in 1: 101
+Sample prime ending in 1: 401
+...
+168 primes in range of 1 to a thousand.
+
+prime_factors
+prime factors of 12: 2 2 3
+prime factors of 13: 13
+prime factors of 876,512,779: 211 4154089
+
+are_coprime
+Are 21 and 22 coprime? yes
+Are 21 and 24 coprime? no
+
+goldbach
+Number must be > 2 and even: 11 is not.
+4 = 2 + 2
+6 = 3 + 3
+...
+32 = 3 + 29
+32 = 13 + 19
+...
+100 = 3 + 97
+100 = 11 + 89
+...
+```
+
+对于 `goldbach` 函数,即使一个相当小的偶数值(例如 18)也许存在多个一对质数之和的组合(在这种情况下,5+13 和 7+11)。因此这种多个质数对是使得尝试证明哥德巴赫猜想变得复杂的因素之一。
+
+### 封装使用库的 Python 程序
+
+与 C 不同,Python 不是一个静态编译语言,这意味着 Python 客户示例程序必须访问动态版本而非静态版本的 `primes` 库。为了能这样做,Python 中有众多的支持外部语言接口(FFI)的模块(标准的或第三方的),它们允许用一种语言编写的程序来调用另一种语言编写的函数。Python 中的 `ctypes` 是一个标准的、相对简单的允许 Python 代码调用 C 函数的 FFI。
+
+任何 FFI 都面临挑战,因为对接的语言不大可能会具有完全相同的数据类型。例如:`primes` 库使用 C 语言类型 `unsigned int`,而 Python 并不具有这种类型;因此 `ctypes` FFI 将 C 语言中的 `unsigned int` 类型映射为 Python 中的 `int` 类型。在 `primes` 库中发布的四个 `extern` C 函数中,有两个在具有显式 `ctypes` 配置的 Python 中会表现得更好。
+
+C 函数 `prime_factors` 和 `goldbach` 返回 `void` 而不是返回一个具体类型,但是 `ctypes` 默认会将 C 语言中的 `void` 替换为 Python 语言中的 `int`。当从 Python 代码中调用时,这两个 C 函数会从栈中返回一个随机整数值(因此,该值无任何意义)。然而,可以对 `ctypes` 进行配置,让这些函数返回 `None` (Python 中为 `null` 类型)。下面是对 `prime_factors` 函数的配置:
+
+```
+primes.prime_factors.restype = None
+```
+
+可以用类似的语句处理 `goldbach` 函数。
+
+下面的交互示例(在 Python3 中)展示了在 Python 客户程序和 `primes` 库之间的接口是简单明了的。
+
+```
+>>> from ctypes import cdll
+
+>>> primes = cdll.LoadLibrary("libshprimes.so") ## 逻辑名
+
+>>> primes.is_prime(13)
+1
+>>> primes.is_prime(12)
+0
+
+>>> primes.are_coprimes(8, 24)
+0
+>>> primes.are_coprimes(8, 25)
+1
+
+>>> primes.prime_factors.restype = None
+>>> primes.goldbach.restype = None
+
+>>> primes.prime_factors(72)
+2 2 2 3 3
+
+>>> primes.goldbach(32)
+32 = 3 + 29
+32 = 13 + 19
+```
+
+在 `primes` 库中的函数只使用一个简单数据类型:`unsigned int`。如果这个 C 语言库使用复杂的类型如结构体,如果库函数传递和返回指向结构体的指针,那么比 `ctypes` 更强大的 FFI 更适合作为一个在 Python 语言和 C 语言之间的平滑接口。尽管如此,`ctypes` 示例展示了一个 Python 客户程序可以使用 C 语言编写的库。值得注意的是,用作科学计算的流行的 `Numpy` 库是用 C 语言编写的,然后在高级 Python API 中公开。
+
+简单的 `primes` 库和高级的 `Numpy` 库强调了 C 语言仍然是编程语言中的通用语言。几乎每一个语言都可以与 C 语言交互,同时通过 C 语言也可以和任何其他语言交互。Python 很容易和 C 语言交互,作为另外一个例子,当 [Panama 项目](https://openjdk.java.net/projects/panama) 成为 Java Native Interface(JNI)一个替代品后,Java 语言和 C 语言交互也会变的很容易。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/2/linux-software-libraries
+
+作者:[Marty Kalin][a]
+选题:[lujun9972][b]
+译者:[萌新阿岩](https://github.com/mengxinayan)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mkalindepauledu
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
+[2]: https://en.wikipedia.org/wiki/Christian_Goldbach
+[3]: https://condor.depaul.edu/mkalin
+[4]: http://www.opengroup.org/onlinepubs/009695399/functions/printf.html
+[5]: http://www.opengroup.org/onlinepubs/009695399/functions/sqrt.html
+[6]: https://openjdk.java.net/projects/panama
diff --git a/published/202105/20210212 Network address translation part 2 - the conntrack tool.md b/published/202105/20210212 Network address translation part 2 - the conntrack tool.md
new file mode 100644
index 0000000000..6a779f4a74
--- /dev/null
+++ b/published/202105/20210212 Network address translation part 2 - the conntrack tool.md
@@ -0,0 +1,133 @@
+[#]: collector: (lujun9972)
+[#]: translator: (cooljelly)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13373-1.html)
+[#]: subject: (Network address translation part 2 – the conntrack tool)
+[#]: via: (https://fedoramagazine.org/network-address-translation-part-2-the-conntrack-tool/)
+[#]: author: (Florian Westphal https://fedoramagazine.org/author/strlen/)
+
+网络地址转换(NAT)之连接跟踪工具
+======
+
+
+
+这是有关网络地址转换(NAT)的系列文章中的第二篇。之前的第一篇文章介绍了 [如何使用 iptables/nftables 的报文跟踪功能][2] 来定位 NAT 相关的连接问题。作为第二部分,本文介绍 `conntrack` 命令,它允许你查看和修改被跟踪的连接。
+
+### 引言
+
+通过 iptables 或 nftables 配置的 NAT 建立在 netfilters 连接跟踪子系统之上。`conntrack` 命令作为 “conntrack-tools” 软件包的一部分,用于查看和更改连接状态表。
+
+### 连接跟踪状态表
+
+连接跟踪子系统会跟踪它看到的所有报文流。运行 `sudo conntrack -L` 可查看其内容:
+
+```
+tcp 6 43184 ESTABLISHED src=192.168.2.5 dst=10.25.39.80 sport=5646 dport=443 src=10.25.39.80 dst=192.168.2.5 sport=443 dport=5646 [ASSURED] mark=0 use=1
+tcp 6 26 SYN_SENT src=192.168.2.5 dst=192.168.2.10 sport=35684 dport=443 [UNREPLIED] src=192.168.2.10 dst=192.168.2.5 sport=443 dport=35684 mark=0 use=1
+udp 17 29 src=192.168.8.1 dst=239.255.255.250 sport=48169 dport=1900 [UNREPLIED] src=239.255.255.250 dst=192.168.8.1 sport=1900 dport=48169 mark=0 use=1
+```
+
+上述显示结果中,每行表示一个连接跟踪项。你可能会注意到,每行相同的地址和端口号会出现两次,而且第二次出现的源地址/端口对和目标地址/端口对会与第一次正好相反!这是因为每个连接跟踪项会先后两次被插入连接状态表。第一个四元组(源地址、目标地址、源端口、目标端口)记录的是原始方向的连接信息,即发送者发送报文的方向。而第二个四元组则记录的是连接跟踪子系统期望收到的对端回复报文的连接信息。这解决了两个问题:
+
+ 1. 如果报文匹配到一个 NAT 规则,例如 IP 地址伪装,相应的映射信息会记录在链接跟踪项的回复方向部分,并自动应用于同一条流的所有后续报文。
+ 2. 即使一条流经过了地址或端口的转换,也可以成功在连接状态表中查找到回复报文的四元组信息。
+
+原始方向的(第一个显示的)四元组信息永远不会改变:它就是发送者发送的连接信息。NAT 操作只会修改回复方向(第二个)四元组,因为这是接受者看到的连接信息。修改第一个四元组没有意义:netfilter 无法控制发起者的连接状态,它只能在收到/转发报文时对其施加影响。当一个报文未映射到现有连接表项时,连接跟踪可以为其新建一个表项。对于 UDP 报文,该操作会自动进行。对于 TCP 报文,连接跟踪可以配置为只有 TCP 报文设置了 [SYN 标志位][3] 才新建表项。默认情况下,连接跟踪会允许从流的中间报文开始创建,这是为了避免对启用连接跟踪之前就存在的流处理出现问题。
+
+### 连接跟踪状态表和 NAT
+
+如上一节所述,回复方向的四元组包含 NAT 信息。你可以通过命令过滤输出经过源地址 NAT 或目标地址 NAT 的连接跟踪项。通过这种方式可以看到一个指定的流经过了哪种类型的 NAT 转换。例如,运行 `sudo conntrack -L -p tcp –src-nat` 可显示经过源 NAT 的连接跟踪项,输出结果类似于以下内容:
+
+```
+tcp 6 114 TIME_WAIT src=10.0.0.10 dst=10.8.2.12 sport=5536 dport=80 src=10.8.2.12 dst=192.168.1.2 sport=80 dport=5536 [ASSURED]
+```
+
+这个连接跟踪项表示一条从 10.0.0.10:5536 到 10.8.2.12:80 的连接。与前面示例不同的是,回复方向的四元组不是原始方向四元组的简单翻转:源地址已修改。目标主机(10.8.2.12)将回复数据包发送到 192.168.1.2,而不是 10.0.0.10。每当 10.0.0.10 发送新的报文时,具有此连接跟踪项的路由器会将源地址替换为 192.168.1.2。当 10.8.2.12 发送回复报文时,该路由器将目的地址修改回 10.0.0.10。上述源 NAT 行为源自一条 [NFT 伪装][4] 规则:
+
+```
+inet nat postrouting meta oifname "veth0" masquerade
+```
+
+其他类型的 NAT 规则,例如目标地址 DNAT 规则或重定向规则,其连接跟踪项也会以类似的方式显示,回复方向四元组的远端地址或端口与原始方向四元组的远端地址或端口不同。
+
+### 连接跟踪扩展
+
+连接跟踪的记帐功能和时间戳功能是两个有用的扩展功能。运行 `sudo sysctl net.netfilter.nf_conntrack_acct=1` 可以在运行 `sudo conntrack -L` 时显示每个流经过的字节数和报文数。运行 `sudo sysctl net.netfilter.nf_conntrack_timestamp=1` 为每个连接记录一个开始时间戳,之后每次运行 `sudo conntrack -L` 时都可以显示这个流从开始经过了多少秒。在上述命令中增加 `–output ktimestamp` 选项也可以看到流开始的绝对时间。
+
+### 插入和更改连接跟踪项
+
+你可以手动为状态表添加连接跟踪项,例如:
+
+```
+sudo conntrack -I -s 192.168.7.10 -d 10.1.1.1 --protonum 17 --timeout 120 --sport 12345 --dport 80
+```
+
+这项命令通常被 conntrackd 用于状态复制,即将主防火墙的连接跟踪项复制到备用防火墙系统。于是当切换发生的时候,备用系统可以接管已经建立的连接且不会造成中断。连接跟踪还可以存储报文的带外元数据,例如连接跟踪标记和连接跟踪标签。可以用更新选项(`-U`)来修改它们:
+
+```
+sudo conntrack -U -m 42 -p tcp
+```
+
+这条命令将所有的 TCP 流的连接跟踪标记修改为 42。
+
+### 删除连接跟踪项
+
+在某些情况下,你可能想从状态表中删除条目。例如,对 NAT 规则的修改不会影响表中已存在流的经过报文。因此对 UDP 长连接(例如像 VXLAN 这样的隧道协议),删除表项可能很有意义,这样新的 NAT 转换规则才能生效。可以通过 `sudo conntrack -D` 命令附带可选的地址和端口列表选项,来删除相应的表项,如下例所示:
+
+```
+sudo conntrack -D -p udp --src 10.0.12.4 --dst 10.0.0.1 --sport 1234 --dport 53
+```
+
+### 连接跟踪错误计数
+
+`conntrack` 也可以输出统计数字:
+
+```
+# sudo conntrack -S
+cpu=0 found=0 invalid=130 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=10
+cpu=1 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=0
+cpu=2 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=1
+cpu=3 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=0
+```
+
+大多数计数器将为 0。`Found` 和 `insert` 数将始终为 0,它们只是为了后向兼容。其他错误计数包括:
+
+ * `invalid`:报文既不匹配已有连接跟踪项,也未创建新连接。
+ * `insert_failed`:报文新建了一个连接,但插入状态表时失败。这在 NAT 引擎在伪装时恰好选择了重复的源地址和端口时可能出现。
+ * `drop`:报文新建了一个连接,但是没有可用的内存为其分配新的状态条目。
+ * `early_drop`:连接跟踪表已满。为了接受新的连接,已有的未看到双向报文的连接被丢弃。
+ * `error`:icmp(v6) 收到与已知连接不匹配的 icmp 错误数据包。
+ * `search_restart`:查找过程由于另一个 CPU 的插入或删除操作而中断。
+ * `clash_resolve`:多个 CPU 试图插入相同的连接跟踪条目。
+
+除非经常发生,这些错误条件通常无害。一些错误可以通过针对预期工作负载调整连接跟踪子系统的参数来降低其发生概率,典型的配置包括 `net.netfilter.nf_conntrack_buckets` 和 `net.netfilter.nf_conntrack_max` 参数。可在 [nf_conntrack-sysctl 文档][5] 中查阅相应配置参数的完整列表。
+
+当报文状态是 `invalid` 时,请使用 `sudo sysctl net.netfilter.nf_conntrack_log_invalid=255` 来获取更多信息。例如,当连接跟踪遇到一个所有 TCP 标志位均为 0 的报文时,将记录以下内容:
+
+```
+nf_ct_proto_6: invalid tcp flag combination SRC=10.0.2.1 DST=10.0.96.7 LEN=1040 TOS=0x00 PREC=0x00 TTL=255 ID=0 PROTO=TCP SPT=5723 DPT=443 SEQ=1 ACK=0
+```
+
+### 总结
+
+本文介绍了如何检查连接跟踪表和存储在跟踪流中的 NAT 信息。本系列的下一部分将延伸讨论连接跟踪工具和连接跟踪事件框架。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/network-address-translation-part-2-the-conntrack-tool/
+
+作者:[Florian Westphal][a]
+选题:[lujun9972][b]
+译者:[cooljelly](https://github.com/cooljelly)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/strlen/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/02/network-address-translation-part-2-816x345.jpg
+[2]: https://linux.cn/article-13364-1.html
+[3]: https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure
+[4]: https://wiki.nftables.org/wiki-nftables/index.php/Performing_Network_Address_Translation_(NAT)#Masquerading
+[5]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/networking/nf_conntrack-sysctl.rst
diff --git a/published/202105/20210218 Not an engineer- Find out where you belong.md b/published/202105/20210218 Not an engineer- Find out where you belong.md
new file mode 100644
index 0000000000..a043bab7fc
--- /dev/null
+++ b/published/202105/20210218 Not an engineer- Find out where you belong.md
@@ -0,0 +1,106 @@
+[#]: collector: (lujun9972)
+[#]: translator: (max27149)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13445-1.html)
+[#]: subject: (Not an engineer? Find out where you belong)
+[#]: via: (https://opensource.com/article/21/2/advice-non-technical)
+[#]: author: (Dawn Parzych https://opensource.com/users/dawnparzych)
+
+不是程序员?那就找到自己的定位
+===
+
+> 无论你是已经工作了几十年的还是刚开始从业的非工程型技术人,此建议都可以帮助你确定你的位置归属。
+
+
+
+在 [本系列第一篇文章][2] 中 ,我解释了将人员和角色分为“技术”或“非技术”类别的问题。在 [第二篇文章][3] 中,我为不写代码的人分享了一些技术岗位角色。这一次,我将把这次探索总结为——“技术或非技术意味着什么”,并提供一些能够在职业发展上帮到你的建议。
+
+无论你是已经从事技术工作数十年,或是刚刚起步,还是正在寻求职业变更,请考虑本文中来自非技术人员但在技术角色方面取得成功的人士的建议。
+
+> “不要把你的工作和身份捆绑起来 —— 把它们分开。”
+>
+> —— Adam Gordon Bell,Earthly Technologies 开发者关系部
+
+转换角色,并不意味着你的技能会消失且你不再具有价值。如果你担任了新角色,则需要专注于该角色的关键技能。培养技能是需要时间的。花点时间,找出新职位的重要技能。
+
+如果你管理工程师们,请鼓励他们提升技术技能的同时发展非工程技能,这些技能往往能比编程能力和技术技能对职业发展和成功产生更显著的变化。
+
+### 做你自己
+
+> “不要让其他人定义你是技术人员还是非技术人员。什么是技术人员,什么不是技术人员,以及这是否重要,是人们必须自己搞清楚的事情。”
+>
+> —— Adam Gordon Bell
+
+> “永远不要用‘我不是技术人员’为开头进行对话。因为很可能让对方产生‘这点我需要提醒你’的想法,这在面试的时候可从来不会留下好印象,而且还有可能会让人觉得你对自己技能缺乏信心。”
+>
+> —— Mary Thengvall,Camunda 开发者关系总监
+
+避免刻板成见;不是所有的工程师都喜欢《星球大战》或《星际迷航》。不是所有工程师都穿连帽卫衣。工程师也可以和别人交流。
+
+> “单单就你的行为举止,旁人就有很多关于技术或非技术方面的看法。在办公室工作的时候,我会穿裙子,因为只有这样我才能舒服一点。”
+>
+> —— Shailvi Wakhlu,Strava 高级数据总监
+
+### 了解你的价值
+
+正如我在第一篇文章中讨论的那样,被打上“非技术”的标签会导致 [冒充者综合症][4]。承认自己的价值,不要在自己身上贴上“非技术”标签,因为它会限制你的收入潜力和职业发展。
+
+> “人们之所以把我重新包装成其他东西,是因为他们认为我和工程师的刻板印象不一样。我很高兴我没有听这些人的话,因为他们本质上是在告诉我,在我拥有的技能之外,去找一份低薪的工作。”
+>
+> —— Shailvi Wakhlu
+
+> “年轻的或者女性技术人,特别是刚接触技术的女性,更容易患上冒名综合症,认为自己技术不够好。比如,‘哦,我只会前端。’,什么叫你*只会*前端?前端也很难的好吧。”
+>
+> —— Liz Harris
+
+### 寻找那些可以提升价值并帮到人们的地方
+
+你不需要创建 PR 就可以参与开源。
+
+> “当有人想为开源项目做点贡献时,我总是对他说,‘不要想着,得是一个提交才行、得提一个 PR 才可以。’这就好像,‘不行。怎么才能为那个项目贡献点价值呢?’ 如果你没时间提交 PR,那你是不是提个议题并把要点写下来?”
+>
+> —— Eddie Jaoude,Jaoude Studios 开源程序员
+
+### 思维的多样性有助于事业成功
+
+看看所有角色和人员的价值和贡献。不要根据头衔将人归到同能力的一组。
+
+> “要认识到,所有人(包括自己在内),在任何时候,以及事情全貌的重要性。创造力这个事儿不应该由自我驱动。要知道,对于你所做的事情,你可以做的更好,也可以做的更糟。不要害怕寻求帮助,知道到我们在一起。”
+>
+> —— Therese Eberhard,电影/广告和视频场景画师
+
+> “在我参加过的黑客马拉松中,我们都是技术人员,组建了一支四五个硬核程序员组成的强大团队,但我们输了。我不骗你,我们输了。在新冠疫情之前,我赢了前六次的黑客马拉松,而且当时团队中一半的人属于其他领域的专家。在我们赢过的比赛中,大多数人会认为团队一半人是非技术的,尽管我不喜欢这个术语,因为这像是给团队/项目贴金。我们之所以获胜,是因为我们对所构建的东西有很多不同的看法。”
+>
+> —— Eddie Jaoude
+
+> “我们越能摆脱‘技术/非技术’、‘开发人员/非开发人员’的标签,并理解到一个连续统一的整体存在,我们就越能全力以赴地雇用到合适的人来做这项工作,只要不被你需要‘技术团队’的假设所困扰。”
+>
+> —— Mary Thengvall
+
+我们的社区和团队越多样化,它们的包容性就越大。
+
+> “老实说,无论是从社区角度还是从产品角度,我认为,总的来说,最重要的事情都是,我们应该确保我们建立的是一个包容性的社区,这不仅是为了我们的产品,也不仅是为了我们正在使用的技术,还为了整个人类社会,我想……我敢打赌,如果我们做到了这一点,那么作为人类,我们就比过去更进步了。”
+>
+> —— Leon Stigter,Lightbend 高级产品经理
+
+如果你以非程序员的技术身份工作,你会给那些认为自己“非技术”的人(或被他人认为是“非技术”的人)提供什么建议? 在评论中分享你的见解。
+
+---
+
+via: https://opensource.com/article/21/2/advice-non-technical
+
+作者:[Dawn Parzych][a]
+选题:[lujun9972][b]
+译者:[max27149](https://github.com/max27149)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dawnparzych
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/career_journey_road_gps_path_map_520.png?itok=PpL6jJgY (Looking at a map for career journey)
+[2]: https://linux.cn/article-13168-1.html
+[3]: https://linux.cn/article-13178-1.html
+[4]: https://opensource.com/business/15/9/tips-avoiding-impostor-syndrome
+
diff --git a/published/202105/20210325 How to use the Linux sed command.md b/published/202105/20210325 How to use the Linux sed command.md
new file mode 100644
index 0000000000..fa8818a8e2
--- /dev/null
+++ b/published/202105/20210325 How to use the Linux sed command.md
@@ -0,0 +1,184 @@
+[#]: subject: "How to use the Linux sed command"
+[#]: via: "https://opensource.com/article/21/3/sed-cheat-sheet"
+[#]: author: "Seth Kenlon https://opensource.com/users/seth"
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13417-1.html"
+
+使用 sed 命令进行复制、剪切和粘贴
+======
+
+> 了解 sed 的基本用法,然后下载我们的备忘单,方便快速地参考 Linux 流编辑器。
+
+
+
+很少有 Unix 命令像 `sed`、[grep][2] 和 [awk][3] 一样出名,它们经常组合在一起,可能是因为它们具有奇怪的名称和强大的文本解析能力。它们还在一些语法和逻辑上有相似之处。虽然它们都能用于文本解析,但都有其特殊性。本文研究 `sed` 命令,它是一个 流编辑器。
+
+我之前写过关于 [sed][4] 以及它的远亲 [ed][5] 的文章。要熟悉 `sed`,对 `ed` 有一点了解是有帮助的,因为这有助于你熟悉缓冲区的概念。本文假定你熟悉 `sed` 的基本知识,这意味着你至少已经运行过经典的 `s/foo/bar` 风格的查找和替换命令。
+
+- 下载我们的免费 [sed 备忘录][6]
+
+### 安装 sed
+
+如果你使用的是 Linux、BSD 或 macOS,那么它们已经安装了 GNU 的或 BSD 的 sed。这些是原始 `sed` 命令的独特重新实现。虽然它们很相似,但也有一些细微的差别。本文已经在 Linux 和 NetBSD 版本上进行了测试,所以你可以使用你的计算机上找到的任何 sed,但是对于 BSD sed,你必须使用短选项(例如 `-n` 而不是 `--quiet`)。
+
+GNU sed 通常被认为是功能最丰富的 sed,因此无论你是否运行 Linux,你可能都想要尝试一下。如果在 Ports 树中找不到 GNU sed(在非 Linux 系统上通常称为 gsed),你可以从 GNU 网站 [下载源代码][7]。 安装 GNU sed 的好处是,你可以使用它的额外功能,但是如果需要可移植性,还可以限制它以遵守 sed 的 [POSIX][8] 规范。
+
+MacOS 用户可以在 [MacPorts][9] 或 [Homebrew][10] 上找到 GNU sed。
+
+在 Windows 上,你可以通过 [Chocolatey][12] 来 [安装 GNU sed][11]。
+
+### 了解模式空间和保留空间
+
+sed 一次只能处理一行。因为它没有可视化模式,所以会创建一个 模式空间,这是一个内存空间,其中包含来自输入流的当前行(删除了尾部的任何换行符)。填充模式空间后,sed 将执行你的指令。当命令执行完时,sed 将模式空间中的内容打印到输出流,默认是 **标准输出**,但是可以将输出重定向到文件,甚至使用 `--in-place=.bak` 选项重定向到同一文件。
+
+然后,循环从下一个输入行再次开始。
+
+为了在遍历文件时提供一点灵活性,sed 还提供了保留空间(有时也称为 保留缓冲区),即 sed 内存中为临时数据存储保留的空间。你可以将保留空间当作剪贴板,实际上,这正是本文所演示的内容:如何使用 sed 复制/剪切和粘贴。
+
+首先,创建一个示例文本文件,其内容如下:
+
+```
+Line one
+Line three
+Line two
+```
+
+### 复制数据到保留空间
+
+要将内容放置在 sed 的保留空间,使用 `h` 或 `H` 命令。小写的 `h` 告诉 sed 覆盖保留空间中的当前内容,而大写的 `H` 告诉 sed 将数据追加到保留空间中已经存在的内容之后。
+
+单独使用,什么都看不到:
+
+```
+$ sed --quiet -e '/three/ h' example.txt
+$
+```
+
+`--quiet`(缩写为 `-n`)选项禁止显示所有输出,但 sed 执行了我的搜索需求。在这种情况下,sed 选择包含字符串 `three` 的任何行,并将其复制到保留空间。我没有告诉 sed 打印任何东西,所以没有输出。
+
+### 从保留空间复制数据
+
+要了解保留空间,你可以从保留空间复制内容,然后使用 `g` 命令将其放入模式空间,观察会发生什么:
+
+```
+$ sed -n -e '/three/h' -e 'g;p' example.txt
+
+Line three
+Line three
+```
+
+第一个空白行是因为当 sed 第一次复制内容到模式空间时,保留空间为空。
+
+接下来的两行包含 `Line three` 是因为这是从第二行开始的保留空间。
+
+该命令使用两个唯一的脚本(`-e`)纯粹是为了帮助提高可读性和组织性。将步骤划分为单独的脚本可能会很有用,但是从技术上讲,以下命令与一个脚本语句一样有效:
+
+```
+$ sed -n -e '/three/h ; g ; p' example.txt
+
+Line three
+Line three
+```
+
+### 将数据追加到模式空间
+
+`G` 命令会将一个换行符和保留空间的内容添加到模式空间。
+
+```
+$ sed -n -e '/three/h' -e 'G;p' example.txt
+Line one
+
+Line three
+Line three
+Line two
+Line three
+```
+
+此输出的前两行同时包含模式空间(`Line one`)的内容和空的保留空间。接下来的两行与搜索文本(`three`)匹配,因此它既包含模式空间又包含保留空间。第三行的保留空间没有变化,因此在模式空间(`Line two`)的末尾是保留空间(仍然是 `Line three`)。
+
+### 用 sed 剪切和粘贴
+
+现在你知道了如何将字符串从模式空间转到保留空间并再次返回,你可以设计一个 sed 脚本来复制、删除,然后在文档中粘贴一行。例如,将示例文件的 `Line three` 挪至第三行,sed 可以解决这个问题:
+
+```
+$ sed -n -e '/three/ h' -e '/three/ d' \
+-e '/two/ G;p' example.txt
+Line one
+Line two
+Line three
+```
+
+ * 第一个脚本找到包含字符串 `three` 的行,并将其从模式空间复制到保留空间,替换当前保留空间中的任何内容。
+ * 第二个脚本删除包含字符串 `three` 的任何行。这样就完成了与文字处理器或文本编辑器中的 _剪切_ 动作等效的功能。
+ * 最后一个脚本找到包含字符串 `two` 的行,并将保留空间的内容_追加_到模式空间,然后打印模式空间。
+
+任务完成。
+
+### 使用 sed 编写脚本
+
+再说一次,使用单独的脚本语句纯粹是为了视觉和心理上的简单。剪切和粘贴命令作为一个脚本同样有效:
+
+```
+$ sed -n -e '/three/ h ; /three/ d ; /two/ G ; p' example.txt
+Line one
+Line two
+Line three
+```
+
+它甚至可以写在一个专门的脚本文件中:
+
+```
+#!/usr/bin/sed -nf
+
+/three/h
+/three/d
+/two/ G
+p
+```
+
+要运行该脚本,将其加入可执行权限,然后用示例文件尝试:
+
+```
+$ chmod +x myscript.sed
+$ ./myscript.sed example.txt
+Line one
+Line two
+Line three
+```
+
+当然,你需要解析的文本越可预测,则使用 sed 解决问题越容易。发明 sed 操作(例如复制和粘贴)的“配方”通常是不切实际的,因为触发操作的条件可能因文件而异。但是,你对 sed 命令的使用越熟练,就越容易根据需要解析的输入来设计复杂的动作。
+
+重要的事情是识别不同的操作,了解 sed 何时移至下一行,并预测模式和保留空间包含的内容。
+
+### 下载备忘单
+
+sed 很复杂。虽然它只有十几个命令,但它灵活的语法和原生功能意味着它充满了无限的潜力。为了充分利用 sed,我曾经参考过一些巧妙的单行命令,但是直到我开始发明(有时是重新发明)自己的解决方案时,我才觉得自己真正开始学习 sed 了 。如果你正在寻找命令提示和语法方面的有用技巧,[下载我们的 sed 备忘单][6],然后开始一劳永逸地学习 sed!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/sed-cheat-sheet
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 "Penguin with green background"
+[2]: https://opensource.com/article/21/3/grep-cheat-sheet
+[3]: https://opensource.com/article/20/9/awk-ebook
+[4]: https://opensource.com/article/20/12/sed
+[5]: https://opensource.com/article/20/12/gnu-ed
+[6]: https://opensource.com/downloads/sed-cheat-sheet
+[7]: http://www.gnu.org/software/sed/
+[8]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[9]: https://opensource.com/article/20/11/macports
+[10]: https://opensource.com/article/20/6/homebrew-mac
+[11]: https://chocolatey.org/packages/sed
+[12]: https://opensource.com/article/20/3/chocolatey
\ No newline at end of file
diff --git a/published/202105/20210330 Access Python package index JSON APIs with requests.md b/published/202105/20210330 Access Python package index JSON APIs with requests.md
new file mode 100644
index 0000000000..437bd5c3ea
--- /dev/null
+++ b/published/202105/20210330 Access Python package index JSON APIs with requests.md
@@ -0,0 +1,208 @@
+[#]: subject: "Access Python package index JSON APIs with requests"
+[#]: via: "https://opensource.com/article/21/3/python-package-index-json-apis-requests"
+[#]: author: "Ben Nuttall https://opensource.com/users/bennuttall"
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13356-1.html"
+
+使用 requests 访问 Python 包索引(PyPI)的 JSON API
+======
+
+> PyPI 的 JSON API 是一种机器可直接使用的数据源,你可以访问和你浏览网站时相同类型的数据。
+
+
+
+PyPI(Python 软件包索引)提供了有关其软件包信息的 JSON API。本质上,它是机器可以直接使用的数据源,与你在网站上直接访问是一样的的。例如,作为人类,我可以在浏览器中打开 [Numpy][2] 项目页面,点击左侧相关链接,查看有哪些版本,哪些文件可用以及发行日期和支持的 Python 版本等内容:
+
+![NumPy project page][3]
+
+但是,如果我想编写一个程序来访问此数据,则可以使用 JSON API,而不必在这些页面上抓取和解析 HTML。
+
+顺便说一句:在旧的 PyPI 网站上,还托管在 `pypi.python.org` 时,NumPy 的项目页面位于 `pypi.python.org/pypi/numpy`,访问其 JSON API 也很简单,只需要在最后面添加一个 `/json` ,即 `https://pypi.org/pypi/numpy/json`。现在,PyPI 网站托管在 `pypi.org`,NumPy 的项目页面是 `pypi.org/project/numpy`。新站点不会有单独的 JSON API URL,但它仍像以前一样工作。因此,你不必在 URL 后添加 `/json`,只要记住 URL 就够了。
+
+你可以在浏览器中打开 NumPy 的 JSON API URL,Firefox 很好地渲染了数据:
+
+![JSON rendered in Firefox][5]
+
+你可以查看 `info`,`release` 和 `urls` 其中的内容。或者,你可以将其加载到 Python Shell 中,以下是几行入门教程:
+
+```
+import requests
+url = "https://pypi.org/pypi/numpy/json"
+r = requests.get(url)
+data = r.json()
+```
+
+获得数据后(调用 `.json()` 提供了该数据的 [字典][6]),你可以对其进行查看:
+
+![Inspecting data][7]
+
+查看 `release` 中的键:
+
+![Inspecting keys in releases][8]
+
+这表明 `release` 是一个以版本号为键的字典。选择一个并查看以下内容:
+
+![Inspecting version][9]
+
+每个版本都包含一个列表,`release` 包含 24 项。但是每个项目是什么?由于它是一个列表,因此你可以索引第一项并进行查看:
+
+![Indexing an item][10]
+
+这是一个字典,其中包含有关特定文件的详细信息。因此,列表中的 24 个项目中的每一个都与此特定版本号关联的文件相关,即在 列出的 24 个文件。
+
+你可以编写一个脚本在可用数据中查找内容。例如,以下的循环查找带有 sdist(源代码包)的版本,它们指定了 `requires_python` 属性并进行打印:
+
+```
+for version, files in data['releases'].items():
+ for f in files:
+ if f.get('packagetype') == 'sdist' and f.get('requires_python'):
+ print(version, f['requires_python'])
+```
+
+![sdist files with requires_python attribute][11]
+
+### piwheels
+
+去年,我在 piwheels 网站上[实现了类似的 API][12]。[piwheels.org][13] 是一个 Python 软件包索引,为树莓派架构提供了 wheel(预编译的二进制软件包)。它本质上是 PyPI 软件包的镜像,但带有 Arm wheel,而不是软件包维护者上传到 PyPI 的文件。
+
+由于 piwheels 模仿了 PyPI 的 URL 结构,因此你可以将项目页面 URL 的 `pypi.org` 部分更改为 `piwheels.org`。它将向你显示类似的项目页面,其中详细说明了构建的版本和可用的文件。由于我喜欢旧站点允许你在 URL 末尾添加 `/json` 的方式,所以我也支持这种方式。NumPy 在 PyPI 上的项目页面为 [pypi.org/project/numpy][14],在 piwheels 上,它是 [piwheels.org/project/numpy][15],而 JSON API 是 [piwheels.org/project/numpy/json][16] 页面。
+
+没有必要重复 PyPI API 的内容,所以我们提供了 piwheels 上可用内容的信息,包括所有已知发行版的列表,一些基本信息以及我们拥有的文件列表:
+
+![JSON files available in piwheels][17]
+
+与之前的 PyPI 例子类似,你可以创建一个脚本来分析 API 内容。例如,对于每个 NumPy 版本,其中有多少 piwheels 文件:
+
+```
+import requests
+
+url = "https://www.piwheels.org/project/numpy/json"
+package = requests.get(url).json()
+
+for version, info in package['releases'].items():
+ if info['files']:
+ print('{}: {} files'.format(version, len(info['files'])))
+ else:
+ print('{}: No files'.format(version))
+```
+
+此外,每个文件都包含一些元数据:
+
+![Metadata in JSON files in piwheels][18]
+
+方便的是 `apt_dependencies` 字段,它列出了使用该库所需的 Apt 软件包。本例中的 NumPy 文件,或者通过 `pip` 安装 Numpy,你还需要使用 Debian 的 `apt` 包管理器安装 `libatlas3-base` 和 `libgfortran`。
+
+以下是一个示例脚本,显示了程序包的 Apt 依赖关系:
+
+
+```
+import requests
+
+def get_install(package, abi):
+ url = 'https://piwheels.org/project/{}/json'.format(package)
+ r = requests.get(url)
+ data = r.json()
+ for version, release in sorted(data['releases'].items(), reverse=True):
+ for filename, file in release['files'].items():
+ if abi in filename:
+ deps = ' '.join(file['apt_dependencies'])
+ print("sudo apt install {}".format(deps))
+ print("sudo pip3 install {}=={}".format(package, version))
+ return
+
+get_install('opencv-python', 'cp37m')
+get_install('opencv-python', 'cp35m')
+get_install('opencv-python-headless', 'cp37m')
+get_install('opencv-python-headless', 'cp35m')
+```
+
+我们还为软件包列表提供了一个通用的 API 入口,其中包括每个软件包的下载统计:
+
+```python
+import requests
+
+url = "https://www.piwheels.org/packages.json"
+packages = requests.get(url).json()
+packages = {
+ pkg: (d_month, d_all)
+ for pkg, d_month, d_all, *_ in packages
+}
+
+package = 'numpy'
+d_month, d_all = packages[package]
+
+print(package, "has had", d_month, "downloads in the last month")
+print(package, "has had", d_all, "downloads in total")
+```
+
+### pip search
+
+`pip search` 因为其 XMLRPC 接口过载而被禁用,因此人们一直在寻找替代方法。你可以使用 piwheels 的 JSON API 来搜索软件包名称,因为软件包的集合是相同的:
+
+```
+#!/usr/bin/python3
+import sys
+
+import requests
+
+PIWHEELS_URL = 'https://www.piwheels.org/packages.json'
+
+r = requests.get(PIWHEELS_URL)
+packages = {p[0] for p in r.json()}
+
+def search(term):
+ for pkg in packages:
+ if term in pkg:
+ yield pkg
+
+if __name__ == '__main__':
+ if len(sys.argv) == 2:
+ results = search(sys.argv[1].lower())
+ for res in results:
+ print(res)
+ else:
+ print("Usage: pip_search TERM")
+```
+
+有关更多信息,参考 piwheels 的 [JSON API 文档][19].
+
+* * *
+
+_本文最初发表在 Ben Nuttall 的 [Tooling Tuesday 博客上][20],经许可转载使用。_
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/3/python-package-index-json-apis-requests
+
+作者:[Ben Nuttall][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/bennuttall
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python_programming_question.png?itok=cOeJW-8r "Python programming language logo with question marks"
+[2]: https://pypi.org/project/numpy/
+[3]: https://opensource.com/sites/default/files/uploads/numpy-project-page.png "NumPy project page"
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://opensource.com/sites/default/files/uploads/pypi-json-firefox.png "JSON rendered in Firefox"
+[6]: https://docs.python.org/3/tutorial/datastructures.html#dictionaries
+[7]: https://opensource.com/sites/default/files/uploads/pypi-json-notebook.png "Inspecting data"
+[8]: https://opensource.com/sites/default/files/uploads/pypi-json-releases.png "Inspecting keys in releases"
+[9]: https://opensource.com/sites/default/files/uploads/pypi-json-inspect.png "Inspecting version"
+[10]: https://opensource.com/sites/default/files/uploads/pypi-json-release.png "Indexing an item"
+[11]: https://opensource.com/sites/default/files/uploads/pypi-json-requires-python.png "sdist files with requires_python attribute "
+[12]: https://blog.piwheels.org/requires-python-support-new-project-page-layout-and-a-new-json-api/
+[13]: https://www.piwheels.org/
+[14]: https://pypi.org/project/numpy
+[15]: https://www.piwheels.org/project/numpy
+[16]: https://www.piwheels.org/project/numpy/json
+[17]: https://opensource.com/sites/default/files/uploads/piwheels-json.png "JSON files available in piwheels"
+[18]: https://opensource.com/sites/default/files/uploads/piwheels-json-numpy.png "Metadata in JSON files in piwheels"
+[19]: https://www.piwheels.org/json.html
+[20]: https://tooling.bennuttall.com/accessing-python-package-index-json-apis-with-requests/
diff --git a/published/202105/20210331 A tool to spy on your DNS queries- dnspeep.md b/published/202105/20210331 A tool to spy on your DNS queries- dnspeep.md
new file mode 100644
index 0000000000..c194b860c8
--- /dev/null
+++ b/published/202105/20210331 A tool to spy on your DNS queries- dnspeep.md
@@ -0,0 +1,154 @@
+[#]: subject: (A tool to spy on your DNS queries: dnspeep)
+[#]: via: (https://jvns.ca/blog/2021/03/31/dnspeep-tool/)
+[#]: author: (Julia Evans https://jvns.ca/)
+[#]: collector: (lujun9972)
+[#]: translator: (wyxplus)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13353-1.html)
+
+dnspeep:监控 DNS 查询的工具
+======
+
+
+
+在过去的几天中,我编写了一个叫作 [dnspeep][1] 的小工具,它能让你看到你电脑中正进行的 DNS 查询,并且还能看得到其响应。它现在只有 [250 行 Rust 代码][2]。
+
+我会讨论如何去尝试它、能做什么、为什么我要编写它,以及当我在开发时所遇到的问题。
+
+### 如何尝试
+
+我构建了一些二进制文件,因此你可以快速尝试一下。
+
+对于 Linux(x86):
+
+```
+wget https://github.com/jvns/dnspeep/releases/download/v0.1.0/dnspeep-linux.tar.gz
+tar -xf dnspeep-linux.tar.gz
+sudo ./dnspeep
+```
+
+对于 Mac:
+
+```
+wget https://github.com/jvns/dnspeep/releases/download/v0.1.0/dnspeep-macos.tar.gz
+tar -xf dnspeep-macos.tar.gz
+sudo ./dnspeep
+```
+
+它需要以超级用户身份运行,因为它需要访问计算机正在发送的所有 DNS 数据包。 这与 `tcpdump` 需要以超级身份运行的原因相同:它使用 `libpcap`,这与 tcpdump 使用的库相同。
+
+如果你不想在超级用户下运行下载的二进制文件,你也能在 查看源码并且自行编译。
+
+### 输出结果是什么样的
+
+以下是输出结果。每行都是一次 DNS 查询和响应:
+
+```
+$ sudo dnspeep
+query name server IP response
+A firefox.com 192.168.1.1 A: 44.235.246.155, A: 44.236.72.93, A: 44.236.48.31
+AAAA firefox.com 192.168.1.1 NOERROR
+A bolt.dropbox.com 192.168.1.1 CNAME: bolt.v.dropbox.com, A: 162.125.19.131
+```
+
+这些查询是来自于我在浏览器中访问的 `neopets.com`,而 `bolt.dropbox.com` 查询是因为我正在运行 Dropbox 代理,并且我猜它不时会在后台运行,因为其需要同步。
+
+### 为什么我要开发又一个 DNS 工具?
+
+之所以这样做,是因为我认为当你不太了解 DNS 时,DNS 似乎真的很神秘!
+
+你的浏览器(和你电脑上的其他软件)一直在进行 DNS 查询,我认为当你能真正看到请求和响应时,似乎会有更多的“真实感”。
+
+我写这个也把它当做一个调试工具。我想“这是 DNS 的问题?”的时候,往往很难回答。我得到的印象是,当尝试检查问题是否由 DNS 引起时,人们经常使用试错法或猜测,而不是仅仅查看计算机所获得的 DNS 响应。
+
+### 你可以看到哪些软件在“秘密”使用互联网
+
+我喜欢该工具的一方面是,它让我可以感知到我电脑上有哪些程序正使用互联网!例如,我发现在我电脑上,某些软件出于某些理由不断地向 `ping.manjaro.org` 发送请求,可能是为了检查我是否已经连上互联网了。
+
+实际上,我的一个朋友用这个工具发现,他的电脑上安装了一些以前工作时的企业监控软件,但他忘记了卸载,因此你甚至可能发现一些你想要删除的东西。
+
+### 如果你不习惯的话, tcpdump 会令人感到困惑
+
+当我试图向人们展示他们的计算机正在进行的 DNS 查询时,我的第一感是想“好吧,使用 tcpdump”!而 `tcpdump` 确实可以解析 DNS 数据包!
+
+例如,下方是一次对 `incoming.telemetry.mozilla.org.` 的 DNS 查询结果:
+
+```
+11:36:38.973512 wlp3s0 Out IP 192.168.1.181.42281 > 192.168.1.1.53: 56271+ A? incoming.telemetry.mozilla.org. (48)
+11:36:38.996060 wlp3s0 In IP 192.168.1.1.53 > 192.168.1.181.42281: 56271 3/0/0 CNAME telemetry-incoming.r53-2.services.mozilla.com., CNAME prod.data-ingestion.prod.dataops.mozgcp.net., A 35.244.247.133 (180)
+```
+
+绝对可以学着去阅读理解一下,例如,让我们分解一下查询:
+
+`192.168.1.181.42281 > 192.168.1.1.53: 56271+ A? incoming.telemetry.mozilla.org. (48)`
+
+ * `A?` 意味着这是一次 A 类型的 DNS **查询**
+ * `incoming.telemetry.mozilla.org.` 是被查询的名称
+ * `56271` 是 DNS 查询的 ID
+ * `192.168.1.181.42281` 是源 IP/端口
+ * `192.168.1.1.53` 是目的 IP/端口
+ * `(48)` 是 DNS 报文长度
+
+在响应报文中,我们可以这样分解:
+
+`56271 3/0/0 CNAME telemetry-incoming.r53-2.services.mozilla.com., CNAME prod.data-ingestion.prod.dataops.mozgcp.net., A 35.244.247.133 (180)`
+
+ * `3/0/0` 是在响应报文中的记录数:3 个回答,0 个权威记录,0 个附加记录。我认为 tcpdump 甚至只打印出回答响应报文。
+ * `CNAME telemetry-incoming.r53-2.services.mozilla.com`、`CNAME prod.data-ingestion.prod.dataops.mozgcp.net.` 和 `A 35.244.247.133` 是三个响应记录。
+ * `56271` 是响应报文 ID,和查询报文的 ID 相对应。这就是你如何知道它是对前一行请求的响应。
+
+我认为,这种格式最难处理的是(作为一个只想查看一些 DNS 流量的人),你必须手动匹配请求和响应,而且它们并不总是相邻的行。这就是计算机擅长的事情!
+
+因此,我决定编写一个小程序(`dnspeep`)来进行匹配,并排除一些我认为多余的信息。
+
+### 我在编写时所遇到的问题
+
+在撰写本文时,我遇到了一些问题:
+
+ * 我必须给 `pcap` 包打上补丁,使其能在 Mac 操作系统上和 Tokio 配合工作([这个更改][3])。这是其中的一个 bug,花了很多时间才搞清楚,用了 1 行代码才解决 :)
+ * 不同的 Linux 发行版似乎有不同的 `libpcap.so` 版本。所以我不能轻易地分发一个动态链接 libpcap 的二进制文件(你可以 [在这里][4] 看到其他人也有同样的问题)。因此,我决定在 Linux 上将 libpcap 静态编译到这个工具中。但我仍然不太了解如何在 Rust 中正确做到这一点作,但我通过将 `libpcap.a` 文件复制到 `target/release/deps` 目录下,然后直接运行 `cargo build`,使其得以工作。
+ * 我使用的 `dns_parser` carte 并不支持所有 DNS 查询类型,只支持最常见的。我可能需要更换一个不同的工具包来解析 DNS 数据包,但目前为止还没有找到合适的。
+ * 因为 `pcap` 接口只提供原始字节(包括以太网帧),所以我需要 [编写代码来计算从开头剥离多少字节才能获得数据包的 IP 报头][5]。我很肯定我还遗漏了一些情形。
+
+我对于给它取名也有过一段艰难的时光,因为已经有许多 DNS 工具了(dnsspy!dnssnoop!dnssniff!dnswatch!)我基本上只是查了下有关“监听”的每个同义词,然后选择了一个看起来很有趣并且还没有被其他 DNS 工具所占用的名称。
+
+该程序没有做的一件事就是告诉你哪个进程进行了 DNS 查询,我发现有一个名为 [dnssnoop][6] 的工具可以做到这一点。它使用 eBPF,看上去很酷,但我还没有尝试过。
+
+### 可能会有许多 bug
+
+我只在 Linux 和 Mac 上简单测试了一下,并且我已知至少有一个 bug(不支持足够多的 DNS 查询类型),所以请在遇到问题时告知我!
+
+尽管这个 bug 没什么危害,因为这 libpcap 接口是只读的。所以可能发生的最糟糕的事情是它得到一些它无法解析的输入,最后打印出错误或是崩溃。
+
+### 编写小型教育工具很有趣
+
+最近,我对编写小型教育的 DNS 工具十分感兴趣。
+
+到目前为止我所编写的工具:
+
+ * (一种进行 DNS 查询的简单方法)
+ * (向你显示在进行 DNS 查询时内部发生的情况)
+ * 本工具(`dnspeep`)
+
+以前我尽力阐述已有的工具(如 `dig` 或 `tcpdump`)而不是编写自己的工具,但是经常我发现这些工具的输出结果让人费解,所以我非常关注以更加友好的方式来看这些相同的信息,以便每个人都能明白他们电脑正在进行的 DNS 查询,而不仅仅是依赖 tcmdump。
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2021/03/31/dnspeep-tool/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://github.com/jvns/dnspeep
+[2]: https://github.com/jvns/dnspeep/blob/f5780dc822df5151f83703f05c767dad830bd3b2/src/main.rs
+[3]: https://github.com/ebfull/pcap/pull/168
+[4]: https://github.com/google/gopacket/issues/734
+[5]: https://github.com/jvns/dnspeep/blob/f5780dc822df5151f83703f05c767dad830bd3b2/src/main.rs#L136
+[6]: https://github.com/lilydjwg/dnssnoop
diff --git a/published/202105/20210412 Scheduling tasks with cron.md b/published/202105/20210412 Scheduling tasks with cron.md
new file mode 100644
index 0000000000..c14e44cd5f
--- /dev/null
+++ b/published/202105/20210412 Scheduling tasks with cron.md
@@ -0,0 +1,202 @@
+[#]: subject: "Scheduling tasks with cron"
+[#]: via: "https://fedoramagazine.org/scheduling-tasks-with-cron/"
+[#]: author: "Darshna Das https://fedoramagazine.org/author/climoiselle/"
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13383-1.html"
+
+使用 cron 调度任务
+======
+
+
+
+cron 是一个调度守护进程,它以指定的时间间隔执行任务,这些任务称为 corn 作业,主要用于自动执行系统维护或管理任务。例如,你可以设置一个 cron 作业来自动执行重复的任务,比如备份数据库或数据,使用最新的安全补丁更新系统,检查磁盘空间使用情况,发送电子邮件等等。 cron 作业可以按分钟、小时、日、月、星期或它们的任意组合运行。
+
+### cron 的一些优点
+
+以下是使用 cron 作业的一些优点:
+
+ * 你可以更好地控制作业的运行时间。例如,你可以精确到分钟、小时、天等。
+ * 它消除了为循环任务逻辑而去写代码的需要,当你不再需要执行任务时,可以直接关闭它。
+ * 作业在不执行时不会占用内存,因此你可以节省内存分配。
+ * 如果一个作业执行失败并由于某种原因退出,它将在适当的时间再次运行。
+
+### 安装 cron 守护进程
+
+幸运的是,Fedora Linux 预先配置了运行重要的系统任务来保持系统更新,有几个实用程序可以运行任务例如 cron、`anacron`、`at` 和 `batch` 。本文只关注 cron 实用程序的安装。cron 和 cronie 包一起安装,cronie 包也提供 `cron` 服务。
+
+要确定软件包是否已经存在,使用 `rpm` 命令:
+
+```
+$ rpm -q cronie
+ Cronie-1.5.2-4.el8.x86_64
+```
+
+如果安装了 cronie ,它将返回 cronie 包的全名。如果你的系统中没有安装,则会显示未安装。
+
+使用以下命令安装:
+
+```
+$ dnf install cronie
+```
+
+### 运行 cron 守护进程
+
+cron 作业由 crond 服务来执行,它会读取配置文件中的信息。在将作业添加到配置文件之前,必须启动 crond 服务,或者安装它。什么是 crond 呢?crond 是 cron 守护程序的简称。要确定 crond 服务是否正在运行,输入以下命令:
+
+```
+$ systemctl status crond.service
+● crond.service - Command Scheduler
+ Loaded: loaded (/usr/lib/systemd/system/crond.service; enabled; vendor pre>
+ Active: active (running) since Sat 2021-03-20 14:12:35 PDT; 1 day 21h ago
+ Main PID: 1110 (crond)
+```
+
+如果你没有看到类似的内容 `Active: active (running) since…`,你需要启动 crond 守护进程。要在当前会话中运行 crond 服务,输入以下命令:
+
+```
+$ systemctl run crond.service
+```
+
+将其配置为开机自启动,输入以下命令:
+
+```
+$ systemctl enable crond.service
+```
+
+如果出于某种原因,你希望停止 crond 服务,按以下方式使用 `stop` 命令:
+
+```
+$ systemctl stop crond.service
+```
+
+要重新启动它,只需使用 `restart` 命令:
+
+```
+$ systemctl restart crond.service
+```
+
+### 定义一个 cron 作业
+
+#### cron 配置
+
+以下是一个 cron 作业的配置细节示例。它定义了一个简单的 cron 作业,将 `git` master 分支的最新更改拉取到克隆的仓库中:
+
+```
+*/59 * * * * username cd /home/username/project/design && git pull origin master
+```
+
+主要有两部分:
+
+ * 第一部分是 `*/59 * * * *`。这表明计时器设置为第 59 分钟执行一次。(LCTT 译注:原文此处有误。)
+ * 该行的其余部分是命令,因为它将从命令行运行。
+ 在此示例中,命令本身包含三个部分:
+ * 作业将以用户 `username` 的身份运行
+ * 它将切换到目录 `/home/username/project/design`
+ * 运行 `git` 命令拉取 master 分支中的最新更改
+
+#### 时间语法
+
+如上所述,时间信息是 cron 作业字符串的第一部分,如上所属。它决定了 cron 作业运行的频率和时间。它按以下顺序包括 5 个部分:
+
+ * 分钟
+ * 小时
+ * 一个月中的某天
+ * 月份
+ * 一周中的某天
+
+下面是一种更图形化的方式来解释语法:
+
+```
+ .--------------- 分钟 (0 - 59)
+ | .------------- 小时 (0 - 23)
+ | | .---------- 一月中的某天 (1 - 31)
+ | | | .------- 月份 (1 - 12) 或 jan、feb、mar、apr …
+ | | | | .---- 一周中的某天 (0-6) (周日=0 或 7)
+ | | | | | 或 sun、mon、tue、wed、thr、fri、sat
+ | | | | |
+ * * * * * user-name command-to-be-executed
+```
+
+#### 星号的使用
+
+星号(`*`)可以用来替代数字,表示该位置的所有可能值。例如,分钟位置上的星号会使它每分钟运行一次。以下示例可能有助于更好地理解语法。
+
+这个 cron 作业将每分钟运行一次:
+
+```
+* * * * [command]
+```
+
+斜杠表示分钟的间隔数。下面的示例将每小时运行 12 次,即每 5 分钟运行一次:
+
+```
+*/5 * * * * [command]
+```
+
+下一个示例将每月的第二天午夜(例如 1 月 2 日凌晨 12:00,2 月 2 日凌晨 12:00 等等):
+
+```
+0 0 2 * * [command]
+```
+
+(LCTT 译注:关于 cron 时间格式,还有更多格式符号,此处没有展开)
+
+#### 使用 crontab 创建一个 cron 作业
+
+cron 作业会在后台运行,它会不断检查 `/etc/crontab` 文件和 `/etc/cron.*/` 以及 `/var/spool/cron/` 目录。每个用户在 `/var/spool/cron/` 中都有一个唯一的 crontab 文件。
+
+不应该直接编辑这些 cron 文件。`crontab` 命令是用于创建、编辑、安装、卸载和列出 cron 作业的方法。
+
+更酷的是,在创建新文件或编辑现有文件后,你无需重新启动 cron。
+
+```
+$ crontab -e
+```
+
+这将打开你现有的 crontab 文件,或者创建一个。调用 `crontab -e` 时,默认情况下会使用 `vi` 编辑器。注意:要使用 Nano 编辑 crontab 文件,可以设置 `EDITOR=nano` 环境变量。
+
+使用 `-l` 选项列出所有 cron 作业。如果需要,使用 `-u` 选项指定一个用户。
+
+```
+$ crontab -l
+$ crontab -u username -l
+```
+
+使用以下命令删除所有 cron 作业:
+
+```
+$ crontab -r
+```
+
+要删除特定用户的作业,你必须以 root 用户身份运行以下命令:
+
+```
+$ crontab -r -u username
+```
+
+感谢你的阅读。cron 作业看起来可能只是系统管理员的工具,但它实际上与许多 Web 应用程序和用户任务有关。
+
+### 参考
+
+Fedora Linux 文档的 [自动化任务][4]
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/scheduling-tasks-with-cron/
+
+作者:[Darshna Das][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/climoiselle/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/03/schedule_with_cron-816x345.jpg
+[2]: https://unsplash.com/@yomex4life?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[3]: https://unsplash.com/s/photos/clock?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[4]: https://docs.fedoraproject.org/en-US/Fedora/12/html/Deployment_Guide/ch-autotasks.html
\ No newline at end of file
diff --git a/published/202105/20210412 Send your scans to a Linux machine over your network.md b/published/202105/20210412 Send your scans to a Linux machine over your network.md
new file mode 100644
index 0000000000..f4169f4076
--- /dev/null
+++ b/published/202105/20210412 Send your scans to a Linux machine over your network.md
@@ -0,0 +1,193 @@
+[#]: subject: (Send your scans to a Linux machine over your network)
+[#]: via: (https://opensource.com/article/21/4/linux-scan-samba)
+[#]: author: (Marc Skinner https://opensource.com/users/marc-skinner)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13395-1.html)
+
+通过网络将你的扫描结果发送到 Linux 机器上
+======
+
+> 设置一个 Samba 共享,使扫描仪可以容易地被网络上的一台 Linux 计算机访问。
+
+
+
+自由软件运动 [因为一台设计不良的打印机][2] 而开始。几十年后,打印机和扫描仪制造商继续重新发明轮子,无视既定的通用协议。因此,每隔一段时间,你就会偶然发现一台打印机或扫描仪似乎无法与你的操作系统配合使用。
+
+最近,我在一台佳能三合一扫描仪(佳能 Maxify MB2720)上遇到了这种情况。我用开源方案解决这个扫描仪的问题。具体来说,我设置了一个 Samba 共享,使扫描仪在我的网络上可用。
+
+[Samba 项目][3] 是一个用于 Linux/Unix 与 Windows 互操作的套件。尽管它是大多数用户从未与之交互的低级代码,但该软件使得在你的本地网络上共享文件变得很容易,而不管使用的是什么平台。
+
+我使用的是 Fedora,所以这些说明应该适用于任何基于 RPM 的 Linux 发行版。对于其他发行版,可能需要做一些小的修改。下面是我的做法。
+
+### 获取佳能工具
+
+从佳能的网站上下载所需的用于 Windows 的 “佳能快速实用工具箱”。该软件是必需的,因为它是配置打印机目标文件夹位置和凭证的唯一方法。完成后,你就不需要再使用该工具了,除非你想做出改变。
+
+在配置打印机之前,你必须在你的 Linux 电脑或服务器上设置一个 Samba 共享。用以下命令安装 Samba:
+
+```
+$ sudo dnf -y install samba
+```
+
+创建 `/etc/smb.conf` 文件,内容如下:
+
+```
+[global]
+ workgroup = WORKGROUP
+ netbios name = MYSERVER
+ security = user
+ #CORE needed for CANON PRINTER SCAN FOLDER
+ min protocol = CORE
+ #NTML AUTHV1 needed for CANON PRINTER SCAN FOLDER
+ ntlm auth = yes
+ passdb backend = tdbsam
+
+ printing = cups
+ printcap name = cups
+ load printers = no
+ cups options = raw
+
+ hosts allow = 127. 192.168.33.
+ max smbd processes = 1000
+
+[homes]
+ comment = Home Directories
+ valid users = %S, %D%w%S
+ browseable = No
+ writable = yes
+ read only = No
+ inherit acls = Yes
+
+[SCANS]
+ comment = MB2720 SCANS
+ path = /mnt/SCANS
+ public = yes
+ writable = yes
+ browseable = yes
+ printable = no
+ force user = tux
+ create mask = 770
+```
+
+在接近结尾的 `force user` 这行中,将用户名从 `tux` 改为你自己的用户名。
+
+不幸的是,佳能打印机不能与高于 CORE 或 NTML v2 认证的服务器信息块([SMB][4])协议一起工作。由于这个原因,Samba 共享必须配置最古老的 SMB 协议和 NTML 认证版本。这无论如何都不理想,而且有安全问题,所以我创建了一个单独的 Samba 服务器,专门用于扫描仪。我的另一台共享所有家庭网络文件的 Samba 服务器仍然使用 SMB 3 和 NTML v2 认证版本。
+
+启动 Samba 服务端服务,并启用它:
+
+```
+$ sudo systemctl start smb
+$ sudo systemctl enable smb
+```
+
+### 创建一个 Samba 用户
+
+创建你的 Samba 用户并为其设置密码:
+
+```
+$ sudo smbpasswd -a tux
+```
+
+在提示符下输入你的密码。
+
+假设你想在 Linux 系统上挂载你的 Samba 扫描仪,你需要做几个步骤。
+
+创建一个 Samba 客户端凭证文件。我的看起来像这样:
+
+```
+$ sudo cat /root/smb-credentials.txt
+username=tux
+password=mySTRONGpassword
+```
+
+改变权限,使其不能被其他人阅读:
+
+```
+$ sudo chmod 640 /root/smb-credentials.txt
+```
+
+创建一个挂载点并将其添加到 `/etc/fstab` 中:
+
+```
+$ sudo mkdir /mnt/MB2720-SCANS
+```
+
+在你的 `/etc/fstab` 中添加以下这行:
+
+```
+//192.168.33.50/SCANS /mnt/MB2720-SCANS cifs vers=3.0,credentials=/root/smb-credentials.txt,gid=1000,uid=1000,_netdev 0 0
+```
+
+这将使用 [CIFS][5] 将 Samba 共享扫描挂载到新的挂载点,强制采用 SMBv3,并使用存储在 `/root/smb-credetials.txt` 中的用户名和密码。它还传递用户的组标识符(GID)和用户标识符(UID),让你拥有 Linux 挂载的全部所有权。`_netdev` 选项是必需的,以便在网络正常后(例如重启后)挂载该挂载点,因为该挂载点需要网络来访问。
+
+### 配置佳能软件
+
+现在你已经创建了 Samba 共享,在服务器上进行了配置,并将该共享配置到 Linux 客户端上,你需要启动“佳能快速实用工具箱”来配置打印机。因为佳能没有为 Linux 发布工具箱,所以这一步需要 Windows。你可以尝试 [在 WINE 上运行它][6],但如果失败了,你就必须向别人借一台 Windows 电脑,或者在 [GNOME Boxes][8] 或 [VirtualBox][9] 中运行一个 [Windows 开发者虚拟机][7]。
+
+打开打印机,然后启动佳能快速实用工具箱。它应该能找到你的打印机。如果不能看到你的打印机,你必须先将打印机配置为 LAN 或无线网络。
+
+在工具箱中,点击“目标文件夹设置”。
+
+![Canon Quick Utility Toolbox][10]
+
+输入打印机管理密码。我的默认密码是 “canon”。
+
+单击“添加”按钮。
+
+![Add destination folder][12]
+
+在表格中填写“显示名”、“目标位置共享文件夹名称”,以及你的 Samba “域名/用户名”和“密码”。
+
+我把 “PIN 码”留空,但如果你想要求每次从打印机扫描时都要输入 PIN 码,你可以设置一个。这在办公室里很有用,每个用户都有自己的 Samba 共享和 PIN 码来保护他们的扫描。
+
+点击“连接测试”来验证表格数据。
+
+点击 “OK” 按钮。
+
+点击 “注册到打印机”,将你的配置保存到打印机上。
+
+![Register to Printer ][13]
+
+一切都设置好了。点击“退出”。你现在已经完成了 Windows 的操作,可能还有工具箱,除非你需要改变什么。
+
+### 开始扫描
+
+你现在可以从打印机扫描,并从其 LCD 菜单中选择你的“目标文件夹”。扫描结果将直接保存到 Samba 共享中,你可以从你的 Linux 电脑上访问该共享。
+
+为方便起见,用以下命令在你的 Linux 桌面或家目录上创建一个符号链接:
+
+```
+$ sudo ln -sd /mnt/MB2720-SCANS /home/tux/Desktop/MB2720-SCANS
+```
+
+这就是全部内容了!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/linux-scan-samba
+
+作者:[Marc Skinner][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/marc-skinner
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_paper_folder.png?itok=eIJWac15 (Files in a folder)
+[2]: https://opensource.com/article/18/2/pivotal-moments-history-open-source
+[3]: http://samba.org/
+[4]: https://en.wikipedia.org/wiki/Server_Message_Block
+[5]: https://searchstorage.techtarget.com/definition/Common-Internet-File-System-CIFS
+[6]: https://opensource.com/article/21/2/linux-wine
+[7]: https://developer.microsoft.com/en-us/windows/downloads/virtual-machines/
+[8]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
+[9]: https://www.virtualbox.org/
+[10]: https://opensource.com/sites/default/files/uploads/canontoolbox.png (Canon Quick Utility Toolbox)
+[11]: https://creativecommons.org/licenses/by-sa/4.0/
+[12]: https://opensource.com/sites/default/files/add_destination_folder.png (Add destination folder)
+[13]: https://opensource.com/sites/default/files/uploads/canonregistertoprinter.png (Register to Printer )
diff --git a/published/202105/20210414 4 tips for context switching in Git.md b/published/202105/20210414 4 tips for context switching in Git.md
new file mode 100644
index 0000000000..a557074975
--- /dev/null
+++ b/published/202105/20210414 4 tips for context switching in Git.md
@@ -0,0 +1,178 @@
+[#]: subject: (4 tips for context switching in Git)
+[#]: via: (https://opensource.com/article/21/4/context-switching-git)
+[#]: author: (Olaf Alders https://opensource.com/users/oalders)
+[#]: collector: (lujun9972)
+[#]: translator: (Chao-zhi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13422-1.html)
+
+Git 中上下文切换的 4 种方式
+======
+
+> 比较 Git 中四种切换分支的方法的优缺点。
+
+
+
+所有大量使用 Git 的人都会用到某种形式的上下文切换。有时这只会给你的工作流程增加少量的开销,但有时,这可能是一段痛苦的经历。
+
+让我们用以下这个例子来讨论一些常见的上下文切换策略的优缺点:
+
+> 假设你在一个名为 `feature-X` 的分支中工作。你刚刚发现你需要解决一个无关的问题。这不能在 `feature-X` 分支中完成。你需要在一个新的分支 `feature-Y` 中完成这项工作。
+
+### 方案 1:暂存 + 分支
+
+解决此问题最常见的工作流程可能如下所示:
+
+ 1. 停止分支 `feature-X` 上的工作
+ 2. `git stash`
+ 3. `git checkout -b feature-Y origin/main`
+ 4. 一顿鼓捣,解决 `feature-Y` 的问题
+ 5. `git checkout feature-X` 或 `git switch -`
+ 6. `git stash pop`
+ 7. 继续在 `feature-X` 中工作
+
+**优点:** 这种方法的优点在于,对于简单的更改,这是一个相当简单的工作流程。它可以很好地工作,特别是对于小型仓库。
+
+**缺点:** 使用此工作流程时,一次只能有一个工作区。另外,根据你的仓库的状态,使用暂存是一个麻烦的环节。
+
+### 方案 2:WIP 提交 + 分支
+
+这个解决方案和前一个非常相似,但是它使用 WIP(正在进行的工作)提交而不是暂存。当你准备好切换回来,而不是弹出暂存时,`git reset HEAD~1` 会展开 WIP 提交,你可以自由地继续,就像之前的方案一样,但不会触及暂存。
+
+ 1. 停止分支 `feature-X` 上的工作
+ 2. `git add -u`(仅仅添加修改和删除的文件)
+ 3. `git commit -m "WIP"`
+ 4. `git checkout -b feature-Y origin/master`
+ 5. 一顿鼓捣,解决 `feature-Y` 的问题
+ 6. `git checkout feature-X` 或 `git switch -`
+ 7. `git reset HEAD~1`
+
+**优点:** 对于简单的更改,这是一个简单的工作流,也适合于小型仓库。你不需要使用暂存。
+
+**缺点:** 任何时候都只能有一个工作区。此外,如果你或你的代码审阅者不够谨慎,WIP 提交可能会合并到最终产品。
+
+使用此工作流时,你**永远**不要想着将 `--hard` 添加到 `git reset`。如果你不小心这样做了,你应该能够使用 `git reflog` 恢复提交,但是你最好完全避免这种情况发生,否则你会听到心碎的声音。
+
+### 方案 3:克隆一个新仓库
+
+在这个解决方案中,不是创建新的分支,而是为每个新的功能分支创建存储库的新克隆。
+
+**优点:** 你可以同时在多个工作区中工作。你不需要 `git stash` 或者是 WIP 提交。
+
+**缺点:** 需要考虑仓库的大小,因为这可能会占用大量磁盘空间(浅层克隆可以帮助解决这种情况,但它们可能并不总是很合适。)此外,你的仓库克隆将互不可知。因为他们不能互相追踪,所以你必须手动追踪你的克隆的源仓库。如果需要 git 钩子,则需要为每个新克隆设置它们。
+
+### 方案 4:git 工作树
+
+要使用此解决方案,你可能需要了解 `git add worktree`。如果你不熟悉 Git 中的工作树,请不要难过。许多人多年来都对这个概念一无所知。
+
+#### 什么是工作树?
+
+将工作树视为仓库中属于项目的文件。本质上,这是一种工作区。你可能没有意识到你已经在使用工作树了。开始使用 Git 时,你将自动获得第一个工作树。
+
+```
+$ mkdir /tmp/foo && cd /tmp/foo
+$ git init
+$ git worktree list
+/tmp 0000000 [master]
+```
+
+你可以在以上代码看到,甚至在第一次提交前你就有了一个工作树。接下来去尝试再添加一个工作树到你的项目中吧。
+
+#### 添加一个工作树
+
+想要添加一个新的工作树你需要提供:
+
+ 1. 硬盘上的一个位置
+ 2. 一个分支名
+ 3. 添加哪些分支
+
+```
+$ git clone https://github.com/oalders/http-browserdetect.git
+$ cd http-browserdetect/
+$ git worktree list
+/Users/olaf/http-browserdetect 90772ae [master]
+
+$ git worktree add ~/trees/oalders/feature-X -b oalders/feature-X origin/master
+$ git worktree add ~/trees/oalders/feature-Y -b oalders/feature-Y e9df3c555e96b3f1
+
+$ git worktree list
+/Users/olaf/http-browserdetect 90772ae [master]
+/Users/olaf/trees/oalders/feature-X 90772ae [oalders/feature-X]
+/Users/olaf/trees/oalders/feature-Y e9df3c5 [oalders/feature-Y]
+```
+
+与大多数其他 Git 命令一样,你需要在仓库路径下使用此命令。一旦创建了工作树,就有了隔离的工作环境。Git 仓库会跟踪工作树在磁盘上的位置。如果 Git 钩子已经在父仓库中设置好了,那么它们也可以在工作树中使用。
+
+请注意到,每个工作树只使用父仓库磁盘空间的一小部分。在这种情况下,工作树需要只大约三分之一的原始磁盘空间。这这非常适合进行扩展。如果你的仓库达到了千兆字节的级别,你就会真正体会到工作树对硬盘空间的节省。
+
+```
+$ du -sh /Users/olaf/http-browserdetect
+2.9M
+
+$ du -sh /Users/olaf/trees/oalders/feature-X
+1.0M
+```
+
+**优点:** 你可以同时在多个工作区中工作。你不需要使用暂存。Git 会跟踪所有的工作树。你不需要设置 Git 钩子。这也比 `git clone` 更快,并且可以节省网络流量,因为你可以在飞行模式下执行此操作。你还可以更高效地使用磁盘空间,而无需借助于浅层克隆。
+
+**缺点:** 这是个需要你额外学习和记忆的新东西,但是如果你能养成使用这个功能的习惯,它会给你丰厚的回报。
+
+#### 额外的小技巧
+
+有很多方式可以清除工作树,最受欢迎的方式是使用 Git 来移除工作树:
+
+```
+git worktree remove /Users/olaf/trees/oalders/feature-X
+```
+
+如果你喜欢 RM 大法,你也可以用 `rm -rf` 来删除工作树。
+
+```
+rm -rf /Users/olaf/trees/oalders/feature-X
+```
+
+但是,如果执行此操作,则可能需要使用 `git worktree prune` 清理所有剩余的文件。或者你现在可以跳过清理,这将在将来的某个时候通过 `git gc` 自行完成。
+
+#### 注意事项
+
+如果你准备尝试 `git worktree`,请记住以下几点:
+
+* 删除工作树并不会删除该分支。
+* 可以在工作树中切换分支。
+* 你不能在多个工作树中同时签出同一个分支。
+* 像其他命令一样,`git worktree` 需要从仓库内运行。
+* 你可以同时拥有许多工作树。
+* 要从同一个本地仓库签出创建工作树,否则它们将互不可知。
+
+#### git rev-parse
+
+最后一点注意:在使用 `git worktree` 时,仓库根所在的位置可能取决于上下文。幸运的是,`git rev parse` 可以让你区分这两者。
+
+* 要查找父仓库的根目录,请执行以下操作:
+ ```
+ git rev-parse --git-common-dir
+ ```
+* 要查找你当前所在仓库的根目录,请执行:
+ ```
+ git rev-parse --show-toplevel
+ ```
+
+### 根据你的需要选择最好的方法
+
+就像很多事情一样,TIMTOWDI(条条大道通罗马)。重要的是你要找到一个适合你需要的工作流程。你的需求可能因手头的问题而异。也许你偶尔会发现自己将 `git worktree` 作为版本控制工具箱中的一个方便工具。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/context-switching-git
+
+作者:[Olaf Alders][a]
+选题:[lujun9972][b]
+译者:[Chao-zhi](https://github.com/Chao-zhi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/oalders
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_screen_windows_files.png?itok=kLTeQUbY (Computer screen with files or windows open)
diff --git a/published/202105/20210416 Metro Exodus is Finally Here on Steam for Linux.md b/published/202105/20210416 Metro Exodus is Finally Here on Steam for Linux.md
new file mode 100644
index 0000000000..6a70a602d6
--- /dev/null
+++ b/published/202105/20210416 Metro Exodus is Finally Here on Steam for Linux.md
@@ -0,0 +1,61 @@
+[#]: subject: (Metro Exodus is Finally Here on Steam for Linux)
+[#]: via: (https://news.itsfoss.com/metro-exodus-steam/)
+[#]: author: (Asesh Basu https://news.itsfoss.com/author/asesh/)
+[#]: collector: (lujun9972)
+[#]: translator: (alim0x)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13370-1.html)
+
+《地铁:离去》终于来到了 Steam for Linux
+======
+
+> 在其他平台上推出后,《地铁:离去》正式登陆 Linux/GNU 平台。准备好体验最好的射击游戏之一了吗?
+
+
+
+《地铁:离去》是一款长久以来深受粉丝喜爱的游戏,现在终于来到了 Linux 平台。在超过两年的漫长等待之后,Linux 用户终于可以上手《地铁》三部曲的第三部作品。虽然先前已经有一些非官方移植的版本,但这个版本是 4A Games 发布的官方版本。
+
+《地铁:离去》是一款第一人称射击游戏,拥有华丽的光线跟踪画面,故事背景设置在横跨俄罗斯广阔土地的荒野之上。这条精彩的故事线横跨了从春、夏、秋到核冬天的整整一年。游戏结合了快节奏的战斗和隐身以及探索和生存,可以轻而易举地成为 Linux 中最具沉浸感的游戏之一。
+
+### 我的 PC 可以运行它吗?
+
+作为一款图形计算密集型游戏,你得有像样的硬件来运行以获得不错的帧率。这款游戏重度依赖光线追踪来让画面看起来更棒。
+
+运行游戏的最低要求需要 **Intel Core i5 4400**、**8 GB** 内存,以及最低 **NVIDIA GTX670** 或 **AMD Radeon R9 380** 的显卡。推荐配置是 **Intel Core i7 4770K** 搭配 **GTX1070** 或 **RX 5500XT**。
+
+这是开发者提及的官方配置清单:
+
+![][1]
+
+《地铁:离去》是付费游戏,你需要花费 39.99 美元来获取这个最新最棒的版本。
+
+如果你在游玩的时候遇到持续崩溃的情况,检查一下你的显卡驱动以及 Linux 内核版本。有人反馈了一些相关的问题,但不是普遍性的问题。
+
+### 从哪获取游戏?
+
+Linux 版本的游戏可以从 [Steam][2] for Linux 获取。如果你已经购买了游戏,它会自动出现在你的 Steam for Linux 游戏库内。
+
+- [Metro Exodus (Steam)][2]
+
+如果你还没有安装 Steam,你可以参考我们的教程:[在 Ubuntu 上安装 Steam][3] 和 [在 Fedora 上安装 Steam][4]。
+
+你的 Steam 游戏库中已经有《地铁:离去》了吗?准备购买一份吗?可以在评论区写下你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://news.itsfoss.com/metro-exodus-steam/
+
+作者:[Asesh Basu][a]
+选题:[lujun9972][b]
+译者:[alim0x](https://github.com/alim0x)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://news.itsfoss.com/author/asesh/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/METRO-EXODUS-LINUX-System-Requirements.jpg?w=1454&ssl=1
+[2]: https://store.steampowered.com/app/412020/Metro_Exodus/
+[3]: https://itsfoss.com/install-steam-ubuntu-linux/
+[4]: https://itsfoss.com/install-steam-fedora/
diff --git a/published/202105/20210416 Play a fun math game with Linux commands.md b/published/202105/20210416 Play a fun math game with Linux commands.md
new file mode 100644
index 0000000000..64cdaf210d
--- /dev/null
+++ b/published/202105/20210416 Play a fun math game with Linux commands.md
@@ -0,0 +1,199 @@
+[#]: subject: (Play a fun math game with Linux commands)
+[#]: via: (https://opensource.com/article/21/4/math-game-linux-commands)
+[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13358-1.html)
+
+用 Linux 命令玩一个有趣的数学游戏
+======
+
+> 在家玩流行的英国游戏节目 “Countdown” 中的数字游戏。
+
+
+
+像许多人一样,我在大流行期间看了不少新的电视节目。我最近发现了一个英国的游戏节目,叫做 [Countdown][2],参赛者在其中玩两种游戏:一种是 _单词_ 游戏,他们试图从杂乱的字母中找出最长的单词;另一种是 _数字_ 游戏,他们从随机选择的数字中计算出一个目标数字。因为我喜欢数学,我发现自己被数字游戏所吸引。
+
+数字游戏可以为你的下一个家庭游戏之夜增添乐趣,所以我想分享我自己的一个游戏变体。你以一组随机数字开始,分为 1 到 10 的“小”数字和 15、20、25,以此类推,直到 100 的“大”数字。你从大数字和小数字中挑选六个数字的任何组合。
+
+接下来,你生成一个 200 到 999 之间的随机“目标”数字。然后用你的六个数字进行简单的算术运算,尝试用每个“小”和“大”数字计算出目标数字,但使用不能超过一次。如果你能准确地计算出目标数字,你就能得到最高分,如果距离目标数字 10 以内就得到较低的分数。
+
+例如,如果你的随机数是 75、100、2、3、4 和 1,而你的目标数是 505,你可以说 `2+3=5`,`5×100=500`,`4+1=5`,以及 `5+500=505`。或者更直接地:`(2+3)×100 + 4 + 1 = 505`。
+
+### 在命令行中随机化列表
+
+我发现在家里玩这个游戏的最好方法是从 1 到 10 的池子里抽出四个“小”数字,从 15 到 100 的 5 的倍数中抽出两个“大”数字。你可以使用 Linux 命令行来为你创建这些随机数。
+
+让我们从“小”数字开始。我希望这些数字在 1 到 10 的范围内。你可以使用 Linux 的 `seq` 命令生成一个数字序列。你可以用几种不同的方式运行 `seq`,但最简单的形式是提供序列的起始和结束数字。要生成一个从 1 到 10 的列表,你可以运行这个命令:
+
+```
+$ seq 1 10
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+```
+
+为了随机化这个列表,你可以使用 Linux 的 `shuf`(“shuffle”,打乱)命令。`shuf` 将随机化你给它的东西的顺序,通常是一个文件。例如,如果你把 `seq` 命令的输出发送到 `shuf` 命令,你会收到一个 1 到 10 之间的随机数字列表:
+
+```
+$ seq 1 10 | shuf
+3
+6
+8
+10
+7
+4
+5
+2
+1
+9
+```
+
+要从 1 到 10 的列表中只选择四个随机数,你可以将输出发送到 `head` 命令,它将打印出输入的前几行。使用 `-4` 选项来指定 `head` 只打印前四行:
+
+```
+$ seq 1 10 | shuf | head -4
+6
+1
+8
+4
+```
+
+注意,这个列表与前面的例子不同,因为 `shuf` 每次都会生成一个随机顺序。
+
+现在你可以采取下一步措施来生成“大”数字的随机列表。第一步是生成一个可能的数字列表,从 15 开始,以 5 为单位递增,直到达到 100。你可以用 Linux 的 `seq` 命令生成这个列表。为了使每个数字以 5 为单位递增,在 `seq` 命令中插入另一个选项来表示 _步进_:
+
+```
+$ seq 15 5 100
+15
+20
+25
+30
+35
+40
+45
+50
+55
+60
+65
+70
+75
+80
+85
+90
+95
+100
+```
+
+就像以前一样,你可以随机化这个列表,选择两个“大”数字:
+
+```
+$ seq 15 5 100 | shuf | head -2
+75
+40
+```
+
+### 用 Bash 生成一个随机数
+
+我想你可以用类似的方法从 200 到 999 的范围内选择游戏的目标数字。但是生成单个随机数的最简单的方案是直接在 Bash 中使用 `RANDOM` 变量。当你引用这个内置变量时,Bash 会生成一个大的随机数。要把它放到 200 到 999 的范围内,你需要先把随机数放到 0 到 799 的范围内,然后加上 200。
+
+要把随机数放到从 0 开始的特定范围内,你可以使用**模数**算术运算符。模数计算的是两个数字相除后的 _余数_。如果我用 801 除以 800,结果是 1,余数是 1(模数是 1)。800 除以 800 的结果是 1,余数是 0(模数是 0)。而用 799 除以 800 的结果是 0,余数是 799(模数是 799)。
+
+Bash 通过 `$(())` 结构支持算术展开。在双括号之间,Bash 将对你提供的数值进行算术运算。要计算 801 除以 800 的模数,然后加上 200,你可以输入:
+
+```
+$ echo $(( 801 % 800 + 200 ))
+201
+```
+
+通过这个操作,你可以计算出一个 200 到 999 之间的随机目标数:
+
+```
+$ echo $(( RANDOM % 800 + 200 ))
+673
+```
+
+你可能想知道为什么我在 Bash 语句中使用 `RANDOM` 而不是 `$RANDOM`。在算术扩展中, Bash 会自动扩展双括号内的任何变量. 你不需要在 `$RANDOM` 变量上的 `$` 来引用该变量的值, 因为 Bash 会帮你做这件事。
+
+### 玩数字游戏
+
+让我们把所有这些放在一起,玩玩数字游戏。产生两个随机的“大”数字, 四个随机的“小”数值,以及目标值:
+
+```
+$ seq 15 5 100 | shuf | head -2
+75
+100
+$ seq 1 10 | shuf | head -4
+4
+3
+10
+2
+$ echo $(( RANDOM % 800 + 200 ))
+868
+```
+
+我的数字是 **75**、**100**、**4**、**3**、**10** 和 **2**,而我的目标数字是 **868**。
+
+如果我用每个“小”和“大”数字做这些算术运算,并不超过一次,我就能接近目标数字了:
+
+```
+10×75 = 750
+750+100 = 850
+
+然后:
+
+4×3 = 12
+850+12 = 862
+862+2 = 864
+```
+
+只相差 4 了,不错!但我发现这样可以用每个随机数不超过一次来计算出准确的数字:
+
+```
+4×2 = 8
+8×100 = 800
+
+然后:
+
+75-10+3 = 68
+800+68 = 868
+```
+
+或者我可以做 _这些_ 计算来准确地得到目标数字。这只用了六个随机数中的五个:
+
+```
+4×3 = 12
+75+12 = 87
+
+然后:
+
+87×10 = 870
+870-2 = 868
+```
+
+试一试 _Countdown_ 数字游戏,并在评论中告诉我们你做得如何。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/math-game-linux-commands
+
+作者:[Jim Hall][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jim-hall
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/edu_math_formulas.png?itok=B59mYTG3 (Math formulas in green writing)
+[2]: https://en.wikipedia.org/wiki/Countdown_%28game_show%29
diff --git a/published/202105/20210417 How to Download Ubuntu via Torrent -Absolute Beginner-s Tip.md b/published/202105/20210417 How to Download Ubuntu via Torrent -Absolute Beginner-s Tip.md
new file mode 100644
index 0000000000..d4228a0c9d
--- /dev/null
+++ b/published/202105/20210417 How to Download Ubuntu via Torrent -Absolute Beginner-s Tip.md
@@ -0,0 +1,81 @@
+[#]: subject: (How to Download Ubuntu via Torrent [Absolute Beginner’s Tip])
+[#]: via: (https://itsfoss.com/download-ubuntu-via-torrent/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13386-1.html)
+
+初级:如何通过 Torrent 下载 Ubuntu
+======
+
+
+
+下载 Ubuntu 是非常直接简单的。你可以去它的 [官方网站][1],点击 [桌面下载部分][2],选择合适的 Ubuntu 版本并点击下载按钮。
+
+![][3]
+
+Ubuntu 是以一个超过 2.5GB 大小的单一镜像形式提供的。直接下载对于拥有高速网络连接的人来说效果很好。
+
+然而,如果你的网络连接很慢或不稳定,你将很难下载这样一个大文件。在这个过程中,下载可能会中断几次,或者可能需要几个小时。
+
+![Direct download may take several hours for slow internet connections][4]
+
+### 通过 Torrent 下载 Ubuntu
+
+如果你也困扰于受限数据或网络连接过慢,使用下载管理器或 torrent 将是一个更好的选择。我不打算在这个快速教程中讨论什么是 torrent。你只需要知道,通过 torrent,你可以在多个会话内下载一个大文件。
+
+好的是,Ubuntu 实际上提供了通过 torrent 的下载。不好的是,它隐藏在网站上,如果你不熟悉它,很难猜到在哪。
+
+如果你想通过 torrent 下载 Ubuntu,请到你所选择的 Ubuntu 版本中寻找**其他下载方式**。
+
+![][5]
+
+点击这个“**alternative downloads and torrents**” 链接,它将打开一个新的网页。**在这个页面向下滚动**,看到 BitTorrent 部分。你会看到下载所有可用版本的 torrent 文件的选项。如果你要在你的个人电脑或笔记本电脑上使用 Ubuntu,你应该选择桌面版本。
+
+![][6]
+
+阅读 [这篇文章以获得一些关于你应该使用哪个 Ubuntu 版本的指导][7]。考虑到你要使用这个发行版,了解 [Ubuntu LTS 和非 LTS 版本会有所帮助][8]。
+
+#### 你是如何使用下载的 torrent 文件来获取 Ubuntu 的?
+
+我推测你知道如何使用 torrent。如果没有,让我为你快速总结一下。
+
+你已经下载了一个几 KB 大小的 .torrent 文件。你需要下载并安装一个 Torrent 应用,比如 uTorrent 或 Deluge 或 BitTorrent。
+
+我建议在 Windows 上使用 [uTorrent][9]。如果你使用的是某个 Linux 发行版,你应该已经有一个 [像 Transmission 这样的 torrent 客户端][10]。如果没有,你可以从你的发行版的软件管理器中安装它。
+
+当你安装了 Torrent 应用,运行它。现在拖放你从 Ubuntu 网站下载的 .torrent 文件。你也可以使用菜单中的打开选项。
+
+当 torrent 文件被添加到 Torrent 应用中,它就开始下载该文件。如果你关闭了系统,下载就会暂停。再次启动 Torrent 应用,下载就会从同一个地方恢复。
+
+当下载 100% 完成后,你可以用它来 [全新安装 Ubuntu][11] 或 [与 Windows 双启动][12]。
+
+享受 Ubuntu :)
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/download-ubuntu-via-torrent/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://ubuntu.com
+[2]: https://ubuntu.com/download/desktop
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/download-ubuntu.png?resize=800%2C325&ssl=1
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/slow-direct-download-ubuntu.png?resize=800%2C365&ssl=1
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/ubuntu-torrent-download.png?resize=800%2C505&ssl=1
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/ubuntu-torrent-download-option.png?resize=800%2C338&ssl=1
+[7]: https://itsfoss.com/which-ubuntu-install/
+[8]: https://itsfoss.com/long-term-support-lts/
+[9]: https://www.utorrent.com/
+[10]: https://itsfoss.com/best-torrent-ubuntu/
+[11]: https://itsfoss.com/install-ubuntu/
+[12]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
diff --git a/published/202105/20210419 21 reasons why I think everyone should try Linux.md b/published/202105/20210419 21 reasons why I think everyone should try Linux.md
new file mode 100644
index 0000000000..d21535f086
--- /dev/null
+++ b/published/202105/20210419 21 reasons why I think everyone should try Linux.md
@@ -0,0 +1,167 @@
+[#]: subject: (21 reasons why I think everyone should try Linux)
+[#]: via: (https://opensource.com/article/21/4/linux-reasons)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (ShuyRoy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13404-1.html)
+
+每个人都应该尝试 Linux 的 21 个理由
+======
+
+> 游戏、交易、预算、艺术、编程等等,这些都只是任何人都可以使用 Linux 的众多方式中的一种。
+
+
+
+当我在度假时,我经常会去一家或者多家的二手书店。我经常能够找到我想读的一本好书,而且我总是以 “我在度假;我应该用这本书来犒劳自己” 来为不可避免的购买行为辩护。这很有效,我用这种方式获得了一些我最喜欢的书。但是,买一本好书在生活中很常见,这个理由经不起推敲。事实上,我不需要为买一本好书来找理由。事情都是这样的,我可以在任何时候做我想做的事。但不知何故,有一个理由似乎确实能让这个过程更有趣。
+
+在我的日常生活中,我会收到很多关于 Linux 的问题。有时候我会不自觉地滔滔不绝地讲述开源软件的历史,或者共享资源的知识和利益。有时候,我会设法提到一些我喜欢的 Linux 上的特性,然后对这些好处进行逆向工程以便它们可以在其它的操作系统上享用。这些讨论经常是有趣且有益的,但只有一个问题:这些讨论都没有回答大家真正要问的问题。
+
+当一个人问你关于 Linux 的问题时,他们经常希望你能够给他们一些使用 Linux 的理由。当然,也有例外。从来没有听过“Linux”的人们可能会问一些字面定义。但是当你的朋友或者同事吐露出他们对当前的操作系统有些不满意的时候,解释一下你为什么喜欢 Linux 可能更好,而不是告诉他们为什么 Linux 是一个比专有系统更好的选择。换句话说,你不需要销售演示,你需要的是度假照片(如果你是个书虫的话,也可以是度假时买的一本书)。
+
+为了达到这个目的,下面是我喜欢 Linux 的 21 个原因,分别在 21 个不同的场合讲给 21 个不同的人。
+
+### 游戏
+
+![Gaming on Linux][2]
+
+说到玩电脑,最明显的活动之一就是玩游戏,说到玩游戏,我很喜欢。我很高兴花一个晚上玩一个 8 位的益智游戏或者 epic 工作室的一个 AAA 级游戏。其它时候,我还会沉浸在棋盘游戏或者角色扮演游戏(RPG)中。
+
+这些我都是 [在 Linux 系统的电脑上做的][4]。
+
+### 办公
+
+![LibreOffice][5]
+
+一种方法并不适合所有人。这对帽子和办公室工作来说都是如此。看到同事们被困在一个不适合他们的单一工作流程中,我感到很痛苦,我喜欢 Linux 鼓励用户找到他们喜欢的工具。我曾使用过的应用大到套件(例如 LibreOffice 和 OpenOffice),小到轻量级文字处理器(如 Abiword),再到最小的文本编辑器(利用 Pandoc 进行转换)。
+
+不管我周围的用户被限制在什么范围内,我都可以 [自由地使用可以在我的电脑上工作的最好的工具][6],并且以我希望的方式工作。
+
+### 选择
+
+![Linux login screen][7]
+
+开源最有价值的特性之一是用户在使用这些软件的时候是可以信任它的。这种信任来自于好友网络,他们可以阅读他们所使用的应用程序和操作系统的源代码。也就是说,即使你不知道源代码的好坏,你也可以在 [开源社区][8] 中结交一些知道的朋友。这些都是 Linux 用户在探索他们运行的发行版时建立的重要联系。如果你不信任构建和维护的发行版的社区,你可以去找其它的发行版。我们都是这样做的,这是有许多发行版可供选择的优势之一。
+
+[Linux 提供了可选择的特性][9]。一个强大的社区,充满了真实的人际关系,结合 Linux 提供的选择自由,所有这些都让用户对他们运行的软件有信心。因为我读过一些源码,也因为我信任哪些维护我没读过的代码的人,[所以我信任 Linux][10]。
+
+### 预算
+
+![Skrooge][11]
+
+做预算并不有趣,但是很重要。我很早就认识到,在业余时间做一些不起眼的工作,就像我学会了一种 _免费_ 的操作系统(Linux!)一样。预算不是为了追踪你的钱,而是为了追踪你的习惯。这意味着无论你是靠薪水生活,还是正在计划退休,你都应该 [保持预算][12]。
+
+如果你在美国,你甚至可以 [用 Linux 来交税][13]。
+
+### 艺术
+
+![MyPaint][14]
+
+不管你是画画还是做像素艺术、[编辑视频][15] 还是随性记录,你都可以在 Linux 上创建出色的内容。我所见过的一些最优秀的艺术作品都是使用一些非“行业标准”的工具随意创作出来的,并且你可能会惊讶于你所看到的许多内容都是基于同样的方式创造出来的。Linux 是一个不会被宣扬的引擎,但它是具有强大功能的引擎,驱动着独立艺术家和大型制作人。
+
+尝试使用 Linux 来 [创作一些艺术作品][16]。
+
+### 编程
+
+![NetBeans][17]
+
+听着,用 Linux 来编程几乎是定论。仅次于服务器管理,开源和 Linux 是一个明显的组合。这其中有 [许多原因][18],但我这里给出了一个有趣的原因。我在发明新东西时遇到了很多障碍,所以我最不希望的就是操作系统或者软件工具开发包(SDK)成为失败的原因。在 Linux 上,我可以访问一切,字面意义上的一切。
+
+### 封包
+
+![Packaging GNOME software][19]
+
+当他们在谈编程的时候,没有人谈封包。作为一个开发者,你必须将你的代码提供给您的用户,否则你将没有任何用户。Linux 使得开发人员可以轻松地 [发布应用程序][20],用户也可以轻松地 [安装这些应用程序][21]。
+
+令很多人感到惊讶的是 [Linux 可以像运行本地程序一样运行许多 Windows 应用程序][22]。你不应该期望一个 Windows 应用可以在 Linux 上执行。不过,许多主要的通用应用要么已经在 Linux 上原生存在,要么可以通过名为 Wine 的兼容层运行。
+
+
+### 技术
+
+![Data center][23]
+
+如果你正在找一份 IT 工作,Linux 是很好的第一步。作为一个曾经为了更快地渲染视频而误入 Linux 的前艺术系学生,我说的是经验之谈。
+
+尖端技术发生在 Linux 上。Linux 驱动着大部分的互联网、世界上最快的超级计算机以及云本身。现在,Linux 驱动着 [边缘计算][26],将云数据中心的能力与分散的节点相结合,以实现快速响应。
+
+不过,你不需要从最顶层开始。你可以学习在笔记本电脑或者台式机上[自动][27]完成任务,并通过一个 [好的终端][28] 远程控制系统。
+
+Linux 对你的新想法是开放的,并且 [可以进行定制][29]。
+
+### 分享文件
+
+![Beach with cloudy sky][30]
+
+无论你是一个新手系统管理员,还是仅仅是要将一个将文件分发给室友,Linux 都可以使 [文件共享变得轻而易举][31]。
+
+### 多媒体
+
+![Waterfall][32]
+
+在所有关于编程和服务器的讨论中,人们有时把 Linux 想象成一个充满绿色的 1 和 0 的黑屏。对于我们这些使用它的人来说,Linux 也能 [播放你所有的媒体][33],这并不令人惊讶。
+
+### 易于安装
+
+![CentOS installation][34]
+
+以前从来没有安装过操作系统吗?Linux 非常简单。一步一步来,Linux 安装程序会手把手带你完成操作系统的安装,让你在一个小时内感觉到自己是个电脑专家。
+
+[来安装 Linux 吧][35]!
+
+### 试一试 Linux
+
+![Porteus][36]
+
+如果你还没有准备好安装 Linux,你可以 _试一试_ Linux。不知道如何开始?它没有你想象的那么吓人。这里给了一些你 [一开始需要考虑的事情][37]。然后选择下载一个发行版,并想出你自己使用 Linux 的 21 个理由。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/linux-reasons
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[ShuyRoy](https://github.com/ShuyRoy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
+[2]: https://opensource.com/sites/default/files/uploads/game_0ad-egyptianpyramids.jpg (Gaming on Linux)
+[3]: https://creativecommons.org/licenses/by-sa/4.0/
+[4]: https://opensource.com/article/21/2/linux-gaming
+[5]: https://opensource.com/sites/default/files/uploads/office_libreoffice.jpg (LibreOffice)
+[6]: https://linux.cn/article-13133-1.html
+[7]: https://opensource.com/sites/default/files/uploads/trust_sddm.jpg (Linux login screen)
+[8]: https://opensource.com/article/21/2/linux-community
+[9]: https://linux.cn/article-13284-1.html
+[10]: https://opensource.com/article/21/2/open-source-security
+[11]: https://opensource.com/sites/default/files/uploads/skrooge_1.jpg (Skrooge)
+[12]: https://opensource.com/article/21/2/linux-skrooge
+[13]: https://opensource.com/article/21/2/linux-tax-software
+[14]: https://opensource.com/sites/default/files/uploads/art_mypaint.jpg (MyPaint)
+[15]: https://opensource.com/article/21/2/linux-python-video
+[16]: https://linux.cn/article-13157-1.html
+[17]: https://opensource.com/sites/default/files/uploads/programming_java-netbeans.jpg (NetBeans)
+[18]: https://opensource.com/article/21/2/linux-programming
+[19]: https://opensource.com/sites/default/files/uploads/packaging_gnome-software.png (Packaging GNOME software)
+[20]: https://opensource.com/article/21/2/linux-packaging
+[21]: https://linux.cn/article-13160-1.html
+[22]: https://opensource.com/article/21/2/linux-wine
+[23]: https://opensource.com/sites/default/files/uploads/edge_taylorvick-unsplash.jpg (Data center)
+[24]: https://unsplash.com/@tvick
+[25]: https://unsplash.com/license
+[26]: https://opensource.com/article/21/2/linux-edge-computing
+[27]: https://opensource.com/article/21/2/linux-automation
+[28]: https://linux.cn/article-13186-1.html
+[29]: https://opensource.com/article/21/2/linux-technology
+[30]: https://opensource.com/sites/default/files/uploads/cloud_beach-sethkenlon.jpg (Beach with cloudy sky)
+[31]: https://linux.cn/article-13192-1.html
+[32]: https://opensource.com/sites/default/files/uploads/media_waterfall.jpg (Waterfall)
+[33]: https://opensource.com/article/21/2/linux-media-players
+[34]: https://opensource.com/sites/default/files/uploads/install_centos8.jpg (CentOS installation)
+[35]: https://linux.cn/article-13164-1.html
+[36]: https://opensource.com/sites/default/files/uploads/porteus_0.jpg (Porteus)
+[37]: https://opensource.com/article/21/2/try-linux
diff --git a/published/202105/20210420 5 ways to protect your documents with open source software.md b/published/202105/20210420 5 ways to protect your documents with open source software.md
new file mode 100644
index 0000000000..ec773ff7b5
--- /dev/null
+++ b/published/202105/20210420 5 ways to protect your documents with open source software.md
@@ -0,0 +1,145 @@
+[#]: subject: (5 ways to protect your documents with open source software)
+[#]: via: (https://opensource.com/article/21/4/secure-documents-open-source)
+[#]: author: (Ksenia Fedoruk https://opensource.com/users/ksenia-fedoruk)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13428-1.html)
+
+用开源软件保护你的文件的 5 种方法
+======
+
+> 控制你自己的数据,使未经授权的用户无法访问它。
+
+
+
+用户完全有权利关心他们数据的安全和保障。当你在计算机上创建数据时,希望对其进行独家控制是合理的。
+
+有许多方法保护你的文件。在文件系统层面,你可以 [加密你的硬盘][2] 或 [只是加密一个文件][3]。不过,一个好的办公套件为你提供了更多的选择,我收集了五种我用开源软件保护文件的方法。
+
+### 5 种保护你的文件的方法
+
+#### 1、将文件保存在安全的云存储服务中
+
+自托管一个开源的内容管理系统(CMS)平台可以让你完全控制你的数据。你的所有数据都留在你的服务器上,你可以控制谁可以访问它。
+
+**选项:** [Nextcloud][4]、[ownCloud][5]、[Pydio][6] 和 [Seafile][7]
+
+所有这些都提供了存储、同步和共享文件和文件夹、管理内容、文件版本等功能。它们可以很容易地取代 Dropbox、Google Drive 和其他专有的云存储,不用将你的数据放在你不拥有、不维护、不管理的服务器上。
+
+上面列出的开源的自托管方式符合 GDPR 和其他保护用户数据的国际法规。它们提供备份和数据恢复选项、审计和监控工具、权限管理和数据加密。
+
+![Pydio 审计控制][8]
+
+*Pydio 细胞中的审计控制。(来源:[Pydio.com][9])*
+
+#### 2、启用静态、传输和端到端的加密功能
+
+我们经常笼统地谈论数据加密,但在加密文件时有几个方面需要考虑:
+
+ * 通过**静态加密**(或磁盘加密),你可以保护存储在你的基础设施内或硬盘上的数据。
+ * 在使用 HTTPS 等协议时,**传输加密**会保护流量形式的数据。它可以保护你的数据在从一个地方移动到另一个地方时不被拦截和转换。当你把文件上传到你的云端时,这很重要。
+ * **端到端加密**(E2EE)通过在一端加密,在另一端解密来保护数据。除非有解密密钥,否则任何第三方都无法读取你的文件,即使他们干扰了这个过程并获得了这个文件的权限。
+
+**选项:** CryptPad、ownCloud、ONLYOFFICE 工作区、Nextcloud 和 Seafile
+
+ownCloud、ONLYOFFICE 工作区、Nextcloud 和 Seafile 支持所有三层的加密。但它们在实现端到端加密的方式上有所不同。
+
+ * 在 ownCloud 中,有一个 E2EE 插件,允许你对文件夹共享进行加密。
+ * 在 Nextcloud 中,桌面客户端有一个文件夹级别的选项。
+ * Seafile 通过创建加密库来提供客户端的 E2EE。
+ * [ONLYOFFICE 工作区][10] 不仅允许你在存储和共享文件时对其进行加密,而且还允许你在“私人房间”中实时安全地共同编辑文件。加密数据是自动生成和传输的,并且是自己加密的 —— 你不需要保留或记住任何密码。
+ * 正如其名称所示,[CryptPad][11] 是完全私有的。所有的内容都是由你的浏览器进行加密和解密的。这意味着文件、聊天记录和文件在你登录的会话之外是无法阅读的。即使是服务管理员也无法得到你的信息。
+
+![加密的 CryptPad 存储][12]
+
+*加密的 CryptPad 存储。(来源:[Cryptpad.fr][13])*
+
+#### 3、使用数字签名
+
+数字签名可以让你验证你是文件内容的原作者,并且没有对其进行过修改。
+
+**选项:** LibreOffice Writer、ONLYOFFICE 桌面编辑器、OpenESignForms 和 SignServer
+
+[LibreOffice][14] 和 [ONLYOFFICE][15] 套件提供了一个对文件数字签名的集成工具。你可以添加一个在文档文本中可见的签名行,并允许你向其他用户请求签名。
+
+一旦你应用了数字签名,任何人都不能编辑该文件。如果有人修改文档,签名就会失效,这样你就会知道内容被修改了。
+
+在 ONLYOFFICE 中,你可以在 LibreOffice 中签名 OOXML 文件(例如,DOCX、XLSX、PPTX)作为 ODF 和 PDF。如果你试图在 LibreOffice 中签名一个 OOXML 文件,该签名将被标记为“只有部分文件被签署”。
+
+![ONLYOFFICE 中的数字签名][16]
+
+*ONLYOFFICE 中的数字签名。 (来源:[ONLYOFFICE帮助中心][17])*
+
+[SignServer][18] 和 [Open eSignForms][19] 是免费的电子签名服务,如果你不需要在编辑器中直接签名文件,你可以使用它们。这两个工具都可以让你处理文档,SignServer 还可以让你签名包括 Java 在内的代码,并应用时间戳。
+
+#### 4、添加水印
+
+水印可避免你的内容在未经授权的情况下被重新分发,并保护你的文件可能包含的任何机密信息。
+
+**选项:**Nextcloud 中的 Collabora Online 或 ONLYOFFICE Docs
+
+当与 Nextcloud 集成时,[ONLYOFFICE Docs][20] 和 [Collabora][21] 允许你在文件、电子表格和演示文稿中嵌入水印。要激活水印功能,必须以管理员身份登录你的 Nextcloud 实例,并在解决方案的设置页面上进入**安全视图设置**。
+
+你可以使用占位符将默认的水印替换成你自己的文本。在打开文件时,水印将针对每个用户单独显示。你也可以定义组来区分将看到水印的用户,并选择必须显示水印的共享类型。
+
+![水印][22]
+
+*水印 (Ksenia Fedoruk, [CC BY-SA 4.0][23])*
+
+你也可以在 LibreOffice 和 ONLYOFFICE 桌面应用程序中的文档中插入水印。然而,在这种情况下,它只是一个放置在主文本层下的文本或图像,任何人都可以轻易地删除它。
+
+#### 5、用密码保护文件
+
+密码保护允许你安全地存储和交换本地文件。如果有人访问你的桌面或通过电子邮件或其他方法得到受保护的文件,他们不知道密码就无法打开它。
+
+**选项:** Apache OpenOffice、LibreOffice 和 ONLYOFFICE 桌面编辑器
+
+所有这三种解决方案都提供了为你的敏感文件设置密码的能力。
+
+如果一个受保护的文档对你很重要,强烈建议你使用密码管理器保存密码或记住它,因为 LibreOffice、ONLYOFFICE 和 [OpenOffice][24] 不提供密码恢复选项。因此,如果你忘记或丢失了密码,就没有办法恢复或重置密码并打开文件。
+
+### 你的数据属于你
+
+使用这些方法中的一种或多种来保护你的文件,以保持更安全的在线活动。现在是 21 世纪,计算机太先进了,不能冒险把你的数据交给你无法控制的服务。使用开源,掌握你的数字生活的所有权。
+
+你最喜欢的安全使用文档的工具是什么?请在评论中分享它们。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/secure-documents-open-source
+
+作者:[Ksenia Fedoruk][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksenia-fedoruk
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/documents_papers_file_storage_work.png?itok=YlXpAqAJ (Filing papers and documents)
+[2]: https://opensource.com/article/21/3/encryption-luks
+[3]: https://opensource.com/article/21/3/luks-truecrypt
+[4]: https://nextcloud.com/
+[5]: https://owncloud.com/
+[6]: https://pydio.com/
+[7]: https://www.seafile.com/en/home/
+[8]: https://opensource.com/sites/default/files/uploads/pydiocells.png (Pydio audit control)
+[9]: http://pydio.com
+[10]: https://www.onlyoffice.com/workspace.aspx
+[11]: https://cryptpad.fr/
+[12]: https://opensource.com/sites/default/files/uploads/cryptdrive.png (Encrypted CryptPad storage)
+[13]: http://cryptpad.fr
+[14]: https://www.libreoffice.org/
+[15]: https://www.onlyoffice.com/desktop.aspx
+[16]: https://opensource.com/sites/default/files/uploads/onlyoffice_digitalsig.png (Digital signature in ONLYOFFICE)
+[17]: http://helpcenter.onlyoffice.com
+[18]: https://www.signserver.org/
+[19]: https://github.com/OpenESignForms
+[20]: https://www.onlyoffice.com/office-for-nextcloud.aspx
+[21]: https://www.collaboraoffice.com/
+[22]: https://opensource.com/sites/default/files/uploads/onlyoffice_watermark.png (Watermark)
+[23]: https://creativecommons.org/licenses/by-sa/4.0/
+[24]: https://www.openoffice.org/
diff --git a/published/202105/20210420 A beginner-s guide to network management.md b/published/202105/20210420 A beginner-s guide to network management.md
new file mode 100644
index 0000000000..7d5e004bbf
--- /dev/null
+++ b/published/202105/20210420 A beginner-s guide to network management.md
@@ -0,0 +1,203 @@
+[#]: subject: "A beginner's guide to network management"
+[#]: via: "https://opensource.com/article/21/4/network-management"
+[#]: author: "Seth Kenlon https://opensource.com/users/seth"
+[#]: collector: "lujun9972"
+[#]: translator: "ddl-hust"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13374-1.html"
+
+网络管理初学者指南
+======
+
+> 了解网络是如何工作的,以及使用开源工具进行网络性能调优的一些窍门。
+
+
+
+大多数人每一天至少会接触到两种类型的网络。当你打开计算机或者移动设备,设备连接到本地 WiFi,本地 WiFi 然后连接到所谓“互联网”的互联网络。
+
+但是网络实际上是如何工作的?你的设备如何能够找到互联网、共享打印机或文件共享?这些东西如何知道响应你的设备?系统管理员用什么措施来优化网络的性能?
+
+开源思想在网络技术领域根深蒂固,因此任何想更多了解网络的人,可以免费获得网络相关的资源。本文介绍了使用开源技术的网络管理相关的基础知识。
+
+### 网络是什么?
+
+计算机网络是由两台或者多台计算机组成的、互相通信的集合。为了使得网络能够工作,网络上一台计算机必须能够找到其他计算机,且通信必须能够从一台计算机到达另外一台。为了解决这一需求,开发和定义了两种不同的通信协议:TCP 和 IP。
+
+#### 用于传输的 TCP 协议
+
+为了使得计算机之间能够通信,它们之间必须有一种传输信息的手段。人说话产生的声音是通过声波来传递的,计算机是通过以太网电缆、无线电波或微波传输的数字信号进行通信的。这方面的规范被正式定义为 [TCP 协议][2]。
+
+#### 用于寻址的 IP 协议
+
+计算机必须有一些识别手段才能相互寻址。当人类相互称呼时,我们使用名字和代名词。当计算机相互寻址时,它们使用 IP 地址,如 `192.168.0.1`,IP 地址可以被映射到名称上,如“Laptop”、“Desktop”、“Tux” 或 “Penguin”。这方面的规范被定义为 [IP 协议][3]。
+
+### 最小配置设置
+
+最简单的网络是一个两台计算机的网络,使用称为“交叉电缆”的特殊布线方式的以太网电缆。交叉电缆将来自一台计算机的信号连接并传输到另一台计算机上的适当受体。还有一些交叉适配器可以将标准的以太网转换为交叉电缆。
+
+![Crossover cable][4]
+
+由于在这两台计算机之间没有路由器,所有的网络管理都必须在每台机器上手动完成,因此这是一个很好的网络基础知识的入门练习。
+
+用一根交叉电缆,你可以把两台计算机连接在一起。因为这两台计算机是直接连接的,没有网络控制器提供指导,所以这两台计算机都不用做什么创建网络或加入网络的事情。通常情况下,这项任务会由交换机和 DHCP 服务器或路由器来提示,但在这个简单的网络设置中,这一切都由你负责。
+
+要创建一个网络,你必须先为每台计算机分配一个 IP 地址,为自行分配而保留的地址从 169.254 开始,这是一个约定俗成的方式,提醒你本 IP 段是一个闭环系统。
+
+#### 找寻网络接口
+
+首先,你必须知道你正在使用什么网络接口。以太网端口通常用 “eth” 加上一个从 0 开始的数字来指定,但有些设备用不同的术语来表示接口。你可以用 `ip` 命令来查询计算机上的接口:
+
+```
+$ ip address show
+1: lo: mtu 65536 ...
+ link/loopback 00:00:00:00:00:00 brd ...
+ inet 127.0.0.1/8 scope host lo
+ valid_lft forever preferred_lft forever
+ inet6 ::1/128 scope host
+ valid_lft forever preferred_lft forever
+2: eth0: ...
+ link/ether dc:a6:32:be:a3:e1 brd ...
+3: wlan0: ...
+ link/ether dc:a6:32:be:a3:e2 brd ...
+```
+
+在这个例子中,`eth0` 是正确的接口名称。然而,在某些情况下,你会看到 `en0` 或 `enp0s1` 或类似的东西,所以在使用设备名称之前,一定要先检查它。
+
+#### 分配 IP 地址
+
+通常情况下,IP 地址是从路由器获得的,路由器在网络上广播提供地址。当一台计算机连接到一个网络时,它请求一个地址。路由器通过介质访问控制(MAC)地址识别设备(注意这个 MAC 与苹果 Mac 电脑无关),并被分配 IP 地址。这就是计算机在网络上找到彼此的方式。
+
+在本文的简单网络中,没有路由器来分配 IP 地址及注册设备,因此我们需要手动分配 IP 地址,使用 `ip` 命令来给计算机分配 IP 地址:
+
+```
+$ sudo ip address add 169.254.0.1 dev eth0
+```
+
+给另外一台计算机分配 IP 地址,将 IP 地址增 1:
+
+```
+$ sudo ip address add 169.254.0.2 dev eth0
+```
+
+现在计算机有了交叉电缆作为通信介质,有了独一无二的 IP 地址用来识别身份。但是这个网络还缺少一个重要成分:计算机不知道自己是网络的一部分。
+
+#### 设置路由
+
+路由器另外的一个功能是设置从一个地方到另一个地方的网络路径,称作路由表,路由表可以简单的看作网络的城市地图。
+
+虽然现在我们还没有设置路由表,但是我们可以通过 `route` 命令来查看路由表:
+
+```
+$ route
+Kernel IP routing table
+Destination | Gateway | Genmask | Flags|Metric|Ref | Use | Iface
+$
+```
+
+同样,你可以通过 `ip` 命令来查看路由表:
+
+```
+$ ip route
+$
+```
+
+通过 `ip` 命令添加一条路由信息:
+
+```
+$ sudo ip route \
+ add 169.254.0.0/24 \
+ dev eth0 \
+ proto static
+```
+
+这条命令为 `eth0` 接口添加一个地址范围(从 `169.254.0.0` 开始到 `169.254.0.255` 结束)的路由。它将路由协议设置为“静态”,表示作为管理员的你创建了这个路由,作为对该范围内的任何动态路由进行覆盖。
+
+通过 `route` 命令来查询路由表:
+
+```
+$ route
+Kernel IP routing table
+Destination | Gateway | Genmask | ... | Iface
+link-local | 0.0.0.0 | 255.255.255.0 | ... | eth0
+```
+
+或者使用`ip`命令从不同角度来查询路由表:
+
+```
+$ ip route
+169.254.0.0/24 dev eth0 proto static scope link
+```
+
+#### 探测相邻网络
+
+现在,你的网络有了传输方式、寻址方法以及网络路由。你可以联系到你的计算机以外的主机。向另一台计算机发送的最简单的信息是一个 “呯”,这也是产生该信息的命令的名称(`ping`)。
+
+```
+$ ping -c1 169.254.0.2
+64 bytes from 169.254.0.2: icmp_seq=1 ttl=64 time=0.233 ms
+
+--- 169.254.0.2 ping statistics ---
+1 packets transmitted, 1 received, 0% packet loss, time 0ms
+rtt min/avg/max/mdev = 0.244/0.244/0.244/0.000 ms
+```
+
+你可以通过下面的命令看到与你交互的邻居:
+
+```
+$ ip neighbour
+169.254.0.2 dev eth0 lladdr e8:6a:64:ac:ef:7c STALE
+```
+
+### 通过交换机扩展你的网络
+
+只需要双节点的网络并不多。为了解决这个问题,人们开发了特殊的硬件,称为网络“交换机”。网络交换机允许你将几条以太网电缆连接到它上面,它将消息不加区分地从发送消息的计算机分发到交换机上所有监听的计算机。除了拥有与预期接收者相匹配的 IP 地址的计算机外,其他所有计算机都会忽略该信息。这使得网络变得相对嘈杂,但这是物理上,将一组计算机连接在一起的简单方法。
+
+在大多数现代家庭网络中,用于物理电缆的物理交换机并不实用。所以 WiFi 接入点代替了物理交换机。WiFi 接入点的功能与交换机相同:它允许许多计算机连接到它并在它们之间传递信息。
+
+接入互联网不仅仅是一种期望,它通常是家庭网络存在的原因。没有接入互联网的交换机或 WiFi 接入点不是很有用,但要将你的网络连接到另一个网络,你需要一个路由器。
+
+#### 添加路由器
+
+实际上,本地网络连接了许多设备,并且越来越多的设备具备联网能力,使得网络的规模呈数量级级别增长。
+
+手动配置网络是不切实际的,因此这些任务分配给网络中特定的节点来处理,网络中每台计算机运行一个后台守护进程,以填充从网络上的权威服务器收到的网络设置。家庭网络中,这些工作通常被整合到一个小型嵌入式设备中,通常由你的互联网服务提供商(ISP)提供,称为**路由器**(人们有时错误地将其称为调制解调器)。在一个大型网络中,每项工作通常被分配到一个单独的专用服务器上,以确保专用服务器能够专注于自己的工作以及保证工作弹性。这些任务包括:
+
+- DHCP 服务器,为加入网络的设备分配和跟踪 IP 地址
+- DNS 服务器将诸如域名 [redhat.com][7] 转换成 IP 地址 `209.132.183.105`
+- [防火墙][8] 保护你的网络免受不需要的传入流量或被禁止的传出流量
+- 路由器有效传输网络流量,作为其他网络(如互联网)的网关,并进行网络地址转换(NAT)
+
+你现在的网络上可能有一个路由器,它可能管理着所有这些任务,甚至可能更多。感谢像 VyOS 这样的项目,现在你可以运行 [自己的开源路由器][9]。对于这样一个项目,你应该使用一台专门的计算机,至少有两个网络接口控制器(NIC):一个连接到你的 ISP,另一个连接到交换机,或者更有可能是一个 WiFi 接入点。
+
+### 扩大你的知识规模
+
+无论你的网络上有多少设备,或你的网络连接到多少其他网络,其原则仍然与你的双节点网络相同。你需要一种传输方式,一种寻址方案,以及如何路由到网络的知识。
+
+### 网络知识速查表
+
+了解网络是如何运作的,对管理网络至关重要。除非你了解你的测试结果,否则你无法排除问题,除非你知道哪些命令能够与你的网络设备交互,否则你无法运行测试。对于重要的网络命令的基本用法以及你可以用它们提取什么样的信息,[请下载我们最新的网络速查表][10]。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/network-management
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[ddl-hust](https://github.com/ddl-hust)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/gears_devops_learn_troubleshooting_lightbulb_tips_520.png?itok=HcN38NOk "Tips and gears turning"
+[2]: https://tools.ietf.org/html/rfc793
+[3]: https://tools.ietf.org/html/rfc791
+[4]: https://opensource.com/sites/default/files/uploads/crossover.jpg "Crossover cable"
+[5]: https://creativecommons.org/licenses/by-sa/4.0/
+[6]: https://opensource.com/article/17/4/build-your-own-name-server
+[7]: http://redhat.com
+[8]: https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd
+[9]: https://opensource.com/article/20/1/open-source-networking
+[10]: https://opensource.com/downloads/cheat-sheet-networking
\ No newline at end of file
diff --git a/published/202105/20210420 Application observability with Apache Kafka and SigNoz.md b/published/202105/20210420 Application observability with Apache Kafka and SigNoz.md
new file mode 100644
index 0000000000..e61e766e37
--- /dev/null
+++ b/published/202105/20210420 Application observability with Apache Kafka and SigNoz.md
@@ -0,0 +1,135 @@
+[#]: subject: (Application observability with Apache Kafka and SigNoz)
+[#]: via: (https://opensource.com/article/21/4/observability-apache-kafka-signoz)
+[#]: author: (Nitish Tiwari https://opensource.com/users/tiwarinitish86)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13352-1.html)
+
+使用 Apache Kafka 和 SigNoz 实现应用可观测性
+======
+
+> SigNoz 帮助开发者使用最小的精力快速实现他们的可观测性目标。
+
+
+
+SigNoz 是一个开源的应用可观察性平台。SigNoz 是用 React 和 Go 编写的,它从头到尾都是为了让开发者能够以最小的精力尽快实现他们的可观察性目标。
+
+本文将详细介绍该软件,包括架构、基于 Kubernetes 的部署以及一些常见的 SigNoz 用途。
+
+### SigNoz 架构
+
+SigNoz 将几个组件捆绑在一起,创建了一个可扩展的、耦合松散的系统,很容易上手使用。其中一些最重要的组件有:
+
+ * OpenTelemetry Collector
+ * Apache Kafka
+ * Apache Druid
+
+[OpenTelemetry Collector][2] 是跟踪或度量数据收集引擎。这使得 SigNoz 能够以行业标准格式获取数据,包括 Jaeger、Zipkin 和 OpenConsensus。之后,收集的数据被转发到 Apache Kafka。
+
+SigNoz 使用 Kafka 和流处理器来实时获取大量的可观测数据。然后,这些数据被传递到 Apache Druid,它擅长于存储这些数据,用于短期和长期的 SQL 分析。
+
+当数据被扁平化并存储在 Druid 中,SigNoz 的查询服务可以查询并将数据传递给 SigNoz React 前端。然后,前端为用户创建漂亮的图表,使可观察性数据可视化。
+
+![SigNoz architecture][3]
+
+### 安装 SigNoz
+
+SigNoz 的组件包括 Apache Kafka 和 Druid。这些组件是松散耦合的,并协同工作,以确保终端用户的无缝体验。鉴于这些组件,最好将 SigNoz 作为 Kubernetes 或 Docker Compose(用于本地测试)上的微服务组合来运行。
+
+这个例子使用基于 Kubernetes Helm Chart 的部署在 Kubernetes 上安装 SigNoz。作为先决条件,你需要一个 Kubernetes 集群。如果你没有可用的 Kubernetes 集群,你可以使用 [MiniKube][5] 或 [Kind][6] 等工具,在你的本地机器上创建一个测试集群。注意,这台机器至少要有 4GB 的可用空间才能工作。
+
+当你有了可用的集群,并配置了 kubectl 来与集群通信,运行:
+
+```
+$ git clone https://github.com/SigNoz/signoz.git && cd signoz
+$ helm dependency update deploy/kubernetes/platform
+$ kubectl create ns platform
+$ helm -n platform install signoz deploy/kubernetes/platform
+$ kubectl -n platform apply -Rf deploy/kubernetes/jobs
+$ kubectl -n platform apply -f deploy/kubernetes/otel-collector
+```
+
+这将在集群上安装 SigNoz 和相关容器。要访问用户界面 (UI),运行 `kubectl port-forward` 命令。例如:
+
+```
+$ kubectl -n platform port-forward svc/signoz-frontend 3000:3000
+```
+
+现在你应该能够使用本地浏览器访问你的 SigNoz 仪表板,地址为 `http://localhost:3000`。
+
+现在你的可观察性平台已经建立起来了,你需要一个能产生可观察性数据的应用来进行可视化和追踪。对于这个例子,你可以使用 [HotROD][7],一个由 Jaegar 团队开发的示例应用。
+
+要安装它,请运行:
+
+```
+$ kubectl create ns sample-application
+$ kubectl -n sample-application apply -Rf sample-apps/hotrod/
+```
+
+### 探索功能
+
+现在你应该有一个已经安装合适仪表的应用,并可在演示设置中运行。看看 SigNoz 仪表盘上的指标和跟踪数据。当你登录到仪表盘的主页时,你会看到一个所有已配置的应用列表,这些应用正在向 SigNoz 发送仪表数据。
+
+![SigNoz dashboard][8]
+
+#### 指标
+
+当你点击一个特定的应用时,你会登录到该应用的主页上。指标页面显示最近 15 分钟的信息(这个数字是可配置的),如应用的延迟、平均吞吐量、错误率和应用目前访问最高的接口。这让你对应用的状态有一个大概了解。任何错误、延迟或负载的峰值都可以立即看到。
+
+![Metrics in SigNoz][9]
+
+#### 追踪
+
+追踪页面按时间顺序列出了每个请求的高层细节。当你发现一个感兴趣的请求(例如,比预期时间长的东西),你可以点击追踪,查看该请求中发生的每个行为的单独时间跨度。下探模式提供了对每个请求的彻底检查。
+
+![Tracing in SigNoz][10]
+
+![Tracing in SigNoz][11]
+
+#### 用量资源管理器
+
+大多数指标和跟踪数据都非常有用,但只在一定时期内有用。随着时间的推移,数据在大多数情况下不再有用。这意味着为数据计划一个适当的保留时间是很重要的。否则,你将为存储支付更多的费用。用量资源管理器提供了每小时、每一天和每一周获取数据的概况。
+
+![SigNoz Usage Explorer][12]
+
+### 添加仪表
+
+到目前为止,你一直在看 HotROD 应用的指标和追踪。理想情况下,你会希望对你的应用进行检测,以便它向 SigNoz 发送可观察数据。参考 SigNoz 网站上的[仪表概览][13]。
+
+SigNoz 支持一个与供应商无关的仪表库,OpenTelemetry,作为配置仪表的主要方式。OpenTelemetry 提供了各种语言的仪表库,支持自动和手动仪表。
+
+### 了解更多
+
+SigNoz 帮助开发者快速开始度量和跟踪应用。要了解更多,你可以查阅 [文档][14],加入[社区][15],并访问 [GitHub][16] 上的源代码。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/observability-apache-kafka-signoz
+
+作者:[Nitish Tiwari][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/tiwarinitish86
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/ship_captain_devops_kubernetes_steer.png?itok=LAHfIpek (Ship captain sailing the Kubernetes seas)
+[2]: https://github.com/open-telemetry/opentelemetry-collector
+[3]: https://opensource.com/sites/default/files/uploads/signoz_architecture.png (SigNoz architecture)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://minikube.sigs.k8s.io/docs/start/
+[6]: https://kind.sigs.k8s.io/docs/user/quick-start/
+[7]: https://github.com/jaegertracing/jaeger/tree/master/examples/hotrod
+[8]: https://opensource.com/sites/default/files/uploads/signoz_dashboard.png (SigNoz dashboard)
+[9]: https://opensource.com/sites/default/files/uploads/signoz_applicationmetrics.png (Metrics in SigNoz)
+[10]: https://opensource.com/sites/default/files/uploads/signoz_tracing.png (Tracing in SigNoz)
+[11]: https://opensource.com/sites/default/files/uploads/signoz_tracing2.png (Tracing in SigNoz)
+[12]: https://opensource.com/sites/default/files/uploads/signoz_usageexplorer.png (SigNoz Usage Explorer)
+[13]: https://signoz.io/docs/instrumentation/overview/
+[14]: https://signoz.io/docs/
+[15]: https://github.com/SigNoz/signoz#community
+[16]: https://github.com/SigNoz/signoz
diff --git a/published/202105/20210421 Build smaller containers.md b/published/202105/20210421 Build smaller containers.md
new file mode 100644
index 0000000000..5d54b9d024
--- /dev/null
+++ b/published/202105/20210421 Build smaller containers.md
@@ -0,0 +1,345 @@
+[#]: subject: (Build smaller containers)
+[#]: via: (https://fedoramagazine.org/build-smaller-containers/)
+[#]: author: (Daniel Schier https://fedoramagazine.org/author/danielwtd/)
+[#]: collector: (lujun9972)
+[#]: translator: (ShuyRoy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13382-1.html)
+
+如何构建更小的容器
+======
+
+
+
+使用容器工作是很多用户和开发者的日常任务。容器开发者经常需要频繁地(重新)构建容器镜像。如果你开发容器,你有想过减小镜像的大小吗?较小的镜像有一些好处。在下载的时候所需要的带宽更少,而且在云环境中运行的时候也可以节省开销。而且在 Fedora [CoreOS][4]、[IoT][5] 以及[Silverblue][6] 上使用较小的容器镜像可以提升整体系统性能,因为这些操作系统严重依赖于容器工作流。这篇文章将会提供一些减小容器镜像大小的技巧。
+
+### 工具
+
+以下例子所用到的主机操作系统是 Fedora Linux 33。例子使用 [Podman][7] 3.1.0 和[Buildah][8] 1.2.0。Podman 和 Buildah 已经预装在大多数 Fedora Linux 变种中。如果你没有安装 Podman 和 Buildah,可以用下边的命令安装:
+
+```
+$ sudo dnf install -y podman buildah
+```
+
+### 任务
+
+从一个基础的例子开始。构建一个满足以下需求的 web 容器:
+
+ * 容器必须基于 Fedora Linux
+ * 使用 Apache httpd web 服务器
+ * 包含一个定制的网站
+ * 容器应该比较小
+
+下边的步骤也适用于比较复杂的镜像。
+
+### 设置
+
+首先,创建一个工程目录。这个目录将会包含你的网站和容器文件:
+
+```
+$ mkdir smallerContainer
+$ cd smallerContainer
+$ mkdir files
+$ touch files/index.html
+```
+
+制作一个简单的登录页面。对于这个演示,你可以将下面的 HTML 复制到 `index.html` 文件中。
+
+```
+
+
+
+
+ Container Page
+
+
+
+
+
+ Fedora
+
+ Podman
+
+ Buildah
+
+ Skopeo
+
+ CRI-O
+
+
+
+
+
+```
+
+此时你可以选择在浏览器中测试上面的 `index.html` 文件:
+
+```
+$ firefox files/index.html
+```
+
+最后,创建一个容器文件。这个文件可以命名为 `Dockerfile` 或者 `Containerfile`:
+
+```
+$ touch Containerfile
+```
+
+现在你应该有了一个工程目录,并且该目录中的文件系统布局如下:
+
+```
+smallerContainer/
+|- files/
+| |- index.html
+|
+|- Containerfile
+```
+
+### 构建
+
+现在构建镜像。下边的每个阶段都会添加一层改进来帮助减小镜像的大小。你最终会得到一系列镜像,但只有一个 `Containerfile`。
+
+#### 阶段 0:一个基本的容器镜像
+
+你的新镜像将会非常简单,它只包含强制性步骤。在 `Containerfile` 中添加以下内容:
+
+```
+# 使用 Fedora 33 作为基镜像
+FROM registry.fedoraproject.org/fedora:33
+
+# 安装 httpd
+RUN dnf install -y httpd
+
+# 复制这个网站
+COPY files/* /var/www/html/
+
+# 设置端口为 80/tcp
+EXPOSE 80
+
+# 启动 httpd
+CMD ["httpd", "-DFOREGROUND"]
+```
+
+在上边的文件中有一些注释来解释每一行内容都是在做什么。更详细的步骤:
+
+ 1. 在 `FROM registry.fedoraproject.org/fedora:33` 的基础上创建一个构建容器
+ 2. 运行命令: `dnf install -y httpd`
+ 3. 将与 `Containerfile` 有关的文件拷贝到容器中
+ 4. 设置 `EXPOSE 80` 来说明哪个端口是可以自动设置的
+ 5. 设置一个 `CMD` 指令来说明如果从这个镜像创建一个容器应该运行什么
+
+运行下边的命令从工程目录创建一个新的镜像:
+
+```
+$ podman image build -f Containerfile -t localhost/web-base
+```
+
+使用一下命令来查看你的镜像的属性。注意你的镜像的大小(467 MB)。
+
+```
+$ podman image ls
+REPOSITORY TAG IMAGE ID CREATED SIZE
+localhost/web-base latest ac8c5ed73bb5 5 minutes ago 467 MB
+registry.fedoraproject.org/fedora 33 9f2a56037643 3 months ago 182 MB
+```
+
+以上这个例子中展示的镜像在现在占用了467 MB的空间。剩下的阶段将会显著地减小镜像的大小。但是首先要验证镜像是否能够按照预期工作。
+
+输入以下命令来启动容器:
+
+```
+$ podman container run -d --name web-base -P localhost/web-base
+```
+
+输入以下命令可以列出你的容器:
+
+```
+$ podman container ls
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+d24063487f9f localhost/web-base httpd -DFOREGROUN... 2 seconds ago Up 3 seconds ago 0.0.0.0:46191->80/tcp web-base
+```
+
+以上展示的容器正在运行,它正在监听的端口是 `46191` 。从运行在主机操作系统上的 web 浏览器转到 `localhost:46191` 应该呈现你的 web 页面:
+
+```
+$ firefox localhost:46191
+```
+
+#### 阶段 1:清除缓存并将残余的内容从容器中删除
+
+为了优化容器镜像的大小,第一步应该总是执行“清理”。这将保证安装和打包所残余的内容都被删掉。这个过程到底需要什么取决于你的容器。对于以上的例子,只需要编辑 `Containerfile` 让它包含以下几行。
+
+```
+[...]
+# Install httpd
+RUN dnf install -y httpd && \
+ dnf clean all -y
+[...]
+```
+
+构建修改后的 `Containerfile` 来显著地减小镜像(这个例子中是 237 MB)。
+
+```
+$ podman image build -f Containerfile -t localhost/web-clean
+$ podman image ls
+REPOSITORY TAG IMAGE ID CREATED SIZE
+localhost/web-clean latest f0f62aece028 6 seconds ago 237 MB
+```
+
+#### 阶段 2:删除文档和不需要的依赖包
+
+许多包在安装时会被建议拉下来,包含一些弱依赖和文档。这些在容器中通常是不需要的,可以删除。 `dnf` 命令有选项可以表明它不需要包含弱依赖或文档。
+
+再次编辑 `Containerfile` ,并在 `dnf install` 行中添加删除文档和弱依赖的选项:
+
+```
+[...]
+# Install httpd
+RUN dnf install -y httpd --nodocs --setopt install_weak_deps=False && \
+ dnf clean all -y
+[...]
+```
+
+构建经过以上修改后的 `Containerfile` 可以得到一个更小的镜像(231 MB)。
+
+```
+$ podman image build -f Containerfile -t localhost/web-docs
+$ podman image ls
+REPOSITORY TAG IMAGE ID CREATED SIZE
+localhost/web-docs latest 8a76820cec2f 8 seconds ago 231 MB
+```
+
+#### 阶段 3:使用更小的容器基镜像
+
+前面的阶段结合起来,使得示例镜像的大小减少了一半。但是仍然还有一些途径来进一步减小镜像的大小。这个基镜像 `registry.fedoraproject.org/fedora:33` 是通用的。它提供了一组软件包,许多人希望这些软件包预先安装在他们的 Fedora Linux 容器中。但是,通用的 Fedora Linux 基镜像中提供的包通常必须要的更多。Fedora 项目也为那些希望只从基本包开始,然后只添加所需内容来实现较小总镜像大小的用户提供了一个 `fedora-minimal` 镜像。
+
+使用 `podman image search` 来查找 `fedora-minimal` 镜像,如下所示:
+
+```
+$ podman image search fedora-minimal
+INDEX NAME DESCRIPTION STARS OFFICIAL AUTOMATED
+fedoraproject.org registry.fedoraproject.org/fedora-minimal 0
+```
+
+`fedora-minimal` 基镜像不包含 [DNF][9],而是倾向于使用不需要 Python 的较小的 [microDNF][10]。当 `registry.fedoraproject.org/fedora:33` 被 `registry.fedoraproject.org/fedora-minimal:33` 替换后,需要用 `microdnf` 命令来替换 `dnf`。
+
+```
+# 使用 Fedora minimal 33 作为基镜像
+FROM registry.fedoraproject.org/fedora-minimal:33
+
+# 安装 httpd
+RUN microdnf install -y httpd --nodocs --setopt install_weak_deps=0 && \
+ microdnf clean all -y
+[...]
+```
+使用 `fedora-minimal` 重新构建后的镜像大小如下所示 (169 MB):
+
+```
+$ podman image build -f Containerfile -t localhost/web-docs
+$ podman image ls
+REPOSITORY TAG IMAGE ID CREATED SIZE
+localhost/web-minimal latest e1603bbb1097 7 minutes ago 169 MB
+```
+
+最开始的镜像大小是 **467 MB**。结合以上每个阶段所提到的方法,进行重新构建之后可以得到最终大小为 **169 MB** 的镜像。最终的 _总_ 镜像大小比最开始的 _基_ 镜像小了 182 MB!
+
+### 从零开始构建容器
+
+前边的内容使用一个容器文件和 Podman 来构建一个新的镜像。还有最后一个方法要展示——使用 Buildah 来从头构建一个容器。Podman 使用与 Buildah 相同的库来构建容器。但是 Buildah 被认为是一个纯构建工具。Podman 被设计来是为了代替 Docker 的。
+
+使用 Buildah 从头构建的容器是空的——它里边什么都 _没有_ 。所有的东西都需要安装或者从容器外复制。幸运地是,使用 Buildah 相当简单。下边是一个从头开始构建镜像的小的 Bash 脚本。除了运行这个脚本,你也可以在终端逐条地运行脚本中的命令,来更好的理解每一步都是做什么的。
+
+```
+#!/usr/bin/env bash
+set -o errexit
+
+# 创建一个容器
+CONTAINER=$(buildah from scratch)
+
+# 挂载容器文件系统
+MOUNTPOINT=$(buildah mount $CONTAINER)
+
+# 安装一个基本的文件系统和最小的包以及 nginx
+dnf install -y --installroot $MOUNTPOINT --releasever 33 glibc-minimal-langpack httpd --nodocs --setopt install_weak_deps=False
+
+dnf clean all -y --installroot $MOUNTPOINT --releasever 33
+
+# 清除
+buildah unmount $CONTAINER
+
+# 复制网站
+buildah copy $CONTAINER 'files/*' '/var/www/html/'
+
+# 设置端口为 80/tcp
+buildah config --port 80 $CONTAINER
+
+# 启动 httpd
+buildah config --cmd "httpd -DFOREGROUND" $CONTAINER
+
+# 将容器保存为一个镜像
+buildah commit --squash $CONTAINER web-scratch
+```
+
+或者,可以通过将上面的脚本传递给 Buildah 来构建镜像。注意不需要 root 权限。
+
+```
+$ buildah unshare bash web-scratch.sh
+$ podman image ls
+REPOSITORY TAG IMAGE ID CREATED SIZE
+localhost/web-scratch latest acca45fc9118 9 seconds ago 155 MB
+```
+
+最后的镜像只有 **155 MB**!而且 [攻击面][11] 也减少了。甚至在最后的镜像中都没有安装 DNF(或者 microDNF)。
+
+### 结论
+
+构建一个比较小的容器镜像有许多优点。减少所需要的带宽、磁盘占用以及攻击面,都会得到更好的镜像。只用很少的更改来减小镜像的大小很简单。许多更改都可以在不改变结果镜像的功能下完成。
+
+只保存所需的二进制文件和配置文件来构建非常小的镜像也是可能的。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/build-smaller-containers/
+
+作者:[Daniel Schier][a]
+选题:[lujun9972][b]
+译者:[ShuyRoy](https://github.com/Shuyroy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/danielwtd/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/04/podman-smaller-1-816x345.jpg
+[2]: https://unsplash.com/@errbodysaycheese?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[3]: https://unsplash.com/s/photos/otter?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[4]: https://fedoramagazine.org/getting-started-with-fedora-coreos/
+[5]: https://getfedora.org/en/iot/
+[6]: https://fedoramagazine.org/what-is-silverblue/
+[7]: https://podman.io/
+[8]: https://buildah.io/
+[9]: https://github.com/rpm-software-management/dnf
+[10]: https://github.com/rpm-software-management/microdnf
+[11]: https://en.wikipedia.org/wiki/Attack_surface
diff --git a/published/202105/20210422 Running Linux Apps In Windows Is Now A Reality.md b/published/202105/20210422 Running Linux Apps In Windows Is Now A Reality.md
new file mode 100644
index 0000000000..b28e1eb194
--- /dev/null
+++ b/published/202105/20210422 Running Linux Apps In Windows Is Now A Reality.md
@@ -0,0 +1,117 @@
+[#]: subject: (Running Linux Apps In Windows Is Now A Reality)
+[#]: via: (https://news.itsfoss.com/linux-gui-apps-wsl/)
+[#]: author: (Jacob Crume https://news.itsfoss.com/author/jacob/)
+[#]: collector: (lujun9972)
+[#]: translator: (Kevin3599)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13376-1.html)
+
+在 Windows 中运行基于 Linux 的应用程序已经成为现实
+======
+
+> 微软宣布对其 WSL 进行重大改进,使你能够轻松地运行 Linux 图形化应用程序。
+
+
+
+当微软在 2016 年发布 “Windows subsystem for Linux”(也就是 WSL)的时候显然有夸大宣传的嫌疑,当时人们梦想着无需重启就可以同时运行基于 Windows 和 Linux 的应用程序,令人可惜的是,WSL 只能运行 Linux 终端程序。
+
+去年,微软再次尝试去颠覆 Windows 的应用生态,这一次,他们替换了老旧的模拟核心,转而使用了真正的 Linux 核心,这一变化使你可以 [在 Windows 中运行 Linux 应用程序][2]。
+
+### WSL 图形化应用的初步预览
+
+
+
+从技术上讲,用户最初确实在 WSL 上获得了对 Linux 图形化应用程序的支持,但仅限于使用第三方 X 服务器时。这通常是不稳定的、缓慢、难以设置,并且使人们有隐私方面的顾虑。
+
+结果是小部分 Linux 爱好者(碰巧运行 Windows),他们具有设置 X 服务器的能力。但是,这些爱好者对没有硬件加速支持感到失望。
+
+所以,较为明智的方法是在 WSL 上只运行基于命令行的程序。
+
+**但是现在这个问题得到了改善**。现在,微软 [正式支持][4] 了 Linux 图形化应用程序,我们很快就能够享受硬件加速了,
+
+### 面向大众的 Linux 图形化应用程序:WSLg
+
+![图片来源:Microsoft Devblogs][5]
+
+随着微软发布新的 WSL,有了一系列巨大的改进,它们包括:
+
+ * GPU 硬件加速
+ * 开箱即用的音频和麦克风支持
+ * 自动启用 X 服务器和 Pulse 音频服务
+
+有趣的是,开发者们给这个功能起了一个有趣的外号 “WSLg”。
+
+这些功能将使在 WSL 上运行 Linux 应用程序几乎与运行原生应用程序一样容易,同时无需占用过多性能资源。
+
+因此,你可以尝试运行 [自己喜欢的 IDE][6]、特定于 Linux 的测试用例以及诸如 [CAD][7] 之类的各种软件。
+
+#### Linux 应用的 GPU 硬件加速
+
+![图片鸣谢:Microsoft Devblogs][8]
+
+以前在 Windows 上运行图形化 Linux 程序的最大问题之一是它们无法使用硬件加速。当用户尝试移动窗口和执行任何需要对 GPU 性能有要求的任务时候,它常常陷入缓慢卡顿的局面。
+
+根据微软发布的公告:
+
+> “作为此次更新的一部分,我们也启用了对 3D 图形的 GPU 加速支持,多亏了 Mesa 21.0 中完成的工作,所有的复杂 3D 渲染的应用程序都可以利用 OpenGL 在 Windows 10 上使用 GPU 为这些应用程序提供硬件加速。”
+
+这是一个相当实用的改进,这对用户在 WSL 下运行需求强大 GPU 性能的应用程序提供了莫大帮助。
+
+#### 开箱即用的音频和麦克风支持!
+
+如果想要良好的并行 Windows 和 Linux 程序,好的音频支持是必不可少的,随着新的 WSL 发布,音频得到开箱即用的支持,这都要归功于随着 X 服务器一同启动的 Pulse 音频服务。
+
+微软解释说:
+
+> “WSL 上的 Linux 图形化应用程序还将包括开箱即用的音频和麦克风支持。这一令人兴奋的改进将使你的应用程序可以播放音频提示并调用麦克风,适合构建、测试或使用电影播放器、电信应用程序等。”
+
+如果我们希望 Linux 变得更加普及,这是一项关键功能。这也将允许 Windows 应用的开发人员更好地将其应用移植到 Linux。
+
+#### 自动启动所有必需的服务器
+
+![图片鸣谢:Microsoft Devblogs][9]
+
+以前,你必须先手动启动 [PulseAudio][10] 和 [X 服务器][11],然后才能运行应用程序。现在,微软已经实现了一项服务,可以检查 Linux 应用程序是否正在运行,然后自动启动所需的服务器。
+
+这使得用户更容易在 Windows 上运行 Linux 应用程序。
+
+微软声称这些改动会显著提升用户体验。
+
+> “借助此功能,我们将启动一个配套的系统分发包,其中包含 Wayland、X 服务器、Pulse 音频服务以及使 Linux 图形化应用程序与 Windows 通信所需的所有功能。使用完图形化应用程序并终止 WSL 发行版后,系统分发包也会自动结束其会话。”
+
+这些组件的结合使 Linux 图形化应用程序与常规 Windows 程序并行运行更为简单。
+
+### 总结
+
+有了这些新功能,微软似乎正在竭尽全力使 Linux 应用程序在 Windows 上运行。随着越来越多的用户在 Windows 上运行 Linux 应用程序,我们可能会看到更多的用户转向 Linux。特别是因为他们习惯的应用程序能够运行。
+
+如果这种做法取得了成功(并且微软几年后仍未将其雪藏),它将结束 5 年来对将 Linux 应用引入 Windows 的探索。如果你想了解更多信息,可以查看 [发行公告][12]。
+
+你对在 Windows 上运行 Linux 图形化应用程序怎么看?请在下面留下你的评论。
+
+--------------------------------------------------------------------------------
+
+via: https://news.itsfoss.com/linux-gui-apps-wsl/
+
+作者:[Jacob Crume][a]
+选题:[lujun9972][b]
+译者:[Kevin3599](https://github.com/Kevin3599)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://news.itsfoss.com/author/jacob/
+[b]: https://github.com/lujun9972
+[1]: https://docs.microsoft.com/en-us/windows/wsl/
+[2]: https://itsfoss.com/run-linux-apps-windows-wsl/
+[3]: https://i0.wp.com/i.ytimg.com/vi/f8_nvJzuaSU/hqdefault.jpg?w=780&ssl=1
+[4]: https://devblogs.microsoft.com/commandline/the-initial-preview-of-gui-app-support-is-now-available-for-the-windows-subsystem-for-linux-2/
+[5]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/gedit-wsl-gui.png?w=800&ssl=1
+[6]: https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
+[7]: https://itsfoss.com/cad-software-linux/
+[8]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/gpu-acceleration-wsl.png?w=800&ssl=1
+[9]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/wslg-architecture.png?w=800&ssl=1
+[10]: https://www.freedesktop.org/wiki/Software/PulseAudio/
+[11]: https://x.org/wiki/
+[12]: https://blogs.windows.com/windows-insider/2021/04/21/announcing-windows-10-insider-preview-build-21364/
diff --git a/published/202105/20210423 What-s New in Ubuntu MATE 21.04.md b/published/202105/20210423 What-s New in Ubuntu MATE 21.04.md
new file mode 100644
index 0000000000..870b8c13fc
--- /dev/null
+++ b/published/202105/20210423 What-s New in Ubuntu MATE 21.04.md
@@ -0,0 +1,107 @@
+[#]: subject: (What’s New in Ubuntu MATE 21.04)
+[#]: via: (https://news.itsfoss.com/ubuntu-mate-21-04-release/)
+[#]: author: (Asesh Basu https://news.itsfoss.com/author/asesh/)
+[#]: collector: (lujun9972)
+[#]: translator: (Kevin3599)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13349-1.html)
+
+Ubuntu MATE 21.04 更新,多项新功能来袭
+======
+
+> 与 Yaru 团队合作,Ubuntu MATE 带来了一个主题大修、一系列有趣的功能和性能改进。
+
+
+
+自从 18.10 发行版以来,Yaru 一直都是 Ubuntu 的默认用户桌面,今年,Yaru 团队与Canonical Design 和 Ubuntu 桌面团队携手合作,为 Ubuntu MATE 21.04 创建了新的外观界面。
+
+### Ubuntu MATE 21.04 有什么新变化?
+
+以下就是 Ubuntu MATE 21.04 此次发布中的关键变化:
+
+#### MATE 桌面
+
+此次更新的 MATE 桌面相比以往并没有较大改动,此次只是修复了错误 BUG 同时更新了语言翻译,Debian 中的 MATE 软件包已经更新,用户可以下载所有的 BUG 修复和更新。
+
+#### Avatana 指示器
+
+![][1]
+
+这是一个控制面板指示器(也称为系统托盘)的动作、布局和行为的系统。现在,你可以从控制中心更改 Ayatana 指示器的设置。
+
+添加了一个新的打印机标识,并删除了 RedShift 以保持稳定。
+
+#### Yaru MATE 主题
+
+Yaru MATE 现在是 Yaru 主题的派生产品。Yaru MATE 将提供浅色和深色主题,浅色作为默认主题。来确保更好的应用程序兼容性。
+
+从现在开始,用户可以使用 GTK 2.x、3.x、4.x 浅色和深色主题,也可以使用 Suru 图标以及一些新的图标。
+
+LibreOffice 在 MATE 上会有新的默认桌面图标,字体对比度也得到了改善。你会发现阅读小字体文本或远距离阅读更加容易。
+
+如果在系统层面选择了深色模式,网站将维持深色。要让网站和系统的其它部分一起使用深色主题,只需启用 Yaru MATE 深色主题即可。
+
+现在,Macro、Metacity 和 Compiz 的管理器主题使用了矢量图标。这意味着,如果你的屏幕较大,图标不会看起来像是像素画,又是一个小细节!
+
+#### Yaru MATE Snap 包
+
+尽管你现在无法安装 MATE 主题,但是不要着急,它很快就可以了。gtk-theme-yaru-mate 和 icon-theme-yaru-mate Snap 包是预安装的,可以在需要将主题连接到兼容的 Snap 软件包时使用。
+
+根据官方发布的公告,Snapd 很快就会自动将你的主题连接到兼容的 Snap 包:
+
+> Snapd 很快就能自动安装与你当前活动主题相匹配的主题的 snap 包。我们创建的 snap 包已经准备好在该功能可用时与之整合。
+
+#### Mutiny 布局的新变化
+
+![应用了深色主题的 Mutiny 布局][2]
+
+Mutiny 布局模仿了 Unity 的桌面布局。删除了 MATE 软件坞小应用,并且对 Mutiny 布局进行了优化以使用 Plank。Plank 会被系统自动应用主题。这是通过 Mate Tweak 切换到 Mutiny 布局完成的。Plank 的深色和浅色 Yaru 主题都包含在内。
+
+其他调整和更新使得 Mutiny 在不改变整体风格的前提下具备了更高的可靠性
+
+#### 主要应用升级
+
+ * Firefox 87(火狐浏览器)
+ * LibreOffice 7.1.2.2(办公软件)
+ * Evolution 3.40(邮件)
+ * Celluloid 0.20(视频播放器)
+
+#### 其他更改
+
+ * Linux 命令的忠实用户会喜欢在 Ubuntu MATE 中默认安装的 `neofetch`、`htop` 和 `inxi` 之类的命令。
+ * 树莓派的 21.04 版本很快将会发布。
+ * Ubuntu MATE 上没有离线升级选项。
+ * 针对侧边和底部软件坞引入了新的 Plank 主题,使其与 Yaru MATE 的配色方案相匹配。
+ * Yaru MATE 的窗口管理器为侧边平铺的窗口应用了简洁的边缘风格。
+ * Ubuntu MATE 欢迎窗口有多种色彩可供选择。
+ * Yaru MATE 主题和图标主题的快照包已在 Snap Store 中发布。
+ * 为 Ubuntu MATE 20.04 LTS 的用户发布了 Yaru MATE PPA。
+
+### 下载 Ubuntu MATE 21.04
+
+你可以从官网上下载镜像:
+
+- [Ubuntu MATE 21.04][3]
+
+如果你对此感兴趣,[请查看发行说明][4]。
+
+你对尝试新的 Yaru MATE 感到兴奋吗?你觉得怎么样?请在下面的评论中告诉我们。
+
+--------------------------------------------------------------------------------
+
+via: https://news.itsfoss.com/ubuntu-mate-21-04-release/
+
+作者:[Asesh Basu][a]
+选题:[lujun9972][b]
+译者:[Kevin3599](https://github.com/Kevin3599)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://news.itsfoss.com/author/asesh/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/yaru-mate-mutiny-dark.jpg?resize=1568%2C882&ssl=1
+[2]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/yaru-mate-mutiny-dark.jpg?resize=1568%2C882&ssl=1
+[3]: https://ubuntu-mate.org/download/
+[4]: https://discourse.ubuntu.com/t/hirsute-hippo-release-notes/19221
\ No newline at end of file
diff --git a/published/202105/20210424 Making computers more accessible and sustainable with Linux.md b/published/202105/20210424 Making computers more accessible and sustainable with Linux.md
new file mode 100644
index 0000000000..b405dcb76d
--- /dev/null
+++ b/published/202105/20210424 Making computers more accessible and sustainable with Linux.md
@@ -0,0 +1,74 @@
+[#]: subject: (Making computers more accessible and sustainable with Linux)
+[#]: via: (https://opensource.com/article/21/4/linux-free-geek)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13362-1.html)
+
+用 Linux 使计算机更容易使用和可持续
+======
+
+> Free Geek 是一个非营利组织,通过向有需要的人和团体提供 Linux 电脑,帮助减少数字鸿沟。
+
+
+
+有很多理由选择 Linux 作为你的桌面操作系统。在 [为什么每个人都应该选择 Linux][2] 中,Seth Kenlon 强调了许多选择 Linux 的最佳理由,并为人们提供了许多开始使用该操作系统的方法。
+
+这也让我想到了我通常向人们介绍 Linux 的方式。这场大流行增加了人们上网购物、远程教育以及与家人和朋友 [通过视频会议][3] 联系的需求。
+
+我和很多有固定收入的退休人员一起工作,他们并不特别精通技术。对于这些人中的大多数人来说,购买电脑是一项充满担忧的大投资。我的一些朋友和客户对在大流行期间去零售店感到不舒服,而且他们完全不熟悉如何买电脑,无论是台式机还是笔记本电脑,即使在非大流行时期。他们来找我,询问在哪里买,要注意些什么。
+
+我总是想看到他们得到一台 Linux 电脑。他们中的许多人买不起名牌供应商出售的 Linux 设备。直到最近,我一直在为他们购买翻新的设备,然后用 Linux 改装它们。
+
+但是,当我发现 [Free Geek][4] 时,这一切都改变了,这是一个位于俄勒冈州波特兰的非营利组织,它的使命是“可持续地重复使用技术,实现数字访问,并提供教育,以创建一个使人们能够实现其潜力的社区。”
+
+Free Geek 有一个 eBay 商店,我在那里以可承受的价格购买了几台翻新的笔记本电脑。他们的电脑都安装了 [Linux Mint][5]。 事实上,电脑可以立即使用,这使得向 [新用户介绍 Linux][6] 很容易,并帮助他们快速体验操作系统的力量。
+
+### 让电脑继续使用,远离垃圾填埋场
+
+Oso Martin 在 2000 年地球日发起了 Free Geek。该组织为其志愿者提供课程和工作计划,对他们进行翻新和重建捐赠电脑的培训。志愿者们在服务 24 小时后还会收到一台捐赠的电脑。
+
+这些电脑在波特兰的 Free Geek 实体店和 [网上][7] 出售。该组织还通过其项目 [Plug Into Portland][8]、[Gift a Geekbox][9] 以及[组织][10]和[社区资助][11]向有需要的人和实体提供电脑。
+
+该组织表示,它已经“从垃圾填埋场翻新了 200 多万件物品,向非营利组织、学校、社区变革组织和个人提供了 75000 多件技术设备,并从 Free Geek 学习者那里提供了 5000 多课时”。
+
+### 参与其中
+
+自成立以来,Free Geek 已经从 3 名员工发展到近 50 名员工,并得到了世界各地的认可。它是波特兰市的 [数字包容网络][12] 的成员。
+
+你可以在 [Twitter][13]、[Facebook][14]、[LinkedIn][15]、[YouTube][16] 和 [Instagram][17] 上与 Free Geek 联系。你也可以订阅它的[通讯][18]。从 Free Geek 的 [商店][19] 购买物品,可以直接支持其工作,减少数字鸿沟。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/linux-free-geek
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/wfh_work_home_laptop_work.png?itok=VFwToeMy (Working from home at a laptop)
+[2]: https://opensource.com/article/21/2/try-linux
+[3]: https://opensource.com/article/20/8/linux-laptop-video-conferencing
+[4]: https://www.freegeek.org/
+[5]: https://opensource.com/article/21/4/restore-macbook-linux
+[6]: https://opensource.com/article/18/12/help-non-techies
+[7]: https://www.ebay.com/str/freegeekbasicsstore
+[8]: https://www.freegeek.org/our-programs/plug-portland
+[9]: https://www.freegeek.org/our-programs/gift-geekbox
+[10]: https://www.freegeek.org/our-programs-grants/organizational-hardware-grants
+[11]: https://www.freegeek.org/our-programs-grants/community-hardware-grants
+[12]: https://www.portlandoregon.gov/oct/73860
+[13]: https://twitter.com/freegeekpdx
+[14]: https://www.facebook.com/freegeekmothership
+[15]: https://www.linkedin.com/company/free-geek/
+[16]: https://www.youtube.com/user/FreeGeekMothership
+[17]: https://www.instagram.com/freegeekmothership/
+[18]: https://app.e2ma.net/app2/audience/signup/1766417/1738557/?v=a
+[19]: https://www.freegeek.org/shop
diff --git a/published/202105/20210425 Play retro video games on Linux with this open source project.md b/published/202105/20210425 Play retro video games on Linux with this open source project.md
new file mode 100644
index 0000000000..4117da3f5c
--- /dev/null
+++ b/published/202105/20210425 Play retro video games on Linux with this open source project.md
@@ -0,0 +1,119 @@
+[#]: subject: (Play retro video games on Linux with this open source project)
+[#]: via: (https://opensource.com/article/21/4/scummvm-retro-gaming)
+[#]: author: (Joshua Allen Holm https://opensource.com/users/holmja)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13433-1.html)
+
+用这个开源项目在 Linux 上玩复古视频游戏
+======
+
+> ScummVM 是在现代硬件上玩老式视频游戏的最直接的方法之一。
+
+
+
+玩冒险游戏一直是我使用计算机经验的一个重要部分。从最早的基于文本的冒险游戏到 2D 像素艺术、全动态视频和 3D 游戏,冒险游戏类型为我提供了很多美好的回忆。
+
+有时我想重温那些老游戏,但它们很多都是在 Linux 出现之前发布的,那么我如何去重玩这些游戏呢?我使用 [ScummVM][2],说实话,这是我最喜欢的开源项目之一。
+
+### 什么是 ScummVM
+
+![ScummVM][3]
+
+ScummVM 是一个设计用来在现代硬件上玩老式冒险游戏的程序。ScummVM 最初是为了运行使用卢卡斯艺术的疯狂豪宅脚本创作工具(SCUMM)开发的游戏,现在支持许多不同的游戏引擎。它可以支持几乎所有经典的雪乐山娱乐和卢卡斯艺术的冒险游戏,以及其他发行商的大量冒险游戏。ScummVM 并不支持所有的冒险游戏(目前),但它可以用来玩数百种冒险游戏。ScummVM 可用于多个平台,包括 Windows、macOS、Linux、Android、iOS 和一些游戏机。
+
+### 为什么使用 ScummVM
+
+有很多方法可以在现代硬件上玩老游戏,但它们往往比使用 ScummVM 更复杂。[DOSBox][5] 可以用来玩 DOS 游戏,但它需要调整设置,使其以正确的速度进行游戏。Windows 游戏可以用 [WINE][6] 来玩,但这需要游戏及其安装程序都与 WINE 兼容。
+
+即使游戏可以在 WINE 下运行,一些游戏仍然不能在现代硬件上很好地运行,因为硬件的速度太快了。这方面的一个例子是《国王密使 6》中的一个谜题,它涉及将点燃的鞭炮带到某个地方。在现代硬件上,鞭炮爆炸的速度太快了,这使得在角色不死很多次的情况下不可能到达正确的位置。
+
+ScummVM 消除了其他玩复古冒险游戏的方法中存在的许多问题。如果是 ScummVM 支持的游戏,那么它的配置和玩都很简单。在大多数情况下,将游戏文件从原始游戏光盘复制到一个目录,并在 ScummVM 中添加该目录,就可以玩该游戏了。对于多张光盘上的游戏,可能需要重命名一些文件以避免文件名冲突。需要哪些数据文件的说明以及任何重命名的说明都记录在 [每个支持的游戏][7] 的 ScummVM 维基页面上。
+
+ScummVM 的一个奇妙之处在于,每一个新版本都会增加对更多游戏的支持。ScummVM 2.2.0 增加了对十几种互动小说解释器的支持,这意味着 ScummVM 现在可以玩数百种基于文本的冒险游戏。ScummVM 的开发分支应该很快就会变成 2.3.0 版本,它整合了 [ResidualVM][8] 对 3D 冒险游戏的支持,所以现在 ScummVM 可以用来玩《冥界狂想曲》、《》和《最长的旅程》。其开发分支最近还增加了对使用 [Adventure Game Studio][9] 创建的游戏的支持,这为 ScummVM 增加了成百上千的游戏。
+
+### 如何安装 ScummVM
+
+如果你想从你的 Linux 发行版的仓库中安装 ScummVM,过程非常简单。你只需要运行一个命令。然而,你的发行版可能会提供一个旧版本的 ScummVM,它不像最新版本那样支持许多游戏,所以要记住这一点。
+
+在 Debian/Ubuntu 上安装 ScummVM:
+
+```
+sudo apt install scummvm
+```
+
+在 Fedora 上安装 ScummVM:
+
+```
+sudo dnf install scummvm
+```
+
+#### 使用 Flatpak 或 Snap 安装 ScummVM
+
+ScummVM 也可以以 Flatpak 和 Snap 的形式提供。如果你使用这些方式之一,你可以使用以下命令来安装相关的版本,它应该总是 ScummVM 的最新版本。
+
+```
+flatpak install flathub org.scummvm.ScummVM
+```
+
+或
+
+```
+snap install scummvm
+```
+
+#### 编译 ScummVM 的开发分支
+
+如果你想尝试 ScummVM 尚未稳定的开发分支中的最新和主要的功能,你可以通过编译 ScummVM 的源代码来实现。请注意,开发分支是不断变化的,所以事情可能不总是正确的。如果你仍有兴趣尝试开发分支,请按照下面的说明进行。
+
+首先,你需要为你的发行版准备必要的开发工具和库,这些工具和库在 ScummVM 维基上的 [编译 ScummVM/GCC][10] 页面列出。
+
+一旦你安装了先决条件,运行以下命令:
+
+```
+git clone
+cd scummvm
+./configure
+make
+sudo make install
+```
+
+### 向 ScummVM 添加游戏
+
+将游戏添加到 ScummVM 是你在游戏前需要做的最后一件事。如果你的收藏集中没有任何支持的冒险游戏,你可以从 [ScummVM 游戏][11] 页面下载 11 个精彩的游戏。你还可以从 [GOG.com][12] 购买许多 ScummVM 支持的游戏。如果你从 GOG.com 购买了游戏,并需要从 GOG 下载中提取游戏文件,你可以使用 [innoextract][13] 工具。
+
+大多数游戏需要放在自己的目录中(唯一的例外是由单个数据文件组成的游戏),所以最好先创建一个目录来存储你的 ScummVM 游戏。你可以使用命令行或图形化文件管理器来完成这个工作。在哪里存储游戏并不重要(除了 ScummVM Flatpak,它是一个沙盒,要求游戏存储在 `~/Documents` 目录中)。创建这个目录后,将每个游戏的数据文件放在各自的子目录中。
+
+一旦文件被复制到你想要的地方,运行 ScummVM,并通过点击“Add Game…”将游戏添加到收藏集中,在打开的文件选择器对话框中选择适当的目录,并点击“Choose”。如果 ScummVM 正确检测到游戏,它将打开其设置选项。如果你想的话,你可以从各个标签中选择高级配置选项(也可以在以后通过使用“Edit Game…”按钮进行更改),或者你可以直接点击“OK”,以默认选项添加游戏。如果没有检测到游戏,请查看 ScummVM 维基上的 [支持的游戏][14] 页面,以了解特定游戏的数据文件可能需要的特殊说明的细节。
+
+现在唯一要做的就是在 ScummVM 的游戏列表中选择游戏,点击“Start”,享受重温旧爱或首次体验经典冒险游戏的乐趣。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/scummvm-retro-gaming
+
+作者:[Joshua Allen Holm][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/holmja
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/open_gaming_games_roundup_news.png?itok=KM0ViL0f (Gaming artifacts with joystick, GameBoy, paddle)
+[2]: https://www.scummvm.org/
+[3]: https://opensource.com/sites/default/files/uploads/scummvm.png (ScummVM)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://www.dosbox.com/
+[6]: https://www.winehq.org/
+[7]: https://wiki.scummvm.org/index.php?title=Category:Supported_Games
+[8]: https://www.residualvm.org/
+[9]: https://www.adventuregamestudio.co.uk/
+[10]: https://wiki.scummvm.org/index.php/Compiling_ScummVM/GCC
+[11]: https://www.scummvm.org/games/
+[12]: https://www.gog.com/
+[13]: https://constexpr.org/innoextract/
+[14]: https://wiki.scummvm.org/index.php/Category:Supported_Games
diff --git a/published/202105/20210426 3 beloved USB drive Linux distros.md b/published/202105/20210426 3 beloved USB drive Linux distros.md
new file mode 100644
index 0000000000..505b90a5e2
--- /dev/null
+++ b/published/202105/20210426 3 beloved USB drive Linux distros.md
@@ -0,0 +1,87 @@
+[#]: subject: (3 beloved USB drive Linux distros)
+[#]: via: (https://opensource.com/article/21/4/usb-drive-linux-distro)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13355-1.html)
+
+爱了!3 个受欢迎的 U 盘 Linux 发行版
+======
+
+> 开源技术人员对此深有体会。
+
+
+
+Linux 用户几乎都会记得他们第一次发现无需实际安装,就可以用 Linux 引导计算机并在上面运行。当然,许多用户都知道可以引导计算机进入操作系统安装程序,但是 Linux 不同:它根本就不需要安装!你的计算机甚至不需要有一个硬盘。你可以通过一个 U 盘运行 Linux 几个月甚至几 _年_。
+
+自然,有几种不同的 “临场” Linux 发行版可供选择。我们向我们的作者们询问了他们的最爱,他们的回答如下。
+
+### 1、Puppy Linux
+
+“作为一名前 **Puppy Linux** 开发者,我对此的看法自然有些偏见,但 Puppy 最初吸引我的地方是:
+
+ * 它专注于第三世界国家容易获得的低端和老旧硬件。这为买不起最新的现代系统的贫困地区开放了计算能力
+ * 它能够在内存中运行,可以利用该能力提供一些有趣的安全优势
+ * 它在一个单一的 SFS 文件中处理用户文件和会话,使得备份、恢复或移动你现有的桌面/应用/文件到另一个安装中只需一个拷贝命令”
+
+—— [JT Pennington][2]
+
+“对我来说,一直就是 **Puppy Linux**。它启动迅速,支持旧硬件。它的 GUI 很容易就可以说服别人第一次尝试 Linux。” —— [Sachin Patil][3]
+
+“Puppy 是真正能在任何机器上运行的临场发行版。我有一台废弃的 microATX 塔式电脑,它的光驱坏了,也没有硬盘(为了数据安全,它已经被拆掉了),而且几乎没有多少内存。我把 Puppy 插入它的 SD 卡插槽,运行了好几年。” —— [Seth Kenlon][4]
+
+“我在使用 U 盘上的 Linux 发行版没有太多经验,但我把票投给 **Puppy Linux**。它很轻巧,非常适用于旧机器。” —— [Sergey Zarubin][5]
+
+### 2、Fedora 和 Red Hat
+
+“我最喜欢的 USB 发行版其实是 **Fedora Live USB**。它有浏览器、磁盘工具和终端仿真器,所以我可以用它来拯救机器上的数据,或者我可以浏览网页或在需要时用 ssh 进入其他机器做一些工作。所有这些都不需要在 U 盘或在使用中的机器上存储任何数据,不会在受到入侵时被泄露。” —— [Steve Morris][6]
+
+“我曾经用过 Puppy 和 DSL。如今,我有两个 U 盘:**RHEL7** 和 **RHEL8**。 这两个都被配置为完整的工作环境,能够在 UEFI 和 BIOS 上启动。当我有问题要解决而又面对随机的硬件时,在现实生活中这就是时间的救星。” —— [Steven Ellis][7]
+
+### 3、Porteus
+
+“不久前,我安装了 Porteus 系统每个版本的虚拟机。很有趣,所以有机会我会再试试它们。每当提到微型发行版的话题时,我总是想起我记得的第一个使用的发行版:**tomsrtbt**。它总是安装适合放在软盘上来设计。我不知道它现在有多大用处,但我想我应该把它也算上。” —— [Alan Formy-Duval][8]
+
+“作为一个 Slackware 的长期用户,我很欣赏 **Porteus** 提供的 Slack 的最新版本和灵活的环境。你可以用运行在内存中的 Porteus 进行引导,这样就不需要把 U 盘连接到你的电脑上,或者你可以从驱动器上运行,这样你就可以保留你的修改。打包应用很容易,而且 Slacker 社区有很多现有的软件包。这是我唯一需要的实时发行版。” —— [Seth Kenlon][4]
+
+### 其它:Knoppix
+
+“我已经有一段时间没有使用过 **Knoppix** 了,但我曾一度经常使用它来拯救那些被恶意软件破坏的 Windows 电脑。它最初于 2000 年 9 月发布,此后一直在持续开发。它最初是由 Linux 顾问 Klaus Knopper 开发并以他的名字命名的,被设计为临场 CD。我们用它来拯救由于恶意软件和病毒而变得无法访问的 Windows 系统上的用户文件。” —— [Don Watkins][9]
+
+“Knoppix 对临场 Linux 影响很大,但它也是对盲人用户使用最方便的发行版之一。它的 [ADRIANE 界面][10] 被设计成可以在没有视觉显示器的情况下使用,并且可以处理任何用户可能需要从计算机上获得的所有最常见的任务。” —— [Seth Kenlon][11]
+
+### 选择你的临场 Linux
+
+有很多没有提到的,比如 [Slax][12](一个基于 Debian 的实时发行版)、[Tiny Core][13]、[Slitaz][14]、[Kali][15](一个以安全为重点的实用程序发行版)、[E-live][16],等等。如果你有一个空闲的 U 盘,请把 Linux 放在上面,在任何时候都可以在任何电脑上使用 Linux!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/usb-drive-linux-distro
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
+[2]: https://opensource.com/users/jtpennington
+[3]: https://opensource.com/users/psachin
+[4]: http://opensource.com/users/seth
+[5]: https://opensource.com/users/sergey-zarubin
+[6]: https://opensource.com/users/smorris12
+[7]: https://opensource.com/users/steven-ellis
+[8]: https://opensource.com/users/alanfdoss
+[9]: https://opensource.com/users/don-watkins
+[10]: https://opensource.com/life/16/7/knoppix-adriane-interface
+[11]: https://opensource.com/article/21/4/opensource.com/users/seth
+[12]: http://slax.org
+[13]: http://www.tinycorelinux.net/
+[14]: http://www.slitaz.org/en/
+[15]: http://kali.org
+[16]: https://www.elivecd.org/
diff --git a/published/202105/20210427 An Open-Source App to Control All Your RGB Lighting Settings.md b/published/202105/20210427 An Open-Source App to Control All Your RGB Lighting Settings.md
new file mode 100644
index 0000000000..b9a5ec566e
--- /dev/null
+++ b/published/202105/20210427 An Open-Source App to Control All Your RGB Lighting Settings.md
@@ -0,0 +1,92 @@
+[#]: subject: (An Open-Source App to Control All Your RGB Lighting Settings)
+[#]: via: (https://itsfoss.com/openrgb/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13377-1.html)
+
+OpenRGB:一个控制所有 RGB 灯光设置的开源应用
+======
+
+> OpenRGB 是一个有用的开源工具,可以一个工具管理所有的 RGB 灯光。让我们来了解一下它。
+
+
+
+无论是你的键盘、鼠标、CPU 风扇、AIO,还是其他连接的外围设备或组件,Linux 都没有官方软件支持来控制 RGB 灯光。
+
+而 OpenRGB 似乎是一个适用于 Linux 的多合一 RGB 灯光控制工具。
+
+### OpenRGB:多合一的 RGB 灯光控制中心
+
+![][1]
+
+是的,你可能会找到不同的工具来调整设置,如 **Piper** 专门 [在 Linux 上配置游戏鼠标][2]。但是,如果你有各种组件或外设,要把它们都设置成你喜欢的 RGB 颜色,那将是一件很麻烦的事情。
+
+OpenRGB 是一个令人印象深刻的工具,它不仅专注于 Linux,也可用于 Windows 和 MacOS。
+
+它不仅仅是一个将所有 RGB 灯光设置放在一个工具下的想法,而是旨在摆脱所有需要安装来调整灯光设置的臃肿软件。
+
+即使你使用的是 Windows 系统的机器,你可能也知道像 Razer Synapse 这样的软件工具是占用资源的,并伴随着它们的问题。因此,OpenRGB 不仅仅局限于 Linux 用户,还适用于每一个希望调整 RGB 设置的用户。
+
+它支持大量设备,但你不应该期待对所有设备的支持。
+
+### OpenRGB 的特点
+
+![][3]
+
+它在提供简单的用户体验的同时,赋予了你许多有用的功能。其中的一些特点是:
+
+ * 轻便的用户界面
+ * 跨平台支持
+ * 能够使用插件扩展功能
+ * 设置颜色和效果
+ * 能够保存和加载配置文件
+ * 查看设备信息
+ * 连接 OpenRGB 的多个实例,在多台电脑上同步灯光
+
+![][4]
+
+除了上述所有的特点外,你还可以很好地控制照明区域、色彩模式、颜色等。
+
+### 在 Linux 中安装 OpenRGB
+
+你可以在其官方网站上找到 AppImage 文件和 DEB 包。对于 Arch Linux 用户,你也可以在 [AUR][5] 中找到它。
+
+如需更多帮助,你可以参考我们的 [AppImage 指南][6]和[安装 DEB 文件的方法][7]来设置。
+
+官方网站应该也可以让你下载其他平台的软件包。但是,如果你想探索更多关于它的信息或自己编译它,请前往它的 [GitLab 页面][8]。
+
+- [OpenRGB][9]
+
+### 总结
+
+尽管我没有很多支持 RGB 的设备/组件,但我可以成功地调整我的罗技 G502 鼠标。
+
+如果你想摆脱多个应用,用一个轻量级的界面来管理你所有的 RGB 灯光,我肯定会推荐你试一试。
+
+你已经试过它了吗?欢迎在评论中分享你对它的看法!
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/openrgb/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/openrgb.jpg?resize=800%2C406&ssl=1
+[2]: https://itsfoss.com/piper-configure-gaming-mouse-linux/
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/openrgb-supported-devices.jpg?resize=800%2C404&ssl=1
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/openrgb-logi.jpg?resize=800%2C398&ssl=1
+[5]: https://itsfoss.com/aur-arch-linux/
+[6]: https://itsfoss.com/use-appimage-linux/
+[7]: https://itsfoss.com/install-deb-files-ubuntu/
+[8]: https://gitlab.com/CalcProgrammer1/OpenRGB
+[9]: https://openrgb.org/
diff --git a/published/202105/20210427 Fedora Linux 34 is officially here.md b/published/202105/20210427 Fedora Linux 34 is officially here.md
new file mode 100644
index 0000000000..ac0df71962
--- /dev/null
+++ b/published/202105/20210427 Fedora Linux 34 is officially here.md
@@ -0,0 +1,75 @@
+[#]: subject: (Fedora Linux 34 is officially here!)
+[#]: via: (https://fedoramagazine.org/announcing-fedora-34/)
+[#]: author: (Matthew Miller https://fedoramagazine.org/author/mattdm/)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13365-1.html)
+
+Fedora Linux 34 各版本介绍
+======
+
+
+
+今天(4/27),我很高兴地与大家分享成千上万的 Fedora 项目贡献者的辛勤工作成果:我们的最新版本,Fedora Linux 34 来了!我知道你们中的很多人一直在等待。我在社交媒体和论坛上看到的“它出来了吗?”的期待比我记忆中的任何一个版本都多。所以,如果你想的话,不要再等了,[现在升级][2] 或者去 [获取 Fedora][3] 下载一个安装镜像。或者,如果你想先了解更多,请继续阅读。
+
+你可能注意到的第一件事是我们漂亮的新标志。这个新标志是由 Fedora 设计团队根据广大社区的意见开发的,它在保持 Fedoraness 的同时解决了我们旧标志的很多技术问题。请继续关注以新设计为特色的 Fedora 宣传品。
+
+### 适合各种使用场景的 Fedora Linux
+
+Fedora Editions 面向桌面、服务器、云环境和物联网等各种特定场景。
+
+Fedora Workstation 专注于台式机,尤其是面向那些希望获得“正常使用”的 Linux 操作系统体验的软件开发者。这个版本的带来了 [GNOME 40][4],这是专注、无干扰计算的下一步。无论你使用触控板、键盘还是鼠标,GNOME 40 都带来了导航方面的改进。应用网格和设置已经被重新设计,以使交互更加直观。你可以从 3 月份的 [Fedora Magazine][5] 文章中阅读更多的变化和原因。
+
+Fedora CoreOS 是一个新兴的 Fedora 版本。它是一个自动更新的最小化操作系统,用于安全和大规模地运行容器化工作负载。它提供了几个更新流,跟随它之后大约每两周自动更新一次,当前,next 流基于 Fedora Linux 34,随后是 testing 流和 stable 流。你可以从 [下载页面][6] 中找到关于跟随 next 流的已发布工件的信息,以及在 [Fedora CoreOS 文档][7] 中找到如何使用这些工件的信息。
+
+Fedora IoT 为物联网生态系统和边缘计算场景提供了一个强大的基础。在这个版本中,我们改善了对流行的 ARM 设备的支持,如 Pine64、RockPro64 和 Jetson Xavier NX。一些 i.MX8 片上系统设备,如 96boards Thor96 和 Solid Run HummingBoard-M 的硬件支持也有所改善。此外,Fedora IoT 34 改进了对用于自动系统恢复的硬件看门狗的支持。
+
+当然,我们不仅仅提供 Editions。[Fedora Spins][8] 和 [Labs][9] 针对不同的受众和使用情况,例如 [Fedora Jam][10],它允许你释放你内心的音乐家,以及像新的 Fedora i3 Spin 这样的桌面环境,它提供了一个平铺的窗口管理器。还有,别忘了我们的备用架构。[ARM AArch64 Power 和 S390x][11]。
+
+### 一般性改进
+
+无论你使用的是 Fedora 的哪个变种,你都会得到开源世界所能提供的最新成果。秉承我们的 “[First][12]” 原则,我们已经更新了关键的编程语言和系统库包,包括 Ruby 3.0 和 Golang 1.16。在 Fedora KDE Plasma 中,我们已经从 X11 切换到 Wayland 作为默认。
+
+在 Fedora Linux 33 中 BTRFS 作为桌面变体中的默认文件系统引入之后,我们又引入了 [BTRFS 文件系统的透明压缩][13]。
+
+我们很高兴你能试用这个新发布版本!现在就去 下载它。或者如果你已经在运行 Fedora Linux,请按照 [简易升级说明][2]。关于 Fedora Linux 34 的新功能的更多信息,请看 [发行说明][14]。
+
+### 万一出现问题……
+
+如果你遇到了问题,请查看 [Fedora 34 常见问题页面][15],如果你有问题,请访问我们的 Ask Fedora 用户支持平台。
+
+### 谢谢各位
+
+感谢在这个发布周期中为 Fedora 项目做出贡献的成千上万的人,特别是那些在大流行期间为使这个版本按时发布而付出额外努力的人。Fedora 是一个社区,很高兴看到我们如此互相支持!
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/announcing-fedora-34/
+
+作者:[Matthew Miller][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/mattdm/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/04/f34-final-816x345.jpg
+[2]: https://docs.fedoraproject.org/en-US/quick-docs/upgrading/
+[3]: https://getfedora.org
+[4]: https://forty.gnome.org/
+[5]: https://fedoramagazine.org/fedora-34-feature-focus-updated-activities-overview/
+[6]: https://getfedora.org/en/coreos
+[7]: https://docs.fedoraproject.org/en-US/fedora-coreos/
+[8]: https://spins.fedoraproject.org/
+[9]: https://labs.fedoraproject.org/
+[10]: https://labs.fedoraproject.org/en/jam/
+[11]: https://alt.fedoraproject.org/alt/
+[12]: https://docs.fedoraproject.org/en-US/project/#_first
+[13]: https://fedoramagazine.org/fedora-workstation-34-feature-focus-btrfs-transparent-compression/
+[14]: https://docs.fedoraproject.org/en-US/fedora/f34/release-notes/
+[15]: https://fedoraproject.org/wiki/Common_F34_bugs
+[16]: https://hopin.com/events/fedora-linux-34-release-party
diff --git a/published/202105/20210427 Perform Linux memory forensics with this open source tool.md b/published/202105/20210427 Perform Linux memory forensics with this open source tool.md
new file mode 100644
index 0000000000..85fd06058b
--- /dev/null
+++ b/published/202105/20210427 Perform Linux memory forensics with this open source tool.md
@@ -0,0 +1,485 @@
+[#]: subject: (Perform Linux memory forensics with this open source tool)
+[#]: via: (https://opensource.com/article/21/4/linux-memory-forensics)
+[#]: author: (Gaurav Kamathe https://opensource.com/users/gkamathe)
+[#]: collector: (lujun9972)
+[#]: translator: (ShuyRoy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13425-1.html)
+
+使用开源工具进行 Linux 内存取证
+======
+
+> 利用 Volatility 找出应用程序、网络连接、内核模块、文件等方面的情况。
+
+
+
+计算机的操作系统和应用使用主内存(RAM)来执行不同的任务。这种易失性内存包含大量关于运行应用、网络连接、内核模块、打开的文件以及几乎所有其他的内容信息,但这些信息每次计算机重启的时候都会被清除。
+
+内存取证是一种从内存中找到和抽取这些有价值的信息的方式。[Volatility][2] 是一种使用插件来处理这类信息的开源工具。但是,存在一个问题:在你处理这些信息前,必须将物理内存转储到一个文件中,而 Volatility 没有这种能力。
+
+因此,这篇文章分为两部分:
+
+ * 第一部分是处理获取物理内存并将其转储到一个文件中。
+ * 第二部分使用 Volatility 从这个内存转储中读取并处理这些信息。
+
+我在本教程中使用了以下测试系统,不过它可以在任何 Linux 发行版上工作:
+
+```
+$ cat /etc/redhat-release
+Red Hat Enterprise Linux release 8.3 (Ootpa)
+$
+$ uname -r
+4.18.0-240.el8.x86_64
+$
+```
+
+> **注意事项:** 部分 1 涉及到编译和加载一个内核模块。不要担心:它并不像听起来那么困难。
+>
+> 一些指南:
+>
+> * 按照以下的步骤。
+> * 不要在生产系统或你的主要计算机上尝试任何这些步骤。
+> * 始终使用测试的虚拟机(VM)来尝试,直到你熟悉使用这些工具并理解它们的工作原理为止。
+
+### 安装需要的包
+
+在开始之前安装必要的工具。如果你经常使用基于 Debian 的发行版,可以使用 `apt-get` 命令。这些包大多数提供了需要的内核信息和工具来编译代码:
+
+```
+$ yum install kernel-headers kernel-devel gcc elfutils-libelf-devel make git libdwarf-tools python2-devel.x86_64-y
+```
+
+### 部分 1:使用 LiME 获取内存并将其转储到一个文件中
+
+在开始分析内存之前,你需要一个内存转储供你使用。在实际的取证活动中,这可能来自一个被破坏或者被入侵的系统。这些信息通常会被收集和存储来分析入侵是如何发生的及其影响。由于你可能没有可用的内存转储,你可以获取你的测试 VM 的内存转储,并使用它来执行内存取证。
+
+Linux 内存提取器([LiME][3])是一个在 Linux 系统上获取内存很常用的工具。使用以下命令获得 LiME:
+
+```
+$ git clone https://github.com/504ensicsLabs/LiME.git
+$
+$ cd LiME/src/
+$
+$ ls
+deflate.c disk.c hash.c lime.h main.c Makefile Makefile.sample tcp.c
+$
+```
+
+#### 构建 LiME 内核模块
+
+在 `src` 文件夹下运行 `make` 命令。这会创建一个以 .ko 为扩展名的内核模块。理想情况下,在 `make` 结束时,`lime.ko` 文件会使用格式 `lime-.ko` 被重命名。
+
+```
+$ make
+make -C /lib/modules/4.18.0-240.el8.x86_64/build M="/root/LiME/src" modules
+make[1]: Entering directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
+
+<< 删节 >>
+
+make[1]: Leaving directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
+strip --strip-unneeded lime.ko
+mv lime.ko lime-4.18.0-240.el8.x86_64.ko
+$
+$
+$ ls -l lime-4.18.0-240.el8.x86_64.ko
+-rw-r--r--. 1 root root 25696 Apr 17 14:45 lime-4.18.0-240.el8.x86_64.ko
+$
+$ file lime-4.18.0-240.el8.x86_64.ko
+lime-4.18.0-240.el8.x86_64.ko: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), BuildID[sha1]=1d0b5cf932389000d960a7e6b57c428b8e46c9cf, not stripped
+$
+```
+
+#### 加载LiME 内核模块
+
+现在是时候加载内核模块来获取系统内存了。`insmod` 命令会帮助加载内核模块;模块一旦被加载,会在你的系统上读取主内存(RAM)并且将内存的内容转储到命令行所提供的 `path` 目录下的文件中。另一个重要的参数是 `format`;保持 `lime` 的格式,如下所示。在插入内核模块之后,使用 `lsmod` 命令验证它是否真的被加载。
+
+```
+$ lsmod | grep lime
+$
+$ insmod ./lime-4.18.0-240.el8.x86_64.ko "path=../RHEL8.3_64bit.mem format=lime"
+$
+$ lsmod | grep lime
+lime 16384 0
+$
+```
+
+你应该看到给 `path` 命令的文件已经创建好了,而且文件大小与你系统的物理内存(RAM)大小相同(并不奇怪)。一旦你有了内存转储,你就可以使用 `rmmod` 命令删除该内核模块:
+
+```
+$
+$ ls -l ~/LiME/RHEL8.3_64bit.mem
+-r--r--r--. 1 root root 4294544480 Apr 17 14:47 /root/LiME/RHEL8.3_64bit.mem
+$
+$ du -sh ~/LiME/RHEL8.3_64bit.mem
+4.0G /root/LiME/RHEL8.3_64bit.mem
+$
+$ free -m
+ total used free shared buff/cache available
+Mem: 3736 220 366 8 3149 3259
+Swap: 4059 8 4051
+$
+$ rmmod lime
+$
+$ lsmod | grep lime
+$
+```
+
+#### 内存转储中是什么?
+
+这个内存转储文件只是原始数据,就像使用 `file` 命令可以看到的一样。你不可能通过手动去理解它;是的,在这里边有一些 ASCII 字符,但是你无法用编辑器打开这个文件并把它读出来。`hexdump` 的输出显示,最初的几个字节是 `EmiL`;这是因为你的请求格式在上面的命令行中是 `lime`:
+
+```
+$ file ~/LiME/RHEL8.3_64bit.mem
+/root/LiME/RHEL8.3_64bit.mem: data
+$
+
+$ hexdump -C ~/LiME/RHEL8.3_64bit.mem | head
+00000000 45 4d 69 4c 01 00 00 00 00 10 00 00 00 00 00 00 |EMiL............|
+00000010 ff fb 09 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
+00000020 b8 fe 4c cd 21 44 00 32 20 00 00 2a 2a 2a 2a 2a |..L.!D.2 ..*****|
+00000030 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |****************|
+00000040 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 20 00 20 |************* . |
+00000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
+*
+00000080 00 00 00 00 00 00 00 00 00 00 00 00 70 78 65 6c |............pxel|
+00000090 69 6e 75 78 2e 30 00 00 00 00 00 00 00 00 00 00 |inux.0..........|
+000000a0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
+$
+```
+
+### 部分 2:获得 Volatility 并使用它来分析你的内存转储
+
+现在你有了要分析的示例内存转储,使用下面的命令获取 Volatility 软件。Volatility 已经用 Python 3 重写了,但是本教程使用的是用 Python 2 写的原始的 Volatility 包。如果你想用 Volatility 3 进行实验,可以从合适的 Git 仓库下载它,并在以下命令中使用 Python 3 而不是 Python 2:
+
+```
+$ git clone https://github.com/volatilityfoundation/volatility.git
+$
+$ cd volatility/
+$
+$ ls
+AUTHORS.txt contrib LEGAL.txt Makefile PKG-INFO pyinstaller.spec resources tools vol.py
+CHANGELOG.txt CREDITS.txt LICENSE.txt MANIFEST.in pyinstaller README.txt setup.py volatility
+$
+```
+
+Volatility 使用两个 Python 库来实现某些功能,所以使用以下命令来安装它们。否则,在你运行 Volatility 工具时,你可能看到一些导入错误;你可以忽略它们,除非你正在运行的插件需要这些库;这种情况下,工具将会报错:
+
+```
+$ pip2 install pycrypto
+$ pip2 install distorm3
+```
+
+#### 列出 Volatility 的 Linux 配置文件
+
+你将要运行的第一个 Volatility 命令列出了可用的 Linux 配置文件,运行 Volatility 命令的主要入口点是 `vol.py` 脚本。使用 Python 2 解释器调用它并提供 `--info` 选项。为了缩小输出,查找以 Linux 开头的字符串。正如你所看到的,并没有很多 Linux 配置文件被列出:
+
+```
+$ python2 vol.py --info | grep ^Linux
+Volatility Foundation Volatility Framework 2.6.1
+LinuxAMD64PagedMemory - Linux-specific AMD 64-bit address space.
+$
+```
+
+#### 构建你自己的 Linux 配置文件
+
+Linux 发行版是多种多样的,并且是为不同架构而构建的。这就是为什么配置文件是必要的 —— Volatility 在提取信息前必须知道内存转储是从哪个系统和架构获得的。有一些 Volatility 命令可以找到这些信息;但是这个方法很费时。为了加快速度,可以使用以下命令构建一个自定义的 Linux 配置文件:
+
+移动到 Volatility 仓库的 `tools/linux`目录下,运行 `make` 命令:
+
+```
+$ cd tools/linux/
+$
+$ pwd
+/root/volatility/tools/linux
+$
+$ ls
+kcore Makefile Makefile.enterprise module.c
+$
+$ make
+make -C //lib/modules/4.18.0-240.el8.x86_64/build CONFIG_DEBUG_INFO=y M="/root/volatility/tools/linux" modules
+make[1]: Entering directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
+<< 删节 >>
+make[1]: Leaving directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
+$
+```
+
+你应该看到一个新的 `module.dwarf` 文件。你也需要 `/boot` 目录下的 `System.map` 文件,因为它包含了所有与当前运行的内核相关的符号:
+
+```
+$ ls
+kcore Makefile Makefile.enterprise module.c module.dwarf
+$
+$ ls -l module.dwarf
+-rw-r--r--. 1 root root 3987904 Apr 17 15:17 module.dwarf
+$
+$ ls -l /boot/System.map-4.18.0-240.el8.x86_64
+-rw-------. 1 root root 4032815 Sep 23 2020 /boot/System.map-4.18.0-240.el8.x86_64
+$
+$
+```
+
+要创建一个自定义配置文件,移动回到 Volatility 目录并且运行下面的命令。第一个参数提供了一个自定义 .zip 文件,文件名是你自己命名的。我经常使用操作系统和内核版本来命名。下一个参数是前边创建的 `module.dwarf` 文件,最后一个参数是 `/boot` 目录下的 `System.map` 文件:
+
+```
+$
+$ cd volatility/
+$
+$ zip volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip tools/linux/module.dwarf /boot/System.map-4.18.0-240.el8.x86_64
+ adding: tools/linux/module.dwarf (deflated 91%)
+ adding: boot/System.map-4.18.0-240.el8.x86_64 (deflated 79%)
+$
+```
+
+现在自定义配置文件就准备好了,所以在前边给出的位置检查一下 .zip 文件是否被创建好。如果你想知道 Volatility 是否检测到这个自定义配置文件,再一次运行 `--info` 命令。现在,你应该可以在下边的列出的内容中看到新的配置文件:
+
+```
+$
+$ ls -l volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip
+-rw-r--r--. 1 root root 1190360 Apr 17 15:20 volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip
+$
+$
+$ python2 vol.py --info | grep Redhat
+Volatility Foundation Volatility Framework 2.6.1
+LinuxRedhat8_3_4_18_0-240x64 - A Profile for Linux Redhat8.3_4.18.0-240 x64
+$
+$
+```
+
+#### 开始使用 Volatility
+
+现在你已经准备好去做一些真正的内存取证了。记住,Volatility 是由自定义的插件组成的,你可以针对内存转储来获得信息。命令的通用格式是:
+
+```
+python2 vol.py -f --profile=
+```
+
+有了这些信息,运行 `linux_banner` 插件来看看你是否可从内存转储中识别正确的发行版信息:
+
+```
+$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_banner --profile=LinuxRedhat8_3_4_18_0-240x64
+Volatility Foundation Volatility Framework 2.6.1
+Linux version 4.18.0-240.el8.x86_64 ([mockbuild@vm09.test.com][4]) (gcc version 8.3.1 20191121 (Red Hat 8.3.1-5) (GCC)) #1 SMP Wed Sep 23 05:13:10 EDT 2020
+$
+```
+
+#### 找到 Linux 插件
+
+到现在都很顺利,所以现在你可能对如何找到所有 Linux 插件的名字比较好奇。有一个简单的技巧:运行 `--info` 命令并抓取 `linux_` 字符串。有各种各样的插件可用于不同的用途。这里列出一部分:
+
+```
+$ python2 vol.py --info | grep linux_
+Volatility Foundation Volatility Framework 2.6.1
+linux_apihooks - Checks for userland apihooks
+linux_arp - Print the ARP table
+linux_aslr_shift - Automatically detect the Linux ASLR shift
+
+<< 删节 >>
+
+linux_banner - Prints the Linux banner information
+linux_vma_cache - Gather VMAs from the vm_area_struct cache
+linux_volshell - Shell in the memory image
+linux_yarascan - A shell in the Linux memory image
+$
+```
+
+使用 `linux_psaux` 插件检查内存转储时系统上正在运行哪些进程。注意列表中的最后一个命令:它是你在转储之前运行的 `insmod` 命令。
+
+```
+$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_psaux --profile=LinuxRedhat8_3_4_18_0-240x64
+Volatility Foundation Volatility Framework 2.6.1
+Pid Uid Gid Arguments
+1 0 0 /usr/lib/systemd/systemd --switched-root --system --deserialize 18
+2 0 0 [kthreadd]
+3 0 0 [rcu_gp]
+4 0 0 [rcu_par_gp]
+861 0 0 /usr/libexec/platform-python -Es /usr/sbin/tuned -l -P
+869 0 0 /usr/bin/rhsmcertd
+875 0 0 /usr/libexec/sssd/sssd_be --domain implicit_files --uid 0 --gid 0 --logger=files
+878 0 0 /usr/libexec/sssd/sssd_nss --uid 0 --gid 0 --logger=files
+
+<< 删节 >>
+
+11064 89 89 qmgr -l -t unix -u
+227148 0 0 [kworker/0:0]
+227298 0 0 -bash
+227374 0 0 [kworker/u2:1]
+227375 0 0 [kworker/0:2]
+227884 0 0 [kworker/0:3]
+228573 0 0 insmod ./lime-4.18.0-240.el8.x86_64.ko path=../RHEL8.3_64bit.mem format=lime
+228576 0 0
+$
+```
+
+想要知道系统的网络状态吗?运行 `linux_netstat` 插件来找到在内存转储期间网络连接的状态:
+
+```
+$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_netstat --profile=LinuxRedhat8_3_4_18_0-240x64
+Volatility Foundation Volatility Framework 2.6.1
+UNIX 18113 systemd/1 /run/systemd/private
+UNIX 11411 systemd/1 /run/systemd/notify
+UNIX 11413 systemd/1 /run/systemd/cgroups-agent
+UNIX 11415 systemd/1
+UNIX 11416 systemd/1
+
+<< 删节 >>
+$
+```
+
+接下来,使用 `linux_mount` 插件来看在内存转储期间哪些文件系统被挂载:
+
+```
+$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_mount --profile=LinuxRedhat8_3_4_18_0-240x64
+Volatility Foundation Volatility Framework 2.6.1
+tmpfs /sys/fs/cgroup tmpfs ro,nosuid,nodev,noexec
+cgroup /sys/fs/cgroup/pids cgroup rw,relatime,nosuid,nodev,noexec
+systemd-1 /proc/sys/fs/binfmt_misc autofs rw,relatime
+sunrpc /var/lib/nfs/rpc_pipefs rpc_pipefs rw,relatime
+/dev/mapper/rhel_kvm--03--guest11-root / xfs rw,relatime
+tmpfs /dev/shm tmpfs rw,nosuid,nodev
+selinuxfs /sys/fs/selinux selinuxfs rw,relatime
+
+<< 删节 >>
+
+cgroup /sys/fs/cgroup/net_cls,net_prio cgroup rw,relatime,nosuid,nodev,noexec
+cgroup /sys/fs/cgroup/cpu,cpuacct cgroup rw,relatime,nosuid,nodev,noexec
+bpf /sys/fs/bpf bpf rw,relatime,nosuid,nodev,noexec
+cgroup /sys/fs/cgroup/memory cgroup ro,relatime,nosuid,nodev,noexec
+cgroup /sys/fs/cgroup/cpuset cgroup rw,relatime,nosuid,nodev,noexec
+mqueue /dev/mqueue mqueue rw,relatime
+$
+```
+
+好奇哪些内核模块被加载了吗?Volatility 也为这个提供了一个插件 `linux_lsmod`:
+
+```
+$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_lsmod --profile=LinuxRedhat8_3_4_18_0-240x64
+Volatility Foundation Volatility Framework 2.6.1
+ffffffffc0535040 lime 20480
+ffffffffc0530540 binfmt_misc 20480
+ffffffffc05e8040 sunrpc 479232
+<< 删节 >>
+ffffffffc04f9540 nfit 65536
+ffffffffc0266280 dm_mirror 28672
+ffffffffc025e040 dm_region_hash 20480
+ffffffffc0258180 dm_log 20480
+ffffffffc024bbc0 dm_mod 151552
+$
+```
+
+想知道哪些文件被哪些进程打开了吗?使用 `linux_bash` 插件可以列出这些信息:
+
+```
+$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_bash --profile=LinuxRedhat8_3_4_18_0-240x64 -v
+Volatility Foundation Volatility Framework 2.6.1
+Pid Name Command Time Command
+-------- -------------------- ------------------------------ -------
+ 227221 bash 2021-04-17 18:38:24 UTC+0000 lsmod
+ 227221 bash 2021-04-17 18:38:24 UTC+0000 rm -f .log
+ 227221 bash 2021-04-17 18:38:24 UTC+0000 ls -l /etc/zzz
+ 227221 bash 2021-04-17 18:38:24 UTC+0000 cat ~/.vimrc
+ 227221 bash 2021-04-17 18:38:24 UTC+0000 ls
+ 227221 bash 2021-04-17 18:38:24 UTC+0000 cat /proc/817/cwd
+ 227221 bash 2021-04-17 18:38:24 UTC+0000 ls -l /proc/817/cwd
+ 227221 bash 2021-04-17 18:38:24 UTC+0000 ls /proc/817/
+<< 删节 >>
+ 227298 bash 2021-04-17 18:40:30 UTC+0000 gcc prt.c
+ 227298 bash 2021-04-17 18:40:30 UTC+0000 ls
+ 227298 bash 2021-04-17 18:40:30 UTC+0000 ./a.out
+ 227298 bash 2021-04-17 18:40:30 UTC+0000 vim prt.c
+ 227298 bash 2021-04-17 18:40:30 UTC+0000 gcc prt.c
+ 227298 bash 2021-04-17 18:40:30 UTC+0000 ./a.out
+ 227298 bash 2021-04-17 18:40:30 UTC+0000 ls
+$
+```
+
+想知道哪些文件被哪些进程打开了吗?使用 `linux_lsof` 插件可以列出这些信息:
+
+```
+$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_lsof --profile=LinuxRedhat8_3_4_18_0-240x64
+Volatility Foundation Volatility Framework 2.6.1
+Offset Name Pid FD Path
+------------------ ------------------------------ -------- -------- ----
+0xffff9c83fb1e9f40 rsyslogd 71194 0 /dev/null
+0xffff9c83fb1e9f40 rsyslogd 71194 1 /dev/null
+0xffff9c83fb1e9f40 rsyslogd 71194 2 /dev/null
+0xffff9c83fb1e9f40 rsyslogd 71194 3 /dev/urandom
+0xffff9c83fb1e9f40 rsyslogd 71194 4 socket:[83565]
+0xffff9c83fb1e9f40 rsyslogd 71194 5 /var/log/messages
+0xffff9c83fb1e9f40 rsyslogd 71194 6 anon_inode:[9063]
+0xffff9c83fb1e9f40 rsyslogd 71194 7 /var/log/secure
+
+<< 删节 >>
+
+0xffff9c8365761f40 insmod 228573 0 /dev/pts/0
+0xffff9c8365761f40 insmod 228573 1 /dev/pts/0
+0xffff9c8365761f40 insmod 228573 2 /dev/pts/0
+0xffff9c8365761f40 insmod 228573 3 /root/LiME/src/lime-4.18.0-240.el8.x86_64.ko
+$
+```
+
+#### 访问 Linux 插件脚本位置
+
+通过读取内存转储和处理这些信息,你可以获得更多的信息。如果你会 Python,并且好奇这些信息是如何被处理的,可以到存储所有插件的目录,选择一个你感兴趣的,并看看 Volatility 是如何获得这些信息的:
+
+```
+$ ls volatility/plugins/linux/
+apihooks.py common.py kernel_opened_files.py malfind.py psaux.py
+apihooks.pyc common.pyc kernel_opened_files.pyc malfind.pyc psaux.pyc
+arp.py cpuinfo.py keyboard_notifiers.py mount_cache.py psenv.py
+arp.pyc cpuinfo.pyc keyboard_notifiers.pyc mount_cache.pyc psenv.pyc
+aslr_shift.py dentry_cache.py ld_env.py mount.py pslist_cache.py
+aslr_shift.pyc dentry_cache.pyc ld_env.pyc mount.pyc pslist_cache.pyc
+<< 删节 >>
+check_syscall_arm.py __init__.py lsmod.py proc_maps.py tty_check.py
+check_syscall_arm.pyc __init__.pyc lsmod.pyc proc_maps.pyc tty_check.pyc
+check_syscall.py iomem.py lsof.py proc_maps_rb.py vma_cache.py
+check_syscall.pyc iomem.pyc lsof.pyc proc_maps_rb.pyc vma_cache.pyc
+$
+$
+```
+
+我喜欢 Volatility 的理由是他提供了许多安全插件。这些信息很难手动获取:
+
+```
+linux_hidden_modules - Carves memory to find hidden kernel modules
+linux_malfind - Looks for suspicious process mappings
+linux_truecrypt_passphrase - Recovers cached Truecrypt passphrases
+```
+
+Volatility 也允许你在内存转储中打开一个 shell,所以你可以运行 shell 命令来代替上面所有命令,并获得相同的信息:
+
+```
+$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_volshell --profile=LinuxRedhat8_3_4_18_0-240x64 -v
+Volatility Foundation Volatility Framework 2.6.1
+Current context: process systemd, pid=1 DTB=0x1042dc000
+Welcome to volshell! Current memory image is:
+file:///root/LiME/RHEL8.3_64bit.mem
+To get help, type 'hh()'
+>>>
+>>> sc()
+Current context: process systemd, pid=1 DTB=0x1042dc000
+>>>
+```
+
+### 接下来的步骤
+
+内存转储是了解 Linux 内部情况的好方法。试一试 Volatility 的所有插件,并详细研究它们的输出。然后思考这些信息如何能够帮助你识别入侵或安全问题。深入了解这些插件的工作原理,甚至尝试改进它们。如果你没有找到你想做的事情的插件,那就写一个并提交给 Volatility,这样其他人也可以使用它。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/linux-memory-forensics
+
+作者:[Gaurav Kamathe][a]
+选题:[lujun9972][b]
+译者:[RiaXu](https://github.com/ShuyRoy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gkamathe
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/brain_computer_solve_fix_tool.png?itok=okq8joti (Brain on a computer screen)
+[2]: https://github.com/volatilityfoundation/volatility
+[3]: https://github.com/504ensicsLabs/LiME
+[4]: mailto:mockbuild@vm09.test.com
diff --git a/published/202105/20210427 What-s new in Fedora Workstation 34.md b/published/202105/20210427 What-s new in Fedora Workstation 34.md
new file mode 100644
index 0000000000..88369c6f6a
--- /dev/null
+++ b/published/202105/20210427 What-s new in Fedora Workstation 34.md
@@ -0,0 +1,106 @@
+[#]: subject: (What’s new in Fedora Workstation 34)
+[#]: via: (https://fedoramagazine.org/whats-new-fedora-34-workstation/)
+[#]: author: (Christian Fredrik Schaller https://fedoramagazine.org/author/uraeus/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13359-1.html)
+
+Fedora Workstation 34 中的新变化
+======
+
+
+
+Fedora Workstation 34 是我们领先的操作系统的最新版本,这次你将获得重大改进。最重要的是,你可以从 [官方网站][2] 下载它。我听到你在问,有什么新的东西?好吧,让我们来介绍一下。
+
+### GNOME 40
+
+[GNOME 40][3] 是对 GNOME 桌面的一次重大更新,Fedora 社区成员在其设计和实现过程中发挥了关键作用,因此你可以确信 Fedora 用户的需求被考虑在内。
+
+当你登录到 GNOME 40 桌面时,首先注意到的就是你现在会被直接带到一个重新设计的概览屏幕。你会注意到仪表盘已经移到了屏幕的底部。GNOME 40 的另一个主要变化是虚拟工作空间现在是水平摆放的,这使 GNOME 与其他大多数桌面更加一致,因此应该使新用户更容易适应 GNOME 和 Fedora。
+
+我们还做了一些工作来改善桌面中的手势支持,用三根手指水平滑动来切换工作空间,用三根手指垂直滑动来调出概览。
+
+![][4]
+
+更新后的概览设计带来了一系列其他改进,包括:
+
+ * 仪表盘现在将收藏的和未收藏的运行中的应用程序分开。这使得可以清楚了解哪些应用已经被收藏,哪些未收藏。
+ * 窗口缩略图得到了改进,现在每个窗口上都有一个应用程序图标,以帮助识别。
+ * 当工作区被设置为在所有显示器上显示时,工作区切换器现在会显示在所有显示器上,而不仅仅是主显示器。
+ * 应用启动器的拖放功能得到了改进,可以更轻松地自定义应用程序网格的排列方式。
+
+GNOME 40 中的变化经历了大量的用户测试,到目前为止反应非常正面,所以我们很高兴能将它们介绍给 Fedora 社区。更多信息请见 [forty.gnome.org][3] 或 [GNOME 40 发行说明][5]。
+
+### 应用程序的改进
+
+GNOME “天气”为这个版本进行了重新设计,具有两个视图,一个是未来 48 小时的小时预报,另一个是未来 10 天的每日预报。
+
+新版本现在显示了更多的信息,并且更适合移动设备,因为它支持更窄的尺寸。
+
+![][6]
+
+其他被改进的应用程序包括“文件”、“地图”、“软件”和“设置”。更多细节请参见 [GNOME 40 发行说明][5]。
+
+### PipeWire
+
+PipeWire 是新的音频和视频服务器,由 Wim Taymans 创建,他也共同创建了 GStreamer 多媒体框架。到目前为止,它只被用于视频捕获,但在 Fedora Workstation 34 中,我们也开始将其用于音频,取代 PulseAudio。
+
+PipeWire 旨在与 PulseAudio 和 Jack 兼容,因此应用程序通常应该像以前一样可以工作。我们还与 Firefox 和 Chrome 合作,确保它们能与 PipeWire 很好地配合。OBS Studio 也即将支持 PipeWire,所以如果你是一个播客,我们已经帮你搞定了这些。
+
+PipeWire 在专业音频界获得了非常积极的回应。谨慎地说,从一开始就可能有一些专业音频应用不能完全工作,但我们会源源不断收到测试报告和补丁,我们将在 Fedora Workstation 34 的生命周期内使用这些报告和补丁来延续专业音频 PipeWire 的体验。
+
+### 改进的 Wayland 支持
+
+我们预计将在 Fedora Workstation 34 的生命周期内解决在专有的 NVIDIA 驱动之上运行 Wayland 的支持。已经支持在 NVIDIA 驱动上运行纯 Wayland 客户端。然而,当前还缺少对许多应用程序使用的 Xwayland 兼容层的支持。这就是为什么当你安装 NVIDIA 驱动时,Fedora 仍然默认为 X.Org。
+
+我们正在 [与 NVIDIA 上游合作][7],以确保 Xwayland 能在 Fedora 中使用 NVIDIA 硬件加速。
+
+### QtGNOME 平台和 Adwaita-Qt
+
+Jan Grulich 继续他在 QtGNOME 平台和 Adawaita-qt 主题上的出色工作,确保 Qt 应用程序与 Fedora 工作站的良好整合。多年来,我们在 Fedora 中使用的 Adwaita 主题已经发生了演变,但随着 QtGNOME 平台和 Adwaita-Qt 在 Fedora 34 中的更新,Qt 应用程序将更接近于 Fedora Workstation 34 中当前的 GTK 风格。
+
+作为这项工作的一部分,Fedora Media Writer 的外观和风格也得到了改进。
+
+![][8]
+
+### Toolbox
+
+Toolbox 是我们用于创建与主机系统隔离的开发环境的出色工具,它在 Fedora 34 上有了很多改进。例如,我们在改进 Toolbox 的 CI 系统集成方面做了大量的工作,以避免在我们的环境中出现故障时导致 Toolbox 停止工作。
+
+我们在 Toolbox 的 RHEL 集成方面投入了大量的工作,这意味着你可以很容易地在 Fedora 系统上建立一个容器化的 RHEL 环境,从而方便地为 RHEL 服务器和云实例做开发。现在在 Fedora 上创建一个 RHEL 环境就像运行:`toolbox create -distro rhel -release 8.4` 一样简单。
+
+这给你提供了一个最新桌面的优势:支持最新硬件,同时能够以一种完全原生的方式进行针对 RHEL 的开发。
+
+![][9]
+
+### Btrfs
+
+自 Fedora 33 以来,Fedora Workstation 一直使用 Btrfs 作为其默认文件系统。Btrfs 是一个现代文件系统,由许多公司和项目开发。Workstation 采用 Btrfs 是通过 Facebook 和 Fedora 社区之间的奇妙合作实现的。根据到目前为止的用户反馈,人们觉得与旧的 ext4 文件系统相比,Btrfs 提供了更快捷、更灵敏的体验。
+
+在 Fedora 34 中,新安装的 Workstation 系统现在默认使用 Btrfs 透明压缩。与未压缩的 Btrfs 相比,这可以节省 20-40% 的大量磁盘空间。它也增加了 SSD 和其他闪存介质的寿命。
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/whats-new-fedora-34-workstation/
+
+作者:[Christian Fredrik Schaller][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/uraeus/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/04/f34-workstation-816x345.jpg
+[2]: https://getfedora.org/workstation
+[3]: https://forty.gnome.org/
+[4]: https://lh3.googleusercontent.com/xDklMWAGBWvRGRp2kby-XKr6b0Jvan8Obmn11sfmkKnsnXizKePYV9aWdEgyxmJetcvwMifYRUm6TcPRCH9szZfZOE9pCpv2bkjQhnq2II05Yu6o_DjEBmqTlRUGvvUyMN_VRtq8zkk2J7GUmA
+[5]: https://help.gnome.org/misc/release-notes/40.0/
+[6]: https://lh6.googleusercontent.com/pQ3IIAvJDYrdfXoTUnrOcCQBjtpXqd_5Rmbo4xwxIj2qMCXt7ZxJEQ12OoV7yUSF8zpVR0VFXkMP0M8UK1nLbU7jhgQPJAHPayzjAscQmTtqqGsohyzth6-xFDjUXogmeFmcP-yR9GWXfXv-yw
+[7]: https://gitlab.freedesktop.org/xorg/xserver/-/merge_requests/587
+[8]: https://lh6.googleusercontent.com/PDXxFS7SBFGI-3jRtR-TmqupvJRxy_CbWTfjB4sc1CKyO1myXkqfpg4jGHQJRK2e1vUh1KD_jyBsy8TURwCIkgAJcETCOlSPFBabqB5yDeWj3cvygOOQVe3X0tLFjuOz3e-ZX6owNZJSqIEHOQ
+[9]: https://lh6.googleusercontent.com/dVRCL14LGE9WpmdiH3nI97OW2C1TkiZqREvBlHClNKdVcYvR1nZpZgWfup_GP5SN17iQtSJf59FxX2GYqoajXbdXLRfOwAREn7gVJ1fa_bspmcTZ81zkUQC4tNUx3f7D7uD7Peeg2Zc9Kldpww
diff --git a/published/202105/20210429 Encrypting and decrypting files with OpenSSL.md b/published/202105/20210429 Encrypting and decrypting files with OpenSSL.md
new file mode 100644
index 0000000000..a3cbe64aec
--- /dev/null
+++ b/published/202105/20210429 Encrypting and decrypting files with OpenSSL.md
@@ -0,0 +1,440 @@
+[#]: subject: "Encrypting and decrypting files with OpenSSL"
+[#]: via: "https://opensource.com/article/21/4/encryption-decryption-openssl"
+[#]: author: "Gaurav Kamathe https://opensource.com/users/gkamathe"
+[#]: collector: "lujun9972"
+[#]: translator: "MjSeven"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13368-1.html"
+
+使用 OpenSSL 加密和解密文件
+======
+
+> OpenSSL 是一个实用工具,它可以确保其他人员无法打开你的敏感和机密消息。
+
+
+
+加密是对消息进行编码的一种方法,这样可以保护消息的内容免遭他人窥视。一般有两种类型:
+
+ 1. 密钥加密或对称加密
+ 2. 公钥加密或非对称加密
+
+密钥加密使用相同的密钥进行加密和解密,而公钥加密使用不同的密钥进行加密和解密。每种方法各有利弊。密钥加密速度更快,而公钥加密更安全,因为它解决了安全共享密钥的问题,将它们结合在一起可以最大限度地利用每种类型的优势。
+
+### 公钥加密
+
+公钥加密使用两组密钥,称为密钥对。一个是公钥,可以与你想要秘密通信的任何人自由共享。另一个是私钥,应该是一个秘密,永远不会共享。
+
+公钥用于加密。如果某人想与你交流敏感信息,你可以将你的公钥发送给他们,他们可以使用公钥加密消息或文件,然后再将其发送给你。私钥用于解密。解密发件人加密的消息的唯一方法是使用私钥。因此,它们被称为“密钥对”,它们是相互关联的。
+
+### 如何使用 OpenSSL 加密文件
+
+[OpenSSL][2] 是一个了不起的工具,可以执行各种任务,例如加密文件。本文使用安装了 OpenSSL 的 Fedora 计算机。如果你的机器上没有,则可以使用软件包管理器进行安装:
+
+```
+alice $ cat /etc/fedora-release
+Fedora release 33 (Thirty Three)
+alice $
+alice $ openssl version
+OpenSSL 1.1.1i FIPS 8 Dec 2020
+alice $
+```
+
+要探索文件加密和解密,假如有两个用户 Alice 和 Bob,他们想通过使用 OpenSSL 交换加密文件来相互通信。
+
+#### 步骤 1:生成密钥对
+
+在加密文件之前,你需要生成密钥对。你还需要一个密码短语,每当你使用 OpenSSL 时都必须使用该密码短语,因此务必记住它。
+
+Alice 使用以下命令生成她的一组密钥对:
+
+```
+alice $ openssl genrsa -aes128 -out alice_private.pem 1024
+```
+
+此命令使用 OpenSSL 的 [genrsa][3] 命令生成一个 1024 位的公钥/私钥对。这是可以的,因为 RSA 算法是不对称的。它还使用了 aes128 对称密钥算法来加密 Alice 生成的私钥。
+
+输入命令后,OpenSSL 会提示 Alice 输入密码,每次使用密钥时,她都必须输入该密码:
+
+```
+alice $ openssl genrsa -aes128 -out alice_private.pem 1024
+Generating RSA private key, 1024 bit long modulus (2 primes)
+..........+++++
+..................................+++++
+e is 65537 (0x010001)
+Enter pass phrase for alice_private.pem:
+Verifying - Enter pass phrase for alice_private.pem:
+alice $
+alice $
+alice $ ls -l alice_private.pem
+-rw-------. 1 alice alice 966 Mar 22 17:44 alice_private.pem
+alice $
+alice $ file alice_private.pem
+alice_private.pem: PEM RSA private key
+alice $
+```
+
+Bob 使用相同的步骤来创建他的密钥对:
+
+```
+bob $ openssl genrsa -aes128 -out bob_private.pem 1024
+Generating RSA private key, 1024 bit long modulus (2 primes)
+..................+++++
+............................+++++
+e is 65537 (0x010001)
+Enter pass phrase for bob_private.pem:
+Verifying - Enter pass phrase for bob_private.pem:
+bob $
+bob $ ls -l bob_private.pem
+-rw-------. 1 bob bob 986 Mar 22 13:48 bob_private.pem
+bob $
+bob $ file bob_private.pem
+bob_private.pem: PEM RSA private key
+bob $
+```
+
+如果你对密钥文件感到好奇,可以打开命令生成的 .pem 文件,但是你会看到屏幕上的一堆文本:
+
+
+```
+alice $ head alice_private.pem
+-----BEGIN RSA PRIVATE KEY-----
+Proc-Type: 4,ENCRYPTED
+DEK-Info: AES-128-CBC,E26FAC1F143A30632203F09C259200B9
+
+pdKj8Gm5eeAOF0RHzBx8l1tjmA1HSSvy0RF42bOeb7sEVZtJ6pMnrJ26ouwTQnkL
+JJjUVPPHoKZ7j4QpwzbPGrz/hVeMXVT/y33ZEEA+3nrobwisLKz+Q+C9TVJU3m7M
+/veiBO9xHMGV01YBNeic7MqXBkhIrNZW6pPRfrbjsBMBGSsL8nwJbb3wvHhzPkeM
+e+wtt9S5PWhcnGMj3T+2mtFfW6HWpd8Kdp60z7Nh5mhA9+5aDWREfJhJYzl1zfcv
+Bmxjf2wZ3sFJNty+sQVajYfk6UXMyJIuWgAjnqjw6c3vxQi0KE3NUNZYO93GQgEF
+pyAnN9uGUTBCDYeTwdw8TEzkyaL08FkzLfFbS2N9BDksA3rpI1cxpxRVFr9+jDBz
+alice $
+```
+
+要查看密钥的详细信息,可以使用以下 OpenSSL 命令打开 .pem 文件并显示内容。你可能想知道在哪里可以找到另一个配对的密钥,因为这是单个文件。你观察的很细致,获取公钥的方法如下:
+
+```
+alice $ openssl rsa -in alice_private.pem -noout -text
+Enter pass phrase for alice_private.pem:
+RSA Private-Key: (1024 bit, 2 primes)
+modulus:
+ 00:bd:e8:61:72:f8:f6:c8:f2:cc:05:fa:07:aa:99:
+ 47:a6:d8:06:cf:09:bf:d1:66:b7:f9:37:29:5d:dc:
+ c7:11:56:59:d7:83:b4:81:f6:cf:e2:5f:16:0d:47:
+ 81:fe:62:9a:63:c5:20:df:ee:d3:95:73:dc:0a:3f:
+ 65:d3:36:1d:c1:7d:8b:7d:0f:79:de:80:fc:d2:c0:
+ e4:27:fc:e9:66:2d:e2:7e:fc:e6:73:d1:c9:28:6b:
+ 6a:8a:e8:96:9d:65:a0:8a:46:e0:b8:1f:b0:48:d4:
+ db:d4:a3:7f:0d:53:36:9a:7d:2e:e7:d8:f2:16:d3:
+ ff:1b:12:af:53:22:c0:41:51
+publicExponent: 65537 (0x10001)
+
+<< 截断 >>
+
+exponent2:
+ 6e:aa:8c:6e:37:d0:57:37:13:c0:08:7e:75:43:96:
+ 33:01:99:25:24:75:9c:0b:45:3c:a2:39:44:69:84:
+ a4:64:48:f4:5c:bc:40:40:bf:84:b8:f8:0f:1d:7b:
+ 96:7e:16:00:eb:49:da:6b:20:65:fc:a9:20:d9:98:
+ 76:ca:59:e1
+coefficient:
+ 68:9e:2e:fa:a3:a4:72:1d:2b:60:61:11:b1:8b:30:
+ 6e:7e:2d:f9:79:79:f2:27:ab:a0:a0:b6:45:08:df:
+ 12:f7:a4:3b:d9:df:c5:6e:c7:e8:81:29:07:cd:7e:
+ 47:99:5d:33:8c:b7:fb:3b:a9:bb:52:c0:47:7a:1c:
+ e3:64:90:26
+alice $
+```
+
+#### 步骤 2:提取公钥
+
+注意,公钥是你可以与他人自由共享的密钥,而你必须将私钥保密。因此,Alice 必须提取她的公钥,并将其保存到文件中:
+
+```
+alice $ openssl rsa -in alice_private.pem -pubout > alice_public.pem
+Enter pass phrase for alice_private.pem:
+writing RSA key
+alice $
+alice $ ls -l *.pem
+-rw-------. 1 alice alice 966 Mar 22 17:44 alice_private.pem
+-rw-rw-r--. 1 alice alice 272 Mar 22 17:47 alice_public.pem
+alice $
+```
+
+你可以使用与之前相同的方式查看公钥详细信息,但是这次,输入公钥 .pem 文件:
+
+```
+alice $
+alice $ openssl rsa -in alice_public.pem -pubin -text -noout
+RSA Public-Key: (1024 bit)
+Modulus:
+ 00:bd:e8:61:72:f8:f6:c8:f2:cc:05:fa:07:aa:99:
+ 47:a6:d8:06:cf:09:bf:d1:66:b7:f9:37:29:5d:dc:
+ c7:11:56:59:d7:83:b4:81:f6:cf:e2:5f:16:0d:47:
+ 81:fe:62:9a:63:c5:20:df:ee:d3:95:73:dc:0a:3f:
+$
+```
+
+Bob 可以按照相同的过程来提取他的公钥并将其保存到文件中:
+
+```
+bob $ openssl rsa -in bob_private.pem -pubout > bob_public.pem
+Enter pass phrase for bob_private.pem:
+writing RSA key
+bob $
+bob $ ls -l *.pem
+-rw-------. 1 bob bob 986 Mar 22 13:48 bob_private.pem
+-rw-r--r--. 1 bob bob 272 Mar 22 13:51 bob_public.pem
+bob $
+```
+
+#### 步骤 3:交换公钥
+
+这些公钥在 Alice 和 Bob 彼此交换之前没有太大用处。有几种共享公钥的方法,例如使用 `scp` 命令将密钥复制到彼此的工作站。
+
+将 Alice 的公钥发送到 Bob 的工作站:
+
+```
+alice $ scp alice_public.pem bob@bob-machine-or-ip:/path/
+```
+
+将 Bob 的公钥发送到 Alice 的工作站:
+
+```
+bob $ scp bob_public.pem alice@alice-machine-or-ip:/path/
+```
+
+现在,Alice 有了 Bob 的公钥,反之亦然:
+
+```
+alice $ ls -l bob_public.pem
+-rw-r--r--. 1 alice alice 272 Mar 22 17:51 bob_public.pem
+alice $
+```
+
+```
+bob $ ls -l alice_public.pem
+-rw-r--r--. 1 bob bob 272 Mar 22 13:54 alice_public.pem
+bob $
+```
+
+#### 步骤 4:使用公钥交换加密的消息
+
+假设 Alice 需要与 Bob 秘密交流。她将秘密信息写入文件中,并将其保存到 `top_secret.txt` 中。由于这是一个普通文件,因此任何人都可以打开它并查看其内容,这里并没有太多保护:
+
+
+```
+alice $
+alice $ echo "vim or emacs ?" > top_secret.txt
+alice $
+alice $ cat top_secret.txt
+vim or emacs ?
+alice $
+```
+
+要加密此秘密消息,Alice 需要使用 `openssls -encrypt` 命令。她需要为该工具提供三个输入:
+
+ 1. 秘密消息文件的名称
+ 2. Bob 的公钥(文件)
+ 3. 加密后新文件的名称
+
+```
+alice $ openssl rsautl -encrypt -inkey bob_public.pem -pubin -in top_secret.txt -out top_secret.enc
+alice $
+alice $ ls -l top_secret.*
+-rw-rw-r--. 1 alice alice 128 Mar 22 17:54 top_secret.enc
+-rw-rw-r--. 1 alice alice 15 Mar 22 17:53 top_secret.txt
+alice $
+alice $
+```
+
+加密后,原始文件仍然是可见的,而新创建的加密文件在屏幕上看起来像乱码。这样,你可以确定秘密消息已被加密:
+
+```
+alice $ cat top_secret.txt
+vim or emacs ?
+alice $
+alice $ cat top_secret.enc
+�s��uM)M&>��N��}dmCy92#1X�q��v���M��@��E�~��1�k~&PU�VhHL�@^P��(��zi�M�4p�e��g+R�1�Ԁ���s�������q_8�lr����C�I-��alice $
+alice $
+alice $
+alice $ hexdump -C ./top_secret.enc
+00000000 9e 73 12 8f e3 75 4d 29 4d 26 3e bf 80 4e a0 c5 |.s...uM)M&>..N..|
+00000010 7d 64 6d 43 79 39 32 23 31 58 ce 71 f3 ba 95 a6 |}dmCy92#1X.q....|
+00000020 c0 c0 76 17 fb f7 bf 4d ce fc 40 e6 f4 45 7f db |..v....M..@..E..|
+00000030 7e ae c0 31 f8 6b 10 06 7e 26 50 55 b5 05 56 68 |~..1.k..~&PU..Vh|
+00000040 48 4c eb 40 5e 50 fe 19 ea 28 a8 b8 7a 13 69 d7 |HL.@^P...(..z.i.|
+00000050 4d b0 34 70 d8 65 d5 07 95 67 2b 52 ea 31 aa d4 |M.4p.e...g+R.1..|
+00000060 80 b3 a8 ec a1 73 ed a7 f9 17 c3 13 d4 fa c1 71 |.....s.........q|
+00000070 5f 38 b9 6c 07 72 81 a6 fe af 43 a6 49 2d c4 ee |_8.l.r....C.I-..|
+00000080
+alice $
+alice $ file top_secret.enc
+top_secret.enc: data
+alice $
+```
+
+删除秘密消息的原始文件是安全的,这样确保任何痕迹都没有:
+
+```
+alice $ rm -f top_secret.txt
+```
+
+现在,Alice 需要再次使用 `scp` 命令将此加密文件通过网络发送给 Bob 的工作站。注意,即使文件被截获,其内容也会是加密的,因此内容不会被泄露:
+
+```
+alice $ scp top_secret.enc bob@bob-machine-or-ip:/path/
+```
+
+如果 Bob 使用常规方法尝试打开并查看加密的消息,他将无法看懂该消息:
+
+```
+bob $ ls -l top_secret.enc
+-rw-r--r--. 1 bob bob 128 Mar 22 13:59 top_secret.enc
+bob $
+bob $ cat top_secret.enc
+�s��uM)M&>��N��}dmCy92#1X�q��v���M��@��E�~��1�k~&PU�VhHL�@^P��(��zi�M�4p�e��g+R�1�Ԁ���s�������q_8�lr����C�I-��bob $
+bob $
+bob $ hexdump -C top_secret.enc
+00000000 9e 73 12 8f e3 75 4d 29 4d 26 3e bf 80 4e a0 c5 |.s...uM)M&>..N..|
+00000010 7d 64 6d 43 79 39 32 23 31 58 ce 71 f3 ba 95 a6 |}dmCy92#1X.q....|
+00000020 c0 c0 76 17 fb f7 bf 4d ce fc 40 e6 f4 45 7f db |..v....M..@..E..|
+00000030 7e ae c0 31 f8 6b 10 06 7e 26 50 55 b5 05 56 68 |~..1.k..~&PU..Vh|
+00000040 48 4c eb 40 5e 50 fe 19 ea 28 a8 b8 7a 13 69 d7 |HL.@^P...(..z.i.|
+00000050 4d b0 34 70 d8 65 d5 07 95 67 2b 52 ea 31 aa d4 |M.4p.e...g+R.1..|
+00000060 80 b3 a8 ec a1 73 ed a7 f9 17 c3 13 d4 fa c1 71 |.....s.........q|
+00000070 5f 38 b9 6c 07 72 81 a6 fe af 43 a6 49 2d c4 ee |_8.l.r....C.I-..|
+00000080
+bob $
+```
+
+#### 步骤 5:使用私钥解密文件
+
+Bob 需要使用 OpenSSL 来解密消息,但是这次使用的是 `-decrypt` 命令行参数。他需要向工具程序提供以下信息:
+
+ 1. 加密的文件(从 Alice 那里得到)
+ 2. Bob 的私钥(用于解密,因为文件是用 Bob 的公钥加密的)
+ 3. 通过重定向保存解密输出的文件名
+
+```
+bob $ openssl rsautl -decrypt -inkey bob_private.pem -in top_secret.enc > top_secret.txt
+Enter pass phrase for bob_private.pem:
+bob $
+```
+
+现在,Bob 可以阅读 Alice 发送给他的秘密消息:
+
+```
+bob $ ls -l top_secret.txt
+-rw-r--r--. 1 bob bob 15 Mar 22 14:02 top_secret.txt
+bob $
+bob $ cat top_secret.txt
+vim or emacs ?
+bob $
+```
+
+Bob 需要回复 Alice,因此他将秘密回复写在一个文件中:
+
+```
+bob $ echo "nano for life" > reply_secret.txt
+bob $
+bob $ cat reply_secret.txt
+nano for life
+bob $
+```
+
+#### 步骤 6:使用其他密钥重复该过程
+
+为了发送消息,Bob 采用和 Alice 相同的步骤,但是由于该消息是发送给 Alice 的,因此他需要使用 Alice 的公钥来加密文件:
+
+```
+bob $ openssl rsautl -encrypt -inkey alice_public.pem -pubin -in reply_secret.txt -out reply_secret.enc
+bob $
+bob $ ls -l reply_secret.enc
+-rw-r--r--. 1 bob bob 128 Mar 22 14:03 reply_secret.enc
+bob $
+bob $ cat reply_secret.enc
+�F݇��.4"f�1��\��{o$�M��I{5�|�\�l͂�e��Y�V��{�|!$c^a
+ �*Ԫ\vQ�Ϡ9����'��ٮsP��'��Z�1W�n��k���J�0�I;P8������&:bob $
+bob $
+bob $ hexdump -C ./reply_secret.enc
+00000000 92 46 dd 87 04 bc a7 2e 34 22 01 66 1a 13 31 db |.F......4".f..1.|
+00000010 c4 5c b4 8e 7b 6f d4 b0 24 d2 4d 92 9b 49 7b 35 |.\..{o..$.M..I{5|
+00000020 da 7c ee 5c bb 6c cd 82 f1 1b 92 65 f1 8d f2 59 |.|.\.l.....e...Y|
+00000030 82 56 81 80 7b 89 07 7c 21 24 63 5e 61 0c ae 2a |.V..{..|!$c^a..*|
+00000040 d4 aa 5c 76 51 8d cf a0 39 04 c1 d7 dc f0 ad 99 |..\vQ...9.......|
+00000050 27 ed 8e de d9 ae 02 73 50 e0 dd 27 13 ae 8e 5a |'......sP..'...Z|
+00000060 12 e4 9a 31 57 b3 03 6e dd e1 16 7f 6b c0 b3 8b |...1W..n....k...|
+00000070 4a cf 30 b8 49 3b 50 38 e0 9f 84 f6 83 da 26 3a |J.0.I;P8......&:|
+00000080
+bob $
+bob $ # remove clear text secret message file
+bob $ rm -f reply_secret.txt
+```
+
+Bob 通过 `scp` 将加密的文件发送至 Alice 的工作站:
+
+```
+$ scp reply_secret.enc alice@alice-machine-or-ip:/path/
+```
+
+如果 Alice 尝试使用常规工具去阅读加密的文本,她将无法理解加密的文本:
+
+```
+alice $
+alice $ ls -l reply_secret.enc
+-rw-r--r--. 1 alice alice 128 Mar 22 18:01 reply_secret.enc
+alice $
+alice $ cat reply_secret.enc
+�F݇��.4"f�1��\��{o$�M��I{5�|�\�l͂�e��Y�V��{�|!$c^a
+ �*Ԫ\vQ�Ϡ9����'��ٮsP��'��Z�1W�n��k���J�0�I;P8������&:alice $
+alice $
+alice $
+alice $ hexdump -C ./reply_secret.enc
+00000000 92 46 dd 87 04 bc a7 2e 34 22 01 66 1a 13 31 db |.F......4".f..1.|
+00000010 c4 5c b4 8e 7b 6f d4 b0 24 d2 4d 92 9b 49 7b 35 |.\..{o..$.M..I{5|
+00000020 da 7c ee 5c bb 6c cd 82 f1 1b 92 65 f1 8d f2 59 |.|.\.l.....e...Y|
+00000030 82 56 81 80 7b 89 07 7c 21 24 63 5e 61 0c ae 2a |.V..{..|!$c^a..*|
+00000040 d4 aa 5c 76 51 8d cf a0 39 04 c1 d7 dc f0 ad 99 |..\vQ...9.......|
+00000050 27 ed 8e de d9 ae 02 73 50 e0 dd 27 13 ae 8e 5a |'......sP..'...Z|
+00000060 12 e4 9a 31 57 b3 03 6e dd e1 16 7f 6b c0 b3 8b |...1W..n....k...|
+00000070 4a cf 30 b8 49 3b 50 38 e0 9f 84 f6 83 da 26 3a |J.0.I;P8......&:|
+00000080
+alice $
+```
+
+所以,她使用 OpenSSL 解密消息,只不过这次她提供了自己的私钥并将输出保存到文件中:
+
+```
+alice $ openssl rsautl -decrypt -inkey alice_private.pem -in reply_secret.enc > reply_secret.txt
+Enter pass phrase for alice_private.pem:
+alice $
+alice $ ls -l reply_secret.txt
+-rw-rw-r--. 1 alice alice 14 Mar 22 18:02 reply_secret.txt
+alice $
+alice $ cat reply_secret.txt
+nano for life
+alice $
+```
+
+### 了解 OpenSSL 的更多信息
+
+OpenSSL 在加密界是真正的瑞士军刀。除了加密文件外,它还可以执行许多任务,你可以通过访问 OpenSSL [文档页面][4]来找到使用它的所有方式,包括手册的链接、 《OpenSSL Cookbook》、常见问题解答等。要了解更多信息,尝试使用其自带的各种加密算法,看看它是如何工作的。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/encryption-decryption-openssl
+
+作者:[Gaurav Kamathe][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gkamathe
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003601_05_mech_osyearbook2016_security_cc.png?itok=3V07Lpko "A secure lock."
+[2]: https://www.openssl.org/
+[3]: https://www.openssl.org/docs/man1.0.2/man1/genrsa.html
+[4]: https://www.openssl.org/docs/
\ No newline at end of file
diff --git a/published/202105/20210429 Experiencing the -e- OS- The Open Source De-Googled Android Version.md b/published/202105/20210429 Experiencing the -e- OS- The Open Source De-Googled Android Version.md
new file mode 100644
index 0000000000..6a957af93e
--- /dev/null
+++ b/published/202105/20210429 Experiencing the -e- OS- The Open Source De-Googled Android Version.md
@@ -0,0 +1,132 @@
+[#]: subject: (Experiencing the /e/ OS: The Open Source De-Googled Android Version)
+[#]: via: (https://itsfoss.com/e-os-review/)
+[#]: author: (Dimitrios https://itsfoss.com/author/dimitrios/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13442-1.html)
+
+体验 /e/ OS:开源的去谷歌化的安卓
+======
+
+
+
+/e/ 安卓操作系统是一个以隐私为导向的去谷歌化的移动操作系统,是 Lineage OS 的复刻,由 Mandrake Linux(现在的 [Mandriva Linux][2])的创建者 [Gaël Duval][1] 于 2018 年中期创立。
+
+尽管安卓在 2007 年成为了一个开源项目,但当安卓得到普及时,谷歌使用专有软件取代了一些操作系统元素。/e/ 基金会用 [MicroG][3] 取代了其中的专有的应用程序和服务,这是一个开源的替代框架,可以最大限度地减少跟踪和设备活动。
+
+我们收到的 [Fairphone 3][4] 预装了 /e/ OS,这是一个来自 /e/ 基金会的 [以道德的方式创造的智能手机][5]。我使用了一个月这个设备,然后把它返还给了他们,我将分享我对这个隐私设备的体验。我忘了截图,所以我将分享来自官方网站的通用图片。
+
+### 在道德的 Fairphone 设备上体验 /e/ 移动操作系统
+
+在我进一步说明之前,让我澄清一下,Fairphone 3 并不是使用 /e/ 的唯一选择。如果你要从他们那里购买设备,/e/ 基金会会给你 [一些智能手机的选择][6]。
+
+你不需要购买设备来使用 /e/ OS。按照 /e/ 基金会的说法,你可以 [在 100 多个支持的设备上使用它][7]。
+
+尽管我很喜欢使用 Fairphone 3,而且我的个人信仰与 Fairphone 的宣言一致,但我不会把注意力放在设备上,而只是放在 /e/ OS 上。
+
+#### 有评级隐私的应用程序
+
+![][8]
+
+我把 Fairphone 3 作为我的日常使用设备用了几天时间,以比较与我的“普通”安卓手机在现实中的使用情况。
+
+首先,我想看看我使用的所有应用程序是否都可以在 /e/ 基金会创建的“[应用商店][9]”上找到。/e/ 应用商店包含有隐私评级的应用程序。
+
+![/e/ OS 应用商店有应用程序的隐私评级][10]
+
+我可以找到许多应用程序,包括来自谷歌的应用程序。这意味着,如果有人真的想使用一些谷歌的服务,它仍然可以作为一个选项来下载。尽管与其他安卓设备不同,没有强行将谷歌服务塞进你的嘴里。
+
+虽然有很多应用程序,但我无法找到我在英国使用的手机银行应用程序。我不得不承认,手机银行应用程序可以在一定程度上促进便利。作为替代方案,我不得不在需要时进入电脑使用网上银行平台。
+
+从可用性的角度来看,/e/ OS 可以取代我的“标准”安卓操作系统,但会有一些小插曲,比如银行应用程序。
+
+#### 如果不是谷歌的,那是什么?
+
+想知道 /e/ OS 使用哪些基本的应用程序,而不是谷歌的那些?这里有一个快速列表:
+
+ * [魔法地球][11] —— 逐向道路导航
+ * 浏览器 —— Chromium 的一个非谷歌复刻版本
+ * 邮件 —— [K9-mail][12] 的一个复刻
+ * 短信 —— QKSMS 的一个复刻
+ * 照相机 —— OpenCamera 的一个复刻
+ * 天气 —— GoodWeather 的一个复刻
+ * OpenTasks —— 任务组织者
+ * 日历:[Etar calendar][13] 的一个复刻
+
+#### Bliss Launcher 和整体设计
+
+![][14]
+
+/e/ OS 的默认启动程序被称为 “Bliss Launcher”,其目的是为了获得有吸引力的外观和感觉。对我来说,这个设计感觉与 iOS 相似。
+
+通过向左滑动面板,你可以访问 /e/ 选择的一些有用的小工具。
+
+![][15]
+
+ * 搜索:快速搜索预装的应用程序或搜索 Web
+ * APP 建议:前 4 个最常用的应用程序将出现在这个小部件上
+ * 天气:天气小部件显示的是当地的天气。它不会自动检测位置,需要进行配置。
+ * 编辑:如果你想在屏幕上有更多的小部件,你可以通过点击“编辑”按钮添加它们。
+
+总而言之,用户界面是干净整洁的简单明了,增强了愉快的用户体验。 * 天气。天气小部件显示的是当地的天气。它不会自动检测位置,需要进行配置。
+ * 编辑:如果你想在屏幕上有更多的小部件,你可以通过点击编辑按钮添加它们。
+
+总而言之,用户界面干净整洁、简单明了,增强了愉快的用户体验。
+
+#### 去谷歌化和面向隐私的操作系统
+
+如前所述,/e/ 操作系统是一个去谷歌化的操作系统,它基于 [Lineage OS][16] 的开源核心。所有的谷歌应用程序已经被删除,谷歌服务已经被 MicroG 框架所取代。/e/ OS 仍然与所有的安卓应用兼容。
+
+主要的隐私功能:
+
+ * 谷歌搜索引擎已被 DuckDuckGo 等替代品取代
+ * 谷歌服务已被 microG 框架所取代
+ * 使用替代的默认应用程序,而不是谷歌应用程序
+ * 取消了对谷歌服务器的连接检查
+ * NTP 服务器已被替换为标准的 NTP 服务:pool.ntp.org
+ * DNS 默认服务器由 9.9.9.9 取代,可以根据用户的选择进行编辑
+ * 地理定位是在 GPS 的基础上使用 Mozilla 定位服务
+
+> 隐私声明
+>
+> 请注意,使用由 /e/ 基金会提供的智能手机并不自动意味着无论你做什么都能保证你的隐私。分享你的个人信息的社交媒体应用程序应在你的意识下使用。
+
+### 结论
+
+我成为安卓用户已经超过十年了。/e/ OS 给我带来了积极的惊喜。关注隐私的用户可以发现这个解决方案非常吸引人,而且根据所选择的应用程序和设置,可以再次感觉到使用智能手机的安全。
+
+如果你是一个有隐私意识的技术专家,并且能够自己找到解决问题的方法,我向你推荐它。对于那些习惯于谷歌主流服务的人来说,/e/ 生态系统可能会让他们不知所措。
+
+你使用过 /e/ OS 吗?你的使用经验如何?你怎么看这些关注隐私的项目?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/e-os-review/
+
+作者:[Dimitrios][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/dimitrios/
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Ga%C3%ABl_Duval
+[2]: https://en.wikipedia.org/wiki/Mandriva_Linux
+[3]: https://en.wikipedia.org/wiki/MicroG
+[4]: https://esolutions.shop/shop/e-os-fairphone-3-fr/
+[5]: https://www.fairphone.com/en/story/?ref=header
+[6]: https://esolutions.shop/shop/
+[7]: https://doc.e.foundation/devices/
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/e-ecosystem.png?resize=768%2C510&ssl=1
+[9]: https://e.foundation/e-os-available-applications/
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/04/e-os-apps-privacy-ratings.png?resize=300%2C539&ssl=1
+[11]: https://www.magicearth.com/
+[12]: https://k9mail.app/
+[13]: https://github.com/Etar-Group/Etar-Calendar
+[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/fairphone.jpg?resize=600%2C367&ssl=1
+[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/e-bliss-launcher.jpg?resize=300%2C533&ssl=1
+[16]: https://lineageos.org/
diff --git a/published/202105/20210429 Linux tips for using GNU Screen.md b/published/202105/20210429 Linux tips for using GNU Screen.md
new file mode 100644
index 0000000000..969c31dcfb
--- /dev/null
+++ b/published/202105/20210429 Linux tips for using GNU Screen.md
@@ -0,0 +1,96 @@
+[#]: subject: (Linux tips for using GNU Screen)
+[#]: via: (https://opensource.com/article/21/4/gnu-screen-cheat-sheet)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (ddl-hust)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13387-1.html)
+
+使用 GNU Screen 的小技巧
+======
+
+> 学习基本的 GNU Screen 终端复用技术,然后下载我们的终端命令备忘录,以便你能够熟悉常用的快捷方式。
+
+
+
+对于一般用户而言,命令行终端窗口可能是令人困惑和神秘的。但随着你对 Linux 终端的进一步了解,你很快就会意识到它的高效和强大。不过,也不需要很长时间,你就会想让终端变得更加高效,除了将更多的终端放到你的终端,还有什么高好的方法能够提升你的终端效率呢?
+
+### 终端复用
+
+终端的许多优点之一是它是一个集中控制的界面。它是一个能让你访问数百个应用程序的窗口,而你与每一个应用程序进行交互所需要的只是一个键盘。但是,现代计算机几乎总是有多余的处理能力,而且现代计算机专家喜欢多任务处理,导致一个窗口处理数百个应用程序的能力是相当有限的。
+
+解决这一问题的常见答案是终端复用:即将虚拟终端叠放在一起,然后在它们之间移动的能力。通过终端复用器,你保持了集中控制,但是当你进行多任务时,你能够进行终端切换。更好的是,你能够在终端中拆分屏幕,使得在同一时间显示多个屏幕窗口。
+
+### 选择合适的复用器
+
+一些终端提供类似的功能,有标签式界面和分割式视图,但也有细微的差别。首先,这些终端的功能依赖于图形化的桌面环境。其次,许多图形化的终端功能需要鼠标交互或使用不方便的键盘快捷键。终端复用器的功能在文本控制台上和在图形桌面上一样好用,而且键位绑定是针对常见的终端序列设计的,很方便。
+
+现有两种流行的复用器:[tmux][2] 和 [GNU Screen][3]。尽管你与它们互动的方式略有不同,但它们做同样的事情,而且大多具有相同的功能。这篇文章是 GNU Screen 的入门指南。关于 tmux 的相关介绍,请阅读 Kevin Sonney 的 [tmux 介绍][4]。
+
+### 使用 GNU Screen
+
+GNU Screen 的基本用法很简单,通过 `screen` 命令启动,你将进入 Screen 会话的第 0 个窗口。在你决定需要一个新的终端提示符前,你可能很难注意到有什么变化。
+
+当一个终端窗口被某项活动占用(比如,你启动了文本编辑器 [Vim][5] 或 [Jove][6] 或者你在处理音视频,或运行批处理任务),你可以新建一个窗口。要打开一个新的窗口,按 `Ctrl+A`,释放,然后按 `c`。这将在你现有窗口的基础上创建一个新的窗口。
+
+你会知道当前你是在一个新的窗口中,因为你的终端除了默认的提示符外,似乎没有任何东西。当然,你的另一个终端仍然存在,它只是躲在新窗口的后面。要遍历打开的窗口,按 `Ctrl+A`,释放,然后按 `n`(表示下一个)或按 `p`(表示上一个)。在只打开两个窗口的情况下, `n` 和 `p` 的功能是一样的,但你可以随时打开更多的窗口(`Ctrl+A`,然后 `c` ),并在它们之间切换。
+
+### 分屏
+
+GNU Screen 的默认行为更像移动设备的屏幕,而不是桌面:你一次只能看到一个窗口。如果你因为喜欢多任务而使用 GNU Screen ,那么只关注一个窗口可能看起来是一种退步。幸运的是,GNU Screen 可以让你把终端分成窗口中的窗口。
+
+要创建一个水平分割窗口,按 `Ctrl+A`,然后按 `s` 。这将把一个窗口置于另一个窗口之上,就像窗格一样。然而,在你告诉它要显示什么之前,分割的空间是没有用途的。因此,在创建一个分割窗后,你可以用 `Ctrl+A` ,然后用 `Tab` 移动到分割窗中。一旦进入,使用 `Ctrl+A` 然后 `n` 浏览所有可用的窗口,直到你想显示的内容出现在分割窗格中。
+
+你也可以按 `Ctrl+A` 然后按 `|` (这是一个管道字符,在大多数键盘上通过按下 `shift` 键加上 `\`)创建垂直分割窗口。
+
+### 自定义 GNU Screen
+
+ GNU Screen 使用基于 `Ctrl+A` 的快捷键。根据你的习惯,这可能会让你感觉非常自然,也可能非常不方便,因为你可能会用 `Ctrl+A` 来移动到一行的开头。无论怎样,GNU Screen 允许通过 `.screenrc` 配置文件进行各种定制。你可以用这个来改变触发键的绑定(称为 “转义” 键绑定)。
+
+```
+escape ^jJ
+```
+
+你还可以添加一个状态行,以帮助你在 Screen 会话中保持自己不迷失。
+
+```
+# status bar, with current window highlighted
+hardstatus alwayslastline
+hardstatus string '%{= kG}[%{G}%H%? %1`%?%{g}][%= %{= kw}%-w%{+b yk} %n*%t%?(%u)%? %{-}%+w %=%{g}][%{B}%m/%d %{W}%C%A%{g}]'
+
+# enable 256 colors
+attrcolor b ".I"
+termcapinfo xterm 'Co#256:AB=\E[48;5;%dm:AF=\E[38;5;%dm'
+defbce on
+```
+
+在有多个窗口打开的会话中,有一个时刻提醒哪些窗口具有焦点活动,哪些窗口有后台活动的提醒器特别有用。它类似一种终端的任务管理器。
+
+### 下载备忘单
+
+当你学习 GNU Screen 的使用方法时,需要记住很多新的键盘命令。有些命令你马上就能记住,但那些你不常使用的命令可能就很难记住了。你可以按 `Ctrl+A` 然后再按 `?` 来访问 GNU Screen 的帮助界面,但如果你更喜欢一些可以打印出来并放在键盘边的东西,请 [下载我们的 GNU Screen 备忘单][7]。
+
+学习 GNU Screen 是提高你使用你最喜欢的 [终端模拟器][8] 的效率和敏捷性的一个好方法。请试一试吧!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/gnu-screen-cheat-sheet
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[ddl-hust](https://github.com/ddl-hust)
+校对:[wxy](https://github.com/wxy)
+
+本文由[LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/)荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/terminal_command_linux_desktop_code.jpg?itok=p5sQ6ODE (Terminal command prompt on orange background)
+[2]: https://github.com/tmux/tmux/wiki
+[3]: https://www.gnu.org/software/screen/
+[4]: https://opensource.com/article/20/1/tmux-console
+[5]: https://opensource.com/tags/vim
+[6]: https://opensource.com/article/17/1/jove-lightweight-alternative-vim
+[7]: https://opensource.com/downloads/gnu-screen-cheat-sheet
+[8]: https://opensource.com/article/21/2/linux-terminals
diff --git a/published/202105/20210430 Access an alternate internet with OpenNIC.md b/published/202105/20210430 Access an alternate internet with OpenNIC.md
new file mode 100644
index 0000000000..5381d44ab5
--- /dev/null
+++ b/published/202105/20210430 Access an alternate internet with OpenNIC.md
@@ -0,0 +1,139 @@
+[#]: subject: (Access an alternate internet with OpenNIC)
+[#]: via: (https://opensource.com/article/21/4/opennic-internet)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13393-1.html)
+
+用 OpenNIC 访问另一个互联网
+======
+
+> 在超级信息高速公路上绕行。
+
+
+
+用传奇的 DNS 黑客 Dan Kaminsky 的话说,“事实证明,互联网对全球社会而言意义重大”。为了使互联网发挥作用,计算机必须能够在最复杂的网络万维网(WWW)中找到彼此。这是几十年前给政府工作人员和学术界 IT 人员提出的问题,而今天我们使用的正是他们的解决方案。然而,他们实际上并不是在寻求建立 互联网,他们是在为 互联网络(实际上是 级联网,即“级联的网络”,但这个术语最终不再流行)定义规范,它是一个互连的网络的通用术语。
+
+根据这些规范,网络使用数字组合,作为每台在线计算机的一种家地址,并为每个网站分配一个人性化但高度结构化的“主机名”(如 `example.com`)。由于用户主要是通过网站 _名称_ 与互联网互动,可以说互联网的运作只是因为我们都同意一个标准化的命名方案。如果有足够多的人决定使用不同的命名方案,互联网的工作方式 _可能_ 会有所不同。一群用户可以形成一个平行的互联网,它使用相同的物理基础设施(电缆、卫星和其他传输方式,将数据从一个地方传送到另一个地方),但使用不同的方法将主机名与编号地址联系起来。
+
+事实上,这已经存在了,这篇文章展示了你如何访问它。
+
+### 了解名称服务器
+
+术语“互联网”实际上是 互联 和 网络 这两个术语的组合,因为这正是它的本质。就像一个城市里的邻里、一个国家里的城市、或一个大陆里的国家,或一个星球里的大陆一样,互联网通过将数据从一个家庭或办公室网络传输到数据中心和服务器房或其他家庭或办公室网络而跨越了全球。这是一项艰巨的任务,但它并非没有先例。毕竟,电话公司很久以前就把世界连接起来了,在那之前,电报和邮政服务也是这样做的。
+
+在电话或邮件系统中,有一份名单,无论是正式的还是非正式的,都将人名与实际地址联系起来。它过去以电话簿的形式传递到家里,该电话簿是社区内每个电话所有者的目录。邮局的运作方式不同:他们通常依靠寄信人知道预定收信人的姓名和地址,但邮政编码和城市名称被用来把信送到正确的邮局。无论哪种方式,都需要有一个标准的组织方案。
+
+对于计算机来说,[IP 协议][2] 描述了必须如何设置互联网上的地址格式。域名服务器 [(DNS) 协议][3] 描述了如何将人性化名称分配给 IP 以及从 IP 解析。无论你使用的是 IPv4 还是 IPv6,其想法都是一样的:当一个节点(可能是一台计算机或通往另一个网络的网关)加入一个网络时,它被分配一个 IP 地址。
+
+如果你愿意,你可以在 [ICANN][4](一个帮助协调互联网上的网站名称的非营利组织)注册一个域名,并将该名称指向该 IP。没有要求你“拥有”该 IP 地址。任何人都可以将任何域名指向任何 IP 地址。唯一的限制是,一次只能有一个人拥有一个特定的域名,而且域名必须遵循公认的 DNS 命名方案。
+
+域名及其相关 IP 地址的记录被输入到 DNS 中。当你在浏览器中导航到一个网站时,它会迅速查询 DNS 网络,以找到与你所输入(或从搜索引擎点击)的任何 URL 相关的 IP 地址。
+
+### 一个不同的 DNS
+
+为了避免在谁拥有哪个域名的问题上发生争论,大多数域名注册商对域名注册收取一定的费用。该费用通常是象征性的,有时甚至是 0 美元(例如,`freenom.com` 提供免费的 `.tk`、`.ml`、`.gq` 和 `.cf` 域名,先到先得)。
+
+在很长一段时间里,只有几个“顶级”域名,包括 `.org`、`.edu` 和 `.com`。现在有很多,包括 `.club`、`.biz`、`.name`、`.international` 等等。本质上它们就是字母组合,但是,有很多潜在的顶级域名是无效的,如 `.null`。如果你试图导航到一个以 `.null` 结尾的网站,那么你不会成功。它不能注册,也不是域名服务器的有效条目,而且它根本就不存在。
+
+[OpenNIC项目][5] 已经建立了一个备用的 DNS 网络,将域名解析为 IP 地址,但它包括目前互联网不使用的名字。可用的顶级域名包括:
+
+ * .geek
+ * .indy
+ * .bbs
+ * .gopher
+ * .o
+ * .libre
+ * .oss
+ * .dyn
+ * .null
+
+你可以在这些(以及更多的)顶级域名中注册一个域名,并在 OpenNIC 的 DNS 系统上注册,使它们映射到你选择的 IP 地址。
+
+换句话说,一个网站可能存在于 OpenNIC 网络中,但对于不使用 OpenNIC 名称服务器的人来说,仍然无法访问。这绝不是一种安全措施,甚至不是一种混淆手段。这只是一种有意识的选择,在 _超级信息高速公路上绕行_ 。
+
+### 如何使用 OpenNIC 的 DNS 服务器
+
+要访问 OpenNIC 网站,你必须配置你的计算机使用 OpenNIC 的 DNS 服务器。幸运的是,这并不是一个非此即彼的选择。通过使用一个 OpenNIC 的 DNS 服务器,你可以同时访问 OpenNIC 和标准网络。
+
+要配置你的 Linux 电脑使用 OpenNIC 的 DNS 服务器,你可以使用 [nmcli][6] 命令,这是 Network Manager 的一个终端界面。在开始配置之前,请访问 [opennic.org][5],寻找离你最近的 OpenNIC DNS 服务器。与标准 DNS 和 [边缘计算][7] 一样,服务器在地理上离你越近,你的浏览器查询时的延迟就越少。
+
+下面是如何使用 OpenNIC:
+
+1、首先,获得一个连接列表:
+
+```
+$ sudo nmcli connection
+NAME TYPE DEVICE
+Wired connection 1 802-3-ethernet eth0
+MyPersonalWifi 802-11-wireless wlan0
+ovpn-phx2-tcp vpn --
+```
+
+你的连接肯定与这个例子不同,但要关注第一栏。这提供了你的连接的可读名称。在这个例子中,我将配置我的以太网连接,但这个过程对无线连接是一样的。
+
+2、现在你知道了需要修改的连接的名称,使用 `nmcli` 更新其 `ipv4.dns` 属性:
+
+```
+$ sudo nmcli con modify "Wired connection 1" ipv4.dns "134.195.4.2"
+```
+
+在这个例子中,`134.195.4.2` 是离我最近的服务器。
+
+3、防止 Network Manager 使用你路由器设置的内容自动更新 `/etc/resolv.conf`:
+
+```
+$ sudo nmcli con modify "Wired connection 1" ipv4.ignore-auto-dns yes
+```
+
+4、将你的网络连接关闭,然后再次启动,以实例化新的设置:
+
+```
+$ sudo nmcli con down "Wired connection 1"
+$ sudo nmcli con up "Wired connection 1"
+```
+
+完成了。你现在正在使用 OpenNIC 的 DNS 服务器。
+
+#### 路由器上的 DNS
+
+你可以通过对你的路由器做这样的修改,将你的整个网络设置为使用 OpenNIC。你将不必配置你的计算机的连接,因为路由器将自动提供正确的 DNS 服务器。我无法演示这个,因为路由器的接口因制造商而异。此外,一些互联网服务提供商 (ISP) 不允许你修改名称服务器的设置,所以这并不总是一种选择。
+
+### 测试 OpenNIC
+
+为了探索你所解锁的“其他”互联网,尝试在你的浏览器中导航到 `grep.geek`。如果你输入 `http://grep.geek`,那么你的浏览器就会带你到 OpenNIC 的搜索引擎。如果你只输入 `grep.geek`,那么你的浏览器会干扰你,把你带到你的默认搜索引擎(如 [Searx][8] 或 [YaCy][9]),并在窗口的顶部提供一个导航到你首先请求的页面。
+
+![OpenNIC][10]
+
+不管怎么说,你最终还是来到了 `grep.geek`,现在可以在网上搜索 OpenNIC 的版本了。
+
+### 广阔天地
+
+互联网旨在成为一个探索、发现和平等访问的地方。OpenNIC 利用现有的基础设施和技术帮助确保这些东西。它是一个可选择的互联网替代方案。如果这些想法吸引了你,那就试一试吧!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/4/opennic-internet
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LAW-Internet_construction_9401467_520x292_0512_dc.png?itok=RPkPPtDe (An intersection of pipes.)
+[2]: https://tools.ietf.org/html/rfc791
+[3]: https://tools.ietf.org/html/rfc1035
+[4]: https://www.icann.org/resources/pages/register-domain-name-2017-06-20-en
+[5]: http://opennic.org
+[6]: https://opensource.com/article/20/7/nmcli
+[7]: https://opensource.com/article/17/9/what-edge-computing
+[8]: http://searx.me
+[9]: https://opensource.com/article/20/2/open-source-search-engine
+[10]: https://opensource.com/sites/default/files/uploads/did-you-mean.jpg (OpenNIC)
+[11]: https://creativecommons.org/licenses/by-sa/4.0/
diff --git a/published/202105/20210501 Chrome Browser Keeps Detecting Network Change in Linux- Here-s How to Fix it.md b/published/202105/20210501 Chrome Browser Keeps Detecting Network Change in Linux- Here-s How to Fix it.md
new file mode 100644
index 0000000000..d111cd3755
--- /dev/null
+++ b/published/202105/20210501 Chrome Browser Keeps Detecting Network Change in Linux- Here-s How to Fix it.md
@@ -0,0 +1,96 @@
+[#]: subject: "Chrome Browser Keeps Detecting Network Change in Linux? Here’s How to Fix it"
+[#]: via: "https://itsfoss.com/network-change-detected/"
+[#]: author: "Abhishek Prakash https://itsfoss.com/author/abhishek/"
+[#]: collector: "lujun9972"
+[#]: translator: "HuengchI"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-13389-1.html"
+
+Linux 下 Chrome 浏览器一直报“检测到网络变化”,修复方法来了
+======
+
+
+
+过去几天,我在 Ubuntu Linux系统上遇到了一个奇怪的问题。我用的是 Firefox 浏览器和 [Brave 浏览器][1]。Brave 浏览器一直报“network change detection”错误,几乎每次刷新都报错,但是在 Firefox 浏览器中一切正常。
+
+![][2]
+
+这个问题严重到了几乎不能使用浏览器的地步。我不能用 [Feedly][3] 来从我最喜欢的网站浏览信息流,每一个搜索结果都要多次刷新,网站也需要多次刷新。
+
+作为替代,我尝试 [在 Ubuntu 上安装 Chrome 浏览器][4]。但是问题依然存在。我还 [在 Linux 上安装了微软 Edge][5],但是问题依旧。基本上,任何 Chromium 内核的浏览器都会持续报“ERR_NETWORK_CHANGED”错误。
+
+幸运地是,我找到了一个方法来修复这个问题。我将会把解决步骤分享给你,如果你也遇到了同样的问题,这将能够帮到你。
+
+### 解决基于 Chromium 内核的浏览器频繁报“network change detection”错的问题
+
+对我而言,关闭网络设置中的 IPv6 是一个有效的诀窍。虽然现在我还不确定是什么导致了这个故障,但是 IPv6 会在很多系统中导致错误并不是什么鲜为人知的事。如果你的系统,路由器和其他设备用了 IPv6 而不是古老却好用的 IPv4,那么你就可能遭遇和我相同的网络连接故障。
+
+幸亏,[关闭 Ubuntu 的 IPv6][6] 并不算难。有好几种方法都能够达到目的,我将会分享一个大概是最容易的方法。这个方法就是用 GRUB 来关闭 IPv6。
+
+> 新手注意!
+>
+> 如果你不习惯于用命令行和终端,请额外注意这些步骤。仔细的阅读这些操作说明。
+
+#### 第 1 步:打开 GRUB 配置文件以编辑
+
+打开终端。用下面的命令来在 Nano 编辑器中打开 GRUB 配置文件。这里你需要输入你的账户密码。
+
+```
+sudo nano /etc/default/grub
+```
+
+我希望你懂得一点 [使用 Nano 编辑器][7] 的方法。使用方向键移动光标,找到以`GRUB_CMDLINE_LINUX` 开头的这行。把它的值修改成这样:
+
+```
+GRUB_CMDLINE_LINUX="ipv6.disable=1"
+```
+
+注意引号和空格。不要动其他行。
+
+![][8]
+
+使用 `Ctrl+x` 快捷键保存更改。按 `Y` 或者回车确认。
+
+#### 第 2 步:更新 GRUB
+
+你已经修改了 GRUB 引导器的配置,但是在你更新 GRUB 之前这些更改都不会生效。使用下面的命令来更新:
+
+```
+sudo update-grub
+```
+
+![][9]
+
+现在当你重启系统之后,IPv6 将会被关闭了。你不应该再遇到网络中断的故障了。
+
+你可能会想为什么我没提从网络设置中关掉 IPv6。这是因为目前 Ubuntu 用了 [Netplan][10] 来管理网络配置,似乎在网络设置中做出的更改并没有被完全应用到 Netplan 中。我试过虽然在网络设置中关掉了 IPv6,但是这个问题并没有被解决,直到我用了上述命令行的方法。
+
+即使过了这么多年,IPv6 的支持还是没有成熟,并且持续引发了很多故障。比如关闭 IPv6 有时候能 [提高 Linux 下的 Wi-Fi 速度][11]。够扯吧?
+
+不管怎样,我希望上述小方法也能够帮助你解决系统中的“network change detection”故障。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/network-change-detected/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[HuengchI](https://github.com/HuengchI)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/brave-web-browser/
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/network-change-detected.png?resize=800%2C418&ssl=1
+[3]: https://feedly.com/
+[4]: https://itsfoss.com/install-chrome-ubuntu/
+[5]: https://itsfoss.com/microsoft-edge-linux/
+[6]: https://itsfoss.com/disable-ipv6-ubuntu-linux/
+[7]: https://itsfoss.com/nano-editor-guide/
+[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/disabling-ipv6-via-grub.png?resize=800%2C453&ssl=1
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/04/updating-grub-ubuntu.png?resize=800%2C434&ssl=1
+[10]: https://netplan.io/
+[11]: https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/
diff --git a/published/202105/20210502 Fedora Vs Red Hat- Which Linux Distro Should You Use and Why.md b/published/202105/20210502 Fedora Vs Red Hat- Which Linux Distro Should You Use and Why.md
new file mode 100644
index 0000000000..c721782052
--- /dev/null
+++ b/published/202105/20210502 Fedora Vs Red Hat- Which Linux Distro Should You Use and Why.md
@@ -0,0 +1,183 @@
+[#]: subject: (Fedora Vs Red Hat: Which Linux Distro Should You Use and Why?)
+[#]: via: (https://itsfoss.com/fedora-vs-red-hat/)
+[#]: author: (Sarvottam Kumar https://itsfoss.com/author/sarvottam/)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13372-1.html)
+
+Fedora 和红帽 Linux:你应该使用哪个,为什么?
+======
+
+Fedora 和红帽 Linux。这两个 Linux 发行版都属于同一个组织,都使用 RPM 包管理器,都提供桌面版和服务器版。这两个 Linux 发行版对操作系统世界都有较大的影响。
+
+这就是为什么在这两个类似的发行版之间比较容易混淆的原因。在这篇文章中,我将讨论红帽 Linux 和 Fedora 的相似之处和区别。
+
+如果你想在两者之间做出选择,或者只是想了解来自同一组织的两个发行版的概念,这将对你有所帮助。
+
+### Fedora 和红帽 Linux 的区别
+
+![][1]
+
+我们先来谈谈这两个发行版的区别。
+
+#### 社区版与企业版
+
+早在 1995 年,红帽 Linux 就有了它的第一个正式版本,它是作为盒装产品出售的。它也被称为红帽商业 Linux。
+
+后来在 2003 年,红帽把红帽 Linux 变成了完全以企业客户为中心的红帽企业 Linux(RHEL)。从那时起,红帽 Linux 就是一个企业版的 Linux 发行版。
+
+它的意思是,你必须订阅并付费才能使用红帽 Linux,因为它不是作为一个免费的操作系统。甚至所有的软件、错误修复和安全支持都只对那些拥有红帽订阅的人开放。
+
+当红帽 Linux 变成 RHEL 时,它也导致了 Fedora 项目的成立,该项目负责 Fedora Linux的开发。
+
+与红帽不同,Fedora 是一个社区版的 Linux 发行版,每个人都可以免费使用,包括错误修复和其他服务。
+
+尽管红帽公司赞助了 Fedora 项目,但 Fedora Linux 主要由一个独立的开源社区维护。
+
+#### 免费与付费
+
+好吧,你会发现大多数的 Linux 发行版都可以免费下载。Fedora Linux 也是这样一个发行版,它的桌面版、服务器版、所有其他版本和 Spin 版都是免费 [可下载][2] 的。
+
+还有一些 Linux 发行版,你必须付费购买。红帽企业 Linux 就是这样一个流行的基于 Linux 的操作系统,它是需要付费的。
+
+除了价格为 99 美元的 RHEL [开发者版本][3],你必须支付超过 100 美元才能购买 [其他 RHEL 版本][4],用于服务器、虚拟数据中心和台式机。
+
+然而,如果你碰巧是一个个人开发者,而不是一个组织或团队,你可以加入 [红帽开发者计划][5]。根据该计划,你可以在 12 个月内免费获得红帽企业 Linux 包括其他产品的使用权。
+
+#### 上游还是下游
+
+Fedora 是 RHEL 的上游,RHEL 是 Fedora 的下游。这意味着当 Fedora 的新版本发布时,红帽公司会利用 Fedora 的源代码,在其下一个版本中加入所需的功能。
+
+当然,红帽公司也会在合并到自己的 RHEL 代码库之前测试这些拉来的代码。
+
+换句话说,Fedora Linux 作为红帽公司的一个试验场,首先检查功能,然后将其纳入 RHEL 系统中。
+
+#### 发布周期
+
+为了给操作系统的所有组件提供定期更新,RHEL 和 Fedora 都遵循一个标准的定点发布模式。
+
+Fedora 大约每六个月发布一个新版本(主要在四月和十月),并提供长达 13 个月的维护支持。
+
+红帽 Linux 每年发布一个特定系列的新的定点版本,大约 5 年后发布一个主要版本。红帽 Linux 的每个主要版本都要经过四个生命周期阶段,从 5 年的支持到使用附加订阅的 10 年的延长寿命阶段。
+
+#### 尝鲜 Linux 发行版
+
+当涉及到创新和新技术时,Fedora 比 RHEL 更积极。即使 Fedora 不遵循 [滚动发布模式][6],它也是以早期提供尝鲜技术而闻名的发行版。
+
+这是因为 Fedora 定期将软件包更新到最新版本,以便在每六个月后提供一个最新的操作系统。
+
+如果你知道,[GNOME 40][7] 是 GNOME 桌面环境的最新版本,上个月才发布。而 Fedora 的最新稳定版 [版本 34][8] 确实包含了它,而 RHEL 的最新稳定版 8.3 仍然带有 GNOME 3.32。
+
+#### 文件系统
+
+在选择操作系统时,你是否把系统中数据的组织和检索放在了很重要的位置?如果是的话,在决定选择 Red Hat 和 Fedora 之前,你应该了解一下 XFS 和 Btrfs 文件系统。
+
+那是在 2014 年,RHEL 7.0 用 XFS 取代 Ext4 作为其默认文件系统。从那时起,红帽在每个版本中都默认有一个 XFS 64 位日志文件系统。
+
+虽然 Fedora 是红帽 Linux 的上游,但 Fedora 继续使用 Ext4,直到去年 [Fedora 33][9] 引入 [Btrfs 作为默认文件系统][10]。
+
+有趣的是,红帽在最初发布的 RHEL 6 中包含了 Btrfs 作为“技术预览”。后来,红帽放弃了使用 Btrfs 的计划,因此在 2019 年从 RHEL 8 和后来发布的主要版本中完全 [删除][11] 了它。
+
+#### 可用的变体
+
+与 Fedora 相比,红帽 Linux 的版本数量非常有限。它主要适用于台式机、服务器、学术界、开发者、虚拟服务器和 IBM Power LE。
+
+而 Fedora 除了桌面、服务器和物联网的官方版本外,还提供不可变的桌面 Silverblue 和专注于容器的 Fedora CoreOS。
+
+不仅如此,Fedora 也有特定目的的定制变体,称为 [Fedora Labs][12]。每个 ISO 都为专业人士、神经科学、设计师、游戏玩家、音乐家、学生和科学家打包了一套软件。
+
+想要 Fedora 中不同的桌面环境吗?你也可以查看官方的 [Fedora Spins][13],它预先配置了几种桌面环境,如 KDE、Xfce、LXQT、LXDE、Cinnamon 和 i3 平铺窗口管理器。
+
+![Fedora Cinnamon Spin][14]
+
+此外,如果你想在新软件登陆稳定版 Fedora 之前就得到它,Fedora Rawhide 是另一个基于滚动发布模式的版本。
+
+### Fedora 和红帽 Linux 的相似之处
+
+除了不同之处,Fedora 和红帽 Linux 也有几个共同点。
+
+#### 母公司
+
+红帽公司是支持 Fedora 项目和 RHEL 的共同公司,在开发和财务方面都有支持。
+
+即使红帽公司在财务上赞助 Fedora 项目,Fedora 也有自己的理事会,在没有红帽公司干预的情况下监督其发展。
+
+#### 开源产品
+
+在你认为红帽 Linux 要收钱,那么它怎么能成为一个开源产品之前,我建议阅读我们的 [文章][15],它分析了关于 FOSS 和开源的一切。
+
+作为一个开源软件,并不意味着你可以免费得到它,有时它可能要花钱。红帽公司是一个已经在开源中建立了业务的开源公司。
+
+Fedora 和红帽 Linux 都是开源的操作系统。所有的 Fedora 软件包都可以在 [这里][16] 得到源代码和在 [这里][2] 得到已经打包好的软件。
+
+然而,就红帽 Linux 而言,源代码也 [免费提供][17] 给任何人。但与 Fedora 不同的是,你需要为使用可运行的代码付费,要么你可以自由地自行构建。
+
+你支付给红帽的订阅费实际上是用于系统维护和技术支持。
+
+#### 桌面环境和初始系统
+
+Fedora 和红帽 Linux 的旗舰桌面版采用了 GNOME 图形界面。所以,如果你已经熟悉了 GNOME,从任何一个发行版开始都不会有太大的问题。
+
+![GNOME 桌面][18]
+
+你是少数讨厌 SystemD 初始化系统的人吗?如果是这样,那么 Fedora 和红帽 Linux 都不适合你,因为它们都默认支持并使用 SystemD。
+
+总之,如果你想用 Runit 或 OpenRC 等其他初始化系统代替它,也不是不可能,但我认为这不是一个好主意。
+
+#### 基于 RPM 的发行版
+
+如果你已经精通使用 YUM、RPM 或 DNF 命令行工具来处理 RPM 软件包,赞一个!你可以在这两个基于 RPM 的发行版中选一个。
+
+默认情况下,红帽 Linux 使用 RPM(红帽包管理器)来安装、更新、删除和管理 RPM 软件包。
+
+Fedora 在 2015 年的 Fedora 21 之前使用 YUM(黄狗更新器修改版)。从 Fedora 22 开始,它现在使用 DNF(时髦版 Yum)代替 YUM 作为默认的 [软件包管理器][19]。
+
+### Fedora 或红帽 Linux:你应该选择哪一个?
+
+坦率地说,这真的取决于你是谁以及你为什么要使用它。如果你是一个初学者、开发者,或者是一个想用它来提高生产力或学习 Linux 的普通用户,Fedora 可以是一个不错的选择。
+
+它可以帮助你轻松地设置系统,进行实验,节省资金,还可以成为 Fedora 项目的一员。让我提醒你,Linux 的创造者 [Linus Torvalds][20] 在他的主要工作站上使用 Fedora Linux。
+
+然而,这绝对不意味着你也应该使用 Fedora。如果你碰巧是一个企业,考虑到 Fedora 的支持生命周期在一年内就会结束,你可能会重新考虑选择它。
+
+而且,如果你不喜欢每个新版本的快速变化,你可能不喜欢尝鲜的 Fedora 来满足你的服务器和业务需求。
+
+使用企业版红帽,你可以得到高稳定性、安全性和红帽专家工程师为你的大型企业提供的支持品质。
+
+那么,你是愿意每年升级你的服务器并获得免费的社区支持,还是购买订阅以获得超过 5 年的生命周期和专家技术支持?决定权在你。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/fedora-vs-red-hat/
+
+作者:[Sarvottam Kumar][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/sarvottam/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/05/fedora-vs-red-hat.jpg?resize=800%2C450&ssl=1
+[2]: https://getfedora.org/
+[3]: https://www.redhat.com/en/store/red-hat-enterprise-linux-developer-suite
+[4]: https://www.redhat.com/en/store/linux-platforms
+[5]: https://developers.redhat.com/register/
+[6]: https://itsfoss.com/rolling-release/
+[7]: https://news.itsfoss.com/gnome-40-release/
+[8]: https://news.itsfoss.com/fedora-34-release/
+[9]: https://itsfoss.com/fedora-33/
+[10]: https://itsfoss.com/btrfs-default-fedora/
+[11]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/considerations_in_adopting_rhel_8/file-systems-and-storage_considerations-in-adopting-rhel-8#btrfs-has-been-removed_file-systems-and-storage
+[12]: https://labs.fedoraproject.org/
+[13]: https://spins.fedoraproject.org/
+[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/Fedora-Cinnamon-Spin.jpg?resize=800%2C450&ssl=1
+[15]: https://itsfoss.com/what-is-foss/
+[16]: https://src.fedoraproject.org/
+[17]: http://ftp.redhat.com/pub/redhat/linux/enterprise/
+[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/04/GNOME-desktop.jpg?resize=800%2C450&ssl=1
+[19]: https://itsfoss.com/package-manager/
+[20]: https://itsfoss.com/linus-torvalds-facts/
diff --git a/published/202105/20210503 Configure WireGuard VPNs with NetworkManager.md b/published/202105/20210503 Configure WireGuard VPNs with NetworkManager.md
new file mode 100644
index 0000000000..2c46177c34
--- /dev/null
+++ b/published/202105/20210503 Configure WireGuard VPNs with NetworkManager.md
@@ -0,0 +1,238 @@
+[#]: subject: (Configure WireGuard VPNs with NetworkManager)
+[#]: via: (https://fedoramagazine.org/configure-wireguard-vpns-with-networkmanager/)
+[#]: author: (Maurizio Garcia https://fedoramagazine.org/author/malgnuz/)
+[#]: collector: (lujun9972)
+[#]: translator: (DCOLIVERSUN)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13379-1.html)
+
+用 NetworkManager 配置 WireGuard 虚拟私有网络
+======
+
+
+
+虚拟私有网络应用广泛。如今有各种方案可供使用,用户可通过这些方案访问任意类型的资源,同时保持其机密性与隐私性。
+
+最近,WireGuard 因为其简单性、速度与安全性成为最广泛使用的虚拟私有网络协议之一。WireGuard 最早应用于 Linux 内核,但目前可以用在其他平台,例如 iOS、Android 等。
+
+WireGuard 使用 UDP 作为其传输协议,并在 Critokey Routing(CKR)的基础上建立对等节点之间的通信。每个对等节点(无论是服务器或客户端)都有一对密钥(公钥与私钥),公钥与许可 IP 间建立通信连接。有关 WireGuard 更多信息请访问其 [主页][4]。
+
+本文描述了如何在两个对等节点(PeerA 与 PeerB)间设置 WireGuard。两个节点均运行 Fedora Linux 系统,使用 NetworkManager 进行持久性配置。
+
+### WireGuard 设置与网络配置
+
+在 PeerA 与 PeerB 之间建立持久性虚拟私有网络连接只需三步:
+
+ 1. 安装所需软件包。
+ 2. 生成密钥对。
+ 3. 配置 WireGuard 接口。
+
+### 安装
+
+在两个对等节点(PeerA 与 PeerB)上安装 `wireguard-tools` 软件包:
+
+```
+$ sudo -i
+# dnf -y install wireguard-tools
+```
+
+这个包可以从 Fedora Linux 更新库中找到。它在 `/etc/wireguard/` 中创建一个配置目录。在这里你将创建密钥和接口配置文件。
+
+### 生成密钥对
+
+现在,使用 `wg` 工具在每个节点上生成公钥与私钥:
+
+```
+# cd /etc/wireguard
+# wg genkey | tee privatekey | wg pubkey > publickey
+```
+
+### 在 PeerA 上配置 WireGuard 接口
+
+WireGuard 接口命名规则为 `wg0`、`wg1` 等等。完成下述步骤为 WireGuard 接口创建配置:
+
+ * PeerA 节点上配置想要的 IP 地址与掩码。
+ * 该节点监听的 UDP 端口。
+ * PeerA 的私钥。
+
+```
+# cat << EOF > /etc/wireguard/wg0.conf
+[Interface]
+Address = 172.16.1.254/24
+SaveConfig = true
+ListenPort = 60001
+PrivateKey = mAoO2RxlqRvCZZoHhUDiW3+zAazcZoELrYbgl+TpPEc=
+
+[Peer]
+PublicKey = IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw=
+AllowedIPs = 172.16.1.2/32
+EOF
+```
+
+允许 UDP 流量通过节点监听的端口:
+
+```
+# firewall-cmd --add-port=60001/udp --permanent --zone=public
+# firewall-cmd --reload
+success
+```
+
+最后,将接口配置文件导入 NetworkManager。这样,WireGuard 接口在重启后将持续存在。
+
+```
+# nmcli con import type wireguard file /etc/wireguard/wg0.conf
+Connection 'wg0' (21d939af-9e55-4df2-bacf-a13a4a488377) successfully added.
+```
+
+验证 `wg0`的状态:
+
+```
+# wg
+interface: wg0
+ public key: FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8=
+ private key: (hidden)
+ listening port: 60001
+
+peer: IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw=
+ allowed ips: 172.16.1.2/32
+
+# nmcli -p device show wg0
+
+===============================================================================
+ Device details (wg0)
+===============================================================================
+GENERAL.DEVICE: wg0
+-------------------------------------------------------------------------------
+GENERAL.TYPE: wireguard
+-------------------------------------------------------------------------------
+GENERAL.HWADDR: (unknown)
+-------------------------------------------------------------------------------
+GENERAL.MTU: 1420
+-------------------------------------------------------------------------------
+GENERAL.STATE: 100 (connected)
+-------------------------------------------------------------------------------
+GENERAL.CONNECTION: wg0
+-------------------------------------------------------------------------------
+GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveC>
+-------------------------------------------------------------------------------
+IP4.ADDRESS[1]: 172.16.1.254/24
+IP4.GATEWAY: --
+IP4.ROUTE[1]: dst = 172.16.1.0/24, nh = 0.0.0.0, mt =>
+-------------------------------------------------------------------------------
+IP6.GATEWAY: --
+-------------------------------------------------------------------------------
+```
+
+上述输出显示接口 `wg0` 已连接。现在,它可以和虚拟私有网络 IP 地址为 172.16.1.2 的对等节点通信。
+
+### 在 PeerB 上配置 WireGuard 接口
+
+现在可以在第二个对等节点上创建 `wg0` 接口的配置文件了。确保你已经完成以下步骤:
+
+ * PeerB 节点上设置 IP 地址与掩码。
+ * PeerB 的私钥。
+ * PeerA 的公钥。
+ * PeerA 的 IP 地址或主机名、监听 WireGuard 流量的 UDP 端口。
+
+```
+# cat << EOF > /etc/wireguard/wg0.conf
+[Interface]
+Address = 172.16.1.2
+SaveConfig = true
+PrivateKey = UBiF85o7937fBK84c2qLFQwEr6eDhLSJsb5SAq1lF3c=
+
+[Peer]
+PublicKey = FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8=
+AllowedIPs = 172.16.1.254/32
+Endpoint = peera.example.com:60001
+EOF
+```
+
+最后一步是将接口配置文件导入 NetworkManager。如上所述,这一步是重启后保持 WireGuard 接口持续存在的关键。
+
+```
+# nmcli con import type wireguard file /etc/wireguard/wg0.conf
+Connection 'wg0' (39bdaba7-8d91-4334-bc8f-85fa978777d8) successfully added.
+```
+
+验证 `wg0` 的状态:
+
+```
+# wg
+interface: wg0
+ public key: IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw=
+ private key: (hidden)
+ listening port: 47749
+
+peer: FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8=
+ endpoint: 192.168.124.230:60001
+ allowed ips: 172.16.1.254/32
+
+# nmcli -p device show wg0
+
+===============================================================================
+ Device details (wg0)
+===============================================================================
+GENERAL.DEVICE: wg0
+-------------------------------------------------------------------------------
+GENERAL.TYPE: wireguard
+-------------------------------------------------------------------------------
+GENERAL.HWADDR: (unknown)
+-------------------------------------------------------------------------------
+GENERAL.MTU: 1420
+-------------------------------------------------------------------------------
+GENERAL.STATE: 100 (connected)
+-------------------------------------------------------------------------------
+GENERAL.CONNECTION: wg0
+-------------------------------------------------------------------------------
+GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveC>
+-------------------------------------------------------------------------------
+IP4.ADDRESS[1]: 172.16.1.2/32
+IP4.GATEWAY: --
+-------------------------------------------------------------------------------
+IP6.GATEWAY: --
+-------------------------------------------------------------------------------
+```
+
+上述输出显示接口 `wg0` 已连接。现在,它可以和虚拟私有网络 IP 地址为 172.16.1.254 的对等节点通信。
+
+### 验证节点间通信
+
+完成上述步骤后,两个对等节点可以通过虚拟私有网络连接相互通信,以下是 ICMP 测试结果:
+
+```
+[root@peerb ~]# ping 172.16.1.254 -c 4
+PING 172.16.1.254 (172.16.1.254) 56(84) bytes of data.
+64 bytes from 172.16.1.254: icmp_seq=1 ttl=64 time=0.566 ms
+64 bytes from 172.16.1.254: icmp_seq=2 ttl=64 time=1.33 ms
+64 bytes from 172.16.1.254: icmp_seq=3 ttl=64 time=1.67 ms
+64 bytes from 172.16.1.254: icmp_seq=4 ttl=64 time=1.47 ms
+```
+
+在这种情况下,如果你在 PeerA 端口 60001 上捕获 UDP 通信,则将看到依赖 WireGuard 协议的通信过程和加密的数据:
+
+![捕获依赖 WireGuard 协议的节点间 UDP 流量][5]
+
+## 总结
+
+虚拟私有网络很常见。在用于部署虚拟私有网络的各种协议和工具中,WireGuard 是一种简单、轻巧和安全的选择。它可以在对等节点之间基于 CryptoKey 路由建立安全的点对点连接,过程非常简单。此外,NetworkManager 支持 WireGuard 接口,允许重启后进行持久配置。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/configure-wireguard-vpns-with-networkmanager/
+
+作者:[Maurizio Garcia][a]
+选题:[lujun9972][b]
+译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/malgnuz/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2021/05/wireguard-nm-816x345.jpg
+[2]: https://youtu.be/0eiXMGfZc60?t=633
+[3]: https://www.youtube.com/c/HighTreason610/featured
+[4]: https://www.wireguard.com/
+[5]: https://fedoramagazine.org/wp-content/uploads/2021/04/capture-1024x601.png
diff --git a/published/202105/20210504 5 ways the Star Wars universe embraces open source.md b/published/202105/20210504 5 ways the Star Wars universe embraces open source.md
new file mode 100644
index 0000000000..100fff6490
--- /dev/null
+++ b/published/202105/20210504 5 ways the Star Wars universe embraces open source.md
@@ -0,0 +1,102 @@
+[#]: subject: (5 ways the Star Wars universe embraces open source)
+[#]: via: (https://opensource.com/article/21/5/open-source-star-wars)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13367-1.html)
+
+《星球大战》的世界拥抱开源的 5 种方式
+======
+
+> 与《星球大战》一起成长的过程中,我学到了很多关于开源的知识。
+
+
+
+让我们先说清楚一件事:在现实生活中,《星球大战》特许经营权没有任何开放性(尽管其所有者确实发布了 [一些开源代码][2])。《星球大战》是一个严格控制的资产,没有任何东西是在自由文化许可证下出版的。抛开任何关于 [文化形象应该成为伴随它们成长的人们的财产][3] 的争论,本文邀请你走进《星球大战》的世界,想象你是很久以前的一个电脑用户,在一个遥远的星系里……
+
+### 机器人
+
+> “但我还要去托西站弄些电力转换器呢。”
+> —— 卢克•天行者
+
+在乔治•卢卡斯拍摄他的第一部《星球大战》电影之前,他导演了一部名为《美国涂鸦》的电影,这是一部以上世纪 60 年代为背景的成长电影。这部电影的部分背景是改装车和街头赛车文化,一群机械修理工在车库里花了好几个小时,无休止地改装他们的汽车。今天仍然可以这样做,但大多数汽车爱好者会告诉你,“经典”汽车改装起来容易得多,因为它们主要使用机械部件而不是技术部件,而且它们以一种可预测的方式使用普通部件。
+
+我一直把卢克和他的朋友们看作是对同样怀旧的科幻小说诠释。当然,花哨的新战斗堡垒是高科技,可以摧毁整个星球,但当 [防爆门不能正确打开][4] 或监禁层的垃圾压实机开始压扁人时,你会怎么做?如果你没有一个备用的 R2 机器人与主机对接,你就没辙了。卢克对修理和维护“机器人”的热情以及他在修理蒸发器和 X 翼飞机方面的天赋从第一部电影中就可以看出。
+
+看到塔图因星球对待技术的态度,我不禁相信,大多数常用设备都是大众的技术。卢克并没有为 C-3PO 或 R2-D2 签订最终用户许可协议。当他让 C-3PO 在热油浴中放松时,或者当楚巴卡在兰多的云城重新组装他时,并没有使他的保修失效。同样,汉•索罗和楚巴卡从来没有把千年隼带到经销商那里去购买经批准的零件。
+
+我无法证明这都是开源技术。鉴于电影中大量的终端用户维修和定制,我相信在星战世界中,技术是开放的,[用户是有拥有和维修的常识的][5]。
+
+### 加密和隐写术
+
+> “帮助我,欧比旺•克诺比。你是我唯一的希望。”
+> —— 莱亚公主
+
+诚然,《星球大战》世界中的数字身份认证很难理解,但如果有一点是明确的,加密和隐写术对叛军的成功至关重要。而当你身处叛军时,你就不能依靠公司的标准,怀疑它们是由你正在斗争的邪恶帝国批准的。当 R2-D2 隐瞒莱娅公主绝望的求救时,它的记忆库中没有任何后门,而叛军在潜入敌方领土时努力获得认证凭证(这是一个旧的口令,但它通过检查了)。
+
+加密不仅仅是一个技术问题。它是一种通信形式,在历史上有这样的例子。当政府试图取缔加密时,就是在努力取缔社区。我想这也是“叛乱”本应抵制的一部分。
+
+### 光剑
+
+> “我看到你已经打造了新的光剑,你的技能现在已经完成了。”
+> —— 达斯•维德
+
+在《帝国反击战》中,天行者卢克失去了他标志性的蓝色光剑,同时他的手也被邪恶霸主达斯•维德砍断。在下一部电影《绝地归来》中,卢克展示了他自己打造的绿色光剑 —— 每一个粉丝都为之着迷。
+
+虽然没有明确说明绝地武士的激光剑的技术规格是开源的,但有一定的暗指。例如,没有迹象表明卢克在制造他的武器之前必须从拥有版权的公司获得设计许可。他没有与一家高科技工厂签订合同来生产他的剑。
+
+他自己打造了它,作为一种成年仪式。也许制造如此强大的武器的方法是绝地武士团所守护的秘密;再者,也许这只是描述开源的另一种方式。我所知道的所有编码知识都是从值得信赖的导师、某些互联网 UP 主、精心撰写的博客文章和技术讲座中学到的。
+
+严密保护的秘密?还是对任何寻求知识的人开放的信息?
+
+根据我在原三部曲中看到的绝地武士秩序,我选择相信后者。
+
+### 伊沃克文化
+
+> “Yub nub!”
+> —— 伊沃克人
+
+恩多的伊沃克人与帝国其他地区的文化形成了鲜明的对比。他们热衷于集体生活、分享饮食和故事到深夜。他们自己制作武器、陷阱和安全防火墙,还有他们自己的树顶村庄。作为象征意义上的弱者,他们不可能摆脱帝国的占领。他们通过咨询礼仪机器人做了研究,汇集了他们的资源,并在关键时刻发挥了作用。当陌生人进入他们的家时,他们并没有拒绝他们。相反,他们帮助他们(在确定他们毕竟不是食物之后)。当他们面对令人恐惧的技术时,他们就参与其中并从中学习。
+
+伊沃克人是《星球大战》世界中开放文化和开源的庆典。他们是我们应该努力的社区:分享信息、分享知识、接受陌生人和进步的技术,以及维护捍卫正义的决心。
+
+### 原力
+
+> “原力将与你同在,永远。”
+> —— 欧比旺•克诺比
+
+在最初的电影中,甚至在新生的衍生宇宙中(最初的衍生宇宙小说,也是我个人的最爱,是《心灵之眼的碎片》,其中卢克从一个叫哈拉的女人那里学到了更多关于原力的知识),原力只是:一种任何人都可以学习使用的力量。它不是一种与生俱来的天赋,而是一门需要掌握的强大学科。
+
+![衍生宇宙的最开始][6]
+
+相比之下,邪恶的西斯人对他们的知识是保护性的,只邀请少数人加入他们的行列。他们可能认为自己有一个群体,但这正是看似随意的排他性的模式。
+
+我不知道对开源和开放文化还有什么更好的比喻。永远存在被认为是排他的危险,因为爱好者似乎总是在“人群中”。但现实是,每个人都可以加入这些邀请,而且任何人都可以回到源头(字面意思是源代码或资产)。
+
+### 愿源与你同在
+
+作为一个社区,我们的任务是要问,我们如何能让人明白,无论我们拥有什么知识,都不是为了成为特权信息,而是一种任何人都可以学习使用的力量,以改善他们的世界。
+
+套用欧比旺•克诺比的不朽名言:“使用源”。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/5/open-source-star-wars
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tobias-cornille-light-sabres-unsplash.jpg?itok=rYwXA2CX (Man with lasers in night sky)
+[2]: https://disney.github.io/
+[3]: https://opensource.com/article/18/1/creative-commons-real-world
+[4]: https://www.hollywoodreporter.com/heat-vision/star-wars-40th-anniversary-head-banging-stormtrooper-explains-classic-blunder-1003769
+[5]: https://www.eff.org/issues/right-to-repair
+[6]: https://opensource.com/sites/default/files/20210501_100930.jpg (The very beginning of the expanded universe)
diff --git a/published/202105/20210504 Keep multiple Linux distros on a USB with this open source tool.md b/published/202105/20210504 Keep multiple Linux distros on a USB with this open source tool.md
new file mode 100644
index 0000000000..dc17b8fd95
--- /dev/null
+++ b/published/202105/20210504 Keep multiple Linux distros on a USB with this open source tool.md
@@ -0,0 +1,92 @@
+[#]: subject: (Keep multiple Linux distros on a USB with this open source tool)
+[#]: via: (https://opensource.com/article/21/5/linux-ventoy)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13361-1.html)
+
+神器:在一个 U 盘上放入多个 Linux 发行版
+======
+
+> 用 Ventoy 创建多启动 U 盘,你将永远不会缺少自己喜欢的 Linux 发行版。
+
+
+
+给朋友和邻居一个可启动 U 盘,里面包含你最喜欢的 Linux 发行版,是向 Linux 新手介绍我们都喜欢的 Linux 体验的好方法。仍然有许多人从未听说过 Linux,把你喜欢的发行版放在一个可启动的 U 盘上是让他们进入 Linux 世界的好办法。
+
+几年前,我在给一群中学生教授计算机入门课。我们使用旧笔记本电脑,我向学生们介绍了 Fedora、Ubuntu 和 Pop!_OS。下课后,我给每个学生一份他们喜欢的发行版的副本,让他们带回家安装在自己选择的电脑上。他们渴望在家里尝试他们的新技能。
+
+### 把多个发行版放在一个驱动器上
+
+最近,一个朋友向我介绍了 Ventoy,它(根据其 [GitHub 仓库][2])是 “一个开源工具,可以为 ISO/WIM/IMG/VHD(x)/EFI 文件创建可启动的 USB 驱动器”。与其为每个我想分享的 Linux 发行版创建单独的驱动器,我可以在一个 U 盘上放入我喜欢的 _所有_ Linux 发行版!
+
+![USB 空间][3]
+
+正如你所能想到的那样,U 盘的大小决定了你能在上面容纳多少个发行版。在一个 16GB 的 U 盘上,我放置了 Elementary 5.1、Linux Mint Cinnamon 5.1 和 Linux Mint XFCE 5.1......但仍然有 9.9GB 的空间。
+
+### 获取 Ventoy
+
+Ventoy 是开源的,采用 [GPLv3][5] 许可证,可用于 Windows 和 Linux。有很好的文档介绍了如何在 Windows 上下载和安装 Ventoy。Linux 的安装是通过命令行进行的,所以如果你不熟悉这个过程,可能会有点混乱。然而,其实很容易。
+
+首先,[下载 Ventoy][6]。我把存档文件下载到我的桌面上。
+
+接下来,使用 `tar` 命令解压 `ventoy-x.y.z-linux.tar.gz` 档案(但要用你下载的版本号替换 `x.y.z`)(为了保持简单,我在命令中使用 `*` 字符作为任意通配符):
+
+```
+$ tar -xvf ventoy*z
+```
+
+这个命令将所有必要的文件提取到我桌面上一个名为 `ventoy-x.y.z` 的文件夹中。
+
+你也可以使用你的 Linux 发行版的存档管理器来完成同样的任务。下载和提取完成后,你就可以把 Ventoy 安装到你的 U 盘上了。
+
+### 在 U 盘上安装 Ventoy 和 Linux
+
+把你的 U 盘插入你的电脑。改变目录进入 Ventoy 的文件夹,并寻找一个名为 `Ventoy2Disk.sh` 的 shell 脚本。你需要确定你的 U 盘的正确挂载点,以便这个脚本能够正常工作。你可以通过在命令行上发出 `mount` 命令或者使用 [GNOME 磁盘][7] 来找到它,后者提供了一个图形界面。后者显示我的 U 盘被挂载在 `/dev/sda`。在你的电脑上,这个位置可能是 `/dev/sdb` 或 `/dev/sdc` 或类似的位置。
+
+![GNOME 磁盘中的 USB 挂载点][8]
+
+下一步是执行 Ventoy shell 脚本。因为它被设计成不加选择地复制数据到一个驱动器上,我使用了一个假的位置(`/dev/sdX`)来防止你复制/粘贴错误,所以用你想覆盖的实际驱动器的字母替换后面的 `X`。
+
+**让我重申**:这个 shell 脚本的目的是把数据复制到一个驱动器上, _破坏该驱动器上的所有数据。_ 如果该驱动器上有你关心的数据,在尝试这个方法之前,先把它备份! 如果你不确定你的驱动器的位置,在你继续进行之前,请验证它,直到你完全确定为止。
+
+一旦你确定了你的驱动器的位置,就运行这个脚本:
+
+```
+$ sudo sh Ventoy2Disk.sh -i /dev/sdX
+```
+
+这样就可以格式化它并将 Ventoy 安装到你的 U 盘上。现在你可以复制和粘贴所有适合放在 U 盘上的 Linux 发行版文件。如果你在电脑上用新创建的 U 盘引导,你会看到一个菜单,上面有你复制到 U 盘上的发行版。
+
+![Ventoy 中的 Linux 发行版][9]
+
+### 构建一个便携式的动力源
+
+Ventoy 是你在钥匙串上携带多启动 U 盘的关键(钥匙),这样你就永远不会缺少你所依赖的发行版。你可以拥有一个全功能的桌面、一个轻量级的发行版、一个纯控制台的维护工具,以及其他你想要的东西。
+
+我从来没有在没有 Linux 发行版的情况下离开家,你也不应该。拿上 Ventoy、一个 U 盘,和一串 ISO。你不会后悔的。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/21/5/linux-ventoy
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/markus-winkler-usb-unsplash.jpg?itok=5ZXDp0V4 (USB drive)
+[2]: https://github.com/ventoy/Ventoy
+[3]: https://opensource.com/sites/default/files/uploads/ventoy1.png (USB space)
+[4]: https://creativecommons.org/licenses/by-sa/4.0/
+[5]: https://www.ventoy.net/en/doc_license.html
+[6]: https://github.com/ventoy/Ventoy/releases
+[7]: https://wiki.gnome.org/Apps/Disks
+[8]: https://opensource.com/sites/default/files/uploads/usb-mountpoint.png (USB mount point in GNOME Disks)
+[9]: https://opensource.com/sites/default/files/uploads/ventoy_distros.jpg (Linux distros in Ventoy)
diff --git a/published/202105/20210505 Drop telnet for OpenSSL.md b/published/202105/20210505 Drop telnet for OpenSSL.md
new file mode 100644
index 0000000000..5258c011e0
--- /dev/null
+++ b/published/202105/20210505 Drop telnet for OpenSSL.md
@@ -0,0 +1,187 @@
+[#]: subject: (Drop telnet for OpenSSL)
+[#]: via: (https://opensource.com/article/21/5/drop-telnet-openssl)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-13381-1.html)
+
+用 OpenSSL 替代 telnet
+======
+
+> Telnet 缺乏加密,这使得 OpenSSL 成为连接远程系统的更安全的选择。
+
+
+
+[telnet][2] 命令是最受欢迎的网络故障排除工具之一,从系统管理员到网络爱好者都可以使用。在网络计算的早期,`telnet` 被用来连接到一个远程系统。你可以用 `telnet` 访问一个远程系统的端口,登录并在该主机上运行命令。
+
+由于 `telnet` 缺乏加密功能,它在很大程度上已经被 OpenSSL 取代了这项工作。然而,作为一种智能的 `ping`,`telnet` 的作用仍然存在(甚至在某些情况下至今仍然存在)。虽然 `ping` 命令是一个探测主机响应的好方法,但这是它能做的 _全部_。另一方面,`telnet` 不仅可以确认一个活动端口,而且还可以与该端口的服务进行交互。即便如此,由于大多数现代网络服务都是加密的,`telnet` 的作用可能要小得多,这取决于你想实现什么。
+
+### OpenSSL s_client
+
+对于大多数曾经需要 `telnet` 的任务,我现在使用 OpenSSL 的 `s_client` 命令。(我在一些任务中使用 [curl][3],但那些情况下我可能无论如何也不会使用 `telnet`)。大多数人都知道 [OpenSSL][4] 是一个加密的库和框架,但不是所有人都意识到它也是一个命令。`openssl` 命令的 `s_client` 组件实现了一个通用的 SSL 或 TLS 客户端,帮助你使用 SSL 或 TLS 连接到远程主机。它是用来测试的,至少在内部使用与该库相同的功能。
+
+### 安装 OpenSSL
+
+OpenSSL 可能已经安装在你的 Linux 系统上了。如果没有,你可以用你的发行版的软件包管理器安装它:
+
+```
+$ sudo dnf install openssl
+```
+
+在 Debian 或类似的系统上:
+
+```
+$ sudo apt install openssl
+```
+
+安装后,验证它的响应是否符合预期:
+
+```
+$ openssl version
+OpenSSL x.y.z FIPS
+```
+
+### 验证端口访问
+
+最基本的 `telnet` 用法是一个看起来像这样的任务:
+
+```
+$ telnet mail.example.com 25
+Trying 98.76.54.32...
+Connected to example.com.
+Escape character is '^]'.
+```
+
+在此示例中,这将与正在端口 25(可能是邮件服务器)监听的任意服务打开一个交互式会话。只要你获得访问权限,就可以与该服务进行通信。
+
+如果端口 25 无法访问,连接就会被拒绝。
+
+OpenSSL 也是类似的,尽管通常较少互动。要验证对一个端口的访问:
+
+```
+$ openssl s_client -connect example.com:80
+CONNECTED(00000003)
+140306897352512:error:1408F10B:SSL [...]
+
+no peer certificate available
+
+No client certificate CA names sent
+
+SSL handshake has read 5 bytes and written 309 bytes
+Verification: OK
+
+New, (NONE), Cipher is (NONE)
+Secure Renegotiation IS NOT supported
+Compression: NONE
+Expansion: NONE
+No ALPN negotiated
+Early data was not sent
+Verify return code: 0 (ok)
+```
+
+但是,这仅是目标性 `ping`。从输出中可以看出,没有交换 SSL 证书,所以连接立即终止。为了充分利用 `openssl s_client`,你必须连接加密的端口。
+
+### 交互式 OpenSSL
+
+Web 浏览器和 Web 服务器进行交互,可以使指向 80 端口的流量实际上被转发到 443,这是保留给加密 HTTP 流量的端口。知道了这一点,你就可以用 `openssl` 命令连接到加密的端口,并与在其上运行的任何网络服务进行交互。
+
+首先,使用 SSL 连接到一个端口。使用 `-showcerts` 选项会使 SSL 证书打印到你的终端上,一开始的输出要比 telnet 要冗长得多:
+
+```
+$ openssl s_client -connect example.com:443 -showcerts
+[...]
+ 0080 - 52 cd bd 95 3d 8a 1e 2d-3f 84 a0 e3 7a c0 8d 87 R...=..-?...z...
+ 0090 - 62 d0 ae d5 95 8d 82 11-01 bc 97 97 cd 8a 30 c1 b.............0.
+ 00a0 - 54 78 5c ad 62 5b 77 b9-a6 35 97 67 65 f5 9b 22 Tx\\.b[w..5.ge.."
+ 00b0 - 18 8a 6a 94 a4 d9 7e 2f-f5 33 e8 8a b7 82 bd 94 ..j...~/.3......
+
+ Start Time: 1619661100
+ Timeout : 7200 (sec)
+ Verify return code: 0 (ok)
+ Extended master secret: no
+ Max Early Data: 0
+-
+read R BLOCK
+```
+
+你被留在一个交互式会话中。最终,这个会话将关闭,但如果你及时行动,你可以向服务器发送 HTTP 信号:
+
+```
+[...]
+GET / HTTP/1.1
+HOST: example.com
+```
+
+按**回车键**两次,你会收到 `example.com/index.html` 的数据:
+
+```
+[...]
+
+
+
Example Domain
+
This domain is for use in illustrative examples in documents. You may use this
+ domain in literature without prior coordination or asking for permission.
+
More information...
+