mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
a20d7a898c
@ -1,9 +1,13 @@
|
||||
Part-III 树莓派自建 NAS 云盘之云盘构建
|
||||
树莓派自建 NAS 云盘之——云盘构建
|
||||
======
|
||||
|
||||
用树莓派 NAS 云盘来保护数据的安全!
|
||||
> 用自行托管的树莓派 NAS 云盘来保护数据的安全!
|
||||
|
||||
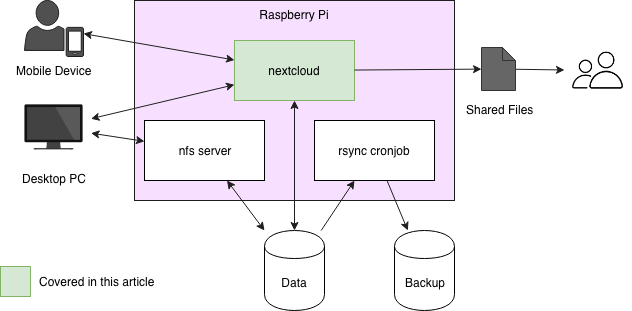
在前面两篇文章中(译注:文章链接 [Part-I][1],[Part-II][2]),我们讨论了用树莓派搭建一个 NAS(network-attached storage) 所需要的一些 [软硬件环境及其操作步骤][1]。我们还制定了适当的 [备份策略][2] 来保护NAS上的数据。本文中,我们将介绍讨论利用 [Nestcloud][3] 来方便快捷的存储、获取以及分享你的数据。
|
||||

|
||||
|
||||
在前面两篇文章中,我们讨论了用树莓派搭建一个 NAS 云盘所需要的一些 [软硬件环境及其操作步骤][1]。我们还制定了适当的 [备份策略][2] 来保护 NAS 上的数据。本文中,我们将介绍讨论利用 [Nestcloud][3] 来方便快捷的存储、获取以及分享你的数据。
|
||||
|
||||
|
||||
|
||||
### 必要的准备工作
|
||||
|
||||
@ -13,13 +17,13 @@ Part-III 树莓派自建 NAS 云盘之云盘构建
|
||||
|
||||
### 安装 Nextcloud
|
||||
|
||||
为了在树莓派(参考 [Part-I][1] 中步骤设置)中运行 Nextcloud,首先用命令 **apt** 安装 以下的一些依赖软件包。
|
||||
为了在树莓派(参考 [第一篇][1] 中步骤设置)中运行 Nextcloud,首先用命令 `apt` 安装 以下的一些依赖软件包。
|
||||
|
||||
```
|
||||
sudo apt install unzip wget php apache2 mysql-server php-zip php-mysql php-dom php-mbstring php-gd php-curl
|
||||
```
|
||||
|
||||
其次,下载 Nextcloud。在树莓派中利用 **wget** 下载其 [最新的版本][5]。在 [Part-I] 文章中,我们将两个磁盘驱动器连接到树莓派,一个用于存储当前数据,另一个用于备份。这里在数据存储盘上安装 Nextcloud,以确保每晚自动备份数据。
|
||||
其次,下载 Nextcloud。在树莓派中利用 `wget` 下载其 [最新的版本][5]。在 [第一篇][1] 文章中,我们将两个磁盘驱动器连接到树莓派,一个用于存储当前数据,另一个用于备份。这里在数据存储盘上安装 Nextcloud,以确保每晚自动备份数据。
|
||||
|
||||
```
|
||||
sudo mkdir -p /nas/data/nextcloud
|
||||
@ -37,27 +41,27 @@ sudo chown -R www-data:www-data /nas/data/nextcloud
|
||||
|
||||
如上所述,Nextcloud 安装完毕。之前安装依赖软件包时就已经安装了 MySQL 数据库来存储 Nextcloud 的一些重要数据(例如,那些你创建的可以访问 Nextcloud 的用户的信息)。如果你更愿意使用 Pstgres 数据库,则上面的依赖软件包需要做一些调整。
|
||||
|
||||
以 root 权限启动 MySQL:
|
||||
以 root 权限启动 MySQL:
|
||||
|
||||
```
|
||||
sudo mysql
|
||||
```
|
||||
|
||||
这将会打开 SQL 提示符界面,在那里可以插入如下指令--使用数据库连接密码替换其中的占位符--为 Nextcloud 创建一个数据库。
|
||||
这将会打开 SQL 提示符界面,在那里可以插入如下指令——使用数据库连接密码替换其中的占位符——为 Nextcloud 创建一个数据库。
|
||||
|
||||
```
|
||||
CREATE USER nextcloud IDENTIFIED BY '<insert-password-here>';
|
||||
CREATE USER nextcloud IDENTIFIED BY '<这里插入密码>';
|
||||
CREATE DATABASE nextcloud;
|
||||
GRANT ALL ON nextcloud.* TO nextcloud;
|
||||
```
|
||||
|
||||
按 **Ctrl+D** 或输入 **quit** 退出 SQL 提示符界面。
|
||||
按 `Ctrl+D` 或输入 `quit` 退出 SQL 提示符界面。
|
||||
|
||||
### Web 服务器配置
|
||||
|
||||
Nextcloud 可以配置以适配于 Nginx 服务器或者其他 Web 服务器运行的环境。但本文中,我决定在我的树莓派 NAS 中运行 Apache 服务器(如果你有其他效果更好的服务器选择方案,不妨也跟我分享一下)。
|
||||
|
||||
首先为你的 Nextcloud 域名创建一个虚拟主机,创建配置文件 **/etc/apache2/sites-available/001-netxcloud.conf**,在其中输入下面的参数内容。修改其中 ServerName 为你的域名。
|
||||
首先为你的 Nextcloud 域名创建一个虚拟主机,创建配置文件 `/etc/apache2/sites-available/001-netxcloud.conf`,在其中输入下面的参数内容。修改其中 `ServerName` 为你的域名。
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
@ -78,13 +82,13 @@ a2ensite 001-nextcloud
|
||||
sudo systemctl reload apache2
|
||||
```
|
||||
|
||||
现在,你应该可以通过浏览器中输入域名访问到 web 服务器了。这里我推荐使用 HTTPS 协议而不是 HTTP 协议来访问 Nextcloud。一个简单而且免费的方法就是利用 [Certbot][7] 下载 [Let's Encrypt][6] 证书,然后设置定时任务自动刷新。这样就避免了自签证书等的麻烦。参考 [如何在树莓派中安装][8] Certbot 。在配置 Certbot 的时候,你甚至可以配置将 HTTP 自动转到 HTTPS ,例如访问 **<http://nextcloud.pi-nas.com>** 自动跳转到 **<https://nextcloud.pi-nas.com>**。注意,如果你的树莓派 NAS 运行在家庭路由器的下面,别忘了设置路由器的 443 端口和 80 端口转发。
|
||||
现在,你应该可以通过浏览器中输入域名访问到 web 服务器了。这里我推荐使用 HTTPS 协议而不是 HTTP 协议来访问 Nextcloud。一个简单而且免费的方法就是利用 [Certbot][7] 下载 [Let's Encrypt][6] 证书,然后设置定时任务自动刷新。这样就避免了自签证书等的麻烦。参考 [如何在树莓派中安装][8] Certbot 。在配置 Certbot 的时候,你甚至可以配置将 HTTP 自动转到 HTTPS ,例如访问 `http://nextcloud.pi-nas.com` 自动跳转到 `https://nextcloud.pi-nas.com`。注意,如果你的树莓派 NAS 运行在家庭路由器的下面,别忘了设置路由器的 443 端口和 80 端口转发。
|
||||
|
||||
### 配置 Nextcloud
|
||||
|
||||
最后一步,通过浏览器访问 Nextcloud 来配置它。在浏览器中输入域名地址,插入上文中的数据库设置信息。这里,你可以创建 Nextcloud 管理员用户。默认情况下,数据保存目录在在 Nextcloud 目录下,所以你也无需修改我们在 [Part-II][2] 一文中设置的备份策略。
|
||||
最后一步,通过浏览器访问 Nextcloud 来配置它。在浏览器中输入域名地址,插入上文中的数据库设置信息。这里,你可以创建 Nextcloud 管理员用户。默认情况下,数据保存目录在在 Nextcloud 目录下,所以你也无需修改我们在 [第二篇][2] 一文中设置的备份策略。
|
||||
|
||||
然后,页面会跳转到 Nextcloud 登陆界面,用刚才创建的管理员用户登陆。在设置页面中会有基础操作教程和安全安装教程(这里是访问 <https://nextcloud.pi-nas.com/>settings/admin)。
|
||||
然后,页面会跳转到 Nextcloud 登陆界面,用刚才创建的管理员用户登陆。在设置页面中会有基础操作教程和安全安装教程(这里是访问 `https://nextcloud.pi-nas.com/settings/admin`)。
|
||||
|
||||
恭喜你,到此为止,你已经成功在树莓派中安装了你自己的云 Nextcloud。去 Nextcloud 主页 [下载 Nextcloud 客户端][9],客户端可以同步数据并且离线访问服务器。移动端甚至可以上传图片等资源,然后电脑桌面都可以去访问它们。
|
||||
|
||||
@ -95,13 +99,13 @@ via: https://opensource.com/article/18/9/host-cloud-nas-raspberry-pi
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ntlx
|
||||
[1]: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
[2]: https://opensource.com/article/18/8/automate-backups-raspberry-pi
|
||||
[1]: https://linux.cn/article-10104-1.html?utm_source=index&utm_medium=more
|
||||
[2]: https://linux.cn/article-10112-1.html
|
||||
[3]: https://nextcloud.com/
|
||||
[4]: https://sourceforge.net/p/ddclient/wiki/Home/
|
||||
[5]: https://nextcloud.com/install/#instructions-server
|
||||
@ -1,35 +1,35 @@
|
||||
三个开源的分布式追踪工具
|
||||
======
|
||||
|
||||
这几个工具对复杂软件系统中的实时事件做了可视化,能帮助你快速发现性能问题。
|
||||
> 这几个工具对复杂软件系统中的实时事件做了可视化,能帮助你快速发现性能问题。
|
||||
|
||||

|
||||
|
||||
分布式追踪系统能够从头到尾地追踪分布式系统中的请求,跨越多个应用、服务、数据库以及像代理这样的中间件。它能帮助你更深入地理解系统中到底发生了什么。追踪系统以图形化的方式,展示出每个已知步骤以及某个请求在每个步骤上的耗时。
|
||||
分布式追踪系统能够从头到尾地追踪跨越了多个应用、服务、数据库以及像代理这样的中间件的分布式软件的请求。它能帮助你更深入地理解系统中到底发生了什么。追踪系统以图形化的方式,展示出每个已知步骤以及某个请求在每个步骤上的耗时。
|
||||
|
||||
用户可以通过这些展示来判断系统的哪个环节有延迟或阻塞,当请求失败时,运维和开发人员可以看到准确的问题源头,而不需要去测试整个系统,比如用二叉查找树的方法去定位问题。在开发迭代的过程中,追踪系统还能够展示出可能引起性能变化的环节。通过异常行为的警告自动地感知到性能在退化,总是比客户告诉你要好。
|
||||
用户可以通过这些展示来判断系统的哪个环节有延迟或阻塞,当请求失败时,运维和开发人员可以看到准确的问题源头,而不需要去测试整个系统,比如用二叉查找树的方法去定位问题。在开发迭代的过程中,追踪系统还能够展示出可能引起性能变化的环节。通过异常行为的警告自动地感知到性能的退化,总是比客户告诉你要好。
|
||||
|
||||
追踪是怎么工作的呢?给每个请求分配一个特殊 ID,这个 ID 通常会插入到请求头部中。它唯一标识了对应的事务。一般把事务叫做 trace,trace 是抽象整个事务的概念。每一个 trace 由 span 组成,span 代表着一次请求中真正执行的操作,比如一次服务调用,一次数据库请求等。每一个 span 也有自己唯一的 ID。span 之下也可以创建子 span,子 span 可以有多个父 span。
|
||||
这种追踪是怎么工作的呢?给每个请求分配一个特殊 ID,这个 ID 通常会插入到请求头部中。它唯一标识了对应的事务。一般把事务叫做<ruby>踪迹<rt>trace</rt></ruby>,“踪迹”是整个事务的抽象概念。每一个“踪迹”由<ruby>单元<rt>span</rt></ruby>组成,“单元”代表着一次请求中真正执行的操作,比如一次服务调用,一次数据库请求等。每一个“单元”也有自己唯一的 ID。“单元”之下也可以创建子“单元”,子“单元”可以有多个父“单元”。
|
||||
|
||||
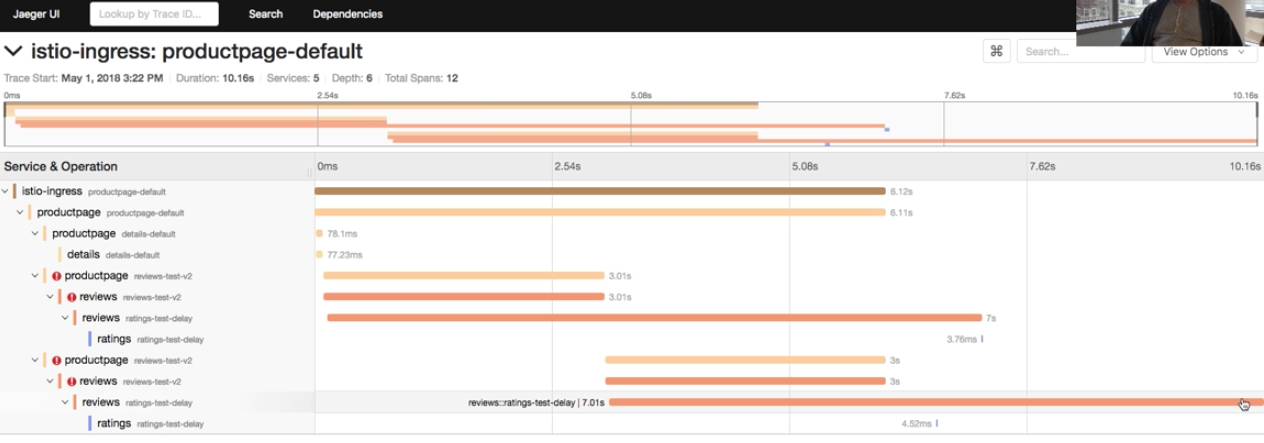
当一次事务(或者说 trace)运行过之后,就可以在追踪系统的表示层上搜索了。有几个工具可以用作表示层,我们下文会讨论,不过,我们先看下面的图,它是我在 [Istio walkthrough][2] 视频教程中提到的 [Jaeger][1] 界面,展示了单个 trace 中的多个 span。很明显,这个图能让你一目了然地对事务有更深的了解。
|
||||
当一次事务(或者说踪迹)运行过之后,就可以在追踪系统的表示层上搜索了。有几个工具可以用作表示层,我们下文会讨论,不过,我们先看下面的图,它是我在 [Istio walkthrough][2] 视频教程中提到的 [Jaeger][1] 界面,展示了单个踪迹中的多个单元。很明显,这个图能让你一目了然地对事务有更深的了解。
|
||||
|
||||
|
||||
|
||||
这个 demo 使用了 Istio 内置的 OpenTracing 实现,所以我甚至不需要修改自己的应用代码就可以获得追踪数据。我也用到了 Jaeger,它是兼容 OpenTracing 的。
|
||||
这个演示使用了 Istio 内置的 OpenTracing 实现,所以我甚至不需要修改自己的应用代码就可以获得追踪数据。我也用到了 Jaeger,它是兼容 OpenTracing 的。
|
||||
|
||||
那么 OpenTracing 到底是什么呢?我们来看看。
|
||||
|
||||
### OpenTracing API
|
||||
|
||||
[OpenTracing][3] 是源自 [Zipkin][4] 的规范,以提供跨平台兼容性。它提供了对厂商中立的 API,用来向应用程序添加追踪功能并将追踪数据发送到分布式的追踪系统。按照 OpenTracing 规范编写的库,可以被任何兼容 OpenTracing 的系统使用。采用这个开放标准的开源工具有 Zipkin,Jaeger,和 Appdash 等。甚至像 [Datadog][5] 和 [Instana][6] 这种付费工具也在采用。因为现在 OpenTracing 已经无处不在,这样的趋势有望继续发展下去。
|
||||
[OpenTracing][3] 是源自 [Zipkin][4] 的规范,以提供跨平台兼容性。它提供了对厂商中立的 API,用来向应用程序添加追踪功能并将追踪数据发送到分布式的追踪系统。按照 OpenTracing 规范编写的库,可以被任何兼容 OpenTracing 的系统使用。采用这个开放标准的开源工具有 Zipkin、Jaeger 和 Appdash 等。甚至像 [Datadog][5] 和 [Instana][6] 这种付费工具也在采用。因为现在 OpenTracing 已经无处不在,这样的趋势有望继续发展下去。
|
||||
|
||||
### OpenCensus
|
||||
|
||||
OpenTracing 已经说过了,可 [OpenCensus][7] 又是什么呢?它在搜索结果中老是出现。它是一个和 OpenTracing 完全不同或者互补的竞争标准吗?
|
||||
|
||||
这个问题的答案取决于你的提问对象。我先尽我所能地解释一下他们的不同(按照我的理解):OpenCensus 更加全面或者说它包罗万象。OpenTracing 专注于建立开放的 API 和规范,而不是为每一种开发语言和追踪系统都提供开放的实现。OpenCensus 不仅提供规范,还提供开发语言的实现,和连接协议,而且它不仅只做追踪,还引入了额外的度量指标,这些一般不在分布式追踪系统的职责范围。
|
||||
这个问题的答案取决于你的提问对象。我先尽我所能地解释一下它们的不同(按照我的理解):OpenCensus 更加全面或者说它包罗万象。OpenTracing 专注于建立开放的 API 和规范,而不是为每一种开发语言和追踪系统都提供开放的实现。OpenCensus 不仅提供规范,还提供开发语言的实现,和连接协议,而且它不仅只做追踪,还引入了额外的度量指标,这些一般不在分布式追踪系统的职责范围。
|
||||
|
||||
使用 OpenCensus,我们能够在运行着应用程序的主机上查看追踪数据,但它也有个可插拔的导出器系统,用于导出数据到中心聚合器。目前 OpenCensus 团队提供的导出器包括 Zipkin,Prometheus,Jaeger,Stackdriver,Datadog 和 SignalFx,不过任何人都可以创建一个导出器。
|
||||
使用 OpenCensus,我们能够在运行着应用程序的主机上查看追踪数据,但它也有个可插拔的导出器系统,用于导出数据到中心聚合器。目前 OpenCensus 团队提供的导出器包括 Zipkin、Prometheus、Jaeger、Stackdriver、Datadog 和 SignalFx,不过任何人都可以创建一个导出器。
|
||||
|
||||
依我看这两者有很多重叠的部分,没有哪个一定比另外一个好,但是重要的是,要知道它们做什么事情和不做什么事情。OpenTracing 主要是一个规范,具体的实现和独断的设计由其他人来做。OpenCensus 更加独断地为本地组件提供了全面的解决方案,但是仍然需要其他系统做远程的聚合。
|
||||
|
||||
@ -39,23 +39,23 @@ OpenTracing 已经说过了,可 [OpenCensus][7] 又是什么呢?它在搜索
|
||||
|
||||
Zipkin 是最早出现的这类工具之一。 谷歌在 2010 年发表了介绍其内部追踪系统 Dapper 的[论文][8],Twitter 以此为基础开发了 Zipkin。Zipkin 的开发语言 Java,用 Cassandra 或 ElasticSearch 作为可扩展的存储后端,这些选择能满足大部分公司的需求。Zipkin 支持的最低 Java 版本是 Java 6,它也使用了 [Thrift][9] 的二进制通信协议,Thrift 在 Twitter 的系统中很流行,现在作为 Apache 项目在托管。
|
||||
|
||||
这个系统包括上报器(客户端),数据收集器,查询服务和一个 web 界面。Zipkin 只传输一个带事务上下文的 trace ID 来告知接收者追踪的进行,所以说在生产环境中是安全的。每一个客户端收集到的数据,会异步地传输到数据收集器。收集器把这些 span 的数据存到数据库,web 界面负责用可消费的格式展示这些数据给用户。客户端传输数据到收集器有三种方式:HTTP,Kafka 和 Scribe。
|
||||
这个系统包括上报器(客户端)、数据收集器、查询服务和一个 web 界面。Zipkin 只传输一个带事务上下文的踪迹 ID 来告知接收者追踪的进行,所以说在生产环境中是安全的。每一个客户端收集到的数据,会异步地传输到数据收集器。收集器把这些单元的数据存到数据库,web 界面负责用可消费的格式展示这些数据给用户。客户端传输数据到收集器有三种方式:HTTP、Kafka 和 Scribe。
|
||||
|
||||
[Zipkin 社区][10] 还提供了 [Brave][11],一个跟 Zipkin 兼容的 Java 客户端的实现。由于 Brave 没有任何依赖,所以它不会拖累你的项目,也不会使用跟你们公司标准不兼容的库来搞乱你的项目。除 Brave 之外,还有很多其他的 Zipkin 客户端实现,因为 Zipkin 和 OpenTracing 标准是兼容的,所以这些实现也能用到其他的分布式追踪系统中。流行的 Spring 框架中一个叫 [Spring Cloud Sleuth][12] 的分布式追踪组件,它和 Zipkin 是兼容的。
|
||||
[Zipkin 社区][10] 还提供了 [Brave][11],一个跟 Zipkin 兼容的 Java 客户端的实现。由于 Brave 没有任何依赖,所以它不会拖累你的项目,也不会使用跟你们公司标准不兼容的库来搞乱你的项目。除 Brave 之外,还有很多其他的 Zipkin 客户端实现,因为 Zipkin 和 OpenTracing 标准是兼容的,所以这些实现也能用到其他的分布式追踪系统中。流行的 Spring 框架中一个叫 [Spring Cloud Sleuth][12] 的分布式追踪组件,它和 Zipkin 是兼容的。
|
||||
|
||||
#### Jaeger
|
||||
|
||||
[Jaeger][1] 来自 Uber,是一个比较新的项目,[CNCF][13] (云原生计算基金会)已经把 Jaeger 托管为孵化项目。Jaeger 使用 Golang 开发,因此你不用担心在服务器上安装依赖的问题,也不用担心开发语言的解释器或虚拟机的开销。和 Zipkin 类似,Jaeger 也支持用 Cassandra 和 ElasticSearch 做可扩展的存储后端。Jaeger 也完全兼容 OpenTracing 标准。
|
||||
[Jaeger][1] 来自 Uber,是一个比较新的项目,[CNCF][13](云原生计算基金会)已经把 Jaeger 托管为孵化项目。Jaeger 使用 Golang 开发,因此你不用担心在服务器上安装依赖的问题,也不用担心开发语言的解释器或虚拟机的开销。和 Zipkin 类似,Jaeger 也支持用 Cassandra 和 ElasticSearch 做可扩展的存储后端。Jaeger 也完全兼容 OpenTracing 标准。
|
||||
|
||||
Jaeger 的架构跟 Zipkin 很像,有客户端(上报器),数据收集器,查询服务和一个 web 界面,不过它还有一个在各个服务器上运行着的代理,负责在服务器本地做数据聚合。代理通过一个 UDP 连接接收数据,然后分批处理,发送到数据收集器。收集器接收到的数据是 [Thrift][14] 协议的格式,它把数据存到 Cassandra 或者 ElasticSearch 中。查询服务能直接访问数据库,并给 web 界面提供所需的信息。
|
||||
Jaeger 的架构跟 Zipkin 很像,有客户端(上报器)、数据收集器、查询服务和一个 web 界面,不过它还有一个在各个服务器上运行着的代理,负责在服务器本地做数据聚合。代理通过一个 UDP 连接接收数据,然后分批处理,发送到数据收集器。收集器接收到的数据是 [Thrift][14] 协议的格式,它把数据存到 Cassandra 或者 ElasticSearch 中。查询服务能直接访问数据库,并给 web 界面提供所需的信息。
|
||||
|
||||
默认情况下,Jaeger 客户端不会采集所有的追踪数据,只抽样了 0.1% 的( 1000 个采 1 个)追踪数据。对大多数系统来说,保留所有的追踪数据并传输的话就太多了。不过,通过配置代理可以调整这个值,客户端会从代理获取自己的配置。这个抽样并不是完全随机的,并且正在变得越来越好。Jaeger 使用概率抽样,试图对是否应该对新踪迹进行抽样进行有根据的猜测。 自适应采样已经在[路线图][15],它将通过添加额外的,能够帮助做决策的上下文,来改进采样算法。
|
||||
默认情况下,Jaeger 客户端不会采集所有的追踪数据,只抽样了 0.1% 的( 1000 个采 1 个)追踪数据。对大多数系统来说,保留所有的追踪数据并传输的话就太多了。不过,通过配置代理可以调整这个值,客户端会从代理获取自己的配置。这个抽样并不是完全随机的,并且正在变得越来越好。Jaeger 使用概率抽样,试图对是否应该对新踪迹进行抽样进行有根据的猜测。 [自适应采样已经在路线图当中][15],它将通过添加额外的、能够帮助做决策的上下文来改进采样算法。
|
||||
|
||||
#### Appdash
|
||||
|
||||
[Appdash][16] 也是一个用 Golang 写的分布式追踪系统,和 Jaeger 一样。Appdash 是 [Sourcegraph][17] 公司基于谷歌的 Dapper 和 Twitter 的 Zipkin 开发的。同样的,它也支持 Opentracing 标准,不过这是后来添加的功能,依赖了一个与默认组件不同的组件,因此增加了风险和复杂度。
|
||||
|
||||
从高层次来看,Appdash 的架构主要有三个部分:客户端,本地收集器和远程收集器。因为没有很多文档,所以这个架构描述是基于对系统的测试以及查看源码。写代码时需要把 Appdash 的客户端添加进来。 Appdash 提供了 Python,Golang 和 Ruby 的实现,不过 OpenTracing 库可以与 Appdash 的 OpenTracing 实现一起使用。 客户端收集 span 数据,并将它们发送到本地收集器。然后,本地收集器将数据发送到中心的 Appdash 服务器,这个服务器上运行着自己的本地收集器,它的本地收集器是其他所有节点的远程收集器。
|
||||
从高层次来看,Appdash 的架构主要有三个部分:客户端、本地收集器和远程收集器。因为没有很多文档,所以这个架构描述是基于对系统的测试以及查看源码。写代码时需要把 Appdash 的客户端添加进来。Appdash 提供了 Python、Golang 和 Ruby 的实现,不过 OpenTracing 库可以与 Appdash 的 OpenTracing 实现一起使用。 客户端收集单元数据,并将它们发送到本地收集器。然后,本地收集器将数据发送到中心的 Appdash 服务器,这个服务器上运行着自己的本地收集器,它的本地收集器是其他所有节点的远程收集器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -64,7 +64,7 @@ via: https://opensource.com/article/18/9/distributed-tracing-tools
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[belitex](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,123 @@
|
||||
Minikube 入门:笔记本上的 Kubernetes
|
||||
======
|
||||
|
||||
> 运行 Minikube 的分步指南。
|
||||
|
||||

|
||||
|
||||
在 [Hello Minikube][1] 教程页面上 Minikube 被宣传为基于 Docker 运行 Kubernetes 的一种简单方法。 虽然该文档非常有用,但它主要是为 MacOS 编写的。 你可以深入挖掘在 Windows 或某个 Linux 发行版上的使用说明,但它们不是很清楚。 许多文档都是针对 Debian / Ubuntu 用户的,比如[安装 Minikube 的驱动程序][2]。
|
||||
|
||||
这篇指南旨在使得在基于 RHEL/Fedora/CentOS 的操作系统上更容易安装 Minikube。
|
||||
|
||||
### 先决条件
|
||||
|
||||
1. 你已经[安装了 Docker][3]。
|
||||
2. 你的计算机是一个基于 RHEL / CentOS / Fedora 的工作站。
|
||||
3. 你已经[安装了正常运行的 KVM2 虚拟机管理程序][4]。
|
||||
4. 你有一个可以工作的 docker-machine-driver-kvm2。 以下命令将安装该驱动程序:
|
||||
|
||||
```
|
||||
curl -Lo docker-machine-driver-kvm2 https://storage.googleapis.com/minikube/releases/latest/docker-machine-driver-kvm2 \
|
||||
chmod +x docker-machine-driver-kvm2 \
|
||||
&& sudo cp docker-machine-driver-kvm2 /usr/local/bin/ \
|
||||
&& rm docker-machine-driver-kvm2
|
||||
```
|
||||
|
||||
### 下载、安装和启动Minikube
|
||||
|
||||
1、为你要即将下载的两个文件创建一个目录,两个文件分别是:[minikube][5] 和 [kubectl][6]。
|
||||
|
||||
2、打开终端窗口并运行以下命令来安装 minikube。
|
||||
|
||||
```
|
||||
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
|
||||
```
|
||||
|
||||
请注意,minikube 版本(例如,minikube-linux-amd64)可能因计算机的规格而有所不同。
|
||||
|
||||
3、`chmod` 加执行权限。
|
||||
|
||||
```
|
||||
chmod +x minikube
|
||||
```
|
||||
|
||||
4、将文件移动到 `/usr/local/bin` 路径下,以便你能将其作为命令运行。
|
||||
|
||||
```
|
||||
mv minikube /usr/local/bin
|
||||
```
|
||||
|
||||
5、使用以下命令安装 `kubectl`(类似于 minikube 的安装过程)。
|
||||
|
||||
```
|
||||
curl -Lo kubectl https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
|
||||
```
|
||||
|
||||
使用 `curl` 命令确定最新版本的Kubernetes。
|
||||
|
||||
6、`chmod` 给 `kubectl` 加执行权限。
|
||||
|
||||
```
|
||||
chmod +x kubectl
|
||||
```
|
||||
|
||||
7、将 `kubectl` 移动到 `/usr/local/bin` 路径下作为命令运行。
|
||||
|
||||
```
|
||||
mv kubectl /usr/local/bin
|
||||
```
|
||||
|
||||
8、 运行 `minikube start` 命令。 为此,你需要有虚拟机管理程序。 我使用过 KVM2,你也可以使用 Virtualbox。 确保是以普通用户而不是 root 身份运行以下命令,以便为用户而不是 root 存储配置。
|
||||
|
||||
```
|
||||
minikube start --vm-driver=kvm2
|
||||
```
|
||||
|
||||
这可能需要一段时间,等一会。
|
||||
|
||||
9、 Minikube 应该下载并启动。 使用以下命令确保成功。
|
||||
|
||||
```
|
||||
cat ~/.kube/config
|
||||
```
|
||||
|
||||
10、 执行以下命令以运行 Minikube 作为上下文环境。 上下文环境决定了 `kubectl` 与哪个集群交互。 你可以在 `~/.kube/config` 文件中查看所有可用的上下文环境。
|
||||
|
||||
```
|
||||
kubectl config use-context minikube
|
||||
```
|
||||
|
||||
11、再次查看 `config` 文件以检查 Minikube 是否存在上下文环境。
|
||||
|
||||
```
|
||||
cat ~/.kube/config
|
||||
```
|
||||
|
||||
12、最后,运行以下命令打开浏览器查看 Kubernetes 仪表板。
|
||||
|
||||
```
|
||||
minikube dashboard
|
||||
```
|
||||
|
||||
现在 Minikube 已启动并运行,请阅读[通过 Minikube 在本地运行 Kubernetes][7] 这篇官网教程开始使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/getting-started-minikube
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://kubernetes.io/docs/tutorials/hello-minikube
|
||||
[2]: https://github.com/kubernetes/minikube/blob/master/docs/drivers.md
|
||||
[3]: https://docs.docker.com/install
|
||||
[4]: https://github.com/kubernetes/minikube/blob/master/docs/drivers.md#kvm2-driver
|
||||
[5]: https://github.com/kubernetes/minikube/releases
|
||||
[6]: https://kubernetes.io/docs/tasks/tools/install-kubectl/#install-kubectl-binary-using-curl
|
||||
[7]: https://kubernetes.io/docs/setup/minikube
|
||||
@ -1,3 +1,5 @@
|
||||
fuowang 翻译中
|
||||
|
||||
9 Best Free Video Editing Software for Linux In 2017
|
||||
======
|
||||
**Brief: Here are best video editors for Linux, their feature, pros and cons and how to install them on your Linux distributions.**
|
||||
|
||||
@ -1,160 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
How to configure multiple websites with Apache web server
|
||||
======
|
||||
|
||||

|
||||
In my [last post][1], I explained how to configure an Apache web server for a single website. It turned out to be very easy. In this post, I will show you how to serve multiple websites using a single instance of Apache.
|
||||
|
||||
Note: I wrote this article on a virtual machine using Fedora 27 with Apache 2.4.29. If you have another distribution or release of Fedora, the commands you will use and the locations and content of the configuration files may be different.
|
||||
|
||||
As my previous article mentioned, all of the configuration files for Apache are located in `/etc/httpd/conf` and `/etc/httpd/conf.d`. The data for the websites is located in `/var/www` by default. With multiple websites, you will need to provide multiple locations, one for each site you host.
|
||||
|
||||
### Name-based virtual hosting
|
||||
|
||||
With name-based virtual hosting, you can use a single IP address for multiple websites. Modern web servers, including Apache, use the `hostname` portion of the specified URL to determine which virtual web host responds to the page request. This requires only a little more configuration than for a single site.
|
||||
|
||||
Even if you are starting with only a single website, I recommend that you set it up as a virtual host, which will make it easier to add more sites later. In this article, I'll pick up where we left off in the previous article, so you'll need to set up the original website, a name-based virtual website.
|
||||
|
||||
### Preparing the original website
|
||||
|
||||
Before you set up a second website, you need to get name-based virtual hosting working for the existing site. If you do not have an existing website, [go back and create one now][1].
|
||||
|
||||
Once you have your site, add the following stanza to the bottom of its `/etc/httpd/conf/httpd.conf` configuration file (adding this stanza is the only change you need to make to the `httpd.conf` file):
|
||||
```
|
||||
<VirtualHost 127.0.0.1:80>
|
||||
|
||||
DocumentRoot /var/www/html
|
||||
|
||||
ServerName www.site1.org
|
||||
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
This will be the first virtual host stanza, and it should remain first, to make it the default definition. That means that HTTP access to the server by IP address, or by another name that resolves to this IP address but that does not have a specific named host configuration stanza, will be directed to this virtual host. All other virtual host configuration stanzas should follow this one.
|
||||
|
||||
You also need to set up your websites with entries in `/etc/hosts` to provide name resolution. Last time, we just used the IP address for `localhost`. Normally, this would be done using whichever name service you use; for example, Google or Godaddy. For your test website, do this by adding a new name to the `localhost` line in `/etc/hosts`. Add the entries for both websites so you don't need to edit this file again later. The result looks like this:
|
||||
```
|
||||
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 www.site1.org www.site2.org
|
||||
|
||||
```
|
||||
|
||||
Let’s also change the `/var/www/html/index.html` file to be a little more explicit. It should look like this (with some additional text to identify this as website number 1):
|
||||
```
|
||||
<h1>Hello World</h1>
|
||||
|
||||
|
||||
|
||||
Web site 1.
|
||||
|
||||
```
|
||||
|
||||
Restart the HTTPD server to enable the changes to the `httpd` configuration. You can then look at the website using the Lynx text mode browser from the command line.
|
||||
```
|
||||
[root@testvm1 ~]# systemctl restart httpd
|
||||
|
||||
[root@testvm1 ~]# lynx www.site1.org
|
||||
|
||||
|
||||
|
||||
Hello World
|
||||
|
||||
Web site 1.
|
||||
|
||||
<snip>
|
||||
|
||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||
|
||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||
|
||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||
|
||||
```
|
||||
|
||||
You can see that the revised content for the original website is displayed and that there are no obvious errors. Press the “Q” key, followed by “Y” to exit the Lynx web browser.
|
||||
|
||||
### Configuring the second website
|
||||
|
||||
Now you are ready to set up the second website. Create a new website directory structure with the following command:
|
||||
```
|
||||
[root@testvm1 html]# mkdir -p /var/www/html2
|
||||
|
||||
```
|
||||
|
||||
Notice that the second website is simply a second `html` directory in the same `/var/www` directory as the first site.
|
||||
|
||||
Now create a new index file, `/var/www/html2/index.html`, with the following content (this index file is a bit different, to distinguish it from the one for the original website):
|
||||
```
|
||||
<h1>Hello World -- Again</h1>
|
||||
|
||||
|
||||
|
||||
Web site 2.
|
||||
|
||||
```
|
||||
|
||||
Create a new configuration stanza in `httpd.conf` for the second website and place it below the previous virtual host stanza (the two should look very similar). This stanza tells the web server where to find the HTML files for the second site.
|
||||
```
|
||||
<VirtualHost 127.0.0.1:80>
|
||||
|
||||
DocumentRoot /var/www/html2
|
||||
|
||||
ServerName www.site2.org
|
||||
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
Restart HTTPD again and use Lynx to view the results.
|
||||
```
|
||||
[root@testvm1 httpd]# systemctl restart httpd
|
||||
|
||||
[root@testvm1 httpd]# lynx www.site2.org
|
||||
|
||||
|
||||
|
||||
Hello World -- Again
|
||||
|
||||
|
||||
|
||||
Web site 2.
|
||||
|
||||
|
||||
|
||||
<snip>
|
||||
|
||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||
|
||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||
|
||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||
|
||||
```
|
||||
|
||||
Here I have compressed the resulting output to fit this space. The difference in the page indicates that this is the second website. To show both websites at the same time, open another terminal session and use the Lynx web browser to view the other site.
|
||||
|
||||
### Other considerations
|
||||
|
||||
This simple example shows how to serve up two websites with a single instance of the Apache HTTPD server. Configuring the virtual hosts becomes a bit more complex when other factors are considered.
|
||||
|
||||
For example, you may want to use some CGI scripts for one or both of these websites. To do this, you would create directories for the CGI programs in `/var/www`: `/var/www/cgi-bin` and `/var/www/cgi-bin2`, to be consistent with the HTML directory naming. You would then need to add configuration directives to the virtual host stanzas to specify the directory location for the CGI scripts. Each website could also have directories from which files could be downloaded; this would also require entries in the appropriate virtual host stanza.
|
||||
|
||||
The [Apache website][2] describes other methods for managing multiple websites, as well as configuration options from performance tuning to security.
|
||||
|
||||
Apache is a powerful web server that can be used to manage websites ranging from simple to highly complex. Although its overall share is shrinking, Apache remains the single most commonly used HTTPD server on the Internet.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[2]:https://httpd.apache.org/docs/2.4/
|
||||
@ -1,4 +1,3 @@
|
||||
KevinSJ 翻译中
|
||||
6 open source tools for writing a book
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by way-ww
|
||||
|
||||
Why Linux users should try Rust
|
||||
======
|
||||
|
||||
|
||||
@ -1,188 +0,0 @@
|
||||
Open Source Logging Tools for Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you’re a Linux systems administrator, one of the first tools you will turn to for troubleshooting are log files. These files hold crucial information that can go a long way to help you solve problems affecting your desktops and servers. For many sysadmins (especially those of an old-school sort), nothing beats the command line for checking log files. But for those who’d rather have a more efficient (and possibly modern) approach to troubleshooting, there are plenty of options.
|
||||
|
||||
In this article, I’ll highlight a few such tools available for the Linux platform. I won’t be getting into logging tools that might be specific to a certain service (such as Kubernetes or Apache), and instead will focus on tools that work to mine the depths of all that magical information written into /var/log.
|
||||
|
||||
Speaking of which…
|
||||
|
||||
### What is /var/log?
|
||||
|
||||
If you’re new to Linux, you might not know what the /var/log directory contains. However, the name is very telling. Within this directory is housed all of the log files from the system and any major service (such as Apache, MySQL, MariaDB, etc.) installed on the operating system. Open a terminal window and issue the command cd /var/log. Follow that with the command ls and you’ll see all of the various systems that have log files you can view (Figure 1).
|
||||
|
||||
![/var/log/][2]
|
||||
|
||||
Figure 1: Our ls command reveals the logs available in /var/log/.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Say, for instance, you want to view the syslog log file. Issue the command less syslog and you can scroll through all of the gory details of that particular log. But what if the standard terminal isn’t for you? What options do you have? Plenty. Let’s take a look at few such options.
|
||||
|
||||
### Logs
|
||||
|
||||
If you use the GNOME desktop (or other, as Logs can be installed on more than just GNOME), you have at your fingertips a log viewer that mainly just adds the slightest bit of GUI goodness over the log files to create something as simple as it is effective. Once installed (from the standard repositories), open Logs from the desktop menu, and you’ll be treated to an interface (Figure 2) that allows you to select from various types of logs (Important, All, System, Security, and Hardware), as well as select a boot period (from the top center drop-down), and even search through all of the available logs.
|
||||
|
||||
![Logs tool][5]
|
||||
|
||||
Figure 2: The GNOME Logs tool is one of the easiest GUI log viewers you’ll find for Linux.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Logs is a great tool, especially if you’re not looking for too many bells and whistles getting in the way of you viewing crucial log entries, so you can troubleshoot your systems.
|
||||
|
||||
### KSystemLog
|
||||
|
||||
KSystemLog is to KDE what Logs is to GNOME, but with a few more features to add into the mix. Although both make it incredibly simple to view your system log files, only KSystemLog includes colorized log lines, tabbed viewing, copy log lines to the desktop clipboard, built-in capability for sending log messages directly to the system, read detailed information for each log line, and more. KSystemLog views all the same logs found in GNOME Logs, only with a different layout.
|
||||
|
||||
From the main window (Figure 3), you can view any of the different log (from System Log, Authentication Log, X.org Log, Journald Log), search the logs, filter by Date, Host, Process, Message, and select log priorities.
|
||||
|
||||
![KSystemLog][7]
|
||||
|
||||
Figure 3: The KSystemLog main window.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
If you click on the Window menu, you can open a new tab, where you can select a different log/filter combination to view. From that same menu, you can even duplicate the current tab. If you want to manually add a log to a file, do the following:
|
||||
|
||||
1. Open KSystemLog.
|
||||
|
||||
2. Click File > Add Log Entry.
|
||||
|
||||
3. Create your log entry (Figure 4).
|
||||
|
||||
4. Click OK
|
||||
|
||||
|
||||
![log entry][9]
|
||||
|
||||
Figure 4: Creating a manual log entry with KSystemLog.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
KSystemLog makes viewing logs in KDE an incredibly easy task.
|
||||
|
||||
### Logwatch
|
||||
|
||||
Logwatch isn’t a fancy GUI tool. Instead, logwatch allows you to set up a logging system that will email you important alerts. You can have those alerts emailed via an SMTP server or you can simply view them on the local machine. Logwatch can be found in the standard repositories for almost every distribution, so installation can be done with a single command, like so:
|
||||
|
||||
```
|
||||
sudo apt-get install logwatch
|
||||
```
|
||||
|
||||
Or:
|
||||
|
||||
```
|
||||
sudo dnf install logwatch
|
||||
```
|
||||
|
||||
During the installation, you will be required to select the delivery method for alerts (Figure 5). If you opt to go the local mail delivery only, you’ll need to install the mailutils app (so you can view mail locally, via the mail command).
|
||||
|
||||
![ Logwatch][11]
|
||||
|
||||
Figure 5: Configuring Logwatch alert sending method.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
All Logwatch configurations are handled in a single file. To edit that file, issue the command sudo nano /usr/share/logwatch/default.conf/logwatch.conf. You’ll want to edit the MailTo = option. If you’re viewing this locally, set that to the Linux username you want the logs sent to (such as MailTo = jack). If you are sending these logs to an external email address, you’ll also need to change the MailFrom = option to a legitimate email address. From within that same configuration file, you can also set the detail level and the range of logs to send. Save and close that file.
|
||||
Once configured, you can send your first mail with a command like:
|
||||
|
||||
```
|
||||
logwatch --detail Med --mailto ADDRESS --service all --range today
|
||||
Where ADDRESS is either the local user or an email address.
|
||||
|
||||
```
|
||||
|
||||
For more information on using Logwatch, issue the command man logwatch. Read through the manual page to see the different options that can be used with the tool.
|
||||
|
||||
### Rsyslog
|
||||
|
||||
Rsyslog is a convenient way to send remote client logs to a centralized server. Say you have one Linux server you want to use to collect the logs from other Linux servers in your data center. With Rsyslog, this is easily done. Rsyslog has to be installed on all clients and the centralized server (by issuing a command like sudo apt-get install rsyslog). Once installed, create the /etc/rsyslog.d/server.conf file on the centralized server, with the contents:
|
||||
|
||||
```
|
||||
# Provide UDP syslog reception
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
|
||||
# Provide TCP syslog reception
|
||||
$ModLoad imtcp
|
||||
$InputTCPServerRun 514
|
||||
|
||||
# Use custom filenaming scheme
|
||||
$template FILENAME,"/var/log/remote/%HOSTNAME%.log"
|
||||
*.* ?FILENAME
|
||||
|
||||
$PreserveFQDN on
|
||||
|
||||
```
|
||||
|
||||
Save and close that file. Now, on every client machine, create the file /etc/rsyslog.d/client.conf with the contents:
|
||||
|
||||
```
|
||||
$PreserveFQDN on
|
||||
$ActionQueueType LinkedList
|
||||
$ActionQueueFileName srvrfwd
|
||||
$ActionResumeRetryCount -1
|
||||
$ActionQueueSaveOnShutdown on
|
||||
*.* @@SERVER_IP:514
|
||||
|
||||
```
|
||||
|
||||
Where SERVER_IP is the IP address of your centralized server. Save and close that file. Restart rsyslog on all machines with the command:
|
||||
|
||||
```
|
||||
sudo systemctl restart rsyslog
|
||||
|
||||
```
|
||||
|
||||
You can now view the centralized log files with the command (run on the centralized server):
|
||||
|
||||
```
|
||||
tail -f /var/log/remote/*.log
|
||||
|
||||
```
|
||||
|
||||
The tail command allows you to view those files as they are written to, in real time. You should see log entries appear that include the client hostname (Figure 6).
|
||||
|
||||
![Rsyslog][13]
|
||||
|
||||
Figure 6: Rsyslog showing entries for a connected client.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Rsyslog is a great tool for creating a single point of entry for viewing the logs of all of your Linux servers.
|
||||
|
||||
### More where that came from
|
||||
|
||||
This article only scratched the surface of the logging tools to be found on the Linux platform. And each of the above tools is capable of more than what is outlined here. However, this overview should give you a place to start your long day's journey into the Linux log file.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][14]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/10/open-source-logging-tools-linux
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[1]: /files/images/logs1jpg
|
||||
[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_1.jpg?itok=8yO2q1rW (/var/log/)
|
||||
[3]: /licenses/category/used-permission
|
||||
[4]: /files/images/logs2jpg
|
||||
[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_2.jpg?itok=kF6V46ZB (Logs tool)
|
||||
[6]: /files/images/logs3jpg
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_3.jpg?itok=PhrIzI1N (KSystemLog)
|
||||
[8]: /files/images/logs4jpg
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_4.jpg?itok=OxsGJ-TJ (log entry)
|
||||
[10]: /files/images/logs5jpg
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_5.jpg?itok=GeAR551e (Logwatch)
|
||||
[12]: /files/images/logs6jpg
|
||||
[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_6.jpg?itok=ira8UZOr (Rsyslog)
|
||||
[14]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,120 +0,0 @@
|
||||
translating by distant1219
|
||||
|
||||
Command line quick tips: Reading files different ways
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fedora is delightful to use as a graphical operating system. You can point and click your way through just about any task easily. But you’ve probably seen there is a powerful command line under the hood. To try it out in a shell, just open the Terminal application in your Fedora system. This article is one in a series that will show you some common command line utilities.
|
||||
|
||||
In this installment you’ll learn how to read files in different ways. If you open a Terminal to do some work on your system, chances are good that you’ll need to read a file or two.
|
||||
|
||||
### The whole enchilada
|
||||
|
||||
The **cat** command is well known to terminal users. When you **cat** a file, you’re simply displaying the whole file to the screen. Really what’s happening under the hood is the file is read one line at a time, then each line is written to the screen.
|
||||
|
||||
Imagine you have a file with one word per line, called myfile. To make this clear, the file will contain the word equivalent for a number on each line, like this:
|
||||
|
||||
```
|
||||
|
||||
one
|
||||
two
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
So if you **cat** that file, you’ll see this output:
|
||||
|
||||
```
|
||||
|
||||
$ cat myfile
|
||||
one
|
||||
two
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
Nothing too surprising there, right? But here’s an interesting twist. You can also **cat** that file backward. For this, use the **tac** command. (Note that Fedora takes no blame for this debatable humor!)
|
||||
|
||||
```
|
||||
|
||||
$ tac myfile
|
||||
five
|
||||
four
|
||||
three
|
||||
two
|
||||
one
|
||||
|
||||
```
|
||||
|
||||
The **cat** file also lets you ornament the file in different ways, in case that’s helpful. For instance, you can number lines:
|
||||
|
||||
```
|
||||
|
||||
$ cat -n myfile
|
||||
1 one
|
||||
2 two
|
||||
3 three
|
||||
4 four
|
||||
5 five
|
||||
|
||||
```
|
||||
|
||||
There are additional options that will show special characters and other features. To learn more, run the command **man cat** , and when done just hit **q** to exit back to the shell.
|
||||
|
||||
### Picking over your food
|
||||
|
||||
Often a file is too long to fit on a screen, and you may want to be able to go through it like a document. In that case, try the **less** command:
|
||||
|
||||
```
|
||||
|
||||
$ less myfile
|
||||
|
||||
```
|
||||
|
||||
You can use your arrow keys as well as **PgUp/PgDn** to move around the file. Again, you can use the **q** key to quit back to the shell.
|
||||
|
||||
There’s actually a **more** command too, based on an older UNIX command. If it’s important to you to still see the file when you’re done, you might want to use it. The **less** command brings you back to the shell the way you left it, and clears the display of any sign of the file you looked at.
|
||||
|
||||
### Just the appetizer (or dessert)
|
||||
|
||||
Sometimes the output you want is just the beginning of a file. For instance, the file might be so long that when you **cat** the whole thing, the first few lines scroll past before you can see them. The **head** command will help you grab just those lines:
|
||||
|
||||
```
|
||||
|
||||
$ head -n 2 myfile
|
||||
one
|
||||
two
|
||||
|
||||
```
|
||||
|
||||
In the same way, you can use **tail** to just grab the end of a file:
|
||||
|
||||
```
|
||||
|
||||
$ tail -n 3 myfile
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
Of course these are only a few simple commands in this area. But they’ll get you started when it comes to reading files.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-reading-files-different-ways/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Happy birthday, KDE: 11 applications you never knew existed
|
||||
======
|
||||
Which fun or quirky app do you need today?
|
||||
|
||||
@ -0,0 +1,246 @@
|
||||
How to Enable or Disable Services on Boot in Linux Using chkconfig and systemctl Command
|
||||
======
|
||||
It’s a important topic for Linux admin (such a wonderful topic) so, everyone must be aware of this and practice how to use this in the efficient way.
|
||||
|
||||
In Linux, whenever we install any packages which has services or daemons. By default all the services “init & systemd” scripts will be added into it but it wont enabled.
|
||||
|
||||
Hence, we need to enable or disable the service manually if it’s required. There are three major init systems are available in Linux which are very famous and still in use.
|
||||
|
||||
### What is init System?
|
||||
|
||||
In Linux/Unix based operating systems, init (short for initialization) is the first process that started during the system boot up by the kernel.
|
||||
|
||||
It’s holding a process id (PID) of 1. It will be running in the background continuously until the system is shut down.
|
||||
|
||||
Init looks at the `/etc/inittab` file to decide the Linux run level then it starts all other processes & applications in the background as per the run level.
|
||||
|
||||
BIOS, MBR, GRUB and Kernel processes were kicked up before hitting init process as part of Linux booting process.
|
||||
|
||||
Below are the available run levels for Linux (There are seven runlevels exist, from zero to six).
|
||||
|
||||
* **`0:`** halt
|
||||
* **`1:`** Single user mode
|
||||
* **`2:`** Multiuser, without NFS
|
||||
* **`3:`** Full multiuser mode
|
||||
* **`4:`** Unused
|
||||
* **`5:`** X11 (GUI – Graphical User Interface)
|
||||
* **`:`** reboot
|
||||
|
||||
|
||||
|
||||
Below three init systems are widely used in Linux.
|
||||
|
||||
* System V (Sys V)
|
||||
* Upstart
|
||||
* systemd
|
||||
|
||||
|
||||
|
||||
### What is System V (Sys V)?
|
||||
|
||||
System V (Sys V) is one of the first and traditional init system for Unix like operating system. init is the first process that started during the system boot up by the kernel and it’s a parent process for everything.
|
||||
|
||||
Most of the Linux distributions started using traditional init system called System V (Sys V) first. Over the years, several replacement init systems were released to address design limitations in the standard versions such as launchd, the Service Management Facility, systemd and Upstart.
|
||||
|
||||
But systemd has been adopted by several major Linux distributions over the traditional SysV init systems.
|
||||
|
||||
### What is Upstart?
|
||||
|
||||
Upstart is an event-based replacement for the /sbin/init daemon which handles starting of tasks and services during boot, stopping them during shutdown and supervising them while the system is running.
|
||||
|
||||
It was originally developed for the Ubuntu distribution, but is intended to be suitable for deployment in all Linux distributions as a replacement for the venerable System-V init.
|
||||
|
||||
It was used in Ubuntu from 9.10 to Ubuntu 14.10 & RHEL 6 based systems after that they are replaced with systemd.
|
||||
|
||||
### What is systemd?
|
||||
|
||||
Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the traditional SysV init systems.
|
||||
|
||||
systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the first process get started by kernel and holding PID 1.
|
||||
|
||||
It’s a parant process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart. systemctl is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
|
||||
|
||||
systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and you can see the system hierarchy by exploring `/cgroup/systemd` file.
|
||||
|
||||
### How to Enable or Disable Services on Boot Using chkconfig Commmand?
|
||||
|
||||
The chkconfig utility is a command-line tool that allows you to specify in which
|
||||
runlevel to start a selected service, as well as to list all available services along with their current setting.
|
||||
|
||||
Also, it will allows us to enable or disable a services from the boot. Make sure you must have superuser privileges (either root or sudo) to use this command.
|
||||
|
||||
All the services script are located on `/etc/rd.d/init.d`.
|
||||
|
||||
### How to list All Services in run-level
|
||||
|
||||
The `-–list` parameter displays all the services along with their current status (What run-level the services are enabled or disabled).
|
||||
|
||||
```
|
||||
# chkconfig --list
|
||||
NetworkManager 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
abrt-ccpp 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
.
|
||||
.
|
||||
```
|
||||
|
||||
### How to check the Status of Specific Service
|
||||
|
||||
If you would like to see a particular service status in run-level then use the following format and grep the required service.
|
||||
|
||||
In this case, we are going to check the `auditd` service status in run-level.
|
||||
|
||||
```
|
||||
# chkconfig --list| grep auditd
|
||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
```
|
||||
|
||||
### How to Enable a Particular Service on Run Levels
|
||||
|
||||
Use `--level` parameter to enable a service in the required run-level. In this case, we are going to enable `httpd` service on run-level 3 and 5.
|
||||
|
||||
```
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
### How to Disable a Particular Service on Run Levels
|
||||
|
||||
Use `--level` parameter to disable a service in the required run-level. In this case, we are going to enable `httpd` service on run-level 3 and 5.
|
||||
|
||||
```
|
||||
# chkconfig --level 35 httpd off
|
||||
```
|
||||
|
||||
### How to Add a new Service to the Startup List
|
||||
|
||||
The `-–add` parameter allows us to add any new service to the startup. By default, it will turn on level 2, 3, 4 and 5 automatically for that service.
|
||||
|
||||
```
|
||||
# chkconfig --add nagios
|
||||
```
|
||||
|
||||
### How to Remove a Service from Startup List
|
||||
|
||||
Use `--del` parameter to remove the service from the startup list. Here, we are going to remove the Nagios service from the startup list.
|
||||
|
||||
```
|
||||
# chkconfig --del nagios
|
||||
```
|
||||
|
||||
### How to Enable or Disable Services on Boot Using systemctl Command?
|
||||
|
||||
systemctl is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
|
||||
|
||||
All the created systemd unit files are located on `/etc/systemd/system/`.
|
||||
|
||||
### How to list All Services
|
||||
|
||||
Use the following command to list all the services which included enabled and disabled.
|
||||
|
||||
```
|
||||
# systemctl list-unit-files --type=service
|
||||
UNIT FILE STATE
|
||||
arp-ethers.service disabled
|
||||
auditd.service enabled
|
||||
[email protected] enabled
|
||||
blk-availability.service disabled
|
||||
brandbot.service static
|
||||
[email protected] static
|
||||
chrony-wait.service disabled
|
||||
chronyd.service enabled
|
||||
cloud-config.service enabled
|
||||
cloud-final.service enabled
|
||||
cloud-init-local.service enabled
|
||||
cloud-init.service enabled
|
||||
console-getty.service disabled
|
||||
console-shell.service disabled
|
||||
[email protected] static
|
||||
cpupower.service disabled
|
||||
crond.service enabled
|
||||
.
|
||||
.
|
||||
150 unit files listed.
|
||||
```
|
||||
|
||||
If you would like to see a particular service status then use the following format and grep the required service. In this case, we are going to check the `httpd` service status.
|
||||
|
||||
```
|
||||
# systemctl list-unit-files --type=service | grep httpd
|
||||
httpd.service disabled
|
||||
```
|
||||
|
||||
### How to Enable a Particular Service on boot
|
||||
|
||||
Use the following systemctl command format to enable a particular service. To enable a service, it will create a symlink. The same can be found below.
|
||||
|
||||
```
|
||||
# systemctl enable httpd
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
|
||||
```
|
||||
|
||||
Run the following command to double check whether the services is enabled or not on boot.
|
||||
|
||||
```
|
||||
# systemctl is-enabled httpd
|
||||
enabled
|
||||
```
|
||||
|
||||
### How to Disable a Particular Service on boot
|
||||
|
||||
Use the following systemctl command format to disable a particular service. When you run the command, it will remove a symlink which was created by you while enabling the service. The same can be found below.
|
||||
|
||||
```
|
||||
# systemctl disable httpd
|
||||
Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.
|
||||
```
|
||||
|
||||
Run the following command to double check whether the services is disabled or not on boot.
|
||||
|
||||
```
|
||||
# systemctl is-enabled httpd
|
||||
disabled
|
||||
```
|
||||
|
||||
### How to Check the current run level
|
||||
|
||||
Use the following systemctl command to verify which run-level you are in. Still “runlevel” command works with systemd, however runlevels is a legacy concept in systemd so, i would advise you to use systemctl command for all activity.
|
||||
|
||||
We are in `run-level 3`, the same is showing below as `multi-user.target`.
|
||||
|
||||
```
|
||||
# systemctl list-units --type=target
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
basic.target loaded active active Basic System
|
||||
cloud-config.target loaded active active Cloud-config availability
|
||||
cryptsetup.target loaded active active Local Encrypted Volumes
|
||||
getty.target loaded active active Login Prompts
|
||||
local-fs-pre.target loaded active active Local File Systems (Pre)
|
||||
local-fs.target loaded active active Local File Systems
|
||||
multi-user.target loaded active active Multi-User System
|
||||
network-online.target loaded active active Network is Online
|
||||
network-pre.target loaded active active Network (Pre)
|
||||
network.target loaded active active Network
|
||||
paths.target loaded active active Paths
|
||||
remote-fs.target loaded active active Remote File Systems
|
||||
slices.target loaded active active Slices
|
||||
sockets.target loaded active active Sockets
|
||||
swap.target loaded active active Swap
|
||||
sysinit.target loaded active active System Initialization
|
||||
timers.target loaded active active Timers
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-enable-or-disable-services-on-boot-in-linux-using-chkconfig-and-systemctl-command/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,93 @@
|
||||
Kali Linux: What You Must Know Before Using it – FOSS Post
|
||||
======
|
||||

|
||||
|
||||
Kali Linux is the industry’s leading Linux distribution in penetration testing and ethical hacking. It is a distribution that comes shipped with tons and tons of hacking and penetration tools and software by default, and is widely recognized in all parts of the world, even among Windows users who may not even know what Linux is.
|
||||
|
||||
Because of the latter, many people are trying to get alone with Kali Linux although they don’t even understand the basics of a Linux system. The reasons may vary from having fun, faking being a hacker to impress a girlfriend or simply trying to hack the neighbors’ WiFi network to get a free Internet, all of which is a bad thing to do if you are planning to use Kali Linux.
|
||||
|
||||
Here are some tips that you should know before even planning to use Kali Linux
|
||||
|
||||
### Kali Linux is Not for Beginners
|
||||
|
||||

|
||||
Kali Linux Default GNOME Desktop
|
||||
|
||||
If you are someone who has just started to use Linux few months ago, or if you are don’t consider yourself to be above average in terms of knowledge, then Kali Linux is not for you. If you are going to ask stuff like “How do I install Steam on Kali? How do I make my printer work on Kali? How do I solve the APT sources error on Kali”? Then Kali Linux is not suitable for you.
|
||||
|
||||
Kali Linux is mainly made for professionals wanting to run penetration testing suits or people who want to learn ethical hacking and digital forensics. But even if you were from the latter, the average Kali Linux user is expected to face a lot of trouble while using Kali Linux for his day-to-day usage. He’s also expected to take a very careful approach to how he uses the tools and software, it’s not just “let’s install it and run everything”. Every tool must be carefully used, every software you install must be carefully examined.
|
||||
|
||||
**Good Read:** [What are the components of a Linux system?][1]
|
||||
|
||||
Stuff which the average Linux user can’t do normally. A better approach would be to spend few weeks learning about Linux and its daemons, services, software, distributions and the way it works, and then watch few dozens of videos and courses about ethical hacking, and only then, try to use Kali to apply what you learned.
|
||||
|
||||
### it Can Get You Hacked
|
||||
|
||||

|
||||
Kali Linux Hacking & Testing Tools
|
||||
|
||||
In a normal Linux system, there’s one account for normal user and one separate account for root. This is not the case in Kali Linux. Kali Linux uses the root account by default and doesn’t provide you with a normal user account. This is because almost all security tools available in Kali do require root privileges, and to avoid asking you for root password every minute, they designed it that way.
|
||||
|
||||
Of course, you could simply create a normal user account and start using it. Well, it’s still not recommended because that’s not how the Kali Linux system design is meant to work. You’ll face a lot of problems then in using programs, opening ports, debugging software, discovering why this thing doesn’t work only to discover that it was a weird privilege bug. You will also be annoyed by all the tools that will require you to enter the password each time you try to do anything on your system.
|
||||
|
||||
Now, since you are forced to use it in as a root user, all the software you run on your system will also run with root privileges. This is bad if you don’t know what you are doing, because if there’s a vulnerability in Firefox for example and you visit one of the infected dark web sites, the hacker will be able to get full root permissions on your PC and hack you, which would have been limited if you were using a normal user account. Also, some tools that you may install and use can open ports and leak information without your knowledge, so if you are not extremely careful, people can hack you in the same way you may try to hack them.
|
||||
|
||||
If you visit Facebook groups related to Kali Linux on few occasions, you’ll notice that almost a quarter of the posts in these groups are people calling for help because someone hacked them.
|
||||
|
||||
### it Can Get You in Jail
|
||||
|
||||
Kali Linux provide the software as it is. Then, it is your own responsibility alone of how you use them.
|
||||
|
||||
In most advanced countries around the world, using penetration testing tools against public WiFi networks or the devices of others can easily get you in jail. Now don’t think that you can’t be tracked just because you are using Kali, many systems are configured to have complex logging devices to simply track whoever tries to listen or hack their networks, and you may stumble upon one of these, and it will destroy you life.
|
||||
|
||||
Don’t ever use Kali Linux tools against devices/networks which do not belong to you or given explicit permission to try hacking them. If you say that you didn’t know what you were doing, it won’t be accepted as an excuse in a court.
|
||||
|
||||
### Modified Kernel and Software
|
||||
|
||||
Kali is [based][2] on Debian (Testing branch, which means that Kali Linux uses a rolling release model), so it uses most of the software architecture from there, and you will find most of the software in Kali Linux just as they are in Debian.
|
||||
|
||||
However, some packages were modified to harden security and fix some possible vulnerabilities. The Linux kernel that Kali uses for example is patched to allow wireless injection on various devices. These patches are not normally available in the vanilla kernel. Also, Kali Linux does not depend on Debian servers and mirrors, but builds the packages by its own servers. Here’s the default software sources in the latest release:
|
||||
|
||||
```
|
||||
deb http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
deb-src http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
```
|
||||
|
||||
That’s why, for some specific software, you will find a different behaviour when using the same program in Kali Linux or using it in Fedora, for example. You can see a full list of Kali Linux software from [git.kali.org][3]. You can also find our [own generated list of installed packages][4] on Kali Linux (GNOME).
|
||||
|
||||
More importantly, Kali Linux official documentation extremely suggests to NOT add any other 3rd-party software repositories, because since Kali Linux is a rolling release and depends on Debian Testing, you will most likely break your system by just adding a new repository source due to dependencies conflicts and package hooks.
|
||||
|
||||
### Don’t Install Kali Linux
|
||||
|
||||

|
||||
Running wpscan on fosspost.org using Kali Linux
|
||||
|
||||
I use Kali Linux on rare occasions to test the software and servers I deploy. However, I will never dare to install it and use it as a primary system.
|
||||
|
||||
If you are going to use it as a primary system, then you will have to keep your own personal files, password, data and everything else on your system. You will also need to install tons of daily-use software in order to ease your life. But as we mentioned above, using Kali Linux is very risky and should be done very carefully, and if you get hacked, you will lose all your data and it may get exposed to a wider audience. Your personal information can also be used to track you if you are doing non-legal stuff. You may even destroy your data by yourself if you are not careful about how you use the tools.
|
||||
|
||||
Even professional white hackers don’t recommend installing it as a primary system, but rather, use it from USB to just do your penetration testing work and then leave back to your normal Linux distribution.
|
||||
|
||||
### The Bottom Line
|
||||
|
||||
As you may see now, using Kali is not an easy decision to take lightly. If you are planning to be a whiter hacker and you need to use Kali to learn, then go for it after learning the basics and spending few months with a normal system. But be careful for what you are doing to avoid being in trouble.
|
||||
|
||||
If you are planning to use Kali or if you need any help, I’ll be happy to hear your thoughts in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/articles/must-know-before-using-kali-linux
|
||||
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fosspost.org/author/mhsabbagh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fosspost.org/articles/what-are-the-components-of-a-linux-distribution
|
||||
[2]: https://www.kali.org/news/kali-linux-rolling-edition-2016-1/
|
||||
[3]: http://git.kali.org
|
||||
[4]: https://paste.ubuntu.com/p/bctSVWwpVw/
|
||||
@ -0,0 +1,82 @@
|
||||
Running Linux containers as a non-root with Podman
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux containers are processes with certain isolation features provided by a Linux kernel — including filesystem, process, and network isolation. Containers help with portability — applications can be distributed in container images along with their dependencies, and run on virtually any Linux system with a container runtime.
|
||||
|
||||
Although container technologies exist for a very long time, Linux containers were widely popularized by Docker. The word “Docker” can refer to several different things, including the container technology and tooling, the community around that, or the Docker Inc. company. However, in this article, I’ll be using it to refer to the technology and the tooling that manages Linux containers.
|
||||
|
||||
### What is Docker
|
||||
|
||||
[Docker][1] is a daemon that runs on your system as root, and manages running containers by leveraging features of the Linux kernel. Apart from running containers, it also makes it easy to manage container images — interacting with container registries, storing images, managing container versions, etc. It basically supports all the operations you need to run individual containers.
|
||||
|
||||
But even though Docker is very a handy tool for managing Linux containers, it has two drawbacks: it is a daemon that needs to run on your system, and it needs to run with root privileges which might have certain security implications. Both of those, however, are being addressed by Podman.
|
||||
|
||||
### Introducing Podman
|
||||
|
||||
[Podman][2] is a container runtime providing a very similar features as Docker. And as already hinted, it doesn’t require any daemon to run on your system, and it can also run without root privileges. So let’s have a look at some examples of using Podman to run Linux containers.
|
||||
|
||||
#### Running containers with Podman
|
||||
|
||||
One of the simplest examples could be running a Fedora container, printing “Hello world!” in the command line:
|
||||
|
||||
```
|
||||
$ podman run --rm -it fedora:28 echo "Hello world!"
|
||||
```
|
||||
|
||||
Building an image using the common Dockerfile works the same way as it does with Docker:
|
||||
|
||||
```
|
||||
$ cat Dockerfile
|
||||
FROM fedora:28
|
||||
RUN dnf -y install cowsay
|
||||
|
||||
$ podman build . -t hello-world
|
||||
... output omitted ...
|
||||
|
||||
$ podman run --rm -it hello-world cowsay "Hello!"
|
||||
```
|
||||
|
||||
To build containers, Podman calls another tool called Buildah in the background. You can read a recent [post about building container images with Buildah][3] — not just using the typical Dockerfile.
|
||||
|
||||
Apart from building and running containers, Podman can also interact with container registries. To log in to a container registry, for example the widely used Docker Hub, run:
|
||||
|
||||
```
|
||||
$ podman login docker.io
|
||||
```
|
||||
|
||||
To push the image I just built, I just need to tag so it refers to the specific container registry and my personal namespace, and then simply push it.
|
||||
|
||||
```
|
||||
$ podman -t hello-world docker.io/asamalik/hello-world
|
||||
$ podman push docker.io/asamalik/hello-world
|
||||
```
|
||||
|
||||
By the way, have you noticed how I run everything as a non-root user? Also, there is no big fat daemon running on my system!
|
||||
|
||||
#### Installing Podman
|
||||
|
||||
Podman is available by default on [Silverblue][4] — a new generation of Linux Workstation for container-based workflows. To install it on any Fedora release, simply run:
|
||||
|
||||
```
|
||||
$ sudo dnf install podman
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/running-containers-with-podman/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.docker.com/
|
||||
[2]: https://podman.io/
|
||||
[3]: https://fedoramagazine.org/daemon-less-container-management-buildah/
|
||||
[4]: https://silverblue.fedoraproject.org/
|
||||
@ -0,0 +1,78 @@
|
||||
Turn Your Old PC into a Retrogaming Console with Lakka Linux
|
||||
======
|
||||
**If you have an old computer gathering dust, you can turn it into a PlayStation like retrogaming console with Lakka Linux distribution. **
|
||||
|
||||
You probably already know that there are [Linux distributions specially crafted for reviving older computers][1]. But did you know about a Linux distribution that is created for the sole purpose of turning your old computer into a retro-gaming console?
|
||||
|
||||
![Lakka is a Linux distribution specially for retrogaming][2]
|
||||
|
||||
Meet [Lakka][3], a lightweight Linux distribution that will transform your old or low-end computer (like Raspberry Pi) into a complete retrogaming console,
|
||||
|
||||
When I say retrogaming console, I am serious about the console part. If you have ever used a PlayStation of Xbox, you know what a typical console interface looks like.
|
||||
|
||||
Lakka provides a similar interface and a similar experience. I’ll talk about the ‘experience’ later. Have a look at the interface first.
|
||||
|
||||
<https://itsfoss.com/wp-content/uploads/2018/10/lakka-linux-gaming-console.webm>
|
||||
Lakka Retrogaming interface
|
||||
|
||||
### Lakka: Linux distributions for retrogaming
|
||||
|
||||
Lakka is the official Linux distribution of [RetroArch][4] and the [Libretro][5] ecosystem.
|
||||
|
||||
RetroArch is a frontend for retro game emulators and game engines. The interface you saw in the video above is nothing but RetroArch. If you just want to play retro games, you can simply install RetroArch in your current Linux distribution.
|
||||
|
||||
Lakka provides Libretro core with RetroArch. So you get a preconfigured operating system that you can install or plug in the live USB and start playing games.
|
||||
|
||||
Lakka is lightweight and you can install it on most old systems or single board computers like Raspberry Pi.
|
||||
|
||||
It supports a huge number of emulators. You just need to download the ROMs on your system and Lakka will play the games from these ROMs. You can find the list supported emulators and hardware [here][6].
|
||||
|
||||
It enables you to run classic games on a wide range of computers and consoles through its slick graphical interface. Settings are also unified so configuration is done once and for all.
|
||||
|
||||
Let me summarize the main features of Lakka:
|
||||
|
||||
* PlayStation like interface with RetroArch
|
||||
* Support for a number of retro game emulators
|
||||
* Supports up to 5 players gaming on the same system
|
||||
* Savestates allow you to save your progress at any moment in the game
|
||||
* You can improve the look of your old games with various graphical filters
|
||||
* You can join multiplayer games over the network
|
||||
* Out of the box support for a number of joypads like XBOX360, Dualshock 3, and 8bitdo
|
||||
* Unlike trophies and badges by connecting to [RetroAchievements][7]
|
||||
|
||||
|
||||
|
||||
### Getting Lakka
|
||||
|
||||
Before you go on installing Lakka you should know that it is still under development so expect a few bugs here and there.
|
||||
|
||||
Keep in mind that Lakka only supports MBR partitioning. So if it doesn’t read your hard drive while installing, this could be a reason.
|
||||
|
||||
The [FAQ section of the project][8] answers the common doubts, so please refer to it for any further questions.
|
||||
|
||||
[Get Lakka][9]
|
||||
|
||||
Do you like playing retro games? What emulators do you use? Have you ever used Lakka before? Share your views with us in the comments section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lakka-retrogaming-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/lakka-retrogaming-linux.jpeg
|
||||
[3]: http://www.lakka.tv/
|
||||
[4]: https://www.retroarch.com/
|
||||
[5]: https://www.libretro.com/
|
||||
[6]: http://www.lakka.tv/powerful/
|
||||
[7]: https://retroachievements.org/
|
||||
[8]: http://www.lakka.tv/doc/FAQ/
|
||||
[9]; http://www.lakka.tv/disclaimer/
|
||||
@ -0,0 +1,153 @@
|
||||
如何使用 Apache Web 服务器配置多个站点
|
||||
|
||||
=====
|
||||
|
||||

|
||||
|
||||
在我的[上一篇文章][1]中,我解释了如何为单个站点配置 Apache Web 服务器,事实证明这很容易。在这篇文章中,我将向你展示如何使用单个 Apache 实例来服务多个站点。
|
||||
|
||||
注意:我写这篇文章的环境是 Fedora 27 虚拟机,配置了 Apache 2.4.29。如果你有另一个 Fedora 的发行版,那么你使用的命令以及配置文件的位置和内容可能会有所不同。
|
||||
|
||||
正如我之前的文章中提到的,Apache 的所有配置文件都位于 `/etc/httpd/conf` 和 `/etc/httpd/conf.d`。默认情况下,站点的数据位于 `/var/www` 中。对于多个站点,你需要提供多个位置,每个位置对应托管的站点。
|
||||
|
||||
### 基于名称的虚拟主机
|
||||
|
||||
使用基于名称的虚拟主机,你可以为多个站点使用一个 IP 地址。现代 Web 服务器,包括 Apache,使用指定 URL 的 `hostname` 部分来确定哪个虚拟 Web 主机响应页面请求。这仅仅需要比一个站点更多的配置。
|
||||
|
||||
即使你只从单个站点开始,我也建议你将其设置为虚拟主机,这样可以在以后更轻松地添加更多站点。在本文中,我将在上一篇文章中介绍我们停止的位置,因此你需要设置原始站点,即基于名称的虚拟站点。
|
||||
|
||||
### 准备原始站点
|
||||
|
||||
在设置第二个站点之前,你需要为现有网站提供基于名称的虚拟主机。如果你现在没有网站,[请返回并立即创建一个][1]。
|
||||
|
||||
一旦你有了站点,将以下内容添加到 `/etc/httpd/conf/httpd.conf` 配置文件的底部(添加此内容是你需要对 `httpd.conf` 文件进行的唯一更改):
|
||||
```
|
||||
<VirtualHost 127.0.0.1:80>
|
||||
|
||||
DocumentRoot /var/www/html
|
||||
|
||||
ServerName www.site1.org
|
||||
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
这将是第一个虚拟主机节(to 校正:这里虚拟主机节不太清除),它应该保持为第一个,以使其成为默认定义。这意味着通过 IP 地址或解析为此 IP 地址但没有特定命名主机配置节的其它名称对服务器的 HTTP 访问将定向到此虚拟主机。所有其它虚拟主机配置节都应遵循此节。
|
||||
|
||||
你还需要使用 `/etc/hosts` 中的条目设置你的网站以提供名称解析。上次,我们只使用了 `localhost` 的 IP 地址。通常,这可以使用你使用的任何名称服务来完成,例如 Google 或 Godaddy。对于你的测试网站,通过在 `/etc/hosts` 中的 `localhost` 行添加一个新名称来完成此操作。添加两个网站的条目,方便你以后不需再次编辑此文件。结果如下:
|
||||
```
|
||||
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 www.site1.org www.site2.org
|
||||
```
|
||||
|
||||
让我们将 `/var/www/html/index.html` 文件改变得更加明显一点。它应该看起来像这样(带有一些额外的文本来识别这是站点 1):
|
||||
```
|
||||
<h1>Hello World</h1>
|
||||
|
||||
Web site 1.
|
||||
|
||||
```
|
||||
|
||||
重新启动 HTTPD 服务器,已启用对 `httpd` 配置的更改。然后,你可以从命令行使用 Lynx 文本模式查看网站。
|
||||
```
|
||||
[root@testvm1 ~]# systemctl restart httpd
|
||||
|
||||
[root@testvm1 ~]# lynx www.site1.org
|
||||
|
||||
Hello World
|
||||
|
||||
Web site 1.
|
||||
|
||||
<snip>
|
||||
|
||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||
|
||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||
|
||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||
|
||||
```
|
||||
|
||||
你可以看到原始网站的修改内容,没有明显的错误,先按下 "Q" 键,然后按 "Y" 退出 Lynx Web 浏览器。
|
||||
|
||||
### 配置第二个站点
|
||||
|
||||
现在你已经准备好建立第二个网站。使用以下命令创建新的网站目录结构:
|
||||
```
|
||||
[root@testvm1 html]# mkdir -p /var/www/html2
|
||||
|
||||
```
|
||||
|
||||
注意,第二个站点只是第二个 `html` 目录,与第一个站点位于同一 `/var/www` 目录下。
|
||||
|
||||
现在创建一个新的索引文件 `/var/www/html2/index.html`,其中包含以下内容(此索引文件稍有不同,以区别于原始网站):
|
||||
```
|
||||
<h1>Hello World -- Again</h1>
|
||||
|
||||
Web site 2.
|
||||
|
||||
```
|
||||
|
||||
在 `httpd.conf` 中为第二个站点创建一个新的配置节,并将其放在上一个虚拟主机节下面(这两个应该看起来非常相似)。此节告诉 Web 服务器在哪里可以找到第二个站点的 HTML 文件。
|
||||
```
|
||||
<VirtualHost 127.0.0.1:80>
|
||||
|
||||
DocumentRoot /var/www/html2
|
||||
|
||||
ServerName www.site2.org
|
||||
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
重启 HTTPD,并使用 Lynx 来查看结果。
|
||||
```
|
||||
[root@testvm1 httpd]# systemctl restart httpd
|
||||
|
||||
[root@testvm1 httpd]# lynx www.site2.org
|
||||
|
||||
|
||||
|
||||
Hello World -- Again
|
||||
|
||||
|
||||
|
||||
Web site 2.
|
||||
|
||||
|
||||
|
||||
<snip>
|
||||
|
||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||
|
||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||
|
||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||
|
||||
```
|
||||
|
||||
在这里,我压缩了输出结果以适应这个空间。页面的差异表明这是第二个站点。要同时显示两个站点,请打开另一个终端会话并使用 Lynx Web 浏览器查看另一个站点。
|
||||
|
||||
### 其他考虑
|
||||
|
||||
这个简单的例子展示了如何使用 Apache HTTPD 服务器的单个实例来服务于两个站点。当考虑其他因素时,配置虚拟主机会变得有点复杂。
|
||||
|
||||
例如,你可能希望为这些网站中的一个或全部使用一些 CGI 脚本。为此,你可能为 CGI 程序在 `/var/www` 目录下创建一些目录:`/var/www/cgi-bin` 和 `/var/www/cgi-bin2`,以与 HTML 目录命名一致。然后,你需要将配置指令添加到虚拟主机节,以指定 CGI 脚本的目录位置。每个站点可以有下载文件的目录。这还需要相应虚拟主机节中的条目。
|
||||
|
||||
[Apache 网站][2]描述了管理多个站点的其他方法,以及从性能调优到安全性的配置选项。
|
||||
|
||||
Apache 是一个强大的 Web 服务器,可以用来管理从简单到高度复杂的网站。尽管其总体市场份额在缩小,但它仍然是互联网上最常用的 HTTPD 服务器。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[2]:https://httpd.apache.org/docs/2.4/
|
||||
187
translated/tech/20181005 Open Source Logging Tools for Linux.md
Normal file
187
translated/tech/20181005 Open Source Logging Tools for Linux.md
Normal file
@ -0,0 +1,187 @@
|
||||
Linux 上的开源日志工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你是一位 Linux 系统管理员,你进行故障排除的第一个工具就是日志文件。这些文件会保留关键的信息,可以在很长一段时间内帮你去解决影响你桌面和服务器的问题。对于许多系统管理员(特别是对于老手),在命令行上没有什么比检查日志文件更好的方式了。但是对于那些想要更高效(也可能是更现代)的排除故障的人,这里也有许多的选择。
|
||||
|
||||
在这篇文章中,我将会罗列一些在 Linux 平台上一些值得一用的工具。一些特定于某项服务(例如 Kubernetes 或者 Apache)的日志工具将不会出现在该清单中,取而代之的将会是那些能够挖掘写入 /var/log 的所有神奇信息深度的工具。
|
||||
|
||||
|
||||
### 什么是 /var/log?
|
||||
|
||||
如果你是刚开始使用 Linux ,你可能不知道 /var/log 目录都包含了些什么。然而,这个名字已经说明了一切。这个目录收容了所有系统以及安装在系统上的主要服务(如 Apache,MySQL,MariaDB 等)的日志信息。打开一个终端窗口键入 ``` cd /var/log ``` 命令,接着键入 ```ls``` 命令,您将看到所有可以查看的日志文件。(图 1)
|
||||
|
||||
![/var/log/][2]
|
||||
|
||||
图 1:```ls``` 命令显示在 /var/log 下可用的日志。
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
如果你想查看 syslog 日志文件。运行 ```less syslog``` 命令,你就可以滚动查看特定日志的所有细节。但是如果标准的终端不适合你?你还有什么选择呢?其实有很多。让我们来看看以下几个选择。
|
||||
|
||||
### Logs
|
||||
|
||||
如果你使用 Gnome 桌面(或是其他的桌面,Logs 不仅能安装在 Gnome),你就已经有了这样的一个工具了,它仅仅在日志文件上加上了一个轻量的图形化界面,却使得查看日志的过程更加简单和高效。(从标准库中)安装完成后,从桌面菜单中打开 Logs,然后你将看到一个(图 2 的)界面,在这里允许你从各种类型的日志中进行选择(重要、所有、系统、安全和硬件),也可以选择一个启动时段 (从顶部中间的下拉菜单中),甚至是从所有可用的日志中进行搜索。
|
||||
|
||||
![Logs tool][5]
|
||||
|
||||
图 2:Gnome 日志工具是你可以找到的为 Linux 最简易的日志图形化软件之一。
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
Logs 是一个非常好的工具,特别是如果你不想要太多花里胡哨,妨碍你查看日志的功能,Logs 对于你查看系统日志来说就是一个很好的工具。
|
||||
|
||||
### KSystemLog
|
||||
|
||||
KSystemLog 是 KDE 的,Logs 是 GNOME 的,但是有许多功能都融合到了里面。尽管两者都使得查看系统的日志文件变得非常简单,但只有 KsystemLog 有彩色的日志行、分页查看、复制日志行到桌面剪贴板、内置直接发送日志信息到系统的功能、详细阅读每行日志的信息、以及更多。KSystemLog 查看的所有日志都可以从 Gnome 的 Logs 中找到,只是各有不同的格式。
|
||||
|
||||
从主窗口上(图 3),你可以看到许多不同的日志(来自于系统日志,认证日志,X.org 日志,Journald 日志),通过日期、拥有者、进程、信息选择一个日志优先级可以过滤日志。
|
||||
|
||||
![KSystemLog][7]
|
||||
|
||||
图 3:KSystemLog 主界面
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
如果你点击窗口菜单,你可以打开一个新的标签,你可以在里面选择一个不同的日志/筛选组合去查看。在同一个标签中,你甚至可以复制当前标签。你可以通过以下操作,手动添加一个日志到一个文件中。
|
||||
|
||||
1. 打开 KSystemLog。
|
||||
|
||||
2. 点击文件的标签 > 添加日志入口
|
||||
|
||||
3. 创建你的日志入口(图 4)。
|
||||
|
||||
4. 点击 OK。
|
||||
|
||||
|
||||
|
||||
![log entry][9]
|
||||
|
||||
图 4:使用 KystemLog 创建一个手册日志
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
KsystemLogs 使得在 KDE 下查看日志变为一个非常简单的操作。
|
||||
|
||||
### Logwatch
|
||||
|
||||
Logwatch 不是一个花俏的图形化工具。相反,Logwatch 允许你设置一个日志记录系统 e-mail 给你重要的警告。你可以通过一个 SMTP 服务 e-mail 这些重要通知,或者你可以只是在本地机器上查看。你可以在几乎所有发行版的标准库中找到 Logwatch,所以可以使用一个简单的命令完成安装:
|
||||
|
||||
```
|
||||
sudo apt-get install logwatch
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
sudo dnf install logwatch
|
||||
```
|
||||
|
||||
在安装期间,你需要选择一个发送警告的方式(图 5)。如果你选择仅以本地邮件的方式发达,你需要安装 mailutils(这样你就能通过 ```mail``` 命令查看本地邮件)。
|
||||
|
||||
![ Logwatch][11]
|
||||
|
||||
图 5:配置 Logwatch 警告发送方式
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
所有的 Logwatch 配置文件都被放在一个文件中。可以使用 ``` sudo nano /usr/share/logwatch/default.conf/logwatch.conf``` 命令编辑该文件。你可能想要编辑 MailTo = 选项。如果你是在本地查看日志,设置这项为你想要为你想要接收日志的 Linux 用户名(例如 MailTo = jack)。如果你想要发送这些日志到一个外部的邮件地址,你需要修改 MailTo = 为一个正确的邮件地址。在同一个配置文件中你还可以设置日志的细节层级和发送范围。保存并关闭该文件。设置成功后,你就可以使用以下命令发送你的第一封邮件:
|
||||
|
||||
```
|
||||
logwatch --detail Med --mailto ADDRESS --service all --range today
|
||||
Where ADDRESS is either the local user or an email address.
|
||||
|
||||
```
|
||||
|
||||
使用 ```man logwatch``` 可以查看更多有关使用 Logwatch 的信息。通过阅读手册页可以看到这个工具的不同选项。
|
||||
|
||||
### Rsyslog
|
||||
|
||||
Rsyslog 是一个发送远程客户端的日志到集群服务的简便方式。你只有一台服务器,但你想收集在你数据中心的其他 Linux 服务的日志。有了 Rsyslog,这可以很方便的实现。Rsyslog 必须被安装在所有的客户端和集群服务上(通过运行```sudo apt-get install rsyslog```)。 安装完成后,在集群服务上创建 /etc/rsyslog.d/server.conf 文件,包含以下内容:
|
||||
|
||||
```
|
||||
# Provide UDP syslog reception
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
|
||||
# Provide TCP syslog reception
|
||||
$ModLoad imtcp
|
||||
$InputTCPServerRun 514
|
||||
|
||||
# Use custom filenaming scheme
|
||||
$template FILENAME,"/var/log/remote/%HOSTNAME%.log"
|
||||
*.* ?FILENAME
|
||||
|
||||
$PreserveFQDN on
|
||||
|
||||
```
|
||||
|
||||
保存并退出这个文件。现在,在任意一台客户端机器上,创建这个文件 /etc/rsyslog.d/client.conf,包含以下内容:
|
||||
|
||||
```
|
||||
$PreserveFQDN on
|
||||
$ActionQueueType LinkedList
|
||||
$ActionQueueFileName srvrfwd
|
||||
$ActionResumeRetryCount -1
|
||||
$ActionQueueSaveOnShutdown on
|
||||
*.* @@SERVER_IP:514
|
||||
|
||||
```
|
||||
|
||||
SERVER_IP 处是你的集群服务的 IP 地址。保存并关闭该文件。使用以下命令在所有机器上重启 rsyslog。
|
||||
|
||||
```
|
||||
sudo systemctl restart rsyslog
|
||||
|
||||
```
|
||||
|
||||
你现在可以使用以下命令(运行在集群服务器上)查看集群日志文件。
|
||||
|
||||
```
|
||||
tail -f /var/log/remote/*.log
|
||||
|
||||
```
|
||||
|
||||
```tail``` 命令允许你实时查看写入这些文件中的内容。你应该可以看到包含主机名的日志条目(图 6)。
|
||||
|
||||
![Rsyslog][13]
|
||||
|
||||
图 6:Rsyslog 为一个已连接的客户端显示条目。
|
||||
|
||||
[经许可使用][3]
|
||||
|
||||
如果你想要为你的 Linux 服务器上的所有用户,创建单一的日志查看入口点, Rsyslog 是一个非常好的工具。
|
||||
|
||||
### 了解更多
|
||||
|
||||
这篇文章仅仅搜集了为 Linux 平台创建的日志记录工具的一点皮毛。上述每个工具都能够比此处概述的内容做到更多。这篇梗概应该会对你开始你漫长的日志记录历程有一点帮助。
|
||||
|
||||
你可以从 Linux 基金会和 edx 的免费课程 ["Introduction to Linux" ][14]了解更多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/10/open-source-logging-tools-linux
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[1]: /files/images/logs1jpg
|
||||
[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_1.jpg?itok=8yO2q1rW (/var/log/)
|
||||
[3]: /licenses/category/used-permission
|
||||
[4]: /files/images/logs2jpg
|
||||
[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_2.jpg?itok=kF6V46ZB (Logs tool)
|
||||
[6]: /files/images/logs3jpg
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_3.jpg?itok=PhrIzI1N (KSystemLog)
|
||||
[8]: /files/images/logs4jpg
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_4.jpg?itok=OxsGJ-TJ (log entry)
|
||||
[10]: /files/images/logs5jpg
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_5.jpg?itok=GeAR551e (Logwatch)
|
||||
[12]: /files/images/logs6jpg
|
||||
[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/logs_6.jpg?itok=ira8UZOr (Rsyslog)
|
||||
[14]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,123 +0,0 @@
|
||||
Minikube入门:笔记本上的Kubernetes
|
||||
======
|
||||
运行Minikube的分步指南。
|
||||
|
||||

|
||||
|
||||
在[Hello Minikube][1]教程页面上Minikube被宣传为基于Docker运行Kubernetes的一种简单方法。 虽然该文档非常有用,但它主要是为MacOS编写的。 你可以深入挖掘在Windows或某个Linux发行版上的使用说明,但它们不是很清楚。 许多文档都是针对Debian / Ubuntu用户的,比如[安装Minikube的驱动程序][2]。
|
||||
|
||||
### 先决条件
|
||||
|
||||
1. 你已经[安装了Docker][3]。
|
||||
2. 你的计算机是一个RHEL / CentOS / 基于Fedora的工作站。
|
||||
3. 你已经[安装了正常运行的KVM2虚拟机管理程序][4]。
|
||||
4. 你有一个运行的**docker-machine-driver-kvm2**。 以下命令将安装驱动程序:
|
||||
|
||||
```
|
||||
curl -Lo docker-machine-driver-kvm2 https://storage.googleapis.com/minikube/releases/latest/docker-machine-driver-kvm2 \
|
||||
chmod +x docker-machine-driver-kvm2 \
|
||||
&& sudo cp docker-machine-driver-kvm2 /usr/local/bin/ \
|
||||
&& rm docker-machine-driver-kvm2
|
||||
```
|
||||
|
||||
### 下载,安装和启动Minikube
|
||||
|
||||
1. 为你要即将下载的两个文件创建一个目录,两个文件分别是:[minikube][5]和[kubectl][6]。
|
||||
|
||||
|
||||
2. 打开终端窗口并运行以下命令来安装minikube。
|
||||
|
||||
```
|
||||
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
|
||||
```
|
||||
|
||||
请注意,minikube版本(例如,minikube-linux-amd64)可能因计算机的规格而有所不同。
|
||||
|
||||
3. **chmod**加执行权限。
|
||||
|
||||
```
|
||||
chmod +x minikube
|
||||
```
|
||||
|
||||
4. 将文件移动到**/usr/local/bin**路径下,以便你能将其作为命令运行。
|
||||
|
||||
```
|
||||
mv minikube /usr/local/bin
|
||||
```
|
||||
|
||||
5. 使用以下命令安装kubectl(类似于minikube的安装过程)。
|
||||
|
||||
```
|
||||
curl -Lo kubectl https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
|
||||
```
|
||||
|
||||
使用**curl**命令确定最新版本的Kubernetes。
|
||||
|
||||
6. **chmod**给kubectl加执行权限。
|
||||
|
||||
```
|
||||
chmod +x kubectl
|
||||
```
|
||||
|
||||
7. 将kubectl移动到**/usr/local/bin**路径下作为命令运行。
|
||||
|
||||
```
|
||||
mv kubectl /usr/local/bin
|
||||
```
|
||||
|
||||
8. 运行**minikube start**命令。 为此,你需要有虚拟机管理程序。 我使用过KVM2,你也可以使用Virtualbox。 确保是用户而不是root身份运行以下命令,以便为用户而不是root存储配置。
|
||||
|
||||
```
|
||||
minikube start --vm-driver=kvm2
|
||||
```
|
||||
|
||||
这可能需要一段时间,等一会。
|
||||
|
||||
9. Minikube应该下载并开始。 使用以下命令确保成功。
|
||||
|
||||
```
|
||||
cat ~/.kube/config
|
||||
```
|
||||
|
||||
10. 执行以下命令以运行Minikube作为上下文。 上下文决定了kubectl与哪个集群交互。 你可以在~/.kube/config文件中查看所有可用的上下文。
|
||||
|
||||
```
|
||||
kubectl config use-context minikube
|
||||
```
|
||||
|
||||
11. 再次查看**config** 文件以检查Minikube是否存在上下文。
|
||||
|
||||
```
|
||||
cat ~/.kube/config
|
||||
```
|
||||
|
||||
12. 最后,运行以下命令打开浏览器查看Kubernetes仪表板。
|
||||
|
||||
```
|
||||
minikube dashboard
|
||||
```
|
||||
|
||||
本指南旨在使RHEL / Fedora / CentOS操作系统用户操作更轻松。
|
||||
|
||||
现在Minikube已启动并运行,请阅读[通过Minikube在本地运行Kubernetes][7]这篇官网教程开始使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/getting-started-minikube
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://kubernetes.io/docs/tutorials/hello-minikube
|
||||
[2]: https://github.com/kubernetes/minikube/blob/master/docs/drivers.md
|
||||
[3]: https://docs.docker.com/install
|
||||
[4]: https://github.com/kubernetes/minikube/blob/master/docs/drivers.md#kvm2-driver
|
||||
[5]: https://github.com/kubernetes/minikube/releases
|
||||
[6]: https://kubernetes.io/docs/tasks/tools/install-kubectl/#install-kubectl-binary-using-curl
|
||||
[7]: https://kubernetes.io/docs/setup/minikube
|
||||
@ -0,0 +1,116 @@
|
||||
命令行快速提示: 读取文件的不同方式
|
||||
======
|
||||
|
||||

|
||||
|
||||
作为图形操作系统,Fedora 的使用是令人愉快的。你可以轻松地点按,完成任何任务。 但你可能已经看到了,在引擎盖下还有一个强大的命令行。 想要在 shell 下使用,只需要在 Fedora 系统中打开你的命令行应用程序。 这篇文章是向你展示命令行使用方法的系列之一。
|
||||
|
||||
在这部分,你将学习如何以不同的方式读取文件,如果你在系统中打开一个命令行,你就有可能需要读取一个或两个文件。
|
||||
|
||||
### 一应俱全的大餐
|
||||
|
||||
对命令行终端的用户来说, **cat** 命令众所周知。 当你 **cat** 一个文件,你很容易的把整个文件内容展示在你的屏幕上。而真正发生在引擎盖下的是文件一次读取一行, 然后一行一行写入屏幕。
|
||||
|
||||
假设你有一个文件,叫做 myfile, 这个文件每行只有一个单词。为了简单起见,每行的单词就是这行的行号,就像这样:
|
||||
|
||||
```
|
||||
|
||||
one
|
||||
two
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
所以如果你 **cat** 这个文件,你就会看到如下输出:
|
||||
|
||||
```
|
||||
|
||||
$ cat myfile
|
||||
one
|
||||
two
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
并没有太惊喜,不是吗? 但是有个有趣的转折,只要使用 **tac** 命令,你可以从后往前 **cat** 这个文件。(请注意, Fedora 对这种有争议的幽默不承担任何责任!)
|
||||
```
|
||||
|
||||
$ tac myfile
|
||||
five
|
||||
four
|
||||
three
|
||||
two
|
||||
one
|
||||
|
||||
```
|
||||
|
||||
**cat** 命令允许你以不同的方式装饰输出,比如,你可以输出行号:
|
||||
|
||||
```
|
||||
|
||||
$ cat -n myfile
|
||||
1 one
|
||||
2 two
|
||||
3 three
|
||||
4 four
|
||||
5 five
|
||||
|
||||
```
|
||||
|
||||
还有其他选项将显示特殊字符和其他功能。 要了解更多, 请运行 **man cat** 命令, 看完之后, 按 **q** 即可退出回到 shell。
|
||||
|
||||
### 挑选你的食物
|
||||
|
||||
通常, 文件太长, 无法全部显示在屏幕上, 您可能希望能够像文档一样查看它。 这种情况下,可以试试 **less** 命令:
|
||||
|
||||
```
|
||||
|
||||
$ less myfile
|
||||
|
||||
```
|
||||
|
||||
你可以用方向键,也可以用 **PgUp/PgDn** 来查看文件, 按 **q** 就可以退回到 shell。
|
||||
|
||||
实际上,还有一个 **more** 命令,它是基于在旧的 UNIX 系统命令的。如果在退回 shell 后仍想看到该文件, 则可能需要使用它。**less** 命令使你回到你离开 shell 之前的样子,并且清除屏幕上你看到的所有的文件内容。
|
||||
|
||||
### 一点披萨或甜点
|
||||
|
||||
有时, 你所需的输出只是文件的开头。 比如,有一个非常长的文件,当你使用 **cat** 命令时,会显示这个文件所有内容,前几行的内容很容易滚动过去,导致你看不到。**head** 命令会帮你获取文件的前几行:
|
||||
|
||||
```
|
||||
|
||||
$ head -n 2 myfile
|
||||
one
|
||||
two
|
||||
|
||||
```
|
||||
同样,你会用 **tail** 命令来查看文件的末尾几行:
|
||||
|
||||
```
|
||||
|
||||
$ tail -n 3 myfile
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
当然, 这些只是在这个领域的几个简单的命令。但当涉及到阅读文件时,你就能容易地开始。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-reading-files-different-ways/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
Loading…
Reference in New Issue
Block a user