mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
commit
a1bda05237
@ -2,9 +2,9 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,寻到一个便捷的方法去重新安装之前的应用并且重置其设置是很有用的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,如果有个便捷的方法来重新安装之前的应用并且重置其设置会很方便的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
|
||||
Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用及其主题和设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
Aptik(自动包备份和恢复)是一个可以用在Ubuntu,Linux Mint 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用和主题、用户设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
|
||||
注意:当我们在此文章中说到输入某些东西的时候,如果被输入的内容被引号包裹,请不要将引号一起输入进去,除非我们有特殊说明。
|
||||
|
||||
@ -16,7 +16,7 @@ Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和
|
||||
|
||||

|
||||
|
||||
输入下边的命令到提示符旁边,来确保资源库已经是最新版本。
|
||||
在命令行提示符输入下边的命令,来确保资源库已经是最新版本。
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -86,11 +86,11 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||
接下来,“Downloaded Packages (APT Cache)”的项目只对重装同样版本的Ubuntu有用处。它会备份下你系统缓存(/var/cache/apt/archives)中的包。如果你是升级系统的话,可以跳过这个条目,因为针对新系统的包会比现有系统缓存中的包更加新一些。
|
||||
|
||||
备份和回复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
备份和恢复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
|
||||
如果你是重装相同版本的Ubuntu系统的话,点击 “Downloaded Packages (APT Cache)” 右侧的 “Backup” 按钮来备份系统缓存中的包。
|
||||
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现的。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
|
||||

|
||||
|
||||
@ -104,7 +104,7 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||

|
||||
|
||||
名为 “packages.list” and “packages-installed.list” 的两个文件出现在了备份目录中,并且一个用来通知你备份完成的对话框出现。点击 ”OK“关闭它。
|
||||
备份目录中出现了两个名为 “packages.list” 和“packages-installed.list” 的文件,并且会弹出一个通知你备份完成的对话框。点击 ”OK“关闭它。
|
||||
|
||||
注意:“packages-installed.list”文件包含了所有的包,而 “packages.list” 在包含了所有包的前提下还指出了那些包被选择上了。
|
||||
|
||||
@ -120,27 +120,27 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||

|
||||
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击”OK“,关掉。
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击“OK”关掉。
|
||||
|
||||

|
||||
|
||||
来自 “/usr/share/themes” 目录的主题和来自 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要取消到一些然后点击 “Backup” 进行备份。
|
||||
放在 “/usr/share/themes” 目录的主题和放在 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要的、取消一些不要的,然后点击 “Backup” 进行备份。
|
||||
|
||||

|
||||
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击”OK“关闭它。
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击“OK”关闭它。
|
||||
|
||||

|
||||
|
||||
一旦你完成了需要的备份,点击主界面左上角的”X“关闭 Aptik 。
|
||||
一旦你完成了需要的备份,点击主界面左上角的“X”关闭 Aptik 。
|
||||
|
||||

|
||||
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时取阅。
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时查看。
|
||||
|
||||

|
||||
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中让其可被使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -148,7 +148,7 @@ via: http://www.howtogeek.com/206454/how-to-backup-and-restore-your-apps-and-ppa
|
||||
|
||||
作者:Lori Kaufman
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,166 @@
|
||||
文件轻松比对,伟大而自由的比较软件们
|
||||
================================================================================
|
||||
|
||||
文件比较工具用于比较计算机上的文件的内容,找到他们之间相同与不同之处。比较的结果通常被称为diff。
|
||||
|
||||
diff同时也是一个基于控制台的、能输出两个文件之间不同之处的著名的文件比较程序的名字。diff是于二十世纪70年代早期,在Unix操作系统上被开发出来的。diff将会把两个文件之间不同之处的部分进行输出。
|
||||
|
||||
Linux拥有很多不错的GUI工具,能使你能清楚的看到两个文件或同一文件不同版本之间的不同之处。这次我从自己最喜欢的GUI比较工具中选出了五个推荐给大家。除了其中的一个,其他的都是开源的。
|
||||
|
||||
这些应用程序可以让你更清楚的看到文件或目录的差别,能合并有差异的文件,可以解决冲突并将其输出成一个新的文件或补丁,其也用于那些预览和备注文件改动的产品上(比如,在源代码合并到源文件树之前,要先接受源代码的改变)。因此它们是非常重要的软件开发工具。它们可以帮助开发人员们对文件进行处理,不停的把文件转来转去。这些比较工具不仅仅能用于显示源代码文件中的不同之处;他们还适用于很多种的文本文件。可视化的特性使文件比较变得容易、简单。
|
||||
|
||||
----------
|
||||
|
||||
###Meld
|
||||
|
||||

|
||||
|
||||
Meld是一个适用于Gnome桌面的、开源的、图形化的文件差异查看和合并的应用程序。它支持2到3个文件的同时比较、递归式的目录比较、处于版本控制(Bazaar, Codeville, CVS, Darcs, Fossil SCM, Git, Mercurial, Monotone, Subversion)之下的目录比较。还能够手动或自动合并文件差异。
|
||||
|
||||
Meld的重点在于帮助开发人员比较和合并多个源文件,并在他们最喜欢的版本控制系统下能直观的浏览改动过的地方。
|
||||
|
||||
功能包括
|
||||
|
||||
- 原地编辑文件,即时更新
|
||||
- 进行两到三个文件的比较及合并
|
||||
- 在显示的差异和冲突之间的导航
|
||||
- 使用插入、改变和冲突这几种标记可视化展示本地和全局的差异
|
||||
- 内置正则表达式文本过滤器,可以忽略不重要的差异
|
||||
- 语法高亮度显示(使用可选的gtksourceview)
|
||||
- 将两到三个目录中的文件逐个进行比较,显示新建,缺失和替换过的文件
|
||||
- 对任何有冲突或差异的文件直接打开比较界面
|
||||
- 可以过滤文件或目录以避免以忽略某些差异
|
||||
- 被改动区域的自动合并模式使合并更容易
|
||||
- 也有一个简单的文件管理
|
||||
- 支持多种版本控制系统,包括Git, Mercurial, Bazaar 和 SVN
|
||||
- 在提交前开启文件比较来检查改动的地方和内容
|
||||
- 查看文件版本状态
|
||||
- 还能进行简单的版本控制操作(例如,提交、更新、添加、移动或删除文件)
|
||||
- 继承自同一文件的两个文件进行自动合并
|
||||
- 标注并在中间的窗格显示所有有冲突的变更的基础版本
|
||||
- 显示并合并同一文件的无关的独立修改
|
||||
- 锁定只读性质的基础文件以避免出错
|
||||
- 可以整合到已有的命令行界面中,包括gitmergetool
|
||||
- 国际化支持
|
||||
- 可视化使文件比较更简单
|
||||
|
||||
- 网址: [meldmerge.org][1]
|
||||
- 开发人员: Kai Willadsen
|
||||
- 证书: GNU GPL v2
|
||||
- 版本号: 1.8.5
|
||||
|
||||
----------
|
||||
|
||||
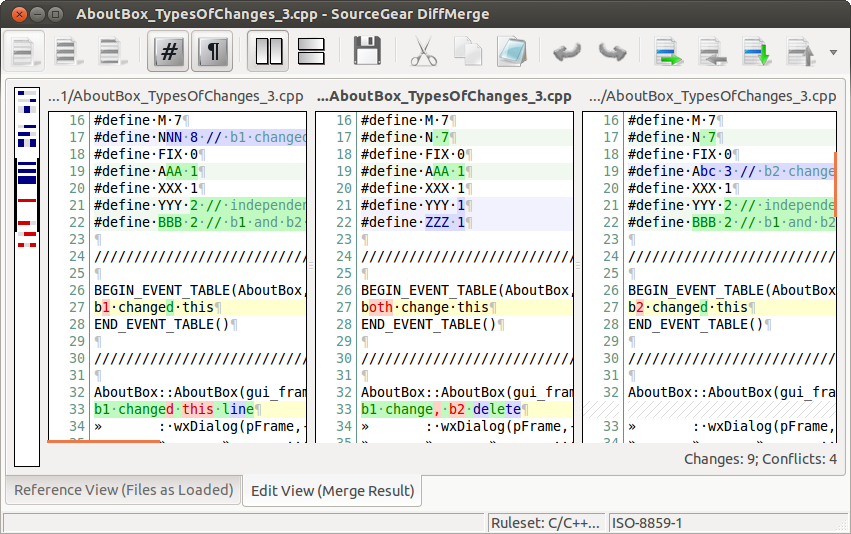
###DiffMerge
|
||||
|
||||
|
||||
|
||||
DiffMerge是一个可以在Linux、Windows和OS X上运行的,可以可视化文件的比较和合并的应用软件。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 图形化显示两个文件之间的差别。包括插入行,高亮标注以及对编辑的全面支持
|
||||
- 图形化显示三个文件之间的差别。(安全的前提下)允许自动合并,并对最终文件可以随意编辑
|
||||
- 并排显示两个文件夹的比较,显示哪一个文件只存在于其中一个文件夹而不存在于另外的一个文件夹,还能一对一的将完全相同的、等价的或不同的文件配对
|
||||
- 规则设置和选项让你可以个性化它的外观和行为
|
||||
- 基于Unicode,可以导入多种编码的字符
|
||||
- 跨平台工具
|
||||
|
||||
- 网址: [sourcegear.com/diffmerge][2]
|
||||
- 开发人员: SourceGear LLC
|
||||
- 证书: Licensed for use free of charge (not open source)
|
||||
- 版本号: 4.2
|
||||
|
||||
----------
|
||||
|
||||
###xxdiff
|
||||
|
||||

|
||||
|
||||
xxdiff是个开源的图形化的可进行文件、目录比较及合并的工具。
|
||||
|
||||
xxdiff可以用于显示两到三个文件或两个目录的差别,还能产生一个合并后的版本。被比较的两到三个文件会并排显示,并将有区别的文字内容用不同颜色高亮显示以便于识别。
|
||||
|
||||
这个程序是个非常重要的软件开发工具。他可以图形化的显示两个文件或目录之间的差别,合并有差异的文件,其也用于那些预览和备注文件改动的产品上(比如,在源代码合并到源文件树之前,要先接受源代码的改变)
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较两到三个文件,或是两个目录(浅层或递归)
|
||||
- 横向高亮显示差异
|
||||
- 交互式的文件合并,可视化的输出和保存
|
||||
- 可以辅助合并的评论/监管
|
||||
- 自动合并文件中时不合并 CVS 冲突,并以两个文件显示以便于解决冲突
|
||||
- 可以用其它的比较程序计算差异:适用于GNU diff、SGI diff和ClearCase的cleardiff,以及所有与这些程序输出相似的文件比较程序。
|
||||
- 可以使用资源文件实现完全的个性化设置
|
||||
- 用起来感觉和Rudy Wortel或SGI的xdiff差不多,与桌面系统无关
|
||||
- 功能和输出可以和脚本轻松集成
|
||||
|
||||
- 网址: [furius.ca/xxdiff][3]
|
||||
- 开发人员: Martin Blais
|
||||
- 证书: GNU GPL
|
||||
- 版本号: 4.0
|
||||
|
||||
----------
|
||||
|
||||
###Diffuse
|
||||
|
||||

|
||||
|
||||
Diffuse是个开源的图形化工具,可用于合并和比较文本文件。Diffuse能够比较任意数量的文件,并排显示,并提供手动行匹配调整,能直接编辑文件。Diffuse还能从bazaar、CVS、darcs, git, mercurial, monotone, Subversion和GNU RCS 库中获取版本用于比较及合并。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较任意数量的文件,并排显示(多方合并)
|
||||
- 行匹配可以被用户人工矫正
|
||||
- 直接编辑文件
|
||||
- 语法高亮
|
||||
- 支持Bazaar, CVS, Darcs, Git, Mercurial, Monotone, RCS, Subversion和SVK
|
||||
- 支持Unicode
|
||||
- 可无限撤销
|
||||
- 易用的键盘导航
|
||||
|
||||
- 网址: [diffuse.sourceforge.net][]
|
||||
- 开发人员: Derrick Moser
|
||||
- 证书: GNU GPL v2
|
||||
- 版本号: 0.4.7
|
||||
|
||||
----------
|
||||
|
||||
###Kompare
|
||||
|
||||

|
||||
|
||||
Kompare是个开源的GUI前端程序,可以对不同源文件之间差异的可视化和合并。Kompare可以比较文件或文件夹内容的差异。Kompare支持很多种diff格式,并提供各种选项来设置显示的信息级别。
|
||||
|
||||
不论你是个想比较源代码的开发人员,还是只想比较一下研究论文手稿与最终文档的差异,Kompare都是个有用的工具。
|
||||
|
||||
Kompare是KDE桌面环境的一部分。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较两个文本文件
|
||||
- 递归式比较目录
|
||||
- 显示diff产生的补丁
|
||||
- 将补丁合并到一个已存在的目录
|
||||
- 可以让你在编译时更轻松
|
||||
|
||||
- 网址: [www.caffeinated.me.uk/kompare/][5]
|
||||
- 开发者: The Kompare Team
|
||||
- 证书: GNU GPL
|
||||
- 版本号: Part of KDE
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/2014062814400262/FileComparisons.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://meldmerge.org/
|
||||
[2]:https://sourcegear.com/diffmerge/
|
||||
[3]:http://furius.ca/xxdiff/
|
||||
[4]:http://diffuse.sourceforge.net/
|
||||
[5]:http://www.caffeinated.me.uk/kompare/
|
||||
@ -0,0 +1,64 @@
|
||||
Linux上几款好用的字幕编辑器
|
||||
================================================================================
|
||||
如果你经常看国外的大片,你应该会喜欢带字幕版本而不是有国语配音的版本。我在法国长大,童年的记忆里充满了迪斯尼电影。但是这些电影因为有了法语的配音而听起来很怪。如果现在有机会能看原始的版本,我想,对于大多数的人来说,字幕还是必须的。我很高兴能为家人制作字幕。给我带来希望的是,Linux 也不乏有很多花哨、开源的字幕编辑器。总之一句话,文中Linux上字幕编辑器的列表并不详尽,你可以告诉我哪一款是你认为最好的字幕编辑器。
|
||||
|
||||
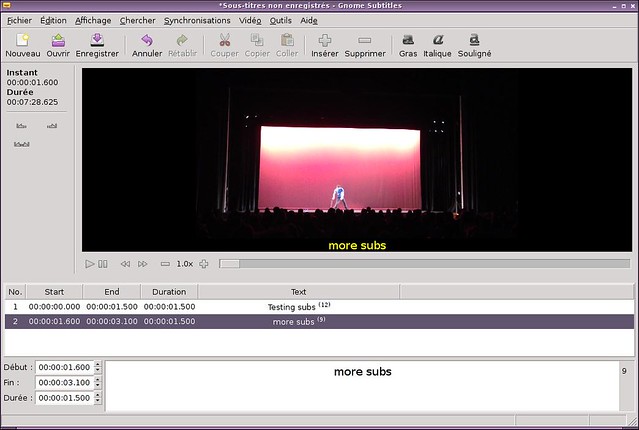
### 1. Gnome Subtitles ###
|
||||
|
||||
|
||||
|
||||
当有现有字幕需要快速编辑时,[Gnome Subtitles][1] 是我的一个选择。你可以载入视频,载入字幕文本,然后就可以即刻开始了。我很欣赏其对于易用性和高级特性之间的平衡。它带有一个同步工具以及一个拼写检查工具。最后但同样重要的的一点,这么好用最主要的是因为它的快捷键:当你编辑很多的台词的时候,你最好把你的手放在键盘上,使用其内置的快捷键来移动。
|
||||
|
||||
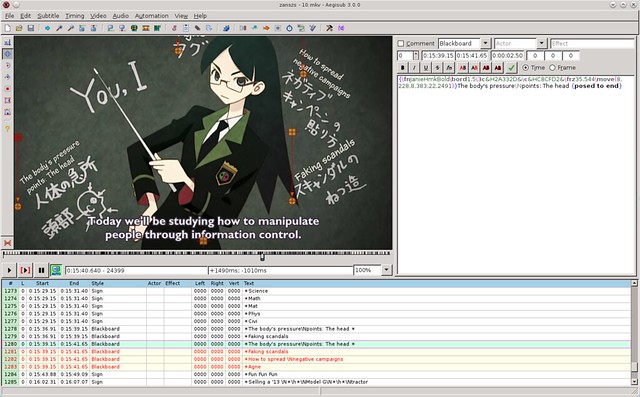
### 2. Aegisub ###
|
||||
|
||||
|
||||
|
||||
[Aegisub][2] 已经是一款高级别的复杂字幕编辑器。仅仅是界面就反映出了一定的学习曲线。但是,除了它吓人的样子以外,Aegisub 是一个非常完整的软件,提供的工具远远超出你能想象的。和Gnome Subtitles 一样,Aegisub也采用了所见即所得(WYSIWYG:what you see is what you get)的处理方式。但是是一个全新的高度:可以再屏幕上任意拖动字幕,也可以在另一边查看音频的频谱,并且可以利用快捷键做任何的事情。除此以外,它还带有一个汉字工具,有一个kalaok模式,并且你可以导入lua 脚本让它自动完成一些任务。我希望你在用之前,先去阅读下它的[指南][3]。
|
||||
|
||||
### 3. Gaupol ###
|
||||
|
||||

|
||||
|
||||
另一个操作复杂的软件是[Gaupol][4],不像Aegisub ,Gaupol 很容易上手而且采用了一个和Gnome Subtitles 很像的界面。但是在这些相对简单背后,它拥有很多很必要的工具:快捷键、第三方扩展、拼写检查,甚至是语音识别(由[CMU Sphinx][5]提供)。这里也提一个缺点,我注意到有时候在测试的时候也,软件会有消极怠工的表现,不是很严重,但是也足以让我更有理由喜欢Gnome Subtitles了。
|
||||
|
||||
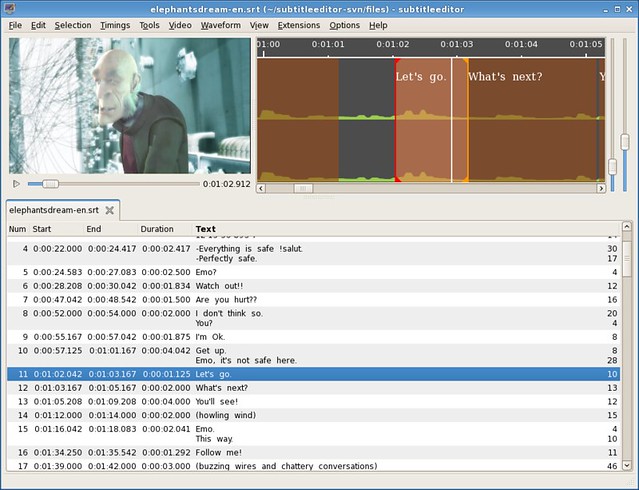
### 4. Subtitle Editor ###
|
||||
|
||||
|
||||
|
||||
[Subtitle Editor][6]和 Gaupol 很像,但是它的界面有点不太直观,特性也只是稍微的高级一点点。我很欣赏的一点是,它可以定义“关键帧”,而且提供所有的同步选项。然而,多一点的图标,或者是少一点的文字都能提供界面的特性。作为一个值得称赞的字幕编辑器,Subtitle Editor 可以模仿“作家”打字的效果,虽然我不确定它是否特别有用。最后但同样重要的一点,重定义快捷键的功能很实用。
|
||||
|
||||
### 5. Jubler ###
|
||||
|
||||

|
||||
|
||||
[Jubler][7]是一个用Java编写并有多平台支持的字幕编辑器。我对它的界面印象特别深刻。在上面我确实看出了Java特点的东西,但是,它仍然是经过精心的构造和构思的。像Aegisub 一样,你可以再屏幕上任意的拖动字幕,让你有愉快的体验而不单单是打字。它也可以为字幕自定义一个风格,在另外的一个轨道播放音频,翻译字幕,或者是是做拼写检查。不过,要注意的是,你需要事先安装好媒体播放器并且正确的配置,如果你想完整的使用Jubler。我把这些归功于在[官方页面][8]下载了脚本以后其简便的安装方式。
|
||||
|
||||
### 6. Subtitle Composer ###
|
||||
|
||||

|
||||
|
||||
[Subtitle Composer][9]被视为“KDE里的字幕作曲家”,它能够唤起对很多传统功能的回忆。伴随着KDE界面,我们充满了期待。我们自然会说到快捷键,我特别喜欢这个功能。除此之外,Subtitle Composer 与上面提到的编辑器最大的不同地方就在于,它可以执行用JavaScript,Python,甚至是Ruby写成的脚本。软件带有几个例子,肯定能够帮助你很好的学习使用这些特性的语法。
|
||||
|
||||
最后,不管你是否喜欢,都来为你的家庭编辑几个字幕吧,重新同步整个轨道,或者是一切从头开始,那么Linux 有很好的工具给你。对我来说,快捷键和易用性使得各个工具有差异,想要更高级别的使用体验,脚本和语音识别就成了很便利的一个功能。
|
||||
|
||||
你会使用哪个字幕编辑器,为什么?你认为还有没有更好用的字幕编辑器这里没有提到的?在评论里告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://gnomesubtitles.org/
|
||||
[2]:http://www.aegisub.org/
|
||||
[3]:http://docs.aegisub.org/3.2/Main_Page/
|
||||
[4]:http://home.gna.org/gaupol/
|
||||
[5]:http://cmusphinx.sourceforge.net/
|
||||
[6]:http://home.gna.org/subtitleeditor/
|
||||
[7]:http://www.jubler.org/
|
||||
[8]:http://www.jubler.org/download.html
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
@ -1,22 +1,22 @@
|
||||
Linux用户应该了解一下开源硬件
|
||||
Linux用户,你们真的了解开源硬件吗?
|
||||
================================================================================
|
||||
> Linux用户不了解一点开源硬件制造相关的事情,他们将会很失望。
|
||||
> Linux用户不了解一点开源硬件制造相关的事情,他们就会经常陷入失望的情绪中。
|
||||
|
||||
商业软件和免费软件已经互相纠缠很多年了,但是这俩经常误解对方。这并不奇怪 -- 对一方来说是生意,而另一方只是一种生活方式。但是,这种误解会给人带来痛苦,这也是为什么值得花精力去揭露这里面的内幕。
|
||||
|
||||
一个逐渐普遍的现象:对开源硬件的不断尝试,不管是Canonical,Jolla,MakePlayLive,或者其他几个。不管是评论员或终端用户,一般的免费软件用户会为新的硬件平台发布表现出过分的狂热,然后因为不断延期有所醒悟,最终放弃整个产品。
|
||||
一个逐渐普遍的现象:对开源硬件的不断尝试,不管是Canonical,Jolla,MakePlayLive,或者其他公司。无论是评论员或是终端用户,通常免费软件用户都会为新的硬件平台发布表现出过分的狂热,然后因为不断延期有所醒悟,直到最终放弃整个产品。
|
||||
|
||||
这是一个没有人获益的怪圈,而且滋生出不信任 - 都是因为一般的Linux用户根本不知道这些新闻背后发生的事情。
|
||||
这是一个没有人获益的怪圈,而且常常滋生出不信任 - 都是因为一般的Linux用户根本不知道这些新闻背后发生的事情。
|
||||
|
||||
我个人对于把产品推向市场的经验很有限。但是,我还不知道谁能有所突破。推出一个开源硬件或其他产品到市场仍然不仅仅是个残酷的生意,而且严重不利于新加入的厂商。
|
||||
我个人对于把产品推向市场的经验很有限。但是,我还没听说谁能有所突破。推出一个开源硬件或其他产品到市场仍然不仅仅是个残酷的生意,而且严重不利于新进厂商。
|
||||
|
||||
### 寻找合作伙伴 ###
|
||||
|
||||
不管是数码产品的生产还是分销都被相对较少的一些公司控制着,有时需要数月的预订。利润率也会很低,所以就像那些购买古老情景喜剧的电影工作室一样,生成商一般也希望复制当前热销产品的成功。像Aaron Seigo在谈到他花精力开发Vivaldi平板时告诉我的,生产商更希望能由其他人去承担开发新产品的风险。
|
||||
不管是数码产品的生产还是分销都被相对较少的一些公司控制着,有时需要数月的预订。利润率也会很低,所以就像那些购买古老情景喜剧的电影工作室一样,生产商一般也希望复制当前热销产品的成功。像Aaron Seigo在谈到他花精力开发Vivaldi平板时告诉我的,生产商更希望能由其他人去承担开发新产品的风险。
|
||||
|
||||
不仅如此,他们更希望和那些有现成销售记录的有可能带来可复制生意的人合作。
|
||||
不仅如此,他们更希望和那些有现成销售记录的有可能带来长期客户生意的人合作。
|
||||
|
||||
而且,一般新加入的厂商所关心的产品只有几千的量。芯片制造商更愿意和苹果或三星合作,因为它们的订单很可能是几百K。
|
||||
而且,一般新加入的厂商所关心的产品只有几千的量。芯片制造商更愿意和苹果或三星这样的公司合作,因为它们的订单很可能是几十上百万的量。
|
||||
|
||||
面对这种情形,开源硬件制造者们可能会发现他们在工厂的列表中被淹没了,除非能找到二线或三线厂愿意尝试一下小批量生产新产品。
|
||||
|
||||
@ -28,9 +28,9 @@ Linux用户应该了解一下开源硬件
|
||||
|
||||
这样必然会引起潜在用户的批评,但是开源硬件制造者没得选,只能折中他们的愿景。寻找其他生产商也不能解决问题,有一个原因是这样做意味着更多延迟,但是更多的是因为完全免授权费的硬件是不存在的。像三星这样的业内巨头对免费硬件没有任何兴趣,而作为新人,开源硬件制造者也没有影响力去要求什么。
|
||||
|
||||
更何况,就算有免费硬件,生产商也不能保证会用在下一批生产中。制造者们会轻易地发现他们每次需要生产的时候都要重打一样的仗。
|
||||
更何况,就算有免费硬件,生产商也不能保证会用在下一批生产中。制造者们会轻易地发现他们每次需要生产的时候都要重打一次一模一样的仗。
|
||||
|
||||
这些都还不够,这个时候开源硬件制造者们也许已经花了6-12个月时间来讨价还价。机会来了,产业标准已经变更,他们也许为了升级产品规格又要从头来过。
|
||||
这些都还不够,这个时候开源硬件制造者们也许已经花了6-12个月时间来讨价还价。等机会终于来了,产业标准却已经变更,于是他们可能为了升级产品规格又要从头来过。
|
||||
|
||||
### 短暂而且残忍的货架期 ###
|
||||
|
||||
@ -42,15 +42,15 @@ Linux用户应该了解一下开源硬件
|
||||
|
||||
### 衡量整件怪事 ###
|
||||
|
||||
在这里我只是粗略地概括了一下,但是任何涉足过制造的人会认出我形容成标准的东西。而更糟糕的是,开源硬件制造者们通常在这个过程中才会有所觉悟。不可避免,他们也会犯错,从而带来更多的延迟。
|
||||
在这里我只是粗略地概括了一下,但是任何涉足过制造的人会认同我形容为行业标准的东西。而更糟糕的是,开源硬件制造者们通常只有在亲身经历过后才会有所觉悟。不可避免,他们也会犯错,从而带来更多的延迟。
|
||||
|
||||
但重点是,一旦你对整个过程有所了解,你对另一个开源硬件进行尝试的消息的反应就会改变。这个过程意味着,除非哪家公司处于严格的保密模式,对于产品将于六个月内发布的声明会很快会被证实是过期的推测。很可能是12-18个月,而且面对之前提过的那些困难很可能意味着这个产品永远不会真正发布。
|
||||
但重点是,一旦你对整个过程有所了解,你对另一个开源硬件进行尝试的新闻的反应就会改变。这个过程意味着,除非哪家公司处于严格的保密模式,对于产品将于六个月内发布的声明会很快会被证实是过期的推测。很可能是12-18个月,而且面对之前提过的那些困难很可能意味着这个产品永远都不会真正发布。
|
||||
|
||||
举个例子,就像我写的,人们等待第一代Steam Machines面世,它是一台基于Linux的游戏主机。他们相信Steam Machines能彻底改变Linux和游戏。
|
||||
|
||||
作为一个市场分类,Steam Machines也许比其他新产品更有优势,因为参与开发的人员至少有开发软件产品的经验。然而,整整一年过去了Steam Machines的开发成果都还只有原型机,而且直到2015年中都不一定能买到。面对硬件生产的实际情况,就算有一半能见到阳光都是很幸运了。而实际上,能发布2-4台也许更实际。
|
||||
|
||||
我做出这个预测并没有考虑个体努力。但是,对硬件生产的理解,比起那些Linux和游戏的黄金年代之类的预言,我估计这个更靠谱。如果我错了也会很开心,但是事实不会改变:让人吃惊的不是如此多的Linux相关硬件产品失败了,而是那些即使是短暂的成功的产品。
|
||||
我做出这个预测并没有考虑个体努力。但是,对硬件生产的理解,比起那些Linux和游戏的黄金年代之类的预言,我估计这个更靠谱。如果我错了也会很开心,但是事实不会改变:让人吃惊的不是如此多的Linux相关硬件产品失败了,而是那些虽然短暂但却成功的产品。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -58,7 +58,7 @@ via: http://www.datamation.com/open-source/what-linux-users-should-know-about-op
|
||||
|
||||
作者:[Bruce Byfield][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,17 @@
|
||||
如何在 Linux 上使用 HAProxy 配置 HTTP 负载均衡器
|
||||
使用 HAProxy 配置 HTTP 负载均衡器
|
||||
================================================================================
|
||||
随着基于 Web 的应用和服务的增多,IT 系统管理员肩上的责任也越来越重。当遇到不可预期的事件如流量达到高峰,流量增大或者内部的挑战比如硬件的损坏或紧急维修,无论如何,你的 Web 应用都必须要保持可用性。甚至现在流行的 devops 和持续交付也可能威胁到你的 Web 服务的可靠性和性能的一致性。
|
||||
随着基于 Web 的应用和服务的增多,IT 系统管理员肩上的责任也越来越重。当遇到不可预期的事件如流量达到高峰,流量增大或者内部的挑战比如硬件的损坏或紧急维修,无论如何,你的 Web 应用都必须要保持可用性。甚至现在流行的 devops 和持续交付(CD)也可能威胁到你的 Web 服务的可靠性和性能的一致性。
|
||||
|
||||
不可预测,不一直的性能表现是你无法接受的。但是我们怎样消除这些缺点呢?大多数情况下一个合适的负载均衡解决方案可以解决这个问题。今天我会给你们介绍如何使用 [HAProxy][1] 配置 HTTP 负载均衡器。
|
||||
不可预测,不一致的性能表现是你无法接受的。但是我们怎样消除这些缺点呢?大多数情况下一个合适的负载均衡解决方案可以解决这个问题。今天我会给你们介绍如何使用 [HAProxy][1] 配置 HTTP 负载均衡器。
|
||||
|
||||
###什么是 HTTP 负载均衡? ###
|
||||
|
||||
HTTP 负载均衡是一个网络解决方案,它将发入的 HTTP 或 HTTPs 请求分配至一组提供相同的 Web 应用内容的服务器用于响应。通过将请求在这样的多个服务器间进行均衡,负载均衡器可以防止服务器出现单点故障,可以提升整体的可用性和响应速度。它还可以让你能够简单的通过添加或者移除服务器来进行横向扩展或收缩,对工作负载进行调整。
|
||||
HTTP 负载均衡是一个网络解决方案,它将进入的 HTTP 或 HTTPs 请求分配至一组提供相同的 Web 应用内容的服务器用于响应。通过将请求在这样的多个服务器间进行均衡,负载均衡器可以防止服务器出现单点故障,可以提升整体的可用性和响应速度。它还可以让你能够简单的通过添加或者移除服务器来进行横向扩展或收缩,对工作负载进行调整。
|
||||
|
||||
### 什么时候,什么情况下需要使用负载均衡? ###
|
||||
|
||||
负载均衡可以提升服务器的使用性能和最大可用性,当你的服务器开始出现高负载时就可以使用负载均衡。或者你在为一个大型项目设计架构时,在前端使用负载均衡是一个很好的习惯。当你的环境需要扩展的时候它会很有用。
|
||||
|
||||
|
||||
### 什么是 HAProxy? ###
|
||||
|
||||
HAProxy 是一个流行的开源的 GNU/Linux 平台下的 TCP/HTTP 服务器的负载均衡和代理软件。HAProxy 是单线程,事件驱动架构,可以轻松的处理 [10 Gbps 速率][2] 的流量,在生产环境中被广泛的使用。它的功能包括自动健康状态检查,自定义负载均衡算法,HTTPS/SSL 支持,会话速率限制等等。
|
||||
@ -24,13 +23,13 @@ HAProxy 是一个流行的开源的 GNU/Linux 平台下的 TCP/HTTP 服务器的
|
||||
### 准备条件 ###
|
||||
|
||||
你至少要有一台,或者最好是两台 Web 服务器来验证你的负载均衡的功能。我们假设后端的 HTTP Web 服务器已经配置好并[可以运行][3]。
|
||||
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already [up and running][3].
|
||||
|
||||
|
||||
### 在 Linux 中安装 HAProxy ###
|
||||
## 在 Linux 中安装 HAProxy ##
|
||||
|
||||
对于大多数的发行版,我们可以使用发行版的包管理器来安装 HAProxy。
|
||||
|
||||
#### 在 Debian 中安装 HAProxy ####
|
||||
### 在 Debian 中安装 HAProxy ###
|
||||
|
||||
在 Debian Wheezy 中我们需要添加源,在 /etc/apt/sources.list.d 下创建一个文件 "backports.list" ,写入下面的内容
|
||||
|
||||
@ -41,25 +40,25 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
# apt get update
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 Ubuntu 中安装 HAProxy ####
|
||||
### 在 Ubuntu 中安装 HAProxy ###
|
||||
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 CentOS 和 RHEL 中安装 HAProxy ####
|
||||
### 在 CentOS 和 RHEL 中安装 HAProxy ###
|
||||
|
||||
# yum install haproxy
|
||||
|
||||
### 配置 HAProxy ###
|
||||
## 配置 HAProxy ##
|
||||
|
||||
本教程假设有两台运行的 HTTP Web 服务器,它们的 IP 地址是 192.168.100.2 和 192.168.100.3。我们将负载均衡配置在 192.168.100.4 的这台服务器上。
|
||||
|
||||
为了让 HAProxy 工作正常,你需要修改 /etc/haproxy/haproxy.cfg 中的一些选项。我们会在这一节中解释这些修改。一些配置可能因 GNU/Linux 发行版的不同而变化,这些会被标注出来。
|
||||
|
||||
#### 1. 配置日志功能 ####
|
||||
### 1. 配置日志功能 ###
|
||||
|
||||
你要做的第一件事是为 HAProxy 配置日志功能,在排错时日志将很有用。日志配置可以在 /etc/haproxy/haproxy.cfg 的 global 段中找到他们。下面是针对不同的 Linux 发型版的 HAProxy 日志配置。
|
||||
|
||||
**CentOS 或 RHEL:**
|
||||
#### CentOS 或 RHEL:####
|
||||
|
||||
在 CentOS/RHEL中启用日志,将下面的:
|
||||
|
||||
@ -82,7 +81,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
**Debian 或 Ubuntu:**
|
||||
####Debian 或 Ubuntu:####
|
||||
|
||||
在 Debian 或 Ubuntu 中启用日志,将下面的内容
|
||||
|
||||
@ -106,7 +105,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
#### 2. 设置默认选项 ####
|
||||
### 2. 设置默认选项 ###
|
||||
|
||||
下一步是设置 HAProxy 的默认选项。在 /etc/haproxy/haproxy.cfg 的 default 段中,替换为下面的配置:
|
||||
|
||||
@ -124,7 +123,7 @@ You will need at least one, or preferably two web servers to verify functionalit
|
||||
|
||||
上面的配置是当 HAProxy 为 HTTP 负载均衡时建议使用的,但是并不一定是你的环境的最优方案。你可以自己研究 HAProxy 的手册并配置它。
|
||||
|
||||
#### 3. Web 集群配置 ####
|
||||
### 3. Web 集群配置 ###
|
||||
|
||||
Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡中的大多数设置都在这里。现在我们会创建一些基本配置,定义我们的节点。将配置文件中从 frontend 段开始的内容全部替换为下面的:
|
||||
|
||||
@ -141,14 +140,14 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
"listen webfarm *:80" 定义了负载均衡器监听的地址和端口。为了教程的需要,我设置为 "\*" 表示监听在所有接口上。在真实的场景汇总,这样设置可能不太合适,应该替换为可以从 internet 访问的那个网卡接口。
|
||||
"listen webfarm \*:80" 定义了负载均衡器监听的地址和端口。为了教程的需要,我设置为 "*" 表示监听在所有接口上。在真实的场景汇总,这样设置可能不太合适,应该替换为可以从 internet 访问的那个网卡接口。
|
||||
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
|
||||
上面的设置定义了,负载均衡器的状态统计信息可以通过 http://<load-balancer-IP>/haproxy?stats 访问。访问需要简单的 HTTP 认证,用户名为 "haproxy" 密码为 "stats"。这些设置可以替换为你自己的认证方式。如果你不需要状态统计信息,可以完全禁用掉。
|
||||
上面的设置定义了,负载均衡器的状态统计信息可以通过 http://\<load-balancer-IP>/haproxy?stats 访问。访问需要简单的 HTTP 认证,用户名为 "haproxy" 密码为 "stats"。这些设置可以替换为你自己的认证方式。如果你不需要状态统计信息,可以完全禁用掉。
|
||||
|
||||
下面是一个 HAProxy 统计信息的例子
|
||||
|
||||
@ -160,7 +159,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
- **source**:对请求的客户端 IP 地址进行哈希计算,根据哈希值和服务器的权重将请求调度至后端服务器。
|
||||
- **uri**:对 URI 的左半部分(问号之前的部分)进行哈希,根据哈希结果和服务器的权重对请求进行调度
|
||||
- **url_param**:根据每个 HTTP GET 请求的 URL 查询参数进行调度,使用固定的请求参数将会被调度至指定的服务器上
|
||||
- **hdr(name**):根据 HTTP 首部中的 <name> 字段来进行调度
|
||||
- **hdr(name**):根据 HTTP 首部中的 \<name> 字段来进行调度
|
||||
|
||||
"cookie LBN insert indirect nocache" 这一行表示我们的负载均衡器会存储 cookie 信息,可以将后端服务器池中的节点与某个特定会话绑定。节点的 cookie 存储为一个自定义的名字。这里,我们使用的是 "LBN",你可以指定其他的名称。后端节点会保存这个 cookie 的会话。
|
||||
|
||||
@ -169,25 +168,25 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
上面是我们的 Web 服务器节点的定义。服务器有由内部名称(如web01,web02),IP 地址和唯一的 cookie 字符串表示。cookie 字符串可以自定义,我这里使用的是简单的 node1,node2 ... node(n)
|
||||
|
||||
### 启动 HAProxy ###
|
||||
## 启动 HAProxy ##
|
||||
|
||||
如果你完成了配置,现在启动 HAProxy 并验证是否运行正常。
|
||||
|
||||
#### 在 Centos/RHEL 中启动 HAProxy ####
|
||||
### 在 Centos/RHEL 中启动 HAProxy ###
|
||||
|
||||
让 HAProxy 开机自启,使用下面的命令
|
||||
|
||||
# chkconfig haproxy on
|
||||
# service haproxy start
|
||||
|
||||
当然,防火墙需要开放 80 端口,想下面这样
|
||||
当然,防火墙需要开放 80 端口,像下面这样
|
||||
|
||||
**CentOS/RHEL 7 的防火墙**
|
||||
####CentOS/RHEL 7 的防火墙####
|
||||
|
||||
# firewallcmd permanent zone=public addport=80/tcp
|
||||
# firewallcmd reload
|
||||
|
||||
**CentOS/RHEL 6 的防火墙**
|
||||
####CentOS/RHEL 6 的防火墙####
|
||||
|
||||
把下面内容加至 /etc/sysconfig/iptables 中的 ":OUTPUT ACCEPT" 段中
|
||||
|
||||
@ -197,9 +196,9 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
# service iptables restart
|
||||
|
||||
#### 在 Debian 中启动 HAProxy ####
|
||||
### 在 Debian 中启动 HAProxy ###
|
||||
|
||||
#### 启动 HAProxy ####
|
||||
启动 HAProxy
|
||||
|
||||
# service haproxy start
|
||||
|
||||
@ -207,7 +206,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
A INPUT p tcp dport 80 j ACCEPT
|
||||
|
||||
#### 在 Ubuntu 中启动HAProxy ####
|
||||
### 在 Ubuntu 中启动HAProxy ###
|
||||
|
||||
让 HAProxy 开机自动启动在 /etc/default/haproxy 中配置
|
||||
|
||||
@ -221,7 +220,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
# ufw allow 80
|
||||
|
||||
### 测试 HAProxy ###
|
||||
## 测试 HAProxy ##
|
||||
|
||||
检查 HAProxy 是否工作正常,我们可以这样做
|
||||
|
||||
@ -239,7 +238,7 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
$ curl http://192.168.100.4/test.php
|
||||
|
||||
我们多次使用这个命令此时,会发现交替的输出下面的内容(因为使用了轮询算法):
|
||||
我们多次运行这个命令此时,会发现交替的输出下面的内容(因为使用了轮询算法):
|
||||
|
||||
Server IP: 192.168.100.2
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
@ -251,13 +250,13 @@ Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡
|
||||
|
||||
如果我们停掉一台后端 Web 服务,curl 命令仍然正常工作,请求被分发至另一台可用的 Web 服务器。
|
||||
|
||||
### 总结 ###
|
||||
## 总结 ##
|
||||
|
||||
现在你有了一个完全可用的负载均衡器,以轮询的模式对你的 Web 节点进行负载均衡。还可以去实验其他的配置选项以适应你的环境。希望这个教程可以帮会组你们的 Web 项目有更好的可用性。
|
||||
现在你有了一个完全可用的负载均衡器,以轮询的模式对你的 Web 节点进行负载均衡。还可以去实验其他的配置选项以适应你的环境。希望这个教程可以帮助你们的 Web 项目有更好的可用性。
|
||||
|
||||
你可能已经发现了,这个教程只包含单台负载均衡的设置。这意味着我们仍然有单点故障的问题。在真实场景中,你应该至少部署 2 台或者 3 台负载均衡以防止意外发生,但这不是本教程的范围。
|
||||
|
||||
如果 你有任何问题或建议,请在评论中提出,我会尽我的努力回答。
|
||||
如果你有任何问题或建议,请在评论中提出,我会尽我的努力回答。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -265,11 +264,11 @@ via: http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[Liao](https://github.com/liaoishere)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://www.haproxy.org/
|
||||
[2]:http://www.haproxy.org/10g.html
|
||||
[3]:http://xmodulo.com/how-to-install-lamp-server-on-ubuntu.html
|
||||
[3]:http://linux.cn/article-1567-1.html
|
||||
@ -0,0 +1,87 @@
|
||||
如何在Ubuntu上转换图像、音频和视频格式
|
||||
================================================================================
|
||||
|
||||
如果你的工作中需要接触到各种不同编码格式的图像、音频和视频,那么你很有可能正在使用多个工具来转换这些多种多样的媒体格式。如果存在一个能够处理所有图像/音频/视频格式的多合一转换工具,那就太好了。
|
||||
|
||||
[Format Junkie][1] 就是这样一个多合一的媒体转换工具,它有着极其友好的用户界面。更棒的是它是一个免费软件。你可以使用 Format Junkie 来转换几乎所有的流行格式的图像、音频、视频和归档文件(或称压缩文件),所有这些只需要简单地点击几下鼠标而已。
|
||||
|
||||
### 在Ubuntu 12.04, 12.10 和 13.04 上安装 Format Junkie ###
|
||||
|
||||
Format Junkie 可以通过 Ubuntu PPA format-junkie-team 进行安装。这个PPA支持Ubuntu 12.04, 12.10 和 13.04。在以上任意一种Ubuntu版本中安装Format Junkie的话,简单的执行以下命令即可:
|
||||
|
||||
$ sudo add-apt-repository ppa:format-junkie-team/release
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### 将 Format Junkie 安装到 Ubuntu 13.10 ###
|
||||
|
||||
如果你正在运行Ubuntu 13.10 (Saucy Salamander),你可以按照以下步骤下载 .deb 安装包来进行安装。由于Format Junkie 的 .deb 安装包只有很少的依赖包,所以使用 [gdebi deb installer][2] 来安装它。
|
||||
|
||||
在32位版Ubuntu 13.10上:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
在32位版Ubuntu 13.10上:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### 将 Format Junkie 安装到 Ubuntu 14.04 或之后版本 ###
|
||||
|
||||
现有可供使用的官方 Format Junkie .deb 文件需要 libavcodec-extra-53,不过它从Ubuntu 14.04开始就已经过时了。所以如果你想在Ubuntu 14.04或之后版本上安装Format Junkie,可以使用以下的第三方PPA来代替。
|
||||
|
||||
$ sudo add-apt-repository ppa:jon-severinsson/ffmpeg
|
||||
$ sudo add-apt-repository ppa:noobslab/apps
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
|
||||
### 如何使用 Format Junkie ###
|
||||
|
||||
安装完成后,只需运行以下命令即可启动 Format Junkie:
|
||||
|
||||
$ formatjunkie
|
||||
|
||||
#### 使用 Format Junkie 来转换音频、视频、图像和归档格式 ####
|
||||
|
||||
就像下方展示的一样,Format Junkie 的用户界面简单而且直观。在顶部的音频、视频、图像和iso媒体四个标签当中点击你需要的那个。你可以根据需要添加任意数量的文件用于批量转换。添加文件后,选择输出格式,直接点击 "Start Converting" 按钮进行转换。
|
||||
|
||||

|
||||
|
||||
Format Junkie支持以下媒体格式间的转换:
|
||||
|
||||
- **Audio**: mp3, wav, ogg, wma, flac, m4r, aac, m4a, mp2.
|
||||
- **Video**: avi, ogv, vob, mp4, 3gp, wmv, mkv, mpg, mov, flv, webm.
|
||||
- **Image**: jpg, png, ico, bmp, svg, tif, pcx, pdf, tga, pnm.
|
||||
- **Archive**: iso, cso.
|
||||
|
||||
#### 用 Format Junkie 进行字幕编码 ####
|
||||
|
||||
除了媒体转换,Format Junkie 可提供了字幕编码的图形界面。实际的字幕编码是由MEncoder来完成的。为了使用Format Junkie的字幕编码接口,首先你需要安装MEencoder。
|
||||
|
||||
$ sudo apt-get install mencoder
|
||||
|
||||
然后点击Format Junkie 中的 "Advanced"标签。选择 AVI/subtitle 文件来进行编码,如下所示:
|
||||
|
||||

|
||||
|
||||
总而言之,Format Junkie 是一个非常易于使用和多才多艺的媒体转换工具。但也有一个缺陷,它不允许对转换进行任何定制化(例如:比特率,帧率,采样频率,图像质量,尺寸)。所以这个工具推荐给正在寻找一个简单易用的媒体转换工具的新手使用。
|
||||
|
||||
喜欢这篇文章吗?请在下面发表评论吧。多谢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/how-to-convert-image-audio-and-video-formats-on-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://launchpad.net/format-junkie
|
||||
[2]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
@ -1,11 +1,10 @@
|
||||
“ntpq -p”命令输出详解
|
||||
网络时间的那些事情及 ntpq 详解
|
||||
================================================================================
|
||||
[Gentoo][1](也许其他发行版也是?)中 ["ntp -q" 的 man page][2] 只有简短的描述:“*打印出服务器已知的节点列表和它们的状态概要信息。*”
|
||||
[Gentoo][1](也许其他发行版也是?)中 ["ntpq -p" 的 man page][2] 只有简短的描述:“*打印出该服务器已知的节点列表和它们的状态概要信息。*”
|
||||
|
||||
我还没见到关于这个命令的说明文档,因此这里对此作一个总结,可以补充进 "[man ntpq][3]" man page 中。更多的细节见这里 “[ntpq – standard NTP query program][4]”(原作者),和 [其他关于 man ntpq 的例子][5].
|
||||
我还没见到关于这个命令的说明文档,因此这里对此作一个总结,可以补充进 "[man ntpq][3]" man page 中。更多的细节见这里 “[ntpq – 标准 NTP 请求程序][4]”(原作者),和 [其他关于 man ntpq 的例子][5].
|
||||
|
||||
[NTP][6] 是一个设计用于通过 [udp][9] 网络 ([WAN][7] 或者 [LAN][8]) 来同步计算机时钟的协议。引用 [Wikipedia – NTP][10]:
|
||||
[NTP][6] is a protocol designed to synchronize the clocks of computers over a ([WAN][7] or [LAN][8]) [udp][9] network. From [Wikipedia – NTP][10]:
|
||||
|
||||
> 网络时间协议(英语:Network Time Protocol,NTP)一种协议和软件实现,用于通过使用有网络延迟的报文交换网络同步计算机系统间的时钟。最初由美国特拉华大学的 David L. Mills 设计,现在仍然由他和志愿者小组维护,它于 1985 年之前开始使用,是因特网中最老的协议之一。
|
||||
|
||||
@ -28,10 +27,10 @@
|
||||
- **st** – 远程节点或服务器的 [Stratum][17](级别,NTP 时间同步是分层的)
|
||||
- **t** – 类型 (u: [unicast(单播)][18] 或 [manycast(选播)][19] 客户端, b: [broadcast(广播)][20] 或 [multicast(多播)][21] 客户端, l: 本地时钟, s: 对称节点(用于备份), A: 选播服务器, B: 广播服务器, M: 多播服务器, 参见“[Automatic Server Discovery][22]“)
|
||||
- **when** – 最后一次同步到现在的时间 (默认单位为秒, “h”表示小时,“d”表示天)
|
||||
- **poll** – 同步的频率:[rfc5905][23]建议在 NTPv4 中这个值的范围在 4 (16s) 至 17 (36h) 之间(2的指数次秒),然而观察发现这个值的实际大小在一个小的多的范围内 :64 (2的6次方)秒 至 1024 (2的10次方)秒
|
||||
- **poll** – 同步的频率:[rfc5905][23]建议在 NTPv4 中这个值的范围在 4 (16秒) 至 17 (36小时) 之间(即2的指数次秒),然而观察发现这个值的实际大小在一个小的多的范围内 :64 (2^6 )秒 至 1024 (2^10 )秒
|
||||
- **reach** – 一个8位的左移移位寄存器值,用来测试能否和服务器连接,每成功连接一次它的值就会增加,以 [8 进制][24]显示
|
||||
- **delay** – 从本地到远程节点或服务器通信的往返时间(毫秒)
|
||||
- **offset** – 主机与远程节点或服务器时间源的时间偏移量,offset 越接近于0,主机和 NTP 服务器的时间越接近([方均根][25]表示,单位为毫秒)
|
||||
- **offset** – 主机与远程节点或服务器时间源的时间偏移量,offset 越接近于0,主机和 NTP 服务器的时间越接近(以[方均根][25]表示,单位为毫秒)
|
||||
- **jitter** – 与远程节点同步的时间源的平均偏差(多个时间样本中的 offset 的偏差,单位是毫秒),这个数值的绝对值越小,主机的时间就越精确
|
||||
|
||||
#### 字段的统计代码 ####
|
||||
@ -47,7 +46,7 @@
|
||||
- “**-**” – 已不再使用
|
||||
- “**#**” – 良好的远程节点或服务器但是未被使用 (不在按同步距离排序的前六个节点中,作为备用节点使用)
|
||||
- “**+**” – 良好的且优先使用的远程节点或服务器(包含在组合算法中)
|
||||
- “*****” – 当前作为优先主同步对象的远程节点或服务器
|
||||
- “*” – 当前作为优先主同步对象的远程节点或服务器
|
||||
- “**o**” – PPS 节点 (当优先节点是有效时)。实际的系统同步是源于秒脉冲信号(pulse-per-second,PPS),可能通过PPS 时钟驱动或者通过内核接口。
|
||||
|
||||
参考 [Clock Select Algorithm][27].
|
||||
@ -74,9 +73,9 @@
|
||||
- **.WWV.** – [WWV][46] (HF, Ft. Collins, CO, America) 标准时间无线电接收器
|
||||
- **.WWVB.** – [WWVB][47] (LF, Ft. Collins, CO, America) 标准时间无线电接收器
|
||||
- **.WWVH.** – [WWVH][48] (HF, Kauai, HI, America) 标准时间无线电接收器
|
||||
- **.GOES.** – 美国 [静止环境观测卫星][49];
|
||||
- **.GOES.** – 美国[静止环境观测卫星][49];
|
||||
- **.GPS.** – 美国 [GPS][50];
|
||||
- **.GAL.** – [伽利略定位系统][51] 欧洲 [GNSS][52];
|
||||
- **.GAL.** – [伽利略定位系统][51]欧洲 [GNSS][52];
|
||||
- **.ACST.** – 选播服务器
|
||||
- **.AUTH.** – 认证错误
|
||||
- **.AUTO.** – Autokey (NTP 的一种认证机制)顺序错误
|
||||
@ -105,7 +104,7 @@ NTP 协议是高精度的,使用的精度小于纳秒(2的 -32 次方)。
|
||||
|
||||
#### “ntpq -c rl”输出参数 ####
|
||||
|
||||
- **precision** 为四舍五入值,且为 2 的幂数。因此精度为 2 的 *precision* 此幂(秒)
|
||||
- **precision** 为四舍五入值,且为 2 的幂数。因此精度为 2^precision (秒)
|
||||
- **rootdelay** – 与同步网络中主同步服务器的总往返延时。注意这个值可以是正数或者负数,取决于时钟的精度。
|
||||
- **rootdisp** – 相对于同步网络中主同步服务器的偏差(秒)
|
||||
- **tc** – NTP 算法 [PLL][59] (phase locked loop,锁相环路) 或 [FLL][60] (frequency locked loop,锁频回路) 时间常量
|
||||
@ -122,20 +121,20 @@ Jitter (也叫 timing jitter) 表示短期变化大于10HZ 的频率, wander
|
||||
|
||||
NTP 软件维护一系列连续更新的频率变化的校正值。对于设置正确的稳定系统,在非拥塞的网络中,现代硬件的 NTP 时钟同步通常与 UTC 标准时间相差在毫秒内。(在千兆 LAN 网络中可以达到何种精度?)
|
||||
|
||||
对于 UTC 时间,[闰秒][62] 可以每两年插入一次用于同步地球自传的变化。注意本地时间为[夏令时][63]时时间会有一小时的变化。在重同步之前客户端设备会使用独立的 UTC 时间,除非客户端使用了偏移校准。
|
||||
对于 UTC 时间,[闰秒 leap second ][62] 可以每两年插入一次用于同步地球自传的变化。注意本地时间为[夏令时][63]时时间会有一小时的变化。在重同步之前客户端设备会使用独立的 UTC 时间,除非客户端使用了偏移校准。
|
||||
|
||||
#### [闰秒发生时会怎样][64] ####
|
||||
|
||||
> 闰秒发生时,会对当天时间增加或减少一秒。闰秒的调整在 UTC 时间当天的最后一秒。如果增加一秒,UTC 时间会出现 23:59:60。即 23:59:59 到 0:00:00 之间实际上需要 2 秒钟。如果减少一秒,时间会从 23:59:58 跳至 0:00:00 。另见 [The Kernel Discipline][65].
|
||||
|
||||
好了… 间隔阈值(step threshold)的真实值是多少: 125ms 还是 128ms? PLL/FLL tc 的单位是什么 (log2 s? ms?)?在非拥塞的千兆 LAN 中时间节点间的精度能达到多少?
|
||||
那么… 间隔阈值(step threshold)的真实值是多少: 125ms 还是 128ms? PLL/FLL tc 的单位是什么 (log2 s? ms?)?在非拥塞的千兆 LAN 中时间节点间的精度能达到多少?
|
||||
|
||||
感谢 Camilo M 和 Chris B的评论。 欢迎校正错误和更多细节的探讨。
|
||||
|
||||
谢谢
|
||||
Martin
|
||||
|
||||
### 外传 ###
|
||||
### 附录 ###
|
||||
|
||||
- [NTP 的纪元][66] 从 1900 开始而 UNIX 的从 1970开始.
|
||||
- [时间校正][67] 是逐渐进行的,因此时间的完全同步可能会画上几个小时。
|
||||
@ -152,7 +151,7 @@ Martin
|
||||
|
||||
- [ntpq – 标准 NTP 查询程序][77]
|
||||
- [The Network Time Protocol (NTP) 分布][78]
|
||||
- NTP 的简明 [历史][79]
|
||||
- NTP 的简明[历史][79]
|
||||
- 一个更多细节的简明历史 “Mills, D.L., A brief history of NTP time: confessions of an Internet timekeeper. Submitted for publication; please do not cite or redistribute” ([pdf][80])
|
||||
- [NTP RFC][81] 标准文档
|
||||
- Network Time Protocol (Version 3) RFC – [txt][82], or [pdf][83]. Appendix E, The NTP Timescale and its Chronometry, p70, 包含了对过去 5000 年我们的计时系统的变化和关系的有趣解释。
|
||||
@ -165,7 +164,7 @@ Martin
|
||||
|
||||
### 其他 ###
|
||||
|
||||
SNTP (Simple Network Time Protocol, [RFC 4330][91],简单未落协议)基本上也是NTP,但是缺少一些基于 [RFC 1305][92] 实现的 NTP 的一些不再需要的内部算法。
|
||||
SNTP (Simple Network Time Protocol, [RFC 4330][91],简单网络协议)基本上也是NTP,但是少了一些基于 [RFC 1305][92] 实现的 NTP 的一些不再需要的内部算法。
|
||||
|
||||
Win32 时间 [Windows Time Service][93] 是 SNTP 的非标准实现,没有精度的保证,并假设精度几乎有 1-2 秒的范围。(因为没有系统时间变化校正)
|
||||
|
||||
@ -184,7 +183,7 @@ via: http://nlug.ml1.co.uk/2012/01/ntpq-p-output/831
|
||||
|
||||
作者:Martin L
|
||||
译者:[Liao](https://github.com/liaosishere)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
66
published/20141108 When hackers grow old.md
Normal file
66
published/20141108 When hackers grow old.md
Normal file
@ -0,0 +1,66 @@
|
||||
ESR:黑客年暮
|
||||
================================================================================
|
||||
近来我一直在与某资深开源开发团队中的多个成员缠斗,尽管密切关注我的人们会在读完本文后猜到是哪个组织,但我不会在这里说出这个组织的名字。
|
||||
|
||||
怎么让某些人进入 21 世纪就这么难呢?真是的...
|
||||
|
||||
我快 56 岁了,也就是大部分年轻人会以为的我将时不时朝他们发出诸如“滚出我的草坪”之类歇斯底里咆哮的年龄。但事实并非如此 —— 我发现,尤其是在技术背景之下,我变得与我的年龄非常不相称。
|
||||
|
||||
在我这个年龄的大部分人确实变成了爱发牢骚、墨守成规的老顽固。并且,尴尬的是,偶尔我会成为那个打断谈话的人,我会指出他们某个在 1995 年(或者在某些特殊情况下,1985 年)时很适合的方法... 几十年后的今天就不再是好方法了。
|
||||
|
||||
为什么是我?因为年轻人在我的同龄人中很难有什么说服力。如果有人想让那帮老头改变主意,首先他得是自己同龄人中具有较高思想觉悟的佼佼者。即便如此,在与习惯做斗争的过程中,我也比看起来花费了更多的时间。
|
||||
|
||||
年轻人犯下无知的错误是可以被原谅的。他们还年轻。年轻意味着缺乏经验,缺乏经验通常会导致片面的判断。我很难原谅那些经历了足够多本该有经验的人,却被*长期的固化思维*蒙蔽,无法发觉近在咫尺的东西。
|
||||
|
||||
(补充一下:我真的不是保守党拥护者。那些和我争论政治的,无论保守党还是非保守党都没有注意到这点,我觉得这颇有点嘲讽的意味。)
|
||||
|
||||
那么,现在我们来讨论下 GNU 更新日志文件(ChangeLog)这件事。在 1985 年的时候,这是一个不错的主意,甚至可以说是必须的。当时的想法是用单独的更新日志条目来记录多个相关文件的变更情况。用这种方式来对那些存在版本缺失或者非常原始的版本进行版本控制确实不错。当时我也*在场*,所以我知道这些。
|
||||
|
||||
不过即使到了 1995 年,甚至 21 世纪早期,许多版本控制系统仍然没有太大改进。也就是说,这些版本控制系统并非对批量文件的变化进行分组再保存到一条记录上,而是对每个变化的文件分别进行记录并保存到不同的地方。CVS,当时被广泛使用的版本控制系统,仅仅是模拟日志变更 —— 并且在这方面表现得很糟糕,导致大多数人不再依赖这个功能。即便如此,更新日志文件的出现依然是必要的。
|
||||
|
||||
但随后,版本控制系统 Subversion 于 2003 年发布 beta 版,并于 2004 年发布 1.0 正式版,Subversion 真正实现了更新日志记录功能,得到了人们的广泛认可。它与一年后兴起的分布式版本控制系统(Distributed Version Control System,DVCS)共同引发了主流世界的激烈争论。因为如果你在项目上同时使用了分布式版本控制与更新日志文件记录的功能,它们将会因为争夺相同元数据的控制权而产生不可预料的冲突。
|
||||
|
||||
有几种不同的方法可以折衷解决这个问题。一种是继续将更新日志作为代码变更的授权记录。这样一来,你基本上只能得到简陋的、形式上的提交评论数据。
|
||||
|
||||
另一种方法是对提交的评论日志进行授权。如果你这样做了,不久后你就会开始思忖为什么自己仍然对所有的日志更新条目进行记录。提交元数据与变化的代码具有更好的相容性,毕竟这才是当初设计它的目的。
|
||||
|
||||
(现在,试想有这样一个项目,同样本着把项目做得最好的想法,但两拨人却做出了完全不同的选择。因此你必须同时阅读更新日志和评论日志以了解到底发生了什么。最好在矛盾激化前把问题解决....)
|
||||
|
||||
第三种办法是尝试同时使用以上两种方法 —— 在更新日志条目中,以稍微变化后的的格式复制一份评论数据,将其作为评论提交的一部分。这会导致各种你意想不到的问题,最具代表性的就是它不符合“真理的单点性(single point of truth)”原理;只要其中有拷贝文件损坏,或者日志文件条目被修改,这就不再是同步时数据匹配的问题,它将导致在其后参与进来的人试图搞清人们是怎么想的时候变得非常困惑。(LCTT 译注:《[程序员修炼之道][1]》(The Pragmatic Programmer):任何一个知识点在系统内都应当有一个唯一、明确、权威的表述。根据Brian Kernighan的建议,把这个原则称为“真理的单点性(Single Point of Truth)”或者SPOT原则。)
|
||||
|
||||
或者,正如这个*我就不说出具体名字的特定项目*所做的,它的高层开发人员在电子邮件中最近声明说,提交可以包含多个更新日志条目,并且提交的元数据与更新日志是无关的。这导致我们直到现在还得不断进行记录。
|
||||
|
||||
当时我读到邮件的时候都要吐了。什么样的傻瓜才会意识不到这是自找麻烦 —— 事实上,在 DVCS 中针对可靠的提交日志有很好的浏览工具,围绕更新日志文件的整个定制措施只会成为负担和拖累。
|
||||
|
||||
唉,这是比较特殊的笨蛋:变老的并且思维僵化了的黑客。所有的合理化改革他都会极力反对。他所遵循的行事方法在几十年前是有效的,但现在只能适得其反。如果你试图向他解释这些不仅仅和 git 的摘要信息有关,同时还为了正确适应当前的工具集,以便实现更新日志的去条目化... 呵呵,那你就准备好迎接无法忍受、无法想象的疯狂对话吧。
|
||||
|
||||
的确,它成功激怒了我。这样那样的胡言乱语使这个项目变成了很难完成的工作。而且,同样的糟糕还体现在他们吸引年轻开发者的过程中,我认为这是真正的问题。相关 Google+ 社区的人员数量已经达到了 4 位数,他们大部分都是孩子,还没有成长起来。显然外界已经接受了这样的信息:这个项目的开发者都是部落中地位根深蒂固的崇高首领,最好的崇拜方式就是远远的景仰着他们。
|
||||
|
||||
这件事给我的最大触动就是每当我要和这些部落首领较量时,我都会想:有一天我也会这样吗?或者更糟的是,我看到的只是如同镜子一般对我自己的真实写照,而我自己却浑然不觉?我的意思是,我所得到的印象来自于他的网站,这个特殊的笨蛋要比我年轻。年轻至少 15 岁呢。
|
||||
|
||||
我总是认为自己的思路很清晰。当我和那些比我聪明的人打交道时我不会受挫,我只会因为那些思路跟不上我、看不清事实的人而沮丧。但这种自信也许只是邓宁·克鲁格效应(Dunning-Krueger effect)在我身上的消极影响,我并不确定这意味着什么。很少有什么事情会让我感到害怕;而这件事在让我害怕的事情名单上是名列前茅的。
|
||||
|
||||
另一件让人不安的事是当我逐渐变老的时候,这样的矛盾发生得越来越频繁。不知怎的,我希望我的黑客同行们能以更加优雅的姿态老去,即使身体老去也应该保持一颗年轻的心灵。有些人确实是这样;但可惜绝大多数人都不是。真令人悲哀。
|
||||
|
||||
我不确定我的职业生涯会不会完美收场。假如我最后成功避免了思维僵化(注意我说的是假如),我想我一定知道其中的部分原因,但我不确定这种模式是否可以被复制 —— 为了达成目的也许得在你的头脑中发生一些复杂的化学反应。尽管如此,无论对错,请听听我给年轻黑客以及其他有志青年的建议。
|
||||
|
||||
你们——对的,也包括你——一定无法在你中年老年的时候保持不错的心灵,除非你能很好的控制这点。你必须不断地去磨练你的内心、在你还年轻的时候完成自己的种种心愿,你必须把这些行为养成一种习惯直到你老去。
|
||||
|
||||
有种说法是中年人锻炼身体的最佳时机是 30 岁以前。我以为同样的方法,坚持我以上所说的习惯能让你在 56 岁,甚至 65 岁的时候仍然保持灵活的头脑。挑战你的极限,使不断地挑战自己成为一种习惯。立刻离开安乐窝,由此当你以后真正需要它的时候你可以建立起自己的安乐窝。
|
||||
|
||||
你必须要清楚的了解这点;还有一个可选择的挑战是你选择一个可以实现的目标并且为了这个目标不断努力。这个月我要学习 Go 语言。不是指游戏,我早就玩儿过了(虽然玩儿的不是太好)。并不是因为工作需要,而是因为我觉得是时候来扩展下我自己了。
|
||||
|
||||
保持这个习惯。永远不要放弃。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=6485
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://book.51cto.com/art/200809/88490.htm
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||
你能快速定位CPU性能回退的问题么? 如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。
|
||||
|
||||
辛亏有了[CPU火焰图][1](flame graphs),CPU使用率的问题一般都比较好定位。但要处理性能回退问题,就要在修改前后的火焰图间,不断切换对比,来找出问题所在,这感觉就是像在太阳系中搜寻冥王星。虽然,这种方法可以解决问题,但我觉得应该会有更好的办法。
|
||||
幸亏有了[CPU火焰图][1](flame graphs),CPU使用率的问题一般都比较好定位。但要处理性能回退问题,就要在修改前后的火焰图之间,不断切换对比,来找出问题所在,这感觉就是像在太阳系中搜寻冥王星。虽然,这种方法可以解决问题,但我觉得应该会有更好的办法。
|
||||
|
||||
所以,下面就隆重介绍**红/蓝差分火焰图(red/blue differential flame graphs)**:
|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
|
||||
这张火焰图中各火焰的形状和大小都是和第二次抓取的profile文件对应的CPU火焰图是相同的。(其中,y轴表示栈的深度,x轴表示样本的总数,栈帧的宽度表示了profile文件中该函数出现的比例,最顶层表示正在运行的函数,再往下就是调用它的栈)
|
||||
|
||||
在下面这个案例展示了,在系统升级后,一个工作负载的CPU使用率上升了。 下面是对应的CPU火焰图([SVG格式][4])
|
||||
在下面这个案例展示了,在系统升级后,一个工作载荷的CPU使用率上升了。 下面是对应的CPU火焰图([SVG格式][4])
|
||||
|
||||
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" type="image/svg+xml" width=720 height=296>
|
||||
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" width=720 />
|
||||
@ -22,7 +22,7 @@
|
||||
|
||||
通常,在标准的火焰图中栈帧和栈塔的颜色是随机选择的。 而在红/蓝差分火焰图中,使用不同的颜色来表示两个profile文件中的差异部分。
|
||||
|
||||
在第二个profile中deflate_slow()函数以及它后续调用的函数运行的次数要比前一次更多,所以在上图中这个栈帧被标为了红色。可以看出问题的原因是ZFS的压缩功能被使能了,而在系统升级前这项功能是关闭的。
|
||||
在第二个profile中deflate_slow()函数以及它后续调用的函数运行的次数要比前一次更多,所以在上图中这个栈帧被标为了红色。可以看出问题的原因是ZFS的压缩功能被启用了,而在系统升级前这项功能是关闭的。
|
||||
|
||||
这个例子过于简单,我甚至可以不用差分火焰图也能分析出来。但想象一下,如果是在分析一个微小的性能下降,比如说小于5%,而且代码也更加复杂的时候,问题就为那么好处理了。
|
||||
|
||||
@ -69,7 +69,9 @@ difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠
|
||||
在上面的例子中"func_a()->func_b()->func_c()" 代表调用栈,这个调用栈在profile1文件中共出现了31次,在profile2文件中共出现了33次。然后,使用flamegraph.pl脚本处理这3列数据,会自动生成一张红/蓝差分火焰图。
|
||||
|
||||
### 其他选项 ###
|
||||
|
||||
再介绍一些有用的选项:
|
||||
|
||||
**difffolded.pl -n**:这个选项会把两个profile文件中的数据规范化,使其能相互匹配上。如果你不这样做,抓取到所有栈的统计值肯定会不相同,因为抓取的时间和CPU负载都不同。这样的话,看上去要么就是一片红(负载增加),要么就是一片蓝(负载下降)。-n选项对第一个profile文件进行了平衡,这样你就可以得到完整红/蓝图谱。
|
||||
|
||||
**difffolded.pl -x**: 这个选项会把16进制的地址删掉。 profiler时常会无法将地址转换为符号,这样的话栈里就会有16进制地址。如果这个地址在两个profile文件中不同,这两个栈就会认为是不同的栈,而实际上它们是相同的。遇到这样的问题就用-x选项搞定。
|
||||
@ -77,6 +79,7 @@ difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠
|
||||
**flamegraph.pl --negate**: 用于颠倒红/蓝配色。 在下面的章节中,会用到这个功能。
|
||||
|
||||
### 不足之处 ###
|
||||
|
||||
虽然我的红/蓝差分火焰图很有用,但实际上还是有一个问题:如果一个代码执行路径完全消失了,那么在火焰图中就找不到地方来标注蓝色。你只能看到当前的CPU使用情况,而不知道为什么会变成这样。
|
||||
|
||||
一个办法是,将对比顺序颠倒,画一个相反的差分火焰图。例如:
|
||||
@ -95,12 +98,13 @@ difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠
|
||||
|
||||
这样,把前面生成diff2.svg一并使用,我们就能得到:
|
||||
|
||||
- **diff1.svg**: 宽度是以修改前profile文件为基准, 颜色表明将要发生的情况
|
||||
- **diff2.svg**: 宽度以修改后的profile文件为基准,颜色表明已经发生的情况
|
||||
- **diff1.svg**: 宽度是以修改前profile文件为基准,颜色表明将要发生的情况
|
||||
- **diff2.svg**: 宽度是以修改后profile文件为基准,颜色表明已经发生的情况
|
||||
|
||||
如果是在做功能验证测试,我会同时生成这两张图。
|
||||
|
||||
### CPI 火焰图 ###
|
||||
|
||||
这些脚本开始是被使用在[CPI火焰图][8]的分析上。与比较修改前后的profile文件不同,在分析CPI火焰图时,可以分析CPU工作周期与停顿周期的差异变化,这样可以凸显出CPU的工作状态来。
|
||||
|
||||
### 其他的差分火焰图 ###
|
||||
@ -110,6 +114,7 @@ difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠
|
||||
也有其他人做过类似的工作。[Robert Mustacchi][10]在不久前也做了一些尝试,他使用的方法类似于代码检视时的标色风格:只显示了差异的部分,红色表示新增(上升)的代码路径,蓝色表示删除(下降)的代码路径。一个关键的差别是栈帧的宽度只体现了差异的样本数。右边是一个例子。这个是个很好的主意,但在实际使用中会感觉有点奇怪,因为缺失了完整profile文件的上下文作为背景,这张图显得有些难以理解。
|
||||
|
||||
[][12]
|
||||
|
||||
Cor-Paul Bezemer也制作了一种差分显示方法[flamegraphdiff][13],他同时将3张火焰图放在同一张图中,修改前后的标准火焰图各一张,下面再补充了一张差分火焰图,但栈帧宽度也是差异的样本数。 上图是一个[例子][14]。在差分图中将鼠标移到栈帧上,3张图中同一栈帧都会被高亮显示。这种方法中补充了两张标准的火焰图,因此解决了上下文的问题。
|
||||
|
||||
我们3人的差分火焰图,都各有所长。三者可以结合起来使用:Cor-Paul方法中上方的两张图,可以用我的diff1.svg 和 diff2.svg。下方的火焰图可以用Robert的方式。为保持一致性,下方的火焰图可以用我的着色方式:蓝->白->红。
|
||||
@ -128,7 +133,7 @@ via: http://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -24,11 +24,11 @@
|
||||
|
||||
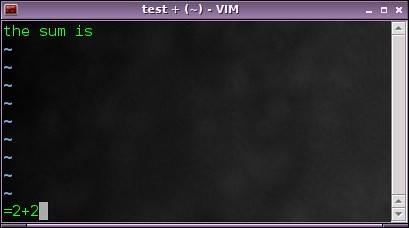
|
||||
|
||||
然后 4 会被插入到文件中。
|
||||
然后计算结果“4 ”会被插入到文件中。
|
||||
|
||||
### 查找重复的连续的单词 ###
|
||||
|
||||
当你很快地打字时,很有可能会连续输入同一个单词两次,就像 this this。这种错误可能骗过任何一个人,即使是你自己重新阅读一边也不可避免。幸运的是,有一个简单的正则表达式可以用来预防这个错误。使用搜索命令(默认时 `/`)然后输入:
|
||||
当你很快地打字时,很有可能会连续输入同一个单词两次,就像 this this。这种错误可能骗过任何一个人,即使是你自己重新阅读一遍也不可避免。幸运的是,有一个简单的正则表达式可以用来预防这个错误。使用搜索命令(默认时 `/`)然后输入:
|
||||
|
||||
\(\<\w\+\>\)\_s*\1
|
||||
|
||||
@ -72,7 +72,7 @@
|
||||
|
||||
`gg` 把光标移动到 Vim 缓冲区的第一行,`V` 进入可视模式,`G` 把光标移动到缓冲区的最后一行。因此,`ggVG` 使可视模式覆盖这个当前缓冲区。最后 `g?` 使用 ROT13 对整个区域进行编码。
|
||||
|
||||
注意它应该被映射到一个最长使用的键。它对字母符号也可以很好地工作。要对它进行撤销,最好的方法就是使用撤销命令:`u`。
|
||||
注意它可以被映射到一个最常使用的键。它对字母符号也可以很好地工作。要对它进行撤销,最好的方法就是使用撤销命令:`u`。
|
||||
|
||||
###自动补全 ###
|
||||
|
||||
@ -110,7 +110,7 @@
|
||||
|
||||
### 按时间回退文件 ###
|
||||
|
||||
Vim 会记录文件的更改,你很容易可以回退到之前某个时间。该命令时相当直观的。比如:
|
||||
Vim 会记录文件的更改,你很容易可以回退到之前某个时间。该命令是相当直观的。比如:
|
||||
|
||||
:earlier 1m
|
||||
|
||||
@ -122,7 +122,7 @@ Vim 会记录文件的更改,你很容易可以回退到之前某个时间。
|
||||
|
||||
### 删除标记内部的文字 ###
|
||||
|
||||
当我开始使用 Vim 时一件我总是想很方便做的事情是如何轻松的删除方括号或圆括号里的内容。转到开始的标记,然后使用下面的语法:
|
||||
当我开始使用 Vim 时,一件我总是想很方便做的事情是如何轻松的删除方括号或圆括号里的内容。转到开始的标记,然后使用下面的语法:
|
||||
|
||||
di[标记]
|
||||
|
||||
@ -164,11 +164,11 @@ Vim 会记录文件的更改,你很容易可以回退到之前某个时间。
|
||||
|
||||
### 把光标下的文字置于屏幕中央 ###
|
||||
|
||||
所有要做的事情都包含在标题中。如果你想强制滚动屏幕来把光标下的文字置于屏幕的中央,在可视模式中使用命令(译者注:在普通模式中也可以):
|
||||
我们所要做的事情如标题所示。如果你想强制滚动屏幕来把光标下的文字置于屏幕的中央,在可视模式中使用命令(译者注:在普通模式中也可以):
|
||||
|
||||
zz
|
||||
|
||||
### 跳到上一个/下一个 位置 ###
|
||||
### 跳到上一个/下一个位置 ###
|
||||
|
||||
当你编辑一个很大的文件时,经常要做的事是在某处进行修改,然后跳到另外一处。如果你想跳回之前修改的地方,使用命令:
|
||||
|
||||
@ -196,7 +196,7 @@ Vim 会记录文件的更改,你很容易可以回退到之前某个时间。
|
||||
|
||||
总的来说,这一系列命令是在我读了许多论坛主题和 [Vim Tips wiki][3](如果你想学习更多关于编辑器的知识,我非常推荐这篇文章) 之后收集起来的。
|
||||
|
||||
如果你还知道哪些非常有用但你认为大多数人并不知道的命令,可以随意在评论中分享出来。就像引言中所说的,一个“鲜为人知但很有用的”命令是很主观的,但分享出来总是好的。
|
||||
如果你还知道哪些非常有用但你认为大多数人并不知道的命令,可以随意在评论中分享出来。就像引言中所说的,一个“鲜为人知但很有用的”命令也许只是你自己的看法,但分享出来总是好的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -204,7 +204,7 @@ via: http://xmodulo.com/useful-vim-commands.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,195 @@
|
||||
使用 nice、cpulimit 和 cgroups 限制 cpu 占用率
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
Linux内核是一名了不起的马戏表演者,它在进程和系统资源间小心地玩着杂耍,并保持系统的能够正常运转。 同时,内核也很公正:它将资源公平地分配给各个进程。
|
||||
|
||||
但是,如果你需要给一个重要进程提高优先级时,该怎么做呢? 或者是,如何降低一个进程的优先级? 又或者,如何限制一组进程所使用的资源呢?
|
||||
|
||||
**答案是需要由用户来为内核指定进程的优先级**
|
||||
|
||||
大部分进程启动时的优先级是相同的,因此Linux内核会公平地进行调度。 如果想让一个CPU密集型的进程运行在较低优先级,那么你就得事先配置好调度器。
|
||||
|
||||
下面介绍3种控制进程运行时间的方法:
|
||||
|
||||
- 使用 nice 命令手动降低任务的优先级。
|
||||
- 使用 cpulimit 命令不断的暂停进程,以控制进程所占用处理能力不超过特定限制。
|
||||
- 使用linux内建的**control groups(控制组)**功能,它提供了限制进程资源消耗的机制。
|
||||
|
||||
我们来看一下这3个工具的工作原理和各自的优缺点。
|
||||
|
||||
### 模拟高cpu占用率 ###
|
||||
|
||||
在分析这3种技术前,我们要先安装一个工具来模拟高CPU占用率的场景。我们会用到CentOS作为测试系统,并使用[Mathomatic toolkit][1]中的质数生成器来模拟CPU负载。
|
||||
|
||||
很不幸,在CentOS上这个工具没有预编译好的版本,所以必须要从源码进行安装。先从 http://mathomatic.orgserve.de/mathomatic-16.0.5.tar.bz2 这个链接下载源码包并解压。然后进入 **mathomatic-16.0.5/primes** 文件夹,运行 **make** 和 **sudo make install** 进行编译和安装。这样,就把 **matho-primes** 程序安装到了 **/usr/local/bin** 目录中。
|
||||
|
||||
接下来,通过命令行运行:
|
||||
|
||||
/usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
程序运行后,将输出从0到9999999999之间的质数。因为我们并不需要这些输出结果,直接将输出重定向到/dev/null就好。
|
||||
|
||||
现在,使用top命令就可以看到matho-primes进程榨干了你所有的cpu资源。
|
||||
|
||||

|
||||
|
||||
好了,接下来(按q键)退出 top 并杀掉 matho-primes 进程(使用 fg 命令将进程切换到前台,再按 CTRL+C)
|
||||
|
||||
### nice命令 ###
|
||||
|
||||
下来介绍一下nice命令的使用方法,nice命令可以修改进程的优先级,这样就可以让进程运行得不那么频繁。 **这个功能在运行cpu密集型的后台进程或批处理作业时尤为有用。** nice值的取值范围是[-20,19],-20表示最高优先级,而19表示最低优先级。 Linux进程的默认nice值为0。使用nice命令(不带任何参数时)可以将进程的nice值设置为10。这样调度器就会将此进程视为较低优先级的进程,从而减少cpu资源的分配。
|
||||
|
||||
下面来看一个例子,我们同时运行两个 **matho-primes** 进程,一个使用nice命令来启动运行,而另一个正常启动运行:
|
||||
|
||||
nice matho-primes 0 9999999999 > /dev/null &
|
||||
matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
再运行top命令。
|
||||
|
||||
|
||||

|
||||
|
||||
看到没,正常运行的进程(nice值为0)获得了更多的cpu运行时间,相反的,用nice命令运行的进程占用的cpu时间会较少(nice值为10)。
|
||||
|
||||
在实际使用中,如果你要运行一个CPU密集型的程序,那么最好用nice命令来启动它,这样就可以保证其他进程获得更高的优先级。 也就是说,即使你的服务器或者台式机在重载的情况下,也可以快速响应。
|
||||
|
||||
nice 还有一个关联命令叫做 renice,它可以在运行时调整进程的 nice 值。使用 renice 命令时,要先找出进程的 PID。下面是一个例子:
|
||||
|
||||
renice +10 1234
|
||||
|
||||
其中,1234是进程的 PID。
|
||||
|
||||
测试完 **nice** 和 **renice** 命令后,记得要将 **matho-primes** 进程全部杀掉。
|
||||
|
||||
### cpulimit命令 ###
|
||||
|
||||
接下来介绍 **cpulimit** 命令的用法。 **cpulimit** 命令的工作原理是为进程预设一个 cpu 占用率门限,并实时监控进程是否超出此门限,若超出则让该进程暂停运行一段时间。cpulimit 使用 SIGSTOP 和 SIGCONT 这两个信号来控制进程。它不会修改进程的 nice 值,而是通过监控进程的 cpu 占用率来做出动态调整。
|
||||
|
||||
cpulimit 的优势是可以控制进程的cpu使用率的上限值。但与 nice 相比也有缺点,那就是即使 cpu 是空闲的,进程也不能完全使用整个 cpu 资源。
|
||||
|
||||
在 CentOS 上,可以用下面的方法来安装它:
|
||||
|
||||
wget -O cpulimit.zip https://github.com/opsengine/cpulimit/archive/master.zip
|
||||
unzip cpulimit.zip
|
||||
cd cpulimit-master
|
||||
make
|
||||
sudo cp src/cpulimit /usr/bin
|
||||
|
||||
上面的命令行,会先从从 GitHub 上将源码下载到本地,然后再解压、编译、并安装到 /usr/bin 目录下。
|
||||
|
||||
cpulimit 的使用方式和 nice 命令类似,但是需要用户使用 **-l** 选项显式地定义进程的 cpu 使用率上限值。举例说明:
|
||||
|
||||
cpulimit -l 50 matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||

|
||||
|
||||
从上面的例子可以看出 matho-primes 只使用了50%的 cpu 资源,剩余的 cpu 时间都在 idle。
|
||||
|
||||
cpulimit 还可以在运行时对进程进行动态限制,使用 **-p** 选项来指定进程的 PID,下面是一个实例:
|
||||
|
||||
cpulimit -l 50 -p 1234
|
||||
|
||||
其中,1234是进程的 PID。
|
||||
|
||||
### cgroups 命令集 ###
|
||||
|
||||
最后介绍,功能最为强大的控制组(cgroups)的用法。cgroups 是 Linux 内核提供的一种机制,利用它可以指定一组进程的资源分配。 具体来说,使用 cgroups,用户能够限定一组进程的 cpu 占用率、系统内存消耗、网络带宽,以及这几种资源的组合。
|
||||
|
||||
对比nice和cpulimit,**cgroups 的优势**在于它可以控制一组进程,不像前者仅能控制单进程。同时,nice 和 cpulimit 只能限制 cpu 使用率,而 cgroups 则可以限制其他进程资源的使用。
|
||||
|
||||
对 cgroups 善加利用就可以控制好整个子系统的资源消耗。就拿 CoreOS 作为例子,这是一个专为大规模服务器部署而设计的最简化的 Linux 发行版本,它的 upgrade 进程就是使用 cgroups 来管控。这样,系统在下载和安装升级版本时也不会影响到系统的性能。
|
||||
|
||||
下面做一下演示,我们将创建两个控制组(cgroups),并对其分配不同的 cpu 资源。这两个控制组分别命名为“cpulimited”和“lesscpulimited”。
|
||||
|
||||
使用 cgcreate 命令来创建控制组,如下所示:
|
||||
|
||||
sudo cgcreate -g cpu:/cpulimited
|
||||
sudo cgcreate -g cpu:/lesscpulimited
|
||||
|
||||
其中“-g cpu”选项用于设定 cpu 的使用上限。除 cpu 外,cgroups 还提供 cpuset、memory、blkio 等控制器。cpuset 控制器与 cpu 控制器的不同在于,cpu 控制器只能限制一个 cpu 核的使用率,而 cpuset 可以控制多个 cpu 核。
|
||||
|
||||
cpu 控制器中的 cpu.shares 属性用于控制 cpu 使用率。它的默认值是 1024,我们将 lesscpulimited 控制组的 cpu.shares 设为1024(默认值),而 cpulimited 设为512,配置后内核就会按照2:1的比例为这两个控制组分配资源。
|
||||
|
||||
要设置cpulimited 组的 cpu.shares 为 512,输入以下命令:
|
||||
|
||||
sudo cgset -r cpu.shares=512 cpulimited
|
||||
|
||||
使用 cgexec 命令来启动控制组的运行,为了测试这两个控制组,我们先用cpulimited 控制组来启动 matho-primes 进程,命令行如下:
|
||||
|
||||
sudo cgexec -g cpu:cpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
打开 top 可以看到,matho-primes 进程占用了所有的 cpu 资源。
|
||||
|
||||

|
||||
|
||||
因为只有一个进程在系统中运行,不管将其放到哪个控制组中启动,它都会尽可能多的使用cpu资源。cpu 资源限制只有在两个进程争夺cpu资源时才会生效。
|
||||
|
||||
那么,现在我们就启动第二个 matho-primes 进程,这一次我们在 lesscpulimited 控制组中来启动它:
|
||||
|
||||
sudo cgexec -g cpu:lesscpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
再打开 top 就可以看到,cpu.shares 值大的控制组会得到更多的 cpu 运行时间。
|
||||
|
||||

|
||||
|
||||
现在,我们再在 cpulimited 控制组中增加一个 matho-primes 进程:
|
||||
|
||||
sudo cgexec -g cpu:cpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||

|
||||
|
||||
看到没,两个控制组的 cpu 的占用率比例仍然为2:1。其中,cpulimited 控制组中的两个 matho-primes 进程获得的cpu 时间基本相当,而另一组中的 matho-primes 进程显然获得了更多的运行时间。
|
||||
|
||||
更多的使用方法,可以在 Red Hat 上查看详细的 cgroups 使用[说明][2]。(当然CentOS 7也有)
|
||||
|
||||
### 使用Scout来监控cpu占用率 ###
|
||||
|
||||
监控cpu占用率最为简单的方法是什么?[Scout][3] 工具能够监控能够自动监控进程的cpu使用率和内存使用情况。
|
||||
|
||||

|
||||
|
||||
[Scout][3]的触发器(trigger)功能还可以设定 cpu 和内存的使用门限,超出门限时会自动产生报警。
|
||||
|
||||
从这里可以获取 [Scout][4] 的试用版。
|
||||
|
||||
### 总结 ###
|
||||
|
||||

|
||||
|
||||
计算机的系统资源是非常宝贵的。上面介绍的这3个工具能够帮助大家有效地管理系统资源,特别是cpu资源:
|
||||
|
||||
- **nice**可以一次性调整进程的优先级。
|
||||
- **cpulimit**在运行cpu密集型任务且要保持系统的响应性时会很有用。
|
||||
- **cgroups**是资源管理的瑞士军刀,同时在使用上也很灵活。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.scoutapp.com/articles/2014/11/04/restricting-process-cpu-usage-using-nice-cpulimit-and-cgroups
|
||||
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.mathomatic.org/
|
||||
[2]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_and_Linux_Containers_Guide/chap-Introduction_to_Control_Groups.html
|
||||
[3]:https://scoutapp.com/
|
||||
[4]:https://scoutapp.com/
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,7 +1,6 @@
|
||||
用Grub启动ISO镜像
|
||||
================================================================================
|
||||
如果你需要使用多个Linux发行版,你没有那么多的选项。你可以安装到你的物理机或虚拟机中,也可以以live模式从ISO文件启动。第二个选择,如果对硬盘空间需求更少,就有点麻烦,因为你需要将ISO文件写入到USB棒或CD来启动。但是,这里有另外一个可选的折中方案:把ISO镜像放在硬盘中,然后以live模式来启动。该方案比完全安装更省空间,但是功能完备,这对于缓慢的虚拟机而言是个不错的替代方案。下面我将介绍怎样使用流行的Grub启动加载器来实现该方案。
|
||||
|
||||
如果你想要使用多个Linux发行版,你没有那么多的选择。你要么安装到你的物理机或虚拟机中,要么以live模式从ISO文件启动。第二个选择,对硬盘空间需求较小,只是有点麻烦,因为你需要将ISO文件写入到U盘或CD/DVD中来启动。不过,这里还有另外一个可选的折中方案:把ISO镜像放在硬盘中,然后以live模式来启动。该方案比完全安装更省空间,而且功能也完备,这对于缓慢的虚拟机而言是个不错的替代方案。下面我将介绍怎样使用流行的Grub启动加载器来实现该方案。
|
||||
|
||||
很明显,你将需要使用到Grub,这是几乎所有现代Linux发行版都使用的。你也需要你所想用的Linux版本的ISO文件,将它下载到本地磁盘。最后,你需要知道启动分区在哪里,并怎样在Grub中描述。对于此,请使用以下命令:
|
||||
|
||||
@ -31,7 +30,7 @@
|
||||
[some specific] arguments
|
||||
}
|
||||
|
||||
例如,如果你想要从ISO文件启动Ubuntu,那么你就是想要添加该行到40_custom文件:
|
||||
例如,如果你想要从ISO文件启动Ubuntu,那么你就是想要添加如下行到40_custom文件:
|
||||
|
||||
menuentry "Ubuntu 14.04 (LTS) Live Desktop amd64" {
|
||||
set isofile="/boot/ubuntu-14.04-desktop-amd64.iso"
|
||||
@ -62,7 +61,7 @@
|
||||
initrd (loop)/isolinux/initrd0.img
|
||||
}
|
||||
|
||||
注意,参数可根据发行版进行修改。有幸的是,有许多地方你可以查阅。我喜欢这一个,但是还有很多其它的。同时,请考虑你放置ISO文件的地方。如果你的家目录被加密或者无法被访问到,你可能更喜欢将这些文件放到像例子中的启动分区。但是,请首先确保有足够的空间。
|
||||
注意,参数可根据发行版进行修改。幸运的是,有许多地方你可以查阅到。我喜欢这个发行版,但是还有很多其它的发行版你可以启动。同时,请注意你放置ISO文件的地方。如果你的家目录被加密或者无法被访问到,你可能更喜欢将这些文件放到像例子中的启动分区。但是,请首先确保启动分区有足够的空间。
|
||||
|
||||
最后,不要忘了保存40_custom文件并使用以下命令来更新grub:
|
||||
|
||||
@ -92,7 +91,7 @@
|
||||
|
||||
可以显示DBAN选项,让你选择清除驱动器。**当心,因为它仍然十分危险**。
|
||||
|
||||
小结一下,对于ISO文件和Grub有很多事情可做:从快速live会话到用你的指尖来破坏一切,都可以满足你。下一步是启动一些关注隐私的发行版如[Tails][2]。
|
||||
小结一下,对于ISO文件和Grub有很多事情可做:从快速live会话到一键毁灭,都可以满足你。之后,你也可以试试启动一些针对隐私方面的发行版,如[Tails][2]。
|
||||
|
||||
你认为从Grub启动一个ISO这个主意怎样?这是不是你想要做的呢?为什么呢?请在下面留言。
|
||||
|
||||
@ -102,7 +101,7 @@ via: http://xmodulo.com/boot-iso-image-from-grub.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,30 +1,34 @@
|
||||
硬盘监控和分析神器——Smartctl
|
||||
硬盘监控和分析工具——Smartctl
|
||||
================================================================================
|
||||
**Smartctl**(自监控,分析和报告技术)是类Unix系统下实施SMART任务命令行套件或工具,它用于打印SMART**自检**和**错误日志**,启用并禁用SMRAT**自动检测**,以及初始化设备自检。
|
||||
**Smartctl**(S.M.A.R.T 自监控,分析和报告技术)是类Unix系统下实施SMART任务命令行套件或工具,它用于打印SMART**自检**和**错误日志**,启用并禁用SMRAT**自动检测**,以及初始化设备自检。
|
||||
|
||||
Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以对智能磁盘进行错误检查,并将与**硬件RAID**上相关的磁盘信息摘录下来。
|
||||
Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以对智能磁盘进行错误检查,并将与**硬件RAID**相关的磁盘信息摘录下来。
|
||||
|
||||
在本帖中,我们将讨论smartctl命令的一些实用样例。如果你的Linux上海没有安装smartctl,请按以下步骤来安装。
|
||||
|
||||
### Ubuntu中smartctl的安装 ###
|
||||
### 安装 Smartctl ###
|
||||
|
||||
**对于 Ubuntu**
|
||||
|
||||
$ sudo apt-get install smartmontools
|
||||
|
||||
### Redhat / CentOS中smartctl的安装 ###
|
||||
**对于 CentOS & RHEL**
|
||||
|
||||
# yum install smartmontools
|
||||
|
||||
**启动Smartctl服务**
|
||||
###启动Smartctl服务###
|
||||
|
||||
**对于Ubuntu**
|
||||
**对于 Ubuntu**
|
||||
|
||||
$ sudo /etc/init.d/smartmontools start
|
||||
|
||||
**对于CentOS & RHEL**
|
||||
**对于 CentOS & RHEL**
|
||||
|
||||
# service smartd start ; chkconfig smartd on
|
||||
|
||||
**样例:1 检查针对磁盘的Smart负载量**
|
||||
### 样例 ###
|
||||
|
||||
#### 样例:1 检查磁盘的 Smart 功能是否启用
|
||||
|
||||
root@linuxtechi:~# smartctl -i /dev/sdb
|
||||
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-3.13.0-32-generic] (local build)
|
||||
@ -46,9 +50,9 @@ Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以
|
||||
SMART support is: Available - device has SMART capability.
|
||||
SMART support is: Enabled
|
||||
|
||||
这里‘/dev/sdb’是你的硬盘。上面输出中的最后两行显示了SMART负载量已启用。
|
||||
这里‘/dev/sdb’是你的硬盘。上面输出中的最后两行显示了SMART功能已启用。
|
||||
|
||||
**样例:2 为磁盘启用Smart负载量**
|
||||
#### 样例:2 启用磁盘的 Smart 功能
|
||||
|
||||
root@linuxtechi:~# smartctl -s on /dev/sdb
|
||||
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-3.13.0-32-generic] (local build)
|
||||
@ -57,7 +61,7 @@ Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以
|
||||
=== START OF ENABLE/DISABLE COMMANDS SECTION ===
|
||||
SMART Enabled.
|
||||
|
||||
**样例:3 为磁盘禁用Smart负载量**
|
||||
#### 样例:3 禁用磁盘的 Smart 功能
|
||||
|
||||
root@linuxtechi:~# smartctl -s off /dev/sdb
|
||||
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-3.13.0-32-generic] (local build)
|
||||
@ -66,12 +70,12 @@ Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以
|
||||
=== START OF ENABLE/DISABLE COMMANDS SECTION ===
|
||||
SMART Disabled. Use option -s with argument 'on' to enable it.
|
||||
|
||||
**样例:4 为磁盘显示详细Smart信息**
|
||||
#### 样例:4 显示磁盘的详细 Smart 信息
|
||||
|
||||
root@linuxtechi:~# smartctl -a /dev/sdb // For IDE drive
|
||||
root@linuxtechi:~# smartctl -a -d ata /dev/sdb // For SATA drive
|
||||
|
||||
**样例:5 显示磁盘总体健康状况**
|
||||
#### 样例:5 显示磁盘总体健康状况
|
||||
|
||||
root@linuxtechi:~# smartctl -H /dev/sdb
|
||||
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-3.13.0-32-generic] (local build)
|
||||
@ -84,7 +88,7 @@ Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以
|
||||
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
|
||||
190 Airflow_Temperature_Cel 0x0022 067 045 045 Old_age Always In_the_past 33 (Min/Max 25/33)
|
||||
|
||||
**样例:6 使用long和short选项测试硬盘**
|
||||
#### 样例:6 使用long和short选项测试硬盘
|
||||
|
||||
**Long测试**
|
||||
|
||||
@ -126,7 +130,7 @@ Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以
|
||||
|
||||
**注意**:short测试将花费最多2分钟,而在long测试中没有时间限制,因为它会读取并验证磁盘的每个段。
|
||||
|
||||
**样例:7 查看驱动器的自检结果**
|
||||
#### 样例:7 查看驱动器的自检结果
|
||||
|
||||
root@linuxtechi:~# smartctl -l selftest /dev/sdb
|
||||
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-3.13.0-32-generic] (local build)
|
||||
@ -138,7 +142,7 @@ Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以
|
||||
# 1 Short offline Completed: read failure 90% 492 210841222
|
||||
# 2 Extended offline Completed: read failure 90% 492 210841222
|
||||
|
||||
**样例:8 计算测试时间估值**
|
||||
#### 样例:8 计算测试时间估值
|
||||
|
||||
root@linuxtechi:~# smartctl -c /dev/sdb
|
||||
smartctl 6.2 2013-07-26 r3841 [x86_64-linux-3.13.0-32-generic] (local build)
|
||||
@ -178,7 +182,7 @@ Smartctl对于Linux物理服务器十分有用,在这些服务器上,可以
|
||||
SCT Feature Control supported.
|
||||
SCT Data Table supported.
|
||||
|
||||
**样例:9 显示磁盘错误日志**
|
||||
#### 样例:9 显示磁盘错误日志
|
||||
|
||||
root@linuxtechi:~# smartctl -l error /dev/sdb
|
||||
|
||||
@ -219,7 +223,7 @@ via: http://www.linuxtechi.com/smartctl-monitoring-analysis-tool-hard-drive/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -13,7 +13,7 @@ Postfix邮件服务器的配置与安全加固
|
||||
service sendmail stop
|
||||
yum remove sendmail
|
||||
|
||||
Postfix包含了**两个配置文件main.cf和master.cf**,对于基本的配置,你需要修改main.cf。同时,postfix可以像shell变量一样定义参数,并通过美元符号来调用。这些参数不需要再使用前定义,Postfix只在运行中需要时才会查询某个参数。
|
||||
Postfix包含了**两个配置文件main.cf和master.cf**,对于基本的配置,你需要修改main.cf。同时,postfix可以像shell变量一样定义参数,并通过$来调用。这些参数不需要再使用前定义,Postfix只在运行中需要时才会查询某个参数。
|
||||
|
||||
### 配置postfix ###
|
||||
|
||||
@ -21,23 +21,23 @@ Postfix包含了**两个配置文件main.cf和master.cf**,对于基本的配
|
||||
|
||||
去掉以下行的注释
|
||||
|
||||
#Add the hostname of your machine
|
||||
# 你的主机名
|
||||
myhostname = yourhostname.com
|
||||
|
||||
#From Domain to be used when mail is sent from this linux machine
|
||||
# 你的发件域
|
||||
myorigin = $myhostname
|
||||
|
||||
#The network interface to receive mail on, I prefer localhost as I only want emails from this system to be delivered
|
||||
# 指定用于接收邮件的网络接口,这里指定 localhost 是因为我们只用来接受本地的程序投递
|
||||
inet_interfaces = localhost
|
||||
|
||||
# The protocol to use when postfix will make or accept a connection. You can use “all” if you want to enable IPv6 support
|
||||
# 指定所使用的协议,可以使用“all”来增加 IPv6 支持
|
||||
inet_protocols = ipv4
|
||||
|
||||
|
||||
#Domains to receive email for
|
||||
# 指定所接受的邮件域
|
||||
mydestination = $myhostname, localhost.$mydomain, localhost
|
||||
|
||||
#Only forward emails for the local machine and not machines on the network.
|
||||
# 仅转发本地主机的邮件,而不是主机所在的网络
|
||||
mynetworks_style = host
|
||||
|
||||
启动postfix
|
||||
@ -48,13 +48,13 @@ Postfix包含了**两个配置文件main.cf和master.cf**,对于基本的配
|
||||
|
||||
echo test mail | mail -s "test" leo@techarena51.com && sudo tail -f /var/log/maillog
|
||||
|
||||
#Logs should output the following
|
||||
# 输出的日志类似如下
|
||||
Aug 25 14:16:21 vps postfix/smtp[32622]: E6A372DC065D: to=, relay=smtp.mailserver.org[50.56.21.176], delay=0.8, delays=0.1/0/0.43/0.27, dsn=2.0.0, status=sent (250 Great success)
|
||||
Aug 25 14:16:21 vps postfix/qmgr[5355]: E6A372DC065D: removed
|
||||
|
||||
但是,上述配置并不够,因为邮件服务大多数时候都会被垃圾邮件挤满,你需要添加SPF、PTR和DKIM记录。你的邮件仍然可能被当作垃圾邮件来投递,因为你的IP地址被列入了黑名单,大多数时候是因为你的vps先前被入侵了。
|
||||
但是,上述配置并不够,因为邮件服务大多数时候都会被垃圾邮件挤满,你需要添加SPF、PTR和DKIM记录。即便如此,你的邮件仍然可能被当作垃圾邮件来投递,因为你的IP地址被列入了黑名单,大多数时候是因为你的vps先前被入侵了。
|
||||
|
||||
另外一种选择,或者说是更好的方式是使用第三方邮件提供商提供的邮件服务,如Gmail,或者甚至是Mailgun。我使用Mailgun,因为它们提供了每个月10000封免费电子邮件,而Gmail则提供了每天100封左右的邮件。
|
||||
还有另外一种选择,或者说是更好的方式是使用第三方邮件提供商提供的邮件服务,如Gmail,或者甚至是Mailgun。我使用Mailgun,因为它们提供了每个月10000封免费电子邮件,而Gmail则提供了每天100封左右的邮件。
|
||||
|
||||
在“/etc/postfix/main.cf”中,你需要添加“smtp.mailgun.com”作为你的“转发主机”,并启用“SASL”验证,这样postfix就可以连接并验证到远程Mailgun服务器。
|
||||
|
||||
@ -77,21 +77,21 @@ Postfix本身不会实施“SASL”验证,因此你需要安装“cyrus-sasl-p
|
||||
|
||||
### 使用TLS加固Postfix安全 ###
|
||||
|
||||
Postfix支持TLS,它是SSL的后继者,允许你使用基于密钥的验证来加密数据。我推荐你阅读http://www.postfix.org/TLS_README.html,以了解tls是怎么和postfix一起工作的。
|
||||
Postfix支持TLS,它是SSL的后继者,允许你使用基于密钥的验证来加密数据。我推荐你阅读 http://www.postfix.org/TLS_README.html ,以了解TLS是怎么和postfix一起工作的。
|
||||
|
||||
为了使用TLS,你需要生成一个私钥和一个由证书授权机构颁发的证书。在本例中,我将使用自颁发的证书。
|
||||
|
||||
sudo yum install mod_ssl openssl
|
||||
# Generate private key
|
||||
# 生成私钥
|
||||
openssl genrsa -out smtp.key 2048
|
||||
|
||||
# Generate CSR
|
||||
# 生成 CSR
|
||||
openssl req -new -key smtp.key -out smtp.csr
|
||||
|
||||
# Generate Self Signed Key
|
||||
# 生成自签名的钥匙
|
||||
openssl x509 -req -days 365 -in smtp.csr -signkey smtp.key -out smtp.crt
|
||||
|
||||
# Copy the files to the correct locations
|
||||
# 将文件复制到正确的位置
|
||||
cp smtp.crt /etc/pki/tls/certs
|
||||
cp smtp.key /etc/pki/tls/private/smtp.key
|
||||
cp smtp.csr /etc/pki/tls/private/smtp.csr
|
||||
@ -109,10 +109,10 @@ Postfix支持TLS,它是SSL的后继者,允许你使用基于密钥的验证
|
||||
smtp_tls_CAfile = /etc/ssl/certs/ca.crt
|
||||
smtp_tls_loglevel = 1
|
||||
|
||||
安全级别“may”意味着宣告对远程SMTP客户端上的STARTTLS的支持,但是客户端不需要使用加密。我在这里用它作为每个[mailgun文档][1],但是如果你想要强制使用TLS加密,可以使用“encrypt”。
|
||||
安全级别“may”意味着宣告对远程SMTP客户端上的STARTTLS的支持,但是客户端不需要使用加密。我在这里按照[mailgun文档][1]提示使用“may”,但是如果你想要强制使用TLS加密,可以使用“encrypt”。
|
||||
|
||||
service postfix restart
|
||||
#Send a test email
|
||||
# 发送一封测试邮件
|
||||
echo test mail | mail -s "test" test@yourdomain.com && sudo tail -f /var/log/maillog
|
||||
|
||||
你应该会看到以下信息
|
||||
@ -122,7 +122,7 @@ Postfix支持TLS,它是SSL的后继者,允许你使用基于密钥的验证
|
||||
|
||||
如果一切正常,你可以注释掉以下参数。
|
||||
|
||||
“smtp_tls_loglevel = 1”
|
||||
“smtp\_tls\_loglevel = 1”
|
||||
|
||||
对于故障排除,我推荐你阅读[Postfix小建议和排障命令][2]
|
||||
|
||||
@ -132,7 +132,7 @@ via: http://techarena51.com/index.php/configure-secure-postfix-email-server/
|
||||
|
||||
作者:[Leo G][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,17 +2,17 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
我上网时最担心的一件事情是,我该如何确保我的数据安全和隐私。在搜索答案的过程中,我找到了很多保持匿名的方法,比如使用代理网站。但是使用第三方的服务不能完全保证。我需要的是有一款软件可以我自己安装并运行,那样我就能确保只有我才能访问数据。
|
||||
我上网时最担心的一件事情是,我该如何确保我的数据安全和隐私。在搜索答案的过程中,我找到了很多保持匿名的方法,比如使用代理网站。但是使用第三方的服务不能完全保证。我需要的是有一款软件可以让我自己安装并运行,那样我就能确保只有我才能访问数据。
|
||||
|
||||
这款软件叫什么呢?
|
||||
|
||||
它叫VPN服务,就是虚拟隐私网络的简称。它允许访问时通过SSL加密你的数据。因为是加密的连接,所以你的ISP不能看到你的浏览信息。
|
||||
|
||||
在本篇Linux教程中,我会在CentOS 7上安装一个OpenVPN服务。OpenVPN很容易使用,开源且拥有基于社区的支持。它的客户端有Windows、Android和Mac。
|
||||
在本篇Linux教程中,我会在CentOS 7上安装一个OpenVPN服务。OpenVPN很容易使用,开源且拥有社区的支持。它的客户端支持Windows、[Android][1]和Mac。
|
||||
|
||||
### 第一步: 在你的Linux机器或者 [VPS][1]上安装OpenVPN服务 ###
|
||||
### 第一步: 在你的Linux机器或者 VPS 上安装OpenVPN服务 ###
|
||||
|
||||
从https://openvpn.net/index.php/access-server/download-openvpn-as-sw.html下载安装包,Ubuntu用户也可以找到合适的安装包并安装。
|
||||
从 https://openvpn.net/index.php/access-server/download-openvpn-as-sw.html 下载安装包,Ubuntu用户也可以找到合适的安装包并安装。
|
||||
|
||||
[leo@vps ]$ cd /tmp
|
||||
[leo@vps tmp]$ wget http://swupdate.openvpn.org/as/openvpn-as-2.0.10-CentOS7.x86_64.rpm
|
||||
@ -61,11 +61,10 @@ via: http://techarena51.com/index.php/how-to-install-an-opensource-vpn-server-on
|
||||
|
||||
作者:[Leo G][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://techarena51.com/
|
||||
[1]:https://play.google.com/store/apps/details?id=net.openvpn.openvpn&hl=en
|
||||
[2]:http://supportinc.net/vps-hosting.php
|
||||
[3]:https://openvpn.net/index.php/access-server/docs/admin-guides-sp-859543150/howto-connect-client-configuration.html
|
||||
@ -0,0 +1,186 @@
|
||||
10个重要的Linux ps命令实战
|
||||
================================================================================
|
||||
Linux作为Unix的衍生操作系统,Linux内建有查看当前进程的工具。这个工具能在命令行中使用。
|
||||
|
||||
### PS 命令是什么 ###
|
||||
|
||||
查看它的man手册可以看到,ps命令能够给出当前系统中进程的快照。它能捕获系统在某一事件的进程状态。如果你想不断更新查看的这个状态,可以使用top命令。
|
||||
|
||||
ps命令支持三种使用的语法格式
|
||||
|
||||
1. UNIX 风格,选项可以组合在一起,并且选项前必须有“-”连字符
|
||||
2. BSD 风格,选项可以组合在一起,但是选项前不能有“-”连字符
|
||||
3. GNU 风格的长选项,选项前有两个“-”连字符
|
||||
|
||||
我们能够混用这几种风格,但是可能会发生冲突。本文使用 UNIX 风格的ps命令。这里有在日常生活中使用较多的ps命令的例子。
|
||||
|
||||
### 1. 不加参数执行ps命令 ###
|
||||
|
||||
这是一个基本的 **ps** 使用。在控制台中执行这个命令并查看结果。
|
||||
|
||||

|
||||
|
||||
结果默认会显示4列信息。
|
||||
|
||||
- PID: 运行着的命令(CMD)的进程编号
|
||||
- TTY: 命令所运行的位置(终端)
|
||||
- TIME: 运行着的该命令所占用的CPU处理时间
|
||||
- CMD: 该进程所运行的命令
|
||||
|
||||
这些信息在显示时未排序。
|
||||
|
||||
### 2. 显示所有当前进程 ###
|
||||
|
||||
使用 **-a** 参数。**-a 代表 all**。同时加上x参数会显示没有控制终端的进程。
|
||||
|
||||
$ ps -ax
|
||||
|
||||
这个命令的结果或许会很长。为了便于查看,可以结合less命令和管道来使用。
|
||||
|
||||
$ ps -ax | less
|
||||
|
||||

|
||||
|
||||
### 3. 根据用户过滤进程 ###
|
||||
|
||||
在需要查看特定用户进程的情况下,我们可以使用 **-u** 参数。比如我们要查看用户'pungki'的进程,可以通过下面的命令:
|
||||
|
||||
$ ps -u pungki
|
||||
|
||||

|
||||
|
||||
### 4. 通过cpu和内存使用来过滤进程 ###
|
||||
|
||||
也许你希望把结果按照 CPU 或者内存用量来筛选,这样你就找到哪个进程占用了你的资源。要做到这一点,我们可以使用 **aux 参数**,来显示全面的信息:
|
||||
|
||||
$ ps -aux | less
|
||||
|
||||

|
||||
|
||||
当结果很长时,我们可以使用管道和less命令来筛选。
|
||||
|
||||
默认的结果集是未排好序的。可以通过 **--sort**命令来排序。
|
||||
|
||||
根据 **CPU 使用**来升序排序
|
||||
|
||||
$ ps -aux --sort -pcpu | less
|
||||
|
||||

|
||||
|
||||
根据 **内存使用** 来升序排序
|
||||
|
||||
$ ps -aux --sort -pmem | less
|
||||
|
||||

|
||||
|
||||
我们也可以将它们合并到一个命令,并通过管道显示前10个结果:
|
||||
|
||||
$ ps -aux --sort -pcpu,+pmem | head -n 10
|
||||
|
||||
### 5. 通过进程名和PID过滤 ###
|
||||
|
||||
使用 **-C 参数**,后面跟你要找的进程的名字。比如想显示一个名为getty的进程的信息,就可以使用下面的命令:
|
||||
|
||||
$ ps -C getty
|
||||
|
||||

|
||||
|
||||
如果想要看到更多的细节,我们可以使用-f参数来查看格式化的信息列表:
|
||||
|
||||
$ ps -f -C getty
|
||||
|
||||

|
||||
|
||||
### 6. 根据线程来过滤进程 ###
|
||||
|
||||
如果我们想知道特定进程的线程,可以使用**-L 参数**,后面加上特定的PID。
|
||||
|
||||
$ ps -L 1213
|
||||
|
||||

|
||||
|
||||
### 7. 树形显示进程 ###
|
||||
|
||||
有时候我们希望以树形结构显示进程,可以使用 **-axjf** 参数。
|
||||
|
||||
$ps -axjf
|
||||
|
||||

|
||||
|
||||
或者可以使用另一个命令。
|
||||
|
||||
$ pstree
|
||||
|
||||

|
||||
|
||||
### 8. 显示安全信息 ###
|
||||
|
||||
如果想要查看现在有谁登入了你的服务器。可以使用ps命令加上相关参数:
|
||||
|
||||
$ ps -eo pid,user,args
|
||||
|
||||
**参数 -e** 显示所有进程信息,**-o 参数**控制输出。**Pid**,**User 和 Args**参数显示**PID,运行应用的用户**和**该应用**。
|
||||
|
||||

|
||||
|
||||
能够与**-e 参数** 一起使用的关键字是**args, cmd, comm, command, fname, ucmd, ucomm, lstart, bsdstart 和 start**。
|
||||
|
||||
### 9. 格式化输出root用户(真实的或有效的UID)创建的进程 ###
|
||||
|
||||
系统管理员想要查看由root用户运行的进程和这个进程的其他相关信息时,可以通过下面的命令:
|
||||
|
||||
$ ps -U root -u root u
|
||||
|
||||
**-U 参数**按真实用户ID(RUID)筛选进程,它会从用户列表中选择真实用户名或 ID。真实用户即实际创建该进程的用户。
|
||||
|
||||
**-u** 参数用来筛选有效用户ID(EUID)。
|
||||
|
||||
最后的**u**参数用来决定以针对用户的格式输出,由**User, PID, %CPU, %MEM, VSZ, RSS, TTY, STAT, START, TIME 和 COMMAND**这几列组成。
|
||||
|
||||
这里有上面的命令的输出结果:
|
||||
|
||||

|
||||
|
||||
### 10. 使用PS实时监控进程状态 ###
|
||||
|
||||
ps 命令会显示你系统当前的进程状态,但是这个结果是静态的。
|
||||
|
||||
当有一种情况,我们需要像上面第四点中提到的通过CPU和内存的使用率来筛选进程,并且我们希望结果能够每秒刷新一次。为此,我们可以**将ps命令和watch命令结合起来**。
|
||||
|
||||
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu’
|
||||
|
||||

|
||||
|
||||
如果输出太长,我们也可以限制它,比如前20条,我们可以使用**head**命令来做到。
|
||||
|
||||
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu | head 20’
|
||||
|
||||

|
||||
|
||||
这里的动态查看并不像top或者htop命令一样。**但是使用ps的好处是**你能够定义显示的字段,你能够选择你想查看的字段。
|
||||
|
||||
举个例子,**如果你只需要看名为'pungki'用户的信息**,你可以使用下面的命令:
|
||||
|
||||
$ watch -n 1 ‘ps -aux -U pungki u --sort -pmem, -pcpu | head 20’
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
你也许每天都会使用ps命令来监控你的Linux系统。但是事实上,你可以通过ps命令的参数来生成各种你需要的报表。
|
||||
|
||||
ps命令的另一个优势是ps是各种 Linux系统都默认安装的,因此你只要用就行了。
|
||||
|
||||
不要忘了通过 man ps来查看更多的参数。(LCTT 译注:由于 ps 命令古老而重要,所以它在不同的 UNIX、BSD、Linux 等系统中的参数不尽相同,因此如果你用的不是 Linux 系统,请查阅你的文档了解具体可用的参数。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/linux-ps-command-examples/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[johnhoow](https://github.com/johnhoow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
@ -2,39 +2,27 @@
|
||||
================================================================================
|
||||
今天我们将会向你展示如何使用 **lsblk** 和 **blkid** 工具来查找关于块设备的信息,我们使用的是一台安装了 CentOS 7.0 的机器。
|
||||
|
||||
## lsblk ##
|
||||
|
||||
**lsblk** 是一个 Linux 工具,它会显示有关你系统里所有可用块设备的信息。它从 [sysfs 文件系统][1] 中获取信息。默认情况下,这个工具将会以树状格式显示(除了内存虚拟磁盘外的)所有块设备。
|
||||
|
||||
### lsblk 默认输出 ###
|
||||
|
||||
默认情况下 lsblk 会将块设备输出为树状格式:
|
||||
|
||||
**NAME**
|
||||
- **NAME** —— 设备的名称
|
||||
|
||||
—— 设备的名称
|
||||
- **MAJ:MIN** —— Linux 操作系统中的每个设备都以一个文件表示,对块(磁盘)设备来说,这里用主次设备编号来描述设备。
|
||||
|
||||
**MAJ:MIN**
|
||||
- **RM** —— 可移动设备。如果这是一个可移动设备将显示 1,否则显示 0。
|
||||
|
||||
—— Linux 操作系统中的每个设备都以一个文件表示,对块(磁盘)设备来说,这里用主次设备编号来描述设备。
|
||||
- **TYPE** —— 设备的类型
|
||||
|
||||
**RM**
|
||||
- **MOUNTPOINT** —— 设备挂载的位置
|
||||
|
||||
—— 可移动设备。如果这是一个可移动设备将显示 1,否则显示 0。
|
||||
- **RO** —— 对于只读文件系统,这里会显示 1,否则显示 0。
|
||||
|
||||
**TYPE**
|
||||
|
||||
—— 设备的类型
|
||||
|
||||
**MOUNTPOINT**
|
||||
|
||||
—— 设备挂载的位置
|
||||
|
||||
**RO**
|
||||
|
||||
—— 对于只读文件系统,这里会显示 1,否则显示 0。
|
||||
|
||||
**SIZE**
|
||||
|
||||
—— 设备的容量
|
||||
- **SIZE** —— 设备的容量
|
||||
|
||||

|
||||
|
||||
@ -54,12 +42,14 @@
|
||||
|
||||
### 在脚本中使用 ###
|
||||
|
||||
高级技巧:如果你想要在脚本中使用而不希望表头被显示出来,你可以这样使用 -n 选项:
|
||||
高级技巧:如果你想要在脚本中使用而希望剔除表头,你可以这样使用 -n 选项:
|
||||
|
||||
lsblk -ln
|
||||
|
||||

|
||||
|
||||
## blkid ##
|
||||
|
||||
**blkid** 命令是一个命令行工具,它可以显示关于可用块设备的信息。它可以识别一个块设备内容的类型(如文件系统、交换区)以及从内容的元数据(如卷标或 UUID 字段)中获取属性(如 tokens 和键值对)。它主要有两类作用:用指定的键值对搜索一个设备,或是显示一个或多个设备的键值对。
|
||||
|
||||
### blkid 使用方法 ###
|
||||
@ -84,7 +74,7 @@
|
||||
|
||||
### 详细信息 ###
|
||||
|
||||
如果你想要获取更多详细信息,你可以使用 -p 和 -o udev 选项来将它们用漂亮的格式显示出来,像这样:
|
||||
如果你想要获取更多详细信息,你可以使用 -p 和 -o udev 选项来将它们用整齐的格式显示出来,像这样:
|
||||
|
||||
# blkid -po udev /dev/sda1
|
||||
|
||||
@ -102,7 +92,7 @@ via: http://linoxide.com/linux-command/linux-command-lsblk-blkid/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,37 +1,40 @@
|
||||
四招搞定Linux内核热补丁
|
||||
不重启不当机!Linux内核热补丁的四种技术
|
||||
================================================================================
|
||||

|
||||
Credit: Shutterstock
|
||||
|
||||
多种技术在竞争成为实现inux内核热补丁的最优方案。
|
||||
供图: Shutterstock
|
||||
|
||||
有多种技术在竞争成为实现Linux内核热补丁的最优方案。
|
||||
|
||||
没人喜欢重启机器,尤其是涉及到一个内核问题的最新补丁程序。
|
||||
为达到不重启的目的,目前有3个项目在朝这方面努力,将为大家提供对内核进行运行时打热补丁的机制,这样就可以做到完全不重启机器。
|
||||
|
||||
为达到不重启的目的,目前有3个项目在朝这方面努力,将为大家提供内核升级时打热补丁的机制,这样就可以做到完全不重启机器。
|
||||
|
||||
### Ksplice项目 ###
|
||||
|
||||
首先要介绍的项目是Ksplice,它是热补丁技术的创始者,并于2008年建立了与项目同名的公司。Ksplice在替换新内核时,不需要预先修改;只需要一个diff文件,将内核的修改点列全即可。Ksplice公司免费提供软件,但技术支持是需要收费的,目前能够支持大部分常用的Linux发行版本。
|
||||
首先要介绍的项目是Ksplice,它是热补丁技术的创始者,并于2008年建立了与项目同名的公司。Ksplice在替换新内核时,不需要预先修改;只需要一个diff文件,列出内核即将接受的修改即可。Ksplice公司免费提供软件,但技术支持是需要收费的,目前能够支持大部分常用的Linux发行版本。
|
||||
|
||||
但在2011年[Oracle收购了这家公司][1]后,情况发生了变化。 这项功能被合入到Oracle的Linux发行版本中,且只对Oralcle的版本提供技术更新。 这就导致,其他内核hacker们开始寻找替代Ksplice的方法,以避免缴纳Oracle税。
|
||||
但在2011年[Oracle收购了这家公司][1]后,情况发生了变化。 这项功能被合入到Oracle自己的Linux发行版本中,只对Oralcle自己提供技术更新。 这就导致,其他内核hacker们开始寻找替代Ksplice的方法,以避免缴纳Oracle税。
|
||||
|
||||
### Kgraft项目 ###
|
||||
|
||||
2014年2月,Suse提供了一个很好的解决方案:[Kgraft][2],该技术以GPLv2/GPLv3混合许可证发布,且Suse不会将其作为一个专有的实现。Kgraft被[提交][3]到Linux内核主线,很有可能被内核主线采用。目前Suse已经把此技术集成到[Suse Linux Enterprise Server 12][4]。
|
||||
2014年2月,Suse提供了一个很好的解决方案:[Kgraft][2],该内核更新技术以GPLv2/GPLv3混合许可证发布,且Suse不会将其作为一个专有发明封闭起来。Kgraft被[提交][3]到Linux内核主线,很有可能被内核主线采用。目前Suse已经把此技术集成到[Suse Linux Enterprise Server 12][4]。
|
||||
|
||||
Kgraft和Ksplice在工作原理上很相似,都是使用一组diff文件来计算内核中需要修改的部分。但与Ksplice不同的是,Kgraft在做替换时,不需要完全停止内核。 在打补丁时,正在运行的函数可以先使用老版本中对应的部分,当补丁打完后就可以切换新的版本。
|
||||
Kgraft和Ksplice在工作原理上很相似,都是使用一组diff文件来计算内核中需要修改的部分。但与Ksplice不同的是,Kgraft在做替换时,不需要完全停止内核。 在打补丁时,正在运行的函数可以先使用老版本或新内核中对应的部分,当补丁打完后就可以完全切换新的版本。
|
||||
|
||||
### Kpatch项目 ###
|
||||
|
||||
Red Hat也提出了他们的内核热补丁技术。同样是在今年年初 -- 与Suse在这方面的工作差不多 -- [Kpatch][5]的工作原理也和Kgraft相似。
|
||||
Red Hat也提出了他们的内核热补丁技术。同样是在2014年初 -- 与Suse在这方面的工作差不多 -- [Kpatch][5]的工作原理也和Kgraft相似。
|
||||
|
||||
主要的区别点在于,正如Red Hat的Josh Poimboeuf[总结][6]的那样,Kpatch不能将内核调用重定向到老版本。相反,它会等待所有函数调用都停止时,再切换到新内核。Red Hat的工程师认为这种方法更为安全,且更容易维护,缺点就是在打补丁的过程中会带来更大的延迟。
|
||||
主要的区别点在于,正如Red Hat的Josh Poimboeuf[总结][6]的那样,Kpatch并不将内核调用重定向到老版本。相反,它会等待所有函数调用都停止时,再切换到新内核。Red Hat的工程师认为这种方法更为安全,且更容易维护,缺点就是在打补丁的过程中会带来更大的延迟。
|
||||
|
||||
和Kgraft一样,Kpatch不仅仅能在Red Hat的发行版本上可以使用,同时也被提交到了内核主线,作为一个可能的候选。 坏消息是Red Hat还未将此技术集成到产品中。 它只是被合入到了Red Hat Enterprise Linux 7的技术预览版中。
|
||||
和Kgraft一样,Kpatch不仅仅可以在Red Hat的发行版本上使用,同时也被提交到了内核主线,作为一个可能的候选。 坏消息是Red Hat还未将此技术集成到产品中。 它只是被合入到了Red Hat Enterprise Linux 7的技术预览版中。
|
||||
|
||||
### ...也许 Kgraft + Kpatch更合适? ###
|
||||
|
||||
Red Hat的工程师Seth Jennings在2014年11月初,提出了[第四种解决方案][7]。将Kgraft和Kpatch结合起来, 补丁包用这两种方式都可以。在新的方法中,Jennings提出,“热补丁核心为其他内核模块提供了热补丁的注册机制”, 通过这种方法,打补丁的过程 -- 更准确的说,如何处理运行时内核调用 --可以被更加有序的进行。
|
||||
Red Hat的工程师Seth Jennings在2014年11月初,提出了[第四种解决方案][7]。将Kgraft和Kpatch结合起来, 补丁包用这两种方式都可以。在新的方法中,Jennings提出,“热补丁核心为其他内核模块提供了一个热补丁的注册接口”, 通过这种方法,打补丁的过程 -- 更准确的说,如何处理运行时内核调用 --可以被更加有序的组织起来。
|
||||
|
||||
这项新建议也意味着两个方案都还需要更长的时间,才能被linux内核正式采纳。尽管Suse步子迈得更快,并把Kgraft应用到了最新的enterprise版本中。让我们也关注一下Red Hat和Linux官方近期的动态。
|
||||
这项新建议也意味着两个方案都还需要更长的时间,才能被linux内核正式采纳。尽管Suse步子迈得更快,并把Kgraft应用到了最新的enterprise版本中。让我们也关注一下Red Hat和Canonical近期是否会跟进。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -40,7 +43,7 @@ via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-fo
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[tinyeyeser](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -51,4 +54,4 @@ via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-fo
|
||||
[4]:http://www.infoworld.com/article/2838421/linux/suse-linux-enterprise-12-goes-light-on-docker-heavy-on-reliability.html
|
||||
[5]:https://github.com/dynup/kpatch
|
||||
[6]:https://lwn.net/Articles/597123/
|
||||
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||
@ -1,38 +1,39 @@
|
||||
How to install Cacti (Monitoring tool) on ubuntu 14.10 server
|
||||
怎样在 Ubuntu 14.10 Server 上安装 Cacti(监控工具)
|
||||
怎样在 Ubuntu 14.10 Server 上安装 Cacti
|
||||
================================================================================
|
||||
Cacti 是一个网络绘图解决方案,它被设计用来管理 RRDTool (一个 Linux 数据存储和绘图工具)的数据存储和绘图的强大功能。Cacti 提供一个快速的轮询器,高级的绘图模版,多种数据获取方法和用户管理功能,并且可以开箱即用。所有的这些都被打包进一个直观,易用的界面,可用于监控简单的 LAN 网络,乃至包含成百上千设备的复杂网络。
|
||||
|
||||
Cacti 是一个完善的网络监控的图形化解决方案,它被设计用来发挥 RRDTool (一个 Linux 数据存储和绘图工具)的数据存储和绘图的强大功能。Cacti 提供一个快速的轮询器,高级的绘图模版,多种数据获取方法和用户管理功能,并且可以开箱即用。所有的这些都被打包进一个直观,易用的界面,可用于监控简单的 LAN 网络,乃至包含成百上千设备的复杂网络。
|
||||
|
||||
### 功能 ###
|
||||
|
||||
#### 绘图 ####
|
||||
|
||||
无上限的监控图条目(graph item),每个图形可以视情况使用 Cacti 中的 CDEFs (Calculation Define,可以对图形输出结果进行计算)或者数据源。
|
||||
没有数量限制的监控图条目(graph item),每个图形可以视情况使用 Cacti 中的 CDEFs (Calculation Define,可以对图形输出结果进行计算)或者数据源。
|
||||
|
||||
自动将 GPRINT 条目分组至 AREA,STACK 和 LINE[1-3] 中,可以对图形进行快速重排序。
|
||||
自动将 GPRINT 条目分组至 AREA,STACK 和 LINE[1-3] 中,来对监控图条目进行快速重排序。
|
||||
|
||||
自动填充功能使得图形的说明整齐排列。
|
||||
自动填充功能支持整齐排列图形内的说明项。
|
||||
|
||||
可以使用 RRDTool 中内置的 CDEF 数学函数对图形数据进行处理。这些 CDEF 函数可以定义在 Cacti 中,并且每一个图形都可以使用它们。
|
||||
|
||||
支持所有的 RRDTool 图形类型包括 AREA,STACK,LINE[1-3],GPRINT,COMMENT,VRULE 和 HRULE。
|
||||
支持所有的 RRDTool 图形类型,包括 AREA,STACK,LINE[1-3],GPRINT,COMMENT,VRULE 和 HRULE。
|
||||
|
||||
#### 数据源 ####
|
||||
|
||||
数据源可以使用 RRDTool 的 "create" 和 "update" 功能创建。每一个数据源可以用来收集本地或者远程的数据,并将数据输出给图形。
|
||||
数据源可以使用 RRDTool 的 "create" 和 "update" 功能创建。每一个数据源可以用来收集本地或者远程的数据,并将数据输出成图形。
|
||||
|
||||
支持包含多个数据源的 RRD 文件,并可以使用存储在本地文件系统中任何位置的 RRD 文件。
|
||||
可以自定义轮询归档(RRA)设置,用户可以在存储数据时使用非标准的时间间隔(标准时间间隔是5分钟,30分钟,2小时 和 1天)。
|
||||
|
||||
可以自定义轮询归档(RRA)设置,用户可以在存储数据时使用非标准的时间间隔(标准时间间隔是5分钟,30分钟,2小时和 1天)。
|
||||
|
||||
#### 数据收集 ####
|
||||
|
||||
Cacti 包含一个 "data input" 机制,可以让用户定义自定义的脚本用来收集数据。每个脚本可以包含调用参数,每次创建调用此脚本的数据源时输入相应的调用参数(如 IP 地址)。
|
||||
Cacti 包含一个 "data input" 机制,可以让用户定义自定义的脚本用来收集数据。每个脚本可以包含调用参数,每次调用此脚本的创建数据源时必须输入相应的调用参数(如 IP 地址)。
|
||||
|
||||
支持 SNMP 功能,可以使用 php-snmp,ucd-snmp 或者 net-snmp。
|
||||
|
||||
可以基于索引来使用 SNMP 或者脚本收集数据。例如,可以列出一个服务器上所有网卡接口或者已挂载分区的索引列表。集成的绘图模版可以用来一键为主机创建图形。
|
||||
可以基于索引来使用 SNMP 或者脚本收集数据。例如,可以列出一个服务器上所有网卡接口或者已挂载分区的索引列表。其集成的绘图模版可以用来为主机一键创建图形。
|
||||
|
||||
提供一个基于 PHP 的轮询器用于执行脚本,收集 SNMP数据并更新数据至 RRD 文件中。
|
||||
提供了一个基于 PHP 的轮询器执行脚本,可以收集 SNMP数据并更新数据至 RRD 文件中。
|
||||
|
||||
#### 模版 ####
|
||||
|
||||
@ -44,7 +45,7 @@ Cacti 包含一个 "data input" 机制,可以让用户定义自定义的脚本
|
||||
|
||||
#### 图形展示 ####
|
||||
|
||||
图形树允许用户创建「图形层次结构」并将图形放至树中。这种方法可以方便的管理大量图形。
|
||||
图形树模式允许用户创建「图形层次结构」并将图形放至树中。这种方法可以方便的管理大量图形。
|
||||
|
||||
列表模式将所有图形的链接在一个大列表中展示出来,链接指向用户创建的图形。
|
||||
|
||||
@ -55,7 +56,10 @@ Cacti 包含一个 "data input" 机制,可以让用户定义自定义的脚本
|
||||
用户管理功能允许管理员创建用户并分配给用户访问 Cacti 接口的不同级别的权限。
|
||||
|
||||
权限可以为每个用户指定其对每个图形的权限,这适用于主机租用的场景。
|
||||
|
||||
每个用户可以保存他自己的图形显示模式。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
#### 系统准备 ####
|
||||
|
||||
@ -123,7 +127,7 @@ via: http://www.ubuntugeek.com/how-to-install-cacti-monitoring-tool-on-ubuntu-14
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[Liao](https://github.com/liaoishere)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,17 +2,18 @@ Linux 下五款出色的流媒体客户端
|
||||
================================================================================
|
||||
数字流媒体这几天几乎占据了我音乐收听的全部时间。近年来我为了收藏 CD 花费了数量可观的费用;但它们中的大部分现在正静静地躺在满是灰尘的角落里。基本上所有的音乐流媒体服务所提供的的音质都不如 CD 的,但它们受欢迎的原因很大程度上在于其便捷性,而非高度保真的音质再现。音乐流媒体不仅造成了 CD 销量的大幅减少;也使数字音乐的下载开始缓慢下滑。这种趋势还会继续下去。音乐发烧友现在或许也想要拥抱音乐流媒体服务了,某些音乐流媒体服务商如 Tidal 提供了无损的音乐流媒体服务,其中包含了 25 万首比特率为 1411kbps 的 FLAC 格式的音乐。
|
||||
|
||||
尽管 CD 暂时不会消失,但音乐流媒体服务商却无法协调和那些不满从音乐托管服务中收取的租金的唱片公司及音乐家之间的问题。这一切仍然处于变化之中;我们看到了今年 Led Zeppelin, Pink Floyd, Metallica 签名支持流媒体服务,但仍然有部分知名的老牌乐队如 Beatles, Radiohead 以及 AC/DC 拒绝将自己的作品放到流媒体上供粉丝收听。即使当某个唱片公司或者音乐家已经授权给流媒体服务商访问自己的作品,但只要音乐家发表声明就可以在第一时间将其作品从流媒体服务下架。本月(2014 年 11 月),Taylor Swift 请求将她的所有音乐作品从 Spotify 的流媒体服务下架。有些人还是更偏向于“拥有”他们的音乐,但这看起来像是一种快要过时了的欣赏音乐的方式。
|
||||
尽管 CD 暂时不会消失,但音乐流媒体服务商却无法调和那些不满从音乐托管服务中收取的租金的唱片公司及音乐家之间的问题。这一切仍然处于变化之中;我们看到了今年 Led Zeppelin, Pink Floyd, Metallica 签名支持流媒体服务,但仍然有部分知名的老牌乐队如 Beatles, Radiohead 以及 AC/DC 拒绝将自己的作品放到流媒体上供粉丝收听。即使当某个唱片公司或者音乐家已经授权给流媒体服务商访问自己的作品,但只要音乐家发表声明就可以在第一时间将其作品从流媒体服务下架。本月(2014 年 11 月),Taylor Swift 请求将她的所有音乐作品从 Spotify 的流媒体服务下架。有些人还是更偏向于“拥有”他们的音乐,但这看起来像是一种快要过时了的欣赏音乐的方式。
|
||||
|
||||
使用 Linux 平台来收听流媒体音乐服务的方法已经逐渐成熟。在 Linux 平台下,你可以找到许多客户端,通过它们你可以使用大部分的音乐流媒体服务;我希望 TIDAL 能在今后合适的时候发行 Linux 桌面客户端,而不是仅仅依赖 web 播放器。本文精选的这些应用都是非常出色的。另外 Amarok,pianobar 还有 Tomahawk 也表现得很不错。
|
||||
|
||||

|
||||
### Spotify
|
||||
|
||||

|
||||
|
||||
Spotify 是一种专有的 P2P 音乐流媒体服务,允许用户收听点播曲目或专辑。Spotify 将自己描述为“音乐圣殿。快捷、简易、免费的服务”。Spotify 分别为普通的移动端和桌面端用户提供了 96kbps 和 160kbps 比特率的流媒体服务,并且为高级用户提供了 Ogg Vorbis 格式的 320kbps 比特率的流媒体服务。Spotify 为普通用户提供了免费但是有广告的服务,以及无广告的订阅账户服务。
|
||||
|
||||
Spotify 是很奇妙的服务,向用户们提供了涵盖各种类型的数量众多的音乐,如:流行乐、另类摇滚、古典乐、铁克诺电音、摇滚乐等。这是发现新音乐的好方法。Spotify 得到了包括 Sony BMG,EMI,Universal 以及 Warner Music 在内的主流唱片公司,以及 Labrador Records,The Orchard,Alligator Records,Merlin,CD Baby,INgrooves 等独立唱片唱片公司和分销网络,甚至 Chandos,Naxos,EMI Classic,Warner Classics,Denon Essentials 这些古典唱片公司的支持,还有更多的公司在这里就不一一列举了。
|
||||
|
||||
Spotify 的音乐涵盖范围还在继续以惊人的步伐扩张着。
|
||||
|
||||
Spotify 现在并没有发行官方版的 Linux 客户端。不过,开发团队已经推出了针对 Linux 的客户端预览版,并且表现得还不错。因为仍然是预览版,所以没有得到官方的支持。
|
||||
@ -34,9 +35,8 @@ Spotify 流媒体服务现已支持以下地区/国家:安道尔,阿根廷
|
||||
- 许可证:专有许可证
|
||||
- 当前版本:预览版
|
||||
|
||||
----------
|
||||
|
||||

|
||||
### Pithos
|
||||
|
||||

|
||||
|
||||
@ -69,9 +69,8 @@ Pandora 音乐服务只能通过美国的 IP 地址使用。不过,非美国
|
||||
- 许可证:GNU GPL v3
|
||||
- 当前版本:1.0.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
### Clementine
|
||||
|
||||

|
||||
|
||||
@ -80,6 +79,7 @@ Clementine 基于 Amarok 开发,是一款跨平台的轻量级现代化音乐
|
||||
Clementine 在 Amarok 1.4 的基础上开发。
|
||||
|
||||
**特色包括:**
|
||||
|
||||
- 检索、播放本地音乐库
|
||||
- 从 Last.fm 和 SomaFM 收听互联网电台
|
||||
- 标签式播放列表,支持导入导出 M3U,XSPF,PLS 及 ASX 格式的播放列表
|
||||
@ -110,9 +110,8 @@ Clementine 在 Amarok 1.4 的基础上开发。
|
||||
- 许可证:GNU GPL v3
|
||||
- 当前版本:1.2
|
||||
|
||||
----------
|
||||
|
||||

|
||||
### Nuvola Player
|
||||
|
||||

|
||||
|
||||
@ -151,9 +150,8 @@ Nuvola Player 是一个免费的开源项目,能够整合云端音乐到你的
|
||||
- 许可证:2-Clause BSD license
|
||||
- 当前版本:2.4.3
|
||||
|
||||
----------
|
||||
|
||||

|
||||
### Atraci
|
||||
|
||||

|
||||
|
||||
@ -185,7 +183,7 @@ via: http://www.linuxlinks.com/article/20141116052055674/MusicStreaming.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
如何在Ubuntu上使用MultiSystem创建多启动USB
|
||||
如何在Ubuntu上使用MultiSystem创建多启动USB盘
|
||||
================================================================================
|
||||
|
||||
### 介绍 ###
|
||||
|
||||
一些人并不知道**MultiSystem**是一个小型的开源软件来在Linux系统中创建多启动usb盘。使用这个工具,我们可以在USB中创建任意多的可启动Linux发行版。你所要的只是网络链接(之在MultiSystem安装的时候需要),以及一个足够大的USB盘,这取决于你想在USB盘中放入发行版的数量。
|
||||
也许还有不少人不知道**MultiSystem**,它是一个用来在Linux系统中创建多启动usb盘的小型的开源软件。使用这个工具,我们可以在USB中创建任意多的可启动Linux发行版。你所需要的只是网络链接(只在MultiSystem安装的时候需要),以及一个足够大的USB盘,这取决于你想在USB盘中放入发行版的数量。
|
||||
|
||||
### 在 Ubuntu 14.10/14.04 安装MultiSystem ###
|
||||
|
||||
@ -14,18 +15,18 @@
|
||||
|
||||
#### 使用 PPA 安装: ####
|
||||
|
||||
相应地,你可以用下面的命令来更简单地使用PPA来安装MultiSystem。
|
||||
当然,你也可以用下面的命令来更简单地使用PPA来安装MultiSystem。
|
||||
|
||||
sudo apt-add-repository 'deb http://liveusb.info/multisystem/depot all main'
|
||||
wget -q -O - http://liveusb.info/multisystem/depot/multisystem.asc | sudo apt-key add -
|
||||
sudo apt-get update
|
||||
sudo apt-get install multisystem
|
||||
|
||||
安装玩之后,它会自动打开。只要点击关闭按钮退出。
|
||||
安装完之后,它会自动打开MultiSystem。只要点击关闭按钮退出。
|
||||
|
||||
### 安装之后 ###
|
||||
|
||||
安装完成后,插入你的USB,并通过Unity Dash或者菜单运行MultiSystem。
|
||||
MultiSystem 安装完成后,可以插入你的USB,并通过Unity Dash或者菜单运行MultiSystem。
|
||||
|
||||

|
||||
|
||||
@ -33,7 +34,7 @@
|
||||
|
||||

|
||||
|
||||
选择USB设备,点击**确认**按钮。你可能会看到下面的错误窗口。不必担心,它说的是USB设备没有标签。点击OK让MultiSystem自动设置标签。
|
||||
选择USB设备,点击**确认**按钮。如果你看到下面的错误窗口,不必担心,它说的是USB设备没有标签。点击OK让MultiSystem自动设置标签。
|
||||
|
||||

|
||||
|
||||
@ -47,7 +48,7 @@
|
||||
|
||||
### 使用 ###
|
||||
|
||||
MultiSystem非常容易使用。将ISO文件拖入MultiSystem窗口中。如果这不能用,点击底部的**cd 按钮**来选择ISO文件。
|
||||
MultiSystem非常容易使用。将ISO文件拖入MultiSystem窗口中。如果不行的话,点击底部的**cd 按钮**来选择ISO文件。
|
||||
|
||||

|
||||
|
||||
@ -65,24 +66,24 @@ MultiSystem非常容易使用。将ISO文件拖入MultiSystem窗口中。如果
|
||||
|
||||

|
||||
|
||||
额外地,MultiSystem含有一些额外的选项:
|
||||
此外,MultiSystem含有一些其它的选项:
|
||||
|
||||
- Grub 设置;
|
||||
- Grub 和 Burg 的bootloader更新;
|
||||
- 下载 LiveCD;
|
||||
- VirtualBox 安装;
|
||||
- 格式化USB盘;
|
||||
- 还有更多选项。
|
||||
- Grub 设置
|
||||
- Grub 和 Burg 的bootloader更新
|
||||
- 下载 LiveCD
|
||||
- VirtualBox 安装
|
||||
- 格式化USB盘
|
||||
- 还有更多选项
|
||||
|
||||
要浏览额外的选项列表,进入MultiSystem的**菜单**标签。
|
||||
这些额外选项可以在MultiSystem的**菜单**标签里面看到。
|
||||
|
||||

|
||||
|
||||
同样,你可以在Ubuntu中使用QEMU或者Oracle VirtualBox测试多启动USB盘。
|
||||
同样,你也可以在Ubuntu中使用QEMU或者Oracle VirtualBox测试多启动USB盘。
|
||||
|
||||

|
||||
|
||||
MultiSystem工具是我测试到现在最棒和最有用的一款工具。这款工具对那些想要在他们的机器上安装多个系统的人是非常有用的。在你外出的时候,你不必再携带CD/DVD袋了。只要买一个16GB或者32GB的USB就行,并把所有你想要的系统都放在里面,就像老板一样安装系统。
|
||||
MultiSystem工具是我测试到现在最棒和最有用的一款工具。这款工具对那些想要在他们的机器上安装多个系统的人是非常有用的。在你外出的时候,你不必再携带CD/DVD袋了。只要买一个16GB或者32GB的USB就行,并下载所有你想要的系统,随心所欲的安装系统即可。
|
||||
|
||||
并且,一个对于Windows系统用户的好消息是它也支持Windows系统。我在Windows 7上测试过,它可以工作!
|
||||
|
||||
@ -94,7 +95,7 @@ via: http://www.unixmen.com/create-multiboot-usb-ubuntu-using-multisystem/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
如何手动删除Oracle 11g数?据库
|
||||
如何手动删除Oracle 11g数据库
|
||||
================================================================================
|
||||
下面的步骤会家你如何在Linux环境下手动删除Oracle 11g数据库。
|
||||
下面的步骤会教你如何在Linux环境下手动删除Oracle 11g数据库。
|
||||
|
||||
我在Centos 6上安装了Oralce 11G数据库。
|
||||
|
||||
@ -15,7 +15,7 @@
|
||||
|
||||
**在SQL*Plus中关闭数据库,接着退出SQL*Plus**
|
||||
|
||||
sqlplus " / as sysdba'
|
||||
sqlplus "/ as sysdba"
|
||||
|
||||
----------
|
||||
|
||||
@ -26,7 +26,7 @@
|
||||
|
||||
在Oralce Linux账户中:
|
||||
|
||||
lsnrctl stop
|
||||
lsnrctl stop
|
||||
|
||||
回忆一下之前的文件路径;在删除这些文件的时候作为一个检查项。记住:你备份了数据库了么?当准备好之后,就删除你的数据文件吧,同样还有你的日志文件、控制文件和临时文件。
|
||||
|
||||
@ -44,7 +44,7 @@ via: http://www.unixmen.com/manually-delete-oracle-11g-database/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,29 +1,29 @@
|
||||
如何从终端以后台模式运行Linux程序
|
||||
如何在终端下以后台模式运行Linux程序
|
||||
===
|
||||
|
||||

|
||||
|
||||
Linux终端窗口。
|
||||
*Linux终端窗口*
|
||||
|
||||
这是一个简短但是非常有用的教程:它向你展示从终端运行Linux应用程序的同时,如何保证终端仍然在控制之中。
|
||||
这是一个简短但是非常有用的教程:它向你展示从终端运行Linux应用程序的同时,如何保证终端仍然可以操作。
|
||||
|
||||
在Linux中有许多方式可以打开一个终端,这主要取决于你分类的选择和桌面环境。
|
||||
在Linux中有许多方式可以打开一个终端,这主要取决于你的发行版的选择和桌面环境。
|
||||
|
||||
使用Ubuntu,你可以使用CTRL + ALT + T组合键打开一个终端。你也可以点击超级键(Windows键)打开一个终端窗口。在键盘上,[打开Ubuntu Dash][1],然后搜索"TERM"。点击"Term"图标将会打开一个终端窗口。
|
||||
使用Ubuntu的话,你可以使用CTRL + ALT + T组合键打开一个终端。你也可以点击超级键(Windows键)打开一个终端窗口。在键盘上,[打开Ubuntu Dash][1],然后搜索"TERM"。点击"Term"图标将会打开一个终端窗口。
|
||||
|
||||
其他诸如XFCE, KDE, LXDE, Cinnamon和MATE的桌面环境,你将会在菜单中发现终端。还有一些分类会把终端图标放在入口处,或者在面板上放置终端启动器。
|
||||
其他诸如XFCE, KDE, LXDE, Cinnamon和MATE的桌面环境,你将会在菜单中发现“终端”这个应用。还有一些发行版会把终端图标放在菜单项,或者在面板上放置终端启动器。
|
||||
|
||||
你可以在终端输入一个程序的名字来启动一个应用。举例,你可以通过输入"firefox"启动火狐浏览器。
|
||||
你可以在终端里面输入一个程序的名字来启动一个应用。举例,你可以通过输入"firefox"启动火狐浏览器。
|
||||
|
||||
从终端运行程序的好处是一可以包含额外的选项。
|
||||
从终端运行程序的好处是可以使用额外的选项。
|
||||
|
||||
举个例子,如果你输入下面的命令,一个新的火狐浏览器将会打开,而且默认的搜索引擎将会搜索引用之间的术语:
|
||||
举个例子,如果你输入下面的命令,一个新的火狐浏览器将会打开,而且默认的搜索引擎将会搜索引号之间的词语:
|
||||
|
||||
firefox -search "Linux.About.Com"
|
||||
|
||||
你会发现,如果你运行火狐浏览器,应用程序将被打开,并且控制将会回到终端,这将意味着你可以继续在终端工作。
|
||||
你会发现,如果你运行火狐浏览器,应用程序打开后,控制权将会回到终端(重新出现了命令提示符),这将意味着你可以继续在终端工作。
|
||||
|
||||
通常情况下,如果你通过终端运行一个程序,程序将被打开,并且直到那个程序关闭结束,你将不会重新获得终端的控制权。这是因为你是在前台打开程序的。
|
||||
通常情况下,如果你通过终端运行一个程序,程序打开后,并且直到那个程序关闭结束,你都将不会获得终端的控制权。这是因为你是在前台打开程序的。
|
||||
|
||||
想要从终端运行一个程序,并且立即将终端的控制权返回给你,你需要以后台进程的方式打开程序。
|
||||
|
||||
@ -31,11 +31,11 @@ Linux终端窗口。
|
||||
|
||||
libreoffice &
|
||||
|
||||
在终端中仅仅提供程序的名字,应用程序可能运行不了。如果程序不存在于一个设置了路径变量的文件夹中,你需要指定完成的路径名来运行程序。
|
||||
在终端中仅仅提供程序的名字,应用程序可能运行不了。如果程序不存在于一个设置在PATH 环境变量的文件夹中,你需要指定完整的路径名来运行程序。
|
||||
|
||||
/path/to/yourprogram &
|
||||
|
||||
如果你并不确定一个程序是否存在于Linux文件结构,使用find或者locate命令来查询应用程序。
|
||||
如果你并不确定一个程序是否存在于Linux文件系统中,使用find或者locate命令来查找该应用程序。
|
||||
|
||||
找一个文件的语法如下:
|
||||
|
||||
@ -45,7 +45,7 @@ Linux终端窗口。
|
||||
|
||||
find / -name firefox
|
||||
|
||||
输出会很快掠过,所以你可以以管道的方式控制输出的多少:
|
||||
输出会很快滚动出很多,所以你可以以管道的方式控制输出的多少:
|
||||
|
||||
find / -name firefox | more
|
||||
|
||||
@ -57,26 +57,25 @@ find命令将会返回因权限拒绝而发生错误的文件夹数量,这些
|
||||
|
||||
sudo find / -name firefox | more
|
||||
|
||||
如果你知道你想寻找的文件在你的当前文件夹结构中,你可以一个点代替先前的斜线,如下:
|
||||
如果你知道你想寻找的文件在你的当前文件夹中,你可以一个点代替先前的斜线,如下:
|
||||
|
||||
sudo find . -name firefox | more
|
||||
|
||||
你可能不需要sudo来提升权限。如果你在home文件夹结构中寻找文件,sudo就不需要。
|
||||
你可能不需要sudo来提升权限。如果你在home文件夹中寻找文件,sudo就不需要。
|
||||
|
||||
一些应用程序需要提升用户权限来运行,你可能得到一个缺少权限的错误,除非你使用一个具有足够权限的用户,或者使用sudo提升你的权限。
|
||||
|
||||
下面是一个小花招。如果你运行一个程序,而且它需要提升权限来运行,输入下面命令:
|
||||
下面是一个小花招。如果你运行一个程序,而且它需要提升权限来运行,输入下面命令来提升权限重新执行:
|
||||
|
||||
sudo !!
|
||||
|
||||
---
|
||||
|
||||
via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-T
|
||||
he-Terminal-In-Background-Mode.htm
|
||||
via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-The-Terminal-In-Background-Mode.htm
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中>
|
||||
国](http://linux.cn/) 荣誉推出
|
||||
@ -1,24 +1,22 @@
|
||||
10个检测Linux内存使用情况的‘free’命令
|
||||
检测 Linux 内存使用情况的 free 命令的10个例子
|
||||
===
|
||||
|
||||
**Linux**是最有名的开源操作系统之一,它拥有着极其巨大的指令集。确定**物理内存**和**交换内存**所有可用空间的最重要,也是唯一的方法是使用“**free**”命令。
|
||||
**Linux**是最有名的开源操作系统之一,它拥有着极其巨大的命令集。确定**物理内存**和**交换内存**所有可用空间的最重要、也是唯一的方法是使用“**free**”命令。
|
||||
|
||||
Linux “**free**”命令通过给出**Linux/Unix**操作系统中内核已使用的**buffers**情况,来提供**物理内存**和**交换内存**的总使用量和可用量。
|
||||
Linux “**free**”命令可以给出类**Linux/Unix**操作系统中**物理内存**和**交换内存**的总使用量、可用量及内核使用的**缓冲区**情况。
|
||||
|
||||

|
||||
|
||||
这篇文章提供一些带有参数选项的“**free**”命令,这些命令对于你更好地利用你的内存会有帮助。
|
||||
这篇文章提供一些各种参数选项的“**free**”命令,这些命令对于你更好地利用你的内存会有帮助。
|
||||
|
||||
### 1. 显示你的系统内存 ###
|
||||
|
||||
free命令用于检测**物理内存**和**交换内存**已使用量和可用量(单位为**KB**)。下面演示命令的使用情况。
|
||||
free命令用于检测**物理内存**和**交换内存**已使用量和可用量(默认单位为**KB**)。下面演示命令的使用情况。
|
||||
|
||||
# free
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912548 109080 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912548 109080 0 120368 655548
|
||||
-/+ buffers/cache: 136632 884996
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
@ -28,21 +26,18 @@ ed
|
||||
|
||||
# free -b
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1046147072 934420480 111726592 0 123256832 6712811
|
||||
52
|
||||
total used free shared buffers cached
|
||||
Mem: 1046147072 934420480 111726592 0 123256832 671281152
|
||||
-/+ buffers/cache: 139882496 906264576
|
||||
Swap: 4294959104 0 4294959104
|
||||
|
||||
### 3. 以千字节为单位显示内存 ###
|
||||
|
||||
加上**-k**参数的free命令,以(KB)**千字节**为单位显示内存大小。
|
||||
加上**-k**参数的free命令(默认单位,所以可以不用使用它),以(KB)**千字节**为单位显示内存大小。
|
||||
|
||||
# free -k
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
-/+ buffers/cache: 136604 885024
|
||||
Swap: 4194296 0 4194296
|
||||
@ -53,10 +48,8 @@ ed
|
||||
|
||||
# free -m
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 997 891 106 0 117 6
|
||||
40
|
||||
total used free shared buffers cached
|
||||
Mem: 997 891 106 0 117 640
|
||||
-/+ buffers/cache: 133 864
|
||||
Swap: 4095 0 4095
|
||||
|
||||
@ -66,8 +59,7 @@ ed
|
||||
|
||||
# free -g
|
||||
total used free shared buffers cached
|
||||
Mem: 0 0 0 0 0
|
||||
0
|
||||
Mem: 0 0 0 0 0 0
|
||||
-/+ buffers/cache: 0 0
|
||||
Swap: 3 0 3
|
||||
|
||||
@ -77,10 +69,8 @@ ed
|
||||
|
||||
# free -t
|
||||
|
||||
total used free shared buffers cache
|
||||
d
|
||||
Mem: 1021628 912520 109108 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
-/+ buffers/cache: 136604 885024
|
||||
Swap: 4194296 0 4194296
|
||||
Total: 5215924 912520 4303404
|
||||
@ -91,10 +81,8 @@ d
|
||||
|
||||
# free -o
|
||||
|
||||
total used free shared buffers cache
|
||||
d
|
||||
Mem: 1021628 912520 109108 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
### 8. 定期时间间隔更新内存状态 ###
|
||||
@ -103,10 +91,8 @@ d
|
||||
|
||||
# free -s 5
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912368 109260 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912368 109260 0 120368 655548
|
||||
-/+ buffers/cache: 136452 885176
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
@ -116,10 +102,8 @@ ed
|
||||
|
||||
# free -l
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912368 109260 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912368 109260 0 120368 655548
|
||||
Low: 890036 789064 100972
|
||||
High: 131592 123304 8288
|
||||
-/+ buffers/cache: 136452 885176
|
||||
@ -139,7 +123,7 @@ via: http://www.tecmint.com/check-memory-usage-in-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中>
|
||||
国](http://linux.cn/) 荣誉推出
|
||||
@ -1,10 +1,10 @@
|
||||
在Ubuntu上找出可用的网络适配器
|
||||
如何在Ubuntu上找出可用的网络适配器
|
||||
================================================================================
|
||||
想知道**在Linux中你正在使用的网卡是什么吗?** 在Linux中很容易就找出网卡的生产商。打开一个终端并输入下面的额命令:
|
||||
|
||||
sudo lshw -C network
|
||||
|
||||
如果上面的命令不能在sudo下使用,那就移除sudo。它的输出看上去有点奇怪但是很有用。
|
||||
如果上面的命令不能在sudo下使用,那就别用 sudo 的特权模式。它的输出看上去有点奇怪但是很有用。
|
||||
|
||||

|
||||
|
||||
@ -36,7 +36,7 @@
|
||||
>
|
||||
> resources: irq:18 memory:b0600000-b0607fff memory:b0400000-b05fffff
|
||||
|
||||
如你所见,我Macbook Air上的无线网卡是BCM4360,这是一款在Ubuntu下面经常无法检测无线网络的很容易出问题的网卡。
|
||||
如你所见,我Macbook Air上的无线网卡是BCM4360,这是一款在Ubuntu下面很容易出现无法检测无线网络问题的网卡。
|
||||
|
||||
[lshw][1] 命令实际上死用来列出硬件的,因此命令的名字是lshw。带上网络的选项后,就会只过滤出网络硬件了。
|
||||
|
||||
@ -82,7 +82,7 @@
|
||||
>
|
||||
> 04:00.0 SATA controller: Marvell Technology Group Ltd. 88SS9183 PCIe SSD Controller (rev 14)
|
||||
|
||||
这些命令会同时列出有线和无线的网卡。你应该注意到上面的输出中显示我的系统中没有有线网卡。因为我使用的是Macbook Air,他没有以太网端口
|
||||
这些命令会同时列出有线和无线的网卡。你应该注意到上面的输出中显示我的系统中没有有线网卡。因为我使用的是Macbook Air,它没有以太网端口
|
||||
|
||||
我希望这边文章可以帮助你找到你系统中的网卡。欢迎提出问题和建议。
|
||||
|
||||
@ -92,7 +92,7 @@ via: http://itsfoss.com/find-network-adapter-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,28 +1,29 @@
|
||||
在 Mac OS X 系统中创建可启动的 Ubuntu USB 驱动盘
|
||||
在 Mac OS X 系统中创建用于 Mac 的 Ubuntu USB 启动盘
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
上个月,在戴尔的服务中心丢失我的笔记本后,我买了一台 Macbook Air 笔记本。买回来后我首先做的一些事就是给机器装上双系统,使 Ubuntu Linux 和 Mac OS X 都可用。随后的文章我会介绍如何在 Macbook 上安装 Linux ,刚开始我们需要学习 **如何在 Mac 的 OS X 系统中创建可启动的 Ubuntu USB 驱动盘**。
|
||||
上个月,在戴尔的服务中心丢失我的笔记本后,我买了一台 Macbook Air 笔记本。买回来后我首先做的一些事就是给机器装上双系统,使 Ubuntu Linux 和 Mac OS X 都可用。随后的文章我会介绍如何在 Macbook 上安装 Linux ,刚开始我们需要学习 **如何在 Mac OS X 系统中创建用于 Mac 的 Ubuntu USB 启动盘**。
|
||||
|
||||
在 Ubuntu 系统或 Windows 系统中创建可启动的 USB 是非常容易的,但在 Mac OS X 系统中就没这么简单了。这就是为什么 Ubuntu 的官方指南上,在 Mac 中安装 live Ubuntu 推荐使用磁盘安装而不是 USB 的原因。考虑到我的 Macbook Air 既没有 CD 驱动也没有 DVD 驱动,所以我更愿意在 Mac OS X 下创建一个 live USB.
|
||||
在 Ubuntu 系统或 Windows 系统中创建可启动的 USB 是非常容易的,但在 Mac OS X 系统中就没这么简单了。这就是为什么 Ubuntu 的官方指南上,在 Mac 中安装 live Ubuntu 推荐使用光盘安装而不是 USB 的原因。考虑到我的 Macbook Air 既没有 CD 驱动也没有 DVD 驱动,所以我更愿意在 Mac OS X 下创建一个 live USB。
|
||||
|
||||
### 在 Mac OS X 下创建可启动 USB 驱动盘###
|
||||
|
||||
如前所述,在 Mac OS X 上创建对于像 Ubuntu 或任何其它可引导的操作系统这样的可启动 USB 盘是个极其麻烦的过程。但请别担心,按照下面的步骤一步一步操作就行。让我们就开始创建一个可启动的 USB 盘的操作吧:
|
||||
如前所述,在 Mac OS X 上创建对于像 Ubuntu 或任何其它可引导的操作系统这样的可启动 USB 盘是个比较麻烦的过程。但请别担心,按照下面的步骤一步一步操作就行。让我们就开始创建一个可启动的 USB 盘的操作吧:
|
||||
|
||||
#### 步骤 1: 格式化 USB 驱动盘 ####
|
||||
|
||||
苹果是以它自定义的标准而闻名的,所以 Mac OS X 系统有自己的文件系统类型就好不奇怪了,它的文件系统叫做 Mac OS 扩展或 [HFS 插件][1]。因此,您需要做的第一件事就是用 Mac OS 扩展文件系统来格式化您的 USB 驱动盘。
|
||||
苹果是以它自定义的标准而闻名的,所以 Mac OS X 系统有自己的文件系统类型就毫不奇怪了,它的文件系统叫做 Mac OS 扩展或 [HFS 插件][1]。因此,您需要做的第一件事就是用 Mac OS 扩展文件系统来格式化您的 USB 驱动盘。
|
||||
|
||||
要格式化 USB 盘,插入 USB 钥匙链。从 Launchpad(在底部面板上的一个火箭形状的图标)上前往**磁盘工具**应用程序。
|
||||
要格式化 USB 盘,请先插入 USB 盘。从 Launchpad(在底部面板上的一个火箭形状的图标)上前往**磁盘工具**应用程序。
|
||||
|
||||

|
||||
|
||||
- 在磁盘工具中,从左手边的面板上选择 USB 驱动盘来格式化。
|
||||
- 在磁盘工具中,从左手边的面板上选择你的 USB 盘来格式化。
|
||||
- 点击右边面板的**分区**标签。
|
||||
- 从下拉菜单中,选择 **1 分区**。
|
||||
- 给这驱动盘起个您想要的名字。
|
||||
- 接下来,切换来**格式化成 Mac OS 扩展 (日志型)**
|
||||
- 接下来,切换分区格式为**格式化成 Mac OS 扩展 (日志型)**
|
||||
|
||||
下面的截屏将会对您有所帮助。
|
||||
|
||||
@ -32,7 +33,7 @@
|
||||
|
||||

|
||||
|
||||
当所有的都已经设置完了后,仅仅只需点击**应用**按纽。它会弹出一个要格式化 USB 驱动盘的警告消息,当然是要点击分区按纽来格式化 USB 驱动盘拉。
|
||||
当所有都已经设置完了后,仅仅只需点击**应用**按纽。它会弹出一个要格式化 USB 驱动盘的警告消息,当然是要点击分区按纽来格式化 USB 驱动盘拉。
|
||||
|
||||
#### 步骤 2: 下载 Ubuntu ####
|
||||
|
||||
@ -50,15 +51,15 @@
|
||||
|
||||

|
||||
|
||||
您可能已经注意到我并没有新转换出的文件加上 IMG 后缀。这是没问题的,因为后缀只是个标志,它代表的是文件类型并不是文件的扩展名。转换出来的文件可能会被 Mac OS X 系统自动加上个 .dmg 后缀。别担心,这是正常的。
|
||||
您可能已经注意到我并没有新转换出的文件加上 IMG 后缀。这是没问题的,因为后缀只是个标志,重要的是文件类型并不是文件的扩展名。转换出来的文件可能会被 Mac OS X 系统自动加上个 .dmg 后缀。别担心,这是正常的。
|
||||
|
||||
#### 步骤 4: 获得 USB 驱动盘的设备号 ####
|
||||
#### 步骤 4: 获得 USB 盘的设备号 ####
|
||||
|
||||
接下来的事情就是获得 USB 驱动盘的设备号。在终端中运行如下命令:
|
||||
接下来的事情就是获得 USB 盘的设备号。在终端中运行如下命令:
|
||||
|
||||
diskutil list
|
||||
|
||||
它会列出系统中当前可用的所有‘磁盘’信息。从它的大小上您应该能识别出此 USB 驱动盘。为了避免混淆,我建议您只插入一个 USB 盘。我的示例中,设置号是 2 (一个大小为 8G 的 USB): /dev/disk2
|
||||
它会列出系统中当前可用的所有‘磁盘’信息。从它的大小上您应该能识别出此 USB 盘。为了避免混淆,我建议您只插入一个 USB 盘。我的示例中,设置号是 2 (一个大小为 8G 的 USB): /dev/disk2
|
||||
|
||||

|
||||
|
||||
@ -110,11 +111,11 @@ N 当然指的是我们前面使用过的设备号,在我的示例中是 2 :
|
||||
|
||||
diskutil eject /dev/disk2
|
||||
|
||||
一旦弹出,点击前面出现那对话框上的**忽略**按纽。现在您的可启动 USB 磁盘已经创建好了,把它从系统中移除。
|
||||
一旦弹出,点击前面出现那对话框上的**忽略**按纽。现在您的可启动 USB 磁盘已经创建好了,把它拔下来吧。
|
||||
|
||||
#### 步骤 7: 检查您新创建的可启动 USB 盘 ####
|
||||
|
||||
一旦您在 Mac OS X 中完成了创建一个 live USB 这么重大的任务,是时候测试您的幸成果了。
|
||||
一旦您在 Mac OS X 中完成了创建一个 live USB 这么重大的任务,是时候测试您的新成果了。
|
||||
|
||||
- 插入可启动 USB 盘,重启系统。
|
||||
- 在苹果启动的时候,一直按着 option (或 alt)键。
|
||||
@ -128,7 +129,7 @@ N 当然指的是我们前面使用过的设备号,在我的示例中是 2 :
|
||||
|
||||

|
||||
|
||||
我希望这篇教程对您想要在 Mac OS X 下创建可启动的 Ubuntu 系统 USB 驱动盘。在接下来的一篇文章中您会学到怎么样安装 OS X 和 Ubuntu 双系统。请继续关注。
|
||||
我希望这篇教程对您想要在 Mac OS X 下创建可启动的 Ubuntu 系统 USB 驱动盘有所帮助。在接下来的一篇文章中您会学到怎么样安装 OS X 和 Ubuntu 双系统。请继续关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -136,7 +137,7 @@ via: http://itsfoss.com/create-bootable-ubuntu-usb-drive-mac-os/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -11,9 +11,9 @@ Jetty被广泛用于多种项目和产品,都可以在开发环境和生产环
|
||||
- 灵活和可扩展
|
||||
- 小足迹
|
||||
- 可嵌入
|
||||
- 异步
|
||||
- 异步支持
|
||||
- 企业弹性扩展
|
||||
- Apache和Eclipse双重许可
|
||||
- Apache和Eclipse双重许可证
|
||||
|
||||
### ubuntu 14.10 server上安装Jetty 9 ###
|
||||
|
||||
@ -71,10 +71,9 @@ Java将会安装到/usr/lib/jvm/java-8-openjdk-i386,同时在该目录下会
|
||||
|
||||
#### ** ERROR: JETTY_HOME not set, you need to set it or install in a standard location ####
|
||||
|
||||
你需要确保在/etc/default/jetty文件中设置了正确的Jetty家目录路径,
|
||||
你可以使用以下URL来测试jetty
|
||||
你需要确保在/etc/default/jetty文件中设置了正确的Jetty家目录路径,你可以使用以下URL来测试jetty。
|
||||
|
||||
Jetty现在应该运行在8085端口,打开浏览器并访问http://serverip:8085,你应该可以看到Jetty屏幕。
|
||||
Jetty现在应该运行在8085端口,打开浏览器并访问http://服务器IP:8085,你应该可以看到Jetty屏幕。
|
||||
|
||||
#### Jetty服务检查 ####
|
||||
|
||||
@ -96,7 +95,7 @@ via: http://www.ubuntugeek.com/install-jetty-9-java-servlet-engine-and-webserver
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,20 +1,19 @@
|
||||
Linux FAQs with Answers--How to disable Apport internal error reporting on Ubuntu
|
||||
有问必答--如何禁止Ubuntu的Apport内部错误报告程序
|
||||
Linux有问必答:如何禁止Ubuntu的Apport内部错误报告程序
|
||||
================================================================================
|
||||
> **问题**:在桌面版Ubuntu中,我经常遇到一些弹窗窗口,警告我Ubuntu发生了内部错误,问我要不要发送错误报告。每次软件崩溃都要烦扰我,我如何才能关掉这个错误报告功能呢?
|
||||
|
||||
Ubuntu桌面版预安装了Apport,它是一个错误收集系统,会收集软件崩溃、未处理异常和其他,包括程序bug,并为调试目的生成崩溃报告。当一个应用程序崩溃或者出现Bug时候,Apport就会通过弹窗警告用户并且询问用户是否提交崩溃报告。你也许也看到过下面的消息。
|
||||
Ubuntu桌面版预装了Apport,它是一个错误收集系统,会收集软件崩溃、未处理异常和其他,包括程序bug,并为调试目的生成崩溃报告。当一个应用程序崩溃或者出现Bug时候,Apport就会通过弹窗警告用户并且询问用户是否提交崩溃报告。你也许也看到过下面的消息。
|
||||
|
||||
- "Sorry, the application XXXX has closed unexpectedly."
|
||||
- "对不起,应用程序XXXX意外关闭了"
|
||||
- "对不起,应用程序XXXX意外关闭了。"
|
||||
- "Sorry, Ubuntu XX.XX has experienced an internal error."
|
||||
- "对不起,Ubuntu XX.XX 经历了一个内部错误"
|
||||
- "对不起,Ubuntu XX.XX 发生了一个内部错误。"
|
||||
- "System program problem detected."
|
||||
- "系统程序问题发现"
|
||||
- "检测到系统程序问题。"
|
||||
|
||||
|
||||
|
||||
也许因为应用一直崩溃,频繁的错误报告会使人心烦。也许你担心Apport会收集和上传你的Ubuntu系统的敏感信息。无论什么原因,你需要关掉Apport的错误报告功能。
|
||||
也许因为应用一直崩溃,频繁的错误报告会使人心烦。也许你担心Apport会收集和上传你的Ubuntu系统的敏感信息。无论什么原因,你想关掉Apport的错误报告功能。
|
||||
|
||||
### 临时关闭Apport错误报告 ###
|
||||
|
||||
@ -41,6 +40,6 @@ Ubuntu桌面版预安装了Apport,它是一个错误收集系统,会收集
|
||||
via: http://ask.xmodulo.com/disable-apport-internal-error-reporting-ubuntu.html
|
||||
|
||||
译者:[VicYu/Vic020](http://www.vicyu.net/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,10 +1,10 @@
|
||||
如何在Linux的命令行中使用Evernote
|
||||
================================================================================
|
||||
这周让我们继续什么学习如个使用Linux命令行管理和组织信息。在命令行中管理[你的个人花费][1]后,我建议你在命令行中管理你的笔记,特别地是,当你笔记放在Evernote中时。为防止你从来没有听说过,[Evernote][2]专门有一个用户有好的在线服务用来在不同的设备间同步笔记。除了提供花哨的基于Web的API,Evernote还发布了在Windows、Mac、[Android][3]和iOS上的客户端。然而至今还没有官方的Linux客户端可用。老实说在众多的非官方Linux程序中,一个程序一出现就吸引了所有的命令行爱好者:[Geeknote][4]
|
||||
这周让我们继续学习如何使用Linux命令行管理和组织信息。在命令行中管理[你的个人花费][1]后,我建议你在命令行中管理你的笔记,特别是当你用Evernote记录笔记时。要是你从来没有听说过它,[Evernote][2] 专门有一个用户友好的在线服务可以在不同的设备间同步笔记。除了提供花哨的基于Web的API,Evernote还发布了在Windows、Mac、[Android][3]和iOS上的客户端。然而至今还没有官方的Linux客户端可用。老实说在众多的非官方Linux客户端中,有一个程序一出现就吸引了所有的命令行爱好者,它就是[Geeknote][4]。
|
||||
|
||||
### Geeknote 的安装 ###
|
||||
|
||||
Geeknote使用Python开发的。因此,在开始之前请确保你已经安装了Python(最好是2.7的版本)和git。
|
||||
Geeknote是使用Python开发的。因此,在开始之前请确保你已经安装了Python(最好是2.7的版本)和git。
|
||||
|
||||
#### 在 Debian、 Ubuntu 和 Linux Mint 中 ####
|
||||
|
||||
@ -26,38 +26,38 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
### Geeknote 的基本使用 ###
|
||||
|
||||
一旦你安装玩Geeknote后,你应该将Geeknote与你的Evernote账号关联:
|
||||
一旦你安装完Geeknote后,你应该将Geeknote与你的Evernote账号关联:
|
||||
|
||||
$ geeknote login
|
||||
|
||||
接着输入你的emial地址、密码、和你的二步验证码。如果你没有后者,忽略它并按下回车。
|
||||
接着输入你的email地址、密码和你的二步验证码。如果你没有后者的话,忽略它并按下回车。
|
||||
|
||||

|
||||
|
||||
很明显,你需要一个Evernote账号来完成这些,因此先去注册。
|
||||
显然你需要一个Evernote账号来完成这些,因此先去注册吧。
|
||||
|
||||
一旦完成这一切之后,你就可以开始了,创建新的笔记并编辑它们。
|
||||
完成这些之后,你就可以开始创建新的笔记并编辑它们了。
|
||||
|
||||
但是首先,你需要设置你最喜欢的文本编辑器:
|
||||
不过首先,你还需要设置你最喜欢的文本编辑器:
|
||||
|
||||
$ geeknote settings --editor vim
|
||||
|
||||
接着,常规创建一条新笔记的语法是:
|
||||
然后,一般创建一条新笔记的语法是:
|
||||
|
||||
$ geeknote create --title [title of the new note] (--content [content] --tags [comma-separated tags] --notebook [comma-separated notebooks])
|
||||
|
||||
上面的命令中,只有‘title’是必须的,它会与一条新笔记的标题相关联。其他的标注可以为笔记添加额外的元数据:添加标签来与你的笔记关联、指定放在那个笔记本里。同样,如果你的标题或者内容还有空格,不要忘记将它们放在引号中。
|
||||
上面的命令中,只有‘title’是必须的,它会与一条新笔记的标题相关联。其他的标注可以为笔记添加额外的元数据:添加标签来与你的笔记关联、指定放在那个笔记本里。同样,如果你的标题或者内容中有空格,不要忘记将它们放在引号中。
|
||||
|
||||
|
||||
比如:
|
||||
|
||||
$ geeknote create --title "My note" --content "This is a test note" --tags "finance, business, important" --notebook "Family"
|
||||
|
||||
通常上,下一步就是编辑你的笔记。语法很相似:
|
||||
然后,你可以编辑你的笔记。语法很相似:
|
||||
|
||||
$ geeknote edit --note [title of the note to edit] (--title [new title] --tags [new tags] --notebook [new notebooks])
|
||||
|
||||
注意可选的参数如标题、标签和笔记本,用来修改笔记的元数据。比如,你可以用下面的命令重命名笔记:
|
||||
注意可选的参数如新的标题、标签和笔记本,用来修改笔记的元数据。你也可以用下面的命令重命名笔记:
|
||||
|
||||
$ geeknote edit --note [old title] --title [new title]
|
||||
|
||||
@ -65,13 +65,13 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
$ geeknote find --search [text-to-search] --tags [comma-separated tags] --notebook [comma-separated notebooks] --date [date-or-date-range] --content-search
|
||||
|
||||
默认上,上面的命令会通过标题搜索笔记。 用"--content-search"选项,就可以搜索它们的内容。
|
||||
默认地上面的命令会通过标题搜索笔记。 用"--content-search"选项,就可以按内容搜索。
|
||||
|
||||
比如:
|
||||
|
||||
$ geeknote find --search "*restaurant" --notebooks "Family" --date 31.03.2014-31.08.2014
|
||||
|
||||
显示制定标题的笔记:
|
||||
显示指定标题的笔记:
|
||||
|
||||
$ geeknote show [title]
|
||||
|
||||
@ -89,13 +89,13 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
小心这是真正的删除。它会从云存储中删除这条笔记。
|
||||
|
||||
最后有很多的选项来管理标签和笔记本。我想最有用的是显示笔记本列表。
|
||||
最后有很多的选项来管理标签和笔记本。我想最有用的就是显示笔记本列表。
|
||||
|
||||
$ geeknote notebook-list
|
||||
|
||||
|
||||
|
||||
下面的非常相像。你可以猜到,可以用下面的命令列出所有的标签:
|
||||
下面的命令非常相像。你可以猜到,可以用下面的命令列出所有的标签:
|
||||
|
||||
$ geeknote tag-list
|
||||
|
||||
@ -107,27 +107,25 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
$ geeknote tag-create --title [tag title]
|
||||
|
||||
一旦你了解了窍门,很明显语法是非常连贯且明确的。
|
||||
一旦你了解了窍门,很明显这些语法是非常自然明确的。
|
||||
|
||||
如果你想要了解更多,不要忘记查看[官方文档][6]。
|
||||
|
||||
### 福利 ###
|
||||
|
||||
As a bonus, Geeknote comes with the utility gnsync, which allows for file synchronization between your Evernote account and your local computer. However, I find its syntax a bit dry:
|
||||
福利的是,Geeknote自带的gnsync工具可以让你在Evernote和本地计算机之间同步。然而,我发现它的语法有点枯燥:
|
||||
作为福利,Geeknote自带的gnsync工具可以让你在Evernote和本地计算机之间同步。不过,我发现它的语法有点枯燥:
|
||||
|
||||
$ gnsync --path [where to sync] (--mask [what kind of file to sync] --format [in which format] --logpath [where to write the log] --notebook [which notebook to use])
|
||||
|
||||
下面是这些的意义。
|
||||
|
||||
下面是这些参数的意义。
|
||||
|
||||
- **--path /home/adrien/Documents/notes/**: 与Evernote同步笔记的位置。
|
||||
- **--mask "*.txt"**: 只同步纯文本文件。默认上,gnsync会尝试同步所有文件。
|
||||
- **--mask "*.txt"**: 只同步纯文本文件。默认gnsync会尝试同步所有文件。
|
||||
- **--format markdown**: 你希望它们是纯文本或者markdown格式(默认是纯文本)。
|
||||
- **--logpath /home/adrien/gnsync.log**: 同步日志的位置。为防出错,gnsync会在那里写入日志信息。
|
||||
- **--notebook "Family"**: 同步哪个笔记本中的笔记。如果你那里留空,程序会创建一个以你同步文件夹命令的笔记本。
|
||||
- **--notebook "Family"**: 同步哪个笔记本中的笔记。如果留空,程序会创建一个以你同步文件夹命令的笔记本。
|
||||
|
||||
总结来说,Geeknote是一款花哨的Evernote的命令行客户端。我个人不常使用Evernote,但它仍然很漂亮和有用。命令行一方面让它变得很极客且很容易与shell脚本结合。同样,还有Git上fork出来的Geeknote,在ArchLinux AUR上称为[geeknote-improved-git][7],貌似它有更多的特性和比其他分支更积极的开发。但在我看来,还很值得再看看。
|
||||
总的来说,Geeknote是一款漂亮的Evernote的命令行客户端。我个人不常使用Evernote,但它仍然很漂亮和有用。命令行一方面让它变得很极客且很容易与shell脚本结合。此外,在Git上还有Geeknote的一个分支项目,在ArchLinux AUR上称为[geeknote-improved-git][7],貌似它有更多的特性和比其他分支更积极的开发。我觉得值得去看看。
|
||||
|
||||
你认为Geeknote怎么样? 有什么你想用的么?或者你更喜欢使用传统的程序?在评论区中让我们知道。
|
||||
|
||||
@ -137,7 +135,7 @@ via: http://xmodulo.com/evernote-command-line-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
NetHack
|
||||
也许是有史以来最好的游戏:NetHack
|
||||
================================================================================
|
||||
## 一直以来最好的游戏? ##
|
||||
|
||||
**这款游戏非常容易让你上瘾。你可能需要花费一生的时间来掌握它。许多人玩了几十年也没有通关。欢迎来到 NetHack 的世界...**
|
||||
|
||||
不管你信不信,在 NetHack 里你见到字母 D 的时候你会被吓着。但是当你看见一个 % 的时候,你将会欣喜若狂。(忘了说 ^,你看见它将会更激动)在你寻思我们的脑子是不是烧坏了并准备关闭浏览器标签之前,请给我们一点时间解释:这些符号分别代表龙、食物以及陷阱。欢迎来到 NetHack 的世界,在这里你的想象力需要发挥巨大的作用。
|
||||
不管你信不信,在 NetHack 里你见到字母 **D** 的时候你会被吓着。但是当你看见一个 **%** 的时候,你将会欣喜若狂。(忘了说 **\^**,你看见它将会更激动)在你寻思我们的脑子是不是烧坏了并准备关闭浏览器标签之前,请给我们一点时间解释:这些符号分别代表龙、食物以及陷阱。欢迎来到 NetHack 的世界,在这里你的想象力需要发挥巨大的作用。
|
||||
|
||||
如你所见,NetHack 是一款文字模式的游戏:它仅仅使用标准终端字符集来刻画玩家、敌人、物品还有环境。游戏的图形版是存在的,不过 NetHack 的骨灰级玩家们都倾向于不去使用它们,问题在于假如你使用图形界面,当你通过 SSH 登录到你的古董级的运行着 NetBSD 的 Amiga 3000 上时,你还能进行游戏吗?在某些方面,NetHack 和 Vi 非常相似 - 几乎被移植到了现存的所有的操作系统上,并且依赖都非常少。
|
||||
|
||||
@ -16,68 +15,68 @@ NetHack
|
||||
|
||||
|
||||
|
||||
NetHack 界面
|
||||
*NetHack 界面*
|
||||
|
||||
### 也许是最古老的仍在开发的游戏里 ###
|
||||
|
||||
名非其实,NetHack 并不是一款网络游戏。它只不过是基于一款出现较早的名为 Hack 的地牢探险类游戏开发出来的,而这款 Hack 游戏是 1980 年的游戏 Rogue 的后代。NetHack 在 1987 年发布了第一个版本,并于 2003 年发布了 3.4.3 版本,尽管在这期间一直没有加入新的功能,但各种补丁、插件,以及衍生作品还是在网络上疯狂流传。这使得它可以说是最古老的、拥有众多对游戏乐此不疲的粉丝的游戏。当你访问 [www.reddit.com/r/nethack][1] 之后,你就会了解我们的意思了 - 骨灰级的 NetHack 的玩家们仍然聚集在一起讨论新的策略、发现和技巧。偶尔你也可以发现 NetHack 的元老级玩家在历经千辛万苦终于通关之后发出的欢呼。
|
||||
|
||||
|
||||
但怎样才能通关呢?首先,NetHack 被设定在既大又深的地牢中。游戏开始时你在最顶层 - 第 1 层 - 你的目标是不断往下深入直到你找到一个非常宝贵的物品,护身符 Yendor。通常来说 Yendor 在 第 20 层或者更深的地方,但它是可以变化的。随着你在地牢的不断深入,你会遇到各种各样的怪物、陷阱以及 NPC;有些会试图杀掉你,有些会挡在你前进的路上,还有些... 总而言之,在你靠近 TA 们之前你永远不知道 TA 们会怎样。
|
||||
|
||||
> 要学习的有太多太多,绝大多数物品只有在和其他物品同时使用的情况下才会发挥最好的效果。
|
||||
|
||||
是 NetHack 如此引人入胜的原因是游戏中所加入的大量物品。武器、盔甲、附魔书、戒指、宝石 - 要学习的有太多太多,绝大多数物品只有在和其他物品同时使用的情况下才会发挥最好的效果。怪物在死亡后经常会掉落一些有用的物品,以及某些物品如果你不正确使用的话会产生及其不良的作用。你可以在地牢找到商店,里面有许多看似平凡实则非常有用的物品,,不过别指望店主能给你详细的描述。你只能靠自己的经验来了解各个物品的用途。有些物品确实没有太大用处,NetHack 中有很多的恶搞元素 - 比如你可以把一块奶油砸到自己的脸上。
|
||||
使 NetHack 如此引人入胜的原因是游戏中所加入的大量物品。武器、盔甲、附魔书、戒指、宝石 - 要学习的有太多太多,绝大多数物品只有在和其他物品同时使用的情况下才会发挥最好的效果。怪物在死亡后经常会掉落一些有用的物品,以及某些物品如果你不正确使用的话会产生及其不良的作用。你可以在地牢找到商店,里面有许多看似平凡实则非常有用的物品,不过别指望店主能给你详细的描述。你只能靠自己的经验来了解各个物品的用途。有些物品确实没有太大用处,NetHack 中有很多的恶搞元素 - 比如你可以把一块奶油砸到自己的脸上。
|
||||
|
||||
不过在你踏入地牢之前,NetHack 会询问你要选择哪种角色进行游戏。你可以为你接下来的地牢之行选择骑士、修道士、巫师,或者卑微的旅者,还有许多其他的角色类型。每种角色都有其独特的优势与弱点,NetHack 的重度玩家喜欢选择那些相对较弱的角色来挑战游戏。你懂的,这样可以向其他玩家炫耀自己的实力。
|
||||
|
||||
> ## 情报不会降低游戏的乐趣 ##
|
||||
> **情报不会降低游戏的乐趣**
|
||||
|
||||
> 用 NetHack 的说法来讲,“情报员”给指其他玩家提供关于怪物、物品、武器和盔甲信息的玩家。理论上来说,完全可以不借助任何外来信息而通关,但几乎没有几个玩家能做到,游戏实在是太难了。因此使用情报并不会被视为一件糟糕的事情 - 但是一开始由你自己来探索游戏和解决难题,这样才会获得更多的乐趣,只有当你遇到瓶颈的时候再去使用那些情报。
|
||||
|
||||
> 在这里给出一个比较有名的情报站点 [www.statslab.cam.ac.uk/~eva/nethack/spoilerlist.html][2],其中的情报被分为了不同的类别。游戏中随机发生的事,比如在喷泉旁饮水可能导致的不同结果,从这里你可以得知已确定的不同结果的发生概率。
|
||||
>
|
||||
> ### 你的首次地牢之行 ###
|
||||
|
||||
NetHack 几乎可以在所有的主流操作系统以及 Linux 发行版上运行,因此你可以通过 "apt-get install nethack" 或者 "yum install nethack" 等适合你用的发行版的命令来安装游戏。安装完毕后,在一个命令行窗口中键入 "nethack" 就可以开始游戏了。游戏开始时系统会询问是否为你随机挑选一位角色 - 但作为一个新手,你最好自己从里面挑选一位比较强的角色。所以,你应该点 "n",然后点 "v" 以选取女武神(Valkyrie),最后点 "d" 选择成为侏儒(dwarf)。
|
||||
### 你的首次地牢之行 ###
|
||||
|
||||
NetHack 几乎可以在所有的主流操作系统以及 Linux 发行版上运行,因此你可以通过 "apt-get install nethack" 或者 "yum install nethack" 等适合你用的发行版的命令来安装游戏。安装完毕后,在一个命令行窗口中键入 "nethack" 就可以开始游戏了。游戏开始时系统会询问是否为你随机挑选一位角色 - 但作为一个新手,你最好自己从里面挑选一位比较强的角色。所以,你应该点 "n",然后点 "v" 以选取女武神(Valkyrie),而点 "d" 会选择成为侏儒(dwarf)。
|
||||
|
||||
接着 NetHack 上会显示出剧情,说你的神正在寻找护身符 Yendor,你的目标就是找到它并将它带给神。阅读完毕后点击空格键(其他任何时候当你见到屏幕上的 "-More-" 时都可以这样)。接着就让我们出发 - 开始地牢之行吧!
|
||||
|
||||
先前已经介绍过了,你的角色用 @ 来表示。你可以看见角色所出房间周围的墙壁,房间里显示点的那些地方是你可以移动的空间。首先,你得明白怎样移动角色:h、j、k 以及 l。(是的,和 Vim 中移动光标的操作相同)这些操作分别会使角色向向左、向下、向上以及向右移动。你也可以通过 y、u、b 和 n 来使角色斜向移动。在你熟悉如何控制角色移动前你最好在房间里来回移动你的角色。
|
||||
先前已经介绍过了,你的角色用 @ 来表示。你可以看见角色所出房间周围的墙壁,房间里显示“点”的那些地方是你可以移动的空间。首先,你得明白怎样移动角色:h、j、k 以及 l。(是的,和 Vim 中移动光标的操作相同)这些操作分别会使角色向向左、向下、向上以及向右移动。你也可以通过 y、u、b 和 n 来使角色斜向移动。在你熟悉如何控制角色移动前你最好在房间里来回移动你的角色。
|
||||
|
||||
NetHack 采用了回合制,因此即使你不进行任何动作,游戏仍然在进行。这是你可以提前计划你的行动。你可以看见一个 "d" 字符或者 "f" 字符在房间里来回移动:这是你的宠物狗/猫,(通常情况下)它们 不会伤害你而是帮助你击杀怪物。但是宠物也会被惹怒 - 它们偶尔也会抢在你接近食物或者怪物尸体之前吃掉它们。
|
||||
NetHack 采用了回合制,因此即使你不进行任何动作,游戏仍然在进行。这是你可以提前计划你的行动。你可以看见一个 "d" 字符或者 "f" 字符在房间里来回移动:这是你的宠物狗/猫,(通常情况下)它们不会伤害你而是帮助你击杀怪物。但是宠物也会被惹怒 - 它们偶尔也会抢在你接近食物或者怪物尸体之前吃掉它们。
|
||||
|
||||
|
||||
|
||||
点击 “i” 列出你当前携带的物品清单
|
||||
*点击 “i” 列出你当前携带的物品清单*
|
||||
|
||||
### 门后有什么? ###
|
||||
|
||||
接下来,让我们离开房间。房间四周的墙壁某处会有缝隙,可能是 "+" 号。"+" 号表示一扇关闭的门,这时你应该靠近它然后点击 "o" 来开门。接着系统会询问你开门的方向,假如门在你的左方,就点击 "h"。(如果门被卡住了,就多试几次)然后你就可以看见门后的走廊了,它们由 "#" 号表示,沿着走廊前进直到你找到另一个房间。
|
||||
|
||||
地牢之行中你会见到各种各样的物品。某些物品,比如金币(由 "$" 号表示)会被自动捡起来;至于另一些物品,你只能站在上面按下逗号键手动拾起。如果同一位置有多个物品,系统会给你显示一个列表,你只要通过合适的案件选择列表中你想要的物品最后按下 "Enter" 键即可。任何时间你都可以点击 "i" 键在屏幕上列出你当前携带的物品清单。
|
||||
地牢之行中你会见到各种各样的物品。某些物品,比如金币(由 "$" 号表示)会被自动捡起来;至于另一些物品,你只能站在上面按下逗号键手动拾起。如果同一位置有多个物品,系统会给你显示一个列表,你只要通过合适的按键选择列表中你想要的物品最后按下 "Enter" 键即可。任何时间你都可以点击 "i" 键在屏幕上列出你当前携带的物品清单。
|
||||
|
||||
如果看见了怪物该怎么办?在游戏早期,你可能会遇到的怪物会用符号 "d"、"x" 和 ":" 表示。想要攻击的话,只要简单地朝怪物的方向移动即可。系统会在屏幕顶部通过信息显示来告诉你你的攻击是否成功 - 以及怪物做出了何种反应。早期的怪物很容易击杀,所以你可以毫不费力地打败他们,但请留意底部状态栏里显示的角色的 HP 值。
|
||||
如果看见了怪物该怎么办?在游戏早期,你可能会遇到的怪物会用符号 "d"、"x" 和 ":" 表示。想要攻击的话,只要简单地朝怪物的方向移动即可。系统会在屏幕顶部通过信息显示来告诉你攻击是否成功 - 以及怪物做出了何种反应。早期的怪物很容易击杀,所以你可以毫不费力地打败他们,但请留意底部状态栏里显示的角色的 HP 值。
|
||||
|
||||
> 早期的怪物很容易击杀,但请留意角色的 HP 值。
|
||||
|
||||
如果怪物死后掉落了一具尸体("%"),你可以点击逗号进行拾取,并点击 "e" 来食用。(在任何时候系统提示你选择一件物品,你都可以从物品列表中点击相应的按键,或者点击 "?" 来查询迷你菜单。)主意!有些尸体是有毒的,这些知识你将在日后的冒险中逐渐学会掌握。
|
||||
如果怪物死后掉落了一具尸体("%"),你可以点击逗号进行拾取,并点击 "e" 来食用。(在任何时候系统提示你选择一件物品,你都可以从物品列表中点击相应的按键,或者点击 "?" 来查询迷你菜单。)注意!有些尸体是有毒的,这些知识你将在日后的冒险中逐渐学会掌握。
|
||||
|
||||
如果你在走廊里行进时遇到了死胡同,你可以点击 "s" 进行搜寻直到找到一扇门。这会花费时间,但是你由此加速了游戏进程:输入 "10" 并点击 "s" 你将一下搜索 10 次。这将花费游戏中进行 10 次动作的时间,不过如果你正在饥饿状态,你将有可能会被饿死。
|
||||
如果你在走廊里行进时遇到了死胡同,你可以点击 "s" 进行搜寻直到找到一扇门。这会花费时间,但是你可以这样加速游戏进程:输入 "10" 并点击 "s" 你将一下搜索 10 次。这将花费游戏中进行 10 次动作的时间,不过如果你正在饥饿状态,你将有可能会被饿死!
|
||||
|
||||
通常你可以在地牢顶部找到 "{"(喷泉)以及 "!"(药水)。当你找到喷泉的时候,你可以站在上面并点击 "q" 键开始 “畅饮(quaff)” - 引用后会得到积极的到致命的多种效果。当你找到药水的时候,将其拾起并点击 "q" 来引用。如果你找到一个商店,你可以拾取其中的物品并在离开前点击 "p" 键进行支付。当你负重过大时,你可以点击 "d" 键丢掉一些东西。
|
||||
通常你可以在地牢顶部找到 "{"(喷泉)以及 "!"(药水)。当你找到喷泉的时候,你可以站在上面并点击 "q" 键开始 “畅饮(quaff)” - 引用后会得到从振奋的到致命的多种效果。当你找到药水的时候,将其拾起并点击 "q" 来饮用。如果你找到一个商店,你可以拾取其中的物品并在离开前点击 "p" 键进行支付。当你负重过大时,你可以点击 "d" 键丢掉一些东西。
|
||||
|
||||
|
||||
|
||||
现在已经有带音效的 3D 版 Nethack 了,如:Falcon’s Eye
|
||||
*现在已经有带音效的 3D 版 Nethack 了,如:Falcon’s Eye*
|
||||
|
||||
> ## 愚蠢的死法 ##
|
||||
> **愚蠢的死法**
|
||||
|
||||
> 在 NetHack 玩家中流行着一个缩写词 "YASD" - 又一种愚蠢的死法(Yet Another Stupid Death)。这个缩写词表示了玩家由于自身的的愚蠢或者粗心大意导致了角色的死亡。我们搜集了很多这类死法,但我们最喜欢的是下面描述的:
|
||||
> 在 NetHack 玩家中流行着一个缩写词 "YASD" - 又一种愚蠢的死法(Yet Another Stupid Death)。这个缩写词表示了玩家由于自身的的愚蠢或者粗心大意导致了角色的死亡。我们搜集了很多这类死法,但我们最喜欢的是下面这种死法:
|
||||
|
||||
> 我们正在商店浏览商品,这时一条蛇突然从药剂后面跳了出来。在杀死蛇之后,系统弹出一条信息提醒我们角色饥饿值过低了,因此我们顺手食用了蛇的尸体。坏事了!这使得我们的角色失明,导致我们的角色再也不能看见商店里的其他角色及地上的商品了。我们试图离开商店,但在慌乱中却撞在了店主身上并攻击了他。这种做法激怒了店主:他立即向我们的角色使用了火球术。我们试图逃到商店外的走廊上,但却在逃亡的过程中被烧死。
|
||||
|
||||
> 如果你有类似的死法,一定要来我们的论坛告诉我们。不要担心 - 没有人会嘲笑你。经历这样的死法也是你在 NetHack 的世界里不断成长的一部分。
|
||||
> 如果你有类似的死法,一定要来我们的论坛告诉我们。不要担心 - 没有人会嘲笑你。经历这样的死法也是你在 NetHack 的世界里不断成长的一部分。哈哈。
|
||||
|
||||
### 武装自己 ###
|
||||
|
||||
@ -85,7 +84,7 @@ NetHack 采用了回合制,因此即使你不进行任何动作,游戏仍然
|
||||
|
||||
在靠近掉在地下的装备之前最好检查一下身上的东西。点击 ";"(分号)后,"Pick an object"(选择一样物品)选项将出现在屏幕顶部。选择该选项,使用移动键直到选中你想要检查的物品,然后点击 ":"(冒号)。接着屏幕顶部将出现这件物品的描述。
|
||||
|
||||
因为你的目标是不断深入地牢直到找到护身符 Yendor,所以请随时留意周围的 "<" 和 ">" 符号。这两个符号分别表示向上和向下的楼梯,你可以用与之对应的按键来上楼或下楼。注意!如果你想让宠物跟随你进入下/上一层地牢,下/上楼前请确保你的宠物在你邻近的方格内。若果你想退出,点击 "S"(大写的 s)来保存进度,输入 #quit 退出游戏。当你再次运行 NetHack 时,系统将会自动读取你上次退出时的游戏进度。
|
||||
因为你的目标是不断深入地牢直到找到护身符 Yendor,所以请随时留意周围的 "<" 和 ">" 符号。这两个符号分别表示向上和向下的楼梯,你可以用与之对应的按键来上楼或下楼。注意!如果你想让宠物跟随你进入下/上一层地牢,下/上楼前请确保你的宠物在你邻近的方格内。若果你想退出,点击 "S"(大写的)来保存进度,输入 #quit 退出游戏。当你再次运行 NetHack 时,系统将会自动读取你上次退出时的游戏进度。
|
||||
|
||||
我们就不继续剧透了,地牢深处还有更多的神秘细节、陌生的 NPC 以及不为人知的秘密等着你去发掘。那么,我们再给你点建议:当你遇到了让你困惑不已的物品时,你可以尝试去 NetHack 维基 [http://nethack.wikia.com][3] 进行搜索。你也可以在 [www.nethack.org/v343/Guidebook.html][4] 找到一本非常不错(尽管很长)的指导手册。最后,祝游戏愉快!
|
||||
|
||||
@ -95,7 +94,7 @@ via: http://www.linuxvoice.com/nethack/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
一个用%显示Linux命令进度预计完成时间的伟大工具
|
||||
一个可以显示Linux命令运行进度的伟大工具
|
||||
================================================================================
|
||||
Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任何核心组件命令的进度。它使用文件描述信息来确定一个命令的进度,比如cp命令。**cv**之美在于,它能够和其它Linux命令一起使用,比如你所知道的watch以及I/O重定向命令。这样,你就可以在脚本中使用,或者你能想到的所有方式,别让你的想象力束缚住你。
|
||||
Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任何核心组件命令(如:cp、mv、dd、tar、gzip、gunzip、cat、grep、fgrep、egrep、cut、sort、xz、exiting)的进度。它使用文件描述信息来确定一个命令的进度,比如cp命令。**cv**之美在于,它能够和其它Linux命令一起使用,比如你所知道的watch以及I/O重定向命令。这样,你就可以在脚本中使用,或者你能想到的所有方式,别让你的想象力束缚住你。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
你可以从cv的[github仓库那儿][1]下载所需的源文件。把zip文件下载下来后,将它解压缩,然后进入到解压后的文件夹。
|
||||
|
||||
该程序依赖于**ncurses library**。如果你已经在你的Linux系统中安装了ncurses,那么cv的安装过程对你而言就是那么得轻松写意。
|
||||
该程序需要**ncurses library**。如果你已经在你的Linux系统中安装了ncurses,那么cv的安装过程对你而言就是那么的轻松写意。
|
||||
|
||||
通过以下两个简单步骤来进行编译和安装吧。
|
||||
|
||||
@ -23,20 +23,21 @@ Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任
|
||||
|
||||
$ cv
|
||||
|
||||
如果没有核心组件命令在运行,那么cv程序会退出,并告诉你:No coreutils is running。
|
||||
如果没有核心组件命令在运行,那么cv程序会退出,并告诉你:没有核心组件命令在运行。
|
||||
|
||||

|
||||
|
||||
要有效使用该程序,请在你系统上运行某个核心组件程序。在本例中,我们将使用**cp**命令。
|
||||
|
||||
当拷贝一个打文件时,你就可以看到进度了,以百分比显示。
|
||||
当拷贝一个打文件时,你就可以看到当前进度了,以百分比显示。
|
||||
|
||||

|
||||
|
||||
### 添加选项到cv ###
|
||||
### 添加选项到 cv ###
|
||||
|
||||
你也可以添加几个选项到cv命令,就像其它命令一样。一个有用的选项是让你了解到拷贝或移动大文件时的预计剩余时间。
|
||||
添加**-w**选项,它会帮你做以上这些事。
|
||||
|
||||
添加**-w**选项,它就会帮你显示预计的剩余时间。
|
||||
|
||||
$ cv -w
|
||||
|
||||
@ -46,9 +47,9 @@ Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任
|
||||
|
||||
$ cv -wq
|
||||
|
||||
### cv和watch命令 ###
|
||||
### cv 和 watch 命令 ###
|
||||
|
||||
watch是一个用于周期性运行程序并显示输出结果的程序。有时候,你可能想要看看命令运行期间的状况而不想存储数据到日志文件中。在这种情况下,watch就会派上用场了,它可以和cv一起使用。
|
||||
watch是一个用于周期性运行程序并显示输出结果的程序。有时候,你可能想要持续看看命令运行状况而不想将 cv 的结果存储到日志文件中。在这种情况下,watch就会派上用场了,它可以和cv一起使用。
|
||||
|
||||
$ watch cv -qw
|
||||
|
||||
@ -58,7 +59,7 @@ watch是一个用于周期性运行程序并显示输出结果的程序。有时
|
||||
|
||||
### 在日志文件中查看输出结果 ###
|
||||
|
||||
正如所承诺的那样,你可以使用cv来重定向它的输出结果到一个日志文件。这功能在命令运行太快而看不到任何有意义的内容时特别有用。
|
||||
正如其所承诺的那样,你可以使用cv来重定向它的输出结果到一个日志文件。这功能在命令运行太快而看不到任何有意义的内容时特别有用。
|
||||
|
||||
要在日志文件中查看进度,你仅仅需要重定向输出结果,就像下面这样。
|
||||
|
||||
@ -81,7 +82,7 @@ watch是一个用于周期性运行程序并显示输出结果的程序。有时
|
||||
|
||||
但是,要获取上述手册页,你必须执行make install来安装cv。
|
||||
|
||||
耶!现在,你的Linux工具箱中又多了个伟大的工具。
|
||||
耶!现在,你的Linux工具箱中又多了个伟大的工具。 你学会么?亲自去试试吧~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -89,7 +90,7 @@ via: http://linoxide.com/linux-command/tool-show-command-progress/
|
||||
|
||||
作者:[Allan Mbugua][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
================================================================================
|
||||
**Chrony**是一个开源而自由的应用,它能帮助你保持系统时钟与时钟服务器同步,因此让你的时间保持精确。它由两个程序组成,分别是chronyd和chronyc。chronyd是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机获取或丢失时间的比率,并对此进行补偿。chronyc提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上干这些事,也可以在一台不同的远程计算机上干这些事。
|
||||
**Chrony**是一个开源的自由软件,它能帮助你保持系统时钟与时钟服务器(NTP)同步,因此让你的时间保持精确。它由两个程序组成,分别是chronyd和chronyc。chronyd是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机增减时间的比率,并对此进行补偿。chronyc提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上工作,也可以在一台不同的远程计算机上工作。
|
||||
|
||||
在像CentOS 7之类基于RHEL的操作系统上,已经默认安装有Chrony。
|
||||
|
||||
@ -10,19 +10,17 @@ CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
|
||||
**server** - 该参数可以多次用于添加时钟服务器,必须以"server "格式使用。一般而言,你想添加多少服务器,就可以添加多少服务器。
|
||||
|
||||
Example:
|
||||
server 0.centos.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
|
||||
**stratumweight** - stratumweight指令设置当chronyd从可用源中选择同步源时,每个层应该添加多少距离到同步距离。默认情况下,CentOS中设置为0,让chronyd在选择源时忽略层。
|
||||
**stratumweight** - stratumweight指令设置当chronyd从可用源中选择同步源时,每个层应该添加多少距离到同步距离。默认情况下,CentOS中设置为0,让chronyd在选择源时忽略源的层级。
|
||||
|
||||
**driftfile** - chronyd程序的主要行为之一,就是根据实际时间计算出计算机获取或丢失时间的比率,将它记录到一个文件中是最合理的,它会在重启后为系统时钟作出补偿,甚至它可能有机会从时钟服务器获得好的估值。
|
||||
**driftfile** - chronyd程序的主要行为之一,就是根据实际时间计算出计算机增减时间的比率,将它记录到一个文件中是最合理的,它会在重启后为系统时钟作出补偿,甚至可能的话,会从时钟服务器获得较好的估值。
|
||||
|
||||
**rtcsync** - rtcsync指令将启用一个内核模式,在该模式中,系统时间每11分钟会拷贝到实时时钟(RTC)。
|
||||
|
||||
**allow / deny** - 这里你可以指定一台主机、子网,或者网络以允许或拒绝NTP连接到扮演时钟服务器的机器。
|
||||
|
||||
Examples:
|
||||
allow 192.168.4.5
|
||||
deny 192.168/16
|
||||
|
||||
@ -30,11 +28,10 @@ CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
|
||||
**bindcmdaddress** - 该指令允许你限制chronyd监听哪个网络接口的命令包(由chronyc执行)。该指令通过cmddeny机制提供了一个除上述限制以外可用的额外的访问控制等级。
|
||||
|
||||
Example:
|
||||
bindcmdaddress 127.0.0.1
|
||||
bindcmdaddress ::1
|
||||
|
||||
**makestep** - 通常,chronyd将根据需求通过减慢或加速时钟,使得系统逐步纠正所有时间偏差。在某些特定情况下,系统时钟可能会漂移过快,导致该回转过程消耗很长的时间来纠正系统时钟。该指令强制chronyd在调整期大于某个阀值时调停系统时钟,但只有在因为chronyd启动时间超过指定限制(可使用负值来禁用限制),没有更多时钟更新时才生效。
|
||||
**makestep** - 通常,chronyd将根据需求通过减慢或加速时钟,使得系统逐步纠正所有时间偏差。在某些特定情况下,系统时钟可能会漂移过快,导致该调整过程消耗很长的时间来纠正系统时钟。该指令强制chronyd在调整期大于某个阀值时步进调整系统时钟,但只有在因为chronyd启动时间超过指定限制(可使用负值来禁用限制),没有更多时钟更新时才生效。
|
||||
|
||||
### 使用chronyc ###
|
||||
|
||||
@ -66,7 +63,7 @@ via: http://linoxide.com/linux-command/chrony-time-sync/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,64 @@
|
||||
Calife:一个轻量级的sudo替代品
|
||||
================================================================================
|
||||
Calife会在登录为另外一个用户前输入自己的密码(如果没有提供登录名,默认是登录为root),在验证具有正确的权限后,就会切换到该用户及其组身份,并就会执行一个shell。如果 calife 是由 root 执行的,不需要密码,会执行一个所需的用户ID的shell。
|
||||
|
||||
所用的shell是用户自身所用的,除非在calife.auth配置文件中指定了某个shell。如果在命令行指定了“-”选项,就会读取该用户的环境文件,该shell就像是一个登录shell。这和su的惯常用法不同。
|
||||
|
||||
只有在calife.auth中指定的用户才能使用此方法通过calife成为另外一个用户。calife.auth安装位置处于/etc/calife.auth。
|
||||
|
||||
### Calife特性 ###
|
||||
|
||||
这里给出了一个关于calife特性的扩展列表:
|
||||
|
||||
- 你可以完整保留你的环境变量和shell别名
|
||||
- 它可以全程记录会话的开始到结束
|
||||
- 你可以列出每个许可使用calife的用户,那样,你就可以用户赋予主管权限而不必提供root密码
|
||||
- 你可以在配置文件中指定哪个组可以使用:只要使用@staff或者%staff,那么所有staff组中的成员都将具有访问calife的权限
|
||||
- 通过calife也可以登录成为那些没有家目录或甚至没有shell的用户。如果你想要成为uucp或者甚至是bin,那会很方便
|
||||
- 你可以让calife在会话结束时运行一个指定的系统级的脚本(例如,发送一封邮件告知以root身份做了哪些事)
|
||||
|
||||
### ubuntu中安装calife ###
|
||||
|
||||
打开终端,然后运行以下命令
|
||||
|
||||
sudo apt-get install calife
|
||||
|
||||
### 使用Calife ###
|
||||
|
||||
### 语法 ###
|
||||
|
||||
calife [-] [login]
|
||||
|
||||
详情请参与calife手册页
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/calife-a-lightweight-alternative-to-sudo.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,8 +1,8 @@
|
||||
Linux 有问必答--Linux 中如何安装 7zip
|
||||
Linux有问必答:Linux 中如何安装 7zip
|
||||
================================================================================
|
||||
> **问题**: 我需要要从 ISO 映像中获取某些文件,为此我想要使用 7zip 程序。那么我应该如何安装 7zip 软件呢,[在 Linux 发布版本上完全安装]?
|
||||
|
||||
7zip 是一款开源的归档应用程序,开始是为 Windows 系统而开发的。它能对多种格式的档案文件进行打包或解包处理,除了支持原生的 7z 格式的文档外,还支持包括 XZ、GZIP、TAR、ZIP 和 BZIP2 等这些格式。 一般地,7zip 也常用来解压 RAR、DEB、RPM 和 ISO 等格式的文件。除了简单的归档功能,7zip 还具有支持 AES-256 算法加密以及自解压和建立多卷存档功能。在以 POSIX 协议为标准的系统上(Linux、Unix、BSD),原生的 7zip 程序被移植过来并被命名为 p7zip(“POSIX 7zip” 的简称)。
|
||||
7zip 是一款开源的归档应用程序,开始是为 Windows 系统而开发的。它能对多种格式的档案文件进行打包或解包处理,除了支持其原生的 7z 格式的文档外,还支持包括 XZ、GZIP、TAR、ZIP 和 BZIP2 等这些格式。 通常,7zip 也用来解压 RAR、DEB、RPM 和 ISO 等格式的文件。除了简单的归档功能,7zip 还具有支持 AES-256 算法加密以及自解压和建立多卷存档功能。在支持 POSIX 标准的系统上(Linux、Unix、BSD),原生的 7zip 程序被移植过来并被命名为 p7zip(“POSIX 7zip” 的简称)。
|
||||
|
||||
下面介绍如何在 Linux 中安装 7zip (或 p7zip)。
|
||||
|
||||
@ -23,7 +23,7 @@ Linux 有问必答--Linux 中如何安装 7zip
|
||||
基于红帽的发布系统上提供了两个 7zip 的软件包。
|
||||
|
||||
- **p7zip**: 包含 7za 命令,支持 7z、ZIP、GZIP、CAB、ARJ、BZIP2、TAR、CPIO、RPM 和 DEB 格式。
|
||||
- **p7zip-plugins**: 包含 7z 命令,额外的插件,它扩展了 7za 命令(例如 支持 ISO 格式的抽取)。
|
||||
- **p7zip-plugins**: 包含 7z 命令,额外的插件,它扩展了 7za 命令(例如支持 ISO 格式的抽取)。
|
||||
|
||||
在 CentOS/RHEL 系统中,在运行下面命令前您需要确保 [EPEL 资源库][1] 可用,但在 Fedora 系统中就不需要额外的资源库了。
|
||||
|
||||
@ -37,11 +37,11 @@ Linux 有问必答--Linux 中如何安装 7zip
|
||||
|
||||
|
||||
|
||||
使用 “a” 选项就可以创建一个归档文件,它可以创建 7z、XZ、GZIP、TAR、 ZIP 和 BZIP2 这几种格式的文件。如果指定的归档文件已经存在的话,它会把文件“添加”到存在的归档中,而不是覆盖原有归档文件。
|
||||
使用 “a” 选项就可以创建一个归档文件,它可以创建 7z、XZ、GZIP、TAR、 ZIP 和 BZIP2 这几种格式的文件。如果指定的归档文件已经存在的话,它会把文件“附加”到存在的归档中,而不是覆盖原有归档文件。
|
||||
|
||||
$ 7z a <archive-filename> <list-of-files>
|
||||
|
||||
使用 “e” 选项可以抽取出一个归档文件,抽取出的文件会放在当前目录。抽取支持的格式比创建时支持的格式要多的多,包括 7z、XZ、GZIP、TAR、ZIP、BZIP2、LZMA2、CAB、ARJ、CPIO、RPM、ISO 和 DEB 这些格式。
|
||||
使用 “e” 选项可以抽取一个归档文件,抽取出的文件会放在当前目录。抽取支持的格式比创建时支持的格式要多的多,包括 7z、XZ、GZIP、TAR、ZIP、BZIP2、LZMA2、CAB、ARJ、CPIO、RPM、ISO 和 DEB 这些格式。
|
||||
|
||||
$ 7z e <archive-filename>
|
||||
|
||||
@ -67,8 +67,8 @@ Linux 有问必答--Linux 中如何安装 7zip
|
||||
via:http://ask.xmodulo.com/install-7zip-linux.html
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[1]:http://linux.cn/article-2324-1.html
|
||||
@ -1,10 +1,8 @@
|
||||
Translated by H-mudcup
|
||||
|
||||
2014年Linux界发生的好事,坏事和丑事
|
||||
================================================================================
|
||||

|
||||
|
||||
2014年已经接近尾声,现在正是盘点**2014年Linux大事件**的时候。整整一年,我们关注了有关Linux和开源的一些好事,坏事和丑事。让我们来快速回顾一下2014对于Linux是怎样的一年。
|
||||
2014年已经过去,现在正是盘点**2014年Linux大事件**的时候。整整一年,我们关注了有关Linux和开源的一些好事,坏事和丑事。让我们来快速回顾一下2014对于Linux是怎样的一年。
|
||||
|
||||
### 好事 ###
|
||||
|
||||
@ -14,7 +12,7 @@ Translated by H-mudcup
|
||||
|
||||

|
||||
|
||||
从使用Wine到[使用Chrome的测试功能][1],为了能让Netflix能在Linux上工作,Linux用户曾尝试了各种方法。好消息是Netflix终于在2014年带来了Linux的本地支持。这让所有能使用Netflix的地区的Linux用户的脸上浮现出了微笑。想在[美国以外的地区使用Netflix][2](或其他官方授权使用Netflix的国家之外)的人还是得靠其他的方法。
|
||||
从使用Wine到[使用Chrome的测试功能][1],为了能让Netflix能在Linux上工作,Linux用户曾尝试了各种方法。好消息是Netflix终于在2014年带来了Linux的本地支持。这让所有能使用Netflix的地区的Linux用户的脸上浮现出了微笑。不过,想在[美国以外的地区使用Netflix][2](或其他官方授权使用Netflix的国家之外)的人还是得靠其他的方法。
|
||||
|
||||
#### 欧洲国家采用开源/Linux ####
|
||||
|
||||
@ -30,19 +28,19 @@ Translated by H-mudcup
|
||||
|
||||
### 坏事 ###
|
||||
|
||||
Linux在2014年并不是一帆风顺。某些事件的发生损坏了Linux/开源的形象。
|
||||
Linux在2014年并不是一帆风顺。某些事件的发生败坏了Linux/开源的形象。
|
||||
|
||||
#### Heartbleed心血 ####
|
||||
#### Heartbleed 心血漏洞 ####
|
||||
|
||||

|
||||
|
||||
在今年的四月份,检测到[OpenSSL][8]有一个缺陷。这个漏洞被命名为[Heartbleed心血][9]。他影响了包括Facebook和Google在内的50多万个“安全”网站。这项漏洞可以真正的允许任何人读取系统的内存,并能因此给予用于加密数据流的密匙的访问权限。[xkcd上的漫画以更简单的方式解释了心血][10]。不必说,这个漏洞在OpenSSL的更新中被修复了。
|
||||
在今年的四月份,检测到[OpenSSL][8]有一个缺陷。这个漏洞被命名为[Heartbleed心血漏洞][9]。他影响了包括Facebook和Google在内的50多万个“安全”网站。这项漏洞可以真正的允许任何人读取系统的内存,并能因此给予用于加密数据流的密匙的访问权限。[xkcd上的漫画以更简单的方式解释了心血漏洞][10]。自然,这个漏洞在OpenSSL的更新中被修复了。
|
||||
|
||||
#### Shellshock ####
|
||||
#### Shellshock 破壳漏洞 ####
|
||||
|
||||

|
||||
|
||||
好像有个心血还不够似的,在Bash里的一个缺陷更严重的震撼了Linux世界。这个漏洞被命名为[Shellshock][11]。这个漏洞把Linux往远程攻击的危险深渊又推了一把。这项漏洞是通过黑客的DDoS攻击暴露出来的。升级一下Bash版本应该能修复这个问题。
|
||||
好像有个心血漏洞还不够似的,在Bash里的一个缺陷更严重的震撼了Linux世界。这个漏洞被命名为[Shellshock 破壳漏洞][11]。这个漏洞把Linux往远程攻击的危险深渊又推了一把。这项漏洞是通过黑客的DDoS攻击暴露出来的。升级一下Bash版本应该能修复这个问题。
|
||||
|
||||
#### Ubuntu Phone和Steam控制台 ####
|
||||
|
||||
@ -52,13 +50,13 @@ Linux在2014年并不是一帆风顺。某些事件的发生损坏了Linux/开
|
||||
|
||||
### 丑事 ###
|
||||
|
||||
systemd的归属战变得不知廉耻。
|
||||
是否采用 systemd 的争论变得让人羞耻。
|
||||
|
||||
### systemd大论战 ###
|
||||
|
||||

|
||||
|
||||
用init还是systemd的争吵已经进行了一段时间了。但是在2014年当systemd准备在包括Debian, Ubuntu, OpenSUSE, Arch Linux and Fedora几个主流Linux分布中替代init时,事情变得不知廉耻了起来。它是如此的一发不可收拾,以至于它已经不限于boycottsystemd.org这类网站了。Lennart Poettering(systemd的首席开发人员及作者)在一条Google Plus状态上声明,说那些反对systemd的人在“收集比特币来雇杀手杀他”。Lennart还声称开源社区“是个恶心得不能待的地方”。人们吵得越来越离谱以至于把Debian分裂成了一个新的操作系统,称为[Devuan][15]。
|
||||
用init还是systemd的争吵已经进行了一段时间了。但是在2014年当systemd准备在包括Debian, Ubuntu, OpenSUSE, Arch Linux 和 Fedora几个主流Linux分布中替代init时,事情变得不知廉耻了起来。它是如此的一发不可收拾,以至于它已经不限于boycottsystemd.org这类网站了。Lennart Poettering(systemd的首席开发人员及作者)在一条Google Plus状态上声明,说那些反对systemd的人在“收集比特币来雇杀手杀他”。Lennart还声称开源社区“是个恶心得不能待的地方”。人们吵得越来越离谱以至于把Debian分裂成了一个新的操作系统,称为[Devuan][15]。
|
||||
|
||||
### 还有诡异的事 ###
|
||||
|
||||
@ -81,10 +79,10 @@ via: http://itsfoss.com/biggest-linux-stories-2014/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/watch-netflix-in-ubuntu-14-04/
|
||||
[1]:http://linux.cn/article-3024-1.html
|
||||
[2]:http://itsfoss.com/easiest-watch-netflix-hulu-usa/
|
||||
[3]:http://itsfoss.com/french-city-toulouse-saved-1-million-euro-libreoffice/
|
||||
[4]:http://itsfoss.com/italian-city-turin-open-source/
|
||||
[3]:http://linux.cn/article-3575-1.html
|
||||
[4]:http://linux.cn/article-3602-1.html
|
||||
[5]:http://itsfoss.com/170-primary-public-schools-geneva-switch-ubuntu/
|
||||
[6]:http://itsfoss.com/german-town-gummersbach-completes-switch-open-source/
|
||||
[7]:http://itsfoss.com/windows-10-inspired-linux/
|
||||
@ -95,8 +93,8 @@ via: http://itsfoss.com/biggest-linux-stories-2014/
|
||||
[12]:http://itsfoss.com/ubuntu-phone-specification-release-date-pricing/
|
||||
[13]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[14]:https://plus.google.com/+LennartPoetteringTheOneAndOnly/posts/J2TZrTvu7vd
|
||||
[15]:http://debianfork.org/
|
||||
[16]:http://thenewstack.io/microsoft-professes-love-for-linux-adds-support-for-coreos-cloudera-and-host-of-new-features/
|
||||
[15]:http://linux.cn/article-4512-1.html
|
||||
[16]:http://linux.cn/article-4056-1.html
|
||||
[17]:http://www.theregister.co.uk/2001/06/02/ballmer_linux_is_a_cancer/
|
||||
[18]:http://azure.microsoft.com/en-us/
|
||||
[19]:http://www.zdnet.com/article/top-five-linux-contributor-microsoft/
|
||||
@ -4,7 +4,9 @@ Windows和Ubuntu双系统,修复UEFI引导的两种办法
|
||||
|
||||
这里有两种修复EFI启动引导的方法,使Ubuntu可以正常启动
|
||||
|
||||
 "将GRUB2设置为启动引导"
|
||||

|
||||
|
||||
*将GRUB2设置为启动引导*
|
||||
|
||||
### 1. 启用GRUB引导 ###
|
||||
|
||||
@ -18,22 +20,22 @@ Windows和Ubuntu双系统,修复UEFI引导的两种办法
|
||||
|
||||
可以按照以下几个步骤将GRUB2设置为默认的引导程序:
|
||||
|
||||
1.登录Windows 8
|
||||
2.转到桌面
|
||||
3.右击开始按钮,选择管理员命令行
|
||||
4.输入 mountvol g: (将你的EFI目录结构映射到G盘)
|
||||
5.输入 cd g:\EFI
|
||||
6.当你输入 dir 列出文件夹内容时,你可以看到一个Ubuntu的文件夹
|
||||
7.这里的参数可以是grubx64.efi或者shimx64.efi
|
||||
8.运行下列命令将grub64.efi设置为启动引导程序:
|
||||
1. 登录Windows 8
|
||||
2. 转到桌面
|
||||
3. 右击开始按钮,选择管理员命令行
|
||||
4. 输入 mountvol g: /s (这将你的EFI目录结构映射到G盘)
|
||||
5. 输入 cd g:\EFI
|
||||
6. 当你输入 dir 列出文件夹内容时,你可以看到一个Ubuntu的文件夹
|
||||
7. 这里的参数可以是grubx64.efi或者shimx64.efi
|
||||
8. 运行下列命令将grub64.efi设置为启动引导程序:
|
||||
bcdedit /set {bootmgr} path \EFI\ubuntu\grubx64.efi
|
||||
9.重启你的电脑
|
||||
10.你将会看到一个包含Ubuntu和Windows选项的GRUB菜单
|
||||
11.如果你的电脑仍然直接启动到Windows,重复步骤1到7,但是这次输入:
|
||||
9. 重启你的电脑
|
||||
10. 你将会看到一个包含Ubuntu和Windows选项的GRUB菜单
|
||||
11. 如果你的电脑仍然直接启动到Windows,重复步骤1到7,但是这次输入:
|
||||
bcdedit /set {bootmgr} path \EFI\ubuntu\shimx64.efi
|
||||
12.重启你的电脑
|
||||
12. 重启你的电脑
|
||||
|
||||
这里你做的事情是登录Windows管理员命令行,将EFI引导区映射到磁盘上,来查看Ubuntu的引导程序是否安装成功,然后选择grubx64.efi或者shimx64.efi作为引导程序。
|
||||
这里你做的事情就是登录Windows管理员命令行,将EFI引导区映射到磁盘上,来查看Ubuntu的引导程序是否安装成功,然后选择grubx64.efi或者shimx64.efi作为引导程序。
|
||||
|
||||
那么[grubx64.efi和shimx64.efi有什么区别呢][4]?在安全启动(serureboot)关闭的情况下,你可以使用grubx64.efi。如果安全启动打开则需要选择shimx64.efi。
|
||||
|
||||
@ -41,28 +43,30 @@ bcdedit /set {bootmgr} path \EFI\ubuntu\shimx64.efi
|
||||
|
||||
### 2.使用rEFInd引导Ubuntu和Windows双系统 ###
|
||||
|
||||

|
||||
|
||||
[rEFInd引导程序][5]会以图标的方式列出你所有的操作系统。因此,你可以通过点击相应的图标来启动Windows、Ubuntu或者优盘中的操作系统。
|
||||
|
||||
[点击这里][6]下载rEFInd for Windows 8。
|
||||
|
||||
下载和解压以后,按照以下的步骤安装rEFInd。
|
||||
|
||||
1.返回桌面
|
||||
2.右击开始按钮,选择管理员命令行
|
||||
3.输入 mountvol g: (将你的EFI目录结构映射到G盘)
|
||||
4.进入解压的rEFInd目录。例如:
|
||||
cd c:\users\gary\downloads\refind-bin-0.8.4\refind-bin-0.8.4
|
||||
1. 返回桌面
|
||||
2. 右击开始按钮,选择管理员命令行
|
||||
3. 输入 mountvol g: /s (这将你的EFI目录结构映射到G盘)
|
||||
4. 进入解压的rEFInd目录。例如:
|
||||
cd c:\users\gary\downloads\refind-bin-0.8.4\refind-bin-0.8.4 。
|
||||
当你输入 dir 命令,你可以看到一个refind目录
|
||||
5.输入如下命令将refind拷贝到EFI引导区
|
||||
5. 输入如下命令将refind拷贝到EFI引导区
|
||||
xcopy /E refind g:\EFI\refind\
|
||||
6.输入如下命令进入refind文件夹
|
||||
6. 输入如下命令进入refind文件夹
|
||||
cd g:\EFI\refind
|
||||
7.重命名示例配置文件
|
||||
7. 重命名示例配置文件
|
||||
rename refind.conf-sample refind.conf
|
||||
8.运行如下命令将rEFind设置为引导程序
|
||||
8. 运行如下命令将rEFind设置为引导程序
|
||||
bcdedit /set {bootmgr} path \EFI\refind\refind_x64.efi
|
||||
9.重启你的电脑
|
||||
10.你将会看到一个包含Ubuntu和Windows的图形菜单
|
||||
9. 重启你的电脑
|
||||
10. 你将会看到一个包含Ubuntu和Windows的图形菜单
|
||||
|
||||
这个过程和选择GRUB引导程序十分相似。
|
||||
|
||||
@ -72,17 +76,20 @@ bcdedit /set {bootmgr} path \EFI\refind\refind_x64.efi
|
||||
|
||||
希望这篇文章可以解决有些人在安装Ubuntu和Windows 8.1双系统时出现的问题。如果你仍然有问题,可以通过上面的电邮和我进行交流。
|
||||
|
||||
---
|
||||
via: http://linux.about.com/od/LinuxNewbieDesktopGuide/tp/3-Ways-To-Fix-The-UEFI-Bootloader-When-Dual-Booting-Windows-And-Ubuntu.htm
|
||||
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[zhouj-sh](https://github.com/zhouj-sh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
via:http://linux.about.com/od/LinuxNewbieDesktopGuide/tp/3-Ways-To-Fix-The-UEFI-Bootloader-When-Dual-Booting-Windows-And-Ubuntu.htm
|
||||
[a]:http://linux.about.com/bio/Gary-Newell-132058.htm
|
||||
[1]:http://linux.about.com/od/LinuxNewbieDesktopGuide/ss/The-Ultimate-Windows-81-And-Ubuntu-
|
||||
[2]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows_3.htm#step-heading
|
||||
[3]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows.htm
|
||||
[1]:http://linux.cn/article-3178-1.html
|
||||
[2]:http://linux.cn/article-3178-1.html#4_3289
|
||||
[3]:http://linux.cn/article-3178-1.html#4_1717
|
||||
[4]:https://wiki.ubuntu.com/SecurityTeam/SecureBoot
|
||||
[5]:http://www.rodsbooks.com/refind/installing.html#windows
|
||||
[6]:http://sourceforge.net/projects/refind/files/0.8.4/refind-bin-0.8.4.zip/download
|
||||
@ -2,13 +2,13 @@
|
||||
================================================================================
|
||||
这里,我们将展示如何在一台Ubuntu 14.04或CentOS 6.5/7上安装Bugzilla。Bugzilla是一款基于web,用来记录跟踪缺陷数据库的bug跟踪软件,它同时是一款免费及开源软件(FOSS),它的bug跟踪系统允许个人和开发团体有效地记录下他们产品的一些突出问题。尽管是"免费"的,Bugzilla依然有很多其它同类产品所没有的“珍贵”特性。因此,Bugzilla很快就变成了全球范围内数以千计的组织最喜欢的bug管理工具。
|
||||
|
||||
Bugzilla对于不同状况的适应能力非常强。如今它们应用在各个不同的IT领域,系统管理员部署管理、芯片设计和部署问题跟踪(制作前后),还有为那些诸如Redhat,NASA,Linux-Mandrake和VA Systems这些名家提供软硬件bug跟踪。
|
||||
Bugzilla对于不同使用场景的适应能力非常强。如今它们应用在各个不同的IT领域,如系统管理中的部署管理、芯片设计及部署的问题跟踪(制造前期和后期),还有为那些诸如Redhat,NASA,Linux-Mandrake和VA Systems这些著名公司提供软硬件bug跟踪。
|
||||
|
||||
### 1. 安装依赖程序 ###
|
||||
|
||||
安装Bugzilla相当**简单**。这篇文章特别针对Ubuntu 14.04和CentOS 6.5两个版本(不过也适用于更老的版本)。
|
||||
|
||||
为了获取并能在Ubuntu或CentOS系统中运行Bugzilla,我们要安装Apache网络服务器(允许SSL),MySQL数据库服务器和一些需要来安装并配置Bugzilla的工具。
|
||||
为了获取并能在Ubuntu或CentOS系统中运行Bugzilla,我们要安装Apache网络服务器(启用SSL),MySQL数据库服务器和一些需要来安装并配置Bugzilla的工具。
|
||||
|
||||
要在你的服务器上安装使用Bugzilla,你需要安装好以下程序:
|
||||
|
||||
@ -29,14 +29,13 @@ Bugzilla对于不同状况的适应能力非常强。如今它们应用在各个
|
||||
|
||||
**Ubuntu版本:**
|
||||
|
||||
$ sudo apt-get install apache2 mysql-server libapache2-mod-perl2
|
||||
libapache2-mod-perl2-dev libapache2-mod-perl2-doc perl postfix make gcc g++
|
||||
$ sudo apt-get install apache2 mysql-server libapache2-mod-perl2 libapache2-mod-perl2-dev libapache2-mod-perl2-doc perl postfix make gcc g++
|
||||
|
||||
**CentOS版本:**
|
||||
|
||||
$ sudo yum install httpd mod_ssl mysql-server mysql php-mysql gcc perl* mod_perl-devel
|
||||
|
||||
**注意:请在shell或者终端下运行所有的命令并且确保你用root用户(sudo)连接机器。**
|
||||
**注意:请在shell或者终端下运行所有的命令并且确保你用root用户(sudo)操作机器。**
|
||||
|
||||
### 2. 启动Apache服务 ###
|
||||
|
||||
@ -115,7 +114,6 @@ CentOS 6.5和Ubuntu 14.04 Trusty两个版本:
|
||||
# cd /var/www/html/
|
||||
|
||||
# mv -v bugzilla-4.5.2 bugzilla
|
||||
|
||||
|
||||
|
||||
**注意**:这里,**/var/www/html/bugzilla/**就是**Bugzilla主目录**.
|
||||
@ -194,7 +192,7 @@ via: http://linoxide.com/tools/install-bugzilla-ubuntu-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -6,7 +6,7 @@ Docker的镜像并不安全!
|
||||
|
||||
起初我以为这条信息引自Docker[大力推广][1]的镜像签名系统,因此也就没有继续跟进。后来,研究加密摘要系统的时候——Docker用这套系统来对镜像进行安全加固——我才有机会更深入的发现,逻辑上整个与镜像安全相关的部分具有一系列系统性问题。
|
||||
|
||||
Docker所报告的,一个已下载的镜像经过“验证”,它基于的仅仅是一个标记清单(signed manifest),而Docker却从未根据清单对镜像的校验和进行验证。一名攻击者以此可以提供任意所谓具有标记清单的镜像。一系列严重漏洞的大门就此敞开。
|
||||
Docker所报告的,一个已下载的镜像经过“验证”,它基于的仅仅是一个标记清单(signed manifest),而Docker却从未据此清单对镜像的校验和进行验证。一名攻击者以此可以提供任意所谓具有标记清单的镜像。一系列严重漏洞的大门就此敞开。
|
||||
|
||||
镜像经由HTTPS服务器下载后,通过一个未加密的管道流进入Docker守护进程:
|
||||
|
||||
@ -14,7 +14,7 @@ Docker所报告的,一个已下载的镜像经过“验证”,它基于的
|
||||
|
||||
这条管道的性能没有问题,但是却完全没有经过加密。不可信的输入在签名验证之前是不应当进入管道的。不幸的是,Docker在上面处理镜像的三个步骤中,都没有对校验和进行验证。
|
||||
|
||||
然而,不论Docker如何[声明][2],实际上镜像的校验和从未经过校验。下面是Docker与镜像校验和的验证相关的代码[片段][3],即使我提交了校验和不匹配的镜像,都无法触发警告信息。
|
||||
然而,不论Docker如何[声明][2],实际上镜像的校验和(Checksum)从未经过校验。下面是Docker与镜像校验和的验证相关的代码[片段][3],即使我提交了校验和不匹配的镜像,都无法触发警告信息。
|
||||
|
||||
if img.Checksum != "" && img.Checksum != checksum {
|
||||
log.Warnf("image layer checksum mismatch: computed %q,
|
||||
@ -29,7 +29,7 @@ Docker支持三种压缩算法:gzip、bzip2和xz。前两种使用Go的标准
|
||||
|
||||
第三种压缩算法,xz,比较有意思。因为没有现成的Go实现,Docker 通过[执行(exec)][5]`xz`二进制命令来实现解压缩。
|
||||
|
||||
xz二进制程序来自于[XZ Utils][6]项目,由[大概][7]2万行C代码生成而来。而C语言不是一门内存安全的语言。这意味着C程序的恶意输入,在这里也就是Docker镜像的XZ Utils解包程序,潜在地可能会执行任意代码。
|
||||
xz二进制程序来自于[XZ Utils][6]项目,由[大概][7]2万行C代码生成而来。而C语言不是一门内存安全的语言。这意味着C程序的恶意输入,在这里也就是Docker镜像的XZ Utils解包程序,潜在地存在可能会执行任意代码的风险。
|
||||
|
||||
Docker以root权限*运行* `xz` 命令,更加恶化了这一潜在威胁。这意味着如果在`xz`中出现了一个漏洞,对`docker pull`命令的调用就会导致用户整个系统的完全沦陷。
|
||||
|
||||
@ -39,7 +39,6 @@ Docker以root权限*运行* `xz` 命令,更加恶化了这一潜在威胁。
|
||||
|
||||
由于其生成校验和的步骤固定,它解码不可信数据的过程就有可能被设计成[攻破tarsum的代码][9]。这里潜在的攻击既包括拒绝服务攻击,还有逻辑上的漏洞攻击,可能导致文件被感染、忽略、进程被篡改、植入等等,这一切攻击的同时,校验和可能都是不变的。
|
||||
|
||||
|
||||
**解包**
|
||||
|
||||
解包的过程包括tar解码和生成硬盘上的文件。这一过程尤其危险,因为在解包写入硬盘的过程中有另外三个[已报告的漏洞][10]。
|
||||
@ -60,8 +59,7 @@ Docker的工具包[libtrust][11],号称“通过一个分布式的信任图表
|
||||
|
||||
### 补救 ###
|
||||
|
||||
研究结束前,我[报告][15]了一些在tarsum系统中发现的问题,但是截至目前我报告的这些问题仍然
|
||||
没有修复。
|
||||
研究结束前,我[报告][15]了一些在tarsum系统中发现的问题,但是截至目前我报告的这些问题仍然没有修复。
|
||||
|
||||
要改进Docker镜像下载系统的安全问题,我认为应当有以下措施:
|
||||
|
||||
@ -79,16 +77,18 @@ Docker的工具包[libtrust][11],号称“通过一个分布式的信任图表
|
||||
|
||||
作为将更新框架加入Docker的一部分,还应当加入一个本地密钥存储池,将root密钥与registry的地址进行映射,这样用户就可以拥有他们自己的签名密钥,而不必使用Docker公司的了。
|
||||
|
||||
我注意到使用Docker公司非官方的宿主仓库往往会是一种非常糟糕的用户体验。当没有技术上的原因时,Docker也会将第三方的仓库内容降为二等地位来看待。这个问题不仅仅是生态问题,还是一个终端用户的安全问题。针对第三方仓库的全方位、去中心化的安全模型即必须又迫切。我希望Docker公司在重新设计他们的安全模型和镜像认证系统时能采纳这一点。
|
||||
我注意到使用非Docker公司官方的第三方仓库往往会是一种非常糟糕的用户体验。Docker也会将第三方的仓库内容降为二等地位来看待,即使不因为技术上的原因。这个问题不仅仅是生态问题,还是一个终端用户的安全问题。针对第三方仓库的全方位、去中心化的安全模型既必须又迫切。我希望Docker公司在重新设计他们的安全模型和镜像认证系统时能采纳这一点。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
Docker用户应当意识到负责下载镜像的代码是非常不安全的。用户们应当只下载那些出处没有问题的镜像。目前,这里的“没有问题”并不包括Docker公司的“可信(trusted)”镜像,例如官方的Ubuntu和其他基础镜像。
|
||||
Docker用户应当意识到负责下载镜像的代码是非常不安全的。用户们应当只下载那些出处没有问题的镜像。目前,这里的“没有问题”并**不**包括Docker公司的“可信(trusted)”镜像,例如官方的Ubuntu和其他基础镜像。
|
||||
|
||||
最好的选择就是在本地屏蔽 `index.docker.io`,然后使用`docker load`命令在导入Docker之前手动下载镜像并对其进行验证。Red Hat的安全博客有一篇[很好的文章][18],大家可以看看。
|
||||
|
||||
感谢Lewis Marshall指出tarsum从未真正验证。
|
||||
|
||||
参考
|
||||
|
||||
- [校验和的代码][19]
|
||||
- [cloc][20]介绍了18141行没有空格没有注释的C代码,以及5900行的header代码,版本号为v5.2.0。
|
||||
- [Android中也发现了][21]类似的bug,能够感染已签名包中的任意文件。同样出现问题的还有[Windows的Authenticode][22]认证系统,二进制文件会被篡改。
|
||||
@ -101,7 +101,7 @@ via: https://titanous.com/posts/docker-insecurity
|
||||
|
||||
作者:[titanous][a]
|
||||
译者:[Mr小眼儿](http://blog.csdn.net/tinyeyeser)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
2015:开源已经完胜,但这并不是结束
|
||||
================================================================================
|
||||
> 在 2014 年的完胜后,接下来会如何?
|
||||
|
||||
新年伊始,习惯上都是回顾已经走过的一年。但只要一直关注我们,就会很容易获得过去一年的总结:开源已经全胜。让我们从头开始说起吧:
|
||||
|
||||
**超级计算机**: Linux 在超级计算机系统 500 强的名单上占据绝对的主导地位这本身就令其它操作系统很尴尬。[2014年11月的数据][1]显示前500系统中的485个系统都在运行着 Linux 的发布系统,而仅仅只有一台运行着 Windows 系统。如果您看看所用的处理器数量,这数据更是让人惊叹。截止到目前,运行 Linux 系统的处理器有 22,851,693 个之多,而 windows 系统仅仅只有 30,720。这意味着什么?Linux 不仅仅是占据主导地位,在大型系统中已经是绝对的霸主了。
|
||||
|
||||
**云计算**: 去年, Linux 基金会撰写了一个有趣的[报告][2],是关于大公司在云端使用 Linux 的情况的。它发现 75% 的大公司在使用 Linux 系统作为他们的主要平台,相对的使用 Windows 系统的只占 23%。因为需要考虑云端和非云端的因素,它们已经混淆在一起了,所以很难把这比例对应到真实的市场份额里。但是,鉴于当前云计算的流行度,可以很确定的说明 Linux 使用的高速增长。事实上,同样的调查发现,在云端的 Linux 部署率已经从 45% 增长到 79%,而对于 Windows 来说已经从 45% 下降到 36%。当然了,某些人可能认为 Linux 基金会在这块上并不是完全公正无私的,但即使是有私心或是因统计的不确定性而有失公允,事情也正朝着预料的正确方向迈进。
|
||||
|
||||
**Web 服务器**: 开源已经统治这个行业近20年 - 取得了一份很惊人的成绩。然而,最近在市场份额上出现了一些有趣的变动:一点就是,在 Web 服务器的总计数上,微软的 IIS 服务已经超越了 Apache 服务。但正如 Netcraft 公司其最近的[分析][3]解释所说的那样,这儿还有很多令人大饱眼福的地方呢:
|
||||
|
||||
> 这是网站总数持续大幅回落以来的第二个月,从一月份以来,本月达到了最低点。与十一月份情况一样,损失的仅仅只是集中在一小部分的主机提供商中,只占了5200万主机名数的十大点。这点损失相比于激活的站点和网站来说不是一个数据级的,所以造不成什么影响,但激活的这些站点大部分都是广告类的链接页面池,基本上没有原创的内容。大多数这些站点都是运行在微软的 IIS 服务器上的,所以在2014年7月份的调查中 IIS 的使用数就超过了 Apache。然而,近期跌势已导致其市场份额下降到 29.8%,现在已经低于Apache 10个百分点了。
|
||||
|
||||
这表明,微软的所谓“激增”更多的是表象,而事实并非如此,它的大多数增加都是基于没什么有用内容的链接页面池。事实上,Netcraft公司的关于活动网站的数据给我们描绘了一幅完全不同的图表:Apache 拥有 50.57% 的市场份额,nginx 的是 14.73% 位居第二;微软的 IIS 很无力,占到了相当微弱的 11.72%。这意味着在活跃 Web 服务器市场上开源大约有65%的份额 - 虽然没有超级计算机那么高的水平,但也还不错。
|
||||
|
||||
**移动设备系统**. 目前,开源的大军主要是 Andriod 为基础在不断高歌猛进。最新数据表明,在2014年第三季度的智能手机出货量中,Andriod 设备的市场份额从去年同期的 81.4% 上升到了 [83.6%][4]。苹果的从去年同期的 13.4% 下降到 12.3%。对于平板电脑来说,Android 平板遵循同样的轨迹:在2014年第二季度,Android 平板的占有率达到[全球平板电脑的销量的75%][5]左右,而苹果的只有25%。
|
||||
|
||||
**嵌入式系统**: 虽然很难量化 Linux 在的重要的嵌入式系统市场的市场份额,但来一个自 2013 年的研究数字表明,[按规划,大约一半的嵌入式系统][6]将会采用 Linux。
|
||||
|
||||
**物联网**: 在很多方面上可以把它们简单的认为是嵌入式系统的另外一个化身,不同之处在于它们被设计为一直在线的。虽然现在谈论它的市场份额还有点为时过早,但如我在[讨论栏目][7]里说的,AllSeen 的物联网开源框架正进行的如火如荼。他们所缺少的也最引入注目的事情只是还没有任何可信任的闭源项目对手。因此,很有可能物联网将会通过开源的方式来达到 Linux 在超级计算机中的占有率这样的水平。
|
||||
|
||||
当然了,这个阶段的成功也带来了一些问题:我们将何去何从?鉴于开源将会使很多成功的行业达到饱和点,想必唯一的办法就是下跌吗?要回答这个问题,我建议浏览下 Christopher Kelty 于2013年写的一篇供同行参阅、发人深省的文章,有个耐人寻味的标题“[天下没有免费的软件][8]”。下面是他的开头段:
|
||||
|
||||
> 自由软件并不存在。在我写了一整本书后,我莫名的忧伤。但这也是我写进文章的一个观点。自由软件和与它一体两面的开源正在不断的变化着。它并不是一直持续不变的,不稳定、不固定、不持久,这正是它的特色的一部分。
|
||||
|
||||
换句话说,无论2014年带给我们多少惊人的免费软件,我们也确信2015年会更多更丰富,因为进化是永无止境的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-3592314/
|
||||
|
||||
作者:[lyn Moody][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworlduk.com/author/glyn-moody/
|
||||
[1]:http://www.top500.org/statistics/list/
|
||||
[2]:http://www.linuxfoundation.org/publications/linux-foundation/linux-end-user-trends-report-2014
|
||||
[3]:http://news.netcraft.com/archives/2014/12/18/december-2014-web-server-survey.html
|
||||
[4]:http://www.cnet.com/news/android-stays-unbeatable-in-smartphone-market-for-now/
|
||||
[5]:http://timesofindia.indiatimes.com/tech/tech-news/Android-tablet-market-share-hits-70-in-Q2-iPads-slip-to-25-Survey/articleshow/38966512.cms
|
||||
[6]:http://linuxgizmos.com/embedded-developers-prefer-linux-love-android/
|
||||
[7]:http://www.computerworlduk.com/blogs/open-enterprise/allseen-3591023/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
@ -2,20 +2,19 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu默认自带了很多字体。但你或许对这些字体还不满意。因此,你可以做的是在**Ubuntu 14.04、 14.10或者像Linux Mint其他的系统中安装额外的字体**。
|
||||
Ubuntu默认自带了很多字体。但有时候你或许对这些字体还不满意。因此,你可以做的是在**Ubuntu 14.04、 14.10或者像Linux Mint之类的其它Linux系统中安装额外的字体**。
|
||||
|
||||
### 第一步: 获取字体 ###
|
||||
|
||||
第一步也是最重要的,下载你选择的字体。现在你或许在考虑从哪里下载字体。不要担心,Google搜索可以给你提供几个免费的字体网站。你可以先去看看[ Lost Type 的字体][1]。[Squirrel的字体][2]同样也是一个下载字体的好地方。
|
||||
第一步也是最重要的一步,下载你选择的字体。现在你或许在考虑从哪里下载字体。不要担心,Google搜索可以给你提供几个免费的字体网站。你可以先去看看[ Lost Type 的字体][1]。[Squirrel][2]同样也是一个下载字体的好地方。
|
||||
|
||||
### 第二步:在Ubuntu中安装新字体 ###
|
||||
|
||||
Font Viewer. In here, you can see the option to install the font in top right corner:
|
||||
下载的字体文件可能是一个压缩包。先解压它。大多数字体文件的格式是[TTF][3] (TrueType Fonts) 或者[OTF][4] (OpenType Fonts)。无论是哪种,只要双击字体文件。它会自动用字体查看器打开。这里你可以在右上角看到安装安装选项。
|
||||
下载的字体文件可能是一个压缩包,先解压它。大多数字体文件的格式是[TTF][3] (TrueType字体) 或者[OTF][4] (OpenType字体)。无论是哪种,只要双击字体文件。它会自动用字体查看器打开。这里你可以在右上角看到安装选项。
|
||||
|
||||

|
||||
|
||||
在安装字体时不会看到其他信息。几秒钟后,你会看到状态变成已安装。不用猜,这就是已安装的字体。
|
||||
在安装字体时不会看到其他信息。几秒钟后,你会看到状态变成已安装。不用猜,字体已经安装完毕。
|
||||
|
||||

|
||||
|
||||
@ -23,20 +22,20 @@ Font Viewer. In here, you can see the option to install the font in top right co
|
||||
|
||||
### 第二步:在Linux上一次安装几个字体 ###
|
||||
|
||||
我没有打错。这仍旧是第二步但是只是是一个备选方案。我上面看到的在Ubuntu中安装字体的方法是不错的。但是这有一个小问题。当你有20个新字体要安装时。一个个单独双击即繁琐又麻烦。你不这么认为么?
|
||||
我没有打错。这仍旧是第二步但是只是一个备选方案。我们上面看到的在Ubuntu中安装字体的方法是不错的。但是这有一个小问题。当你有20个新字体要安装时。一个个单独双击即繁琐又麻烦。你不这么认为么?
|
||||
|
||||
要在Ubuntu中一次安装几个字体,你要做的是创建一个.fonts文件夹,如果在你的家目录下还不存在这个目录的话。并把解压后的TTF和OTF文件复制到这个文件夹内。
|
||||
要在Ubuntu中一次安装几个字体,你唯一要做的是在你的家目录下创建一个.fonts文件夹,如果它不存在的话。并把解压后的TTF和OTF文件复制到这个文件夹内。
|
||||
|
||||
在文件管理器中进入家目录。按下Ctrl+H [显示Ubuntu中的隐藏文件][5]。 右键创建一个文件夹并命名为.fonts。 这里的点很重要。在Linux中,在文件的前面加上点意味在普通的视图中都会隐藏。
|
||||
|
||||
#### 备选方案: ####
|
||||
|
||||
另外你可以安装字体管理程序来以GUI的形式管理字体。要在Ubuntu中安装字体管理程序,打开终端并输入下面的命令:
|
||||
另外你可以安装字体管理程序,在图形用户界面管理字体。要在Ubuntu中安装字体管理程序,打开终端并输入下面的命令:
|
||||
|
||||
sudo apt-get install font-manager
|
||||
|
||||
Open the Font Manager from Unity Dash. You can see installed fonts and option to install new fonts, remove existing fonts etc here.
|
||||
从Unity Dash中打开字体管理器。你可以看到已安装的字体和安装新字体、删除字体等选项。
|
||||
|
||||
从Unity Dash中打开字体管理器。在这里你可以看到已安装的字体和安装新字体、删除字体等选项。
|
||||
|
||||

|
||||
|
||||
@ -44,7 +43,7 @@ Open the Font Manager from Unity Dash. You can see installed fonts and option to
|
||||
|
||||
sudo apt-get remove font-manager
|
||||
|
||||
我希望这篇文章可以帮助你在Ubuntu或其他Linux系统上安装字体。如果你有任何问题或建议请让我知道。
|
||||
我希望这篇文章可以帮助你在Ubuntu或其它Linux系统上安装字体。如果你有任何问题或建议请在下方评论中告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -52,7 +51,7 @@ via: http://itsfoss.com/install-fonts-ubuntu-1404-1410/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -61,4 +60,4 @@ via: http://itsfoss.com/install-fonts-ubuntu-1404-1410/
|
||||
[2]:http://www.fontsquirrel.com/
|
||||
[3]:http://en.wikipedia.org/wiki/TrueType
|
||||
[4]:http://en.wikipedia.org/wiki/OpenType
|
||||
[5]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
[5]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
@ -0,0 +1,64 @@
|
||||
Linux 有问必答:如何在Ubuntu或者Debian中启动后进入命令行
|
||||
================================================================================
|
||||
> **提问**:我运行的是Ubuntu桌面,但是我希望启动后临时进入命令行。有什么简便的方法可以启动进入终端?
|
||||
|
||||
Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),它们可以让计算机启动自动进入一个基于GUI的登录环境。然而,如果你要直接启动进入终端怎么办? 比如,你在排查桌面相关的问题或者想要运行一个不需要GUI的应用程序。
|
||||
|
||||
注意虽然你可以通过按下Ctrl+Alt+F1到F6临时从桌面GUI切换到虚拟终端。然而,在这种情况下你的桌面GUI仍在后台运行,这不同于纯文本模式启动。
|
||||
|
||||
在Ubuntu或者Debian桌面中,你可以通过传递合适的内核参数在启动时启动文本模式。
|
||||
|
||||
### 启动临时进入命令行 ###
|
||||
|
||||
如果你想要禁止桌面GUI并临时进入一次文本模式,你可以使用GRUB菜单。
|
||||
|
||||
首先,打开你的电脑。当你看到初始的GRUB菜单时,按下‘e’。
|
||||
|
||||
|
||||
|
||||
接着会进入下一屏,这里你可以修改内核启动选项。向下滚动到以“linux”开始的行,这里就是内核参数的列表。删除参数列表中的“quiet”和“splash”。在参数列表中添加“text”。
|
||||
|
||||
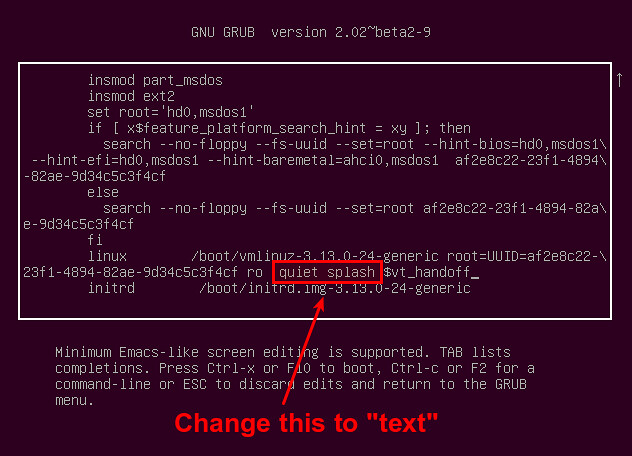
|
||||
|
||||
升级的内核选项列表看上去像这样。按下Ctrl+x继续启动。这会以详细模式启动控制台一次(LCTT译注:由于没有保存修改,所以下次重启还会进入 GUI)。
|
||||
|
||||

|
||||
|
||||
### 永久启动进入命令行 ###
|
||||
|
||||
如果你想要永久启动进入命令行,你需要[更新定义了内核启动参数GRUB设置][1]。
|
||||
|
||||
在文本编辑器中打开默认的GRUB配置文件。
|
||||
|
||||
$ sudo vi /etc/default/grub
|
||||
|
||||
查找以GRUB\_CMDLINE\_LINUX\_DEFAULT开头的行,并用“#”注释这行。这会禁止初始屏幕,而启动详细模式(也就是说显示详细的的启动过程)。
|
||||
|
||||
更改GRUB_CMDLINE_LINUX="" 成:
|
||||
|
||||
GRUB_CMDLINE_LINUX="text"
|
||||
|
||||
接下来取消“#GRUB_TERMINAL=console”的注释。
|
||||
|
||||
更新后的GRUB配置看上去像下面这样。
|
||||
|
||||
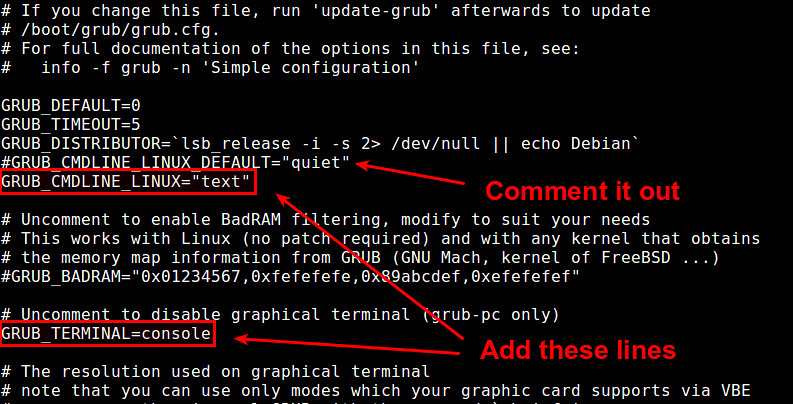
|
||||
|
||||
最后,使用update-grub命令来基于这些更改重新生成/boot下的GRUB2配置文件。
|
||||
|
||||
$ sudo update-grub
|
||||
|
||||
这时,你的桌面应该可以从GUI启动切换到控制台启动了。可以通过重启验证。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/boot-into-command-line-ubuntu-debian.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/add-kernel-boot-parameters-via-grub-linux.html
|
||||
@ -0,0 +1,50 @@
|
||||
交友网站的2000万用户数据遭泄露
|
||||
----------
|
||||
*泄露数据包括Gmail、Hotmail以及Yahoo邮箱*
|
||||
|
||||

|
||||
|
||||
#一名黑客非法窃取了在线交友网站Topface一个包含2000万用户资料的数据库。
|
||||
|
||||
目前并不清楚这些数据是否已经公开,但是根据某些未公开页面的消息说,某个网名为“Mastermind”的人声称掌握着这些数据。
|
||||
|
||||
#泄露数据列表涵盖了全世界数百个域名
|
||||
|
||||
此人号称泄露数据的内容100%真实有效,而Easy Solutions的CTO,Daniel Ingevaldson 周日在一篇博客中说道,泄露数据包括Hotmail、Yahoo和Gmail等邮箱地址。
|
||||
|
||||
Easy Solutions是一家位于美国的公司,提供多个不同平台的网络检测与安全防护产品。
|
||||
|
||||
据Ingevaldson所说,泄露的数据中,700万来自于Hotmail,250万来自于Yahoo,220万来自于Gmail.com。
|
||||
|
||||
我们并不清楚这些数据是可以直接登录邮箱账户的用户名和密码,还是登录交友网站的账户。另外,也不清楚这些数据在数据库中是加密状态还是明文存在的。
|
||||
|
||||
邮箱地址常常被用于在线网站的登录用户名,用户可以凭借唯一密码进行登录。然而重复使用同一个密码是许多用户的常用作法,同一个密码可以登录许多在线账户。
|
||||
|
||||
[Ingevaldson 还说](1):“看起来,这些数据事实上涵盖了全世界数百个域名。除了原始被黑的网页,黑客和不法分子很可能利用窃取的帐密进行暴库、自动扫描、危害包括银行业、旅游业以及email提供商在内的多个网站。”
|
||||
|
||||
#预计将披露更多信息
|
||||
|
||||
据我们的多个消息源爆料,数据的泄露源就是Topface,一个包含9000万用户的在线交友网站。其总部位于俄罗斯圣彼得堡,超过50%的用户来自于俄罗斯以外的国家。
|
||||
|
||||
我们联系了Topface,向他们求证最近是否遭受了可能导致如此大量数据泄露的网络攻击;但目前我们仍未收到该公司的回复。
|
||||
|
||||
攻击者可能无需获得非法访问权限就窃取了这些数据,Easy Solutions 推测攻击者很可能针对网站客户端使用钓鱼邮件直接获取到了用户数据。
|
||||
|
||||
我们无法通过Easy Solutions的在线网站联系到他们,但我们已经尝试了其他交互通讯方式,目前正在等待更多信息的披露。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
|
||||
本文发布时间:26 Jan 2015, 10:20 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://newblog.easysol.net/dating-site-breached/
|
||||
@ -1,47 +1,49 @@
|
||||
在CentOS7.0 VPS上搭建 Bind Chroot DNS 服务器
|
||||
在 CentOS7.0 上搭建 Chroot 的 Bind DNS 服务器
|
||||
====================
|
||||
|
||||
BIND(Berkeley internet Name Daemon)也叫做NAMED是现今互联网上使用最为广泛的DNS 服务器程序。这篇文章将要讲述如何在 chroot jail (chroot “监牢”,所谓“监牢”就是指通过chroot机制来更改某个进程所能看到的根目录,即将某进程限制在指定目录中,保证该进程只能对该目录及其子目录的文件有所动作,从而保证整个服务器的安全)中运行 BIND,这样它就无法访问文件系统中除“jail”以外的其它部分。例如,在这篇文章中,我会将BIND的运行根目录改为/var/named/chroot/。当然,对于BIND来说,这个目录就是/(根目录)。 “jail”(监牢,下同)是一个软件机制,其功能是使得某个程序无法访问规定区域之外的资源,同样也为了增强安全性。Bind Chroot DNS 服务器的默认“jail”为/var/named/chroot。你可以按照下列步骤,在CentOS 7.0 虚拟专用服务器(VPS)上部署 Bind Chroot DNS 服务器。
|
||||
BIND(Berkeley internet Name Daemon)也叫做NAMED,是现今互联网上使用最为广泛的DNS 服务器程序。这篇文章将要讲述如何在 chroot 监牢中运行 BIND,这样它就无法访问文件系统中除“监牢”以外的其它部分。
|
||||
|
||||
1. 安装Bind Chroot DNS 服务器:
|
||||
例如,在这篇文章中,我会将BIND的运行根目录改为 /var/named/chroot/。当然,对于BIND来说,这个目录就是 /(根目录)。 “jail”(监牢,下同)是一个软件机制,其功能是使得某个程序无法访问规定区域之外的资源,同样也为了增强安全性(LCTT 译注:chroot “监牢”,所谓“监牢”就是指通过chroot机制来更改某个进程所能看到的根目录,即将某进程限制在指定目录中,保证该进程只能对该目录及其子目录的文件进行操作,从而保证整个服务器的安全)。Bind Chroot DNS 服务器的默认“监牢”为 /var/named/chroot。你可以按照下列步骤,在CentOS 7.0 上部署 Bind Chroot DNS 服务器。
|
||||
|
||||
[root@centos7 ~]# yum install bind-chroot bind -y
|
||||
### 1、安装Bind Chroot DNS 服务器
|
||||
|
||||
2. 拷贝bind相关文件,准备bind chroot 环境
|
||||
[root@centos7 ~]# yum install bind-chroot bind -y
|
||||
|
||||
[root@centos7 ~]# cp -R /usr/share/doc/bind-*/sample/var/named/* /var/named/chroot/var/named/
|
||||
### 2、拷贝bind相关文件,准备bind chroot 环境
|
||||
|
||||
3. 在bind chroot 的目录中创建相关文件
|
||||
[root@centos7 ~]# cp -R /usr/share/doc/bind-*/sample/var/named/* /var/named/chroot/var/named/
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/cache_dump.db
|
||||
### 3、在bind chroot 的目录中创建相关文件
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named_stats.txt
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/cache_dump.db
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named_mem_stats.txt
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named_stats.txt
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named.run
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named_mem_stats.txt
|
||||
|
||||
[root@centos7 ~]# mkdir /var/named/chroot/var/named/dynamic
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named.run
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/dynamic/managed-keys.bind
|
||||
[root@centos7 ~]# mkdir /var/named/chroot/var/named/dynamic
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/dynamic/managed-keys.bind
|
||||
|
||||
|
||||
4. 将 Bind 锁定文件设置为可写:
|
||||
### 4、 将 Bind 锁定文件设置为可写
|
||||
|
||||
[root@centos7 ~]# chmod -R 777 /var/named/chroot/var/named/data
|
||||
[root@centos7 ~]# chmod -R 777 /var/named/chroot/var/named/dynamic
|
||||
[root@centos7 ~]# chmod -R 777 /var/named/chroot/var/named/data
|
||||
[root@centos7 ~]# chmod -R 777 /var/named/chroot/var/named/dynamic
|
||||
|
||||
5. 将 /etc/named.conf 拷贝到 bind chroot目录
|
||||
### 5、 将 /etc/named.conf 拷贝到 bind chroot目录
|
||||
|
||||
[root@centos7 ~]# cp -p /etc/named.conf /var/named/chroot/etc/named.conf
|
||||
[root@centos7 ~]# cp -p /etc/named.conf /var/named/chroot/etc/named.conf
|
||||
|
||||
6. 在/etc/named.conf中对 bind 进行配置。在文件尾添加 example.local 域信息:
|
||||
### 6、 在/etc/named.conf中对 bind 进行配置。
|
||||
|
||||
[root@centos7 ~]# vi /var/named/chroot/etc/named.conf
|
||||
|
||||
在 named.conf 中创建转发域(Forward Zone)与反向域(Reverse Zone):
|
||||
在 named.conf 文件尾添加 **example.local** 域信息, 创建转发域(Forward Zone)与反向域(Reverse Zone)(LCTT 译注:这里example.local 并非一个真实有效的互联网域名,而是通常用于本地测试的一个域名;如果你需要做权威 DNS 解析,你可以将你拥有的域名如这里所示配置解析。):
|
||||
|
||||
[root@centos7 ~]# vi /var/named/chroot/etc/named.conf
|
||||
|
||||
--
|
||||
..
|
||||
..
|
||||
zone "example.local" {
|
||||
@ -56,7 +58,7 @@ BIND(Berkeley internet Name Daemon)也叫做NAMED是现今互联网上使用
|
||||
..
|
||||
..
|
||||
|
||||
named.conf 完全配置
|
||||
named.conf 完全配置如下:
|
||||
|
||||
//
|
||||
// named.conf
|
||||
@ -123,9 +125,9 @@ named.conf 完全配置
|
||||
include "/etc/named.rfc1912.zones";
|
||||
include "/etc/named.root.key";
|
||||
|
||||
7. 为 example.local 域名创建转发域与反向域文件
|
||||
### 7、 为 example.local 域名创建转发域与反向域文件
|
||||
|
||||
a)创建转发域
|
||||
#### a)创建转发域
|
||||
|
||||
[root@centos7 ~]# vi /var/named/chroot/var/named/example.local.zone
|
||||
|
||||
@ -154,11 +156,11 @@ a)创建转发域
|
||||
ns1 IN A 192.168.0.70
|
||||
ns2 IN A 192.168.0.80
|
||||
|
||||
b)创建反向域
|
||||
#### b)创建反向域
|
||||
|
||||
[root@centos7 ~]# vi /var/named/chroot/var/named/192.168.0.zone
|
||||
|
||||
----
|
||||
--
|
||||
|
||||
;
|
||||
; Addresses and other host information.
|
||||
@ -175,7 +177,9 @@ b)创建反向域
|
||||
|
||||
70.0.168.192.in-addr.arpa. IN PTR mx.example.local.
|
||||
70.0.168.192.in-addr.arpa. IN PTR ns1.example.local.
|
||||
80.0.168.192.in-addr.arpa. IN PTR ns2.example.local.。开机自启动 bind-chroot 服务:
|
||||
80.0.168.192.in-addr.arpa. IN PTR ns2.example.local.。
|
||||
|
||||
### 8、开机自启动 bind-chroot 服务:
|
||||
|
||||
[root@centos7 ~]# /usr/libexec/setup-named-chroot.sh /var/named/chroot on
|
||||
[root@centos7 ~]# systemctl stop named
|
||||
@ -184,15 +188,13 @@ b)创建反向域
|
||||
[root@centos7 ~]# systemctl enable named-chroot
|
||||
ln -s '/usr/lib/systemd/system/named-chroot.service' '/etc/systemd/system/multi-user.target.wants/named-chroot.service'
|
||||
|
||||
[跳转到档案页,阅读更多文章][1]
|
||||
|
||||
------------------
|
||||
|
||||
via: http://www.ehowstuff.com/how-to-setup-bind-chroot-dns-server-on-centos-7-0-vps/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
Linux下如何过滤、分割以及合并 pcap 文件
|
||||
=============
|
||||
|
||||
如果你是个网络管理员,并且你的工作包括测试一个[入侵侦测系统][1]或一些网络访问控制策略,那么你通常需要抓取数据包并且在离线状态下分析这些文件。当需要保存捕获的数据包时,我们会想到 libpcap 的数据包格式被广泛使用于许多开源的嗅探工具以及捕包程序。如果 pcap 文件被用于入侵测试或离线分析的话,那么在将他们[注入][2]网络之前通常要先对 pcap 文件进行一些操作。
|
||||
如果你是一个测试[入侵侦测系统][1]或一些网络访问控制策略的网络管理员,那么你经常需要抓取数据包并在离线状态下分析这些文件。当需要保存捕获的数据包时,我们一般会存储为 libpcap 的数据包格式 pcap,这是一种被许多开源的嗅探工具以及捕包程序广泛使用的格式。如果 pcap 文件被用于入侵测试或离线分析的话,那么在将他们[注入][2]网络之前通常要先对 pcap 文件进行一些操作。
|
||||
|
||||
|
||||
|
||||
@ -9,9 +9,9 @@ Linux下如何过滤、分割以及合并 pcap 文件
|
||||
|
||||
### Editcap 与 Mergecap###
|
||||
|
||||
Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非常有用的命令行工具集。其中包括 editcap 与 mergecap。editcap 是一个万能的 pcap 编辑器,它可以过滤并且能以多种方式来分割 pcap 文件。mergecap 可以将多个 pcap 文件合并为一个。 这篇文章就是基于这些 Wireshark 命令行工具。
|
||||
Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它带了一套非常有用的命令行工具集。其中包括 editcap 与 mergecap。editcap 是一个万能的 pcap 编辑器,它可以过滤并且能以多种方式来分割 pcap 文件。mergecap 可以将多个 pcap 文件合并为一个。 这篇文章就是基于这些 Wireshark 命令行工具的。
|
||||
|
||||
如果你已经安装过Wireshark了,那么这些工具已经在你的系统中了。如果还没装的话,那么我们接下来就安装 Wireshark 命令行工具。 需要注意的是,在基于 Debian 的发行版上我们可以不用安装 Wireshark GUI 而仅安装 命令行工具,但是在 Red Hat 及 基于它的发行版中则需要安装整个 Wireshark 包。
|
||||
如果你已经安装过 Wireshark 了,那么这些工具已经在你的系统中了。如果还没装的话,那么我们接下来就安装 Wireshark 命令行工具。 需要注意的是,在基于 Debian 的发行版上我们可以不用安装 Wireshark GUI 而仅安装命令行工具,但是在 Red Hat 及 基于它的发行版中则需要安装整个 Wireshark 包。
|
||||
|
||||
**Debian, Ubuntu 或 Linux Mint**
|
||||
|
||||
@ -27,15 +27,15 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
|
||||
通过 editcap, 我们能以很多不同的规则来过滤 pcap 文件中的内容,并且将过滤结果保存到新文件中。
|
||||
|
||||
首先,以“起止时间”来过滤 pcap 文件。 " - A < start-time > and " - B < end-time > 选项可以过滤出处在这个时间段到达的数据包(如,从 2:30 ~ 2:35)。时间的格式为 “ YYYY-MM-DD HH:MM:SS"。
|
||||
首先,以“起止时间”来过滤 pcap 文件。 " - A < start-time > 和 " - B < end-time > 选项可以过滤出在这个时间段到达的数据包(如,从 2:30 ~ 2:35)。时间的格式为 “ YYYY-MM-DD HH:MM:SS"。
|
||||
|
||||
$ editcap -A '2014-12-10 10:11:01' -B '2014-12-10 10:21:01' input.pcap output.pcap
|
||||
$ editcap -A '2014-12-10 10:11:01' -B '2014-12-10 10:21:01' input.pcap output.pcap
|
||||
|
||||
也可以从某个文件中提取指定的 N 个包。下面的命令行从 input.pcap 文件中提取100个包(从 401 到 500)并将它们保存到 output.pcap 中:
|
||||
|
||||
$ editcap input.pcap output.pcap 401-500
|
||||
|
||||
使用 "-D< dup-window >" (dup-window可以看成是对比的窗口大小,仅与此范围内的包进行对比)选项可以提取出重复包。每个包都依次与它之前的 < dup-window > -1 个包对比长度与MD5值,如果有匹配的则丢弃。
|
||||
使用 "-D < dup-window >" (dup-window可以看成是对比的窗口大小,仅与此范围内的包进行对比)选项可以提取出重复包。每个包都依次与它之前的 < dup-window > -1 个包对比长度与MD5值,如果有匹配的则丢弃。
|
||||
|
||||
$ editcap -D 10 input.pcap output.pcap
|
||||
|
||||
@ -71,13 +71,13 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
|
||||
如果要忽略时间戳,仅仅想以命令行中的顺序来合并文件,那么使用 -a 选项即可。
|
||||
|
||||
例如,下列命令会将 input.pcap文件的内容写入到 output.pcap, 并且将 input2.pcap 的内容追加在后面。
|
||||
例如,下列命令会将 input.pcap 文件的内容写入到 output.pcap, 并且将 input2.pcap 的内容追加在后面。
|
||||
|
||||
$ mergecap -a -w output.pcap input.pcap input2.pcap
|
||||
|
||||
###总结###
|
||||
|
||||
在这篇指导中,我演示了多个 editcap、 mergecap 操作 pcap 文件的案例。除此之外,还有其它的相关工具,如 [reordercap][3]用于将数据包重新排序,[text2pcap][4] 用于将pcap 文件转换为 文本格式, [pcap-diff][5]用于比较 pcap 文件的异同,等等。当进行网络入侵测试及解决网络问题时,这些工具与[包注入工具][6]非常实用,所以最好了解他们。
|
||||
在这篇指导中,我演示了多个 editcap、 mergecap 操作 pcap 文件的例子。除此之外,还有其它的相关工具,如 [reordercap][3]用于将数据包重新排序,[text2pcap][4] 用于将 pcap 文件转换为文本格式, [pcap-diff][5]用于比较 pcap 文件的异同,等等。当进行网络入侵测试及解决网络问题时,这些工具与[包注入工具][6]非常实用,所以最好了解他们。
|
||||
|
||||
你是否使用过 pcap 工具? 如果用过的话,你用它来做过什么呢?
|
||||
|
||||
@ -86,8 +86,8 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
via: http://xmodulo.com/filter-split-merge-pcap-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
systemd-nspawn 指南
|
||||
systemd-nspawn 快速指南
|
||||
===========================
|
||||
我目前已从 chroot(译者注:chroot可以构建类似沙盒的环境,建议各位同学先了解chroot) 迁移到 systemd-nspawn,同时我写了一篇快速指南。简单的说,我强烈建议正在使用 systemd 的用户从 chroot 转为 systemd-nspawn,因为只要你的内核配置正确的话,它几乎没有什么缺点。
|
||||
|
||||
@ -6,11 +6,11 @@ systemd-nspawn 指南
|
||||
|
||||
###chroot 面临的挑战
|
||||
|
||||
大多数交互环境下,仅运行chroot还不够。通常还要挂载 /proc, /sys,另外为了确保不会出现类似“丢失 ptys”之类的错误,我们还得 bind(译者注:bind 是 mount 的一个选项) 挂载 /dev。如果你使用 tmpfs,你可能想要以 tmpfs 类型挂载新的 tmp, var/tmp。接下来你可能还想将其他的挂载点 bind 到 chroot 中。这些都不是特别难,但是一般情况下要写一个脚本来管理它。
|
||||
大多数交互环境下,仅运行chroot还不够。通常还要挂载 /proc, /sys,另外为了确保不会出现类似“丢失 ptys”之类的错误,我们还得 bind(译者注:bind 是 mount 的一个选项) 挂载 /dev。如果你使用 tmpfs,你可能想要以 tmpfs 类型挂载新的 tmp、 var/tmp。接下来你可能还想将其他的挂载点 bind 到 chroot 中。这些都不是特别难,但是一般情况下要写一个脚本来管理它。
|
||||
|
||||
现在我按照日常计划执行备份操作,当然有一些不必备份的数据如 tmp 目录,或任何 bind 挂载的内容。当我配置了一个新的 chroot 意味着我要更新我的备份配置了,但我经常忘记这点,因为大多数时间里 chroot 挂载点并没有运行。当这些挂载点任然存在的情况下执行备份的话,那么备份中会多出很多不需要的内容。
|
||||
现在我按照日常计划执行备份操作,当然有一些不必备份的数据如 tmp 目录,或任何 bind 挂载的内容。当我配置了一个新的 chroot 后就意味着我要更新我的备份配置了,但我经常忘记这点,因为大多数时间里 chroot 挂载点并没有运行。当这些挂载点仍然存在的情况下执行备份的话,那么备份中会多出很多不需要的内容。
|
||||
|
||||
当 bind 挂载点包含其他挂载点时(比如挂载时使用 -rbind 选项),这种情况下 systemd 的默认处理方式略有不同。在 bind 挂载中卸载一些东西时,systemd 会将处于 bind 另一边的目录也卸载掉。想像一下,如果我卸载了 chroot 中以bind 挂载 /dev 的某个目录后发现主机上的 /dev/pts 与 /dev/shm 也不见了,我肯定会很吃惊。不过好像有其他方法可以避免,但是这不是我们此次讨论的重点。
|
||||
当 bind 挂载点包含其他挂载点时(比如挂载时使用 -rbind 选项),这种情况下 systemd 的默认处理方式略有不同。在 bind 挂载中卸载一些东西时,systemd 会将处于 bind 另一边的目录也卸载掉。想像一下,如果我卸载了 chroot 中以 bind 挂载 /dev 的某个目录后,发现主机上的 /dev/pts 与 /dev/shm 也不见了,我肯定会很吃惊。不过好像有其他方法可以避免,但是这不是我们此次讨论的重点。
|
||||
|
||||
### Systemd-nspawn 优点
|
||||
|
||||
@ -39,25 +39,25 @@ Systemd-nspawn 用于启动一个容器,并且它的最简模式就可以像 c
|
||||
|
||||
像 chroot 那样启动 namespace 是非常简单的:
|
||||
|
||||
systemd-nspawn -D .
|
||||
systemd-nspawn -D .
|
||||
|
||||
也可以像 chroot 那样退出。在内部可以运行 mount 并且可以看到默认它已将 /dev 与 /tmp 准备好了。 ”.“就是 chroot 的路径,也就是当前路径。在它内部运行的是 bash。
|
||||
|
||||
如果要添加一些 bind 挂载点也非常简便:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage
|
||||
systemd-nspawn -D . --bind /usr/portage
|
||||
|
||||
现在,容器中的 /usr/portage 就与主机的对应目录绑定起来了,我们无需 sync /etc。如果想要绑定到指定的路径,只要在原路径后添加 ”:dest“,相当于 chroot 的 root(--bind foo 与 --bind foo:foo是一样的)。
|
||||
现在,容器中的 /usr/portage 就与主机的对应目录绑定起来了,我们无需 sync /etc。如果想要绑定到指定的路径,只要在原路径后添加 ”:dest“,相当于 chroot 的 root(--bind foo 与 --bind foo:foo是一样的)。
|
||||
|
||||
如果容器具有 init 功能并且可以在内部运行,可以通过添加 -b 选项启动它:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage -b
|
||||
systemd-nspawn -D . --bind /usr/portage -b
|
||||
|
||||
可以观察到 init 的运作。关闭容器会自动退出。
|
||||
|
||||
如果容器内运行了 systemd ,你可以使用 -h 选项将它的日志重定向到主机的systemd日志:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage -j -b
|
||||
systemd-nspawn -D . --bind /usr/portage -j -b
|
||||
|
||||
使用 nspawn 注册容器以便它能够在 machinectl 中显示。如此可以方便的在主机上对它进行操作,如启动新的 getty, ssh 连接,关机等。
|
||||
|
||||
@ -68,8 +68,8 @@ Systemd-nspawn 用于启动一个容器,并且它的最简模式就可以像 c
|
||||
via: http://rich0gentoo.wordpress.com/2014/07/14/quick-systemd-nspawn-guide/
|
||||
|
||||
作者:[rich0][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,35 +0,0 @@
|
||||
Turla espionage operation infects Linux systems with malware
|
||||
================================================================================
|
||||

|
||||
|
||||
> A newly identified Linux backdoor program is tied to the Turla cyberespionage campaign, researchers from Kaspersky Lab said
|
||||
|
||||
A newly discovered malware program designed to infect Linux systems is tied to a sophisticated cyberespionage operation of Russian origin dubbed Epic Turla, security researchers found.
|
||||
|
||||
The Turla campaign, also known as Snake or Uroburos, [was originally uncovered in February][1], but goes back several years. The massive operation infected computers at government organizations, embassies, military installations, education and research institutions and pharmaceutical companies in over 45 countries.
|
||||
|
||||
The newly identified Turla component for Linux was uploaded recently to a multi-engine antivirus scanning service and was described by security researchers from antivirus vendor Kaspersky Lab as "a previously unknown piece of a larger puzzle."
|
||||
|
||||
"So far, every single Turla sample we've encountered was designed for the Microsoft Windows family, 32 and 64 bit operating systems," the Kaspersky researchers said Monday in a [blog post][2]. "The newly discovered Turla sample is unusual in the fact that it's the first Turla sample targeting the Linux operating system that we have discovered."
|
||||
|
||||
The Turla Linux malware is based on an open-source backdoor program called cd00r developed in 2000. It allows attackers to execute arbitrary commands on a compromised system, but doesn't require elevated privileges or root access to function and listens to commands received via hidden TCP/UDP packets, making it stealthy.
|
||||
|
||||
"It can't be discovered via netstat, a commonly used administrative tool," said the Kaspersky researchers, who are still analyzing the malware's functionality.
|
||||
|
||||
"We suspect that this component was running for years at a victim site, but do not have concrete data to support that statement just yet," they said.
|
||||
|
||||
Since their blog post Monday, the Kaspersky researchers also found a second Turla Linux component that appears to be a separate malware program.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/2857129/turla-espionage-operation-infects-linux-systems-with-malware.html
|
||||
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Lucian-Constantin/
|
||||
[1]:http://news.techworld.com/security/3505688/invisible-russian-cyberweapon-stalked-us-and-ukraine-since-2005-new-research-reveals/
|
||||
[2]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
@ -1,25 +0,0 @@
|
||||
Git 2.2.1 Released To Fix Critical Security Issue
|
||||
================================================================================
|
||||
|
||||
|
||||
Git 2.2.1 was released this afternoon to fix a critical security vulnerability in Git clients. Fortunately, the vulnerability doesn't plague Unix/Linux users but rather OS X and Windows.
|
||||
|
||||
Today's Git vulnerability affects those using the Git client on case-insensitive file-systems. On case-insensitive platforms like Windows and OS X, committing to .Git/config could overwrite the user's .git/config and could lead to arbitrary code execution. Fortunately with most Phoronix readers out there running Linux, this isn't an issue thanks to case-sensitive file-systems.
|
||||
|
||||
Besides the attack vector from case insensitive file-systems, Windows and OS X's HFS+ would map some strings back to .git too if certain characters are present, which could lead to overwriting the Git config file. Git 2.2.1 addresses these issues.
|
||||
|
||||
More details via the [Git 2.2.1 release announcement][1] and [GitHub has additional details][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=MTg2ODA
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://article.gmane.org/gmane.linux.kernel/1853266
|
||||
[2]:https://github.com/blog/1938-git-client-vulnerability-announced
|
||||
@ -1,28 +0,0 @@
|
||||
New 64-bit Linux Kernel Vulnerabilities Disclosed This Week
|
||||
================================================================================
|
||||

|
||||
|
||||
For those that didn't hear the news yet, multiple Linux x86_64 vulnerabilities were made public this week.
|
||||
|
||||
With CVE-2014-9322 that's now public, there's a local privilege escalation issue affecting all kernel versions prior to Linux 3.17.5. CVE-2014-9322 is described as "privilege escalation due to incorrect handling of a #SS fault caused
|
||||
by an IRET instruction. In particular, if IRET executes on a writeable kernel stack (this was always the case before 3.16 and is sometimes the case on 3.16 and newer), the assembly function general_protection will execute with the user's gsbase and the kernel's gsbase swapped. This is likely to be easy to exploit for privilege escalation, except on systems with SMAP or UDEREF. On those systems, assuming that the mitigation works correctly, the impact of this bug may be limited to massive memory corruption and an eventual crash or reboot."
|
||||
|
||||
Fortunately, it's fixed [in Linux kernel Git since late November][1]. CVE-2014-9322 is linked to CVE-2014-9090, which is also corrected by the fixes in Git.
|
||||
|
||||
There's also two x86_64 kernel bugs related to espfix. "The next two bugs are related to espfix. The IRET instruction has IMO a blatant design flaw: IRET to a 16-bit user stack segment will leak bits 31:16 of the kernel stack pointer. This flaw exists on 32-bit and 64-bit systems. 32-bit Linux kernels have mitigated this leak for a long time, and 64-bit Linux kernels have mitigated this leak since 3.16. The mitigation is called espfix."
|
||||
|
||||
Fixes for CVE-2014-8133 and CVE-2014-8134 are in KVM and Linux kernel Git as of a few days ago. More details on these x86_64 vulnerabilities via [this oss-sec posting][2]. These issues were uncovered by Andy Lutomirski at AMA Capital Management.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=MTg2NzY
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/arch/x86/kernel/entry_64.S?id=6f442be2fb22be02cafa606f1769fa1e6f894441
|
||||
[2]:http://seclists.org/oss-sec/2014/q4/1052
|
||||
@ -0,0 +1,33 @@
|
||||
Ubuntu 15.04 to Integrate Linux Kernel 3.19 Branch Soon
|
||||
----
|
||||
*A new kernel branch is being tracked by Ubuntu*
|
||||
|
||||
|
||||
|
||||
#The Linux kernel is one of the most important components in a distribution and Ubuntu users are interested to know what will be used in the stable edition for the 15.04 branch, which is scheduled to arrive in a couple of months.
|
||||
|
||||
The Ubuntu and the Linux kernel development cycles are not in sync and it's hard to anticipate what version will eventually land in Ubuntu 15.04. For now, Ubuntu 15.04 (Vivid Vervet) is using Linux kernel 3.18, but the developers are already looking to implement the 3.19 branch.
|
||||
|
||||
"Our Vivid kernel remains based on the v3.18.2 upstream stable kernel, but we'll be rebasing to v3.18.3 shortly. We'll also be re-basing our unstable branch to v3.19-rc5 and get that uploaded to our team PPA soon," [said](1) Canonical's Joseph Salisbury.
|
||||
|
||||
Linux kernel 3.19 is still under development and it will take a few weeks to see a stable version, but it's enough time to implement it in Ubuntu and test it properly. It won't be possible to get the 3.20 branch, for example, even if it launches before the April 23.
|
||||
|
||||
You can [download Ubuntu 15.04](2) right now from Softpedia and give it a spin. It's a daily build and it contains all the improvements made so far to the distribution.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
|
||||
本文发布时间:25 Jan 2015, 20:39 GMT
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://lists.ubuntu.com/archives/ubuntu-devel/2015-January/038644.html
|
||||
[2]:http://linux.softpedia.com/get/Linux-Distributions/Ubuntu-Vivid-Vervet-103651.shtml
|
||||
@ -0,0 +1,49 @@
|
||||
Bug in Wi-Fi Direct Android Implementation Causes Denial of Service
|
||||
----
|
||||
*Google marks the issue as having low severity, is not in a hurry to fix it*
|
||||
|
||||

|
||||
|
||||
#A vulnerability in the way Android handles Wi-Fi Direct connections leads to rebooting the device when searching for peers to connect to, which can be anything from other phones, cameras, gaming devices, computers, or printers.
|
||||
|
||||
The Wi-Fi Direct technology allows devices capable of wireless connection to establish communication directly, without the need to join a local network.
|
||||
|
||||
##Security company insisted on proper coordination for a fix
|
||||
|
||||
The vulnerability allows an attacker to send a specially crafted 802.11 Probe Response frame to the device and crashes it due to an unhandled exception occurring on the WiFi monitoring class.
|
||||
|
||||
Core Security discovered the flaw (CVE-2014-0997) through its CoreLabs team, and reported it to Google back in September 2014. The vendor acknowledged it but classified the glitch as having low severity, with no timeline for a fix being provided.
|
||||
|
||||
The same answer was received by Core Security each time they contacted the Android security team to inform of a timeframe for rolling out a fix. The last reply of this kind was received on January 20, meaning that there is no patch for the time being. On Monday, the security company made their findings public.
|
||||
|
||||
The security company created a (proof-of-concept)[1] to demonstrate the validity of the results obtained during their research.
|
||||
|
||||
According to the technical details of the vulnerability, some Android devices can be induced a denial-of-service condition if they receive a malformed wpa_supplicant event, which makes available the interface between the wireless driver and the Android platform framework.
|
||||
|
||||
##Google is not in a hurry to eliminate the problem
|
||||
|
||||
The relaxed stance from the Android security team regarding the issue may be on account of the fact that denial-of-service condition occurs only for a short period of time, when scanning for peers.
|
||||
|
||||
More than this, the result is not severe in nature as it consists in rebooting the device. There is no risk of data exfiltration or an attack that could lead to this, which would make it unappealing to a threat actor. On the other hand, a patch should be provided regardless, in order to mitigate any potential future risks.
|
||||
|
||||
Core Security says that the issue was not detected on Android 5.0.1 and above, and among the devices affected they found Nexus 5 and 4 running version 4.4.4 of the mobile operating system, LG D806 and Samsung SM-T310 with Android 4.2.2, and Motorola RAZR HD with build 4.1.2 of the OS.
|
||||
|
||||
For the time being, mitigation consists in refraining from using Wi-Fi Direct or updating to a non-vulnerable version of Android.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Bug-In-Wi-Fi-Direct-Android-Implementation-Causes-Denial-of-Service-471299.shtml
|
||||
|
||||
本文发布时间:27 Jan 2015, 09:11 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://www.coresecurity.com/advisories/android-wifi-direct-denial-service
|
||||
@ -1,148 +0,0 @@
|
||||
Top 4 Linux download managers
|
||||
================================================================================
|
||||
**Improve and better manage your web downloads for mirroring, mass grabs or just better control over your files**
|
||||
|
||||
Download managers seem to be old news these days, but there are still some excellent uses for them. We compare the top four of them on Linux.
|
||||
|
||||
### [uGet][1] ###
|
||||
|
||||
Advertised as lightweight and full- featured like a majority of other Linux apps, uGet can handle multi- threaded streams, includes filters and can integrate with an undefined selection of web browsers. It’s been around for over ten years now, starting out as UrlGet, and can also run on Windows.
|
||||
|
||||

|
||||
uGet is actually very full-featured, with a lot of the kind of functions that advanced torrent clients use
|
||||
|
||||
#### Interface ####
|
||||
|
||||
uGet reminds us of any number of torrent client interfaces, with categories for Active, Finished, Paused and so on for the different downloads. Although there is a lot of information to take in, it’s all presented very cleanly and clearly. The main downloading controls are easy to access, with more advanced ones alongside them.
|
||||
|
||||
#### Integration ####
|
||||
|
||||
While it can see into the clipboard for URLs, uGet doesn’t natively integrate into browsers like Chromium and Firefox. Still, there are add-ons for both these browsers that allow them to connect to uGet: Firefox via FlashGot and Chromium with a dedicated plug-in. Not ideal, but good enough.
|
||||
|
||||
#### Features ####
|
||||
|
||||
uGet’s maturity affords it a range of features, including advanced scheduling to switch downloading on and off, batch download via the clipboard and the ability to change which file types it looks for in the clipboard. There are plug-in options, but not a huge amount.
|
||||
|
||||
#### Availability ####
|
||||
|
||||
While it’s also available in most major distro repos, the uGet website includes regularly updated binaries for a variety of popular distributions as well as easily accessible source code. It runs on GTK 3+ so it has a smaller footprint in some desktop environments than others, although we’d say it’s worth the extra dependancies in KDE or other Qt desktops.
|
||||
|
||||
#### Overall ####
|
||||
|
||||
8/10
|
||||
|
||||
We very much like uGet – its wide variety of features and popularity have allowed it to develop quite a lot to be an all-encompassing solution to download management, with some decent integration with Linux browsers.
|
||||
|
||||
### [KGet][2] ###
|
||||
|
||||
KDE’s own download manager seems to have been originally designed to work with Konqueror, the KDE web browser. It comes with the kind of features we’re looking for in this test: control of multiple downloads and the ability to run a checksum alongside the downloaded product.
|
||||
|
||||

|
||||
You need to manually activate the ability to keep an eye on the clipboard for links
|
||||
|
||||
#### Interface ####
|
||||
|
||||
As expected of a KDE app, KGet fits the aesthetic style of the desktop environment with similar icons and curves throughout. It’s quite a simple design as well, with only the most necessary functions available on the main toolbars and a minimal view of the current downloads.
|
||||
|
||||
#### Integration ####
|
||||
|
||||
KGet natively integrates with KDE’s Konqueror browser, although it’s not the most popular. Support for it in Firefox is done via FlashGot as usual, but there’s no real way to do it in Chromium. You can turn on a feature that asks if you want to download copied URLs, however it doesn’t parse the clipboard very well and sometimes wants to download text.
|
||||
|
||||
#### Features ####
|
||||
|
||||
The selection of features available are not that high. No scheduling, no batch operations and generally an almost bare-minimum amount of downloading features. The clipboard-scanning feature is a nice idea but it’s a bit buggy. It’s a little weird as the Settings menu looks like it’s designed to have more settings and options.
|
||||
|
||||
#### Availability ####
|
||||
|
||||
While it doesn’t come by default with a KDE install, it is available for any distro that supports KDE. It does need a few KDE libraries to run though, and it’s a bit tricky to find the source code. There isn’t a selection of binaries that you can use with a few distros either.
|
||||
|
||||
#### Overall ####
|
||||
|
||||
6/10
|
||||
|
||||
KGet doesnt really offer users a huge amount more than the download manager in the majority of popular browsers, although at least you can use it while the browsers are otherwise turned off.
|
||||
|
||||
### [DownThemAll!][3] ###
|
||||
|
||||
DownThemAll, being somewhat platform-independent, comes to Linux by way of Firefox as an add- on. This limits it somewhat to use with only Firefox, however as one of the most popular browsers in the world its tighter integration may be just what some are looking for in a download manager.
|
||||
|
||||

|
||||
There are actually a whole lot of options available for DownThemAll! that make it very flexible
|
||||
|
||||
#### Interface ####
|
||||
|
||||
Part of the integration in Firefox allows DownThemAll! to slot into the standard aesthetic of the browser, with right-clicking bringing up options alongside the normal downloading ones. The extra dialog menus are generally themed after Firefox as well, while the main download window is clean and based on its own design
|
||||
|
||||
#### Integration ####
|
||||
|
||||
It doesn’t integrate system-wide but its ability to camouflage itself with Firefox makes it seem like an extra part of the original browser. It can also run alongside the normal downloader if you want, and can find specific link types on a webpage with little manual filtering, and no need for copy and pasting.
|
||||
|
||||
#### Features ####
|
||||
|
||||
With the ability to control how many downloads can happen at once, limit bandwidth when not idle and advanced auto or manual filtering, DownThemAll! is full of excellent features that aid mass downloading. The One Click function also allows it to very quickly start downloads to a pre- determined folder faster than normal download functions.
|
||||
|
||||
#### Availability ####
|
||||
|
||||
Firefox is available on just about every distro and other operating system around, which makes DownThemAll! just as prolific. Unfortunately this is a double-edged sword, as Firefox may not be your browser of choice. It also adds a little weight to the browser, which isn’t the lightest to begin with.
|
||||
|
||||
#### Overall ####
|
||||
|
||||
7/10
|
||||
|
||||
DownThemAll! is excellent and if you use Firefox you may not need to use anything else. Not everyone uses Firefox as their preferred browser though, and it needs to be left on for the manager to start running.
|
||||
|
||||
### [Steadyflow][4] ###
|
||||
|
||||
Easily available in Ubuntu and some Debian-based distros, Steadyflow may be limited in terms of where you can get it but it’s got a reputation in some circles as one of the better managers available for any distro. It can read the clipboard for URLs, use GNOME’s preset proxies and has many other features.
|
||||
|
||||

|
||||
The settings in Steady flow are extremely limiting and somewhat difficult to access
|
||||
|
||||
#### Interface ####
|
||||
|
||||
Steadyflow is quite simple in appearance with a pleasant, clean interface that doesn’t clutter the download window. The dialog for adding downloads is simple enough, with basic options for how to treat it and where the file should live. It’s nothing we can really complain about, although it does remind us of the lack of features in the app.
|
||||
|
||||
#### Integration ####
|
||||
|
||||
Reading copied URLs is as standard and there’s a plug-in for Chromium to integrate with that. Again, you can use FlashGot to link it up to Firefox if that’s your preferred browser. You can’t really edit what it parses from the clipboard though and there’s no batch ability like in uGet and DownThemAll!
|
||||
|
||||
#### Features ####
|
||||
|
||||
Extremely lacking in features and the Options menu is very limited as well. The Pause and Resume function also doesn’t seem to work – a basic part of any browser’s file download features. Still, notifications and default action on finished files can be edited, along with an option to run a script once downloads are finished.
|
||||
|
||||
#### Availability ####
|
||||
|
||||
Only available on Ubuntu and there’s no easy way to get the source code for the app either. This means while it’s easily obtainable on all Ubuntu- based distros, it’s limited to these types of distros. As it’s not even the best download manager available on Linux, that shouldn’t be too big of a concern.
|
||||
|
||||
#### Overall ####
|
||||
|
||||
5/10
|
||||
|
||||
Frankly, not that good. With very basic options and limited to only working on Ubuntu, Steadyflow doesn’t do enough to differentiate itself from the standard downloading options you’ll get on your web browser.
|
||||
|
||||
### And the winner is… ###
|
||||
|
||||
#### uGet ####
|
||||
|
||||
In this test we’ve proven that there is a place for download managers on modern computers, even if the better ones have cribbed from the torrent clients that seem to have usurped them. While torrenting may be a more effective way for some, with ISPs getting wiser to torrent traffic some people may get better results with a good download manager. Not only are transfer caps imposed by most major ISPs, some are even beginning to slow- down or even block torrent traffic in peak hours – even legal traffic such as distro ISOs and other free software are throttled.
|
||||
|
||||
Steadyflow seems to be a very popular solution for this, but our usage and tests showed an underdeveloped and weak product. The much older uGet was the star of the show, with an amazing selection of features that can aid in downloading single items or filtering through an entire webpage for relevant items to grab. The same goes for DownThemAll!, the excellent Firefox add-on that, while stuck with Firefox, has just about the same level of features, albeit with better integration.
|
||||
|
||||
If you’re choosing between the two it really comes down to what your preferred browser is and whether you need to have downloads and uploads going around the clock. DownThemAll! requires Firefox running, whereas uGet runs on its own, saving a lot of resources and electricity in the process – obviously this makes uGet a much better prospect for 24-hour data transferring and it really isn’t a major hassle to set up big batch downloads, or even just get the download information from your browser.
|
||||
|
||||
Give download managers another chance. You will not be disappointed with the results.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxuser.co.uk/reviews/top-4-linux-download-managers
|
||||
|
||||
作者:Rob Zwetsloot
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://bit.ly/1mx4Uwz
|
||||
[2]:http://bit.ly/1lilqU9
|
||||
[3]:http://bit.ly/1lilqU9
|
||||
[4]:http://bit.ly/1lilymS
|
||||
@ -1,3 +1,4 @@
|
||||
(translating by runningwater)
|
||||
Compact Text Editors Great for Remote Editing and Much More
|
||||
================================================================================
|
||||
A text editor is software used for editing plain text files. This type of software has many different uses including modifying configuration files, writing programming language source code, jotting down thoughts, or even making a grocery list. Given that editors can be used for such a diverse range of activities, it is worth spending the time finding an editor that best suites your preferences.
|
||||
@ -207,7 +208,7 @@ nano, like Pico, is keyboard-oriented, controlled with control keys.
|
||||
via: http://www.linuxlinks.com/article/20141011073917230/TextEditors.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,104 +0,0 @@
|
||||
[zhouj-sh translating...]
|
||||
2 Ways To Fix The UEFI Bootloader When Dual Booting Windows And Ubuntu
|
||||
================================================================================
|
||||
The main problem that users experience after following my [tutorials for dual booting Ubuntu and Windows 8][1] is that their computer continues to boot directly into Windows 8 with no option for running Ubuntu.
|
||||
|
||||
Here are two ways to fix the EFI boot loader to get the Ubuntu portion to boot correctly.
|
||||
|
||||

|
||||
|
||||
### 1. Make GRUB The Active Bootloader ###
|
||||
|
||||
There are a few things that may have gone wrong during the installation.
|
||||
|
||||
In theory if you have managed to install Ubuntu in the first place then you will have [turned off fast boot][2].
|
||||
|
||||
Hopefully you [followed this guide to create a bootable UEFI Ubuntu USB drive][3] as this installs the correct UEFI boot loader.
|
||||
|
||||
If you have done both of these things as part of the installation, the bit that may have gone wrong is the part where you set GRUB2 as the boot manager.
|
||||
|
||||
To set GRUB2 as the default bootloader follow these steps:
|
||||
|
||||
1.Login to Windows 8
|
||||
2.Go to the desktop
|
||||
3.Right click on the start button and choose administrator command prompt
|
||||
4.Type mountvol g: /s (This maps your EFI folder structure to the G drive).
|
||||
5.Type cd g:\EFI
|
||||
6.When you do a directory listing you will see a folder for Ubuntu. Type dir.
|
||||
7.There should be options for grubx64.efi and shimx64.efi
|
||||
8.Run the following command to set grubx64.efi as the bootloader:
|
||||
|
||||
bcdedit /set {bootmgr} path \EFI\ubuntu\grubx64.efi
|
||||
|
||||
9:Reboot your computer
|
||||
10:You should now have a GRUB menu appear with options for Ubuntu and Windows.
|
||||
11:If your computer still boots straight to Windows repeat steps 1 through 7 again but this time type:
|
||||
|
||||
bcdedit /set {bootmgr} path \EFI\ubuntu\shimx64.efi
|
||||
|
||||
12:Reboot your computer
|
||||
|
||||
What you are doing here is logging into the Windows administration command prompt, mapping a drive to the EFI partition so that you can see where the Ubuntu bootloaders are installed and then either choosing grubx64.efi or shimx64.efi as the bootloader.
|
||||
|
||||
So [what is the difference between grubx64.efi and shimx64.efi][4]? You should choose grubx64.efi if secureboot is turned off. If secureboot is turned on you should choose shimx64.efi.
|
||||
|
||||
In my steps above I have suggested trying one and then trying another. The other option is to install one and then turn secure boot on or off within the UEFI firmware for your computer depending on the bootloader you chose.
|
||||
|
||||
### 2. Use rEFInd To Dual Boot Windows 8 And Ubuntu ###
|
||||
The [rEFInd boot loader][5] works by listing all of your operating systems as icons. You will therefore be able to boot Windows, Ubuntu and operating systems from USB drives simply by clicking the appropriate icon.
|
||||
|
||||
To download rEFInd for Windows 8 [click here][6].
|
||||
|
||||
After you have downloaded the file extract the zip file.
|
||||
|
||||
Now follow these steps to install rEFInd.
|
||||
|
||||
1.Go to the desktop
|
||||
2.Right click on the start button and choose administrator command prompt
|
||||
3.Type mountvol g: /s (This maps your EFI folder structure to the G drive)
|
||||
4.Navigate to the extracted rEFInd folder. For example:
|
||||
|
||||
cd c:\users\gary\downloads\refind-bin-0.8.4\refind-bin-0.8.4
|
||||
|
||||
When you type dir you should see a folder for refind
|
||||
5.Type the following to copy refind to the EFI partition:
|
||||
|
||||
xcopy /E refind g:\EFI\refind\
|
||||
|
||||
6.Type the following to navigate to the refind folder
|
||||
|
||||
cd g:\EFI\refind
|
||||
|
||||
7.Rename the sample configuration file:
|
||||
|
||||
rename refind.conf-sample refind.conf
|
||||
8.Run the following command to set rEFInd as the bootloader
|
||||
|
||||
bcdedit /set {bootmgr} path \EFI\refind\refind_x64.efi
|
||||
|
||||
9.Reboot your computer
|
||||
10.You should now have a menu similar to the image above with options to boot Windows and Ubuntu
|
||||
|
||||
This process is fairly similar to choosing the GRUB bootloader.
|
||||
|
||||
Basically it involves downloading rEFInd, extracting the files. copying the files to the EFI partition, renaming the configuration file and then setting rEFInd as the boot loader.
|
||||
|
||||
### Summary ###
|
||||
|
||||
Hopefully this guide has solved the issues that some of you have been having with dual booting Ubuntu and Windows 8.1. If you are still having issues feel free to get back in touch using the email link above.
|
||||
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
via:http://linux.about.com/od/LinuxNewbieDesktopGuide/tp/3-Ways-To-Fix-The-UEFI-Bootloader-When-Dual-Booting-Windows-And-Ubuntu.htm
|
||||
[a]:http://linux.about.com/bio/Gary-Newell-132058.htm
|
||||
[1]:http://linux.about.com/od/LinuxNewbieDesktopGuide/ss/The-Ultimate-Windows-81-And-Ubuntu-
|
||||
[2]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows_3.htm#step-heading
|
||||
[3]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows.htm
|
||||
[4]:https://wiki.ubuntu.com/SecurityTeam/SecureBoot
|
||||
[5]:http://www.rodsbooks.com/refind/installing.html#windows
|
||||
[6]:http://sourceforge.net/projects/refind/files/0.8.4/refind-bin-0.8.4.zip/download
|
||||
@ -1,59 +0,0 @@
|
||||
This App Can Write a Single ISO to 20 USB Drives Simultaneously
|
||||
================================================================================
|
||||
**If I were to ask you to burn a single Linux ISO to 17 USB thumb drives how would you go about doing it?**
|
||||
|
||||
Code savvy folks would write a little bash script to automate the process, and a large number would use a GUI tool like the USB Startup Disk Creator to burn the ISO to each drive in turn, one by one. But the rest of us would fast conclude that neither method is ideal.
|
||||
|
||||
### Problem > Solution ###
|
||||
|
||||
|
||||
|
||||
GNOME MultiWriter in action
|
||||
|
||||
Richard Hughes, a GNOME developer, faced a similar dilemma. He wanted to create a number of USB drives pre-loaded with an OS, but wanted a tool simple enough for someone like his dad to use.
|
||||
|
||||
His response was to create a **brand new app** that combines both approaches into one easy to use tool.
|
||||
|
||||
It’s called “[GNOME MultiWriter][1]” and lets you write a single ISO or IMG to multiple USB drives at the same time.
|
||||
|
||||
It nixes the need to customize or create a command line script and relinquishes the need to waste an afternoon performing an identical set of actions on repeat.
|
||||
|
||||
All you need is this app, an ISO, some thumb-drives and lots of empty USB ports.
|
||||
|
||||
### Use Cases and Installing ###
|
||||
|
||||

|
||||
|
||||
The app can be installed on Ubuntu
|
||||
|
||||
The app has a pretty defined usage scenario, that being situations where USB sticks pre-loaded with an OS or live image are being distributed.
|
||||
|
||||
That being said, it should work just as well for anyone wanting to create a solitary bootable USB stick, too — and since I’ve never once successfully created a bootable image from Ubuntu’s built-in disk creator utility, working alternatives are welcome news to me!
|
||||
|
||||
Hughes, the developer, says it **supports up to 20 USB drives**, each being between 1GB and 32GB in size.
|
||||
|
||||
The drawback (for now) is that GNOME MultiWriter is not a finished, stable product. It works, but at this early blush there are no pre-built binaries to install or a PPA to add to your overstocked software sources.
|
||||
|
||||
If you know your way around the usual configure/make process you can get it up and running in no time. On Ubuntu 14.10 you may also need to install the following packages first:
|
||||
|
||||
sudo apt-get install gnome-common yelp-tools libcanberra-gtk3-dev libudisks2-dev gobject-introspection
|
||||
|
||||
If you get it up and running, give it a whirl and let us know what you think!
|
||||
|
||||
Bugs and pull requests can be longed on the GitHub page for the project, which is where you’ll also found tarball downloads for manual installation.
|
||||
|
||||
- [GNOME MultiWriter on Github][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/gnome-multiwriter-iso-usb-utility
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/hughsie/gnome-multi-writer/
|
||||
[2]:https://github.com/hughsie/gnome-multi-writer/
|
||||
@ -0,0 +1,111 @@
|
||||
Best GNOME Shell Themes For Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
Themes are the best way to customize your Linux desktop. If you [install GNOME on Ubuntu 14.04][1] or 14.10, you might want to change the default theme and give it a different look. To help you in this task, I have compiled here a **list of best GNOME shell themes for Ubuntu** or any other Linux OS that has GNOME shell installed on it. But before we see the list, let’s first see how to change install new themes in GNOME Shell.
|
||||
|
||||
### Install themes in GNOME Shell ###
|
||||
|
||||
To install new themes in GNOME with Ubuntu, you can use Gnome Tweak Tool which is available in software repository in Ubuntu. Open a terminal and use the following command:
|
||||
|
||||
sudo apt-get install gnome-tweak-tool
|
||||
|
||||
Alternatively, you can use themes by putting them in ~/.themes directory. I have written a detailed tutorial on [how to install and use themes in GNOME Shell][2], in case you need it.
|
||||
|
||||
### Best GNOME Shell themes ###
|
||||
|
||||
The themes listed here are tested on GNOME Shell 3.10.4 but it should work for all version of GNOME 3 and higher. For the sake of mentioning, the themes are not in any kind of priority order. Let’s have a look at the best GNOME themes:
|
||||
|
||||
#### Numix ####
|
||||
|
||||

|
||||
|
||||
No list can be completed without the mention of [Numix themes][3]. These themes got so popular that it encouraged [Numix team to work on a new Linux OS, Ozon][4]. Considering their design work with Numix theme, it won’t be exaggeration to call it one of the [most beautiful Linux OS][5] releasing in near future.
|
||||
|
||||
To install Numix theme in Ubuntu based distributions, use the following commands:
|
||||
|
||||
sudo apt-add-repository ppa:numix/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install numix-icon-theme-circle
|
||||
|
||||
#### Elegance Colors ####
|
||||
|
||||

|
||||
|
||||
Another beautiful theme from Satyajit Sahoo, who is also a member of Numix team. [Elegance Colors][6] has its own PPA so that you can easily install it:
|
||||
|
||||
sudo add-apt-repository ppa:satyajit-happy/themes
|
||||
sudo apt-get update
|
||||
sudo apt-get install gnome-shell-theme-elegance-colors
|
||||
|
||||
#### Moka ####
|
||||
|
||||

|
||||
|
||||
[Moka][7] is another mesmerizing theme that is always included in the list of beautiful themes. Designed by the same developer who gave us Unity Tweak Tool, Moka is a must try:
|
||||
|
||||
sudo add-apt-repository ppa:moka/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install moka-gnome-shell-theme
|
||||
|
||||
#### Viva ####
|
||||
|
||||

|
||||
|
||||
Based on Gnome’s default Adwaita theme, Viva is a nice theme with shades of black and oranges. You can download Viva from the link below.
|
||||
|
||||
- [Download Viva GNOME Shell Theme][8]
|
||||
|
||||
#### Ciliora-Prima ####
|
||||
|
||||

|
||||
|
||||
Previously known as Zukitwo Dark, Ciliora-Prima has square icons theme. Theme is available in three versions that are slightly different from each other. You can download it from the link below.
|
||||
|
||||
- [Download Ciliora-Prima GNOME Shell Theme][9]
|
||||
|
||||
#### Faience ####
|
||||
|
||||

|
||||
|
||||
Faience has been a popular theme for quite some time and rightly so. You can install Faience using the PPA below for GNOME 3.10 and higher.
|
||||
|
||||
sudo add-apt-repository ppa:tiheum/equinox
|
||||
sudo apt-get update
|
||||
sudo apt-get install faience-theme
|
||||
|
||||
#### Paper [Incomplete] ####
|
||||
|
||||

|
||||
|
||||
Ever since Google talked about Material Design, people have been going gaga over it. Paper GTK theme, by Sam Hewitt (of Moka Project), is inspired by Google Material design and currently under development. Which means you will not have the best experience with Paper at the moment. But if your a bit experimental, like me, you can definitely give it a try.
|
||||
|
||||
sudo add-apt-repository ppa:snwh/pulp
|
||||
sudo apt-get update
|
||||
sudo apt-get install paper-gtk-theme
|
||||
|
||||
That concludes my list. If you are trying to give a different look to your Ubuntu, you should also try the list of [best icon themes for Ubuntu 14.04][10].
|
||||
|
||||
How do you find this list of **best GNOME Shell themes**? Which one is your favorite among the one listed here? And if it’s not listed here, do let us know which theme you think is the best GNOME Shell theme.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/gnome-shell-themes-ubuntu-1404/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/how-to-install-gnome-in-ubuntu-14-04/
|
||||
[2]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[3]:https://numixproject.org/
|
||||
[4]:http://itsfoss.com/numix-linux-distribution/
|
||||
[5]:http://itsfoss.com/new-beautiful-linux-2015/
|
||||
[6]:http://satya164.deviantart.com/art/Gnome-Shell-Elegance-Colors-305966388
|
||||
[7]:http://mokaproject.com/
|
||||
[8]:https://github.com/vivaeltopo/gnome-shell-theme-viva
|
||||
[9]:http://zagortenay333.deviantart.com/art/Ciliora-Prima-Shell-451947568
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -0,0 +1,83 @@
|
||||
What is a good IDE for C/C++ on Linux
|
||||
================================================================================
|
||||
"A real coder doesn't use an IDE, a real coder uses [insert a text editor name here] with such and such plugins." We all heard that somewhere. Yet, as much as one can agree with that statement, an IDE remains quite useful. An IDE is easy to set up and use out of the box. Hence there is no better way to start coding a project from scratch. So for this post, let me present you with my list of good IDEs for C/C++ on Linux. Why is C/C++ specifically? Because C is my favorite language, and we need to start somewhere. Also note that there are in general a lot of ways to code in C, so in order to trim down the list, I only selected "real out-of-the-box IDE", not text editors like Gedit or Vim pumped with [plugins][1]. Not that this alternative is bad in any way, just that the list will go on forever if I include text editors.
|
||||
|
||||
### 1. Code::Blocks ###
|
||||
|
||||
|
||||
|
||||
Starting all out with my personal favorite, [Code::Blocks][2] is a simple and fast IDE for C/C++ exclusively. Like any respectable IDE, it integrates syntax highlighting, bookmarking, word completion, project management, and a debugger. Where it shines is via its simple plugin system which adds indispensable tools like Valgrind and CppCheck, and less indispensable like a Tetris mini-game. But my reason for liking it particularly is for its coherent set of handy shortcuts, and the large number of options that never feel too overwhelming.
|
||||
|
||||
### 2. Eclipse ###
|
||||
|
||||
|
||||
|
||||
I know that I said only "real out-of-the-box IDE" and not a text editor pumped with plugins, but [Eclipse][3] is a "real out-of-the-box IDE." It's just that Eclipse needs a little [plugin][4] (or a variant) to code in C. So I technically did not contradict myself. And it would have been impossible to make an IDE list without mentioning the behemoth that is Eclipse. Like it or not, Eclipse remains a great tool to code in Java. And thanks to the [CDT Project][5], it is possible to program in C/C++ too. You will benefit from all the power of Eclipse and its traditional features like word completion, code outline, code generator, and advanced refactoring. What it lacks in my opinion is the lightness of Code::Blocks. It is still very heavy and takes time to load. But if your machine can take it, or if you are a hardcore Eclipse fan, it is a very safe option.
|
||||
|
||||
### 3. Geany ###
|
||||
|
||||
|
||||
|
||||
With a lot less features but a lot more flexibility, [Geany][6] is at the opposite of Eclipse. But what it lacks (like a debugger for example), Geany makes it up with nice little features: a space for note taking, creation from template, code outline, customizable shortcuts, and plugins management. Geany is still closer to an extensive text editor than an IDE here. However I keep it in the list for its lightness and its well designed interface.
|
||||
|
||||
### 4. MonoDevelop ###
|
||||
|
||||
|
||||
|
||||
Another monster to add to the list, [MonoDevelop][7] has a very unique feel derived from its look and interface. I personally love its project management and its integrated version control system. The plugin system is also pretty amazing. But for some reason, all the options and the support for all kind of programming languages make it feel a bit overwhelming to me. It remains a great tool that I used many times in the past, but just not my number one when dealing with "simplistic" C.
|
||||
|
||||
### 5. Anjuta ###
|
||||
|
||||
|
||||
|
||||
With a very strong "GNOME feeling" attached to it, [Anjuta][8]'s appearance is a hit or miss. I tend to see it as an advanced version of Geany with a debugger included, but the interface is actually a lot more elaborate. I do enjoy the tab system to switch between the project, folders, and code outline view. I would have liked maybe a bit more shortcuts to move around in a file. However, it is a good tool, and offers outstanding compilation and build options, which can support the most specific needs.
|
||||
|
||||
### 6. Komodo Edit ###
|
||||
|
||||
|
||||
|
||||
I was not very familiar with [Komodo Edit][9], but after trying it a few days, it surprised me with many many good things. First, the tab-based navigation is always appreciable. Then the fancy looking code outline reminds me a lot of Sublime Text. Furthermore, the macro system and the file comparator make Komodo Edit very practical. Its plugin library makes it almost perfect. "Almost" because I do not find the shortcuts as nice as in other IDEs. Also, I would enjoy more specific C/C++ tools, and this is typically the flaw of general IDEs. Yet, very enjoyable software.
|
||||
|
||||
### 7. NetBeans ###
|
||||
|
||||
|
||||
|
||||
Just like Eclipse, impossible to avoid this beast. With navigation via tabs, project management, code outline, change history tracking, and a plethora of tools, [NetBeans][10] might be the most complete IDE out there. I could list for half a page all of its amazing features. But that will tip you off too easily about its main disadvantage, it might be too big. As great as it is, I prefer plugin based software because I doubt that anyone will need both Git and Mercurial integration for the same project. Call me crazy. But if you have the patience to master all of its options, you will be pretty much become the master of IDEs everywhere.
|
||||
|
||||
### 8. KDevelop ###
|
||||
|
||||
|
||||
|
||||
For all KDE fans out there, [KDevelop][11] might be the answer to your prayers. With a lot of configuration options, KDevelop is yours if you manage to seize it. Call me superficial but I never really got past the interface. But it's too bad for me as the editor itself packs quite a punch with a lot of navigation options and customizable shortcuts. The debugger is also very advanced and will take a bit of practice to master. However, this patience will be rewarded with this very flexible IDE's full power. And it gets special credits for its amazing embedded documentation.
|
||||
|
||||
### 9. CodeLite ###
|
||||
|
||||
|
||||
|
||||
Finally, last for not least, [CodeLite][12] shows that you can take a traditional formula and still get something with its own feeling attached to it. If the interface really reminded me of Code::Blocks and Anjuta at first, I was just blown away by the extensive plugin library. Whether you want to diff a file, insert a copyright block, define an abbreviation, or push your work on Git, there is a plugin for you. If I had to nitpick, I would say that it lacks a few navigation shortcuts for my taste, but that's really it.
|
||||
|
||||
To conclude, I hope that this list had you discover new IDEs for coding in your favorite language. While Code::Blocks remains my favorite, it has some serious challengers. Also we are far from covering all the ways to code in C/C++ using an IDE on Linux. So if you have another one to propose, let us know in the comments. Also if you would like me to cover IDEs for a different language next, also let us know in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-ide-for-c-cpp-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/turn-vim-full-fledged-ide.html
|
||||
[2]:http://www.codeblocks.org/
|
||||
[3]:https://eclipse.org/
|
||||
[4]:http://xmodulo.com/how-to-set-up-c-cpp-development-environment-in-eclipse.html
|
||||
[5]:https://eclipse.org/cdt/
|
||||
[6]:http://www.geany.org/
|
||||
[7]:http://www.monodevelop.com/
|
||||
[8]:http://anjuta.org/
|
||||
[9]:http://komodoide.com/komodo-edit/
|
||||
[10]:https://netbeans.org/
|
||||
[11]:https://www.kdevelop.org/
|
||||
[12]:http://codelite.org/
|
||||
@ -0,0 +1,76 @@
|
||||
Cutegram: A Better Telegram Client For GNU/Linux
|
||||
================================================================================
|
||||
No need for a introduction to **Telegram**, right? Telegram is a popular free Instant messenger application that can be used to chat with your friends all over the world. Unlike Whatsapp, Telegram is free forever, no ads, no subscription fees. And, the Telegram client is open source too. Telegram is available for many different platforms, including Linux, Android, iOS, Windows Phone, Windows, and Mac OS X. The messages which are sending using telegram are highly encrypted and self-destructive. It is very secure, and there is no limit on the size of your media and chats.
|
||||
|
||||
You can install and use Telegram desktop on your Debian/Ubuntu systems as mentioned in [our previous tutorial][1]. However, a new telegram client called **Cutegram** is available now to make your chat experience more fun and easy.
|
||||
|
||||
### What is Cutegram? ###
|
||||
|
||||
Cutegram is a free and opensource telegram clients for GNU/Linux focusing on user friendly, compatibility with Linux desktop environments and easy to use. Cutegram using Qt5, QML, libqtelegram, libappindication, AsemanQtTools technologies and Faenza icons and Twitter emojies graphic sets. It’s free and released under GPLv3 license.
|
||||
|
||||
### Install Cutegram ###
|
||||
|
||||
Head over to the Cutegram homepage and download the latest version of your distribution’s choice. As I use Ubuntu 64 bit, I downloaded the .deb file.
|
||||
|
||||
wget http://aseman.co/downloads/cutegram/cutegram_1.0.2-1-amd64.deb
|
||||
|
||||
Now, Install Cutegram as shown below.
|
||||
|
||||
sudo apt-get install gdebi
|
||||
sudo gdebi cutegram_1.0.2-1-amd64.deb
|
||||
|
||||
For other distributions, run the following commands.
|
||||
|
||||
**64bit:**
|
||||
|
||||
wget http://aseman.co/downloads/cutegram/cutegram-1.0.2-linux-x64-installer.run
|
||||
|
||||
**32 bit:**
|
||||
|
||||
wget http://aseman.co/downloads/cutegram/cutegram-1.0.2-linux-installer.run
|
||||
|
||||
Set executable permission:
|
||||
|
||||
chmod + cutegram-1.0.2-linux*.run
|
||||
|
||||
And, install it as shown below.
|
||||
|
||||
sudo ./cutegram-1.0.2-linux*.run
|
||||
|
||||
### Usage ###
|
||||
|
||||
Launch Cutegram either from Menu or Unity dash. From the login screen, select your country, and enter your mobile number, finally click **Login**.
|
||||
|
||||

|
||||
|
||||
A code will be sent to your mobile number. Enter the code and click **Sign in**.
|
||||
|
||||

|
||||
|
||||
There you go.
|
||||
|
||||

|
||||
|
||||
Start Chatting!
|
||||
|
||||

|
||||
|
||||
And, you can set a profile picture, start new chat/group chat, or secret chat from using the buttons on the left pane.
|
||||
|
||||
Stay happy! Cheers!!
|
||||
|
||||
For more details, check the [Cutegram website][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/cutegram-better-telegram-client-gnulinux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.unixmen.com/install-telegram-desktop-via-ppa/
|
||||
[2]:http://aseman.co/en/products/cutegram/
|
||||
@ -0,0 +1,88 @@
|
||||
su-kaiyao translating
|
||||
|
||||
4 Best Modern Open Source Code Editors For Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Looking for **best programming editors in Linux**? If you ask the old school Linux users, their answer would be Vi, Vim, Emacs, Nano etc. But I am not talking about them. I am going to talk about new age, cutting edge, great looking, sleek and yet powerful, feature rich **best open source code editors for Linux** that would enhance your programming experience.
|
||||
|
||||
### Best modern Open Source editors for Linux ###
|
||||
|
||||
I use Ubuntu as my main desktop and hence I have provided installation instructions for Ubuntu based distributions. But this doesn’t make this list as **best text editors for Ubuntu** because the list is apt for any Linux distribution. Just to add, the list is not in any particular priority order.
|
||||
|
||||
#### Brackets ####
|
||||
|
||||

|
||||
|
||||
[Brackets][1] is an open source code editor from [Adobe][2]. Brackets focuses exclusively on the needs of web designers with built in support for HTML, CSS and Java Script. It’s light weight and yet powerful. It provides you with inline editing and live preview. There are plenty of plugins available to further enhance your experience with Brackets.
|
||||
|
||||
To [install Brackets in Ubuntu][3] and Ubuntu based distributions such as Linux Mint, you can use this unofficial PPA:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
|
||||
For other Linux distributions, you can get the source code as well as binaries for Linux, OS X and Windows on its website.
|
||||
|
||||
- [Download Brackets Source Code and Binaries][5]
|
||||
|
||||
#### Atom ####
|
||||
|
||||

|
||||
|
||||
[Atom][5] is another modern and sleek looking open source editor for programmers. Atom is developed by Github and promoted as a “hackable text editor for the 21st century”. The looks of Atom resembles a lot like Sublime Text editor, a hugely popular but closed source text editors among programmers.
|
||||
|
||||
Atom has recently released .deb and .rpm packages so that one can easily install Atom in Debian and Fedora based Linux distributions. Of course, its source code is available as well.
|
||||
|
||||
- [Download Atom .deb][6]
|
||||
- [Download Atom .rpm][7]
|
||||
- [Get Atom source code][8]
|
||||
|
||||
#### Lime Text ####
|
||||
|
||||

|
||||
|
||||
So you like Sublime Text editor but you are not comfortable with the fact that it is not open source. No worries. We have an [open source clone of Sublime Text][9], called [Lime Text][10]. It is built on Go, HTML and QT. The reason behind cloning of Sublime Text is that there are numerous bugs in Sublime Text 2 and Sublime Text 3 is in beta since forever. There are no transparency in its development, on whether the bugs are being fixed or not.
|
||||
|
||||
So open source lovers, rejoice and get the source code of Lime Text from the link below:
|
||||
|
||||
- [Get Lime Text Source Code][11]
|
||||
|
||||
#### Light Table ####
|
||||
|
||||

|
||||
|
||||
Flaunted as “the next generation code editor”, [Light Table][12] is another modern looking, feature rich open source editor which is more of an IDE than a mere text editor. There are numerous extensions available to enhance its capabilities. Inline evaluation is what you would love in it. You have to use it to believe how useful Light Table actually is.
|
||||
|
||||
- [Get Light Table Source Code][13]
|
||||
|
||||
### What’s your pick? ###
|
||||
|
||||
No, we are not limited to just four code editors in Linux. The list was about modern editors for programmers. Of course you have plenty of other options such as [Notepad++ alternative Notepadqq][14] or [SciTE][15] and many more. So, among these four, which one is your favorite code editor for Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://brackets.io/
|
||||
[2]:http://www.adobe.com/
|
||||
[3]:http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]:https://github.com/adobe/brackets/releases
|
||||
[5]:https://atom.io/
|
||||
[6]:https://atom.io/download/deb
|
||||
[7]:https://atom.io/download/rpm
|
||||
[8]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[9]:http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[10]:http://limetext.org/
|
||||
[11]:https://github.com/limetext/lime
|
||||
[12]:http://lighttable.com/
|
||||
[13]:https://github.com/LightTable/LightTable
|
||||
[14]:http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[15]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
128
sources/share/20150126 CD Audio Grabbers--Graphical Based.md
Normal file
128
sources/share/20150126 CD Audio Grabbers--Graphical Based.md
Normal file
@ -0,0 +1,128 @@
|
||||
CD Audio Grabbers - Graphical Based
|
||||
================================================================================
|
||||
CD audio grabbers are designed to extract ("rip") the raw digital audio (in a format commonly called CDDA) from a compact disc to a file or other output. This type of software enables a user to encode the digital audio into a variety of formats, and download and upload disc info from freedb, an internet compact disc database.
|
||||
|
||||
Is copying CDs legal? Under US copyright law, converting an original CD to digital files for personal use has been cited as qualifying as 'fair use'. However, US copyright law does not explicitly allow or forbid making copies of a personally-owned audio CD, and case law has not yet established what specific scenarios are permitted as fair use. The copyright position is much clearer in the UK. From 2014 it become legal for UK citizens to make copies of CDs, MP3s, DVD, Blu-rays and e-books. This only applies if the individual owns the physical media being ripped, and the copy is made only for their own private use. For other countries in the European Union, member nations can allow a private copy exception too.
|
||||
|
||||
If you are not sure what the position is for the country you live in, please check your local copyright law to make sure that you are on the right side of the law before using the software featured in this two page article.
|
||||
|
||||
To some extent, it may seem a bit of a chore to rip CDs. Streaming services like Spotify and Google Play Music offer access to a huge library of music in a convenient form, and without having to rip your CD collection. However, if you already have a large CD collection, it is still desirable to be able to convert your CDs to enjoy on mobile devices like smartphones, tablets, and portable MP3 players.
|
||||
|
||||
This two page article highlights my favorite audio CD grabbers. I pick the best four graphical audio grabbers, and the best four console audio grabbers. All of the utilities are released under an open source license.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
fre:ac is an open source audio converter and CD ripper that supports a wide range of popular formats and encoders. The utility currently converts between MP3, MP4/M4A, WMA, Ogg Vorbis, FLAC, AAC, WAV and Bonk formats. It comes with several different presents for the LAME encoder.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Easy to learn and use
|
||||
- Converter for MP3, MP4/M4A, WMA, Ogg Vorbis, FLAC, AAC, WAV and Bonk formats
|
||||
- Integrated CD ripper with CDDB/freedb title database support
|
||||
- Multi-core optimized encoders to speed up conversions on modern PCs
|
||||
- Full Unicode support for tags and file names
|
||||
- Easy to learn and use, still offers expert options when you need them
|
||||
- Joblists
|
||||
- Can use Winamp 2 input plugins
|
||||
- Multilingual user interface available in 41 languages
|
||||
|
||||
- Website: [freac.org][1]
|
||||
- Developer: Robert Kausch
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 20141005
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Audex is an easy to use open source audio CD ripping application. Whilst it is in a fairly early stage of development, this KDE desktop tool is stable, slick and simple to use.
|
||||
|
||||
The assistant is able to create profiles for LAME, OGG Vorbis (oggenc), FLAC, FAAC (AAC/MP4) and RIFF WAVE. Beyond the assistant you can define your own profile, which means, that Audex works together with commmand line encoders in general.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Extract with CDDA Paranoia
|
||||
- Extract and encode run parallel
|
||||
- Filename editing with local and remote CDDB/FreeDB database
|
||||
- Submit new entries to CDDB/FreeDB database
|
||||
- Metadata correction tools like capitalize etc
|
||||
- Multi-profile extraction (with one commandline-encoder per profile)
|
||||
- Fetch covers from the internet and store them in the database
|
||||
- Create playlists, cover and template-based-info files in target directory
|
||||
- Create extraction and encoding protocols
|
||||
- Transfer files to a FTP-server
|
||||
- Internationalization support
|
||||
|
||||
- Website: [kde.maniatek.com/audex][2]
|
||||
- Developer: Marco Nelles
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 0.79
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Sound Juicer is a lean CD ripper using GTK+ and GStreamer. It extracts audio from CDs and converts it into audio files. Sound Juicer can also play audio tracks directly from the CD, offering a preview before ripping.
|
||||
|
||||
It supports any audio codec supported by a GStreamer plugin, including MP3, Ogg Vorbis, FLAC, and uncompressed PCM formats.
|
||||
|
||||
It is an established part of the GNOME desktop environment.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Automatic track tagging via CDDB
|
||||
- Encoding to ogg / vorbis, FLAC and raw WAV
|
||||
- Easy to configure encoding path
|
||||
- Multiple genres
|
||||
- Internationalization support
|
||||
|
||||
- Website: [burtonini.com][3]
|
||||
- Developer: Ross Burton
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 3.14
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
ripperX is an open source graphical interface for ripping CD audio tracks and encoding them to Ogg, MP2, MP3, or FLAC formats. It's goal is to be easy to use, requiring only a few mouse clicks to convert an entire album. It supports CDDB lookups for album and track information.
|
||||
|
||||
It uses cdparanoia to convert (i.e. "rip") CD audio tracks to WAV files, and then calls the Vorbis/Ogg encoder oggenc to convert the WAV to an OGG file. It can also call flac to perform lossless compression on the WAV file, resulting in a FLAC file.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Very simple to use
|
||||
- Rip audio CD tracks into WAV, MP3, OGG, or FLAC files
|
||||
- Supports CDDB lookups
|
||||
- Supports ID3v2 tags
|
||||
- Pause the ripping process
|
||||
|
||||
- Website: [sourceforge.net/projects/ripperx][4]
|
||||
- Developer: Marc André Tanner
|
||||
- License: MIT/X Consortium License
|
||||
- Version Number: 2.8.0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150125043738417/AudioGrabbersGraphical.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.freac.org/
|
||||
[2]:http://kde.maniatek.com/audex/
|
||||
[3]:http://burtonini.com/blog/computers/sound-juicer
|
||||
[4]:http://sourceforge.net/projects/ripperx/
|
||||
@ -0,0 +1,60 @@
|
||||
Meet Vivaldi — A New Web Browser Built for Power Users
|
||||
================================================================================
|
||||
|
||||
|
||||
**A brand new web browser has arrived this week that aims to meet the needs of power users — and it’s already available for Linux.**
|
||||
|
||||
Vivaldi is the name of this new browser and it has been launched as a tech preview (read: a beta without the responsibility) for 64-bit Linux machines, Windows and Mac. It is built — shock — on the tried-and-tested open-source frameworks of Chromium, Blink and Google’s open-source V8 JavaScript engine (among other projects).
|
||||
|
||||
Does the world really want another browser? Vivaldi, the brain child of former Opera Software CEO Jon von Tetzchner, is less concerned about want and more about need.
|
||||
|
||||
Vivaldi is being built with the sort of features that keyboard preferring tab addicts need. It is not being pitched at users who find Firefox perplexing or whose sole criticism of Chrome is that it moved the bookmarks button.
|
||||
|
||||
That’s not tacky marketing spiel either. Despite the ‘technical preview’ badge it comes with, Vivaldi is already packed with features that demonstrate its power user slant.
|
||||
|
||||
Plenty of folks feel left behind and underserved by the simplified, paired back offerings other software companies are producing. Vivaldi, even at this early juncture, looks well placed to succeed in winning them over.
|
||||
|
||||
### Vivaldi Features ###
|
||||
|
||||
A few of Vivaldi’s key features already present include:
|
||||
|
||||

|
||||
|
||||
**Quick Commands** (Ctrl + Q) is an in-app HUD that lets you quickly filter through settings, options and features, be it opening a bookmark or hiding the status bar, using your keyboard. No clicks needed.
|
||||
|
||||
**Tab Stacks** let you clean up your workspace by grouping separate tabs into one, and then using a keyboard command or the tab preview picker to switch between them.
|
||||
|
||||

|
||||
|
||||
A collapsible **side panel** that houses extra features (just like old Opera) including a (not yet working) mail client, contacts, bookmarks browser and note taking section that lets you take and annotate screenshots.
|
||||
|
||||
A bunch of other features are on offer too, including customizable keyboard shortcuts, a tabs bar that can be set on any edge of the browser (or hidden entirely), privacy options and a speed dial with folders.
|
||||
|
||||
### Opera Mark II ###
|
||||
|
||||
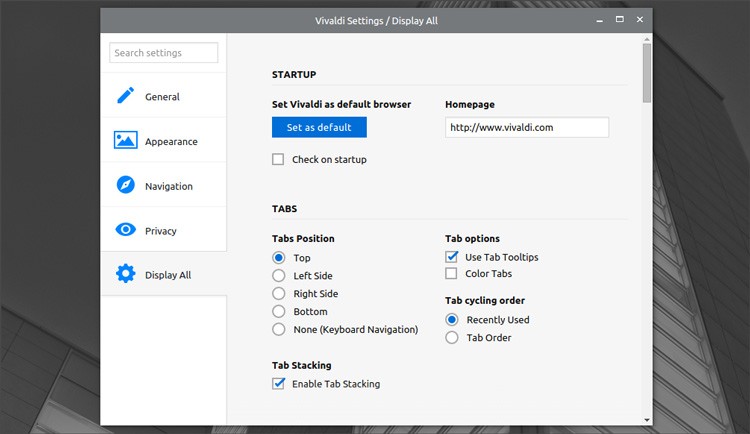
|
||||
|
||||
It’s not a leap to see Vivaldi as the true successor to Opera post-Presto (Opera’s old, proprietary rendering engine). Opera (which also pushed out a minor new update today) has split out many of its “power user” features as it chases a lighter, more manageable set of features.
|
||||
|
||||
Vivaldi wants to pick up the baggage Opera has been so keen to offload. And while that might not help it grab marketshare it will see it grab the attention of power users, many of whom will no doubt already be using Linux.
|
||||
|
||||
### Download ###
|
||||
|
||||
Interested in taking it for a spin? You can. Vivaldi is available to download for Windows, Mac and 64-bit Linux distributions. On the latter you have a choice of Debian or RPM installer.
|
||||
|
||||
Bear in mind that it’s not finished and that more features (including extensions, sync and more) are planned for future builds.
|
||||
|
||||
- [Download Vivaldi Tech Preview for Linux][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/vivaldi-web-browser-linux-download-power-users
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://vivaldi.com/#Download
|
||||
@ -1,116 +0,0 @@
|
||||
The awesomely epic guide to KDE
|
||||
================================================================================
|
||||
**Everything you ever wanted to know about KDE (but were too afraid of the number of possible solutions to ask).**
|
||||
|
||||
Desktops on Linux. They’re a concept completely alien to users of other operating systems because they never having to think about them. Desktops must feel like the abstract idea of time to the Amondawa tribe, a thought that doesn’t have any use until you’re in a different environment. But here it is – on Linux you don’t have to use the graphical environment lurking beneath your mouse cursor. You can change it for something completely different. If you don’t like windows, switch to xmonad. If you like full-screen apps, try Gnome. And if you’re after the most powerful and configurable point-and-click desktop, there’s KDE.
|
||||
|
||||
KDE is wonderful, as they all are in their own way. But in our opinion, KDE in particular suffers from poor default configuration and a rather allusive learning curve. This is doubly frustrating, firstly because it has been quietly growing more brilliant over the last couple of years, and secondly, because KDE should be the first choice for users unhappy with their old desktop – in particular, Windows 8 users pining for an interface that makes sense.
|
||||
|
||||
But fear not. We’re going to use a decade’s worth of KDE firefighting to bring you the definitive guide to making KDE look good and function slightly more like how you might expect it to. We’re not going to look at KDE’s applications, other than perhaps Dolphin; we’re instead going to look at the functionality in the desktop environment itself. And while our guinea pig distribution is going to be Mageia, this guide will be equally applicable to any recent KDE desktop running from almost any distribution, so don’t let the default Mageia background put you off.
|
||||
|
||||
### Fonts ###
|
||||
|
||||
A great first target for getting your system looking good is its selection of fonts. It used to be the case that many of us would routinely copy fonts across from a Windows installation, getting the professional Ariel and Helvetica font rendering that was missing from Linux at the time. But thanks to generic quality fonts such as DejaVu and Nimbus Sans/Roman, this isn’t a problem any more. But it’s still worth finding a font you prefer, as there are now so many great alternatives to choose between.
|
||||
|
||||
The best source of free fonts we’ve found is [www.fontsquirrel.com][1] – it hosts the Roboto, Roboto Slab (Hello!) and Roboto Condensed (Hello!) typefaces used throughout our magazine, and also on the Nexus 5 smartphone (Roboto was developed for use in the Ice Cream Sandwich version of the Android mobile operating system).
|
||||
|
||||
TrueType fonts, with their **.ttf** file extensions, are incredibly easy to install from KDE. Download the zip file, right-click and select something from the Extract menu. Now all you need to do is drag a selection across the TrueType fonts you want to install and select ‘Install’ from the right-click Actions menu. KDE will take care of the rest.
|
||||
|
||||
Another brilliant thing about KDE is that you can change all the fonts at once. Open the System Settings panel and click on Application Appearances, followed by the fonts tab, and click on Adjust All Fonts. Now just select a font from the requester. Most KDE applications will update with your choice immediately, while other applications, such as Firefox, will require a restart. Either way, it’s a quick and effective way of experimenting with your desktop’s usability and appearance. We’d recommend either Open Sans or the thinner Aller fonts.
|
||||
|
||||
|
||||
Most distributions don’t include decent fonts. But KDE enables you to quickly install new ones and apply them to your desktop.
|
||||
|
||||
### Eye candy ###
|
||||
|
||||
One of KDE’s most secret features is that backgrounds can be dynamic. We don’t find much use for this when it comes to the desktops that tells us the weather outside the window, but we do like backgrounds that dynamically grab images from the internet. With most distributions you’ll need to install something for this to work. Just search for **plasma-wallpaper** in your distribution’s package manager. Our favourite is **plasma-wallpaper-potd**, as this installs easy access to update-able wallpaper images from a variety of sources.
|
||||
|
||||
Changing a desktop background is easy with KDE, but it’s not intuitive. Mageia, for example, defaults to using ‘Folder’ view, as this is closer to the traditional desktop where files from the Desktop folder in your home directory are displayed on the background, and the whole desktop works like a file manager. Right-click and select ‘Folder Settings’ if this is the view you’re using. Alternatively, KDE defaults to ‘Desktop’, where the background is clear apart from any widgets you add yourself, and files and folders are considered links to the sources. The menu item in this mode is labelled Desktop Settings. The View Configuration panel that changes the background is the same, however, and you need to make your changes in the Wallpaper drop-down menu. We’d recommend Picture Of The Day as the wallpaper, and the Astronomy Picture Of The Day as the image source.
|
||||
|
||||
Another default option we think is crazy is the blue glow that surrounds the active window. While every other desktop uses a slightly deeper drop-shadow, KDE’s active window looks like it’s bathed in radioactive light. The solution to this lies in the default theme, and this can be changed by going to KDE’s System Settings control panel and selecting Workspace Appearance. On the first page, which is labelled Window Decorations, you’ll find that Oxygen is nearly always selected, and it’s this theme that contains the option to change the blue glow. Just click on the Configure Decoration button, flip to the Shadows tab and disable Active Window Glow’. Alternatively, if you’d like active windows to have a more pronounced shadow, change the inner and outer colours to black.
|
||||
|
||||
You may have seen the option to download wallpapers, for example, from within a KDE window, and you can see this now by clicking on the Get New Decorations button. Themes are subjective, but our favourite combination is currently the Chrome window decoration (it looks identical to Google’s default theme for its browser) with the Aya desktop theme. The term ‘desktop theme’ is a bit of a misnomer, as it doesn’t encapsulate every setting as you might expect. Instead it controls how generic desktop elements are rendered. The most visible of these elements is the launch panel, and changing the desktop theme will usually have a dramatic effect on its appearance, but you’ll also notice a difference in the widgets system.
|
||||
|
||||
The final graphical flourish we’d suggest is to change the icon set that KDE uses. There’s nothing wrong with the default Oxygen set, but there are better options. Unfortunately, this is where the ‘Get New Themes’ download option often fails, probably because icon packages are large and can overwhelm the personal storage space often reserved for projects like these. We’d suggest going to [kde-look.org][2] and browsing its icon collections. Open up the Icons panel from KDE’s System Settings, click on the Icons tab followed by Install Theme File and point the requester at the location of the archive you just downloaded. KDE will take it from there and add the icon set to the list in the panel. Try Kotenza for a flat theme, or keep an eye on Nitrux development.
|
||||
|
||||
|
||||
Remove the blue glow and change a few of the display options, and KDE starts to look pretty good in our opinion.
|
||||
|
||||
### The panel ###
|
||||
|
||||
Our next target is going to be the panel at the bottom of the screen. This has become a little dated, especially if you’re using KDE on a large or high-resolution display, so our first suggestion is to re-scale and centre it for your screen. The key to moving screen components in KDE is making sure they’re unlocked, and this accomplished by right-clicking on the ‘plasma’ cashew in the top-right of the display where the current activity is listed. Only when widgets are unlocked can you re-size the panel, and even add new applications from the launch menu.
|
||||
|
||||
With widgets unlocked, click on the cashew on the side of the panel followed by More Settings and select Centre for panel alignment. With this enabled you can re-size the panel using the sliders on either side and the panel itself will always stay in the middle of your screen. Just pretend you’re working on indentation on a word processor and you’ll get the idea. You can also change its height when the sliders are visible by dragging the central height widget, and to the left of this, you can drag the panel to a different edge on your screen. The top edge works quite well, but many of KDE’s applets don’t work well when stacked vertically on the left or right edges of the display.
|
||||
|
||||
There are two different kinds of task manager applets that come with KDE. The default displays each running application as a title bar in the panel, but this takes up quite a bit of space. The alternative task manager displays only the icon of the application, which we think is much more useful. Mageia defaults to the icon version, but most others – and KDE itself – prefer the title bar applet. To change this, click on the cashew again and hover over the old applet so that the ‘X’ appears, then click on this ‘X’ to remove the applet from the panel. Now click on Add Widgets, find the two task managers and drag the icon version on to your panel. You can re-arrange any other applets in this mode by dragging them to the left and right.
|
||||
|
||||
By default, the Icon-Only task manager will only display icons for tasks running on the current desktop, which we think is counterintuitive, as it’s more convenient to see all of the applications you may have running and to quickly switch between whatever desktops on which they may be running with a simple click. To change this behaviour, right-click on the applet and select the Settings menu option and the Behaviour tab in the next window. Deselect ‘Only Show Tasks From The Current Desktop’, and perhaps ‘Only Show Tasks From The Current Activity’ if you use KDE’s activities.
|
||||
|
||||
Another alteration we like to make is to reconfigure the virtual desktops applet from showing four desktops as a 2×2, which doesn’t look too good on a small panel, to 4×1. This can be done by right-clicking on the applet, selecting Pager Settings and then clicking on the Virtual Desktops tabs and changing the number of rows to ‘1’.
|
||||
|
||||
Finally, there’s the launch menu. Mageia has switched this from the new style of application launcher to the old style originally seen in Microsoft Windows. We prefer the former because of its search field, but the two can be switched by right-clicking the icon and selecting the Switch To… menu option.
|
||||
|
||||
If you find the hover-select action of this mode annoying, where moving the mouse over one of the categories automatically selects it, you can disable it by right-clicking on the launcher, selecting Launcher Settings from the menu and disabling ‘Switch Tabs On Hover’ from the General settings page. It’s worth reiterating that many of these menu options are only available when widgets are unlocked, so don’t despair if you don’t see the correct menu entry at first.
|
||||
|
||||
> ### Activities ###
|
||||
>
|
||||
> No article on KDE would be complete without some discussion of what KDE calls Activities. In many ways, Activities are a solution waiting for a problem. They’re meta-virtual desktops that allow you to group desktop configuration and applications together. You may have an activity for photo editing, for example, or one for working and another for the internet. If you’ve got a touchscreen laptop, activities could be used to switch between an Android-style app launcher (the Search and Launch mode from the Desktop Settings panel), and the regular desktop mode. We use a single activity as a default for screenshots, for instance, while another activity switches everything to the file manager desktop mode. But the truth is that you have to understand what they are before you can find a way of using them.
|
||||
>
|
||||
> Some installations of KDE will include the Activity applet in the toolbar. Its red, blue and green dots can be clicked on to open the activity manager, or you can click on the Plasma cashew in the top-right and select Activities. This will open the bar at the bottom of the screen, which lists activities installed and primed on your system. Clicking on any will switch between them; as will pressing the meta key (usually the Windows key) and Tab.
|
||||
>
|
||||
> We’d suggest that finding a fast way to switch between activities, such as with a keyboard shortcut or with the Activity Bar widget is the key to using them more. With the Activity Manager open, clicking on Create Activity lets you either clone the current desktop, add a blank desktop or create a new activity from a list of templates. Clone works well if you want to add some default applications to the desktop for your current setup. To remove an activity, switch to another one and press the Stop and Delete buttons from the Activity Manager.
|
||||
|
||||
### Upgraded launch menu ###
|
||||
|
||||
You may want to look into replacing the default launch menu entirely. If you open the Add Widgets view, for instance, and search for menus, you’ll see several results. Our current favourite is called Application Launcher (QML). It provides the same kind of functionality as the default menu, but has a cleaner interface after you’ve enlarged the initial window. But if we’re being honest, we don’t use the launcher that much. We prefer to do most launching through KRunner, which is the seemingly simple requester that appears when you hold Alt+F2.
|
||||
|
||||
KRunner is better than the default launcher, because you can type this shortcut from anywhere, regardless of which applications are running or where your mouse is located. When you start to type the name of the application you want to run into KRunner, you’ll see the results filtered in real time beneath the entry field – press Enter to launch the top choice.
|
||||
|
||||
KRunner is capable of so much more. You can type in calculations like **=sin(90)**, for example, and see the result in real time. You can search Google with **gg**: or Wikipedia with **wp**: followed by the search terms, and add many other operations through installable modules. To make best use of this awesome KDE feature, make sure you’ve got the **plasma-addons** package installed, and search for **runner** on your distribution’s package manager. When you next launch KRunner and click on the tool icon to the left of the search bar, you’ll see a wide variety of plugins that can do all kinds of things with the text you type in. In classic KDE style, many don’t include instructions on how to use them, so here’s our breakdown of the most useful things you can do with KRunner:
|
||||
|
||||
|
||||
|
||||
### File management ###
|
||||
|
||||
File management may not be the most exciting subject in Linux, but it is one we all seem to spend a lot of time doing, whether that’s moving a download into a better folder, or copying photos from a camera. The old file manager, Konqueror, was one of the best reasons for using KDE in the first place, and while Konqueror has been superseded by Dolphin in KDE 4.x, it’s still knocking around – even if it is labelled a web browser.
|
||||
|
||||
If you open Konqueror and enter the URL as **file:/**, it turns back into that file manager of old, with many of its best features intact. You can click on the lower status bar, for example, and split the view vertically or horizontally, into other views. You can fill the view with proportionally sized blocks by selecting Preview File Size View from the right-click menu, and preview many other file types without ever leaving Konqueror.
|
||||
|
||||
Mageia uses a double-click for most options, whereas we prefer a single click. This can be changed from the System-Settings panel by opening Input Devices, clicking on Mouse and enabling ‘Single-click To Open Files And Folders’. If you’ve become used to Apple’s reverse scroll, you’ll also find an option here to reverse the scroll direction on Linux.
|
||||
|
||||
Konqueror is a great application, but it hasn’t been a focus of KDE development for a considerable period of time. Dolphin has replaced it, and while this is a much simplified file manager, it does inherit some of Konqueror’s best features. You can still split the view, for instance, albeit one only once, and only horizontally, from the toolbar. You can also view lots of metadata. Select the Details View and right-click on the column headings for the files, and you can add columns that list the word counts in text files, or an image’s size and orientation, or the artist, title and duration of an audio file, all from within the contents of the data. This is KDE’s semantic desktop in action, and it’s been growing in functionality for the last couple of years. Apple’s OS X, for example, has only just started pushing its ability to tag files and applications – we’ve been able to do this from KDE for a long time. We don’t know any other desktop that comes close to providing that level of control.
|
||||
|
||||
### Window management ###
|
||||
|
||||
KDE has a comprehensive set of windowing functions as well as graphical effects. They’re all part of the window manager, KWin, rather than the desktop, which is what we’ve been dealing with so far. It’s the window manager’s job to handle the positioning, moving and rendering of your windows, which is why they can be replaced without switching the whole desktop. You might want to try KWin on the RazorQt desktop, for example, to get the best of both the minimal environment RazorQt offers and the power of KDE’s window manager.
|
||||
|
||||
The easiest way to get to KWin’s configuration settings is to right-click on the title bar of any window (this is usually the most visible element of any window manager), and select Window Manager Settings from the More Actions menu.
|
||||
|
||||
The Task Switcher is the tool that appears when you press Alt+Tab, and continually pressing those two keys will switch between all running applications on the current desktop. You can also use cursor keys to move left and right through the list. These settings are mostly sensibly configured, but you may want to include All Other Desktops in the Filter Windows By section, as that will allow you to quickly switch to applications running on other desktops. We also like the Cover Switch visualisation rather than the Thumbnails view, and you can even configure the perceived distance of the windows by clicking on the toolbar icon.
|
||||
|
||||
The next page on the window manager control module handles what happens at the edges of your screen. At the very least, we prefer to enable Switch Desktop On Edge by selecting Only When Moving Windows from the drop-down list. This means that when you drag a window to one edge, the virtual desktop will switch beneath, effectively dragging the window on to a new virtual desktop.
|
||||
|
||||
The great thing about enabling this only for dragged windows is that it doesn’t interfere with KDE’s fantastic window snapping feature. When you drag a window close to the left or right edge, for instance, KDE displays a ghosted window where your window will snap to if you release the mouse. This is a great way of turning KDE into a tiling window manager, where you can easily have two windows split down the middle of the screen area. Moving a window into any of the corners will also give you the ability to neatly arrange your windows to occupy a quarter of the screen, which is ideal for large displays.
|
||||
|
||||
We also enable a mode similar to Mission Control on OS X when the cursor is in the region of the top-left corner of the screen. On the screen edge layout, click on the dot in the top-right of the screen (or any other point you’d prefer) and select Desktop Grid from the drop-down menu that appears. Now when you move to the top-right of your display, you’ll get an overview of all your virtual desktops, any of which can be chosen with a click.
|
||||
|
||||
Two pages down in the configuration module, there’s a page called Focus. This is an old idea where you can change whether a window becomes active when you click on it, or when you roll your mouse cursor over it. KDE adds another twist to this by providing a slider that progresses from click to a strict hover policy, where the window under the cursor always becomes active. We prefer to use one of the middle options – Focus Follows Mouse – as this chooses the most obvious window to activate for us without making too many mistakes, and it means we seldom click to focus. We also reduce the focus delay to 200ms, but this will depend on how you feel about the feature after using it for a while.
|
||||
|
||||
KDE has so many features, many of which only come to light when you start to use the desktop. It really is a case of developers often adding things and then telling no one. But we feel KDE is worth the effort, and unlikely some other desktops, is unlikely to change too much in the transition from 4.x to 5. That means the time you spend learning how to use KDE now is an investment. Dive in!.
|
||||
|
||||

|
||||
KDE visual effects (click for larger)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/desktops/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://www.fontsquirrel.com/
|
||||
[2]:http://kde-look.org/
|
||||
@ -1,119 +0,0 @@
|
||||
Interview: Thomas Voß of Mir
|
||||
================================================================================
|
||||
**Mir was big during the space race and it’s a big part of Canonical’s unification strategy. We talk to one of its chief architects at mission control.**
|
||||
|
||||
Not since the days of 2004, when X.org split from XFree86, have we seen such exciting developments in the normally prosaic realms of display servers. These are the bits that run behind your desktop, making sure Gnome, KDE, Xfce and the rest can talk to your graphics hardware, your screen and even your keyboard and mouse. They have a profound effect on your system’s performance and capabilities. And where we once had one, we now have two more – Wayland and Mir, and both are competing to win your affections in the battle for an X replacement.
|
||||
|
||||
We spoke to Wayland’s Daniel Stone in issue 6 of Linux Voice, so we thought it was only fair to give equal coverage to Mir, Canonical’s own in-house X replacement, and a project that has so far courted controversy with some of its decisions. Which is why we headed to Frankfurt and asked its Technical Architect, Thomas Voß, for some background context…
|
||||
|
||||

|
||||
|
||||
**Linux Voice: Let’s go right back to the beginning, and look at what X was originally designed for. X solved the problems that were present 30 years ago, where people had entirely different needs, right?**
|
||||
|
||||
**Thomas Voß**: It was mainframes. It was very expensive mainframe computers with very cheap terminals, trying to keep the price as low as possible. And one of the first and foremost goals was: “Hey, I want to be able to distribute my UI across the network, ideally compressed and using as little data as possible”. So a lot of the decisions in X were motivated by that.
|
||||
|
||||
A lot of the graphics languages that X supports even today have been motivated by that decision. The X developers started off in a 2D world; everything was a 2D graphics language, the X way of drawing rectangles. And it’s present today. So X is not necessarily bad in that respect; it still solves a lot of use cases, but it’s grown over time.
|
||||
|
||||
One of the reasons is that X is a protocol, in essence. So a lot of things got added to the protocol. The problem with adding things to a protocol is that they tend to stick. To use a 2D graphics language as an example, XVideo is something that no-one really likes today. It’s difficult to support and the GPU vendors actually cry out in pain when you start talking about XVideo. It’s somewhat bloated, and it’s just old. It’s an old proven technology – and I’m all for that. I actually like X for a lot of things, and it was a good source of inspiration. But then when you look at your current use cases and the current setup we are in, where convergence is one of the buzzwords – massively overrated obviously – but at the heart of convergence lies the fact that you want to scale across different form factors.
|
||||
|
||||
**LV: And convergence is big for Canonical isn’t it?**
|
||||
|
||||
**Thomas**: It’s big, I think, for everyone, especially over time. But convergence is a use case that was always of interest to us. So we always had this idea that we want one codebase. We don’t want a situation like Apple has with OS X and iOS, which are two different codebases. We basically said “Look, whatever we want to do, we want to do it from one codebase, because it’s more efficient.” We don’t want to end up in the situation where we have to be maintaining two, three or four separate codebases.
|
||||
|
||||
That’s where we were coming from when we were looking at X, and it was just too bloated. And we looked at a lot of alternatives. We started looking at how Mac OS X was doing things. We obviously didn’t have access to the source code, but if you see the transition from OS 9 to OS X, it was as if they entirely switched to one graphics language. It was pre-PostScript at that time. But they chose one graphics language, and that’s it. From that point on, when you choose a graphics language, things suddenly become more simple to do. Today’s graphics language is EGL ES, so there was inspiration for us to say we were converged on GL and EGL. From our perspective, that’s the least common denominator.
|
||||
|
||||
> We basically said: whatever we want to do, we want to do it from one codebase, because it’s more efficient.
|
||||
|
||||
Obviously there are disadvantages to having only one graphics language, but the benefits outweigh the disadvantages. And I think that’s a common theme in the industry. Android made the same decision to go that way. Even Wayland to a certain degree has been doing that. They have to support EGL and GL, simply because it’s very convenient for app developers and toolkit developers – an open graphics language. That was the part that inspired us, and we wanted to have this one graphics language and support it well. And that takes a lot of craft.
|
||||
|
||||
So, once you can say: no more weird 2D API, no more weird phong API, and everything is mapped out to GL, you’re way better off. And you can distill down the scope of the overall project to something more manageable. So it went from being impossible to possible. And then there was me, being very opinionated. I don’t believe in extensibility from the beginning – traditionally in Linux everything is super extensible, which has got benefits for a certain audience.
|
||||
|
||||
If you think about the audience of the display server, it’s one of the few places in the system where you’ve got three audiences. So you’ve got the users, who don’t care, or shouldn’t care, about the display server.
|
||||
|
||||
**LV: It’s transparent to them.**
|
||||
|
||||
**Thomas**: Yes, it’s pixels, right? That’s all they care about. It should be smooth. It should be super nice to use. But the display server is not their main concern. It obviously feeds into a user experience, quite significantly, but there are a lot of other parts in the system that are important as well.
|
||||
|
||||
Then you’ve got developers who care about the display server in terms of the API. Obviously we said we want to satisfy this audience, and we want to provide a super-fast experience for users. It should be rock solid and stable. People have been making fun of us and saying “yeah, every project wants to be rock solid and stable”. Cool – so many fail in doing that, so let’s get that down and just write out what we really want to achieve.
|
||||
|
||||
And then you’ve got developers, and the moment you expose an API to them, or a protocol, you sign a contract with them, essentially. So they develop to your API – well, many app developers won’t directly because they’ll be using toolkits – but at some point you’ve got developers who sign up to your API.
|
||||
|
||||

|
||||
|
||||
**LV: The developers writing the toolkits, then?**
|
||||
|
||||
**Thomas**: We do a lot of work in that arena, but in general it’s a contract that we have with normal app developers. And we said: look, we don’t want the API or contract to be super extensible and trying to satisfy every need out there. We want to understand what people really want to do, and we want to commit to one API and contract. Not five different variants of the contract, but we want to say: look, this is what we support and we, as Canonical and as the Mir maintainers, will sign up to.
|
||||
|
||||
So I think that’s a very good thing. You can buy into specific shells sitting on top of Mir, but you can always assume a certain base level of functionality that we will always provide in terms of window management, in terms of rendering capabilities, and so on and so forth. And funnily enough, that also helps with convergence. Because once you start thinking about the API as very important, you really start thinking about convergence. And what happens if we think about form factor and we transfer from a phone to a tablet to a desktop to a fridge?
|
||||
|
||||
**LV: And whatever might come!**
|
||||
|
||||
**Thomas**: Right, right. How do we account for future developments? And we said we don’t feel comfortable making Mir super extensible, because it will just grow. Either it will just grow and grow, or you will end up with an organisation that just maintains your protocol and protocol extensions.
|
||||
|
||||
**LV: So that’s looking at Mir in relation to X. The obvious question is comparing Mir to Wayland – so what is it that Mir does, that Wayland doesn’t?**
|
||||
|
||||
**Thomas**: This might sound picky, but we have to distinguish what Wayland really is. Wayland is a protocol specification which is interesting because the value proposition is somewhat difficult. You’ve got a protocol and you’ve got a reference implementation. Specifically, when we started, Weston was still a test bed and everything being developed ended up in there.
|
||||
|
||||
No one was buying into that; no one was saying, “Look, we’re moving this to production-level quality with a bona fide protocol layer that is frozen and stable for a specific version that caters to application authors”. If you look at the Ubuntu repository today, or in Debian, there’s Wayland-cursor-whatever, so they have extensions already. So that’s a bit different from our approach to Mir, from my perspective at least.
|
||||
|
||||
There was this protocol that the Wayland developers finished and back then, before we did Mir and I looked into all of this, I wrote a Wayland compositor in Go, just to get to know things.
|
||||
|
||||
**LV: As you do!**
|
||||
|
||||
**Thomas**: And I said: you know, I don’t think a protocol is a good way of approaching this because versioning a protocol in a packaging scenario is super difficult. But versioning a C API, or any sort of API that has a binary stability contract, is way easier and we are way more experienced at that. So, in that respect, we are different in that we are saying the protocol is an implementation detail, at least up to a certain point.
|
||||
|
||||
I’m pretty sure for version 1.0, which we will call a golden release, we will open up the protocol for communication purposes. Under the covers it’s Google buffers and sockets. So we’ll say: this is the API, work against that, and we’re committed to it.
|
||||
|
||||
That’s one thing, and then we said: OK, there’s Weston, but we cannot use Weston because it’s not working on Android, the driver model is not well defined, and there’s so much work that we would have to do to actually implement a Wayland compositor. And then we are in a situation where we would have to cut out a set of functionality from the Wayland protocol and commit to that, no matter what happens, and ultimately that would be a fork, over time, right?.
|
||||
|
||||
**LV: It’s a difficult concept for many end users, who just want to see something working.**
|
||||
|
||||
**Thomas**: Right, and even from a developer’s perspective – and let’s jump to the political part – I find it somewhat difficult to have a party owning a protocol definition and another party building the reference implementations. Now, Gnome and KDE do two different Wayland compositors. I don’t see the benefit in that, to be quite frank, so the value proposition is difficult to my mind.
|
||||
|
||||
The driver model in Mir and Wayland is ultimately not that different – it’s GL/EGL based. That is kind of the denominator that you will find in both things, which is actually a good thing, because if you look at the contract to application developers and toolkit developers, most of them don’t want Mir or Wayland. They talk ELG and GL, and at that point, it’s not that much of a problem to support both.
|
||||
|
||||
> If there had been a full reference implementation of Wayland, our decision might have been different.
|
||||
|
||||
So we did this work for porting the Chromium browser to Mir. We actually took the Chromium Wayland back-end, factored out all the common pieces to EGL and GL ES, and split it up into Wayland and Mir.
|
||||
|
||||
And I think from a user’s or application developer’s perspective, the difference is not there. I think, in retrospect, if there would have been something like a full reference implementation of Wayland, where a company had signed up to provide something that is working, and committed to a certain protocol version, our decision might have been different. But there just wasn’t. It was five years out there, Wayland, Wayland, Wayland, and there was nothing that we could build upon.
|
||||
|
||||
**LV: The main experience we’ve had is with RebeccaBlackOS, which has Weston and Wayland, because, like you say, there’s no that much out there running it.**
|
||||
|
||||
**Thomas**: Right. I find Wayland impressive, obviously, but I think Mir will be significantly more relevant than Wayland in two years time. We just keep on bootstrapping everything, and we’ve got things working across multiple platforms. Are there issues, and are there open questions to solve? Most likely. We never said we would come up with the perfect solution in version 1. That was not our goal. I don’t think software should be built that way. So it just should be iterated.
|
||||
|
||||

|
||||
|
||||
**LV: When was Mir originally planned for? Which Ubuntu release? Because it has been pushed back a couple of times.**
|
||||
|
||||
**Thomas**: Well, we originally planned to have it by 14.04. That was the kind of stretch goal, because it highly depends on the availability of proprietary graphics drivers. So you can’t ship an LTS [Long Term Support] release of Ubuntu on a new display server without supporting the hardware of the big guys.
|
||||
|
||||
**LV: We thought that would be quite ambitious anyway – a Long Term Support release with a whole new display server!**
|
||||
|
||||
**Thomas**: Yes, it was ambitious – but for a reason. If you don’t set a stretch goal, and probably fail in reaching it, and then re-evaluate how you move forward, it’s difficult to drive a project. So if you just keep it evolving and evolving and evolving, and you don’t have a checkpoint at some point…
|
||||
|
||||
**LV: That’s like a lot of open source projects. Inkscape is still on 0.48 or something, and it works, it’s reliable, but they never get to 1.0. Because they always say: “Oh let’s add this feature, and that feature”, and the rest of us are left thinking: just release 1.0 already!.**
|
||||
|
||||
**Thomas**: And I wouldn’t actually tie it to a version number. To me, that is secondary. To me, the question is whether we call this ready for broad public consumption on all of the hardware versions we want to support?
|
||||
|
||||
In Canonical, as a company, we have OEM contracts and we are enabling Ubuntu on a host of devices, and laptops and whatever, so we have to deliver on those contracts. And the question is, can we do that? No. Well, you never like a ‘no’.
|
||||
|
||||
> The question is whether we call this ready for broad public consumption on the hardware we want to support.
|
||||
|
||||
Usually, when you encounter a problem and you tackle it, and you start thinking how to solve the problem, that’s more beneficial than never hearing a no. That’s kind of what we were aiming for. Ubuntu 14.04 was a stretch goal – everyone was aware of that and we didn’t reach it. Fine, cool. Let’s go on.
|
||||
|
||||
So how do we stage ourself for the next cycle, until an LTS? Now we have this initiative where we have a daily testable image with Unity 8 and Mir. It’s not super usable because it’s just essentially the tethered UI that you are seeing there, but still it’s something that we didn’t have a year ago. And for me, that’s a huge gain.
|
||||
|
||||
And ultimately, before we can ship something, before any new display server can ship in an LTS release, you need to have buy-in from the GPU vendors. That’s what you need.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/interview-thomas-vos-of-mir/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
@ -1,131 +0,0 @@
|
||||
FOSS and the Fear Factor
|
||||
================================================================================
|
||||

|
||||
|
||||
> "'Many eyes' is a complete and total myth," said SoylentNews' hairyfeet. "I bet my last dollar that if you looked at every.single.package. that makes up your most popular distros and then looked at how many have actually downloaded the source for those various packages, you'd find that there is less than 30 percent ... that are downloaded by anybody but the guys that actually maintain the things."
|
||||
|
||||
In a world that's been dominated for far too long by the [Systemd Inferno][1], Linux fans will have to be forgiven if they seize perhaps a bit too gleefully upon the scraps of cheerful news that come along on any given day.
|
||||
|
||||
Of course, for cheerful news, there's never any better place to look than the [Reglue][2] effort. Run by longtime Linux advocate and all-around-hero-for-kids Ken Starks, as alert readers [may recall][3], Reglue just last week launched a brand-new [fundraising effort][4] on Indiegogo to support its efforts over the coming year.
|
||||
|
||||
Since 2005, Reglue has placed more than 1,600 donated and then refurbished computers into the homes of financially disadvantaged kids in Central Texas. Over the next year, it aims to place 200 more, as well as paying for the first 90 days of Internet connection for each of them.
|
||||
|
||||
"As overused as the term is, the 'Digital Divide' is alive and well in some parts of America," Starks explained. "We will bridge that divide where we can."
|
||||
|
||||
How's that for a heaping helping of hope and inspiration?
|
||||
|
||||
### Windows as Attack Vector ###
|
||||
|
||||

|
||||
|
||||
Offering discouraged FOSS fans a bit of well-earned validation, meanwhile -- and perhaps even a bit of levity -- is the news that Russian hackers apparently have begun using Windows as a weapon against the rest of the world.
|
||||
|
||||
"Russian hackers use Windows against NATO" is the [headline][5] over at Fortune, making it plain for all the world to see that Windows isn't the bastion of security some might say it is.
|
||||
|
||||
The sarcasm is [knee-deep][6] in the comments section on Google+ over that one.
|
||||
|
||||
### 'Hackers Shake Confidence' ###
|
||||
|
||||
Of course, malicious hacking is no laughing matter, and the FOSS world has gotten a bitter taste of the effects for itself in recent months with the Heartbleed and Shellshock flaws, to name just two.
|
||||
|
||||
Has it been enough to scare Linux aficionados away?
|
||||
|
||||
That essentially is [the suggestion][7] over at Bloomberg, whose story, entitled "Hackers Shake Confidence in 1980s Free Software Idealism," has gotten more than a few FOSS fans' knickers in a twist.
|
||||
|
||||
### 'No Software Is Perfect' ###
|
||||
|
||||
"None of this has shaken my confidence in the slightest," asserted [Linux Rants][8] blogger Mike Stone down at the blogosphere's Broken Windows Lounge, for instance.
|
||||
|
||||
"I remember a time when you couldn't put a Windows machine on the network without firewall software or it would be infected with viruses/malware in seconds," he explained. "I don't recall the articles claiming that confidence had been shaken in Microsoft.
|
||||
|
||||
"The fact of the matter is that no software is perfect, not even FOSS, but it comes closer than the alternatives," Stone opined.
|
||||
|
||||
### 'My Faith Is Just Fine' ###
|
||||
|
||||
"It is hard to even begin to get into where the Bloomberg article fails," began consultant and [Slashdot][9] blogger Gerhard Mack.
|
||||
|
||||
"For one, decompilers have existed for ages and allow black hats to find flaws in proprietary software, so the black-hats can find problems but cannot admit they found them let alone fix them," Mack explained. "Secondly, it has been a long time since most open source was volunteer-written, and most contributions need to be paid.
|
||||
|
||||
"The author goes on to rip into people who use open source for not contributing monetarily, when most of the listed companies are already Linux Foundation members, so they are already contributing," he added.
|
||||
|
||||
In short, "my faith in open source is just fine, and no clickbait Bloomberg article will change that," Mack concluded.
|
||||
|
||||
### 'The Author Is Wrong' ###
|
||||
|
||||
"Clickbait" is also the term Google+ blogger Alessandro Ebersol chose to describe the Bloomberg account.
|
||||
|
||||
"I could not see the point the author was trying to make, except sensationalism and views," he told Linux Girl.
|
||||
|
||||
"The author is wrong," Ebersol charged. "He should educate himself on the topic. The flaws are results of lack of funding, and too many corporations taking advantage of free software and giving nothing back."
|
||||
|
||||
Moreover, "I still believe that a piece of code that can be studied and checked by many is far more secure than a piece made by a few," Google+ blogger Gonzalo Velasco C. chimed in.
|
||||
|
||||
"All the rumors that FLOSS is as weak as proprietary software are only [FUD][10] -- period," he said. "It is even more sad when it comes from private companies that drink in the FLOSS fountain."
|
||||
|
||||
### 'Source Helps Ensure Security' ###
|
||||
|
||||
Chris Travers, a [blogger][11] who works on the [LedgerSMB][12] project, had a similar view.
|
||||
|
||||
"I do think that having the source available helps ensure security for well-designed, well-maintained software," he began.
|
||||
|
||||
"Those of us who do development on such software must necessarily approach the security process under a different set of constraints than proprietary vendors do," Travers explained.
|
||||
|
||||
"Since our code changes are public, when we release a security fix this also provides effectively full disclosure," he said, "ensuring that the concerns for unpatched systems are higher than they would be for proprietary solutions absent full disclosure."
|
||||
|
||||
At the same time, "this disclosure cuts both ways, as software security vendors can use this to provide further testing and uncover more problems," Travers pointed out. "In the long run, this leads to more secure software, but in the short run it has security costs for users."
|
||||
|
||||
Bottom line: "If there is good communication with the community, if there is good software maintenance and if there is good design," he said, "then the software will be secure."
|
||||
|
||||
### 'Source Code Isn't Magic Fairy Dust' ###
|
||||
|
||||
SoylentNews blogger hairyfeet had a very different view.
|
||||
|
||||
"'Many eyes' is a complete and total myth," hairyfeet charged. "I bet my last dollar that if you looked at every.single.package. that makes up your most popular distros and then looked at how many have actually downloaded the source for those various packages, you'd find that there is less than 30 percent of the packages that are downloaded by anybody but the guys that actually maintain the things.
|
||||
|
||||
"How many people have done a code audit on Firefox? [LibreOffice][13]? Gimp? I bet you won't find a single one, because everybody ASSUMES that somebody else did it," he added.
|
||||
|
||||
"At the end of the day, Wall Street is finding out what guys like me have been saying for years: Source code isn't magic fairy dust that makes the bugs go away," hairyfeet observed.
|
||||
|
||||
### 'No One Actually Looked at It' ###
|
||||
|
||||
"The problem with [SSL][14] was that everyone assumed the code was good, but almost no one had actually looked at, so you never had the 'many eyeballs' making the bugs shallow," Google+ blogger Kevin O'Brien conceded.
|
||||
|
||||
Still, "I think the methodology and the idealism are separable," he suggested. "Open source is a way of writing software in which the value created for everyone is much greater than the value captured by any one entity, which is why it is so powerful.
|
||||
|
||||
"The idea that corporate contributions somehow sully the purity is a stupid idea," added O'Brien. "Corporate involvement is not inherently bad; what is bad is trying to lock other people out of the value created. Many companies handle this well, such as Red Hat."
|
||||
|
||||
### 'The Right Way to Do IT' ###
|
||||
|
||||
Last but not least, "my confidence in FLOSS is unshaken," blogger [Robert Pogson][15] declared.
|
||||
|
||||
"After all, I need software to run my computers, and as bad as some flaws are in FLOSS, that vulnerability pales into insignificance compared to the flaws in that other OS -- you know, the one that thinks images are executable and has so much complexity that no one, not even M$ with its $billions, can fix."
|
||||
|
||||
FOSS is "the right way to do IT," Pogson added. "The world can and does make its own software, and the world has more and better programmers than the big corporations.
|
||||
|
||||
"Those big corporations use FLOSS and should support FLOSS," he maintained, offering "thanks to the corporations who hire FLOSS programmers; sponsor websites, mirrors and projects; and who give back code -- the fuel in the FLOSS economy."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/FOSS-and-the-Fear-Factor-81221.html
|
||||
|
||||
作者:Katherine Noyes
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.linuxinsider.com/perl/story/80980.html
|
||||
[2]:http://www.reglue.org/
|
||||
[3]:http://www.linuxinsider.com/story/78422.html
|
||||
[4]:https://www.indiegogo.com/projects/deleting-the-digital-divide-one-computer-at-a-time
|
||||
[5]:http://fortune.com/video/2014/10/14/russian-hackers-use-windows-against-nato/
|
||||
[6]:https://plus.google.com/+KatherineNoyes/posts/DQvRMekLHV4
|
||||
[7]:http://www.bloomberg.com/news/2014-10-14/hackers-shake-confidence-in-1980s-free-software-idealism.html
|
||||
[8]:http://linuxrants.com/
|
||||
[9]:http://slashdot.org/
|
||||
[10]:http://en.wikipedia.org/wiki/Fear,_uncertainty_and_doubt
|
||||
[11]:http://ledgersmbdev.blogspot.com/
|
||||
[12]:http://www.ledgersmb.org/
|
||||
[13]:http://www.libreoffice.org/
|
||||
[14]:http://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[15]:http://mrpogson.com/
|
||||
@ -1,115 +0,0 @@
|
||||
Calculate Linux Provides Consistency by Design
|
||||
================================================================================
|
||||

|
||||
|
||||
> Calculate Linux has a rather interesting strategy for desktop environments. It is characterized by two flavors with the same look and feel. That does not mean that the inherent functionality of the KDE and Xfce desktops are compromised. Rather, the Calculate Linux developers did what you seldom see within a Linux distribution with more than one desktop option: They unified the design.
|
||||
|
||||
Calculate Linux 14 is a distribution designed with home and SMB users in mind. It is optimized for rapid deployment in corporate environments as well.
|
||||
|
||||
Calculate gives users something no other Linux distro makes possible. The Xfce desktop session is customized to imitate the look of the [KDE][1] desktop environment.
|
||||
|
||||
This design approach goes a long way toward making Calculate Linux a one-distro-fits-all solution. Individual users or entire departments within an organization can fine-tune user preferences and features without changing the common appearance or performance.
|
||||
|
||||
Calculate Linux 14, developed by Alexander Tratsevskiy in Russia, is not your typical cookie-cutter type of Linux OS. This latest version, released Sept. 5, is a rolling-release distribution that provides a number of preconfigured features.
|
||||
|
||||
It uses a source-based approach to package management to optimize the software. This in part comes from its roots as a Gentoo Linux-based distribution.
|
||||
|
||||
Calculate Linux comes in three more versions to expand its reach. Calculate Directory Server is for servers, and Calculate Linux Scratch for building customized systems. The Calculate Media Center is a distro to run a home multimedia center.
|
||||
|
||||
### What's New ###
|
||||
|
||||
This latest version of Calculate ships with a few new features, including notification of software updates and an improved administration panel.
|
||||
|
||||
This release adds an improved graphical user interface for Calculate Utilities. It also provides various kernel and other software package updates.
|
||||
|
||||
It comes in 32-bit or 64-bit builds that include two desktop options for personal/business use: KDE and Xfce. A boot menu lets users choose to run the Calculate live desktop environment from RAM for added performance or with a command line interface only.
|
||||
|
||||
Why two choices? Users get better performance on low-end computers using the lightweight desktop environment that comes with Xfce. This is the second release containing this option. It solves the problem of not being able to run the KDE edition of Calculate Linux on underpowered hardware.
|
||||
|
||||
### Designing Details ###
|
||||
|
||||
Calculate Linux has a rather interesting strategy for desktop environments. It is characterized by two flavors with one common design.
|
||||
|
||||
That does not mean that the inherent functionality of the KDE and Xfce desktops are compromised. Rather, the Calculate Linux developers did what you seldom see within a Linux distribution with more than one desktop option.
|
||||
|
||||
Typically, KDE by design is much more animation based. By design, Xfce has fewer visual frills in keeping with its lightweight philosophy. Most KDE distributions place the panel bar at the bottom and do not have a Docky-style launcher anywhere in the desktop decor.
|
||||
|
||||
In Calculate Linux, a classic style application menu, task switcher and system tray are configured at the top of the screen in both desktop versions. At the bottom of the display, there is a hidden quick-launch bar that pops up when the mouse pointer strays toward the lower edge of the screen.
|
||||
|
||||
> 
|
||||
> Calculate Linux has a unified design that makes KDE and Xfce desktops look nearly the same. The panel and menu display are very nontraditional as seen in this KDE desktop view.
|
||||
|
||||
This duality ties the two desktops together. Both the KDE and the Xfce versions have right-click access to some of the most commonly used system commands and features.
|
||||
|
||||
### Look and Feel ###
|
||||
|
||||
Whether you run the KDE or the Xfce desktops, the panel design is the same. The menu falls from the top left corner as a single box with the same categories in both versions.
|
||||
|
||||
> 
|
||||
> The Xfce desktop in Calculate Linux is almost totally indistinguishable from its KDE counterpart.
|
||||
|
||||
Hover the mouse over the right edge of the menu box to see the category contents slide out to the right of the box. Only then do you see a varying range of applications to launch with a click.
|
||||
|
||||
The same operation governs the popup launcher bar hidden at the bottom of the screen. Some of the offerings are desktop-specific, however.
|
||||
|
||||
> 
|
||||
> Calculate Linux embeds a popup launch dock in both the KDE and Xfce desktop editions.
|
||||
|
||||
For example, the bottom dock in both desktop versions launches the Chromium Web browser, [LibreOffice][3], GIMP, SMPlayer and Leafpad (simple text editor). The KDE dock launches kcalc, digikam, Amarok and k3b disk burner. Xfce launches Galculator, Clementine and xfburn.
|
||||
|
||||
### Designed to Differ ###
|
||||
|
||||
One difference is the KDE version has an added button where expected along the upper right edge of the screen. It also has a Widgets button near the far right end of the top panel.
|
||||
|
||||
These provide access to the activities layout where you choose the style of desktop typical of KDE. These are: Grid, Newspaper, Folder, Grouping and Search & Launch.
|
||||
|
||||
A second style difference between the two desktop versions is the inclusion of widgets with the KDE version. These desktop widgets personalize the desktop items.
|
||||
|
||||
### Feature Folly ###
|
||||
|
||||
The Calculate Desktop edition, both KDE and Xfce, creates a user profile when it loads. This profile is fully integrated with Calculate Directory Server. Roaming profiles also are supported. Auto-tuning applications at logon are based on the server settings.
|
||||
|
||||
The approach greatly simplifies the setup and maintenance roles for users with no IT department to support the computer system. The desktop version functions simply as a standalone operating system. No server is needed. However, enterprise and SMB environments can pair the desktop version with the server version for seamless integration.
|
||||
|
||||
Either way, the common set of toolbars, desktop applications and basic settings are easier to configure for desktop and server use, regardless of the desktop environment choice.
|
||||
|
||||
You can install Calculate Linux on a USB thumb drive or a USB hard drive with a choice of these volume formats: ext4, ext3, ext2, reiserfs, btrfs, xfs, jfs, nilfs2 or fat32.
|
||||
|
||||
### Gentler Gentoo ###
|
||||
|
||||
The Gentoo distro in its own right installs applications compiled from source. It uses a software packaging system called "Portage" to semi-automate this process. It also uses the command-line compiling system run by Emerge.
|
||||
|
||||
Calculate's developers soften this Gentoo-based software compiling process somewhat, but it is still more complex than using a community-managed automated software binary repository.
|
||||
|
||||
Calculate Linux is fully compatible with Gentoo repositories and support for binary repository updates. System files are updated via Portage throughout the distribution life cycle.
|
||||
|
||||
### Bottom Line ###
|
||||
|
||||
Calculate Linux is a well-tooled Linux distro that makes consistency in design job number one. It is highly configurable and is optimized for nearly every computing circumstance.
|
||||
|
||||
It runs a full-blown KDE desktop on upper-end hardware, and provides the same look and feel with Xfce on low-end gear. Calculate Linux runs from a hard drive installation or by loading directly into RAM.
|
||||
|
||||
It could offer home and SMB users an effective distro alternative. However, typical for Gentoo-based distros, Calculate Linux's weak point is the lack of a full-fledged binary software repository system.
|
||||
|
||||
### Want to Suggest a Review? ###
|
||||
|
||||
Is there a Linux software application or distro you'd like to suggest for review? Something you love or would like to get to know?
|
||||
|
||||
Please [email your ideas to me][4], and I'll consider them for a future Linux Picks and Pans column.
|
||||
|
||||
And use the Talkback feature below to add your comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Calculate-Linux-Provides-Consistency-by-Design-81242.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.calculate-linux.org/
|
||||
[2]:http://www.kde.org/
|
||||
[3]:http://www.libreoffice.org/
|
||||
[4]:jack.germain@newsroom.ectnews.com
|
||||
@ -1,136 +0,0 @@
|
||||
Debian's Civil War: Has It Really Come to This?
|
||||
================================================================================
|
||||

|
||||
|
||||
**"The 'new' Debian would be rather weak," said blogger Robert Pogson. "Would it have the hundreds of mirrors that make Debian wonderful? I doubt that. Debian is a great distro. Disemboweling it out of spite is just wrong. Why can't we come to some amicable agreement? Why do we have to race at full speed to the edge of a cliff when we don't know if we can stop?"**
|
||||
|
||||
Well it seems no matter how loudly we here in the Linux blogosphere try to hum a happy tune or discuss [cheerful FOSS matters][1], we just can't seem to drown out the shouts and screams coming from those standing too close to the Systemd Inferno.
|
||||
|
||||
Stand back, people! It's dangerous!
|
||||
|
||||
The embers, of course, [had been hot][2] for some time already before the blaze [flared sky-high][3] a few months ago. Now, the conflagration appears to be completely out of control.
|
||||
|
||||
Need proof? Two words: [Debian fork][4].
|
||||
|
||||
That's right: Debian, the granddaddy of Linux distributions and embodiment of everything so many FOSS fans hold dear, may be forked, and it's apparently all because of Systemd.
|
||||
|
||||
A more upsetting development would be hard to conceive.
|
||||
|
||||
### 'Roll Up Your Sleeves' ###
|
||||
|
||||

|
||||
|
||||
"Debian today is haunted by the tendency to betray its own mandate, a base principle of the Free Software movement: put the user's rights first," explained the anonymous developers behind the Debian Fork site. "What is happening now instead is that through a so-called 'do-ocracy,' developers and package maintainers are imposing their choices on users."
|
||||
|
||||
Their conclusion: "Roll up your sleeves, we may need to fork Debian."
|
||||
|
||||
Quick as a flash, [word traveled][5] to [Slashdot][6], [LXer][7] and beyond.
|
||||
|
||||
Down at the Linux blogosphere's Punchy Penguin Saloon, a profound hush fell as soon as the news arrived. Fortunately, it lasted only a fraction of a second.
|
||||
|
||||
### 'I Say Go for It' ###
|
||||
|
||||
"Freedom of choice implies the freedom to be a complete idiot, and clearly Free Software has its share," Google+ blogger Kevin O'Brien said.
|
||||
|
||||
"I have been skeptical about Systemd, but I have trouble believing there are enough people this crazy to actually pull off a fork of Debian," O'Brien added. "I predict a year from now we won't remember what this was all about."
|
||||
|
||||
On the other hand: "I say go for it if you're that passionate about it," offered [Linux Rants][8] blogger Mike Stone. "This is Linux we're talking about, after all, and Linux is open source. Anybody should always feel free to do what they want with Linux, as long as they're willing to share.
|
||||
|
||||
"The fact that SysVinit will still be available on standard Debian kind of makes forking it over Systemd seem a little silly, but I'm not going to stand in the way of anybody that wants to fork any FOSS for their own use," Stone added.
|
||||
|
||||
Indeed, "Linux's strength is also its Achilles' Heel," Google+ blogger Rodolfo Saenz opined. 'In the Linux world, forking is inevitable. It is part of Linux's evolution."
|
||||
|
||||
### 'A Lot of Misinformation' ###
|
||||
|
||||
At the same time, "I think if they were likely to actually fork Debian, they would have just gone and done it rather than throw a massive public temper tantrum," consultant and Slashdot blogger Gerhard Mack suggested.
|
||||
|
||||
"Secondly, I think there is a lot of misinformation out there about what Systemd does and how it works," Mack added. 'At the beginning of all of this I was very worried about the stability and security of the systems I maintain after reading the nerd rage on Slashdot, The Register, and sites like [Boycott Systemd][9], so I looked into Systemd for myself.
|
||||
|
||||
"What I have discovered is that they seem to be confusing Systemd with things that are bundled with Systemd but run separately using a 'least privilege needed for the task' type design," he explained. "There are things I don't like, such as the binary logs, but then I can just configure it to run through syslogd as usual and ignore the binary logs."
|
||||
|
||||
Particularly "hilarious," Mack added, is that people "suggest that only desktops need to boot quickly," he said. "I have seen some automated systems that load VMs on demand, and they would be much more effective if they booted faster."
|
||||
|
||||
### 'I'm Really Confused' ###
|
||||
|
||||
It will be "a sad day if Debian forks over this Systemd thing," longtime Debian user [Robert Pogson][10] told Linux Girl.
|
||||
|
||||
"I am one of the haters, I guess," Pogson said. "I see adopting Systemd as something that kept Jessie's bug count high for months. I just don't see the need for it. I've read that some desktop users complain that Systemd is all for server users and I've read that some server users complain that Systemd is all for desktop users. I'm both and I'm really confused."
|
||||
|
||||
Meanwhile, "do I need to learn a lot about Systemd to use it?" Pogson wondered. "I'm too old to learn too many new tricks. Does it give me any benefits, or is it just a nuisance?
|
||||
|
||||
"I see faster booting as a rather small benefit for a lot of nuisance value like binary logs... what's with that?" he added. "I've learned to use grep on current logs to get what I need. Hiding them is just making GNU/Linux more like that other OS. Yuck!"
|
||||
|
||||
### 'Nonfree Software Is the Real Enemy' ###
|
||||
|
||||
Debian is an organization of roughly a thousand developers, Pogson pointed out.
|
||||
|
||||
"They work hard and make the world a better place," he said. "Forcing them to choose which fork to take is really cruel and unusual punishment for such generous people. If the fork is 50/50, Debian might take years of recruitment to recover. That does no one any good.
|
||||
|
||||
"The 'new' Debian would be rather weak," Pogson added. "Would it have the hundreds of mirrors that make Debian wonderful? I doubt that. Debian is a great distro. Disemboweling it out of spite is just wrong. Why can't we come to some amicable agreement? Why do we have to race at full speed to the edge of a cliff when we don't know if we can stop?"
|
||||
|
||||
Bottom line: "If this civil war gets any worse, I may switch back to Debian Stable/Wheezy, my 'bomb shelter,' in the hope that I can wait for peace to break out," he concluded. "I don't need the drama. Bill Gates must be laughing at this waste of energy. Nonfree software is the real enemy -- not folks building/using Debian GNU/Linux."
|
||||
|
||||
### 'It Is What Happens' ###
|
||||
|
||||
It is a sad development, Google+ blogger Gonzalo Velasco C. agreed.
|
||||
|
||||
At the same time, "it is what happens in the FLOSS world when you don't listen to your peers and users and listen to others that have their own (commercial) agenda and 'suggest' you use a tool as hungry as Systemd, regardless of its merits and modernism comparing to old sisVinit," he said.
|
||||
|
||||
"There are a lot of technical discussions and arguments out there, and Debian must show it is neither deaf nor blind and re-discuss the issue," he added.
|
||||
|
||||
### Red Hat's Influence ###
|
||||
|
||||
"Do the users wish to be beholden to [Red Hat's][11] corporate roadmap? If the answer is 'no,' then a fork is the only choice left open, as it's pretty plain to see that Debian will go Systemd whether their users like it or not," SoylentNews blogger hairyfeet said.
|
||||
|
||||
"It all comes down to cloud computing, and RH intends to foist its version of SVCHOSTS for Linux onto Debian and Ubuntu," he added. "The reason why is obvious: it gives them pretty much every major Linux distro, as they are nearly all built on RH, Debian or Ubuntu."
|
||||
|
||||
So, the answer is simple, hairyfeet said: "If you want RH calling the shots, then stay; if not, fork."
|
||||
|
||||
### 'Seems Like a Lot of Work' ###
|
||||
|
||||
Of course, there's nothing to prevent a fork, Google+ blogger Brett Legree pointed out.
|
||||
|
||||
"If someone wants to do it, that's their choice," he noted.
|
||||
|
||||
"Seems like a lot of work, though," Legree added. "I mean, I figure that most people wouldn't care either way what init system is being used, and those who do know can probably figure out how to configure Debian (or whatever) to use a different init system. That's been possible up to now, and I'd expect it will continue to be so."
|
||||
|
||||
Forks are a lot of work to maintain, agreed Chris Travers, a [blogger][12] who works on the [LedgerSMB][13] project.
|
||||
|
||||
"Trust me -- I know from experience, as LedgerSMB began life as a fork of SQL-Ledger," Travers said.
|
||||
|
||||
Still, "there are huge differences in philosophy between init scripts and Systemd, and this is an area where there is probably room for a good Unix-like distro to keep the old ways," Travers said. "There are certainly worse things than forks developing. This being said, I wonder if people who really want Unix should instead switch to the BSDs."
|
||||
|
||||
### 'Like Killing Mosquitoes With Shotguns' ###
|
||||
|
||||
The Debian community was not aware of everything the changes in the init system would bring, Google+ blogger Alessandro Ebersol suggested. "They thought it was a non-issue."
|
||||
|
||||
Now that "a large number of Debian sysadmins are not pleased," however, forking would be "an extreme measure," he said, "and a last resort. There are still a lot of things that can be done."
|
||||
|
||||
After all, Debian is "the GNU/Linux that runs on anything, in any *nix setup -- remember the Debian BSD flavor, and that Debian BSD will have to be accommodated to work with the new init system," Ebersol pointed out.
|
||||
|
||||
"So, I believe all is not lost for Debian, but a fork, right now, is too extreme, like killing mosquitoes with shotguns," he concluded. "There's still time and place to make peace and amendments in the Debian community."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/81262.html
|
||||
|
||||
作者:[Katherine Noyes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://twitter.com/noyesk
|
||||
[1]:http://www.reglue.org/
|
||||
[2]:http://www.linuxinsider.com/story/80472.html
|
||||
[3]:http://www.linuxinsider.com/story/80980.html
|
||||
[4]:http://debianfork.org/
|
||||
[5]:http://linux.slashdot.org/story/14/10/20/1944226/debians-systemd-adoption-inspires-threat-of-fork
|
||||
[6]:http://slashdot.org/
|
||||
[7]:http://lxer.com/module/forums/t/35625/
|
||||
[8]:http://linuxrants.com/
|
||||
[9]:http://boycottsystemd.org/
|
||||
[10]:http://mrpogson.com/
|
||||
[11]:http://www.redhat.com/
|
||||
[12]:http://ledgersmbdev.blogspot.com/
|
||||
[13]:http://www.ledgersmb.org/
|
||||
@ -1,92 +0,0 @@
|
||||
[translating by KayGuoWhu]
|
||||
A brief history of Linux malware
|
||||
================================================================================
|
||||
A look at some of the worms and viruses and Trojans that have plagued Linux throughout the years.
|
||||
|
||||
### Nobody’s immune ###
|
||||
|
||||

|
||||
|
||||
Although not as common as malware targeting Windows or even OS X, security threats to Linux have become both more numerous and more severe in recent years. There are a couple of reasons for that – the mobile explosion has meant that Android (which is Linux-based) is among the most attractive targets for malicious hackers, and the use of Linux as a server OS for and in the data center has also grown – but Linux malware has been around in some form since well before the turn of the century. Have a look.
|
||||
|
||||
### Staog (1996) ###
|
||||
|
||||

|
||||
|
||||
The first recognized piece of Linux malware was Staog, a rudimentary virus that tried to attach itself to running executables and gain root access. It didn’t spread very well, and it was quickly patched out in any case, but the concept of the Linux virus had been proved.
|
||||
|
||||
### Bliss (1997) ###
|
||||
|
||||

|
||||
|
||||
If Staog was the first, however, Bliss was the first to grab the headlines – though it was a similarly mild-mannered infection, trying to grab permissions via compromised executables, and it could be deactivated with a simple shell switch. It even kept a neat little log, [according to online documentation from Ubuntu][1].
|
||||
|
||||
### Ramen/Cheese (2001) ###
|
||||
|
||||

|
||||
|
||||
Cheese is the malware you actually want to get – certain Linux worms, like Cheese, may actually have been beneficial, patching the vulnerabilities the earlier Ramen worm used to infect computers in the first place. (Ramen was so named because it replaced web server homepages with a goofy image saying that “hackers looooove noodles.”
|
||||
|
||||
### Slapper (2002) ###
|
||||
|
||||

|
||||
|
||||
The Slapper worm struck in 2002, infecting servers via an SSL bug in Apache. That predates Heartbleed by 12 years, if you’re keeping score at home.
|
||||
|
||||
### Badbunny (2007) ###
|
||||
|
||||

|
||||
|
||||
Badbunny was an OpenOffice macro worm that carries a sophisticated script payload that worked on multiple platforms – even though the only effect of a successful infection was to download a raunchy pic of a guy in a bunny suit, er, doing what bunnies are known to do.
|
||||
|
||||
### Snakso (2012) ###
|
||||
|
||||

|
||||
Image courtesy [TechWorld UK][2]
|
||||
|
||||
The Snakso rootkit targeted specific versions of the Linux kernel to directly mess with TCP packets, injecting iFrames into traffic generated by the infected machine and pushing drive-by downloads.
|
||||
|
||||
### Hand of Thief (2013) ###
|
||||
|
||||

|
||||
|
||||
Hand of Thief is a commercial (sold on Russian hacker forums) Linux Trojan creator that made quite a splash when it was introduced last year. RSA researchers, however, discovered soon after that [it wasn’t quite as dangerous as initially thought][3].
|
||||
|
||||
### Windigo (2014) ###
|
||||
|
||||

|
||||
|
||||
Image courtesy [freezelight][4]
|
||||
|
||||
Windigo is a complex, large-scale cybercrime operation that targeted tens of thousands of Linux servers, causing them to produce spam and serve drive-by malware and redirect links. It’s still out there, according to ESET security, [so admins should tread carefully][5].
|
||||
|
||||
### Shellshock/Mayhem (2014) ###
|
||||
|
||||

|
||||
|
||||
Striking at the terminal strikes at the heart of Linux, which is why the recent Mayhem attacks – which targeted the so-called Shellshock vulnerabilities in Linux’s Bash command-line interpreter using a specially crafted ELF library – were so noteworthy. Researchers at Yandex said that the network [had snared 1,400 victims as of July][6].
|
||||
|
||||
### Turla (2014) ###
|
||||
|
||||

|
||||
|
||||
A large-scale campaign of cyberespionage emanating from Russia, called Epic Turla by researchers, was found to have a new Linux-focused component earlier this week. It’s apparently [based on a backdoor access program from all the way back in 2000 called cd00r][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2858742/linux/a-brief-history-of-linux-malware.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Jon-Gold/
|
||||
[1]:https://help.ubuntu.com/community/Linuxvirus
|
||||
[2]:http://news.techworld.com/security/3412075/linux-users-targeted-by-mystery-drive-by-rootkit/
|
||||
[3]:http://www.networkworld.com/article/2168938/network-security/dangerous-linux-trojan-could-be-sign-of-things-to-come.html
|
||||
[4]:https://www.flickr.com/photos/63056612@N00/155554663
|
||||
[5]:http://www.welivesecurity.com/2014/04/10/windigo-not-windigone-linux-ebury-updated/
|
||||
[6]:http://www.pcworld.com/article/2825032/linux-botnet-mayhem-spreads-through-shellshock-exploits.html
|
||||
[7]:http://www.computerworld.com/article/2857129/turla-espionage-operation-infects-linux-systems-with-malware.html
|
||||
@ -1,102 +0,0 @@
|
||||
Docker CTO Solomon Hykes to Devs: Have It Your Way
|
||||
================================================================================
|
||||

|
||||
|
||||
**"We made a very conscious effort with Docker to insert the technology into an existing toolbox. We did not want to turn the developer's world upside down on the first day. ... We showed them incremental improvements so that over time the developers discovered more things they could do with Docker. So the developers could transition into the new architecture using the new tools at their own pace."**
|
||||
|
||||
[Docker][1] in the last two years has moved from an obscure Linux project to one of the most popular open source technologies in cloud computing.
|
||||
|
||||
Project developers have witnessed millions of Docker Engine downloads. Hundreds of Docker groups have formed in 40 countries. Many more companies are announcing Docker integration. Even Microsoft will ship Windows 10 with Docker preinstalled.
|
||||
|
||||

|
||||
|
||||
Solomon Hykes
|
||||
Founder and CTO of Docker
|
||||
|
||||
"That caught a lot of people by surprise," Docker founder and CTO Solomon Hykes told LinuxInsider.
|
||||
|
||||
Docker is an open platform for developers and sysadmins to build, ship and run distributed applications. It uses a Docker engine along with a portable, lightweight runtime and packaging tool. It also needs the Docker Hub and a cloud service for sharing applications and automating workflows.
|
||||
|
||||
Docker provides a vehicle for developers to quickly assemble their applications from components. It eliminates the friction between development, quality assurance and production environments. Thus, IT can ship applications faster and run them unchanged on laptops, on data center virtual machines, and in any cloud.
|
||||
|
||||
In this exclusive interview, LinuxInsider discusses with Solomon Hykes why Docker is revitalizing Linux and the cloud.
|
||||
|
||||
**LinuxInsider: You have said that Docker's success is more the result of being in the right place at the right time for a trend that's much bigger than Docker. Why is that important to users?**
|
||||
|
||||
**Solomon Hykes**: There is always an element of being in the right place at the right time. We worked on this concept for a long time. Until recently, the market was not ready for this kind of technology. Then it was, and we were there. Also, we were very deliberate to make the technology flexible and very easy to get started using.
|
||||
|
||||
**LI: Is Docker a new cloud technology or merely a new way to do cloud storage?**
|
||||
|
||||
**Hykes**: Containers in themselves are just an enabler. The really big story is how it changes the software model enormously. Developers are creating new kinds of applications. They are building applications that do not run on only one machine. There is a need for completely new architecture. At the heart of that is independence from the machine.
|
||||
|
||||
The problem for the developer is to create the kind of software that can run independently on any kind of machine. You need to package it up so it can be moved around. You need to cross that line. That is what containers do.
|
||||
|
||||
**LI: How analogous is the software technology to traditional cargo shipping in containers?**
|
||||
|
||||
**Hykes**: That is a very apt example. It is the same thing for shipping containers. The innovation is not in the box. It is in how the automation handles millions of those boxes moving around. That is what is important.
|
||||
|
||||
**LI: How is Docker affecting the way developers build their applications?**
|
||||
|
||||
**Hykes**: The biggest way is it helps them structure their applications for a better distributive system. Another distributive application is Gmail. It does not run on just one application. It is distributive. Developers can package the application as a series of services. That is their style of reasoning when they design. It brings the tooling up to the level of design.
|
||||
|
||||
**LI: What led you to this different architecture approach?**
|
||||
|
||||
**Hykes**: What is interesting about this process is that we did not invent this model. It was there. If you look around, you see this trend where developers are increasingly building distributive applications where the tooling is inadequate. Many people have tried to deal with the existing tooling level. This is a new architecture. When you come up with tools that support this new model, the logical thing to do is tell the developer that the tools are out of date and are inadequate. So throw away the old tools and here are the new tools.
|
||||
|
||||
**LI: How much friction did you encounter from developers not wanting to throw away their old tools?**
|
||||
|
||||
**Hykes**: That approach sounds perfectly reasonable and logical. But in fact it is very hard to get developers to throw away their tools. And for IT departments the same thing is very true. They have legacy performance to support. So most of these attempts to move into next-generation tools have failed. They ask too much of the developers from day one.
|
||||
|
||||
**LI: How did you combat that reaction from developers?**
|
||||
|
||||
**Hykes**: We made a very conscious effort with Docker to insert the technology into an existing toolbox. We did not want to turn the developer's world upside down on the first day. Instead, we showed them incremental improvements so that over time the developers discovered more things they could do with Docker. So the developers could transition into the new architecture using the new tools at their own pace. That makes all the difference in the world.
|
||||
|
||||
**LI: What reaction are you seeing from this strategy?**
|
||||
|
||||
**Hykes**: When I ask people using Docker today how revolutionary it is, some say they are not using it in a revolutionary way. It is just a little improvement in my toolbox. That is the point. Others say that they jumped all in on the first day. Both responses are OK. Everyone can take their time moving toward that new model.
|
||||
|
||||
**LI: So is it a case of integrating Docker into existing platforms, or is a complete swap of technology required to get the full benefit?**
|
||||
|
||||
**Hykes**: Developers can go either way. There is a lot of demand for Docker native. But there is a whole ecosystem of new tools and companies competing to build brand new platforms entirely build on top of Docker. Over time the world is trending towards Docker native, but there is no rush. We totally support the idea of developers using bits and pieces of Docker in their existing platform forever. We encourage that.
|
||||
|
||||
**LI: What about Docker's shared Linux kernel architecture?**
|
||||
|
||||
**Hykes**: There are two steps involved in answering that question. What Docker does is become a layer on top of the Linux kernel. It exposes an abstraction function. It takes advantage of the underlying system. It has access to all of the Linux features. It also takes advantage of the networking stack and the storage subsystem. It uses the abstraction feature to map what developers need.
|
||||
|
||||
**LI: How detailed a process is this for developers?**
|
||||
|
||||
**Hykes**: As a developer, when I make an application I need a run-time that can run my application in a sandbox environment. I need a packaging system that makes it easy to move it around to other machines. I need a networking model that allows my application to talk to the outside world. I need storage, etc. We abstract ... the gritty details of whatever the kernel does right now.
|
||||
|
||||
**LI: Why does this benefit the developer?**
|
||||
|
||||
**Hykes**: There are two really big advantages to that. The first is simplicity. Developers can actually be productive now because that abstraction is easier for them to comprehend and is designed for that. The system APIs are designed for the system. What the developer needs is a consistent abstraction that works everywhere.
|
||||
|
||||
The second advantage is that over time you can support more systems. For example, early on Docker could only work on a single distribution of Linux under very narrow versions of the kernel. Over time, we expanded the surface area for the number of systems out there that Docker supports natively. So now you can run Docker on every major Linux distribution and in combination with many more networking and storage features.
|
||||
|
||||
**LI: Does this functionality trickle down to nondevelopers, or is the benefit solely targeting developers?**
|
||||
|
||||
**Hykes**: Every time we expand that surface area, every single developer that uses the Docker abstraction benefits from that too. So every application running Docker gets the added functionality every time the Docker community adds to the expansion. That is the thing that benefits all users. Without that universal expansion, every single developer would not have time to invest to update. There is just too much to support.
|
||||
|
||||
**LI: What about Microsoft's recent announcement that it was shipping Docker support with Windows?**
|
||||
|
||||
**Hykes**: If you think of Docker as a very narrow and very simple tool, then why would you roll out support for Windows? The whole point is that over time, you can expand the reach of that abstraction. Windows works very differently, obviously. But now that Microsoft has committed to adding features to Windows 10, it exposes the functionality required to run Docker. That is real exciting.
|
||||
|
||||
Docker still has to be ported to Windows, but Microsoft has committed to contributing in a major way to the port. Realize how far Microsoft has come in doing this. Microsoft is doing this fully upstream in a completely native, open source way. Everyone installing Windows 10 will get Docker preinstalled.
|
||||
|
||||
**LI: What lies ahead for growing Docker's feature set and user base?**
|
||||
|
||||
**Hykes**: The community has a lot of features on the drawing board. Most of them have to do with more improved tools for developers to build better distributive applications. A toolkit implies having a series of tools with each tool designed for one job.
|
||||
|
||||
In each of these subsystems, there is a need for new tools. In each of these areas, you will see an enormous amount of activity in the community in terms of contributions and designs. In that regard, the Docker project is enormously ambitious. The ability to address each of these areas will ensure that developers have a huge array of choices without fragmentation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Docker-CTO-Solomon-Hykes-to-Devs-Have-It-Your-Way-81504.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.docker.com/
|
||||
@ -1,48 +0,0 @@
|
||||
(translating by runningwater)
|
||||
2015: Open Source Has Won, But It Isn't Finished
|
||||
================================================================================
|
||||
> After the wins of 2014, what's next?
|
||||
|
||||
At the beginning of a new year, it's traditional to look back over the last 12 months. But as far as this column is concerned, it's easy to summarise what happened then: open source has won. Let's take it from the top:
|
||||
|
||||
**Supercomputers**. Linux is so dominant on the Top 500 Supercomputers lists it is almost embarrassing. The [November 2014 figures][1] show that 485 of the top 500 systems were running some form of Linux; Windows runs on just one. Things are even more impressive if you look at the numbers of cores involved. Here, Linux is to be found on 22,851,693 of them, while Windows is on just 30,720; what that means is that not only does Linux dominate, it is particularly strong on the bigger systems.
|
||||
|
||||
**Cloud computing**. The Linux Foundation produced an interesting [report][2] last year, which looked at the use of Linux in the cloud by large companies. It found that 75% of them use Linux as their primary platform there, against just 23% that use Windows. It's hard to translate that into market share, since the mix between cloud and non-cloud needs to be factored in; however, given the current popularity of cloud computing, it's safe to say that the use of Linux is high and increasing. Indeed, the same survey found Linux deployments in the cloud have increased from 65% to 79%, while those for Windows have fallen from 45% to 36%. Of course, some may not regard the Linux Foundation as totaly disinterested here, but even allowing for that, and for statistical uncertainties, it's pretty clear which direction things are moving in.
|
||||
|
||||
**Web servers**. Open source has dominated this sector for nearly 20 years - an astonishing record. However, more recently there's been some interesting movement in market share: at one point, Microsoft's IIS managed to overtake Apache in terms of the total number of Web servers. But as Netcraft explains in its most recent [analysis][3], there's more than meets the eye here:
|
||||
|
||||
> This is the second month in a row where there has been a large drop in the total number of websites, giving this month the lowest count since January. As was the case in November, the loss has been concentrated at just a small number of hosting companies, with the ten largest drops accounting for over 52 million hostnames. The active sites and web facing computers metrics were not affected by the loss, with the sites involved being mostly advertising linkfarms, having very little unique content. The majority of these sites were running on Microsoft IIS, causing it to overtake Apache in the July 2014 survey. However the recent losses have resulted in its market share dropping to 29.8%, leaving it now over 10 percentage points behind Apache.
|
||||
|
||||
As that indicates, Microsoft's "surge" was more apparent than real, and largely based on linkfarms with little useful content. Indeed, Netcraft's figures for active sites paints a very different picture: Apache has 50.57% market share, with nginx second on 14.73%; Microsoft IIS limps in with a rather feeble 11.72%. This means that open source has around 65% of the active Web server market - not quite at the supercomputer level, but pretty good.
|
||||
|
||||
**Mobile systems**. Here, the march of open source as the foundation of Android continues. Latest figures show that Android accounted for [83.6%][4] of smartphone shipments in the third quarter of 2014, up from 81.4% in the same quarter the previous year. Apple achieved 12.3%, down from 13.4%. As far as tablets are concerned, Android is following a similar trajectory: for the second quarter of 2014, Android notched up around [75% of global tablet sales][5], while Apple was on 25%.
|
||||
|
||||
**Embedded systems**. Although it's much harder to quantify the market share of Linux in the important embedded system market, but figures from one 2013 study indicated that around [half of planned embedded systems][6] would use it.
|
||||
|
||||
**Internet of Things**. In many ways this is simply another incarnation of embedded systems, with the difference that they are designed to be online, all the time. It's too early to talk of market share, but as I've [discussed][7] recently, AllSeen's open source framework is coming on apace. What's striking by their absence are any credible closed-source rivals; it therefore seems highly likely that the Internet of Things will see supercomputer-like levels of open source adoption.
|
||||
|
||||
Of course, this level of success always begs the question: where do we go from here? Given that open source is approaching saturation levels of success in many sectors, surely the only way is down? In answer to that question, I recommend a thought-provoking essay from 2013 written by Christopher Kelty for the Journal of Peer Production, with the intriguing title of "[There is no free software.][8]" Here's how it begins:
|
||||
|
||||
> Free software does not exist. This is sad for me, since I wrote a whole book about it. But it was also a point I tried to make in my book. Free software—and its doppelganger open source—is constantly becoming. Its existence is not one of stability, permanence, or persistence through time, and this is part of its power.
|
||||
|
||||
In other words, whatever amazing free software 2014 has already brought us, we can be sure that 2015 will be full of yet more of it, as it continues its never-ending evolution.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-3592314/
|
||||
|
||||
作者:[lyn Moody][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworlduk.com/author/glyn-moody/
|
||||
[1]:http://www.top500.org/statistics/list/
|
||||
[2]:http://www.linuxfoundation.org/publications/linux-foundation/linux-end-user-trends-report-2014
|
||||
[3]:http://news.netcraft.com/archives/2014/12/18/december-2014-web-server-survey.html
|
||||
[4]:http://www.cnet.com/news/android-stays-unbeatable-in-smartphone-market-for-now/
|
||||
[5]:http://timesofindia.indiatimes.com/tech/tech-news/Android-tablet-market-share-hits-70-in-Q2-iPads-slip-to-25-Survey/articleshow/38966512.cms
|
||||
[6]:http://linuxgizmos.com/embedded-developers-prefer-linux-love-android/
|
||||
[7]:http://www.computerworlduk.com/blogs/open-enterprise/allseen-3591023/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
@ -0,0 +1,29 @@
|
||||
Linus Tells Wired Leap Second Irrelevant
|
||||
================================================================================
|
||||

|
||||
|
||||
Two larger publications today featured Linux and the effect of the upcoming leap second. The Register today said that the leap second effects of the past are no longer an issue. Coincidentally, Wired talked to Linus Torvalds about the same issue today as well.
|
||||
|
||||
**Linus Torvalds** spoke with Wired's Robert McMillan about the approaching leap second due to be added in June. The Register said the last leap second in 2012 took out Mozilla, StumbleUpon, Yelp, FourSquare, Reddit and LinkedIn as well as several major airlines and travel reservation services that ran Linux. Torvalds told Wired today that the kernel is patched and he doesn't expect too many issues this time around. [He said][1], "Just take the leap second as an excuse to have a small nonsensical party for your closest friends. Wear silly hats, get a banner printed, and get silly drunk. That’s exactly how relevant it should be to most people."
|
||||
|
||||
**However**, The Register said not everyone agrees with Torvalds' sentiments. They quote Daily Mail saying, "The year 2015 will have an extra second — which could wreak havoc on the infrastructure powering the Internet," then remind us of the Y2K scare that ended up being a non-event. The Register's Gavin [Clarke concluded][2]:
|
||||
|
||||
> No reason the Penguins were caught sans pants.
|
||||
|
||||
> Now they've gone belt and braces.
|
||||
|
||||
The take-away is: move along, nothing to see here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/linus-tells-wired-leap-second-irrelevant
|
||||
|
||||
作者:[Susan Linton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/susan-linton
|
||||
[1]:http://www.wired.com/2015/01/torvalds_leapsecond/
|
||||
[2]:http://www.theregister.co.uk/2015/01/09/leap_second_bug_linux_hysteria/
|
||||
@ -0,0 +1,36 @@
|
||||
diff -u: What's New in Kernel Development
|
||||
================================================================================
|
||||
**David Drysdale** wanted to add Capsicum security features to Linux after he noticed that FreeBSD already had Capsicum support. Capsicum defines fine-grained security privileges, not unlike filesystem capabilities. But as David discovered, Capsicum also has some controversy surrounding it.
|
||||
|
||||
Capsicum has been around for a while and was described in a USENIX paper in 2010: [http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf][1].
|
||||
|
||||
Part of the controversy is just because of the similarity with capabilities. As Eric Biderman pointed out during the discussion, it would be possible to implement features approaching Capsicum's as an extension of capabilities, but implementing Capsicum directly would involve creating a whole new (and extensive) abstraction layer in the kernel. Although David argued that capabilities couldn't actually be extended far enough to match Capsicum's fine-grained security controls.
|
||||
|
||||
Capsicum also was controversial within its own developer community. For example, as Eric described, it lacked a specification for how to revoke privileges. And, David pointed out that this was because the community couldn't agree on how that could best be done. David quoted an e-mail sent by Ben Laurie to the cl-capsicum-discuss mailing list in 2011, where Ben said, "It would require additional book-keeping to find and revoke outstanding capabilities, which requires knowing how to reach capabilities, and then whether they are derived from the capability being revoked. It also requires an authorization model for revocation. The former two points mean additional overhead in terms of data structure operations and synchronisation."
|
||||
|
||||
Given the ongoing controversy within the Capsicum developer community and the corresponding lack of specification of key features, and given the existence of capabilities that already perform a similar function in the kernel and the invasiveness of Capsicum patches, Eric was opposed to David implementing Capsicum in Linux.
|
||||
|
||||
But, given the fact that capabilities are much coarser-grained than Capsicum's security features, to the point that capabilities can't really be extended far enough to mimic Capsicum's features, and given that FreeBSD already has Capsicum implemented in its kernel, showing that it can be done and that people might want it, it seems there will remain a lot of folks interested in getting Capsicum into the Linux kernel.
|
||||
|
||||
Sometimes it's unclear whether there's a bug in the code or just a bug in the written specification. Henrique de Moraes Holschuh noticed that the Intel Software Developer Manual (vol. 3A, section 9.11.6) said quite clearly that microcode updates required 16-byte alignment for the P6 family of CPUs, the Pentium 4 and the Xeon. But, the code in the kernel's microcode driver didn't enforce that alignment.
|
||||
|
||||
In fact, Henrique's investigation uncovered the fact that some Intel chips, like the Xeon X5550 and the second-generation i5 chips, needed only 4-byte alignment in practice, and not 16. However, to conform to the documented specification, he suggested fixing the kernel code to match the spec.
|
||||
|
||||
Borislav Petkov objected to this. He said Henrique was looking for problems where there weren't any. He said that Henrique simply had discovered a bug in Intel's documentation, because the alignment issue clearly wasn't a problem in the real world. He suggested alerting the Intel folks to the documentation problem and moving on. As he put it, "If the processor accepts the non-16-byte-aligned update, why do you care?"
|
||||
|
||||
But, as H. Peter Anvin remarked, the written spec was Intel's guarantee that certain behaviors would work. If the kernel ignored the spec, it could lead to subtle bugs later on. And, Bill Davidsen said that if the kernel ignored the alignment requirement, and "if the requirement is enforced in some future revision, and updates then fail in some insane way, the vendor is justified in claiming 'I told you so'."
|
||||
|
||||
The end result was that Henrique sent in some patches to make the microcode driver enforce the 16-byte alignment requirement.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/diff-u-whats-new-kernel-development-6
|
||||
|
||||
作者:[Zack Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/801501
|
||||
[1]:http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf
|
||||
82
sources/talk/20150114 Why Mac users don't switch to Linux.md
Normal file
82
sources/talk/20150114 Why Mac users don't switch to Linux.md
Normal file
@ -0,0 +1,82 @@
|
||||
[Translating by Stevearzh]
|
||||
Why Mac users don’t switch to Linux
|
||||
================================================================================
|
||||
Linux and Mac users share at least one common thing: they prefer not to use Windows. But after that the two groups part company and tend to go their separate ways. But why don’t more Mac users switch to Linux? Is there something that prevents Mac users from making the jump?
|
||||
|
||||
[Datamation took a look at these questions][1] and tried to answer them. Datamation’s conclusion was that it’s really about the applications and workflow, not the operating system:
|
||||
|
||||
> …there are some instances where replacing existing applications with new options isn’t terribly practical – both in workflow and in overall functionality. This is an area where, sadly, Apple has excelled in. So while it’s hardly “impossible” to get around these issues, they are definitely a large enough challenge that it will give the typical Mac enthusiast pause.
|
||||
>
|
||||
> But outside of Web developers, honestly, I don’t see Mac users “en masse,” seeking to disrupt their workflows for the mere idea of avoiding the upgrade to OS X Yosemite. Granted, having seen Yosemite up close – Mac users who are considered power users will absolutely find this change-up to be hideous. However, despite poor OS X UI changes, the core workflow for existing Mac users will remain largely unchanged and unchallenged.
|
||||
>
|
||||
> No, I believe Linux adoption will continue to be sporadic and random. Ever-growing, but not something that is easily measured or accurately calculated.
|
||||
|
||||
I agree to a certain extent with Datamation’s take on the importance of applications and workflows, both things are important and matter in the choice of a desktop operating system. But I think there’s something more going on with Mac users than just that. I believe that there’s a different mentality that exists between Linux and Mac users, and I think that’s the real reason why many Mac users don’t switch to Linux.
|
||||
|
||||

|
||||
|
||||
### It’s all about control for Linux users ###
|
||||
|
||||
Linux users tend to want control over their computing experience, they want to be able to change things to make them the way that they want them. One simply cannot do that in the same way with OS X or any other Apple products. With Apple you get what they give you for the most part.
|
||||
|
||||
For Mac (and iOS) users this is fine, they seem mostly content to stay within Apple’s walled garden and live according to whatever standards and options Apple gives them. But this is totally unacceptable to most Linux users. People who move to Linux usually come from Windows, and it’s there that they develop their loathing for someone else trying to define or control their computing experiences.
|
||||
|
||||
And once someone like that has tasted the freedom that Linux offers, it’s almost impossible for them to want to go back to living under the thumb of Apple, Microsoft or anyone else. You’d have to pry Linux from their cold, dead fingers before they’d accept the computing experience created for them Apple or Microsoft.
|
||||
|
||||
But you won’t find that same determination to have control among most Mac users. For them it’s mostly about getting the most out of whatever Apple has done with OS X in its latest update. They tend to adjust fairly quickly to new versions of OS X and even when unhappy with Apple’s changes they seem content to continue living within Apple’s walled garden.
|
||||
|
||||
So the need for control is a huge difference between Mac and Linux users. I don’t see it as a problem though since it just reflects the reality of two very different attitudes toward using computers.
|
||||
|
||||
### Mac users need Apple’s support mechanisms ###
|
||||
|
||||
Linux users are also different in the sense that they don’t mind getting their hands dirty by getting “under the hood” of their computers. Along with control comes the personal responsibility of making sure that their Linux systems work well and efficiently, and digging into the operating system is something that many Linux users have no problem doing.
|
||||
|
||||
When a Linux user needs to fix something, chances are they will attempt to do so immediately themselves. If that doesn’t work then they’ll seek additional information online from other Linux users and work through the problem until it has been resolved.
|
||||
|
||||
But Mac users are most likely not going to do that to the same extent. That is probably one of the reasons why Apple stores are so popular and why so many Mac users opt to buy Apple Care when they get a new Mac. A Mac user can simply take his or her computer to the Apple store and ask someone to fix it for them. There they can belly up to the Genius Bar and have their computer looked at by someone Apple has paid to fix it.
|
||||
|
||||
Most Linux users would blanche at the thought of doing such a thing. Who wants some guy you don’t even know to lay hands on your computer and start trying to fix it for you? Some Linux users would shudder at the very idea of such a thing happening.
|
||||
|
||||
So it would be hard for a Mac user to switch to Linux and suddenly be bereft of the support from Apple that he or she was used to getting in the past. Some Mac users might feel very vulnerable and uncertain if they were cut off from the Apple mothership in terms of support.
|
||||
|
||||
### Mac users love Apple’s hardware ###
|
||||
|
||||
The Datamation article focused on software, but I believe that hardware also matters to Mac users. Most Apple customers tend to love Apple’s hardware. When they buy a Mac, they aren’t just buying it for OS X. They are also buying Apple’s industrial design expertise and that can be an important differentiator for Mac users. Mac users are willing to pay more because they perceive that the overall value they are getting from Apple for a Mac is worth it.
|
||||
|
||||
Linux users, on the other hand, seem less concerned by such things. I think they tend to focus more on cost and less on the looks or design of their computer hardware. For them it’s probably about getting the most value from the hardware at the lowest cost. They aren’t in love with the way their computer hardware looks in the same way that some Mac users probably are, and so they don’t make buying decisions based on it.
|
||||
|
||||
I think both points of view on hardware are equally valid. It ultimately gets down to the needs of the individual user and what matters to them when they choose to buy or, in the case of some Linux users, build their computer. Value is the key for both groups, and each has its own perceptions of what constitutes real value in a computer.
|
||||
|
||||
Of course it is [possible to run Linux on a Mac][2], directly or indirectly via virtual machine. So a user that really liked Apple’s hardware does have the option of keeping their Mac but installing Linux on it.
|
||||
|
||||
### Too many Linux distros to choose from? ###
|
||||
|
||||
Another reason that might make it hard for a Mac user to move to Linux is the sheer number of distributions to choose from in the world of Linux. While most Linux users probably welcome the huge diversity of distros available, it could also be very confusing for a Mac user who hasn’t learned to navigate those choices.
|
||||
|
||||
Over time I think a Mac user would learn and adjust by figuring out which distribution worked best for him or her. But in the short term it might be a very daunting hurdle to overcome after being used to OS X for a long period of time. I don’t think it’s insurmountable, but it’s definitely something that is worth mentioning here.
|
||||
|
||||
Of course we do have helpful resources like [DistroWatch][3] and even my own [Desktop Linux Reviews][4] blog that can help people find the right Linux distribution. Plus there are many articles available about “the best Linux distro” and that sort of thing that Mac users can use as resources when trying to figure out the distribution they want to use.
|
||||
|
||||
But one of the reasons why Apple customers buy Macs is the simplicity and all-in-one solution that they offer in terms of the hardware and software being unified by Apple. So I am not sure how many Mac users would really want to spend the time trying to find the right Linux distribution. It might be something that puts them off really considering the switch to Linux.
|
||||
|
||||
### Mac users are apples and Linux users are oranges ###
|
||||
|
||||
I see nothing wrong with Mac and Linux users going their separate ways. I think we’re just talking about two very different groups of people, and it’s a good thing that both groups can find and use the operating system and software that they prefer. Let Mac users enjoy OS X and let Linux users enjoy Linux, and hopefully both groups will be happy and content with their computers.
|
||||
|
||||
Every once in a while a Mac user might stray over to Linux or vice versa, but for the most part I think the two groups live in different worlds and mostly prefer to stay separate and apart from one another. I generally don’t compare the two because when you get right down to it, it’s really just a case of apples and oranges.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jimlynch.com/linux-articles/why-mac-users-dont-switch-to-linux/
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://jimlynch.com/author/Jim/
|
||||
[1]:http://www.datamation.com/open-source/why-linux-isnt-winning-over-mac-users-1.html
|
||||
[2]:http://www.howtogeek.com/187410/how-to-install-and-dual-boot-linux-on-a-mac/
|
||||
[3]:http://distrowatch.com/
|
||||
[4]:http://desktoplinuxreviews.com/
|
||||
@ -0,0 +1,44 @@
|
||||
Linus Torvalds responds to Ars about diversity, niceness in open source
|
||||
================================================================================
|
||||
> Acknowledges diversity factors, says "we're different in so many other ways."
|
||||
|
||||

|
||||
See, sometimes Linus isn't flicking people off.
|
||||
|
||||
Athanasios Kasampalis
|
||||
|
||||
On Thursday, Linux legend Linus Torvalds sent a lengthy statement to Ars Technica responding to [statements he made in Auckland, New Zealand earlier that day about diversity and "niceness"][2] in the open source sector.
|
||||
|
||||
"What I wanted to say [at the keynote]—and clearly must have done very badly—is that one of the great things about open source is exactly the fact that different people are so different," Torvalds wrote via e-mail. "I think people sometimes look at it as being just 'programmers,' which is not true. It's about all the people who are more oriented toward commercial things, too. It's about all those people who are interested in legal issues—and the social ones, too!"
|
||||
|
||||
Torvalds spoke to what he thought was a larger concept of "diversity" than what has been mentioned a lot in recent stories on the topic, including economic disparity, language, and culture (even between neighboring European countries). "There's a lot of talk about gender and sexual preferences and race, but we're different in so many other ways, too," he wrote.
|
||||
|
||||
"'Open source' as a term and as a movement hasn't been about 'you have to be a believer,'" Torvalds added. "It's not a religion. It's not an 'us vs them' thing. We've been able to work with all those 'evil commercial interests' and companies who also do proprietary software. And I think that was one of the things that the Linux community (and others—don't get me wrong, it's not unique to us) did and does well."
|
||||
|
||||
Torvalds also talked about progress since the GPL vs. BSD "flame wars" from the '80s and early '90s, saying that the open source movement brought more technology and less "ideology" to the sector. "Which is not to say that a lot of people aren't around because they believe it's the 'ethical' thing to do (I do myself too)," Torvalds added, "but you don't have to believe that, and you can just do it because it's the most fun, or the most efficient way to do technology development."
|
||||
|
||||
### “This ‘you have to be nice’ seems very popular in the US” ###
|
||||
|
||||
He then sent a second e-mail to Ars about the topic of "niceness" that came up during the keynote. He said that his return to his Auckland hotel was delayed by "like three hours" because of hallway conversations about this very topic.
|
||||
|
||||
"I don't know where you happen to be based, but this 'you have to be nice' seems to be very popular in the US," Torvalds continued, calling the concept an "ideology."
|
||||
|
||||
"The same way we have developers and marketing people and legal people who speak different languages, I think we can have some developers who are used to—and prefer—a more confrontational style, and still **also** have people who don't," he wrote.
|
||||
|
||||
He lambasted the "brainstorming" model of having a criticism-free bubble to bounce ideas off of. "Maybe it works for some people, but I happen to simply not believe in it," he said. "I'd rather be really confrontational, and bad ideas should be [taken] down aggressively. Even good ideas need to be vigorously defended."
|
||||
|
||||
"Maybe it's just because I like arguing," Torvalds added. "I'm just not a huge believer in politeness and sensitivity being preferable over bluntly letting people know your feelings. But I also understand that other people are driven away by cursing and crass language when it all gets a bit too carried away." To that point, Torvalds said that the open source movement might simply need more "people who are good at mediating," as opposed to asking developers to calm their own tone or attitude.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/business/2015/01/linus-torvalds-responds-to-ars-about-diversity-niceness-in-open-source/
|
||||
|
||||
作者:[Sam Machkovech][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/samred/
|
||||
[1]:https://secure.flickr.com/photos/12693492@N04/1338136415/in/photolist-33fikv-3jXFce-3ALpLy-4m6Shj-4pADUg-4pHwcW-4rNTR7-4GMhKc-4HM2qp-4JSHKa-4PomQo-4SKxMo-58LBYf-5iVNX6-5tXbB8-5xi67A-5A8rRc-5C8fAT-5Ccxjw-5EcYvx-5UoNTc-5UoVJK-5Uti6q-5UuiX2-5UuE2B-5UyEJu-5UyHMf-5UyJ2G-5UFbXP-5UFg8Z-5UFhwV-5UKDkG-5UKDP9-5UTHGv-5XM2s2-5YFmLu-65N31L-6pSwh7-6trmfx-6H2uZP-6JVV4V-71qkot-71BBbk-72vuYo-73j9yB-79aQ2a-79bfqe-79EKPH-79EXvD-79PuG5-7a4BxF
|
||||
[2]:http://arstechnica.com/business/2015/01/linus-torvalds-on-why-he-isnt-nice-i-dont-care-about-you/
|
||||
@ -0,0 +1,41 @@
|
||||
Ubuntu 15.04 Finally Lets You Set Menus To ‘Always Show’
|
||||
================================================================================
|
||||
**If you hate the way that Unity’s global menus fade out of view after you mouse away, Ubuntu 15.04 has a little extra to win you around.**
|
||||
|
||||

|
||||
|
||||
The latest build of Unity for Ubuntu 15.04, currently sitting in the ‘proposed’ channel, offers an option to **make app menus visible in Ubuntu**.
|
||||
|
||||
No fading, no timeout, no missing menus.
|
||||
|
||||
The drawback for now is that it can currently only be enabled through a dconf switch and not a regular user-facing option.
|
||||
|
||||
I’d hope (if not expect) that an option to set the feature is added to the Ubuntu System Settings > Appearance section as development continues.
|
||||
|
||||
Right now, if you’re on Ubuntu 15.04 and have the “Proposed” update channel enabled, you should find this switch waiting in **com > canonical > unity >** ‘always show menus’.
|
||||
|
||||
### Better Late Than Never? ###
|
||||
|
||||
Developers plan to backport the option to Ubuntu 14.04 LTS in the next SRU (assuming nothing unexpected crops up during testing).
|
||||
|
||||
Locally Integrated Menus (LIM) debuted in Ubuntu 14.04 LTS to much appreciation, being widely seen as the best compromise between those who liked the simplicity of the “hidden” approach and those who disliked the mouse and trackpad aerobics using it required.
|
||||
|
||||
While locally integrated menus brought us half way to silencing the criticisms levelled at this aspect of Unity, the default “fade in/fade out” behaviour left an itch unscratched.
|
||||
|
||||
The past few releases of Ubuntu has seen proactive addressing of concerns and issues experienced by its earlier UX decisions. After several years on the ‘to do’ list [we finally got Locally Integrated Menus last year][1], as well as an unsupported [option to minimise and restore apps to the Unity Launcher][2] by clicking on their icon.
|
||||
|
||||
A year on from that we finally get an option to make application menus always show, no matter where our mouse is. Better late than never, right?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/ubuntu-15-04-always-show-menu-bar-option
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/2014/02/locally-integrated-menus-ubuntu-14-04
|
||||
[2]:http://www.omgubuntu.co.uk/2014/03/minimize-click-launcher-option-ubuntu-14-04
|
||||
@ -0,0 +1,91 @@
|
||||
Did this JavaScript break the console?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
Just doing some JavaScript stuff in google chrome (don't want to try in other browsers for now, in case this is really doing real damage) and I'm not sure why this seemed to break my console.
|
||||
|
||||
```javascript
|
||||
>var x = "http://www.foo.bar/q?name=%%this%%";
|
||||
<undefined
|
||||
>x
|
||||
```
|
||||
|
||||
After x (and enter) the console stops working... I restarted chrome and now when I do a simple
|
||||
|
||||
```javascript
|
||||
console.clear();
|
||||
```
|
||||
|
||||
It's giving me
|
||||
|
||||
```javascript
|
||||
Console was cleared
|
||||
```
|
||||
|
||||
And not clearing the console. Now in my scripts console.log's do not register and I'm wondering what is going on. 99% sure it has to do with the double percent signs (%%).
|
||||
|
||||
Anyone know what I did wrong or better yet, how to fix the console?
|
||||
|
||||
[A bug report for this issue has been filed here.][1]
|
||||
Edit: Feeling pretty dumb, but I had Preserve log checked... That's why the console wasn't clearing.
|
||||
|
||||
#A:
|
||||
|
||||
As discussed in the comments, there are actually many different ways of constructing a string that causes this issue, and it is not necessary for there to be two percent signs in most cases.
|
||||
|
||||
```TXT
|
||||
http://example.com/%
|
||||
http://%%%
|
||||
http://ab%
|
||||
http://%ab
|
||||
http://%zz
|
||||
```
|
||||
|
||||
However, it's not just the presence of a percent sign that breaks the Chrome console, as when we enter the following well-formed URL, the console continues to work properly and produces a clickable link.
|
||||
|
||||
```TXT
|
||||
http://ab%20cd
|
||||
```
|
||||
|
||||
Additionally, the strings `http://%`, and `http://%%` will also print properly, since Chrome will not auto-link a URL-link string unless the [`http://`][2] is followed by at least 3 characters.
|
||||
|
||||
From here I hypothesized that the issue must be in the process of linking a URL string in the console, likely in the process of decoding a malformed URL. I remembered that the JavaScript function `decodeURI` will throw an exception if given a malformed URL, and since Chrome's developer tools are largely written in JavaScript, could this be the issue that is evidently crashing the developer console?
|
||||
|
||||
To test this theory, I ran Chrome by the command link, to see if any errors were being logged.
|
||||
|
||||
Indeed, the same error you would see if you ran decodeURI on a malformed URL (i.e. decodeURI('http://example.com/%')) was being printed to the console:
|
||||
|
||||
>[4810:1287:0107/164725:ERROR:CONSOLE(683)] "Uncaught URIError: URI malformed", source: chrome-devtools://devtools/bundled/devtools.js (683)
|
||||
>So, I opened the URL 'chrome-devtools://devtools/bundled/devtools.js' in Chrome, and on line 683, I found the following.
|
||||
|
||||
```javascript
|
||||
{var parsedURL=new WebInspector.ParsedURL(decodeURI(url));var origin;var folderPath;var name;if(parsedURL.isValid){origin=parsedURL.scheme+"://"+parsedURL.host;if(parsedURL.port)
|
||||
```
|
||||
|
||||
As we can see, `decodeURI(url)` is being called on the URL without any error checking, thus throwing the exception and crashing the developer console.
|
||||
|
||||
A real fix for this issue will come from adding error handling to the Chrome console code, but in the meantime, one way to avoid the issue would be to wrap the string in a complex data type like an array to prevent parsing when logging.
|
||||
|
||||
```javascript
|
||||
var x = "http://example.com/%";
|
||||
console.log([x]);
|
||||
```
|
||||
|
||||
Thankfully, the broken console issue does not persist once the tab is closed, and will not affect other tabs.
|
||||
|
||||
###Update:
|
||||
|
||||
Apparently, the issue can persist across tabs and restarts if Preserve Log is checked. Uncheck this if you are having this issue.
|
||||
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27828804/did-this-javascript-break-the-console/27830948#27830948)
|
||||
|
||||
作者:[Alexander O'Mara][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/3155639/alexander-omara
|
||||
[1]:https://code.google.com/p/chromium/issues/detail?id=446975
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/decodeURI
|
||||
96
sources/talk/20150121 If a 32-bit integer overflows.md
Normal file
96
sources/talk/20150121 If a 32-bit integer overflows.md
Normal file
@ -0,0 +1,96 @@
|
||||
KayGuoWhu translating
|
||||
If a 32-bit integer overflows, can we use a 40-bit structure instead of a 64-bit long one?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
If, say, a 32-bit integer is overflowing, instead of upgrading int to long, can we make use of some 40-bit type if we need a range only within 240, so that we save 24 (64-40) bits for every integer?
|
||||
|
||||
If so, how?
|
||||
|
||||
I have to deal with billions and space is a bigger constraint.
|
||||
|
||||
#A:
|
||||
|
||||
##Yes, but...
|
||||
|
||||
It is certainly possible, but it is usually nonsensical (for any program that doesn't use billions of these numbers):
|
||||
|
||||
```C
|
||||
#include <stdint.h> // don't want to rely on something like long long
|
||||
struct bad_idea
|
||||
{
|
||||
uint64_t var : 40;
|
||||
};
|
||||
```
|
||||
|
||||
Here, var will indeed have a width of 40 bits at the expense of much less efficient code generated (it turns out that "much" is very much wrong -- the measured overhead is a mere 1-2%, see timings below), and usually to no avail. Unless you have need for another 24-bit value (or an 8 and 16 bit value) which you wish to pack into the same structure, alignment will forfeit anything that you may gain.
|
||||
|
||||
In any case, unless you have billions of these, the effective difference in memory consumption will not be noticeable (but the extra code needed to manage the bit field will be noticeable!).
|
||||
|
||||
###Note:
|
||||
|
||||
The question has in the mean time been updated to reflect that indeed billions of numbers are needed, so this may be a viable thing to do, presumed that you take measures not to lose the gains due to structure alignment and padding, i.e. either by storing something else in the remaining 24 bits or by storing your 40-bit values in structures of 8 each or multiples thereof).
|
||||
Saving three bytes a billion times is worthwhile as it will require noticeably fewer memory pages and thus cause fewer cache and TLB misses, and above all page faults (a single page fault weighting tens of millions instructions).
|
||||
|
||||
While the above snippet does not make use of the remaining 24 bits (it merely demonstrates the "use 40 bits" part), something akin to the following will be necessary to really make the approach useful in a sense of preserving memory -- presumed that you indeed have other "useful" data to put in the holes:
|
||||
|
||||
```C
|
||||
struct using_gaps
|
||||
{
|
||||
uint64_t var : 40;
|
||||
uint64_t useful_uint16 : 16;
|
||||
uint64_t char_or_bool : 8;
|
||||
};
|
||||
```
|
||||
|
||||
Structure size and alignment will be equal to a 64 bit integer, so nothing is wasted if you make e.g. an array of a billion such structures (even without using compiler-specific extensions). If you don't have use for an 8-bit value, you could also use an 48-bit and a 16-bit value (giving a bigger overflow margin).
|
||||
Alternatively you could, at the expense of usability, put 8 40-bit values into a structure (least common multiple of 40 and 64 being 320 = 8*40). Of course then your code which accesses elements in the array of structures will become much more complicated (though one could probably implement an operator[] that restores the linear array functionality and hides the structure complexity).
|
||||
|
||||
Update:
|
||||
Wrote a quick test suite, just to see what overhead the bitfields (and operator overloading with bitfield refs) would have. Posted code (due to length) at gcc.godbolt.org, test output from my Win7-64 machine is:
|
||||
|
||||
```TXT
|
||||
Running test for array size = 1048576
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 2 1 35 35 1
|
||||
uint64_t 0 3 3 35 35 1
|
||||
bad40_t 0 5 3 35 35 1
|
||||
packed40_t 0 7 4 48 49 1
|
||||
|
||||
|
||||
Running test for array size = 16777216
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 38 14 560 555 8
|
||||
uint64_t 0 81 22 565 554 17
|
||||
bad40_t 0 85 25 565 561 16
|
||||
packed40_t 0 151 75 765 774 16
|
||||
|
||||
|
||||
Running test for array size = 134217728
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 312 100 4480 4441 65
|
||||
uint64_t 0 648 172 4482 4490 130
|
||||
bad40_t 0 682 193 4573 4492 130
|
||||
packed40_t 0 1164 552 6181 6176 130
|
||||
```
|
||||
|
||||
What one can see is that the extra overhead of bitfields is neglegible, but the operator overloading with bitfield reference as a convenience thing is rather drastic (about 3x increase) when accessing data linearly in a cache-friendly manner. On the other hand, on random access it barely even matters.
|
||||
|
||||
These timings suggest that simply using 64-bit integers would be better since they are still faster overall than bitfields (despite touching more memory), but of course they do not take into account the cost of page faults with much bigger datasets. It might look very different once you run out of physical RAM (I didn't test that).
|
||||
|
||||
------
|
||||
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27705409/if-a-32-bit-integer-overflows-can-we-use-a-40-bit-structure-instead-of-a-64-bit/27705562#27705562)
|
||||
|
||||
作者:[Damon][a][Michael Kohne][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/572743/damon
|
||||
[b]:http://stackoverflow.com/users/5801/michael-kohne
|
||||
@ -0,0 +1,53 @@
|
||||
How are C data types “supported directly by most computers”?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
I am reading K&R's *The C Programming Language*” and came across this statement [Introduction, p. 3]:
|
||||
|
||||
>Because the data types and control structures provided by C are supported directly by most computers, the run-time library required to implement self-contained programs is tiny.
|
||||
|
||||
What does the bolded statement mean? Is there an example of a data type or a control structure that isn't supported directly by a computer?
|
||||
|
||||
#A:
|
||||
|
||||
Yes, there are data types not directly supported.
|
||||
|
||||
On many embedded systems, there is no hardware floating point unit. So, when you write code like this:
|
||||
|
||||
```C
|
||||
float x = 1.0f, y = 2.0f;
|
||||
return x + y;
|
||||
```
|
||||
|
||||
It gets translated into something like this:
|
||||
|
||||
```C
|
||||
unsigned x = 0x3f800000, y = 0x40000000;
|
||||
return _float_add(x, y);
|
||||
```
|
||||
|
||||
Then the compiler or standard library has to supply an implementation of `_float_add()`, which takes up memory on your embedded system. If you're counting bytes on a really tiny system, this can add up.
|
||||
|
||||
Another common example is 64-bit integers (`long long` in the C standard since 1999), which are not directly supported by 32-bit systems. Old SPARC systems didn't support integer multiplication, so multiplication had to be supplied by the runtime. There are other examples.
|
||||
|
||||
##Other languages
|
||||
|
||||
By comparison, other languages have more complicated primitives.
|
||||
|
||||
For example, a Lisp symbol requires a lot of runtime support, just like tables in Lua, strings in Python, arrays in Fortran, et cetera. The equivalent types in C are usually either not part of the standard library at all (no standard symbols or tables) or they are much simpler and don't require much runtime support (arrays in C are basically just pointers, nul-terminated strings are almost as simple).
|
||||
|
||||
##Control structures
|
||||
|
||||
A notable control structure missing from C is exception handling. Nonlocal exit is limited to `setjmp()` and `longjmp()`, which just save and restore certain parts of processor state. By comparison, the C++ runtime has to walk the stack and call destructors and exception handlers.
|
||||
|
||||
----
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27977522/how-are-c-data-types-supported-directly-by-most-computers/27977605#27977605)
|
||||
|
||||
作者:[Dietrich Epp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/82294/dietrich-epp
|
||||
@ -0,0 +1,72 @@
|
||||
Top 10 FOSS legal developments of 2014
|
||||
================================================================================
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
The year 2014 continued the trend of the increasing importance of legal issues for the FOSS community. Continuing [the tradition of looking back][1] over the top ten legal developments in FOSS, my selection of the top ten issues for 2014 is as follows:
|
||||
|
||||
### 1. Courts interpret General Public License version 2 (GPLv2) ###
|
||||
|
||||
The GPLv2 continues to be the most widely used and most important license for free and open source software. Black Duck Software estimates that 16 billion lines of code are licensed under the GPLv2. Despite its importance, the GPLv2 has been the subject of very few court decisions, and virtually all of the most important terms of the GPLv2 have not been interpreted by courts. This lack of court decisions is about to change due to the five interrelated cases arising from an attempt by Versata Software, Inc. (Versata) to terminate its software license to Ameriprise Financial, Inc. Versata’s product included software licensed by Ximpleware, Inc. (Ximpleware) under the GPLv2, but Versata had not complied with the terms of the GPLv2. Ximpleware sued Versata and eight of its customers for both copyright and patent infringement. (For a more detailed description of the facts [read this article][2].) This dispute is important because Ximpleware is the first commercial enforcer of the GPLv2 in which the courts are likely to issue decisions and Ximpleware is seeking monetary damages rather than compliance.
|
||||
|
||||
### 2. GPL guides ###
|
||||
|
||||
Two of the most important organizations enforcing the GPL family of licenses recently provided [guidance on compliance][3]: On October 31, the Software Freedom Law Center published the second version of their Practical Guide to GPL Compliance. Several days later, the Software Conservancy and the Free Software Foundation published the first version of their guide, the Copyleft, and the GNU General Public License: [A Comprehensive Tutorial and Guide][4]. These guides are required reading for anyone managing FOSS.
|
||||
|
||||
### 3. EU Commission (EC) to revise FOSS policy ###
|
||||
|
||||
Governments are one of the most important users of software but have had a mixed record in using and contributing to FOSS (free and open source software). The EC recently announced that it intends to remove the barriers that may hinder code contributions to FOSS projects. In particular, the EC wants to clarify legal aspects, including intellectual property rights, copyright, and which author or authors to name when submitting code to the upstream repositories. Pierre Damas, Head of Sector at the Directorate General for IT, [hopes that such clarification][5] will motivate many of the EC’s software developers and functionaries to promote the use of FOSS at the EC.
|
||||
|
||||
### 4. Validation of FOSS business model by Hortonworks IPO ###
|
||||
|
||||
Hortonworks provides services and support for the Hadoop data analysis software managed by the Apache Software Foundation. Hortonworks is one of three venture backed companies based on the Hadoop software. Hortonworks went public this fall and immediately rose 65% in share price, valuing the company at over $1 billion. The market for Hadoop products, software, and services is projected to reach $50.2 billion in 2020, up from $1.5 billion in 2012.
|
||||
|
||||
### 5. Core Infrastructure Initiative ###
|
||||
|
||||
The Linux Foundation put together [a consortium of companies][6] to support the many smaller open source projects that are critical to software ecosystem, such as OpenSSL. This effort was a response to the Heartbleed problem with OpenSSL in 2013, which I described in last year’s summary. This consortium is a great example of the ability of the FOSS community to come together to solve community problems.
|
||||
|
||||
### 6. Linux SCO case terminated again ###
|
||||
|
||||
The lawsuit by Santa Cruz Operations, Inc. (SCO) against IBM claiming that Linux includes Unix code was once a potentially major challenge to FOSS. Despite losing its suit against Novell, the bankruptcy court allowed SCO to continue its suit against IBM. I thought this case [had been concluded in 2008][7], but Judge Nuffer appears to have put the case to rest on December 15, 2014. He dismissed the case against IBM based on the decisions in the Novell case (although SCO could still appeal once again):
|
||||
|
||||
*It is further ORDERED that, with respect to all remaining claims and counterclaims, SCO is bound by, and may not here re-litigate, the rulings in the Novell Judgment that Novell (not SCO) owns the copyrights to the pre-1996 UNIX source code, and that Novell waived SCO’s contract claims against IBM for alleged breaches of the licensing agreements pursuant to which IBM licensed such source code.*
|
||||
|
||||
### 7. FOSS trademark issues ###
|
||||
|
||||
The use of trademarks in FOSS projects continues to raise issues. This year brought the settlement of the dispute over the “Python” mark between the Python Software Foundation and Veber, a small hosting company in the UK. Veber had decided to use "Python" in branding certain of its products and services. In addition, the OpenStack Foundation is working through the application of trademarks to the OpenStack project through its [DefCore committee][8].
|
||||
|
||||
### 8. Use of FOSS by commercial companies expands ###
|
||||
|
||||
We have discussed in the past how many large companies are using FOSS as an explicit strategy to build their software. Jim Zemlin, Executive Director of the Linux Foundation, has described this strategic use of FOSS as external “research and development.” His conclusions are supported by Gartner who noted that “the top tech companies are still spending tens of billions of dollars on software research and development, the smart ones are leveraging open source for 80 percent of the code and spending their money on the remaining 20 percent, which represents their program’s ‘special sauce.’” The scope of this trend was emphasized by Microsoft’s announcement that it was “open sourcing” the .NET software framework (this software is used by millions of developers to build and operate websites and other large online applications).
|
||||
|
||||
### 9. Rockstar Consortium threat evaporates ###
|
||||
|
||||
The Rockstar Consortium was formed by Microsoft, Blackberry, Ericsson, Sony, and Apple to exploit the 6,000 patents from Nortel Networks. The Rockstar Consortium sued Google for infringement of the Android operating system. This litigation was aimed at fundamental functions of the Android operating system and could have had a significant effect on the Android ecosystem. The Rockstar Consortium settled its litigation with Google this year, but then sold 4,000 of its patents to RPX, the patent defense firm (financed by a number of companies as well as RPX). The remaining patents were distributed to the members of the Rockstar Consortium.
|
||||
|
||||
### 10. Android litigation ###
|
||||
|
||||
The litigation surrounding Android continued this year, with significant developments in the patent litigation between Apple Computer, Inc. (Apple) and Samsung Electronics, Inc. (Samsung) and the copyright litigation over the Java APIs between Oracle Corporation (Oracle) and Google, Inc. (Google). Apple and Samsung have agreed to end patent disputes in nine countries, but they will continue the litigation in the US. As I stated last year, the Rockstar Consortium was a wild card in this dispute. However, the Rockstar Consortium settled its litigation with Google this year and sold off its patents, so it will no longer be a risk to the Android ecosystem.
|
||||
|
||||
The copyright litigation regarding the copyrightability of the Java APIs was brought back to life by the Court of Appeals for the Federal Circuit (CAFC) decision which overturned [the District Court decision][9]. The District Court had found that Google was not liable for copyright infringement for its admitted copying of the Java APIs: the court found that the Java APIs were either not copyrightable or their use by Google was protected by various defenses to copyright. The CAFC overturned both the decision and the analysis and remanded the case to the District Court for a review of the fair use defense raised by Google. Subsequently, Google filed an appeal to the Supreme Court. The impact of a finding that Google was liable for copyright infringement in this case would have a dramatic effect on Android and, depending on the reasoning, would have a ripple effect across the interpretation of the scope of the “copyleft” terms of the GPL family of licenses which use APIs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/law/15/1/top-foss-legal-developments-2014
|
||||
|
||||
作者:[Mark Radcliffe][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/mradcliffe
|
||||
[1]:http://lawandlifesiliconvalley.com/blog/?p=853
|
||||
[2]:http://opensource.com/law/14/12/gplv2-court-decisions-versata
|
||||
[3]:http://www.softwarefreedom.org/resources/
|
||||
[4]:http://www.copyleft.org/guide/
|
||||
[5]:https://joinup.ec.europa.eu/community/osor/news/european-commission-update-its-open-source-policy
|
||||
[6]:http://www.linuxfoundation.org/programs/core-infrastructure-initiative
|
||||
[7]:http://lawandlifesiliconvalley.com/blog/?m=200812
|
||||
[8]:https://wiki.openstack.org/wiki/Governance/CoreDefinition
|
||||
[9]:http://law.justia.com/cases/federal/appellate-courts/cafc/13-1021/13-1021-2014-05-09.html
|
||||
126
sources/talk/20150122 Top 10 open source projects of 2014.md
Normal file
126
sources/talk/20150122 Top 10 open source projects of 2014.md
Normal file
@ -0,0 +1,126 @@
|
||||
Top 10 open source projects of 2014
|
||||
================================================================================
|
||||

|
||||
|
||||
Image credits : [CC0 Public Domain][1], modifications by Jen Wike Huger
|
||||
|
||||
Every year we collect the best of the best open source projects covered on Opensource.com. [Last year's list of 10 projects][2] guided people working and interested in tech throughout 2014. Now, we're setting you up for 2015 with a brand new list of accomplished open source projects.
|
||||
|
||||
Some faces are new. Some have been around and just keep rocking it. Let's dive in!
|
||||
|
||||
## Top 10 open source projects in 2014 ##
|
||||
|
||||
### Docker ###
|
||||
|
||||
[application container platform][3]
|
||||
|
||||
"In the same way that power management and virtualisation has allowed us to get maximum engineering benefit from our server utilisation, the problem of how to really solve first world problems in virtualisation has remained prevalent. Docker's open sourcing in 2013 can really align itself with these pivotal moments in the evolution of open source—providing the extensible building blocks allowing us as engineers and architects to extend distributed platforms like never before." —Richard Morrell, [Senior software engineer Petazzoni on the breathtaking growth of Docker][4].
|
||||
|
||||
**Interview**: VP of Services for Docker talks to Jodi Biddle in [Why is Docker the new craze in virtualization and cloud computing?][5] "I think it's the lightweight nature of Docker combined with the workflow. It's fast, easy to use and a developer-centric DevOps-ish tool. Its mission is basically: make it easy to package and ship code." —James Turnbull.
|
||||
|
||||
### Kubernetes ###
|
||||
|
||||
[orchestration system for containers][6]
|
||||
|
||||
"One of the projects you're starting to hear a lot about in the orchestration space is [Kubernetes][7], which came out of Google's internal container work. It aims to provide features such as high availability and replication, service discovery, and service aggregation." —Gordon Haff, [Open source accelerating the pace of software][8].
|
||||
|
||||
### Taiga ###
|
||||
|
||||
[project management platform][9]
|
||||
|
||||
"It’s almost always the case that the project management tool doesn’t reflect the actual project scenario. One solution to this is using a tool that is intuitive and fits alongside the developer's normal workflow. Additionally, a tool that is quick to update and attracts users to use it. [Taiga][10] is an open source project management tool that aims to solve the basic problem of software usability." —Nitish Tiwari, [Taiga, a new open source project management tool with focus on usability][11].
|
||||
|
||||
### Apache Mesos ###
|
||||
|
||||
[cluster manager][12]
|
||||
|
||||
"[Apache Mesos][13] is a cluster manager that provides efficient resource isolation and sharing across distributed applications or frameworks. It sits between the application layer and the operating system and makes it easier to deploy and manage applications in large-scale clustered environments more efficiently. It can run many applications on a dynamically shared pool of nodes. Prominent users of Mesos include Twitter, Airbnb, MediaCrossing, Xogito and Categorize. —Sachin P Bappalige, [Open source datacenter computing with Apache Mesos][14].
|
||||
|
||||
Interview: Head of Open Source at Twitter talks to Jason Hibbets in [Scale like Twitter with Apache Mesos][15]. "As of today, Twitter has over 270 million active users which produces 500+ million tweets a day, up to 150k+ tweets per second, and more than 100TB+ of compressed data per day. Architecturally, Twitter is mostly composed of services, mostly written in the open source project [Finagle][16], representing the core nouns of the platform such as the user service, timeline service, and so on. Mesos allows theses services to scale to tens of thousands of bare-metal machines and leverage a shared pool of servers across data centers." —Chris Aniszczyk
|
||||
|
||||
### OpenStack ###
|
||||
|
||||
[cloud computing platform][17]
|
||||
|
||||
"As OpenStack continues to mature and slowly make its way into production environments, the focus on the user is continuing to grow. And so, to better meet the needs of users, the community is working hard to get users to meet the next step of engagement by highlighting those users who are change agents both in their organization and within the OpenStack community at large: the superusers." —Jason Baker, [What is an OpenStack superuser][18]?
|
||||
|
||||
**Interview**: Infrastructure manager at CERN talks to Jason Hibbets in [How OpenStack powers the research at CERN][19]. "At CERN, the European Organization for Nuclear Research physicists and engineers are probing the fundamental structure of the universe. In order to do this, we use some of the world's largest and most complex scientific instruments such as the Large Hadron Collider, a 27 KM ring 100m underground on the border between France and Switzerland. OpenStack provides the infrastructure cloud which is used to provide much of the compute resources for this processing." —Tim Bell.
|
||||
|
||||
### Ansible ###
|
||||
|
||||
[IT automation tool][20]
|
||||
|
||||
"A lot of what I want to do is enable people to not only have more free time for beer, but to have more free time for their own projects, their own ideas, and to do new an interesting things." —[Michael DeHaan, Making your IT infrastructure boring with Ansible][21].
|
||||
|
||||
**Interview**: CTO of Ansible talks to Jen Krieger in [Behind the scenes with CTO Michael DeHaan of Ansible][22]. "I like to quote Star Trek 2 a lot. We definitely optimize for 'the needs of the many'. I know Spock dies after he says that, but he does get to come back." —Michael DeHaan
|
||||
|
||||
### ownCloud ###
|
||||
|
||||
[cloud storage tool][23]
|
||||
|
||||
"I was looking for an easy way how to have all my online storage services, such as Google Drive and Dropbox, integrated with my Linux desktop without using some nasty hack, and I finally have a solution that works. I'm here to share it with you. This is not rocket science really, all I did was a little bit of documentation reading, and a couple of clicks." —Jiri Folta, [Using ownCloud to integrate Dropbox, Google Drive, and more in Gnome][24].
|
||||
|
||||
**Listed**: Top 5 open source alternatives: "ownCloud does most everything that the proprietary names do and it keeps control of your information in your hands." —Scott Nesbitt, [Five open source alternatives to popular web apps][25].
|
||||
|
||||
### Apache Hadoop ###
|
||||
|
||||
[framework for big data][26]
|
||||
|
||||
"Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware. Hadoop is an Apache top-level project being built and used by a global community of contributors and users. It is licensed under the Apache License 2.0." —Sachin P Bappalige, [An introduction to Apache Hadoop for big data][27].
|
||||
|
||||
### Drupal ###
|
||||
|
||||
[content management system (CMS)][28]
|
||||
|
||||
"When it was released in 2011, Drupal 7 was the most accessible open source content management system (CMS) available. I expect that this will be true until the release of Drupal 8. Web accessibility requires constant vigilance and will be something that will always need attention in any piece of software striving to meet the Web Content Accessibility Guidelines (WCAG) 2.0 guidelines." —Mike Gifford, [Drupal 8's accessibility advantage][29].
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||
[foundation for software defined networking][30]
|
||||
|
||||
"We are seeing more and more that the networking functions traditionally done in the datacenter by dedicated, almost exclusively proprietary hardware and software combinations, are now being defined through software. Leading that charge within the open source community has been the [OpenDaylight Project][31], a collaborative project through the [Linux Foundation][32] working to define the needs which software defined networking may fill and coordinating the efforts of individuals and companies worldwide to create an open source solution to software defined networking (SDN)." —Jason Baker, [Define your network in software with OpenDaylight][33].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/business/14/12/top-10-open-source-projects-2014
|
||||
|
||||
作者:[Jen Wike Huger][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/jen-wike
|
||||
[1]:http://pixabay.com/en/lightbulb-lamp-light-hotspot-336193/
|
||||
[2]:http://opensource.com/life/13/12/top-open-source-projects-2013
|
||||
[3]:https://www.docker.com/
|
||||
[4]:http://opensource.com/business/14/7/interview-jerome-petazzoni-docker
|
||||
[5]:https://opensource.com/business/14/7/why-docker-new-craze-virtualization-and-cloud-computing
|
||||
[6]:http://kubernetes.io/
|
||||
[7]:https://cloud.google.com/compute/docs/containers
|
||||
[8]:http://opensource.com/business/14/11/open-source-accelerating-pace-software
|
||||
[9]:https://taiga.io/
|
||||
[10]:https://github.com/taigaio
|
||||
[11]:https://opensource.com/business/14/10/taiga-open-source-project-management-tool
|
||||
[12]:http://mesos.apache.org/
|
||||
[13]:http://mesos.apache.org/
|
||||
[14]:https://opensource.com/business/14/9/open-source-datacenter-computing-apache-mesos
|
||||
[15]:https://opensource.com/business/14/8/interview-chris-aniszczyk-twitter-apache-mesos
|
||||
[16]:https://twitter.github.io/finagle/
|
||||
[17]:http://www.openstack.org/
|
||||
[18]:https://opensource.com/business/14/5/what-is-openstack-superuser
|
||||
[19]:https://opensource.com/business/14/10/interview-tim-bell-cern-it-operating-systems
|
||||
[20]:http://www.ansible.com/home
|
||||
[21]:https://opensource.com/business/14/12/ansible-it-infrastructure
|
||||
[22]:https://opensource.com/business/14/10/interview-michael-dehaan-ansible
|
||||
[23]:http://owncloud.org/
|
||||
[24]:https://opensource.com/life/14/12/using-owncloud-integrate-dropbox-google-drive-gnome
|
||||
[25]:https://opensource.com/life/14/10/five-open-source-alternatives-popular-web-apps
|
||||
[26]:http://hadoop.apache.org/
|
||||
[27]:http://opensource.com/life/14/8/intro-apache-hadoop-big-data
|
||||
[28]:https://www.drupal.org/
|
||||
[29]:http://opensource.com/business/14/5/new-release-drupal-8-accessibility-advantage
|
||||
[30]:http://www.opendaylight.org/
|
||||
[31]:http://www.opendaylight.org/
|
||||
[32]:http://www.linuxfoundation.org/
|
||||
[33]:http://opensource.com/business/14/5/defining-your-network-software-opendaylight
|
||||
@ -0,0 +1,43 @@
|
||||
Why does C++ promote an int to a float when a float cannot represent all int values?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
Say I have the following:
|
||||
|
||||
```C
|
||||
int i = 23;
|
||||
float f = 3.14;
|
||||
if (i == f) // do something
|
||||
```
|
||||
|
||||
The i will be promoted to a float and the two float numbers will be compared, but can a float represent all int values? Why not promote both the int and the float to a double?
|
||||
|
||||
#A:
|
||||
|
||||
When `int` is promoted to `unsigned` in the integral promotions, negative values are also lost (which leads to such fun as `0u < -1` being true).
|
||||
|
||||
Like most mechanisms in C (that are inherited in C++), the usual arithmetic conversions should be understood in terms of hardware operations. The makers of C were very familiar with the assembly language of the machines with which they worked, and they wrote C to make immediate sense to themselves and people like themselves when writing things that would until then have been written in assembly (such as the UNIX kernel).
|
||||
|
||||
Now, processors, as a rule, do not have mixed-type instructions (add float to double, compare int to float, etc.) because it would be a huge waste of real estate on the wafer -- you'd have to implement as many times more opcodes as you want to support different types. That you only have instructions for "add int to int," "compare float to float", "multiply unsigned with unsigned" etc. makes the usual arithmetic conversions necessary in the first place -- they are a mapping of two types to the instruction family that makes most sense to use with them.
|
||||
|
||||
From the point of view of someone who's used to writing low-level machine code, if you have mixed types, the assembler instructions you're most likely to consider in the general case are those that require the least conversions. This is particularly the case with floating points, where conversions are runtime-expensive, and particularly back in the early 1970s, when C was developed, computers were slow, and when floating point calculations were done in software. This shows in the usual arithmetic conversions -- only one operand is ever converted (with the single exception of `long/unsigned int`, where the `long` may be converted to `unsigned long`, which does not require anything to be done on most machines. Perhaps not on any where the exception applies).
|
||||
|
||||
So, the usual arithmetic conversions are written to do what an assembly coder would do most of the time: you have two types that don't fit, convert one to the other so that it does. This is what you'd do in assembler code unless you had a specific reason to do otherwise, and to people who are used to writing assembler code and do have a specific reason to force a different conversion, explicitly requesting that conversion is natural. After all, you can simply write
|
||||
|
||||
```C
|
||||
if((double) i < (double) f)
|
||||
```
|
||||
|
||||
It is interesting to note in this context, by the way, that `unsigned` is higher in the hierarchy than `int`, so that comparing `int` with `unsigned` will end in an unsigned comparison (hence the `0u < -1` bit from the beginning). I suspect this to be an indicator that people in olden times considered `unsigned` less as a restriction on `int` than as an extension of its value range: We don't need the sign right now, so let's use the extra bit for a larger value range. You'd use it if you had reason to expect that an `int` would overflow -- a much bigger worry in a world of 16-bit ints.
|
||||
|
||||
----
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/28010565/why-does-c-promote-an-int-to-a-float-when-a-float-cannot-represent-all-int-val/28011249#28011249)
|
||||
|
||||
作者:[wintermute][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/4301306/wintermute
|
||||
31
sources/talk/20150127 Windows 10 versus Linux.md
Normal file
31
sources/talk/20150127 Windows 10 versus Linux.md
Normal file
@ -0,0 +1,31 @@
|
||||
Windows 10 versus Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Windows 10 seemed to dominate the headlines today, even in many Linux circles. Leading the pack is Brian Fagioli at betanews.com saying Windows 10 is ringing the death knell for Linux desktops. Microsoft announced today that Windows 10 will be free for loyal Windows users and Steven J. Vaughan-Nichols said it's the newest Open Source company. Then Matt Hartley compares Windows 10 to Ubuntu and Jesse Smith reviews Windows 10 from a Linux user's perspective.
|
||||
|
||||
**Windows 10** was the talk around water coolers today with Microsoft's [announcement][1] that it would be free for Windows 7 and up users. Here in Linuxland, that didn't go unnoticed. Brian Fagioli at betanews.com, a self-proclaimed Linux fan, said today, "Windows 10 closes the door entirely. The year of the Linux desktop will never happen. Rest in peace." [Fagioli explained][2] that Microsoft listened to user complaints and not only addressed them but improved way beyond that. He said Linux missed the boat by failing to capitalize on the Windows 8 unpopularity and ultimate failure. Then he concluded that we on the fringe must accept our "shattered dreams" thanks to Windows 10.
|
||||
|
||||
**H**owever, Jesse Smith, of Distrowatch.com fame, said Microsoft isn't making it easy to find the download, but it is possible and he did it. The installer was simple enough except for the partitioner, which was quite limited and almost scary. After finally getting into Windows 10, Smith said the layout was "sparce" without a lot of the distractions folks hated about 7. The menu is back and the start screen is gone. A new package manager looks a lot like Ubuntu's and Android's according to Smith, but requires an online Microsoft account to use. [Smith concludes][3] in part, "Windows 10 feels like a beta for an early version of Android, a consumer operating system that is designed to be on-line all the time. It does not feel like an operating system I would use to get work done."
|
||||
|
||||
**S**mith's [full article][4] compares Windows 10 to Linux quite a bit, but Matt Hartley today posted an actual Windows 10 vs Linux report. [He said][5] both installers were straightforward and easy Windows still doesn't dual boot easily and Windows provides encryption by default but Ubuntu offers it as an option. At the desktop Hartley said Windows 10 "is struggling to let go of its Windows 8 roots." He thought the Windows Store looks more polished than Ubuntu's but didn't really like the "tile everything" approach to newly installed apps. In conclusion, Hartley said, "The first issue is that it's going to be a free upgrade for a lot of Windows users. This means the barrier to entry and upgrade is largely removed. Second, it seems this time Microsoft has really buckled down on listening to what their users want."
|
||||
|
||||
**S**teven J. Vaughan-Nichols today said that Microsoft is the newest Open Source company; not because it's going to be releasing Windows 10 as a free upgrade but because Microsoft is changing itself from a software company to a software as a service company. And, according to Vaughan-Nichols, Microsoft needs Open Source to do it. They've been working on it for years beginning with Novell/SUSE. Not only that, they've been releasing software as Open Source as well (whatever the motives). [Vaughan-Nichols concluded][6], "Most people won't see it, but Microsoft -- yes Microsoft -- has become an open-source company."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/windows-10-versus-linux
|
||||
|
||||
作者:[Susan Linton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/susan-linton
|
||||
[1]:https://news.google.com/news/section?q=microsoft+windows+10+free&ie=UTF-8&oe=UTF-8
|
||||
[2]:http://betanews.com/2015/01/25/windows-10-is-the-final-nail-in-the-coffin-for-the-linux-desktop/
|
||||
[3]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
|
||||
[4]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
|
||||
[5]:http://www.datamation.com/open-source/windows-vs-linux-the-2015-version-1.html
|
||||
[6]:http://www.zdnet.com/article/microsoft-the-open-source-company/
|
||||
153
sources/talk/20150128 The top 10 rookie open source projects.md
Normal file
153
sources/talk/20150128 The top 10 rookie open source projects.md
Normal file
@ -0,0 +1,153 @@
|
||||
The top 10 rookie open source projects
|
||||
================================================================================
|
||||
Black Duck presents its Open Source Rookies of the Year -- the 10 most exciting, active new projects germinated by the global open source community
|
||||
|
||||

|
||||
|
||||
### Open Source Rookies of the Year ###
|
||||
|
||||
Each year sees the start of thousands of new open source projects. Only a handful gets real traction. Some projects gain momentum by building on existing, well-known technologies; others truly break new ground. Many projects are created to solve a simple development problem, while others begin with loftier intentions shared by like-minded developers around the world.
|
||||
|
||||
Since 2009, the open source software logistics company Black Duck has identified the [Open Source Rookies of the Year][1], based on activity tracked by its [Open Hub][2] (formerly Ohloh) site. This year, we're delighted to present 10 winners and two honorable mentions for 2015, selected from thousands of open source projects. Using a weighted scoring system, points were awarded based on project activity, the pace of commits, and several other factors.
|
||||
|
||||
Open source has become the industry's engine of innovation. This year, for example, growth in projects related to Docker containerization trumped every other rookie area -- and not coincidentally reflected the most exciting area of enterprise technology overall. At the very least, the projects described here provide a window on what the global open source developer community is thinking, which is fast becoming a good indicator of where we're headed.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3] is a collection of [Ansible][4] playbooks and roles, scalable from one container to an entire data center. Founder Maciej Delmanowski open-sourced DebOps to ensure his work outlived his current work environment and could grow in strength and depth from outside contributors.
|
||||
|
||||
DebOps began at a small university in Poland that ran its own data center, where everything was configured by hand. Crashes sometimes led to days of downtime -- and Delmanowski realized that a configuration management system was needed. Starting with a Debian base, DebOps is a group of Ansible playbooks that configure an entire data infrastructure. The project has been implemented in many different working environments, and the founders plan to continue supporting and improving it as time goes on.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Code Combat ###
|
||||
|
||||

|
||||
|
||||
The traditional pen-and-paper way of learning falls short for technical subjects. Games, however, are all about engagement -- which is why the founders of [CodeCombat][5] went about creating a multiplayer programming game to teach people how to code.
|
||||
|
||||
At its inception, CodeCombat was an idea for a startup, but the founders decided to create an open source project instead. The idea blossomed within the community, and the project gained contributors at a steady rate. A mere two months after its launch, the game was accepted into Google’s Summer of Code. The game reaches a broad audience and is available in 45 languages. CodeCombat hopes to become the standard for people who want to learn to code and have fun at the same time.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6] is a peer-to-peer cloud storage network that implements end-to-end encryption, enabling users to transfer and share data without reliance on a third party. Based on bitcoin blockchain technology and peer-to-peer protocols, Storj provides secure, private, and encrypted cloud storage.
|
||||
|
||||
Opponents of cloud-based data storage worry about cost efficiencies and vulnerability to attack. Intended to address both concerns, Storj is a private cloud storage marketplace where space is purchased and traded via Storjcoin X (SJCX). Files uploaded to Storj are shredded, encrypted, and stored across the community. File owners are the sole individuals who possess keys to the encrypted information.
|
||||
|
||||
The proof of concept for this decentralized cloud storage marketplace was first presented at the Texas Bitcoin Conference Hackathon in 2014. After winning first place in the hackathon, the project founders and leaders used open forums, Reddit, bitcoin forums, and social media to grow an active community, now an essential part of the Storj decision-making process.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Neovim ###
|
||||
|
||||

|
||||
|
||||
Since its inception in 1991, Vim has been a beloved text editor adopted by millions of software developers. [Neovim][6] is the next generation.
|
||||
|
||||
The software development ecosystem has experienced exponential growth and innovation over the past 23 years. Neovim founder Thiago de Arruda knew that Vim was lacking in modern-day features and development speed. Although determined to preserve the signature features of Vim, the community behind Neovim seeks to improve and evolve the technology of its favorite text editor. Crowdfunding initially enabled de Arruda to focus six uninterrupted months on launching this endeavor. He credits the Neovim community for supporting the project and for inspiring him to continue contributing.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
Former Googlers are bringing a big-company data solution to open source in the form of [CockroachDB][8], a scalable, geo-replicated, transactional data store.
|
||||
|
||||
To maintain the terabytes of data transacted over its global online properties, Google developed Spanner. This powerful tool provides Google with scalability, survivability, and transactionality -- qualities that the team behind CockroachDB is serving up to the open source community. Like an actual cockroach, CockroachDB can survive without its head, tolerating the failure of any node. This open source project has a devoted community of experienced contributors, actively cultivated by the founders via social media, GitHub, networking, conferences, and meet-ups.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
In introducing containerized software development to the open source community, [Docker][9] has become the backbone of a strong, innovative set of tools and technologies. [Kubernetes][10], which Google introduced last June, is an open source container management tool used to accelerate development and simplify operations.
|
||||
|
||||
Google has been using containers for years in its internal operations. At the summer 2014 DockerCon, the Internet giant open-sourced Kubernetes, which was developed to meet the needs of the exponentially growing Docker ecosystem. Through collaborations with other organizations and projects, such as Red Hat and CoreOS, Kubernetes project managers have grown their project to be the No. 1 downloaded tool on the Docker Hub. The Kubernetes team hopes to expand the project and grow the community, so software developers can spend less time managing infrastructure and more time building the apps they want.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
[OpenBazaar][11] is a decentralized marketplace for trading with anyone using bitcoin. The proof of concept for OpenBazaar was born at a hackathon, where its founders combined BitTorent, bitcoin, and traditional financial server methodologies to create a censorship-resistant trading platform. The OpenBazaar team sought new members, and before long they were able to expand the OpenBazaar community immensely. The table stakes of OpenBazaar -- transparency and a common goal to revolutionize trade and commerce -- are helping founders and contributors work toward a real-world, uncontrolled, and decentralized marketplace.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: IPFS ###
|
||||
|
||||

|
||||
|
||||
[IPFS (InterPlanetary File System)][12] is a global, versioned, peer-to-peer file system.It synthesizes many of the ideas behind Git, BitTorrent, and HTTP to bring a new data and data structure transport protocol to the open Web.
|
||||
|
||||
Open source is known for developing simple solutions to complex problems that result in many innovations, but these powerful projects represent only one slice of the open source community. IFPS belong to a more radical group whose proof of concept seems daring, outrageous, and even unattainable -- in this case, a peer-to-peer distributed file system that seeks to connect all computing devices. This possible HTTP replacement maintains a community through multiple mediums, including the Git community and an IRC channel that has more than 100 current contributors. This “crazy” idea will be available for alpha testing in 2015.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] is a daemon that collects, aggregates, processes, and exports information about running containers, providing container users with an understanding of resource usage and performance characteristics. For each container, cAdvisor keeps resource isolation parameters, historical resource usage, histograms of complete historical resource usage, and network statistics. This data is exported by container and across machines.
|
||||
|
||||
cAdvisor can run on most Linux distros and supports many container types, including Docker. It has become the de facto monitoring agent for containers, has been integrated into many systems, and is one of the most downloaded images on the Docker Hub. The team hopes to grow cAdvisor to understand application performance more deeply and to integrate this information into clusterwide systems.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14] provides a common configuration to launch infrastructure, from physical and virtual servers to email and DNS providers. The idea is to encompass everything from custom in-house solutions to services offered by public cloud platforms. Once launched, Terraform enables ops to change infrastructure safely and efficiently as the configuration evolves.
|
||||
|
||||
Working at a devops company, Terraform.io's founders identified a pain point in codifying the knowledge required to build a complete data center, from plugged-in servers to a fully networked and functional data center. Infrastructure is described using a high-level configuration syntax, which allows a blueprint of your data center to be versioned and treated as you would any other code. Sponsorship from the well-respected open source company HashiCorp helped launch the project.
|
||||
|
||||
### Honorable mention: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15] provides fast, isolated development environments using [Docker][16]. It moves the configuration required to orchestrate Docker into a simple fig.yml file. It handles all the work of building and running containers and forwarding their ports, as well as sharing volumes and linking them.
|
||||
|
||||
Orchard formed Fig last year to create a new system of tools to make Docker work. It was developed as a way of setting up development environments with Docker, enabling users to define the exact environment for their apps, while also running databases and caches inside Docker. Fig solved a major pain point for developers. Docker fully supports this open source project and [recently purchased Orchard][17] to expand the reach of Fig.
|
||||
|
||||
### Honorable mention: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18] is a Continuous Integration platform built on Docker and [written in Go][19]. The Drone project grew out of frustration with existing available technologies and processes for setting up development environments.
|
||||
|
||||
Drone provides a simple approach to automated testing and continuous delivery: Simply pick a Docker image tailored to your needs, connect GitHub, and commit. Drone uses Docker containers to provision isolated testing environments, giving every project complete control over its stack without the burden of traditional server administration. The community behind Drone is 100 contributors strong and hopes to bring this project to the enterprise and to mobile app development.
|
||||
|
||||
### Open source rookies ###
|
||||
|
||||

|
||||
|
||||
- [Open Source Rookies of the 2014 Year][20]
|
||||
- [InfoWorld's 2015 Technology of the Year Award winners][21]
|
||||
- [Bossies: The Best of Open Source Software Awards][22]
|
||||
- [15 essential open source tools for Windows admins][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
@ -1,98 +0,0 @@
|
||||
The history of Android
|
||||
================================================================================
|
||||
### Android 2.1—the discovery (and abuse) of animations ###
|
||||
|
||||
Android 2.1 came out with the launch of the Nexus One, which was only three months after the release of 2.0. The new OS wasn't a huge release, so it still kept the codename "Éclair." Android development was chugging along at an unheard-of pace, with Google averaging a new OS release every two-and-a-half months over the last 15 months.
|
||||
|
||||
Thanks mostly to the marketing efforts of Verizon and the "Droid" line of phones, Android was gaining in popularity. The OS was still considered ugly, though, and while the Android engineers at the time seemed to have almost no formal design training, in Android 2.1 they tried to spruce things up a bit by slathering on heavy-handed animation effects wherever they could. The result was an OS that seemed to be desperately trying to prove that it could do animation effects. Many of the new additions felt more like tech demos than user-experience improvements.
|
||||
|
||||

|
||||
The lock and home screens from Android 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Android 2.0's rotary dial lock screen was kicked to the curb after only one version and replaced with the same pull tabs the incoming call screen used. The lock screen clock was an attempt at a uniquely Android font, but as typefaces go, it was pretty hideous looking.
|
||||
|
||||
One of the biggest features in Android 2.1 was "Live Wallpapers"—interactive or moving images that could be set as the wallpaper. The default Live Wallpaper was a grid of squares with blue, red, yellow, and green lights continually streaking across it. Tapping on the screen would send lights firing out in all four directions from the center of your tap. While Live Wallpapers looked neat (and was a unique feature over the iPhone), the animated backgrounds sucked up battery power and CPU cycles. It seemed to make the whole phone run a little slower.
|
||||
|
||||
On the home screen, the default Google Search widget was given a lot more padding and now sits centered in its row. Page indicators now lived in the bottom left and right corners of the screen, and the number of home screen pages jumped from three to five. The app drawer tab at the bottom was replaced with an icon showing a grid of squares, a metaphor that Google still uses today.
|
||||
|
||||
|
||||
A picture showing the app drawer design and a composite image showing the app selection for Android 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
With the new app drawer icon came a totally new app drawer. Instead of a tabbed container that lifted up from the bottom of the screen, the app drawer displayed as a full-screen interface. The carbon fiber weave was removed, and the background switched to a plain black background—a decision that would stick around all the way up to KitKat.
|
||||
|
||||
Google decided to add a floating, semi-transparent home icon to the bottom of the app drawer to give people an easy way out of the full-screen tab interface. This could be seen as a precursor to the on-screen home button that was introduced in Android 4.0.
|
||||
|
||||
The app drawer was given a tacky graphics effect, too. While scrolling, the icons at the top and bottom of the list would bend inward and appear to move deeper into the phone, sort of like the opening scroll in Star Wars.
|
||||
|
||||
There were a few changes to the icons. "Amazon MP3" and "Alarm Clock" both lost their first names, along with their premium alphabetical real-estate at the top of the app drawer. Two new apps showed up: News and Weather, and Google Voice, which was Google's telecommunication service. Since the Nexus One was not a Verizon phone, Verizon's Visual Voicemail app was dumped.
|
||||
|
||||
|
||||
The revamped clock app.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Along with the name change, the clock app got a total revamp. Tapping on the clock shortcut no longer opened the alarms page; instead it went to a "desk clock" interface (left picture, above) with a background that matched the wallpaper. The clock used the same font from the lock screen, pulling in weather from the new News And Weather app.
|
||||
|
||||
The new alarm page cleaned up a lot of the weirder design decisions made in the old version. The analog clock and selectable clock designs were dead. The checkboxes were replaced with a green on/off light, which was much easier to parse than "gray check/green check." While it might be hard to see from the thumbnail (click for a bigger version), the old alarm design displayed AM and PM next to the time. The 2.1 design did away with that, only showing the relevant meridian. A digital clock was placed at the bottom, and the clock icon took you back to the desk clock interface.
|
||||
|
||||
|
||||
The Gallery and individual image screens from 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Google's desire to improve the look of Android was most evident in the 2.1 Gallery, which was all about heavy-handed animation effects and transparencies. When the app opened, individual pictures flew in from the top of the screen and shuffled into little piles that made up an album. When opening an album, the picture stack separated, and the photos slid into a grid formation. Everything you touched would pop open, squish, and stretch like a spring-loaded piece of Jell-o.
|
||||
|
||||
There was no "normal" background for the Gallery. It would randomly pick a picture on the screen and heavily distort it for use as a background image. When that picture scrolled off-screen, it would pick a new background image, so the tone of the background always matched your pictures.
|
||||
|
||||
The top left of the screen housed a breadcrumbs bar. It displayed your current location and any folders between you and the main screen—it could be thought of as an early precursor to the "Up" button that would debut in Android 3.0. In the top right was a link to the camera app, which still sported the same faux-leather design that debuted in Android 1.6—the two designs could not be more different.
|
||||
|
||||
While the camera was another weird, one-off design, never was the wild UI disparity between Android apps more apparent than in the new Gallery. It didn't use Android buttons, menus, or any of the existing UI paradigms. It even hid the status bar in every screen—you could barely tell you were looking at Android.
|
||||
|
||||
In the individual photo view, you could finally swipe between images, which removed the need for chunky left and right arrows. For some reason, the color-matched background wasn't on this screen. It was the only part of the app where the background is black. Zoom controls were in the top-right (still no pinch zoom), and commands were held in a single strip along the bottom of the screen. Hitting the "menu" button (software or hardware) didn't bring up a 2×3 grid of options like every other app—the items in the bottom strip just changed from two options to three other options.
|
||||
|
||||
|
||||
The animation-filled Gallery app.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The first picture, above, shows an album view. You could scroll horizontally through a large album or use the fast scroll bar at the bottom of the screen. Long pressing on a picture (or, bizarrely, pressing the hardware menu button) would bring up a "checkbox" interface, where you could tap on several pictures to select them. After you've selected pictures, you could then batch share, delete, or rotate them.
|
||||
|
||||
The menus on this screen and the next individual picture screen were semi-transparent speech bubbles that would spring out of their respective buttons when tapped on. Again, this was about as far away from the normal Android conventions as you could get. The Gallery was also one of the first apps to have an overscroll effect. When you hit the end of the photo wall, the entire surface would skew in the direction of the scrolling.
|
||||
|
||||
The 2.1 Gallery was the first photo client to show your cloud-stored Picasa photos along with local pictures. These were marked with a white camera shutter icon in the bottom left corner of a thumbnail. This would later become Google+ Photos.
|
||||
|
||||
No Android app before or since had looked like the gallery. There was good reason for that—it wasn’t made by Google! The app was farmed out to Cooliris, who didn't bother following a single existing Android UI paradigm. While the app was usable, all the animations and effects made it seem like a case of style over substance.
|
||||
|
||||

|
||||
The "News and Weather" app showing... the news and weather.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Compare the Gallery to the other new Android 2.1 app: News And Weather. While the Gallery was a transparency-filled animation fest, News And Weather was all about dark gradients and contrasting colors. This app powered the weather display on the desk clock app, and it even came with a home screen widget. The first screen just showed the weather and a six-day forecast for your current location. Along the top of the screens were tabs, next to the city name was a small "i" button that would bring up a temperature and precipitation graph. You could slide your finger along the graph to get exact temperatures and precipitation for any given minute.
|
||||
|
||||
The big innovation in this app was swipeable tabs, an idea that would eventually become a standard Android UI convention. After the weather were a bunch of user configurable news tabs, and besides tapping on the tabs to switch to them, you could just swipe horizontally across the screen and the tab would change. The news tabs all showed a list of news headlines that were almost always truncated to the point that you had no idea what the story was about. When opening a webpage from this app, it didn't load the browser. Instead, it opened the story within the app complete with a weird white border.
|
||||
|
||||
|
||||
Google Maps showing off some Labs features, the new widget designs, the only screen we can access in Google Voice, and the new tabbed music design.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Widgets in 2.1 were all redesigned, with almost everything receiving a black gradient, and made better use of the available space. The clock changed back to a circle, and the calendar got a blue top, which matched the app a little more closely. Google Voice will start up, but the sign-in is broken—this is as far as you can get.
|
||||
|
||||
The oft-neglected Music app got a minor update. The four-button home screen was removed completely, and tabs for each music display mode were added to the top of the screen. This meant when opening the app, you were immediately presented with a list of music, instead of a navigational page. Unlike the News and Weather app, these newly installed tabs here could not be swiped between.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,4 +1,4 @@
|
||||
The history of Android
|
||||
【translating】The history of Android
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -101,4 +101,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
[3]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[4]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,86 +0,0 @@
|
||||
How to convert image, audio and video formats on Ubuntu
|
||||
================================================================================
|
||||
If you need to work with a variety of image, audio and video files encoded in all sorts of different formats, you are probably using more than one tools to convert among all those heterogeneous media formats. If there is a versatile all-in-one media conversion tool that is capable of dealing with all different image/audio/video formats, that will be awesome.
|
||||
|
||||
[Format Junkie][1] is one such all-in-one media conversion tool with an extremely user-friendly GUI. Better yet, it is free software! With Format Junkie, you can convert image, audio, video and archive files of pretty much all the popular formats simply with a few mouse clicks.
|
||||
|
||||
### Install Format Junkie on Ubuntu 12.04, 12.10 and 13.04 ###
|
||||
|
||||
Format Junkie is available for installation via Ubuntu PPA format-junkie-team. This PPA supports Ubuntu 12.04, 12.10 and 13.04. To install Format Junkie on one of those Ubuntu releases, simply run the following.
|
||||
|
||||
$ sudo add-apt-repository ppa:format-junkie-team/release
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### Install Format Junkie on Ubuntu 13.10 ###
|
||||
|
||||
If you are running Ubuntu 13.10 (Saucy Salamander), you can download and install .deb package for Ubuntu 13.04 as follows. Since the .deb package for Format Junkie requires quite a few dependent packages, install it using [gdebi deb installer][2].
|
||||
|
||||
On 32-bit Ubuntu 13.10:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
On 64-bit Ubuntu 13.10:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### Install Format Junkie on Ubuntu 14.04 or Later ###
|
||||
|
||||
The currently available official Format Junkie .deb file requires libavcodec-extra-53 which has become obsolete starting from Ubuntu 14.04. Thus if you want to install Format Junkie on Ubuntu 14.04 or later, you can use the following third-party PPA repositories instead.
|
||||
|
||||
$ sudo add-apt-repository ppa:jon-severinsson/ffmpeg
|
||||
$ sudo add-apt-repository ppa:noobslab/apps
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
|
||||
### How to Use Format Junkie ###
|
||||
|
||||
To start Format Junkie after installation, simply run:
|
||||
|
||||
$ formatjunkie
|
||||
|
||||
#### Convert audio, video, image and archive formats with Format Junkie ####
|
||||
|
||||
The user interface of Format Junkie is pretty simple and intuitive, as shown below. To choose among audio, video, image and iso media, click on one of four tabs at the top. You can add as many files as you want for batch conversion. After you add files, and select output format, simply click on "Start Converting" button to convert.
|
||||
|
||||

|
||||
|
||||
Format Junkie supports conversion among the following media formats:
|
||||
|
||||
- **Audio**: mp3, wav, ogg, wma, flac, m4r, aac, m4a, mp2.
|
||||
- **Video**: avi, ogv, vob, mp4, 3gp, wmv, mkv, mpg, mov, flv, webm.
|
||||
- **Image**: jpg, png, ico, bmp, svg, tif, pcx, pdf, tga, pnm.
|
||||
- **Archive**: iso, cso.
|
||||
|
||||
#### Subtitle encoding with Format Junkie ####
|
||||
|
||||
Besides media conversion, Format Junkie also provides GUI for subtitle encoding. Actual subtitle encoding is done by MEncoder. In order to do subtitle encoding via Format Junkie interface, first you need to install MEencoder.
|
||||
|
||||
$ sudo apt-get install mencoder
|
||||
|
||||
Then click on "Advanced" tab on Format Junkie. Choose AVI/subtitle files to use for encoding, as shown below.
|
||||
|
||||

|
||||
|
||||
Overall, Format Junkie is an extremely easy-to-use and versatile media conversion tool. One drawback, though, is that it does not allow any sort of customization during conversion (e.g., bitrate, fps, sampling frequency, image quality, size). So this tool is recommended for newbies who are looking for an easy-to-use simple media conversion tool.
|
||||
|
||||
Enjoyed this post? I will appreciate your like/share buttons on Facebook, Twitter and Google+.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/how-to-convert-image-audio-and-video-formats-on-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://launchpad.net/format-junkie
|
||||
[2]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
@ -1,6 +1,8 @@
|
||||
What is good audio editing software on Linux
|
||||
Translating by ly0
|
||||
|
||||
Linux下一些蛮不错的音频编辑软件
|
||||
================================================================================
|
||||
Whether you are an amateur musician or just a student recording his professor, you need to edit and work with audio recordings. If for a long time such task was exclusively attributed to Macintosh, this time is over, and Linux now has what it takes to do the job. In short, here is a non-exhaustive list of good audio editing software, fit for different tasks and needs.
|
||||
无论你是一个业余的音乐家或者仅仅是一个上课撸教授音的学,你总是需要和录音打交道。如果你有很长的时间仅仅用Mac干这种事情,那么可以和这个过程说拜拜了,现在Linux也可以干同样的事情。简而言之,这里有一个简单但是不错的音频编辑软件列表,来满足你对不同任务和需求。
|
||||
|
||||
### 1. Audacity ###
|
||||
|
||||
@ -78,4 +80,4 @@ via: http://xmodulo.com/good-audio-editing-software-linux.html
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
[20]:
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by shipsw
|
||||
|
||||
|
||||
Auditd - Tool for Security Auditing on Linux Server
|
||||
================================================================================
|
||||
First of all , we wish all our readers **Happy & Prosperous New YEAR 2015** from our Linoxide team. So lets start this new year explaining about Auditd tool.
|
||||
@ -200,4 +203,4 @@ via: http://linoxide.com/how-tos/auditd-tool-security-auditing/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
[1]:http://linoxide.com/tools/wajig-package-management-debian/
|
||||
[1]:http://linoxide.com/tools/wajig-package-management-debian/
|
||||
|
||||
@ -1,207 +0,0 @@
|
||||
How to configure fail2ban to protect Apache HTTP server
|
||||
================================================================================
|
||||
An Apache HTTP server in production environments can be under attack in various different ways. Attackers may attempt to gain access to unauthorized or forbidden directories by using brute-force attacks or executing evil scripts. Some malicious bots may scan your websites for any security vulnerability, or collect email addresses or web forms to send spams to.
|
||||
|
||||
Apache HTTP server comes with comprehensive logging capabilities capturing various abnormal events indicative of such attacks. However, it is still non-trivial to systematically parse detailed Apache logs and react to potential attacks quickly (e.g., ban/unban offending IP addresses) as they are perpetrated in the wild. That is when `fail2ban` comes to the rescue, making a sysadmin's life easier.
|
||||
|
||||
`fail2ban` is an open-source intrusion prevention tool which detects various attacks based on system logs and automatically initiates prevention actions e.g., banning IP addresses with `iptables`, blocking connections via /etc/hosts.deny, or notifying the events via emails. fail2ban comes with a set of predefined "jails" which use application-specific log filters to detect common attacks. You can also write custom jails to deter any specific attack on an arbitrary application.
|
||||
|
||||
In this tutorial, I am going to demonstrate how you can configure fail2ban to protect your Apache HTTP server. I assume that you have Apache HTTP server and fail2ban already installed. Refer to [another tutorial][1] for fail2ban installation.
|
||||
|
||||
### What is a Fail2ban Jail ###
|
||||
|
||||
Let me go over more detail on fail2ban jails. A jail defines an application-specific policy under which fail2ban triggers an action to protect a given application. fail2ban comes with several jails pre-defined in /etc/fail2ban/jail.conf, for popular applications such as Apache, Dovecot, Lighttpd, MySQL, Postfix, [SSH][2], etc. Each jail relies on application-specific log filters (found in /etc/fail2ban/fileter.d) to detect common attacks. Let's check out one example jail: SSH jail.
|
||||
|
||||
[ssh]
|
||||
enabled = true
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry = 6
|
||||
banaction = iptables-multiport
|
||||
|
||||
This SSH jail configuration is defined with several parameters:
|
||||
|
||||
- **[ssh]**: the name of a jail with square brackets.
|
||||
- **enabled**: whether the jail is activated or not.
|
||||
- **port**: a port number to protect (either numeric number of well-known name).
|
||||
- **filter**: a log parsing rule to detect attacks with.
|
||||
- **logpath**: a log file to examine.
|
||||
- **maxretry**: maximum number of failures before banning.
|
||||
- **banaction**: a banning action.
|
||||
|
||||
Any parameter defined in a jail configuration will override a corresponding `fail2ban-wide` default parameter. Conversely, any parameter missing will be assgined a default value defined in [DEFAULT] section.
|
||||
|
||||
Predefined log filters are found in /etc/fail2ban/filter.d, and available actions are in /etc/fail2ban/action.d.
|
||||
|
||||
|
||||
|
||||
If you want to overwrite `fail2ban` defaults or define any custom jail, you can do so by creating **/etc/fail2ban/jail.local** file. In this tutorial, I am going to use /etc/fail2ban/jail.local.
|
||||
|
||||
### Enable Predefined Apache Jails ###
|
||||
|
||||
Default installation of `fail2ban` offers several predefined jails and filters for Apache HTTP server. I am going to enable those built-in Apache jails. Due to slight differences between Debian and Red Hat configurations, let me provide fail2ban jail configurations for them separately.
|
||||
|
||||
#### Enable Apache Jails on Debian or Ubuntu ####
|
||||
|
||||
To enable predefined Apache jails on a Debian-based system, create /etc/fail2ban/jail.local as follows.
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect potential search for exploits and php vulnerabilities
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
Since none of the jails above specifies an action, all of these jails will perform a default action when triggered. To find out the default action, look for "banaction" under [DEFAULT] section in /etc/fail2ban/jail.conf.
|
||||
|
||||
banaction = iptables-multiport
|
||||
|
||||
In this case, the default action is iptables-multiport (defined in /etc/fail2ban/action.d/iptables-multiport.conf). This action bans an IP address using iptables with multiport module.
|
||||
|
||||
After enabling jails, you must restart fail2ban to load the jails.
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
#### Enable Apache Jails on CentOS/RHEL or Fedora ####
|
||||
|
||||
To enable predefined Apache jails on a Red Hat based system, create /etc/fail2ban/jail.local as follows.
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect spammer robots crawling email addresses
|
||||
[apache-badbots]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-badbots
|
||||
logpath = /var/log/httpd/*access_log
|
||||
bantime = 172800
|
||||
maxretry = 1
|
||||
|
||||
# detect potential search for exploits and php <a href="http://xmodulo.com/recommend/penetrationbook" style="" target="_blank" rel="nofollow" >vulnerabilities</a>
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to execute non-existing scripts that
|
||||
# are associated with several popular web services
|
||||
# e.g. webmail, phpMyAdmin, WordPress
|
||||
port = http,https
|
||||
filter = apache-botsearch
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
Note that the default action for all these jails is iptables-multiport (defined as "banaction" under [DEFAULT] in /etc/fail2ban/jail.conf). This action bans an IP address using iptables with multiport module.
|
||||
|
||||
After enabling jails, you must restart fail2ban to load the jails in fail2ban.
|
||||
|
||||
On Fedora or CentOS/RHEL 7:
|
||||
|
||||
$ sudo systemctl restart fail2ban
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
### Check and Manage Fail2ban Banning Status ###
|
||||
|
||||
Once jails are activated, you can monitor current banning status with fail2ban-client command-line tool.
|
||||
|
||||
To see a list of active jails:
|
||||
|
||||
$ sudo fail2ban-client status
|
||||
|
||||
To see the status of a particular jail (including banned IP list):
|
||||
|
||||
$ sudo fail2ban-client status [name-of-jail]
|
||||
|
||||
|
||||
|
||||
You can also manually ban or unban IP addresses.
|
||||
|
||||
To ban an IP address with a particular jail:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] banip [ip-address]
|
||||
|
||||
To unban an IP address blocked by a particular jail:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] unbanip [ip-address]
|
||||
|
||||
### Summary ###
|
||||
|
||||
This tutorial explains how a fail2ban jail works and how to protect an Apache HTTP server using built-in Apache jails. Depending on your environments and types of web services you need to protect, you may need to adapt existing jails, or write custom jails and log filters. Check outfail2ban's [official Github page][3] for more up-to-date examples of jails and filters.
|
||||
|
||||
Are you using fail2ban in any production environment? Share your experience.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-fail2ban-apache-http-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[2]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[3]:https://github.com/fail2ban/fail2ban
|
||||
@ -1,111 +0,0 @@
|
||||
hi ! 让我来翻译
|
||||
|
||||
How to debug a C/C++ program with Nemiver debugger
|
||||
================================================================================
|
||||
If you read [my post on GDB][1], you know how important and useful a debugger I think can be for a C/C++ program. However, if a command line debugger like GDB sounds more like a problem than a solution to you, you might be more interested in Nemiver. [Nemiver][2] is a GTK+-based standalone graphical debugger for C/C++ programs, using GDB as its back-end. Admirable for its speed and stability, Nemiver is a very reliable debugger filled with goodies.
|
||||
|
||||
### Installation of Nemiver ###
|
||||
|
||||
For Debian based distributions, it should be pretty straightforward:
|
||||
|
||||
$ sudo apt-get install nemiver
|
||||
|
||||
For Arch Linux:
|
||||
|
||||
$ sudo pacman -S nemiver
|
||||
|
||||
For Fedora:
|
||||
|
||||
$ sudo yum install nemiver
|
||||
|
||||
If you prefer compiling yourself, the latest sources are available from [GNOME website][3].
|
||||
|
||||
As a bonus, it integrates very well with the GNOME environment.
|
||||
|
||||
### Basic Usage of Nemiver ###
|
||||
|
||||
Start Nemiver with the command:
|
||||
|
||||
$ nemiver
|
||||
|
||||
You can also summon it with an executable with:
|
||||
|
||||
$ nemiver [path to executable to debug]
|
||||
|
||||
Note that Nemiver will be much more helpful if the executable is compiled in debug mode (the -g flag with GCC).
|
||||
|
||||
A good thing is that Nemiver is really fast to load, so you should instantly see the main screen in the default layout.
|
||||
|
||||
|
||||
|
||||
By default, a breakpoint has been placed in the first line of the main function. This gives you the time to recognize the basic debugger functions:
|
||||
|
||||

|
||||
|
||||
- Next line (mapped to F6)
|
||||
- Step inside a function (F7)
|
||||
- Step out of a function (Shift+F7)
|
||||
|
||||
But maybe my personal favorite is the option "Run to cursor" which makes the program run until a precise line under your cursor, and is by default mapped to F11.
|
||||
|
||||
Next, the breakpoints are also easy to use. The quick way to lay a breakpoint at a line is using F8. But Nemiver also has a more complex menu under "Debug" which allows you to set up a breakpoint at a particular function, line number, location of binary file, or even at an event like an exception, a fork, or an exec.
|
||||
|
||||
|
||||
|
||||
You can also watch a variable by tracking it. In "Debug" you can inspect an expression by giving its name and examining it. It is then possible to add it to the list of controlled variable for easy access. This is probably one of the most useful aspects as I have never been a huge fan of hovering over a variable to get its value. Note that hovering does work though. And to make it even better, Nemiver is capable of watching a struct, and giving you the values of all the member variables.
|
||||
|
||||
|
||||
|
||||
Talking about easy access to information, I also really appreciate the layout of the program. By default, the code is in the upper half and the tabs in the lower part. This grants you access to a terminal for output, a context tracker, a breakpoints list, register addresses, memory map, and variable control. But note that under "Edit" "Preferences" "Layout" you can select different layouts, including a dynamic one for you to modify.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
And naturally, once you set up all your breakpoints, watch-points, and layout, you can save your session under “File” for easy retrieval in case you close Nemiver.
|
||||
|
||||
### Advanced Usage of Nemiver ###
|
||||
|
||||
So far, we talked about the basic features of Nemiver, i.e., what you need to get started and debug simple programs immediately. If you have more advanced needs, and especially more complex programs, you might be more interested in some of these features mentioned here.
|
||||
|
||||
#### Debugging a running process ####
|
||||
|
||||
Nemiver allows you to attach to a running process for debugging. Under the "File" menu, you can filter the list of running processes, and connect to a process.
|
||||
|
||||

|
||||
|
||||
#### Debugging a program remotely over a TCP connection ####
|
||||
|
||||
Nemiver supports remote-debugging, where you set up a lightweight debug server on a remote machine, and launch Nemiver from another machine to debug a remote target hosted by the debug server. Remote debugging can be useful if you cannot run full-fledged Nemiver or GDB on the remote machine for some reason. Under the "File" menu, specify the binary, shared library location, and the address and port.
|
||||
|
||||
|
||||
|
||||
#### Using your own GDB binary to debug ####
|
||||
|
||||
In case you compiled Nemiver yourself, you can specify a new location for GDB under "Edit" "Preferences" "Debug". This option can be useful if you want to use a custom version of GDB in Nemiver for some reason.
|
||||
|
||||
#### Follow a child or parent process ####
|
||||
|
||||
Nemiver is capable of following a child or parent process in case your program forks. To enable this feature, go to "Preferences" under "Debugger" tab.
|
||||
|
||||
|
||||
|
||||
To conclude, Nemiver is probably my favorite program for debugging without an IDE. It even beats GDB in my opinion, and [command line][4] programs generally have a good grip on me. So if you have never used it, I really recommend it. I can only congratulate the team behind it for giving us such a reliable and stable program.
|
||||
|
||||
What do you think of Nemiver? Would you consider it for standalone debugging? Or do you still stick to an IDE? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/debug-program-nemiver-debugger.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/gdb-command-line-debugger.html
|
||||
[2]:https://wiki.gnome.org/Apps/Nemiver
|
||||
[3]:https://download.gnome.org/sources/nemiver/0.9/
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
@ -0,0 +1,135 @@
|
||||
What are useful command-line network monitors on Linux
|
||||
================================================================================
|
||||
Network monitoring is a critical IT function for businesses of all sizes. The goal of network monitoring can vary. For example, the monitoring activity can be part of long-term network provisioning, security protection, performance troubleshooting, network usage accounting, and so on. Depending on its goal, network monitoring is done in many different ways, such as performing packet-level sniffing, collecting flow-level statistics, actively injecting probes into the network, parsing server logs, etc.
|
||||
|
||||
While there are many dedicated network monitoring systems capable of 24/7/365 monitoring, you can also leverage command-line network monitors in certain situations, where a dedicated monitor is an overkill. If you are a system admin, you are expected to have hands-on experience with some of well known CLI network monitors. Here is a list of **popular and useful command-line network monitors on Linux**.
|
||||
|
||||
### Packet-Level Sniffing ###
|
||||
|
||||
In this category, monitoring tools capture individual packets on the wire, dissect their content, and display decoded packet content or packet-level statistics. These tools conduct network monitoring from the lowest level, and as such, can possibly do the most fine-grained monitoring at the cost of network I/O and analysis efforts.
|
||||
|
||||
1. **dhcpdump**: a comman-line DHCP traffic sniffer capturing DHCP request/response traffic, and displays dissected DHCP protocol messages in a human-friendly format. It is useful when you are troubleshooting DHCP related issues.
|
||||
|
||||
2. **[dsniff][1]**: a collection of command-line based sniffing, spoofing and hijacking tools designed for network auditing and penetration testing. They can sniff various information such as passwords, NSF traffic, email messages, website URLs, and so on.
|
||||
|
||||
3. **[httpry][2]**: an HTTP packet sniffer which captures and decode HTTP requests and response packets, and display them in a human-readable format.
|
||||
|
||||
4. **IPTraf**: a console-based network statistics viewer. It displays packet-level, connection-level, interface-level, protocol-level packet/byte counters in real-time. Packet capturing can be controlled by protocol filters, and its operation is full menu-driven.
|
||||
|
||||
|
||||
|
||||
5. **[mysql-sniffer][3]**: a packet sniffer which captures and decodes packets associated with MySQL queries. It displays the most frequent or all queries in a human-readable format.
|
||||
|
||||
6. **[ngrep][4]**: grep over network packets. It can capture live packets, and match (filtered) packets against regular expressions or hexadecimal expressions. It is useful for detecting and storing any anomalous traffic, or for sniffing particular patterns of information from live traffic.
|
||||
|
||||
7. **[p0f][5]**: a passive fingerprinting tool which, based on packet sniffing, reliably identifies operating systems, NAT or proxy settings, network link types and various other properites associated with an active TCP connection.
|
||||
|
||||
8. **pktstat**: a command-line tool which analyzes live packets to display connection-level bandwidth usages as well as descriptive information of protocols involved (e.g., HTTP GET/POST, FTP, X11).
|
||||
|
||||
|
||||
|
||||
9. **Snort**: an intrusion detection and prevention tool which can detect/prevent a variety of backdoor, botnets, phishing, spyware attacks from live traffic based on rule-driven protocol analysis and content matching.
|
||||
|
||||
10. **tcpdump**: a command-line packet sniffer which is capable of capturing nework packets on the wire based on filter expressions, dissect the packets, and dump the packet content for packet-level analysis. It is widely used for any kinds of networking related troubleshooting, network application debugging, or [security][6] monitoring.
|
||||
|
||||
11. **tshark**: a command-line packet sniffing tool that comes with Wireshark GUI program. It can capture and decode live packets on the wire, and show decoded packet content in a human-friendly fashion.
|
||||
|
||||
### Flow-/Process-/Interface-Level Monitoring ###
|
||||
|
||||
In this category, network monitoring is done by classifying network traffic into flows, associated processes or interfaces, and collecting per-flow, per-process or per-interface statistics. Source of information can be libpcap packet capture library or sysfs kernel virtual filesystem. Monitoring overhead of these tools is low, but packet-level inspection capabilities are missing.
|
||||
|
||||
12. **bmon**: a console-based bandwidth monitoring tool which shows various per-interface information, including not-only aggregate/average RX/TX statistics, but also a historical view of bandwidth usage.
|
||||
|
||||
|
||||
|
||||
13. **[iftop][7]**: a bandwidth usage monitoring tool that can shows bandwidth usage for individual network connections in real time. It comes with ncurses-based interface to visualize bandwidth usage of all connections in a sorted order. It is useful for monitoring which connections are consuming the most bandwidth.
|
||||
|
||||
14. **nethogs**: a process monitoring tool which offers a real-time view of upload/download bandwidth usage of individual processes or programs in an ncurses-based interface. This is useful for detecting bandwidth hogging processes.
|
||||
|
||||
15. **netstat**: a command-line tool that shows various statistics and properties of the networking stack, such as open TCP/UDP connections, network interface RX/TX statistics, routing tables, protocol/socket statistics. It is useful when you diagnose performance and resource usage related problems of the networking stack.
|
||||
|
||||
16. **[speedometer][8]**: a console-based traffic monitor which visualizes the historical trend of an interface's RX/TX bandwidth usage with ncurses-drawn bar charts.
|
||||
|
||||
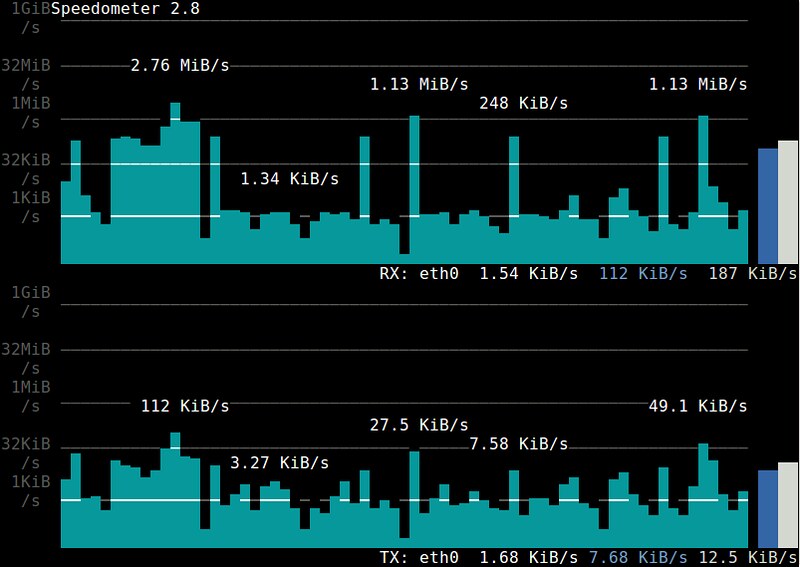
|
||||
|
||||
17. **[sysdig][9]**: a comprehensive system-level debugging tool with a unified interface for investigating different Linux subsystems. Its network monitoring module is capable of monitoring, either online or offline, various per-process/per-host networking statistics such as bandwidth usage, number of connections/requests, etc.
|
||||
|
||||
18. **tcptrack**: a TCP connection monitoring tool which displays information of active TCP connections, including source/destination IP addresses/ports, TCP state, and bandwidth usage.
|
||||
|
||||
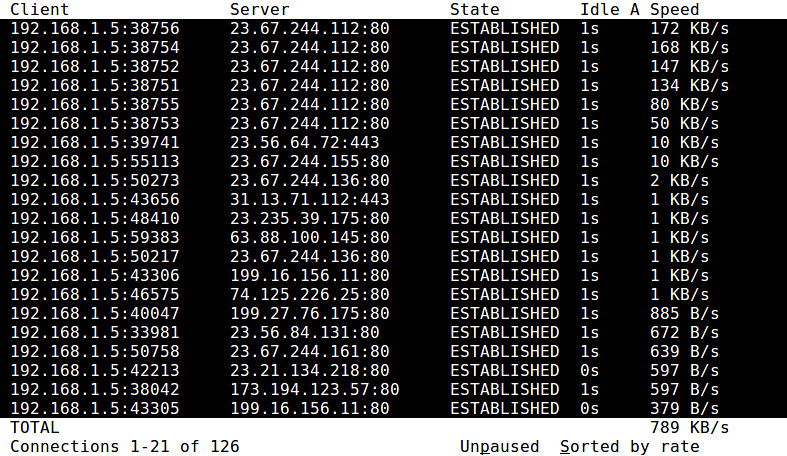
|
||||
|
||||
19. **vnStat**: a command-line traffic monitor which maintains a historical view of RX/TX bandwidh usage (e.g., current, daily, monthly) on a per-interface basis. Running as a background daemon, it collects and stores interface statistics on bandwidth rate and total bytes transferred.
|
||||
|
||||
### Active Network Monitoring ###
|
||||
|
||||
Unlike passive monitoring tools presented so far, tools in this category perform network monitoring by actively "injecting" probes into the network and collecting corresponding responses. Monitoring targets include routing path, available bandwidth, loss rates, delay, jitter, system settings or vulnerabilities, and so on.
|
||||
|
||||
20. **[dnsyo][10]**: a DNS monitoring tool which can conduct DNS lookup from open resolvers scattered across more than 1,500 different networks. It is useful when you check DNS propagation or troubleshoot DNS configuration.
|
||||
|
||||
21. **[iperf][11]**: a TCP/UDP bandwidth measurement utility which can measure maximum available bandwidth between two end points. It measures available bandwidth by having two hosts pump out TCP/UDP probe traffic between them either unidirectionally or bi-directionally. It is useful when you test the network capacity, or tune the parameters of network stack. A variant called [netperf][12] exists with more features and better statistics.
|
||||
|
||||
22. **[netcat][13]/socat**: versatile network debugging tools capable of reading from, writing to, or listen on TCP/UDP sockets. They are often used alongside with other programs or scripts for backend network transfer or port listening.
|
||||
|
||||
23. **nmap**: a command-line port scanning and network discovery utility. It relies on a number of TCP/UDP based scanning techniques to detect open ports, live hosts, or existing operating systems on the local network. It is useful when you audit local hosts for vulnerabilities or build a host map for maintenance purpose. [zmap][14] is an alernative scanning tool with Internet-wide scanning capability.
|
||||
|
||||
24. ping: a network testing tool which works by exchaning ICMP echo and reply packets with a remote host. It is useful when you measure round-trip-time (RTT) delay and loss rate of a routing path, as well as test the status or firewall rules of a remote system. Variations of ping exist with fancier interface (e.g., [noping][15]), multi-protocol support (e.g., [hping][16]) or parallel probing capability (e.g., [fping][17]).
|
||||
|
||||
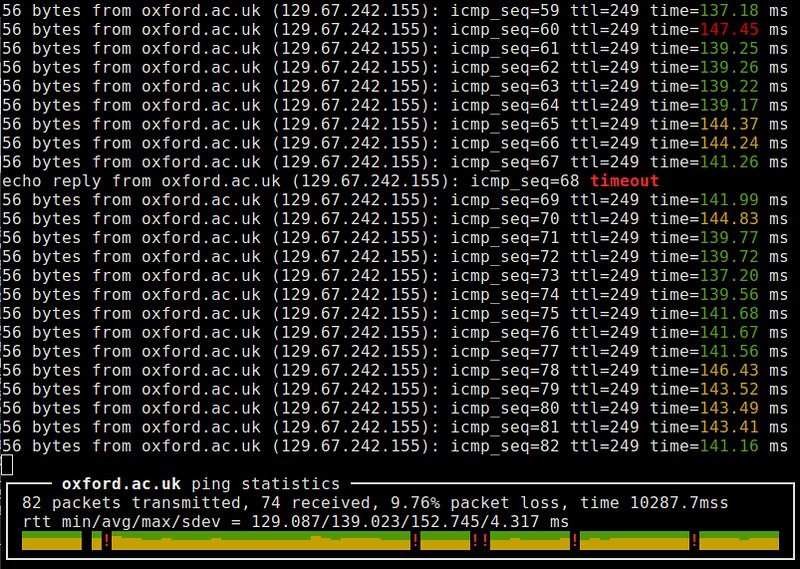
|
||||
|
||||
25. **[sprobe][18]**: a command-line tool that heuristically infers the bottleneck bandwidth between a local host and any arbitrary remote IP address. It uses TCP three-way handshake tricks to estimate the bottleneck bandwidth. It is useful when troubleshooting wide-area network performance and routing related problems.
|
||||
|
||||
26. **traceroute**: a network discovery tool which reveals a layer-3 routing/forwarding path from a local host to a remote host. It works by sending TTL-limited probe packets and collecting ICMP responses from intermediate routers. It is useful when troubleshooting slow network connections or routing related problems. Variations of traceroute exist with better RTT statistics (e.g., [mtr][19]).
|
||||
|
||||
### Application Log Parsing ###
|
||||
|
||||
In this category, network monitoring is targeted at a specific server application (e.g., web server or database server). Network traffic generated or consumed by a server application is monitored by analyzing its log file. Unlike network-level monitors presented in earlier categories, tools in this category can analyze and monitor network traffic from application-level.
|
||||
|
||||
27. **[GoAccess][20]**: a console-based interactive viewer for Apache and Nginx web server traffic. Based on access log analysis, it presents a real-time statistics of a number of metrics including daily visits, top requests, client operating systems, client locations, client browsers, in a scrollable view.
|
||||
|
||||
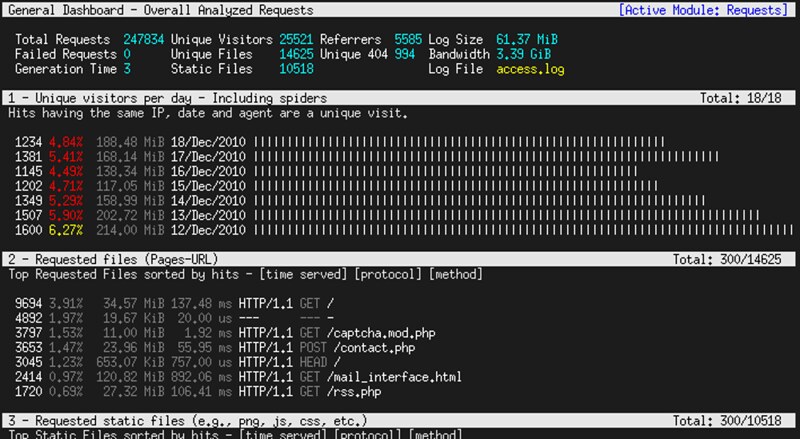
|
||||
|
||||
28. **[mtop][21]**: a command-line MySQL/MariaDB server moniter which visualizes the most expensive queries and current database server load. It is useful when you optimize MySQL server performance and tune server configurations.
|
||||
|
||||
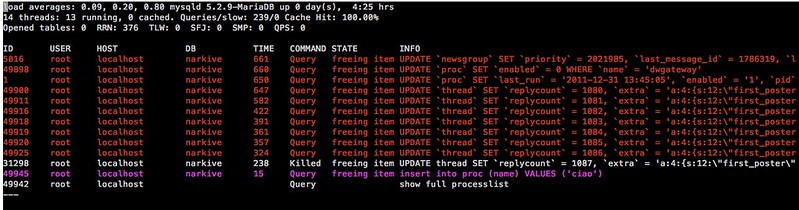
|
||||
|
||||
29. **[ngxtop][22]**: a traffic monitoring tool for Nginx and Apache web server, which visualizes web server traffic in a top-like interface. It works by parsing a web server's access log file and collecting traffic statistics for individual destinations or requests.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, I presented a wide variety of command-line network monitoring tools, ranging from the lowest packet-level monitors to the highest application-level network monitors. Knowing which tool does what is one thing, and choosing which tool to use is another, as any single tool cannot be a universal solution for your every need. A good system admin should be able to decide which tool is right for the circumstance at hand. Hopefully the list helps with that.
|
||||
|
||||
You are always welcome to improve the list with your comment!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/useful-command-line-network-monitors-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.monkey.org/~dugsong/dsniff/
|
||||
[2]:http://xmodulo.com/monitor-http-traffic-command-line-linux.html
|
||||
[3]:https://github.com/zorkian/mysql-sniffer
|
||||
[4]:http://ngrep.sourceforge.net/
|
||||
[5]:http://lcamtuf.coredump.cx/p0f3/
|
||||
[6]:http://xmodulo.com/recommend/firewallbook
|
||||
[7]:http://xmodulo.com/how-to-install-iftop-on-linux.html
|
||||
[8]:https://excess.org/speedometer/
|
||||
[9]:http://xmodulo.com/monitor-troubleshoot-linux-server-sysdig.html
|
||||
[10]:http://xmodulo.com/check-dns-propagation-linux.html
|
||||
[11]:https://iperf.fr/
|
||||
[12]:http://www.netperf.org/netperf/
|
||||
[13]:http://xmodulo.com/useful-netcat-examples-linux.html
|
||||
[14]:https://zmap.io/
|
||||
[15]:http://noping.cc/
|
||||
[16]:http://www.hping.org/
|
||||
[17]:http://fping.org/
|
||||
[18]:http://sprobe.cs.washington.edu/
|
||||
[19]:http://xmodulo.com/better-alternatives-basic-command-line-utilities.html#mtr_link
|
||||
[20]:http://goaccess.io/
|
||||
[21]:http://mtop.sourceforge.net/
|
||||
[22]:http://xmodulo.com/monitor-nginx-web-server-command-line-real-time.html
|
||||
1113
sources/tech/20150115 Get back your privacy and control.md
Normal file
1113
sources/tech/20150115 Get back your privacy and control.md
Normal file
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,87 @@
|
||||
How to Install Cherokee Lightweight Web Server on Ubuntu 14.04
|
||||
================================================================================
|
||||
**Cherokee** is an free and open source high performance, lightweight, full-featured web server and running on major platform (Linux, Mac OS X, Solaris, and BSD). It is compatible with TLS/SSL,FastCGI, SCGI, PHP, uWSGI, SSI, CGI, LDAP, HTTP proxying, video streaming, content caching, traffic shaping, virtual hosts, Apache compatible log files, and load balancing.
|
||||
|
||||
Today we'll explains how to install and configure the Light Weight Cherokeeweb server on Ubuntu Server edition 14.04 LTS (Trusty) and should also work with 12.04, 12.10 and 13. 04, just skip the modification of source list.
|
||||
|
||||
Step by step install and configure the Cherokee web server on Ubuntu Server edition
|
||||
|
||||
### 1. Updating Ubuntu Package Index ###
|
||||
|
||||
First, Login into Ubuntu Server and make sure your ubuntu server update, run the following commands one by one, and install any available updates:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get upgrade
|
||||
|
||||
### 2. Adding PPA ###
|
||||
|
||||
Add the PPA cherokee webserver. by running the following commands
|
||||
|
||||
sudo add-apt-repository ppa:cherokee-webserver
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
Now, only for servers running Ubuntu 14.04 LTS (Trusty) follow this step below
|
||||
|
||||
cd /etc/apt/sources.list.d
|
||||
|
||||
nano cherokee-webserver-ppa-trusty.list
|
||||
|
||||
replace:
|
||||
|
||||
deb http://ppa.launchpad.net/cherokee-webserver/ppa/ubuntu trusty main
|
||||
|
||||
to:
|
||||
|
||||
deb http://ppa.launchpad.net/cherokee-webserver/ppa/ubuntu saucy main
|
||||
|
||||
**then again run:**
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
### 3. Installing Cherokee Web Server using apt-get ###
|
||||
|
||||
Enter the following command to install the Cherokee web server including Module SSL
|
||||
|
||||
sudo apt-get install cherokee cherokee-admin cherokee-doc libcherokee-mod-libssl libcherokee-mod-streaming libcherokee-mod-rrd
|
||||
|
||||
### 4. Configuring Cherokee ###
|
||||
|
||||
sudo service cherokee start
|
||||
|
||||
The best part about using its Web Server is being able to manage all of its configurations through a simple to use web interface. This interface, known as cherokee-admin, is the recommended means of administering cherokee web server through web browser. Start cherokee-admin by running the following command:
|
||||
|
||||
sudo cherokee-admin
|
||||
|
||||
**Note: The cherokee-admin will display the administration user name, One-time Password and administration web interface.**
|
||||
|
||||
**Note down your One-Time password. You will need this when you login to its admin web interface.**
|
||||
|
||||
By default, cherokee-admin can only accessed from localhost. If you need to access the admin for other network address using the parameter ‘**-b**’. If you doesn’t mention any ip address, it will automatically listen to all network interfaces. Then you can connect to cherokee-admin from other network address.
|
||||
|
||||
sudo cherokee-admin -b
|
||||
|
||||
If you need to access its admin from specific network address
|
||||
|
||||
sudo cherokee-admin -b 192.168.1.102
|
||||
|
||||
### 5. Browse your Cherokee Admin Panel ###
|
||||
|
||||
Now you can access the administration panel from you favorite browser by typing http://hostname_or_IP:9090/ for me its http://127.0.0.1:9090/, it will appear on your browser like this:
|
||||
|
||||

|
||||
|
||||
Hurray, we have successfully installed and configured Cherokee Web Server in our Ubuntu Server.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-cherokee-lightweight-web-server-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,97 @@
|
||||
How to Remember and Restore Running Applications on Next Logon
|
||||
================================================================================
|
||||
You have made some apps running in your Ubuntu and don't want to stop the process, just managed your windows and opened your stuffs needed to work. Then, something else demands your attention or you have battery low in your machine and you have to shut down. No worries. You can have Ubuntu remember all your running applications and restore them the next time you log in.
|
||||
|
||||
Now, to make our Ubuntu remember the applications you have running in our current session and restore them the next time our log in, We will use the dconf-editor. This tool replaces the gconf-editor available in previous versions of Ubuntu but is not available by default. To install the dconf-editor, you need to run sudo apt-get install dconf-editor.
|
||||
|
||||
$ sudo apt-get install dconf-tools
|
||||
|
||||
Once the dconf-editor is installed, you can open dconf-editor from Application Menu. Or you can run it from terminal or run command (alt+f2):
|
||||
|
||||
$ dconf-editor
|
||||
|
||||
In the “dconf Editor” window, click the right arrow next to “org” in the left pane to expand that branch of the tree.
|
||||
|
||||

|
||||
|
||||
Under “org”, click the right arrow next to “gnome.”
|
||||
|
||||

|
||||
|
||||
Under “gnome,” click “gnome-session”. In the right pane, select the “auto-save-session” check box to turn on the option.
|
||||
|
||||

|
||||
|
||||
After you check or tick it, close the “Dconf Editor” by clicking the close button (X) in the upper-left corner of the window which is by default.
|
||||
|
||||

|
||||
|
||||
The next time you log out and log back in, all of your running applications will be restored.
|
||||
|
||||
Hurray, we have successfully configured our Ubuntu 14.04 LTS "Trusty" to remember automatically running applications from our last session.
|
||||
|
||||
Now, on this same tutorial, we'll gonna also learn **how to enable hibernation in our Ubuntu 14.04 LTS**:
|
||||
|
||||
Before getting started, press Ctrl+ALt+T on your keyboard to open the terminal. When it opens, run:
|
||||
|
||||
sudo pm-hibernate
|
||||
|
||||
After your computer turns off, switch it back on. Did your open applications re-open? If hibernate doesn’t work, check if your swap partition is at least as large as your available RAM.
|
||||
|
||||
You can check your Swap Area Partition Size from System Monitor, you can get it from the App Menu or run command in terminal.
|
||||
|
||||
$ gnome-system-monitor
|
||||
|
||||
### Enable Hibernate in System Tray Menu: ###
|
||||
|
||||
The indicator-session was updated to use logind instead of upower. Hibernate is disabled by default in both upower and logind.
|
||||
|
||||
To re-enable hibernate, run the commands below one by one to edit the config file:
|
||||
|
||||
sudo -i
|
||||
|
||||
cd /var/lib/polkit-1/localauthority/50-local.d/
|
||||
|
||||
gedit com.ubuntu.enable-hibernate.pkla
|
||||
|
||||
**Tips: if the config file does not work for you, try another one by changing /var/lib to /etc in the code.**
|
||||
|
||||
Copy and paste below lines into the file and save it.
|
||||
|
||||
[Re-enable hibernate by default in upower]
|
||||
Identity=unix-user:*
|
||||
Action=org.freedesktop.upower.hibernate
|
||||
ResultActive=yes
|
||||
|
||||
[Re-enable hibernate by default in logind]
|
||||
Identity=unix-user:*
|
||||
Action=org.freedesktop.login1.hibernate
|
||||
ResultActive=yes
|
||||
|
||||
Restart your computer and done.
|
||||
|
||||
### Hibernate your laptop when lid is closed: ###
|
||||
|
||||
1.Edit “/etc/systemd/logind.conf” via command:
|
||||
|
||||
$ sudo nano /etc/systemd/logind.conf
|
||||
|
||||
2. Change the line **#HandleLidSwitch=suspend to HandleLidSwitch=hibernate** and save the file.
|
||||
|
||||
3. Run command below or just restart your computer to apply changes:
|
||||
|
||||
$ sudo restart systemd-logind
|
||||
|
||||
That’s it. Enjoy! Now, we have both dconf and hibernation on :) Now, your Ubuntu will completely remember your opened apps and stuffs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/remember-running-applications-ubuntu/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,58 @@
|
||||
‘Unity Greeter Badges’ Brings Missing Session Icons to Ubuntu Login Screen
|
||||
================================================================================
|
||||

|
||||
|
||||
**A new package available in Ubuntu 15.04 solves a petty gripe I have with the Unity Greeter: the lack of branded icons for alternative desktop sessions like Cinnamon.**
|
||||
|
||||
I know it’s a minor quibble; it’s a visual paper cut with minimal impact for most. But the inconsistency niggles me because Ubuntu ships with icons for a number of sessions, including Unity, GNOME and KDE. Other DEs, including some of its own flavors like Xubuntu, default to showing a plain white dot in the session switcher list and the main user pod.
|
||||
|
||||
The inconsistency these dots create jars, even if it is only for a fleeting moment, not just in design. It’s in usability too. Branded glyphs are helpful in letting us know what session we’re about to log in to.
|
||||
|
||||
For instance, can you tell what session this is?
|
||||
|
||||

|
||||
|
||||
Budgie? Maybe MATE? Could be Cinnamon…I’d have to click on it and check first.
|
||||
|
||||
It doesn’t have to be this way. The Unity Greeter is built such that the developers of desktop environments can ship badges that appear in the Greeter (and some do). But in many cases, like MATE whose packages are imported from upstream Debian, the inclination to carry an “Ubuntu-specific patch” is either not desirable or not possible.
|
||||
|
||||
### A Solution Is Badged ###
|
||||
|
||||
Experienced Debian maintainer [Doug Torrance][1] has a solution to fix this usability paper cut. Rather than rely on desktop makers themselves to add branded badges to their packages, and rather than burden Ubuntu with the responsibility of maintaining it, Torrance has created a separate ‘unity-greeter-badges’ package to house them.
|
||||
|
||||
In assuming responsibility for providing the session glyphs directly, this package ensure that new and old window managers, session and desktops alike are catered for.
|
||||
|
||||
Among the 30 or so desktop environments it bundles new session badges for are:
|
||||
|
||||
- Xubuntu
|
||||
- Cinnamon
|
||||
- MATE
|
||||
- Cairo-Dock
|
||||
- Xmonad
|
||||
- Awesome
|
||||
- OpenBox
|
||||
- Pantheon
|
||||
|
||||
The best part is that ‘**Unity-Greeter-Badges**’ has been accepted into Ubuntu 15.04. That means Torrance’s package will be available to install directly, no PPAs or downloads needed. In not being part of a core package like the Unity Greeter it can be updated with newer icons in a more efficient and timely manner.
|
||||
|
||||
If you’re running Ubuntu 15.04 you will find the package available to install from the Software Center in the coming days.
|
||||
|
||||
Don’t want to wait until 15.04? Torrance has made .deb installers for Ubuntu 14.04 LTS and Ubuntu 14.10 users.
|
||||
|
||||
- [Download unity-greeter-badges for Ubuntu 14.04][2]
|
||||
- [Download unity-greeter-badges for Ubuntu 14.10][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/unity-greeter-badges-brings-missing-session-icons-ubuntu-login-screen
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://launchpad.net/~profzoom
|
||||
[2]:https://launchpad.net/~profzoom/+archive/ubuntu/misc/+files/unity-greeter-badges_0.1-0ubuntu1%7E201412111501%7Eubuntu14.04.1_all.deb
|
||||
[3]:https://launchpad.net/~profzoom/+archive/ubuntu/misc/+files/unity-greeter-badges_0.1-0ubuntu1%7E201412111501%7Eubuntu14.10.1_all.deb
|
||||
@ -0,0 +1,206 @@
|
||||
How to Monitor Network Usage with nload in Linux
|
||||
================================================================================
|
||||
nload is a free linux utility that can help the linux user or sysadmin to monitor network traffic and bandwidth usage in real time by providing two simple graphs: one per incoming traffic and one for outgoing traffic.
|
||||
|
||||
I really like to use **nload** to display information on my screen about the current download speed, the total incoming traffic, and the average download speed. The graphs reported by nload tool are very easy to interpret and what is the most important thing they are very helpful.
|
||||
|
||||
According to the manual pages it monitors all network devices by default, but you can easily specify the device you want to monitor and also switch between different network devices using the arrow keys. There are many options avaliable such as -t to determine refresh interval of the display in milliseconds (the default value of interval is 500), -m to show multiple devices at the same time(traffic graphs are not shown when this option is used), -u to set the type of unit used for the display of traffic numbers and many others that we are going to explore and practise in this tutorial.
|
||||
|
||||
### How to install nload on your linux machine ###
|
||||
|
||||
**Ubuntu** and **Fedora** users can easily install nload from the default repositories.
|
||||
|
||||
Install nload on Ubuntu by using the following command.
|
||||
|
||||
sudo apt-get install nload
|
||||
|
||||
Install nload on Fedora by using the following command.
|
||||
|
||||
sudo yum install nload
|
||||
|
||||
What about **CentOS** users? Just type the following command on your machine and you will get nload installed.
|
||||
|
||||
sudo yum install nload
|
||||
|
||||
The following command will help you to install nload on OpenBSD systems.
|
||||
|
||||
sudo pkg_add -i nload
|
||||
|
||||
A very effective way to install software on linux machine is to compile by source as you can download and install the latest version which usually means better performance, cool features and less bugs.
|
||||
|
||||
### How to install nload from source ###
|
||||
|
||||
The first thing you need to do before installing nload from source you need to download it and to do this I like to use the wget uility which is available by default on many linux machines. This free utility helps linux users to download files from the web in a non-interactive way and has support for the following protocols.
|
||||
|
||||
- HTTP
|
||||
- HTTPS
|
||||
- FTP
|
||||
|
||||
Change directory to **/tmp** by using the following command.
|
||||
|
||||
cd /tmp
|
||||
|
||||
Now type the following command in your terminal to download the latest version of nload on your linux machine.
|
||||
|
||||
wget http://www.roland-riegel.de/nload/nload-0.7.4.tar.gz
|
||||
|
||||
If you don't like to use the linux wget utility you can easily download it from the [official][1] source by just a mouse click.
|
||||
|
||||
The download will finish in no time as it is a small software. The next step is to untar the file you downloaded with the help of the **tar** utility.
|
||||
|
||||
The tar archiving utility can be used to store and extract files from a tape or disk archive. There are many options available in this tool but we need the followings to perform our operation:
|
||||
|
||||
1. **-x** to extract files from an archive
|
||||
1. **-v** to run in verbose mode
|
||||
1. **-f** to specify the files
|
||||
|
||||
For example:
|
||||
|
||||
tar xvf example.tar
|
||||
|
||||
Now that you learned how to use the tar utility I am very sure you know how to untar .tar archives from the commandline.
|
||||
|
||||
tar xvf nload-0.7.4.tar.gz
|
||||
|
||||
Then use the cd command to change directory to nload*.
|
||||
|
||||
cd nload*
|
||||
|
||||
It looks like this on my system.
|
||||
|
||||
oltjano@baby:/tmp/nload-0.7.4$
|
||||
|
||||
Now run the command
|
||||
|
||||
./configure
|
||||
|
||||
to to configure the package for your system.
|
||||
|
||||
./configure
|
||||
|
||||
Alot of stuff is going to be displayed on your screen. The following screenshot demonstrates how it is going to look like.
|
||||
|
||||

|
||||
|
||||
Then compile the nload with the following command.
|
||||
|
||||
make
|
||||
|
||||

|
||||
|
||||
And finally install nload on your linux machine with the following command.
|
||||
|
||||
sudo make install
|
||||
|
||||

|
||||
|
||||
Now that the installation of nload is finished it is time for you to learn how to use it.
|
||||
|
||||
### How to use nload ###
|
||||
|
||||
I like to explore so type the following command on your terminal.
|
||||
|
||||
nload
|
||||
|
||||
What do you see?
|
||||
|
||||
I get the following.
|
||||
|
||||

|
||||
|
||||
As you can see from the above screenshot I get information on:
|
||||
|
||||
### Incoming Traffic ###
|
||||
|
||||
#### Current download speed ####
|
||||
|
||||

|
||||
|
||||
#### Average download speed ####
|
||||
|
||||

|
||||
|
||||
#### Minimum download speed ####
|
||||
|
||||

|
||||
|
||||
#### Maximum download speed ####
|
||||
|
||||

|
||||
|
||||
#### Total incoming traffic in bytes by default ####
|
||||
|
||||

|
||||
|
||||
### Outgoing Traffic ###
|
||||
|
||||
The same goes for outgoing traffic.
|
||||
|
||||
#### Some useful options of nload ####
|
||||
|
||||
Use the option
|
||||
|
||||
-u
|
||||
|
||||
to set set the type of unit used for the display of traffic numbers.
|
||||
|
||||
The following command will help you to use the MBit/s unit.
|
||||
|
||||
nload -u m
|
||||
|
||||
The following screenshot shows the result of the above command.
|
||||
|
||||

|
||||
|
||||
Try the following command and see the results.
|
||||
|
||||
nload -u g
|
||||
|
||||

|
||||
|
||||
There is also the option **-U**. According to the manual pages it is same as the option -u but only for an amount of data. I tested this option and to be honest it very helpful when you want to check the total amount of traffic be it incoming or outgoing.
|
||||
|
||||
nload -U G
|
||||
|
||||

|
||||
|
||||
As you can see from the above screenshot the command **nload -U G** helps to display the total amount of data (incoming or outgoing) in Gbyte.
|
||||
|
||||
Another useful option I like to use with nload is the option **-t**. This option is used to refresh interval of display in milliseconds which is 500 by default.
|
||||
|
||||
I like to experiment a little by using the following command.
|
||||
|
||||
nload -t 130
|
||||
|
||||
So what the above command does is that it sets the display to refresh every 130 milliseconds. It is recommended to no specify refresh intervals shorter than about 100 milliseconds as nload will generate reports with mistakes during the calculations.
|
||||
|
||||
Another option is **-a**. It is used when you want to set the length in seconds of the time window for average calculation which is 300 seconds by default.
|
||||
|
||||
What if you want to monitor a specific network device? It is very easy to do that, just specify the device or the list of devices you want to monitor like shown below.
|
||||
|
||||
nload wlan0
|
||||
|
||||

|
||||
|
||||
The following syntax can help to monitor specific multiple devices.
|
||||
|
||||
nload [options] device1 device2 devicen
|
||||
|
||||
For example use the following command to monitor eth0 and wlan0.
|
||||
|
||||
nload wlan0 eth0
|
||||
|
||||
And if you run the command nload without any option it will monitor all auto-detected devices, you can display graphs for each one of them by using the right and left arrow keys.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/monitoring-2/monitor-network-usage-nload/
|
||||
|
||||
作者:[Oltjano Terpollari][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/oltjano/
|
||||
[1]:http://www.roland-riegel.de/nload/nload-0.7.4.tar.gz
|
||||
@ -0,0 +1,69 @@
|
||||
How to apply image effects to pictures on Raspberry Pi
|
||||
================================================================================
|
||||
Like a common pocket camera which has a built-in function to add various effects on captured photos, [Raspberry Pi camera board][1] ("raspi cam") can actually do the same. With the help of raspistill camera control options, we can add the image effects function like we have in a pocket camera.
|
||||
|
||||
There are [three comman-line applications][2] which can be utilized for [taking videos or pictures][3] with raspi cam, and one of them is the raspistill application. The raspistill tool offers various camera control options such as sharpness, contrast, brightness, saturation, ISO, exposure, automatic white balance (AWB), image effects.
|
||||
|
||||
In this article I will show how to apply exposure, AWB, and other image effects with raspistill while capturing pictures using raspi cam. To automate the process, I wrote a simple Python script which takes pictures and automatically applies a series of image effects to the pictures. The raspi cam documentation describes available types of the exposure, AWB, and image effects. In total, the raspi cam offers 16 types of image effects, 12 types of exposure, and 10 types of AWB values.
|
||||
|
||||
The simple Python script looks like the following.
|
||||
|
||||
#!/usb/bin/python
|
||||
import os
|
||||
import time
|
||||
import subprocess
|
||||
list_ex=['auto','night']
|
||||
list_awb=['auto','cloud',flash']
|
||||
list_ifx=['blur','cartoon','colourswap','emboss','film','gpen','hatch','negative','oilpaint','posterise','sketch','solarise','watercolour']
|
||||
x=0
|
||||
for ex in list_ex:
|
||||
for awb in list_awb:
|
||||
for ifx in list_ifx:
|
||||
x=x+1
|
||||
filename='img_'+ex+'_'+awb+'_'+ifx+'.jpg'
|
||||
cmd='raspistill -o '+filename+' -n -t 1000 -ex '+ex+' -awb '+awb+' -ifx '+ifx+' -w 640 -h 480'
|
||||
pid=subprocess.call(cmd,shell=True)
|
||||
print "["+str(x)+"]-"+ex+"_"+awb+"_"+ifx+".jpg"
|
||||
time.sleep(0.25)
|
||||
print "End of image capture"
|
||||
|
||||
The Python script operates as follows. First, create three array/list variable for the exposure, AWB and image effects. In the example, we use 2 types of exposure, 3 types of AWB, and 13 types of image effects values. Then make nested loops for applying the value of the three variables that we have. Inside the nested loop, execute the raspistill application. We specify (1) the output filename; (2) exposure value; (3) AWB value; (4) image effect value; (5) the time to take a photo, which is set to 1 second; and (6) the size of the photo, which is set to 640x480px. This Python script will create 78 different versions of a captured photo with a combination of 2 types of exposure, 3 types of AWB, and 13 types of image effects.
|
||||
|
||||
To execute the Python script, simply type:
|
||||
|
||||
$ python name_of_this_script.py
|
||||
|
||||
Here is the first round of the sample result.
|
||||
|
||||

|
||||
|
||||
### Bonus ###
|
||||
|
||||
For those who are more interested, there is another way to access and control the raspi cam besides raspistill. [Picamera][4] a pure Python interface which provides APIs for accessing and controlling raspi cam, so that one can build a complex program for utilizing raspi cam according to their needs. If you are skilled at Python, picamera is a good feature-complete interface for implementing your raspi cam project. The picamera interface is included by default in the recent image of Raspbian. If your [Raspberry Pi][5] operating system is not new or not Raspbian, you can install it on your system as follows.
|
||||
|
||||
First, install pip on your system by following [this guideline][6].
|
||||
|
||||
Then, install picamera as follows.
|
||||
|
||||
$ sudo pip install picamera
|
||||
|
||||
Refer to the [official documentation][7] on how to use picamera.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/apply-image-effects-pictures-raspberrypi.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/kristophorus
|
||||
[1]:http://xmodulo.com/go/picam
|
||||
[2]:http://www.raspberrypi.org/documentation/usage/camera/raspicam/
|
||||
[3]:http://xmodulo.com/install-raspberry-pi-camera-board.html
|
||||
[4]:https://pypi.python.org/pypi/picamera
|
||||
[5]:http://xmodulo.com/go/raspberrypi
|
||||
[6]:http://ask.xmodulo.com/install-pip-linux.html
|
||||
[7]:http://picamera.readthedocs.org/
|
||||
@ -0,0 +1,115 @@
|
||||
Linux FAQs with Answers--How to check CPU info on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to know detailed information about the CPU processor of my computer. What are the available methods to check CPU information on Linux?
|
||||
|
||||
Depending on your need, there are various pieces of information you may need to know about the CPU processor(s) of your computer, such as CPU vendor name, model name, clock speed, number of sockets/cores, L1/L2/L3 cache configuration, available processor capabilities (e.g., hardware virtualization, AES, MMX, SSE), and so on. In Linux, there are many command line or GUI-based tools that are used to show detailed information about your CPU hardware.
|
||||
|
||||
### 1. /proc/cpuinfo ###
|
||||
|
||||
The simpliest method is to check /proc/cpuinfo. This virtual file shows the configuration of available CPU hardware.
|
||||
|
||||
$ more /proc/cpuinfo
|
||||
|
||||
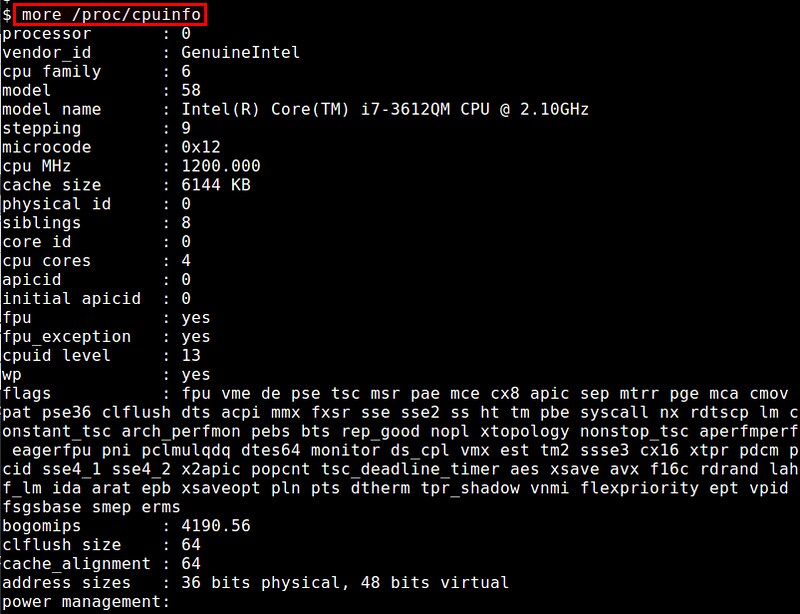
|
||||
|
||||
By inspecting this file, you can [identify][1] the number of physical processors, the number of cores per CPU, available CPU flags, and a number of other things.
|
||||
|
||||
### 2. cpufreq-info ###
|
||||
|
||||
The cpufreq-info command (which is part of **cpufrequtils** package) collects and reports CPU frequency information from the kernel/hardware. The command shows the hardware frequency that the CPU currently runs at, as well as the minimum/maximum CPU frequency allowed, CPUfreq policy/statistics, and so on. To check up on CPU #0:
|
||||
|
||||
$ cpufreq-info -c 0
|
||||
|
||||

|
||||
|
||||
### 3. cpuid ###
|
||||
|
||||
The cpuid command-line utility is a dedicated CPU information tool that displays verbose information about CPU hardware by using [CPUID functions][2]. Reported information includes processor type/family, CPU extensions, cache/TLB configuration, power management features, etc.
|
||||
|
||||
$ cpuid
|
||||
|
||||
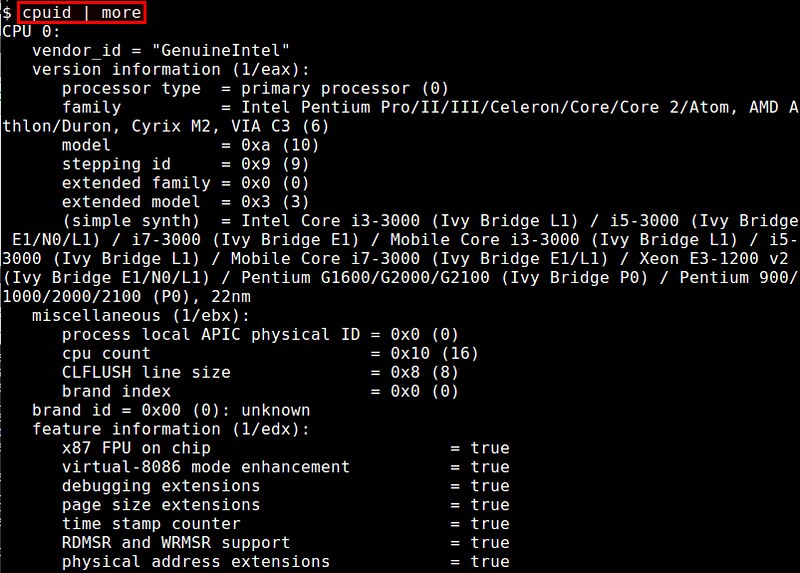
|
||||
|
||||
### 4. dmidecode ###
|
||||
|
||||
The dmidecode command collects detailed information about system hardware directly from DMI data of the BIOS. Reported CPU information includes CPU vendor, version, CPU flags, maximum/current clock speed, (enabled) core count, L1/L2/L3 cache configuration, and so on.
|
||||
|
||||
$ sudo dmidecode
|
||||
|
||||
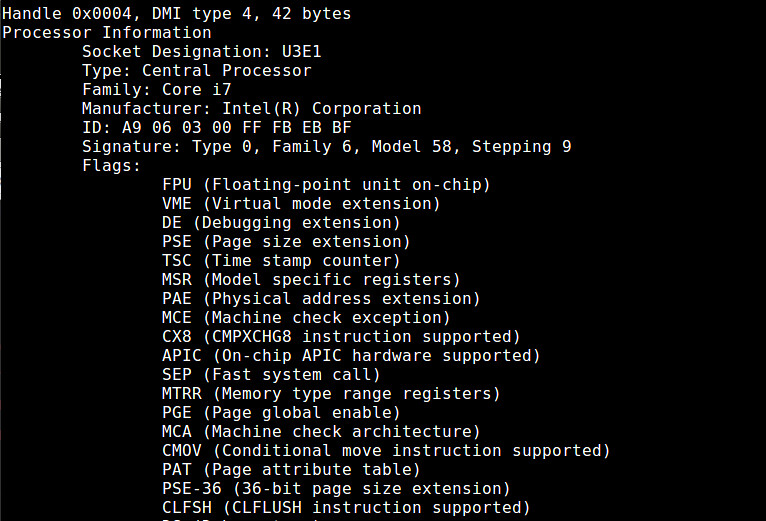
|
||||
|
||||
### 5. hardinfo ###
|
||||
|
||||
The hardinfo is a GUI-based system information tool which can give you an easy-to-understand summary of your CPU hardware, as well as other hardware components of your system.
|
||||
|
||||
$ hardinfo
|
||||
|
||||
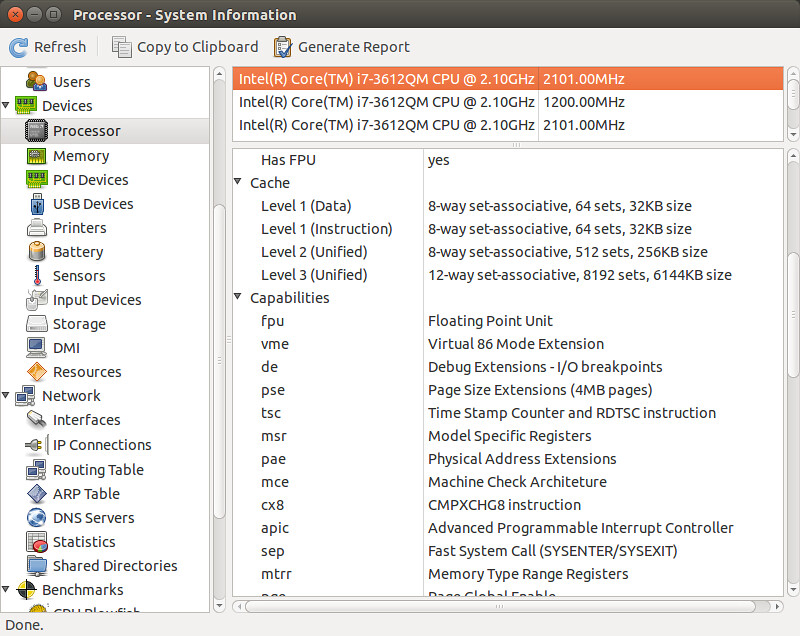
|
||||
|
||||
### 6. i7z ###
|
||||
|
||||
i7z is a real-time CPU reporting tool dedicated to Intel Core i3, i5 and i7 CPUs. It can display various per-core information in real time, such as Turbo Boost states, CPU frequencies, CPU power states, temperature measurements, and so on. i7z runs in either ncurses-based console mode or QT based GUI.
|
||||
|
||||
$ sudo i7z
|
||||
|
||||
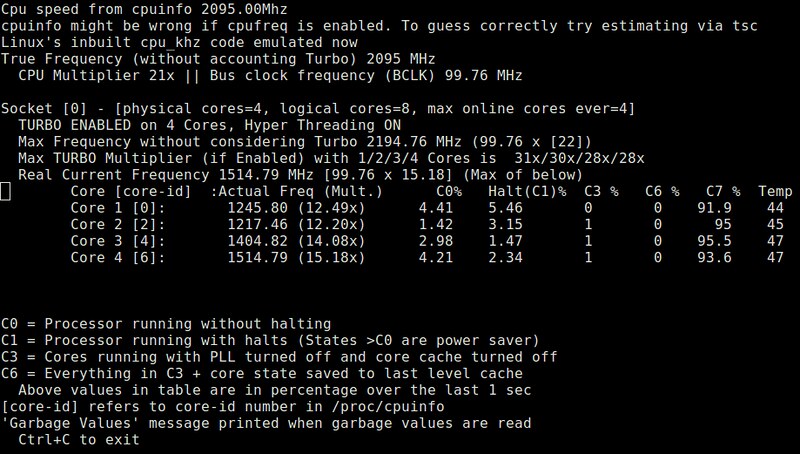
|
||||
|
||||
### 8. likwid-topology ###
|
||||
|
||||
[likwid][3] (Like I Knew What I'm Doing) is a collection of command-line tools to measure, configure and display hardware related properties. Among them is likwid-topology which shows CPU hardware (thread/cache/NUMA) topology information. It can also identify processor families (e.g., Intel Core 2, AMD Shanghai).
|
||||
|
||||
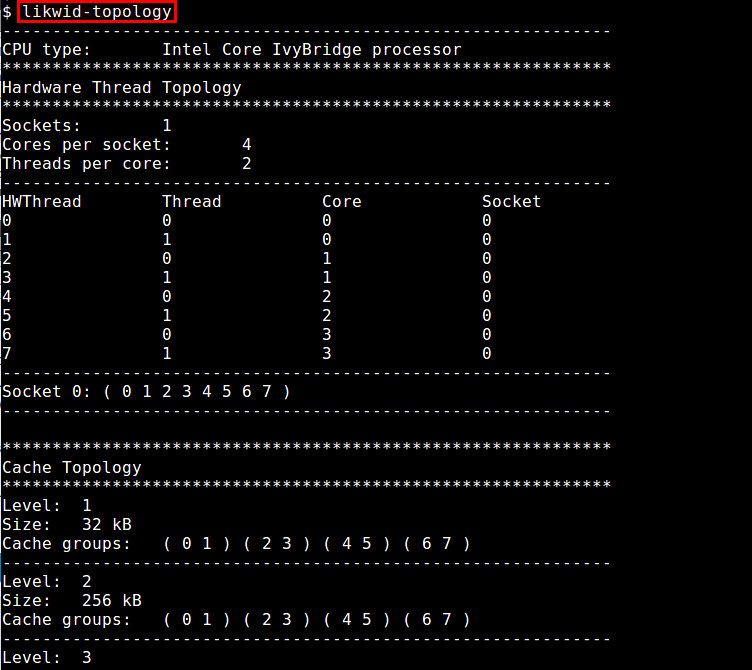
|
||||
|
||||
### 9. lscpu ###
|
||||
|
||||
The lscpu command summarizes /etc/cpuinfo content in a more user-friendly format, e.g., the number of (online/offline) CPUs, cores, sockets, NUMA nodes.
|
||||
|
||||
$ lscpu
|
||||
|
||||
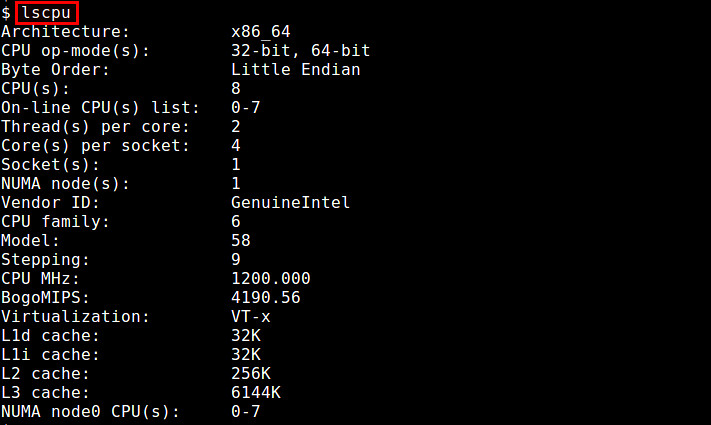
|
||||
|
||||
### 10. lshw ###
|
||||
|
||||
The **lshw** command is a comprehensive hardware query tool. Unlike other tools, lshw requires root privilege because it query DMI information in system BIOS. It can report the total number of cores and enabled cores, but miss out on information such as L1/L2/L3 cache configuration. The GTK version lshw-gtk is also available.
|
||||
|
||||
$ sudo lshw -class processor
|
||||
|
||||
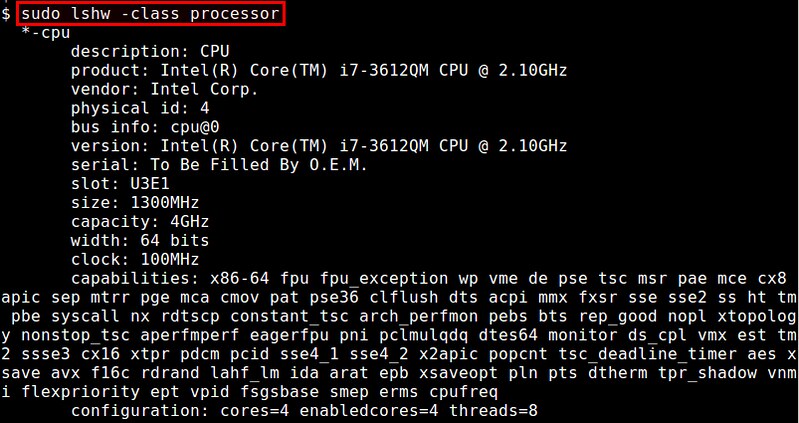
|
||||
|
||||
### 11. lstopo ###
|
||||
|
||||
The lstopo command (contained in [hwloc][4] package) visualizes the topology of the system which is composed of CPUs, cache, memory and I/O devices. This command is useful to identify the processor architecture and NUMA topology of the system.
|
||||
|
||||
$ lstopo
|
||||
|
||||
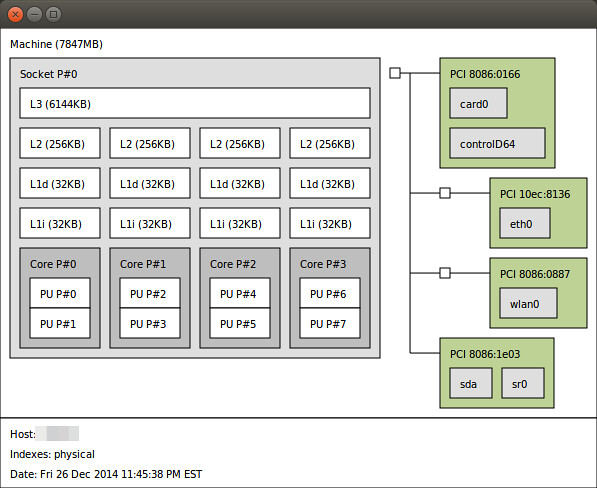
|
||||
|
||||
### 12. numactl ###
|
||||
|
||||
Originally developed to set the NUMA scheduling and memeory placement policy of Linux processes, the numactl command can also show information about NUMA topology of the CPU hardware from the command line.
|
||||
|
||||
$ numactl --hardware
|
||||
|
||||

|
||||
|
||||
### 13. x86info ###
|
||||
|
||||
x86info is a command-line tool for showing x86-based CPU information. Reported information includes CPU model, number of threads/cores, clock speed, TLB cache configuration, supported feature flags, etc.
|
||||
|
||||
$ x86info --all
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-cpu-info-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-find-number-of-cpu-cores-on.html
|
||||
[2]:http://en.wikipedia.org/wiki/CPUID
|
||||
[3]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[4]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
@ -0,0 +1,207 @@
|
||||
Syncthing: A Private, And Secure Tool To Sync Files/Folders Between Computers
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
**Syncthing** is a free, Open Source tool that can be used to sync files/folders between your networked computers. Unlike other sync tools, such as **BitTorrent Sync** or **Dropbox**, Syncthing transfers data directly from one system to another system, and It is completely open source, secure and private. All of your precious data will be stored in your system so that you can have full control over your files and folders, and none of them are stored in any third party systems. Also, you deserve to choose where it is stored, if it is shared with some third party and how it’s transmitted over the Internet.
|
||||
|
||||
All communication is encrypted using TLS, so your data is very secure from the prying eyes. Syncthing has a responsive and powerful WebGUI which will help the users to easily add, delete and manage directories to be synced over network. Using Syncthing, you can sync multiple folders to multiple systems at a time. Syncthing is very simple, portable, yet powerful tool in terms of installation and usage. Since all files/folders are directly transferred from one computer to another computer, you don’t have to worry about purchasing extra space from your Cloud provider. All you need is very stable LAN/WAN connection and enough disk space on your systems. It supports all modern operating systems, including GNU/Linux, Windows, Mac OS X, and ofcourse Android.
|
||||
|
||||
### Installation ###
|
||||
|
||||
For the purpose of this tutorial, We will be using two systems, one is running with Ubuntu 14.04 LTS, and another one is running with Ubuntu 14.10 server. To easily recognize these two systems, we will be calling them using names **system1**, and **system2**.
|
||||
|
||||
### System1 Details: ###
|
||||
|
||||
- **OS**: Ubuntu 14.04 LTS server;
|
||||
- **Hostname**: server1.unixmen.local;
|
||||
- **IP Address**: 192.168.1.150.
|
||||
- **System user**: sk (You can use your own)
|
||||
- **Sync Directory**: /home/Sync/ (Will be created by default by Syncthing)
|
||||
|
||||
### System2 Details: ###
|
||||
|
||||
- **OS**: Ubuntu 14.10 server;
|
||||
- **Hostname**: server.unixmen.local;
|
||||
- **IP Address**: 192.168.1.151.
|
||||
- **System user**: sk (You can use your own)
|
||||
- **Sync Directory**: /home/Sync/ (Will be created by default by Syncthing)
|
||||
|
||||
### Creating User For Syncthing On System 1 & System2: ###
|
||||
|
||||
Run the following commands on both system to create the user for Syncthing and the directory to be synced between two systems:
|
||||
|
||||
sudo useradd sk
|
||||
sudo passwd sk
|
||||
|
||||
### Install Syncthing On System1 And System2: ###
|
||||
|
||||
You should do the following steps on both System 1 and System 2.
|
||||
|
||||
Download the latest version from the [official download page][1]. As I am using 64bit system, I downloaded the 6bbit package.
|
||||
|
||||
wget https://github.com/syncthing/syncthing/releases/download/v0.10.20/syncthing-linux-amd64-v0.10.20.tar.gz
|
||||
|
||||
Extract the download file:
|
||||
|
||||
tar xzvf syncthing-linux-amd64-v0.10.20.tar.gz
|
||||
|
||||
Cd to the extracted folder:
|
||||
|
||||
cd syncthing-linux-amd64-v0.10.20/
|
||||
|
||||
Copy the excutable file “syncthing” to **$PATH**:
|
||||
|
||||
sudo cp syncthing /usr/local/bin/
|
||||
|
||||
Now, run the following command to run the syncthing for the first time.
|
||||
|
||||
syncthing
|
||||
|
||||
When you run the above command, syncthing will generate a configuration and some keys and then start the admin GUI in your browser. You should see something like below.
|
||||
|
||||
Sample output:
|
||||
|
||||
[monitor] 15:40:27 INFO: Starting syncthing
|
||||
15:40:27 INFO: Generating RSA key and certificate for syncthing...
|
||||
[BQXVO] 15:40:34 INFO: syncthing v0.10.20 (go1.4 linux-386 default) unknown-user@syncthing-builder 2015-01-13 16:27:47 UTC
|
||||
[BQXVO] 15:40:34 INFO: My ID: BQXVO3D-VEBIDRE-MVMMGJI-ECD2PC3-T5LT3JB-OK4Z45E-MPIDWHI-IRW3NAZ
|
||||
[BQXVO] 15:40:34 INFO: No config file; starting with empty defaults
|
||||
[BQXVO] 15:40:34 INFO: Edit /home/sk/.config/syncthing/config.xml to taste or use the GUI
|
||||
[BQXVO] 15:40:34 INFO: Starting web GUI on http://127.0.0.1:8080/
|
||||
[BQXVO] 15:40:34 INFO: Loading HTTPS certificate: open /home/sk/.config/syncthing/https-cert.pem: no such file or directory
|
||||
[BQXVO] 15:40:34 INFO: Creating new HTTPS certificate
|
||||
[BQXVO] 15:40:34 INFO: Generating RSA key and certificate for server1...
|
||||
[BQXVO] 15:41:01 INFO: Starting UPnP discovery...
|
||||
[BQXVO] 15:41:07 INFO: Starting local discovery announcements
|
||||
[BQXVO] 15:41:07 INFO: Starting global discovery announcements
|
||||
[BQXVO] 15:41:07 OK: Ready to synchronize default (read-write)
|
||||
[BQXVO] 15:41:07 INFO: Device BQXVO3D-VEBIDRE-MVMMGJI-ECD2PC3-T5LT3JB-OK4Z45E-MPIDWHI-IRW3NAZ is "server1" at [dynamic]
|
||||
[BQXVO] 15:41:07 INFO: Completed initial scan (rw) of folder default
|
||||
|
||||
Syncthing has been successfully initialized, and the Web admin interface can be accessed using URL: **http://localhost:8080** from your browser. As you see in the above output, syncthing has automatically created a folder called **default** for you, in a directory called **Sync** in your **home** directory.
|
||||
|
||||
By default, Syncthing WebGUI will only be accessed from the localhost itself. To access the WebGUI from the remote systems, you need to do the following changes on both systems.
|
||||
|
||||
First, stop the Syncthing initialization process by pressing the CTRL+C. Now, you will be returned back to the Terminal.
|
||||
|
||||
Edit file **config.xml**,
|
||||
|
||||
sudo nano ~/.config/syncthing/config.xml
|
||||
|
||||
Find this directive:
|
||||
|
||||
[...]
|
||||
<gui enabled="true" tls="false">
|
||||
<address>127.0.0.1:8080</address>
|
||||
<apikey>-Su9v0lW80JWybGjK9vNK00YDraxXHGP</apikey>
|
||||
</gui>
|
||||
[...]
|
||||
|
||||
In the **<address>** field, change **127.0.0.1:8080** to **0.0.0.0:8080**. So, your config.xml will look like below.
|
||||
|
||||
<gui enabled="true" tls="false">
|
||||
<address>0.0.0.0:8080</address>
|
||||
<apikey>-Su9v0lW80JWybGjK9vNK00YDraxXHGP</apikey>
|
||||
</gui>
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Now, start again the Syncthing initialization on both systems by entering the following command:
|
||||
|
||||
syncthing
|
||||
|
||||
### Access the WebGUI ###
|
||||
|
||||
Now, open your browser **http://ip-address:8080/**. You will see the following screen,
|
||||
|
||||

|
||||
|
||||
The WebGUI has two panes. In the left pane, you may see the list of folders to be synced. As I mentioned before, the folder **default** has been automatically created for you while initializing Syncthing. If you want to sync more folders, you can add using **Add Folder** button.
|
||||
|
||||
In the right pane, you see the number of devices connected. Currently there is only one device, the computer you are running this on.
|
||||
|
||||
### Configure Syncthing Web GUI ###
|
||||
|
||||
For the security enhancement, let us enable TLS, and setup administrative user and password to access the WebGUI. To od that, click on the gear button and select **Settings** on the top right corner.
|
||||
|
||||

|
||||
|
||||
Enter the admin username/password. In my case it is admin/ubuntu. You should use some strong password. And, check the box that says: **Use HTTPS for GUI**.
|
||||
|
||||

|
||||
|
||||
Click Save button. Now, you’ll be asked to restart the Syncthing to activate the changes. Click Restart.
|
||||
|
||||

|
||||
|
||||
Selection_005Refresh you web browser. You’ll see the SSL warning like below. Click on the button that says: **I understand the Risks**. And, click Add Exception button to add this page to the browser trusted lists.
|
||||
|
||||

|
||||
|
||||
Enter the administrative user and password which we configured in the previous steps. In my case it’s **admin/ubuntu**.
|
||||
|
||||

|
||||
|
||||
We have secured the WebGUI now. Don’t forget to do the same steps on both server.
|
||||
|
||||
### Connect Servers To Each Other ###
|
||||
|
||||
To sync folders between systems, you must told them about each other. This is accomplished by exchanging “device IDs”. You can find it in the web GUI by selecting the “gear menu” (top right) and “Show ID”.
|
||||
|
||||
For example, here is my System 1 ID.
|
||||
|
||||

|
||||
|
||||
Copy the ID, and go to the another system (system 2) WebGUI. From the second system (system 2) WebGUI window, click on the Add Device on the right side.
|
||||
|
||||

|
||||
|
||||
The following screen should appear. Paste the **System 1 ID** in the Device section. Enter the Device name(optional). In the Addresses field, you can either enter the IP address of the other system or leave it as default. The default value is **dynamic**. Finally, select the folder to be synced. In our case, the sync folder is **default**.
|
||||
|
||||

|
||||
|
||||
Once you done, click on the save button. You’ll be asked to restart the Syncthing. Click Restart button to activate the changes.
|
||||
|
||||
Now, go to the **System 1** WebUI, you’ll see a request has been sent from the System 2 to connect and sync. Click **Add** button. Now, the System 2 will ask the System 1 to share and sync the folder called “default”. Click **Share** button.
|
||||
|
||||

|
||||
|
||||
Next restart the Syncthing service on the System 1 to activate the changes.
|
||||
|
||||

|
||||
|
||||
Wait for few seconds, approximately 60 seconds, and you’ll see the two systems have been successfully connected and synced to each other.
|
||||
|
||||
You can verify it under the Add Device section of the WebGUI.
|
||||
|
||||
System 1 WebGUI console after adding System 2:
|
||||
|
||||

|
||||
|
||||
System 2 WebGUI console after adding System 1:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Now, put any file or folder in any one of the systems “**default**” folder. You may see the file/folder will be synced to the other system automatically.
|
||||
|
||||
That’s it! Happy Sync’ing!!
|
||||
|
||||
Cheers!!!
|
||||
|
||||
- [Syncthing Website][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/syncthing-private-secure-tool-sync-filesfolders-computers/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://github.com/syncthing/syncthing/releases/tag/v0.10.20
|
||||
[2]:http://syncthing.net/
|
||||
@ -0,0 +1,56 @@
|
||||
Linux FAQs with Answers--How to use yum to download a RPM package without installing it
|
||||
================================================================================
|
||||
> **Question**: I want to download a RPM package from Red Hat's standard repositories. Can I use yum command to download a RPM package without installing it?
|
||||
|
||||
yum is the default package manager for Red Hat based systems, such as CentOS, Fedora or RHEL. Using yum, you can install or update a RPM package while resolving its package dependencies automatically. What if you want to download a RPM package without installing it on the system? For example, you may want to archive some RPM packages for later use or to install them on another machine.
|
||||
|
||||
Here is how to download a RPM package from yum repositories.
|
||||
|
||||
### Method One: Yum ###
|
||||
|
||||
The yum command itself can be used to download a RPM package. The standard yum command offers '--downloadonly' option for this purpose.
|
||||
|
||||
$ sudo yum install --downloadonly <package-name>
|
||||
|
||||
By default, a downloaded RPM package will be saved in:
|
||||
|
||||
/var/cache/yum/x86_64/[centos/fedora-version]/[repository]/packages
|
||||
|
||||
In the above, [repository] is the name of the repository (e.g., base, fedora, updates) from which the package is downloaded.
|
||||
|
||||
If you want to download a package to a specific directory (e.g., /tmp):
|
||||
|
||||
$ sudo yum install --downloadonly --downloaddir=/tmp <package-name>
|
||||
|
||||
Note that if a package to download has any unmet dependencies, yum will download all dependent packages as well. None of them will be installed.
|
||||
|
||||
One important thing is that on CentOS/RHEL 6 or earlier, you will need to install a separate yum plugin (called yum-plugin-downloadonly) to be able to use '--downloadonly' command option:
|
||||
|
||||
$ sudo yum install yum-plugin-downloadonly
|
||||
|
||||
Without this plugin, you will get the following error with yum:
|
||||
|
||||
Command line error: no such option: --downloadonly
|
||||
|
||||
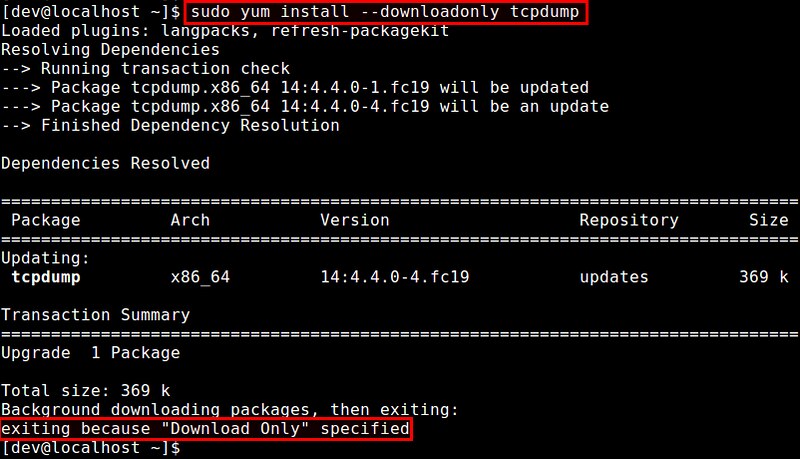
|
||||
|
||||
### Method Two: Yumdownloader ###
|
||||
|
||||
Another method to download a RPM package is via a dedicated package downloader tool called yumdownloader. This tool is part of yum-utils package which contains a suite of helper tools for yum package manager.
|
||||
|
||||
$ sudo yum install yum-utils
|
||||
|
||||
To download a RPM package:
|
||||
|
||||
$ sudo yumdownloader <package-name>
|
||||
|
||||
The downloaded package will be saved in the current directory. You need to use root privilege because yumdownloader will update package index files during downloading. Unlike yum command above, none of the dependent package(s) will be downloaded.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/yum-download-rpm-package.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,78 @@
|
||||
[xieborui translating]How to Boot Linux ISO Images Directly From Your Hard Drive
|
||||
================================================================================
|
||||
Hi all, today we'll teach you an awesome interesting stuff related with the Operating System Disk Image and Booting. Now, try many OS you like without installing them in your Physical Hard Drive and without burning DVDs or USBs.
|
||||
|
||||
We can boot Linux ISO files directly from your hard drive with Linux’s GRUB2 boot loader. We can boot any Linux Distribution's using this method without creating bootable USBs, Burn DVDs, etc but the changes made will be temporary.
|
||||
|
||||

|
||||
|
||||
### 1. Get the ISO of the Linux Distributions: ###
|
||||
|
||||
Here, we're gonna create Menu of Ubuntu 14.04 LTS "Trusty" and Linux Mint 17.1 LTS "Rebecca" so, we downloaded them from their official site:
|
||||
|
||||
Ubuntu from : [http://ubuntu.com/][1] And Linux Mint from: [http://linuxmint.com/][2]
|
||||
|
||||
You can download ISO files of required linux distributions from their respective websites. If you have mirror of the iso files hosted near your area or country, it is recommended if you have no sufficient internet download speed.
|
||||
|
||||
### 2. Determine the Hard Drive Partition’s Path ###
|
||||
|
||||
GRUB uses a different “device name” scheme than Linux does. On a Linux system, /dev/sda0 is the first partition on the first hard disk — **a** means the first hard disk and **0** means its first partition. In GRUB, (hd0,1) is equivalent to /dev/sda0. The **0** means the first hard disk, while **1** means the first partition on it. In other words, in a GRUB device name, the disk numbers start counting at 0 and the partition numbers start counting at 1. For example, (hd3,6) refers to the sixth partition on the fourth hard disk.
|
||||
|
||||
You can use the **fdisk -l** command to view this information. On Ubuntu, open a Terminal and run the following command:
|
||||
|
||||
$ sudo fdisk -l
|
||||
|
||||

|
||||
|
||||
You’ll see a list of Linux device paths, which you can convert to GRUB device names on your own. For example, below we can see the system partition is /dev/sda1 — so that’s (hd0,1) for GRUB.
|
||||
|
||||
### 3. Adding boot menu to Grub2 ###
|
||||
|
||||
The easiest way to add a custom boot entry is to edit the /etc/grub.d/40_custom script. This file is designed for user-added custom boot entries. After editing the file, the contents of your /etc/defaults/grub file and the /etc/grub.d/ scripts will be combined to create a /boot/grub/grub.cfg file. You shouldn't edit this file by hand. It’s designed to be automatically generated from settings you specify in other files.
|
||||
|
||||
So we’ll need to open the /etc/grub.d/40_custom file for editing with root privileges. On Ubuntu, you can do this by opening a Terminal window and running the following command:
|
||||
|
||||
$ sudo nano /etc/grub.d/40_custom
|
||||
|
||||
Unless we’ve added other custom boot entries, we should see a mostly empty file. We'll need to add one or more ISO-booting sections to the file below the commented lines.
|
||||
|
||||
=====
|
||||
menuentry “Ubuntu 14.04 ISO” {
|
||||
set isofile=”/home/linoxide/Downloads/ubuntu-14.04.1-desktop-amd64.iso”
|
||||
loopback loop (hd0,1)$isofile
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
menuentry "Linux Mint 17.1 Cinnamon ISO" {
|
||||
set isofile=”/home/linoxide/Downloads/mint-17.1-desktop-amd64.iso”
|
||||
loopback loop (hd0,1)$isofile
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
|
||||

|
||||
|
||||
**Important Note**: Different Linux distributions require different boot entries with different boot options. The GRUB Live ISO Multiboot project offers a variety of [menu entries for different Linux distributions][3]. You should be able to adapt these example menu entries for the ISO file you want to boot. You can also just perform a web search for the name and release number of the Linux distribution you want to boot along with “boot from ISO in GRUB” to find more information.
|
||||
|
||||
### 4. Updating Grub2 ###
|
||||
|
||||
To make the custom menu entries active, we'll run "sudo update-grub"
|
||||
|
||||
sudo update-grub
|
||||
|
||||
Hurray, we have successfully added our brand new linux distribution's ISO to our GRUB Menu. Now, we'll be able to boot them and enjoy trying them. You can add many distributions and try them all. Note that the changes made in those OS will don't be kept preserved, which means you'll loose changes made in that distros after the restart.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/boot-linux-iso-images-directly-hard-drive/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://ubuntu.com/
|
||||
[2]:http://linuxmint.com/
|
||||
[3]:http://git.marmotte.net/git/glim/tree/grub2
|
||||
@ -0,0 +1,74 @@
|
||||
Translating by Medusar
|
||||
|
||||
How to make a file immutable on Linux
|
||||
================================================================================
|
||||
Suppose you want to write-protect some important files on Linux, so that they cannot be deleted or tampered with by accident or otherwise. In other cases, you may want to prevent certain configuration files from being overwritten automatically by software. While changing their ownership or permission bits on the files by using chown or chmod is one way to deal with this situation, this is not a perfect solution as it cannot prevent any action done with root privilege. That is when chattr comes in handy.
|
||||
|
||||
chattr is a Linux command which allows one to set or unset attributes on a file, which are separate from the standard (read, write, execute) file permission. A related command is lsattr which shows which attributes are set on a file. While file attributes managed by chattr and lsattr are originally supported by EXT file systems (EXT2/3/4) only, this feature is now available on many other native Linux file systems such as XFS, Btrfs, ReiserFS, etc.
|
||||
|
||||
In this tutorial, I am going to demonstrate how to use chattr to make files immutable on Linux.
|
||||
|
||||
chattr and lsattr commands are a part of e2fsprogs package which comes pre-installed on all modern Linux distributions.
|
||||
|
||||
Basic syntax of chattr is as follows.
|
||||
|
||||
$ chattr [-RVf] [operator][attribute(s)] files...
|
||||
|
||||
The operator can be '+' (which adds selected attributes to attribute list), '-' (which removes selected attributes from attribute list), or '=' (which forces selected attributes only).
|
||||
|
||||
Some of available attributes are the following.
|
||||
|
||||
- **a**: can be opened in append mode only.
|
||||
- **A**: do not update atime (file access time).
|
||||
- **c**: automatically compressed when written to disk.
|
||||
- **C**: turn off copy-on-write.
|
||||
- **i**: set immutable.
|
||||
- **s**: securely deleted with automatic zeroing.
|
||||
|
||||
### Immutable Attribute ###
|
||||
|
||||
To make a file immutable, you can add "immutable" attribute to the file as follows. For example, to write-protect /etc/passwd file:
|
||||
|
||||
$ sudo chattr +i /etc/passwd
|
||||
|
||||
Note that you must use root privilege to set or unset "immutable" attribute on a file. Now verify that "immutable" attribute is added to the file successfully.
|
||||
|
||||
$ lsattr /etc/passwd
|
||||
|
||||
Once the file is set immutable, this file is impervious to change for any user. Even the root cannot modify, remove, overwrite, move or rename the file. You will need to unset the immutable attribute before you can tamper with the file again.
|
||||
|
||||
To unset the immutable attribute, use the following command:
|
||||
|
||||
$ sudo chattr -i /etc/passwd
|
||||
|
||||
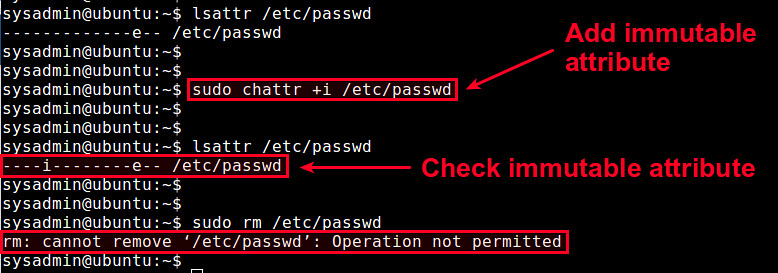
|
||||
|
||||
If you want to make a whole directory (e.g., /etc) including all its content immutable at once recursively, use "-R" option:
|
||||
|
||||
$ sudo chattr -R +i /etc
|
||||
|
||||
### Append Only Attribute ###
|
||||
|
||||
Another useful attribute is "append-only" attribute which forces a file to grow only. You cannot overwrite or delete a file with "append-only" attribute set. This attribute can be useful when you want to prevent a log file from being cleared by accident.
|
||||
|
||||
Similar to immutable attribute, you can turn a file into "append-only" mode by:
|
||||
|
||||
$ sudo chattr +a /var/log/syslog
|
||||
|
||||
Note that when you copy an immutable or append-only file to another file, those attributes will not be preserved on the newly created file.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I showed how to use chattr and lsattr commands to manage additional file attributes to prevent (accidental or otherwise) file tampering. Beware that you cannot rely on chattr as a security measure as one can easily undo immutability. One possible way to address this limitation is to restrict the availability of chattr command itself, or drop kernel capability CAP_LINUX_IMMUTABLE. For more details on chattr and available attributes, refer to its man page.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/make-file-immutable-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user