mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
a14fbf2c3b
@ -1,12 +1,12 @@
|
||||
7 个驱动开源发展的社区
|
||||
================================================================================
|
||||
不久前,开源模式还被成熟的工业厂商以怀疑的态度认作是叛逆小孩的玩物。如今,开放的倡议和基金会在一长列的供应商提供者的支持下正蓬勃发展,而他们将开源模式视作创新的关键。
|
||||
不久前,开源模式还被成熟的工业级厂商以怀疑的态度认作是叛逆小孩的玩物。如今,开源的促进会和基金会在一长列的供应商提供者的支持下正蓬勃发展,而他们将开源模式视作创新的关键。
|
||||
|
||||

|
||||
|
||||
### 技术的开放发展驱动着创新 ###
|
||||
|
||||
在过去的 20 几年间,技术的开放发展已被视作驱动创新的关键因素。即使那些以前将开源视作威胁的公司也开始接受这个观点 — 例如微软,如今它在一系列的开源倡议中表现活跃。到目前为止,大多数的开放发展都集中在软件方面,但甚至这个也正在改变,因为社区已经开始向开源硬件倡议方面聚拢。这里有 7 个成功地在硬件和软件方面同时促进和发展开源技术的组织。
|
||||
在过去的 20 几年间,技术的开源推进已被视作驱动创新的关键因素。即使那些以前将开源视作威胁的公司也开始接受这个观点 — 例如微软,如今它在一系列的开源的促进会中表现活跃。到目前为止,大多数的开源推进都集中在软件方面,但甚至这个也正在改变,因为社区已经开始向开源硬件倡议方面聚拢。这里介绍 7 个成功地在硬件和软件方面同时促进和发展开源技术的组织。
|
||||
|
||||
### OpenPOWER 基金会 ###
|
||||
|
||||
@ -16,21 +16,21 @@
|
||||
|
||||
IBM 通过开放其基于 Power 架构的硬件和软件技术,向使用 Power IP 的独立硬件产品提供许可证等方式为基金会的建立播下种子。如今超过 70 个成员共同协作来为基于 Linux 的数据中心提供自定义的开放服务器,组件和硬件。
|
||||
|
||||
今年四月,在比最新基于 x86 系统快 50 倍的数据分析能力的新的 POWER8 处理器的服务器的基础上, OpenPOWER 推出了一个技术路线图。七月, IBM 和 Google 发布了一个固件堆栈。十月见证了 NVIDIA GPU 带来加速 POWER8 系统的能力和来自 Tyan 的第一个 OpenPOWER 参考服务器。
|
||||
去年四月,在比最新基于 x86 系统快 50 倍的数据分析能力的新的 POWER8 处理器的服务器的基础上, OpenPOWER 推出了一个技术路线图。七月, IBM 和 Google 发布了一个固件堆栈。去年十月见证了 NVIDIA GPU 带来加速 POWER8 系统的能力和来自 Tyan 的第一个 OpenPOWER 参考服务器。
|
||||
|
||||
### Linux 基金会 ###
|
||||
|
||||

|
||||
|
||||
于 2000 年建立的 [Linux 基金会][2] 如今成为掌控着历史上最大的开源协同发展成果,它有着超过 180 个合作成员和许多独立成员及学生成员。它赞助核心 Linux 开发者的工作并促进、保护和推进 Linux 操作系统和协作软件的开发。
|
||||
于 2000 年建立的 [Linux 基金会][2] 如今成为掌控着历史上最大的开源协同开发成果,它有着超过 180 个合作成员和许多独立成员及学生成员。它赞助 Linux 核心开发者的工作并促进、保护和推进 Linux 操作系统,并协调软件的协作开发。
|
||||
|
||||
它最为成功的协作项目包括 Code Aurora Forum (一个拥有为移动无线产业服务的企业财团),MeeGo (一个为移动设备和 IVI (注:指的是车载消息娱乐设备,为 In-Vehicle Infotainment 的简称) 构建一个基于 Linux 内核的操作系统的项目) 和 Open Virtualization Alliance (开放虚拟化联盟,它促进自由和开源软件虚拟化解决方案的采用)。
|
||||
它最为成功的协作项目包括 Code Aurora Forum (一个拥有为移动无线产业服务的企业财团),MeeGo (一个为移动设备和 IVI [注:指的是车载消息娱乐设备,为 In-Vehicle Infotainment 的简称] 构建一个基于 Linux 内核的操作系统的项目) 和 Open Virtualization Alliance (开放虚拟化联盟,它促进自由和开源软件虚拟化解决方案的采用)。
|
||||
|
||||
### 开放虚拟化联盟 ###
|
||||
|
||||

|
||||
|
||||
[开放虚拟化联盟(OVA)][3] 的存在目的为:通过提供使用案例和对具有互操作性的通用接口和 API 的发展提供支持,来促进自由、开源软件的虚拟化解决方案例如 KVM 的采用。KVM 将 Linux 内核转变为一个虚拟机管理程序。
|
||||
[开放虚拟化联盟(OVA)][3] 的存在目的为:通过提供使用案例和对具有互操作性的通用接口和 API 的发展提供支持,来促进自由、开源软件的虚拟化解决方案,例如 KVM 的采用。KVM 将 Linux 内核转变为一个虚拟机管理程序。
|
||||
|
||||
如今, KVM 已成为和 OpenStack 共同使用的最为常见的虚拟机管理程序。
|
||||
|
||||
@ -40,31 +40,31 @@ IBM 通过开放其基于 Power 架构的硬件和软件技术,向使用 Power
|
||||
|
||||
原本作为一个 IaaS(基础设施即服务) 产品由 NASA 和 Rackspace 于 2010 年启动,[OpenStack 基金会][4] 已成为最大的开源项目聚居地之一。它拥有超过 200 家公司成员,其中包括 AT&T, AMD, Avaya, Canonical, Cisco, Dell 和 HP。
|
||||
|
||||
大约以 6 个月为一个发行周期,基金会的 OpenStack 项目被发展用来通过一个基于 Web 的仪表盘,命令行工具或一个 RESTful 风格的 API 来控制或调配流经一个数据中心的处理存储池和网络资源。至今为止,基金会支持的协作发展已经孕育出了一系列 OpenStack 组件,其中包括 OpenStack Compute(一个云计算网络控制器,它是一个 IaaS 系统的主要部分),OpenStack Networking(一个用以管理网络和 IP 地址的系统) 和 OpenStack Object Storage(一个可扩展的冗余存储系统)。
|
||||
大约以 6 个月为一个发行周期,基金会的 OpenStack 项目开发用于通过一个基于 Web 的仪表盘,命令行工具或一个 RESTful 风格的 API 来控制或调配流经一个数据中心的处理存储池和网络资源。至今为止,基金会支持的协同开发已经孕育出了一系列 OpenStack 组件,其中包括 OpenStack Compute(一个云计算网络控制器,它是一个 IaaS 系统的主要部分),OpenStack Networking(一个用以管理网络和 IP 地址的系统) 和 OpenStack Object Storage(一个可扩展的冗余存储系统)。
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||

|
||||
|
||||
作为来自 Linux 基金会的另一个协作项目, [OpenDaylight][5] 是一个由诸如 Dell, HP, Oracle 和 Avaya 等行业厂商于 2013 年 4 月建立的联合倡议。它的任务是建立一个由社区主导,开放,有工业支持的针对 Software-Defined Networking (SDN) 的包含代码和蓝图的框架。其思路是提供一个可直接部署的全功能 SDN 平台,而不需要其他组件,供应商可提供附件组件和增强组件。
|
||||
作为来自 Linux 基金会的另一个协作项目, [OpenDaylight][5] 是一个由诸如 Dell, HP, Oracle 和 Avaya 等行业厂商于 2013 年 4 月建立的联合倡议。它的任务是建立一个由社区主导、开源、有工业支持的针对软件定义网络( SDN: Software-Defined Networking)的包含代码和蓝图的框架。其思路是提供一个可直接部署的全功能 SDN 平台,而不需要其他组件,供应商可提供附件组件和增强组件。
|
||||
|
||||
### Apache 软件基金会 ###
|
||||
|
||||

|
||||
|
||||
[Apache 软件基金会 (ASF)][7] 是将近 150 个顶级项目的聚居地,这些项目涵盖从开源企业级自动化软件到与 Apache Hadoop 相关的分布式计算的整个生态系统。这些项目分发企业级、可免费获取的软件产品,而 Apache 协议则是为了让无论是商业用户还是个人用户更方便地部署 Apache 的产品。
|
||||
[Apache 软件基金会 (ASF)][7] 是将近 150 个顶级项目的聚居地,这些项目涵盖从开源的企业级自动化软件到与 Apache Hadoop 相关的分布式计算的整个生态系统。这些项目分发企业级、可免费获取的软件产品,而 Apache 协议则是为了让无论是商业用户还是个人用户更方便地部署 Apache 的产品。
|
||||
|
||||
ASF 于 1999 年作为一个会员制,非盈利公司注册,其核心为精英 — 要成为它的成员,你必须首先在基金会的一个或多个协作项目中做出积极贡献。
|
||||
ASF 是 1999 年成立的一个会员制,非盈利公司,以精英为其核心 — 要成为它的成员,你必须首先在基金会的一个或多个协作项目中做出积极贡献。
|
||||
|
||||
### 开放计算项目 ###
|
||||
|
||||

|
||||
|
||||
作为 Facebook 重新设计其 Oregon 数据中心的副产物, [开放计算项目][7] 旨在发展针对数据中心的开放硬件解决方案。 OCP 是一个由廉价、无浪费的服务器,针对 Open Rack(为数据中心设计的机架标准,来让机架集成到数据中心的基础设施中) 的模块化 I/O 存储和一个相对 "绿色" 的数据中心设计方案等构成。
|
||||
作为 Facebook 重新设计其 Oregon 数据中心的副产物, [开放计算项目][7] 旨在发展针对数据中心的开源硬件解决方案。 OCP 是一个由廉价无浪费的服务器、针对 Open Rack(为数据中心设计的机架标准,来让机架集成到数据中心的基础设施中) 的模块化 I/O 存储和一个相对 "绿色" 的数据中心设计方案等构成。
|
||||
|
||||
OCP 董事会成员包括来自 Facebook,Intel,Goldman Sachs,Rackspace 和 Microsoft 的代表。
|
||||
|
||||
OCP 最近宣布了许可证的两个选择: 一个类似 Apache 2.0 的允许衍生工作的许可证和一个更规范的鼓励回滚到原有软件的更改的许可证。
|
||||
OCP 最近宣布了有两种可选的许可证: 一个类似 Apache 2.0 的允许衍生工作的许可证,和一个更规范的鼓励将更改回馈到原有软件的许可证。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -72,7 +72,7 @@ via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities
|
||||
|
||||
作者:[Thor Olavsrud][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,20 +1,20 @@
|
||||
如何在 Ubuntu 中管理和使用 LVM(Logical Volume Management,逻辑卷管理)
|
||||
如何在 Ubuntu 中管理和使用 逻辑卷管理 LVM
|
||||
================================================================================
|
||||

|
||||
|
||||
在我们之前的文章中,我们介绍了[什么是 LVM 以及能用 LVM 做什么][1],今天我们会给你介绍一些 LVM 的主要管理工具,使得你在设置和扩展安装时更游刃有余。
|
||||
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是,你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘驱动汇集而成或是一个软件磁盘阵列。
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘汇集而成的或是一个软件磁盘阵列。
|
||||
|
||||
要管理 LVM,这里有很多可用的 GUI 工具,但要真正理解 LVM 配置发生的事情,最好要知道一些命令行工具。这当你在一个服务器或不提供 GUI 工具的发行版上管理 LVM 时尤为有用。
|
||||
|
||||
LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以下其中之一开头:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
- Physical Volume (物理卷) = pv
|
||||
- Volume Group (卷组)= vg
|
||||
- Logical Volume (逻辑卷)= lv
|
||||
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组使得你的操作系统能使用指定的空间。
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组,使得你的操作系统能使用指定的空间。
|
||||
|
||||
### 可下载的 LVM 备忘单 ###
|
||||
|
||||
@ -26,7 +26,7 @@ LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以
|
||||
|
||||
### 如何查看当前 LVM 信息 ###
|
||||
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置好的开始点。
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令可以和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置的好起点。
|
||||
|
||||
display 命令会格式化输出信息,因此比 s 命令更易于理解。对每个命令你会看到名称和 pv/vg 的路径,它还会给出空闲和已使用空间的信息。
|
||||
|
||||
@ -40,17 +40,17 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||
#### 创建物理卷 ####
|
||||
|
||||
我们会从一个完全新的没有任何分区和信息的硬盘驱动开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
我们会从一个全新的没有任何分区和信息的硬盘开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
|
||||
> 注意:记住所有的命令都要以 root 身份运行或者在命令前面添加 'sudo' 。
|
||||
|
||||
fdisk -l
|
||||
|
||||
如果之前你的硬盘驱动从没有格式化或分区,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
如果之前你的硬盘从未格式化或分区过,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
|
||||

|
||||
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在驱动上创建一个新的分区。
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在磁盘上创建一个新的分区。
|
||||
|
||||
这里有大量能创建新分区的 GUI 工具,包括 [Gparted][2],但由于我们已经打开了终端,我们将使用 fdisk 命令创建需要的分区。
|
||||
|
||||
@ -62,9 +62,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
以指定的顺序输入命令创建一个使用新硬盘驱动 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或相应多个分区,我建议使用 GParted 或自己了解关于 fdisk 命令的使用。
|
||||
以指定的顺序输入命令创建一个使用新硬盘 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或想要多个分区,我建议使用 GParted 或自己了解一下关于 fdisk 命令的使用。
|
||||
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何信息。**
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何有用的信息。**
|
||||
|
||||
- n = 创建新分区
|
||||
- p = 创建主分区
|
||||
@ -79,9 +79,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
- t = 更改分区类型
|
||||
- 8e = 更改为 LVM 分区类型
|
||||
|
||||
核实并将信息写入硬盘驱动器。
|
||||
核实并将信息写入硬盘。
|
||||
|
||||
- p = 查看分区设置使得写入更改到磁盘之前可以回看
|
||||
- p = 查看分区设置使得在写入更改到磁盘之前可以回看
|
||||
- w = 写入更改到磁盘
|
||||
|
||||

|
||||
@ -102,7 +102,7 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
|
||||
#### 创建逻辑卷 ####
|
||||
|
||||
@ -112,7 +112,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 所以 lvcreate 命令知道从什么卷获取空间。
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 以便 lvcreate 命令知道从什么卷获取空间。
|
||||
|
||||
#### 格式化并挂载逻辑卷 ####
|
||||
|
||||
@ -131,7 +131,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
#### 重新设置逻辑卷大小 ####
|
||||
|
||||
逻辑卷的一个好处是你能使你的共享物理变大或变小而不需要移动所有东西到一个更大的硬盘驱动。另外,你可以添加新的硬盘驱动并同时扩展你的卷组。或者如果你有一个不使用的硬盘驱动,你可以从卷组中移除它使得逻辑卷变小。
|
||||
逻辑卷的一个好处是你能使你的存储物理地变大或变小,而不需要移动所有东西到一个更大的硬盘。另外,你可以添加新的硬盘并同时扩展你的卷组。或者如果你有一个不使用的硬盘,你可以从卷组中移除它使得逻辑卷变小。
|
||||
|
||||
这里有三个用于使物理卷、卷组和逻辑卷变大或变小的基础工具。
|
||||
|
||||
@ -147,9 +147,9 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
按照上面创建新分区并更改分区类型为 LVM(8e) 的步骤安装一个新硬盘驱动。然后用 pvcreate 命令创建一个 LVM 能识别的物理卷。
|
||||
|
||||
#### 添加新硬盘驱动到卷组 ####
|
||||
#### 添加新硬盘到卷组 ####
|
||||
|
||||
要添加新的硬盘驱动到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
要添加新的硬盘到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
|
||||
这会添加新物理卷到已存在的卷组中。
|
||||
|
||||
@ -189,7 +189,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
1. 调整文件系统大小 (调整之前确保已经移动文件到硬盘驱动安全的地方)
|
||||
1. 减小逻辑卷 (除了 + 可以扩展大小,你也可以用 - 压缩大小)
|
||||
1. 用 vgreduce 从卷组中移除硬盘驱动
|
||||
1. 用 vgreduce 从卷组中移除硬盘
|
||||
|
||||
#### 备份逻辑卷 ####
|
||||
|
||||
@ -197,7 +197,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该照片可以用于在不同的硬盘驱动上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的“照片”,该“照片”可以用于在不同的硬盘上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
|
||||
要创建一个快照,我们需要创建拥有足够空闲空间的逻辑卷,用于保存我们备份的时候会写入该逻辑卷的任何新信息。如果驱动并不是经常写入,你可以使用很小的一个存储空间。备份完成的时候我们只需要移除临时逻辑卷,原始逻辑卷会和往常一样。
|
||||
|
||||
@ -209,7 +209,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为驱动实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为该硬盘实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
|
||||
#### 挂载新快照 ####
|
||||
|
||||
@ -222,7 +222,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||
#### 复制快照和删除逻辑卷 ####
|
||||
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘驱动或者打包所有文件到一个文件。
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘或者打包所有文件到一个文件。
|
||||
|
||||
**注意:tar -c 会创建一个归档文件,-f 要指出归档文件的名称和路径。要获取 tar 命令的帮助信息,可以在终端中输入 man tar。**
|
||||
|
||||
@ -230,7 +230,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
记住备份发生的时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
记住备份时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
|
||||
备份完成后,卸载卷并移除临时快照。
|
||||
|
||||
@ -259,10 +259,10 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[1]:https://linux.cn/article-5953-1.html
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -1,26 +1,25 @@
|
||||
什么是逻辑分区管理工具,它怎么在Ubuntu启用?
|
||||
什么是逻辑分区管理 LVM ,如何在Ubuntu中使用?
|
||||
================================================================================
|
||||
> 逻辑分区管理(LVM)是每一个主流Linux发行版都含有的磁盘管理选项。无论你是否需要设置存储池或者只需要动态创建分区,LVM就是你正在寻找的。
|
||||
|
||||
> 逻辑分区管理(LVM)是每一个主流Linux发行版都含有的磁盘管理选项。无论是你需要设置存储池,还是只想动态创建分区,那么LVM就是你正在寻找的。
|
||||
|
||||
### 什么是 LVM? ###
|
||||
|
||||
逻辑分区管理是一个存在于磁盘/分区和操作系统之间的一个抽象层。在传统的磁盘管理中,你的操作系统寻找有哪些磁盘可用(/dev/sda、/dev/sdb等等)接着这些磁盘有哪些可用的分区(如/dev/sda1、/dev/sda2等等)。
|
||||
逻辑分区管理是一个存在于磁盘/分区和操作系统之间的一个抽象层。在传统的磁盘管理中,你的操作系统寻找有哪些磁盘可用(/dev/sda、/dev/sdb等等),并且这些磁盘有哪些可用的分区(如/dev/sda1、/dev/sda2等等)。
|
||||
|
||||
在LVM下,磁盘和分区可以抽象成一个设备中含有多个磁盘和分区。你的操作系统将不会知道这些区别,因为LVM只会给操作系统展示你设置的卷组(磁盘)和逻辑卷(分区)
|
||||
在LVM下,磁盘和分区可以抽象成一个含有多个磁盘和分区的设备。你的操作系统将不会知道这些区别,因为LVM只会给操作系统展示你设置的卷组(磁盘)和逻辑卷(分区)
|
||||
|
||||
,因此可以很容易地动态调整和创建新的磁盘和分区。除此之外,LVM带来你的文件系统不具备的功能。比如,ext3不支持实时快照,但是如果你正在使用LVM你可以不卸载磁盘的情况下做一个逻辑卷的快照。
|
||||
因为卷组和逻辑卷并不物理地对应到影片,因此可以很容易地动态调整和创建新的磁盘和分区。除此之外,LVM带来了你的文件系统所不具备的功能。比如,ext3不支持实时快照,但是如果你正在使用LVM你可以不卸载磁盘的情况下做一个逻辑卷的快照。
|
||||
|
||||
### 你什么时候该使用LVM? ###
|
||||
|
||||
在使用LVM之前首先得考虑的一件事是你要用你的磁盘和分区完成什么。一些发行版如Fedora已经默认安装了LVM。
|
||||
在使用LVM之前首先得考虑的一件事是你要用你的磁盘和分区来做什么。注意,一些发行版如Fedora已经默认安装了LVM。
|
||||
|
||||
如果你使用的是一台只有一块磁盘的Ubuntu笔记本电脑,并且你不需要像实时快照这样的扩展功能,那么你或许不需要LVM。如果I想要轻松地扩展或者想要将多块磁盘组成一个存储池,那么LVM或许正式你郑寻找的。
|
||||
如果你使用的是一台只有一块磁盘的Ubuntu笔记本电脑,并且你不需要像实时快照这样的扩展功能,那么你或许不需要LVM。如果你想要轻松地扩展或者想要将多块磁盘组成一个存储池,那么LVM或许正是你所寻找的。
|
||||
|
||||
### 在Ubuntu中设置LVM ###
|
||||
|
||||
使用LVM首先要了解的一件事是没有简单的方法将已经存在传统的分区转换成逻辑分区。可以将它移到一个使用LVM的新分区下,但是这并不会在本篇中提到;反之我们将全新安装一台Ubuntu 10.10来设置LVM
|
||||
|
||||

|
||||
使用LVM首先要了解的一件事是,没有一个简单的方法可以将已有的传统分区转换成逻辑卷。可以将数据移到一个使用LVM的新分区下,但是这并不会在本篇中提到;在这里,我们将全新安装一台Ubuntu 10.10来设置LVM。(LCTT 译注:本文针对的是较老的版本,新的版本已经不需如此麻烦了)
|
||||
|
||||
要使用LVM安装Ubuntu你需要使用另外的安装CD。从下面的链接中下载并烧录到CD中或者[使用unetbootin创建一个USB盘][1]。
|
||||
|
||||
@ -64,7 +63,7 @@ via: http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-
|
||||
|
||||
作者:[How-To Geek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,62 +0,0 @@
|
||||
Translating by XLCYun.
|
||||
A Week With GNOME As My Linux Desktop: What They Get Right & Wrong - Page 3 - GNOME Applications
|
||||
================================================================================
|
||||
### Applications ###
|
||||
|
||||
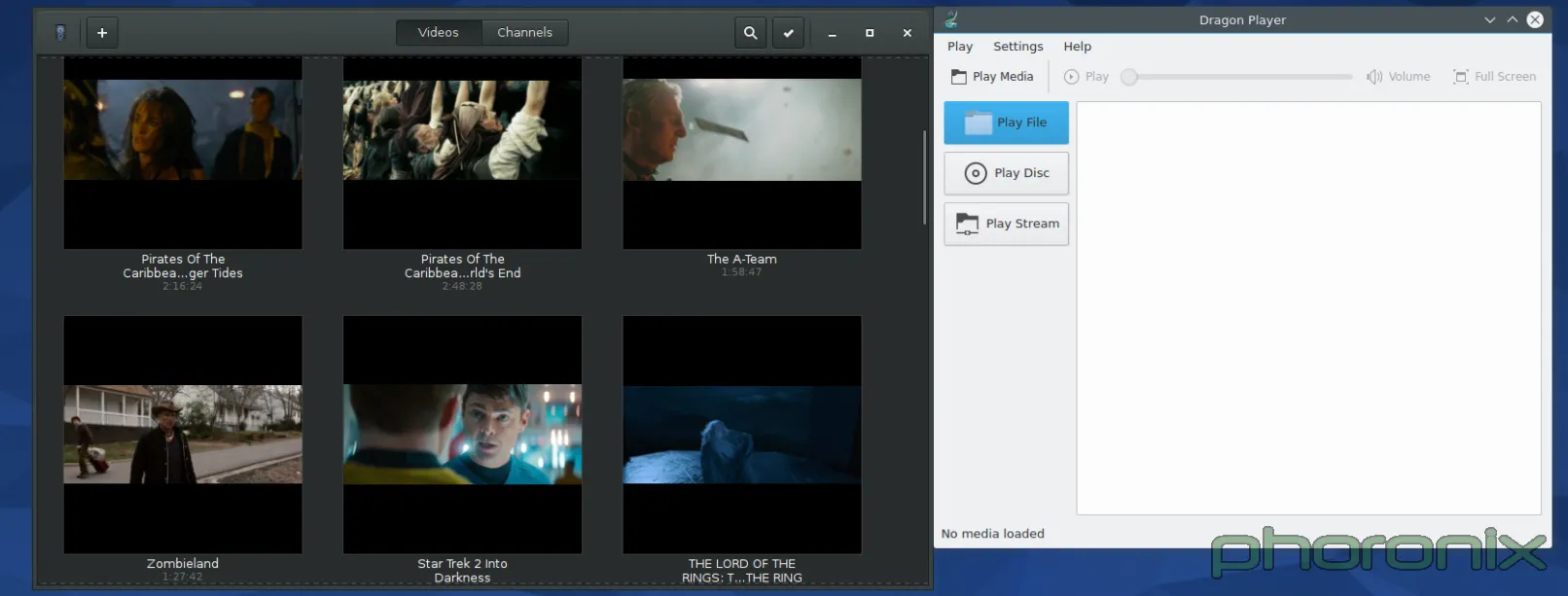
|
||||
|
||||
This is the one area where things are basically a wash. Each environment has a few applications that are really nice, and a few that are not so great. Once again though, Gnome gets the little things right in a way that KDE completely misses. None of KDE's applications are bad or broken, that's not what I'm saying. They function. But that's about it. To use an analogy: they passed the test, but they sure didn't get any where close to 100% on it.
|
||||
|
||||
Gnome on left, KDE on right. Dragon performs perfectly fine, it has clearly marked buttons for playing a file, URL, or a disc, just as you can do under Gnome Videos... but Gnome takes it one extra little step further in the name of convenience and user friendliness: they show all the videos detected under your system by default, without you having to do anything. KDE has Baloo-- just as they had Nepomuk before that-- why not use them? They've got a list video files that are freely accessible... but don't make use of the feature.
|
||||
|
||||
Moving on... Music Players.
|
||||
|
||||
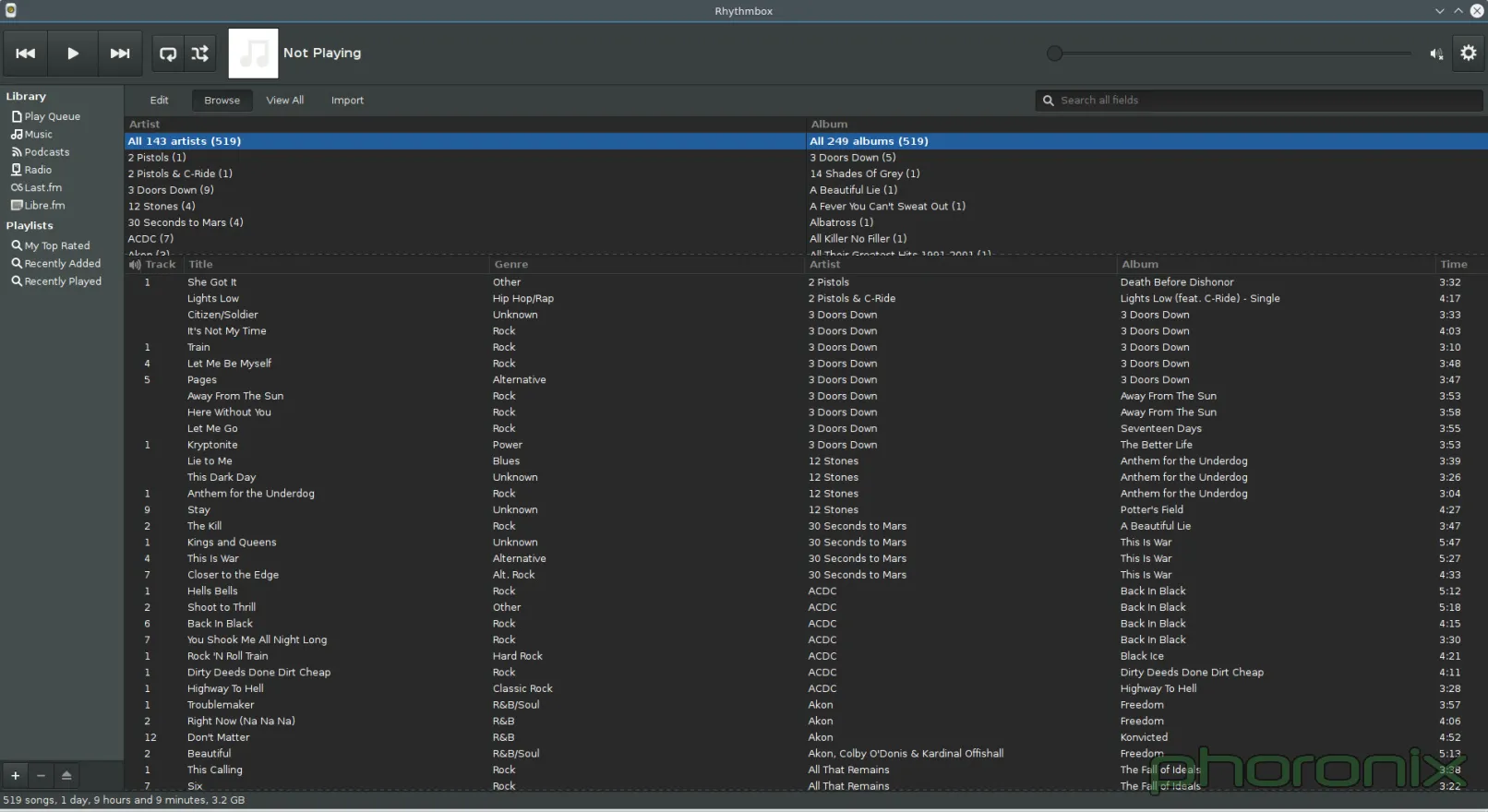
|
||||
|
||||
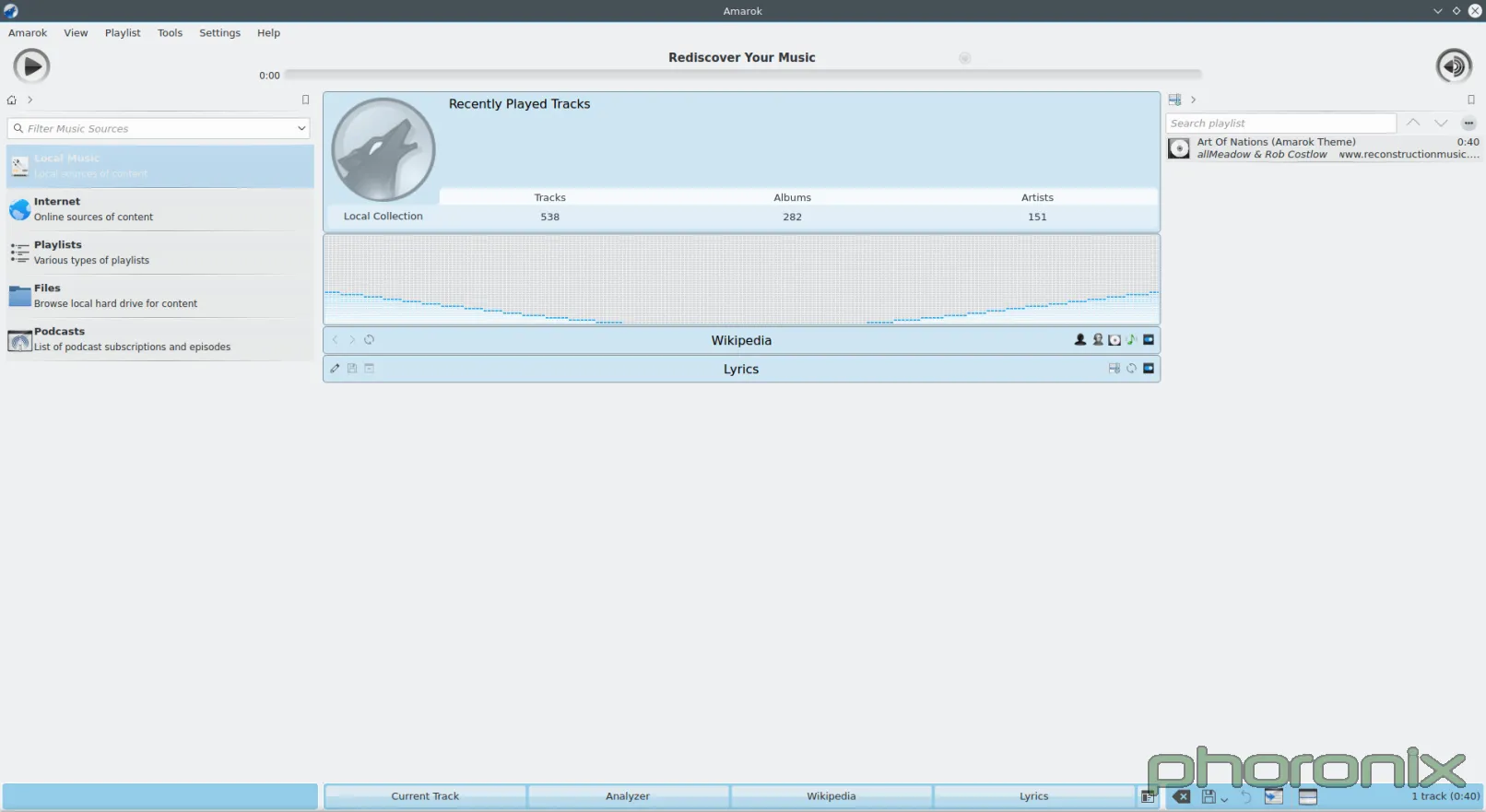
|
||||
|
||||
Both of these applications, Rhythmbox on the left and Amarok on the right were opened up and then a screenshot was immediately taken, nothing was clicked, or altered. See the difference? Rhythmbox looks like a music player. It's direct, there's obvious ways to sort the results, it knows what is trying to be and what it's job is: to play music.
|
||||
|
||||
Amarok feels like one of the tech demos, or library demos where someone puts every option and extension they possible can all inside one application in order to show them off-- it's never something that gets shipped as production, it's just there to show off bits and pieces. And that's exactly what Amarok feels like: its someone trying to show off every single possible cool thing they shove into a media player without ever stopping to think "Wait, what were trying to write again? An app to play music?"
|
||||
|
||||
Just look at the default layout. What is front and center for the user? A visualizer and Wikipedia integration-- the largest and most prominent column on the page. What's the second largest? Playlist list. Third largest, aka smallest? The actual music listing. How on earth are these sane defaults for a core application?
|
||||
|
||||
Software Managers! Something that has seen a lot of push in recent years and will likely only see a bigger push in the months to come. Unfortunately, it's another area where KDE was so close... and then fell on its face right at the finish line.
|
||||
|
||||

|
||||
|
||||
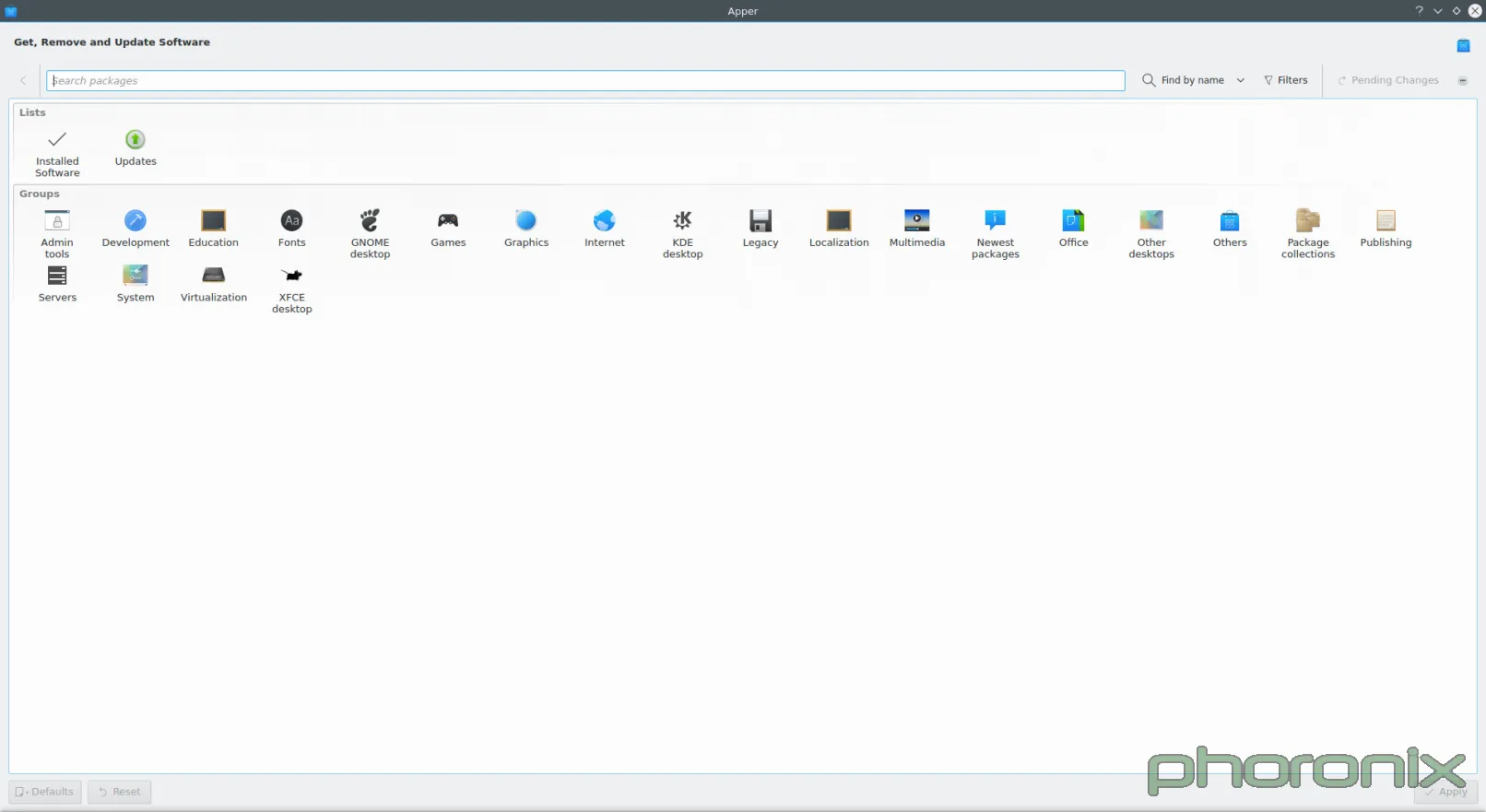
|
||||
|
||||

|
||||
|
||||
Gnome Software is probably my new favorite software center, minus one gripe which I will get to in a bit. Muon, I wanted to like you. I really did. But you are a design nightmare. When the VDG was drawing up plans for you (mockup below), you looked pretty slick. Good use of white space, clean design, nice category listing, your whole not-being-split-into-two-applications.
|
||||
|
||||
|
||||
|
||||
Then someone got around to coding you and doing your actual UI, and I can only guess they were drunk while they did it.
|
||||
|
||||
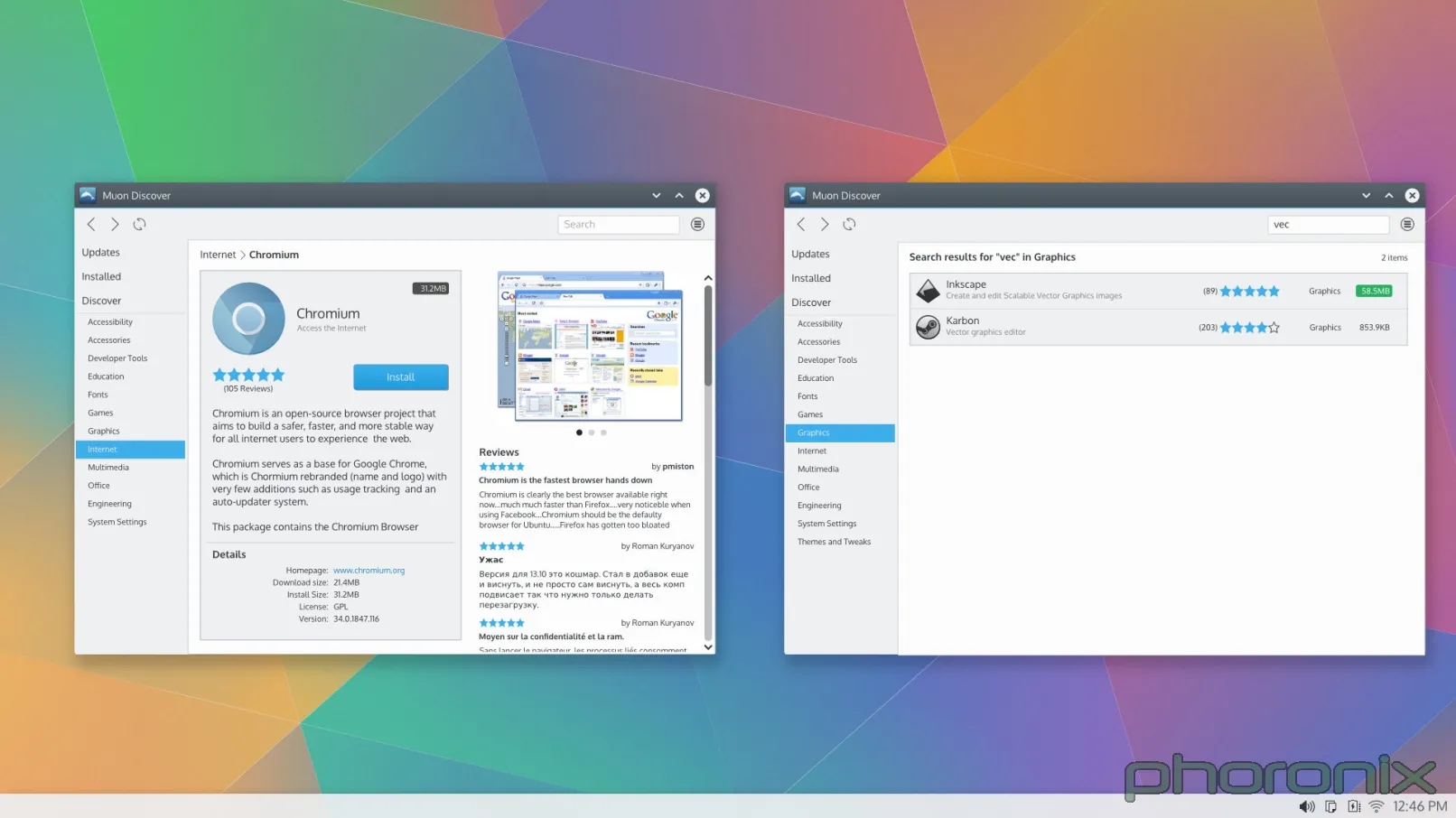
Let's look at Gnome Software. What's smack dab in the middle? The application, its screenshots, its description, etc. What's smack dab in the middle of Muon? Gigantic waste of white space. Gnome Software also includes the lovely convenience feature of putting a "Launch" button right there in case you already have an application installed. Convenience and ease of use are important, people. Honestly, JUST having things in Muon be centered aligned would probably make things look better already.
|
||||
|
||||
What's along the top edge of Gnome Software, like a tab listing? All Software, Installed, Updates. Clean language, direct, to the point. Muon? Well, we have "Discover", which works okay as far as language goes, and then we have Installed, and then nothing. Where's updates?
|
||||
|
||||
Well.. the developers decided to split updates off into its own application, thus requiring you to open two applications to handle your software-- one to install it, and one to update it-- going against every Software Center paradigm that has ever existed since the Synaptic graphical package manager.
|
||||
|
||||
I'm not going to show it in a screenshot just because I don't want to have to clean up my system afterwards, but if you go into Muon and start installing something the way it shows that is by adding a little tab to the bottom of your screen with the application's name. That tab doesn't go away when the application is done installing either, so if you're installing a lot of applications at a single time then you'll just slowly accumulate tabs along the bottom that you then have to go through and clean up manually, because if you don't then they grow off the screen and you have to swipe through them all to get to the most recent ones. Think: opening 50 tabs in Firefox. Major annoyance, major inconvenience.
|
||||
|
||||
I did say I would bash on Gnome a bit, and I meant it. Muon does get one thing very right that Gnome Software doesn't. Under the settings bar Muon has an option for "Show Technical Packages" aka: compilers, software libraries, non-graphical applications, applications without AppData, etc. Gnome doesn't. If you want to install any of those you have to drop down to the terminal. I think that's wrong. I certainly understand wanting to push AppData but I think they pushed it too soon. What made me realize Gnome didn't have this setting was when I went to install PowerTop and couldn't get Gnome to display it-- no AppData, no "Show Technical Packages" setting.
|
||||
|
||||
Doubly unfortunate is the fact that you can't "just use apper" if you're under KDE since...
|
||||
|
||||
|
||||
|
||||
Apper's support for installing local packages has been broken for since Fedora 19 or so, almost two years. I love the attention to detail and quality.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=3
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,121 +0,0 @@
|
||||
|
||||
Translating by dingdongnigetou
|
||||
|
||||
Understanding Shell Commands Easily Using “Explain Shell” Script in Linux
|
||||
================================================================================
|
||||
While working on Linux platform all of us need help on shell commands, at some point of time. Although inbuilt help like man pages, whatis command is helpful, but man pages output are too lengthy and until and unless one has some experience with Linux, it is very difficult to get any help from massive man pages. The output of whatis command is rarely more than one line which is not sufficient for newbies.
|
||||
|
||||

|
||||
|
||||
Explain Shell Commands in Linux Shell
|
||||
|
||||
There are third-party application like ‘cheat‘, which we have covered here “[Commandline Cheat Sheet for Linux Users][1]. Although Cheat is an exceptionally good application which shows help on shell command even when computer is not connected to Internet, it shows help on predefined commands only.
|
||||
|
||||
There is a small piece of code written by Jackson which is able to explain shell commands within the bash shell very effectively and guess what the best part is you don’t need to install any third party package. He named the file containing this piece of code as `'explain.sh'`.
|
||||
|
||||
#### Features of Explain Utility ####
|
||||
|
||||
- Easy Code Embedding.
|
||||
- No third-party utility needed to be installed.
|
||||
- Output just enough information in course of explanation.
|
||||
- Requires internet connection to work.
|
||||
- Pure command-line utility.
|
||||
- Able to explain most of the shell commands in bash shell.
|
||||
- No root Account involvement required.
|
||||
|
||||
**Prerequisite**
|
||||
|
||||
The only requirement is `'curl'` package. In most of the today’s latest Linux distributions, curl package comes pre-installed, if not you can install it using package manager as shown below.
|
||||
|
||||
# apt-get install curl [On Debian systems]
|
||||
# yum install curl [On CentOS systems]
|
||||
|
||||
### Installation of explain.sh Utility in Linux ###
|
||||
|
||||
We have to insert the below piece of code as it is in the `~/.bashrc` file. The code should be inserted for each user and each `.bashrc` file. It is suggested to insert the code to the user’s .bashrc file only and not in the .bashrc of root user.
|
||||
|
||||
Notice the first line of code that starts with hash `(#)` is optional and added just to differentiate rest of the codes of .bashrc.
|
||||
|
||||
# explain.sh marks the beginning of the codes, we are inserting in .bashrc file at the bottom of this file.
|
||||
|
||||
# explain.sh begins
|
||||
explain () {
|
||||
if [ "$#" -eq 0 ]; then
|
||||
while read -p "Command: " cmd; do
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$cmd"
|
||||
done
|
||||
echo "Bye!"
|
||||
elif [ "$#" -eq 1 ]; then
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$1"
|
||||
else
|
||||
echo "Usage"
|
||||
echo "explain interactive mode."
|
||||
echo "explain 'cmd -o | ...' one quoted command to explain it."
|
||||
fi
|
||||
}
|
||||
|
||||
### Working of explain.sh Utility ###
|
||||
|
||||
After inserting the code and saving it, you must logout of the current session and login back to make the changes taken into effect. Every thing is taken care of by the ‘curl’ command which transfer the input command and flag that need explanation to the mankier server and then print just necessary information to the Linux command-line. Not to mention to use this utility you must be connected to internet always.
|
||||
|
||||
Let’s test few examples of command which I don’t know the meaning with explain.sh script.
|
||||
|
||||
**1. I forgot what ‘du -h‘ does. All I need to do is:**
|
||||
|
||||
$ explain 'du -h'
|
||||
|
||||

|
||||
|
||||
Get Help on du Command
|
||||
|
||||
**2. If you forgot what ‘tar -zxvf‘ does, you may simply do:**
|
||||
|
||||
$ explain 'tar -zxvf'
|
||||
|
||||

|
||||
|
||||
Tar Command Help
|
||||
|
||||
**3. One of my friend often confuse the use of ‘whatis‘ and ‘whereis‘ command, so I advised him.**
|
||||
|
||||
Go to Interactive Mode by simply typing explain command on the terminal.
|
||||
|
||||
$ explain
|
||||
|
||||
and then type the commands one after another to see what they do in one window, as:
|
||||
|
||||
Command: whatis
|
||||
Command: whereis
|
||||
|
||||

|
||||
|
||||
Whatis Whereis Commands Help
|
||||
|
||||
To exit interactive mode he just need to do Ctrl + c.
|
||||
|
||||
**4. You can ask to explain more than one command chained by pipeline.**
|
||||
|
||||
$ explain 'ls -l | grep -i Desktop'
|
||||
|
||||

|
||||
|
||||
Get Help on Multiple Commands
|
||||
|
||||
Similarly you can ask your shell to explain any shell command. All you need is a working Internet connection. The output is generated based upon the explanation needed from the server and hence the output result is not customizable.
|
||||
|
||||
For me this utility is really helpful and it has been honored being added to my .bashrc. Let me know what is your thought on this project? How it can useful for you? Is the explanation satisfactory?
|
||||
|
||||
Provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explain-shell-commands-in-the-linux-shell/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cheat-command-line-cheat-sheet-for-linux-users/
|
||||
@ -2,13 +2,13 @@
|
||||
================================================================================
|
||||
物联网(Internet of Things, IoT) 时代即将来临。很快,过不了几年,我们就会问自己当初是怎么在没有物联网的情况下生存的,就像我们现在怀疑过去没有手机的年代。Canonical 就是一个物联网快速发展却还是开放市场下的竞争者。这家公司宣称自己把赌注压到了IoT 上,就像他们已经在“云”上做过的一样。。在今年一月底,Canonical 启动了一个基于Ubuntu Core 的小型操作系统,名字叫做 [Ubuntu Snappy Core][1] 。
|
||||
|
||||
Snappy 是一种用来替代deb 的新的打包格式,是一个用来更新系统的前端,从CoreOS、红帽子和其他地方借鉴了原子更新这个想法。很快树莓派2 代投入市场,Canonical 就发布了用于树莓派的Snappy Core 版本。第一代树莓派因为是基于ARMv6 ,而Ubuntu 的ARM 镜像是基于ARMv7 ,所以不能运行ubuntu 。不过这种状况现在改变了,Canonical 通过发布用于RPI2 的镜像,抓住机会澄清了Snappy 就是一个用于云计算,特别是IoT 的系统。
|
||||
Snappy 是一种用来替代deb 的新的打包格式,是一个用来更新系统的前端,从CoreOS、红帽子和其他系统借鉴了**原子更新**这个想法。树莓派2 代投入市场,Canonical 很快就发布了用于树莓派的Snappy Core 版本。而第一代树莓派因为是基于ARMv6 ,Ubuntu 的ARM 镜像是基于ARMv7 ,所以不能运行ubuntu 。不过这种状况现在改变了,Canonical 通过发布用于RPI2 的镜像,抓住机会证明了Snappy 就是一个用于云计算,特别是用于物联网的系统。
|
||||
|
||||
Snappy 同样可以运行在其它像Amazon EC2, Microsofts Azure, Google's Compute Engine 这样的云端上,也可以虚拟化在KVM、Virtuabox 和vagrant 上。Canonical 已经拥抱了微软、谷歌、Docker、OpenStack 这些重量级选手,同时也与一些小项目达成合作关系。除了一些创业公司,像Ninja Sphere、Erle Robotics,还有一些开发板生产商比如Odroid、Banana Pro, Udoo, PCDuino 和Parallella 、全志。Snappy Core 也希望很快能运行在路由器上,来帮助改进路由器生产商目前很少更新固件的策略。
|
||||
Snappy 同样可以运行在其它像Amazon EC2, Microsofts Azure, Google的 Compute Engine 这样的云端上,也可以虚拟化在KVM、Virtuabox 和vagrant 上。Canonical Ubuntu 已经拥抱了微软、谷歌、Docker、OpenStack 这些重量级选手,同时也与一些小项目达成合作关系。除了一些创业公司,比如Ninja Sphere、Erle Robotics,还有一些开发板生产商,比如Odroid、Banana Pro, Udoo, PCDuino 和Parallella 、全志,Snappy 也提供了支持。Snappy Core 同时也希望尽快运行到路由器上来帮助改进路由器生产商目前很少更新固件的策略。
|
||||
|
||||
接下来,让我们看看怎么样在树莓派2 上运行Snappy。
|
||||
|
||||
用于树莓派2 的Snappy 镜像可以从 [Raspberry Pi 网站][2] 上下载。解压缩出来的镜像必须[写到一个至少8GB 大小的SD 卡][3]。尽管原始系统很小,但是院子升级和回滚功能会蚕食不小的空间。使用Snappy 启动树莓派2 后你就可以使用默认用户名和密码(都是ubuntu)登录系统。
|
||||
用于树莓派2 的Snappy 镜像可以从 [Raspberry Pi 网站][2] 上下载。解压缩出来的镜像必须[写到一个至少8GB 大小的SD 卡][3]。尽管原始系统很小,但是原子升级和回滚功能会占用不小的空间。使用Snappy 启动树莓派2 后你就可以使用默认用户名和密码(都是ubuntu)登录系统。
|
||||
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@ sudo 已经配置好了可以直接用,安全起见,你应该使用以下命
|
||||
|
||||
或者也可以使用`adduser` 为你添加一个新用户。
|
||||
|
||||
因为RPI缺少硬件始终,而Snappy 不知道这一点,所以系统会有一个小bug:处理命令时会报很多错。不过这个很容易解决:
|
||||
因为RPI缺少硬件时钟,而Snappy 并不知道这一点,所以系统会有一个小bug:处理某些命令时会报很多错。不过这个很容易解决:
|
||||
|
||||
使用这个命令来确认这个bug 是否影响:
|
||||
|
||||
@ -36,7 +36,7 @@ sudo 已经配置好了可以直接用,安全起见,你应该使用以下命
|
||||
|
||||
$ sudo apt-get update && sudo apt-get distupgrade
|
||||
|
||||
现在将不会让你通过,因为Snappy 会使用它自己精简过的、基于dpkg 的包管理系统。这是做是应为Snappy 会运行很多嵌入式程序,而你也会想着所有事情尽可能的简化。
|
||||
不过这时系统不会让你通过,因为Snappy 使用它自己精简过的、基于dpkg 的包管理系统。这么做的原因是Snappy 会运行很多嵌入式程序,而同时你也会想着所有事情尽可能的简化。
|
||||
|
||||
让我们来看看最关键的部分,理解一下程序是如何与Snappy 工作的。运行Snappy 的SD 卡上除了boot 分区外还有3个分区。其中的两个构成了一个重复的文件系统。这两个平行文件系统被固定挂载为只读模式,并且任何时刻只有一个是激活的。第三个分区是一个部分可写的文件系统,用来让用户存储数据。通过更新系统,标记为'system-a' 的分区会保持一个完整的文件系统,被称作核心,而另一个平行文件系统仍然会是空的。
|
||||
|
||||
@ -52,13 +52,13 @@ sudo 已经配置好了可以直接用,安全起见,你应该使用以下命
|
||||
|
||||
$ sudo snappy versions -a
|
||||
|
||||
经过更新-重启的操作,你应该可以看到被激活的核心已经被改变了。
|
||||
经过更新-重启两步操作,你应该可以看到被激活的核心已经被改变了。
|
||||
|
||||
因为到目前为止我们还没有安装任何软件,下面的命令:
|
||||
|
||||
$ sudo snappy update ubuntu-core
|
||||
|
||||
将会生效,而且如果你打算仅仅更新特定的OS,这也是一个办法。如果出了问题,你可以使用下面的命令回滚:
|
||||
将会生效,而且如果你打算仅仅更新特定的OS 版本,这也是一个办法。如果出了问题,你可以使用下面的命令回滚:
|
||||
|
||||
$ sudo snappy rollback ubuntu-core
|
||||
|
||||
@ -77,7 +77,7 @@ sudo 已经配置好了可以直接用,安全起见,你应该使用以下命
|
||||
via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -36,7 +36,7 @@
|
||||
|
||||
|
||||
|
||||
切换到上流的Breeve主题……突然间,我抱怨的大部分问题都被完善了。通用图标,所有东西都放在了屏幕中央,但不是那么重要的被放到了一边。因为屏幕顶部和底部都是同样的空白,在中间也就酝酿出了一种美好的和谐。还是有一个输入框来切换会话,但既然电源按钮被做成了通用图标,那么这点还算可以原谅。当然gnome还是有一些很好的附加物,例如音量小程序和可访问按钮,但Breeze总归是Fedora的KDE主题的一个进步。
|
||||
切换到upstream的Breeve主题……突然间,我抱怨的大部分问题都被完善了。通用图标,所有东西都放在了屏幕中央,但不是那么重要的被放到了一边。因为屏幕顶部和底部都是同样的空白,在中间也就酝酿出了一种美好的和谐。还是有一个输入框来切换会话,但既然电源按钮被做成了通用图标,那么这点还算可以原谅。当然gnome还是有一些很好的附加物,例如音量小程序和可访问按钮,但Breeze总归是Fedora的KDE主题的一个进步。
|
||||
|
||||
到Windows(Windows 8和10之前)或者OS X中去,你会看到类似的东西——非常简洁的,“不挡你道”的锁屏与登录界面,它们都没有输入框或者其它分散视觉的小工具。这是一种有效的不分散人注意力的设计。Fedora……默认装有Breeze。VDG在Breeze主题设计上干得不错。可别糟蹋了它。
|
||||
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
将GNOME作为我的Linux桌面的一周: 他们做对的与做错的 - 第三节 - GNOME应用
|
||||
================================================================================
|
||||
### 应用 ###
|
||||
|
||||

|
||||
|
||||
这是一个基本上一潭死水的地方。每一个桌面环境都有一些非常好的和不怎么样的应用。再次强调,Gnome把那些KDE完全错失的小细节给做对了。我不是想说KDE中有哪些应用不好。他们都能工作。但仅此而已。也就是说:它们合格了,但确实还没有达到甚至接近100分。
|
||||
|
||||
Gnome的在左边,KDE的在右边。Dragon运行得很好,清晰的标出了播放文件、URL或和光盘的按钮,正如你在Gnome Videos中能做到的一样……但是在便利的文件名和用户的友好度方面,Gnome多走了一小步。它默认显示了在你的电脑上检测到的所有影像文件,不需要你做任何事情。KDE有Baloo——正如之前有Nepomuk——为什么不使用它们?它们能列出可读取的影像文件……但却没被使用。
|
||||
|
||||
下一步……音乐播放器
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
这两个应用,左边的Rhythmbox和右边的Amarok,都是打开后没有做任何修改直接截屏的。看到差别了吗?Rhythmbox看起来像个音乐播放器,直接了当,排序文件的方法也很清晰,它知道它应该是什么样的,它的工作是什么:就是播放音乐。
|
||||
|
||||
Amarok感觉就像是某个人为了展示而把所有的扩展和选项都尽可能地塞进一个应用程序中去而做出来的一个技术演示产品(tech demos),或者一个库演示产品(library demos)——而这些是不应该做为产品装进去的,它只应该展示一些零碎的东西。而Amarok给人的感觉却是这样的:好像是某个人想把每一个感觉可能很酷的东西都塞进一个媒体播放器里,甚至都不停下来想“我想写啥来着?一个播放音乐的应用?”
|
||||
|
||||
看看默认布局就行了。前面和中心都呈现了什么?一个可视化工具和维基集成(wikipedia integration)——占了整个页面最大和最显眼的区域。第二大的呢?播放列表。第三大,同时也是最小的呢?真正的音乐列表。这种默认设置对于一个核心应用来说,怎么可能称得上理智?
|
||||
|
||||
软件管理器!它在最近几年当中有很大的进步,而且接下来的几个月中,很可能只能看到它更大的进步。不幸的是,这是另一个地方KDE做得差一点点就能……但还是在终点线前摔了脸。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Gnome软件中心可能是我最新的最爱,先放下牢骚等下再发。Muon, 我想爱上你,真的。但你就是个设计上的梦魇。当VDG给你画设计草稿时(模型在下面),你看起来真漂亮。白色空间用得很好,设计简洁,类别列表也很好,你的整个“不要分开做成两个应用程序”的设计都很不错。
|
||||
|
||||

|
||||
|
||||
接着就有人为你写代码,实现真正的UI,但是,我猜这些家伙当时一定是喝醉了。
|
||||
|
||||
我们来看看Gnome软件中心。正中间是什么?软件,软件截图和软件描述等等。Muon的正中心是什么?白白浪费的大块白色空间。Gnome软件中心还有一个贴心便利特点,那就是放了一个“运行“的按钮在那儿,以防你已经安装了这个软件。便利性和易用性很重要啊,大哥。说实话,仅仅让Muon把东西都居中对齐了可能看起来的效果都要好得多。
|
||||
|
||||
Gnome软件中心沿着顶部的东西是什么,像个标签列表?所有软件,已安装软件,软件升级。语言简洁,直接,直指要点。Muon,好吧,我们有个”发现“,这个语言表达上还算差强人意,然后我们又有一个”已安装软件“,然后,就没有然后了。软件升级哪去了?
|
||||
|
||||
好吧……开发者决定把升级独立分开成一个应用程序,这样你就得打开两个应用程序才能管理你的软件——一个用来安装,一个用来升级——自从有了新得立图形软件包管理器以来,首次有这种破天荒的设计,与任何已存的软件中心的设计范例相违背。
|
||||
|
||||
我不想贴上截图给你们看,因为我不想等下还得清理我的电脑,如果你进入Muon安装了什么,那么它就会在屏幕下方根据安装的应用名创建一个标签,所以如果你一次性安装很多软件的话,那么下面的标签数量就会慢慢的增长,然后你就不得不手动检查清除它们,因为如果你不这样做,当标签增长到超过屏幕显示时,你就不得不一个个找过去来才能找到最近正在安装的软件。想想:在火狐浏览器打开50个标签。太烦人,太不方便!
|
||||
|
||||
我说过我会给Gnome一点打击,我是认真的。Muon有一点做得比Gnome软件中心做得好。在Muon的设置栏下面有个“显示技术包”,即:编辑器,软件库,非图形应用程序,无AppData的应用等等(AppData,软件包中的一个特殊文件,用于专门存储软件的信息,译注)。Gnome则没有。如果你想安装其中任何一项你必须跑到终端操作。我想这是他们做得不对的一点。我完全理解他们推行AppData的心情,但我想他们太急了(推行所有软件包带有AppData,是Gnome软件中心的目标之一,译注)。我是在想安装PowerTop,而Gnome不显示这个软件时我才发现这点的——没有AppData,没有“显示技术包“设置。
|
||||
|
||||
更不幸的事实是你不能“用Apper就行了”,自从……
|
||||
|
||||

|
||||
|
||||
Apper对安装本地软件包的支持大约在Fedora 19时就中止了,几乎两年了。我喜欢那种对细节与质量的关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=3
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,118 @@
|
||||
在Linux中利用"Explain Shell"脚本更容易地理解Shell命令
|
||||
================================================================================
|
||||
在某些时刻, 当我们在Linux平台上工作时我们所有人都需要shell命令的帮助信息。 尽管内置的帮助像man pages、whatis命令是有帮助的, 但man pages的输出非常冗长, 除非是个有linux经验的人,不然从大量的man pages中获取帮助信息是非常困难的,而whatis命令的输出很少超过一行, 这对初学者来说是不够的。
|
||||
|
||||

|
||||
|
||||
在Linux Shell中解释Shell命令
|
||||
|
||||
有一些第三方应用程序, 像我们在[Commandline Cheat Sheet for Linux Users][1]提及过的'cheat'命令。Cheat是个杰出的应用程序,即使计算机没有联网也能提供shell命令的帮助, 但是它仅限于预先定义好的命令。
|
||||
|
||||
Jackson写了一小段代码,它能非常有效地在bash shell里面解释shell命令,可能最美之处就是你不需要安装第三方包了。他把包含这段代码的的文件命名为”explain.sh“。
|
||||
|
||||
#### Explain工具的特性 ####
|
||||
|
||||
- 易嵌入代码。
|
||||
- 不需要安装第三方工具。
|
||||
- 在解释过程中输出恰到好处的信息。
|
||||
- 需要网络连接才能工作。
|
||||
- 纯命令行工具。
|
||||
- 可以解释bash shell里面的大部分shell命令。
|
||||
- 无需root账户参与。
|
||||
|
||||
**先决条件**
|
||||
|
||||
唯一的条件就是'curl'包了。 在如今大多数Linux发行版里面已经预安装了culr包, 如果没有你可以按照下面的命令来安装。
|
||||
|
||||
# apt-get install curl [On Debian systems]
|
||||
# yum install curl [On CentOS systems]
|
||||
|
||||
### 在Linux上安装explain.sh工具 ###
|
||||
|
||||
我们要将下面这段代码插入'~/.bashrc'文件(LCTT注: 若没有该文件可以自己新建一个)中。我们必须为每个用户以及对应的'.bashrc'文件插入这段代码,笔者建议你不要加在root用户下。
|
||||
|
||||
我们注意到.bashrc文件的第一行代码以(#)开始, 这个是可选的并且只是为了区分余下的代码。
|
||||
|
||||
# explain.sh 标记代码的开始, 我们将代码插入.bashrc文件的底部。
|
||||
|
||||
# explain.sh begins
|
||||
explain () {
|
||||
if [ "$#" -eq 0 ]; then
|
||||
while read -p "Command: " cmd; do
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$cmd"
|
||||
done
|
||||
echo "Bye!"
|
||||
elif [ "$#" -eq 1 ]; then
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$1"
|
||||
else
|
||||
echo "Usage"
|
||||
echo "explain interactive mode."
|
||||
echo "explain 'cmd -o | ...' one quoted command to explain it."
|
||||
fi
|
||||
}
|
||||
|
||||
### explain.sh工具的使用 ###
|
||||
|
||||
在插入代码并保存之后,你必须退出当前的会话然后重新登录来使改变生效(LCTT注:你也可以直接使用命令“source~/.bashrc”来让改变生效)。每件事情都是交由‘curl’命令处理, 它负责将需要解释的命令以及命令选项传送给mankier服务,然后将必要的信息打印到Linux命令行。不必说的就是使用这个工具你总是需要连接网络。
|
||||
|
||||
让我们用explain.sh脚本测试几个笔者不懂的命令例子。
|
||||
|
||||
**1.我忘了‘du -h’是干嘛用的, 我只需要这样做:**
|
||||
|
||||
$ explain 'du -h'
|
||||
|
||||

|
||||
|
||||
获得du命令的帮助
|
||||
|
||||
**2.如果你忘了'tar -zxvf'的作用,你可以简单地如此做:**
|
||||
|
||||
$ explain 'tar -zxvf'
|
||||
|
||||

|
||||
|
||||
Tar命令帮助
|
||||
|
||||
**3.我的一个朋友经常对'whatis'以及'whereis'命令的使用感到困惑,所以我建议他:**
|
||||
|
||||
在终端简单的地敲下explain命令进入交互模式。
|
||||
|
||||
$ explain
|
||||
|
||||
然后一个接着一个地输入命令,就能在一个窗口看到他们各自的作用:
|
||||
|
||||
Command: whatis
|
||||
Command: whereis
|
||||
|
||||

|
||||
|
||||
Whatis/Whereis命令的帮助
|
||||
|
||||
你只需要使用“Ctrl+c”就能退出交互模式。
|
||||
|
||||
**4. 你可以通过管道来请求解释更多的命令。**
|
||||
|
||||
$ explain 'ls -l | grep -i Desktop'
|
||||
|
||||

|
||||
|
||||
获取多条命令的帮助
|
||||
|
||||
同样地,你可以请求你的shell来解释任何shell命令。 前提是你需要一个可用的网络。输出的信息是基于解释的需要从服务器中生成的,因此输出的结果是不可定制的。
|
||||
|
||||
对于我来说这个工具真的很有用并且它已经荣幸地添加在我的.bashrc文件中。你对这个项目有什么想法?它对你有用么?它的解释令你满意吗?请让我知道吧!
|
||||
|
||||
请在下面评论为我们提供宝贵意见,喜欢并分享我们以及帮助我们得到传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explain-shell-commands-in-the-linux-shell/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cheat-command-line-cheat-sheet-for-linux-users/
|
||||
@ -0,0 +1,217 @@
|
||||
在 Linux 中使用"两个磁盘"创建 RAID 1(镜像) - 第3部分
|
||||
================================================================================
|
||||
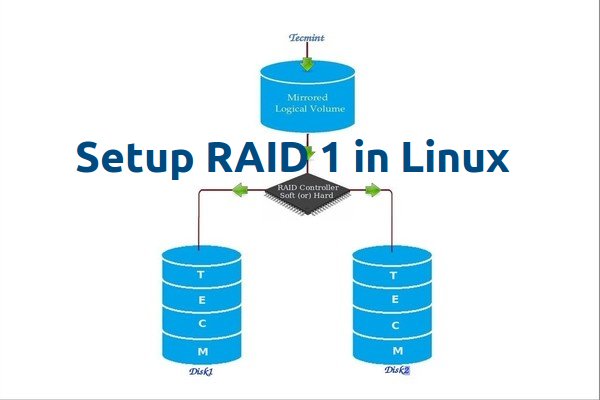
RAID 镜像意味着相同数据的完整克隆(或镜像)写入到两个磁盘中。创建 RAID1 至少需要两个磁盘,它的读取性能或者可靠性比数据存储容量更好。
|
||||
|
||||
|
||||
|
||||
|
||||
在 Linux 中设置 RAID1
|
||||
|
||||
创建镜像是为了防止因硬盘故障导致数据丢失。镜像中的每个磁盘包含数据的完整副本。当一个磁盘发生故障时,相同的数据可以从其它正常磁盘中读取。而后,可以从正在运行的计算机中直接更换发生故障的磁盘,无需任何中断。
|
||||
|
||||
### RAID 1 的特点 ###
|
||||
|
||||
-镜像具有良好的性能。
|
||||
|
||||
-磁盘利用率为50%。也就是说,如果我们有两个磁盘每个500GB,总共是1TB,但在镜像中它只会显示500GB。
|
||||
|
||||
-在镜像如果一个磁盘发生故障不会有数据丢失,因为两个磁盘中的内容相同。
|
||||
|
||||
-读取数据会比写入性能更好。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
|
||||
创建 RAID 1 至少要有两个磁盘,你也可以添加更多的磁盘,磁盘数需为2,4,6,8的两倍。为了能够添加更多的磁盘,你的系统必须有 RAID 物理适配器(硬件卡)。
|
||||
|
||||
这里,我们使用软件 RAID 不是硬件 RAID,如果你的系统有一个内置的物理硬件 RAID 卡,你可以从它的 UI 组件或使用 Ctrl + I 键来访问它。
|
||||
|
||||
需要阅读: [Basic Concepts of RAID in Linux][1]
|
||||
|
||||
#### 在我的服务器安装 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.226
|
||||
Hostname : rd1.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
|
||||
本文将指导你使用 mdadm (创建和管理 RAID 的)一步一步的建立一个软件 RAID 1 或镜像在 Linux 平台上。但同样的做法也适用于其它 Linux 发行版如 RedHat,CentOS,Fedora 等等。
|
||||
|
||||
### 第1步:安装所需要的并且检查磁盘 ###
|
||||
|
||||
1.正如我前面所说,在 Linux 中我们需要使用 mdadm 软件来创建和管理 RAID。所以,让我们用 yum 或 apt-get 的软件包管理工具在 Linux 上安装 mdadm 软件包。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
|
||||
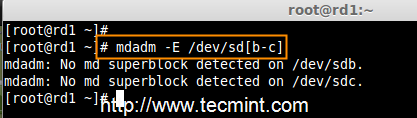
2. 一旦安装好‘mdadm‘包,我们需要使用下面的命令来检查磁盘是否已经配置好。
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
|
||||
|
||||
检查 RAID 的磁盘
|
||||
|
||||
|
||||
正如你从上面图片看到的,没有检测到任何超级块,这意味着还没有创建RAID。
|
||||
|
||||
### 第2步:为 RAID 创建分区 ###
|
||||
|
||||
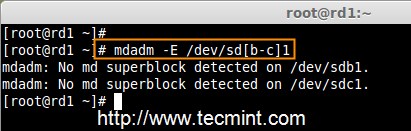
3. 正如我提到的,我们最少使用两个分区 /dev/sdb 和 /dev/sdc 来创建 RAID1。我们首先使用‘fdisk‘命令来创建这两个分区并更改其类型为 raid。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
按照下面的说明
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 按两次回车键默认将整个容量分配给它。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 按 ‘L’,列出所有可用的类型。
|
||||
- 按 ‘t’ 修改分区类型。
|
||||
- 键入 ‘fd’ 设置为Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
|
||||

|
||||
|
||||
创建磁盘分区
|
||||
|
||||
在创建“/dev/sdb”分区后,接下来按照同样的方法创建分区 /dev/sdc 。
|
||||
|
||||
# fdisk /dev/sdc
|
||||
|
||||

|
||||
|
||||
创建第二个分区
|
||||
|
||||
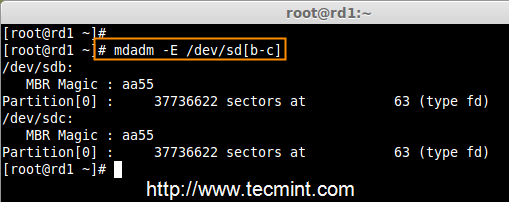
4. 一旦这两个分区创建成功后,使用相同的命令来检查 sdb & sdc 分区并确认 RAID 分区的类型如上图所示。
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
|
||||
|
||||
验证分区变化
|
||||
|
||||
|
||||
|
||||
检查 RAID 类型
|
||||
|
||||
**注意**: 正如你在上图所看到的,在 sdb1 和 sdc1 中没有任何对 RAID 的定义,这就是我们没有检测到超级块的原因。
|
||||
|
||||
### 步骤3:创建 RAID1 设备 ###
|
||||
|
||||
5.接下来使用以下命令来创建一个名为 /dev/md0 的“RAID1”设备并验证它
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[b-c]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
创建RAID设备
|
||||
|
||||
6. 接下来使用如下命令来检查 RAID 设备类型和 RAID 阵列
|
||||
|
||||
# mdadm -E /dev/sd[b-c]1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查 RAID 设备类型
|
||||
|
||||

|
||||
|
||||
检查 RAID 设备阵列
|
||||
|
||||
从上图中,人们很容易理解,RAID1 已经使用的 /dev/sdb1 和 /dev/sdc1 分区被创建,你也可以看到状态为 resyncing。
|
||||
|
||||
### 第4步:在 RAID 设备上创建文件系统 ###
|
||||
|
||||
7. 使用 ext4 为 md0 创建文件系统并挂载到 /mnt/raid1 .
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
创建 RAID 设备文件系统
|
||||
|
||||
8. 接下来,挂载新创建的文件系统到“/mnt/raid1”,并创建一些文件,验证在挂载点的数据
|
||||
|
||||
# mkdir /mnt/raid1
|
||||
# mount /dev/md0 /mnt/raid1/
|
||||
# touch /mnt/raid1/tecmint.txt
|
||||
# echo "tecmint raid setups" > /mnt/raid1/tecmint.txt
|
||||
|
||||

|
||||
|
||||
挂载 RAID 设备
|
||||
|
||||
9.为了在系统重新启动自动挂载 RAID1,需要在 fstab 文件中添加条目。打开“/etc/fstab”文件并添加以下行。
|
||||
|
||||
/dev/md0 /mnt/raid1 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 设备
|
||||
|
||||
10. 运行“mount -a”,检查 fstab 中的条目是否有错误
|
||||
# mount -av
|
||||
|
||||
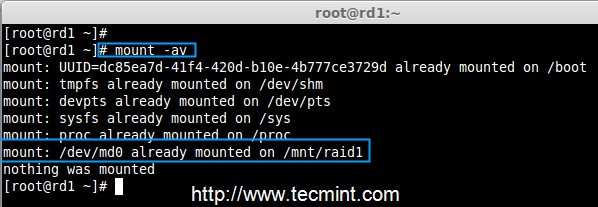
|
||||
|
||||
检查 fstab 中的错误
|
||||
|
||||
11. 接下来,使用下面的命令保存 raid 的配置到文件“mdadm.conf”中。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
保存 Raid 的配置
|
||||
|
||||
上述配置文件在系统重启时会读取并加载 RAID 设备。
|
||||
|
||||
### 第5步:在磁盘故障后检查数据 ###
|
||||
|
||||
12.我们的主要目的是,即使在任何磁盘故障或死机时必须保证数据是可用的。让我们来看看,当任何一个磁盘不可用时会发生什么。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
验证 Raid 设备
|
||||
|
||||
在上面的图片中,我们可以看到在 RAID 中有2个设备是可用的并且 Active Devices 是2.现在让我们看看,当一个磁盘拔出(移除 sdc 磁盘)或损坏后会发生什么。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
测试 RAID 设备
|
||||
|
||||
现在,在上面的图片中你可以看到,一个磁盘不见了。我从虚拟机上删除了一个磁盘。此时让我们来检查我们宝贵的数据。
|
||||
|
||||
# cd /mnt/raid1/
|
||||
# cat tecmint.txt
|
||||
|
||||
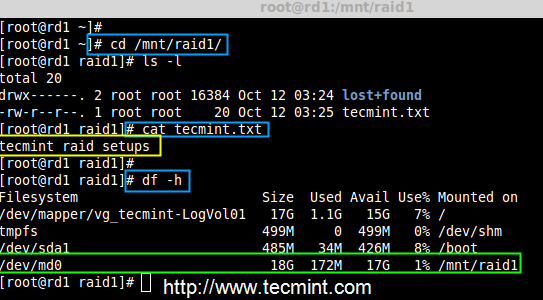
|
||||
|
||||
验证 RAID 数据
|
||||
|
||||
你有没有看到我们的数据仍然可用。由此,我们可以知道 RAID 1(镜像)的优势。在接下来的文章中,我们将看到如何设置一个 RAID 5 条带化分布式奇偶校验。希望这可以帮助你了解 RAID 1(镜像)是如何工作的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid1-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
@ -0,0 +1,285 @@
|
||||
|
||||
在 Linux 中创建 RAID 5(条带化与分布式奇偶校验) - 第4部分
|
||||
================================================================================
|
||||
在 RAID 5 中,条带化数据跨多个驱磁盘使用分布式奇偶校验。分布式奇偶校验的条带化意味着它将奇偶校验信息和条带中的数据分布在多个磁盘上,它将有很好的数据冗余。
|
||||
|
||||

|
||||
|
||||
在 Linux 中配置 RAID 5
|
||||
|
||||
对于此 RAID 级别它至少应该有三个或更多个磁盘。RAID 5 通常被用于大规模生产环境中花费更多的成本来提供更好的数据冗余性能。
|
||||
|
||||
#### 什么是奇偶校验? ####
|
||||
|
||||
奇偶校验是在数据存储中检测错误最简单的一个方法。奇偶校验信息存储在每个磁盘中,比如说,我们有4个磁盘,其中一个磁盘空间被分割去存储所有磁盘的奇偶校验信息。如果任何一个磁盘出现故障,我们可以通过更换故障磁盘后,从奇偶校验信息重建得到原来的数据。
|
||||
|
||||
#### RAID 5 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能
|
||||
- 支持冗余和容错。
|
||||
- 支持热备份。
|
||||
- 将失去一个磁盘的容量存储奇偶校验信息。
|
||||
- 单个磁盘发生故障后不会丢失数据。我们可以更换故障硬盘后从奇偶校验信息中重建数据。
|
||||
- 事务处理读操作会更快。
|
||||
- 由于奇偶校验占用资源,写操作将是缓慢的。
|
||||
- 重建需要很长的时间。
|
||||
|
||||
#### 要求 ####
|
||||
创建 RAID 5 最少需要3个磁盘,你也可以添加更多的磁盘,前提是你要有多端口的专用硬件 RAID 控制器。在这里,我们使用“mdadm”包来创建软件 RAID。
|
||||
|
||||
mdadm 是一个允许我们在 Linux 下配置和管理 RAID 设备的包。默认情况下 RAID 没有可用的配置文件,我们在创建和配置 RAID 后必须将配置文件保存在一个单独的文件中,例如:mdadm.conf。
|
||||
|
||||
在进一步学习之前,我建议你通过下面的文章去了解 Linux 中 RAID 的基础知识。
|
||||
|
||||
- [Basic Concepts of RAID in Linux – Part 1][1]
|
||||
- [Creating RAID 0 (Stripe) in Linux – Part 2][2]
|
||||
- [Setting up RAID 1 (Mirroring) in Linux – Part 3][3]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.227
|
||||
Hostname : rd5.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
Disk 3 [20GB] : /dev/sdd
|
||||
|
||||
这篇文章是 RAID 系列9教程的第4部分,在这里我们要建立一个软件 RAID 5(分布式奇偶校验)使用三个20GB(名为/dev/sdb, /dev/sdc 和 /dev/sdd)的磁盘在 Linux 系统或服务器中上。
|
||||
|
||||
### 第1步:安装 mdadm 并检验磁盘 ###
|
||||
|
||||
1.正如我们前面所说,我们使用 CentOS 6.5 Final 版本来创建 RAID 设置,但同样的做法也适用于其他 Linux 发行版。
|
||||
|
||||
# lsb_release -a
|
||||
# ifconfig | grep inet
|
||||
|
||||

|
||||
|
||||
CentOS 6.5 摘要
|
||||
|
||||
2. 如果你按照我们的 RAID 系列去配置的,我们假设你已经安装了“mdadm”包,如果没有,根据你的 Linux 发行版使用下面的命令安装。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
|
||||
3. “mdadm”包安装后,先使用‘fdisk‘命令列出我们在系统上增加的三个20GB的硬盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
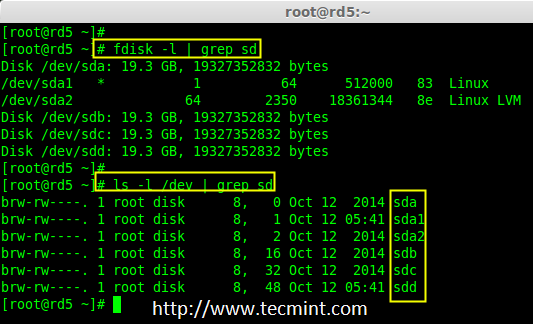
|
||||
|
||||
安装 mdadm 工具
|
||||
|
||||
4. 现在该检查这三个磁盘是否存在 RAID 块,使用下面的命令来检查。
|
||||
|
||||
# mdadm -E /dev/sd[b-d]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
|
||||
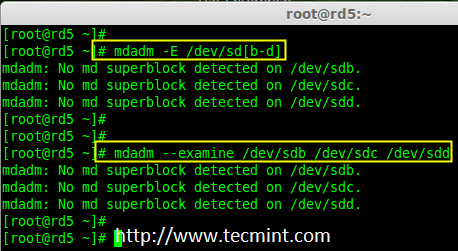
|
||||
|
||||
检查 Raid 磁盘
|
||||
|
||||
**注意**: 上面的图片说明,没有检测到任何超级块。所以,这三个磁盘中没有定义 RAID。让我们现在开始创建一个吧!
|
||||
|
||||
### 第2步:为磁盘创建 RAID 分区 ###
|
||||
|
||||
5. 首先,在创建 RAID 前我们要为磁盘分区(/dev/sdb, /dev/sdc 和 /dev/sdd),在进行下一步之前,先使用‘fdisk’命令进行分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
|
||||
#### 创建 /dev/sdb 分区 ####
|
||||
|
||||
请按照下面的说明在 /dev/sdb 硬盘上创建分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。选择主分区是因为还没有定义过分区。
|
||||
- 接下来选择分区号为1。默认就是1.
|
||||
- 这里是选择柱面大小,我们没必要选择指定的大小,因为我们需要为 RAID 使用整个分区,所以只需按两次 Enter 键默认将整个容量分配给它。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 改变分区类型,按 ‘L’可以列出所有可用的类型。
|
||||
- 按 ‘t’ 修改分区类型。
|
||||
- 这里使用‘fd’设置为 RAID 的类型。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
|
||||

|
||||
|
||||
创建 sdb 分区
|
||||
|
||||
**注意**: 我们仍要按照上面的步骤来创建 sdc 和 sdd 的分区。
|
||||
|
||||
#### 创建 /dev/sdc 分区 ####
|
||||
|
||||
现在,通过下面的截图给出创建 sdc 和 sdd 磁盘分区的方法,或者你可以按照上面的步骤。
|
||||
|
||||
# fdisk /dev/sdc
|
||||
|
||||

|
||||
|
||||
创建 sdc 分区
|
||||
|
||||
#### 创建 /dev/sdd 分区 ####
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||

|
||||
|
||||
创建 sdd 分区
|
||||
|
||||
6. 创建分区后,检查三个磁盘 sdb, sdc, sdd 的变化。
|
||||
|
||||
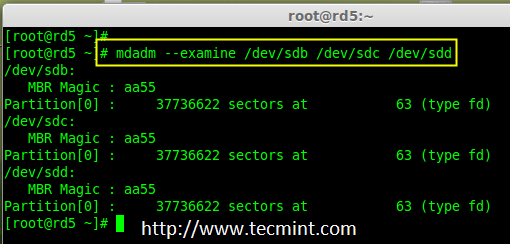
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
|
||||
or
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
|
||||
|
||||
检查磁盘变化
|
||||
|
||||
**注意**: 在上面的图片中,磁盘的类型是 fd。
|
||||
|
||||
7.现在在新创建的分区检查 RAID 块。如果没有检测到超级块,我们就能够继续下一步,创建一个新的 RAID 5 的设置在这些磁盘中。
|
||||
|
||||
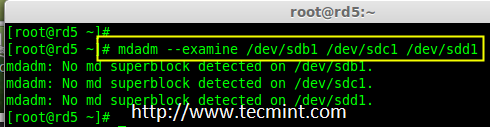
|
||||
|
||||
在分区中检查 Raid
|
||||
|
||||
### 第3步:创建 md 设备 md0 ###
|
||||
|
||||
8. 现在创建一个 RAID 设备“md0”(即 /dev/md0)使用所有新创建的分区(sdb1, sdc1 and sdd1) ,使用以下命令。
|
||||
|
||||
# mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1
|
||||
|
||||
or
|
||||
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1
|
||||
|
||||
9. 创建 RAID 设备后,检查并确认 RAID,包括设备和从 mdstat 中输出的 RAID 级别。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
验证 Raid 设备
|
||||
|
||||
如果你想监视当前的创建过程,你可以使用‘watch‘命令,使用 watch ‘cat /proc/mdstat‘,它会在屏幕上显示且每隔1秒刷新一次。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||
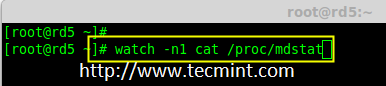
|
||||
|
||||
监控 Raid 5 过程
|
||||
|
||||

|
||||
|
||||
Raid 5 过程概要
|
||||
|
||||
10. 创建 RAID 后,使用以下命令验证 RAID 设备
|
||||
|
||||
# mdadm -E /dev/sd[b-d]1
|
||||
|
||||

|
||||
|
||||
验证 Raid 级别
|
||||
|
||||
**注意**: 因为它显示三个磁盘的信息,上述命令的输出会有点长。
|
||||
|
||||
11. 接下来,验证 RAID 阵列的假设,这包含正在运行 RAID 的设备,并开始重新同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
验证 Raid 阵列
|
||||
|
||||
### 第4步:为 md0 创建文件系统###
|
||||
|
||||
12. 在挂载前为“md0”设备创建 ext4 文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
创建 md0 文件系统
|
||||
|
||||
13.现在,在‘/mnt‘下创建目录 raid5,然后挂载文件系统到 /mnt/raid5/ 下并检查下挂载点的文件,你会看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid5
|
||||
# mount /dev/md0 /mnt/raid5/
|
||||
# ls -l /mnt/raid5/
|
||||
|
||||
14. 在挂载点 /mnt/raid5 下创建几个文件,并在其中一个文件中添加一些内容然后去验证。
|
||||
|
||||
# touch /mnt/raid5/raid5_tecmint_{1..5}
|
||||
# ls -l /mnt/raid5/
|
||||
# echo "tecmint raid setups" > /mnt/raid5/raid5_tecmint_1
|
||||
# cat /mnt/raid5/raid5_tecmint_1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
挂载 Raid 设备
|
||||
|
||||
15. 我们需要在 fstab 中添加条目,否则系统重启后将不会显示我们的挂载点。然后编辑 fstab 文件添加条目,在文件尾追加以下行,如下图所示。挂载点会根据你环境的不同而不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid5 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 5
|
||||
|
||||
16. 接下来,运行‘mount -av‘命令检查 fstab 条目中是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
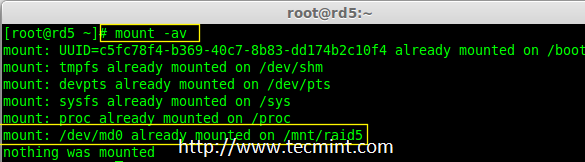
|
||||
|
||||
检查 Fstab 错误
|
||||
|
||||
### 第5步:保存 Raid 5 的配置 ###
|
||||
|
||||
17. 在前面章节已经说过,默认情况下 RAID 没有配置文件。我们必须手动保存。如果此步不跟 RAID 设备将不会存在 md0,它将会跟一些其他数子。
|
||||
|
||||
所以,我们必须要在系统重新启动之前保存配置。如果配置保存它在系统重新启动时会被加载到内核中然后 RAID 也将被加载。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
保存 Raid 5 配置
|
||||
|
||||
注意:保存配置将保持 RAID 级别的稳定性在 md0 设备中。
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
18.备用磁盘有什么用?它是非常有用的,如果我们有一个备用磁盘,当我们阵列中的任何一个磁盘发生故障后,这个备用磁盘会主动添加并重建进程,并从其他磁盘上同步数据,所以我们可以在这里看到冗余。
|
||||
|
||||
更多关于添加备用磁盘和检查 RAID 5 容错的指令,请阅读下面文章中的第6步和第7步。
|
||||
|
||||
- [Add Spare Drive to Raid 5 Setup][4]
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经看到了如何使用三个磁盘配置一个 RAID 5 。在接下来的文章中,我们将看到如何故障排除并且当 RAID 5 中的一个磁盘损坏后如何恢复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-5-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
[3]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[4]:http://www.tecmint.com/create-raid-6-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user