mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-31 23:30:11 +08:00
commit
9fdf910fde
38
sources/news/20150202 The Pirate Bay Is Now Back Online.md
Normal file
38
sources/news/20150202 The Pirate Bay Is Now Back Online.md
Normal file
@ -0,0 +1,38 @@
|
||||
The Pirate Bay Is Now Back Online
|
||||
------
|
||||
*The website was closed for about seven weeks*
|
||||

|
||||
##After being [raided](1) by the police almost two months ago, (in)famous torrent website The Pirate Bay is now back online. Those who thought the website will never return will be either disappointed or happy given that The Pirate Bay seems to live once again.
|
||||
|
||||
In order to celebrate its coming back, The Pirate Bay admins have posted a Phoenix bird on the front page, which signifies the fact that the website can't be killed only damaged.
|
||||
|
||||
About two weeks after The Pirate Bay was raided the domain miraculously came back to life. Soon after a countdown appeared on the temporary homepage of The Pirate Bay indicating that the website is almost ready for a comeback.
|
||||
|
||||
The countdown hinted to February 1, as the possible date for The Pirate Bay's comeback, but it looks like those who manage the website manage to pull it out one day earlier.
|
||||
|
||||
Beginning today, those who have accounts on The Pirate Bay can start downloading the torrents they want. Other than the Phoenix on the front page there are no other messages that might point to the resurrection The Pirate Bay except for the fact that it's now operational.
|
||||
|
||||
Admins of the website said a few weeks ago they will find ways to manage and optimize The Pirate Bay, so that there will be minimal chances for the website to be closed once again. Let's see how it lasts this time.
|
||||
|
||||
##Another version of The Pirate Bay may be launched soon
|
||||
|
||||
In related news, one of the members of the original staff was dissatisfied with the decisions made by the majority regarding some of the changes made in the way admins interact with the website.
|
||||
|
||||
He told [Torrentfreak](2) earlier this week that he, along with a few others, will open his version of The Pirate Bay, which they claim will be the "real" one.
|
||||
|
||||
------
|
||||
via:http://news.softpedia.com/news/The-Pirate-Bay-Is-Now-Back-Online-471802.shtml
|
||||
|
||||
本文发布时间:31 Jan 2015, 22:49 GMT
|
||||
|
||||
作者:[Cosmin Vasile][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/cosmin-vasile
|
||||
[1]:http://news.softpedia.com/news/The-Pirate-Bay-Is-Down-December-9-2014-466987.shtml
|
||||
[2]:http://torrentfreak.com/pirate-bay-back-online-150131/
|
||||
@ -1,88 +0,0 @@
|
||||
su-kaiyao translating
|
||||
|
||||
4 Best Modern Open Source Code Editors For Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Looking for **best programming editors in Linux**? If you ask the old school Linux users, their answer would be Vi, Vim, Emacs, Nano etc. But I am not talking about them. I am going to talk about new age, cutting edge, great looking, sleek and yet powerful, feature rich **best open source code editors for Linux** that would enhance your programming experience.
|
||||
|
||||
### Best modern Open Source editors for Linux ###
|
||||
|
||||
I use Ubuntu as my main desktop and hence I have provided installation instructions for Ubuntu based distributions. But this doesn’t make this list as **best text editors for Ubuntu** because the list is apt for any Linux distribution. Just to add, the list is not in any particular priority order.
|
||||
|
||||
#### Brackets ####
|
||||
|
||||

|
||||
|
||||
[Brackets][1] is an open source code editor from [Adobe][2]. Brackets focuses exclusively on the needs of web designers with built in support for HTML, CSS and Java Script. It’s light weight and yet powerful. It provides you with inline editing and live preview. There are plenty of plugins available to further enhance your experience with Brackets.
|
||||
|
||||
To [install Brackets in Ubuntu][3] and Ubuntu based distributions such as Linux Mint, you can use this unofficial PPA:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
|
||||
For other Linux distributions, you can get the source code as well as binaries for Linux, OS X and Windows on its website.
|
||||
|
||||
- [Download Brackets Source Code and Binaries][5]
|
||||
|
||||
#### Atom ####
|
||||
|
||||

|
||||
|
||||
[Atom][5] is another modern and sleek looking open source editor for programmers. Atom is developed by Github and promoted as a “hackable text editor for the 21st century”. The looks of Atom resembles a lot like Sublime Text editor, a hugely popular but closed source text editors among programmers.
|
||||
|
||||
Atom has recently released .deb and .rpm packages so that one can easily install Atom in Debian and Fedora based Linux distributions. Of course, its source code is available as well.
|
||||
|
||||
- [Download Atom .deb][6]
|
||||
- [Download Atom .rpm][7]
|
||||
- [Get Atom source code][8]
|
||||
|
||||
#### Lime Text ####
|
||||
|
||||

|
||||
|
||||
So you like Sublime Text editor but you are not comfortable with the fact that it is not open source. No worries. We have an [open source clone of Sublime Text][9], called [Lime Text][10]. It is built on Go, HTML and QT. The reason behind cloning of Sublime Text is that there are numerous bugs in Sublime Text 2 and Sublime Text 3 is in beta since forever. There are no transparency in its development, on whether the bugs are being fixed or not.
|
||||
|
||||
So open source lovers, rejoice and get the source code of Lime Text from the link below:
|
||||
|
||||
- [Get Lime Text Source Code][11]
|
||||
|
||||
#### Light Table ####
|
||||
|
||||

|
||||
|
||||
Flaunted as “the next generation code editor”, [Light Table][12] is another modern looking, feature rich open source editor which is more of an IDE than a mere text editor. There are numerous extensions available to enhance its capabilities. Inline evaluation is what you would love in it. You have to use it to believe how useful Light Table actually is.
|
||||
|
||||
- [Get Light Table Source Code][13]
|
||||
|
||||
### What’s your pick? ###
|
||||
|
||||
No, we are not limited to just four code editors in Linux. The list was about modern editors for programmers. Of course you have plenty of other options such as [Notepad++ alternative Notepadqq][14] or [SciTE][15] and many more. So, among these four, which one is your favorite code editor for Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://brackets.io/
|
||||
[2]:http://www.adobe.com/
|
||||
[3]:http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]:https://github.com/adobe/brackets/releases
|
||||
[5]:https://atom.io/
|
||||
[6]:https://atom.io/download/deb
|
||||
[7]:https://atom.io/download/rpm
|
||||
[8]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[9]:http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[10]:http://limetext.org/
|
||||
[11]:https://github.com/limetext/lime
|
||||
[12]:http://lighttable.com/
|
||||
[13]:https://github.com/LightTable/LightTable
|
||||
[14]:http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[15]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
@ -1,96 +0,0 @@
|
||||
KayGuoWhu translating
|
||||
If a 32-bit integer overflows, can we use a 40-bit structure instead of a 64-bit long one?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
If, say, a 32-bit integer is overflowing, instead of upgrading int to long, can we make use of some 40-bit type if we need a range only within 240, so that we save 24 (64-40) bits for every integer?
|
||||
|
||||
If so, how?
|
||||
|
||||
I have to deal with billions and space is a bigger constraint.
|
||||
|
||||
#A:
|
||||
|
||||
##Yes, but...
|
||||
|
||||
It is certainly possible, but it is usually nonsensical (for any program that doesn't use billions of these numbers):
|
||||
|
||||
```C
|
||||
#include <stdint.h> // don't want to rely on something like long long
|
||||
struct bad_idea
|
||||
{
|
||||
uint64_t var : 40;
|
||||
};
|
||||
```
|
||||
|
||||
Here, var will indeed have a width of 40 bits at the expense of much less efficient code generated (it turns out that "much" is very much wrong -- the measured overhead is a mere 1-2%, see timings below), and usually to no avail. Unless you have need for another 24-bit value (or an 8 and 16 bit value) which you wish to pack into the same structure, alignment will forfeit anything that you may gain.
|
||||
|
||||
In any case, unless you have billions of these, the effective difference in memory consumption will not be noticeable (but the extra code needed to manage the bit field will be noticeable!).
|
||||
|
||||
###Note:
|
||||
|
||||
The question has in the mean time been updated to reflect that indeed billions of numbers are needed, so this may be a viable thing to do, presumed that you take measures not to lose the gains due to structure alignment and padding, i.e. either by storing something else in the remaining 24 bits or by storing your 40-bit values in structures of 8 each or multiples thereof).
|
||||
Saving three bytes a billion times is worthwhile as it will require noticeably fewer memory pages and thus cause fewer cache and TLB misses, and above all page faults (a single page fault weighting tens of millions instructions).
|
||||
|
||||
While the above snippet does not make use of the remaining 24 bits (it merely demonstrates the "use 40 bits" part), something akin to the following will be necessary to really make the approach useful in a sense of preserving memory -- presumed that you indeed have other "useful" data to put in the holes:
|
||||
|
||||
```C
|
||||
struct using_gaps
|
||||
{
|
||||
uint64_t var : 40;
|
||||
uint64_t useful_uint16 : 16;
|
||||
uint64_t char_or_bool : 8;
|
||||
};
|
||||
```
|
||||
|
||||
Structure size and alignment will be equal to a 64 bit integer, so nothing is wasted if you make e.g. an array of a billion such structures (even without using compiler-specific extensions). If you don't have use for an 8-bit value, you could also use an 48-bit and a 16-bit value (giving a bigger overflow margin).
|
||||
Alternatively you could, at the expense of usability, put 8 40-bit values into a structure (least common multiple of 40 and 64 being 320 = 8*40). Of course then your code which accesses elements in the array of structures will become much more complicated (though one could probably implement an operator[] that restores the linear array functionality and hides the structure complexity).
|
||||
|
||||
Update:
|
||||
Wrote a quick test suite, just to see what overhead the bitfields (and operator overloading with bitfield refs) would have. Posted code (due to length) at gcc.godbolt.org, test output from my Win7-64 machine is:
|
||||
|
||||
```TXT
|
||||
Running test for array size = 1048576
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 2 1 35 35 1
|
||||
uint64_t 0 3 3 35 35 1
|
||||
bad40_t 0 5 3 35 35 1
|
||||
packed40_t 0 7 4 48 49 1
|
||||
|
||||
|
||||
Running test for array size = 16777216
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 38 14 560 555 8
|
||||
uint64_t 0 81 22 565 554 17
|
||||
bad40_t 0 85 25 565 561 16
|
||||
packed40_t 0 151 75 765 774 16
|
||||
|
||||
|
||||
Running test for array size = 134217728
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 312 100 4480 4441 65
|
||||
uint64_t 0 648 172 4482 4490 130
|
||||
bad40_t 0 682 193 4573 4492 130
|
||||
packed40_t 0 1164 552 6181 6176 130
|
||||
```
|
||||
|
||||
What one can see is that the extra overhead of bitfields is neglegible, but the operator overloading with bitfield reference as a convenience thing is rather drastic (about 3x increase) when accessing data linearly in a cache-friendly manner. On the other hand, on random access it barely even matters.
|
||||
|
||||
These timings suggest that simply using 64-bit integers would be better since they are still faster overall than bitfields (despite touching more memory), but of course they do not take into account the cost of page faults with much bigger datasets. It might look very different once you run out of physical RAM (I didn't test that).
|
||||
|
||||
------
|
||||
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27705409/if-a-32-bit-integer-overflows-can-we-use-a-40-bit-structure-instead-of-a-64-bit/27705562#27705562)
|
||||
|
||||
作者:[Damon][a][Michael Kohne][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/572743/damon
|
||||
[b]:http://stackoverflow.com/users/5801/michael-kohne
|
||||
@ -1,76 +0,0 @@
|
||||
zpl1025
|
||||
Test drive Linux with nothing but a flash drive
|
||||
================================================================================
|
||||

|
||||
Image by : Opensource.com
|
||||
|
||||
Maybe you’ve heard about Linux and are intrigued by it. So intrigued that you want to give it a try. But you might not know where to begin.
|
||||
|
||||
You’ve probably done a bit of research online and have run across terms like dual booting and virtualization. Those terms might mean nothing to you, and you’re definitely not ready to sacrifice the operating system that you’re currently using to give Linux a try. So what can you do?
|
||||
|
||||
If you have a USB flash drive lying around, you can test drive Linux by creating a live USB. It’s a USB flash drive that contains an operating system that can start from the flash drive. It doesn’t take much technical ability to create one. Let’s take a look at how to do that and how to run Linux using a live USB.
|
||||
|
||||
### What you’ll need ###
|
||||
|
||||
Aside from a desktop or laptop computer, you’ll need:
|
||||
|
||||
- A blank USB flash drive—preferably one that has a capacity of 4 GB or more.
|
||||
- An [ISO image][1] (an archive of the contents of a hard disk) of the Linux distribution that you want to try. More about this in a moment.
|
||||
- An application called [Unetbootin][2], an open source tool, cross platform tool that creates a live USB. You don’t need to be running Linux to use it. In the instructions that below, I’m running Unetbootin on a MacBook.
|
||||
|
||||
### Getting to work ###
|
||||
|
||||
Plug your flash drive into a USB port on your computer and then fire up Unetbootin. You’ll be asked for the password that you use to log into your computer.
|
||||
|
||||

|
||||
|
||||
Remember the ISO image that was mentioned a few moments ago? There are two ways you can get one: either by downloading it from the website of the Linux distribution that you want to try, or by having Unetbootin download it for you. To do that latter, click **Select Distribution** at the top of the window, choose the distribution that you want to download, and then click **Select Version** to select the version of the distribution that you want to try.
|
||||
|
||||

|
||||
|
||||
Or, you can download the distribution yourself. Usually, the Linux distributions that I want to try aren’t in the list. If you go the second route, click **Disk image** and then click the button to search for the .iso file that you downloaded.
|
||||
|
||||
Notice the **Space used to preserve files across reboots (Ubuntu only)** option? If you’re testing Ubuntu or one of its derivatives (like Lubuntu or Xubuntu), you can set aside a few megabytes of space on your flash drive to save files like web browser bookmarks or documents that you create. When you load Ubuntu from the flash drive again, you can reuse those files.
|
||||
|
||||

|
||||
|
||||
Once the ISO image is loaded, click **OK**. It takes anywhere from a couple of minutes to 10 minutes for Unetbootin to create the live USB.
|
||||
|
||||

|
||||
|
||||
### Testing out the live USB ###
|
||||
|
||||
This is the point where you have to embrace your inner geek a bit. Not too much, but you will be taking a peek into the innards of your computer by going into the [BIOS][3]. Your computer’s BIOS starts various bits of hardware and controls where the computer’s operating system starts, or boots, from.
|
||||
|
||||
The BIOS usually looks for the operating system in this order (or something like it): hard drive, then CD-ROM or DVD drive, and then an external drive. You’ll want to change that order so that the external drive (in this case, your live USB) is the one that the BIOS checks first.
|
||||
|
||||
To do that, restart your computer with the flash drive plugged into a USB port. When you see the message **Press F2 to enter setup**, do just that. On some computers, the key might be F10.
|
||||
|
||||
In the BIOS, use the right arrow key on your keyboard to navigate to the **Boot** menu. You’ll see a list of drives on your computer. Use the down arrow key on your keyboard to navigate to the item labeled **USB HDD** and then press **F6** to move that item to the top of the list.
|
||||
|
||||
Once you’ve done that, press **F10** to save the changes. You’ll be kicked out of the BIOS and your computer will start up. After a short amount of time, you’ll be presented with a menu listing the options for starting the Linux distribution you’re trying out. Select **Run without installing** (or the menu item closest to it).
|
||||
|
||||
Once the desktop loads, you can connect to a wireless or wired network, browse the web, and give the pre-installed software a whirl. You can also check to see if, for example, your printer or scanner works with the Linux distribution you’re testing. If you really, really want to you can also fiddle at the command line.
|
||||
|
||||
### What to expect ###
|
||||
|
||||
Depending on the Linux distribution you’re testing and the speed of the flash drive you’re using, the operating system might take longer to load and it might run a bit slower than it would if it was installed on your hard drive.
|
||||
|
||||
As well, you’ll only have the basic software that the Linux distribution packs out of the box. You generally get a web browser, a word processor, a text editor, a media player, an image viewer, and a set of utilities. That should be enough to give you a feel for what it’s like to use Linux.
|
||||
|
||||
If you decide that you like using Linux, you can install it from the flash drive by double clicking on the installer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://en.wikipedia.org/wiki/ISO_image
|
||||
[2]:http://unetbootin.sourceforge.net/
|
||||
[3]:http://en.wikipedia.org/wiki/BIOS
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by mtunique
|
||||
Moving to Docker
|
||||
================================================================================
|
||||

|
||||
@ -53,7 +54,7 @@ In the following articles we'll see how to setup a semi-automated Docker based d
|
||||
via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -78,4 +79,4 @@ via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
[20]:
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
How to Bind Apache Tomcat to IPv4 in Centos / Redhat
|
||||
================================================================================
|
||||
Hi all, today we'll learn how to bind tomcat to ipv4 in CentOS 7 Linux Distribution.
|
||||
|
||||
**Apache Tomcat** is an open source web server and servlet container developed by the [Apache Software Foundation][1]. It implements the Java Servlet, JavaServer Pages (JSP), Java Unified Expression Language and Java WebSocket specifications from Sun Microsystems and provides a web server environment for Java code to run in.
|
||||
|
||||
Binding Tomcat to IPv4 is necessary if we have our server not working due to the default binding of our tomcat server to IPv6. As we know IPv6 is the modern way of assigning IP address to a device and is not in complete practice these days but may come into practice in soon future. So, currently we don't need to switch our tomcat server to IPv6 due to no use and we should bind it to IPv4.
|
||||
|
||||
Before thinking to bind to IPv4, we should make sure that we've got tomcat installed in our CentOS 7. Here's is a quick tutorial on [how to install tomcat 8 in CentOS 7.0 Server][2].
|
||||
|
||||
### 1. Switching to user tomcat ###
|
||||
|
||||
First of all, we'll gonna switch user to **tomcat** user. We can do that by running **su - tomcat** in a shell or terminal.
|
||||
|
||||
# su - tomcat
|
||||
|
||||

|
||||
|
||||
### 2. Finding Catalina.sh ###
|
||||
|
||||
Now, we'll First Go to bin directory inside the directory of Apache Tomcat installation which is usually under **/usr/share/apache-tomcat-8.0.x/bin/** where x is sub version of the Apache Tomcat Release. In my case, its **/usr/share/apache-tomcat-8.0.18/bin/** as I have version 8.0.18 installed in my CentOS 7 Server.
|
||||
|
||||
$ cd /usr/share/apache-tomcat-8.0.18/bin
|
||||
|
||||
**Note: Please replace 8.0.18 to the version of Apache Tomcat installed in your system. **
|
||||
|
||||
Inside the bin folder, there is a script file named catalina.sh . Thats the script file which we'll gonna edit and add a line of configuration which will bind tomcat to IPv4 . You can see that file by running **ls** into a terminal or shell.
|
||||
|
||||
$ ls
|
||||
|
||||

|
||||
|
||||
### 3. Configuring Catalina.sh ###
|
||||
|
||||
Now, we'll add **JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"** to that scripting file catalina.sh at the end of the file as shown in the figure below. We can edit the file using our favorite text editing software like nano, vim, etc. Here, we'll gonna use nano.
|
||||
|
||||
$ nano catalina.sh
|
||||
|
||||

|
||||
|
||||
Then, add to the file as shown below:
|
||||
|
||||
**JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"**
|
||||
|
||||

|
||||
|
||||
Now, as we've added the configuration to the file, we'll now save and exit nano.
|
||||
|
||||
### 4. Restarting ###
|
||||
|
||||
Now, we'll restart our tomcat server to get our configuration working. We'll need to first execute shutdown.sh and then startup.sh .
|
||||
|
||||
$ ./shutdown.sh
|
||||
|
||||
Now, well run execute startup.sh as:
|
||||
|
||||
$ ./startup.sh
|
||||
|
||||

|
||||
|
||||
This will restart our tomcat server and the configuration will be loaded which will ultimately bind the server to IPv4.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray, finally we'have got our tomcat server bind to IPv4 running in our CentOS 7 Linux Distribution. Binding to IPv4 is easy and is necessary if your Tomcat server is bind to IPv6 which will infact will make your tomcat server not working as IPv6 is not used these days and may come into practice in coming future. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/bind-apache-tomcat-ipv4-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.apache.org/
|
||||
[2]:http://linoxide.com/linux-how-to/install-tomcat-8-centos-7/
|
||||
@ -0,0 +1,186 @@
|
||||
How to create and show a presentation from the command line on Linux
|
||||
================================================================================
|
||||
When you prepare a talk for audience, the first thing that will probably come to your mind is shiny presentation charts filled with fancy diagrams, graphics and animation effects. Fine. No one can deny the power of visually charming presentation. However, not all presentations need to be Ted talk quality. Often times, the purpose of a presentation is to convey specific information, which can easily be done with textual messages. In such cases, your time can be better spent on gathering information and checking facts, rather than searching for good-looking graphics from Google Image.
|
||||
|
||||
In the world of Linux, you can do presentation in several different ways, e.g., Impress for multimedia-rich content, [Impress.js][1] for stunning visualization, Beamer for hardcore LaTex users, and so on. If you are looking for a simple means to create and show a textual presentation, look no further. [mdp][2] can get the job done for you.
|
||||
|
||||
### What is Mdp? ###
|
||||
|
||||
mdp is an ncurses-based command-line presentation tool for Linux. What I like about mdp is its [markdown][3] support, which makes it easy to create slides with familiar markdown format. Naturally, it becomes painless to publish the slides in HTML format as well. Another plus is its support for UTF-8 character encoding, which comes in handy when showing non-English characters (e.g., Greek or Cyrillic alphabets).
|
||||
|
||||
### Install Mdp on Linux ###
|
||||
|
||||
Installation of mdp is mostly painless due to its light dependency requirement (i.e., ncursesw).
|
||||
|
||||
#### Debian, Ubuntu or their derivatives ####
|
||||
|
||||
$ sudo apt-get install git gcc make libncursesw5-dev
|
||||
$ git clone https://github.com/visit1985/mdp.git
|
||||
$ cd mdp
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
#### Fedora or CentOS/RHEL ####
|
||||
|
||||
$ sudo yum install git gcc make ncurses-devel
|
||||
$ git clone https://github.com/visit1985/mdp.git
|
||||
$ cd mdp
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
#### Arch Linux ####
|
||||
|
||||
On Arch Linux, you can easily install mdp from [AUR][4].
|
||||
|
||||
### Create a Presentation from the Command Line ###
|
||||
|
||||
Once you installed mdp, you can easily create a presentation by using your favorite text editor. If you are familiar with markdown, it will take no time to master mdp. For those of you who are not familiar with markdown, starting with an example is the best way to learn mdp.
|
||||
|
||||
Here is a 6-page sample presentation for your reference.
|
||||
|
||||
%title: Sample Presentation made with mdp (Xmodulo.com)
|
||||
%author: Dan Nanni
|
||||
%date: 2015-01-28
|
||||
|
||||
-> This is a slide title <-
|
||||
=========
|
||||
|
||||
-> mdp is a command-line based presentation tool with markdown support. <-
|
||||
|
||||
*_Features_*
|
||||
|
||||
* Multi-level headers
|
||||
* Code block formatting
|
||||
* Nested quotes
|
||||
* Nested list
|
||||
* Text highlight and underline
|
||||
* Citation
|
||||
* UTF-8 special characters
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of nested list <-
|
||||
|
||||
This is an example of multi-level headers and a nested list.
|
||||
|
||||
# first-level title
|
||||
|
||||
second-level
|
||||
------------
|
||||
|
||||
- *item 1*
|
||||
- sub-item 1
|
||||
- sub-sub-item 1
|
||||
- sub-sub-item 2
|
||||
- sub-sub-item 3
|
||||
- sub-item 2
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of code block formatting <-
|
||||
|
||||
This example shows how to format a code snippet.
|
||||
|
||||
1 /* Hello World program */
|
||||
2
|
||||
3 #include <stdio.h>
|
||||
4
|
||||
5 int main()
|
||||
6 {
|
||||
7 printf("Hello World");
|
||||
8 return 0;
|
||||
9 }
|
||||
|
||||
This example shows inline code: `sudo reboot`
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
-> # Example of nested quotes <-
|
||||
|
||||
This is an example of nested quotes.
|
||||
|
||||
# three-level nested quotes
|
||||
|
||||
> This is the first-level quote.
|
||||
>> This is the second-level quote
|
||||
>> and continues.
|
||||
>>> *This is the third-level quote, and so on.*
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
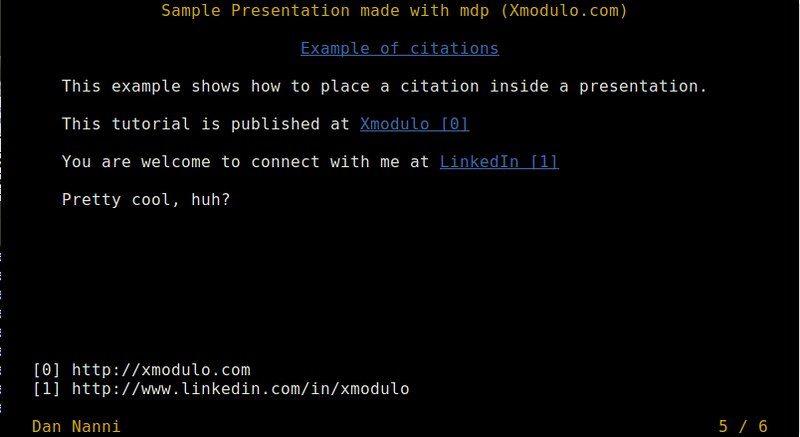
-> # Example of citations <-
|
||||
|
||||
This example shows how to place a citation inside a presentation.
|
||||
|
||||
This tutorial is published at [Xmodulo](http://xmodulo.com)
|
||||
|
||||
You are welcome to connect with me at [LinkedIn](http://www.linkedin.com/in/xmodulo)
|
||||
|
||||
Pretty cool, huh?
|
||||
|
||||
-------------------------------------------------
|
||||
|
||||
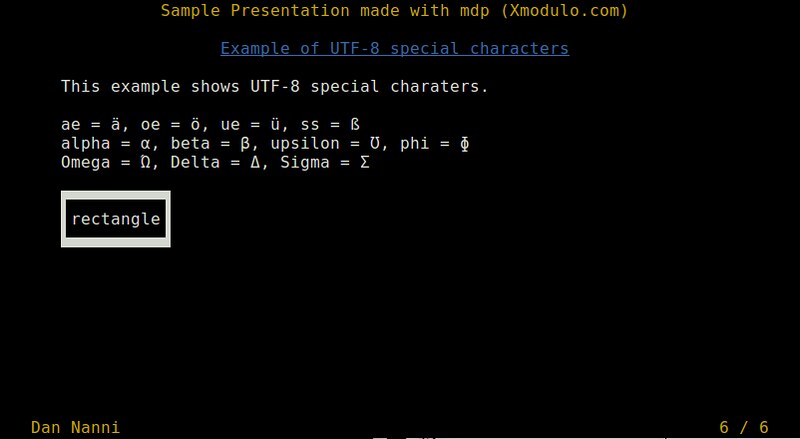
-> # Example of UTF-8 special characters <-
|
||||
|
||||
This example shows UTF-8 special characters.
|
||||
|
||||
ae = ä, oe = ö, ue = ü, ss = ß
|
||||
alpha = ?, beta = ?, upsilon = ?, phi = ?
|
||||
Omega = ?, Delta = ?, Sigma = ?
|
||||
|
||||
???????????
|
||||
?rectangle?
|
||||
???????????
|
||||
|
||||
### Show a Presentation from the Command Line ###
|
||||
|
||||
Once you save the above code as slide.md text file, you can show the presentation by simply running:
|
||||
|
||||
$ mdp slide.md
|
||||
|
||||
You can navigate the presentation by pressing Enter/Space/Page-Down/Down-Arrow (next slide), Backspace/Page-Up/Up-Arrow (previous slide), Home (first slide), End (last slide), or numeric-N (N-th slide).
|
||||
|
||||
The title of the presentation appears on top of each slide, and your name and page number are shown at the bottom.
|
||||
|
||||
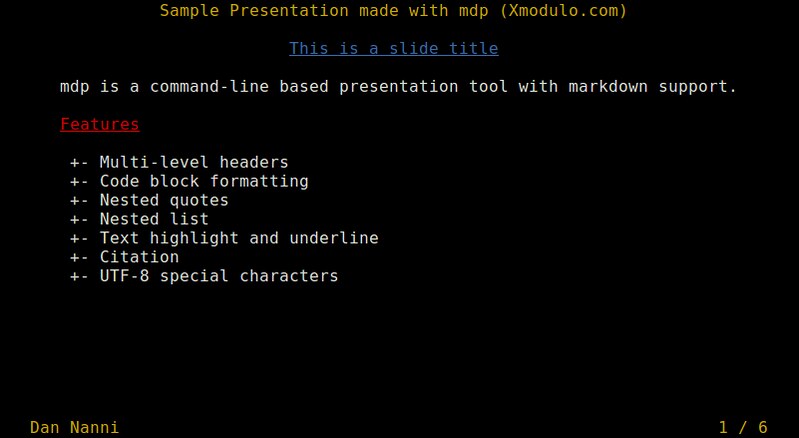
|
||||
|
||||
This is an example of a nested list and multi-level headers.
|
||||
|
||||
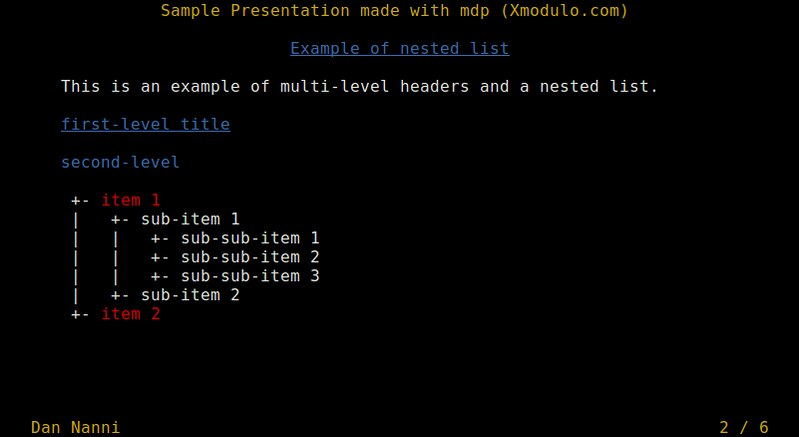
|
||||
|
||||
This is an example of a code snippet and inline code.
|
||||
|
||||
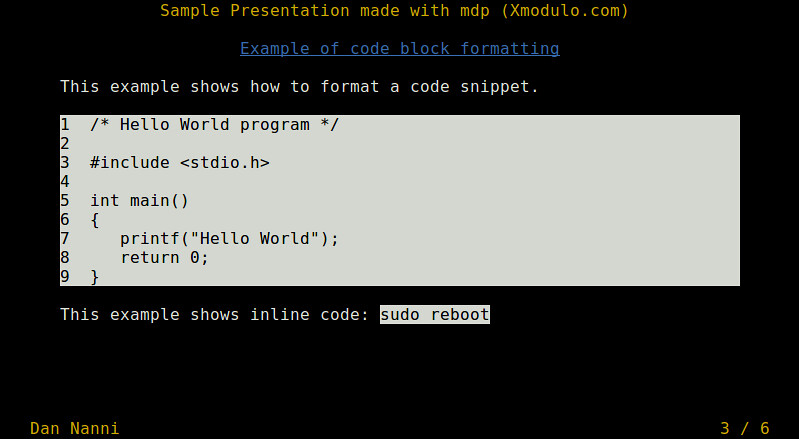
|
||||
|
||||
This is an example of nested quotes.
|
||||
|
||||
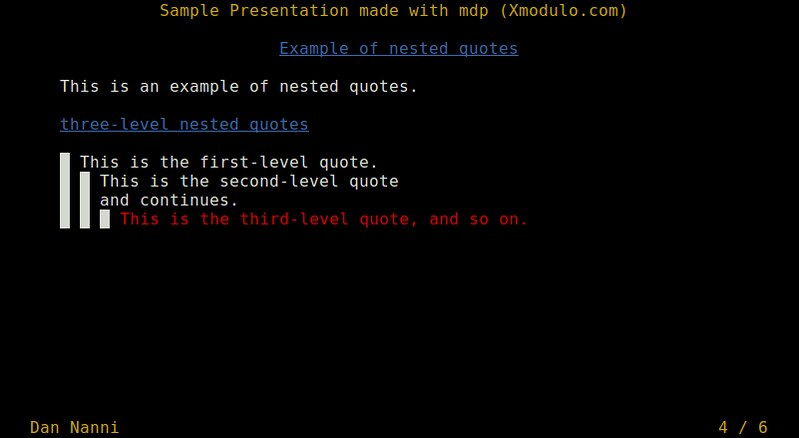
|
||||
|
||||
This is an example of placing citations.
|
||||
|
||||
|
||||
|
||||
This is an example of UTF-8 special characters.
|
||||
|
||||
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial, I showed you how to use mdp to create and show a presentation from the command line. Its markdown compatibility saves us the trouble and hassle of having to learn any new formatting, which is an advantage compared to [tpp][5], another command-line presentation tool. Due to its limitations, mdp may not qualify as your default presentation tool, but there should be definitely a use case for that. What do you think of mdp? Do you prefer something else?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/presentation-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://bartaz.github.io/impress.js/
|
||||
[2]:https://github.com/visit1985/mdp
|
||||
[3]:http://daringfireball.net/projects/markdown/
|
||||
[4]:https://aur.archlinux.org/packages/mdp-git/
|
||||
[5]:http://www.ngolde.de/tpp.html
|
||||
@ -0,0 +1,201 @@
|
||||
How to filter BGP routes in Quagga BGP router
|
||||
================================================================================
|
||||
In the [previous tutorial][1], we demonstrated how to turn a CentOS box into a BGP router using Quagga. We also covered basic BGP peering and prefix exchange setup. In this tutorial, we will focus on how we can control incoming and outgoing BGP prefixes by using **prefix-list** and **route-map**.
|
||||
|
||||
As described in earlier tutorials, BGP routing decisions are made based on the prefixes received/advertised. To ensure error-free routing, it is recommended that you use some sort of filtering mechanism to control these incoming and outgoing prefixes. For example, if one of your BGP neighbors starts advertising prefixes which do not belong to them, and you accept such bogus prefixes by mistake, your traffic can be sent to that wrong neighbor, and end up going nowhere (so-called "getting blackholed"). To make sure that such prefixes are not received or advertised to any neighbor, you can use prefix-list and route-map. The former is a prefix-based filtering mechanism, while the latter is a more general prefix-based policy mechanism used to fine-tune actions.
|
||||
|
||||
We will show you how to use prefix-list and route-map in Quagga.
|
||||
|
||||
### Topology and Requirement ###
|
||||
|
||||
In this tutorial, we assume the following topology.
|
||||
|
||||

|
||||
|
||||
Service provider A has already established an eBGP peering with service provider B, and they are exchanging routing information between them. The AS and prefix details are as stated below.
|
||||
|
||||
- **Peering block**: 192.168.1.0/24
|
||||
- **Service provider A**: AS 100, prefix 10.10.0.0/16
|
||||
- **Service provider B**: AS 200, prefix 10.20.0.0/16
|
||||
|
||||
In this scenario, service provider B wants to receive only prefixes 10.10.10.0/23, 10.10.10.0/24 and 10.10.11.0/24 from provider A.
|
||||
|
||||
### Quagga Installation and BGP Peering ###
|
||||
|
||||
In the [previous tutorial][1], we have already covered the method of installing Quagga and setting up BGP peering. So we will not go through the details here. Nonetheless, I am providing a summary of BGP configuration and prefix advertisements:
|
||||
|
||||

|
||||
|
||||
The above output indicates that the BGP peering is up. Router-A is advertising multiple prefixes towards router-B. Router-B, on the other hand, is advertising a single prefix 10.20.0.0/16 to router-A. Both routers are receiving the prefixes without any problems.
|
||||
|
||||
### Creating Prefix-List ###
|
||||
|
||||
In a router, a prefix can be blocked with either an ACL or prefix-list. Using prefix-list is often preferred to ACLs since prefix-list is less processor intensive than ACLs. Also, prefix-list is easier to create and maintain.
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23
|
||||
|
||||
The above command creates prefix-list called 'DEMO-FRFX' that allows only 192.168.0.0/23.
|
||||
|
||||
Another great feature of prefix-list is that we can specify a range of subnet mask(s). Take a look at the following example:
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 192.168.0.0/23 le 24
|
||||
|
||||
The above command creates prefix-list called 'DEMO-PRFX' that permits prefixes between 192.168.0.0/23 and /24, which are 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24. The 'le' operator means less than or equal to. You can also use 'ge' operator for greater than or equal to.
|
||||
|
||||
A single prefix-list statement can have multiple permit/deny actions. Each statement is assigned a sequence number which can be determined automatically or specified manually.
|
||||
|
||||
Multiple prefix-list statements are parsed one by one in the increasing order of sequence numbers. When configuring prefix-list, we should keep in mind that there is always an **implicit deny** at the end of all prefix-list statements. This means that anything that is not explicitly allowed will be denied.
|
||||
|
||||
To allow everything, we can use the following prefix-list statement which allows any prefix starting from 0.0.0.0/0 up to anything with subnet mask /32.
|
||||
|
||||
ip prefix-list DEMO-PRFX permit 0.0.0.0/0 le 32
|
||||
|
||||
Now that we know how to create prefix-list statements, we will create prefix-list called 'PRFX-LST' that will allow prefixes required in our scenario.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# ip prefix-list PRFX-LST permit 10.10.10.0/23 le 24
|
||||
|
||||
### Creating Route-Map ###
|
||||
|
||||
Besides prefix-list and ACLs, there is yet another mechanism called route-map, which can control prefixes in a BGP router. In fact, route-map can fine-tune possible actions more flexibly on the prefixes matched with an ACL or prefix-list.
|
||||
|
||||
Similar to prefix-list, a route-map statement specifies permit or deny action, followed by a sequence number. Each route-map statement can have multiple permit/deny actions with it. For example:
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
|
||||
The above statement creates route-map called 'DEMO-RMAP', and adds permit action with sequence 10. Now we will use match command under sequence 10.
|
||||
|
||||
router-a(config-route-map)# match (press ? in the keyboard)
|
||||
|
||||
----------
|
||||
|
||||
as-path Match BGP AS path list
|
||||
community Match BGP community list
|
||||
extcommunity Match BGP/VPN extended community list
|
||||
interface match first hop interface of route
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
metric Match metric of route
|
||||
origin BGP origin code
|
||||
peer Match peer address
|
||||
probability Match portion of routes defined by percentage value
|
||||
tag Match tag of route
|
||||
|
||||
As we can see, route-map can match many attributes. We will match a prefix in this tutorial.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
|
||||
The match command will match the IP addresses permitted by the prefix-list 'DEMO-PRFX' created earlier (i.e., prefixes 192.168.0.0/23, 192.168.0.0/24 and 192.168.1.0/24).
|
||||
|
||||
Next, we can modify the attributes by using the set command. The following example shows possible use cases of set.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set (press ? in keyboard)
|
||||
|
||||
----------
|
||||
|
||||
aggregator BGP aggregator attribute
|
||||
as-path Transform BGP AS-path attribute
|
||||
atomic-aggregate BGP atomic aggregate attribute
|
||||
comm-list set BGP community list (for deletion)
|
||||
community BGP community attribute
|
||||
extcommunity BGP extended community attribute
|
||||
forwarding-address Forwarding Address
|
||||
ip IP information
|
||||
ipv6 IPv6 information
|
||||
local-preference BGP local preference path attribute
|
||||
metric Metric value for destination routing protocol
|
||||
metric-type Type of metric
|
||||
origin BGP origin code
|
||||
originator-id BGP originator ID attribute
|
||||
src src address for route
|
||||
tag Tag value for routing protocol
|
||||
vpnv4 VPNv4 information
|
||||
weight BGP weight for routing table
|
||||
|
||||
As we can see, the set command can be used to change many attributes. For a demonstration purpose, we will set BGP local preference.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
|
||||
Just like prefix-list, there is an implicit deny at the end of all route-map statements. So we will add another permit statement in sequence number 20 to permit everything.
|
||||
|
||||
route-map DEMO-RMAP permit 10
|
||||
match ip address prefix-list DEMO-PRFX
|
||||
set local-preference 500
|
||||
!
|
||||
route-map DEMO-RMAP permit 20
|
||||
|
||||
The sequence number 20 does not have a specific match command, so it will, by default, match everything. Since the decision is permit, everything will be permitted by this route-map statement.
|
||||
|
||||
If you recall, our requirement is to only allow/deny some prefixes. So in our scenario, the set command is not necessary. We will just use one permit statement as follows.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# route-map RMAP permit 10
|
||||
router-b(config-route-map)# match ip address prefix-list PRFX-LST
|
||||
|
||||
This route-map statement should do the trick.
|
||||
|
||||
### Applying Route-Map ###
|
||||
|
||||
Keep in mind that ACLs, prefix-list and route-map are not effective unless they are applied to an interface or a BGP neighbor. Just like ACLs or prefix-list, a single route-map statement can be used with any number of interfaces or neighbors. However, any one interface or a neighbor can support only one route-map statement for inbound, and one for outbound traffic.
|
||||
|
||||
We will apply the created route-map to the BGP configuration of router-B for neighbor 192.168.1.1 with incoming prefix advertisement.
|
||||
|
||||
router-b# conf terminal
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# neighbor 192.168.1.1 route-map RMAP in
|
||||
|
||||
Now, we check the routes advertised and received by using the following commands.
|
||||
|
||||
For advertised routes:
|
||||
|
||||
show ip bgp neighbor-IP advertised-routes
|
||||
|
||||
For received routes:
|
||||
|
||||
show ip bgp neighbor-IP routes
|
||||
|
||||

|
||||
|
||||
You can see that while router-A is advertising four prefixes towards router-B, router-B is accepting only three prefixes. If we check the range, we can see that only the prefixes that are allowed by route-map are visible on router-B. All other prefixes are discarded.
|
||||
|
||||
**Tip**: If there is no change in the received prefixes, try resetting the BGP session using the command: "clear ip bgp neighbor-IP". In our case:
|
||||
|
||||
clear ip bgp 192.168.1.1
|
||||
|
||||
As we can see, the requirement has been met. We can create similar prefix-list and route-map statements in routers A and B to further control inbound and outbound prefixes.
|
||||
|
||||
I am summarizing the configuration in one place so you can see it all at a glance.
|
||||
|
||||
router bgp 200
|
||||
network 10.20.0.0/16
|
||||
neighbor 192.168.1.1 remote-as 100
|
||||
neighbor 192.168.1.1 route-map RMAP in
|
||||
!
|
||||
ip prefix-list PRFX-LST seq 5 permit 10.10.10.0/23 le 24
|
||||
!
|
||||
route-map RMAP permit 10
|
||||
match ip address prefix-list PRFX-LST
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial, we showed how we can filter BGP routes in Quagga by defining prefix-list and route-map. We also demonstrated how we can combine prefix-list with route-map to fine-control incoming prefixes. You can create your own prefix-list and route-map in a similar way to match your network requirements. These tools are one of the most effective ways to protect the production network from route poisoning and advertisement of bogon routes.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
@ -0,0 +1,87 @@
|
||||
4个最流行的Linux平台开源代码编辑器
|
||||
===
|
||||
|
||||

|
||||
|
||||
寻找**Linux平台最棒的代码编辑器**?如果你询问那些很早就玩Linux的人,他们会回答是Vi, Vim, Emacs, Nano等。但是,我今天不讨论那些。我将谈论一些新时代, 最权威的, 漂亮的, 时髦但十分强大, 功能丰富的**最好的Linux平台开源代码编辑器**,它们将会提升你的编程经验。
|
||||
|
||||
### Linux平台最时髦的开源代码编辑器 ###
|
||||
|
||||
我使用Ubunt作为我的主桌面,所以我提供的安装说明是基于Ubuntu发布的操作系统。但是这并不意味着本文列表就可以作为**Ubuntu最好的文本编辑器**,因为本列表是适用于任何Linux发布操作系统的。而且,列表的介绍顺序并没有特定的优先级别。
|
||||
|
||||
#### Brackets ####
|
||||
|
||||

|
||||
|
||||
[Brackets][1]是出自[Adobe][2]的一个开源代码编辑器。它专门关注web设计者的需求,内置支持HTML, CSS和Java Script。它轻量级,但却十分强大,提供在线编辑和实时预览。而且,为了你能更好地体验Brackets,你可以使用许多可用的插件。
|
||||
|
||||
为了[在Ubuntu][3],以及其余基于Ubuntu发布的版本,诸如Linux Minit上安装Brackets,你可以使用这个非官方的PPA源:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
|
||||
其他的Linux发行版本,你可以通过下载源代码或相应Linux, OS X和Windows的二进制文件,进行安装。
|
||||
|
||||
- [下载Brackets源码和二进制文件][5]
|
||||
|
||||
#### Atom ####
|
||||
|
||||

|
||||
|
||||
[Atom][5]是为程序员准备的另一个时髦开源代码编辑器。Atom由Github开发,被誉为“21世纪可破解的文本编辑器”。Atom的界面和Sublime Text编辑器十分相似。Sublime Text是一个十分流行但闭源的文本编辑器。
|
||||
|
||||
Atom最近已经发布了 .deb 和 .rpm包,所以在Debian和基于Fedora的Linux版本上安装很简单。当然,你也可以获取它的源代码。
|
||||
|
||||
- [下载Atom .deb][6]
|
||||
- [下载Atom .rpm][7]
|
||||
- [获取Atom源代码][8]
|
||||
|
||||
#### Lime Text ###
|
||||
|
||||

|
||||
|
||||
如果你喜欢Sublime Text,但是你对它的闭源十分反感。别担心,我们有一个[Sublime Text的开源克隆][9],叫做[Lime Text][10]。它基于Go, HTML和QT构造。说它是Sublime Text的克隆,背后原因是Sublime Text2仍有许多bug,而且Sublime Text3到目前为止仍处于测试版本。Sublime Text的开发过程中的bug是否修复,外界并不知情。
|
||||
|
||||
所以,开源爱好者们,你们可以很开心地通过下面的连接获得Lime Text的源码:
|
||||
|
||||
- [获取Lime Text源码][11]
|
||||
|
||||
#### Light Table ####
|
||||
|
||||

|
||||
|
||||
被誉为“下一个时代的代码编辑器”,[Light Table][12]是另一个时髦,功能丰富的开源编辑器,它更像是一个IDE,而非仅仅是一个文本编辑器。并且,有许多可以提高其性能的扩展方法。内联评价将是你会爱上它的原因。你一定要去使用看看,这样你才会体会它的实用之处。
|
||||
|
||||
- [获取Light Table的源码][13]
|
||||
|
||||
### 你的选择是什么? ###
|
||||
|
||||
在Linux平台,我们不能只局限于这四种代码编辑器。这份列表仅介绍了一些时髦的,可供程序员使用的编辑器。当然,你也有许多其他的选择,比如[Notepad++的替代品Notepadqq][14]或者[SciTE][15],等等还有其余一些。所以,这四个中,你最喜欢哪个呢?
|
||||
|
||||
---
|
||||
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://brackets.io/
|
||||
[2]:http://www.adobe.com/
|
||||
[3]:http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]:https://github.com/adobe/brackets/releases
|
||||
[5]:https://atom.io/
|
||||
[6]:https://atom.io/download/deb
|
||||
[7]:https://atom.io/download/rpm
|
||||
[8]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[9]:http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[10]:http://limetext.org/
|
||||
[11]:https://github.com/limetext/lime
|
||||
[12]:http://lighttable.com/
|
||||
[13]:https://github.com/LightTable/LightTable
|
||||
[14]:http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[15]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
93
translated/talk/20150121 If a 32-bit integer overflows.md
Normal file
93
translated/talk/20150121 If a 32-bit integer overflows.md
Normal file
@ -0,0 +1,93 @@
|
||||
如果使用32位整型会溢出,那么是否可以使用一个40位结构体代替64位长整型?
|
||||
---------
|
||||
|
||||
#问题:
|
||||
假如说,使用32位的整型会溢出,在不考虑使用长整型的情况下,如果我们只需要表示2的40次方范围内的数,是否可以利用某些40位长的数据类型来表示呢?这样的话,每个整型数就可以节省24位的空间。
|
||||
|
||||
如果可以,该怎么做?
|
||||
|
||||
需求是:我现在必须处理数以亿计的数字,所以在存储空间上受到了很大的限制。
|
||||
|
||||
#回答:
|
||||
|
||||
##可以是可以,但是……
|
||||
|
||||
这种方法的确可行,但这么做通常没什么意义(因为几乎没有程序需要处理多达十亿的数字):
|
||||
|
||||
```C
|
||||
#include <stdint.h> // 不要考虑使用long long类型
|
||||
struct bad_idea
|
||||
{
|
||||
uint64_t var : 40;
|
||||
};
|
||||
```
|
||||
|
||||
在这里,变量var占据40位大小,但是以生成代码时拥有非常低的运行效率来换取的(事实证明“非常”二字言过其实了——测试中程序开销仅仅增加了1%到2%,正如下面的测试时间所示),而且这么做通常没什么用。除非你还需要保存一个24位的值(或者是8位、16位的值),这样你皆可以它们放到同一个结构中。不然的话,因为对齐内存地址产生的开销会抵消这么做带来的好处。
|
||||
|
||||
在任何情况下,除非你是真的需要保存数以亿计的数字,否则这样做给内存消耗带来的好处是可以忽略不计的(但是为了处理这些位字段的额外代码量是不可忽略的!)。
|
||||
|
||||
###说明:
|
||||
|
||||
在此期间,这个问题已经被更新了,是为了说明实际上确实有需要处理数以亿计数字的情况。假设,采取某些措施来防止因为结构体对齐和填充抵消好处(比如在后24位中存储其它的内容,或者使用多个8位来存储40位),那么这么做就变得有意义了。
|
||||
如果有十亿个数,每个数都节省三个字节的空间,那么这么做就非常有用了。因为使用更小的空间存储要求更少的内存页,也就会产生更少的cache和TLB不命中和内存缺页(单个缺页会产生数以千万计的指令(译者注:直译是这样,但语义说不通!))。
|
||||
|
||||
尽管上面提到的情况不足以充分利用到剩余的24位(它仅仅使用了40位部分),如果确实在剩余位中放入了有用的数据,那么使用类似下面的方法会使得这种思路就管理内存而言显得非常有用。
|
||||
|
||||
```C
|
||||
struct using_gaps
|
||||
{
|
||||
uint64_t var : 40;
|
||||
uint64_t useful_uint16 : 16;
|
||||
uint64_t char_or_bool : 8;
|
||||
};
|
||||
```
|
||||
|
||||
结构体大小和对齐长度等于64位整型的大小,所以只要使用得当就不会浪费空间,比如对一个保存10亿个数的数组使用这个结构(不考虑使用指定编译器的扩展)。如果你不会用到一个8位的值,那么你可以使用一个48位和16位的值(giving a bigger overflow margin)。
|
||||
或者以牺牲可用性为代价,把8个64位的值放入这样的结构体中(或者使用40和64的组合使得其和满足320)。当然,在这种情况下,通过代码去访问数组结构体中的元素会变得非常麻烦(尽管一种方法是实现一个operator[]在功能上还原线性数组,隐藏结构体的复杂性)。
|
||||
|
||||
更新:
|
||||
|
||||
我写了一个快速测试工具,只是为了获得位字段的开销(以及伴随位字段引用的重载操作)。由于长度限制将代码发布在gcc.godbolt.org上,在本人64位Win7上的测试结果如下:
|
||||
|
||||
```TXT
|
||||
运行测试的数组大小为1048576
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 2 1 35 35 1
|
||||
uint64_t 0 3 3 35 35 1
|
||||
bad40_t 0 5 3 35 35 1
|
||||
packed40_t 0 7 4 48 49 1
|
||||
|
||||
运行测试的数组大小为16777216
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 38 14 560 555 8
|
||||
uint64_t 0 81 22 565 554 17
|
||||
bad40_t 0 85 25 565 561 16
|
||||
packed40_t 0 151 75 765 774 16
|
||||
|
||||
运行测试的数组大小为134177228
|
||||
what alloc seq(w) seq(r) rand(w) rand(r) free
|
||||
-----------------------------------------------------------
|
||||
uint32_t 0 312 100 4480 4441 65
|
||||
uint64_t 0 648 172 4482 4490 130
|
||||
bad40_t 0 682 193 4573 4492 130
|
||||
packed40_t 0 1164 552 6181 6176 130
|
||||
```
|
||||
|
||||
我们看到,位字段的额外开销是微不足道的,但是当以友好的方式线性访问数据时伴随位字段引用的操作符重载产生的开销则相当显著(大概有3倍)。在另一方面,随机访问产生的开销则无足轻重。
|
||||
|
||||
这些时间表明简单的使用64位整型会更好,因为它们在整体性能上要比位字段好(尽管占用更多的内存),但是显然它们并没有考虑随着数据集增大带来的缺页开销。一旦程序内存超过RAM大小,结果可能就不一样了(未亲自考证)。
|
||||
|
||||
------
|
||||
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27705409/if-a-32-bit-integer-overflows-can-we-use-a-40-bit-structure-instead-of-a-64-bit/27705562#27705562)
|
||||
|
||||
作者:[Damon][a][Michael Kohne][b]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/572743/damon
|
||||
[b]:http://stackoverflow.com/users/5801/michael-kohne
|
||||
@ -0,0 +1,75 @@
|
||||
试试只用U盘加载Linux系统
|
||||
================================================================================
|
||||

|
||||
图片来源:Opensource.com
|
||||
|
||||
也许你听过Linux并对它有点好奇,终于想要实际体验一下,但可能不知道从哪儿开始。
|
||||
|
||||
很可能你已经在网上搜索过一些信息,然后遇到一些像双系统和虚拟机这样的词汇。它们对你来说也许太专业了,所以你肯定不会仅仅为了尝试一下Linux而牺牲正在使用的操作系统。那我们该怎么办?
|
||||
|
||||
如果你手上正好有个U盘的话,那就可以试试做一个USB Linux启动盘。它是一个包含了整个操作系统并可以直接引导开机的U盘。创建它并不需要什么专业技术能力,让我们来看看怎么做,以及如何从USB引导进入Linux系统。
|
||||
|
||||
### 你需要准备的 ###
|
||||
|
||||
除了一台台式机或笔记本电脑外,你还需要:
|
||||
|
||||
- 一个空白的U盘-最好容量能有4GB或更多。
|
||||
- 一个你想尝试的Linux发行版[ISO镜像][1](一种把所有磁盘内容打包起来的档案文件)。待会再详细介绍。
|
||||
- 一个叫[Unetbootin][2]的应用程序,它是一个开源的,跨平台的工具,用来创建USB启动盘。运行它并不需要启动Linux。在下面的教程中,我是在MacBook上运行的Unetbootiin。
|
||||
|
||||
### 开始干活 ###
|
||||
|
||||
把U盘插到你电脑的USB端口上,然后启动Unetbootin。然后会要求你输入电脑的登录密码。
|
||||
|
||||

|
||||
|
||||
还记得之前提到的ISO镜像文件吗?有两种方式可以获得:要么自己从你想尝试的Linux发行版网站上下载,或者让Unetbootin帮你下载。还是选后者,在窗口顶部点击**选择发行版**,选择你想下载的发行版,然后点击**选择版本**来选择你希望尝试的发行版版本。
|
||||
|
||||

|
||||
|
||||
或者,你也可以自己下载发行版。通常,我想尝试的Linux发行版都没有在列表中。如果选择另一个方向,点击**磁盘镜像**,然后点击按钮来选择你下载好的.iso文件。
|
||||
|
||||
注意到下面的选项**预留每次重新启动后保存文件的空间(仅Ubuntu有效)**吗?如果你尝试的是Ubuntu或它的任一个衍生版(比如Lubuntu或Xubuntu),你可以在U盘上留出几M空间用来保存文件,比如网页书签或你自己创建的文档。当用这个U盘下次启动Ubuntu的时候,你可以继续使用这些文件。
|
||||
|
||||

|
||||
|
||||
在加载好ISO镜像后,点击**确定**。Unetbootin大概需要不到10分钟来创建USB启动盘。
|
||||
|
||||

|
||||
|
||||
### 检验USB启动盘 ###
|
||||
|
||||
这个时候,你需要拥抱一下自己内在的极客精神。不会太难,不过你将需要进入[BIOS][3]去偷看一下你电脑内部空间。你的电脑的BIOS会加载各种硬件,并控制电脑操作系统的引导或启动。
|
||||
|
||||
BIOS通常会按这个顺序搜索操作系统(或者类似的顺序):硬盘,然后是CD/DVD光驱,然后是外部存储设备。你需要调整这个顺序,让外部存储设备(在这里,意味着你的U盘启动盘)成为BIOS第一个搜索的设备。
|
||||
|
||||
要做到这个,把U盘插到电脑上再重启电脑。在看到提示信息**Press F2 to enter setup**之后,按它要求的做。在有的电脑上,这个键可能是F10。
|
||||
|
||||
在BIOS里,用键盘上的向右方向键切换到**Boot**菜单。然后你将看到你电脑上的驱动器列表。使用键盘上的向下方向键选中名字为**USB HDD**的选项,然后按下**F6**移动这个选项到列表的顶部。
|
||||
|
||||
完成后,按下**F10**来保存改动。然后你会从BIOS里被踢出来,然后电脑会自己启动。等一小会,你就会看到一个你正在尝试的Linux发行版的启动菜单。选择**Run without installing**(或者最接近的选项)。
|
||||
|
||||
在进入桌面后,你可以连接上无线或有线网络,看看网页,试一试预装的软件。你还可以看看,比如说,你的打印机或扫描仪是否能在你试的这个发行版下正常工作。你要是真的想不开,也可以去摸一下命令行。
|
||||
|
||||
### 能干什么 ###
|
||||
|
||||
根据你尝试的Linux发行版和你使用的U盘的速度,操作系统可能会需要更长的时间来加载,而且很可能比直接装到硬盘上会慢一点。
|
||||
|
||||
还有,你也只能运行Linux发行版里预装好的基本软件。通常会有网页浏览器,一个文字处理软件,一个文本编辑器,一个媒体播放器,一个相片浏览器,以及一套实用工具。这些应该足够给你使用Linux的感觉了。
|
||||
|
||||
如果你决定使用Linux,你可以双击安装器从U盘安装到硬盘。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://en.wikipedia.org/wiki/ISO_image
|
||||
[2]:http://unetbootin.sourceforge.net/
|
||||
[3]:http://en.wikipedia.org/wiki/BIOS
|
||||
@ -0,0 +1,124 @@
|
||||
如何在CentOS 7.0上为Subverison安装Websvn
|
||||
================================================================================
|
||||
大家好,今天我们会在CentOS 7.0 上为subversion安装WebSVN。
|
||||
|
||||
WebSVN提供了Svbverion中的各种方法来查看你的仓库。我们可以看到任何给定版本的任何文件或者目录的日志并且看到所有文件改动、添加、删除的列表。我们同样可以看到两个版本间的不同来知道特定版本改动了什么。
|
||||
|
||||
|
||||
### 特性 ###
|
||||
|
||||
WebSVN提供了下面这些特性:
|
||||
|
||||
- 易于使用的用户界面
|
||||
- 可定制的模板系统
|
||||
- 色彩化的文件列表
|
||||
- blame 视图
|
||||
- 日志信息查询
|
||||
- RSS支持
|
||||
- [更多][1]
|
||||
|
||||
由于使用PHP写成,WebSVN同样易于移植和安装。
|
||||
|
||||
现在我们将为Subverison(Apache SVN)安装WebSVN。请确保你的服务器上已经安装了Apache SVN。如果你还没有安装,你可以在本教程中安装。
|
||||
|
||||
After you installed Apache SVN(Subversion), you'll need to follow the easy steps below.安装完Apache SVN(Subversion)后,你需要以下几步。
|
||||
|
||||
### 1. 下载 WebSVN ###
|
||||
|
||||
你可以从官方网站http://www.websvn.info/download/中下载WebSVN。我们首先进入/var/www/html/并在这里下载安装包。
|
||||
|
||||
$ sudo -s
|
||||
|
||||
**请在shell或者终端中执行上面的命令,因为我们需要切换到root权限来对系统限制区域有访问权。**
|
||||
|
||||
# cd /var/www/html
|
||||
# wget http://websvn.tigris.org/files/documents/1380/49057/websvn-2.3.3.zip
|
||||
|
||||

|
||||
|
||||
这里,我下载的是最新的2.3.3版本的websvn。你可以从这个网站得到链接。你可以用你要安装的包的链接来替换上面的链接。
|
||||
|
||||
### 2. 解压下载的zip ###
|
||||
|
||||
# unzip websvn-2.3.3.zip
|
||||
|
||||
# mv websvn-2.3.3 websvn
|
||||
|
||||

|
||||
|
||||
### 3. 安装php ###
|
||||
|
||||
# yum install php
|
||||
|
||||

|
||||
|
||||
### 4. 编辑WebSVN配置 ###
|
||||
|
||||
现在,我们需要拷贝位于/var/www/html/websvn/include的distconfig.php为config.php,并且接着编辑配置文件。
|
||||
|
||||
# cd /var/www/html/websvn/include
|
||||
|
||||
# cp distconfig.php config.php
|
||||
|
||||
# nano config.php
|
||||
|
||||
现在我们需要按如下改变文件。这完成之后,请保存病退出。
|
||||
|
||||
// Configure these lines if your commands aren't on your path.
|
||||
//
|
||||
$config->setSVNCommandPath('/usr/bin'); // e.g. c:\\program files\\subversion\\bin
|
||||
$config->setDiffPath('/usr/bin');
|
||||
|
||||
// For syntax colouring, if option enabled...
|
||||
$config->setEnscriptPath('/usr/bin');
|
||||
$config->setSedPath('/bin');
|
||||
|
||||
// For delivered tarballs, if option enabled...
|
||||
$config->setTarPath('/bin');
|
||||
|
||||
// For delivered GZIP'd files and tarballs, if option enabled...
|
||||
$config->setGZipPath('/bin');
|
||||
|
||||
//
|
||||
$config->parentPath('/svn/');
|
||||
|
||||
$extEnscript[".pl"] = "perl";
|
||||
$extEnscript[".py"] = "python";
|
||||
$extEnscript[".sql"] = "sql";
|
||||
$extEnscript[".java"] = "java";
|
||||
$extEnscript[".html"] = "html";
|
||||
$extEnscript[".xml"] = "html";
|
||||
$extEnscript[".thtml"] = "html";
|
||||
$extEnscript[".tpl"] = "html";
|
||||
$extEnscript[".sh"] = "bash";
|
||||
|
||||

|
||||
|
||||
### 5. 启动 WebSVN ###
|
||||
|
||||
现在,我们将近完成了。现在需要重启Apache服务。你可以用下面的命令。
|
||||
|
||||
# systemctl restart httpd.service
|
||||
|
||||
接着我们在浏览器中打开WebSVN,输入http://Ip-address/websvn,或者你在本地的话,你可以输入http://localhost/websvn。
|
||||
|
||||

|
||||
|
||||
**注意**: 如果你遇到一个像"Unable to find "enscript" tool at location "/usr/bin/enscript"这样的问题,那么你需要使用“yum install enscript”安装enscript来修复这个问题。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
好了,我们已经在CentOS 7上哇安城WebSVN的安装了。这个教程同样适用于RHEL 7。WebSVN提供了Svbverion中的各种方法来查看你的仓库。你可以看到任何给定版本的任何文件或者目录的日志并且看到所有文件改动、添加、删除的列表。如果你有任何问题、评论、反馈请在下面的评论栏中留下,来让我们知道该添加什么和改进。谢谢!享受WebSVN吧。:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-websvn-subversion-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.websvn.info/features/
|
||||
@ -0,0 +1,76 @@
|
||||
tespeed - 测试网速的Python工具
|
||||
================================================================================
|
||||
许多电脑呆子知道可以用**speedtest.net**测试网速,但是这个不能在测试中给你足够的控制。Linux用户喜欢在终端中输入命令来完成任务,至少对我是这样的。
|
||||
|
||||
tespeed是一款有很多特性的python工具,可以在终端在测试网速。根据文档,它利用了speedtest.net的服务器,但是用户可以手动指定。
|
||||
|
||||
最初作者用php语言写了tespeed工具,并且证明了ISP提供的网络远低于它广告中所说的那样。但是事情并不是一直如它们想的那样,因此作者移植他的php脚本到python中并且他的工具在github中已经有180个star了。
|
||||
|
||||
这意味着**alot**。
|
||||
|
||||
### 如何在linux中测试tespeed ###
|
||||
|
||||
在你电脑上运行这个python程序前先确保系统已经满足了这个工具的依赖。tespeed依赖下面两个包:
|
||||
|
||||
- lxml
|
||||
- SocksiPy
|
||||
|
||||
你可以用pip包管理系统来安装lxml,只要用下面的命令就行。
|
||||
|
||||
pip install lxml
|
||||
|
||||
现在我们需要输入下面的命令来下载安装SocksiPy。
|
||||
|
||||
wget http://sourceforge.net/projects/socksipy/files/socksipy/SocksiPy%201.00/SocksiPy.zip/
|
||||
|
||||
下载完成后 解压**SocksiPy.zip**病运行下面的命令来克隆tespeed仓库到你本地机器中。
|
||||
|
||||
git clone https://github.com/Janhouse/tespeed.git
|
||||
|
||||
接着把SocksiPy文件夹放到你克隆下来的tespeed项目中。现在我们要像截图那样在SocksPy中的**__init__.py**下面创建一个空文件。
|
||||
|
||||

|
||||
|
||||
现在我们已经解决了项目的依赖问题,我们可以用下面的命令运行了。
|
||||
|
||||
python tespeed.py
|
||||
|
||||
接下来就会发生一些神奇的事了。程序会测试你的下载和上传速度并且在你的终端中用漂亮的颜色显示出来。
|
||||
|
||||

|
||||
|
||||
在tespeed中有很多选项,如**-ls**来现实服务器,**-p**来指定代理服务器, **-s**来阻止调试(STDERR)输出, 还有很多我们会在本教程中探索。
|
||||
|
||||
如果你想要结果现实成MB,你可以在**python tespeed.py** 后面接上选项 **-mib**。
|
||||
|
||||
python tespeed.py -mib
|
||||
|
||||
在你使用了-mib选项后你可以看到计量网速的单位改变了。
|
||||
|
||||

|
||||
|
||||
我非常喜欢用的一个选项是-w,它可以把标准输出转化成CSV格式。
|
||||
|
||||
python tespeed.py -w
|
||||
|
||||
使用下面的命令来列出服务器。
|
||||
|
||||
python tespeed -ls
|
||||
|
||||
运行上面的命令后,你会看到可以用于测试上传和下载速度的服务器列表。我的列表非常长,所以我不会在教程中共享了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
=tespeed的确是一款帮助用户在终端中测试上传和下载速度的高性能python脚本。它支持很多的选项并且你可以指定列表中你想使用的服务器。继续使用tespeed并在留言区写下你们的体验吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/tespeed-python-tool-test-internet-speed/
|
||||
|
||||
作者:[Oltjano Terpollari][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/oltjano/
|
||||
Loading…
Reference in New Issue
Block a user