mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'upstream/master'
This commit is contained in:
commit
9f71da54e1
22
Makefile
22
Makefile
@ -1,3 +1,6 @@
|
||||
DIR_PATTERN := (news|talk|tech)
|
||||
NAME_PATTERN := [0-9]{8} [a-zA-Z0-9_.,() -]*\.md
|
||||
|
||||
RULES := rule-source-added \
|
||||
rule-translation-requested \
|
||||
rule-translation-completed \
|
||||
@ -18,28 +21,31 @@ $(CHANGE_FILE):
|
||||
git --no-pager diff $(TRAVIS_BRANCH) FETCH_HEAD --no-renames --name-status > $@
|
||||
|
||||
rule-source-added:
|
||||
[ $(shell grep '^A\s*sources/[^\/]*/[a-zA-Z0-9_.,\(\) \-]*\.md' $(CHANGE_FILE) | wc -l) -ge 1 ]
|
||||
[ $(shell grep -v '^A\s*sources/[^\/]*/[a-zA-Z0-9_.,\(\) \-]*\.md' $(CHANGE_FILE) | wc -l) = 0 ]
|
||||
echo 'Unmatched Files:'
|
||||
egrep -v '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) || true
|
||||
echo '[End of Unmatched Files]'
|
||||
[ $(shell egrep '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) -ge 1 ]
|
||||
[ $(shell egrep -v '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 0 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-requested:
|
||||
[ $(shell grep '^M\s*sources/[^\/]*/[a-zA-Z0-9_.,\(\) \-]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^M\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-completed:
|
||||
[ $(shell grep '^D\s*sources/[^\/]*/[a-zA-Z0-9_.,\(\) \-]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell grep '^A\s*translated/[^\/]*/[a-zA-Z0-9_.,\(\) \-]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^D\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^A\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-revised:
|
||||
[ $(shell grep '^M\s*translated/[^\/]*/[a-zA-Z0-9_.,\(\) \-]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^M\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-published:
|
||||
[ $(shell grep '^D\s*translated/[^\/]*/[a-zA-Z0-9_.,\(\) \-]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell grep '^A\s*published/[a-zA-Z0-9_.,\(\) \-]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^D\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^A\s*"?published/$(NAME_PATTERN)' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
@ -61,6 +61,8 @@ LCTT 的组成
|
||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
||||
* 2017/11/21 鉴于 qhwdw 快速而上佳的翻译质量,提升 qhwdw 为新的 Core 成员。
|
||||
* 2017/11/19 wxy 在上海交大举办的 2017 中国开源年会上做了演讲:《[如何以翻译贡献参与开源社区](https://linux.cn/article-9084-1.html)》。
|
||||
* 2018/01/11 提升 lujun9972 成为核心成员,并加入选题组。
|
||||
|
||||
核心成员
|
||||
-------------------------------
|
||||
@ -88,6 +90,7 @@ LCTT 的组成
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @qhwdw,
|
||||
- 核心成员 @lujun9972
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
|
||||
84
published/20090127 Anatomy of a Program in Memory.md
Normal file
84
published/20090127 Anatomy of a Program in Memory.md
Normal file
@ -0,0 +1,84 @@
|
||||
剖析内存中的程序之秘
|
||||
============================================================
|
||||
|
||||
内存管理是操作系统的核心任务;它对程序员和系统管理员来说也是至关重要的。在接下来的几篇文章中,我将从实践出发着眼于内存管理,并深入到它的内部结构。虽然这些概念很通用,但示例大都来自于 32 位 x86 架构的 Linux 和 Windows 上。这第一篇文章描述了在内存中程序如何分布。
|
||||
|
||||
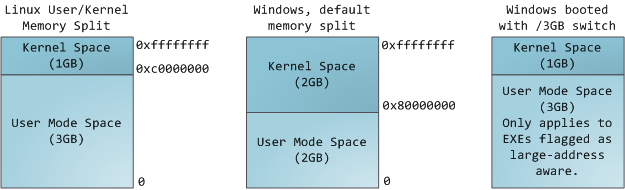
在一个多任务操作系统中的每个进程都运行在它自己的内存“沙箱”中。这个沙箱是一个<ruby>虚拟地址空间<rt>virtual address space</rt></ruby>,在 32 位的模式中它总共有 4GB 的内存地址块。这些虚拟地址是通过内核<ruby>页表<rt>page table</rt></ruby>映射到物理地址的,并且这些虚拟地址是由操作系统内核来维护,进而被进程所消费的。每个进程都有它自己的一组页表,但是这里有点玄机。一旦虚拟地址被启用,这些虚拟地址将被应用到这台电脑上的 _所有软件_,_包括内核本身_。因此,一部分虚拟地址空间必须保留给内核使用:
|
||||
|
||||
|
||||
|
||||
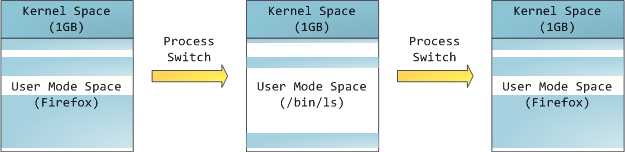
但是,这并**不是**说内核就使用了很多的物理内存,恰恰相反,它只使用了很少一部分可用的地址空间映射到其所需要的物理内存。内核空间在内核页表中被标记为独占使用于 [特权代码][1] (ring 2 或更低),因此,如果一个用户模式的程序尝试去访问它,将触发一个页面故障错误。在 Linux 中,内核空间是始终存在的,并且在所有进程中都映射相同的物理内存。内核代码和数据总是可寻址的,准备随时去处理中断或者系统调用。相比之下,用户模式中的地址空间,在每次进程切换时都会发生变化:
|
||||
|
||||
|
||||
|
||||
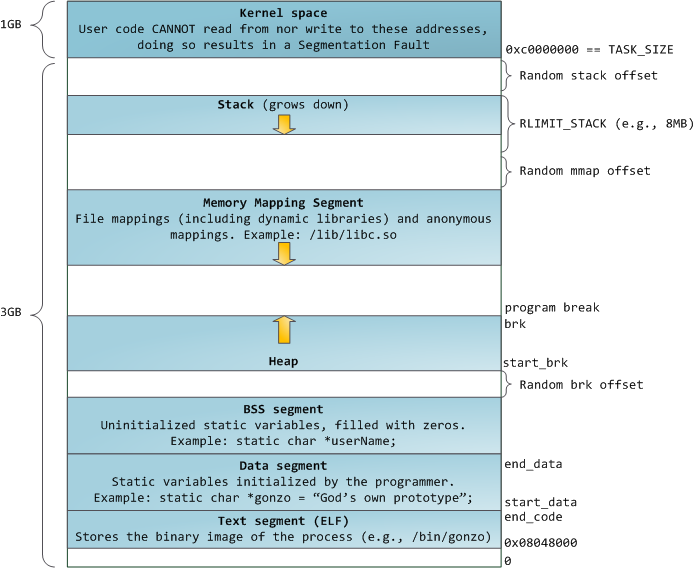
蓝色的区域代表映射到物理地址的虚拟地址空间,白色的区域是尚未映射的部分。在上面的示例中,众所周知的内存“饕餮” Firefox 使用了大量的虚拟内存空间。在地址空间中不同的条带对应了不同的内存段,像<ruby>堆<rt>heap</rt></ruby>、<ruby>栈<rt>stack</rt></ruby>等等。请注意,这些段只是一系列内存地址的简化表示,它与 [Intel 类型的段][2] _并没有任何关系_ 。不过,这是一个在 Linux 进程的标准段布局:
|
||||
|
||||
|
||||
|
||||
当计算机还是快乐、安全的时代时,在机器中的几乎每个进程上,那些段的起始虚拟地址都是**完全相同**的。这将使远程挖掘安全漏洞变得容易。漏洞利用经常需要去引用绝对内存位置:比如在栈中的一个地址,一个库函数的地址,等等。远程攻击可以闭着眼睛选择这个地址,因为地址空间都是相同的。当攻击者们这样做的时候,人们就会受到伤害。因此,地址空间随机化开始流行起来。Linux 会通过在其起始地址上增加偏移量来随机化[栈][3]、[内存映射段][4]、以及[堆][5]。不幸的是,32 位的地址空间是非常拥挤的,为地址空间随机化留下的空间不多,因此 [妨碍了地址空间随机化的效果][6]。
|
||||
|
||||
在进程地址空间中最高的段是栈,在大多数编程语言中它存储本地变量和函数参数。调用一个方法或者函数将推送一个新的<ruby>栈帧<rt>stack frame</rt></ruby>到这个栈。当函数返回时这个栈帧被删除。这个简单的设计,可能是因为数据严格遵循 [后进先出(LIFO)][7] 的次序,这意味着跟踪栈内容时不需要复杂的数据结构 —— 一个指向栈顶的简单指针就可以做到。推入和弹出也因此而非常快且准确。也可能是,持续的栈区重用往往会在 [CPU 缓存][8] 中保持活跃的栈内存,这样可以加快访问速度。进程中的每个线程都有它自己的栈。
|
||||
|
||||
向栈中推送更多的而不是刚合适的数据可能会耗尽栈的映射区域。这将触发一个页面故障,在 Linux 中它是通过 [`expand_stack()`][9] 来处理的,它会去调用 [`acct_stack_growth()`][10] 来检查栈的增长是否正常。如果栈的大小低于 `RLIMIT_STACK` 的值(一般是 8MB 大小),那么这是一个正常的栈增长和程序的合理使用,否则可能是发生了未知问题。这是一个栈大小按需调节的常见机制。但是,栈的大小达到了上述限制,将会发生一个栈溢出,并且,程序将会收到一个<ruby>段故障<rt>Segmentation Fault</rt></ruby>错误。当映射的栈区为满足需要而扩展后,在栈缩小时,映射区域并不会收缩。就像美国联邦政府的预算一样,它只会扩张。
|
||||
|
||||
动态栈增长是 [唯一例外的情况][11] ,当它去访问一个未映射的内存区域,如上图中白色部分,是允许的。除此之外的任何其它访问未映射的内存区域将触发一个页面故障,导致段故障。一些映射区域是只读的,因此,尝试去写入到这些区域也将触发一个段故障。
|
||||
|
||||
在栈的下面,有内存映射段。在这里,内核将文件内容直接映射到内存。任何应用程序都可以通过 Linux 的 [`mmap()`][12] 系统调用( [代码实现][13])或者 Windows 的 [`CreateFileMapping()`][14] / [`MapViewOfFile()`][15] 来请求一个映射。内存映射是实现文件 I/O 的方便高效的方式。因此,它经常被用于加载动态库。有时候,也被用于去创建一个并不匹配任何文件的匿名内存映射,这种映射经常被用做程序数据的替代。在 Linux 中,如果你通过 [`malloc()`][16] 去请求一个大的内存块,C 库将会创建这样一个匿名映射而不是使用堆内存。这里所谓的“大”表示是超过了`MMAP_THRESHOLD` 设置的字节数,它的缺省值是 128 kB,可以通过 [`mallopt()`][17] 去调整这个设置值。
|
||||
|
||||
接下来讲的是“堆”,就在我们接下来的地址空间中,堆提供运行时内存分配,像栈一样,但又不同于栈的是,它分配的数据生存期要长于分配它的函数。大多数编程语言都为程序提供了堆管理支持。因此,满足内存需要是编程语言运行时和内核共同来做的事情。在 C 中,堆分配的接口是 [`malloc()`][18] 一族,然而在支持垃圾回收的编程语言中,像 C#,这个接口使用 `new` 关键字。
|
||||
|
||||
如果在堆中有足够的空间可以满足内存请求,它可以由编程语言运行时来处理内存分配请求,而无需内核参与。否则将通过 [`brk()`][19] 系统调用([代码实现][20])来扩大堆以满足内存请求所需的大小。堆管理是比较 [复杂的][21],在面对我们程序的混乱分配模式时,它通过复杂的算法,努力在速度和内存使用效率之间取得一种平衡。服务一个堆请求所需要的时间可能是非常可观的。实时系统有一个 [特定用途的分配器][22] 去处理这个问题。堆也会出现 _碎片化_ ,如下图所示:
|
||||
|
||||

|
||||
|
||||
最后,我们抵达了内存的低位段:BSS、数据、以及程序文本。在 C 中,静态(全局)变量的内容都保存在 BSS 和数据中。它们之间的不同之处在于,BSS 保存 _未初始化的_ 静态变量的内容,它的值在源代码中并没有被程序员设置。BSS 内存区域是 _匿名_ 的:它没有映射到任何文件上。如果你在程序中写这样的语句 `static int cntActiveUsers`,`cntActiveUsers` 的内容就保存在 BSS 中。
|
||||
|
||||
反过来,数据段,用于保存在源代码中静态变量 _初始化后_ 的内容。这个内存区域是 _非匿名_ 的。它映射了程序的二进值镜像上的一部分,包含了在源代码中给定初始化值的静态变量内容。因此,如果你在程序中写这样的语句 `static int cntWorkerBees = 10`,那么,`cntWorkerBees` 的内容就保存在数据段中,并且初始值为 `10`。尽管可以通过数据段映射到一个文件,但是这是一个私有内存映射,意味着,如果改变内存,它并不会将这种变化反映到底层的文件上。必须是这样的,否则,分配的全局变量将会改变你磁盘上的二进制文件镜像,这种做法就太不可思议了!
|
||||
|
||||
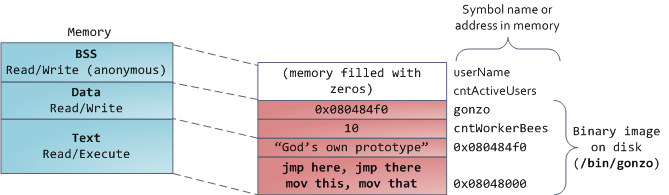
用图去展示一个数据段是很困难的,因为它使用一个指针。在那种情况下,指针 `gonzo` 的_内容_(一个 4 字节的内存地址)保存在数据段上。然而,它并没有指向一个真实的字符串。而这个字符串存在于文本段中,文本段是只读的,它用于保存你的代码中的类似于字符串常量这样的内容。文本段也会在内存中映射你的二进制文件,但是,如果你的程序写入到这个区域,将会触发一个段故障错误。尽管在 C 中,它比不上从一开始就避免这种指针错误那么有效,但是,这种机制也有助于避免指针错误。这里有一个展示这些段和示例变量的图:
|
||||
|
||||
|
||||
|
||||
你可以通过读取 `/proc/pid_of_process/maps` 文件来检查 Linux 进程中的内存区域。请记住,一个段可以包含很多的区域。例如,每个内存映射的文件一般都在 mmap 段中的它自己的区域中,而动态库有类似于 BSS 和数据一样的额外的区域。下一篇文章中我们将详细说明“<ruby>区域<rt>area</rt></ruby>”的真正含义是什么。此外,有时候人们所说的“<ruby>数据段<rt>data segment</rt></ruby>”是指“<ruby>数据<rt>data</rt></ruby> + BSS + 堆”。
|
||||
|
||||
你可以使用 [nm][23] 和 [objdump][24] 命令去检查二进制镜像,去显示它们的符号、地址、段等等。最终,在 Linux 中上面描述的虚拟地址布局是一个“弹性的”布局,这就是这几年来的缺省情况。它假设 `RLIMIT_STACK` 有一个值。如果没有值的话,Linux 将恢复到如下所示的“经典” 布局:
|
||||
|
||||
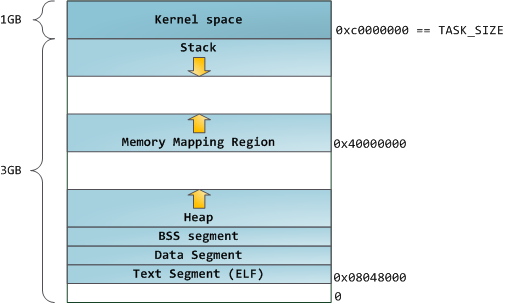
|
||||
|
||||
这就是虚拟地址空间布局。接下来的文章将讨论内核如何对这些内存区域保持跟踪、内存映射、文件如何读取和写入、以及内存使用数据的意义。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
|
||||
[2]:http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729
|
||||
[6]:http://www.stanford.edu/~blp/papers/asrandom.pdf
|
||||
[7]:http://en.wikipedia.org/wiki/Lifo
|
||||
[8]:http://duartes.org/gustavo/blog/post/intel-cpu-caches
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544
|
||||
[11]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692
|
||||
[12]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27
|
||||
[14]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[15]:http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[20]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248
|
||||
[21]:http://g.oswego.edu/dl/html/malloc.html
|
||||
[22]:http://rtportal.upv.es/rtmalloc/
|
||||
[23]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html
|
||||
[24]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html
|
||||
@ -0,0 +1,231 @@
|
||||
在不重启的情况下为 Vmware Linux 客户机添加新硬盘
|
||||
======
|
||||
|
||||
作为一名系统管理员,我经常需要用额外的硬盘来扩充存储空间或将系统数据从用户数据中分离出来。我将告诉你在将物理块设备加到虚拟主机的这个过程中,如何将一个主机上的硬盘加到一台使用 VMWare 软件虚拟化的 Linux 客户机上。
|
||||
|
||||
你可以显式的添加或删除一个 SCSI 设备,或者重新扫描整个 SCSI 总线而不用重启 Linux 虚拟机。本指南在 Vmware Server 和 Vmware Workstation v6.0 中通过测试(更老版本应该也支持)。所有命令在 RHEL、Fedora、CentOS 和 Ubuntu Linux 客户机 / 主机操作系统下都经过了测试。
|
||||
|
||||
### 步骤 1:添加新硬盘到虚拟客户机
|
||||
|
||||
首先,通过 vmware 硬件设置菜单添加硬盘。点击 “VM > Settings”
|
||||
|
||||
![Fig.01:Vmware Virtual Machine Settings ][1]
|
||||
|
||||
或者你也可以按下 `CTRL + D` 也能进入设置对话框。
|
||||
|
||||
点击 “Add” 添加新硬盘到客户机:
|
||||
|
||||
![Fig.02:VMWare adding a new hardware][2]
|
||||
|
||||
选择硬件类型为“Hard disk”然后点击 “Next”:
|
||||
|
||||
![Fig.03 VMware Adding a new disk wizard ][3]
|
||||
|
||||
选择 “create a new virtual disk” 然后点击 “Next”:
|
||||
|
||||
![Fig.04:Vmware Wizard Disk ][4]
|
||||
|
||||
设置虚拟磁盘类型为 “SCSI” ,然后点击 “Next”:
|
||||
|
||||
![Fig.05:Vmware Virtual Disk][5]
|
||||
|
||||
按需要设置最大磁盘大小,然后点击 “Next”
|
||||
|
||||
![Fig.06:Finalizing Disk Virtual Addition ][6]
|
||||
|
||||
最后,选择文件存放位置然后点击 “Finish”。
|
||||
|
||||
### 步骤 2:重新扫描 SCSI 总线,在不重启虚拟机的情况下添加 SCSI 设备
|
||||
|
||||
输入下面命令重新扫描 SCSI 总线:
|
||||
|
||||
```
|
||||
echo "- - -" > /sys/class/scsi_host/host# /scan
|
||||
fdisk -l
|
||||
tail -f /var/log/message
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
![Linux Vmware Rescan New Scsi Disk Without Reboot][7]
|
||||
|
||||
你需要将 `host#` 替换成真实的值,比如 `host0`。你可以通过下面命令来查出这个值:
|
||||
|
||||
`# ls /sys/class/scsi_host`
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
host0
|
||||
```
|
||||
|
||||
然后输入下面过命令来请求重新扫描:
|
||||
|
||||
```
|
||||
echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
fdisk -l
|
||||
tail -f /var/log/message
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
```
|
||||
Jul 18 16:29:39 localhost kernel: Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Jul 18 16:29:39 localhost kernel: Type: Direct-Access ANSI SCSI revision: 02
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:1: Beginning Domain Validation
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:1: Domain Validation skipping write tests
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:1: Ending Domain Validation
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:1: FAST-40 WIDE SCSI 80.0 MB/s ST (25 ns, offset 127)
|
||||
Jul 18 16:29:39 localhost kernel: SCSI device sdb: 2097152 512-byte hdwr sectors (1074 MB)
|
||||
Jul 18 16:29:39 localhost kernel: sdb: Write Protect is off
|
||||
Jul 18 16:29:39 localhost kernel: sdb: cache data unavailable
|
||||
Jul 18 16:29:39 localhost kernel: sdb: assuming drive cache: write through
|
||||
Jul 18 16:29:39 localhost kernel: SCSI device sdb: 2097152 512-byte hdwr sectors (1074 MB)
|
||||
Jul 18 16:29:39 localhost kernel: sdb: Write Protect is off
|
||||
Jul 18 16:29:39 localhost kernel: sdb: cache data unavailable
|
||||
Jul 18 16:29:39 localhost kernel: sdb: assuming drive cache: write through
|
||||
Jul 18 16:29:39 localhost kernel: sdb: unknown partition table
|
||||
Jul 18 16:29:39 localhost kernel: sd 0:0:1:0: Attached scsi disk sdb
|
||||
Jul 18 16:29:39 localhost kernel: sd 0:0:1:0: Attached scsi generic sg1 type 0
|
||||
Jul 18 16:29:39 localhost kernel: Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Jul 18 16:29:39 localhost kernel: Type: Direct-Access ANSI SCSI revision: 02
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:2: Beginning Domain Validation
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:2: Domain Validation skipping write tests
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:2: Ending Domain Validation
|
||||
Jul 18 16:29:39 localhost kernel: target0:0:2: FAST-40 WIDE SCSI 80.0 MB/s ST (25 ns, offset 127)
|
||||
Jul 18 16:29:39 localhost kernel: SCSI device sdc: 2097152 512-byte hdwr sectors (1074 MB)
|
||||
Jul 18 16:29:39 localhost kernel: sdc: Write Protect is off
|
||||
Jul 18 16:29:39 localhost kernel: sdc: cache data unavailable
|
||||
Jul 18 16:29:39 localhost kernel: sdc: assuming drive cache: write through
|
||||
Jul 18 16:29:39 localhost kernel: SCSI device sdc: 2097152 512-byte hdwr sectors (1074 MB)
|
||||
Jul 18 16:29:39 localhost kernel: sdc: Write Protect is off
|
||||
Jul 18 16:29:39 localhost kernel: sdc: cache data unavailable
|
||||
Jul 18 16:29:39 localhost kernel: sdc: assuming drive cache: write through
|
||||
Jul 18 16:29:39 localhost kernel: sdc: unknown partition table
|
||||
Jul 18 16:29:39 localhost kernel: sd 0:0:2:0: Attached scsi disk sdc
|
||||
Jul 18 16:29:39 localhost kernel: sd 0:0:2:0: Attached scsi generic sg2 type 0
|
||||
```
|
||||
|
||||
#### 如何删除 /dev/sdc 这块设备?
|
||||
|
||||
除了重新扫描整个总线外,你也可以使用下面命令添加或删除指定磁盘:
|
||||
|
||||
```
|
||||
# echo 1 > /sys/block/devName/device/delete
|
||||
# echo 1 > /sys/block/sdc/device/delete
|
||||
```
|
||||
|
||||
#### 如何添加 /dev/sdc 这块设备?
|
||||
|
||||
使用下面语法添加指定设备:
|
||||
|
||||
```
|
||||
# echo "scsi add-single-device <H> <B> <T> <L>" > /proc/scsi/scsi
|
||||
```
|
||||
|
||||
这里,
|
||||
|
||||
* <H>:主机
|
||||
* <B>:总线(通道)
|
||||
* <T>:目标 (Id)
|
||||
* <L>:LUN 号
|
||||
|
||||
例如。使用参数 `host#0`,`bus#0`,`target#2`,以及 `LUN#0` 来添加 `/dev/sdc`,则输入:
|
||||
|
||||
```
|
||||
# echo "scsi add-single-device 0 0 2 0">/proc/scsi/scsi
|
||||
# fdisk -l
|
||||
# cat /proc/scsi/scsi
|
||||
```
|
||||
|
||||
结果输出:
|
||||
|
||||
```
|
||||
Attached devices:
|
||||
Host: scsi0 Channel: 00 Id: 00 Lun: 00
|
||||
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Type: Direct-Access ANSI SCSI revision: 02
|
||||
Host: scsi0 Channel: 00 Id: 01 Lun: 00
|
||||
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Type: Direct-Access ANSI SCSI revision: 02
|
||||
Host: scsi0 Channel: 00 Id: 02 Lun: 00
|
||||
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
|
||||
Type: Direct-Access ANSI SCSI revision: 02
|
||||
```
|
||||
|
||||
### 步骤 #3:格式化新磁盘
|
||||
|
||||
现在使用 [fdisk 并通过 mkfs.ext3][8] 命令创建分区:
|
||||
|
||||
```
|
||||
# fdisk /dev/sdc
|
||||
### [if you want ext3 fs] ###
|
||||
# mkfs.ext3 /dev/sdc3
|
||||
### [if you want ext4 fs] ###
|
||||
# mkfs.ext4 /dev/sdc3
|
||||
```
|
||||
|
||||
### 步骤 #4:创建挂载点并更新 /etc/fstab
|
||||
|
||||
```
|
||||
# mkdir /disk3
|
||||
```
|
||||
|
||||
打开 `/etc/fstab` 文件,输入:
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
```
|
||||
|
||||
加入下面这行:
|
||||
|
||||
```
|
||||
/dev/sdc3 /disk3 ext3 defaults 1 2
|
||||
```
|
||||
|
||||
若是 ext4 文件系统则加入:
|
||||
|
||||
```
|
||||
/dev/sdc3 /disk3 ext4 defaults 1 2
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
#### 可选操作:为分区加标签
|
||||
|
||||
[你可以使用 e2label 命令为分区加标签 ][9]。假设,你想要为 `/backupDisk` 这块新分区加标签,则输入:
|
||||
|
||||
```
|
||||
# e2label /dev/sdc1 /backupDisk
|
||||
```
|
||||
|
||||
详情参见 "[Linux 分区的重要性 ][10]。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,也是一名经验丰富的系统管理员,还是 Linux 操作系统 /Unix shell 脚本培训师。他曾服务过全球客户并与多个行业合作过,包括 IT,教育,国防和空间研究,以及非盈利机构。你可以在 [Twitter][11],[Facebook][12],[Google+][13] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/vmware-add-a-new-hard-disk-without-rebooting-guest.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2009/07/virtual-machine-settings-1.png (Vmware Virtual Machine Settings )
|
||||
[2]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-add-hardware-wizard-2.png (VMWare adding a new hardware)
|
||||
[3]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-add-hardware-anew-disk-3.png (VMware Adding a new disk wizard )
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-add-hardware-4.png (Vmware Wizard Disk )
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2009/07/add-hardware-5.png (Vmware Virtual Disk)
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-final-disk-file-add-hdd-6.png (Finalizing Disk Virtual Addition)
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/07/vmware-linux-rescan-hard-disk.png (Linux Vmware Rescan New Scsi Disk Without Reboot)
|
||||
[8]:https://www.cyberciti.biz/faq/linux-disk-format/
|
||||
[9]:https://www.cyberciti.biz/faq/linux-modify-partition-labels-command-to-change-diskname/
|
||||
[10]:https://www.cyberciti.biz/faq/linux-partition-howto-set-labels/>how%20to%20label%20a%20Linux%20partition</a>%E2%80%9D%20for%20more%20info.</p><h2>Conclusion</h2><p>The%20VMware%20guest%20now%20has%20an%20additional%20virtualized%20storage%20device.%20%20The%20procedure%20works%20for%20all%20physical%20block%20devices,%20this%20includes%20CD-ROM,%20DVD%20and%20floppy%20devices.%20Next,%20time%20I%20will%20write%20about%20adding%20an%20additional%20virtualized%20storage%20device%20using%20XEN%20software.</p><h2>See%20also</h2><ul><li><a%20href=
|
||||
[11]:https://twitter.com/nixcraft
|
||||
[12]:https://facebook.com/nixcraft
|
||||
[13]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,584 @@
|
||||
30 个方便的 Bash shell 别名
|
||||
======
|
||||
|
||||
bash <ruby>别名<rt>alias</rt></ruby>只不过是指向命令的快捷方式而已。`alias` 命令允许用户只输入一个单词就运行任意一个命令或一组命令(包括命令选项和文件名)。执行 `alias` 命令会显示一个所有已定义别名的列表。你可以在 [~/.bashrc][1] 文件中自定义别名。使用别名可以在命令行中减少输入的时间,使工作更流畅,同时增加生产率。
|
||||
|
||||
本文通过 30 个 bash shell 别名的实际案例演示了如何创建和使用别名。
|
||||
|
||||
![30 Useful Bash Shell Aliase For Linux/Unix Users][2]
|
||||
|
||||
### bash alias 的那些事
|
||||
|
||||
bash shell 中的 alias 命令的语法是这样的:
|
||||
|
||||
```
|
||||
alias [alias-name[=string]...]
|
||||
```
|
||||
|
||||
#### 如何列出 bash 别名
|
||||
|
||||
输入下面的 [alias 命令][3]:
|
||||
|
||||
```
|
||||
alias
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
```
|
||||
alias ..='cd ..'
|
||||
alias amazonbackup='s3backup'
|
||||
alias apt-get='sudo apt-get'
|
||||
...
|
||||
```
|
||||
|
||||
`alias` 命令默认会列出当前用户定义好的别名。
|
||||
|
||||
#### 如何定义或者创建一个 bash shell 别名
|
||||
|
||||
使用下面语法 [创建别名][4]:
|
||||
|
||||
```
|
||||
alias name =value
|
||||
alias name = 'command'
|
||||
alias name = 'command arg1 arg2'
|
||||
alias name = '/path/to/script'
|
||||
alias name = '/path/to/script.pl arg1'
|
||||
```
|
||||
|
||||
举个例子,输入下面命令并回车就会为常用的 `clear`(清除屏幕)命令创建一个别名 `c`:
|
||||
|
||||
```
|
||||
alias c = 'clear'
|
||||
```
|
||||
|
||||
然后输入字母 `c` 而不是 `clear` 后回车就会清除屏幕了:
|
||||
|
||||
```
|
||||
c
|
||||
```
|
||||
|
||||
#### 如何临时性地禁用 bash 别名
|
||||
|
||||
下面语法可以[临时性地禁用别名][5]:
|
||||
|
||||
```
|
||||
## path/to/full/command
|
||||
/usr/bin/clear
|
||||
## call alias with a backslash ##
|
||||
\c
|
||||
## use /bin/ls command and avoid ls alias ##
|
||||
command ls
|
||||
```
|
||||
|
||||
#### 如何删除 bash 别名
|
||||
|
||||
使用 [unalias 命令来删除别名][6]。其语法为:
|
||||
|
||||
```
|
||||
unalias aliasname
|
||||
unalias foo
|
||||
```
|
||||
|
||||
例如,删除我们之前创建的别名 `c`:
|
||||
|
||||
```
|
||||
unalias c
|
||||
```
|
||||
|
||||
你还需要用文本编辑器删掉 [~/.bashrc 文件][1] 中的别名定义(参见下一部分内容)。
|
||||
|
||||
#### 如何让 bash shell 别名永久生效
|
||||
|
||||
别名 `c` 在当前登录会话中依然有效。但当你登出或重启系统后,别名 `c` 就没有了。为了防止出现这个问题,将别名定义写入 [~/.bashrc file][1] 中,输入:
|
||||
|
||||
```
|
||||
vi ~/.bashrc
|
||||
```
|
||||
|
||||
输入下行内容让别名 `c` 对当前用户永久有效:
|
||||
|
||||
```
|
||||
alias c = 'clear'
|
||||
```
|
||||
|
||||
保存并关闭文件就行了。系统级的别名(也就是对所有用户都生效的别名)可以放在 `/etc/bashrc` 文件中。请注意,`alias` 命令内建于各种 shell 中,包括 ksh,tcsh/csh,ash,bash 以及其他 shell。
|
||||
|
||||
#### 关于特权权限判断
|
||||
|
||||
可以将下面代码加入 `~/.bashrc`:
|
||||
|
||||
```
|
||||
# if user is not root, pass all commands via sudo #
|
||||
if [ $UID -ne 0 ]; then
|
||||
alias reboot='sudo reboot'
|
||||
alias update='sudo apt-get upgrade'
|
||||
fi
|
||||
```
|
||||
|
||||
#### 定义与操作系统类型相关的别名
|
||||
|
||||
可以将下面代码加入 `~/.bashrc` [使用 case 语句][7]:
|
||||
|
||||
```
|
||||
### Get os name via uname ###
|
||||
_myos="$(uname)"
|
||||
|
||||
### add alias as per os using $_myos ###
|
||||
case $_myos in
|
||||
Linux) alias foo='/path/to/linux/bin/foo';;
|
||||
FreeBSD|OpenBSD) alias foo='/path/to/bsd/bin/foo' ;;
|
||||
SunOS) alias foo='/path/to/sunos/bin/foo' ;;
|
||||
*) ;;
|
||||
esac
|
||||
```
|
||||
|
||||
### 30 个 bash shell 别名的案例
|
||||
|
||||
你可以定义各种类型的别名来节省时间并提高生产率。
|
||||
|
||||
#### #1:控制 ls 命令的输出
|
||||
|
||||
[ls 命令列出目录中的内容][8] 而你可以对输出进行着色:
|
||||
|
||||
```
|
||||
## Colorize the ls output ##
|
||||
alias ls = 'ls --color=auto'
|
||||
|
||||
## Use a long listing format ##
|
||||
alias ll = 'ls -la'
|
||||
|
||||
## Show hidden files ##
|
||||
alias l.= 'ls -d . .. .git .gitignore .gitmodules .travis.yml --color=auto'
|
||||
```
|
||||
|
||||
#### #2:控制 cd 命令的行为
|
||||
|
||||
```
|
||||
## get rid of command not found ##
|
||||
alias cd..= 'cd ..'
|
||||
|
||||
## a quick way to get out of current directory ##
|
||||
alias ..= 'cd ..'
|
||||
alias ...= 'cd ../../../'
|
||||
alias ....= 'cd ../../../../'
|
||||
alias .....= 'cd ../../../../'
|
||||
alias .4= 'cd ../../../../'
|
||||
alias .5= 'cd ../../../../..'
|
||||
```
|
||||
|
||||
#### #3:控制 grep 命令的输出
|
||||
|
||||
[grep 命令是一个用于在纯文本文件中搜索匹配正则表达式的行的命令行工具][9]:
|
||||
|
||||
```
|
||||
## Colorize the grep command output for ease of use (good for log files)##
|
||||
alias grep = 'grep --color=auto'
|
||||
alias egrep = 'egrep --color=auto'
|
||||
alias fgrep = 'fgrep --color=auto'
|
||||
```
|
||||
|
||||
#### #4:让计算器默认开启 math 库
|
||||
|
||||
```
|
||||
alias bc = 'bc -l'
|
||||
```
|
||||
|
||||
#### #4:生成 sha1 数字签名
|
||||
|
||||
```
|
||||
alias sha1 = 'openssl sha1'
|
||||
```
|
||||
|
||||
#### #5:自动创建父目录
|
||||
|
||||
[mkdir 命令][10] 用于创建目录:
|
||||
|
||||
```
|
||||
alias mkdir = 'mkdir -pv'
|
||||
```
|
||||
|
||||
#### #6:为 diff 输出着色
|
||||
|
||||
你可以[使用 diff 来一行行第比较文件][11] 而一个名为 `colordiff` 的工具可以为 diff 输出着色:
|
||||
|
||||
```
|
||||
# install colordiff package :)
|
||||
alias diff = 'colordiff'
|
||||
```
|
||||
|
||||
#### #7:让 mount 命令的输出更漂亮,更方便人类阅读
|
||||
|
||||
```
|
||||
alias mount = 'mount |column -t'
|
||||
```
|
||||
|
||||
#### #8:简化命令以节省时间
|
||||
|
||||
```
|
||||
# handy short cuts #
|
||||
alias h = 'history'
|
||||
alias j = 'jobs -l'
|
||||
```
|
||||
|
||||
#### #9:创建一系列新命令
|
||||
|
||||
```
|
||||
alias path = 'echo -e ${PATH//:/\\n}'
|
||||
alias now = 'date +"%T"'
|
||||
alias nowtime =now
|
||||
alias nowdate = 'date +"%d-%m-%Y"'
|
||||
```
|
||||
|
||||
#### #10:设置 vim 为默认编辑器
|
||||
|
||||
```
|
||||
alias vi = vim
|
||||
alias svi = 'sudo vi'
|
||||
alias vis = 'vim "+set si"'
|
||||
alias edit = 'vim'
|
||||
```
|
||||
|
||||
#### #11:控制网络工具 ping 的输出
|
||||
|
||||
```
|
||||
# Stop after sending count ECHO_REQUEST packets #
|
||||
alias ping = 'ping -c 5'
|
||||
|
||||
# Do not wait interval 1 second, go fast #
|
||||
alias fastping = 'ping -c 100 -s.2'
|
||||
```
|
||||
|
||||
#### #12:显示打开的端口
|
||||
|
||||
使用 [netstat 命令][12] 可以快速列出服务区中所有的 TCP/UDP 端口:
|
||||
|
||||
```
|
||||
alias ports = 'netstat -tulanp'
|
||||
```
|
||||
|
||||
#### #13:唤醒休眠的服务器
|
||||
|
||||
[Wake-on-LAN (WOL) 是一个以太网标准][13],可以通过网络消息来开启服务器。你可以使用下面别名来[快速激活 nas 设备][14] 以及服务器:
|
||||
|
||||
```
|
||||
## replace mac with your actual server mac address #
|
||||
alias wakeupnas01 = '/usr/bin/wakeonlan 00:11:32:11:15:FC'
|
||||
alias wakeupnas02 = '/usr/bin/wakeonlan 00:11:32:11:15:FD'
|
||||
alias wakeupnas03 = '/usr/bin/wakeonlan 00:11:32:11:15:FE'
|
||||
```
|
||||
|
||||
#### #14:控制防火墙 (iptables) 的输出
|
||||
|
||||
[Netfilter 是一款 Linux 操作系统上的主机防火墙][15]。它是 Linux 发行版中的一部分,且默认情况下是激活状态。[这里列出了大多数 Liux 新手防护入侵者最常用的 iptables 方法][16]。
|
||||
|
||||
```
|
||||
## shortcut for iptables and pass it via sudo#
|
||||
alias ipt = 'sudo /sbin/iptables'
|
||||
|
||||
# display all rules #
|
||||
alias iptlist = 'sudo /sbin/iptables -L -n -v --line-numbers'
|
||||
alias iptlistin = 'sudo /sbin/iptables -L INPUT -n -v --line-numbers'
|
||||
alias iptlistout = 'sudo /sbin/iptables -L OUTPUT -n -v --line-numbers'
|
||||
alias iptlistfw = 'sudo /sbin/iptables -L FORWARD -n -v --line-numbers'
|
||||
alias firewall =iptlist
|
||||
```
|
||||
|
||||
#### #15:使用 curl 调试 web 服务器 / CDN 上的问题
|
||||
|
||||
```
|
||||
# get web server headers #
|
||||
alias header = 'curl -I'
|
||||
|
||||
# find out if remote server supports gzip / mod_deflate or not #
|
||||
alias headerc = 'curl -I --compress'
|
||||
```
|
||||
|
||||
#### #16:增加安全性
|
||||
|
||||
```
|
||||
# do not delete / or prompt if deleting more than 3 files at a time #
|
||||
alias rm = 'rm -I --preserve-root'
|
||||
|
||||
# confirmation #
|
||||
alias mv = 'mv -i'
|
||||
alias cp = 'cp -i'
|
||||
alias ln = 'ln -i'
|
||||
|
||||
# Parenting changing perms on / #
|
||||
alias chown = 'chown --preserve-root'
|
||||
alias chmod = 'chmod --preserve-root'
|
||||
alias chgrp = 'chgrp --preserve-root'
|
||||
```
|
||||
|
||||
#### #17:更新 Debian Linux 服务器
|
||||
|
||||
[apt-get 命令][17] 用于通过因特网安装软件包 (ftp 或 http)。你也可以一次性升级所有软件包:
|
||||
|
||||
```
|
||||
# distro specific - Debian / Ubuntu and friends #
|
||||
# install with apt-get
|
||||
alias apt-get= "sudo apt-get"
|
||||
alias updatey = "sudo apt-get --yes"
|
||||
|
||||
# update on one command
|
||||
alias update = 'sudo apt-get update && sudo apt-get upgrade'
|
||||
```
|
||||
|
||||
#### #18:更新 RHEL / CentOS / Fedora Linux 服务器
|
||||
|
||||
[yum 命令][18] 是 RHEL / CentOS / Fedora Linux 以及其他基于这些发行版的 Linux 上的软件包管理工具:
|
||||
|
||||
```
|
||||
## distrp specifc RHEL/CentOS ##
|
||||
alias update = 'yum update'
|
||||
alias updatey = 'yum -y update'
|
||||
```
|
||||
|
||||
#### #19:优化 sudo 和 su 命令
|
||||
|
||||
```
|
||||
# become root #
|
||||
alias root = 'sudo -i'
|
||||
alias su = 'sudo -i'
|
||||
```
|
||||
|
||||
#### #20:使用 sudo 执行 halt/reboot 命令
|
||||
|
||||
[shutdown 命令][19] 会让 Linux / Unix 系统关机:
|
||||
```
|
||||
# reboot / halt / poweroff
|
||||
alias reboot = 'sudo /sbin/reboot'
|
||||
alias poweroff = 'sudo /sbin/poweroff'
|
||||
alias halt = 'sudo /sbin/halt'
|
||||
alias shutdown = 'sudo /sbin/shutdown'
|
||||
```
|
||||
|
||||
#### #21:控制 web 服务器
|
||||
|
||||
```
|
||||
# also pass it via sudo so whoever is admin can reload it without calling you #
|
||||
alias nginxreload = 'sudo /usr/local/nginx/sbin/nginx -s reload'
|
||||
alias nginxtest = 'sudo /usr/local/nginx/sbin/nginx -t'
|
||||
alias lightyload = 'sudo /etc/init.d/lighttpd reload'
|
||||
alias lightytest = 'sudo /usr/sbin/lighttpd -f /etc/lighttpd/lighttpd.conf -t'
|
||||
alias httpdreload = 'sudo /usr/sbin/apachectl -k graceful'
|
||||
alias httpdtest = 'sudo /usr/sbin/apachectl -t && /usr/sbin/apachectl -t -D DUMP_VHOSTS'
|
||||
```
|
||||
|
||||
#### #22:与备份相关的别名
|
||||
|
||||
```
|
||||
# if cron fails or if you want backup on demand just run these commands #
|
||||
# again pass it via sudo so whoever is in admin group can start the job #
|
||||
# Backup scripts #
|
||||
alias backup = 'sudo /home/scripts/admin/scripts/backup/wrapper.backup.sh --type local --taget /raid1/backups'
|
||||
alias nasbackup = 'sudo /home/scripts/admin/scripts/backup/wrapper.backup.sh --type nas --target nas01'
|
||||
alias s3backup = 'sudo /home/scripts/admin/scripts/backup/wrapper.backup.sh --type nas --target nas01 --auth /home/scripts/admin/.authdata/amazon.keys'
|
||||
alias rsnapshothourly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnapshot.sh --type remote --target nas03 --auth /home/scripts/admin/.authdata/ssh.keys --config /home/scripts/admin/scripts/backup/config/adsl.conf'
|
||||
alias rsnapshotdaily = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnapshot.sh --type remote --target nas03 --auth /home/scripts/admin/.authdata/ssh.keys --config /home/scripts/admin/scripts/backup/config/adsl.conf'
|
||||
alias rsnapshotweekly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnapshot.sh --type remote --target nas03 --auth /home/scripts/admin/.authdata/ssh.keys --config /home/scripts/admin/scripts/backup/config/adsl.conf'
|
||||
alias rsnapshotmonthly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnapshot.sh --type remote --target nas03 --auth /home/scripts/admin/.authdata/ssh.keys --config /home/scripts/admin/scripts/backup/config/adsl.conf'
|
||||
alias amazonbackup =s3backup
|
||||
```
|
||||
|
||||
#### #23:桌面应用相关的别名 - 按需播放的 avi/mp3 文件
|
||||
|
||||
```
|
||||
## play video files in a current directory ##
|
||||
# cd ~/Download/movie-name
|
||||
# playavi or vlc
|
||||
alias playavi = 'mplayer *.avi'
|
||||
alias vlc = 'vlc *.avi'
|
||||
|
||||
# play all music files from the current directory #
|
||||
alias playwave = 'for i in *.wav; do mplayer "$i"; done'
|
||||
alias playogg = 'for i in *.ogg; do mplayer "$i"; done'
|
||||
alias playmp3 = 'for i in *.mp3; do mplayer "$i"; done'
|
||||
|
||||
# play files from nas devices #
|
||||
alias nplaywave = 'for i in /nas/multimedia/wave/*.wav; do mplayer "$i"; done'
|
||||
alias nplayogg = 'for i in /nas/multimedia/ogg/*.ogg; do mplayer "$i"; done'
|
||||
alias nplaymp3 = 'for i in /nas/multimedia/mp3/*.mp3; do mplayer "$i"; done'
|
||||
|
||||
# shuffle mp3/ogg etc by default #
|
||||
alias music = 'mplayer --shuffle *'
|
||||
```
|
||||
|
||||
#### #24:设置系统管理相关命令的默认网卡
|
||||
|
||||
[vnstat 一款基于终端的网络流量检测器][20]。[dnstop 是一款分析 DNS 流量的终端工具][21]。[tcptrack 和 iftop 命令显示][22] TCP/UDP 连接方面的信息,它监控网卡并显示其消耗的带宽。
|
||||
|
||||
```
|
||||
## All of our servers eth1 is connected to the Internets via vlan / router etc ##
|
||||
alias dnstop = 'dnstop -l 5 eth1'
|
||||
alias vnstat = 'vnstat -i eth1'
|
||||
alias iftop = 'iftop -i eth1'
|
||||
alias tcpdump = 'tcpdump -i eth1'
|
||||
alias ethtool = 'ethtool eth1'
|
||||
|
||||
# work on wlan0 by default #
|
||||
# Only useful for laptop as all servers are without wireless interface
|
||||
alias iwconfig = 'iwconfig wlan0'
|
||||
```
|
||||
|
||||
#### #25:快速获取系统内存,cpu 使用,和 gpu 内存相关信息
|
||||
|
||||
```
|
||||
## pass options to free ##
|
||||
alias meminfo = 'free -m -l -t'
|
||||
|
||||
## get top process eating memory
|
||||
alias psmem = 'ps auxf | sort -nr -k 4'
|
||||
alias psmem10 = 'ps auxf | sort -nr -k 4 | head -10'
|
||||
|
||||
## get top process eating cpu ##
|
||||
alias pscpu = 'ps auxf | sort -nr -k 3'
|
||||
alias pscpu10 = 'ps auxf | sort -nr -k 3 | head -10'
|
||||
|
||||
## Get server cpu info ##
|
||||
alias cpuinfo = 'lscpu'
|
||||
|
||||
## older system use /proc/cpuinfo ##
|
||||
##alias cpuinfo='less /proc/cpuinfo' ##
|
||||
|
||||
## get GPU ram on desktop / laptop##
|
||||
alias gpumeminfo = 'grep -i --color memory /var/log/Xorg.0.log'
|
||||
```
|
||||
|
||||
#### #26:控制家用路由器
|
||||
|
||||
`curl` 命令可以用来 [重启 Linksys 路由器][23]。
|
||||
|
||||
```
|
||||
# Reboot my home Linksys WAG160N / WAG54 / WAG320 / WAG120N Router / Gateway from *nix.
|
||||
alias rebootlinksys = "curl -u 'admin:my-super-password' 'http://192.168.1.2/setup.cgi?todo=reboot'"
|
||||
|
||||
# Reboot tomato based Asus NT16 wireless bridge
|
||||
alias reboottomato = "ssh admin@192.168.1.1 /sbin/reboot"
|
||||
```
|
||||
|
||||
#### #27 wget 默认断点续传
|
||||
|
||||
[GNU wget 是一款用来从 web 下载文件的自由软件][25]。它支持 HTTP,HTTPS,以及 FTP 协议,而且它也支持断点续传:
|
||||
|
||||
```
|
||||
## this one saved by butt so many times ##
|
||||
alias wget = 'wget -c'
|
||||
```
|
||||
|
||||
#### #28 使用不同浏览器来测试网站
|
||||
|
||||
```
|
||||
## this one saved by butt so many times ##
|
||||
alias ff4 = '/opt/firefox4/firefox'
|
||||
alias ff13 = '/opt/firefox13/firefox'
|
||||
alias chrome = '/opt/google/chrome/chrome'
|
||||
alias opera = '/opt/opera/opera'
|
||||
|
||||
#default ff
|
||||
alias ff =ff13
|
||||
|
||||
#my default browser
|
||||
alias browser =chrome
|
||||
```
|
||||
|
||||
#### #29:关于 ssh 别名的注意事项
|
||||
|
||||
不要创建 ssh 别名,代之以 `~/.ssh/config` 这个 OpenSSH SSH 客户端配置文件。它的选项更加丰富。下面是一个例子:
|
||||
|
||||
```
|
||||
Host server10
|
||||
Hostname 1.2.3.4
|
||||
IdentityFile ~/backups/.ssh/id_dsa
|
||||
user foobar
|
||||
Port 30000
|
||||
ForwardX11Trusted yes
|
||||
TCPKeepAlive yes
|
||||
```
|
||||
|
||||
然后你就可以使用下面语句连接 server10 了:
|
||||
|
||||
```
|
||||
$ ssh server10
|
||||
```
|
||||
|
||||
#### #30:现在该分享你的别名了
|
||||
|
||||
```
|
||||
## set some other defaults ##
|
||||
alias df = 'df -H'
|
||||
alias du = 'du -ch'
|
||||
|
||||
# top is atop, just like vi is vim
|
||||
alias top = 'atop'
|
||||
|
||||
## nfsrestart - must be root ##
|
||||
## refresh nfs mount / cache etc for Apache ##
|
||||
alias nfsrestart = 'sync && sleep 2 && /etc/init.d/httpd stop && umount netapp2:/exports/http && sleep 2 && mount -o rw,sync,rsize=32768,wsize=32768,intr,hard,proto=tcp,fsc natapp2:/exports /http/var/www/html && /etc/init.d/httpd start'
|
||||
|
||||
## Memcached server status ##
|
||||
alias mcdstats = '/usr/bin/memcached-tool 10.10.27.11:11211 stats'
|
||||
alias mcdshow = '/usr/bin/memcached-tool 10.10.27.11:11211 display'
|
||||
|
||||
## quickly flush out memcached server ##
|
||||
alias flushmcd = 'echo "flush_all" | nc 10.10.27.11 11211'
|
||||
|
||||
## Remove assets quickly from Akamai / Amazon cdn ##
|
||||
alias cdndel = '/home/scripts/admin/cdn/purge_cdn_cache --profile akamai'
|
||||
alias amzcdndel = '/home/scripts/admin/cdn/purge_cdn_cache --profile amazon'
|
||||
|
||||
## supply list of urls via file or stdin
|
||||
alias cdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile akamai --stdin'
|
||||
alias amzcdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile amazon --stdin'
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
本文总结了 *nix bash 别名的多种用法:
|
||||
|
||||
1. 为命令设置默认的参数(例如通过 `alias ethtool='ethtool eth0'` 设置 ethtool 命令的默认参数为 eth0)。
|
||||
2. 修正错误的拼写(通过 `alias cd..='cd ..'`让 `cd..` 变成 `cd ..`)。
|
||||
3. 缩减输入。
|
||||
4. 设置系统中多版本命令的默认路径(例如 GNU/grep 位于 `/usr/local/bin/grep` 中而 Unix grep 位于 `/bin/grep` 中。若想默认使用 GNU grep 则设置别名 `grep='/usr/local/bin/grep'` )。
|
||||
5. 通过默认开启命令(例如 `rm`,`mv` 等其他命令)的交互参数来增加 Unix 的安全性。
|
||||
6. 为老旧的操作系统(比如 MS-DOS 或者其他类似 Unix 的操作系统)创建命令以增加兼容性(比如 `alias del=rm`)。
|
||||
|
||||
我已经分享了多年来为了减少重复输入命令而使用的别名。若你知道或使用的哪些 bash/ksh/csh 别名能够减少输入,请在留言框中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://bash.cyberciti.biz/guide/~/.bashrc
|
||||
[2]:https://www.cyberciti.biz/tips/wp-content/uploads/2012/06/Getting-Started-With-Bash-Shell-Aliases-For-Linux-Unix.jpg
|
||||
[3]:https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html (See Linux/Unix alias command examples for more info)
|
||||
[4]:https://bash.cyberciti.biz/guide/Create_and_use_aliases
|
||||
[5]:https://www.cyberciti.biz/faq/bash-shell-temporarily-disable-an-alias/
|
||||
[6]:https://bash.cyberciti.biz/guide/Create_and_use_aliases#How_do_I_remove_the_alias.3F
|
||||
[7]:https://bash.cyberciti.biz/guide/The_case_statement
|
||||
[8]:https://www.cyberciti.biz/faq/ls-command-to-examining-the-filesystem/
|
||||
[9]:https://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/
|
||||
[10]:https://www.cyberciti.biz/faq/linux-make-directory-command/
|
||||
[11]:https://www.cyberciti.biz/faq/how-do-i-compare-two-files-under-linux-or-unix/
|
||||
[12]:https://www.cyberciti.biz/faq/how-do-i-find-out-what-ports-are-listeningopen-on-my-linuxfreebsd-server/
|
||||
[13]:https://www.cyberciti.biz/tips/linux-send-wake-on-lan-wol-magic-packets.html
|
||||
[14]:https://bash.cyberciti.biz/misc-shell/simple-shell-script-to-wake-up-nas-devices-computers/
|
||||
[15]:https://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/ (iptables CentOS/RHEL/Fedora tutorial)
|
||||
[16]:https://www.cyberciti.biz/tips/linux-iptables-examples.html
|
||||
[17]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[18]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[19]:https://www.cyberciti.biz/faq/howto-shutdown-linux/
|
||||
[20]:https://www.cyberciti.biz/tips/keeping-a-log-of-daily-network-traffic-for-adsl-or-dedicated-remote-linux-box.html
|
||||
[21]:https://www.cyberciti.biz/faq/dnstop-monitor-bind-dns-server-dns-network-traffic-from-a-shell-prompt/
|
||||
[22]:https://www.cyberciti.biz/faq/check-network-connection-linux/
|
||||
[23]:https://www.cyberciti.biz/faq/reboot-linksys-wag160n-wag54-wag320-wag120n-router-gateway/
|
||||
[24]:https:/cdn-cgi/l/email-protection
|
||||
[25]:https://www.cyberciti.biz/tips/wget-resume-broken-download.html
|
||||
113
published/20140210 Three steps to learning GDB.md
Normal file
113
published/20140210 Three steps to learning GDB.md
Normal file
@ -0,0 +1,113 @@
|
||||
三步上手 GDB
|
||||
===============
|
||||
|
||||
调试 C 程序,曾让我很困扰。然而当我之前在写我的[操作系统][2]时,我有很多的 Bug 需要调试。我很幸运的使用上了 qemu 模拟器,它允许我将调试器附加到我的操作系统。这个调试器就是 `gdb`。
|
||||
|
||||
我得解释一下,你可以使用 `gdb` 先做一些小事情,因为我发现初学它的时候真的很混乱。我们接下来会在一个小程序中,设置断点,查看内存。.
|
||||
|
||||
### 1、 设断点
|
||||
|
||||
如果你曾经使用过调试器,那你可能已经会设置断点了。
|
||||
|
||||
下面是一个我们要调试的程序(虽然没有任何 Bug):
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
void do_thing() {
|
||||
printf("Hi!\n");
|
||||
}
|
||||
int main() {
|
||||
do_thing();
|
||||
}
|
||||
```
|
||||
|
||||
另存为 `hello.c`. 我们可以使用 `dbg` 调试它,像这样:
|
||||
|
||||
```
|
||||
bork@kiwi ~> gcc -g hello.c -o hello
|
||||
bork@kiwi ~> gdb ./hello
|
||||
```
|
||||
|
||||
以上是带调试信息编译 `hello.c`(为了 `gdb` 可以更好工作),并且它会给我们醒目的提示符,就像这样:
|
||||
|
||||
```
|
||||
(gdb)
|
||||
```
|
||||
|
||||
我们可以使用 `break` 命令设置断点,然后使用 `run` 开始调试程序。
|
||||
|
||||
```
|
||||
(gdb) break do_thing
|
||||
Breakpoint 1 at 0x4004f8
|
||||
(gdb) run
|
||||
Starting program: /home/bork/hello
|
||||
|
||||
Breakpoint 1, 0x00000000004004f8 in do_thing ()
|
||||
```
|
||||
|
||||
程序暂停在了 `do_thing` 开始的地方。
|
||||
|
||||
我们可以通过 `where` 查看我们所在的调用栈。
|
||||
|
||||
```
|
||||
(gdb) where
|
||||
#0 do_thing () at hello.c:3
|
||||
#1 0x08050cdb in main () at hello.c:6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
### 2、 阅读汇编代码
|
||||
|
||||
使用 `disassemble` 命令,我们可以看到这个函数的汇编代码。棒级了,这是 x86 汇编代码。虽然我不是很懂它,但是 `callq` 这一行是 `printf` 函数调用。
|
||||
|
||||
```
|
||||
(gdb) disassemble do_thing
|
||||
Dump of assembler code for function do_thing:
|
||||
0x00000000004004f4 <+0>: push %rbp
|
||||
0x00000000004004f5 <+1>: mov %rsp,%rbp
|
||||
=> 0x00000000004004f8 <+4>: mov $0x40060c,%edi
|
||||
0x00000000004004fd <+9>: callq 0x4003f0
|
||||
0x0000000000400502 <+14>: pop %rbp
|
||||
0x0000000000400503 <+15>: retq
|
||||
```
|
||||
|
||||
你也可以使用 `disassemble` 的缩写 `disas`。
|
||||
|
||||
### 3、 查看内存
|
||||
|
||||
当调试我的内核时,我使用 `gdb` 的主要原因是,以确保内存布局是如我所想的那样。检查内存的命令是 `examine`,或者使用缩写 `x`。我们将使用`x`。
|
||||
|
||||
通过阅读上面的汇编代码,似乎 `0x40060c` 可能是我们所要打印的字符串地址。我们来试一下。
|
||||
|
||||
```
|
||||
(gdb) x/s 0x40060c
|
||||
0x40060c: "Hi!"
|
||||
```
|
||||
|
||||
的确是这样。`x/s` 中 `/s` 部分,意思是“把它作为字符串展示”。我也可以“展示 10 个字符”,像这样:
|
||||
|
||||
```
|
||||
(gdb) x/10c 0x40060c
|
||||
0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';'
|
||||
0x400614: 52 '4' 0 '\000'
|
||||
```
|
||||
|
||||
你可以看到前四个字符是 `H`、`i`、`!` 和 `\0`,并且它们之后的是一些不相关的东西。
|
||||
|
||||
我知道 `gdb` 很多其他的东西,但是我仍然不是很了解它,其中 `x` 和 `break` 让我获得很多。你还可以阅读 [do umentation for examining memory][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[Torival](https://github.com/Torival)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/spytools
|
||||
[2]:https://jvns.ca/blog/categories/kernel
|
||||
[3]:https://twitter.com/mgedmin
|
||||
[4]:https://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56
|
||||
@ -0,0 +1,176 @@
|
||||
如何让 curl 命令通过代理访问
|
||||
======
|
||||
|
||||
我的系统管理员给我提供了如下代理信息:
|
||||
|
||||
```
|
||||
IP: 202.54.1.1
|
||||
Port: 3128
|
||||
Username: foo
|
||||
Password: bar
|
||||
```
|
||||
|
||||
该设置在 Google Chrome 和 Firefox 浏览器上很容易设置。但是我要怎么把它应用到 `curl` 命令上呢?我要如何让 curl 命令使用我在 Google Chrome 浏览器上的代理设置呢?
|
||||
|
||||
很多 Linux 和 Unix 命令行工具(比如 `curl` 命令,`wget` 命令,`lynx` 命令等)使用名为 `http_proxy`,`https_proxy`,`ftp_proxy` 的环境变量来获取代理信息。它允许你通过代理服务器(使用或不使用用户名/密码都行)来连接那些基于文本的会话和应用。
|
||||
|
||||
本文就会演示一下如何让 `curl` 通过代理服务器发送 HTTP/HTTPS 请求。
|
||||
|
||||
### 让 curl 命令使用代理的语法
|
||||
|
||||
语法为:
|
||||
|
||||
```
|
||||
## Set the proxy address of your uni/company/vpn network ##
|
||||
export http_proxy=http://your-ip-address:port/
|
||||
|
||||
## http_proxy with username and password
|
||||
export http_proxy=http://user:password@your-proxy-ip-address:port/
|
||||
|
||||
## HTTPS version ##
|
||||
export https_proxy=https://your-ip-address:port/
|
||||
export https_proxy=https://user:password@your-proxy-ip-address:port/
|
||||
```
|
||||
|
||||
另一种方法是使用 `curl` 命令的 `-x` 选项:
|
||||
|
||||
```
|
||||
curl -x <[protocol://][user:password@]proxyhost[:port]> url
|
||||
--proxy <[protocol://][user:password@]proxyhost[:port]> url
|
||||
--proxy http://user:password@Your-Ip-Here:Port url
|
||||
-x http://user:password@Your-Ip-Here:Port url
|
||||
```
|
||||
|
||||
### 在 Linux 上的一个例子
|
||||
|
||||
首先设置 `http_proxy`:
|
||||
|
||||
```
|
||||
## proxy server, 202.54.1.1, port: 3128, user: foo, password: bar ##
|
||||
export http_proxy=http://foo:bar@202.54.1.1:3128/
|
||||
export https_proxy=$http_proxy
|
||||
## Use the curl command ##
|
||||
curl -I https://www.cyberciti.biz
|
||||
curl -v -I https://www.cyberciti.biz
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
```
|
||||
* Rebuilt URL to: www.cyberciti.biz/
|
||||
* Trying 202.54.1.1...
|
||||
* Connected to 1202.54.1.1 (202.54.1.1) port 3128 (#0)
|
||||
* Proxy auth using Basic with user 'foo'
|
||||
> HEAD HTTP://www.cyberciti.biz/ HTTP/1.1
|
||||
> Host: www.cyberciti.biz
|
||||
> Proxy-Authorization: Basic x9VuUml2xm0vdg93MtIz
|
||||
> User-Agent: curl/7.43.0
|
||||
> Accept: */*
|
||||
> Proxy-Connection: Keep-Alive
|
||||
>
|
||||
< HTTP/1.1 200 OK
|
||||
HTTP/1.1 200 OK
|
||||
< Server: nginx
|
||||
Server: nginx
|
||||
< Date: Sun, 17 Jan 2016 11:49:21 GMT
|
||||
Date: Sun, 17 Jan 2016 11:49:21 GMT
|
||||
< Content-Type: text/html; charset=UTF-8
|
||||
Content-Type: text/html; charset=UTF-8
|
||||
< Vary: Accept-Encoding
|
||||
Vary: Accept-Encoding
|
||||
< X-Whom: Dyno-l1-com-cyber
|
||||
X-Whom: Dyno-l1-com-cyber
|
||||
< Vary: Cookie
|
||||
Vary: Cookie
|
||||
< Link: <http://www.cyberciti.biz/wp-json/>; rel="https://api.w.org/"
|
||||
Link: <http://www.cyberciti.biz/wp-json/>; rel="https://api.w.org/"
|
||||
< X-Frame-Options: SAMEORIGIN
|
||||
X-Frame-Options: SAMEORIGIN
|
||||
< X-Content-Type-Options: nosniff
|
||||
X-Content-Type-Options: nosniff
|
||||
< X-XSS-Protection: 1; mode=block
|
||||
X-XSS-Protection: 1; mode=block
|
||||
< X-Cache: MISS from server1
|
||||
X-Cache: MISS from server1
|
||||
< X-Cache-Lookup: MISS from server1:3128
|
||||
X-Cache-Lookup: MISS from server1:3128
|
||||
< Connection: keep-alive
|
||||
Connection: keep-alive
|
||||
|
||||
<
|
||||
* Connection #0 to host 10.12.249.194 left intact
|
||||
```
|
||||
|
||||
本例中,我来下载一个 pdf 文件:
|
||||
|
||||
```
|
||||
$ export http_proxy="vivek:myPasswordHere@10.12.249.194:3128/"
|
||||
$ curl -v -O http://dl.cyberciti.biz/pdfdownloads/b8bf71be9da19d3feeee27a0a6960cb3/569b7f08/cms/631.pdf
|
||||
```
|
||||
|
||||
也可以使用 `-x` 选项:
|
||||
|
||||
```
|
||||
curl -x 'http://vivek:myPasswordHere@10.12.249.194:3128' -v -O https://dl.cyberciti.biz/pdfdownloads/b8bf71be9da19d3feeee27a0a6960cb3/569b7f08/cms/631.pdf
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
![Fig.01:curl in action \(click to enlarge\)][2]
|
||||
|
||||
### Unix 上的一个例子
|
||||
|
||||
```
|
||||
$ curl -x http://prox_server_vpn:3128/ -I https://www.cyberciti.biz/faq/howto-nginx-customizing-404-403-error-page/
|
||||
```
|
||||
|
||||
### socks 协议怎么办呢?
|
||||
|
||||
语法也是一样的:
|
||||
|
||||
```
|
||||
curl -x socks5://[user:password@]proxyhost[:port]/ url
|
||||
curl --socks5 192.168.1.254:3099 https://www.cyberciti.biz/
|
||||
```
|
||||
|
||||
### 如何让代理设置永久生效?
|
||||
|
||||
编辑 `~/.curlrc` 文件:
|
||||
|
||||
```
|
||||
$ vi ~/.curlrc
|
||||
```
|
||||
|
||||
添加下面内容:
|
||||
|
||||
```
|
||||
proxy = server1.cyberciti.biz:3128
|
||||
proxy-user = "foo:bar"
|
||||
```
|
||||
|
||||
保存并关闭该文件。另一种方法是在你的 `~/.bashrc` 文件中创建一个别名:
|
||||
|
||||
```
|
||||
## alias for curl command
|
||||
## set proxy-server and port, the syntax is
|
||||
## alias curl="curl -x {your_proxy_host}:{proxy_port}"
|
||||
alias curl = "curl -x server1.cyberciti.biz:3128"
|
||||
```
|
||||
|
||||
记住,代理字符串中可以使用 `protocol://` 前缀来指定不同的代理协议。使用 `socks4://`,`socks4a://`,`socks5:// `或者 `socks5h://` 来指定使用的 SOCKS 版本。若没有指定协议或者使用 `http://` 表示 HTTP 协议。若没有指定端口号则默认为 `1080`。`-x` 选项的值要优先于环境变量设置的值。若不想走代理,而环境变量总设置了代理,那么可以通过设置代理为空值(`""`)来覆盖环境变量的值。[详细信息请参阅 `curl` 的 man 页 ][3]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/linux-unix-curl-command-with-proxy-username-password-http-options/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2016/01/curl-download-output-300x141.jpg
|
||||
[2]:https://www.cyberciti.biz/media/new/faq/2016/01/curl-download-output.jpg
|
||||
[3]:https://curl.haxx.se/docs/manpage.html
|
||||
239
published/20160625 Trying out LXD containers on our Ubuntu.md
Normal file
239
published/20160625 Trying out LXD containers on our Ubuntu.md
Normal file
@ -0,0 +1,239 @@
|
||||
在 Ubuntu 上体验 LXD 容器
|
||||
======
|
||||
|
||||
本文的主角是容器,一种类似虚拟机但更轻量级的构造。你可以轻易地在你的 Ubuntu 桌面系统中创建一堆容器!
|
||||
|
||||
虚拟机会虚拟出整个电脑让你来安装客户机操作系统。**相比之下**,容器**复用**了主机的 Linux 内核,只是简单地 **包容** 了我们选择的根文件系统(也就是运行时环境)。Linux 内核有很多功能可以将运行的 Linux 容器与我们的主机分割开(也就是我们的 Ubuntu 桌面)。
|
||||
|
||||
Linux 本身需要一些手工操作来直接管理他们。好在,有 LXD(读音为 Lex-deeh),这是一款为我们管理 Linux 容器的服务。
|
||||
|
||||
我们将会看到如何:
|
||||
|
||||
1. 在我们的 Ubuntu 桌面上配置容器,
|
||||
2. 创建容器,
|
||||
3. 安装一台 web 服务器,
|
||||
4. 测试一下这台 web 服务器,以及
|
||||
5. 清理所有的东西。
|
||||
|
||||
### 设置 Ubuntu 容器
|
||||
|
||||
如果你安装的是 Ubuntu 16.04,那么你什么都不用做。只要安装下面所列出的一些额外的包就行了。若你安装的是 Ubuntu 14.04.x 或 Ubuntu 15.10,那么按照 [LXD 2.0 系列(二):安装与配置][1] 来进行一些操作,然后再回来。
|
||||
|
||||
确保已经更新了包列表:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
```
|
||||
|
||||
安装 `lxd` 包:
|
||||
|
||||
```
|
||||
sudo apt install lxd
|
||||
```
|
||||
|
||||
若你安装的是 Ubuntu 16.04,那么还可以让你的容器文件以 ZFS 文件系统的格式进行存储。Ubuntu 16.04 的 Linux kernel 包含了支持 ZFS 必要的内核模块。若要让 LXD 使用 ZFS 进行存储,我们只需要安装 ZFS 工具包。没有 ZFS,容器会在主机文件系统中以单独的文件形式进行存储。通过 ZFS,我们就有了写入时拷贝等功能,可以让任务完成更快一些。
|
||||
|
||||
安装 `zfsutils-linux` 包(若你安装的是 Ubuntu 16.04.x):
|
||||
|
||||
```
|
||||
sudo apt install zfsutils-linux
|
||||
```
|
||||
|
||||
安装好 LXD 后,包安装脚本应该会将你加入 `lxd` 组。该组成员可以使你无需通过 `sudo` 就能直接使用 LXD 管理容器。根据 Linux 的习惯,**你需要先登出桌面会话然后再登录** 才能应用 `lxd` 的组成员关系。(若你是高手,也可以通过在当前 shell 中执行 `newgrp lxd` 命令,就不用重登录了)。
|
||||
|
||||
在开始使用前,LXD 需要初始化存储和网络参数。
|
||||
|
||||
运行下面命令:
|
||||
|
||||
```
|
||||
$ sudo lxd init
|
||||
Name of the storage backend to use (dir or zfs): zfs
|
||||
Create a new ZFS pool (yes/no)? yes
|
||||
Name of the new ZFS pool: lxd-pool
|
||||
Would you like to use an existing block device (yes/no)? no
|
||||
Size in GB of the new loop device (1GB minimum): 30
|
||||
Would you like LXD to be available over the network (yes/no)? no
|
||||
Do you want to configure the LXD bridge (yes/no)? yes
|
||||
> You will be asked about the network bridge configuration. Accept all defaults and continue.
|
||||
Warning: Stopping lxd.service, but it can still be activated by:
|
||||
lxd.socket
|
||||
LXD has been successfully configured.
|
||||
$ _
|
||||
```
|
||||
|
||||
我们在一个(单独)的文件而不是块设备(即分区)中构建了一个文件系统来作为 ZFS 池,因此我们无需进行额外的分区操作。在本例中我指定了 30GB 大小,这个空间取之于根(`/`) 文件系统中。这个文件就是 `/var/lib/lxd/zfs.img`。
|
||||
|
||||
行了!最初的配置完成了。若有问题,或者想了解其他信息,请阅读 https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/ 。
|
||||
|
||||
### 创建第一个容器
|
||||
|
||||
所有 LXD 的管理操作都可以通过 `lxc` 命令来进行。我们通过给 `lxc` 不同参数来管理容器。
|
||||
|
||||
```
|
||||
lxc list
|
||||
```
|
||||
|
||||
可以列出所有已经安装的容器。很明显,这个列表现在是空的,但这表示我们的安装是没问题的。
|
||||
|
||||
```
|
||||
lxc image list
|
||||
```
|
||||
|
||||
列出可以用来启动容器的(已经缓存的)镜像列表。很明显这个列表也是空的,但这也说明我们的安装是没问题的。
|
||||
|
||||
```
|
||||
lxc image list ubuntu:
|
||||
```
|
||||
|
||||
列出可以下载并启动容器的远程镜像。而且指定了显示 Ubuntu 镜像。
|
||||
|
||||
```
|
||||
lxc image list images:
|
||||
```
|
||||
|
||||
列出可以用来启动容器的(已经缓存的)各种发行版的镜像列表。这会列出各种发行版的镜像比如 Alpine、Debian、Gentoo、Opensuse 以及 Fedora。
|
||||
|
||||
让我们启动一个 Ubuntu 16.04 容器,并称之为 `c1`:
|
||||
|
||||
```
|
||||
$ lxc launch ubuntu:x c1
|
||||
Creating c1
|
||||
Starting c1
|
||||
$
|
||||
```
|
||||
|
||||
我们使用 `launch` 动作,然后选择镜像 `ubuntu:x` (`x` 表示 Xenial/16.04 镜像),最后我们使用名字 `c1` 作为容器的名称。
|
||||
|
||||
让我们来看看安装好的首个容器,
|
||||
|
||||
```
|
||||
$ lxc list
|
||||
|
||||
+---------|---------|----------------------|------|------------|-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+---------|---------|----------------------|------|------------|-----------+
|
||||
| c1 | RUNNING | 10.173.82.158 (eth0) | | PERSISTENT | 0 |
|
||||
+---------|---------|----------------------|------|------------|-----------+
|
||||
```
|
||||
|
||||
我们的首个容器 c1 已经运行起来了,它还有自己的 IP 地址(可以本地访问)。我们可以开始用它了!
|
||||
|
||||
### 安装 web 服务器
|
||||
|
||||
我们可以在容器中运行命令。运行命令的动作为 `exec`。
|
||||
|
||||
```
|
||||
$ lxc exec c1 -- uptime
|
||||
11:47:25 up 2 min,0 users,load average:0.07,0.05,0.04
|
||||
$ _
|
||||
```
|
||||
|
||||
在 `exec` 后面,我们指定容器、最后输入要在容器中运行的命令。该容器的运行时间只有 2 分钟,这是个新出炉的容器:-)。
|
||||
|
||||
命令行中的 `--` 跟我们 shell 的参数处理过程有关。若我们的命令没有任何参数,则完全可以省略 `-`。
|
||||
|
||||
```
|
||||
$ lxc exec c1 -- df -h
|
||||
```
|
||||
|
||||
这是一个必须要 `-` 的例子,由于我们的命令使用了参数 `-h`。若省略了 `-`,会报错。
|
||||
|
||||
然后我们运行容器中的 shell 来更新包列表。
|
||||
|
||||
```
|
||||
$ lxc exec c1 bash
|
||||
root@c1:~# apt update
|
||||
Ign http://archive.ubuntu.com trusty InRelease
|
||||
Get:1 http://archive.ubuntu.com trusty-updates InRelease [65.9 kB]
|
||||
Get:2 http://security.ubuntu.com trusty-security InRelease [65.9 kB]
|
||||
...
|
||||
Hit http://archive.ubuntu.com trusty/universe Translation-en
|
||||
Fetched 11.2 MB in 9s (1228 kB/s)
|
||||
Reading package lists... Done
|
||||
root@c1:~# apt upgrade
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
...
|
||||
Processing triggers for man-db (2.6.7.1-1ubuntu1) ...
|
||||
Setting up dpkg (1.17.5ubuntu5.7) ...
|
||||
root@c1:~# _
|
||||
```
|
||||
|
||||
我们使用 nginx 来做 web 服务器。nginx 在某些方面要比 Apache web 服务器更酷一些。
|
||||
|
||||
```
|
||||
root@c1:~# apt install nginx
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
...
|
||||
Setting up nginx-core (1.4.6-1ubuntu3.5) ...
|
||||
Setting up nginx (1.4.6-1ubuntu3.5) ...
|
||||
Processing triggers for libc-bin (2.19-0ubuntu6.9) ...
|
||||
root@c1:~# _
|
||||
```
|
||||
|
||||
让我们用浏览器访问一下这个 web 服务器。记住 IP 地址为 10.173.82.158,因此你需要在浏览器中输入这个 IP。
|
||||
|
||||
[![lxd-nginx][2]][3]
|
||||
|
||||
让我们对页面文字做一些小改动。回到容器中,进入默认 HTML 页面的目录中。
|
||||
|
||||
```
|
||||
root@c1:~# cd /var/www/html/
|
||||
root@c1:/var/www/html# ls -l
|
||||
total 2
|
||||
-rw-r--r-- 1 root root 612 Jun 25 12:15 index.nginx-debian.html
|
||||
root@c1:/var/www/html#
|
||||
```
|
||||
|
||||
使用 nano 编辑文件,然后保存:
|
||||
|
||||
[![lxd-nginx-nano][4]][5]
|
||||
|
||||
之后,再刷一下页面看看,
|
||||
|
||||
[![lxd-nginx-modified][6]][7]
|
||||
|
||||
### 清理
|
||||
|
||||
让我们清理一下这个容器,也就是删掉它。当需要的时候我们可以很方便地创建一个新容器出来。
|
||||
|
||||
```
|
||||
$ lxc list
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
| c1 | RUNNING | 10.173.82.169 (eth0) | | PERSISTENT | 0 |
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
$ lxc stop c1
|
||||
$ lxc delete c1
|
||||
$ lxc list
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
```
|
||||
|
||||
我们停止(关闭)这个容器,然后删掉它了。
|
||||
|
||||
本文至此就结束了。关于容器有很多玩法。而这只是配置 Ubuntu 并尝试使用容器的第一步而已。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.simos.info/author/simos/
|
||||
[1]:https://linux.cn/article-7687-1.html
|
||||
[2]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx.png?resize=564%2C269&ssl=1
|
||||
[3]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx.png?ssl=1
|
||||
[4]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-nano.png?resize=750%2C424&ssl=1
|
||||
[5]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-nano.png?ssl=1
|
||||
[6]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-modified.png?resize=595%2C317&ssl=1
|
||||
[7]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-modified.png?ssl=1
|
||||
255
published/20160808 Top 10 Command Line Games For Linux.md
Normal file
255
published/20160808 Top 10 Command Line Games For Linux.md
Normal file
@ -0,0 +1,255 @@
|
||||
十大 Linux 命令行游戏
|
||||
======
|
||||
|
||||
概要: 本文列举了 Linux 中最好的命令行游戏。
|
||||
|
||||
Linux 从来都不是游戏的首选操作系统,尽管近日来 [Linux 的游戏][1]提供了很多,你也可以从许多资源[下载到 Linux 游戏][2]。
|
||||
|
||||
也有专门的 [游戏版 Linux][3]。没错,确实有。但是今天,我们并不是要欣赏游戏版 Linux。
|
||||
|
||||
Linux 有一个超过 Windows 的优势。它拥有一个强大的 Linux 终端。在 Linux 终端上,你可以做很多事情,包括玩 **命令行游戏**。
|
||||
|
||||
当然,我们都是 Linux 终端的骨灰粉。终端游戏轻便、快速、有地狱般的魔力。而这最有意思的事情是,你可以在 Linux 终端上重温大量经典游戏。
|
||||
|
||||
### 最好的 Linux 终端游戏
|
||||
|
||||
来揭秘这张榜单,找出 Linux 终端最好的游戏。
|
||||
|
||||
#### 1. Bastet
|
||||
|
||||
谁还没花上几个小时玩[俄罗斯方块][4]?它简单而且容易上瘾。 Bastet 就是 Linux 版的俄罗斯方块。
|
||||
|
||||
![Linux 终端游戏 Bastet][5]
|
||||
|
||||
使用下面的命令获取 Bastet:
|
||||
|
||||
```
|
||||
sudo apt install bastet
|
||||
```
|
||||
|
||||
运行下列命令,在终端上开始这个游戏:
|
||||
|
||||
```
|
||||
bastet
|
||||
```
|
||||
|
||||
使用空格键旋转方块,方向键控制方块移动。
|
||||
|
||||
#### 2. Ninvaders
|
||||
|
||||
Space Invaders(太空侵略者)。我仍记得这个游戏里,和我兄弟为了最高分而比拼。这是最好的街机游戏之一。
|
||||
|
||||
![Linux 终端游戏 nInvaders][6]
|
||||
|
||||
复制粘贴这段代码安装 Ninvaders。
|
||||
|
||||
```
|
||||
sudo apt-get install ninvaders
|
||||
```
|
||||
|
||||
使用下面的命令开始游戏:
|
||||
|
||||
```
|
||||
ninvaders
|
||||
```
|
||||
|
||||
方向键移动太空飞船。空格键射击外星人。
|
||||
|
||||
[推荐阅读:2016 你可以开始的 Linux 游戏 Top 10][21]
|
||||
|
||||
#### 3. Pacman4console
|
||||
|
||||
是的,这个就是街机之王。Pacman4console 是最受欢迎的街机游戏 Pacman(吃豆人)的终端版。
|
||||
|
||||
![Linux 命令行吃豆豆游戏 Pacman4console][7]
|
||||
|
||||
使用以下命令获取 pacman4console:
|
||||
|
||||
```
|
||||
sudo apt-get install pacman4console
|
||||
```
|
||||
|
||||
打开终端,建议使用最大的终端界面。键入以下命令启动游戏:
|
||||
|
||||
```
|
||||
pacman4console
|
||||
```
|
||||
|
||||
使用方向键控制移动。
|
||||
|
||||
#### 4. nSnake
|
||||
|
||||
记得在老式诺基亚手机里玩的贪吃蛇游戏吗?
|
||||
|
||||
这个游戏让我在很长时间内着迷于手机。我曾经设计过各种姿态去获得更长的蛇身。
|
||||
|
||||
![nsnake : Linux 终端上的贪吃蛇游戏][8]
|
||||
|
||||
我们拥有 [Linux 终端上的贪吃蛇游戏][9] 得感谢 [nSnake][9]。使用下面的命令安装它:
|
||||
|
||||
```
|
||||
sudo apt-get install nsnake
|
||||
```
|
||||
|
||||
键入下面的命令开始游戏:
|
||||
|
||||
```
|
||||
nsnake
|
||||
```
|
||||
|
||||
使用方向键控制蛇身并喂它。
|
||||
|
||||
#### 5. Greed
|
||||
|
||||
Greed 有点像 Tron(类似贪吃蛇的进化版),但是减少了速度,也没那么刺激。
|
||||
|
||||
你当前的位置由闪烁的 ‘@’ 表示。你被数字所环绕,你可以在四个方向任意移动。
|
||||
|
||||
你选择的移动方向上标识的数字,就是你能移动的步数。你将重复这个步骤。走过的路不能再走,如果你无路可走,游戏结束。
|
||||
|
||||
似乎我让它听起来变得更复杂了。
|
||||
|
||||
![Greed : 命令行上的 Tron][10]
|
||||
|
||||
通过下列命令获取 Greed:
|
||||
|
||||
```
|
||||
sudo apt-get install greed
|
||||
```
|
||||
|
||||
通过下列命令启动游戏,使用方向键控制游戏。
|
||||
|
||||
```
|
||||
greed
|
||||
```
|
||||
|
||||
#### 6. Air Traffic Controller
|
||||
|
||||
还有什么比做飞行员更有意思的?那就是空中交通管制员。在你的终端中,你可以模拟一个空中交通系统。说实话,在终端里管理空中交通蛮有意思的。
|
||||
|
||||
![Linux 空中交通管理员][11]
|
||||
|
||||
使用下列命令安装游戏:
|
||||
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
atc
|
||||
```
|
||||
|
||||
ATC 不是孩子玩的游戏。建议查看官方文档。
|
||||
|
||||
#### 7. Backgammon(双陆棋)
|
||||
|
||||
无论之前你有没有玩过 [双陆棋][12],你都应该看看这个。 它的说明书和控制手册都非常友好。如果你喜欢,可以挑战你的电脑或者你的朋友。
|
||||
|
||||
![Linux 终端上的双陆棋][13]
|
||||
|
||||
使用下列命令安装双陆棋:
|
||||
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
backgammon
|
||||
```
|
||||
|
||||
当你提示游戏规则时,回复 ‘y’ 即可。
|
||||
|
||||
#### 8. Moon Buggy
|
||||
|
||||
跳跃、开火。欢乐时光不必多言。
|
||||
|
||||
![Moon buggy][14]
|
||||
|
||||
使用下列命令安装游戏:
|
||||
|
||||
```
|
||||
sudo apt-get install moon-buggy
|
||||
```
|
||||
|
||||
使用下列命令启动游戏:
|
||||
|
||||
```
|
||||
moon-buggy
|
||||
```
|
||||
|
||||
空格跳跃,‘a’ 或者 ‘l’射击。尽情享受吧。
|
||||
|
||||
#### 9. 2048
|
||||
|
||||
2048 可以活跃你的大脑。[2048][15] 是一个策咯游戏,很容易上瘾。以获取 2048 分为目标。
|
||||
|
||||
![Linux 终端上的 2048][16]
|
||||
|
||||
复制粘贴下面的命令安装游戏:
|
||||
|
||||
```
|
||||
wget https://raw.githubusercontent.com/mevdschee/2048.c/master/2048.c
|
||||
|
||||
gcc -o 2048 2048.c
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
./2048
|
||||
```
|
||||
|
||||
#### 10. Tron
|
||||
|
||||
没有动作类游戏,这张榜单怎么可能结束?
|
||||
|
||||
![Linux 终端游戏 Tron][17]
|
||||
|
||||
是的,Linux 终端可以实现这种精力充沛的游戏 Tron。为接下来迅捷的反应做准备吧。无需被下载和安装困扰。一个命令即可启动游戏,你只需要一个网络连接:
|
||||
|
||||
```
|
||||
ssh sshtron.zachlatta.com
|
||||
```
|
||||
|
||||
如果有别的在线游戏者,你可以多人游戏。了解更多:[Linux 终端游戏 Tron][18]。
|
||||
|
||||
### 你看上了哪一款?
|
||||
|
||||
伙计,十大 Linux 终端游戏都分享给你了。我猜你现在正准备键入 `ctrl+alt+T`(终端快捷键) 了。榜单中那个是你最喜欢的游戏?或者你有其它的终端游戏么?尽情分享吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-command-line-games-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[CYLeft](https://github.com/CYleft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://linux.cn/article-7316-1.html
|
||||
[2]:https://itsfoss.com/download-linux-games/
|
||||
[3]:https://itsfoss.com/manjaro-gaming-linux/
|
||||
[4]:https://en.wikipedia.org/wiki/Tetris
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/bastet.jpg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/ninvaders.jpg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/pacman.jpg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/nsnake.jpg
|
||||
[9]:https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/greed.jpg
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/atc.jpg
|
||||
[12]:https://en.wikipedia.org/wiki/Backgammon
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/backgammon.jpg
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/moon-buggy.jpg
|
||||
[15]:https://itsfoss.com/2048-offline-play-ubuntu/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/2048.jpg
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/tron.jpg
|
||||
[18]:https://itsfoss.com/play-tron-game-linux-terminal/
|
||||
[19]:https://twitter.com/abhishek_pc
|
||||
[20]:https://itsfoss.com/linux-gaming-guide/
|
||||
[21]:https://itsfoss.com/best-linux-games/
|
||||
@ -0,0 +1,135 @@
|
||||
当你在 Linux 上启动一个进程时会发生什么?
|
||||
===========================================================
|
||||
|
||||
本文是关于 fork 和 exec 是如何在 Unix 上工作的。你或许已经知道,也有人还不知道。几年前当我了解到这些时,我惊叹不已。
|
||||
|
||||
我们要做的是启动一个进程。我们已经在博客上讨论了很多关于**系统调用**的问题,每当你启动一个进程或者打开一个文件,这都是一个系统调用。所以你可能会认为有这样的系统调用:
|
||||
|
||||
```
|
||||
start_process(["ls", "-l", "my_cool_directory"])
|
||||
```
|
||||
|
||||
这是一个合理的想法,显然这是它在 DOS 或 Windows 中的工作原理。我想说的是,这并不是 Linux 上的工作原理。但是,我查阅了文档,确实有一个 [posix_spawn][2] 的系统调用基本上是这样做的,不过这不在本文的讨论范围内。
|
||||
|
||||
### fork 和 exec
|
||||
|
||||
Linux 上的 `posix_spawn` 是通过两个系统调用实现的,分别是 `fork` 和 `exec`(实际上是 `execve`),这些都是人们常常使用的。尽管在 OS X 上,人们使用 `posix_spawn`,而 `fork` 和 `exec` 是不提倡的,但我们将讨论的是 Linux。
|
||||
|
||||
Linux 中的每个进程都存在于“进程树”中。你可以通过运行 `pstree` 命令查看进程树。树的根是 `init`,进程号是 1。每个进程(`init` 除外)都有一个父进程,一个进程都可以有很多子进程。
|
||||
|
||||
所以,假设我要启动一个名为 `ls` 的进程来列出一个目录。我是不是只要发起一个进程 `ls` 就好了呢?不是的。
|
||||
|
||||
我要做的是,创建一个子进程,这个子进程是我(`me`)本身的一个克隆,然后这个子进程的“脑子”被吃掉了,变成 `ls`。
|
||||
|
||||
开始是这样的:
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
```
|
||||
|
||||
然后运行 `fork()`,生成一个子进程,是我(`me`)自己的一份克隆:
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
|-- clone of me
|
||||
```
|
||||
|
||||
然后我让该子进程运行 `exec("ls")`,变成这样:
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
|-- ls
|
||||
```
|
||||
|
||||
当 ls 命令结束后,我几乎又变回了我自己:
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
|-- ls (zombie)
|
||||
```
|
||||
|
||||
在这时 `ls` 其实是一个僵尸进程。这意味着它已经死了,但它还在等我,以防我需要检查它的返回值(使用 `wait` 系统调用)。一旦我获得了它的返回值,我将再次恢复独自一人的状态。
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
```
|
||||
|
||||
### fork 和 exec 的代码实现
|
||||
|
||||
如果你要编写一个 shell,这是你必须做的一个练习(这是一个非常有趣和有启发性的项目。Kamal 在 Github 上有一个很棒的研讨会:[https://github.com/kamalmarhubi/shell-workshop][3])。
|
||||
|
||||
事实证明,有了 C 或 Python 的技能,你可以在几个小时内编写一个非常简单的 shell,像 bash 一样。(至少如果你旁边能有个人多少懂一点,如果没有的话用时会久一点。)我已经完成啦,真的很棒。
|
||||
|
||||
这就是 `fork` 和 `exec` 在程序中的实现。我写了一段 C 的伪代码。请记住,[fork 也可能会失败哦。][4]
|
||||
|
||||
```
|
||||
int pid = fork();
|
||||
// 我要分身啦
|
||||
// “我”是谁呢?可能是子进程也可能是父进程
|
||||
if (pid == 0) {
|
||||
// 我现在是子进程
|
||||
// “ls” 吃掉了我脑子,然后变成一个完全不一样的进程
|
||||
exec(["ls"])
|
||||
} else if (pid == -1) {
|
||||
// 天啊,fork 失败了,简直是灾难!
|
||||
} else {
|
||||
// 我是父进程耶
|
||||
// 继续做一个酷酷的美男子吧
|
||||
// 需要的话,我可以等待子进程结束
|
||||
}
|
||||
```
|
||||
|
||||
### 上文提到的“脑子被吃掉”是什么意思呢?
|
||||
|
||||
进程有很多属性:
|
||||
|
||||
* 打开的文件(包括打开的网络连接)
|
||||
* 环境变量
|
||||
* 信号处理程序(在程序上运行 Ctrl + C 时会发生什么?)
|
||||
* 内存(你的“地址空间”)
|
||||
* 寄存器
|
||||
* 可执行文件(`/proc/$pid/exe`)
|
||||
* cgroups 和命名空间(与 Linux 容器相关)
|
||||
* 当前的工作目录
|
||||
* 运行程序的用户
|
||||
* 其他我还没想到的
|
||||
|
||||
当你运行 `execve` 并让另一个程序吃掉你的脑子的时候,实际上几乎所有东西都是相同的! 你们有相同的环境变量、信号处理程序和打开的文件等等。
|
||||
|
||||
唯一改变的是,内存、寄存器以及正在运行的程序,这可是件大事。
|
||||
|
||||
### 为何 fork 并非那么耗费资源(写入时复制)
|
||||
|
||||
你可能会问:“如果我有一个使用了 2GB 内存的进程,这是否意味着每次我启动一个子进程,所有 2 GB 的内存都要被复制一次?这听起来要耗费很多资源!”
|
||||
|
||||
事实上,Linux 为 `fork()` 调用实现了<ruby>写时复制<rt>copy on write</rt></ruby>,对于新进程的 2GB 内存来说,就像是“看看旧的进程就好了,是一样的!”。然后,当如果任一进程试图写入内存,此时系统才真正地复制一个内存的副本给该进程。如果两个进程的内存是相同的,就不需要复制了。
|
||||
|
||||
### 为什么你需要知道这么多
|
||||
|
||||
你可能会说,好吧,这些细节听起来很厉害,但为什么这么重要?关于信号处理程序或环境变量的细节会被继承吗?这对我的日常编程有什么实际影响呢?
|
||||
|
||||
有可能哦!比如说,在 Kamal 的博客上有一个很有意思的 [bug][5]。它讨论了 Python 如何使信号处理程序忽略了 `SIGPIPE`。也就是说,如果你从 Python 里运行一个程序,默认情况下它会忽略 `SIGPIPE`!这意味着,程序从 Python 脚本和从 shell 启动的表现会**有所不同**。在这种情况下,它会造成一个奇怪的问题。
|
||||
|
||||
所以,你的程序的环境(环境变量、信号处理程序等)可能很重要,都是从父进程继承来的。知道这些,在调试时是很有用的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2016/10/04/exec-will-eat-your-brain/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/favorite
|
||||
[2]:http://man7.org/linux/man-pages/man3/posix_spawn.3.html
|
||||
[3]:https://github.com/kamalmarhubi/shell-workshop
|
||||
[4]:https://rachelbythebay.com/w/2014/08/19/fork/
|
||||
[5]:http://kamalmarhubi.com/blog/2015/06/30/my-favourite-bug-so-far-at-the-recurse-center/
|
||||
64
published/20170131 Book review Ours to Hack and to Own.md
Normal file
64
published/20170131 Book review Ours to Hack and to Own.md
Normal file
@ -0,0 +1,64 @@
|
||||
书评:《Ours to Hack and to Own》
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
私有制的时代看起来似乎结束了,在这里我将不仅仅讨论那些由我们中的许多人引入到我们的家庭与生活的设备和软件,我也将讨论这些设备与应用依赖的平台与服务。
|
||||
|
||||
尽管我们使用的许多服务是免费的,但我们对它们并没有任何控制权。本质上讲,这些企业确实控制着我们所看到的、听到的以及阅读到的内容。不仅如此,许多企业还在改变工作的本质。他们正使用封闭的平台来助长由全职工作到[零工经济][2]的转变,这种方式提供极少的安全性与确定性。
|
||||
|
||||
这项行动对于网络以及每一个使用与依赖网络的人产生了广泛的影响。仅仅二十多年前的对开放互联网的想象正在逐渐消逝,并迅速地被一块难以穿透的幕帘所取代。
|
||||
|
||||
一种逐渐流行的补救办法就是建立<ruby>[平台合作社][3]<rt>platform cooperatives</rt></ruby>, 即由他们的用户所拥有的电子化平台。正如这本书[《Ours to Hack and to Own》][4]所阐述的,平台合作社背后的观点与开源有许多相同的根源。
|
||||
|
||||
学者 Trebor Scholz 和作家 Nathan Schneider 已经收集了 40 篇论文,探讨平台合作社作为普通人可使用的工具的增长及需求,以提升开放性并对闭源系统的不透明性及各种限制予以还击。
|
||||
|
||||
### 何处适合开源
|
||||
|
||||
任何平台合作社核心及接近核心的部分依赖于开源;不仅开源技术是必要的,构成开源开放性、透明性、协同合作以及共享的准则与理念同样不可或缺。
|
||||
|
||||
在这本书的介绍中,Trebor Scholz 指出:
|
||||
|
||||
> 与斯诺登时代的互联网黑盒子系统相反,这些平台需要使它们的数据流透明来辨别自身。他们需要展示客户与员工的数据在哪里存储,数据出售给了谁以及数据用于何种目的。
|
||||
|
||||
正是对开源如此重要的透明性,促使平台合作社如此吸引人,并在目前大量已有平台之中成为令人耳目一新的变化。
|
||||
|
||||
开源软件在《Ours to Hack and to Own》所分享的平台合作社的构想中必然充当着重要角色。开源软件能够为群体建立助推合作社的技术基础设施提供快速而不算昂贵的途径。
|
||||
|
||||
Mickey Metts 在论文中这样形容, “邂逅你的友邻技术伙伴。" Metts 为一家名为 Agaric 的企业工作,这家企业使用 Drupal 为团体及小型企业建立他们不能自行完成的平台。除此以外, Metts 还鼓励任何想要建立并运营自己的企业的公司或合作社的人接受自由开源软件。为什么呢?因为它是高质量的、并不昂贵的、可定制的,并且你能够与由乐于助人而又热情的人们组成的大型社区产生联系。
|
||||
|
||||
### 不总是开源的,但开源总在
|
||||
|
||||
这本书里不是所有的论文都关注或提及开源的;但是,开源方式的关键元素——合作、社区、开放治理以及电子自由化——总是在其间若隐若现。
|
||||
|
||||
事实上正如《Ours to Hack and to Own》中许多论文所讨论的,建立一个更加开放、基于平常人的经济与社会区块,平台合作社会变得非常重要。用 Douglas Rushkoff 的话讲,那会是类似 Creative Commons 的组织“对共享知识资源的私有化”的补偿。它们也如 Barcelona 的 CTO Francesca Bria 所描述的那样,是“通过确保市民数据安全性、隐私性和权利的系统”来运营他们自己的“分布式通用数据基础架构”的城市。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
如果你在寻找改变互联网以及我们工作的方式的蓝图,《Ours to Hack and to Own》并不是你要寻找的。这本书与其说是用户指南,不如说是一种宣言。如书中所说,《Ours to Hack and to Own》让我们略微了解如果我们将开源方式准则应用于社会及更加广泛的世界我们能够做的事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Scott Nesbitt ——作家、编辑、雇佣兵、 <ruby>虎猫牛仔<rt>Ocelot wrangle</rt></ruby>、丈夫与父亲、博客写手、陶器收藏家。Scott 正是做这样的一些事情。他还是大量写关于开源软件文章与博客的长期开源用户。你可以在 Twitter、Github 上找到他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/review-book-ours-to-hack-and-own
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[darsh8](https://github.com/darsh8)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/1/review-book-ours-to-hack-and-own?rate=dgkFEuCLLeutLMH2N_4TmUupAJDjgNvFpqWqYCbQb-8
|
||||
[2]:https://en.wikipedia.org/wiki/Access_economy
|
||||
[3]:https://en.wikipedia.org/wiki/Platform_cooperative
|
||||
[4]:http://www.orbooks.com/catalog/ours-to-hack-and-to-own/
|
||||
[5]:https://opensource.com/user/14925/feed
|
||||
[6]:https://opensource.com/users/scottnesbitt
|
||||
99
published/20170209 INTRODUCING DOCKER SECRETS MANAGEMENT.md
Normal file
99
published/20170209 INTRODUCING DOCKER SECRETS MANAGEMENT.md
Normal file
@ -0,0 +1,99 @@
|
||||
Docker 涉密信息管理介绍
|
||||
====================================
|
||||
|
||||
容器正在改变我们对应用程序和基础设施的看法。无论容器内的代码量是大还是小,容器架构都会引起代码如何与硬件相互作用方式的改变 —— 它从根本上将其从基础设施中抽象出来。对于容器安全来说,在 Docker 中,容器的安全性有三个关键组成部分,它们相互作用构成本质上更安全的应用程序。
|
||||
|
||||

|
||||
|
||||
构建更安全的应用程序的一个关键因素是与系统和其他应用程序进行安全通信,这通常需要证书、令牌、密码和其他类型的验证信息凭证 —— 通常称为应用程序<ruby>涉密信息<rt>secrets</rt></ruby>。我们很高兴可以推出 Docker Secrets,这是一个容器原生的解决方案,它是加强容器安全的<ruby>可信赖交付<rt>Trusted Delivery</rt></ruby>组件,用户可以在容器平台上直接集成涉密信息分发功能。
|
||||
|
||||
有了容器,现在应用程序是动态的,可以跨越多种环境移植。这使得现存的涉密信息分发的解决方案略显不足,因为它们都是针对静态环境。不幸的是,这导致了应用程序涉密信息管理不善的增加,在不安全的、土造的方案中(如将涉密信息嵌入到 GitHub 这样的版本控制系统或者同样糟糕的其它方案),这种情况十分常见。
|
||||
|
||||
### Docker 涉密信息管理介绍
|
||||
|
||||
根本上我们认为,如果有一个标准的接口来访问涉密信息,应用程序就更安全了。任何好的解决方案也必须遵循安全性实践,例如在传输的过程中,对涉密信息进行加密;在不用的时候也对涉密数据进行加密;防止涉密信息在应用最终使用时被无意泄露;并严格遵守最低权限原则,即应用程序只能访问所需的涉密信息,不能多也不能不少。
|
||||
|
||||
通过将涉密信息整合到 Docker 编排,我们能够在遵循这些确切的原则下为涉密信息的管理问题提供一种解决方案。
|
||||
|
||||
下图提供了一个高层次视图,并展示了 Docker swarm 模式体系架构是如何将一种新类型的对象 —— 一个涉密信息对象,安全地传递给我们的容器。
|
||||
|
||||

|
||||
|
||||
在 Docker 中,涉密信息是任意的数据块,比如密码、SSH 密钥、TLS 凭证,或者任何其他本质上敏感的数据。当你将一个涉密信息加入 swarm 集群(通过执行 `docker secret create` )时,利用在引导新集群时自动创建的[内置证书颁发机构][17],Docker 通过相互认证的 TLS 连接将密钥发送给 swarm 集群管理器。
|
||||
|
||||
```
|
||||
$ echo "This is a secret" | docker secret create my_secret_data -
|
||||
```
|
||||
|
||||
一旦,涉密信息到达某个管理节点,它将被保存到内部的 Raft 存储区中。该存储区使用 NACL 开源加密库中的 Salsa20、Poly1305 加密算法生成的 256 位密钥进行加密,以确保从来不会把任何涉密信息数据写入未加密的磁盘。将涉密信息写入到内部存储,赋予了涉密信息跟其它 swarm 集群数据一样的高可用性。
|
||||
|
||||
当 swarm 集群管理器启动时,包含涉密信息的加密 Raft 日志通过每一个节点独有的数据密钥进行解密。此密钥以及用于与集群其余部分通信的节点 TLS 证书可以使用一个集群级的加密密钥进行加密。该密钥称为“解锁密钥”,也使用 Raft 进行传递,将且会在管理器启动的时候使用。
|
||||
|
||||
当授予新创建或运行的服务权限访问某个涉密信息权限时,其中一个管理器节点(只有管理器可以访问被存储的所有涉密信息)会通过已经建立的 TLS 连接将其分发给正在运行特定服务的节点。这意味着节点自己不能请求涉密信息,并且只有在管理器提供给他们的时候才能访问这些涉密信息 —— 严格地控制请求涉密信息的服务。
|
||||
|
||||
```
|
||||
$ docker service create --name="redis" --secret="my_secret_data" redis:alpine
|
||||
```
|
||||
|
||||
未加密的涉密信息被挂载到一个容器,该容器位于 `/run/secrets/<secret_name>` 的内存文件系统中。
|
||||
|
||||
```
|
||||
$ docker exec $(docker ps --filter name=redis -q) ls -l /run/secrets
|
||||
total 4
|
||||
-r--r--r-- 1 root root 17 Dec 13 22:48 my_secret_data
|
||||
```
|
||||
|
||||
如果一个服务被删除或者被重新安排在其他地方,集群管理器将立即通知所有不再需要访问该涉密信息的节点,这些节点将不再有权访问该应用程序的涉密信息。
|
||||
|
||||
```
|
||||
$ docker service update --secret-rm="my_secret_data" redis
|
||||
|
||||
$ docker exec -it $(docker ps --filter name=redis -q) cat /run/secrets/my_secret_data
|
||||
|
||||
cat: can't open '/run/secrets/my_secret_data': No such file or directory
|
||||
```
|
||||
|
||||
查看 [Docker Secret 文档][18]以获取更多信息和示例,了解如何创建和管理您的涉密信息。同时,特别感谢 [Laurens Van Houtven](https://www.lvh.io/) 与 Docker 安全和核心团队合作使这一特性成为现实。
|
||||
|
||||
### 通过 Docker 更安全地使用应用程序
|
||||
|
||||
Docker 涉密信息旨在让开发人员和 IT 运营团队可以轻松使用,以用于构建和运行更安全的应用程序。它是首个被设计为既能保持涉密信息安全,并且仅在特定的容器需要它来进行必要的涉密信息操作的时候使用。从使用 Docker Compose 定义应用程序和涉密数据,到 IT 管理人员直接在 Docker Datacenter 中部署的 Compose 文件,涉密信息、网络和数据卷都将加密并安全地与应用程序一起传输。
|
||||
|
||||
更多相关学习资源:
|
||||
|
||||
* [1.13 Docker 数据中心具有 Secrets、安全扫描、容量缓存等新特性][7]
|
||||
* [下载 Docker][8] 且开始学习
|
||||
* [在 Docker 数据中心尝试使用 secrets][9]
|
||||
* [阅读文档][10]
|
||||
* 参与 [即将进行的在线研讨会][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/02/docker-secrets-management/
|
||||
|
||||
作者:[Ying Li][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[imquanquan](https://github.com/imquanquan), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/yingli/
|
||||
[1]:http://www.linkedin.com/shareArticle?mini=true&url=http://dockr.ly/2k6gnOB&title=Introducing%20Docker%20Secrets%20Management&summary=Containers%20are%20changing%20how%20we%20view%20apps%20and%20infrastructure.%20Whether%20the%20code%20inside%20containers%20is%20big%20or%20small,%20container%20architecture%20introduces%20a%20change%20to%20how%20that%20code%20behaves%20with%20hardware%20-%20it%20fundamentally%20abstracts%20it%20from%20the%20infrastructure.%20Docker%20believes%20that%20there%20are%20three%20key%20components%20to%20container%20security%20and%20...
|
||||
[2]:http://www.reddit.com/submit?url=http://dockr.ly/2k6gnOB&title=Introducing%20Docker%20Secrets%20Management
|
||||
[3]:https://plus.google.com/share?url=http://dockr.ly/2k6gnOB
|
||||
[4]:http://news.ycombinator.com/submitlink?u=http://dockr.ly/2k6gnOB&t=Introducing%20Docker%20Secrets%20Management
|
||||
[5]:https://twitter.com/share?text=Get+safer+apps+for+dev+and+ops+w%2F+new+%23Docker+secrets+management+&via=docker&related=docker&url=http://dockr.ly/2k6gnOB
|
||||
[6]:https://twitter.com/share?text=Get+safer+apps+for+dev+and+ops+w%2F+new+%23Docker+secrets+management+&via=docker&related=docker&url=http://dockr.ly/2k6gnOB
|
||||
[7]:http://dockr.ly/AppSecurity
|
||||
[8]:https://www.docker.com/getdocker
|
||||
[9]:http://www.docker.com/trial
|
||||
[10]:https://docs.docker.com/engine/swarm/secrets/
|
||||
[11]:http://www.docker.com/webinars
|
||||
[12]:https://blog.docker.com/author/yingli/
|
||||
[13]:https://blog.docker.com/tag/container-security/
|
||||
[14]:https://blog.docker.com/tag/docker-security/
|
||||
[15]:https://blog.docker.com/tag/secrets-management/
|
||||
[16]:https://blog.docker.com/tag/security/
|
||||
[17]:https://docs.docker.com/engine/swarm/how-swarm-mode-works/pki/
|
||||
[18]:https://docs.docker.com/engine/swarm/secrets/
|
||||
[19]:https://lvh.io%29/
|
||||
268
published/20170319 ftrace trace your kernel functions.md
Normal file
268
published/20170319 ftrace trace your kernel functions.md
Normal file
@ -0,0 +1,268 @@
|
||||
ftrace:跟踪你的内核函数!
|
||||
============================================================
|
||||
|
||||
大家好!今天我们将去讨论一个调试工具:ftrace,之前我的博客上还没有讨论过它。还有什么能比一个新的调试工具更让人激动呢?
|
||||
|
||||
这个非常棒的 ftrace 并不是个新的工具!它大约在 Linux 的 2.6 内核版本中就有了,时间大约是在 2008 年。[这一篇是我用谷歌能找到的最早的文档][10]。因此,如果你是一个调试系统的“老手”,可能早就已经使用它了!
|
||||
|
||||
我知道,ftrace 已经存在了大约 2.5 年了(LCTT 译注:距本文初次写作时),但是还没有真正的去学习它。假设我明天要召开一个专题研究会,那么,关于 ftrace 应该讨论些什么?因此,今天是时间去讨论一下它了!
|
||||
|
||||
### 什么是 ftrace?
|
||||
|
||||
ftrace 是一个 Linux 内核特性,它可以让你去跟踪 Linux 内核的函数调用。为什么要这么做呢?好吧,假设你调试一个奇怪的问题,而你已经得到了你的内核版本中这个问题在源代码中的开始的位置,而你想知道这里到底发生了什么?
|
||||
|
||||
每次在调试的时候,我并不会经常去读内核源代码,但是,极个别的情况下会去读它!例如,本周在工作中,我有一个程序在内核中卡死了。查看到底是调用了什么函数,能够帮我更好的理解在内核中发生了什么,哪些系统涉及其中!(在我的那个案例中,它是虚拟内存系统)。
|
||||
|
||||
我认为 ftrace 是一个十分好用的工具(它肯定没有 `strace` 那样使用广泛,也比它难以使用),但是它还是值得你去学习。因此,让我们开始吧!
|
||||
|
||||
### 使用 ftrace 的第一步
|
||||
|
||||
不像 `strace` 和 `perf`,ftrace 并不是真正的 **程序** – 你不能只运行 `ftrace my_cool_function`。那样太容易了!
|
||||
|
||||
如果你去读 [使用 ftrace 调试内核][11],它会告诉你从 `cd /sys/kernel/debug/tracing` 开始,然后做很多文件系统的操作。
|
||||
|
||||
对于我来说,这种办法太麻烦——一个使用 ftrace 的简单例子像是这样:
|
||||
|
||||
```
|
||||
cd /sys/kernel/debug/tracing
|
||||
echo function > current_tracer
|
||||
echo do_page_fault > set_ftrace_filter
|
||||
cat trace
|
||||
```
|
||||
|
||||
这个文件系统是跟踪系统的接口(“给这些神奇的文件赋值,然后该发生的事情就会发生”)理论上看起来似乎可用,但是它不是我的首选方式。
|
||||
|
||||
幸运的是,ftrace 团队也考虑到这个并不友好的用户界面,因此,它有了一个更易于使用的界面,它就是 `trace-cmd`!!!`trace-cmd` 是一个带命令行参数的普通程序。我们后面将使用它!我在 LWN 上找到了一个 `trace-cmd` 的使用介绍:[trace-cmd: Ftrace 的一个前端][12]。
|
||||
|
||||
### 开始使用 trace-cmd:让我们仅跟踪一个函数
|
||||
|
||||
首先,我需要去使用 `sudo apt-get install trace-cmd` 安装 `trace-cmd`,这一步很容易。
|
||||
|
||||
对于第一个 ftrace 的演示,我决定去了解我的内核如何去处理一个页面故障。当 Linux 分配内存时,它经常偷懒,(“你并不是_真的_计划去使用内存,对吗?”)。这意味着,当一个应用程序尝试去对分配给它的内存进行写入时,就会发生一个页面故障,而这个时候,内核才会真正的为应用程序去分配物理内存。
|
||||
|
||||
我们开始使用 `trace-cmd` 并让它跟踪 `do_page_fault` 函数!
|
||||
|
||||
```
|
||||
$ sudo trace-cmd record -p function -l do_page_fault
|
||||
plugin 'function'
|
||||
Hit Ctrl^C to stop recording
|
||||
```
|
||||
|
||||
我将它运行了几秒钟,然后按下了 `Ctrl+C`。 让我大吃一惊的是,它竟然产生了一个 2.5MB 大小的名为 `trace.dat` 的跟踪文件。我们来看一下这个文件的内容!
|
||||
|
||||
```
|
||||
$ sudo trace-cmd report
|
||||
chrome-15144 [000] 11446.466121: function: do_page_fault
|
||||
chrome-15144 [000] 11446.467910: function: do_page_fault
|
||||
chrome-15144 [000] 11446.469174: function: do_page_fault
|
||||
chrome-15144 [000] 11446.474225: function: do_page_fault
|
||||
chrome-15144 [000] 11446.474386: function: do_page_fault
|
||||
chrome-15144 [000] 11446.478768: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.480172: function: do_page_fault
|
||||
chrome-1830 [003] 11446.486696: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.488983: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.489034: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.489045: function: do_page_fault
|
||||
|
||||
```
|
||||
|
||||
看起来很整洁 – 它展示了进程名(chrome)、进程 ID(15144)、CPU ID(000),以及它跟踪的函数。
|
||||
|
||||
通过察看整个文件,(`sudo trace-cmd report | grep chrome`)可以看到,我们跟踪了大约 1.5 秒,在这 1.5 秒的时间段内,Chrome 发生了大约 500 个页面故障。真是太酷了!这就是我们做的第一个 ftrace!
|
||||
|
||||
### 下一个 ftrace 技巧:我们来跟踪一个进程!
|
||||
|
||||
好吧,只看一个函数是有点无聊!假如我想知道一个程序中都发生了什么事情。我使用一个名为 Hugo 的静态站点生成器。看看内核为 Hugo 都做了些什么事情?
|
||||
|
||||
在我的电脑上 Hugo 的 PID 现在是 25314,因此,我使用如下的命令去记录所有的内核函数:
|
||||
|
||||
```
|
||||
sudo trace-cmd record --help # I read the help!
|
||||
sudo trace-cmd record -p function -P 25314 # record for PID 25314
|
||||
```
|
||||
|
||||
`sudo trace-cmd report` 输出了 18,000 行。如果你对这些感兴趣,你可以看 [这里是所有的 18,000 行的输出][13]。
|
||||
|
||||
18,000 行太多了,因此,在这里仅摘录其中几行。
|
||||
|
||||
当系统调用 `clock_gettime` 运行的时候,都发生了什么:
|
||||
|
||||
```
|
||||
compat_SyS_clock_gettime
|
||||
SyS_clock_gettime
|
||||
clockid_to_kclock
|
||||
posix_clock_realtime_get
|
||||
getnstimeofday64
|
||||
__getnstimeofday64
|
||||
arch_counter_read
|
||||
__compat_put_timespec
|
||||
```
|
||||
|
||||
这是与进程调试相关的一些东西:
|
||||
|
||||
```
|
||||
cpufreq_sched_irq_work
|
||||
wake_up_process
|
||||
try_to_wake_up
|
||||
_raw_spin_lock_irqsave
|
||||
do_raw_spin_lock
|
||||
_raw_spin_lock
|
||||
do_raw_spin_lock
|
||||
walt_ktime_clock
|
||||
ktime_get
|
||||
arch_counter_read
|
||||
walt_update_task_ravg
|
||||
exiting_task
|
||||
|
||||
```
|
||||
|
||||
虽然你可能还不理解它们是做什么的,但是,能够看到所有的这些函数调用也是件很酷的事情。
|
||||
|
||||
### “function graph” 跟踪
|
||||
|
||||
这里有另外一个模式,称为 `function_graph`。除了它既可以进入也可以退出一个函数外,其它的功能和函数跟踪器是一样的。[这里是那个跟踪器的输出][14]
|
||||
|
||||
```
|
||||
sudo trace-cmd record -p function_graph -P 25314
|
||||
```
|
||||
|
||||
同样,这里只是一个片断(这次来自 futex 代码):
|
||||
|
||||
```
|
||||
| futex_wake() {
|
||||
| get_futex_key() {
|
||||
| get_user_pages_fast() {
|
||||
1.458 us | __get_user_pages_fast();
|
||||
4.375 us | }
|
||||
| __might_sleep() {
|
||||
0.292 us | ___might_sleep();
|
||||
2.333 us | }
|
||||
0.584 us | get_futex_key_refs();
|
||||
| unlock_page() {
|
||||
0.291 us | page_waitqueue();
|
||||
0.583 us | __wake_up_bit();
|
||||
5.250 us | }
|
||||
0.583 us | put_page();
|
||||
+ 24.208 us | }
|
||||
```
|
||||
|
||||
我们看到在这个示例中,在 `futex_wake` 后面调用了 `get_futex_key`。这是在源代码中真实发生的事情吗?我们可以检查一下!![这里是在 Linux 4.4 中 futex_wake 的定义][15] (我的内核版本是 4.4)。
|
||||
|
||||
为节省时间我直接贴出来,它的内容如下:
|
||||
|
||||
```
|
||||
static int
|
||||
futex_wake(u32 __user *uaddr, unsigned int flags, int nr_wake, u32 bitset)
|
||||
{
|
||||
struct futex_hash_bucket *hb;
|
||||
struct futex_q *this, *next;
|
||||
union futex_key key = FUTEX_KEY_INIT;
|
||||
int ret;
|
||||
WAKE_Q(wake_q);
|
||||
|
||||
if (!bitset)
|
||||
return -EINVAL;
|
||||
|
||||
ret = get_futex_key(uaddr, flags & FLAGS_SHARED, &key, VERIFY_READ);
|
||||
```
|
||||
|
||||
如你所见,在 `futex_wake` 中的第一个函数调用真的是 `get_futex_key`! 太棒了!相比阅读内核代码,阅读函数跟踪肯定是更容易的找到结果的办法,并且让人高兴的是,还能看到所有的函数用了多长时间。
|
||||
|
||||
### 如何知道哪些函数可以被跟踪
|
||||
|
||||
如果你去运行 `sudo trace-cmd list -f`,你将得到一个你可以跟踪的函数的列表。它很简单但是也很重要。
|
||||
|
||||
### 最后一件事:事件!
|
||||
|
||||
现在,我们已经知道了怎么去跟踪内核中的函数,真是太酷了!
|
||||
|
||||
还有一类我们可以跟踪的东西!有些事件与我们的函数调用并不相符。例如,你可能想知道当一个程序被调度进入或者离开 CPU 时,都发生了什么事件!你可能想通过“盯着”函数调用计算出来,但是,我告诉你,不可行!
|
||||
|
||||
由于函数也为你提供了几种事件,因此,你可以看到当重要的事件发生时,都发生了什么事情。你可以使用 `sudo cat /sys/kernel/debug/tracing/available_events` 来查看这些事件的一个列表。
|
||||
|
||||
我查看了全部的 sched_switch 事件。我并不完全知道 sched_switch 是什么,但是,我猜测它与调度有关。
|
||||
|
||||
```
|
||||
sudo cat /sys/kernel/debug/tracing/available_events
|
||||
sudo trace-cmd record -e sched:sched_switch
|
||||
sudo trace-cmd report
|
||||
```
|
||||
|
||||
输出如下:
|
||||
|
||||
```
|
||||
16169.624862: Chrome_ChildIOT:24817 [112] S ==> chrome:15144 [120]
|
||||
16169.624992: chrome:15144 [120] S ==> swapper/3:0 [120]
|
||||
16169.625202: swapper/3:0 [120] R ==> Chrome_ChildIOT:24817 [112]
|
||||
16169.625251: Chrome_ChildIOT:24817 [112] R ==> chrome:1561 [112]
|
||||
16169.625437: chrome:1561 [112] S ==> chrome:15144 [120]
|
||||
|
||||
```
|
||||
|
||||
现在,可以很清楚地看到这些切换,从 PID 24817 -> 15144 -> kernel -> 24817 -> 1561 -> 15114。(所有的这些事件都发生在同一个 CPU 上)。
|
||||
|
||||
### ftrace 是如何工作的?
|
||||
|
||||
ftrace 是一个动态跟踪系统。当我们开始 ftrace 内核函数时,**函数的代码会被改变**。让我们假设去跟踪 `do_page_fault` 函数。内核将在那个函数的汇编代码中插入一些额外的指令,以便每次该函数被调用时去提示跟踪系统。内核之所以能够添加额外的指令的原因是,Linux 将额外的几个 NOP 指令编译进每个函数中,因此,当需要的时候,这里有添加跟踪代码的地方。
|
||||
|
||||
这是一个十分复杂的问题,因为,当不需要使用 ftrace 去跟踪我的内核时,它根本就不影响性能。而当我需要跟踪时,跟踪的函数越多,产生的开销就越大。
|
||||
|
||||
(或许有些是不对的,但是,我认为的 ftrace 就是这样工作的)
|
||||
|
||||
### 更容易地使用 ftrace:brendan gregg 的工具及 kernelshark
|
||||
|
||||
正如我们在文件中所讨论的,你需要去考虑很多的关于单个的内核函数/事件直接使用 ftrace 都做了些什么。能够做到这一点很酷!但是也需要做大量的工作!
|
||||
|
||||
Brendan Gregg (我们的 Linux 调试工具“大神”)有个工具仓库,它使用 ftrace 去提供关于像 I/O 延迟这样的各种事情的信息。这是它在 GitHub 上全部的 [perf-tools][16] 仓库。
|
||||
|
||||
这里有一个权衡,那就是这些工具易于使用,但是你被限制仅能用于 Brendan Gregg 认可并做到工具里面的方面。它包括了很多方面!:)
|
||||
|
||||
另一个工具是将 ftrace 的输出可视化,做的比较好的是 [kernelshark][17]。我还没有用过它,但是看起来似乎很有用。你可以使用 `sudo apt-get install kernelshark` 来安装它。
|
||||
|
||||
### 一个新的超能力
|
||||
|
||||
我很高兴能够花一些时间去学习 ftrace!对于任何内核工具,不同的内核版本有不同的功效,我希望有一天你能发现它很有用!
|
||||
|
||||
### ftrace 系列文章的一个索引
|
||||
|
||||
最后,这里是我找到的一些 ftrace 方面的文章。它们大部分在 LWN (Linux 新闻周刊)上,它是 Linux 的一个极好的资源(你可以购买一个 [订阅][18]!)
|
||||
|
||||
* [使用 Ftrace 调试内核 - part 1][1] (Dec 2009, Steven Rostedt)
|
||||
* [使用 Ftrace 调试内核 - part 2][2] (Dec 2009, Steven Rostedt)
|
||||
* [Linux 函数跟踪器的秘密][3] (Jan 2010, Steven Rostedt)
|
||||
* [trace-cmd:Ftrace 的一个前端][4] (Oct 2010, Steven Rostedt)
|
||||
* [使用 KernelShark 去分析实时调试器][5] (2011, Steven Rostedt)
|
||||
* [Ftrace: 神秘的开关][6] (2014, Brendan Gregg)
|
||||
* 内核文档:(它十分有用) [Documentation/ftrace.txt][7]
|
||||
* 你能跟踪的事件的文档 [Documentation/events.txt][8]
|
||||
* linux 内核开发上的一些 ftrace 设计文档 (不是有用,而是有趣!) [Documentation/ftrace-design.txt][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/03/19/getting-started-with-ftrace/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://lwn.net/Articles/365835/
|
||||
[2]:https://lwn.net/Articles/366796/
|
||||
[3]:https://lwn.net/Articles/370423/
|
||||
[4]:https://lwn.net/Articles/410200/
|
||||
[5]:https://lwn.net/Articles/425583/
|
||||
[6]:https://lwn.net/Articles/608497/
|
||||
[7]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/ftrace.txt
|
||||
[8]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/events.txt
|
||||
[9]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/ftrace-design.txt
|
||||
[10]:https://lwn.net/Articles/290277/
|
||||
[11]:https://lwn.net/Articles/365835/
|
||||
[12]:https://lwn.net/Articles/410200/
|
||||
[13]:https://gist.githubusercontent.com/jvns/e5c2d640f7ec76ed9ed579be1de3312e/raw/78b8425436dc4bb5bb4fa76a4f85d5809f7d1ef2/trace-cmd-report.txt
|
||||
[14]:https://gist.githubusercontent.com/jvns/f32e9b06bcd2f1f30998afdd93e4aaa5/raw/8154d9828bb895fd6c9b0ee062275055b3775101/function_graph.txt
|
||||
[15]:https://github.com/torvalds/linux/blob/v4.4/kernel/futex.c#L1313-L1324
|
||||
[16]:https://github.com/brendangregg/perf-tools
|
||||
[17]:https://lwn.net/Articles/425583/
|
||||
[18]:https://lwn.net/subscribe/Info
|
||||
185
published/20170426 Important Docker commands for Beginners.md
Normal file
185
published/20170426 Important Docker commands for Beginners.md
Normal file
@ -0,0 +1,185 @@
|
||||
为小白准备的重要 Docker 命令说明
|
||||
======
|
||||
|
||||
在早先的教程中,我们学过了[在 RHEL CentOS 7 上安装 Docker 并创建 docker 容器][1]。 在本教程中,我们会学习管理 docker 容器的其他命令。
|
||||
|
||||
### Docker 命令语法
|
||||
|
||||
```
|
||||
$ docker [option] [command] [arguments]
|
||||
```
|
||||
|
||||
要列出 docker 支持的所有命令,运行
|
||||
|
||||
```
|
||||
$ docker
|
||||
```
|
||||
|
||||
我们会看到如下结果,
|
||||
|
||||
```
|
||||
attach Attach to a running container
|
||||
build Build an image from a Dockerfile
|
||||
commit Create a new image from a container's changes
|
||||
cp Copy files/folders between a container and the local filesystem
|
||||
create Create a new container
|
||||
diff Inspect changes on a container's filesystem
|
||||
events Get real time events from the server
|
||||
exec Run a command in a running container
|
||||
export Export a container's filesystem as a tar archive
|
||||
history Show the history of an image
|
||||
images List images
|
||||
import Import the contents from a tarball to create a filesystem image
|
||||
info Display system-wide information
|
||||
inspect Return low-level information on a container or image
|
||||
kill Kill a running container
|
||||
load Load an image from a tar archive or STDIN
|
||||
login Log in to a Docker registry
|
||||
logout Log out from a Docker registry
|
||||
logs Fetch the logs of a container
|
||||
network Manage Docker networks
|
||||
pause Pause all processes within a container
|
||||
port List port mappings or a specific mapping for the CONTAINER
|
||||
ps List containers
|
||||
pull Pull an image or a repository from a registry
|
||||
push Push an image or a repository to a registry
|
||||
rename Rename a container
|
||||
restart Restart a container
|
||||
rm Remove one or more containers
|
||||
rmi Remove one or more images
|
||||
run Run a command in a new container
|
||||
save Save one or more images to a tar archive
|
||||
search Search the Docker Hub for images
|
||||
start Start one or more stopped containers
|
||||
stats Display a live stream of container(s) resource usage statistics
|
||||
stop Stop a running container
|
||||
tag Tag an image into a repository
|
||||
top Display the running processes of a container
|
||||
unpause Unpause all processes within a container
|
||||
update Update configuration of one or more containers
|
||||
version Show the Docker version information
|
||||
volume Manage Docker volumes
|
||||
wait Block until a container stops, then print its exit code
|
||||
```
|
||||
|
||||
要进一步查看某个命令支持的选项,运行:
|
||||
|
||||
```
|
||||
$ docker docker-subcommand info
|
||||
```
|
||||
|
||||
就会列出 docker 子命令所支持的选项了。
|
||||
|
||||
### 测试与 Docker Hub 的连接
|
||||
|
||||
默认,所有镜像都是从 Docker Hub 中拉取下来的。我们可以从 Docker Hub 上传或下载操作系统镜像。为了检查我们是否能够正常地通过 Docker Hub 上传/下载镜像,运行
|
||||
|
||||
```
|
||||
$ docker run hello-world
|
||||
```
|
||||
|
||||
结果应该是:
|
||||
|
||||
```
|
||||
Hello from Docker.
|
||||
This message shows that your installation appears to be working correctly.
|
||||
…
|
||||
```
|
||||
|
||||
输出结果表示你可以访问 Docker Hub 而且也能从 Docker Hub 下载 docker 镜像。
|
||||
|
||||
### 搜索镜像
|
||||
|
||||
搜索容器的镜像,运行
|
||||
|
||||
```
|
||||
$ docker search Ubuntu
|
||||
```
|
||||
|
||||
我们应该会得到可用的 Ubuntu 镜像的列表。记住,如果你想要的是官方的镜像,请检查 `official` 这一列上是否为 `[OK]`。
|
||||
|
||||
### 下载镜像
|
||||
|
||||
一旦搜索并找到了我们想要的镜像,我们可以运行下面语句来下载它:
|
||||
|
||||
```
|
||||
$ docker pull Ubuntu
|
||||
```
|
||||
|
||||
要查看所有已下载的镜像,运行:
|
||||
|
||||
```
|
||||
$ docker images
|
||||
```
|
||||
|
||||
### 运行容器
|
||||
|
||||
使用已下载镜像来运行容器,使用下面命令:
|
||||
|
||||
```
|
||||
$ docker run -it Ubuntu
|
||||
```
|
||||
|
||||
这里,使用 `-it` 会打开一个 shell 与容器交互。容器启动并运行后,我们就可以像普通机器那样来使用它了,我们可以在容器中执行任何命令。
|
||||
|
||||
### 显示所有的 docker 容器
|
||||
|
||||
要列出所有 docker 容器,运行:
|
||||
|
||||
```
|
||||
$ docker ps
|
||||
```
|
||||
|
||||
会输出一个容器列表,每个容器都有一个容器 id 标识。
|
||||
|
||||
### 停止 docker 容器
|
||||
|
||||
要停止 docker 容器,运行:
|
||||
|
||||
```
|
||||
$ docker stop container-id
|
||||
```
|
||||
|
||||
### 从容器中退出
|
||||
|
||||
要从容器中退出,执行:
|
||||
|
||||
```
|
||||
$ exit
|
||||
```
|
||||
|
||||
### 保存容器状态
|
||||
|
||||
容器运行并更改后(比如安装了 apache 服务器),我们可以保存容器状态。这会在本地系统上保存新创建镜像。
|
||||
|
||||
运行下面语句来提交并保存容器状态:
|
||||
|
||||
```
|
||||
$ docker commit 85475ef774 repository/image_name
|
||||
```
|
||||
|
||||
这里,`commit` 命令会保存容器状态,`85475ef774`,是容器的容器 id,`repository`,通常为 docker hub 上的用户名 (或者新加的仓库名称)`image_name`,是新镜像的名称。
|
||||
|
||||
我们还可以使用 `-m` 和 `-a` 来添加更多信息。通过 `-m`,我们可以留个信息说 apache 服务器已经安装好了,而 `-a` 可以添加作者名称。
|
||||
|
||||
像这样:
|
||||
|
||||
```
|
||||
docker commit -m "apache server installed"-a "Dan Daniels" 85475ef774 daniels_dan/Cent_container
|
||||
```
|
||||
|
||||
我们的教程至此就结束了,本教程讲解了一下 Docker 中的那些重要的命令,如有疑问,欢迎留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/important-docker-commands-beginners/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/create-first-docker-container-beginners-guide/
|
||||
125
published/20170502 A beginner-s guide to Raspberry Pi 3.md
Normal file
125
published/20170502 A beginner-s guide to Raspberry Pi 3.md
Normal file
@ -0,0 +1,125 @@
|
||||
树莓派 3 的新手指南
|
||||
======
|
||||
> 这个教程将帮助你入门<ruby>树莓派 3<rt>Raspberry Pi 3</rt></ruby>。
|
||||
|
||||

|
||||
|
||||
这篇文章是我的使用树莓派 3 创建新项目的每周系列文章的一部分。该系列的这个第一篇文章专注于入门,它主要讲安装 Raspbian 和 PIXEL 桌面,以及设置网络和其它的基本组件。
|
||||
|
||||
### 你需要:
|
||||
|
||||
* 一台树莓派 3
|
||||
* 一个 5v 2mAh 带 USB 接口的电源适配器
|
||||
* 至少 8GB 容量的 Micro SD 卡
|
||||
* Wi-Fi 或者以太网线
|
||||
* 散热片
|
||||
* 键盘和鼠标
|
||||
* 一台 PC 显示器
|
||||
* 一台用于准备 microSD 卡的 Mac 或者 PC
|
||||
|
||||
现在有很多基于 Linux 操作系统可用于树莓派,你可以直接安装它,但是,如果你是第一次接触树莓派,我推荐使用 NOOBS,它是树莓派官方的操作系统安装器,它安装操作系统到该设备的过程非常简单。
|
||||
|
||||
在你的电脑上从 [这个链接][1] 下载 NOOBS。它是一个 zip 压缩文件。如果你使用的是 MacOS,可以直接双击它,MacOS 会自动解压这个文件。如果你使用的是 Windows,右键单击它,选择“解压到这里”。
|
||||
|
||||
如果你运行的是 Linux 桌面,如何去解压 zip 文件取决于你的桌面环境,因为,不同的桌面环境下解压文件的方法不一样,但是,使用命令行可以很容易地完成解压工作。
|
||||
|
||||
```
|
||||
$ unzip NOOBS.zip
|
||||
```
|
||||
|
||||
不管它是什么操作系统,打开解压后的文件,你看到的应该是如下图所示的样子:
|
||||
|
||||
![content][3]
|
||||
|
||||
现在,在你的 PC 上插入 Micro SD 卡,将它格式化成 FAT32 格式的文件系统。在 MacOS 上,使用磁盘实用工具去格式化 Micro SD 卡:
|
||||
|
||||
![format][4]
|
||||
|
||||
在 Windows 上,只需要右键单击这个卡,然后选择“格式化”选项。如果是在 Linux 上,不同的桌面环境使用不同的工具,就不一一去讲解了。在这里我写了一个教程,[在 Linux 上使用命令行界面][5] 去格式化 SD 卡为 Fat32 文件系统。
|
||||
|
||||
在你的卡格式成了 FAT32 格式的文件系统后,就可以去拷贝下载的 NOOBS 目录的内容到这个卡的根目录下。如果你使用的是 MacOS 或者 Linux,可以使用 `rsync` 将 NOOBS 的内容传到 SD 卡的根目录中。在 MacOS 或者 Linux 中打开终端应用,然后运行如下的 rsync 命令:
|
||||
|
||||
```
|
||||
rsync -avzP /path_of_NOOBS /path_of_sdcard
|
||||
```
|
||||
|
||||
一定要确保选择了 SD 卡的根目录,在我的案例中(在 MacOS 上),它是:
|
||||
|
||||
```
|
||||
rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/
|
||||
```
|
||||
|
||||
或者你也可以拷贝粘贴 NOOBS 目录中的内容。一定要确保将 NOOBS 目录中的内容全部拷贝到 Micro SD 卡的根目录下,千万不能放到任何的子目录中。
|
||||
|
||||
现在可以插入这张 MicroSD 卡到树莓派 3 中,连接好显示器、键盘鼠标和电源适配器。如果你拥有有线网络,我建议你使用它,因为有线网络下载和安装操作系统更快。树莓派将引导到 NOOBS,它将提供一个供你去选择安装的分发版列表。从第一个选项中选择 Raspbian,紧接着会出现如下图的画面。
|
||||
|
||||
![raspi config][6]
|
||||
|
||||
在你安装完成后,树莓派将重新启动,你将会看到一个欢迎使用树莓派的画面。现在可以去配置它,并且去运行系统更新。大多数情况下,我们都是在没有外设的情况下使用树莓派的,都是使用 SSH 基于网络远程去管理它。这意味着你不需要为了管理树莓派而去为它接上鼠标、键盘和显示器。
|
||||
|
||||
开始使用它的第一步是,配置网络(假如你使用的是 Wi-Fi)。点击顶部面板上的网络图标,然后在出现的网络列表中,选择你要配置的网络并为它输入正确的密码。
|
||||
|
||||
![wireless][7]
|
||||
|
||||
恭喜您,无线网络的连接配置完成了。在进入下一步的配置之前,你需要找到你的网络为树莓派分配的 IP 地址,因为远程管理会用到它。
|
||||
|
||||
打开一个终端,运行如下的命令:
|
||||
|
||||
```
|
||||
ifconfig
|
||||
```
|
||||
|
||||
现在,记下这个设备的 `wlan0` 部分的 IP 地址。它一般显示为 “inet addr”。
|
||||
|
||||
现在,可以去启用 SSH 了,在树莓派上打开一个终端,然后打开 `raspi-config` 工具。
|
||||
|
||||
```
|
||||
sudo raspi-config
|
||||
```
|
||||
|
||||
树莓派的默认用户名和密码分别是 “pi” 和 “raspberry”。在上面的命令中你会被要求输入密码。树莓派配置工具的第一个选项是去修改默认密码,我强烈推荐你修改默认密码,尤其是你基于网络去使用它的时候。
|
||||
|
||||
第二个选项是去修改主机名,如果在你的网络中有多个树莓派时,主机名用于区分它们。一个有意义的主机名可以很容易在网络上识别每个设备。
|
||||
|
||||
然后进入到接口选项,去启用摄像头、SSH、以及 VNC。如果你在树莓派上使用了一个涉及到多媒体的应用程序,比如,家庭影院系统或者 PC,你也可以去改变音频输出选项。缺省情况下,它的默认输出到 HDMI 接口,但是,如果你使用外部音响,你需要去改变音频输出设置。转到树莓派配置工具的高级配置选项,选择音频,然后选择 “3.5mm” 作为默认输出。
|
||||
|
||||
[小提示:使用箭头键去导航,使用回车键去选择]
|
||||
|
||||
一旦应用了所有的改变, 树莓派将要求重新启动。你可以从树莓派上拔出显示器、鼠标键盘,以后可以通过网络来管理它。现在可以在你的本地电脑上打开终端。如果你使用的是 Windows,你可以使用 Putty 或者去读我的文章 - 怎么在 Windows 10 上安装 Ubuntu Bash。
|
||||
|
||||
在你的本地电脑上输入如下的 SSH 命令:
|
||||
|
||||
```
|
||||
ssh pi@IP_ADDRESS_OF_Pi
|
||||
```
|
||||
|
||||
在我的电脑上,这个命令是这样的:
|
||||
|
||||
```
|
||||
ssh pi@10.0.0.161
|
||||
```
|
||||
|
||||
输入它的密码,你登入到树莓派了!现在你可以从一台远程电脑上去管理你的树莓派。如果你希望通过因特网去管理树莓派,可以去阅读我的文章 - [如何在你的计算机上启用 RealVNC][8]。
|
||||
|
||||
在该系列的下一篇文章中,我将讲解使用你的树莓派去远程管理你的 3D 打印机。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3176488/linux/a-beginner-s-guide-to-raspberry-pi-3.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://www.raspberrypi.org/downloads/noobs/
|
||||
[2]:http://idgenterprise.selz.com
|
||||
[3]:https://images.techhive.com/images/article/2017/03/content-100711633-large.jpg
|
||||
[4]:https://images.techhive.com/images/article/2017/03/format-100711635-large.jpg
|
||||
[5]:http://www.cio.com/article/3176034/linux/how-to-format-an-sd-card-in-linux.html
|
||||
[6]:https://images.techhive.com/images/article/2017/03/raspi-config-100711634-large.jpg
|
||||
[7]:https://images.techhive.com/images/article/2017/03/wireless-100711636-large.jpeg
|
||||
[8]:http://www.infoworld.com/article/3171682/internet-of-things/how-to-access-your-raspberry-pi-remotely-over-the-internet.html
|
||||
[9]:https://www.infoworld.com/contributor-network/signup.html
|
||||
@ -0,0 +1,153 @@
|
||||
哪一种 Ubuntu 官方版本最适合你?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
*Ubuntu Budgie 只是为数不多的 Ubuntu 官方认可的<ruby>特色版本<rt>flavor</rt></ruby>之一。Jack Wallen(杰克沃伦)将讲述一下它们之间的重要的区别。*
|
||||
|
||||
Ubuntu Linux 有一些官方认可的<ruby>特色版本<rt>flavor</rt></ruby>,还有一些<ruby>衍生版本<rt>derivative distribution</rt></ruby>:
|
||||
|
||||
* [Kubuntu][9] - KDE 桌面版 Ubuntu
|
||||
* [Lubuntu][10] - LXDE 桌面版 Ubuntu
|
||||
* [Mythbuntu][11] - MythTV 版 Ubuntu
|
||||
* [Ubuntu Budgie][12] - Budgie 桌面版 Ubuntu
|
||||
* [Xubuntu][8] - Xfce 桌面版 Ubuntu
|
||||
|
||||
就在不久前(本文写于 2017 年 5 月),官方的 Ubuntu Linux 包括了其自己打造的 Unity 桌面版和第六个被认可的特色版本:Ubuntu GNOME —— Ubuntu 的 GNOME 桌面环境。
|
||||
|
||||
当<ruby>马克·沙特尔沃思<rt>Mark Shuttleworth</rt></ruby>决定要否决 Unity 的时候,这个选择对于 Canonical 来说就很明显了——是为了让 GNOME 成为 Ubuntu Linux 的官方桌面环境。从 Ubuntu 18.04(2018 年 4 月)开始,我们将仅剩下这个官方发行版和四种官方认可的特色版本。(LCTT 译注:从 17.10 就没有 Unity 版本了)
|
||||
|
||||
对于那些已经融入 Linux 社区的人来说,就像一些非常简单的数学问题一样——你知道你喜欢哪个 Linux 桌面,在 Ubuntu、Kubuntu、Lubuntu、Mythbuntu、Ubuntu Budgie 和 Xubuntu 之间做出选择不要太容易了。但那些还没有被灌输 Linux 思想的人可不会认为这是一个如此简单的决定。
|
||||
|
||||
为此,我认为帮助新用户决定选择对他们来说哪个特色版本最好可能是至关重要的。毕竟,从一开始就选择一个不合适的发行版是一种不太理想的体验。
|
||||
|
||||
因此,如果你正考虑选择哪个 Ubuntu 的特色版本,如果你想让你的体验尽可能地不痛苦,请继续往下看。
|
||||
|
||||
### Ubuntu
|
||||
|
||||
我将从 Ubuntu 的官方特色版本开始。我会有点扭曲时间线,跳过 Unity 不谈,直接进入即将到来的基于 GNOME 的发行版(LCTT 译注:本文写作半年后发布的 Ubuntu 17.10 是第一个官方的 GNOME Ubuntu 发行版)。除了 GNOME 是一个极其稳定且易于使用的桌面环境之外,选择官方的特色版本的一个很好的理由是:支持服务。这个 Ubuntu 的官方特色版本是由 Canonical 提供商业支持的。您可以每年花费 $150.00 为 Ubuntu 桌面版购买 [官方支持服务][20]。当然,对于这一级别的支持,最少要购买 50 个桌面的支持服务。而对于个人来说,最好的支持是 [Ubuntu 论坛][21],[Ubuntu 文档][22],或者[社区帮助维基][23]。
|
||||
|
||||
在商业支持之外,选择 Ubuntu 官方特色版本的原因是,如果你想要一个现代的、功能齐全的桌面的话,它是非常可靠和易用的。 GNOME 被设计成完美地适合桌面和笔记本电脑桌面的平台(图 1)。与它的前代的 Unity 不同,GNOME 可以更方便地定制以适合你的需要。如果你不喜欢摆弄桌面,不要担心,GNOME 工作的很好。事实上,GNOME 开箱即用的体验也许是市场上最优秀的桌面之一,甚至可以与 Mac OS X 媲美(或者更好)。如果修补和调整是你的主要的兴趣所在,你会发现 GNOME 在一定程度上是受限制的。 [GNOME 调整工具][24]和[GNOME Shell 扩展][25]只会比你想要的提供的更多。
|
||||
|
||||

|
||||
|
||||
*图 1:带有 Unity 味道 GNOME 桌面也许就会是我们在 Ubuntu 18.04 上所看到的。*
|
||||
|
||||
### Kubuntu
|
||||
|
||||
<ruby>[K 桌面环境][26]<rt>K Desktop Environment</rt></ruby>(即 KDE)与 GNOME 长期并存,有时被误解为一个较少见的桌面。但随着 KDE Plasma 5 的发布,情况发生了变化。KDE 已经成为一个强大的、高效的、稳定的桌面,它正在一步步地成为最好的桌面系统。但是你为什么要选择 Kubuntu 而不是 Ubuntu 官方版本呢?这个问题的答案很简单——你习惯了 Windows XP / 7 桌面模式。开始菜单、任务栏、系统托盘,等等,KDE 拥有这些乃至更多,所有的这些都会让你觉得你在使用过去和现在的最好的技术。事实上,如果你正在寻找一款最像 Windows 7 的 Ubuntu 官方特色版本,除了它你就找不到更好的了。
|
||||
|
||||
Kubuntu 的优点之一是,你会发现它比你以前使用过的任何 Windows 版本都灵活,而且同样可靠/友好。不要觉得因为 KDE 提供的桌面有点类似于 Windows 7,它就没有现代特色。事实上,Kubuntu 对类 Windows 7 的界面进行了很好的处理,并更新了它以满足更现代的审美(图 2)。
|
||||
|
||||

|
||||
|
||||
*图 2: Kubuntu 在老式用户体验上提供了现代感受。*
|
||||
|
||||
Ubuntu 官方版本并不是提供桌面支持的唯一特色版本。Kubuntu 用户也可以购买[商业支持][27]。注意,它不便宜,一个小时的支持服务将花费你 103.88 美元。
|
||||
|
||||
### Lubuntu
|
||||
|
||||
如果你正在寻找一个易于使用的桌面,要非常快(以便旧硬件感受如新),而且要比你曾经使用的任何桌面都灵活,那么 Lubuntu 就是你想要的。对 Lubuntu 唯一的警告是,你看到更加空荡的桌面,也许你已经习惯了。Lubuntu 使用 [LXDE 桌面][28],并包含一个延续了轻量级主题的应用程序列表。因此,如果你想在桌面上寻找极速快感的体验,Lubuntu 可能是个不错的选择。
|
||||
|
||||
然而,对 Lubuntu 有一个提醒,对于一些用户来说,这可能会影响他们选择它。由于 Lubuntu 的低配,其预先安装的应用程序可能无法胜任任务。例如,取而代之成熟的办公套件的是,您将发现 [AibWord 字处理器][29]和 [Gnumeric 图表][30]工具。别误会,这两个都是很好的工具。然而,如果你正在寻找一款适合商业使用的软件,你会发现它们缺乏友好的支持。另一方面,如果你想要安装更多的以工作为中心的工具(例如 LibreOffice),Lubuntu 包括了新立得软件包管理器可以简化第三方软件的安装。
|
||||
|
||||
和有限的默认软件一起,Lubuntu 提供了一个简单易用的桌面(图 3),任何人都可以马上开始使用,几乎没有学习曲线。
|
||||
|
||||

|
||||
|
||||
*图 3:Lubuntu 软件的贫乏,换来的是速度和简单性。*
|
||||
|
||||
### Mythbuntu
|
||||
|
||||
Mythbuntu 在这里是一种奇怪的鸟,因为它不是真正的桌面变体。相反,Mythbuntu 是 Ubuntu 多媒体工场设计的一个特殊的特色版本。使用 Mythbuntu 需要电视调谐器和电视输出卡。而且,在安装过程中,还需要采取一些额外的步骤(如选择如何设置前端/后端,以及设置您的红外遥控器)。
|
||||
|
||||
如果您碰巧拥有该硬件(以及创建您自己的由 Ubuntu 驱动的娱乐系统的愿望),Mythbuntu 就是您想要的发行版。一旦安装了 Mythbuntu,就会提示您通过设置采集卡、录制设置、视频源和输入连接(图4)。
|
||||
|
||||

|
||||
|
||||
*图 4:准备设置 Mythbuntu。*
|
||||
|
||||
### Ubuntu Budgie
|
||||
|
||||
Ubuntu Budgie 是一个新加入到官方特色版本列表的小成员。它使用 Budgie 桌面,这是一个非常漂亮和现代的 Linux 操作系统,它可以满足任何类型的用户。Ubuntu Budgie 的目标是创建一个优雅简洁的桌面界面。而这个任务已经完成了。如果你正在寻找一个漂亮的桌面,想在非常稳定的 Ubuntu Linux 平台上工作,你只需看看 Ubuntu Budgie 就可以了。
|
||||
|
||||
在 Ubuntu 上添加这个特殊的版本到官方版本列表中是 Canonical 的一个聪明的举动。随着 Unity 的消失,他们需要一个能提供 Unity 的优雅的桌面。Budgie 的定制非常简单,其所包含的软件列表可以让你立即开始工作和上网浏览。
|
||||
|
||||
而且,与许多用户在 Unity 中遇到的学习曲线不同,Ubuntu Budgie 的开发者/设计者们做了一件非常出色的工作,让我们保有 Ubuntu 的熟悉感。点击“开始”按钮,会显示一个相当标准的应用程序菜单。Budgie 还包括一个易于使用的 Dock(图 5),它包含了用于快速访问的应用程序启动器。
|
||||
|
||||

|
||||
|
||||
*图 5:这是一个漂亮的桌面。*
|
||||
|
||||
在 Ubuntu Budgie 中发现的另一个很好的功能是侧边栏可以快速显示和隐藏。这个侧边栏包含了小应用和通知。有了这个功能,你的桌面就会变得非常有用,同时还免除杂乱。
|
||||
|
||||
最后,如果你在寻找一个稍有不同,但又非常现代的桌面——其特色与功能在其他发行版本中找不到 —— 那么 Ubuntu Budgie 就是你想要的。
|
||||
|
||||
### Xubuntu
|
||||
|
||||
另一种很好地提供了低配支持的 Ubuntu 官方特色版本是 [Xubuntu][32]。Xubuntu 和 Lubuntu 的区别在于, Lubuntu 使用 LXDE 桌面,而 Xubuntu 使用[Xfce][33]。差别就是这个轻量级桌面,它比 Lubuntu 更具可配置性,也包括了更适合商务的 LibreOffice 办公套件。
|
||||
|
||||
Xubuntu 对任何人来说都是开箱即用的,无论是否有经验。但是,不要认为看起来熟悉就意味着这个 Ubuntu 特色版本可以让你马上随心所欲。如果你既想要 Ubuntu 传统的开箱即用,也想要经过大量调整成为一个更现代的桌面, 那么 Xubuntu 就是你想要的。
|
||||
|
||||
我一直很喜欢 Xubuntu 的一个非常方便的附加功能(就像之前的 Enlightenment),就是通过在桌面的任何地方右键点击打开“开始”菜单(图 6),这样可以非常有效的提高使用效率。
|
||||
|
||||

|
||||
|
||||
*图 6:Xubuntu 可以通过右键点击桌面的任何地方来打开“开始”菜单。*
|
||||
|
||||
### 选择由你
|
||||
|
||||
总有一款 Ubuntu 的特色版本可以满足所需——选择哪一个取决于你。你自己可以问一下这些问题,例如:
|
||||
|
||||
* 你有什么需要?
|
||||
* 你喜欢与哪种类型的桌面交互?
|
||||
* 你的硬件老化了吗?
|
||||
* 你喜欢 Windows XP / 7的感觉吗?
|
||||
* 你想要一个多媒体系统吗?
|
||||
|
||||
你对以上问题的回答将会很好地决定 Ubuntu 的哪一种特色版本适合你。好消息是,任何选择都不能算错。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/5/which-official-ubuntu-flavor-best-you
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://www.linux.com/licenses/category/used-permission
|
||||
[8]:http://xubuntu.org/
|
||||
[9]:http://www.kubuntu.org/
|
||||
[10]:http://lubuntu.net/
|
||||
[11]:http://www.mythbuntu.org/
|
||||
[12]:https://ubuntubudgie.org/
|
||||
[13]:https://www.linux.com/files/images/ubuntuflavorajpg
|
||||
[14]:https://www.linux.com/files/images/ubuntuflavorbjpg
|
||||
[15]:https://www.linux.com/files/images/ubuntuflavorcjpg
|
||||
[16]:https://www.linux.com/files/images/ubuntuflavordjpg
|
||||
[17]:https://www.linux.com/files/images/ubuntuflavorejpg
|
||||
[18]:https://www.linux.com/files/images/xubuntujpg
|
||||
[19]:https://www.linux.com/files/images/ubuntubudgiejpg
|
||||
[20]:https://buy.ubuntu.com/collections/ubuntu-advantage-for-desktop
|
||||
[21]:https://ubuntuforums.org/
|
||||
[22]:https://help.ubuntu.com/?_ga=2.155705979.1922322560.1494162076-828730842.1481046109
|
||||
[23]:https://help.ubuntu.com/community/CommunityHelpWiki?_ga=2.155705979.1922322560.1494162076-828730842.1481046109
|
||||
[24]:https://apps.ubuntu.com/cat/applications/gnome-tweak-tool/
|
||||
[25]:https://extensions.gnome.org/
|
||||
[26]:https://www.kde.org/
|
||||
[27]:https://kubuntu.emerge-open.com/buy
|
||||
[28]:http://lxde.org/
|
||||
[29]:https://www.abisource.com/
|
||||
[30]:http://www.gnumeric.org/
|
||||
[31]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[32]:https://xubuntu.org/
|
||||
[33]:https://www.xfce.org/
|
||||
@ -0,0 +1,112 @@
|
||||
检查系统和硬件信息的命令
|
||||
======
|
||||
|
||||
你们好,Linux 爱好者们,在这篇文章中,我将讨论一些作为系统管理员重要的事。众所周知,作为一名优秀的系统管理员意味着要了解有关 IT 基础架构的所有信息,并掌握有关服务器的所有信息,无论是硬件还是操作系统。所以下面的命令将帮助你了解所有的硬件和系统信息。
|
||||
|
||||
### 1 查看系统信息
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
```
|
||||
|
||||
![uname command][2]
|
||||
|
||||
它会为你提供有关系统的所有信息。它会为你提供系统的内核名、主机名、内核版本、内核发布号、硬件名称。
|
||||
|
||||
### 2 查看硬件信息
|
||||
|
||||
```
|
||||
$ lshw
|
||||
```
|
||||
|
||||
![lshw command][4]
|
||||
|
||||
使用 `lshw` 将在屏幕上显示所有硬件信息。
|
||||
|
||||
### 3 查看块设备(硬盘、闪存驱动器)信息
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
```
|
||||
|
||||
![lsblk command][6]
|
||||
|
||||
`lsblk` 命令在屏幕上打印关于块设备的所有信息。使用 `lsblk -a` 可以显示所有块设备。
|
||||
|
||||
### 4 查看 CPU 信息
|
||||
|
||||
```
|
||||
$ lscpu
|
||||
```
|
||||
|
||||
![lscpu command][8]
|
||||
|
||||
`lscpu` 在屏幕上显示所有 CPU 信息。
|
||||
|
||||
### 5 查看 PCI 信息
|
||||
|
||||
```
|
||||
$ lspci
|
||||
```
|
||||
|
||||
![lspci command][10]
|
||||
|
||||
所有的网络适配器卡、USB 卡、图形卡都被称为 PCI。要查看他们的信息使用 `lspci`。
|
||||
|
||||
`lspci -v` 将提供有关 PCI 卡的详细信息。
|
||||
|
||||
`lspci -t` 会以树形格式显示它们。
|
||||
|
||||
### 6 查看 USB 信息
|
||||
|
||||
```
|
||||
$ lsusb
|
||||
```
|
||||
|
||||
![lsusb command][12]
|
||||
|
||||
要查看有关连接到机器的所有 USB 控制器和设备的信息,我们使用 `lsusb`。
|
||||
|
||||
### 7 查看 SCSI 信息
|
||||
|
||||
```
|
||||
$ lsscsi
|
||||
```
|
||||
|
||||
![lsscsi][14]
|
||||
|
||||
要查看 SCSI 信息输入 `lsscsi`。`lsscsi -s` 会显示分区的大小。
|
||||
|
||||
### 8 查看文件系统信息
|
||||
|
||||
```
|
||||
$ fdisk -l
|
||||
```
|
||||
|
||||
![fdisk command][16]
|
||||
|
||||
使用 `fdisk -l` 将显示有关文件系统的信息。虽然 `fdisk` 的主要功能是修改文件系统,但是也可以创建新分区,删除旧分区(详情在我以后的教程中)。
|
||||
|
||||
就是这些了,我的 Linux 爱好者们。建议你在**[这里][17]**和**[这里][18]**的文章中查看关于另外的 Linux 命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/commands-system-hardware-info/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[2]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/uname.jpg?resize=664%2C69
|
||||
[4]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/lshw.jpg?resize=641%2C386
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/lsblk.jpg?resize=646%2C162
|
||||
[8]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/lscpu.jpg?resize=643%2C216
|
||||
[10]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/lspci.jpg?resize=644%2C238
|
||||
[12]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/lsusb.jpg?resize=645%2C37
|
||||
[14]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/lsscsi.jpg?resize=639%2C110
|
||||
[16]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fdisk.jpg?resize=656%2C335
|
||||
[17]:http://linuxtechlab.com/linux-commands-beginners-part-1/
|
||||
[18]:http://linuxtechlab.com/linux-commands-beginners-part-2/
|
||||
@ -1,14 +1,13 @@
|
||||
Reddit 的浏览计数
|
||||
Reddit 如何实现大规模的帖子浏览计数
|
||||
======================
|
||||
|
||||

|
||||
|
||||
|
||||
我们希望更好地将 Reddit 的规模传达给我们的用户。到目前为止,投票得分和评论数量是特定文章活动的主要指标。然而,Reddit 有许多访问者在没有投票或评论的情况下阅读内容。我们希望建立一个能够捕捉到帖子阅读数量的系统。然后将数量展示给内容创建者和版主,以便他们更好地了解特定帖子上的活动。
|
||||
我们希望更好地将 Reddit 的规模传达给我们的用户。到目前为止,投票得分和评论数量是特定的帖子活动的主要指标。然而,Reddit 有许多访问者在没有投票或评论的情况下阅读内容。我们希望建立一个能够捕捉到帖子阅读数量的系统。然后将该数量展示给内容创建者和版主,以便他们更好地了解特定帖子上的活动。
|
||||
|
||||

|
||||
|
||||
在这篇文章中,我们将讨论我们如何伸缩地实现计数。
|
||||
在这篇文章中,我们将讨论我们如何大规模地实现计数。
|
||||
|
||||
### 计数方法
|
||||
|
||||
@ -19,20 +18,20 @@ Reddit 的浏览计数
|
||||
* 显示的数量与实际的误差在百分之几。
|
||||
* 系统必须能够在生产环境运行,并在事件发生后几秒内处理事件。
|
||||
|
||||
满足这四项要求比听起来要复杂得多。为了实时保持准确的计数,我们需要知道某个特定的用户是否曾经访问过这个帖子。要知道这些信息,我们需要存储先前访问过每个帖子的用户组,然后在每次处理新帖子时查看该组。这个解决方案的一个原始实现是将唯一的用户集作为散列表存储在内存中,并且以发布 ID 作为关键字。
|
||||
满足这四项要求比听起来要复杂得多。为了实时保持准确的计数,我们需要知道某个特定的用户是否曾经访问过这个帖子。要知道这些信息,我们需要存储先前访问过每个帖子的用户组,然后在每次处理对该帖子的新访问时查看该组。这个解决方案的一个原始实现是将这个唯一用户的集合作为散列表存储在内存中,并且以帖子 ID 作为键名。
|
||||
|
||||
这种方法适用于较少浏览量的文章,但一旦文章流行,阅读人数迅速增加,这种方法很难扩展。几个热门的帖子有超过一百万的唯一读者!对于这种帖子,对于内存和 CPU 来说影响都很大,因为要存储所有的 ID,并频繁地查找集合,看看是否有人已经访问过。
|
||||
这种方法适用于浏览量较少的文章,但一旦文章流行,阅读人数迅速增加,这种方法很难扩展。有几个热门的帖子有超过一百万的唯一读者!对于这种帖子,对于内存和 CPU 来说影响都很大,因为要存储所有的 ID,并频繁地查找集合,看看是否有人已经访问过。
|
||||
|
||||
由于我们不能提供精确的计数, 我们研究了几个不同的[基数估计][1] 算法。我们考虑了两个非常符合我们期望的选择:
|
||||
由于我们不能提供精确的计数,我们研究了几个不同的[基数估计][1]算法。我们考虑了两个非常符合我们期望的选择:
|
||||
|
||||
1. 线性概率计数方法,非常准确,但要计数的集合越大,则线性地需要更多的内存。
|
||||
2. 基于 [HyperLogLog][2](HLL)的计数方法。HLL 随集合大小次线性增长,但不能提供与线性计数器相同的准确度。
|
||||
2. 基于 [HyperLogLog][2](HLL)的计数方法。HLL 随集合大小<ruby>次线性<rt>sub-linearly</rt></ruby>增长,但不能提供与线性计数器相同的准确度。
|
||||
|
||||
要了解 HLL 真正节省的空间大小,考虑到右侧图片包括顶部的文章。它有超过 100 万的唯一用户。如果我们存储 100 万个唯一用户 ID,并且每个用户 ID 是 8 个字节长,那么我们需要 8 兆内存来计算单个帖子的唯一用户数!相比之下,使用 HLL 进行计数会占用更少的内存。每个实现的内存量是不一样的,但是对于[这个实现][3],我们可以使用仅仅 12 千字节的空间计算超过一百万个 ID,这将是原始空间使用量的 0.15%!
|
||||
要了解 HLL 真正节省的空间大小,看一下这篇文章顶部包括的 r/pics 帖子。它有超过 100 万的唯一用户。如果我们存储 100 万个唯一用户 ID,并且每个用户 ID 是 8 个字节长,那么我们需要 8 兆内存来计算单个帖子的唯一用户数!相比之下,使用 HLL 进行计数会占用更少的内存。每个实现的内存量是不一样的,但是对于[这个实现][3],我们可以使用仅仅 12 千字节的空间计算超过一百万个 ID,这将是原始空间使用量的 0.15%!
|
||||
|
||||
([这篇关于高可伸缩性的文章][5]很好地概述了上述两种算法。)
|
||||
|
||||
许多 HLL 实现使用了上述两种方法的组合,即对于小集合以线性计数开始并且一旦大小达到特定点就切换到 HLL。前者通常被称为 “稀疏” HLL 表达,而后者被称为“密集” HLL 表达。混合的方法是非常有利的,因为它可以提供准确的结果,同时保留适度的内存占用量。这个方法在[Google 的 HyperLogLog++ 论文][6]中有更详细的描述。
|
||||
许多 HLL 实现使用了上述两种方法的组合,即对于小集合以线性计数开始,并且一旦大小达到特定点就切换到 HLL。前者通常被称为 “稀疏” HLL 表达,而后者被称为“密集” HLL 表达。混合的方法是非常有利的,因为它可以提供准确的结果,同时保留适度的内存占用量。这个方法在 [Google 的 HyperLogLog++ 论文][6]中有更详细的描述。
|
||||
|
||||
虽然 HLL 算法是相当标准的,但在我们的实现中我们考虑使用三种变体。请注意,对于内存中的 HLL 实现,我们只关注 Java 和 Scala 实现,因为我们主要在数据工程团队中使用 Java 和 Scala。
|
||||
|
||||
@ -46,7 +45,7 @@ Reddit 的数据管道主要围绕 [Apache Kafka][7]。当用户查看帖子时
|
||||
|
||||
从这里,浏览计数系统有两个按顺序运行的组件。我们的计数架构的第一部分是一个名为 [Nazar][8] 的 Kafka 消费者,它将读取来自 Kafka 的每个事件,并通过我们编制的一组规则来确定是否应该计算一个事件。我们给它起了这个名字是因为 Nazar 是一个保护你免受邪恶的眼形护身符,Nazar 系统是一个“眼睛”,它可以保护我们免受不良因素的影响。Nazar 使用 Redis 保持状态,并跟踪不应计算浏览的潜在原因。我们可能无法统计事件的一个原因是,由于同一用户在短时间内重复浏览的结果。Nazar 接着将改变事件,添加一个布尔标志表明是否应该被计数,然后再发回 Kafka 事件。
|
||||
|
||||
这是这个项目要说的第二部分。我们有第二个叫做 [Abacus][9] 的 Kafka 消费者,它实际上对视浏览进行计数,并使计数在网站和客户端可见。Abacus 读取 Nazar 输出的 Kafka 事件。接着,根据 Nazar 的决定,它将计算或跳过本次浏览。如果事件被标记为计数,那么 Abacus 首先检查 Redis 中是否存在已经存在与事件对应的帖子的 HLL 计数器。如果计数器已经在 Redis 中,那么 Abacus 向 Redis 发出一个 [PFADD][10] 的请求。如果计数器还没有在 Redis 中,那么 Abacus 向 Cassandra 集群发出请求,我们用这个集群来持久化 HLL 计数器和原始计数,并向 Redis 发出一个 [SET][11] 请求来添加过滤器。这种情况通常发生在人们查看已经被 Redis 删除的旧帖的时候。
|
||||
这是这个项目要说的第二部分。我们有第二个叫做 [Abacus][9] 的 Kafka 消费者,它实际上对浏览进行计数,并使计数在网站和客户端可见。Abacus 读取 Nazar 输出的 Kafka 事件。接着,根据 Nazar 的决定,它将计算或跳过本次浏览。如果事件被标记为计数,那么 Abacus 首先检查 Redis 中是否存在已经存在与事件对应的帖子的 HLL 计数器。如果计数器已经在 Redis 中,那么 Abacus 向 Redis 发出一个 [PFADD][10] 的请求。如果计数器还没有在 Redis 中,那么 Abacus 向 Cassandra 集群发出请求,我们用这个集群来持久化 HLL 计数器和原始计数,并向 Redis 发出一个 [SET][11] 请求来添加过滤器。这种情况通常发生在人们查看已经被 Redis 删除的旧帖的时候。
|
||||
|
||||
为了保持对可能从 Redis 删除的旧帖子的维护,Abacus 定期将 Redis 的完整 HLL 过滤器以及每个帖子的计数记录到 Cassandra 集群中。 Cassandra 的写入以 10 秒一组分批写入,以避免超载。下面是一个高层的事件流程图。
|
||||
|
||||
@ -63,9 +62,9 @@ Reddit 的数据管道主要围绕 [Apache Kafka][7]。当用户查看帖子时
|
||||
|
||||
via: https://redditblog.com/2017/05/24/view-counting-at-reddit/
|
||||
|
||||
作者:[Krishnan Chandra ][a]
|
||||
作者:[Krishnan Chandra][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,127 @@
|
||||
使用 Vi/Vim 编辑器:高级概念
|
||||
======
|
||||
|
||||
早些时候我们已经讨论了一些关于 VI/VIM 编辑器的基础知识,但是 VI 和 VIM 都是非常强大的编辑器,还有很多其他的功能可以和编辑器一起使用。在本教程中,我们将学习 VI/VIM 编辑器的一些高级用法。
|
||||
|
||||
(**推荐阅读**:[使用 VI 编辑器:基础知识] [1])
|
||||
|
||||
### 使用 VI/VIM 编辑器打开多个文件
|
||||
|
||||
要打开多个文件,命令将与打开单个文件相同。我们只要添加第二个文件的名称。
|
||||
|
||||
```
|
||||
$ vi file1 file2 file 3
|
||||
```
|
||||
|
||||
要浏览到下一个文件,我们可以(在 vim 命令模式中)使用:
|
||||
|
||||
```
|
||||
:n
|
||||
```
|
||||
|
||||
或者我们也可以使用
|
||||
|
||||
```
|
||||
:e filename
|
||||
```
|
||||
|
||||
### 在编辑器中运行外部命令
|
||||
|
||||
我们可以在 vi 编辑器内部运行外部的 Linux/Unix 命令,也就是说不需要退出编辑器。要在编辑器中运行命令,如果在插入模式下,先返回到命令模式,我们使用 BANG 也就是 `!` 接着是需要使用的命令。运行命令的语法是:
|
||||
|
||||
```
|
||||
:! command
|
||||
```
|
||||
|
||||
这是一个例子:
|
||||
|
||||
```
|
||||
:! df -H
|
||||
```
|
||||
|
||||
### 根据模板搜索
|
||||
|
||||
要在文本文件中搜索一个单词或模板,我们在命令模式下使用以下两个命令:
|
||||
|
||||
* 命令 `/` 代表正向搜索模板
|
||||
* 命令 `?` 代表正向搜索模板
|
||||
|
||||
这两个命令都用于相同的目的,唯一不同的是它们搜索的方向。一个例子是:
|
||||
|
||||
如果在文件的开头向前搜索,
|
||||
|
||||
```
|
||||
:/ search pattern
|
||||
```
|
||||
|
||||
如果在文件末尾向后搜索,
|
||||
|
||||
```
|
||||
:? search pattern
|
||||
```
|
||||
|
||||
### 搜索并替换一个模式
|
||||
|
||||
我们可能需要搜索和替换我们的文本中的单词或模式。我们不是从整个文本中找到单词的出现的地方并替换它,我们可以在命令模式中使用命令来自动替换单词。使用搜索和替换的语法是:
|
||||
|
||||
```
|
||||
:s/pattern_to_be_found/New_pattern/g
|
||||
```
|
||||
|
||||
假设我们想要将单词 “alpha” 用单词 “beta” 代替,命令就是这样:
|
||||
|
||||
```
|
||||
:s/alpha/beta/g
|
||||
```
|
||||
|
||||
如果我们只想替换第一个出现的 “alpha”,那么命令就是:
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/
|
||||
```
|
||||
|
||||
### 使用 set 命令
|
||||
|
||||
我们也可以使用 set 命令自定义 vi/vim 编辑器的行为和外观。下面是一些可以使用 set 命令修改 vi/vim 编辑器行为的选项列表:
|
||||
|
||||
```
|
||||
:set ic ' 在搜索时忽略大小写
|
||||
|
||||
:set smartcase ' 搜索强制区分大小写
|
||||
|
||||
:set nu ' 在每行开始显示行号
|
||||
|
||||
:set hlsearch ' 高亮显示匹配的单词
|
||||
|
||||
:set ro ' 将文件类型更改为只读
|
||||
|
||||
:set term ' 打印终端类型
|
||||
|
||||
:set ai ' 设置自动缩进
|
||||
|
||||
:set noai ' 取消自动缩进
|
||||
```
|
||||
|
||||
其他一些修改 vi 编辑器的命令是:
|
||||
|
||||
```
|
||||
:colorscheme ' 用来改变编辑器的配色方案 。(仅适用于 VIM 编辑器)
|
||||
|
||||
:syntax on ' 为 .xml、.html 等文件打开颜色方案。(仅适用于VIM编辑器)
|
||||
```
|
||||
|
||||
这篇结束了本系列教程,请在下面的评论栏中提出你的疑问/问题或建议。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/working-vi-editor-basics/
|
||||
@ -1,29 +1,29 @@
|
||||
为什么车企纷纷招聘计算机安全专家
|
||||
============================================================
|
||||
|
||||
Photo
|
||||

|
||||
来自 CloudFlare 公司的网络安全专家 Marc Rogers(左)和来自 Lookout 的 Kevin Mahaffey 能够通过直接连接在汽车上的笔记本电脑控制特斯拉的进行许多操作。图为他们在 CloudFlare 的大厅里的的熔岩灯前的合影,这些熔岩灯被用来生成密匙。纽约时报 CreditChristie Hemm Klok 拍摄
|
||||
|
||||
大约在七年前,伊朗的数位顶级核科学家经历过一系列形式类似的暗杀:凶手的摩托车接近他们乘坐的汽车,把磁性炸弹吸附在汽车上,然后逃离并引爆炸弹。
|
||||
来自 CloudFlare 公司的网络安全专家 Marc Rogers(左)和来自 Lookout 的 Kevin Mahaffey 能够通过直接连接在汽车上的笔记本电脑控制特斯拉汽车进行许多操作。图为他们在 CloudFlare 的大厅里的的熔岩灯前的合影,这些熔岩灯被用来生成密匙。(纽约时报 CreditChristie Hemm Klok 拍摄)
|
||||
|
||||
大约在七年前,伊朗的几位顶级核科学家经历过一系列形式类似的暗杀:凶手的摩托车接近他们乘坐的汽车,把磁性炸弹吸附在汽车上,然后逃离并引爆炸弹。
|
||||
|
||||
安全专家们警告人们,再过 7 年,凶手们不再需要摩托车或磁性炸弹。他们所需要的只是一台笔记本电脑和发送给无人驾驶汽车的一段代码——让汽车坠桥、被货车撞扁或者在高速公路上突然抛锚。
|
||||
|
||||
汽车制造商眼中的无人驾驶汽车。在黑客眼中只是一台可以达到时速 100 公里的计算机。
|
||||
|
||||
网络安全公司CloudFlare的首席安全研究员马克·罗杰斯(Marc Rogers)说:“它们已经不再是汽车了。它们是装在车轮上的数据中心。从外界接收的每一条数据都可以作为黑客的攻击载体。“
|
||||
网络安全公司 CloudFlare 的首席安全研究员<ruby>马克·罗杰斯<rt>Marc Rogers</rt></ruby>说:“它们已经不再是汽车了。它们是装在车轮上的数据中心。从外界接收的每一条数据都可以作为黑客的攻击载体。“
|
||||
|
||||
两年前,两名“白帽”黑客——寻找系统漏洞并修复它们的研究员,而不是利用漏洞来犯罪的破坏者(Cracker)——成功地在数里之外用电脑获得了一辆 Jeep Cherokee 的控制权。他们控制汽车撞击一个放置在高速公路中央的假人(在场景设定中是一位紧张的记者),直接终止了假人的一生。
|
||||
两年前,两名“白帽”黑客(寻找系统漏洞并修复它们的研究员,而不是利用漏洞来犯罪的<ruby>破坏者<rt>Cracker</rt></ruby>)成功地在数里之外用电脑获得了一辆 Jeep Cherokee 的控制权。他们控制汽车撞击一个放置在高速公路中央的假人(在场景设定中是一位紧张的记者),直接终止了假人的一生。
|
||||
|
||||
黑客 Chris Valasek 和 Charlie Miller(现在是 Uber 和滴滴的安全研究人员)发现了一条 [由 Jeep 娱乐系统通向仪表板的电路][10]。他们利用这条线路控制了车辆转向、刹车和变速——他们在高速公路上撞击假人所需的一切。
|
||||
|
||||
Miller 先生上周日在 Twitter 上写道:“汽车被黑客入侵成为头条新闻,但是人们要清楚,没有人的汽车被坏人入侵过。 这些只是研究人员的测试。”
|
||||
Miller 先生上周日在 Twitter 上写道:“汽车被黑客入侵成为头条新闻,但是人们要清楚,没有谁的汽车被坏人入侵过。 这些只是研究人员的测试。”
|
||||
|
||||
尽管如此,Miller 和 Valasek 的研究使 Jeep 汽车的制造商菲亚特克莱斯勒(Fiat Chrysler)付出了巨大的代价,因为这个安全漏洞,菲亚特克莱斯勒被迫召回了 140 万辆汽车。
|
||||
尽管如此,Miller 和 Valasek 的研究使 Jeep 汽车的制造商<ruby>菲亚特克莱斯勒<rt>Fiat Chrysler</rt></ruby>付出了巨大的代价,因为这个安全漏洞,菲亚特克莱斯勒被迫召回了 140 万辆汽车。
|
||||
|
||||
毫无疑问,后来通用汽车首席执行官玛丽·巴拉(Mary Barra)把网络安全作为公司的首要任务。现在,计算机网络安全领域的人才在汽车制造商和高科技公司推进的无人驾驶汽车项目中的需求量很大。
|
||||
毫无疑问,后来通用汽车首席执行官<ruby>玛丽·巴拉<rt>Mary Barra</rt></ruby>把网络安全作为公司的首要任务。现在,计算机网络安全领域的人才在汽车制造商和高科技公司推进的无人驾驶汽车项目中的需求量很大。
|
||||
|
||||
优步 、[特斯拉][11]、苹果和中国的滴滴一直在积极招聘像 Miller 先生和 Valasek 先生这样的白帽黑客,传统的网络安全公司和学术界也有这样的趋势。
|
||||
优步 、特斯拉、苹果和中国的滴滴一直在积极招聘像 Miller 先生和 Valasek 先生这样的白帽黑客,传统的网络安全公司和学术界也有这样的趋势。
|
||||
|
||||
去年,特斯拉挖走了苹果 iOS 操作系统的安全经理 Aaron Sigel。优步挖走了 Facebook 的白帽黑客 Chris Gates。Miller 先生在发现 Jeep 的漏洞后就职于优步,然后被滴滴挖走。计算机安全领域已经有数十名优秀的工程师加入无人驾驶汽车项目研究的行列。
|
||||
|
||||
@ -31,19 +31,19 @@ Miller 先生说,他离开了优步的一部分原因是滴滴给了他更自
|
||||
|
||||
Miller 星期六在 Twitter 上写道:“汽车制造商对待网络攻击的威胁似乎更加严肃,但我仍然希望有更大的透明度。”
|
||||
|
||||
像许多大型科技公司一样,特斯拉和菲亚特克莱斯勒也开始给那些发现并提交漏洞的黑客们提供奖励。通用汽车公司也做了类似的事情,但批评人士认为通用汽车公司的计划与科技公司提供的计划相比诚意不足,迄今为止还收效甚微。
|
||||
像许多大型科技公司一样,特斯拉和菲亚特克莱斯勒也开始给那些发现并提交漏洞的黑客们提供奖励。通用汽车公司也做了类似的事情,但批评人士认为通用汽车公司的计划与科技公司们提供的计划相比诚意不足,迄今为止还收效甚微。
|
||||
|
||||
在 Miller 和 Valasek 发现 Jeep 漏洞的一年后,他们又向人们演示了所有其他可能危害乘客安全的方式,包括劫持车辆的速度控制系统,猛打方向盘或在高速行驶下拉动手刹——这一切都是由汽车外的电脑操作的。(在测试中使用的汽车最后掉进路边的沟渠,他们只能寻求当地拖车公司的帮助)
|
||||
|
||||
虽然他们必须在 Jeep 车上才能做到这一切,但这也证明了入侵的可能性。
|
||||
|
||||
在 Jeep 被入侵之前,华盛顿大学和加利福尼亚大学圣地亚哥分校的安全研究人员第一个通过蓝牙远程控制轿车并控制其刹车。研究人员警告汽车公司:汽车联网程度越高,被入侵的可能性就越大。
|
||||
在 Jeep 被入侵之前,华盛顿大学和加利福尼亚大学圣地亚哥分校的[安全研究人员][12]第一个通过蓝牙远程控制轿车并控制其刹车。研究人员警告汽车公司:汽车联网程度越高,被入侵的可能性就越大。
|
||||
|
||||
2015年,安全研究人员们发现了入侵高度软件化的特斯拉 Model S 的途径。Rogers 先生和网络安全公司 Lookout 的首席技术官凯文·马哈菲(Kevin Mahaffey)找到了一种通过直接连接在汽车上的笔记本电脑控制特斯拉汽车的方法。
|
||||
2015 年,安全研究人员们发现了入侵高度软件化的特斯拉 Model S 的途径。Rogers 先生和网络安全公司 Lookout 的首席技术官<ruby>凯文·马哈菲<rt>Kevin Mahaffey</rt></ruby>找到了一种通过直接连接在汽车上的笔记本电脑控制特斯拉汽车的方法。
|
||||
|
||||
一年后,来自中国腾讯的一支团队做了更进一步的尝试。他们入侵了一辆行驶中的特斯拉 Model S 并控制了其刹车器。和 Jeep 不同,特斯拉可以通过远程安装补丁来修复安全漏洞,这使得黑客的远程入侵也变的可能。
|
||||
一年后,来自中国腾讯的一支团队做了更进一步的尝试。他们入侵了一辆行驶中的特斯拉 Model S 并控制了其刹车器达12 米远。和 Jeep 不同,特斯拉可以通过远程安装补丁来修复那些可能被黑的安全漏洞。
|
||||
|
||||
以上所有的例子中,入侵者都是无恶意的白帽黑客或者安全研究人员。但是给无人驾驶汽车制造商的教训是惨重的。
|
||||
以上所有的例子中,入侵者都是无恶意的白帽黑客或者安全研究人员,但是给无人驾驶汽车制造商的教训是惨重的。
|
||||
|
||||
黑客入侵汽车的动机是无穷的。在得知 Rogers 先生和 Mahaffey 先生对特斯拉 Model S 的研究之后,一位中国 app 开发者和他们联系、询问他们是否愿意分享或者出售他们发现的漏洞。(这位 app 开发者正在寻找后门,试图在特斯拉的仪表盘上偷偷安装 app)
|
||||
|
||||
@ -51,25 +51,25 @@ Miller 星期六在 Twitter 上写道:“汽车制造商对待网络攻击的
|
||||
|
||||
但随着越来越多的无人驾驶和半自动驾驶的汽车驶入公路,它们将成为更有价值的目标。安全专家警告道:无人驾驶汽车面临着更复杂、更多面的入侵风险,每一辆新无人驾驶汽车的加入,都使这个系统变得更复杂,而复杂性不可避免地带来脆弱性。
|
||||
|
||||
20年前,平均每辆汽车有100万行代码,通用汽车公司的2010雪佛兰Volt有大约1000万行代码——比一架F-35战斗机的代码还要多。
|
||||
20 年前,平均每辆汽车有 100 万行代码,通用汽车公司的 2010 [雪佛兰 Volt][13] 有大约 1000 万行代码——比一架 [F-35 战斗机][14]的代码还要多。
|
||||
|
||||
如今, 平均每辆汽车至少有1亿行代码。无人驾驶汽车公司预计不久以后它们将有2亿行代码。当你停下来考虑:平均每1000行代码有15到50个缺陷,那么潜在的可利用缺陷就会以很快的速度增加。
|
||||
如今, 平均每辆汽车至少有 1 亿行代码。无人驾驶汽车公司预计不久以后它们将有 2 亿行代码。当你停下来考虑:平均每 1000 行代码有 15 到 50 个缺陷,那么潜在的可利用缺陷就会以很快的速度增加。
|
||||
|
||||
“计算机最大的安全威胁仅仅是数据被删除,但无人驾驶汽车一旦出现安全事故,失去的却是乘客的生命。”一家致力于解决汽车安全问题的以色列初创公司 Karamba Security 的联合创始人 David Barzilai 说。
|
||||
|
||||
安全专家说道:要想真正保障无人驾驶汽车的安全,汽车制造商必须想办法避免所有可能产生的漏洞——即使漏洞不可避免。其中最大的挑战,是汽车制造商和软件开发商们之间的缺乏合作经验。
|
||||
|
||||
网络安全公司 Lookout 的 Mahaffey 先生说:“新的革命已经出现,我们不能固步自封,应该寻求新的思维。我们需要像发明出安全气囊那样的人来解决安全漏洞,但我们现在还没有看到行业内有人做出改变。“
|
||||
网络安全公司 Lookout 的 Mahaffey 先生说:“新的革命已经出现,我们不能固步自封,应该寻求新的思维。我们需要像发明出安全气囊那样的人来解决安全漏洞,但我们现在还没有看到行业内有人做出改变。”
|
||||
|
||||
Mahaffey 先生说:”在这场无人驾驶汽车的竞争中,那些最注重软件的公司将会成为最后的赢家“
|
||||
Mahaffey 先生说:“在这场无人驾驶汽车的竞争中,那些最注重软件的公司将会成为最后的赢家。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html
|
||||
|
||||
作者:[NICOLE PERLROTH ][a]
|
||||
作者:[NICOLE PERLROTH][a]
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
使用 fdisk 和 fallocate 命令创建交换分区
|
||||
======
|
||||
|
||||
交换分区在物理内存(RAM)被填满时用来保持内存中的内容。当 RAM 被耗尽,Linux 会将内存中不活动的页移动到交换空间中,从而空出内存给系统使用。虽然如此,但交换空间不应被认为是物理内存的替代品。
|
||||
|
||||
大多数情况下,建议交换内存的大小为物理内存的 1 到 2 倍。也就是说如果你有 8GB 内存, 那么交换空间大小应该介于8-16 GB。
|
||||
|
||||
若系统中没有配置交换分区,当内存耗尽后,系统可能会杀掉正在运行中的进程/应用,从而导致系统崩溃。在本文中,我们将学会如何为 Linux 系统添加交换分区,我们有两个办法:
|
||||
|
||||
- 使用 fdisk 命令
|
||||
- 使用 fallocate 命令
|
||||
|
||||
### 第一个方法(使用 fdisk 命令)
|
||||
|
||||
通常,系统的第一块硬盘会被命名为 `/dev/sda`,而其中的分区会命名为 `/dev/sda1` 、 `/dev/sda2`。 本文我们使用的是一块有两个主分区的硬盘,两个分区分别为 `/dev/sda1`、 `/dev/sda2`,而我们使用 `/dev/sda3` 来做交换分区。
|
||||
|
||||
首先创建一个新分区,
|
||||
|
||||
```
|
||||
$ fdisk /dev/sda
|
||||
```
|
||||
|
||||
按 `n` 来创建新分区。系统会询问你从哪个柱面开始,直接按回车键使用默认值即可。然后系统询问你到哪个柱面结束, 这里我们输入交换分区的大小(比如 1000MB)。这里我们输入 `+1000M`。
|
||||
|
||||
![swap][2]
|
||||
|
||||
现在我们创建了一个大小为 1000MB 的磁盘了。但是我们并没有设置该分区的类型,我们按下 `t` 然后回车,来设置分区类型。
|
||||
|
||||
现在我们要输入分区编号,这里我们输入 `3`,然后输入磁盘分类号,交换分区的分区类型为 `82` (要显示所有可用的分区类型,按下 `l` ) ,然后再按下 `w` 保存磁盘分区表。
|
||||
|
||||
![swap][4]
|
||||
|
||||
再下一步使用 `mkswap` 命令来格式化交换分区:
|
||||
|
||||
```
|
||||
$ mkswap /dev/sda3
|
||||
```
|
||||
|
||||
然后激活新建的交换分区:
|
||||
|
||||
```
|
||||
$ swapon /dev/sda3
|
||||
```
|
||||
|
||||
然而我们的交换分区在重启后并不会自动挂载。要做到永久挂载,我们需要添加内容到 `/etc/fstab` 文件中。打开 `/etc/fstab` 文件并输入下面行:
|
||||
|
||||
```
|
||||
$ vi /etc/fstab
|
||||
|
||||
/dev/sda3 swap swap default 0 0
|
||||
```
|
||||
|
||||
保存并关闭文件。现在每次重启后都能使用我们的交换分区了。
|
||||
|
||||
### 第二种方法(使用 fallocate 命令)
|
||||
|
||||
我推荐用这种方法因为这个是最简单、最快速的创建交换空间的方法了。`fallocate` 是最被低估和使用最少的命令之一了。 `fallocate` 命令用于为文件预分配块/大小。
|
||||
|
||||
使用 `fallocate` 创建交换空间,我们首先在 `/` 目录下创建一个名为 `swap_space` 的文件。然后分配 2GB 到 `swap_space` 文件:
|
||||
|
||||
```
|
||||
$ fallocate -l 2G /swap_space
|
||||
```
|
||||
|
||||
我们运行下面命令来验证文件大小:
|
||||
|
||||
```
|
||||
$ ls -lh /swap_space
|
||||
```
|
||||
|
||||
然后更改文件权限,让 `/swap_space` 更安全:
|
||||
|
||||
```
|
||||
$ chmod 600 /swap_space
|
||||
```
|
||||
|
||||
这样只有 root 可以读写该文件了。我们再来格式化交换分区(LCTT 译注:虽然这个 `swap_space` 是个文件,但是我们把它当成是分区来挂载):
|
||||
|
||||
```
|
||||
$ mkswap /swap_space
|
||||
```
|
||||
|
||||
然后启用交换空间:
|
||||
|
||||
```
|
||||
$ swapon -s
|
||||
```
|
||||
|
||||
每次重启后都要重新挂载磁盘分区。因此为了使之持久化,就像上面一样,我们编辑 `/etc/fstab` 并输入下面行:
|
||||
|
||||
```
|
||||
/swap_space swap swap sw 0 0
|
||||
```
|
||||
|
||||
保存并退出文件。现在我们的交换分区会一直被挂载了。我们重启后可以在终端运行 `free -m` 来检查交换分区是否生效。
|
||||
|
||||
我们的教程至此就结束了,希望本文足够容易理解和学习,如果有任何疑问欢迎提出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-swap-using-fdisk-fallocate/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=668%2C211
|
||||
[2]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk.jpg?resize=668%2C211
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=620%2C157
|
||||
[4]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk-swap-select.jpg?resize=620%2C157
|
||||
73
published/20170804 Add speech to your Fedora system.md
Normal file
73
published/20170804 Add speech to your Fedora system.md
Normal file
@ -0,0 +1,73 @@
|
||||
为你的 Fedora 系统增添发音功能
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fedora 工作站默认带有一个小软件,叫做 espeak。它是一个声音合成器 -- 也就是转换文本为声音的软件。
|
||||
|
||||
在当今这个世界,发音设备已经非常普遍了。在智能电话、Amazon Alexa,甚至火车站的公告栏中都有声音合成器。而且,现在合成声音已经跟人类的声音很类似了。我们生活在 80bandaid 的科幻电影里!
|
||||
|
||||
与前面提到的这些工具相比,espeak 的发音听起来有一点原始。但最终 espeak 可以产生不错的发音效果。而且不管你觉得它有没有用,至少它可以给你带来一些乐趣。
|
||||
|
||||
### 运行 espeak
|
||||
|
||||
你可以在命令行为 espeak 设置各种参数。包括:
|
||||
|
||||
* 振幅(`-a`)
|
||||
* 音高调整 (`-p`)
|
||||
* 读句子的速度 (`-s`)
|
||||
* 单词间的停顿时间 (`-g`)
|
||||
|
||||
每个选项都能产生不同的效果,你可以通过调整它们来让发音更加清晰。
|
||||
|
||||
你也可以通过命令行选项来选择不同的变音。比如,`-ven+m3` 表示另一种英式男音,而 `-ven+f1` 表示英式女音。你也可以尝试其他语言的发音。运行下面命令可以查看支持的语言列表:
|
||||
|
||||
```
|
||||
espeak --voices
|
||||
```
|
||||
|
||||
要注意,很多非英语的语言发音现在还处于实验阶段。
|
||||
|
||||
若要创建相应的 WAV 文件而不是真的讲出来,则可以使用 `-w` 选项:
|
||||
|
||||
```
|
||||
espeak -w out.wav "Audio file test"
|
||||
```
|
||||
|
||||
espeak 还能读出文件的内容。
|
||||
|
||||
```
|
||||
espeak -f plaintextfile
|
||||
```
|
||||
|
||||
你也可以通过标准输入传递要发音的文本。举个简单的例子,通过这种方式,你可以创建一个发音盒子,当事件发生时使用声音通知你。你的备份完成了?将下面命令添加到脚本的最后试试效果:
|
||||
|
||||
```
|
||||
echo "Backup completed" | espeak -s 160 -a 100 -g 4
|
||||
```
|
||||
|
||||
假如有日志文件中出现错误了:
|
||||
|
||||
```
|
||||
tail -1F /your/log/file | grep --line-buffered 'ERROR' | espeak
|
||||
```
|
||||
|
||||
或者你也可以创建一个报时钟表,每分钟报一次时:
|
||||
|
||||
```
|
||||
while true; do date +%S | grep '00' && date +%H:%M | espeak; sleep 1; done
|
||||
```
|
||||
|
||||
你会发现,espeak 的使用场景仅仅受你的想象所限制。享受你这会发音的 Fedora 系统吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/add-speech-fedora-system/
|
||||
|
||||
作者:[Alessio Ciregia][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://alciregi.id.fedoraproject.org/
|
||||
@ -0,0 +1,147 @@
|
||||
让 history 命令显示日期和时间
|
||||
======
|
||||
|
||||
我们都对 `history` 命令很熟悉。它将终端上 bash 执行过的所有命令存储到 `.bash_history` 文件中,来帮助我们复查用户之前执行过的命令。
|
||||
|
||||
默认情况下 `history` 命令直接显示用户执行的命令而不会输出运行命令时的日期和时间,即使 `history` 命令记录了这个时间。
|
||||
|
||||
运行 `history` 命令时,它会检查一个叫做 `HISTTIMEFORMAT` 的环境变量,这个环境变量指明了如何格式化输出 `history` 命令中记录的这个时间。
|
||||
|
||||
若该值为 null 或者根本没有设置,则它跟大多数系统默认显示的一样,不会显示日期和时间。
|
||||
|
||||
`HISTTIMEFORMAT` 使用 `strftime` 来格式化显示时间(`strftime` - 将日期和时间转换为字符串)。`history` 命令输出日期和时间能够帮你更容易地追踪问题。
|
||||
|
||||
* `%T`: 替换为时间(`%H:%M:%S`)。
|
||||
* `%F`: 等同于 `%Y-%m-%d` (ISO 8601:2000 标准日期格式)。
|
||||
|
||||
下面是 `history` 命令默认的输出。
|
||||
|
||||
```
|
||||
# history
|
||||
1 yum install -y mysql-server mysql-client
|
||||
2 service mysqld start
|
||||
3 sysdig proc.name=sshd
|
||||
4 sysdig -c topprocs_net
|
||||
5 sysdig proc.name=sshd
|
||||
6 sysdig proc.name=sshd | more
|
||||
7 sysdig fd.name=/var/log/auth.log | more
|
||||
8 sysdig fd.name=/var/log/mysqld.log
|
||||
9 sysdig -cl
|
||||
10 sysdig -i httplog
|
||||
11 sysdig -i proc_exec_time
|
||||
12 sysdig -i topprocs_cpu
|
||||
13 sysdig -c topprocs_cpu
|
||||
14 sysdig -c tracers_2_statsd
|
||||
15 sysdig -c topfiles_bytes
|
||||
16 sysdig -c topprocs_cpu
|
||||
17 sysdig -c topprocs_cpu "fd.name contains sshd"
|
||||
18 sysdig -c topprocs_cpu "proc.name contains sshd"
|
||||
19 csysdig
|
||||
20 sysdig -c topprocs_cpu
|
||||
21 rpm --import https://s3.amazonaws.com/download.draios.com/DRAIOS-GPG-KEY.public
|
||||
22 curl -s -o /etc/yum.repos.d/draios.repo http://download.draios.com/stable/rpm/draios.repo
|
||||
23 yum install -y epel-release
|
||||
24 yum update
|
||||
25 yum makecache
|
||||
26 yum -y install kernel-devel-$(uname -r)
|
||||
27 yum -y install sysdig
|
||||
28 sysdig
|
||||
29 yum install httpd mysql
|
||||
30 service httpd start
|
||||
```
|
||||
|
||||
根据需求,有三种不同的设置环境变量的方法。
|
||||
|
||||
* 临时设置当前用户的环境变量
|
||||
* 永久设置当前/其他用户的环境变量
|
||||
* 永久设置所有用户的环境变量
|
||||
|
||||
**注意:** 不要忘了在最后那个单引号前加上空格,否则输出会很混乱的。
|
||||
|
||||
### 方法 1:
|
||||
|
||||
运行下面命令为为当前用户临时设置 `HISTTIMEFORMAT` 变量。这会一直生效到下次重启。
|
||||
|
||||
```
|
||||
# export HISTTIMEFORMAT='%F %T '
|
||||
```
|
||||
|
||||
### 方法 2:
|
||||
|
||||
将 `HISTTIMEFORMAT` 变量加到 `.bashrc` 或 `.bash_profile` 文件中,让它永久生效。
|
||||
|
||||
```
|
||||
# echo 'HISTTIMEFORMAT="%F %T "' >> ~/.bashrc
|
||||
或
|
||||
# echo 'HISTTIMEFORMAT="%F %T "' >> ~/.bash_profile
|
||||
```
|
||||
|
||||
运行下面命令来让文件中的修改生效。
|
||||
|
||||
```
|
||||
# source ~/.bashrc
|
||||
或
|
||||
# source ~/.bash_profile
|
||||
|
||||
```
|
||||
|
||||
### 方法 3:
|
||||
|
||||
将 `HISTTIMEFORMAT` 变量加入 `/etc/profile` 文件中,让它对所有用户永久生效。
|
||||
|
||||
```
|
||||
# echo 'HISTTIMEFORMAT="%F %T "' >> /etc/profile
|
||||
```
|
||||
|
||||
运行下面命令来让文件中的修改生效。
|
||||
|
||||
```
|
||||
# source /etc/profile
|
||||
```
|
||||
|
||||
输出结果为:
|
||||
|
||||
```
|
||||
# history
|
||||
1 2017-08-16 15:30:15 yum install -y mysql-server mysql-client
|
||||
2 2017-08-16 15:30:15 service mysqld start
|
||||
3 2017-08-16 15:30:15 sysdig proc.name=sshd
|
||||
4 2017-08-16 15:30:15 sysdig -c topprocs_net
|
||||
5 2017-08-16 15:30:15 sysdig proc.name=sshd
|
||||
6 2017-08-16 15:30:15 sysdig proc.name=sshd | more
|
||||
7 2017-08-16 15:30:15 sysdig fd.name=/var/log/auth.log | more
|
||||
8 2017-08-16 15:30:15 sysdig fd.name=/var/log/mysqld.log
|
||||
9 2017-08-16 15:30:15 sysdig -cl
|
||||
10 2017-08-16 15:30:15 sysdig -i httplog
|
||||
11 2017-08-16 15:30:15 sysdig -i proc_exec_time
|
||||
12 2017-08-16 15:30:15 sysdig -i topprocs_cpu
|
||||
13 2017-08-16 15:30:15 sysdig -c topprocs_cpu
|
||||
14 2017-08-16 15:30:15 sysdig -c tracers_2_statsd
|
||||
15 2017-08-16 15:30:15 sysdig -c topfiles_bytes
|
||||
16 2017-08-16 15:30:15 sysdig -c topprocs_cpu
|
||||
17 2017-08-16 15:30:15 sysdig -c topprocs_cpu "fd.name contains sshd"
|
||||
18 2017-08-16 15:30:15 sysdig -c topprocs_cpu "proc.name contains sshd"
|
||||
19 2017-08-16 15:30:15 csysdig
|
||||
20 2017-08-16 15:30:15 sysdig -c topprocs_cpu
|
||||
21 2017-08-16 15:30:15 rpm --import https://s3.amazonaws.com/download.draios.com/DRAIOS-GPG-KEY.public
|
||||
22 2017-08-16 15:30:15 curl -s -o /etc/yum.repos.d/draios.repo http://download.draios.com/stable/rpm/draios.repo
|
||||
23 2017-08-16 15:30:15 yum install -y epel-release
|
||||
24 2017-08-16 15:30:15 yum update
|
||||
25 2017-08-16 15:30:15 yum makecache
|
||||
26 2017-08-16 15:30:15 yum -y install kernel-devel-$(uname -r)
|
||||
27 2017-08-16 15:30:15 yum -y install sysdig
|
||||
28 2017-08-16 15:30:15 sysdig
|
||||
29 2017-08-16 15:30:15 yum install httpd mysql
|
||||
30 2017-08-16 15:30:15 service httpd start
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/display-date-time-linux-bash-history-command/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
@ -0,0 +1,385 @@
|
||||
在 RHEL/CentOS 系统上使用 YUM history 命令回滚升级操作
|
||||
======
|
||||
|
||||
为服务器打补丁是 Linux 系统管理员的一项重要任务,为的是让系统更加稳定,性能更加优化。厂商经常会发布一些安全/高危的补丁包,相关软件需要升级以防范潜在的安全风险。
|
||||
|
||||
Yum (Yellowdog Update Modified) 是 CentOS 和 RedHat 系统上用的 RPM 包管理工具,`yum history` 命令允许系统管理员将系统回滚到上一个状态,但由于某些限制,回滚不是在所有情况下都能成功,有时 `yum` 命令可能什么都不做,有时可能会删掉一些其他的包。
|
||||
|
||||
我建议你在升级之前还是要做一个完整的系统备份,而 `yum history` 并不能用来替代系统备份的。系统备份能让你将系统还原到任意时候的节点状态。
|
||||
|
||||
**推荐阅读:**
|
||||
|
||||
- [在 RHEL/CentOS 系统上使用 YUM 命令管理软件包][1]
|
||||
- [在 Fedora 系统上使用 DNF (YUM 的一个分支)命令管理软件包 ][2]
|
||||
- [如何让 history 命令显示日期和时间][3]
|
||||
|
||||
某些情况下,安装的应用程序在升级了补丁之后不能正常工作或者出现一些错误(可能是由于库不兼容或者软件包升级导致的),那该怎么办呢?
|
||||
|
||||
与应用开发团队沟通,并找出导致库和软件包的问题所在,然后使用 `yum history` 命令进行回滚。
|
||||
|
||||
**注意:**
|
||||
|
||||
* 它不支持回滚 selinux,selinux-policy-*,kernel,glibc (以及依赖 glibc 的包,比如 gcc)。
|
||||
* 不建议将系统降级到更低的版本(比如 CentOS 6.9 降到 CentOS 6.8),这会导致系统处于不稳定的状态
|
||||
|
||||
让我们先来看看系统上有哪些包可以升级,然后挑选出一些包来做实验。
|
||||
|
||||
```
|
||||
# yum update
|
||||
Loaded plugins: fastestmirror, security
|
||||
Setting up Update Process
|
||||
Loading mirror speeds from cached hostfile
|
||||
epel/metalink | 12 kB 00:00
|
||||
* epel: mirror.csclub.uwaterloo.ca
|
||||
base | 3.7 kB 00:00
|
||||
dockerrepo | 2.9 kB 00:00
|
||||
draios | 2.9 kB 00:00
|
||||
draios/primary_db | 13 kB 00:00
|
||||
epel | 4.3 kB 00:00
|
||||
epel/primary_db | 5.9 MB 00:00
|
||||
extras | 3.4 kB 00:00
|
||||
updates | 3.4 kB 00:00
|
||||
updates/primary_db | 2.5 MB 00:00
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package git.x86_64 0:1.7.1-8.el6 will be updated
|
||||
---> Package git.x86_64 0:1.7.1-9.el6_9 will be an update
|
||||
---> Package httpd.x86_64 0:2.2.15-60.el6.centos.4 will be updated
|
||||
---> Package httpd.x86_64 0:2.2.15-60.el6.centos.5 will be an update
|
||||
---> Package httpd-tools.x86_64 0:2.2.15-60.el6.centos.4 will be updated
|
||||
---> Package httpd-tools.x86_64 0:2.2.15-60.el6.centos.5 will be an update
|
||||
---> Package perl-Git.noarch 0:1.7.1-8.el6 will be updated
|
||||
---> Package perl-Git.noarch 0:1.7.1-9.el6_9 will be an update
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
=================================================================================================
|
||||
Package Arch Version Repository Size
|
||||
=================================================================================================
|
||||
Updating:
|
||||
git x86_64 1.7.1-9.el6_9 updates 4.6 M
|
||||
httpd x86_64 2.2.15-60.el6.centos.5 updates 836 k
|
||||
httpd-tools x86_64 2.2.15-60.el6.centos.5 updates 80 k
|
||||
perl-Git noarch 1.7.1-9.el6_9 updates 29 k
|
||||
|
||||
Transaction Summary
|
||||
=================================================================================================
|
||||
Upgrade 4 Package(s)
|
||||
|
||||
Total download size: 5.5 M
|
||||
Is this ok [y/N]: n
|
||||
```
|
||||
|
||||
你会发现 `git` 包可以被升级,那我们就用它来实验吧。运行下面命令获得软件包的版本信息(当前安装的版本和可以升级的版本)。
|
||||
|
||||
```
|
||||
# yum list git
|
||||
Loaded plugins: fastestmirror, security
|
||||
Setting up Update Process
|
||||
Loading mirror speeds from cached hostfile
|
||||
* epel: mirror.csclub.uwaterloo.ca
|
||||
Installed Packages
|
||||
git.x86_64 1.7.1-8.el6 @base
|
||||
Available Packages
|
||||
git.x86_64 1.7.1-9.el6_9 updates
|
||||
```
|
||||
|
||||
运行下面命令来将 `git` 从 `1.7.1-8` 升级到 `1.7.1-9`。
|
||||
|
||||
```
|
||||
# yum update git
|
||||
Loaded plugins: fastestmirror, presto
|
||||
Setting up Update Process
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: repos.lax.quadranet.com
|
||||
* epel: fedora.mirrors.pair.com
|
||||
* extras: mirrors.seas.harvard.edu
|
||||
* updates: mirror.sesp.northwestern.edu
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package git.x86_64 0:1.7.1-8.el6 will be updated
|
||||
--> Processing Dependency: git = 1.7.1-8.el6 for package: perl-Git-1.7.1-8.el6.noarch
|
||||
---> Package git.x86_64 0:1.7.1-9.el6_9 will be an update
|
||||
--> Running transaction check
|
||||
---> Package perl-Git.noarch 0:1.7.1-8.el6 will be updated
|
||||
---> Package perl-Git.noarch 0:1.7.1-9.el6_9 will be an update
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
=================================================================================================
|
||||
Package Arch Version Repository Size
|
||||
=================================================================================================
|
||||
Updating:
|
||||
git x86_64 1.7.1-9.el6_9 updates 4.6 M
|
||||
Updating for dependencies:
|
||||
perl-Git noarch 1.7.1-9.el6_9 updates 29 k
|
||||
|
||||
Transaction Summary
|
||||
=================================================================================================
|
||||
Upgrade 2 Package(s)
|
||||
|
||||
Total download size: 4.6 M
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
Setting up and reading Presto delta metadata
|
||||
Processing delta metadata
|
||||
Package(s) data still to download: 4.6 M
|
||||
(1/2): git-1.7.1-9.el6_9.x86_64.rpm | 4.6 MB 00:00
|
||||
(2/2): perl-Git-1.7.1-9.el6_9.noarch.rpm | 29 kB 00:00
|
||||
-------------------------------------------------------------------------------------------------
|
||||
Total 5.8 MB/s | 4.6 MB 00:00
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Updating : perl-Git-1.7.1-9.el6_9.noarch 1/4
|
||||
Updating : git-1.7.1-9.el6_9.x86_64 2/4
|
||||
Cleanup : perl-Git-1.7.1-8.el6.noarch 3/4
|
||||
Cleanup : git-1.7.1-8.el6.x86_64 4/4
|
||||
Verifying : git-1.7.1-9.el6_9.x86_64 1/4
|
||||
Verifying : perl-Git-1.7.1-9.el6_9.noarch 2/4
|
||||
Verifying : git-1.7.1-8.el6.x86_64 3/4
|
||||
Verifying : perl-Git-1.7.1-8.el6.noarch 4/4
|
||||
|
||||
Updated:
|
||||
git.x86_64 0:1.7.1-9.el6_9
|
||||
|
||||
Dependency Updated:
|
||||
perl-Git.noarch 0:1.7.1-9.el6_9
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
验证升级后的 `git` 版本.
|
||||
|
||||
```
|
||||
# yum list git
|
||||
Installed Packages
|
||||
git.x86_64 1.7.1-9.el6_9 @updates
|
||||
|
||||
或
|
||||
# rpm -q git
|
||||
git-1.7.1-9.el6_9.x86_64
|
||||
```
|
||||
|
||||
现在我们成功升级这个软件包,可以对它进行回滚了。步骤如下。
|
||||
|
||||
### 使用 YUM history 命令回滚升级操作
|
||||
|
||||
首先,使用下面命令获取 yum 操作的 id。下面的输出很清晰地列出了所有需要的信息,例如操作 id、谁做的这个操作(用户名)、操作日期和时间、操作的动作(安装还是升级)、操作影响的包数量。
|
||||
|
||||
```
|
||||
# yum history
|
||||
或
|
||||
# yum history list all
|
||||
Loaded plugins: fastestmirror, presto
|
||||
ID | Login user | Date and time | Action(s) | Altered
|
||||
-------------------------------------------------------------------------------
|
||||
13 | root | 2017-08-18 13:30 | Update | 2
|
||||
12 | root | 2017-08-10 07:46 | Install | 1
|
||||
11 | root | 2017-07-28 17:10 | E, I, U | 28 EE
|
||||
10 | root | 2017-04-21 09:16 | E, I, U | 162 EE
|
||||
9 | root | 2017-02-09 17:09 | E, I, U | 20 EE
|
||||
8 | root | 2017-02-02 10:45 | Install | 1
|
||||
7 | root | 2016-12-15 06:48 | Update | 1
|
||||
6 | root | 2016-12-15 06:43 | Install | 1
|
||||
5 | root | 2016-12-02 10:28 | E, I, U | 23 EE
|
||||
4 | root | 2016-10-28 05:37 | E, I, U | 13 EE
|
||||
3 | root | 2016-10-18 12:53 | Install | 1
|
||||
2 | root | 2016-09-30 10:28 | E, I, U | 31 EE
|
||||
1 | root | 2016-07-26 11:40 | E, I, U | 160 EE
|
||||
```
|
||||
|
||||
上面命令显示有两个包受到了影响,因为 `git` 还升级了它的依赖包 `perl-Git`。 运行下面命令来查看关于操作的详细信息。
|
||||
|
||||
```
|
||||
# yum history info 13
|
||||
Loaded plugins: fastestmirror, presto
|
||||
Transaction ID : 13
|
||||
Begin time : Fri Aug 18 13:30:52 2017
|
||||
Begin rpmdb : 420:f5c5f9184f44cf317de64d3a35199e894ad71188
|
||||
End time : 13:30:54 2017 (2 seconds)
|
||||
End rpmdb : 420:d04a95c25d4526ef87598f0dcaec66d3f99b98d4
|
||||
User : root
|
||||
Return-Code : Success
|
||||
Command Line : update git
|
||||
Transaction performed with:
|
||||
Installed rpm-4.8.0-55.el6.x86_64 @base
|
||||
Installed yum-3.2.29-81.el6.centos.noarch @base
|
||||
Installed yum-plugin-fastestmirror-1.1.30-40.el6.noarch @base
|
||||
Installed yum-presto-0.6.2-1.el6.noarch @anaconda-CentOS-201207061011.x86_64/6.3
|
||||
Packages Altered:
|
||||
Updated git-1.7.1-8.el6.x86_64 @base
|
||||
Update 1.7.1-9.el6_9.x86_64 @updates
|
||||
Updated perl-Git-1.7.1-8.el6.noarch @base
|
||||
Update 1.7.1-9.el6_9.noarch @updates
|
||||
history info
|
||||
|
||||
```
|
||||
|
||||
运行下面命令来回滚 `git` 包到上一个版本。
|
||||
|
||||
```
|
||||
# yum history undo 13
|
||||
Loaded plugins: fastestmirror, presto
|
||||
Undoing transaction 53, from Fri Aug 18 13:30:52 2017
|
||||
Updated git-1.7.1-8.el6.x86_64 @base
|
||||
Update 1.7.1-9.el6_9.x86_64 @updates
|
||||
Updated perl-Git-1.7.1-8.el6.noarch @base
|
||||
Update 1.7.1-9.el6_9.noarch @updates
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: repos.lax.quadranet.com
|
||||
* epel: fedora.mirrors.pair.com
|
||||
* extras: repo1.dal.innoscale.net
|
||||
* updates: mirror.vtti.vt.edu
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package git.x86_64 0:1.7.1-8.el6 will be a downgrade
|
||||
---> Package git.x86_64 0:1.7.1-9.el6_9 will be erased
|
||||
---> Package perl-Git.noarch 0:1.7.1-8.el6 will be a downgrade
|
||||
---> Package perl-Git.noarch 0:1.7.1-9.el6_9 will be erased
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
=================================================================================================
|
||||
Package Arch Version Repository Size
|
||||
=================================================================================================
|
||||
Downgrading:
|
||||
git x86_64 1.7.1-8.el6 base 4.6 M
|
||||
perl-Git noarch 1.7.1-8.el6 base 29 k
|
||||
|
||||
Transaction Summary
|
||||
=================================================================================================
|
||||
Downgrade 2 Package(s)
|
||||
|
||||
Total download size: 4.6 M
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
Setting up and reading Presto delta metadata
|
||||
Processing delta metadata
|
||||
Package(s) data still to download: 4.6 M
|
||||
(1/2): git-1.7.1-8.el6.x86_64.rpm | 4.6 MB 00:00
|
||||
(2/2): perl-Git-1.7.1-8.el6.noarch.rpm | 29 kB 00:00
|
||||
-------------------------------------------------------------------------------------------------
|
||||
Total 3.4 MB/s | 4.6 MB 00:01
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Installing : perl-Git-1.7.1-8.el6.noarch 1/4
|
||||
Installing : git-1.7.1-8.el6.x86_64 2/4
|
||||
Cleanup : perl-Git-1.7.1-9.el6_9.noarch 3/4
|
||||
Cleanup : git-1.7.1-9.el6_9.x86_64 4/4
|
||||
Verifying : git-1.7.1-8.el6.x86_64 1/4
|
||||
Verifying : perl-Git-1.7.1-8.el6.noarch 2/4
|
||||
Verifying : git-1.7.1-9.el6_9.x86_64 3/4
|
||||
Verifying : perl-Git-1.7.1-9.el6_9.noarch 4/4
|
||||
|
||||
Removed:
|
||||
git.x86_64 0:1.7.1-9.el6_9 perl-Git.noarch 0:1.7.1-9.el6_9
|
||||
|
||||
Installed:
|
||||
git.x86_64 0:1.7.1-8.el6 perl-Git.noarch 0:1.7.1-8.el6
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
回滚后,使用下面命令来检查降级包的版本。
|
||||
|
||||
```
|
||||
# yum list git
|
||||
或
|
||||
# rpm -q git
|
||||
git-1.7.1-8.el6.x86_64
|
||||
```
|
||||
|
||||
### 使用YUM downgrade 命令回滚升级
|
||||
|
||||
此外,我们也可以使用 YUM `downgrade` 命令回滚升级。
|
||||
|
||||
```
|
||||
# yum downgrade git-1.7.1-8.el6 perl-Git-1.7.1-8.el6
|
||||
Loaded plugins: search-disabled-repos, security, ulninfo
|
||||
Setting up Downgrade Process
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package git.x86_64 0:1.7.1-8.el6 will be a downgrade
|
||||
---> Package git.x86_64 0:1.7.1-9.el6_9 will be erased
|
||||
---> Package perl-Git.noarch 0:1.7.1-8.el6 will be a downgrade
|
||||
---> Package perl-Git.noarch 0:1.7.1-9.el6_9 will be erased
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
=================================================================================================
|
||||
Package Arch Version Repository Size
|
||||
=================================================================================================
|
||||
Downgrading:
|
||||
git x86_64 1.7.1-8.el6 base 4.6 M
|
||||
perl-Git noarch 1.7.1-8.el6 base 29 k
|
||||
|
||||
Transaction Summary
|
||||
=================================================================================================
|
||||
Downgrade 2 Package(s)
|
||||
|
||||
Total download size: 4.6 M
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
(1/2): git-1.7.1-8.el6.x86_64.rpm | 4.6 MB 00:00
|
||||
(2/2): perl-Git-1.7.1-8.el6.noarch.rpm | 28 kB 00:00
|
||||
-------------------------------------------------------------------------------------------------
|
||||
Total 3.7 MB/s | 4.6 MB 00:01
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Installing : perl-Git-1.7.1-8.el6.noarch 1/4
|
||||
Installing : git-1.7.1-8.el6.x86_64 2/4
|
||||
Cleanup : perl-Git-1.7.1-9.el6_9.noarch 3/4
|
||||
Cleanup : git-1.7.1-9.el6_9.x86_64 4/4
|
||||
Verifying : git-1.7.1-8.el6.x86_64 1/4
|
||||
Verifying : perl-Git-1.7.1-8.el6.noarch 2/4
|
||||
Verifying : git-1.7.1-9.el6_9.x86_64 3/4
|
||||
Verifying : perl-Git-1.7.1-9.el6_9.noarch 4/4
|
||||
|
||||
Removed:
|
||||
git.x86_64 0:1.7.1-9.el6_9 perl-Git.noarch 0:1.7.1-9.el6_9
|
||||
|
||||
Installed:
|
||||
git.x86_64 0:1.7.1-8.el6 perl-Git.noarch 0:1.7.1-8.el6
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
注意: 你也需要降级依赖包,否则它会删掉当前版本的依赖包而不是对依赖包做降级,因为 `downgrade` 命令无法处理依赖关系。
|
||||
|
||||
### 至于 Fedora 用户
|
||||
|
||||
命令是一样的,只需要将包管理器名称从 `yum` 改成 `dnf` 就行了。
|
||||
|
||||
```
|
||||
# dnf list git
|
||||
# dnf history
|
||||
# dnf history info
|
||||
# dnf history undo
|
||||
# dnf list git
|
||||
# dnf downgrade git-1.7.1-8.el6 perl-Git-1.7.1-8.el6
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/rollback-fallback-updates-downgrade-packages-centos-rhel-fedora/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[2]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[3]:https://www.2daygeek.com/display-date-time-linux-bash-history-command/
|
||||
214
published/20170915 12 ip Command Examples for Linux Users.md
Normal file
214
published/20170915 12 ip Command Examples for Linux Users.md
Normal file
@ -0,0 +1,214 @@
|
||||
12 个 ip 命令范例
|
||||
======
|
||||
|
||||
一年又一年,我们一直在使用 `ifconfig` 命令来执行网络相关的任务,比如检查和配置网卡信息。但是 `ifconfig` 已经不再被维护,并且在最近版本的 Linux 中被废除了! `ifconfig` 命令已经被 `ip` 命令所替代了。
|
||||
|
||||
`ip` 命令跟 `ifconfig` 命令有些类似,但要强力的多,它有许多新功能。`ip` 命令完成很多 `ifconfig` 命令无法完成的任务。
|
||||
|
||||
![IP-command-examples-Linux][2]
|
||||
|
||||
本教程将会讨论 `ip` 命令的 12 中最常用法,让我们开始吧。
|
||||
|
||||
### 案例 1:检查网卡信息
|
||||
|
||||
检查网卡的诸如 IP 地址,子网等网络信息,使用 `ip addr show` 命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip addr show
|
||||
|
||||
或
|
||||
|
||||
[linuxtechi@localhost]$ ip a s
|
||||
```
|
||||
|
||||
这会显示系统中所有可用网卡的相关网络信息,不过如果你想查看某块网卡的信息,则命令为:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip addr show enp0s3
|
||||
```
|
||||
|
||||
这里 `enp0s3` 是网卡的名字。
|
||||
|
||||
![IP-addr-show-commant-output][4]
|
||||
|
||||
### 案例 2:启用/禁用网卡
|
||||
|
||||
使用 `ip` 命令来启用一个被禁用的网卡:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip link set enp0s3 up
|
||||
```
|
||||
|
||||
而要禁用网卡则使用 `down` 触发器:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip link set enp0s3 down
|
||||
```
|
||||
|
||||
### 案例 3:为网卡分配 IP 地址以及其他网络信息
|
||||
|
||||
要为网卡分配 IP 地址,我们使用下面命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.50/255.255.255.0 dev enp0s3
|
||||
```
|
||||
|
||||
也可以使用 `ip` 命令来设置广播地址。默认是没有设置广播地址的,设置广播地址的命令为:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr add broadcast 192.168.0.255 dev enp0s3
|
||||
```
|
||||
|
||||
我们也可以使用下面命令来根据 IP 地址设置标准的广播地址:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.10/24 brd + dev enp0s3
|
||||
```
|
||||
|
||||
如上面例子所示,我们可以使用 `brd` 代替 `broadcast` 来设置广播地址。
|
||||
|
||||
### 案例 4:删除网卡中配置的 IP 地址
|
||||
|
||||
若想从网卡中删掉某个 IP,使用如下 `ip` 命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr del 192.168.0.10/24 dev enp0s3
|
||||
```
|
||||
|
||||
### 案例 5:为网卡添加别名(假设网卡名为 enp0s3)
|
||||
|
||||
添加别名,即为网卡添加不止一个 IP,执行下面命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip addr add 192.168.0.20/24 dev enp0s3 label enp0s3:1
|
||||
```
|
||||
|
||||
![ip-command-add-alias-linux][6]
|
||||
|
||||
### 案例 6:检查路由/默认网关的信息
|
||||
|
||||
查看路由信息会给我们显示数据包到达目的地的路由路径。要查看网络路由信息,执行下面命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip route show
|
||||
```
|
||||
|
||||
![ip-route-command-output][8]
|
||||
|
||||
在上面输出结果中,我们能够看到所有网卡上数据包的路由信息。我们也可以获取特定 IP 的路由信息,方法是:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip route get 192.168.0.1
|
||||
```
|
||||
|
||||
### 案例 7:添加静态路由
|
||||
|
||||
我们也可以使用 IP 来修改数据包的默认路由。方法是使用 `ip route` 命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip route add default via 192.168.0.150/24
|
||||
```
|
||||
|
||||
这样所有的网络数据包通过 `192.168.0.150` 来转发,而不是以前的默认路由了。若要修改某个网卡的默认路由,执行:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip route add 172.16.32.32 via 192.168.0.150/24 dev enp0s3
|
||||
```
|
||||
|
||||
### 案例 8:删除默认路由
|
||||
|
||||
要删除之前设置的默认路由,打开终端然后运行:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip route del 192.168.0.150/24
|
||||
```
|
||||
|
||||
**注意:** 用上面方法修改的默认路由只是临时有效的,在系统重启后所有的改动都会丢失。要永久修改路由,需要修改或创建 `route-enp0s3` 文件。将下面这行加入其中:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo vi /etc/sysconfig/network-scripts/route-enp0s3
|
||||
|
||||
172.16.32.32 via 192.168.0.150/24 dev enp0s3
|
||||
```
|
||||
|
||||
保存并退出该文件。
|
||||
|
||||
若你使用的是基于 Ubuntu 或 debian 的操作系统,则该要修改的文件为 `/etc/network/interfaces`,然后添加 `ip route add 172.16.32.32 via 192.168.0.150/24 dev enp0s3` 这行到文件末尾。
|
||||
|
||||
### 案例 9:检查所有的 ARP 记录
|
||||
|
||||
ARP,是<ruby>地址解析协议<rt>Address Resolution Protocol</rt></ruby>的缩写,用于将 IP 地址转换为物理地址(也就是 MAC 地址)。所有的 IP 和其对应的 MAC 明细都存储在一张表中,这张表叫做 ARP 缓存。
|
||||
|
||||
要查看 ARP 缓存中的记录,即连接到局域网中设备的 MAC 地址,则使用如下 ip 命令:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip neigh
|
||||
```
|
||||
|
||||
![ip-neigh-command-linux][10]
|
||||
|
||||
### 案例 10:修改 ARP 记录
|
||||
|
||||
删除 ARP 记录的命令为:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip neigh del 192.168.0.106 dev enp0s3
|
||||
```
|
||||
|
||||
若想往 ARP 缓存中添加新记录,则命令为:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ sudo ip neigh add 192.168.0.150 lladdr 33:1g:75:37:r3:84 dev enp0s3 nud perm
|
||||
```
|
||||
|
||||
这里 `nud` 的意思是 “neghbour state”(网络邻居状态),它的值可以是:
|
||||
|
||||
* `perm` - 永久有效并且只能被管理员删除
|
||||
* `noarp` - 记录有效,但在生命周期过期后就允许被删除了
|
||||
* `stale` - 记录有效,但可能已经过期
|
||||
* `reachable` - 记录有效,但超时后就失效了
|
||||
|
||||
### 案例 11:查看网络统计信息
|
||||
|
||||
通过 `ip` 命令还能查看网络的统计信息,比如所有网卡上传输的字节数和报文数,错误或丢弃的报文数等。使用 `ip -s link` 命令来查看:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip -s link
|
||||
```
|
||||
|
||||
![ip-s-command-linux][12]
|
||||
|
||||
### 案例 12:获取帮助
|
||||
|
||||
若你想查看某个上面例子中没有的选项,那么你可以查看帮助。事实上对任何命令你都可以寻求帮助。要列出 `ip` 命令的所有可选项,执行:
|
||||
|
||||
```
|
||||
[linuxtechi@localhost]$ ip help
|
||||
```
|
||||
|
||||
记住,`ip` 命令是一个对 Linux 系统管理来说特别重要的命令,学习并掌握它能够让配置网络变得容易。本教程就此结束了,若有任何建议欢迎在下面留言框中留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/ip-command-examples-for-linux-users/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/plugins/lazy-load/images/1x1.trans.gif
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2017/09/IP-command-examples-Linux.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2017/09/IP-command-examples-Linux.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2017/09/IP-addr-show-commant-output.jpg
|
||||
[5]:https://www.linuxtechi.com/wp-content/uploads/2017/09/IP-addr-show-commant-output.jpg
|
||||
[6]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-command-add-alias-linux.jpg
|
||||
[7]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-command-add-alias-linux.jpg
|
||||
[8]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-route-command-output.jpg
|
||||
[9]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-route-command-output.jpg
|
||||
[10]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-neigh-command-linux.jpg
|
||||
[11]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-neigh-command-linux.jpg
|
||||
[12]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-s-command-linux.jpg
|
||||
[13]:https://www.linuxtechi.com/wp-content/uploads/2017/09/ip-s-command-linux.jpg
|
||||
@ -0,0 +1,77 @@
|
||||
在 Linux 的终端上伪造一个好莱坞黑客的屏幕
|
||||
=============
|
||||
|
||||
摘要:这是一个简单的小工具,可以把你的 Linux 终端变为好莱坞风格的黑客入侵的实时画面。
|
||||
|
||||
我攻进去了!
|
||||
|
||||
你可能会几乎在所有的好莱坞电影里面会听说过这句话,此时的荧幕正在显示着一个入侵的画面。那可能是一个黑色的终端伴随着 ASCII 码、图标和连续不断变化的十六进制编码以及一个黑客正在击打着键盘,仿佛他/她正在打一段愤怒的论坛回复。
|
||||
|
||||
但是那是好莱坞大片!黑客们想要在几分钟之内破解进入一个网络系统除非他花费了几个月的时间来研究它。不过现在我先把对好莱坞黑客的评论放在一边。
|
||||
|
||||
因为我们将会做相同的事情,我们将会伪装成为一个好莱坞风格的黑客。
|
||||
|
||||
这个小工具运行一个脚本在你的 Linux 终端上,就可以把它变为好莱坞风格的实时入侵终端:
|
||||
|
||||
![在 Linux 上的Hollywood 入侵终端][1]
|
||||
|
||||
看到了吗?就像这样,它甚至在后台播放了一个 Mission Impossible 主题的音乐。此外每次运行这个工具,你都可以获得一个全新且随机的入侵的终端。
|
||||
|
||||
让我们看看如何在 30 秒之内成为一个好莱坞黑客。
|
||||
|
||||
|
||||
### 如何安装 Hollywood 入侵终端在 Linux 之上
|
||||
|
||||
这个工具非常适合叫做 Hollywood 。从根本上说,它运行在 Byobu ——一个基于文本的窗口管理器,而且它会创建随机数量、随机尺寸的分屏,并在每个里面运行一个混乱的文字应用。
|
||||
|
||||
[Byobu][2] 是一个在 Ubuntu 上由 Dustin Kirkland 开发的有趣工具。在其他文章之中还有更多关于它的有趣之处,让我们先专注于安装这个工具。
|
||||
|
||||
Ubuntu 用户可以使用简单的命令安装 Hollywood:
|
||||
|
||||
```
|
||||
sudo apt install hollywood
|
||||
```
|
||||
|
||||
如果上面的命令不能在你的 Ubuntu 或其他例如 Linux Mint、elementary OS、Zorin OS、Linux Lite 等等基于 Ubuntu 的 Linux 发行版上运行,你可以使用下面的 PPA 来安装:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:hollywood/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install byobu hollywood
|
||||
```
|
||||
|
||||
你也可以在它的 GitHub 仓库之中获得其源代码: [Hollywood 在 GitHub][3] 。
|
||||
|
||||
一旦安装好,你可以使用下面的命令运行它,不需要使用 sudo :
|
||||
|
||||
```
|
||||
hollywood
|
||||
```
|
||||
|
||||
因为它会先运行 Byosu ,你将不得不使用 `Ctrl+C` 两次并再使用 `exit` 命令来停止显示入侵终端的脚本。
|
||||
|
||||
这里面有一个伪装好莱坞入侵的视频。 https://youtu.be/15-hMt8VZ50
|
||||
|
||||
这是一个让你朋友、家人和同事感到吃惊的有趣小工具,甚至你可以在酒吧里给女孩们留下深刻的印象,尽管我不认为这对你在那方面有任何的帮助,
|
||||
|
||||
并且如果你喜欢 Hollywood 入侵终端,或许你也会喜欢另一个可以[让 Linux 终端产生 Sneaker 电影效果的工具][5]。
|
||||
|
||||
如果你知道更多有趣的工具,可以在下面的评论栏里分享给我们。
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://itsfoss.com/hollywood-hacker-screen/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[Drshu](https://github.com/Drshu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09/hollywood-hacking-linux-terminal.jpg
|
||||
[2]: http://byobu.co/
|
||||
[3]: https://github.com/dustinkirkland/hollywood
|
||||
[4]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[5]: https://itsfoss.com/sneakers-movie-effect-linux/
|
||||
@ -0,0 +1,147 @@
|
||||
如何在 Linux 上让一段时间不活动的用户自动登出
|
||||
======
|
||||
|
||||

|
||||
|
||||
让我们想象这么一个场景。你有一台服务器经常被网络中各系统的很多个用户访问。有可能出现某些用户忘记登出会话让会话保持会话处于连接状态。我们都知道留下一个处于连接状态的用户会话是一件多么危险的事情。有些用户可能会借此故意做一些损坏系统的事情。而你,作为一名系统管理员,会去每个系统上都检查一遍用户是否有登出吗?其实这完全没必要的。而且若网络中有成百上千台机器,这也太耗时了。不过,你可以让用户在本机或 SSH 会话上超过一定时间不活跃的情况下自动登出。本教程就将教你如何在类 Unix 系统上实现这一点。一点都不难。跟我做。
|
||||
|
||||
### 在 Linux 上实现一段时间后自动登出非活动用户
|
||||
|
||||
有三种实现方法。让我们先来看第一种方法。
|
||||
|
||||
#### 方法 1:
|
||||
|
||||
编辑 `~/.bashrc` 或 `~/.bash_profile` 文件:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ vi ~/.bash_profile
|
||||
```
|
||||
|
||||
将下面行加入其中:
|
||||
|
||||
```
|
||||
TMOUT=100
|
||||
```
|
||||
|
||||
这会让用户在停止动作 100 秒后自动登出。你可以根据需要定义这个值。保存并关闭文件。
|
||||
|
||||
运行下面命令让更改生效:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ source ~/.bash_profile
|
||||
```
|
||||
|
||||
现在让会话闲置 100 秒。100 秒不活动后,你会看到下面这段信息,并且用户会自动退出会话。
|
||||
|
||||
```
|
||||
timed out waiting for input: auto-logout
|
||||
Connection to 192.168.43.2 closed.
|
||||
```
|
||||
|
||||
该设置可以轻易地被用户所修改。因为,`~/.bashrc` 文件被用户自己所拥有。
|
||||
|
||||
要修改或者删除超时设置,只需要删掉上面添加的行然后执行 `source ~/.bashrc` 命令让修改生效。
|
||||
|
||||
此外,用户也可以运行下面命令来禁止超时:
|
||||
|
||||
```
|
||||
$ export TMOUT=0
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ unset TMOUT
|
||||
```
|
||||
|
||||
若你想阻止用户修改该设置,使用下面方法代替。
|
||||
|
||||
#### 方法 2:
|
||||
|
||||
以 root 用户登录。
|
||||
|
||||
创建一个名为 `autologout.sh` 的新文件。
|
||||
|
||||
```
|
||||
# vi /etc/profile.d/autologout.sh
|
||||
```
|
||||
|
||||
加入下面内容:
|
||||
|
||||
```
|
||||
TMOUT=100
|
||||
readonly TMOUT
|
||||
export TMOUT
|
||||
```
|
||||
|
||||
保存并退出该文件。
|
||||
|
||||
为它添加可执行权限:
|
||||
|
||||
```
|
||||
# chmod +x /etc/profile.d/autologout.sh
|
||||
```
|
||||
|
||||
现在,登出或者重启系统。非活动用户就会在 100 秒后自动登出了。普通用户即使想保留会话连接但也无法修改该配置了。他们会在 100 秒后强制退出。
|
||||
|
||||
这两种方法对本地会话和远程会话都适用(即本地登录的用户和远程系统上通过 SSH 登录的用户)。下面让我们来看看如何实现只自动登出非活动的 SSH 会话,而不自动登出本地会话。
|
||||
|
||||
#### 方法 3:
|
||||
|
||||
这种方法,我们只会让 SSH 会话用户在一段时间不活动后自动登出。
|
||||
|
||||
编辑 `/etc/ssh/sshd_config` 文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
添加/修改下面行:
|
||||
|
||||
```
|
||||
ClientAliveInterval 100
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
|
||||
保存并退出该文件。重启 sshd 服务让改动生效。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart sshd
|
||||
```
|
||||
|
||||
现在,在远程系统通过 ssh 登录该系统。100 秒后,ssh 会话就会自动关闭了,你也会看到下面消息:
|
||||
|
||||
```
|
||||
$ Connection to 192.168.43.2 closed by remote host.
|
||||
Connection to 192.168.43.2 closed.
|
||||
```
|
||||
|
||||
现在,任何人从远程系统通过 SSH 登录本系统,都会在 100 秒不活动后自动登出了。
|
||||
|
||||
希望本文能对你有所帮助。我马上还会写另一篇实用指南。如果你觉得我们的指南有用,请在您的社交网络上分享,支持 我们!
|
||||
|
||||
祝您好运!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/auto-logout-inactive-users-period-time-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
104
published/20170918 Linux fmt command - usage and examples.md
Normal file
104
published/20170918 Linux fmt command - usage and examples.md
Normal file
@ -0,0 +1,104 @@
|
||||
Linux 的 fmt 命令用法与案例
|
||||
======
|
||||
|
||||
有时你会发现需要格式化某个文本文件中的内容。比如,该文本文件每行一个单词,而任务是把所有的单词都放在同一行。当然,你可以手工来做,但没人喜欢手工做这么耗时的工作。而且,这只是一个例子 - 事实上的任务可能千奇百怪。
|
||||
|
||||
好在,有一个命令可以满足至少一部分的文本格式化的需求。这个工具就是 `fmt`。本教程将会讨论 `fmt` 的基本用法以及它提供的一些主要功能。文中所有的命令和指令都在 Ubuntu 16.04LTS 下经过了测试。
|
||||
|
||||
### Linux fmt 命令
|
||||
|
||||
`fmt` 命令是一个简单的文本格式化工具,任何人都能在命令行下运行它。它的基本语法为:
|
||||
|
||||
```
|
||||
fmt [-WIDTH] [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
它的 man 页是这么说的:
|
||||
|
||||
> 重新格式化文件中的每一个段落,将结果写到标准输出。选项 `-WIDTH` 是 `--width=DIGITS` 形式的缩写。
|
||||
|
||||
下面这些问答方式的例子应该能让你对 `fmt` 的用法有很好的了解。
|
||||
|
||||
### Q1、如何使用 fmt 来将文本内容格式成同一行?
|
||||
|
||||
使用 `fmt` 命令的基本形式(省略任何选项)就能做到这一点。你只需要将文件名作为参数传递给它。
|
||||
|
||||
```
|
||||
fmt [file-name]
|
||||
```
|
||||
|
||||
下面截屏是命令的执行结果:
|
||||
|
||||
[![format contents of file in single line][1]][2]
|
||||
|
||||
你可以看到文件中多行内容都被格式化成同一行了。请注意,这并不会修改原文件(file1)。
|
||||
|
||||
### Q2、如何修改最大行宽?
|
||||
|
||||
默认情况下,`fmt` 命令产生的输出中的最大行宽为 75。然而,如果你想的话,可以用 `-w` 选项进行修改,它接受一个表示新行宽的数字作为参数值。
|
||||
|
||||
```
|
||||
fmt -w [n] [file-name]
|
||||
```
|
||||
|
||||
下面这个例子把行宽削减到了 20:
|
||||
|
||||
[![change maximum line width][3]][4]
|
||||
|
||||
### Q3、如何让 fmt 突出显示第一行?
|
||||
|
||||
这是通过让第一行的缩进与众不同来实现的,你可以使用 `-t` 选项来实现。
|
||||
|
||||
```
|
||||
fmt -t [file-name]
|
||||
```
|
||||
|
||||
[![make fmt highlight the first line][5]][6]
|
||||
|
||||
### Q4、如何使用 fmt 拆分长行?
|
||||
|
||||
fmt 命令也能用来对长行进行拆分,你可以使用 `-s` 选项来应用该功能。
|
||||
|
||||
```
|
||||
fmt -s [file-name]
|
||||
```
|
||||
|
||||
下面是一个例子:
|
||||
|
||||
[![make fmt split long lines][7]][8]
|
||||
|
||||
### Q5、如何在单词与单词之间,句子之间用空格分开?
|
||||
|
||||
fmt 命令提供了一个 `-u` 选项,这会在单词与单词之间用单个空格分开,句子之间用两个空格分开。你可以这样用:
|
||||
|
||||
```
|
||||
fmt -u [file-name]
|
||||
```
|
||||
|
||||
注意,在我们的案例中,这个功能是默认开启的。
|
||||
|
||||
### 总结
|
||||
|
||||
没错,`fmt` 提供的功能不多,但不代表它的应用就不广泛。因为你永远不知道什么时候会用到它。在本教程中,我们已经讲解了 `fmt` 提供的主要选项。若想了解更多细节,请查看该工具的 [man 页][9]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-fmt-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/linux_fmt_command/fmt-basic-usage.png
|
||||
[2]:https://www.howtoforge.com/images/linux_fmt_command/big/fmt-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_fmt_command/fmt-w-option.png
|
||||
[4]:https://www.howtoforge.com/images/linux_fmt_command/big/fmt-w-option.png
|
||||
[5]:https://www.howtoforge.com/images/linux_fmt_command/fmt-t-option.png
|
||||
[6]:https://www.howtoforge.com/images/linux_fmt_command/big/fmt-t-option.png
|
||||
[7]:https://www.howtoforge.com/images/linux_fmt_command/fmt-s-option.png
|
||||
[8]:https://www.howtoforge.com/images/linux_fmt_command/big/fmt-s-option.png
|
||||
[9]:https://linux.die.net/man/1/fmt
|
||||
76
published/20170919 What Are Bitcoins.md
Normal file
76
published/20170919 What Are Bitcoins.md
Normal file
@ -0,0 +1,76 @@
|
||||
比特币是什么?
|
||||
======
|
||||
|
||||

|
||||
|
||||
<ruby>[比特币][1]<rt>Bitcoin</rt></ruby> 是一种数字货币或者说是电子现金,依靠点对点技术来完成交易。 由于使用点对点技术作为主要网络,比特币提供了一个类似于<ruby>管制经济<rt>managed economy</rt></ruby>的社区。 这就是说,比特币消除了货币管理的集中式管理方式,促进了货币的社区管理。 大部分比特币数字现金的挖掘和管理软件也是开源的。
|
||||
|
||||
第一个比特币软件是由<ruby>中本聪<rt>Satoshi Nakamoto</rt></ruby>开发的,基于开源的密码协议。 比特币最小单位被称为<ruby>聪<rt>Satoshi</rt></ruby>,它基本上是一个比特币的百万分之一(0.00000001 BTC)。
|
||||
|
||||
人们不能低估比特币在数字经济中消除的界限。 例如,比特币消除了由中央机构对货币进行的管理控制,并将控制和管理提供给整个社区。 此外,比特币基于开放源代码密码协议的事实使其成为一个开放的领域,其中存在价值波动、通货紧缩和通货膨胀等严格的活动。 当许多互联网用户正在意识到他们在网上完成交易的隐私性时,比特币正在变得比以往更受欢迎。 但是,对于那些了解暗网及其工作原理的人们,可以确认有些人早就开始使用它了。
|
||||
|
||||
不利的一面是,比特币在匿名支付方面也非常安全,可能会对安全或个人健康构成威胁。 例如,暗网市场是进口药物甚至武器的主要供应商和零售商。 在暗网中使用比特币有助于这种犯罪活动。 尽管如此,如果使用得当,比特币有许多的好处,可以消除一些由于集中的货币代理管理导致的经济上的谬误。 另外,比特币允许在世界任何地方交换现金。 比特币的使用也可以减少货币假冒、印刷或贬值。 同时,依托对等网络作为骨干网络,促进交易记录的分布式权限,交易会更加安全。
|
||||
|
||||
比特币的其他优点包括:
|
||||
|
||||
- 在网上商业世界里,比特币促进资金安全和完全控制。这是因为买家受到保护,以免商家可能想要为较低成本的服务额外收取钱财。买家也可以选择在交易后不分享个人信息。此外,由于隐藏了个人信息,也就保护了身份不被盗窃。
|
||||
- 对于主要的常见货币灾难,比如如丢失、冻结或损坏,比特币是一种替代品。但是,始终都建议对比特币进行备份并使用密码加密。
|
||||
- 使用比特币进行网上购物和付款时,收取的费用少或者不收取。这就提高了使用时的可承受性。
|
||||
- 与其他电子货币不同,商家也面临较少的欺诈风险,因为比特币交易是无法逆转的。即使在高犯罪率和高欺诈的时刻,比特币也是有用的,因为在公开的公共总账(区块链)上难以对付某个人。
|
||||
- 比特币货币也很难被操纵,因为它是开源的,密码协议是非常安全的。
|
||||
- 交易也可以随时随地进行验证和批准。这是数字货币提供的灵活性水准。
|
||||
|
||||
还可以阅读 - [Bitkey:专用于比特币交易的 Linux 发行版][2]
|
||||
|
||||
### 如何挖掘比特币和完成必要的比特币管理任务的应用程序
|
||||
|
||||
在数字货币中,比特币挖矿和管理需要额外的软件。有许多开源的比特币管理软件,便于进行支付,接收付款,加密和备份比特币,还有很多的比特币挖掘软件。有些网站,比如:通过查看广告赚取免费比特币的 [Freebitcoin][4],MoonBitcoin 是另一个可以免费注册并获得比特币的网站。但是,如果有空闲时间和相当多的人脉圈参与,会很方便。有很多提供比特币挖矿的网站,可以轻松注册然后开始挖矿。其中一个主要秘诀就是尽可能引入更多的人构建成一个大型的网络。
|
||||
|
||||
与比特币一起使用时需要的应用程序包括比特币钱包,使得人们可以安全的持有比特币。这就像使用实物钱包来保存硬通货币一样,而这里是以数字形式存在的。钱包可以在这里下载 —— [比特币-钱包][6]。其他类似的应用包括:与比特币钱包类似的[区块链][7]。
|
||||
|
||||
下面的屏幕截图分别显示了 Freebitco 和 MoonBitco 这两个挖矿网站。
|
||||
|
||||
[][8]
|
||||
|
||||
[][9]
|
||||
|
||||
获得比特币的方式多种多样。其中一些包括比特币挖矿机的使用,比特币在交易市场的购买以及免费的比特币在线采矿。比特币可以在 [MtGox][10](LCTT 译注:本文比较陈旧,此交易所已经倒闭),[bitNZ][11],[Bitstamp][12],[BTC-E][13],[VertEx][14] 等等这些网站买到,这些网站都提供了开源开源应用程序。这些应用包括:Bitminter、[5OMiner][15],[BFG Miner][16] 等等。这些应用程序使用一些图形卡和处理器功能来生成比特币。在个人电脑上开采比特币的效率在很大程度上取决于显卡的类型和采矿设备的处理器。(LCTT 译注:目前个人挖矿已经几乎毫无意义了)此外,还有很多安全的在线存储用于备份比特币。这些网站免费提供比特币存储服务。比特币管理网站的例子包括:[xapo][17] , [BlockChain][18] 等。在这些网站上注册需要有效的电子邮件和电话号码进行验证。 Xapo 通过电话应用程序提供额外的安全性,无论何时进行新的登录都需要做请求验证。
|
||||
|
||||
### 比特币的缺点
|
||||
|
||||
使用比特币数字货币所带来的众多优势不容忽视。 但是,由于比特币还处于起步阶段,因此遇到了几个阻力点。 例如,大多数人没有完全意识到比特币数字货币及其工作方式。 缺乏意识可以通过教育和意识的创造来缓解。 比特币用户也面临波动,因为比特币的需求量高于可用的货币数量。 但是,考虑到更长的时间,很多人开始使用比特币的时候,波动性会降低。
|
||||
|
||||
### 改进点
|
||||
|
||||
基于[比特币技术][19]的起步,仍然有变化的余地使其更安全更可靠。 考虑到更长的时间,比特币货币将会发展到足以提供作为普通货币的灵活性。 为了让比特币成功,除了给出有关比特币如何工作及其好处的信息之外,还需要更多人了解比特币。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/
|
||||
[1]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[2]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[3]:http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
[4]:https://freebitco.in/?r=2167375
|
||||
[5]:http://moonbit.co.in/?ref=c637809a5051
|
||||
[6]:https://bitcoin.org/en/choose-your-wallet
|
||||
[7]:https://blockchain.info/wallet/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png
|
||||
[10]:http://mtgox.com/
|
||||
[11]:https://en.bitcoin.it/wiki/BitNZ
|
||||
[12]:https://www.bitstamp.net/
|
||||
[13]:https://btc-e.com/
|
||||
[14]:https://www.vertexinc.com/
|
||||
[15]:https://www.downloadcloud.com/bitcoin-miner-software.html
|
||||
[16]:https://github.com/luke-jr/bfgminer
|
||||
[17]:https://xapo.com/
|
||||
[18]:https://www.blockchain.com/
|
||||
[19]:https://en.wikipedia.org/wiki/Bitcoin
|
||||
@ -0,0 +1,69 @@
|
||||
创建一个简易 APT 仓库
|
||||
======
|
||||
|
||||
作为我工作的一部分,我所维护的 [PATHspider][5] 依赖于 [cURL][6] 和 [PycURL][7]中的一些[刚刚][8][被][9]合并或仍在[等待][10]被合并的功能。我需要构建一个包含这些 Debian 包的 Docker 容器,所以我需要快速构建一个 APT 仓库。
|
||||
|
||||
Debian 仓库本质上可以看作是一个静态的网站,而且内容是经过 GPG 签名的,所以它不一定需要托管在某个可信任的地方(除非可用性对你的程序来说是至关重要的)。我在 [Netlify][11](一个静态的网站主机)上托管我的博客,我认为它很合适这种情况。他们也[支持开源项目][12]。
|
||||
|
||||
你可以用下面的命令安装 netlify 的 CLI 工具:
|
||||
|
||||
```
|
||||
sudo apt install npm
|
||||
sudo npm install -g netlify-cli
|
||||
```
|
||||
|
||||
设置仓库的基本步骤是:
|
||||
|
||||
```
|
||||
mkdir repository
|
||||
cp /path/to/*.deb repository/
|
||||
cd repository
|
||||
apt-ftparchive packages . > Packages
|
||||
apt-ftparchive release . > Release
|
||||
gpg --clearsign -o InRelease Release
|
||||
netlify deploy
|
||||
```
|
||||
|
||||
当你完成这些步骤后,并在 Netlify 上创建了一个新的网站,你也可以通过 Web 界面来管理这个网站。你可能想要做的一些事情是为你的仓库设置自定义域名,或者使用 Let's Encrypt 启用 HTTPS。(如果你打算启用 HTTPS,请确保命令中有 `apt-transport-https`。)
|
||||
|
||||
要将这个仓库添加到你的 apt 源:
|
||||
|
||||
```
|
||||
gpg --export -a YOURKEYID | sudo apt-key add -
|
||||
echo "deb https://SUBDOMAIN.netlify.com/ /" | sudo tee -a /etc/apt/sources.list
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
你会发现这些软件包是可以安装的。注意下 [APT pinnng][13],因为你可能会发现,根据你的策略,仓库上的较新版本实际上并不是首选版本。
|
||||
|
||||
**更新**:如果你想要一个更适合平时使用的解决方案,请参考 [repropro][14]。如果你想让最终用户将你的 apt 仓库作为第三方仓库添加到他们的系统中,请查看 [Debian wiki 上的这个页面][15],其中包含关于如何指导用户使用你的仓库。
|
||||
|
||||
**更新 2**:有一位评论者指出用 [aptly][16],它提供了更多的功能,并消除了 repropro 的一些限制。我从来没有用过 aptly,所以不能评论具体细节,但从网站看来,这是一个很好的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iain.learmonth.me/blog/2017/2017w383/
|
||||
|
||||
作者:[Iain R. Learmonth][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iain.learmonth.me
|
||||
[1]:https://iain.learmonth.me/tags/netlify/
|
||||
[2]:https://iain.learmonth.me/tags/debian/
|
||||
[3]:https://iain.learmonth.me/tags/apt/
|
||||
[4]:https://iain.learmonth.me/tags/foss/
|
||||
[5]:https://pathspider.net
|
||||
[6]:http://curl.haxx.se/
|
||||
[7]:http://pycurl.io/
|
||||
[8]:https://github.com/pycurl/pycurl/pull/456
|
||||
[9]:https://github.com/pycurl/pycurl/pull/458
|
||||
[10]:https://github.com/curl/curl/pull/1847
|
||||
[11]:http://netlify.com/
|
||||
[12]:https://www.netlify.com/open-source/
|
||||
[13]:https://wiki.debian.org/AptPreferences
|
||||
[14]:https://mirrorer.alioth.debian.org/
|
||||
[15]:https://wiki.debian.org/DebianRepository/UseThirdParty
|
||||
[16]:https://www.aptly.info/
|
||||
79
published/20170924 Simulate System Loads.md
Normal file
79
published/20170924 Simulate System Loads.md
Normal file
@ -0,0 +1,79 @@
|
||||
在 Linux 上简单模拟系统负载的方法
|
||||
======
|
||||
|
||||
系统管理员通常需要探索在不同负载对应用性能的影响。这意味着必须要重复地人为创造负载。当然,你可以通过专门的工具来实现,但有时你可能不想也无法安装新工具。
|
||||
|
||||
每个 Linux 发行版中都自带有创建负载的工具。他们不如专门的工具那么灵活,但它们是现成的,而且无需专门学习。
|
||||
|
||||
### CPU
|
||||
|
||||
下面命令会创建 CPU 负荷,方法是通过压缩随机数据并将结果发送到 `/dev/null`:
|
||||
|
||||
```
|
||||
cat /dev/urandom | gzip -9 > /dev/null
|
||||
```
|
||||
|
||||
如果你想要更大的负荷,或者系统有多个核,那么只需要对数据进行压缩和解压就行了,像这样:
|
||||
|
||||
```
|
||||
cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
|
||||
```
|
||||
|
||||
按下 `CTRL+C` 来终止进程。
|
||||
|
||||
### 内存占用
|
||||
|
||||
下面命令会减少可用内存的总量。它是通过在内存中创建文件系统然后往里面写文件来实现的。你可以使用任意多的内存,只需哟往里面写入更多的文件就行了。
|
||||
|
||||
首先,创建一个挂载点,然后将 ramfs 文件系统挂载上去:
|
||||
|
||||
```
|
||||
mkdir z
|
||||
mount -t ramfs ramfs z/
|
||||
```
|
||||
|
||||
第二步,使用 `dd` 在该目录下创建文件。这里我们创建了一个 128M 的文件:
|
||||
|
||||
```
|
||||
dd if=/dev/zero of=z/file bs=1M count=128
|
||||
```
|
||||
|
||||
文件的大小可以通过下面这些操作符来修改:
|
||||
|
||||
- `bs=` 块大小。可以是任何数字后面接上 `B`(表示字节),`K`(表示 KB),`M`( 表示 MB)或者 `G`(表示 GB)。
|
||||
- `count=` 要写多少个块。
|
||||
|
||||
### 磁盘 I/O
|
||||
|
||||
创建磁盘 I/O 的方法是先创建一个文件,然后使用 `for` 循环来不停地拷贝它。
|
||||
|
||||
下面使用命令 `dd` 创建了一个全是零的 1G 大小的文件:
|
||||
|
||||
```
|
||||
dd if=/dev/zero of=loadfile bs=1M count=1024
|
||||
```
|
||||
|
||||
下面命令用 `for` 循环执行 10 次操作。每次都会拷贝 `loadfile` 来覆盖 `loadfile1`:
|
||||
|
||||
```
|
||||
for i in {1..10}; do cp loadfile loadfile1; done
|
||||
```
|
||||
|
||||
通过修改 `{1..10}` 中的第二个参数来调整运行时间的长短。(LCTT 译注:你的 Linux 系统中的默认使用的 `cp` 命令很可能是 `cp -i` 的别名,这种情况下覆写会提示你输入 `y` 来确认,你可以使用 `-f` 参数的 `cp` 命令来覆盖此行为,或者直接用 `/bin/cp` 命令。)
|
||||
|
||||
若你想要一直运行,直到按下 `CTRL+C` 来停止,则运行下面命令:
|
||||
|
||||
```
|
||||
while true; do cp loadfile loadfile1; done
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/create-system-load/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
148
published/20170925 A Commandline Fuzzy Search Tool For Linux.md
Normal file
148
published/20170925 A Commandline Fuzzy Search Tool For Linux.md
Normal file
@ -0,0 +1,148 @@
|
||||
Pick:一款 Linux 上的命令行模糊搜索工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我们要讲的是一款有趣的命令行工具,名叫 Pick。它允许用户通过 ncurses(3X) 界面来从一系列选项中进行选择,而且还支持模糊搜索的功能。当你想要选择某个名字中包含非英文字符的目录或文件时,这款工具就很有用了。你根本都无需学习如何输入非英文字符。借助 Pick,你可以很方便地进行搜索、选择,然后浏览该文件或进入该目录。你甚至无需输入任何字符来过滤文件/目录。这很适合那些有大量目录和文件的人来用。
|
||||
|
||||
### 安装 Pick
|
||||
|
||||
对 Arch Linux 及其衍生品来说,Pick 放在 [AUR][1] 中。因此 Arch 用户可以使用类似 [Pacaur][2],[Packer][3],以及 [Yaourt][4] 等 AUR 辅助工具来安装它。
|
||||
|
||||
```
|
||||
pacaur -S pick
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
packer -S pick
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
yaourt -S pick
|
||||
```
|
||||
|
||||
Debian,Ubuntu,Linux Mint 用户则可以通过运行下面命令来安装 Pick。
|
||||
|
||||
```
|
||||
sudo apt-get install pick
|
||||
```
|
||||
|
||||
其他的发行版则可以从[这里][5]下载最新的安装包,然后按照下面的步骤来安装。在写本指南时,其最新版为 1.9.0。
|
||||
|
||||
```
|
||||
wget https://github.com/calleerlandsson/pick/releases/download/v1.9.0/pick-1.9.0.tar.gz
|
||||
tar -zxvf pick-1.9.0.tar.gz
|
||||
cd pick-1.9.0/
|
||||
```
|
||||
|
||||
使用下面命令进行配置:
|
||||
|
||||
```
|
||||
./configure
|
||||
```
|
||||
|
||||
最后,构建并安装 Pick:
|
||||
|
||||
```
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
通过将它与其他命令集成能够大幅简化你的工作。我这里会给出一些例子,让你理解它是怎么工作的。
|
||||
|
||||
让们先创建一堆目录。
|
||||
|
||||
```
|
||||
mkdir -p abcd/efgh/ijkl/mnop/qrst/uvwx/yz/
|
||||
```
|
||||
|
||||
现在,你想进入目录 `/ijkl/`。你有两种选择。可以使用 `cd` 命令:
|
||||
|
||||
```
|
||||
cd abcd/efgh/ijkl/
|
||||
```
|
||||
|
||||
或者,创建一个[快捷方式][6] 或者说别名指向这个目录,这样你可以迅速进入该目录。
|
||||
|
||||
但,使用 `pick` 命令则问题变得简单的多。看下面这个例子。
|
||||
|
||||
```
|
||||
cd $(find . -type d | pick)
|
||||
```
|
||||
|
||||
这个命令会列出当前工作目录下的所有目录及其子目录,你可以用上下箭头选择你想进入的目录,然后按下回车就行了。
|
||||
|
||||
像这样:
|
||||
|
||||
![][8]
|
||||
|
||||
而且,它还会根据你输入的内容过滤目录和文件。比如,当我输入 “or” 时会显示如下结果。
|
||||
|
||||
![][9]
|
||||
|
||||
这只是一个例子。你也可以将 `pick` 命令跟其他命令一起混用。
|
||||
|
||||
这是另一个例子。
|
||||
|
||||
```
|
||||
find -type f | pick | xargs less
|
||||
```
|
||||
|
||||
该命令让你选择当前目录中的某个文件并用 `less` 来查看它。
|
||||
|
||||
![][10]
|
||||
|
||||
还想看其他例子?还有呢。下面命令让你选择当前目录下的文件或目录,并将之迁移到其他地方去,比如这里我们迁移到 `/home/sk/ostechnix`。
|
||||
|
||||
```
|
||||
mv "$(find . -maxdepth 1 |pick)" /home/sk/ostechnix/
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
通过上下按钮选择要迁移的文件,然后按下回车就会把它迁移到 `/home/sk/ostechnix/` 目录中的。
|
||||
|
||||
![][12]
|
||||
|
||||
从上面的结果中可以看到,我把一个名叫 `abcd` 的目录移动到 `ostechnix` 目录中了。
|
||||
|
||||
使用方式是无限的。甚至 Vim 编辑器上还有一个叫做 [pick.vim][13] 的插件让你在 Vim 中选择更加方便。
|
||||
|
||||
要查看详细信息,请参阅它的 man 页。
|
||||
|
||||
```
|
||||
man pick
|
||||
```
|
||||
|
||||
我们的讲解至此就结束了。希望这款工具能给你们带来帮助。如果你觉得我们的指南有用的话,请将它分享到您的社交网络上,并向大家推荐我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/pick-commandline-fuzzy-search-tool-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://aur.archlinux.org/packages/pick/
|
||||
[2]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[3]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[4]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[5]:https://github.com/calleerlandsson/pick/releases/
|
||||
[6]:https://www.ostechnix.com/create-shortcuts-frequently-used-directories-shell/
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_001-3.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_002-1.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_004-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_005.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_006-1.png
|
||||
[13]:https://github.com/calleerlandsson/pick.vim/
|
||||
@ -0,0 +1,140 @@
|
||||
6 个例子让初学者掌握 free 命令
|
||||
======
|
||||
|
||||
在 Linux 系统上,有时你可能想从命令行快速地了解系统的已使用和未使用的内存空间。如果你是一个 Linux 新手,有个好消息:有一条系统内置的命令可以显示这些信息:`free`。
|
||||
|
||||
在本文中,我们会讲到 free 命令的基本用法以及它所提供的一些重要的功能。文中提到的所有命令和用法都是在 Ubuntu 16.04LTS 上测试过的。
|
||||
|
||||
### Linux free 命令
|
||||
|
||||
让我们看一下 `free` 命令的语法:
|
||||
|
||||
```
|
||||
free [options]
|
||||
```
|
||||
|
||||
free 命令的 man 手册如是说:
|
||||
|
||||
> `free` 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。这些信息是从 `/proc/meminfo` 中得到的。
|
||||
|
||||
接下来我们用问答的方式了解一下 `free` 命令是怎么工作的。
|
||||
|
||||
### Q1. 怎么用 free 命令查看已使用和未使用的内存?
|
||||
|
||||
这很容易,您只需不加任何参数地运行 `free` 这条命令就可以了:
|
||||
|
||||
```
|
||||
free
|
||||
```
|
||||
|
||||
这是 `free` 命令在我的系统上的输出:
|
||||
|
||||
[![view used and available memory using free command][1]][2]
|
||||
|
||||
这些列是什么意思呢?
|
||||
|
||||
[![Free command columns][3]][4]
|
||||
|
||||
- `total` - 安装的内存的总量(等同于 `/proc/meminfo` 中的 `MemTotal` 和 `SwapTotal`)
|
||||
- `used` - 已使用的内存(计算公式为:`used` = `total` - `free` - `buffers` - `cache`)
|
||||
- `free` - 未被使用的内存(等同于 `/proc/meminfo` 中的 `MemFree` 和 `SwapFree`)
|
||||
- `shared` - 通常是临时文件系统使用的内存(等同于 `/proc/meminfo` 中的 `Shmem`;自内核 2.6.32 版本可用,不可用则显示为 `0`)
|
||||
- `buffers` - 内核缓冲区使用的内存(等同于 `/proc/meminfo` 中的 `Buffers`)
|
||||
- `cache` - 页面缓存和 Slab 分配机制使用的内存(等同于 `/proc/meminfo` 中的 `Cached` 和 `Slab`)
|
||||
- `buff/cache` - `buffers` 与 `cache` 之和
|
||||
- `available` - 在不计算交换空间的情况下,预计可以被新启动的应用程序所使用的内存空间。与 `cache` 或者 `free` 部分不同,这一列把页面缓存计算在内,并且不是所有的可回收的 slab 内存都可以真正被回收,因为可能有被占用的部分。(等同于 `/proc/meminfo` 中的 `MemAvailable`;自内核 3.14 版本可用,自内核 2.6.27 版本开始模拟;在其他版本上这个值与 `free` 这一列相同)
|
||||
|
||||
### Q2. 如何更改显示的单位呢?
|
||||
|
||||
如果需要的话,你可以更改内存的显示单位。比如说,想要内存以兆为单位显示,你可以用 `-m` 这个参数:
|
||||
|
||||
```
|
||||
free -m
|
||||
```
|
||||
|
||||
[![free command display metrics change][5]][6]
|
||||
|
||||
同样地,你可以用 `-b` 以字节显示、`-k` 以 KB 显示、`-m` 以 MB 显示、`-g` 以 GB 显示、`--tera` 以 TB 显示。
|
||||
|
||||
### Q3. 怎么显示可读的结果呢?
|
||||
|
||||
`free` 命令提供了 `-h` 这个参数使输出转化为可读的格式。
|
||||
|
||||
```
|
||||
free -h
|
||||
```
|
||||
|
||||
用这个参数,`free` 命令会自己决定用什么单位显示内存的每个数值。例如:
|
||||
|
||||
[![diplsy data fromm free command in human readable form][7]][8]
|
||||
|
||||
### Q4. 怎么让 free 命令以一定的时间间隔持续运行?
|
||||
|
||||
您可以用 `-s` 这个参数让 `free` 命令以一定的时间间隔持续地执行。您需要传递给命令行一个数字参数,做为这个时间间隔的秒数。
|
||||
|
||||
例如,使 `free` 命令每隔 3 秒执行一次:
|
||||
|
||||
```
|
||||
free -s 3
|
||||
```
|
||||
|
||||
如果您需要 `free` 命令只执行几次,您可以用 `-c` 这个参数指定执行的次数:
|
||||
|
||||
```
|
||||
free -s 3 -c 5
|
||||
```
|
||||
|
||||
上面这条命令可以确保 `free` 命令每隔 3 秒执行一次,总共执行 5 次。
|
||||
|
||||
注:这个功能目前在 Ubuntu 系统上还存在 [问题][9],所以并未测试。
|
||||
|
||||
### Q5. 怎么使 free 基于 1000 计算内存,而不是 1024?
|
||||
|
||||
如果您指定 `free` 用 MB 来显示内存(用 `-m` 参数),但又想基于 1000 来计算结果,可以用 `--sj` 这个参数来实现。下图展示了用与不用这个参数的结果:
|
||||
|
||||
[![How to make free use power of 1000 \(not 1024\) while displaying memory figures][10]][11]
|
||||
|
||||
### Q6. 如何使 free 命令显示每一列的总和?
|
||||
|
||||
如果您想要 `free` 命令显示每一列的总和,你可以用 `-t` 这个参数。
|
||||
|
||||
```
|
||||
free -t
|
||||
```
|
||||
|
||||
如下图所示:
|
||||
|
||||
[![How to make free display total of columns][12]][13]
|
||||
|
||||
请注意 `Total` 这一行出现了。
|
||||
|
||||
### 总结
|
||||
|
||||
`free` 命令对于系统管理来讲是个极其有用的工具。它有很多参数可以定制化您的输出,易懂易用。我们在本文中也提到了很多有用的参数。练习完之后,请您移步至 [man 手册][14]了解更多内容。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-free-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/linux_free_command/free-command-output.png
|
||||
[2]:https://www.howtoforge.com/images/linux_free_command/big/free-command-output.png
|
||||
[3]:https://www.howtoforge.com/images/linux_free_command/free-output-columns.png
|
||||
[4]:https://www.howtoforge.com/images/linux_free_command/big/free-output-columns.png
|
||||
[5]:https://www.howtoforge.com/images/linux_free_command/free-m-option.png
|
||||
[6]:https://www.howtoforge.com/images/linux_free_command/big/free-m-option.png
|
||||
[7]:https://www.howtoforge.com/images/linux_free_command/free-h.png
|
||||
[8]:https://www.howtoforge.com/images/linux_free_command/big/free-h.png
|
||||
[9]:https://bugs.launchpad.net/ubuntu/+source/procps/+bug/1551731
|
||||
[10]:https://www.howtoforge.com/images/linux_free_command/free-si-option.png
|
||||
[11]:https://www.howtoforge.com/images/linux_free_command/big/free-si-option.png
|
||||
[12]:https://www.howtoforge.com/images/linux_free_command/free-t-option.png
|
||||
[13]:https://www.howtoforge.com/images/linux_free_command/big/free-t-option.png
|
||||
[14]:https://linux.die.net/man/1/free
|
||||
@ -0,0 +1,160 @@
|
||||
如何轻松地寻找 GitHub 上超棒的项目和资源
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 GitHub 网站上每天都会新增上百个项目。由于 GitHub 上有成千上万的项目,要在上面搜索好的项目简直要累死人。好在,有那么一伙人已经创建了一些这样的列表。其中包含的类别五花八门,如编程、数据库、编辑器、游戏、娱乐等。这使得我们寻找在 GitHub 上托管的项目、软件、资源、库、书籍等其他东西变得容易了很多。有一个 GitHub 用户更进了一步,创建了一个名叫 `Awesome-finder` 的命令行工具,用来在 awesome 系列的仓库中寻找超棒的项目和资源。该工具可以让我们不需要离开终端(当然也就不需要使用浏览器了)的情况下浏览 awesome 列表。
|
||||
|
||||
在这篇简单的说明中,我会向你演示如何方便地在类 Unix 系统中浏览 awesome 列表。
|
||||
|
||||
### Awesome-finder - 方便地寻找 GitHub 上超棒的项目和资源
|
||||
|
||||
#### 安装 Awesome-finder
|
||||
|
||||
使用 `pip` 可以很方便地安装该工具,`pip` 是一个用来安装使用 Python 编程语言开发的程序的包管理器。
|
||||
|
||||
在 Arch Linux 及其衍生发行版中(比如 Antergos,Manjaro Linux),你可以使用下面命令安装 `pip`:
|
||||
|
||||
```
|
||||
sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
在 RHEL,CentOS 中:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
```
|
||||
sudo yum install python-pip
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
sudo dnf install epel-release
|
||||
sudo dnf install python-pip
|
||||
```
|
||||
|
||||
在 Debian,Ubuntu,Linux Mint 上:
|
||||
|
||||
```
|
||||
sudo apt-get install python-pip
|
||||
```
|
||||
|
||||
在 SUSE,openSUSE 上:
|
||||
```
|
||||
sudo zypper install python-pip
|
||||
```
|
||||
|
||||
`pip` 安装好后,用下面命令来安装 'Awesome-finder'。
|
||||
|
||||
```
|
||||
sudo pip install awesome-finder
|
||||
```
|
||||
|
||||
#### 用法
|
||||
|
||||
Awesome-finder 会列出 GitHub 网站中如下这些主题(其实就是仓库)的内容:
|
||||
|
||||
* awesome
|
||||
* awesome-android
|
||||
* awesome-elixir
|
||||
* awesome-go
|
||||
* awesome-ios
|
||||
* awesome-java
|
||||
* awesome-javascript
|
||||
* awesome-php
|
||||
* awesome-python
|
||||
* awesome-ruby
|
||||
* awesome-rust
|
||||
* awesome-scala
|
||||
* awesome-swift
|
||||
|
||||
该列表会定期更新。
|
||||
|
||||
比如,要查看 `awesome-go` 仓库中的列表,只需要输入:
|
||||
|
||||
```
|
||||
awesome go
|
||||
```
|
||||
|
||||
你就能看到用 “Go” 写的所有流行的东西了,而且这些东西按字母顺序进行了排列。
|
||||
|
||||
![][2]
|
||||
|
||||
你可以通过 上/下 箭头在列表中导航。一旦找到所需要的东西,只需要选中它,然后按下回车键就会用你默认的 web 浏览器打开相应的链接了。
|
||||
|
||||
类似的,
|
||||
|
||||
* `awesome android` 命令会搜索 awesome-android 仓库。
|
||||
* `awesome awesome` 命令会搜索 awesome 仓库。
|
||||
* `awesome elixir` 命令会搜索 awesome-elixir。
|
||||
* `awesome go` 命令会搜索 awesome-go。
|
||||
* `awesome ios` 命令会搜索 awesome-ios。
|
||||
* `awesome java` 命令会搜索 awesome-java。
|
||||
* `awesome javascript` 命令会搜索 awesome-javascript。
|
||||
* `awesome php` 命令会搜索 awesome-php。
|
||||
* `awesome python` 命令会搜索 awesome-python。
|
||||
* `awesome ruby` 命令会搜索 awesome-ruby。
|
||||
* `awesome rust` 命令会搜索 awesome-rust。
|
||||
* `awesome scala` 命令会搜索 awesome-scala。
|
||||
* `awesome swift` 命令会搜索 awesome-swift。
|
||||
|
||||
而且,它还会随着你在提示符中输入的内容而自动进行筛选。比如,当我输入 `dj` 后,他会显示与 Django 相关的内容。
|
||||
|
||||
![][3]
|
||||
|
||||
若你想从最新的 `awesome-<topic>`( 而不是用缓存中的数据) 中搜索,使用 `-f` 或 `-force` 标志:
|
||||
|
||||
```
|
||||
awesome <topic> -f (--force)
|
||||
```
|
||||
|
||||
像这样:
|
||||
|
||||
```
|
||||
awesome python -f
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
awesome python --force
|
||||
```
|
||||
|
||||
上面命令会显示 awesome-python GitHub 仓库中的列表。
|
||||
|
||||
很棒,对吧?
|
||||
|
||||
要退出这个工具的话,按下 ESC 键。要显示帮助信息,输入:
|
||||
|
||||
```
|
||||
awesome -h
|
||||
```
|
||||
|
||||
本文至此就结束了。希望本文能对你产生帮助。如果你觉得我们的文章对你有帮助,请将他们分享到你的社交网络中去,造福大众。我们马上还有其他好东西要来了。敬请期待!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_008-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_009.png
|
||||
[4]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=reddit (Click to share on Reddit)
|
||||
[5]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=twitter (Click to share on Twitter)
|
||||
[6]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=facebook (Click to share on Facebook)
|
||||
[7]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=google-plus-1 (Click to share on Google+)
|
||||
[8]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=linkedin (Click to share on LinkedIn)
|
||||
[9]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=pocket (Click to share on Pocket)
|
||||
[10]:whatsapp://send?text=How%20To%20Easily%20Find%20Awesome%20Projects%20And%20Resources%20Hosted%20In%20GitHub%20https%3A%2F%2Fwww.ostechnix.com%2Feasily-find-awesome-projects-resources-hosted-github%2F (Click to share on WhatsApp)
|
||||
[11]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=telegram (Click to share on Telegram)
|
||||
[12]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=email (Click to email this to a friend)
|
||||
[13]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/#print (Click to print)
|
||||
@ -0,0 +1,82 @@
|
||||
微服务和容器:需要去防范的 5 个“坑”
|
||||
======
|
||||
|
||||
> 微服务与容器天生匹配,但是你需要避开一些常见的陷阱。
|
||||
|
||||

|
||||
|
||||
因为微服务和容器是 [天生的“一对”][1],所以一起来使用它们,似乎也就不会有什么问题。当我们将这对“天作之合”投入到生产系统后,你就会发现,随着你的 IT 基础的提升,等待你的将是大幅上升的成本。是不是这样的?
|
||||
|
||||
(让我们等一下,等人们笑声过去)
|
||||
|
||||
是的,很遗憾,这并不是你所希望的结果。虽然这两种技术的组合是非常强大的,但是,如果没有很好的规划和适配,它们并不能发挥出强大的性能来。在前面的文章中,我们整理了如果你想 [使用它们你应该掌握的知识][2]。但是,那些都是组织在容器中使用微服务时所遇到的常见问题。
|
||||
|
||||
事先了解这些可能出现的问题,能够帮你避免这些问题,为你的成功奠定更坚实的基础。
|
||||
|
||||
微服务和容器技术的出现是基于组织的需要、知识、资源等等更多的现实的要求。Mac Browning 说,“他们最常犯的一个 [错误] 是试图一次就想‘搞定’一切”,他是 [DigitalOcean][3] 的工程部经理。“而真正需要面对的问题是,你的公司应该采用什么样的容器和微服务。”
|
||||
|
||||
**[ 努力向你的老板和同事去解释什么是微服务?阅读我们的入门读本[如何简单明了地解释微服务][4]。]**
|
||||
|
||||
Browning 和其他的 IT 专业人员分享了他们遇到的,在组织中使用容器化微服务时的五个陷阱,特别是在他们的生产系统生命周期的早期时候。在你的组织中需要去部署微服务和容器时,了解这些知识,将有助于你去评估微服务和容器化的部署策略。
|
||||
|
||||
### 1、 在部署微服务和容器化上,试图同时从零开始
|
||||
|
||||
如果你刚开始从完全的单例应用开始改变,或者如果你的组织在微服务和容器化上还没有足够的知识储备,那么,请记住:微服务和容器化并不是拴在一起、不可分别部署的。这就意味着,你可以发挥你公司内部专家的技术特长,先从部署其中的一个开始。Sungard Availability Services][5] 的资深 CTO 架构师 Kevin McGrath 建议,通过首先使用容器化来为你的团队建立知识和技能储备,通过对现有应用或者新应用进行容器化部署,接着再将它们迁移到微服务架构,这样才能最终感受到它们的优势所在。
|
||||
|
||||
McGrath 说,“微服务要想运行的很好,需要公司经过多年的反复迭代,这样才能实现快速部署和迁移”,“如果组织不能实现快速迁移,那么支持微服务将很困难。实现快速迁移,容器化可以帮助你,这样就不用担心业务整体停机”。
|
||||
|
||||
### 2、 从一个面向客户的或者关键的业务应用开始
|
||||
|
||||
对组织来说,一个相关陷阱恰恰就是从容器、微服务、或者两者同时起步:在尝试征服一片丛林中的雄狮之前,你应该先去征服处于食物链底端的一些小动物,以取得一些实践经验。
|
||||
|
||||
在你的学习过程中可以预期会有一些错误出现 —— 你是希望这些错误发生在面向客户的关键业务应用上,还是,仅对 IT 或者其他内部团队可见的低风险应用上?
|
||||
|
||||
DigitalOcean 的 Browning 说,“如果整个生态系统都是新的,为了获取一些微服务和容器方面的操作经验,那么,将它们先应用到影响面较低的区域,比如像你的持续集成系统或者内部工具,可能是一个低风险的做法。”你获得这方面的经验以后,当然会将这些技术应用到为客户提供服务的生产系统上。而现实情况是,不论你准备的如何周全,都不可避免会遇到问题,因此,需要提前为可能出现的问题制定应对之策。
|
||||
|
||||
### 3、 在没有合适的团队之前引入了太多的复杂性
|
||||
|
||||
由于微服务架构的弹性,它可能会产生复杂的管理需求。
|
||||
|
||||
作为 [Red Hat][6] 技术的狂热拥护者,[Gordon Haff][7] 最近写道,“一个符合 OCI 标准的容器运行时本身管理单个容器是很擅长的,但是,当你开始使用多个容器和容器化应用时,并将它们分解为成百上千个节点后,管理和编配它们将变得极为复杂。最终,你将需要回过头来将容器分组来提供服务 —— 比如,跨容器的网络、安全、测控”。
|
||||
|
||||
Haff 提示说,“幸运的是,由于容器是可移植的,并且,与之相关的管理栈也是可移植的”。“这时出现的编配技术,比如像 [Kubernetes][8] ,使得这种 IT 需求变得简单化了”(更多内容请查阅 Haff 的文章:[容器化为编写应用带来的 5 个优势][1])。
|
||||
|
||||
另外,你需要合适的团队去做这些事情。如果你已经有 [DevOps shop][9],那么,你可能比较适合做这种转换。因为,从一开始你已经聚集了相关技能的人才。
|
||||
|
||||
Mike Kavis 说,“随着时间的推移,部署了越来越多的服务,管理起来会变得很不方便”,他是 [Cloud Technology Partners][10] 的副总裁兼首席云架构设计师。他说,“在 DevOps 的关键过程中,确保各个领域的专家 —— 开发、测试、安全、运营等等 —— 全部都参与进来,并且在基于容器的微服务中,在构建、部署、运行、安全方面实现协作。”
|
||||
|
||||
### 4、 忽视重要的需求:自动化
|
||||
|
||||
除了具有一个合适的团队之外,那些在基于容器化的微服务部署比较成功的组织都倾向于以“实现尽可能多的自动化”来解决固有的复杂性。
|
||||
|
||||
Carlos Sanchez 说,“实现分布式架构并不容易,一些常见的挑战,像数据持久性、日志、排错等等,在微服务架构中都会变得很复杂”,他是 [CloudBees][11] 的资深软件工程师。根据定义,Sanchez 提到的分布式架构,随着业务的增长,将变成一个巨大无比的繁重的运营任务。“服务和组件的增殖,将使得运营自动化变成一项非常强烈的需求”。Sanchez 警告说。“手动管理将限制服务的规模”。
|
||||
|
||||
### 5、 随着时间的推移,微服务变得越来越臃肿
|
||||
|
||||
在一个容器中运行一个服务或者软件组件并不神奇。但是,这样做并不能证明你就一定在使用微服务。Manual Nedbal, [ShieldX Networks][12] 的 CTO,他警告说,IT 专业人员要确保,随着时间的推移,微服务仍然是微服务。
|
||||
|
||||
Nedbal 说,“随着时间的推移,一些软件组件积累了大量的代码和特性,将它们放在一个容器中将会产生并不需要的微服务,也不会带来相同的优势”,也就是说,“随着组件的变大,工程师需要找到合适的时机将它们再次分解”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/9/using-microservices-containers-wisely-5-pitfalls-avoid
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/8/5-advantages-containers-writing-applications
|
||||
[2]:https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time
|
||||
[3]:https://www.digitalocean.com/
|
||||
[4]:https://enterprisersproject.com/article/2017/8/how-explain-microservices-plain-english?sc_cid=70160000000h0aXAAQ
|
||||
[5]:https://www.sungardas.com/
|
||||
[6]:https://www.redhat.com/en
|
||||
[7]:https://enterprisersproject.com/user/gordon-haff
|
||||
[8]:https://www.redhat.com/en/containers/what-is-kubernetes
|
||||
[9]:https://enterprisersproject.com/article/2017/8/devops-jobs-how-spot-great-devops-shop
|
||||
[10]:https://www.cloudtp.com/
|
||||
[11]:https://www.cloudbees.com/
|
||||
[12]:https://www.shieldx.com/
|
||||
@ -0,0 +1,106 @@
|
||||
通过 Linux 命令行连接 Wifi
|
||||
======
|
||||
|
||||
目标:仅使用命令行工具来配置 WiFi
|
||||
|
||||
发行版:适用主流的那些发行版
|
||||
|
||||
要求:安装了无线网卡的 Linux 并且拥有 root 权限。
|
||||
|
||||
难度:简单
|
||||
|
||||
约定:
|
||||
|
||||
* `#` - 需要使用 root 权限来执行指定命令,可以直接使用 root 用户来执行,也可以使用 `sudo` 命令
|
||||
* `$` - 可以使用普通用户来执行指定命令
|
||||
|
||||
|
||||
### 简介
|
||||
|
||||
许多人喜欢用图形化的工具来管理电脑,但也有很多人不喜欢这样做。如果你比较喜欢命令行工具,管理 WiFi 会是件很痛苦的事情。然而,事情本不该如此。
|
||||
|
||||
wpa_supplicant 可以作为命令行工具来用。使用一个简单的配置文件就可以很容易设置号 WiFi。
|
||||
|
||||
### 扫描网络
|
||||
|
||||
若你已经知道了网络的信息,就可以跳过这一步。如果不了解的话,则这是一个找出网络信息的好方法。
|
||||
|
||||
wpa_supplicant 中有一个工具叫做 `wpa_cli`,它提供了一个命令行接口来管理你的 WiFi 连接。事实上你可以用它来设置任何东西,但是设置一个配置文件看起来要更容易一些。
|
||||
|
||||
使用 root 权限运行 `wpa_cli`,然后扫描网络。
|
||||
|
||||
```
|
||||
# wpa_cli
|
||||
> scan
|
||||
```
|
||||
|
||||
扫描过程要花上一点时间,并且会显示所在区域的那些网络。记住你想要连接的那个网络。然后输入 `quit` 退出。
|
||||
|
||||
### 生成配置块并且加密你的密码
|
||||
|
||||
还有更方便的工具可以用来设置配置文件。它接受网络名称和密码作为参数,然后生成一个包含该网路配置块(其中的密码被加密处理了)的配置文件。
|
||||
|
||||
```
|
||||
# wpa_passphrase networkname password > /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
### 裁剪你的配置
|
||||
|
||||
现在你已经有了一个配置文件了,这个配置文件就是 `/etc/wpa_supplicant/wpa_supplicant.conf`。其中的内容并不多,只有一个网络块,其中有网络名称和密码,不过你可以在此基础上对它进行修改。
|
||||
|
||||
用喜欢的编辑器打开该文件,首先删掉说明密码的那行注释。然后,将下面行加到配置最上方。
|
||||
|
||||
```
|
||||
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=wheel
|
||||
```
|
||||
|
||||
这一行只是让 `wheel` 组中的用户可以管理 wpa_supplicant。这会方便很多。
|
||||
|
||||
其他的内容则添加到网络块中。
|
||||
|
||||
如果你要连接到一个隐藏网络,你可以添加下面行来通知 wpa_supplicant 先扫描该网络。
|
||||
|
||||
```
|
||||
scan_ssid=1
|
||||
```
|
||||
|
||||
下一步,设置协议以及密钥管理方面的配置。下面这些是 WPA2 相关的配置。
|
||||
|
||||
```
|
||||
proto=RSN
|
||||
key_mgmt=WPA-PSK
|
||||
```
|
||||
|
||||
`group` 和 `pairwise` 配置告诉 wpa_supplicant 你是否使用了 CCMP、TKIP,或者两者都用到了。为了安全考虑,你应该只用 CCMP。
|
||||
|
||||
```
|
||||
group=CCMP
|
||||
pairwise=CCMP
|
||||
```
|
||||
|
||||
最后,设置网络优先级。越高的值越会优先连接。
|
||||
|
||||
```
|
||||
priority=10
|
||||
```
|
||||
|
||||
![Complete WPA_Supplicant Settings][1]
|
||||
|
||||
保存配置然后重启 wpa_supplicant 来让改动生效。
|
||||
|
||||
### 结语
|
||||
|
||||
当然,该方法并不是用于即时配置无线网络的最好方法,但对于定期连接的网络来说,这种方法非常有效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/connect-to-wifi-from-the-linux-command-line
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
[1]:https://linuxconfig.org/images/wpa-cli-config.jpg
|
||||
@ -0,0 +1,97 @@
|
||||
如何在 Linux 中从 PDF 创建视频
|
||||
======
|
||||
|
||||

|
||||
|
||||
我在我的平板电脑中收集了大量的 PDF 文件,其中主要是 Linux 教程。有时候我懒得在平板电脑上看。我认为如果我能够从 PDF 创建视频,并在大屏幕设备(如电视机或计算机)中观看会更好。虽然我对 [FFMpeg][1] 有一些经验,但我不知道如何使用它来创建视频。经过一番 Google 搜索,我想出了一个很好的解决方案。对于那些想从一组 PDF 文件制作视频文件的人,请继续阅读。这并不困难。
|
||||
|
||||
### 在 Linux 中从 PDF 创建视频
|
||||
|
||||
为此,你需要在系统中安装 “FFMpeg” 和 “ImageMagick”。
|
||||
|
||||
要安装 FFMpeg,请参考以下链接。
|
||||
|
||||
- [在 Linux 上安装 FFMpeg][2]
|
||||
|
||||
Imagemagick 可在大多数 Linux 发行版的官方仓库中找到。
|
||||
|
||||
在 Arch Linux 以及 Antergos、Manjaro Linux 等衍生产品上,运行以下命令进行安装。
|
||||
|
||||
```
|
||||
sudo pacman -S imagemagick
|
||||
```
|
||||
|
||||
Debian、Ubuntu、Linux Mint:
|
||||
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
Fedora:
|
||||
|
||||
```
|
||||
sudo dnf install imagemagick
|
||||
```
|
||||
|
||||
RHEL、CentOS、Scientific Linux:
|
||||
|
||||
```
|
||||
sudo yum install imagemagick
|
||||
```
|
||||
|
||||
SUSE、 openSUSE:
|
||||
|
||||
```
|
||||
sudo zypper install imagemagick
|
||||
```
|
||||
|
||||
在安装 ffmpeg 和 imagemagick 之后,将你的 PDF 文件转换成图像格式,如 PNG 或 JPG,如下所示。
|
||||
|
||||
```
|
||||
convert -density 400 input.pdf picture.png
|
||||
```
|
||||
|
||||
这里,`-density 400` 指定输出图像的水平分辨率。
|
||||
|
||||
上面的命令会将指定 PDF 的所有页面转换为 PNG 格式。PDF 中的每个页面都将被转换成 PNG 文件,并保存在当前目录中,文件名为: `picture-1.png`、 `picture-2.png` 等。根据选择的 PDF 的页数,这将需要一些时间。
|
||||
|
||||
将 PDF 中的所有页面转换为 PNG 格式后,运行以下命令以从 PNG 创建视频文件。
|
||||
|
||||
```
|
||||
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
* `-r 1/10` :每张图像显示 10 秒。
|
||||
* `-i picture-%01d.png` :读取以 `picture-` 开头,接着是一位数字(`%01d`),最后以 `.png` 结尾的所有图片。如果图片名称带有 2 位数字(也就是 `picture-10.png`、`picture11.png` 等),在上面的命令中使用(`%02d`)。
|
||||
* `-c:v libx264`:输出的视频编码器(即 h264)。
|
||||
* `-r 30` :输出视频的帧率
|
||||
* `-pix_fmt yuv420p`:输出的视频分辨率
|
||||
* `video.mp4`:以 .mp4 格式输出视频文件。
|
||||
|
||||
好了,视频文件完成了!你可以在任何支持 .mp4 格式的设备上播放它。接下来,我需要找到一种方法来为我的视频插入一个很酷的音乐。我希望这也不难。
|
||||
|
||||
如果你想要更高的分辨率,你不必重新开始。只要将输出的视频文件转换为你选择的任何其他更高/更低的分辨率,比如说 720p,如下所示。
|
||||
|
||||
```
|
||||
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
```
|
||||
|
||||
请注意,使用 ffmpeg 创建视频需要一台配置好的 PC。在转换视频时,ffmpeg 会消耗大量系统资源。我建议在高端系统中这样做。
|
||||
|
||||
就是这些了。希望你觉得这个有帮助。还会有更好的东西。敬请关注!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-video-pdf-files-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
[2]:https://www.ostechnix.com/install-ffmpeg-linux/
|
||||
@ -0,0 +1,180 @@
|
||||
python-hwinfo:使用 Linux 系统工具展示硬件信息概况
|
||||
==========
|
||||
|
||||
到目前为止,我们已经介绍了大部分获取 Linux 系统硬件信息和配置的工具,不过也有许多命令可用于相同目的。
|
||||
|
||||
而且,一些工具会显示所有硬件组件的详细信息,或只显示特定设备的信息。
|
||||
|
||||
在这个系列中, 今天我们讨论一下关于 [python-hwinfo][1], 它是一个展示硬件信息概况的工具之一,并且其配置简洁。
|
||||
|
||||
### 什么是 python-hwinfo
|
||||
|
||||
这是一个通过解析系统工具(例如 `lspci` 和 `dmidecode`)的输出,来检查硬件和设备的 Python 库。
|
||||
|
||||
它提供了一个简单的命令行工具,可以用来检查本地、远程的主机和记录的信息。用 `sudo` 运行该命令以获得最大的信息。
|
||||
|
||||
另外,你可以提供服务器 IP 或者主机名、用户名和密码,在远程的服务器上执行它。当然你也可以使用这个工具查看其它工具捕获的输出(例如 `demidecode` 输出的 `dmidecode.out`,`/proc/cpuinfo` 输出的 `cpuinfo`,`lspci -nnm` 输出的 `lspci-nnm.out`)。
|
||||
|
||||
建议阅读:
|
||||
|
||||
- [Inxi:一个功能强大的获取 Linux 系统信息的命令行工具][2]
|
||||
- [Dmidecode:获取 Linux 系统硬件信息的简易方式][3]
|
||||
- [LSHW (Hardware Lister): 一个在 Linux 上获取硬件信息的漂亮工具][4]
|
||||
- [hwinfo (Hardware Info):一个在 Linux 上检测系统硬件信息的漂亮工具][5]
|
||||
- [如何使用 lspci、lsscsi、lsusb 和 lsblk 获取 Linux 系统设备信息][6]
|
||||
|
||||
### Linux 上如何安装 python-hwinfo
|
||||
|
||||
在绝大多数 Linux 发行版,都可以通过 pip 包安装。为了安装 python-hwinfo, 确保你的系统已经有 Python 和python-pip 包作为先决条件。
|
||||
|
||||
`pip` 是 Python 附带的一个包管理工具,在 Linux 上安装 Python 包的推荐工具之一。
|
||||
|
||||
在 Debian/Ubuntu 平台,使用 [APT-GET 命令][7] 或者 [APT 命令][8] 安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo apt install python-pip
|
||||
```
|
||||
|
||||
在 RHEL/CentOS 平台,使用 [YUM 命令][9]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo yum install python-pip python-devel
|
||||
```
|
||||
|
||||
在 Fedora 平台,使用 [DNF 命令][10]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo dnf install python-pip
|
||||
```
|
||||
|
||||
在 Arch Linux 平台,使用 [Pacman 命令][11]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
在 openSUSE 平台,使用 [Zypper 命令][12]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo zypper python-pip
|
||||
```
|
||||
|
||||
最后,执行下面的 `pip` 命令安装 python-hwinfo。
|
||||
|
||||
```
|
||||
$ sudo pip install python-hwinfo
|
||||
```
|
||||
|
||||
### 怎么在本地机器使用 python-hwinfo
|
||||
|
||||
执行下面的命令,检查本地机器现有的硬件。输出很清楚和整洁,这是我在其他命令中没有看到的。
|
||||
|
||||
它的输出分为了五类:
|
||||
|
||||
* Bios Info(BIOS 信息): BIOS 供应商名称、系统产品名称、系统序列号、系统唯一标识符、系统制造商、BIOS 发布日期和BIOS 版本。
|
||||
* CPU Info(CPU 信息):处理器编号、供应商 ID,CPU 系列代号、型号、步进编号、型号名称、CPU 主频。
|
||||
* Ethernet Controller Info(网卡信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称、子供应商 ID,子设备名称、子设备 ID。
|
||||
* Storage Controller Info(存储设备信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称,子供应商 ID、子设备名称、子设备 ID。
|
||||
* GPU Info(GPU 信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称、子供应商 ID、子设备名称、子设备 ID。
|
||||
|
||||
|
||||
```
|
||||
$ sudo hwinfo
|
||||
|
||||
Bios Info:
|
||||
|
||||
+----------------------+--------------------------------------+
|
||||
| Key | Value |
|
||||
+----------------------+--------------------------------------+
|
||||
| bios_vendor_name | IBM |
|
||||
| system_product_name | System x3550 M3: -[6102AF1]- |
|
||||
| system_serial_number | RS2IY21 |
|
||||
| chassis_type | Rack Mount Chassis |
|
||||
| system_uuid | 4C4C4544-0051-3210-8052-B2C04F323132 |
|
||||
| system_manufacturer | IBM |
|
||||
| socket_count | 2 |
|
||||
| bios_release_date | 10/21/2014 |
|
||||
| bios_version | -[VLS211TSU-2.51]- |
|
||||
| socket_designation | Socket 1, Socket 2 |
|
||||
+----------------------+--------------------------------------+
|
||||
|
||||
CPU Info:
|
||||
|
||||
+-----------+--------------+------------+-------+----------+------------------------------------------+----------+
|
||||
| processor | vendor_id | cpu_family | model | stepping | model_name | cpu_mhz |
|
||||
+-----------+--------------+------------+-------+----------+------------------------------------------+----------+
|
||||
| 0 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
|
||||
| 1 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
|
||||
| 2 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
|
||||
| 3 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-1607 0 @ 3.00GHz | 1200.000 |
|
||||
| 4 | GenuineIntel | 6 | 45 | 7 | Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz | 1200.000 |
|
||||
+-----------+--------------+------------+-------+----------+------------------------------------------+----------+
|
||||
|
||||
Ethernet Controller Info:
|
||||
|
||||
+-------------------+-----------+---------------------------------+-----------+-------------------+--------------+---------------------------------+--------------+
|
||||
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
|
||||
+-------------------+-----------+---------------------------------+-----------+-------------------+--------------+---------------------------------+--------------+
|
||||
| Intel Corporation | 8086 | I350 Gigabit Network Connection | 1521 | Intel Corporation | 8086 | I350 Gigabit Network Connection | 1521 |
|
||||
+-------------------+-----------+---------------------------------+-----------+-------------------+--------------+---------------------------------+--------------+
|
||||
|
||||
Storage Controller Info:
|
||||
|
||||
+-------------------+-----------+----------------------------------------------+-----------+----------------+--------------+----------------+--------------+
|
||||
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
|
||||
+-------------------+-----------+----------------------------------------------+-----------+----------------+--------------+----------------+--------------+
|
||||
| Intel Corporation | 8086 | C600/X79 series chipset IDE-r Controller | 1d3c | Dell | 1028 | [Device 05d2] | 05d2 |
|
||||
| Intel Corporation | 8086 | C600/X79 series chipset SATA RAID Controller | 2826 | Dell | 1028 | [Device 05d2] | 05d2 |
|
||||
+-------------------+-----------+----------------------------------------------+-----------+----------------+--------------+----------------+--------------+
|
||||
|
||||
GPU Info:
|
||||
|
||||
+--------------------+-----------+-----------------------+-----------+--------------------+--------------+----------------+--------------+
|
||||
| vendor_name | vendor_id | device_name | device_id | subvendor_name | subvendor_id | subdevice_name | subdevice_id |
|
||||
+--------------------+-----------+-----------------------+-----------+--------------------+--------------+----------------+--------------+
|
||||
| NVIDIA Corporation | 10de | GK107GL [Quadro K600] | 0ffa | NVIDIA Corporation | 10de | [Device 094b] | 094b |
|
||||
+--------------------+-----------+-----------------------+-----------+--------------------+--------------+----------------+--------------+
|
||||
|
||||
```
|
||||
|
||||
### 怎么在远处机器上使用 python-hwinfo
|
||||
|
||||
执行下面的命令检查远程机器现有的硬件,需要远程机器 IP,用户名和密码:
|
||||
|
||||
```
|
||||
$ hwinfo -m x.x.x.x -u root -p password
|
||||
```
|
||||
|
||||
### 如何使用 python-hwinfo 读取记录的输出
|
||||
|
||||
执行下面的命令,检查本地机器现有的硬件。输出很清楚和整洁,这是我在其他命令中没有看到的。
|
||||
|
||||
```
|
||||
$ hwinfo -f [Path to file]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/python-hwinfo-check-display-system-hardware-configuration-information-linux/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[Torival](https://github.com/Torival)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/rdobson/python-hwinfo
|
||||
[2]:https://linux.cn/article-8424-1.html
|
||||
[3]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[4]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[5]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
[6]:https://www.2daygeek.com/check-system-hardware-devices-bus-information-lspci-lsscsi-lsusb-lsblk-linux/
|
||||
[7]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[10]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[11]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[12]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
|
||||
|
||||
@ -0,0 +1,55 @@
|
||||
最重要的 Firefox 命令行选项
|
||||
======
|
||||
|
||||
Firefox web 浏览器支持很多命令行选项,可以定制它启动的方式。
|
||||
|
||||
你可能已经接触过一些了,比如 `-P "配置文件名"` 指定浏览器启动加载时的配置文件,`-private` 开启一个私有会话。
|
||||
|
||||
本指南会列出对 FIrefox 来说比较重要的那些命令行选项。它并不包含所有的可选项,因为很多选项只用于特定的目的,对一般用户来说没什么价值。
|
||||
|
||||
你可以在 Firefox 开发者网站上看到[完整][1] 的命令行选项列表。需要注意的是,很多命令行选项对其它基于 Mozilla 的产品一样有效,甚至对某些第三方的程序也有效。
|
||||
|
||||
### 重要的 Firefox 命令行选项
|
||||
|
||||
![firefox command line][2]
|
||||
|
||||
#### 配置文件相关选项
|
||||
|
||||
- `-CreateProfile 配置文件名` -- 创建新的用户配置信息,但并不立即使用它。
|
||||
- `-CreateProfile "配置文件名 存放配置文件的目录"` -- 跟上面一样,只是指定了存放配置文件的目录。
|
||||
- `-ProfileManager`,或 `-P` -- 打开内置的配置文件管理器。
|
||||
- `-P "配置文件名"` -- 使用指定的配置文件启动 Firefox。若指定的配置文件不存在则会打开配置文件管理器。只有在没有其他 Firefox 实例运行时才有用。
|
||||
- `-no-remote` -- 与 `-P` 连用来创建新的浏览器实例。它允许你在同一时间运行多个配置文件。
|
||||
|
||||
#### 浏览器相关选项
|
||||
|
||||
- `-headless` -- 以无头模式(LCTT 译注:无显示界面)启动 Firefox。Linux 上需要 Firefox 55 才支持,Windows 和 Mac OS X 上需要 Firefox 56 才支持。
|
||||
- `-new-tab URL` -- 在 Firefox 的新标签页中加载指定 URL。
|
||||
- `-new-window URL` -- 在 Firefox 的新窗口中加载指定 URL。
|
||||
- `-private` -- 以隐私浏览模式启动 Firefox。可以用来让 Firefox 始终运行在隐私浏览模式下。
|
||||
- `-private-window` -- 打开一个隐私窗口。
|
||||
- `-private-window URL` -- 在新的隐私窗口中打开 URL。若已经打开了一个隐私浏览窗口,则在那个窗口中打开 URL。
|
||||
- `-search 单词` -- 使用 FIrefox 默认的搜索引擎进行搜索。
|
||||
- - `url URL` -- 在新的标签页或窗口中加载 URL。可以省略这里的 `-url`,而且支持打开多个 URL,每个 URL 之间用空格分离。
|
||||
|
||||
#### 其他选项
|
||||
|
||||
- `-safe-mode` -- 在安全模式下启动 Firefox。在启动 Firefox 时一直按住 Shift 键也能进入安全模式。
|
||||
- `-devtools` -- 启动 Firefox,同时加载并打开开发者工具。
|
||||
- `-inspector URL` -- 使用 DOM Inspector 查看指定的 URL
|
||||
- `-jsconsole` -- 启动 Firefox,同时打开浏览器终端。
|
||||
- `-tray` -- 启动 Firefox,但保持最小化。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/
|
||||
|
||||
作者:[Martin Brinkmann][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ghacks.net/author/martin/
|
||||
[1]:https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options
|
||||
[2]:https://cdn.ghacks.net/wp-content/uploads/2017/10/firefox-command-line.png
|
||||
81
published/20171011 What is a firewall.md
Normal file
81
published/20171011 What is a firewall.md
Normal file
@ -0,0 +1,81 @@
|
||||
什么是防火墙?
|
||||
=====
|
||||
|
||||
> 流行的防火墙是多数组织主要的边界防御。
|
||||
|
||||

|
||||
|
||||
基于网络的防火墙已经在美国企业无处不在,因为它们证实了抵御日益增长的威胁的防御能力。
|
||||
|
||||
通过网络测试公司 NSS 实验室最近的一项研究发现,高达 80% 的美国大型企业运行着下一代防火墙。研究公司 IDC 评估防火墙和相关的统一威胁管理市场的营业额在 2015 是 76 亿美元,预计到 2020 年底将达到 127 亿美元。
|
||||
|
||||
**如果你想升级,这里是《[当部署下一代防火墙时要考虑什么》][1]**
|
||||
|
||||
### 什么是防火墙?
|
||||
|
||||
防火墙作为一个边界防御工具,其监控流量——要么允许它、要么屏蔽它。 多年来,防火墙的功能不断增强,现在大多数防火墙不仅可以阻止已知的一些威胁、执行高级访问控制列表策略,还可以深入检查流量中的每个数据包,并测试包以确定它们是否安全。大多数防火墙都部署为用于处理流量的网络硬件,和允许终端用户配置和管理系统的软件。越来越多的软件版防火墙部署到高度虚拟化的环境中,以在被隔离的网络或 IaaS 公有云中执行策略。
|
||||
|
||||
随着防火墙技术的进步,在过去十年中创造了新的防火墙部署选择,所以现在对于部署防火墙的最终用户来说,有了更多选择。这些选择包括:
|
||||
|
||||
### 有状态的防火墙
|
||||
|
||||
当防火墙首次创造出来时,它们是无状态的,这意味着流量所通过的硬件当单独地检查被监视的每个网络流量包时,屏蔽或允许是隔离的。从 1990 年代中后期开始,防火墙的第一个主要进展是引入了状态。有状态防火墙在更全面的上下文中检查流量,同时考虑到网络连接的工作状态和特性,以提供更全面的防火墙。例如,维持这个状态的防火墙可以允许某些流量访问某些用户,同时对其他用户阻塞同一流量。
|
||||
|
||||
### 基于代理的防火墙
|
||||
|
||||
这些防火墙充当请求数据的最终用户和数据源之间的网关。在传递给最终用户之前,所有的流量都通过这个代理过滤。这通过掩饰信息的原始请求者的身份来保护客户端不受威胁。
|
||||
|
||||
### Web 应用防火墙(WAF)
|
||||
|
||||
这些防火墙位于特定应用的前面,而不是在更广阔的网络的入口或者出口上。基于代理的防火墙通常被认为是保护终端客户的,而 WAF 则被认为是保护应用服务器的。
|
||||
|
||||
### 防火墙硬件
|
||||
|
||||
防火墙硬件通常是一个简单的服务器,它可以充当路由器来过滤流量和运行防火墙软件。这些设备放置在企业网络的边缘,位于路由器和 Internet 服务提供商(ISP)的连接点之间。通常企业可能在整个数据中心部署十几个物理防火墙。 用户需要根据用户基数的大小和 Internet 连接的速率来确定防火墙需要支持的吞吐量容量。
|
||||
|
||||
### 防火墙软件
|
||||
|
||||
通常,终端用户部署多个防火墙硬件端和一个中央防火墙软件系统来管理该部署。 这个中心系统是配置策略和特性的地方,在那里可以进行分析,并可以对威胁作出响应。
|
||||
|
||||
### 下一代防火墙(NGFW)
|
||||
|
||||
多年来,防火墙增加了多种新的特性,包括深度包检查、入侵检测和防御以及对加密流量的检查。下一代防火墙(NGFW)是指集成了许多先进的功能的防火墙。
|
||||
|
||||
#### 有状态的检测
|
||||
|
||||
阻止已知不需要的流量,这是基本的防火墙功能。
|
||||
|
||||
#### 反病毒
|
||||
|
||||
在网络流量中搜索已知病毒和漏洞,这个功能有助于防火墙接收最新威胁的更新,并不断更新以保护它们。
|
||||
|
||||
#### 入侵防御系统(IPS)
|
||||
|
||||
这类安全产品可以部署为一个独立的产品,但 IPS 功能正逐步融入 NGFW。 虽然基本的防火墙技术可以识别和阻止某些类型的网络流量,但 IPS 使用更细粒度的安全措施,如签名跟踪和异常检测,以防止不必要的威胁进入公司网络。 这一技术的以前版本是入侵检测系统(IDS),其重点是识别威胁而不是遏制它们,已经被 IPS 系统取代了。
|
||||
|
||||
#### 深度包检测(DPI)
|
||||
|
||||
DPI 可作为 IPS 的一部分或与其结合使用,但其仍然成为一个 NGFW 的重要特征,因为它提供细粒度分析流量的能力,可以具体到流量包头和流量数据。DPI 还可以用来监测出站流量,以确保敏感信息不会离开公司网络,这种技术称为数据丢失防御(DLP)。
|
||||
|
||||
#### SSL 检测
|
||||
|
||||
安全套接字层(SSL)检测是一个检测加密流量来测试威胁的方法。随着越来越多的流量进行加密,SSL 检测成为 NGFW 正在实施的 DPI 技术的一个重要组成部分。SSL 检测作为一个缓冲区,它在送到最终目的地之前解码流量以检测它。
|
||||
|
||||
#### 沙盒
|
||||
|
||||
这个是被卷入 NGFW 中的一个较新的特性,它指防火墙接收某些未知的流量或者代码,并在一个测试环境运行,以确定它是否存在问题的能力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3230457/lan-wan/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html
|
||||
|
||||
作者:[Brandon Butler][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Brandon-Butler/
|
||||
[1]:https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
|
||||
|
||||
175
published/20171012 Install and Use YouTube-DL on Ubuntu 16.04.md
Normal file
175
published/20171012 Install and Use YouTube-DL on Ubuntu 16.04.md
Normal file
@ -0,0 +1,175 @@
|
||||
在 Ubuntu 16.04 上安装并使用 YouTube-DL
|
||||
======
|
||||
|
||||
Youtube-dl 是一个自由开源的命令行视频下载工具,可以用来从 Youtube 等类似的网站上下载视频,目前它支持的网站除了 Youtube 还有 Facebook、Dailymotion、Google Video、Yahoo 等等。它构架于 pygtk 之上,需要 Python 的支持来运行。它支持很多操作系统,包括 Windows、Mac 以及 Unix。Youtube-dl 还有断点续传、下载整个频道或者整个播放清单中的视频、添加自定义的标题、代理等等其他功能。
|
||||
|
||||
本文中,我们将来学习如何在 Ubuntu 16.04 上安装并使用 Youtube-dl 和 Youtube-dlg。我们还会学习如何以不同质量,不同格式来下载 Youtube 中的视频。
|
||||
|
||||
### 前置需求
|
||||
|
||||
* 一台运行 Ubuntu 16.04 的服务器。
|
||||
* 非 root 用户但拥有 sudo 特权。
|
||||
|
||||
让我们首先用下面命令升级系统到最新版:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
然后重启系统应用这些变更。
|
||||
|
||||
### 安装 Youtube-dl
|
||||
|
||||
默认情况下,Youtube-dl 并不在 Ubuntu-16.04 仓库中。你需要从官网上来下载它。使用 `curl` 命令可以进行下载:
|
||||
|
||||
首先,使用下面命令安装 `curl`:
|
||||
|
||||
```
|
||||
sudo apt-get install curl -y
|
||||
```
|
||||
|
||||
然后,下载 `youtube-dl` 的二进制包:
|
||||
|
||||
```
|
||||
curl -L https://yt-dl.org/latest/youtube-dl -o /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
接着,用下面命令更改 `youtube-dl` 二进制包的权限:
|
||||
|
||||
```
|
||||
sudo chmod 755 /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
`youtube-dl` 算是安装好了,现在可以进行下一步了。
|
||||
|
||||
### 使用 Youtube-dl
|
||||
|
||||
运行下面命令会列出 `youtube-dl` 的所有可选项:
|
||||
|
||||
```
|
||||
youtube-dl --h
|
||||
```
|
||||
|
||||
`youtube-dl` 支持多种视频格式,像 Mp4,WebM,3gp,以及 FLV 都支持。你可以使用下面命令列出指定视频所支持的所有格式:
|
||||
|
||||
```
|
||||
youtube-dl -F https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
如下所示,你会看到该视频所有可能的格式:
|
||||
|
||||
```
|
||||
[info] Available formats for j_JgXJ-apXs:
|
||||
format code extension resolution note
|
||||
139 m4a audio only DASH audio 56k , m4a_dash container, mp4a.40.5@ 48k (22050Hz), 756.44KiB
|
||||
249 webm audio only DASH audio 56k , opus @ 50k, 724.28KiB
|
||||
250 webm audio only DASH audio 69k , opus @ 70k, 902.75KiB
|
||||
171 webm audio only DASH audio 110k , vorbis@128k, 1.32MiB
|
||||
251 webm audio only DASH audio 122k , opus @160k, 1.57MiB
|
||||
140 m4a audio only DASH audio 146k , m4a_dash container, mp4a.40.2@128k (44100Hz), 1.97MiB
|
||||
278 webm 256x144 144p 97k , webm container, vp9, 24fps, video only, 1.33MiB
|
||||
160 mp4 256x144 DASH video 102k , avc1.4d400c, 24fps, video only, 731.53KiB
|
||||
133 mp4 426x240 DASH video 174k , avc1.4d4015, 24fps, video only, 1.36MiB
|
||||
242 webm 426x240 240p 221k , vp9, 24fps, video only, 1.74MiB
|
||||
134 mp4 640x360 DASH video 369k , avc1.4d401e, 24fps, video only, 2.90MiB
|
||||
243 webm 640x360 360p 500k , vp9, 24fps, video only, 4.15MiB
|
||||
135 mp4 854x480 DASH video 746k , avc1.4d401e, 24fps, video only, 6.11MiB
|
||||
244 webm 854x480 480p 844k , vp9, 24fps, video only, 7.27MiB
|
||||
247 webm 1280x720 720p 1155k , vp9, 24fps, video only, 9.21MiB
|
||||
136 mp4 1280x720 DASH video 1300k , avc1.4d401f, 24fps, video only, 9.66MiB
|
||||
248 webm 1920x1080 1080p 1732k , vp9, 24fps, video only, 14.24MiB
|
||||
137 mp4 1920x1080 DASH video 2217k , avc1.640028, 24fps, video only, 15.28MiB
|
||||
17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k
|
||||
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
|
||||
43 webm 640x360 medium , vp8.0, vorbis@128k
|
||||
18 mp4 640x360 medium , avc1.42001E, mp4a.40.2@ 96k
|
||||
22 mp4 1280x720 hd720 , avc1.64001F, mp4a.40.2@192k (best)
|
||||
```
|
||||
|
||||
然后使用 `-f` 指定你想要下载的格式,如下所示:
|
||||
|
||||
```
|
||||
youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
该命令会下载 640x360 分辨率的 mp4 格式的视频:
|
||||
|
||||
```
|
||||
[youtube] j_JgXJ-apXs: Downloading webpage
|
||||
[youtube] j_JgXJ-apXs: Downloading video info webpage
|
||||
[youtube] j_JgXJ-apXs: Extracting video information
|
||||
[youtube] j_JgXJ-apXs: Downloading MPD manifest
|
||||
[download] Destination: B.A. PASS 2 Trailer no 2 _ Filmybox-j_JgXJ-apXs.mp4
|
||||
[download] 100% of 6.90MiB in 00:47
|
||||
```
|
||||
|
||||
如果你想以 mp3 音频的格式下载 Youtube 视频,也可以做到:
|
||||
|
||||
```
|
||||
youtube-dl https://www.youtube.com/watch?v=j_JgXJ-apXs -x --audio-format mp3
|
||||
```
|
||||
|
||||
你也可以下载指定频道中的所有视频,只需要把频道的 URL 放到后面就行,如下所示:
|
||||
|
||||
```
|
||||
youtube-dl -citw https://www.youtube.com/channel/UCatfiM69M9ZnNhOzy0jZ41A
|
||||
```
|
||||
|
||||
若你的网络需要通过代理,那么可以使用 `--proxy` 来下载视频:
|
||||
|
||||
```
|
||||
youtube-dl --proxy http://proxy-ip:port https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
若想一条命令下载多个 Youtube 视频,那么首先把所有要下载的 Youtube 视频 URL 存在一个文件中(假设这个文件叫 `youtube-list.txt`),然后运行下面命令:
|
||||
|
||||
```
|
||||
youtube-dl -a youtube-list.txt
|
||||
```
|
||||
|
||||
### 安装 Youtube-dl GUI
|
||||
|
||||
若你想要图形化的界面,那么 `youtube-dlg` 是你最好的选择。`youtube-dlg` 是一款由 wxPython 所写的免费而开源的 `youtube-dl` 界面。
|
||||
|
||||
该工具默认也不在 Ubuntu 16.04 仓库中。因此你需要为它添加 PPA。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,更新软件包仓库并安装 `youtube-dlg`:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install youtube-dlg -y
|
||||
```
|
||||
|
||||
安装好 Youtube-dl 后,就能在 Unity Dash 中启动它了:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
[![][4]][5]
|
||||
|
||||
现在你只需要将 URL 粘贴到上图中的 URL 域就能下载视频了。Youtube-dlg 对于那些不太懂命令行的人来说很有用。
|
||||
|
||||
### 结语
|
||||
|
||||
恭喜你!你已经成功地在 Ubuntu 16.04 服务器上安装好了 youtube-dl 和 youtube-dlg。你可以很方便地从 Youtube 及任何 youtube-dl 支持的网站上以任何格式和任何大小下载视频了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-and-use-youtube-dl-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/Screenshot-of-youtube-dl-dash.png
|
||||
[3]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dash.png
|
||||
[4]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/Screenshot-of-youtube-dl-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/install_and_use_youtube_dl_on_ubuntu_1604/big/Screenshot-of-youtube-dl-dashboard.png
|
||||
@ -0,0 +1,59 @@
|
||||
修复 Debian 中的 vim 奇怪行为
|
||||
======
|
||||
|
||||
我一直在想,为什么我服务器上 vim 为什么在鼠标方面表现得如此愚蠢:不能像平时那样跳转、复制、粘贴。尽管在 `/etc/vim/vimrc.local` 中已经设置了。
|
||||
|
||||
```
|
||||
set mouse=
|
||||
```
|
||||
|
||||
最后我终于知道为什么了,多谢 bug [#864074][1] 并且修复了它。
|
||||
|
||||
![][2]
|
||||
|
||||
原因是,当没有 `~/.vimrc` 的时候,vim 在 `vimrc.local` **之后**加载 `defaults.vim`,从而覆盖了几个设置。
|
||||
|
||||
在 `/etc/vim/vimrc` 中有一个注释(虽然我没有看到)解释了这一点:
|
||||
|
||||
```
|
||||
" Vim will load $VIMRUNTIME/defaults.vim if the user does not have a vimrc.
|
||||
" This happens after /etc/vim/vimrc(.local) are loaded, so it will override
|
||||
" any settings in these files.
|
||||
" If you don't want that to happen, uncomment the below line to prevent
|
||||
" defaults.vim from being loaded.
|
||||
" let g:skip_defaults_vim = 1
|
||||
```
|
||||
|
||||
我同意这是在正常安装 vim 后设置 vim 的好方法,但 Debian 包可以做得更好。在错误报告中清楚地说明了这个问题:如果没有 `~/.vimrc`,`/etc/vim/vimrc.local` 中的设置被覆盖。
|
||||
|
||||
这在Debian中是违反直觉的 - 而且我也不知道其他包中是否采用类似的方法。
|
||||
|
||||
由于 `defaults.vim` 中的设置非常合理,所以我希望使用它,但只修改了一些我不同意的项目,比如鼠标。最后,我在 `/etc/vim/vimrc.local` 中做了以下操作:
|
||||
|
||||
```
|
||||
if filereadable("/usr/share/vim/vim80/defaults.vim")
|
||||
source /usr/share/vim/vim80/defaults.vim
|
||||
endif
|
||||
" now set the line that the defaults file is not reloaded afterwards!
|
||||
let g:skip_defaults_vim = 1
|
||||
|
||||
" turn of mouse
|
||||
set mouse=
|
||||
" other override settings go here
|
||||
```
|
||||
|
||||
可能有更好的方式来获得一个不依赖于 vim 版本的通用加载语句, 但现在我对此很满意。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.preining.info/blog/2017/10/fixing-vim-in-debian/
|
||||
|
||||
作者:[Norbert Preining][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.preining.info/blog/author/norbert/
|
||||
[1]:https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=864074
|
||||
[2]:https://www.preining.info/blog/wp-content/uploads/2017/10/fixing-debian-vim.jpg
|
||||
@ -0,0 +1,65 @@
|
||||
如何解决 check_mk 出现 “Cannot fetch deployment URL via curl” 的错误
|
||||
======
|
||||
|
||||
本文解释了 “ERROR Cannot fetch deployment URL via curl:Couldn't resolve host。The given remote host was not resolved。” 的原因及其解决方案。
|
||||
|
||||
![ERROR Cannot fetch deployment URL via curl:Couldn't resolve host。The given remote host was not resolved。][1]
|
||||
|
||||
`check_mk` 是一个帮你配置 [nagios][2] 监控服务器的工具。然后在配置其中一台机器时,我遇到了下面的错误:
|
||||
|
||||
```
|
||||
ERROR Cannot fetch deployment URL via curl:Couldn't resolve host。The given remote host was not resolved。
|
||||
```
|
||||
|
||||
该错误是在我使用下面命令尝试将该机器注册到监控服务器时发生的:
|
||||
|
||||
```
|
||||
root@kerneltalks# /usr/bin/cmk-update-agent register -s monitor.kerneltalks.com -i master -H `hostname` -p http -U omdadmin -S ASFKWEFUNSHEFKG -v
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
- `-s` 指明监控服务器
|
||||
- `-i` 指定服务器上 Check_MK 站点的名称
|
||||
- `-H` 指定 agent 所在的主机名
|
||||
- `-p` 为协议,可以是 http 或 https (默认为 https)
|
||||
- `-U` 允许下载 agent 的用户 ID
|
||||
- `-S` 为密码。用户的自动操作密码(当是自动用户时)
|
||||
|
||||
从错误中可以看出,命令无法解析监控服务器的 DNS 名称 `monitor.kerneltalks.com`。
|
||||
|
||||
### 解决方案:
|
||||
|
||||
超级简单。检查 `/etc/resolv.conf`,确保你的 DNS 配置正确。如果还解决不了这个问题那么你可以直接在 [/etc/hosts][3] 中指明它的 IP。
|
||||
|
||||
```
|
||||
root@kerneltalks# cat /etc/hosts
|
||||
10.0.10.9 monitor.kerneltalks.com
|
||||
```
|
||||
|
||||
这就搞定了。你现在可以成功注册了。
|
||||
|
||||
```
|
||||
root@kerneltalks # /usr/bin/cmk-update-agent register -s monitor.kerneltalks.com -i master -H `hostname` -p http -U omdadmin -S ASFKWEFUNSHEFKG -v
|
||||
Going to register agent at deployment server
|
||||
Successfully registered agent for deployment.
|
||||
You can now update your agent by running 'cmk-update-agent -v'
|
||||
Saved your registration settings to /etc/cmk-update-agent.state.
|
||||
```
|
||||
|
||||
另外,你也可以为 `-s` 直接指定 IP 地址,就没那么多事了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/troubleshooting/check_mk-register-cannot-fetch-deployment-url-via-curl-error/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a4.kerneltalks.com/wp-content/uploads/2017/10/resolve-check_mk-error.png
|
||||
[2]:https://www.nagios.org/
|
||||
[3]:https://kerneltalks.com/linux/understanding-etc-hosts-file/
|
||||
181
published/20171019 3 Simple Excellent Linux Network Monitors.md
Normal file
181
published/20171019 3 Simple Excellent Linux Network Monitors.md
Normal file
@ -0,0 +1,181 @@
|
||||
三款简单而优秀的 Linux 网络监视工具
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 通过 `iftop`、 `nethogs` 和 `vnstat` 详细了解你的网络连接状态。
|
||||
|
||||
你可以通过这三个 Linux 命令了解当前网络的大量信息。`iftop` 通过进程号跟踪网络连接,`nethogs` 快速告知你哪些进程在占用你的带宽,而 `vnstat` 以一个良好的轻量级守护进程在后台运行,并实时记录你的网络使用情况。
|
||||
|
||||
### iftop
|
||||
|
||||
令人称赞的 `iftop` 可以监听您指定的网络接口,并以 top 的样式呈现。
|
||||
|
||||
这是一个不错的小工具,可以用于找出网络拥塞,测速和维持网络流量总量。看到自己到底在用多少带宽往往是非常惊人的,尤其是对于我们这些仍然记得电话线路、调制解调器,“高速”到令人惊叫的 kb 和实时波特率的老人们。我们在很久之前就不再使用波特率,转而钟情于比特率。波特率用于衡量信号变化,尽管有时候与比特率相同,但大多数情况下并非如此。
|
||||
|
||||
如果你只有一个网络接口,直接运行 `iftop` 即可。不过 `iftop` 需要 root 权限:
|
||||
|
||||
```
|
||||
$ sudo iftop
|
||||
```
|
||||
|
||||
如果你有多个网络接口,那就指定你要监控的接口:
|
||||
|
||||
```
|
||||
$ sudo iftop -i wlan0
|
||||
```
|
||||
|
||||
就像 `top` 命令一样,你可以在命令运行时更改显示选项:
|
||||
|
||||
* `h` 切换帮助界面。
|
||||
* `n` 是否解析域名。
|
||||
* `s` 切换源地址的显示,`d` 则切换目的地址的显示。
|
||||
* `S` 是否显示端口号。
|
||||
* `N` 是否解析端口;若关闭解析则显示端口号。
|
||||
* `t` 切换文本显示界面。默认的显示方式需要 ncurses。我个人认为图 1 的显示方式在组织性和可读性都更加良好。
|
||||
* `p` 暂停显示更新。
|
||||
* `q` 退出程序。
|
||||
|
||||

|
||||
|
||||
*图 1:组织性和可读性良好的文本显示。*
|
||||
|
||||
当你切换显示设置的时候,`iftop` 并不会中断监测流量。当然你也可以单独监测一台主机。而这需要该主机的 IP 地址和子网掩码。现在,我很好奇 Pandora(LCTT 译注:一家美国的电台公司)能给我贫瘠的带宽带来多大的负载。因此我首先使用 dig 命令找到他们的 IP 地址:
|
||||
|
||||
```
|
||||
$ dig A pandora.com
|
||||
[...]
|
||||
;; ANSWER SECTION:
|
||||
pandora.com. 267 IN A 208.85.40.20
|
||||
pandora.com. 267 IN A 208.85.40.50
|
||||
```
|
||||
|
||||
那子网掩码呢?[ipcalc][9] 会告诉我们:
|
||||
|
||||
```
|
||||
$ ipcalc -b 208.85.40.20
|
||||
Address: 208.85.40.20
|
||||
Netmask: 255.255.255.0 = 24
|
||||
Wildcard: 0.0.0.255
|
||||
=>
|
||||
Network: 208.85.40.0/24
|
||||
```
|
||||
|
||||
现在,将 IP 地址和子网掩码提供给 `iftop`:
|
||||
|
||||
```
|
||||
$ sudo iftop -F 208.85.40.20/24 -i wlan0
|
||||
```
|
||||
|
||||
很棒的不是么?而我也很惊奇地发现,Pandora 在我的网络上,每小时大约使用 500kb。并且就像大多数流媒体服务一样,Pandora 的流量在迅速增长,并依靠缓存稳定下来。
|
||||
|
||||
你可以使用 `-G` 选项对 IPv6 地址执行相同的操作。查阅友好的 man 可以帮助你了解 `iftop` 的其他功能,包括使用个人配置文件自定义你的默认选项,以及使用自定义过滤(请参阅 [PCAP-FILTER][10] 来获取过滤指南)。
|
||||
|
||||
### nethogs
|
||||
|
||||
当你想要快速了解是谁在吸取你的带宽的时候,`nethogs` 是个快速而简单的方法。你需要以 root 身份运行并指定要监听的接口。它会给你显示大量的应用程序及其进程号,所以如果你想的话,你可以借此杀死任一进程。
|
||||
|
||||
```
|
||||
$ sudo nethogs wlan0
|
||||
|
||||
nethogs version 0.8.1
|
||||
|
||||
PID USER PROGRAM DEV SENT RECEIVED
|
||||
7690 carla /usr/lib/firefox wlan0 12.494 556.580 KB/sec
|
||||
5648 carla .../chromium-browser wlan0 0.052 0.038 KB/sec
|
||||
TOTAL 12.546 556.618 KB/sec
|
||||
```
|
||||
|
||||
`nethogs` 并没有多少选项:在 kb/s、kb、b、mb之间循环,按接收和发送的数据包排序,调整刷新延迟。具体请看`man nethogs`,或者是运行 `nethogs -h`。
|
||||
|
||||
### vnstat
|
||||
|
||||
[vnstat][11]是最容易使用的网络数据收集工具。它十分轻量并且不需要 root 权限。它以守护进程在后台运行,因此可以实时地记录你的网络数据。单个 `vnstat` 命令就可以显示所累计的数据。
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0
|
||||
Database updated: Tue Oct 17 08:36:38 2017
|
||||
|
||||
wlan0 since 10/17/2017
|
||||
|
||||
rx: 45.27 MiB tx: 3.77 MiB total: 49.04 MiB
|
||||
|
||||
monthly
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
Oct '17 45.27 MiB | 3.77 MiB | 49.04 MiB | 0.28 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 85 MiB | 5 MiB | 90 MiB |
|
||||
|
||||
daily
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
today 45.27 MiB | 3.77 MiB | 49.04 MiB | 12.96 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 125 MiB | 8 MiB | 133 MiB |
|
||||
```
|
||||
|
||||
默认情况下它会显示所有的网络接口。使用 `-i` 选项来选择某个接口。也可以像这样合并多个接口的数据:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0+eth0+eth1
|
||||
```
|
||||
|
||||
你可以通过这几种方式过滤数据显示:
|
||||
|
||||
* `-h` 按小时显示统计信息。
|
||||
* `-d` 按天显示统计信息.
|
||||
* `-w` 和 `-m` 分别按周和月份来显示统计信息。
|
||||
* 使用 `-l` 选项查看实时更新。
|
||||
|
||||
以下这条命令将会删除 wlan1 的数据库并不再监视它:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan1 --delete
|
||||
```
|
||||
|
||||
而下面这条命令将会为你的一个网络接口创建一个别名。这个例子使用了 Ubuntu 16.04 的一个有线接口名称:
|
||||
|
||||
```
|
||||
$ vnstat -u -i enp0s25 --nick eth0
|
||||
```
|
||||
|
||||
默认情况下,vnstat 会监视 eth0。你可以在 `/etc/vnstat.conf` 对它进行修改,或者在你的家目录下创建你自己的个人配置文件。请参阅 `man vnstat` 以获取完整的指南。
|
||||
|
||||
你也可以安装 `vnstati` 来创建简单的彩图(图 2):
|
||||
|
||||
```
|
||||
$ vnstati -s -i wlx7cdd90a0a1c2 -o vnstat.png
|
||||
```
|
||||
|
||||

|
||||
|
||||
*图 2:你可以使用vnstati来创建简单的彩图。*
|
||||
|
||||
请参阅 `man vnstati` 以获取完整的选项。
|
||||
|
||||
|
||||
_欲了解 Linux 的更多信息,可以通过学习 Linux 基金会和 edX 的免费课程,[“Linux 入门”][7]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-simple-excellent-linux-network-monitors
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[KeyLD](https://github.com/KeyLD)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/files/images/fig-1png-8
|
||||
[5]:https://www.linux.com/files/images/fig-2png-5
|
||||
[6]:https://www.linux.com/files/images/bannerpng-3
|
||||
[7]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[8]:http://www.ex-parrot.com/pdw/iftop/
|
||||
[9]:https://www.linux.com/learn/intro-to-linux/2017/8/how-calculate-network-addresses-ipcalc
|
||||
[10]:http://www.tcpdump.org/manpages/pcap-filter.7.html
|
||||
[11]:http://humdi.net/vnstat/
|
||||
@ -0,0 +1,169 @@
|
||||
让我们使用 PC 键盘在终端演奏钢琴
|
||||
======
|
||||

|
||||
|
||||
厌倦了工作?那么来吧,让我们弹弹钢琴!是的,你没有看错,根本不需要真的钢琴。我们可以用 PC 键盘在命令行下就能弹钢琴。向你们介绍一下 `piano-rs` —— 这是一款用 Rust 语言编写的,可以让你用 PC 键盘在终端弹钢琴的简单工具。它自由开源,基于 MIT 协议。你可以在任何支持 Rust 的操作系统中使用它。
|
||||
|
||||
### piano-rs:使用 PC 键盘在终端弹钢琴
|
||||
|
||||
#### 安装
|
||||
|
||||
确保系统已经安装了 Rust 编程语言。若还未安装,运行下面命令来安装它。
|
||||
|
||||
```
|
||||
curl https://sh.rustup.rs -sSf | sh
|
||||
```
|
||||
|
||||
(LCTT 译注:这种直接通过 curl 执行远程 shell 脚本是一种非常危险和不成熟的做法。)
|
||||
|
||||
安装程序会问你是否默认安装还是自定义安装还是取消安装。我希望默认安装,因此输入 `1` (数字一)。
|
||||
|
||||
```
|
||||
info: downloading installer
|
||||
|
||||
Welcome to Rust!
|
||||
|
||||
This will download and install the official compiler for the Rust programming
|
||||
language, and its package manager, Cargo.
|
||||
|
||||
It will add the cargo, rustc, rustup and other commands to Cargo's bin
|
||||
directory, located at:
|
||||
|
||||
/home/sk/.cargo/bin
|
||||
|
||||
This path will then be added to your PATH environment variable by modifying the
|
||||
profile files located at:
|
||||
|
||||
/home/sk/.profile
|
||||
/home/sk/.bash_profile
|
||||
|
||||
You can uninstall at any time with rustup self uninstall and these changes will
|
||||
be reverted.
|
||||
|
||||
Current installation options:
|
||||
|
||||
default host triple: x86_64-unknown-linux-gnu
|
||||
default toolchain: stable
|
||||
modify PATH variable: yes
|
||||
|
||||
1) Proceed with installation (default)
|
||||
2) Customize installation
|
||||
3) Cancel installation
|
||||
1
|
||||
|
||||
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
|
||||
223.6 KiB / 223.6 KiB (100 %) 215.1 KiB/s ETA: 0 s
|
||||
info: latest update on 2017-10-12, rust version 1.21.0 (3b72af97e 2017-10-09)
|
||||
info: downloading component 'rustc'
|
||||
38.5 MiB / 38.5 MiB (100 %) 459.3 KiB/s ETA: 0 s
|
||||
info: downloading component 'rust-std'
|
||||
56.7 MiB / 56.7 MiB (100 %) 220.6 KiB/s ETA: 0 s
|
||||
info: downloading component 'cargo'
|
||||
3.7 MiB / 3.7 MiB (100 %) 173.5 KiB/s ETA: 0 s
|
||||
info: downloading component 'rust-docs'
|
||||
4.1 MiB / 4.1 MiB (100 %) 224.0 KiB/s ETA: 0 s
|
||||
info: installing component 'rustc'
|
||||
info: installing component 'rust-std'
|
||||
info: installing component 'cargo'
|
||||
info: installing component 'rust-docs'
|
||||
info: default toolchain set to 'stable'
|
||||
|
||||
stable installed - rustc 1.21.0 (3b72af97e 2017-10-09)
|
||||
|
||||
Rust is installed now. Great!
|
||||
|
||||
To get started you need Cargo's bin directory ($HOME/.cargo/bin) in your PATH
|
||||
environment variable. Next time you log in this will be done automatically.
|
||||
|
||||
To configure your current shell run source $HOME/.cargo/env
|
||||
```
|
||||
|
||||
登出然后重启系统来将 cargo 的 bin 目录纳入 `PATH` 变量中。
|
||||
|
||||
校验 Rust 是否正确安装:
|
||||
|
||||
```
|
||||
$ rustc --version
|
||||
rustc 1.21.0 (3b72af97e 2017-10-09)
|
||||
```
|
||||
|
||||
太棒了!Rust 成功安装了。是时候构建 piano-rs 应用了。
|
||||
|
||||
使用下面命令克隆 Piano-rs 仓库:
|
||||
|
||||
```
|
||||
git clone https://github.com/ritiek/piano-rs
|
||||
```
|
||||
|
||||
上面命令会在当前工作目录创建一个名为 `piano-rs` 的目录并下载所有内容到其中。进入该目录:
|
||||
|
||||
```
|
||||
cd piano-rs
|
||||
```
|
||||
|
||||
最后,运行下面命令来构建 Piano-rs:
|
||||
|
||||
```
|
||||
cargo build --release
|
||||
```
|
||||
|
||||
编译过程要花上一阵子。
|
||||
|
||||
#### 用法
|
||||
|
||||
编译完成后,在 `piano-rs` 目录中运行下面命令:
|
||||
|
||||
```
|
||||
./target/release/piano-rs
|
||||
```
|
||||
|
||||
这就是我们在终端上的钢琴键盘了!可以开始弹指一些音符了。按下按键可以弹奏相应音符。使用 **左/右** 方向键可以在弹奏时调整音频。而,使用 **上/下** 方向键可以在弹奏时调整音长。
|
||||
|
||||
![][2]
|
||||
|
||||
Piano-rs 使用与 [multiplayerpiano.com][3] 一样的音符和按键。另外,你可以使用[这些音符][4] 来学习弹指各种流行歌曲。
|
||||
|
||||
要查看帮助。输入:
|
||||
|
||||
```
|
||||
$ ./target/release/piano-rs -h
|
||||
|
||||
piano-rs 0.1.0
|
||||
Ritiek Malhotra <ritiekmalhotra123@gmail.com>
|
||||
Play piano in the terminal using PC keyboard.
|
||||
|
||||
USAGE:
|
||||
piano-rs [OPTIONS]
|
||||
|
||||
FLAGS:
|
||||
-h, --help Prints help information
|
||||
-V, --version Prints version information
|
||||
|
||||
OPTIONS:
|
||||
-c, --color <COLOR> Color of block to generate when a note is played (Default: "red")
|
||||
-d, --duration <DURATION> Duration to play each note for, where 0 means till the end of note (Default: 0)
|
||||
-s, --sequence <SEQUENCE> Frequency sequence from 0 to 5 to begin with (Default: 2)
|
||||
```
|
||||
|
||||
我必须承认这是个超级酷的项目。对于那些买不起钢琴的人,很推荐使用这款应用。
|
||||
|
||||
祝你周末愉快!!
|
||||
|
||||
此致敬礼!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/let-us-play-piano-terminal-using-pc-keyboard/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/10/Piano.png
|
||||
[3]:http://www.multiplayerpiano.com/
|
||||
[4]:https://pastebin.com/CX1ew0uB
|
||||
156
published/20171030 How To Create Custom Ubuntu Live CD Image.md
Normal file
156
published/20171030 How To Create Custom Ubuntu Live CD Image.md
Normal file
@ -0,0 +1,156 @@
|
||||
如何创建定制的 Ubuntu Live CD 镜像
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天让我们来讨论一下如何创建 Ubuntu Live CD 的定制镜像(ISO)。我们以前可以使用 [Pinguy Builder][1] 完成这项工作。但是,现在它似乎停止维护了。最近 Pinguy Builder 的官方网站似乎没有任何更新。幸运的是,我找到了另一种创建 Ubuntu Live CD 镜像的工具。使用 Cubic 即 **C**ustom **Ub**untu **I**SO **C**reator 的首字母缩写,这是一个用来创建定制的可启动的 Ubuntu Live CD(ISO)镜像的 GUI 应用程序。
|
||||
|
||||
Cubic 正在积极开发,它提供了许多选项来轻松地创建一个定制的 Ubuntu Live CD ,它有一个集成的 chroot 命令行环境(LCTT 译注:chroot —— Change Root,也就是改变程序执行时所参考的根目录位置),在那里你可以定制各种方面,比如安装新的软件包、内核,添加更多的背景壁纸,添加更多的文件和文件夹。它有一个直观的 GUI 界面,在 live 镜像创建过程中可以轻松的利用导航(可以利用点击鼠标来回切换)。您可以创建一个新的自定义镜像或修改现有的项目。因为它可以用来制作 Ubuntu live 镜像,所以我相信它可以用在制作其他 Ubuntu 的发行版和衍生版镜像中,比如 Linux Mint。
|
||||
|
||||
### 安装 Cubic
|
||||
|
||||
Cubic 的开发人员已经做出了一个 PPA 来简化安装过程。要在 Ubuntu 系统上安装 Cubic ,在你的终端上运行以下命令:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:cubic-wizard/release
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 6494C6D6997C215E
|
||||
sudo apt update
|
||||
sudo apt install cubic
|
||||
```
|
||||
|
||||
### 利用 Cubic 创建 Ubuntu Live CD 的定制镜像
|
||||
|
||||
安装完成后,从应用程序菜单或 dock 启动 Cubic。这是在我在 Ubuntu 16.04 LTS 桌面系统中 Cubic 的样子。
|
||||
|
||||
为新项目选择一个目录。它是保存镜像文件的目录。
|
||||
|
||||
![][3]
|
||||
|
||||
请注意,Cubic 不是创建您当前系统的 Live CD 镜像,而是利用 Ubuntu 的安装 CD 来创建一个定制的 Live CD,因此,你应该有一个最新的 ISO 镜像。
|
||||
|
||||
选择您存储 Ubuntu 安装 ISO 镜像的路径。Cubic 将自动填写您定制操作系统的所有细节。如果你愿意,你可以改变细节。单击 Next 继续。
|
||||
|
||||
![][4]
|
||||
|
||||
接下来,来自源安装介质中的压缩的 Linux 文件系统将被提取到项目的目录(在我们的例子中目录的位置是 `/home/ostechnix/custom_ubuntu`)。
|
||||
|
||||
![][5]
|
||||
|
||||
一旦文件系统被提取出来,将自动加载到 chroot 环境。如果你没有看到终端提示符,请按几次回车键。
|
||||
|
||||
![][6]
|
||||
|
||||
在这里可以安装任何额外的软件包,添加背景图片,添加软件源列表,添加最新的 Linux 内核和所有其他定制到你的 Live CD 。
|
||||
|
||||
例如,我希望 `vim` 安装在我的 Live CD 中,所以现在就要安装它。
|
||||
|
||||
![][7]
|
||||
|
||||
我们不需要使用 `sudo`,因为我们已经在具有最高权限(root)的环境中了。
|
||||
|
||||
类似地,如果需要,可以安装更多的任何版本 Linux 内核。
|
||||
|
||||
```
|
||||
apt install linux-image-extra-4.10.0-24-generic
|
||||
```
|
||||
|
||||
此外,您还可以更新软件源列表(添加或删除软件存储库列表):
|
||||
|
||||
![][8]
|
||||
|
||||
修改源列表后,不要忘记运行 `apt update` 命令来更新源列表:
|
||||
|
||||
```
|
||||
apt update
|
||||
```
|
||||
|
||||
另外,您还可以向 Live CD 中添加文件或文件夹。复制文件或文件夹(右击它们并选择复制或者利用 `CTRL+C`),在终端右键单击(在 Cubic 窗口内),选择 “Paste file(s)”,最后点击 Cubic 向导底部的 “Copy”。
|
||||
|
||||
![][9]
|
||||
|
||||
**Ubuntu 17.10 用户注意事项**
|
||||
|
||||
> 在 Ubuntu 17.10 系统中,DNS 查询可能无法在 chroot 环境中工作。如果您正在制作一个定制的 Ubuntu 17.10 Live 镜像,您需要指向正确的 `resolve.conf` 配置文件:
|
||||
|
||||
>```
|
||||
ln -sr /run/systemd/resolve/resolv.conf /run/systemd/resolve/stub-resolv.conf
|
||||
```
|
||||
|
||||
> 要验证 DNS 解析工作,运行:
|
||||
|
||||
> ```
|
||||
cat /etc/resolv.conf
|
||||
ping google.com
|
||||
```
|
||||
|
||||
如果你想的话,可以添加你自己的壁纸。要做到这一点,请切换到 `/usr/share/backgrounds/` 目录,
|
||||
|
||||
```
|
||||
cd /usr/share/backgrounds
|
||||
```
|
||||
|
||||
并将图像拖放到 Cubic 窗口中。或复制图像,右键单击 Cubic 终端窗口并选择 “Paste file(s)” 选项。此外,确保你在 `/usr/share/gnome-backproperties` 的XML文件中添加了新的壁纸,这样你可以在桌面上右键单击新添加的图像选择 “Change Desktop Background” 进行交互。完成所有更改后,在 Cubic 向导中单击 “Next”。
|
||||
|
||||
接下来,选择引导到新的 Live ISO 镜像时使用的 Linux 内核版本。如果已经安装了其他版本内核,它们也将在这部分中被列出。然后选择您想在 Live CD 中使用的内核。
|
||||
|
||||
![][10]
|
||||
|
||||
在下一节中,选择要从您的 Live 映像中删除的软件包。在使用定制的 Live 映像安装完 Ubuntu 操作系统后,所选的软件包将自动删除。在选择要删除的软件包时,要格外小心,您可能在不知不觉中删除了一个软件包,而此软件包又是另外一个软件包的依赖包。
|
||||
|
||||
![][11]
|
||||
|
||||
接下来, Live 镜像创建过程将开始。这里所要花费的时间取决于你定制的系统规格。
|
||||
|
||||
![][12]
|
||||
|
||||
镜像创建完成后后,单击 “Finish”。Cubic 将显示新创建的自定义镜像的细节。
|
||||
|
||||
如果你想在将来修改刚刚创建的自定义 Live 镜像,不要选择“ Delete all project files, except the generated disk image and the corresponding MD5 checksum file”(除了生成的磁盘映像和相应的 MD5 校验和文件之外,删除所有的项目文件**) ,Cubic 将在项目的工作目录中保留自定义图像,您可以在将来进行任何更改。而不用从头再来一遍。
|
||||
|
||||
要为不同的 Ubuntu 版本创建新的 Live 镜像,最好使用不同的项目目录。
|
||||
|
||||
### 利用 Cubic 修改 Ubuntu Live CD 的定制镜像
|
||||
|
||||
从菜单中启动 Cubic ,并选择一个现有的项目目录。单击 “Next” 按钮,您将看到以下三个选项:
|
||||
|
||||
1. Create a disk image from the existing project. (从现有项目创建一个磁盘映像。)
|
||||
2. Continue customizing the existing project.(继续定制现有项目。)
|
||||
3. Delete the existing project.(删除当前项目。)
|
||||
|
||||
![][13]
|
||||
|
||||
第一个选项将允许您从现有项目中使用之前所做的自定义设置创建一个新的 Live ISO 镜像。如果您丢失了 ISO 镜像,您可以使用第一个选项来创建一个新的。
|
||||
|
||||
第二个选项允许您在现有项目中进行任何其他更改。如果您选择此选项,您将再次进入 chroot 环境。您可以添加新的文件或文件夹,安装任何新的软件,删除任何软件,添加其他的 Linux 内核,添加桌面背景等等。
|
||||
|
||||
第三个选项将删除现有的项目,所以您可以从头开始。选择此选项将删除所有文件,包括新生成的 ISO 镜像文件。
|
||||
|
||||
我用 Cubic 做了一个定制的 Ubuntu 16.04 LTS 桌面 Live CD 。就像这篇文章里描述的一样。如果你想创建一个 Ubuntu Live CD, Cubic 可能是一个不错的选择。
|
||||
|
||||
就这些了,再会!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-custom-ubuntu-live-cd-image/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/pinguy-builder-build-custom-ubuntu-os/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-4.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-6.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-5.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-7.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-8.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-10-1.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-12-1.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-13.png
|
||||
79
published/20171031 Migrating to Linux- An Introduction.md
Normal file
79
published/20171031 Migrating to Linux- An Introduction.md
Normal file
@ -0,0 +1,79 @@
|
||||
迁移到 Linux :入门介绍
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 这个新文章系列将帮你从其他操作系统迁移到 Linux。
|
||||
|
||||
运行 Linux 的计算机系统到遍布在每个角落。Linux 运行着从谷歌搜索到“脸书”等等各种互联网服务。Linux 也在很多设备上运行,包括我们的智能手机、电视,甚至汽车。当然,Linux 也可以运行在您的桌面系统上。如果您是 Linux 新手,或者您想在您的桌面计算机上尝试一些不同的东西,这篇文章将简要地介绍其基础知识,并帮助您从另一个系统迁移到 Linux。
|
||||
|
||||
切换到不同的操作系统可能是一个挑战,因为每个操作系统都提供了不同的操作方法。其在一个系统上的<ruby>习惯<rt>second nature</rt></ruby>可能会对另一个系统的使用形成阻挠,因此我们需要到网上或书本上查找怎样操作。
|
||||
|
||||
### Windows 与 Linux 的区别
|
||||
|
||||
(LCTT 译注:本节标题 Vive la différence ,来自于法语,意即“差异万岁”——来自于 wiktionary)
|
||||
|
||||
要开始使用 Linux,您可能会注意到,Linux 的打包方式不同。在其他操作系统中,许多组件被捆绑在一起,只是该软件包的一部分。然而,在 Linux 中,每个组件都被分别调用。举个例子来说,在 Windows 下,图形界面只是操作系统的一部分。而在 Linux 下,您可以从多个图形环境中进行选择,比如 GNOME、KDE Plasma、Cinnamon 和 MATE 等。
|
||||
|
||||
从更高层面上看,一个 Linux 包括以下内容:
|
||||
|
||||
1. 内核
|
||||
2. 驻留在磁盘上的系统程序和文件
|
||||
3. 图形环境
|
||||
4. 包管理器
|
||||
5. 应用程序
|
||||
|
||||
### 内核
|
||||
|
||||
操作系统的核心称为<ruby>内核<rt>kernel</rt></ruby>。内核是引擎罩下的引擎。它允许多个应用程序同时运行,并协调它们对公共服务和设备的访问,从而使所有设备运行顺畅。
|
||||
|
||||
### 系统程序和文件
|
||||
|
||||
系统程序以标准的文件和目录的层次结构位于磁盘上。这些系统程序和文件包括后台运行的服务(称为<ruby>守护进程<rt>deamon</rt></ruby>)、用于各种操作的实用程序、配置文件和日志文件。
|
||||
|
||||
这些系统程序不是在内核中运行,而是执行基本系统操作的程序——例如,设置日期和时间,以及连接网络以便你可以上网。
|
||||
|
||||
这里包含了<ruby>初始化<rt>init</rt></ruby>程序——它是最初运行的程序。该程序负责启动所有后台服务(如 Web 服务器)、启动网络连接和启动图形环境。这个初始化程序将根据需要启动其它系统程序。
|
||||
|
||||
其他系统程序为简单的任务提供便利,比如添加用户和组、更改密码和配置磁盘。
|
||||
|
||||
### 图形环境
|
||||
|
||||
图形环境实际上只是更多的系统程序和文件。图形环境提供了常用的带有菜单的窗口、鼠标指针、对话框、状态和指示器等。
|
||||
|
||||
需要注意的是,您不是必须需要使用原本安装的图形环境。如果你愿意,你可以把它换成其它的。每个图形环境都有不同的特性。有些看起来更像 Apple OS X,有些看起来更像 Windows,有些则是独特的而不试图模仿其他的图形界面。
|
||||
|
||||
### 包管理器
|
||||
|
||||
对于来自不同操作系统的人来说,<ruby>包管理器<rt>package manager</rt></ruby>比较难以掌握,但是现在有一个人们非常熟悉的类似的系统——应用程序商店。软件包系统实际上就是 Linux 的应用程序商店。您可以使用包管理器来选择您想要的应用程序,而不是从一个网站安装这个应用程序,而从另一个网站来安装那个应用程序。然后,包管理器会从预先构建的开源应用程序的中心仓库安装应用程序。
|
||||
|
||||
### 应用程序
|
||||
|
||||
Linux 附带了许多预安装的应用程序。您可以从包管理器获得更多。许多应用程序相当棒,另外一些还需要改进。有时,同一个应用程序在 Windows 或 Mac OS 或 Linux 上运行的版本会不同。
|
||||
|
||||
例如,您可以使用 Firefox 浏览器和 Thunderbird (用于电子邮件)。您可以使用 LibreOffice 作为 Microsoft Office 的替代品,并通过 Valve 的 Steam 程序运行游戏。您甚至可以在 Linux 上使用 WINE 来运行一些 Windows 原生的应用程序。
|
||||
|
||||
### 安装 Linux
|
||||
|
||||
第一步通常是安装 Linux 发行版。你可能听说过 Red Hat、Ubuntu、Fedora、Arch Linux 和 SUSE,等等。这些都是 Linux 的不同发行版。
|
||||
|
||||
如果没有 Linux 发行版,则必须分别安装每个组件。许多组件是由不同人群开发和提供的,因此单独安装每个组件将是一项冗长而乏味的任务。幸运的是,构建发行版的人会为您做这项工作。他们抓取所有的组件,构建它们,确保它们可以在一起工作,然后将它们打包在一个单一的安装套件中。
|
||||
|
||||
各种发行版可能会做出不同的选择、使用不同的组件,但它仍然是 Linux。在一个发行版中开发的应用程序通常在其他发行版上运行的也很好。
|
||||
|
||||
如果你是一个 Linux 初学者,想尝试 Linux,我推荐[安装 Ubuntu][1]。还有其他的发行版也可以尝试: Linux Mint、Fedora、Debian、Zorin OS、Elementary OS 等等。在以后的文章中,我们将介绍 Linux 系统的其他方面,并提供关于如何开始使用 Linux 的更多信息。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.ubuntu.com/download/desktop
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,51 @@
|
||||
autorandr:自动调整屏幕布局
|
||||
======
|
||||
|
||||
像许多笔记本用户一样,我经常将笔记本插入到不同的显示器上(桌面上有多台显示器,演示时有投影机等)。运行 `xrandr` 命令或点击界面非常繁琐,编写脚本也不是很好。
|
||||
|
||||
最近,我遇到了 [autorandr][1],它使用 EDID(和其他设置)检测连接的显示器,保存 `xrandr` 配置并恢复它们。它也可以在加载特定配置时运行任意脚本。我已经打包了它,目前仍在 NEW 状态。如果你不能等待,[这是 deb][2],[这是 git 仓库][3]。
|
||||
|
||||
要使用它,只需安装软件包,并创建你的初始配置(我这里用的名字是 `undocked`):
|
||||
|
||||
```
|
||||
autorandr --save undocked
|
||||
```
|
||||
|
||||
然后,连接你的笔记本(或者插入你的外部显示器),使用 `xrandr`(或其他任何)更改配置,然后保存你的新配置(我这里用的名字是 workstation):
|
||||
|
||||
```
|
||||
autorandr --save workstation
|
||||
```
|
||||
|
||||
对你额外的配置(或当你有新的配置)进行重复操作。
|
||||
|
||||
`autorandr` 有 `udev`、`systemd` 和 `pm-utils` 钩子,当新的显示器出现时 `autorandr --change` 应该会立即运行。如果需要,也可以手动运行 `autorandr --change` 或 `autorandr - load workstation`。你也可以在加载配置后在 `~/.config/autorandr/$PROFILE/postswitch` 添加自己的脚本来运行。由于我运行 i3,我的工作站配置如下所示:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
xrandr --dpi 92
|
||||
xrandr --output DP2-2 --primary
|
||||
i3-msg '[workspace="^(1|4|6)"] move workspace to output DP2-2;'
|
||||
i3-msg '[workspace="^(2|5|9)"] move workspace to output DP2-3;'
|
||||
i3-msg '[workspace="^(3|8)"] move workspace to output DP2-1;'
|
||||
```
|
||||
|
||||
它适当地修正了 dpi,设置主屏幕(可能不需要?),并移动 i3 工作区。你可以通过在配置文件目录中添加一个 `block` 钩子来安排配置永远不会运行。
|
||||
|
||||
如果你定期更换显示器,请看一下!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.donarmstrong.com/posts/autorandr/
|
||||
|
||||
作者:[Don Armstrong][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.donarmstrong.com
|
||||
[1]:https://github.com/phillipberndt/autorandr
|
||||
[2]:https://www.donarmstrong.com/autorandr_1.2-1_all.deb
|
||||
[3]:https://git.donarmstrong.com/deb_pkgs/autorandr.git
|
||||
87
published/20171107 The long goodbye to C.md
Normal file
87
published/20171107 The long goodbye to C.md
Normal file
@ -0,0 +1,87 @@
|
||||
与 C 语言长别离
|
||||
==========================================
|
||||
|
||||
这几天来,我在思考那些正在挑战 C 语言的系统编程语言领袖地位的新潮语言,尤其是 Go 和 Rust。思考的过程中,我意识到了一个让我震惊的事实 —— 我有着 35 年的 C 语言经验。每周我都要写很多 C 代码,但是我已经记不清楚上一次我 _创建一个新的 C 语言项目_ 是在什么时候了。
|
||||
|
||||
如果你完全不认为这种情况令人震惊,那你很可能不是一个系统程序员。我知道有很多程序员使用更高级的语言工作。但是我把大部分时间都花在了深入打磨像 NTPsec、 GPSD 以及 giflib 这些东西上。熟练使用 C 语言在这几十年里一直就是我的专长。但是,现在我不仅是不再使用 C 语言写新的项目,甚至我都记不清我是什么时候开始这样做的了,而且……回头想想,我觉得这都不是本世纪发生的事情。
|
||||
|
||||
这个对于我来说是件大事,因为如果你问我,我的五个最核心软件开发技能是什么,“C 语言专家” 一定是你最有可能听到的之一。这也激起了我的思考。C 语言的未来会怎样 ?C 语言是否正像当年的 COBOL 语言一样,在辉煌之后,走向落幕?
|
||||
|
||||
我恰好是在 C 语言迅猛发展,并把汇编语言以及其它许多编译型语言挤出主流存在的前几年开始编程的。那场过渡大约是在 1982 到 1985 年之间。在那之前,有很多编译型语言争相吸引程序员的注意力,那些语言中还没有明确的领导者;但是在那之后,小众的语言就直接毫无声息的退出了舞台。主流的语言(FORTRAN、Pascal、COBOL)则要么只限于老代码,要么就是固守单一领域,再就是在 C 语言的边缘领域顶着愈来愈大的压力苟延残喘。
|
||||
|
||||
而在那以后,这种情形持续了近 30 年。尽管在应用程序开发上出现了新的动向: Java、 Perl、 Python, 以及许许多多不是很成功的竞争者。起初我很少关注这些语言,这很大一部分是因为在它们的运行时的开销对于当时的实际硬件来说太大。因此,这就使得 C 的成功无可撼动;为了使用和对接大量已有的 C 语言代码,你得使用 C 语言写新代码(一部分脚本语言尝试过打破这种壁垒,但是只有 Python 有可能取得成功)。
|
||||
|
||||
回想起来,我在 1997 年使用脚本语言写应用时本应该注意到这些语言的更重要的意义的。当时我写的是一个名为 SunSITE 的帮助图书管理员做源码分发的辅助软件,当时使用的是 Perl 语言。
|
||||
|
||||
这个应用完全是用来处理文本输入的,而且只需要能够应对人类的反应速度即可(大概 0.1 秒),因此使用 C 或者别的没有动态内存分配以及字符串类型的语言来写就会显得很傻。但是在当时,我仅仅是把其视为一个试验,而完全没有想到我几乎再也不会在一个新项目的第一个文件里敲下 `int main(int argc, char **argv)` 这样的 C 语言代码了。
|
||||
|
||||
我说“几乎”,主要是因为 1999 年的 [SNG][3]。 我想那是我最后一个用 C 从头开始写的项目了。
|
||||
|
||||
在那之后我写的所有的 C 代码都是在为那些上世纪已经存在的老项目添砖加瓦,或者是在维护诸如 GPSD 以及 NTPsec 一类的项目。
|
||||
|
||||
当年我本不应该使用 C 语言写 SNG 的。因为在那个年代,摩尔定律的快速迭代使得硬件愈加便宜,使得像 Perl 这样的语言的执行效率也不再是问题。仅仅三年以后,我可能就会毫不犹豫地使用 Python 而不是 C 语言来写 SNG。
|
||||
|
||||
在 1997 年我学习了 Python, 这对我来说是一道分水岭。这个语言很美妙 —— 就像我早年使用的 Lisp 一样,而且 Python 还有很酷的库!甚至还完全遵循了 POSIX!还有一个蛮好用的对象系统!Python 没有把 C 语言挤出我的工具箱,但是我很快就习惯了在只要能用 Python 时就写 Python ,而只在必须使用 C 语言时写 C。
|
||||
|
||||
(在此之后,我开始在我的访谈中指出我所谓的 “Perl 的教训” ,也就是任何一个没能实现和 C 语言语义等价的遵循 POSIX 的语言_都注定要失败_。在计算机科学的发展史上,很多学术语言的骨骸俯拾皆是,原因是这些语言的设计者没有意识到这个重要的问题。)
|
||||
|
||||
显然,对我来说,Python 的主要优势之一就是它很简单,当我写 Python 时,我不再需要担心内存管理问题或者会导致核心转储的程序崩溃 —— 对于 C 程序员来说,处理这些问题烦的要命。而不那么明显的优势恰好在我更改语言时显现,我在 90 年代末写应用程序和非核心系统服务的代码时,为了平衡成本与风险都会倾向于选择具有自动内存管理但是开销更大的语言,以抵消之前提到的 C 语言的缺陷。而在仅仅几年之前(甚至是 1990 年),那些语言的开销还是大到无法承受的;那时硬件产业的发展还在早期阶段,没有给摩尔定律足够的时间来发挥威力。
|
||||
|
||||
尽量地在 C 语言和 Python 之间选择 C —— 只要是能的话我就会从 C 语言转移到 Python 。这是一种降低工程复杂程度的有效策略。我将这种策略应用在了 GPSD 中,而针对 NTPsec , 我对这个策略的采用则更加系统化。这就是我们能把 NTP 的代码库大小削减四分之一的原因。
|
||||
|
||||
但是今天我不是来讲 Python 的。尽管我觉得它在竞争中脱颖而出,Python 也未必真的是在 2000 年之前彻底结束我在新项目上使用 C 语言的原因,因为在当时任何一个新的学院派的动态语言都可以让我不再选择使用 C 语言。也有可能是在某段时间里在我写了很多 Java 之后,我才慢慢远离了 C 语言。
|
||||
|
||||
我写这个回忆录是因为我觉得我并非特例,在世纪之交,同样的发展和转变也改变了不少 C 语言老手的编码习惯。像我一样,他们在当时也并没有意识到这种转变正在发生。
|
||||
|
||||
在 2000 年以后,尽管我还在使用 C/C++ 写之前的项目,比如 GPSD ,游戏韦诺之战以及 NTPsec,但是我的所有新项目都是使用 Python 的。
|
||||
|
||||
有很多程序是在完全无法在 C 语言下写出来的,尤其是 [reposurgeon][4] 以及 [doclifter][5] 这样的项目。由于 C 语言受限的数据类型本体论以及其脆弱的底层数据管理问题,尝试用 C 写的话可能会很恐怖,并注定失败。
|
||||
|
||||
甚至是对于更小的项目 —— 那些可以在 C 中实现的东西 —— 我也使用 Python 写,因为我不想花不必要的时间以及精力去处理内核转储问题。这种情况一直持续到去年年底,持续到我创建我的第一个 Rust 项目,以及成功写出第一个[使用 Go 语言的项目][6]。
|
||||
|
||||
如前文所述,尽管我是在讨论我的个人经历,但是我想我的经历体现了时代的趋势。我期待新潮流的出现,而不是仅仅跟随潮流。在 98 年的时候,我就是 Python 的早期使用者。来自 [TIOBE][7] 的数据则表明,在 Go 语言脱胎于公司的实验项目并刚刚从小众语言中脱颖而出的几个月内,我就开始实现自己的第一个 Go 语言项目了。
|
||||
|
||||
总而言之:直到现在第一批有可能挑战 C 语言的传统地位的语言才出现。我判断这个的标准很简单 —— 只要这个语言能让我等 C 语言老手接受不再写 C 的事实,这个语言才 “有可能” 挑战到 C 语言的地位 —— 来看啊,这有个新编译器,能把 C 转换到新语言,现在你可以让他完成你的_全部工作_了 —— 这样 C 语言的老手就会开心起来。
|
||||
|
||||
Python 以及和其类似的语言对此做的并不够好。使用 Python 实现 NTPsec(以此举例)可能是个灾难,最终会由于过高的运行时开销以及由于垃圾回收机制导致的延迟变化而烂尾。如果需求是针对单个用户且只需要以人类能接受的速度运行,使用 Python 当然是很好的,但是对于以 _机器的速度_ 运行的程序来说就不总是如此了 —— 尤其是在很高的多用户负载之下。这不只是我自己的判断 —— 因为拿 Go 语言来说,它的存在主要就是因为当时作为 Python 语言主要支持者的 Google 在使用 Python 实现一些工程的时候也遭遇了同样的效能痛点。
|
||||
|
||||
Go 语言就是为了解决 Python 搞不定的那些大多由 C 语言来实现的任务而设计的。尽管没有一个全自动语言转换软件让我很是不爽,但是使用 Go 语言来写系统程序对我来说不算麻烦,我发现我写 Go 写的还挺开心的。我的很多 C 编码技能还可以继续使用,我还收获了垃圾回收机制以及并发编程机制,这何乐而不为?
|
||||
|
||||
([这里][8]有关于我第一次写 Go 的经验的更多信息)
|
||||
|
||||
本来我想把 Rust 也视为 “C 语言要过时了” 的例证,但是在学习并尝试使用了这门语言编程之后,我觉得[这种语言现在还没有做好准备][9]。也许 5 年以后,它才会成为 C 语言的对手。
|
||||
|
||||
随着 2017 的尾声来临,我们已经发现了一个相对成熟的语言,其和 C 类似,能够胜任 C 语言的大部分工作场景(我在下面会准确描述),在几年以后,这个语言界的新星可能就会取得成功。
|
||||
|
||||
这件事意义重大。如果你不长远地回顾历史,你可能看不出来这件事情的伟大性。_三十年了_ —— 这几乎就是我作为一个程序员的全部生涯,我们都没有等到一个 C 语言的继任者,也无法遥望 C 之后的系统编程会是什么样子的。而现在,我们面前突然有了后 C 时代的两种不同的展望和未来……
|
||||
|
||||
……另一种展望则是下面这个语言留给我们的。我的一个朋友正在开发一个他称之为 “Cx” 的语言,这个语言在 C 语言上做了很少的改动,使得其能够支持类型安全;他的项目的目的就是要创建一个能够在最少人力参与的情况下把古典 C 语言修改为新语言的程序。我不会指出这位朋友的名字,免得给他太多压力,让他做出太多不切实际的保证。但是他的实现方法真的很是有意思,我会尽量给他募集资金。
|
||||
|
||||
现在,我们看到了可以替代 C 语言实现系统编程的三种不同的可能的道路。而就在两年之前,我们的眼前还是一片漆黑。我重复一遍:这件事情意义重大。
|
||||
|
||||
我是在说 C 语言将要灭绝吗?不是这样的,在可预见的未来里,C 语言还会是操作系统的内核编程以及设备固件编程的主流语言,在这些场景下,尽力压榨硬件性能的古老规则还在奏效,尽管它可能不是那么安全。
|
||||
|
||||
现在那些将要被 C 的继任者攻破的领域就是我之前提到的我经常涉及的领域 —— 比如 GPSD 以及 NTPsec、系统服务以及那些因为历史原因而使用 C 语言写的进程。还有就是以 DNS 服务器以及邮件传输代理 —— 那些需要以机器速度而不是人类的速度运行的系统程序。
|
||||
|
||||
现在我们可以对后 C 时代的未来窥见一斑,即上述这类领域的代码都可以使用那些具有强大内存安全特性的 C 语言的替代者实现。Go 、Rust 或者 Cx ,无论是哪个,都可能使 C 的存在被弱化。比如,如果我现在再来重新实现一遍 NTP ,我可能就会毫不犹豫的使用 Go 语言去完成。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7711
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[yunfengHe](https://github.com/yunfengHe), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711
|
||||
[3]:http://sng.sourceforge.net/
|
||||
[4]:http://www.catb.org/esr/reposurgeon/
|
||||
[5]:http://www.catb.org/esr/doclifter/
|
||||
[6]:http://www.catb.org/esr/loccount/
|
||||
[7]:https://www.tiobe.com/tiobe-index/
|
||||
[8]:https://blog.ntpsec.org/2017/02/07/grappling-with-go.html
|
||||
[9]:http://esr.ibiblio.org/?p=7303
|
||||
@ -0,0 +1,166 @@
|
||||
通过实例学习 tcpdump 命令
|
||||
======
|
||||
|
||||
`tcpdump` 是一个很常用的网络包分析工具,可以用来显示通过网络传输到本系统的 TCP/IP 以及其他网络的数据包。`tcpdump` 使用 libpcap 库来抓取网络报,这个库在几乎在所有的 Linux/Unix 中都有。
|
||||
|
||||
`tcpdump` 可以从网卡或之前创建的数据包文件中读取内容,也可以将包写入文件中以供后续使用。必须是 root 用户或者使用 sudo 特权来运行 `tcpdump`。
|
||||
|
||||
在本文中,我们将会通过一些实例来演示如何使用 `tcpdump` 命令,但首先让我们来看看在各种 Linux 操作系统中是如何安装 `tcpdump` 的。
|
||||
|
||||
- 推荐阅读:[使用 iftop 命令监控网络带宽 ][1]
|
||||
|
||||
### 安装
|
||||
|
||||
`tcpdump` 默认在几乎所有的 Linux 发行版中都可用,但若你的 Linux 上没有的话,使用下面方法进行安装。
|
||||
|
||||
#### CentOS/RHEL
|
||||
|
||||
使用下面命令在 CentOS 和 RHEL 上安装 `tcpdump`,
|
||||
|
||||
```
|
||||
$ sudo yum install tcpdump*
|
||||
```
|
||||
|
||||
#### Fedora
|
||||
|
||||
使用下面命令在 Fedora 上安装 `tcpdump`:
|
||||
|
||||
```
|
||||
$ dnf install tcpdump
|
||||
```
|
||||
|
||||
#### Ubuntu/Debian/Linux Mint
|
||||
|
||||
在 Ubuntu/Debain/Linux Mint 上使用下面命令安装 `tcpdump`:
|
||||
|
||||
```
|
||||
$ apt-get install tcpdump
|
||||
```
|
||||
|
||||
安装好 `tcpdump` 后,现在来看一些例子。
|
||||
|
||||
### 案例演示
|
||||
|
||||
#### 从所有网卡中捕获数据包
|
||||
|
||||
运行下面命令来从所有网卡中捕获数据包:
|
||||
|
||||
```
|
||||
$ tcpdump -i any
|
||||
```
|
||||
|
||||
#### 从指定网卡中捕获数据包
|
||||
|
||||
要从指定网卡中捕获数据包,运行:
|
||||
|
||||
```
|
||||
$ tcpdump -i eth0
|
||||
```
|
||||
|
||||
#### 将捕获的包写入文件
|
||||
|
||||
使用 `-w` 选项将所有捕获的包写入文件:
|
||||
|
||||
```
|
||||
$ tcpdump -i eth1 -w packets_file
|
||||
```
|
||||
|
||||
#### 读取之前产生的 tcpdump 文件
|
||||
|
||||
使用下面命令从之前创建的 tcpdump 文件中读取内容:
|
||||
|
||||
```
|
||||
$ tcpdump -r packets_file
|
||||
```
|
||||
|
||||
#### 获取更多的包信息,并且以可读的形式显示时间戳
|
||||
|
||||
要获取更多的包信息同时以可读的形式显示时间戳,使用:
|
||||
|
||||
```
|
||||
$ tcpdump -ttttnnvvS
|
||||
```
|
||||
|
||||
#### 查看整个网络的数据包
|
||||
|
||||
要获取整个网络的数据包,在终端执行下面命令:
|
||||
|
||||
```
|
||||
$ tcpdump net 192.168.1.0/24
|
||||
```
|
||||
|
||||
#### 根据 IP 地址查看报文
|
||||
|
||||
要获取指定 IP 的数据包,不管是作为源地址还是目的地址,使用下面命令:
|
||||
|
||||
```
|
||||
$ tcpdump host 192.168.1.100
|
||||
```
|
||||
|
||||
要指定 IP 地址是源地址或是目的地址则使用:
|
||||
|
||||
```
|
||||
$ tcpdump src 192.168.1.100
|
||||
$ tcpdump dst 192.168.1.100
|
||||
```
|
||||
|
||||
#### 查看某个协议或端口号的数据包
|
||||
|
||||
要查看某个协议的数据包,运行下面命令:
|
||||
|
||||
```
|
||||
$ tcpdump ssh
|
||||
```
|
||||
|
||||
要捕获某个端口或一个范围的数据包,使用:
|
||||
|
||||
```
|
||||
$ tcpdump port 22
|
||||
$ tcpdump portrange 22-125
|
||||
```
|
||||
|
||||
我们也可以与 `src` 和 `dst` 选项连用来捕获指定源端口或指定目的端口的报文。
|
||||
|
||||
我们还可以使用“与” (`and`,`&&`)、“或” (`or`,`||` ) 和“非”(`not`,`!`) 来将两个条件组合起来。当我们需要基于某些条件来分析网络报文是非常有用。
|
||||
|
||||
#### 使用“与”
|
||||
|
||||
可以使用 `and` 或者符号 `&&` 来将两个或多个条件组合起来。比如:
|
||||
|
||||
```
|
||||
$ tcpdump src 192.168.1.100 && port 22 -w ssh_packets
|
||||
```
|
||||
|
||||
#### 使用“或”
|
||||
|
||||
“或”会检查是否匹配命令所列条件中的其中一条,像这样:
|
||||
|
||||
```
|
||||
$ tcpdump src 192.168.1.100 or dst 192.168.1.50 && port 22 -w ssh_packets
|
||||
$ tcpdump port 443 or 80 -w http_packets
|
||||
```
|
||||
|
||||
#### 使用“非”
|
||||
|
||||
当我们想表达不匹配某项条件时可以使用“非”,像这样:
|
||||
|
||||
```
|
||||
$ tcpdump -i eth0 src port not 22
|
||||
```
|
||||
|
||||
这会捕获 eth0 上除了 22 号端口的所有通讯。
|
||||
|
||||
我们的教程至此就结束了,在本教程中我们讲解了如何安装并使用 `tcpdump` 来捕获网络数据包。如有任何疑问或建议,欢迎留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/learn-use-tcpdump-command-examples/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/monitoring-network-bandwidth-iftop-command/
|
||||
@ -0,0 +1,98 @@
|
||||
如何解决 Linux 中“磁盘空间不足”的问题
|
||||
======
|
||||
|
||||

|
||||
|
||||
明明有很多剩余空间,但 Linux 系统依然提示没有空间剩余。为什么会这样呢?Linux 偶尔会有一些令人沮丧的模糊的错误消息出现,而这就是其中一种。不过这种错误通常都是由某几种因素导致的。
|
||||
|
||||
### 通过 du 和 df 检查磁盘空间
|
||||
|
||||
在开始行动前,最好先检查一下是否磁盘上是否确实还有空间剩余。虽然桌面环境的工具也很不错,但命令行上的工具更直接,要好的多。
|
||||
|
||||
![Linux Filesystem du][1]
|
||||
|
||||
首先让我们看看 `du` 命令。用它来检查问题磁盘所在的挂载点目录。本文假设出问题的分区挂载点为根目录。
|
||||
|
||||
```
|
||||
sudo du -sh /
|
||||
```
|
||||
|
||||
![Linux Filesystem df][2]
|
||||
|
||||
由于它要遍历磁盘中的所有文件,因此需要花费一点时间。现在再让我们试试 `df`。
|
||||
|
||||
```
|
||||
sudo df -h
|
||||
```
|
||||
|
||||
把根目录和在其中挂载的文件系统加在这条命令的后面。比如,若你的有一个独立的磁盘挂载到 `/home`,那么除了根目录之外,你也需要把它加进来。使用空间的总和应该跟你 `du` 命令得到的结果接近。否则的话,就说明可能有已删除文件的文件被进程占用。
|
||||
|
||||
当然,这里主要专注点在于这些命令的结果是否要小于磁盘的大小。如果确实小于磁盘大小,那么很明显有很多地方不对劲。
|
||||
|
||||
**相关**:[使用 Agedu 分析硬盘空间使用状况 ][3]
|
||||
|
||||
### 可能的原因
|
||||
|
||||
这里列出了一些产生这种情况的主要原因。若你发现 `du` 和 `df` 的结果之间有差别,那么可以直接检查第一项原因。否则从第二项原因开始检查。
|
||||
|
||||
#### 已删除文件被进程所占用
|
||||
|
||||
有时,文件可能已经被删掉了,但有进程依然在使用它。在进程运行期间,Linux 不会释放该文件的存储空间。你需要找出这个进程然后重启这个进程。
|
||||
|
||||
![Check processes for deleted files][4]
|
||||
|
||||
使用下面命令来定位进程。
|
||||
|
||||
```
|
||||
sudo lsof / | grep deleted
|
||||
```
|
||||
|
||||
这应该会列出出问题的进程了,然后重启该进程。
|
||||
|
||||
```
|
||||
sudo systemctl restart service_name
|
||||
```
|
||||
|
||||
#### i 节点不够了
|
||||
|
||||
![Linux check filesystem inodes][5]
|
||||
|
||||
文件系统中有一些称为 “<ruby>i 节点<rt>inode</rt></ruby>” 的元数据,其用来保存文件的相关信息。很多文件系统中的 i 节点数量是固定的,因此很可能 i 节点已经耗尽了而文件系统本身还没有用完。你可以使用 `df` 来检查。
|
||||
|
||||
```
|
||||
sudo df -i /
|
||||
```
|
||||
|
||||
比较一下已用的 i 节点和总共的 i 节点数量。如果没有可用的 i 节点了,那么很不幸,你也无法扩充 i 节点。删除一些无用的和过期的文件来释放一些 i 节点吧。
|
||||
|
||||
#### 环块
|
||||
|
||||
最后一个很常见的问题就是坏的文件系统块。除非另有标记,否则操作系统很可能会认为这些块都是可用的,这会导致文件系统损坏或者硬盘坏死。最好是使用带 `-cc` 标志的 `fsck` 搜索并标记出这些块。记住,你不能使用正在使用的文件系统(LCTT 译注:即包含坏块的文件系统)中的 `fsck` 命令。你应该会要用到 live CD。
|
||||
|
||||
```
|
||||
sudo fsck -vcck /dev/sda2
|
||||
```
|
||||
|
||||
很明显,这里需要使用你想检查的磁盘路径取代命令中的磁盘位置。另外,要注意,这恐怕会花上很长一段时间。
|
||||
|
||||
**相关**:[使用 fsck 检查并修复你的文件系统 [Linux]][6]
|
||||
|
||||
希望这些方案能解决你的问题。这种问题在任何情况下都不是那么容易诊断的。但是,在运气好的情况下,你可以把文件系统清理干净并让你的硬盘再次正常工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/fix-linux-no-space-left-on-device-error/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/10/no-space-du.jpg (Linux Filesystem du)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/10/no-space-df.jpg (Linux Filesystem df)
|
||||
[3]:https://www.maketecheasier.com/agedu-analyze-hard-disk-space-usage-in-linux/ (Use Agedu to Analyze Hard Disk Space Usage in Linux)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/10/no-space-process.jpg (Check processes for deleted files)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/10/no-space-inode.jpg (Linux check filesystem inodes)
|
||||
[6]:https://www.maketecheasier.com/check-repair-filesystem-fsck-linux/ (Check and Repair Your Filesystem With fsck [Linux])
|
||||
@ -0,0 +1,59 @@
|
||||
安全专家的需求正在快速增长
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 来自 Dice 和 Linux 基金会的“开源工作报告”发现,未来对具有安全经验的专业人员的需求很高。
|
||||
|
||||
对安全专业人员的需求是真实的。在 [Dice.com][4] 多达 75,000 个职位中,有 15% 是安全职位。[福布斯][6] 称:“根据网络安全数据工具 [CyberSeek][5],在美国每年有 4 万个信息安全分析师的职位空缺,雇主正在努力填补其他 20 万个与网络安全相关的工作。”我们知道,安全专家的需求正在快速增长,但感兴趣的程度还较低。
|
||||
|
||||
### 安全是要关注的领域
|
||||
|
||||
根据我的经验,很少有大学生对安全工作感兴趣,所以很多人把安全视为商机。入门级技术专家对业务分析师或系统分析师感兴趣,因为他们认为,如果想学习和应用核心 IT 概念,就必须坚持分析师工作或者更接近产品开发的工作。事实并非如此。
|
||||
|
||||
事实上,如果你有兴趣成为商业领导者,那么安全是要关注的领域 —— 作为一名安全专业人员,你必须端到端地了解业务,你必须看大局来给你的公司带来优势。
|
||||
|
||||
### 无所畏惧
|
||||
|
||||
分析师和安全工作并不完全相同。公司出于必要继续合并工程和安全工作。企业正在以前所未有的速度进行基础架构和代码的自动化部署,从而提高了安全作为所有技术专业人士日常生活的一部分的重要性。在我们的 [Linux 基金会的开源工作报告][7]中,42% 的招聘经理表示未来对有安全经验的专业人士的需求很大。
|
||||
|
||||
在安全方面从未有过更激动人心的时刻。如果你随时掌握最新的技术新闻,就会发现大量的事情与安全相关 —— 数据泄露、系统故障和欺诈。安全团队正在不断变化,快节奏的环境中工作。真正的挑战在于在保持甚至改进最终用户体验的同时,积极主动地进行安全性,发现和消除漏洞。
|
||||
|
||||
### 增长即将来临
|
||||
|
||||
在技术的任何方面,安全将继续与云一起成长。企业越来越多地转向云计算,这暴露出比组织里比过去更多的安全漏洞。随着云的成熟,安全变得越来越重要。
|
||||
|
||||
条例也在不断完善 —— 个人身份信息(PII)越来越广泛。许多公司都发现他们必须投资安全来保持合规,避免成为头条新闻。由于面临巨额罚款,声誉受损以及行政工作安全,公司开始越来越多地为安全工具和人员安排越来越多的预算。
|
||||
|
||||
### 培训和支持
|
||||
|
||||
即使你不选择一个专门的安全工作,你也一定会发现自己需要写安全的代码,如果你没有这个技能,你将开始一场艰苦的战斗。如果你的公司提供在工作中学习的话也是可以的,但我建议结合培训、指导和不断的实践。如果你不使用安全技能,你将很快在快速进化的恶意攻击的复杂性中失去它们。
|
||||
|
||||
对于那些寻找安全工作的人来说,我的建议是找到组织中那些在工程、开发或者架构领域最为强大的人员 —— 与他们和其他团队进行交流,做好实际工作,并且确保在心里保持大局。成为你的组织中一个脱颖而出的人,一个可以写安全的代码,同时也可以考虑战略和整体基础设施健康状况的人。
|
||||
|
||||
### 游戏最后
|
||||
|
||||
越来越多的公司正在投资安全性,并试图填补他们的技术团队的开放角色。如果你对管理感兴趣,那么安全是值得关注的地方。执行层领导希望知道他们的公司正在按规则行事,他们的数据是安全的,并且免受破坏和损失。
|
||||
|
||||
明智地实施和有战略思想的安全是受到关注的。安全对高管和消费者之类至关重要 —— 我鼓励任何对安全感兴趣的人进行培训和贡献。
|
||||
|
||||
_现在[下载][2]完整的 2017 年开源工作报告_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/os-jobs-report/2017/11/security-jobs-are-hot-get-trained-and-get-noticed
|
||||
|
||||
作者:[BEN COLLEN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bencollen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:http://bit.ly/2017OSSjobsreport
|
||||
[3]:https://www.linux.com/files/images/security-skillspng
|
||||
[4]:http://www.dice.com/
|
||||
[5]:http://cyberseek.org/index.html#about
|
||||
[6]:https://www.forbes.com/sites/jeffkauflin/2017/03/16/the-fast-growing-job-with-a-huge-skills-gap-cyber-security/#292f0a675163
|
||||
[7]:http://media.dice.com/report/the-2017-open-source-jobs-report-employers-prioritize-hiring-open-source-professionals-with-latest-skills/
|
||||
144
published/20171119 10 Best LaTeX Editors For Linux.md
Normal file
144
published/20171119 10 Best LaTeX Editors For Linux.md
Normal file
@ -0,0 +1,144 @@
|
||||
10 款 Linux 平台上最好的 LaTeX 编辑器
|
||||
======
|
||||
|
||||
**简介:一旦你克服了 LaTeX 的学习曲线,就没有什么比 LaTeX 更棒了。下面介绍的是针对 Linux 和其他平台的最好的 LaTeX 编辑器。**
|
||||
|
||||
### LaTeX 是什么?
|
||||
|
||||
[LaTeX][1] 是一个文档制作系统。与纯文本编辑器不同,在 LaTeX 编辑器中你不能只写纯文本,为了组织文档的内容,你还必须使用一些 LaTeX 命令。
|
||||
|
||||
![LaTeX 示例][3]
|
||||
|
||||
LaTeX 编辑器一般用在出于学术目的的科学研究文档或书籍的出版,最重要的是,当你需要处理包含众多复杂数学符号的文档时,它能够为你带来方便。当然,使用 LaTeX 编辑器是很有趣的,但它也并非总是很有用,除非你对所要编写的文档有一些特别的需求。
|
||||
|
||||
### 为什么你应当使用 LaTeX?
|
||||
|
||||
好吧,正如我前面所提到的那样,使用 LaTeX 编辑器便意味着你有着特定的需求。为了捣腾 LaTeX 编辑器,并不需要你有一颗极客的头脑。但对于那些使用一般文本编辑器的用户来说,它并不是一个很有效率的解决方法。
|
||||
|
||||
假如你正在寻找一款工具来精心制作一篇文档,同时你对花费时间在格式化文本上没有任何兴趣,那么 LaTeX 编辑器或许正是你所寻找的那款工具。在 LaTeX 编辑器中,你只需要指定文档的类型,它便会相应地为你设置好文档的字体种类和大小尺寸。正是基于这个原因,难怪它会被认为是 [给作家的最好开源工具][4] 之一。
|
||||
|
||||
但请务必注意: LaTeX 编辑器并不是自动化的工具,你必须首先学会一些 LaTeX 命令来让它能够精确地处理文本的格式。
|
||||
|
||||
### 针对 Linux 平台的 10 款最好 LaTeX 编辑器
|
||||
|
||||
事先说明一下,以下列表并没有一个明确的先后顺序,序号为 3 的编辑器并不一定比序号为 7 的编辑器优秀。
|
||||
|
||||
#### 1、 LyX
|
||||
|
||||
![][5]
|
||||
|
||||
[LyX][6] 是一个开源的 LaTeX 编辑器,即是说它是网络上可获取到的最好的文档处理引擎之一。LyX 帮助你集中于你的文章,并忘记对单词的格式化,而这些正是每个 LaTeX 编辑器应当做的。LyX 能够让你根据文档的不同,管理不同的文档内容。一旦安装了它,你就可以控制文档中的很多东西了,例如页边距、页眉、页脚、空白、缩进、表格等等。
|
||||
|
||||
假如你正忙着精心撰写科学类文档、研究论文或类似的文档,你将会很高兴能够体验到 LyX 的公式编辑器,这也是其特色之一。 LyX 还包括一系列的教程来入门,使得入门没有那么多的麻烦。
|
||||
|
||||
#### 2、 Texmaker
|
||||
|
||||
![][7]
|
||||
|
||||
[Texmaker][8] 被认为是 GNOME 桌面环境下最好的 LaTeX 编辑器之一。它呈现出一个非常好的用户界面,带来了极好的用户体验。它也被称之为最实用的 LaTeX 编辑器之一。假如你经常进行 PDF 的转换,你将发现 TeXmaker 相比其他编辑器更加快速。在你书写的同时,你也可以预览你的文档最终将是什么样子的。同时,你也可以观察到可以很容易地找到所需要的符号。
|
||||
|
||||
Texmaker 也提供一个扩展的快捷键支持。你有什么理由不试着使用它呢?
|
||||
|
||||
#### 3、 TeXstudio
|
||||
|
||||
![][9]
|
||||
|
||||
假如你想要一个这样的 LaTeX 编辑器:它既能为你提供相当不错的自定义功能,又带有一个易用的界面,那么 [TeXstudio][10] 便是一个完美的选择。它的 UI 确实很简单,但是不粗糙。 TeXstudio 带有语法高亮,自带一个集成的阅读器,可以让你检查参考文献,同时还带有一些其他的辅助工具。
|
||||
|
||||
它同时还支持某些酷炫的功能,例如自动补全,链接覆盖,书签,多游标等等,这使得书写 LaTeX 文档变得比以前更加简单。
|
||||
|
||||
TeXstudio 的维护很活跃,对于新手或者高级写作者来说,这使得它成为一个引人注目的选择。
|
||||
|
||||
#### 4、 Gummi
|
||||
|
||||
![][11]
|
||||
|
||||
[Gummi][12] 是一个非常简单的 LaTeX 编辑器,它基于 GTK+ 工具箱。当然,在这个编辑器中你找不到许多华丽的选项,但如果你只想能够立刻着手写作, 那么 Gummi 便是我们给你的推荐。它支持将文档输出为 PDF 格式,支持语法高亮,并帮助你进行某些基础的错误检查。尽管在 GitHub 上它已经不再被活跃地维护,但它仍然工作地很好。
|
||||
|
||||
#### 5、 TeXpen
|
||||
|
||||
![][13]
|
||||
|
||||
[TeXpen][14] 是另一个简洁的 LaTeX 编辑器。它为你提供了自动补全功能。但其用户界面或许不会让你感到印象深刻。假如你对用户界面不在意,又想要一个超级容易的 LaTeX 编辑器,那么 TeXpen 将满足你的需求。同时 TeXpen 还能为你校正或提高在文档中使用的英语语法和表达式。
|
||||
|
||||
#### 6、 ShareLaTeX
|
||||
|
||||
![][15]
|
||||
|
||||
[ShareLaTeX][16] 是一款在线 LaTeX 编辑器。假如你想与某人或某组朋友一同协作进行文档的书写,那么这便是你所需要的。
|
||||
|
||||
它提供一个免费方案和几种付费方案。甚至来自哈佛大学和牛津大学的学生也都使用它来进行个人的项目。其免费方案还允许你添加一位协作者。
|
||||
|
||||
其付费方案允许你与 GitHub 和 Dropbox 进行同步,并且能够记录完整的文档修改历史。你可以为你的每个方案选择多个协作者。对于学生,它还提供单独的计费方案。
|
||||
|
||||
#### 7、 Overleaf
|
||||
|
||||
![][17]
|
||||
|
||||
[Overleaf][18] 是另一款在线的 LaTeX 编辑器。它与 ShareLaTeX 类似,它为专家和学生提供了不同的计费方案。它也提供了一个免费方案,使用它你可以与 GitHub 同步,检查你的修订历史,或添加多个合作者。
|
||||
|
||||
在每个项目中,它对文件的数目有所限制。所以在大多数情况下如果你对 LaTeX 文件非常熟悉,这并不会为你带来不便。
|
||||
|
||||
#### 8、 Authorea
|
||||
|
||||
![][19]
|
||||
|
||||
[Authorea][20] 是一个美妙的在线 LaTeX 编辑器。当然,如果考虑到价格,它可能不是最好的一款。对于免费方案,它有 100 MB 的数据上传限制和每次只能创建一个私有文档。而付费方案则提供更多的额外好处,但如果考虑到价格,它可能不是最便宜的。你应该选择 Authorea 的唯一原因应该是因为其用户界面。假如你喜爱使用一款提供令人印象深刻的用户界面的工具,那就不要错过它。
|
||||
|
||||
#### 9、 Papeeria
|
||||
|
||||
![][21]
|
||||
|
||||
[Papeeria][22] 是在网络上你能够找到的最为便宜的 LaTeX 在线编辑器,如果考虑到它和其他的编辑器一样可信赖的话。假如你想免费地使用它,则你不能使用它开展私有项目。但是,如果你更偏爱公共项目,它允许你创建不限数目的项目,添加不限数目的协作者。它的特色功能是有一个非常简便的画图构造器,并且在无需额外费用的情况下使用 Git 同步。假如你偏爱付费方案,它赋予你创建 10 个私有项目的能力。
|
||||
|
||||
#### 10、 Kile
|
||||
|
||||
![Kile LaTeX 编辑器][23]
|
||||
|
||||
位于我们最好 LaTeX 编辑器清单的最后一位是 [Kile][24] 编辑器。有些朋友对 Kile 推崇备至,很大程度上是因为其提供某些特色功能。
|
||||
|
||||
Kile 不仅仅是一款编辑器,它还是一款类似 Eclipse 的 IDE 工具,提供了针对文档和项目的一整套环境。除了快速编译和预览功能,你还可以使用诸如命令的自动补全 、插入引用,按照章节来组织文档等功能。你真的应该使用 Kile 来见识其潜力。
|
||||
|
||||
Kile 在 Linux 和 Windows 平台下都可获取到。
|
||||
|
||||
### 总结
|
||||
|
||||
所以上面便是我们推荐的 LaTeX 编辑器,你可以在 Ubuntu 或其他 Linux 发行版本中使用它们。
|
||||
|
||||
当然,我们可能还遗漏了某些可以在 Linux 上使用并且有趣的 LaTeX 编辑器。如若你正好知道它们,请在下面的评论中让我们知晓。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/LaTeX-editors-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://www.LaTeX-project.org/
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/latex-sample-example.jpeg
|
||||
[4]:https://itsfoss.com/open-source-tools-writers/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/lyx_latex_editor.jpg
|
||||
[6]:https://www.LyX.org/
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/texmaker_latex_editor.jpg
|
||||
[8]:http://www.xm1math.net/texmaker/
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/tex_studio_latex_editor.jpg
|
||||
[10]:https://www.texstudio.org/
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/gummi_latex_editor.jpg
|
||||
[12]:https://github.com/alexandervdm/gummi
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/texpen_latex_editor.jpg
|
||||
[14]:https://sourceforge.net/projects/texpen/
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/sharelatex.jpg
|
||||
[16]:https://www.shareLaTeX.com/
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/overleaf.jpg
|
||||
[18]:https://www.overleaf.com/
|
||||
[19]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/authorea.jpg
|
||||
[20]:https://www.authorea.com/
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/papeeria_latex_editor.jpg
|
||||
[22]:https://www.papeeria.com/
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/kile-latex-800x621.png
|
||||
[24]:https://kile.sourceforge.io/
|
||||
87
published/20171120 Adopting Kubernetes step by step.md
Normal file
87
published/20171120 Adopting Kubernetes step by step.md
Normal file
@ -0,0 +1,87 @@
|
||||
一步步采用 Kubernetes
|
||||
============================================================
|
||||
|
||||
### 为什么选择 Docker 和 Kubernetes 呢?
|
||||
|
||||
容器允许我们构建、发布和运行分布式应用。它们使应用程序摆脱了机器限制,可以让我们以一定的方式创建一个复杂的应用程序。
|
||||
|
||||
使用容器编写应用程序可以使开发、QA 更加接近生产环境(如果你努力这样做的话)。通过这样做,可以更快地发布修改,并且可以更快地测试整个系统。
|
||||
|
||||
[Docker][1] 这个容器式平台就是为此为生,可以使软件独立于云提供商。
|
||||
|
||||
但是,即使使用容器,移植应用程序到任何一个云提供商(或私有云)所需的工作量也是不可忽视的。应用程序通常需要自动伸缩组、持久远程磁盘、自动发现等。但是每个云提供商都有不同的机制。如果你想使用这些功能,很快你就会变的依赖于云提供商。
|
||||
|
||||
这正是 [Kubernetes][2] 登场的时候。它是一个容器<ruby>编排<rt>orchestration</rt></ruby>系统,它允许您以一定的标准管理、缩放和部署应用程序的不同部分,并且成为其中的重要工具。它的可移植抽象层兼容主要云的提供商(Google Cloud,Amazon Web Services 和 Microsoft Azure 都支持 Kubernetes)。
|
||||
|
||||
可以这样想象一下应用程序、容器和 Kubernetes。应用程序可以视为一条身边的鲨鱼,它存在于海洋中(在这个例子中,海洋就是您的机器)。海洋中可能还有其他一些宝贵的东西,但是你不希望你的鲨鱼与小丑鱼有什么关系。所以需要把你的鲨鱼(你的应用程序)移动到一个密封的水族馆中(容器)。这很不错,但不是特别的健壮。你的水族馆可能会被打破,或者你想建立一个通道连接到其他鱼类生活的另一个水族馆。也许你想要许多这样的水族馆,以防需要清洁或维护……这正是应用 Kubernetes 集群的作用。
|
||||
|
||||

|
||||
|
||||
*进化到 Kubernetes*
|
||||
|
||||
主流云提供商对 Kubernetes 提供了支持,从开发环境到生产环境,它使您和您的团队能够更容易地拥有几乎相同的环境。这是因为 Kubernetes 不依赖专有软件、服务或基础设施。
|
||||
|
||||
事实上,您可以在您的机器中使用与生产环境相同的部件启动应用程序,从而缩小了开发和生产环境之间的差距。这使得开发人员更了解应用程序是如何构建在一起的,尽管他们可能只负责应用程序的一部分。这也使得在开发流程中的应用程序更容易的快速完成测试。
|
||||
|
||||
### 如何使用 Kubernetes 工作?
|
||||
|
||||
随着更多的人采用 Kubernetes,新的问题出现了;应该如何针对基于集群环境进行开发?假设有 3 个环境,开发、质量保证和生产, 他们如何适应 Kubernetes?这些环境之间仍然存在着差异,无论是在开发周期(例如:在运行中的应用程序中我的代码的变化上花费时间)还是与数据相关的(例如:我不应该在我的质量保证环境中测试生产数据,因为它里面有敏感信息)。
|
||||
|
||||
那么,我是否应该总是在 Kubernetes 集群中编码、构建映像、重新部署服务,在我编写代码时重新创建部署和服务?或者,我是否不应该尽力让我的开发环境也成为一个 Kubernetes 集群(或一组集群)呢?还是,我应该以混合方式工作?
|
||||
|
||||
|
||||
|
||||
*用本地集群进行开发*
|
||||
|
||||
如果继续我们之前的比喻,上图两边的洞表示当使其保持在一个开发集群中的同时修改应用程序的一种方式。这通常通过[卷][4]来实现
|
||||
|
||||
### Kubernetes 系列
|
||||
|
||||
本 Kubernetes 系列资源是开源的,可以在这里找到: [https://github.com/red-gate/ks][5] 。
|
||||
|
||||
我们写这个系列作为以不同的方式构建软件的练习。我们试图约束自己在所有环境中都使用 Kubernetes,以便我们可以探索这些技术对数据和数据库的开发和管理造成影响。
|
||||
|
||||
这个系列从使用 Kubernetes 创建基本的 React 应用程序开始,并逐渐演变为能够覆盖我们更多开发需求的系列。最后,我们将覆盖所有应用程序的开发需求,并且理解在数据库生命周期中如何最好地迎合容器和集群。
|
||||
|
||||
以下是这个系列的前 5 部分:
|
||||
|
||||
1. ks1:使用 Kubernetes 构建一个 React 应用程序
|
||||
2. ks2:使用 minikube 检测 React 代码的更改
|
||||
3. ks3:添加一个提供 API 的 Python Web 服务器
|
||||
4. ks4:使 minikube 检测 Python 代码的更改
|
||||
5. ks5:创建一个测试环境
|
||||
|
||||
本系列的第二部分将添加一个数据库,并尝试找出最好的方式来开发我们的应用程序。
|
||||
|
||||
通过在各种环境中运行 Kubernetes,我们被迫在解决新问题的同时也尽量保持开发周期。我们不断尝试 Kubernetes,并越来越习惯它。通过这样做,开发团队都可以对生产环境负责,这并不困难,因为所有环境(从开发到生产)都以相同的方式进行管理。
|
||||
|
||||
### 下一步是什么?
|
||||
|
||||
我们将通过整合数据库和练习来继续这个系列,以找到使用 Kubernetes 获得数据库生命周期的最佳体验方法。
|
||||
|
||||
这个 Kubernetes 系列是由 Redgate 研发部门 Foundry 提供。我们正在努力使数据和容器的管理变得更加容易,所以如果您正在处理数据和容器,我们希望听到您的意见,请直接联系我们的开发团队。 [_foundry@red-gate.com_][6]
|
||||
|
||||
* * *
|
||||
|
||||
我们正在招聘。您是否有兴趣开发产品、创建[未来技术][7] 并采取类似创业的方法(没有风险)?看看我们的[软件工程师 - 未来技术][8]的角色吧,并阅读更多关于在 [英国剑桥][9]的 Redgate 工作的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ingeniouslysimple/adopting-kubernetes-step-by-step-f93093c13dfe
|
||||
|
||||
作者:[santiago arias][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@santiaago?source=post_header_lockup
|
||||
[1]:https://www.docker.com/what-docker
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.google.co.uk/search?biw=723&bih=753&tbm=isch&sa=1&ei=p-YCWpbtN8atkwWc8ZyQAQ&q=nemo+fish&oq=nemo+fish&gs_l=psy-ab.3..0i67k1l2j0l2j0i67k1j0l5.5128.9271.0.9566.9.9.0.0.0.0.81.532.9.9.0....0...1.1.64.psy-ab..0.9.526...0i7i30k1j0i7i10i30k1j0i13k1j0i10k1.0.FbAf9xXxTEM
|
||||
[4]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[5]:https://github.com/red-gate/ks
|
||||
[6]:mailto:foundry@red-gate.com
|
||||
[7]:https://www.red-gate.com/foundry/
|
||||
[8]:https://www.red-gate.com/our-company/careers/current-opportunities/software-engineer-future-technologies
|
||||
[9]:https://www.red-gate.com/our-company/careers/living-in-cambridge
|
||||
@ -0,0 +1,82 @@
|
||||
直接保存文件至 Google Drive 并用十倍的速度下载回来
|
||||
=============
|
||||
|
||||
![][image-1]
|
||||
|
||||
最近我不得不给我的手机下载更新包,但是当我开始下载的时候,我发现安装包过于庞大。大约有 1.5 GB。
|
||||
|
||||
![使用 Chrome 下载 MIUI 更新][image-2]
|
||||
|
||||
考虑到这个下载速度至少需要花费 1 至 1.5 小时来下载,并且说实话我并没有这么多时间。现在我下载速度可能会很慢,但是我的 ISP 有 Google Peering (Google 对等操作)。这意味着我可以在所有的 Google 产品中获得一个惊人的速度,例如Google Drive, YouTube 和 PlayStore。
|
||||
|
||||
所以我找到一个网络服务叫做 [savetodrive][2]。这个网站可以从网页上直接保存文件到你的 Google Drive 文件夹之中。之后你就可以从你的 Google Drive 上面下载它,这样的下载速度会快很多。
|
||||
|
||||
现在让我们来看看如何操作。
|
||||
|
||||
### 第一步
|
||||
|
||||
获得文件的下载链接,将它复制到你的剪贴板。
|
||||
|
||||
### 第二步
|
||||
|
||||
前往链接 [savetodrive][2] 并且点击相应位置以验证身份。
|
||||
|
||||
![savetodrive 将文件保存到 Google Drive ][image-3]
|
||||
|
||||
这将会请求获得使用你 Google Drive 的权限,点击 “Allow”。
|
||||
|
||||
![请求获得 Google Drive 的使用权限][image-4]
|
||||
|
||||
### 第三步
|
||||
|
||||
你将会再一次看到下面的页面,此时仅仅需要输入下载链接在链接框中,并且点击 “Upload”。
|
||||
|
||||
![savetodrive 直接给 Google Drive 上传文件][image-5]
|
||||
|
||||
你将会开始看到上传进度条,可以看到上传速度达到了 48 Mbps,所以上传我这个 1.5 GB 的文件需要 30 至 35 秒。一旦这里完成了,进入你的 Google Drive 你就可以看到刚才上传的文件。
|
||||
|
||||
![Google Drive savetodrive][image-6]
|
||||
|
||||
这里的文件中,文件名开头是 *miui* 的就是我刚才上传的,现在我可以用一个很快的速度下载下来。
|
||||
|
||||
![如何从浏览器上下载 MIUI 更新][image-7]
|
||||
|
||||
可以看到我的下载速度大概是 5 Mbps ,所以我下载这个文件只需要 5 到 6 分钟。
|
||||
|
||||
所以就是这样的,我经常用这样的方法下载文件,最令人惊讶的是,这个服务是完全免费的。
|
||||
|
||||
----
|
||||
|
||||
|
||||
|
||||
via: http://www.theitstuff.com/save-files-directly-google-drive-download-10-times-faster
|
||||
|
||||
作者:[Rishabh Kandari](http://www.theitstuff.com/author/reevkandari)
|
||||
译者:[Drshu][10]
|
||||
校对:[wxy][11]
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
[1]: http://www.theitstuff.com/wp-content/uploads/2017/11/Save-Files-Directly-To-Google-Drive-And-Download-10-Times-Faster.jpg
|
||||
[2]: https://savetodrive.net/
|
||||
[3]: http://www.savetodrive.net
|
||||
[4]: http://www.theitstuff.com/wp-content/uploads/2017/10/3-1.png
|
||||
[5]: http://www.theitstuff.com/wp-content/uploads/2017/10/authenticate-google-account.jpg
|
||||
[6]: http://www.theitstuff.com/wp-content/uploads/2017/10/6-2.png
|
||||
[7]: http://www.theitstuff.com/wp-content/uploads/2017/10/7-2-e1508772046583.png
|
||||
[8]: http://www.theitstuff.com/wp-content/uploads/2017/10/8-e1508772110385.png
|
||||
[9]: http://www.theitstuff.com/author/reevkandari
|
||||
[10]: https://github.com/Drshu
|
||||
[11]: https://github.com/wxy
|
||||
[12]: https://github.com/LCTT/TranslateProject
|
||||
[13]: https://linux.cn/
|
||||
|
||||
[image-1]: http://www.theitstuff.com/wp-content/uploads/2017/11/Save-Files-Directly-To-Google-Drive-And-Download-10-Times-Faster.jpg
|
||||
[image-2]: http://www.theitstuff.com/wp-content/uploads/2017/10/1-2-e1508771706462.png
|
||||
[image-3]: http://www.theitstuff.com/wp-content/uploads/2017/10/3-1.png
|
||||
[image-4]: http://www.theitstuff.com/wp-content/uploads/2017/10/authenticate-google-account.jpg
|
||||
[image-5]: http://www.theitstuff.com/wp-content/uploads/2017/10/6-2.png
|
||||
[image-6]: http://www.theitstuff.com/wp-content/uploads/2017/10/7-2-e1508772046583.png
|
||||
[image-7]: http://www.theitstuff.com/wp-content/uploads/2017/10/8-e1508772110385.png
|
||||
@ -0,0 +1,113 @@
|
||||
迁移到 Linux:磁盘、文件、和文件系统
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 在你的主要桌面计算机上安装和使用 Linux 将帮你快速熟悉你需要的工具和方法。
|
||||
|
||||
这是我们的迁移到 Linux 系列文章的第二篇。如果你错过了第一篇,[你可以在这里找到它][4]。就如之前提到过的,为什么要迁移到 Linux 的有几个原因。你可以在你的工作中为 Linux 开发和使用代码,或者,你可能只是想去尝试一下新事物。
|
||||
|
||||
不论是什么原因,在你主要使用的桌面计算机上拥有一个 Linux,将帮助你快速熟悉你需要的工具和方法。在这篇文章中,我将介绍 Linux 的文件、文件系统和磁盘。
|
||||
|
||||
### 我的 C:\ 在哪里?
|
||||
|
||||
如果你是一个 Mac 用户,Linux 对你来说应该非常熟悉,Mac 使用的文件、文件系统、和磁盘与 Linux 是非常接近的。另一方面,如果你的使用经验主要是 Windows,访问 Linux 下的磁盘可能看上去有点困惑。一般,Windows 给每个磁盘分配一个盘符(像 C:\)。而 Linux 并不是这样。而在你的 Linux 系统中它是一个单一的文件和目录的层次结构。
|
||||
|
||||
让我们看一个示例。假设你的计算机使用了一个主硬盘、一个有 `Books` 和 `Videos` 目录的 CD-ROM 、和一个有 `Transfer` 目录的 U 盘,在你的 WIndows 下,你应该看到的是下面的样子:
|
||||
|
||||
```
|
||||
C:\ [硬盘]
|
||||
├ System
|
||||
├ System32
|
||||
├ Program Files
|
||||
├ Program Files (x86)
|
||||
└ <更多目录>
|
||||
|
||||
D:\ [CD-ROM]
|
||||
├ Books
|
||||
└ Videos
|
||||
|
||||
E:\ [U 盘]
|
||||
└ Transfer
|
||||
```
|
||||
|
||||
而一个典型的 Linux 系统却是这样:
|
||||
|
||||
```
|
||||
/ (最顶级的目录,称为根目录) [硬盘]
|
||||
├ bin
|
||||
├ etc
|
||||
├ lib
|
||||
├ sbin
|
||||
├ usr
|
||||
├ <更多目录>
|
||||
└ media
|
||||
└ <你的用户名>
|
||||
├ cdrom [CD-ROM]
|
||||
│ ├ Books
|
||||
│ └ Videos
|
||||
└ Kingme_USB [U 盘]
|
||||
└ Transfer
|
||||
```
|
||||
|
||||
如果你使用一个图形化环境,通常,Linux 中的文件管理器将出现看起来像驱动器的图标的 CD-ROM 和 USB 便携式驱动器,因此,你根本就无需知道介质所在的目录。
|
||||
|
||||
### 文件系统
|
||||
|
||||
Linux 称这些东西为文件系统。文件系统是在介质(比如,硬盘)上保持跟踪所有的文件和目录的一组结构。如果没有用于存储数据的文件系统,我们所有的信息就会混乱,我们就不知道哪个块属于哪个文件。你可能听到过一些类似 ext4、XFS 和 Btrfs 之类的名字,这些都是 Linux 文件系统。
|
||||
|
||||
每种保存有文件和目录的介质都有一个文件系统在上面。不同的介质类型可能使用了为它优化过的特定的文件系统。比如,CD-ROM 使用 ISO9660 或者 UDF 文件系统类型。USB 便携式驱动器一般使用 FAT32,以便于它们可以很容易去与其它计算机系统共享。
|
||||
|
||||
Windows 也使用文件系统。不过,我们不会过多的讨论它。例如,当你插入一个 CD-ROM,Windows 将读取 ISO9660 文件系统结构,分配一个盘符给它,然后,在盘符(比如,D:\)下显示文件和目录。当然,如果你深究细节,从技术角度说,Windows 是分配一个盘符给一个文件系统,而不是整个驱动器。
|
||||
|
||||
使用同样的例子,Linux 也读取 ISO9660 文件系统结构,但它不分配盘符,它附加文件系统到一个目录(这个过程被称为<ruby>挂载<rt>mount</rt></ruby>)。Linux 将随后在所挂载的目录(比如是, `/media/<your user name>/cdrom` )下显示 CD-ROM 上的文件和目录。
|
||||
|
||||
因此,在 Linux 上回答 “我的 C:\ 在哪里?” 这个问题,答案是,这里没有 C:\,它们工作方式不一样。
|
||||
|
||||
### 文件
|
||||
|
||||
Windows 将文件和目录(也被称为文件夹)存储在它的文件系统中。但是,Linux 也让你将其它的东西放到文件系统中。这些其它类型的东西是文件系统的原生的对象,并且,它们和普通文件实际上是不同的。除普通文件和目录之外,Linux 还允许你去创建和使用<ruby>硬链接<rt>hard link</rt></ruby>、<ruby>符号链接<rt>symbolic link</rt></ruby>、<ruby>命名管道<rt>named pipe</rt></ruby>、<ruby>设备节点<rt>device node</rt></ruby>、和<ruby>套接字<rt>socket</rt></ruby>。在这里,我们不展开讨论所有的文件系统对象的类型,但是,这里有几种经常使用到的需要知道。
|
||||
|
||||
硬链接用于为文件创建一个或者多个别名。指向磁盘上同样内容的每个别名的名字是不同的。如果在一个文件名下编辑文件,这个改变也同时出现在其它的文件名上。例如,你有一个 `MyResume_2017.doc`,它还有一个被称为 `JaneDoeResume.doc` 的硬链接。(注意,硬链接是从命令行下,使用 `ln` 的命令去创建的)。你可以找到并编辑 `MyResume_2017.doc`,然后,然后找到 `JaneDoeResume.doc`,你发现它保持了跟踪 —— 它包含了你所有的更新。
|
||||
|
||||
符号链接有点像 Windows 中的快捷方式。文件系统的入口包含一个到其它文件或者目录的路径。在很多方面,它们的工作方式和硬链接很相似,它们可以创建一个到其它文件的别名。但是,符号链接也可以像文件一样给目录创建一个别名,并且,符号链接可以指向到不同介质上的不同文件系统,而硬链接做不到这些。(注意,你可以使用带 `-s` 选项的 `ln` 命令去创建一个符号链接)
|
||||
|
||||
### 权限
|
||||
|
||||
Windows 和 Linux 另一个很大的区别是涉及到文件系统对象(文件、目录、及其它)的权限。Windows 在文件和目录上实现了一套非常复杂的权限。例如,用户和用户组可以有权限去读取、写入、运行、修改等等。用户和用户组可以授权访问除例外以外的目录中的所有内容,也可以不允许访问除例外的目录中的所有内容。
|
||||
|
||||
然而,大多数使用 Windows 的人并不会去使用特定的权限;因此,当他们发现在 Linux 上是强制使用一套默认权限时,他们感到非常惊讶!Linux 通过使用 SELinux 或者 AppArmor 可以强制执行一套更复杂的权限。但是,大多数 Linux 安装版都只是使用了内置的默认权限。
|
||||
|
||||
在默认的权限中,文件系统中的每个条目都有一套为它的文件所有者、文件所在的组、和其它人的设置的权限。这些权限允许他们:读取、写入和运行。给它们的权限是有层次继承的。首先,它检查这个(登入的)用户是否为该文件所有者和拥有的权限。如果不是,然后检查这个用户是否在文件所在的组中和该组拥有的权限。如果不是,然后它再检查其它人拥有的权限。这里设置了其它人的权限。但是,这里设置的三套权限大多数情况下都会使用其中的一套。
|
||||
|
||||
如果你使用命令行,你输入 `ls -l`,你可以看到如下所表示的权限:
|
||||
|
||||
```
|
||||
rwxrw-r-- 1 stan dndgrp 25 Oct 33rd 25:01 rolldice.sh
|
||||
```
|
||||
|
||||
最前面的字母,`rwxrw-r--`,展示了权限。在这个例子中,所有者(stan)可以读取、写入和运行这个文件(前面的三个字母,`rwx`);dndgrp 组的成员可以读取和写入这个文件,但是不能运行(第二组的三个字母,`rw-`);其它人仅可以读取这个文件(最后的三个字母,`r--`)。
|
||||
|
||||
(注意,在 Windows 中去生成一个可运行的脚本,你生成的文件要有一个特定的扩展名,比如 `.bat`,而在 Linux 中,扩展名在操作系统中没有任何意义。而是需要去设置这个文件可运行的权限)
|
||||
|
||||
如果你收到一个 “permission denied” 错误,可能是你去尝试运行了一个要求管理员权限的程序或者命令,或者你去尝试访问一个你的帐户没有访问权限的文件。如果你尝试去做一些要求管理员权限的事,你必须切换登入到一个被称为 `root` 的用户帐户。或者通过在命令行使用一个被称为 `sudo` 的辅助程序。它可以临时允许你以 `root` 权限运行。当然,`sudo` 工具,也会要求你输入密码,以确保你真的有权限。
|
||||
|
||||
### 硬盘文件系统
|
||||
|
||||
Windows 主要使用一个被称为 NTFS 的硬盘文件系统。在 Linux 上,你也可以选一个你希望去使用的硬盘文件系统。不同的文件系统类型呈现不同的特性和不同的性能特征。现在主流的原生 Linux 的文件系统是 Ext4。但是,在安装 Linux 的时候,你也有丰富的文件系统类型可供选择,比如,Ext3(Ext4 的前任)、XFS、Btrfs、UBIFS(用于嵌入式系统)等等。如果你不确定要使用哪一个,Ext4 是一个很好的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
|
||||
作者:[JOHN BONESIO][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[3]:https://www.linux.com/files/images/butterflies-8075511920jpg
|
||||
[4]:https://linux.cn/article-9212-1.html
|
||||
132
published/20171128 A generic introduction to Gitlab CI.md
Normal file
132
published/20171128 A generic introduction to Gitlab CI.md
Normal file
@ -0,0 +1,132 @@
|
||||
Gitlab CI 常规介绍
|
||||
======
|
||||
|
||||
在 [fleetster][1], 我们搭建了自己的 [Gitlab][2] 实例,而且我们大量使用了 [Gitlab CI][3]。我们的设计师和测试人员也都在用它,也很喜欢用它,它的那些高级功能特别棒。
|
||||
|
||||
Gitlab CI 是一个功能非常强大的持续集成系统,有很多不同的功能,而且每次发布都会增加新的功能。它的技术文档也很丰富,但是对那些要在已经配置好的 Gitlab 上使用它的用户来说,它缺乏一个一般性介绍。设计师或者测试人员是无需知道如何通过 Kubernetes 来实现自动伸缩,也无需知道“镜像”和“服务”之间的不同的。
|
||||
|
||||
但是,他仍然需要知道什么是“管道”,知道如何查看部署到一个“环境”中的分支。因此,在本文中,我会尽可能覆盖更多的功能,重点放在最终用户应该如何使用它们上;在过去的几个月里,我向我们团队中的某些人包括开发者讲解了这些功能:不是所有人都知道<ruby>持续集成<rt>Continuous Integration</rt></ruby>(CI)是个什么东西,也不是所有人都用过 Gitlab CI。
|
||||
|
||||
如果你想了解为什么持续集成那么重要,我建议阅读一下 [这篇文章][4],至于为什么要选择 Gitlab CI 呢,你可以去看看 [Gitlab.com][3] 上的说明。
|
||||
|
||||
### 简介
|
||||
|
||||
开发者保存更改代码的动作叫做一次<ruby>提交<rt>commit</rt></ruby>。然后他可以将这次提交<ruby>推送<rt>push</rt></ruby>到 Gitlab 上,这样可以其他开发者就可以<ruby>复查<rt>review</rt></ruby>这些代码了。
|
||||
|
||||
Gitlab CI 配置好后,Gitlab 也能对这个提交做出一些处理。该处理的工作由一个<ruby>运行器<rt>runner</rt></ruby>来执行的。所谓运行器基本上就是一台服务器(也可以是其他的东西,比如你的 PC 机,但我们可以简单称其为服务器)。这台服务器执行 `.gitlab-ci.yml` 文件中指令,并将执行结果返回给 Gitlab 本身,然后在 Gitlab 的图形化界面上显示出来。
|
||||
|
||||
开发者完成一项新功能的开发或完成一个 bug 的修复后(这些动作通常包含了多次的提交),就可以发起一个<ruby>合并请求<rt>merge request</rt></ruby>,团队其他成员则可以在这个合并请求中对代码及其实现进行<ruby>评论<rt>comment</rt></ruby>。
|
||||
|
||||
我们随后会看到,由于 Gitlab CI 提供的两大特性,<ruby>环境<rt>environment</rt></ruby> 与 <ruby>制品<rt>artifact</rt></ruby>,使得设计者和测试人员也能(而且真的需要)参与到这个过程中来,提供反馈以及改进意见。
|
||||
|
||||
### <ruby>管道<rt>pipeline</rt></ruby>
|
||||
|
||||
每个推送到 Gitlab 的提交都会产生一个与该提交关联的<ruby>管道<rt>pipeline</rt></ruby>。若一次推送包含了多个提交,则管道与最后那个提交相关联。管道就是一个分成不同<ruby>阶段<rt>stage</rt></ruby>的<ruby>作业<rt>job</rt></ruby>的集合。
|
||||
|
||||
同一阶段的所有作业会并发执行(在有足够运行器的前提下),而下一阶段则只会在上一阶段所有作业都运行并返回成功后才会开始。
|
||||
|
||||
只要有一个作业失败了,整个管道就失败了。不过我们后面会看到,这其中有一个例外:若某个作业被标注成了手工运行,那么即使失败了也不会让整个管道失败。
|
||||
|
||||
阶段则只是对批量的作业的一个逻辑上的划分,若前一个阶段执行失败了,则后一个执行也没什么意义了。比如我们可能有一个<ruby>构建<rt>build</rt></ruby>阶段和一个<ruby>部署<rt>deploy</rt></ruby>阶段,在构建阶段运行所有用于构建应用的作业,而在部署阶段,会部署构建出来的应用程序。而部署一个构建失败的东西是没有什么意义的,不是吗?
|
||||
|
||||
同一阶段的作业之间不能有依赖关系,但它们可以依赖于前一阶段的作业运行结果。
|
||||
|
||||
让我们来看一下 Gitlab 是如何展示阶段与阶段状态的相关信息的。
|
||||
|
||||
![pipeline-overview][5]
|
||||
|
||||
![pipeline-status][6]
|
||||
|
||||
### <ruby>作业<rt>job</rt></ruby>
|
||||
|
||||
作业就是运行器要执行的指令集合。你可以实时地看到作业的输出结果,这样开发者就能知道作业为什么失败了。
|
||||
|
||||
作业可以是自动执行的,也就是当推送提交后自动开始执行,也可以手工执行。手工作业必须由某个人手工触发。手工作业也有其独特的作用,比如,实现自动化部署,但只有在有人手工授权的情况下才能开始部署。这是限制哪些人可以运行作业的一种方式,这样只有信赖的人才能进行部署,以继续前面的实例。
|
||||
|
||||
作业也可以建构出<ruby>制品<rt>artifacts</rt></ruby>来以供用户下载,比如可以构建出一个 APK 让你来下载,然后在你的设备中进行测试; 通过这种方式,设计者和测试人员都可以下载应用并进行测试,而无需开发人员的帮助。
|
||||
|
||||
除了生成制品外,作业也可以部署`环境`,通常这个环境可以通过 URL 访问,让用户来测试对应的提交。
|
||||
|
||||
做作业状态与阶段状态是一样的:实际上,阶段的状态就是继承自作业的。
|
||||
|
||||
![running-job][7]
|
||||
|
||||
### <ruby>制品<rt>Artifacts</rt></ruby>
|
||||
|
||||
如前所述,作业能够生成制品供用户下载来测试。这个制品可以是任何东西,比如 Windows 上的应用程序,PC 生成的图片,甚至 Android 上的 APK。
|
||||
|
||||
那么,假设你是个设计师,被分配了一个合并请求:你需要验证新设计的实现!
|
||||
|
||||
要该怎么做呢?
|
||||
|
||||
你需要打开该合并请求,下载这个制品,如下图所示。
|
||||
|
||||
每个管道从所有作业中搜集所有的制品,而且一个作业中可以有多个制品。当你点击下载按钮时,会有一个下拉框让你选择下载哪个制品。检查之后你就可以评论这个合并请求了。
|
||||
|
||||
你也可以从没有合并请求的管道中下载制品 ;-)
|
||||
|
||||
我之所以关注合并请求是因为通常这正是测试人员、设计师和相关人员开始工作的地方。
|
||||
|
||||
但是这并不意味着合并请求和管道就是绑死在一起的:虽然它们结合的很好,但两者之间并没有什么关系。
|
||||
|
||||
![download-artifacts][8]
|
||||
|
||||
### <ruby>环境<rt>environment</rt></ruby>
|
||||
|
||||
类似的,作业可以将某些东西部署到外部服务器上去,以便你可以通过合并请求本身访问这些内容。
|
||||
|
||||
如你所见,<ruby>环境<rt>environment</rt></ruby>有一个名字和一个链接。只需点击链接你就能够转至你的应用的部署版本上去了(当前,前提是配置是正确的)。
|
||||
|
||||
Gitlab 还有其他一些很酷的环境相关的特性,比如 <ruby>[监控][9]<rt>monitoring</rt></ruby>,你可以通过点击环境的名字来查看。
|
||||
|
||||
![environment][10]
|
||||
|
||||
### 总结
|
||||
|
||||
这是对 Gitlab CI 中某些功能的一个简单介绍:它非常强大,使用得当的话,可以让整个团队使用一个工具完成从计划到部署的工具。由于每个月都会推出很多新功能,因此请时刻关注 [Gitlab 博客][11]。
|
||||
|
||||
若想知道如何对它进行设置或想了解它的高级功能,请参阅它的[文档][12]。
|
||||
|
||||
在 fleetster,我们不仅用它来跑测试,而且用它来自动生成各种版本的软件,并自动发布到测试环境中去。我们也自动化了其他工作(构建应用并将之发布到 Play Store 中等其它工作)。
|
||||
|
||||
说起来,**你是否想和我以及其他很多超棒的人一起在一个年轻而又富有活力的办公室中工作呢?** 看看 fleetster 的这些[招聘职位][13] 吧!
|
||||
|
||||
赞美 Gitlab 团队 (和其他在空闲时间提供帮助的人),他们的工作太棒了!
|
||||
|
||||
若对本文有任何问题或回馈,请给我发邮件:[riccardo@rpadovani.com][14] 或者[发推给我][15]:-) 你可以建议我增加内容,或者以更清晰的方式重写内容(英文不是我的母语)。
|
||||
|
||||
|
||||
那么,再见吧,
|
||||
|
||||
R.
|
||||
|
||||
P.S:如果你觉得本文有用,而且希望我们写出其他文章的话,请问您是否愿意帮我[买杯啤酒给我][17] 让我进入 [鲍尔默峰值][16]?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://rpadovani.com/introduction-gitlab-ci
|
||||
|
||||
作者:[Riccardo][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://rpadovani.com
|
||||
[1]:https://www.fleetster.net
|
||||
[2]:https://gitlab.com/
|
||||
[3]:https://about.gitlab.com/gitlab-ci/
|
||||
[4]:https://about.gitlab.com/2015/02/03/7-reasons-why-you-should-be-using-ci/
|
||||
[5]:https://img.rpadovani.com/posts/pipeline-overview.png
|
||||
[6]:https://img.rpadovani.com/posts/pipeline-status.png
|
||||
[7]:https://img.rpadovani.com/posts/running-job.png
|
||||
[8]:https://img.rpadovani.com/posts/download-artifacts.png
|
||||
[9]:https://gitlab.com/help/ci/environments.md
|
||||
[10]:https://img.rpadovani.com/posts/environment.png
|
||||
[11]:https://about.gitlab.com/
|
||||
[12]:https://docs.gitlab.com/ee/ci/README.html
|
||||
[13]:https://www.fleetster.net/fleetster-team.html
|
||||
[14]:mailto:riccardo@rpadovani.com
|
||||
[15]:https://twitter.com/rpadovani93
|
||||
[16]:https://www.xkcd.com/323/
|
||||
[17]:https://rpadovani.com/donations
|
||||
@ -0,0 +1,76 @@
|
||||
修复 Linux / Unix / OS X / BSD 系统控制台上的显示乱码
|
||||
======
|
||||
|
||||
有时我的探索会在屏幕上输出一些奇怪的东西。比如,有一次我不小心用 `cat` 命令查看了一下二进制文件的内容 —— `cat /sbin/*`。这种情况下你将无法再访问终端里的 bash/ksh/zsh 了。大量的奇怪字符充斥了你的终端。这些字符会隐藏你输入的内容和要显示的字符,取而代之的是一些奇怪的符号。要清理掉这些屏幕上的垃圾可以使用以下方法。本文就将向你描述在 Linux/ 类 Unix 系统中如何真正清理终端屏幕或者重置终端。
|
||||
|
||||
### clear 命令
|
||||
|
||||
`clear` 命令会清理掉屏幕内容,连带它的回滚缓存区一起也会被清理掉。(LCTT 译注:这种情况下你输入的字符回显也是乱码,不必担心,正确输入后回车即可生效。)
|
||||
|
||||
```
|
||||
$ clear
|
||||
```
|
||||
|
||||
你也可以按下 `CTRL+L` 来清理屏幕。然而,`clear` 命令并不会清理掉终端屏幕(LCTT 译注:这句话比较难理解,应该是指的运行 `clear` 命令并不是真正的把以前显示的内容删掉,你还是可以通过向上翻页看到之前显示的内容)。使用下面的方法才可以真正地清空终端,使你的终端恢复正常。
|
||||
|
||||
### 使用 reset 命令修复显示
|
||||
|
||||
下面图片中,控制台的屏幕上充满了垃圾信息:
|
||||
|
||||
[![Fig.01:Bash fix the display][1]][2]
|
||||
|
||||
要修复正常显示,只需要输入 `reset` 命令。它会为你再初始化一次终端:
|
||||
|
||||
```
|
||||
$ reset
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
$ tput reset
|
||||
```
|
||||
|
||||
如果 `reset` 命令还不行,那么输入下面命令来让绘画回复到正常状态:
|
||||
|
||||
```
|
||||
$ stty sane
|
||||
```
|
||||
|
||||
按下 `CTRL + L` 来清理屏幕(或者输入 `clear` 命令):
|
||||
|
||||
```
|
||||
$ clear
|
||||
```
|
||||
|
||||
### 使用 ANSI 转义序列来真正地清空 bash 终端
|
||||
|
||||
另一种选择是输入下面的 ANSI 转义序列:
|
||||
|
||||
```
|
||||
clear
|
||||
echo -e "\033c"
|
||||
```
|
||||
|
||||
下面是这两个命令的输出示例:
|
||||
|
||||
[![Animated gif 01:Fix Unix Console Gibberish Command Demo][3]][4]
|
||||
|
||||
更多信息请阅读 `stty` 和 `reset` 的 man 页: stty(1),reset(1),bash(1)。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/bash-fix-the-display.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2006/08/bash-fix-terminal.png
|
||||
[2]:https://www.cyberciti.biz/media/uploads/tips/2006/08/bash-fix-terminal.png
|
||||
[3]:https://www.cyberciti.biz/media/new/tips/2006/08/unix-linux-console-gibberish.gif
|
||||
[4]:https://www.cyberciti.biz/tips/bash-fix-the-display.html/unix-linux-console-gibberish
|
||||
@ -0,0 +1,206 @@
|
||||
动态连接的诀窍:使用 LD_PRELOAD 去欺骗、注入特性和研究程序
|
||||
=============
|
||||
|
||||
**本文假设你具备基本的 C 技能**
|
||||
|
||||
Linux 完全在你的控制之中。虽然从每个人的角度来看似乎并不总是这样,但是高级用户喜欢去控制它。我将向你展示一个基本的诀窍,在很大程度上你可以去影响大多数程序的行为,它并不仅是好玩,在有时候也很有用。
|
||||
|
||||
### 一个让我们产生兴趣的示例
|
||||
|
||||
让我们以一个简单的示例开始。先乐趣,后科学。
|
||||
|
||||
|
||||
*random_num.c:*
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <time.h>
|
||||
|
||||
int main(){
|
||||
srand(time(NULL));
|
||||
int i = 10;
|
||||
while(i--) printf("%d\n",rand()%100);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
我相信,它足够简单吧。我不使用任何参数来编译它,如下所示:
|
||||
|
||||
```
|
||||
gcc random_num.c -o random_num
|
||||
```
|
||||
|
||||
我希望它输出的结果是明确的:从 0-99 中选择的十个随机数字,希望每次你运行这个程序时它的输出都不相同。
|
||||
|
||||
现在,让我们假装真的不知道这个可执行程序的出处。甚至将它的源文件删除,或者把它移动到别的地方 —— 我们已不再需要它了。我们将对这个程序的行为进行重大的修改,而你并不需要接触到它的源代码,也不需要重新编译它。
|
||||
|
||||
因此,让我们来创建另外一个简单的 C 文件:
|
||||
|
||||
*unrandom.c:*
|
||||
|
||||
```
|
||||
int rand(){
|
||||
return 42; //the most random number in the universe
|
||||
}
|
||||
```
|
||||
|
||||
我们将编译它进入一个共享库中。
|
||||
|
||||
```
|
||||
gcc -shared -fPIC unrandom.c -o unrandom.so
|
||||
```
|
||||
|
||||
因此,现在我们已经有了一个可以输出一些随机数的应用程序,和一个定制的库,它使用一个常数值 `42` 实现了一个 `rand()` 函数。现在 …… 就像运行 `random_num` 一样,然后再观察结果:
|
||||
|
||||
```
|
||||
LD_PRELOAD=$PWD/unrandom.so ./random_nums
|
||||
```
|
||||
|
||||
如果你想偷懒或者不想自动亲自动手(或者不知什么原因猜不出发生了什么),我来告诉你 —— 它输出了十次常数 42。
|
||||
|
||||
如果先这样执行
|
||||
|
||||
```
|
||||
export LD_PRELOAD=$PWD/unrandom.so
|
||||
```
|
||||
|
||||
然后再以正常方式运行这个程序,这个结果也许会更让你吃惊:一个未被改变过的应用程序在一个正常的运行方式中,看上去受到了我们做的一个极小的库的影响 ……
|
||||
|
||||
**等等,什么?刚刚发生了什么?**
|
||||
|
||||
是的,你说对了,我们的程序生成随机数失败了,因为它并没有使用 “真正的” `rand()`,而是使用了我们提供的的那个 —— 它每次都返回 `42`。
|
||||
|
||||
**但是,我们*告诉过*它去使用真实的那个。我们编程让它去使用真实的那个。另外,在创建那个程序的时候,假冒的 `rand()` 甚至并不存在!**
|
||||
|
||||
这句话并不完全正确。我们只能告诉它去使用 `rand()`,但是我们不能去选择哪个 `rand()` 是我们希望我们的程序去使用的。
|
||||
|
||||
当我们的程序启动后,(为程序提供所需要的函数的)某些库被加载。我们可以使用 `ldd` 去学习它是怎么工作的:
|
||||
|
||||
```
|
||||
$ ldd random_nums
|
||||
linux-vdso.so.1 => (0x00007fff4bdfe000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f48c03ec000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007f48c07e3000)
|
||||
```
|
||||
|
||||
正如你看到的输出那样,它列出了被程序 `random_nums` 所需要的库的列表。这个列表是构建进可执行程序中的,并且它是在编译时决定的。在你的机器上的具体的输出可能与示例有所不同,但是,一个 `libc.so` 肯定是有的 —— 这个文件提供了核心的 C 函数。它包含了 “真正的” `rand()`。
|
||||
|
||||
我使用下列的命令可以得到一个全部的函数列表,我们看一看 libc 提供了哪些函数:
|
||||
|
||||
```
|
||||
nm -D /lib/libc.so.6
|
||||
```
|
||||
|
||||
这个 `nm` 命令列出了在一个二进制文件中找到的符号。`-D` 标志告诉它去查找动态符号,因为 `libc.so.6` 是一个动态库。这个输出是很长的,但它确实在列出的很多标准函数中包括了 `rand()`。
|
||||
|
||||
现在,在我们设置了环境变量 `LD_PRELOAD` 后发生了什么?这个变量 **为一个程序强制加载一些库**。在我们的案例中,它为 `random_num` 加载了 `unrandom.so`,尽管程序本身并没有这样去要求它。下列的命令可以看得出来:
|
||||
|
||||
```
|
||||
$ LD_PRELOAD=$PWD/unrandom.so ldd random_nums
|
||||
linux-vdso.so.1 => (0x00007fff369dc000)
|
||||
/some/path/to/unrandom.so (0x00007f262b439000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f262b044000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007f262b63d000)
|
||||
```
|
||||
|
||||
注意,它列出了我们当前的库。实际上这就是代码为什么得以运行的原因:`random_num` 调用了 `rand()`,但是,如果 `unrandom.so` 被加载,它调用的是我们所提供的实现了 `rand()` 的库。很清楚吧,不是吗?
|
||||
|
||||
### 更清楚地了解
|
||||
|
||||
这还不够。我可以用相似的方式注入一些代码到一个应用程序中,并且用这种方式它能够像个正常的函数一样工作。如果我们使用一个简单的 `return 0` 去实现 `open()` 你就明白了。我们看到这个应用程序就像发生了故障一样。这是 **显而易见的**, 真实地去调用原始的 `open()`:
|
||||
|
||||
*inspect_open.c:*
|
||||
|
||||
```
|
||||
int open(const char *pathname, int flags){
|
||||
/* Some evil injected code goes here. */
|
||||
return open(pathname,flags); // Here we call the "real" open function, that is provided to us by libc.so
|
||||
}
|
||||
```
|
||||
|
||||
嗯,不对。这将不会去调用 “原始的” `open(...)`。显然,这是一个无休止的递归调用。
|
||||
|
||||
怎么去访问这个 “真正的” `open()` 函数呢?它需要去使用程序接口进行动态链接。它比听起来更简单。我们来看一个完整的示例,然后,我将详细解释到底发生了什么:
|
||||
|
||||
*inspect_open.c:*
|
||||
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <dlfcn.h>
|
||||
|
||||
typedef int (*orig_open_f_type)(const char *pathname, int flags);
|
||||
|
||||
int open(const char *pathname, int flags, ...)
|
||||
{
|
||||
/* Some evil injected code goes here. */
|
||||
|
||||
orig_open_f_type orig_open;
|
||||
orig_open = (orig_open_f_type)dlsym(RTLD_NEXT,"open");
|
||||
return orig_open(pathname,flags);
|
||||
}
|
||||
```
|
||||
|
||||
`dlfcn.h` 是我们后面用到的 `dlsym` 函数所需要的。那个奇怪的 `#define` 是命令编译器去允许一些非标准的东西,我们需要它来启用 `dlfcn.h` 中的 `RTLD_NEXT`。那个 `typedef` 只是创建了一个函数指针类型的别名,它的参数等同于原始的 `open` —— 它现在的别名是 `orig_open_f_type`,我们将在后面用到它。
|
||||
|
||||
我们定制的 `open(...)` 的主体是由一些代码构成。它的最后部分创建了一个新的函数指针 `orig_open`,它指向原始的 `open(...)` 函数。为了得到那个函数的地址,我们请求 `dlsym` 在动态库堆栈上为我们查找下一个 `open()` 函数。最后,我们调用了那个函数(传递了与我们的假冒 `open()` 一样的参数),并且返回它的返回值。
|
||||
|
||||
我使用下面的内容作为我的 “邪恶的注入代码”:
|
||||
|
||||
*inspect_open.c (片段):*
|
||||
|
||||
```
|
||||
printf("The victim used open(...) to access '%s'!!!\n",pathname); //remember to include stdio.h!
|
||||
```
|
||||
|
||||
要编译它,我需要稍微调整一下编译参数:
|
||||
|
||||
```
|
||||
gcc -shared -fPIC inspect_open.c -o inspect_open.so -ldl
|
||||
```
|
||||
|
||||
我增加了 `-ldl`,因此,它将这个共享库链接到 `libdl` —— 它提供了 `dlsym` 函数。(不,我还没有创建一个假冒版的 `dlsym` ,虽然这样更有趣)
|
||||
|
||||
因此,结果是什么呢?一个实现了 `open(...)` 函数的共享库,除了它有 _输出_ 文件路径的意外作用以外,其它的表现和真正的 `open(...)` 函数 **一模一样**。:-)
|
||||
|
||||
如果这个强大的诀窍还没有说服你,是时候去尝试下面的这个示例了:
|
||||
|
||||
```
|
||||
LD_PRELOAD=$PWD/inspect_open.so gnome-calculator
|
||||
```
|
||||
|
||||
我鼓励你去看看自己实验的结果,但是简单来说,它实时列出了这个应用程序可以访问到的每个文件。
|
||||
|
||||
我相信它并不难想像为什么这可以用于去调试或者研究未知的应用程序。请注意,这个特定诀窍并不完整,因为 `open()` 并不是唯一一个打开文件的函数 …… 例如,在标准库中也有一个 `open64()`,并且为了完整地研究,你也需要为它去创建一个假冒的。
|
||||
|
||||
### 可能的用法
|
||||
|
||||
如果你一直跟着我享受上面的过程,让我推荐一个使用这个诀窍能做什么的一大堆创意。记住,你可以在不损害原始应用程序的同时做任何你想做的事情!
|
||||
|
||||
1. ~~获得 root 权限~~。你想多了!你不会通过这种方法绕过安全机制的。(一个专业的解释是:如果 ruid != euid,库不会通过这种方法预加载的。)
|
||||
2. 欺骗游戏:**取消随机化**。这是我演示的第一个示例。对于一个完整的工作案例,你将需要去实现一个定制的 `random()` 、`rand_r()`、`random_r()`,也有一些应用程序是从 `/dev/urandom` 之类的读取,你可以通过使用一个修改过的文件路径来运行原始的 `open()` 来把它们重定向到 `/dev/null`。而且,一些应用程序可能有它们自己的随机数生成算法,这种情况下你似乎是没有办法的(除非,按下面的第 10 点去操作)。但是对于一个新手来说,它看起来很容易上手。
|
||||
3. 欺骗游戏:**让子弹飞一会** 。实现所有的与时间有关的标准函数,让假冒的时间变慢两倍,或者十倍。如果你为时间测量和与时间相关的 `sleep` 或其它函数正确地计算了新的值,那么受影响的应用程序将认为时间变慢了(你想的话,也可以变快),并且,你可以体验可怕的 “子弹时间” 的动作。或者 **甚至更进一步**,你的共享库也可以成为一个 DBus 客户端,因此你可以使用它进行实时的通讯。绑定一些快捷方式到定制的命令,并且在你的假冒的时间函数上使用一些额外的计算,让你可以有能力按你的意愿去启用和禁用慢进或快进任何时间。
|
||||
4. 研究应用程序:**列出访问的文件**。它是我演示的第二个示例,但是这也可以进一步去深化,通过记录和监视所有应用程序的文件 I/O。
|
||||
5. 研究应用程序:**监视因特网访问**。你可以使用 Wireshark 或者类似软件达到这一目的,但是,使用这个诀窍你可以真实地控制基于 web 的应用程序发送了什么,不仅是看看,而是也能影响到交换的数据。这里有很多的可能性,从检测间谍软件到欺骗多用户游戏,或者分析和逆向工程使用闭源协议的应用程序。
|
||||
6. 研究应用程序:**检查 GTK 结构** 。为什么只局限于标准库?让我们在所有的 GTK 调用中注入一些代码,因此我们就可以知道一个应用程序使用了哪些组件,并且,知道它们的构成。然后这可以渲染出一个图像或者甚至是一个 gtkbuilder 文件!如果你想去学习一些应用程序是怎么管理其界面的,这个方法超级有用!
|
||||
7. **在沙盒中运行不安全的应用程序**。如果你不信任一些应用程序,并且你可能担心它会做一些如 `rm -rf /` 或者一些其它不希望的文件活动,你可以通过修改传递到文件相关的函数(不仅是 `open` ,也包括删除目录等)的参数,来重定向所有的文件 I/O 操作到诸如 `/tmp` 这样地方。还有更难的诀窍,如 chroot,但是它也给你提供更多的控制。它可以更安全地完全 “封装”,但除非你真的知道你在做什么,不要以这种方式真的运行任何恶意软件。
|
||||
8. **实现特性** 。[zlibc][1] 是明确以这种方法运行的一个真实的库;它可以在访问文件时解压文件,因此,任何应用程序都可以在无需实现解压功能的情况下访问压缩数据。
|
||||
9. **修复 bug**。另一个现实中的示例是:不久前(我不确定现在是否仍然如此)Skype(它是闭源的软件)从某些网络摄像头中捕获视频有问题。因为 Skype 并不是自由软件,源文件不能被修改,这就可以通过使用预加载一个解决了这个问题的库的方式来修复这个 bug。
|
||||
10. 手工方式 **访问应用程序拥有的内存**。请注意,你可以通过这种方式去访问所有应用程序的数据。如果你有类似的软件,如 CheatEngine/scanmem/GameConqueror 这可能并不会让人惊讶,但是,它们都要求 root 权限才能工作,而 `LD_PRELOAD` 则不需要。事实上,通过一些巧妙的诀窍,你注入的代码可以访问所有的应用程序内存,从本质上看,是因为它是通过应用程序自身得以运行的。你可以修改这个应用程序能修改的任何东西。你可以想像一下,它允许你做许多的底层的侵入…… ,但是,关于这个主题,我将在某个时候写一篇关于它的文章。
|
||||
|
||||
这里仅是一些我想到的创意。我希望你能找到更多,如果你做到了 —— 通过下面的评论区共享出来吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://rafalcieslak.wordpress.com/2013/04/02/dynamic-linker-tricks-using-ld_preload-to-cheat-inject-features-and-investigate-programs/
|
||||
|
||||
作者:[Rafał Cieślak][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://rafalcieslak.wordpress.com/
|
||||
[1]:http://www.zlibc.linux.lu/index.html
|
||||
|
||||
|
||||
@ -1,86 +1,80 @@
|
||||
Linux 用户的逻辑卷管理指南
|
||||
逻辑卷管理(LVM) Linux 用户指南
|
||||
============================================================
|
||||
|
||||
")
|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
管理磁盘空间对系统管理员来说是一件重要的日常工作。因为磁盘空间耗尽而去启动一系列的耗时而又复杂的任务,来提升磁盘分区中可用的磁盘空间。它会要求系统离线。通常会涉及到安装一个新的硬盘、引导至恢复模式或者单用户模式、在新硬盘上创建一个分区和一个文件系统、挂载到临时挂载点去从一个太小的文件系统中移动数据到较大的新位置、修改 /etc/fstab 文件内容去反映出新分区的正确设备名、以及重新引导去重新挂载新的文件系统到正确的挂载点。
|
||||
管理磁盘空间对系统管理员来说是一件重要的日常工作。一旦磁盘空间耗尽就需要进行一系列耗时而又复杂的任务,以提升磁盘分区中可用的磁盘空间。它也需要系统离线才能处理。通常这种任务会涉及到安装一个新的硬盘、引导至恢复模式或者单用户模式、在新硬盘上创建一个分区和一个文件系统、挂载到临时挂载点去从一个太小的文件系统中移动数据到较大的新位置、修改 `/etc/fstab` 文件的内容来反映出新分区的正确设备名、以及重新引导来重新挂载新的文件系统到正确的挂载点。
|
||||
|
||||
我想告诉你的是,当 LVM (逻辑卷管理)首次出现在 Fedora Linux 中时,我是非常抗拒它的。我最初的反应是,我并不需要在我和我的设备之间有这种额外的抽象层。结果是我错了,逻辑卷管理是非常有用的。
|
||||
|
||||
LVM 让磁盘空间管理非常灵活。它提供的功能诸如在文件系统已挂载和活动时,很可靠地增加磁盘空间到一个逻辑卷和它的文件系统中,并且,它允许你将多个物理磁盘和分区融合进一个可以分割成逻辑卷的单个卷组中。
|
||||
LVM 让磁盘空间管理非常灵活。它提供的功能诸如在文件系统已挂载和活动时,很可靠地增加磁盘空间到一个逻辑卷和它的文件系统中,并且,它也允许你将多个物理磁盘和分区融合进一个可以分割成逻辑卷(LV)的单个卷组(VG)中。
|
||||
|
||||
卷管理也允许你去减少分配给一个逻辑卷的磁盘空间数量,但是,这里有两个要求,第一,卷必须是未挂载的。第二,在卷空间调整之前,文件系统本身的空间大小必须被减少。
|
||||
卷管理也允许你去减少分配给一个逻辑卷的磁盘空间数量,但是,这里有两个要求,第一,卷必须是未挂载的。第二,在卷空间调整之前,文件系统本身的空间大小必须先被减少。
|
||||
|
||||
有一个重要的提示是,文件系统本身必须允许重新调整大小的操作。当重新提升文件系统大小的时候,EXT2、3、和 4 文件系统都允许离线(未挂载状态)或者在线(挂载状态)重新调整大小。你应该去认真了解你打算去调整的文件系统的详细情况,去验证它们是否可以完全调整大小,尤其是否可以在线调整大小。
|
||||
有一个重要的提示是,文件系统本身必须允许重新调整大小的操作。当重新提升文件系统大小的时候,EXT2、3 和 4 文件系统都允许离线(未挂载状态)或者在线(挂载状态)重新调整大小。你应该去认真了解你打算去调整的文件系统的详细情况,去验证它们是否可以完全调整大小,尤其是否可以在线调整大小。
|
||||
|
||||
### 在使用中扩展一个文件系统
|
||||
### 即时扩展一个文件系统
|
||||
|
||||
在我安装一个新的发行版到我的生产用机器中之前,我总是喜欢在一个 VirtualBox 虚拟机中运行这个新的发行版一段时间,以确保它没有任何的致命的问题存在。在几年前的一个早晨,我在我的主要使用的工作站上的虚拟机中安装一个新发行的 Fedora 版本。我认为我有足够的磁盘空间分配给安装虚拟机的主文件系统。但是,我错了,大约在第三个安装时,我耗尽了我的文件系统的空间。幸运的是,VirtualBox 检测到了磁盘空间不足的状态,并且暂停了虚拟机,然后显示了一个明确指出问题所在的错误信息。
|
||||
在我安装一个新的发行版到我的生产用机器中之前,我总是喜欢在一个 VirtualBox 虚拟机中运行这个新的发行版一段时间,以确保它没有任何的致命的问题存在。在几年前的一个早晨,我在我的主要使用的工作站上的虚拟机中安装了一个新发行的 Fedora 版本。我认为我有足够的磁盘空间分配给安装虚拟机的主文件系统。但是,我错了,大约在安装到三分之一时,我耗尽了我的文件系统的空间。幸运的是,VirtualBox 检测到了磁盘空间不足的状态,并且暂停了虚拟机,然后显示了一个明确指出问题所在的错误信息。
|
||||
|
||||
请注意,这个问题并不是虚拟机磁盘太小造成的,而是由于宿主机上空间不足,导致虚拟机上的虚拟磁盘在宿主机上的逻辑卷中没有足够的空间去扩展。
|
||||
|
||||
因为许多现在的发行版都缺省使用了逻辑卷管理,并且在我的卷组中有一些可用的空余空间,我可以分配额外的磁盘空间到适当的逻辑卷,然后在使用中扩展宿主机的文件系统。这意味着我不需要去重新格式化整个硬盘,以及重新安装操作系统或者甚至是重启机器。我不过是分配了一些可用空间到适当的逻辑卷中,并且重新调整了文件系统的大小 — 所有的这些操作都在文件系统在线并且运行着程序的状态下进行的,虚拟机也一直使用着宿主机文件系统。在调整完逻辑卷和文件系统的大小之后,我恢复了虚拟机的运行,并且继续进行安装过程,就像什么问题都没有发生过一样。
|
||||
因为许多现在的发行版都缺省使用了逻辑卷管理,并且在我的卷组中有一些可用的空余空间,我可以分配额外的磁盘空间到适当的逻辑卷,然后即时扩展宿主机的文件系统。这意味着我不需要去重新格式化整个硬盘,以及重新安装操作系统或者甚至是重启机器。我不过是分配了一些可用空间到适当的逻辑卷中,并且重新调整了文件系统的大小 —— 所有的这些操作都在文件系统在线并且运行着程序的状态下进行的,虚拟机也一直使用着宿主机文件系统。在调整完逻辑卷和文件系统的大小之后,我恢复了虚拟机的运行,并且继续进行安装过程,就像什么问题都没有发生过一样。
|
||||
|
||||
虽然这种问题你可能从来也没有遇到过,但是,许多人都遇到过重要程序在运行过程中发生磁盘空间不足的问题。而且,虽然许多程序,尤其是 Windows 程序,并不像 VirtualBox 一样写的很好,且富有弹性,Linux 逻辑卷管理可以使它在不丢失数据的情况下去恢复,也不需要去进行耗时的安装过程。
|
||||
|
||||
### LVM 结构
|
||||
|
||||
逻辑卷管理的磁盘环境结构如下面的图 1 所示。逻辑卷管理允许多个单独的硬盘和/或磁盘分区组合成一个单个的卷组(VG)。卷组然后可以再划分为逻辑卷(LV)或者被用于分配成一个大的单一的卷。普通的文件系统,如EXT3 或者 EXT4,可以创建在一个逻辑卷上。
|
||||
逻辑卷管理的磁盘环境结构如下面的图 1 所示。逻辑卷管理允许多个单独的硬盘和/或磁盘分区组合成一个单个的卷组(VG)。卷组然后可以再划分为逻辑卷(LV)或者被用于分配成一个大的单一的卷。普通的文件系统,如 EXT3 或者 EXT4,可以创建在一个逻辑卷上。
|
||||
|
||||
在图 1 中,两个完整的物理硬盘和一个第三块硬盘的一个分区组合成一个单个的卷组。在这个卷组中创建了两个逻辑卷,和一个文件系统,比如,可以在每个逻辑卷上创建一个 EXT3 或者 EXT4 的文件系统。
|
||||
在图 1 中,两个完整的物理硬盘和一个第三块硬盘的一个分区组合成一个单个的卷组。在这个卷组中创建了两个逻辑卷和文件系统,比如,可以在每个逻辑卷上创建一个 EXT3 或者 EXT4 的文件系统。
|
||||
|
||||

|
||||
|
||||
_图 1: LVM 允许组合分区和整个硬盘到卷组中_
|
||||
_图 1: LVM 允许组合分区和整个硬盘到卷组中_
|
||||
|
||||
在一个主机上增加磁盘空间是非常简单的,在我的经历中,这种事情是很少的。下面列出了基本的步骤。你也可以创建一个完整的新卷组或者增加新的空间到一个已存在的逻辑卷中,或者创建一个新的逻辑卷。
|
||||
|
||||
### 增加一个新的逻辑卷
|
||||
|
||||
有时候需要在主机上增加一个新的逻辑卷。例如,在被提示包含我的 VirtualBox 虚拟机的虚拟磁盘的 /home 文件系统被填满时,我决定去创建一个新的逻辑卷,用于去存储虚拟机数据,包含虚拟磁盘。这将在我的 /home 文件系统中释放大量的空间,并且也允许我去独立地管理虚拟机的磁盘空间。
|
||||
有时候需要在主机上增加一个新的逻辑卷。例如,在被提示包含我的 VirtualBox 虚拟机的虚拟磁盘的 `/home` 文件系统被填满时,我决定去创建一个新的逻辑卷,以存储包含虚拟磁盘在内的虚拟机数据。这将在我的 `/home` 文件系统中释放大量的空间,并且也允许我去独立地管理虚拟机的磁盘空间。
|
||||
|
||||
增加一个新的逻辑卷的基本步骤如下:
|
||||
|
||||
1. 如有需要,安装一个新硬盘。
|
||||
|
||||
2. 可选 1: 在硬盘上创建一个分区
|
||||
|
||||
2. 可选: 在硬盘上创建一个分区。
|
||||
3. 在硬盘上创建一个完整的物理卷(PV)或者一个分区。
|
||||
|
||||
4. 分配新的物理卷到一个已存在的卷组(VG)中,或者创建一个新的卷组。
|
||||
|
||||
5. 从卷空间中创建一个新的逻辑卷(LV)。
|
||||
|
||||
6. 在新的逻辑卷中创建一个文件系统。
|
||||
|
||||
7. 在 /etc/fstab 中增加适当的条目以挂载文件系统。
|
||||
|
||||
7. 在 `/etc/fstab` 中增加适当的条目以挂载文件系统。
|
||||
8. 挂载文件系统。
|
||||
|
||||
为了更详细的介绍,接下来将使用一个示例作为一个实验去教授关于 Linux 文件系统的知识。
|
||||
|
||||
### 示例
|
||||
#### 示例
|
||||
|
||||
这个示例展示了怎么用命令行去扩展一个已存在的卷组,并给它增加更多的空间,在那个空间上创建一个新的逻辑卷,然后在逻辑卷上创建一个文件系统。这个过程一直在运行和挂载的文件系统上执行。
|
||||
这个示例展示了怎么用命令行去扩展一个已存在的卷组,并给它增加更多的空间,在那个空间上创建一个新的逻辑卷,然后在逻辑卷上创建一个文件系统。这个过程一直在运行着和已挂载的文件系统上执行。
|
||||
|
||||
警告:仅 EXT3 和 EXT4 文件系统可以在运行和挂载状态下调整大小。许多其它的文件系统,包括 BTRFS 和 ZFS 是不能这样做的。
|
||||
|
||||
### 安装硬盘
|
||||
##### 安装硬盘
|
||||
|
||||
如果在系统中现有硬盘上的卷组中没有足够的空间去增加,那么可能需要去增加一块新的硬盘,然后去创建空间增加到逻辑卷中。首先,安装物理硬盘,然后,接着执行后面的步骤。
|
||||
如果在系统中现有硬盘上的卷组中没有足够的空间可以增加,那么可能需要去增加一块新的硬盘,然后创建空间增加到逻辑卷中。首先,安装物理硬盘,然后,接着执行后面的步骤。
|
||||
|
||||
### 从硬盘上创建物理卷
|
||||
##### 从硬盘上创建物理卷
|
||||
|
||||
首先需要去创建一个新的物理卷(PV)。使用下面的命令,它假设新硬盘已经分配为 /dev/hdd。
|
||||
首先需要去创建一个新的物理卷(PV)。使用下面的命令,它假设新硬盘已经分配为 `/dev/hdd`。
|
||||
|
||||
```
|
||||
pvcreate /dev/hdd
|
||||
```
|
||||
|
||||
在新硬盘上创建一个任意分区并不是必需的。创建的物理卷将被逻辑卷管理器识别为一个新安装的未处理的磁盘或者一个类型为 83 的Linux 分区。如果你想去使用整个硬盘,创建一个分区并没有什么特别的好处,以及另外的物理卷部分的元数据所使用的磁盘空间。
|
||||
在新硬盘上创建一个任意分区并不是必需的。创建的物理卷将被逻辑卷管理器识别为一个新安装的未处理的磁盘或者一个类型为 83 的 Linux 分区。如果你想去使用整个硬盘,创建一个分区并没有什么特别的好处,而且元数据所用的磁盘空间也能用做 PV 的一部分使用。
|
||||
|
||||
### 扩展已存在的卷组
|
||||
##### 扩展已存在的卷组
|
||||
|
||||
在这个示例中,我将扩展一个已存在的卷组,而不是创建一个新的;你可以选择其它的方式。在物理磁盘已经创建之后,扩展已存在的卷组(VG)去包含新 PV 的空间。在这个示例中,已存在的卷组命名为:MyVG01。
|
||||
|
||||
@ -88,7 +82,7 @@ pvcreate /dev/hdd
|
||||
vgextend /dev/MyVG01 /dev/hdd
|
||||
```
|
||||
|
||||
### 创建一个逻辑卷
|
||||
##### 创建一个逻辑卷
|
||||
|
||||
首先,在卷组中从已存在的空余空间中创建逻辑卷。下面的命令创建了一个 50 GB 大小的 LV。这个卷组的名字为 MyVG01,然后,逻辑卷的名字为 Stuff。
|
||||
|
||||
@ -96,7 +90,7 @@ vgextend /dev/MyVG01 /dev/hdd
|
||||
lvcreate -L +50G --name Stuff MyVG01
|
||||
```
|
||||
|
||||
### 创建文件系统
|
||||
##### 创建文件系统
|
||||
|
||||
创建逻辑卷并不会创建文件系统。这个任务必须被单独执行。下面的命令在新创建的逻辑卷中创建了一个 EXT4 文件系统。
|
||||
|
||||
@ -104,7 +98,7 @@ lvcreate -L +50G --name Stuff MyVG01
|
||||
mkfs -t ext4 /dev/MyVG01/Stuff
|
||||
```
|
||||
|
||||
### 增加一个文件系统卷标
|
||||
##### 增加一个文件系统卷标
|
||||
|
||||
增加一个文件系统卷标,更易于在文件系统以后出现问题时识别它。
|
||||
|
||||
@ -112,20 +106,78 @@ mkfs -t ext4 /dev/MyVG01/Stuff
|
||||
e2label /dev/MyVG01/Stuff Stuff
|
||||
```
|
||||
|
||||
### 挂载文件系统
|
||||
##### 挂载文件系统
|
||||
|
||||
在这个时候,你可以创建一个挂载点,并在 /etc/fstab 文件系统中添加合适的条目,以挂载文件系统。
|
||||
在这个时候,你可以创建一个挂载点,并在 `/etc/fstab` 文件系统中添加合适的条目,以挂载文件系统。
|
||||
|
||||
你也可以去检查并校验创建的卷是否正确。你可以使用 **df**、**lvs**、和 **vgs** 命令去做这些工作。
|
||||
你也可以去检查并校验创建的卷是否正确。你可以使用 `df`、`lvs` 和 `vgs` 命令去做这些工作。
|
||||
|
||||
### 在 LVM 文件系统中调整逻辑卷大小
|
||||
|
||||
从 Unix 的第一个版本开始,对文件系统的扩展需求就一直伴随,Linux 也不例外。随着有了逻辑卷管理(LVM),现在更加容易了。
|
||||
|
||||
1. 如有需要,安装一个新硬盘。
|
||||
2. 可选: 在硬盘上创建一个分区。
|
||||
3. 在硬盘上创建一个完整的物理卷(PV)或者一个分区。
|
||||
4. 分配新的物理卷到一个已存在的卷组(VG)中,或者创建一个新的卷组。
|
||||
5. 从卷空间中创建一个新的逻辑卷(LV),或者用卷组中部分或全部空间扩展已有的逻辑卷。
|
||||
6. 如果创建了新的逻辑卷,那么在上面创建一个文件系统。如果对已有的逻辑卷增加空间,使用 `resize2fs` 命令来增大文件系统来填满逻辑卷。
|
||||
7. 在 `/etc/fstab` 中增加适当的条目以挂载文件系统。
|
||||
8. 挂载文件系统。
|
||||
|
||||
|
||||
#### 示例
|
||||
|
||||
这个示例展示了怎么用命令行去扩展一个已存在的卷组。它会给 `/Staff` 文件系统增加大约 50GB 的空间。这将生成一个可用于挂载的文件系统,在 Linux 2.6 内核(及更高)上可即时使用 EXT3 和 EXT4 文件系统。我不推荐你用于任何关键系统,但是这是可行的,我已经成功了好多次;即使是在根(`/`)文件系统上。是否使用自己把握风险。
|
||||
|
||||
警告:仅 EXT3 和 EXT4 文件系统可以在运行和挂载状态下调整大小。许多其它的文件系统,包括 BTRFS 和 ZFS 是不能这样做的。
|
||||
|
||||
##### 安装硬盘
|
||||
|
||||
如果在系统中现有硬盘上的卷组中没有足够的空间可以增加,那么可能需要去增加一块新的硬盘,然后创建空间增加到逻辑卷中。首先,安装物理硬盘,然后,接着执行后面的步骤。
|
||||
|
||||
##### 从硬盘上创建物理卷
|
||||
|
||||
首先需要去创建一个新的物理卷(PV)。使用下面的命令,它假设新硬盘已经分配为 `/dev/hdd`。
|
||||
|
||||
```
|
||||
pvcreate /dev/hdd
|
||||
```
|
||||
|
||||
在新硬盘上创建一个任意分区并不是必需的。创建的物理卷将被逻辑卷管理器识别为一个新安装的未处理的磁盘或者一个类型为 83 的 Linux 分区。如果你想去使用整个硬盘,创建一个分区并没有什么特别的好处,而且元数据所用的磁盘空间也能用做 PV 的一部分使用。
|
||||
|
||||
##### 增加物理卷到已存在的卷组
|
||||
|
||||
在这个示例中,我将使用一个新的物理卷来扩展一个已存在的卷组。在物理卷已经创建之后,扩展已存在的卷组(VG)去包含新 PV 的空间。在这个示例中,已存在的卷组命名为:MyVG01。
|
||||
|
||||
```
|
||||
vgextend /dev/MyVG01 /dev/hdd
|
||||
```
|
||||
|
||||
##### 扩展逻辑卷
|
||||
|
||||
首先,在卷组中从已存在的空余空间中创建逻辑卷。下面的命令创建了一个 50 GB 大小的 LV。这个卷组的名字为 MyVG01,然后,逻辑卷的名字为 Stuff。
|
||||
|
||||
```
|
||||
lvcreate -L +50G --name Stuff MyVG01
|
||||
```
|
||||
|
||||
##### 扩展文件系统
|
||||
|
||||
如果你使用了 `-r` 选项,扩展逻辑卷也将扩展器文件系统。如果你不使用 `-r` 选项,该操作不行单独执行。下面的命令在新调整大小的逻辑卷中调整了文件系统大小。
|
||||
|
||||
```
|
||||
resize2fs /dev/MyVG01/Stuff
|
||||
```
|
||||
|
||||
你也可以去检查并校验调整大小的卷是否正确。你可以使用 `df`、`lvs` 和 `vgs` 命令去做这些工作。
|
||||
|
||||
### 提示
|
||||
|
||||
过去几年来,我学习了怎么去做让逻辑卷管理更加容易的一些知识,希望这些提示对你有价值。
|
||||
|
||||
* 除非你有一个明确的原因去使用其它的文件系统外,推荐使用可扩展的文件系统。除了 EXT2、3、和 4 外,并不是所有的文件系统都支持调整大小。EXT 文件系统不但速度快,而且它很高效。在任何情况下,如果默认的参数不能满足你的需要,它们(指的是文件系统参数)可以通过一位知识丰富的系统管理员来调优它。
|
||||
|
||||
* 使用有意义的卷和卷组名字。
|
||||
|
||||
* 使用 EXT 文件系统标签
|
||||
|
||||
我知道,像我一样,大多数的系统管理员都抗拒逻辑卷管理。我希望这篇文章能够鼓励你至少去尝试一个 LVM。如果你能那样做,我很高兴;因为,自从我使用它之后,我的硬盘管理任务变得如此的简单。
|
||||
@ -133,9 +185,9 @@ e2label /dev/MyVG01/Stuff Stuff
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][10]
|
||||
[][10]
|
||||
|
||||
David Both - 是一位 Linux 和开源软件的倡导者,住在 Raleigh, North Carolina。他在 IT 行业工作了 40 多年,在 IBM 工作了 20 多年。在 IBM 期间,他在 1981 年为最初的 IBM PC 编写了第一个培训课程。他曾教授红帽的 RHCE 课程,并在 MCI Worldcom、Cisco和 North Carolina 工作。他已经使用 Linux 和开源软件工作了将近 20 年。... [more about David Both][7][More about me][8]
|
||||
David Both 是一位 Linux 和开源软件的倡导者,住在 Raleigh, North Carolina。他在 IT 行业工作了 40 多年,在 IBM 工作了 20 多年。在 IBM 期间,他在 1981 年为最初的 IBM PC 编写了第一个培训课程。他曾教授红帽的 RHCE 课程,并在 MCI Worldcom、Cisco和 North Carolina 工作。他已经使用 Linux 和开源软件工作了将近 20 年。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -143,7 +195,7 @@ via: https://opensource.com/business/16/9/linux-users-guide-lvm
|
||||
|
||||
作者:[David Both](a)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,92 @@
|
||||
如何在 Linux 启动时自动启动 LXD 容器
|
||||
======
|
||||
|
||||
Q:我正在使用基于 LXD(“Linux 容器”)的虚拟机。如何在 Linux 系统中启动时自动启动 LXD 容器?
|
||||
|
||||
当 LXD 在启动时运行,你就可以随时启动容器。你需要将 `boot.autostart` 设置为 `true`。你可以使用 `boot.autostart.priority`(默认值为 `0`)选项来定义启动容器的顺序(从最高开始)。你也可以使用 `boot.autostart.delay`(默认值 `0`)选项定义在启动一个容器后等待几秒后启动另一个容器。
|
||||
|
||||
### 语法
|
||||
|
||||
上面讨论的关键字可以使用 `lxc` 工具用下面的语法来设置:
|
||||
|
||||
```
|
||||
$ lxc config set {vm-name} {key} {value}
|
||||
$ lxc config set {vm-name} boot.autostart {true|false}
|
||||
$ lxc config set {vm-name} boot.autostart.priority integer
|
||||
$ lxc config set {vm-name} boot.autostart.delay integer
|
||||
```
|
||||
|
||||
### 如何在 Ubuntu Linux 16.10 中让 LXD 容器在启动时启动?
|
||||
|
||||
输入以下命令:
|
||||
|
||||
```
|
||||
$ lxc config set {vm-name} boot.autostart true
|
||||
```
|
||||
|
||||
设置一个 LXD 容器名称 “nginx-vm” 以在启动时启动
|
||||
|
||||
```
|
||||
$ lxc config set nginx-vm boot.autostart true
|
||||
```
|
||||
|
||||
你可以使用以下语法验证设置:
|
||||
|
||||
```
|
||||
$ lxc config get {vm-name} boot.autostart
|
||||
$ lxc config get nginx-vm boot.autostart
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
true
|
||||
```
|
||||
|
||||
你可以使用下面的语法在启动容器后等待 10 秒钟后启动另一个容器:
|
||||
|
||||
```
|
||||
$ lxc config set nginx-vm boot.autostart.delay 10
|
||||
```
|
||||
|
||||
最后,通过设置最高值来定义启动容器的顺序。确保 db_vm 容器首先启动,然后再启动 nginx_vm。
|
||||
|
||||
```
|
||||
$ lxc config set db_vm boot.autostart.priority 100
|
||||
$ lxc config set nginx_vm boot.autostart.priority 99
|
||||
```
|
||||
|
||||
使用[下面的 bash 循环在 Linux 上查看所有][1]配置值:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
echo 'The current values of each vm boot parameters:'
|
||||
for c in db_vm nginx_vm memcache_vm
|
||||
do
|
||||
echo "*** VM: $c ***"
|
||||
for v in boot.autostart boot.autostart.priority boot.autostart.delay
|
||||
do
|
||||
echo "Key: $v => $(lxc config get $c $v) "
|
||||
done
|
||||
echo ""
|
||||
done
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.01: Get autostarting LXD containers values using a bash shell script][2]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-auto-start-lxd-containers-at-boot-time-in-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[2]:https://www.cyberciti.biz/media/new/faq/2017/02/Autostarting-LXD-containers-values.jpg
|
||||
@ -1,45 +1,51 @@
|
||||
使用 molly-guard 保护你的 Linux/Unix 机器不会被错误地关机/重启
|
||||
======
|
||||
我去!又是这样。 我还以为我登录到家里的服务器呢。 结果 [重启的居然是数据库服务器 ][1]。 另外我也有时会在错误终端内输入 "[shutdown -h 0][2]" 命令。 我知道有些人 [经常会犯这个错误 ][3]。
|
||||
![我的愤怒无从容忍 ][4]
|
||||
|
||||
我去!又是这样。 我还以为我登录到家里的服务器呢。 结果 [重启的居然是数据库服务器][1]。 另外我也有时会在错误终端内输入 "[shutdown -h 0][2]" 命令。 我知道有些人 [经常会犯这个错误 ][3]。
|
||||
|
||||
![我的愤怒无从容忍][4]
|
||||
|
||||
有办法解决这个问题吗?我真的只能忍受这种随机重启和关机的痛苦吗? 虽说人总是要犯错的,但总不能一错再错吧。
|
||||
|
||||
最新我在 tweet 上发了一通牢骚:
|
||||
|
||||
> I seems to run into this stuff again and again :( Instead of typing:
|
||||
> sudo virsh reboot d1
|
||||
> 我总是一遍又一遍地犯下同样的错误 :( 本来应该输入:
|
||||
> `sudo virsh reboot d1`
|
||||
>
|
||||
> I just typed & rebooted my own box
|
||||
> sudo reboot d1
|
||||
> 却总是输错重启了自己的电脑
|
||||
> `sudo reboot d1`
|
||||
>
|
||||
> -- nixCraft (@nixcraft) [February 19,2017][5]
|
||||
|
||||
|
||||
结果收到了一些建议。我们来试一下。
|
||||
|
||||
### 向你引荐 molly guard
|
||||
|
||||
Molly-Guard **尝试阻止你不小心关闭或重启 Linux 服务器**。它在 Debian/Ubuntu 中的包描述为:
|
||||
|
||||
> The package installs a shell script that overrides the existing shutdown/reboot/halt/poweroff/coldreboot/pm-hibernate/pm-suspend* commands and first runs a set of scripts,which all have to exit successfully, before molly-guard invokes the real command。 One of the scripts checks for existing SSH sessions。 If any of the four commands are called interactively over an SSH session, the shell script prompts you to enter the name of the host you wish to shut down。 This should adequately prevent you from accidental shutdowns and reboots。
|
||||
> 这个包会安装一个 shell 脚本来屏蔽现有的 `shutdown`/`reboot`/`halt`/`poweroff`/`coldreboot`/`pm-hibernate`/`pm-suspend*` 命令。 `molly-gurad` 会首先运行一系列的脚本,只有在所有的脚本都返回成功的条件下, 才会调用真正的命令。 其中一个脚本会检查是否存在 SSH 会话。 如果是通过 SSH 会话调用的命令, shell 脚本会提示你输入相关闭主机的名称。 这应该足够防止你发生意外的关机或重启了。
|
||||
|
||||
貌似 [molly-guard][6] 还是个专有名词:
|
||||
貌似 [molly-guard][6] 还是个<ruby>专有名词<rt>Jargon File</rt></ruby>:
|
||||
|
||||
> A shield to prevent tripping of some Big Red Switch by clumsy or ignorant hands。Originally used of the plexiglass covers improvised for the BRS on an IBM 4341 after a programmer's toddler daughter (named Molly) frobbed it twice in one day。 Later generalized to covers over stop/reset switches on disk drives and networking equipment。 In hardware catalogues, you'll see the much less interesting description "guarded button"。
|
||||
> 一种用于防止由于笨拙或者不小心触碰道大红开关的屏障。最初指的临时盖在 IBM 4341 的大红按钮上的有机玻璃,因为有一个程序员蹒跚学步的女儿(名叫 Molly)一天之内重启了它两次。 后来这个东西也被用来盖住磁盘和网络设备上的停止/重启按钮。在硬件目录中,你很少会看到 “guarded button” 这样无趣的描述"。
|
||||
|
||||
### 如何安装 molly guard
|
||||
|
||||
使用 [apt-get command][7] 或者 [apt command][8] 来搜索并安装 molly-guard:
|
||||
使用 [`apt-get` 命令][7] 或者 [`apt` 命令][8] 来搜索并安装 molly-guard:
|
||||
|
||||
```
|
||||
$ apt search molly-guard
|
||||
$ sudo apt-get install molly-guard
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
[![Fig.01: Installing molly guard on Linux][9]][10]
|
||||
|
||||
### 测试一下
|
||||
|
||||
输入 [reboot 命令 ][11] 和 shutdown 命令:
|
||||
输入 [`reboot` 命令 ][11] 和 `shutdown` 命令:
|
||||
|
||||
```
|
||||
$ sudo reboot
|
||||
# reboot
|
||||
@ -49,9 +55,13 @@ $ shutdown -h 0
|
||||
### sudo virsh reboot vm_name_here
|
||||
$ sudo reboot vm_name_here
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
![Fig.02: Molly guard saved my butt ;\)][12]
|
||||
我超级喜欢 molly-guard。因此我将下行内容加入到 apt-debian-ubuntu-common.yml 文件中了:
|
||||
|
||||
我超级喜欢 molly-guard。因此我将下行内容加入到 `apt-debian-ubuntu-common.yml` 文件中了:
|
||||
|
||||
```
|
||||
- apt:
|
||||
name: molly-guard
|
||||
@ -60,7 +70,7 @@ $ sudo reboot vm_name_here
|
||||
|
||||
是的。我使用 Ansible 在所有的 Debian 和 Ubuntu 服务器上都自动安装上它了。
|
||||
|
||||
**相关** : [My 10 UNIX Command Line Mistakes][13]
|
||||
**相关** : [我的 10 大 UNIX 命令行错误][13]
|
||||
|
||||
### 如果我的 Linux 发行版或者 Unix 系统(比如 FreeBSD) 没有 molly-guard 怎么办呢?
|
||||
|
||||
@ -71,16 +81,19 @@ alias reboot = "echo 'Are you sure?' If so, run /sbin/reboot"
|
||||
alias shutdown = "echo 'Are you sure?' If so, run /sbin/shutdown"
|
||||
```
|
||||
|
||||
你也可以 [临时取消别名机制运行真正的命令 ][15]。比如要运行 reboot 可以这样:
|
||||
你也可以 [临时取消别名机制运行真正的命令][15]。比如要运行 reboot 可以这样:
|
||||
|
||||
```
|
||||
# \reboot
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
# /sbin/reboot
|
||||
```
|
||||
另外你也可以写一个 [shell/perl/python 脚本来调用这些命令并要求 ][16] 确认 reboot/halt/shutdown 的选项。
|
||||
|
||||
另外你也可以写一个 [shell/perl/python 脚本来调用这些命令并要求][16] 确认 `reboot`/`halt`/`shutdown` 的选项。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -88,7 +101,7 @@ via: https://www.cyberciti.biz/hardware/how-to-protects-linux-and-unix-machines-
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
105
published/201712/20170530 How to Improve a Legacy Codebase.md
Normal file
105
published/201712/20170530 How to Improve a Legacy Codebase.md
Normal file
@ -0,0 +1,105 @@
|
||||
如何改善遗留的代码库
|
||||
=================
|
||||
|
||||
在每一个程序员、项目管理员、团队领导的一生中,这都会至少发生一次。原来的程序员早已离职去度假了,给你留下了一坨几百万行屎一样的、勉强支撑公司运行的代码和(如果有的话)跟代码驴头不对马嘴的文档。
|
||||
|
||||
你的任务:带领团队摆脱这个混乱的局面。
|
||||
|
||||
当你的第一反应(逃命)过去之后,你开始去熟悉这个项目。公司的管理层都在关注着你,所以项目只能成功;然而,看了一遍代码之后却发现失败几乎是不可避免。那么该怎么办呢?
|
||||
|
||||
幸运(不幸)的是我已经遇到好几次这种情况了,我和我的小伙伴发现将这坨热气腾腾的屎变成一个健康可维护的项目是一个有丰厚利润的业务。下面这些是我们的一些经验:
|
||||
|
||||
### 备份
|
||||
|
||||
在开始做任何事情之前备份与之可能相关的所有文件。这样可以确保不会丢失任何可能会在另外一些地方很重要的信息。一旦修改了其中一些文件,你可能花费一天或者更多天都解决不了这个愚蠢的问题。配置数据通常不受版本控制,所以特别容易受到这方面影响,如果定期备份数据时连带着它一起备份了,还是比较幸运的。所以谨慎总比后悔好,复制所有东西到一个绝对安全的地方并不要轻易碰它,除非这些文件是只读模式。
|
||||
|
||||
### 重要的先决条件:必须确保代码能够在生产环境下构建运行并产出
|
||||
|
||||
之前我假设环境已经存在,所以完全丢了这一步,但 Hacker News 的众多网友指出了这一点,并且事实证明他们是对的:第一步是确认你知道在生产环境下运行着什么东西,也意味着你需要在你的设备上构建一个跟生产环境上运行的版本每一个字节都一模一样的版本。如果你找不到实现它的办法,一旦你将它投入生产环境,你很可能会遭遇一些预料之外的糟糕事情。确保每一部分都尽力测试,之后在你足够确信它能够很好的运行的时候将它部署生产环境下。无论它运行的怎么样都要做好能够马上切换回旧版本的准备,确保日志记录下了所有情况,以便于接下来不可避免的 “验尸” 。
|
||||
|
||||
### 冻结数据库
|
||||
|
||||
直到你修改代码结束之前尽可能冻结你的数据库,在你已经非常熟悉代码库和遗留代码之后再去修改数据库。在这之前过早的修改数据库的话,你可能会碰到大问题,你会失去让新旧代码和数据库一起构建稳固的基础的能力。保持数据库完全不变,就能比较新的逻辑代码和旧的逻辑代码运行的结果,比较的结果应该跟预期的没有差别。
|
||||
|
||||
### 写测试
|
||||
|
||||
在你做任何改变之前,尽可能多的写一些端到端测试和集成测试。确保这些测试能够正确的输出,并测试你对旧的代码运行的各种假设(准备好应对一些意外状况)。这些测试有两个重要的作用:其一,它们能够在早期帮助你抛弃一些错误观念,其二,这些测试在你写新代码替换旧代码的时候也有一定防护作用。
|
||||
|
||||
要自动化测试,如果你有 CI 的使用经验可以用它,并确保在你提交代码之后 CI 能够快速的完成所有测试。
|
||||
|
||||
### 日志监控
|
||||
|
||||
如果旧设备依然可用,那么添加上监控功能。在一个全新的数据库,为每一个你能想到的事件都添加一个简单的计数器,并且根据这些事件的名字添加一个函数增加这些计数器。用一些额外的代码实现一个带有时间戳的事件日志,你就能大概知道发生多少事件会导致另外一些种类的事件。例如:用户打开 APP 、用户关闭 APP 。如果这两个事件导致后端调用的数量维持长时间的不同,这个数量差就是当前打开的 APP 的数量。如果你发现打开 APP 比关闭 APP 多的时候,你就必须要知道是什么原因导致 APP 关闭了(例如崩溃)。你会发现每一个事件都跟其它的一些事件有许多不同种类的联系,通常情况下你应该尽量维持这些固定的联系,除非在系统上有一个明显的错误。你的目标是减少那些错误的事件,尽可能多的在开始的时候通过使用计数器在调用链中降低到指定的级别。(例如:用户支付应该得到相同数量的支付回调)。
|
||||
|
||||
这个简单的技巧可以将每一个后端应用变成一个像真实的簿记系统一样,而像一个真正的簿记系统,所有数字必须匹配,如果它们在某个地方对不上就有问题。
|
||||
|
||||
随着时间的推移,这个系统在监控健康方面变得非常宝贵,而且它也是使用源码控制修改系统日志的一个好伙伴,你可以使用它确认 BUG 引入到生产环境的时间,以及对多种计数器造成的影响。
|
||||
|
||||
我通常保持每 5 分钟(一小时 12 次)记录一次计数器,但如果你的应用生成了更多或者更少的事件,你应该修改这个时间间隔。所有的计数器公用一个数据表,每一个记录都只是简单的一行。
|
||||
|
||||
### 一次只修改一处
|
||||
|
||||
不要陷入在提高代码或者平台可用性的同时添加新特性或者是修复 BUG 的陷阱。这会让你头大,因为你现在必须在每一步操作想好要出什么样的结果,而且会让你之前建立的一些测试失效。
|
||||
|
||||
### 修改平台
|
||||
|
||||
如果你决定转移你的应用到另外一个平台,最主要的是跟之前保持一模一样。如果你觉得需要,你可以添加更多的文档和测试,但是不要忘记这一点,所有的业务逻辑和相互依赖要跟从前一样保持不变。
|
||||
|
||||
### 修改架构
|
||||
|
||||
接下来处理的是改变应用的结构(如果需要)。这一点上,你可以自由的修改高层的代码,通常是降低模块间的横向联系,这样可以降低代码活动期间对终端用户造成的影响范围。如果旧代码很庞杂,那么现在正是让它模块化的时候,将大段代码分解成众多小的部分,不过不要改变量和数据结构的名字。
|
||||
|
||||
Hacker News 的 [mannykannot][1] 网友指出,修改高层代码并不总是可行,如果你特别不幸的话,你可能为了改变一些架构必须付出沉重的代价。我赞同这一点也应该在这里加上提示,因此这里有一些补充。我想额外补充的是如果你修改高层代码的时候修改了一点点底层代码,那么试着只修改一个文件或者最坏的情况是只修改一个子系统,尽可能限制修改的范围。否则你可能很难调试刚才所做的更改。
|
||||
|
||||
### 底层代码的重构
|
||||
|
||||
现在,你应该非常理解每一个模块的作用了,准备做一些真正的工作吧:重构代码以提高其可维护性并且使代码做好添加新功能的准备。这很可能是项目中最消耗时间的部分,记录你所做的任何操作,在你彻底的记录并且理解模块之前不要对它做任何修改。之后你可以自由的修改变量名、函数名以及数据结构以提高代码的清晰度和统一性,然后请做测试(情况允许的话,包括单元测试)。
|
||||
|
||||
### 修复 bug
|
||||
|
||||
现在准备做一些用户可见的修改,战斗的第一步是修复很多积累了几年的 bug。像往常一样,首先证实 bug 仍然存在,然后编写测试并修复这个 bug,你的 CI 和端对端测试应该能避免一些由于不太熟悉或者一些额外的事情而犯的错误。
|
||||
|
||||
### 升级数据库
|
||||
|
||||
如果你在一个坚实且可维护的代码库上完成所有工作,你就可以选择更改数据库模式的计划,或者使用不同的完全替换数据库。之前完成的步骤能够帮助你更可靠的修改数据库而不会碰到问题,你可以完全的测试新数据库和新代码,而之前写的所有测试可以确保你顺利的迁移。
|
||||
|
||||
### 按着路线图执行
|
||||
|
||||
祝贺你脱离的困境并且可以准备添加新功能了。
|
||||
|
||||
### 任何时候都不要尝试彻底重写
|
||||
|
||||
彻底重写是那种注定会失败的项目。一方面,你在一个未知的领域开始,所以你甚至不知道构建什么,另一方面,你会把所有的问题都推到新系统马上就要上线的前一天。非常不幸的是,这也是你失败的时候。假设业务逻辑被发现存在问题,你会得到异样的眼光,那时您会突然明白为什么旧系统会用某种奇怪的方式来工作,最终也会意识到能将旧系统放在一起工作的人也不都是白痴。在那之后。如果你真的想破坏公司(和你自己的声誉),那就重写吧,但如果你是聪明人,你会知道彻底重写系统根本不是一个可选的选择。
|
||||
|
||||
### 所以,替代方法:增量迭代工作
|
||||
|
||||
要解开这些线团最快方法是,使用你熟悉的代码中任何的元素(它可能是外部的,也可能是内核模块),试着使用旧的上下文去增量改进。如果旧的构建工具已经不能用了,你将必须使用一些技巧(看下面),但至少当你开始做修改的时候,试着尽力保留已知的工作。那样随着代码库的提升你也对代码的作用更加理解。一个典型的代码提交应该最多两三行。
|
||||
|
||||
### 发布!
|
||||
|
||||
每一次的修改都发布到生产环境,即使一些修改不是用户可见的。使用最少的步骤也是很重要的,因为当你缺乏对系统的了解时,有时候只有生产环境能够告诉你问题在哪里。如果你只做了一个很小的修改之后出了问题,会有一些好处:
|
||||
|
||||
* 很容易弄清楚出了什么问题
|
||||
* 这是一个改进流程的好位置
|
||||
* 你应该马上更新文档展示你的新见解
|
||||
|
||||
### 使用代理的好处
|
||||
|
||||
如果你做 web 开发那就谢天谢地吧,可以在旧系统和用户之间加一个代理。这样你能很容易的控制每一个网址哪些请求定向到旧系统,哪些请求定向到新系统,从而更轻松更精确的控制运行的内容以及谁能够看到运行系统。如果你的代理足够的聪明,你可以使用它针对个别 URL 把一定比例的流量发送到新系统,直到你满意为止。如果你的集成测试也能连接到这个接口那就更好了。
|
||||
|
||||
### 是的,但这会花费很多时间!
|
||||
|
||||
这就取决于你怎样看待它了。的确,在按照以上步骤优化代码时会有一些重复的工作步骤。但是它确实有效,而这里介绍的任何一个步骤都是假设你对系统的了解比现实要多。我需要保持声誉,也真的不喜欢在工作期间有负面的意外。如果运气好的话,公司系统已经出现问题,或者有可能会严重影响到客户。在这样的情况下,我比较喜欢完全控制整个流程得到好的结果,而不是节省两天或者一星期。如果你更多地是牛仔的做事方式,并且你的老板同意可以接受冒更大的风险,那可能试着冒险一下没有错,但是大多数公司宁愿采取稍微慢一点但更确定的胜利之路。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jacquesmattheij.com/improving-a-legacy-codebase
|
||||
|
||||
作者:[Jacques Mattheij][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[JianqinWang](https://github.com/JianqinWang), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jacquesmattheij.com/
|
||||
[1]:https://news.ycombinator.com/item?id=14445661
|
||||
@ -0,0 +1,251 @@
|
||||
GIT 命令“从初学到专业”完整进阶指南
|
||||
===========
|
||||
|
||||
在[之前的教程][1]中,我们已经学习了在机器上安装 git。本教程,我们将讨论如何使用 git,比如与 git 一起使用的各种命令。所以我们开始吧,
|
||||
|
||||
- 推荐阅读:[如何在 Linux 上安装 GIT (Ubuntu 和 CentOS)][1]
|
||||
|
||||
### 设置用户信息
|
||||
|
||||
这应该是安装完 git 的第一步。我们将添加用户信息 (用户名和邮箱),所以当我们提交代码时,会产生带有用户信息的提交信息,这使得跟踪提交过程变得更容易。要添加用户信息,命令是 `git config`:
|
||||
|
||||
```
|
||||
$ git config --global user.name "Daniel"
|
||||
$ git config --global user.email "dan.mike@xyz.com"
|
||||
```
|
||||
|
||||
添加完用户信息之后,通过运行下面命令,我们将检查这些信息是否成功更新。
|
||||
|
||||
```
|
||||
$ git config --list
|
||||
```
|
||||
|
||||
我们应该能够看到输出的用户信息。
|
||||
|
||||
### GIT 命令
|
||||
#### 新建一个仓库
|
||||
|
||||
为了建立一个新仓库,运行如下命令:
|
||||
|
||||
```
|
||||
$ git init
|
||||
```
|
||||
|
||||
#### 查找一个仓库
|
||||
|
||||
为了查找一个仓库,命令如下:
|
||||
|
||||
```
|
||||
$ git grep "repository"
|
||||
```
|
||||
|
||||
#### 与远程仓库连接
|
||||
|
||||
为了与远程仓库连接,运行如下命令:
|
||||
|
||||
```
|
||||
$ git remote add origin remote_server
|
||||
```
|
||||
|
||||
然后检查所有配置的远程服务器,运行如下命令:
|
||||
|
||||
```
|
||||
$ git remote -v
|
||||
```
|
||||
|
||||
#### 克隆一个仓库
|
||||
|
||||
为了从本地服务器克隆一个仓库,运行如下代码:
|
||||
|
||||
```
|
||||
$ git clone repository_path
|
||||
```
|
||||
|
||||
如果我们想克隆远程服务器上的一个仓库,那克隆这个仓库的命令是:
|
||||
|
||||
```
|
||||
$ git clone repository_path
|
||||
```
|
||||
|
||||
#### 在仓库中列出分支
|
||||
|
||||
为了检查所有可用的和当前工作的分支列表,执行:
|
||||
|
||||
```
|
||||
$ git branch
|
||||
```
|
||||
|
||||
#### 创建新分支
|
||||
|
||||
创建并使用一个新分支,命令是:
|
||||
|
||||
```
|
||||
$ git checkout -b 'branchname'
|
||||
```
|
||||
|
||||
#### 删除一个分支
|
||||
|
||||
为了删除一个分支,执行:
|
||||
|
||||
```
|
||||
$ git branch -d 'branchname'
|
||||
```
|
||||
|
||||
为了删除远程仓库的一个分支,执行:
|
||||
|
||||
```
|
||||
$ git push origin:'branchname'
|
||||
```
|
||||
|
||||
#### 切换到另一个分支
|
||||
|
||||
从当前分支切换到另一个分支,使用
|
||||
|
||||
```
|
||||
$ git checkout 'branchname'
|
||||
```
|
||||
|
||||
#### 添加文件
|
||||
|
||||
添加文件到仓库,执行:
|
||||
|
||||
```
|
||||
$ git add filename
|
||||
```
|
||||
|
||||
#### 文件状态
|
||||
|
||||
检查文件状态 (那些将要提交或者添加的文件),执行:
|
||||
|
||||
```
|
||||
$ git status
|
||||
```
|
||||
|
||||
#### 提交变更
|
||||
|
||||
在我们添加一个文件或者对一个文件作出变更之后,我们通过运行下面命令来提交代码:
|
||||
|
||||
```
|
||||
$ git commit -a
|
||||
```
|
||||
|
||||
提交变更到 head 但不提交到远程仓库,命令是:
|
||||
|
||||
```
|
||||
$ git commit -m "message"
|
||||
```
|
||||
|
||||
#### 推送变更
|
||||
|
||||
推送对该仓库 master 分支所做的变更,运行:
|
||||
|
||||
```
|
||||
$ git push origin master
|
||||
```
|
||||
|
||||
#### 推送分支到仓库
|
||||
|
||||
推送对单一分支做出的变更到远程仓库,运行:
|
||||
|
||||
```
|
||||
$ git push origin 'branchname'
|
||||
```
|
||||
|
||||
推送所有分支到远程仓库,运行:
|
||||
|
||||
```
|
||||
$ git push -all origin
|
||||
```
|
||||
|
||||
#### 合并两个分支
|
||||
|
||||
合并另一个分支到当前活动分支,使用命令:
|
||||
|
||||
```
|
||||
$ git merge 'branchname'
|
||||
```
|
||||
|
||||
#### 从远端服务器合并到本地服务器
|
||||
|
||||
从远端服务器下载/拉取变更到到本地服务器的工作目录,运行:
|
||||
|
||||
```
|
||||
$ git pull
|
||||
```
|
||||
|
||||
#### 检查合并冲突
|
||||
|
||||
查看对库文件的合并冲突,运行:
|
||||
|
||||
```
|
||||
$ git diff -base 'filename'
|
||||
```
|
||||
|
||||
查看所有冲突,运行:
|
||||
|
||||
```
|
||||
$ git diff
|
||||
```
|
||||
|
||||
如果我们在合并之前想预览所有变更,运行:
|
||||
|
||||
```
|
||||
$ git diff 'source-branch' 'target-branch'
|
||||
```
|
||||
|
||||
#### 创建标记
|
||||
|
||||
创建标记来标志任一重要的变更,运行:
|
||||
|
||||
```
|
||||
$ git tag 'tag number' 'commit id'
|
||||
```
|
||||
|
||||
通过运行以下命令,我们可以查找 commit id :
|
||||
|
||||
```
|
||||
$ git log
|
||||
```
|
||||
#### 推送标记
|
||||
|
||||
推送所有创建的标记到远端服务器,运行:
|
||||
|
||||
```
|
||||
$ git push -tags origin
|
||||
```
|
||||
|
||||
#### 回复做出的变更
|
||||
|
||||
如果我们想用 head 中最后一次变更来替换对当前工作树的变更,运行:
|
||||
|
||||
```
|
||||
$ git checkout -'filename'
|
||||
```
|
||||
|
||||
我们也可以从远端服务器获取最新的历史,并且将它指向本地仓库的 master 分支,而不是丢弃掉所有本地所做所有变更。为了这么做,运行:
|
||||
|
||||
```
|
||||
$ git fetch origin
|
||||
$ git reset -hard master
|
||||
```
|
||||
|
||||
好了,伙计们。这些就是我们使用 git 服务器的命令。我们将会很快为大家带来更有趣的教程。如果你希望我们对某个特定话题写一个教程,请通过下面的评论箱告诉我们。像往常一样, 欢迎您的各种意见和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/beginners-to-pro-guide-for-git-commands/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[liuxinyu123](https://github.com/liuxinyu123)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/install-git-linux-ubuntu-centos/
|
||||
[2]:/cdn-cgi/l/email-protection
|
||||
[3]:http://linuxtechlab.com/scheduling-important-jobs-crontab/
|
||||
[4]:https://www.facebook.com/linuxtechlab/
|
||||
[5]:https://twitter.com/LinuxTechLab
|
||||
[6]:https://plus.google.com/+linuxtechlab
|
||||
[7]:http://linuxtechlab.com/contact-us-2/
|
||||
@ -0,0 +1,103 @@
|
||||
用 Ansible Container 去管理 Linux 容器
|
||||
============================================================
|
||||
|
||||
> Ansible Container 解决了 Dockerfile 的不足,并对容器化项目提供了完整的管理。
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
我喜欢容器,并且每天都使用这个技术。即便如此,容器并不完美。不过,在过去几个月里,一系列项目已经解决了我遇到的一些问题。
|
||||
|
||||
我刚开始时,用 [Docker][11] 使用容器,这个项目使得这种技术非常流行。除了使用这个容器引擎之外,我学到了怎么去使用 [docker-compose][6] 以及怎么去用它管理我的项目。使用它使得我的生产力猛增!一个命令就可以运行我的项目,而不管它有多复杂。因此,我太高兴了。
|
||||
|
||||
使用一段时间之后,我发现了一些问题。最明显的问题是创建容器镜像的过程。Docker 工具使用一个定制的文件格式作为生成容器镜像的依据:Dockerfile。这个格式易于学习,并且很短的一段时间之后,你就可以自己制作容器镜像了。但是,一旦你希望进一步掌握它或者考虑到复杂场景,问题就会出现。
|
||||
|
||||
让我们打断一下,先去了解一个不同的东西:[Ansible][22] 的世界。你知道它吗?它棒极了,是吗?你不这么认为?好吧,是时候去学习一些新事物了。Ansible 是一个允许你通过写一些任务去管理你的基础设施,并在你选择的环境中运行它们的项目。不需要去安装和设置任何的服务;你可以从你的笔记本电脑中很容易地做任何事情。许多人已经接受 Ansible 了。
|
||||
|
||||
想像一下这样的场景:你在 Ansible 中,你写了很多的 Ansible <ruby>角色<rt>role</rt></ruby>和<ruby>剧本<rt>playbook</rt></ruby>,你可以用它们去管理你的基础设施,并且你想把它们运用到容器中。你应该怎么做?通过 shell 脚本和 Dockerfile 去写容器镜像定义?听起来好像不对。
|
||||
|
||||
来自 Ansible 开发团队的一些人问到这个问题,并且他们意识到,人们每天编写和使用的那些同样的 Ansible 角色和剧本也可以用来制作容器镜像。但是 Ansible 能做到的不止这些 —— 它可以被用于去管理容器化项目的完整生命周期。从这些想法中,[Ansible Container][12] 项目诞生了。它利用已有的 Ansible 角色转变成容器镜像,甚至还可以被用于生产环境中从构建到部署的完整生命周期。
|
||||
|
||||
现在让我们讨论一下,我之前提到过的在 Dockerfile 环境中的最佳实践问题。这里有一个警告:这将是非常具体且技术性的。出现最多的三个问题有:
|
||||
|
||||
### 1、 在 Dockerfile 中内嵌的 Shell 脚本
|
||||
|
||||
当写 Dockerfile 时,你可以指定会由 `/bin/sh -c` 解释执行的脚本。它类似如下:
|
||||
|
||||
```
|
||||
RUN dnf install -y nginx
|
||||
```
|
||||
|
||||
这里 `RUN` 是一个 Dockerfile 指令,其它的都是参数(它们传递给 shell)。但是,想像一个更复杂的场景:
|
||||
|
||||
```
|
||||
RUN set -eux; \
|
||||
\
|
||||
# this "case" statement is generated via "update.sh"
|
||||
%%ARCH-CASE%%; \
|
||||
\
|
||||
url="https://golang.org/dl/go${GOLANG_VERSION}.${goRelArch}.tar.gz"; \
|
||||
wget -O go.tgz "$url"; \
|
||||
echo "${goRelSha256} *go.tgz" | sha256sum -c -; \
|
||||
```
|
||||
|
||||
这仅是从 [golang 官方镜像][13] 中拿来的一段。它看起来并不好看,是不是?
|
||||
|
||||
### 2、 解析 Dockerfile 并不容易
|
||||
|
||||
Dockerfile 是一个没有正式规范的新格式。如果你需要在你的基础设施(比如,让构建过程自动化一点)中去处理 Dockerfile 将会很复杂。仅有的规范是 [这个代码][14],它是 **dockerd** 的一部分。问题是你不能使用它作为一个<ruby>库<rt>library</rt></ruby>来使用。最容易的解决方案是你自己写一个解析器,然后祈祷它运行的很好。使用一些众所周知的标记语言不是更好吗?比如,YAML 或者 JSON。
|
||||
|
||||
### 3、 管理困难
|
||||
|
||||
如果你熟悉容器镜像的内部结构,你可能知道每个镜像是由<ruby>层<rt>layer</rt></ruby>构成的。一旦容器被创建,这些层就使用联合文件系统技术堆叠在一起(像煎饼一样)。问题是,你并不能显式地管理这些层 — 你不能说,“这儿开始一个新层”,你被迫使用一种可读性不好的方法去改变你的 Dockerfile。最大的问题是,必须遵循一套最佳实践以去达到最优结果 — 新来的人在这个地方可能很困难。
|
||||
|
||||
### Ansible 语言和 Dockerfile 比较
|
||||
|
||||
相比 Ansible,Dockerfile 的最大缺点,也是 Ansible 的优点,作为一个语言,Ansible 更强大。例如,Dockerfile 没有直接的变量概念,而 Ansible 有一个完整的模板系统(变量只是它其中的一个特性)。Ansible 包含了很多更易于使用的模块,比如,[wait_for][15],它可以被用于服务就绪检查,比如,在处理之前等待服务准备就绪。在 Dockerfile 中,做任何事情都通过一个 shell 脚本。因此,如果你想去找出已准备好的服务,它必须使用 shell(或者独立安装)去做。使用 shell 脚本的其它问题是,它会变得很复杂,维护成为一种负担。很多人已经发现了这个问题,并将这些 shell 脚本转到 Ansible。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][18]
|
||||
|
||||
Tomas Tomecek - 工程师、Hacker、演讲者、Tinker、Red Hatter。喜欢容器、linux、开源软件、python 3、rust、zsh、tmux。[More about me][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/dockerfiles-ansible-container
|
||||
|
||||
作者:[Tomas Tomecek][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomastomecek
|
||||
[1]:https://www.ansible.com/how-ansible-works?intcmp=701f2000000h4RcAAI
|
||||
[2]:https://www.ansible.com/ebooks?intcmp=701f2000000h4RcAAI
|
||||
[3]:https://www.ansible.com/quick-start-video?intcmp=701f2000000h4RcAAI
|
||||
[4]:https://docs.ansible.com/ansible/latest/intro_installation.html?intcmp=701f2000000h4RcAAI
|
||||
[5]:https://opensource.com/article/17/10/dockerfiles-ansible-container?imm_mid=0f9013&cmp=em-webops-na-na-newsltr_20171201&rate=Wiw_0D6PK_CAjqatYu_YQH0t1sNHEF6q09_9u3sYkCY
|
||||
[6]:https://github.com/docker/compose
|
||||
[7]:http://sched.co/BxIW
|
||||
[8]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[9]:https://opensource.com/users/tomastomecek
|
||||
[10]:https://opensource.com/user/175651/feed
|
||||
[11]:https://opensource.com/tags/docker
|
||||
[12]:https://www.ansible.com/ansible-container
|
||||
[13]:https://github.com/docker-library/golang/blob/master/Dockerfile-debian.template#L14
|
||||
[14]:https://github.com/moby/moby/tree/master/builder/dockerfile
|
||||
[15]:http://docs.ansible.com/wait_for_module.html
|
||||
[16]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[17]:http://events.linuxfoundation.org/events/open-source-summit-europe/program/schedule
|
||||
[18]:https://opensource.com/users/tomastomecek
|
||||
[19]:https://opensource.com/users/tomastomecek
|
||||
[20]:https://opensource.com/users/tomastomecek
|
||||
[21]:https://opensource.com/article/17/10/dockerfiles-ansible-container?imm_mid=0f9013&cmp=em-webops-na-na-newsltr_20171201#comments
|
||||
[22]:https://opensource.com/tags/ansible
|
||||
[23]:https://opensource.com/tags/containers
|
||||
[24]:https://opensource.com/tags/ansible
|
||||
[25]:https://opensource.com/tags/docker
|
||||
[26]:https://opensource.com/tags/open-source-summit
|
||||
|
||||
|
||||
@ -1,21 +1,21 @@
|
||||
怎么用源代码安装软件 … 以及如何卸载它
|
||||
详解如何用源代码安装软件,以及如何卸载它
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
_简介:这篇文章详细介绍了在 Linux 中怎么用源代码安装程序,以及怎么去卸载源代码安装的程序。_
|
||||
_简介:这篇文章详细介绍了在 Linux 中怎么用源代码安装程序,以及怎么去卸载用源代码安装的程序。_
|
||||
|
||||
你的 Linux 分发版的其中一个最大的优点就是它的包管理器和相关的软件库。正是因为它们,你才可以去下载所需的工具和资源,以及在你的计算机上完全自动化地安装一个新软件。
|
||||
Linux 发行版的一个最大的优点就是它的包管理器和相关的软件库。通过它们提供的资源和工具,你才能够以完全自动化的方式在你的计算机上下载和安装软件。
|
||||
|
||||
但是,尽管他们付出了很多的努力,包维护者仍然没法做到处理好每个用到的依赖,也不可能将所有的可用软件都打包进去。因此,仍然存在需要你自已去编译和安装一个新软件的情形。对于我来说,到目前为止,最主要的原因是,当我需要去运行一个特定的版本时我还要编译一些软件。或者,我想去修改源代码或使用一些想要的编译选项。
|
||||
但是,尽管付出了很多的努力,包维护者仍然没法照顾好每种情况,也不可能将所有的可用软件都打包进去。因此,仍然存在需要你自已去编译和安装一个新软件的情形。对于我来说,到目前为止,最主要的原因是,我编译一些软件是我需要去运行一个特定的版本。或者是我想去修改源代码或使用一些想要的编译选项。
|
||||
|
||||
如果你也属于后一种情况,那你已经知道你应该做什么了。但是,对于绝大多数的 Linux 用户来说,第一次从源代码中编译和安装一个软件看上去像是一个入门的仪式:它让很多人感到恐惧;但是,如果你能克服困难,你将可能进入一个全新的世界,并且,如果你做到了,那么你将成为社区中享有特权的一部分人。
|
||||
如果你也属于后一种情况,那你已经知道你应该怎么做了。但是,对于绝大多数的 Linux 用户来说,第一次从源代码中编译和安装一个软件看上去像是一个入门仪式:它让很多人感到恐惧;但是,如果你能克服困难,你将可能进入一个全新的世界,并且,如果你做到了,那么你将成为社区中享有特权的一部分人。
|
||||
|
||||
[Suggested readHow To Install And Remove Software In Ubuntu [Complete Guide]][8]
|
||||
- [建议阅读:怎样在 Ubuntu 中安装和删除软件(完全指南)][8]
|
||||
|
||||
### A. 在 Linux 中从源代码开始安装软件
|
||||
|
||||
这正是我们要做的。因为这篇文章的需要,我要在我的系统上安装 [NodeJS][9] 8.1.1。它是个完全真实的版本。这个版本在 Debian 仓库中不可用:
|
||||
这正是我们要做的。因为这篇文章的需要,我要在我的系统上安装 [NodeJS][9] 8.1.1。它是个完全真实的版本。这个版本在 Debian 仓库中没有:
|
||||
|
||||
```
|
||||
sh$ apt-cache madison nodejs | grep amd64
|
||||
@ -26,7 +26,7 @@ sh$ apt-cache madison nodejs | grep amd64
|
||||
nodejs | 0.10.29~dfsg-1~bpo70+1 | http://ftp.fr.debian.org/debian wheezy-backports/main amd64 Packages
|
||||
```
|
||||
|
||||
### 第 1 步:从 GitHub 上获取源代码
|
||||
#### 第 1 步:从 GitHub 上获取源代码
|
||||
|
||||
像大多数开源项目一样,NodeJS 的源代码可以在 GitHub:[https://github.com/nodejs/node][10] 上找到。
|
||||
|
||||
@ -34,19 +34,19 @@ sh$ apt-cache madison nodejs | grep amd64
|
||||
|
||||

|
||||
|
||||
如果你不熟悉 [GitHub][11]、[git][12] 或者提到的其它的包含这个软件源代码的 [版本管理系统][13],以及多年来对该软件的所有修改的历史,最终找到该软件的最早版本。对于开发者来说,保持它的历史版本有很多好处。对现在的我来说,其中一个好处是可以得到任何一个给定时间点的项目源代码。更准确地说,当我希望的 8.1.1 版发布时,我可以像他们一样第一时间得到源代码。即便他们有很多的修改。
|
||||
如果你不熟悉 [GitHub][11],[git][12] 或者提到的其它 [版本管理系统][13]包含了这个软件的源代码,以及多年来对该软件的所有修改的历史。甚至可以回溯到该软件的最早版本。对于开发者来说,保留它的历史版本有很多好处。如今对我来说,其中一个好处是可以得到任何一个给定时间点的项目源代码。更准确地说,我可以得到我所要的 8.1.1 发布时的源代码。即便从那之后他们有了很多的修改。
|
||||
|
||||

|
||||
|
||||
在 GitHub 上,你可以使用 “branch” 按钮导航到这个软件的不同版本。[在 Git 中 “Branch” 和 “tags” 相关的一些概念][14]。总的来说,开发者创建 “branch” 和 “tags” 在项目历史中对重要事件保持跟踪,就像当她们启用一个新特性或者发布一个新版本。在这里先不详细介绍了,所有你想知道的都可以看 _tagged_ 的 “v8.1.1” 版本。
|
||||
在 GitHub 上,你可以使用 “branch” (分支)按钮导航到这个软件的不同版本。[“分支” 和 “标签” 是 Git 中一些相关的概念][14]。总的来说,开发者创建 “分支” 和 “标签” 来在项目历史中对重要事件保持跟踪,比如当他们启用一个新特性或者发布一个新版本时。在这里先不详细介绍了,你现在只需要知道我在找被标记为 “v8.1.1” 的版本。
|
||||
|
||||

|
||||
|
||||
在选择了 “v8.1.1” 标签后,页面被刷新,最显著的变化是标签现在作为 URL 的一部分出现。另外,你可能会注意到文件改变数据也不同。在源代码树上,你可以看到现在已经创建了 v8.1.1 标签。在某种意义上,你也可以认为像 git 这样的版本管理工具是一个时光穿梭机,允许你返回进入到以前的项目历史中。
|
||||
在选择了 “v8.1.1” 标签后,页面被刷新,最显著的变化是标签现在作为 URL 的一部分出现。另外,你可能会注意到文件改变日期也有所不同。你现在看到的源代码树是创建了 v8.1.1 标签时的代码。在某种意义上,你也可以认为像 git 这样的版本管理工具是一个时光穿梭机,允许你在项目历史中来回穿梭。
|
||||
|
||||

|
||||
|
||||
在这个时候,我们可以下载 NodeJS 8.1.1 的源代码。你不要错过大的蓝色按钮,建议下载一个项目的 ZIP 压缩包。对于我来说,为讲解的目的,我从命令行中下载并解压这个 ZIP 压缩包。但是,如果你更喜欢使用一个 [GUI][15] 工具,不用担心,你可以这样做:
|
||||
此时,我们可以下载 NodeJS 8.1.1 的源代码。你不要忘记去点那个建议的大的蓝色按钮来下载一个项目的 ZIP 压缩包。对于我来说,为讲解的目的,我从命令行中下载并解压这个 ZIP 压缩包。但是,如果你更喜欢使用一个 [GUI][15] 工具,不用担心,你可以取代下面的命令方式:
|
||||
|
||||
```
|
||||
wget https://github.com/nodejs/node/archive/v8.1.1.zip
|
||||
@ -54,7 +54,7 @@ unzip v8.1.1.zip
|
||||
cd node-8.1.1/
|
||||
```
|
||||
|
||||
下载一个 ZIP 包它做的很好,但是如果你希望去做 “like a pro”,我建议你直接使用 `git` 工具去下载源代码。它一点也不复杂 — 并且如果你是第一次使用一个工具,它将是一个很好的开端,你以后将经常用到它:
|
||||
下载一个 ZIP 包就可以,但是如果你希望“像个专家一样”,我建议你直接使用 `git` 工具去下载源代码。它一点也不复杂 — 并且如果你是第一次使用该工具,它将是一个很好的开端,你以后将经常用到它:
|
||||
|
||||
```
|
||||
# first ensure git is installed on your system
|
||||
@ -66,9 +66,9 @@ sh$ git clone --depth 1 \
|
||||
sh$ cd node/
|
||||
```
|
||||
|
||||
顺便说一下,如果你想发布任何项目,正好可以考虑把这篇文章的第一部分做为一个总体介绍。后面,为了帮你排除常问题,我们将更详细地解释基于 Debian 和基于 ReadHat 的发布。
|
||||
顺便说一下,如果你有任何问题,这篇文章的第一部分只是做一个总体介绍而已。后面,为了帮你排除常见问题,我们将基于 Debian 和基于 RedHat 的发行版更详细地解释。
|
||||
|
||||
不管怎样,在你使用 `git` 或者作为一个 ZIP 压缩包下载了源代码后,你现在应该在当前的目录下提取源代码文件:
|
||||
不管怎样,在你使用 `git` 或者作为一个 ZIP 压缩包下载了源代码后,在当前目录下就有了同样的源代码文件:
|
||||
|
||||
```
|
||||
sh$ ls
|
||||
@ -78,51 +78,51 @@ benchmark CODE_OF_CONDUCT.md CONTRIBUTING.md lib node.g
|
||||
BSDmakefile COLLABORATOR_GUIDE.md deps LICENSE README.md vcbuild.bat
|
||||
```
|
||||
|
||||
### 第 2 步:理解程序的构建系统
|
||||
#### 第 2 步:理解程序的构建系统
|
||||
|
||||
构建系统就是我们通常所说的 "编译源代码”, 其实,编译只是从源代码中生成一个可使用的软件的其中一个阶段。一个构建系统是一套工具,在具体的实践中,为了完全构建一个软件,仅仅需要发出几个命令就可以自动并清晰地完成这些不同的任务。
|
||||
构建系统就是我们通常所说的“编译源代码”,其实,编译只是从源代码中生成一个可使用的软件的其中一个阶段。构建系统是一套工具,用于自动处置不同的任务,以便可以仅通过几个命令就能构建整个软件。
|
||||
|
||||
虽然概念很简单,实际上编译做了很多事情。因为不同的项目或者编程语言可能要求不一样,或者是因为编程体验,或者因为支持的平台、或者因为历史的原因,或者 … 或者 … 选择或创建其它的构建系统的原因有很多。所有的这些都说明可用的不同的解决方案有很多。
|
||||
虽然概念很简单,实际上编译做了很多事情。因为不同的项目或者编程语言也许有不同的要求,或者因为编程者的好恶,或者因为支持的平台、或者因为历史的原因,等等等等 … 选择或创建另外一个构建系统的原因几乎数不清。这方面有许多种不同的解决方案。
|
||||
|
||||
NodeJS 使用一个 [GNU 风格的构建系统][16]。在开源社区中这是一个很流行的选择。一旦开始,将进入一段精彩的旅程。
|
||||
NodeJS 使用一种 [GNU 风格的构建系统][16]。这在开源社区中这是一个很流行的选择。由此开始,你将进入一段精彩的旅程。
|
||||
|
||||
写出和调优一个构建系统是一个非常复杂的任务。但是,作为 “终端用户” 来说, GNU 风格的构建系统使用两个工具来构建它们:`configure` 和 `make`。
|
||||
写出和调优一个构建系统是一个非常复杂的任务。但是,作为 “终端用户” 来说,GNU 风格的构建系统使用两个工具让他们免于此难:`configure` 和 `make`。
|
||||
|
||||
`configure` 文件是项目专用的脚本,为了确保项目可以被构建,它将检查目标系统配置和可用功能,最后使用当前平台专用的脚本来处理构建工作。
|
||||
`configure` 文件是个项目专用的脚本,它将检查目标系统的配置和可用功能,以确保该项目可以被构建,并最终吻合当前平台的特性。
|
||||
|
||||
一个典型的 `configure` 作业的重要部分是去构建 `Makefile`。这个文件包含有效构建项目所需的指令。
|
||||
一个典型的 `configure` 任务的重要部分是去构建 `Makefile`。这个文件包含了有效构建项目所需的指令。
|
||||
|
||||
([`make` 工具][17]),另一方面,一个 POSIX 工具可用于任何类 Unix 系统。它将读取项目专用的 `Makefile` 然后执行所需的操作去构建和安装你的程序。
|
||||
另一方面,[`make` 工具][17],这是一个可用于任何类 Unix 系统的 POSIX 工具。它将读取项目专用的 `Makefile` 然后执行所需的操作去构建和安装你的程序。
|
||||
|
||||
但是,在 Linux 的世界中,你仍然有一些原因去定制你自己专用的构建。
|
||||
但是,在 Linux 的世界中,你仍然有一些定制你自己专用的构建的理由。
|
||||
|
||||
```
|
||||
./configure --help
|
||||
```
|
||||
|
||||
`configure -help` 命令将展示所有你可用的配置选项。再强调一下,它是项目专用的。说实话,有时候,在你完全理解每个配置选项的作用之前,你需要深入到项目中去好好研究。
|
||||
`configure -help` 命令将展示你可用的所有配置选项。再强调一下,这是非常的项目专用。说实话,有时候,在你完全理解每个配置选项的作用之前,你需要深入到项目中去好好研究。
|
||||
|
||||
但是,这里至少有一个标准的 GNU 自动化工具选项,它就是众所周知的 `--prefix` 选项。它与文件系统的层次结构有关,它是你软件要安装的位置。
|
||||
不过,这里至少有一个标准的 GNU 自动化工具选项是你该知道的,它就是众所周知的 `--prefix` 选项。它与文件系统的层次结构有关,它是你软件要安装的位置。
|
||||
|
||||
[Suggested read8 Vim Tips And Tricks That Will Make You A Pro User][18]
|
||||
#### 第 3 步:文件系统层次化标准(FHS)
|
||||
|
||||
### 第 3 步:文件系统层次化标准(FHS)
|
||||
|
||||
大部分典型的 Linux 分发版的文件系统层次结构都遵从 [文件系统层次化标准(FHS)][19]。
|
||||
大部分典型的 Linux 发行版的文件系统层次结构都遵从 [文件系统层次化标准(FHS)][19]。
|
||||
|
||||
这个标准说明了你的系统中各种目录的用途,比如,`/usr`、`/tmp`、`/var` 等等。
|
||||
|
||||
当使用 GNU 自动化工具 _和大多数其它的构建系统_ 时,它的默认安装位置都在你的系统的 `/usr/local` 目录中。依据 FHS 中 _“/usr/local 层级是为系统管理员安装软件的位置使用的,它在系统软件更新时是覆盖安全的。它可以被用于一个主机组中,在 /usr 中找不到的、可共享的程序和数据”_ ,因此,它是一个非常好的选择。
|
||||
当使用 GNU 自动化工具 _和大多数其它的构建系统_ 时,它会把新软件默认安装在你的系统的 `/usr/local` 目录中。这是依据 FHS 中 _“`/usr/local` 层级是为系统管理员本地安装软件时使用的,它在系统软件更新覆盖时是安全的。它也可以用于存放在一组主机中共享,但又没有放到 /usr 中的程序和数据”_,因此,它是一个非常好的选择。
|
||||
|
||||
`/usr/local` 层次以某种方式复制了 root 目录,并且你可以在 `/usr/local/bin` 这里找到可执行程序,在 `/usr/local/lib` 中是库,在 `/usr/local/share` 中是架构依赖文件,等等。
|
||||
`/usr/local` 层级以某种方式复制了根目录,你可以在 `/usr/local/bin` 这里找到可执行程序,在 `/usr/local/lib` 中找到库,在 `/usr/local/share` 中找到架构无关的文件,等等。
|
||||
|
||||
使用 `/usr/local` 树作为你定制安装的软件位置的唯一问题是,你的软件将在这里混杂在一起。尤其是你安装了多个软件之后,将很难去准确地跟踪 `/usr/local/bin` 和 `/usr/local/lib` 到底属于哪个软件。它虽然不足以在你的系统上产生问题。毕竟,`/usr/bin` 是很混乱的。但是,它在你想去手工卸载已安装的软件时会将成为一个问题。
|
||||
使用 `/usr/local` 树作为你定制安装的软件位置的唯一问题是,你的软件的文件将在这里混杂在一起。尤其是你安装了多个软件之后,将很难去准确地跟踪 `/usr/local/bin` 和 `/usr/local/lib` 中的哪个文件到底属于哪个软件。它虽然不会导致系统的问题。毕竟,`/usr/bin` 也是一样混乱的。但是,有一天你想去卸载一个手工安装的软件时它会将成为一个问题。
|
||||
|
||||
去解决这个问题,我通常喜欢安装定制的软件到 `/opt` 子目录下。再次引用 FHS:
|
||||
要解决这个问题,我通常喜欢安装定制的软件到 `/opt` 子目录下。再次引用 FHS:
|
||||
|
||||
_“`/opt` 是为安装应用程序插件软件包而保留的。一个包安装在 `/opt` 下必须在 `/opt/<package>` 或者 `/opt/<provider>` 目录中独立定位到它的静态文件,`<package>` 处是所说的那个软件名的名字,而 `<provider>` 处是提供者的 LANANA 注册名字。”_(译者注:LANANA 是指 The Linux Assigned Names And Numbers Authority,http://www.lanana.org/ )
|
||||
> “`/opt` 是为安装附加的应用程序软件包而保留的。
|
||||
|
||||
> 包安装在 `/opt` 下的软件包必须将它的静态文件放在单独的 `/opt/<package>` 或者 `/opt/<provider>` 目录中,此处 `<package>` 是所说的那个软件名的名字,而 `<provider>` 处是提供者的 LANANA 注册名字。”(LCTT 译注:LANANA 是指 [The Linux Assigned Names And Numbers Authority](http://www.lanana.org/)。 )
|
||||
|
||||
因此,我们将在 `/opt` 下创建一个子目录,用于我们定制的 NodeJS 的安装。并且,如果有一天我想去卸载它,我只是很简单地去删除那个目录:
|
||||
因此,我们将在 `/opt` 下创建一个子目录,用于我们定制的 NodeJS 安装。并且,如果有一天我想去卸载它,我只是很简单地去删除那个目录:
|
||||
|
||||
```
|
||||
sh$ sudo mkdir /opt/node-v8.1.1
|
||||
@ -140,7 +140,7 @@ sh$ make -j9 && echo ok
|
||||
# is blocked by an I/O operation.
|
||||
```
|
||||
|
||||
在你运行完成 `make` 命令之后,如果有任何的除了 “ok” 以外的信息,将意味着在构建过程中有错误。比如,我们使用一个 `-j` 选项去运行一个并行构建,在构建系统的大量输出过程中,检索错误信息并不是件很容易的事。
|
||||
在你运行完成 `make` 命令之后,如果有任何的除了 “ok” 以外的信息,将意味着在构建过程中有错误。当我们使用一个 `-j` 选项去运行并行构建时,在构建系统的大量输出过程中,检索错误信息并不是件很容易的事。
|
||||
|
||||
在这种情况下,只能是重新开始 `make`,并且不要使用 `-j` 选项。这样错误将会出现在输出信息的最后面:
|
||||
|
||||
@ -163,9 +163,9 @@ v8.1.1
|
||||
|
||||
### B. 如果在源代码安装的过程中出现错误怎么办?
|
||||
|
||||
我上面介绍的是大多数的文档丰富的项目在“构建指令”页面上你所看到的。但是,本文的目标是让你从源代码开始去编译你的第一个软件,它可能要花一些时间去研究一些常见的问题。因此,我将再次重新开始一遍整个过程,但是,这次是在一个最新的、最小化安装的 Debian 9.0 和 CentOS 7.0 系统上。因此,你可能看到很多的错误和我怎么去解决它。
|
||||
我上面介绍的大多是你能在文档完备的项目的“构建指令”页面上看到。但是,本文的目标是让你从源代码开始去编译你的第一个软件,它可能要花一些时间去研究一些常见的问题。因此,我将再次重新开始一遍整个过程,但是,这次是在一个最新的、最小化安装的 Debian 9.0 和 CentOS 7.0 系统上。因此,你可能看到我遇到的错误以及我怎么去解决它。
|
||||
|
||||
### 从 Debian 9.0 中 “Stretch” 开始
|
||||
#### 从 Debian 9.0 中 “Stretch” 开始
|
||||
|
||||
```
|
||||
itsfoss@debian:~$ git clone --depth 1 \
|
||||
@ -174,7 +174,7 @@ itsfoss@debian:~$ git clone --depth 1 \
|
||||
-bash: git: command not found
|
||||
```
|
||||
|
||||
这个问题非常容易去诊断和解决。仅仅是去安装这个 `git` 包:
|
||||
这个问题非常容易去诊断和解决。去安装这个 `git` 包即可:
|
||||
|
||||
```
|
||||
itsfoss@debian:~$ sudo apt-get install git
|
||||
@ -205,7 +205,7 @@ Node.js configure error: No acceptable C compiler found!
|
||||
it in a non-standard prefix.
|
||||
```
|
||||
|
||||
很显然,编译一个项目,你需要一个编译器。NodeJS 是使用 [C++ language][20] 写的,我们需要一个 C++ [编译器][21]。在这里我将安装 `g++`,它就是为这个目的写的 GNU C++ 编译器:
|
||||
很显然,编译一个项目,你需要一个编译器。NodeJS 是使用 [C++ 语言][20] 写的,我们需要一个 C++ [编译器][21]。在这里我将安装 `g++`,它就是为这个目的写的 GNU C++ 编译器:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo apt-get install g++
|
||||
@ -237,9 +237,9 @@ v8.1.1
|
||||
|
||||
成功!
|
||||
|
||||
请注意:我将安装各种工具一步一步去展示怎么去诊断编译问题,以及展示怎么去解决这些问题。但是,如果你搜索关于这个主题的更多文档,或者读其它的教程,你将发现,很多分发版有一个 “meta-packages”,它像一个伞一样去安装一系列的或者全部的常用工具用于编译软件。在基于 Debian 的系统上,你或许遇到过 [构建要素][22] 包,它就是这种用作。在基于 Red Hat 的分发版中,它将是 _“开发工具”_ 组。
|
||||
请注意:我将一次又一次地安装各种工具去展示怎么去诊断编译问题,以及展示怎么去解决这些问题。但是,如果你搜索关于这个主题的更多文档,或者读其它的教程,你将发现,很多发行版有一个 “meta-packages”,它包罗了安装一些或者全部的用于编译软件的常用工具。在基于 Debian 的系统上,你或许遇到过 [build-essentials][22] 包,它就是这种用作。在基于 Red Hat 的发行版中,它将是 _“Development Tools”_ 组。
|
||||
|
||||
### 在 CentOS 7.0 上
|
||||
#### 在 CentOS 7.0 上
|
||||
|
||||
```
|
||||
[itsfoss@centos ~]$ git clone --depth 1 \
|
||||
@ -279,7 +279,7 @@ Node.js configure error: No acceptable C compiler found!
|
||||
it in a non-standard prefix.
|
||||
```
|
||||
|
||||
你知道的:NodeJS 是使用 C++ 语言写的,但是,我的系统缺少合适的编译器。Yum 可以帮到你。因为,我不是一个合格的 CentOS 用户,在因特网上准确地找到包含 g++ 编译器的包的名字是很困难的。这个页面会指导我:[https://superuser.com/questions/590808/yum-install-gcc-g-doesnt-work-anymore-in-centos-6-4][23]
|
||||
你知道的:NodeJS 是使用 C++ 语言写的,但是,我的系统缺少合适的编译器。Yum 可以帮到你。因为,我不是一个合格的 CentOS 用户,我实际上是在互联网上搜索到包含 g++ 编译器的包的确切名字的。这个页面指导了我:[https://superuser.com/questions/590808/yum-install-gcc-g-doesnt-work-anymore-in-centos-6-4][23] 。
|
||||
|
||||
```
|
||||
[itsfoss@centos node]$ sudo yum install gcc-c++
|
||||
@ -309,9 +309,9 @@ v8.1.1
|
||||
|
||||
### C. 从源代码中对要安装的软件做一些改变
|
||||
|
||||
你从源代码中安装一个软件,可能是因为你的分发仓库中没有一个可用的特定版本。或者因为你想去 _修改_ 那个程序。也可能是修复一个 bug 或者增加一个特性。毕竟,开源软件这些都可以做到。因此,我将抓住这个机会,让你亲自体验怎么去编译你自己的软件。
|
||||
从源代码中安装一个软件,可能是因为你的分发仓库中没有一个可用的特定版本。或者因为你想去 _修改_ 那个程序。也可能是修复一个 bug 或者增加一个特性。毕竟,开源软件这些都可以做到。因此,我将抓住这个机会,让你亲自体验怎么去编译你自己的软件。
|
||||
|
||||
在这里,我将在 NodeJS 源代码上生成一个主要的改变。然后,我们将看到我们的改变将被纳入到软件的编译版本中:
|
||||
在这里,我将在 NodeJS 源代码上做一个微小改变。然后,我们将看到我们的改变将被纳入到软件的编译版本中:
|
||||
|
||||
用你喜欢的 [文本编辑器][24](如,vim、nano、gedit、 … )打开文件 `node/src/node.cc`。然后,尝试找到如下的代码片段:
|
||||
|
||||
@ -351,7 +351,7 @@ index bbce1022..a5618b57 100644
|
||||
PrintHelp();
|
||||
```
|
||||
|
||||
在你改变的行之前,你将看到一个 “-” (减号标志)。而在改变之后的行前面有一个 “+” (加号标志)。
|
||||
在你前面改变的那行之前,你将看到一个 “-” (减号标志)。而在改变之后的行前面有一个 “+” (加号标志)。
|
||||
|
||||
现在可以去重新编译并重新安装你的软件了:
|
||||
|
||||
@ -363,37 +363,37 @@ ok
|
||||
|
||||
这个时候,可能失败的唯一原因就是你改变代码时的输入错误。如果就是这种情况,在文本编辑器中重新打开 `node/src/node.cc` 文件并修复错误。
|
||||
|
||||
一旦你管理的一个编译和安装的新修改版本的 NodeJS,将可以去检查你的修改是否包含到软件中:
|
||||
一旦你完成了新修改版本的 NodeJS 的编译和安装,就可以去检查你的修改是否包含到软件中:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ /opt/node/bin/node --version
|
||||
v8.1.1 (compiled by myself)
|
||||
```
|
||||
|
||||
恭喜你!你生成了开源程序中你的第一个改变!
|
||||
恭喜你!你对开源程序做出了你的第一个改变!
|
||||
|
||||
### D. 让 shell 定位到定制构建的软件
|
||||
### D. 让 shell 找到我们定制构建的软件
|
||||
|
||||
到目前为止,你可能注意到,我通常启动我新编译的 NodeJS 软件是通过指定一个到二进制文件的绝对路径。
|
||||
到目前为止,你可能注意到,我通常启动我新编译的 NodeJS 软件是通过指定到该二进制文件的绝对路径。
|
||||
|
||||
```
|
||||
/opt/node/bin/node
|
||||
```
|
||||
|
||||
这是可以正常工作的。但是,这样太麻烦。实际上有两种办法可以去解决这个问题。但是,去理解它们,你必须首先明白,你的 shell 定位可执行文件是进入到通过在[环境变量][26]`PATH` 中指定的目录去查找的。
|
||||
这是可以正常工作的。但是,这样太麻烦。实际上有两种办法可以去解决这个问题。但是,去理解它们,你必须首先明白,你的 shell 定位可执行文件是通过在[环境变量][26] `PATH` 中指定的目录里面查找的。
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ echo $PATH
|
||||
/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
|
||||
```
|
||||
|
||||
在 Debian 系统上,如果你不指定一个精确的目录做为命令名字的一部分,shell 将首先在 `/usr/local/bin` 中查找可执行程序,如果没有找到,然后进入 `/usr/bin` 中查找,如果没有找到,然后进入 `/bin`查找,如果没有找到,然后进入 `/usr/local/games` 查找,如果没有找到,然后进入 `/usr/games` 查找,如果没有找到,那么,shell 将报告一个错误,_“command not found”_。
|
||||
在这个 Debian 系统上,如果你不指定一个精确的目录做为命令名字的一部分,shell 将首先在 `/usr/local/bin` 中查找可执行程序;如果没有找到,然后进入 `/usr/bin` 中查找;如果没有找到,然后进入 `/bin`查找;如果没有找到,然后进入 `/usr/local/games` 查找;如果没有找到,然后进入 `/usr/games` 查找;如果没有找到,那么,shell 将报告一个错误,_“command not found”_。
|
||||
|
||||
由此,我们可以知道有两种方法去确保命令可以被 shell 访问到:通过将它增加到已经配置好的 `PATH` 目录中,或者将包含可执行程序的目录添加到 `PATH` 中。
|
||||
由此,我们可以知道有两种方法去确保命令可以被 shell 访问到:将它(该二进制程序)增加到已经配置好的 `PATH` 目录中,或者将包含可执行程序的目录添加到 `PATH` 中。
|
||||
|
||||
### 从 /usr/local/bin 中添加一个链接
|
||||
#### 从 /usr/local/bin 中添加一个链接
|
||||
|
||||
仅从 `/opt/node/bin` 中 _拷贝_ 节点二进制可执行文件到 `/usr/local/bin` 是将是一个错误的做法。因为,如果这么做,可执行程序将无法定位到在 `/opt/node/` 中的其它需要的组件。(常见的做法是软件在它自己的位置去定位它所需要的资源文件)
|
||||
只是从 `/opt/node/bin` 中 _拷贝_ NodeJS 二进制可执行文件到 `/usr/local/bin` 是一个错误的做法。因为,如果这么做,该可执行程序将无法定位到在 `/opt/node/` 中的需要的其它组件。(软件以它自己的位置去定位它所需要的资源文件是常见的做法)
|
||||
|
||||
因此,传统的做法是去使用一个符号链接:
|
||||
|
||||
@ -405,11 +405,11 @@ itsfoss@debian:~/node$ node --version
|
||||
v8.1.1 (compiled by myself)
|
||||
```
|
||||
|
||||
这一个简单而有效的解决办法,尤其是,如果一个软件包是由好几个众所周知的可执行程序组成的,因为,你将为每个用户调用命令创建一个符号链接。例如,如果你熟悉 NodeJS,你知道应用的 `npm` 组件,也是 `/usr/local/bin` 中的符号链接。这只是,我让你做了一个练习。
|
||||
这一个简单而有效的解决办法,尤其是,如果一个软件包是由好几个众所周知的可执行程序组成的,因为,你将为每个用户调用的命令创建一个符号链接。例如,如果你熟悉 NodeJS,你知道应用的 `npm` 组件,也应该从 `/usr/local/bin` 做个符号链接。我把这个留给你做练习。
|
||||
|
||||
### 修改 PATH
|
||||
#### 修改 PATH
|
||||
|
||||
首先,如果你尝试前面的解决方案,先移除前面创建的节点符号链接,去从一个干净的状态开始:
|
||||
首先,如果你尝试过前面的解决方案,请先移除前面创建的节点符号链接,去从一个干净的状态开始:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ sudo rm /usr/local/bin/node
|
||||
@ -417,7 +417,7 @@ itsfoss@debian:~/node$ which -a node || echo not found
|
||||
not found
|
||||
```
|
||||
|
||||
现在,这里有一个不可思议的命令去改变你的 `PATH`:
|
||||
现在,这里有一个改变你的 `PATH` 的魔法命令:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ export PATH="/opt/node/bin:${PATH}"
|
||||
@ -425,7 +425,7 @@ itsfoss@debian:~/node$ echo $PATH
|
||||
/opt/node/bin:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
|
||||
```
|
||||
|
||||
简单说就是,我用前面的内容替换了环境变量 `PATH` 中原先的内容,但是通过一个 `/opt/node/bin` 的前缀。因此,你可以想像一下,shell 将先进入到 `/opt/node/bin` 目录中查找可执行程序。我们也可以使用 `which` 命令去确认一下:
|
||||
简单说就是,我用环境变量 `PATH` 之前的内容前缀了一个 `/opt/node/bin` 替换了其原先的内容。因此,你可以想像一下,shell 将先进入到 `/opt/node/bin` 目录中查找可执行程序。我们也可以使用 `which` 命令去确认一下:
|
||||
|
||||
```
|
||||
itsfoss@debian:~/node$ which -a node || echo not found
|
||||
@ -434,7 +434,7 @@ itsfoss@debian:~/node$ node --version
|
||||
v8.1.1 (compiled by myself)
|
||||
```
|
||||
|
||||
鉴于 “link” 解决方案是永久的,只要创建到 `/usr/local/bin`的符号链接就行了,而对 `PATH` 的改变仅对进入到当前的 shell 生效。你可以自己做一些研究,如何做到对 `PATH` 的永久改变。给你一个提示,可以将它写到你的 “profile” 中。如果你找到这个解决方案,不要犹豫,通过下面的评论区共享给其它的读者!
|
||||
鉴于 “符号链接” 解决方案是永久的,只要创建到 `/usr/local/bin` 的符号链接就行了,而对 `PATH` 的改变仅影响到当前的 shell。你可以自己做一些研究,如何做到对 `PATH` 的永久改变。给你一个提示,可以将它写到你的 “profile” 中。如果你找到这个解决方案,不要犹豫,通过下面的评论区共享给其它的读者!
|
||||
|
||||
### E. 怎么去卸载刚才从源代码中安装的软件
|
||||
|
||||
@ -444,7 +444,7 @@ v8.1.1 (compiled by myself)
|
||||
sudo rm -rf /opt/node-v8.1.1
|
||||
```
|
||||
|
||||
注意:`sudo` 和 `rm -rf` 是 “非常危险的鸡尾酒!”,一定要在按下 “enter” 键之前多检查几次你的命令。你不会得到任何的确认信息,并且如果你删除了错误的目录它是不可恢复的 …
|
||||
注意:`sudo` 和 `rm -rf` 是 “非常危险的鸡尾酒”!一定要在按下回车键之前多检查几次你的命令。你不会得到任何的确认信息,并且如果你删除了错误的目录它是不可恢复的 …
|
||||
|
||||
然后,如果你修改了你的 `PATH`,你可以去恢复这些改变。它一点也不复杂。
|
||||
|
||||
@ -460,9 +460,9 @@ itsfoss@debian:~/node$ sudo find /usr/local/bin \
|
||||
|
||||
### 等等? 依赖地狱在哪里?
|
||||
|
||||
一个最终结论是,如果你读过有关的编译定制软件的文档,你可能听到关于 [依赖地狱][27] 的说法。那是在你能够成功编译一个软件之前,对那种烦人情况的一个呢称,你必须首先编译一个前提条件所需要的库,它又可能要求其它的库,而这些库有可能与你的系统上已经安装的其它软件不兼容。
|
||||
作为最终的讨论,如果你读过有关的编译定制软件的文档,你可能听到关于 <ruby>[依赖地狱][27]<rt>dependency hell</rt></ruby> 的说法。那是在你能够成功编译一个软件之前,对那种烦人情况的一个别名,你必须首先编译一个前提条件所需要的库,它又可能要求其它的库,而这些库有可能与你的系统上已经安装的其它软件不兼容。
|
||||
|
||||
作为你的分发版的包维护者的工作的一部分,去真正地解决那些依赖关系,确保你的系统上的各种软件都使用了可兼容的库,并且按正确的顺序去安装。
|
||||
发行版的软件包维护者的部分工作,就是实际去地解决那些依赖地狱,确保你的系统上的各种软件都使用了兼容的库,并且按正确的顺序去安装。
|
||||
|
||||
在这篇文章中,我特意选择了 NodeJS 去安装,是因为它几乎没有依赖。我说 “几乎” 是因为,实际上,它 _有_ 依赖。但是,这些源代码的依赖已经预置到项目的源仓库中(在 `node/deps` 子目录下),因此,在你动手编译之前,你不用手动去下载和安装它们。
|
||||
|
||||
@ -478,9 +478,9 @@ itsfoss@debian:~/node$ sudo find /usr/local/bin \
|
||||
|
||||
via: https://itsfoss.com/install-software-from-source-code/
|
||||
|
||||
作者:[Sylvain Leroux ][a]
|
||||
作者:[Sylvain Leroux][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,70 +1,55 @@
|
||||
GitHub 欢迎所有 CI 工具
|
||||
GitHub 欢迎一切 CI 工具
|
||||
====================
|
||||
|
||||
|
||||
[][11]
|
||||
|
||||
持续集成([CI][12])工具可以帮助你在每次提交时执行测试,并将[报告结果][13]提交到合并请求,从而帮助维持团队的质量标准。结合持续交付([CD][14])工具,你还可以在多种配置上测试你的代码,运行额外的性能测试,并自动执行每个步骤[直到产品][15]。
|
||||
持续集成([CI][12])工具可以帮助你在每次提交时执行测试,并将[报告结果][13]提交到合并请求,从而帮助维持团队的质量标准。结合持续交付([CD][14])工具,你还可以在多种配置上测试你的代码,运行额外的性能测试,并自动执行每个步骤,[直到进入产品阶段][15]。
|
||||
|
||||
有几个[与 GitHub 集成][16]的 CI 和 CD 工具,其中一些可以在 [GitHub Marketplace][17] 中点击几下安装。有了这么多的选择,你可以选择最好的工具 - 即使它不是与你的系统预集成的工具。
|
||||
有几个[与 GitHub 集成][16]的 CI 和 CD 工具,其中一些可以在 [GitHub Marketplace][17] 中点击几下安装。有了这么多的选择,你可以选择最好的工具 —— 即使它不是与你的系统预集成的工具。
|
||||
|
||||
最适合你的工具取决于许多因素,其中包括:
|
||||
|
||||
* 编程语言和程序架构
|
||||
|
||||
* 你计划支持的操作系统和浏览器
|
||||
|
||||
* 你团队的经验和技能
|
||||
|
||||
* 扩展能力和增长计划
|
||||
|
||||
* 依赖系统的地理分布和使用的人
|
||||
|
||||
* 打包和交付目标
|
||||
|
||||
当然,无法为所有这些情况优化你的 CI 工具。构建它们的人需要选择哪些情况服务更好,何时优先考虑复杂性而不是简单性。例如,如果你想测试针对一个平台的用特定语言编写的小程序,那么你就不需要那些可在数十个平台上测试,有许多编程语言和框架的,用来测试嵌入软件控制器的复杂工具。
|
||||
当然,无法为所有这些情况优化你的 CI 工具。构建它们的人需要选择哪些情况下服务更好,何时优先考虑复杂性而不是简单性。例如,如果你想测试针对一个平台的用特定语言编写的小程序,那么你就不需要那些可在数十个平台上测试,有许多编程语言和框架的,用来测试嵌入软件控制器的复杂工具。
|
||||
|
||||
如果你需要一些灵感来挑选最好使用哪个 CI 工具,那么看一下[ Github 上的流行项目][18]。许多人在他们的 README.md 中将他们的集成的 CI/CD 工具的状态显示为徽章。我们还分析了 GitHub 社区中超过 5000 万个仓库中 CI 工具的使用情况,并发现了很多变化。下图显示了根据我们的 pull 请求中使用最多的[提交状态上下文][19],GitHub.com 使用的前 10 个 CI 工具的相对百分比。
|
||||
如果你需要一些灵感来挑选最好使用哪个 CI 工具,那么看一下 [Github 上的流行项目][18]。许多人在他们的 README.md 中将他们的集成的 CI/CD 工具的状态显示为徽章。我们还分析了 GitHub 社区中超过 5000 万个仓库中 CI 工具的使用情况,并发现了很多变化。下图显示了根据我们的拉取请求中使用最多的[提交状态上下文][19],GitHub.com 使用的前 10 个 CI 工具的相对百分比。
|
||||
|
||||
_我们的分析还显示,许多团队在他们的项目中使用多个 CI 工具,使他们能够发挥它们最擅长的。_
|
||||
|
||||
[][20]
|
||||
[][20]
|
||||
|
||||
如果你想查看,下面是团队中使用最多的 10 个工具:
|
||||
|
||||
* [Travis CI][1]
|
||||
|
||||
* [Circle CI][2]
|
||||
|
||||
* [Jenkins][3]
|
||||
|
||||
* [AppVeyor][4]
|
||||
|
||||
* [CodeShip][5]
|
||||
|
||||
* [Drone][6]
|
||||
|
||||
* [Semaphore CI][7]
|
||||
|
||||
* [Buildkite][8]
|
||||
|
||||
* [Wercker][9]
|
||||
|
||||
* [TeamCity][10]
|
||||
|
||||
这只是尝试选择默认的、预先集成的工具,而没有花时间根据任务研究和选择最好的工具,但是对于你的特定情况会有很多[很好的选择][21]。如果你以后改变主意,没问题。当你为特定情况选择最佳工具时,你可以保证量身定制的性能和不再适合时互换的自由。
|
||||
|
||||
准备好了解 CI 工具如何适应你的工作流程了么?
|
||||
|
||||
[浏览 GitHub Marketplace][22]
|
||||
- [浏览 GitHub Marketplace][22]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2463-github-welcomes-all-ci-tools
|
||||
|
||||
作者:[jonico ][a]
|
||||
作者:[jonico][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
系统管理 101:补丁管理
|
||||
============================================================
|
||||
|
||||
就在之前几篇文章,我开始了“系统管理 101”系列文章,用来记录现今许多初级系统管理员,DevOps 工程师或者“全栈”开发者可能不曾接触过的一些系统管理方面的基本知识。按照我原本的设想,该系列文章已经是完结了的。然而后来 WannaCry 恶意软件出现并在补丁管理不善的 Windows 主机网络间爆发。我能想象到那些仍然深陷 2000 年代 Linux 与 Windows 争论的读者听到这个消息可能已经面露优越的微笑。
|
||||
就在之前几篇文章,我开始了“系统管理 101”系列文章,用来记录现今许多初级系统管理员、DevOps 工程师或者“全栈”开发者可能不曾接触过的一些系统管理方面的基本知识。按照我原本的设想,该系列文章已经是完结了的。然而后来 WannaCry 恶意软件出现,并在补丁管理不善的 Windows 主机网络间爆发。我能想象到那些仍然深陷 2000 年代 Linux 与 Windows 争论的读者听到这个消息可能已经面露优越的微笑。
|
||||
|
||||
我之所以这么快就决定再次继续“系统管理 101”文章系列,是因为我意识到在补丁管理方面一些 Linux 系统管理员和 Windows 系统管理员没有差别。实话说,在一些方面甚至做的更差(特别是以运行时间为豪)。所以,这篇文章会涉及 Linux 下补丁管理的基础概念,包括良好的补丁管理该是怎样的,你可能会用到的一些相关工具,以及整个补丁安装过程是如何进行的。
|
||||
我之所以这么快就决定再次继续“系统管理 101”文章系列,是因为我意识到在补丁管理方面一些 Linux 系统管理员和 Windows 系统管理员没有差别。实话说,在一些方面甚至做的更差(特别是以持续运行时间为自豪)。所以,这篇文章会涉及 Linux 下补丁管理的基础概念,包括良好的补丁管理该是怎样的,你可能会用到的一些相关工具,以及整个补丁安装过程是如何进行的。
|
||||
|
||||
### 什么是补丁管理?
|
||||
|
||||
我所说的补丁管理,是指你部署用于升级服务器上软件的系统,不仅仅是把软件更新到最新最好的前沿版本。即使是像 Debian 这样为了“稳定性”持续保持某一特定版本软件的保守派发行版,也会时常发布升级补丁用于修补错误和安全漏洞。
|
||||
|
||||
当然,因为开发者对最新最好版本的需求,你需要派生软件源码并做出修改,或者因为你喜欢给自己额外的工作量,你的组织可能会决定自己维护特定软件的版本,这时你就会遇到问题。理想情况下,你应该已经配置好你的系统,让它在自动构建和打包定制版本软件时使用其它软件所用的同一套持续集成系统。然而,许多系统管理员仍旧在自己的本地主机上按照维基上的文档(但愿是最新的文档)使用过时的方法打包软件。不论使用哪种方法,你都需要明确你所使用的版本有没有安全缺陷,如果有,那必须确保新补丁安装到你定制版本的软件上了。
|
||||
当然,如果你的组织决定自己维护特定软件的版本,要么是因为开发者有最新最好版本的需求,需要派生软件源码并做出修改,要么是因为你喜欢给自己额外的工作量,这时你就会遇到问题。理想情况下,你应该已经配置好你的系统,让它在自动构建和打包定制版本软件时使用其它软件所用的同一套持续集成系统。然而,许多系统管理员仍旧在自己的本地主机上按照维基上的文档(但愿是最新的文档)使用过时的方法打包软件。不论使用哪种方法,你都需要明确你所使用的版本有没有安全缺陷,如果有,那必须确保新补丁安装到你定制版本的软件上了。
|
||||
|
||||
### 良好的补丁管理是怎样的
|
||||
|
||||
@ -17,17 +17,17 @@
|
||||
|
||||
一些组织仍在使用手动方式管理补丁。在这种方式下,当出现一个安全补丁,系统管理员就要凭借记忆,登录到各个服务器上进行检查。在确定了哪些服务器需要升级后,再使用服务器内建的包管理工具从发行版仓库升级这些软件。最后以相同的方式升级剩余的所有服务器。
|
||||
|
||||
手动管理补丁的方式存在很多问题。首先,这么做会使补丁安装成为一个苦力活,安装补丁需要越多人力成本,系统管理员就越可能推迟甚至完全忽略它。其次,手动管理方式依赖系统管理员凭借记忆去跟踪他或她所负责的服务器的升级情况。这非常容易导致有些服务器被遗漏而未能及时升级。
|
||||
手动管理补丁的方式存在很多问题。首先,这么做会使补丁安装成为一个苦力活,安装补丁越多就需要越多人力成本,系统管理员就越可能推迟甚至完全忽略它。其次,手动管理方式依赖系统管理员凭借记忆去跟踪他或她所负责的服务器的升级情况。这非常容易导致有些服务器被遗漏而未能及时升级。
|
||||
|
||||
补丁管理越快速简便,你就越可能把它做好。你应该构建一个系统,用来快速查询哪些服务器运行着特定的软件,以及这些软件的版本号,而且它最好还能够推送各种升级补丁。就个人而言,我倾向于使用 MCollective 这样的编排工具来完成这个任务,但是红帽提供的 Satellite 以及 Canonical 提供的 Landscape 也可以让你在统一的管理接口查看服务器上软件的版本信息,并且安装补丁。
|
||||
补丁管理越快速简便,你就越可能把它做好。你应该构建一个系统,用来快速查询哪些服务器运行着特定的软件,以及这些软件的版本号,而且它最好还能够推送各种升级补丁。就个人而言,我倾向于使用 MCollective 这样的编排工具来完成这个任务,但是红帽提供的 Satellite 以及 Canonical 提供的 Landscape 也可以让你在统一的管理界面上查看服务器的软件版本信息,并且安装补丁。
|
||||
|
||||
补丁安装还应该具有容错能力。你应该具备在不下线的情况下为服务安装补丁的能力。这同样适用于需要重启系统的内核补丁。我采用的方法是把我的服务器划分为不同的高可用组,lb1,app1,rabbitmq1 和 db1 在一个组,而lb2,app2,rabbitmq2 和 db2 在另一个组。这样,我就能一次升级一个组,而无须下线服务。
|
||||
补丁安装还应该具有容错能力。你应该具备在不下线的情况下为服务安装补丁的能力。这同样适用于需要重启系统的内核补丁。我采用的方法是把我的服务器划分为不同的高可用组,lb1、app1、rabbitmq1 和 db1 在一个组,而lb2、app2、rabbitmq2 和 db2 在另一个组。这样,我就能一次升级一个组,而无须下线服务。
|
||||
|
||||
所以,多快才能算快呢?对于少数没有附带服务的软件,你的系统最快应该能够在几分钟到一小时内安装好补丁(例如 bash 的 ShellShock 漏洞)。对于像 OpenSSL 这样需要重启服务的软件,以容错的方式安装补丁并重启服务的过程可能会花费稍多的时间,但这就是编排工具派上用场的时候。我在最近的关于 MCollective 的文章中(查看 2016 年 12 月和 2017 年 1 月的工单)给了几个使用 MCollective 实现补丁管理的例子。你最好能够部署一个系统,以具备容错性的自动化方式简化补丁安装和服务重启的过程。
|
||||
|
||||
如果补丁要求重启系统,像内核补丁,那它会花费更多的时间。再次强调,自动化和编排工具能够让这个过程比你想象的还要快。我能够在一到两个小时内在生产环境中以容错方式升级并重启服务器,如果重启之间无须等待集群同步备份,这个过程还能更快。
|
||||
|
||||
不幸的是,许多系统管理员仍坚信过时的观点,把运行时间作为一种骄傲的象征——鉴于紧急内核补丁大约每年一次。对于我来说,这只能说明你没有认真对待系统的安全性。
|
||||
不幸的是,许多系统管理员仍坚信过时的观点,把持续运行时间(uptime)作为一种骄傲的象征——鉴于紧急内核补丁大约每年一次。对于我来说,这只能说明你没有认真对待系统的安全性!
|
||||
|
||||
很多组织仍然使用无法暂时下线的单点故障的服务器,也因为这个原因,它无法升级或者重启。如果你想让系统更加安全,你需要去除过时的包袱,搭建一个至少能在深夜维护时段重启的系统。
|
||||
|
||||
@ -41,9 +41,9 @@ Kyle Rankin 是高级安全与基础设施架构师,其著作包括: Linux H
|
||||
|
||||
via: https://www.linuxjournal.com/content/sysadmin-101-patch-management
|
||||
|
||||
作者:[Kyle Rankin ][a]
|
||||
作者:[Kyle Rankin][a]
|
||||
译者:[haoqixu](https://github.com/haoqixu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user