mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
9f1ce38f72
32
sources/Deciphering Top.md
Normal file
32
sources/Deciphering Top.md
Normal file
@ -0,0 +1,32 @@
|
||||
Deciphering Top
|
||||
================================================================================
|
||||
When curious about the performance of a server, one of the first places I stop is "top". Top is not perfect, not by a long shot, but it does provide a decent point in time snapshot of the server, and attempts to answer the question of "what is going on right now?". Unfortunatly, the output of top can easily be misinterpreted if you do not have a good understanding of the different fields of data presented.
|
||||
|
||||
I'm not going to go through the [man page][2] for top, when you have the time and inclination it is always there waiting for you. What I would like to do is point out a few highlights of how I use it to get a quick overview of the system and hopefully get a direction I should go next. Top is often my first stop in troubleshooting, but it is rarely my only stop.
|
||||
|
||||
[][1]
|
||||
|
||||
The very first thing I look at in top is the load average, in the top right hand corner of the screen. The load average is computed based on a number of statistics gathered, but can generally be thought of as the amount of work the CPU is being asked to do. If your machine has a single CPU core, than a load average of one would mean that the machine was perfectly loaded and had sufficient power to accomplish all tasks during the time it was sampled. Likewise, if the load average is two, the single CPU machine was overloaded, and would have needed two available cores to accomplish the work it was being asked to do in the same amount of time. With todays 8, 16, and 32 core servers shipping, I need to think twice when considering the load average. If I need to check, I press "1" in top, which will drop down a list of all CPU cores so I can get a quick count for comparison.
|
||||
|
||||
The second item I check is the first process listed, and the ninth column over, labled "%CPU". The explanation for this column is novel:
|
||||
|
||||
> The task's share of the elapsed CPU time since the last screen update, expressed as a percentage of total CPU time. In a true SMP environment, if 'Irix mode' is Off, top will operate in 'Solaris mode' where a task's cpu usage will be divided by the total number of CPUs. You toggle 'Irix/Solaris' modes with the 'I' interactive command.
|
||||
|
||||
Clear as mud, right? The main idea to keep in mind is that if a single process has gone berzerk for one reason or antoher, it will probably show up listed first in top, with a rather extreme number for %CPU.
|
||||
|
||||
The next area I glance at is the "Cpu(s):" line, in the center of the header block. Specifically, I'm interested in the %us, which is user processes, %sy, for system processes, %id, which is idle time, and %wa, which is the percent of time the CPU had processes that were waiting on a response from an I/O stream to execute. This percentage should always be close to zero, and anything higher than 5% should be looked at closer.
|
||||
|
||||
Lastly, I like to check the system up time, shown in the top left hand corner. If I'm having problems with a server, and the server was recently rebooted, there may be a correlation there, perhaps a daemon that didn't start.
|
||||
|
||||
All of these checks take only a few seconds. I may leave top running for a few minutes and watch the processes, CPU, and load if I'm just observing, but normally I'm in and out of top fairly quickly. Top is one of those fantastic sysadmin tools that is built to give you a quick overview of the health of your system, and allow you to quickly diagnose potential problems.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/deciphering-top
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.flickr.com/photos/51724787@N06/10847969205/
|
||||
[2]:http://www.linuxmanpages.com/man1/top.1.php
|
||||
67
sources/Five Examples Of The ping Utility.md
Normal file
67
sources/Five Examples Of The ping Utility.md
Normal file
@ -0,0 +1,67 @@
|
||||
Five Examples Of The ping Utility
|
||||
================================================================================
|
||||
### What is ping Utility? ###
|
||||
|
||||
Before going through some real world examples of the ping utility, let me explain what this commandline tool is and its purpose. The ping utility is used to test the reachability of a host on an Internet Protocol (IP) network. Its names comes from the active sonar method which is used to create a pulse of sound (ping) under the water and listening to echo requests from surrounding objects. This method is the best way to explain how the network ping utility works. The ping utility sends echo requests to a host and waits for an ICMP response.
|
||||
|
||||
Some Examples Of The ping Utility In Practice:
|
||||
|
||||
### Find Out The Ip Address Of A Host ###
|
||||
|
||||
Sometimes you need the ip address of a host, you can use the ping tool like shown in Figure 1. Just type the ping command and after it type the hostname.
|
||||
|
||||
ping www.omgubuntu.com
|
||||
|
||||

|
||||
|
||||
### Find Out The Version Of The ping Utility You Are Using ###
|
||||
|
||||
The -V flag can be used to find out which version of the ping tool you have. Type the following command and it will display the current version of the ping utility.
|
||||
|
||||
ping -V
|
||||
|
||||
As you can see from Figure 2, I am using ping utility, iputils-sss20101006.
|
||||
|
||||

|
||||
|
||||
### Exit Pinging ###
|
||||
|
||||
When you ping a machine with the ‘ping host’ command, pinging doesn’t stop and you have to pres CTRL+C to stop it, or you can use the -c (count) option to send a specified number of packets. When using the -c option, after the number of packets specified by the network admin (user whatever) is sent, the pinging process stops automatically instead of pressing CTRL+C.
|
||||
|
||||
ping -c 13 127.0.0.1
|
||||
|
||||
The above command is used to send 13 packets to my localhost.
|
||||
|
||||

|
||||
|
||||
As you can see from Figure 3 i did not press CTRL+C to exit pinging,it stopped automatically.
|
||||
|
||||
### Specify The Interval Between Packets ###
|
||||
|
||||
Did you know that ping sends a packet every second? Do you like to speed up or slow down? The -i option can be used to specify the interval between packets. Use the following commands to send packets very fast or very slow.
|
||||
|
||||
### Send A Packet Every 0.13 Seconds ###
|
||||
|
||||
ping -i 0.13
|
||||
|
||||

|
||||
|
||||
### Send A Packet Every 13 Seconds ###
|
||||
|
||||
ping -i 13
|
||||
|
||||
### Combine the -i option with -c option ###
|
||||
|
||||
ping -c 13 -i 3
|
||||
|
||||
It will take 39 seconds to send 13 packets with the specified interval of 3 seconds.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/five-examples-ping-utility/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,80 @@
|
||||
How to create desktop shortcut or launcher on Linux
|
||||
================================================================================
|
||||
If you have a program you use regularly on Linux desktop, you may want to create a "desktop shortcut", so you can launch the program by simply clicking on the shortcut. While most GUI programs automatically create their desktop shortcut during installation, some GUI programs or terminal applications may require you to set up associated shortcuts manually.
|
||||
|
||||
In this tutorial, I will describe **how to create a desktop shortcut or launcher on various Linux desktops**.
|
||||
|
||||
A desktop shortcut is represented by a corresponding .desktop file which contains meta information of a given app (e.g., name of the app, launch command, location of icon file, etc.). Desktop shortcut files are placed in **/usr/share/applications** or **~/.local/share/applications**. The former directory stores desktop shortcuts that are available for every user, while the latter folder contains shortcuts created for a particular user only.
|
||||
|
||||
### Create a Desktop Shortcut From the Command Line ###
|
||||
|
||||
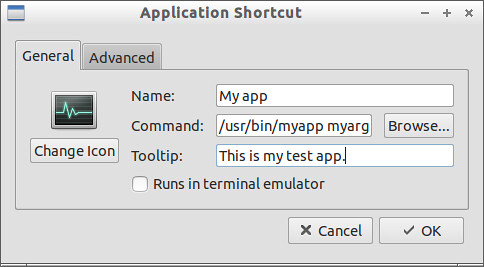
To manually create a desktop shortcut for a particular program or command, you can create a .desktop file using any text editor, and place it in either /usr/share/applications or ~/.local/share/applications. A typical .desktop file looks like the following.
|
||||
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Version=1.0 # version of an app.
|
||||
Name[en_US]=yEd # name of an app.
|
||||
GenericName=GUI Port Scanner # longer name of an app.
|
||||
Exec=java -jar /opt/yed-3.11.1/yed.jar # command used to launch an app.
|
||||
Terminal=false # whether an app requires to be run in a terminal.
|
||||
Icon[en_US]=/opt/yed-3.11.1/icons/yicon32.png # location of icon file.
|
||||
Type=Application # type.
|
||||
Categories=Application;Network;Security; # categories in which this app should be listed.
|
||||
Comment[en_US]=yEd Graph Editor # comment which appears as a tooltip.
|
||||
|
||||
Besides manually create .desktop file, there are various desktop-specific ways to create an application shortcut, which I am going to cover in the rest of the tutorial.
|
||||
|
||||
### Create a Desktop Shortcut on GNOME Desktop ###
|
||||
|
||||
In GNOME desktop, you can use gnome-desktop-item-edit to configure a desktop shortcut easily.
|
||||
|
||||
$ gnome-desktop-item-edit ~/.local/share/applications --create-new
|
||||
|
||||
In this example, gnome-desktop-item-edit will automatically create a desktop launcher file in ~/.local/share/applications. To customize icon location and other info, you may have to edit the .desktop file manually afterward.
|
||||
|
||||
If gnome-desktop-item-edit is not available (e.g., on Ubuntu), you can install it as follows.
|
||||
|
||||
$ sudo apt-get install --no-install-recommends gnome-panel
|
||||
|
||||
### Create a Desktop Shortcut on KDE Desktop ###
|
||||
|
||||
kickoff is the default application launcher in KDE desktop. Adding a new application shortcut to kickoff is straightforward.
|
||||
|
||||
First right-click on kickoff icon located at the left bottom corner of your desktop, and then choose "Edit Applications" menu.
|
||||
|
||||
[][1]
|
||||
|
||||
Click on an appropriate category (e.g., "Utilities") under which you want to create a shortcut, and click on "New Item" button on the top. Type in the name of the app.
|
||||
|
||||
[][2]
|
||||
|
||||
Finally, fill in the meta information of the app being launched by the shortcut.
|
||||
|
||||
[][3]
|
||||
|
||||
### Create a Desktop Shortcut on Xfce Desktop ###
|
||||
|
||||
If you are on Xfce desktop, right-click on the desktop background, and then select "Create Launcher" menu. Then fill out the details of the shortcut.
|
||||
|
||||
### Create a Desktop Shortcut on Cinnamon Desktop ###
|
||||
|
||||
If you are on Linux Mint Cinnamon desktop, you can create an application launcher by right-clicking on the desktop background, and selecting "Create Launcher" menu.
|
||||
|
||||
### Create a Desktop Shortcut on LXDE Desktop ###
|
||||
|
||||
On LXDE desktop, simply right click on the desktop background, and choose "Create New Shortcut".
|
||||
|
||||
[][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2013/11/create-desktop-shortcut-launcher-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.flickr.com/photos/xmodulo/10848506344/
|
||||
[2]:http://www.flickr.com/photos/xmodulo/10848418496/
|
||||
[3]:http://www.flickr.com/photos/xmodulo/10848506284/
|
||||
[4]:http://www.flickr.com/photos/xmodulo/10848922593/
|
||||
@ -0,0 +1,27 @@
|
||||
Suse Linux Enterprise expands regular support to 10 years
|
||||
================================================================================
|
||||
**Suse expands general support on customer requests**
|
||||
|
||||
Suse Linux Enterprise (SLE) version 11 and up will come with 10 years of general support instead of the seven years offered up to now, in a move that matches services from competitors.
|
||||
|
||||
"We will move to a new life cycle of Suse Linux Enterprise," said Nils Brauckmann, president and general manager for Suse, during his keynote at the Susecon 2013 conference in Lake Buena Vista, Florida. A [video][1] of the keynote was posted on YouTube.
|
||||
|
||||
"Suse Linux Enterprise 11 is the first major version to receive 10 years of general support followed by 3 years of extended support (LTSS). We consider this the new standard Suse Linux Enterprise life cycle going forward, covering versions 12 and on as well," said Gerald Pfeifer, senior director of Suse product management and operations, in an email Wednesday. Suse sells open-source Linux software to businesses.
|
||||
|
||||
Suse offers different packages for extended support. Extending the support to 13 years will cost US$60,000 for up to 100 servers and $80,000 for up to 500 servers, said Pfeifer. Support for an unlimited number of servers can be extended for $125,000 he said, adding that these are standard prices that Suse has been using for several years.
|
||||
|
||||
By moving from a seven-plus-three-year support cycle to a 10-plus-three-year support cycle, customers get more time under general support, Brauckmann said during his keynote. The decision to increase the support cycle was made a couple of weeks ago and is a direct reaction to customer requests, he added.
|
||||
|
||||
Suse's general support extension follows Red Hat's move in January last year to extend the life cycle of Red Hat Enterprise Linux (RHEL) 5 and 6 from seven to 10 years, in response to enterprise customer demand.
|
||||
|
||||
Oracle Linux, which is based on RHEL, expanded its life cycle support from eight to 10 years in February last year. CentOS, an Enterprise Linux distribution that is based on a rebuild of RHEL, has also been offering 10-year support as a standard for a while.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/operating-systems/382610/suse-linux-enterprise-expands-regular-support-10-years
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.youtube.com/watch?v=T0W4izFu_WM
|
||||
@ -0,0 +1,134 @@
|
||||
21 The Linux Kernel: Configuring the Kernel Part 17
|
||||
================================================================================
|
||||
|
||||
|
||||
Aloha! This next article will cover various drivers.
|
||||
|
||||
First, the "virtio console" is a virtual console that is used with hypervisors.
|
||||
|
||||
The "IPMI top-level message handler" is a message manager for the IPMI system. IPMI stands for Intelligent Platform Management Interface. IPMI is an interface for managing the system via network without using a shell.
|
||||
|
||||
"/dev/nvram support" permits the system to read and write memory in the real time clock's memory. Generally, this feature is used for saving data during a power loss.
|
||||
|
||||
The next driver supports the Siemens R3964 packet protocol (Siemens R3964 line discipline). This is a device-to-device protocol.
|
||||
|
||||
Now, we can move on to PCMCIA character devices. However, most of the drivers here are vendor/device specific.
|
||||
|
||||
The RAW driver allows block devices to be bound to the device files /dev/raw/rawN (RAW driver (/dev/raw/rawN)). The advantage to this is efficient zero-copy. However, most software will still prefer to access the storage through /dev/sd** or /dev/hd**.
|
||||
|
||||
Next, the maximum number of RAW devices can be supported is set.
|
||||
|
||||
The following driver makes the device file /dev/hpet (HPET - High Precision Event Timer).
|
||||
|
||||
NOTE: Many of you may be wondering why enabling these device file matter. Well, these device files serve as an interface between the software and hardware.
|
||||
|
||||
The HPET timers can be mapped with this driver (Allow mmap of HPET). Mapping is the process of making a list of address in memory of devices and files. The files can then be found faster by getting the address from the memory and then commanding the hard-drive to get the data from the address.
|
||||
|
||||
|
||||
The "Hangcheck timer" is used to detect whether of not the system has locked-up.
|
||||
This timer watches for locked-up processes. As soon as a process freezes, a timer starts. After the timer goes off, if the process has not restarted or closed, then the timer will force the process to close.
|
||||
|
||||
Linus Torvalds Quote: Portability is for people who cannot write new programs.
|
||||
|
||||
The TPM security chip that uses Trusted Computing Group's specification will need this driver (TPM Hardware Support).
|
||||
|
||||
Now, we can move on to I2C devices. I2C stands for Inter-Integrated Circuit and is spoken as "eye two see". However, some people say "eye squared see". I2C is a serial bus standard.
|
||||
|
||||
Some old software used I2C adapters as class devices, but software now does not do that (Enable compatibility bits for old user-space). So, this driver will offer backwards compatibility for older software.
|
||||
|
||||
Next, the I2C device files can be made (I2C device interface).
|
||||
|
||||
I2C can support multiplexing with this driver (I2C bus multiplexing support).
|
||||
|
||||
I2C can support GPIO-controlled multiplexing with this driver (GPIO-based I2C multiplexer).
|
||||
|
||||
Various tests can be performed on I2C and SMBus with this driver for developers (I2C/SMBus Test Stub).
|
||||
|
||||
The I2C system will produce debugging messages with this feature enabled (I2C Core debugging messages).
|
||||
|
||||
The next driver produces additional I2C debugging messages (I2C Algorithm debugging messages).
|
||||
|
||||
Linus Torvalds Quote: The main reason there are no raw devices [in Linux] is that I personally think that raw devices are a stupid idea.
|
||||
|
||||
The following driver will cause the I2C drivers to produce debugging messages (I2C Bus debugging messages).
|
||||
|
||||
Next, we have Serial Peripheral Interface support (SPI support). SPI is a synchronous serial protocol used on SPI buses.
|
||||
|
||||
After that, there is a driver for High speed synchronous Serial Interface support (HSI support). HSI is a synchronous serial protocol.
|
||||
|
||||
PPS can also be supported by the Linux kernel (PPS support).
|
||||
|
||||
The "IP-over-InfiniBand" driver allows IP packets to be transported over InfiniBand.
|
||||
|
||||
After that, there is a debugging driver for IP-over-InfiniBand (IP-over-InfiniBand debugging).
|
||||
|
||||
SCSI's RDMA protocol can also travel over InfiniBand (InfiniBand SCSI RDMA Protocol).
|
||||
|
||||
There is also an extension for the iSCSI protocol to transmit over InfiniBand (iSCSI Extensions for RDMA (iSER)).
|
||||
|
||||
Sometimes, errors occur in the core system that the whole system must know (EDAC (Error Detection And Correction) reporting). This driver sends the core errors to the system. Generally, such low-level errors are reported in the processor and then seen by this driver to let other system processes know about or handle the error.
|
||||
|
||||
This driver provides legacy support for EDAC to use older versions of sysfs (EDAC legacy sysfs).
|
||||
|
||||
EDAC can be set to send debugging information to the logging system of Linux (Debugging).
|
||||
|
||||
Linus Torvalds Quote: Nobody actually creates perfect code the first time around, except me.
|
||||
|
||||
The Machine Check Exceptions (MCEs) are converted to a readable form via this driver (Decode MCEs in human-readable form (only on AMD for now)).
|
||||
MCEs are hardware errors detected by the CPU. MCEs usually trigger kernel panics.
|
||||
|
||||
The decoding process for MCE to a readable form can be injected to test error handling (Simple MCE injection interface over /sysfs).
|
||||
|
||||
The next driver allows errors to be detected in memory and then corrected (Main Memory EDAC (Error Detection And Correction) reporting).
|
||||
|
||||
Next, there are many drivers that detect and correct errors on specific hardware sets.
|
||||
|
||||
Linus Torvalds Quote: Theory and practice sometimes clash. And when that happens, theory loses. Every single time.
|
||||
|
||||
Now, we can move on to the "Real Time Clock". This is commonly abbreviated "RTC". The RTC keeps track of time.
|
||||
|
||||
|
||||
|
||||
The next setting allows us to make the Linux system use the time from the RTC as the time on the "wall clock" (Set system time from RTC on startup and resume). The wall clock is the clock on the desktop or the time seen using the "date" command.
|
||||
|
||||
Alternately, the wall clock can get the time from an NTP server and then sync with the RTC (Set the RTC time based on NTP synchronization).
|
||||
|
||||
Some systems have more than one RTC, so the user must set which is the default (RTC used to set the system time).
|
||||
It is best to make the first one (/dev/rtc0) the primary clock.
|
||||
|
||||
Debugging abilities can be set for the RTC system (RTC debug support).
|
||||
|
||||
The RTC can use various interfaces for giving the operating system the current time. Using sysfs will require this driver (/sys/class/rtc/rtcN (sysfs)) while using proc will require this driver (/proc/driver/rtc (procfs for rtcN)). Special RTC character devices can be made and used (/dev/rtcN (character devices)). The shell command "hwclock" uses /dev/rtc, so the RTC character devices are needed.
|
||||
|
||||
The next driver allows interrupts of the RTC to be emulated on the /dev/ interface (RTC UIE emulation on dev interface). This driver reads the clock time and allows the new time to be retrieved from /dev/.
|
||||
|
||||
The RTC system can be tested with the test driver (Test driver/device).
|
||||
|
||||
Next, we will discuss the Direct Memory Access system.
|
||||
DMA is the process of hardware accessing the memory independently of the processor. DMA increases system performance because the processor will have less to do if the hardware is performing more tasks for itself. Otherwise, the hardware would be waiting for the processor to complete the task.
|
||||
|
||||
The debugging engine is for debugging the DMA system (DMA Engine debugging).
|
||||
|
||||
Next, there are many vendor/device specific drivers for DMA support.
|
||||
|
||||
Some DMA controllers support big endian reading and writing with this driver (Use big endian I/O register access).
|
||||
|
||||
Big endian refers to the arrangement of the binary code. The number system used in English speaking countries places the largest end of the number on the left. For example, in the number 17, the most left numbers place is the tens place which is larger than the ones place. In big endian, each byte is arranged with the largest portion on the left. A byte is eight bits. Example: 10110100. Each place has a value of 128, 64, 32, 16, 8, 4, 2, and 1 respectively. So the byte mentioned converts to the decimal number 180.
|
||||
|
||||
The DMA system can use the network to reduce CPU usage (Network: TCP receive copy offload).
|
||||
|
||||
The "DMA Test Client" is used for testing the DMA system.
|
||||
|
||||
In the next article, we will discuss the display/video drivers. Mahalo!
|
||||
|
||||
REFERENCE: The quotes from Linus Torvalds came from this site: [http://en.wikiquote.org/wiki/Linus_Torvalds][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/threads/the-linux-kernel-configuring-the-kernel-part-17.4875/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://en.wikiquote.org/wiki/Linus_Torvalds
|
||||
@ -0,0 +1,31 @@
|
||||
Ubuntu vs. openSUSE: Weighing different styles of corporate control
|
||||
================================================================================
|
||||
*Ubuntu and openSUSE approach their Linux distros in much different ways. Which do you prefer?*
|
||||
|
||||
It's no secret that a rather large portion of Linux development is funded by companies with a financial interest in seeing Linux be improved. (And, by "Linux," I mean "All the various pieces and parts that make up a complete Linux-based system.") But there is a pretty major difference between how various companies go about that.
|
||||
|
||||
Let's take a look at two high-profile examples: Ubuntu and openSUSE.
|
||||
|
||||
Both are distributions of Linux. Both are large, long-standing and highly successful projects with a large community of both volunteers and paid workers. Yet the difference between the two is fairly extreme, and highly important.
|
||||
|
||||
For Ubuntu, the primary direction is set by the team at Canonical and its head-master, Mark Shuttleworth. Examples such as Unity (Ubuntu's in-house user interface) and Mir (Ubuntu's in-house display server) quickly jump to mind when talking about how Canonical really “steers the ship” of Ubuntu. Goals, projects and priorities put into place by the parent company are, in many cases, simply non-negotiable (so to speak). Ubuntu's Unity user interface, for example, was a must-have for Canonical as it was part of their broader strategy. Some community members love it. Some hate it. But, either way, it's happening.
|
||||
|
||||
But is that bad? I'm not really convinced that it is either good or bad. It's simply how it is with that particular project and company.
|
||||
|
||||
Contrast that with openSUSE, who also has a "corporate master" in the form of, well, SUSE. The key difference there being that SUSE has a commercial offering in the form of "SUSE Linux Enterprise." And, while there is a great deal of technical overlap between openSUSE (the community Linux distro) and SUSE Linux Enterprise (the commercial offering)...the two are not, technically, the same.
|
||||
|
||||
Which means that SUSE, as a company, can afford to take a more “hands-off” approach to working with openSUSE. Sure, they have a vested interest in seeing key bits of technology (such as, say, Btrfs) be improved, tested and packaged with the community distro – as they may wish to include it in the commercial offering – but the separation between the community and commercial systems provides them with a bit more flexibility, in this regard, than Canonical presently has.
|
||||
|
||||
This is similar to the way Red Hat works with the Fedora project, and seems to be a generally successful approach as a mechanism for a company that sells enterprise-level Linux systems to utilize a community Linux distro as a foundation.
|
||||
|
||||
I'll be honest. I see benefits and drawbacks to both models. Both have their challenges in terms of organization and management (and public perception). And, in all reality, there is more in common than not with the two approaches.
|
||||
|
||||
I'd love to hear your thoughts on this. Do you prefer to have a singular captain at the helm of your community-based Linux distro (sort of a "benevolent dictator")? Or do like the big decisions of your Linux distro to be a bit more community-driven? Should companies behind a given flavor of Linux rule with an iron fist, or be more hands-off? Leave your thoughts in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/community/node/84250
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user