mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-06 23:50:16 +08:00
commit
9ed9817483
85
published/20160506 Setup honeypot in Kali Linux.md
Normal file
85
published/20160506 Setup honeypot in Kali Linux.md
Normal file
@ -0,0 +1,85 @@
|
||||
在 Kali Linux 环境下设置蜜罐
|
||||
=========================
|
||||
|
||||
Pentbox 是一个包含了许多可以使渗透测试工作变得简单流程化的工具的安全套件。它是用 Ruby 编写并且面向 GNU / Linux,同时也支持 Windows、MacOS 和其它任何安装有 Ruby 的系统。在这篇短文中我们将讲解如何在 Kali Linux 环境下设置蜜罐。如果你还不知道什么是蜜罐(honeypot),“蜜罐是一种计算机安全机制,其设置用来发现、转移、或者以某种方式,抵消对信息系统的非授权尝试。"
|
||||
|
||||
### 下载 Pentbox:
|
||||
|
||||
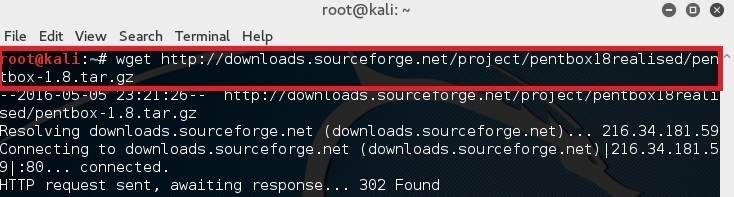
在你的终端中简单的键入下面的命令来下载 pentbox-1.8。
|
||||
|
||||
```
|
||||
root@kali:~# wget http://downloads.sourceforge.net/project/pentbox18realised/pentbox-1.8.tar.gz
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 解压 pentbox 文件
|
||||
|
||||
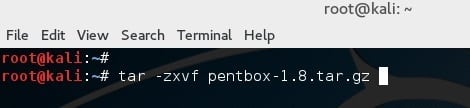
使用如下命令解压文件:
|
||||
|
||||
```
|
||||
root@kali:~# tar -zxvf pentbox-1.8.tar.gz
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 运行 pentbox 的 ruby 脚本
|
||||
|
||||
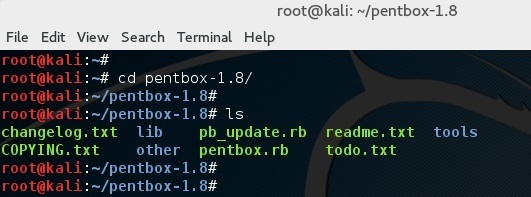
改变目录到 pentbox 文件夹:
|
||||
|
||||
```
|
||||
root@kali:~# cd pentbox-1.8/
|
||||
```
|
||||
|
||||
|
||||
|
||||
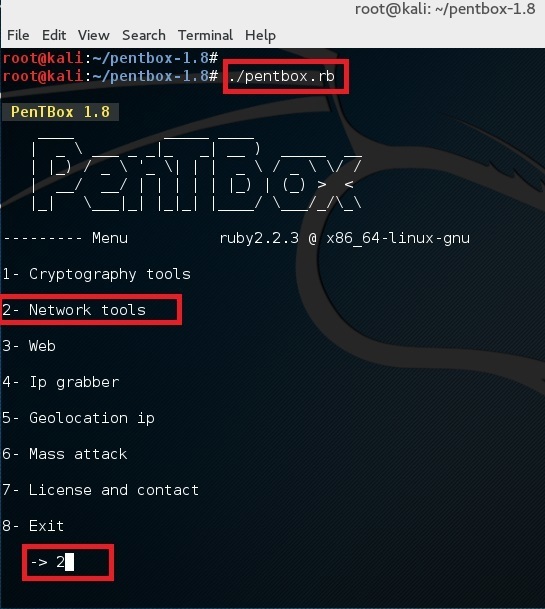
使用下面的命令来运行 pentbox:
|
||||
|
||||
```
|
||||
root@kali:~# ./pentbox.rb
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 设置一个蜜罐
|
||||
|
||||
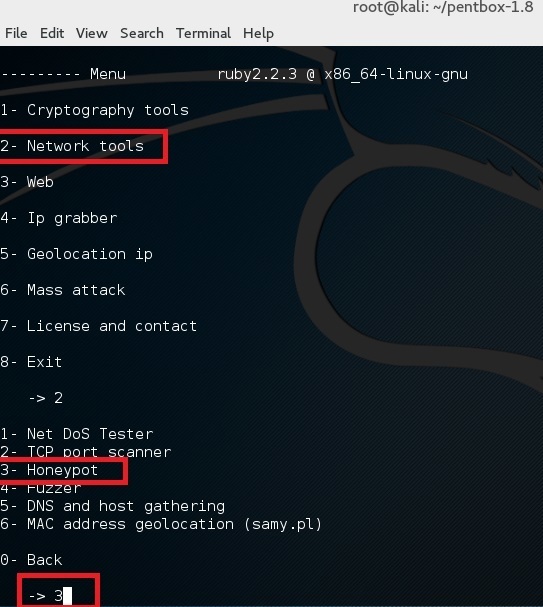
使用选项 2 (Network Tools) 然后是其中的选项 3 (Honeypot)。
|
||||
|
||||
|
||||
|
||||
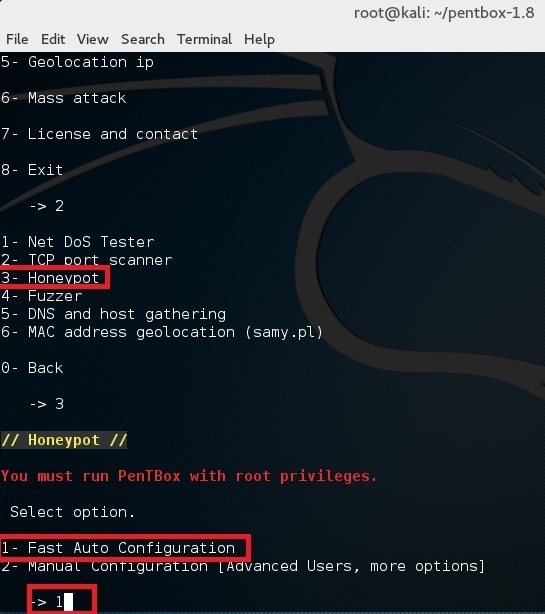
完成让我们执行首次测试,选择其中的选项 1 (Fast Auto Configuration)
|
||||
|
||||
|
||||
|
||||
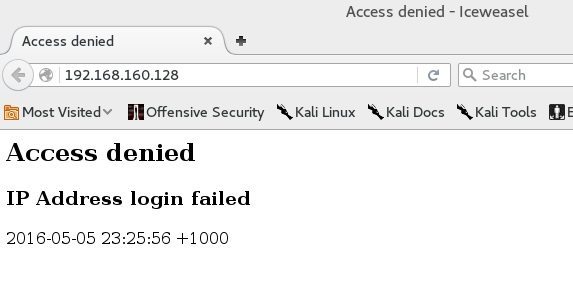
这样就在 80 端口上开启了一个蜜罐。打开浏览器并且打开链接 http://192.168.160.128 (这里的 192.168.160.128 是你自己的 IP 地址。)你应该会看到一个 Access denied 的报错。
|
||||
|
||||
|
||||
|
||||
|
||||
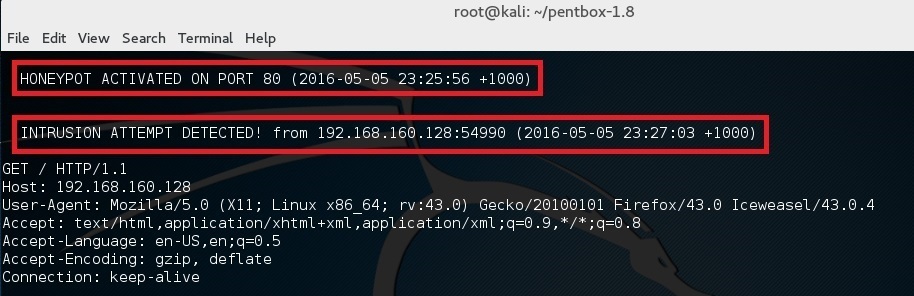
并且在你的终端应该会看到 “HONEYPOT ACTIVATED ON PORT 80” 和跟着的 “INTRUSION ATTEMPT DETECTED”。
|
||||
|
||||
|
||||
|
||||
现在,如果你在同一步选择了选项 2 (Manual Configuration), 你应该看见更多的其它选项:
|
||||
|
||||
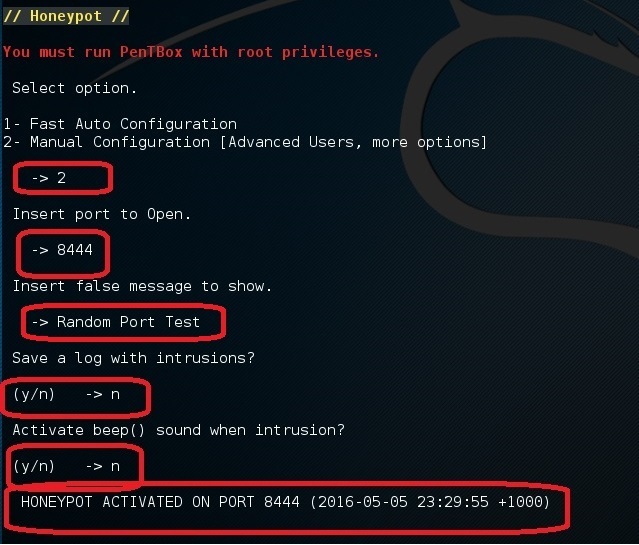
|
||||
|
||||
执行相同的步骤但是这次选择 22 端口 (SSH 端口)。接着在你家里的路由器上做一个端口转发,将外部的 22 端口转发到这台机器的 22 端口上。或者,把这个蜜罐设置在你的云端服务器的一个 VPS 上。
|
||||
|
||||
你将会被有如此多的机器在持续不断地扫描着 SSH 端口而震惊。 你知道你接着应该干什么么? 你应该黑回它们去!桀桀桀!
|
||||
|
||||
如果视频是你的菜的话,这里有一个设置蜜罐的视频:
|
||||
|
||||
<https://youtu.be/NufOMiktplA>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.blackmoreops.com/2016/05/06/setup-honeypot-in-kali-linux/
|
||||
|
||||
作者:[blackmoreops.com][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: blackmoreops.com
|
||||
@ -0,0 +1,46 @@
|
||||
DAISY : 一种 Linux 上可用的服务于视力缺陷者的文本格式
|
||||
=================================================================
|
||||
|
||||
|
||||

|
||||
|
||||
*图片: 由Kate Ter Haar提供图片。 opensource.com 后期修饰。 CC BY-SA 2.0 *
|
||||
|
||||
如果你是盲人或像我一样有视力障碍,你可能经常需要各种软硬件才能做到视觉正常的人们视之为理所当然的事情。这其中之一就是阅读的印刷图书的专用格式:布莱叶盲文(Braille)(假设你知道怎样阅读它)或特殊的文本格式例如DAISY。
|
||||
|
||||
### DAISY 是什么?
|
||||
|
||||
DAISY 是数字化无障碍信息系统(Digital Accessible Information System)的缩写。 它是一种开放的标准,专用于帮助盲人阅读课本、杂志、报纸、小说,以及你想到的各种东西。 它由[ DAISY 联盟][1]创立于上世纪 90 年代中期,该联盟包括的组织们致力于制定出一套标准,可以让以这种方式标记的文本易于阅读、可以跳转、进行注释以及其它的文本操作,就像视觉正常的人能做的一样。
|
||||
|
||||
当前的 DAISY 3.0 版本发布于 2005 年中期,是一个完全重写了的标准。它创建的目的是更容易撰写遵守该规范的书籍。值得注意的是,DAISY 能够仅支持纯文本、或仅是录音(PCM wave 文件格式或者 MP3 格式)、或既有文本也有录音。特殊的软件能阅读这类书,并支持用户设置书签和目录导航,就像正常人阅读印刷书籍一样。
|
||||
|
||||
### DAISY 是怎样工作的呢?
|
||||
|
||||
DAISY,除开特殊的版本,它工作时有点像这样:你拥有自己的主向导文件(在 DAISY 2.02 中是 ncc.html),它包含书籍的元数据,比如作者姓名、版权信息、书籍页数等等。而在 DAISY 3.0 中这个文件是一个有效的 XML 文件,以及一个被强烈建议包含在每一本书中的 DTD(文档类型定义)文件。
|
||||
|
||||
在导航控制文件中,标记精确描述了各个位置——无论是文本导航中当前光标位置还是录音中的毫秒级定位,这让该软件可以跳到确切的位置,就像视力健康的人翻到某个章节一样。值得注意的是这种导航控制文件仅包含书中主要的、最大的书籍组成部分的位置。
|
||||
|
||||
更小的内容组成部分由 SMIL(同步多媒体集成语言(synchronized multimedia integration language))文件处理。导航的层次很大程度上取决于书籍的标记的怎么样。这样设想一下,如果印刷书籍没有章节标题,你就需要花很多的时间来确定自己阅读的位置。如果一本 DAISY 格式的书籍被标记的很差,你可能只能转到书本的开头或者目录。如果书籍被标记的太差了(或者完全没有标记),你的 DAISY 阅读软件很可能会直接忽略它。
|
||||
|
||||
### 为什么需要专门的软件?
|
||||
|
||||
你可能会问,如果 DAISY 仅仅是 HTML、XML、录音文件,为什么还需要使用专门的软件进行阅读和操作。单纯从技术上而言,你并不需要。专业化的软件大多数情况下是为了方便。这就像在 Linux 操作系统中,一个简单的 Web 浏览器可以被用来打开并阅读书籍。如果你在一本 DAISY 3 的书中点击 XML 文件,软件通常做的就是读取那些你赋予访问权限的书籍的名称,并建立一个列表让你点击选择要打开的书。如果书籍被标记的很差,它不会显示在这份清单中。
|
||||
|
||||
创建 DAISY 则完全是另一件事了,通常需要专门的软件,或需要拥有足够的专业知识来修改一个通用的软件以达到这样的目的。
|
||||
|
||||
### 结语
|
||||
|
||||
幸运的是,DAISY 是一个已确立的标准。虽然它在阅读方面表现的很棒,但是需要特殊软件来生产它使得视力缺陷者孤立于正常人眼中的世界,在那里人们可以以各种格式去阅读他们电子化书籍。这就是 DAISY 联盟在 EPUB 格式取得了 DAISY 成功的原因,它的第 3 版支持一种叫做“媒体覆盖”的规范,基本上来说是在 EPUB 电子书中可选增加声频或视频。由于 EPUB 和 DAISY 共享了很多 XML 标记,一些能够阅读 DAISY 的软件能够看到 EPUB 电子书但不能阅读它们。这也就意味着只要网站为我们换到这种开放格式的书籍,我们将会有更多可选的软件来阅读我们的书籍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/daisy-linux-compatible-text-format-visually-impaired
|
||||
|
||||
作者:[Kendell Clark][a]
|
||||
译者:[theArcticOcean](https://github.com/theArcticOcean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kendell-clark
|
||||
[1]: http://www.daisy.org
|
||||
@ -1,32 +1,31 @@
|
||||
Googler:现在可以 Linux 终端下进行 Google 搜索了!
|
||||
Googler:现在可以 Linux 终端下进行 Google 搜索了!
|
||||
============================================
|
||||
|
||||

|
||||
|
||||
一个小问题:你每天做什么事?当然了,好多事情,但是我可以指出一件事,你几乎每天(如果不是每天)都会用 Google 搜索,我说的对吗?
|
||||
一个小问题:你每天做什么事?当然了,好多事情,但是我可以指出一件事,你几乎每天(如果不是每天)都会用 Google 搜索,我说的对吗?(LCTT 译注:Google 是啥?/cry )
|
||||
|
||||
现在,如果你是一位 Linux 用户(我猜你也是),这里有另外一个问题:如果你甚至不用离开终端就可以进行 Google 搜索那岂不是相当棒?甚至不用打开一个浏览器窗口?
|
||||
|
||||
如果你是一位类 Unix 系统的狂热者而且也是喜欢终端界面的人,我知道你的答案是肯定的,而且我认为,接下来你也将喜欢山我今天将要介绍的这个漂亮的小工具。他被称做 Googler。
|
||||
如果你是一位类 [*nix][7] 系统的狂热者而且也是喜欢终端界面的人,我知道你的答案是肯定的,而且我认为,接下来你也将喜欢上我今天将要介绍的这个漂亮的小工具。它被称做 Googler。
|
||||
|
||||
### Googler:在你 linux 终端下的 google
|
||||
|
||||
### Googler:在你 linux 终端下的 google
|
||||
|
||||
Googler 是一个简单的命令行工具用于直接在命令行窗口中进行 google 搜索,Googler 主要支持三种类型的 Google 搜索:
|
||||
Googler 是一个简单的命令行工具,它用于直接在命令行窗口中进行 google 搜索,Googler 主要支持三种类型的 Google 搜索:
|
||||
|
||||
- Google 搜索:简单的 Google 搜索,和在 Google 主页搜索是等效的。
|
||||
- Google 新闻搜索:Google 新闻搜索,和在 Google News 中的搜索一样。
|
||||
- Google 站点搜索:Google 从一个特定的网站搜索结果。
|
||||
|
||||
Googler 用标题,链接和网页摘要来显示搜索结果。搜索出来的结果可以仅通过两个按键就可以在浏览器里面直接打开。
|
||||
Googler 用标题、链接和网页摘要来显示搜索结果。搜索出来的结果可以仅通过两个按键就可以在浏览器里面直接打开。
|
||||
|
||||

|
||||
|
||||
### 在 Ubuntu 下安装 Googler
|
||||
|
||||
先让我们进行软件的安装
|
||||
先让我们进行软件的安装。
|
||||
|
||||
首先确保你的 python 版本大于等于3.3,可以用以下命令查看。
|
||||
首先确保你的 python 版本大于等于 3.3,可以用以下命令查看。
|
||||
|
||||
```
|
||||
python3 --version
|
||||
@ -47,45 +46,55 @@ sudo cp googler-completion.bash /etc/bash_completion.d/
|
||||
|
||||
这样 Googler 就带着命令自动完成特性安装完毕了。
|
||||
|
||||
### 特点&基本用法
|
||||
### 特点 & 基本用法
|
||||
|
||||
如果我们快速浏览它所有的特点,我们会发现 Googler 实际上是一个十分强大的工具,他的一些主要特点就是:
|
||||
如果我们快速浏览它所有的特点,我们会发现 Googler 实际上是一个十分强大的工具,它的一些主要特点就是:
|
||||
|
||||
交互界面:在终端下运行以下命令
|
||||
#### 交互界面
|
||||
|
||||
在终端下运行以下命令:
|
||||
|
||||
```
|
||||
googler
|
||||
```
|
||||
|
||||
交互界面就会被打开,Googler 的开发者,Arun Prakash Jana 称之为提示符,你可以输入?去寻找可用的命令参数
|
||||
交互界面就会被打开,Googler 的开发者 [Arun Prakash Jana][1] 称之为全向提示符(omniprompt),你可以输入 `?` 去寻找可用的命令参数:
|
||||
|
||||

|
||||
|
||||
在提示符处,输入任何搜索词汇关键字去开始搜索,然后你可以输入n或者p去导航到搜索结果的后一页和前一页。
|
||||
在提示符处,输入任何搜索词汇关键字去开始搜索,然后你可以输入`n`或者`p`导航到搜索结果的后一页和前一页。
|
||||
|
||||
为了在浏览器窗口中打开任何搜索结果,直接输入搜索结果的编号,或者你可以输入 o 命令来打开搜索到的网页。
|
||||
- 新闻搜索:如果你想去搜索新闻,直接以N参数启动 Googler:
|
||||
要在浏览器窗口中打开搜索结果,直接输入搜索结果的编号,或者你可以输入 `o` 命令来打开这个搜索网页。
|
||||
|
||||
#### 新闻搜索
|
||||
|
||||
如果你想去搜索新闻,直接以`N`参数启动 Googler:
|
||||
|
||||
```
|
||||
googler -N
|
||||
```
|
||||
|
||||
随后的提示符将会从 Google News 抓取结果。
|
||||
随后的搜索将会从 Google News 抓取结果。
|
||||
|
||||
- 站点搜索:如果你想从某个特定的站点进行搜索,以w【域名】参数启动 Googler:
|
||||
#### 站点搜索
|
||||
|
||||
如果你想从某个特定的站点进行搜索,以`w 域名`参数启动 Googler:
|
||||
|
||||
```
|
||||
googler -w itsfoss.com
|
||||
```
|
||||
|
||||
随后的提示符会只从这个博客中抓取结果!
|
||||
随后的搜索会只从这个博客中抓取结果!
|
||||
|
||||
- 手册页:运行以下命令去查看 Googler 的带着各种用例的手册页:
|
||||
#### 手册页
|
||||
|
||||
运行以下命令去查看 Googler 的带着各种用例的手册页:
|
||||
|
||||
```
|
||||
man googler
|
||||
```
|
||||
|
||||
- Google 领域搜索引擎:
|
||||
#### 指定国家/地区的 Google 搜索引擎
|
||||
|
||||
```
|
||||
googler -c in "hello world"
|
||||
@ -93,29 +102,31 @@ googler -c in "hello world"
|
||||
|
||||
上面的示例命令将会开始从 Google 的印度域名搜索结果(in 代表印度)
|
||||
|
||||
还支持:
|
||||
|
||||
- 通过时间和语言偏好来过滤搜索结果
|
||||
- 支持 Google 查询关键字,例如:site:example.com 或者 filetype:pdf 等等
|
||||
- 支持 Google 查询关键字,例如:`site:example.com` 或者 `filetype:pdf` 等等
|
||||
- 支持 HTTPS 代理
|
||||
- Shell 命令自动补全
|
||||
- 禁用自动拼写纠正
|
||||
|
||||
这里还有更多特性。你可以用 Googler 去满足你的需要。
|
||||
|
||||
Googler也可以和一些基于文本的浏览器整合在一起 ( 例如 – [elinks][2], [links][3], [lynx][4], w3m 等), 所以你甚至都不用离开终端去浏览网页。在 Googler 的 GitHub 工程页可以找到指导。 [Googler 的 GitHub 项目主页][5].
|
||||
Googler 也可以和一些基于文本的浏览器整合在一起(例如:[elinks][2]、[links][3]、[lynx][4]、w3m 等),所以你甚至都不用离开终端去浏览网页。在 [Googler 的 GitHub 项目页][5]可以找到指导。
|
||||
|
||||
如果你想看一下 Googler 不同的特性的视频演示,你可以随意查看GitHub工程页附带的终端记录演示页: [jarun/googler v2.7 quick demo][6].
|
||||
如果你想看一下 Googler 不同的特性的视频演示,方便的话你可以查看 GitHub 项目页附带的终端记录演示页: [jarun/googler v2.7 quick demo][6]。
|
||||
|
||||
### 对于 Googler 的看法?
|
||||
|
||||
尽管 googler 可能并不是对每个人都是必要和渴望的,对于一些不想打开浏览器进行 google 搜索或者仅仅是想花费尽可能多的时间在终端窗口上的人来说,这是一个很棒的工具。你认为呢?
|
||||
尽管 googler 可能并不是对每个人都是必要和渴望的,对于一些不想打开浏览器进行 google 搜索或者就是想泡在终端窗口里面的人来说,这是一个很棒的工具。你认为呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
via: https://itsfoss.com/review-googler-linux/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[LinuxBars](https://github.com/LinuxBars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -126,3 +137,4 @@ via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
[4]: http://lynx.browser.org/
|
||||
[5]: https://github.com/jarun/googler#faq
|
||||
[6]: https://asciinema.org/a/85019
|
||||
[7]: https://en.wikipedia.org/wiki/Unix-like
|
||||
@ -1,85 +0,0 @@
|
||||
wcnnbdk1 Translating
|
||||
Setup honeypot in Kali Linux
|
||||
====
|
||||
|
||||
The Pentbox is a safety kit containing various tools for streamlining PenTest conducting a job easily. It is programmed in Ruby and oriented to GNU / Linux, with support for Windows, MacOS and every systems where Ruby is installed. In this small article we will explain how to set up a honeypot in Kali Linux. If you don’t know what is a honeypot, “a honeypot is a computer security mechanism set to detect, deflect, or, in some manner, counteract attempts at unauthorized use of information systems.”
|
||||
|
||||
### Download Pentbox:
|
||||
|
||||
Simply type in the following command in your terminal to download pentbox-1.8.
|
||||
|
||||
```
|
||||
root@kali:~# wget http://downloads.sourceforge.net/project/pentbox18realised/pentbox-1.8.tar.gz
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Uncompress pentbox files
|
||||
|
||||
Decompressing the file with the following command:
|
||||
|
||||
```
|
||||
root@kali:~# tar -zxvf pentbox-1.8.tar.gz
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Run pentbox ruby script
|
||||
|
||||
Change directory into pentbox folder
|
||||
|
||||
```
|
||||
root@kali:~# cd pentbox-1.8/
|
||||
```
|
||||
|
||||

|
||||
|
||||
Run pentbox using the following command
|
||||
|
||||
```
|
||||
root@kali:~# ./pentbox.rb
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Setup a honeypot
|
||||
|
||||
Use option 2 (Network Tools) and then option 3 (Honeypot).
|
||||
|
||||

|
||||
|
||||
Finally for first test, choose option 1 (Fast Auto Configuration)
|
||||
|
||||

|
||||
|
||||
This opens up a honeypot in port 80. Simply open browser and browse to http://192.168.160.128 (where 192.168.160.128 is your IP Address. You should see an Access denied error.
|
||||
|
||||

|
||||
|
||||
and in the terminal you should see “HONEYPOT ACTIVATED ON PORT 80” followed by “INTRUSION ATTEMPT DETECTED”.
|
||||
|
||||

|
||||
|
||||
Now, if you do the same steps but this time select Option 2 (Manual Configuration), you should see more extra options
|
||||
|
||||

|
||||
|
||||
Do the same steps but select port 22 this time (SSH Port). Then do a port forwarding in your home router to forward port external port 22 to this machines’ port 22. Alternatively, set it up in a VPS in your cloud server.
|
||||
|
||||
You’d be amazed how many bots out there scanning port SSH continuously. You know what you do then? You try to hack them back for the lulz!
|
||||
|
||||
Here’s a video of setting up honeypot if video is your thing:
|
||||
|
||||
<https://youtu.be/NufOMiktplA>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.blackmoreops.com/2016/05/06/setup-honeypot-in-kali-linux/
|
||||
|
||||
作者:[blackmoreops.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: blackmoreops.com
|
||||
@ -0,0 +1,234 @@
|
||||
# Scientific Audio Processing, Part II - How to make basic Mathematical Signal Processing in Audio files using Ubuntu with Octave 4.0
|
||||
|
||||
|
||||
In the [previous tutorial](https://www.howtoforge.com/tutorial/how-to-read-and-write-audio-files-with-octave-4-in-ubuntu/), we saw the simple steps to read, write and playback audio files. We even saw how we can synthesize an audio file from a periodic function such as the cosine function. In this tutorial, we will see how we can do additions to signals, multiplying signals (modulation), and applying some basic mathematical functions to see their effect on the original signal.
|
||||
|
||||
### Adding Signals
|
||||
|
||||
The sum of two signals S1(t) and S2(t) results in a signal R(t) whose value at any instant of time is the sum of the added signal values at that moment. Just like this:
|
||||
|
||||
```
|
||||
R(t) = S1(t) + S2(t)
|
||||
```
|
||||
|
||||
We will recreate the sum of two signals in Octave and see the effect graphically. First, we will generate two signals of different frequencies to see the signal resulting from the sum.
|
||||
|
||||
#### Step 1: Creating two signals of different frequencies (ogg files)
|
||||
|
||||
```
|
||||
>> sig1='cos440.ogg'; %creating the audio file @440 Hz
|
||||
>> sig2='cos880.ogg'; %creating the audio file @880 Hz
|
||||
>> fs=44100; %generating the parameters values (Period, sampling frequency and angular frequency)
|
||||
>> t=0:1/fs:0.02;
|
||||
>> w1=2*pi*440*t;
|
||||
>> w2=2*pi*880*t;
|
||||
>> audiowrite(sig1,cos(w1),fs); %writing the function cos(w) on the files created
|
||||
>> audiowrite(sig2,cos(w2),fs);
|
||||
```
|
||||
|
||||
Here we will plot both signals.
|
||||
|
||||
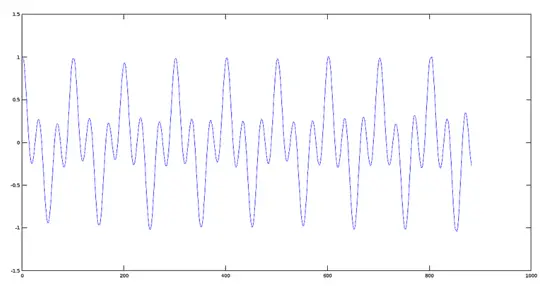
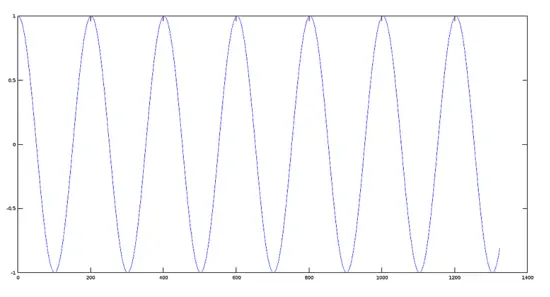
Plot of Signal 1 (440 Hz)
|
||||
|
||||
```
|
||||
>> [y1, fs] = audioread(sig1);
|
||||
>> plot(y1)
|
||||
```
|
||||
|
||||
[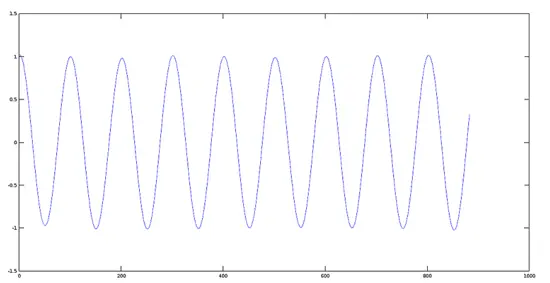](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/plotsignal1.png)
|
||||
|
||||
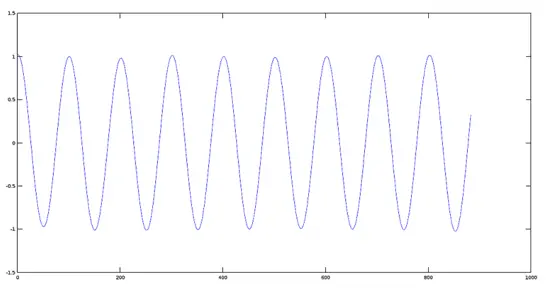
Plot of Signal 2 (880 Hz)
|
||||
|
||||
```
|
||||
>> [y2, fs] = audioread(sig2);
|
||||
>> plot(y2)
|
||||
```
|
||||
|
||||
[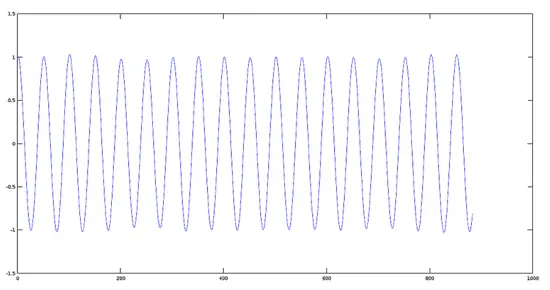](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/plotsignal2.png)
|
||||
|
||||
#### Step 2: Adding two signals
|
||||
|
||||
Now we perform the sum of the two signals created in the previous step.
|
||||
|
||||
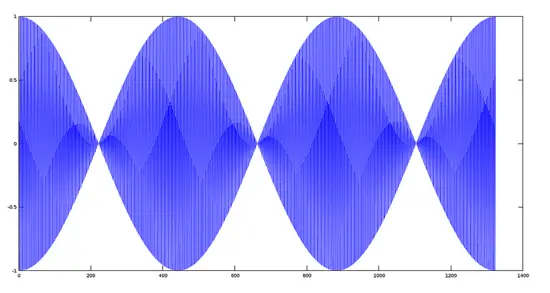
```
|
||||
>> sumres=y1+y2;
|
||||
>> plot(sumres)
|
||||
```
|
||||
|
||||
Plot of Resulting Signal
|
||||
|
||||
[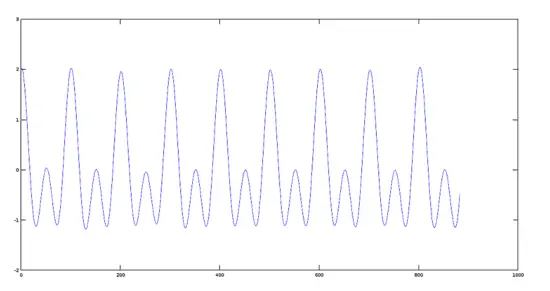](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/plotsum.png)
|
||||
|
||||
The Octaver Effect
|
||||
|
||||
In the Octaver, the sound provided by this effect is characteristic because it emulates the note being played by the musician, either in a lower or higher octave (according as it has been programmed), coupled with sound the original note, ie two notes appear identically sounding.
|
||||
|
||||
#### Step 3: Adding two real signals (example with two musical tracks)
|
||||
|
||||
For this purpose, we will use two tracks of Gregorian Chants (voice sampling).
|
||||
|
||||
Avemaria Track
|
||||
|
||||
First, will read and plot an Avemaria track:
|
||||
|
||||
```
|
||||
>> [y1,fs]=audioread('avemaria_.ogg');
|
||||
>> plot(y1)
|
||||
```
|
||||
|
||||
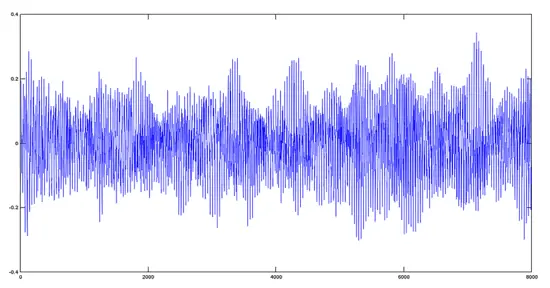
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/avemaria.png)
|
||||
|
||||
Hymnus Track
|
||||
|
||||
Now, will read and plot an hymnus track
|
||||
|
||||
```
|
||||
>> [y2,fs]=audioread('hymnus.ogg');
|
||||
>> plot(y2)
|
||||
```
|
||||
|
||||
[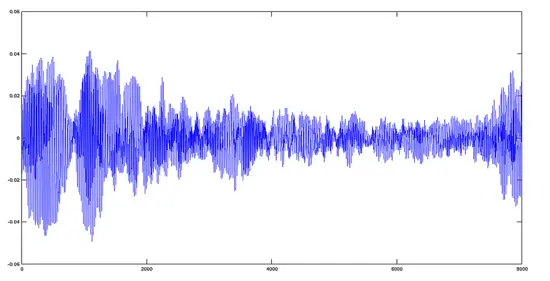](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/hymnus.png)
|
||||
|
||||
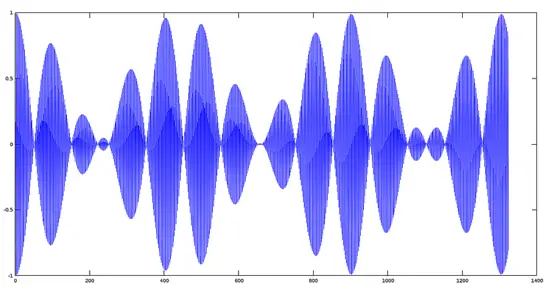
Avemaria + Hymnus Track
|
||||
|
||||
```
|
||||
>> y='avehymnus.ogg';
|
||||
>> audiowrite(y, y1+y2, fs);
|
||||
>> [y, fs]=audioread('avehymnus.ogg');
|
||||
>> plot(y)
|
||||
```
|
||||
|
||||
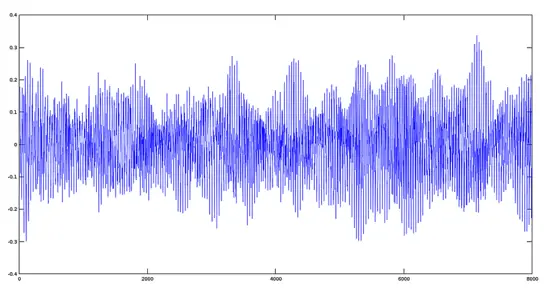
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/avehymnus.png)The result, from the point of view of audio, is that both tracks will sound mixed.
|
||||
|
||||
### Product of two Signals
|
||||
|
||||
To multiply two signals, we have to use an analogous way to the sum. Let´s use the same files created previously.
|
||||
|
||||
```
|
||||
R(t) = S1(t) * S2(t)
|
||||
```
|
||||
|
||||
```
|
||||
>> sig1='cos440.ogg'; %creating the audio file @440 Hz
|
||||
>> sig2='cos880.ogg'; %creating the audio file @880 Hz
|
||||
>> product='prod.ogg'; %creating the audio file for product
|
||||
>> fs=44100; %generating the parameters values (Period, sampling frequency and angular frequency)
|
||||
>> t=0:1/fs:0.02;
|
||||
>> w1=2*pi*440*t;
|
||||
>> w2=2*pi*880*t;
|
||||
>> audiowrite(sig1, cos(w1), fs); %writing the function cos(w) on the files created
|
||||
>> audiowrite(sig2, cos(w2), fs);>> [y1,fs]=audioread(sig1);>> [y2,fs]=audioread(sig2);
|
||||
>> audiowrite(product, y1.*y2, fs); %performing the product
|
||||
>> [yprod,fs]=audioread(product);
|
||||
>> plot(yprod); %plotting the product
|
||||
```
|
||||
|
||||
Note: we have to use the operand '.*' because this product is made, value to value, on the argument files. For more information, please refer to the manual of product operations with matrices of Octave.
|
||||
|
||||
#### Plot of Resulting Product Signal
|
||||
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/plotprod.png)
|
||||
|
||||
#### Graphical effect of multiplying two signals with a big fundamental frequency difference (Principles of Modulation)
|
||||
|
||||
##### Step 1:
|
||||
|
||||
Create an audio frequency signal with a 220Hz frequency.
|
||||
|
||||
```
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:0.03;
|
||||
>> w=2*pi*220*t;
|
||||
>> y1=cos(w);
|
||||
>> plot(y1);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/carrier.png)
|
||||
|
||||
##### Step 2:
|
||||
|
||||
Create a higher frequency modulating signal of 22000 Hz.
|
||||
|
||||
```
|
||||
>> y2=cos(100*w);
|
||||
>> plot(y2);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/modulating.png)
|
||||
|
||||
##### Step 3:
|
||||
|
||||
Multiplying and plotting the two signals.
|
||||
|
||||
```
|
||||
>> plot(y1.*y2);
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/modulated.png)
|
||||
|
||||
### Multiplying a signal by a scalar
|
||||
|
||||
The effect of multiplying a function by a scalar is equivalent to modify their scope and, in some cases, the sign of the phase. Given a scalar K, the product of a function F(t) by the scalar is defined as:
|
||||
|
||||
```
|
||||
R(t) = K*F(t)
|
||||
```
|
||||
|
||||
```
|
||||
>> [y,fs]=audioread('cos440.ogg'); %creating the work files
|
||||
>> res1='coslow.ogg';
|
||||
>> res2='coshigh.ogg';>> res3='cosinverted.ogg';
|
||||
>> K1=0.2; %values of the scalars
|
||||
>> K2=0.5;>> K3=-1;
|
||||
>> audiowrite(res1, K1*y, fs); %product function-scalar
|
||||
>> audiowrite(res2, K2*y, fs);
|
||||
>> audiowrite(res3, K3*y, fs);
|
||||
```
|
||||
|
||||
#### Plot of the Original Signal
|
||||
|
||||
```
|
||||
>> plot(y)
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/originalsignal.png)
|
||||
|
||||
Plot of a Signal reduced in amplitude by 0.2
|
||||
|
||||
```
|
||||
>> plot(res1)
|
||||
```
|
||||
|
||||
[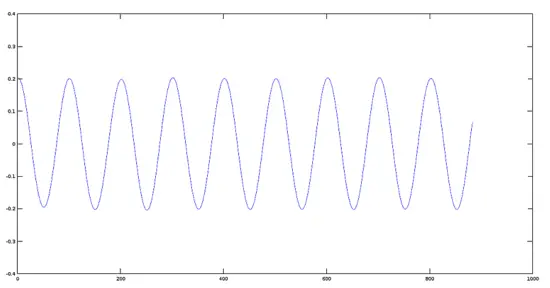](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/coslow.png)
|
||||
|
||||
Plot of a Signal reduced in amplitude by 0.5
|
||||
|
||||
```
|
||||
>> plot(res2)
|
||||
```
|
||||
|
||||
[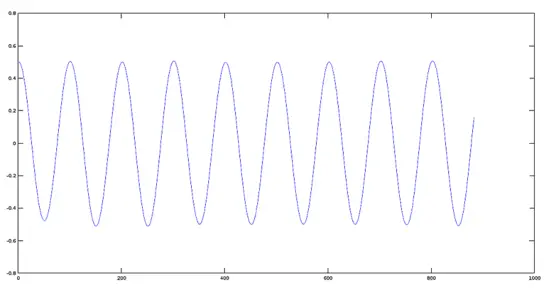](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/coshigh.png)
|
||||
|
||||
Plot of a Signal with inverted phase
|
||||
|
||||
```
|
||||
>> plot(res3)
|
||||
```
|
||||
|
||||
[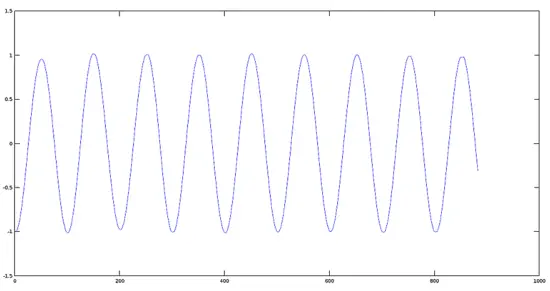](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/cosinverted.png)
|
||||
|
||||
### Conclusion
|
||||
|
||||
The basic mathematical operations, such as algebraic sum, product, and product of a function by a scalar are the backbone of more advanced operations among which are, spectrum analysis, modulation in amplitude, angular modulation, etc. In the next tutorial, we will see how to make such operations and their effects on audio signals.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/octave-audio-signal-processing-ubuntu/
|
||||
|
||||
作者:[David Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/octave-audio-signal-processing-ubuntu/
|
||||
54
sources/tech/20160812 What is copyleft.md
Normal file
54
sources/tech/20160812 What is copyleft.md
Normal file
@ -0,0 +1,54 @@
|
||||
What is copyleft?
|
||||
=============
|
||||
|
||||
|
||||
If you've spent much time in open source projects, you have probably seen the term "copyleft" used. While the term is quite commonly used, many people don't understand it. Software licensing is the subject of at least as much heated debate as text editors or packaging formats. An expert understanding of copyleft would fill many books, but this article can be a starting point on your road to copyleft enlightenment.
|
||||
|
||||
## What is copyright?
|
||||
|
||||
Before we can understand copyleft, we must first introduce the concept of copyright. Copyleft is not a separate legal framework from copyright; copyleft exists within the rules of copyright. So what is copyright?
|
||||
|
||||
The exact definition varies based on jurisdiction, but the essence is this: the author of a work has a limited monopoly on the copying (hence the term "copyright"), performance, etc. of the work. In the United States, the Constitution explicitly tasks Congress for creating copyright laws in order to "promote the Progress of Science and useful Arts."
|
||||
|
||||
Unlike in the past, copyright attaches to a work immediately -- no registration is required. By default, all rights are reserved. That means no one can republish, perform, or modify a work without permission from the author. This permission is a "license" and may come with certain conditions attached.
|
||||
|
||||
For a more thorough introduction to copyright, Coursera's [Copyright for Educators & Librarians](https://www.coursera.org/learn/copyright-for-education) is an excellent resource.
|
||||
|
||||
## What is copyleft?
|
||||
|
||||
Bear with me, but there's one more step to take before we discuss what copyleft is. First, let's examine what open source means. All open source licenses, by the[Open Source Inititative's definition](https://opensource.org/osd) must, among other things, allow distribution in source form. Anyone who receives open source software has the right to inspect and modify the code.
|
||||
|
||||
Where copyleft licenses differ from so-called "permissive" licenses is that copyleft licenses require these same rights to be included in any derivative works. I prefer to think of the distinction in this way: permissive licenses provide the maximum freedom to the immediate downstream developers (including the ability to use the open source code in a closed source project), whereas copyleft licenses provide the maximum freedom through to the end users.
|
||||
|
||||
The GNU Project gives this [simple definition](https://www.gnu.org/philosophy/free-sw.en.html) of copyleft: "the rule that when redistributing the program, you cannot add restrictions to deny other people the central freedoms [of free software]." This can be considered the canonical definition, since the [GNU General Public License](https://www.gnu.org/licenses/gpl.html) (GPL) in its various versions remains the most widely-used copyleft license.
|
||||
|
||||
## Copyleft in software
|
||||
|
||||
While the GPL family are the most popular copyleft licenses, they are by no means the only ones. The [Mozilla Public License](https://www.mozilla.org/en-US/MPL/) and the [Eclipse Public License](https://www.eclipse.org/legal/epl-v10.html) are also very popular. Many [other copyleft licenses](https://tldrlegal.com/licenses/tags/Copyleft) exist with smaller adoption footprints.
|
||||
|
||||
As explained in the previous section, a copyleft license means downstream projects cannot add additional restrictions on the use of the software. This is best illustrated with an example. If I wrote MyCoolProgram and distributed it under a copyleft license, you would have the freedom to use and modify it. You could distribute versions with your changes, but you'd have to give your users the same freedoms I gave you. If I had licensed it under a permissive license, you'd be free to incorporate it into a closed software project that you do not provide the source to.
|
||||
|
||||
But just as important as what you must do with MyCoolProgram is what you don't have to do. You don't have to use the exact same license I did, so long as the terms are compatible (generally downstream projects use the same license for simplicity's sake). You don't have to contribute your changes back to me, but it's generally considered good form, especially when the changes are bug fixes.
|
||||
|
||||
## Copyleft in non-software
|
||||
|
||||
Although the notion of copyleft began in the software world, it exists outside as well. The notion of "do what you want, so long as you preserve the right for others to do the same" is the distinguishing characteristic of the [Creative Commons Attribution-ShareAlike](http://creativecommons.org/licenses/by-sa/4.0/) license used for written work, visual art, etc. (CC BY-SA 4.0 is the default license for contributions to Opensource.com.) The [GNU Free Documentation License ](https://www.gnu.org/licenses/fdl.html)is another example of a copyleft non-software license. The use of software licenses for non-software work is generally discouraged.
|
||||
|
||||
## Should I choose a copyleft license?
|
||||
|
||||
Pages and pages could be (and have been!) written about what type of license should be used for a project. My advice is to first narrow the list of licenses to ones that match your philosophy and your goals for the project. GitHub's[choosealicense.com](http://choosealicense.com/) is a good way to find a license that fits your needs. [tl;drLegal](https://tldrlegal.com/)has plain-language explanations of many common and uncommon software licenses. Also consider the ecosystem that your project lives in. Projects around a specific language or technology will often use the same or similar licenses. If you want your project to be able to play nicely, you may need to make sure the license you choose is compatible.
|
||||
|
||||
For more information about copyleft licensing, check out the [Copyleft Guide](https://copyleft.org/)project.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
133
sources/tech/20160815 How to manage binary blobs with Git.md
Normal file
133
sources/tech/20160815 How to manage binary blobs with Git.md
Normal file
@ -0,0 +1,133 @@
|
||||
part 7 - How to manage binary blobs with Git
|
||||
=====================
|
||||
|
||||
|
||||
In the previous six articles in this series we learned how to manage version control on text files with Git. But what about binary files? Git has extensions for handling binary blobs such as multimedia files, so today we will learn how to manage binary assets with Git.
|
||||
|
||||
One thing everyone seems to agree on is Git is not great for big binary blobs. Keep in mind that a binary blob is different from a large text file; you can use Git on large text files without a problem, but Git can't do much with an impervious binary file except treat it as one big solid black box and commit it as-is.
|
||||
|
||||
Say you have a complex 3D model for the exciting new first person puzzle game you're making, and you save it in a binary format, resulting in a 1 gigabyte file. Yougit commit it once, adding a gigabyte to your repository's history. Later, you give the model a different hair style and commit your update; Git can't tell the hair apart from the head or the rest of the model, so you've just committed another gigabyte. Then you change the model's eye color and commit that small change: another gigabyte. That is three gigabytes for one model with a few minor changes made on a whim. Scale that across all the assets in a game, and you have a serious problem.
|
||||
|
||||
Contrast that to a text file like the .obj format. One commit stores everything, just as with the other model, but an .obj file is a series of lines of plain text describing the vertices of a model. If you modify the model and save it back out to .obj, Git can read the two files line by line, create a diff of the changes, and process a fairly small commit. The more refined the model becomes, the smaller the commits get, and it's a standard Git use case. It is a big file, but it uses a kind of overlay or sparse storage method to build a complete picture of the current state of your data.
|
||||
|
||||
However, not everything works in plain text, and these days everyone wants to work with Git. A solution was required, and several have surfaced.
|
||||
|
||||
[OSTree](https://ostree.readthedocs.io/en/latest/) began as a GNOME project and is intended to manage operating system binaries. It doesn't apply here, so I'll skip it.
|
||||
|
||||
[Git Large File Storage](https://git-lfs.github.com/) (LFS) is an open source project from GitHub that began life as a fork of git-media. [git-media](https://github.com/alebedev/git-media) and [git-annex](https://git-annex.branchable.com/walkthrough/) are extensions to Git meant to manage large files. They are two different approaches to the same problem, and they each have advantages. These aren't official statements from the projects themselves, but in my experience, the unique aspects of each are:
|
||||
|
||||
* git-media is a centralised model, a repository for common assets. You tellgit-media where your large files are stored, whether that is a hard drive, a server, or a cloud storage service, and each user on your project treats that location as the central master location for large assets.
|
||||
* git-annex favors a distributed model; you and your users create repositories, and each repository gets a local .git/annex directory where big files are stored. The annexes are synchronized regularly so that all assets are available to all users as needed. Unless configured otherwise with annex-cost, git-annex prefers local storage before off-site storage.
|
||||
|
||||
Of these options, I've used git-media and git-annex in production, so I'll give you an overview of how they each work.
|
||||
|
||||
```
|
||||
git-media
|
||||
```
|
||||
|
||||
git-media uses Ruby, so you must install a gem for it. Instructions are on the[website](https://github.com/alebedev/git-media). Each user who wants to use git-media needs to install it, but it is cross-platform, so that is not a problem.
|
||||
|
||||
After installing git-media, you must set some Git configuration options. You only need to do this once per machine you use:
|
||||
|
||||
```
|
||||
$ git config filter.media.clean "git-media filter-clean"$ git config filter.media.smudge "git-media filter-smudge"
|
||||
```
|
||||
|
||||
In each repository that you want to use git-media, set an attribute to marry the filters you've just created to the file types you want to classify as media. Don't get confused by the terminology; a better term is "assets," since "media" usually means audio, video, and photos, but you might just as easily classify 3D models, bakes, and textures as media.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
$ echo "*.mp4 filter=media -crlf" >> .gitattributes$ echo "*.mkv filter=media -crlf" >> .gitattributes$ echo "*.wav filter=media -crlf" >> .gitattributes$ echo "*.flac filter=media -crlf" >> .gitattributes$ echo "*.kra filter=media -crlf" >> .gitattributes
|
||||
```
|
||||
|
||||
When you stage a file of those types, the file is copied to .git/media.
|
||||
|
||||
Assuming you have a Git repository on the server already, the final step is to tell your Git repository where the "mothership" is; that is, where the media files will go when they have been pushed for all users to share. Set this in the repository's.git/config file, substituting your own user, host, and path:
|
||||
|
||||
```
|
||||
[git-media]
|
||||
transport = scp
|
||||
autodownload = false #true to pull assets by default
|
||||
scpuser = seth
|
||||
scphost = example.com
|
||||
scppath = /opt/jupiter.git
|
||||
```
|
||||
|
||||
If you have complex SSH settings on your server, such as a non-standard port or path to a non-default SSH key file use .ssh/config to set defaults for the host.
|
||||
|
||||
Life with git-media is mostly normal; you work in your repository, you stage files and blobs alike, and commit them as usual. The only difference in workflow is that at some point along the way, you should sync your secret stockpile of assets (er, media) to the shared repository.
|
||||
|
||||
When you are ready to publish your assets for your team or for your own backup, use this command:
|
||||
|
||||
```
|
||||
$ git media sync
|
||||
```
|
||||
|
||||
To replace a file in git-media with a changed version (for example, an audio file has been sweetened, or a matte painting has been completed, or a video file has been colour graded), you must explicitly tell Git to update the media. This overrides git-media's default to not copy a file if it already exists remotely:
|
||||
|
||||
```
|
||||
$ git update-index --really-refresh
|
||||
```
|
||||
|
||||
When other members of your team (or you, on a different computer) clones the repository, no assets will be downloaded by default unless you have set theautodownload option in .git/config to true. A git media sync cures all ills.
|
||||
|
||||
```
|
||||
git-annex
|
||||
```
|
||||
|
||||
git-annex has a slightly different workflow, and defaults to local repositories, but the basic ideas are the same. You should be able to install git-annex from your distribution's repository, or you can get it from the website as needed. As withgit-media, any user using git-annex must install it on their machine.
|
||||
|
||||
The initial setup is simpler than git-media. To create a bare repository on your server run this command, substituting your own path:
|
||||
|
||||
```
|
||||
$ git init --bare --shared /opt/jupiter.git
|
||||
```
|
||||
|
||||
Then clone it onto your local computer, and mark it as a git-annex location:
|
||||
|
||||
```
|
||||
$ git clone seth@example.com:/opt/jupiter.cloneCloning into 'jupiter.clone'... warning: You appear to have clonedan empty repository. Checking connectivity... done.$ git annex init "seth workstation" init seth workstation ok
|
||||
```
|
||||
|
||||
Rather than using filters to identify media assets or large files, you configure what gets classified as a large file by using the git annex command:
|
||||
|
||||
```
|
||||
$ git annex add bigblobfile.flacadd bigblobfile.flac (checksum) ok(Recording state in Git...)
|
||||
```
|
||||
|
||||
Committing is done as usual:
|
||||
|
||||
```
|
||||
$ git commit -m 'added flac source for sound fx'
|
||||
```
|
||||
|
||||
But pushing is different, because git annex uses its own branch to track assets. The first push you make may need the -u option, depending on how you manage your repository:
|
||||
|
||||
```
|
||||
$ git push -u origin master git-annexTo seth@example.com:/opt/jupiter.git* [new branch] master -> master* [new branch] git-annex -> git-annex
|
||||
```
|
||||
|
||||
As with git-media, a normal git push does not copy your assets to the server, it only sends information about the media. When you're ready to share your assets with the rest of the team, run the sync command:
|
||||
|
||||
```
|
||||
$ git annex sync --content
|
||||
```
|
||||
|
||||
If someone else has shared assets to the server and you need to pull them, git annex sync will prompt your local checkout to pull assets that are not present on your machine, but that exist on the server.
|
||||
|
||||
Both git-media and git-annex are flexible and can use local repositories instead of a server, so they're just as useful for managing private local projects, too.
|
||||
|
||||
Git is a powerful and extensible system, and by now there is really no excuse for not using it. Try it out today!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/8/how-manage-binary-blobs-git-part-7
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
220
sources/tech/20160815 The cost of small modules.md
Normal file
220
sources/tech/20160815 The cost of small modules.md
Normal file
@ -0,0 +1,220 @@
|
||||
The cost of small modules
|
||||
====
|
||||
|
||||
About a year ago I was refactoring a large JavaScript codebase into smaller modules, when I discovered a depressing fact about Browserify and Webpack:
|
||||
|
||||
> “The more I modularize my code, the bigger it gets. ”– Nolan Lawson
|
||||
|
||||
Later on, Sam Saccone published some excellent research on [Tumblr](https://docs.google.com/document/d/1E2w0UQ4RhId5cMYsDcdcNwsgL0gP_S6SDv27yi1mCEY/edit) and [Imgur](https://github.com/perfs/audits/issues/1)‘s page load performance, in which he noted:
|
||||
|
||||
> “Over 400ms is being spent simply walking the Browserify tree.”– Sam Saccone
|
||||
|
||||
In this post, I’d like to demonstrate that small modules can have a surprisingly high performance cost depending on your choice of bundler and module system. Furthermore, I’ll explain why this applies not only to the modules in your own codebase, but also to the modules within dependencies, which is a rarely-discussed aspect of the cost of third-party code.
|
||||
|
||||
### Web perf 101
|
||||
|
||||
The more JavaScript included on a page, the slower that page tends to be. Large JavaScript bundles cause the browser to spend more time downloading, parsing, and executing the script, all of which lead to slower load times.
|
||||
|
||||
Even when breaking up the code into multiple bundles – Webpack [code splitting](https://webpack.github.io/docs/code-splitting.html), Browserify[factor bundles](https://github.com/substack/factor-bundle), etc. – the cost is merely delayed until later in the page lifecycle. Sooner or later, the JavaScript piper must be paid.
|
||||
|
||||
Furthermore, because JavaScript is a dynamic language, and because the prevailing[CommonJS](http://www.commonjs.org/) module system is also dynamic, it’s fiendishly difficult to extract unused code from the final payload that gets shipped to users. You might only need jQuery’s $.ajax, but by including jQuery, you pay the cost of the entire library.
|
||||
|
||||
The JavaScript community has responded to this problem by advocating the use of [small modules](http://substack.net/how_I_write_modules). Small modules have a lot of [aesthetic and practical benefits](http://dailyjs.com/2015/07/02/small-modules-complexity-over-size/) – easier to maintain, easier to comprehend, easier to plug together – but they also solve the jQuery problem by promoting the inclusion of small bits of functionality rather than big “kitchen sink” libraries.
|
||||
|
||||
So in the “small modules” world, instead of doing:
|
||||
|
||||
```
|
||||
var _ = require('lodash')
|
||||
_.uniq([1,2,2,3])
|
||||
```
|
||||
|
||||
You might do:
|
||||
|
||||
```
|
||||
var uniq = require('lodash.uniq')
|
||||
uniq([1,2,2,3])
|
||||
```
|
||||
|
||||
### Packages vs modules
|
||||
|
||||
It’s important to note that, when I say “modules,” I’m not talking about “packages” in the npm sense. When you install a package from npm, it might only expose a single module in its public API, but under the hood it could actually be a conglomeration of many modules.
|
||||
|
||||
For instance, consider a package like [is-array](https://www.npmjs.com/package/is-array). It has no dependencies and only contains[one JavaScript file](https://github.com/retrofox/is-array/blob/d79f1c90c824416b60517c04f0568b5cd3f8271d/index.js#L6-L33), so it has one module. Simple enough.
|
||||
|
||||
Now consider a slightly more complex package like [once](https://www.npmjs.com/package/once), which has exactly one dependency:[wrappy](https://www.npmjs.com/package/wrappy). [Both](https://github.com/isaacs/once/blob/2ad558657e17fafd24803217ba854762842e4178/once.js#L1-L21) [packages](https://github.com/npm/wrappy/blob/71d91b6dc5bdeac37e218c2cf03f9ab55b60d214/wrappy.js#L6-L33) contain one module, so the total module count is 2\. So far, so good.
|
||||
|
||||
Now let’s consider a more deceptive example: [qs](https://www.npmjs.com/package/qs). Since it has zero dependencies, you might assume it only has one module. But in fact, it has four!
|
||||
|
||||
You can confirm this by using a tool I wrote called [browserify-count-modules](https://www.npmjs.com/package/browserify-count-modules), which simply counts the total number of modules in a Browserify bundle:
|
||||
|
||||
```
|
||||
$ npm install qs
|
||||
$ browserify node_modules/qs | browserify-count-modules
|
||||
4
|
||||
```
|
||||
|
||||
This means that a given package can actually contain one or more modules. These modules can also depend on other packages, which might bring in their own packages and modules. The only thing you can be sure of is that each package contains at least one module.
|
||||
|
||||
### Module bloat
|
||||
|
||||
How many modules are in a typical web application? Well, I ran browserify-count-moduleson a few popular Browserify-using sites, and came up with these numbers:
|
||||
|
||||
* [requirebin.com](http://requirebin.com/): 91 modules
|
||||
* [keybase.io](https://keybase.io/): 365 modules
|
||||
* [m.reddit.com](http://m.reddit.com/): 1050 modules
|
||||
* [Apple.com](http://images.apple.com/ipad-air-2/): 1060 modules (Added. [Thanks, Max!](https://twitter.com/denormalize/status/765300194078437376))
|
||||
|
||||
For the record, my own [Pokedex.org](https://pokedex.org/) (the largest open-source site I’ve built) contains 311 modules across four bundle files.
|
||||
|
||||
Ignoring for a moment the raw size of those JavaScript bundles, I think it’s interesting to explore the cost of the number of modules themselves. Sam Saccone has already blown this story wide open in [“The cost of transpiling es2015 in 2016”](https://github.com/samccone/The-cost-of-transpiling-es2015-in-2016#the-cost-of-transpiling-es2015-in-2016), but I don’t think his findings have gotten nearly enough press, so let’s dig a little deeper.
|
||||
|
||||
### Benchmark time!
|
||||
|
||||
I put together [a small benchmark](https://github.com/nolanlawson/cost-of-small-modules) that constructs a JavaScript module importing 100, 1000, and 5000 other modules, each of which merely exports a number. The parent module just sums the numbers together and logs the result:
|
||||
|
||||
```
|
||||
// index.js
|
||||
var total = 0
|
||||
total += require('./module_0')
|
||||
total += require('./module_1')
|
||||
total += require('./module_2')
|
||||
// etc.
|
||||
console.log(total)
|
||||
|
||||
|
||||
// module_1.js
|
||||
module.exports = 1
|
||||
```
|
||||
|
||||
I tested five bundling methods: Browserify, Browserify with the [bundle-collapser](https://www.npmjs.com/package/bundle-collapser) plugin, Webpack, Rollup, and Closure Compiler. For Rollup and Closure Compiler I used ES6 modules, whereas for Browserify and Webpack I used CommonJS, so as not to unfairly disadvantage them (since they would need a transpiler like Babel, which adds its own overhead).
|
||||
|
||||
In order to best simulate a production environment, I used Uglify with the --mangle and--compress settings for all bundles, and served them gzipped over HTTPS using GitHub Pages. For each bundle, I downloaded and executed it 15 times and took the median, noting the (uncached) load time and execution time using performance.now().
|
||||
|
||||
### Bundle sizes
|
||||
|
||||
Before we get into the benchmark results, it’s worth taking a look at the bundle files themselves. Here are the byte sizes (minified but ungzipped) for each bundle ([chart view](https://nolanwlawson.files.wordpress.com/2016/08/min.png)):
|
||||
|
||||
| | 100 modules | 1000 modules | 5000 modules |
|
||||
| --- | --- | --- | --- |
|
||||
| browserify | 7982 | 79987 | 419985 |
|
||||
| browserify-collapsed | 5786 | 57991 | 309982 |
|
||||
| webpack | 3954 | 39055 | 203052 |
|
||||
| rollup | 671 | 6971 | 38968 |
|
||||
| closure | 758 | 7958 | 43955 |
|
||||
|
||||
| | 100 modules | 1000 modules | 5000 modules |
|
||||
| --- | --- | --- | --- |
|
||||
| browserify | 1649 | 13800 | 64513 |
|
||||
| browserify-collapsed | 1464 | 11903 | 56335 |
|
||||
| webpack | 693 | 5027 | 26363 |
|
||||
| rollup | 300 | 2145 | 11510 |
|
||||
| closure | 302 | 2140 | 11789 |
|
||||
|
||||
The way Browserify and Webpack work is by isolating each module into its own function scope, and then declaring a top-level runtime loader that locates the proper module whenever require() is called. Here’s what our Browserify bundle looks like:
|
||||
|
||||
```
|
||||
(function e(t,n,r){function s(o,u){if(!n[o]){if(!t[o]){var a=typeof require=="function"&&require;if(!u&&a)return a(o,!0);if(i)return i(o,!0);var f=new Error("Cannot find module '"+o+"'");throw f.code="MODULE_NOT_FOUND",f}var l=n[o]={exports:{}};t[o][0].call(l.exports,function(e){var n=t[o][1][e];return s(n?n:e)},l,l.exports,e,t,n,r)}return n[o].exports}var i=typeof require=="function"&&require;for(var o=0;o
|
||||
```
|
||||
|
||||
Whereas the Rollup and Closure bundles look more like what you might hand-author if you were just writing one big module. Here’s Rollup:
|
||||
|
||||
```
|
||||
(function () {
|
||||
'use strict';
|
||||
var total = 0
|
||||
total += 0
|
||||
total += 1
|
||||
total += 2
|
||||
// etc.
|
||||
```
|
||||
|
||||
If you understand the inherent cost of functions-within-functions in JavaScript, and of looking up a value in an associative array, then you’ll be in a good position to understand the following benchmark results.
|
||||
|
||||
### Results
|
||||
|
||||
I ran this benchmark on a Nexus 5 with Android 5.1.1 and Chrome 52 (to represent a low- to mid-range device) as well as an iPod Touch 6th generation running iOS 9 (to represent a high-end device).
|
||||
|
||||
Here are the results for the Nexus 5 ([tabular results](https://gist.github.com/nolanlawson/e84ad060a20f0cb7a7c32308b6b46abe)):
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_nexus_5.png)
|
||||
|
||||
And here are the results for the iPod Touch ([tabular results](https://gist.github.com/nolanlawson/45ed2c7fa53da035dfc1e153763b9f93)):
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_ipod.png)
|
||||
|
||||
At 100 modules, the variance between all the bundlers is pretty negligible, but once we get up to 1000 or 5000 modules, the difference becomes severe. The iPod Touch is hurt the least by the choice of bundler, but the Nexus 5, being an aging Android phone, suffers a lot under Browserify and Webpack.
|
||||
|
||||
I also find it interesting that both Rollup and Closure’s execution cost is essentially free for the iPod, regardless of the number of modules. And in the case of the Nexus 5, the runtime costs aren’t free, but they’re still much cheaper for Rollup/Closure than for Browserify/Webpack, the latter of which chew up the main thread for several frames if not hundreds of milliseconds, meaning that the UI is frozen just waiting for the module loader to finish running.
|
||||
|
||||
Note that both of these tests were run on a fast Gigabit connection, so in terms of network costs, it’s really a best-case scenario. Using the Chrome Dev Tools, we can manually throttle that Nexus 5 down to 3G and see the impact ([tabular results](https://gist.github.com/nolanlawson/6269d304c970174c21164288808392ea)):
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_nexus_53g.png)
|
||||
|
||||
Once we take slow networks into account, the difference between Browserify/Webpack and Rollup/Closure is even more stark. In the case of 1000 modules (which is close to Reddit’s count of 1050), Browserify takes about 400 milliseconds longer than Rollup. And that 400ms is no small potatoes, since Google and Bing have both noted that sub-second delays have an[appreciable impact on user engagement](http://radar.oreilly.com/2009/06/bing-and-google-agree-slow-pag.html).
|
||||
|
||||
One thing to note is that this benchmark doesn’t measure the precise execution cost of 100, 1000, or 5000 modules per se, since that will depend on your usage of require(). Inside of these bundles, I’m calling require() once per module, but if you are calling require()multiple times per module (which is the norm in most codebases) or if you are callingrequire() multiple times on-the-fly (i.e. require() within a sub-function), then you could see severe performance degradations.
|
||||
|
||||
Reddit’s mobile site is a good example of this. Even though they have 1050 modules, I clocked their real-world Browserify execution time as much worse than the “1000 modules” benchmark. When profiling on that same Nexus 5 running Chrome, I measured 2.14 seconds for Reddit’s Browserify require() function, and 197 milliseconds for the equivalent function in the “1000 modules” script. (In desktop Chrome on an i7 Surface Book, I also measured it at 559ms vs 37ms, which is pretty astonishing given we’re talking desktop.)
|
||||
|
||||
This suggests that it may be worthwhile to run the benchmark again with multiplerequire()s per module, although in my opinion it wouldn’t be a fair fight for Browserify/Webpack, since Rollup/Closure both resolve duplicate ES6 imports into a single hoisted variable declaration, and it’s also impossible to import from anywhere but the top-level scope. So in essence, the cost of a single import for Rollup/Closure is the same as the cost of n imports, whereas for Browserify/Webpack, the execution cost will increase linearly with n require()s.
|
||||
|
||||
For the purposes of this analysis, though, I think it’s best to just assume that the number of modules is only a lower bound for the performance hit you might feel. In reality, the “5000 modules” benchmark may be a better yardstick for “5000 require() calls.”
|
||||
|
||||
### Conclusions
|
||||
|
||||
First off, the bundle-collapser plugin seems to be a valuable addition to Browserify. If you’re not using it in production, then your bundle will be a bit larger and slower than it would be otherwise (although I must admit the difference is slight). Alternatively, you could switch to Webpack and get an even faster bundle without any extra configuration. (Note that it pains me to say this, since I’m a diehard Browserify fanboy.)
|
||||
|
||||
However, these results clearly show that Webpack and Browserify both underperform compared to Rollup and Closure Compiler, and that the gap widens the more modules you add. Unfortunately I’m not sure [Webpack 2](https://gist.github.com/sokra/27b24881210b56bbaff7) will solve any of these problems, because although they’ll be [borrowing some ideas from Rollup](http://www.2ality.com/2015/12/webpack-tree-shaking.html), they seem to be more focused on the[tree-shaking aspects](http://www.2ality.com/2015/12/bundling-modules-future.html) and not the scope-hoisting aspects. (Update: a better name is “inlining,” and the Webpack team is [working on it](https://github.com/webpack/webpack/issues/2873#issuecomment-240067865).)
|
||||
|
||||
Given these results, I’m surprised Closure Compiler and Rollup aren’t getting much traction in the JavaScript community. I’m guessing it’s due to the fact that (in the case of the former) it has a Java dependency, and (in the case of the latter) it’s still fairly immature and doesn’t quite work out-of-the-box yet (see [Calvin’s Metcalf’s comments](https://github.com/rollup/rollup/issues/552) for a good summary).
|
||||
|
||||
Even without the average JavaScript developer jumping on the Rollup/Closure bandwagon, though, I think npm package authors are already in a good position to help solve this problem. If you npm install lodash, you’ll notice that the main export is one giant JavaScript module, rather than what you might expect given Lodash’s hyper-modular nature (require('lodash/uniq'), require('lodash.uniq'), etc.). For PouchDB, we made a similar decision to [use Rollup as a prepublish step](http://pouchdb.com/2016/01/13/pouchdb-5.2.0-a-better-build-system-with-rollup.html), which produces the smallest possible bundle in a way that’s invisible to users.
|
||||
|
||||
I also created [rollupify](https://github.com/nolanlawson/rollupify) to try to make this pattern a bit easier to just drop-in to existing Browserify projects. The basic idea is to use imports and exports within your own project ([cjs-to-es6](https://github.com/nolanlawson/cjs-to-es6) can help migrate), and then use require() for third-party packages. That way, you still have all the benefits of modularity within your own codebase, while exposing more-or-less one big module to your users. Unfortunately, you still pay the costs for third-party modules, but I’ve found that this is a good compromise given the current state of the npm ecosystem.
|
||||
|
||||
So there you have it: one horse-sized JavaScript duck is faster than a hundred duck-sized JavaScript horses. Despite this fact, though, I hope that our community will eventually realize the pickle we’re in – advocating for a “small modules” philosophy that’s good for developers but bad for users – and improve our tools, so that we can have the best of both worlds.
|
||||
|
||||
### Bonus round! Three desktop browsers
|
||||
|
||||
Normally I like to run performance tests on mobile devices, since that’s where you see the clearest differences. But out of curiosity, I also ran this benchmark on Chrome 52, Edge 14, and Firefox 48 on an i7 Surface Book using Windows 10 RS1\. Here are the results:
|
||||
|
||||
Chrome 52 ([tabular results](https://gist.github.com/nolanlawson/4f79258dc05bbd2c14b85cf2196c6ef0))
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_chrome.png)
|
||||
|
||||
Edge 14 ([tabular results](https://gist.github.com/nolanlawson/726fa47e0723b45e4ee9ecf0cf2fcddb))
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_edge.png)
|
||||
|
||||
Firefox 48 ([tabular results](https://gist.github.com/nolanlawson/7eed17e6ffa18752bf99a9d4bff2941f))
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/modules_firefox.png)
|
||||
|
||||
The only interesting tidbits I’ll call out in these results are:
|
||||
|
||||
1. bundle-collapser is definitely not a slam-dunk in all cases.
|
||||
2. The ratio of network-to-execution time is always extremely high for Rollup and Closure; their runtime costs are basically zilch. ChakraCore and SpiderMonkey eat them up for breakfast, and V8 is not far behind.
|
||||
|
||||
This latter point could be extremely important if your JavaScript is largely lazy-loaded, because if you can afford to wait on the network, then using Rollup and Closure will have the additional benefit of not clogging up the UI thread, i.e. they’ll introduce less jank than Browserify or Webpack.
|
||||
|
||||
Update: in response to this post, JDD has [opened an issue on Webpack](https://github.com/webpack/webpack/issues/2873). There’s also [one on Browserify](https://github.com/substack/node-browserify/issues/1379).
|
||||
|
||||
Update 2: [Ryan Fitzer](https://github.com/nolanlawson/cost-of-small-modules/pull/5) has generously added RequireJS and RequireJS with [Almond](https://github.com/requirejs/almond) to the benchmark, both of which use AMD instead of CommonJS or ES6.
|
||||
|
||||
Testing shows that RequireJS has [the largest bundle sizes](https://gist.github.com/nolanlawson/511e0ce09fed29fed040bb8673777ec5) but surprisingly its runtime costs are [very close to Rollup and Closure](https://gist.github.com/nolanlawson/4e725df00cd1bc9673b25ef72b831c8b). Here are the results for a Nexus 5 running Chrome 52 throttled to 3G:
|
||||
|
||||
[](https://nolanwlawson.files.wordpress.com/2016/08/2016-08-20-14_45_29-small_modules3-xlsx-excel.png)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nolanlawson.com/2016/08/15/the-cost-of-small-modules/?utm_source=javascriptweekly&utm_medium=email
|
||||
|
||||
作者:[Nolan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nolanlawson.com/
|
||||
@ -0,0 +1,99 @@
|
||||
|
||||
|
||||
# 5 REASONS WHY YOU SHOULD BE USING OPENSUSE
|
||||
|
||||
|
||||
|
||||
[](https://itsfoss.com/wp-content/uploads/2016/09/why-opensuse-is-best.jpg)
|
||||
|
||||
Most of the desktop Linux users stay in 3 categories: Debian/Ubuntu, Fedora, Arch Linux. But today, I’ll give you 5 reasons why you should use openSUSE.
|
||||
|
||||
I’ve always found [openSUSE](https://www.opensuse.org/) to be a bit different kind of a Linux distro. I don’t know, but it’s just so shiny and charismatic. The green chameleon looks awesome. But that’s not the reason why openSUSE is the best or better than other Linux distributions.
|
||||
|
||||
Don’t misunderstand me. I run so many different distros for different purposes and appreciate the work people behind these distros are doing to make computing a joy. But openSUSE always felt, well, sacred. You feel me?
|
||||
|
||||
## 5 REASONS WHY OPENSUSE IS BETTER THAN OTHER LINUX DISTRIBUTIONS
|
||||
|
||||
Did I just say that openSUSE is the best Linux distribution? No, I didn’t. There is no one best Linux distribution. It is really up to your needs what you find as your ‘soulmate’.
|
||||
|
||||
But here, I am going to list 5 things that I have found that openSUSE does better than other Linux distros. Let’s see them.
|
||||
|
||||
### #1 COMMUNITY RULES
|
||||
|
||||
openSUSE is a great symbol of community driven projects. I have seen a lot of users complain about changes made by the developers in their favorite distro after an update. But not openSUSE. openSUSE is truly community driven and gives its users what they want. Everytime.
|
||||
|
||||
### #2 ROCK SOLID OS
|
||||
|
||||
Another thing is OS integrity. I can install almost all of the [best Linux desktop environments](https://itsfoss.com/best-linux-desktop-environments/) on the same openSUSE installation which is not possible even on Ubuntu without compromising the stability of the system. This clearly shows how robust the system is. Therefore, openSUSE should appeal to the users who’ll be tinkering a lot under the hood.
|
||||
|
||||
### #3 EASY TO INSTALL SOFTWARE
|
||||
|
||||
We do have lots of awesome package managers in Linux world. From Debian apt-get to the DNF of [Fedora](https://itsfoss.com/fedora-24-review/), all do appeal to the users and sometimes play a great role in attracting users to a particular distro.
|
||||
|
||||
|
||||
|
||||
openSUSE has again brought a great software delivery method to the table. [software.opensuse.org](https://software.opensuse.org/421/en) is a web-portal that you can use to install software from the repository. All you need to do is to go to the link (on your openSUSE OS of course), use the search box to find your desired software. Click “Direct Install”. Done. That’s all.
|
||||
|
||||
Sounds like using Google PlayStore, ain’t it?
|
||||
|
||||
### #4 YAST
|
||||
|
||||
[YaST](https://en.opensuse.org/Portal:YaST) is literally the best control center ANY OS in the world has ever had. No arguments there. You can control everything. Networking, Software Update, all the basic settings. Everything. YaST gives you absolute power over your openSUSE installation, be it the enterprise edition or the personal installation. Convenient and everything at one place.
|
||||
|
||||
### #5 EXCELLENT OUT OF THE BOX EXPERIENCE
|
||||
|
||||
SUSE team is one of the biggest contributors to the Linux kernel. This diligent effort also means that they have excellent support for various hardware.
|
||||
|
||||
With such good hardware support, comes great out-of-the-box experience.
|
||||
|
||||
### #6 THEY MAKE GREAT PARODY VIDEOS
|
||||
|
||||
Wait! There were five reasons that made openSUSE awesome, right?
|
||||
|
||||
But I am forced to write it as [Abhishek](https://itsfoss.com/author/abhishek/) wants to me add that openSUSE is the best because they make great Linux parody videos :)
|
||||
|
||||
Just kidding but do check out the super awesome [Uptime Funk](https://www.youtube.com/watch?v=zbABy9ul11I)and you would know [why SUSE is the coolest Linux](https://itsfoss.com/suse-coolest-linux-enterprise/).
|
||||
|
||||
## LEAP OR TUMBLEWEED? WHICH OPENSUSE SHOULD I USE?
|
||||
|
||||
Now if I have convinced you to use openSUSE, let me tell you about the choices you have when it comes to openSUSE. openSUSE comes in two Distributions. The Leap and the Tumbleweed.
|
||||
|
||||

|
||||
|
||||
Now although both offer a similar experience and a similar environment, There is a decision You must make before choosing which one of these two to imprint on Your hard disk.
|
||||
|
||||
## OPENSUSE : LEAP
|
||||
|
||||
[openSUSE Leap](https://en.opensuse.org/Portal:Leap) is for most people. It has a release cycle of 8 months which is followed orthodoxly. Currently, we have openSUSE 42.1\. It contains all the stable packages and provides the smoothest experience of the two.
|
||||
|
||||
It is highly suitable for Home, Office and for Business computers. It is for people who need a good OS but won’t/can’t keep pampering the OS and need it to move aside and let them work. Once setup, you need not worry about anything and focus on your productivity. I also highly recommend Leap for use in libraries and schools.
|
||||
|
||||
## OPENSUSE: TUMBLEWEED
|
||||
|
||||
The [Tumbleweed version of openSUSE](https://en.opensuse.org/Portal:Tumbleweed) is a rolling release. It very regularly gets updates and always contains the newest set of software running on it. It is recommended for developers, advanced users who want the newest of everything on their system and anybody who wants to contribute to openSUSE.
|
||||
|
||||
|
||||
Let me clarify one thing, though. Tumbleweed is in no way a beta/testing release to the Leap. It is the most bleeding edge stable Linux distro available.
|
||||
|
||||
Tumbleweed gives you the fastest updates, but only after the developers assure for the packages’ stability.
|
||||
|
||||
### YOUR SAY?
|
||||
|
||||
[](https://itsfoss.com/install-antergos-linux/)[](https://itsfoss.com/linux-national-os/)
|
||||
|
||||
Let us know in the comments below what you think of openSUSE? And if you already thinking of using openSUSE, which of the two version would you prefer: Leap or Tumbleweed? Cheers :)
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/why-use-opensuse/?utm_source=newsletter&utm_medium=email&utm_campaign=5_reasons_why_you_should_use_opensuse_and_other_linux_stories&utm_term=2016-09-19
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/aquil/
|
||||
@ -1,42 +0,0 @@
|
||||
DAISY : 一种服务视力缺陷者的linux文本格式
|
||||
=================================================================
|
||||
|
||||
|
||||

|
||||
>图片:
|
||||
由Kate Ter Haar提供图片. opensource.com. CC BY-SA 2.0后期修饰
|
||||
|
||||
如果你像我一样是一个盲人或者有视力障碍,你经常会为了看见人们认为理所应当看得见的东西而要求不同层次的软件或硬件。 在这其中就有为阅读印刷图书的专用格式: 盲字印(假设你知道怎样阅读它)或 特殊的文本格式例如DAISY.
|
||||
|
||||
### DAISY是什么?
|
||||
DAISY代表着一种数字化无障碍信息系统。 它是一种开方的标准,专用于服务盲人阅读教科书,杂志,报纸,小说等。 它是在90年代中期被一个叫[小雏菊联盟][1]的组织发明,这个组织致力于创造出一套进行文本标记的标准,它可以使得特殊群体像视觉正常的人一样,更加容易的阅读,跳过内容,进行注释和其他文本操作。
|
||||
|
||||
现在的DAISY 3.0版本是在2005年中期发布的,是一个完整的重写的标准。 它以更加容易遵守规范进行写书的目的被创造出来。 值得注意的是,DAISY仅支持纯文本,录音(PCM波形文件格式或者MPEG播放器的III格式),或文本和录音的组合。专业化的软件能阅读这类书并支持设置书签,使得视力缺陷者像正常人一样阅读印刷书籍。
|
||||
|
||||
### DAISY是怎样工作的呢?
|
||||
DAISY, 忽略特别的版本,它工作时有点像这样: 读者拥有自己的向导文件(DAISY 2.02中的ncc.html),它包含书籍的元数据,比如作者的姓名,版权信息,书籍的页数等等。在DAISY 3.0中他是一种有效的XML文件,和DTD(文档类型定义)被强烈建议包含在每一本书中。
|
||||
|
||||
在导航控制文件中,标记精确描述了各个位置——无论是文本导航中插入符号的偏移量还是录音中定位至毫秒,这让软件像视力健康的人一样准确定位到相关的位置。值得注意的是这种导航文件仅有书中主要的,重要的内容的位置。
|
||||
|
||||
最小的内容部分由SMIL(同步多媒体集成语言)处理。导航的质量很大程度上决定于书籍的标记。这样设想一下,如果书籍没有章节标题,你需要花很多的时间来确定自己阅读的位置。如果一本DAISY格式的书籍被标记的很差, 你可能只能到书本的开头或者目录。如果书籍被标记的很差(或者完全丢失了标记),你的DAISY阅读软件很可能会简单的忽略它。
|
||||
|
||||
### 为什么需要专门的软件?
|
||||
如果DAISY仅仅是HTML,XML,录音文件,还需要使用专门的软件进行阅读和操作,你可能会问为什么。单纯从技术上而言,你并不需要。专业化的软件大多数情况下是为了方便。这就像,在linux操作系统中,一个简单的web浏览器可以被用来打开并阅读书籍。如果你在一本DAISY 3 的书中点击XML文件,软件通常会阅读你赋予相应权限的书脊并一个你点击打开的书籍清单。如果书籍被标记的很差,它不会显示在这份清单中。
|
||||
|
||||
创建DAISY则完全是另一件事了,通常需要专门的软件或需要拥有足够的知识来修改软件来达到这样的目的。
|
||||
|
||||
### 结语
|
||||
幸运的是,DAISY是一个确定了的标准。虽然它在阅读方面表现的很棒,但它需要专业软件进行生产的事实使得视力缺陷者不属于正常者看见的世界,相反这类人生活在使用各种文本格式进行电子阅读的世界中。这就是小雏菊联盟在EPUB格式上研制DAISY成功的原因,第3版,支持“媒体覆盖”。即在EPUB电子书中增加声频或视频。由于EPUB分享很多的DAISY XML标记文本,很多软件都能阅读DAISY,能看EPUB电子书但不能阅读。这也就意味着只要网站提供这种开放格式的书籍,我们将会由更多的软件选择来阅读我们的书籍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
资源来自: https://opensource.com/life/16/5/daisy-linux-compatible-text-format-visually-impaired
|
||||
|
||||
作者:[Kendell Clark][a]
|
||||
译者:[theArcticOcean](https://github.com/theArcticOcean)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kendell-clark
|
||||
[1]: http://www.daisy.org
|
||||
Loading…
Reference in New Issue
Block a user