mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-22 23:00:57 +08:00
commit
9e3d29b248
@ -28,13 +28,13 @@ LCTT 已经拥有几百名活跃成员,并欢迎更多的 Linux 志愿者加
|
||||
加入的成员,请:
|
||||
|
||||
1. 修改你的 QQ 群名片为“译者-您的_GitHub_ID”。
|
||||
2. 阅读 [WIKI](http://lctt.github.io/wiki) 了解如何开始。
|
||||
2. 阅读 [WIKI](https://lctt.github.io/wiki) 了解如何开始。
|
||||
3. 遇到不解之处,请在群内发问。
|
||||
|
||||
如何开始
|
||||
-------------------------------
|
||||
|
||||
请阅读 [WIKI](http://lctt.github.io/wiki)。如需要协助,请在群内发问。
|
||||
请阅读 [WIKI](https://lctt.github.io/wiki)。如需要协助,请在群内发问。
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
|
||||
@ -0,0 +1,482 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (ezio)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10676-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 10 Input01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室之树莓派:课程 10 输入01
|
||||
======
|
||||
|
||||
欢迎进入输入课程系列。在本系列,你将会学会如何使用键盘接收输入给树莓派。我们将会从揭示输入开始本课,然后转向更传统的文本提示符。
|
||||
|
||||
这是第一堂输入课,会教授一些关于驱动和链接的理论,同样也包含键盘的知识,最后以在屏幕上显示文本结束。
|
||||
|
||||
### 1、开始
|
||||
|
||||
希望你已经完成了 OK 系列课程,这会对你完成屏幕系列课程很有帮助。很多 OK 课程上的文件会被使用而不会做解释。如果你没有这些文件,或者希望使用一个正确的实现,可以从该堂课的[下载页][1]下载模板。如果你使用你自己的实现,请删除调用了 `SetGraphicsAddress` 之后全部的代码。
|
||||
|
||||
### 2、USB
|
||||
|
||||
如你所知,树莓派 B 型有两个 USB 接口,通常用来连接一个鼠标和一个键盘。这是一个非常好的设计决策,USB 是一个非常通用的接口,很多种设备都可以使用它。这就很容易为它设计新外设,很容易为它编写设备驱动,而且通过 USB 集线器可以非常容易扩展。还能更好吗?当然是不能,实际上对一个操作系统开发者来说,这就是我们的噩梦。USB 标准太大了。我是说真的,在你思考如何连接设备之前,它的文档将近 700 页。
|
||||
|
||||
> USB 标准的设计目的是通过复杂的软件来简化硬件交互。
|
||||
|
||||
我和很多爱好操作系统的开发者谈过这些,而他们全部都说几句话:不要抱怨。“实现这个需要花费很久时间”,“你不可能写出关于 USB 的教程”,“收益太小了”。在很多方面,他们是对的,我不可能写出一个关于 USB 标准的教程,那得花费几周时间。我同样不能教授如何为全部所有的设备编写外设驱动,所以使用自己写的驱动是没什么用的。然而,即便不能做到最好,我仍然可以获取一个正常工作的 USB 驱动,拿一个键盘驱动,然后教授如何在操作系统中使用它们。我开始寻找可以运行在一个甚至不知道文件是什么的操作系统的自由驱动,但是我一个都找不到,它们都太高层了,所以我尝试写一个。大家说的都对,这耗费了我几周时间。然而我可以高兴的说我做的这些工作没有获取操作系统以外的帮助,并且可以和鼠标和键盘通信。这绝不是完整的、高效的,或者正确的,但是它能工作。驱动是以 C 编写的,而且有兴趣的可以在下载页找到全部源代码。
|
||||
|
||||
所以,这一个教程不会是 USB 标准的课程(一点也没有)。实际上我们将会看到如何使用其他人的代码。
|
||||
|
||||
### 3、链接
|
||||
|
||||
既然我们要引进外部代码到操作系统,我们就需要谈一谈<ruby>链接<rt>linking</rt></ruby>。链接是一种过程,可以在程序或者操作系统中链接函数。这意味着当一个程序生成之后,我们不必要编写每一个函数(几乎可以肯定,实际上并非如此)。链接就是我们做的用来把我们程序和别人代码中的函数连结在一起。这个实际上已经在我们的操作系统进行了,因为链接器把所有不同的文件链接在一起,每个都是分开编译的。
|
||||
|
||||
> 链接允许我们制作可重用的代码库,所有人都可以在他们的程序中使用。
|
||||
|
||||
有两种链接方式:静态和动态。静态链接就像我们在制作自己的操作系统时进行的。链接器找到全部函数的地址,然后在链接结束前,将这些地址都写入代码中。动态链接是在程序“完成”之后。当程序加载后,动态链接器检查程序,然后在操作系统的库找到所有不在程序里的函数。这就是我们的操作系统最终应该能够完成的一项工作,但是现在所有东西都将是静态链接的。
|
||||
|
||||
> 程序经常调用调用库,这些库会调用其它的库,直到最终调用了我们写的操作系统的库。
|
||||
|
||||
我编写的 USB 驱动程序适合静态编译。这意味着我给你的是每个文件的编译后的代码,然后链接器找到你的代码中的那些没有实现的函数,就将这些函数链接到我的代码。在本课的 [下载页][1] 是一个 makefile 和我的 USB 驱动,这是接下来需要的。下载并使用这个 makefile 替换你的代码中的 makefile, 同事将驱动放在和这个 makefile 相同的文件夹。
|
||||
|
||||
### 4、键盘
|
||||
|
||||
为了将输入传给我们的操作系统,我们需要在某种程度上理解键盘是如何实际工作的。键盘有两种按键:普通键和修饰键。普通按键是字母、数字、功能键,等等。它们构成了键盘上几乎全部按键。修饰键是多达 8 个的特殊键。它们是左 shift、右 shift、左 ctrl、右 ctrl、左 alt、右 alt、左 GUI 和右 GUI。键盘可以检测出所有的组合中那个修饰键被按下了,以及最多 6 个普通键。每次一个按钮变化了(例如,是按下了还是释放了),键盘就会报告给电脑。通常,键盘也会有 3 个 LED 灯,分别指示大写锁定,数字键锁定,和滚动锁定,这些都是由电脑控制的,而不是键盘自己。键盘也可能有更多的灯,比如电源、静音,等等。
|
||||
|
||||
对于标准 USB 键盘,有一个按键值的表,每个键盘按键都一个唯一的数字,每个可能的 LED 也类似。下面的表格列出了前 126 个值。
|
||||
|
||||
表 4.1 USB 键盘值
|
||||
|
||||
| 序号 | 描述 | 序号 | 描述 | 序号 | 描述 | 序号 | 描述 |
|
||||
| ------ | ---------------------- | ------ | -------------------- | ----------- | ----------------------- | -------- | ---------------------- |
|
||||
| 4 | `a` 和 `A` | 5 | `b` 和 `B` | 6 | `c` 和 `C` | 7 | `d` 和 `D` |
|
||||
| 8 | `e` 和 `E` | 9 | `f` 和 `F` | 10 | `g` 和 `G` | 11 | `h` 和 `H` |
|
||||
| 12 | `i` 和 `I` | 13 | `j` 和 `J` | 14 | `k` 和 `K` | 15 | `l` 和 `L` |
|
||||
| 16 | `m` 和 `M` | 17 | `n` 和 `N` | 18 | `o` 和 `O` | 19 | `p` 和 `P` |
|
||||
| 20 | `q` 和 `Q` | 21 | `r` 和 `R` | 22 | `s` 和 `S` | 23 | `t` 和 `T` |
|
||||
| 24 | `u` 和 `U` | 25 | `v` 和 `V` | 26 | `w` 和 `W` | 27 | `x` 和 `X` |
|
||||
| 28 | `y` 和 `Y` | 29 | `z` 和 `Z` | 30 | `1` 和 `!` | 31 | `2` 和 `@` |
|
||||
| 32 | `3` 和 `#` | 33 | `4` 和 `$` | 34 | `5` 和 `%` | 35 | `6` 和 `^` |
|
||||
| 36 | `7` 和 `&` | 37 | `8` 和 `*` | 38 | `9` 和 `(` | 39 | `0` 和 `)` |
|
||||
| 40 | `Return`(`Enter`) | 41 | `Escape` | 42 | `Delete`(`Backspace`) | 43 | `Tab` |
|
||||
| 44 | `Spacebar` | 45 | `-` 和 `_` | 46 | `=` 和 `+` | 47 | `[` 和 `{` |
|
||||
| 48 | `]` 和 `}` | 49 | `\` 和 `|` | 50 | `#` 和 `~` | 51 | `;` 和 `:` |
|
||||
| 52 | `'` 和 `"` | 53 | \` 和 `~` | 54 | `,` 和 `<` | 55 | `.` 和 `>` |
|
||||
| 56 | `/` 和 `?` | 57 | `Caps Lock` | 58 | `F1` | 59 | `F2` |
|
||||
| 60 | `F3` | 61 | `F4` | 62 | `F5` | 63 | `F6` |
|
||||
| 64 | `F7` | 65 | `F8` | 66 | `F9` | 67 | `F10` |
|
||||
| 68 | `F11` | 69 | `F12` | 70 | `Print Screen` | 71 | `Scroll Lock` |
|
||||
| 72 | `Pause` | 73 | `Insert` | 74 | `Home` | 75 | `Page Up` |
|
||||
| 76 | `Delete forward` | 77 | `End` | 78 | `Page Down` | 79 | `Right Arrow` |
|
||||
| 80 | `Left Arrow` | 81 | `Down Arrow` | 82 | `Up Arrow` | 83 | `Num Lock` |
|
||||
| 84 | 小键盘 `/` | 85 | 小键盘 `*` | 86 | 小键盘 `-` | 87 | 小键盘 `+` |
|
||||
| 88 | 小键盘 `Enter` | 89 | 小键盘 `1` 和 `End` | 90 | 小键盘 `2` 和 `Down Arrow` | 91 | 小键盘 `3` 和 `Page Down` |
|
||||
| 92 | 小键盘 `4` 和 `Left Arrow` | 93 | 小键盘 `5` | 94 | 小键盘 `6` 和 `Right Arrow` | 95 | 小键盘 `7` 和 `Home` |
|
||||
| 96 | 小键盘 `8` 和 `Up Arrow` | 97 | 小键盘 `9` 和 `Page Up` | 98 | 小键盘 `0` 和 `Insert` | 99 | 小键盘 `.` 和 `Delete` |
|
||||
| 100 | `\` 和 `|` | 101 | `Application` | 102 | `Power` | 103 | 小键盘 `=` |
|
||||
| 104 | `F13` | 105 | `F14` | 106 | `F15` | 107 | `F16` |
|
||||
| 108 | `F17` | 109 | `F18` | 110 | `F19` | 111 | `F20` |
|
||||
| 112 | `F21` | 113 | `F22` | 114 | `F23` | 115 | `F24` |
|
||||
| 116 | `Execute` | 117 | `Help` | 118 | `Menu` | 119 | `Select` |
|
||||
| 120 | `Stop` | 121 | `Again` | 122 | `Undo` | 123 | `Cut` |
|
||||
| 124 | `Copy` | 125 | `Paste` | 126 | `Find` | 127 | `Mute` |
|
||||
| 128 | `Volume Up` | 129 | `Volume Down` | | | | |
|
||||
|
||||
完全列表可以在[HID 页表 1.12][2]的 53 页,第 10 节找到。
|
||||
|
||||
### 5、车轮后的螺母
|
||||
|
||||
通常,当你使用其他人的代码,他们会提供一份自己代码的总结,描述代码都做了什么,粗略介绍了是如何工作的,以及什么情况下会出错。下面是一个使用我的 USB 驱动的相关步骤要求。
|
||||
|
||||
> 这些总结和代码的描述组成了一个 API - 应用程序产品接口。
|
||||
|
||||
表 5.1 CSUD 中和键盘相关的函数
|
||||
|
||||
| 函数 | 参数 | 返回值 | 描述 |
|
||||
| ----------------------- | ----------------------- | ----------------------- | -----------------------|
|
||||
| `UsbInitialise` | 无 | `r0` 是结果码 | 这个方法是一个集多种功能于一身的方法,它加载 USB 驱动程序,枚举所有设备并尝试与它们通信。这种方法通常需要大约一秒钟的时间来执行,但是如果插入几个 USB 集线器,执行时间会明显更长。在此方法完成之后,键盘驱动程序中的方法就可用了,不管是否确实插入了键盘。返回代码如下解释。|
|
||||
| `UsbCheckForChange` | 无 | 无 | 本质上提供与 `UsbInitialise` 相同的效果,但不提供相同的一次初始化。该方法递归地检查每个连接的集线器上的每个端口,如果已经添加了新设备,则添加它们。如果没有更改,这应该是非常快的,但是如果连接了多个设备的集线器,则可能需要几秒钟的时间。|
|
||||
| `KeyboardCount` | 无 | `r0` 是计数 | 返回当前连接并检测到的键盘数量。`UsbCheckForChange` 可能会对此进行更新。默认情况下最多支持 4 个键盘。可以通过这个驱动程序访问多达这么多的键盘。|
|
||||
| `KeyboardGetAddress` | `r0` 是索引 | `r0` 是地址 | 检索给定键盘的地址。所有其他函数都需要一个键盘地址,以便知道要访问哪个键盘。因此,要与键盘通信,首先要检查计数,然后检索地址,然后使用其他方法。注意,在调用 `UsbCheckForChange` 之后,此方法返回的键盘顺序可能会改变。|
|
||||
| `KeyboardPoll` | `r0` 是地址 | `r0` 是结果码 | 从键盘读取当前键状态。这是通过直接轮询设备来操作的,与最佳实践相反。这意味着,如果没有频繁地调用此方法,可能会错过一个按键。所有读取方法只返回上次轮询时的值。|
|
||||
| `KeyboardGetModifiers` | `r0` 是地址 | `r0` 是修饰键状态 | 检索上次轮询时修饰键的状态。这是两边的 `shift` 键、`alt` 键和 `GUI` 键。这回作为一个位字段返回,这样,位 0 中的 1 表示左控件被保留,位 1 表示左 `shift`,位 2 表示左 `alt` ,位 3 表示左 `GUI`,位 4 到 7 表示前面几个键的右版本。如果有问题,`r0` 包含 0。|
|
||||
| `KeyboardGetKeyDownCount` | `r0` 是地址 | `r0` 是计数 | 检索当前按下键盘的键数。这排除了修饰键。这通常不能超过 6。如果有错误,这个方法返回 0。|
|
||||
| `KeyboardGetKeyDown` | `r0` 是地址,`r1` 键号 | `r0` 是扫描码 | 检索特定按下键的扫描码(见表 4.1)。通常,要计算出哪些键是按下的,可以调用 `KeyboardGetKeyDownCount`,然后多次调用 `KeyboardGetKeyDown` ,将 `r1` 的值递增,以确定哪些键是按下的。如果有问题,返回 0。可以(但不建议这样做)在不调用 `KeyboardGetKeyDownCount` 的情况下调用此方法将 0 解释为没有按下的键。注意,顺序或扫描代码可以随机更改(有些键盘按数字排序,有些键盘按时间排序,没有任何保证)。|
|
||||
| `KeyboardGetKeyIsDown` | `r0` 是地址,`r1` 扫描码 | `r0` 是状态 | 除了 `KeyboardGetKeyDown` 之外,还可以检查按下的键中是否有特定的扫描码。如果没有,返回 0;如果有,返回一个非零值。当检测特定的扫描码(例如寻找 `ctrl+c`)时更快。出错时,返回 0。|
|
||||
| `KeyboardGetLedSupport` | `r0` 是地址 | `r0` 是 LED | 检查特定键盘支持哪些 LED。第 0 位代表数字锁定,第 1 位代表大写锁定,第 2 位代表滚动锁定,第 3 位代表合成,第 4 位代表假名,第 5 位代表电源,第 6 位代表 Shift ,第 7 位代表静音。根据 USB 标准,这些 LED 都不是自动更新的(例如,当检测到大写锁定扫描代码时,必须手动设置大写锁定 LED)。|
|
||||
| `KeyboardSetLeds` | `r0` 是地址, `r1` 是 LED | `r0` 是结果码 | 试图打开/关闭键盘上指定的 LED 灯。查看下面的结果代码值。参见 `KeyboardGetLedSupport` 获取 LED 的值。|
|
||||
|
||||
有几种方法返回“返回值”。这些都是 C 代码的老生常谈了,就是用数字代表函数调用发生了什么。通常情况, 0 总是代表操作成功。下面的是驱动用到的返回值。
|
||||
|
||||
> 返回值是一种处理错误的简单方法,但是通常更优雅的解决途径会出现于更高层次的代码。
|
||||
|
||||
表 5.2 - CSUD 返回值
|
||||
|
||||
| 代码 | 描述 |
|
||||
| ---- | ----------------------------------------------------------------------- |
|
||||
| 0 | 方法成功完成。 |
|
||||
| -2 | 参数:函数调用了无效参数。 |
|
||||
| -4 | 设备:设备没有正确响应请求。 |
|
||||
| -5 | 不匹配:驱动不适用于这个请求或者设备。 |
|
||||
| -6 | 编译器:驱动没有正确编译,或者被破坏了。 |
|
||||
| -7 | 内存:驱动用尽了内存。 |
|
||||
| -8 | 超时:设备没有在预期的时间内响应请求。 |
|
||||
| -9 | 断开连接:被请求的设备断开连接,或者不能使用。 |
|
||||
|
||||
驱动的通常用法如下:
|
||||
|
||||
1. 调用 `UsbInitialise`
|
||||
2. 调用 `UsbCheckForChange`
|
||||
3. 调用 `KeyboardCount`
|
||||
4. 如果返回 0,重复步骤 2。
|
||||
5. 针对你支持的每个键盘:
|
||||
1. 调用 `KeyboardGetAddress`
|
||||
2. 调用 `KeybordGetKeyDownCount`
|
||||
3. 针对每个按下的按键:
|
||||
1. 检查它是否已经被按下了
|
||||
2. 保存按下的按键
|
||||
4. 针对每个保存的按键:
|
||||
3. 检查按键是否被释放了
|
||||
4. 如果释放了就删除
|
||||
6. 根据按下/释放的案件执行操作
|
||||
7. 重复步骤 2
|
||||
|
||||
最后,你可以对键盘做所有你想做的任何事了,而这些方法应该允许你访问键盘的全部功能。在接下来的两节课,我们将会着眼于完成文本终端的输入部分,类似于大部分的命令行电脑,以及命令的解释。为了做这些,我们将需要在更有用的形式下得到一个键盘输入。你可能注意到我的驱动是(故意的)没有太大帮助,因为它并没有方法来判断是否一个按键刚刚按下或释放了,它只有方法来判断当前那个按键是按下的。这就意味着我们需要自己编写这些方法。
|
||||
|
||||
### 6、可用更新
|
||||
|
||||
首先,让我们实现一个 `KeyboardUpdate` 方法,检查第一个键盘,并使用轮询方法来获取当前的输入,以及保存最后一个输入来对比。然后我们可以使用这个数据和其它方法来将扫描码转换成按键。这个方法应该按照下面的说明准确操作:
|
||||
|
||||
> 重复检查更新被称为“轮询”。这是针对驱动 IO 中断而言的,这种情况下设备在准备好后会发一个信号。
|
||||
|
||||
1. 提取一个保存好的键盘地址(初始值为 0)。
|
||||
2. 如果不是 0 ,进入步骤 9.
|
||||
3. 调用 `UsbCheckForChange` 检测新键盘。
|
||||
4. 调用 `KeyboardCount` 检测有几个键盘在线。
|
||||
5. 如果返回 0,意味着没有键盘可以让我们操作,只能退出了。
|
||||
6. 调用 `KeyboardGetAddress` 参数是 0,获取第一个键盘的地址。
|
||||
7. 保存这个地址。
|
||||
8. 如果这个值是 0,那么退出,这里应该有些问题。
|
||||
9. 调用 `KeyboardGetKeyDown` 6 次,获取每次按键按下的值并保存。
|
||||
10. 调用 `KeyboardPoll`
|
||||
11. 如果返回值非 0,进入步骤 3。这里应该有些问题(比如键盘断开连接)。
|
||||
|
||||
要保存上面提到的值,我们将需要下面 `.data` 段的值。
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 2
|
||||
KeyboardAddress:
|
||||
.int 0
|
||||
KeyboardOldDown:
|
||||
.rept 6
|
||||
.hword 0
|
||||
.endr
|
||||
```
|
||||
|
||||
```
|
||||
.hword num 直接将半字的常数插入文件。
|
||||
```
|
||||
|
||||
```
|
||||
.rept num [commands] .endr 复制 `commands` 命令到输出 num 次。
|
||||
```
|
||||
|
||||
试着自己实现这个方法。对此,我的实现如下:
|
||||
|
||||
1、我们加载键盘的地址。
|
||||
|
||||
```
|
||||
.section .text
|
||||
.globl KeyboardUpdate
|
||||
KeyboardUpdate:
|
||||
push {r4,r5,lr}
|
||||
|
||||
kbd .req r4
|
||||
ldr r0,=KeyboardAddress
|
||||
ldr kbd,[r0]
|
||||
```
|
||||
|
||||
2、如果地址非 0,就说明我们有一个键盘。调用 `UsbCheckForChanges` 慢,所以如果一切正常,我们要避免调用这个函数。
|
||||
|
||||
```
|
||||
teq kbd,#0
|
||||
bne haveKeyboard$
|
||||
```
|
||||
|
||||
3、如果我们一个键盘都没有,我们就必须检查新设备。
|
||||
|
||||
```
|
||||
getKeyboard$:
|
||||
bl UsbCheckForChange
|
||||
```
|
||||
|
||||
4、如果有新键盘添加,我们就会看到这个。
|
||||
|
||||
```
|
||||
bl KeyboardCount
|
||||
```
|
||||
|
||||
5、如果没有键盘,我们就没有键盘地址。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
ldreq r1,=KeyboardAddress
|
||||
streq r0,[r1]
|
||||
beq return$
|
||||
```
|
||||
|
||||
6、让我们获取第一个键盘的地址。你可能想要支持更多键盘。
|
||||
|
||||
```
|
||||
mov r0,#0
|
||||
bl KeyboardGetAddress
|
||||
```
|
||||
|
||||
7、保存键盘地址。
|
||||
|
||||
```
|
||||
ldr r1,=KeyboardAddress
|
||||
str r0,[r1]
|
||||
```
|
||||
|
||||
8、如果我们没有键盘地址,这里就没有其它活要做了。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
beq return$
|
||||
mov kbd,r0
|
||||
```
|
||||
|
||||
9、循环查询全部按键,在 `KeyboardOldDown` 保存下来。如果我们询问的太多了,返回 0 也是正确的。
|
||||
|
||||
```
|
||||
saveKeys$:
|
||||
mov r0,kbd
|
||||
mov r1,r5
|
||||
bl KeyboardGetKeyDown
|
||||
|
||||
ldr r1,=KeyboardOldDown
|
||||
add r1,r5,lsl #1
|
||||
strh r0,[r1]
|
||||
add r5,#1
|
||||
cmp r5,#6
|
||||
blt saveKeys$
|
||||
```
|
||||
|
||||
10、现在我们得到了新的按键。
|
||||
|
||||
```
|
||||
mov r0,kbd
|
||||
bl KeyboardPoll
|
||||
```
|
||||
|
||||
11、最后我们要检查 `KeyboardOldDown` 是否工作了。如果没工作,那么我们可能是断开连接了。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
bne getKeyboard$
|
||||
|
||||
return$:
|
||||
pop {r4,r5,pc}
|
||||
.unreq kbd
|
||||
```
|
||||
|
||||
有了我们新的 `KeyboardUpdate` 方法,检查输入变得简单,固定周期调用这个方法就行,而它甚至可以检查键盘是否断开连接,等等。这是一个有用的方法,因为我们实际的按键处理会根据条件不同而有所差别,所以能够用一个函数调以它的原始方式获取当前的输入是可行的。下一个方法我们希望它是 `KeyboardGetChar`,简单的返回下一个按下的按钮的 ASCII 字符,或者如果没有按键按下就返回 0。这可以扩展到支持如果它按下一个特定时间当做多次按下按键,也支持锁定键和修饰键。
|
||||
|
||||
如果我们有一个 `KeyWasDown` 方法可以使这个方法有用起来,如果给定的扫描代码不在 `KeyboardOldDown` 值中,它只返回 0,否则返回一个非零值。你可以自己尝试一下。与往常一样,可以在下载页面找到解决方案。
|
||||
|
||||
### 7、查找表
|
||||
|
||||
`KeyboardGetChar` 方法如果写得不好,可能会非常复杂。有 100 多种扫描码,每种代码都有不同的效果,这取决于 shift 键或其他修饰符的存在与否。并不是所有的键都可以转换成一个字符。对于一些字符,多个键可以生成相同的字符。在有如此多可能性的情况下,一个有用的技巧是查找表。查找表与物理意义上的查找表非常相似,它是一个值及其结果的表。对于一些有限的函数,推导出答案的最简单方法就是预先计算每个答案,然后通过检索返回正确的答案。在这种情况下,我们可以在内存中建立一个序列的值,序列中第 n 个值就是扫描代码 n 的 ASCII 字符代码。这意味着如果一个键被按下,我们的方法只需要检测到,然后从表中检索它的值。此外,我们可以为当按住 shift 键时的值单独创建一个表,这样按下 shift 键就可以简单地换个我们用的表。
|
||||
|
||||
> 在编程的许多领域,程序越大,速度越快。查找表很大,但是速度很快。有些问题可以通过查找表和普通函数的组合来解决。
|
||||
|
||||
在 `.section .data` 命令之后,复制下面的表:
|
||||
|
||||
```
|
||||
.align 3
|
||||
KeysNormal:
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 'a', 'b', 'c', 'd'
|
||||
.byte 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l'
|
||||
.byte 'm', 'n', 'o', 'p', 'q', 'r', 's', 't'
|
||||
.byte 'u', 'v', 'w', 'x', 'y', 'z', '1', '2'
|
||||
.byte '3', '4', '5', '6', '7', '8', '9', '0'
|
||||
.byte '\n', 0x0, '\b', '\t', ' ', '-', '=', '['
|
||||
.byte ']', '\\\', '#', ';', '\'', '`', ',', '.'
|
||||
.byte '/', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
|
||||
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
|
||||
.byte '8', '9', '0', '.', '\\\', 0x0, 0x0, '='
|
||||
|
||||
.align 3
|
||||
KeysShift:
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 'A', 'B', 'C', 'D'
|
||||
.byte 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L'
|
||||
.byte 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T'
|
||||
.byte 'U', 'V', 'W', 'X', 'Y', 'Z', '!', '"'
|
||||
.byte '£', '$', '%', '^', '&', '*', '(', ')'
|
||||
.byte '\n', 0x0, '\b', '\t', ' ', '_', '+', '{'
|
||||
.byte '}', '|', '~', ':', '@', '¬', '<', '>'
|
||||
.byte '?', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
|
||||
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
|
||||
.byte '8', '9', '0', '.', '|', 0x0, 0x0, '='
|
||||
```
|
||||
|
||||
这些表直接将前 104 个扫描码映射到 ASCII 字符作为一个字节表。我们还有一个单独的表来描述 `shift` 键对这些扫描码的影响。我使用 ASCII `null` 字符(`0`)表示所有没有直接映射的 ASCII 键(例如功能键)。退格映射到 ASCII 退格字符(8 表示 `\b`),`enter` 映射到 ASCII 新行字符(10 表示 `\n`), `tab` 映射到 ASCII 水平制表符(9 表示 `\t`)。
|
||||
|
||||
> `.byte num` 直接插入字节常量 num 到文件。
|
||||
|
||||
.
|
||||
|
||||
> 大部分的汇编器和编译器识别转义序列;如 `\t` 这样的字符序列会插入该特殊字符。
|
||||
|
||||
`KeyboardGetChar` 方法需要做以下工作:
|
||||
|
||||
1. 检查 `KeyboardAddress` 是否返回 `0`。如果是,则返回 0。
|
||||
2. 调用 `KeyboardGetKeyDown` 最多 6 次。每次:
|
||||
1. 如果按键是 0,跳出循环。
|
||||
2. 调用 `KeyWasDown`。 如果返回是,处理下一个按键。
|
||||
3. 如果扫描码超过 103,进入下一个按键。
|
||||
4. 调用 `KeyboardGetModifiers`
|
||||
5. 如果 `shift` 是被按着的,就加载 `KeysShift` 的地址,否则加载 `KeysNormal` 的地址。
|
||||
6. 从表中读出 ASCII 码值。
|
||||
7. 如果是 0,进行下一个按键,否则返回 ASCII 码值并退出。
|
||||
3. 返回 0。
|
||||
|
||||
|
||||
试着自己实现。我的实现展示在下面:
|
||||
|
||||
1、简单的检查我们是否有键盘。
|
||||
|
||||
```
|
||||
.globl KeyboardGetChar
|
||||
KeyboardGetChar:
|
||||
ldr r0,=KeyboardAddress
|
||||
ldr r1,[r0]
|
||||
teq r1,#0
|
||||
moveq r0,#0
|
||||
moveq pc,lr
|
||||
```
|
||||
|
||||
2、`r5` 将会保存按键的索引,`r4` 保存键盘的地址。
|
||||
|
||||
```
|
||||
push {r4,r5,r6,lr}
|
||||
kbd .req r4
|
||||
key .req r6
|
||||
mov r4,r1
|
||||
mov r5,#0
|
||||
keyLoop$:
|
||||
mov r0,kbd
|
||||
mov r1,r5
|
||||
bl KeyboardGetKeyDown
|
||||
```
|
||||
|
||||
2.1、 如果扫描码是 0,它要么意味着有错,要么说明没有更多按键了。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
beq keyLoopBreak$
|
||||
```
|
||||
|
||||
2.2、如果按键已经按下了,那么他就没意义了,我们只想知道按下的按键。
|
||||
|
||||
```
|
||||
mov key,r0
|
||||
bl KeyWasDown
|
||||
teq r0,#0
|
||||
bne keyLoopContinue$
|
||||
```
|
||||
|
||||
|
||||
2.3、如果一个按键有个超过 104 的扫描码,它将会超出我们的表,所以它是无关的按键。
|
||||
|
||||
```
|
||||
cmp key,#104
|
||||
bge keyLoopContinue$
|
||||
```
|
||||
|
||||
2.4、我们需要知道修饰键来推断字符。
|
||||
|
||||
```
|
||||
mov r0,kbd
|
||||
bl KeyboardGetModifiers
|
||||
```
|
||||
|
||||
5. 当将字符更改为其 shift 变体时,我们要同时检测左 `shift` 键和右 `shift` 键。记住,`tst` 指令计算的是逻辑和,然后将其与 0 进行比较,所以当且仅当移位位都为 0 时,它才等于 0。
|
||||
|
||||
```
|
||||
tst r0,#0b00100010
|
||||
ldreq r0,=KeysNormal
|
||||
ldrne r0,=KeysShift
|
||||
```
|
||||
|
||||
2.6、现在我们可以从查找表加载按键了。
|
||||
|
||||
```
|
||||
ldrb r0,[r0,key]
|
||||
```
|
||||
|
||||
2.7、如果查找码包含一个 0,我们必须继续。为了继续,我们要增加索引,并检查是否到 6 次了。
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
bne keyboardGetCharReturn$
|
||||
keyLoopContinue$:
|
||||
add r5,#1
|
||||
cmp r5,#6
|
||||
blt keyLoop$
|
||||
```
|
||||
|
||||
|
||||
3、在这里我们返回我们的按键,如果我们到达 `keyLoopBreak$` ,然后我们就知道这里没有按键被握住,所以返回 0。
|
||||
|
||||
```
|
||||
keyLoopBreak$:
|
||||
mov r0,#0
|
||||
keyboardGetCharReturn$:
|
||||
pop {r4,r5,r6,pc}
|
||||
.unreq kbd
|
||||
.unreq key
|
||||
```
|
||||
|
||||
### 8、记事本操作系统
|
||||
|
||||
现在我们有了 `KeyboardGetChar` 方法,可以创建一个操作系统,只打印出用户对着屏幕所写的内容。为了简单起见,我们将忽略所有非常规的键。在 `main.s`,删除 `bl SetGraphicsAddress` 之后的所有代码。调用 `UsbInitialise`,将 `r4` 和 `r5` 设置为 0,然后循环执行以下命令:
|
||||
|
||||
1. 调用 `KeyboardUpdate`
|
||||
2. 调用 `KeyboardGetChar`
|
||||
3. 如果返回 0,跳转到步骤 1
|
||||
4. 复制 `r4` 和 `r5` 到 `r1` 和 `r2` ,然后调用 `DrawCharacter`
|
||||
5. 把 `r0` 加到 `r4`
|
||||
6. 如果 `r4` 是 1024,将 `r1` 加到 `r5`,然后设置 `r4` 为 0。
|
||||
7. 如果 `r5` 是 768,设置 `r5` 为0
|
||||
8. 跳转到步骤 1
|
||||
|
||||
现在编译,然后在树莓派上测试。你几乎可以立即开始在屏幕上输入文本。如果没有工作,请参阅我们的故障排除页面。
|
||||
|
||||
当它工作时,祝贺你,你已经实现了与计算机的接口。现在你应该开始意识到,你几乎已经拥有了一个原始的操作系统。现在,你可以与计算机交互、发出命令,并在屏幕上接收反馈。在下一篇教程[输入02][3]中,我们将研究如何生成一个全文本终端,用户在其中输入命令,然后计算机执行这些命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/hut1_12v2.pdf
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html
|
||||
@ -0,0 +1,197 @@
|
||||
iWant:一个去中心化的点对点共享文件的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
不久之前,我们编写了一个指南,内容是一个文件共享实用程序,名为 [transfer.sh][1],它是一个免费的 Web 服务,允许你在 Internet 上轻松快速地共享文件,还有 [PSiTransfer][2],一个简单的开源自托管文件共享解决方案。今天,我们将看到另一个名为 “iWant” 的文件共享实用程序。它是一个基于命令行的自由开源的去中心化点对点文件共享应用程序。
|
||||
|
||||
你可能想知道,它与其它文件共享应用程序有什么不同?以下是 iWant 的一些突出特点。
|
||||
|
||||
* 它是一个命令行应用程序。这意味着你不需要消耗内存来加载 GUI 实用程序。你只需要一个终端。
|
||||
* 它是去中心化的。这意味着你的数据不会在任何中心位置存储。因此,不会因为中心点失败而失败。
|
||||
* iWant 允许中断下载,你可以在以后随时恢复。你不需要从头开始下载,它会从你停止的位置恢复下载。
|
||||
* 共享目录中文件所作的任何更改(如删除、添加、修改)都会立即反映在网络中。
|
||||
* 就像种子一样,iWant 从多个节点下载文件。如果任何节点离开群组或未能响应,它将继续从另一个节点下载。
|
||||
* 它是跨平台的,因此你可以在 GNU/Linux、MS Windows 或者 Mac OS X 中使用它。
|
||||
|
||||
### 安装 iWant
|
||||
|
||||
iWant 可以使用 PIP 包管理器轻松安装。确保你在 Linux 发行版中安装了 pip。如果尚未安装,参考以下指南。
|
||||
|
||||
[如何使用 Pip 管理 Python 包](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
安装 pip 后,确保你有以下依赖项:
|
||||
|
||||
* libffi-dev
|
||||
* libssl-dev
|
||||
|
||||
比如说,在 Ubuntu 上,你可以使用以下命令安装这些依赖项:
|
||||
|
||||
```
|
||||
$ sudo apt-get install libffi-dev libssl-dev
|
||||
```
|
||||
|
||||
安装完所有依赖项后,使用以下命令安装 iWant:
|
||||
|
||||
```
|
||||
$ sudo pip install iwant
|
||||
```
|
||||
|
||||
现在我们的系统中已经有了 iWant,让我们来看看如何使用它来通过网络传输文件。
|
||||
|
||||
### 用法
|
||||
|
||||
首先,使用以下命令启动 iWant 服务器:
|
||||
|
||||
(LCTT 译注:虽然这个软件是叫 iWant,但是其命令名为 `iwanto`,另外这个软件至少一年没有更新了。)
|
||||
|
||||
```
|
||||
$ iwanto start
|
||||
```
|
||||
|
||||
第一次启动时,iWant 会询问想要分享和下载文件夹的位置,所以需要输入两个文件夹的位置。然后,选择要使用的网卡。
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Shared/Download folder details looks empty..
|
||||
Note: Shared and Download folder cannot be the same
|
||||
SHARED FOLDER(absolute path):/home/sk/myshare
|
||||
DOWNLOAD FOLDER(absolute path):/home/sk/mydownloads
|
||||
Network interface available
|
||||
1. lo => 127.0.0.1
|
||||
2. enp0s3 => 192.168.43.2
|
||||
Enter index of the interface:2
|
||||
now scanning /home/sk/myshare
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
Updating Leader 56f6d5e8-654e-11e7-93c8-08002712f8c1
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
connecting to 192.168.43.2:1235 for hashdump
|
||||
```
|
||||
|
||||
如果你看到类似上面的输出,你可以立即开始使用 iWant 了。
|
||||
|
||||
同样,在网络中的所有系统上启动 iWant 服务,指定有效的分享和下载文件夹的位置,并选择合适的网卡。
|
||||
|
||||
iWant 服务将继续在当前终端窗口中运行,直到你按下 `CTRL+C` 退出为止。你需要打开一个新选项卡或新的终端窗口来使用 iWant。
|
||||
|
||||
iWant 的用法非常简单,它的命令很少,如下所示。
|
||||
|
||||
* `iwanto start` – 启动 iWant 服务。
|
||||
* `iwanto search <name>` – 查找文件。
|
||||
* `iwanto download <hash>` – 下载一个文件。
|
||||
* `iwanto share <path>` – 更改共享文件夹的位置。
|
||||
* `iwanto download to <destination>` – 更改下载文件夹位置。
|
||||
* `iwanto view config` – 查看共享和下载文件夹。
|
||||
* `iwanto –version` – 显示 iWant 版本。
|
||||
* `iwanto -h` – 显示帮助信息。
|
||||
|
||||
让我向你展示一些例子。
|
||||
|
||||
#### 查找文件
|
||||
|
||||
要查找一个文件,运行:
|
||||
|
||||
```
|
||||
$ iwanto search <filename>
|
||||
|
||||
```
|
||||
|
||||
请注意,你无需指定确切的名称。
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ iwanto search command
|
||||
```
|
||||
|
||||
上面的命令将搜索包含 “command” 字符串的所有文件。
|
||||
|
||||
我的 Ubuntu 系统会输出:
|
||||
|
||||
```
|
||||
Filename Size Checksum
|
||||
------------------------------------------- ------- --------------------------------
|
||||
/home/sk/myshare/THE LINUX COMMAND LINE.pdf 3.85757 efded6cc6f34a3d107c67c2300459911
|
||||
```
|
||||
|
||||
#### 下载文件
|
||||
|
||||
你可以在你的网络上的任何系统下载文件。要下载文件,只需提供文件的哈希(校验和),如下所示。你可以使用 `iwanto search` 命令获取共享的哈希值。
|
||||
|
||||
```
|
||||
$ iwanto download efded6cc6f34a3d107c67c2300459911
|
||||
```
|
||||
|
||||
文件将保存在你的下载位置,在本文中是 `/home/sk/mydownloads/` 位置。
|
||||
|
||||
```
|
||||
Filename: /home/sk/mydownloads/THE LINUX COMMAND LINE.pdf
|
||||
Size: 3.857569 MB
|
||||
```
|
||||
|
||||
#### 查看配置
|
||||
|
||||
要查看配置,例如共享和下载文件夹的位置,运行:
|
||||
|
||||
```
|
||||
$ iwanto view config
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Shared folder:/home/sk/myshare
|
||||
Download folder:/home/sk/mydownloads
|
||||
```
|
||||
|
||||
#### 更改共享和下载文件夹的位置
|
||||
|
||||
你可以更改共享文件夹和下载文件夹。
|
||||
|
||||
```
|
||||
$ iwanto share /home/sk/ostechnix
|
||||
```
|
||||
|
||||
现在,共享位置已更改为 `/home/sk/ostechnix`。
|
||||
|
||||
同样,你可以使用以下命令更改下载位置:
|
||||
|
||||
```
|
||||
$ iwanto download to /home/sk/Downloads
|
||||
```
|
||||
|
||||
要查看所做的更改,运行命令:
|
||||
|
||||
```
|
||||
$ iwanto view config
|
||||
```
|
||||
|
||||
#### 停止 iWant
|
||||
|
||||
一旦你不想用 iWant 了,可以按下 `CTRL+C` 退出。
|
||||
|
||||
如果它不起作用,那可能是由于防火墙或你的路由器不支持多播。你可以在 `~/.iwant/.iwant.log` 文件中查看所有日志。有关更多详细信息,参阅最后提供的项目的 GitHub 页面。
|
||||
|
||||
差不多就是全部了。希望这个工具有所帮助。下次我会带着另一个有趣的指南再次来到这里。
|
||||
|
||||
干杯!
|
||||
|
||||
### 资源
|
||||
|
||||
-[iWant GitHub](https://github.com/nirvik/iWant)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/iwant-decentralized-peer-peer-file-sharing-commandline-application/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/easy-fast-way-share-files-internet-command-line/
|
||||
[2]:https://www.ostechnix.com/psitransfer-simple-open-source-self-hosted-file-sharing-solution/
|
||||
101
published/20180118 Rediscovering make- the power behind rules.md
Normal file
101
published/20180118 Rediscovering make- the power behind rules.md
Normal file
@ -0,0 +1,101 @@
|
||||
重新发现 make: 规则背后的力量
|
||||
======
|
||||
|
||||

|
||||
|
||||
我过去认为 makefile 只是一种将一组组的 shell 命令列出来的简便方法;过了一段时间我了解到它们是有多么的强大、灵活以及功能齐全。这篇文章带你领略其中一些有关规则的特性。
|
||||
|
||||
> 备注:这些全是针对 GNU Makefile 的,如果你希望支持 BSD Makefile ,你会发现有些新的功能缺失。感谢 [zge][5] 指出这点。
|
||||
|
||||
### 规则
|
||||
|
||||
<ruby>规则<rt>rule</rt></ruby>是指示 `make` 应该如何并且何时构建一个被称作为<ruby>目标<rt>target</rt></ruby>的文件的指令。目标可以依赖于其它被称作为<ruby>前提<rt>prerequisite</rt></ruby>的文件。
|
||||
|
||||
你会指示 `make` 如何按<ruby>步骤<rt>recipe</rt></ruby>构建目标,那就是一套按照出现顺序一次执行一个的 shell 命令。语法像这样:
|
||||
|
||||
```
|
||||
target_name : prerequisites
|
||||
recipe
|
||||
```
|
||||
|
||||
一但你定义好了规则,你就可以通过从命令行执行以下命令构建目标:
|
||||
|
||||
```
|
||||
$ make target_name
|
||||
```
|
||||
|
||||
目标一经构建,除非前提改变,否则 `make` 会足够聪明地不再去运行该步骤。
|
||||
|
||||
### 关于前提的更多信息
|
||||
|
||||
前提表明了两件事情:
|
||||
|
||||
* 当目标应当被构建时:如果其中一个前提比目标更新,`make` 假定目的应当被构建。
|
||||
* 执行的顺序:鉴于前提可以反过来在 makefile 中由另一套规则所构建,它们同样暗示了一个执行规则的顺序。
|
||||
|
||||
如果你想要定义一个顺序但是你不想在前提改变的时候重新构建目标,你可以使用一种特别的叫做“<ruby>唯顺序<rt>order only</rt></ruby>”的前提。这种前提可以被放在普通的前提之后,用管道符(`|`)进行分隔。
|
||||
|
||||
### 样式
|
||||
|
||||
为了便利,`make` 接受目标和前提的样式。通过包含 `%` 符号可以定义一种样式。这个符号是一个可以匹配任何长度的文字符号或者空隔的通配符。以下有一些示例:
|
||||
|
||||
* `%`:匹配任何文件
|
||||
* `%.md`:匹配所有 `.md` 结尾的文件
|
||||
* `prefix%.go`:匹配所有以 `prefix` 开头以 `.go` 结尾的文件
|
||||
|
||||
### 特殊目标
|
||||
|
||||
有一系列目标名字,它们对于 `make` 来说有特殊的意义,被称作<ruby>特殊目标<rt>special target</rt></ruby>。
|
||||
|
||||
你可以在这个[文档][1]发现全套特殊目标。作为一种经验法则,特殊目标以点开始后面跟着大写字母。
|
||||
|
||||
以下是几个有用的特殊目标:
|
||||
|
||||
- `.PHONY`:向 `make` 表明此目标的前提可以被当成伪目标。这意味着 `make` 将总是运行,无论有那个名字的文件是否存在或者上次被修改的时间是什么。
|
||||
- `.DEFAULT`:被用于任何没有指定规则的目标。
|
||||
- `.IGNORE`:如果你指定 `.IGNORE` 为前提,`make` 将忽略执行步骤中的错误。
|
||||
|
||||
### 替代
|
||||
|
||||
当你需要以你指定的改动方式改变一个变量的值,<ruby>替代<rt>substitution</rt></ruby>就十分有用了。
|
||||
|
||||
替代的格式是 `$(var:a=b)`,它的意思是获取变量 `var` 的值,用值里面的 `b` 替代词末尾的每个 `a` 以代替最终的字符串。例如:
|
||||
|
||||
```
|
||||
foo := a.o
|
||||
bar : = $(foo:.o=.c) # sets bar to a.c
|
||||
```
|
||||
|
||||
注意:特别感谢 [Luis Lavena][2] 让我们知道替代的存在。
|
||||
|
||||
### 档案文件
|
||||
|
||||
档案文件是用来一起将多个数据文档(类似于压缩文件的概念)收集成一个文件。它们由 `ar` Unix 工具所构建。`ar` 可以用于为任何目的创建档案,但除了[静态库][3],它已经被 `tar` 大量替代。
|
||||
|
||||
在 `make` 中,你可以使用一个档案文件中的单独一个成员作为目标或者前提,就像这样:
|
||||
|
||||
```
|
||||
archive(member) : prerequisite
|
||||
recipe
|
||||
```
|
||||
|
||||
### 最后的想法
|
||||
|
||||
关于 `make` 还有更多可探索的,但是至少这是一个起点,我强烈鼓励你去查看[文档][4],创建一个笨拙的 makefile 然后就可以探索它了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/rediscovering-make-power-behind-rules/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://www.gnu.org/software/make/manual/make.html#Special-Targets
|
||||
[2]:https://twitter.com/luislavena/
|
||||
[3]:http://tldp.org/HOWTO/Program-Library-HOWTO/static-libraries.html
|
||||
[4]:https://www.gnu.org/software/make/manual/make.html
|
||||
[5]:https://lobste.rs/u/zge
|
||||
229
published/20180205 Rancher - Container Management Application.md
Normal file
229
published/20180205 Rancher - Container Management Application.md
Normal file
@ -0,0 +1,229 @@
|
||||
Rancher:一个全面的可用于产品环境的容器管理平台
|
||||
======
|
||||
|
||||
Docker 作为一款容器化应用的新兴软件,被大多数 IT 公司使用来减少基础设施平台的成本。
|
||||
|
||||
通常,没有 GUI 的 Docker 软件对于 Linux 管理员来说很容易,但是对于开发者来就有点困难。当把它搬到生产环境上来,那么它对 Linux 管理员来说也相当不友好。那么,轻松管理 Docker 的最佳解决方案是什么呢?
|
||||
|
||||
唯一的办法就是提供 GUI。Docker API 允许第三方应用接入 Docker。在市场上有许多 Docker GUI 应用。我们已经写过一篇关于 Portainer 应用的文章。今天我们来讨论另一个应用,Rancher。
|
||||
|
||||
容器让软件开发更容易,让开发者更快的写代码、更好的运行它们。但是,在生产环境上运行容器却很困难。
|
||||
|
||||
**推荐阅读:** [Portainer:一个简单的 Docker 管理图形工具][1]
|
||||
|
||||
### Rancher 简介
|
||||
|
||||
[Rancher][2] 是一个全面的容器管理平台,它可以让容器在各种基础设施平台的生产环境上部署和运行更容易。它提供了诸如多主机网络、全局/本地负载均衡和卷快照等基础设施服务。它整合了原生 Docker 的管理能力,如 Docker Machine 和 Docker Swarm。它提供了丰富的用户体验,让 DevOps 管理员在更大规模的生产环境上运行 Docker。
|
||||
|
||||
访问以下文章可以了解 Linux 系统上安装 Docker。
|
||||
|
||||
**推荐阅读:**
|
||||
|
||||
- [如何在 Linux 上安装 Docker][3]
|
||||
- [如何在 Linux 上使用 Docker 镜像][4]
|
||||
- [如何在 Linux 上使用 Docker 容器][5]
|
||||
- [如何在 Docker 容器内安装和运行应用][6]
|
||||
|
||||
### Rancher 特性
|
||||
|
||||
* 可以在两分钟内安装 Kubernetes。
|
||||
* 一键启动应用(90 个流行的 Docker 应用)。
|
||||
* 部署和管理 Docker 更容易。
|
||||
* 全面的生产级容器管理平台。
|
||||
* 可以在生产环境上快速部署容器。
|
||||
* 强大的自动部署和运营容器技术。
|
||||
* 模块化基础设施服务。
|
||||
* 丰富的编排工具。
|
||||
* Rancher 支持多种认证机制。
|
||||
|
||||
### 怎样安装 Rancher
|
||||
|
||||
由于 Rancher 是以轻量级的 Docker 容器方式运行,所以它的安装非常简单。Rancher 是由一组 Docker 容器部署的。只需要简单的启动两个容器就能运行 Rancher。一个容器用作管理服务器,另一个容器在各个节点上作为代理。在 Linux 系统下简单的运行下列命令就能部署 Rancher。
|
||||
|
||||
Rancher 服务器提供了两个不同的安装包标签如 `stable` 和 `latest`。下列命令将会拉取适合的 Rancher 镜像并安装到你的操作系统上。Rancher 服务器仅需要两分钟就可以启动。
|
||||
|
||||
* `latest`:这个标签是他们的最新开发构建。这些构建将通过 Rancher CI 的自动化框架进行验证,不建议在生产环境使用。
|
||||
* `stable`:这是最新的稳定发行版本,推荐在生产环境使用。
|
||||
|
||||
Rancher 的安装方法有多种。在这篇教程中我们仅讨论两种方法。
|
||||
|
||||
* 以单一容器的方式安装 Rancher(内嵌 Rancher 数据库)
|
||||
* 以单一容器的方式安装 Rancher(外部数据库)
|
||||
|
||||
### 方法 - 1
|
||||
|
||||
运行下列命令以单一容器的方式安装 Rancher 服务器(内嵌数据库)
|
||||
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:stable
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:latest
|
||||
```
|
||||
|
||||
### 方法 - 2
|
||||
|
||||
你可以在启动 Rancher 服务器时指向外部数据库,而不是使用自带的内部数据库。首先创建所需的数据库,数据库用户为同一个。
|
||||
|
||||
```
|
||||
> CREATE DATABASE IF NOT EXISTS cattle COLLATE = 'utf8_general_ci' CHARACTER SET = 'utf8';
|
||||
> GRANT ALL ON cattle.* TO 'cattle'@'%' IDENTIFIED BY 'cattle';
|
||||
> GRANT ALL ON cattle.* TO 'cattle'@'localhost' IDENTIFIED BY 'cattle';
|
||||
```
|
||||
|
||||
运行下列命令启动 Rancher 去连接外部数据库。
|
||||
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 8080:8080 rancher/server \
|
||||
--db-host myhost.example.com --db-port 3306 --db-user username --db-pass password --db-name cattle
|
||||
```
|
||||
|
||||
如果你想测试 Rancher 2.0,使用下列的命令去启动。
|
||||
|
||||
```
|
||||
$ sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/server:preview
|
||||
```
|
||||
|
||||
### 通过 GUI 访问 & 安装 Rancher
|
||||
|
||||
浏览器输入 `http://hostname:8080` 或 `http://server_ip:8080` 去访问 rancher GUI.
|
||||
|
||||
![][8]
|
||||
|
||||
### 怎样注册主机
|
||||
|
||||
注册你的主机 URL 允许它连接到 Rancher API。这是一次性设置。
|
||||
|
||||
接下来,点击主菜单下面的 “Add a Host” 链接或者点击主菜单上的 “INFRASTRUCTURE >> Add Hosts”,点击 “Save” 按钮。
|
||||
|
||||
![][9]
|
||||
|
||||
默认情况下,Rancher 里的访问控制认证禁止了访问,因此我们首先需要通过一些方法打开访问控制认证,否则任何人都不能访问 GUI。
|
||||
|
||||
点击 “>> Admin >> Access Control”,输入下列的值最后点击 “Enable Authentication” 按钮去打开它。在我这里,是通过 “local authentication” 的方式打开的。
|
||||
|
||||
* “Login UserName”: 输入你期望的登录名
|
||||
* “Full Name”: 输入你的全名
|
||||
* “Password”: 输入你期望的密码
|
||||
* “Confirm Password”: 再一次确认密码
|
||||
|
||||
![][10]
|
||||
|
||||
注销然后使用新的登录凭证重新登录:
|
||||
|
||||
![][11]
|
||||
|
||||
现在,我能看到本地认证已经被打开。
|
||||
|
||||
![][12]
|
||||
|
||||
### 怎样添加主机
|
||||
|
||||
注册你的主机后,它将带你进入下一个页面,在那里你能选择不同云服务提供商的 Linux 主机。我们将添加一个主机运行 Rancher 服务,因此选择“custom”选项然后输入必要的信息。
|
||||
|
||||
在第 4 步输入你服务器的公有 IP,运行第 5 步列出的命令,最后点击 “close” 按钮。
|
||||
|
||||
```
|
||||
$ sudo docker run -e CATTLE_AGENT_IP="192.168.56.2" --rm --privileged -v /var/run/docker.sock:/var/run/docker.sock -v /var/lib/rancher:/var/lib/rancher rancher/agent:v1.2.11 http://192.168.56.2:8080/v1/scripts/16A52B9BE2BAB87BB0F5:1546214400000:ODACe3sfis5V6U8E3JASL8jQ
|
||||
|
||||
INFO: Running Agent Registration Process, CATTLE_URL=http://192.168.56.2:8080/v1
|
||||
INFO: Attempting to connect to: http://192.168.56.2:8080/v1
|
||||
INFO: http://192.168.56.2:8080/v1 is accessible
|
||||
INFO: Configured Host Registration URL info: CATTLE_URL=http://192.168.56.2:8080/v1 ENV_URL=http://192.168.56.2:8080/v1
|
||||
INFO: Inspecting host capabilities
|
||||
INFO: Boot2Docker: false
|
||||
INFO: Host writable: true
|
||||
INFO: Token: xxxxxxxx
|
||||
INFO: Running registration
|
||||
INFO: Printing Environment
|
||||
INFO: ENV: CATTLE_ACCESS_KEY=9946BD1DCBCFEF3439F8
|
||||
INFO: ENV: CATTLE_AGENT_IP=192.168.56.2
|
||||
INFO: ENV: CATTLE_HOME=/var/lib/cattle
|
||||
INFO: ENV: CATTLE_REGISTRATION_ACCESS_KEY=registrationToken
|
||||
INFO: ENV: CATTLE_REGISTRATION_SECRET_KEY=xxxxxxx
|
||||
INFO: ENV: CATTLE_SECRET_KEY=xxxxxxx
|
||||
INFO: ENV: CATTLE_URL=http://192.168.56.2:8080/v1
|
||||
INFO: ENV: DETECTED_CATTLE_AGENT_IP=172.17.0.1
|
||||
INFO: ENV: RANCHER_AGENT_IMAGE=rancher/agent:v1.2.11
|
||||
INFO: Launched Rancher Agent: e83b22afd0c023dabc62404f3e74abb1fa99b9a178b05b1728186c9bfca71e8d
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
等待几秒钟后新添加的主机将会出现。点击 “Infrastructure >> Hosts” 页面。
|
||||
|
||||
![][14]
|
||||
|
||||
### 怎样查看容器
|
||||
|
||||
只需要点击下列位置就能列出所有容器。点击 “Infrastructure >> Containers” 页面。
|
||||
|
||||
![][15]
|
||||
|
||||
### 怎样创建容器
|
||||
|
||||
非常简单,只需点击下列位置就能创建容器。
|
||||
|
||||
点击 “Infrastructure >> Containers >> Add Container” 然后输入每个你需要的信息。为了测试,我将创建一个 `latest` 标签的 CentOS 容器。
|
||||
|
||||
![][16]
|
||||
|
||||
在同样的列表位置,点击 “ Infrastructure >> Containers”。
|
||||
|
||||
![][17]
|
||||
|
||||
点击容器名展示容器的性能信息,如 CPU、内存、网络和存储。
|
||||
|
||||
![][18]
|
||||
|
||||
选择特定容器,然后点击最右边的“三点”按钮或者点击“Actions”按钮对容器进行管理,如停止、启动、克隆、重启等。
|
||||
|
||||
![][19]
|
||||
|
||||
如果你想控制台访问容器,只需要点击 “Actions” 按钮中的 “Execute Shell” 选项即可。
|
||||
|
||||
![][20]
|
||||
|
||||
### 怎样从应用目录部署容器
|
||||
|
||||
Rancher 提供了一个应用模版目录,让部署变的很容易,只需要单击一下就可以。
|
||||
它维护了多数流行应用,这些应用由 Rancher 社区贡献。
|
||||
|
||||
![][21]
|
||||
|
||||
点击 “Catalog >> All >> Choose the required application”,最后点击 “Launch” 去部署。
|
||||
|
||||
![][22]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/portainer-a-simple-docker-management-gui/
|
||||
[2]:http://rancher.com/
|
||||
[3]:https://www.2daygeek.com/install-docker-on-centos-rhel-fedora-ubuntu-debian-oracle-archi-scentific-linux-mint-opensuse/
|
||||
[4]:https://www.2daygeek.com/list-search-pull-download-remove-docker-images-on-linux/
|
||||
[5]:https://www.2daygeek.com/create-run-list-start-stop-attach-delete-interactive-daemonized-docker-containers-on-linux/
|
||||
[6]:https://www.2daygeek.com/install-run-applications-inside-docker-containers/
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-1.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-2.png
|
||||
[10]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-3.png
|
||||
[11]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-3a.png
|
||||
[12]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-4.png
|
||||
[13]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-5.png
|
||||
[14]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-6.png
|
||||
[15]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-7.png
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-8.png
|
||||
[17]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-9.png
|
||||
[18]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-10.png
|
||||
[19]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-11.png
|
||||
[20]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-12.png
|
||||
[21]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-13.png
|
||||
[22]:https://www.2daygeek.com/wp-content/uploads/2018/02/Install-rancher-container-management-application-in-linux-14.png
|
||||
@ -0,0 +1,132 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10683-1.html)
|
||||
[#]: subject: (Oomox – Customize And Create Your Own GTK2, GTK3 Themes)
|
||||
[#]: via: (https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/)
|
||||
[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
|
||||
|
||||
Oomox:定制和创建你自己的 GTK2、GTK3 主题
|
||||
======
|
||||
|
||||

|
||||
|
||||
主题和可视化定制是 Linux 的主要优势之一。由于所有代码都是开源的,因此你可以比 Windows/Mac OS 更大程度上地改变 Linux 系统的外观和行为方式。GTK 主题可能是人们定制 Linux 桌面的最流行方式。GTK 工具包被各种桌面环境使用,如 Gnome、Cinnamon、Unity、XFC E和 budgie。这意味着为 GTK 制作的单个主题只需很少的修改就能应用于任何这些桌面环境。
|
||||
|
||||
有很多非常高品质的流行 GTK 主题,例如 **Arc**、**Numix** 和 **Adapta**。但是如果你想自定义这些主题并创建自己的视觉设计,你可以使用 **Oomox**。
|
||||
|
||||
Oomox 是一个图形应用,可以完全使用自己的颜色、图标和终端风格自定义和创建自己的 GTK 主题。它自带几个预设,你可以在 Numix、Arc 或 Materia 主题样式上创建自己的 GTK 主题。
|
||||
|
||||
### 安装 Oomox
|
||||
|
||||
在 Arch Linux 及其衍生版中:
|
||||
|
||||
Oomox 可以在 [AUR][1] 中找到,所以你可以使用任何 AUR 助手程序安装它,如 [yay][2]。
|
||||
|
||||
```
|
||||
$ yay -S oomox
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu/Linux Mint 中,在[这里][3]下载 `oomox.deb` 包并按如下所示进行安装。在写本指南时,最新版本为 `oomox_1.7.0.5.deb`。
|
||||
|
||||
```
|
||||
$ sudo dpkg -i oomox_1.7.0.5.deb
|
||||
$ sudo apt install -f
|
||||
```
|
||||
|
||||
在 Fedora 上,Oomox 可以在第三方 **COPR** 仓库中找到。
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable tcg/themes
|
||||
$ sudo dnf install oomox
|
||||
```
|
||||
|
||||
Oomox 也有 [Flatpak 应用][4]。确保已按照[本指南][5]中的说明安装了 Flatpak。然后,使用以下命令安装并运行 Oomox:
|
||||
|
||||
```
|
||||
$ flatpak install flathub com.github.themix_project.Oomox
|
||||
$ flatpak run com.github.themix_project.Oomox
|
||||
```
|
||||
|
||||
对于其他 Linux 发行版,请进入 Github 上的 Oomox 项目页面(本指南末尾给出链接),并从源代码手动编译和安装。
|
||||
|
||||
### 自定义并创建自己的 GTK2、GTK3 主题
|
||||
|
||||
#### 主题定制
|
||||
|
||||
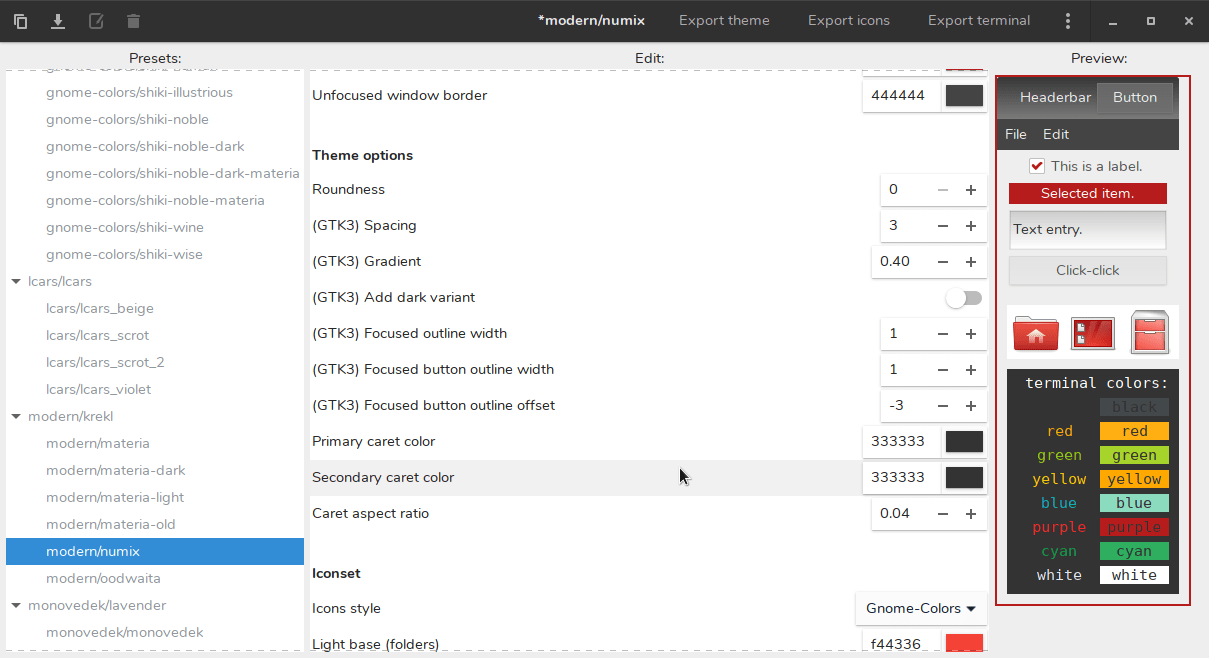
|
||||
|
||||
你可以更改几乎每个 UI 元素的颜色,例如:
|
||||
|
||||
1. 标题
|
||||
2. 按钮
|
||||
3. 标题内的按钮
|
||||
4. 菜单
|
||||
5. 选定的文字
|
||||
|
||||
在左边,有许多预设主题,如汽车主题、现代主题,如 Materia 和 Numix,以及复古主题。在窗口的顶部,有一个名为**主题样式**的选项,可让你设置主题的整体视觉样式。你可以在 Numix、Arc 和 Materia 之间进行选择。
|
||||
|
||||
使用某些像 Numix 这样的样式,你甚至可以更改标题渐变,边框宽度和面板透明度等内容。你还可以为主题添加黑暗模式,该模式将从默认主题自动创建。
|
||||
|
||||
|
||||
|
||||
#### 图标集定制
|
||||
|
||||
你可以自定义用于主题图标的图标集。有两个选项:Gnome Colors 和 Archdroid。你可以更改图标集的基础和笔触颜色。
|
||||
|
||||
#### 终端定制
|
||||
|
||||
你还可以自定义终端颜色。该应用有几个预设,但你可以为每个颜色,如红色,绿色,黑色等自定义确切的颜色代码。你还可以自动交换前景色和背景色。
|
||||
|
||||
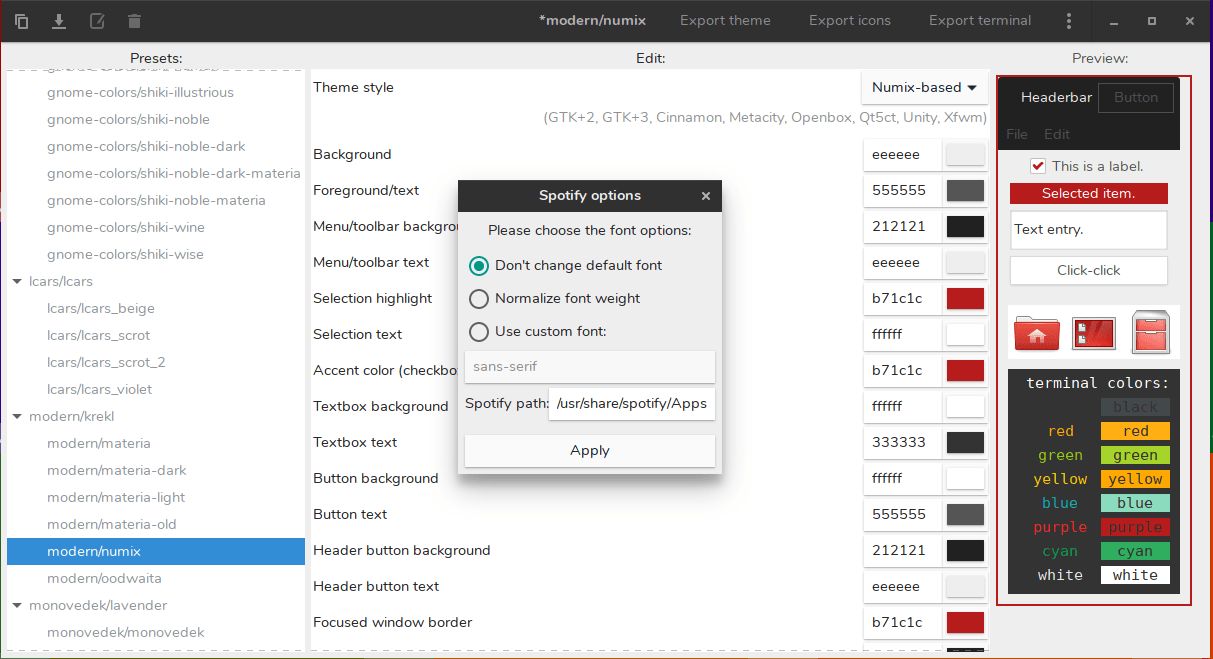
#### Spotify 主题
|
||||
|
||||
这个应用的一个独特功能是你可以根据喜好定义 spotify 主题。你可以更改 spotify 的前景色、背景色和强调色来匹配整体的 GTK 主题。
|
||||
|
||||
然后,只需按下“应用 Spotify 主题”按钮,你就会看到这个窗口:
|
||||
|
||||
|
||||
|
||||
点击应用即可。
|
||||
|
||||
#### 导出主题
|
||||
|
||||
根据自己的喜好自定义主题后,可以通过单击左上角的重命名按钮重命名主题:
|
||||
|
||||

|
||||
|
||||
然后,只需点击“导出主题”将主题导出到你的系统。
|
||||
|
||||
|
||||
|
||||
你也可以只导出图标集或终端主题。
|
||||
|
||||
之后你可以打开桌面环境中的任何可视化自定义应用,例如基于 Gnome 桌面的 Tweaks,或者 “XFCE 外观设置”。选择你导出的 GTK 或者 shell 主题。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你是一个 Linux 主题迷,并且你确切知道系统中的每个按钮、每个标题应该怎样,Oomox 值得一试。 对于极致的定制者,它可以让你几乎更改系统外观的所有内容。对于那些只想稍微调整现有主题的人来说,它有很多很多预设,所以你可以毫不费力地得到你想要的东西。
|
||||
|
||||
你试过吗? 你对 Oomox 有什么看法? 请在下面留言!
|
||||
|
||||
### 资源
|
||||
|
||||
- [Oomox GitHub 仓库](https://github.com/themix-project/oomox)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://aur.archlinux.org/packages/oomox/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[3]: https://github.com/themix-project/oomox/releases
|
||||
[4]: https://flathub.org/apps/details/com.github.themix_project.Oomox
|
||||
[5]: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
212
published/20181108 My Google-free Android life.md
Normal file
212
published/20181108 My Google-free Android life.md
Normal file
@ -0,0 +1,212 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10677-1.html)
|
||||
[#]: subject: (My Google-free Android life)
|
||||
[#]: via: (https://lushka.al/my-android-setup/)
|
||||
[#]: author: (Anxhelo Lushka https://lushka.al/)
|
||||
|
||||
我的去 Google 化的安卓之旅
|
||||
======
|
||||
> 一篇介绍如何在你的生活中和设备里去 Google 化的文章。
|
||||
|
||||
最近人们经常问我有关我手机的事情,比如安卓怎么安装,怎样绕过 Google Service 使用手机。好吧,这篇文章就来详细的解决那些问题。我尽可能让这篇文章适合初学者,因此我会慢慢介绍,一个一个来讲并且附上截图,你就能更好地看到它是怎样运作的。
|
||||
|
||||
首先我会告诉你为什么 Google Services(在我看来)对你的设备不好。我可以一言以概之,并让你看 [Richard Stallman][2] 写的这篇[文章][1],但我决定抓住几个要点附在这。
|
||||
|
||||
* 要用<ruby>非自由软件<rt>Nonfree software</rt></ruby>
|
||||
* 大体上,大多数 Google Services 需要运行在非自由的 Javascript 代码之上。现如今,如果禁用掉 Javascript,什么都没有了,甚至 Google 帐号都需要运行非自由软件(由站点发送的 JavaScript),对于登录也是。
|
||||
* 被监视
|
||||
* Google 悄悄地把它的<ruby>广告跟踪方式<rt>ad-tracking profiles</rt></ruby>与浏览方式结合在一起,并存储了每个用户的大量数据。
|
||||
* 服务条款
|
||||
* Google 会终止转卖了 Pixel 手机的用户账户。他们无法访问帐户下保存在 Google Services 中的所有邮件和文档。
|
||||
* 审查
|
||||
* Amazon 和 Google 切断了<ruby>域前置<rt>domain-fronting</rt></ruby>,该技术能使身处某些国家的人们访问到在那里禁止的通信系统。
|
||||
* Google 已经同意为巴基斯坦政府执行特殊的 Youtube 审查,删除对立观点。这将有助于压制异议。
|
||||
* Youtube 的“content ID”会自动删除已发布的视频,这并不包含在版权法中。
|
||||
|
||||
这只是几个原因,你可以阅读上面我提到的 RMS 的文章,他详细解释了这几点。尽管听起来骇人听闻,但这些行为在现实生活中已经每天在发生。
|
||||
|
||||
### 下一步,我的搭建教程
|
||||
|
||||
我有一款[小米红米 Note 5 Pro][3] 智能手机(代号 whyred),生产于中国的[小米][4]。它是 4 个月之前(距写这篇文章的时候)我花了大约 185 欧元买的。
|
||||
|
||||
现在你也许会想,“但你为什么买中国品牌,他们不可靠”。是的,它不是通常你所期望的(品牌)所生产的,例如三星(人们通常会将它和安卓联系在一起,这显然是错的)、一加、诺基亚等。但你应当知道几乎所有的手机都生产于中国。
|
||||
|
||||
我选择这款手机有几个原因,首先当然是价格。它是一款<ruby>性价比<rt>budget-friendly</rt></ruby>相当高的产品,大多数人都能买得起。下一个原因是说明书上的规格(不仅仅是),在这个<ruby>价位<rt>price tag</rt></ruby>上相当合适。拥有 6 英尺屏幕(<ruby>全高清分辨率<rt>Full HD resolution</rt></ruby>),4000 毫安电池(一流的电池寿命),4GB RAM,64GB 存储,双后摄像头(12 MP + 5 MP),一个带闪光灯的前摄像头(13 MP)和一个高性能的<ruby>骁龙<rt>Snapdragon</rt></ruby> 636,它可能是那时候最好的选择。
|
||||
|
||||
随之而来的问题是 [MIUI][5],大多数小米设备所附带的安卓外壳(除了 Android One 项目设备)。是的,它没有那么可怕,它有一些额外的功能,但问题在更深的地方。小米设备如此便宜(据我所知销售利润仅有 5-10%)的一个原因是**他们在系统里伴随 MIUI 添加了数据挖掘和广告**。这样的话,系统应用需要额外不必要的权限来获取你的数据并且进行广告轰炸,从中获取利润。
|
||||
|
||||
更有趣的是,所包含的“天气”应用想要访问我的联系人并且拨打电话,如果它仅是显示天气的话为什么需要访问联系人呢。另一个例子是“录音机”应用,它也需要联系人和网络权限,可能想把录音发送回小米。
|
||||
|
||||
为了解决它,我不得不格式化手机并且摆脱 MIUI。在市场上近来的手机上这就变得极为艰难。
|
||||
|
||||
格式化手机的想法很简单,删除掉现有的系统然后安装一个新的喜欢的系统(这次是原生安卓)。为了实现它,你先得解锁 [bootloader][6]。
|
||||
|
||||
> bootloader 是一个在计算机完成自检后为其加载操作系统或者运行环境的计算机程序。—[维基百科][7]
|
||||
|
||||
问题是小米关于解锁 bootloader 有明确的政策。几个月之前,流程就像这样:你需向小米[申请][8]解锁代码,并提供真实的原因,但不是每次都成功,因为他们可以拒绝你的请求并且不提供理由。
|
||||
|
||||
现在,流程变了。你要从小米那下载一个软件,叫做 [Mi Unlock][9],在 Windows 电脑上安装它,在手机的[开发者模式中打开调试选项][10],重启到 bootloader 模式(关机状态下长按向下音量键 + 电源键)并将手机连接到电脑上,开始一个叫做“许可”的流程。这个过程会在小米的服务器上启动一个定时器,允许你**在 15 天之后解锁手机**(在一些少数情况下或者一个月,完全随机)。
|
||||
|
||||
![Mi Unlock app][11]
|
||||
|
||||
15 天过去后,重新连接手机并重复之前的步骤,这时候按下解锁键,你的 bootloader 就会解锁,并且能够安装其他 ROM(系统)。**注意,确保你已经备份好了数据,因为解锁 bootloader 会清空手机。**
|
||||
|
||||
下一步就是找一个兼容的系统([ROM][12])。我在 [XDA 开发者论坛上][13]找了个遍,它是 Android 开发者和用户们交流想法、应用等东西的地方。幸运的是,我的手机相当流行,因此论坛上有它[专门的版块][14]。在那儿,我略过一些流行的 ROM 并决定使用 [AOSiP ROM][15]。(AOSiP 代表<ruby>安卓开源 illusion 项目<rt>Android Open Source illusion Project</rt></ruby>)
|
||||
|
||||
> **校订**:有人发邮件告诉我说文章里写的就是[/e/][16]的目的与所做的事情。我想说谢谢你的帮助,但完全不是这样。我关于 /e/ 的看法背后的原因可以见此[网站][17],但我仍会在此列出一些原因。
|
||||
|
||||
> eelo 是一个从 Kickstarter 和 IndieGoGo 上集资并超过 200K € 的“基金会”,承诺创造一个开放、安全且保护隐私的移动 OS 和网页服务器。
|
||||
|
||||
> 1. 他们的 OS 基于 LineageOS 14.1 (Android 7.1) 且搭载 microG 和其他开源应用,此系统已经存在很长一段时间了并且现在叫做 [Lineage for microG][18]。
|
||||
> 2. 所有的应用程序并非从源代码构建,而是从 [APKPure][19] 上下载安装包并推送进 ROM,不知道那些安装包中是否包含<ruby>专有代码<rt>proprietary code</rt></ruby>或<ruby>恶意软件<rt>malware</rt></ruby>。
|
||||
> 3. 有一段时间,它们就那样随意地从代码中删除 Lineage 的<ruby>版权标头<rt>copyright header</rt></ruby>并加入自己的。
|
||||
> 4. 他们喜欢删除负面反馈并且监视用户 Telegram 群聊中的舆论。
|
||||
|
||||
> 总而言之,我**不建议使用 /e/** ROM。(至少现在)
|
||||
|
||||
另一件你有可能要做的事情是获取手机的 [root 权限][20],让它真正的成为你的手机,并且修改系统中的文件,例如使用系统范围的 adblocker 等。为了实现它,我决定使用 [Magisk][21],一个天赐的应用,它由一个学生开发,可以帮你获取设备的 root 权限并安装一种叫做[模块][22]的东西,基本上是软件。
|
||||
|
||||
下载 ROM 和 Magisk 之后,我得在手机上安装它们。为了完成安装,我将文件移动到了 SD 卡上。现在,若要安装系统,我需要使用 [恢复系统][23]。我用的是较为普遍的 [TWRP][24](代表 TeamWin Recovery Project)。
|
||||
|
||||
要安装恢复系统(听起来有点难,我知道),我需要将文件[烧录][20]进手机。为了完成烧录,我将手机用一个叫做 [ADB 的工具][25]连接上电脑(Fedora Linux 系统)。使用命令让自己定制的恢复系统覆盖掉原先的。
|
||||
|
||||
```
|
||||
fastboot flash recovery twrp.img
|
||||
```
|
||||
|
||||
完成之后,我关掉手机并按住音量上和电源键,直到 TWRP 界面显示。这意味着我进行顺利,并且它已经准备好接收我的指令。
|
||||
|
||||
![TWRP screen][26]
|
||||
|
||||
下一步是**发送擦除命令**,在你第一次为手机安装自定义 ROM 时是必要的。如上图所示,擦除命令会清除掉<ruby>数据<rt>Data</rt></ruby>,<ruby>缓存<rt>Cache</rt></ruby>和 Dalvik 。(这里也有高级选项让我们可以勾选以删除掉系统,如果我们不再需要旧系统的话)
|
||||
|
||||
这需要几分钟去完成,之后,你的手机基本上就干净了。现在是时候**安装系统了**。通过按下主屏幕上的安装按钮,我们选择之前添加进的 zip 文件(ROM 文件)并滑动屏幕安装它。下一步,我们需要安装 Magisk,它可以给我们访问设备的 root 权限。
|
||||
|
||||
> **校订**:一些有经验的安卓用户或发烧友也许注意到了,手机上不包含 [GApps](谷歌应用)。这在安卓世界里称之为 GApps-less,一个 GAps 应用也不安装。
|
||||
|
||||
> 注意有一个不好之处在于若不安装 Google Services 有的应用无法正常工作,例如它们的通知也许会花更长的时间到达或者根本不起作用。(对我来说这一点是最影响应用程序使用的)原因是这些应用使用了 [Google Cloud Messaging][28](现在叫做 [Firebase][29])唤醒手机并推送通知。
|
||||
|
||||
> 你可以通过安装使用 [microG][30](部分地)解决它,microG 提供一些 Google Services 的特性且允许你拥有更多的控制。我不建议使用它,因为它仍然有助于 Google Services 并且你不一定信任它。但是,如果你没法<ruby>立刻放弃使用<rt>go cold turkey on it</rt><ruby>,只想慢慢地退出谷歌,这便是一个好的开始。
|
||||
|
||||
都成功地安装之后,现在我们重启手机,就进入了主屏幕。
|
||||
|
||||
### 下一个部分,安装应用并配置一切
|
||||
|
||||
事情开始变得简单了。为了安装应用,我使用了 [F-Droid][31],一个可替代的应用商店,里面**只包含自由及开源应用**。如果这里没有你要的应用,你可以使用 [Aurora Store][32],一个从应用商店里下载应用且不需要使用谷歌帐号或被追踪的客户端。
|
||||
|
||||
F-Droid 里面有名为 repos 的东西,它是一个包含你可以安装应用的“仓库”。我使用默认的仓库,并从 [IzzyOnDroid][33] 添加了另一个,它有更多默认仓库中没有的应用,并且它更新地更频繁。
|
||||
|
||||
![My repos][34]
|
||||
|
||||
从下面你可以发现我所安装的应用清单,它们替代的应用与用途。
|
||||
|
||||
- [AdAway](https://f-droid.org/en/packages/org.adaway) > 系统广告拦截器,使用 hosts 文件拦截所有的广告
|
||||
- [AfWall+](https://f-droid.org/en/packages/dev.ukanth.ufirewall) > 一个防火墙,可以阻止不想要的连接
|
||||
- [Amaze](https://f-droid.org/en/packages/com.amaze.filemanager) > 替代系统的文件管理器,允许文件的 root 访问权限,并且拥有 zip/unzip 功能
|
||||
- [Ameixa](https://f-droid.org/en/packages/org.xphnx.ameixa) > 大多数应用的图标包
|
||||
- [andOTP](https://f-droid.org/en/packages/org.shadowice.flocke.andotp) > 替代谷歌验证器/Authy,一个可以用来登录启用了<ruby>双因子验证<rt>2FA</rt></ruby>的网站账户的 TOTP 应用,可以使用 PIN 码备份和锁定
|
||||
- [AnySoftKeyboard/AOSP Keyboard](https://f-droid.org/packages/com.menny.android.anysoftkeyboard/) > 开源键盘,它有许多主题和语言包,我也是该[项目](https://anysoftkeyboard.github.io/)的一员
|
||||
- [Audio Recorder](https://f-droid.org/en/packages/com.github.axet.audiorecorder) > 如其名字,允许你从麦克风录制不同格式的音频文件
|
||||
- [Battery Charge Limit](https://f-droid.org/en/packages/com.slash.batterychargelimit) > 当到 80% 时自动停止充电,降低<ruby>电池磨损<rt>battery wear</rt></ruby>并增加寿命
|
||||
- [DAVx5](https://f-droid.org/en/packages/at.bitfire.davdroid) > 这是我最常用的应用之一,对我来说它基本上替代了谷歌联系人、谷歌日历和谷歌 Tasks,它连接着我的 Nextcloud 环境可以让我完全控制自己的数据
|
||||
- [Document Viewer](https://f-droid.org/en/packages/org.sufficientlysecure.viewer) > 一个可以打开数百种文件格式的查看器应用,快速、轻量
|
||||
- [Deezloader Remix](https://gitlab.com/Nick80835/DeezLoader-Android/) > 让我可以在 Deezer 上下载高质量 MP3 的应用
|
||||
- [Easy xkcd](https://f-droid.org/en/packages/de.tap.easy_xkcd) > xkcd 漫画阅读器,我喜欢这些 xkcd 漫画
|
||||
- [Etar](https://f-droid.org/en/packages/ws.xsoh.etar) > 日历应用,替代谷歌日历,与 DAVx5 一同工作
|
||||
- [FastHub-Libre](https://f-droid.org/en/packages/com.fastaccess.github.libre) > 一个 GitHub 客户端,完全 FOSS(自由及开源软件),非常实用如果你像我一样喜欢使用 Github 的话
|
||||
- [Fennec F-Droid](https://f-droid.org/en/packages/org.mozilla.fennec_fdroid) > 替代谷歌 Chrome 和其他类似的应用,一个为 F-Droid 打造的火狐浏览器,不含专有二进制代码并允许安装扩展提升浏览体验
|
||||
- [Gadgetbridge](https://f-droid.org/en/packages/nodomain.freeyourgadget.gadgetbridge) > 替代小米运动,可以用来配对小米硬件的应用,追踪你的健康、步数、睡眠等。
|
||||
- [K-9 Mail](https://f-droid.org/en/packages/com.fsck.k9) > 邮件客户端,替代 GMail 应用,可定制并可以添加多个账户
|
||||
- [Lawnchair](https://f-droid.org/en/packages/ch.deletescape.lawnchair.plah) > 启动器,可以替代 Nova Launcher 或 Pixel Launcher,允许自定义和各种改变,也支持图标包
|
||||
- [Mattermost](https://f-droid.org/en/packages/com.mattermost.mattermost) > 可以连接 Mattermost 服务器的应用。Mattermost 是一个 Slack 替代品
|
||||
- [NewPipe](https://f-droid.org/en/packages/org.schabi.newpipe) > 最好的 YouTube 客户端(我认为),可以替代 YoubTube,它完全是 FOSS,免除 YouTube 广告,占用更少空间,允许背景播放,允许下载视频/音频等。试一试吧
|
||||
- [Nextcloud SMS](https://f-droid.org/en/packages/fr.unix_experience.owncloud_sms) > 允许备份/同步 SMS 到我的 Nextcloud 环境
|
||||
- [Nextcloud Notes](https://f-droid.org/en/packages/it.niedermann.owncloud.notes) > 允许我创建,修改,删除,分享笔记并同步/备份到 Nextcloud 环境
|
||||
- [OpenTasks](https://f-droid.org/en/packages/org.dmfs.tasks) > 允许我创建、修改、删除任务并同步到我的 Nextcloud 环境
|
||||
- [OsmAnd~](https://f-droid.org/en/packages/net.osmand.plus) > 一个地图应用,使用 [OpenStreetMap](https://openstreetmap.org/),允许下载离线地图和导航
|
||||
- [QKSMS](https://f-droid.org/en/packages/com.moez.QKSMS) > 我最喜欢的短信应用,可以替代原来的 Messaging 应用,拥有漂亮的界面,拥有备份、个性化、延迟发送等特性。
|
||||
- [Resplash/Mysplash](https://f-droid.org/en/packages/com.wangdaye.mysplash) > 允许你无限地从 [Unsplash](https://unsplash.com/) 下载无数的漂亮壁纸,全都可以免费使用和修改。
|
||||
- [ScreenCam](https://f-droid.org/en/packages/com.orpheusdroid.screenrecorder) > 一个录屏工具,允许各样的自定义和录制模式,没有广告并且免费
|
||||
- [SecScanQR](https://f-droid.org/en/packages/de.t_dankworth.secscanqr) > 二维码识别应用,快速轻量
|
||||
- [Send Reduced Free](https://f-droid.org/en/packages/mobi.omegacentauri.SendReduced) > 这个应用可以在发送之前通过移除 PII(<ruby>个人识别信息<rt>personally identifiable information</rt></ruby>)和减小尺寸,让你立即分享大图
|
||||
- [Slide](https://f-droid.org/en/packages/me.ccrama.redditslide/) > 开源 Reddit 客户端
|
||||
- [Telegram FOSS](https://f-droid.org/en/packages/org.telegram.messenger) > 没有追踪和 Google Services 的纯净版 Telegram 安卓客户端
|
||||
- [TrebleShot](https://f-droid.org/en/packages/com.genonbeta.TrebleShot) > 这个天才般的应用可以让你通过 WIFI 分享文件给其它设备,真的超快,甚至无需连接网络
|
||||
- [Tusky](https://f-droid.org/en/packages/com.keylesspalace.tusky) > Tusky 是 [Mastodon](https://joinmastodon.org/) 平台的客户端(替代 Twitter)
|
||||
- [Unit Converter Ultimate](https://f-droid.org/en/packages/com.physphil.android.unitconverterultimate) > 这款应用可以一键在 200 种单位之间来回转换,非常快并且完全离线
|
||||
- [Vinyl Music Player](https://f-droid.org/en/packages/com.poupa.vinylmusicplayer) > 我首选的音乐播放器,可以替代谷歌音乐播放器或其他你已经安装的音乐播放器,它有漂亮的界面和许多特性
|
||||
- [VPN Hotspot](https://f-droid.org/en/packages/be.mygod.vpnhotspot) > 这款应用可以让我打开热点的时候分享 VPN,因此我可以在笔记本上什么都不用做就可以安全地浏览网页
|
||||
|
||||
这些差不多就是我列出的一张**最实用的 F-Droid 应用**清单,但不巧,这些并不是所有应用。我使用的专有应用如下(我知道,我也许听起来是一个伪君子,但并不是所有的应用都可以替代,至少现在不是):
|
||||
|
||||
* Google Camera(与 Camera API 2 结合起来,需要 F-Droid 的基本的 microG 才能工作)
|
||||
* Instagram
|
||||
* MyVodafoneAL (运营商应用)
|
||||
* ProtonMail (email 应用)
|
||||
* Titanium Backup(备份应用数据,wifi 密码,通话记录等)
|
||||
* WhatsApp (专有的端到端聊天应用,几乎我认识的所有人都有它)
|
||||
|
||||
差不多就是这样,这就是我用的手机上所有的应用。**配置非常简单明了,我可以给几点提示**。
|
||||
|
||||
1. 仔细阅读和检查应用的权限,不要无脑地点“安装”。
|
||||
2. 尽可能多地使用开源应用,它们即尊重你的隐私又是免费的(且自由)。
|
||||
3. 尽可能地使用 VPN,找一个有名气的,别用免费的,否则你将被收割数据然后成为产品。
|
||||
4. 不要一直打开 WIFI/移动数据/定位,有可能引起安全隐患。
|
||||
5. 不要只依赖指纹解锁,或者尽可能只用 PIN/密码/模式解锁,因为生物数据可以被克隆后针对你,例如解锁你的手机盗取你的数据。
|
||||
|
||||
作为坚持读到这儿的奖励,**一张主屏幕的截图奉上**
|
||||
|
||||
![Screenshot][35]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lushka.al/my-android-setup/
|
||||
|
||||
作者:[Anxhelo Lushka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/luuming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://lushka.al/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://stallman.org/google.html
|
||||
[2]: https://en.wikipedia.org/wiki/Richard_Stallman
|
||||
[3]: https://www.gsmarena.com/xiaomi_redmi_note_5_pro-8893.php
|
||||
[4]: https://en.wikipedia.org/wiki/Xiaomi
|
||||
[5]: https://en.wikipedia.org/wiki/MIUI
|
||||
[6]: https://forum.xda-developers.com/wiki/Bootloader
|
||||
[7]: https://en.wikipedia.org/wiki/Booting
|
||||
[8]: https://en.miui.com/unlock/
|
||||
[9]: http://www.miui.com/unlock/apply.php
|
||||
[10]: https://www.youtube.com/watch?v=7zhEsJlivFA
|
||||
[11]: https://lushka.al//assets/img/posts/mi-unlock.png
|
||||
[12]: https://www.xda-developers.com/what-is-custom-rom-android/
|
||||
[13]: https://forum.xda-developers.com/
|
||||
[14]: https://forum.xda-developers.com/redmi-note-5-pro
|
||||
[15]: https://forum.xda-developers.com/redmi-note-5-pro/development/rom-aosip-8-1-t3804473
|
||||
[16]: https://e.foundation
|
||||
[17]: https://ewwlo.xyz/evil
|
||||
[18]: https://lineage.microg.org/
|
||||
[19]: https://apkpure.com/
|
||||
[20]: https://lifehacker.com/5789397/the-always-up-to-date-guide-to-rooting-any-android-phone
|
||||
[21]: https://forum.xda-developers.com/apps/magisk/official-magisk-v7-universal-systemless-t3473445
|
||||
[22]: https://forum.xda-developers.com/apps/magisk
|
||||
[23]: http://www.smartmobilephonesolutions.com/content/android-system-recovery
|
||||
[24]: https://dl.twrp.me/whyred/
|
||||
[25]: https://developer.android.com/studio/command-line/adb
|
||||
[26]: https://lushka.al//assets/img/posts/android-twrp.png
|
||||
[27]: https://opengapps.org/
|
||||
[28]: https://developers.google.com/cloud-messaging/
|
||||
[29]: https://firebase.google.com/docs/cloud-messaging/
|
||||
[30]: https://microg.org/
|
||||
[31]: https://f-droid.org/
|
||||
[32]: https://f-droid.org/en/packages/com.dragons.aurora/
|
||||
[33]: https://android.izzysoft.de/repo
|
||||
[34]: https://lushka.al//assets/img/posts/android-fdroid-repos.jpg
|
||||
[35]: https://lushka.al//assets/img/posts/android-screenshot.jpg
|
||||
[36]: https://creativecommons.org/licenses/by-nc-sa/4.0/
|
||||
@ -0,0 +1,113 @@
|
||||
10 款你可以通过 Wine 在 Linux 上玩的游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux *确实* 能玩游戏,而且还能玩不少游戏。独立游戏在 Linux 平台上蓬勃发展,顶级的独立游戏也常常会在发售首日便发布 Linux 版本。然而,3A 游戏大作的开发者们却常常忽略 Linux,所以你不会很快就能玩上身边朋友们谈论正火的那些游戏。
|
||||
|
||||
但情况还没有糟透。Wine —— 一个能使 Windows 应用在类似 Linux、BSD 和 OS X 上运行的兼容层,在支持的游戏数量和性能表现上都取得了巨大进步。很多游戏大作都可以在 Wine 的支持下运行。你不能完全释放本机性能,但还是可以跑起来游戏,运行也还算流畅,当然这也要取决与你的系统配置。下面我们来盘点一下这些可能会令你大吃一惊的可以通过 Wine 在 Linux 上玩的游戏。(LCTT 译注:本文原文发表于 2017 年,有些信息可能有所过时。)
|
||||
|
||||
### 10、魔兽世界
|
||||
|
||||
![World of Warcraft Wine][1]
|
||||
|
||||
这款经典的 MMORPG 之王仍旧坚挺并保持活力。虽然这不是一款以画面见长的游戏,但想要开到全画质也需要费一些功夫。魔兽世界已经在 Wine 的支持下运行了很多年。到了最新资料片发布时,魔兽世界为它的 Mac 版本提供了 OpenGL 支持,使得游戏也可以很轻松地在 Linux 下运行。这已经不再是个问题了。
|
||||
|
||||
你需要通过 DX9 来运行游戏并从 [Gallium Nine][2] 补丁来获得一些性能提升,不过你也可以放心大胆地在 Linux 中下副本了。
|
||||
|
||||
### 9、上古卷轴 5:天际
|
||||
|
||||
![Skyrim Wine][3]
|
||||
|
||||
上古卷轴 5 已经不是款新游戏了,但它的 mod 社区依旧活跃。如果你的 Linux 系统有足够资源的话,你可以很轻松地加上很多很多 mod。需要记住的是 Wine 运行时要比游戏占用更多的系统资源,所以使用 mod 时也要考虑这一点。
|
||||
|
||||
### 8、星际争霸 II
|
||||
|
||||
![StarCraft II Wine][4]
|
||||
|
||||
星际争霸 II 是成为市场上最受欢迎的 RTS 游戏之一,并且在 Wine 下运作良好。它实际上也是 Wine 下表现最好的游戏之一。
|
||||
|
||||
考虑到这款游戏本身的竞技性,你当然希望游戏能够流畅地运行。不过不用担心,只要你的硬件够用就绝对没问题。
|
||||
|
||||
这是一个你可以从 “staging” 补丁获益的例子,所以在你设置游戏时请继续使用它们。
|
||||
|
||||
### 7、辐射 3 / 辐射:新维加斯
|
||||
|
||||
![Fallout 3 Wine][5]
|
||||
|
||||
在你提问之前,辐射 4 已经很快就准备就绪,也许就在你正读这篇文章的时候就可以玩了。就目前而言,辐射 3 和 辐射:新维加斯都能在有没有 mod 的情况下良好运行。这些游戏在 Wine 下运行地非常好,甚至还能加载大量 mod 来保持游戏的新鲜性和趣味性。在辐射 4 获得全面支持前玩这些旧作也不算是个很大的妥协。
|
||||
|
||||
### 6、Doom (2016)
|
||||
|
||||
![Doom Wine][6]
|
||||
|
||||
Doom(毁灭战士)是过去几年中最刺激的射击游戏之一。在 Wine 支持下并加载 “staging” 补丁可以流畅地运行最新版本。单人模式和多人模式都有很棒的游戏体验,而且也不需要花费大量时间来配置 Wine 和调整设置。所以你想在 Linux 上体验 3A 级射击游戏的话,不妨尝试一下 Doom 。
|
||||
|
||||
### 5、激战 2
|
||||
|
||||
![Guild Wars 2 Wine][7]
|
||||
|
||||
激战 2 是一款无月卡(买断制)的融合了多人和迷宫探险元素的游戏。它在市场上很受欢迎,并自称在游戏中有着很多创新。你同样可以通过 Wine 在 Linux 上玩到这款游戏。
|
||||
|
||||
激战 2 也不算一款很老的 MMO 游戏。它试图以图像表现来保持现代风格,并具有着相当高分辨率的纹理和视觉效果。所有这些特点都能在 Wine 下顺利运行。
|
||||
|
||||
### 4、英雄联盟
|
||||
|
||||
![League Of Legends Wine][8]
|
||||
|
||||
在 MOBA 游戏的世界中有两个强者:DoTA2 和英雄联盟。Valve 已经将 DoTA2 移植到 Linux 上很久了,但玩家们却从没在 Linux 上玩过英雄联盟。如果你是 Linux 的使用者并热衷英雄联盟,你还是可以通过 Wine 来玩这款你最爱的 MOBA 游戏。
|
||||
|
||||
英雄联盟是个很有趣的例子。它的游戏本身运行良好,但安装程序却会因为需要 Adobe Air 而中断。一些安装程序脚本例如 Lutris 和 PlayOnLinux 能帮你通过这一步骤。一旦安装完毕,你就可以毫无困难地运行游戏,甚至在激烈的战况中依旧畅快玩耍。
|
||||
|
||||
### 3、炉石传说
|
||||
|
||||
![HearthStone Wine][9]
|
||||
|
||||
炉石传说是一款流行且令人上瘾的免费卡牌游戏,你可在各种平台上来一局……除了 Linux。不过别担心,在 Wine 中你可以轻松玩到这款游戏。炉石并不大,所以即使在最低配置的系统里也都能玩,这是个好消息。不过由于它的竞技性所以还是要对游戏性能有一定要求。
|
||||
|
||||
玩炉石不需要任何特殊配置和补丁,直接开玩!
|
||||
|
||||
### 2、巫师 3
|
||||
|
||||
![Witcher 3 Wine][10]
|
||||
|
||||
你不是唯一一个对在这份榜单中看到了巫师 3 而感到吃惊的人。在最新版 “stage” 补丁的支持下,你终于可以在 Linux 中体验这款游戏了。尽管最初承诺会有原生版本,但 Linux 玩家还是等了很久才迎来了巫师系列的第三部。
|
||||
|
||||
不过最好不要指望一切都能完美运行。巫师 3 *刚刚* 得到支持,有些内容可能还不会达到预期。也就是说,如果你只能用 Liux 来玩游戏,并且愿意处理一些问题。那么你也可以享受到这款完美游戏带来的初体验了。
|
||||
|
||||
### 1、守望先锋
|
||||
|
||||
![Overwatch Wine][11]
|
||||
|
||||
最后,让我们来谈谈 Linux 玩家心中的另一个“白鲸”。很多人认为守望先锋会像大多数暴雪游戏一样,在发售当日就能在 Wine 上获得支持。不过情况非常不同,因为守望先锋只支持 DX11,这也正是 Wine 面临的一个痛点。
|
||||
|
||||
守望先锋目前还不能拥有最佳性能表现,但是你还是可以通过装有特殊补丁的 Wine 和包括“staging”在内的一系列定制补丁包来运行游戏。这也说明了 Linux 玩家们真的很渴望游玩这款游戏,以至于自己开发了一套补丁来为它提供支持。
|
||||
|
||||
这份榜单当然会遗漏一些其他游戏。大多数是由于受欢迎程度或只能从 Wine 中得到有限的支持。其他暴雪游戏,如“风暴英雄”和“暗黑破坏神 3”也能很好地运行,但这样来写就会使暴雪游戏霸占这份榜单,这不是我们想突出的重点。
|
||||
|
||||
如果你正打算玩以上任一款游戏,请使用 Wine 的 [Gallium Nine][2] 版本并装载“staging”补丁,否则游戏可能无法正常运行。“staging”中装载的最新补丁和提升要比正式的 Wine 发行版提供的内容要早很多,使用它会令你在性能上处于领先地位。
|
||||
|
||||
说到进步,Wine 目前在对 DirectX11 的支持有了很大进步。对于 Windows 玩家这可能不算什么,但对于 Linux 玩家来说绝对算是一件大事。大多数游戏新作支持 DX11 和 DX12,而最新版本的 Wine 仍只是支持 DX9。有了 DX11 的支持,Wine 将会让很多过去无法在 Linux 上玩的游戏运行起来。所以,定期查看你最喜欢的 Windows 游戏是否也可以开始在 Wine 上运行,你可能会非常惊喜。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/games-play-on-linux-with-wine/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[Modrisco](https://github.com/Modrisco)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/09/wow.jpg (World of Warcraft Wine)
|
||||
[2]:https://www.maketecheasier.com/install-wine-gallium-nine-linux
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/09/skyrim.jpg (Skyrim Wine)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/09/sc2.jpg (StarCraft II Wine)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/09/Fallout_3.jpg (Fallout 3 Wine)
|
||||
[6]:https://www.maketecheasier.com/assets/uploads/2017/09/doom.jpg (Doom Wine)
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/09/gw2.jpg (Guild Wars 2 Wine)
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2017/09/League_of_legends.jpg (League Of Legends Wine)
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/09/HearthStone.jpg (HearthStone Wine)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/09/witcher3.jpg (Witcher 3 Wine)
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2017/09/Overwatch.jpg (Overwatch Wine)
|
||||
209
published/201903/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
Normal file
209
published/201903/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
Normal file
@ -0,0 +1,209 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (GraveAccent)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10664-1.html)
|
||||
[#]: subject: (JSON vs XML vs TOML vs CSON vs YAML)
|
||||
[#]: via: (https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/)
|
||||
[#]: author: (Tim Anderson https://www.zionandzion.com)
|
||||
|
||||
JSON、XML、TOML、CSON、YAML 大比拼
|
||||
======
|
||||
|
||||
### 一段超级严肃的关于样本序列化的集合、子集和超集的文字
|
||||
|
||||
我是一名开发者,我读代码,我写代码,我写会写代码的代码,我写会写出供其它代码读的代码的代码。这些都非常火星语,但是有其美妙之处。然而,最后一点,写会写出供其它代码读的代码的代码,可以很快变得比这段文字更费解。有很多方法可以做到这一点。一种不那么复杂而且开发者社区最爱的方式是数据序列化。对于那些不了解我刚刚抛给你的时髦词的人,数据序列化是从一个系统获取一些信息,将其转换为其它系统可以读取的格式,然后将其传递给其它系统的过程。
|
||||
|
||||
虽然[数据序列化格式][1]多到可以埋葬哈利法塔,但它们大多分为两类:
|
||||
|
||||
* 易于人类读写,
|
||||
* 易于机器读写。
|
||||
|
||||
很难两全其美,因为人类喜欢让我们更具表现力的松散类型和灵活格式标准,而机器倾向于被确切告知一切事情而没有二义性和细节缺失,并且认为“严格规范”才是它们最爱的口味。
|
||||
|
||||
由于我是一名 web 开发者,而且我们是一个创建网站的机构,我们将坚持使用 web 系统可以理解或不需要太多努力就能理解的特殊格式,而且对人类可读性特别有用的格式:XML、JSON、TOML、CSON 以及 YAML。每个都有各自的优缺点和适当的用例场景。
|
||||
|
||||
### 事实最先
|
||||
|
||||
回到互联网的早期,[一些非常聪明的家伙][2]决定整合一种让每个系统都能理解的标准语言,并创造性地将其命名为<ruby>标准通用标记语言<rt>Standard Generalized Markup Language</rt></ruby>(简称 SGML)。SGML 非常灵活,发布者也很好地定义了它。它成为了 XML、SVG 和 HTML 等语言之父。所有这三个都符合 SGML 规范,可是它们都是规则更严格、灵活性更少的子集。
|
||||
|
||||
最终,人们开始看到非常小、简洁、易读且易于生成的数据的好处,这些数据可以在系统之间以编程的方式共享,而开销很小。大约在那个时候,JSON 诞生了并且能够满足所有的需求。而另一方面,其它语言也开始出现以处理更多的专业用例,如 CSON,TOML 和 YAML。
|
||||
|
||||
### XML:不行了
|
||||
|
||||
原本,XML 语言非常灵活且易于编写,但它的缺点是冗长,人类难以阅读、计算机非常难以读取,并且有很多语法对于传达信息并不是完全必要的。
|
||||
|
||||
今天,它在 web 上的数据序列化的用途已经消失了。除非你在编写 HTML 或者 SVG,否则你不太能在许多其它地方看到 XML。一些过时的系统今天仍在使用它,但是用它传递数据往往太重了。
|
||||
|
||||
我已经可以听到 XML 老爷爷开始在它们的石碑上乱写为什么 XML 是了不起的,所以我将提供一个小小的补充:XML 可以很容易地由系统和人读写。然而,真的,我的意思是荒谬的,很难创建一个可以规范的读取它的系统。这是一个简单美观的 XML 示例:
|
||||
|
||||
```
|
||||
<book id="bk101">
|
||||
<author>Gambardella, Matthew</author>
|
||||
<title>XML Developer's Guide</title>
|
||||
<genre>Computer</genre>
|
||||
<price>44.95</price>
|
||||
<publish_date>2000-10-01</publish_date>
|
||||
<description>An in-depth look at creating applications
|
||||
with XML.</description>
|
||||
</book>
|
||||
```
|
||||
|
||||
太棒了。易于阅读、理解、写入,也容易编码一个可以读写它的系统。但请考虑这个例子:
|
||||
|
||||
```
|
||||
<!DOCTYPE r [ <!ENTITY y "a]>b"> ]>
|
||||
<r>
|
||||
<a b="&y;>" />
|
||||
<![CDATA[[a>b <a>b <a]]>
|
||||
<?x <a> <!-- <b> ?> c --> d
|
||||
</r>
|
||||
```
|
||||
|
||||
这上面是 100% 有效的 XML。几乎不可能阅读、理解或推理。编写可以使用和理解这个的代码将花费至少 36 根头发和 248 磅咖啡渣。我们没有那么多时间或咖啡,而且我们大多数老程序员们现在都是秃头。所以,让它活在我们的记忆里,就像 [css hacks][3]、[IE 6 浏览器][4] 和[真空管][5]一样好了。
|
||||
|
||||
### JSON:并列聚会
|
||||
|
||||
好吧,我们都同意,XML = 差劲。那么,好的替代品是什么?<ruby>JavaScript 对象表示法<rt>JavaScript Object Notation</rt></ruby>,简称 JSON。JSON(读起来像 Jason 这个名字) 是 Brendan Eich 发明的,并且得到了伟大而强力的 [JavaScript 意见领袖][6] Douglas Crockford 的推广。它现在几乎用在任何地方。这种格式很容易由人和机器编写,按规范中的严格规则[解析][7]也相当容易,并且灵活 —— 允许深层嵌套数据,支持所有的原始数据类型,及将集合解释为数组或对象。JSON 成为了将数据从一个系统传输到另一个系统的事实标准。几乎所有语言都有内置读写它的功能。
|
||||
|
||||
JSON语法很简单。方括号表示数组,花括号表示记录,由冒号分隔的两个值分别表示属性或“键”(在左边)、值(在右边)。所有键必须用双引号括起来:
|
||||
|
||||
```
|
||||
{
|
||||
"books": [
|
||||
{
|
||||
"id": "bk102",
|
||||
"author": "Crockford, Douglas",
|
||||
"title": "JavaScript: The Good Parts",
|
||||
"genre": "Computer",
|
||||
"price": 29.99,
|
||||
"publish_date": "2008-05-01",
|
||||
"description": "Unearthing the Excellence in JavaScript"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
这对你来说应该是完全有意义的。它简洁明了,并且从 XML 中删除了大量额外废话,并传达相同数量的信息。JSON 现在是王道,本文剩下的部分会介绍其它语言格式,这些格式只不过是 JSON 的简化版,尝试让其更简洁或对人类更易读,可结构还是非常相似的。
|
||||
|
||||
### TOML: 缩短到彻底的利他主义
|
||||
|
||||
TOML(<ruby>Tom 的显而易见的最小化语言<rt>Tom’s Obvious, Minimal Language</rt></ruby>)允许以相当快捷、简洁的方式定义深层嵌套的数据结构。名字中的 Tom 是指发明者 [Tom Preston Werner][8],他是一位活跃于我们行业的创造者和软件开发人员。与 JSON 相比,语法有点尴尬,更类似 [ini 文件][9]。这不是一个糟糕的语法,但是需要一些时间适应。
|
||||
|
||||
```
|
||||
[[books]]
|
||||
id = 'bk101'
|
||||
author = 'Crockford, Douglas'
|
||||
title = 'JavaScript: The Good Parts'
|
||||
genre = 'Computer'
|
||||
price = 29.99
|
||||
publish_date = 2008-05-01T00:00:00+00:00
|
||||
description = 'Unearthing the Excellence in JavaScript'
|
||||
```
|
||||
|
||||
TOML 中集成了一些很棒的功能,例如多行字符串、保留字符的自动转义、日期、时间、整数、浮点数、科学记数法和“表扩展”等数据类型。最后一点是特别的,是 TOML 如此简洁的原因:
|
||||
|
||||
```
|
||||
[a.b.c]
|
||||
d = 'Hello'
|
||||
e = 'World'
|
||||
```
|
||||
|
||||
以上扩展到以下内容:
|
||||
|
||||
```
|
||||
{
|
||||
"a": {
|
||||
"b": {
|
||||
"c": {
|
||||
"d": "Hello"
|
||||
"e": "World"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用 TOML,你可以肯定在时间和文件长度上会节省不少。很少有系统使用它或非常类似的东西作为配置,这是它最大的缺点。根本没有很多语言或库可以用来解释 TOML。
|
||||
|
||||
### CSON: 特定系统所包含的简单样本
|
||||
|
||||
首先,有两个 CSON 规范。 一个代表 CoffeeScript Object Notation,另一个代表 Cursive Script Object Notation。后者不经常使用,所以我们不会关注它。我们只关注 CoffeeScript。
|
||||
|
||||
[CSON][10] 需要一点介绍。首先,我们来谈谈 CoffeeScript。[CoffeeScript][11] 是一种通过运行编译器生成 JavaScript 的语言。它允许你以更加简洁的语法编写 JavaScript 并[转译][12]成实际的 JavaScript,然后你可以在你的 web 应用程序中使用它。CoffeeScript 通过删除 JavaScript 中必需的许多额外语法,使编写 JavaScript 变得更容易。CoffeeScript 摆脱的一个大问题是花括号 —— 不需要它们。同样,CSON 是没有大括号的 JSON。它依赖于缩进来确定数据的层次结构。CSON 非常易于读写,并且通常比 JSON 需要更少的代码行,因为没有括号。
|
||||
|
||||
CSON 还提供一些 JSON 不提供的额外细节。多行字符串非常容易编写,你可以通过使用 `#` 符号开始一行来输入[注释][13],并且不需要用逗号分隔键值对。
|
||||
|
||||
```
|
||||
books: [
|
||||
id: 'bk102'
|
||||
author: 'Crockford, Douglas'
|
||||
title: 'JavaScript: The Good Parts'
|
||||
genre: 'Computer'
|
||||
price: 29.99
|
||||
publish_date: '2008-05-01'
|
||||
description: 'Unearthing the Excellence in JavaScript'
|
||||
]
|
||||
```
|
||||
|
||||
这是 CSON 的大问题。它是 <ruby>CoffeScript 对象表示法<rt>CoffeeScript Object Notation</rt></ruby>。也就是说你要用 CoffeeScript 解析/标记化/lex/转译或其它方式来使用 CSON。CoffeeScript 是读取数据的系统。如果数据序列化的目的是允许数据从一个系统传递到另一个系统,这里我们有一个只能由单个系统读取的数据序列化格式,这使得它与防火火柴、防水海绵或者叉匙恼人的脆弱叉子部分一样有用。
|
||||
|
||||
如果这种格式被其它系统也采用,那它在开发者世界中可能非常有用。但到目前为止这基本上没有发生,所以在 PHP 或 JAVA 等替代语言中使用它是不行的。
|
||||
|
||||
### YAML:年轻人的呼喊
|
||||
|
||||
开发人员感到高兴,因为 YAML 来自[一个 Python 的贡献者][14]。YAML 具有与 CSON 相同的功能集和类似的语法,有一系列新功能,以及几乎所有 web 编程语言都可用的解析器。它还有一些额外的功能,如循环引用、软包装、多行键、类型转换标签、二进制数据、对象合并和[集合映射][15]。它具有非常好的可读性和可写性,并且是 JSON 的超集,因此你可以在 YAML 中使用完全合格的 JSON 语法并且一切正常工作。你几乎不需要引号,它可以解释大多数基本数据类型(字符串、整数、浮点数、布尔值等)。
|
||||
|
||||
```
|
||||
books:
|
||||
- id: bk102
|
||||
author: Crockford, Douglas
|
||||
title: 'JavaScript: The Good Parts'
|
||||
genre: Computer
|
||||
price: 29.99
|
||||
publish_date: !!str 2008-05-01
|
||||
description: Unearthing the Excellence in JavaScript
|
||||
```
|
||||
|
||||
业界的年轻人正在迅速采用 YAML 作为他们首选的数据序列化和系统配置格式。他们这样做很机智。YAML 具有像 CSON 一样简洁的所有好处,以及与 JSON 一样的数据类型解释的所有功能。YAML 像加拿大人容易相处一样容易阅读。
|
||||
|
||||
YAML 有两个问题,对我而言,第一个是大问题。在撰写本文时,YAML 解析器尚未内置于多种语言,因此你需要使用第三方库或扩展来为你选择的语言解析 .yaml 文件。这不是什么大问题,可似乎大多数为 YAML 创建解析器的开发人员都选择随机将“附加功能”放入解析器中。有些允许[标记化][16],有些允许[链引用][17],有些甚至允许内联计算。这一切都很好(某种意义上),只是这些功能都不是规范的一部分,因此很难在其他语言的其他解析器中找到。这导致系统限定,你最终遇到了与 CSON 相同的问题。如果你使用仅在一个解析器中找到的功能,则其他解析器将无法解释输入。大多数这些功能都是无意义的,不属于数据集,而是属于你的应用程序逻辑,因此最好简单地忽略它们和编写符合规范的 YAML。
|
||||
|
||||
第二个问题是很少有解析器完全实现规范。所有的基本要素都有,但是很难找到一些更复杂和更新的东西,比如软包装、文档标记和首选语言的循环引用。我还没有看到对这些东西的刚需,所以希望它们不让你很失望。考虑到上述情况,我倾向于保持 [1.1 规范][18] 中呈现的更成熟的功能集,而避免在 [1.2 规范][19] 中找到的新东西。然而,编程是一个不断发展的怪兽,所以当你读完这篇文章时,你或许就可以使用 1.2 规范了。
|
||||
|
||||
### 最终哲学
|
||||
|
||||
这是最后一段话。每个序列化语言都应该以个案标准的方式评价。当涉及机器的可读性时,有些<ruby>无出其右<rt>the bee’s knees</rt></ruby>。对于人类可读性,有些<ruby>名至实归<rt>the cat’s meow</rt></ruby>,有些只是<ruby>金玉其外<rt>gilded turds</rt></ruby>。以下是最终细分:如果你要编写供其他代码阅读的代码,请使用 YAML。如果你正在编写能写出供其他代码读取的代码的代码,请使用 JSON。最后,如果你正在编写将代码转译为供其他代码读取的代码的代码,请重新考虑你的人生选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/
|
||||
|
||||
作者:[Tim Anderson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.zionandzion.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Comparison_of_data_serialization_formats
|
||||
[2]: https://en.wikipedia.org/wiki/Standard_Generalized_Markup_Language#History
|
||||
[3]: https://www.quirksmode.org/css/csshacks.html
|
||||
[4]: http://www.ie6death.com/
|
||||
[5]: https://en.wikipedia.org/wiki/Vacuum_tube
|
||||
[6]: https://twitter.com/BrendanEich/status/773403975865470976
|
||||
[7]: https://en.wikipedia.org/wiki/Parsing#Parser
|
||||
[8]: https://en.wikipedia.org/wiki/Tom_Preston-Werner
|
||||
[9]: https://en.wikipedia.org/wiki/INI_file
|
||||
[10]: https://github.com/bevry/cson#what-is-cson
|
||||
[11]: http://coffeescript.org/
|
||||
[12]: https://en.wikipedia.org/wiki/Source-to-source_compiler
|
||||
[13]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
|
||||
[14]: http://clarkevans.com/
|
||||
[15]: http://exploringjs.com/es6/ch_maps-sets.html
|
||||
[16]: https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm
|
||||
[17]: https://en.wikipedia.org/wiki/Fluent_interface
|
||||
[18]: http://yaml.org/spec/1.1/current.html
|
||||
[19]: http://www.yaml.org/spec/1.2/spec.html
|
||||
283
published/201903/20180719 Building tiny container images.md
Normal file
283
published/201903/20180719 Building tiny container images.md
Normal file
@ -0,0 +1,283 @@
|
||||
如何打造更小巧的容器镜像
|
||||
======
|
||||
> 五种优化 Linux 容器大小和构建更小的镜像的方法。
|
||||
|
||||
|
||||
|
||||
[Docker][1] 近几年的爆炸性发展让大家逐渐了解到容器和容器镜像的概念。尽管 Linux 容器技术在很早之前就已经出现,但这项技术近来的蓬勃发展却还是要归功于 Docker 对用户友好的命令行界面以及使用 Dockerfile 格式轻松构建镜像的方式。纵然 Docker 大大降低了入门容器技术的难度,但构建一个兼具功能强大、体积小巧的容器镜像的过程中,有很多技巧需要了解。
|
||||
|
||||
### 第一步:清理不必要的文件
|
||||
|
||||
这一步和在普通服务器上清理文件没有太大的区别,而且要清理得更加仔细。一个小体积的容器镜像在传输方面有很大的优势,同时,在磁盘上存储不必要的数据的多个副本也是对资源的一种浪费。因此,这些技术对于容器来说应该比有大量专用内存的服务器更加需要。
|
||||
|
||||
清理容器镜像中的缓存文件可以有效缩小镜像体积。下面的对比是使用 `dnf` 安装 [Nginx][2] 构建的镜像,分别是清理和没有清理 yum 缓存文件的结果:
|
||||
|
||||
```
|
||||
# Dockerfile with cache
|
||||
FROM fedora:28
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
RUN dnf install -y nginx
|
||||
|
||||
-----
|
||||
|
||||
# Dockerfile w/o cache
|
||||
FROM fedora:28
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
RUN dnf install -y nginx \
|
||||
&& dnf clean all \
|
||||
&& rm -rf /var/cache/yum
|
||||
|
||||
-----
|
||||
|
||||
[chris@krang] $ docker build -t cache -f Dockerfile .
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}"
|
||||
| head -n 1
|
||||
cache: 464 MB
|
||||
|
||||
[chris@krang] $ docker build -t no-cache -f Dockerfile-wo-cache .
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
|
||||
no-cache: 271 MB
|
||||
```
|
||||
|
||||
从上面的结果来看,清理缓存文件的效果相当显著。和清除了元数据和缓存文件的容器镜像相比,不清除的镜像体积接近前者的两倍。除此以外,包管理器缓存文件、Ruby gem 的临时文件、nodejs 缓存文件,甚至是下载的源码 tarball 最好都全部清理掉。
|
||||
|
||||
### 层:一个潜在的隐患
|
||||
|
||||
很不幸(当你往下读,你会发现这是不幸中的万幸),根据容器中的层的概念,不能简单地向 Dockerfile 中写一句 `RUN rm -rf /var/cache/yum` 就完事儿了。因为 Dockerfile 的每一条命令都以一个层的形式存储,并一层层地叠加。所以,如果你是这样写的:
|
||||
|
||||
```
|
||||
RUN dnf install -y nginx
|
||||
RUN dnf clean all
|
||||
RUN rm -rf /var/cache/yum
|
||||
```
|
||||
|
||||
你的容器镜像就会包含三层,而 `RUN dnf install -y nginx` 这一层仍然会保留着那些缓存文件,然后在另外两层中被移除。但缓存实际上仍然是存在的,当你把一个文件系统挂载在另外一个文件系统之上时,文件仍然在那里,只不过你见不到也访问不到它们而已。
|
||||
|
||||
在上一节的示例中,你会看到正确的做法是将几条命令链接起来,在产生缓存文件的同一条 Dockerfile 指令里把缓存文件清理掉:
|
||||
|
||||
```
|
||||
RUN dnf install -y nginx \
|
||||
&& dnf clean all \
|
||||
&& rm -rf /var/cache/yum
|
||||
```
|
||||
|
||||
这样就把几条命令连成了一条命令,在最终的镜像中只占用一个层。这样只会浪费一点缓存的好处,稍微多耗费一点点构建容器镜像的时间,但被清理掉的缓存文件就不会留存在最终的镜像中了。作为一个折衷方法,只需要把一些相关的命令(例如 `yum install` 和 `yum clean all`、下载文件、解压文件、移除 tarball 等等)连接成一个命令,就可以在最终的容器镜像中节省出大量体积,你也能够利用 Docker 的缓存加快开发速度。
|
||||
|
||||
层还有一个更隐蔽的特性。每一层都记录了文件的更改,这里的更改并不仅仅已有的文件累加起来,而是包括文件属性在内的所有更改。因此即使是对文件使用了 `chmod` 操作也会被在新的层创建文件的副本。
|
||||
|
||||
下面是一次 `docker images` 命令的输出内容。其中容器镜像 `layer_test_1` 是在 CentOS 基础镜像中增加了一个 1GB 大小的文件后构建出来的镜像,而容器镜像 `layer_test_2` 是使用了 `FROM layer_test_1` 语句创建出来的,除了执行一条 `chmod u+x` 命令没有做任何改变。
|
||||
|
||||
```
|
||||
layer_test_2 latest e11b5e58e2fc 7 seconds ago 2.35 GB
|
||||
layer_test_1 latest 6eca792a4ebe 2 minutes ago 1.27 GB
|
||||
```
|
||||
|
||||
如你所见,`layer_test_2` 镜像比 `layer_test_1` 镜像大了 1GB 以上。尽管事实上 `layer_test_1` 只是 `layer_test_2` 的前一层,但隐藏在这第二层中有一个额外的 1GB 的文件。在构建容器镜像的过程中,如果在单独一层中进行移动、更改、删除文件,都会出现类似的结果。
|
||||
|
||||
### 专用镜像和公用镜像
|
||||
|
||||
有这么一个亲身经历:我们部门重度依赖于 [Ruby on Rails][3],于是我们开始使用容器。一开始我们就建立了一个正式的 Ruby 的基础镜像供所有的团队使用,为了简单起见(以及在“这就是我们自己在服务器上瞎鼓捣的”想法的指导下),我们使用 [rbenv][4] 将 Ruby 最新的 4 个版本都安装到了这个镜像当中,目的是让开发人员只用这个单一的镜像就可以将使用不同版本 Ruby 的应用程序迁移到容器中。我们当时还认为这是一个虽然非常大但兼容性相当好的镜像,因为这个镜像可以同时满足各个团队的使用。
|
||||
|
||||
实际上这是费力不讨好的。如果维护独立的、版本略微不同的镜像中,可以很轻松地实现镜像的自动化维护。同时,选择特定版本的特定镜像,还有助于在引入破坏性改变,在应用程序接近生命周期结束前提前做好预防措施,以免产生不可控的后果。庞大的公用镜像也会对资源造成浪费,当我们后来将这个庞大的镜像按照 Ruby 版本进行拆分之后,我们最终得到了共享一个基础镜像的多个镜像,如果它们都放在一个服务器上,会额外多占用一点空间,但是要比安装了多个版本的巨型镜像要小得多。
|
||||
|
||||
这个例子也不是说构建一个灵活的镜像是没用的,但仅对于这个例子来说,从一个公共镜像创建根据用途而构建的镜像最终将节省存储资源和维护成本,而在受益于公共基础镜像的好处的同时,每个团队也能够根据需要来做定制化的配置。
|
||||
|
||||
### 从零开始:将你需要的内容添加到空白镜像中
|
||||
|
||||
有一些和 Dockerfile 一样易用的工具可以轻松创建非常小的兼容 Docker 的容器镜像,这些镜像甚至不需要包含一个完整的操作系统,就可以像标准的 Docker 基础镜像一样小。
|
||||
|
||||
我曾经写过一篇[关于 Buildah 的文章][5],我想在这里再一次推荐一下这个工具。因为它足够的灵活,可以使用宿主机上的工具来操作一个空白镜像并安装打包好的应用程序,而且这些工具不会被包含到镜像当中。
|
||||
|
||||
Buildah 取代了 `docker build` 命令。可以使用 Buildah 将容器的文件系统挂载到宿主机上并进行交互。
|
||||
|
||||
下面来使用 Buildah 实现上文中 Nginx 的例子(现在忽略了缓存的处理):
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
set -o errexit
|
||||
|
||||
# Create a container
|
||||
container=$(buildah from scratch)
|
||||
|
||||
# Mount the container filesystem
|
||||
mountpoint=$(buildah mount $container)
|
||||
|
||||
# Install a basic filesystem and minimal set of packages, and nginx
|
||||
dnf install --installroot $mountpoint --releasever 28 glibc-minimal-langpack nginx --setopt install_weak_deps=false -y
|
||||
|
||||
# Save the container to an image
|
||||
buildah commit --format docker $container nginx
|
||||
|
||||
# Cleanup
|
||||
buildah unmount $container
|
||||
|
||||
# Push the image to the Docker daemon’s storage
|
||||
buildah push nginx:latest docker-daemon:nginx:latest
|
||||
|
||||
```
|
||||
|
||||
你会发现这里使用的已经不再是 Dockerfile 了,而是普通的 Bash 脚本,而且是从框架(或空白)镜像开始构建的。上面这段 Bash 脚本将容器的根文件系统挂载到了宿主机上,然后使用宿主机的命令来安装应用程序,这样的话就不需要把软件包管理器放置到容器镜像中了。
|
||||
|
||||
这样所有无关的内容(基础镜像之外的部分,例如 `dnf`)就不再会包含在镜像中了。在这个例子当中,构建出来的镜像大小只有 304 MB,比使用 Dockerfile 构建的镜像减少了 100 MB 以上。
|
||||
|
||||
```
|
||||
[chris@krang] $ docker images |grep nginx
|
||||
docker.io/nginx buildah 2505d3597457 4 minutes ago 304 MB
|
||||
```
|
||||
|
||||
注:这个镜像是使用上面的构建脚本构建的,镜像名称中前缀的 `docker.io` 只是在推送到镜像仓库时加上的。
|
||||
|
||||
对于一个 300MB 级别的容器基础镜像来说,能缩小 100MB 已经是很显著的节省了。使用软件包管理器来安装 Nginx 会带来大量的依赖项,如果能够使用宿主机直接从源代码对应用程序进行编译然后构建到容器镜像中,节省出来的空间还可以更多,因为这个时候可以精细的选用必要的依赖项,非必要的依赖项一概不构建到镜像中。
|
||||
|
||||
[Tom Sweeney][6] 有一篇文章《[用 Buildah 构建更小的容器][7]》,如果你想在这方面做深入的优化,不妨参考一下。
|
||||
|
||||
通过 Buildah 可以构建一个不包含完整操作系统和代码编译工具的容器镜像,大幅缩减了容器镜像的体积。对于某些类型的镜像,我们可以进一步采用这种方式,创建一个只包含应用程序本身的镜像。
|
||||
|
||||
### 使用静态链接的二进制文件来构建镜像
|
||||
|
||||
按照这个思路,我们甚至可以更进一步舍弃容器内部的管理和构建工具。例如,如果我们足够专业,不需要在容器中进行排错调试,是不是可以不要 Bash 了?是不是可以不要 [GNU 核心套件][8]了?是不是可以不要 Linux 基础文件系统了?如果你使用的编译型语言支持[静态链接库][9],将应用程序所需要的所有库和函数都编译成二进制文件,那么程序所需要的函数和库都可以复制和存储在二进制文件本身里面。
|
||||
|
||||
这种做法在 [Golang][10] 社区中已经十分常见,下面我们使用由 Go 语言编写的应用程序进行展示:
|
||||
|
||||
以下这个 Dockerfile 基于 golang:1.8 镜像构建一个小的 Hello World 应用程序镜像:
|
||||
|
||||
```
|
||||
FROM golang:1.8
|
||||
|
||||
ENV GOOS=linux
|
||||
ENV appdir=/go/src/gohelloworld
|
||||
|
||||
COPY ./ /go/src/goHelloWorld
|
||||
WORKDIR /go/src/goHelloWorld
|
||||
|
||||
RUN go get
|
||||
RUN go build -o /goHelloWorld -a
|
||||
|
||||
CMD ["/goHelloWorld"]
|
||||
```
|
||||
|
||||
构建出来的镜像中包含了二进制文件、源代码以及基础镜像层,一共 716MB。但对于应用程序运行唯一必要的只有编译后的二进制文件,其余内容在镜像中都是多余的。
|
||||
|
||||
如果在编译的时候通过指定参数 `CGO_ENABLED=0` 来禁用 `cgo`,就可以在编译二进制文件的时候忽略某些函数的 C 语言库:
|
||||
|
||||
```
|
||||
GOOS=linux CGO_ENABLED=0 go build -a goHelloWorld.go
|
||||
```
|
||||
|
||||
编译出来的二进制文件可以加到一个空白(或框架)镜像:
|
||||
|
||||
```
|
||||
FROM scratch
|
||||
COPY goHelloWorld /
|
||||
CMD ["/goHelloWorld"]
|
||||
```
|
||||
|
||||
来看一下两次构建的镜像对比:
|
||||
|
||||
```
|
||||
[ chris@krang ] $ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
goHello scratch a5881650d6e9 13 seconds ago 1.55 MB
|
||||
goHello builder 980290a100db 14 seconds ago 716 MB
|
||||
```
|
||||
|
||||
从镜像体积来说简直是天差地别了。基于 golang:1.8 镜像构建出来带有 goHelloWorld 二进制的镜像(带有 `builder` 标签)体积是基于空白镜像构建的只包含该二进制文件的镜像的 460 倍!后者的整个镜像大小只有 1.55MB,也就是说,有 713MB 的数据都是非必要的。
|
||||
|
||||
正如上面提到的,这种缩减镜像体积的方式在 Golang 社区非常流行,因此不乏这方面的文章。[Kelsey Hightower][11] 有一篇[文章][12]专门介绍了如何处理这些库的依赖关系。
|
||||
|
||||
### 压缩镜像层
|
||||
|
||||
除了前面几节中讲到的将多个命令链接成一个命令的技巧,还可以对镜像进行压缩。镜像压缩的实质是导出它,删除掉镜像构建过程中的所有中间层,然后保存镜像的当前状态为单个镜像层。这样可以进一步将镜像缩小到更小的体积。
|
||||
|
||||
在 Docker 1.13 之前,压缩镜像层的的过程可能比较麻烦,需要用到 `docker-squash` 之类的工具来导出容器的内容并重新导入成一个单层的镜像。但 Docker 在 Docker 1.13 中引入了 `--squash` 参数,可以在构建过程中实现同样的功能:
|
||||
|
||||
```
|
||||
FROM fedora:28
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
RUN dnf install -y nginx
|
||||
RUN dnf clean all
|
||||
RUN rm -rf /var/cache/yum
|
||||
|
||||
[chris@krang] $ docker build -t squash -f Dockerfile-squash --squash .
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
|
||||
squash: 271 MB
|
||||
```
|
||||
|
||||
通过这种方式使用 Dockerfile 构建出来的镜像有 271MB 大小,和上面连接多条命令的方案构建出来的镜像体积一样,因此这个方案也是有效的,但也有一个潜在的问题,而且是另一种问题。
|
||||
|
||||
“什么?还有另外的问题?”
|
||||
|
||||
好吧,有点像以前一样的问题,以另一种方式引发了问题。
|
||||
|
||||
### 过头了:过度压缩、太小太专用了
|
||||
|
||||
容器镜像之间可以共享镜像层。基础镜像或许大小上有几 Mb,但它只需要拉取/存储一次,并且每个镜像都能复用它。所有共享基础镜像的实际镜像大小是基础镜像层加上每个特定改变的层的差异内容,因此,如果有数千个基于同一个基础镜像的容器镜像,其体积之和也有可能只比一个基础镜像大不了多少。
|
||||
|
||||
因此,这就是过度使用压缩或专用镜像层的缺点。将不同镜像压缩成单个镜像层,各个容器镜像之间就没有可以共享的镜像层了,每个容器镜像都会占有单独的体积。如果你只需要维护少数几个容器镜像来运行很多容器,这个问题可以忽略不计;但如果你要维护的容器镜像很多,从长远来看,就会耗费大量的存储空间。
|
||||
|
||||
回顾上面 Nginx 压缩的例子,我们能看出来这种情况并不是什么大的问题。在这个镜像中,有 Fedora 操作系统和 Nginx 应用程序,没有缓存,并且已经被压缩。但我们一般不会使用一个原始的 Nginx,而是会修改配置文件,以及引入其它代码或应用程序来配合 Nginx 使用,而要做到这些,Dockerfile 就变得更加复杂了。
|
||||
|
||||
如果使用普通的镜像构建方式,构建出来的容器镜像就会带有 Fedora 操作系统的镜像层、一个安装了 Nginx 的镜像层(带或不带缓存)、为 Nginx 作自定义配置的其它多个镜像层,而如果有其它容器镜像需要用到 Fedora 或者 Nginx,就可以复用这个容器镜像的前两层。
|
||||
|
||||
```
|
||||
[ App 1 Layer ( 5 MB) ] [ App 2 Layer (6 MB) ]
|
||||
[ Nginx Layer ( 21 MB) ] ------------------^
|
||||
[ Fedora Layer (249 MB) ]
|
||||
```
|
||||
|
||||
如果使用压缩镜像层的构建方式,Fedora 操作系统会和 Nginx 以及其它配置内容都被压缩到同一层里面,如果有其它容器镜像需要使用到 Fedora,就必须重新引入 Fedora 基础镜像,这样每个容器镜像都会额外增加 249MB 的大小。
|
||||
|
||||
```
|
||||
[ Fedora + Nginx + App 1 (275 MB)] [ Fedora + Nginx + App 2 (276 MB) ]
|
||||
```
|
||||
|
||||
当你构建了大量在功能上趋于分化的的小型容器镜像时,这个问题就会暴露出来了。
|
||||
|
||||
就像生活中的每一件事一样,关键是要做到适度。根据镜像层的实现原理,如果一个容器镜像变得越小、越专用化,就越难和其它容器镜像共享基础的镜像层,这样反而带来不好的效果。
|
||||
|
||||
对于仅在基础镜像上做微小变动构建出来的多个容器镜像,可以考虑共享基础镜像层。如上所述,一个镜像层本身会带有一定的体积,但只要存在于镜像仓库中,就可以被其它容器镜像复用。这种情况下,数千个镜像也许要比单个镜像占用更少的空间。
|
||||
|
||||
```
|
||||
[ specific app ] [ specific app 2 ]
|
||||
[ customizations ]--------------^
|
||||
[ base layer ]
|
||||
```
|
||||
|
||||
一个容器镜像变得越小、越专用化,就越难和其它容器镜像共享基础的镜像层,最终会不必要地占用越来越多的存储空间。
|
||||
|
||||
```
|
||||
[ specific app 1 ] [ specific app 2 ] [ specific app 3 ]
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
减少处理容器镜像时所需的存储空间和带宽的方法有很多,其中最直接的方法就是减小容器镜像本身的大小。在使用容器的过程中,要经常留意容器镜像是否体积过大,根据不同的情况采用上述提到的清理缓存、压缩到一层、将二进制文件加入在空白镜像中等不同的方法,将容器镜像的体积缩减到一个有效的大小。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/building-container-images
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://www.docker.com/
|
||||
[2]:https://www.nginx.com/
|
||||
[3]:https://rubyonrails.org/
|
||||
[4]:https://github.com/rbenv/rbenv
|
||||
[5]:https://opensource.com/article/18/6/getting-started-buildah
|
||||
[6]:https://twitter.com/TSweeneyRedHat
|
||||
[7]:https://opensource.com/article/18/5/containers-buildah
|
||||
[8]:https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[9]:https://en.wikipedia.org/wiki/Static_library
|
||||
[10]:https://golang.org/
|
||||
[11]:https://twitter.com/kelseyhightower
|
||||
[12]:https://medium.com/@kelseyhightower/optimizing-docker-images-for-static-binaries-b5696e26eb07
|
||||
|
||||
121
published/201903/20180930 A Short History of Chaosnet.md
Normal file
121
published/201903/20180930 A Short History of Chaosnet.md
Normal file
@ -0,0 +1,121 @@
|
||||
Chaosnet 简史
|
||||
===
|
||||
|
||||
如果你输入 `dig` 命令对 `google.com` 进行 DNS 查询,你会得到如下答复:
|
||||
|
||||
```
|
||||
$ dig google.com
|
||||
|
||||
; <<>> DiG 9.10.6 <<>> google.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27120
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 512
|
||||
;; QUESTION SECTION:
|
||||
;google.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
google.com. 194 IN A 216.58.192.206
|
||||
|
||||
;; Query time: 23 msec
|
||||
;; SERVER: 8.8.8.8#53(8.8.8.8)
|
||||
;; WHEN: Fri Sep 21 16:14:48 CDT 2018
|
||||
;; MSG SIZE rcvd: 55
|
||||
```
|
||||
|
||||
这个输出一部分描述了你的问题(`google.com` 的 IP 地址是什么?),另一部分则详细描述了你收到的回答。在<ruby>答案区段<rt>ANSWER SECTION</rt></ruby>里,`dig` 为我们找到了一个包含五个字段的记录。从左数第四个字段 `A` 定义了这个记录的类型 —— 这是一个地址记录。在 `A` 的右边,第五个字段告知我们 `google.com` 的 IP 地址是 `216.58.192.206`。第二个字段,`194` 则代表这个记录的缓存时间是 194 秒。
|
||||
|
||||
那么,`IN` 字段告诉了我们什么呢?令人尴尬的是,在很长的一段时间里,我都认为这是一个介词。那时候我认为 DNS 记录大概是表达了“在 `A` 记录里,`google.com` 的 IP 地址是 `216.58.192.206`。”后来我才知道 `IN` 是 “internet” 的简写。`IN` 这一个部分告诉了我们这个记录分属的<ruby>类别<rt>class</rt></ruby>。
|
||||
|
||||
那么,除了 “internet” 之外,DNS 记录还会有什么别的类别吗?这究竟意味着什么?你怎么去搜寻一个*不位于* internet 上的地址?看起来 `IN` 是唯一一个可能有意义的值。而且的确,如果你尝试去获得除了 `IN` 之外的,关于 `google.com` 的记录的话,DNS 服务器通常不能给出恰当的回应。以下就是我们尝试向 `8.8.8.8`(谷歌公共 DNS 服务器)询问在 `HS` 类别里 `google.com` 的 IP 地址。我们得到了状态为 `SERVFAIL` 的回复。
|
||||
|
||||
```
|
||||
$ dig -c HS google.com
|
||||
|
||||
; <<>> DiG 9.10.6 <<>> -c HS google.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31517
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 512
|
||||
;; QUESTION SECTION:
|
||||
;google.com. HS A
|
||||
|
||||
;; Query time: 34 msec
|
||||
;; SERVER: 8.8.8.8#53(8.8.8.8)
|
||||
;; WHEN: Tue Sep 25 14:48:10 CDT 2018
|
||||
;; MSG SIZE rcvd: 39
|
||||
```
|
||||
|
||||
所以说,除了 `IN` 以外的类别没有得到广泛支持,但它们的确是存在的。除了 `IN` 之外,DNS 记录还有 `HS`(我们刚刚看到的)和 `CH` 这两个类别。`HS` 类是为一个叫做 [Hesiod][1] 的系统预留的,它可以利用 DNS 来存储并让用户访问一些文本资料。它通常在本地环境中作为 [LDAP][2] 的替代品使用。而 `CH` 这个类别,则是为 Chaosnet 预留的。
|
||||
|
||||
如今,大家都在使用 TCP/IP 协议族。这两种协议(TCP 及 UDP)是绝大部分电脑远程连接采用的协议。不过我觉得,从互联网的垃圾堆里翻出了一个布满灰尘,绝迹已久,被人们遗忘的系统,也是一件令人愉悦的事情。那么,Chaosnet 是什么?为什么它像恐龙一样,走上了毁灭的道路呢?
|
||||
|
||||
### 在 MIT 的机房里
|
||||
|
||||
Chaosnet 是在 1970 年代,由 MIT 人工智能实验室的研究员们研发的。它是一个宏伟目标的一部分 —— 设计并制造一个能比其他通用电脑更高效率运行 Lisp 代码的机器。
|
||||
|
||||
Lisp 是 MIT 教授 John McCarthy 的造物,他亦是人工智能领域的先驱者。在 1960 年发布的[一篇论文][3]中,他首次描述了 Lisp 这个语言。在 1962 年,Lisp 的编译器和解释器诞生了。Lisp 引入了非常多的新特性,这些特性在现在看来是每一门编程语言不可或缺的一部分。它是第一门拥有垃圾回收器的语言,是第一个有 REPL(Read-eval-print-loop:交互式解析器)的语言,也是第一个支持动态类型的语言。在人工智能领域工作的程序员们都十分喜爱这门语言,比如说,大名鼎鼎的 [SHRDLU][4] 就是用它写的。这个程序允许人们使用自然语言,向机器下达挪动玩具方块这样的命令。
|
||||
|
||||
Lisp 的缺点是它太慢了。跟其它语言相比,Lisp 需要使用两倍的时间来执行相同的操作。因为 Lisp 在运行中仍会检查变量类型,而不仅是编译过程中。在 MIT 的 IBM 7090 上,它的垃圾回收器也需要长达一秒钟的时间来执行。[^1] 这个性能问题急需解决,因为 AI 研究者们试图搭建类似 SHRDLU 的应用。他们需要程序与使用者进行实时互动。因此,在 1970 年代的晚期,MIT 人工智能实验室的研究员们决定去建造一个能更高效运行 Lisp 的机器来解决这个问题。这些“Lisp 机器”们拥有更大的存储和更精简的指令集,更加适合 Lisp。类型检查由专门的电路完成,因此在 Lisp 运行速度的提升上达成了质的飞跃。跟那时流行的计算机系统不同,这些机器并不支持分时,整台电脑的资源都用来运行一个单独的 Lisp 程序。每一个用户都会得到他自己单独的 CPU。MIT 的 <ruby>Lisp 机器小组<rt>Lisp Machine Group</rt></ruby>在一个备忘录里提到,这些功能是如何让 Lisp 运行变得更简单的:
|
||||
|
||||
> Lisp 机器是个人电脑。这意味着处理器和主内存并不是分时复用的,每个人都能得到单独属于自己的处理器和内存。这个个人运算系统由许多处理器组成,每个处理器都有它们自己的内存和虚拟内存。当一个用户登录时,他就会被分配一个处理器,在他的登录期间这个处理器是独属于他的。当他登出,这个处理器就会重新可用,等待被分配给下一个用户。通过采取这种方法,当前用户就不用和其他用户竞争内存的使用,他经常使用的内存页也能保存在处理器核心里,因此页面换出的情况被显著降低了。这个 Lisp 机器解决了分时 Lisp 机器的一个基本问题。[^2]
|
||||
|
||||
这个 Lisp 机器跟我们认知的现代个人电脑有很大的不同。该小组原本希望今后用户不用直接面对 Lisp 机器,而是面对终端。那些终端会与位于别处的 Lisp 机器进行连接。虽然每个用户都有自己专属的处理器,但那些处理器在工作时会发出很大的噪音,因此它们最好是位于机房,而不是放在本应安静的办公室里。[^3] 这些处理器会通过一个“完全分布式控制”的高速本地网络共享访问一个文件系统和设备,例如打印机。[^4] 这个网络的名字就是 Chaosnet。
|
||||
|
||||
Chaosnet 既是硬件标准也是软件协议。它的硬件标准与以太网类似,事实上 Chaosnet 软件协议是运行在以太网之上的。这个软件协议在网络层和传输层之间交互,它并不像 TCP/IP,而总是控制着本地网络。Lisp 机器小组的一个成员 David Moon 写的另一个备忘录中提到,Chaosnet “目前并不打算为低速链接、高信噪链接、多路径、长距离链接做特别的优化。” [^5] 他们专注于打造一个在小型网络里表现极佳的协议。
|
||||
|
||||
因为 Chaosnet 连接在 Lisp 处理器和文件系统之间,所以速度十分重要。网络延迟会严重拖慢一些像打开文本文档这种简单操作的速度,为了提高速度,Chaosnet 结合了在<ruby><rb>Network Control Program</rb>网络控制程序</ruby>中使用的一些改进方法,随后的 Arpanet 项目中也使用了这些方法。据 Moon 所说,“为了突破诸如在 Arpanet 中发现的速率瓶颈,很有必要采纳新的设计。目前来看,瓶颈在于由多个链接分享控制链接,而且在下一个信息发送之前,我们需要知道本次信息已经送达。” [^6] Chaosnet 协议族的批量 ACK 包跟当今 TCP 的差不多,它减少了 1/3 到一半的需要传输的包的数量。
|
||||
|
||||
因为绝大多数 Lisp 机器使用较短的单线进行连接,所以 Chaosnet 可以使用较为简单的路由算法。Moon 在 Chaosnet 路由方案中写道“预计要适配的网络架构十分简单,很少有多个路径,而且每个节点之间的距离很短。所以我认为没有必要进行复杂的方案设计。” [^7] 因为 Chaosnet 采用的算法十分简单,所以实现它也很容易。与之对比明显,其实现程序据说只有 Arpanet 网络控制程序的一半。[^8]
|
||||
|
||||
Chaosnet 的另一个特性是,它的地址只有 16 位,是 IPv4 地址的一半。所以这也意味着 Chaosnet 只能在局域网里工作。Chaosnet 也不会去使用端口号;当一个进程试图连接另一个机器上的另外一个进程时,需要首先初始化连接,获取一个特定的目标“<ruby>联系名称<rt>contact name</rt></ruby>”。这个联系名称一般是某个特定服务的名字。比方说,一个主机试图使用 `TELNET` 作为联系名称,连接另一个主机。我认为它的工作方式在实践中有点类似于 TCP,因为有些非常著名的服务也会拥有联系名称,比如运行在 80 端口上的 `HTTP` 服务。
|
||||
|
||||
在 1986 年,[RFC 973][5] 通过了将 Chaosnet DNS 类别加入域名解析系统的决议。它替代了一个早先出现的类别 `CSNET`。`CSNET` 是为了支持一个名叫<ruby>计算机科学网络<rt>Computer Science Network</rt></ruby>而被制造出来的协议。我并不知道为什么 Chaosnet 能被域名解析系统另眼相待。很多别的协议族也有资格加入 DNS,但是却被忽略了。比如 DNS 的主要架构师之一 Paul Mockapetris 提到说在他原本的构想里,<ruby>施乐<rt>Xerox</rt></ruby>的网络协议应该被包括在 DNS 里。[^9] 但是它并没有被加入。Chaosnet 被加入的原因大概是因为 Arpanet 项目和互联网的早期工作,有很多都在麻省剑桥的博尔特·贝拉尼克—纽曼公司,他们的雇员和 MIT 大多有紧密的联系。在这一小撮致力于发展计算机网络人中,Chaosnet 这个协议应该较为有名。
|
||||
|
||||
Chaosnet 随着 Lisp 机器的衰落渐渐变得不那么流行。尽管在一小段时间内 Lisp 机器有实际的商业产品 —— Symbolics 和 Lisp Machines Inc 在 80 年代售卖了这些机器。但它们很快被更便宜的微型计算机替代。这些计算机没有特殊制造的回路,但也可以快速运行 Lisp。Chaosnet 被制造出来的目的之一是解决一些 Apernet 协议的原始设计缺陷,但现在 TCP/IP 协议族同样能够解决这些问题了。
|
||||
|
||||
### 壳中幽灵
|
||||
|
||||
非常不幸的是,在互联网中留存的关于 Chaosnet 的资料不多。RFC 675 —— TCP/IP 的初稿于 1974 年发布,而 Chasnet 于 1975 年开始开发。[^10] 但 TCP/IP 最终征服了整个互联网世界,Chaosnet 则被宣布技术性死亡。尽管 Chaosnet 有可能影响了接下来 TCP/IP 的发展,可我并没有找到能够支持这个猜测的证据。
|
||||
|
||||
唯一一个可见的 Chaosnet 残留就是 DNS 的 `CH` 类。这个事实让我着迷。`CH` 类别是那被遗忘的幽魂 —— 在 TCP/IP 广泛部署中存在的一个替代协议 Chaosnet 的最后栖身之地。至少对于我来说,这件事情是十分让人激动。它告诉我关于 Chaosnet 的最后一丝痕迹,仍然藏在我们日常使用的网络基础架构之中。DNS 的 `CH` 类别是有趣的数码考古学遗迹。但它同时也是活生生的标识,提醒着我们互联网并非天生完整成型的,TCP/IP 不是唯一一个能够让计算机们交流的协议。“万维网”也远远不是我们这全球交流系统所能有的,最酷的名字。
|
||||
|
||||
|
||||
[^1]: LISP 1.5 Programmer’s Manual, The Computation Center and Research Laboratory of Electronics, 90, accessed September 30, 2018, http://www.softwarepreservation.org/projects/LISP/book/LISP%201.5%20Programmers%20Manual.pdf
|
||||
[^2]: Lisp Machine Progress Report (Artificial Intelligence Memo 444), MIT Artificial Intelligence Laboratory, August, 1977, 3, accessed September 30, 2018, https://dspace.mit.edu/bitstream/handle/1721.1/5751/AIM-444.pdf.
|
||||
[^3]: Lisp Machine Progress Report (Artificial Intelligence Memo 444), 4.
|
||||
[^4]: 同上
|
||||
[^5]: Chaosnet (Artificial Intelligence Memo 628), MIT Artificial Intelligence Laboratory, June, 1981, 1, accessed September 30, 2018, https://dspace.mit.edu/bitstream/handle/1721.1/6353/AIM-628.pdf.
|
||||
[^6]: 同上
|
||||
[^7]: Chaosnet (Artificial Intelligence Memo 628), 16.
|
||||
[^8]: Chaosnet (Artificial Intelligence Memo 628), 9.
|
||||
[^9]: Paul Mockapetris and Kevin Dunlap, “The Design of the Domain Name System,” Computer Communication Review 18, no. 4 (August 1988): 3, accessed September 30, 2018, http://www.cs.cornell.edu/people/egs/615/mockapetris.pdf.
|
||||
[^10]: Chaosnet (Artificial Intelligence Memo 628), 1.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/09/30/chaosnet.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[acyanbird](https://github.com/acyanbird)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Hesiod_(name_service)
|
||||
[2]: https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol
|
||||
[3]: http://www-formal.stanford.edu/jmc/recursive.pdf
|
||||
[4]: https://en.wikipedia.org/wiki/SHRDLU
|
||||
[5]: https://tools.ietf.org/html/rfc973
|
||||
[6]: https://twitter.com/TwoBitHistory
|
||||
[7]: https://twobithistory.org/feed.xml
|
||||
[8]: https://twitter.com/TwoBitHistory/status/1041485204802756608?ref_src=twsrc%5Etfw
|
||||
129
published/201903/20190124 What does DevOps mean to you.md
Normal file
129
published/201903/20190124 What does DevOps mean to you.md
Normal file
@ -0,0 +1,129 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MZqk)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10671-1.html)
|
||||
[#]: subject: (What does DevOps mean to you?)
|
||||
[#]: via: (https://opensource.com/article/19/1/what-does-devops-mean-you)
|
||||
[#]: author: (Girish Managoli https://opensource.com/users/gammay)
|
||||
|
||||
DevOps 对你意味着什么?
|
||||
======
|
||||
|
||||
> 6 位专家为你解析 DevOps 及其实现、实践和哲学的关键。
|
||||
|
||||

|
||||
|
||||
如果你问 10 个人关于 DevOps 的问题,你会得到 12 个答案。这是对于 DevOps 的意见和期望的多样性的结果,更不用说它在实践中的差异。
|
||||
|
||||
为了解读 DevOps 的悖论,我们找到了最了解它的人 —— 这个行业的顶尖从业者。这些人熟悉 DevOps,了解技术的来龙去脉,并且已经有了多年 DevOps 实践。他们的观点应该能鼓励、刺激和激发你对 DevOps 的想法。
|
||||
|
||||
### DevOps 对你意味着什么?
|
||||
|
||||
让我们从基本原理开始。我们不能只在教科书上寻找答案,而应该需要知道专家们怎么说。
|
||||
|
||||
简而言之,专家们说的是关于 DevOps 的原则、实践和工具。
|
||||
|
||||
IBM 数字企业集团 DevOps 商业平台领导者 [Ann Marie Fred][1],说,“对于我来说,DevOps 是一套实践和原则,旨在使团队在设计、开发、交付和操作软件方面有更好的效率。”
|
||||
|
||||
据红帽资深 DevOps 布道者 [Daniel Oh][2],“通常来说,DevOps 促使企业基于当前的 IT 发展与应用开发、IT 运维和安全协议的流程和工具。”
|
||||
|
||||
Tactec 战略解决方案的创始人 [Brent Reed][3],谈及了利益相关者的持续改进,“DevOps 对我来说意味着包括了一种思维方式的工作方式,它允许持续改进运维绩效,进而提升组织绩效,从而让利益相关者受益。”
|
||||
|
||||
许多专家也强调 DevOps 文化。Ann Marie 说,“这也是持续改进和学习的问题。它涉及的是人和文化,以及工具和技术。”
|
||||
|
||||
美国保监会 (NAIC) 首席架构师兼 DevOps 领导者 [Dan Barker][4],“DevOps 主要是关于文化…它将几个独立的领域聚集在一起,如精益生产、[公正文化][5] 和持续的学习。我认为文化是最关键和最难执行的。”
|
||||
|
||||
Atos 的 DevOps 负责人 [Chris Baynham-Hughes][6],说,“[DevOps] 实践是通过组织内的文化、流程和工具的发展而被采用的。重点是文化变革,DevOps 文化借鉴的关键是协作、试验、快速反馈和持续改进。”
|
||||
|
||||
云架构师 [Geoff Purdy][7],谈及敏捷和反馈,“缩短和放大反馈回路。我们希望团队在几分钟内而不是几周内获得反馈。”
|
||||
|
||||
但在最后,Daniel 通过解释开源和开源文化是如何让他以简单快捷的方式实现目标来强调这点,“在推动 DevOps 中,最重要的事情应该是开源文化而不是具体的工具或复杂的解决方案。”
|
||||
|
||||
### 你认为哪些 DevOps 实践有效?
|
||||
|
||||
专家列举的那些最佳实践是普遍存在的,但又各不相同。
|
||||
|
||||
Ann Marie 表示:“一些十分强大灵活的项目管理[实践],能在职能、独立的小组之间打破壁垒;全自动化持续部署,蓝/绿部署实现零时间停机状态;开发人员设置自己的监控和警告,无缝自我修复,自动化的安全性与合规性。”
|
||||
|
||||
Chris 说,“特别的突破是倾情合作、持续改进、开放领导、缩短业务距离、从垂直孤岛转向横向/跨功能的产品团队、工作透明化、相互影响、Mobius 循环、缩短反馈回路、自动化(从环境到 CI/CD)。”
|
||||
|
||||
Brent 支持“发展学习文化,包括 TTD [测试驱动开发] 和 BDD [行为驱动开发]捕获事件,并通过持续集成和持续交付从设计、构建和测试到实施在生产环境上一系列事件的自动化。测试采用故障优先的方法,能够自动化集成和交付流程,并在整个生命周期中包含快速反馈。”
|
||||
|
||||
Geoff 强调自动化配置。“选择一个自动化配置,对我的团队来说非常有效。更具体地说从版本控制代码库中自动配置。”
|
||||
|
||||
Dan 则玩的开心,“ 我们做了很多不同的事情来建立 DevOps 文化。我们举办 ‘午餐 & 学习’ 活动,提供免费的食物来鼓励大家一起学习。我们买书,分组学习。”
|
||||
|
||||
### 你如何激励你的团队实现 DevOps 这个目标?
|
||||
|
||||
Daniel 强调“自动化的问题就是为了减少 DevOps 计划中来自多个团队的异议,你应该鼓励你的团队提高开发、测试与 IT 运营的自动化能力,以及新的流程和程序。例如,Linux 容器是实现 DevOps 自动化功能的关键工具。”
|
||||
|
||||
Geoff 很是赞同,“机械化的劳作,你有讨厌现在做的任务吗?很棒。如果可能的话,让它们消失。不行,那就让它们自动化。它能使工作不会变得太枯燥,因为工作总是在变化。”
|
||||
|
||||
Dan、Ann Marie 和 Brent 强调团队的执行力。
|
||||
|
||||
Dan 说,“在 NAIC,我们有个很好的奖励系统来鼓励特定的行为。我们有多个级别的奖项,其中两个奖项可以由任何人颁布给某人。我们也会颁奖给完成重要任务的团队,但我们通常只奖励给个人贡献者。”
|
||||
|
||||
Ann Marie 表示,“我所在地区的团队最大的动力是看见其他人成功。我们每周都会彼此回放一次,其中一部分是分享我们从尝试新工具或实践中学到的东西。团队热衷于他们现在做的事情,并愿意帮助其他人开始,相信更多的团队很快也会加入进来。”
|
||||
|
||||
Brent 表示赞同。“让每个人学习,并掌握同样的基础知识至关重要……我喜欢从评估什么能帮助团队实现目标[以及]产品负责人和用户需要提供的内容入手。”
|
||||
|
||||
Chris 推荐采用双管齐下的方法。“运行可以每周可以实现的小目标,并且[在这]可以看到他们正在运做的功能工作之外的进展,庆祝你所取得的进步。”
|
||||
|
||||
### DevOps 和敏捷开发如何协同工作?
|
||||
|
||||
这是一个重要的问题,因为 DevOps 和敏捷开发都是现代软件开发的基石。
|
||||
|
||||
DevOps 是一个软件开发的过程,专注与沟通与协作,以促进快速部署应用程序和产品。而敏捷开发是一种开发方法,涉及持续开发、连续迭代和连续测试,以实现可预测和可交付的成果质量。
|
||||
|
||||
那么,它们又有怎样的联系?让我们去问问专家吧。
|
||||
|
||||
在 Brent 来看,“DevOps != 敏捷。其次 敏捷 != Scrum 流程……敏捷工具和工作方式支撑着 DevOps 策略和目标,它们是如此融合在一起的。”
|
||||
|
||||
Chris 说,“对我而言敏捷是 DevOps 的一个基本组件。当然,我们可以讨论如何在非敏捷开发环境中采用 DevOps 文化,但最终表明,提高软件设计方式的灵活性是采用 DevOps 成熟读的一个关键指标。”
|
||||
|
||||
Dan 将 DevOps 与更伟大的 [敏捷宣言][8] 联系起来。“我在谈到敏捷时总会引用敏捷宣言来设置基准,而有许多实现中并不关注该宣言。当你阅读这份宣言时,你会发现它确实从开发的角度描述了 DevOps。因此,将敏捷融入 DevOps 文化非常容易,因为敏捷关注于沟通、协作、变化的灵活性以及快速地投入生产。”
|
||||
|
||||
Geoff 认为 “DevOps 是敏捷实施的众多实现之一。敏捷本质上是一套原则,而 DevOps 则是体现这些原则的文化、流程和工具链。”
|
||||
|
||||
Ann Marie 简洁说明,“敏捷是 DevOps 的先决条件。DevOps 使敏捷变得更加有效。”
|
||||
|
||||
### DevOps 是否受益于开源?
|
||||
|
||||
这个问题得到了所有参与者的热烈肯定,然后解释了他们看到的好处。
|
||||
|
||||
Ann Marie 说,“我们站在巨人的肩膀上,在已有的基础之上发展。拉取请求和代码评审的开源模式,对 DevOps 团队维护软件很有效果。”
|
||||
|
||||
Chris 赞同 DevOps “毫无疑问”受益于开源。“从设计和工具方面(例如,Ansible),到流程和人员方面,通分享行业内的故事和开源社区的领导。”
|
||||
|
||||
Geoff 提到一个好处是“基层的采纳”。免费的软件不需要签署购买申请。团队发现了满足他们需求的工具,可以自行进行修改。[然后]在它之上构建,并为更大的社区提供更好的功能。如此往复。
|
||||
|
||||
开源已经向 DevOps 展示着“就像开源软件开发者正在做的那样,采用更好的方式来克服新的变化”,Daniel 说。
|
||||
|
||||
Brent 同意道 “DevOps 从开源中获益良多。一种方法是使用这些工具来理解它们是如何加速 DevOps 的目标和策略;在自动化、自动伸缩、虚拟化和容器化等关键方面对开发人员和操作人员进行培训,如果不引入使 DevOps 更加容易的技术支持,就很难实现这些特性。”
|
||||
|
||||
Dan 指出了 DevOps 和开源之间的双向共生关系,“做好开源需要 DevOps 文化。大多数开源项目都具有非常开放的沟通结构,很少有不透明的地方。对于 Devops 实践者来说,这实际上是一个很好的学习机会,可以让他们了解到可能需要将什么引入自己的组织中。此外能够使用来自社区与组织类似的工具来鼓励自己的文化成长。我喜欢用 GitLab 作为这种共生关系的一个例子。当我把 GitLab 带入一家公司时,我们得到了一个很棒的工具,但我们真正购买的是他们独特的文化,通过我们与他们的互动以及我们的贡献带来了巨大价值。他们的工具也可以为 DevOps 组织提供更多东西,而他们的文化已经在我引入它的公司中引起了他们的敬畏。”
|
||||
|
||||
现在我们的 DevOps 专家已经参与进来了,请在评论中分享你对 DevOps 的理解,以及向我们提出其他问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/what-does-devops-mean-you
|
||||
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MZqk](https://github.com/MZqk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gammay
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twitter.com/DukeAMO
|
||||
[2]: https://twitter.com/danieloh30?lang=en
|
||||
[3]: https://twitter.com/brentareed
|
||||
[4]: https://twitter.com/barkerd427
|
||||
[5]: https://psnet.ahrq.gov/resources/resource/1582
|
||||
[6]: https://twitter.com/onlychrisbh?lang=en
|
||||
[7]: https://twitter.com/geoff_purdy
|
||||
[8]: https://agilemanifesto.org/
|
||||
@ -1,40 +1,42 @@
|
||||
[#]:collector:(lujun9972)
|
||||
[#]:translator:(lujun9972)
|
||||
[#]:reviewer:()
|
||||
[#]:publisher:()
|
||||
[#]:url:()
|
||||
[#]:subject:(IRCvsIRL:HowtorunagoodIRCmeeting)
|
||||
[#]:via:(https://opensource。com/article/19/2/irc-vs-irl-meetings)
|
||||
[#]:author:(Ben Cotton https://opensource。com/users/bcotton)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10670-1.html)
|
||||
[#]: subject: (IRCvsIRL:HowtorunagoodIRCmeeting)
|
||||
[#]: via: (https://opensource。com/article/19/2/irc-vs-irl-meetings)
|
||||
[#]: author: (Ben Cotton https://opensource.com/users/bcotton)
|
||||
|
||||
IRC vs IRL: 如何召开一个良好的 IRC 会议
|
||||
IRC vs IRL:如何召开一个良好的 IRC 会议
|
||||
======
|
||||
若你遵守这些最佳实践,InternetRelayChat 会议可以很好滴推进项目进展。
|
||||

|
||||
|
||||
开展任何形式的会议都是门艺术。很多人已经学会了开展面对面会议和电话会议,但是 [InternetRelayChat][1](IRC) 会议因其特殊的性质有别于"现实 (inreallife)"(IRL) 会议。本文将会分享 IRC 这种会议形式的优势和劣势以及帮你更有效地领导 IRC 会议的小技巧。
|
||||
> 若你遵守这些最佳实践,Internet Relay Chat(IRC)会议可以很好滴推进项目进展。
|
||||
|
||||
为什么是 IRC? 虽说现在有大量的实时聊天工具可供选择,[IRC 依然是开源项目的基石 ][2]。若你的项目使用其他沟通工具,也不要紧。这里大多数的建议都适用于同步的文本聊天机制,只需要进行一些微调。
|
||||

|
||||
|
||||
开展任何形式的会议都是门艺术。很多人已经学会了开展面对面会议和电话会议,但是 [Internet Relay Chat][1](IRC)会议因其特殊的性质有别于“<ruby>现实<rt>in real life</rt></ruby>”(IRL) 会议。本文将会分享 IRC 这种会议形式的优势和劣势,以及帮你更有效地领导 IRC 会议的小技巧。
|
||||
|
||||
为什么用 IRC? 虽说现在有大量的实时聊天工具可供选择,[IRC 依然是开源项目的基石][2]。若你的项目使用其他沟通工具,也不要紧。这里大多数的建议都适用于同步的文本聊天机制,只需要进行一些微调。
|
||||
|
||||
### IRC 会议的挑战
|
||||
|
||||
与面对面会议相比,IRC 会议会遇到一些挑战。你应该直到一个人结束谈话到下一个人开始谈话之间的间隙吧?在 IRC 中这更糟糕,因为人们需要输入他们的所想。这比说话要更慢,—而且不像谈话一样—你不知道别人什么时候在组织消息。主持人在要求回复或转到下一主题前必须等待很长一段时间。而想要发言的人需要先插入一个简短的信息(例如,一个句号)来让主持人知道(他需要发言)。
|
||||
与面对面会议相比,IRC 会议会遇到一些挑战。你应该知道一个人结束谈话到下一个人开始谈话之间会有间隙吧?在 IRC 中这更糟糕,因为人们需要输入他们的所想。这比说话要更慢,而且不像谈话,你不知道别人什么时候在组织消息。主持人在要求回复或转到下一主题前必须等待很长一段时间。而想要发言的人需要先插入一个简短的信息(例如,一个句号)来让主持人知道(他需要发言)。
|
||||
|
||||
IRC 会议还缺少其他方法中能够获得的那些元数据。你无法通过文本了解面部表情和语调。这意味着你必须小心你的措辞。
|
||||
|
||||
而且 IRC 会议很容易让人分心。至少在面对面会议中,当某人正在看搞笑的猫咪图片时,你可以看到他面带笑容而且在不合时宜的时候发出笑声。在 IRC 中,除非他们不小心粘贴了错误的短信,否者甚至都没有同伴的压力来让他们假装专注。你甚至可以同时参加多个 IRC 会议。我就这么做过,但如果你需要积极参与这些会议,那就很危险了。
|
||||
而且 IRC 会议很容易让人分心。至少在面对面会议中,当某人正在看搞笑的猫咪图片时,你可以看到他面带笑容而且在不合时宜的时候发出笑声。在 IRC 中,除非他们不小心粘贴了错误的短信,否则甚至都没有同伴的压力来让他们假装专注。你甚至可以同时参加多个 IRC 会议。我就这么做过,但如果你需要积极参与这些会议,那就很危险了。
|
||||
|
||||
### IRC 会议的优势
|
||||
|
||||
IRC 会议也有某些独一无二的优势。IRC 是一个非常轻资源的媒介。它并不怎么消耗带宽和 CPU。这降低了参与的门槛,这对贫困这和正在路上的人都是有利的。对于志愿者来说,这意味着他们可以在工作日参加会议。同时它也意味着参与者无需寻找一个安静的地方来让他们沟通而不打扰到周围的人。
|
||||
IRC 会议也有某些独一无二的优势。IRC 是一个非常轻资源的媒介。它并不怎么消耗带宽和 CPU。这降低了参与的门槛,这对贫困这和发展中的人都是有利的。对于志愿者来说,这意味着他们可以在工作日参加会议。同时它也意味着参与者无需寻找一个安静的地方来让他们沟通而不打扰到周围的人。
|
||||
|
||||
借助会议机器人,IRC 可以立即生成会议记录。在 Fedora 中,我们使用 Zodbot,Debian 的 [Meetbot][3] 的一个实例,来记录会议并提供交互。会议结束后,会议记录和完整的日志立即可供社区使用。这减少了开展会议的管理开销。
|
||||
借助会议机器人,IRC 可以立即生成会议记录。在 Fedora 中,我们使用 Zodbot(Debian 的 [Meetbot][3] 的一个实例)来记录会议并提供交互。会议结束后,会议记录和完整的日志立即可供社区使用。这减少了开展会议的管理开销。
|
||||
|
||||
### 这跟普通会议类似,但有所不同
|
||||
|
||||
通过 IRC 或其他基于文本的媒介进行会议意味着以稍微不同寻常的方式来看待会议。虽然它缺少一些更高带宽沟通模式的有点,但它也有自己的有点。开展 IRC 会议可以让你有机会开发出各种规则,而这些规则有助于你开展各种类型的会议。
|
||||
通过 IRC 或其他基于文本的媒介进行会议意味着以稍微不同寻常的方式来看待会议。虽然它缺少一些更高带宽沟通模式的优点,但它也有自己的优点。开展 IRC 会议可以让你有机会开发出各种规则,而这些规则有助于你开展各种类型的会议。
|
||||
|
||||
与任何会议一样,IRC 会议最好有明确的日程和目的。一个好的会议主持者知道什么时候让谈话继续下去以及什么时候将话题拉回来。并没有什么硬性规定—这是一门艺术。但 IRC 在这方面有一个优势。通过这是频道主题为会议的当前主题,人们可以看到他们应该谈论的内容。
|
||||
与任何会议一样,IRC 会议最好有明确的日程和目的。一个好的会议主持者知道什么时候让谈话继续下去以及什么时候将话题拉回来。并没有什么硬性规定,这是一门艺术。但 IRC 在这方面有一个优势。通过设置频道主题为会议的当前主题,人们可以看到他们应该谈论的内容。
|
||||
|
||||
如果你的项目尚未实施过同步会议,你应该考虑一下。对于项目成员分布在不同时区的项目,找到一个大家都认可的时间来组织会议很难。你不能把会议作为你唯一的协调方式。但他们可以是项目工作的重要组成部分。
|
||||
|
||||
@ -45,7 +47,7 @@ via: https://opensource.com/article/19/2/irc-vs-irl-meetings
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,96 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10667-1.html)
|
||||
[#]: subject: (ManageYourMirrorswithArchLinuxMirrorlistManager)
|
||||
[#]: via: (https://itsfoss。com/archlinux-mirrorlist-manager)
|
||||
[#]: author: (JohnPaulhttps://itsfoss.com/author/john/)
|
||||
|
||||
使用 Arch Linux 镜像列表管理器来管理你的镜像
|
||||
======
|
||||
|
||||
> Arch Linux 镜像列表管理器是一个简单的图形化程序,它让你可以方便地管理 Arch Linux 中的镜像。
|
||||
|
||||
对于 Linux 用户来说,保持镜像列表规整非常重要。今天我们来介绍一个用来管理 Arch 镜像列表的应用程序。
|
||||
|
||||
![Arch Linux Mirrorlist Manager][1]
|
||||
|
||||
*Arch Linux Mirrorlist Manager*
|
||||
|
||||
### 什么是镜像?
|
||||
|
||||
给新手的话,Linux 操作系统有赖于分布全球的的一系列服务器。这些服务器包含了特定发行版的所有可用的软件包的一样的副本。这就是为什么它们被称为“镜像”。
|
||||
|
||||
这些服务器的最终目标时让每个国家都有多个镜像。这样就能让当地的用户可以快速升级系统。然而,这并不绝对。有时别国的镜像反而更快。
|
||||
|
||||
### ArchLinux 镜像列表管理器让在 Arch Linux 中管理镜像更简单
|
||||
|
||||
![Arch Linux Mirrorlist Manager][2]
|
||||
|
||||
*主界面*
|
||||
|
||||
在 Arch 中[管理并对有效镜像进行排序][3] 不是个简单的事情。它需要用到很长的命令。还好,有人想出了一个解决方案。
|
||||
|
||||
去年,[RizwanHasan][4] 用 Python 编写了一个名为 [Arch Linux 镜像列表管理器][5] 的 Qt 应用程序。你可能对 Rizwan 这个名字感到眼熟,因为这不是第一次我们在本站介绍他做的玩意了。一年多前,我介绍过一个名为 [MagpieOS][6] 的基于 Arch 的新 Linux 发行版就是 Rizwan 创造的。我想 Rizwan 创造 MagpieOS 的经历激励了他创建了这个程序。
|
||||
|
||||
Arch Linux 镜像列表管理器的功能并不多。它让你根据回应速度对镜像进行排序,并可以根据数量和国家进行过滤。
|
||||
|
||||
也就是说,若你在德国,你可以限制只保留在位于德国的最快的 3 个镜像。
|
||||
|
||||
### 安装 Arch Linux 镜像列表管理器
|
||||
|
||||
> **它仅适用于 Arch Linux 用户**
|
||||
|
||||
> 注意! Arch Linux 镜像列表管理器只能应用于 Arch linux 发行版. 不要在其他基于 Arch 的发行版中使用它,除非你能确定该发行版使用的是 Arch 镜像。否则,你将会遇到我在 Manjaro 中遇到的问题(在下面章节解释).
|
||||
|
||||
---
|
||||
|
||||
> **Manjaro 中的镜像管理器替代品**
|
||||
|
||||
> 当使用类 Arch 的系统时, 我选择了 Manjaro。在开始本文之前,我在 Manjaro 及其上安装了 Arch Linux 镜像列表管理器。它很快就对有效镜像进行了排序并保存到我的镜像列表中。
|
||||
|
||||
> 然后我尝试进行系统更新却立即遇到了问题。当 ArchLinux 镜像列表管理器对我系统使用的镜像进行排序时,它使用普通的 Arch 镜像替换了我的 Manjaro 镜像。(Manjaro 基于 Arch,但却有着自己的镜像,这是因为开发团队会在推送软件包之前对所有这些软件包进行测试以保证不会出现系统崩溃的 BUG。)还好,Manjaro 论坛帮我修复了这个错误。
|
||||
|
||||
> 若你是 Manjaro 用户,请不要重蹈我的覆辙。Arch Linux 镜像列表管理器 仅适用于 Arch 以及使用 Arch 镜像的衍生版本。
|
||||
|
||||
> 幸运的是,manjaro 有一个简单易用的终端程序来管理镜像列表。那就是 [Pacman-mirrors][7]。跟 ArchLinux 镜像列表管理器一样,你可以根据回应速度进行排序。只需要运行 `sudo pacman-mirrors --fasttrack` 即可。若你像将结果局限在最快的 5 个镜像,可以运行 `sudo pacman-mirrors --fasttrack 5`。要像将结果局限在某个或某几个国家,运行 `sudo pacman-mirrors --country Germany,Spain,Austria`。你可以通过运行 `sudo pacman-mirrors --geoip` 来将结果局限在自己国家。更多关于 Pacman-mirrors 的信息请参见 [Manjaro wiki][7]。
|
||||
|
||||
> 运行 Pacman-mirrors 后,你还需要运行 `sudo pacman -Syyu` 来同步软件包数据库并升级系统。
|
||||
|
||||
> 注意:Pacman-mirrors 仅仅适用于 **Manjaro**。
|
||||
|
||||
Arch Linux 镜像列表管理器包含在 [ArchUserRepository][8] 中。高级 Arch 用户可以直接从 [theGitHubpage][9] 下载 PKGBUILD。
|
||||
|
||||
### 对 Arch Linux Mirrorlist Manager 的最后思考
|
||||
|
||||
虽然 [Arch Linux 镜像列表管理器][5] 对我不太有用,我很高兴有它的存在。这说明 Linux 用户正在努力让 Linux 更加易于使用。正如我之前说过的,在 Arch 中管理镜像并不容易。Rizwan 的小工具可以让 Arch 对新手更加友好。
|
||||
|
||||
你有用过 Arch Linux 镜像列表管理器吗?你是怎么管理 Arch 镜像的?请在下面的评论告诉我。
|
||||
|
||||
如果你觉的本文有趣的话,请花点时间将它分享到社交媒体中去。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/archlinux-mirrorlist-manager
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/mirrorlist-manager2.png?ssl=1
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/mirrorlist-manager4.jpg?ssl=1
|
||||
[3]: https://wiki.archlinux.org/index.php/Mirrors
|
||||
[4]: https://github.com/Rizwan-Hasan
|
||||
[5]: https://github.com/Rizwan-Hasan/ArchLinux-Mirrorlist-Manager
|
||||
[6]: https://itsfoss.com/magpieos/
|
||||
[7]: https://wiki.manjaro.org/index.php?title=Pacman-mirrors
|
||||
[8]: https://aur.archlinux.org/packages/mirrorlist-manager
|
||||
[9]: https://github.com/Rizwan-Hasan/MagpieOS-Packages/tree/master/ArchLinux-Mirrorlist-Manager
|
||||
[10]: http://reddit.com/r/linuxusersgroup
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (leommxj)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10657-1.html)
|
||||
[#]: subject: (5 Ways To Generate A Random/Strong Password In Linux Terminal)
|
||||
[#]: via: (https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-linux-terminal/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,9 +10,7 @@
|
||||
在 Linux 终端下生成随机/强密码的五种方法
|
||||
======
|
||||
|
||||
最近我们在网站上发表过一篇关于 **[密码强度与密码分数检查][1]** 的文章。
|
||||
|
||||
它可以帮助你检查你的密码的强度和分数。
|
||||
最近我们在网站上发表过一篇关于 [检查密码复杂性/强度和评分][1] 的文章。它可以帮助你检查你的密码的强度和评分。
|
||||
|
||||
我们可以手工创建我们需要的密码。但如果你想要为多个用户或服务器生成密码,解决方案是什么呢?
|
||||
|
||||
@ -20,57 +18,55 @@
|
||||
|
||||
这些工具可以为你生成高强度随机密码。如果你想要为多个用户和服务器更新密码,请继续读下去。
|
||||
|
||||
这些工具易于使用,这也是我喜欢用它们的原因。默认情况下它们会生成一个足够强壮的密码,你也可以通过使用其他可用的选项来生成一个超强的密码。
|
||||
这些工具易于使用,这也是我喜欢用它们的原因。默认情况下它们会生成一个足够健壮的密码,你也可以通过使用其他可用的选项来生成一个超强的密码。
|
||||
|
||||
它会帮助你生成符合下列要求的超强密码。密码长度至少有 12-15 个字符,包括字母(大写及小写),数字及特殊符号。
|
||||
|
||||
工具如下:
|
||||
|
||||
* `pwgen:` pwgen 程序生成易于人类记忆并且尽可能安全的密码。
|
||||
* `openssl:` openssl 是一个用来从 shell 中调用 OpenSSL 加密库提供的多种密码学函数的命令行工具。
|
||||
* `gpg:` OpenPGP 加密/签名工具。
|
||||
* `mkpasswd:` 生成新密码,可以选择直接应用给一名用户。
|
||||
* `makepasswd:` makepasswd 使用 /dev/urandom 生成真随机密码,比起好记它更重视安全性。
|
||||
* `/dev/urandom file` 两个特殊的字符文件 /dev/random 和 /dev/urandom (自 Linux 1.3.30 起) 提供了内核随机数生成器的接口。
|
||||
* `md5sum:` md5sum 是一个用来计算及校验 128-bit MD5 哈希的程序。
|
||||
* `sha256sum:` sha256sum 被设计用来使用 SHA-256 算法(SHA-2系列,摘要长度为256位)校验数据完整性。
|
||||
* `sha1pass:` sha1pass 生成一个 SHA1 密码哈希。在命令缺少盐值的情况下,将会生成一个随机的盐值向量。
|
||||
|
||||
|
||||
* `pwgen`:生成易于人类记忆并且尽可能安全的密码。
|
||||
* `openssl`:是一个用来从 shell 中调用 OpenSSL 加密库提供的多种密码学函数的命令行工具。
|
||||
* `gpg`:OpenPGP 加密/签名工具。
|
||||
* `mkpasswd`:生成新密码,可以选择直接设置给一名用户。
|
||||
* `makepasswd`:使用 `/dev/urandom` 生成真随机密码,比起好记它更重视安全性。
|
||||
* `/dev/urandom` 文件:两个特殊的字符文件 `/dev/random` 和 `/dev/urandom` (自 Linux 1.3.30 起出现)提供了内核随机数生成器的接口。
|
||||
* `md5sum`:是一个用来计算及校验 128 位 MD5 哈希的程序。
|
||||
* `sha256sum`:被设计用来使用 SHA-256 算法(SHA-2 系列,摘要长度为 256 位)校验数据完整性。
|
||||
* `sha1pass`:生成一个 SHA1 密码哈希。在命令缺少盐值的情况下,将会生成一个随机的盐值向量。
|
||||
|
||||
### 怎么用 pwgen 命令在 linux 下生成一个随机的强壮密码?
|
||||
|
||||
pwgen 程序生成易于人类记忆并且尽可能安全的密码。
|
||||
`pwgen` 程序生成易于人类记忆并且尽可能安全的密码。
|
||||
|
||||
易于人类记忆的密码永远都不会像完全随机的密码一样安全。
|
||||
|
||||
使用 `-s` 选项来生成完全随机,难于记忆的密码。由于我们记不住,这些密码应该只用于机器。
|
||||
|
||||
在 **`Fedora`** 系统中,使用 **[DNF 命令][2]** 来安装 pwgen。
|
||||
在 Fedora 系统中,使用 [DNF 命令][2] 来安装 `pwgen`。
|
||||
|
||||
```
|
||||
$ sudo dnf install pwgen
|
||||
```
|
||||
|
||||
在 **`Debian/Ubuntu`** 系统中,使用 **[APT-GET 命令][3]** 或 **[APT 命令][4]** 来安装 pwgen。
|
||||
在 Debian/Ubuntu 系统中,使用 [APT-GET 命令][3] 或 [APT 命令][4] 来安装 `pwgen`。
|
||||
|
||||
```
|
||||
$ sudo apt install pwgen
|
||||
```
|
||||
|
||||
在 **`Arch Linux`** 系统中,使用 **[Pacman 命令][5]** 来安装 pwgen。
|
||||
在 Arch Linux 系统中,使用 [Pacman 命令][5] 来安装 `pwgen`。
|
||||
|
||||
```
|
||||
$ sudo pacman -S pwgen
|
||||
```
|
||||
|
||||
在 **`RHEL/CentOS`** 系统中,使用 **[YUM 命令][6]** 来安装 pwgen。
|
||||
在 RHEL/CentOS 系统中,使用 [YUM 命令][6] 来安装 `pwgen`。
|
||||
|
||||
```
|
||||
$ sudo yum install pwgen
|
||||
```
|
||||
|
||||
在 **`openSUSE Leap`** 系统中,使用 **[Zypper 命令][7]** 来安装pwgen。
|
||||
在 openSUSE Leap 系统中,使用 [Zypper 命令][7] 来安装 `pwgen`。
|
||||
|
||||
```
|
||||
$ sudo zypper install pwgen
|
||||
@ -106,7 +102,7 @@ Sid1aeji mohj4Ko7 lieDi0pe Zeemah6a thuevu2E phi4Ohsh paiKeix1 ooz1Ceph
|
||||
ahV4yore ue2laePh fu1eThui qui7aePh Fahth1nu ohk9puLo aiBeez0b Neengai5
|
||||
```
|
||||
|
||||
生成安全的随机密码,使用 pwgen 命令的 `-s` 选项。
|
||||
生成安全的随机密码,使用 `pwgen` 命令的 `-s` 选项。
|
||||
|
||||
```
|
||||
$ pwgen -s
|
||||
@ -132,14 +128,14 @@ C6RqDQMy gKt28c9O ZCi0tQKE 0Ekdjh3P ox2vWOMI 14XF4gwc nYA0L6tV rRN3lekn
|
||||
lmwZNjz1 4ovmJAr7 shPl9o5f FFsuNwj0 F2eVkqGi 7gw277RZ nYE7gCLl JDn05S5N
|
||||
```
|
||||
|
||||
假设你想要生成五个14字符长的密码,方法如下。
|
||||
假设你想要生成 5 个 14 字符长的密码,方法如下:
|
||||
|
||||
```
|
||||
$ pwgen -s 14 5
|
||||
7YxUwDyfxGVTYD em2NT6FceXjPfT u8jlrljbrclcTi IruIX3Xu0TFXRr X8M9cB6wKNot1e
|
||||
```
|
||||
|
||||
如果你真的想要生成20个超强随机密码,方法如下。
|
||||
如果你真的想要生成 20 个超强随机密码,方法如下:
|
||||
|
||||
```
|
||||
$ pwgen -cnys 14 20
|
||||
@ -151,16 +147,16 @@ mQ3E=vfGfZ,5[B #zmj{i5|ZS){jg Ht_8i7OqJ%N`~2 443fa5iJ\W-L?] ?Qs$o=vz2vgQBR
|
||||
|
||||
### 如何在 Linux 下使用 openssl 命令生成随机强密码?
|
||||
|
||||
openssl 是一个用来从 shell 中调用 OpenSSL 加密库提供的多种密码学函数的命令行工具。
|
||||
`openssl` 是一个用来从 shell 中调用 OpenSSL 加密库提供的多种密码学函数的命令行工具。
|
||||
|
||||
像下面这样运行 openssl 命令可以生成一个14字符长的随机强密码。
|
||||
像下面这样运行 `openssl` 命令可以生成一个 14 字符长的随机强密码。
|
||||
|
||||
```
|
||||
$ openssl rand -base64 14
|
||||
WjzyDqdkWf3e53tJw/c=
|
||||
```
|
||||
|
||||
如果你想要生成十个14字符长的随机强密码,将 openssl 命令与 for 循环结合起来使用。
|
||||
如果你想要生成 10 个 14 字符长的随机强密码,将 `openssl` 命令与 `for` 循环结合起来使用。
|
||||
|
||||
```
|
||||
$ for pw in {1..10}; do openssl rand -base64 14; done
|
||||
@ -178,9 +174,9 @@ ktpBpCSQFOD+5kIIe7Y=
|
||||
|
||||
### 如何在 Linux 下使用 gpg 命令生成随机强密码?
|
||||
|
||||
gpg 是 Gnu Privacy Guard (GnuPG) 中的 OpenPGP 实现部分。它是一个提供 OpenPGP 标准的数字加密与签名服务的工具。gpg 具有完整的密钥管理功能和其他完整 OpenPGP 实现应该具备的全部功能。
|
||||
`gpg` 是 Gnu Privacy Guard (GnuPG) 中的 OpenPGP 实现部分。它是一个提供 OpenPGP 标准的数字加密与签名服务的工具。`gpg` 具有完整的密钥管理功能和其他完整 OpenPGP 实现应该具备的全部功能。
|
||||
|
||||
下面这样执行 gpg 命令来生成一个14字符长的随机强密码。
|
||||
下面这样执行 `gpg` 命令来生成一个 14 字符长的随机强密码。
|
||||
|
||||
```
|
||||
$ gpg --gen-random --armor 1 14
|
||||
@ -189,7 +185,7 @@ $ gpg2 --gen-random --armor 1 14
|
||||
jq1mtY4gBa6gIuJrggM=
|
||||
```
|
||||
|
||||
如果想要使用 gpg 生成十个14字符长的随机强密码,像下面这样使用 for 循环。
|
||||
如果想要使用 `gpg` 生成 10 个 14 字符长的随机强密码,像下面这样使用 `for` 循环。
|
||||
|
||||
```
|
||||
$ for pw in {1..10}; do gpg --gen-random --armor 1 14; done
|
||||
@ -209,33 +205,33 @@ eJjhtA6oHhBrUpLY4fM=
|
||||
|
||||
### 如何在 Linux 下使用 mkpasswd 命令生成随机强密码?
|
||||
|
||||
mkpasswd 生成密码并可以自动将其应用在用户上。不加任何参数的情况下,mkpasswd 返回一个新的密码。它是 expect 软件包的一部分,所以想要使用 mkpasswd 命令,你需要安装 expect 软件包。
|
||||
`mkpasswd` 生成密码并可以自动将其为用户设置。不加任何参数的情况下,`mkpasswd` 返回一个新的密码。它是 expect 软件包的一部分,所以想要使用 `mkpasswd` 命令,你需要安装 expect 软件包。
|
||||
|
||||
在 **`Fedora`** 系统中,使用 **[DNF 命令][2]** 来安装 mkpasswd。
|
||||
在 Fedora 系统中,使用 [DNF 命令][2] 来安装 `mkpasswd`。
|
||||
|
||||
```
|
||||
$ sudo dnf install expect
|
||||
```
|
||||
|
||||
在 **`Debian/Ubuntu`** 系统中,使用 **[APT-GET 命令][3]** 或 **[APT 命令][4]** 来安装 mkpasswd。
|
||||
在 Debian/Ubuntu 系统中,使用 [APT-GET 命令][3] 或 [APT 命令][4] 来安装 `mkpasswd`。
|
||||
|
||||
```
|
||||
$ sudo apt install expect
|
||||
```
|
||||
|
||||
在 **`Arch Linux`** 系统中,使用 **[Pacman 命令][5]** 来安装 mkpasswd。
|
||||
在 Arch Linux 系统中,使用 [Pacman 命令][5] 来安装 `mkpasswd`。
|
||||
|
||||
```
|
||||
$ sudo pacman -S expect
|
||||
```
|
||||
|
||||
在 **`RHEL/CentOS`** 系统中,使用 **[YUM 命令][6]** 来安装 mkpasswd。
|
||||
在 RHEL/CentOS 系统中,使用 [YUM 命令][6] 来安装 `mkpasswd`。
|
||||
|
||||
```
|
||||
$ sudo yum install expect
|
||||
```
|
||||
|
||||
在 **`openSUSE Leap`** 系统中,使用 **[Zypper 命令][7]** 来安装 mkpasswd。
|
||||
在 openSUSE Leap 系统中,使用 [Zypper 命令][7] 来安装 `mkpasswd`。
|
||||
|
||||
```
|
||||
$ sudo zypper install expect
|
||||
@ -248,21 +244,21 @@ $ mkpasswd
|
||||
37_slQepD
|
||||
```
|
||||
|
||||
像下面这样执行 mkpasswd 命令可以生成一个14字符长的随机强密码。
|
||||
像下面这样执行 `mkpasswd` 命令可以生成一个 14 字符长的随机强密码。
|
||||
|
||||
```
|
||||
$ mkpasswd -l 14
|
||||
W1qP1uv=lhghgh
|
||||
```
|
||||
|
||||
像下面这样执行 mkpasswd 命令 来生成一个14字符长,包含大小写字母、数字和特殊字符的随机强密码。
|
||||
像下面这样执行 `mkpasswd` 命令 来生成一个 14 字符长,包含大小写字母、数字和特殊字符的随机强密码。
|
||||
|
||||
```
|
||||
$ mkpasswd -l 14 -d 3 -C 3 -s 3
|
||||
3aad!bMWG49"t,
|
||||
```
|
||||
|
||||
如果你想要生成十个14字符长的随机强密码(包括大小写字母、数字和特殊字符),使用 for 循环和 mkpasswd 命令。
|
||||
如果你想要生成 10 个 14 字符长的随机强密码(包括大小写字母、数字和特殊字符),使用 `for` 循环和 `mkpasswd` 命令。
|
||||
|
||||
```
|
||||
$ for pw in {1..10}; do mkpasswd -l 14 -d 3 -C 3 -s 3; done
|
||||
@ -278,10 +274,9 @@ $of?Rj9kb2N(1J
|
||||
Tu9m56+Ev_Yso(
|
||||
```
|
||||
|
||||
### How To Generate A Random Strong Password In Linux Using makepasswd Command?
|
||||
### 如何在 Linux 下使用 makepasswd 命令生成随机强密码?
|
||||
|
||||
makepasswd 使用 /dev/urandom 生成真随机密码,跟易于记忆相比它更注重安全性。它也可以加密命令行中给出的明文密码。
|
||||
`makepasswd` 使用 `/dev/urandom` 生成真随机密码,与易于记忆相比它更注重安全性。它也可以加密命令行中给出的明文密码。
|
||||
|
||||
在终端中执行 `makepasswd` 命令来生成一个随机密码。
|
||||
|
||||
@ -290,14 +285,14 @@ $ makepasswd
|
||||
HdCJafVaN
|
||||
```
|
||||
|
||||
在终端中像下面这样执行 makepasswd 命令来生成14字符长的随机强密码。
|
||||
在终端中像下面这样执行 `makepasswd` 命令来生成 14 字符长的随机强密码。
|
||||
|
||||
```
|
||||
$ makepasswd --chars 14
|
||||
HxJDv5quavrqmU
|
||||
```
|
||||
|
||||
像下面这样执行 makepasswd 来生成十个14字符长的随机强密码。
|
||||
像下面这样执行 `makepasswd` 来生成 10 个 14 字符长的随机强密码。
|
||||
|
||||
```
|
||||
$ makepasswd --chars 14 --count 10
|
||||
@ -317,28 +312,28 @@ M2TMCEoahzLNYC
|
||||
|
||||
如果你还在寻找其他的方案,下面的工具也可以用来在 Linux 中生成随机密码。
|
||||
|
||||
**使用 md5sum** md5sum 是一个用来计算及校验 128-bit MD5 哈希的程序。
|
||||
使用 `md5sum`:它是一个用来计算及校验 128 位 MD5 哈希的程序。
|
||||
|
||||
```
|
||||
$ date | md5sum
|
||||
9baf96fb6e8cbd99601d97a5c3acc2c4 -
|
||||
```
|
||||
|
||||
**使用 /dev/urandom:** 两个特殊的字符文件 /dev/random 和 /dev/urandom (自 Linux 1.3.30 起) 提供了内核随机数生成器的接口。/dev/random 的主设备号为1,次设备号为8。/dev/urandom 主设备号为1,次设备号为9。
|
||||
使用 `/dev/urandom`: 两个特殊的字符文件 `/dev/random` 和 `/dev/urandom` (自 Linux 1.3.30 起出现)提供了内核随机数生成器的接口。`/dev/random` 的主设备号为 1,次设备号为 8。`/dev/urandom` 主设备号为 1,次设备号为 9。
|
||||
|
||||
```
|
||||
$ cat /dev/urandom | tr -dc 'a-zA-Z0-9' | head -c 14
|
||||
15LQB9J84Btnzz
|
||||
```
|
||||
|
||||
**使用 sha256sum:** sha256sum 被设计用来使用 SHA-256 算法(SHA-2系列,摘要长度为256位)校验数据完整性。
|
||||
使用 `sha256sum`:它被设计用来使用 SHA-256 算法(SHA-2 系列,摘要长度为 256 位)校验数据完整性。
|
||||
|
||||
```
|
||||
$ date | sha256sum
|
||||
a114ae5c458ae0d366e1b673d558d921bb937e568d9329b525cf32290478826a -
|
||||
```
|
||||
|
||||
**使用 sha1pass:** sha1pass 生成一个 SHA1 密码哈希。在命令缺少盐值的情况下,将会生成一个随机的盐值向量。
|
||||
使用 `sha1pass`:它生成一个 SHA1 密码哈希。在命令缺少盐值的情况下,将会生成一个随机的盐值向量。
|
||||
|
||||
```
|
||||
$ sha1pass
|
||||
@ -351,14 +346,14 @@ via: https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-lin
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[leommx](https://github.com/leommxj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[leommxj](https://github.com/leommxj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/
|
||||
[1]: https://linux.cn/article-10623-1.html
|
||||
[2]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
@ -1,15 +1,17 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10661-1.html)
|
||||
[#]: subject: (3 popular programming languages you can learn with Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/programming-languages-raspberry-pi)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
可以使用树莓派学习的 3 种流行编程语言
|
||||
树莓派使用入门:可以使用树莓派学习的 3 种流行编程语言
|
||||
======
|
||||
通过树莓派学习编程,让你在就业市场上更值钱。
|
||||
|
||||
> 通过树莓派学习编程,让你在就业市场上更值钱。
|
||||
|
||||

|
||||
|
||||
在本系列的上一篇文章中,我分享了 [教孩子们使用树莓派编程][1] 的一些方式。理论上,这些资源并不局限于只适用于孩子们,成人也是可以使用的。但是学习就业市场上急需的编程语言,可以让你得到更好的机会。
|
||||
@ -24,7 +26,7 @@
|
||||
|
||||
### Java
|
||||
|
||||
虽然 [Java][6] 已经不像以前那样引人注目了,但它仍然在世界各地的大学和企业中占据着重要的地位。因此,即便是一些人对我建议新手学习 Java 持反对意见,但我仍然强烈推荐大家去学习 Java;之所以这么做,原因之一是,它仍然很流行,原因之二是,它有大量的便于你学习的图书、课程、和其它的可用信息。在树莓派上学习它,你可以从使用 Java 集成开发环境 [BlueJ][7] 开始。
|
||||
虽然 [Java][6] 已经不像以前那样引人注目了,但它仍然在世界各地的大学和企业中占据着重要的地位。因此,即便是一些人对我建议新手学习 Java 持反对意见,但我仍然强烈推荐大家去学习 Java;之所以这么做,原因之一是,它仍然很流行,原因之二是,它有大量的便于你学习的图书、课程和其它的可用信息。在树莓派上学习它,你可以从使用 Java 集成开发环境 [BlueJ][7] 开始。
|
||||
|
||||
|
||||
|
||||
@ -34,7 +36,7 @@
|
||||
|
||||
### 其它编程语言
|
||||
|
||||
如果这里没有列出你想学习的编程语言,别失望。你可以使用你的树莓派去编译或解释任何你选择的语言,包括 C、C++、PHP、和 Ruby,这种可能性还是很大的。
|
||||
如果这里没有列出你想学习的编程语言,别失望。你可以使用你的树莓派去编译或解释任何你选择的语言,包括 C、C++、PHP 和 Ruby,这种可能性还是很大的。
|
||||
|
||||
微软的 [Visual Studio Code][11] 也可以运行在 [树莓派][12] 上。它是来自微软的开源代码编辑器,它支持多种标记和编程语言。
|
||||
|
||||
@ -45,13 +47,13 @@ via: https://opensource.com/article/19/3/programming-languages-raspberry-pi
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/19/2/teach-kids-program-raspberry-pi
|
||||
[1]: https://linux.cn/article-10653-1.html
|
||||
[2]: https://opensource.com/resources/python
|
||||
[3]: https://www.economist.com/graphic-detail/2018/07/26/python-is-becoming-the-worlds-most-popular-coding-language
|
||||
[4]: https://thonny.org/
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (sanfusu)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10668-1.html)
|
||||
[#]: subject: (Blockchain 2.0: Revolutionizing The Financial System [Part 2])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/)
|
||||
[#]: author: (Ostechnix https://www.ostechnix.com/author/editor/)
|
||||
|
||||
区块链 2.0:金融体系改革(二)
|
||||
======
|
||||
|
||||

|
||||
|
||||
这是我们区块链 2.0 系列的第二部分。区块链可以改变个人和机构处理他们财务状况的方式。本文着眼于现有货币体系如何演变,以及新的区块链系统如何为货币演变的下一个关键步骤带来改变。
|
||||
|
||||
两个关键思想将为本文奠定基础。**PayPal** 在推出之时,其运营操作上具有革命性。该公司收集、处理和确认大量的消费者数据,以促进各种在线交易,从而切实允许 eBay 等平台成长为可信赖的商业来源,并为全球数字支付系统奠定基准。其二,虽然要强调的是更为重要的关键思想,但却是一个存在性问题。我们都使用金钱或货币来满足我们的日常需求。一张 10 美元的账单可以让你从最喜欢的咖啡店买到一两杯咖啡,从而开始美好的一天。事实上,我们各方面都依赖于各自的国家货币。
|
||||
|
||||
当然,自从**易货系统**开始决定你的早餐是什么起,人类已经度过了漫长的时间。但是,货币到底是什么?谁或什么赋予它的价值?正如流行的谣言所说,去银行并给他们一美元钞票就可以获得货币“符号”所代表的真正价值吗?
|
||||
|
||||
大多数问题的答案都不存在。即便是给出了答案,最多也是不可思议的模糊和主观。早在文明开始建立小城镇的那一天,被统治者认为是合法的本地货币,几乎总是由那个社会中宝贵的东西组成。人们认为印第安人使用干胡椒进行交易,而古希腊人和罗马人则使用[盐][1]交易。渐渐地,这些史前启蒙文明中的大部分都采用贵重金属和石头作为代币进行交易。金币、银饰和红宝石开始与“价值”同名。随着工业革命,人们开始印刷这些交易凭证,我们终于似乎看到了对纸币需求的呼吁。纸币可靠且廉价,只要国家为其用户所持纸币提供担保,纸币所代表的“价值”可以在需要时,由同等价值的黄金或硬通货作支撑,人们便乐于使用它们。但是,如果你仍然认为你现在持有的纸币具有相同的保证,那么你就错了。我们目前生活在一个几乎所有主要货币都在全球流通的时代,经济学家称之为[法定货币][2]。缺少价值的纸片只能得到你所居住的国家的保证支持。法定货币的确切性质以及为什么它们可能是一个有缺陷的系统属于经济领域,我们目前不会涉及。
|
||||
|
||||
事实上,所有这一历史中与本篇文章相关的唯一的一点是,文明开始使用暗示或代表商品和服务的贸易价值的代币,而不是非实际的易货系统。代币,当然,这也是加密货币背后的关键概念。它们没有任何固有的价值。它们的价值取决于采用该特定平台的人数、采用者对系统的信任,当然还有监管实体本身的背景(如果有监管实体的话)。**比特币(BTC)**的高价格和市值并非巧合,它们是业内第一个加密货币并且有很多早期采用者。加密货币背后的最终真理使其如此重要而又具有如此难以理解的复杂性。这是“金钱”自然演变的下一步。有些人理解这一点,有些人仍然认为坚实的货币概念中“真正的”货币总是由某种[内在价值支持][3]。虽然已经有无数关于这种困境的辩论和研究,但仍没有着眼于区块链的未来。
|
||||
|
||||
例如,**厄瓜多尔**在 2015 年成为头条新闻,因为它声称计划开发和发布[自己的国家加密货币][4]。虽然官方尝试是为了援助和支持他们现有的货币体系。从那时起,其他国家及其监管机构已经或正在起草文件来控制加密货币的“流行病”,其中一些已经发布了框架,以创建区块链和加密货币开发的路线图。[德国][5]被认为正在长期投资区块链项目,以简化其税收和金融系统。发展中国家的银行正在加入一个名为银行链的体系中,用以合作创建**私有区块链**以提高他们的效率并优化其运营。
|
||||
|
||||
现在,当我们将故事的两端结合在一起时,还记得在休闲历史课之前首次提到 PayPal 吗?专家们将比特币(BTC)的采用率与 PayPal 的采用率进行了比较。消费者最初有所犹豫,只有少数早期采用者准备好使用上述产品,但随后更广泛的采用逐渐成为类似平台的标杆态势。比特币(BTC)已经成为类似加密货币平台的基准,而主要硬币包括[以太坊(ETH)和瑞波(XRP)][6]。采用正在稳步增加,法律和监管框架也正在制定以支持它,积极的研究和开发也在进行中。与 PayPal 不同,专家认为,利用区块链技术为其数字基础设施提供加密货币和平台将很快成为标准规范而非个例。
|
||||
|
||||
尽管 2018 年加密货币价格的上涨可以被称为经济泡沫,但公司和政府仍在继续投资开发自己的区块链平台和金融代币。为了抵制和预防未来发生这样的事件,并同时同时继续在该领域投资,替代传统加密货币的**稳定币**已经开发成功。
|
||||
|
||||
金融巨头**摩根大通**推出了他们自己的用于企业的区块链解决方案,名为**Quorum**,用来处理被称为 [JPM 硬币][7]的稳定币。每个这样的 JPM 硬币都与 1 美元挂钩,其价值由母公司在支持法律框架下保证。像这样的平台使大型金融交易更容易通过互联网瞬间传输数百万或数十亿美元,而不必依赖 SWIFT 这样的传统银行系统,这些系统有着冗长的过程,而且本身已有数十年历史。
|
||||
|
||||
为了让区块链的精微之处可供所有人使用,以太坊平台允许第三方利用他们的区块链,或从中派生代币以创建和管理他们自己对**区块链-协议-令牌**三元组的主张,从而推动更广泛的标准采纳,并付出更少的基础工作量。
|
||||
|
||||
区块链允许通过网络快速创建、记录和交易现有金融工具的数字版本,而无需第三方监控。该系统固有的安全性和安保特性使整个过程完全安全,并且不受欺诈和篡改的影响,这基本上是现有金融工具需要第三方监控的唯一原因。政府和监管机构在金融服务和工具方面涉及的另一个领域是透明度和审计。通过区块链,银行和其他金融机构将能够维护完全透明、分层,几乎永久保存和防篡改的所有交易记录,使审计任务几乎无用。通过利用区块链,可以使当前金融系统和服务行业急需的发展和变化成为可能。分布式、防篡改、接近永久性存储和快速执行的平台对于银行家和政府监管机构来说都是非常有价值的,他们在这方面的投资似乎[很有用][8]。
|
||||
|
||||
在本系列的下一篇文章中,我们将了解公司如何使用区块链来提供下一代金融服务。纵观在行业中创造涟漪的个别公司后,我们将探讨区块链下的经济未来会如何发展。
|
||||
|
||||
----------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/
|
||||
|
||||
作者: [Ostechnix][a]
|
||||
选题: [lujun9972][b]
|
||||
译者: [sanfusu](https://github.com/sanfusu)
|
||||
校对: [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/)荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.seasalt.com/history-of-salt
|
||||
[2]: https://www.investopedia.com/terms/f/fiatmoney.asp
|
||||
[3]: https://bitcoin.org/en/faq#who-created-bitcoin
|
||||
[4]: https://99bitcoins.com/official-ecuador-cryptocurrency/
|
||||
[5]: https://cointelegraph.com/news/german-government-to-introduce-blockchain-strategy-in-mid-2019
|
||||
[6]: https://coinmarketcap.com/currencies/bitcoin/
|
||||
[7]: https://www.jpmorgan.com/global/news/digital-coin-payments
|
||||
[8]: https://www.pwc.com/jg/en/media-release/global-fintech-survey-2017.html
|
||||
@ -0,0 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10663-1.html)
|
||||
[#]: subject: (Get cooking with GNOME Recipes on Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/get-cooking-with-gnome-recipes-on-fedora/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
|
||||
|
||||
在 Fedora 上使用 GNOME Recipes 烹饪
|
||||
======
|
||||
|
||||

|
||||
|
||||
你喜欢烹饪吗?在 Fedora 中寻找管理食谱的更好方法么? GNOME Recipes 是一个非常棒的应用,可以在 Fedora 中安装,用于保存和组织你的食谱。
|
||||
|
||||
![][1]
|
||||
|
||||
GNOME Recipes 是 GNOME 项目中的食谱管理工具。它有现代 GNOME 应用的视觉风格,类似于 GNOME “软件”,但它是针对食物的。
|
||||
|
||||
### 安装 GNOME Recipes
|
||||
|
||||
Recipes 可从第三方 Flathub 仓库安装。如果你之前从未安装过 Flathub 的应用,请使用以下指南进行设置:
|
||||
|
||||
- [在 Fedora 上安装 Flathub 应用](https://fedoramagazine.org/install-flathub-apps-fedora/)
|
||||
|
||||
正确设置 Flathub 作为软件源后,你将能够通过 GNOME “软件”搜索和安装 Recipes。
|
||||
|
||||
### 食谱管理
|
||||
|
||||
Recipes 能让你手动添加自己的食谱集合,包括照片、配料、说明,以及更多的元数据,如准备时间、烹饪风格和辛辣程度。
|
||||
|
||||
![][2]
|
||||
|
||||
当输入新的食谱时,GNOME Recipes 可为该食谱选择一系列不同的测量单位,如温度等,让你可以轻松地切换单位。
|
||||
|
||||
### 社区食谱
|
||||
|
||||
除了手动输入你喜欢的菜肴供你自己使用外,它还能让你查找、使用和贡献食谱给社区。此外,你可以标记你的喜爱的食谱,并通过大量的食谱元数据搜索菜谱。
|
||||
|
||||
![][3]
|
||||
|
||||
### 分步指导
|
||||
|
||||
GNOME Recipes 中一个非常棒的小功能是分步全屏模式。当你准备做饭时,只需激活此模式,将笔记本电脑拿到厨房,你就可以全屏显示烹饪方法中的当前步骤。此外,当食物在烤箱中时,你可以在这个模式下设置定时器。
|
||||
|
||||
![][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/get-cooking-with-gnome-recipes-on-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-06-19-45-06-1024x727.png
|
||||
[2]: https://fedoramagazine.org/wp-content/uploads/2019/03/gnome-recipes1-1024x727.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-06-20-08-45-1024x725.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-06-20-39-44-1024x640.png
|
||||
@ -1,15 +1,16 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10665-1.html)
|
||||
[#]: subject: (How to keep your Raspberry Pi updated)
|
||||
[#]: via: (https://opensource.com/article/19/3/how-raspberry-pi-update)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
如何更新树莓派
|
||||
树莓派使用入门:如何更新树莓派
|
||||
======
|
||||
在我们的树莓派入门指南的第七篇学习如何给树莓派打补丁。
|
||||
> 在我们的树莓派入门指南的第七篇学习如何给树莓派打补丁。
|
||||
|
||||

|
||||
|
||||
像平板电脑、手机和笔记本电脑一样,你需要更新树莓派。最新的增强功能不仅可以使你的派运行顺畅,还可以让它更安全,特别是在如果你连接到网络的情况下。我们的树莓派入门指南中的第七篇会分享两条关于让派良好运行的建议。
|
||||
@ -18,26 +19,31 @@
|
||||
|
||||
更新 Raspbian 有[两步][1]:
|
||||
|
||||
1. 在终端中输入:**sudo apt-get update**。
|
||||
该命令的 **sudo** 让你以 admin(也就是 root)运行 **apt-get update**。请注意,**apt-get update** 不会在系统上安装任何新东西,而是将更新需要更新的包和依赖项列表。
|
||||
1. 在终端中输入:`sudo apt-get update`。
|
||||
|
||||
该命令的 `sudo` 让你以管理员(也就是 root)运行 `apt-get update`。请注意,`apt-get update` 不会在系统上安装任何新东西,而是将更新需要更新的包和依赖项列表。
|
||||
2. 接着输入:`sudo apt-get dist-upgrade`。
|
||||
|
||||
摘自文档:“一般来说,定期执行此操作将使你的安装保持最新,因为它将等同于 [raspberrypi.org/downloads][2] 中发布的最新镜像。”
|
||||
|
||||
2. 接着输入:**sudo apt-get dist-upgrade**。
|
||||
摘自文档:”一般来说,定期执行此操作将使你的安装保持最新,因为它将等同于 [raspberrypi.org/downloads][2] 中发布的最新镜像。“
|
||||
|
||||
|
||||
### 小心 rpi-update
|
||||
|
||||
Raspbian 带有另一个名为 [rpi-update][3] 的更新工具。此程序可用于将派升级到最新固件,该固件可能会或者不会有损坏/问题。你可能会发现如何使用的信息,但是建议你永远不要使用这个程序,除非你有充分的理由这样做。
|
||||
Raspbian 带有另一个名为 [rpi-update][3] 的更新工具。此程序可用于将派升级到最新固件,不管该固件是不是有损坏或问题。你可能会发现一些如何使用它的信息,但是建议你永远不要使用这个程序,除非你有充分的理由这样做。
|
||||
|
||||
一句话:保持系统更新!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://opensource.com/article/19/3/how-raspberry-pi-update
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/documentation/raspbian/updating.md
|
||||
@ -1,22 +1,24 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10669-1.html)
|
||||
[#]: subject: (How to use your Raspberry Pi for entertainment)
|
||||
[#]: via: (https://opensource.com/article/19/3/raspberry-pi-entertainment)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
如何用树莓派来娱乐
|
||||
树莓派使用入门:如何用树莓派来娱乐
|
||||
======
|
||||
在我们的树莓派使用入门的第八篇文章中,我们将学习如何使用树莓派观看 Netflix 上的影片和用它来听音乐。
|
||||
|
||||
> 在我们的树莓派使用入门的第八篇文章中,我们将学习如何使用树莓派观看 Netflix 上的影片和用它来听音乐。
|
||||
|
||||

|
||||
|
||||
到目前为止,本系列文章已经学习了很多话题 — 如何 [挑选][1]、[购买][2]、[设置][3]、和 [更新][4] 你的树莓派,以及 [儿童][5] 和 [成人][6] 如何使用它来做的不同的事情(包括学习 [Linux][7])。今天我们换一个话题,将学习一些娱乐方面的内容!我们将学习如何使用树莓派来做一些娱乐方面的事情,明天我们继续这个话题,将用它来玩游戏。
|
||||
|
||||
### 观看电视和电影
|
||||
|
||||
你可以使用你的树莓派和 [开源媒体中心][8] (OSMC) 去 [观看 Netflix][9]!OSMC 是一个基于 [Kodi][10] 项目的系统,你可以使用它来播放来自本地网络、附加存储、以及互联网上的多媒体。它因为良好的功能特性而在媒体播放应用界中拥有非常好的口碑。
|
||||
你可以使用你的树莓派和 [开源媒体中心][8] (OSMC) 去 [观看 Netflix][9]!OSMC 是一个基于 [Kodi][10] 项目的系统,你可以使用它来播放来自本地网络、附加存储以及互联网上的多媒体。它因为良好的功能特性而在媒体播放应用界中拥有非常好的口碑。
|
||||
|
||||
NOOBS(我们在本系列的 [第三篇文章][11] 中介绍过它)可以让你在你的树莓派中很容易地 [安装 OSMC][12]。在 NOOBS 中也提供了另外一个基于 Kodi 项目的媒体播放系统,它的名字叫 [LibreELEC][13]。
|
||||
|
||||
@ -33,23 +35,23 @@ via: https://opensource.com/article/19/3/raspberry-pi-entertainment
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/19/3/which-raspberry-pi-choose
|
||||
[2]: https://opensource.com/article/19/2/how-buy-raspberry-pi
|
||||
[3]: https://opensource.com/article/19/2/how-boot-new-raspberry-pi
|
||||
[4]: https://opensource.com/article/19/2/how-keep-your-raspberry-pi-updated-and-patched
|
||||
[5]: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
|
||||
[6]: https://opensource.com/article/19/2/3-popular-programming-languages-you-can-learn-raspberry-pi
|
||||
[7]: https://opensource.com/article/19/2/learn-linux-raspberry-pi
|
||||
[1]: https://linux.cn/article-10611-1.html
|
||||
[2]: https://linux.cn/article-10615-1.html
|
||||
[3]: https://linux.cn/article-10644-1.html
|
||||
[4]: https://linux.cn/article-10665-1.html
|
||||
[5]: https://linux.cn/article-10653-1.html
|
||||
[6]: https://linux.cn/article-10661-1.html
|
||||
[7]: https://linux.cn/article-10645-1.html
|
||||
[8]: https://osmc.tv/
|
||||
[9]: https://www.dailydot.com/upstream/netflix-raspberry-pi/
|
||||
[10]: http://kodi.tv/
|
||||
[11]: https://opensource.com/article/19/3/how-boot-new-raspberry-pi
|
||||
[11]: https://linux.cn/article-10644-1.html
|
||||
[12]: https://www.raspberrypi.org/documentation/usage/kodi/
|
||||
[13]: https://libreelec.tv/
|
||||
[14]: https://github.com/pimusicbox/pimusicbox/tree/master
|
||||
@ -1,57 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10673-1.html)
|
||||
[#]: subject: (How To Navigate Inside A Directory/Folder In Linux Without CD Command?)
|
||||
[#]: via: (https://www.2daygeek.com/navigate-switch-directory-without-using-cd-command-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Navigate Inside A Directory/Folder In Linux Without CD Command?
|
||||
如何在 Linux 中不使用 CD 命令进入目录/文件夹?
|
||||
======
|
||||
|
||||
As everybody know that we can’t navigate inside a directory in Linux without CD command.
|
||||
众所周知,如果没有 `cd` 命令,我们无法 Linux 中切换目录。这个没错,但我们有一个名为 `shopt` 的 Linux 内置命令能帮助我们解决这个问题。
|
||||
|
||||
Yes that’s true but we have the Linux built-in command called `shopt` that help us to solve this issue.
|
||||
[shopt][1] 是一个 shell 内置命令,用于设置和取消设置各种 bash shell 选项,由于它已安装,因此我们不需要再次安装它。
|
||||
|
||||
[shopt][1] is a shell builtin command to set and unset various bash shell options, which is installed so, we no need to install it again.
|
||||
是的,我们可以在启用此选项后,可以不使用 `cd` 命令切换目录。
|
||||
|
||||
Yes we can navigate inside a directory without CD command after enabling this option.
|
||||
我们将在本文中向你展示如何操作。这是一个小的调整,但对于那些从 Windows 迁移到 Linux 的新手来说非常有用。
|
||||
|
||||
We will show you, how to do this in this article. This is a small tweak but it’s very useful for newbies who all are moving from Windows to Linux.
|
||||
这对 Linux 管理员没用,因为我们不会在没有 `cd` 命令的情况下切换到该目录,因为我们对此有经验。
|
||||
|
||||
This is not useful for Linux administrator because we won’t navigate to the directory without CD command, as we had a good practices on this.
|
||||
|
||||
If you are trying to navigate a directory/folder in Linux without cd command, you will be getting the following error message. This is common in Linux.
|
||||
如果你尝试在没有 `cd` 命令的情况下切换 Linux 的目录/文件夹,你将看到以下错误消息。这在 Linux 中很常见。
|
||||
|
||||
```
|
||||
$ Documents/
|
||||
bash: Documents/: Is a directory
|
||||
```
|
||||
|
||||
To achieve this, we need to append the following values in a user `.bashrc` file.
|
||||
为此,我们需要在用户 `.bashrc` 中追加以下值。
|
||||
|
||||
### What Is the .bashrc File?
|
||||
### 什么是 .bashrc ?
|
||||
|
||||
The “.bashrc” file is a shell script which is run every time a user opens a new shell in interactive mode.
|
||||
`.bashrc` 是一个 shell 脚本,每次用户以交互模式打开新 shell 时都会运行该脚本。
|
||||
|
||||
You can add any command in that file that you want to type at the command prompt.
|
||||
你可以在该文件中添加要在命令提示符下输入的任何命令。
|
||||
|
||||
The .bashrc file itself contains a series of configurations for the terminal session. This includes setting up or enabling: colouring, completion, the shell history, command aliases and more.
|
||||
`.bashrc` 文件本身包含终端会话的一系列配置。包括设置和启用:着色、补全,shell 历史,命令别名等。
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
加入这一行:
|
||||
|
||||
```
|
||||
shopt -s autocd
|
||||
```
|
||||
|
||||
Run the following command to make the changes to take effect.
|
||||
运行以下命令使更改生效。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
We have done all the configuration. Simple do the testing on this to confirm whether this working or not.
|
||||
我们已完成所有配置。简单地对此进行测试以确认这是否有效。
|
||||
|
||||
```
|
||||
$ Documents/
|
||||
@ -68,12 +70,14 @@ $ pwd
|
||||
```
|
||||
|
||||
![][3]
|
||||
Yes, it’s working fine as expected.
|
||||
|
||||
However, it’s working fine in `fish shell` without making any changes in the `.bashrc` file.
|
||||
是的,它正如预期的那样正常工作。
|
||||
|
||||
而且,它在 fish shell 中工作正常,而无需对 `.bashrc` 进行任何更改。
|
||||
|
||||
![][4]
|
||||
|
||||
If you would like to perform this action for temporarily then use the following commands (set/unset). This will go away when you reboot the system.
|
||||
如果要暂时执行此操作,请使用以下命令(`set`/`unset`)。重启系统时,它将消失。
|
||||
|
||||
```
|
||||
# shopt -s autocd
|
||||
@ -87,7 +91,7 @@ autocd on
|
||||
autocd off
|
||||
```
|
||||
|
||||
shopt command is offering so many other options and if you want to verify those, run the following command.
|
||||
`shopt` 命令提供了许多其他选项,如果要验证这些选项,请运行以下命令。
|
||||
|
||||
```
|
||||
$ shopt
|
||||
@ -146,9 +150,9 @@ sourcepath on
|
||||
xpg_echo off
|
||||
```
|
||||
|
||||
I had found few other utilities, that are help us to navigate a directory faster in Linux compared with cd command.
|
||||
此外,我找到了一些其他程序,它们可以帮助我们在 Linux 中比 `cd` 命令更快地切换目录。
|
||||
|
||||
Those are pushd, popd, up shell script and bd utility. We will cover these topics in the upcoming articles.
|
||||
它们是 `pushd`、`popd`、`up` shell 脚本和 `bd` 工具。我们将在接下来的文章中介绍这些主题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -156,8 +160,8 @@ via: https://www.2daygeek.com/navigate-switch-directory-without-using-cd-command
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhs852)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10656-1.html)
|
||||
[#]: subject: (How to host your own webfonts)
|
||||
[#]: via: (https://opensource.com/article/19/3/webfonts)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
@ -14,7 +14,7 @@
|
||||
|
||||
![开源字体][1]
|
||||
|
||||
字体对许多计算机用户来说可能都是很神秘的东西。举个例子,你在制作好一张很酷的传单之后,你需要将它送到某个地方去打印,结果发现,你设计的所有字体都变成了 Arial,这多半是因为打印店没用安装你设计用到的那些字体。不过,我们仍有很多方法来避免这种情况:你可以将它封装为 PDF,或是列出所需字体。不过,我们总会忘记一些事情,所以这仍是一个问题。
|
||||
字体对许多计算机用户来说可能都是很神秘的东西。举个例子,你在制作好一张很酷的传单之后,你需要将它送到某个地方去打印,结果发现,你设计的所有字体都变成了 Arial,这多半是因为打印店没用安装你设计用到的那些字体。不过,我们仍有很多方法来避免这种情况:你可以将这些使用特定字体的单词转换为路径,你也可以将它封装为 PDF,或是把开源字体封装到你的设计文件中,或者至少列出所需字体。不过,我们总会忘记一些事情,所以这仍是一个问题。
|
||||
|
||||
Web 上也有类似的问题。如果你对 CSS 有所了解,你可能会见过这种声明:
|
||||
|
||||
@ -22,25 +22,25 @@ Web 上也有类似的问题。如果你对 CSS 有所了解,你可能会见
|
||||
h1 { font-family: "Times New Roman", Times, serif; }
|
||||
```
|
||||
|
||||
这是设计师正在尝试定义网站使用要用到的特定字体,如果用户没有安装 Times New Roman 这个字体,便会回落到另一个字体;如果用户也没有安装 Times 这个字体,便再次回落。这种方法比使用图片更好,但是在没有字体托管的情况下,这仍是一种棘手且不雅观的方法。不过,在早期的互联网时代,我们不得不这样做。
|
||||
这是设计师正在尝试定义网站使用要用到的特定字体,如果用户没有安装 Times New Roman 这个字体,便会回落到另一个字体;如果用户也没有安装 Times 这个字体,便再次回落。它比使用图片而不是文本更好一些,但是在没有字体托管的情况下,这仍是一种棘手且不雅观的方法。不过,在早期的互联网时代,我们不得不这样做。
|
||||
|
||||
### 在线字体
|
||||
|
||||
在线字体的登场,把字体管理从客户端搬上了服务端。如今网页上的字体通常由服务器为客户端渲染,而不是请求浏览器从用户的系统中查找字体。谷歌和其它供应商托管了许多开源字体,网站设计师们可以很轻松的用 CSS 来引用它们。
|
||||
在线字体的登场,把字体管理从客户端搬上了服务端。如今网页上的字体通常由服务器为客户端渲染,而不是要求浏览器从用户的系统中查找字体。谷歌和其它供应商托管了许多开源字体,网站设计师们可以很轻松的用 CSS 来引用它们。
|
||||
|
||||
不过,问题是,引用这些字体并不是不花费任何代价的。虽然引用它们免费,但是像谷歌这样的大头喜欢跟踪那些引用它们资源的网站,其中就包括了字体资源。如果你不想你的网站帮谷歌记录每个人的活动,你可以自己托管在线字体。别觉得这很难,它其实是很简单的,大概流程就是上传字体到你的主机,再使用一个简单的 CSS 便可完成。这样做还有个好处,你的网站能更快地加载,因为它会在加载每个页面的时候进行更少的外部调用。
|
||||
不过,问题是,引用这些字体并不是不花费任何代价的。虽然引用它们免费,但是像谷歌这样的巨头喜欢跟踪那些引用它们资源的网站,其中就包括了字体资源。如果你不想你的网站帮谷歌记录每个人的活动,你可以自己托管在线字体。别觉得这很难,它其实是很简单的,大概流程就是上传字体到你的主机,再使用一个简单的 CSS 便可完成。这样做还有个好处,你的网站能更快地加载,因为它会在加载每个页面的时候进行更少的外部调用。
|
||||
|
||||
### 自托管在线字体
|
||||
|
||||
首先,你需要一个开源字体。如果你没有了解过那些令人费解的软件协议,你可能会感到很疑惑,特别是很多字体看起来都是免费的。我们中应该很少有人有字体付费意识,但是他们却在电脑上安装了一些高价的字体。不过,多亏了授权协议,它使得你的电脑可以和 [复制和再分发行为未经过法律允许][2] 一起运送往任何地方。像 Arial、Verdana、Calibri、Georgia、Impact、Lucida 和 Lucida Grande、Times 和 Times New Roman、Trebuchet、Geneva 以及其它的很多字体都是被微软、苹果和 Adobe 这种大公司所拥有的。如果你购买了一台预装了 Windows 或 macOS 的电脑,你就获得了使用这些字体的权利,但是你并没有获得那些禁止上传至服务器字体的所有权(除非额外说明)。
|
||||
首先,你需要一个开源字体。如果你没有了解过那些令人费解的软件协议,你可能会感到很疑惑,特别是很多字体看起来都是免费的。我们中应该很少有人有字体付费意识,但是他们却在电脑上安装了一些高价的字体。不过,由于授权协议,它使得你的电脑也许带着一些 [法律上不允许复制和再分发][2] 的字体。像 Arial、Verdana、Calibri、Georgia、Impact、Lucida 和 Lucida Grande、Times 和 Times New Roman、Trebuchet、Geneva 以及其它的很多字体都是被微软、苹果和 Adobe 这种大公司所拥有的。如果你购买了一台预装了 Windows 或 macOS 的电脑,你就获得了使用这些字体的权利,但是你并没有拥有那些字体,也没有被许可上传它们至服务器(除非额外说明)。
|
||||
|
||||
幸运的事,开源热潮在很久以前席卷了字体界。然后就有了许多优秀的开源字体合集,比如 [The League of Moveable Type][3]、[Font Library][4] 以及 [Omnibus Type][5],甚至还有一些来自 [Google][6] 和 [Adobe][7] 的字体。
|
||||
幸运的事,开源热潮在很久以前就席卷了字体界。然后就有了许多优秀的开源字体的合集和项目,比如 [The League of Moveable Type][3]、[Font Library][4] 以及 [Omnibus Type][5],甚至还有一些来自 [Google][6] 和 [Adobe][7] 的字体。
|
||||
|
||||
常见的字体格式有 TTF、OTF、WOFF、EOT 等。因为 Sorts Mill Goudy 发行过 <ruby>WOFF<rt>Web Open Font Format</rt></ruby>(互联网开放字体格式,Mozilla 参与了部分开发)版本,所以下文中我会用它来做例子。当然,其它字体的方法也是一样的。
|
||||
|
||||
假设你想在你的网站上使用 [Sorts Mill Goudy][8] 这个字体:
|
||||
|
||||
1. 将字体文件 **GoudyStM-webfont.woff** 上传至你的服务器:
|
||||
1、将字体文件 `GoudyStM-webfont.woff` 上传至你的服务器:
|
||||
|
||||
```
|
||||
scp GoudyStM-webfont.woff seth@example.com:~/www/fonts/
|
||||
@ -48,7 +48,7 @@ scp GoudyStM-webfont.woff seth@example.com:~/www/fonts/
|
||||
|
||||
你的主机可能带有像 cPanel 这样的图形化工具,通过它们上传也是一样的。
|
||||
|
||||
2. 在你网站的 CSS 文件中,添加 **@font-face** 语句,添加后应该和这个差不多:
|
||||
2、在你网站的 CSS 文件中,添加 `@font-face` 语句,添加后应该和这个差不多:
|
||||
|
||||
```
|
||||
@font-face {
|
||||
@ -57,11 +57,11 @@ scp GoudyStM-webfont.woff seth@example.com:~/www/fonts/
|
||||
}
|
||||
```
|
||||
|
||||
**font-family** 的值是你来决定的。这是一个易于理解的名字,它决定了要使用的字体。我在这里使用“titlefont”作为例子,因为我希望它被用来显示标题字体。你也可以使用“officialfont”和“myfont”这样的名字。
|
||||
`font-family` 的值是你来决定的。这是一个易于理解的名字,它用于放在使用字体名的地方。我在这里使用 “titlefont” 作为例子,是因为我希望它被用来显示标题字体。你也可以使用 “officialfont” 和 “myfont” 这样的名字。
|
||||
|
||||
**src** 值是你字体文件的路径。这是你服务器上字体的路径。在这里,我用 **fonts** 目录来作为示例,它和 **css** 在一个文件夹里。你服务器的文件结构可能和我的不一样,所以你需要调整一下这个路径。记住一点,一个点意味着*工作目录*,两个点则代表*父目录*。
|
||||
`src` 值是你字体文件的路径。这是你服务器上字体的路径。在这里,我用 `fonts` 目录来作为示例,它和 `css` 在一个文件夹里。你服务器的文件结构可能和我的不一样,所以你需要调整一下这个路径。记住一点,一个点意味着*工作目录*,两个点则代表*父目录*。
|
||||
|
||||
3. 现在,你已经定义了字体的名字和目录,你可以用指定的 CSS 类或 ID 来调用它了。举个例子,如果你希望以 Sorts Mill Goudy 字体来渲染 **<h1>**,只需要在 CSS 规则中加入你自己的字体名称:
|
||||
3、现在,你已经定义了字体的名字和目录,你可以在任何指定的 CSS 类或 ID 来调用它了。举个例子,如果你希望以 Sorts Mill Goudy 字体来渲染 `<h1>`,只需要在 CSS 规则中加入你自己的字体名称:
|
||||
|
||||
```
|
||||
h1 { font-family: "titlefont", serif; }
|
||||
@ -69,7 +69,6 @@ h1 { font-family: "titlefont", serif; }
|
||||
|
||||
现在,你已经成功地托管并使用你自己的字体了。
|
||||
|
||||
|
||||
![在线字体的实际效果][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -79,7 +78,7 @@ via: https://opensource.com/article/19/3/webfonts
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zhs852](https://github.com/zhs852)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
136
published/201903/20190321 How to add new disk in Linux.md
Normal file
136
published/201903/20190321 How to add new disk in Linux.md
Normal file
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (luckyele)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10658-1.html)
|
||||
[#]: subject: (How to add new disk in Linux)
|
||||
[#]: via: (https://kerneltalks.com/hardware-config/how-to-add-new-disk-in-linux/)
|
||||
[#]: author: (kerneltalks https://kerneltalks.com)
|
||||
|
||||
如何在 Linux 中添加新磁盘
|
||||
======
|
||||
|
||||
> 在 Linux 机器中添加磁盘的逐步过程。
|
||||
|
||||
![New disk addition in Linux][1]
|
||||
|
||||
本文将向你介绍在 Linux 机器中添加新磁盘的步骤。将原始磁盘添加到 Linux 机器可能非常依赖于你所拥有的服务器类型,但是一旦将磁盘提供给机器,将其添加到挂载点的过程几乎相同。
|
||||
|
||||
**目标**:向服务器添加新的 10GB 磁盘,并使用 lvm 和新创建的卷组创建 5GB 装载点。
|
||||
|
||||
### 向 Linux 机器添加原始磁盘
|
||||
|
||||
如果你使用的是 AWS EC2 Linux 服务器,可以 [按照以下步骤][2] 添加原始磁盘。如果使用的是 VMware Linux VM,那么需要按照不同的步骤来添加磁盘。如果你正在运行物理机架设备/刀片服务器,那么添加磁盘将是一项物理任务。
|
||||
|
||||
一旦磁盘物理/虚拟地连接到 Linux 机器上,它将被内核识别,就可以开始了。
|
||||
|
||||
### 识别 Linux 最新添加的磁盘
|
||||
|
||||
原始磁盘连接后,需要让内核去 [扫描新磁盘][3]。在新版中,它主要是由内核自动完成。
|
||||
|
||||
第一件事是在内核中识别新添加的磁盘及其名称。实现这一点的方法有很多,以下作少量列举:
|
||||
|
||||
* 可以在添加/扫描磁盘前后观察 `lsblk` 输出,以获取新的磁盘名。
|
||||
* 检查 `/dev` 文件系统中新创建的磁盘文件。匹配文件和磁盘添加时间的时间戳。
|
||||
* 观察 `fdisk-l` 添加/扫描磁盘前后的输出,以获取新的磁盘名。
|
||||
|
||||
在本示例中,我使用的是 AWS EC2 服务器,向服务器添加了 5GB 磁盘。我的 lsblk 输出如下:
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
xvda 202:0 0 10G 0 disk
|
||||
├─xvda1 202:1 0 1M 0 part
|
||||
└─xvda2 202:2 0 10G 0 part /
|
||||
xvdf 202:80 0 10G 0 disk
|
||||
```
|
||||
|
||||
可以看到 `xvdf` 是新添加的磁盘。完整路径是 `/dev/xvdf`。
|
||||
|
||||
### 在 LVM 中添加新磁盘
|
||||
|
||||
我们这里使用 LVM,因为它是 Linux 平台上广泛使用的非常灵活的卷管理器。确认 lvm 或 lvm2 软件包[已经安装在系统上][4]。如未安装,请 [安装 lvm/lvm2 程序包][5]。
|
||||
|
||||
现在,我们将在逻辑卷管理器中添加这个原始磁盘,并从中创建 10GB 的挂接点。所用到的命令如下:
|
||||
|
||||
* [pvcreate][6]
|
||||
* [vgcreate][7]
|
||||
* [lvcreate][8]
|
||||
|
||||
如果要将磁盘添加到现有挂接点,并使用其空间来[扩展挂接点][9] ,则 `vgcreate` 应替换为 `vgextend`。
|
||||
|
||||
会话示例输出如下:
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# pvcreate /dev/xvdf
|
||||
Physical volume "/dev/xvdf" successfully created.
|
||||
[root@kerneltalks ~]# vgcreate vgdata /dev/xvdf
|
||||
Volume group "vgdata" successfully created
|
||||
[root@kerneltalks ~]# lvcreate -L 5G -n lvdata vgdata
|
||||
Logical volume "lvdata" created.
|
||||
```
|
||||
|
||||
现在,已完成逻辑卷创建。你需要使用所选的文件系统格式化它,并将其挂载。在这里选择 ext4 文件系统,并使用 `mkfs.ext4` 进行格式化。
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# mkfs.ext4 /dev/vgdata/lvdata
|
||||
mke2fs 1.42.9 (28-Dec-2013)
|
||||
Filesystem label=
|
||||
OS type: Linux
|
||||
Block size=4096 (log=2)
|
||||
Fragment size=4096 (log=2)
|
||||
Stride=0 blocks, Stripe width=0 blocks
|
||||
327680 inodes, 1310720 blocks
|
||||
65536 blocks (5.00%) reserved for the super user
|
||||
First data block=0
|
||||
Maximum filesystem blocks=1342177280
|
||||
40 block groups
|
||||
32768 blocks per group, 32768 fragments per group
|
||||
8192 inodes per group
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376, 294912, 819200, 884736
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (32768 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
### 在挂载点上从新磁盘挂载卷
|
||||
|
||||
使用 `mount` 命令,在 `/data` 安装点上安装已创建并格式化的 5GB 逻辑卷。
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# mount /dev/vgdata/lvdata /data
|
||||
[root@kerneltalks ~]# df -Ph /data
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vgdata-lvdata 4.8G 20M 4.6G 1% /data
|
||||
```
|
||||
|
||||
使用 `df` 命令验证挂载点。如上所述,你都完成了!你可以在 [/etc/fstab][10] 中添加一个条目,以便在重新启动时保持此装载。
|
||||
|
||||
你已将 10GB 磁盘连接到 Linux 计算机,并创建了 5GB 挂载点!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/hardware-config/how-to-add-new-disk-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[luckyele](https://github.com/luckyele)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://kerneltalks.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/kerneltalks.com/wp-content/uploads/2019/03/How-to-add-new-disk-in-Linux.png?ssl=1
|
||||
[2]: https://kerneltalks.com/cloud-services/how-to-add-ebs-disk-on-aws-linux-server/
|
||||
[3]: https://kerneltalks.com/disk-management/howto-scan-new-lun-disk-linux-hpux/
|
||||
[4]: https://kerneltalks.com/tools/check-package-installed-linux/
|
||||
[5]: https://kerneltalks.com/tools/package-installation-linux-yum-apt/
|
||||
[6]: https://kerneltalks.com/disk-management/lvm-command-tutorials-pvcreate-pvdisplay/
|
||||
[7]: https://kerneltalks.com/disk-management/lvm-commands-tutorial-vgcreate-vgdisplay-vgscan/
|
||||
[8]: https://kerneltalks.com/disk-management/lvm-commands-tutorial-lvcreate-lvdisplay-lvremove/
|
||||
[9]: https://kerneltalks.com/disk-management/extend-file-system-online-lvm/
|
||||
[10]: https://kerneltalks.com/config/understanding-etcfstab-file/
|
||||
@ -1,15 +1,16 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10682-1.html)
|
||||
[#]: subject: (Emulators and Native Linux games on the Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/play-games-raspberry-pi)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
|
||||
|
||||
树莓派上的模拟器和原生 Linux 游戏
|
||||
树莓派使用入门:树莓派上的模拟器和原生 Linux 游戏
|
||||
======
|
||||
树莓派是一个很棒的游戏平台。在我们的系列文章的第九篇中学习如何开始使用树莓派。
|
||||
|
||||
> 树莓派是一个很棒的游戏平台。在我们的系列文章的第九篇中学习如何开始使用树莓派。
|
||||
|
||||

|
||||
|
||||
@ -17,13 +18,13 @@
|
||||
|
||||
### 使用模拟器玩游戏
|
||||
|
||||
模拟器是一种能让你在树莓派上玩不同系统,不同年代游戏的软件。在如今众多的模拟器中,[RetroPi][2] 是树莓派中最受欢迎的。你可以用它来玩 Apple II、Amiga、Atari 2600、Commodore 64、Game Boy Advance 和[其他许多][3]游戏。
|
||||
模拟器是一种能让你在树莓派上玩不同系统、不同年代游戏的软件。在如今众多的模拟器中,[RetroPi][2] 是树莓派中最受欢迎的。你可以用它来玩 Apple II、Amiga、Atari 2600、Commodore 64、Game Boy Advance 和[其他许多][3]游戏。
|
||||
|
||||
如果 RetroPi 听起来有趣,请阅读[这些说明][4]开始使用,玩得开心!
|
||||
|
||||
### 原生 Linux 游戏
|
||||
|
||||
树莓派的操作系统 Raspbian 上也有很多原生 Linux 游戏。“Make Use Of” 有一篇关于如何在树莓派上[玩 10 个老经典游戏][5]如 Doom 和 Nuke Dukem 3D 的文章。
|
||||
树莓派的操作系统 Raspbian 上也有很多原生 Linux 游戏。“Make Use Of” 有一篇关于如何在树莓派上[玩 10 个老经典游戏][5],如 Doom 和 Nuke Dukem 3D 的文章。
|
||||
|
||||
你也可以将树莓派用作[游戏服务器][6]。例如,你可以在树莓派上安装 Terraria、Minecraft 和 QuakeWorld 服务器。
|
||||
|
||||
@ -34,13 +35,13 @@ via: https://opensource.com/article/19/3/play-games-raspberry-pi
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
|
||||
[1]: https://linux.cn/article-10653-1.html
|
||||
[2]: https://retropie.org.uk/
|
||||
[3]: https://retropie.org.uk/about/systems
|
||||
[4]: https://opensource.com/article/19/1/retropie
|
||||
325
published/20190318 10 Python image manipulation tools.md
Normal file
325
published/20190318 10 Python image manipulation tools.md
Normal file
@ -0,0 +1,325 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10679-1.html)
|
||||
[#]: subject: (10 Python image manipulation tools)
|
||||
[#]: via: (https://opensource.com/article/19/3/python-image-manipulation-tools)
|
||||
[#]: author: (Parul Pandey https://opensource.com/users/parul-pandey)
|
||||
|
||||
10 个 Python 图像编辑工具
|
||||
======
|
||||
|
||||
> 以下提到的这些 Python 工具在编辑图像、操作图像底层数据方面都提供了简单直接的方法。
|
||||
|
||||
![][1]
|
||||
|
||||
当今的世界充满了数据,而图像数据就是其中很重要的一部分。但只有经过处理和分析,提高图像的质量,从中提取出有效地信息,才能利用到这些图像数据。
|
||||
|
||||
常见的图像处理操作包括显示图像,基本的图像操作,如裁剪、翻转、旋转;图像的分割、分类、特征提取;图像恢复;以及图像识别等等。Python 作为一种日益风靡的科学编程语言,是这些图像处理操作的最佳选择。同时,在 Python 生态当中也有很多可以免费使用的优秀的图像处理工具。
|
||||
|
||||
下文将介绍 10 个可以用于图像处理任务的 Python 库,它们在编辑图像、查看图像底层数据方面都提供了简单直接的方法。
|
||||
|
||||
### 1、scikit-image
|
||||
|
||||
[scikit-image][2] 是一个结合 [NumPy][3] 数组使用的开源 Python 工具,它实现了可用于研究、教育、工业应用的算法和应用程序。即使是对于刚刚接触 Python 生态圈的新手来说,它也是一个在使用上足够简单的库。同时它的代码质量也很高,因为它是由一个活跃的志愿者社区开发的,并且通过了<ruby>同行评审<rt>peer review</rt></ruby>。
|
||||
|
||||
#### 资源
|
||||
|
||||
scikit-image 的[文档][4]非常完善,其中包含了丰富的用例。
|
||||
|
||||
#### 示例
|
||||
|
||||
可以通过导入 `skimage` 使用,大部分的功能都可以在它的子模块中找到。
|
||||
|
||||
<ruby>图像滤波<rt>image filtering</rt></ruby>:
|
||||
|
||||
```
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
from skimage import data,filters
|
||||
|
||||
image = data.coins() # ... or any other NumPy array!
|
||||
edges = filters.sobel(image)
|
||||
plt.imshow(edges, cmap='gray')
|
||||
```
|
||||
|
||||
![Image filtering in scikit-image][6]
|
||||
|
||||
使用 [match_template()][7] 方法实现<ruby>模板匹配<rt>template matching</rt></ruby>:
|
||||
|
||||
![Template matching in scikit-image][9]
|
||||
|
||||
在[展示页面][10]可以看到更多相关的例子。
|
||||
|
||||
### 2、NumPy
|
||||
|
||||
[NumPy][11] 提供了对数组的支持,是 Python 编程的一个核心库。图像的本质其实也是一个包含像素数据点的标准 NumPy 数组,因此可以通过一些基本的 NumPy 操作(例如切片、<ruby>掩膜<rt>mask</rt></ruby>、<ruby>花式索引<rt>fancy indexing</rt></ruby>等),就可以从像素级别对图像进行编辑。通过 NumPy 数组存储的图像也可以被 skimage 加载并使用 matplotlib 显示。
|
||||
|
||||
#### 资源
|
||||
|
||||
在 NumPy 的[官方文档][11]中提供了完整的代码文档和资源列表。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 NumPy 对图像进行<ruby>掩膜<rt>mask</rt></ruby>操作:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
from skimage import data
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
image = data.camera()
|
||||
type(image)
|
||||
numpy.ndarray #Image is a NumPy array:
|
||||
|
||||
mask = image < 87
|
||||
image[mask]=255
|
||||
plt.imshow(image, cmap='gray')
|
||||
```
|
||||
|
||||
![NumPy][13]
|
||||
|
||||
### 3、SciPy
|
||||
|
||||
像 NumPy 一样,[SciPy][14] 是 Python 的一个核心科学计算模块,也可以用于图像的基本操作和处理。尤其是 SciPy v1.1.0 中的 [scipy.ndimage][15] 子模块,它提供了在 n 维 NumPy 数组上的运行的函数。SciPy 目前还提供了<ruby>线性和非线性滤波<rt>linear and non-linear filtering</rt></ruby>、<ruby>二值形态学<rt>binary morphology</rt></ruby>、<ruby>B 样条插值<rt>B-spline interpolation</rt></ruby>、<ruby>对象测量<rt>object measurements</rt></ruby>等方面的函数。
|
||||
|
||||
#### 资源
|
||||
|
||||
在[官方文档][16]中可以查阅到 `scipy.ndimage` 的完整函数列表。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 SciPy 的[高斯滤波][17]对图像进行模糊处理:
|
||||
|
||||
```
|
||||
from scipy import misc,ndimage
|
||||
|
||||
face = misc.face()
|
||||
blurred_face = ndimage.gaussian_filter(face, sigma=3)
|
||||
very_blurred = ndimage.gaussian_filter(face, sigma=5)
|
||||
|
||||
#Results
|
||||
plt.imshow(<image to be displayed>)
|
||||
```
|
||||
|
||||
![Using a Gaussian filter in SciPy][19]
|
||||
|
||||
### 4、PIL/Pillow
|
||||
|
||||
PIL (Python Imaging Library) 是一个免费 Python 编程库,它提供了对多种格式图像文件的打开、编辑、保存的支持。但在 2009 年之后 PIL 就停止发布新版本了。幸运的是,还有一个 PIL 的积极开发的分支 [Pillow][20],它的安装过程比 PIL 更加简单,支持大部分主流的操作系统,并且还支持 Python 3。Pillow 包含了图像的基础处理功能,包括像素点操作、使用内置卷积内核进行滤波、颜色空间转换等等。
|
||||
|
||||
#### 资源
|
||||
|
||||
Pillow 的[官方文档][21]提供了 Pillow 的安装说明自己代码库中每一个模块的示例。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 Pillow 中的 ImageFilter 模块实现图像增强:
|
||||
|
||||
```
|
||||
from PIL import Image,ImageFilter
|
||||
#Read image
|
||||
im = Image.open('image.jpg')
|
||||
#Display image
|
||||
im.show()
|
||||
|
||||
from PIL import ImageEnhance
|
||||
enh = ImageEnhance.Contrast(im)
|
||||
enh.enhance(1.8).show("30% more contrast")
|
||||
```
|
||||
|
||||
![Enhancing an image in Pillow using ImageFilter][23]
|
||||
|
||||
- [源码][24]
|
||||
|
||||
### 5、OpenCV-Python
|
||||
|
||||
OpenCV(Open Source Computer Vision 库)是计算机视觉领域最广泛使用的库之一,[OpenCV-Python][25] 则是 OpenCV 的 Python API。OpenCV-Python 的运行速度很快,这归功于它使用 C/C++ 编写的后台代码,同时由于它使用了 Python 进行封装,因此调用和部署的难度也不大。这些优点让 OpenCV-Python 成为了计算密集型计算机视觉应用程序的一个不错的选择。
|
||||
|
||||
#### 资源
|
||||
|
||||
入门之前最好先阅读 [OpenCV2-Python-Guide][26] 这份文档。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 OpenCV-Python 中的<ruby>金字塔融合<rt>Pyramid Blending</rt></ruby>将苹果和橘子融合到一起:
|
||||
|
||||
|
||||
![Image blending using Pyramids in OpenCV-Python][28]
|
||||
|
||||
- [源码][29]
|
||||
|
||||
### 6、SimpleCV
|
||||
|
||||
[SimpleCV][30] 是一个开源的计算机视觉框架。它支持包括 OpenCV 在内的一些高性能计算机视觉库,同时不需要去了解<ruby>位深度<rt>bit depth</rt></ruby>、文件格式、<ruby>色彩空间<rt>color space</rt></ruby>之类的概念,因此 SimpleCV 的学习曲线要比 OpenCV 平缓得多,正如它的口号所说,“将计算机视觉变得更简单”。SimpleCV 的优点还有:
|
||||
|
||||
* 即使是刚刚接触计算机视觉的程序员也可以通过 SimpleCV 来实现一些简易的计算机视觉测试
|
||||
* 录像、视频文件、图像、视频流都在支持范围内
|
||||
|
||||
#### 资源
|
||||
|
||||
[官方文档][31]简单易懂,同时也附有大量的学习用例。
|
||||
|
||||
#### 示例
|
||||
|
||||
![SimpleCV][33]
|
||||
|
||||
### 7、Mahotas
|
||||
|
||||
[Mahotas][34] 是另一个 Python 图像处理和计算机视觉库。在图像处理方面,它支持滤波和形态学相关的操作;在计算机视觉方面,它也支持<ruby>特征计算<rt>feature computation</rt></ruby>、<ruby>兴趣点检测<rt>interest point detection</rt></ruby>、<ruby>局部描述符<rt>local descriptors</rt></ruby>等功能。Mahotas 的接口使用了 Python 进行编写,因此适合快速开发,而算法使用 C++ 实现,并针对速度进行了优化。Mahotas 尽可能做到代码量少和依赖项少,因此它的运算速度非常快。可以参考[官方文档][35]了解更多详细信息。
|
||||
|
||||
#### 资源
|
||||
|
||||
[文档][36]包含了安装介绍、示例以及一些 Mahotas 的入门教程。
|
||||
|
||||
#### 示例
|
||||
|
||||
Mahotas 力求使用少量的代码来实现功能。例如这个 [Finding Wally][37] 游戏:
|
||||
|
||||
![Finding Wally problem in Mahotas][39]
|
||||
|
||||
![Finding Wally problem in Mahotas][42]
|
||||
|
||||
- [源码][40]
|
||||
|
||||
### 8、SimpleITK
|
||||
|
||||
[ITK][43](Insight Segmentation and Registration Toolkit)是一个为开发者提供普适性图像分析功能的开源、跨平台工具套件,[SimpleITK][44] 则是基于 ITK 构建出来的一个简化层,旨在促进 ITK 在快速原型设计、教育、解释语言中的应用。SimpleITK 作为一个图像分析工具包,它也带有[大量的组件][45],可以支持常规的滤波、图像分割、<ruby>图像配准<rt>registration</rt></ruby>功能。尽管 SimpleITK 使用 C++ 编写,但它也支持包括 Python 在内的大部分编程语言。
|
||||
|
||||
#### 资源
|
||||
|
||||
有很多 [Jupyter Notebooks][46] 用例可以展示 SimpleITK 在教育和科研领域中的应用,通过这些用例可以看到如何使用 Python 和 R 利用 SimpleITK 来实现交互式图像分析。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 Python + SimpleITK 实现的 CT/MR 图像配准过程:
|
||||
|
||||
![SimpleITK animation][48]
|
||||
|
||||
- [源码][49]
|
||||
|
||||
### 9、pgmagick
|
||||
|
||||
[pgmagick][50] 是使用 Python 封装的 GraphicsMagick 库。[GraphicsMagick][51] 通常被认为是图像处理界的瑞士军刀,因为它强大而又高效的工具包支持对多达 88 种主流格式图像文件的读写操作,包括 DPX、GIF、JPEG、JPEG-2000、PNG、PDF、PNM、TIFF 等等。
|
||||
|
||||
#### 资源
|
||||
|
||||
pgmagick 的 [GitHub 仓库][52]中有相关的安装说明、依赖列表,以及详细的[使用指引][53]。
|
||||
|
||||
#### 示例
|
||||
|
||||
图像缩放:
|
||||
|
||||
![Image scaling in pgmagick][55]
|
||||
|
||||
- [源码][56]
|
||||
|
||||
边缘提取:
|
||||
|
||||
![Edge extraction in pgmagick][58]
|
||||
|
||||
- [源码][59]
|
||||
|
||||
### 10、Pycairo
|
||||
|
||||
[Cairo][61] 是一个用于绘制矢量图的二维图形库,而 [Pycairo][60] 是用于 Cairo 的一组 Python 绑定。矢量图的优点在于做大小缩放的过程中不会丢失图像的清晰度。使用 Pycairo 可以在 Python 中调用 Cairo 的相关命令。
|
||||
|
||||
#### 资源
|
||||
|
||||
Pycairo 的 [GitHub 仓库][62]提供了关于安装和使用的详细说明,以及一份简要介绍 Pycairo 的[入门指南][63]。
|
||||
|
||||
#### 示例
|
||||
|
||||
使用 Pycairo 绘制线段、基本图形、<ruby>径向渐变<rt>radial gradients</rt></ruby>:
|
||||
|
||||
![Pycairo][65]
|
||||
|
||||
- [源码][66]
|
||||
|
||||
### 总结
|
||||
|
||||
以上就是 Python 中的一些有用的图像处理库,无论你有没有听说过、有没有使用过,都值得试用一下并了解它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/python-image-manipulation-tools
|
||||
|
||||
作者:[Parul Pandey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/parul-pandey
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/daisy_gimp_art_design.jpg?itok=6kCxAKWO
|
||||
[2]: https://scikit-image.org/
|
||||
[3]: http://docs.scipy.org/doc/numpy/reference/index.html#module-numpy
|
||||
[4]: http://scikit-image.org/docs/stable/user_guide.html
|
||||
[5]: /file/426206
|
||||
[6]: https://opensource.com/sites/default/files/uploads/1-scikit-image.png "Image filtering in scikit-image"
|
||||
[7]: http://scikit-image.org/docs/dev/auto_examples/features_detection/plot_template.html#sphx-glr-auto-examples-features-detection-plot-template-py
|
||||
[8]: /file/426211
|
||||
[9]: https://opensource.com/sites/default/files/uploads/2-scikit-image.png "Template matching in scikit-image"
|
||||
[10]: https://scikit-image.org/docs/dev/auto_examples
|
||||
[11]: http://www.numpy.org/
|
||||
[12]: /file/426216
|
||||
[13]: https://opensource.com/sites/default/files/uploads/3-numpy.png "NumPy"
|
||||
[14]: https://www.scipy.org/
|
||||
[15]: https://docs.scipy.org/doc/scipy/reference/ndimage.html#module-scipy.ndimage
|
||||
[16]: https://docs.scipy.org/doc/scipy/reference/tutorial/ndimage.html#correlation-and-convolution
|
||||
[17]: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.gaussian_filter.html
|
||||
[18]: /file/426221
|
||||
[19]: https://opensource.com/sites/default/files/uploads/4-scipy.png "Using a Gaussian filter in SciPy"
|
||||
[20]: https://python-pillow.org/
|
||||
[21]: https://pillow.readthedocs.io/en/3.1.x/index.html
|
||||
[22]: /file/426226
|
||||
[23]: https://opensource.com/sites/default/files/uploads/5-pillow.png "Enhancing an image in Pillow using ImageFilter"
|
||||
[24]: http://sipi.usc.edu/database/
|
||||
[25]: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_setup/py_intro/py_intro.html
|
||||
[26]: https://github.com/abidrahmank/OpenCV2-Python-Tutorials
|
||||
[27]: /file/426236
|
||||
[28]: https://opensource.com/sites/default/files/uploads/6-opencv.jpeg "Image blending using Pyramids in OpenCV-Python"
|
||||
[29]: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_pyramids/py_pyramids.html#pyramids
|
||||
[30]: http://simplecv.org/
|
||||
[31]: http://examples.simplecv.org/en/latest/
|
||||
[32]: /file/426241
|
||||
[33]: https://opensource.com/sites/default/files/uploads/7-_simplecv.png "SimpleCV"
|
||||
[34]: https://mahotas.readthedocs.io/en/latest/
|
||||
[35]: https://openresearchsoftware.metajnl.com/articles/10.5334/jors.ac/
|
||||
[36]: https://mahotas.readthedocs.io/en/latest/install.html
|
||||
[37]: https://blog.clarifai.com/wheres-waldo-using-machine-learning-to-find-all-the-waldos
|
||||
[38]: /file/426246
|
||||
[39]: https://opensource.com/sites/default/files/uploads/8-mahotas.png "Finding Wally problem in Mahotas"
|
||||
[40]: https://mahotas.readthedocs.io/en/latest/wally.html
|
||||
[41]: /file/426251
|
||||
[42]: https://opensource.com/sites/default/files/uploads/9-mahotas.png "Finding Wally problem in Mahotas"
|
||||
[43]: https://itk.org/
|
||||
[44]: http://www.simpleitk.org/
|
||||
[45]: https://itk.org/ITK/resources/resources.html
|
||||
[46]: http://insightsoftwareconsortium.github.io/SimpleITK-Notebooks/
|
||||
[47]: /file/426256
|
||||
[48]: https://opensource.com/sites/default/files/uploads/10-simpleitk.gif "SimpleITK animation"
|
||||
[49]: https://github.com/InsightSoftwareConsortium/SimpleITK-Notebooks/blob/master/Utilities/intro_animation.py
|
||||
[50]: https://pypi.org/project/pgmagick/
|
||||
[51]: http://www.graphicsmagick.org/
|
||||
[52]: https://github.com/hhatto/pgmagick
|
||||
[53]: https://pgmagick.readthedocs.io/en/latest/
|
||||
[54]: /file/426261
|
||||
[55]: https://opensource.com/sites/default/files/uploads/11-pgmagick.png "Image scaling in pgmagick"
|
||||
[56]: https://pgmagick.readthedocs.io/en/latest/cookbook.html#scaling-a-jpeg-image
|
||||
[57]: /file/426266
|
||||
[58]: https://opensource.com/sites/default/files/uploads/12-pgmagick.png "Edge extraction in pgmagick"
|
||||
[59]: https://pgmagick.readthedocs.io/en/latest/cookbook.html#edge-extraction
|
||||
[60]: https://pypi.org/project/pycairo/
|
||||
[61]: https://cairographics.org/
|
||||
[62]: https://github.com/pygobject/pycairo
|
||||
[63]: https://pycairo.readthedocs.io/en/latest/tutorial.html
|
||||
[64]: /file/426271
|
||||
[65]: https://opensource.com/sites/default/files/uploads/13-pycairo.png "Pycairo"
|
||||
[66]: http://zetcode.com/gfx/pycairo/basicdrawing/
|
||||
|
||||
@ -0,0 +1,152 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "FSSlc"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10675-1.html"
|
||||
[#]: subject: "3 Ways To Check Whether A Port Is Open On The Remote Linux System?"
|
||||
[#]: via: "https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/"
|
||||
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||
|
||||
查看远程 Linux 系统中某个端口是否开启的 3 种方法
|
||||
======
|
||||
|
||||
这是一个很重要的话题,不仅对 Linux 管理员而言,对于我们大家而言也非常有帮助。我的意思是说对于工作在 IT 基础设施行业的用户来说,了解这个话题也是非常有用的。他们需要在执行下一步操作前,检查 Linux 服务器上某个端口是否开启。
|
||||
|
||||
假如这个端口没有被开启,则他们会直接找 Linux 管理员去开启它。如果这个端口已经开启了,则我们需要和应用团队来商量下一步要做的事。
|
||||
|
||||
在本篇文章中,我们将向你展示如何检查某个端口是否开启的 3 种方法。
|
||||
|
||||
这个目标可以使用下面的 Linux 命令来达成:
|
||||
|
||||
* `nc`:netcat 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
|
||||
* `nmap`:(“Network Mapper”)是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络。
|
||||
* `telnet`:被用来交互地通过 TELNET 协议与另一台主机通信。
|
||||
|
||||
### 如何使用 nc(netcat)命令来查看远程 Linux 系统中某个端口是否开启?
|
||||
|
||||
`nc` 即 `netcat`。`netcat` 是一个简单的 Unix 工具,它使用 TCP 或 UDP 协议去读写网络连接间的数据。
|
||||
|
||||
它被设计成为一个可信赖的后端工具,可被直接使用或者简单地被其他程序或脚本调用。
|
||||
|
||||
与此同时,它也是一个富含功能的网络调试和探索工具,因为它可以创建你所需的几乎所有类型的连接,并且还拥有几个内置的有趣功能。
|
||||
|
||||
`netcat` 有三类功能模式,它们分别为连接模式、监听模式和隧道模式。
|
||||
|
||||
`nc`(`netcat`)命令的一般语法:
|
||||
|
||||
```
|
||||
$ nc [-options] [HostName or IP] [PortNumber]
|
||||
```
|
||||
|
||||
在下面的例子中,我们将检查远程 Linux 系统中的 22 端口是否开启。
|
||||
|
||||
假如端口是开启的,你将获得类似下面的输出。
|
||||
|
||||
```
|
||||
# nc -zvw3 192.168.1.8 22
|
||||
Connection to 192.168.1.8 22 port [tcp/ssh] succeeded!
|
||||
```
|
||||
|
||||
命令详解:
|
||||
|
||||
* `nc`:即执行的命令主体;
|
||||
* `z`:零 I/O 模式(被用来扫描);
|
||||
* `v`:显式地输出;
|
||||
* `w3`:设置超时时间为 3 秒;
|
||||
* `192.168.1.8`:目标系统的 IP 地址;
|
||||
* `22`:需要验证的端口。
|
||||
|
||||
当检测到端口没有开启,你将获得如下输出:
|
||||
|
||||
```
|
||||
# nc -zvw3 192.168.1.95 22
|
||||
nc: connect to 192.168.1.95 port 22 (tcp) failed: Connection refused
|
||||
```
|
||||
|
||||
### 如何使用 nmap 命令来查看远程 Linux 系统中某个端口是否开启?
|
||||
|
||||
`nmap`(“Network Mapper”)是一个用于网络探索和安全审计的开源工具,被设计用来快速地扫描大规模网络,尽管对于单个主机它也同样能够正常工作。
|
||||
|
||||
`nmap` 以一种新颖的方式,使用裸 IP 包来决定网络中的主机是否可达,这些主机正提供什么服务(应用名和版本号),它们运行的操作系统(系统的版本),它们正在使用的是什么包过滤软件或者防火墙,以及其他额外的特性。
|
||||
|
||||
尽管 `nmap` 通常被用于安全审计,许多系统和网络管理员发现在一些日常任务(例如罗列网络资产、管理服务升级的计划、监视主机或者服务是否正常运行)中,它也同样十分有用。
|
||||
|
||||
`nmap` 的一般语法:
|
||||
|
||||
```
|
||||
$ nmap [-options] [HostName or IP] [-p] [PortNumber]
|
||||
```
|
||||
|
||||
假如端口是开启的,你将获得如下的输出:
|
||||
|
||||
```
|
||||
# nmap 192.168.1.8 -p 22
|
||||
|
||||
Starting Nmap 7.70 ( https://nmap.org ) at 2019-03-16 03:37 IST Nmap scan report for 192.168.1.8 Host is up (0.00031s latency).
|
||||
|
||||
PORT STATE SERVICE
|
||||
|
||||
22/tcp open ssh
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 13.06 seconds
|
||||
```
|
||||
|
||||
假如端口没有开启,你将得到类似下面的结果:
|
||||
|
||||
```
|
||||
# nmap 192.168.1.8 -p 80
|
||||
Starting Nmap 7.70 ( https://nmap.org ) at 2019-03-16 04:30 IST
|
||||
Nmap scan report for 192.168.1.8
|
||||
Host is up (0.00036s latency).
|
||||
|
||||
PORT STATE SERVICE
|
||||
80/tcp closed http
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 13.07 seconds
|
||||
```
|
||||
|
||||
### 如何使用 telnet 命令来查看远程 Linux 系统中某个端口是否开启?
|
||||
|
||||
`telnet` 命令被用来交互地通过 TELNET 协议与另一台主机通信。
|
||||
|
||||
`telnet` 命令的一般语法:
|
||||
|
||||
```
|
||||
$ telnet [HostName or IP] [PortNumber]
|
||||
```
|
||||
|
||||
假如探测成功,你将看到类似下面的输出:
|
||||
|
||||
```
|
||||
$ telnet 192.168.1.9 22
|
||||
Trying 192.168.1.9...
|
||||
Connected to 192.168.1.9.
|
||||
Escape character is '^]'.
|
||||
SSH-2.0-OpenSSH_5.3
|
||||
^]
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
||||
假如探测失败,你将看到类似下面的输出:
|
||||
|
||||
```
|
||||
$ telnet 192.168.1.9 80
|
||||
Trying 192.168.1.9...
|
||||
telnet: Unable to connect to remote host: Connection refused
|
||||
```
|
||||
|
||||
当前,我们只找到上面 3 种方法来查看远程 Linux 系统中某个端口是否开启,假如你发现了其他方法可以达到相同的目的,请在下面的评论框中告知我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,4 +1,3 @@
|
||||
name1e5s translating
|
||||
The Rise and Demise of RSS
|
||||
======
|
||||
There are two stories here. The first is a story about a vision of the web’s future that never quite came to fruition. The second is a story about how a collaborative effort to improve a popular standard devolved into one of the most contentious forks in the history of open-source software development.
|
||||
|
||||
@ -1,119 +0,0 @@
|
||||
acyanbird translating
|
||||
A Short History of Chaosnet
|
||||
======
|
||||
If you fire up `dig` and run a DNS query for `google.com`, you will get a response somewhat like the following:
|
||||
|
||||
```
|
||||
$ dig google.com
|
||||
|
||||
; <<>> DiG 9.10.6 <<>> google.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27120
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 512
|
||||
;; QUESTION SECTION:
|
||||
;google.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
google.com. 194 IN A 216.58.192.206
|
||||
|
||||
;; Query time: 23 msec
|
||||
;; SERVER: 8.8.8.8#53(8.8.8.8)
|
||||
;; WHEN: Fri Sep 21 16:14:48 CDT 2018
|
||||
;; MSG SIZE rcvd: 55
|
||||
```
|
||||
|
||||
The output contains both a section describing the “question” you asked (“What is the IP address of `google.com`?”) and a section describing the answer you received. In the answer section, we see that `dig` found a single record with what looks to be five fields. The record’s type is indicated by the `A` in the fourth field from the left—this is an “address” record. To the right of the `A`, in the fifth field, we can see that the IP address for `google.com` is `216.58.192.206`. The `194` value in the second field specifies how long in seconds this particular record can be cached.
|
||||
|
||||
What does the `IN` field tell us? For an embarrassingly long time, I thought `IN` functioned as a preposition, so that every DNS record was saying something like “`google.com` is in `A` and has IP address `216.58.192.206`.” It turns out that `IN` actually stands for “internet.” The `IN` part of a DNS record tells us the record’s class.
|
||||
|
||||
Why might a DNS record have a class other than “internet”? What would that even mean? How do you search for a host that isn’t on the internet? It would seem that `IN` is the only value that could possibly make sense here. Indeed, when you try to ask for the address of `google.com` while specifying that you expect a record with a class other than `IN`, the DNS server you are asking will probably complain. In the below, when we try to ask for the IP address of `google.com` using the `HS` class, the name server at `8.8.8.8` (Google Public DNS) returns a status of `SERVFAIL`:
|
||||
|
||||
```
|
||||
$ dig -c HS google.com
|
||||
|
||||
; <<>> DiG 9.10.6 <<>> -c HS google.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31517
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 512
|
||||
;; QUESTION SECTION:
|
||||
;google.com. HS A
|
||||
|
||||
;; Query time: 34 msec
|
||||
;; SERVER: 8.8.8.8#53(8.8.8.8)
|
||||
;; WHEN: Tue Sep 25 14:48:10 CDT 2018
|
||||
;; MSG SIZE rcvd: 39
|
||||
```
|
||||
|
||||
So classes other than `IN` aren’t widely supported. But they do exist. In addition to `IN`, DNS records can have the `HS` class (as we’ve just seen) or the `CH` class. The `HS` class is reserved for use by a system called [Hesiod][1] that stores and distributes simple textual data using the Domain Name System. It is typically used in local environments as a stand-in for [LDAP][2]. The `CH` class is reserved for something called Chaosnet.
|
||||
|
||||
Today, the world belongs to TCP/IP. Those two protocols (together with UDP) govern most of the remote communication that happens between computers. But I think it’s wonderful that you can still find, hidden in the plumbing of the internet, traces of this other, long-extinct, evocatively named system. What was Chaosnet? And why did it go the way of the dinosaurs?
|
||||
|
||||
### A Machine Room at MIT
|
||||
|
||||
Chaosnet was developed in the 1970s by researchers at the MIT Artificial Intelligence Lab. It was created as a part of a larger effort to design and build a machine that could run the Lisp programming language more efficiently than a general-purpose computer.
|
||||
|
||||
Lisp was the brainchild of MIT professor John McCarthy, who pioneered the field of artificial intelligence. He first described Lisp to the world in [a paper][3] published in 1960. By 1962, an interpreter and a compiler had been written. Lisp introduced an astounding number of features that today we consider standard for many programming languages. It was the first language to have a garbage collector. It was the first to have a REPL. And it was the first to support dynamic typing. It found favor among programmers working in artificial intelligence and—to name just one example—was used to develop the famous [SHRDLU][4] demonstration, which allowed a human to dictate simple actions involving toy blocks to a computer in natural language.
|
||||
|
||||
The problem with Lisp was that it could be slow. Simple operations could take twice as long to execute as was typical with other languages because Lisp variables were type-checked at runtime and not just during compilation. Lisp’s garbage collector was known to take up to an entire second to run on the IBM 7090 at MIT. These performance issues were especially unwelcome because the AI researchers using Lisp were trying to build applications like SHRDLU that interacted with users in real time. In the late 1970s, a group of MIT Artificial Intelligence Lab researchers decided to address these problems by building machines specifically designed to run Lisp programs. These “Lisp machines” had more memory and a compact instruction set better-suited to Lisp. Type-checking would be done by dedicated circuitry, speeding it up by orders of magnitude. And unlike most computer systems at the time, Lisp machines would not be time-shared, since ambitious Lisp programs needed all the resources a computer had available. Each user would be assigned his or her own CPU. In a memo, the Lisp Machine Group at MIT described how this would make Lisp programming significantly easier:
|
||||
|
||||
> The Lisp Machine is a personal computer. Personal computing means that the processor and main memory are not time-division multiplexed, instead each person gets his own. The personal computation system consists of a pool of processors, each with its own main memory, and its own disk for swapping. When a user logs in, he is assigned a processor, and he has exclusive use of it for the duration of the session. When he logs out, the processor is returned to the pool, for the next person to use. This way, there is no competition from other users for memory; the pages the user is frequently referring to remain in core, and so swapping overhead is considerably reduced. Thus the Lisp Machine solves a basic problem of the time-sharing Lisp system.
|
||||
|
||||
The Lisp machine would be a personal computer in a different sense than the one we think of today. As the Lisp Machine Group originally envisioned it, users would sit down in their offices not in front of their own Lisp machines but in front of terminals. The terminals would be connected to the actual Lisp machine, which would be elsewhere. Even though each user would be assigned his or her own processor, the processors would still be “kept off in a machine room,” since they would make noise and take up space and thus be “unwelcome office companions.” The processors would share access to a file system and to devices like printers via a high-speed local network “with completely distributed control.” That network was Chaosnet.
|
||||
|
||||
Chaosnet is both a hardware standard and a software protocol. The hardware standard resembles Ethernet, and in fact the Chaosnet software protocol was eventually run over Ethernet. The software protocol, which specifies both network-layer and transport-layer interactions, was, unlike TCP/IP, always meant to govern a local network. In another memo released by the MIT Artificial Intelligence Lab, David Moon, a member of the Lisp Machine Group, explained that Chaosnet “contains no special provisions for things such as low-speed links, noisy links, multiple paths, and long-distance links with significant transit time.” The focus was instead on designing a protocol that could outperform other protocols on a small network.
|
||||
|
||||
Speed was important because Chaosnet sat between each Lisp processor and the file system. Network delays would significantly slow rudimentary operations like viewing the contents of a text document. To be fast enough, Chaosnet incorporated several improvements over the Network Control Program then in use on Arpanet. According to Moon, “it was important to design out bottlenecks such as are found in Arpanet, for instance the control-link which is shared between multiple connections and the need to acknowledge each message before the next message is sent.” The Chaosnet protocol batches packet acknowledgments in much the same way that TCP does today and so reduced the number of packets that needed to be transmitted by a half to a third.
|
||||
|
||||
Chaosnet could also get away with a relatively simple routing algorithm, since most hosts on the Lisp machine network were probably connected by a single, short wire. Moon wrote that the Chaosnet routing scheme “is predicated on the assumption that the network geometry is simple, there are few multiple paths, and the length of any path is quite short. This makes more sophisticated schemes unnecessary.” The simplicity of the algorithm meant that implementing the Chaosnet protocol was easy. The implementation program was supposedly half the size of the Arpanet Network Control Program.
|
||||
|
||||
The Chaosnet protocol has other idiosyncrasies. A Chaosnet address is only 16 bits, half the size of an IPv4 address, which makes sense given that Chaosnet was only ever meant to work on a local network. Chaosnet also doesn’t use port numbers; instead, a process that wants to connect to another process on a different machine first makes a connection request that specifies a target “contact name.” That contact name is often just the name of a particular service. For example, one host may try to connect to another host using the contact name `TELNET`. In practice, I assume this works more or less just like TCP, since something well-known like port 80 might as well have the contact name `HTTP`.
|
||||
|
||||
The Chaosnet DNS class was added to the Domain Name System by [RFC 973][5] in 1986. It replaced another class that had been available early on, the `CSNET` class, which was there to support a network called the Computer Science Network. I haven’t been able to figure out why Chaosnet was picked out for special treatment by the Domain Name System. There were other protocol families that could have been added but never were. For example, Paul Mockapetris, one of the principal architects of the Domain Name System, has written that he originally imagined that DNS would include a class for Xerox’s network protocol. That never happened. Chaosnet may have been added just because so much of the early work on Arpanet and the internet happened at Bolt, Beranek and Newman in Cambridge, Massachusetts, whose employees were often connected in some way with MIT. Chaosnet was probably well-known among the then relatively small group of people working on computer networks.
|
||||
|
||||
Usage of Chaosnet presumably waned as Lisp machines became less and less popular. Though Lisp machines were for a short time commercially viable products—sold by companies such as Symbolics and Lisp Machines Inc. during the 1980s—they were soon displaced by cheaper microcomputers that could run Lisp just as quickly without special-purpose circuitry. TCP/IP also fixed many of the issues with the original Arpanet protocols that Chaosnet had been created to circumvent.
|
||||
|
||||
### Ghost in the Shell
|
||||
|
||||
There unfortunately isn’t a huge amount of information still around about Chaosnet. RFC 675, which was essentially the first draft of TCP/IP, was published in 1974. Chaosnet was first developed in 1975. TCP/IP eventually conquered the world, but Chaosnet seems to have been a technological dead end. Though it’s possible that Chaosnet influenced subsequent work on TCP/IP, I haven’t found any specific examples of that happening.
|
||||
|
||||
The only really visible remnant of Chaosnet is the `CH` DNS class. There’s something about that fact that I find strangely fascinating. The `CH` class is a vestigial ghost of an alternative network protocol in a world that has long since settled on TCP/IP. It’s exciting, at least to me, to know that the last traces of Chaosnet still lurk out there in the infrastructure of our networked society. The `CH` DNS class is a fun artifact of digital archaeology. But it’s also a living reminder that the internet was not born fully formed, that TCP/IP is not the only way to connect computers to each other, and that “the internet” is far from the coolest name we could have had for our global communication system.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][6] on Twitter or subscribe to the [RSS feed][7] to make sure you know when a new post is out.
|
||||
|
||||
Previously on TwoBitHistory…
|
||||
|
||||
> Where did RSS come from? Why are there so many competing formats? Why don't people seem to use it that much anymore?
|
||||
>
|
||||
> Answers to these questions and many more in this week's post about RSS:<https://t.co/BsCN5GQidR>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [September 17, 2018][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/09/30/chaosnet.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Hesiod_(name_service)
|
||||
[2]: https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol
|
||||
[3]: http://www-formal.stanford.edu/jmc/recursive.pdf
|
||||
[4]: https://en.wikipedia.org/wiki/SHRDLU
|
||||
[5]: https://tools.ietf.org/html/rfc973
|
||||
[6]: https://twitter.com/TwoBitHistory
|
||||
[7]: https://twobithistory.org/feed.xml
|
||||
[8]: https://twitter.com/TwoBitHistory/status/1041485204802756608?ref_src=twsrc%5Etfw
|
||||
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing changes in open source projects)
|
||||
[#]: via: (https://opensource.com/article/19/3/managing-changes-open-source-projects)
|
||||
[#]: author: (Ben Cotton (Red Hat, Community Moderator) https://opensource.com/users/bcotton)
|
||||
|
||||
Managing changes in open source projects
|
||||
======
|
||||
|
||||
Here's how to create a visible change process to support the community around an open source project.
|
||||
|
||||
![scrabble letters: "time for change"][1]
|
||||
|
||||
Why bother having a process for proposing changes to your open source project? Why not just let people do what they're doing and merge the features when they're ready? Well, you can certainly do that if you're the only person on the project. Or maybe if it's just you and a few friends.
|
||||
|
||||
But if the project is large, you might need to coordinate how some of the changes land. Or, at the very least, let people know a change is coming so they can adjust if it affects the parts they work on. A visible change process is also helpful to the community. It allows them to give feedback that can improve your idea. And if nothing else, it lets people know what's coming so that they can get excited, and maybe get you a little bit of coverage on Opensource.com or the like. Basically, it's "here's what I'm going to do" instead of "here's what I did," and it might save you some headaches as you scramble to QA right before your release.
|
||||
|
||||
So let's say I've convinced you that having a change process is a good idea. How do you build one?
|
||||
|
||||
**[Watch my talk on this topic]**
|
||||
<https://www.youtube.com/embed/cVV1K3Junkc>
|
||||
|
||||
### Right-size your change process
|
||||
|
||||
Before we start talking about what a change process looks like, I want to make it very clear that this is not a one-size-fits-all situation. The smaller your project is—mainly in the number of contributors—the less process you'll probably need. As [Richard Hackman says][2], the number of communication channels in a team goes up exponentially with the number of people on the team. In community-driven projects, this becomes even more complicated as people come and go, and even your long-time contributors might not be checking in every day. So the change process consolidates those communication channels into a single area where people can quickly check to see if they care and then get back to whatever it is they do.
|
||||
|
||||
At one end of the scale, there's the command-line Twitter client I maintain. The change process there is, "I pick something I want to work on, probably make a Git branch for it but I might forget that, merge it, and tag a release when I'm out of stuff that I can/want to do." At the other end is Fedora. Fedora isn't really a single project; it's a program of related projects that mostly move in the same direction. More than 200 people a week touch Fedora in a technical sense: spec file maintenance, build submission, etc. This doesn't even include the untold number of people who are working on the upstreams. And these upstreams all have their own release schedules and their own processes for how features land and when. Nobody can keep up with everything on their own, so the change process brings important changes to light.
|
||||
|
||||
### Decide who needs to review changes
|
||||
|
||||
One of the first things you need to consider when putting together a change process for your community is: "who needs to review changes?" This isn't necessarily approving the changes; we'll come to that shortly. But are there people who should take a look early in the process? Maybe your release engineering or infrastructure teams need to review them to make sure they don't require changes to build infrastructure. Maybe you have a legal review process to make sure licenses are in order. Or maybe you just have a change wrangler who looks to make sure all the required information is included. Or you may choose to do none of these and have change proposals go directly to the community.
|
||||
|
||||
But this brings up the next step. Do you want full community feedback or only a select group to provide feedback? My preference, and what we do in Fedora, is to publish changes to the community before they're approved. But the structure of your community may fit a model where some approval body signs off on the change before it is sent to the community as an announcement.
|
||||
|
||||
### Determine who approves changes
|
||||
|
||||
Even if you lack any sort of organizational structure, someone ends up approving changes. This should reflect the norms and values of your community. The simplest form of approval is the person who proposed the change implements it. Easy peasy! In loosely organized communities, that might work. Fully democratic communities might put it to a community-wide vote. If a certain number or proportion of members votes in favor, the change is approved. Other communities may give that power to an individual or group. They could be responsible for the entire project or certain subsections.
|
||||
|
||||
In Fedora, change approval is the role of the Fedora Engineering Steering Committee (FESCo). This is a nine-person body elected by community members. This gives the community the ability to remove members who are not acting in the best interests of the project but also enables relatively quick decisions without large overhead.
|
||||
|
||||
In much of this article, I am simply presenting information, but I'm going to take a moment to be opinionated. For any project with a significant contributor base, a model where a small body makes approval decisions is the right approach. A pure democracy can be pretty messy. People who may have no familiarity with the technical ramifications of a change will be able to cast a binding vote. And that process is subject to "brigading," where someone brings along a large group of otherwise-uninterested people to support their position. Think about what it might look like if someone proposed changing the default text editor. Would the decision process be rational?
|
||||
|
||||
### Plan how to enforce changes
|
||||
|
||||
The other advantage of having a defined approval body is it can mediate conflicts between changes. What happens if two proposed changes conflict? Or if a change turns out to have a negative impact? Someone needs to have the authority to say "this isn't going in after all" or make sure conflicting changes are brought into agreement. Your QA team and processes will be a part of this, and maybe they're the ones who will make the final call.
|
||||
|
||||
It's relatively straightforward to come up with a plan if a change doesn't work as expected or is incomplete by the deadline. If you require a contingency plan as part of the change process, then you implement that plan. The harder part is: what happens if someone makes a change that doesn't go through your change process? Here's a secret your friendly project manager doesn't want you to know: you can't force people to go through your process, particularly in community projects.
|
||||
|
||||
So if something sneaks in and you don't discover it until you have a release candidate, you have a couple of options: you can let it in, or you can get someone to forcibly remove it. In either case, you'll have someone who is very unhappy. Either the person who made the change, because you kicked their work out, or the people who had to deal with the breakage it caused. (If it snuck in without anyone noticing, then it's probably not that big of a deal.)
|
||||
|
||||
The answer, in either case, is going to be social pressure to follow the process. Processes are sometimes painful to follow, but a well-designed and well-maintained process will give more benefit than it costs. In this case, the benefit may be identifying breakages sooner or giving other developers a chance to take advantage of new features that are offered. And it can help prevent slips in the release schedule or hero effort from your QA team.
|
||||
|
||||
### Implement your change process
|
||||
|
||||
So we've thought about the life of a change proposal in your project. Throw in some deadlines that make sense for your release cadence, and you can now come up with the policy—but how do you implement it?
|
||||
|
||||
First, you'll want to identify the required information for a change proposal. At a minimum, I'd suggest the following. You may have more requirements depending on the specifics of what your community is making and how it operates.
|
||||
|
||||
* Name and summary
|
||||
* Benefit to the project
|
||||
* Scope
|
||||
* Owner
|
||||
* Test plan
|
||||
* Dependencies and impacts
|
||||
* Contingency plan
|
||||
|
||||
|
||||
|
||||
You'll also want one or several change wranglers. These aren't gatekeepers so much as shepherds. They may not have the ability to approve or reject change proposals, but they are responsible for moving the proposals through the process. They check the proposal for completeness, submit it to the appropriate bodies, make appropriate announcements, etc. You can have people wrangle their own changes, but this can be a specialized task and will generally benefit from a dedicated person who does this regularly, instead of making community members do it less frequently.
|
||||
|
||||
And you'll need some tooling to manage these changes. This could be a wiki page, a kanban board, a ticket tracker, something else, or a combination of these. But basically, you want to be able to track their state and provide some easy reporting on the status of changes. This makes it easier to know what is complete, what is at risk, and what needs to be deferred to a later release. You can use whatever works best for you, but in general, you'll want to minimize copy-and-pasting and maximize scriptability.
|
||||
|
||||
### Remember to iterate
|
||||
|
||||
Your change process may seem perfect. Then people will start using it. You'll discover edge cases you didn't consider. You'll find that the community hates a certain part of it. Decisions that were once valid will become invalid over time as technology and society change. In Fedora, our Features process revealed itself to be ambiguous and burdensome, so it was refined into the [Changes][3] process we use today. Even though the Changes process is much better than its predecessor, we still adjust it here and there to make sure it's best meeting the needs of the community.
|
||||
|
||||
When designing your process, make sure it fits the size and values of your community. Consider who gets a voice and who gets a vote in approving changes. Come up with a plan for how you'll handle incomplete changes and other exceptions. Decide who will guide the changes through the process and how they'll be tracked. And once you design your change policy, write it down in a place that's easy for your community to find so that they can follow it. But most of all, remember that the process is here to serve the community; the community is not here to serve the process.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/managing-changes-open-source-projects
|
||||
|
||||
作者:[Ben Cotton (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/change_words_scrabble_letters.jpg?itok=mbRFmPJ1 (scrabble letters: "time for change")
|
||||
[2]: https://hbr.org/2009/05/why-teams-dont-work
|
||||
[3]: https://fedoraproject.org/wiki/Changes/Policy
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why DevOps is the most important tech strategy today)
|
||||
[#]: via: (https://opensource.com/article/19/3/devops-most-important-tech-strategy)
|
||||
[#]: author: (Kelly AlbrechtWilly-Peter Schaub https://opensource.com/users/ksalbrecht/users/brentaaronreed/users/wpschaub/users/wpschaub/users/ksalbrecht)
|
||||
|
||||
Why DevOps is the most important tech strategy today
|
||||
======
|
||||
Clearing up some of the confusion about DevOps.
|
||||
![CICD with gears][1]
|
||||
|
||||
Many people first learn about [DevOps][2] when they see one of its outcomes and ask how it happened. It's not necessary to understand why something is part of DevOps to implement it, but knowing that—and why a DevOps strategy is important—can mean the difference between being a leader or a follower in an industry.
|
||||
|
||||
Maybe you've heard some the incredible outcomes attributed to DevOps, such as production environments that are so resilient they can handle thousands of releases per day while a "[Chaos Monkey][3]" is running around randomly unplugging things. This is impressive, but on its own, it's a weak business case, essentially burdened with [proving a negative][4]: The DevOps environment is resilient because a serious failure hasn't been observed… yet.
|
||||
|
||||
There is a lot of confusion about DevOps and many people are still trying to make sense of it. Here's an example from someone in my LinkedIn feed:
|
||||
|
||||
> Recently attended few #DevOps sessions where some speakers seemed to suggest #Agile is a subset of DevOps. Somehow, my understanding was just the opposite.
|
||||
>
|
||||
> Would like to hear your thoughts. What do you think is the relationship between Agile and DevOps?
|
||||
>
|
||||
> 1. DevOps is a subset of Agile
|
||||
> 2. Agile is a subset of DevOps
|
||||
> 3. DevOps is an extension of Agile, starts where Agile ends
|
||||
> 4. DevOps is the new version of Agile
|
||||
>
|
||||
|
||||
|
||||
Tech industry professionals have been weighing in on the LinkedIn post with a wide range of answers. How would you respond?
|
||||
|
||||
### DevOps' roots in lean and agile
|
||||
|
||||
DevOps makes a lot more sense if we start with the strategies of Henry Ford and the Toyota Production System's refinements of Ford's model. Within this history is the birthplace of lean manufacturing, which has been well studied. In [_Lean Thinking_][5], James P. Womack and Daniel T. Jones distill it into five principles:
|
||||
|
||||
1. Specify the value desired by the customer
|
||||
2. Identify the value stream for each product providing that value and challenge all of the wasted steps currently necessary to provide it
|
||||
3. Make the product flow continuously through the remaining value-added steps
|
||||
4. Introduce pull between all steps where continuous flow is possible
|
||||
5. Manage toward perfection so that the number of steps and the amount of time and information needed to serve the customer continually falls
|
||||
|
||||
|
||||
|
||||
Lean seeks to continuously remove waste and increase the flow of value to the customer. This is easily recognizable and understood through a core tenet of lean: single piece flow. We can do a number of activities to learn why moving single pieces at a time is magnitudes faster than batches of many pieces; the [Penny Game][6] and the [Airplane Game][7] are two of them. In the Penny Game, if a batch of 20 pennies takes two minutes to get to the customer, they get the whole batch after waiting two minutes. If you move one penny at a time, the customer gets the first penny in about five seconds and continues getting pennies until the 20th penny arrives approximately 25 seconds later.
|
||||
|
||||
This is a huge difference, but not everything in life is as simple and predictable as the penny in the Penny Game. This is where agile comes in. We certainly see lean principles on high-performing agile teams, but these teams need more than lean to do what they do.
|
||||
|
||||
To be able to handle the unpredictability and variance of typical software development tasks, agile methodology focuses on awareness, deliberation, decision, and action to adjust course in the face of a constantly changing reality. For example, agile frameworks (like scrum) increase awareness with ceremonies like the daily standup and the sprint review. If the scrum team becomes aware of a new reality, the framework allows and encourages them to adjust course if necessary.
|
||||
|
||||
For teams to make these types of decisions, they need to be self-organizing in a high-trust environment. High-performing agile teams working this way achieve a fast flow of value while continuously adjusting course, removing the waste of going in the wrong direction.
|
||||
|
||||
### Optimal batch size
|
||||
|
||||
To understand the power of DevOps in software development, it helps to understand the economics of batch size. Consider the following U-curve optimization illustration from Donald Reinertsen's _[Principles of Product Development Flow][8]:_
|
||||
|
||||
![U-curve optimization illustration of optimal batch size][9]
|
||||
|
||||
This can be explained with an analogy about grocery shopping. Suppose you need to buy some eggs and you live 30 minutes from the store. Buying one egg (far left on the illustration) at a time would mean a 30-minute trip each time. This is your _transaction cost_. The _holding cost_ might represent the eggs spoiling and taking up space in your refrigerator over time. The _total cost_ is the _transaction cost_ plus your _holding cost_. This U-curve explains why, for most people, buying a dozen eggs at a time is their _optimal batch size_. If you lived next door to the store, it'd cost you next to nothing to walk there, and you'd probably buy a smaller carton each time to save room in your refrigerator and enjoy fresher eggs.
|
||||
|
||||
This U-curve optimization illustration can shed some light on why productivity increases significantly in successful agile transformations. Consider the effect of agile transformation on decision making in an organization. In traditional hierarchical organizations, decision-making authority is centralized. This leads to larger decisions made less frequently by fewer people. An agile methodology will effectively reduce an organization's transaction cost for making decisions by decentralizing the decisions to where the awareness and information is the best known: across the high-trust, self-organizing agile teams.
|
||||
|
||||
The following animation shows how reducing transaction cost shifts the optimal batch size to the left. You can't understate the value to an organization in making faster decisions more frequently.
|
||||
|
||||
![U-curve optimization illustration][10]
|
||||
|
||||
### Where does DevOps fit in?
|
||||
|
||||
Automation is one of the things DevOps is most known for. The previous illustration shows the value of automation in great detail. Through automation, we reduce our transaction costs to nearly zero, essentially getting our testing and deployments for free. This lets us take advantage of smaller and smaller batch sizes of work. Smaller batches of work are easier to understand, commit to, test, review, and know when they are done. These smaller batch sizes also contain less variance and risk, making them easier to deploy and, if something goes wrong, to troubleshoot and recover from. With automation combined with a solid agile practice, we can get our feature development very close to single piece flow, providing value to customers quickly and continuously.
|
||||
|
||||
More traditionally, DevOps is understood as a way to knock down the walls of confusion between the dev and ops teams. In this model, development teams develop new features, while operations teams keep the system stable and running smoothly. Friction occurs because new features from development introduce change into the system, increasing the risk of an outage, which the operations team doesn't feel responsible for—but has to deal with anyway. DevOps is not just trying to get people working together, it's more about trying to make more frequent changes safely in a complex environment.
|
||||
|
||||
We can look to [Ron Westrum][11] for research about achieving safety in complex organizations. In researching why some organizations are safer than others, he found that an organization's culture is predictive of its safety. He identified three types of culture: Pathological, Bureaucratic, and Generative. He found that the Pathological culture was predictive of less safety and the Generative culture was predictive of more safety (e.g., far fewer plane crashes or accidental hospital deaths in his main areas of research).
|
||||
|
||||
![Three types of culture identified by Ron Westrum][12]
|
||||
|
||||
Effective DevOps teams achieve a Generative culture with lean and agile practices, showing that speed and safety are complementary, or two sides of the same coin. By reducing the optimal batch sizes of decisions and features to become very small, DevOps achieves a faster flow of information and value while removing waste and reducing risk.
|
||||
|
||||
In line with Westrum's research, change can happen easily with safety and reliability improving at the same time. When an agile DevOps team is trusted to make its own decisions, we get the tools and techniques DevOps is most known for today: automation and continuous delivery. Through this automation, transaction costs are reduced further than ever, and a near single piece lean flow is achieved, creating the potential for thousands of decisions and releases per day, as we've seen happen in high-performing DevOps organizations.
|
||||
|
||||
### Flow, feedback, learning
|
||||
|
||||
DevOps doesn't stop there. We've mainly been talking about DevOps achieving a revolutionary flow, but lean and agile practices are further amplified through similar efforts that achieve faster feedback loops and faster learning. In the [_DevOps Handbook_][13], the authors explain in detail how, beyond its fast flow, DevOps achieves telemetry across its entire value stream for fast and continuous feedback. Further, leveraging the [kaizen][14] bursts of lean and the [retrospectives][15] of scrum, high-performing DevOps teams will continuously drive learning and continuous improvement deep into the foundations of their organizations, achieving a lean manufacturing revolution in the software product development industry.
|
||||
|
||||
### Start with a DevOps assessment
|
||||
|
||||
The first step in leveraging DevOps is, either after much study or with the help of a DevOps consultant and coach, to conduct an assessment across a suite of dimensions consistently found in high-performing DevOps teams. The assessment should identify weak or non-existent team norms that need improvement. Evaluate the assessment's results to find quick wins—focus areas with high chances for success that will produce high-impact improvement. Quick wins are important for gaining the momentum needed to tackle more challenging areas. The teams should generate ideas that can be tried quickly and start to move the needle on the DevOps transformation.
|
||||
|
||||
After some time, the team should reassess on the same dimensions to measure improvements and identify new high-impact focus areas, again with fresh ideas from the team. A good coach will consult, train, mentor, and support as needed until the team owns its own continuous improvement and achieves near consistency on all dimensions by continually reassessing, experimenting, and learning.
|
||||
|
||||
In the [second part][16] of this article, we'll look at results from a DevOps survey in the Drupal community and see where the quick wins are most likely to be found.
|
||||
|
||||
* * *
|
||||
|
||||
_Rob_ _Bayliss and Kelly Albrecht will present[DevOps: Why, How, and What][17] and host a follow-up [Birds of a][18]_ [_Feather_][18] _[discussion][18] at [DrupalCon 2019][19] in Seattle, April 8-12._
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/devops-most-important-tech-strategy
|
||||
|
||||
作者:[Kelly AlbrechtWilly-Peter Schaub][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksalbrecht/users/brentaaronreed/users/wpschaub/users/wpschaub/users/ksalbrecht
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://opensource.com/resources/devops
|
||||
[3]: https://github.com/Netflix/chaosmonkey
|
||||
[4]: https://en.wikipedia.org/wiki/Burden_of_proof_(philosophy)#Proving_a_negative
|
||||
[5]: https://www.amazon.com/dp/B0048WQDIO/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
|
||||
[6]: https://youtu.be/5t6GhcvKB8o?t=54
|
||||
[7]: https://www.shmula.com/paper-airplane-game-pull-systems-push-systems/8280/
|
||||
[8]: https://www.amazon.com/dp/B00K7OWG7O/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
|
||||
[9]: https://opensource.com/sites/default/files/uploads/batch_size_optimal_650.gif (U-curve optimization illustration of optimal batch size)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/batch_size_650.gif (U-curve optimization illustration)
|
||||
[11]: https://en.wikipedia.org/wiki/Ron_Westrum
|
||||
[12]: https://opensource.com/sites/default/files/uploads/information_flow.png (Three types of culture identified by Ron Westrum)
|
||||
[13]: https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002/ref=sr_1_3?keywords=DevOps+handbook&qid=1553197361&s=books&sr=1-3
|
||||
[14]: https://en.wikipedia.org/wiki/Kaizen
|
||||
[15]: https://www.scrum.org/resources/what-is-a-sprint-retrospective
|
||||
[16]: https://opensource.com/article/19/3/where-drupal-community-stands-devops-adoption
|
||||
[17]: https://events.drupal.org/seattle2019/sessions/devops-why-how-and-what
|
||||
[18]: https://events.drupal.org/seattle2019/bofs/devops-getting-started
|
||||
[19]: https://events.drupal.org/seattle2019
|
||||
@ -0,0 +1,115 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Continuous response: The essential process we're ignoring in DevOps)
|
||||
[#]: via: (https://opensource.com/article/19/3/continuous-response-devops)
|
||||
[#]: author: (Randy Bias https://opensource.com/users/randybias)
|
||||
|
||||
Continuous response: The essential process we're ignoring in DevOps
|
||||
======
|
||||
You probably practice CI and CD, but if you aren't thinking about
|
||||
continuous response, you aren't really doing DevOps.
|
||||
![CICD with gears][1]
|
||||
|
||||
Continuous response (CR) is an overlooked link in the DevOps process chain. The two other major links—[continuous integration (CI) and continuous delivery (CD)][2]—are well understood, but CR is not. Yet, CR is the essential element of follow-through required to make customers happy and fulfill the promise of greater speed and agility. At the heart of the DevOps movement is the need for greater velocity and agility to bring businesses into our new digital age. CR plays a pivotal role in enabling this.
|
||||
|
||||
### Defining CR
|
||||
|
||||
We need a crisp definition of CR to move forward with breaking it down. To put it into context, let's revisit the definitions of continuous integration (CI) and continuous delivery (CD). Here are Gartner's definitions when I wrote this them down in 2017:
|
||||
|
||||
> [Continuous integration][3] is the practice of integrating, building, testing, and delivering functional software on a scheduled, repeatable, and automated basis.
|
||||
>
|
||||
> Continuous delivery is a software engineering approach where teams keep producing valuable software in short cycles while ensuring that the software can be reliably released at any time.
|
||||
|
||||
I propose the following definition for CR:
|
||||
|
||||
> Continuous response is a practice where developers and operators instrument, measure, observe, and manage their deployed software looking for changes in performance, resiliency, end-user behavior, and security posture and take corrective actions as necessary.
|
||||
|
||||
We can argue about whether these definitions are 100% correct. They are good enough for our purposes, which is framing the definition of CR in rough context so we can understand it is really just the last link in the chain of a holistic cycle.
|
||||
|
||||
![The holistic DevOps cycle][4]
|
||||
|
||||
What is this multi-colored ring, you ask? It's the famous [OODA Loop][5]. Before continuing, let's touch on what the OODA Loop is and why it's relevant to DevOps. We'll keep it brief though, as there is already a long history between the OODA Loop and DevOps.
|
||||
|
||||
#### A brief aside: The OODA Loop
|
||||
|
||||
At the heart of core DevOps thinking is using the OODA Loop to create a proactive process for evolving and responding to changing environments. A quick [web search][6] makes it easy to learn the long history between the OODA Loop and DevOps, but if you want the deep dive, I highly recommend [The Tao of Boyd: How to Master the OODA Loop][7].
|
||||
|
||||
Here is the "evolved OODA Loop" presented by John Boyd:
|
||||
|
||||
![OODA Loop][8]
|
||||
|
||||
The most important thing to understand about the OODA Loop is that it's a cognitive process for adapting to and handling changing circumstances.
|
||||
|
||||
The second most important thing to understand about the OODA Loop is, since it is a thought process that is meant to evolve, it depends on driving feedback back into the earlier parts of the cycle as you iterate.
|
||||
|
||||
As you can see in the diagram above, CI, CD, and CR are all their own isolated OODA Loops within the overall DevOps OODA Loop. The key here is that each OODA Loop is an evolving thought process for how test, release, and success are measured. Simply put, those who can execute on the OODA Loop fastest will win.
|
||||
|
||||
Put differently, DevOps wants to drive speed (executing the OODA Loop faster) combined with agility (taking feedback and using it to constantly adjust the OODA Loop). This is why CR is a vital piece of the DevOps process. We must drive production feedback into the DevOps maturation process. The DevOps notion of Culture, Automation, Measurement, and Sharing ([CAMS][9]) partially but inadequately captures this, whereas CR provides a much cleaner continuation of CI/CD in my mind.
|
||||
|
||||
### Breaking CR down
|
||||
|
||||
CR has more depth and breadth than CI or CD. This is natural, given that what we're categorizing is the post-deployment process by which our software is taking a variety of actions from autonomic responses to analytics of customer experience. I think, when it's broken down, there are three key buckets that CR components fall into. Each of these three areas forms a complete OODA Loop; however, the level of automation throughout the OODA Loop varies significantly.
|
||||
|
||||
The following table will help clarify the three areas of CR:
|
||||
|
||||
CR Type | Purpose | Examples
|
||||
---|---|---
|
||||
Real-time | Autonomics for availability and resiliency | Auto-scaling, auto-healing, developer-in-the-loop automated responses to real-time failures, automated root-cause analysis
|
||||
Analytic | Feature/fix pipeline | A/B testing, service response times, customer interaction models
|
||||
Predictive | History-based planning | Capacity planning, hardware failure prediction models, cost-basis analysis
|
||||
|
||||
_Real-time CR_ is probably the best understood of the three. This kind of CR is where our software has been instrumented for known issues and can take an immediate, automated response (autonomics). Examples of known issues include responding to high or low demand (e.g., elastic auto-scaling), responding to expected infrastructure resource failures (e.g., auto-healing), and responding to expected distributed application failures (e.g., circuit breaker pattern). In the future, we will see machine learning (ML) and similar technologies applied to automated root-cause analysis and event correlation, which will then provide a path towards "no ops" or "zero ops" operational models.
|
||||
|
||||
_Analytic CR_ is still the most manual of the CR processes. This kind of CR is focused primarily on observing end-user experience and providing feedback to the product development cycle to add features or fix existing functionality. Examples of this include traditional A/B website testing, measuring page-load times or service-response times, post-mortems of service failures, and so on.
|
||||
|
||||
_Predictive CR_ , due to the resurgence of AI and ML, is one of the innovation areas in CR. It uses historical data to predict future needs. ML techniques are allowing this area to become more fully automated. Examples include automated and predictive capacity planning (primarily for the infrastructure layer), automated cost-basis analysis of service delivery, and real-time reallocation of infrastructure resources to resolve capacity and hardware failure issues before they impact the end-user experience.
|
||||
|
||||
### Diving deeper on CR
|
||||
|
||||
CR, like CI or CD, is a DevOps process supported by a set of underlying tools. CI and CD are not Jenkins, unit tests, or automated deployments alone. They are a process flow. Similarly, CR is a process flow that begins with the delivery of new code via CD, which open source tools like [Spinnaker][10] give us. CR is not monitoring, machine learning, or auto-scaling, but a diverse set of processes that occur after code deployment, supported by a variety of tools. CR is also different in two specific ways.
|
||||
|
||||
First, it is different because, by its nature, it is broader. The general software development lifecycle (SDLC) process means that most [CI/CD processes][11] are similar. However, code running in production differs from app to app or service to service. This means that CR differs as well.
|
||||
|
||||
Second, CR is different because it is nascent. Like CI and CD before it, the process and tools existed before they had a name. Over time, CI/CD became more normalized and easier to scope. CR is new, hence there is lots of room to discuss what's in or out. I welcome your comments in this regard and hope you will run with these ideas.
|
||||
|
||||
### CR: Closing the loop on DevOps
|
||||
|
||||
DevOps arose because of the need for greater service delivery velocity and agility. Essentially, DevOps is an extension of agile software development practices to an operational mindset. It's a direct response to the flexibility and automation possibilities that cloud computing affords. However, much of the thinking on DevOps to date has focused on deploying the code to production and ends there. But our jobs don't end there. As professionals, we must also make certain our code is behaving as expected, we are learning as it runs in production, and we are taking that learning back into the product development process.
|
||||
|
||||
This is where CR lives and breathes. DevOps without CR is the same as saying there is no OODA Loop around the DevOps process itself. It's like saying that operators' and developers' jobs end with the code being deployed. We all know this isn't true. Customer experience is the ultimate measurement of our success. Can people use the software or service without hiccups or undue friction? If not, we need to fix it. CR is the final link in the DevOps chain that enables delivering the truest customer experience.
|
||||
|
||||
If you aren't thinking about continuous response, you aren't doing DevOps. Share your thoughts on CR, and tell me what you think about the concept and the definition.
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on[The Essential DevOps Process We're Ignoring: Continuous Response][12], which originally appeared on the Cloudscaling blog under a [CC BY 4.0][13] license and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/continuous-response-devops
|
||||
|
||||
作者:[Randy Bias][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/randybias
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://opensource.com/article/18/8/what-cicd
|
||||
[3]: https://www.gartner.com/doc/3187420/guidance-framework-continuous-integration-continuous
|
||||
[4]: https://opensource.com/sites/default/files/uploads/holistic-devops-cycle-smaller.jpeg (The holistic DevOps cycle)
|
||||
[5]: https://en.wikipedia.org/wiki/OODA_loop
|
||||
[6]: https://www.google.com/search?q=site%3Ablog.b3k.us+ooda+loop&rlz=1C5CHFA_enUS730US730&oq=site%3Ablog.b3k.us+ooda+loop&aqs=chrome..69i57j69i58.8660j0j4&sourceid=chrome&ie=UTF-8#q=devops+ooda+loop&*
|
||||
[7]: http://www.artofmanliness.com/2014/09/15/ooda-loop/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/ooda-loop-2-1.jpg (OODA Loop)
|
||||
[9]: https://itrevolution.com/devops-culture-part-1/
|
||||
[10]: https://www.spinnaker.io
|
||||
[11]: https://opensource.com/article/18/12/cicd-tools-sysadmins
|
||||
[12]: http://cloudscaling.com/blog/devops/the-essential-devops-process-were-ignoring-continuous-response/
|
||||
[13]: https://creativecommons.org/licenses/by/4.0/
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why do organizations have open secrets?)
|
||||
[#]: via: (https://opensource.com/open-organization/19/3/open-secrets-bystander-effect)
|
||||
[#]: author: (Laura Hilliger https://opensource.com/users/laurahilliger/users/maryjo)
|
||||
|
||||
Why do organizations have open secrets?
|
||||
======
|
||||
Everyone sees something, but no one says anything—that's the bystander
|
||||
effect. And it's damaging your organizational culture.
|
||||
![][1]
|
||||
|
||||
[The five characteristics of an open organization][2] must work together to ensure healthy and happy communities inside our organizations. Even the most transparent teams, departments, and organizations require equal doses of additional open principles—like inclusivity and collaboration—to avoid dysfunction.
|
||||
|
||||
The "open secrets" phenomenon illustrates the limitations of transparency when unaccompanied by additional open values. [A recent article in Harvard Business Review][3] explored the way certain organizational issues—widely apparent but seemingly impossible to solve—lead to discomfort in the workforce. Authors Insiya Hussain and Subra Tangirala performed a number of studies, and found that the more people in an organization who knew about a particular "secret," be it a software bug or a personnel issue, the less likely any one person would be to report the issue or otherwise _do_ something about it.
|
||||
|
||||
Hussain and Tangirala explain that so-called "open secrets" are the result of a [bystander effect][4], which comes into play when people think, "Well, if _everyone_ knows, surely _I_ don't need to be the one to point it out." The authors mention several causes of this behavior, but let's take a closer look at why open secrets might be circulating in your organization—with an eye on what an open leader might do to [create a safe space for whistleblowing][5].
|
||||
|
||||
### 1\. Fear
|
||||
|
||||
People don't want to complain about a known problem only to have their complaint be the one that initiates the quality assurance, integrity, or redress process. What if new information emerges that makes their report irrelevant? What if they are simply _wrong_?
|
||||
|
||||
At the root of all bystander behavior is fear—fear of repercussions, fear of losing reputation or face, or fear that the very thing you've stood up against turns out to be a non-issue for everyone else. Going on record as "the one who reported" carries with it a reputational risk that is very intimidating.
|
||||
|
||||
The first step to ensuring that your colleagues report malicious behavior, code, or _whatever_ needs reporting is to create a fear-free workplace. We're inundated with the idea that making a mistake is bad or wrong. We're taught that we have to "protect" our reputations. However, the qualities of a good and moral character are _always_ subjective.
|
||||
|
||||
_Tip for leaders_ : Reward courage and strength every time you see it, regardless of whether you deem it "necessary." For example, if in a meeting where everyone except one person agrees on something, spend time on that person's concerns. Be patient and kind in helping that person change their mind, and be open minded about that person being able to change yours. Brains work in different ways; never forget that one person might have a perspective that changes the lay of the land.
|
||||
|
||||
### 2\. Policies
|
||||
|
||||
Usually, complaint procedures and policies are designed to ensure fairness towards all parties involved in the complaint. Discouraging false reporting and ensuring such fairness in situations like these is certainly a good idea. But policies might actually deter people from standing up—because a victim might be discouraged from reporting an experience if the formal policy for reporting doesn't make them feel protected. Standing up to someone in a position of power and saying "Your behavior is horrid, and I'm not going to take it" isn't easy for anyone, but it's particularly difficult for marginalized groups.
|
||||
|
||||
The "open secrets" phenomenon illustrates the limitations of transparency when unaccompanied by additional open values.
|
||||
|
||||
To ensure fairness to all parties, we need to adjust for victims. As part of making the decision to file a report, a victim will be dealing with a variety of internal fears. They'll wonder what might happen to their self-worth if they're put in a situation where they have to talk to someone about their experience. They'll wonder if they'll be treated differently if they're the one who stands up, and how that will affect their future working environments and relationships. Especially in a situation involving an open secret, asking a victim to be strong is asking them to have to trust that numerous other people will back them up. This fear shouldn't be part of their workplace experience; it's just not fair.
|
||||
|
||||
Remember that if one feels responsible for a problem (e.g., "Crap, that's _my code_ that's bringing down the whole server!"), then that person might feel fear at pointing out the mistake. _The important thing is dealing with the situation, not finding someone to blame._ Policies that make people feel personally protected—no matter what the situation—are absolutely integral to ensuring the organization deals with open secrets.
|
||||
|
||||
_Tip for leaders_ : Make sure your team's or organization's policy regarding complaints makes anonymous reporting possible. Asking a victim to "go on record" puts them in the position of having to defend their perspective. If they feel they're the victim of harassment, they're feeling as if they are harassed _and_ being asked to defend their experience. This means they're doing double the work of the perpetrator, who only has to defend themselves.
|
||||
|
||||
### 3\. Marginalization
|
||||
|
||||
Women, LGBTQ people, racial minorities, people with physical disabilities, people who are neuro-atypical, and other marginalized groups often find themselves in positions that them feel routinely dismissed, disempowered, disrespected—and generally dissed. These feelings are valid (and shouldn't be too surprising to anyone who has spent some time looking at issues of diversity and inclusion). Our emotional safety matters, and we tend to be quite protective of it—even if it means letting open secrets go unaddressed.
|
||||
|
||||
Marginalized groups have enough worries weighing on them, even when they're _not_ running the risk of damaging their relationships with others at work. Being seen and respected in both an organization and society more broadly is difficult enough _without_ drawing potentially negative attention.
|
||||
|
||||
Policies that make people feel personally protected—no matter what the situation—are absolutely integral to ensuring the organization deals with open secrets.
|
||||
|
||||
Luckily, in recent years attitudes towards marginalized groups have become visible, and we as a society have begun to talk about our experiences as "outliers." We've also come to realize that marginalized groups aren't actually "outliers" at all; we can thank the colorful, beautiful internet for that.
|
||||
|
||||
_Tip for leaders_ : Diversity and inclusion plays a role in dispelling open secrets. Make sure your diversity and inclusion practices and policies truly encourage a diverse workplace.
|
||||
|
||||
### Model the behavior
|
||||
|
||||
The best way to create a safe workplace and give people the ability to call attention to pervasive problems found within it is to _model the behaviors that you want other people to display_. Dysfunction occurs in cultures that don't pay attention to and value the principles upon which they are built. In order to discourage bystander behavior, transparent, inclusive, adaptable and collaborative communities must create policies that support calling attention to open secrets and then empathetically dealing with whatever the issue may be.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/3/open-secrets-bystander-effect
|
||||
|
||||
作者:[Laura Hilliger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/laurahilliger/users/maryjo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_secret_ingredient_520x292.png?itok=QbKzJq-N
|
||||
[2]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[3]: https://hbr.org/2019/01/why-open-secrets-exist-in-organizations
|
||||
[4]: https://www.psychologytoday.com/us/basics/bystander-effect
|
||||
[5]: https://opensource.com/open-organization/19/2/open-leaders-whistleblowers
|
||||
@ -0,0 +1,139 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (9 open source tools for building a fault-tolerant system)
|
||||
[#]: via: (https://opensource.com/article/19/3/tools-fault-tolerant-system)
|
||||
[#]: author: (Bryant Son (Red Hat, Community Moderator) https://opensource.com/users/brson)
|
||||
|
||||
9 open source tools for building a fault-tolerant system
|
||||
======
|
||||
|
||||
Maximize uptime and minimize problems with these open source tools.
|
||||
|
||||
![magnifying glass on computer screen, finding a bug in the code][1]
|
||||
|
||||
I've always been interested in web development and software architecture because I like to see the broader picture of a working system. Whether you are building a mobile app or a web application, it has to be connected to the internet to exchange data among different modules, which means you need a web service.
|
||||
|
||||
If you use a cloud system as your application's backend, you can take advantage of greater computing power, as the backend service will scale horizontally and vertically and orchestrate different services. But whether or not you use a cloud backend, it's important to build a _fault-tolerant system_ —one that is resilient, stable, fast, and safe.
|
||||
|
||||
To understand fault-tolerant systems, let's use Facebook, Amazon, Google, and Netflix as examples. Millions and billions of users access these platforms simultaneously while transmitting enormous amounts of data via peer-to-peer and user-to-server networks, and you can be sure there are also malicious users with bad intentions, like hacking or denial-of-service (DoS) attacks. Even so, these platforms can operate 24 hours a day and 365 days a year without downtime.
|
||||
|
||||
Although machine learning and smart algorithms are the backbones of these systems, the fact that they achieve consistent service without a single minute of downtime is praiseworthy. Their expensive hardware and gigantic datacenters certainly matter, but the elegant software designs supporting the services are equally important. And the fault-tolerant system is one of the principles to build such an elegant system.
|
||||
|
||||
### Two behaviors that cause problems in production
|
||||
|
||||
Here's another way to think of a fault-tolerant system. When you run your application service locally, everything seems to be fine. Great! But when you promote your service to the production environment, all hell breaks loose. In a situation like this, a fault-tolerant system helps by addressing two problems: Fail-stop behavior and Byzantine behavior.
|
||||
|
||||
#### Fail-stop behavior
|
||||
|
||||
Fail-stop behavior is when a running system suddenly halts or a few parts of the system fail. Server downtime and database inaccessibility fall under this category. For example, in the diagram below, Service 1 can't communicate with Service 2 because Service 2 is inaccessible:
|
||||
|
||||
![Fail-stop behavior due to Service 2 downtime][2]
|
||||
|
||||
But the problem can also occur if there is a network problem between the services, like this:
|
||||
|
||||
![Fail-stop behavior due to network failure][3]
|
||||
|
||||
#### Byzantine behavior
|
||||
|
||||
Byzantine behavior is when the system continuously runs but doesn't produce the expected behavior (e.g., wrong data or an invalid value).
|
||||
|
||||
Byzantine failure can happen if Service 2 has corrupted data or values, even though the service looks to be operating just fine, like in this example:
|
||||
|
||||
![Byzantine failure due to corrupted service][4]
|
||||
|
||||
Or, there can be a malicious middleman intercepting between the services and injecting unwanted data:
|
||||
|
||||
![Byzantine failure due to malicious middleman][5]
|
||||
|
||||
Neither fail-stop nor Byzantine behavior is a desired situation, so we need ways to prevent or fix them. That's where fault-tolerant systems come into play. Following are eight open source tools that can help you address these problems.
|
||||
|
||||
### Tools for building a fault-tolerant system
|
||||
|
||||
Although building a truly practical fault-tolerant system touches upon in-depth _distributed computing theory_ and complex computer science principles, there are many software tools—many of them, like the following, open source—to alleviate undesirable results by building a fault-tolerant system.
|
||||
|
||||
#### Circuit-breaker pattern: Hystrix and Resilience4j
|
||||
|
||||
The [circuit-breaker pattern][6] is a technique that helps to return a prepared dummy response or a simple response when a service fails:
|
||||
|
||||
![Circuit breaker pattern][7]
|
||||
|
||||
Netflix's open source **[Hystrix][8]** is the most popular implementation of the circuit-breaker pattern.
|
||||
|
||||
Many companies where I've worked previously are leveraging this wonderful tool. Surprisingly, Netflix announced that it will no longer update Hystrix. (Yeah, I know.) Instead, Netflix recommends using an alternative solution like [**Resilence4j**][9], which supports Java 8 and functional programming, or an alternative practice like [Adaptive Concurrency Limit][10].
|
||||
|
||||
#### Load balancing: Nginx and HaProxy
|
||||
|
||||
Load balancing is one of the most fundamental concepts in a distributed system and must be present to have a production-quality environment. To understand load balancers, we first need to understand the concept of _redundancy_. Every production-quality web service has multiple servers that provide redundancy to take over and maintain services when servers go down.
|
||||
|
||||
![Load balancer][11]
|
||||
|
||||
Think about modern airplanes: their dual engines provide redundancy that allows them to land safely even if an engine catches fire. (It also helps that most commercial airplanes have state-of-art, automated systems.) But, having multiple engines (or servers) means that there must be some kind of scheduling mechanism to effectively route the system when something fails.
|
||||
|
||||
A load balancer is a device or software that optimizes heavy traffic transactions by balancing multiple server nodes. For instance, when thousands of requests come in, the load balancer acts as the middle layer to route and evenly distribute traffic across different servers. If a server goes down, the load balancer forwards requests to the other servers that are running well.
|
||||
|
||||
There are many load balancers available, but the two best-known ones are Nginx and HaProxy.
|
||||
|
||||
[**Nginx**][12] is more than a load balancer. It is an HTTP and reverse proxy server, a mail proxy server, and a generic TCP/UDP proxy server. Companies like Groupon, Capital One, Adobe, and NASA use it.
|
||||
|
||||
[**HaProxy**][13] is also popular, as it is a free, very fast and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications. Many large internet companies, including GitHub, Reddit, Twitter, and Stack Overflow, use HaProxy. Oh and yes, Red Hat Enterprise Linux also supports HaProxy configuration.
|
||||
|
||||
#### Actor model: Akka
|
||||
|
||||
The [actor model][14] is a concurrency design pattern that delegates responsibility when an _actor_ , which is a primitive unit of computation, receives a message. An actor can create even more actors and delegate the message to them.
|
||||
|
||||
[**Akka**][15] is one of the most well-known tools for the actor model implementation. The framework supports Java and Scala, which are both based on JVM.
|
||||
|
||||
#### Asynchronous, non-blocking I/O using messaging queue: Kafka and RabbitMQ
|
||||
|
||||
Multi-threaded development has been popular in the past, but this practice has been discouraged and replaced with asynchronous, non-blocking I/O patterns. For Java, this is explicitly stated in its [Enterprise Java Bean (EJB) specifications][16]:
|
||||
|
||||
> "An enterprise bean must not use thread synchronization primitives to synchronize execution of multiple instances.
|
||||
>
|
||||
> "The enterprise bean must not attempt to manage threads. The enterprise bean must not attempt to start, stop, suspend, or resume a thread, or to change a thread's priority or name. The enterprise bean must not attempt to manage thread groups."
|
||||
|
||||
Now, there are other practices like stream APIs and actor models. But messaging queues like [**Kafka**][17] and [**RabbitMQ**][18] offer the out-of-box support for asynchronous and non-blocking IO features, and they are powerful open source tools that can be replacements for threads by handling concurrent processes.
|
||||
|
||||
#### Other options: Eureka and Chaos Monkey
|
||||
|
||||
Other useful tools for fault-tolerant systems include monitoring tools, such as Netflix's **[Eureka][19]** , and stress-testing tools, like **[Chaos Monkey][20]**. They aim to discover potential issues earlier by testing in lower environments, like integration (INT), quality assurance (QA), and user acceptance testing (UAT), to prevent potential problems before moving to the production environment.
|
||||
|
||||
* * *
|
||||
|
||||
What open source tools are you using for building a fault-tolerant system? Please share your favorites in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/tools-fault-tolerant-system
|
||||
|
||||
作者:[Bryant Son (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/mistake_bug_fix_find_error.png?itok=PZaz3dga (magnifying glass on computer screen, finding a bug in the code)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/1_errordowntimeservice.jpg (Fail-stop behavior due to Service 2 downtime)
|
||||
[3]: https://opensource.com/sites/default/files/uploads/2_errordowntimenetwork.jpg (Fail-stop behavior due to network failure)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/3_byzantinefailuremalicious.jpg (Byzantine failure due to corrupted service)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/4_byzantinefailuremiddleman.jpg (Byzantine failure due to malicious middleman)
|
||||
[6]: https://martinfowler.com/bliki/CircuitBreaker.html
|
||||
[7]: https://opensource.com/sites/default/files/uploads/5_circuitbreakerpattern.jpg (Circuit breaker pattern)
|
||||
[8]: https://github.com/Netflix/Hystrix/wiki
|
||||
[9]: https://github.com/resilience4j/resilience4j
|
||||
[10]: https://medium.com/@NetflixTechBlog/performance-under-load-3e6fa9a60581
|
||||
[11]: https://opensource.com/sites/default/files/uploads/7_loadbalancer.jpg (Load balancer)
|
||||
[12]: https://www.nginx.com
|
||||
[13]: https://www.haproxy.org
|
||||
[14]: https://en.wikipedia.org/wiki/Actor_model
|
||||
[15]: https://akka.io
|
||||
[16]: https://jcp.org/aboutJava/communityprocess/final/jsr220/index.html
|
||||
[17]: https://kafka.apache.org
|
||||
[18]: https://www.rabbitmq.com
|
||||
[19]: https://github.com/Netflix/eureka
|
||||
[20]: https://github.com/Netflix/chaosmonkey
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Kubeflow is evolving without ksonnet)
|
||||
[#]: via: (https://opensource.com/article/19/4/kubeflow-evolution)
|
||||
[#]: author: (Jonathan Gershater (Red Hat) https://opensource.com/users/jgershat/users/jgershat)
|
||||
|
||||
How Kubeflow is evolving without ksonnet
|
||||
======
|
||||
There are big differences in how open source communities handle change compared to closed source vendors.
|
||||
![Chat bubbles][1]
|
||||
|
||||
Many software projects depend on modules that are run as separate open source projects. When one of those modules loses support (as is inevitable), the community around the main project must determine how to proceed.
|
||||
|
||||
This situation is happening right now in the [Kubeflow][2] community. Kubeflow is an evolving open source platform for developing, orchestrating, deploying, and running scalable and portable machine learning workloads on [Kubernetes][3]. Recently, the primary supporter of the Kubeflow component [ksonnet][4] announced that it would [no longer support][5] the software.
|
||||
|
||||
When a piece of software loses support, the decision-making process (and the outcome) differs greatly depending on whether the software is open source or closed source.
|
||||
|
||||
### A cellphone analogy
|
||||
|
||||
To illustrate the differences in how an open source community and a closed source/single software vendor proceed when a component loses support, let's use an example from hardware design.
|
||||
|
||||
Suppose you buy cellphone Model A and it stops working. When you try to get it repaired, you discover the manufacturer is out of business and no longer offering support. Since the cellphone's design is proprietary and closed, no other manufacturers can support it.
|
||||
|
||||
Now, suppose you buy cellphone Model B, it stops working, and its manufacturer is also out of business and no longer offering support. However, Model B's design is open, and another company is in business manufacturing, repairing and upgrading Model B cellphones.
|
||||
|
||||
This illustrates one difference between software written using closed and open source principles. If the vendor of a closed source software solution goes out of business, support disappears with the vendor, unless the vendor sells the software's design and intellectual property. But, if the vendor of an open source solution goes out of business, there is no intellectual property to sell. By the principles of open source, the source code is available for anyone to use and modify, under license, so another vendor can continue to maintain the software.
|
||||
|
||||
### How Kubeflow is evolving without ksonnet
|
||||
|
||||
The ramification of ksonnet's backers' decision to cease development illustrates Kubeflow's open and collaborative design process. Kubeflow's designers have several options, such as replacing ksonnet, adopting and developing ksonnet, etc. Because Kubeflow is an open source project, all options are discussed in the open on the Kubeflow mailing list. Some of the community's suggestions include:
|
||||
|
||||
> * Should we look at projects that are CNCF/Apache projects e.g. [helm][6]
|
||||
> * I would opt for back to the basics. KISS. How about plain old jsonnet + kubectl + makefile/scripts ? Thats how e.g. the coreos [prometheus operator][7] does it. It would also lower the entry barrier (no new tooling) and let vendors of k8s (gke, openshift, etc) easily build on top of that.
|
||||
> * I vote for using a simple, _programmatic_ context, be it manual jsonnet + kubectl, or simple Python scripts + Python K8s client, or any tool be can build on top of these.
|
||||
>
|
||||
|
||||
|
||||
The members of the mailing list are discussing and debating alternatives to ksonnet and will arrive at a decision to continue development. What I love about the open source way of adapting is that it's done communally. Unlike closed source software, which is often designed by one vendor, the organizations that are members of an open source project can collaboratively steer the project in the direction they best see fit. As Kubeflow evolves, it will benefit from an open, collaborative decision-making framework.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/kubeflow-evolution
|
||||
|
||||
作者:[Jonathan Gershater (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jgershat/users/jgershat
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_communication_team.png?itok=CYfZ_gE7 (Chat bubbles)
|
||||
[2]: https://www.kubeflow.org/
|
||||
[3]: https://github.com/kubernetes
|
||||
[4]: https://ksonnet.io/
|
||||
[5]: https://blogs.vmware.com/cloudnative/2019/02/05/welcoming-heptio-open-source-projects-to-vmware/
|
||||
[6]: https://landscape.cncf.io
|
||||
[7]: https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user