mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
校对部分
This commit is contained in:
parent
4bd14d1d30
commit
9e1e088660
@ -33,17 +33,17 @@
|
||||
|
||||
### 臭名昭著的 SunSpider 案例
|
||||
|
||||
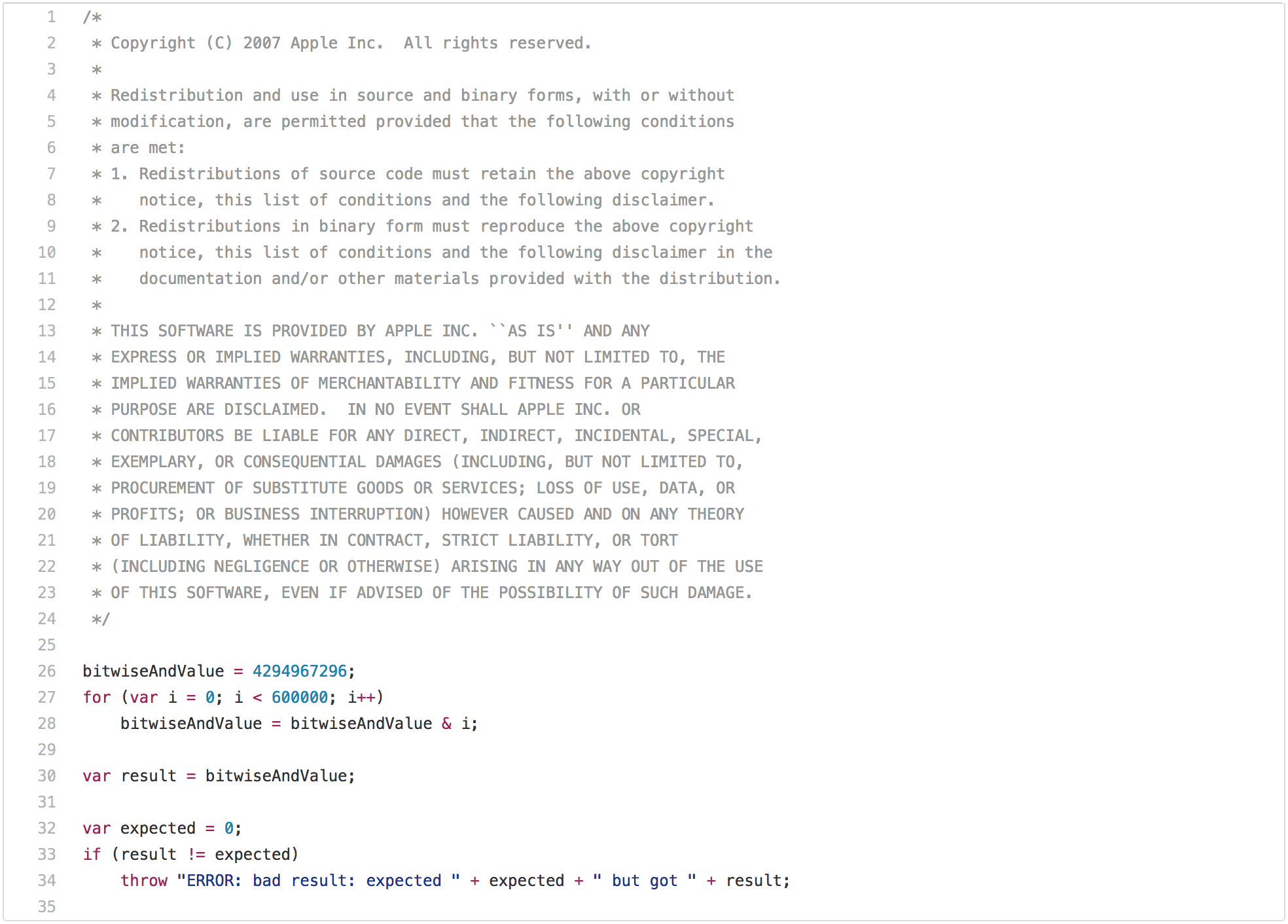
一篇关于传统 JavaScript 基准测试的博客如果没有指出 SunSpider 明显的问题是不完整的。让我们从性能测试的最佳实践开始,它在现实场景中不是很适用:[`bitops-bitwise-and.js` 性能测试][39]
|
||||
一篇关于传统 JavaScript 基准测试的博客如果没有指出 SunSpider 那个明显的问题是不完整的。让我们从性能测试的最佳实践开始,它在现实场景中不是很适用:[bitops-bitwise-and.js` 性能测试][39]。
|
||||
|
||||
[][40]
|
||||
|
||||
有一些算法需要进行快速的位运算,特别是从 `C/C++` 转译成 JavaScript 的地方,所以快速执行按位操作确实有点意义。然而,现实场景中的网页可能不关心引擎是否可以执行位运算,并且能否在循环中比另一个引擎快两倍。但是再盯着这段代码几秒钟,你可能会注意到,在第一次循环迭代之后 `bitwiseAndValue` 将变成 `0`,并且在接下来的 599999 次迭代中将保持为 `0`。所以一旦你在此获得好性能,即在体面的硬件上所有测试均低于 5ms,在经过尝试之后意识到,只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 [loop peeling][41] 后面的死代码),现在你可以开始玩弄这个基准了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 `bitwiseAndValue` 是全局对象的常规属性还是在执行脚本之前不存在,全局对象或者它的原型上必须没有拦截器。但如果你真的想要赢得这个基准测试,并且你愿意全力以赴,那么你可以在不到 1ms 的时间内完成这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
|
||||
有一些算法需要进行快速的 AND 位运算,特别是从 `C/C++` 转译成 JavaScript 的地方,所以快速执行该操作确实有点意义。然而,现实场景中的网页可能不关心引擎在循环中执行 AND 位运算是否比另一个引擎快两倍。但是再盯着这段代码几秒钟后,你可能会注意到在第一次循环迭代之后 `bitwiseAndValue` 将变成 `0`,并且在接下来的 599999 次迭代中将保持为 `0`。所以一旦你让此获得了好的性能,比如在差不多的硬件上所有测试均低于 5ms,在经过尝试之后你会意识到,只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 [loop peeling][41] 后面的死代码),那你现在就可以开始玩弄这个基准测试了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 `bitwiseAndValue` 是全局对象的常规属性还是在执行脚本之前不存在,全局对象或者它的原型上必须没有拦截器。但如果你真的想要赢得这个基准测试,并且你愿意全力以赴,那么你可以在不到 1ms 的时间内完成这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
|
||||
|
||||
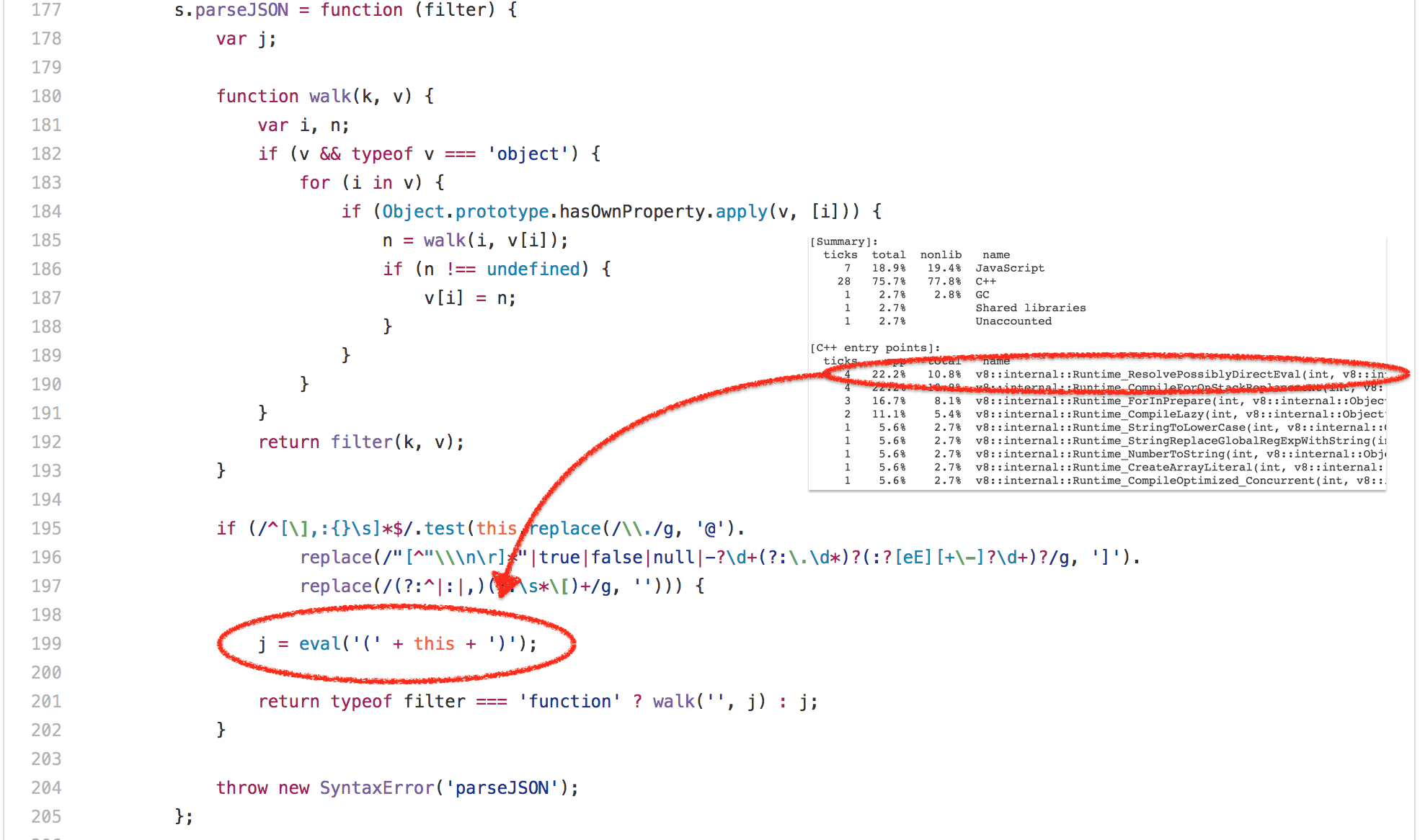
好吧,那么 [`bitops-bitwise-and.js`][42] 测试彻底肯定是微基准最失败的案例。让我们继续转移到 SunSpider 中更逼真的场景——[`string-tagcloud.js`][43] 测试,它的底层运行着一个较早版本的 `json.js polyfill`。该测试可以说看起来比位运算测试更合理,但是查看基准的配置之后立刻显示:大量的时间浪费在一条 `eval` 表达式(高达 20% 的总执行时间被用于解析和编译,再加上实际执行编译后代码的 10% 的时间)。
|
||||
好吧,那么 [bitops-bitwise-and.js][42] 测试彻底肯定是微基准最失败的案例。让我们继续转移到 SunSpider 中更逼真的场景——[string-tagcloud.js][43] 测试,它基本上是运行一个较早版本的 `json.js polyfill`。该测试可以说看起来比位运算测试更合理,但是花点时间查看基准的配置之后立刻会发现:大量的时间浪费在一条 `eval` 表达式(高达 20% 的总执行时间被用于解析和编译,再加上实际执行编译后代码的 10% 的时间)。
|
||||
|
||||
[][44]
|
||||
|
||||
仔细看看,这个 `eval` 只执行了一次,并传递一个 `JSON` 格式的字符串,它包含一个由 2501 个含有 `tag` 和 `popularity` 属性的对象组成的数组:
|
||||
仔细看看,这个 `eval` 只执行了一次,并传递一个 JSON 格式的字符串,它包含一个由 2501 个含有 `tag` 和 `popularity` 属性的对象组成的数组:
|
||||
|
||||
```
|
||||
([
|
||||
@ -83,7 +83,7 @@
|
||||
])
|
||||
```
|
||||
|
||||
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 `JSON` 并生成适当的对象图的开销将更加低廉。所以,加快这个基准测试的一个小把戏就是模拟 `eval`,并尝试总是将数据首先作为 `JSON` 解析,然后再回溯到真实的解析、编译、执行,直到尝试读取 `JSON` 失败(尽管需要一些额外的黑魔法来跳过括号)。早在 2007 年,这甚至不算是一个坏点子,因为没有 [`JSON.parse`][45],不过在 2017 年这只是 JavaScript 引擎的技术债,可能会让 `eval` 的合法使用遥遥无期。
|
||||
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 JSON 并生成适当的对象图的开销将更加低廉。所以,加快这个基准测试的一个小把戏就是模拟 `eval`,并尝试总是将数据首先作为 JSON 解析,如果以 JSON 方式读取失败,才回退进行真实的解析、编译、执行(尽管需要一些额外的黑魔法来跳过括号)。早在 2007 年,这甚至不算是一个坏点子,因为没有 [JSON.parse][45],不过在 2017 年这只是 JavaScript 引擎的技术债,可能会让 `eval` 的合法使用遥遥无期。
|
||||
|
||||
```
|
||||
--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
|
||||
@ -99,7 +99,7 @@
|
||||
}
|
||||
```
|
||||
|
||||
事实上,将基准测试更新到现代 JavaScript 会立刻提升性能,正如今天的 `V8 LKGR` 从 36ms 降到了 26ms,性能足足提升了 30%!
|
||||
事实上,将基准测试更新到现代 JavaScript 会立刻会性能暴增,正如今天的 `V8 LKGR` 从 36ms 降到了 26ms,性能足足提升了 30%!
|
||||
|
||||
```
|
||||
$ node string-tagcloud.js.ORIG
|
||||
@ -111,9 +111,9 @@ v8.0.0-pre
|
||||
$
|
||||
```
|
||||
|
||||
这是静态基准和性能测试套件常见的一个问题。今天,没有人会正儿八经地用 `eval` 解析 `JSON` 数据(不仅是因为性能问题,还出于严重的安全性考虑),而是坚持为所有代码使用诞生于五年前的 [`JSON.parse`][46]。事实上,使用 `eval` 解析 `JSON` 可能会被视作生产环境的一个漏洞!所以引擎作者致力于新代码的性能所作的努力并没有反映在这个古老的基准中,相反地,使用 `eval` 来赢得 `string-tagcloud.js` 测试是没有必要的。
|
||||
这是静态基准和性能测试套件常见的一个问题。今天,没有人会正儿八经地用 `eval` 解析 `JSON` 数据(不仅是因为性能问题,还出于严重的安全性考虑),而是坚持为最近五年写的代码使用 [JSON.parse][46]。事实上,使用 `eval` 解析 JSON 可能会被视作产品级代码的的一个漏洞!所以引擎作者致力于新代码的性能所作的努力并没有反映在这个古老的基准中,相反地,而是使得 `eval` 不必要地~~更智能~~复杂化,从而赢得 `string-tagcloud.js` 测试。
|
||||
|
||||
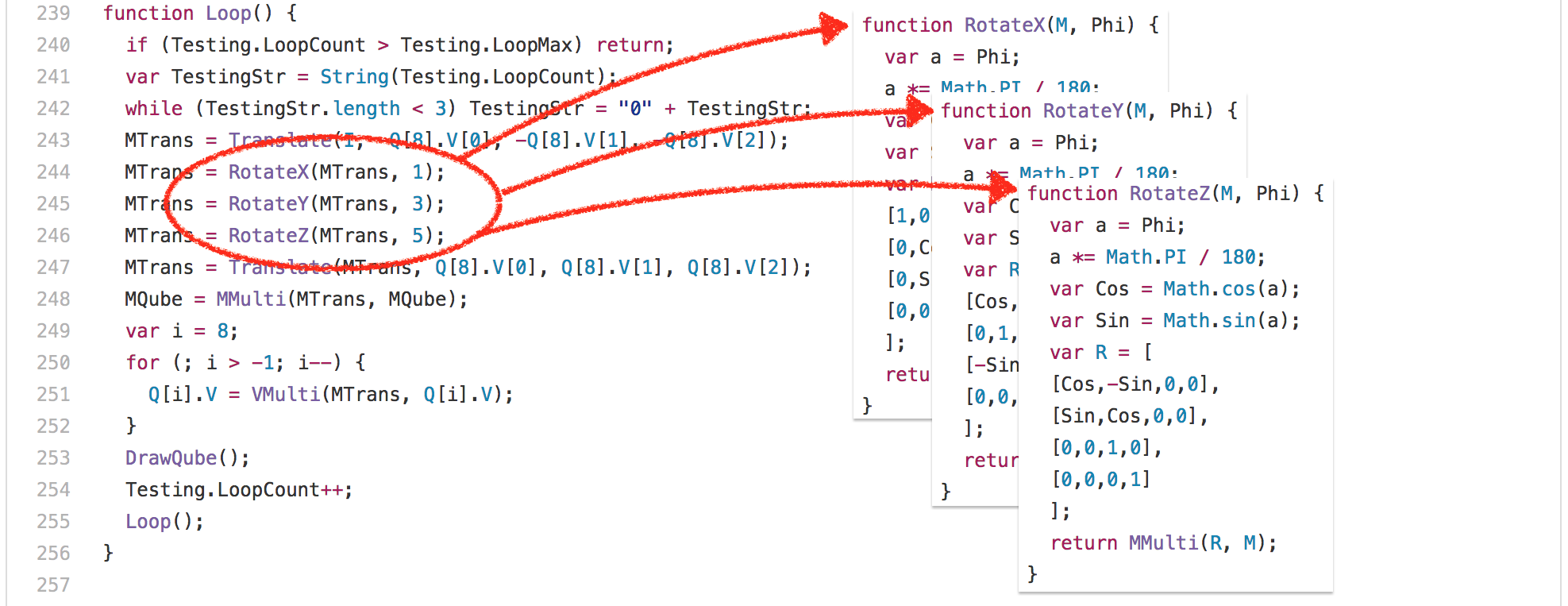
好吧,让我们看看另一个例子:[`3d-cube.js`][47]。这个基准测试做了很多矩阵运算,即便是最聪明的编译器仅仅执行这个运算都做不了这么多。基本上,基准测试花了大量的时间执行 `Loop` 函数及其调用的函数。
|
||||
好吧,让我们看看另一个例子:[3d-cube.js][47]。这个基准测试做了很多矩阵运算,即便是最聪明的编译器对此也无可奈何,只能说执行而已。基本上,该基准测试花了大量的时间执行 `Loop` 函数及其调用的函数。
|
||||
|
||||
[][48]
|
||||
|
||||
@ -121,55 +121,59 @@ $
|
||||
|
||||
[][49]
|
||||
|
||||
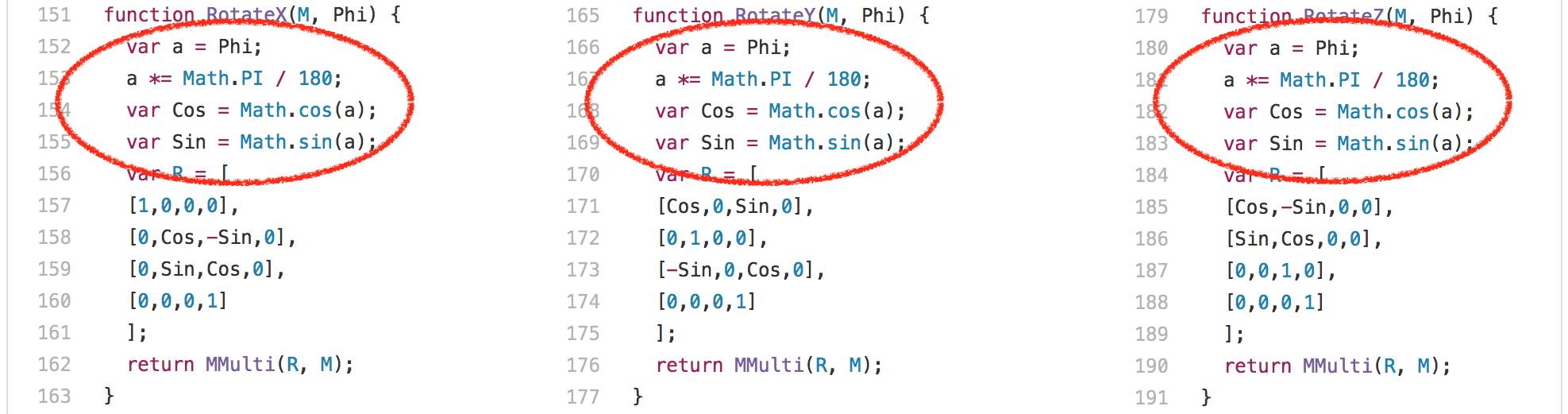
这意味着我们基本上总是为 [`Math.sin`][50] 和 [`Math.cos`][51] 计算相同的值,每次执行都要计算 204 次。只有 3 个不同的输入值:
|
||||
这意味着我们基本上总是为 [Math.sin][50] 和 [Math.cos][51] 计算相同的值,每次执行都要计算 204 次。只有 3 个不同的输入值:
|
||||
|
||||
* 0.017453292519943295,
|
||||
* 0.05235987755982989,
|
||||
* 0.017453292519943295
|
||||
* 0.05235987755982989
|
||||
* 0.08726646259971647
|
||||
|
||||
显然,你可以在这里做的一件事情就是通过缓存以前的计算值来避免重复计算相同的正弦值和余弦值。事实上,这是 V8 以前的做法,而其它引擎例如 `SpiderMonkey` 仍然这样做。我们从 V8 中删除了所谓的超载缓存,因为缓存的开销在现实中的工作负载是不可忽视的,你不可能总是在一行代码中计算相同的值,这在其它地方倒不稀奇。当我们在 2013 和 2014 年移除这个特定的基准优化时,我们对 SunSpider 基准产生了强烈的冲击,但我们完全相信,优化基准并没有任何意义,同时以这种方式批判现实场景中的使用案例。
|
||||
显然,你可以在这里做的一件事情就是通过缓存以前的计算值来避免重复计算相同的正弦值和余弦值。事实上,这是 V8 以前的做法,而其它引擎例如 `SpiderMonkey` 目前仍然在这样做。我们从 V8 中删除了所谓的<ruby>超载缓存<rt>transcendental cache</rt></ruby>,因为缓存的开销在实际的工作负载中是不可忽视的,你不可能总是在一行代码中计算相同的值,这在其它地方倒不稀奇。当我们在 2013 和 2014 年移除这个特定的基准优化时,我们对 SunSpider 基准产生了强烈的冲击,但我们完全相信,为基准而优化并没有任何意义,并同时以这种方式批判了现实场景中的使用案例。
|
||||
|
||||
[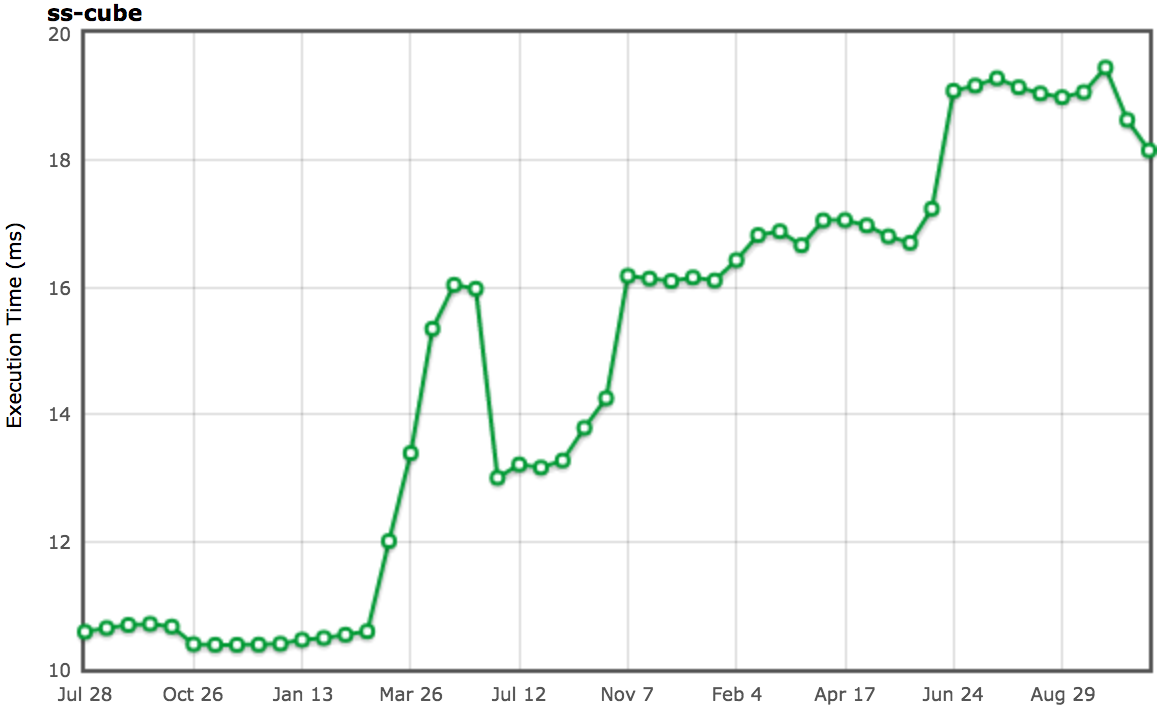][52]
|
||||
|
||||
显然,处理恒定正弦/余弦输入的更好的方法是一个内联的启发式算法,它试图平衡内联因素与其它不同的因素,例如在调用位置优先选择内联,其中恒定折叠可以是有益的,例如在 `RotateX`、`RotateY` 和 `RotateZ` 中调用边界值的案例。但是出于各种原因,这对于 `Crankshaft` 编译器并不可行。使用 `Ignition` 和 `TurboFan` 倒是一个明智的选择,我们已经在开发更好的[内联启发式算法][53]。
|
||||
(来源:[arewefastyet.com](https://arewefastyet.com/#machine=12&view=single&suite=ss&subtest=cube&start=1343350217&end=1415382608))
|
||||
|
||||
### 垃圾回收是有害的
|
||||
显然,处理恒定正弦/余弦输入的更好的方法是一个内联的启发式算法,它试图平衡内联因素与其它不同的因素,例如在调用位置优先选择内联,其中<ruby>常量叠算<rt>constant folding</rt></ruby>可以是有益的,例如在 `RotateX`、`RotateY` 和 `RotateZ` 调用位置的案例中。但是出于各种原因,这对于 `Crankshaft` 编译器并不可行。使用 `Ignition` 和 `TurboFan` 倒是一个明智的选择,我们已经在开发更好的[内联启发式算法][53]。
|
||||
|
||||
除了这些非常具体的测试问题,SunSpider 还有一个根本的问题:总体执行时间。目前 V8 在体面的英特尔硬件上运行整个基准测试大概只需要 200ms(使用默认配置)。次要的 `GC` 在 1ms 到 25ms 之间(取决于新空间中的活对象和旧空间的碎片),而主 `GC` 暂停可以浪费掉 30ms(甚至不考虑增量标记的开销),这超过了 SunSpider 套件总体执行时间的 10%!因此,任何不想因 `GC` 循环而造成减速 10-20% 的引擎,必须用某种方式确保它在运行 SunSpider 时不会触发 `GC`。
|
||||
#### 垃圾回收(GC)是有害的
|
||||
|
||||
除了这些非常具体的测试问题,SunSpider 基准测试还有一个根本性的问题:总体执行时间。目前 V8 在适当的英特尔硬件上运行整个基准测试大概只需要 200ms(使用默认配置)。<ruby>次垃圾回收<rt>minor GC</rt></ruby>在 1ms 到 25ms 之间(取决于新空间中的存活对象和旧空间的碎片),而<ruby>主垃圾回收<rt>major GC</rt></ruby>暂停的话可以轻松减掉 30ms(甚至不考虑增量标记的开销),这超过了 SunSpider 套件总体执行时间的 10%!因此,任何不想因垃圾回收循环而造成减速 10-20% 的引擎,必须用某种方式确保它在运行 SunSpider 时不会触发垃圾回收。
|
||||
|
||||
[][54]
|
||||
|
||||
就实现而言,有不同的方案,不过就我所知,没有一个在现实场景中产生了任何积极的影响。V8 使用了一个相当简单的技巧:由于每个 SunSpider 套件都运行在一个新的 `<iframe>` 中,这对应于 V8 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 SunSpider 测试花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们在实际运行测试的时候不会触发 `GC`。这个技巧很好,99.9% 的案例没有与实际用途冲突;除了每时每刻,无论你在做什么,都让你看起来像是 V8 的 SunSpider 测试驱动程序,那么你可能会遇到困难,或许你可以通过强制 `GC` 来解决,不过这对你的应用可能会有负面影响。所以紧记一点:**不要让你的应用看起来像 SunSpider!**
|
||||
就实现而言,有不同的方案,不过就我所知,没有一个在现实场景中产生了任何积极的影响。V8 使用了一个相当简单的技巧:由于每个 SunSpider 套件都运行在一个新的 `<iframe>` 中,这对应于 V8 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 SunSpider 测试每个花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们在实际运行测试的时候不会触发垃圾回收。这个技巧运行的很好,在 99.9% 的案例中没有与实际用途冲突;除了时不时的你可能会受到打击,不管出于什么原因,如果你做的事情让你看起来像是 V8 的 SunSpider 测试驱动程序,你就可能被强制的垃圾回收打击到,这有可能对你的应用导致负面影响。所以谨记一点:**不要让你的应用看起来像 SunSpider!**
|
||||
|
||||
我可以继续展示更多 SunSpider 示例,但我不认为这非常有用。到目前为止,应该清楚的是,SunSpider 为刷新业绩而做的进一步优化在现实场景中没有带来任何好处。事实上,世界可能会因为没有 SunSpider 而更美好,因为引擎可以放弃只是用于 SunSpider 的奇淫技巧,甚至可以伤害到现实中的用例。不幸的是,SunSpider 仍然被(科技)媒体大量地用来比较他们眼中的浏览器性能,或者甚至用来比较手机!所以手机制造商和安卓制造商对于让 SunSpider(以及其它现在毫无意义的基准 `FWIW`) 上的 Chrome 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 SunSpider 中得分较高的旧版 V8,向他们的用户展示各种未修复的安全漏洞(在新版中早已被修复),并保护用户免受最新版本的 V8 的任何现实场景的性能优势!
|
||||
我可以继续展示更多 SunSpider 示例,但我不认为这非常有用。到目前为止,应该清楚的是,为刷新 SunSpider 评分而做的进一步优化在现实场景中没有带来任何好处。事实上,世界可能会因为没有 SunSpider 而更美好,因为引擎可以放弃只是用于 SunSpider 的奇淫技巧,或者甚至可以伤害到现实中的用例。不幸的是,SunSpider 仍然被(科技)媒体大量地用来比较他们眼中的浏览器性能,或者甚至用来比较手机!所以手机制造商和安卓制造商对于让 SunSpider(以及其它现在毫无意义的基准 FWIW) 上的 Chrome 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 SunSpider 中得分较高的旧版 V8,将他们的用户置于各种未修复的安全漏洞之下(在新版中早已被修复),而让用户被最新版本的 V8 带来的任何现实场景的性能优势拒之门外!
|
||||
|
||||
[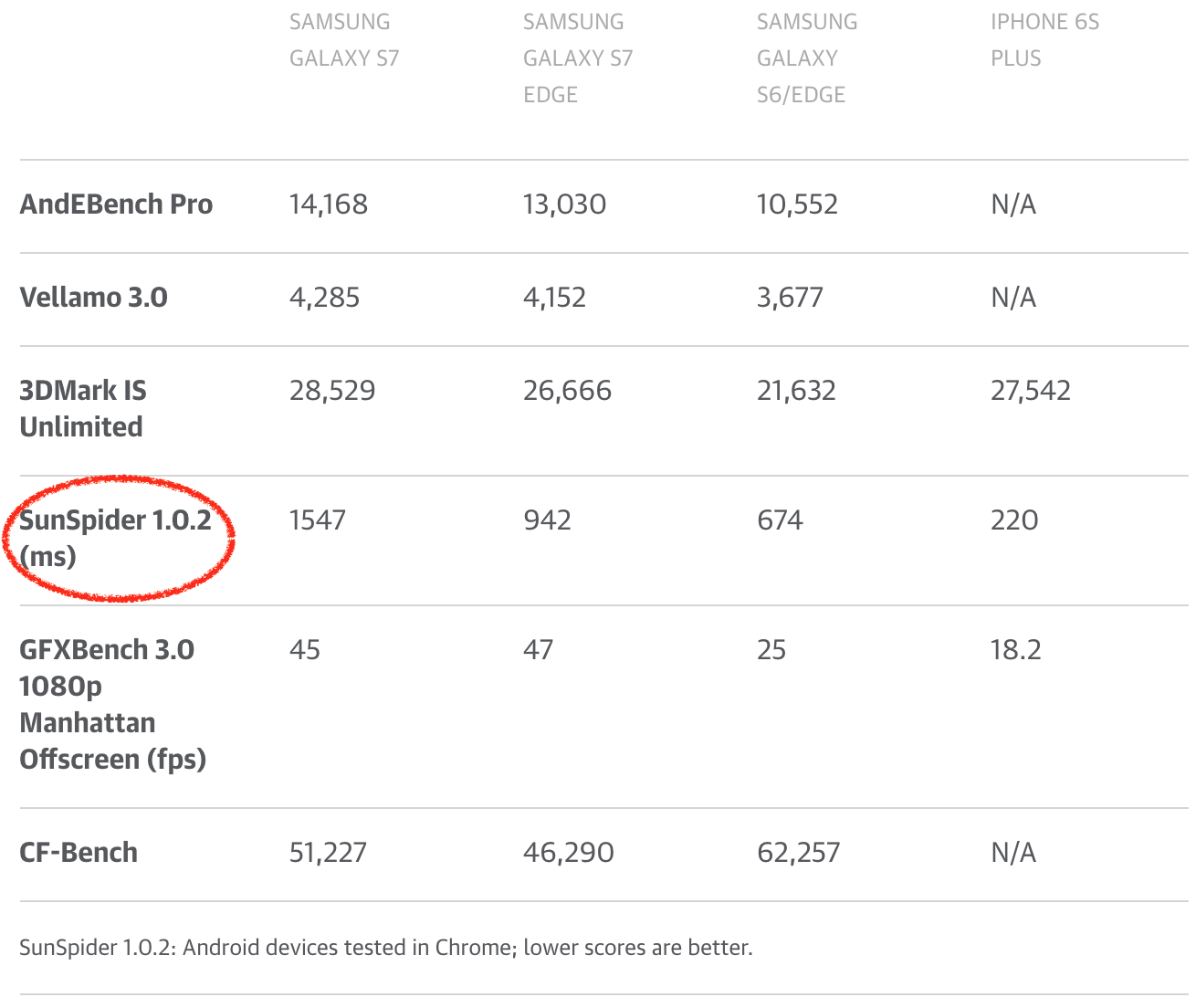][55]
|
||||
|
||||
作为 JavaScript 社区的一员,如果我们真的想认真对待 JavaScript 领域现实场景的性能,我们需要让各大技术媒体停止使用传统的 JavaScript 基准来比较浏览器或手机。我看到的一个好处是能够在每个浏览器中运行一个基准测试,并比较它的得分,但是请使用一个与当今世界相关的基准,例如真实的 `web` 页面;如果你觉得需要通过浏览器基准来比较两部手机,请至少考虑使用 [Speedometer][56]。
|
||||
(来源:[www.engadget.com](https://www.engadget.com/2016/03/08/galaxy-s7-and-s7-edge-review/))
|
||||
|
||||
### 轻松一刻
|
||||
作为 JavaScript 社区的一员,如果我们真的想认真对待 JavaScript 领域的现实场景的性能,我们需要让各大技术媒体停止使用传统的 JavaScript 基准来比较浏览器或手机。能够在每个浏览器中运行一个基准测试,并比较它的得分自然是好的,但是请使用一个与当今世界相关的基准,例如真实的 web 页面;如果你觉得需要通过浏览器基准来比较两部手机,请至少考虑使用 [Speedometer][56]。
|
||||
|
||||
#### 轻松一刻
|
||||
|
||||

|
||||
|
||||
我一直很喜欢这个 [Myles Borins][57] 谈话,所以我不得不无耻地向他偷师。现在我们从 SunSpider 的谴责中回过头来,让我们继续检查其它经典基准。
|
||||
|
||||
### 不是那么详细的 Kraken 案例
|
||||
### 不是那么显眼的 Kraken 案例
|
||||
|
||||
Kraken 基准是 [Mozilla 于 2010 年 9 月 发布的][58],据说它包含了现实场景应用的片段/内核,并且与 SunSpider 相比少了一个微基准。我不想花太多时间在 Kraken 上,因为我认为它不像 SunSpider 和 Octane 一样对 JavaScript 性能有着深远的影响,所以我将强调一个特别的案例——[`audio-oscillator.js`][59] 测试。
|
||||
Kraken 基准是 [Mozilla 于 2010 年 9 月 发布的][58],据说它包含了现实场景应用的片段/内核,并且与 SunSpider 相比少了一个微基准。我不想在 Kraken 上花太多口舌,因为我认为它不像 SunSpider 和 Octane 一样对 JavaScript 性能有着深远的影响,所以我将强调一个特别的案例——[audio-oscillator.js][59] 测试。
|
||||
|
||||
[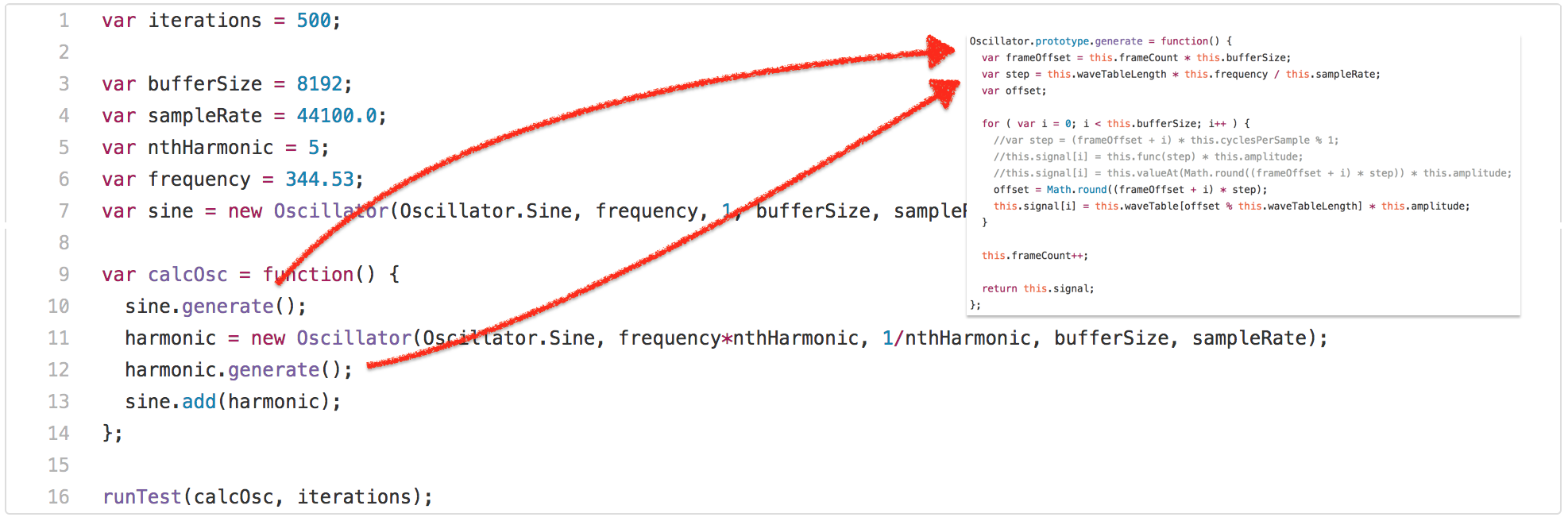][60]
|
||||
|
||||
正如你所见,测试调用了 `calcOsc` 函数 500 次。`calcOsc` 首先在全局的正弦 `Oscillator` 上调用 `generate`,然后创建一个新的 `Oscillator`,调用 `generate` 并将其添加到全局正弦的 `oscillator`。没有详细说明测试为什么是这样做的,让我们看看 `Oscillator` 原型上的 `generate` 方法。
|
||||
正如你所见,测试调用了 `calcOsc` 函数 500 次。`calcOsc` 首先在全局的 `sine` `Oscillator` 上调用 `generate`,然后创建一个新的 `Oscillator`,调用它的 `generate` 方法并将其添加到全局的 `sine` `Oscillator` 里。没有详细说明测试为什么是这样做的,让我们看看 `Oscillator` 原型上的 `generate` 方法。
|
||||
|
||||
[][61]
|
||||
|
||||
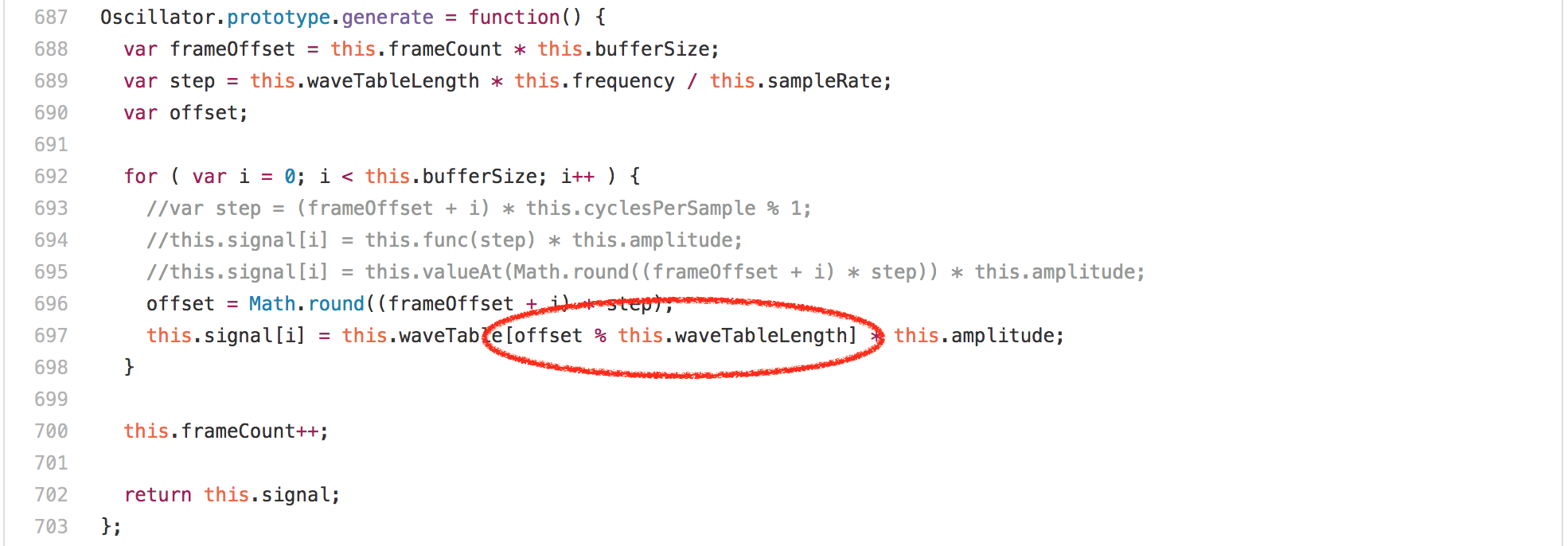
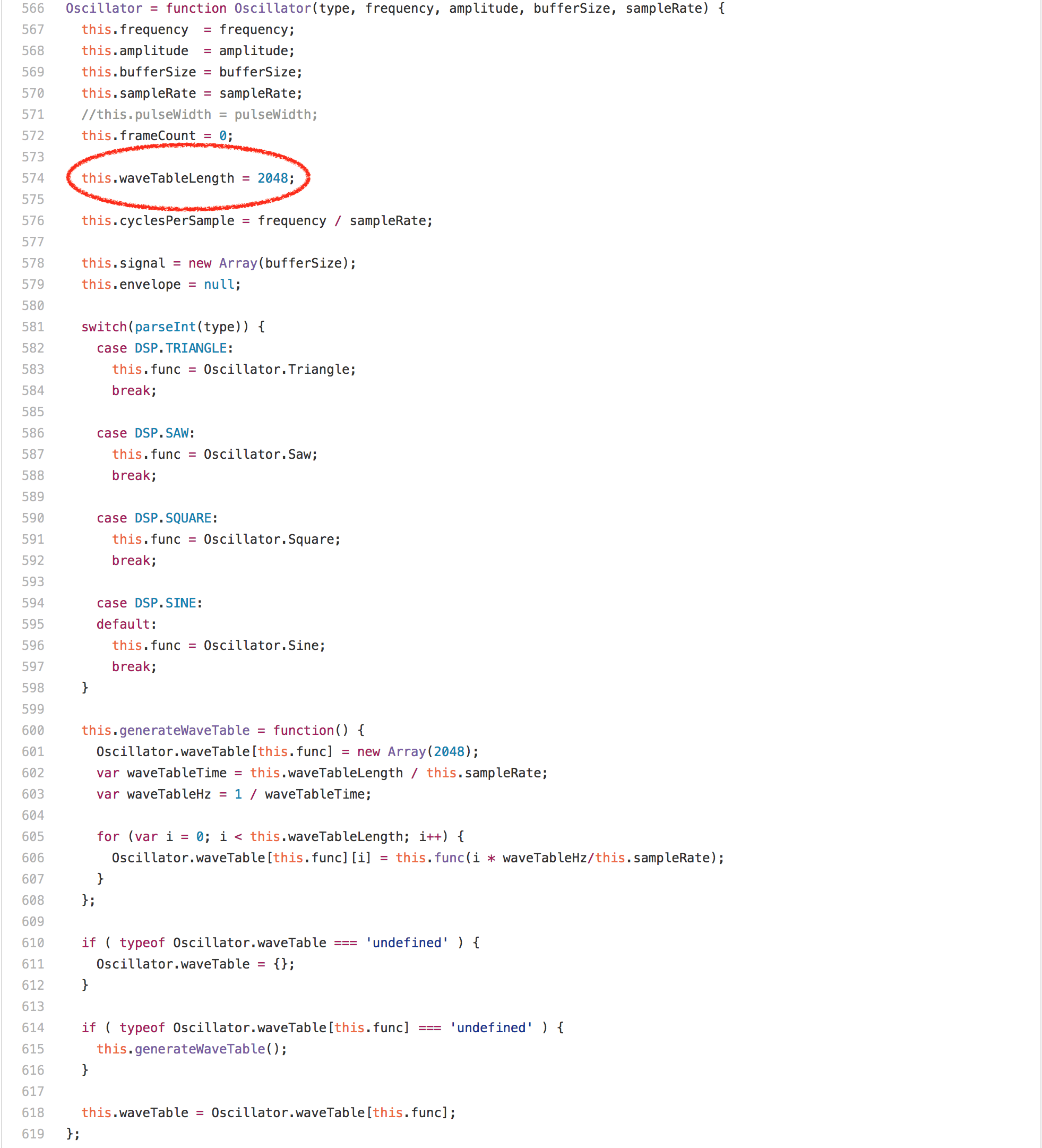
看看代码,你会期望这是被循环中的数组访问或者乘法或者 [`Math.round`][62] 调用所主导的,但令人惊讶的是 `offset % this.waveTableLength` 表达式完全支配了 `Oscillator.prototype.generate` 的运行。在任何的英特尔机器上的分析器中运行此基准测试显示,超过 20% 的通过数据都归功于我们为模数生成的 `idiv` 指令。然而一个有趣的发现是,`Oscillator` 实例的 `waveTableLength` 字段总是包含相同的值——2048,因为它在 `Oscillator` 构造器中只分配一次。
|
||||
让我们看看代码,你也许会觉得这里主要是循环中的数组访问或者乘法或者 [Math.round][62] 调用,但令人惊讶的是 `offset % this.waveTableLength` 表达式完全支配了 `Oscillator.prototype.generate` 的运行。在任何的英特尔机器上的分析器中运行此基准测试显示,超过 20% 的时间占用都属于我们为模数生成的 `idiv` 指令。然而一个有趣的发现是,`Oscillator` 实例的 `waveTableLength` 字段总是包含相同的值——2048,因为它在 `Oscillator` 构造器中只分配一次。
|
||||
|
||||
[][63]
|
||||
|
||||
如果我们知道整数模数运算的右边是 2 的幂,我们可以生成[更好的代码][64],显然完全避免了英特尔上的 `idiv` 指令。所以我们需要获取一种信息使 `this.waveTableLength` 从 `Oscillator` 构造器到 `Oscillator.prototype.generate` 中的模运算都是 2048。一个显而易见的方法是尝试依赖于将所有内容内嵌到 `calcOsc` 函数,并让 `load/store` 消除为我们进行的常量传播,但这对于在 `calcOsc` 函数之外分配的正弦振荡器无效。
|
||||
如果我们知道整数模数运算的右边是 2 的幂,我们可以生成显然[更好的代码][64],完全避免了英特尔上的 `idiv` 指令。所以我们需要获取一种信息使 `this.waveTableLength` 从 `Oscillator` 构造器到 `Oscillator.prototype.generate` 中的模运算都是 2048。一个显而易见的方法是尝试依赖于将所有内容内嵌到 `calcOsc` 函数,并让 `load/store` 消除为我们进行的常量传播,但这对于在 `calcOsc` 函数之外分配的 `sine` `oscillator` 无效。
|
||||
|
||||
因此,我们所做的就是添加支持跟踪某些常数值作为模运算符的右侧反馈。这在 V8 中是有意义的,因为我们为诸如 `+`、`*` 和 `%` 的二进制操作跟踪类型反馈,这意味着操作者跟踪输入的类型和产生的输出类型(参见最近圆桌讨论关于[动态语言的快速运算][65]的幻灯片)。当然,用 `fullcodegen` 和 `Crankshaft` 挂接起来也是相当容易的,`MOD` 的 `BinaryOpIC` 也可以跟踪两个右边的已知权。
|
||||
因此,我们所做的就是添加支持跟踪某些常数值作为模运算符的右侧反馈。这在 V8 中是有意义的,因为我们为诸如 `+`、`*` 和 `%` 的二进制操作跟踪类型反馈,这意味着操作者跟踪输入的类型和产生的输出类型(参见最近的圆桌讨论中关于[动态语言的快速运算][65]的幻灯片)。当然,用 `fullcodegen` 和 `Crankshaft` 挂接起来也是相当容易的,`MOD` 的 `BinaryOpIC` 也可以跟踪右边已知的 2 的冥。
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
@ -179,7 +183,7 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
$
|
||||
```
|
||||
|
||||
显示表明 `BinaryOpIC` 正在为模数的右侧拾取适当的恒定反馈,并正确跟踪左侧始终是一个小整数(V8 的 `Smi` 说),我们也总是产生一个小的整数结果 。 使用 `--print-opt-code -code-comments` 查看生成的代码,很快就显示出,`Crankshaft` 利用反馈在 `Oscillator.prototype.generate` 中为整数模数生成一个有效的代码序列:
|
||||
事实上,以默认配置运行的 V8 (带有 Crankshaft 和 fullcodegen)表明 `BinaryOpIC` 正在为模数的右侧拾取适当的恒定反馈,并正确跟踪左侧始终是一个小整数(以 V8 的话叫做 `Smi`),我们也总是产生一个小整数结果。 使用 `--print-opt-code -code-comments` 查看生成的代码,很快就显示出,`Crankshaft` 利用反馈在 `Oscillator.prototype.generate` 中为整数模数生成一个有效的代码序列:
|
||||
|
||||
```
|
||||
[...SNIP...]
|
||||
@ -203,11 +207,11 @@ $
|
||||
[...SNIP...]
|
||||
```
|
||||
|
||||
所以你看到我们加载 `this.waveTableLength`(`rbx` 持有 `this` 的引用)的值,检查它仍然是 2048(十六进制的 0x800),如果是这样,只是执行一个按位操作和适当的掩码 0x7ff(`r11` 包含循环感应变量 `i` 的值),而不是使用 `idiv` 指令(注意保留左侧的符号)。
|
||||
所以你看到我们加载 `this.waveTableLength`(`rbx` 持有 `this` 的引用)的值,检查它仍然是 2048(十六进制的 0x800),如果是这样,就只用适当的掩码 0x7ff(`r11` 包含循环感应变量 `i` 的值)执行一个位操作 AND ,而不是使用 `idiv` 指令(注意保留左侧的符号)。
|
||||
|
||||
### 过度专业化的问题
|
||||
#### 过度特定的问题
|
||||
|
||||
所以这个技巧酷毙了,但正如许多基准关注的技巧都有一个主要的缺点:太过于专业了!一旦右侧发生变化,所有优化过的代码需要重构(假设右手始终是两个不再拥有的权),任何进一步的优化尝试都必须再次使用 `idiv`,因为 `BinaryOpIC` 很可能以 `Smi * Smi -> Smi` 的形式报告反馈。例如,假设我们实例化另一个 `Oscillator`,在其上设置不同的 `waveTableLength`,并为振荡器调用 `generate`,那么即使实际上有趣的 `Oscillator` 不受影响,我们也会损失 20% 的性能(例如,引擎在这里实行非局部惩罚)。
|
||||
所以这个技巧酷毙了,但正如许多基准关注的技巧都有一个主要的缺点:太过于特定了!一旦右侧发生变化,所有优化过的代码就失去了优化(假设右手始终是不再处理的 2 的冥),任何进一步的优化尝试都必须再次使用 `idiv`,因为 `BinaryOpIC` 很可能以 `Smi * Smi -> Smi` 的形式报告反馈。例如,假设我们实例化另一个 `Oscillator`,在其上设置不同的 `waveTableLength`,并为 `Oscillator` 调用 `generate`,那么即使我们实际上感兴趣的 `Oscillator` 不受影响,我们也会损失 20% 的性能(例如,引擎在这里实行非局部惩罚)。
|
||||
|
||||
```
|
||||
--- audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
|
||||
@ -224,7 +228,7 @@ $
|
||||
sine.generate();
|
||||
```
|
||||
|
||||
将原始的 `audio-oscillator.js` 执行时间与包含额外未使用的 `Oscillator` 实例与修改的 `waveTableLength` 的版本进行比较,可以显示预期的结果:
|
||||
将原始的 `audio-oscillator.js` 执行时间与包含额外未使用的 `Oscillator` 实例与修改的 `waveTableLength` 的版本进行比较,显示的是预期的结果:
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
|
||||
@ -234,9 +238,9 @@ Time (audio-oscillator-once): 81 ms.
|
||||
$
|
||||
```
|
||||
|
||||
这是一个非常可怕的性能悬崖的例子:假设开发人员为库编写代码,并使用某些样本输入值进行仔细的调整和优化,性能是体面的。现在,用户开始使用该库读取性能日志,但不知何故从性能悬崖下降,因为她/他正在以一种稍微不同的方式使用库,即以某种方式污染某种 `BinaryOpIC` 的类型反馈,并且遭受 20% 的减速(与该库作者的测量相比),该库的作者和用户都无法解释,这似乎是随机的。
|
||||
这是一个非常可怕的性能悬崖的例子:假设开发人员编写代码库,并使用某些样本输入值进行仔细的调整和优化,性能是体面的。现在,用户读过了性能说明开始使用该库,但不知何故从性能悬崖下降,因为她/他正在以一种稍微不同的方式使用库,即特定的 `BinaryOpIC` 的某种污染方式的类型反馈,并且遭受 20% 的减速(与该库作者的测量相比),该库的作者和用户都无法解释,这似乎是随机的。
|
||||
|
||||
现在这在 JavaScript 领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 JavaScript 的性能是基于乐观的假设和猜测的事实。我们已经花了 **大量** 时间和精力来试图找到避免这些性能悬崖的方法,不过依旧提供(几乎)相同的性能。事实证明,尽可能避免 `idiv` 是很有意义的,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 `TurboFan` 的做法有异于 `Crankshaft` 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化两个右手侧的(未知)权看起来像这样(在伪代码中):
|
||||
现在这种情况在 JavaScript 领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 JavaScript 的性能是基于乐观的假设和猜测。我们已经花了 **大量** 时间和精力来试图找到避免这些性能悬崖的方法,而仍提供了(几乎)相同的性能。事实证明,尽可能避免 `idiv` 是很有意义的,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 `TurboFan` 的做法有异于 `Crankshaft` 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化右手侧的(未知的) 2 的冥看起来像这样(伪代码):
|
||||
|
||||
```
|
||||
if 0 < rhs then
|
||||
@ -265,7 +269,7 @@ Time (audio-oscillator-once): 69 ms.
|
||||
$
|
||||
```
|
||||
|
||||
基准和过度专业化的问题在于基准可以给你提示在哪里可以看看以及该怎么做,但它不告诉你你应该走多远,不能保护优化。例如,所有 JavaScript 引擎都使用基准来防止性能下降,但是运行 Kraken 不能保护我们在 `TurboFan` 中的一般方法,即我们可以将 `TurboFan` 中的模优化降级到过度专业版本的 `Crankshaft`,而基准不会告诉我们却在倒退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们做的相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不会任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度专业化将支配一切,你会有一个真正的、可接受的、巨大的性能悬崖线。
|
||||
基准和过度特定化的问题在于基准可以给你提示可以看看哪里以及该怎么做,但它不告诉你应该做到什么程度,不能保护合理优化。例如,所有 JavaScript 引擎都使用基准来防止性能回退,但是运行 Kraken 不能保护我们在 `TurboFan` 中使用的常规方法,即我们可以将 `TurboFan` 中的模优化降级到过度特定的版本的 `Crankshaft`,而基准不会告诉我们性能回退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不能任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度特定化将支配一切,你会有一个真正的、非常好的可接受的性能,以及巨大的性能悬崖线。
|
||||
|
||||
Kraken 测试还有许多其它的问题,不过现在让我们继续讨论过去五年中最有影响力的 JavaScript 基准测试—— Octane 测试。
|
||||
|
||||
@ -328,11 +332,11 @@ function(t) {
|
||||
}
|
||||
```
|
||||
|
||||
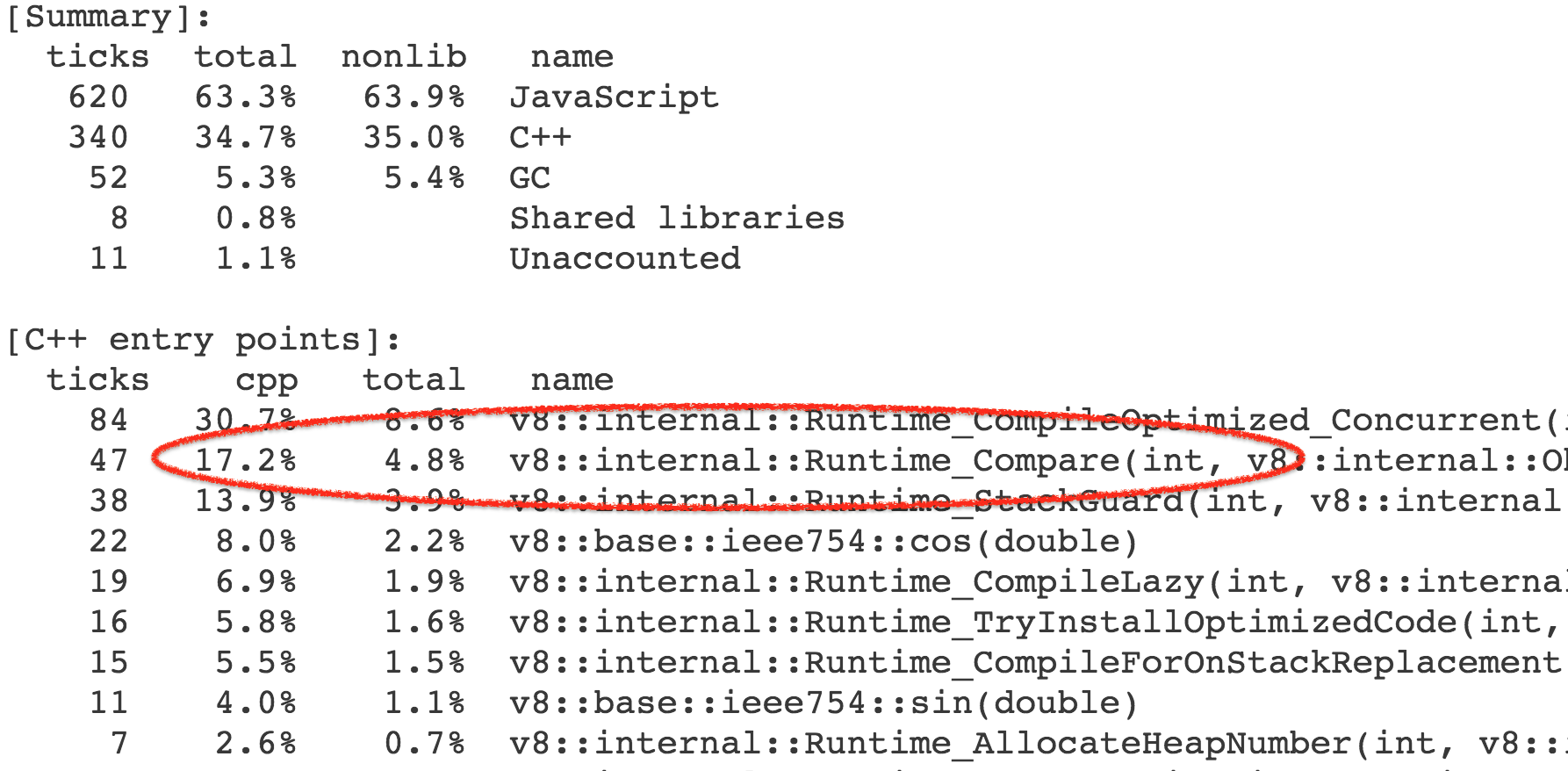
更准确地说,时间并不是开销在这个函数本身,而是由此触发的操作和内置库函数。结果,我们花费了基准调用的总体执行时间的 4-7% 在 [`Compare` 运行时函数][76]上,它实现了[抽象关系][77]比较的一般情况。
|
||||
更准确地说,时间并不是开销在这个函数本身,而是由此触发的操作和内置库函数。结果,我们花费了基准调用的总体执行时间的 4-7% 在 [Compare` 运行时函数][76]上,它实现了[抽象关系][77]比较的一般情况。
|
||||
|
||||
|
||||
|
||||
几乎所有对运行时函数的调用都来自 [`CompareICStub`][78],它用于内部函数中的两个关系比较:
|
||||
几乎所有对运行时函数的调用都来自 [CompareICStub][78],它用于内部函数中的两个关系比较:
|
||||
|
||||
```
|
||||
x.proxyA = t < m ? t : m;
|
||||
@ -343,12 +347,12 @@ x.proxyB = t >= m ? t : m;
|
||||
|
||||
1. 调用 [ToPrimitive][12](`t`, `hint Number`)。
|
||||
2. 运行 [OrdinaryToPrimitive][13](`t`, `"number"`),因为这里没有 `Symbol.toPrimitive`。
|
||||
3. 执行 `t.valueOf()`,这会获得 `t` 自身的值,因为它调用了默认的 [`Object.prototype.valueOf`][14]。
|
||||
4. 接着执行 `t.toString()`,这会生成 `"[object Object]"`,因为调用了默认的 [`Object.prototype.toString`][15],并且没有找到 `L` 的 [`Symbol.toStringTag`][16]。
|
||||
3. 执行 `t.valueOf()`,这会获得 `t` 自身的值,因为它调用了默认的 [Object.prototype.valueOf][14]。
|
||||
4. 接着执行 `t.toString()`,这会生成 `"[object Object]"`,因为调用了默认的 [Object.prototype.toString][15],并且没有找到 `L` 的 [Symbol.toStringTag][16]。
|
||||
5. 调用 [ToPrimitive][17](`m`, `hint Number`)。
|
||||
6. 运行 [OrdinaryToPrimitive][18](`m`, `"number"`),因为这里没有 `Symbol.toPrimitive`。
|
||||
7. 执行 `m.valueOf()`,这会获得 `m` 自身的值,因为它调用了默认的 [`Object.prototype.valueOf`][19]。
|
||||
8. 接着执行 `m.toString()`,这会生成 `"[object Object]"`,因为调用了默认的 [`Object.prototype.toString`][20],并且没有找到 `L` 的 [`Symbol.toStringTag`][21]。
|
||||
7. 执行 `m.valueOf()`,这会获得 `m` 自身的值,因为它调用了默认的 [Object.prototype.valueOf][19]。
|
||||
8. 接着执行 `m.toString()`,这会生成 `"[object Object]"`,因为调用了默认的 [Object.prototype.toString][20],并且没有找到 `L` 的 [Symbol.toStringTag][21]。
|
||||
9. 执行比较 `"[object Object]" < "[object Object]"`,结果是 `false`。
|
||||
|
||||
至于 `t >= m` 亦复如是,它总会输出 `true`。所以这里是一个漏洞——使用抽象关系比较这种方法没有意义。而利用它的方法是使编译器常数折叠,即给基准打补丁:
|
||||
@ -410,7 +414,7 @@ $
|
||||
|
||||
由此可见,在检测 `global_init` 和避免昂贵的预解析步骤我们几乎提升了 2 倍。我们不太确定这是否会对真实用例产生负面影响,不过保证你在预解析大函数的时候将会受益匪浅(因为它们不会立即执行)。
|
||||
|
||||
让我们来看看另一个稍有争议的基准测试:[`splay.js`][89] 测试,一个用于处理伸展树(二叉查找树的一种)和练习自动内存管理子系统(也被成为垃圾回收器)的数据操作基准。它自带一个延迟测试,这会引导 `Splay` 代码通过频繁的测量检测点,检测点之间的长时间停顿表明垃圾回收器的延迟很高。此测试测量延迟暂停的频率,将它们分类到桶中,并以较低的分数惩罚频繁的长暂停。这听起来很棒!没有 `GC` 停顿,没有垃圾。纸上谈兵到此为止。让我们看看这个基准,以下是整个伸展树业务的核心:
|
||||
让我们来看看另一个稍有争议的基准测试:[splay.js][89] 测试,一个用于处理伸展树(二叉查找树的一种)和练习自动内存管理子系统(也被成为垃圾回收器)的数据操作基准。它自带一个延迟测试,这会引导 `Splay` 代码通过频繁的测量检测点,检测点之间的长时间停顿表明垃圾回收器的延迟很高。此测试测量延迟暂停的频率,将它们分类到桶中,并以较低的分数惩罚频繁的长暂停。这听起来很棒!没有 `GC` 停顿,没有垃圾。纸上谈兵到此为止。让我们看看这个基准,以下是整个伸展树业务的核心:
|
||||
|
||||
[][90]
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user