mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
9deec94ded
@ -1,36 +1,33 @@
|
||||
什么是 Linux 服务器以及你的业务为什么需要它?
|
||||
什么是 Linux 服务器,你的业务为什么需要它?
|
||||
=====
|
||||
|
||||
> 想寻找一个稳定、安全的基础来为您的企业应用程序的未来提供动力?Linux 服务器可能是答案。
|
||||
|
||||

|
||||
IT 组织力求通过提高生产力和提供更快速的服务来提供商业价值,同时保持足够的灵活性,将云,容器和配置自动化等创新融入其中。现代的工作负载,无论是裸机,虚拟机,容器,还是私有云或公共云,都预计是可移植且可扩展的。支持所有的这些需要一个现代且安全的平台。
|
||||
|
||||
通往创新最直接的途径并不总是一条直线。随着私有云和公共云,多种体系架构和虚拟化的日益普及,当今的数据中心就像一个球一样,基础设施的选择各不相同,从而带来了维度和深度。就像飞行员依赖空中交通管制员提供持续更新一样,数字化转型之旅应该由像 Linux 这样可信赖的操作系统来指导,以提供持续更新的技术,以及对云,容器和配置自动化等创新的最有效和安全的访问。
|
||||
IT 组织力求通过提高生产力和提供更快速的服务来提供商业价值,同时保持足够的灵活性,将云、容器和配置自动化等创新融入其中。现代的工作任务,无论是裸机、虚拟机、容器,还是私有云或公共云,都需要是可移植且可扩展的。支持所有的这些需要一个现代且安全的平台。
|
||||
|
||||
Linux 是一个家族,它围绕 Linux 内核构建的免费开源软件操作系统。最初开发的基于 Intel x86 架构的个人电脑,此后比起任何其他操作系统,Linux 被移植到更多的平台上。得益于基于 Linux 内核的 Android 操作系统在智能手机上的主导地位,Linux 拥有所有通用操作系统中最大的安装基数。Linux 也是服务器和大型计算机等“大型机”系统的主要操作系统,也是 [TOP500][1] 超级计算机上唯一使用的操作系统。
|
||||
通往创新最直接的途径并不总是一条直线。随着私有云和公共云、多种体系架构和虚拟化的日益普及,当今的数据中心就像一个球一样,基础设施的选择各不相同,从而带来了维度和深度。就像飞行员依赖空中交通管制员提供持续更新一样,数字化转型之旅应该由像 Linux 这样可信赖的操作系统来指引,以提供持续更新的技术,以及对云、容器和配置自动化等创新的最有效和安全的访问。
|
||||
|
||||
为了利用这一功能,许多企业公司已经采用具有高性能的 Linux 开源操作系统的服务器。这些旨在处理最苛刻的业务应用程序要求,如网络和系统管理,数据库管理和 Web 服务。Linux 服务器通常选择其他服务器操作系统(to 校正者:这句话望细心理解),以保证它们的稳定性,安全性和灵活性。领先的 Linux 服务器操作系统包括 [Debian][2], [Ubuntu Server][3], [CentOS][4], [Slackware][5]和[Gentoo][6]。
|
||||
Linux 是一个家族,它围绕 Linux 内核构建的自由、开源软件操作系统。最初开发的是基于 Intel x86 架构的个人电脑,此后比起任何其他操作系统,Linux 被移植到更多的平台上。得益于基于 Linux 内核的 Android 操作系统在智能手机上的主导地位,Linux 拥有所有通用操作系统中最大的安装基数。Linux 也是服务器和大型计算机等“大型机”系统的主要操作系统,也是 [TOP500][1] 超级计算机上唯一使用的操作系统。
|
||||
|
||||
在企业级工作负载中,你应该考虑企业级 Linux 服务器上的哪些功能和优势?首先,通过对 Linux 和 Windows 管理员都熟悉的接口,内置的安全控制和可管理的扩展使你可以专注于业务增长,而不是对安全漏洞和昂贵的管理配置错误担心。你选择的 Linux 服务器应提供安全技术和认证,并保持增强以抵御入侵,保护你的数据,并满足一个开放源代码项目或特定系统供应商的合规性。它应该:
|
||||
为了利用这一功能,许多企业公司已经采用具有高性能的 Linux 开源操作系统的服务器。这些旨在处理最苛刻的业务应用程序要求,如网络和系统管理、数据库管理和 Web 服务。出于其稳定性、安全性和灵活性,通常选择 Linux 服务器而不是其他服务器操作系统。位居前列的 Linux 服务器操作系统包括 [Debian][2]、 [Ubuntu Server][3]、 [CentOS][4]、[Slackware][5] 和 [Gentoo][6]。
|
||||
|
||||
* 使用集中式身份管理和[安全增强型 Linux][7](SELinux),强制访问控制(MAC)等集成控制功能来**安全地交付资源**。这是[通用的标准][8] 和 [FIPS 140-2 认证][9]。并且第一个 Linux 容器框架支持是通用的标准认证。(to 校正:这段话不怎么通顺)
|
||||
|
||||
* **自动执行法规遵从和安全配置修复** 应贯穿于你的系统和容器。通过像 OpenSCAP 的图像扫描,它应该检查,补救漏洞和配置安全基准,包括针对 [PCI-DSS][12], [DISA STIG][13] 等的[国家清单程序][11]内容。另外,它应该在整个混合环境中集中和扩展配置修复。
|
||||
在企业级工作任务中,你应该考虑企业级 Linux 服务器上的哪些功能和优势?首先,通过对 Linux 和 Windows 管理员都熟悉的界面,内置的安全控制和可管理的扩展使你可以专注于业务增长,而不是对安全漏洞和昂贵的管理配置错误担心。你选择的 Linux 服务器应提供安全技术和认证,并保持增强以抵御入侵,保护你的数据,而且满足一个开放源代码项目或特定系统供应商的合规性。它应该:
|
||||
|
||||
* 使用集中式身份管理和[安全增强型 Linux][7](SELinux)、强制访问控制(MAC)等集成控制功能来**安全地交付资源**,这是[通用标准认证][8] 和 [FIPS 140-2 认证][9],并且第一个 Linux 容器框架支持也是通用标准认证。
|
||||
* **自动执行法规遵从和安全配置修复** 应贯穿于你的系统和容器。通过像 OpenSCAP 的映像扫描,它应该可以检查、补救漏洞和配置安全基准,包括针对 [PCI-DSS][12]、 [DISA STIG][13] 等的[国家清单程序][11]内容。另外,它应该在整个混合环境中集中和扩展配置修复。
|
||||
* **持续接收漏洞安全更新**,从上游社区或特定的系统供应商,如有可能,可在下一工作日补救并提供所有关键问题,以最大限度地降低业务影响。
|
||||
|
||||
作为混合数据中心的基础,Linux 服务器应提供平台可管理性和与传统管理和自动化基础设施的灵活集成。与非付费的 Linux 基础设施相比,这将节省 IT 员工的时间并减少意外停机的情况。它应该:
|
||||
|
||||
* 通过内置功能 **加速整个数据中心的映像构建,部署和补丁管理**,并丰富系统生命周期管理,配置和增强的修补等等。
|
||||
|
||||
* 通过一个 **简单易用的 web 界面管理单个系统**,包括存储,网络,容器,服务等等。
|
||||
|
||||
* 通过使用 [Ansible][14], [Chef][15], [Salt][16], [Puppet][17] 等原生配置管理工具,可以跨异构多个环境实现 **自动化一致性和合规性**,并通过系统角色减少脚本返工。
|
||||
|
||||
* 通过内置功能 **加速整个数据中心的映像构建、部署和补丁管理**,并丰富系统生命周期管理,配置和增强的修补等等。
|
||||
* 通过一个 **简单易用的 web 界面管理单个系统**,包括存储、网络、容器、服务等等。
|
||||
* 通过使用 [Ansible][14]、 [Chef][15]、 [Salt][16]、 [Puppet][17] 等原生配置管理工具,可以跨多个异构环境实现 **自动化一致性和合规性**,并通过系统角色减少脚本返工。
|
||||
* 通过就地升级 **简化平台更新**,消除机器迁移和应用程序重建的麻烦。
|
||||
|
||||
* 通过使用预测分析工具自动识别和修复异常情况及其根本原因,在技术问题影响业务运营之前 **解决技术问题**。
|
||||
|
||||
Linux 服务器正在在全球范围内推动创新。作为一个企业工作负载的平台,Linux 服务器应该为运行当下和未来业务的应用程序提供稳定,安全和性能驱动的基础。
|
||||
Linux 服务器正在在全球范围内推动创新。作为一个企业工作任务的平台,Linux 服务器应该为运行当下和未来业务的应用程序提供稳定,安全和性能驱动的基础。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -39,7 +36,7 @@ via: https://opensource.com/article/18/5/what-linux-server
|
||||
作者:[Daniel Oh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,77 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How to improve ROI on automation: 4 tips
|
||||
======
|
||||
|
||||

|
||||
Automation technologies have generated plenty of buzz during the past few years. COOs and operations teams (and indeed, other business functions) are thrilled at the prospect of being able to redefine how costs have historically increased as work volume rose.
|
||||
|
||||
Robotic process automation (RPA) seems to promise the Holy Grail to operations: "Our platform provides out-of-box features to meet most of your daily process needs - checking email, saving attachments, getting data, updating forms, generating reports, file and folder operations. Building bots can be as easy as configuring these features and chaining them together, rather than asking IT to build them." It's a seductive conversation.
|
||||
|
||||
Lower cost, fewer errors, better compliance with procedures - the benefits seem real and achievable to COOs and operations leaders. The fact that RPA tools promise to pay for themselves from the operational savings (with short payback periods) makes the business case even more attractive.
|
||||
|
||||
Automation conversations tend to follow a similar script: COOs and their teams want to know how automating operations can benefit them. They want to know about RPA platform features and capabilities, and they want to see real-world examples of automation in action. The journey from this point to a proof-of-concept implementation is often short.
|
||||
|
||||
**[ For advice on implementing AI technology, see our related article, [Crafting your AI strategy: 3 tips][1]. ]**
|
||||
|
||||
But the reality of automation benefits can sometimes lag behind expectations. Companies that adopt RPA may find themselves questioning its ROI after implementation. Some express disappointment about not seeing the expected savings, and confusion as to why.
|
||||
|
||||
## Are you automating the wrong things?
|
||||
|
||||
What could explain the gap between the promise and reality of operational automation in these cases? To analyze this, let's explore what typically happens after the decision to proceed with an automation proof-of-concept project (or a full-blown implementation, even) has been made.
|
||||
|
||||
After deciding that automation is the path to take, the COO typically asks operational leaders and their teams to decide which processes or tasks should be automated. While participation should be encouraged, this type of decision-making sometimes leads to sub-optimal choices in automation candidates. There are a few reasons for this:
|
||||
|
||||
First, team leaders often have a "narrow field of deep vision:" They know their processes and tasks well, but might not be deeply familiar with those that they do not participate in (especially if they have not had wide operations exposure). This means that they are able to identify good automation candidates within their own scope of work, but not necessarily across the entire operations landscape. Softer factors like "I want my process to be picked as the first automation candidate" can also come into play.
|
||||
|
||||
Second, candidate process selection can sometimes be driven by matching automation features and capabilities rather than by the value of automation. A common misunderstanding is that any task that includes activities like email or folder monitoring, downloads, calculations, etc. is automatically a good candidate for automation. If automating such tasks doesn't provide value to the organization, they are not the right candidates.
|
||||
|
||||
So what can leaders do to ensure that their automation implementation delivers the ROI they are seeking? Take these four steps, up front:
|
||||
|
||||
## 1. Educate your teams
|
||||
|
||||
It's very likely that people in your operations team, from the COO downward, have heard of RPA and operational automation. It's equally likely that they have many questions and concerns. It is critical to address these issues before you start your implementation.
|
||||
|
||||
Proactively educating the operations team can go a long way in drumming up enthusiasm and buy-in for automation. Training can focus on what automation and bots are, what role they play in a typical process, which processes and tasks are best positioned for automation, and what the expected benefits of automation are.
|
||||
|
||||
**Recommendation** : Ask your automation partner to conduct these team education sessions, with your moderation: They will likely be eager to assist. The leadership should shape the message before it is delivered to the broader team.
|
||||
|
||||
"The first step in automation is to get to know your processes better."
|
||||
|
||||
## 2. Examine your internal processes
|
||||
|
||||
The first step in automation is to get to know your processes better. Every RPA implementation should be preceded by a process inventory, activity analysis, and cost/value mapping exercise.
|
||||
|
||||
It's critical to understand where the value add (or cost, if value is unavailable) happens in the process. And this needs to be done at a granular level for each process or every task.
|
||||
|
||||
This will help you identify and prioritize the right candidates for automation. Because of the sheer number of tasks that can or may need to be automated, processes typically get automated in phases, so prioritization is key.
|
||||
|
||||
**Recommendation** : Set up a small working team, with participation from each group within Operations. Nominate a coordinator from each group - typically a group leader or team manager. Conduct a workshop at the group level to build the process inventory, identify candidate processes, and drive buy-in. Your automation partners are likely to have accelerators - questionnaires, scorecards etc. - that can help you speed up this activity.
|
||||
|
||||
## 3. Provide strong direction on business priorities
|
||||
|
||||
Implementations often involve driving consensus (and sometimes tie-breaking) between operations teams on process selection and automation priorities, based on business value. Though team participation remains a critical part of the analysis and implementation exercises, leaders should own final decision-making.
|
||||
|
||||
**Recommendation** : Schedule regular sessions to get updates from the working teams. In addition to factors like driving consensus and buy-in, teams will also look to leaders for directional decisions on ROI, platform selection, and automation prioritization at the group level.
|
||||
|
||||
## 4. CIO and COO should drive close cooperation
|
||||
|
||||
Automation rollouts are much smoother when there is close cooperation between the operations and technology teams. The COO needs to help drive this coordination with the CIO's team.
|
||||
|
||||
Involvement and oversight of the COO and other operations leaders are critical for successful automation implementations.
|
||||
|
||||
**Recommendation** : The COO and CIO team should set up a joint working group (a "war room") with the third-party automation partners. Responsibilities for each participant should be clearly demarcated and tracked on an ongoing basis. Ideally, the COO and CIO should dedicate at least one resource to the group, at least during the initial rollouts.
|
||||
|
||||
Automation can create significant value for an organization. However, to achieve optimal returns on the investment in their automation journey, CIOs must map before they leap.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-4-tips
|
||||
|
||||
作者:[Rajesh Kamath][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/rajesh-kamath
|
||||
[1]:https://enterprisersproject.com/article/2017/11/crafting-your-ai-strategy-3-tips?sc_cid=70160000000h0aXAAQ
|
||||
@ -1,115 +0,0 @@
|
||||
translating by amwps290
|
||||
How to clean up your data in the command line
|
||||
======
|
||||

|
||||
|
||||
I work part-time as a data auditor. Think of me as a proofreader who works with tables of data rather than pages of prose. The tables are exported from relational databases and are usually fairly modest in size: 100,000 to 1,000,000 records and 50 to 200 fields.
|
||||
|
||||
I haven't seen an error-free data table, ever. The messiness isn't limited, as you might think, to duplicate records, spelling and formatting errors, and data items placed in the wrong field. I also find:
|
||||
|
||||
* broken records spread over several lines because data items had embedded line breaks
|
||||
* data items in one field disagreeing with data items in another field, in the same record
|
||||
* records with truncated data items, often because very long strings were shoehorned into fields with 50- or 100-character limits
|
||||
* character encoding failures producing the gibberish known as [mojibake][1]
|
||||
* invisible [control characters][2], some of which can cause data processing errors
|
||||
* [replacement characters][3] and mysterious question marks inserted by the last program that failed to understand the data's character encoding
|
||||
|
||||
|
||||
|
||||
Cleaning up these problems isn't hard, but there are non-technical obstacles to finding them. The first is everyone's natural reluctance to deal with data errors. Before I see a table, the data owners or managers may well have gone through all five stages of Data Grief:
|
||||
|
||||
1. There are no errors in our data.
|
||||
2. Well, maybe there are a few errors, but they're not that important.
|
||||
3. OK, there are a lot of errors; we'll get our in-house people to deal with them.
|
||||
4. We've started fixing a few of the errors, but it's time-consuming; we'll do it when we migrate to the new database software.
|
||||
5. We didn't have time to clean the data when moving to the new database; we could use some help.
|
||||
|
||||
|
||||
|
||||
The second progress-blocking attitude is the belief that data cleaning requires dedicated applications—either expensive proprietary programs or the excellent open source program [OpenRefine][4]. To deal with problems that dedicated applications can't solve, data managers might ask a programmer for help—someone good with [Python][5] or [R][6].
|
||||
|
||||
But data auditing and cleaning generally don't require dedicated applications. Plain-text data tables have been around for many decades, and so have text-processing tools. Open up a Bash shell and you have a toolbox loaded with powerful text processors like `grep`, `cut`, `paste`, `sort`, `uniq`, `tr`, and `awk`. They're fast, reliable, and easy to use.
|
||||
|
||||
I do all my data auditing on the command line, and I've put many of my data-auditing tricks on a ["cookbook" website][7]. Operations I do regularly get stored as functions and shell scripts (see the example below).
|
||||
|
||||
Yes, a command-line approach requires that the data to be audited have been exported from the database. And yes, the audit results need to be edited later within the database, or (database permitting) the cleaned data items need to be imported as replacements for the messy ones.
|
||||
|
||||
But the advantages are remarkable. `awk` will process a few million records in seconds on a consumer-grade desktop or laptop. Uncomplicated regular expressions will find all the data errors you can imagine. And all of this will happen safely outside the database structure: Command-line auditing cannot affect the database, because it works with data liberated from its database prison.
|
||||
|
||||
Readers who trained on Unix will be smiling smugly at this point. They remember manipulating data on the command line many years ago in just these ways. What's happened since then is that processing power and RAM have increased spectacularly, and the standard command-line tools have been made substantially more efficient. Data auditing has never been faster or easier. And now that Microsoft Windows 10 can run Bash and GNU/Linux programs, Windows users can appreciate the Unix and Linux motto for dealing with messy data: Keep calm and open a terminal.
|
||||
|
||||
|
||||
![Tshirt, Keep Calm and Open A Terminal][9]
|
||||
|
||||
Photo by Robert Mesibov, CC BY
|
||||
|
||||
### An example
|
||||
|
||||
Suppose I want to find the longest data item in a particular field of a big table. That's not really a data auditing task, but it will show how shell tools work. For demonstration purposes, I'll use the tab-separated table `full0`, which has 1,122,023 records (plus a header line) and 49 fields, and I'll look in field number 36. (I get field numbers with a function explained [on my cookbook site][10].)
|
||||
|
||||
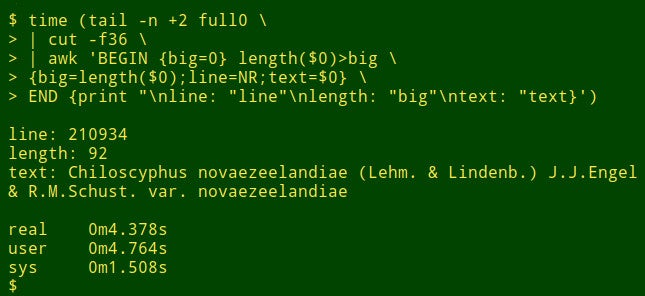
The command begins by using `tail` to remove the header line from `full0`. The result is piped to `cut`, which extracts the decapitated field 36. Next in the pipeline is `awk`. Here the variable `big` is initialized to a value of 0; then `awk` tests the length of the data item in the first record. If the length is bigger than 0, `awk` resets `big` to the new length and stores the line number (NR) in the variable `line` and the whole data item in the variable `text`. `awk` then processes each of the remaining 1,122,022 records in turn, resetting the three variables when it finds a longer data item. Finally, it prints out a neatly separated list of line numbers, length of data item, and full text of the longest data item. (In the following code, the commands have been broken up for clarity onto several lines.)
|
||||
```
|
||||
<code>tail -n +2 full0 \
|
||||
|
||||
> | cut -f36 \
|
||||
|
||||
> | awk 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
> {big=length($0);line=NR;text=$0} \
|
||||
|
||||
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
|
||||
|
||||
```
|
||||
|
||||
How long does this take? About 4 seconds on my desktop (core i5, 8GB RAM):
|
||||
|
||||
|
||||
|
||||
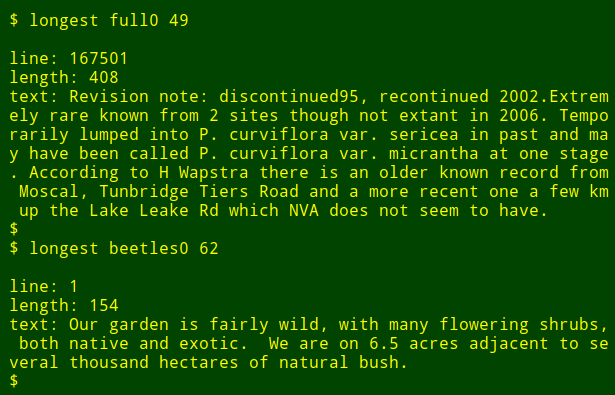
Now for the neat part: I can pop that long command into a shell function, `longest`, which takes as its arguments the filename `($1)` and the field number `($2)`:
|
||||

|
||||
|
||||
I can then re-run the command as a function, finding longest data items in other fields and in other files without needing to remember how the command is written:
|
||||
|
||||
|
||||
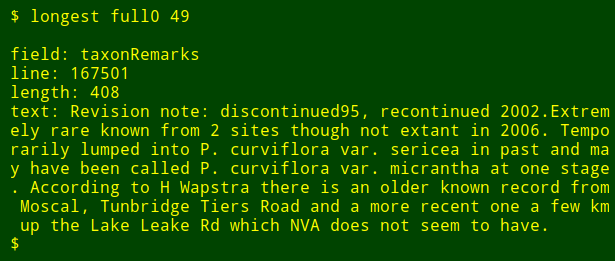
As a final tweak, I can add to the output the name of the numbered field I'm searching. To do this, I use `head` to extract the header line of the table, pipe that line to `tr` to convert tabs to new lines, and pipe the resulting list to `tail` and `head` to print the `$2th` field name on the list, where `$2` is the field number argument. The field name is stored in the shell variable `field` and passed to `awk` for printing as the internal `awk` variable `fld`.
|
||||
```
|
||||
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
|
||||
|
||||
tail -n +2 "$1" \
|
||||
|
||||
| cut -f"$2" | \
|
||||
|
||||
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
{big=length($0);line=NR;text=$0}
|
||||
|
||||
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
Note that if I'm looking for the longest data item in a number of different fields, all I have to do is press the Up Arrow key to get the last `longest` command, then backspace the field number and enter a new one.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/command-line-data-auditing
|
||||
|
||||
作者:[Bob Mesibov][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bobmesibov
|
||||
[1]:https://en.wikipedia.org/wiki/Mojibake
|
||||
[2]:https://en.wikipedia.org/wiki/Control_character
|
||||
[3]:https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character
|
||||
[4]:http://openrefine.org/
|
||||
[5]:https://www.python.org/
|
||||
[6]:https://www.r-project.org/about.html
|
||||
[7]:https://www.polydesmida.info/cookbook/index.html
|
||||
[8]:/file/399116
|
||||
[9]:https://opensource.com/sites/default/files/uploads/terminal_tshirt.jpg (Tshirt, Keep Calm and Open A Terminal)
|
||||
[10]:https://www.polydesmida.info/cookbook/functions.html#fields
|
||||
@ -1,111 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
What version of Linux am I running?
|
||||
======
|
||||
|
||||

|
||||
|
||||
The question "what version of Linux" can mean two different things. Strictly speaking, Linux is the kernel, so the question can refer specifically to the kernel's version number, or "Linux" can be used more colloquially to refer to the entire distribution, as in Fedora Linux or Ubuntu Linux.
|
||||
|
||||
`apt`, `dnf`, `yum`, or some other command to install packages.
|
||||
|
||||
Both are important, and you may need to know one or both answers to fix a problem with a system. For example, knowing the installed kernel version might help diagnose an issue with proprietary drivers, and identifying what distribution is running will help you quickly figure out if you should be using, or some other command to install packages.
|
||||
|
||||
The following will help you find out what version of the Linux kernel and/or what Linux distribution is running on a system.
|
||||
|
||||
### How to find the Linux kernel version
|
||||
|
||||
To find out what version of the Linux kernel is running, run the following command:
|
||||
```
|
||||
uname -srm
|
||||
|
||||
```
|
||||
|
||||
Alternatively, the command can be run by using the longer, more descriptive, versions of the various flags:
|
||||
```
|
||||
uname --kernel-name --kernel-release --machine
|
||||
|
||||
```
|
||||
|
||||
Either way, the output should look similar to the following:
|
||||
```
|
||||
Linux 4.16.10-300.fc28.x86_64 x86_64
|
||||
|
||||
```
|
||||
|
||||
This gives you (in order): the kernel name, the version of the kernel, and the type of hardware the kernel is running on. In this case, the kernel is Linux version 4.16.10-300.fc28.x86_64 running on an x86_64 system.
|
||||
|
||||
More information about the `uname` command can be found by running `man uname`.
|
||||
|
||||
### How to find the Linux distribution
|
||||
|
||||
There are several ways to figure out what distribution is running on a system, but the quickest way is the check the contents of the `/etc/os-release` file. This file provides information about a distribution including, but not limited to, the name of the distribution and its version number. The os-release file in some distributions contains more details than in others, but any distribution that includes an os-release file should provide a distribution's name and version.
|
||||
|
||||
To view the contents of the os-release file, run the following command:
|
||||
```
|
||||
cat /etc/os-release
|
||||
|
||||
```
|
||||
|
||||
On Fedora 28, the output looks like this:
|
||||
```
|
||||
NAME=Fedora
|
||||
|
||||
VERSION="28 (Workstation Edition)"
|
||||
|
||||
ID=fedora
|
||||
|
||||
VERSION_ID=28
|
||||
|
||||
PLATFORM_ID="platform:f28"
|
||||
|
||||
PRETTY_NAME="Fedora 28 (Workstation Edition)"
|
||||
|
||||
ANSI_COLOR="0;34"
|
||||
|
||||
CPE_NAME="cpe:/o:fedoraproject:fedora:28"
|
||||
|
||||
HOME_URL="https://fedoraproject.org/"
|
||||
|
||||
SUPPORT_URL="https://fedoraproject.org/wiki/Communicating_and_getting_help"
|
||||
|
||||
BUG_REPORT_URL="https://bugzilla.redhat.com/"
|
||||
|
||||
REDHAT_BUGZILLA_PRODUCT="Fedora"
|
||||
|
||||
REDHAT_BUGZILLA_PRODUCT_VERSION=28
|
||||
|
||||
REDHAT_SUPPORT_PRODUCT="Fedora"
|
||||
|
||||
REDHAT_SUPPORT_PRODUCT_VERSION=28
|
||||
|
||||
PRIVACY_POLICY_URL="https://fedoraproject.org/wiki/Legal:PrivacyPolicy"
|
||||
|
||||
VARIANT="Workstation Edition"
|
||||
|
||||
VARIANT_ID=workstation
|
||||
|
||||
```
|
||||
|
||||
As the example above shows, Fedora's os-release file provides the name of the distribution and the version, but it also identifies the installed variant (the "Workstation Edition"). If we ran the same command on Fedora 28 Server Edition, the contents of the os-release file would reflect that on the `VARIANT` and `VARIANT_ID` lines.
|
||||
|
||||
Sometimes it is useful to know if a distribution is like another, so the os-release file can contain an `ID_LIKE` line that identifies distributions the running distribution is based on or is similar to. For example, Red Hat Enterprise Linux's os-release file includes an `ID_LIKE` line stating that RHEL is like Fedora, and CentOS's os-release file states that CentOS is like RHEL and Fedora. The `ID_LIKE` line is very helpful if you are working with a distribution that is based on another distribution and need to find instructions to solve a problem.
|
||||
|
||||
CentOS's os-release file makes it clear that it is like RHEL, so documentation and questions and answers in various forums about RHEL should (in most cases) apply to CentOS. CentOS is designed to be a near clone of RHEL, so it is more compatible with its `LIKE` than some entries that might be found in the `ID_LIKE` field, but checking for answers about a "like" distribution is always a good idea if you cannot find the information you are seeking for the running distribution.
|
||||
|
||||
More information about the os-release file can be found by running `man os-release`.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/linux-version
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
@ -1,36 +1,41 @@
|
||||
How To Convert DEB Packages Into Arch Linux Packages
|
||||
======
|
||||
# 将 DEB 软件包转换成 Arch Linux 软件包
|
||||
|
||||

|
||||
|
||||
We already learned how to [**build packages for multiple platforms**][1], and how to **[build packages from source][2]**. Today, we are going to learn how to convert DEB packages into Arch Linux packages. You might ask, **AUR** is the large software repository on the planet, and almost all software are available in it. Why would I need to convert a DEB package into Arch Linux package? True! However, some packages cannot be compiled (closed source packages) or cannot be built from AUR for various reasons like error during compiling or unavailable files. Or, the developer is too lazy to build a package in AUR or s/he doesn 't like to create an AUR package. In such cases, we can use this quick and dirty method to convert DEB packages into Arch Linux packages.
|
||||
我们已经学会了如何[**为多个平台构建包**][1],以及如何从[**源代码构建包**][2]。 今天,我们将学习如何将 DEB 包转换为 Arch Linux 包。 您可能会问,AUR 是这个星球上的大型软件存储库,几乎所有的软件都可以在其中使用。 为什么我需要将 DEB 软件包转换为 Arch Linux 软件包? 这的确没错! 但是,某些软件包无法编译(封闭源代码软件包),或者由于各种原因(如编译时出错或文件不可用)而无法从 AUR 生成。 或者,开发人员懒得在 AUR 中构建一个包,或者他/她不想创建 AUR 包。 在这种情况下,我们可以使用这种快速但有点粗糙的方法将 DEB 包转换成 Arch Linux 包。
|
||||
|
||||
### Debtap - Convert DEB Packages Into Arch Linux Packages
|
||||
### Debtap - 将 DEB 包转换成 Arch Linux 包
|
||||
|
||||
For this purpose, we are going to use an utility called **" Debtap"**. It stands **DEB** **T** o **A** rch (Linux) **P** ackage. Debtap is available in AUR, so you can install it using the AUR helper tools such as [**Pacaur**][3], [**Packer**][4], or [**Yaourt**][5].
|
||||
为此,我们将使用名为 “Debtap” 的实用程序。 它代表了 **DEB** **T** o **A** rch (Linux) **P** ackage。 Debtap 在 AUR 中可以使用,因此您可以使用 AUR 辅助工具(如 [Pacaur][3],[Packer][4] 或 [Yaourt][5] )来安装它。
|
||||
|
||||
使用 pacaur 安装 debtap 运行:
|
||||
|
||||
To unstall debtap using pacaur, run:
|
||||
```
|
||||
pacaur -S debtap
|
||||
```
|
||||
|
||||
Using Packer:
|
||||
使用 Packer 安装:
|
||||
|
||||
```
|
||||
packer -S debtap
|
||||
```
|
||||
|
||||
Using Yaourt:
|
||||
使用 Yaourt 安装:
|
||||
|
||||
```
|
||||
yaourt -S debtap
|
||||
```
|
||||
|
||||
Also, your Arch system should have **bash,** **binutils** , **pkgfile** and **fakeroot ** packages installed.
|
||||
同时,你的 Arch 系统也应该已经安装好了 **bash**, **binutils** ,**pkgfile** 和 **fakeroot** 包。
|
||||
|
||||
在安装 Debtap 和所有上述依赖关系之后,运行以下命令来创建/更新 pkgfile 和 debtap 数据库。
|
||||
|
||||
After installing Debtap and all above mentioned dependencies, run the following command to create/update pkgfile and debtap database.
|
||||
```
|
||||
sudo debtap -u
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
示例输出是:
|
||||
|
||||
```
|
||||
==> Synchronizing pkgfile database...
|
||||
:: Updating 6 repos...
|
||||
@ -68,20 +73,22 @@ Sample output would be:
|
||||
==> All steps successfully completed!
|
||||
```
|
||||
|
||||
You must run the above command at least once.
|
||||
你至少需要运行上述命令一次
|
||||
|
||||
Now, it's time for package conversion.
|
||||
现在是时候开始转换包了。
|
||||
|
||||
比如说要使用 debtap 转换包 **Quadrapassel**,你可以这样做:
|
||||
|
||||
To convert any DEB package, say **Quadrapassel** , to Arch Linux package using debtap, do:
|
||||
```
|
||||
debtap quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
The above command will convert the given .deb file into a Arch Linux package. You will be asked to enter the name of the package maintainer and license. Just enter them and hit ENTER key to start the conversion process.
|
||||
上述的命令会将 DEB 包文件转换为 Arch Linux 包。你需要输入包的维护者和许可证,输入他们,然后按下回车键就可以开始转换了。
|
||||
|
||||
The package conversion will take from a few seconds to several minutes depending upon your CPU speed. Grab a cup of coffee.
|
||||
包转换的过程可能依赖于你的 CPU 的速度从几秒到几分钟不等。喝一杯咖啡等一等。
|
||||
|
||||
示例输出:
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
==> Extracting package data...
|
||||
==> Fixing possible directories structure differencies...
|
||||
@ -109,24 +116,28 @@ gsettings-backend
|
||||
==> Removing leftover files...
|
||||
```
|
||||
|
||||
**Note:** Quadrapassel package is already available in the Arch Linux official repositories. I used it just for demonstration purpose.
|
||||
**注**:Quadrapassel 在 Arch Linux 官方的软件库中早已可用,我只是用它来说明一下。
|
||||
|
||||
如果在包转化的过程中,你不想回答任何问题,使用 **-q** 略过除了编辑元数据的所有问题。
|
||||
|
||||
If you don't want to answer any questions during package conversion, use **-q** flag to bypass all questions, except for editing metadata file(s).
|
||||
```
|
||||
debtap -q quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
To bypass all questions (not recommended though), use -Q flag.
|
||||
为了略过所有的问题(不推荐),使用 -Q。
|
||||
|
||||
```
|
||||
debtap -Q quadrapassel_3.22.0-1.1_arm64.deb
|
||||
```
|
||||
|
||||
Once the conversion is done, you can install the newly converted package using "pacman" in your Arch system as shown below.
|
||||
转换完成后,您可以使用 “pacman” 在 Arch 系统中安装新转换的软件包,如下所示。
|
||||
|
||||
```
|
||||
sudo pacman -U <package-name>
|
||||
```
|
||||
|
||||
To display the help section, use **-h** flag:
|
||||
显示帮助文档,使用 -h:
|
||||
|
||||
```
|
||||
$ debtap -h
|
||||
Syntax: debtap [options] package_filename
|
||||
@ -143,11 +154,11 @@ Options:
|
||||
-P --P -Pkgbuild --Pkgbuild Generate a PKGBUILD file only
|
||||
```
|
||||
|
||||
And, that's all for now folks. Hope this utility helps. If you find our guides useful, please spend a moment to share them on your social, professional networks and support OSTechNix!
|
||||
这就是现在要讲的。希望这个工具有所帮助。如果你发现我们的指南有用,请花一点时间在你的社交、专业网络分享并在 OSTechNix 支持我们!
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
更多的好东西来了。请继续关注!
|
||||
|
||||
Cheers!
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
@ -156,7 +167,7 @@ Cheers!
|
||||
via: https://www.ostechnix.com/convert-deb-packages-arch-linux-packages/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,76 @@
|
||||
如何提升自动化的 ROI:4 个小提示
|
||||
======
|
||||
|
||||

|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对成本随着工作量的增加而增加的这一事实可以重新定义而感到震惊。
|
||||
|
||||
机器人流程自动化(RPA)似乎预示着运营的圣杯(Holy Grail):“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处即实用可行度又高。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
|
||||
自动化的谈论都趋向于类似的话题:COO 们和他们的团队想知道,自动化操作能够给他们带来什么好处。他们想知道 RPA 平台特性和功能,以及自动化在现实中的真实案例。从这一点到概念验证的实现过程通常很短暂。
|
||||
|
||||
**[ 在实现人工智能技术方面的建议,可以查看我们相关的文章,[制定你的人工智能策略:3 个小提示][1]]**。
|
||||
|
||||
但是自动化带来的现实好处有时候可能比你所预期的时间要晚。采用 RPA 的公司在其实施后可能会对它们自身的 ROI 提出一些质疑。一些人没有看到预期之中的成本节省,并对其中的原因感到疑惑。
|
||||
|
||||
## 你是不是自动化了错误的东西?
|
||||
|
||||
在这些情况下,自动化的愿景和现实之间的差距是什么呢?我们来分析一下它,在决定去继续进行一个自动化验证项目(甚至是一个成熟的实践)之后,我们来看一下通常会发生什么。
|
||||
|
||||
在确定实施自动化所采用的路径之后,COO 一般会问运营领导和他的团队们,应该在哪个流程或者任务上实施自动化。虽然从原则上说应该鼓励他们参与进来,但是有时候这种方式产生的决策往往会产生一个次优选择。原因如下:
|
||||
|
||||
首先,团队领导经常会是“视野较窄”:他们对自己的流程和任务非常熟悉,但是对他们不参与的流程和任务并不是那么熟悉(特别是在他们没有太多运营经验的情况下)。这意味着他们在自己的工作领域内可能会找出比较适合自动化的候选者,但是在跨整个运营的其它领域中可能并不一定会找出最适合的。另外其它的像“我希望我的流程成为第一个实施自动化的候选者”这样的“软性”因素也会影响决定。
|
||||
|
||||
其次,候选流程的选择有时候会被自动化特性和能力的匹配度所支配,而不是根据自动化所带来的价值所决定的。一个常见的误解是,任何包括像电子邮件或目录监视、下载、计算等活动的任务都是自动化的最佳候选者。如果对这些任务实施自动化不能为组织产生价值,那么它们就不是正确的候选者。
|
||||
|
||||
那么,对于领导们来说,怎么才能确保实施自动化能够带来他们想要的 ROI 呢?实现这个目标有四步:
|
||||
|
||||
## 1. 教育团队
|
||||
|
||||
在你的团队中,从 COO 职位以下的人中,很有可能都听说过 RPA 和运营自动化。同样很有可能他们都有许多的问题和担心。在你开始启动实施之前解决这些问题和担心是非常重要的。
|
||||
|
||||
对运营团队进行积极的教育可以大大地提升他们对自动化的热情和信心。培训主要关注于自动化和机器人是什么,它们在流程中一般扮演什么样的角色,哪个流程和任务最适合自动化,以及自动化的预期好处是什么。
|
||||
|
||||
**建议**:邀请你的自动化合作伙伴去进行这些团队教育工作,你要有所控制:他们可能会非常乐意帮助你。在领导层将这些传播到更大范围的团队之前,你应该对他们的教育内容进行把关。
|
||||
|
||||
“实施自动化的第一步是更好地理解你的流程。”
|
||||
|
||||
## 2. 审查内部流程
|
||||
|
||||
实施自动化的第一步是更好地理解你的流程。每个 RPA 实施之前都应该进行流程清单、动作分析、以及成本/价值的绘制练习。
|
||||
|
||||
这些练习对于理解流程中何处价值产生(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
|
||||
这将有助你去识别和优先考虑最合适的自动化候选者。由于能够或者可能需要自动化的任务数量较多,流程一般需要分段实施自动化,因此优先级很重要。
|
||||
|
||||
**建议**:设置一个小的工作团队,每个运营团队都参与其中。从每个运营团队中提名一个协调人 —— 一般是运营团队的领导或者团队管理者。在团队级别上组织一次研讨会,去构建流程清单、识别候选流程、以及推动购买。你的自动化合作伙伴很可能有“加速器” —— 调查问卷、计分卡等等 —— 这些将帮助你加速完成这项活动。
|
||||
|
||||
## 3. 为优先业务提供强有力的指导
|
||||
|
||||
实施自动化经常会涉及到在运营团队之间,基于业务价值对流程选择和自动化优先级上要达成共识(有时候是打破平衡)虽然团队的参与仍然是分析和实施的关键部分,但是领导仍然应该是最终的决策者。
|
||||
|
||||
**建议**:安排定期会议从工作团队中获取最新信息。除了像推动达成共识和购买之外,工作团队还应该在团队层面上去查看领导们关于 ROI、平台选择、以及自动化优先级上的指导性决定。
|
||||
|
||||
## 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
|
||||
当运营团队和技术团队紧密合作时,自动化的实施将异常顺利。COO 需要去帮助推动与 CIO 团队的合作。
|
||||
|
||||
COO 和其他运营领导人的参与和监督对成功实施自动化是至关重要的。
|
||||
|
||||
**建议**:COO 和 CIO 团队应该与第三方的自动化合作伙伴共同设立一个联合工作组(一个“战场”)。对每个参与者的责任进行明确的界定并持续跟踪。理想情况下,COO 和 CIO 应该至少有一个投入到联合工作组中,至少在初始发布中应该是这样。
|
||||
|
||||
自动化可以为组织创造重要的价值。然而为了在自动化中获得最优的投资回报,CIO 们必须在“入坑”之前做好规划。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-4-tips
|
||||
|
||||
作者:[Rajesh Kamath][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/rajesh-kamath
|
||||
[1]:https://enterprisersproject.com/article/2017/11/crafting-your-ai-strategy-3-tips?sc_cid=70160000000h0aXAAQ
|
||||
@ -0,0 +1,115 @@
|
||||
# 在命令行中整理数据
|
||||
|
||||

|
||||
|
||||
我兼职做数据审计。把我想象成一个校对者,处理数据表格而不是一页一页的文章。这些表是从关系数据库导出的,并且规模相当小:100,000 到 1,000,000条记录,50 到 200个字段。
|
||||
|
||||
我从来没有见过没有错误的数据表。您可能认为,这种混乱并不局限于重复记录、拼写和格式错误以及放置在错误字段中的数据项。我还发现:
|
||||
|
||||
* 损坏的记录分布在几行上,因为数据项具有内嵌的换行符
|
||||
* 在同一记录中一个字段中的数据项与另一个字段中的数据项不一致
|
||||
* 使用截断数据项的记录,通常是因为非常长的字符串被硬塞到具有50或100字符限制的字段中
|
||||
* 字符编码失败产生称为[乱码][1]
|
||||
* 不可见的[控制字符][2],其中一些会导致数据处理错误
|
||||
* 由上一个程序插入的[替换字符][3]和神秘的问号,这导致了不知道数据的编码是什么
|
||||
|
||||
解决这些问题并不困难,但找到它们存在非技术障碍。首先,每个人都不愿处理数据错误。在我看到表格之前,数据所有者或管理人员可能已经经历了数据悲伤的所有五个阶段:
|
||||
|
||||
1. 我们的数据没有错误。
|
||||
|
||||
1. 好吧,也许有一些错误,但它们并不重要。
|
||||
2. 好的,有很多错误; 我们会让我们的内部人员处理它们。
|
||||
3. 我们已经开始修复一些错误,但这很耗时间; 我们将在迁移到新的数据库软件时执行此操作。
|
||||
4. 1.移至新数据库时,我们没有时间整理数据; 我们可以使用一些帮助。
|
||||
|
||||
第二个阻碍进展的是相信数据整理需要专用的应用程序——要么是昂贵的专有程序,要么是优秀的开源程序 [OpenRefine][4] 。为了解决专用应用程序无法解决的问题,数据管理人员可能会向程序员寻求帮助,比如擅长 [Python][5] 或 [R][6] 的人。
|
||||
|
||||
但是数据审计和整理通常不需要专用的应用程序。纯文本数据表已经存在了几十年,文本处理工具也是如此。打开 Bash shell,您将拥有一个工具箱,其中装载了强大的文本处理器,如 `grep`、`cut`、`paste`、`sort`、`uniq`、`tr` 和 `awk`。它们快速、可靠、易于使用。
|
||||
|
||||
我在命令行上执行所有的数据审计工作,并且在 “[cookbook][7]” 网站上发布了许多数据审计技巧。我经常将操作存储为函数和 shell 脚本(参见下面的示例)。
|
||||
|
||||
是的,命令行方法要求将要审计的数据从数据库中导出。 是的,审计结果需要稍后在数据库中进行编辑,或者(数据库允许)整理的数据项作为替换杂乱的数据项导入其中。
|
||||
|
||||
但其优势是显著的。awk 将在普通的台式机或笔记本电脑上以几秒钟的时间处理数百万条记录。不复杂的正则表达式将找到您可以想象的所有数据错误。所有这些都将安全地发生在数据库结构之外:命令行审计不会影响数据库,因为它使用从数据库中释放的数据。
|
||||
|
||||
受过 Unix 培训的读者此时会沾沾自喜。他们还记得许多年前用这些方法操纵命令行上的数据。从那时起,计算机的处理能力和 RAM 得到了显著提高,标准命令行工具的效率大大提高。数据审计从来都不是更快或更容易的。现在微软的 Windows 10 可以运行 Bash 和 GNU/Linux 程序了,Windows 用户也可以用 Unix 和 Linux 的座右铭来处理混乱的数据:保持冷静,打开一个终端。
|
||||
|
||||
|
||||
![Tshirt, Keep Calm and Open A Terminal][9]
|
||||
|
||||
图片:Robert Mesibov,CC BY
|
||||
|
||||
### 例子:
|
||||
|
||||
假设我想在一个大的表中的特定字段中找到最长的数据项。 这不是一个真正的数据审计任务,但它会显示 shell 工具的工作方式。 为了演示目的,我将使用制表符分隔的表 `full0` ,它有 1,122,023 条记录(加上一个标题行)和 49 个字段,我会查看 36 号字段.(我得到字段编号的函数在我的[网站][10]上有解释)
|
||||
|
||||
首先,使用 `tail` 命令从表 `full0` 移除标题行,结果管道至 `cut` 命令,截取第 36 个字段,接下来,管道至 `awk` ,这里有一个初始化为 0 的变量 `big` ,然后 `awk` 开始检测第一行数据项的长度,如果长度大于 0 , `awk` 将会设置 `big` 变量为新的长度,同时存储行数到变量 `line` 中。整个数据项存储在变量 `text` 中。然后 `awk` 开始轮流处理剩余的 1,122,022 记录项。同时,如果发现更长的数据项时,更新 3 个变量。最后,它打印出行号,数据项的长度,以及最长数据项的内容。(在下面的代码中,为了清晰起见,将代码分为几行)
|
||||
|
||||
```
|
||||
<code>tail -n +2 full0 \
|
||||
|
||||
> | cut -f36 \
|
||||
|
||||
> | awk 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
> {big=length($0);line=NR;text=$0} \
|
||||
|
||||
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
|
||||
|
||||
```
|
||||
|
||||
大约花了多长时间?我的电脑大约用了 4 秒钟(core i5,8GB RAM);
|
||||
|
||||

|
||||
|
||||
现在我可以将这个长长的命令封装成一个 shell 函数,`longest`,它把第一个参数认为是文件名,第二个参数认为是字段号:
|
||||
|
||||

|
||||
|
||||
现在,我重新运行这个命令,在另一个文件中找另一个字段中最长的数据项而不需要去记忆命令是如何写的:
|
||||
|
||||

|
||||
|
||||
最后调整一下,我还可以输出我要查询字段的名称,我只需要使用 `head` 命令抽取表格第一行的标题行,然后将结果管道至 `tr` 命令,将制表位转换为换行,然后将结果管道至 `tail` 和 `head` 命令,打印出第二个参数在列表中名称,第二个参数就是字段号。字段的名字就存储到变量 `field` 中,然后将他传向 `awk` ,通过变量 `fld` 打印出来。(译者注:按照下面的代码,编号的方式应该是从右向左)
|
||||
|
||||
```
|
||||
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
|
||||
|
||||
tail -n +2 "$1" \
|
||||
|
||||
| cut -f"$2" | \
|
||||
|
||||
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
{big=length($0);line=NR;text=$0}
|
||||
|
||||
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
注意,如果我在多个不同的字段中查找最长的数据项,我所要做的就是按向上箭头来获得最后一个最长的命令,然后删除字段号并输入一个新的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/command-line-data-auditing
|
||||
|
||||
作者:[Bob Mesibov][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bobmesibov
|
||||
[1]:https://en.wikipedia.org/wiki/Mojibake
|
||||
[2]:https://en.wikipedia.org/wiki/Control_character
|
||||
[3]:https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character
|
||||
[4]:http://openrefine.org/
|
||||
[5]:https://www.python.org/
|
||||
[6]:https://www.r-project.org/about.html
|
||||
[7]:https://www.polydesmida.info/cookbook/index.html
|
||||
[8]:/file/399116
|
||||
[9]:https://opensource.com/sites/default/files/uploads/terminal_tshirt.jpg "Tshirt, Keep Calm and Open A Terminal"
|
||||
[10]:https://www.polydesmida.info/cookbook/functions.html#fields
|
||||
106
translated/tech/20180612 What version of Linux am I running.md
Normal file
106
translated/tech/20180612 What version of Linux am I running.md
Normal file
@ -0,0 +1,106 @@
|
||||
我正在运行的 Linux 是什么版本?
|
||||
=====
|
||||
|
||||

|
||||
|
||||
“Linux 是什么版本?”这个问题可能意味着两个不同的东西。严格地说,Linux 是内核,所以问题可以特指内核的版本号,或者 “Linux” 可以更通俗地用来指整个发行版,就像在 Fedora Linux 或 Ubuntu Linux 中一样。
|
||||
|
||||
两者都很重要,你可能需要知道其中一个或全部答案来修复系统中的问题。例如,了解已安装的内核版本可能有助于诊断带有专有驱动程序的问题,并且确定正在运行的发行版将帮助你快速确定是否应该使用 `apt`, `dnf`, `yum` 或其他命令来安装软件包。
|
||||
|
||||
以下内容将帮助你了解 Linux 内核的版本和/或系统上正在运行的 Linux 发行版是什么。
|
||||
|
||||
### 如何找到 Linux 内核版本
|
||||
|
||||
要找出哪个 Linux 内核版本正在运行,运行以下命令:
|
||||
```
|
||||
uname -srm
|
||||
|
||||
```
|
||||
|
||||
或者,可以使用更长,更具描述性的各种标志的版本来运行该命令:
|
||||
```
|
||||
uname --kernel-name --kernel-release --machine
|
||||
|
||||
```
|
||||
|
||||
无论哪种方式,输出都应该类似于以下内容:
|
||||
```
|
||||
Linux 4.16.10-300.fc28.x86_64 x86_64
|
||||
|
||||
```
|
||||
|
||||
这为你提供了(按顺序):内核名称,内核版本以及运行内核的硬件类型。在上面的情况下,内核是 Linux 4.16.10-300.fc28.x86_64 ,运行于 x86_64 系统。
|
||||
|
||||
有关 `uname` 命令的更多信息可以通过运行 `man uname` 找到。
|
||||
|
||||
### 如何找出 Linux 发行版
|
||||
|
||||
有几种方法可以确定系统上运行的是哪个发行版,但最快的方法是检查 `/etc/os-release` 文件的内容。此文件提供有关发行版的信息,包括但不限于发行版名称及其版本号。某些发行版的 os-release 文件包含比其他发行版更多的细节,但任何包含 os-release 文件的发行版都应该提供发行版的名称和版本。
|
||||
|
||||
要查看 os-release 文件的内容,运行以下命令:
|
||||
```
|
||||
cat /etc/os-release
|
||||
|
||||
```
|
||||
|
||||
在 Fedora 28 中,输出如下所示:
|
||||
```
|
||||
NAME=Fedora
|
||||
|
||||
VERSION="28 (Workstation Edition)"
|
||||
|
||||
ID=fedora
|
||||
|
||||
VERSION_ID=28
|
||||
|
||||
PLATFORM_ID="platform:f28"
|
||||
|
||||
PRETTY_NAME="Fedora 28 (Workstation Edition)"
|
||||
|
||||
ANSI_COLOR="0;34"
|
||||
|
||||
CPE_NAME="cpe:/o:fedoraproject:fedora:28"
|
||||
|
||||
HOME_URL="https://fedoraproject.org/"
|
||||
|
||||
SUPPORT_URL="https://fedoraproject.org/wiki/Communicating_and_getting_help"
|
||||
|
||||
BUG_REPORT_URL="https://bugzilla.redhat.com/"
|
||||
|
||||
REDHAT_BUGZILLA_PRODUCT="Fedora"
|
||||
|
||||
REDHAT_BUGZILLA_PRODUCT_VERSION=28
|
||||
|
||||
REDHAT_SUPPORT_PRODUCT="Fedora"
|
||||
|
||||
REDHAT_SUPPORT_PRODUCT_VERSION=28
|
||||
|
||||
PRIVACY_POLICY_URL="https://fedoraproject.org/wiki/Legal:PrivacyPolicy"
|
||||
|
||||
VARIANT="Workstation Edition"
|
||||
|
||||
VARIANT_ID=workstation
|
||||
|
||||
```
|
||||
|
||||
如上面那个例子展示的那样,Fedora 的 os-release 文件提供了发行版的名称和版本,但它也标识已安装的变体("Workstation Edition")。如果我们在 Fedora 28 服务器版本上运行相同的命令,os-release 文件的内容会反映在 `VARIANT` 和 `VARIANT_ID` 行中。
|
||||
|
||||
有时候知道一个发行版是否与另一个发行版相似非常有用,因此 os-release 文件可以包含一个 `ID_LIKE` 行,用于标识正在运行的是基于什么的发行版或类似的发行版。例如,Red Hat Linux 企业版的 os-release 文件包含 `ID_LIKE` 行,声明 RHEL 与 Fedora 类似;CentOS 的 os-release 文件声明 CentOS 与 RHEL 和 Fedora 类似。如果你正在使用基于另一个发行版的发行版并需要查找解决问题的说明,那么 `ID_LIKE` 行非常有用。
|
||||
|
||||
CentOS 的 os-release 文件清楚地表明它就像 RHEL 一样,所以在各种论坛中关于 RHEL 的文档,问题和答案应该(大多数情况下)适用于 CentOS。CentOS 被设计成一个克隆版 RHEL,因此相比 `ID_LIKE` 字段中的某些记录,它与 `LIKE` 字段更兼容。如果你找不到正在运行的发行版的信息,检查有关 “like” 发行版的答案总是一个好主意。
|
||||
|
||||
有关 os-release 文件的更多信息可以通过运行 `man os-release` 命令来查找。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/linux-version
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
Loading…
Reference in New Issue
Block a user