mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
9d50cd1756
@ -104,10 +104,10 @@ Arch Linux 也因其丰富的 Wiki 帮助文档而大受推崇。该系统基于
|
||||
][23]
|
||||
|
||||
输入下面的命令来检查网络连接。
|
||||
|
||||
|
||||
```
|
||||
ping google.com
|
||||
```
|
||||
```
|
||||
|
||||
这个单词 ping 表示网路封包搜寻。你将会看到下面的返回信息,表明 Arch Linux 已经连接到外网了。这是执行安装过程中的很关键的一点。(LCTT 译注:或许你 ping 不到那个不存在的网站,你选个存在的吧。)
|
||||
|
||||
@ -117,8 +117,8 @@ ping google.com
|
||||
|
||||
输入如下命令清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
在开始安装之前,你得先为硬盘分区。输入 `fdisk -l` ,你将会看到当前系统的磁盘分区情况。注意一开始你给 Arch Linux 系统分配的 20 GB 存储空间。
|
||||
@ -137,8 +137,8 @@ clear
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
|
||||
你将看到 `gpt`、`dos`、`sgi` 和 `sun` 类型,选择 `dos` 选项,然后按回车。
|
||||
@ -185,8 +185,8 @@ cfdisk
|
||||
|
||||
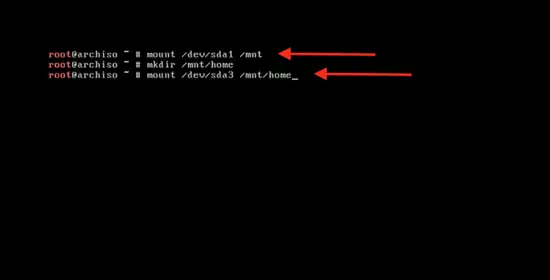
以同样的方式创建逻辑分区。在“退出(quit)”选项按回车键,然后输入下面的命令来清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
[
|
||||
@ -195,21 +195,21 @@ clear
|
||||
|
||||
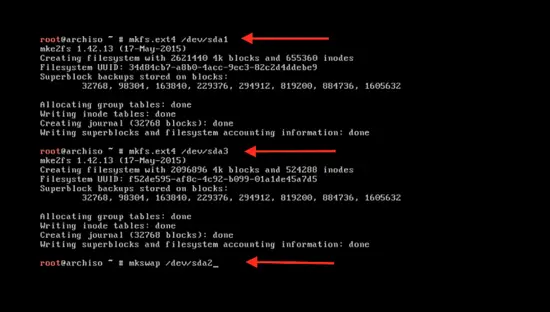
输入下面的命令来格式化新建的分区:
|
||||
|
||||
```
|
||||
```
|
||||
mkfs.ext4 /dev/sda1
|
||||
```
|
||||
```
|
||||
|
||||
这里的 `sda1` 是分区名。使用同样的命令来格式化第二个分区 `sda3` :
|
||||
|
||||
```
|
||||
```
|
||||
mkfs.ext4 /dev/sda3
|
||||
```
|
||||
```
|
||||
|
||||
格式化 swap 分区:
|
||||
|
||||
```
|
||||
```
|
||||
mkswap /dev/sda2
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -217,14 +217,14 @@ mkswap /dev/sda2
|
||||
|
||||
使用下面的命令来激活 swap 分区:
|
||||
|
||||
```
|
||||
swapon /dev/sda2
|
||||
```
|
||||
swapon /dev/sda2
|
||||
```
|
||||
|
||||
输入 clear 命令清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
[
|
||||
@ -233,9 +233,9 @@ clear
|
||||
|
||||
输入下面的命令来挂载主分区以开始系统安装:
|
||||
|
||||
```
|
||||
mount /dev/sda1 / mnt
|
||||
```
|
||||
```
|
||||
mount /dev/sda1 /mnt
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -245,9 +245,9 @@ mount /dev/sda1 / mnt
|
||||
|
||||
输入下面的命令来引导系统启动:
|
||||
|
||||
```
|
||||
```
|
||||
pacstrap /mnt base base-devel
|
||||
```
|
||||
```
|
||||
|
||||
可以看到系统正在同步数据包。
|
||||
|
||||
@ -263,9 +263,9 @@ pacstrap /mnt base base-devel
|
||||
|
||||
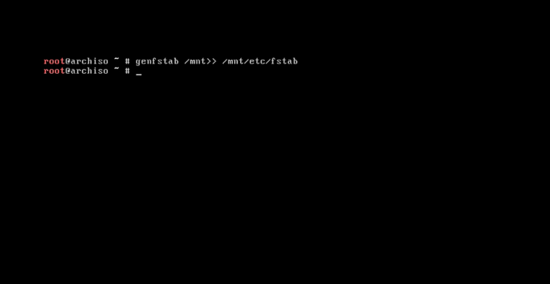
系统基本软件安装完成后,输入下面的命令来创建 fstab 文件:
|
||||
|
||||
```
|
||||
```
|
||||
genfstab /mnt>> /mnt/etc/fstab
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -275,14 +275,14 @@ genfstab /mnt>> /mnt/etc/fstab
|
||||
|
||||
输入下面的命令来更改系统的根目录为 Arch Linux 的安装目录:
|
||||
|
||||
```
|
||||
```
|
||||
arch-chroot /mnt /bin/bash
|
||||
```
|
||||
```
|
||||
|
||||
现在来更改语言配置:
|
||||
|
||||
```
|
||||
nano /etc/local.gen
|
||||
```
|
||||
nano /etc/locale.gen
|
||||
```
|
||||
|
||||
[
|
||||
@ -297,9 +297,9 @@ nano /etc/local.gen
|
||||
|
||||
输入下面的命令来激活它:
|
||||
|
||||
```
|
||||
```
|
||||
locale-gen
|
||||
```
|
||||
```
|
||||
|
||||
按回车。
|
||||
|
||||
@ -309,8 +309,8 @@ locale-gen
|
||||
|
||||
使用下面的命令来创建 `/etc/locale.conf` 配置文件:
|
||||
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
|
||||
然后按回车。现在你就可以在配置文件中输入下面一行内容来为系统添加语言:
|
||||
@ -326,9 +326,9 @@ LANG=en_US.UTF-8
|
||||
][44]
|
||||
|
||||
输入下面的命令来同步时区:
|
||||
|
||||
|
||||
```
|
||||
ls user/share/zoneinfo
|
||||
ls /usr/share/zoneinfo
|
||||
```
|
||||
|
||||
下面你将看到整个世界的时区列表。
|
||||
@ -339,9 +339,9 @@ ls user/share/zoneinfo
|
||||
|
||||
输入下面的命令来选择你所在的时区:
|
||||
|
||||
```
|
||||
```
|
||||
ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
```
|
||||
```
|
||||
|
||||
或者你可以从下面的列表中选择其它名称。
|
||||
|
||||
@ -351,8 +351,8 @@ ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
|
||||
使用下面的命令来设置标准时间:
|
||||
|
||||
```
|
||||
hwclock --systohc –utc
|
||||
```
|
||||
hwclock --systohc --utc
|
||||
```
|
||||
|
||||
硬件时钟已同步。
|
||||
@ -363,8 +363,8 @@ hwclock --systohc –utc
|
||||
|
||||
设置 root 帐号密码:
|
||||
|
||||
```
|
||||
passwd
|
||||
```
|
||||
passwd
|
||||
```
|
||||
|
||||
按回车。 然而输入你想设置的密码,按回车确认。
|
||||
@ -377,9 +377,9 @@ passwd
|
||||
|
||||
使用下面的命令来设置主机名:
|
||||
|
||||
```
|
||||
```
|
||||
nano /etc/hostname
|
||||
```
|
||||
```
|
||||
|
||||
然后按回车。输入你想设置的主机名称,按 `control + x` ,按 `y` ,再按回车 。
|
||||
|
||||
@ -389,9 +389,9 @@ nano /etc/hostname
|
||||
|
||||
启用 dhcpcd :
|
||||
|
||||
```
|
||||
```
|
||||
systemctl enable dhcpcd
|
||||
```
|
||||
```
|
||||
|
||||
这样在下一次系统启动时, dhcpcd 将会自动启动,并自动获取一个 IP 地址:
|
||||
|
||||
@ -403,9 +403,9 @@ systemctl enable dhcpcd
|
||||
|
||||
最后一步,输入以下命令来初始化 grub 安装。输入以下命令:
|
||||
|
||||
```
|
||||
```
|
||||
pacman –S grub os-rober
|
||||
```
|
||||
```
|
||||
|
||||
然后按 `y` ,将会下载相关程序。
|
||||
|
||||
@ -415,14 +415,14 @@ pacman –S grub os-rober
|
||||
|
||||
使用下面的命令来将启动加载程序安装到硬盘上:
|
||||
|
||||
```
|
||||
```
|
||||
grub-install /dev/sda
|
||||
```
|
||||
```
|
||||
|
||||
然后进行配置:
|
||||
|
||||
```
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
[
|
||||
@ -431,9 +431,9 @@ grub-mkconfig -o /boot/grub/grub.cfg
|
||||
|
||||
最后重启系统:
|
||||
|
||||
```
|
||||
```
|
||||
reboot
|
||||
```
|
||||
```
|
||||
|
||||
然后按回车 。
|
||||
|
||||
@ -459,7 +459,7 @@ reboot
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-arch-linux-on-virtualbox/
|
||||
|
||||
译者简介:
|
||||
译者简介:
|
||||
|
||||
rusking:春城初春/春水初生/春林初盛/春風十裏不如妳
|
||||
|
||||
|
||||
@ -1,28 +1,24 @@
|
||||
在 Kubernetes 上运行一个 Python 应用程序
|
||||
============================================================
|
||||
|
||||
### 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。
|
||||
> 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。
|
||||
|
||||

|
||||
图片来源:opensource.com
|
||||
|
||||
Kubernetes 是一个具备部署、维护、和可伸缩特性的开源平台。它在提供可移植性、可扩展性、以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
|
||||
Kubernetes 是一个具备部署、维护和可伸缩特性的开源平台。它在提供可移植性、可扩展性以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
|
||||
|
||||
不论你的 Python 应用程序是简单还是复杂,Kubernetes 都可以帮你高效地部署和伸缩它们,在有限的资源范围内滚动升级新特性。
|
||||
|
||||
在本文中,我将描述在 Kubernetes 上部署一个简单的 Python 应用程序的过程,它包括:
|
||||
|
||||
* 创建 Python 容器镜像
|
||||
|
||||
* 发布容器镜像到镜像注册中心
|
||||
|
||||
* 使用持久卷
|
||||
|
||||
* 在 Kubernetes 上部署 Python 应用程序
|
||||
|
||||
### 必需条件
|
||||
|
||||
你需要 Docker、kubectl、以及这个 [源代码][10]。
|
||||
你需要 Docker、`kubectl` 以及这个 [源代码][10]。
|
||||
|
||||
Docker 是一个构建和承载已发布的应用程序的开源平台。可以参照 [官方文档][11] 去安装 Docker。运行如下的命令去验证你的系统上运行的 Docker:
|
||||
|
||||
@ -40,7 +36,7 @@ WARNING: No memory limit support
|
||||
WARNING: No swap limit support
|
||||
```
|
||||
|
||||
kubectl 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 kubectl:
|
||||
`kubectl` 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 `kubectl`:
|
||||
|
||||
```
|
||||
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
|
||||
@ -56,9 +52,9 @@ curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s
|
||||
|
||||
### 创建一个 Python 容器镜像
|
||||
|
||||
为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 `Docker file` 中的指令来自动化构建镜像。
|
||||
为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 Dockerfile 中的指令来自动化构建镜像。
|
||||
|
||||
这是我们的 Python 应用程序的 `Docker file`:
|
||||
这是我们的 Python 应用程序的 Dockerfile:
|
||||
|
||||
```
|
||||
FROM python:3.6
|
||||
@ -90,7 +86,7 @@ VOLUME ["/app-data"]
|
||||
CMD ["python", "app.py"]
|
||||
```
|
||||
|
||||
这个 `Docker file` 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
|
||||
这个 Dockerfile 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
|
||||
|
||||
### 构建一个 Python Docker 镜像
|
||||
|
||||
@ -128,45 +124,45 @@ Kubernetes 支持许多的持久存储提供商,包括 AWS EBS、CephFS、Glus
|
||||
|
||||
为使用 CephFS 存储 Kubernetes 的容器数据,我们将创建两个文件:
|
||||
|
||||
persistent-volume.yml
|
||||
`persistent-volume.yml` :
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
kind: PersistentVolume
|
||||
metadata:
|
||||
name: app-disk1
|
||||
namespace: k8s_python_sample_code
|
||||
name: app-disk1
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
capacity:
|
||||
storage: 50Gi
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
cephfs:
|
||||
monitors:
|
||||
- "172.17.0.1:6789"
|
||||
user: admin
|
||||
secretRef:
|
||||
name: ceph-secret
|
||||
readOnly: false
|
||||
capacity:
|
||||
storage: 50Gi
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
cephfs:
|
||||
monitors:
|
||||
- "172.17.0.1:6789"
|
||||
user: admin
|
||||
secretRef:
|
||||
name: ceph-secret
|
||||
readOnly: false
|
||||
```
|
||||
|
||||
persistent_volume_claim.yaml
|
||||
`persistent_volume_claim.yaml`:
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: appclaim1
|
||||
namespace: k8s_python_sample_code
|
||||
name: appclaim1
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
resources:
|
||||
requests:
|
||||
storage: 10Gi
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
resources:
|
||||
requests:
|
||||
storage: 10Gi
|
||||
```
|
||||
|
||||
现在,我们将使用 kubectl 去添加持久卷并声明到 Kubernetes 集群中:
|
||||
现在,我们将使用 `kubectl` 去添加持久卷并声明到 Kubernetes 集群中:
|
||||
|
||||
```
|
||||
$ kubectl create -f persistent-volume.yml
|
||||
@ -185,16 +181,16 @@ $ kubectl create -f persistent-volume-claim.yml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
k8s-app: k8s_python_sample_code
|
||||
name: k8s_python_sample_code
|
||||
namespace: k8s_python_sample_code
|
||||
labels:
|
||||
k8s-app: k8s_python_sample_code
|
||||
name: k8s_python_sample_code
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
type: NodePort
|
||||
ports:
|
||||
- port: 5035
|
||||
selector:
|
||||
k8s-app: k8s_python_sample_code
|
||||
type: NodePort
|
||||
ports:
|
||||
- port: 5035
|
||||
selector:
|
||||
k8s-app: k8s_python_sample_code
|
||||
```
|
||||
|
||||
使用下列的内容创建部署文件并将它命名为 `k8s_python_sample_code.deployment.yml`:
|
||||
@ -227,7 +223,7 @@ spec:
|
||||
claimName: appclaim1
|
||||
```
|
||||
|
||||
最后,我们使用 kubectl 将应用程序部署到 Kubernetes:
|
||||
最后,我们使用 `kubectl` 将应用程序部署到 Kubernetes:
|
||||
|
||||
```
|
||||
$ kubectl create -f k8s_python_sample_code.deployment.yml $ kubectl create -f k8s_python_sample_code.service.yml
|
||||
@ -248,15 +244,15 @@ kubectl get services
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13] Joannah Nanjekye - Straight Outta 256 , 只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息][8]
|
||||
[][13] Joannah Nanjekye - Straight Outta 256,只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/running-python-application-kubernetes
|
||||
|
||||
作者:[Joannah Nanjekye ][a]
|
||||
作者:[Joannah Nanjekye][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,25 @@
|
||||
供应链管理方面的 5 个开源软件工具
|
||||
======
|
||||
|
||||
> 跟踪您的库存和您需要的材料,用这些供应链管理工具制造产品。
|
||||
|
||||

|
||||
|
||||
本文最初发表于 2016 年 1 月 14 日,最后的更新日期为 2018 年 3 月 2 日。
|
||||
|
||||
如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
|
||||
如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数以百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
|
||||
|
||||
保持对货品、供应商、客户的持续跟踪,并且所有与它们相关的变动部分都会从中受益,并且,在某些情况下完全依赖专门的软件来帮助管理这些工作流。在本文中,我们将去了解一些免费的和开源的供应链管理方面的软件,以及它们的其中一些功能。
|
||||
保持对货品、供应商、客户的持续跟踪,而且所有与它们相关的变动部分都会受益于这些用来帮助管理工作流的专门软件,而在某些情况下需要完全依赖这些软件。在本文中,我们将去了解一些自由及开源的供应链管理方面的软件,以及它们的其中一些功能。
|
||||
|
||||
供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是合法性、最低品质要求、还是社会和环境的合规性。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
|
||||
供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是否是出于法律要求、最低品质要求、还是社会和环境责任。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
|
||||
|
||||
由于它的本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
|
||||
由于其本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
|
||||
|
||||
### Apache OFBiz
|
||||
|
||||
[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,目录、电子商务网站、帐户、和销售点,它在供应链管理方面的主要功能关注于仓库管理、履行、订单、和生产管理。它的可定制性很强,但是,它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层、和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
|
||||
[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,分类、电子商务网站、会计和 POS,它在供应链管理方面的主要功能关注于仓库管理、履行、订单和生产管理。它的可定制性很强,但是,对应的它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
|
||||
|
||||
Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 license][6] 授权的。
|
||||
Apache OFBiz 的源代码在其 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 许可证][6] 授权的。
|
||||
|
||||
如果你对它感兴趣,你也可以去查看 [opentaps][7],它是在 OFBiz 之上构建的。Opentaps 强化了 OFBiz 的用户界面,并且添加了 ERP 和 CRM 的核心功能,包括仓库管理、采购和计划。它是按 [AGPL 3.0][8] 授权使用的,对于不接受开源授权的组织,它也提供了商业授权。
|
||||
|
||||
@ -25,25 +27,25 @@ Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz
|
||||
|
||||
[OpenBoxes][9] 是一个供应链管理和存货管理项目,最初的主要设计目标是为了医疗行业中的药品跟踪管理,但是,它可以通过修改去跟踪任何类型的货品和相关的业务流。它有一个需求预测工具,可以基于历史订单数量、存储跟踪、支持多种场所、过期日期跟踪、销售点支持等进行预测,并且它还有许多其它功能,这使它成为医疗行业的理想选择,但是,它也可以用于其它行业。
|
||||
|
||||
它在 [Eclipse Public License][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
|
||||
它在 [Eclipse 公开许可证][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
|
||||
|
||||
### OpenLMIS
|
||||
|
||||
与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由络克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达 盖茨基金会。
|
||||
与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由洛克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达·盖茨基金会。
|
||||
|
||||
OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 license][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
|
||||
OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 许可证][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
|
||||
|
||||
### Odoo
|
||||
|
||||
你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和销售点连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
|
||||
你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和 POS 连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
|
||||
|
||||
Odoo 既有软件即服务的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
|
||||
Odoo 既有软件即服务(SaaS)的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
|
||||
|
||||
### xTuple
|
||||
|
||||
[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是帐务、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
|
||||
[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了其传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是会计、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
|
||||
|
||||
xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去 fork 它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
|
||||
xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去复刻它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
|
||||
|
||||
就这些,当然了,还有其它的可以帮你处理供应链管理的开源软件。如果你知道还有更好的软件,请在下面的评论区告诉我们。
|
||||
|
||||
@ -53,14 +55,14 @@ via: https://opensource.com/tools/supply-chain-management
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://en.wikipedia.org/wiki/Supply_chain_management
|
||||
[2]:https://opensource.com/business/14/7/top-5-open-source-crm-tools
|
||||
[3]:https://opensource.com/resources/top-4-open-source-erp-systems
|
||||
[3]:https://linux.cn/article-9785-1.html
|
||||
[4]:http://ofbiz.apache.org/
|
||||
[5]:http://ofbiz.apache.org/source-repositories.html
|
||||
[6]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
43
published/20180702 My first sysadmin mistake.md
Normal file
43
published/20180702 My first sysadmin mistake.md
Normal file
@ -0,0 +1,43 @@
|
||||
我的第一个系统管理员错误
|
||||
======
|
||||
|
||||
> 如何在崩溃的局面中集中精力寻找解决方案。
|
||||
|
||||

|
||||
|
||||
如果你在 IT 领域工作,你知道事情永远不会像你想象的那样完好。在某些时候,你会遇到错误或出现问题,你最终必须解决问题。这就是系统管理员的工作。
|
||||
|
||||
作为人类,我们都会犯错误。我们不是已经犯错,就是即将犯错。结果,我们最终还必须解决自己的错误。总是这样。我们都会失误、敲错字母或犯错。
|
||||
|
||||
作为一名年轻的系统管理员,我艰难地学到了这一课。我犯了一个大错。但是多亏了上级的指导,我学会了不去纠缠于我的错误,而是制定一个“错误策略”来做正确的事情。从错误中吸取教训。克服它,继续前进。
|
||||
|
||||
我的第一份工作是一家小公司的 Unix 系统管理员。真的,我是一名生嫩的系统管理员,但我大部分时间都独自工作。我们是一个小型 IT 团队,只有我们三个人。我是 20 或 30 台 Unix 工作站和服务器的唯一系统管理员。另外两个支持 Windows 服务器和桌面。
|
||||
|
||||
任何阅读这篇文章的系统管理员都不会对此感到意外,作为一个不成熟的初级系统管理员,我最终在错误的目录中运行了 `rm` 命令——作为 root 用户。我以为我正在为我们的某个程序删除一些陈旧的缓存文件。相反,我错误地清除了 `/etc` 目录中的所有文件。糟糕。
|
||||
|
||||
我意识到犯了错误是看到了一条错误消息,“`rm` 无法删除某些子目录”。但缓存目录应该只包含文件!我立即停止了 `rm` 命令,看看我做了什么。然后我惊慌失措。一下子,无数个想法涌入了我的脑中。我刚刚销毁了一台重要的服务器吗?系统会怎么样?我会被解雇吗?
|
||||
|
||||
幸运的是,我运行的是 `rm *` 而不是 `rm -rf *`,因此我只删除了文件。子目录仍在那里。但这并没有让我感觉更好。
|
||||
|
||||
我立刻去找我的主管告诉她我做了什么。她看到我对自己的错误感到愚蠢,但这是我犯的。尽管紧迫,她花了几分钟时间跟我做了一些指导。她说:“你不是第一个这样做的人,在你这种情况下,别人会怎么做?”这帮助我平静下来并专注。我开始更少考虑我刚刚做的愚蠢事情,而更多地考虑我接下来要做的事情。
|
||||
|
||||
我做了一个简单的策略:不要重启服务器。使用相同的系统作为模板,并重建 `/etc` 目录。
|
||||
|
||||
制定了行动计划后,剩下的就很容易了。只需运行正确的命令即可从另一台服务器复制 `/etc` 文件并编辑配置,使其与系统匹配。多亏了我对所有东西都做记录的习惯,我使用已有的文档进行最后的调整。我避免了完全恢复服务器,这意味着一个巨大的宕机事件。
|
||||
|
||||
可以肯定的是,我从这个错误中吸取了教训。在接下来作为系统管理员的日子中,我总是在运行任何命令之前确认我所在的目录。
|
||||
|
||||
我还学习了构建“错误策略”的价值。当事情出错时,恐慌并思考接下来可能发生的所有坏事是很自然的。这是人性。但是制定一个“错误策略”可以帮助我不再担心出了什么问题,而是专注于让事情变得更好。我仍然会想一下,但是知道我接下来的步骤可以让我“克服它”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/my-first-sysadmin-mistake
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
@ -1,51 +1,55 @@
|
||||
6 个用于了解互联网工作原理的 RFC
|
||||
6 个可以帮你理解互联网工作原理的 RFC
|
||||
======
|
||||
|
||||
> 以及 3 个有趣的 RFC。
|
||||
|
||||

|
||||
|
||||
阅读源码是开源软件的重要组成部分。这意味着用户可以查看代码并了解做了什么。
|
||||
|
||||
但“阅读源码”并不仅适用于代码。理解代码实现的标准同样重要。这些标准由[互联网工程任务组][1](IETF)发布的称为“注释请求”(RFC)的文档中编写的。多年来已经发布了数以千计的 RFC,因此我们收集了一些我们的贡献者认为必读的内容。
|
||||
但“阅读源码”并不仅适用于代码。理解代码实现的标准同样重要。这些标准编写在由<ruby>[互联网工程任务组][1]<rt>Internet Engineering Task Force</rt></ruby>(IETF)发布的称为“<ruby>意见征集<rt>Requests for Comment</rt></ruby>”(RFC)的文档中。多年来已经发布了数以千计的 RFC,因此我们收集了一些我们的贡献者认为必读的内容。
|
||||
|
||||
### 6 个必读的 RFC
|
||||
|
||||
#### RFC 2119-在 RFC 中用于指示需求级别的关键字
|
||||
#### RFC 2119 - 在 RFC 中用于指示需求级别的关键字
|
||||
|
||||
这是一个快速阅读,但它对了解其他 RFC 非常重要。 [RFC 2119][2] 定义了后续 RFC 中使用的需求级别。 “MAY” 究竟意味着什么?如果标准说 “SHOULD”,你真的必须这样做吗?通过为需求提供明确定义的分类,RFC 2119 有助于避免歧义。
|
||||
这是一个快速阅读,但它对了解其它 RFC 非常重要。 [RFC 2119][2] 定义了后续 RFC 中使用的需求级别。 “MAY” 究竟意味着什么?如果标准说 “SHOULD”,你*真的*必须这样做吗?通过为需求提供明确定义的分类,RFC 2119 有助于避免歧义。
|
||||
|
||||
#### RFC 3339 - 互联网上的日期和时间:时间戳
|
||||
|
||||
时间是全世界程序员的祸根。 [RFC 3339][3] 定义了如何格式化时间戳。基于 [ISO 8601][4] 标准,3339 为我们提供了一种表达时间的常用方法。例如,像星期几这样的冗余信息不应该包含在存储的时间戳中,因为它很容易计算。
|
||||
|
||||
#### RFC 1918—私有互联网的地址分配
|
||||
#### RFC 1918 - 私有互联网的地址分配
|
||||
|
||||
有属于每个人的互联网,也有只属于你的互联网。专用网络一直在使用,[RFC 1918][5] 定义了这些网络。当然,你可以在路由器上设置路由公网地址,但这是一个坏主意。或者,你可以将未使用的公共 IP 地址视为内部网络。在任何一种情况下都表明你从未阅读过 RFC 1918。
|
||||
有属于每个人的互联网,也有只属于你的互联网。私有网络一直在使用,[RFC 1918][5] 定义了这些网络。当然,你可以在路由器上设置在内部使用公网地址,但这是一个坏主意。或者,你可以将未使用的公共 IP 地址视为内部网络。在任何一种情况下都表明你从未阅读过 RFC 1918。
|
||||
|
||||
#### RFC 1912—常见的 DNS 操作和配置错误
|
||||
#### RFC 1912 - 常见的 DNS 操作和配置错误
|
||||
|
||||
一切都是 #@%@ DNS 问题,对吧? [RFC 1912][6] 列出了管理员在试图保持互联网运行时所犯的错误。虽然它是在 1996 年发布的,但 DNS(以及人们犯的错误)并没有真正改变这么多。为了理解我们为什么首先需要 DNS,请考虑[ RFC 289-What we hope is an official list of host names]][7]如今看起来像什么。
|
||||
一切都是 #@%@ 的 DNS 问题,对吧? [RFC 1912][6] 列出了管理员在试图保持互联网运行时所犯的错误。虽然它是在 1996 年发布的,但 DNS(以及人们犯的错误)并没有真正改变这么多。为了理解我们为什么首先需要 DNS,如今我们再来看看 [RFC 289 - 我们希望正式的主机列表是什么样子的][7] 就知道了。
|
||||
|
||||
#### RFC 2822—互联网邮件格式
|
||||
#### RFC 2822 — 互联网邮件格式
|
||||
|
||||
想想你知道什么是有效的电子邮件地址么?如果不接受我地址中 “+” 的站点的数量是任何迹象, 你就不会。 [RFC 2822][8] 定义了有效的电子邮件地址。它还详细介绍了电子邮件的其余部分。
|
||||
想想你知道什么是有效的电子邮件地址么?如果你知道有多少个站点不接受我邮件地址中 “+” 的话,你就知道你知道不知道了。 [RFC 2822][8] 定义了有效的电子邮件地址。它还详细介绍了电子邮件的其余部分。
|
||||
|
||||
#### RFC 7231—超文本传输协议(HTTP/1.1):语义和内容
|
||||
#### RFC 7231 - 超文本传输协议(HTTP/1.1):语义和内容
|
||||
|
||||
当你停下来思考它时,我们在网上做的几乎所有东西都依赖于 HTTP。 [RFC 7231][9] 是该协议的最新更新。它有超过 100 页,定义了方法、头和状态代码。
|
||||
想想看,几乎我们在网上做的一切都依赖于 HTTP。 [RFC 7231][9] 是该协议的最新更新。它有超过 100 页,定义了方法、请求头和状态代码。
|
||||
|
||||
### 3个应该阅读的 RFC
|
||||
### 3 个应该阅读的 RFC
|
||||
|
||||
好吧,并非每个RFC都是严肃的业务。
|
||||
好吧,并非每个 RFC 都是严肃的。
|
||||
|
||||
#### RFC 1149—在禽类载体上传输 IP 数据报的标准
|
||||
#### RFC 1149 - 在禽类载体上传输 IP 数据报的标准
|
||||
|
||||
网络以多种不同方式传递数据包。 [RFC 1149][10] 描述了鸽子载体的使用。当我距离州际高速公路一英里以外时,它们的可靠性不会低于我的移动提供商。
|
||||
|
||||
#### RFC 2324—超文本咖啡壶控制协议(HTCPCP/1.0)
|
||||
#### RFC 2324 — 超文本咖啡壶控制协议(HTCPCP/1.0)
|
||||
|
||||
咖啡对于完成工作非常重要,当然,我们需要一个用于管理咖啡壶的程序化界面。 [RFC 2324][11] 定义了一个用于与咖啡壶交互的协议,并添加了 HTTP 418(“我是一个茶壶”)。
|
||||
|
||||
#### RFC 69—M.I.T.的分发列表更改
|
||||
#### RFC 69 — M.I.T.的分发列表更改
|
||||
|
||||
[RFC 69] [12]是否是第一个误导取消订阅请求的发布示例?
|
||||
[RFC 69][12] 是否是第一个误导取消订阅请求的发布示例?
|
||||
|
||||
你必须阅读的 RFC 是什么(无论它们是否严肃)?在评论中分享你的列表。
|
||||
|
||||
@ -56,7 +60,7 @@ via: https://opensource.com/article/18/7/requests-for-comments-to-know
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,161 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Check Which Groups A User Belongs To On Linux
|
||||
======
|
||||
Adding a user into existing group is one of the regular activity for Linux admin. This is daily activity for some of the administrator who’s working one big environments.
|
||||
|
||||
Even i am performing such a activity on daily in my environment due to business requirement. It’s one of the important command which helps you to identify existing groups on your environment.
|
||||
|
||||
Also these commands helps you to identify which groups a user belongs to. All the users are listed in `/etc/passwd` file and groups are listed in `/etc/group`.
|
||||
|
||||
Whatever command we use, that will fetch the information from these files. Also, each command has their unique feature which helps user to get the required information alone.
|
||||
|
||||
### What Is /etc/passwd?
|
||||
|
||||
`/etc/passwd` is a text file that contains each user information, which is necessary to login Linux system. It maintain useful information about users such as username, password, user ID, group ID, user ID info, home directory and shell. The passwd file contain every user details as a single line with seven fields as described above.
|
||||
```
|
||||
$ grep "daygeek" /etc/passwd
|
||||
daygeek:x:1000:1000:daygeek,,,:/home/daygeek:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
### What Is /etc/group?
|
||||
|
||||
`/etc/group` is a text file that defines which groups a user belongs to. We can add multiple users into single group. It allows user to access other users files and folders as Linux permissions are organized into three classes, user, group, and others. It maintain useful information about group such as Group name, Group password, Group ID (GID) and Member list. each on a separate line. The group file contain every group details as a single line with four fields as described above.
|
||||
|
||||
This can be performed by using below methods.
|
||||
|
||||
* `groups:`Show All Members of a Group.
|
||||
* `id:`Print user and group information for the specified username.
|
||||
* `lid:`It display user’s groups or group’s users.
|
||||
* `getent:`get entries from Name Service Switch libraries.
|
||||
* `grep`grep stands for “global regular expression print” which prints matching pattern.
|
||||
|
||||
|
||||
|
||||
### What Is groups Command?
|
||||
|
||||
groups command prints the names of the primary and any supplementary groups for each given username.
|
||||
```
|
||||
$ groups daygeek
|
||||
daygeek : daygeek adm cdrom sudo dip plugdev lpadmin sambashare
|
||||
|
||||
```
|
||||
|
||||
If you would like to check list of groups associated with current user. Just run **“group”** command alone without any username.
|
||||
```
|
||||
$ groups
|
||||
daygeek adm cdrom sudo dip plugdev lpadmin sambashare
|
||||
|
||||
```
|
||||
|
||||
### What Is id Command?
|
||||
|
||||
id stands for identity. print real and effective user and group IDs. To print user and group information for the specified user, or for the current user.
|
||||
```
|
||||
$ id daygeek
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
|
||||
```
|
||||
|
||||
If you would like to check list of groups associated with current user. Just run **“id”** command alone without any username.
|
||||
```
|
||||
$ id
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
|
||||
```
|
||||
|
||||
### What Is lid Command?
|
||||
|
||||
It display user’s groups or group’s users. Displays information about groups containing user name, or users contained in group name. This command required privileges to run.
|
||||
```
|
||||
$ sudo lid daygeek
|
||||
adm(gid=4)
|
||||
cdrom(gid=24)
|
||||
sudo(gid=27)
|
||||
dip(gid=30)
|
||||
plugdev(gid=46)
|
||||
lpadmin(gid=108)
|
||||
daygeek(gid=1000)
|
||||
sambashare(gid=124)
|
||||
|
||||
```
|
||||
|
||||
### What Is getent Command?
|
||||
|
||||
The getent command displays entries from databases supported by the Name Service Switch libraries, which are configured in /etc/nsswitch.conf.
|
||||
```
|
||||
$ getent group | grep daygeek
|
||||
adm:x:4:syslog,daygeek
|
||||
cdrom:x:24:daygeek
|
||||
sudo:x:27:daygeek
|
||||
dip:x:30:daygeek
|
||||
plugdev:x:46:daygeek
|
||||
lpadmin:x:118:daygeek
|
||||
daygeek:x:1000:
|
||||
sambashare:x:128:daygeek
|
||||
|
||||
```
|
||||
|
||||
If you would like to print only associated groups name then include **“awk”** command along with above command.
|
||||
```
|
||||
$ getent group | grep daygeek | awk -F: '{print $1}'
|
||||
adm
|
||||
cdrom
|
||||
sudo
|
||||
dip
|
||||
plugdev
|
||||
lpadmin
|
||||
daygeek
|
||||
sambashare
|
||||
|
||||
```
|
||||
|
||||
Run the below command to print only primary group information.
|
||||
```
|
||||
$ getent group daygeek
|
||||
daygeek:x:1000:
|
||||
|
||||
```
|
||||
|
||||
### What Is grep Command?
|
||||
|
||||
grep stands for “global regular expression print” which prints matching pattern from the file.
|
||||
```
|
||||
$ grep "daygeek" /etc/group
|
||||
adm:x:4:syslog,daygeek
|
||||
cdrom:x:24:daygeek
|
||||
sudo:x:27:daygeek
|
||||
dip:x:30:daygeek
|
||||
plugdev:x:46:daygeek
|
||||
lpadmin:x:118:daygeek
|
||||
daygeek:x:1000:
|
||||
sambashare:x:128:daygeek
|
||||
|
||||
```
|
||||
|
||||
If you would like to print only associated groups name then include **“awk”** command along with above command.
|
||||
```
|
||||
$ grep "daygeek" /etc/group | awk -F: '{print $1}'
|
||||
adm
|
||||
cdrom
|
||||
sudo
|
||||
dip
|
||||
plugdev
|
||||
lpadmin
|
||||
daygeek
|
||||
sambashare
|
||||
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Malware Found On The Arch User Repository (AUR)
|
||||
======
|
||||
|
||||
|
||||
@ -1,41 +0,0 @@
|
||||
我的第一个系统管理员错误
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你在 IT 领域工作,你知道事情永远不会像你想象的那样完好。在某些时候,你会遇到错误或出现问题,你最终必须解决问题。这是系统管理员的工作。
|
||||
|
||||
作为人类,我们都会犯错误。有时,我们是过程中的错误,或者我们出了什么问题。结果,我们最终必须解决自己的错误。它们会发生。我们都犯错误,错别字或故障。
|
||||
|
||||
作为一名年轻的系统管理员,我艰难地学到了这一课。我犯了一个大错。但是多亏了上级的指导,我学会了不去纠缠于我的错误,而是制定一个“错误策略”来设置正确的事情。从错误中吸取教训。克服它,继续前进。
|
||||
|
||||
我的第一份工作是一家小公司的 Unix 系统管理员。真的,我是一名初级系统管理员,但我大部分时间都独自工作。我们是一个小型 IT 团队,只有我们三个人。我是 20 或 30 台 Unix 工作站和服务器的唯一系统管理员。另外两个支持 Windows 服务器和桌面。
|
||||
|
||||
任何阅读这篇文章的系统管理员都不会惊讶地发现,作为一个不成熟的初级系统管理员,我最终在错误的目录中运行了 `rm` 命令。作为 root,我以为我正在为我们的某个程序删除一些陈旧的缓存文件。相反,我错误地清除了 `/ etc` 目录中的所有文件。糟糕。
|
||||
|
||||
我意识到反了错误是看到了一条错误消息,`rm` 无法删除某些子目录。但缓存目录应该只包含文件!我立即停止了 `rm` 命令,看着我做了什么。然后我惊慌失措。一下子,无数个想法涌入了我的脑中。我刚刚销毁了一台重要的服务器吗?系统会发生什么?我会被解雇吗?
|
||||
|
||||
幸运的是,我运行的是 `rm *` 而不是 `rm -rf *`,因此我只删除了文件。子目录仍在那里。但这并没有让我感觉更好。
|
||||
|
||||
我立刻去找我的主管告诉她我做了什么。她看到我对自己的错误感到愚蠢,但是我犯的。尽管紧迫,她花了几分钟时间跟我做了一些指导。 她说:“你不是第一个这样做的人,在你这种情况下,别人会怎么做?”这帮助我平静下来并专注。我开始更少考虑我刚刚做的愚蠢事情,而更多地考虑我接下来要做的事情。
|
||||
|
||||
我做了一个简单的策略:不要重启服务器。使用相同的系统作为模板,并重新创建 `/ etc` 目录。
|
||||
|
||||
制定了行动计划后,剩下的就很容易了。只需运行正确的命令即可从另一台服务器复制 `/ etc` 文件并编辑配置,使其与系统匹配。多亏了我对所有东西都做记录,我使用现有的文档进行最后的调整。我避免了完全恢复服务器,这意味着一个巨大的中断。
|
||||
|
||||
可以肯定的是,我从这个错误中吸取了教训。在接下来作为系统管理员的日子中,我总是在运行任何命令之前确认我所在的目录。
|
||||
|
||||
我还学习了构建“错误策略”的价值。当事情出错时,恐慌并思考接下来可能发生的所有坏事是很自然的。这是人性。但是制定一个“错误策略”可以帮助我不再担心出了什么问题,而是专注于让事情变得更好。我仍然会想一下,但是知道我接下来的步骤可以让我“克服它”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/my-first-sysadmin-mistake
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
@ -0,0 +1,159 @@
|
||||
如何在 Linux 上检查用户所属组
|
||||
======
|
||||
将用户添加到现有组是 Linux 管理员的常规活动之一。这是一些在大环境中工作的管理员的日常活动。
|
||||
|
||||
即使我因为业务需求而在我的环境中每天都在进行这样的活动。它是帮助你识别环境中现有组的重要命令之一。
|
||||
|
||||
此外,这些命令还可以帮助你识别用户所属的组。所有用户都列在 `/etc/passwd` 中,组列在 `/etc/group` 中。
|
||||
|
||||
无论我们使用什么命令,都将从这些文件中获取信息。此外,每个命令都有其独特的功能,可帮助用户单独获取所需的信息。
|
||||
|
||||
### 什么是 /etc/passwd?
|
||||
|
||||
`/etc/passwd` 是一个文本文件,其中包含登录 Linux 系统所必需的每个用户信息。它维护有用的用户信息,如用户名、密码、用户 ID、组 ID、用户 ID 信息、家目录和 shell。passwd 每行包含了用户的详细信息,共有如上所述的 7 个字段。
|
||||
```
|
||||
$ grep "daygeek" /etc/passwd
|
||||
daygeek:x:1000:1000:daygeek,,,:/home/daygeek:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
### 什么是 /etc/group?
|
||||
|
||||
`/etc/group` 是一个文本文件,用于定义用户所属的组。我们可以将多个用户添加到单个组中。它允许用户访问其他用户文件和文件夹,因为 Linux 权限分为三类,用户、组和其他。它维护有关组的有用信息,例如组名、组密码,组 ID(GID)和成员列表。每个都在一个单独的行。组文件每行包含了每个组的详细信息,共有 4 个如上所述字段。
|
||||
|
||||
这可以通过使用以下方法来执行。
|
||||
|
||||
* `groups:` 显示一个组的所有成员。
|
||||
* `id:` 打印指定用户名的用户和组信息。
|
||||
* `lid:` 显示用户的组或组的用户。
|
||||
* `getent:` 从 Name Service Switch 库中获取条目。
|
||||
* `grep:` 代表“全局正则表达式打印”(global regular expression print),它能打印匹配的模式。
|
||||
|
||||
|
||||
|
||||
### 什么是组命令?
|
||||
|
||||
groups 命令打印每个给定用户名的主要组和任何补充组的名称。
|
||||
```
|
||||
$ groups daygeek
|
||||
daygeek : daygeek adm cdrom sudo dip plugdev lpadmin sambashare
|
||||
|
||||
```
|
||||
|
||||
如果要检查与当前用户关联的组列表。只需运行 **“group”** 命令,无需带任何用户名。
|
||||
```
|
||||
$ groups
|
||||
daygeek adm cdrom sudo dip plugdev lpadmin sambashare
|
||||
|
||||
```
|
||||
|
||||
### 什么是 id 命令?
|
||||
|
||||
id 代表身份。打印真实有效的用户和组 ID。打印指定用户或当前用户的用户和组信息。
|
||||
```
|
||||
$ id daygeek
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
|
||||
```
|
||||
|
||||
如果要检查与当前用户关联的组列表。只运行 **“id”** 命令,无需带任何用户名。
|
||||
```
|
||||
$ id
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
|
||||
```
|
||||
|
||||
### 什么是 lid 命令?
|
||||
|
||||
它显示用户的组或组的用户。显示有关包含用户名的组或组名称中包含的用户的信息。此命令需要管理员权限。
|
||||
```
|
||||
$ sudo lid daygeek
|
||||
adm(gid=4)
|
||||
cdrom(gid=24)
|
||||
sudo(gid=27)
|
||||
dip(gid=30)
|
||||
plugdev(gid=46)
|
||||
lpadmin(gid=108)
|
||||
daygeek(gid=1000)
|
||||
sambashare(gid=124)
|
||||
|
||||
```
|
||||
|
||||
### 什么是 getent 命令?
|
||||
|
||||
getent 命令显示 Name Service Switch 库支持的数据库中的条目,它们在 /etc/nsswitch.conf 中配置。
|
||||
```
|
||||
$ getent group | grep daygeek
|
||||
adm:x:4:syslog,daygeek
|
||||
cdrom:x:24:daygeek
|
||||
sudo:x:27:daygeek
|
||||
dip:x:30:daygeek
|
||||
plugdev:x:46:daygeek
|
||||
lpadmin:x:118:daygeek
|
||||
daygeek:x:1000:
|
||||
sambashare:x:128:daygeek
|
||||
|
||||
```
|
||||
|
||||
如果你只想打印关联的组名称,请在上面的命令中使用 **“awk”**。
|
||||
```
|
||||
$ getent group | grep daygeek | awk -F: '{print $1}'
|
||||
adm
|
||||
cdrom
|
||||
sudo
|
||||
dip
|
||||
plugdev
|
||||
lpadmin
|
||||
daygeek
|
||||
sambashare
|
||||
|
||||
```
|
||||
|
||||
运行以下命令仅打印主群组信息。
|
||||
```
|
||||
$ getent group daygeek
|
||||
daygeek:x:1000:
|
||||
|
||||
```
|
||||
|
||||
### 什么是 grep 命令?
|
||||
|
||||
grep 代表“全局正则表达式打印”(global regular expression print),它能打印文件匹配的模式。
|
||||
```
|
||||
$ grep "daygeek" /etc/group
|
||||
adm:x:4:syslog,daygeek
|
||||
cdrom:x:24:daygeek
|
||||
sudo:x:27:daygeek
|
||||
dip:x:30:daygeek
|
||||
plugdev:x:46:daygeek
|
||||
lpadmin:x:118:daygeek
|
||||
daygeek:x:1000:
|
||||
sambashare:x:128:daygeek
|
||||
|
||||
```
|
||||
|
||||
如果你只想打印关联的组名称,请在上面的命令中使用 **“awk”**。
|
||||
```
|
||||
$ grep "daygeek" /etc/group | awk -F: '{print $1}'
|
||||
adm
|
||||
cdrom
|
||||
sudo
|
||||
dip
|
||||
plugdev
|
||||
lpadmin
|
||||
daygeek
|
||||
sambashare
|
||||
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
Loading…
Reference in New Issue
Block a user