mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
9c3742f781
@ -1,11 +1,13 @@
|
||||
全球化思考:怎样克服交流中的文化差异
|
||||
======
|
||||
这有一些建议帮助你的全球化开发团队能够更好地理解你们的讨论并能参与其中。
|
||||
|
||||
> 这有一些建议帮助你的全球化开发团队能够更好地理解你们的讨论并能参与其中。
|
||||
|
||||
|
||||
|
||||
几周前,我见证了两位同事之间一次有趣的互动,他们分别是 Jason,我们的一位美国员工,和 Raj,一位来自印度的访问工作人员。
|
||||
|
||||
Raj 在印度时,他一般会通过电话参加美国中部时间上午 9 点的每日立会,现在他到美国工作了,就可以和组员们坐在同一间会议室里开会了。Jason 拦下了 Raj,说:“ Raj 你要去哪?你不是一直和我们开电话会议吗?你突然出现在会议室里我还不太适应。” Raj 听了说,“是这样吗?没问题。”就回到自己工位前准备和以前一样参加电话会议了。
|
||||
Raj 在印度时,他一般会通过电话参加美国中部时间上午 9 点的每日立会,现在他到美国工作了,就可以和组员们坐在同一间会议室里开会了。Jason 拦下了 Raj,说:“Raj 你要去哪?你不是一直和我们开电话会议吗?你突然出现在会议室里我还不太适应。” Raj 听了说,“是这样吗?没问题。”就回到自己工位前准备和以前一样参加电话会议了。
|
||||
|
||||
我去找 Raj,问他为什么不去参加每日立会,Raj 说 Jason 让自己给组员们打电话参会,而与此同时,Jason 也在会议室等着 Raj 来参加立会。
|
||||
|
||||
@ -19,7 +21,7 @@ Jason 明显是在开玩笑,但 Raj 把它当真了。这就是在两人互相
|
||||
|
||||
现在是全球化时代,我们的同事很可能不跟我们面对面接触,甚至不在同一座城市,来自不同的国家。越来越多的技术公司拥有全球化的工作场所,和来自世界各地的员工,他们有着不同的背景和经历。这种多样性使得技术公司能够在这个快速发展的科技大环境下拥有更强的竞争力。
|
||||
|
||||
但是这种地域的多样性也会给团队带来挑战。管理和维持团高性能的团队发展对于同地协作的团队来说就有着很大难度,对于有着多样背景成员的全球化团队来说,无疑更加困难。成员之间的交流会发生延迟,误解时有发生,成员之间甚至会互相怀疑,这些都会影响着公司的成功。
|
||||
但是这种地域的多样性也会给团队带来挑战。管理和维持高性能的团队发展对于同地协作的团队来说就有着很大难度,对于有着多样背景成员的全球化团队来说,无疑更加困难。成员之间的交流会发生延迟,误解时有发生,成员之间甚至会互相怀疑,这些都会影响着公司的成功。
|
||||
|
||||
到底是什么因素让全球化交流间发生误解呢?我们可以参照 Erin Meyer 的书《[文化地图][2]》,她在书中将全球文化分为八个类型,其中美国文化被分为低语境文化,与之相对的,日本为高语境文化。
|
||||
|
||||
@ -71,7 +73,7 @@ Jason 明显是在开玩笑,但 Raj 把它当真了。这就是在两人互相
|
||||
|
||||
保持长久关系最好的方法是和你的组员们单独见面。如果你的公司可以报销这些费用,那么努力去和组员们见面吧。和一起工作了很长时间的组员们见面能够使你们的关系更加坚固。我所在的公司就有着周期性交换员工的传统,每隔一段时间,世界各地的员工就会来到美国工作,美国员工再到其他分部工作。
|
||||
|
||||
另一种聚齐组员们的机会的研讨会。研讨会创造的不仅是学习和培训的机会,你还可以挤出一些时间和组员们培养感情。
|
||||
另一种聚齐组员们的机会是研讨会。研讨会创造的不仅是学习和培训的机会,你还可以挤出一些时间和组员们培养感情。
|
||||
|
||||
在如今,全球化经济不断发展,拥有来自不同国家和地区的员工对维持一个公司的竞争力来说越来越重要。即使组员们来自世界各地,团队中会出现一些交流问题,但拥有一支国际化的高绩效团队不是问题。如果你在工作中有什么促进团队交流的小窍门,请在评论中告诉我们吧。
|
||||
|
||||
@ -83,7 +85,7 @@ via: https://opensource.com/article/18/10/think-global-communication-challenges
|
||||
作者:[Avindra Fernando][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11691-1.html)
|
||||
[#]: subject: (Easily Upload Text Snippets To Pastebin-like Services From Commandline)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-easily-upload-text-snippets-to-pastebin-like-services-from-commandline/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
@ -12,7 +12,7 @@
|
||||
|
||||

|
||||
|
||||
每当需要在线共享代码片段时,我们想到的第一个便是 Pastebin.com,这是 Paul Dixon 于 2002 年推出的在线文本共享网站。现在,有几种可供选择的文本共享服务可以上传和共享文本片段、错误日志、配置文件、命令输出或任何类型的文本文件。如果你碰巧经常使用各种类似于 Pastebin 的服务来共享代码,那么这对你来说确实是个好消息。向 Wgetpaste 打个招呼吧,它是一个命令行 BASH 实用程序,可轻松地将文本摘要上传到类似 pastebin 的服务中。使用 Wgetpaste 脚本,任何人都可以与自己的朋友、同事或想在类似 Unix 的系统中的命令行中查看/使用/查看代码的人快速共享文本片段。
|
||||
每当需要在线共享代码片段时,我们想到的第一个便是 Pastebin.com,这是 Paul Dixon 于 2002 年推出的在线文本共享网站。现在,有几种可供选择的文本共享服务可以上传和共享文本片段、错误日志、配置文件、命令输出或任何类型的文本文件。如果你碰巧经常使用各种类似于 Pastebin 的服务来共享代码,那么这对你来说确实是个好消息。向 Wgetpaste 打个招呼吧,它是一个命令行 BASH 实用程序,可轻松地将文本摘要上传到类似 Pastebin 的服务中。使用 Wgetpaste 脚本,任何人都可以与自己的朋友、同事或想在类似 Unix 的系统中的命令行中查看/使用/审查代码的人快速共享文本片段。
|
||||
|
||||
### 安装 Wgetpaste
|
||||
|
||||
@ -84,7 +84,7 @@ Your paste can be seen here: https://paste.pound-python.org/show/eO0aQjTgExP0wT5
|
||||
|
||||
|
||||
|
||||
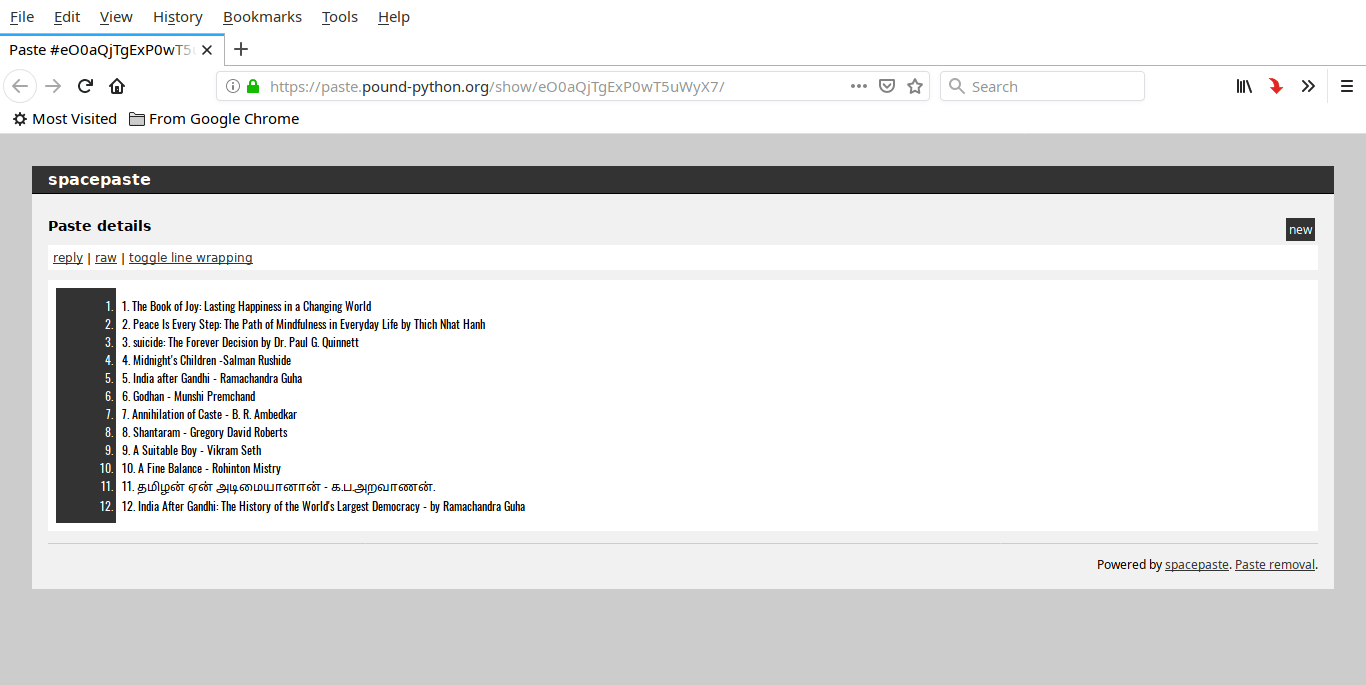
你也可以使用 `tee` 命令显示粘贴的内容,而不是盲目地上传它们。
|
||||
你也可以使用 `tee` 命令显示粘贴的内容,而不是盲目地上传它们。
|
||||
|
||||
为此,请使用如下的 `-t` 选项。
|
||||
|
||||
@ -233,7 +233,7 @@ via: https://www.ostechnix.com/how-to-easily-upload-text-snippets-to-pastebin-li
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,57 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( luming)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11693-1.html)
|
||||
[#]: subject: (Easy means easy to debug)
|
||||
[#]: via: (https://arp242.net/weblog/easy.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
简单就是易于调试
|
||||
======
|
||||
对于框架、库或者工具来说,怎样做才算是“简单”?也许有很多的定义,但我的理解通常是易于调试。我经常见到人们宣传某个特定的程序、框架、库、文件格式是简单的,因为它们会说“看,我只需要这么一点工作量就能够完成某项工作,这太简单了”。非常好,但并不完善。
|
||||
|
||||
对于框架、库或者工具来说,怎样做才算是“简单”?也许有很多的定义,但我的理解通常是**易于调试**。我经常见到人们宣传某个特定的程序、框架、库、文件格式或者其它什么东西是简单的,因为他们会说“看,我只需要这么一点工作量就能够完成某项工作,这太简单了”。非常好,但并不完善。
|
||||
|
||||
你可能只编写一次软件,但几乎总要经历好几个调试周期。注意我说的调试周期并不意味着“代码里面有 bug 你需要修复”,而是说“我需要再看一下这份代码来修复 bug”。为了调试代码,你需要理解它,因此“易于调试”延伸来讲就是“易于理解”。
|
||||
|
||||
抽象使得程序易于编写,但往往是以难以理解为代价。有时候这是一个很好的折中,但通常不是。大体上,如果能使程序在日后易于理解和调试,我很乐意花更多的时间来写一些东西,因为这样可以省时间。
|
||||
抽象使得程序易于编写,但往往是以难以理解为代价。有时候这是一个很好的折中,但通常不是。大体上,如果能使程序在日后易于理解和调试,我很乐意花更多的时间来写一些东西,因为这样实际上更省时间。
|
||||
|
||||
简洁并不是让程序易于调试的唯一方法,但它也许是最重要的。良好的文档也是,但不幸的是它太少了。(注意,质量并不取决于字数!)
|
||||
简洁并不是让程序易于调试的**唯一**方法,但它也许是最重要的。良好的文档也是,但不幸的是好的文档太少了。(注意,质量并**不**取决于字数!)
|
||||
|
||||
这种影响是真是存在的。难以调试的程序会有更多的 bug,即使最初的 bug 数量与易于调试的程序完全相同,这简简单单是因为修复 bug 更加困难、更花时间。
|
||||
这种影响是真是存在的。难以调试的程序会有更多的 bug,即使最初的 bug 数量与易于调试的程序完全相同,而是因为修复 bug 更加困难、更花时间。
|
||||
|
||||
在公司的环境中,把时间花在难以修复的 bug 上通常被认为是不划算的投资。而在开源的环境下,人们花的时间会更少。(大多数项目都有一个或多个定期的维护者,但成百上千的贡献者提交的仅只是几个补丁)
|
||||
|
||||
这并不全是 1974 年由 Brian W. Kernighan 和 P. J. Plauger 合著的小说《编程风格的元素》中的观点:
|
||||
---
|
||||
|
||||
这并不全是 1974 年由 Brian W. Kernighan 和 P. J. Plauger 合著的《<ruby>编程风格的元素<rt>The Elements of Programming Style</rt></ruby>》中的观点:
|
||||
|
||||
> 每个人都知道调试比起编写程序困难两倍。当你写程序的时候耍小聪明,那么将来应该怎么去调试?
|
||||
|
||||
我见过许多写起来精妙,但却导致难以调试的代码。我会在下面列出几种样例。争论这些东西本身有多坏并不是我的本意,我仅想强调对于“易于使用”和“易于调试”之间的折中。
|
||||
* <ruby>ORM<rt>对象关系映射</rt></ruby> 库可以让数据库查询变得简单,代价是一旦你想解决某个问题,事情就变得难以理解。
|
||||
我见过许多看起来写起来“极尽精妙”,但却导致难以调试的代码。我会在下面列出几种样例。争论这些东西本身有多坏并不是我的本意,我仅想强调对于“易于使用”和“易于调试”之间的折中。
|
||||
|
||||
* 许多测试框架让调试变得困难。Ruby 的 rspec 就是一个很好的例子。有一次我不小心使用错了,结果花了很长时间搞清楚哪里出了问题(因为它给出错误提示非常含糊)。
|
||||
* <ruby>ORM<rt>对象关系映射</rt></ruby> 库可以让数据库查询变得简单,代价是一旦你想解决某个问题,事情就变得难以理解。
|
||||
* 许多测试框架让调试变得困难。Ruby 的 rspec 就是一个很好的例子。有一次我不小心使用错了,结果花了很长时间搞清楚**究竟**哪里出了问题(因为它给出错误提示非常含糊)。
|
||||
|
||||
我在《[测试并非万能][1]》这篇文章中写了更多关于以上的例子。
|
||||
|
||||
* 我用过的许多 JavaScript 框架都很难完全理解。Clever(LCTT 译注:一种 JS 框架)的声明语句一向很有逻辑,直到某条语句和你的预期不符,这时你就只能指望 Stack Overflow 上的某篇文章或 GitHub 上的某个回帖来帮助你了。
|
||||
|
||||
这些函数库确实让任务变得非常简单,使用它们也没有什么错。但通常人们都过于关注“易于使用”而忽视了“易于调试”这一点。
|
||||
我在《[测试并非万能][1]》这篇文章中写了更多关于以上的例子。
|
||||
* 我用过的许多 JavaScript 框架都很难完全理解。Clever(LCTT 译注:一种 JS 框架)的语句一向很有逻辑,直到某条语句不能如你预期的工作,这时你就只能指望 Stack Overflow 上的某篇文章或 GitHub 上的某个回帖来帮助你了。
|
||||
|
||||
这些函数库**确实**让任务变得非常简单,使用它们也没有什么错。但通常人们都过于关注“易于使用”而忽视了“易于调试”这一点。
|
||||
* Docker 非常棒,并且让许多事情变得非常简单,直到你看到了这条提示:
|
||||
```
|
||||
|
||||
```
|
||||
ERROR: for elasticsearch Cannot start service elasticsearch:
|
||||
oci runtime error: container_linux.go:247: starting container process caused "process_linux.go:258:
|
||||
applying cgroup configuration for process caused \"failed to write 898 to cgroup.procs: write
|
||||
/sys/fs/cgroup/cpu,cpuacct/docker/b13312efc203e518e3864fc3f9d00b4561168ebd4d9aad590cc56da610b8dd0e/cgroup.procs:
|
||||
invalid argument\""
|
||||
```
|
||||
或者这条:
|
||||
```
|
||||
|
||||
或者这条:
|
||||
|
||||
```
|
||||
ERROR: for elasticsearch Cannot start service elasticsearch: EOF
|
||||
```
|
||||
那么...现在看起来呢?
|
||||
|
||||
那么...你怎么看?
|
||||
* `Systemd` 比起 `SysV`、`init.d` 脚本更加简单,因为编写 `systemd` 单元文件比起编写 `shell` 脚本更加方便。这也是 Lennart Poetterin 在他的 [systemd 神话][2] 中解释 `systemd` 为何简单时使用的论点。
|
||||
|
||||
我非常赞同 Poettering 的观点——也可以看 [shell 脚本陷阱][3] 这篇文章。但是这种角度并不全面。单元文件简单的背后意味着 `systemd` 作为一个整体要复杂的多,并且用户确实会受到它的影响。看看我遇到的这个[问题][4]和为它所做的[修复][5]。看起来很简单吗?
|
||||
我非常赞同 Poettering 的观点——也可以看 [shell 脚本陷阱][3] 这篇文章。但是这种角度并不全面。单元文件简单的背后意味着 `systemd` 作为一个整体要复杂的多,并且用户确实会受到它的影响。看看我遇到的这个[问题][4]和为它所做的[修复][5]。看起来很简单吗?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -61,7 +66,7 @@ via: https://arp242.net/weblog/easy.html
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -71,4 +76,4 @@ via: https://arp242.net/weblog/easy.html
|
||||
[2]: http://0pointer.de/blog/projects/the-biggest-myths.html
|
||||
[3]:https://www.arp242.net/shell-scripting-trap.html
|
||||
[4]:https://unix.stackexchange.com/q/185495/33645
|
||||
[5]:https://cgit.freedesktop.org/systemd/systemd/commit/?id=6e392c9c45643d106673c6643ac8bf4e65da13c1
|
||||
[5]:https://cgit.freedesktop.org/systemd/systemd/commit/?id=6e392c9c45643d106673c6643ac8bf4e65da13c1
|
||||
140
published/20191017 How to type emoji on Linux.md
Normal file
140
published/20191017 How to type emoji on Linux.md
Normal file
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11702-1.html)
|
||||
[#]: subject: (How to type emoji on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/10/how-type-emoji-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在 Linux 系统中输入 emoji
|
||||
======
|
||||
|
||||
> 使用 GNOME 桌面可以让你在文字中轻松加入 emoji。
|
||||
|
||||

|
||||
|
||||
emoji 是潜藏在 Unicode 字符空间里的有趣表情图,它们已经风靡于整个互联网。emoji 可以用来在社交媒体上表示自己的心情状态,也可以作为重要文件名的视觉标签,总之它们的各种用法层出不穷。在 Linux 系统中有很多种方式可以输入 Unicode 字符,但 GNOME 桌面能让你更轻松地查找和输入 emoji。
|
||||
|
||||
![Emoji in Emacs][2]
|
||||
|
||||
### 准备工作
|
||||
|
||||
首先,你需要一个运行 [GNOME][3] 桌面的 Linux 系统。
|
||||
|
||||
同时还需要安装一款支持 emoji 的字体。符合这个要求的字体有很多,使用你喜欢的软件包管理器直接搜索 `emoji` 并选择一款安装就可以了。
|
||||
|
||||
例如在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf search emoji
|
||||
emoji-picker.noarch : An emoji selection tool
|
||||
unicode-emoji.noarch : Unicode Emoji Data Files
|
||||
eosrei-emojione-fonts.noarch : A color emoji font
|
||||
twitter-twemoji-fonts.noarch : Twitter Emoji for everyone
|
||||
google-android-emoji-fonts.noarch : Android Emoji font released by Google
|
||||
google-noto-emoji-fonts.noarch : Google “Noto Emoji” Black-and-White emoji font
|
||||
google-noto-emoji-color-fonts.noarch : Google “Noto Color Emoji” colored emoji font
|
||||
[...]
|
||||
```
|
||||
|
||||
对于 Ubuntu 或者 Debian,需要使用 `apt search`。
|
||||
|
||||
在这篇文章中,我会使用 [Google Noto Color Emoji][4] 这款字体为例。
|
||||
|
||||
### 设置
|
||||
|
||||
要开始设置,首先打开 GNOME 的设置面板。
|
||||
|
||||
1、在左边侧栏中,选择“<ruby>地区与语言<rt>Region & Language</rt></ruby>”类别。
|
||||
|
||||
2、点击“<ruby>输入源<rt>Input Sources</rt></ruby>”选项下方的加号(+)打开“<ruby>添加输入源<rt>Add an Input Source</rt></ruby>”面板。
|
||||
|
||||
![Add a new input source][5]
|
||||
|
||||
3、在“<ruby>添加输入源<rt>Add an Input Source</rt></ruby>”面板中,点击底部的菜单按钮。
|
||||
|
||||
![Add an Input Source panel][6]
|
||||
|
||||
4、滑动到列表底部并选择“<ruby>其它<rt>Other</rt></ruby>”。
|
||||
|
||||
5、在“<ruby>其它<rt>Other</rt></ruby>”列表中,找到“<ruby>其它<rt>Other</rt></ruby>(<ruby>快速输入<rt>Typing Booster</rt></ruby>)”。
|
||||
|
||||
![Find Other \(Typing Booster\) in inputs][7]
|
||||
|
||||
6、点击右上角的“<ruby>添加<rt>Add</rt></ruby>”按钮,将输入源添加到 GNOME 桌面。
|
||||
|
||||
以上操作完成之后,就可以关闭设置面板了。
|
||||
|
||||
#### 切换到快速输入
|
||||
|
||||
现在 GNOME 桌面的右上角会出现一个新的图标,一般情况下是当前语言的双字母缩写(例如英语是 en,世界语是 eo,西班牙语是 es,等等)。如果你按下了<ruby>超级键<rt>Super key</rt></ruby>(也就是键盘上带有 Linux 企鹅/Windows 徽标/Mac Command 标志的键)+ 空格键的组合键,就会切换到输入列表中的下一个输入源。在这里,我们只有两个输入源,也就是默认语言和快速输入。
|
||||
|
||||
你可以尝试使用一下这个组合键,观察图标的变化。
|
||||
|
||||
#### 配置快速输入
|
||||
|
||||
在快速输入模式下,点击右上角的输入源图标,选择“<ruby>Unicode 符号和 emoji 联想<rt>Unicode symbols and emoji predictions</rt></ruby>”选项,设置为“<ruby>开<rt>On</rt></ruby>”。
|
||||
|
||||
![Set Unicode symbols and emoji predictions to On][8]
|
||||
|
||||
现在快速输入模式已经可以输入 emoji 了。这正是我们现在所需要的,当然快速输入模式的功能也并不止于此。
|
||||
|
||||
### 输入 emoji
|
||||
|
||||
在快速输入模式下,打开一个文本编辑器,或者网页浏览器,又或者是任意一种支持输入 Unicode 字符的软件,输入“thumbs up”,快速输入模式就会帮你迅速匹配的 emoji 了。
|
||||
|
||||
![Typing Booster searching for emojis][9]
|
||||
|
||||
要退出 emoji 模式,只需要再次使用超级键+空格键的组合键,输入源就会切换回你的默认输入语言。
|
||||
|
||||
### 使用其它切换方式
|
||||
|
||||
如果你觉得“超级键+空格键”这个组合用起来不顺手,你也可以换成其它键的组合。在 GNOME 设置面板中选择“<ruby>设备<rt>Device</rt></ruby>”→“<ruby>键盘<rt>Keyboard</rt></ruby>”。
|
||||
|
||||
在“<ruby>键盘<rt>Keyboard</rt></ruby>”页面中,将“<ruby>切换到下一个输入源<rt>Switch to next input source</rt></ruby>”更改为你喜欢的组合键。
|
||||
|
||||
![Changing keystroke combination in GNOME settings][10]
|
||||
|
||||
### 输入 Unicode
|
||||
|
||||
实际上,现代键盘的设计只是为了输入 26 个字母以及尽可能多的数字和符号。但 ASCII 字符的数量已经比键盘上能看到的字符多得多了,遑论上百万个 Unicode 字符。因此,如果你想要在 Linux 应用程序中输入 Unicode,但又不想使用快速输入,你可以尝试一下 Unicode 输入。
|
||||
|
||||
1. 打开任意一种支持输入 Unicode 字符的软件,但仍然使用你的默认输入语言
|
||||
2. 使用 `Ctrl+Shift+U` 组合键进入 Unicode 输入模式
|
||||
3. 在 Unicode 输入模式下,只需要输入某个 Unicode 字符的对应序号,就实现了对这个 Unicode 字符的输入。例如 `1F44D` 对应的是 👍,而 `2620` 则对应了 ☠。想要查看所有 Unicode 字符的对应序号,可以参考 [Unicode 规范][11]。
|
||||
|
||||
### emoji 的实用性
|
||||
|
||||
emoji 可以让你的文本变得与众不同,这就是它们有趣和富有表现力的体现。同时 emoji 也有很强的实用性,因为它们本质上是 Unicode 字符,在很多支持自定义字体的地方都可以用到它们,而且跟使用其它常规字符没有什么太大的差别。因此,你可以使用 emoji 来对不同的文件做标记,在搜索的时候就可以使用 emoji 把这些文件快速筛选出来。
|
||||
|
||||
![Labeling a file with emoji][12]
|
||||
|
||||
你可以在 Linux 中尽情地使用 emoji,因为 Linux 是一个对 Unicode 友好的环境,未来也会对 Unicode 有着越来越好的支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/how-type-emoji-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc-lead_cat-keyboard.png?itok=fuNmiGV- "A cat under a keyboard."
|
||||
[2]: https://opensource.com/sites/default/files/uploads/emacs-emoji.jpg "Emoji in Emacs"
|
||||
[3]: https://www.gnome.org/
|
||||
[4]: https://www.google.com/get/noto/help/emoji/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/gnome-setting-region-add.png "Add a new input source"
|
||||
[6]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-list.png "Add an Input Source panel"
|
||||
[7]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-other-typing-booster.png "Find Other (Typing Booster) in inputs"
|
||||
[8]: https://opensource.com/sites/default/files/uploads/emoji-input-on.jpg "Set Unicode symbols and emoji predictions to On"
|
||||
[9]: https://opensource.com/sites/default/files/uploads/emoji-input.jpg "Typing Booster searching for emojis"
|
||||
[10]: https://opensource.com/sites/default/files/uploads/gnome-setting-keyboard-switch-input.jpg "Changing keystroke combination in GNOME settings"
|
||||
[11]: http://unicode.org/emoji/charts/full-emoji-list.html
|
||||
[12]: https://opensource.com/sites/default/files/uploads/file-label.png "Labeling a file with emoji"
|
||||
|
||||
@ -1,24 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11699-1.html)
|
||||
[#]: subject: (How internet security works: TLS, SSL, and CA)
|
||||
[#]: via: (https://opensource.com/article/19/11/internet-security-tls-ssl-certificate-authority)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brson)
|
||||
|
||||
互联网的安全是如何保证的:TLS,SSL,和 CA
|
||||
互联网的安全是如何保证的:TLS、SSL 和 CA
|
||||
======
|
||||
你的浏览器里的锁的图标的后面是什么?
|
||||
|
||||
> 你的浏览器里的锁的图标的后面是什么?
|
||||
|
||||
![Lock][1]
|
||||
|
||||
每天你都会重复这件事很多次,你访问网站,这个网站需要你用用户名或者电子邮件地址,和你的密码来进行登录。银行网站,社交网站,电子邮件服务,电子商务网站,和新闻网站。这里只在使用了这种机制的网站中列举了其中一小部分。
|
||||
每天你都会重复这件事很多次,访问网站,网站需要你用你的用户名或者电子邮件地址和你的密码来进行登录。银行网站、社交网站、电子邮件服务、电子商务网站和新闻网站。这里只在使用了这种机制的网站中列举了其中一小部分。
|
||||
|
||||
每次你登陆进一个这种类型的网站时,你实际上是在说:“是的,我信任这个网站,所以我愿意把我的个人信息共享给它。”这些数据可能包含你的姓名,性别,实际地址,电子邮箱地址,有时候甚至会包括你的信用卡信息。
|
||||
每次你登录进一个这种类型的网站时,你实际上是在说:“是的,我信任这个网站,所以我愿意把我的个人信息共享给它。”这些数据可能包含你的姓名、性别、实际地址、电子邮箱地址,有时候甚至会包括你的信用卡信息。
|
||||
|
||||
但是你怎么知道你可以信任这个网站?换个方式问,为了让你可以信任它,网站应该如何保护你的交易?
|
||||
|
||||
本文旨在阐述使网站变得安全的机制。我会首先论述 web 协议 http 和 https,以及传输层安全(TLS)的概念,后者是互联网协议(IP)层中的加密协议之一。然后,我会解释证书颁发机构和自签名证书,以及它们如何帮助保护一个网站。最后,我会介绍一些开源的工具,你可以使用它们来创建和管理你的证书。
|
||||
本文旨在阐述使网站变得安全的机制。我会首先论述 web 协议 http 和 https,以及<ruby>传输层安全<rt>Transport Layer Security</rt></ruby>(TLS)的概念,后者是<ruby>互联网协议<rt>Internet Protocol</rt></ruby>(IP)层中的加密协议之一。然后,我会解释<ruby>证书颁发机构<rt>certificate authority</rt></ruby>和自签名证书,以及它们如何帮助保护一个网站。最后,我会介绍一些开源的工具,你可以使用它们来创建和管理你的证书。
|
||||
|
||||
### 通过 https 保护路由
|
||||
|
||||
@ -26,13 +28,13 @@
|
||||
|
||||
![Certificate information][2]
|
||||
|
||||
默认情况下,如果一个网站使用的是 http 协议,那么它是不安全的。通过网站主机配置一个证书并添加到路由,可以把这个网站从一个不安全的 http 网站变为一个安全的 https 网站。那个锁图标通常表示这个网站是受 https 保护的。
|
||||
默认情况下,如果一个网站使用的是 http 协议,那么它是不安全的。为通过网站主机的路由添加一个配置过的证书,可以把这个网站从一个不安全的 http 网站变为一个安全的 https 网站。那个锁图标通常表示这个网站是受 https 保护的。
|
||||
|
||||
点击证书来查看网站的 CA,根据你的浏览器,你可能需要下载证书来查看它。
|
||||
|
||||
![Certificate information][3]
|
||||
|
||||
点击证书来查看网站的 CA,根据你的浏览器,你可能需要下载证书来查看它。
|
||||
在这里,你可以了解有关 Opensource.com 证书的信息。例如,你可以看到 CA 是 DigiCert,并以 Opensource.com 的名称提供给 Red Hat。
|
||||
|
||||
这个证书信息可以让终端用户检查该网站是否可以安全访问。
|
||||
|
||||
@ -42,19 +44,19 @@
|
||||
|
||||
### 带有 TLS 和 SSL 的互联网协议
|
||||
|
||||
TLS 是旧版安全套接字层协议(SSL)的最新版本。理解这一点的最好方法就是仔细理解 IP 的不同协议层。
|
||||
TLS 是旧版<ruby>安全套接字层协议<rt>Secure Socket Layer</rt></ruby>(SSL)的最新版本。理解这一点的最好方法就是仔细理解互联网协议的不同协议层。
|
||||
|
||||
![IP layers][4]
|
||||
|
||||
我们知道当今的互联网是由6个层面组成的:物理层,数据链路层,网络层,传输层,安全层,应用层。物理层是基础,这一层是最接近实际的硬件设备的。应用层是最抽象的一层,是最接近终端用户的一层。安全层可以被认为是应用层的一部分,TLS 和 SSL,是被设计用来在一个计算机网络中提供通信安全的加密协议,它们位于安全层中。
|
||||
我们知道当今的互联网是由 6 个层面组成的:物理层、数据链路层、网络层、传输层、安全层、应用层。物理层是基础,这一层是最接近实际的硬件设备的。应用层是最抽象的一层,是最接近终端用户的一层。安全层可以被认为是应用层的一部分,TLS 和 SSL,是被设计用来在一个计算机网络中提供通信安全的加密协议,它们位于安全层中。
|
||||
|
||||
这个过程可以确保终端用户使用网络服务时,通信的安全性和保密性。
|
||||
|
||||
### 证书颁发机构和自签名证书
|
||||
|
||||
CA 是受信任的组织,它可以颁发数字证书。
|
||||
<ruby>证书颁发机构<rt>Certificate authority</rt></ruby>(CA)是受信任的组织,它可以颁发数字证书。
|
||||
|
||||
TLS 和 SSL 可以使连接更安全,但是这个加密机制需要一种方式来验证它;这就是 SSL/TLS 证书。TLS 使用了一种叫做非对称加密的加密机制,这个机制有一对称为私钥和公钥的安全密钥。(这是一个非常复杂的主题,超出了本文的讨论范围,但是如果你想去了解这方面的东西,你可以阅读“密码学和公钥密码基础体系简介”)你要知道的基础内容是,证书颁发机构们,比如 GlobalSign, DigiCert,和 GoDaddy,它们是受人们信任的可以颁发证书的供应商,它们颁发的证书可以用于验证网站使用的 TLS/SSL 证书。网站使用的证书是导入到主机服务器里的,用于保护网站。
|
||||
TLS 和 SSL 可以使连接更安全,但是这个加密机制需要一种方式来验证它;这就是 SSL/TLS 证书。TLS 使用了一种叫做非对称加密的加密机制,这个机制有一对称为私钥和公钥的安全密钥。(这是一个非常复杂的主题,超出了本文的讨论范围,但是如果你想去了解这方面的东西,你可以阅读“[密码学和公钥密码基础体系简介][5]”)你要知道的基础内容是,证书颁发机构们,比如 GlobalSign、DigiCert 和 GoDaddy,它们是受人们信任的可以颁发证书的供应商,它们颁发的证书可以用于验证网站使用的 TLS/SSL 证书。网站使用的证书是导入到主机服务器里的,用于保护网站。
|
||||
|
||||
然而,如果你只是要测试一下正在开发中的网站或服务,CA 证书可能对你而言太昂贵或者是太复杂了。你必须有一个用于生产目的的受信任的证书,但是开发者和网站管理员需要有一种更简单的方式来测试网站,然后他们才能将其部署到生产环境中;这就是自签名证书的来源。
|
||||
|
||||
@ -62,48 +64,50 @@ TLS 和 SSL 可以使连接更安全,但是这个加密机制需要一种方
|
||||
|
||||
### 生成证书的开源工具
|
||||
|
||||
有几种开源工具可以用来管理 TLS/SSL 证书。其中最著名的就是 openssl,这个工具包含在很多 Linux 发行版中和 macos 中。当然,你也可以使用其他开源工具。
|
||||
有几种开源工具可以用来管理 TLS/SSL 证书。其中最著名的就是 openssl,这个工具包含在很多 Linux 发行版中和 MacOS 中。当然,你也可以使用其他开源工具。
|
||||
|
||||
| Tool Name | Description | License |
|
||||
| 工具名 | 描述 | 许可证 |
|
||||
| --------- | ------------------------------------------------------------------------------ | --------------------------------- |
|
||||
| OpenSSL | 实现 TLS 和加密库的最著名的开源工具 | Apache License 2.0 |
|
||||
| EasyRSA | 用于构建 PKI CA 的命令行实用工具 | GPL v2 |
|
||||
| CFSSL | 来自 cloudflare 的 PKI/TLS 瑞士军刀 | BSD 2-Clause "Simplified" License |
|
||||
| Lemur | 来自网飞的 TLS创建工具 | Apache License 2.0 |
|
||||
| [OpenSSL][7] | 实现 TLS 和加密库的最著名的开源工具 | Apache License 2.0 |
|
||||
| [EasyRSA][8] | 用于构建 PKI CA 的命令行实用工具 | GPL v2 |
|
||||
| [CFSSL][9] | 来自 cloudflare 的 PKI/TLS 瑞士军刀 | BSD 2-Clause "Simplified" License |
|
||||
| [Lemur][10] | 来自<ruby>网飞<rt>Netflix</rt></ruby>的 TLS 创建工具 | Apache License 2.0 |
|
||||
|
||||
如果你的目的是扩展和对用户友好,网飞的 Lemur 是一个很有趣的选择。你在网飞的技术博客上可以查看更多有关它的信息。
|
||||
如果你的目的是扩展和对用户友好,网飞的 Lemur 是一个很有趣的选择。你在[网飞的技术博客][6]上可以查看更多有关它的信息。
|
||||
|
||||
### 如何创建一个 Openssl 证书
|
||||
|
||||
你可以靠自己来创建证书,下面这个案例就是使用 Openssl 生成一个自签名证书。
|
||||
|
||||
1. 使用 openssl 命令行生成一个私钥:
|
||||
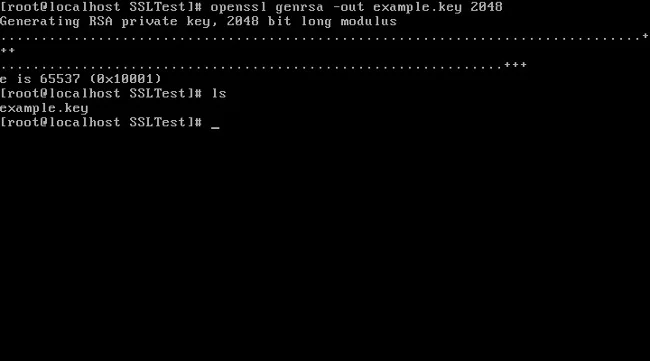
1、使用 `openssl` 命令行生成一个私钥:
|
||||
|
||||
```
|
||||
openssl genrsa -out example.key 2048
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. 使用在第一步中生成的私钥来创建一个证书签名请求(CSR):
|
||||
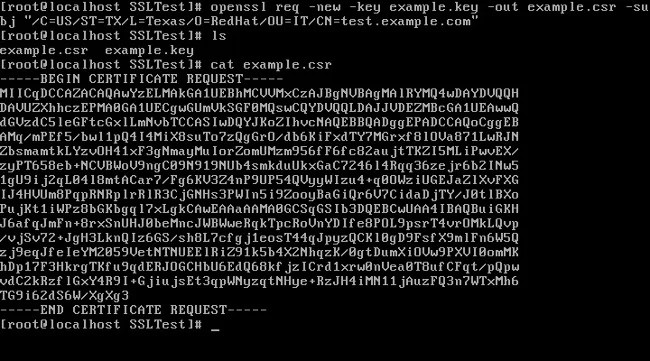
2、使用在第一步中生成的私钥来创建一个<ruby>证书签名请求<rt>certificate signing request</rt></ruby>(CSR):
|
||||
|
||||
```
|
||||
openssl req -new -key example.key -out example.csr \
|
||||
-subj "/C=US/ST=TX/L=Dallas/O=Red Hat/OU=IT/CN=test.example.com"
|
||||
openssl req -new -key example.key -out example.csr -subj "/C=US/ST=TX/L=Dallas/O=Red Hat/OU=IT/CN=test.example.com"
|
||||
```
|
||||
|
||||
|
||||
|
||||
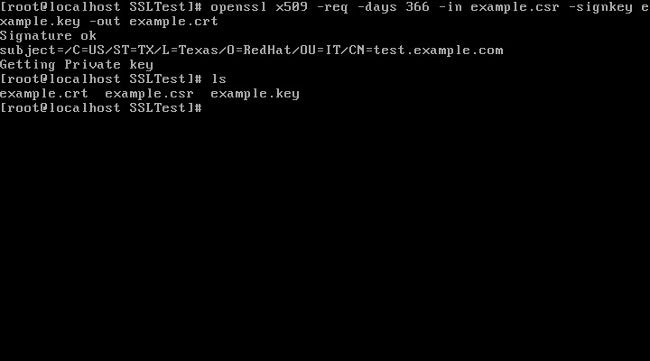
3. 使用你的 CSR 和私钥创建一个证书:
|
||||
3、使用你的 CSR 和私钥创建一个证书:
|
||||
|
||||
```
|
||||
openssl x509 -req -days 366 -in example.csr \
|
||||
-signkey example.key -out example.crt
|
||||
openssl x509 -req -days 366 -in example.csr -signkey example.key -out example.crt
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 了解更多关于互联网安全的知识
|
||||
|
||||
如果你想要了解更多关于互联网安全和网站安全的知识,请看我为这篇文章一起制作的 Youtube 视频。
|
||||
|
||||
<https://youtu.be/r0F1Hlcmjsk>
|
||||
- <https://youtu.be/r0F1Hlcmjsk>
|
||||
|
||||
你有什么问题?发在评论里让我们知道。
|
||||
|
||||
@ -114,7 +118,7 @@ via: https://opensource.com/article/19/11/internet-security-tls-ssl-certificate-
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -126,3 +130,7 @@ via: https://opensource.com/article/19/11/internet-security-tls-ssl-certificate-
|
||||
[4]: https://opensource.com/sites/default/files/uploads/3_internetprotocol.jpg
|
||||
[5]: https://opensource.com/article/18/5/cryptography-pki
|
||||
[6]: https://medium.com/netflix-techblog/introducing-lemur-ceae8830f621
|
||||
[7]: https://www.openssl.org/
|
||||
[8]: https://github.com/OpenVPN/easy-rsa
|
||||
[9]: https://github.com/cloudflare/cfssl
|
||||
[10]: https://github.com/Netflix/lemur
|
||||
140
published/20191127 How to write a Python web API with Flask.md
Normal file
140
published/20191127 How to write a Python web API with Flask.md
Normal file
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hj24)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11701-1.html)
|
||||
[#]: subject: (How to write a Python web API with Flask)
|
||||
[#]: via: (https://opensource.com/article/19/11/python-web-api-flask)
|
||||
[#]: author: (Rachel Waston https://opensource.com/users/rachelwaston)
|
||||
|
||||
如何使用 Flask 编写 Python Web API
|
||||
======
|
||||
|
||||
> 这是一个快速教程,用来展示如何通过 Flask(目前发展最迅速的 Python 框架之一)来从服务器获取数据。
|
||||
|
||||
![spiderweb diagram][1]
|
||||
|
||||
[Python][2] 是一个以语法简洁著称的高级的、面向对象的程序语言。它一直都是一个用来构建 RESTful API 的顶级编程语言。
|
||||
|
||||
[Flask][3] 是一个高度可定制化的 Python 框架,可以为开发人员提供用户访问数据方式的完全控制。Flask 是一个基于 Werkzeug 的 [WSGI][4] 工具包和 Jinja 2 模板引擎的”微框架“。它是一个被设计来开发 RESTful API 的 web 框架。
|
||||
|
||||
Flask 是 Python 发展最迅速的框架之一,很多知名网站如:Netflix、Pinterest 和 LinkedIn 都将 Flask 纳入了它们的开发技术栈。下面是一个简单的示例,展示了 Flask 是如何允许用户通过 HTTP GET 请求来从服务器获取数据的。
|
||||
|
||||
### 初始化一个 Flask 应用
|
||||
|
||||
首先,创建一个你的 Flask 项目的目录结构。你可以在你系统的任何地方来做这件事。
|
||||
|
||||
```
|
||||
$ mkdir tutorial
|
||||
$ cd tutorial
|
||||
$ touch main.py
|
||||
$ python3 -m venv env
|
||||
$ source env/bin/activate
|
||||
(env) $ pip3 install flask-restful
|
||||
Collecting flask-restful
|
||||
Downloading https://files.pythonhosted.org/packages/17/44/6e49...8da4/Flask_RESTful-0.3.7-py2.py3-none-any.whl
|
||||
Collecting Flask>=0.8 (from flask-restful)
|
||||
[...]
|
||||
```
|
||||
|
||||
### 导入 Flask 模块
|
||||
|
||||
然后,在你的 `main.py` 代码中导入 `flask` 模块和它的 `flask_restful` 库:
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
from flask_restful import Resource, Api
|
||||
|
||||
app = Flask(__name__)
|
||||
api = Api(app)
|
||||
|
||||
class Quotes(Resource):
|
||||
def get(self):
|
||||
return {
|
||||
'William Shakespeare': {
|
||||
'quote': ['Love all,trust a few,do wrong to none',
|
||||
'Some are born great, some achieve greatness, and some greatness thrust upon them.']
|
||||
},
|
||||
'Linus': {
|
||||
'quote': ['Talk is cheap. Show me the code.']
|
||||
}
|
||||
}
|
||||
|
||||
api.add_resource(Quotes, '/')
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True)
|
||||
```
|
||||
|
||||
### 运行 app
|
||||
|
||||
Flask 包含一个内建的用于测试的 HTTP 服务器。来测试一下这个你创建的简单的 API:
|
||||
|
||||
```
|
||||
(env) $ python main.py
|
||||
* Serving Flask app "main" (lazy loading)
|
||||
* Environment: production
|
||||
WARNING: This is a development server. Do not use it in a production deployment.
|
||||
Use a production WSGI server instead.
|
||||
* Debug mode: on
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
启动开发服务器时将启动 Flask 应用程序,该应用程序包含一个名为 `get` 的方法来响应简单的 HTTP GET 请求。你可以通过 `wget`、`curl` 命令或者任意的 web 浏览器来测试它。
|
||||
|
||||
```
|
||||
$ curl http://localhost:5000
|
||||
{
|
||||
"William Shakespeare": {
|
||||
"quote": [
|
||||
"Love all,trust a few,do wrong to none",
|
||||
"Some are born great, some achieve greatness, and some greatness thrust upon them."
|
||||
]
|
||||
},
|
||||
"Linus": {
|
||||
"quote": [
|
||||
"Talk is cheap. Show me the code."
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
要查看使用 Python 和 Flask 的类似 Web API 的更复杂版本,请导航至美国国会图书馆的 [Chronicling America][5] 网站,该网站可提供有关这些信息的历史报纸和数字化报纸。
|
||||
|
||||
### 为什么使用 Flask?
|
||||
|
||||
Flask 有以下几个主要的优点:
|
||||
|
||||
1. Python 很流行并且广泛被应用,所以任何熟悉 Python 的人都可以使用 Flask 来开发。
|
||||
2. 它轻巧而简约。
|
||||
3. 考虑安全性而构建。
|
||||
4. 出色的文档,其中包含大量清晰,有效的示例代码。
|
||||
|
||||
还有一些潜在的缺点:
|
||||
|
||||
1. 它轻巧而简约。但如果你正在寻找具有大量捆绑库和预制组件的框架,那么这可能不是最佳选择。
|
||||
2. 如果必须围绕 Flask 构建自己的框架,则你可能会发现维护自定义项的成本可能会抵消使用 Flask 的好处。
|
||||
|
||||
|
||||
如果你要构建 Web 程序或 API,可以考虑选择 Flask。它功能强大且健壮,并且其优秀的项目文档使入门变得容易。试用一下,评估一下,看看它是否适合你的项目。
|
||||
|
||||
在本课中了解更多信息关于 Python 异常处理以及如何以安全的方式进行操作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/python-web-api-flask
|
||||
|
||||
作者:[Rachel Waston][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hj24](https://github.com/hj24)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rachelwaston
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web-cms-build-howto-tutorial.png?itok=bRbCJt1U (spiderweb diagram)
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://palletsprojects.com/p/flask/
|
||||
[4]: https://en.wikipedia.org/wiki/Web_Server_Gateway_Interface
|
||||
[5]: https://chroniclingamerica.loc.gov/about/api
|
||||
@ -1,31 +1,31 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11696-1.html)
|
||||
[#]: subject: (3 easy steps to update your apps to Python 3)
|
||||
[#]: via: (https://opensource.com/article/19/12/update-apps-python-3)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
将你的应用迁移到 Python 3 的三个步骤
|
||||
======
|
||||
Python 2 气数将尽,是时候将你的项目从 Python 2 迁移到 Python 3 了。
|
||||
|
||||
![Hands on a keyboard with a Python book ][1]
|
||||
> Python 2 气数将尽,是时候将你的项目从 Python 2 迁移到 Python 3 了。
|
||||
|
||||
Python 2.x 很快就要[失去官方支持][2]了,尽管如此,从 Python 2 迁移到 Python 3 却并没有想象中那么难。我在上周用了一个晚上的时间将一个 3D 渲染器及其对应的 [PySide][3] 迁移到 Python 3,回想起来,尽管在迁移过程中无可避免地会遇到一些牵一发而动全身的修改,但整个过程相比起痛苦的重构来说简直是出奇地简单。
|
||||

|
||||
|
||||
Python 2.x 很快就要[失去官方支持][2]了,尽管如此,从 Python 2 迁移到 Python 3 却并没有想象中那么难。我在上周用了一个晚上的时间将一个 3D 渲染器的前端代码及其对应的 [PySide][3] 迁移到 Python 3,回想起来,尽管在迁移过程中无可避免地会遇到一些牵一发而动全身的修改,但整个过程相比起痛苦的重构来说简直是出奇地简单。
|
||||
|
||||
每个人都别无选择地有各种必须迁移的原因:或许是觉得已经拖延太久了,或许是依赖了某个在 Python 2 下不再维护的模块。但如果你仅仅是想通过做一些事情来对开源做贡献,那么把一个 Python 2 应用迁移到 Python 3 就是一个简单而又有意义的做法。
|
||||
|
||||
无论你从 Python 2 迁移到 Python 3 的原因是什么,这都是一项重要的任务。按照以下三个步骤,可以让你把任务完成得更加清晰。
|
||||
|
||||
### 1\. 使用 2to3
|
||||
### 1、使用 2to3
|
||||
|
||||
从几年前开始,Python 在你或许还不知道的情况下就已经自带了一个名叫 [2to3][4] 的脚本,它可以帮助你实现大部分代码从 Python 2 到 Python 3 的自动转换。
|
||||
|
||||
下面是一段使用 Python 2.6 编写的代码:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
@ -39,12 +39,12 @@ print ord(mystring[-1])
|
||||
```
|
||||
$ 2to3 example.py
|
||||
RefactoringTool: Refactored example.py
|
||||
\--- example.py (original)
|
||||
+++ example.py (refactored)
|
||||
--- example.py (original)
|
||||
+++ example.py (refactored)
|
||||
@@ -1,5 +1,5 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
-mystring = u'abcdé'
|
||||
-print ord(mystring[-1])
|
||||
+mystring = 'abcdé'
|
||||
@ -53,8 +53,7 @@ RefactoringTool: Files that need to be modified:
|
||||
RefactoringTool: example.py
|
||||
```
|
||||
|
||||
在默认情况下,2to3 只会对迁移到 Python 3 时必须作出修改的代码进行标示,在输出结果中显示的 Python 3 代码是直接可用的,但你可以在 2to3 加上 `-w` 或者 `--write` 参数,这样它就可以直接按照给出的方案修改你的 Python 2 代码文件了。
|
||||
|
||||
在默认情况下,`2to3` 只会对迁移到 Python 3 时必须作出修改的代码进行标示,在输出结果中显示的 Python 3 代码是直接可用的,但你可以在 2to3 加上 `-w` 或者 `--write` 参数,这样它就可以直接按照给出的方案修改你的 Python 2 代码文件了。
|
||||
|
||||
```
|
||||
$ 2to3 -w example.py
|
||||
@ -63,17 +62,16 @@ RefactoringTool: Files that were modified:
|
||||
RefactoringTool: example.py
|
||||
```
|
||||
|
||||
2to3 脚本不仅仅对单个文件有效,你还可以把它用于一个目录下的所有 Python 文件,同时它也会递归地对所有子目录下的 Python 文件都生效。
|
||||
`2to3` 脚本不仅仅对单个文件有效,你还可以把它用于一个目录下的所有 Python 文件,同时它也会递归地对所有子目录下的 Python 文件都生效。
|
||||
|
||||
### 2\. 使用 Pylint 或 Pyflakes
|
||||
### 2、使用 Pylint 或 Pyflakes
|
||||
|
||||
有一些不良的代码习惯在 Python 2 下运行是没有异常的,在 Python 3 下运行则会或多或少报出错误,并且这些代码无法通过语法转换来修复,所以 2to3 对它们没有效果,但一旦使用 Python 3 来运行就会产生报错。
|
||||
有一些不良的代码在 Python 2 下运行是没有异常的,在 Python 3 下运行则会或多或少报出错误,这种情况并不鲜见。因为这些不良代码无法通过语法转换来修复,所以 `2to3` 对它们没有效果,但一旦使用 Python 3 来运行就会产生报错。
|
||||
|
||||
对于这种情况,你需要使用 [Pylint][5]、[Pyflakes][6](或封装好的 [flake8][7])这类工具。其中我更喜欢 Pyflakes,它会忽略代码风格上的差异,在这一点上它和 Pylint 不同。尽管代码优美是 Python 的一大特点,但在代码迁移的层面上,“让代码功能保持一致”无疑比“让代码风格保持一致”重要得多/
|
||||
要找出这种问题,你需要使用 [Pylint][5]、[Pyflakes][6](或 [flake8][7] 封装器)这类工具。其中我更喜欢 Pyflakes,它会忽略代码风格上的差异,在这一点上它和 Pylint 不同。尽管代码优美是 Python 的一大特点,但在代码迁移的层面上,“让代码功能保持一致”无疑比“让代码风格保持一致”重要得多。
|
||||
|
||||
以下是 Pyflakes 的输出样例:
|
||||
|
||||
|
||||
```
|
||||
$ pyflakes example/maths
|
||||
example/maths/enum.py:19: undefined name 'cmp'
|
||||
@ -87,7 +85,6 @@ example/maths/enum.py:208: local variable 'e' is assigned to but never used
|
||||
|
||||
值得注意的是第 19 行这个容易产生误导的错误。从输出来看你可能会以为 `cmp` 是一个在使用前未定义的变量,实际上 `cmp` 是 Python 2 的一个内置函数,而它在 Python 3 中被移除了。而且这段代码被放在了 `try` 语句块中,除非认真检查这段代码的输出值,否则这个问题很容易被忽略掉。
|
||||
|
||||
|
||||
```
|
||||
try:
|
||||
result = cmp(self.index, other.index)
|
||||
@ -99,13 +96,12 @@ example/maths/enum.py:208: local variable 'e' is assigned to but never used
|
||||
|
||||
在代码迁移过程中,你会发现很多原本在 Python 2 中能正常运行的函数都发生了变化,甚至直接在 Python 3 中被移除了。例如 PySide 的绑定方式发生了变化、`importlib` 取代了 `imp` 等等。这样的问题只能见到一个解决一个,而涉及到的功能需要重构还是直接放弃,则需要你自己权衡。但目前来说,大多数问题都是已知的,并且有[完善的文档记录][8]。所以难的不是修复问题,而是找到问题,从这个角度来说,使用 Pyflake 是很有必要的。
|
||||
|
||||
### 3\. 修复被破坏的 Python 2 代码
|
||||
### 3、修复被破坏的 Python 2 代码
|
||||
|
||||
尽管 2to3 脚本能够帮助你把代码修改成兼容 Python 3 的形式,但对于一个完整的代码库,它就显得有点无能为力了,因为一些老旧的代码在 Python 3 中可能需要不同的结构来表示。在这样的情况下,只能人工进行修改。
|
||||
尽管 `2to3` 脚本能够帮助你把代码修改成兼容 Python 3 的形式,但对于一个完整的代码库,它就显得有点无能为力了,因为一些老旧的代码在 Python 3 中可能需要不同的结构来表示。在这样的情况下,只能人工进行修改。
|
||||
|
||||
例如以下代码在 Python 2.6 中可以正常运行:
|
||||
|
||||
|
||||
```
|
||||
class CLOCK_SPEED:
|
||||
TICKS_PER_SECOND = 16
|
||||
@ -116,8 +112,7 @@ class FPS:
|
||||
STATS_UPDATE_FREQUENCY = CLOCK_SPEED.TICKS_PER_SECOND
|
||||
```
|
||||
|
||||
类似 2to3 和 Pyflakes 这些自动化工具并不能发现其中的问题,但如果上述代码使用 Python 3 来运行,解释器会认为 `CLOCK_SPEED.TICKS_PER_SECOND` 是未被明确定义的。因此就需要把代码改成面向对象的结构:
|
||||
|
||||
类似 `2to3` 和 Pyflakes 这些自动化工具并不能发现其中的问题,但如果上述代码使用 Python 3 来运行,解释器会认为 `CLOCK_SPEED.TICKS_PER_SECOND` 是未被明确定义的。因此就需要把代码改成面向对象的结构:
|
||||
|
||||
```
|
||||
class CLOCK_SPEED:
|
||||
@ -131,7 +126,7 @@ class FPS:
|
||||
STATS_UPDATE_FREQUENCY = CLOCK_SPEED.TICKS_PER_SECOND()
|
||||
```
|
||||
|
||||
你也许会认为如果把 `TICKS_PER_SECOND()` 改写为一个构造函数能让代码看起来更加简洁,但这样就需要把这个方法的调用形式从 `CLOCK_SPEED.TICKS_PER_SECOND()` 改为 `CLOCK_SPEED()` 了,这样的改动或多或少会对整个库造成一些未知的影响。如果你对整个代码库的结构烂熟于心,那么你确实可以随心所欲地作出这样的修改。但我通常认为,只要我做出了修改,都可能会影响到其它代码中的至少三处地方,因此我更倾向于不使代码的结构发生改变。
|
||||
你也许会认为如果把 `TICKS_PER_SECOND()` 改写为一个构造函数(用 `__init__` 函数设置默认值)能让代码看起来更加简洁,但这样就需要把这个方法的调用形式从 `CLOCK_SPEED.TICKS_PER_SECOND()` 改为 `CLOCK_SPEED()` 了,这样的改动或多或少会对整个库造成一些未知的影响。如果你对整个代码库的结构烂熟于心,那么你确实可以随心所欲地作出这样的修改。但我通常认为,只要我做出了修改,都可能会影响到其它代码中的至少三处地方,因此我更倾向于不使代码的结构发生改变。
|
||||
|
||||
### 坚持信念
|
||||
|
||||
@ -146,14 +141,14 @@ via: https://opensource.com/article/19/12/update-apps-python-3
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python-programming-code-keyboard.png?itok=fxiSpmnd "Hands on a keyboard with a Python book "
|
||||
[2]: https://opensource.com/article/19/11/end-of-life-python-2
|
||||
[2]: https://linux.cn/article-11629-1.html
|
||||
[3]: https://pypi.org/project/PySide/
|
||||
[4]: https://docs.python.org/3.1/library/2to3.html
|
||||
[5]: https://opensource.com/article/19/10/python-pylint-introduction
|
||||
@ -1,18 +1,20 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11695-1.html)
|
||||
[#]: subject: (Annotate screenshots on Linux with Ksnip)
|
||||
[#]: via: (https://opensource.com/article/19/12/annotate-screenshots-linux-ksnip)
|
||||
[#]: author: (Clayton Dewey https://opensource.com/users/cedewey)
|
||||
|
||||
在 Linux 上使用 Ksnip 注释截图
|
||||
======
|
||||
Ksnip 让你能轻松地在 Linux 中创建和标记截图。
|
||||
|
||||
> Ksnip 让你能轻松地在 Linux 中创建和标记截图。
|
||||
|
||||
![a checklist for a team][1]
|
||||
|
||||
我最近从 MacOS 切换到了 [Elementary OS][2],这是一个专注于易用性和隐私性的 Linux 发行版。作为用户体验设计师和免费软件支持者,我会经常截图并进行注释。在尝试了几种不同的工具之后,到目前为止,我最喜欢的工具是 [Ksnip][3],它是 GPLv2 许可下的一种开源工具。
|
||||
我最近从 MacOS 切换到了 [Elementary OS][2],这是一个专注于易用性和隐私性的 Linux 发行版。作为用户体验设计师和自由软件支持者,我会经常截图并进行注释。在尝试了几种不同的工具之后,到目前为止,我最喜欢的工具是 [Ksnip][3],它是 GPLv2 许可下的一种开源工具。
|
||||
|
||||
![Ksnip screenshot][4]
|
||||
|
||||
@ -20,22 +22,19 @@ Ksnip 让你能轻松地在 Linux 中创建和标记截图。
|
||||
|
||||
使用你首选的包管理器安装 Ksnip。我通过 Apt 安装了它:
|
||||
|
||||
|
||||
```
|
||||
`sudo apt-get install ksnip`
|
||||
sudo apt-get install ksnip
|
||||
```
|
||||
|
||||
### 配置
|
||||
|
||||
Ksnip 有许多配置选项,包括:
|
||||
|
||||
* 保存截图的地方
|
||||
* 默认截图的文件名
|
||||
* 图像采集器行为
|
||||
* 光标颜色和宽度
|
||||
* 文字字体
|
||||
|
||||
|
||||
* 保存截图的地方
|
||||
* 默认截图的文件名
|
||||
* 图像采集器行为
|
||||
* 光标颜色和宽度
|
||||
* 文字字体
|
||||
|
||||
你也可以将其与你的 Imgur 帐户集成。
|
||||
|
||||
@ -45,7 +44,7 @@ Ksnip 有许多配置选项,包括:
|
||||
|
||||
Ksnip 提供了大量的[功能][6]。我最喜欢的 Ksnip 部分是它拥有我需要的所有注释工具(还有一个我没想到的工具!)。
|
||||
|
||||
您可以使用以下注释:
|
||||
你可以使用以下注释:
|
||||
|
||||
* 钢笔
|
||||
* 记号笔
|
||||
@ -53,8 +52,6 @@ Ksnip 提供了大量的[功能][6]。我最喜欢的 Ksnip 部分是它拥有
|
||||
* 椭圆
|
||||
* 文字
|
||||
|
||||
|
||||
|
||||
你还可以模糊区域来移除敏感信息。还有使用我最喜欢的新工具:用于在界面上表示步骤的带数字的点。
|
||||
|
||||
### 关于作者
|
||||
@ -63,7 +60,7 @@ Ksnip 提供了大量的[功能][6]。我最喜欢的 Ksnip 部分是它拥有
|
||||
|
||||
当我问到是什么启发了他编写 Ksnip 时,他说:
|
||||
|
||||
>“几年前我从 Windows 切换到 Linux,却没有了在 Windows 中常用的 Windows Snipping Tool。当时的所有其他截图工具要么很大(很多按钮和复杂功能),要么缺少诸如注释等关键功能,所以我决定编写一个简单的 Windows Snipping Tool 克隆版,但是随着时间的流逝,它开始有越来越多的功能。“
|
||||
> “几年前我从 Windows 切换到 Linux,却没有了在 Windows 中常用的 Windows Snipping Tool。当时的所有其他截图工具要么很大(很多按钮和复杂功能),要么缺少诸如注释等关键功能,所以我决定编写一个简单的 Windows Snipping Tool 克隆版,但是随着时间的流逝,它开始有越来越多的功能。“
|
||||
|
||||
这正是我在评估截图工具时发现的。他花时间构建解决方案并免费共享给他人使用,这真是太好了。
|
||||
|
||||
@ -77,7 +74,7 @@ Damir 最需要的是帮助开发 Ksnip。他和他的妻子很快就会有孩
|
||||
|
||||
* * *
|
||||
|
||||
_此文章最初发表在 [Agaric Tech Cooperative 的博客][9]上,并经允许重新发布。_
|
||||
> 此文章最初发表在 [Agaric Tech Cooperative 的博客][9]上,并经允许重新发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -86,7 +83,7 @@ via: https://opensource.com/article/19/12/annotate-screenshots-linux-ksnip
|
||||
作者:[Clayton Dewey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11698-1.html)
|
||||
[#]: subject: (How to configure Openbox for your Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/openbox-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何为 Linux 桌面配置 Openbox
|
||||
======
|
||||
本文是 24 天 Linux 桌面特别系列的一部分。Openbox 窗口管理器占用很小的系统资源、易于配置、使用愉快。
|
||||
![open with sky and grass][1]
|
||||
|
||||
你可能不知道使用过 [Openbox][2] 桌面:尽管 Openbox 本身是一个出色的窗口管理器,但它还是 LXDE 和 LXQT 等桌面环境的窗口管理器“引擎”,它甚至可以管理 KDE 和 GNOME。除了作为多个桌面的基础之外,Openbox 可以说是最简单的窗口管理器之一,可以为那些不想学习所有配置选项的人配置。通过使用基于菜单的 **obconf** 的配置应用,可以像在 GNOME 或 KDE 这样的完整桌面中一样轻松地设置所有常用首选项。
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。Openbox 窗口管理器占用很小的系统资源、易于配置、使用愉快。
|
||||
|
||||

|
||||
|
||||
你可能不知道你使用过 [Openbox][2] 桌面:尽管 Openbox 本身是一个出色的窗口管理器,但它还是 LXDE 和 LXQT 等桌面环境的窗口管理器“引擎”,它甚至可以管理 KDE 和 GNOME。除了作为多个桌面的基础之外,Openbox 可以说是最简单的窗口管理器之一,可以为那些不想学习那么多配置选项的人配置。通过使用基于菜单的 obconf 的配置应用,可以像在 GNOME 或 KDE 这样的完整桌面中一样轻松地设置所有常用首选项。
|
||||
|
||||
### 安装 Openbox
|
||||
|
||||
你可能会在 Linux 发行版的软件仓库中找到 Openbox,但也可以在 [Openbox.org][3] 中找到它。如果你已经在运行其他桌面,那么可以安全地在同一系统上安装 Openbox,因为 Openbox 除了几个配置面板之外,不包括任何捆绑的应用。
|
||||
你可能会在 Linux 发行版的软件仓库中找到 Openbox,也可以在 [Openbox.org][3] 中找到它。如果你已经在运行其他桌面,那么可以安全地在同一系统上安装 Openbox,因为 Openbox 除了几个配置面板之外,不包括任何捆绑的应用。
|
||||
|
||||
安装后,退出当前桌面会话,以便你可以登录 Openbox 桌面。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,这取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该桌面。
|
||||
安装后,退出当前桌面会话,以便你可以登录 Openbox 桌面。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,这取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该选择。
|
||||
|
||||
要使用 GDM 覆盖它:
|
||||
|
||||
@ -30,17 +32,17 @@
|
||||
|
||||
### 配置 Openbox 桌面
|
||||
|
||||
默认情况下,Openbox 包含 **obconf** 应用,你可以使用它来选择和安装主题,修改鼠标行为,设置桌面首选项等。你可能会在仓库中发现其他配置应用,如 **obmenu** ,用于配置窗口管理器的其他部分。
|
||||
默认情况下,Openbox 包含 obconf 应用,你可以使用它来选择和安装主题、修改鼠标行为、设置桌面首选项等。你可能会在仓库中发现其他配置应用,如 obmenu,用于配置窗口管理器的其他部分。
|
||||
|
||||
![Openbox Obconf configuration application][6]
|
||||
|
||||
建立你自己的桌面体验相对容易。它有一些所有常见的桌面组件,例如系统托盘 [stalonetray][7]、任务栏 [Tint2][8] 或 [Xfce4-panel][9] 等几乎你能想到的。任意组合应用,直到拥有梦想的开源桌面为止。
|
||||
构建你自己的桌面环境相对容易。它有一些所有常见的桌面组件,例如系统托盘 [stalonetray][7]、任务栏 [Tint2][8] 或 [Xfce4-panel][9] 等几乎你能想到的。任意组合应用,直到拥有梦想的开源桌面为止。
|
||||
|
||||
![Openbox][10]
|
||||
|
||||
### 为何使用 Openbox
|
||||
|
||||
Openbox 占用很小的系统资源、易于配置、使用愉快。它基本不会弹出,因此会是一个容易熟悉的系统。你永远不会知道你面前的桌面秘密使用了 Openbox 作为窗口管理器(知道如何自定义它会不会很高兴?)。如果开源吸引你,那么试试看 Openbox。
|
||||
Openbox 占用的系统资源很小、易于配置、使用起来很愉悦。它基本不会让你感觉到阻碍,会是一个容易熟悉的系统。你永远不会知道你面前的桌面环境秘密使用了 Openbox 作为窗口管理器(知道如何自定义它会不会很高兴?)。如果开源吸引你,那么试试看 Openbox。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -49,7 +51,7 @@ via: https://opensource.com/article/19/12/openbox-linux-desktop
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,56 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mayunmeiyouming)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11703-1.html)
|
||||
[#]: subject: (What GNOME 2 fans love about the Mate Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/mate-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
GNOME 2 粉丝喜欢 Mate Linux 桌面的什么?
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你还在怀念 GNOME 2,那么 Mate Linux 桌面将满足你的怀旧情怀。
|
||||
|
||||

|
||||
|
||||
如果你以前听过这个传闻:当 GNOME3 第一次发布时,很多 GNOME 用户还没有准备好放弃 GNOME 2。[Mate][2](以<ruby>马黛茶<rt>yerba mate</rt></ruby>植物命名)项目的开始是为了延续 GNOME 2 桌面,刚开始时它使用 GTK 2(GNOME 2 所基于的工具包),然后又合并了 GTK 3。由于 Linux Mint 的简单易用,使得该桌面变得非常流行,并且从那时起,它已经普遍用于 Fedora、Ubuntu、Slackware、Arch 和许多其他 Linux 发行版上。今天,Mate 继续提供一个传统的桌面环境,它的外观和感觉与 GNOME 2 完全一样,使用 GTK 3 工具包。
|
||||
|
||||
你可以在你的 Linux 发行版的软件仓库中找到 Mate,也可以下载并[安装][3]一个把 Mate 作为默认桌面的发行版。不过,在你这样做之前,请注意为了提供完整的桌面体验,所以许多 Mate 应用程序都是随该桌面一起安装的。如果你运行的是不同的桌面,你可能会发现自己有多余的应用程序(两个 PDF 阅读器、两个媒体播放器、两个文件管理器,等等)。所以如果你只想尝试 Mate 桌面,可以在虚拟机(例如 [GNOME box][4])中安装基于 Mate 的发行版。
|
||||
|
||||
### Mate 桌面之旅
|
||||
|
||||
Mate 项目不仅仅可以让你想起来 GNOME 2;它就是 GNOME 2。如果你是 00 年代中期 Linux 桌面的粉丝,至少,你会从中感受到 Mate 的怀旧情怀。我不是 GNOME 2 的粉丝,我更倾向于使用 KDE,但是有一个地方我无法想象没有 GNOME 2:[OpenSolaris][5]。OpenSolaris 项目并没有持续太久,在 Sun Microsystems 被并入 Oracle 之前,Ian Murdock 加入 Sun 时它就显得非常突出,我当时是一个初级的 Solaris 管理员,使用 OpenSolaris 来让自己更多学会那种 Unix 风格。这是我使用过 GNOME 2 的唯一平台(因为我一开始不知道如何更改桌面,后来习惯了它),而今天的 [OpenIndiana project][6] 是 OpenSolaris 的社区延续,它通过 Mate 桌面使用 GNOME 2。
|
||||
|
||||
![Mate on OpenIndiana][7]
|
||||
|
||||
Mate 的布局由左上角的三个菜单组成:应用程序、位置和系统。应用程序菜单提供对系统上安装的所有的应用程序启动器的快速访问。位置菜单提供对常用位置(如家目录、网络文件夹等)的快速访问。系统菜单包含全局选项,如关机和睡眠。右上角是一个系统托盘,屏幕底部有一个任务栏和一个虚拟桌面切换栏。
|
||||
|
||||
就桌面设计而言,这是一种稍微有点奇怪的配置。它从早期的 Linux 桌面、MacFinder 和 Windows 中借用了一些相同的部分,但是又创建了一个独特的配置,这种配置很直观而有些熟悉。Mate 执意保持这个模型,而这正是它的用户喜欢的地方。
|
||||
|
||||
### Mate 和开源
|
||||
|
||||
Mate 是一个最直接的例子,展示了开源如何使开发人员能够对抗项目生命的终结。从理论上讲,GNOME 2 会被 GNOME 3 所取代,但它依然存在,因为一个开发人员建立了该代码的一个分支并继续发展了下去。它的发展势头越来越庞大,更多的开发人员加入进来,并且这个让用户喜爱的桌面比以往任何时候都要更好。并不是所有的软件都有第二次机会,但是开源永远是一个机会,否则就永远没有机会。
|
||||
|
||||
使用和支持开源意味着支持用户和开发人员的自由。而且 Mate 桌面是他们的努力的有力证明。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/mate-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[mayunmeiyouming](https://github.com/mayunmeiyouming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
|
||||
[2]: https://mate-desktop.org/
|
||||
[3]: https://mate-desktop.org/install/
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://en.wikipedia.org/wiki/OpenSolaris
|
||||
[6]: https://www.openindiana.org/documentation/faq/#what-is-openindiana
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-mate-openindiana_675px.jpg (Mate on OpenIndiana)
|
||||
@ -1,20 +1,22 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11706-1.html)
|
||||
[#]: subject: (Get started with Lumina for your Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-lumina-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 Linux 桌面中开始使用 Lumina
|
||||
======
|
||||
本文是 24 天 Linux 桌面特别系列的一部分。Lumina 是快速、合理的基于 Fluxbox 的快捷方式桌面,它具有你无法缺少的所有功能。
|
||||
![Lightbulb][1]
|
||||
|
||||
多年来,有一个基于 FreeBSD 的桌面操作系统(OS),称为 PC-BSD。它旨在作为一般使用的系统,因此值得注意,因为 BSD 主要用于服务器。大多数时候,PC-BSD 默认带 KDE 桌面,但是 KDE 越来越依赖于 Linux 特定的技术,因此有越来越多的 PC-BSD 从中迁移出来。PC-BSD 变成了 [Trident][2],它的默认桌面是 [Lumina][3],它是一组小部件,它们使用与 KDE 相同的基于 Qt 的工具箱,运行在 Fluxbox 窗口管理器中。
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。Lumina 桌面是让你使用快速、合理的基于 Fluxbox 桌面的捷径,它具有你无法缺少的所有功能。
|
||||
|
||||
你可以在 Linux 发行版的软件仓库或 BSD 的 port 树中找到 Lumina 桌面。如果你安装了 Lumina 并且已经在运行另一个桌面,那么你可能会发现有冗余的应用(两个 PDF 阅读器、两个文件管理器,等等),因为 Lumina 包含一些集成的应用。如果你只想尝试 Lumina 桌面,那么可以在虚拟机如 [GNOME Boxes][4] 中安装基于 Lumina 的 BSD 发行版。
|
||||
|
||||
|
||||
多年来,有一个名为 PC-BSD 的基于 FreeBSD 的桌面操作系统(OS)。它旨在作为一个常规使用的系统,因此值得注意,因为 BSD 主要用于服务器。大多数时候,PC-BSD 默认带 KDE 桌面,但是 KDE 越来越依赖于 Linux 特定的技术,因此 PC-BSD 越来越从 KDE 迁离。PC-BSD 变成了 [Trident][2],它的默认桌面是 [Lumina][3],它是一组小部件,它们使用与 KDE 相同的基于 Qt 的工具包,运行在 Fluxbox 窗口管理器上。
|
||||
|
||||
你可以在 Linux 发行版的软件仓库或 BSD 的 ports 树中找到 Lumina 桌面。如果你安装了 Lumina 并且已经在运行另一个桌面,那么你可能会发现有冗余的应用(两个 PDF 阅读器、两个文件管理器,等等),因为 Lumina 包含一些集成的应用。如果你只想尝试 Lumina 桌面,那么可以在虚拟机如 [GNOME Boxes][4] 中安装基于 Lumina 的 BSD 发行版。
|
||||
|
||||
如果在当前的操作系统上安装 Lumina,那么必须注销当前的桌面会话,才能登录到新的会话。默认情况下,会话管理器(SDDM、GDM、LightDM 或 XDM,取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该桌面。
|
||||
|
||||
@ -34,13 +36,13 @@ Lumina 提供了一个简单而轻巧的桌面环境。屏幕底部有一个面
|
||||
|
||||
![Lumina desktop running on Project Trident][7]
|
||||
|
||||
Lumina 与几个 Linux 轻量级桌面非常相似,尤其是 LXQT,不同之处在于 Lumina 完全不依赖于基于 Linux 的桌面框架,例如 ConsoleKit、PolicyKit、D-Bus 或 systemd。对于你而言,这是否具有优势取决于所运行的操作系统。毕竟,如果你运行的是可以访问这些功能的 Linux,那么使用不使用这些特性的桌面可能就没有多大意义,还会减少功能。如果你运行的是 BSD,那么在 Fluxbox 中运行 Lumina 部件意味着你不必从 port 安装 Linux 兼容库。
|
||||
Lumina 与几个 Linux 轻量级桌面非常相似,尤其是 LXQT,不同之处在于 Lumina 完全不依赖于基于 Linux 的桌面框架(例如 ConsoleKit、PolicyKit、D-Bus 或 systemd)。对于你而言,这是否具有优势取决于所运行的操作系统。毕竟,如果你运行的是可以访问这些功能的 Linux,那么使用不使用这些特性的桌面可能就没有多大意义,还会减少功能。如果你运行的是 BSD,那么在 Fluxbox 中运行 Lumina 部件意味着你不必从 ports 安装 Linux 兼容库。
|
||||
|
||||
### 为什么要使用 Lumina
|
||||
|
||||
Lumina 设计简单,没有很多功能,你无法通过安装 Fluxbox 以及自己喜欢的组件来实现([PCManFM][8] 用于文件管理、各种 [LXQt 应用][9 ]、[Tint2][10] 面板等)。但它是开源的,开源用户喜欢寻找避免重复发明轮子的方法(几乎与我们喜欢重新发明轮子一样多)。
|
||||
Lumina 设计简单,它没有很多功能,但是你可以安装 Fluxbox 你喜欢的组件(用于文件管理的 [PCManFM][8]、各种 [LXQt 应用][9]、[Tint2][10] 面板等)。在开源中,开源用户喜欢寻找不要重复发明轮子的方法(几乎与我们喜欢重新发明轮子一样多)。
|
||||
|
||||
Lumina 桌面是快速而合理的基于 Fluxbox 的桌面快捷方式,它具有你无法缺少的所有功能,并且你很少需要调整细节。试一试 Lumina 桌面,看看它是否适合你。
|
||||
Lumina 桌面是让你使用快速、合理的基于 Fluxbox 桌面的捷径,它具有你无法缺少的所有功能,并且你很少需要调整细节。试一试 Lumina 桌面,看看它是否适合你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -49,7 +51,7 @@ via: https://opensource.com/article/19/12/linux-lumina-desktop
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (2020 technology must haves, a guide to Kubernetes etcd, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/12/gartner-ectd-and-more-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
2020 technology must haves, a guide to Kubernetes etcd, and more industry trends
|
||||
======
|
||||
A weekly look at open source community, market, and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [Gartner's top 10 infrastructure and operations trends for 2020][2]
|
||||
|
||||
> “The vast majority of organisations that do not adopt a shared self-service platform approach will find that their DevOps initiatives simply do not scale,” said Winser. "Adopting a shared platform approach enables product teams to draw from an I&O digital toolbox of possibilities, while benefiting from high standards of governance and efficiency needed for scale."
|
||||
|
||||
**The impact**: The breakneck change of technology development and adoption will not slow down next year, as the things you've been reading about for the last two years become things you have to figure out to deal with every day.
|
||||
|
||||
## [A guide to Kubernetes etcd: All you need to know to set up etcd clusters][3]
|
||||
|
||||
> Etcd is a distributed reliable key-value store which is simple, fast and secure. It acts like a backend service discovery and database, runs on different servers in Kubernetes clusters at the same time to monitor changes in clusters and to store state/configuration data that should to be accessed by a Kubernetes master or clusters. Additionally, etcd allows Kubernetes master to support discovery service so that deployed application can declare their availability for inclusion in service.
|
||||
|
||||
**The impact**: This is actually way more than I needed to know about setting up etcd clusters, but now I have a mental model of what that could look like, and you can too.
|
||||
|
||||
## [How the open source model could fuel the future of digital marketing][4]
|
||||
|
||||
> In other words, the broad adoption of open source culture has the power to completely invert the traditional marketing funnel. In the future, prospective customers could be first introduced to “late funnel” materials and then buy into the broader narrative — a complete reversal of how traditional marketing approaches decision-makers today.
|
||||
|
||||
**The impact**: The SEO on this cuts two ways: It can introduce uninitiated marketing people to open source and uninitiated technical people to the ways that technology actually gets adopted. Neat!
|
||||
|
||||
## [Kubernetes integrates interoperability, storage, waits on sidecars][5]
|
||||
|
||||
> In a [recent interview][6], Lachlan Evenson, and was also a lead on the Kubernetes 1.16 release, said sidecar containers was one of the features that team was a “little disappointed” it could not include in their release.
|
||||
>
|
||||
> Guinevere Saenger, software engineer at GitHub and lead for the 1.17 release team, explained that sidecar containers gained increased focus “about a month ago,” and that its implementation “changes the pod spec, so this is a change that affects a lot of areas and needs to be handled with care.” She noted that it did move closer to completion and “will again be prioritized for 1.18.”
|
||||
|
||||
**The impact**: You can read between the lines to understand a lot more about the Kubernetes sausage-making process. It's got governance, tradeoffs, themes, and timeframes; all the stuff that is often invisible to consumers of a project.
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/gartner-ectd-and-more-industry-trends
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://www.information-age.com/gartner-top-10-infrastructure-and-operations-trends-2020-123486509/
|
||||
[3]: https://superuser.openstack.org/articles/a-guide-to-kubernetes-etcd-all-you-need-to-know-to-set-up-etcd-clusters/
|
||||
[4]: https://www.forbes.com/sites/forbescommunicationscouncil/2019/11/19/how-the-open-source-model-could-fuel-the-future-of-digital-marketing/#71b602fb20a5
|
||||
[5]: https://www.sdxcentral.com/articles/news/kubernetes-integrates-interoperability-storage-waits-on-sidecars/2019/12/
|
||||
[6]: https://kubernetes.io/blog/2019/12/06/when-youre-in-the-release-team-youre-family-the-kubernetes-1.16-release-interview/
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Mint 19.3 “Tricia” Released: Here’s What’s New and How to Get it)
|
||||
[#]: via: (https://itsfoss.com/linux-mint-19-3/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Linux Mint 19.3 “Tricia” Released: Here’s What’s New and How to Get it
|
||||
======
|
||||
|
||||
_**Linux Mint 19.3 “Tricia” has been released. See what’s new in it and learn how to upgrade to Linux Mint 19.3.**_
|
||||
|
||||
The Linux Mint team finally announced the release of Linux Mint 19.3 codenamed ‘Tricia’ with useful feature additions along with a ton of improvements under-the-hood.
|
||||
|
||||
This is a point release based on the latest **Ubuntu 18.04.3** and it comes packed with the **Linux kernel 5.0**.
|
||||
|
||||
I downloaded and quickly tested the edition featuring the [Cinnamon 4.4][1] desktop environment. You may also try the Xfce or MATE edition of Linux Mint 19.3.
|
||||
|
||||
### Linux Mint 19.3: What’s New?
|
||||
|
||||
![Linux Mint 19 3 Desktop][2]
|
||||
|
||||
While being an LTS release that will be supported until 2023 – it brings in a couple of useful features and improvements. Let me highlight some of them for you.
|
||||
|
||||
#### System Reports
|
||||
|
||||
![][3]
|
||||
|
||||
Right after installing Linux Mint 19.3 (or upgrading it), you will notice a warning icon on the right side of the panel (taskbar).
|
||||
|
||||
When you click on it, you should be displayed a list of potential issues that you can take care of to ensure the best out of Linux Mint experience.
|
||||
|
||||
For starters, it will suggest that you should create a root password, install a language pack, or update software packages – in the form of a warning. This is particularly useful to make sure that you perform important actions even after following the first set of steps on the welcome screen.
|
||||
|
||||
#### Improved Language Settings
|
||||
|
||||
Along with the ability to install/set a language, you will also get the ability to change the time format.
|
||||
|
||||
So, the language settings are now more useful than ever before.
|
||||
|
||||
#### HiDPI Support
|
||||
|
||||
As a result of [HiDPI][4] support, the system tray icons will look crisp and overall, you should get a pleasant user experience on a high-res display.
|
||||
|
||||
#### New Applications
|
||||
|
||||
![Linux Mint Drawing App][5]
|
||||
|
||||
With the new release, you will n longer find “**GIMP**” pre-installed.
|
||||
|
||||
Even though GIMP is a powerful utility, they decided to add a simpler “**Drawing**” app to let users to easily crop/resize images while being able to tweak it a little.
|
||||
|
||||
Also, **Gnote** replaces **Tomboy** as the default note-taking application on Linux Mint 19.3
|
||||
|
||||
In addition to both these replacements, Celluloid video player has also been added instead of Xplayer. In case you did not know, Celluloid happens to be one of the [best open source video players][6] for Linux.
|
||||
|
||||
#### Cinnamon 4.4 Desktop
|
||||
|
||||
![Cinnamon 4 4 Desktop][7]
|
||||
|
||||
In my case, the new Cinnamon 4.4 desktop experience introduces a couple of new abilities like adjusting/tweaking the panel zones individually as you can see in the screenshot above.
|
||||
|
||||
#### Other Improvements
|
||||
|
||||
There are several other improvements including more customizability options in the file manager and so on.
|
||||
|
||||
You can read more about the detailed changes in the [official release notes][8].
|
||||
|
||||
[Subscribe to our YouTube channel for more Linux videos][9]
|
||||
|
||||
### Linux Mint 19 vs 19.1 vs 19.2 vs 19.3: What’s the difference?
|
||||
|
||||
You probably already know that Linux Mint releases are based on Ubuntu long term support releases. Linux Mint 19 series is based on Ubuntu 18.04 LTS.
|
||||
|
||||
Ubuntu LTS releases get ‘point releases’ on the interval of a few months. Point release basically consists of bug fixes and security updates that have been pushed since the last release of the LTS version. This is similar to the Service Pack concept in Windows XP if you remember it.
|
||||
|
||||
If you are going to download Ubuntu 18.04 which was released in April 2018 in 2019, you’ll get Ubuntu 18.04.2. The ISO image of 18.04.2 will consist of 18.04 and the bug fixes and security updates applied till 18.04.2. Imagine if there were no point releases, then right after [installing Ubuntu 18.04][10], you’ll have to install a few gigabytes of system updates. Not very convenient, right?
|
||||
|
||||
But Linux Mint has it slightly different. Linux Mint has a major release based on Ubuntu LTS release and then it has three minor releases based on Ubuntu LTS point releases.
|
||||
|
||||
Mint 19 was based on Ubuntu 18.04, 19.1 was based on 18.04.1 and Mint 19.2 is based on Ubuntu 18.04.2. Similarly, Mint 19.3 is based on Ubuntu 18.04.3. It is worth noting that all Mint 19.x releases are long term support releases and will get security updates till 2023.
|
||||
|
||||
Now, if you are using Ubuntu 18.04 and keep your system updated, you’ll automatically get updated to 18.04.1, 18.04.2 etc. That’s not the case in Linux Mint.
|
||||
|
||||
Linux Mint minor releases also consist of _feature changes_ along with bug fixes and security updates and this is the reason why updating Linux Mint 19 won’t automatically put you on 19.1.
|
||||
|
||||
Linux Mint gives you the option if you want the new features or not. For example, Mint 19.3 has Cinnamon 4.4 and several other visual changes. If you are happy with the existing features, you can stay on Mint 19.2. You’ll still get the necessary security and maintenance updates on Mint 19.2 till 2023.
|
||||
|
||||
Now that you understand the concept of minor releases and want the latest minor release, let’s see how to upgrade to Mint 19.3.
|
||||
|
||||
### Linux Mint 19.3: How to Upgrade?
|
||||
|
||||
No matter whether you have Linux Mint 19.1 or 19, you can follow these steps to [upgrade Linux Mint version][11].
|
||||
|
||||
**Note**: _You should consider making a system snapshot (just in case) for backup. In addition, the Linux Mint team advises you to disable the screensaver and upgrade Cinnamon spices (if installed) from the System settings._
|
||||
|
||||
![][12]
|
||||
|
||||
1. Launch the Update Manager.
|
||||
2. Now, refresh it to load up the latest available updates (or you can change the mirror if you want).
|
||||
3. Once done, simply click on the Edit button to find “**Upgrade to Linux Mint 19.3 Tricia**” button similar to the image above.
|
||||
4. Finally, just follow the on-screen instructions to easily update it.
|
||||
|
||||
|
||||
|
||||
Based on your internet connection, it should take anything between a couple of minutes to 30 minutes.
|
||||
|
||||
### Don’t see Mint 19.3 update yet? Here’s what you can do
|
||||
|
||||
If you don’t see the option to upgrade to Linux Mint 19.3 Tricia, don’t lose hope. Here are a couple of things you can do.
|
||||
|
||||
#### **Step 1: Make sure to use mint-upgrade-info version 1.1.3**
|
||||
|
||||
Make sure that mint-upgrade-info is updated to version 1.1.3. You can try the install command that will update it to a newer version (if there is any).
|
||||
|
||||
```
|
||||
sudo apt install mint-upgrade-info
|
||||
```
|
||||
|
||||
#### **Step 2: Switch to default software sources**
|
||||
|
||||
Chances are that you are using a mirror closer to you to get faster software downloads. But this could cause a problem as the mirrors might not have the new upgrade info yet.
|
||||
|
||||
Go to Software Source and change the sources to default. Now run the update manager again and see if Mint 19.3 upgrade is available.
|
||||
|
||||
### Download Linux Mint 19.3 ‘Tricia’
|
||||
|
||||
If you want to perform a fresh install, you can easily download the latest available version from the official download page (depending on what edition you want).
|
||||
|
||||
You will also find multiple mirrors available to download the ISOs – feel free to try the nearest mirror for potentially faster download.
|
||||
|
||||
[Linux Mint 19.3][13]
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
Have you tried Linux Mint 19.3 yet? Let me know your thoughts in the comments down below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-mint-19-3/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/linuxmint/cinnamon/releases/tag/4.4.0
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/linux-mint-19-3-desktop.jpg?ssl=1
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/linux-mint-system-report.jpg?ssl=1
|
||||
[4]: https://wiki.archlinux.org/index.php/HiDPI
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/linux-mint-drawing-app.jpg?ssl=1
|
||||
[6]: https://itsfoss.com/video-players-linux/
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/cinnamon-4-4-desktop.jpg?ssl=1
|
||||
[8]: https://linuxmint.com/rel_tricia_cinnamon.php
|
||||
[9]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[10]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[11]: https://itsfoss.com/upgrade-linux-mint-version/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/mintupgrade.png?ssl=1
|
||||
[13]: https://linuxmint.com/download.php
|
||||
@ -0,0 +1,76 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Eliminating gender bias in open source software development, a database of microbes, and more open source news)
|
||||
[#]: via: (https://opensource.com/article/19/12/news-december-21)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
Eliminating gender bias in open source software development, a database of microbes, and more open source news
|
||||
======
|
||||
Catch up on the biggest open source headlines from the past two weeks.
|
||||
![Weekly news roundup with TV][1]
|
||||
|
||||
In this edition of our open source news roundup, we take a look at eliminating gender bias in open source software development, an open source database of microbes, an open source index for cooperatives, and more!
|
||||
|
||||
### Eliminating gender bias from open source development
|
||||
|
||||
It's a sad fact that certain groups, among them women, are woefully underrepresented in open source projects. It's like a bug in the open source development process. Fortunately, there are initiatives to make that under representation a thing of the past. A study out of Oregon State University (OSU) intends to resolve the issue of the lack of women in open source development by "[finding these bugs and proposing redesigns around them][2], leading to more gender-inclusive tools used by software developers."
|
||||
|
||||
The study will look at tools commonly used in open source development — including Eclipse, GitHub, and Hudson — to determine if they "significantly discourage newcomers, especially women, from joining OSS projects." According to Igor Steinmacher, one of the principal investigators of the study, the study will examine "how people use tools because the 'bugs' may be embedded in how the tool was designed, which may place people with different cognitive styles at a disadvantage."
|
||||
|
||||
The developers of the tools being studied will walk through their software and answer questions based on specific personas. The researchers at OSU will suggest ways to redesign the software to eliminate gender bias and will "create a list of best practices for fixing gender-bias bugs in both products and processes."
|
||||
|
||||
### Canadian university compiles open source microbial database
|
||||
|
||||
What do you do when you have a vast amount of data but no way to effectively search and build upon it? You turn it into a database, of course. That's what researchers at Simon Fraser University in British Columbia, along with collaborators from around the globe, did with [information about chemical compounds created by bacteria and fungi][3]. Called the Natural Products Atlas, the database "holds information on nearly 25,000 natural compounds and serves as a knowledge base and repository for the global scientific community."
|
||||
|
||||
Licensed under a Creative Commons Attribution 4.0 International License, the Natural Products Atlas "holds information on nearly 25,000 natural compounds and serves as a knowledge base and repository for the global scientific community." The [website for the Natural Products Atlas][4] hosts the database also includes a number of visualization tools and is fully searchable.
|
||||
|
||||
Roger Linington, an associate professor at SFU who spearheaded the creation of the database, said that having "all the available data in one place and in a standardized format means we can now index natural compounds for anyone to freely access and learn more about."
|
||||
|
||||
### Open source index for cooperatives
|
||||
|
||||
Europe has long been a hotbed of both open source development and open source adoption. While European governments strongly advocate open source, non profits have been following suit. One of those is Cooperatives Europe, which is developing "[open source software to allow users to index co-op information and resources in a standardised way][5]."
|
||||
|
||||
The idea behind the software, called Coop Starter, reinforces the [essential freedoms of free software][6]: it's intended to provide "education, training and information. The software may be used and repurposed by the public for their own needs and on their own infrastructure." Anyone can use it "to reference existing material on co-operative entrepreneurship" and can contribute "by sharing resources and information."
|
||||
|
||||
The [code for Coop Starter][7], along with a related WordPress plugin, is available from Cooperative Europe's GitLab repository.
|
||||
|
||||
#### In other news
|
||||
|
||||
* [Nancy recognised as France’s top digital free and collaborative public service][8]
|
||||
* [Open Source and AI: Ready for primetime in government?][9]
|
||||
* [Open Software Means Kinder Science][10]
|
||||
* [New Open-Source CoE to be launched by Wipro and Oman’s Ministry of Tech & Communication][11]
|
||||
|
||||
|
||||
|
||||
_Thanks, as always, to Opensource.com staff members and [Correspondents][12] for their help this week._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/news-december-21
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
|
||||
[2]: https://techxplore.com/news/2019-12-professors-gender-biased-bugs-open-source-software.html
|
||||
[3]: https://www.sfu.ca/sfunews/stories/2019/12/sfu-global-collaboration-creates-world-s-first-open-source-datab.html
|
||||
[4]: https://www.npatlas.org/joomla/
|
||||
[5]: https://www.thenews.coop/144412/sector/regional-organisations/cooperatives-europe-builds-open-source-index-for-the-co-op-movement/
|
||||
[6]: https://www.gnu.org/philosophy/free-sw.en.html
|
||||
[7]: https://git.happy-dev.fr/startinblox/applications/coop-starter
|
||||
[8]: https://joinup.ec.europa.eu/collection/open-source-observatory-osor/news/territoire-numerique-libre
|
||||
[9]: https://federalnewsnetwork.com/commentary/2019/12/open-source-and-ai-ready-for-primetime-in-government/
|
||||
[10]: https://blogs.scientificamerican.com/observations/open-software-means-kinder-science/
|
||||
[11]: https://www.indianweb2.com/2019/12/11/new-open-source-coe-to-be-launched-by-wipro-and-omans-ministry-of-tech-communication/
|
||||
[12]: https://opensource.com/correspondent-program
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Space-data-as-a-service prepares to take off)
|
||||
[#]: via: (https://www.networkworld.com/article/3489484/space-data-as-a-service-prepares-to-take-off.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Space-data-as-a-service prepares to take off
|
||||
======
|
||||
Development of IoT services in space will require ruggedized edge computing. OrbitsEdge, a vendor has announced a deal with HPE for development.
|
||||
REUTERS/Joe Skipper/File Photo
|
||||
|
||||
Upcoming space commercialization will require hardened edge-computing environments in a small footprint with robust links back to Earth, says vendor [OrbitsEdge][1], which recently announced that it had started collaborating with Hewlett Packard Enterprise on computing-in-orbit solutions.
|
||||
|
||||
OrbitsEdge says it’s the first to provide a commercial [data-center][2] environment for installing in orbit, and will be using HPE’s Edgeline Converged Edge System in a hardened, satellite [micro-data-center][3] platform that it’s selling called SatFrame.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][4]
|
||||
|
||||
The idea is “to run analytics such as artificial intelligence (AI) on the vast amounts of data that will be created as space is commercialized,” says Barbara Stinnett, CEO of OrbitsEdge, in a [press release][5].
|
||||
|
||||
[][6]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][6]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
### Why data in space?
|
||||
|
||||
[IoT][7] data collection along with analysis and experimental testing are two examples of space industrialization that the company gives as use cases for its micro-data center product. However, commercial use of space also includes imagery, communications, weather forecasting and navigation. Space tourism and commercial recovery of space resources, such as mined raw materials from asteroids are likely to be future space-uses, too.
|
||||
|
||||
Also, manufacturing – taking advantage of vacuums and zero-gravity environments – is among the economic activities that could take advantage of number crunching in orbit.
|
||||
|
||||
Additionally, [Cloud Constellation Corp., a company I wrote about in 2017, unrelated to OrbitsEdge or HPE, reckons highly sensitive data should be stored isolated][8] [in][8] [space][8]. That would be the “ultimate air-gap security,” it describes its [SpaceBelt][9] product.
|
||||
|
||||
### Why edge in space?
|
||||
|
||||
OrbitsEdge believes that data must be processed where it is collected, in space, in order to reduce transmission bottlenecks as streams are piped back to Earth stations. “Due to the new wave of low-cost commercial space activity, the bottleneck will get worse,” the company explains on its website.
|
||||
|
||||
What it means is that getting satellites into space is now cheap and is getting cheaper (due primarily to reusable rocket technology), but that there’s a problem getting the information back to traditional cloud environments on the surface of the Earth; there’s not enough backhaul data capacity, and that increases processing costs. Therefore, the cloud needs to move to the data-collection point: It’s “IoT above the cloud,” ObitsEdge cleverly taglines.
|
||||
|
||||
### How it works
|
||||
|
||||
Satellite-mounted solar arrays collect power from the sun. They fill batteries to be used when the satellite is in the shadow of Earth.
|
||||
|
||||
Cooling- and radiation-shielding protect a standard 5U, 19-inch server rack. There’s a separate rack for the avionics. Then integrated, traditional space-to-space, and space-to-ground radio communications handle the comms. Future-proofing is also considered: laser data pipes, too, could be supported, the company says.
|
||||
|
||||
#### On Earth option
|
||||
|
||||
Interestingly, the company is also pitching its no-maintenance, low Earth orbit (LEO)-geared product as being suitable for terrestrial extreme environments, too. OrbitsEdge claims that SatFrame is robust enough for extreme chemical and temperature environments on Earth. Upselling, it also says that one could combine two micro-data centers: a LEO SatFrame running HPE’s Edgeline, communicating with another one in an extreme on-Earth location—one at the Poles, maybe.
|
||||
|
||||
“To keep up with the rate of change and the number of satellites being launched into low Earth orbit, new services have to be made available,” OrbitsEdge says. “Shipping data back to terrestrial clouds is impractical, however today it is the only choice,” it says.
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489484/space-data-as-a-service-prepares-to-take-off.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://orbitsedge.com/
|
||||
[2]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[3]: https://www.networkworld.com/article/3445382/10-hot-micro-data-center-startups-to-watch.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://orbitsedge.com/press-releases/f/orbitsedge-oem-agreement-with-hewlett-packard-enterprise
|
||||
[6]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[7]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||
[8]: https://www.networkworld.com/article/3200242/data-should-be-stored-data-in-space-firm-says.html
|
||||
[9]: http://spacebelt.com/
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How open source eases the shift to a hybrid cloud strategy)
|
||||
[#]: via: (https://opensource.com/article/19/12/open-source-hybrid-cloud)
|
||||
[#]: author: (Bart Copeland https://opensource.com/users/bartcopeland)
|
||||
|
||||
How open source eases the shift to a hybrid cloud strategy
|
||||
======
|
||||
Open source software is key to adopting a multicloud or hybrid cloud
|
||||
strategy.
|
||||
![Person on top of a mountain, arm raise][1]
|
||||
|
||||
Cloud adoption continues to grow as organizations seek to move away from legacy and monolithic strategies. Cloud-specific spending is expected to grow at more than six times the rate of general IT spending through 2020, according to [McKinsey Research][2]. But cloud adoption raises fear of [vendor lock-in][3], which is preventing many companies from going all-in on public cloud. This has led to a rise in multi-cloud and hybrid cloud deployments, which also have their challenges.
|
||||
|
||||
Open source technology is the key to unlocking the value in a hybrid and multi-cloud strategy.
|
||||
|
||||
### What's the appeal of a hybrid cloud strategy?
|
||||
|
||||
The hybrid cloud market is growing rapidly because it offers the benefits of the cloud without some of the drawbacks. It typically costs less to move storage to the cloud than it does to maintain a private data center. At the same time, there are certain mission-critical applications and/or sensitive data that an organization may still want to keep on-premise, which is why hybrid cloud–a mix of private and public, on-prem and off-prem–is appealing.
|
||||
|
||||
This is why [58 percent of enterprises][4] have a hybrid cloud strategy, according to the Rightscale State of the Cloud 2019 report. It is also why IBM acquired Red Hat for the kingly sum of $34 billion. IBM CEO Ginni Rometty noted at the time that hybrid cloud is a $1 trillion market and that IBM’s goal is to be number one in that market.
|
||||
|
||||
### Common challenges of moving to a hybrid cloud strategy
|
||||
|
||||
One challenge is the lack of a strategic plan. According to [McKinsey Research][2], many companies fall into the trap of thinking that simply moving IT systems to the cloud is equivalent to a transformational digital strategy. The "lift and shift" approach is not enough to enjoy all the benefits of the cloud, though.
|
||||
|
||||
Cybersecurity applications provide a good case in point. The traditional perimeter approach to security won’t translate well to the cloud, whose approach must be quite different since a cloud perimeter is nearly impossible to define. If organizations are relying on legacy perimeter security to keep their holdings in the cloud safe, they are in for a nasty surprise.
|
||||
|
||||
Another challenge to effective cloud migration is the status quo. For many companies, it comes down to the mindset of "If it’s not broken, why fix it? If it works fine as it is, why move it?" While many organizations understand the need for and benefits of having newer applications in the cloud, it’s not always obvious whether it also makes sense to move legacy applications over, too. In the case of cybersecurity, it very well may not be, but other applications may be best served with a move to the cloud.
|
||||
|
||||
To further complicate matters, public cloud providers like Microsoft Azure, Google Cloud, and AWS [are not immune to outages][5]. Whatever the reason for downtime–a database glitch, bad weather, overzealous security features–being able to share workloads across clouds can be key in the event of an outage.
|
||||
|
||||
### Bringing it all together with open source
|
||||
|
||||
Hybrid cloud and open source go hand-in-hand. In fact, many of the public cloud providers rely heavily on different open source technologies and technology stacks to run them, so open source can be used easily across both private and public clouds in most situations. Companies like [Red Hat][6], in fact, were built on the concept of facilitating hybrid cloud. Many of its customers are moving toward an open hybrid cloud strategy.
|
||||
|
||||
This is, in part, because open source provides flexibility and helps avoid the issues of cloud vendor lock-in. In addition, open source technologies bring breadth and depth for managers and developers alike; they give developers the tools they enjoy using.
|
||||
|
||||
Though the cloud market is growing quickly, it is not without its limitations and drawbacks. The majority of enterprises have what they call a hybrid cloud strategy, but it may be less strategic than they think since the "lift and shift" approach falls short. Mindsets need to shift as well to overcome the status quo, and organizations need to guard against cloud outages.
|
||||
|
||||
Vital to a multi-cloud approach is managing distributed workloads. Modern software architecture methodologies break monolithic applications into microservices that can be run wherever it makes sense–on-premise, in the cloud, or across both. By leveraging open source technologies from Linux to containers to Kubernetes, organizations can deploy, run and manage workloads in a secure and optimized manner. This kind of open source approach allows organizations to derive benefits far beyond just "lift and shift" in order to become more efficient, run their processes more cost-effectively, and adopt a more flexible operating model.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/open-source-hybrid-cloud
|
||||
|
||||
作者:[Bart Copeland][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bartcopeland
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/developer_mountain_cloud_top_strong_win.jpg?itok=axK3EX-q (Person on top of a mountain, arm raise)
|
||||
[2]: https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/cloud-adoption-to-accelerate-it-modernization
|
||||
[3]: https://searchconvergedinfrastructure.techtarget.com/definition/vendor-lock-in
|
||||
[4]: https://www.flexera.com/about-us/press-center/rightscale-2019-state-of-the-cloud-report-from-flexera-identifies-cloud-adoption-trends.html
|
||||
[5]: https://www.crn.com/slide-shows/cloud/the-10-biggest-cloud-outages-of-2018
|
||||
[6]: https://siliconangle.com/2019/04/12/red-hat-strategy-validated-as-open-hybrid-cloud-goes-mainstream-googlenext19/
|
||||
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (SD-WAN management means more than reviewing logs and parsing events)
|
||||
[#]: via: (https://www.networkworld.com/article/3490333/sd-wan-management-means-more-than-reviewing-logs-and-parsing-events.html)
|
||||
[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
|
||||
|
||||
SD-WAN management means more than reviewing logs and parsing events
|
||||
======
|
||||
Creating a single view of the different types of data requires specialized skills, custom integration and a significant budget. Just look at the SIEM.
|
||||
Getty Images
|
||||
|
||||
By creating a single view of all network data, you can do things better like correlating threat information to identify real attacks or keep a log of packet statistics to better diagnose intermittent networking problems.
|
||||
|
||||
However, to turn data into value with the limitations of traditional systems, we must be creative with the solution. We must find ways to integrate the different repositories in various appliances. It’s not an easy task but an architectural shift that I’ve written about in the past, SASE (Secure Access Service Edge), should help significantly.
|
||||
|
||||
SASE is a new enterprise networking technology category introduced by Gartner in 2019. It represents a change in how we connect our sites, users, and cloud resources.
|
||||
|
||||
[][1]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][1]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
This can be of considerable support, especially when it comes to the challenges faced with SIEM (Security Information and Event Management).
|
||||
|
||||
### Creating a single view is challenging
|
||||
|
||||
Creating a single view of the different types of data requires specialized skills, custom integration, and a significant budget. The SIEM is used to bring data from multiple products, apply rules and orchestrate a variety of platforms to act together. In reality, there is a lot of custom integration involved.
|
||||
|
||||
The questions that surface is; how do logs get into the SIEM when off the network? How do you normalize the data, write the rules to detect for suspicious activity and then investigate if there are legitimate alerts? Unfortunately, the results are terrible for the investment that people make. The SIEM can’t be performed in a small organization. You will need the resources to pull it off.
|
||||
|
||||
### Challenges with the SIEM
|
||||
|
||||
In a previous consultancy role, I experienced first-hand the challenges of running a SIEM. Ultimately, the company had to improve its security monitoring. Like most, they came across the same problem and recognized there was a big gap when it came to detection.
|
||||
|
||||
[The time of 5G is almost here][2]
|
||||
|
||||
When I first came across the potentials of the SIEM, like most, I was thoroughly excited by its hype. Now, there was a tool that allowed me to take my ideas and run them against numerous rich data sets. From these sets, I could get immediately gain insight into threats on the network and act. However, this is far from reality - the SIEM is complex.
|
||||
|
||||
### Different data from different devices
|
||||
|
||||
Both security and networking store and expose data differently. Each of them carries out an individual role and have access to different data. Data can be abstracted from the management, control and data planes to build analytics that can be queried. This results in multiple levels of data available for analysis. Essentially, for this, you need to be an expert in each of these planes.
|
||||
|
||||
Preparing all the data gathered from your entire infrastructure is complicated. Developing a timeline of events requires mastering a range of protocols and APIs just to retrieve the necessary data from networking and security appliances. Therefore, it can be a challenge to find the right data for your problem.
|
||||
|
||||
### First, you need to collect the right data
|
||||
|
||||
Firstly, you need to collect the right data - the SIEM is only as good as the data you feed it with. This emerges the urge for the right data that needs to get loaded to the SIEM. Since the data available with SIEM rules is provided from logs and event data from other software products, the quality of the data comes down to what was first chosen to be logged. This is compounded by the accuracy/availability of the SIEM vendor's connector.
|
||||
|
||||
The data may be fed into the SIEM with Syslog, which requires parsing, loss of data and context from the original source. Evidently, a lot of the times, the SIEM is loaded with useless data. Many often stumble with this first step.
|
||||
|
||||
### Aggregate the data
|
||||
|
||||
When new threats materialize, it’s challenging to gather more data to support the new detection rules. There is also a long lead time associated with collecting new data and putting the brakes on agility. In short, the SIEM requires extensive data collection infrastructure and inter-team collaboration.
|
||||
|
||||
### Normalize the data
|
||||
|
||||
There will also be some kind of normalizing event where the data is cleaned up. Here, data interpretation and normalization technologies are needed to store the event data in a common format for analysis.
|
||||
|
||||
A big claim-to-fame for the SIEM products is that they normalize data input. If you examine a windows security event, there is a big distinction between each of these events. Therefore, it’s recommended not to count on the SIEM products to interpret the inputs they receive.
|
||||
|
||||
### No investigation support
|
||||
|
||||
The SIEM has no investigation support. Hence, once the data is in your SIEM, you must be the one to tell the SIEM what to do with it. It’s like buying an alarm clock without the batteries. Consider an intrusion detection system, we all know that a skilled analyst is required to translate the output into actionable intelligence; a SIEM is no different.
|
||||
|
||||
Typically, the SIEM rules are targeted for detecting the activities of interest rather than investigating them. For example, an event can only tell you that a file was uploaded. However, it tells nothing about what type of site it was uploaded to, where it came from and what the file was.
|
||||
|
||||
This, predominantly, involves investigation between the security analyst and the operations team. Performing the querying and utilizing this information requires specialized skills and knowledge.
|
||||
|
||||
### Deployment/resource-heavy
|
||||
|
||||
A lot of resources are spent to manage SIEM. Time is needed for deploying agents, parsing logs, or performing the upgrade. Concisely, SIEM technology requires 24x7 monitoring and maintenance. By and large, the SIEM takes too long to deploy and some of these stages can even take years to complete. You really need a handful of full-time security analysts to do this. As it stands, there is a worldwide shortage of experienced security analysts.
|
||||
|
||||
### Point solutions address one issue
|
||||
|
||||
The way networking and security have been geared up is that we are sold everything in pieces. We have point solutions that only address one issue. Then there are servers, routers, switches and a variety of security devices. When a device operates within its own domain, it will only see that domain. Therefore, these point solutions need to be integrated so the user can form a picture of what is happening on the network.
|
||||
|
||||
Consider an IDS, it looks at individual packets and tries to ascertain whether there is a threat or not. Practically, it does not have a holistic overall view of what is truly happening in networking. So, when you actually identity there was a problem, you simply don’t have the right information at hand to identify who the user is, what it does and what happened.
|
||||
|
||||
For threat investigation, the user will need to log on to other systems and glue the information. This will result in a high number of false positives in a world that already has alert-fatigue.
|
||||
|
||||
### How SASE can help – a common datastore
|
||||
|
||||
Significantly, SASE converges the functions of both networking and security into a unified and global cloud-native service. Therefore, it pulls data from both the domains into a common data store. There are of course many benefits to this but one of the substantial benefits is troubleshooting.
|
||||
|
||||
SASE vendors could make it very easy to drill deep into the networking and security events that should already be stored and normalized in a common data warehouse. SASE unlocks the potential for super-efficient troubleshooting without the pain of deploying a SIEM.
|
||||
|
||||
A case in point is Cato network’s recent announcement of [Cato Instant*Insight][3]. The new feature to its SASE platform provides a single tool for mining the security and networking event data generated across a customer’s Cato instance. That’s how SASE helps. Profoundly, everything becomes easier when your networking and security data is being gathered by one platform.
|
||||
|
||||
With data pulled together, investigation and analysis become easier. Cato Instant*Insight, for example, organizes the millions of networking and security events tracked by Cato into a single and queryable timeline. Here we have an automated aggregation, faceted search, and a built-in network analysis workbench.
|
||||
|
||||
[Netsurion][4], another SD-WAN vendor, provides a managed SIEM service. This is offered as SOC-as-a-Service. However, with this and other managed SIEMs, there may still be a strong separation between the network domain and a security domain. In the sense that they’re only gathering security data and not network data. Therefore, both NOC and SOC teams have a fragmented view. And the common challenge for the enterprise will still remain.
|
||||
|
||||
With the SIEM, there is no such thing as delivering visibility out-of-the-box. Realistically, it requires extensive custom integration and development. For many companies, SIEMs wasn’t feasible. The integration costs were just too high and too much time was needed to gather baseline data.
|
||||
|
||||
But that’s all premised on a misconception that you continue to build your network from the appliances from different vendors. If you were to replace appliances with a converged cloud infrastructure, then you eliminate much of the challenge of the SIEM.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network. [Want to Join?][5]**
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3490333/sd-wan-management-means-more-than-reviewing-logs-and-parsing-events.html
|
||||
|
||||
作者:[Matt Conran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Matt-Conran/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[2]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[3]: https://www.catonetworks.com/news/it-managers-analyze-1-million-events-in-1-second-at-no-charge-with-cato-instant-insight/
|
||||
[4]: https://www.netsurion.com/solutions/threat-protection
|
||||
[5]: https://www.networkworld.com/contributor-network/signup.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (X factor: Populating the globe with open leaders)
|
||||
[#]: via: (https://opensource.com/open-organization/19/12/open-leaders-x-mozilla)
|
||||
[#]: author: (chadsansing https://opensource.com/users/csansing)
|
||||
|
||||
X factor: Populating the globe with open leaders
|
||||
======
|
||||
Open Leaders X, a growing program supported by Mozilla, aims to
|
||||
cultivate leaders who think and act openly—all over the world.
|
||||
![Leaders are catalysts][1]
|
||||
|
||||
At Mozilla, we think of open leadership as a set of principles, practices, and skills people can use to mobilize their communities to solve shared problems and achieve shared goals. Open leaders design and build projects that empower others to collaborate within inclusive communities.
|
||||
|
||||
[Mozilla's Open Leaders program][2] connects and trains leaders from around the world whose communities can help one another address the challenges and opportunities they face in creating a healthier internet, more trustworthy AI, and better online lives for all.
|
||||
|
||||
### Starting small
|
||||
|
||||
Open Leaders began in 2016 with a face-to-face meeting between dozens of scientists interested in creating more open labs, datasets, methods, and communications. Their passion, questions, and insights helped shape "working open workshops," which quickly developed into an open leadership curriculum reaching hundreds of people online—from all across the open ecosystem.
|
||||
|
||||
What began as a small, collaborative inquiry into the nature and possibilities of open science has become a thriving community of open leaders helping one another infuse their projects and cultures with the principles and practices of openness.
|
||||
|
||||
While [Mozilla staffers][3] have historically organized the program, returning graduates have served as the experts, mentors, and community call co-hosts of each subsequent round of programming, contributing their time and expertise back to the program and its participants. They have also helped us at Mozilla better participate in discussions of engagement, value exchange, sustainability, power-sharing, care, and labor (among many, many other interwoven open topics).
|
||||
|
||||
We are humbled by the notion that a meeting of 25 like-minded people dedicated to opening their practice in science has become a network of hundreds of leaders working to connect their home communities and parts of the open ecosystem—like open art, campaigning, data, education, hardware, government, and software—with the [internet health movement][4] and the push for more [trustworthy AI][5].
|
||||
|
||||
### Growing up
|
||||
|
||||
At Mozilla, we think of open leadership as a set of principles, practices, and skills people can use to mobilize their communities to solve shared problems and achieve shared goals.
|
||||
|
||||
As we tried to think of how best to bring core lessons from the Open Leaders program to the global MozFest community while also sustaining the program, we organized the most recent round of Open Leaders—the last we'll organize for now—as a train-the-trainer program. Working with program graduates, Mozilla staff and fellows, and [leads from 10 different community projects][6], we co-designed Open Leaders X (OLx) to help community members run, connect, and sustain their own open leadership programs. We hoped that by distributing the development and ownership of Open Leaders across the open ecosystem and internet health movement, we could ensure its survival and strengthen its development through community co-ownership. This would allow each program to tailor itself to the needs, challenges, and opportunities each group faces.
|
||||
|
||||
We are so proud of the entire Open Leaders community and especially grateful to our OLx leads and contributors, who took the plunge with us and dove into this new train-the-trainer model. Rather than close the loop on Open Leaders, the decision to make it a community-driven program continues its upward spiral.
|
||||
|
||||
In October, we brought together nearly all 30 of our OLx leads at [MozFest 2019][7], the momentous 10th anniversary of the festival. They launched their programs and issued their calls for applications, as well as their invitations to community members (like you!) to serve as mentors, experts, and guest speakers for each program. In 2020, these 30 leads and their 10 projects will welcome the next 200 open leaders into the community and the internet health movement.
|
||||
|
||||
We look forward to all the new connections we'll make together between these new Open Leaders cohorts and the burgeoning MozFest community. Our goal is to help people across these communities stay connected and engaged with both one another and the open, federated principles and practices of MozFest all year long.
|
||||
|
||||
We can't wait to collaborate, learn together and to discover what's next for Open Leaders, internet health, and more trustworthy AI.
|
||||
|
||||
You are invited to join this work and all of its challenges, learning, and fun! Watch the OLx launch party videos and find links to each program [online][8]!
|
||||
|
||||
You can also check out the [OLx syllabus][9]. You can even look further back at the most recent Open Leaders syllabi from round 7, both the [project track][10] and the [culture track][11]. You can visit [Mozilla Pulse][12], as well, to keep track of each project and [sign up for our newsletter][13] to keep up with our latest programming.
|
||||
|
||||
We hope you'll join the Open Leaders community and visit us at the next MozFest! We can't wait to collaborate, learn together and to discover what's next for Open Leaders, internet health, and more trustworthy AI.
|
||||
|
||||
My theme this week is organizational openness and transparency and today I'd like to highlight a...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/12/open-leaders-x-mozilla
|
||||
|
||||
作者:[chadsansing][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/csansing
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/leaderscatalysts.jpg?itok=f8CwHiKm (Leaders are catalysts)
|
||||
[2]: https://foundation.mozilla.org/en/opportunity/mozilla-open-leaders/
|
||||
[3]: https://foundation.mozilla.org/en/initiatives/open-leadership-events/who-we-are/
|
||||
[4]: https://internethealthreport.org/
|
||||
[5]: https://medium.com/read-write-participate/update-digging-deeper-on-trustworthy-ai-588fcd01a321
|
||||
[6]: https://medium.com/read-write-participate/meet-the-open-leaders-x-cohort-1dc230a4c56a
|
||||
[7]: https://mozillafestival.org
|
||||
[8]: https://foundation.mozilla.org/en/blog/streaming-week-open-leaders-x/
|
||||
[9]: https://docs.google.com/document/d/1rKvMn0uXSoLvOj7t1jEW9JkQePqhGRu37V1YEMeV8Nw/edit
|
||||
[10]: https://docs.google.com/document/d/1G_opVoiO1VXlfjs-xvbbHVaF97jZBE3DH-DWxAEqtT4/edit?usp=sharing
|
||||
[11]: https://docs.google.com/document/d/1dpH_LPZQ2FTUbK1y1tIDrJfYvesFp3Ivwqp1_jju-5E/edit#heading=h.5qlxraoq91j2
|
||||
[12]: https://www.mozillapulse.org/projects?keyword=olx
|
||||
[13]: https://foundation.mozilla.org/en/initiatives/open-leadership-events/
|
||||
135
sources/talk/20191218 Cisco- 5 hot networking trends for 2020.md
Normal file
135
sources/talk/20191218 Cisco- 5 hot networking trends for 2020.md
Normal file
@ -0,0 +1,135 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco: 5 hot networking trends for 2020)
|
||||
[#]: via: (https://www.networkworld.com/article/3505883/cisco-5-hot-networking-trends-for-2020.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco: 5 hot networking trends for 2020
|
||||
======
|
||||
Cisco exec says SD-WAN, Wi-Fi 6, multi-domain control, virtual networking and the evolving role of network engineers will be big in 2020
|
||||
Thinkstock
|
||||
|
||||
[Hot trends][1] in networking for the coming year include [SD-WAN][2], [Wi-Fi 6][3], multi-domain control, virtual networking and the evolving role of the network engineer into that of a network progrmmer, at least according to [Cisco][4].
|
||||
|
||||
They revolve around the changing shape of networking in general, that is the broadening of [data-center][5] operations into the cloud and the implications of that change, said Anand Oswal, senior vice president of engineering in Cisco’s Enterprise Networking Business.
|
||||
|
||||
“These fundamental shifts in where business processes run and how they’re accessed, is changing how we connect our locations together, how we think about security, the economics of networking, and what we ask of the people who take care of them,” Oswal said.
|
||||
|
||||
[][6]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][6]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
[See more predictions about what's big in IT tech for the coming year.][7]
|
||||
|
||||
In [blog][8] outlining the key trends for 2020, Oswal detailed his thoughts about the five areas.
|
||||
|
||||
### Wi-Fi 6 and 5G
|
||||
|
||||
First up, wireless technology – especially Wi-Fi 6 – will get into the enterprise through the employee door and through enterprise access-point refreshes. The latest smartphones from Apple, Samsung, and other manufacturers are Wi-Fi 6 enabled, and Wi-Fi 6 access points are currently shipping to businesses and consumers.
|
||||
|
||||
5G phones are not yet in wide circulation, although that will begin to change in 2020, athough mostly for consumers and towards the end of the year. Oswal wrote that Cisco projects more people will be using Wi-Fi 6 than 5G through 2020.
|
||||
|
||||
2020 will also see the beginning of a big improvement in how people use Wi-Fi networks. The potential growth of the Cisco-lead OpenRoaming project will make joining participating Wi-Fi networks much easier, Oswal said. [OpenRoaming][9], which uses the underlying technology behind HotSpot 2.0/ IEEE 802.11u promises to let users move seamlessly between wireless networks and LTE without interruption -- emulating mobile network connectivity. Current project partners include Samsung, Boingo, and GlobalReach Technologies.
|
||||
|
||||
2020 will also see the adoption of new frequency bands, including the beginning of the rollout of “millimeter wave” (24Ghz to 100Ghz) spectrum for ultra-fast, but short-range 5G as well as Citizens Broadband Radio Service (CBRS), at about 3.5Ghz. This may lead to new _private_ networks that use LTE and 5G technology, especially for IoT applications.
|
||||
|
||||
“We will also see continued progress in opening up the 6GHz range for unlicensed Wi-Fi usage in the United States and the rest of world,” Oswal wrote.
|
||||
|
||||
As for [5G][10] services, some will roll out in 2020 but “almost none of it will be the ultra-high speed connectivity that we have been promised or that we will see in future years,” Oswal said. “With 5G unable to deliver on that promise initially, we will see a lot of high-speed wireless traffic offloaded to Wi-Fi networks.”
|
||||
|
||||
In the long run, “In combination with the improved performance of both Wi-Fi 6 and (eventually) 5G, we are in for a large – and long-lived – period of innovation in access networking,” Oswal wrote.
|
||||
|
||||
### It’s a SD-WAN world
|
||||
|
||||
“We are seeing a ton of momentum in the SD-WAN area as large numbers of companies need secure access to cloud applications,” Oswal said. The dispersal of connectivity – the growth of multicloud networking – will force many businesses to re-tool their networks in favor of SD-WAN technology, he said.
|
||||
|
||||
“Meanwhile the large cloud service providers, like [Amazon, Google, and Microsoft][1], are connecting to networking companies – like Cisco – to forge deep partnership links between networking stacks and services,” Oswal wrote.
|
||||
|
||||
Oswal said he expects such partnerships will only deepen next year, and that concurs with recent analysis by Gartner.
|
||||
|
||||
“SD-WAN is replacing routing and adding application-aware path selection among multiple links, centralized orchestration and native security, as well as other functions. Consequently, it includes incumbent and emerging vendors from multiple markets (namely routing, security, WAN optimization and SD-WAN), each bringing its own differentiators and limitations,” [Gartner wrote][11] in a recent report.
|
||||
|
||||
In addition Oswal said SD-WAN technology is going to lead to a growth in business for managed service providers (MSPs), many more of which will begin to offer SD-WAN as a service.
|
||||
|
||||
“We expect MSPs to grow at about double the rate of the SD-WAN market itself, and expect that MSPs will begin to hyper-specialize, by industry and network size,” Oswal wrote.
|
||||
|
||||
### All-inclusive multi-domain networks
|
||||
|
||||
In the Cisco world, blending typically siloed domains across the enterprise and cloud to the wide-area network is getting easier, and Oswal says that will continue in 2020. The idea is that its key software components – [Application Centric Infrastructure (ACI) and DNA Center][12] – now enable what Cisco calls multidomain integration, which lets customers set policies to apply uniform access controls to users, devices and applications regardless of where they connect to the network.
|
||||
|
||||
ACI is [Cisco’s software-defined networking][13] ([SDN][13]) data-center package, but it also delivers the company’s intent-based networking technology, which brings customers the ability to automatically implement network and policy changes on the fly and ensure data delivery.
|
||||
|
||||
DNA Center is a key package as it features automation capabilities, assurance setting, fabric provisioning and policy-based segmentation for enterprise networks. Cisco DNA Center gives IT teams the ability to control access through policies using software-defined access (SD-Access), automatically provision through Cisco DNA Automation, virtualize devices through Cisco Network Functions Virtualization (NFV), and lower security risks through segmentation and encrypted traffic analysis.
|
||||
|
||||
“For better management, agility, and especially for security, these multiple domains need to work together,” Oswal wrote. “Each domain’s controller needs to work in a coordinated manner to enable automation, analytics and security across the various domains.”
|
||||
|
||||
The next generation of controller-first architectures for network fabrics allows the unified management of loosely coupled systems using APIs and defined data structures for inter-device and inter-domain communication, Oswal wrote. “The intent-based networking model that enterprises began adopting in 2019 is making network management more straightforward by absorbing the complexities of the network,” he wrote.
|
||||
|
||||
### The network as sensor
|
||||
|
||||
The notion of the [network being used for something more important][14] than speeds and feeds has been talked about for a while, but the idea may be coming home to roost next year.
|
||||
|
||||
“With software that is able to profile and classify the devices, end points, and applications – even when they are sending fully encrypted data – the network will be able to place the devices into virtual networks automatically, enable the correct rule set to protect those devices, and eventually identify security issues extremely quickly,” Oswal wrote.
|
||||
|
||||
“Ultimately, systems will be able to remediate issues on their own, or at least file their own help-desk tickets. This becomes increasingly important as networks grow increasingly complex.”
|
||||
|
||||
Oswal said this intelligence could prove useful in wireless networks where the network can collect data on how people and things move through and use physical spaces, such as IoT devices in a business or medical devices in a hospital.
|
||||
|
||||
“That data can directly help facility owners optimize their physical spaces, for productivity, ease of navigation, or even to improve retail sales,” Oswal wrote. “These are capabilities that have been rolling out in 2019, but as business execs become aware of the power of this location data, the use of this technology will begin to snowball.”
|
||||
|
||||
### The network engineer career change
|
||||
|
||||
The growing software-oriented network environment is changing the resume requirements of network professional. “The standard way that network operators work – provisioning network equipment using command-line interfaces like CLI – is nearing the end of the line,” Oswal wrote. “Today, _intent-based networking_ lets us tell the network what we want it to do, and leave the individual device configuration to the larger system itself.”
|
||||
|
||||
Oswal said customers can now program updates, rollouts, and changes using centralized networking controllers*,* rather than working directly with devices or their own unique interfaces.
|
||||
|
||||
“New networks run by APIs require programming skills to manage,” Oswal wrote. “Code is the resource behind the creation of new business solutions. It remains critical for individuals to validate their proficiency with new infrastructure and network engineering concepts.”
|
||||
|
||||
Oswal noted that it will not be an easy change because retraining individuals or whole teams can be expensive, and not everyone will adapt to the new order.
|
||||
|
||||
“For those that do, the benefits are big,” Oswal said. “Network operators will be closer to the businesses they work for, able to better help businesses achieve their digital transformations. The speed and agility they gain thanks to having a programmable network, plus telemetry and analytics, opens up vast new opportunities.”
|
||||
|
||||
This year [Cisco revamped some of its most critical certification][15] and career-development tools in an effort to address the emerging software-oriented network environment. Perhaps one of the biggest additions is the [new set of professional certifications][16] for developers utilizing Cisco’s growing DevNet developer community.
|
||||
|
||||
The Cisco Certified DevNet Associate, Specialist and Professional certifications will cover software development for applications, automation, DevOps, cloud and IoT. They will also target software developers and network engineers who develop software proficiency to develop applications and automated workflows for operational networks and infrastructure.
|
||||
|
||||
Join the Network World communities on [Facebook][17] and [LinkedIn][18] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3505883/cisco-5-hot-networking-trends-for-2020.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html
|
||||
[2]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[3]: https://www.networkworld.com/article/3258807/what-is-802-11ax-wi-fi-and-what-will-it-mean-for-802-11ac.html
|
||||
[4]: https://www.networkworld.com/article/3487831/what-s-hot-for-cisco-in-2020.html
|
||||
[5]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[6]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[7]: https://www.networkworld.com/article/3488562/whats-big-in-it-tech-for-the-coming-year.html
|
||||
[8]: https://blogs.cisco.com/enterprise/enterprise-networking-in-2020-5-trends-to-watch
|
||||
[9]: https://blogs.cisco.com/wireless/openroaming-seamless-across-wi-fi-6-and-5g?oid=psten016624
|
||||
[10]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[11]: https://www.networkworld.com/article/3489480/secure-sd-wan-the-security-vendors-and-their-sd-wan-offerings.html
|
||||
[12]: https://www.networkworld.com/article/3401523/cisco-software-to-make-networks-smarter-safer-more-manageable.html
|
||||
[13]: https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html
|
||||
[14]: https://www.networkworld.com/article/3400382/cisco-will-use-aiml-to-boost-intent-based-networking.html
|
||||
[15]: https://www.networkworld.com/article/3401524/cisco-launches-a-developer-community-cert-program.html
|
||||
[16]: https://www.networkworld.com/article/3446044/are-new-cisco-certs-too-much-network-pros-react.html
|
||||
[17]: https://www.facebook.com/NetworkWorld/
|
||||
[18]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bamboo Systems redesigns server motherboards for greater performance)
|
||||
[#]: via: (https://www.networkworld.com/article/3490385/bamboo-systems-redesigns-server-motherboards-for-greater-performance.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Bamboo Systems redesigns server motherboards for greater performance
|
||||
======
|
||||
Bamboo Systems, formerly Kaleao, claims its motherboard architecture is more power efficient than traditional designs that cater to x86 processors.
|
||||
Thinkstock
|
||||
|
||||
UK chip designer Kaleao has re-launched as Bamboo Systems with some pre-Series A funding and claims its [Arm][1]-based server chips will be considerably more power efficient than the competition.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][2]
|
||||
|
||||
Bamboo is targeting x86 servers, which have a 95% market share, unlike Marvell with its [ThunderX2][3] and Ampere Systems with its [eMAG Arm processors][4]. The company argues that the two Arm processors are no different than x86.
|
||||
|
||||
“Marvell and Ampere are chip manufacturers that have built a chip to pretty much slot into the motherboard and chassis configuration that an Intel/AMD chip would fit into. They are therefore going head on against Intel/AMD as chip manufacturers – and history is showing, not creating a sustainable solution for the OEMs,” says John Goodacre, co-founder and chief scientific officer of Bamboo.
|
||||
|
||||
[][5]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][5]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
The motherboard is changed, but the CPU and software layer are not. Currently the company is in the prototype stage. Its server is based on Samsung Arm Cortex-A57 design, so the CPU itself is not changed. Even though they have essentially thrown out traditional motherboard design, Goodacre said the software is fully compatible and will run unchanged. So Linux and Arm-based apps will all run.
|
||||
|
||||
Goodacre, a 17-year veteran of Arm and researcher at the University of Manchester working on exascale research projects, said just putting more cores in a die in a workstation designed system isn’t the most power efficient way to build scale out power efficient servers.
|
||||
|
||||
“We realized that the system architecture was where your power was consumed more than instruction set. There have been several Arm chips [in servers] and they show the difference in power efficiency in an Arm gives you a few tens of percent. There is very little power efficiency in Arm over x86,” he said.
|
||||
|
||||
What he noticed was that because of the motherboard and all of its ports, like USB and I/O, a lot of power was wasted on the motherboard resources. Kaleo, now Bamboo, redesigned the whole motherboard where things like I/O and memory are pooled, so doubling the processor count doesn’t require doubling of motherboards.
|
||||
|
||||
This means a shared infrastructure with pooling of non-CPU resources and NVMe to scale up storage. A 3U box can hold up to 192 eight-core servers, 42 U.2 SSDs and 192 directly attached SATA 6 drives.
|
||||
|
||||
“The concept of a motherboard is gone. Instead, you put the infrastructure to support processors. We build clusters of machines on boards where the infrastructure is shared across processor elements,” he said.
|
||||
|
||||
The result, he claims, is the Bamboo system can deliver the same amount of web traffic in 10x less server space for 5x less energy. “One rack of our stuff equals 10 racks of the competition,” said Goodacre.
|
||||
|
||||
Bamboo says it will announce more details in early January.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3490385/bamboo-systems-redesigns-server-motherboards-for-greater-performance.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3306447/a-new-arm-based-server-processor-challenges-for-the-data-center.html
|
||||
[2]: https://www.networkworld.com/newsletters/signup.html
|
||||
[3]: https://www.networkworld.com/article/3271073/cavium-launches-thunderx2-arm-based-server-processors.html
|
||||
[4]: https://www.networkworld.com/article/3482248/ampere-preps-an-80-core-arm-processor-for-the-cloud.html
|
||||
[5]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why We Need Interoperable Service Identity?)
|
||||
[#]: via: (https://www.linux.com/articles/why-we-need-interoperable-identity/)
|
||||
[#]: author: (TC CURRIE https://www.linux.com/author/tc_currie/)
|
||||
|
||||
Why We Need Interoperable Service Identity?
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
Interoperable service identity is necessary to secure communication between different cloud providers and different platforms. This presents a challenge with multi-cloud and hybrid deployments. How do you secure service to service communication across those boundaries?
|
||||
|
||||
Evan Gilman, Staff Engineer at [Scytale.io][3] and co-author of _Zero Trust Networks_, illustrates this issue: when you’re in AWS, you’ll use an AWS IAM role in order to identify which instance a certain role should or should not have access to. But in today’s multi-platform world, you can be communicating from AWS to GCP to your on-prem infrastructure. Those systems do not understand what IAM role is because it is AWS-specific.
|
||||
|
||||
This is what Scytale is trying to address. *“*We are bringing a platform-agnostic identity, meaning, an identity that is not specific to a cloud provider or a platform, or any specific kind of technology,” he said.
|
||||
|
||||
**What’s SPIFFE?**
|
||||
|
||||
[Secure Production Identity Framework for Everyone (SPIFFE)][4] is a set of specifications that define interoperability across all tech platforms, such as how to format the name, the shape of the document, how you validate documents, etc. “This SPIFFE level is like a secure dial tone,” Gilman explains. “You pick up the phone, it rings the other side, doesn’t really matter what platform it is or where it’s running or anything like that. The SPIFFE authentication occurs and you get a nice little layer of encryption and some authenticity insurances as well.”
|
||||
|
||||
But at the end of the day, SPIFFE is just a set of documents. SPIRE is the software implementation of the SPIFFE specifications.
|
||||
|
||||
“Think about the way the passports work,” he said. “If you look at passports from different countries, they may be slightly different, but they have similar characteristics like SPIFFE specifications. They’re all the same size. They all have a picture in the same spot. They have the same funny-looking barcode at the bottom, and so on. So, when you show your passport at a country border, they know how to read your passport, no matter what country that passport is from. SPIRE is the passport agency in this analogy. Where does this passport come from? Who gives it to you? How do you get it and how do you do that in an automated fashion?”
|
||||
|
||||
SPIRE implements these SPIFFE specifications and enables workloads and services to get these passports as soon as they boot in a way that is very reliable, scalable, and very highly automated.
|
||||
|
||||
**Zero Trust**
|
||||
|
||||
Gilman is taking the philosophy of Zero Trust — don’t trust anybody whatsoever — and applying it to network infrastructure and service-to-service communication. “We do this by removing all the security functions from the network and making no assumptions about what should or should not be allowed based on IP address,” he said.
|
||||
|
||||
“Instead, we build systems in such a way that they don’t rely on that network to deliver trustworthy information. We use protocols for strong authentication and authorization to try to mitigate any kind of funny business that might happen on the wire.”
|
||||
|
||||
**Into the New Decade**
|
||||
|
||||
For Scytale, Gilman’s biggest push for 2020 is to provide documentation with detailed examples of how to solve different use cases, and how to configure the software to solve those use cases. “Very clear-cut guidance,” he states. “We have a lot of flexibility and features built into the software, but we don’t have conceptual guidelines that can teach people how the internals are working and stuff like that. We button everything up and make the experience really easy to pick up for folks who might not necessarily want to get in the weeds with it. They just want it to work.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/why-we-need-interoperable-identity/
|
||||
|
||||
作者:[TC CURRIE][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/tc_currie/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/wp-content/uploads/2019/12/computer-2930704_1280-696x413.jpg (computer-2930704_1280)
|
||||
[2]: https://www.linux.com/wp-content/uploads/2019/12/computer-2930704_1280.jpg
|
||||
[3]: http://scytale.io/
|
||||
[4]: https://spiffe.io/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by robsean
|
||||
How to create an e-book chapter template in LibreOffice Writer
|
||||
======
|
||||

|
||||
|
||||
@ -1,146 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to type emoji on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/10/how-type-emoji-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
How to type emoji on Linux
|
||||
======
|
||||
The GNOME desktop makes it easy to use emoji in your communications.
|
||||
![A cat under a keyboard.][1]
|
||||
|
||||
Emoji are those fanciful pictograms that snuck into the Unicode character space. They're all the rage online, and people use them for all kinds of surprising things, from signifying reactions on social media to serving as visual labels for important file names. There are many ways to enter Unicode characters on Linux, but the GNOME desktop makes it easy to find and type an emoji.
|
||||
|
||||
![Emoji in Emacs][2]
|
||||
|
||||
### Requirements
|
||||
|
||||
For this easy method, you must be running Linux with the [GNOME][3] desktop.
|
||||
|
||||
You must also have an emoji font installed. There are many to choose from, so do a search for _emoji_ using your favorite software installer application or package manager.
|
||||
|
||||
For example, on Fedora:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf search emoji
|
||||
emoji-picker.noarch : An emoji selection tool
|
||||
unicode-emoji.noarch : Unicode Emoji Data Files
|
||||
eosrei-emojione-fonts.noarch : A color emoji font
|
||||
twitter-twemoji-fonts.noarch : Twitter Emoji for everyone
|
||||
google-android-emoji-fonts.noarch : Android Emoji font released by Google
|
||||
google-noto-emoji-fonts.noarch : Google “Noto Emoji” Black-and-White emoji font
|
||||
google-noto-emoji-color-fonts.noarch : Google “Noto Color Emoji” colored emoji font
|
||||
[...]
|
||||
```
|
||||
|
||||
On Ubuntu or Debian, use **apt search** instead.
|
||||
|
||||
I'm using [Google Noto Color Emoji][4] in this article.
|
||||
|
||||
### Get set up
|
||||
|
||||
To get set up, launch GNOME's Settings application.
|
||||
|
||||
1. In Settings, click the **Region & Language** category in the left column.
|
||||
2. Click the plus symbol (**+**) under the **Input Sources** heading to bring up the **Add an Input Source** panel.
|
||||
|
||||
|
||||
|
||||
![Add a new input source][5]
|
||||
|
||||
3. In the **Add an Input Source** panel, click the hamburger menu at the bottom of the input list.
|
||||
|
||||
|
||||
|
||||
![Add an Input Source panel][6]
|
||||
|
||||
4. Scroll to the bottom of the list and select **Other**.
|
||||
5. In the **Other** list, find **Other (Typing Booster)**. (You can type **boost** in the search field at the bottom to filter the list.)
|
||||
|
||||
|
||||
|
||||
![Find Other \(Typing Booster\) in inputs][7]
|
||||
|
||||
6. Click the **Add** button in the top-right corner of the panel to add the input source to GNOME.
|
||||
|
||||
|
||||
|
||||
Once you've done that, you can close the Settings window.
|
||||
|
||||
#### Switch to Typing Booster
|
||||
|
||||
You now have a new icon in the top-right of your GNOME desktop. By default, it's set to the two-letter abbreviation of your language (**en** for English, **eo** for Esperanto, **es** for Español, and so on). If you press the **Super** key (the key with a Linux penguin, Windows logo, or Mac Command symbol) and the **Spacebar** together on your keyboard, you will switch input sources from your default source to the next on your input list. In this example, you only have two input sources: your default language and Typing Booster.
|
||||
|
||||
Try pressing **Super**+**Spacebar** together and watch the input name and icon change.
|
||||
|
||||
#### Configure Typing Booster
|
||||
|
||||
With the Typing Booster input method active, click the input sources icon in the top-right of your screen, select **Unicode symbols and emoji predictions**, and set it to **On**.
|
||||
|
||||
![Set Unicode symbols and emoji predictions to On][8]
|
||||
|
||||
This makes Typing Booster dedicated to typing emoji, which isn't all Typing Booster is good for, but in the context of this article it's exactly what is needed.
|
||||
|
||||
### Type emoji
|
||||
|
||||
With Typing Booster still active, open a text editor like Gedit, a web browser, or anything that you know understands Unicode characters, and type "_thumbs up_." As you type, Typing Booster searches for matching emoji names.
|
||||
|
||||
![Typing Booster searching for emojis][9]
|
||||
|
||||
To leave emoji mode, press **Super**+**Spacebar** again, and your input source goes back to your default language.
|
||||
|
||||
### Switch the switcher
|
||||
|
||||
If the **Super**+**Spacebar** keyboard shortcut is not natural for you, then you can change it to a different combination. In GNOME Settings, navigate to **Devices** and select **Keyboard**.
|
||||
|
||||
In the top bar of the **Keyboard** window, search for **Input** to filter the list. Set **Switch to next input source** to a key combination of your choice.
|
||||
|
||||
![Changing keystroke combination in GNOME settings][10]
|
||||
|
||||
### Unicode input
|
||||
|
||||
The fact is, keyboards were designed for a 26-letter (or thereabouts) alphabet along with as many numerals and symbols. ASCII has more characters than what you find on a typical keyboard, to say nothing of the millions of characters within Unicode. If you want to type Unicode characters into a modern Linux application but don't want to switch to Typing Booster, then you can use the Unicode input shortcut.
|
||||
|
||||
1. With your default language active, open a text editor like Gedit, a web browser, or any application you know accepts Unicode.
|
||||
2. Press **Ctrl**+**Shift**+**U** on your keyboard to enter Unicode entry mode. Release the keys.
|
||||
3. You are currently in Unicode entry mode, so type a number of a Unicode symbol. For instance, try **1F44D** for a 👍 symbol, or **2620** for a ☠ symbol. To get the number code of a Unicode symbol, you can search the internet or refer to the [Unicode specification][11].
|
||||
|
||||
|
||||
|
||||
### Pragmatic emoji-ism
|
||||
|
||||
Emoji are fun and expressive. They can make your text unique to you. They can also be utilitarian. Because emoji are Unicode characters, they can be used anywhere a font can be used, and they can be used the same way any alphabetic character can be used. For instance, if you want to mark a series of files with a special symbol, you can add an emoji to the name, and you can filter by that emoji in Search.
|
||||
|
||||
![Labeling a file with emoji][12]
|
||||
|
||||
Use emoji all you want because Linux is a Unicode-friendly environment, and it's getting friendlier with every release.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/how-type-emoji-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc-lead_cat-keyboard.png?itok=fuNmiGV- (A cat under a keyboard.)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/emacs-emoji.jpg (Emoji in Emacs)
|
||||
[3]: https://www.gnome.org/
|
||||
[4]: https://www.google.com/get/noto/help/emoji/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/gnome-setting-region-add.png (Add a new input source)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-list.png (Add an Input Source panel)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-other-typing-booster.png (Find Other (Typing Booster) in inputs)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/emoji-input-on.jpg (Set Unicode symbols and emoji predictions to On)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/emoji-input.jpg (Typing Booster searching for emojis)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/gnome-setting-keyboard-switch-input.jpg (Changing keystroke combination in GNOME settings)
|
||||
[11]: http://unicode.org/emoji/charts/full-emoji-list.html
|
||||
[12]: https://opensource.com/sites/default/files/uploads/file-label.png (Labeling a file with emoji)
|
||||
@ -1,99 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create virtual machines with Cockpit in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/create-virtual-machines-with-cockpit-in-fedora/)
|
||||
[#]: author: (Karlis KavacisPaul W. Frields https://fedoramagazine.org/author/karlisk/https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
Create virtual machines with Cockpit in Fedora
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
This article shows you how to install the software you need to use Cockpit to create and manage virtual machines on Fedora 31. Cockpit is [an interactive admin interface][2] that lets you access and manage systems from any supported web browser. With [virt-manager being deprecated][3] users are encouraged to use Cockpit instead, which is meant to replace it.
|
||||
|
||||
Cockpit is an actively developed project, with many plugins available that extend how it works. For example, one such plugin is “Machines,” which interacts with libvirtd and lets users create and manage virtual machines.
|
||||
|
||||
### Installing software
|
||||
|
||||
The required software prerequisites are _libvirt_, _cockpit_ and _cockpit-machines_. To install them on Fedora 31, run the following command from a terminal [using sudo][4]:
|
||||
|
||||
```
|
||||
$ sudo dnf install libvirt cockpit cockpit-machines
|
||||
```
|
||||
|
||||
Cockpit is also included as part of the “Headless Management” package group. This group is useful for a Fedora based server that you only access through a network. In that case, to install it, use this command:
|
||||
|
||||
```
|
||||
$ sudo dnf groupinstall "Headless Management"
|
||||
```
|
||||
|
||||
### Setting up Cockpit services
|
||||
|
||||
After installing the necessary packages it’s time to enable the services. The _libvirtd_ service runs the virtual machines, while Cockpit has a socket activated service to let you access the Web GUI:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable libvirtd --now
|
||||
$ sudo systemctl enable cockpit.socket --now
|
||||
```
|
||||
|
||||
This should be enough to run virtual machines and manage them through Cockpit. Optionally, if you want to access and manage your machine from another device on your network, you need to expose the service to the network. To do this, add a new rule in your firewall configuration:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --zone=public --add-service=cockpit --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
To confirm the services are running and no issues occurred, check the status of the services:
|
||||
|
||||
```
|
||||
$ sudo systemctl status libvirtd
|
||||
$ sudo systemctl status cockpit.socket
|
||||
```
|
||||
|
||||
At this point everything should be working. The Cockpit web GUI should be available at <https://localhost:9090> or <https://127.0.0.1:9090>. Or, enter the local network IP in a web browser on any other device connected to the same network. (Without SSL certificates setup, you may need to allow a connection from your browser.)
|
||||
|
||||
### Creating and installing a machine
|
||||
|
||||
Log into the interface using the user name and password for that system. You can also choose whether to allow your password to be used for administrative tasks in this session.
|
||||
|
||||
Select _Virtual Machines_ and then select _Create VM_ to build a new box. The console gives you several options:
|
||||
|
||||
* Download an OS using Cockpit’s built in library
|
||||
* Use install media already downloaded on the system you’re managing
|
||||
* Point to a URL for an OS installation tree
|
||||
* Boot media over the network via the [PXE][5] protocol
|
||||
|
||||
|
||||
|
||||
Enter all the necessary parameters. Then select _Create_ to power up the new virtual machine.
|
||||
|
||||
At this point, a graphical console appears. Most modern web browsers let you use your keyboard and mouse to interact with the VM console. Now you can complete your installation and use your new VM, just as you would [via virt-manager in the past][6].
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by [Miguel Teixeira][7] on [Flickr][8] (CC BY-SA 2.0)._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/create-virtual-machines-with-cockpit-in-fedora/
|
||||
|
||||
作者:[Karlis KavacisPaul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/karlisk/https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/11/create-vm-cockpit-816x345.jpg
|
||||
[2]: https://cockpit-project.org/
|
||||
[3]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/8.0_release_notes/rhel-8_0_0_release#virtualization_4
|
||||
[4]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[5]: https://en.wikipedia.org/wiki/Preboot_Execution_Environment
|
||||
[6]: https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/
|
||||
[7]: https://flickr.com/photos/miguelteixeira/
|
||||
[8]: https://flickr.com/photos/miguelteixeira/2964851828/
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 interview questions every Kubernetes job candidate should know)
|
||||
[#]: via: (https://opensource.com/article/19/12/kubernetes-interview-questions)
|
||||
[#]: author: (Jessica Repka https://opensource.com/users/jrepka)
|
||||
|
||||
5 interview questions every Kubernetes job candidate should know
|
||||
======
|
||||
If you're interviewing people for Kubernetes-related roles, here's what
|
||||
to ask and why it matters.
|
||||
![Pair programming][1]
|
||||
|
||||
Job interviews are hard for people on both sides of the table, but I've discovered that interviewing candidates for Kubernetes-related jobs has seemed especially hard lately. Why, you ask? For one thing, it's hard to find someone who can answer some of my questions. Also, it has been hard to confirm whether they have the right experience, regardless of their answers to my questions.
|
||||
|
||||
I'll skip over my musings on that topic and get to some questions that you should ask of any job candidate who would be working with [Kubernetes][2].
|
||||
|
||||
### What is Kubernetes?
|
||||
|
||||
I've always found this question to be one of the best ones to ask in interviews. I always hear, "I work with Kubernetes," but when I ask, "what is it?" I never get a confident answer.
|
||||
|
||||
My favorite answer is from [Chris Short][3]: "Just an API with some YAML files."
|
||||
|
||||
While he is not wrong, I'll give you a more detailed version. Kubernetes is a portable container orchestration tool that is used to automate the tasks of managing, monitoring, scaling, and deploying containerized applications.
|
||||
|
||||
I've found that "an orchestration tool for deploying containerized applications" is probably as good as you're going to get as an answer, which in my opinion is good enough. While many believe Kubernetes adds a great deal more, overall, it offers many APIs to add to this core feature: container orchestration.
|
||||
|
||||
In my opinion, this is one of the best questions you can ask in an interview, as it at least proves whether the candidate knows what Kubernetes is.
|
||||
|
||||
### What is the difference between a Kubernetes node and a pod?
|
||||
|
||||
This question reveals a great first look at the complexity of Kubernetes. It shifts the conversation to an architectural overview and can lead to many interesting follow-up details. It has also been explained incorrectly to me an innumerable amount of times.
|
||||
|
||||
A [node][4] is the worker machine. This machine can be a virtual machine (VM) or a physical machine, depending on whether you are running on a hypervisor or on bare metal. The node contains services to run containers, including the kubelet, kube-proxy, and container runtime.
|
||||
|
||||
A [pod][5] includes (1) one or more containers (2) with shared network (3) and storage (4) and the specification on how to run the containers deployed together. All four of these details are important. For bonus points, an applicant could mention that, technically, a pod is the smallest deployable unit Kubernetes can create and manage—not a container.
|
||||
|
||||
The best short answer I've received for this question is: "The node is the worker, and the pod is the thing the containers are in." The distinction matters. Most of a Kubernetes administrator's job depends on knowing when to deploy what, and nodes can be very, very expensive, depending on where they are run. I wouldn't want someone deploying nodes over and over when what they needed to do was deploy a bunch of pods.
|
||||
|
||||
### What is kubectl? (And how do you pronounce it?)
|
||||
|
||||
This question is one of my higher priority questions, but it may not be relevant for you and your team. In my organization, we don't use a graphical interface to manage our Kubernetes environments, which means command-line actions are all we do.
|
||||
|
||||
So what is [kubectl][6]? It is the command-line interface to Kubernetes. You can get and set anything from there, from gathering logs and events to editing deployments and secrets. It's always helpful to pop in a random question about how to use this tool to test the interviewee's familiarity with kubectl.
|
||||
|
||||
How do you pronounce it? Well, that's up to you (there's a big disagreement on the matter), but I will gladly point you to this great video presentation by my friend [Waldo][7].
|
||||
|
||||
### What is a namespace?
|
||||
|
||||
I haven't received an answer to this question on multiple interviews. I am not sure that namespaces are used as often in other environments as they are in the organization I work in. I'll give a short answer here: a namespace is a virtual cluster in a pod. This abstraction is what enables you to keep several virtual clusters in various environments for isolation purposes.
|
||||
|
||||
### What is a container?
|
||||
|
||||
It always helps to know what is being deployed in your pod, because what's a deployment without knowing what you're deploying in it? A container is a standard unit of software that packages up code and all its dependencies. Two optional secondary answers I have received and am OK with include: a) a slimmed-down image of an OS and b) an application running in a limited OS environment. Bonus points if you can name orchestration software that uses containers other than [Docker][8], like your favorite public cloud's container service.
|
||||
|
||||
### Other questions
|
||||
|
||||
If you're wondering why I didn't add more to this list of questions, I have an easy answer for you: these are the minimum set of things _you_ should know when you are asking candidates interview questions. The next set of questions should come from a large list of questions based on your specific team, environment, and organization. As you think through these, try to find interesting questions about how technology interacts with each other to see how people think through infrastructure challenges. Think about recent challenges your team had (outages), ask to walk through deployments step-by-step, or about strategies to improve something your team actively wants to improve (like a reduction to deployment time). The less abstract the questions, the more your asking about skills that will actually matter after the interview.
|
||||
|
||||
**[Read more: [How to prepare for a Kubernetes job interview]][9]**
|
||||
|
||||
No two environments will be the same, and this also applies when you are interviewing people. I mix up questions in every interview. I also have a small environment I can use to test interviewees. I always find that answering the questions is the easiest part, and doing the work is the real test you need to give.
|
||||
|
||||
My last bit of advice for anyone giving interviews: If you meet someone who has potential but none of the experience, give them a chance to prove themselves. I wouldn't have the knowledge and experience I have today if someone hadn't seen the potential of what I could do and given me an opportunity.
|
||||
|
||||
What are other important questions to ask interviewees about Kubernetes? Please add your list in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/kubernetes-interview-questions
|
||||
|
||||
作者:[Jessica Repka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jrepka
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/collab-team-pair-programming-code-keyboard.png?itok=kBeRTFL1 (Pair programming)
|
||||
[2]: https://kubernetes.io/
|
||||
[3]: https://twitter.com/ChrisShort
|
||||
[4]: https://kubernetes.io/docs/concepts/architecture/nodes/
|
||||
[5]: https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[6]: https://kubernetes.io/docs/reference/kubectl/kubectl/
|
||||
[7]: https://opensource.com/article/18/12/kubectl-definitive-pronunciation-guide
|
||||
[8]: https://opensource.com/resources/what-docker
|
||||
[9]: https://enterprisersproject.com/article/2019/2/kubernetes-job-interview-questions-how-prepare
|
||||
@ -0,0 +1,220 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Build a retro Apple desktop with the Linux MLVWM)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-mlvwm-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Build a retro Apple desktop with the Linux MLVWM
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
What if old-school Apple computers were built around open source POSIX?
|
||||
You can find out by building the Macintosh-like Virtual Window Manager.
|
||||
![Person typing on a 1980's computer][1]
|
||||
|
||||
Imagine traveling into an alternate history where the Apple II GS and MacOS 7 were built upon open source [POSIX][2], using all the same conventions as modern Linux, like plain-text configuration files and modular system design. What would such an OS have enabled for its users? You can answer these questions (and more!) with the [Macintosh-like Virtual Window Manager (MLVWM)][3].
|
||||
|
||||
![MLVWM running on Slackware 14.2][4]
|
||||
|
||||
### Installing MLVWM
|
||||
|
||||
MLVWM is not an easy installation, and it's probably not in your distribution's software repository. If you have the time to decipher a poorly translated README file, edit some configuration files, gather and resize some old **.xpm** images, and edit an Xorg preference or two, then you can experience MLVWM. Otherwise, this is a novelty window manager with its latest release back in 2000.
|
||||
|
||||
To compile MLVWM, you must have **imake** installed, which provides the **xmkmf** command. You can install imake from your distribution's software repository, or get it directly from [Freedesktop.org][5]. Assuming you have the **xmkmf** command, change into the directory containing the MLVWM source code, and run these commands to build it:
|
||||
|
||||
|
||||
```
|
||||
$ xmkmf -a
|
||||
$ make
|
||||
```
|
||||
|
||||
After building, the compiled **mlvwm** binary is located in the **mlvwm** directory. Move it to any location [in your path][6] to install it:
|
||||
|
||||
|
||||
```
|
||||
`$ mv mlvwm/mlvwm /usr/local/bin/`
|
||||
```
|
||||
|
||||
#### Editing the config files
|
||||
|
||||
MLVWM is now installed, but it won't launch correctly without adjusting several configuration files and carefully arranging required image files. Sample config files are located in the **sample_rc** directory of the source code you downloaded. Copy the files **Mlvwm-Netscape** and **Mlvwm-Xterm** to your home directory:
|
||||
|
||||
|
||||
```
|
||||
`$ cp sample_rc/Mlvwm-{Netscape,Xterm} $HOME`
|
||||
```
|
||||
|
||||
Move the **Mlvwmrc** file to **$HOME/.mlvwmrc** (yes, you must use a lower-case "m" even though the sample file deceptively begins with a capital letter):
|
||||
|
||||
|
||||
```
|
||||
`$ cp sample_rc/Mlvwmrc $HOME/.mlvwmrc`
|
||||
```
|
||||
|
||||
Open **.mlwmrc** and find lines 54–55, which define the path (the "IconPath") for the pixmap images that MLVWM uses in its menus and UI:
|
||||
|
||||
|
||||
```
|
||||
# Set icon search path. It needs before "Style".
|
||||
IconPath /usr/local/include/X11/pixmaps:/home2/tak/bin/pixmap
|
||||
```
|
||||
|
||||
Adjust the path to match a directory you will fill with your own images (I suggest using **$HOME/.local/share/pixmaps**). MLVWM doesn't provide pixmaps, so it's up to you to provide pixmap icons for the desktop you're building.
|
||||
|
||||
Do this even if you have pixmaps located elsewhere on your system (such as **/usr/share/pixmaps**), because you're going to have to adjust the size of the pixmaps, and you probably don't want to do that on a system-wide level.
|
||||
|
||||
|
||||
```
|
||||
# Set icon search path. It needs before "Style".
|
||||
IconPath /home/seth/.local/share/pixmaps
|
||||
```
|
||||
|
||||
#### Choosing the pixmaps
|
||||
|
||||
You've defined the **.local/share/pixmaps** directory as the source of pixmaps, but neither the directory nor the images exist yet. Create the directory:
|
||||
|
||||
|
||||
```
|
||||
`$ mkdir -p $HOME/.local/share/pixmaps`
|
||||
```
|
||||
|
||||
Right now, the config file assigns images to menu entries and UI elements, but none of those images exist on your system. To fix this, read through the configuration file and locate every **.xpm** image. For each image listed in the config, add an image with the same file name (or change the file name in the config file) to your IconPath directory.
|
||||
|
||||
The **.mlvwmrc** file is well commented, so you can get a general idea of what you're editing. This is just a first pass, anyway. You can always come back and change the look of your desktop later.
|
||||
|
||||
Here are some examples.
|
||||
|
||||
This code block sets the icon in the upper-left corner of the screen:
|
||||
|
||||
|
||||
```
|
||||
# Register the menu
|
||||
Menu Apple, Icon label1.xpm, Stick
|
||||
```
|
||||
|
||||
The **label1.xpm** image is actually provided in the source code download's **pixmap** directory, but I prefer to use **Penguin.xpm** from **/usr/share/pixmaps** (on Slackware). Whatever you use, you must place your custom pixmap in **~/.local/share/pixmaps** and either change the pixmap's name in the configuration or rename the pixmap file to match what's currently in the config file.
|
||||
|
||||
This code block defines the applications listed in the left menu:
|
||||
|
||||
|
||||
```
|
||||
"About this Workstation..." NonSelect, Gray, Action About
|
||||
"" NonSelect
|
||||
"Terminal" Icon mini-display.xpm, Action Exec "kterm" exec kterm -ls
|
||||
"Editor" Action Exec "mule" exec mule, Icon mini-edit.xpm
|
||||
"calculator" Action Exec "xcal" exec xcalc, Icon mini-calc.xpm
|
||||
END
|
||||
```
|
||||
|
||||
By following the same syntax as what you see in the configuration file, you can customize the pixmaps and add your own applications to the menu (for instance, I changed **mule** to **emacs**). This is your gateway to your applications in the MLVWM GUI, so list everything you want quick access to. You may also wish to include a shortcut to your **/usr/share/applications** folder.
|
||||
|
||||
|
||||
```
|
||||
`"Applications" Icon Penguin.xpm, Action Exec "thunar /usr/share/applications" exec thunar /usr/share/applications`
|
||||
```
|
||||
|
||||
Once you're finished editing the configuration file and adding your own images to your IconPath directory, your pixmaps must all be resized to roughly 16x16 pixels. (MLVWM isn't consistent in its defaults, so there's room for variation.) You can do this as a bulk action using ImageMagick:
|
||||
|
||||
|
||||
```
|
||||
`$ for i in ~/.local/share/mlvwm-pixmaps/*xpm ; do convert -resize '16x16^' $i; done`
|
||||
```
|
||||
|
||||
### Starting MLVWM
|
||||
|
||||
The easiest way to get up and running with MLVWM is to let Xorg do the bulk of the work. First, you must create a **$HOME/.xinitrc** file. I borrowed this one from Slackware, which borrowed it from Xorg:
|
||||
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# $XConsortium: xinitrc.cpp,v 1.4 91/08/22 11:41:34 rws Exp $
|
||||
|
||||
userresources=$HOME/.Xresources
|
||||
usermodmap=$HOME/.Xmodmap
|
||||
sysresources=/etc/X11/xinit/.Xresources
|
||||
sysmodmap=/etc/X11/xinit/.Xmodmap
|
||||
|
||||
# merge in defaults and keymaps
|
||||
|
||||
if [ -f $sysresources ]; then
|
||||
xrdb -merge $sysresources
|
||||
fi
|
||||
|
||||
if [ -f $sysmodmap ]; then
|
||||
xmodmap $sysmodmap
|
||||
fi
|
||||
|
||||
if [ -f $userresources ]; then
|
||||
xrdb -merge $userresources
|
||||
fi
|
||||
|
||||
if [ -f $usermodmap ]; then
|
||||
xmodmap $usermodmap
|
||||
fi
|
||||
|
||||
# Start the window manager:
|
||||
if [ -z "$DESKTOP_SESSION" -a -x /usr/bin/ck-launch-session ]; then
|
||||
exec ck-launch-session /usr/local/bin/mlvwm
|
||||
else
|
||||
exec /usr/local/bin/mlvwm
|
||||
fi
|
||||
```
|
||||
|
||||
According to this file, the default action for the **startx** command is to launch MLVWM. However, your distribution may have other ideas about what happens when your graphic server launches (or is killed to be restarted), so this file may do you little good. On many distributions, you can add a **.desktop** file to **/usr/share/xsessions** to have it listed in the GDM or KDM menu, so create a file called **mlvwm.desktop** and enter this text:
|
||||
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=Mlvwm
|
||||
Comment=Macintosh-like virtual window manager
|
||||
Exec=/usr/local/bin/mlvwm
|
||||
TryExec=ck-launch-session /usr/local/bin/mlvwm
|
||||
Type=Application
|
||||
```
|
||||
|
||||
Log out from your desktop session and log back into MLVWM. By default, your session manager (KDM, GDM, or LightDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
|
||||
|
||||
With GDM:
|
||||
|
||||
![][7]
|
||||
|
||||
With SDDM:
|
||||
|
||||
![][8]
|
||||
|
||||
#### Launching with brute force
|
||||
|
||||
If MLVWM fails to start, try installing XDM, a lightweight session manager that doesn't look at **/usr/share/xsessions** and instead just does whatever the authenticated user's **.xinitrc** proscribes.
|
||||
|
||||
![MLVWM][9]
|
||||
|
||||
### Build your own retro Apple
|
||||
|
||||
The MLVWM desktop is unpolished, imperfect, accurate, and loads of fun. Many of the menu options you see are unimplemented, but you can make them active and meaningful.
|
||||
|
||||
This is your chance to step back in time, change history, and make the old-school Apple line of computers a bastion of open source. Be a revisionist, design your own retro Apple desktop, and, most importantly, have fun.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-mlvwm-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/1980s-computer-yearbook.png?itok=eGOYEKK- (Person typing on a 1980's computer)
|
||||
[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[3]: http://www2u.biglobe.ne.jp/~y-miyata/mlvwm.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/advent-mlvwm-file.jpg (MLVWM running on Slackware 14.2)
|
||||
[5]: http://cgit.freedesktop.org/xorg/util/imake
|
||||
[6]: https://opensource.com/article/17/6/set-path-linux
|
||||
[7]: https://opensource.com/sites/default/files/advent-gdm_2.jpg
|
||||
[8]: https://opensource.com/sites/default/files/advent-kdm_1.jpg
|
||||
[9]: https://opensource.com/sites/default/files/uploads/advent-mlvwm-chess.jpg (MLVWM)
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Emacs for Vim users: Getting started with the Spacemacs text editor)
|
||||
[#]: via: (https://opensource.com/article/19/12/spacemacs)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
Emacs for Vim users: Getting started with the Spacemacs text editor
|
||||
======
|
||||
Spacemacs offers all the power of Emacs combined with the keystroke
|
||||
commands and functionality you are used to in Vim.
|
||||
![Hands programming][1]
|
||||
|
||||
I use [Vim][2] a lot. I'm a site reliability engineer (SRE), and Vim is the one thing I know I can access on every machine in our fleet. I also like [Emacs][3], with its wide variety of useful packages, ease of extending, and its many built-in tools. Because they each have their own set of commands, I have to actively switch codes in my head (usually after typing **:wq** in Emacs or trying to **C+X** in Vim). The [Evil][4] package for Emacs helps quite a bit by making Emacs behave more like Vim, but there is some effort required to set it up the first time.
|
||||
|
||||
### Enter Spacemacs
|
||||
|
||||
![Spacemacs splash screen][5]
|
||||
|
||||
[Spacemacs][6] is a set of configurations for Emacs that combines an easy setup, Evil, and a system to manage and set up additional Emacs packages with pre-built configurations to make them easier to use out of the box.
|
||||
|
||||
### Installation and setup
|
||||
|
||||
As I mentioned above, Spacemacs is easy to install. No, really: it takes just one command:
|
||||
|
||||
|
||||
```
|
||||
`git clone https://github.com/syl20bnr/spacemacs ~/.emacs.d`
|
||||
```
|
||||
|
||||
Then just start Emacs. It will prompt you through the basic configuration options and generate a **.spacemacs** configuration file. The defaults are as safe as can be: Vim keybindings, Spacemacs' recommended packages, and the Helm search engine. When the configuration completes, you will see a help screen with some basic information and commands.
|
||||
|
||||
![Spacemacs help screen][7]
|
||||
|
||||
Now Spacemacs is set up and ready to go and will behave like Vim. You can start right away by entering **:e </path/to/file>** to open and edit a file and using good old **:wq** to save (among other commands). As a bonus, if you are a seasoned Emacs user, many of the commands you are used to are still there.
|
||||
|
||||
### Using Spacemacs
|
||||
|
||||
On the main splash screen, you'll notice a lot of information. There are buttons to update Spacemacs and the packages, access different forms of documentation, and open recently edited files.
|
||||
|
||||
Whenever you're not in insert mode, you can press the **Space Bar** to bring up a menu of other available options. The default options include access to the Helm search engine and the basic functions for opening and editing files. As you add packages, they will also show up in the menu. In most special screens (i.e., those that are not a document you are editing), the **q** key will exit the screen.
|
||||
|
||||
### Configuring Spacemacs
|
||||
|
||||
Before getting into Spacemacs' configuration, you need to understand **layers**. Layers are self-contained configuration files that load on top of one another. A layer is comprised of the instructions to download and install the package and any dependencies, as well as the basic configuration and key mappings for the package.
|
||||
|
||||
Spacemacs has quite a few [layers available][8], and more are being added all the time. You can find the complete list in the **~/.emacs.d/layers** directory tree. They are organized by type; to use one, just add it in the main **.spacemacs** configuration file to the **dotspacemacs-configuration-layers** list.
|
||||
|
||||
I generally enable the Git, Version-Control, Markdown, and Colors (theme support) layers. If you are familiar with configuring Emacs, you can also add custom configurations in [Lisp][9] to the **dotspacemacs/user-config** section.
|
||||
|
||||
You can also enable a Nyan Cat progress bar by adding the following line in your layers list:
|
||||
|
||||
|
||||
```
|
||||
`(colors :variables colors-enable-nyan-cat-progress-bar t)`
|
||||
```
|
||||
|
||||
|
||||
|
||||
![Nyan Cat progress bar in Spacemacs][10]
|
||||
|
||||
### Using Org mode in Spacemacs
|
||||
|
||||
One of my other favorite layers is [Org mode][11], probably one of the most popular notes, to-do, and project management applications in the open source world.
|
||||
|
||||
To install Org, just open up the **.spacemacs** file and uncomment the line for **org** under **dotspacemacs-configuration-layers**.
|
||||
|
||||
![Installing Org mode in Spacemacs][12]
|
||||
|
||||
Exit and restart Emacs, and it will download the Org packages and set them up. Type **Space Bar+a**, and you see a new menu item for Org with the hotkey **o**, and the common Org functions—agenda, to-do list, etc.—are under that menu. They are blank until you configure the default Org files. The easiest way to do that is with the built-in Emacs configuration tool, which you can access by typing **Space Bar+?** and searching for **Customize**. When the Customize screen opens, search for **org-agenda-files**. Add a file or two to the list (I used **~/todo.org** and **~/notes.org**), click Apply and Save, then exit Customize.
|
||||
|
||||
![Emacs Customize tool in Spacemacs][13]
|
||||
|
||||
Next, create a file so that Org can read them into the agenda and to-do list. Even if the file is blank, that's OK—it just has to exist. Since I added two files—todo.org and notes.org—to my configuration, I can type **:e todo.org** and **:e notes.org** to open both, and then **:w** to save the blank files.
|
||||
|
||||
Next, enter the Org agenda with **Space Bar+a+o+a** or the Org to-do list with **Space Bar+a+o+t**. If you have added actionable items or scheduled events to the notes or to-do files, you will see them now. You can find out more about Org's structure and syntax in _[Get started with Org mode without Emacs][14]_ or on the [Org mode][11] website.
|
||||
|
||||
![Spacemacs todo.org and the Org todo agenda][15]
|
||||
|
||||
Spacemacs offers all the power of Emacs combined with the keystroke commands and functionality you are used to with Vim. Give it a try, and please let me know what you think in the comments.
|
||||
|
||||
This is a short list of my favorite graphical text editors for Linux that can be classified as IDE...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/spacemacs
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://www.gnu.org/software/emacs
|
||||
[4]: https://www.emacswiki.org/emacs/Evil
|
||||
[5]: https://opensource.com/sites/default/files/uploads/spacemacs_spash.png (Spacemacs splash screen)
|
||||
[6]: https://www.spacemacs.org/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/spacemacs_help.png (Spacemacs help screen)
|
||||
[8]: https://www.spacemacs.org/layers/LAYERS.html
|
||||
[9]: https://en.wikipedia.org/wiki/Lisp_(programming_language)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/nyan-cat-progress.png (Nyan Cat progress bar in Spacemacs)
|
||||
[11]: https://orgmode.org
|
||||
[12]: https://opensource.com/sites/default/files/uploads/spacemacs_org_change.png (Installing Org mode in Spacemacs)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/emacs_customize.png (Emacs Customize tool in Spacemacs)
|
||||
[14]: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
[15]: https://opensource.com/sites/default/files/uploads/spacemacs_org.png (Spacemacs todo.org and the Org todo agenda)
|
||||
@ -0,0 +1,153 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to tell if you’re using a bash builtin in Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3505818/how-to-tell-if-youre-using-a-bash-builtin-in-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How to tell if you’re using a bash builtin in Linux
|
||||
======
|
||||
A built-in is a Linux command that's part of whatever shell you're using. Can you tell what commands are built-ins and which are not?
|
||||
Guenter Guni / Getty Images
|
||||
|
||||
If you’re not sure if you’re running a Linux command or you’re using a bash builtin, don’t stress, it isn’t all that obvious. In fact, you can get very used to commands like **cd** without realizing that they’re part of your shell, unlike commands like **date** and **whoami** that invoke executables (**/bin/date** and **/usr/bin/whoami**).
|
||||
|
||||
Builtins in general are commands that are built into shell interpreters, and bash is especially rich in them, which is a good thing because built-ins by their very nature run a bit faster than commands which have to be loaded into memory when you call them into play.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][1]
|
||||
|
||||
In other words, some commands are built into the shell because they pretty much have to be. After all, a command like **cd** needs to change the shell’s view of the world – or at least its perspective on the file system. Others provide the shell with its special ability to loop and evaluate data – like **case**, **for** and **while** commands. In short, these commands make the shell what it is for all of its devoted users. Still others just make commands run a little faster.
|
||||
|
||||
[][2]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][2]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
To get a list of bash built-ins, all you have to type is “help”.
|
||||
|
||||
```
|
||||
$ help
|
||||
GNU bash, version 5.0.3(1)-release (x86_64-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
Type `help name' to find out more about the function `name'.
|
||||
Use `info bash' to find out more about the shell in general.
|
||||
Use `man -k' or `info' to find out more about commands not in this list.
|
||||
|
||||
A star (*) next to a name means that the command is disabled.
|
||||
|
||||
job_spec [&] history [-c] [-d offset] [n] or history -an>
|
||||
(( expression )) if COMMANDS; then COMMANDS; [ elif COMMANDS>
|
||||
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs -x comm>
|
||||
: kill [-s sigspec | -n signum | -sigspec] pi>
|
||||
[ arg... ] let arg [arg ...]
|
||||
[[ expression ]] local [option] name[=value] ...
|
||||
alias [-p] [name[=value] ... ] logout [n]
|
||||
bg [job_spec ...] mapfile [-d delim] [-n count] [-O origin] [>
|
||||
bind [-lpsvPSVX] [-m keymap] [-f filename] [> popd [-n] [+N | -N]
|
||||
break [n] printf [-v var] format [arguments]
|
||||
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
|
||||
caller [expr] pwd [-LP]
|
||||
case WORD in [PATTERN [| PATTERN]...) COMMAN> read [-ers] [-a array] [-d delim] [-i text]>
|
||||
cd [-L|[-P [-e]] [-@]] [dir] readarray [-d delim] [-n count] [-O origin]>
|
||||
command [-pVv] command [arg ...] readonly [-aAf] [name[=value] ...] or reado>
|
||||
compgen [-abcdefgjksuv] [-o option] [-A acti> return [n]
|
||||
complete [-abcdefgjksuv] [-pr] [-DEI] [-o op> select NAME [in WORDS ... ;] do COMMANDS; d>
|
||||
compopt [-o|+o option] [-DEI] [name ...] set [-abefhkmnptuvxBCHP] [-o option-name] [>
|
||||
continue [n] shift [n]
|
||||
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
|
||||
declare [-aAfFgilnrtux] [-p] [name[=value] .> source filename [arguments]
|
||||
dirs [-clpv] [+N] [-N] suspend [-f]
|
||||
disown [-h] [-ar] [jobspec ... | pid ...] test [expr]
|
||||
echo [-neE] [arg ...] time [-p] pipeline
|
||||
enable [-a] [-dnps] [-f filename] [name ...> times
|
||||
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
|
||||
exec [-cl] [-a name] [command [arguments ...> true
|
||||
exit [n] type [-afptP] name [name ...]
|
||||
export [-fn] [name[=value] ...] or export -> typeset [-aAfFgilnrtux] [-p] name[=value] .>
|
||||
false ulimit [-SHabcdefiklmnpqrstuvxPT] [limit]
|
||||
fc [-e ename] [-lnr] [first] [last] or fc -s> umask [-p] [-S] [mode]
|
||||
fg [job_spec] unalias [-a] name [name ...]
|
||||
for NAME [in WORDS ... ] ; do COMMANDS; don> unset [-f] [-v] [-n] [name ...]
|
||||
for (( exp1; exp2; exp3 )); do COMMANDS; don> until COMMANDS; do COMMANDS; done
|
||||
function name { COMMANDS ; } or name () { CO> variables - Names and meanings of some shel>
|
||||
getopts optstring name [arg] wait [-fn] [id ...]
|
||||
hash [-lr] [-p pathname] [-dt] [name ...] while COMMANDS; do COMMANDS; done
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
You might notice that some of these built-ins (e.g., **echo** and **kill**) also exist as executables.
|
||||
|
||||
```
|
||||
$ ls -l /bin/echo /bin/kill
|
||||
-rwxr-xr-x 1 root root 39256 Sep 5 06:38 /bin/echo
|
||||
-rwxr-xr-x 1 root root 30952 Aug 8 12:46 /bin/kill
|
||||
```
|
||||
|
||||
One quick way to determine whether the command you are using is a bash built-in or not is to use the command “command”. Yes, the command is called “command”. Try it with a **-V** (capital V) option like this:
|
||||
|
||||
```
|
||||
$ command -V command
|
||||
command is a shell builtin
|
||||
$ command -V echo
|
||||
echo is a shell builtin
|
||||
$ command -V date
|
||||
date is hashed (/bin/date)
|
||||
```
|
||||
|
||||
When you see a “command is hashed” message like the one above, that means that the command has been put into a hash table for quicker lookup.
|
||||
|
||||
### **Looking for help in other shells**
|
||||
|
||||
If you switch shells and try running “help”, you’ll notice that some support this command and others do not. You can run a command like this in bash to see what each of the shells on your system will tell you:
|
||||
|
||||
```
|
||||
for shell in `ls /bin/*sh`
|
||||
do
|
||||
echo $shell
|
||||
$shell -c "help"
|
||||
echo ===============
|
||||
done
|
||||
```
|
||||
|
||||
This loop will try running the help command in each of the shells in /bin. The $shell -c (e.g., zsh -c) syntax will run just the single help command in that shell and then exit.
|
||||
|
||||
### How to tell what shell you're currently using
|
||||
|
||||
If you switch shells you can’t depend on $SHELL to tell you what shell you’re currently using because $SHELL is just an environment variable that is set when you log in and doesn't necessarily reflect your current shell. Try **ps -p $$** instead as shown in these examples:
|
||||
|
||||
```
|
||||
$ ps -p $$
|
||||
PID TTY TIME CMD
|
||||
18340 pts/0 00:00:00 bash <==
|
||||
$ /bin/dash
|
||||
$ ps -p $$
|
||||
PID TTY TIME CMD
|
||||
19517 pts/0 00:00:00 dash <==
|
||||
```
|
||||
|
||||
Built-ins are extremely useful and give each shell a lot of its character. If you use some particular shell all of the time, it’s easy to lose track of which commands are part of your shell and which are not. Differentiating a shell built-in from a Linux executable requires only a little extra effort.
|
||||
|
||||
Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3505818/how-to-tell-if-youre-using-a-bash-builtin-in-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
124
sources/tech/20191218 How tracking pixels work.md
Normal file
124
sources/tech/20191218 How tracking pixels work.md
Normal file
@ -0,0 +1,124 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How tracking pixels work)
|
||||
[#]: via: (https://jvns.ca/blog/how-tracking-pixels-work/)
|
||||
[#]: author: (Julia Evans https://jvns.ca/)
|
||||
|
||||
How tracking pixels work
|
||||
======
|
||||
|
||||
I spent some time talking to a reporter yesterday about how advertisers track people on the internet. We had a really fun time looking at Firefox’s developer tools together (I’m not an internet privacy expert, but I do know how to use the network tab in developer tools!) and I learned a few things about how tracking pixels actually work in practice!
|
||||
|
||||
### the question: how does Facebook know that you went to Old Navy?
|
||||
|
||||
I often hear about this slightly creepy internet experience: you’re looking at a product online, and a day later see an ad for the same boots or whatever that you were looking at. This is called “retargeting”, but how does it actually work exactly in practice?
|
||||
|
||||
In this post we’ll experiment a bit and see exactly how Facebook can know what products you’ve looked at online! I’m using Facebook as an example in this blog post just because it’s easy to find websites with Facebook tracking pixels on them but of course almost every internet advertising company does this kind of tracking.
|
||||
|
||||
### the setup: allow third party trackers, turn off my adblocker
|
||||
|
||||
I use Firefox, and by default Firefox blocks a lot of this kind of tracking. So I needed to modify my Firefox privacy settings to get this tracking to work.
|
||||
|
||||
I changed my privacy settings from the default ([screenshot][1]) to a custom setting that allows third-party trackers ([screenshot][2]). I also disabled some privacy extensions I usually have running.
|
||||
|
||||
### tracking pixels: it’s not the gif, it’s the query parameters
|
||||
|
||||
A tracking pixel is a 1x1 gif that sites use to track you. By itself, obviously a tiny 1x1 gif doesn’t do too much. So how do tracking pixels track you? 2 ways:
|
||||
|
||||
1. Sites use the **query parameters** in the tracking pixel to add extra information like the URL of the page you’re visiting. So instead of just requesting `https://www.facebook.com/tr/` (which is a 44-byte 1x1 gif), it’ll request `https://www.facebook.com/tr/?the_website_you're_on`. (email marketers use similar tricks to figure out if you’ve opened an email, by giving the tracking pixel a unique URL)
|
||||
2. Sites send **cookies** with the tracking pixel so that they can tell that the person who visited oldnavy.com is the same as the person who’s using Facebook on the same computer.
|
||||
|
||||
|
||||
|
||||
### the Facebook tracking pixel on Old Navy’s website
|
||||
|
||||
To test this out, I went to look at a product on the Old Navy site with the URL [https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1][3] (a “Soft-Brushed Plaid Topcoat for Men”).
|
||||
|
||||
When I did that, the Javascript running on that page (presumably [this code][4]) sent a request to facebook.com that looks like this in Developer tools: (I censored most of the cookie values because some of them are my login cookies :) )
|
||||
|
||||
![][5]
|
||||
|
||||
Let’s break down what’s happening:
|
||||
|
||||
1. My browser sends a request to ` https://www.facebook.com/tr/?id=937725046402747&ev=PageView&dl=https%3A%2F%2Foldnavy.gap.com%2Fbrowse%2Fproduct.do%3Fpid%3D504753002%26cid%3D1125694%26pcid%3Dxxxxxx0%26vid%3D1%26grid%3Dpds_0_109_1%23pdp-page-content&rl=https%3A%2F%2Foldnavy.gap.com%2Fbrowse%2Fcategory.do%3Fcid%3D1135640%26mlink%3D5155%2Cm_mts_a&if=false&ts=1576684838096&sw=1920&sh=1080&v=2.9.15&r=stable&a=tmtealium&ec=0&o=30&fbp=fb.1.1576684798512.1946041422&it=15xxxxxxxxxx4&coo=false&rqm=GET`
|
||||
2. With that request, it sends a cookie called `fr` which is set to `10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.` (which I guess is my Facebook ad tracking ID)
|
||||
|
||||
|
||||
|
||||
So the three most notable things that are being sent in the tracking pixel query string are:
|
||||
|
||||
* the page I visited: [https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1#pdp-page-content][6]
|
||||
* the page that referred me to that page: [https://oldnavy.gap.com/browse/category.do?cid=1135640&mlink=5155,m_mts_a][7]
|
||||
* an identifier cookie for me: `10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.`
|
||||
|
||||
|
||||
|
||||
### now let’s visit Facebook!
|
||||
|
||||
Next, let’s visit Facebook, where I’m logged in. What cookies is my browser sending Facebook?
|
||||
|
||||
Unsurprisingly, it’s the same `fr` cookie from before: `10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.`. So Facebook now definitely knows that I (Julia Evans, the person with this Facebook account) visited the Old Navy website a couple of minutes ago and looked at a “Soft-Brushed Plaid Topcoat for Men”, because they can use that identifier to match up the data.
|
||||
|
||||
### these cookies are third-party cookies
|
||||
|
||||
The `fr` cookie that Facebook is using to track what websites I go to is called a “third party cookie”, because Old Navy’s website is using it to identify me to a third party (facebook.com). This is different from first-party cookies, which are used to keep you logged in.
|
||||
|
||||
Safari and Firefox both block many third-party cookies by default (which is why I had to change Firefox’s privacy settings to get this experiment to work), and as of today Chrome doesn’t (presumably because Chrome is owned by an ad company).
|
||||
|
||||
### sites have lots of tracking pixels
|
||||
|
||||
Like I expected, sites have **lots** of tracking pixels. For example, wrangler.com loaded 19 different tracking pixels in my browser from a bunch of different domains. The tracking pixels on wrangler.com came from: `ct.pinterest.com`, `af.monetate.net`, `csm.va.us.criteo.net`, `google-analytics.com`, `dpm.demdex.net`, `google.ca`, `a.tribalfusion.com`, `data.photorank.me`, `stats.g.doubleclick.net`, `vfcorp.dl.sc.omtrdc.net`, `ib.adnxs.com`, `idsync.rlcdn.com`, `p.brsrvr.com`, and `adservice.google.com`.
|
||||
|
||||
For most of these trackers, Firefox helpfully pointed out that it would have blocked them if I was using the standard Firefox privacy settings:
|
||||
|
||||
![][8]
|
||||
|
||||
### why browsers matter
|
||||
|
||||
The reason browsers matter so much is that your browser has the final word on what information it sends about you to which websites. The Javascript on the Old Navy’s website can ask your browser to send tracking information about you to Facebook, but your browser doesn’t have to do it! It can decide “oh yeah, I know that facebook.com/tr/ is a tracking pixel, I don’t want my users to be tracked, I’m just not going to send that request”.
|
||||
|
||||
And it can make that behaviour configurable by changing browser settings or installing browser extensions, which is why there are lots of privacy extensions.
|
||||
|
||||
### it’s fun to see how this works!
|
||||
|
||||
I think it’s fun to see how cookies / tracking pixels are used to track you in practice, even if it’s kinda creepy! I sort of knew how this worked before but I’d never actually looked at the cookies on a tracking pixel myself or what kind of information it was sending in its query parameters exactly.
|
||||
|
||||
And if you know how it works, it’s a easier to figure out how to be tracked less!
|
||||
|
||||
### what can you do?
|
||||
|
||||
I do a few small things to get tracked on the internet a little less:
|
||||
|
||||
* install an adblocker (like ublock origin or something), which will block a lot of tracker domains
|
||||
* use Firefox/Safari instead of Chrome (which have stronger default privacy settings right now)
|
||||
* use the [Facebook Container][9] Firefox extension, which takes extra steps to specifically prevent Facebook from tracking you
|
||||
|
||||
|
||||
|
||||
There are still lots of other ways to be tracked on the internet (especially when using mobile apps where you don’t have the same kind of control as with your browser), but I like understanding how this one method of tracking works and think it’s nice to be tracked a little bit less.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/how-tracking-pixels-work/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://jvns.ca/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://jvns.ca/images/trackers.png
|
||||
[2]: https://jvns.ca/images/firefox-insecure-settings.png
|
||||
[3]: https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1
|
||||
[4]: https://developers.facebook.com/docs/facebook-pixel/implementation/
|
||||
[5]: https://jvns.ca/images/fb-old-navy.png
|
||||
[6]: https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1#pdp-page-content
|
||||
[7]: https://oldnavy.gap.com/browse/category.do?cid=1135640&mlink=5155,m_mts_a
|
||||
[8]: https://jvns.ca/images/firefox-helpful.png
|
||||
[9]: https://addons.mozilla.org/en-CA/firefox/addon/facebook-container/
|
||||
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Introduction to automation with Bash scripts)
|
||||
[#]: via: (https://opensource.com/article/19/12/automation-bash-scripts)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
Introduction to automation with Bash scripts
|
||||
======
|
||||
In the first article in this four-part series, learn how to create a
|
||||
simple shell script and why they are the best way to automate tasks.
|
||||
![Person using a laptop][1]
|
||||
|
||||
Sysadmins, those of us who run and manage Linux computers most closely, have direct access to tools that help us work more efficiently. To help you use these tools to their maximum benefit to make your life easier, this series of articles explores using automation in the form of Bash shell scripts. It covers:
|
||||
|
||||
* The advantages of automation with Bash shell scripts
|
||||
* Why using shell scripts is a better choice for sysadmins than compiled languages like C or C++
|
||||
* Creating a set of requirements for new scripts
|
||||
* Creating simple Bash shell scripts from command-line interface (CLI) programs
|
||||
* Enhancing security through using the user ID (UID) running the script
|
||||
* Using logical comparison tools to provide execution flow control for command-line programs and scripts
|
||||
* Using command-line options to control script functionality
|
||||
* Creating Bash functions that can be called from one or more locations within a script
|
||||
* Why and how to license your code as open source
|
||||
* Creating and implementing a simple test plan
|
||||
|
||||
|
||||
|
||||
I previously wrote a series of articles about Bash commands and syntax and creating Bash programs at the command line, which you can find in the references section at the end of this article. But this series of four articles is as much about creating scripts (and some techniques that I find useful) as it is about Bash commands and syntax.
|
||||
|
||||
### Why I use shell scripts
|
||||
|
||||
In Chapter 9 of [_The Linux Philosophy for Sysadmins_][2], I write:
|
||||
|
||||
> "A sysadmin is most productive when thinking—thinking about how to solve existing problems and about how to avoid future problems; thinking about how to monitor Linux computers in order to find clues that anticipate and foreshadow those future problems; thinking about how to make [their] job more efficient; thinking about how to automate all of those tasks that need to be performed whether every day or once a year.
|
||||
>
|
||||
> "Sysadmins are next most productive when creating the shell programs that automate the solutions that they have conceived while appearing to be unproductive. The more automation we have in place, the more time we have available to fix real problems when they occur and to contemplate how to automate even more than we already have."
|
||||
|
||||
This first article explores why shell scripts are an important tool for the sysadmin and the basics of creating a very simple Bash script.
|
||||
|
||||
### Why automate?
|
||||
|
||||
Have you ever performed a long and complex task at the command line and thought, "Glad that's done. Now I never have to worry about it again!"? I have—frequently. I ultimately figured out that almost everything that I ever need to do on a computer (whether mine or one that belongs to an employer or a consulting customer) will need to be done again sometime in the future.
|
||||
|
||||
Of course, I always think that I will remember how I did the task. But, often, the next time is far enough into the future that I forget that I have _ever_ done it, let alone _how_ to do it. I started writing down the steps required for some tasks on bits of paper, then thought, "How stupid of me!" So I transferred those scribbles to a simple notepad application on my computer, until one day, I thought again, "How stupid of me!" If I am going to store this data on my computer, I might as well create a shell script and store it in a standard location, like **/usr/local/bin** or **~/bin**, so I can just type the name of the shell program and let it do all the tasks I used to do manually.
|
||||
|
||||
For me, automation also means that I don't have to remember or recreate the details of how I performed the task in order to do it again. It takes time to remember how to do things and time to type in all the commands. This can become a significant time sink for tasks that require typing large numbers of long commands. Automating tasks by creating shell scripts reduces the typing necessary to perform routine tasks.
|
||||
|
||||
### Shell scripts
|
||||
|
||||
Writing shell programs—also known as scripts—is the best strategy for leveraging my time. Once I write a shell program, I can rerun it as many times as I need to. I can also update my shell scripts to compensate for changes from one release of Linux to the next, installing new hardware and software, changing what I want or need to accomplish with the script, adding new functions, removing functions that are no longer needed, and fixing the not-so-rare bugs in my scripts. These kinds of changes are just part of the maintenance cycle for any type of code.
|
||||
|
||||
Every task performed via the keyboard in a terminal session by entering and executing shell commands can and should be automated. Sysadmins should automate everything we are asked to do or decide needs to be done. Many times, doing the automation upfront saves me time the first time.
|
||||
|
||||
One Bash script can contain anywhere from a few commands to many thousands. I have written Bash scripts with only one or two commands, and I have written a script with over 2,700 lines, more than half of which are comments.
|
||||
|
||||
### Getting started
|
||||
|
||||
Here's a trivial example of a shell script and how to create it. In my earlier series on Bash command-line programming, I used the example from every book on programming I have ever read: "Hello world." From the command line, it looks like this:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ echo "Hello world"
|
||||
Hello world
|
||||
```
|
||||
|
||||
By definition, a program or shell script is a sequence of instructions for the computer to execute. But typing them into the command line every time is quite tedious, especially when the programs are long and complex. Storing them in a file that can be executed with a single command saves time and reduces the possibility for errors to creep in.
|
||||
|
||||
I recommend trying the following examples as a non-root user on a test system or virtual machine (VM). Although the examples are harmless, mistakes do happen, and being safe is always wise.
|
||||
|
||||
The first task is to create a file to contain your program. Use the **touch** command to create the empty file, **hello**, then make it executable:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ touch hello
|
||||
[student@testvm1 ~]$ chmod 774 hello
|
||||
```
|
||||
|
||||
Now, use your favorite editor to add the following line to the file:
|
||||
|
||||
|
||||
```
|
||||
`echo "Hello world"`
|
||||
```
|
||||
|
||||
Save the file and run it from the command line. You can use a separate shell session to execute the scripts in this series:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ ./hello
|
||||
Hello world!
|
||||
```
|
||||
|
||||
This is the simplest Bash program you may ever create—a single statement in a file. For this exercise, your complete shell script will be built around this simple Bash statement. The function of the program is irrelevant for this purpose, and this simple statement allows you to build a program structure—a template for other programs—without being concerned about the logic of a functional purpose. You can concentrate on the basic program structure and creating your template in a very simple way, and you can create and test the template itself rather than a complex functional program.
|
||||
|
||||
### Shebang
|
||||
|
||||
The single statement works fine as long as you use Bash or a shell compatible with the commands used in the script. If no shell is specified in the script, the default shell will be used to execute the script commands.
|
||||
|
||||
The next task is to ensure that the script will run using the Bash shell, even if another shell is the default. This is accomplished with the shebang line. Shebang is the geeky way to describe the **#!** characters that explicitly specify which shell to use when running the script. In this case, that is Bash, but it could be any other shell. If the specified shell is not installed, the script will not run.
|
||||
|
||||
Add the shebang line as the first line of the script, so now it looks like this:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/bash
|
||||
echo "Hello world!"
|
||||
```
|
||||
|
||||
Run the script again—you should see no difference in the result. If you have other shells installed (such as ksh, csh, tcsh, zsh, etc.), start one and run the script again.
|
||||
|
||||
### Scripts vs. compiled programs
|
||||
|
||||
When writing programs to automate—well, everything—sysadmins should always use shell scripts. Because shell scripts are stored in ASCII text format, they can be viewed and modified by humans just as easily as they can by computers. You can examine a shell program and see exactly what it does and whether there are any obvious errors in the syntax or logic. This is a powerful example of what it means to be _open_.
|
||||
|
||||
I know some developers consider shell scripts something less than "true" programming. This marginalization of shell scripts and those who write them seems to be predicated on the idea that the only "true" programming language is one that must be compiled from source code to produce executable code. I can tell you from experience that this is categorically untrue.
|
||||
|
||||
I have used many languages, including BASIC, C, C++, Pascal, Perl, Tcl/Expect, REXX (and some of its variations, including Object REXX), many shell languages (including Korn, csh and Bash), and even some assembly language. Every computer language ever devised has had one purpose: to allow humans to tell computers what to do. When you write a program, regardless of the language you choose, you are giving the computer instructions to perform specific tasks in a specific sequence.
|
||||
|
||||
Scripts can be written and tested far more quickly than compiled languages. Programs usually must be written quickly to meet time constraints imposed by circumstances or the pointy-haired boss. Most scripts that sysadmins write are to fix a problem, to clean up the aftermath of a problem, or to deliver a program that must be operational long before a compiled program could be written and tested.
|
||||
|
||||
Writing a program quickly requires shell programming because it enables a quick response to the needs of the customer—whether that is you or someone else. If there are problems with the logic or bugs in the code, they can be corrected and retested almost immediately. If the original set of requirements is flawed or incomplete, shell scripts can be altered very quickly to meet the new requirements. In general, the need for speed of development in the sysadmin's job overrides the need to make the program run as fast as possible or to use as little as possible in the way of system resources like RAM.
|
||||
|
||||
Most things sysadmins do take longer to figure out how to do than to execute. Thus, it might seem counterproductive to create shell scripts for everything you do. It takes some time to write the scripts and make them into tools that produce reproducible results and can be used as many times as necessary. The time savings come every time you can run the script without having to figure out (again) how to do the task.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
This article didn't get very far with creating a shell script, but it did create a very small one. It also explored the reasons for creating shell scripts and why they are the most efficient option for the system administrator (rather than compiled programs).
|
||||
|
||||
In the next article, you will begin creating a Bash script template that can be used as a starting point for other Bash scripts. The template will ultimately contain a Help facility, a GNU licensing statement, a number of simple functions, and some logic to deal with those options, as well as others that might be needed for the scripts that will be based on this template.
|
||||
|
||||
### Resources
|
||||
|
||||
* [How to program with Bash: Syntax and tools][3]
|
||||
* [How to program with Bash: Logical operators and shell expansions][4]
|
||||
* [How to program with Bash: Loops][5]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_This series of articles is partially based on Volume 2, Chapter 10 of David Both's three-part Linux self-study course, [Using and Administering Linux—Zero to SysAdmin][6]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/automation-bash-scripts
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/laptop_screen_desk_work_chat_text.png?itok=UXqIDRDD (Person using a laptop)
|
||||
[2]: http://www.both.org/?page_id=903
|
||||
[3]: https://opensource.com/article/19/10/programming-bash-syntax-tools
|
||||
[4]: https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions
|
||||
[5]: https://opensource.com/article/19/10/programming-bash-loops
|
||||
[6]: http://www.both.org/?page_id=1183
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux desktops for minimalists: Getting started with LXQt and LXDE)
|
||||
[#]: via: (https://opensource.com/article/19/12/lxqt-lxde-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Linux desktops for minimalists: Getting started with LXQt and LXDE
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
Both LXDE and LXQt aim to provide a lightweight desktop for users who
|
||||
either need it or just prefer it, with minimal setup or configuration
|
||||
required.
|
||||
![Penguins walking on the beach ][1]
|
||||
|
||||
Preserving and resurrecting old computers is a popular part of the Linux hacker's ethos, and one way to help make that possible is with a desktop environment that doesn't use up scarce system resources. After all, the fact that a current version of Linux can run effectively on a computer over 15 years old is quite a feat, but it doesn't make the CPU and RAM any better than the day they were slotted in. There are extremely light desktops available, but there's usually a catch: the user must assemble the parts. Fortunately, a number of lightweight desktops have appeared over the years in an attempt to provide a fast and light desktop with no setup required.
|
||||
|
||||
Two early implementations of this idea were [LXDE][2] and [Razor-qt][3], the former based on GTK (the libraries used by GNOME) and the latter based on Qt (the libraries used by KDE). Coincidentally, the lead maintainer of LXDE discovered [the bliss that is Qt development][4] and decided to port (just as a side project!) the entire desktop to Qt. LXDE, the Qt port of it, and the Razor-qt project were combined to form [LXQt][5], although today, LXDE and LXQt coexist as separate projects.
|
||||
|
||||
Whether you use LXDE or LXQt, their goals are the same: to provide a lightweight desktop for users who either need it or just prefer it, with minimal setup or configuration required. These are drop-in desktops for any Linux or BSD system, whether it's 15 years old, or a new Raspberry Pi, or a hefty workstation that was just assembled. I used LXQt for this article, but everything apart from the GUI toolkit and some application names applies equally to LXQt and LXDE.
|
||||
|
||||
![LXQt on CentOS][6]
|
||||
|
||||
You may find LXQt or LXDE included your distribution's software repository, or you can download and install a distribution that ships LXQt or LXDE as a default desktop. Before you do, though, be aware that an LX* desktop is meant to provide a full desktop experience, so many applications are installed along with the desktop. If you're already running another desktop, you may find yourself with redundant applications (two PDF readers, two media players, two file managers, and so on). If you just want to try the LXQt or LXDE desktop, consider using a desktop virtualization application, such as [GNOME Boxes][7].
|
||||
|
||||
After installing, log out of your current desktop session so you can log into your new desktop. By default, your session manager (KDM, GDM, or LightDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
|
||||
|
||||
With GDM:
|
||||
|
||||
![][8]
|
||||
|
||||
With SDDM:
|
||||
|
||||
![][9]
|
||||
|
||||
### LXQt and LXDE desktop tour
|
||||
|
||||
The desktop layout has a classic look that's familiar to anyone who's used KDE's Plasma desktop or, realistically, any computer within the past two decades. There's an application menu in the lower-left corner, a taskbar for pinned and active applications, and a system tray in the lower-right corner. Because this is a full desktop environment, a few lightweight but robust applications are included. There's a text editor, an excellent file manager called PCManFM on LXDE and PCManFM-Qt on LXQt, configuration panels, a terminal, theme settings, and so on.
|
||||
|
||||
![LXDE desktop on Fedora][10]
|
||||
|
||||
The goal, aside from being light on resources, is to be intuitive, and these desktops excel at that. This isn't the place to look for an innovative new desktop design. The LXDE and LXQt desktops feel like they've been around forever, gliding through user actions with ease, finding just the right balance between explanatory prompts and minimal design. All the default settings are sensible, and 90% of what most users need to do on a desktop is covered (I'm reserving a conservative 10% for unique personal tastes that nobody expects any desktop to guess).
|
||||
|
||||
### To LXDE or to LXQt
|
||||
|
||||
Linux power users know GTK from Qt and sometimes even _care_ about which one they use, but it seems everyone admits it's down to personal taste and, in the end, doesn't actually matter. If you have no preference between GTK and Qt, then whether you use LXDE or LXQt may as well be a flip of a coin. They each have the same admirable goal: to provide a full desktop experience to any Linux computer that needs one, regardless of processor power or amount of RAM. If you're a fan of simplicity, then both desktops will appeal to you, and you're likely to settle into the defaults without spending hours customizing or rearranging anything at all. Sometimes it's refreshing to not care about the details and get straight to work. LXDE and LXQt are determined to bring that convenience to you, so give one a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/lxqt-lxde-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/community-penguins-osdc-lead.png?itok=BmqsAF4A (Penguins walking on the beach )
|
||||
[2]: http://lxde.org
|
||||
[3]: https://web.archive.org/web/20160220061334/http://razor-qt.org/
|
||||
[4]: https://opensource.com/article/17/4/pyqt-versus-wxpython
|
||||
[5]: http://lxqt.org
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-lxqt-file.jpg (LXQt on CentOS)
|
||||
[7]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[8]: https://opensource.com/sites/default/files/advent-gdm_1.jpg
|
||||
[9]: https://opensource.com/sites/default/files/advent-kdm_0.jpg
|
||||
[10]: https://opensource.com/sites/default/files/uploads/advent-lxde.jpg (LXDE desktop on Fedora)
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Make sysadmin work on Fedora easier with screen)
|
||||
[#]: via: (https://fedoramagazine.org/make-sysadmin-work-on-fedora-easier-with-screen/)
|
||||
[#]: author: (Carmine Zaccagnino https://fedoramagazine.org/author/carzacc/)
|
||||
|
||||
Make sysadmin work on Fedora easier with screen
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
When you manage a Linux instance, you’ll find that your job is made much easier by the many tools designed specifically to deal with something specific within the system. For example, if you need to install packages, you have easy-to-use package managers that make that a breeze. If you need to create, resize or delete filesystems, you can do so using tools that are built to be used by humans. The same goes for managing services and browsing logs with [systemd][2] using the _systemctl_ and _journalctl_ commands respectively. The _screen_ tool is another such example.
|
||||
|
||||
You can run all of those tools directly at the command line interface. But if you’re connecting to a server remotely using SSH, sometimes you need another layer between you and the operating system so the command you’re running doesn’t stop if your remote connection terminates. Sysadmins do this to prevent sudden termination in case of a connection issue, but also on purpose to run a command that needs to keep running indefinitely in the background. Enter the _screen_ utility.
|
||||
|
||||
### Introducing screen
|
||||
|
||||
The _screen_ tool allows you to have multiple sessions (called _screens_) that are independent from each other and that you can name, leave and join as you desire. It’s multi-tasking for the remote CLI. You can get started with it simply by running this command:
|
||||
|
||||
```
|
||||
$ screen
|
||||
```
|
||||
|
||||
The command creates a screen and connect you to it: your current session is now a screen. You can run any command that does something and doesn’t automatically terminate after a few seconds. For example, you might call a web app executable or a game server. Then press **Ctrl+A** and, right after that, the **D** key and you will _detach_ from the screen, leaving it running in the background.
|
||||
|
||||
The **Ctrl+A** combination, given that it is part of every _screen_ command, is often shortened in documentation to **C-a**. Then the _detach_ command used earlier can be described simply as **C-a d**.
|
||||
|
||||
#### Getting in and out of sessions
|
||||
|
||||
If you want to connect to that screen again, run _screen -r_ and you will _attach_ to that screen. Just running **screen** will create a new screen, and subsequent _screen -r_ commands will print out something like this:
|
||||
|
||||
```
|
||||
There are several suitable screens on:
|
||||
5589.pts-0.hostname (Detached)
|
||||
5536.pts-0.hostname (Detached)
|
||||
Type "screen [-d] -r [pid.]tty.host" to resume one of them.
|
||||
```
|
||||
|
||||
You can then choose whether to resume the first or the second screen you created by running either one of these commands:
|
||||
|
||||
```
|
||||
$ screen -r 5536
|
||||
$ screen -r 5589
|
||||
```
|
||||
|
||||
Adding the rest of the name of the string is optional in this case.
|
||||
|
||||
#### Named screens
|
||||
|
||||
If you know you’ll have multiple screens, you might want to be able to connect to a screen using a name you choose. This is easier than choosing from a list of numbers that only reflect the process IDs of the screen sessions. To do that, use the _-S_ option as in the following example:
|
||||
|
||||
```
|
||||
$ screen -S mywebapp
|
||||
```
|
||||
|
||||
Then you can resume that screen in the future using this command:
|
||||
|
||||
```
|
||||
$ screen -r mywebapp
|
||||
```
|
||||
|
||||
#### Starting a process in the background using screen
|
||||
|
||||
An optional argument is the command to be executed inside the created session. For example:
|
||||
|
||||
```
|
||||
$ screen -S session_name command args
|
||||
```
|
||||
|
||||
This would be the same as running:
|
||||
|
||||
```
|
||||
$ screen -S session_name
|
||||
```
|
||||
|
||||
…And then running this command inside the _screen_ session:
|
||||
|
||||
```
|
||||
$ command args
|
||||
```
|
||||
|
||||
The screen session will terminate when the command finishes its execution.
|
||||
|
||||
This is made particularly useful by passing the **-dm** option, which starts the screen in the background without attaching to it. For example, you can copy a very large file in the background by running this command:
|
||||
|
||||
```
|
||||
$ screen -S copy -d -m cp /path/to/file /path/to/output
|
||||
```
|
||||
|
||||
### Other screen features
|
||||
|
||||
Now that you’ve seen the basics, let’s see some of the other most commonly used screen features.
|
||||
|
||||
#### Easily switching between windows in a screen
|
||||
|
||||
When inside a screen, you can create a new window using **C-a c**. After you do that, you can switch between the windows using **C-a n** to go to the next one and **C-a p** to go to the previous window. You can destroy (kill) the current window with **C-a k**.
|
||||
|
||||
#### Copying and pasting text
|
||||
|
||||
The screen tool also enables you to copy any text on the screen and paste it later wherever you can type some text.
|
||||
|
||||
The **C-a [** keybinding frees your cursor of any constraints and lets it go anywhere your will takes it using the arrow keys on your keyboard. To select and copy text, move to the start of the string you want to copy, and press **Enter** on the keyboard. Then move the cursor to the end of the text you want to copy and press **Enter** again.
|
||||
|
||||
After you’ve done that, use **C-a ]** to paste that text in your shell. Or you can open a text editor like _vim_ or _nano_ and paste the text you copied there.
|
||||
|
||||
### Important notes about screen
|
||||
|
||||
Here are some other tips to keep in mind when using this utility.
|
||||
|
||||
#### Privileged sessions vs. sudo inside a screen
|
||||
|
||||
What if you need to run a command with root privileges inside screen? You can run either of these commands:
|
||||
|
||||
```
|
||||
$ screen -S sessionname sudo command
|
||||
$ sudo screen -S sessionname command
|
||||
```
|
||||
|
||||
Notice that the second command is like running this command:
|
||||
|
||||
```
|
||||
# screen -S sessionname command
|
||||
```
|
||||
|
||||
Seeing things this way makes it a lot more obvious coupled with the fact that each screen is associated to a user:
|
||||
|
||||
* The first one creates a screen with root privileges that can be accessed by the current user even if, within that screen, they switch to another user or _root_ using the _sudo -i_ command.
|
||||
* The second one creates a screen that can only be accessed by the _root_ user, or by running _sudo screen -r_ as a user with the [appropriate _sudo_ access][3].
|
||||
|
||||
|
||||
|
||||
#### Notes about screen in systemd units
|
||||
|
||||
You might be tempted to run a screen session in the background as part of a systemd unit executed at startup, just like any Unix daemon. That way you can resume the screen session and interact with whatever you ran that way. That can work, but you need to consider that it requires the right setup.
|
||||
|
||||
By default, [systemd assumes][4] services are either _oneshot,_ meaning they set up something and then shut down, or _simple_. A service is simple by default when you create a unit file with no _Type_. What you actually need to do is to set the _Type_ to _forking_, which describes _screen_‘s actual behavior when the **-dm** option is passed. It starts the process and then forks itself, leaving the process running in the background while the foreground process closes.
|
||||
|
||||
If you don’t set that, that _screen_ behavior is interpreted by systemd as the service exiting or failing. This causes systemd to kill the background process when the foreground process exits, which is not what you want.
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by [Vlad Tchompalov][5] on [Unsplash][6]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/make-sysadmin-work-on-fedora-easier-with-screen/
|
||||
|
||||
作者:[Carmine Zaccagnino][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/carzacc/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/12/screen-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/what-is-an-init-system/
|
||||
[3]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]: https://www.freedesktop.org/software/systemd/man/systemd.service.html
|
||||
[5]: https://unsplash.com/@tchompalov?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[6]: https://unsplash.com/s/photos/screen?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,260 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (An Actionable Guide to Enhance Your Online Privacy With Tor)
|
||||
[#]: via: (https://itsfoss.com/tor-guide/)
|
||||
[#]: author: (Community https://itsfoss.com/author/itsfoss/)
|
||||
|
||||
An Actionable Guide to Enhance Your Online Privacy With Tor
|
||||
======
|
||||
|
||||
In a world where technology is rapidly evolving, companies are gathering data and information from users in order to optimize the functionality of their applications as much as possible, privacy has slowly begun to fade and look like a myth.
|
||||
|
||||
Many people believe that completely concealing their identity online is a difficult process that cannot be achieved. But of course, for security experts and for those who are optimistic that anonymity will not be lost, the answer is that we can enhance anonymity on the Internet.
|
||||
|
||||
This can clearly be achieved with the help of _Tor_. Tor stands for The Onion Routing.
|
||||
|
||||
Tor is a free and open source software developed by the [Tor project][1], a non-profit organization focusing on the freedom and privacy of users on the Internet.
|
||||
|
||||
![Tor Onion][2]
|
||||
|
||||
Let’s see below how you can enhance our online privacy with Tor.
|
||||
|
||||
### What is Tor?
|
||||
|
||||
As I mentioned before, Tor is a free open source software which defends users’ privacy. Specifically, The Onion Router software is being used by students, companies, universities, reporters who maybe want to share an idea anonymously for many years. In order to conceal users’ identities, Tor routes traffic through a worldwide overlay network which consisting of thousand of relays.
|
||||
|
||||
![Tor Network][3]
|
||||
|
||||
In addition, it has a very handy functionality as it encrypts the data multiple times, including the next IP address for the node it is intended for, and sends it through a virtual circuit that includes a random node. Each node decrypts a layer of encrypted information in order to reveal the next node. The result is that the remaining encrypted information will be decrypted at the last node without revealing the source IP address. This process builds the Tor circuit.
|
||||
|
||||
### How to install Tor on Linux
|
||||
|
||||
Since Tor is one of the most popular software in the open source community, it can be found in almost every Linux distribution’s repository.
|
||||
|
||||
For Ubuntu-based distributions, it is available in the universe repository. We have a separate article on [installing Tor browser on Ubuntu][4] which you may refer. It also has a few tips on using the browser that you may find useful.
|
||||
|
||||
I am using Debian 10 so I’ll mention the steps for installing Tor on Debian:
|
||||
|
||||
All you have to do is to add the backport repository to our sources.list and then we can easily install Tor and its components. Use the following commands:
|
||||
|
||||
```
|
||||
echo "deb http://deb.debian.org/debian buster-backports main contrib" > /etc/apt/sources.list.d/buster-backports.list
|
||||
|
||||
sudo apt update
|
||||
sudo apt install tor torbrowser-launcher
|
||||
```
|
||||
|
||||
Remember!
|
||||
|
||||
Do not run Tor as root, as it is not secure for your operating system. It is recommended to run it as a normal user.
|
||||
|
||||
### What can you achieve with Tor?
|
||||
|
||||
As we move on, you will see numerous privacy enhancements that can be impressively accomplished with Tor.
|
||||
|
||||
Particularly, below we will see the topics that will be covered:
|
||||
|
||||
* Explore the Tor Network with Tor Browser
|
||||
* Use Tor through Firefox
|
||||
|
||||
|
||||
|
||||
Note: It would be helpful to take into consideration that Tor can be used alongside with many applications, so anyone can privately use the application she/he desires.
|
||||
|
||||
* Create a hidden Tor service
|
||||
* Create a middle Tor relay
|
||||
|
||||
|
||||
|
||||
#### Explore the Tor network with Tor browser
|
||||
|
||||
To connect to the Tor network through the Tor browser, open the application that will be with the rest of your internet applications or type in the terminal:
|
||||
|
||||
```
|
||||
torbrowser-launcher
|
||||
```
|
||||
|
||||
Initially, a window will appear, which allows some settings to be modified in the connection. For example, for users who wish to access the Tor network, and their country does not allow them, they must have the necessary settings for a successful connection.
|
||||
|
||||
![Tor Network Settings][5]
|
||||
|
||||
You can always request a bridge from the Tor Database, [BridgeDB][6].
|
||||
|
||||
If everything is under control, all that’s left is to connect.
|
||||
|
||||
![Tor Browser][7]
|
||||
|
||||
_**Welcome to Tor..**_
|
||||
|
||||
It is worth mentioning that it would be helpful and safe to avoid adding extensions to Tor Browser as it can reveal user’s real location and IP address to the website operators.
|
||||
|
||||
It is also recommended to avoid downloading torrents, to avoid IP revealing.
|
||||
|
||||
_**Let the exploration begin ..**_
|
||||
|
||||
#### How to use Tor through Firefox
|
||||
|
||||
You don’t always need to use the Tor browser. The [awesome Firefox][8] allows you to use Tor network.
|
||||
|
||||
In order to connect to tor network via Firefox, you must first open the tor service. To do this, execute the following command:
|
||||
|
||||
```
|
||||
sudo service tor start
|
||||
```
|
||||
|
||||
To ensure that the tor is active, you can observe the open links. Below you can see the running port, which is the 9050.
|
||||
|
||||
```
|
||||
netstat -nvlp
|
||||
```
|
||||
|
||||
Here’s the output:
|
||||
|
||||
```
|
||||
.. .. .. .. ..
|
||||
|
||||
tcp 0 0 127.0.0.1:9050 0.0.0.0:* LISTEN
|
||||
```
|
||||
|
||||
The only thing left to do is to set Firefox to be connected through Tor proxy.
|
||||
|
||||
Go to Preferences → General → Network Proxy and set the localhost IP and Tor listening port to SOCKS v5 as shows below:
|
||||
|
||||
![Setting Tor in Firefox][9]
|
||||
|
||||
#### How to create a Tor Hidden Service
|
||||
|
||||
Ttry to search for the term “Hidden Wiki”, you will notice that you will not find any hidden content. This is because the content discussed above does not represent the standard domain, but a top-level domain that can be found through Tor. This domain is .onion.
|
||||
|
||||
So let’s see how you can create your own _**secret onion service**_.
|
||||
|
||||
With the installation of Tor, torrc was created. The torrc is the tor configuration file, and its path is /etc/tor/torrc.
|
||||
|
||||
Note: In order for modification to be applied, the ‘#’ symbol must be removed from the start of the line.
|
||||
|
||||
To create the onion service you need to modify the configuration file so that after its modification it contains our service.
|
||||
|
||||
You can open the file with a [command line text editor][10] of your choice. Personally, my favourite text editor is Vim. If Vim is used and you have any difficulty, you can take a look at the following article to make the situation clearer.
|
||||
|
||||
In torrc you will find a lot of content, which can, in any case, be analyzed in a related article. For the time being, we are interested in the line mentioned by “Hidden Service”.
|
||||
|
||||
![][11]
|
||||
|
||||
At first glance, it can be understood that a path, a network address and finally two doors should be set.
|
||||
|
||||
```
|
||||
HiddenServiceDir /var/lib/tor/hidden_service/
|
||||
```
|
||||
|
||||
‘HiddenServiceDir’ denotes the path the hostname will generate, which will then be the user visit point to the secret service created.
|
||||
|
||||
HiddenServicePort 80 127.0.0.1:80
|
||||
|
||||
‘HiddenServicePort’ indicates which address and port the .onion service will be connected to.
|
||||
|
||||
For example, below is the creation of a hidden service named linuxhandbook, which as a port destination will have port 80, as the address will have localhost’s IP and port 80 respectively.
|
||||
|
||||
![][12]
|
||||
|
||||
Finally, the only thing left to complete the creation is to restart the tor service. Once the tor is restarted, the /var/lib/tor// path will have both the public and private secret service key, as well as the hostname file. The ‘Hostname’ file contains the .onion link provided for our onion site.
|
||||
|
||||
Here is the output of my ‘hostname’ file.
|
||||
|
||||
```
|
||||
ogl3kz3nfckz22xp4migfed76fgbofwueytf7z6d2tnlh7vuto3zjjad.onion
|
||||
```
|
||||
|
||||
Just visit this link through your Tor Browser and you will see your up and running server based on a .onion domain.
|
||||
|
||||
![Sample Onion Web Page][13]
|
||||
|
||||
#### How to Create a Middle Tor Relay
|
||||
|
||||
The Tor network, as mentioned before, is an open network, which consists of many nodes. Tor nodes are a creation of volunteers, that is, contributors to enhancing privacy. It is worth noting that the nodes are over 7000 and they are getting bigger day by day. Everyone’s contribution is always acceptable as we expand one of the predominantly largest networks worldwide.
|
||||
|
||||
Tor contains Guard, Middle and Exit Relays. A Guard Relay is the the first relay of a Tor circuit. The Middle Relay is the second hop of the circuit. Guard and Middle Relays are listed in the public list of Tor relays. Exit Relay is the final relay of a tor circuit. It is a crucial relay, as it sends traffic out its destination.
|
||||
|
||||
All relays are meaningful but in this article, we will cover about Middle relays.
|
||||
|
||||
Here’s and image showing middle-relay traffic the last two months.
|
||||
|
||||
![][14]
|
||||
|
||||
Lets see how we can create a middle relay.
|
||||
|
||||
Once again, in order to create your own middle relay, you have to modify the torrc file.
|
||||
|
||||
In any case, as I mentioned above, you can uncomment the lines when you need your configuration to be enabled.
|
||||
|
||||
However, it is feasible to copy the following lines and then modify them.
|
||||
|
||||
```
|
||||
#change the nickname “Linuxhandbook” to a name that you like
|
||||
Nickname Linuxhandbook
|
||||
ORPort 443
|
||||
ExitRelay 0
|
||||
SocksPort 0
|
||||
ControlSocket 0
|
||||
#change the email address below and be aware that it will be published
|
||||
ContactInfo [email protected]
|
||||
```
|
||||
|
||||
An explanation should make the situation clearer.
|
||||
|
||||
* Nickname: Set your own relay name.
|
||||
* ORPort: Set a port which will be the relay’s listening port.
|
||||
* ExitRelay: By default, is set to 0, we want to create a middle relay.
|
||||
|
||||
|
||||
|
||||
Note: tor service needs to be open.
|
||||
|
||||
You should see your middle-relay up and running in Tor Metrics after a few couple of hours. Therefore, it usually takes 3 hours to be published, according to [Tormetrics][15].
|
||||
|
||||
Warning!
|
||||
|
||||
For sure, some of you may have heard of the term “Deep Web”, “Hidden Wiki” and many other services that you haven’t been able to visit yet. Besides, you may have heard that there is content posted on the Tor network which may be illegal.
|
||||
|
||||
In the Tor network, one can find almost anything, such as forums with any kind of discussion. Quite right, since there is no censorship in a network whose entities are anonymous. This is both good and bad at the same time.
|
||||
|
||||
I am not going to give sermons here about what you should use and what you should not use. I believe that you are sensible enough to make that decision.
|
||||
|
||||
In conclusion, you can thoroughly see, that one can, in any case, enhance their privacy as well as defend themselves from Internet censorship. I would love to hear your opinion about Tor.
|
||||
|
||||
##### Panos
|
||||
|
||||
Penetration Tester and Operating System developer
|
||||
|
||||
Panos’ love for Free Open Source Software is invaluable. In his spare time, he observes the night sky with his telescope.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/tor-guide/
|
||||
|
||||
作者:[Community][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/itsfoss/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.torproject.org/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/tor_onion.jpg?ssl=1
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/tor-network-diagram.png?ssl=1
|
||||
[4]: https://itsfoss.com/install-tar-browser-linux/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/tor_browser.png?ssl=1
|
||||
[6]: https://www.bridgedb.org/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/tor_firefox.jpg?ssl=1
|
||||
[8]: https://itsfoss.com/why-firefox/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/tor_settings.png?ssl=1
|
||||
[10]: https://itsfoss.com/command-line-text-editors-linux/
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/create_tor_relay.jpg?ssl=1
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/create_tor_relay_2.jpg?ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/onion_web_page.jpg?ssl=1
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/tor_relay.jpg?ssl=1
|
||||
[15]: https://metrics.torproject.org/
|
||||
236
sources/tech/20191219 Creating a Bash script template.md
Normal file
236
sources/tech/20191219 Creating a Bash script template.md
Normal file
@ -0,0 +1,236 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Creating a Bash script template)
|
||||
[#]: via: (https://opensource.com/article/19/12/bash-script-template)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
Creating a Bash script template
|
||||
======
|
||||
In the second article in this series, create a fairly simple template
|
||||
that you can use as a starting point for other Bash programs, then test
|
||||
it.
|
||||
![A person programming][1]
|
||||
|
||||
In the [first article][2] in this series, you created a very small, one-line Bash script and explored the reasons for creating shell scripts and why they are the most efficient option for the system administrator, rather than compiled programs.
|
||||
|
||||
In this second article, you will begin creating a Bash script template that can be used as a starting point for other Bash scripts. The template will ultimately contain a Help facility, a licensing statement, a number of simple functions, and some logic to deal with those options and others that might be needed for the scripts that will be based on this template.
|
||||
|
||||
### Why create a template?
|
||||
|
||||
Like automation in general, the idea behind creating a template is to be the "[lazy sysadmin][3]." A template contains the basic components that you want in all of your scripts. It saves time compared to adding those components to every new script and makes it easy to start a new script.
|
||||
|
||||
Although it can be tempting to just throw a few command-line Bash statements together into a file and make it executable, that can be counterproductive in the long run. A well-written and well-commented Bash program with a Help facility and the capability to accept command-line options provides a good starting point for sysadmins who maintain the program, which includes the programs that _you_ write and maintain.
|
||||
|
||||
### The requirements
|
||||
|
||||
You should always create a set of requirements for every project you do. This includes scripts, even if it is a simple list with only two or three items on it. I have been involved in many projects that either failed completely or failed to meet the customer's needs, usually due to the lack of a requirements statement or a poorly written one.
|
||||
|
||||
The requirements for this Bash template are pretty simple:
|
||||
|
||||
1. Create a template that can be used as the starting point for future Bash programming projects.
|
||||
2. The template should follow standard Bash programming practices.
|
||||
3. It must include:
|
||||
* A heading section that can be used to describe the function of the program and a changelog
|
||||
* A licensing statement
|
||||
* A section for functions
|
||||
* A Help function
|
||||
* A function to test whether the program user is root
|
||||
* A method for evaluating command-line options
|
||||
|
||||
|
||||
|
||||
### The basic structure
|
||||
|
||||
A basic Bash script has three sections. Bash has no way to delineate sections, but the boundaries between the sections are implicit.
|
||||
|
||||
* All scripts must begin with the shebang (**#!**), and this must be the first line in any Bash program.
|
||||
* The functions section must begin after the shebang and before the body of the program. As part of my need to document everything, I place a comment before each function with a short description of what it is intended to do. I also include comments inside the functions to elaborate further. Short, simple programs may not need functions.
|
||||
* The main part of the program comes after the function section. This can be a single Bash statement or thousands of lines of code. One of my programs has a little over 200 lines of code, not counting comments. That same program has more than 600 comment lines.
|
||||
|
||||
|
||||
|
||||
That is all there is—just three sections in the structure of any Bash program.
|
||||
|
||||
### Leading comments
|
||||
|
||||
I always add more than this for various reasons. First, I add a couple of sections of comments immediately after the shebang. These comment sections are optional, but I find them very helpful.
|
||||
|
||||
The first comment section is the program name and description and a change history. I learned this format while working at IBM, and it provides a method of documenting the long-term development of the program and any fixes applied to it. This is an important start in documenting your program.
|
||||
|
||||
The second comment section is a copyright and license statement. I use GPLv2, and this seems to be a standard statement for programs licensed under GPLv2. If you use a different open source license, that is fine, but I suggest adding an explicit statement to the code to eliminate any possible confusion about licensing. Scott Peterson's article [_The source code is the license_][4] helps explain the reasoning behind this.
|
||||
|
||||
So now the script looks like this:
|
||||
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
################################################################################
|
||||
# scriptTemplate #
|
||||
# #
|
||||
# Use this template as the beginning of a new program. Place a short #
|
||||
# description of the script here. #
|
||||
# #
|
||||
# Change History #
|
||||
# 11/11/2019 David Both Original code. This is a template for creating #
|
||||
# new Bash shell scripts. #
|
||||
# Add new history entries as needed. #
|
||||
# #
|
||||
# #
|
||||
################################################################################
|
||||
################################################################################
|
||||
################################################################################
|
||||
# #
|
||||
# Copyright (C) 2007, 2019 David Both #
|
||||
# [LinuxGeek46@both.org][5] #
|
||||
# #
|
||||
# This program is free software; you can redistribute it and/or modify #
|
||||
# it under the terms of the GNU General Public License as published by #
|
||||
# the Free Software Foundation; either version 2 of the License, or #
|
||||
# (at your option) any later version. #
|
||||
# #
|
||||
# This program is distributed in the hope that it will be useful, #
|
||||
# but WITHOUT ANY WARRANTY; without even the implied warranty of #
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the #
|
||||
# GNU General Public License for more details. #
|
||||
# #
|
||||
# You should have received a copy of the GNU General Public License #
|
||||
# along with this program; if not, write to the Free Software #
|
||||
# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA #
|
||||
# #
|
||||
################################################################################
|
||||
################################################################################
|
||||
################################################################################
|
||||
|
||||
echo "hello world!"
|
||||
```
|
||||
|
||||
Run the revised program to verify that it still works as expected.
|
||||
|
||||
### About testing
|
||||
|
||||
Now is a good time to talk about testing.
|
||||
|
||||
> "_There is always one more bug."_
|
||||
> — Lubarsky's Law of Cybernetic Entomology
|
||||
|
||||
Lubarsky—whoever that might be—is correct. You can never find all the bugs in your code. For every bug I find, there always seems to be another that crops up, usually at a very inopportune time.
|
||||
|
||||
Testing is not just about programs. It is also about verification that problems—whether caused by hardware, software, or the seemingly endless ways users can find to break things—that are supposed to be resolved actually are. Just as important, testing is also about ensuring that the code is easy to use and the interface makes sense to the user.
|
||||
|
||||
Following a well-defined process when writing and testing shell scripts can contribute to consistent and high-quality results. My process is simple:
|
||||
|
||||
1. Create a simple test plan.
|
||||
2. Start testing right at the beginning of development.
|
||||
3. Perform a final test when the code is complete.
|
||||
4. Move to production and test more.
|
||||
|
||||
|
||||
|
||||
#### The test plan
|
||||
|
||||
There are lots of different formats for test plans. I have worked with the full range—from having it all in my head; to a few notes jotted down on a sheet of paper; and all the way to a complex set of forms that require a full description of each test, which functional code it would test, what the test would accomplish, and what the inputs and results should be.
|
||||
|
||||
Speaking as a sysadmin who has been (but is not now) a tester, I try to take the middle ground. Having at least a short written test plan will ensure consistency from one test run to the next. How much detail you need depends upon how formal your development and test functions are.
|
||||
|
||||
The sample test plan documents I found using Google were complex and intended for large organizations with very formal development and test processes. Although those test plans would be good for people with "test" in their job title, they do not apply well to sysadmins' more chaotic and time-dependent working conditions. As in most other aspects of the job, sysadmins need to be creative. So here is a short list of things to consider including in your test plan. Modify it to suit your needs:
|
||||
|
||||
* The name and a short description of the software being tested
|
||||
* A description of the software features to be tested
|
||||
* The starting conditions for each test
|
||||
* The functions to follow for each test
|
||||
* A description of the desired outcome for each test
|
||||
* Specific tests designed to test for negative outcomes
|
||||
* Tests for how the program handles unexpected inputs
|
||||
* A clear description of what constitutes pass or fail for each test
|
||||
* Fuzzy testing, which is described below
|
||||
|
||||
|
||||
|
||||
This list should give you some ideas for creating your test plans. Most sysadmins should keep it simple and fairly informal.
|
||||
|
||||
#### Test early—test often
|
||||
|
||||
I always start testing my shell scripts as soon as I complete the first portion that is executable. This is true whether I am writing a short command-line program or a script that is an executable file.
|
||||
|
||||
I usually start creating new programs with the shell script template. I write the code for the Help function and test it. This is usually a trivial part of the process, but it helps me get started and ensures that things in the template are working properly at the outset. At this point, it is easy to fix problems with the template portions of the script or to modify it to meet needs that the standard template does not.
|
||||
|
||||
Once the template and Help function are working, I move on to creating the body of the program by adding comments to document the programming steps required to meet the program specifications. Now I start adding code to meet the requirements stated in each comment. This code will probably require adding variables that are initialized in that section of the template—which is now becoming a shell script.
|
||||
|
||||
This is where testing is more than just entering data and verifying the results. It takes a bit of extra work. Sometimes I add a command that simply prints the intermediate result of the code I just wrote and verify that. For more complex scripts, I add a **-t** option for "test mode." In this case, the internal test code executes only when the **-t** option is entered on the command line.
|
||||
|
||||
#### Final testing
|
||||
|
||||
After the code is complete, I go back to do a complete test of all the features and functions using known inputs to produce specific outputs. I also test some random inputs to see if the program can handle unexpected input.
|
||||
|
||||
Final testing is intended to verify that the program is functioning essentially as intended. A large part of the final test is to ensure that functions that worked earlier in the development cycle have not been broken by code that was added or changed later in the cycle.
|
||||
|
||||
If you have been testing the script as you add new code to it, you may think there should not be any surprises during the final test. Wrong! There are always surprises during final testing. Always. Expect those surprises, and be ready to spend time fixing them. If there were never any bugs discovered during final testing, there would be no point in doing a final test, would there?
|
||||
|
||||
#### Testing in production
|
||||
|
||||
Huh—what?
|
||||
|
||||
> "Not until a program has been in production for at least six months will the most harmful error be discovered."
|
||||
> — Troutman's Programming Postulates
|
||||
|
||||
Yes, testing in production is now considered normal and desirable. Having been a tester myself, this seems reasonable. "But wait! That's dangerous," you say. My experience is that it is no more dangerous than extensive and rigorous testing in a dedicated test environment. In some cases, there is no choice because there is no test environment—only production.
|
||||
|
||||
Sysadmins are no strangers to the need to test new or revised scripts in production. Anytime a script is moved into production, that becomes the ultimate test. The production environment constitutes the most critical part of that test. Nothing that testers can dream up in a test environment can fully replicate the true production environment.
|
||||
|
||||
The allegedly new practice of testing in production is just the recognition of what sysadmins have known all along. The best test is production—so long as it is not the only test.
|
||||
|
||||
#### Fuzzy testing
|
||||
|
||||
This is another of those buzzwords that initially caused me to roll my eyes. Its essential meaning is simple: have someone bang on the keys until something happens, and see how well the program handles it. But there really is more to it than that.
|
||||
|
||||
Fuzzy testing is a bit like the time my son broke the code for a game in less than a minute with random input. That pretty much ended my attempts to write games for him.
|
||||
|
||||
Most test plans utilize very specific input that generates a specific result or output. Regardless of whether the test defines a positive or negative outcome as a success, it is still controlled, and the inputs and results are specified and expected, such as a specific error message for a specific failure mode.
|
||||
|
||||
Fuzzy testing is about dealing with randomness in all aspects of the test, such as starting conditions, very random and unexpected input, random combinations of options selected, low memory, high levels of CPU contending with other programs, multiple instances of the program under test, and any other random conditions that you can think of to apply to the tests.
|
||||
|
||||
I try to do some fuzzy testing from the beginning. If the Bash script cannot deal with significant randomness in its very early stages, then it is unlikely to get better as you add more code. This is a good time to catch these problems and fix them while the code is relatively simple. A bit of fuzzy testing at each stage is also useful in locating problems before they get masked by even more code.
|
||||
|
||||
After the code is completed, I like to do some more extensive fuzzy testing. Always do some fuzzy testing. I have certainly been surprised by some of the results. It is easy to test for the expected things, but users do not usually do the expected things with a script.
|
||||
|
||||
### Previews of coming attractions
|
||||
|
||||
This article accomplished a little in the way of creating a template, but it mostly talked about testing. This is because testing is a critical part of creating any kind of program. In the next article in this series, you will add a basic Help function along with some code to detect and act on options, such as **-h**, to your Bash script template.
|
||||
|
||||
### Resources
|
||||
|
||||
* [How to program with Bash: Syntax and tools][6]
|
||||
* [How to program with Bash: Logical operators and shell expansions][7]
|
||||
* [How to program with Bash: Loops][8]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_This series of articles is partially based on Volume 2, Chapter 10 of David Both's three-part Linux self-study course, [Using and Administering Linux—Zero to SysAdmin][9]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/bash-script-template
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
|
||||
[2]: https://opensource.com/article/19/12/introduction-automation-bash-scripts
|
||||
[3]: https://opensource.com/article/18/7/how-be-lazy-sysadmin
|
||||
[4]: https://opensource.com/article/17/12/source-code-license
|
||||
[5]: mailto:LinuxGeek46@both.org
|
||||
[6]: https://opensource.com/article/19/10/programming-bash-syntax-tools
|
||||
[7]: https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions
|
||||
[8]: https://opensource.com/article/19/10/programming-bash-loops
|
||||
[9]: http://www.both.org/?page_id=1183
|
||||
@ -0,0 +1,107 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Go mouseless with the Linux Ratpoison window manager)
|
||||
[#]: via: (https://opensource.com/article/19/12/ratpoison-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Go mouseless with the Linux Ratpoison window manager
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
If you'd rather live in a terminal all day and avoid mousing around, the
|
||||
Ratpoison window manager is the solution for you.
|
||||
![Buildings with different color windows][1]
|
||||
|
||||
Maybe you don't like desktops. Maybe even a lightweight window manager seems excessive to you. Maybe all you really use is a graphical user interface (GUI) application or two, and you're otherwise perfectly happy living in a terminal all day. If one or more of these sentiments sound familiar, then [Ratpoison][2] is the solution.
|
||||
|
||||
![Ratpoison][3]
|
||||
|
||||
The Ratpoison window manager models itself after [GNU Screen][4]. All window controls are performed with keyboard shortcuts, so you don't have to grab the mouse just to move a window out of your way. The trade-off is that it's impossibly minimalistic, which is, conveniently, also its greatest strength.
|
||||
|
||||
### Installing Ratpoison
|
||||
|
||||
Install Ratpoison from your distribution's software repository. After installing it, log out of your current desktop session so you can log into your new one. By default, your session manager (KDM, GDM, LightDM, or XDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
|
||||
|
||||
With GDM:
|
||||
|
||||
![][5]
|
||||
|
||||
With SDDM:
|
||||
|
||||
![][6]
|
||||
|
||||
### Ratpoison desktop tour
|
||||
|
||||
The first time you log into Ratpoison, you are greeted by a black screen with some text in the upper-right corner telling you that you can press **Ctrl+t** for help.
|
||||
|
||||
That's all there is to the Ratpoison desktop.
|
||||
|
||||
### Interacting with Ratpoison
|
||||
|
||||
Ratpoison documentation uses Emacs-style notation for keyboard controls, so I'll use the same notation in this article. If you're unfamiliar with Emacs or GNU Screen, it can look confusing at first, so here's explicit instruction on how to "decode" this style of notation. The Control key on your keyboard is written as **C-**. To trigger Ratpoison's command mode, you press **C-t**, which means that you press **Ctrl+t**.
|
||||
|
||||
Since the **C-t** shortcut puts you into command mode, it's expected that some other key sequence will follow. For instance, to launch an xterm window, press **Ctrl+t**, just as you would when opening a new tab in a web browser, then press **c**. This may feel a little unnatural at first, because most of the keyboard shortcuts you're used to probably involve only one action. Ratpoison (and GNU Screen and Emacs) more often involve two.
|
||||
|
||||
The first application you probably should launch is either Emacs or a terminal.
|
||||
|
||||
In Ratpoison, your terminal is your exclusive gateway to the rest of the computer because there's no application menu or icons to click. The default terminal is the humble xterm, and it's available with the **C-t c** shortcut (I remember the **c** as being short for "console").
|
||||
|
||||
#### Launching applications
|
||||
|
||||
I usually start with Emacs instead, because it has most of the features I use anyway, including the **shell** terminal and the **dired** file manager. To start an arbitrary application in Ratpoison, press **C-t** and then the **!** (exclamation point) symbol. This provides a prompt in the upper-right corner of the screen. Type the command for the application you want to start and press **Return** or **Enter** to launch it.
|
||||
|
||||
#### Switching windows
|
||||
|
||||
Each application you launch takes over the entire screen by default. That means if [urxvt][7] is running, and then you launch Emacs, you can no longer interact with urxvt. Because switching back and forth between two application windows is a pretty common task, Ratpoison assigns it to the same keystroke as your usual Ratpoison command: **C-t C-t**. That means you press **Ctrl+t** once, and then **Ctrl+t** a second time. This is a toggle, like the default (at least in KDE and GNOME) behavior of a quick **Alt+Tab**.
|
||||
|
||||
To cycle through all open windows, use **C-t n** for _next_ and **C-t p** for _previous_.
|
||||
|
||||
#### Tiling window manager
|
||||
|
||||
You're free to use Ratpoison as a full-screen viewscreen, but most of us are used to seeing more than one window at a time. To allow that, Ratpoison lets you split your screen into frames or tiles and launch an application within each space.
|
||||
|
||||
![Ratpoison in split-screen mode][8]
|
||||
|
||||
With at least one application open, you can split the screen horizontally with **C-t s** (that's a lowercase "s") or vertically with **C-t S** (that's a capital "S").
|
||||
|
||||
To switch to another frame, use **C-t Tab**.
|
||||
|
||||
To remove another frame, press **C-t R**.
|
||||
|
||||
#### Moving windows in split-screen mode
|
||||
|
||||
Rearranging frames when Ratpoison has been split into several parts is done with the **Ctrl** key and a corresponding **Arrow** key. For instance, suppose you have a vertical split in the top half of your screen and a single frame in the bottom half. If an application is in the top-left frame, and you want to move it to the lower half of the screen, then—with that application active (use **C-t Tab** to get there)—press **C-t** to enter command mode and then **C-Down** (that's **Ctrl** with the **Down arrow** key). The application moves to the bottom half of the screen, with the application that took up the bottom half moving into the top-left.
|
||||
|
||||
To move that application to the top-right frame instead, press **C-t Right** (**Ctrl** with the **Right arrow** key).
|
||||
|
||||
To remove the top-left frame entirely, use **C-t R**. This doesn't kill the application in the frame, it only removes the frame from your viewport. The application that once occupied the frame is sent to the background and can be reached by cycling through the windows as usual (**C-t n**, for instance).
|
||||
|
||||
### Why you need to try Ratpoison
|
||||
|
||||
Ratpoison is a great example of an early (but current) tiling window manager. Other window managers like it exist, and some desktops even borrow concepts from this tradition by offering tiling features (KWin in KDE, for example, has an option to spawn new windows in tiles across the desktop).
|
||||
|
||||
If you've never used a tiling window manager, you owe it to yourself to try at least once. First, make it a goal to use Ratpoison. Then make it a goal to get through a whole afternoon without your mouse. Once you get the hang of it, you might be surprised at how quickly you can work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/ratpoison-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/colors-colorful-box-rectangle.png?itok=doWmqCdf (Buildings with different color windows)
|
||||
[2]: https://www.nongnu.org/ratpoison/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/advent-ratpoison.png (Ratpoison)
|
||||
[4]: https://opensource.com/article/17/3/introduction-gnu-screen
|
||||
[5]: https://opensource.com/sites/default/files/advent-gdm_1.jpg
|
||||
[6]: https://opensource.com/sites/default/files/advent-kdm_0.jpg
|
||||
[7]: https://opensource.com/article/19/10/why-use-rxvt-terminal
|
||||
[8]: https://opensource.com/sites/default/files/uploads/advent-ratpoison-split.jpg (Ratpoison in split-screen mode)
|
||||
192
sources/tech/20191219 Kubernetes namespaces for beginners.md
Normal file
192
sources/tech/20191219 Kubernetes namespaces for beginners.md
Normal file
@ -0,0 +1,192 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Kubernetes namespaces for beginners)
|
||||
[#]: via: (https://opensource.com/article/19/12/kubernetes-namespaces)
|
||||
[#]: author: (Jessica Cherry https://opensource.com/users/jrepka)
|
||||
|
||||
Kubernetes namespaces for beginners
|
||||
======
|
||||
What is a namespace and why do you need it?
|
||||
![Ship captain sailing the Kubernetes seas][1]
|
||||
|
||||
What is in a Kubernetes namespace? As Shakespeare once wrote, which we call a namespace, by any other name, would still be a virtual cluster. By virtual cluster, I mean Kubernetes can offer multiple Kubernetes clusters on a single cluster, much like a virtual machine is an abstraction of its host. According to the [Kubernetes docs][2]:
|
||||
|
||||
> Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces.
|
||||
|
||||
Why do you need to use namespaces? In one word: isolation.
|
||||
|
||||
Isolation has many advantages, including that it supports secure and clean environments. If you are the owner of the infrastructure and are supporting developers, isolation is fairly important. The last thing you need is someone who is unfamiliar with how your cluster is built going and changing the system configuration—and possibly disabling everyone's ability to log in.
|
||||
|
||||
### The namespaces that start it all
|
||||
|
||||
The first three namespaces created in a cluster are always **default**, **kube-system**, and **kube-public**. While you can technically deploy within these namespaces, I recommend leaving these for system configuration and not for your projects.
|
||||
|
||||
* **Default** is for deployments that are not given a namespace, which is a quick way to create a mess that will be hard to clean up if you do too many deployments without the proper information. I leave this alone because it serves that one purpose and has confused me on more than one occasion.
|
||||
* **Kube-system** is for all things relating to, you guessed it, the Kubernetes system. Any deployments to this namespace are playing a dangerous game and can accidentally cause irreparable damage to the system itself. Yes, I have done it; I do not recommend it.
|
||||
* **Kube-public** is readable by everyone, but the namespace is reserved for system usage.
|
||||
|
||||
|
||||
|
||||
### Using namespaces for isolation
|
||||
|
||||
I have used namespaces for isolation in a couple of ways. I use them most often to split many users' projects into separate environments. This is useful in preventing cross-project contamination since namespaces provide independent environments. Users can install multiple versions of Jenkins, for example, and their environmental variables won't collide if they are in different namespaces.
|
||||
|
||||
This separation also helps with cleanup. If development groups are working on various projects that suddenly become obsolete, you can delete the namespace and remove everything in one swift movement with **kubectl delete ns <$NAMESPACENAME>**. (Please make sure it's the right namespace. I deleted the wrong one in production once, and it's not pretty.)
|
||||
|
||||
Be aware that this can cause damage across teams and problems for you if you are the infrastructure owner. For example, if you create a namespace with some special, extra-secure DNS functions and the wrong person deletes it, all of your pods and their running applications will be removed with the namespace. Any use of **delete** should be reviewed by a peer (through [GitOps][3]) before hitting the cluster.
|
||||
|
||||
While the official documentation suggests not using multiple namespaces [with 10 or fewer users][2], I still use them in my own cluster for architectural purposes. The cleaner the cluster, the better.
|
||||
|
||||
### What admins need to know about namespaces
|
||||
|
||||
For starters, namespaces cannot be nested in other namespaces. There can be only one namespace with deployments in it. You don't have to use namespaces for versioned projects, but you can always use the labels to separate versioned apps with the same name. Namespaces divide resources between users using resource quotas; for example, _this namespace can only have x_ _number_ _of nodes_. Finally, all namespaces scope down to a unique name for the resource type.
|
||||
|
||||
### Namespace commands in action
|
||||
|
||||
To try out the following namespace commands, you need to have [Minikube][4], [Helm][5], and the [kubectl][6] command line installed. For information about installing them, see my article [_Security scanning your DevOps pipeline_][7] or each project's homepage. I am using the most recent release of Minikube. The manual installation is fast and has consistently worked correctly the first time.
|
||||
|
||||
To get your first set of namespaces:
|
||||
|
||||
|
||||
```
|
||||
jess@Athena:~$ kubectl get namespace
|
||||
NAME STATUS AGE
|
||||
default Active 5m23s
|
||||
kube-public Active 5m24s
|
||||
kube-system Active 5m24s
|
||||
```
|
||||
|
||||
To create a namespace:
|
||||
|
||||
|
||||
```
|
||||
jess@Athena:~$ kubectl create namespace athena
|
||||
namespace/athena created
|
||||
```
|
||||
|
||||
Now developers can deploy to the namespace you created; for example, here's a small and easy Helm chart:
|
||||
|
||||
|
||||
```
|
||||
jess@Athena:~$ helm install teset-deploy stable/redis --namespace athena
|
||||
NAME: teset-deploy
|
||||
LAST DEPLOYED: Sat Nov 23 13:47:43 2019
|
||||
NAMESPACE: athena
|
||||
STATUS: deployed
|
||||
REVISION: 1
|
||||
TEST SUITE: None
|
||||
NOTES:
|
||||
** Please be patient while the chart is being deployed **
|
||||
Redis can be accessed via port 6379 on the following DNS names from within your cluster:
|
||||
|
||||
teset-deploy-redis-master.athena.svc.cluster.local for read/write operations
|
||||
teset-deploy-redis-slave.athena.svc.cluster.local for read-only operations
|
||||
```
|
||||
|
||||
To get your password:
|
||||
|
||||
|
||||
```
|
||||
`export REDIS_PASSWORD=$(kubectl get secret --namespace athena teset-deploy-redis -o jsonpath="{.data.redis-password}" | base64 --decode)`
|
||||
```
|
||||
|
||||
To connect to your Redis server:
|
||||
|
||||
1. Run a Redis pod that you can use as a client: [code] kubectl run --namespace athena teset-deploy-redis-client --rm --tty -i --restart='Never' \
|
||||
--env REDIS_PASSWORD=$REDIS_PASSWORD \
|
||||
\--image docker.io/bitnami/redis:5.0.7-debian-9-r0 -- bash
|
||||
```
|
||||
2. Connect using the Redis CLI: [code] redis-cli -h teset-deploy-redis-master -a $REDIS_PASSWORD
|
||||
redis-cli -h teset-deploy-redis-slave -a $REDIS_PASSWORD
|
||||
```
|
||||
|
||||
|
||||
|
||||
To connect to your database from outside the cluster:
|
||||
|
||||
|
||||
```
|
||||
kubectl port-forward --namespace athena svc/teset-deploy-redis-master 6379:6379 &
|
||||
redis-cli -h 127.0.0.1 -p 6379 -a $REDIS_PASSWORD
|
||||
```
|
||||
|
||||
Now that this deployment is out, you have a chart deployed in your namespace named **test-deploy**.
|
||||
|
||||
To look at what pods are in your namespace:
|
||||
|
||||
|
||||
```
|
||||
jess@Athena:~$ kubectl get pods --namespace athena
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
teset-deploy-redis-master-0 1/1 Running 0 2m38s
|
||||
teset-deploy-redis-slave-0 1/1 Running 0 2m38s
|
||||
teset-deploy-redis-slave-1 1/1 Running 0 90s
|
||||
```
|
||||
|
||||
At this point, you have officially isolated your application to a single namespace and created one virtual cluster that talks internally only to itself.
|
||||
|
||||
Delete everything with a single command:
|
||||
|
||||
|
||||
```
|
||||
jess@Athena:~$ kubectl delete namespace athena
|
||||
namespace "athena" deleted
|
||||
```
|
||||
|
||||
Because this deletes the application's entire internal configuration, the delete may take some time, depending on how large your deployment is.
|
||||
|
||||
Double-check that everything has been removed:
|
||||
|
||||
|
||||
```
|
||||
jess@Athena:~$ kubectl get pods --all-namespaces
|
||||
NAMESPACE NAME READY STATUS RESTARTS AGE
|
||||
kube-system coredns-5644d7b6d9-4vxv6 1/1 Running 0 32m
|
||||
kube-system coredns-5644d7b6d9-t5wn7 1/1 Running 0 32m
|
||||
kube-system etcd-minikube 1/1 Running 0 31m
|
||||
kube-system kube-addon-manager-minikube 1/1 Running 0 32m
|
||||
kube-system kube-apiserver-minikube 1/1 Running 0 31m
|
||||
kube-system kube-controller-manager-minikube 1/1 Running 0 31m
|
||||
kube-system kube-proxy-5tdmh 1/1 Running 0 32m
|
||||
kube-system kube-scheduler-minikube 1/1 Running 0 31m
|
||||
kube-system storage-provisioner 1/1 Running 0 27m
|
||||
```
|
||||
|
||||
This is a list of all the pods and all the known namespaces where they live. As you can see, the application and namespace you previously made are now gone.
|
||||
|
||||
### Namespaces in practice
|
||||
|
||||
I currently use namespaces for security purposes, including reducing the privileges of users with limitations. You can limit everything—from which roles can access a namespace to their quota levels for cluster resources, like CPUs. For example, I use resource quotas and role-based access control (RBAC) configurations to confirm that a namespace is accessible only by the appropriate service accounts.
|
||||
|
||||
On the isolation side of security, I don't want my home Jenkins application to be accessible over a trusted local network as secure images that have public IP addresses (and thus, I have to assume, could be compromised).
|
||||
|
||||
Namespaces can also be helpful for budgeting purposes if you have a hard budget on how much you can use in your cloud platform for nodes (or, in my case, how much I can deploy before [segfaulting][8] my home server). Although this is out of scope for this article, and it's complicated, it is worth researching and taking advantage of to prevent overextending your cluster.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Namespaces are a great way to isolate projects and applications. This is just a quick introduction to the topic, so I encourage you to do more advanced research on namespaces and use them more in your work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/kubernetes-namespaces
|
||||
|
||||
作者:[Jessica Cherry][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jrepka
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/ship_captain_devops_kubernetes_steer.png?itok=LAHfIpek (Ship captain sailing the Kubernetes seas)
|
||||
[2]: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
[3]: https://www.weave.works/blog/gitops-operations-by-pull-request
|
||||
[4]: https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[5]: https://helm.sh/
|
||||
[6]: https://kubernetes.io/docs/tasks/tools/install-kubectl/
|
||||
[7]: https://opensource.com/article/19/7/security-scanning-your-devops-pipeline
|
||||
[8]: https://en.wikipedia.org/wiki/Segmentation_fault
|
||||
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 ways to volunteer this holiday season)
|
||||
[#]: via: (https://opensource.com/article/19/12/ways-volunteer)
|
||||
[#]: author: (John Jones https://opensource.com/users/johnjones4)
|
||||
|
||||
4 ways to volunteer this holiday season
|
||||
======
|
||||
Looking to spread some holiday cheer? Donate your talents to open source
|
||||
organizations that help communities in need.
|
||||
![Gift box opens with colors coming out][1]
|
||||
|
||||
Social impact happens when leaders deploy individuals and resources to make positive change, but many social efforts are lacking technology resources that are up to the task of serving these change-makers. However, there are organizations helping to accelerate tech for good by connecting developers who want to make a change with communities and nonprofits who desperately need better technology. These organizations often serve specific audiences and recruit specific kinds of technologists, but they all share a common thread: open source.
|
||||
|
||||
As developers, we all seek to participate in the open source community for a variety of reasons. Some participate for professional development, some participate so that they may collaborate with a vast, impressive network of technologists, and others participate because they know their contributions are necessary for the success of a project. Why not also volunteer your talents as a developer to an effort that needs them, and contribute to open source all at the same time? The organizations below are prime examples of how you can do that.
|
||||
|
||||
### Code for America
|
||||
|
||||
Code for America is an example of how government can still be by the people and for the people in the digital age. Through its Brigade Network, the organization has cultivated a national alliance of volunteer programmers, data scientists, concerned citizens, and designers organized in cities all over the United States. These local affiliates host regular meet-ups which are open to the community to both pitch new projects to the group and collaborate on ongoing efforts. To match volunteers with projects, the brigades’ websites often list the specific skills needed for a project such as data analysis, content creation, and JavaScript. While the brigades focus on local issues, shared experiences like natural disasters can foster collaboration. For example, a multi-brigade effort from the New Orleans, Houston, and Tampa Bay teams developed a hurricane response website that can be quickly adapted to different cities when disaster strikes.
|
||||
|
||||
To get involved, visit Code for America’s [website][2] for a list of its over 70 brigades, and a path for individuals to start their own if there is not one already in their community.
|
||||
|
||||
### Code for Change
|
||||
|
||||
Code for Change shows that social impact can start even in high school. A group of high school coders in Indianapolis started their own club to give back to local organizations by creating open source software solutions to issues in their community. Code for Change encourages local organizations to reach out with a project idea, and the student group steps in to develop a completely free and open source solution. The group has developed projects such as "Sapphire," which optimized volunteer management systems for a local refugee organization, and a Civil Rights Commission complaint form that makes it easier for citizens to voice their concerns online.
|
||||
|
||||
For more information on how to create a Code for Change chapter in your own community, [visit their website][3].
|
||||
|
||||
### Python for Good/Ruby for Good
|
||||
|
||||
Python for Good and Ruby for Good are twin annual events in Portland, Oregon and Fairfax, Virginia, that bring people together to develop and program solutions for those respective communities. Over a weekend, individuals get together to hear pitches from local nonprofits and tackle their issues by building open source solutions. In 2017, Ruby For Good participants created "Justice for Juniors," which mentors and tutors current and formerly incarcerated youths to integrate them back into the community. Participants have also created "Diaperbase," an inventory management system that has been used by diaper banks all over the United States. One of the main objectives of these events is to bring organizations and people from seemingly different industries and mindsets to come together for a common good. Companies can sponsor the events, nonprofits can submit project ideas, and people of all skill levels can register to attend the event and contribute. Through their bicoastal efforts, Ruby for Good and Python for Good are living up to their motto of "making the world gooder."
|
||||
|
||||
[Ruby for Good][4] is held in the summer and hosted on George Mason’s campus in Fairfax, Virginia.
|
||||
|
||||
### Social Coder
|
||||
|
||||
UK-based Ed Guiness created Social Coder to bring together volunteers and charities to create and use open source projects for nonprofits across six continents. Social Coder actively recruits a network of skilled IT volunteers from all over the world and matches them to charities and nonprofits registered through Social Coder. Projects can range from simple website updates to entire mobile app development.
|
||||
|
||||
For example, PHASE Worldwide, a small non-governmental association supporting efforts in Nepal, got access to key support and expertise leveraging open source technology because of Social Coder.
|
||||
|
||||
While a bulk of the charities already partnered with Social Coder are based in the UK, organizations in other countries are welcome. Through their website, individuals can register to work on social software projects and connect with organizations and charities seeking their help.
|
||||
|
||||
Individuals interested in volunteering with Social Coder can sign up [here][5].
|
||||
|
||||
The four-day-long siege of a Nairobi mall ended Tuesday with a death toll of more than 60 people –...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/ways-volunteer
|
||||
|
||||
作者:[John Jones][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/johnjones4
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_gift_giveaway_box_520x292.png?itok=w1YQhNH1 (Gift box opens with colors coming out)
|
||||
[2]: https://brigade.codeforamerica.org/
|
||||
[3]: http://codeforchange.herokuapp.com/
|
||||
[4]: https://rubyforgood.org/
|
||||
[5]: https://socialcoder.org/Home/Programmer
|
||||
@ -0,0 +1,183 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Start, Stop & Restart Services in Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/start-stop-restart-services-linux/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
How to Start, Stop & Restart Services in Ubuntu and Other Linux Distributions
|
||||
======
|
||||
|
||||
Services are essential background processes that are usually run while booting up and shut down with the OS.
|
||||
|
||||
If you are a sysadmin, you’ll deal with the service regularly.
|
||||
|
||||
If you are a normal desktop user, you may come across the need to restart a service like [setting up Barrier for sharing mouse and keyboard between computers][1]. or when you are [using ufw to setup firewall][2].
|
||||
|
||||
Today I will show you two different ways you can manage services. You’ll learn to start, stop and restart services in Ubuntu or any other Linux distribution.
|
||||
|
||||
systemd vs init
|
||||
|
||||
Ubuntu and many other distributions these days use systemd instead of the good old init.
|
||||
|
||||
In systemd, you manage sevices with systemctl command.
|
||||
|
||||
In init, you manage service with service command.
|
||||
|
||||
You’ll notice that even though your Linux system uses systemd, it is still able to use the service command (intended to be used with init system). This is because service command is actually redirect to systemctl. It’s sort of backward compatibility introduced by systemd because sysadmins were habitual of using the service command.
|
||||
|
||||
I’ll show both systemctl and service command in this tutorial.
|
||||
|
||||
_I am Ubuntu 18.04 here, but the process (no pun intended) is the same for other versions._
|
||||
|
||||
### Method 1: Managing services in Linux with systemd
|
||||
|
||||
I am starting with systemd because of the obvious reason of its widespread adoption.
|
||||
|
||||
#### 1\. List all services
|
||||
|
||||
In order to manage the services, you first need to know what services are available on your system.
|
||||
|
||||
You can use the systemd command to list all the services on your Linux system:
|
||||
|
||||
```
|
||||
systemctl list-unit-files --type service -all
|
||||
```
|
||||
|
||||
![systemctl list-unit-files][3]
|
||||
|
||||
This command will output the state of all services. The value of a service’s state can be enabled, disabled, masked (inactive until mask is unset), static and generated.
|
||||
|
||||
Combine it with the [grep command][4] and you can **display just the running services**:
|
||||
|
||||
```
|
||||
sudo systemctl | grep running
|
||||
```
|
||||
|
||||
![Display running services systemctl][5]
|
||||
|
||||
Now that you know how to reference all different services, you can start actively managing them.
|
||||
|
||||
**Note:** ***<service-***_**name>**_ _in the commands should be replaced by the name of the service you wish to manage (e.g. network-manager, ufw etc.)._
|
||||
|
||||
#### **2\. Start a** service
|
||||
|
||||
To start a service in Linux, you just need to use its name like this:
|
||||
|
||||
```
|
||||
systemctl start <service-name>
|
||||
```
|
||||
|
||||
#### 3\. **Stop** a service
|
||||
|
||||
To stop a systemd service, you can use the stop option of systemctl command:
|
||||
|
||||
```
|
||||
systemctl stop <service-name>
|
||||
```
|
||||
|
||||
#### 4\. Re**start** a service
|
||||
|
||||
To restart a service in Linux with systemd, you can use:
|
||||
|
||||
```
|
||||
systemctl restart <service-name>
|
||||
```
|
||||
|
||||
#### 5\. Check the status of a service
|
||||
|
||||
You can confirm that you have successfully executed a certain action by printing the service status:
|
||||
|
||||
```
|
||||
systemctl status <service-name>
|
||||
```
|
||||
|
||||
This will output information in the following manner:
|
||||
|
||||
![systemctl status][6]
|
||||
|
||||
That was systemd. Let’s switch to init now.
|
||||
|
||||
### Method 2: Managing services in Linux with init
|
||||
|
||||
The commands in init are also as simple as system.
|
||||
|
||||
#### 1\. List all services
|
||||
|
||||
To list all the Linux services, use
|
||||
|
||||
```
|
||||
service --status-all
|
||||
```
|
||||
|
||||
![service –status-all][7]
|
||||
|
||||
The services preceded by **[ – ]** are **disabled** and those with **[ + ]** are **enabled**.
|
||||
|
||||
#### **2\. Start** a service
|
||||
|
||||
To start a service in Ubuntu and other distributions, use this command:
|
||||
|
||||
```
|
||||
service <service-name> start
|
||||
```
|
||||
|
||||
#### **3\. Stop** a service
|
||||
|
||||
Stopping a service is equally easy.
|
||||
|
||||
```
|
||||
service <service-name> stop
|
||||
```
|
||||
|
||||
#### 4\. Re**start** a service
|
||||
|
||||
If you want to restart a service, the command is:
|
||||
|
||||
```
|
||||
service <service-name> restart
|
||||
```
|
||||
|
||||
#### 5\. Check the status of a service
|
||||
|
||||
Furthermore, to check if your intended result was achieved, you can output the service ****status**:**
|
||||
|
||||
```
|
||||
service <service-name> status
|
||||
```
|
||||
|
||||
This will output information in the following manner:
|
||||
|
||||
![service status][8]
|
||||
|
||||
This will, most importantly, tell you if a certain service is active **(**running**)** or not.
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
Today I detailed two very simple methods of managing services on Ubuntu or any other Linux system. I hope this article was helpful to you.
|
||||
|
||||
Which method do you prefer? Let us know in the comment section below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/start-stop-restart-services-linux/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/keyboard-mouse-sharing-between-computers/
|
||||
[2]: https://itsfoss.com/set-up-firewall-gufw/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_list_services.png?ssl=1
|
||||
[4]: https://linuxhandbook.com/grep-command-examples/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_grep_running.jpg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_status.jpg?ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/service_status_all.png?ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/service_status.jpg?ssl=1
|
||||
@ -0,0 +1,346 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to add a Help facility to your Bash program)
|
||||
[#]: via: (https://opensource.com/article/19/12/help-bash-program)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
How to add a Help facility to your Bash program
|
||||
======
|
||||
In the third article in this series, learn about using functions as you
|
||||
create a simple Help facility for your Bash script.
|
||||
![bash logo on green background][1]
|
||||
|
||||
In the [first article][2] in this series, you created a very small, one-line Bash script and explored the reasons for creating shell scripts and why they are the most efficient option for the system administrator, rather than compiled programs. In the [second article][3], you began the task of creating a fairly simple template that you can use as a starting point for other Bash programs, then explored ways to test it.
|
||||
|
||||
This third of the four articles in this series explains how to create and use a simple Help function. While creating your Help facility, you will also learn about using functions and how to handle command-line options such as **-h**.
|
||||
|
||||
### Why Help?
|
||||
|
||||
Even fairly simple Bash programs should have some sort of Help facility, even if it is fairly rudimentary. Many of the Bash shell programs I write are used so infrequently that I forget the exact syntax of the command I need. Others are so complex that I need to review the options and arguments even when I use them frequently.
|
||||
|
||||
Having a built-in Help function allows you to view those things without having to inspect the code itself. A good and complete Help facility is also a part of program documentation.
|
||||
|
||||
### About functions
|
||||
|
||||
Shell functions are lists of Bash program statements that are stored in the shell's environment and can be executed, like any other command, by typing their name at the command line. Shell functions may also be known as procedures or subroutines, depending upon which other programming language you are using.
|
||||
|
||||
Functions are called in scripts or from the command-line interface (CLI) by using their names, just as you would for any other command. In a CLI program or a script, the commands in the function execute when they are called, then the program flow sequence returns to the calling entity, and the next series of program statements in that entity executes.
|
||||
|
||||
The syntax of a function is:
|
||||
|
||||
|
||||
```
|
||||
`FunctionName(){program statements}`
|
||||
```
|
||||
|
||||
Explore this by creating a simple function at the CLI. (The function is stored in the shell environment for the shell instance in which it is created.) You are going to create a function called **hw**, which stands for "hello world." Enter the following code at the CLI and press **Enter**. Then enter **hw** as you would any other shell command:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ hw(){ echo "Hi there kiddo"; }
|
||||
[student@testvm1 ~]$ hw
|
||||
Hi there kiddo
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
OK, so I am a little tired of the standard "Hello world" starter. Now, list all of the currently defined functions. There are a lot of them, so I am showing just the new **hw** function. When it is called from the command line or within a program, a function performs its programmed task and then exits and returns control to the calling entity, the command line, or the next Bash program statement in a script after the calling statement:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ declare -f | less
|
||||
<snip>
|
||||
hw ()
|
||||
{
|
||||
echo "Hi there kiddo"
|
||||
}
|
||||
<snip>
|
||||
```
|
||||
|
||||
Remove that function because you do not need it anymore. You can do that with the **unset** command:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ unset -f hw ; hw
|
||||
bash: hw: command not found
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
### Creating the Help function
|
||||
|
||||
Open the **hello** program in an editor and add the Help function below to the **hello** program code after the copyright statement but before the **echo "Hello world!"** statement. This Help function will display a short description of the program, a syntax diagram, and short descriptions of the available options. Add a call to the Help function to test it and some comment lines that provide a visual demarcation between the functions and the main portion of the program:
|
||||
|
||||
|
||||
```
|
||||
################################################################################
|
||||
# Help #
|
||||
################################################################################
|
||||
Help()
|
||||
{
|
||||
# Display Help
|
||||
echo "Add description of the script functions here."
|
||||
echo
|
||||
echo "Syntax: scriptTemplate [-g|h|v|V]"
|
||||
echo "options:"
|
||||
echo "g Print the GPL license notification."
|
||||
echo "h Print this Help."
|
||||
echo "v Verbose mode."
|
||||
echo "V Print software version and exit."
|
||||
echo
|
||||
}
|
||||
|
||||
################################################################################
|
||||
################################################################################
|
||||
# Main program #
|
||||
################################################################################
|
||||
################################################################################
|
||||
|
||||
Help
|
||||
echo "Hello world!"
|
||||
```
|
||||
|
||||
The options described in this Help function are typical for the programs I write, although none are in the code yet. Run the program to test it:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ ./hello
|
||||
Add description of the script functions here.
|
||||
|
||||
Syntax: scriptTemplate [-g|h|v|V]
|
||||
options:
|
||||
g Print the GPL license notification.
|
||||
h Print this Help.
|
||||
v Verbose mode.
|
||||
V Print software version and exit.
|
||||
|
||||
Hello world!
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
Because you have not added any logic to display Help only when you need it, the program will always display the Help. Since the function is working correctly, read on to add some logic to display the Help only when the **-h** option is used when you invoke the program at the command line.
|
||||
|
||||
### Handling options
|
||||
|
||||
A Bash script's ability to handle command-line options such as **-h** gives some powerful capabilities to direct the program and modify what it does. In the case of the **-h** option, you want the program to print the Help text to the terminal session and then quit without running the rest of the program. The ability to process options entered at the command line can be added to the Bash script using the **while** command (see [_How to program with Bash: Loops_][4] to learn more about **while**) in conjunction with the **getops** and **case** commands.
|
||||
|
||||
The **getops** command reads any and all options specified at the command line and creates a list of those options. In the code below, the **while** command loops through the list of options by setting the variable **$options** for each. The **case** statement is used to evaluate each option in turn and execute the statements in the corresponding stanza. The **while** statement will continue to evaluate the list of options until they have all been processed or it encounters an exit statement, which terminates the program.
|
||||
|
||||
Be sure to delete the Help function call just before the **echo "Hello world!"** statement so that the main body of the program now looks like this:
|
||||
|
||||
|
||||
```
|
||||
################################################################################
|
||||
################################################################################
|
||||
# Main program #
|
||||
################################################################################
|
||||
################################################################################
|
||||
################################################################################
|
||||
# Process the input options. Add options as needed. #
|
||||
################################################################################
|
||||
# Get the options
|
||||
while getopts ":h" option; do
|
||||
case $option in
|
||||
h) # display Help
|
||||
Help
|
||||
exit;;
|
||||
esac
|
||||
done
|
||||
|
||||
echo "Hello world!"
|
||||
```
|
||||
|
||||
Notice the double semicolon at the end of the exit statement in the case option for **-h**. This is required for each option added to this case statement to delineate the end of each option.
|
||||
|
||||
### Testing
|
||||
|
||||
Testing is now a little more complex. You need to test your program with a number of different options—and no options—to see how it responds. First, test with no options to ensure that it prints "Hello world!" as it should:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ ./hello
|
||||
Hello world!
|
||||
```
|
||||
|
||||
That works, so now test the logic that displays the Help text:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ ./hello -h
|
||||
Add description of the script functions here.
|
||||
|
||||
Syntax: scriptTemplate [-g|h|t|v|V]
|
||||
options:
|
||||
g Print the GPL license notification.
|
||||
h Print this Help.
|
||||
v Verbose mode.
|
||||
V Print software version and exit.
|
||||
```
|
||||
|
||||
That works as expected, so try some testing to see what happens when you enter some unexpected options:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ ./hello -x
|
||||
Hello world!
|
||||
[student@testvm1 ~]$ ./hello -q
|
||||
Hello world!
|
||||
[student@testvm1 ~]$ ./hello -lkjsahdf
|
||||
Add description of the script functions here.
|
||||
|
||||
Syntax: scriptTemplate [-g|h|t|v|V]
|
||||
options:
|
||||
g Print the GPL license notification.
|
||||
h Print this Help.
|
||||
v Verbose mode.
|
||||
V Print software version and exit.
|
||||
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
The program just ignores any options without specific responses without generating any errors. But notice the last entry (with **-lkjsahdf** for options): because there is an **h** in the list of options, the program recognizes it and prints the Help text. This testing has shown that the program doesn't have the ability to handle incorrect input and terminate the program if any is detected.
|
||||
|
||||
You can add another case stanza to the case statement to match any option that doesn't have an explicit match. This general case will match anything you have not provided a specific match for. The case statement now looks like this, with the catch-all match of **\?** as the last case. Any additional specific cases must precede this final one:
|
||||
|
||||
|
||||
```
|
||||
while getopts ":h" option; do
|
||||
case $option in
|
||||
h) # display Help
|
||||
Help
|
||||
exit;;
|
||||
\?) # incorrect option
|
||||
echo "Error: Invalid option"
|
||||
exit;;
|
||||
esac
|
||||
done
|
||||
```
|
||||
|
||||
Test the program again using the same options as before and see how it works now.
|
||||
|
||||
### Where you are
|
||||
|
||||
You have accomplished a good amount in this article by adding the capability to process command-line options and a Help procedure. Your Bash script now looks like this:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/bash
|
||||
################################################################################
|
||||
# scriptTemplate #
|
||||
# #
|
||||
# Use this template as the beginning of a new program. Place a short #
|
||||
# description of the script here. #
|
||||
# #
|
||||
# Change History #
|
||||
# 11/11/2019 David Both Original code. This is a template for creating #
|
||||
# new Bash shell scripts. #
|
||||
# Add new history entries as needed. #
|
||||
# #
|
||||
# #
|
||||
################################################################################
|
||||
################################################################################
|
||||
################################################################################
|
||||
# #
|
||||
# Copyright (C) 2007, 2019 David Both #
|
||||
# [LinuxGeek46@both.org][5] #
|
||||
# #
|
||||
# This program is free software; you can redistribute it and/or modify #
|
||||
# it under the terms of the GNU General Public License as published by #
|
||||
# the Free Software Foundation; either version 2 of the License, or #
|
||||
# (at your option) any later version. #
|
||||
# #
|
||||
# This program is distributed in the hope that it will be useful, #
|
||||
# but WITHOUT ANY WARRANTY; without even the implied warranty of #
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the #
|
||||
# GNU General Public License for more details. #
|
||||
# #
|
||||
# You should have received a copy of the GNU General Public License #
|
||||
# along with this program; if not, write to the Free Software #
|
||||
# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA #
|
||||
# #
|
||||
################################################################################
|
||||
################################################################################
|
||||
################################################################################
|
||||
|
||||
################################################################################
|
||||
# Help #
|
||||
################################################################################
|
||||
Help()
|
||||
{
|
||||
# Display Help
|
||||
echo "Add description of the script functions here."
|
||||
echo
|
||||
echo "Syntax: scriptTemplate [-g|h|t|v|V]"
|
||||
echo "options:"
|
||||
echo "g Print the GPL license notification."
|
||||
echo "h Print this Help."
|
||||
echo "v Verbose mode."
|
||||
echo "V Print software version and exit."
|
||||
echo
|
||||
}
|
||||
|
||||
################################################################################
|
||||
################################################################################
|
||||
# Main program #
|
||||
################################################################################
|
||||
################################################################################
|
||||
################################################################################
|
||||
# Process the input options. Add options as needed. #
|
||||
################################################################################
|
||||
# Get the options
|
||||
while getopts ":h" option; do
|
||||
case $option in
|
||||
h) # display Help
|
||||
Help
|
||||
exit;;
|
||||
\?) # incorrect option
|
||||
echo "Error: Invalid option"
|
||||
exit;;
|
||||
esac
|
||||
done
|
||||
|
||||
echo "Hello world!"
|
||||
```
|
||||
|
||||
Be sure to test this version of the program very thoroughly. Use random inputs and see what happens. You should also try testing valid and invalid options without using the dash (**-**) in front.
|
||||
|
||||
### Next time
|
||||
|
||||
In this article, you added a Help function as well as the ability to process command-line options to display it selectively. The program is getting a little more complex, so testing is becoming more important and requires more test paths in order to be complete.
|
||||
|
||||
The next article will look at initializing variables and doing a bit of sanity checking to ensure that the program will run under the correct set of conditions.
|
||||
|
||||
### Resources
|
||||
|
||||
* [How to program with Bash: Syntax and tools][6]
|
||||
* [How to program with Bash: Logical operators and shell expansions][7]
|
||||
* [How to program with Bash: Loops][4]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_This series of articles is partially based on Volume 2, Chapter 10 of David Both's three-part Linux self-study course, [Using and Administering Linux—Zero to SysAdmin][8]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/help-bash-program
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
|
||||
[2]: https://opensource.com/article/19/12/introduction-automation-bash-scripts
|
||||
[3]: https://opensource.com/article/19/12/creating-bash-script-template
|
||||
[4]: https://opensource.com/article/19/10/programming-bash-loops
|
||||
[5]: mailto:LinuxGeek46@both.org
|
||||
[6]: https://opensource.com/article/19/10/programming-bash-syntax-tools
|
||||
[7]: https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions
|
||||
[8]: http://www.both.org/?page_id=1183
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why Vim fans love the Herbstluftwm Linux window manager)
|
||||
[#]: via: (https://opensource.com/article/19/12/herbstluftwm-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Why Vim fans love the Herbstluftwm Linux window manager
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
If you're a Vim fan, check out herbstluftwm, a tile-based Linux window
|
||||
manager that takes the "Vim way" as inspiration.
|
||||
![OpenStack source code \(Python\) in VIM][1]
|
||||
|
||||
Everybody loves Vim (aside from Dvorak and Emacs users). Vim is so popular that there are entire web browsers dedicated to navigating the web with Vim keybindings, a Vim mode in the wildly popular [Zsh][2] terminal emulator, and even a text editor. There's also a window manager called [herbstluftwm][3] that models itself partly after the "Vim way." Herbstluftwm does away with windows, as such, and replaces them with tiles, or quadrants, into which applications are loaded and used. You use the keyboard (**Alt+h**, **Alt+j**, **Alt+k**, and **Alt+l**) to navigate from one tile to another.
|
||||
|
||||
![Herbstluftwm][4]
|
||||
|
||||
Install herbstluftwm from your distribution's software repository. After installing it, log out of your current desktop session so you can log into your new one. By default, your session manager (KDM, GDM, LightDM, or XDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
|
||||
|
||||
With GDM:
|
||||
|
||||
![][5]
|
||||
|
||||
With SDDM:
|
||||
|
||||
![][6]
|
||||
|
||||
### Herbstluftwm desktop tour
|
||||
|
||||
The first time you log into herbstluftwm, you are greeted with nothing but a green screen with a darker green border around the edges. What you're seeing is the initial tile with no application loaded into it. To start the default application, xterm, press **Alt+Return**.
|
||||
|
||||
The documentation emphasizes the **$HOME/.config/herbstluftwm/autostart** configuration file as a way to start important applications when you log in. For applications you don't necessarily want to start every time you log in, you can use xterm as your launch daemon. As usual, placing an ampersand (**&**) symbol after the command returns control of the shell to you. To start Emacs, for instance:
|
||||
|
||||
|
||||
```
|
||||
`% emacs &`
|
||||
```
|
||||
|
||||
This launches an Emacs window in a new tile and returns you to a prompt.
|
||||
|
||||
![Emacs running in Herbstluftwm][7]
|
||||
|
||||
#### Switching tiles
|
||||
|
||||
To move from one tile to another, use the classic Vim navigation combination of **h**, **j**, **k**, or **l**, along with the **Alt** key. For example, to switch from the terminal to an application in a tile below it (i.e., at the bottom of the screen), press **Alt+j**. To navigate back up, **Alt+k**. Left and right navigations are **Alt+h** and **Alt+l**, respectively.
|
||||
|
||||
#### Split screen
|
||||
|
||||
You can manually split a screen vertically with **Alt+o** and horizontally with **Alt+u**.
|
||||
|
||||
To remove an empty tile, navigate into it and press **Alt+r**.
|
||||
|
||||
### Configuring herbstluftwm
|
||||
|
||||
Aside from the **Alt** keybindings, you communicate with herbstluftwm through the **herbstclient** command. This command can be used interactively from a shell, or you can preserve your preferences in a configuration file.
|
||||
|
||||
You can view all attributes available in Herbstluftwm with:
|
||||
|
||||
|
||||
```
|
||||
`$ herbstclient attr`
|
||||
```
|
||||
|
||||
Herbstluftwm's default behavior is defined in the default config file, which you can copy to your home directory and modify. Upon launch, herbstluftwm executes the commands contained in the config file. For instance, if you find it awkward to use keybindings centered around the **Alt** key, which is traditionally a key reserved for in-application shortcuts, you can change the key used to trigger herbstluftwm actions in the config file:
|
||||
|
||||
|
||||
```
|
||||
% mkdir ~/.config/herbstluftwm
|
||||
% cp /usr/xdg/herbstluftwm/autostart \
|
||||
~/.config/herbstluftwm
|
||||
% sed -i 's/Mod=Mod1/Mod=Mod4/' ~/.config/herbstluftwm
|
||||
% herbstclient reload
|
||||
```
|
||||
|
||||
This changes the herbstluftwm modifier to the Super key (the "Windows" or "Tux" key, depending on your keyboard).
|
||||
|
||||
Using the autostart file, you can set custom keybindings, create tags for applications of a specific type so you can tile applications in a consistent way, and do much more.
|
||||
|
||||
### Why you need to try herbstluftwm
|
||||
|
||||
Herbstluftwm is a fine example of a tiling window manager. It tiles windows by default and lets the user define exceptions to global rules. It uses Vim-like navigation but allows for quick and easy overrides. It's very likely the tiling manager you've been looking for, so try it soon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/herbstluftwm-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/openstack_python_vim_2.jpg?itok=4fza48WU (OpenStack source code (Python) in VIM)
|
||||
[2]: https://opensource.com/article/19/9/getting-started-zsh
|
||||
[3]: https://herbstluftwm.org
|
||||
[4]: https://opensource.com/sites/default/files/uploads/advent-herbsluftwm.png (Herbstluftwm)
|
||||
[5]: https://opensource.com/sites/default/files/advent-gdm_1.jpg
|
||||
[6]: https://opensource.com/sites/default/files/advent-kdm_0.jpg
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-herbsluftwm-emacs.jpg (Emacs running in Herbstluftwm)
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Customize your Linux desktop with KDE Plasma)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-kde-plasma)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Customize your Linux desktop with KDE Plasma
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
If you think there's no such thing as too much opportunity to customize
|
||||
your desktop, KDE Plasma may be for you.
|
||||
![5 pengiuns floating on iceburg][1]
|
||||
|
||||
The Plasma desktop by the KDE community is a pinnacle among open source desktops. KDE got into the Linux desktop market early, but since its foundational Qt toolkit did not have a fully open license at the time, the [GNOME][2] desktop was created. Since then, Qt has become open source, and KDE (and its derivatives, like the [Trinity desktop][3]) has thrived.
|
||||
|
||||
You may find the KDE desktop in your distribution's software repository, or you can download and install a distribution that ships KDE as its default. Before you install, be aware that KDE provides a full, integrated, and robust desktop experience, so several KDE applications are installed along with it. If you're already running a different desktop, you will find yourself with redundant applications (two PDF readers, several media players, two or more file managers, and so on). If you just want to try the KDE desktop without committing to it, you can install a KDE-based distribution in a virtual machine, such as [GNOME Boxes][4], or you can try a bootable OS like [Porteus][5].
|
||||
|
||||
### KDE desktop tour
|
||||
|
||||
The [KDE Plasma][6] desktop is relatively boring at first glance—but in a comforting way. It's got the industry-standard layout: pop-up application menu in the bottom-left corner, taskbar in the middle, system tray on the right. It's exactly what you'd expect from a standard household or business computer.
|
||||
|
||||
![KDE Plasma desktop][7]
|
||||
|
||||
What sets KDE apart, though, is that you can change nearly anything you want. The Qt toolkit can be taken apart and rearranged in some surprising ways, meaning you can essentially design your own desktop using KDE's parts as your foundation. The settings available for how your desktop behaves are vast, too. KDE can act as a standard desktop, a tiling window manager, and anything in between. You can create your own window rules by window class, role, type, title, or any combination thereof, so if you want specific applications to behave differently than everything else, you can create an exception to global settings.
|
||||
|
||||
Furthermore, there's a rich collection of widgets to enable you to customize the way you interface with your desktop. There's a GNOME-like full-screen application launcher, a Unity-like dock launcher and icons-only taskbar, and a traditional taskbar. You can create and place panels on any edge of the screen you want.
|
||||
|
||||
![A slightly customized KDE desktop][8]
|
||||
|
||||
There's so much customization, in fact, that one of the most common critiques of KDE is that it's _too customizable_, so keep in mind that customization is optional. You can use the Plasma desktop in its default configuration, and change things gradually and only as you feel necessary. What matters most about Plasma desktop configuration options isn't their number, but that they're discoverable and intuitive, either in the System Settings application or with a right-click.
|
||||
|
||||
The fact is, on KDE, there's almost never just one way to accomplish any given task, and its users see that as its greatest strength. There's no implied workflow in KDE, only a default. And all defaults can be changed, until everything you need to do with your desktop is second-nature.
|
||||
|
||||
### Consistency and integration
|
||||
|
||||
The KDE community prides itself on consistency and integration, made possible through great developer and community management and the KDE libraries. The developers of KDE aren't just developers of a desktop. They provide a [stunning collection of applications][9], each of them created with KDE libs that extend and standardize common Qt widgets. It's no accident that after using KDE for a few months, whether you open [DigiKam][10] for photo management or Kmail to check email or KTorrent to grab the latest ISO or Dolphin to manage files, your muscle memory takes you where you need to go in the UI before you consciously think about it.
|
||||
|
||||
![KDE on Porteus][11]
|
||||
|
||||
### Try KDE
|
||||
|
||||
KDE has something for everyone. Use its default settings for a smooth, plain-vanilla desktop experience, or customize it to make it your own. It's a stable, attractive, and robust desktop environment that probably has everything you need for whatever you want to do on Linux.
|
||||
|
||||
KDE originally stood for Kool Desktop Environment, but is now known by many as the K Desktop...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-kde-plasma
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
|
||||
[2]: https://opensource.com/article/19/12/gnome-linux-desktop
|
||||
[3]: https://opensource.com/article/19/12/linux-trinity-desktop-environment-tde
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/article/19/6/linux-distros-to-try
|
||||
[6]: https://kde.org/plasma-desktop
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-kde-presskit.jpg (KDE Plasma desktop)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/advent-kde-dock.jpg (A slightly customized KDE desktop)
|
||||
[9]: https://kde.org/applications/
|
||||
[10]: https://opensource.com/life/16/5/how-use-digikam-photo-management
|
||||
[11]: https://opensource.com/sites/default/files/uploads/advent-kde.jpg (KDE on Porteus)
|
||||
154
sources/tech/20191221 Pop-_OS vs Ubuntu- Which One is Better.md
Normal file
154
sources/tech/20191221 Pop-_OS vs Ubuntu- Which One is Better.md
Normal file
@ -0,0 +1,154 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Pop!_OS vs Ubuntu: Which One is Better?)
|
||||
[#]: via: (https://itsfoss.com/pop-os-vs-ubuntu/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Pop!_OS vs Ubuntu: Which One is Better?
|
||||
======
|
||||
|
||||
Well, you might find it easy to pick one from the list of [best Linux distributions][1]. However, it is often confusing to compare two similar Linux distros, just like Pop!_OS vs Ubuntu.
|
||||
|
||||
Interestingly, Pop!_OS is based on [Ubuntu][2]. So, what is the difference between Pop!_OS and Ubuntu? Why should you choose one over other?
|
||||
|
||||
In this article, I’m going to compare Pop!_OS and Ubuntu (both of which happen to be my favorites).
|
||||
|
||||
**Note:** _You might find some of the points opinionated, this article is just a reference for the comparison. With constant developments and updates to Linux distros, a lot can change over time._
|
||||
|
||||
### Comparing Ubuntu and Pop!_OS
|
||||
|
||||
![Pop!_OS Vs Ubuntu][3]
|
||||
|
||||
Spotting the similarity helps you distinguish other differences. So, let me start noting down some of the obvious similarities.
|
||||
|
||||
Like I mentioned, Pop!_OS is a Linux distribution on top of Ubuntu. So, you get all the benefits of using Ubuntu (technically the same thing at its core) when you use Pop!_OS.
|
||||
|
||||
They both ship with the [GNOME desktop environment][4] by default and hence they feature a similar user interface (UI).
|
||||
|
||||
Without going into all the under-the-hood differences, I will be highlighting some important ones here.
|
||||
|
||||
#### User Experience & Theming
|
||||
|
||||
![Pop!_OS][5]
|
||||
|
||||
A lot of users think that Pop!_OS is just Ubuntu with a different skin.
|
||||
|
||||
From my experience, I’ll mention that it is not entirely true.
|
||||
|
||||
Yes, they both rock [GNOME desktop environment][4] – however, Pop!_OS just feels more polished.
|
||||
|
||||
In addition to the look and feel, [Ubuntu customizes the GNOME experience][6] by adding a dock and a few more tricks. You might find it better if you like a customized GNOME experience.
|
||||
|
||||
But, if you prefer a pure GNOME experience, Pop!_OS gives you that by default.
|
||||
|
||||
I cannot convince you enough until you try it out for yourself. But, the overall color scheme, icons, and the theme that goes on in Pop!_OS is arguably more pleasing as a superior user experience.
|
||||
|
||||
It can be a subjective thing – but it is what I observed. You can also check out the video tour for Ubuntu 19.10 to check it out for yourself:
|
||||
|
||||
#### Ease of Installing Third-Party Apps
|
||||
|
||||
![Pop Os PPA][7]
|
||||
|
||||
Ubuntu puts a lot of emphasis on Snap packages. This increases the number of application it offers.
|
||||
|
||||
But there are some major issues with Snap packages. They take too much of disk space and they take a lot of time to start.
|
||||
|
||||
This is why I prefer using the APT version of any application.
|
||||
|
||||
Why am I telling you this?
|
||||
|
||||
Because Pop!_OS has its [own official PPA][8] which is enabled by default. You’ll find some useful applications like Android Studio, TensorFlow in here. No need to download a 1 GB snap package for the Android Studio. Just use [apt-get install][9] and get done with it.
|
||||
|
||||
#### Pre-installed Applications
|
||||
|
||||
![Ubuntu installation slideshow][10]
|
||||
|
||||
It may not be the biggest deal-breaker for some but having a lot of pre-installed apps could affect the experience and performance. Even if it does not affect the performance – some users just prefer fewer pre-installed apps.
|
||||
|
||||
Pop!_OS comes bundled with fewer default apps (potentially less bloatware, if I may call it that) when compared to Ubuntu.
|
||||
|
||||
Yet again, this is something subjective. If you want to have more apps pre-installed, you may consider Ubuntu over Pop!_OS.
|
||||
|
||||
#### Snap Package Support
|
||||
|
||||
![][11]
|
||||
|
||||
For users comfortable with the snap packages, Ubuntu’s software center is a slightly better solution to Pop!_OS shop because you can have snap packages listed right in your software center.
|
||||
|
||||
You cannot filter the snap packages in the software center but it will be easier to install a snap package when you notice one (look at the details for the source of the app as ‘_Snap store_‘ / ‘_Snapcraft_‘) in the Software Center.
|
||||
|
||||
Pop!_OS does support snap packages as well – if you’re confused. But, you won’t find them through the Pop!_OS shop, that’s the only difference here.
|
||||
|
||||
If you are not sure what a snap package is and what it does, you can check out our article on [installing snap apps on Linux][12].
|
||||
|
||||
#### Separate NVIDIA/AMD ISO File
|
||||
|
||||
![ISOs][13]
|
||||
|
||||
Technically, it isn’t a part of the comparison internally but it is a factor that some users care for.
|
||||
|
||||
So, it is worth highlighting that Pop!_OS provides separate ISOs. One for the systems with NVIDIA graphics card and another for systems with/without AMD graphics.
|
||||
|
||||
With Ubuntu 19.10, you get NVIDIA drivers on the Ubuntu ISO but there is no such thing for AMD graphics.
|
||||
|
||||
#### Reliability & Issues
|
||||
|
||||
Unquestionably, both the [distributions are beginner-friendly][14] and quite reliable. You might want to hold on to a Long Term Support (LTS) release if you want better reliability and fewer issues.
|
||||
|
||||
When a new version of Ubuntu comes up, Pop!_OS works on it and potentially fixes the issues that users encounter on Ubuntu’s original release before making the new upgrade available. This gives them a slight edge but that’s nothing substantial because those fixes eventually reach Ubuntu.
|
||||
|
||||
#### Performance
|
||||
|
||||
The performance will highly depend on what you have installed and the hardware configuration you install it on.
|
||||
|
||||
Unless you have a super old system, both distributions seem to perform very well.
|
||||
|
||||
I’m rocking an i5-7400 processor coupled with 16 Gigs of RAM (with a GTX 1050ti Graphics Card) and I find the experience good enough on both the distros.
|
||||
|
||||
Of course, you could manually do a few optimization tweaks to fit your requirements – if either of them does not work out for your hardware configuration.
|
||||
|
||||
But, if you want to get your hands on a System76 laptop, Pop!_OS will prove to be [the Apple of Linux space][15] because Pop!_OS has been tailored for their hardware, unlike Ubuntu.
|
||||
|
||||
#### Hardware Compatibility
|
||||
|
||||
This is definitely something to consider when comparing other Linux distributions. However, in this case, there’s really no significant difference.
|
||||
|
||||
You might consider Pop!_OS to constantly work with newer hardware configurations because they primarily tailor the OS for their laptops with a variety of configurations. And, it’s just an observation – not a fact.
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
I know it’s not easy to choose one among the two popular Linux distro without trying them out. If it’s a possibility, I’ll recommend you to give them both a try while keeping this comparison for reference.
|
||||
|
||||
What’s your choice between these two? Did I miss something in the comparison? Let me know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/pop-os-vs-ubuntu/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-distributions/
|
||||
[2]: https://ubuntu.com/
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/pop_os_vs_ubuntu.png?ssl=1
|
||||
[4]: https://www.gnome.org/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/11/pop-os-UI.jpg?ssl=1
|
||||
[6]: https://itsfoss.com/gnome-tricks-ubuntu/
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/11/pop-os-ppa.jpg?ssl=1
|
||||
[8]: https://launchpad.net/~system76/+archive/ubuntu/pop/
|
||||
[9]: https://itsfoss.com/apt-get-linux-guide/
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-14_tutorial.jpg?resize=800%2C516&ssl=1
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/11/snapcraft.jpg?ssl=1
|
||||
[12]: https://itsfoss.com/install-snap-linux/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/11/iso-amd-nvidia-pop-os.jpg?ssl=1
|
||||
[14]: https://itsfoss.com/best-linux-beginners/
|
||||
[15]: https://www.phoronix.com/scan.php?page=news_item&px=System76-Integrated-Vision
|
||||
288
sources/tech/20191221 Testing your Bash script.md
Normal file
288
sources/tech/20191221 Testing your Bash script.md
Normal file
@ -0,0 +1,288 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Testing your Bash script)
|
||||
[#]: via: (https://opensource.com/article/19/12/testing-bash-script)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
Testing your Bash script
|
||||
======
|
||||
In the fourth and final article in this series on automation with shell
|
||||
scripts, learn about initializing variables and ensuring your program
|
||||
runs correctly.
|
||||
![Team checklist and to dos][1]
|
||||
|
||||
In the [first article][2] in this series, you created your first, very small, one-line Bash script and explored the reasons for creating shell scripts. In the [second article][3], you began creating a fairly simple template that can be a starting point for other Bash programs and began testing it. In the [third article][4], you created and used a simple Help function and learned about using functions and how to handle command-line options such as **-h**.
|
||||
|
||||
This fourth and final article in the series gets into variables and initializing them as well as how to do a bit of sanity testing to help ensure the program runs under the proper conditions. Remember, the objective of this series is to build working code that will be used for a template for future Bash programming projects. The idea is to make getting started on new programming projects easy by having common elements already available in the template.
|
||||
|
||||
### Variables
|
||||
|
||||
The Bash shell, like all programming languages, can deal with variables. A variable is a symbolic name that refers to a specific location in memory that contains a value of some sort. The value of a variable is changeable, i.e., it is variable. If you are not familiar with using variables, read my article [_How to program with Bash: Syntax and tools_][5] before you go further.
|
||||
|
||||
Done? Great! Let's now look at some good practices when using variables.
|
||||
|
||||
I always set initial values for every variable used in my scripts. You can find this in your template script immediately after the procedures as the first part of the main program body, before it processes the options. Initializing each variable with an appropriate value can prevent errors that might occur with uninitialized variables in comparison or math operations. Placing this list of variables in one place allows you to see all of the variables that are supposed to be in the script and their initial values.
|
||||
|
||||
Your little script has only a single variable, **$option**, so far. Set it by inserting the following lines as shown:
|
||||
|
||||
|
||||
```
|
||||
################################################################################
|
||||
################################################################################
|
||||
# Main program #
|
||||
################################################################################
|
||||
################################################################################
|
||||
# Initialize variables
|
||||
option=""
|
||||
################################################################################
|
||||
# Process the input options. Add options as needed. #
|
||||
################################################################################
|
||||
```
|
||||
|
||||
Test this to ensure that everything works as it should and that nothing has broken as the result of this change.
|
||||
|
||||
### Constants
|
||||
|
||||
Constants are variables, too—at least they should be. Use variables wherever possible in command-line interface (CLI) programs instead of hard-coded values. Even if you think you will use a particular value (such as a directory name, a file name, or a text string) just once, create a variable and use it where you would have placed the hard-coded name.
|
||||
|
||||
For example, the message printed as part of the main body of the program is a string literal, **echo "Hello world!"**. Change that to a variable. First, add the following statement to the variable initialization section:
|
||||
|
||||
|
||||
```
|
||||
`Msg="Hello world!"`
|
||||
```
|
||||
|
||||
And now change the last line of the program from:
|
||||
|
||||
|
||||
```
|
||||
`echo "Hello world!"`
|
||||
```
|
||||
|
||||
to:
|
||||
|
||||
|
||||
```
|
||||
`echo "$Msg"`
|
||||
```
|
||||
|
||||
Test the results.
|
||||
|
||||
### Sanity checks
|
||||
|
||||
Sanity checks are simply tests for conditions that need to be true in order for the program to work correctly, such as: the program must be run as the root user, or it must run on a particular distribution and release of that distro. Add a check for _root_ as the running user in your simple program template.
|
||||
|
||||
Testing that the root user is running the program is easy because a program runs as the user that launches it.
|
||||
|
||||
The **id** command can be used to determine the numeric user ID (UID) the program is running under. It provides several bits of information when it is used without any options:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ id
|
||||
uid=1001(student) gid=1001(student) groups=1001(student),5000(dev)
|
||||
```
|
||||
|
||||
Using the **-u** option returns just the user's UID, which is easily usable in your Bash program:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ id -u
|
||||
1001
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
Add the following function to the program. I added it after the Help procedure, but you can place it anywhere in the procedures section. The logic is that if the UID is not zero, which is always the root user's UID, the program exits:
|
||||
|
||||
|
||||
```
|
||||
################################################################################
|
||||
# Check for root. #
|
||||
################################################################################
|
||||
CheckRoot()
|
||||
{
|
||||
if [ `id -u` != 0 ]
|
||||
then
|
||||
echo "ERROR: You must be root user to run this program"
|
||||
exit
|
||||
fi
|
||||
}
|
||||
```
|
||||
|
||||
Now, add a call to the **CheckRoot** procedure just before the variable's initialization. Test this, first running the program as the student user:
|
||||
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ ./hello
|
||||
ERROR: You must be root user to run this program
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
then as the root user:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 student]# ./hello
|
||||
Hello world!
|
||||
[root@testvm1 student]#
|
||||
```
|
||||
|
||||
You may not always need this particular sanity test, so comment out the call to **CheckRoot** but leave all the code in place in the template. This way, all you need to do to use that code in a future program is to uncomment the call.
|
||||
|
||||
### The code
|
||||
|
||||
After making the changes outlined above, your code should look like this:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/bash
|
||||
################################################################################
|
||||
# scriptTemplate #
|
||||
# #
|
||||
# Use this template as the beginning of a new program. Place a short #
|
||||
# description of the script here. #
|
||||
# #
|
||||
# Change History #
|
||||
# 11/11/2019 David Both Original code. This is a template for creating #
|
||||
# new Bash shell scripts. #
|
||||
# Add new history entries as needed. #
|
||||
# #
|
||||
# #
|
||||
################################################################################
|
||||
################################################################################
|
||||
################################################################################
|
||||
# #
|
||||
# Copyright (C) 2007, 2019 David Both #
|
||||
# [LinuxGeek46@both.org][6] #
|
||||
# #
|
||||
# This program is free software; you can redistribute it and/or modify #
|
||||
# it under the terms of the GNU General Public License as published by #
|
||||
# the Free Software Foundation; either version 2 of the License, or #
|
||||
# (at your option) any later version. #
|
||||
# #
|
||||
# This program is distributed in the hope that it will be useful, #
|
||||
# but WITHOUT ANY WARRANTY; without even the implied warranty of #
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the #
|
||||
# GNU General Public License for more details. #
|
||||
# #
|
||||
# You should have received a copy of the GNU General Public License #
|
||||
# along with this program; if not, write to the Free Software #
|
||||
# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA #
|
||||
# #
|
||||
################################################################################
|
||||
################################################################################
|
||||
################################################################################
|
||||
|
||||
################################################################################
|
||||
# Help #
|
||||
################################################################################
|
||||
Help()
|
||||
{
|
||||
# Display Help
|
||||
echo "Add description of the script functions here."
|
||||
echo
|
||||
echo "Syntax: scriptTemplate [-g|h|v|V]"
|
||||
echo "options:"
|
||||
echo "g Print the GPL license notification."
|
||||
echo "h Print this Help."
|
||||
echo "v Verbose mode."
|
||||
echo "V Print software version and exit."
|
||||
echo
|
||||
}
|
||||
|
||||
################################################################################
|
||||
# Check for root. #
|
||||
################################################################################
|
||||
CheckRoot()
|
||||
{
|
||||
# If we are not running as root we exit the program
|
||||
if [ `id -u` != 0 ]
|
||||
then
|
||||
echo "ERROR: You must be root user to run this program"
|
||||
exit
|
||||
fi
|
||||
}
|
||||
|
||||
################################################################################
|
||||
################################################################################
|
||||
# Main program #
|
||||
################################################################################
|
||||
################################################################################
|
||||
|
||||
################################################################################
|
||||
# Sanity checks #
|
||||
################################################################################
|
||||
# Are we rnning as root?
|
||||
# CheckRoot
|
||||
|
||||
# Initialize variables
|
||||
option=""
|
||||
Msg="Hello world!"
|
||||
################################################################################
|
||||
# Process the input options. Add options as needed. #
|
||||
################################################################################
|
||||
# Get the options
|
||||
while getopts ":h" option; do
|
||||
case $option in
|
||||
h) # display Help
|
||||
Help
|
||||
exit;;
|
||||
\?) # incorrect option
|
||||
echo "Error: Invalid option"
|
||||
exit;;
|
||||
esac
|
||||
done
|
||||
|
||||
echo "$Msg"
|
||||
```
|
||||
|
||||
### A final exercise
|
||||
|
||||
You probably noticed that the Help function in your code refers to features that are not in the code. As a final exercise, figure out how to add those functions to the code template you created.
|
||||
|
||||
### Summary
|
||||
|
||||
In this article, you created a couple of functions to perform a sanity test for whether your program is running as root. Your program is getting a little more complex, so testing is becoming more important and requires more test paths to be complete.
|
||||
|
||||
This series looked at a very minimal Bash program and how to build a script up a bit at a time. The result is a simple template that can be the starting point for other, more useful Bash scripts and that contains useful elements that make it easy to start new scripts.
|
||||
|
||||
By now, you get the idea: Compiled programs are necessary and fill a very important need. But for sysadmins, there is always a better way. Always use shell scripts to meet your job's automation needs. Shell scripts are open; their content and purpose are knowable. They can be readily modified to meet different requirements. I have never found anything that I need to do in my sysadmin role that cannot be accomplished with a shell script.
|
||||
|
||||
What you have created so far in this series is just the beginning. As you write more Bash programs, you will find more bits of code that you use frequently and should be included in your program template.
|
||||
|
||||
### Resources
|
||||
|
||||
* [How to program with Bash: Syntax and tools][5]
|
||||
* [How to program with Bash: Logical operators and shell expansions][7]
|
||||
* [How to program with Bash: Loops][8]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_This series of articles is partially based on Volume 2, Chapter 10 of David Both's three-part Linux self-study course, [Using and Administering Linux—Zero to SysAdmin][9]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/testing-bash-script
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/todo_checklist_team_metrics_report.png?itok=oB5uQbzf (Team checklist and to dos)
|
||||
[2]: https://opensource.com/article/19/12/introduction-automation-bash-scripts
|
||||
[3]: https://opensource.com/article/19/12/creating-bash-script-template
|
||||
[4]: https://opensource.com/article/19/12/give-your-bash-program-some-help
|
||||
[5]: https://opensource.com/article/19/10/programming-bash-syntax-tools
|
||||
[6]: mailto:LinuxGeek46@both.org
|
||||
[7]: https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions
|
||||
[8]: https://opensource.com/article/19/10/programming-bash-loops
|
||||
[9]: http://www.both.org/?page_id=1183
|
||||
@ -0,0 +1,179 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create a unique Linux experience with the Unix Desktop Environment)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-unix-desktop-environment-ude)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Create a unique Linux experience with the Unix Desktop Environment
|
||||
======
|
||||
This article is part of a special series of 24 days of Linux desktops.
|
||||
If you're in the mood for something completely unique, then UDE is the
|
||||
desktop you need to try.
|
||||
![Penguins][1]
|
||||
|
||||
When the UDE project started in 1996, the developers took on a bold name—[Unix Desktop Environment (UDE)][2]—and held high hopes of reinventing what a desktop could be. They weren't just trying to redefine Unix desktops; they were trying to change the way users interacted with applications on their system. Windows 95 had just come out, so the idea of managing a make-believe "desktop" filled with "folders" and "windows" meant to mimic a real-world desktop had not won all computer users' mindshare (it still hasn't, but it does at least seem to be a reliably stable option now). There was still room for experimentation in computer user interfaces (UIs), and the UDE project introduced some truly innovative ideas.
|
||||
|
||||
One of UDE's most intriguing concepts is that its windows have no title bars or handles. All window control is performed with a hex menu that appears when a window border is clicked. Windows are moved with a middle-click and resized with a right-click.
|
||||
|
||||
![Unix Desktop Environment][3]
|
||||
|
||||
If you're in the mood for something completely unique, then UDE is the desktop you need to try.
|
||||
|
||||
### Installing UDE
|
||||
|
||||
Your distribution probably doesn't have UDE in its software repository, but it's relatively easy to compile for someone who's used to building software from raw source code.
|
||||
|
||||
I installed UDE on Slackware 14.2, but it doesn't rely on any libraries other than standard Xlibs, so it should work on any Linux or BSD system. The compile process requires build tools, which ship by default on Slackware but are often omitted on other distributions to save space on the initial download. The names of the packages you must install to build from source code vary depending on your distro, so refer to the documentation for specifics. For example, on Debian-based distributions, you can learn about build requirements in [Debian's BuildingTutorial][4] doc, and on Fedora-based distributions, refer to [Fedora's Installing software from source][5] doc. Once you have the build tools installed, you can build UDE the standard [GNU Automake][6] way:
|
||||
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make -j2
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
The default location for installation is **/usr/local**, but you can adjust the paths during the configuration step.
|
||||
|
||||
### Xinitrc and UDE
|
||||
|
||||
The easiest way to get up and running with UDE is to let Xorg do the bulk of the work. First, you must create a **$HOME/.xinitrc** file. I adapted this from scripts bundled in Slackware:
|
||||
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# $XConsortium: xinitrc.cpp,v 1.4 91/08/22 11:41:34 rws Exp $
|
||||
|
||||
userresources=$HOME/.Xresources
|
||||
usermodmap=$HOME/.Xmodmap
|
||||
sysresources=/etc/X11/xinit/.Xresources
|
||||
sysmodmap=/etc/X11/xinit/.Xmodmap
|
||||
|
||||
# merge in defaults and keymaps
|
||||
|
||||
if [ -f $sysresources ]; then
|
||||
xrdb -merge $sysresources
|
||||
fi
|
||||
|
||||
if [ -f $sysmodmap ]; then
|
||||
xmodmap $sysmodmap
|
||||
fi
|
||||
|
||||
if [ -f $userresources ]; then
|
||||
xrdb -merge $userresources
|
||||
fi
|
||||
|
||||
if [ -f $usermodmap ]; then
|
||||
xmodmap $usermodmap
|
||||
fi
|
||||
|
||||
# window manager
|
||||
exec /usr/local/bin/uwm
|
||||
```
|
||||
|
||||
According to this file, the default action for the **startx** command is to launch the **uwm** window manager (which houses UDE). However, your distribution may have other ideas about what happens when your graphic server is launched (or killed to be restarted), so this file may do you little good. On many distributions, you can add a **.desktop** file to **/usr/share/xsessions** to have it listed in the GDM or KDM menu, so create a file called **uwm.desktop** and enter this text:
|
||||
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=UDE
|
||||
Comment=UNIX Desktop Environment
|
||||
Exec=/usr/local/bin/uwm
|
||||
Type=Application
|
||||
```
|
||||
|
||||
Log out from your desktop session and log back into UDE. By default, your session manager (KDM, GDM, or LightDM, depending on your setup) will continue to log you into your previous desktop, so you must override that before logging in.
|
||||
|
||||
With GDM:
|
||||
|
||||
![][7]
|
||||
|
||||
With SDDM:
|
||||
|
||||
![][8]
|
||||
|
||||
#### Launching with brute force
|
||||
|
||||
If UDE fails to start, try installing XDM, a lightweight session manager that doesn't look at **/usr/share/xsessions** and instead just does whatever the authenticated user's **.xinitrc** prescribes.
|
||||
|
||||
### Desktop tour
|
||||
|
||||
When UDE first launches, you may find yourself staring at a black screen. That's the default primary desktop for UDE, and it's blank because no background wallpaper has been set. You can set one for yourself with the **feh** command (you may need to install it from your repository). This command has a few options for setting the background, including **\--bg-fill** to fill the screen with your wallpaper of choice, **\--bg-scale** to scale it to fit, and so on.
|
||||
|
||||
|
||||
```
|
||||
`$ feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg`
|
||||
```
|
||||
|
||||
### Interacting with the desktop
|
||||
|
||||
The next task is to launch an application. UDE provides an application menu, which you can bring up at your mouse pointer's position with a right-click on the desktop. Because you haven't customized the menu yet, your best bet is to launch an **xterm** window so that you can issue arbitrary commands.
|
||||
|
||||
Once you have an xterm window open, you might notice that there's no window decoration. This is the central idea behind UDE: windows are manipulated primarily with a "honeycomb" or hex menu that appears when you left-click on the border of any window.
|
||||
|
||||
![UDE honeycomb menu][9]
|
||||
|
||||
Clockwise from the top hex, the options are:
|
||||
|
||||
* Close
|
||||
* Kill (confirm by selecting the pop-up hex that appears upon mouseover)
|
||||
* Make sticky or send to a different desktop
|
||||
* Maximize
|
||||
* Send behind other windows
|
||||
* Minimize
|
||||
|
||||
|
||||
|
||||
Most of them are self-explanatory, but the minimize option can be confusing because there's no place for windows to be minimized _to_ because there's no taskbar, no docklet, and no desktop icons. To retrieve a minimized window, middle-click on the desktop.
|
||||
|
||||
![UDE middle-click menu][10]
|
||||
|
||||
This presents a menu of virtual desktops, one of which is your current desktop and therefore contains even your minimized applications. Select the minimized application to restore it to your screen.
|
||||
|
||||
### Menus and configuration
|
||||
|
||||
There are example and default config files in **/usr/local/share/uwm/config**, including one for the right-click application menu configuration. The syntax for the menu is simple and well-documented at the top of the file. This code sample changes the browser option from Netscape to Firefox:
|
||||
|
||||
|
||||
```
|
||||
LINE;
|
||||
% ITEM "Netscape":"netscape";
|
||||
ITEM "Firefox":"firefox";
|
||||
LINE;
|
||||
```
|
||||
|
||||
To see your changes, restart UDE from the left-click menu. The **uwmrc** configuration files dictate the layout of UDE, including the size of window borders, fonts, and other stylistic choices. They are
|
||||
|
||||
also well-documented in comments, so look through them and make changes to experiment and find what works best for you.
|
||||
|
||||
### Old innovations, new again
|
||||
|
||||
UDE's interface is strange and new and—if you're intrigued by UI design—very exciting. UDE's design exemplifies the advantages and disadvantages of creating standards in computing. On the one hand, something like UDE is so alien to most users that it's bound to get in the way, yet on the other hand, it's fresh and different and forces users to re-evaluate their workflows, which may result in several unexpected improvements. The reaction you probably have when trying UDE is the same one you're likely to see when you introduce a friend to Linux: What's an old, familiar GNOME or KDE desktop to you is a puzzle to them. But deep down, most of us know the potential benefits of changing the way we look at something we take for granted.
|
||||
|
||||
That said, UDE is unquestionably an experiment, not a finished project. It probably isn't going to be your primary desktop, but it's well worth exploring. This is innovation. It's sometimes messy, sometimes slow, sometimes tumultuous. But it's important, bold, and a heck of a lot of fun.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-unix-desktop-environment-ude
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux-penguins.png?itok=yKOpaJM_ (Penguins)
|
||||
[2]: http://udeproject.sourceforge.net/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/advent-ude.jpg (Unix Desktop Environment)
|
||||
[4]: https://wiki.debian.org/BuildingTutorial
|
||||
[5]: https://docs.pagure.org/docs-fedora/installing-software-from-source.html
|
||||
[6]: https://opensource.com/article/19/7/introduction-gnu-autotools
|
||||
[7]: https://opensource.com/sites/default/files/advent-gdm_2.jpg
|
||||
[8]: https://opensource.com/sites/default/files/advent-kdm_1.jpg
|
||||
[9]: https://opensource.com/sites/default/files/uploads/advent-ude-hex.jpg (UDE honeycomb menu)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/advent-ude-middle.jpg (UDE middle-click menu)
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Update Grub on Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/update-grub/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Update Grub on Ubuntu and Other Linux Distributions
|
||||
======
|
||||
|
||||
In this tutorial, you’ll learn to update grub on Ubuntu or any other Linux distribution. You’ll also learn a thing or two about how this grub update process works.
|
||||
|
||||
### How to update grub
|
||||
|
||||
Ubuntu and many other Linux distributions provide a handy command line utility called update-grub.
|
||||
|
||||
To update grub, all you have to do is to run this command in the terminal with sudo.
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
You should see an output like this:
|
||||
|
||||
```
|
||||
[email protected]:~$ sudo update-grub
|
||||
[sudo] password for abhishek:
|
||||
Sourcing file `/etc/default/grub'
|
||||
Generating grub configuration file ...
|
||||
Found linux image: /boot/vmlinuz-5.0.0-37-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-37-generic
|
||||
Found linux image: /boot/vmlinuz-5.0.0-36-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-36-generic
|
||||
Found linux image: /boot/vmlinuz-5.0.0-31-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-31-generic
|
||||
Found Ubuntu 19.10 (19.10) on /dev/sda4
|
||||
Found MX 19 patito feo (19) on /dev/sdb1
|
||||
Adding boot menu entry for EFI firmware configuration
|
||||
done
|
||||
```
|
||||
|
||||
You may see a similar command called update-grub2. No need to be alarmed or confused between update-grub and update-grub2. Both of these commands do the same action.
|
||||
|
||||
Around ten years ago, when grub2 was just introduced, update-grub2 command was also introduced. Today, update-grub2 is just a symbolic link to update-grub and both update grub2 configuration (because grub2 is the default).
|
||||
|
||||
#### Can’t find update-grub command? Here’s what to do in that case
|
||||
|
||||
It’s possible that your Linux distribution might not have update-grub command available.
|
||||
|
||||
What do you do in that case? How do you update grub on such a Linux distribution?
|
||||
|
||||
There is no need to panic. The update-grub command is simply a stub for running ‘grub-mkconfig -o /boot/grub/grub.cfg’ to generate grub2 config file.
|
||||
|
||||
Which means that you can update grub with the following command on any Linux distribution:
|
||||
|
||||
```
|
||||
sudo grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
Of course, remembering update-grub command is a lot easier than the above command and this is the reason why it was created in the first place.
|
||||
|
||||
### How does update-grub work?
|
||||
|
||||
When you install a Linux distribution, it (usually) asks you to install the [grub boot loader][1].
|
||||
|
||||
Part of grub is installed on the MBR/ESP partition. Rest of the grub lies in /boo/grub directory of the Linux distributions.
|
||||
|
||||
As per its [man page][2], update-grub works by looking into the /boot directory. All the files starting with [vmlinuz-][3] will be treated as kernels and they will get a grub menu entry. It will also add initrd lines for [ramdisk][4] images found with the same version as kernels found.
|
||||
|
||||
It also looks into all disk partitions for other operating systems with [os-prober][5]. If it finds other operating systems, it adds them to the grub menu.
|
||||
|
||||
![Representational image of Grub Menu][6]
|
||||
|
||||
### Why would you need to update grub?
|
||||
|
||||
There could be a number of scenarios when you need to update grub.
|
||||
|
||||
Suppose you changed the grub config file (/etc/default/grub) to [change the default boot order][7] or reduce the default boot time. Your changes won’t take into effect unless you update the grub.
|
||||
|
||||
Another scenario is when you have multiple Linux distributions installed on the same system.
|
||||
|
||||
For example, on my Intel NUC, I have two disks. The first disk had Ubuntu 19.10 and then I installed Ubuntu 18.04 on it. The second OS (Ubuntu 18.04) also installed its own grub and now the grub screen is controlled by Ubuntu 18.04 grub.
|
||||
|
||||
On the second disk, I installed MX Linux but I didn’t install grub this time. I want the existing grub (controlled by Ubuntu 18.04) to handle all the OS entries.
|
||||
|
||||
Now, in this scenario, the grub on Ubuntu 18.04 needs to be updated so that it can see [MX Linux][8].
|
||||
|
||||
![][9]
|
||||
|
||||
As you can see in the image above, when I update the grub, it finds various Linux kernels installed on 18.04 along with Ubuntu 19.10 and MX Linux on different partition.
|
||||
|
||||
If I want MX Linux to control the grub, I can install grub on MX Linux with [grub-install][10] command and then the grub on MX Linux will start controlling the grub screen. You get the gist, right?
|
||||
|
||||
Using a GUI tool like [Grub Customizer][11] is a simpler way to make changes in grub.
|
||||
|
||||
**In the end…**
|
||||
|
||||
Initially, I had intended to keep it a short article as a quick tip. But then I thought of explaining a few things associated with it so that (relatively) new Linux users could learn more than just a simple command.
|
||||
|
||||
Did you like it? Do you have some questions or suggestions? Please feel free to leave a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/update-grub/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[2]: https://manpages.debian.org/testing/grub-legacy/update-grub.8.en.html
|
||||
[3]: https://www.ibm.com/developerworks/community/blogs/mhhaque/entry/anatomy_of_the_initrd_and_vmlinuz?lang=en
|
||||
[4]: https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[5]: https://packages.debian.org/sid/utils/os-prober
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/grub_screen.png?ssl=1
|
||||
[7]: https://itsfoss.com/grub-customizer-ubuntu/
|
||||
[8]: https://mxlinux.org/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/update_grub.png?ssl=1
|
||||
[10]: https://www.gnu.org/software/grub/manual/grub/html_node/Installing-GRUB-using-grub_002dinstall.html
|
||||
[11]: https://itsfoss.com/customize-grub-linux/
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why your Python code needs to be beautiful and explicit)
|
||||
[#]: via: (https://opensource.com/article/19/12/zen-python-beauty-clarity)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
Why your Python code needs to be beautiful and explicit
|
||||
======
|
||||
Welcome to Pythonukkah, a special series about the Zen of Python. On the
|
||||
first day, we celebrate the first two principles: beauty and
|
||||
explicitness.
|
||||
![Searching for code][1]
|
||||
|
||||
Python contributor Tim Peters introduced us to the [Zen of Python][2] in 1999. Twenty years later, its 19 guiding principles continue to be relevant within the community. We start our Pythonukkah celebration—like Hanukkah, a festival of lights—with the first two principles in the Zen of Python: on beauty and explicitness.
|
||||
|
||||
> "Hanukkah is the Festival of Lights,
|
||||
> Instead of one day of presents, we get eight crazy nights."
|
||||
> —Adam Sandler, [_The Hanukkah Song_][3]
|
||||
|
||||
### Beautiful is better than ugly.
|
||||
|
||||
It was in _[Structure and Interpretation of Computer Programs][4]_ (_SICP_) that the point was made: "Programs must be written for people to read and only incidentally for machines to execute." Machines do not care about beauty, but people do.
|
||||
|
||||
A beautiful program is one that is enjoyable to read. This means first that it is consistent. Tools like [Black][5], [flake8][6], and [Pylint][7] are great for making sure things are reasonable on a surface layer.
|
||||
|
||||
But even more important, only humans can judge what humans find beautiful. Code reviews and a collaborative approach to writing code are the only realistic way to build beautiful code. Listening to other people is an important skill in software development.
|
||||
|
||||
Finally, all the tools and processes are moot if the _will_ is not there. Without an appreciation for the importance of beauty, there will never be an emphasis on writing beautiful code.
|
||||
|
||||
This is why this is the first principle: it is a way of making "beauty" a value in the Python community. It immediately answers: "Do we _really_ care about beauty?" We do.
|
||||
|
||||
### Explicit is better than implicit.
|
||||
|
||||
We humans celebrate light and fear the dark. Light helps us make sense of vague images. In the same way, programming with more explicitness helps us make sense of abstract ideas. It is often tempting to make things implicit.
|
||||
|
||||
"Why is **self** explicitly there as the first parameter of methods?"
|
||||
|
||||
There are many technical explanations, but all of them are wrong. It is almost a Python programmer's rite of passage to write a metaclass that makes explicitly listing **self** unnecessary. (If you have never done this before, do so; it makes a great metaclass learning exercise!)
|
||||
|
||||
The reason **self** is explicit is not because the Python core developers did not want to make a metaclass like that the "default" metaclass. The reason it is explicit is because there is one less special case to teach: the first argument is _explicit_.
|
||||
|
||||
Even when Python does allow non-explicit things, such as context variables, we must always ask: Are we sure we need them? Could we not just pass arguments explicitly? Sometimes, for many reasons, this is not feasible. But prioritizing explicitness means, at the least, asking the question and estimating the effort.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/zen-python-beauty-clarity
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_python_programming.png?itok=ynSL8XRV (Searching for code)
|
||||
[2]: https://www.python.org/dev/peps/pep-0020/
|
||||
[3]: https://en.wikipedia.org/wiki/The_Chanukah_Song
|
||||
[4]: https://en.wikipedia.org/wiki/Structure_and_Interpretation_of_Computer_Programs
|
||||
[5]: https://opensource.com/article/19/5/python-black
|
||||
[6]: https://opensource.com/article/19/5/python-flake8
|
||||
[7]: https://opensource.com/article/19/10/python-pylint-introduction
|
||||
@ -7,144 +7,144 @@
|
||||
[#]: via: (https://fosspost.org/tutorials/install-android-8-1-oreo-on-linux)
|
||||
[#]: author: (Python Programmer;Open Source Software Enthusiast. Worked On Developing A Lot Of Free Software. The Founder Of Foss Post;Foss Project. Computer Science Major. )
|
||||
|
||||
Install Android 8.1 Oreo on Linux To Run Apps & Games
|
||||
在 Linux 上安装 Android 8.1 Oreo 来运行应用程序和游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
[android x86][1] is a free and an open source project to port the android system made by Google from the ARM architecture to the x86 architecture, which allow users to run the android system on their desktop machines to enjoy all android functionalities + Apps & games.
|
||||
[android x86][1] 是一个自由开放源码的项目,将谷歌制作的android系统从 ARM 架构移植到 x86 架构, 运行用户在他们的桌面机器上运行 android 系统来享受所有的 android 功能和应用程序及游戏。
|
||||
|
||||
The android x86 project finished porting the android 8.1 Oreo system to the x86 architecture few weeks ago. In this post, we’ll explain how to install it on your Linux system so that you can use your android apps and games any time you want.
|
||||
几周前,android x86 项目完成 android 8.1 Oreo 系统到 x86 架构的移植。在这篇文章中,我们将解释如何在你的 Linux 系统上安装它,以便你能够随时使用你的 android 应用程序和游戏。
|
||||
|
||||
### Installing Android x86 8.1 Oreo on Linux
|
||||
### 在 Linux 上安装 Android x86 8.1 Oreo
|
||||
|
||||
#### Preparing the Environment
|
||||
#### 准备环境
|
||||
|
||||
First, let’s download the android x86 8.1 Oreo system image. You can download it from [this page][2], just click on the “View” button under the android-x86_64-8.1-r1.iso file.
|
||||
首先,让我们下载 android x86 8.1 Oreo 系统镜像。你可以从[这个页面][2]下载它,只需单击 android-x86_64-8.1-r1.iso 文件下 “View” 按钮。
|
||||
|
||||
We are going to use QEMU to run android x86 on our Linux system. QEMU is a very good emulator software, which is also free and open source, and is available in all the major Linux distributions repositories.
|
||||
我们将在我们的 Linux 系统上使用 QEMU 来运行 android x86 。QEMU 是一个非常好的模拟器软件,它也是自由和开放源码的,并且在所有主要的 Linux 发行版存储库中都是可用的。
|
||||
|
||||
To install QEMU on Ubuntu/Linux Mint/Debian:
|
||||
在 Ubuntu/Linux Mint/Debian 上安装 QEMU:
|
||||
|
||||
```
|
||||
sudo apt-get install qemu qemu-kvm libvirt-bin
|
||||
```
|
||||
|
||||
To install QEMU on Fedora:
|
||||
在 Fedora 上安装 QEMU:
|
||||
|
||||
```
|
||||
sudo dnf install qemu qemu-kvm
|
||||
```
|
||||
|
||||
For other distributions, just search for the qemu and qemu-kvm packages and install them.
|
||||
对于其它发行版,只需要搜索 qemu 和 qemu-kvm 软件包,并安装它们。
|
||||
|
||||
After you have installed QEMU, we’ll need to run the following command to create the android.img file, which will be like some sort of an allocated disk space just for the android system. All android files and system will be inside that image file:
|
||||
在你安装 QEMU 后,我们将需要运行下面的命令来创建 android.img 文件,它就像某种分配给 android 系统的磁盘空间。所有 android 文件和系统都将位于该镜像文件中:
|
||||
|
||||
```
|
||||
qemu-img create -f qcow2 android.img 15G
|
||||
```
|
||||
|
||||
Here we are saying that we want to allocate a maximum of 15GB for android, but you can change it to any size you want (make sure it’s at least bigger than 5GB).
|
||||
我们在这里说,我们想为 android 分配一个最大 15GB 的磁盘空间,但是,你可以更改它到你想要的任意大小(确保它至少大于5GB)。
|
||||
|
||||
Now, to start running the android system for the first time, run:
|
||||
现在,首次启动运行 android 系统,运行:
|
||||
|
||||
```
|
||||
sudo qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda android.img -cdrom /home/mhsabbagh/android-x86_64-8.1-r1.iso
|
||||
```
|
||||
|
||||
Replace /home/mhsabbagh/android-x86_64-8.1-r1.iso with the path of the file that you downloaded from the android x86 website. For explaination of other options we are using here, you may refer to [this article][3].
|
||||
将 /home/mhsabbagh/android-x86_64-8.1-r1.iso 替换为你从 android x86 网站下载的文件的路径。我们在这里正在使用的其它选项的解释,你可以参考[这篇文章][3]。
|
||||
|
||||
After you run the above command, the android system will start:
|
||||
在你运行上面的命令后,android 系统将启动:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 39 android 8.1 oreo on linux][4]
|
||||
|
||||
#### Installing the System
|
||||
#### 安装系统
|
||||
|
||||
From this window, choose “Advanced options”, which should lead to the following menu, from which you should choose “Auto_installation” as follows:
|
||||
从这个窗口中,选择 “Advanced options”, 它将引导到下面的菜单,你应如下在其中选择 “Auto_installation” :
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 41 android 8.1 oreo on linux][5]
|
||||
|
||||
After that, the installer will just tell you about whether you want to continue or not, choose Yes:
|
||||
在这以后,安装器将告知你是否想要继续,选择 Yes :
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 43 android 8.1 oreo on linux][6]
|
||||
|
||||
And the installation will carry on without any further instructions from you:
|
||||
接下来,安装器将无需你的指示而继续进行:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 45 android 8.1 oreo on linux][7]
|
||||
|
||||
Finally you’ll receive this message, which indicates that you have successfully installed android 8.1:
|
||||
最后,你将收到这个信息,它表示你已经成功安装 android 8.1 :
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 47 android 8.1 oreo on linux][8]
|
||||
|
||||
For now, just close the QEMU window completely.
|
||||
现在,完全关闭 QEMU 窗口。
|
||||
|
||||
#### Booting and Using Android 8.1 Oreo
|
||||
#### 启动和使用 Android 8.1 Oreo
|
||||
|
||||
Now that the android system is fully installed in your android.img file, you should use the following QEMU command to start it instead of the previous one:
|
||||
现在,android 系统已经完全安装在你的 android.img 文件中,你应该使用下面的 QEMU 命令来启动它,而不是前面的命令:
|
||||
|
||||
```
|
||||
sudo qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda android.img
|
||||
```
|
||||
|
||||
Notice that all we did was that we just removed the -cdrom option and its argument. This is to tell QEMU that we no longer want to boot from the ISO file that we downloaded, but from the installed android system.
|
||||
注意,我们所做的只是移除 -cdrom 选项和它的参数。这是告诉 QEMU ,我们不再想从我们下载的 ISO 文件启动,相反,从安装的 android 系统启动。
|
||||
|
||||
You should see the android booting menu now:
|
||||
你现在能够看到 android 启动菜单:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 49 android 8.1 oreo on linux][9]
|
||||
|
||||
Then you’ll be taken to the first preparation wizard, choose your language and continue:
|
||||
然后,你将带去第一个准备向导,选择你的语言并继续:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 51 android 8.1 oreo on linux][10]
|
||||
|
||||
From here, choose the “Set up as new” option:
|
||||
从这里,选择 “Set up as new” 选项:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 53 android 8.1 oreo on linux][11]
|
||||
|
||||
Then android will ask you about if you want to login to your current Google account. This step is optional, but important so that you can use the Play Store later:
|
||||
然后,android 将询问你是否想登陆到你当前的谷歌账号。这步骤是可选的,但是这很重要,以便你随后可以使用 Play Store :
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 55 android 8.1 oreo on linux][12]
|
||||
|
||||
Then you’ll need to accept the terms and conditions:
|
||||
然后,你将需要接受条款:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 57 android 8.1 oreo on linux][13]
|
||||
|
||||
Now you can choose your current timezone:
|
||||
现在,你可以选择你当前的时区:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 59 android 8.1 oreo on linux][14]
|
||||
|
||||
The system will ask you now if you want to enable any data collection features. If I were you, I’d simply turn them all off like that:
|
||||
系统将询问你是否想启动一些数据收集功能。如果我是你的话,我将简单地关闭它们,像这样:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 61 android 8.1 oreo on linux][15]
|
||||
|
||||
Finally, you’ll have 2 launcher types to choose from, I recommend that you choose the Launcher3 option and make it the default:
|
||||
最后,你将有两种启动类型可供选择,我建议你选择 Launcher3 选项,并使其成为默认项:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 63 android 8.1 oreo on linux][16]
|
||||
|
||||
Then you’ll see your fully-working android system home screen:
|
||||
然后,你将看到完整工作的 android 系统主屏幕:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 65 android 8.1 oreo on linux][17]
|
||||
|
||||
From here now, you can do all the tasks you want; You can use the built-in android apps, or you may browse the settings of your system to adjust it however you like. You may change look and feeling of your system, or you can run Chrome for example:
|
||||
从现在起,你可以做你想做的任何事情;你可以使用内置的 android 应用程序,或者你可以浏览你是系统设置来根据你的喜好进行调整。你可以更改你的系统的外观和体验,或者你可以像示例一样运行 Chrome :
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 67 android 8.1 oreo on linux][18]
|
||||
|
||||
You may start installing some apps like WhatsApp and others from the Google Play store for your own use:
|
||||
你可以从 Google Play store 开始安装一些应用程序程序,像 WhatsApp 和其它的应用程序,以供你自己使用:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 69 android 8.1 oreo on linux][19]
|
||||
|
||||
You can now do whatever you want with your system. Congratulations!
|
||||
你现在可以用你的系统做任何你想做的事。恭喜!
|
||||
|
||||
### How to Easily Run Android 8.1 Oreo Later
|
||||
### 以后如何轻松地运行 Android 8.1 Oreo
|
||||
|
||||
We don’t want to always have to open the terminal window and write that long QEMU command to run the android system, but we want to run it in just 1 click whenever we need that.
|
||||
我们不想总是不得不打开终端窗口,并写那些长长的 QEMU 命令来运行 android 系统,相反,我们想在我们需要时一次单击就运行它。
|
||||
|
||||
To do this, we’ll create a new file under /usr/share/applications called android.desktop with the following command:
|
||||
为此,我们将使用下面的命令在 /usr/share/applications 下创建一个名为 android.desktop 的新文件:
|
||||
|
||||
```
|
||||
sudo nano /usr/share/applications/android.desktop
|
||||
```
|
||||
|
||||
And paste the following contents inside it (Right click and then paste):
|
||||
并在其中粘贴下面的内容(右键单击然后粘贴):
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
@ -158,19 +158,19 @@ StartupNotify=true
|
||||
Categories=GTK;
|
||||
```
|
||||
|
||||
Again, you have to replace /home/mhsabbagh/android.img with the path to the local image on your system. Then save the file (Ctrl + X, then press Y, then Enter).
|
||||
再强调一次,你必需使用你系统上的本地镜像路径来替换 /home/mhsabbagh/android.img 。然后保存文件 (Ctrl + X ,然后按 Y ,然后按 Enter)。
|
||||
|
||||
Notice that we needed to use “pkexec” to run QEMU with root privileges because starting from newer versions, accessing to the KVM technology via libvirt is not allowed for normal users; That’s why it will ask you for the root password each time.
|
||||
注意,我们需要使用 “pkexec” 来使用 root 权限运行 QEMU ,因为从较新的版本开始,普通用户不允许通过 libvirt 访问 KVM 技术;这就是为什么它将每次要求你输入 root 密码的原因。
|
||||
|
||||
Now, you’ll see the android icon in the applications menu all the time, you can simply click it any time you want to use android and the QEMU program will start:
|
||||
现在,你将在应用程序菜单中看到 android 图标,你可以在你想使用 android 的任何时间来简单地单击图标,QEMU 程序将启动:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 71 android 8.1 oreo on linux][20]
|
||||
|
||||
### Conclusion
|
||||
### 总结
|
||||
|
||||
We showed you how install and run android 8.1 Oreo on your Linux system. From now on, it should be much easier on you to do your android-based tasks without some other software like Blutsticks and similar methods. Here, you have a fully-working and functional android system that you can manipulate however you like, and if anything goes wrong, you can simply nuke the image file and run the installation all over again any time you want.
|
||||
我们向你展示如何你的 Linux 系统上安装和运行 android 8.1 Oreo 。从现在起,在没有其它一些软件的(像 Blutsticks 和类似的方法)的情况下,你应该更容易地完成基于 android 的任务。在这里,你有一个完整工作和功能的 android 系统,你可以随心所欲地操作它,如果一些东西出差,你可以简单地核弹攻击镜像文件,然后随时再一次重新运行安装程序。
|
||||
|
||||
Have you tried android x86 before? How was your experience with it?
|
||||
你之前尝试过 android x86 吗?你的经验如何?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -179,7 +179,7 @@ via: https://fosspost.org/tutorials/install-android-8-1-oreo-on-linux
|
||||
|
||||
作者:[Python Programmer;Open Source Software Enthusiast. Worked On Developing A Lot Of Free Software. The Founder Of Foss Post;Foss Project. Computer Science Major.][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create virtual machines with Cockpit in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/create-virtual-machines-with-cockpit-in-fedora/)
|
||||
[#]: author: (Karlis KavacisPaul W. Frields https://fedoramagazine.org/author/karlisk/https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
在 Fedora 中使用 Cockpit 创建虚拟机
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
本文向你展示如何在 Fedora 31 上使用安装 Cockpit 所需软件来创建和管理虚拟机。Cockpit 是一个[交互式管理界面][2],可让你在任何受支持的 Web 浏览器上访问和管理系统。随着 [virt-manager 正逐渐废弃][3],用户被鼓励使用 Cockpit 来替换它。
|
||||
|
||||
Cockpit 是一个积极开发的项目,它有许多扩展其工作的插件。例如,其中一个是 “Machines”,它与 libvirtd 交互并允许用户创建和管理虚拟机。
|
||||
|
||||
### 安装软件
|
||||
|
||||
先决所需软件是 _libvirt _、_ cockpit_ 和 _cockpit-machines_。要将它们安装在 Fedora 31 上,请在终端[使用 sudo][4] 运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install libvirt cockpit cockpit-machines
|
||||
```
|
||||
|
||||
Cockpit 也在 “Headless Management” 软件包组中。该组对于仅通过网络访问的基于 Fedora 的服务器很有用。在这里,请使用以下命令进行安装:
|
||||
|
||||
```
|
||||
$ sudo dnf groupinstall "Headless Management"
|
||||
```
|
||||
|
||||
### 设置 Cockpit 服务
|
||||
|
||||
安装了必要的软件包后,就该启用服务了。 _libvirtd_ 服务运行虚拟机,而 Cockpit 有一个激活的套接字服务,可让你访问 Web GUI:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable libvirtd --now
|
||||
$ sudo systemctl enable cockpit.socket --now
|
||||
```
|
||||
|
||||
这应该足以运行虚拟机并通过 Cockpit 对其进行管理。(可选)如果要从网络上的另一台设备访问并管理计算机,那么需要将该服务开放给网络。为此,请在防火墙配置中添加新规则:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --zone=public --add-service=cockpit --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
要确认服务正在运行并且没有发生任何问题,请检查服务的状态:
|
||||
|
||||
```
|
||||
$ sudo systemctl status libvirtd
|
||||
$ sudo systemctl status cockpit.socket
|
||||
```
|
||||
|
||||
此时一切都应该正常工作。Cockpit Web GUI 应该可通过 <https://localhost:9090> 或 <https://127.0.0.1:9090> 访问。或者,在连接到同一网络的任何其他设备上的 Web 浏览器中输入本地网络 IP。(如果未设置 SSL 证书,那么可能需要允许来自浏览器的连接。)
|
||||
|
||||
### 创建和安装机器
|
||||
|
||||
使用系统的用户名和密码登录界面。你还可以选择是否允许在此会话中将密码用于管理任务。
|
||||
|
||||
选择 _Virtual Machines_,然后选择_ Create VM_ 来创建一台新的虚拟机。控制台为你提供几个选项:
|
||||
|
||||
* 使用 Cockpit 的内置库下载操作系统
|
||||
* 使用系统上已下载的安装媒体
|
||||
* 指向系统安装树的 URL
|
||||
* 通过 [PXE][5] 协议通过网络引导媒体
|
||||
|
||||
|
||||
|
||||
输入所有必要的参数。然后选择 _Create_ 启动新虚拟机。
|
||||
|
||||
此时,将出现一个图形控制台。大多数现代 Web 浏览器都允许你使用键盘和鼠标与 VM 控制台进行交互。现在,你可以完成安装并使用新的 VM,就像[过去通过 virt-manager][6] 一样。
|
||||
|
||||
* * *
|
||||
|
||||
_照片由 [Miguel Teixeira][7] 发布于 [Flickr][8](CC BY-SA 2.0)_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/create-virtual-machines-with-cockpit-in-fedora/
|
||||
|
||||
作者:[Karlis KavacisPaul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/karlisk/https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/11/create-vm-cockpit-816x345.jpg
|
||||
[2]: https://cockpit-project.org/
|
||||
[3]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/8.0_release_notes/rhel-8_0_0_release#virtualization_4
|
||||
[4]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[5]: https://en.wikipedia.org/wiki/Preboot_Execution_Environment
|
||||
[6]: https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/
|
||||
[7]: https://flickr.com/photos/miguelteixeira/
|
||||
[8]: https://flickr.com/photos/miguelteixeira/2964851828/
|
||||
@ -1,147 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hj24)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to write a Python web API with Flask)
|
||||
[#]: via: (https://opensource.com/article/19/11/python-web-api-flask)
|
||||
[#]: author: (Rachel Waston https://opensource.com/users/rachelwaston)
|
||||
|
||||
如何使用Flask编写Python Web API
|
||||
======
|
||||
|
||||
这是一个快速教程,用来展示如何通过Flask(目前发展最迅速的Python框架之一)来从服务器获取数据。
|
||||
![spiderweb diagram][1]
|
||||
|
||||
[Python][2]是一个以语法简洁著称的高级的,面向对象的程序语言。它一直都是一个用来构建RESTful API的顶级编程语言。
|
||||
|
||||
[Flask][3]是一个高度可定制化的Python框架,可以为开发人员提供用户访问数据方式的完全控制。Flask是一个基于Werkzeug的[WSGI][4]工具包和Jinja 2模板引擎的”微框架“。它是一个被设计来开发RESTful API的web框架。
|
||||
|
||||
Flask是Python发展最迅速的框架之一,很多知名网站如:Netflix, Pinterest, 和LinkedIn都将Flask纳入了它们的开发技术栈。下面是一个简单的示例,展示了Flask是如何允许用户通过HTTP GET请求来从服务器获取数据的。
|
||||
|
||||
### 初始化一个Flask应用
|
||||
|
||||
首先,创建一个你的Flask项目的目录结构。你可以在你系统的任何地方来做这件事。
|
||||
|
||||
|
||||
```
|
||||
$ mkdir tutorial
|
||||
$ cd tutorial
|
||||
$ touch main.py
|
||||
$ python3 -m venv env
|
||||
$ source env/bin/activate
|
||||
(env) $ pip3 install flask-restful
|
||||
Collecting flask-restful
|
||||
Downloading <https://files.pythonhosted.org/packages/17/44/6e49...8da4/Flask\_RESTful-0.3.7-py2.py3-none-any.whl>
|
||||
Collecting Flask>=0.8 (from flask-restful)
|
||||
[...]
|
||||
```
|
||||
|
||||
### 导入Flask模块
|
||||
|
||||
Next, import the **flask** module and its **flask_restful** library into your **main.py** code:
|
||||
|
||||
然后,在你的**main.py**代码中导入**flask**模块和它的**flask_restful**库:
|
||||
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
from flask_restful import Resource, Api
|
||||
|
||||
app = Flask(__name__)
|
||||
api = Api(app)
|
||||
|
||||
class Quotes(Resource):
|
||||
def get(self):
|
||||
return {
|
||||
'William Shakespeare': {
|
||||
'quote': ['Love all,trust a few,do wrong to none',
|
||||
'Some are born great, some achieve greatness, and some greatness thrust upon them.']
|
||||
},
|
||||
'Linus': {
|
||||
'quote': ['Talk is cheap. Show me the code.']
|
||||
}
|
||||
}
|
||||
|
||||
api.add_resource(Quotes, '/')
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True)
|
||||
```
|
||||
|
||||
### 运行app
|
||||
|
||||
Flask includes a built-in HTTP server for testing. Test the simple API you built:
|
||||
|
||||
Flask包含一个内建的用于测试的HTTP服务器。来测试一下这个你创建的简单的API:
|
||||
|
||||
|
||||
```
|
||||
(env) $ python main.py
|
||||
* Serving Flask app "main" (lazy loading)
|
||||
* Environment: production
|
||||
WARNING: This is a development server. Do not use it in a production deployment.
|
||||
Use a production WSGI server instead.
|
||||
* Debug mode: on
|
||||
* Running on <http://127.0.0.1:5000/> (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
启动开发服务器时将启动Flask应用程序,该应用程序包含一个名为 **get** 的方法来响应简单的HTTP GET请求。你可以通过 **wget**、**curl** 命令或者任意的web浏览器来测试它。
|
||||
|
||||
|
||||
```
|
||||
$ curl <http://localhost:5000>
|
||||
{
|
||||
"William Shakespeare": {
|
||||
"quote": [
|
||||
"Love all,trust a few,do wrong to none",
|
||||
"Some are born great, some achieve greatness, and some greatness thrust upon them."
|
||||
]
|
||||
},
|
||||
"Linus": {
|
||||
"quote": [
|
||||
"Talk is cheap. Show me the code."
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
要查看使用Python和Flask的类似Web API的更复杂版本,请导航至美国国会图书馆的[Chronicling America] [5]网站,该网站可提供有关这些信息的历史报纸和数字化报纸。
|
||||
|
||||
### 为什么使用 Flask?
|
||||
|
||||
Flask有以下几个主要的优点:
|
||||
|
||||
1. Python很流行并且广泛被应用,所以任何熟悉Python的人都可以使用Flask来开发。
|
||||
2. 它轻巧而简约。
|
||||
3. 考虑安全性而构建。
|
||||
4. 出色的文档,其中包含大量清晰,有效的示例代码。
|
||||
|
||||
还有一些潜在的缺点:
|
||||
|
||||
1. 它轻巧而简约。但如果您正在寻找具有大量捆绑库和预制组件的框架,那么这可能不是最佳选择。
|
||||
2. 如果必须围绕Flask构建自己的框架,则你可能会发现维护自定义项的成本可能会抵消使用Flask的好处。
|
||||
|
||||
|
||||
如果您要构建Web程序或API,可以考虑选择Flask。它功能强大且健壮,并且其优秀的项目文档使入门变得容易。试用一下,评估一下,看看它是否适合您的项目。
|
||||
|
||||
在本课中了解更多信息关于Python异常处理以及如何以安全的方式进行操作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/python-web-api-flask
|
||||
|
||||
作者:[Rachel Waston][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hj24](https://github.com/hj24)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rachelwaston
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web-cms-build-howto-tutorial.png?itok=bRbCJt1U (spiderweb diagram)
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://palletsprojects.com/p/flask/
|
||||
[4]: https://en.wikipedia.org/wiki/Web_Server_Gateway_Interface
|
||||
[5]: https://chroniclingamerica.loc.gov/about/api
|
||||
@ -1,56 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mayunmeiyouming)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What GNOME 2 fans love about the Mate Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/mate-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
GNOME 2粉丝喜欢Mate Linux桌面的什么
|
||||
======
|
||||
本文是24天Linux桌面特别系列的一部分。如果您还记得GNOME 2,那么Mate Linux桌面将满足您的怀旧的情怀。
|
||||
![Linux keys on the keyboard for a desktop computer][1]
|
||||
|
||||
如果你以前听过这个:当GNOME3第一次发布时,很多GNOME用户还没有准备好放弃GNOME2。[Mate] [2](以yerba mate_ plant命名)项目的开始是为了延续GNOME 2桌面,刚开始时使用GTK 2(GNOME 2所基于的工具包),然后又合并了GTK 3。由于Linux Mint的简单易用,使得桌面变得非常流行,并且从那时起,它已经普遍用于Fedora、Ubuntu、Slackware、Arch和许多其他Linux发行版上。今天,Mate继续提供一个传统的桌面环境,它的外观和感觉与GNOME 2完全一样,使用GTK 3工具包。
|
||||
|
||||
您可以在Linux发行版的软件仓库中找到Mate,也可以下载并[安装][3]把Mate作为默认桌面的发行版。不过,在你这样做之前,请注意它是为了提供完整的桌面体验,所以许多Mate应用程序都是随桌面一起安装的。如果您运行的是不同的桌面,您可能会发现自己有多余的应用程序(两个PDF阅读器、两个媒体播放器、两个文件管理器,等等)。如果您只想尝试Mate桌面,可以在虚拟机中安装基于Mate的发行版,例如[GNOME box][4]。
|
||||
|
||||
### Mate桌面之旅
|
||||
|
||||
Mate项目不仅仅唤起了GNOME 2;它是gnome2。如果你是00年代中期Linux桌面的粉丝,至少,你会发现Mate的怀旧情怀。我不是GNOME2的粉丝,我倾向于使用KDE,但是有一个地方我无法想象没有GNOME2:[OpenSolaris][5]。OpenSolaris项目并没有持续太久,当Ian Murdock在被Oracle并入Sun Microsystems之前加入Sun Microsystems时,它变得非常突出,但我当时是一个低级的Solaris管理员,并使用OpenSolaris来教自己更多关于Unix的那种风格。这是我使用GNOME2的唯一平台(因为我一开始不知道如何更改桌面,后来才习惯),而今天的[OpenIndiana project][6]是OpenSolaris的社区延续,它通过Mate桌面使用GNOME2。
|
||||
|
||||
![Mate on OpenIndiana][7]
|
||||
|
||||
Mate的布局由左上角的三个菜单组成:应用程序、位置和系统。应用程序菜单提供对系统上安装的所有的应用程序的启动程序的快速访问。Places菜单提供对常用位置(如主目录、网络文件夹等)的快速访问。系统菜单包含全局选项,如关级和睡眠。右上角是一个系统托盘,屏幕底部有一个任务栏和一个虚拟桌面切换栏。
|
||||
|
||||
就桌面设计而言,它是一种稍微有点奇怪的配置。它从早期的Linux桌面、MacFinder和Windows中借用了相同的部分,但是又创建了一个独特的配置,这种配置很直观,而且很熟悉。Mate故意抵制与这个模型的偏差,这正是它的用户喜欢的地方。
|
||||
|
||||
### Mate和开源
|
||||
|
||||
Mate是一个最直接的例子,展示了开源如何使开发人员能够对抗项目生命的终结。从理论上讲,GNOME2会被GNOME3所取代,但它依然存在,因为一个开发人员建立代码的一个分支并继续进行下去。势头越来越大,更多的开发人员加入进来,并且用户喜爱的桌面比以往任何时候都更好。并不是所有的软件都有第二次机会,但是开源永远是一个机会,否则就永远没有机会。
|
||||
|
||||
使用和支持开源意味着支持用户和开发人员的自由。而且Mate桌面是它们的努力的有力证明。
|
||||
|
||||
探索不同的桌面是一件好事。我最近将开始使用为GNOME 3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/mate-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[mayunmeiyouming](https://github.com/mayunmeiyouming)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
|
||||
[2]: https://mate-desktop.org/
|
||||
[3]: https://mate-desktop.org/install/
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://en.wikipedia.org/wiki/OpenSolaris
|
||||
[6]: https://www.openindiana.org/documentation/faq/#what-is-openindiana
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-mate-openindiana_675px.jpg (Mate on OpenIndiana)
|
||||
Loading…
Reference in New Issue
Block a user