mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-23 21:20:42 +08:00
Translated translated/tech/LFCS/Part 14 - Monitor Linux Processes Resource Usage and Set Process Limits on a Per-User Basis.md
This commit is contained in:
parent
41b416b422
commit
9c36452fa1
@ -1,274 +0,0 @@
|
||||
ictlyh Translating
|
||||
Part 14 - Monitor Linux Processes Resource Usage and Set Process Limits on a Per-User Basis
|
||||
=============================================================================================
|
||||
|
||||
Because of the changes in the LFCS exam requirements effective Feb. 2, 2016, we are adding the necessary topics to the [LFCS series][1] published here. To prepare for this exam, your are highly encouraged to use the [LFCE series][2] as well.
|
||||
|
||||

|
||||
>Monitor Linux Processes and Set Process Limits Per User – Part 14
|
||||
|
||||
Every Linux system administrator needs to know how to verify the integrity and availability of hardware, resources, and key processes. In addition, setting resource limits on a per-user basis must also be a part of his / her skill set.
|
||||
|
||||
In this article we will explore a few ways to ensure that the system both hardware and the software is behaving correctly to avoid potential issues that may cause unexpected production downtime and money loss.
|
||||
|
||||
### Linux Reporting Processors Statistics
|
||||
|
||||
With **mpstat** you can view the activities for each processor individually or the system as a whole, both as a one-time snapshot or dynamically.
|
||||
|
||||
In order to use this tool, you will need to install **sysstat**:
|
||||
|
||||
```
|
||||
# yum update && yum install sysstat [On CentOS based systems]
|
||||
# aptitutde update && aptitude install sysstat [On Ubuntu based systems]
|
||||
# zypper update && zypper install sysstat [On openSUSE systems]
|
||||
```
|
||||
|
||||
Read more about sysstat and it’s utilities at [Learn Sysstat and Its Utilities mpstat, pidstat, iostat and sar in Linux][3]
|
||||
|
||||
Once you have installed **mpstat**, use it to generate reports of processors statistics.
|
||||
|
||||
To display **3** global reports of CPU utilization (`-u`) for all CPUs (as indicated by `-P` ALL) at a 2-second interval, do:
|
||||
|
||||
```
|
||||
# mpstat -P ALL -u 2 3
|
||||
```
|
||||
|
||||
### Sample Output
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:41:07 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:09 IST all 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91
|
||||
11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53
|
||||
11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56
|
||||
|
||||
11:41:09 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:11 IST all 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66
|
||||
11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50
|
||||
11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68
|
||||
11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60
|
||||
|
||||
11:41:11 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:13 IST all 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07
|
||||
11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54
|
||||
11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75
|
||||
11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
|
||||
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
Average: all 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89
|
||||
Average: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87
|
||||
Average: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78
|
||||
Average: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35
|
||||
Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
|
||||
```
|
||||
|
||||
To view the same statistics for a specific **CPU** (**CPU 0** in the following example), use:
|
||||
|
||||
```
|
||||
# mpstat -P 0 -u 2 3
|
||||
```
|
||||
|
||||
### Sample Output
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:42:08 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37
|
||||
11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74
|
||||
Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
|
||||
```
|
||||
|
||||
The output of the above commands shows these columns:
|
||||
|
||||
* `CPU`: Processor number as an integer, or the word all as an average for all processors.
|
||||
* `%usr`: Percentage of CPU utilization while running user level applications.
|
||||
* `%nice`: Same as `%usr`, but with nice priority.
|
||||
* `%sys`: Percentage of CPU utilization that occurred while executing kernel applications. This does not include time spent dealing with interrupts or handling hardware.
|
||||
* `%iowait`: Percentage of time when the given CPU (or all) was idle, during which there was a resource-intensive I/O operation scheduled on that CPU. A more detailed explanation (with examples) can be found [here][4].
|
||||
* `%irq`: Percentage of time spent servicing hardware interrupts.
|
||||
* `%soft`: Same as `%irq`, but with software interrupts.
|
||||
* `%steal`: Percentage of time spent in involuntary wait (steal or stolen time) when a virtual machine, as guest, is “winning” the hypervisor’s attention while competing for the CPU(s). This value should be kept as small as possible. A high value in this field means the virtual machine is stalling – or soon will be.
|
||||
* `%guest`: Percentage of time spent running a virtual processor.
|
||||
* `%idle`: percentage of time when CPU(s) were not executing any tasks. If you observe a low value in this column, that is an indication of the system being placed under a heavy load. In that case, you will need to take a closer look at the process list, as we will discuss in a minute, to determine what is causing it.
|
||||
|
||||
To put the place the processor under a somewhat high load, run the following commands and then execute mpstat (as indicated) in a separate terminal:
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=test.iso bs=1G count=1
|
||||
# mpstat -u -P 0 2 3
|
||||
# ping -f localhost # Interrupt with Ctrl + C after mpstat below completes
|
||||
# mpstat -u -P 0 2 3
|
||||
```
|
||||
|
||||
Finally, compare to the output of **mpstat** under “normal” circumstances:
|
||||
|
||||

|
||||
>Report Linux Processors Related Statistics
|
||||
|
||||
As you can see in the image above, **CPU 0** was under a heavy load during the first two examples, as indicated by the `%idle` column.
|
||||
|
||||
In the next section we will discuss how to identify these resource-hungry processes, how to obtain more information about them, and how to take appropriate action.
|
||||
|
||||
### Reporting Linux Processes
|
||||
|
||||
To list processes sorting them by CPU usage, we will use the well known `ps` command with the `-eo` (to select all processes with user-defined format) and `--sort` (to specify a custom sorting order) options, like so:
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu
|
||||
```
|
||||
|
||||
The above command will only show the `PID`, `PPID`, the command associated with the process, and the percentage of CPU and RAM usage sorted by the percentage of CPU usage in descending order. When executed during the creation of the .iso file, here’s the first few lines of the output:
|
||||
|
||||

|
||||
>Find Linux Processes By CPU Usage
|
||||
|
||||
Once we have identified a process of interest (such as the one with `PID=2822`), we can navigate to `/proc/PID` (`/proc/2822` in this case) and do a directory listing.
|
||||
|
||||
This directory is where several files and subdirectories with detailed information about this particular process are kept while it is running.
|
||||
|
||||
#### For example:
|
||||
|
||||
* `/proc/2822/io` contains IO statistics for the process (number of characters and bytes read and written, among others, during IO operations).
|
||||
* `/proc/2822/attr/current` shows the current SELinux security attributes of the process.
|
||||
* `/proc/2822/cgroup` describes the control groups (cgroups for short) to which the process belongs if the CONFIG_CGROUPS kernel configuration option is enabled, which you can verify with:
|
||||
|
||||
```
|
||||
# cat /boot/config-$(uname -r) | grep -i cgroups
|
||||
```
|
||||
|
||||
If the option is enabled, you should see:
|
||||
|
||||
```
|
||||
CONFIG_CGROUPS=y
|
||||
```
|
||||
|
||||
Using `cgroups` you can manage the amount of allowed resource usage on a per-process basis as explained in Chapters 1 through 4 of the [Red Hat Enterprise Linux 7 Resource Management guide][5], in Chapter 9 of the [openSUSE System Analysis and Tuning guide][6], and in the [Control Groups section of the Ubuntu 14.04 Server documentation][7].
|
||||
|
||||
The `/proc/2822/fd` is a directory that contains one symbolic link for each file descriptor the process has opened. The following image shows this information for the process that was started in tty1 (the first terminal) to create the **.iso** image:
|
||||
|
||||

|
||||
>Find Linux Process Information
|
||||
|
||||
The above image shows that **stdin** (file descriptor **0**), **stdout** (file descriptor **1**), and **stderr** (file descriptor **2**) are mapped to **/dev/zero**, **/root/test.iso**, and **/dev/tty1**, respectively.
|
||||
|
||||
More information about `/proc` can be found in “The `/proc` filesystem” document kept and maintained by Kernel.org, and in the Linux Programmer’s Manual.
|
||||
|
||||
### Setting Resource Limits on a Per-User Basis in Linux
|
||||
|
||||
If you are not careful and allow any user to run an unlimited number of processes, you may eventually experience an unexpected system shutdown or get locked out as the system enters an unusable state. To prevent this from happening, you should place a limit on the number of processes users can start.
|
||||
|
||||
To do this, edit **/etc/security/limits.conf** and add the following line at the bottom of the file to set the limit:
|
||||
|
||||
```
|
||||
* hard nproc 10
|
||||
```
|
||||
|
||||
The first field can be used to indicate either a user, a group, or all of them `(*)`, whereas the second field enforces a hard limit on the number of process (nproc) to **10**. To apply changes, logging out and back in is enough.
|
||||
|
||||
Thus, let’s see what happens if a certain user other than root (either a legitimate one or not) attempts to start a shell fork bomb. If we had not implemented limits, this would initially launch two instances of a function, and then duplicate each of them in a neverending loop. Thus, it would eventually bringing your system to a crawl.
|
||||
|
||||
However, with the above restriction in place, the fork bomb does not succeed but the user will still get locked out until the system administrator kills the process associated with it:
|
||||
|
||||
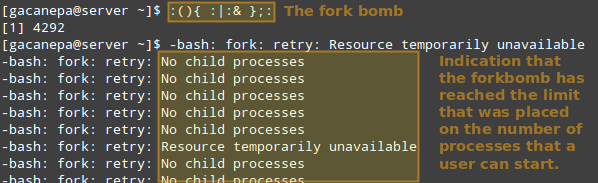
|
||||
>Run Shell Fork Bomb
|
||||
|
||||
**TIP**: Other possible restrictions made possible by **ulimit** are documented in the `limits.conf` file.
|
||||
|
||||
### Linux Other Process Management Tools
|
||||
|
||||
In addition to the tools discussed previously, a system administrator may also need to:
|
||||
|
||||
**a)** Modify the execution priority (use of system resources) of a process using **renice**. This means that the kernel will allocate more or less system resources to the process based on the assigned priority (a number commonly known as “**niceness**” in a range from `-20` to `19`).
|
||||
|
||||
The lower the value, the greater the execution priority. Regular users (other than root) can only modify the niceness of processes they own to a higher value (meaning a lower execution priority), whereas root can modify this value for any process, and may increase or decrease it.
|
||||
|
||||
The basic syntax of renice is as follows:
|
||||
|
||||
```
|
||||
# renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
|
||||
```
|
||||
|
||||
If the argument after the new priority value is not present (empty), it is set to PID by default. In that case, the niceness of process with **PID=identifier** is set to `<new priority>`.
|
||||
|
||||
**b)** Interrupt the normal execution of a process when needed. This is commonly known as [“killing” the process][9]. Under the hood, this means sending the process a signal to finish its execution properly and release any used resources in an orderly manner.
|
||||
|
||||
To [kill a process][10], use the **kill** command as follows:
|
||||
|
||||
```
|
||||
# kill PID
|
||||
```
|
||||
|
||||
Alternatively, you can use [pkill to terminate all processes][11] of a given owner `(-u)`, or a group owner `(-G)`, or even those processes which have a PPID in common `(-P)`. These options may be followed by the numeric representation or the actual name as identifier:
|
||||
|
||||
```
|
||||
# pkill [options] identifier
|
||||
```
|
||||
|
||||
For example,
|
||||
|
||||
```
|
||||
# pkill -G 1000
|
||||
```
|
||||
|
||||
will kill all processes owned by group with `GID=1000`.
|
||||
|
||||
And,
|
||||
|
||||
```
|
||||
# pkill -P 4993
|
||||
```
|
||||
|
||||
will kill all processes whose `PPID is 4993`.
|
||||
|
||||
Before running a `pkill`, it is a good idea to test the results with `pgrep` first, perhaps using the `-l` option as well to list the processes’ names. It takes the same options but only returns the PIDs of processes (without taking any further action) that would be killed if `pkill` is used.
|
||||
|
||||
```
|
||||
# pgrep -l -u gacanepa
|
||||
```
|
||||
|
||||
This is illustrated in the next image:
|
||||
|
||||

|
||||
>Find User Running Processes in Linux
|
||||
|
||||
### Summary
|
||||
|
||||
In this article we have explored a few ways to monitor resource usage in order to verify the integrity and availability of critical hardware and software components in a Linux system.
|
||||
|
||||
We have also learned how to take appropriate action (either by adjusting the execution priority of a given process or by terminating it) under unusual circumstances.
|
||||
|
||||
We hope the concepts explained in this tutorial have been helpful. If you have any questions or comments, feel free to reach us using the contact form below.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/sysstat-commands-to-monitor-linux/
|
||||
[4]: http://veithen.github.io/2013/11/18/iowait-linux.html
|
||||
[5]: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_Guide/index.html
|
||||
[6]: https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.cgroups.html
|
||||
[7]: https://help.ubuntu.com/lts/serverguide/cgroups.html
|
||||
[8]: http://man7.org/linux/man-pages/man5/proc.5.html
|
||||
[9]: http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
[10]: http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[11]: http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -0,0 +1,275 @@
|
||||
LFCS 系列第十四讲: Linux 进程资源使用监控和基于每个用户的进程限制设置
|
||||
=============================================================================================
|
||||
|
||||
由于 2016 年 2 月 2 号开始启用了新的 LFCS 考试要求,我们在已经发表的 [LFCS 系列][1] 基础上增加了一些必要的主题。为了准备考试,同时也建议你看看 [LFCE 系列][2] 文章。
|
||||
|
||||

|
||||
>第十四讲: 监控 Linux 进程并为每个用户设置进程限制
|
||||
|
||||
每个 Linux 系统管理员都应该知道如何验证硬件、资源和主要进程的完整性和可用性。另外,基于每个用户设置资源限制也是其中一项必备技能。
|
||||
|
||||
在这篇文章中,我们会介绍一些能够确保系统硬件和软件正常工作的方法,这些方法能够避免潜在的会导致生产环境下线或钱财损失的问题发生。
|
||||
|
||||
### 报告 Linux 进程统计信息
|
||||
|
||||
你可以使用 **mpstat** 单独查看每个处理器或者系统整体的活动,可以是每次一个快照或者动态更新。
|
||||
|
||||
为了使用这个工具,你首先需要安装 **sysstat**:
|
||||
|
||||
```
|
||||
# yum update && yum install sysstat [基于 CentOS 的系统]
|
||||
# aptitutde update && aptitude install sysstat [基于 Ubuntu 的系统]
|
||||
# zypper update && zypper install sysstat [基于 openSUSE 的系统]
|
||||
```
|
||||
|
||||
你可以在 [在 Linux 中学习 Sysstat 和其中的工具 mpstat、pidstat、iostat 和 sar][3] 了解更多和 sysstat 和其中的工具相关的信息。
|
||||
|
||||
安装完 **mpstat** 之后,就可以使用它生成处理器统计信息的报告。
|
||||
|
||||
你可以使用下面的命令每隔 2 秒显示所有 CPU(用 `-P` ALL 表示) 的 CPU 利用率(`-u`),共显示 **3** 次。
|
||||
|
||||
```
|
||||
# mpstat -P ALL -u 2 3
|
||||
```
|
||||
|
||||
### 事例输出
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:41:07 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:09 IST all 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91
|
||||
11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53
|
||||
11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56
|
||||
|
||||
11:41:09 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:11 IST all 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66
|
||||
11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50
|
||||
11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68
|
||||
11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60
|
||||
|
||||
11:41:11 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:41:13 IST all 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07
|
||||
11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54
|
||||
11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75
|
||||
11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
|
||||
11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57
|
||||
|
||||
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
Average: all 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89
|
||||
Average: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87
|
||||
Average: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78
|
||||
Average: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35
|
||||
Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
|
||||
```
|
||||
|
||||
要查看指定的 **CPU**(在下面的例子中是 **CPU 0**),可以使用:
|
||||
|
||||
```
|
||||
# mpstat -P 0 -u 2 3
|
||||
```
|
||||
|
||||
### 事例输出
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
|
||||
11:42:08 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
|
||||
11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37
|
||||
11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74
|
||||
Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
|
||||
```
|
||||
|
||||
上面命令的输出包括这些列:
|
||||
|
||||
* `CPU`: 整数表示的处理器号或者 all 表示所有处理器的平局值。
|
||||
* `%usr`: 运行在用户级别的应用的 CPU 利用率百分数。
|
||||
* `%nice`: 和 `%usr` 相同,但有 nice 优先级。
|
||||
* `%sys`: 执行内核应用的 CPU 利用率百分比。这不包括用于处理中断或者硬件请求的时间。
|
||||
* `%iowait`: 指定(或所有) CPU 的空闲时间百分比,这表示当前 CPU 处于 I/O 操作密集的状态。更详细的解释(附带示例)可以查看[这里][4]。
|
||||
* `%irq`: 用于处理硬件中断的时间所占百分比。
|
||||
* `%soft`: 和 `%irq` 相同,但是软中断。
|
||||
* `%steal`: 当一个客户虚拟机在竞争 CPU 时,非自主等待(时间片窃取)所占时间的百分比。应该保持这个值尽可能小。如果这个值很大,意味着虚拟机正在或者将要停止运转。
|
||||
* `%guest`: 运行虚拟处理器所用的时间百分比。
|
||||
* `%idle`: CPU(s) 没有运行任何任务所占时间的百分比。如果你观察到这个值很小,意味着系统负载很重。在这种情况下,你需要查看详细的进程列表、以及下面将要讨论的内容来确定这是什么原因导致的。
|
||||
|
||||
运行下面的命令使处理器处于极高负载,然后在另一个终端执行 mpstat 命令:
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=test.iso bs=1G count=1
|
||||
# mpstat -u -P 0 2 3
|
||||
# ping -f localhost # Interrupt with Ctrl + C after mpstat below completes
|
||||
# mpstat -u -P 0 2 3
|
||||
```
|
||||
|
||||
最后,和 “正常” 情况下 **mpstat** 的输出作比较:
|
||||
|
||||

|
||||
> Linux 处理器相关统计信息报告
|
||||
|
||||
正如你在上面图示中看到的,在前面两个例子中,根据 `%idle` 的值可以判断 **CPU 0** 负载很高。
|
||||
|
||||
在下一部分,我们会讨论如何识别资源饥饿型进程,如何获取更多和它们相关的信息,以及如何采取恰当的措施。
|
||||
|
||||
### Linux 进程报告
|
||||
|
||||
我们可以使用有名的 `ps` 命令,用 `-eo` 选项(根据用户定义格式选中所有进程) 和 `--sort` 选项(指定自定义排序顺序)按照 CPU 使用率排序列出进程,例如:
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu
|
||||
```
|
||||
|
||||
上面的命令只会显示 `PID`、`PPID`、和进程相关的命令、 CPU 使用率以及 RAM 使用率,并按照 CPU 使用率降序排序。创建 .iso 文件的时候运行上面的命令,下面是输出的前面几行:
|
||||
|
||||

|
||||
>根据 CPU 使用率查找进程
|
||||
|
||||
一旦我们找到了感兴趣的进程(例如 `PID=2822` 的进程),我们就可以进入 `/proc/PID`(本例中是 `/proc/2822`) 列出目录内容。
|
||||
|
||||
这个目录就是进程运行的时候保存多个关于该进程详细信息的文件和子目录的目录。
|
||||
|
||||
#### 例如:
|
||||
|
||||
* `/proc/2822/io` 包括该进程的 IO 统计信息( IO 操作时的读写字符数)。
|
||||
* `/proc/2822/attr/current` 显示了进程当前的 SELinux 安全属性。
|
||||
* `/proc/2822/attr/current` shows the current SELinux security attributes of the process.
|
||||
* `/proc/2822/cgroup` 如果启用了 CONFIG_CGROUPS 内核设置选项,这会显示该进程所属的控制组(简称 cgroups),你可以使用下面命令验证是否启用了 CONFIG_CGROUPS:
|
||||
|
||||
```
|
||||
# cat /boot/config-$(uname -r) | grep -i cgroups
|
||||
```
|
||||
|
||||
如果启用了该选项,你应该看到:
|
||||
|
||||
```
|
||||
CONFIG_CGROUPS=y
|
||||
```
|
||||
|
||||
根据 [红帽企业版 Linux 7 资源管理指南][5] 第一到四章的内容、[openSUSE 系统分析和调优指南][6] 第九章、[Ubuntu 14.04 服务器文档 Control Groups 章节][7],你可以使用 `cgroups` 管理每个进程允许使用的资源数目。
|
||||
|
||||
`/proc/2822/fd` 这个目录包含每个打开的描述进程的文件的符号链接。下面的截图显示了 tty1(第一个终端) 中创建 **.iso** 镜像进程的相关信息:
|
||||
|
||||

|
||||
>查找 Linux 进程信息
|
||||
|
||||
上面的截图显示 **stdin**(文件描述符 **0**)、**stdout**(文件描述符 **1**)、**stderr**(文件描述符 **2**) 相应地被映射到 **/dev/zero**、 **/root/test.iso** 和 **/dev/tty1**。
|
||||
|
||||
更多关于 `/proc` 信息的可以查看 Kernel.org 维护的 “`/proc` 文件系统” 和 Linux 开发者手册。
|
||||
|
||||
### 在 Linux 中为每个用户设置资源限制
|
||||
|
||||
如果你不够小心、让任意用户使用不受限制的进程数,最终你可能会遇到意外的系统关机或者由于系统进入不可用的状态而被锁住。为了防止这种情况发生,你应该为用户可以启动的进程数目设置上限。
|
||||
|
||||
你可以在 **/etc/security/limits.conf** 文件末尾添加下面一行来设置限制:
|
||||
|
||||
```
|
||||
* hard nproc 10
|
||||
```
|
||||
|
||||
第一个字段可以用来表示一个用户、组或者所有`(*)`, 第二个字段强制限制可以使用的进程数目(nproc) 为 **10**。退出并重新登录就可以使设置生效。
|
||||
|
||||
然后,让我们来看看非 root 用户(合法用户或非法用户) 试图引起 shell fork bomb[WiKi][12] 时会发生什么。如果我们没有设置限制, shell fork bomb 会无限制地启动函数的两个实例,然后无限循环地复制任意一个实例。最终导致你的系统卡死。
|
||||
|
||||
但是,如果使用了上面的限制,fort bomb 就不会成功,但用户仍然会被锁在外面直到系统管理员杀死相关的进程。
|
||||
|
||||

|
||||
>运行 Shell Fork Bomb
|
||||
|
||||
**提示**: `limits.conf` 文件中可以查看其它 **ulimit** 可以更改的限制。
|
||||
|
||||
### 其它 Linux 进程管理工具
|
||||
|
||||
除了上面讨论的工具, 一个系统管理员还可能需要:
|
||||
|
||||
**a)** 通过使用 **renice** 调整执行优先级(系统资源使用)。这意味着内核会根据分配的优先级(众所周知的 “**niceness**”,它是一个范围从 `-20` 到 `19` 的整数)给进程分配更多或更少的系统资源。
|
||||
|
||||
这个值越小,执行优先级越高。普通用户(而非 root)只能调高他们所有的进程的 niceness 值(意味着更低的优先级),而 root 用户可以调高或调低任何进程的 niceness 值。
|
||||
|
||||
renice 命令的基本语法如下:
|
||||
|
||||
```
|
||||
# renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
|
||||
```
|
||||
|
||||
如果没有 new priority 后面的参数(为空),默认就是 PID。在这种情况下, **PID=identifier** 的进程的 niceness 值会被设置为 `<new priority>`。
|
||||
|
||||
**b)** 需要的时候中断一个进程的正常执行。这也就是通常所说的 [“杀死”进程][9]。实质上,这意味着给进程发送一个信号使它恰当地结束运行并以有序的方式释放任何占用的资源。
|
||||
|
||||
按照下面的方式使用 **kill** 命令[杀死进程][10]:
|
||||
|
||||
```
|
||||
# kill PID
|
||||
```
|
||||
|
||||
另外,你也可以使用 [pkill][11] 结束指定用户`(-u)`、指定组`(-G)` 甚至有共同 PPID`(-P)` 的所有进程。这些选项后面可以使用数字或者名称表示的标识符。
|
||||
|
||||
```
|
||||
# pkill [options] identifier
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
# pkill -G 1000
|
||||
```
|
||||
|
||||
会杀死组 `GID=1000` 的所有进程。
|
||||
|
||||
而
|
||||
|
||||
```
|
||||
# pkill -P 4993
|
||||
```
|
||||
|
||||
会杀死 `PPID 是 4993` 的所有进程。
|
||||
|
||||
在运行 `pkill` 之前,先用 `pgrep` 测试结果、或者使用 `-l` 选项列出进程名称是一个很好的办法。它需要和 `pkill` 相同的参数、但是只会返回进程的 PID(而不会有其它操作),而 `pkill` 会杀死进程。
|
||||
|
||||
```
|
||||
# pgrep -l -u gacanepa
|
||||
```
|
||||
|
||||
用下面的图片说明:
|
||||
|
||||

|
||||
>在 Linux 中查找用户运行的进程
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇文章中我们探讨了一些监控资源使用的方法,以便验证 Linux 系统中重要硬件和软件组件的完整性和可用性。
|
||||
|
||||
我们也学习了如何在特殊情况下采取恰当的措施(通过调整给定进程的执行优先级或者结束进程)。
|
||||
|
||||
我们希望本篇中介绍的概念能对你有所帮助。如果你有任何疑问或者评论,可以使用下面的联系方式联系我们。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/sysstat-commands-to-monitor-linux/
|
||||
[4]: http://veithen.github.io/2013/11/18/iowait-linux.html
|
||||
[5]: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_Guide/index.html
|
||||
[6]: https://doc.opensuse.org/documentation/leap/tuning/html/book.sle.tuning/cha.tuning.cgroups.html
|
||||
[7]: https://help.ubuntu.com/lts/serverguide/cgroups.html
|
||||
[8]: http://man7.org/linux/man-pages/man5/proc.5.html
|
||||
[9]: http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
[10]: http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[11]: http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
[12]: https://en.wikipedia.org/wiki/Fork_bomb
|
||||
Loading…
Reference in New Issue
Block a user