mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-06 23:50:16 +08:00
Merge pull request #2796 from GOLinux/master
[Translated]20150518 Linux FAQs with Answers--How to block specific user agents on nginx web server.md
This commit is contained in:
commit
9bbbf2dc34
@ -1,115 +0,0 @@
|
||||
Translating by GOLinux!
|
||||
Linux FAQs with Answers--How to block specific user agents on nginx web server
|
||||
================================================================================
|
||||
> **Question**: I notice that some robots often visit my nginx-powered website and scan it aggressively, ending up wasting a lot of my web server resources. I am trying to block those robots based on their user-agent string. How can I block specific user agent(s) on nginx web server?
|
||||
|
||||
The modern Internet is infested with various malicious robots and crawlers such as malware bots, spambots or content scrapers which are scanning your website in surreptitious ways, for example to detect potential website vulnerabilities, harvest email addresses, or just to steal content from your website. Many of these robots can be identified by their signature "user-agent" string.
|
||||
|
||||
As a first line of defense, you could try to block malicious bots from accessing your website by blacklisting their user-agents in robots.txt file. However, unfortunately this works only for "well-behaving" robots which are designed to obey robots.txt. Many malicious bots can simply ignore robots.txt and scan your website at will.
|
||||
|
||||
An alternative way to block particular robots is to configure your web server, such that it refuses to serve content to requests with certain user-agent strings. This post explains how to **block certain user-agent on nginx web server**.
|
||||
|
||||
### Blacklist Certain User-Agents in Nginx ###
|
||||
|
||||
To configure user-agent block list, open the nginx configuration file of your website, where the server section is defined. This file can be found in different places depending on your nginx setup or Linux distribution (e.g., /etc/nginx/nginx.conf, /etc/nginx/sites-enabled/<your-site>, /usr/local/nginx/conf/nginx.conf, /etc/nginx/conf.d/<your-site>).
|
||||
|
||||
server {
|
||||
listen 80 default_server;
|
||||
server_name xmodulo.com;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
Once you open the config file with the server section, add the following if statement(s) somewhere inside the section.
|
||||
|
||||
server {
|
||||
listen 80 default_server;
|
||||
server_name xmodulo.com;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
# case sensitive matching
|
||||
if ($http_user_agent ~ (Antivirx|Arian) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
# case insensitive matching
|
||||
if ($http_user_agent ~* (netcrawl|npbot|malicious)) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
As you can guess, these if statements match any bad user-string with regular expressions, and return 403 HTTP status code when a match is found. $http_user_agent is a variable that contains the user-agent string of an HTTP request. The '~' operator does case-sensitive matching against user-agent string, while the '~' operator does case-insensitive matching. The '|' operator is logical-OR, so you can put as many user-agent keywords in the if statements, and block them all.
|
||||
|
||||
After modifying the configuration file, you must reload nginx to activate the blocking:
|
||||
|
||||
$ sudo /path/to/nginx -s reload
|
||||
|
||||
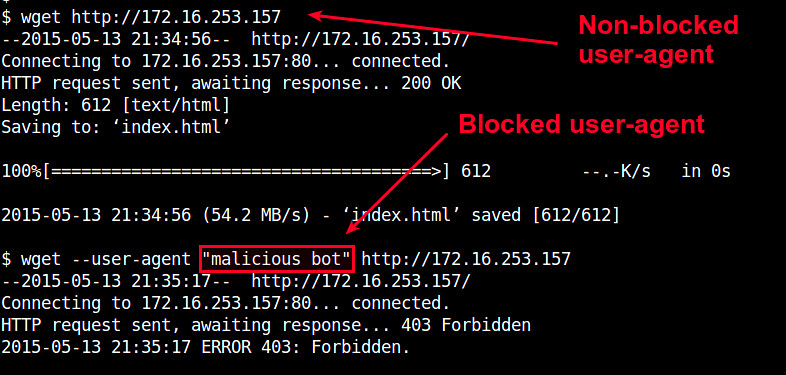
You can test user-agent blocking by using wget with "--user-agent" option.
|
||||
|
||||
$ wget --user-agent "malicious bot" http://<nginx-ip-address>
|
||||
|
||||
|
||||
|
||||
### Manage User-Agent Blacklist in Nginx ###
|
||||
|
||||
So far, I have shown how to block HTTP requests with a few user-agents in nginx. What if you have many different types of crawling bots to block?
|
||||
|
||||
Since the user-agent blacklist can grow very big, it is not a good idea to put them all inside your nginx's server section. Instead, you can create a separate file which lists all blocked user agents. For example, let's create /etc/nginx/useragent.rules, and define a map with all blocked user agents in the following format.
|
||||
|
||||
$ sudo vi /etc/nginx/useragent.rules
|
||||
|
||||
----------
|
||||
|
||||
map $http_user_agent $badagent {
|
||||
default 0;
|
||||
~*malicious 1;
|
||||
~*backdoor 1;
|
||||
~*netcrawler 1;
|
||||
~Antivirx 1;
|
||||
~Arian 1;
|
||||
~webbandit 1;
|
||||
}
|
||||
|
||||
Similar to the earlier setup, '~*' will match a keyword in case-insensitive manner, while '~' will match a keyword using a case-sensitive regular expression. The line that says "default 0" means that any other user-agent not listed in the file will be allowed.
|
||||
|
||||
Next, open an nginx configuration file of your website, which contains http section, and add the following line somewhere inside the http section.
|
||||
|
||||
http {
|
||||
.....
|
||||
include /etc/nginx/useragent.rules
|
||||
}
|
||||
|
||||
Note that this include statement must appear before the server section (this is why we add it inside http section).
|
||||
|
||||
Now open an nginx configuration where your server section is defined, and add the following if statement:
|
||||
|
||||
server {
|
||||
....
|
||||
|
||||
if ($badagent) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
Finally, reload nginx.
|
||||
|
||||
$ sudo /path/to/nginx -s reload
|
||||
|
||||
Now any user-agent which contains a keyword listed in /etc/nginx/useragent.rules will be automatically banned by nginx.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/block-specific-user-agents-nginx-web-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,115 @@
|
||||
Linux有问必答——nginx网络服务器上如何阻挡特定用户代理
|
||||
================================================================================
|
||||
> **问题**: 我注意到有一些机器人经常访问我nginx驱动的网站,并且进行一些攻击性的扫描,导致消耗掉了我的网络服务器的大量资源。我一直尝试着通过用户代理符串来阻挡这些机器人。我怎样才能在nginx网络服务器上阻挡掉特定的用户代理呢?
|
||||
|
||||
现代互联网滋生了大量各种各样的恶意机器人和网络爬虫,比如像恶意软件机器人、垃圾邮件程序或内容刮刀,这些恶意工具一直偷偷摸摸地扫描你的网站,干些诸如检测潜在网站漏洞、收获电子邮件地址,或者只是从你的网站偷取内容。大多数机器人能够通过它们的“用户代理”签名字符串来识别。
|
||||
|
||||
作为第一道防线,你可以尝试通过将这些机器人的用户代理字符串添加入robots.txt文件来阻止这些恶意软件机器人访问你的网站。但是,很不幸的是,该操作只针对那些“行为良好”的机器人,这些机器人被设计遵循robots.txt的规范。许多恶意软件机器人可以很容易地忽略掉robots.txt,然后随意扫描你的网站。
|
||||
|
||||
另一个用以阻挡特定机器人的途径,就是配置你的网络服务器,通过特定的用户代理字符串拒绝要求提供内容的请求。本文就是说明如何**在nginx网络服务器上阻挡特定的用户代理**。
|
||||
|
||||
### 在Nginx中将特定用户代理列入黑名单 ###
|
||||
|
||||
要配置用户代理阻挡列表,请打开你的网站的nginx配置文件,找到服务器定义部分。该文件可能会放在不同的地方,这取决于你的nginx配置或Linux版本(如,/etc/nginx/nginx.conf,/etc/nginx/sites-enabled/<your-site>,/usr/local/nginx/conf/nginx.conf,/etc/nginx/conf.d/<your-site>)。
|
||||
|
||||
server {
|
||||
listen 80 default_server;
|
||||
server_name xmodulo.com;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
在打开该配置文件并找到 server 部分后,添加以下 if 声明到该部分内的某个地方。
|
||||
|
||||
server {
|
||||
listen 80 default_server;
|
||||
server_name xmodulo.com;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
# case sensitive matching
|
||||
if ($http_user_agent ~ (Antivirx|Arian) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
# case insensitive matching
|
||||
if ($http_user_agent ~* (netcrawl|npbot|malicious)) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
如你所想,这些 if 声明使用正则表达式匹配了任意不良用户字符串,并向匹配的对象返回403 HTTP状态码。
|
||||
$http_user_agent是HTTP请求的一个包含有用户代理字符串的变量。‘~’操作符针对用户代理字符串进行大小写敏感匹配,而‘~*’操作符则进行大小写不敏感匹配。‘|’操作符是逻辑或,因此,你可以在 if 声明中放入众多的用户代理关键字,然后将它们全部阻挡掉。
|
||||
|
||||
在修改配置文件后,你必须重新加载nginx以激活阻挡:
|
||||
|
||||
$ sudo /path/to/nginx -s reload
|
||||
|
||||
你可以通过使用带有 “--user-agent” 选项的 wget 测试用户代理阻挡。
|
||||
|
||||
$ wget --user-agent "malicious bot" http://<nginx-ip-address>
|
||||
|
||||

|
||||
|
||||
### 管理Nginx中的用户代理黑名单 ###
|
||||
|
||||
目前为止,我已经展示了在nginx中如何阻挡一些用户代理的HTTP请求。如果你有学多不同类型的网络爬虫机器人要阻挡,又该怎么办呢?
|
||||
|
||||
由于用户代理黑名单会增长得很大,所以将它们放在nginx的server部分不是个好点子。取而代之的是,你可以创建一个独立的文件,在该文件中列出所有被阻挡的用户代理。例如,让我们创建/etc/nginx/useragent.rules,并定义以下面的格式定义所有被阻挡的用户代理的图谱。
|
||||
|
||||
$ sudo vi /etc/nginx/useragent.rules
|
||||
|
||||
----------
|
||||
|
||||
map $http_user_agent $badagent {
|
||||
default 0;
|
||||
~*malicious 1;
|
||||
~*backdoor 1;
|
||||
~*netcrawler 1;
|
||||
~Antivirx 1;
|
||||
~Arian 1;
|
||||
~webbandit 1;
|
||||
}
|
||||
|
||||
与先前的配置类似,‘~*’将匹配以大小写不敏感的方式匹配关键字,而‘~’将使用大小写敏感的正则表达式匹配关键字。“default 0”行所表达的意思是,任何其它文件中未被列出的用户代理将被允许。
|
||||
|
||||
接下来,打开你的网站的nginx配置文件,找到里面包含 http 的部分,然后添加以下行到 http 部分某个位置。
|
||||
|
||||
http {
|
||||
.....
|
||||
include /etc/nginx/useragent.rules
|
||||
}
|
||||
|
||||
注意,该 include 声明必须出现在 server 部分之前(这就是为什么我们将它添加到了 http 部分里)。
|
||||
|
||||
现在,打开nginx配置定义你的服务器的部分,添加以下 if 声明:
|
||||
|
||||
server {
|
||||
....
|
||||
|
||||
if ($badagent) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
最后,重新加载nginx。
|
||||
|
||||
$ sudo /path/to/nginx -s reload
|
||||
|
||||
现在,任何包含有/etc/nginx/useragent.rules中列出的关键字的用户代理将被nginx自动禁止。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/block-specific-user-agents-nginx-web-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
Loading…
Reference in New Issue
Block a user