mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
9bb3165232
101
published/20160429 Why and how I became a software engineer.md
Normal file
101
published/20160429 Why and how I became a software engineer.md
Normal file
@ -0,0 +1,101 @@
|
||||
我成为软件工程师的原因和经历
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
1989 年乌干达首都,坎帕拉。
|
||||
|
||||
我明智的父母决定与其将我留在家里添麻烦,不如把我送到叔叔的办公室学学电脑。几天后,我和另外六、七个小孩,还有一台放置在课桌上的崭新电脑,一起置身于 21 层楼的一间狭小房屋中。很明显我们还不够格去碰那家伙。在长达三周无趣的 DOS 命令学习后,美好时光来到,终于轮到我来输 **copy doc.txt d:** 啦。
|
||||
|
||||
那将文件写入五英寸软盘的奇怪的声音,听起来却像音乐般美妙。那段时间,这块软盘简直成为了我的至宝。我把所有可以拷贝的东西都放在上面了。然而,1989 年的乌干达,人们的生活十分“正统”,相比较而言,捣鼓电脑、拷贝文件还有格式化磁盘就称不上“正统”。于是我不得不专注于自己接受的教育,远离计算机科学,走入建筑工程学。
|
||||
|
||||
之后几年里,我和同龄人一样,干过很多份工作也学到了许多技能。我教过幼儿园的小朋友,也教过大人如何使用软件,在服装店工作过,还在教堂中担任过引座员。在我获取堪萨斯大学的学位时,我正在技术管理员的手下做技术助理,听上去比较神气,其实也就是搞搞学生数据库而已。
|
||||
|
||||
当我 2007 年毕业时,计算机技术已经变得不可或缺。建筑工程学的方方面面都与计算机科学深深的交织在一起,所以我们不经意间学了些简单的编程知识。我对于这方面一直很着迷,但我不得不成为一位“正统”的工程师,由此我发展了一项秘密的私人爱好:写科幻小说。
|
||||
|
||||
在我的故事中,我以我笔下的女主角的形式存在。她们都是编程能力出众的科学家,总是卷入冒险,并用自己的技术发明战胜那些渣渣们,有时甚至要在现场发明新方法。我提到的这些“新技术”,有的是基于真实世界中的发明,也有些是从科幻小说中读到的。这就意味着我需要了解这些技术的原理,而且我的研究使我关注了许多有趣的 reddit 版块和电子杂志。
|
||||
|
||||
### 开源:巨大的宝库
|
||||
|
||||
那几周在 DOS 命令上花费的经历对我影响巨大,我在一些非专业的项目上耗费心血,并占据了宝贵的学习时间。Geocities 刚向所有 Yahoo! 用户开放时,我就创建了一个网站,用于发布一些用小型数码相机拍摄的个人图片。我建立多个免费网站,帮助家人和朋友解决一些他们所遇到的电脑问题,还为教堂搭建了一个图书馆数据库。
|
||||
|
||||
这意味着,我需要一直研究并尝试获取更多的信息,使它们变得更棒。互联网上帝保佑我,让开源进入我的视野。突然之间,30 天试用期和 license 限制对我而言就变成了过去式。我可以完全不受这些限制,继续使用 GIMP、Inkscape 和 OpenOffice。
|
||||
|
||||
### 是正经做些事情的时候了
|
||||
|
||||
我很幸运,有商业伙伴喜欢我的经历。她也是个想象力丰富的人,期待更高效、更便捷的互联世界。我们根据我们以往成功道路中经历的弱点制定了解决方案,但执行却成了一个问题。我们都缺乏给产品带来活力的能力,每当我们试图将想法带到投资人面前时,这表现的尤为突出。
|
||||
|
||||
我们需要学习编程。于是 2015 年夏末,我们来到 Holberton 学校。那是一所座落于旧金山,由社区推进,基于项目教学的学校。
|
||||
|
||||
一天早晨我的商业伙伴来找我,以她独有的方式(每当她有疯狂想法想要拉我入伙时),进行一场对话。
|
||||
|
||||
**Zee**: Gloria,我想和你说点事,在你说“不”前能先听我说完吗?
|
||||
|
||||
**Me**: 不行。
|
||||
|
||||
**Zee**: 为做全栈工程师,咱们申请上一所学校吧。
|
||||
|
||||
**Me**: 什么?
|
||||
|
||||
**Zee**: 就是这,看!就是这所学校,我们要申请这所学校来学习编程。
|
||||
|
||||
**Me**: 我不明白。我们不是正在网上学 Python 和…
|
||||
|
||||
**Zee**: 这不一样。相信我。
|
||||
|
||||
**Me**: 那…
|
||||
|
||||
**Zee**: 这就是不信任我了。
|
||||
|
||||
**Me**: 好吧 … 给我看看。
|
||||
|
||||
### 抛开偏见
|
||||
|
||||
我读到的和我们在网上看的的似乎很相似。这简直太棒了,以至于让人觉得不太真实,但我们还是决定尝试一下,全力以赴,看看结果如何。
|
||||
|
||||
要成为学生,我们需要经历四步选择,不过选择的依据仅仅是天赋和动机,而不是学历和编程经历。筛选便是课程的开始,通过它我们开始学习与合作。
|
||||
|
||||
根据我和我伙伴的经验, Holberton 学校的申请流程比其他的申请流程有趣太多了,就像场游戏。如果你完成了一项挑战,就能通往下一关,在那里有别的有趣的挑战正等着你。我们创建了 Twitter 账号,在 Medium 上写博客,为创建网站而学习 HTML 和 CSS, 打造了一个充满活力的在线社区,虽然在此之前我们并不知晓有谁会来。
|
||||
|
||||
在线社区最吸引人的就是大家有多种多样的使用电脑的经验,而背景和性别不是社区创始人(我们私下里称他们为“The Trinity”)做出选择的因素。大家只是喜欢聚在一块儿交流。我们都行进在通过学习编程来提升自己计算机技术的旅途上。
|
||||
|
||||
相较于其他的的申请流程,我们不需要泄露很多的身份信息。就像我的伙伴,她的名字里看不出她的性别和种族。直到最后一个步骤,在视频聊天的时候, The Trinity 才知道她是一位有色人种女性。迄今为止,促使她达到这个级别的只是她的热情和才华。肤色和性别并没有妨碍或者帮助到她。还有比这更酷的吗?
|
||||
|
||||
获得录取通知书的晚上,我们知道生活将向我们的梦想转变。2016 年 1 月 22 日,我们来到巴特瑞大街 98 号,去见我们的同学们 [Hippokampoiers][2],这是我们的初次见面。很明显,在见面之前,“The Trinity”已经做了很多工作,聚集了一批形形色色的人,他们充满激情与热情,致力于成长为全栈工程师。
|
||||
|
||||
这所学校有种与众不同的体验。每天都是向某一方面编程的一次竭力的冲锋。交给我们的工程,并不会有很多指导,我们需要使用一切可以使用的资源找出解决方案。[Holberton 学校][1] 认为信息来源相较于以前已经大大丰富了。MOOC(大型开放式课程)、教程、可用的开源软件和项目,以及线上社区等等,为我们完成项目提供了足够的知识。加之宝贵的导师团队来指导我们制定解决方案,这所学校变得并不仅仅是一所学校;我们已经成为了求学者的团体。任何对软件工程感兴趣并对这种学习方法感兴趣的人,我都强烈推荐这所学校。在这里的经历会让人有些悲喜交加,但是绝对值得。
|
||||
|
||||
### 开源问题
|
||||
|
||||
我最早使用的开源系统是 [Fedora][3],一个 [Red Hat][4] 赞助的项目。与 一名IRC 成员交流时,她推荐了这款免费的操作系统。 虽然在此之前,我还未独自安装过操作系统,但是这激起了我对开源的兴趣和日常使用计算机时对开源软件的依赖性。我们提倡为开源贡献代码,创造并使用开源的项目。我们的项目就在 Github 上,任何人都可以使用或是向它贡献出自己的力量。我们也会使用或以自己的方式为一些既存的开源项目做出贡献。在学校里,我们使用的大部分工具是开源的,例如 Fedora、[Vagrant][5]、[VirtualBox][6]、[GCC][7] 和 [Discourse][8],仅举几例。
|
||||
|
||||
在向软件工程师行进的路上,我始终憧憬着有朝一日能为开源社区做出一份贡献,能与他人分享我所掌握的知识。
|
||||
|
||||
### 多样性问题
|
||||
|
||||
站在教室里,和 29 位求学者交流心得,真是令人陶醉。学员中 40% 是女性, 44% 是有色人种。当你是一位有色人种且为女性,并身处于这个以缺乏多样性而著名的领域时,这些数字就变得非常重要了。这是高科技圣地麦加上的绿洲,我到达了。
|
||||
|
||||
想要成为一个全栈工程师是十分困难的,你甚至很难了解这意味着什么。这是一条充满挑战但又有丰富回报的旅途。科技推动着未来飞速发展,而你也是美好未来很重要的一部分。虽然媒体在持续的关注解决科技公司的多样化的问题,但是如果能认清自己,清楚自己的背景,知道自己为什么想成为一名全栈工程师,你便能在某一方面迅速成长。
|
||||
|
||||
不过可能最重要的是,告诉大家,女性在计算机的发展史上扮演过多么重要的角色,以帮助更多的女性回归到科技界,而且在给予就业机会时,不会因性别等因素而感到犹豫。女性的才能将会共同影响科技的未来,以及整个世界的未来。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-gloria-bwandungi
|
||||
|
||||
作者:[Gloria Bwandungi][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nappybrain
|
||||
[1]: https://www.holbertonschool.com/
|
||||
[2]: https://twitter.com/hippokampoiers
|
||||
[3]: https://en.wikipedia.org/wiki/Fedora_(operating_system)
|
||||
[4]: https://www.redhat.com/
|
||||
[5]: https://www.vagrantup.com/
|
||||
[6]: https://www.virtualbox.org/
|
||||
[7]: https://gcc.gnu.org/
|
||||
[8]: https://www.discourse.org/
|
||||
@ -1,51 +1,52 @@
|
||||
# aria2 (Command Line Downloader) command examples
|
||||
aria2 (命令行下载器)实例
|
||||
============
|
||||
|
||||
[aria2][4] is a Free, open source, lightweight multi-protocol & multi-source command-line download utility. It supports HTTP/HTTPS, FTP, SFTP, BitTorrent and Metalink. aria2 can be manipulated via built-in JSON-RPC and XML-RPC interfaces. aria2 automatically validates chunks of data while downloading a file. It can download a file from multiple sources/protocols and tries to utilize your maximum download bandwidth. By default all the Linux Distribution included aria2, so we can install easily from official repository. some of the GUI download manager using aria2 as a plugin to improve the download speed like [uget][3].
|
||||
[aria2][4] 是一个自由、开源、轻量级多协议和多源的命令行下载工具。它支持 HTTP/HTTPS、FTP、SFTP、 BitTorrent 和 Metalink 协议。aria2 可以通过内建的 JSON-RPC 和 XML-RPC 接口来操纵。aria2 下载文件的时候,自动验证数据块。它可以通过多个来源或者多个协议下载一个文件,并且会尝试利用你的最大下载带宽。默认情况下,所有的 Linux 发行版都包括 aria2,所以我们可以从官方库中很容易的安装。一些 GUI 下载管理器例如 [uget][3] 使用 aria2 作为插件来提高下载速度。
|
||||
|
||||
#### Aria2 Features
|
||||
### Aria2 特性
|
||||
|
||||
* HTTP/HTTPS GET support
|
||||
* HTTP Proxy support
|
||||
* HTTP BASIC authentication support
|
||||
* HTTP Proxy authentication support
|
||||
* FTP support(active, passive mode)
|
||||
* FTP through HTTP proxy(GET command or tunneling)
|
||||
* Segmented download
|
||||
* Cookie support
|
||||
* It can run as a daemon process.
|
||||
* BitTorrent protocol support with fast extension.
|
||||
* Selective download in multi-file torrent
|
||||
* Metalink version 3.0 support(HTTP/FTP/BitTorrent).
|
||||
* Limiting download/upload speed
|
||||
* 支持 HTTP/HTTPS GET
|
||||
* 支持 HTTP 代理
|
||||
* 支持 HTTP BASIC 认证
|
||||
* 支持 HTTP 代理认证
|
||||
* 支持 FTP (主动、被动模式)
|
||||
* 通过 HTTP 代理的 FTP(GET 命令行或者隧道)
|
||||
* 分段下载
|
||||
* 支持 Cookie
|
||||
* 可以作为守护进程运行。
|
||||
* 支持使用 fast 扩展的 BitTorrent 协议
|
||||
* 支持在多文件 torrent 中选择文件
|
||||
* 支持 Metalink 3.0 版本(HTTP/FTP/BitTorrent)
|
||||
* 限制下载、上传速度
|
||||
|
||||
#### 1) Install aria2 on Linux
|
||||
### 1) Linux 下安装 aria2
|
||||
|
||||
We can easily install aria2 command line downloader to all the Linux Distribution such as Debian, Ubuntu, Mint, RHEL, CentOS, Fedora, suse, openSUSE, Arch Linux, Manjaro, Mageia, etc.. Just fire the below command to install. For CentOS, RHEL systems we need to enable [uget][2] or [RPMForge][1] repository.
|
||||
我们可以很容易的在所有的 Linux 发行版上安装 aria2 命令行下载器,例如 Debian、 Ubuntu、 Mint、 RHEL、 CentOS、 Fedora、 suse、 openSUSE、 Arch Linux、 Manjaro、 Mageia 等等……只需要输入下面的命令安装即可。对于 CentOS、 RHEL 系统,我们需要开启 [uget][2] 或者 [RPMForge][1] 库的支持。
|
||||
|
||||
```
|
||||
[For Debian, Ubuntu & Mint]
|
||||
[对于 Debian、 Ubuntu 和 Mint]
|
||||
$ sudo apt-get install aria2
|
||||
|
||||
[For CentOS, RHEL, Fedora 21 and older Systems]
|
||||
[对于 CentOS、 RHEL、 Fedora 21 和更早些的操作系统]
|
||||
# yum install aria2
|
||||
|
||||
[Fedora 22 and later systems]
|
||||
[Fedora 22 和 之后的系统]
|
||||
# dnf install aria2
|
||||
|
||||
[For suse & openSUSE]
|
||||
[对于 suse 和 openSUSE]
|
||||
# zypper install wget
|
||||
|
||||
[Mageia]
|
||||
# urpmi aria2
|
||||
|
||||
[For Debian, Ubuntu & Mint]
|
||||
[对于 Debian、 Ubuntu 和 Mint]
|
||||
$ sudo pacman -S aria2
|
||||
|
||||
```
|
||||
|
||||
#### 2) Download Single File
|
||||
### 2) 下载单个文件
|
||||
|
||||
The below command will download the file from given URL and stores in current directory, while downloading the file we can see the (date, time, download speed & download progress) of file.
|
||||
下面的命令将会从指定的 URL 中下载一个文件,并且保存在当前目录,在下载文件的过程中,我们可以看到文件的(日期、时间、下载速度和下载进度)。
|
||||
|
||||
```
|
||||
# aria2c https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -62,9 +63,9 @@ Status Legend:
|
||||
|
||||
```
|
||||
|
||||
#### 3) Save the file with different name
|
||||
### 3) 使用不同的名字保存文件
|
||||
|
||||
We can save the file with different name & format while initiate downloading, using -o (lowercase) option. Here we are going to save the filename with owncloud.zip.
|
||||
在初始化下载的时候,我们可以使用 `-o`(小写)选项在保存文件的时候使用不同的名字。这儿我们将要使用 owncloud.zip 文件名来保存文件。
|
||||
|
||||
```
|
||||
# aria2c -o owncloud.zip https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -81,9 +82,9 @@ Status Legend:
|
||||
|
||||
```
|
||||
|
||||
#### 4) Limit download speed
|
||||
### 4) 下载速度限制
|
||||
|
||||
By default aria2 utilize full bandwidth for downloading file and we can’t use anything on server before download completion (Which will affect other service accessing bandwidth). So better use –max-download-limit option to avoid further issue while downloading big size file.
|
||||
默认情况下,aria2 会利用全部带宽来下载文件,在文件下载完成之前,我们在服务器就什么也做不了(这将会影响其他服务访问带宽)。所以在下载大文件时最好使用 `–max-download-limit` 选项来避免进一步的问题。
|
||||
|
||||
```
|
||||
# aria2c --max-download-limit=500k https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -100,9 +101,9 @@ Status Legend:
|
||||
|
||||
```
|
||||
|
||||
#### 5) Download Multiple Files
|
||||
### 5) 下载多个文件
|
||||
|
||||
The below command will download more then on file from the location and stores in current directory, while downloading the file we can see the (date, time, download speed & download progress) of file.
|
||||
下面的命令将会从指定位置下载超过一个的文件并保存到当前目录,在下载文件的过程中,我们可以看到文件的(日期、时间、下载速度和下载进度)。
|
||||
|
||||
```
|
||||
# aria2c -Z https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2 ftp://ftp.gnu.org/gnu/wget/wget-1.17.tar.gz
|
||||
@ -122,11 +123,10 @@ Status Legend:
|
||||
|
||||
```
|
||||
|
||||
#### 6) Resume Incomplete download
|
||||
### 6) 续传未完成的下载
|
||||
|
||||
Make sure, whenever going to download big size of file (eg: ISO Images), i advise you to use -c option which will help us to resume the existing incomplete download from the state and complete as usual when we are facing any network connectivity issue or system problems. Otherwise when you are download again, it will initiate the fresh download and store to different file name (append .1 to the filename automatically). Note: If any interrupt happen, aria2 save file with .aria2 extension.
|
||||
当你遇到一些网络连接问题或者系统问题的时候,并将要下载一个大文件(例如: ISO 镜像文件),我建议你使用 `-c` 选项,它可以帮助我们从该状态续传未完成的下载,并且像往常一样完成。不然的话,当你再次下载,它将会初始化新的下载,并保存成一个不同的文件名(自动的在文件名后面添加 .1 )。注意:如果出现了任何中断,aria2 使用 .aria2 后缀保存(未完成的)文件。
|
||||
|
||||
<iframe marginwidth="0" marginheight="0" scrolling="no" frameborder="0" height="90" width="728" id="_mN_gpt_827143833" style="border-width: 0px; border-style: initial; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline;"></iframe>
|
||||
```
|
||||
# aria2c -c https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
[#db0b08 8.2MiB/21MiB(38%) CN:1 DL:3.1MiB ETA:4s]^C
|
||||
@ -142,7 +142,7 @@ db0b08|INPR| 3.3MiB/s|/opt/owncloud-9.0.0.tar.bz2
|
||||
Status Legend:
|
||||
(INPR):download in-progress.
|
||||
|
||||
aria2 will resume download if the transfer is restarted.
|
||||
如果重新启动传输,aria2 将会恢复下载。
|
||||
|
||||
# aria2c -c https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
[#873d08 21MiB/21MiB(98%) CN:1 DL:2.7MiB]
|
||||
@ -158,9 +158,9 @@ Status Legend:
|
||||
|
||||
```
|
||||
|
||||
#### 7) Get the input from file
|
||||
### 7) 从文件获取输入
|
||||
|
||||
Alternatively wget can get the list of input URL’s from file and start downloading. We need to create a file and store each URL in separate line. Add -i option with aria2 command to perform this action.
|
||||
就像 wget 可以从一个文件获取输入的 URL 列表来下载一样。我们需要创建一个文件,将每一个 URL 存储在单独的行中。ara2 命令行可以添加 `-i` 选项来执行此操作。
|
||||
|
||||
```
|
||||
# aria2c -i test-aria2.txt
|
||||
@ -180,9 +180,9 @@ Status Legend:
|
||||
|
||||
```
|
||||
|
||||
#### 8) Download using 2 connections per host
|
||||
### 8) 每个主机使用两个连接来下载
|
||||
|
||||
The maximum number of connections to one server for each download. By default this will establish one connection to each host. We can establish more then one connection to each host to speedup download by adding -x2 (2 means, two connection) option with aria2 command
|
||||
默认情况,每次下载连接到一台服务器的最大数目,对于一条主机只能建立一条。我们可以通过 aria2 命令行添加 `-x2`(2 表示两个连接)来创建到每台主机的多个连接,以加快下载速度。
|
||||
|
||||
```
|
||||
# aria2c -x2 https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -199,9 +199,9 @@ Status Legend:
|
||||
|
||||
```
|
||||
|
||||
#### 9) Download Torrent Files
|
||||
### 9) 下载 BitTorrent 种子文件
|
||||
|
||||
We can directly download a Torrent files using aria2 command.
|
||||
我们可以使用 aria2 命令行直接下载一个 BitTorrent 种子文件:
|
||||
|
||||
```
|
||||
# aria2c https://torcache.net/torrent/C86F4E743253E0EBF3090CCFFCC9B56FA38451A3.torrent?title=[kat.cr]irudhi.suttru.2015.official.teaser.full.hd.1080p.pathi.team.sr
|
||||
@ -221,27 +221,27 @@ Status Legend:
|
||||
|
||||
```
|
||||
|
||||
#### 10) Download BitTorrent Magnet URI
|
||||
### 10) 下载 BitTorrent 磁力链接
|
||||
|
||||
Also we can directly download a Torrent files through BitTorrent Magnet URI using aria2 command.
|
||||
使用 aria2 我们也可以通过 BitTorrent 磁力链接直接下载一个种子文件:
|
||||
|
||||
```
|
||||
# aria2c 'magnet:?xt=urn:btih:248D0A1CD08284299DE78D5C1ED359BB46717D8C'
|
||||
|
||||
```
|
||||
|
||||
#### 11) Download BitTorrent Metalink
|
||||
### 11) 下载 BitTorrent Metalink 种子
|
||||
|
||||
Also we can directly download a Metalink file using aria2 command.
|
||||
我们也可以通过 aria2 命令行直接下载一个 Metalink 文件。
|
||||
|
||||
```
|
||||
# aria2c https://curl.haxx.se/metalink.cgi?curl=tar.bz2
|
||||
|
||||
```
|
||||
|
||||
#### 12) Download a file from password protected site
|
||||
### 12) 从密码保护的网站下载一个文件
|
||||
|
||||
Alternatively we can download a file from password protected site. The below command will download the file from password protected site.
|
||||
或者,我们也可以从一个密码保护网站下载一个文件。下面的命令行将会从一个密码保护网站中下载文件。
|
||||
|
||||
```
|
||||
# aria2c --http-user=xxx --http-password=xxx https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -250,9 +250,9 @@ Alternatively we can download a file from password protected site. The below com
|
||||
|
||||
```
|
||||
|
||||
#### 13) Read more about aria2
|
||||
### 13) 阅读更多关于 aria2
|
||||
|
||||
If you want to know more option which is available for wget, you can grep the details on your terminal itself by firing below commands..
|
||||
如果你希望了解了解更多选项 —— 它们同时适用于 wget,可以输入下面的命令行在你自己的终端获取详细信息:
|
||||
|
||||
```
|
||||
# man aria2c
|
||||
@ -261,17 +261,15 @@ or
|
||||
|
||||
```
|
||||
|
||||
Enjoy…)
|
||||
谢谢欣赏 …)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/aria2-command-line-download-utility-tool/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,41 +1,43 @@
|
||||
谁需要 GUI?——L[inux 终端生存之道
|
||||
谁需要 GUI?—— Linux 终端生存之道
|
||||
=================================================
|
||||
|
||||
完全在 Linux 终端中生存并不容易,但这绝对是可行的。
|
||||
|
||||

|
||||
|
||||
### 处理常见功能的最佳 Linux shell 应用
|
||||
|
||||
你是否曾想像过完完全全在 Linux 终端里生存?即没有图形桌面。没有现代的 GUI 软件,仅有的就是文本——在 Linux shell 中,除了文本还是文本。这对于大部分人来说可能并不容易,但这是绝对可以逐渐做到的。[我最近在曾是在 30 天内只在 Linux shell 中生存][1]。下边提到的就是我最喜欢用的 shell 应用,它们可以用来处理多数的常用电脑功能(网页浏览、文字处理等)。这些显然有些不足,因为存文本实在是有些艰难。
|
||||
你是否曾想像过完完全全在 Linux 终端里生存?没有图形桌面,没有现代的 GUI 软件,只有文本 —— 在 Linux shell 中,除了文本还是文本。这可能并不容易,但这是绝对可行的。[我最近尝试完全在 Linux shell 中生存30天][1]。下边提到的就是我最喜欢用的 shell 应用,可以用来处理大部分的常用电脑功能(网页浏览、文字处理等)。这些显然有些不足,因为纯文本操作实在是有些艰难。
|
||||
|
||||
|
||||
|
||||
### 在 Linux 终端里发邮件
|
||||
|
||||
为了能在 终端里边发送邮件,我们对可选择性有极度的渴望。很多人会推荐 mutt 和 notmuch,这两个软件都功能强大并且表现非凡,但是我却更喜欢 alpine。为何?不仅是因为它的高效性,而且如果你习惯了像 Thunderbird 之类的 GUI 邮件客户端,你会发现 alpine 的界面与它们非常相似。
|
||||
要在终端里发邮件,选择有很多。很多人会推荐 mutt 和 notmuch,这两个软件都功能强大并且表现非凡,但是我却更喜欢 alpine。为何?不仅是因为它的高效性,还因为如果你习惯了像 Thunderbird 之类的 GUI 邮件客户端,你会发现 alpine 的界面与它们非常相似。
|
||||
|
||||

|
||||
|
||||
### 在 Linux 终端里浏览网页
|
||||
|
||||
我有句号要给你说:[w3m][5]。好吧,我承认这并不是一句话。但 w3m 的确是我在 Linux 终端想的作为 web 浏览器的选择。它能够柔和的将网页呈现出了,并且它也足够强大,让你在像 Google+ 之类的网站上发布消息(尽管方法并不有趣)。实际上 Lynx 可能才是那个基于文本的 Web 浏览器,但 w3m 还是我最想用的。
|
||||
我有一个词要告诉你:[w3m][5]。好吧,我承认这并不是一个真实的词。但 w3m 的确是我在 Linux 终端的 web 浏览器选择。它能够很好的呈现网页,并且它也足够强大,可以用来在像 Google+ 之类的网站上发布消息(尽管方法并不有趣)。 Lynx 可能是基于文本的 Web 浏览器的事实标准,但 w3m 还是我的最爱。
|
||||
|
||||

|
||||
|
||||
### 在 Linux 终端里编辑文本
|
||||
|
||||
对于编辑简单的文本文件,有那么一个应用是我最爱用的。不!不!不是 emacs,同样,也绝对不是 vim。对于编辑文本文件或者简要记下笔记,我喜欢使用 nano。对!就是 nano。它非常简单,易于学习并且使用方便。当然还有更多的软件富含其他特性,但 nano 的使用则是最令人愉快的。
|
||||
对于编辑简单的文本文件,有一个应用是我最的最爱。不!不!不是 emacs,同样,也绝对不是 vim。对于编辑文本文件或者简要记下笔记,我喜欢使用 nano。对!就是 nano。它非常简单,易于学习并且使用方便。当然还有更多的软件具有更多功能,但 nano 的使用是最令人愉快的。
|
||||
|
||||

|
||||
|
||||
### 在 Linux 终端里处理文字
|
||||
|
||||
在一个只有文本的 shell 之中,对于“文本编辑器”和“文字处理程序”实在是没有什么大的区别。但是像我这样需要大量写作的,如果有一些内置应用来长期协同则是非常必要的。而我最爱的就是 wordgrinder。它由足够的工具让我愉快工作——一个菜单驱动的界面(使用快捷键控制)并且支持开放文档、HTML或其他等多种文件格式。
|
||||
在一个只有文本的 shell 之中,“文本编辑器” 和 “文字处理程序” 实在没有什么大的区别。但是像我这样需要大量写作的,有一个专门用于长期写作的软件是非常必要的。而我最爱的就是 wordgrinder。它由足够的工具让我愉快工作——一个菜单驱动的界面(使用快捷键控制)并且支持 OpenDocument、HTML 或其他等多种文件格式。
|
||||
|
||||

|
||||
|
||||
### 在 Linux 终端里听音乐
|
||||
|
||||
当谈到在 shell 中播放音乐(比如 mp3,ogg 等),有一个软件绝对是卫冕之王:[cmus][7]。它支持所有你想得到的文件格式。它的使用超级简单,运行速度超级快,并且只使用系统少量的资源。如此清洁,如此流畅。这才是一个好的应用播发器的样子。
|
||||
当谈到在 shell 中播放音乐(比如 mp3,ogg 等),有一个软件绝对是卫冕之王:[cmus][7]。它支持所有你想得到的文件格式。它的使用超级简单,运行速度超级快,并且只使用系统少量的资源。如此清洁,如此流畅。这才是一个好的音乐播放器的样子。
|
||||
|
||||

|
||||
|
||||
@ -47,7 +49,7 @@
|
||||
|
||||
### 在 Linux 终端里发布推文
|
||||
|
||||
这不是开玩笑!由于 [rainbowstream][10] 的存在,我们已经在终端里发布推文了。尽管我经常遇到一些错误信息,但体验一番之后,它确实可以很好的工作。虽然不能像在网页版 Twitter,也不能像其移动版那样,但这是一个终端版的,来试一试吧。尽管它的功能还未完善,但是用起来还是很酷,不是吗?
|
||||
这不是开玩笑!由于 [rainbowstream][10] 的存在,我们已经可以在终端里发布推文了。尽管我时不时遇到一些 bug,但整体上,它工作得很好。虽然没有网页版 Twitter 或官方移动客户端那么好用,但这是一个终端版的 Twitter,来试一试吧。尽管它的功能还未完善,但是用起来还是很酷,不是吗?
|
||||
|
||||

|
||||
|
||||
@ -59,25 +61,25 @@
|
||||
|
||||
### 在 Linux 终端里管理进程
|
||||
|
||||
可以是 [htop][12]。与 top 相似,但更好用、更美观。有时候,我打开 htop 之后就让它一直运行。这样做是因为,它就是一个音乐视察器——当然,这里显示的是 RAM 和 CPU 使用情况。
|
||||
可以使用 [htop][12]。与 top 相似,但更好用、更美观。有时候,我打开 htop 之后就让它一直运行。没有原因,就是喜欢!从某方面说,它就像将音乐可视化——当然,这里显示的是 RAM 和 CPU 的使用情况。
|
||||
|
||||
|
||||
|
||||
### 在 Linux 终端了管理文件
|
||||
### 在 Linux 终端里管理文件
|
||||
|
||||
在一个纯文本终端里并不意味着你不能享受生活的美好之物。比方说一个出色的文件浏览和管理器。基于这样的场景,[Midnight Commander][13] 则是极其好用的一个。
|
||||
在一个纯文本终端里并不意味着你不能享受生活之美好。比方说一个出色的文件浏览和管理器。这方面,[Midnight Commander][13] 是很好用的。
|
||||
|
||||
|
||||
|
||||
### 在 Linux 终端里管理终端窗口
|
||||
|
||||
如果你需要在终端里工作很长时间,你就需要一个多窗口终端了。基本上,它就是这样一个软件——可以让你将终端回话分割成一个自定义网格,让你同时使用和查看多个终端应用。对于 shell,它相当于一个瓦片时窗口管理器。我最喜欢用的就是 [tmux][14]。但 [GNU Screen][15] 也是很好用的。你可能需要花一些时间来学习怎么使用,但你会用之后,你就会迷上这样的用法。
|
||||
如果要在终端里工作很长时间,就需要一个多窗口终端了。它是这样一个软件 —— 可以将用户终端会话分割成一个自定义网格,从而可以同时使用和查看多个终端应用。对于 shell,它相当于一个平铺式窗口管理器。我最喜欢用的是 [tmux][14]。不过 [GNU Screen][15] 也很好用。学习怎么使用它们可能要花点时间,但一旦会用,就会很方便。
|
||||
|
||||

|
||||
|
||||
### 在 Linux 终端里进行讲稿演示
|
||||
|
||||
不管是 LibreOffice、Google slides、gasp 或者 PowerPoint。我都会在讲稿演示软件花费很多时间。如果这类软件有一个终端版的就美妙了。它应该叫做“[文本演示程序][16]”。很显然,没有图片,只是一个使用简单标记语言将幻灯片放在一起的简单程序。它不可能让你在其中插入猫的图片,但它却可以让你在终端里进行完整的演示。
|
||||
这类软件有 LibreOffice、Google slides、gasp 或者 PowerPoint。我在讲稿演示软件花费很多时间,很高兴有一个终端版的软件。它称做“[文本演示程序(tpp)][16]”。很显然,没有图片,只是一个使用简单标记语言将放在一起的幻灯片展示出来的简单程序。它不可能让你在其中插入猫的图片,但可以让你在终端里进行完整的演示。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -85,7 +87,7 @@ via: http://www.networkworld.com/article/3091139/linux/who-needs-a-gui-how-to-li
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,58 @@
|
||||
为满足当今和未来 IT 需求,培训员工还是雇佣新人?
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
在数字化时代,由于 IT 工具不断更新,技术公司紧随其后,对 IT 技能的需求也不断变化。对于企业来说,寻找和雇佣那些拥有令人垂涎能力的创新人才,是非常不容易的。同时,培训内部员工来使他们接受新的技能和挑战,需要一定的时间,而时间要求常常是紧迫的。
|
||||
|
||||
[Sandy Hill][1] 对 IT 涉及到的多项技术都很熟悉。她作为 [Pegasystems][2] 项目的 IT 总监,负责多个 IT 团队,从应用的部署到数据中心的运营都要涉及。更重要的是,Pegasystems 开发帮助销售、市场、服务以及运营团队流水化操作,以及客户联络的应用。这意味着她需要掌握使用 IT 内部资源的最佳方法,面对公司客户遇到的 IT 挑战。
|
||||
|
||||

|
||||
|
||||
**TEP(企业家项目):这些年你是如何调整培训重心的?**
|
||||
|
||||
**Hill**:在过去的几年中,我们经历了爆炸式的发展,现在我们要实现更多的全球化进程。因此,培训目标是确保每个人都在同一起跑线上。
|
||||
|
||||
我们主要的关注点在培养员工使用新产品和工具上,这些新产品和工具能够推动创新,提高工作效率。例如,我们使用了之前没有的资产管理系统。因此我们需要为全部员工做培训,而不是雇佣那些已经知道该产品的人。当我们正在发展的时候,我们也试图保持紧张的预算和稳定的职员总数。所以,我们更愿意在内部培训而不是雇佣新人。
|
||||
|
||||
**TEP:说说培训方法吧,怎样帮助你的员工发展他们的技能?**
|
||||
|
||||
**Hill**:我要求每一位员工制定一个技术性的和非技术性的训练目标。这作为他们绩效评估的一部分。他们的技术性目标需要与他们的工作职能相符,非技术岗目标则随意,比如着重发展一项软技能,或是学一些专业领域之外的东西。我每年对职员进行一次评估,看看差距和不足之处,以使团队保持全面发展。
|
||||
|
||||
**TEP:你的训练计划能够在多大程度上减轻招聘工作量, 保持职员的稳定性?**
|
||||
|
||||
**Hill**:使我们的职员保持学习新技术的兴趣,可以让他们不断提高技能。让职员知道我们重视他们并且让他们在擅长的领域成长和发展,以此激励他们。
|
||||
|
||||
**TEP:你们发现哪些培训是最有效的?**
|
||||
|
||||
**HILL**:我们使用几种不同的培训方法,认为效果很好。对新的或特殊的项目,我们会由供应商提供培训课程,作为项目的一部分。要是这个方法不能实现,我们将进行脱产培训。我们也会购买一些在线的培训课程。我也鼓励职员每年参加至少一次会议,以了解行业的动向。
|
||||
|
||||
**TEP:哪些技能需求,更适合雇佣新人而不是培训现有员工?**
|
||||
|
||||
**Hill**:这和项目有关。最近有一个项目,需要使用 OpenStack,而我们根本没有这方面的专家。所以我们与一家从事这一领域的咨询公司合作。我们利用他们的专业人员运行该项目,并现场培训我们的内部团队成员。让内部员工学习他们需要的技能,同时还要完成他们的日常工作,是一项艰巨的任务。
|
||||
|
||||
顾问帮助我们确定我们需要的员工人数。这样我们就可以对员工进行评估,看是否存在缺口。如果存在人员上的缺口,我们还需要额外的培训或是员工招聘。我们也确实雇佣了一些合同工。另一个选择是对一些全职员工进行为期六至八周的培训,但我们的项目模式不容许这么做。
|
||||
|
||||
**TEP:最近雇佣的员工,他们的那些技能特别能够吸引到你?**
|
||||
|
||||
**Hill**:在最近的招聘中,我更看重软技能。除了扎实的技术能力外,他们需要能够在团队中进行有效的沟通和工作,要有说服他人,谈判和解决冲突的能力。
|
||||
|
||||
IT 人常常独来独往,不擅社交。然而如今IT 与整个组织结合越来越紧密,为其他业务部门提供有用的更新和状态报告的能力至关重要,可展示 IT 部门存在的重要性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2016/6/training-vs-hiring-meet-it-needs-today-and-tomorrow
|
||||
|
||||
作者:[Paul Desmond][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://enterprisersproject.com/user/paul-desmond
|
||||
[1]: https://enterprisersproject.com/user/sandy-hill
|
||||
[2]: https://www.pega.com/pega-can?&utm_source=google&utm_medium=cpc&utm_campaign=900.US.Evaluate&utm_term=pegasystems&gloc=9009726&utm_content=smAXuLA4U|pcrid|102822102849|pkw|pegasystems|pmt|e|pdv|c|
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,143 @@
|
||||
2016 年 Linux 下五个最佳视频编辑软件
|
||||
=====================================================
|
||||
|
||||

|
||||
|
||||
概要: 在这篇文章中,Tiwo 讨论了 Linux 下最佳视频编辑器的优缺点和在基于 Ubuntu 的发行版中的安装方法。
|
||||
|
||||
在过去,我们已经在类似的文章中讨论了 [Linux 下最佳图像管理应用软件][1],[Linux 上四个最佳的现代开源代码编辑器][2]。今天,我们来看看 Linux 下的最佳视频编辑软件。
|
||||
|
||||
当谈及免费的视频编辑软件,Windows Movie Maker 和 iMovie 是大多数人经常推荐的。
|
||||
|
||||
不幸的是,它们在 GNU/Linux 下都是不可用的。但是你不必担心这个,因为我们已经为你收集了一系列最佳的视频编辑器。
|
||||
|
||||
### Linux下最佳的视频编辑应用程序
|
||||
|
||||
接下来,让我们来看看 Linux 下排名前五的最佳视频编辑软件:
|
||||
|
||||
#### 1. Kdenlive
|
||||
|
||||

|
||||
|
||||
[Kdenlive][3] 是一款来自于 KDE 的自由而开源的视频编辑软件,它提供双视频监视器、多轨时间轴、剪辑列表、可自定义的布局支持、基本效果和基本转换的功能。
|
||||
|
||||
它支持各种文件格式和各种摄像机和相机,包括低分辨率摄像机(Raw 和 AVI DV 编辑):mpeg2、mpeg4 和 h264 AVCHD(小型摄像机和摄像机);高分辨率摄像机文件,包括 HDV 和 AVCHD 摄像机;专业摄像机,包括 XDCAM-HD^TM 流、IMX^TM (D10)流、DVCAM(D10)、DVCAM、DVCPRO^TM 、DVCPRO50^TM 流和 DNxHD^TM 流等等。
|
||||
|
||||
你可以在命令行下运行下面的命令安装 :
|
||||
|
||||
```
|
||||
sudo apt-get install kdenlive
|
||||
```
|
||||
|
||||
或者,打开 Ubuntu 软件中心,然后搜索 Kdenlive。
|
||||
|
||||
#### 2. OpenShot
|
||||
|
||||

|
||||
|
||||
[OpenShot][5] 是我们这个 Linux 视频编辑软件列表中的第二选择。 OpenShot 可以帮助您创建支持过渡、效果、调整音频电平的电影,当然,它也支持大多数格式和编解码器。
|
||||
|
||||
您还可以将电影导出到 DVD,上传到 YouTube、Vimeo、Xbox 360 和许多其他常见的格式。 OpenShot 比 Kdenlive 更简单。 所以如果你需要一个简单界面的视频编辑器,OpenShot 会是一个不错的选择。
|
||||
|
||||
最新的版本是 2.0.7。您可以从终端窗口运行以下命令安装 OpenShot 视频编辑器:
|
||||
|
||||
```
|
||||
sudo apt-get install openshot
|
||||
```
|
||||
|
||||
它需要下载 25 MB,安装后需要 70 MB 硬盘空间。
|
||||
|
||||
#### 3. Flowblade Movie Editor
|
||||
|
||||

|
||||
|
||||
[Flowblade Movie Editor][6] 是一个用于 Linux 的多轨非线性视频编辑器。它是自由而开源的。 它配备了一个时尚而现代的用户界面。
|
||||
|
||||
它是用 Python 编写的,旨在提供一个快速、精确的功能。 Flowblade 致力于在 Linux 和其他自由平台上提供最好的体验。 所以现在没有 Windows 和 OS X 版本。
|
||||
|
||||
要在 Ubuntu 和其他基于 Ubuntu 的系统上安装 Flowblade,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt-get install flowblade
|
||||
```
|
||||
|
||||
#### 4. Lightworks
|
||||
|
||||

|
||||
|
||||
如果你要寻找一个有更多功能的视频编辑软件,这会是答案。 [Lightworks][7] 是一个跨平台的专业的视频编辑器,在 Linux、Mac OS X 和 Windows 系统下都可用。
|
||||
|
||||
它是一个获奖的专业的[非线性编辑][8](NLE)软件,支持高达 4K 的分辨率以及标清和高清格式的视频。
|
||||
|
||||
该应用程序有两个版本:Lightworks 免费版和 Lightworks 专业版。不过免费版本不支持 Vimeo(H.264 / MPEG-4)和 YouTube(H.264 / MPEG-4) - 高达 2160p(4K UHD)、蓝光和 H.264 / MP4 导出选项,以及可配置的位速率设置,但是专业版本支持。
|
||||
|
||||
- Lightworks 免费版
|
||||
- Lightworks 专业版
|
||||
|
||||
专业版本有更多的功能,例如更高的分辨率支持,4K 和蓝光支持等。
|
||||
|
||||
##### 怎么安装Lightworks?
|
||||
|
||||
不同于其他的视频编辑器,安装 Lightwork 不像运行单个命令那么直接。别担心,这不会很复杂。
|
||||
|
||||
- 第1步 – 你可以从 [Lightworks 下载页面][9]下载安装包。这个安装包大约 79.5MB。*请注意:这里没有32 位 Linux 的支持。*
|
||||
- 第2步 – 一旦下载,你可以使用 [Gdebi 软件包安装器][10]来安装。Gdebi 会自动下载依赖关系 :
|
||||

|
||||
- 第3步 – 现在你可以从 Ubuntu 仪表板或您的 Linux 发行版菜单中打开它。
|
||||
- 第4步 – 当你第一次使用它时,需要一个账号。点击 “Not Registerd?” 按钮来注册。别担心,它是免费的。
|
||||
- 第5步 – 在你的账号通过验证后,就可以登录了。
|
||||
|
||||
现在,Lightworks 可以使用了。
|
||||
|
||||
需要 Lightworks 的视频教程? 在 [Lightworks 视频教程页][11]得到它们。
|
||||
|
||||
#### 5. Blender
|
||||
|
||||

|
||||
|
||||
|
||||
Blender 是一个专业的,工业级的开源、跨平台的视频编辑器。在 3D 作品的制作中,是非常受欢迎的。 Blender 已被用于几部好莱坞电影的制作,包括蜘蛛侠系列。
|
||||
|
||||
虽然最初是设计用于制作 3D 模型,但它也可以用于各种格式的视频编辑和输入能力。 该视频编辑器包括:
|
||||
|
||||
- 实时预览、亮度波形、色度矢量示波器和直方图显示
|
||||
- 音频混合、同步、擦除和波形可视化
|
||||
- 多达 32 个插槽用于添加视频、图像、音频、场景、面具和效果
|
||||
- 速度控制、调整图层、过渡、关键帧、过滤器等
|
||||
|
||||
最新的版本可以从 [Blender 下载页][12]下载.
|
||||
|
||||
### 哪一个是最好的视频编辑软件?
|
||||
|
||||
如果你需要一个简单的视频编辑器,OpenShot、Kdenlive 和 Flowblade 是一个不错的选择。这些软件是适合初学者的,并且带有标准规范的系统。
|
||||
|
||||
如果你有一个高性能的计算机,并且需要高级功能,你可以使用 Lightworks。如果你正在寻找更高级的功能, Blender 可以帮助你。
|
||||
|
||||
这就是我写的 5 个最佳的视频编辑软件,它们可以在 Ubuntu、Linux Mint、Elementary 和其他 Linux 发行版下使用。 请与我们分享您最喜欢的视频编辑器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-video-editing-software-linux/
|
||||
|
||||
作者:[Tiwo Satriatama][a]
|
||||
译者:[DockerChen](https://github.com/DockerChen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/tiwo/
|
||||
[1]: https://linux.cn/article-7462-1.html
|
||||
[2]: https://linux.cn/article-7468-1.html
|
||||
[3]: https://kdenlive.org/
|
||||
[4]: https://itsfoss.com/tag/open-source/
|
||||
[5]: http://www.openshot.org/
|
||||
[6]: http://jliljebl.github.io/flowblade/
|
||||
[7]: https://www.lwks.com/
|
||||
[8]: https://en.wikipedia.org/wiki/Non-linear_editing_system
|
||||
[9]: https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206
|
||||
[10]: https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[11]: https://www.lwks.com/videotutorials
|
||||
[12]: https://www.blender.org/download/
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,188 @@
|
||||
写一个 JavaScript 框架:比 setTimeout 更棒的定时执行
|
||||
===================
|
||||
|
||||
这是 [JavaScript 框架系列][2]的第二章。在这一章里,我打算讲一下在浏览器里的异步代码不同执行方式。你将了解定时器和事件循环之间的不同差异,比如 setTimeout 和 Promises。
|
||||
|
||||
这个系列是关于一个开源的客户端框架,叫做 NX。在这个系列里,我主要解释一下写该框架不得不克服的主要困难。如果你对 NX 感兴趣可以参观我们的 [主页][1]。
|
||||
|
||||
这个系列包含以下几个章节:
|
||||
|
||||
1. [项目结构][2]
|
||||
2. 定时执行 (当前章节)
|
||||
3. [沙箱代码评估][3]
|
||||
4. [数据绑定介绍](https://blog.risingstack.com/writing-a-javascript-framework-data-binding-dirty-checking/)
|
||||
5. [数据绑定与 ES6 代理](https://blog.risingstack.com/writing-a-javascript-framework-data-binding-es6-proxy/)
|
||||
6. 自定义元素
|
||||
7. 客户端路由
|
||||
|
||||
### 异步代码执行
|
||||
|
||||
你可能比较熟悉 `Promise`、`process.nextTick()`、`setTimeout()`,或许还有 `requestAnimationFrame()` 这些异步执行代码的方式。它们内部都使用了事件循环,但是它们在精确计时方面有一些不同。
|
||||
|
||||
在这一章里,我将解释它们之间的不同,然后给大家演示怎样在一个类似 NX 这样的先进框架里面实现一个定时系统。不用我们重新做一个,我们将使用原生的事件循环来达到我们的目的。
|
||||
|
||||
### 事件循环
|
||||
|
||||
事件循环甚至没有在 [ES6 规范](http://www.ecma-international.org/ecma-262/6.0/)里提到。JavaScript 自身只有任务(Job)和任务队列(job queue)。更加复杂的事件循环是在 NodeJS 和 HTML5 规范里分别定义的,因为这篇是针对前端的,我会在详细说明后者。
|
||||
|
||||
事件循环可以被看做某个条件的循环。它不停的寻找新的任务来运行。这个循环中的一次迭代叫做一个滴答(tick)。在一次滴答期间执行的代码称为一次任务(task)。
|
||||
|
||||
```
|
||||
while (eventLoop.waitForTask()) {
|
||||
eventLoop.processNextTask()
|
||||
}
|
||||
```
|
||||
任务是同步代码,它可以在循环中调度其它任务。一个简单的调用新任务的方式是 `setTimeout(taskFn)`。不管怎样, 任务可能有很多来源,比如用户事件、网络或者 DOM 操作。
|
||||
|
||||

|
||||
|
||||
### 任务队列
|
||||
|
||||
更复杂一些的是,事件循环可以有多个任务队列。这里有两个约束条件,相同任务源的事件必须在相同的队列,以及任务必须按插入的顺序进行处理。除此之外,浏览器可以做任何它想做的事情。例如,它可以决定接下来处理哪个任务队列。
|
||||
|
||||
```
|
||||
while (eventLoop.waitForTask()) {
|
||||
const taskQueue = eventLoop.selectTaskQueue()
|
||||
if (taskQueue.hasNextTask()) {
|
||||
taskQueue.processNextTask()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
用这个模型,我们不能精确的控制定时。如果用 `setTimeout()`浏览器可能决定先运行完其它几个队列才运行我们的队列。
|
||||
|
||||

|
||||
|
||||
### 微任务队列
|
||||
|
||||
幸运的是,事件循环还提供了一个叫做微任务(microtask)队列的单一队列。当前任务结束的时候,微任务队列会清空每个滴答里的任务。
|
||||
|
||||
```
|
||||
while (eventLoop.waitForTask()) {
|
||||
const taskQueue = eventLoop.selectTaskQueue()
|
||||
if (taskQueue.hasNextTask()) {
|
||||
taskQueue.processNextTask()
|
||||
}
|
||||
|
||||
const microtaskQueue = eventLoop.microTaskQueue
|
||||
while (microtaskQueue.hasNextMicrotask()) {
|
||||
microtaskQueue.processNextMicrotask()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
最简单的调用微任务的方法是 `Promise.resolve().then(microtaskFn)`。微任务按照插入顺序进行处理,并且由于仅存在一个微任务队列,浏览器不会把时间弄乱了。
|
||||
|
||||
此外,微任务可以调度新的微任务,它将插入到同一个队列,并在同一个滴答内处理。
|
||||
|
||||

|
||||
|
||||
### 绘制(Rendering)
|
||||
|
||||
最后是绘制(Rendering)调度,不同于事件处理和分解,绘制并不是在单独的后台任务完成的。它是一个可以运行在每个循环滴答结束时的算法。
|
||||
|
||||
在这里浏览器又有了许多自由:它可能在每个任务以后绘制,但是它也可能在好几百个任务都执行了以后也不绘制。
|
||||
|
||||
幸运的是,我们有 `requestAnimationFrame()`,它在下一个绘制之前执行传递的函数。我们最终的事件模型像这样:
|
||||
|
||||
```
|
||||
while (eventLoop.waitForTask()) {
|
||||
const taskQueue = eventLoop.selectTaskQueue()
|
||||
if (taskQueue.hasNextTask()) {
|
||||
taskQueue.processNextTask()
|
||||
}
|
||||
|
||||
const microtaskQueue = eventLoop.microTaskQueue
|
||||
while (microtaskQueue.hasNextMicrotask()) {
|
||||
microtaskQueue.processNextMicrotask()
|
||||
}
|
||||
|
||||
if (shouldRender()) {
|
||||
applyScrollResizeAndCSS()
|
||||
runAnimationFrames()
|
||||
render()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
现在用我们所知道知识来创建定时系统!
|
||||
|
||||
### 利用事件循环
|
||||
|
||||
和大多数现代框架一样,[NX][1] 也是基于 DOM 操作和数据绑定的。批量操作和异步执行以取得更好的性能表现。基于以上理由我们用 `Promises`、 `MutationObservers` 和 `requestAnimationFrame()`。
|
||||
|
||||
我们所期望的定时器是这样的:
|
||||
|
||||
1. 代码来自于开发者
|
||||
2. 数据绑定和 DOM 操作由 NX 来执行
|
||||
3. 开发者定义事件钩子
|
||||
4. 浏览器进行绘制
|
||||
|
||||
#### 步骤 1
|
||||
|
||||
NX 寄存器对象基于 [ES6 代理](https://ponyfoo.com/articles/es6-proxies-in-depth) 以及 DOM 变动基于[MutationObserver](https://davidwalsh.name/mutationobserver-api) (变动观测器)同步运行(下一节详细介绍)。 它作为一个微任务延迟直到步骤 2 执行以后才做出反应。这个延迟已经在 `Promise.resolve().then(reaction)` 进行了对象转换,并且它将通过变动观测器自动运行。
|
||||
|
||||
#### 步骤 2
|
||||
|
||||
来自开发者的代码(任务)运行完成。微任务由 NX 开始执行所注册。 因为它们是微任务,所以按序执行。注意,我们仍然在同一个滴答循环中。
|
||||
|
||||
#### 步骤 3
|
||||
|
||||
开发者通过 `requestAnimationFrame(hook)` 通知 NX 运行钩子。这可能在滴答循环后发生。重要的是,钩子运行在下一次绘制之前和所有数据操作之后,并且 DOM 和 CSS 改变都已经完成。
|
||||
|
||||
#### 步骤 4
|
||||
|
||||
浏览器绘制下一个视图。这也有可能发生在滴答循环之后,但是绝对不会发生在一个滴答的步骤 3 之前。
|
||||
|
||||
### 牢记在心里的事情
|
||||
|
||||
我们在原生的事件循环之上实现了一个简单而有效的定时系统。理论上讲它运行的很好,但是还是很脆弱,一个轻微的错误可能会导致很严重的 BUG。
|
||||
|
||||
在一个复杂的系统当中,最重要的就是建立一定的规则并在以后保持它们。在 NX 中有以下规则:
|
||||
|
||||
1. 永远不用 `setTimeout(fn, 0)` 来进行内部操作
|
||||
2. 用相同的方法来注册微任务
|
||||
3. 微任务仅供内部操作
|
||||
4. 不要干预开发者钩子运行时间
|
||||
|
||||
#### 规则 1 和 2
|
||||
|
||||
数据反射和 DOM 操作将按照操作顺序执行。这样只要不混合就可以很好的延迟它们的执行。混合执行会出现莫名其妙的问题。
|
||||
|
||||
`setTimeout(fn, 0)` 的行为完全不可预测。使用不同的方法注册微任务也会发生混乱。例如,下面的例子中 microtask2 不会正确地在 microtask1 之前运行。
|
||||
|
||||
```
|
||||
Promise.resolve().then().then(microtask1)
|
||||
Promise.resolve().then(microtask2)
|
||||
```
|
||||
|
||||

|
||||
|
||||
#### 规则 3 和 4
|
||||
|
||||
分离开发者的代码执行和内部操作的时间窗口是非常重要的。混合这两种行为会导致不可预测的事情发生,并且它会需要开发者了解框架内部。我想很多前台开发者已经有过类似经历。
|
||||
|
||||
### 结论
|
||||
|
||||
如果你对 NX 框架感兴趣,可以参观我们的[主页][1]。还可以在 GIT 上找到我们的[源代码][5]。
|
||||
|
||||
在下一节我们再见,我们将讨论 [沙盒化代码执行][4]!
|
||||
|
||||
你也可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.risingstack.com/writing-a-javascript-framework-execution-timing-beyond-settimeout/
|
||||
|
||||
作者:[Bertalan Miklos][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.risingstack.com/author/bertalan/
|
||||
[1]: http://nx-framework.com/
|
||||
[2]: https://blog.risingstack.com/writing-a-javascript-framework-project-structuring/
|
||||
[3]: https://blog.risingstack.com/writing-a-javascript-framework-sandboxed-code-evaluation/
|
||||
[4]: https://blog.risingstack.com/writing-a-javascript-framework-sandboxed-code-evaluation/
|
||||
[5]: https://github.com/RisingStack/nx-framework
|
||||
@ -1,9 +1,11 @@
|
||||
小模块的开销
|
||||
JavaScript 小模块的开销
|
||||
====
|
||||
|
||||
大约一年之前,我在将一个大型 JavaScript 代码库重构为小模块时发现了 Browserify 和 Webpack 中一个令人沮丧的事实:
|
||||
更新(2016/10/30):我写完这篇文章之后,我在[这个基准测试中发了一个错误](https://github.com/nolanlawson/cost-of-small-modules/pull/8),会导致 Rollup 比它预期的看起来要好一些。不过,整体结果并没有明显的不同(Rollup 仍然击败了 Browserify 和 Webpack,虽然它并没有像 Closure 十分好),所以我只是更新了图表。该基准测试包括了 [RequireJS 和 RequireJS Almond 打包器](https://github.com/nolanlawson/cost-of-small-modules/pull/5),所以文章中现在也包括了它们。要看原始帖子,可以查看[历史版本](https://web.archive.org/web/20160822181421/https://nolanlawson.com/2016/08/15/the-cost-of-small-modules/)。
|
||||
|
||||
> “代码越模块化,代码体积就越大。”- Nolan Lawson
|
||||
大约一年之前,我在将一个大型 JavaScript 代码库重构为更小的模块时发现了 Browserify 和 Webpack 中一个令人沮丧的事实:
|
||||
|
||||
> “代码越模块化,代码体积就越大。:< ”- Nolan Lawson
|
||||
|
||||
过了一段时间,Sam Saccone 发布了一些关于 [Tumblr][1] 和 [Imgur][2] 页面加载性能的出色的研究。其中指出:
|
||||
|
||||
@ -15,9 +17,9 @@
|
||||
|
||||
一个页面中包含的 JavaScript 脚本越多,页面加载也将越慢。庞大的 JavaScript 包会导致浏览器花费更多的时间去下载、解析和执行,这些都将加长载入时间。
|
||||
|
||||
即使当你使用如 Webpack [code splitting][3]、Browserify [factor bundles][4] 等工具将代码分解为多个包,时间的花费也仅仅是被延迟到页面生命周期的晚些时候。JavaScript 迟早都将有一笔开销。
|
||||
即使当你使用如 Webpack [code splitting][3]、Browserify [factor bundles][4] 等工具将代码分解为多个包,该开销也仅仅是被延迟到页面生命周期的晚些时候。JavaScript 迟早都将有一笔开销。
|
||||
|
||||
此外,由于 JavaScript 是一门动态语言,同时流行的 [CommonJS][5] 模块也是动态的,所以这就使得在最终分发给用户的代码中剔除无用的代码变得异常困难。譬如你可能只使用到 jQuery 中的 $.ajax,但是通过载入 jQuery 包,你将以整个包为代价。
|
||||
此外,由于 JavaScript 是一门动态语言,同时流行的 [CommonJS][5] 模块也是动态的,所以这就使得在最终分发给用户的代码中剔除无用的代码变得异常困难。譬如你可能只使用到 jQuery 中的 $.ajax,但是通过载入 jQuery 包,你将付出整个包的代价。
|
||||
|
||||
JavaScript 社区对这个问题提出的解决办法是提倡 [小模块][6] 的使用。小模块不仅有许多 [美好且实用的好处][7] 如易于维护,易于理解,易于集成等,而且还可以通过鼓励包含小巧的功能而不是庞大的库来解决之前提到的 jQuery 的问题。
|
||||
|
||||
@ -66,7 +68,7 @@ $ browserify node_modules/qs | browserify-count-modules
|
||||
|
||||
顺带一提,我写过的最大的开源站点 [Pokedex.org][21] 包含了 4 个包,共 311 个模块。
|
||||
|
||||
让我们先暂时忽略这些 JavaScript 包的实际大小,我认为去探索一下一定数量的模块本身开销会事一件有意思的事。虽然 Sam Saccone 的文章 [“2016 年 ES2015 转译的开销”][22] 已经广为流传,但是我认为他的结论还未到达足够深度,所以让我们挖掘的稍微再深一点吧。
|
||||
让我们先暂时忽略这些 JavaScript 包的实际大小,我认为去探索一下一定数量的模块本身开销会是一件有意思的事。虽然 Sam Saccone 的文章 [“2016 年 ES2015 转译的开销”][22] 已经广为流传,但是我认为他的结论还未到达足够深度,所以让我们挖掘的稍微再深一点吧。
|
||||
|
||||
### 测试环节!
|
||||
|
||||
@ -86,13 +88,13 @@ console.log(total)
|
||||
module.exports = 1
|
||||
```
|
||||
|
||||
我测试了五种打包方法:Browserify, 带 [bundle-collapser][24] 插件的 Browserify, Webpack, Rollup 和 Closure Compiler。对于 Rollup 和 Closure Compiler 我使用了 ES6 模块,而对于 Browserify 和 Webpack 则用的 CommonJS,目的是为了不涉及其各自缺点而导致测试的不公平(由于它们可能需要做一些转译工作,如 Babel 一样,而这些工作将会增加其自身的运行时间)。
|
||||
我测试了五种打包方法:Browserify、带 [bundle-collapser][24] 插件的 Browserify、Webpack、Rollup 和 Closure Compiler。对于 Rollup 和 Closure Compiler 我使用了 ES6 模块,而对于 Browserify 和 Webpack 则用的是 CommonJS,目的是为了不涉及其各自缺点而导致测试的不公平(由于它们可能需要做一些转译工作,如 Babel 一样,而这些工作将会增加其自身的运行时间)。
|
||||
|
||||
为了更好地模拟一个生产环境,我将带 -mangle 和 -compress 参数的 Uglify 用于所有的包,并且使用 gzip 压缩后通过 GitHub Pages 用 HTTPS 协议进行传输。对于每个包,我一共下载并执行 15 次,然后取其平均值,并使用 performance.now() 函数来记录载入时间(未使用缓存)与执行时间。
|
||||
为了更好地模拟一个生产环境,我对所有的包采用带 `-mangle` 和 `-compress` 参数的 `Uglify` ,并且使用 gzip 压缩后通过 GitHub Pages 用 HTTPS 协议进行传输。对于每个包,我一共下载并执行 15 次,然后取其平均值,并使用 `performance.now()` 函数来记录载入时间(未使用缓存)与执行时间。
|
||||
|
||||
### 包大小
|
||||
|
||||
在我们查看测试结果之前,我们有必要先来看一眼我们要测试的包文件。一下是每个包最小处理后但并未使用 gzip 压缩时的体积大小(单位:Byte):
|
||||
在我们查看测试结果之前,我们有必要先来看一眼我们要测试的包文件。以下是每个包最小处理后但并未使用 gzip 压缩时的体积大小(单位:Byte):
|
||||
|
||||
| | 100 个模块 | 1000 个模块 | 5000 个模块 |
|
||||
| --- | --- | --- | --- |
|
||||
@ -110,7 +112,7 @@ module.exports = 1
|
||||
| rollup | 300 | 2145 | 11510 |
|
||||
| closure | 302 | 2140 | 11789 |
|
||||
|
||||
Browserify 和 Webpack 的工作方式是隔离各个模块到各自的函数空间,然后声明一个全局载入器,并在每次 require() 函数调用时定位到正确的模块处。下面是我们的 Browserify 包的样子:
|
||||
Browserify 和 Webpack 的工作方式是隔离各个模块到各自的函数空间,然后声明一个全局载入器,并在每次 `require()` 函数调用时定位到正确的模块处。下面是我们的 Browserify 包的样子:
|
||||
|
||||
```
|
||||
(function e(t,n,r){function s(o,u){if(!n[o]){if(!t[o]){var a=typeof require=="function"&&require;if(!u&&a)return a(o,!0);if(i)return i(o,!0);var f=new Error("Cannot find module '"+o+"'");throw f.code="MODULE_NOT_FOUND",f}var l=n[o]={exports:{}};t[o][0].call(l.exports,function(e){var n=t[o][1][e];return s(n?n:e)},l,l.exports,e,t,n,r)}return n[o].exports}var i=typeof require=="function"&&require;for(var o=0;o
|
||||
@ -144,7 +146,7 @@ Browserify 和 Webpack 的工作方式是隔离各个模块到各自的函数空
|
||||
|
||||
在 100 个模块时,各包的差异是微不足道的,但是一旦模块数量达到 1000 个甚至 5000 个时,差异将会变得非常巨大。iPod Touch 在不同包上的差异并不明显,而对于具有一定年代的 Nexus 5 来说,Browserify 和 Webpack 明显耗时更多。
|
||||
|
||||
与此同时,我发现有意思的是 Rollup 和 Closure 的运行开销对于 iPod 而言几乎可以忽略,并且与模块的数量关系也不大。而对于 Nexus 5 来说,运行的开销并非完全可以忽略,但它们仍比 Browserify 或 Webpack 低很多。后者若未在几百毫秒内完成加载则将会占用主线程的好几帧的时间,这就意味着用户界面将冻结并且等待直到模块载入完成。
|
||||
与此同时,我发现有意思的是 Rollup 和 Closure 的运行开销对于 iPod 而言几乎可以忽略,并且与模块的数量关系也不大。而对于 Nexus 5 来说,运行的开销并非完全可以忽略,但 Rollup/Closure 仍比 Browserify/Webpack 低很多。后者若未在几百毫秒内完成加载则将会占用主线程的好几帧的时间,这就意味着用户界面将冻结并且等待直到模块载入完成。
|
||||
|
||||
值得注意的是前面这些测试都是在千兆网速下进行的,所以在网络情况来看,这只是一个最理想的状况。借助 Chrome 开发者工具,我们可以认为地将 Nexus 5 的网速限制到 3G 水平,然后来看一眼这对测试产生的影响([查看表格][30]):
|
||||
|
||||
@ -152,13 +154,13 @@ Browserify 和 Webpack 的工作方式是隔离各个模块到各自的函数空
|
||||
|
||||
一旦我们将网速考虑进来,Browserify/Webpack 和 Rollup/Closure 的差异将变得更为显著。在 1000 个模块规模(接近于 Reddit 1050 个模块的规模)时,Browserify 花费的时间比 Rollup 长大约 400 毫秒。然而 400 毫秒已经不是一个小数目了,正如 Google 和 Bing 指出的,亚秒级的延迟都会 [对用户的参与产生明显的影响][32] 。
|
||||
|
||||
还有一件事需要指出,那就是这个测试并非测量 100 个、1000 个或者 5000 个模块的每个模块的精确运行时间。因为这还与你对 require() 函数的使用有关。在这些包中,我采用的是对每个模块调用一次 require() 函数。但如果你每个模块调用了多次 require() 函数(这在代码库中非常常见)或者你多次动态调用 require() 函数(例如在子函数中调用 require() 函数),那么你将发现明显的性能退化。
|
||||
还有一件事需要指出,那就是这个测试并非测量 100 个、1000 个或者 5000 个模块的每个模块的精确运行时间。因为这还与你对 `require()` 函数的使用有关。在这些包中,我采用的是对每个模块调用一次 `require()` 函数。但如果你每个模块调用了多次 `require()` 函数(这在代码库中非常常见)或者你多次动态调用 `require()` 函数(例如在子函数中调用 `require()` 函数),那么你将发现明显的性能退化。
|
||||
|
||||
Reddit 的移动站点就是一个很好的例子。虽然该站点有 1050 个模块,但是我测量了它们使用 Browserify 的实际执行时间后发现比“1000 个模块”的测试结果差好多。当使用那台运行 Chrome 的 Nexus 5 时,我测出 Reddit 的 Browserify require() 函数耗时 2.14 秒。而那个“1000 个模块”脚本中的等效函数只需要 197 毫秒(在搭载 i7 处理器的 Surface Book 上的桌面版 Chrome,我测出的结果分别为 559 毫秒与 37 毫秒,虽然给出桌面平台的结果有些令人惊讶)。
|
||||
|
||||
这结果提示我们有必要对每个模块使用多个 require() 函数的情况再进行一次测试。不过,我并不认为这对 Browserify 和 Webpack 会是一个公平的测试,因为 Rollup 和 Closure 都会将重复的 ES6 库导入处理为一个的顶级变量声明,同时也阻止了顶层空间以外的其他区域的导入。所以根本上来说,Rollup 和 Closure 中一个导入和多个导入的开销是相同的,而对于 Browserify 和 Webpack,运行开销随 require() 函数的数量线性增长。
|
||||
这结果提示我们有必要对每个模块使用多个 `require()` 函数的情况再进行一次测试。不过,我并不认为这对 Browserify 和 Webpack 会是一个公平的测试,因为 Rollup 和 Closure 都会将重复的 ES6 库导入处理为一个的顶级变量声明,同时也阻止了顶层空间以外的其他区域的导入。所以根本上来说,Rollup 和 Closure 中一个导入和多个导入的开销是相同的,而对于 Browserify 和 Webpack,运行开销随 `require()` 函数的数量线性增长。
|
||||
|
||||
为了我们这个分析的目的,我认为最好假设模块的数量是性能的短板。而事实上,“5000 个模块”也是一个比“5000 个 require() 函数调用”更好的度量标准。
|
||||
为了我们这个分析的目的,我认为最好假设模块的数量是性能的短板。而事实上,“5000 个模块”也是一个比“5000 个 `require()` 函数调用”更好的度量标准。
|
||||
|
||||
### 结论
|
||||
|
||||
@ -168,11 +170,11 @@ Reddit 的移动站点就是一个很好的例子。虽然该站点有 1050 个
|
||||
|
||||
给出这些结果之后,我对 Closure Compiler 和 Rollup 在 JavaScript 社区并没有得到过多关注而感到惊讶。我猜测或许是因为(前者)需要依赖 Java,而(后者)仍然相当不成熟并且未能做到开箱即用(详见 [Calvin’s Metcalf 的评论][37] 中作的不错的总结)。
|
||||
|
||||
即使没有足够数量的 JavaScript 开发者加入到 Rollup 或 Closure 的队伍中,我认为 npm 包作者们也已准备好了去帮助解决这些问题。如果你使用 npm 安装 lodash,你将会发其现主要的导入是一个巨大的 JavaScript 模块,而不是你期望的 Lodash 的超模块(hyper-modular)特性(require('lodash/uniq'),require('lodash.uniq') 等等)。对于 PouchDB,我们做了一个类似的声明以 [使用 Rollup 作为预发布步骤][38],这将产生对于用户而言尽可能小的包。
|
||||
即使没有足够数量的 JavaScript 开发者加入到 Rollup 或 Closure 的队伍中,我认为 npm 包作者们也已准备好了去帮助解决这些问题。如果你使用 npm 安装 lodash,你将会发其现主要的导入是一个巨大的 JavaScript 模块,而不是你期望的 Lodash 的超模块(hyper-modular)特性(`require('lodash/uniq')`,`require('lodash.uniq')` 等等)。对于 PouchDB,我们做了一个类似的声明以 [使用 Rollup 作为预发布步骤][38],这将产生对于用户而言尽可能小的包。
|
||||
|
||||
同时,我创建了 [rollupify][39] 来尝试将这过程变得更为简单一些,只需拖动到已存在的 Browserify 工程中即可。其基本思想是在你自己的项目中使用导入(import)和导出(export)(可以使用 [cjs-to-es6][40] 来帮助迁移),然后使用 require() 函数来载入第三方包。这样一来,你依旧可以在你自己的代码库中享受所有模块化的优点,同时能导出一个适当大小的大模块来发布给你的用户。不幸的是,你依旧得为第三方库付出一些代价,但是我发现这是对于当前 npm 生态系统的一个很好的折中方案。
|
||||
|
||||
所以结论如下:一个大的 JavaScript 包比一百个小 JavaScript 模块要快。尽管这是事实,我依旧希望我们社区能最终发现我们所处的困境————提倡小模块的原则对开发者有利,但是对用户不利。同时希望能优化我们的工具,使得我们可以对两方面都有利。
|
||||
所以结论如下:**一个大的 JavaScript 包比一百个小 JavaScript 模块要快**。尽管这是事实,我依旧希望我们社区能最终发现我们所处的困境————提倡小模块的原则对开发者有利,但是对用户不利。同时希望能优化我们的工具,使得我们可以对两方面都有利。
|
||||
|
||||
### 福利时间!三款桌面浏览器
|
||||
|
||||
@ -205,15 +207,15 @@ Firefox 48 ([查看表格][45])
|
||||
|
||||
[![Nexus 5 (3G) RequireJS 结果][53]](https://nolanwlawson.files.wordpress.com/2016/08/2016-08-20-14_45_29-small_modules3-xlsx-excel.png)
|
||||
|
||||
|
||||
更新 3: 我写了一个 [optimize-js](http://github.com/nolanlawson/optimize-js) ,它会减少一些函数内的函数的解析成本。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nolanlawson.com/2016/08/15/the-cost-of-small-modules/?utm_source=javascriptweekly&utm_medium=email
|
||||
via: https://nolanlawson.com/2016/08/15/the-cost-of-small-modules/
|
||||
|
||||
作者:[Nolan][a]
|
||||
译者:[Yinr](https://github.com/Yinr)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
宽松开源许可证的崛起意味着什么
|
||||
====
|
||||
|
||||
为什么像 GNU GPL 这样的限制性许可证越来越不受青睐。
|
||||
|
||||
“如果你用了任何开源软件, 那么你软件的其他部分也必须开源。” 这是微软前 CEO 巴尔默 2001 年说的, 尽管他说的不对, 还是引发了人们对自由软件的 FUD (恐惧, 不确定和怀疑(fear, uncertainty and doubt))。 大概这才是他的意图。
|
||||
|
||||
对开源软件的这些 FUD 主要与开源许可有关。 现在有许多不同的许可证, 当中有些限制比其他的更严格(也有人称“更具保护性”)。 诸如 GNU 通用公共许可证 (GPL) 这样的限制性许可证使用了 copyleft 的概念。 copyleft 赋予人们自由发布软件副本和修改版的权力, 只要衍生工作保留同样的权力。 bash 和 GIMP 等开源项目就是使用了 GPL(v3)。 还有一个 AGPL( Affero GPL) 许可证, 它为网络上的软件(如 web service)提供了 copyleft 许可。
|
||||
|
||||
这意味着, 如果你使用了这种许可的代码, 然后加入了你自己的专有代码, 那么在一些情况下, 整个代码, 包括你的代码也就遵从这种限制性开源许可证。 Ballmer 说的大概就是这类的许可证。
|
||||
|
||||
但宽松许可证不同。 比如, 只要保留版权声明和许可声明且不要求开发者承担责任, MIT 许可证允许任何人任意使用开源代码, 包括修改和出售。 另一个比较流行的宽松开源许可证是 Apache 许可证 2.0,它还包含了贡献者向用户提供专利授权相关的条款。 使用 MIT 许可证的有 JQuery、.NET Core 和 Rails , 使用 Apache 许可证 2.0 的软件包括安卓, Apache 和 Swift。
|
||||
|
||||
两种许可证类型最终都是为了让软件更有用。 限制性许可证促进了参与和分享的开源理念, 使每一个人都能从软件中得到最大化的利益。 而宽松许可证通过允许人们任意使用软件来确保人们能从软件中得到最多的利益, 即使这意味着他们可以使用代码, 修改它, 据为己有,甚至以专有软件出售,而不做任何回报。
|
||||
|
||||
开源许可证管理公司黑鸭子软件的数据显示, 去年使用最多的开源许可证是限制性许可证 GPL 2.0,份额大约 25%。 宽松许可证 MIT 和 Apache 2.0 次之, 份额分别为 18% 和 16%, 再后面是 GPL 3.0, 份额大约 10%。 这样来看, 限制性许可证占 35%, 宽松许可证占 34%, 几乎是平手。
|
||||
|
||||
但这份当下的数据没有揭示发展趋势。黑鸭子软件的数据显示, 从 2009 年到 2015 年的六年间, MIT 许可证的份额上升了 15.7%, Apache 的份额上升了 12.4%。 在这段时期, GPL v2 和 v3 的份额惊人地下降了 21.4%。 换言之, 在这段时期里, 大量软件从限制性许可证转到宽松许可证。
|
||||
|
||||
这个趋势还在继续。 黑鸭子软件的[最新数据][1]显示, MIT 现在的份额为 26%, GPL v2 为 21%, Apache 2 为 16%, GPL v3 为 9%。 即 30% 的限制性许可证和 42% 的宽松许可证--与前一年的 35% 的限制许可证和 34% 的宽松许可证相比, 发生了重大的转变。 对 GitHub 上使用许可证的[调查研究][2]证实了这种转变。 它显示 MIT 以压倒性的 45% 占有率成为最流行的许可证, 与之相比, GPL v2 只有 13%, Apache 11%。
|
||||
|
||||

|
||||
|
||||
### 引领趋势
|
||||
|
||||
从限制性许可证到宽松许可证,这么大的转变背后是什么呢? 是公司害怕如果使用了限制性许可证的软件,他们就会像巴尔默说的那样,失去自己私有软件的控制权了吗? 事实上, 可能就是如此。 比如, Google 就[禁用了 Affero GPL 软件][3]。
|
||||
|
||||
[Instructional Media + Magic][4] 的主席 Jim Farmer, 是一个教育开源技术的开发者。 他认为很多公司为避免法律问题而不使用限制性许可证。 “问题就在于复杂性。 许可证的复杂性越高, 被他人因为某行为而告上法庭的可能性越高。 高复杂性更可能带来诉讼”, 他说。
|
||||
|
||||
他补充说, 这种对限制性许可证的恐惧正被律师们驱动着, 许多律师建议自己的客户使用 MIT 或 Apache 2.0 许可证的软件, 并明确反对使用 Affero 许可证的软件。
|
||||
|
||||
他说, 这会对软件开发者产生影响, 因为如果公司都避开限制性许可证软件的使用,开发者想要自己的软件被使用, 就更会把新的软件使用宽松许可证。
|
||||
|
||||
但 SalesAgility(开源 SuiteCRM 背后的公司)的 CEO Greg Soper 认为这种到宽松许可证的转变也是由一些开发者驱动的。 “看看像 Rocket.Chat 这样的应用。 开发者本可以选择 GPL 2.0 或 Affero 许可证, 但他们选择了宽松许可证,” 他说。 “这样可以给这个应用最大的机会, 因为专有软件厂商可以使用它, 不会伤害到他们的产品, 且不需要把他们的产品也使用开源许可证。 这样如果开发者想要让第三方应用使用他的应用的话, 他有理由选择宽松许可证。”
|
||||
|
||||
Soper 指出, 限制性许可证致力于帮助开源项目获得成功,方式是阻止开发者拿了别人的代码、做了修改,但不把结果回报给社区。 “Affero 许可证对我们的产品健康发展很重要, 因为如果有人利用了我们的代码开发,做得比我们好, 却又不把代码回报回来, 就会扼杀掉我们的产品,” 他说。 “ 对 Rocket.Chat 则不同, 因为如果它使用 Affero, 那么它会污染公司的知识产权, 所以公司不会使用它。 不同的许可证有不同的使用案例。”
|
||||
|
||||
曾在 Gnome、OpenOffice 工作过,现在是 LibreOffice 的开源开发者的 Michael Meeks 同意 Jim Farmer 的观点,认为许多公司确实出于对法律的担心,而选择使用宽松许可证的软件。 “copyleft 许可证有风险, 但同样也有巨大的益处。 遗憾的是人们都听从律师的, 而律师只是讲风险, 却从不告诉你有些事是安全的。”
|
||||
|
||||
巴尔默发表他的错误言论已经过去 15 年了, 但它产生的 FUD 还是有影响--即使从限制性许可证到宽松许可证的转变并不是他的目的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cio.com/article/3120235/open-source-tools/what-the-rise-of-permissive-open-source-licenses-means.html
|
||||
|
||||
作者:[Paul Rubens][a]
|
||||
译者:[willcoderwang](https://github.com/willcoderwang)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cio.com/author/Paul-Rubens/
|
||||
[1]: https://www.blackducksoftware.com/top-open-source-licenses
|
||||
[2]: https://github.com/blog/1964-open-source-license-usage-on-github-com
|
||||
[3]: http://www.theregister.co.uk/2011/03/31/google_on_open_source_licenses/
|
||||
[4]: http://immagic.com/
|
||||
|
||||
@ -0,0 +1,117 @@
|
||||
在 Linux 上检测硬盘上的坏道和坏块
|
||||
===
|
||||
|
||||
让我们从坏道和坏块的定义开始说起,它们是一块磁盘或闪存上不再能够被读写的部分,一般是由于磁盘表面特定的[物理损坏][7]或闪存晶体管失效导致的。
|
||||
|
||||
随着坏道的继续积累,它们会对你的磁盘或闪存容量产生令人不快或破坏性的影响,甚至可能会导致硬件失效。
|
||||
|
||||
同时还需要注意的是坏块的存在警示你应该开始考虑买块新磁盘了,或者简单地将坏块标记为不可用。
|
||||
|
||||
因此,在这篇文章中,我们通过几个必要的步骤,使用特定的[磁盘扫描工具][6]让你能够判断 Linux 磁盘或闪存是否存在坏道。
|
||||
|
||||
以下就是步骤:
|
||||
|
||||
### 在 Linux 上使用坏块工具检查坏道
|
||||
|
||||
坏块工具可以让用户扫描设备检查坏道或坏块。设备可以是一个磁盘或外置磁盘,由一个如 `/dev/sdc` 这样的文件代表。
|
||||
|
||||
首先,通过超级用户权限执行 [fdisk 命令][5]来显示你的所有磁盘或闪存的信息以及它们的分区信息:
|
||||
|
||||
```
|
||||
$ sudo fdisk -l
|
||||
|
||||
```
|
||||
|
||||
[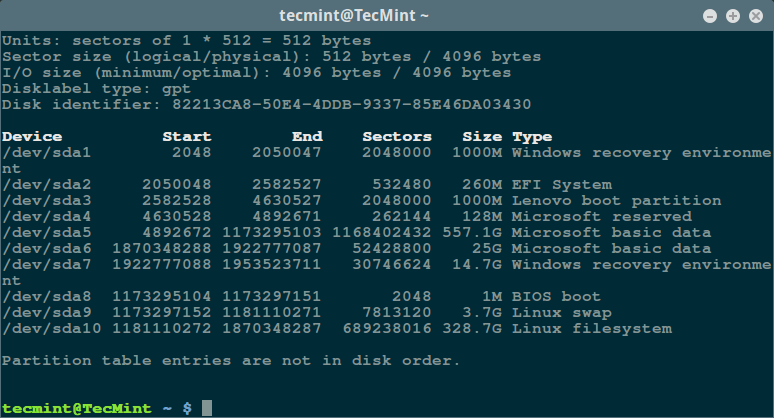][4]
|
||||
|
||||
*列出 Linux 文件系统分区*
|
||||
|
||||
然后用如下命令检查你的 Linux 硬盘上的坏道/坏块:
|
||||
|
||||
```
|
||||
$ sudo badblocks -v /dev/sda10 > badsectors.txt
|
||||
|
||||
```
|
||||
|
||||
[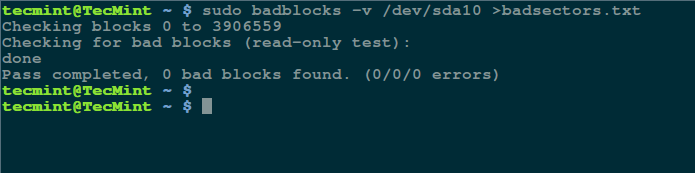][3]
|
||||
|
||||
*在 Linux 上扫描硬盘坏道*
|
||||
|
||||
上面的命令中,badblocks 扫描设备 `/dev/sda10`(记得指定你的实际设备),`-v` 选项让它显示操作的详情。另外,这里使用了输出重定向将操作结果重定向到了文件 `badsectors.txt`。
|
||||
|
||||
如果你在你的磁盘上发现任何坏道,卸载磁盘并像下面这样让系统不要将数据写入回报的扇区中。
|
||||
|
||||
你需要执行 `e2fsck`(针对 ext2/ext3/ext4 文件系统)或 `fsck` 命令,命令中还需要用到 `badsectors.txt` 文件和设备文件。
|
||||
|
||||
`-l` 选项告诉命令将在指定的文件 `badsectors.txt` 中列出的扇区号码加入坏块列表。
|
||||
|
||||
```
|
||||
------------ 针对 for ext2/ext3/ext4 文件系统 ------------
|
||||
$ sudo e2fsck -l badsectors.txt /dev/sda10
|
||||
|
||||
或
|
||||
|
||||
------------ 针对其它文件系统 ------------
|
||||
$ sudo fsck -l badsectors.txt /dev/sda10
|
||||
|
||||
```
|
||||
|
||||
### 在 Linux 上使用 Smartmontools 工具扫描坏道
|
||||
|
||||
这个方法对带有 S.M.A.R.T(Self-Monitoring, Analysis and Reporting Technology,自我监控分析报告技术)系统的现代磁盘(ATA/SATA 和 SCSI/SAS 硬盘以及固态硬盘)更加的可靠和高效。S.M.A.R.T 系统能够帮助检测,报告,以及可能记录它们的健康状况,这样你就可以找出任何可能出现的硬件失效。
|
||||
|
||||
你可以使用以下命令安装 `smartmontools`:
|
||||
|
||||
```
|
||||
------------ 在基于 Debian/Ubuntu 的系统上 ------------
|
||||
$ sudo apt-get install smartmontools
|
||||
|
||||
------------ 在基于 RHEL/CentOS 的系统上 ------------
|
||||
$ sudo yum install smartmontools
|
||||
|
||||
```
|
||||
|
||||
安装完成之后,使用 `smartctl` 控制磁盘集成的 S.M.A.R.T 系统。你可以这样查看它的手册或帮助:
|
||||
|
||||
```
|
||||
$ man smartctl
|
||||
$ smartctl -h
|
||||
|
||||
```
|
||||
|
||||
然后执行 `smartctrl` 命令并在命令中指定你的设备作为参数,以下命令包含了参数 `-H` 或 `--health` 以显示 SMART 整体健康自我评估测试结果。
|
||||
|
||||
```
|
||||
$ sudo smartctl -H /dev/sda10
|
||||
|
||||
```
|
||||
|
||||
[][2]
|
||||
|
||||
*检查 Linux 硬盘健康*
|
||||
|
||||
上面的结果指出你的硬盘很健康,近期内不大可能发生硬件失效。
|
||||
|
||||
要获取磁盘信息总览,使用 `-a` 或 `--all` 选项来显示关于磁盘所有的 SMART 信息,`-x` 或 `--xall` 来显示所有关于磁盘的 SMART 信息以及非 SMART 信息。
|
||||
|
||||
在这个教程中,我们覆盖了有关[磁盘健康诊断][1]的重要话题,你可以下面的反馈区来分享你的想法或提问,并且记得多回来看看。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/check-linux-hard-disk-bad-sectors-bad-blocks/
|
||||
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/defragment-linux-system-partitions-and-directories/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Check-Linux-Hard-Disk-Health.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/10/Scan-Hard-Disk-Bad-Sectors-in-Linux.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/10/List-Linux-Filesystem-Partitions.png
|
||||
[5]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[6]:http://www.tecmint.com/ncdu-a-ncurses-based-disk-usage-analyzer-and-tracker/
|
||||
[7]:http://www.tecmint.com/defragment-linux-system-partitions-and-directories/
|
||||
@ -0,0 +1,108 @@
|
||||
如何按最后修改时间对 ls 命令的输出进行排序
|
||||
============================================================
|
||||
|
||||
Linux 用户常常做的一个事情是,是在命令行[列出目录内容][1]。
|
||||
|
||||
我们已经知道,[ls][2] 和 [dir][3] 是两个可用在列出目录内容的 Linux 命令,前者是更受欢迎的,在大多数情况下,是用户的首选。
|
||||
|
||||
我们列出目录内容时,可以按照不同的标准进行排序,例如文件名、修改时间、添加时间、版本或者文件大小。可以通过指定一个特别的参数来使用这些文件的属性进行排序。
|
||||
|
||||
在这个简洁的 [ls 命令指导][4]中,我们将看看如何通过上次修改时间(日期和时分秒)[排序 ls 命令的输出结果][5] 。
|
||||
|
||||
让我们由执行一些基本的 [ls 命令][6]开始。
|
||||
|
||||
### Linux 基本 ls 命令
|
||||
|
||||
1、 不带任何参数运行 ls 命令将列出当前工作目录的内容。
|
||||
|
||||
```
|
||||
$ ls
|
||||
```
|
||||
|
||||

|
||||
|
||||
*列出工作目录的内容*
|
||||
|
||||
2、要列出任何目录的内容,例如 /etc 目录使用如下命令:
|
||||
|
||||
```
|
||||
$ ls /etc
|
||||
```
|
||||

|
||||
|
||||
*列出工作目录 /etc 的内容*
|
||||
|
||||
3、一个目录总是包含一些隐藏的文件(至少有两个),因此,要展示目录中的所有文件,使用`-a`或`-all`标志:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
```
|
||||
|
||||

|
||||
|
||||
*列出工作目录的隐藏文件*
|
||||
|
||||
4、你还可以打印输出的每一个文件的详细信息,例如文件权限、链接数、所有者名称和组所有者、文件大小、最后修改的时间和文件/目录名称。
|
||||
|
||||
这是由` -l `选项来设置,这意味着一个如下面的屏幕截图般的长长的列表格式。
|
||||
|
||||
```
|
||||
$ ls -l
|
||||
```
|
||||

|
||||
|
||||
*长列表目录内容*
|
||||
|
||||
### 基于日期和基于时刻排序文件
|
||||
|
||||
5、要在目录中列出文件并[对最后修改日期和时间进行排序][11],在下面的命令中使用`-t`选项:
|
||||
|
||||
```
|
||||
$ ls -lt
|
||||
```
|
||||
|
||||

|
||||
|
||||
*按日期和时间排序ls输出内容*
|
||||
|
||||
6、如果你想要一个基于日期和时间的逆向排序文件,你可以使用`-r`选项来工作,像这样:
|
||||
|
||||
```
|
||||
$ ls -ltr
|
||||
```
|
||||
|
||||

|
||||
|
||||
*按日期和时间排序的逆向输出*
|
||||
|
||||
我们将在这里结束,但是,[ls 命令][14]还有更多的使用信息和选项,因此,应该特别注意它或看看其它指南,比如《[每一个用户应该知道 ls 的命令技巧][15]》或《[使用排序命令][16]》。
|
||||
|
||||
最后但并非最不重要的,你可以通过以下反馈部分联系我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sort-ls-output-by-last-modified-date-and-time
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[2]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/linux-dir-command-usage-with-examples/
|
||||
[4]:http://www.tecmint.com/tag/linux-ls-command/
|
||||
[5]:http://www.tecmint.com/sort-command-linux/
|
||||
[6]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/10/List-Content-of-Working-Directory.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/10/List-Contents-of-Directory.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/10/List-Hidden-Files-in-Directory.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/10/ls-Long-List-Format.png
|
||||
[11]:http://www.tecmint.com/find-and-sort-files-modification-date-and-time-in-linux/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/10/Sort-ls-Output-by-Date-and-Time.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2016/10/Sort-ls-Output-Reverse-by-Date-and-Time.png
|
||||
[14]:http://www.tecmint.com/tag/linux-ls-command/
|
||||
[15]:http://www.tecmint.com/linux-ls-command-tricks/
|
||||
[16]:http://www.tecmint.com/linux-sort-command-examples/
|
||||
@ -0,0 +1,98 @@
|
||||
完整指南:在 Linux 上使用 Calibre 创建电子书
|
||||
====
|
||||
|
||||
[][8]
|
||||
|
||||
摘要:这份初学者指南是告诉你如何在 Linux 上用 Calibre 工具快速创建一本电子书。
|
||||
|
||||
自从 Amazon(亚马逊)在多年前开始销售电子书,电子书已经有了质的飞跃发展并且变得越来越流行。好消息是电子书非常容易使用自由开源的工具来被创建。
|
||||
|
||||
在这个教程中,我会告诉你如何在 Linux 上创建一本电子书。
|
||||
|
||||
### 在 Linux 上创建一本电子书
|
||||
|
||||
要创建一本电子书,你可能需要两个软件:一个文本处理器(当然,我使用的是 [LibreOffice][7])和 Calibre 。[Calibre][6] 是一个非常优秀的电子书阅读器,也是一个电子书库的程序。你可以使用它来[在 Linux 上打开 ePub 文件][5]或者管理你收集的电子书。(LCTT 译注:LibreOffice 是 Linux 上用来处理文本的软件,类似于 Windows 的 Office 软件)
|
||||
|
||||
除了这些软件之外,你还需要准备一个电子书封面(1410×2250)和你的原稿。
|
||||
|
||||
### 第一步
|
||||
|
||||
首先,你需要用你的文本处理器程序打开你的原稿。 Calibre 可以自动的为你创建一个书籍目录。要使用到这个功能,你需要在你的原稿中设置每一章的标题样式为 Heading 1,在 LibreOffice 中要做到这个只需要高亮标题并且在段落样式下拉框中选择“Heading 1”即可。
|
||||
|
||||

|
||||
|
||||
如果你想要有子章节,并且希望他们也被加入到目录中,只需要设置这些子章节的标题为 Heading 2。
|
||||
|
||||
做完这些之后,保存你的文档为 HTML 格式文件。
|
||||
|
||||
### 第二步
|
||||
|
||||
在 Calibre 程序里面,点击“添加书籍(Add books)”按钮。在对话框出现后,你可以打开你刚刚存储的 HTML 格式文件,将它加入到 Calibre 中。
|
||||
|
||||

|
||||
|
||||
### 第三步
|
||||
|
||||
一旦这个 HTML 文件加入到 Calibre 库中,选择这个新文件并且点击“编辑元数据(Edit Metadata)”按钮。在这里,你可以添加下面的这些信息:标题(Title)、 作者(Author)、封面图片(cover image)、 描述(description)和其它的一些信息。当你填完之后,点击“Ok”。
|
||||
|
||||

|
||||
|
||||
### 第四步
|
||||
|
||||
现在点击“转换书籍(Covert books)”按钮。
|
||||
|
||||
在新的窗口中,这里会有一些可选项,但是你不会需要使用它们。
|
||||
|
||||

|
||||
|
||||
在新窗口的右上部选择框中,选择 epub 文件格式。Calibre 也有创建 mobi 文件格式的其它选项,但是我发现创建那些文件之后经常出现我意料之外的事情。
|
||||
|
||||

|
||||
|
||||
### 第五步
|
||||
|
||||
在左边新的对话框中,点击“外观(Look & Feel)”。然后勾选中“移除段落间空白(Remove spacing between paragraphs)”
|
||||
|
||||

|
||||
|
||||
接下来,我们会创建一个内容目录。如果不打算在你的书中使用目录,你可以跳过这个步骤。选中“内容目录(Table of Contents)”标签。接下来,点击“一级目录(Level 1 TOC (XPath expression))”右边的魔术棒图标。
|
||||
|
||||

|
||||
|
||||
在这个新的窗口中,在“匹配 HTML 标签(Match HTML tags with tag name)”下的下拉菜单中选择“h1”。点击“OK” 来关闭这个窗口。如果你有子章节,在“二级目录(Level 2 TOC (XPath expression))”下选择“h2”。
|
||||
|
||||

|
||||
|
||||
在我们开始生成电子书前,选择输出 EPUB 文件。在这个新的页面,选择“插入目录(Insert inline Table of Contents)”选项。
|
||||
|
||||

|
||||
|
||||
现在你需要做的是点击“OK”来开始生成电子书。除非你的是一个大文件,否则生成电子书的过程一般都完成的很快。
|
||||
|
||||
到此为止,你就已经创建一本电子书了。
|
||||
|
||||
对一些特别的用户比如他们知道如何写 CSS 样式文件(LCTT 译注:CSS 文件可以用来美化 HTML 页面),Calibre 给了这类用户一个选项来为文章增加 CSS 样式。只需要回到“外观(Look & Feel)”部分,选择“风格(styling)”标签选项。但如果你想创建一个 mobi 格式的文件,因为一些原因,它是不能接受 CSS 样式文件的。
|
||||
|
||||

|
||||
|
||||
好了,是不是感到非常容易?我希望这个教程可以帮助你在 Linux 上创建电子书。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/create-ebook-calibre-linux/
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[chenzhijun](https://github.com/chenzhijun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:http://pinterest.com/pin/create/button/?url=https://itsfoss.com/create-ebook-calibre-linux/&description=How+To+Create+An+Ebook+With+Calibre+In+Linux+%5BComplete+Guide%5D&media=https://itsfoss.com/wp-content/uploads/2016/10/Create-an-eBook-in-Linux.jpg
|
||||
[2]:https://www.linkedin.com/cws/share?url=https://itsfoss.com/create-ebook-calibre-linux/
|
||||
[3]:https://twitter.com/share?original_referer=https%3A%2F%2Fitsfoss.com%2F&source=tweetbutton&text=How+To+Create+An+Ebook+With+Calibre+In+Linux+%5BComplete+Guide%5D&url=https%3A%2F%2Fitsfoss.com%2Fcreate-ebook-calibre-linux%2F&via=%40itsfoss
|
||||
[4]:https://itsfoss.com/fix-updater-issue-pear-os-8/
|
||||
[5]:https://itsfoss.com/open-epub-books-ubuntu-linux/
|
||||
[6]:http://calibre-ebook.com/
|
||||
[7]:https://www.libreoffice.org/
|
||||
[8]:https://itsfoss.com/wp-content/uploads/2016/10/Create-an-eBook-in-Linux.jpg
|
||||
@ -1,12 +1,13 @@
|
||||
# 如何在 Linux 中将文件编码转换为 UTF-8
|
||||
如何在 Linux 中将文件编码转换为 UTF-8
|
||||
===============
|
||||
|
||||
在这篇教程中,我们将解释字符编码的含义,然后给出一些使用命令行工具将使用某种字符编码的文件转化为另一种编码的例子。最后,我们将一起看一看如何在 Linux 下将使用各种字符编码的文件转化为 UTF-8 编码。
|
||||
|
||||
你可能已经知道,计算机是不会理解和存储字符、数字或者任何人类能够理解的东西的,除了二进制数据。一个二进制位只有两种可能的值,也就是 `0` 或 `1`,`真`或`假`,`对`或`错`。其它的任何事物,比如字符、数据和图片,必须要以二进制的形式来表现,以供计算机处理。
|
||||
你可能已经知道,计算机除了二进制数据,是不会理解和存储字符、数字或者任何人类能够理解的东西的。一个二进制位只有两种可能的值,也就是 `0` 或 `1`,`真`或`假`,`是`或`否`。其它的任何事物,比如字符、数据和图片,必须要以二进制的形式来表现,以供计算机处理。
|
||||
|
||||
简单来说,字符编码是一种可以指示电脑来将原始的 0 和 1 解释成实际字符的方式,在这些字符编码中,字符都可以用数字串来表示。
|
||||
简单来说,字符编码是一种可以指示电脑来将原始的 0 和 1 解释成实际字符的方式,在这些字符编码中,字符都以一串数字来表示。
|
||||
|
||||
字符编码方案有很多种,比如 ASCII, ANCI, Unicode 等等。下面是 ASCII 编码的一个例子。
|
||||
字符编码方案有很多种,比如 ASCII、ANCI、Unicode 等等。下面是 ASCII 编码的一个例子。
|
||||
|
||||
```
|
||||
字符 二进制
|
||||
@ -22,11 +23,9 @@ B 01000010
|
||||
$ file -i Car.java
|
||||
$ file -i CarDriver.java
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||

|
||||
|
||||
在 Linux 中查看文件的编码
|
||||
*在 Linux 中查看文件的编码*
|
||||
|
||||
iconv 工具的使用方法如下:
|
||||
|
||||
@ -34,25 +33,21 @@ iconv 工具的使用方法如下:
|
||||
$ iconv option
|
||||
$ iconv options -f from-encoding -t to-encoding inputfile(s) -o outputfile
|
||||
```
|
||||
|
||||
在这里,`-f` 或 `--from-code` 标明了输入编码,而 `-t` 或 `--to-encoding` 指定了输出编码。
|
||||
在这里,`-f` 或 `--from-code` 表明了输入编码,而 `-t` 或 `--to-encoding` 指定了输出编码。
|
||||
|
||||
为了列出所有已有编码的字符集,你可以使用以下命令:
|
||||
|
||||
```
|
||||
$ iconv -l
|
||||
```
|
||||
[
|
||||
|
||||
][2]
|
||||

|
||||
|
||||
列出所有已有编码字符集
|
||||
*列出所有已有编码字符集*
|
||||
|
||||
### 将文件从 ISO-8859-1 编码转换为 UTF-8 编码
|
||||
|
||||
下面,我们将学习如何将一种编码方案转换为另一种编码方案。下面的命令将会将 ISO-8859-1 编码转换为 UTF-8 编码。
|
||||
|
||||
Consider a file named `input.file` which contains the characters:
|
||||
考虑如下文件 `input.file`,其中包含这几个字符:
|
||||
|
||||
```
|
||||
@ -70,17 +65,15 @@ $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file
|
||||
$ cat out.file
|
||||
$ file -i out.file
|
||||
```
|
||||
[
|
||||
|
||||
][1]
|
||||

|
||||
|
||||
在 Linux 中将 ISO-8859-1 转化为 UTF-8
|
||||
*在 Linux 中将 ISO-8859-1 转化为 UTF-8*
|
||||
|
||||
注意:如果输出编码后面添加了 `//IGNORE` 字符串,那些不能被转换的字符将不会被转换,并且在转换后,程序会显示一条错误信息。
|
||||
|
||||
好,如果字符串 `//TRANSLIT` 被添加到了上面例子中的输出编码之后 (UTF-8//TRANSLIT),待转换的字符会尽量采用形译原则。也就是说,如果某个字符在输出编码方案中不能被表示的话,它将会被替换为一个形状比较相似的字符。
|
||||
好,如果字符串 `//TRANSLIT` 被添加到了上面例子中的输出编码之后 (`UTF-8//TRANSLIT`),待转换的字符会尽量采用形译原则。也就是说,如果某个字符在输出编码方案中不能被表示的话,它将会被替换为一个形状比较相似的字符。
|
||||
|
||||
而且,如果一个字符不在输出编码中,而且不能被形译,它将会在输出文件中被一个问号标记 `(?)` 代替。
|
||||
而且,如果一个字符不在输出编码中,而且不能被形译,它将会在输出文件中被一个问号标记 `?` 代替。
|
||||
|
||||
### 将多个文件转换为 UTF-8 编码
|
||||
|
||||
@ -88,13 +81,13 @@ $ file -i out.file
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# 将 values_here 替换为输入编码
|
||||
### 将 values_here 替换为输入编码
|
||||
FROM_ENCODING="value_here"
|
||||
# 输出编码 (UTF-8)
|
||||
### 输出编码 (UTF-8)
|
||||
TO_ENCODING="UTF-8"
|
||||
# 转换命令
|
||||
### 转换命令
|
||||
CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING"
|
||||
# 使用循环转换多个文件
|
||||
### 使用循环转换多个文件
|
||||
for file in *.txt; do
|
||||
$CONVERT "$file" -o "${file%.txt}.utf8.converted"
|
||||
done
|
||||
@ -122,13 +115,11 @@ $ man iconv
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/convert-files-to-utf-8-encoding-in-linux/#
|
||||
via: http://www.tecmint.com/convert-files-to-utf-8-encoding-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,116 @@
|
||||
如何在 Linux 中压缩及解压缩 .bz2 文件
|
||||
============================================================
|
||||
|
||||
对文件进行压缩,可以通过使用较少的字节对文件中的数据进行编码来显著地减小文件的大小,并且在跨网络的[文件的备份和传送][1]时很有用。 另一方面,解压文件意味着将文件中的数据恢复到初始状态。
|
||||
|
||||
Linux 中有几个[文件压缩和解压缩工具][2],比如gzip、7-zip、Lrzip、[PeaZip][3] 等等。
|
||||
|
||||
本篇教程中,我们将介绍如何在 Linux 中使用 bzip2 工具压缩及解压缩`.bz2`文件。
|
||||
|
||||
bzip2 是一个非常有名的压缩工具,并且在大多数主流 Linux 发行版上都有,你可以在你的发行版上用合适的命令来安装它。
|
||||
|
||||
```
|
||||
$ sudo apt install bzip2 [On Debian/Ubuntu]
|
||||
$ sudo yum install bzip2 [On CentOS/RHEL]
|
||||
$ sudo dnf install bzip2 [On Fedora 22+]
|
||||
```
|
||||
|
||||
使用 bzip2 的常规语法是:
|
||||
|
||||
```
|
||||
$ bzip2 option(s) filenames
|
||||
```
|
||||
|
||||
### 如何在 Linux 中使用“bzip2”压缩文件
|
||||
|
||||
你可以如下压缩一个文件,使用`-z`标志启用压缩:
|
||||
|
||||
```
|
||||
$ bzip2 filename
|
||||
或者
|
||||
$ bzip2 -z filename
|
||||
```
|
||||
|
||||
要压缩一个`.tar`文件,使用的命令为:
|
||||
|
||||
```
|
||||
$ bzip2 -z backup.tar
|
||||
```
|
||||
|
||||
重要:bzip2 默认会在压缩及解压缩文件时删除输入文件(原文件),要保留输入文件,使用`-k`或者`--keep`选项。
|
||||
|
||||
此外,`-f`或者`--force`标志会强制让 bzip2 覆盖已有的输出文件。
|
||||
|
||||
```
|
||||
------ 要保留输入文件 ------
|
||||
$ bzip2 -zk filename
|
||||
$ bzip2 -zk backup.tar
|
||||
```
|
||||
|
||||
你也可以设置块的大小,从 100k 到 900k,分别使用`-1`或者`--fast`到`-9`或者`--best`:
|
||||
|
||||
```
|
||||
$ bzip2 -k1 Etcher-linux-x64.AppImage
|
||||
$ ls -lh Etcher-linux-x64.AppImage.bz2
|
||||
$ bzip2 -k9 Etcher-linux-x64.AppImage
|
||||
$ bzip2 -kf9 Etcher-linux-x64.AppImage
|
||||
$ ls -lh Etcher-linux-x64.AppImage.bz2
|
||||
```
|
||||
|
||||
下面的截屏展示了如何使用选项来保留输入文件,强制 bzip2 覆盖输出文件,并且在压缩中设置块的大小。
|
||||
|
||||
|
||||
|
||||
*在 Linux 中使用 bzip2 压缩文件*
|
||||
|
||||
### 如何在 Linux 中使用“bzip2”解压缩文件
|
||||
|
||||
要解压缩`.bz2`文件,确保使用`-d`或者`--decompress`选项:
|
||||
|
||||
```
|
||||
$ bzip2 -d filename.bz2
|
||||
```
|
||||
|
||||
注意:这个文件必须是`.bz2`的扩展名,上面的命令才能使用。
|
||||
|
||||
```
|
||||
$ bzip2 -vd Etcher-linux-x64.AppImage.bz2
|
||||
$ bzip2 -vfd Etcher-linux-x64.AppImage.bz2
|
||||
$ ls -l Etcher-linux-x64.AppImage
|
||||
```
|
||||
|
||||
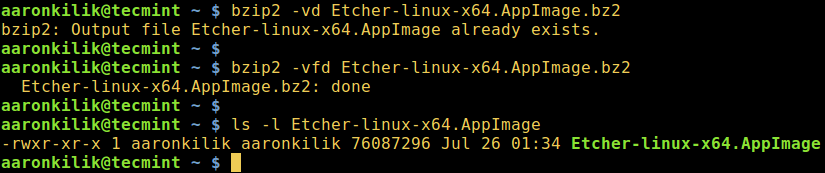
|
||||
|
||||
*在 Linux 中解压 bzip2 文件*
|
||||
|
||||
要浏览 bzip2 的帮助及 man 页面,输入下面的命令:
|
||||
|
||||
```
|
||||
$ bzip2 -h
|
||||
$ man bzip2
|
||||
```
|
||||
|
||||
最后,通过上面简单的阐述,我相信你现在已经可以在 Linux 中压缩及解压缩`bz2`文件了。然而,有任何的问题和反馈,可以在评论区中留言。
|
||||
|
||||
重要的是,你可能想在 Linux 中查看一些重要的 [tar 命令示例][6],以便学习使用 tar 命令来[创建压缩归档文件][7]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-compress-decompress-bz2-files-using-bzip2
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[2]:http://www.tecmint.com/command-line-archive-tools-for-linux/
|
||||
[3]:http://www.tecmint.com/peazip-linux-file-manager-and-file-archive-tool/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/11/Compress-Files-Using-bzip2-in-Linux.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/11/Decompression-bzip2-File-in-Linux.png
|
||||
[6]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
[7]:http://www.tecmint.com/compress-files-and-finding-files-in-linux/
|
||||
|
||||
|
||||
@ -0,0 +1,110 @@
|
||||
在 Linux 上使用 Glyphr 设计自己的字体
|
||||
=============
|
||||
|
||||
LibreOffice 提供了丰富的字体,并且用户可以自由选择和下载增加自己的字体。然而,就算是你想创造自己的字体,也可以非常容易地使用 Glyphr 来做到。Glyphr 是一个新开源的矢量字体设计器,通过直观而易用的图形界面和丰富的功能集可以完成字体设计的方方面面。虽然这个应用还在早期开发阶段,但是已经十分棒了。下面将会有一个简短的快速入门教你如何使用 Glyphr 创建字体并加入到 LibreOffice。
|
||||
|
||||
首先,从[官方 Git 库][14]下载 Glyphr。它提供 32 位和 64 位版本的二进制格式。完成下载后,进入下载文件夹, 解压文件,进入解压后的文件夹,右键点击 Glyphr Studio,选择“Run”。
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
启动应用后会给你三个选项。一个是从头创建一个新的字体集;第二个是读取已经存在的项目,可以是 Glyphr Studio 项目文件,也可以是其他OpenType 字体(otf)或 TrueType 字体(ttf),甚至是 SVG 字体。第三个是读取已有的两个示例之一,然后可以在示例上修改创建。我将会选择第一个选项,并教你一些简单的设计概念。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
完成进入编辑界面后, 你可以从屏幕左边的面板中选择字母,然后在右边的绘制区域设计。我选择 A 字母的图标开始编辑它。
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
要在绘图板上设计一些东西,我们可以从该板的左上角选择矩形、椭圆形或者路径等同处的“形状”工具,也可以使用该工具的第二行的第一项的路径编辑工具。使用任意工具,开始在板上放路径点(path point)来创建形状。添加的点数越多,接下来步骤的形状选项就越多。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
将点移动到不同位置可以获得不同的路径,可以使用路径编辑工具右边的路径编辑,点击形状会出现可编辑点。然后可以把这些点拖到你喜欢的任意位置。
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
最后,形状编辑工具可以让你选择形状并将其拖动到其它位置、更改其尺寸以及旋转。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
其它有用的设计动作集还有左侧面板提供的复制-粘贴、翻转-旋转操作。来看个例子,假设我现在正在创作 B 字母, 我要把已经创建好的上部分镜像到下半部分,保持设计的高度一致性。
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
现在,为了达到这个目的,选择形状编辑工具,选中欲镜像的部分,点击复制操作,然后在其上点击图形,拖放粘帖的形状到你需要的位置,根据你的需要进行水平翻转或者垂直翻转。
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
这款应用在太多地方可以讲述。如果有兴趣深入,可以深入了解数字化编辑、弯曲和引导等等,
|
||||
|
||||
然而,字体并不是仅仅是单个字体的设计,还需要学习字体设计的其他方面。通过应用左上角菜单栏上的“导航”还可以设置特殊字符对之间的字间距、增加连字符、部件、和设置常规字体设置等。
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
最棒的是你可以使用“测试驱动”来使用你的新字体,帮助你判断字体设计如何、间距对不对、尽量来优化你的字体。
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
完成设计和优化后,我们还可以导出 ttf 和 svg 格式的字体。
|
||||
|
||||
[
|
||||
|
||||
][2]
|
||||
|
||||
要将新的字体加入到系统中,打开字体浏览器并点击“安装”按钮。如果它不工作,可以在主目录下创建一个新的文件夹叫做`.fonts`,并将字体复制进去。也可以使用 root 用户打开文件管理器,进入 `/usr/share/fonts/opentype`, 创建一个新的文件夹并粘贴字体文件到里面。然后打开终端,输入命令重建字体缓存:`sudo fc-cache -f -v`。
|
||||
|
||||
在 LibreOffice 中已经可以看见新的字体咯,同样也可以使用你系统中的其它文本应用程序如 Gedit 来测试新字体。
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-design-and-add-your-own-font-on-linux-with-glyphr/
|
||||
|
||||
作者:[Bill Toulas][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_13.png
|
||||
[2]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_12.png
|
||||
[3]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_11.png
|
||||
[4]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_10.png
|
||||
[5]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_9.png
|
||||
[6]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_8.png
|
||||
[7]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_7.png
|
||||
[8]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_6.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_5.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_4.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_3.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_2.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_1.png
|
||||
[14]:https://github.com/glyphr-studio/Glyphr-Studio-Desktop
|
||||
85
published/20161104 Open Source Vs Closed Source.md
Normal file
85
published/20161104 Open Source Vs Closed Source.md
Normal file
@ -0,0 +1,85 @@
|
||||
开源 vs. 闭源
|
||||
===========================
|
||||
|
||||
[][2]
|
||||
|
||||
**开源操作系统**和**闭源操作系统**之间有诸多不同。这里我们仅寥书几笔。
|
||||
|
||||
### 开源是什么?自由!
|
||||
|
||||
[][1]
|
||||
|
||||
这是用户需要知道的最重要的一点。无论我是否打算修改代码,其他人出于善意的修改都不应受到限制。且如果用户喜欢,他们可以分享这个软件。使用**开源**软件,这些都是可能的。
|
||||
|
||||
**闭源**操作系统的许可条款很是吓人。但真的所有人都会看吗?不,许多用户只是点了一下‘Accept’ 而已。
|
||||
|
||||
### 价格
|
||||
|
||||
几乎所有的开源操纵系统是免费的。仅有自愿性质的捐款。且只需有个一个 **CD/DVD 或 USB** 就能将系统安装到所有你想要安装的电脑上。
|
||||
|
||||
闭源操作系统相较于开源 OS 就贵了许多,如果你用它来构建 PC,每台 PC 得你花不少于 $100。
|
||||
|
||||
我们可以用花在闭源软件上的钱去买更好的东西。
|
||||
|
||||
### 选择
|
||||
|
||||
开源操作系统的发行版有很多。如果你不中意眼下的这个,你可以尝试其他的发行版,总能找到适合你的那一个。
|
||||
|
||||
诸如 Ubuntu studio、Bio Linux、Edubuntu、Kali Linux、Qubes、SteamOS 这些发行版,就是针对特定用户群产生的发行版。
|
||||
|
||||
闭源软件有“选择”这种说法吗?我觉得是没有的。
|
||||
|
||||
### 隐私
|
||||
|
||||
**开源操作系统**无需收集用户数据信息。不会根据用户的个性显示广告,也不会把你的信息卖给第三方机构。如果开发者需要资金,他们会要求捐助,或是在他们的网页上打广告。广告的内容也会与 Linux 相关,对我们有益无害。
|
||||
|
||||
你一定知道那个主流的闭源操作系统(名字就不写了,大家都知道的),据说因为收集用户信息这件事,导致多数用户关闭了他们的免费更新服务。多数该系统的用户为了避免升级,将更新功能关闭,他们宁可承担安全风险也不要免费更新。
|
||||
|
||||
### 安全
|
||||
|
||||
开源软件大多安全。究其缘由不仅有市场占有率低这个原因,其本身的构成方式就比较安全。例如, Qubes Os 是最安全的操作系统之一,它将运行的软件相互隔离。
|
||||
|
||||
闭源操作系统向易用性妥协,使其变得愈发脆弱。
|
||||
|
||||
### 硬件支持
|
||||
|
||||
我们中有大多数人,家里还放着那些不想丢的旧 PC,这时一个轻量级的发行版可能会让这些老家伙们重获新生。你可以试试在文章 [5 个适合旧电脑的轻量级 Linux][3] 中罗列的那些轻量级操作系统发行版。基于 Linux 的系统几乎包含所有设备的驱动,所以基本不需要你亲自寻找、安装驱动。
|
||||
|
||||
闭源操作系统时不时中止对旧硬件的支持,迫使用户去购买新的硬件。我们还不得不亲自寻找、安装驱动。
|
||||
|
||||
### 社区支持
|
||||
|
||||
几乎所有的**开源操作系统**都有用户论坛,你可以在那里提问题,并从别的用户那里得到答案。大家在那里分享技巧和窍门,互帮互助。有经验的 Linux 用户往往乐于帮助新手,为此他们常常不遗余力。
|
||||
|
||||
**闭源操作系统**社区和开源操作系统社区简直无法相提并论。提出的问题常常得不到回答。
|
||||
|
||||
### 商业化
|
||||
|
||||
在操作系统上挣钱是非常困难的。(开源)开发者一般通过用户的捐款和在网站上打广告来挣钱。捐款主要用于支付主机的开销和开发者的薪水。
|
||||
|
||||
许多闭源操作系统,不仅仅通过出售软件的使用许可这种方式来赚钱,还会推送广告大赚一票。
|
||||
|
||||
### 垃圾应用
|
||||
|
||||
我承认有些开源操作系统会提供一些我们可能一辈子都不会用到的应用,有些人认为他们是垃圾应用。但是也有发行版只提供最小安装,其中就不包含这些不想要的软件。所以,这不是真正的问题。
|
||||
|
||||
而所有的闭源操作系统中都包含厂商安装的垃圾应用,强制你安装,就像在安装一个干净系统一样。
|
||||
|
||||
开源软件更像是一门哲学。一种分享和学习的方式。甚至还有益于经济。
|
||||
|
||||
我们已经将我们知晓的罗列了出来。如果你觉得我们还漏了些什么,可以评论告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/open-source-vs-closed-source
|
||||
|
||||
作者:[Mohd Sohail][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/mohdsohail
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/what-is-open-source_orig.jpg?250
|
||||
[2]:http://www.linuxandubuntu.com/home/open-source-vs-closed-source
|
||||
[3]:http://www.linuxandubuntu.com/home/5-lightweight-linux-for-old-computers
|
||||
192
published/20161107 Kali Linux – Fresh Installation Guide.md
Normal file
192
published/20161107 Kali Linux – Fresh Installation Guide.md
Normal file
@ -0,0 +1,192 @@
|
||||
全新 Kali Linux 系统安装指南
|
||||
===============
|
||||
|
||||
Kali Linux 系统可以说是在[安全测试方面最好][18]的开箱即用的 Linux 发行版。Kali 下的很多工具软件都可以安装在大多数的 Linux 发行版中,Offensive Security 团队在 Kali 系统的开发过程中投入大量的时间精力来完善这个用于渗透测试和安全审计的 Linux 发行版。
|
||||
|
||||
Kali Linux 是基于 Debian 的面向安全的发行版本。该系统由于预安装了上百个知名的安全工具软件而出名。
|
||||
|
||||
Kali 甚至在信息安全领域还有一个含金量较高的认证叫做“Kali 渗透测试(Pentesting with Kali)”认证。该认证的申请者必须在艰难的 24 小时内成功入侵多台计算机,然后另外 24 小时内完成渗透测试报告并发送给 Offensive Security 的安全人员进行评审。成功通过考试的人将会获得 OSCP 认证证书。
|
||||
|
||||
本安装指南及以后的文章主要是为了帮助个人熟悉 Kali Linux 系统和其中一些工具软件的使用。
|
||||
|
||||
**请谨慎使用 Kali 下的工具,因为其中一些工具如果使用不当将会导致计算机系统损坏。请在合法的途径下使用所有 Kali 系列文章中所包含的信息。**
|
||||
|
||||
### 系统要求
|
||||
|
||||
Kali 系统对硬件有一些最基本的要求及建议。根据用户使用目的,你可以使有更高的配置。这篇文章中假设读者想要把 kali 安装为电脑上唯一的操作系统。
|
||||
|
||||
1. 至少 10GB 的磁盘空间;强烈建议分配更多的存储空间。
|
||||
2. 至少 512MB 的内存;希望有更多的内存,尤其是在图形界面下。
|
||||
3. 支持 USB 或 CD/DVD 启动方式。
|
||||
4. Kali Linux 系统 ISO 镜像下载地址 [https://www.kali.org/downloads/][1]。
|
||||
|
||||
### 使用 dd 命令创建 USB 启动工具
|
||||
|
||||
该文章假设可使用 USB 设备来引导安装系统。注意尽可能的使用 4GB 或者 8GB 的 USB 设备,并且其上的所有数据将会被删除。
|
||||
|
||||
本文作者在使用更大容量的 USB 设备在安装的过程中遇到了问题,但是别的人应该还是可以的。不管怎么说,下面的安装步骤将会清除 USB 设备内的数据。
|
||||
|
||||
在开始之前请务必备份所有数据。用于安装 Kali Linux 系统的 USB 启动设备将在另外一台机器上创建完成。
|
||||
|
||||
第一步是获取 Kali Linux 系统 ISO 镜像文件。本指南将使用最新版的包含 Enlightenment 桌面环境的 Kali Linux 系统进行安装。
|
||||
|
||||
在终端下输入如下命令来获取这个版本的 ISO 镜像文件。
|
||||
|
||||
```
|
||||
$ cd ~/Downloads
|
||||
$ wget -c http://cdimage.kali.org/kali-2016.2/kali-linux-e17-2016.2-amd64.iso
|
||||
```
|
||||
|
||||
上面两个命令将会把 Kali Linux 的 ISO 镜像文件下载到当前用户的 Downloads 目录。
|
||||
|
||||
下一步是把 ISO 镜像写入到 USB 设备中来启动安装程序。我们可以使用 Linux 系统中的 `dd` 命令来完成该操作。首先,该 USB 设备要在 `lsblk` 命令下可找到。
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
```
|
||||
|
||||
|
||||
|
||||
*在 Linux 系统中确认 USB 设备名*
|
||||
|
||||
确定 USB 设备的名字为 `/dev/sdc`,可以使用 dd 工具将 Kali 系统镜像写入到 USB 设备中。
|
||||
|
||||
```
|
||||
$ sudo dd if=~/Downloads/kali-linux-e17-2016.2-amd64.iso of=/dev/sdc
|
||||
```
|
||||
|
||||
**注意:**以上命令需要 root 权限,因此使用 `sudo` 命令或使用 root 账号登录来执行该命令。这个命令会删除 USB 设备中的所有数据。确保已备份所需的数据。
|
||||
|
||||
一旦 ISO 镜像文件完全复制到 USB 设备,接下来可进行 Kali Linux 系统的安装。
|
||||
|
||||
### 安装 Kali Linux 系统
|
||||
|
||||
1、 首先,把 USB 设备插入到要安装 Kali 操作系统的电脑上,然后从 USB 设备引导系统启动。只要成功地从 USB 设备启动系统,你将会看到下面的图形界面,选择“Install”或者“Graphical Install”选项。
|
||||
|
||||
本指南将使用“Graphical Install”方式进行安装。
|
||||
|
||||

|
||||
|
||||
*Kali Linux 启动菜单*
|
||||
|
||||
2、 下面几个界面将会询问用户选择区域设置信息,比如语言、国家,以及键盘布局。
|
||||
|
||||
选择完成之后,系统将会提示用户输入主机名和域名信息。输入合适的环境信息后,点击继续安装。
|
||||
|
||||

|
||||
|
||||
*设置 Kali Linux 系统的主机名*
|
||||
|
||||

|
||||
|
||||
*设置 Kali Linux 系统的域名*
|
||||
|
||||
3、 主机名和域名设置完成后,需要设置 root 用户的密码。请勿忘记该密码。
|
||||
|
||||

|
||||
|
||||
*设置 Kali Linux 系统用户密码*
|
||||
|
||||
4、 密码设置完成之后,安装步骤会提示用户选择时区然后停留在硬盘分区界面。
|
||||
|
||||
如果 Kali Linux 是这个电脑上的唯一操作系统,最简单的选项就是使用“Guided – Use Entire Disk”,然后选择你需要安装 Kali 的存储设备。
|
||||
|
||||

|
||||
|
||||
*选择 Kali Linux 系统安装类型*
|
||||
|
||||

|
||||
|
||||
*选择 Kali Linux 安装磁盘*
|
||||
|
||||
5、 下一步将提示用户在存储设备上进行分区。大多数情况下,我们可以把整个系统安装在一个分区内。
|
||||
|
||||

|
||||
|
||||
*在分区上安装 Kali Linux 系统*
|
||||
|
||||
6、 最后一步是提示用户确认将所有的更改写入到主机硬盘。注意,点确认后将会**清空整个磁盘上的所有数据**。
|
||||
|
||||

|
||||
|
||||
*确认磁盘分区更改*
|
||||
|
||||
7、 一旦确认分区更改,安装包将会进行复制文件的安装过程。安装完成后,你需要设置一个网络镜像源来获取软件包和系统更新。如果你希望使用 Kali 的软件库,确保开启此功能。
|
||||
|
||||

|
||||
|
||||
*配置 Kali Linux 包管理器*
|
||||
|
||||
8、 选择网络镜像源后,系统将会询问你安装 Grub 引导程序。再次说明,本文假设你的电脑上仅安装唯一的 Kali Linux 操作系统。
|
||||
|
||||
在该屏幕上选择“Yes”,用户需要选择要写入引导程序信息的硬盘引导设备。
|
||||
|
||||

|
||||
|
||||
*安装 Grub 引导程序*
|
||||
|
||||
|
||||
|
||||
*选择安装 Grub 引导程序的分区*
|
||||
|
||||
9、 当 Grub 安装完成后,系统将会提醒用户重启机器以进入新安装的 Kali Linux 系统。
|
||||
|
||||

|
||||
|
||||
*Kali Linux 系统安装完成*
|
||||
|
||||
10、 因为本指南使用 Enlightenment 作为 Kali Linux 系统的桌面环境,因此默认情况下是启动进入到 shell 环境。
|
||||
|
||||
使用 root 账号及之前安装过程中设置的密码登录系统,以便运行 Enlightenment 桌面环境。
|
||||
|
||||
登录成功后输入命令`startx`进入 Enlightenment 桌面环境。
|
||||
|
||||
```
|
||||
# startx
|
||||
```
|
||||
|
||||
|
||||
|
||||
*Kali Linux 下进入 Enlightenment 桌面环境*
|
||||
|
||||
初次进入 Enlightenment 桌面环境时,它将会询问用户进行一些首选项配置,然后再运行桌面环境。
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
*Kali Linux Enlightenment 桌面*
|
||||
|
||||
此时,你已经成功地安装了 Kali Linux 系统,并可以使用了。后续的文章我们将探讨 Kali 系统中一些有用的工具以及如何使用这些工具来探测主机及网络方面的安全状况。
|
||||
|
||||
请随意发表任何评论或提出相关的问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/kali-linux-installation-guide/
|
||||
|
||||
作者:[Rob Turner][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/robturner/
|
||||
[1]:https://www.kali.org/downloads/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Kali-Linux-Enlightenment-Desktop.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/10/Start-Enlightenment-Desktop-in-Kali-Linux.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/10/Kali-Linux-Installation-Completed.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/10/Select-Partition-to-Install-GRUB-Boot-Loader.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/10/Install-GRUB-Boot-Loader.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/10/Configure-Kali-Linux-Package-Manager.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/10/Confirm-Disk-Partition-Write-Changes.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/10/Install-Kali-Linux-Files-in-Partition.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/10/Select-Kali-Linux-Installation-Disk.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/10/Select-Kali-Linux-Installation-Type.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/10/Set-Root-User-Password-for-Kali-Linux.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2016/10/Set-Domain-for-Kali-Linux.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/10/Set-Hostname-for-Kali-Linux.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2016/10/Kali-Linux-Boot-Menu.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/10/Find-USB-Device-Name-in-Linux.png
|
||||
[17]:http://www.tecmint.com/best-linux-desktop-environments/
|
||||
[18]:http://www.tecmint.com/best-security-centric-linux-distributions-of-2016/
|
||||
58
published/20161107 When to use NGINX instead of Apache.md
Normal file
58
published/20161107 When to use NGINX instead of Apache.md
Normal file
@ -0,0 +1,58 @@
|
||||
何时 NGINX 将取代 Apache?
|
||||
=====
|
||||
|
||||
> NGINX 和 Apache 两者都是主流的开源 web 服务器,但是据 NGINX 的首席执行官 Gus Robertson 所言,他们有不同的使用场景。此外还有微软,其 web 服务器 IIS 在活跃网站的份额在 20 年间首次跌破 10%。
|
||||
|
||||

|
||||
|
||||
*Apache 是最受欢迎的 web 服务器,不过 NGINX 正逐渐增长,而微软的 IIS 几十年来首次跌破 10%。*
|
||||
|
||||
[NGINX][4] 已经成为第二大 web 服务器。它在很久以前就已经超越了[微软 IIS][5],并且一直在老大 [Apache][6] 的身后穷追不舍。但是,NGINX 的首席执行官Gus Roberston 在接受采访时表示,Apache 和 NGINX 的用户群体不一样。
|
||||
|
||||
“我认为 Apache 是很好的 web 服务器。NGINX 和它的使用场景不同,”Robertson 说。“我们没有把 Apache 当成竞争对手。我们的用户使用 NGINX 来取代硬件负载均衡器和构建微服务,这两个都不是 Apache 的长处。”
|
||||
|
||||
事实上,Robertson 发现许多用户同时使用了这两种开源的 web 服务。“用户会在 Apache 的上层使用 NGINX 来实现负载均衡。我们的架构差异很大,我们可以提供更好的并发 web 服务。”他还表示 NGINX 在云环境中表现更优秀。
|
||||
|
||||
他总结说,“我们是唯一一个仍然在持续增长的 web 服务器,其它的 web 服务器都在慢慢缩小份额。”
|
||||
|
||||
这不太准确。根据 [Netcraft 十月份的网络服务器调查][7],Apache 当月的活跃网站增加得最多,获得了 180 万个新站点,而 NGINX 增加了 40 万个新站点,排在第二位。
|
||||
|
||||
这些增长,加上微软损失的 120 万个活跃站点,导致微软的活跃网站份额下降到 9.27%,这是他们第一次跌破 10%。Apache 的市场份额提高了 0.19%,并继续领跑市场,现在坐拥 46.3% 的活跃站点。尽管如此,多年来 Apache 一直在缓慢下降,而 NGINX 现在上升到了 19%。
|
||||
|
||||
NGINX 的开发者正在努力创造他们的核心开放(open-core )的商业 web 服务器 —— [NGINX Plus][8],通过不断的改进使其变得更有竞争力。NGINX Plus 最新的版本是 [NGINX Plus 11 版(R11)][9],该服务器易于扩展和自定义,并支持更广泛的部署。
|
||||
|
||||
这次最大的补充是 [动态模块][10] 的二进制兼容性。也就是说为 [开源 NGINX 软件][11] 编译的动态模块也可以加载到 NGINX Plus。
|
||||
|
||||
这意味着你可以利用大量的[第三方 NGINX 模块][12] 来扩展 NGINX Plus 的功能,借鉴一系列开源和商业化生产的模块。开发者可以基于支持 NGINX Plus 的内核创建自定义扩展、附加组件和新产品。
|
||||
|
||||
NGINX Plus R11 还增强了其它功能:
|
||||
|
||||
* [提升 TCP/UDP 负载均衡][1] —— 新功能包括 SSL 服务器路由、新的日志功能、附加变量以及改进的代理协议支持。这些新功能增强了调试功能,使你能够支持更广泛的企业应用。
|
||||
* [更好的 IP 定位][2] —— 第三方的 GeoIP2 模块现在已经通过认证,并提供给 NGINX Plus 用户。这个新版本提供比原来的 GeoIP 模块更精准和丰富的位置信息。
|
||||
* [增强的 nginScript 模块][3] —— nginScript 是基于 JavaScript 的 NGINX Plus 的下一代配置语言。新功能可以让你在流(TCP/UDP)模块中即时修改请求和响应数据。
|
||||
|
||||
最终结果?NGINX 准备继续与 Apache 竞争顶级 web 服务器的宝座。至于微软的 IIS?它将逐渐淡出市场。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/when-to-use-nginx-instead-of-apache/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:https://www.nginx.com/blog/nginx-plus-r11-released/?utm_source=nginx-plus-r11-released&utm_medium=blog#r11-tcp-udp-lb
|
||||
[2]:https://www.nginx.com/blog/nginx-plus-r11-released/?utm_source=nginx-plus-r11-released&utm_medium=blog#r11-geoip2
|
||||
[3]:https://www.nginx.com/blog/nginx-plus-r11-released/?utm_source=nginx-plus-r11-released&utm_medium=blog#r11-nginScript
|
||||
[4]:https://www.nginx.com/
|
||||
[5]:https://www.iis.net/
|
||||
[6]:https://httpd.apache.org/
|
||||
[7]:https://news.netcraft.com/archives/2016/10/21/october-2016-web-server-survey.html
|
||||
[8]:https://www.nginx.com/products/
|
||||
[9]:https://www.nginx.com/blog/nginx-plus-r11-released/
|
||||
[10]:https://www.nginx.com/blog/nginx-plus-r11-released/?utm_source=nginx-plus-r11-released&utm_medium=blog#r11-dynamic-modules
|
||||
[11]:https://www.nginx.com/products/download-oss/
|
||||
[12]:https://www.nginx.com/resources/wiki/modules/index.html?utm_source=nginx-plus-r11-released&utm_medium=blog
|
||||
@ -0,0 +1,241 @@
|
||||
在 Kali Linux 下实战 Nmap(网络安全扫描器)
|
||||
========
|
||||
|
||||
在这第二篇 Kali Linux 文章中, 将讨论称为 ‘[nmap][30]‘ 的网络工具。虽然 nmap 不是 Kali 下唯一的一个工具,但它是最[有用的网络映射工具][29]之一。
|
||||
|
||||
- [第一部分-为初学者准备的Kali Linux安装指南][4]
|
||||
|
||||
Nmap, 是 Network Mapper 的缩写,由 Gordon Lyon 维护(更多关于 Mr. Lyon 的信息在这里: [http://insecure.org/fyodor/][28]) ,并被世界各地许多的安全专业人员使用。
|
||||
|
||||
这个工具在 Linux 和 Windows 下都能使用,并且是用命令行驱动的。相对于那些令人害怕的命令行,对于 nmap,在这里有一个美妙的图形化前端叫做 zenmap。
|
||||
|
||||
强烈建议个人去学习 nmap 的命令行版本,因为与图形化版本 zenmap 相比,它提供了更多的灵活性。
|
||||
|
||||
对服务器进行 nmap 扫描的目的是什么?很好的问题。Nmap 允许管理员快速彻底地了解网络上的系统,因此,它的名字叫 Network MAPper 或者 nmap。
|
||||
|
||||
Nmap 能够快速找到活动的主机和与该主机相关联的服务。Nmap 的功能还可以通过结合 Nmap 脚本引擎(通常缩写为 NSE)进一步被扩展。
|
||||
|
||||
这个脚本引擎允许管理员快速创建可用于确定其网络上是否存在新发现的漏洞的脚本。已经有许多脚本被开发出来并且包含在大多数的 nmap 安装中。
|
||||
|
||||
提醒一句 - 使用 nmap 的人既可能是善意的,也可能是恶意的。应该非常小心,确保你不要使用 nmap 对没有明确得到书面许可的系统进行扫描。请在使用 nmap 工具的时候注意!
|
||||
|
||||
#### 系统要求
|
||||
|
||||
1. [Kali Linux][3] (nmap 可以用于其他操作系统,并且功能也和这个指南里面讲的类似)。
|
||||
2. 另一台计算机,并且装有 nmap 的计算机有权限扫描它 - 这通常很容易通过软件来实现,例如通过 [VirtualBox][2] 创建虚拟机。
|
||||
1. 想要有一个好的机器来练习一下,可以了解一下 Metasploitable 2。
|
||||
2. 下载 MS2 :[Metasploitable2][1]。
|
||||
3. 一个可以工作的网络连接,或者是使用虚拟机就可以为这两台计算机建立有效的内部网络连接。
|
||||
|
||||
### Kali Linux – 使用 Nmap
|
||||
|
||||
使用 nmap 的第一步是登录 Kali Linux,如果需要,就启动一个图形会话(本系列的第一篇文章安装了 [Kali Linux 的 Enlightenment 桌面环境] [27])。
|
||||
|
||||
在安装过程中,安装程序将提示用户输入用来登录的“root”用户和密码。 一旦登录到 Kali Linux 机器,使用命令`startx`就可以启动 Enlightenment 桌面环境 - 值得注意的是 nmap 不需要运行桌面环境。
|
||||
|
||||
```
|
||||
# startx
|
||||
|
||||
```
|
||||
|
||||
|
||||
*在 Kali Linux 中启动桌面环境*
|
||||
|
||||
一旦登录到 Enlightenment,将需要打开终端窗口。通过点击桌面背景,将会出现一个菜单。导航到终端可以进行如下操作:应用程序 -> 系统 -> 'Xterm' 或 'UXterm' 或 '根终端'。
|
||||
|
||||
作者是名为 '[Terminator] [25]' 的 shell 程序的粉丝,但是这可能不会显示在 Kali Linux 的默认安装中。这里列出的所有 shell 程序都可用于使用 nmap 。
|
||||
|
||||
|
||||
|
||||
*在 Kali Linux 下启动终端*
|
||||
|
||||
一旦终端启动,nmap 的乐趣就开始了。 对于这个特定的教程,将会创建一个 Kali 机器和 Metasploitable机器之间的私有网络。
|
||||
|
||||
这会使事情变得更容易和更安全,因为私有的网络范围将确保扫描保持在安全的机器上,防止易受攻击的 Metasploitable 机器被其他人攻击。
|
||||
|
||||
### 怎样在我的网络上找到活动主机
|
||||
|
||||
在此示例中,这两台计算机都位于专用的 192.168.56.0/24 网络上。 Kali 机器的 IP 地址为 192.168.56.101,要扫描的 Metasploitable 机器的 IP 地址为 192.168.56.102。
|
||||
|
||||
假如我们不知道 IP 地址信息,但是可以通过快速 nmap 扫描来帮助确定在特定网络上哪些是活动主机。这种扫描称为 “简单列表” 扫描,将 `-sL`参数传递给 nmap 命令。
|
||||
|
||||
```
|
||||
# nmap -sL 192.168.56.0/24
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
*Nmap – 扫描网络上的活动主机*
|
||||
|
||||
悲伤的是,这个初始扫描没有返回任何活动主机。 有时,这是某些操作系统处理[端口扫描网络流量][22]的一个方法。
|
||||
|
||||
###在我的网络中找到并 ping 所有活动主机
|
||||
|
||||
不用担心,在这里有一些技巧可以使 nmap 尝试找到这些机器。 下一个技巧会告诉 nmap 尝试去 ping 192.168.56.0/24 网络中的所有地址。
|
||||
|
||||
```
|
||||
# nmap -sn 192.168.56.0/24
|
||||
|
||||
```
|
||||
|
||||
|
||||
*Nmap – Ping 所有已连接的活动网络主机*
|
||||
|
||||
这次 nmap 会返回一些潜在的主机来进行扫描! 在此命令中,`-sn` 禁用 nmap 的尝试对主机端口扫描的默认行为,只是让 nmap 尝试 ping 主机。
|
||||
|
||||
### 找到主机上的开放端口
|
||||
|
||||
让我们尝试让 nmap 端口扫描这些特定的主机,看看会出现什么。
|
||||
|
||||
```
|
||||
# nmap 192.168.56.1,100-102
|
||||
|
||||
```
|
||||
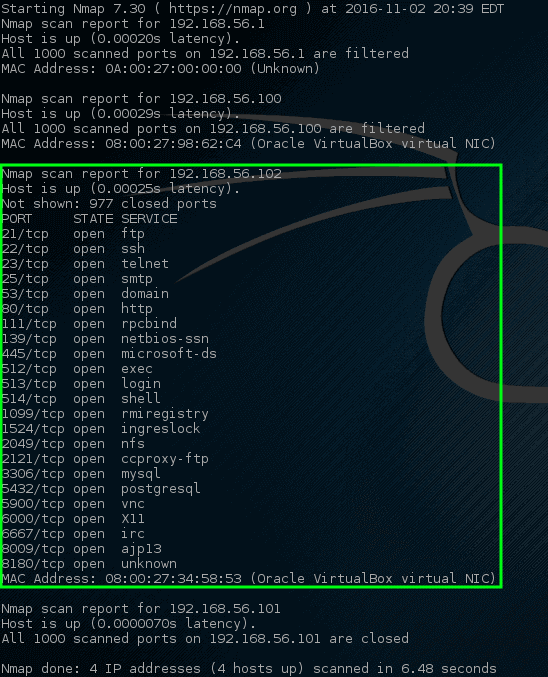
|
||||
|
||||
*Nmap – 在主机上扫描网络端口*
|
||||
|
||||
哇! 这一次 nmap 挖到了一个金矿。 这个特定的主机有相当多的[开放网络端口][19]。
|
||||
|
||||
这些端口全都代表着在此特定机器上的某种监听服务。 我们前面说过,192.168.56.102 的 IP 地址会分配给一台易受攻击的机器,这就是为什么在这个主机上会有这么多[开放端口][18]。
|
||||
|
||||
在大多数机器上打开这么多端口是非常不正常的,所以赶快调查这台机器是个明智的想法。管理员可以检查下网络上的物理机器,并在本地查看这些机器,但这不会很有趣,特别是当 nmap 可以为我们更快地做到时!
|
||||
|
||||
### 找到主机上监听端口的服务
|
||||
|
||||
下一个扫描是服务扫描,通常用于尝试确定机器上什么[服务监听在特定的端口][17]。
|
||||
|
||||
Nmap 将探测所有打开的端口,并尝试从每个端口上运行的服务中获取信息。
|
||||
|
||||
```
|
||||
# nmap -sV 192.168.56.102
|
||||
|
||||
```
|
||||
|
||||
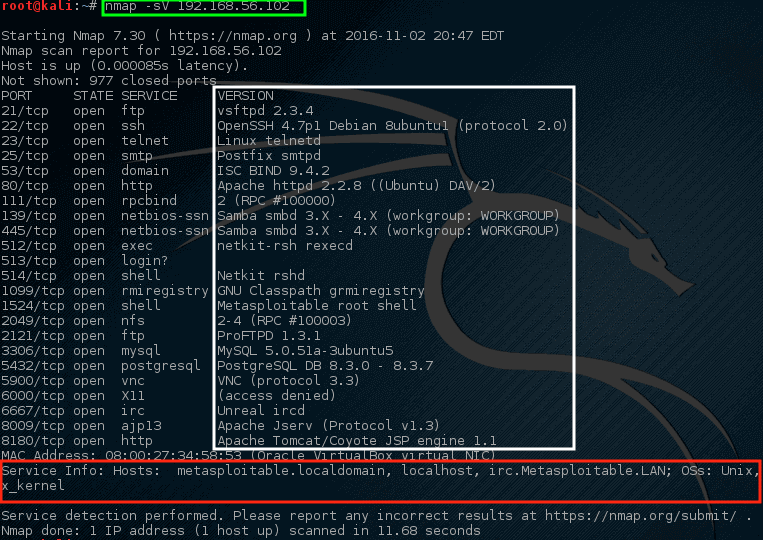
|
||||
|
||||
*Nmap – 扫描网络服务监听端口*
|
||||
|
||||
请注意这次 nmap 提供了一些关于 nmap 在特定端口运行的建议(在白框中突出显示),而且 nmap 也试图确认运行在这台机器上的[这个操作系统的信息][15]和它的主机名(也非常成功!)。
|
||||
|
||||
查看这个输出,应该引起网络管理员相当多的关注。 第一行声称 VSftpd 版本 2.3.4 正在这台机器上运行! 这是一个真正的旧版本的 VSftpd。
|
||||
|
||||
通过查找 ExploitDB,对于这个版本早在 2001 年就发现了一个非常严重的漏洞(ExploitDB ID – 17491)。
|
||||
|
||||
### 发现主机上上匿名 ftp 登录
|
||||
|
||||
让我们使用 nmap 更加清楚的查看这个端口,并且看看可以确认什么。
|
||||
|
||||
```
|
||||
# nmap -sC 192.168.56.102 -p 21
|
||||
|
||||
```
|
||||
|
||||
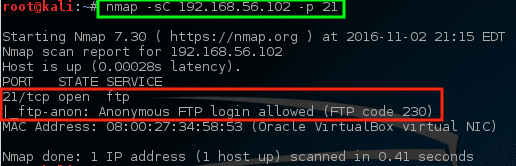
|
||||
|
||||
*Nmap – 扫描机器上的特定端口*
|
||||
|
||||
使用此命令,让 nmap 在主机上的 FTP 端口(`-p 21`)上运行其默认脚本(`-sC`)。 虽然它可能是、也可能不是一个问题,但是 nmap 确实发现在这个特定的服务器[是允许匿名 FTP 登录的][13]。
|
||||
|
||||
### 检查主机上的漏洞
|
||||
|
||||
这与我们早先知道 VSftd 有旧漏洞的知识相匹配,应该引起一些关注。 让我们看看 nmap有没有脚本来尝试检查 VSftpd 漏洞。
|
||||
|
||||
```
|
||||
# locate .nse | grep ftp
|
||||
|
||||
```
|
||||
|
||||
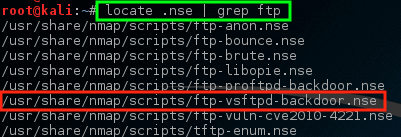
|
||||
|
||||
*Nmap – 扫描 VSftpd 漏洞*
|
||||
|
||||
注意 nmap 已有一个 NSE 脚本已经用来处理 VSftpd 后门问题!让我们尝试对这个主机运行这个脚本,看看会发生什么,但首先知道如何使用脚本可能是很重要的。
|
||||
|
||||
```
|
||||
# nmap --script-help=ftp-vsftd-backdoor.nse
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
*了解 Nmap NSE 脚本使用*
|
||||
|
||||
通过这个描述,很明显,这个脚本可以用来试图查看这个特定的机器是否容易受到先前识别的 ExploitDB 问题的影响。
|
||||
|
||||
让我们运行这个脚本,看看会发生什么。
|
||||
|
||||
```
|
||||
# nmap --script=ftp-vsftpd-backdoor.nse 192.168.56.102 -p 21
|
||||
|
||||
```
|
||||
|
||||
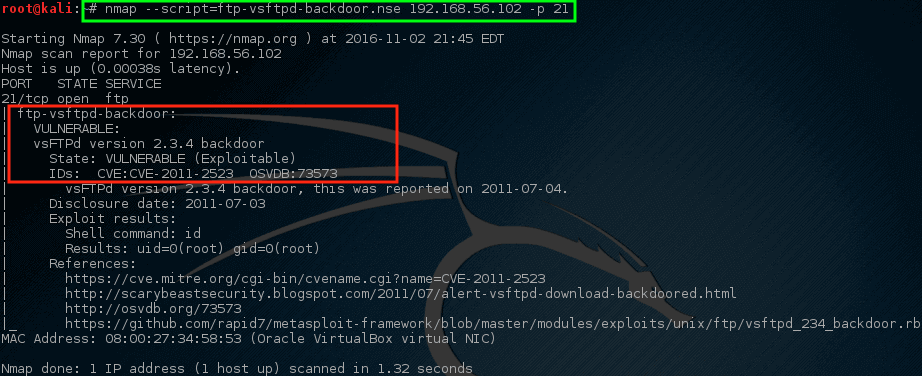
|
||||
|
||||
*Nmap – 扫描易受攻击的主机*
|
||||
|
||||
耶!Nmap 的脚本返回了一些危险的消息。 这台机器可能面临风险,之后可以进行更加详细的调查。虽然这并不意味着机器缺乏对风险的抵抗力和可以被用于做一些可怕/糟糕的事情,但它应该给网络/安全团队带来一些关注。
|
||||
|
||||
Nmap 具有极高的选择性,非常平稳。 到目前为止已经做的大多数扫描, nmap 的网络流量都保持适度平稳,然而以这种方式扫描对个人拥有的网络可能是非常耗时的。
|
||||
|
||||
Nmap 有能力做一个更积极的扫描,往往一个命令就会产生之前几个命令一样的信息。 让我们来看看积极的扫描的输出(注意 - 积极的扫描会触发[入侵检测/预防系统][9]!)。
|
||||
|
||||
```
|
||||
# nmap -A 192.168.56.102
|
||||
|
||||
```
|
||||
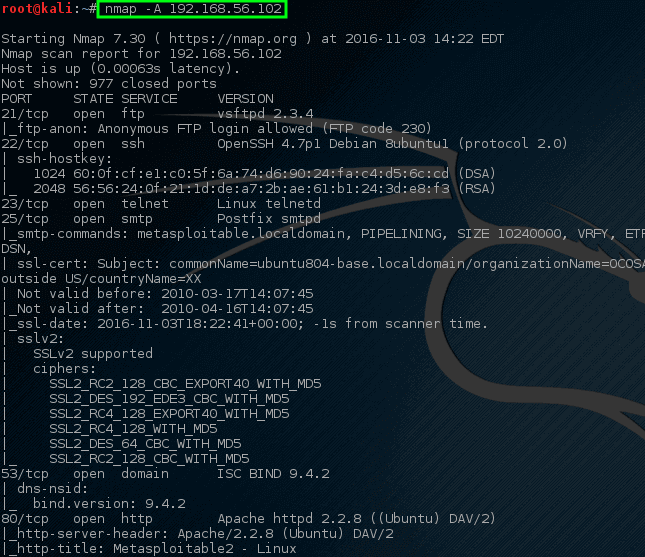
|
||||
|
||||
*Nmap – 在主机上完成网络扫描*
|
||||
|
||||
注意这一次,使用一个命令,nmap 返回了很多关于在这台特定机器上运行的开放端口、服务和配置的信息。 这些信息中的大部分可用于帮助确定[如何保护本机][7]以及评估网络上可能运行的软件。
|
||||
|
||||
这只是 nmap 可用于在主机或网段上找到的许多有用信息的很短的一个列表。强烈敦促个人在个人拥有的网络上继续[以nmap][6] 进行实验。(不要通过扫描其他主机来练习!)。
|
||||
|
||||
有一个关于 Nmap 网络扫描的官方指南,作者 Gordon Lyon,可从[亚马逊](http://amzn.to/2eFNYrD)上获得。
|
||||
|
||||
方便的话可以留下你的评论和问题(或者使用 nmap 扫描器的技巧)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/nmap-network-security-scanner-in-kali-linux/
|
||||
|
||||
作者:[Rob Turner][a]
|
||||
译者:[DockerChen](https://github.com/DockerChen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/robturner/
|
||||
[1]:https://sourceforge.net/projects/metasploitable/files/Metasploitable2/
|
||||
[2]:http://www.tecmint.com/install-virtualbox-on-redhat-centos-fedora/
|
||||
[3]:http://www.tecmint.com/kali-linux-installation-guide
|
||||
[4]:http://www.tecmint.com/kali-linux-installation-guide
|
||||
[5]:http://amzn.to/2eFNYrD
|
||||
[6]:http://www.tecmint.com/nmap-command-examples/
|
||||
[7]:http://www.tecmint.com/security-and-hardening-centos-7-guide/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Network-Host.png
|
||||
[9]:http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Host-for-Vulnerable.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Learn-NSE-Script.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Service-Vulnerability.png
|
||||
[13]:http://www.tecmint.com/setup-ftp-anonymous-logins-in-linux/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Particular-Port-on-Host.png
|
||||
[15]:http://www.tecmint.com/commands-to-collect-system-and-hardware-information-in-linux/
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Network-Services-Ports.png
|
||||
[17]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[18]:http://www.tecmint.com/find-open-ports-in-linux/
|
||||
[19]:http://www.tecmint.com/find-open-ports-in-linux/
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-for-Ports-on-Hosts.png
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Ping-All-Network-Live-Hosts.png
|
||||
[22]:http://www.tecmint.com/audit-network-performance-security-and-troubleshooting-in-linux/
|
||||
[23]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Network.png
|
||||
[24]:http://www.tecmint.com/wp-content/uploads/2016/11/Launch-Terminal-in-Kali-Linux.png
|
||||
[25]:http://www.tecmint.com/terminator-a-linux-terminal-emulator-to-manage-multiple-terminal-windows/
|
||||
[26]:http://www.tecmint.com/wp-content/uploads/2016/11/Start-Desktop-Environment-in-Kali-Linux.png
|
||||
[27]:http://www.tecmint.com/kali-linux-installation-guide
|
||||
[28]:http://insecure.org/fyodor/
|
||||
[29]:http://www.tecmint.com/bcc-best-linux-performance-monitoring-tools/
|
||||
[30]:http://www.tecmint.com/nmap-command-examples/
|
||||
|
||||
106
published/20161109 How to Recover a Deleted File in Linux.md
Normal file
106
published/20161109 How to Recover a Deleted File in Linux.md
Normal file
@ -0,0 +1,106 @@
|
||||
如何在 Linux 中恢复一个删除了的文件
|
||||
==============
|
||||
|
||||
你曾经是否遇到这样的事?当你发现的时候,你已经通过删除键,或者在命令行中使用 `rm` 命令,错误的删除了一个不该删除的文件。
|
||||
|
||||
在第一种情况下,你可以到垃圾箱,[搜索那个文件][6],然后把它复原到原始位置。但是第二种情况又该怎么办呢?你可能知道,Linux 命令行不会把删除的文件转移到任何位置,而是直接把它们移除了,biu~,它们就不复存在了。
|
||||
|
||||
在这篇文章里,将分享一个很有用的技巧来避免此事发生。同时,也会分享一个工具,不小心删除了某些不该删除的文件时,也许用得上。
|
||||
|
||||
### 把删除创建为 `rm -i` 的别名
|
||||
|
||||
当 `-i` 选项配合 `rm` 命令(也包括其他[文件处理命令比如 `cp` 或者 `mv`][5])使用时,在删除文件前会出现一个提示。
|
||||
|
||||
这同样也可以运用到当[复制,移动或重命名一个文件][4],当所在位置已经存在一个和目标文件同名的文件时。
|
||||
|
||||
这个提示会给你第二次机会来考虑是否真的要删除该文件 - 如果你在这个提示上选择确定,那么文件就被删除了。这种情况下,很抱歉,这个技巧并不能防止你的粗心大意。
|
||||
|
||||
为了 `rm -i` 别名替代 `rm` ,这样做:
|
||||
|
||||
```
|
||||
alias rm='rm -i'
|
||||
```
|
||||
|
||||
运行 `alias` 命令可以确定 `rm` 现在已经被别名了:
|
||||
|
||||
|
||||
|
||||
*为 rm 增加别名*
|
||||
|
||||
然而,这只能在当前用户的当前 shell 上有效。为了永久改变,你必须像下面展示的这样把它保存到 `~/.bashrc` 中(一些版本的 Linux 系统可能是 `~/.profile`)。
|
||||
|
||||

|
||||
|
||||
*在 Linux 中永久增添别名*
|
||||
|
||||
为了让 `~/.bashrc`(或 `~/.profile`)中所做的改变立即生效,从当前 shell 中运行文件:
|
||||
|
||||
```
|
||||
. ~/.bashrc
|
||||
```
|
||||
|
||||

|
||||
|
||||
*在 Linux 中激活别名*
|
||||
|
||||
### 取证工具 - Foremost
|
||||
|
||||
但愿你对于你的文件足够小心,当你要从外部磁盘或 USB 设备中恢复丢失的文件时,你只需使用这个工具即可。
|
||||
|
||||
然而,当你意识到你意外的删除了系统中的一个文件并感到恐慌时-不用担心。让我们来看一看 `foremost`,一个用来处理这种状况的取证工具。
|
||||
|
||||
要在 CentOS/RHEL 7 中安装 Foremost,需要首先启用 Repoforge:
|
||||
|
||||
```
|
||||
# rpm -Uvh http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.3-1.el7.rf.x86_64.rpm
|
||||
# yum install foremost
|
||||
```
|
||||
|
||||
然而在 Debian 及其衍生系统中,需这样做:
|
||||
|
||||
```
|
||||
# aptitude install foremost
|
||||
```
|
||||
|
||||
安装完成后,我们做一个简单的测试吧。首先删除 `/boot/images` 目录下一个名为 `nosdos.jpg` 的图像文件:
|
||||
|
||||
```
|
||||
# cd images
|
||||
# rm nosdos.jpg
|
||||
```
|
||||
|
||||
要恢复这个文件,如下所示使用 `foremost`(要先确认所在分区 - 本例中, `/boot` 位于 `/dev/sda1` 分区中)。
|
||||
|
||||
```
|
||||
# foremost -t jpg -i /dev/sda1 -o /home/gacanepa/rescued
|
||||
```
|
||||
|
||||
其中,`/home/gacanepa/rescued` 是另外一个磁盘中的目录 - 请记住,把文件恢复到被删除文件所在的磁盘中不是一个明智的做法。
|
||||
|
||||
如果在恢复过程中,占用了被删除文件之前所在的磁盘分区,就可能无法恢复文件。另外,进行文件恢复操作前不要做任何其他操作。
|
||||
|
||||
当 `foremost` 执行完成以后,恢复的文件(如果可以恢复)将能够在目录 ·/home/gacanepa/rescue/jpg` 中找到。
|
||||
|
||||
##### 总结
|
||||
|
||||
在这篇文章中,我们阐述了如何避免意外删除一个不该删除的文件,以及万一这类事情发生,如何恢复文件。还要警告一下, `foremost` 可能运行很长时间,时间长短取决于分区的大小。
|
||||
|
||||
如果您有什么问题或想法,和往常一样,不要犹豫,告诉我们。可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/recover-deleted-file-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2016/11/Active-Alias-in-Linux.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/11/Add-Alias-Permanently-in-Linux.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/11/Add-Alias-rm-Command.png
|
||||
[4]:http://www.tecmint.com/rename-multiple-files-in-linux/
|
||||
[5]:http://www.tecmint.com/progress-monitor-check-progress-of-linux-commands/
|
||||
[6]:http://www.tecmint.com/linux-find-command-to-search-multiple-filenames-extensions/
|
||||
@ -0,0 +1,43 @@
|
||||
Xfce 桌面新增‘免打扰’模式以及单一应用通知设置的新特性
|
||||
============================================================
|
||||
|
||||
Xfce 的开发者们正忙于把 Xfce 的应用和部件[转移][3]到 GTK3 上,在这个过程中,他们也增加了一些新的特性。
|
||||
|
||||
**“免打扰”**,一个常被要求增加的特性,[最近][4]已登陆到了 xfce-notifyd 0.3.4 (Xfce 通知进程)上。
|
||||
|
||||
更近一步地,**最新的 xfce-notifyd 包括了一个可以在单一应用基础上开启或关闭通知的选项。
|
||||
|
||||
当一个应用发出一个通知以后,这个应用就被加入到到了通知设置的列表里。从通知列表里,你可以控制哪些应用能够显示通知。
|
||||
|
||||
”免打扰“模式和应用特定的通知设置均可在“设置” > “通知” 中找到:
|
||||
|
||||
|
||||
|
||||
现在为止,还没有方法可以访问由于启用”免打扰“模式而错过的消息。然而,可以预期将来会发布**通知记录/维持的特性。**
|
||||
|
||||
最后, xfce-notifyd 0.3.4 的**另一个特性**是**选择在主监视器显示通知**(直到现在,通知都是显示在当前监视器)。这个特性目前在图形设置界面里是没有的,必须使用 `Xfconf`(设置编辑)在 xfce-notifyd 下增添一个叫做 `/primary-monitor`(没有引号)的布尔属性,并设置为 `True` 来启用该特性:
|
||||
|
||||

|
||||
|
||||
**xfce4-notifyd 0.3.4 目前在 PPA 上还没有,但是不久它可能被增添到 [Xfce GTK3 PPA][1]中。**
|
||||
|
||||
**如果你想直接从源代码编译,从[这儿][2]下载。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2016/11/xfce-gets-do-not-disturb-mode-and-per.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.webupd8.org/p/about.html
|
||||
[1]:https://launchpad.net/~xubuntu-dev/+archive/ubuntu/xfce4-gtk3
|
||||
[2]:http://archive.xfce.org/src/apps/xfce4-notifyd/0.3/
|
||||
[3]:https://wiki.xfce.org/releng/4.14/roadmap
|
||||
[4]:http://simon.shimmerproject.org/2016/11/09/xfce4-notifyd-0-3-4-released-do-not-disturb-and-per-application-settings/
|
||||
[5]:https://1.bp.blogspot.com/-fvSesp1ukaQ/WCR8JQVgfiI/AAAAAAAAYl8/IJ1CshVQizs9aG2ClfraVaNjKP3OyxvAgCLcB/s1600/xfce-do-not-disturb.png
|
||||
[6]:https://2.bp.blogspot.com/-M8xZpEHMrq8/WCR9EufvsnI/AAAAAAAAYmA/nLI5JQUtmE0J9TgvNM9ZKGHBdwwBhRH3QCLcB/s1600/xfce-xfconf.png
|
||||
[7]:http://www.webupd8.org/2016/11/xfce-gets-do-not-disturb-mode-and-per.html
|
||||
@ -0,0 +1,84 @@
|
||||
通过安装扩展让 KDE Plasma 5 桌面看起来感觉就像 Windows 10 桌面
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
通过一些步骤,我将告诉你如何把 KDE Plasma 5 桌面变成 Windows 10 桌面。
|
||||
|
||||
|
||||
除了菜单, KDE Plasma 桌面的许多地方已经和 Win 10 桌面非常像了。因此,只需要一点点改动就可以使二者看起来几乎是一样。
|
||||
|
||||
### 开始菜单
|
||||
|
||||
让 KDE Plasma 桌面看起来像 Win 10 桌面的首要以及可能最有标志性的环节是实现 Win 10 的 ‘开始’ 菜单。
|
||||
|
||||
通过安装 [Zren's Tiled Menu][1],这很容易实现。
|
||||
|
||||
#### 安装
|
||||
|
||||
1、 在 KDE Plasma 桌面上单击右键 -> 解锁窗口部件(Unlock Widgets)
|
||||
|
||||
2、 在 KDE Plasma 桌面上单击右键 -> 增添窗口部件( Add Widgets)
|
||||
|
||||
3、 获取新窗口部件 -> 下载新的 Plasma 窗口部件(Download New Plasma Widgets)
|
||||
|
||||
4、 搜索“Tiled Menu” -> 安装(Install)
|
||||
|
||||
#### 激活
|
||||
|
||||
1、 在你当前的菜单按钮上单击右键 -> 替代……(Alternatives…)
|
||||
|
||||
2、 选择 "TIled Mune" ->点击切换(Switch)
|
||||
|
||||
|
||||
|
||||
*KDE Tiled 菜单扩展*
|
||||
|
||||
### 主题
|
||||
|
||||
弄好菜单以后,下一个你可能需要的就是主题。幸运的是, [K10ne][3] 提供了一个 WIn 10 主题体验。
|
||||
|
||||
#### 安装:
|
||||
|
||||
1、 从 Plasma 桌面菜单打开“系统设置(System Settings)” -> 工作空间主题(Workspace Theme)
|
||||
|
||||
2、 从侧边栏选择“桌面主题(Desktop Theme)” -> 获取新主题(Get new Theme)
|
||||
|
||||
3、 搜索“K10ne” -> 安装(Install)
|
||||
|
||||
#### 激活
|
||||
|
||||
1、 从 Plasma 桌面菜单选择“系统设置(System Settings)” -> 工作空间主题(Workspace Theme)
|
||||
|
||||
2、 从侧边栏选择“桌面主题(Desktop Theme)” -> "K10ne"
|
||||
|
||||
3、 应用(Apply)
|
||||
|
||||
### 任务栏
|
||||
|
||||
最后,为了有一个更加完整的体验,你可能也想拥有一个更加 Win 10 风格的任务栏,
|
||||
|
||||
这次,你需要的安装包,叫做“Icons-only Task Manager”, 在大多数 Linux 发行版中,通常会默认安装。如果没有安装,需要通过你的系统的合适通道来获取它。
|
||||
|
||||
#### 激活
|
||||
|
||||
1、 在 Plasma 桌面上单击右键 -> 打开窗口部件(Unlock Widgets)
|
||||
|
||||
2、 在 Plasma 桌面上单击右键 -> 增添部件(Add Widgets)
|
||||
|
||||
3、 把“Icons-only Task Manager”拖放到你的桌面面板的合适位置。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iwf1.com/make-kde-plasma-5-desktop-look-feel-like-windows-10-using-these-extensions/
|
||||
|
||||
作者:[Liron][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iwf1.com/tag/linux
|
||||
[1]:https://github.com/Zren/plasma-applets/tree/master/tiledmenu
|
||||
[2]:http://iwf1.com/wordpress/wp-content/uploads/2016/11/KDE-Tiled-Menu-extension.jpg
|
||||
[3]:https://store.kde.org/p/1153465/
|
||||
89
published/20161114 How to Check Timezone in Linux.md
Normal file
89
published/20161114 How to Check Timezone in Linux.md
Normal file
@ -0,0 +1,89 @@
|
||||
在 Linux 中查看你的时区
|
||||
============================================================
|
||||
|
||||
在这篇短文中,我们将向你简单介绍几种 Linux 下查看系统时区的简单方法。在 Linux 机器中,尤其是生产服务器上的时间管理技能,是在系统管理中一个极其重要的方面。
|
||||
|
||||
Linux 包含多种可用的时间管理工具,比如 `date` 或 `timedatectlcommands`,你可以用它们来获取当前系统时区,也可以[将系统时间与 NTP 服务器同步][1],来自动地、更精确地进行时间管理。
|
||||
|
||||
好,我们一起来看几种查看我们的 Linux 系统时区的不同方法。
|
||||
|
||||
### 1、我们从使用传统的 `date` 命令开始
|
||||
|
||||
使用下面的命令,来看一看我们的当前时区:
|
||||
|
||||
```
|
||||
$ date
|
||||
```
|
||||
|
||||
或者,你也可以使用下面的命令。其中 `%Z` 格式可以输出字符形式的时区,而 `%z` 输出数字形式的时区:
|
||||
|
||||
```
|
||||
$ date +”%Z %z”
|
||||
```
|
||||

|
||||
|
||||
*查看 Linux 时区*
|
||||
|
||||
注意:`date` 的手册页中包含很多输出格式,你可以利用它们,来替换你的 `date` 命令的输出内容:
|
||||
|
||||
```
|
||||
$ man date
|
||||
```
|
||||
|
||||
### 2、接下来,你同样可以用 `timedatectl` 命令
|
||||
|
||||
当你不带任何参数运行它时,这条命令可以像下图一样,输出系统时间概览,其中包含当前时区:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
```
|
||||
|
||||
然后,你可以在命令中提供一条管道,然后用 [grep 命令][3] 来像下面一样,只过滤出时区信息:
|
||||
|
||||
```
|
||||
$ timedatectl | grep “Time zone”
|
||||
```
|
||||
|
||||

|
||||
|
||||
*查看当前 Linux 时区*
|
||||
|
||||
同样,我们可以学习如何使用 timedatectl 来[设置 Linux 时区][5]。
|
||||
|
||||
###3、进一步,显示文件 /etc/timezone 的内容
|
||||
|
||||
使用 [cat 工具][6]显示文件 `/etc/timezone` 的内容,来查看你的时区:
|
||||
|
||||
```
|
||||
$ cat /etc/timezone
|
||||
```
|
||||
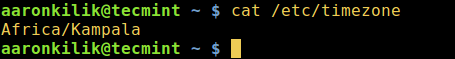
|
||||
|
||||
*在 Linux 中查看时区*
|
||||
|
||||
对于 RHEL/CentOS/Fedora 用户,这里还有一条可以起到同样效果的命令:
|
||||
|
||||
```
|
||||
$ grep ZONE /etc/sysconfig/clock
|
||||
```
|
||||
|
||||
就这些了!别忘了在下面的反馈栏中分享你对于这篇文章中的看法。重要的是:你应该通过这篇 Linux 时区管理指南来学习更多系统时间管理的知识,因为它含有很多易于操作的实例。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/check-linux-timezone
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/install-ntp-server-in-centos/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Find-Linux-Timezone.png
|
||||
[3]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/10/Find-Current-Linux-Timezone.png
|
||||
[5]:http://www.tecmint.com/set-time-timezone-and-synchronize-time-using-timedatectl-command/
|
||||
[6]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/10/Check-Timezone-of-Linux.png
|
||||
@ -0,0 +1,65 @@
|
||||
火狐是否在未经授权的情况下搜集您的数据?
|
||||
===============
|
||||
|
||||

|
||||
|
||||
打包在 Firefox Web 浏览器里面的地理位置服务即使浏览器关闭后也会在后台运行。
|
||||
|
||||
我们还没有从关于浏览器插件丑闻的消息中平复下来。插件原本目的是保卫隐私,[但现在却把信息卖给了第三方公司](https://iwf1.com/shock-this-popular-browser-add-on-sells-your-browsing-history/)。然而更令人愤怒的是其规模完全超出我们的预计。
|
||||
|
||||
**MLS**,即 Mozilla 位置服务,其可以让设备基于类似于 WIFI 接入点、无线电基站和蓝牙信标等基础设施确定其位置。
|
||||
|
||||
MLS 非常像是 Google 位置服务,后者是需要在 Android 设备上打开 GPS 并选择“高精度”模式时使用的服务。
|
||||
|
||||
那些曾经经历过 GPS 问题的人可能会知道这个模式是多么精确。
|
||||
|
||||
MLS 服务除了能够准确地确定您的位置以外,这个服务可以通过使用 WiFi 网络收集两种个人身份信息,包括**愿意贡献到数据库的用户**和**被扫描的 WiFi 设备的所有者**。
|
||||
|
||||
话虽这么说,Mozilla 也提到说你可以选择退出服务,但你真的可以退出吗?
|
||||
|
||||
### 当后台变成你隐私的展台
|
||||
|
||||
作为一个众包项目,为了维护和发展 MLS,Mozilla 事实上非常依赖于用户的贡献,因此他们开发了多种方法以便用户参与进来。
|
||||
|
||||
其中之一,就是被终端用户使用的一款名为 Stumbler 的 Android 应用程序:
|
||||
|
||||
> [Mozilla Stumbler][4] 是一个开源的无线网络扫描器,它为我们的众包位置数据库收集 GPS、蜂窝网络和无线网络元数据。
|
||||
|
||||
这样一来,Stumbler 不仅仅是一个独立的应用程序,同时也是 Firefox 在 Android 设备上提供的一种为 MLS“贡献数据和增强功能”的服务。
|
||||
|
||||
该服务的问题在于它在后台运行,而大多数用户都不知道它,**即使您可能已经禁用它**。
|
||||
|
||||
根据 Mozilla 提供的[信息][4],要启用该服务,您需要打开“设置”菜单(在 Firefox for Android 版本中) -> 打开“隐私”部分 -> 滚动到底部以查看“数据选择”,最后,勾选 Mozilla 位置服务框。
|
||||
|
||||

|
||||
|
||||
*Mozilla 定位服务尚未勾选,但 Stumbler 已开启*
|
||||
|
||||
实际上,你会发现 Stumbler 服务**运行在你的设备后台**,这意味着它几乎不可见,因为它没有接口,即使 MLS 框未被选中,即使“数据选择”复选框都未选中,甚至 Firefox 浏览器本身已被关闭。
|
||||
|
||||
显然,停止 stumbler 的唯一方法是直接结束它。然而,这样做你首先需要一种方法来检测它的运行和结束,最终,这只是一个设备重启前的临时解决方案。
|
||||
|
||||
### 如何保证安全
|
||||
|
||||
为了避免 MLS 收集您的数据,仍然有一些方法值得您尝试一下,希望这些方法不会像在 Firefox for Android 中的MLS 复选框一样被 Mozilla 忽视。
|
||||
|
||||
您可以将您的无线网络 SSID 隐藏或者在 SSID 结尾添加“\_nomap”,例如将您的 SSID 从“myWirelessNetwork”更名为“myWirelessNetwork\_nomap”。这在向 Mozilla 的应用程序暗示,您不希望参与他们的数据收集活动。
|
||||
|
||||
对于 Android 上的 Stumbler 服务,由于是一个服务(而不是进程),您可能无法在运行的进程/最近的应用程序列表中看到它。 因此,使用专用应用程序关闭它或启用“开发人员选项”,并转到“运行服务” -> 点击 Firefox,最后,停止“stumbler”。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iwf1.com/is-mozilla-firefox-collecting-your-data-without-your-consent/
|
||||
|
||||
作者:[Liron][a]
|
||||
译者:[flankershen](https://github.com/flankershen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iwf1.com/is-mozilla-firefox-collecting-your-data-without-your-consent/
|
||||
[1]:https://iwf1.com/shock-this-popular-browser-add-on-sells-your-browsing-history/
|
||||
[2]:https://en.wikipedia.org/wiki/Crowdsourcing
|
||||
[3]:http://iwf1.com/wordpress/wp-content/uploads/2016/11/Mozilla-Location-Services-is-unchecked-yet-Stumler-is-on.jpg
|
||||
[4]: https://location.services.mozilla.com/apps
|
||||
@ -0,0 +1,77 @@
|
||||
现在 Linux 运行在 99.6% 的 TOP500 超级计算机上
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
_简介:虽然 Linux 在桌面操作系统只有 2% 的市场占有率,但是对于超级计算机来说,Linux 用 99% 的市场占有率轻松地获取了统治地位。_
|
||||
|
||||
**Linux 运行在超过 99% 的 TOP500 超级计算机上**,这并不会让人感到惊讶。2015 年我们报道过[“Linux 正运行在超过 97% 的 TOP500 超级计算机上”][13],今年 Linux 表现得更好。
|
||||
|
||||
这些信息是由独立组织 [Top500][4] 收集的,每两年他们会公布已知的最快的 500 台超级计算机的细节。你可以[打开这个网站,用以下条件筛选所需要的信息][15]:国家、使用的操作系统类型、所有者等。别担心,我将会从这份表格中筛选整理出今年几个有趣的事实。
|
||||
|
||||
### Linux 运行在 500 台超级计算机中的 498 台
|
||||
|
||||
如果要将上面的百分比细化到具体数量的话,500 台超级计算机中的 498 台运行着 Linux。剩余的两台超级计算机运行着基于 Unix 的操作系统。直到去年,还有一台超级计算机上在运行 Windows,今年的列表中没有出现 Windows 的身影。或许,这些超级计算机没一台能运行 Windows 10(一语双关)。
|
||||
|
||||
总结一下今年表单上 TOP500 超级计算机所运行操作系统情况:
|
||||
|
||||
* Linux: 498
|
||||
* Unix: 2
|
||||
* Windows: 0
|
||||
|
||||
还有一份总结,它清晰展现了每年 Linux 在 TOP500 超级计算机的份额的变化情况。
|
||||
|
||||
* 2012 年: 94%
|
||||
* [2013][6] 年: 95%
|
||||
* [2014][7] 年: 97%
|
||||
* [2015][8] 年: 97.2%
|
||||
* 2016 年: 99.6%
|
||||
* 2017 年: ???
|
||||
|
||||
另外,最快的前380台超级计算机运行着 Linux,包括在中国的那台最快的超级计算机。排名第 386 和第 387 的超级计算机运行着 Unix,它们同样来自中国。(←_←)
|
||||
|
||||
### 其他关于最快的超级计算机的有趣数据
|
||||
|
||||

|
||||
|
||||
除去 Linux,我在表单中还找到了几个有趣的数据想跟你分享。
|
||||
|
||||
* 全球最快的超级计算机是[神威太湖之光][9]. 它位于中国的[国家超级计算无锡中心][10]。它有着 93PFlops 的速度。
|
||||
* 全球第二快的超级计算机是中国的[天河二号][11],第三的位置则属于美国的 Titan。
|
||||
* 在速度前十的超级计算机中,美国占据了 5 台,日本和中国各有 4 台,瑞士有 1 台。
|
||||
* 美国和中国都各有 171 台超级计算机进入了 TOP500 的榜单中。
|
||||
* 日本有 27 台,法国有 20 台,印度、俄罗斯和沙特阿拉伯各有 5 台进入了榜单中。
|
||||
|
||||
有趣的事实,不是吗?你能点击[这里][18]筛选出属于自己的榜单来获得更多信息。现在我很开心来宣传 Linux 运行在 99% 的 TOP500 超级计算机上,期待下一年能有 100% 的更好成绩。
|
||||
|
||||
当你在阅读这篇文章时,请在社交平台上分享这篇文章,这是 Linux 的一个成就,我们引以为豪~ :P
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-99-percent-top-500-supercomputers
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://twitter.com/share?original_referer=https%3A%2F%2Fitsfoss.com%2F&source=tweetbutton&text=Linux+Now+Runs+On+99.6%25+Of+Top+500+Supercomputers&url=https%3A%2F%2Fitsfoss.com%2Flinux-99-percent-top-500-supercomputers%2F&via=%40itsfoss
|
||||
[2]: https://www.linkedin.com/cws/share?url=https://itsfoss.com/linux-99-percent-top-500-supercomputers/
|
||||
[3]: http://pinterest.com/pin/create/button/?url=https://itsfoss.com/linux-99-percent-top-500-supercomputers/&description=Linux+Now+Runs+On+99.6%25+Of+Top+500+Supercomputers&media=https://itsfoss.com/wp-content/uploads/2016/11/Linux-King-Supercomputer-world-min.jpg
|
||||
[4]: https://twitter.com/share?text=%23Linux+now+runs+on+more+than+99%25+of+top+500+%23supercomputers+in+the+world&via=itsfoss&related=itsfoss&url=https://itsfoss.com/linux-99-percent-top-500-supercomputers/
|
||||
[5]: https://twitter.com/share?text=%23Linux+now+runs+on+more+than+99%25+of+top+500+%23supercomputers+in+the+world&via=itsfoss&related=itsfoss&url=https://itsfoss.com/linux-99-percent-top-500-supercomputers/
|
||||
[6]: https://itsfoss.com/95-percent-worlds-top-500-supercomputers-run-linux/
|
||||
[7]: https://itsfoss.com/97-percent-worlds-top-500-supercomputers-run-linux/
|
||||
[8]: https://itsfoss.com/linux-runs-97-percent-worlds-top-500-supercomputers/
|
||||
[9]: https://en.wikipedia.org/wiki/Sunway_TaihuLight
|
||||
[10]: https://www.top500.org/site/50623
|
||||
[11]: https://en.wikipedia.org/wiki/Tianhe-2
|
||||
[12]: https://itsfoss.com/wp-content/uploads/2016/11/Linux-King-Supercomputer-world-min.jpg
|
||||
[13]: https://itsfoss.com/linux-runs-97-percent-worlds-top-500-supercomputers/
|
||||
[14]: https://www.top500.org/
|
||||
[15]: https://www.top500.org/statistics/sublist/
|
||||
[16]: https://itsfoss.com/wp-content/uploads/2016/11/fastest-supercomputers.png
|
||||
[17]: https://itsfoss.com/digikam-5-0-released-install-it-in-ubuntu-linux/
|
||||
[18]: https://www.top500.org/statistics/sublist/
|
||||
@ -0,0 +1,176 @@
|
||||
如何使用 Apache 控制命令检查它的模块是否已经启用或加载
|
||||
============================================================
|
||||
|
||||
本篇中,我们会简要地讨论 Apache 服务器前端以及如何列出或查看已经启用的 Apache 模块。
|
||||
|
||||
Apache 基于模块化的理念而构建,这样就可以让 web 管理员添加不同的模块来扩展主要的功能及[增强性能][5]。
|
||||
|
||||
常见的 Apache 模块有:
|
||||
|
||||
1. mod_ssl – 提供了 [HTTPS 功能][1]。
|
||||
2. mod_rewrite – 可以用正则表达式匹配 url 样式,并且使用 [.htaccess 技巧][2]来进行透明转发,或者提供 HTTP 状态码回应。
|
||||
3. mod_security – 用于[保护 Apache 免于暴力破解或者 DDoS 攻击][3]。
|
||||
4. mod_status - 用于[监测 Apache 的负载及页面统计][4]。
|
||||
|
||||
在 Linux 中 `apachectl` 或者 `apache2ctl`用于控制 Apache 服务器,是 Apache 的前端。
|
||||
|
||||
你可以用下面的命令显示 `apache2ctl` 的使用信息:
|
||||
|
||||
```
|
||||
$ apache2ctl help
|
||||
或者
|
||||
$ apachectl help
|
||||
```
|
||||
```
|
||||
Usage: /usr/sbin/httpd [-D name] [-d directory] [-f file]
|
||||
[-C "directive"] [-c "directive"]
|
||||
[-k start|restart|graceful|graceful-stop|stop]
|
||||
[-v] [-V] [-h] [-l] [-L] [-t] [-S]
|
||||
Options:
|
||||
-D name : define a name for use in directives
|
||||
-d directory : specify an alternate initial ServerRoot
|
||||
-f file : specify an alternate ServerConfigFile
|
||||
-C "directive" : process directive before reading config files
|
||||
-c "directive" : process directive after reading config files
|
||||
-e level : show startup errors of level (see LogLevel)
|
||||
-E file : log startup errors to file
|
||||
-v : show version number
|
||||
-V : show compile settings
|
||||
-h : list available command line options (this page)
|
||||
-l : list compiled in modules
|
||||
-L : list available configuration directives
|
||||
-t -D DUMP_VHOSTS : show parsed settings (currently only vhost settings)
|
||||
-S : a synonym for -t -D DUMP_VHOSTS
|
||||
-t -D DUMP_MODULES : show all loaded modules
|
||||
-M : a synonym for -t -D DUMP_MODULES
|
||||
-t : run syntax check for config files
|
||||
```
|
||||
`apache2ctl` 可以工作在两种模式下,SysV init 模式和直通模式。在 SysV init 模式下,`apache2ctl` 用如下的简单的单命令形式:
|
||||
|
||||
```
|
||||
$ apachectl command
|
||||
或者
|
||||
$ apache2ctl command
|
||||
```
|
||||
|
||||
比如要启动并检查它的状态,运行这两个命令。如果你是普通用户,使用 [sudo 命令][6]来以 root 用户权限来运行:
|
||||
|
||||
```
|
||||
$ sudo apache2ctl start
|
||||
$ sudo apache2ctl status
|
||||
```
|
||||
```
|
||||
tecmint@TecMint ~ $ sudo apache2ctl start
|
||||
AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1\. Set the 'ServerName' directive globally to suppress this message
|
||||
httpd (pid 1456) already running
|
||||
tecmint@TecMint ~ $ sudo apache2ctl status
|
||||
Apache Server Status for localhost (via 127.0.0.1)
|
||||
|
||||
Server Version: Apache/2.4.18 (Ubuntu)
|
||||
Server MPM: prefork
|
||||
Server Built: 2016-07-14T12:32:26
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
Current Time: Tuesday, 15-Nov-2016 11:47:28 IST
|
||||
Restart Time: Tuesday, 15-Nov-2016 10:21:46 IST
|
||||
Parent Server Config. Generation: 2
|
||||
Parent Server MPM Generation: 1
|
||||
Server uptime: 1 hour 25 minutes 41 seconds
|
||||
Server load: 0.97 0.94 0.77
|
||||
Total accesses: 2 - Total Traffic: 3 kB
|
||||
CPU Usage: u0 s0 cu0 cs0
|
||||
.000389 requests/sec - 0 B/second - 1536 B/request
|
||||
1 requests currently being processed, 4 idle workers
|
||||
|
||||
__W__...........................................................
|
||||
................................................................
|
||||
......................
|
||||
|
||||
Scoreboard Key:
|
||||
"_" Waiting for Connection, "S" Starting up, "R" Reading Request,
|
||||
"W" Sending Reply, "K" Keepalive (read), "D" DNS Lookup,
|
||||
"C" Closing connection, "L" Logging, "G" Gracefully finishing,
|
||||
"I" Idle cleanup of worker, "." Open slot with no current process
|
||||
```
|
||||
|
||||
当在直通模式下,`apache2ctl` 可以用下面的语法带上所有 Apache 的参数:
|
||||
|
||||
```
|
||||
$ apachectl [apache-argument]
|
||||
$ apache2ctl [apache-argument]
|
||||
```
|
||||
|
||||
可以用下面的命令列出所有的 Apache 参数:
|
||||
|
||||
```
|
||||
$ apache2 help [在基于Debian的系统中]
|
||||
$ httpd help [在RHEL的系统中]
|
||||
```
|
||||
|
||||
### 检查启用的 Apache 模块
|
||||
|
||||
因此,为了检测你的 Apache 服务器启动了哪些模块,在你的发行版中运行适当的命令,`-t -D DUMP_MODULES` 是一个用于显示所有启用的模块的 Apache 参数:
|
||||
|
||||
```
|
||||
--------------- 在基于 Debian 的系统中 ---------------
|
||||
$ apache2ctl -t -D DUMP_MODULES
|
||||
或者
|
||||
$ apache2ctl -M
|
||||
```
|
||||
|
||||
```
|
||||
--------------- 在 RHEL 的系统中 ---------------
|
||||
$ apachectl -t -D DUMP_MODULES
|
||||
或者
|
||||
$ httpd -M
|
||||
$ apache2ctl -M
|
||||
```
|
||||
|
||||
```
|
||||
[root@tecmint httpd]# apachectl -M
|
||||
Loaded Modules:
|
||||
core_module (static)
|
||||
mpm_prefork_module (static)
|
||||
http_module (static)
|
||||
so_module (static)
|
||||
auth_basic_module (shared)
|
||||
auth_digest_module (shared)
|
||||
authn_file_module (shared)
|
||||
authn_alias_module (shared)
|
||||
authn_anon_module (shared)
|
||||
authn_dbm_module (shared)
|
||||
authn_default_module (shared)
|
||||
authz_host_module (shared)
|
||||
authz_user_module (shared)
|
||||
authz_owner_module (shared)
|
||||
authz_groupfile_module (shared)
|
||||
authz_dbm_module (shared)
|
||||
authz_default_module (shared)
|
||||
ldap_module (shared)
|
||||
authnz_ldap_module (shared)
|
||||
include_module (shared)
|
||||
....
|
||||
```
|
||||
|
||||
就是这样!在这篇简单的教程中,我们解释了如何使用 Apache 前端工具来列出启动的 apache 模块。记住你可以在下面的反馈表中给我们留下你的问题或者留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/check-apache-modules-enabled
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/install-lets-encrypt-ssl-certificate-to-secure-apache-on-rhel-centos/
|
||||
[2]:http://www.tecmint.com/apache-htaccess-tricks/
|
||||
[3]:http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
|
||||
[4]:http://www.tecmint.com/monitor-apache-web-server-load-and-page-statistics/
|
||||
[5]:http://www.tecmint.com/apache-performance-tuning/
|
||||
[6]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||
|
||||
|
||||
85
published/ubuntu vs ubuntu on windows.md
Normal file
85
published/ubuntu vs ubuntu on windows.md
Normal file
@ -0,0 +1,85 @@
|
||||
Ubuntu 14.04/16.04 与 Windows 10 周年版 Ubuntu Bash 性能对比
|
||||
===========================
|
||||
|
||||
今年初,当 Microsoft 和 Canonical 发布 [Windows 10 Bash 和 Ubuntu 用户空间][1],我尝试做了一些初步性能测试 [Ubuntu on Windows 10 对比 原生 Ubuntu][2],这次我发布更多的,关于原生纯净的 Ubuntu 和基于 Windows 10 的基准对比。
|
||||
|
||||

|
||||
|
||||
Windows 的 Linux 子系统测试完成了所有测试,并随着 Windows 10周年更新放出。 默认的 Ubuntu 用户空间还是 Ubuntu 14.04,但是已经可以升级到 16.04。所以测试首先在 14.04 测试,完成后将系统升级升级到 16.04 版本并重复所有测试。完成所有基于 Windows 的 Ubuntu 子系统测试后,我在同样的系统上干净地安装了 Ubuntu 14.04.5 和 Ubuntu 16.04 LTS 来做性能对比。
|
||||
|
||||

|
||||
|
||||
配置为 Intel i5 6600K Skylake,16G 内存和 256G 东芝 ssd,测试过程中每个操作系统都采用其原生默认配置和软件包。
|
||||
|
||||

|
||||
|
||||
这次 Ubuntu/Bash on Windows 和原生 Ubuntu 对比测试,采用开源软件 [Phoronix 测试套件](http://www.phoronix-test-suite.com/),完全自动化并可重复测试。
|
||||
|
||||

|
||||
|
||||
首先是 SQLite 嵌入式数据库基准测试。这方面开箱即用的 Ubuntu/Bash on Windows 性能是相当的慢,但是如果将环境从 14.04 升级到 16.04 LTS,性能会快很多。然而,对于繁重磁盘操作的任务,原生 Ubuntu Linux 几乎比 Windows 的子系统 Linux 快了近 2 倍。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
编译测试作为额外的繁重磁盘操作测试显示,定制的 Windows 子系统真的成倍的限制了 Ubuntu 性能。
|
||||
|
||||
接下来,是一些使用 Stream 的基本的系统内存速度测试:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
奇怪的是,这些 Stream 内存的基准测试显示 Ubuntu on Windows 的性能比原生的 Ubuntu 好!这个现象同时发生在基于同样的 Windows 却环境不同的 14.04 和 16.04 LTS 上。
|
||||
|
||||
接下来,是一些繁重 CPU 操作测试。
|
||||
|
||||

|
||||
|
||||
通过 Dolfyn 科学测试,Ubuntu On Windows 和原生 Ubuntu 之间的性能其实是相当接近的。 对于 Ubuntu 16.04,由于较新的 GCC 编译器性能衰减,两个平台上的性能都较慢。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
透过 Fhourstones 测试和 John The Ripper 测试表明,通过在 Windows 的 Linux 子系统运行的 Ubuntu 的性能可以非常接近裸机 Ubuntu Linux 性能!
|
||||
|
||||

|
||||
|
||||
类似于 Stream 测试,x264 结果是另一个奇怪的情况,其中最好的性能实际上是使用 Linux 子系统的 Ubuntu On Windows!
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
计时编译基准测试非常利于裸机 Ubuntu Linux。这是应该是由于大型程序编译需要大量读写磁盘,在先前测试已经发现了,这是基于 Windows 的 Linux 子系统缓慢的一大领域。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
许多其他的通用开源基准测试表明,严格的针对 CPU 的测试,Windows 子系统的 Ubuntu 的性能是很接近的,甚至是与原生安装在实际硬件中的 Ubuntu Linux 相等。
|
||||
|
||||
最新的 Windows 的 Linux 子系统,测试结果实际上相当令人印象深刻。让人沮丧的仅仅只是持续缓慢的磁盘/文件系统性能,但是对于受 CPU 限制的工作负载,结果是非常引人注目的。还有很罕见的情况, x264 和 Stream 测试,Ubuntu On Windows 上的性能看起来明显优于运行在实际硬件上 的Ubuntu Linux。
|
||||
|
||||
总的来说,体验是十分愉快的,并且在 Ubuntu/Bash on Windows 也没有遇到任何其他的 bug。如果你有还兴趣了解更多关于 Windows 和 Linux 的基准测试,欢迎留言讨论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=article&item=windows10-anv-wsl&num=1
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.michaellarabel.com/
|
||||
[1]: http://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-User-Space-On-Win10
|
||||
[2]: http://www.phoronix.com/scan.php?page=article&item=windows-10-lxcore&num=1
|
||||
|
||||
@ -1,3 +1,7 @@
|
||||
/*翻译中 WangYueScream LemonDemo*/
|
||||
|
||||
|
||||
|
||||
What is open source
|
||||
===========================
|
||||
|
||||
|
||||
@ -1,68 +0,0 @@
|
||||
/*翻译中 WangYueScream LemonDemo*/
|
||||
|
||||
|
||||
Fedora-powered computer lab at our university
|
||||
==========
|
||||
|
||||

|
||||
|
||||
At the [University of Novi Sad in Serbia, Faculty of Sciences, Department of Mathematics and Informatics][5], we teach our students a lot of things. From an introduction to programming to machine learning, all the courses make them think like great developers and software engineers. The pace is fast and there are many students, so we must have a setup on which we can rely on. We decided to switch our computer lab to Fedora.
|
||||
|
||||
### Previous setup
|
||||
|
||||
Our previous solution was keeping our development software in Windows [virtual machines][4] installed on Ubuntu Linux. This seemed like a good idea at the time. However, there were a couple of drawbacks. Firstly, there were serious performance losses because of running virtual machines. Performance and speed of the operating system was impacted because of this. Also, sometimes virtual machines ran concurrently in another user’s session. This led to serious slowdowns. We were losing precious time on booting the machines and then booting the virtual machines. Lastly, we realized that most of our software was Linux-compatible. Virtual machines weren’t necessary. We had to find a better solution.
|
||||
|
||||
### Enter Fedora!
|
||||
|
||||

|
||||
|
||||
Picture of a computer lab running Fedora Workstation by default
|
||||
|
||||
We thought about replacing the virtual machines with a “bare bones” installation for a while. We decided to go for Fedora for several reasons.
|
||||
|
||||
#### Cutting edge of development
|
||||
|
||||
In our courses, we use many different development tools. Therefore, it is crucial that we always use the latest and greatest development tools available. In Fedora, we found 95% of the tools we needed in the official software repositories! For a few tools, we had to do a manual installation. This was easy in Fedora because you have almost all development tools available out of the box.
|
||||
|
||||
What we realized in this process was that we used a lot of free and open source software and tools. Having all that software always up to date was always going to be a lot of work – but not with Fedora.
|
||||
|
||||
#### Hardware compatibility
|
||||
|
||||
The second reason for choosing Fedora in our computer lab was hardware compatibility. The computers in the lab are new. In the past, there were some problems with older kernel versions. In Fedora, we knew that we would always have a recent kernel. As we expected, everything worked out of the box without any issues.
|
||||
|
||||
We decided that we would go for the [Workstation edition][3] of Fedora with [GNOME desktop environment][2]. Students found it easy, intuitive, and fast to navigate through the operating system. It was important for us that students have an easy environment where they could focus on the tasks at hand and the course itself rather than a complicated or slow user interface.
|
||||
|
||||
#### Powered by freedom
|
||||
|
||||
Lastly, in our department, we value free and open source software greatly. By utilizing such software, students are able to use it freely even when they graduate and start working. In the process, they also learn about Fedora and free and open source software in general.
|
||||
|
||||
### Switching the computer lab
|
||||
|
||||
We took one of the computers and fully set it up manually. That included preparing all the needed scripts and software, setting up remote access, and other important components. We also made one user account per course so students could easily store their files.
|
||||
|
||||
After that one computer was ready, we used a great, free and open source tool called [CloneZilla][1]. CloneZilla let us make a hard drive image for restoration. The image size was around 11GB. We used some fast USB 3.0 flash drives to restore the disk image to the remaining computers. We managed to fully provision and setup twenty-four computers in one hour and fifteen minutes, with just a couple of flash drives.
|
||||
|
||||
### Future work
|
||||
|
||||
All the computers in our computer lab are now exclusively using Fedora (with no virtual machines). The remaining work is to set up some administration scripts for remotely installing software, turning computers on and off, and so forth.
|
||||
|
||||
We would like to thank all Fedora maintainers, packagers, and other contributors. We hope our work encourages other schools and universities to make a switch similar to ours. We happily confirm that Fedora works great for us, and we can also vouch that it would work great for you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-computer-lab-university/
|
||||
|
||||
作者:[Nemanja Milošević][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/nmilosev/
|
||||
[1]:http://clonezilla.org/
|
||||
[2]:https://www.gnome.org/
|
||||
[3]:https://getfedora.org/workstation/
|
||||
[4]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[5]:http://www.dmi.rs/
|
||||
@ -1,57 +0,0 @@
|
||||
willcoderwang translating
|
||||
|
||||
# Would You Consider Riding in a Driverless Car?
|
||||
|
||||

|
||||
|
||||
Technology goes through major movements. The last one we entered into was the wearables phase with the Apple Watch and clones, FitBits, and Google Glass. It seems like the next phase they’ve been working on for quite a while is the driverless car.
|
||||
|
||||
|
||||
These cars, sometimes called autonomous cars, self-driving cars, or robotic cars, would literally drive themselves thanks to technology. They detect their surroundings, such as obstacles and signs, and use GPS to find their way. But would they be safe to drive in? We asked our technology-minded writers, “Would you consider riding in a driverless car?
|
||||
|
||||
### Our Opinion
|
||||
|
||||
**Derrik** reports that he would ride in a driver-less car because “_the technology is there and a lot of smart people have been working on it for a long time._” He admits there are issues with them, but for the most part he believes a lot of the accidents happen when a human does get involved. But if you take humans out of the equation, he thinks riding in a driverless car “_would be incredibly safe_.”
|
||||
|
||||
For **Phil**, these cars give him “the willies,” yet he admits that’s only in the abstract as he’s never ridden in one. He agrees with Derrik that the tech is well developed and knows how it works, but then sees himself as “a_ tough sell being a bit of a luddite at heart._” He admits to even rarely using cruise control. Yet he agrees that a driver relying on it too much would be what would make him feel unsafe.
|
||||
|
||||

|
||||
|
||||
**Robert** agrees that “_the concept is a little freaky,_” but in principle he doesn’t see why cars shouldn’t go in that direction. He notes that planes have gone that route and become much safer, and he believes the accidents we see are mainly “_caused by human error due to over-relying on the technology then not knowing what to do when it fails._”
|
||||
|
||||
He’s a bit of an “anxious passenger” as it is, preferring to have control over the situation, so for him much of it would have to do with where he car is being driven. He’d be okay with it if it was driving in the city at slow speeds but definitely not on “motorways of weaving English country roads with barely enough room for two cars to drive past each other.” He and Phil both see English roads as much different than American ones. He suggests letting others be the guinea pigs and joining in after it’s known to be safe.
|
||||
|
||||
For **Mahesh**, he would definitely ride in a driverless car, as he knows that the companies with these cars “_have robust technology and would never put their customers at risk._” He agrees that it depends on the roads that the cars are being driven on.
|
||||
|
||||
My opinion kind of floats in the middle of all the others. While I’m normally one to jump readily into new technology, putting my life at risk makes it different. I agree that the cars have been in development so long they’re bound to be safe. And frankly there are many drivers on the road that are much more dangerous than driverless cars. But like Robert, I think I’ll let others be the guinea pigs and will welcome the technology once it becomes a bit more commonplace.
|
||||
|
||||
### Your Opinion
|
||||
|
||||
Where do you sit with this issue? Do you trust this emerging technology? Or would you be a nervous nelly in one of these cars? Would you consider driving in a driverless car? Jump into the discussion below in the comments.
|
||||
|
||||
<small style="box-sizing: inherit; font-size: 16px;">Image Credit: [Steve Jurvetson][4] and [Steve Jurvetson at Wikimedia Commons][3]</small>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/riding-driverless-car/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[Laura Tucker][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/lauratucker/
|
||||
[1]:https://www.maketecheasier.com/riding-driverless-car/#comments
|
||||
[2]:https://www.maketecheasier.com/author/lauratucker/
|
||||
[3]:https://commons.m.wikimedia.org/wiki/File:Inside_the_Google_RoboCar_today_with_PlanetLabs.jpg
|
||||
[4]:https://commons.m.wikimedia.org/wiki/File:Jurvetson_Google_driverless_car_trimmed.jpg
|
||||
[5]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[6]:https://www.maketecheasier.com/best-wordpress-video-plugins/
|
||||
[7]:https://www.maketecheasier.com/hidden-google-games/
|
||||
[8]:mailto:?subject=Would%20You%20Consider%20Riding%20in%20a%20Driverless%20Car?&body=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F
|
||||
[9]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F&text=Would+You+Consider+Riding+in+a+Driverless+Car%3F
|
||||
[10]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F
|
||||
[11]:https://www.maketecheasier.com/category/opinion/
|
||||
@ -1,58 +0,0 @@
|
||||
Rusking Translating...
|
||||
|
||||
# Arch Linux: In a world of polish, DIY never felt so good
|
||||
|
||||

|
||||
|
||||
Dig through the annals of Linux journalism and you'll find a surprising amount of coverage of some pretty obscure distros. Flashy new distros like Elementary OS and Solus garner attention for their slick interfaces, and anything shipping with a MATE desktop gets coverage by simple virtue of using MATE.
|
||||
|
||||
Thanks to television shows like _Mr Robot_, I fully expect coverage of even Kali Linux to be on the uptick soon.
|
||||
|
||||
In all that coverage, though, there's one very widely used distro that's almost totally ignored: Arch Linux.
|
||||
|
||||
Arch gets very little coverage for a several reasons, not the least of which is that it's somewhat difficult to install and requires you feel comfortable with the command line to get it working. Worse, from the point of view of anyone trying to appeal to mainstream users, that difficulty is by design - nothing keeps the noobs out like a daunting install process.
|
||||
|
||||
It's a shame, though, because once the installation is complete, Arch is actually - in my experience - far easier to use than any other Linux distro I've tried.
|
||||
|
||||
But yes, installation is a pain. Hand-partitioning, hand-mounting and generating your own `fstab` files takes more time and effort than clicking "install" and merrily heading off to do something else. But the process of installing Arch teaches you a lot. It pulls back the curtain so you can see what's behind it. In fact it makes the curtain disappear entirely. In Arch, _you_ are the person behind the curtain.
|
||||
|
||||
In addition to its reputation for being difficult to install, Arch is justly revered for its customizability, though this is somewhat misunderstood. There is no "default" desktop in Arch. What you want installed on top of the base set of Arch packages is entirely up to you.
|
||||
|
||||
|
||||
|
||||
While you can see this as infinite customizability, you can also see it as totally lacking in customization. For example, unlike - say - Ubuntu there is almost no patching or customization happening in Arch. Arch developers simply pass on what upstream developers have released, end of story. For some this good; you can run "pure" GNOME, for instance. But in other cases, some custom patching can take care of bugs that upstream devs might not prioritize.
|
||||
|
||||
The lack of a default set of applications and desktop system also does not make for tidy reviews - or reviews at all really, since what I install will no doubt be different to what you choose. I happened to select a very minimal setup of bare Openbox, tint2 and dmenu. You might prefer the latest release of GNOME. We'd both be running Arch, but our experiences of it would be totally different. This is of course true of any distro, but most others have a default desktop at least.
|
||||
|
||||
Still there are common elements that together can make the basis of an Arch review. There is, for example, the primary reason I switched - Arch is a rolling release distro. This means two things. First, the latest kernels are delivered as soon as they're available and reasonably stable. This means I can test things that are difficult to test with other distros. The other big win for a rolling distro is that all updates are delivered when they're ready. Not only does this mean newer software sooner, it means there's no massive system updates that might break things.
|
||||
|
||||
Many people feel that Arch is less stable because it's rolling, but in my experience over the last nine months I would argue the opposite.
|
||||
|
||||
I have yet to break anything with an update. I did once have to rollback because my /boot partition wasn't mounted when I updated and changes weren't written, but that was pure user error. Bugs that do surface (like some regressions related to the trackpad on a Dell XPS laptop I was testing) are fixed and updates are available much faster than they would be with a non-rolling distro. In short, I've found Arch's rolling release updates to be far more stable than anything else I've been using along side it. The only caveat I have to add to that is read the wiki and pay close attention to what you're updating.
|
||||
|
||||
This brings us to the main reason I suspect that Arch's appeal is limited - you have to pay attention to what you're doing. Blindly updating Arch is risky - but it's risky with any distro; you've just been conditioned to think it's not because you have no choice.
|
||||
|
||||
All of which leads me to the other major reason I embraced Arch - the [Arch Philosophy][1]. The part in particular that I find appealing is this bit: "[Arch] is targeted at the proficient GNU/Linux user, or anyone with a do-it-yourself attitude who is willing to read the documentation, and solve their own problems."
|
||||
|
||||
As Linux moves further into the mainstream developers seem to feel a greater need to smooth over all the rough areas - as if mirroring the opaque user experience of proprietary software were somehow the apex of functionality.
|
||||
|
||||
Strange though it sounds in this day and age, there are many of us who actually prefer to configure things ourselves. In this sense Arch may well be the last refuge of the DIY Linux user. ®
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theregister.co.uk/2016/11/02/arch_linux_taster/
|
||||
|
||||
作者:[Scott Gilbertson][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/1785
|
||||
[1]:https://wiki.archlinux.org/index.php/Arch_Linux
|
||||
[2]:http://www.theregister.co.uk/Author/1785
|
||||
[3]:https://www.linkedin.com/shareArticle?mini=true&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&summary=Last%20refuge%20for%20purists
|
||||
[4]:http://twitter.com/share?text=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&via=theregister
|
||||
[5]:http://www.reddit.com/submit?url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good
|
||||
@ -1,87 +0,0 @@
|
||||
[
|
||||

|
||||
][2]There are many differences between **open source operating system** and **closed source operating system**. Here we have written few of them.
|
||||
|
||||
### What Is Open Source? It's Freedom!
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
This is the most important thing that a user should possess. I may or may not be modifying the code but someone who wants to modify the code for good purposes should not be restricted. And a user should be allowed to share the software if he likes it. And this is all possible with **open source** software.
|
||||
|
||||
The **closed source** operating systems have really scaring license terms. Moreover do all the people read the license terms?, Nope, most of them just click ‘Accept’.
|
||||
|
||||
* * *
|
||||
|
||||
### Cost
|
||||
|
||||
Nearly all of the open source operating systems are free of cost. People only donate voluntarily. And a single installation **CD/DVD or USB** can be used to install the OS in as many computers as possible.
|
||||
|
||||
Closed source operating systems are very costly when compared with open source OSs and if you are building a PC, it may cost you at least $100 per PC.
|
||||
|
||||
We could use the money that we may spend on closed source software to buy better.
|
||||
|
||||
### Choice
|
||||
|
||||
There are numerous open source operating systems out there. So if you don’t like a distro then you can try others and at least a single operating system will be suitable for you.
|
||||
|
||||
Distros like Ubuntu studio, Bio Linux, Edubuntu, Kali Linux, Qubes, SteamOS are some of the distros that are created for the particular type of users.
|
||||
|
||||
Is there anything called choice in closed source operating systems? I don’t think so.
|
||||
|
||||
### Privacy
|
||||
|
||||
There is no need for **Open source operating systems** to collect user data. They are not going show any personalized ads or sell your data to third parties. If the developers need money they will ask for donations or display ads on their website. ADs will always be related to Linux, so it also helps us.
|
||||
|
||||
You might have known how a major closed source operating system(you know what its name is) is said to be collecting users data which caused many people to turn down their free upgrade offer. Many users of that OS had even turned off updates to avoid any upgrade, it means they preferred security risk to free upgrade.
|
||||
|
||||
### Security
|
||||
|
||||
Open source software are mostly secure. They are not secure because of less market share but the way they are made. Qubes Os is one of the most secure OS that isolates the running software from one another.
|
||||
|
||||
Closed source operating systems compromise security for usability making them more vulnerable.
|
||||
|
||||
### Hardware support
|
||||
|
||||
Many of us might have an old PC that we don’t want to throw away and at that situation lightweight distros that are capable of giving a new life to them. Here is a list of lightweight operating systems you can try these distros [5 Lightweight Linux for old computers][3]. Linux based OSs comes with drivers for almost all devices, so there won’t be any need to search and install drivers.
|
||||
|
||||
Many a time closed source operating systems scrap support for older hardware forcing the user to buy new hardware. We may have to search and install drivers ourself.
|
||||
|
||||
### Community Support
|
||||
|
||||
Nearly all of the **open source OSes** have user forums where you can ask questions and get answers from other users. People share tips and tricks and help each other. Experienced Linux users love to help newbies, so they always try their best to help them.
|
||||
|
||||
**Closed source OSes **community is not even comparable to open source OS community. Questions asked might even go unanswered.
|
||||
|
||||
### Monetisation
|
||||
|
||||
Making many out of OSes will be tough. Developers accept donations from users and get some money from ads that are displayed on their website. Most of the donations are used to pay hosting bills and developers’ salary.
|
||||
|
||||
Many of the closed source OSes not only make money from licensing their software but also through targeted ads.
|
||||
|
||||
### Crapware
|
||||
|
||||
I accept some of the open source operating systems provide some software that we may not use in our lifetime and some people consider them as crapware. But there are distros that provide the minimal installation that contain no unwanted software. So, crapware is not really a problem.
|
||||
|
||||
All the closed source operating systems contain crapware installed by the manufacturer and will force as to do a clean installation.
|
||||
|
||||
Open source software is more like a philosophy . It’s a way of sharing and learning. It’s even good for the economy.
|
||||
So, we have listed things that we know. If you think we have missed some points, then please do comment and let us know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/open-source-vs-closed-source
|
||||
|
||||
作者:[Mohd Sohail][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/mohdsohail
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/what-is-open-source_orig.jpg?250
|
||||
[2]:http://www.linuxandubuntu.com/home/open-source-vs-closed-source
|
||||
[3]:http://www.linuxandubuntu.com/home/5-lightweight-linux-for-old-computers
|
||||
@ -1,3 +1,5 @@
|
||||
fuowang翻译中
|
||||
|
||||
WattOS: A Rock-Solid, Lightning-Fast, Lightweight Linux Distro For All
|
||||
=============================
|
||||
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
willcoderewang 翻译中
|
||||
|
||||
How To Manually Backup Your SMS / MMS Messages On Android?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
If you’re switching a device or upgrading your system, making a backup of your data might be of crucial importance.
|
||||
|
||||
|
||||
One of the places where our important data may lie, is in our SMS / MMS messages, be it of sentimental or utilizable value, backing it up might prove quite useful.
|
||||
|
||||
However, unlike our photos, videos or song files which can be transferred and backed up with relative ease, backing our SMS / MMS usually proves to be a bit more complicated task that commonly require involving a third party-app or service.
|
||||
|
||||
### Why Do It Manually?
|
||||
|
||||
Although there currently exist quite a bit of different apps that might take care of backing SMS and MMS for you, you may want to consider doing it manually for the following reasons:
|
||||
|
||||
1. Apps **may not work** on different devices or different Android versions.
|
||||
2. Apps may backup your data by uploading it to the Internet cloud therefore requiring you to **jeopardize the safety** of your content.
|
||||
3. By backing up manually, you have complete control over where your data goes and what it goes through, thus **limiting the risk of spyware** in the process.
|
||||
4. Doing it manually can be overall **less time consuming, easier and more straightforward**than any other way.
|
||||
|
||||
### How To Backup SMS / MMS Manually?
|
||||
|
||||
To backup your SMS / MMS messages manually you’ll need to have an Android tool called [adb][1]installed on your computer.
|
||||
|
||||
Now, the important thing to know regarding SMS / MMS is that Android stores them in a database commonly named **mmssms.db.**
|
||||
|
||||
Since the location of that database may differ between one device to another and also because other SMS apps can create databases of their own, such as, gommssms.db created by GO SMS app, the first thing you’d want to do is to search for these databases.
|
||||
|
||||
So, open up your CLI tool (I use Linux Terminal, you may use Windows CMD or PowerShell) and issue the following commands:
|
||||
|
||||
Note: below is a series of commands needed for the task and later is the explanation of what each command does.
|
||||
|
||||
`
|
||||
adb root
|
||||
|
||||
adb shell
|
||||
|
||||
find / -name "*mmssms*"
|
||||
|
||||
exit
|
||||
|
||||
adb pull /PATH/TO/mmssms.db /PATH/TO/DESTINATION/FOLDER
|
||||
|
||||
`
|
||||
|
||||
#### Explanation:
|
||||
|
||||
We start with adb root command in order to start adb in root mode – so that we’ll have permissions to reach system protected files as well.
|
||||
|
||||
“adb shell” is used to get inside the device shell.
|
||||
|
||||
Next, the “find” command is used to search for the databases. (in my case it’s found in: /data/data/com.android.providers.telephony/databases/mmssms.db)
|
||||
|
||||
* Tip: if your Terminal prints too many irrelevant results, try refining your “find” parameters (google it).
|
||||
|
||||
[
|
||||
|
||||
][2]
|
||||
|
||||
Android SMS&MMS databases
|
||||
|
||||
Then we use exit command in order to exit back to our local system directory.
|
||||
|
||||
Lastly, adb pull is used to copy the database files into a folder on our computer.
|
||||
|
||||
Now, once you’re ready to restore your SMS / MMS messages, whether it’s on a new device or a new system version, simply search again for the location of mmssms on the new system and replace it with the one you’ve backed.
|
||||
|
||||
Use adb push to replace it, e.g: adb push ~/Downloads/mmssms.db /data/data/com.android.providers.telephony/databases/mmssms.db
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iwf1.com/how-to-manually-backup-your-sms-mms-messages-on-android/
|
||||
|
||||
作者:[Liron ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iwf1.com/tag/android
|
||||
[1]:http://developer.android.com/tools/help/adb.html
|
||||
[2]:http://iwf1.com/wordpress/wp-content/uploads/2016/10/Android-SMSMMS-databases.jpg
|
||||
@ -0,0 +1,101 @@
|
||||
Yinux 翻译中
|
||||
Livepatch – Apply Critical Security Patches to Ubuntu Linux Kernel Without Rebooting
|
||||
============================================================
|
||||
|
||||
If you are a system administrator in charge of maintaining critical systems in enterprise environments, we are sure you know two important things:
|
||||
|
||||
1) Finding a downtime window to install security patches in order to handle kernel or operating system vulnerabilities can be difficult. If the company or business you work for does not have security policies in place, operations management may end up favoring uptime over the need to solve vulnerabilities. Additionally, internal bureaucracy can cause delays in granting approvals for a downtime. Been there myself.
|
||||
|
||||
2) Sometimes you can’t really afford a downtime, and should be prepared to mitigate any potential exposures to malicious attacks some other way.
|
||||
|
||||
The good news is that Canonical has recently released (actually, a couple of days ago) its Livepatchservice to apply critical kernel patches to Ubuntu 16.04 (64-bit edition / 4.4.x kernel) without the need for a later reboot. Yes, you read that right: with Livepatch, you don’t need to restart your Ubuntu 16.04 server in order for the security patches to take effect.
|
||||
|
||||
### Signing up for Ubuntu Livepatch
|
||||
|
||||
In order to use Canonical Livepatch Service, you need to sign up at [https://auth.livepatch.canonical.com/][1] and indicate if you are a regular Ubuntu user or an Advantage subscriber (paid option). All Ubuntu users can link up to 3 different machines to Livepatch through the use of a token:
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Canonical Livepatch Service
|
||||
|
||||
In the next step you will be prompted to enter your Ubuntu One credentials or sign up for a new account. If you choose the latter, you will need to confirm your email address in order to finish your registration:
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Ubuntu One Confirmation Mail
|
||||
|
||||
Once you click on the link above to confirm your email address, you’ll be ready to go back to [https://auth.livepatch.canonical.com/][4] and get your Livepatch token.
|
||||
|
||||
### Getting and Using your Livepatch Token
|
||||
|
||||
To begin, copy the unique token assigned to your Ubuntu One account:
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Canonical Livepatch Token
|
||||
|
||||
Then go to a terminal and type:
|
||||
|
||||
```
|
||||
$ sudo snap install canonical-livepatch
|
||||
```
|
||||
|
||||
The above command will install the livepatch, whereas
|
||||
|
||||
```
|
||||
$ sudo canonical-livepatch enable [YOUR TOKEN HERE]
|
||||
```
|
||||
|
||||
will enable it for your system. If this last command indicates it can’t find canonical-livepatch, make sure `/snap/bin` has been added to your path. A workaround consists of changing your working directory to `/snap/bin` and do.
|
||||
|
||||
```
|
||||
$ sudo ./canonical-livepatch enable [YOUR TOKEN HERE]
|
||||
```
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Install Livepatch in Ubuntu
|
||||
|
||||
Overtime, you’ll want to check the description and the status of patches applied to your kernel. Fortunately, this is as easy as doing.
|
||||
|
||||
```
|
||||
$ sudo ./canonical-livepatch status --verbose
|
||||
```
|
||||
|
||||
as you can see in the following image:
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Check Livepatch Status in Ubuntu
|
||||
|
||||
Having enabled Livepatch on your Ubuntu server, you will be able to reduce planned and unplanned downtimes at a minimum while keeping your system secure. Hopefully Canonical’s initiative will award you a pat on the back by management – or better yet, a raise.
|
||||
|
||||
Feel free to let us know if you have any questions about this article. Just drop us a note using the comment form below and we will get back to you as soon as possible.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/livepatch-install-critical-security-patches-to-ubuntu-kernel
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[Yinux](https://github.com/Yinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://auth.livepatch.canonical.com/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Canonical-Livepatch-Service.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/10/Ubuntu-One-Confirmation-Mail.png
|
||||
[4]:https://auth.livepatch.canonical.com/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/10/Livepatch-Token.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/10/Install-Livepatch-in-Ubuntu.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/10/Check-Livepatch-Status.png
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
HOW TO SHARE STEAM GAME FILES BETWEEN LINUX AND WINDOWS
|
||||
============
|
||||
|
||||
|
||||
@ -1,552 +0,0 @@
|
||||
OneNewLife translating
|
||||
|
||||
# Getting Started with Webpack 2
|
||||
|
||||

|
||||
|
||||
Webpack 2 will be out of beta [once the documentation has been finished][26]. But that doesn’t mean you can’t start using version 2 now if you know how to configure it.
|
||||
|
||||
### What is Webpack?
|
||||
|
||||
At its simplest, Webpack is a module bundler for your JavaScript. However, since its release it’s evolved into a manager of all your front-end code (either intentionally or by the community’s will).
|
||||
|
||||
|
||||
|
||||
|
||||
A task runner such as _Gulp _can handle many different preprocessers and transpilers, but in all cases, it will take a source _input_ and crunch it into a compiled _output. _However, it does this on a case-by-case basis with no concern for the system at large. That is the burden of the developer: to pick up where the task runner left off and find the proper way for all these moving parts to mesh together in production.
|
||||
|
||||
Webpack attempts to lighten the developer load a bit by asking a bold question: _what if there were a part of the development process that handled dependencies on its own? What if we could simply write code in such a way that the build process managed itself, based on only what was necessary in the end?_
|
||||
|
||||
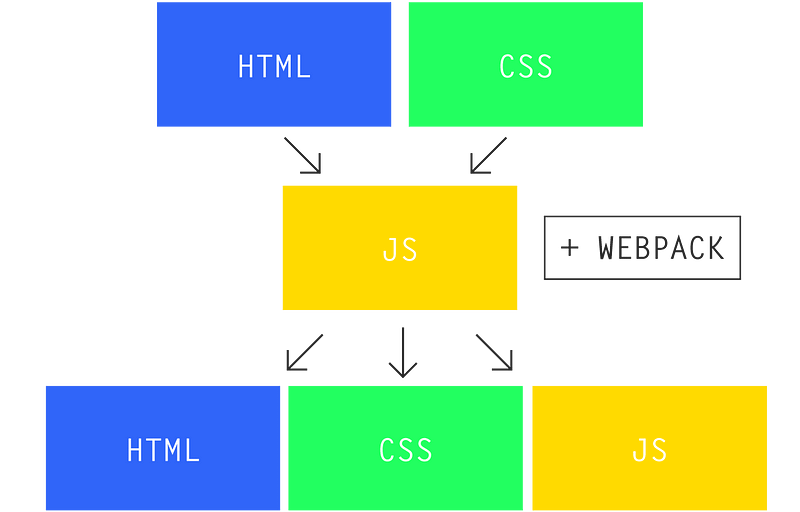
|
||||
|
||||
If you’ve been a part of the web community for the past few years, you already know the preferred method of solving a problem: _build this with JavaScript._And so Webpack attempts to make the build process easier by passing dependencies through JavaScript. But the true power of its design isn’t simply the code _management_ part; it’s that this management layer is 100% valid JavaScript (with Node features). Webpack gives you the ability to write valid JavaScript that has a better sense of the system at large.
|
||||
|
||||
In other words: _you don’t write code for Webpack. You write code for your projec_t. And Webpack keeps up (with some config, of course).
|
||||
|
||||
In a nutshell, if you’ve ever struggled with any of the following:
|
||||
|
||||
* Accidentally including stylesheets and JS libraries you don’t need into production, bloating the size
|
||||
* Encountering scoping issues—both from CSS and JavaScript
|
||||
* Finding a good system for using Node/Bower modules in your JavaScript, or relying on a crazy backend configuration to properly utilize those modules
|
||||
* Needing to optimize asset delivery better but fearing you’ll break something
|
||||
|
||||
…then you could benefit from Webpack. It handles all the above effortlessly by letting JavaScript worry about your dependencies and load order instead of your developer brain. The best part? Webpack can even run purely on the server side, meaning you can still build [progressively-enhanced][25] websites using Webpack.
|
||||
|
||||
### First Steps
|
||||
|
||||
We’ll use [Yarn][24] (`brew install yarn`) in this tutorial instead of `npm`, but it’s totally up to you; they do the same thing. From our project folder, we’ll run the following in a terminal window to add Webpack 2 to both our global packages and our local project:
|
||||
|
||||
```
|
||||
yarn global add webpack@2.1.0-beta.25 webpack-dev-server@2.1.0-beta.9
|
||||
yarn add --dev webpack@2.1.0-beta.25 webpack-dev-server@2.1.0-beta.9
|
||||
```
|
||||
|
||||
We’ll then declare a webpack configuration with a `webpack.config.js` file in the root of our project directory:
|
||||
|
||||
```
|
||||
`'use strict';
|
||||
|
||||
const webpack = require("webpack");
|
||||
|
||||
module.exports = {
|
||||
context: __dirname + "/src",
|
||||
entry: {
|
||||
app: "./app.js",
|
||||
},
|
||||
output: {
|
||||
path: __dirname + "/dist",
|
||||
filename: "[name].bundle.js",
|
||||
},
|
||||
};`
|
||||
```
|
||||
|
||||
_Note: _`___dirname_`_ refers to the root of your project._
|
||||
|
||||
Remember that Webpack “knows” what’s going in your project? It _knows_ by reading your code (don’t worry; it signed an NDA). Webpack basically does the following:
|
||||
|
||||
1. Starting from the `context` folder, …
|
||||
2. … it looks for `entry` filenames …
|
||||
3. … and reads the content. Every `import` ([ES6][7]) or `require()` (Node) dependency it finds as it parses the code, it bundles for the final build. It then searches _those_ dependencies, and those dependencies’ dependencies, until it reaches the very end of the “tree”—only bundling what it needed to, and nothing else.
|
||||
4. From there, Webpack bundles everything to the `output.path` folder, naming it using the `output.filename` naming template (`[name]` gets replaced with the object key from `entry`)
|
||||
|
||||
So if our `src/app.js` file looked something like this (assuming we ran `yarn add --dev moment` beforehand):
|
||||
|
||||
```
|
||||
'use strict';
|
||||
```
|
||||
|
||||
```
|
||||
import moment from 'moment';
|
||||
var rightNow = moment().format('MMMM Do YYYY, h:mm:ss a');
|
||||
console.log( rightNow );
|
||||
```
|
||||
|
||||
```
|
||||
// "October 23rd 2016, 9:30:24 pm"
|
||||
```
|
||||
|
||||
We’d run
|
||||
|
||||
```
|
||||
webpack -p
|
||||
```
|
||||
|
||||
_Note: The _`_p_`_ flag is “production” mode and uglifies/minifies output._
|
||||
|
||||
And it would output a `dist/app.bundle.js` that logged the current date & time to the console. Note that Webpack automatically knew what `'moment'`referred to (although if you had a `moment.js` file in your directory, by default Webpack would have prioritized this over your `moment` Node module).
|
||||
|
||||
### Working with Multiple Files
|
||||
|
||||
You can specify any number of entry/output points you wish by modifying only the `entry` object.
|
||||
|
||||
#### Multiple files, bundled together
|
||||
|
||||
```
|
||||
`'use strict';
|
||||
|
||||
const webpack = require("webpack");
|
||||
|
||||
module.exports = {
|
||||
context: __dirname + "/src",
|
||||
entry: {
|
||||
app: ["./home.js", "./events.js", "./vendor.js"],
|
||||
},
|
||||
output: {
|
||||
path: __dirname + "/dist",
|
||||
filename: "[name].bundle.js",
|
||||
},
|
||||
};`
|
||||
```
|
||||
|
||||
Will all be bundled together as one `dist/app.bundle.js` file, in array order.
|
||||
|
||||
#### Multiple files, multiple outputs
|
||||
|
||||
```
|
||||
`const webpack = require("webpack");
|
||||
|
||||
module.exports = {
|
||||
context: __dirname + "/src",
|
||||
entry: {
|
||||
home: "./home.js",
|
||||
events: "./events.js",
|
||||
contact: "./contact.js",
|
||||
},
|
||||
output: {
|
||||
path: __dirname + "/dist",
|
||||
filename: "[name].bundle.js",
|
||||
},
|
||||
};`
|
||||
```
|
||||
|
||||
Alternately, you may choose to bundle multiple JS files to break up parts of your app. This will be bundled as 3 files: `dist/home.bundle.js`, `dist/events.bundle.js`, and `dist/contact.bundle.js`.
|
||||
|
||||
#### Advanced auto-bundling
|
||||
|
||||
If you’re breaking up your application into multiple `output` bundles (useful if one part of your app has a ton of JS you don’t need to load up front), there’s a likelihood you may be duplicating code across those files, because it will resolve each dependency separately from one another. Fortunately, Webpack has a built-in _CommonsChunk_ plugin to handle this:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
```
|
||||
|
||||
```
|
||||
plugins: [
|
||||
new webpack.optimize.CommonsChunkPlugin({
|
||||
name: "commons",
|
||||
filename: "commons.js",
|
||||
minChunks: 2,
|
||||
}),
|
||||
],
|
||||
```
|
||||
|
||||
```
|
||||
// …
|
||||
};
|
||||
```
|
||||
|
||||
Now, across your `output` files, if you have any modules that get loaded `2` or more times (set by `minChunks`), it will bundle that into a `commons.js` file which you can then cache on the client side. This will result in an additional header request, sure, but you prevent the client from downloading the same libraries more than once. So there are many scenarios where this is a net gain for speed.
|
||||
|
||||
### Developing
|
||||
|
||||
Webpack actually has its own development server, so whether you’re developing a static site or are just prototyping your front-end, it’s perfect for either. To get that running, just add a `devServer` object to `webpack.config.js`:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
context: __dirname + "/src",
|
||||
entry: {
|
||||
app: "./app.js",
|
||||
},
|
||||
output: {
|
||||
filename: "[name].bundle.js",
|
||||
path: __dirname + "/dist/assets",
|
||||
publicPath: "/assets", // New
|
||||
},
|
||||
devServer: {
|
||||
contentBase: __dirname + "/src", // New
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
Now make a `src/index.html` file that has:
|
||||
|
||||
```
|
||||
<script src="/assets/app.bundle.js"></script>
|
||||
```
|
||||
|
||||
… and from your terminal, run:
|
||||
|
||||
```
|
||||
webpack-dev-server
|
||||
```
|
||||
|
||||
Your server is now running at `localhost:8080`. _Note how _`_/assets_`_ in the script tag matches _`_output.publicPath_`_—you can name this whatever you want (useful if you need a CDN)._
|
||||
|
||||
Webpack will hotload any JavaScript changes as you make them without the need to refresh your browser. However, any changes to the`webpack.config.js` file will require a server restart to take effect.
|
||||
|
||||
### Globally-accessible methods
|
||||
|
||||
Need to use some of your functions from a global namespace? Simply set `output.library` within `webpack.config.js`:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
output: {
|
||||
library: 'myClassName',
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
… and it will attach your bundle to a `window.myClassName` instance. So using that name scope, you could call methods available to that entry point (you can read more about this setting [on the documentation][23]).
|
||||
|
||||
### Loaders
|
||||
|
||||
Up until now, we’ve only covered working with JavaScript. It’s important to start with JavaScript because _that’s the only language Webpack speaks_. We can work with virtually any file type, as long as we pass it into JavaScript. We do that with _Loaders_.
|
||||
|
||||
A loader can refer to a preprocessor such as Sass, or a transpiler such as Babel. On NPM, they’re usually named `*-loader` such as `sass-loader` or `babel-loader`.
|
||||
|
||||
#### Babel + ES6
|
||||
|
||||
If we wanted to use ES6 via [Babel][22] in our project, we’d first install the appropriate loaders locally:
|
||||
|
||||
```
|
||||
yarn add --dev babel-loader babel-core babel-preset-es2015
|
||||
```
|
||||
|
||||
… and then add it to `webpack.config.js` so Webpack knows where to use it.
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
```
|
||||
|
||||
```
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.js$/,
|
||||
use: [{
|
||||
loader: "babel-loader",
|
||||
options: { presets: ["es2015"] }
|
||||
}],
|
||||
},
|
||||
|
||||
// Loaders for other file types can go here
|
||||
```
|
||||
|
||||
```
|
||||
],
|
||||
},
|
||||
```
|
||||
|
||||
```
|
||||
// …
|
||||
};
|
||||
```
|
||||
|
||||
_A note for Webpack 1 users: the core concept for Loaders remains the same, but the syntax has improved. Until they finish the docs this may/may not be the exact preferred syntax._
|
||||
|
||||
This looks for the `/\.js$/` RegEx search for any files that end in `.js` to be loaded via Babel. Webpack relies on RegEx tests to give you complete control—it doesn’t limit you to file extensions or assume your code must be organized in a certain way. For example: maybe your `/my_legacy_code/` folder isn’t written in ES6\. So you could modify the `test` above to be `/^((?!my_legacy_folder).)*\.js$/` which would exclude that specific folder, but process the rest with Babel.
|
||||
|
||||
#### CSS + Style Loader
|
||||
|
||||
If we wanted to only load CSS as our application needed, we could do that as well. Let’s say we have an `index.js` file. We’ll import it from there:
|
||||
|
||||
```
|
||||
import styles from './assets/stylesheets/application.css';
|
||||
```
|
||||
|
||||
We’ll get the following error: `You may need an appropriate loader to handle this file type`. Remember that Webpack can only understand JavaScript, so we’ll have to install the appropriate loader:
|
||||
|
||||
```
|
||||
yarn add --dev css-loader style-loader
|
||||
```
|
||||
|
||||
… and then add a rule to `webpack.config.js`:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
```
|
||||
|
||||
```
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.css$/,
|
||||
use: ["style-loader", "css-loader"],
|
||||
},
|
||||
```
|
||||
|
||||
```
|
||||
// …
|
||||
],
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
_Loaders are processed in __reverse array order__. That means _`_css-loader_`_ will run before _`_style-loader_`_._
|
||||
|
||||
You may notice that even in production builds, this actually bundles your CSS in with your bundled JavaScript, and `style-loader` manually writes your styles to the `<head>`. At first glance it may seem a little kooky, but slowly starts to make more sense the more you think about it. You’ve saved a header request—saving valuable time on some connections—and if you’re loading your DOM with JavaScript anyway, this essentially eliminates [FOUC][21] on its own.
|
||||
|
||||
You’ll also notice that—out of the box—Webpack has automatically resolved all of your `@import` queries by packaging those files together as one (rather than relying on CSS’s default import which can result in gratuitious header requests and slow-loading assets).
|
||||
|
||||
Loading CSS from your JS is pretty amazing, because you now can modularize your CSS in powerful new ways. Say you loaded `button.css`only through `button.js`. This would mean if `button.js` is never actually used_, _its CSS wouldn’t bloat out our production build. If you adhere to component-oriented CSS practices such as SMACSS or BEM, you see the value in pairing your CSS more closely with your markup + JavaScript.
|
||||
|
||||
#### CSS + Node modules
|
||||
|
||||
We can use Webpack to take advantage of importing Node modules using Node’s `~` prefix. If we ran `yarn add normalize.css`, we could use:
|
||||
|
||||
```
|
||||
@import "~normalize.css";
|
||||
```
|
||||
|
||||
… and take full advantage of NPM managing our third party styles for us—versioning and all—without any copy + pasting on our part. Further, getting Webpack to bundle CSS for us has obvious advantages over using CSS’s default import, saving the client from gratuitous header requests and slow load times.
|
||||
|
||||
_Update: this and the following section have been updated for accuracy, no longer confusing using CSS Modules to simply import Node modules. Thanks to _[_Albert Fernández_][20]_ for the help!_
|
||||
|
||||
#### CSS Modules
|
||||
|
||||
You may have heard of [CSS Modules][19], which takes the _C_ out of _CSS_. It typically works best only if you’re building the DOM with JavaScript, but in essence, it magically scopes your CSS classes to the JavaScript file that loaded it ([learn more about it here][18]). If you plan on using it, CSS Modules comes packaged with `css-loader` (`yarn add --dev css-loader`):
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
```
|
||||
|
||||
```
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.css$/,
|
||||
use: [
|
||||
"style-loader",
|
||||
{ loader: "css-loader", options: { modules: true } }
|
||||
],
|
||||
},
|
||||
```
|
||||
|
||||
```
|
||||
// …
|
||||
],
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
_Note: for _`_css-loader_`_ we’re now using the __expanded object syntax__ to pass an option to it. You can use a string instead as shorthand to use the default options, as we’re still doing with _`_style-loader_`_._
|
||||
|
||||
* * *
|
||||
|
||||
It’s worth noting that you can actually drop the `~` when importing Node Modules with CSS Modules enabled (e.g.: `@import "normalize.css";`). However, you may encounter build errors now when you `@import` your own CSS. If you’re getting “can’t find ___” errors, try adding a `resolve` object to `webpack.config.js` to give Webpack a better understanding of your intended module order.
|
||||
|
||||
```
|
||||
const path = require("path");
|
||||
```
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
//…
|
||||
```
|
||||
|
||||
```
|
||||
resolve: {
|
||||
modules: [path.resolve(__dirname, "src"), "node_modules"]
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
We specified our source directory first, and then `node_modules`. So Webpack will handle resolution a little better, first looking through our source directory and then the installed Node modules, in that order (replace `"src"` and `"node_modules"` with your source and Node module directories, respectively).
|
||||
|
||||
#### Sass
|
||||
|
||||
Need to use Sass? No problem. Install:
|
||||
|
||||
```
|
||||
yarn add --dev sass-loader node-sass
|
||||
```
|
||||
|
||||
And add another rule:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
```
|
||||
|
||||
```
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.(sass|scss)$/,
|
||||
use: [
|
||||
"style-loader",
|
||||
"css-loader",
|
||||
"sass-loader",
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
// …
|
||||
],
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
Then when your Javascript calls for an `import` on a `.scss` or `.sass` file, Webpack will do its thing.
|
||||
|
||||
#### CSS bundled separately
|
||||
|
||||
Maybe you’re dealing with progressive enhancement; maybe you need a separate CSS file for some other reason. We can do that easily by swapping out `style-loader` with `extract-text-webpack-plugin` in our config without having to change any code. Take our example `app.js` file:
|
||||
|
||||
```
|
||||
import styles from './assets/stylesheets/application.css';
|
||||
```
|
||||
|
||||
Let’s install the plugin locally (we need the beta version for this as of Oct 2016)…
|
||||
|
||||
```
|
||||
yarn add --dev extract-text-webpack-plugin@2.0.0-beta.4
|
||||
```
|
||||
|
||||
… and add to `webpack.config.js`:
|
||||
|
||||
```
|
||||
const ExtractTextPlugin = require("extract-text-webpack-plugin");
|
||||
```
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
```
|
||||
|
||||
```
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.css$/,
|
||||
use: [
|
||||
ExtractTextPlugin.extract("css"),
|
||||
{ loader: "css-loader", options: { modules: true } },
|
||||
],
|
||||
},
|
||||
|
||||
// …
|
||||
]
|
||||
},
|
||||
plugins: [
|
||||
new ExtractTextPlugin({
|
||||
filename: "[name].bundle.css",
|
||||
allChunks: true,
|
||||
}),
|
||||
],
|
||||
};
|
||||
```
|
||||
|
||||
Now when running `webpack -p` you’ll also notice an `app.bundle.css` file in your `output` directory. Simply add a `<link>` tag to that file in your HTML as you would normally.
|
||||
|
||||
#### HTML
|
||||
|
||||
As you might have guessed, there’s also an `[html-loader][6]`[ plugin][17] for Webpack. However, when we get to loading HTML with JavaScript, this is about the point where we branch off into a myriad of differing approaches, and I can’t think of one single example that would set you up for whatever you’re planning on doing next. Typically, you’d load HTML for the purpose of using JavaScript-flavored markup such as [JSX][16] or [Mustache][15] or [Handlebars][14] to be used within a larger system such as [React][13], [Angular][12], [Vue][11], or [Ember][10].
|
||||
|
||||
So I’ll end the tutorial here: you _can_ load markup with Webpack, but by this point you’ll be making your own decisions about your architecture that neither I nor Webpack can make for you. But using the above examples for reference and searching for the right loaders on NPM should be enough to get you going.
|
||||
|
||||
### Thinking in Modules
|
||||
|
||||
In order to get the most out of Webpack, you’ll have to think in modules—small, reusable, self-contained processes that do one thing and one thing well. That means taking something like this:
|
||||
|
||||
```
|
||||
└── js/
|
||||
└── application.js // 300KB of spaghetti code
|
||||
```
|
||||
|
||||
… and turning it into this:
|
||||
|
||||
```
|
||||
└── js/
|
||||
├── components/
|
||||
│ ├── button.js
|
||||
│ ├── calendar.js
|
||||
│ ├── comment.js
|
||||
│ ├── modal.js
|
||||
│ ├── tab.js
|
||||
│ ├── timer.js
|
||||
│ ├── video.js
|
||||
│ └── wysiwyg.js
|
||||
│
|
||||
└── application.js // ~ 1KB of code; imports from ./components/
|
||||
```
|
||||
|
||||
The result is clean, reusable code. Each individual component depends on `import`-ing its own dependencies, and `export`-ing what it wants to make public to other modules. Pair this with Babel + ES6, and you can utilize [JavaScript Classes][9] for great modularity, and _don’t-think-about-it _scoping that just works.
|
||||
|
||||
For more on modules, see [this excellent article by Preethi Kasreddy][8].
|
||||
|
||||
* * *
|
||||
|
||||
### Further Reading
|
||||
|
||||
* [What’s New in Webpack 2][5]
|
||||
* [Webpack Config docs][4]
|
||||
* [Webpack Examples][3]
|
||||
* [React + Webpack Starter Kit][2]
|
||||
* [Webpack How-to][1]
|
||||
|
||||
</section>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.madewithenvy.com/getting-started-with-webpack-2-ed2b86c68783#.oozfpppao
|
||||
|
||||
作者:[Drew Powers][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.madewithenvy.com/@an_ennui
|
||||
[1]:https://github.com/petehunt/webpack-howto
|
||||
[2]:https://github.com/kriasoft/react-starter-kit
|
||||
[3]:https://github.com/webpack/webpack/tree/master/examples
|
||||
[4]:https://webpack.js.org/configuration/
|
||||
[5]:https://gist.github.com/sokra/27b24881210b56bbaff7
|
||||
[6]:https://github.com/webpack/html-loader
|
||||
[7]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/import
|
||||
[8]:https://medium.freecodecamp.com/javascript-modules-a-beginner-s-guide-783f7d7a5fcc
|
||||
[9]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes
|
||||
[10]:http://emberjs.com/
|
||||
[11]:http://vuejs.org/
|
||||
[12]:https://angularjs.org/
|
||||
[13]:https://facebook.github.io/react/
|
||||
[14]:http://handlebarsjs.com/
|
||||
[15]:https://github.com/janl/mustache.js/
|
||||
[16]:https://jsx.github.io/
|
||||
[17]:https://github.com/webpack/html-loader
|
||||
[18]:https://github.com/css-modules/css-modules
|
||||
[19]:https://github.com/css-modules/css-modules
|
||||
[20]:https://medium.com/u/901a038e32e5
|
||||
[21]:https://en.wikipedia.org/wiki/Flash_of_unstyled_content
|
||||
[22]:https://babeljs.io/
|
||||
[23]:https://webpack.js.org/concepts/output/#output-library
|
||||
[24]:https://yarnpkg.com/
|
||||
[25]:https://www.smashingmagazine.com/2009/04/progressive-enhancement-what-it-is-and-how-to-use-it/
|
||||
[26]:https://github.com/webpack/webpack/issues/1545#issuecomment-255446425
|
||||
@ -1,121 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
How to Check Bad Sectors or Bad Blocks on Hard Disk in Linux
|
||||
===
|
||||
|
||||
Let us start by defining a bad sector/block, it’s a section on a disk drive or flash memory that can not be read from or written to anymore, as a result of a fixed [physical damage on the disk][7] surface or failed flash memory transistors.
|
||||
|
||||
As bad sectors continue to accumulate, they can undesirably or destructively affect your disk drive or flash memory capacity or even lead to a possible hardware failure.
|
||||
|
||||
It is also important to note that the presence of bad blocks should alert you to start thinking of getting a new disk drive or simply mark the bad blocks as unusable.
|
||||
|
||||
Therefore, in this article, we will go through the necessary steps that can enable you determine the presence or absence of bad sectors on your Linux disk drive or flash memory using certain [disk scanning utilities][6].
|
||||
|
||||
That said, below are the methods:
|
||||
|
||||
### Check Bad Sectors in Linux Disks Using badblocks Tool
|
||||
|
||||
A badblocks program enables users to scan a device for bad sectors or blocks. The device can be a hard disk or an external disk drive, represented by a file such as /dev/sdc.
|
||||
|
||||
Firstly, use the [fdisk command][5] with superuser privileges to display information about all your disk drives or flash memory plus their partitions:
|
||||
|
||||
```
|
||||
$ sudo fdisk -l
|
||||
|
||||
```
|
||||
|
||||
[][4]
|
||||
|
||||
List Linux Filesystem Partitions
|
||||
|
||||
Then scan your Linux disk drive to check for bad sectors/blocks by typing:
|
||||
|
||||
```
|
||||
$ sudo badblocks -v /dev/sda10 > badsectors.txt
|
||||
|
||||
```
|
||||
|
||||
[][3]
|
||||
|
||||
Scan Hard Disk Bad Sectors in Linux
|
||||
|
||||
In the command above, badblocks is scanning device /dev/sda10 (remember to specify your actual device) with the `-v` enabling it to display details of the operation. In addition, the results of the operation are stored in the file badsectors.txt by means of output redirection.
|
||||
|
||||
In case you discover any bad sectors on your disk drive, unmount the disk and instruct the operating system not to write to the reported sectors as follows.
|
||||
|
||||
You will need to employ e2fsck (for ext2/ext3/ext4 file systems) or fsck command with the badsectors.txt file and the device file as in the command below.
|
||||
|
||||
The `-l` option tells the command to add the block numbers listed in the file specified by filename (badsectors.txt) to the list of bad blocks.
|
||||
|
||||
```
|
||||
------------ Specifically for ext2/ext3/ext4 file-systems ------------
|
||||
$ sudo e2fsck -l badsectors.txt /dev/sda10
|
||||
|
||||
OR
|
||||
|
||||
------------ For other file-systems ------------
|
||||
$ sudo fsck -l badsectors.txt /dev/sda10
|
||||
|
||||
```
|
||||
|
||||
### Scan Bad Sectors on Linux Disk Using Smartmontools
|
||||
|
||||
This method is more reliable and efficient for modern disks (ATA/SATA and SCSI/SAS hard drives and solid-state drives) which ship in with a S.M.A.R.T (Self-Monitoring, Analysis and Reporting Technology) system that helps detect, report and possibly log their health status, so that you can figure out any impending hardware failures.
|
||||
|
||||
You can install smartmontools by running the command below:
|
||||
|
||||
```
|
||||
------------ On Debian/Ubuntu based systems ------------
|
||||
$ sudo apt-get install smartmontools
|
||||
|
||||
------------ On RHEL/CentOS based systems ------------
|
||||
$ sudo yum install smartmontools
|
||||
|
||||
```
|
||||
|
||||
Once the installation is complete, use smartctl which controls the S.M.A.R.T system integrated into a disk. You can look through its man page or help page as follows:
|
||||
|
||||
```
|
||||
$ man smartctl
|
||||
$ smartctl -h
|
||||
|
||||
```
|
||||
|
||||
Now execute the smartctrl command and name your specific device as an argument as in the following command, the flag `-H` or `--health` is included to display the SMART overall health self-assessment test result.
|
||||
|
||||
```
|
||||
$ sudo smartctl -H /dev/sda10
|
||||
|
||||
```
|
||||
|
||||
[][2]
|
||||
|
||||
Check Linux Hard Disk Health
|
||||
|
||||
The result above indicates that your hard disk is healthy, and may not experience hardware failures any soon.
|
||||
|
||||
For an overview of disk information, use the `-a` or `--all` option to print out all SMART information concerning a disk and `-x` or `--xall` which displays all SMART and non-SMART information about a disk.
|
||||
|
||||
In this tutorial, we covered a very important topic concerning [disk drive health diagnostics][1], you can reach us via the feedback section below to share your thoughts or ask any questions and remember to always stay connected to Tecmint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/check-linux-hard-disk-bad-sectors-bad-blocks/
|
||||
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/defragment-linux-system-partitions-and-directories/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Check-Linux-Hard-Disk-Health.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/10/Scan-Hard-Disk-Bad-Sectors-in-Linux.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/10/List-Linux-Filesystem-Partitions.png
|
||||
[5]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[6]:http://www.tecmint.com/ncdu-a-ncurses-based-disk-usage-analyzer-and-tracker/
|
||||
[7]:http://www.tecmint.com/defragment-linux-system-partitions-and-directories/
|
||||
@ -1,453 +0,0 @@
|
||||
DTrace for Linux 2016
|
||||
===========
|
||||
|
||||
|
||||
|
||||
With the final major capability for BPF tracing (timed sampling) merging in Linux 4.9-rc1, the Linux kernel now has raw capabilities similar to those provided by DTrace, the advanced tracer from Solaris. As a long time DTrace user and expert, this is an exciting milestone! On Linux, you can now analyze the performance of applications and the kernel using production-safe low-overhead custom tracing, with latency histograms, frequency counts, and more.
|
||||
|
||||
There have been many tracing projects for Linux, but the technology that finally merged didn’t start out as a tracing project at all: it began as enhancements to Berkeley Packet Filter (BPF). At first, these enhancements allowed BPF to redirect packets to create software-defined networks. Later on, support for tracing events was added, enabling programmatic tracing in Linux.
|
||||
|
||||
While BPF currently lacks a high-level language like DTrace, the front-ends available have been enough for me to create many BPF tools, some based on my older [DTraceToolkit][37]. In this post I'll describe how you can use these tools, the front-ends available, and discuss where the technology is going next.
|
||||
|
||||
### Screenshots
|
||||
|
||||
I've been adding BPF-based tracing tools to the open source [bcc][36] project (thanks to Brenden Blanco, of PLUMgrid, for leading bcc development). See the [bcc install][35] instructions. It will add a collection of tools under /usr/share/bcc/tools, including the following.
|
||||
|
||||
Tracing new processes:
|
||||
|
||||
```
|
||||
# **execsnoop**
|
||||
PCOMM PID RET ARGS
|
||||
bash 15887 0 /usr/bin/man ls
|
||||
preconv 15894 0 /usr/bin/preconv -e UTF-8
|
||||
man 15896 0 /usr/bin/tbl
|
||||
man 15897 0 /usr/bin/nroff -mandoc -rLL=169n -rLT=169n -Tutf8
|
||||
man 15898 0 /usr/bin/pager -s
|
||||
nroff 15900 0 /usr/bin/locale charmap
|
||||
nroff 15901 0 /usr/bin/groff -mtty-char -Tutf8 -mandoc -rLL=169n -rLT=169n
|
||||
groff 15902 0 /usr/bin/troff -mtty-char -mandoc -rLL=169n -rLT=169n -Tutf8
|
||||
groff 15903 0 /usr/bin/grotty
|
||||
|
||||
```
|
||||
|
||||
Histogram of disk I/O latency:
|
||||
|
||||
```
|
||||
# **biolatency -m**
|
||||
Tracing block device I/O... Hit Ctrl-C to end.
|
||||
^C
|
||||
msecs : count distribution
|
||||
0 -> 1 : 96 |************************************ |
|
||||
2 -> 3 : 25 |********* |
|
||||
4 -> 7 : 29 |*********** |
|
||||
8 -> 15 : 62 |*********************** |
|
||||
16 -> 31 : 100 |**************************************|
|
||||
32 -> 63 : 62 |*********************** |
|
||||
64 -> 127 : 18 |****** |
|
||||
|
||||
```
|
||||
|
||||
Tracing common ext4 operations slower than 5 milliseconds:
|
||||
|
||||
```
|
||||
# **ext4slower 5**
|
||||
Tracing ext4 operations slower than 5 ms
|
||||
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
21:49:45 supervise 3570 W 18 0 5.48 status.new
|
||||
21:49:48 supervise 12770 R 128 0 7.55 run
|
||||
21:49:48 run 12770 R 497 0 16.46 nsswitch.conf
|
||||
21:49:48 run 12770 R 1680 0 17.42 netflix_environment.sh
|
||||
21:49:48 run 12770 R 1079 0 9.53 service_functions.sh
|
||||
21:49:48 run 12772 R 128 0 17.74 svstat
|
||||
21:49:48 svstat 12772 R 18 0 8.67 status
|
||||
21:49:48 run 12774 R 128 0 15.76 stat
|
||||
21:49:48 run 12777 R 128 0 7.89 grep
|
||||
21:49:48 run 12776 R 128 0 8.25 ps
|
||||
21:49:48 run 12780 R 128 0 11.07 xargs
|
||||
21:49:48 ps 12776 R 832 0 12.02 libprocps.so.4.0.0
|
||||
21:49:48 run 12779 R 128 0 13.21 cut
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
Tracing new active TCP connections (connect()):
|
||||
|
||||
```
|
||||
# **tcpconnect**
|
||||
PID COMM IP SADDR DADDR DPORT
|
||||
1479 telnet 4 127.0.0.1 127.0.0.1 23
|
||||
1469 curl 4 10.201.219.236 54.245.105.25 80
|
||||
1469 curl 4 10.201.219.236 54.67.101.145 80
|
||||
1991 telnet 6 ::1 ::1 23
|
||||
2015 ssh 6 fe80::2000:bff:fe82:3ac fe80::2000:bff:fe82:3ac 22
|
||||
|
||||
```
|
||||
|
||||
Tracing DNS latency by tracing getaddrinfo()/gethostbyname() library calls:
|
||||
|
||||
```
|
||||
# **gethostlatency**
|
||||
TIME PID COMM LATms HOST
|
||||
06:10:24 28011 wget 90.00 www.iovisor.org
|
||||
06:10:28 28127 wget 0.00 www.iovisor.org
|
||||
06:10:41 28404 wget 9.00 www.netflix.com
|
||||
06:10:48 28544 curl 35.00 www.netflix.com.au
|
||||
06:11:10 29054 curl 31.00 www.plumgrid.com
|
||||
06:11:16 29195 curl 3.00 www.facebook.com
|
||||
06:11:25 29404 curl 72.00 foo
|
||||
06:11:28 29475 curl 1.00 foo
|
||||
|
||||
```
|
||||
|
||||
Interval summaries of VFS operations by type:
|
||||
|
||||
```
|
||||
# **vfsstat**
|
||||
TIME READ/s WRITE/s CREATE/s OPEN/s FSYNC/s
|
||||
18:35:32: 231 12 4 98 0
|
||||
18:35:33: 274 13 4 106 0
|
||||
18:35:34: 586 86 4 251 0
|
||||
18:35:35: 241 15 4 99 0
|
||||
|
||||
```
|
||||
|
||||
Tracing off-CPU time with kernel and user stack traces (summarized in kernel), for a given PID:
|
||||
|
||||
```
|
||||
# **offcputime -d -p 24347**
|
||||
Tracing off-CPU time (us) of PID 24347 by user + kernel stack... Hit Ctrl-C to end.
|
||||
^C
|
||||
[...]
|
||||
ffffffff810a9581 finish_task_switch
|
||||
ffffffff8185d385 schedule
|
||||
ffffffff81085672 do_wait
|
||||
ffffffff8108687b sys_wait4
|
||||
ffffffff81861bf6 entry_SYSCALL_64_fastpath
|
||||
--
|
||||
00007f6733a6b64a waitpid
|
||||
- bash (24347)
|
||||
4952
|
||||
|
||||
ffffffff810a9581 finish_task_switch
|
||||
ffffffff8185d385 schedule
|
||||
ffffffff81860c48 schedule_timeout
|
||||
ffffffff810c5672 wait_woken
|
||||
ffffffff8150715a n_tty_read
|
||||
ffffffff815010f2 tty_read
|
||||
ffffffff8122cd67 __vfs_read
|
||||
ffffffff8122df65 vfs_read
|
||||
ffffffff8122f465 sys_read
|
||||
ffffffff81861bf6 entry_SYSCALL_64_fastpath
|
||||
--
|
||||
00007f6733a969b0 read
|
||||
- bash (24347)
|
||||
1450908
|
||||
|
||||
```
|
||||
|
||||
Tracing MySQL query latency (via a USDT probe):
|
||||
|
||||
```
|
||||
# **mysqld_qslower `pgrep -n mysqld`**
|
||||
Tracing MySQL server queries for PID 14371 slower than 1 ms...
|
||||
TIME(s) PID MS QUERY
|
||||
0.000000 18608 130.751 SELECT * FROM words WHERE word REGEXP '^bre.*n$'
|
||||
2.921535 18608 130.590 SELECT * FROM words WHERE word REGEXP '^alex.*$'
|
||||
4.603549 18608 24.164 SELECT COUNT(*) FROM words
|
||||
9.733847 18608 130.936 SELECT count(*) AS count FROM words WHERE word REGEXP '^bre.*n$'
|
||||
17.864776 18608 130.298 SELECT * FROM words WHERE word REGEXP '^bre.*n$' ORDER BY word
|
||||
|
||||
```
|
||||
|
||||
Using the trace multi-tool to watch login requests, by instrumenting the pam library:
|
||||
|
||||
```
|
||||
# **trace 'pam:pam_start "%s: %s", arg1, arg2'**
|
||||
TIME PID COMM FUNC -
|
||||
17:49:45 5558 sshd pam_start sshd: root
|
||||
17:49:47 5662 sudo pam_start sudo: root
|
||||
17:49:49 5727 login pam_start login: bgregg
|
||||
|
||||
```
|
||||
|
||||
Many tools have usage messages (-h), and all should have man pages and text files of example output in the bcc project.
|
||||
|
||||
### Out of necessity
|
||||
|
||||
In 2014, Linux tracing had some kernel summary features (from ftrace and perf_events), but outside those we still had to dump-and-post-process data – a decades old technique that has high overhead at scale. You couldn't frequency count process names, function names, stack traces, or other arbitrary data in the kernel. You couldn't save variables in one probe event, and then retrieve them in another, which meant that you couldn't measure latency (or time deltas) in custom places, and you couldn't create in-kernel latency histograms. You couldn't trace USDT probes. You couldn't even write custom programs. DTrace could do all these, but only on Solaris or BSD. On Linux, some out-of-tree tracers like SystemTap could serve these needs, but brought their own challenges. (For the sake of completeness: yes, you _could_ write kprobe-based kernel modules – but practically no one did.)
|
||||
|
||||
In 2014 I joined the Netflix cloud performance team. Having spent years as a DTrace expert, it might have seemed crazy for me to move to Linux. But I had some motivations, in particular seeking a greater challenge: performance tuning the Netflix cloud, with its rapid application changes, microservice architecture, and distributed systems. Sometimes this job involves systems tracing, for which I'd previously used DTrace. Without DTrace on Linux, I began by using what was built in to the Linux kernel, ftrace and perf_events, and from them made a toolkit of tracing tools ([perf-tools][34]). They have been invaluable. But I couldn't do some tasks, particularly latency histograms and stack trace counting. We needed kernel tracing to be programmatic.
|
||||
|
||||
### What happened?
|
||||
|
||||
BPF adds programmatic capabilities to the existing kernel tracing facilities (tracepoints, kprobes, uprobes). It has been enhanced rapidly in the Linux 4.x series.
|
||||
|
||||
Timed sampling was the final major piece, and it landed in Linux 4.9-rc1 ([patchset][33]). Many thanks to Alexei Starovoitov (now working on BPF at Facebook), the lead developer behind these BPF enhancements.
|
||||
|
||||
The Linux kernel now has the following features built in (added between 2.6 and 4.9):
|
||||
|
||||
* Dynamic tracing, kernel-level (BPF support for kprobes)
|
||||
* Dynamic tracing, user-level (BPF support for uprobes)
|
||||
* Static tracing, kernel-level (BPF support for tracepoints)
|
||||
* Timed sampling events (BPF with perf_event_open)
|
||||
* PMC events (BPF with perf_event_open)
|
||||
* Filtering (via BPF programs)
|
||||
* Debug output (bpf_trace_printk())
|
||||
* Per-event output (bpf_perf_event_output())
|
||||
* Basic variables (global & per-thread variables, via BPF maps)
|
||||
* Associative arrays (via BPF maps)
|
||||
* Frequency counting (via BPF maps)
|
||||
* Histograms (power-of-2, linear, and custom, via BPF maps)
|
||||
* Timestamps and time deltas (bpf_ktime_get_ns(), and BPF programs)
|
||||
* Stack traces, kernel (BPF stackmap)
|
||||
* Stack traces, user (BPF stackmap)
|
||||
* Overwrite ring buffers (perf_event_attr.write_backward)
|
||||
|
||||
The front-end we are using is bcc, which provides both Python and lua interfaces. bcc adds:
|
||||
|
||||
* Static tracing, user-level (USDT probes via uprobes)
|
||||
* Debug output (Python with BPF.trace_pipe() and BPF.trace_fields())
|
||||
* Per-event output (BPF_PERF_OUTPUT macro and BPF.open_perf_buffer())
|
||||
* Interval output (BPF.get_table() and table.clear())
|
||||
* Histogram printing (table.print_log2_hist())
|
||||
* C struct navigation, kernel-level (bcc rewriter maps to bpf_probe_read())
|
||||
* Symbol resolution, kernel-level (ksym(), ksymaddr())
|
||||
* Symbol resolution, user-level (usymaddr())
|
||||
* BPF tracepoint support (via TRACEPOINT_PROBE)
|
||||
* BPF stack trace support (incl. walk method for stack frames)
|
||||
* Various other helper macros and functions
|
||||
* Examples (under /examples)
|
||||
* Many tools (under /tools)
|
||||
* Tutorials (/docs/tutorial*.md)
|
||||
* Reference guide (/docs/reference_guide.md)
|
||||
|
||||
I'd been holding off on this post until the last major feature was integrated, and now it has been in 4.9-rc1\. There are still some minor missing things we have workarounds for, and additional things we might do, but what we have right now is worth celebrating. Linux now has advanced tracing capabilities built in.
|
||||
|
||||
### Safety
|
||||
|
||||
BPF and its enhancements are designed to be production safe, and it is used today in large scale production environments. But if you're determined, you may be able to still find a way to hang the kernel. That experience should be the exception rather than the rule, and such bugs will be fixed fast, especially since BPF is part of Linux. All eyes are on Linux.
|
||||
|
||||
We did hit a couple of non-BPF bugs during development that needed to be fixed: rcu not reentrant, which could cause kernel hangs for funccount and was fixed by the "bpf: map pre-alloc" patchset in 4.6, and with a workaround in bcc for older kernels. And a uprobe memory accounting issue, which failed uprobe allocations, and was fixed by the "uprobes: Fix the memcg accounting" patch in 4.8 and backported to earlier kernels (eg, it's in the current 4.4.27 and 4.4.0-45.66).
|
||||
|
||||
### Why did Linux tracing take so long?
|
||||
|
||||
Prior work had been split among several other tracers: there was never a consolidated effort on any single one. For more about this and other issues, see my 2014 [tracing summit talk][32]. One thing I didn't note there was the counter effect of partial solutions: some companies had found another tracer (SystemTap or LTTng) was sufficient for their specific needs, and while they have been happy to hear about BPF, contributing to its development wasn't a priority given their existing solution.
|
||||
|
||||
BPF has only been enhanced to do tracing in the last two years. This process could have gone faster, but early on there were zero full-time engineers working on BPF tracing. Alexei Starovoitov (BPF lead), Brenden Blanco (bcc lead), myself, and others, all had other priorities. I tracked my hours on this at Netflix (voluntarily), and I've spent around 7% of my time on BPF/bcc. It wasn't that much of a priority, in part because we had our own workarounds (including my perf-tools, which work on older kernels).
|
||||
|
||||
Now that BPF tracing has arrived, there's already tech companies on the lookout for BPF skills. I can still highly recommend [Netflix][31]. (If you're trying to hire _me_ for BPF skills, then I'm still very happy at Netflix!.)
|
||||
|
||||
### Ease of use
|
||||
|
||||
What might appear to be the largest remaining difference between DTrace and bcc/BPF is ease of use. But it depends on what you're doing with BPF tracing. Either you are:
|
||||
|
||||
* **Using BPF tools/metrics**: There should be no difference. Tools behave the same, GUIs can access similar metrics. Most people will use BPF in this way.
|
||||
* **Developing tools/metrics**: bcc right now is much harder. DTrace has its own concise language, D, similar to awk, whereas bcc uses existing languages (C and Python or lua) with libraries. A bcc tool in C+Python may be a _lot_ more code than a D-only tool: 10x the lines, or more. However, many DTrace tools used shell wrapping to provide arguments and error checking, inflating the code to a much bigger size. The coding difficulty is also different: the rewriter in bcc can get fiddly, which makes some scripts much more complicated to develop (extra bpf_probe_read()s, requiring more knowledge of BPF internals). This situation should improve over time as improvements are planned.
|
||||
* **Running common one-liners**: Fairly similar. DTrace could do many with the "dtrace" command, whereas bcc has a variety of multitools: trace, argdist, funccount, funclatency, etc.
|
||||
* **Writing custom ad hoc one-liners**: With DTrace this was trivial, and accelerated advanced analysis by allowing rapid custom questions to be posed and answered by the system. bcc is currently limited by its multitools and their scope.
|
||||
|
||||
In short, if you're an end user of BPF tools, you shouldn't notice these differences. If you're an advanced user and tool developer (like me), bcc is a lot more difficult right now.
|
||||
|
||||
To show a current example of the bcc Python front-end, here's the code for tracing disk I/O and printing I/O size as a histogram:
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
from time import sleep
|
||||
|
||||
# load BPF program
|
||||
b = BPF(text="""
|
||||
#include <uapi/linux/ptrace.h>
|
||||
#include <linux/blkdev.h>
|
||||
|
||||
BPF_HISTOGRAM(dist);
|
||||
|
||||
int kprobe__blk_account_io_completion(struct pt_regs *ctx, struct request *req)
|
||||
{
|
||||
dist.increment(bpf_log2l(req->__data_len / 1024));
|
||||
return 0;
|
||||
}
|
||||
""")
|
||||
|
||||
# header
|
||||
print("Tracing... Hit Ctrl-C to end.")
|
||||
|
||||
# trace until Ctrl-C
|
||||
try:
|
||||
sleep(99999999)
|
||||
except KeyboardInterrupt:
|
||||
print
|
||||
|
||||
# output
|
||||
b["dist"].print_log2_hist("kbytes")
|
||||
|
||||
```
|
||||
|
||||
Note the embedded C (text=) in the Python code.
|
||||
|
||||
This gets the job done, but there's also room for improvement. Fortunately, we have time to do so: it will take many months before people are on Linux 4.9 and can use BPF, so we have time to create tools and front-ends.
|
||||
|
||||
### A higher-level language
|
||||
|
||||
An easier front-end, such as a higher-level language, may not improve adoption as much as you might imagine. Most people will use the canned tools (and GUIs), and only some of us will actually write them. But I'm not opposed to a higher-level language either, and some already exist, like SystemTap:
|
||||
|
||||
```
|
||||
#!/usr/bin/stap
|
||||
/*
|
||||
* opensnoop.stp Trace file open()s. Basic version of opensnoop.
|
||||
*/
|
||||
|
||||
probe begin
|
||||
{
|
||||
printf("\n%6s %6s %16s %s\n", "UID", "PID", "COMM", "PATH");
|
||||
}
|
||||
|
||||
probe syscall.open
|
||||
{
|
||||
printf("%6d %6d %16s %s\n", uid(), pid(), execname(), filename);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Wouldn't it be nice if we could have the SystemTap front-end with all its language integration and tapsets, with the high-performance kernel built in BPF back-end? Richard Henderson of Red Hat has already begun work on this, and has released an [initial version][30]!
|
||||
|
||||
There's also [ply][29], an entirely new higher-level language for BPF:
|
||||
|
||||
```
|
||||
#!/usr/bin/env ply
|
||||
|
||||
kprobe:SyS_*
|
||||
{
|
||||
$syscalls[func].count()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This is also promising.
|
||||
|
||||
Although, I think the real challenge for tool developers won't be the language: it will be knowing what to do with these new superpowers.
|
||||
|
||||
### How you can contribute
|
||||
|
||||
* **Promotion**: There are currently no marketing efforts for BPF tracing. Some companies know it and are using it (Facebook, Netflix, Github, and more), but it'll take years to become widely known. You can help by sharing articles and resources with others in the industry.
|
||||
* **Education**: You can write articles, give meetup talks, and contribute to bcc documentation. Share case studies of how BPF has solved real issues, and provided value to your company.
|
||||
* **Fix bcc issues**: See the [bcc issue list][19], which includes bugs and feature requests.
|
||||
* **File bugs**: Use bcc/BPF, and file bugs as you find them.
|
||||
* **New tools**: There are more observability tools to develop, but please don't be hasty: people are going to spend hours learning and using your tool, so make it as intuitive and excellent as possible (see my [docs][18]). As Mike Muuss has said about his [ping][17] program: "If I'd known then that it would be my most famous accomplishment in life, I might have worked on it another day or two and added some more options."
|
||||
* **High-level language**: If the existing bcc front-end languages really bother you, maybe you can come up with something much better. If you build it in bcc you can leverage libbcc. Or, you could help the SystemTap BPF or ply efforts.
|
||||
* **GUI integration**: Apart from the bcc CLI observability tools, how can this new information be visualized? Latency heat maps, flame graphs, and more.
|
||||
|
||||
### Other Tracers
|
||||
|
||||
What about SystemTap, ktap, sysdig, LTTng, etc? It's possible that they all have a future, either by using BPF, or by becoming better at what they specifically do. Explaining each will be a blog post by itself.
|
||||
|
||||
And DTrace itself? We're still using it at Netflix, on our FreeBSD-based CDN.
|
||||
|
||||
### Further bcc/BPF Reading
|
||||
|
||||
I've written a [bcc/BPF Tool End-User Tutorial][28], a [bcc Python Developer's Tutorial][27], a [bcc/BPF Reference Guide][26], and contributed useful [/tools][25], each with an [example.txt][24] file and [man page][23]. My prior posts about bcc & BPF include:
|
||||
|
||||
* [eBPF: One Small Step][16] (we later just called it BPF)
|
||||
* [bcc: Taming Linux 4.3+ Tracing Superpowers][15]
|
||||
* [Linux eBPF Stack Trace Hack][14] (stack traces are now officially supported)
|
||||
* [Linux eBPF Off-CPU Flame Graph][13] (" " ")
|
||||
* [Linux Wakeup and Off-Wake Profiling][12] (" " ")
|
||||
* [Linux Chain Graph Prototype][11] (" " ")
|
||||
* [Linux eBPF/bcc uprobes][10]
|
||||
* [Linux BPF Superpowers][9]
|
||||
* [Ubuntu Xenial bcc/BPF][8]
|
||||
* [Linux bcc Tracing Security Capabilities][7]
|
||||
* [Linux MySQL Slow Query Tracing with bcc/BPF][6]
|
||||
* [Linux bcc ext4 Latency Tracing][5]
|
||||
* [Linux bcc/BPF Run Queue (Scheduler) Latency][4]
|
||||
* [Linux bcc/BPF Node.js USDT Tracing][3]
|
||||
* [Linux bcc tcptop][2]
|
||||
* [Linux 4.9's Efficient BPF-based Profiler][1]
|
||||
|
||||
I've also given a talk about bcc/BPF, at Facebook's Performance@Scale event: [Linux BPF Superpowers][22]. In December, I'm giving a tutorial and talk on BPF/bcc at [USENIX LISA][21] in Boston.
|
||||
|
||||
### Acknowledgements
|
||||
|
||||
* Van Jacobson and Steve McCanne, who created the original BPF as a packet filter.
|
||||
* Barton P. Miller, Jeffrey K. Hollingsworth, and Jon Cargille, for inventing dynamic tracing, and publishing the paper: "Dynamic Program Instrumentation for Scalable Performance Tools", Scalable High-performance Conputing Conference (SHPCC), Knoxville, Tennessee, May 1994.
|
||||
* kerninst (ParaDyn, UW-Madison), an early dynamic tracing tool that showed the value of dynamic tracing (late 1990's).
|
||||
* Mathieu Desnoyers (of LTTng), the lead developer of kernel markers that led to tracepoints.
|
||||
* IBM developed kprobes as part of DProbes. DProbes was combined with LTT to provide Linux dynamic tracing in 2000, but wasn't integrated.
|
||||
* Bryan Cantrill, Mike Shapiro, and Adam Leventhal (Sun Microsystems), the core developers of DTrace, an awesome tool which proved that dynamic tracing could be production safe and easy to use (2004). Given the mechanics of dynamic tracing, this was a crucial turning point for the technology: that it became safe enough to be shipped _by default in Solaris_, an OS known for reliability.
|
||||
* The many Sun Microsystems staff in marketing, sales, training, and other roles, for promoting DTrace and creating the awareness and desire for advanced system tracing.
|
||||
* Roland McGrath (at Red Hat), the lead developer of utrace, which became uprobes.
|
||||
* Alexei Starovoitov (PLUMgrid, then Facebook), the lead developer of enhanced BPF: the programmatic kernel components necessary.
|
||||
* Many other Linux kernel engineers who contributed feedback, code, testing, and their own patchsets for the development of enhanced BPF (search lkml for BPF): Wang Nan, Daniel Borkmann, David S. Miller, Peter Zijlstra, and many others.
|
||||
* Brenden Blanco (PLUMgrid), the lead developer of bcc.
|
||||
* Sasha Goldshtein (Sela) developed tracepoint support in bcc, developed the most powerful bcc multitools trace and argdist, and contributed to USDT support.
|
||||
* Vicent Martí and others at Github engineering, for developing the lua front-end for bcc, and contributing parts of USDT.
|
||||
* Allan McAleavy, Mark Drayton, and other bcc contributors for various improvements.
|
||||
|
||||
Thanks to Netflix for providing the environment and support where I've been able to contribute to BPF and bcc tracing, and help get them done. I've also contributed to tracing in general over the years by developing tracing tools (using TNF/prex, DTrace, SystemTap, ktap, ftrace, perf, and now bcc/BPF), and books, blogs, and talks.
|
||||
|
||||
Finally, thanks to [Deirdré][20] for editing another post.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Linux doesn't have DTrace (the language), but it now does, in a way, have the DTraceToolkit (the tools).
|
||||
|
||||
The Linux 4.9 kernel has the final capabilities needed to support modern tracing, via enhancments to its built-in BPF engine. The hardest part is now done: kernel support. Future work now includes more performance CLI tools, alternate higher-level languages, and GUIs.
|
||||
|
||||
For customers of performance analysis products, this is also good news: you can now ask for latency histograms and heatmaps, CPU and off-CPU flame graphs, better latency breakdowns, and lower-cost instrumentation. Per-packet tracing and processing in user space is now the old inefficient way.
|
||||
|
||||
So when are you going to upgrade to Linux 4.9? Once it is officially released, new performance tools await: apt-get install bcc-tools.
|
||||
|
||||
Enjoy!
|
||||
|
||||
Brendan
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2016-10-27/dtrace-for-linux-2016.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com/
|
||||
[1]:http://www.brendangregg.com/blog/2016-10-21/linux-efficient-profiler.html
|
||||
[2]:http://www.brendangregg.com/blog/2016-10-15/linux-bcc-tcptop.html
|
||||
[3]:http://www.brendangregg.com/blog/2016-10-12/linux-bcc-nodejs-usdt.html
|
||||
[4]:http://www.brendangregg.com/blog/2016-10-08/linux-bcc-runqlat.html
|
||||
[5]:http://www.brendangregg.com/blog/2016-10-06/linux-bcc-ext4dist-ext4slower.html
|
||||
[6]:http://www.brendangregg.com/blog/2016-10-04/linux-bcc-mysqld-qslower.html
|
||||
[7]:http://www.brendangregg.com/blog/2016-10-01/linux-bcc-security-capabilities.html
|
||||
[8]:http://www.brendangregg.com/blog/2016-06-14/ubuntu-xenial-bcc-bpf.html
|
||||
[9]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[10]:http://www.brendangregg.com/blog/2016-02-08/linux-ebpf-bcc-uprobes.html
|
||||
[11]:http://www.brendangregg.com/blog/2016-02-05/ebpf-chaingraph-prototype.html
|
||||
[12]:http://www.brendangregg.com/blog/2016-02-01/linux-wakeup-offwake-profiling.html
|
||||
[13]:http://www.brendangregg.com/blog/2016-01-20/ebpf-offcpu-flame-graph.html
|
||||
[14]:http://www.brendangregg.com/blog/2016-01-18/ebpf-stack-trace-hack.html
|
||||
[15]:http://www.brendangregg.com/blog/2015-09-22/bcc-linux-4.3-tracing.html
|
||||
[16]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[17]:http://ftp.arl.army.mil/~mike/ping.html
|
||||
[18]:https://github.com/iovisor/bcc/blob/master/CONTRIBUTING-SCRIPTS.md
|
||||
[19]:https://github.com/iovisor/bcc/issues
|
||||
[20]:http://www.brendangregg.com/blog/2016-07-23/deirdre.html
|
||||
[21]:https://www.usenix.org/conference/lisa16
|
||||
[22]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[23]:https://github.com/iovisor/bcc/tree/master/man/man8
|
||||
[24]:https://github.com/iovisor/bcc/tree/master/tools
|
||||
[25]:https://github.com/iovisor/bcc/tree/master/tools
|
||||
[26]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[27]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[28]:https://github.com/iovisor/bcc/blob/master/docs/tutorial.md
|
||||
[29]:https://wkz.github.io/ply/
|
||||
[30]:https://lkml.org/lkml/2016/6/14/749
|
||||
[31]:http://www.brendangregg.com/blog/2016-03-30/working-at-netflix-2016.html
|
||||
[32]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux
|
||||
[33]:https://lkml.org/lkml/2016/9/1/831
|
||||
[34]:https://github.com/brendangregg/perf-tools
|
||||
[35]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[36]:https://github.com/iovisor/bcc
|
||||
[37]:https://github.com/opendtrace/toolkit
|
||||
[38]:https://raw.githubusercontent.com/brendangregg/bcc/master/images/bcc_tracing_tools_2016.png
|
||||
@ -1,104 +0,0 @@
|
||||
HOW TO CREATE AN EBOOK WITH CALIBRE IN LINUX [COMPLETE GUIDE]
|
||||
====
|
||||
|
||||
|
||||
[][8]
|
||||
|
||||
_Brief: This beginner’s guide shows you how to quickly create an ebook with Calibre tool in Linux._
|
||||
|
||||
Ebooks have been growing by leaps and bounds in popularity since Amazon started selling them several years ago. The good news is that they are very easy to create with Free and Open Source tools.
|
||||
|
||||
In this tutorial, I’ll show you how to create an eBook in Linux.
|
||||
|
||||
### CREATING AN EBOOK IN LINUX
|
||||
|
||||
To create an ebook you’ll need two pieces of software: a word processor (I’ll be using [LibreOffice][7], of course) and Calibre. [Calibre][6]is a great ebook reader and library program. You can use it to [open ePub files in Linux][5] or to manage your collection of eBooks.
|
||||
|
||||
Besides this software, you also need an ebook cover (1410×2250) and your manuscript.
|
||||
|
||||
### STEP 1
|
||||
|
||||
First, you need to open your manuscript with your word processor. Calibre can automatically create a table of contents for you. In order to do so, you need to set the chapter titles into your manuscript to Heading 1\. Just highlight the chapter titles and selection “Heading 1” from the paragraph style drop down box.
|
||||
|
||||

|
||||
|
||||
If you plan to have sub-chapters and want them to be added to the TOC, then make all those titles Heading 2.
|
||||
|
||||
Now, save your document as an HTML file.
|
||||
|
||||
### STEP 2
|
||||
|
||||
In Calibre, click the “Add books” button. After the dialog box appears, you can browse to where your HTML file is located and add it to the program.
|
||||
|
||||

|
||||
|
||||
### STEP 3
|
||||
|
||||
Once the new HTML file is added to the Calibre library, select the new file and click the “Edit metadata” button. From here you can add the following information: Title, Author, cover image, description and more. When you’re done, click “OK”.
|
||||
|
||||

|
||||
|
||||
### STEP 4
|
||||
|
||||
Now click the “Convert books” button.
|
||||
|
||||
In the new windows, there are quite a few options available, but you don’t need to use them all.
|
||||
|
||||
[Suggested ReadFix Pear Updater Issue In Pear OS 8][4]
|
||||
|
||||

|
||||
|
||||
From the top right of the new screen, you select epub. Calibre also gives your the option to create a mobi file, but I found that those files didn’t always work the way I wanted them to.
|
||||
|
||||

|
||||
|
||||
### STEP 5
|
||||
|
||||
Click the “Look & Feel” tab from the left side of the new dialog box. Now, select the “Remove spacing between paragraphs”.
|
||||
|
||||

|
||||
|
||||
Next, we will create the table of contents. If don’t plan to use a table of contents in your book, you skip this step. Select the Table of Contents tab. From there, click on the select the wand icon to the right of “Level 1 TOC (XPath expression)”.
|
||||
|
||||

|
||||
|
||||
In the new window, select “h1” from the drop down menu under “Match HTML tags with tag name”. Click “OK” to close the window. If you set up sub-chapters, set the “Level 2 TOC (XPath expression)” to h2.
|
||||
|
||||

|
||||
|
||||
Before we start the conversion, select EPUB Output. On the new page, select the “Insert inline Table of Contents” option.
|
||||
|
||||

|
||||
|
||||
Now all you have to do is click “OK” to start the conversion process. Unless you have a huge file, the conversion should finish fairly quickly.
|
||||
|
||||
There you go, you just created a quick ebook
|
||||
|
||||
For the more advanced users who know how to write CSS, Calibre gives your the option to add CSS styling to your text. Just go to the “Look & Feel” section and select the styling tab. If you try to do this with mobi, it won’t accept all of the styling for some reason.
|
||||
|
||||

|
||||
|
||||
Well, that was fairly easy, isn’t it? I hope this tutorial helped you to create eBooks in Linux.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/create-ebook-calibre-linux/
|
||||
|
||||
作者:[John Paul ][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:http://pinterest.com/pin/create/button/?url=https://itsfoss.com/create-ebook-calibre-linux/&description=How+To+Create+An+Ebook+With+Calibre+In+Linux+%5BComplete+Guide%5D&media=https://itsfoss.com/wp-content/uploads/2016/10/Create-an-eBook-in-Linux.jpg
|
||||
[2]:https://www.linkedin.com/cws/share?url=https://itsfoss.com/create-ebook-calibre-linux/
|
||||
[3]:https://twitter.com/share?original_referer=https%3A%2F%2Fitsfoss.com%2F&source=tweetbutton&text=How+To+Create+An+Ebook+With+Calibre+In+Linux+%5BComplete+Guide%5D&url=https%3A%2F%2Fitsfoss.com%2Fcreate-ebook-calibre-linux%2F&via=%40itsfoss
|
||||
[4]:https://itsfoss.com/fix-updater-issue-pear-os-8/
|
||||
[5]:https://itsfoss.com/open-epub-books-ubuntu-linux/
|
||||
[6]:http://calibre-ebook.com/
|
||||
[7]:https://www.libreoffice.org/
|
||||
[8]:https://itsfoss.com/wp-content/uploads/2016/10/Create-an-eBook-in-Linux.jpg
|
||||
@ -0,0 +1,102 @@
|
||||
###Translating by rusking
|
||||
|
||||
4 Useful Way to Know Plugged USB Device Name in Linux
|
||||
============================================================
|
||||
|
||||
As a newbie, one of the many [things you should master in Linux][1] is identification of devices attached to your system. It may be your computer’s hard disk, an external hard drive or removable media such USB drive or SD Memory card.
|
||||
|
||||
Using USB drives for file transfer is so common today, and for those (new Linux users) who prefer to use the command line, learning the different ways to identify a USB device name is very important, when you need to format it.
|
||||
|
||||
Once you attach a device to your system such as a USB, especially on a desktop, it is automatically mounted to a given directory, normally under /media/username/device-label and you can then access the files in it from that directory. However, this is not the case with a server where you have to[ manually mount a device][2] and specify its mount point.
|
||||
|
||||
Linux identifies devices using special device files stored in `/dev` directory. Some of the files you will find in this directory include `/dev/sda` or `/dev/hda` which represents your first master drive, each partition will be represented by a number such as `/dev/sda1` or `/dev/hda1` for the first partition and so on.
|
||||
|
||||
```
|
||||
$ ls /dev/sda*
|
||||
```
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
List All Linux Device Names
|
||||
|
||||
Now let’s find out device names using some different command-line tools as shown:
|
||||
|
||||
### Find Out Plugged USB Device Name Using df Command
|
||||
|
||||
To view each device attached to your system as well as its mount point, you can use the [df command][4](checks Linux disk space utilization) as shown in the image below:
|
||||
|
||||
```
|
||||
$ df -h
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Find USB Device Name Using df Command
|
||||
|
||||
### Use lsblk Command to Find USB Device Name
|
||||
|
||||
You can also use the [lsblk command (list block devices)][6] which lists all block devices attached to your system like so:
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
List Linux Block Devices
|
||||
|
||||
### Identify USB Device Name with fdisk Utility
|
||||
|
||||
[fdisk is a powerful utility][8] which prints out the partition table on all your block devices, a USB drive inclusive, you can run it will root privileges as follows:
|
||||
|
||||
```
|
||||
$ sudo fdisk -l
|
||||
```
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
List Partition Table of Block Devices
|
||||
|
||||
### Determine USB Device Name with dmesg Command
|
||||
|
||||
dmesg is an important command that prints or controls the kernel ring buffer, a data structure which [stores information about the kernel’s operations][10].
|
||||
|
||||
Run the command below to view kernel operation messages which will as well print information about your USB device:
|
||||
|
||||
```
|
||||
$ dmesg
|
||||
```
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
dmesg – Prints USB Device Name
|
||||
|
||||
That is all for now, in this article, we have covered different approaches of how to find out a USB device name from the command line. You can also share with us any other methods for the same purpose or perhaps offer us your thoughts about the article via the response section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/find-usb-device-name-in-linux
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/mount-filesystem-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/10/List-All-Linux-Device-Names.png
|
||||
[4]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/10/Find-USB-Device-Name.png
|
||||
[6]:http://www.tecmint.com/commands-to-collect-system-and-hardware-information-in-linux/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/10/List-Linux-Block-Devices.png
|
||||
[8]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/10/List-Partition-Table.png
|
||||
[10]:http://www.tecmint.com/dmesg-commands/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/10/dmesg-shows-kernel-information.png
|
||||
@ -1,3 +1,5 @@
|
||||
【翻译中】 by jayjay823
|
||||
|
||||
# 5 Best FPS Games For Linux
|
||||
|
||||

|
||||
|
||||
@ -1,111 +0,0 @@
|
||||
# How to design and add your own font on Linux with Glyphr
|
||||
|
||||
LibreOffice already offers a galore of fonts, and users can always download and add more. However, if you want to create your own custom font, you can do it easily by using Glyphr. Glyphr is a new open source vector font designer with an intuitive and easy to use graphical interface and a rich set of features that will take care every aspect of the font design. Although the application is still in early development, it is already pretty good. Here’s a quick guide showing how to design your own custom fonts on Glyphr, and how to add them on LibreOffice once you’re done.
|
||||
|
||||
First of all, we need to download Glyphr from the official git repository ([https://github.com/glyphr-studio/Glyphr-Studio-Desktop][14]). It is available in binary form, in both 32 and 64 bits. Once the file is downloaded, navigate to the destination, unzip the file, enter the newly created folder, right click on the “Glyphr Studio” binary file and select “Run”.
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
This will launch the application giving you three options. One is to create a new font set from scratch. The second is to load an existing project that can be of a Glyphr Studio Project form, and Open or True Type font, or an SVG font. The third is to load one of the two example sets so that you can modify these instead of working on a new set from the ground up. I will select the first option to showcase a few basic design concepts.
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Once you enter the editor screen, you may select the letter that you want to design from the panel on the left side of the screen, and then indulge in the design work on the drawing area that is on the right. I will start with the letter “A” by clicking on its icon.
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
To design something on the drawing board, we can select either the “shapes” tools from the top left of the board which are a rectangle, an oval, and a path share, or use the first item of the second row of the tools that is the path editing tool. Click on that and start putting points on the board to create shapes. The more points you add, the greater the shaping options that you’ll have on the next step.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
To move the points and thus share the path differently, you will need to select the path edit tool that is to the right of the path editing tool and click on the shape to reveal the points. Then you may drag them into position as you like.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Finally, the shape edit tool lets you select a shape and drag it into position, change its dimension or even rotate it.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Another useful set of design actions are the copy-paste, flip-rotate options that are offered on the left panel after you enter the letter design phase. For example, let’s suppose that I am creating the “B” letter of my font set, and that I want to mirror the upper side of what I’ve done to the bottom so as to keep a good level of coherence in the design.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Now, to do this, I must choose the shape editing tool to select the part that I want to mirror, click on the copy action, then click on the past right above it, drag the pasted shape where I want it to be and then click on the flip horizontally or vertically depending on what I am trying to achieve.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
There are tons of more things that I could showcase in the design aspect of the application, but there’s really no point in doing so. If you’re interested you can dive in and discover the numerical-based editing, the curving, the guiding, and many more.
|
||||
|
||||
Fonts however aren’t only about individual letters design, and you can discover other aspects of the font design by clicking on the “Navigate” menu on the top left of the application and adjust the kerning between specific pairs of characters, add ligatures, add components, and set general font settings.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
You may even give your new font a “test drive” so that you can get the idea of how well your font settings and kerning works and what to do in order to optimize them.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
After the design and optimization are done, you may export your new font set on either a true type font format, or an svg.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
To add the font on your system, open it with the font viewer and click on the “Install” option. If that doesn’t work, create a new folder in your home directory named as “.fonts” and place the font file inside it. Alternatively, you may open the file manager as root, navigate to /usr/share/fonts/opentype, create a new folder there and paste the font file inside. Then open a terminal and run this command to clear the cache: “sudo fc-cache -f -v”
|
||||
|
||||
This should add the new font on LibreOffice, and also to any other text application in your system like Gedit for example.
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-design-and-add-your-own-font-on-linux-with-glyphr/
|
||||
|
||||
作者:[Bill Toulas][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_13.png
|
||||
[2]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_12.png
|
||||
[3]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_11.png
|
||||
[4]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_10.png
|
||||
[5]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_9.png
|
||||
[6]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_8.png
|
||||
[7]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_7.png
|
||||
[8]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_6.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_5.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_4.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_3.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_2.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-design-and-add-your-own-font-on-linux-with-glyphr/big/pic_1.png
|
||||
[14]:https://github.com/glyphr-studio/Glyphr-Studio-Desktop
|
||||
@ -0,0 +1,109 @@
|
||||
CLOUD FOCUSED LINUX DISTROS FOR PEOPLE WHO BREATHE ONLINE
|
||||
============================================================
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
_Brief: We list some _Cloud centric_ Linux distributions that might be termed as real Linux alternatives to Chrome OS._
|
||||
|
||||
The world is moving to cloud-based services and we all know the kind of love that Chrome OS got. Well, it does deserve respect. It’s super fast, light, power-efficient, minimalistic, beautifully designed and utilizes the full potential of cloud that technology permits today.
|
||||
|
||||
Although [Chrome OS][7] is exclusively available only for Google’s hardware, there are other means to experience the potential of cloud computing right on your laptop or desktop.
|
||||
|
||||
As I have repeatedly said, there is always something for everybody in the Linux domain, be it [Linux distributions that look like Windows][8] or Mac OS. Linux is all about sharing, love and some really bleeding edge computing experience. Let’s crack this list right away!
|
||||
|
||||
### 1\. CUB LINUX
|
||||
|
||||

|
||||
|
||||
It is not Chrome OS. But the above image is featuring the desktop of [Cub Linux][9]. Say what?
|
||||
|
||||
Cub Linux is no news for Linux users. But if you already did not know, Cub Linux is the web focused Linux distro that is inspired from mainstream Chrome OS. It is also the open source brother of Chrome OS from mother Linux.
|
||||
|
||||
Chrome OS has the Chrome Browser as it’s primary component. Not so long ago, a project by name [Chromixium OS][10] was started to recreate Chrome OS like experience by using the Chromium Browser in place of Chrome Browser. Due to some legal issues, the name was later changed to Cub Linux (Chromium+Ubuntu).
|
||||
|
||||

|
||||
|
||||
Well, history apart, as the name hints, Cub Linux is based on Ubuntu, features the lightweight Openbox Desktop Environment. The Desktop is customized to give a Chrome OS impression and looks really neat.
|
||||
|
||||
In the apps department, you can install the web applications from the Chrome web store and all the Ubuntu software. Yup, with all the snappy apps of the Chrome OS, You’ll still get the Ubuntu goodies.
|
||||
|
||||
As far as the performance is concerned, the operating system is super fast thanks to its Openbox Desktop Environment. Based on Ubuntu Linux, the stability of Cub Linux is unquestionable. The desktop itself is a treat to the eyes with all its smooth animations and beautiful UI.
|
||||
|
||||
[Suggested Read[Year 2013 For Linux] 2 Linux Distributions Discontinued][11]
|
||||
|
||||
I suggest Cub Linux to anybody who spends most their times on a browser and do some home tasks now and then. Well, a browser is all you need and a browser is exactly what you’ll get.
|
||||
|
||||
### 2\. PEPPERMINT OS
|
||||
|
||||
A good number of people look towards Linux because they want a no-BS computing experience. Some people do not really like the hassle of an anti-virus, a defragmenter, a cleaner etcetera as they want an operating system and not a baby. And I must say Peppermint OS is really good at being no-BS. [Peppermint OS][12] developers have put a good amount of effort in understanding the user requirements and needs.
|
||||
|
||||

|
||||
|
||||
There is a very small number of selected software included by default. The traditional ideology of including a couple apps from every software category is ditched here for good. The power to customize the computer as per needs has been given to the user. By the way, do we really need to install so many applications when we can get web alternatives for almost all the applications?
|
||||
|
||||
Ice
|
||||
|
||||
Ice is a utile little tool that converts your favorite and most used websites into desktop applications that you can directly launch from your desktop or the menu. It’s what we call a site-specific browser.
|
||||
|
||||

|
||||
|
||||
Love facebook? Why not make a facebook web app on your desktop for quick launch? While there are people complaining about a decent Google drive application for Linux, Ice allows you to access Drive with just a click. Not just Drive, the functionality of Ice is limited only by your imagination.
|
||||
|
||||
Peppermint OS 7 is based on Ubuntu 16.04\. It not only provides a smooth, rock solid performance but also a very swift response. A heavily customizes LXDE will be your home screen. And the customization I’m speaking about is driven to achieve both a snappy performance as well as visual appeal.
|
||||
|
||||
Peppermint OS hits more of a middle ground in the cloud-native operating system types. Although the skeleton of the OS is designed to support the speedy cloudy apps, the native Ubuntu application play well too. If you are someone like me who wants an OS that is balanced in online-offline capabilities, [Peppermint OS is for you][13].
|
||||
|
||||
[Suggested ReadPennsylvania High School Distributes 1,700 Ubuntu Laptops to Students][14]
|
||||
|
||||
### 3.APRICITY OS
|
||||
|
||||
[Apricity OS][15] stole the show for being one of the top aesthetically pleasing Linux distros out there. It’s just gorgeous. It’s like the Mona Lisa of the Linux domain. But, there’s more to it than just the looks.
|
||||
|
||||

|
||||
|
||||
The prime reason [Apricity OS][16] makes this list is because of its simplicity. While OS desktop design is getting chaotic and congested with elements (and I’m not talking only about non-Linux operating systems), Apricity de-clutters everything and simplifies the very basic human-desktop interaction. Gnome desktop environment is customized beautifully here. They made it really simpler.
|
||||
|
||||
The pre-installed software list is really small. Almost all Linux distros have the same pre-installed software. But Apricity OS has a completely new set of software. Chrome instead of Firefox. I was really waiting for this. I mean why not give us what’s rocking out there?
|
||||
|
||||
Apricity OS also features the Ice tool that we discussed in the last segment. But instead of Firefox, Chrome browser is used in website-desktop integration. Apricity OS has Numix Circle icons by default and everytime you add a popular webapp, there will be a beautiful icon placed on your Dock.
|
||||
|
||||

|
||||
|
||||
See what I mean?
|
||||
|
||||
Apricity OS is based on Arch Linux. (So anybody looking for a quick start with Arch, and a beautiful at that one, download that Apricity ISO [here][17]) Apricity fully upholds the Arch principle of freedom of choice. Within just 10 minutes on the Ice, and you’ll have all your favorite webapps set up.
|
||||
|
||||
Gorgeous backgrounds, minimalistic desktop and a great functionality. These make Apricity OS a really great choice for setting up an amazing cloud-centric system. It’ll take 5 mins for Apricity OS to make you fall in love with it. I mean it.
|
||||
|
||||
There you have it, people. Cloud-centric Linux distros for online dwellers. Do give us your take on the webapp-native app topic. Don’t forget to share.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cloud-focused-linux-distros/
|
||||
|
||||
作者:[Aquil Roshan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://itsfoss.com/author/aquil/
|
||||
[2]:https://itsfoss.com/cloud-focused-linux-distros/#comments
|
||||
[3]:https://twitter.com/share?original_referer=https%3A%2F%2Fitsfoss.com%2F&source=tweetbutton&text=Cloud+Focused+Linux+Distros+For+People+Who+Breathe+Online&url=https%3A%2F%2Fitsfoss.com%2Fcloud-focused-linux-distros%2F&via=%40itsfoss
|
||||
[4]:https://www.linkedin.com/cws/share?url=https://itsfoss.com/cloud-focused-linux-distros/
|
||||
[5]:http://pinterest.com/pin/create/button/?url=https://itsfoss.com/cloud-focused-linux-distros/&description=Cloud+Focused+Linux+Distros+For+People+Who+Breathe+Online&media=https://itsfoss.com/wp-content/uploads/2016/11/cloud-centric-Linux-distributions.jpg
|
||||
[6]:https://itsfoss.com/wp-content/uploads/2016/11/cloud-centric-Linux-distributions.jpg
|
||||
[7]:https://en.wikipedia.org/wiki/Chrome_OS
|
||||
[8]:https://itsfoss.com/windows-like-linux-distributions/
|
||||
[9]:https://cublinux.com/
|
||||
[10]:https://itsfoss.com/chromixiumos-released/
|
||||
[11]:https://itsfoss.com/year-2013-linux-2-linux-distributions-discontinued/
|
||||
[12]:https://peppermintos.com/
|
||||
[13]:https://peppermintos.com/
|
||||
[14]:https://itsfoss.com/pennsylvania-high-school-ubuntu/
|
||||
[15]:https://apricityos.com/
|
||||
[16]:https://itsfoss.com/apricity-os/
|
||||
[17]:https://apricityos.com/
|
||||
@ -1,221 +0,0 @@
|
||||
# Kali Linux – Fresh Installation Guide
|
||||
|
||||
Kali Linux is arguably one of the best out of the box [Linux distributions available for security testing][18]. While many of the tools in Kali can be installed in most Linux distributions, the Offensive Security team developing Kali has put countless hours into perfecting their ready to boot security distribution.
|
||||
|
||||
Kali Linux is a Debian based, security distribution. The distribution comes pre-loaded with hundreds of well known security tools and has gained quite a name for itself.
|
||||
|
||||
Kali even has an industry respected certification available called “Pentesting with Kali”. The certification is a rigorous 24 hour challenge in which applicants must successfully compromise a number of computers with another 24 hours to write up a professional penetration test report that is sent to and graded by the personnel at Offensive Security. Successfully passing this exam will allow the test taker to obtain the OSCP credential.
|
||||
|
||||
The focus of this guide and future articles is to help individuals become more familiar with Kali Linux and several of the tools available within the distribution.
|
||||
|
||||
Please be sure to use extreme caution with the tools included with Kali as many of them can accidentally be used in a manner that will break computer systems. The information contained within all of these Kali articles is intended for legal usages.
|
||||
|
||||
#### System Requirements
|
||||
|
||||
Kali has some minimum suggested specifications for hardware. Depending upon the intended use, more may be desired. This guide will be assuming that the reader will want to install Kali as the only operating system on the computer.
|
||||
|
||||
1. At least 10GB of disk space; strongly encouraged to have more
|
||||
2. At least 512MB of ram; more is encouraged especially for graphical environments
|
||||
3. USB or CD/DVD boot support
|
||||
4. Kali Linux ISO available from [https://www.kali.org/downloads/][1]
|
||||
|
||||
#### Create a Bootable USB Using dd Command
|
||||
|
||||
This guide will be assuming that a USB drive is available to use as the installation media. Take note that the USB drive should be as close to 4/8GB as possible and ALL DATA WILL BE REMOVED!
|
||||
|
||||
The author has had issues with larger USB drives but some may still work. Regardless, following the next few steps WILL RESULT IN DATA LOSS ON THE USB DRIVE.
|
||||
|
||||
Please be sure to backup all data before proceeding. This bootable Kali Linux USB drive is going to be created from another Linux machine.
|
||||
|
||||
Step 1 is to obtain the Kali Linux ISO. This guide is going to use the current newest version of Kali with the Enlightenment [Linu desktop environment][17].
|
||||
|
||||
To obtain this version, type the following into a terminal.
|
||||
|
||||
```
|
||||
$ cd ~/Downloads
|
||||
$ wget -c http://cdimage.kali.org/kali-2016.2/kali-linux-e17-2016.2-amd64.iso
|
||||
|
||||
```
|
||||
|
||||
The two commands above will download the Kali Linux ISO into the current user’s ‘Downloads’ folder.
|
||||
|
||||
The next process is to write the ISO to a USB drive to boot the installer. To accomplish this we can use the ‘dd’tool within Linux. First, the disk name needs to be located with lsblk command though.
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Find Out USB Device Name in Linux
|
||||
|
||||
With the name of the USB drive determined as `/dev/sdc`, the Kali ISO can be written to the drive with the ‘dd’tool.
|
||||
|
||||
```
|
||||
$ sudo dd if=~/Downloads/kali-linux-e17-2016.2-amd64.iso of=/dev/sdc
|
||||
|
||||
```
|
||||
|
||||
Important: The above command requires root privileges so utilize sudo or login as the root user to run the command. Also this command will REMOVE EVERYTHING on the USB drive. Be sure to backup needed data.
|
||||
|
||||
Once the ISO is copied over to the USB drive, proceed further to install Kali Linux.
|
||||
|
||||
### Installation of Kali Linux Distribution
|
||||
|
||||
1. First, plug the USB drive into the respective computer that Kali should be installed upon and proceed to boot to the USB drive. Upon successful booting to the USB drive, the user will be presented with the following screen and should proceed with the ‘Install’ or ‘Graphical Install’ options.
|
||||
|
||||
This guide will be using the ‘Graphical Install’ method.
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Kali Linux Boot Menu
|
||||
|
||||
2. The next couple of screens will ask the user to select locale information such as language, country, and keyboard layout.
|
||||
|
||||
Once through the locale information, the installer will prompt for a hostname and domain for this install. Provide the appropriate information for the environment and continue installing.
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Set Hostname for Kali Linux
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Set Domain for Kali Linux
|
||||
|
||||
3. After setting up the hostname and domain name, the root user’s password needs to be set. DO NOT FORGET THIS PASSWORD.
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Set Root User Password for Kali Linux
|
||||
|
||||
4. After setting the password is set, the installer will prompt for time zone data and then pause at the disk partitioning.
|
||||
|
||||
If Kali will be the only operating on the machine, the easiest option is to use ‘Guided – Use Entire Disk’ and then select the storage device you wish to install Kali.
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Select Kali Linux Installation Type
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Select Kali Linux Installation Disk
|
||||
|
||||
5. The next question will prompt the user to determine the partitioning on the storage device. Most installs can simply put all data on one partition though.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Install Kali Linux Files in Partition
|
||||
|
||||
6. The final step with ask the user to confirm all changes to be made to the disk on the host machine. Be aware that continuing will ERASE DATA ON THE DISK.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Confirm Disk Partition Write Changes
|
||||
|
||||
7. Once confirming the partition changes, the installer will run through the process of installing the files. Once it is completed, the system will want to setup a network mirror to obtain future pieces of software and updates. Be sure to enable this functionality if you wish to use the Kali repositories.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Configure Kali Linux Package Manager
|
||||
|
||||
8. After selecting a network mirror, the system will ask to install grub. Again this guide is assuming that Kali is to be the only operating system on this computer.
|
||||
|
||||
Selecting ‘Yes’ on this screen will allow the user to pick the device to write the necessary boot loader information to the hard drive to boot Kali.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Install GRUB Boot Loader
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Select Partition to Install GRUB Boot Loader
|
||||
|
||||
9. Once the installer finishes installing GRUB to the disk, it will alert the user to reboot the machine to boot into the newly installed Kali machine.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Kali Linux Installation Completed
|
||||
|
||||
10. Since this guide installed Enlightenment as the Kali desktop environment, it will likely default boot into a shell.
|
||||
|
||||
In order to launch Enlightenment, log in as the user ‘root‘ with the password created earlier in the installation process.
|
||||
|
||||
Once logged in all that needs to be issued to start Enlightenment is the command ‘startx‘.
|
||||
|
||||
```
|
||||
# startx
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Start Enlightenment Desktop in Kali Linux
|
||||
|
||||
The first time that Enlightenment is run, it will ask the user for some configuration preferences and then launch the Desktop Environment.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Kali Linux Enlightenment Desktop
|
||||
|
||||
At this point, Kali is successfully installed and ready to be used! Upcoming articles will walk through the tools available within Kali and how the can be utilized to test the security posture of hosts and networks. Please feel free to post any comments or questions below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/kali-linux-installation-guide/
|
||||
|
||||
作者:[Rob Turner][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/robturner/
|
||||
[1]:https://www.kali.org/downloads/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Kali-Linux-Enlightenment-Desktop.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/10/Start-Enlightenment-Desktop-in-Kali-Linux.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/10/Kali-Linux-Installation-Completed.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/10/Select-Partition-to-Install-GRUB-Boot-Loader.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/10/Install-GRUB-Boot-Loader.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/10/Configure-Kali-Linux-Package-Manager.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/10/Confirm-Disk-Partition-Write-Changes.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/10/Install-Kali-Linux-Files-in-Partition.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/10/Select-Kali-Linux-Installation-Disk.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/10/Select-Kali-Linux-Installation-Type.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/10/Set-Root-User-Password-for-Kali-Linux.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2016/10/Set-Domain-for-Kali-Linux.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/10/Set-Hostname-for-Kali-Linux.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2016/10/Kali-Linux-Boot-Menu.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/10/Find-USB-Device-Name-in-Linux.png
|
||||
[17]:http://www.tecmint.com/best-linux-desktop-environments/
|
||||
[18]:http://www.tecmint.com/best-security-centric-linux-distributions-of-2016/
|
||||
@ -1,249 +0,0 @@
|
||||
DockerChen翻译中
|
||||
|
||||
# A Practical Guide to Nmap (Network Security Scanner) in Kali Linux
|
||||
|
||||
In the second Kali Linux article, the network tool known as ‘[nmap][30]‘ will be discussed. While nmap isn’t a Kali only tool, it is one of the most [useful network mapping tools][29] in Kali.
|
||||
|
||||
1. [Kali Linux Installation Guide for Beginners – Part 1][4]
|
||||
|
||||
Nmap, short for Network Mapper, is maintained by Gordon Lyon (more about Mr. Lyon here: [http://insecure.org/fyodor/][28]) and is used by many security professionals all over the world.
|
||||
|
||||
The utility works in both Linux and Windows and is command line (CLI) driven. However for those a little more timid of the command line, there is a wonderful graphical frontend for nmap called zenmap.
|
||||
|
||||
It is strongly recommended that individuals learn the CLI version of nmap as it provides much more flexibility when compared to the zenmap graphical edition.
|
||||
|
||||
What purpose does nmap server? Great question. Nmap allows for an administrator to quickly and thoroughly learn about the systems on a network, hence the name, Network MAPper or nmap.
|
||||
|
||||
Nmap has the ability to quickly locate live hosts as well as services associated with that host. Nmap’s functionality can be extended even further with the Nmap Scripting Engine, often abbreviated as NSE.
|
||||
|
||||
This scripting engine allows administrators to quickly create a script that can be used to determine if a newly discovered vulnerability exists on their network. Many scripts have been developed and included with most nmap installs.
|
||||
|
||||
A word of caution – nmap is a commonly used by people with both good and bad intentions. Extreme caution should be taken to ensure that you aren’t using nmap against systems that permission has not be explicitlyprovided in a written/legal agreement. Please use caution when using the nmap tool.
|
||||
|
||||
#### System Requirements
|
||||
|
||||
1. [Kali Linux][3] (nmap is available in other operating systems and functions similar to this guide).
|
||||
2. Another computer and permission to scan that computer with nmap – This is often easily done with software such as [VirtualBox][2] and the creation of a virtual machine.
|
||||
1. For a good machine to practice with, please read about Metasploitable 2
|
||||
2. Download for MS2 [Metasploitable2][1]
|
||||
3. A valid working connection to a network or if using virtual machines, a valid internal network connection for the two machines.
|
||||
|
||||
### Kali Linux – Working with Nmap
|
||||
|
||||
The first step to working with nmap is to log into the Kali Linux machine and if desired, start a graphical session (This first article in this series installed [Kali Linux with the Enlightenment Desktop Environment][27]).
|
||||
|
||||
During the installation, the installer would have prompted the user for a ‘root‘ user password which will be needed to login. Once logged in to the Kali Linux machine, using the command ‘startx‘ the Enlightenment Desktop Environment can be started – it is worth noting that nmap doesn’t require a desktop environment to run.
|
||||
|
||||
```
|
||||
# startx
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][26]
|
||||
|
||||
Start Desktop Environment in Kali Linux
|
||||
|
||||
Once logged into Enlightenment, a terminal window will need to be opened. By clicking on the desktop background, a menu will appear. Navigating to a terminal can be done as follows: Applications -> System ->‘Xterm‘ or ‘UXterm‘ or ‘Root Terminal‘.
|
||||
|
||||
The author is a fan of the shell program called ‘[Terminator][25]‘ but this may not show up in a default install of Kali Linux. All shell programs listed will work for the purposes of nmap.
|
||||
|
||||
[
|
||||

|
||||
][24]
|
||||
|
||||
Launch Terminal in Kali Linux
|
||||
|
||||
Once a terminal has been launched, the nmap fun can begin. For this particular tutorial, a private network with a Kali machine and a Metasploitable machine was created.
|
||||
|
||||
This made things easier and safer since the private network range would ensure that scans remained on safe machines and prevents the vulnerable Metasploitable machine from being compromised by someone else.
|
||||
|
||||
In this example, both of the machines are on a private 192.168.56.0 /24 network. The Kali machine has an IP address of 192.168.56.101 and the Metasploitable machine to be scanned has an IP address of 192.168.56.102.
|
||||
|
||||
Let’s say though that the IP address information was unavailable. A quick nmap scan can help to determine what is live on a particular network. This scan is known as a ‘Simple List’ scan hence the `-sL` arguments passed to the nmap command.
|
||||
|
||||
```
|
||||
# nmap -sL 192.168.56.0/24
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][23]
|
||||
|
||||
Nmap – Scan Network for Live Hosts
|
||||
|
||||
Sadly, this initial scan didn’t return any live hosts. Sometimes this is a factor of the way certain Operating Systems handle [port scan network traffic][22].
|
||||
|
||||
Not to worry though, there are some tricks that nmap has available to try to find these machines. This next trick will tell nmap to simply try to ping all the addresses in the 192.168.56.0/24 network.
|
||||
|
||||
```
|
||||
# nmap -sn 192.168.56.0/24
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
Nmap – Ping All Connected Live Network Hosts
|
||||
|
||||
This time nmap returns some prospective hosts for scanning! In this command, the `-sn` disables nmap’s default behavior of attempting to port scan a host and simply has nmap try to ping the host.
|
||||
|
||||
Let’s try letting nmap port scan these specific hosts and see what turns up.
|
||||
|
||||
```
|
||||
# nmap 192.168.56.1,100-102
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
Nmap – Network Ports Scan on Host
|
||||
|
||||
Wow! This time nmap hit a gold mine. This particular host has quite a bit of [open network ports][19].
|
||||
|
||||
These ports all indicate some sort of listening service on this particular machine. Recalling from earlier, the 192.168.56.102 IP address is assigned to the metasploitable vulnerable machine hence why there are so many [open ports on this host][18].
|
||||
|
||||
Having this many ports open on most machines is highly abnormal so it may be a wise idea to investigate this machine a little closer. Administrators could track down the physical machine on the network and look at the machine locally but that wouldn’t be much fun especially when nmap could do it for us much quicker!
|
||||
|
||||
This next scan is a service scan and is often used to try to determine what [service may be listening on a particular port][17] on a machine.
|
||||
|
||||
Nmap will probe all of the open ports and attempt to banner grab information from the services running on each port.
|
||||
|
||||
```
|
||||
# nmap -sV 192.168.56.102
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Nmap – Scan Network Services Listening of Ports
|
||||
|
||||
Notice this time nmap provided some suggestions on what nmap thought might be running on this particular port (highlighted in the white box). Also nmap also tried to [determine information about the operating system][15]running on this machine as well as its hostname (with great success too!).
|
||||
|
||||
Looking through this output should raise quite a few concerns for a network administrator. The very first line claims that VSftpd version 2.3.4 is running on this machine! That’s a REALLY old version of VSftpd.
|
||||
|
||||
Searching through ExploitDB, a serious vulnerability was found back in 2011 for this particular version (ExploitDB ID – 17491).
|
||||
|
||||
Let’s have nmap take a closer look at this particular port and see what can be determined.
|
||||
|
||||
```
|
||||
# nmap -sC 192.168.56.102 -p 21
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Nmap – Scan Particular Post on Machine
|
||||
|
||||
With this command, nmap was instructed to run its default script (-sC) on the FTP port (-p 21) on the host. While it may or may not be an issue, nmap did find out that [anonymous FTP login is allowed][13] on this particular server.
|
||||
|
||||
This paired with the earlier knowledge about VSftd having an old vulnerability should raise some concern though. Let’s see if nmap has any scripts that attempt to check for the VSftpd vulnerability.
|
||||
|
||||
```
|
||||
# locate .nse | grep ftp
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Nmap – Scan VSftpd Vulnerability
|
||||
|
||||
Notice that nmap has a NSE script already built for the VSftpd backdoor problem! Let’s try running this script against this host and see what happens but first it may be important to know how to use the script.
|
||||
|
||||
```
|
||||
# nmap --script-help=ftp-vsftd-backdoor.nse
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Learn Nmap NSE Script Usage
|
||||
|
||||
Reading through this description, it is clear that this script can be used to attempt to see if this particular machine is vulnerable to ExploitDB issue identified earlier.
|
||||
|
||||
Let’s run the script and see what happens.
|
||||
|
||||
```
|
||||
# nmap --script=ftp-vsftpd-backdoor.nse 192.168.56.102 -p 21
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Nmap – Scan Host for Vulnerable
|
||||
|
||||
Yikes! Nmap’s script returned some dangerous news. This machine is likely a good candidate for a serious investigation. This doesn’t mean that the machine is compromised and being used for horrible/terrible things but it should bring some concerns to the network/security teams.
|
||||
|
||||
Nmap has the ability to be extremely selective and extremely quite. Most of what has been done so far has attempted to keep nmap’s network traffic moderately quiet however scanning a personally owned network in this fashion can be extremely time consuming.
|
||||
|
||||
Nmap has the ability to do a much more aggressive scan that will often yield much of the same information but in one command instead of several. Let’s take a look at the output of an aggressive scan (Do note – an aggressive scan can set off [intrusion detection/prevention systems][9]!).
|
||||
|
||||
```
|
||||
# nmap -A 192.168.56.102
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Nmap – Complete Network Scan on Host
|
||||
|
||||
Notice this time, with one command, nmap has returned a lot of the information it returned earlier about the open ports, services, and configurations running on this particular machine. Much of this information can be used to help determine [how to protect this machine][7] as well as to evaluate what software may be on a network.
|
||||
|
||||
This was just a short, short list of the many useful things that nmap can be used to find on a host or network segment. It is strongly urged that individuals continue to [experiment with nmap][6] in a controlled manner on a network that is owned by the individual (Do not practice by scanning other entities!).
|
||||
|
||||
There is a official guide on Nmap Network Scanning by author Gordon Lyon, available from Amazon.
|
||||
|
||||
<center style="border: 0px; font-style: inherit; font-variant: inherit; font-weight: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline;">[
|
||||

|
||||
][5]</center>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/nmap-network-security-scanner-in-kali-linux/
|
||||
|
||||
作者:[Rob Turner][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/robturner/
|
||||
[1]:https://sourceforge.net/projects/metasploitable/files/Metasploitable2/
|
||||
[2]:http://www.tecmint.com/install-virtualbox-on-redhat-centos-fedora/
|
||||
[3]:http://www.tecmint.com/kali-linux-installation-guide
|
||||
[4]:http://www.tecmint.com/kali-linux-installation-guide
|
||||
[5]:http://amzn.to/2eFNYrD
|
||||
[6]:http://www.tecmint.com/nmap-command-examples/
|
||||
[7]:http://www.tecmint.com/security-and-hardening-centos-7-guide/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Network-Host.png
|
||||
[9]:http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Host-for-Vulnerable.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Learn-NSE-Script.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Service-Vulnerability.png
|
||||
[13]:http://www.tecmint.com/setup-ftp-anonymous-logins-in-linux/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Particular-Port-on-Host.png
|
||||
[15]:http://www.tecmint.com/commands-to-collect-system-and-hardware-information-in-linux/
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Network-Services-Ports.png
|
||||
[17]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[18]:http://www.tecmint.com/find-open-ports-in-linux/
|
||||
[19]:http://www.tecmint.com/find-open-ports-in-linux/
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-for-Ports-on-Hosts.png
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Ping-All-Network-Live-Hosts.png
|
||||
[22]:http://www.tecmint.com/audit-network-performance-security-and-troubleshooting-in-linux/
|
||||
[23]:http://www.tecmint.com/wp-content/uploads/2016/11/Nmap-Scan-Network.png
|
||||
[24]:http://www.tecmint.com/wp-content/uploads/2016/11/Launch-Terminal-in-Kali-Linux.png
|
||||
[25]:http://www.tecmint.com/terminator-a-linux-terminal-emulator-to-manage-multiple-terminal-windows/
|
||||
[26]:http://www.tecmint.com/wp-content/uploads/2016/11/Start-Desktop-Environment-in-Kali-Linux.png
|
||||
[27]:http://www.tecmint.com/kali-linux-installation-guide
|
||||
[28]:http://insecure.org/fyodor/
|
||||
[29]:http://www.tecmint.com/bcc-best-linux-performance-monitoring-tools/
|
||||
[30]:http://www.tecmint.com/nmap-command-examples/
|
||||
@ -1,119 +0,0 @@
|
||||
ucasFL translating
|
||||
# How to Recover a Deleted File in Linux
|
||||
|
||||
Did this ever happen to you? You realized that you had mistakenly deleted a file – either through the Del key, or using `rm` in the command line.
|
||||
|
||||
In the first case, you can always go to the Trash, [search for the file][6], and restore it to its original location. But what about the second case? As I am sure you probably know, the Linux command line does not send removed files anywhere – it REMOVES them. Bum. They’re gone.
|
||||
|
||||
In this article we will share a tip that may be helpful to prevent this from happening to you, and a tool that you may consider using if at any point you are careless enough to do it anyway.
|
||||
|
||||
### Create an alias to ‘rm -i’
|
||||
|
||||
The `-i` switch, when used with rm (and also other [file-manipulation tools such as cp or mv][5]) causes a prompt to appear before removing a file.
|
||||
|
||||
The same applies to [copying, moving, or renaming a file][4] in a location where one with the same name exists already.
|
||||
|
||||
This prompt gives you a second chance to consider if you actually want to remove the file – if you confirm the prompt, it will be gone. In that case, I’m sorry but this tip will not protect you from your own carelessness.
|
||||
|
||||
To replace rm with an alias to `'rm -i'`, do:
|
||||
|
||||
```
|
||||
alias rm='rm -i'
|
||||
|
||||
```
|
||||
|
||||
The alias command will confirm that rm is now aliased:
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Add Alias rm Command
|
||||
|
||||
However, this will only last during the current user session in the current shell. To make the change permanent, you will have to save it to `~/.bashrc` (some distributions may use `~/.profile` instead) as shown below:
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Add Alias Permanently in Linux
|
||||
|
||||
In order for the changes in `~/.bashrc` (or `~/.profile`) to take effect immediately, source the file from the current shell:
|
||||
|
||||
```
|
||||
. ~/.bashr
|
||||
|
||||
```
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
Active Alias in Linux
|
||||
|
||||
### The forensics tool – Foremost
|
||||
|
||||
Hopefully, you will be careful with your files and will only need to use this tool while recovering a lost file from an external disk or USB drive.
|
||||
|
||||
However, if you realize you accidentally removed a file in your system and are going to panic – don’t. Let’s take a look at foremost, a forensics tool that was designed for this kind of scenarios.
|
||||
|
||||
To install foremost in CentOS/RHEL 7, you will need to enable Repoforge first:
|
||||
|
||||
```
|
||||
# rpm -Uvh http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.3-1.el7.rf.x86_64.rpm
|
||||
# yum install foremost
|
||||
|
||||
```
|
||||
|
||||
Whereas in Debian and derivatives, just do
|
||||
|
||||
```
|
||||
# aptitude install foremost
|
||||
|
||||
```
|
||||
|
||||
Once the installation has completed, let’s proceed with a simple test. We will begin by removing an image file named `nosdos.jpg` from the /boot/images directory:
|
||||
|
||||
```
|
||||
# cd images
|
||||
# rm nosdos.jpg
|
||||
|
||||
```
|
||||
|
||||
To recover it, use foremost as follows (you’ll need to identify the underlying partition first – `/dev/sda1` is where `/boot` resides in this case):
|
||||
|
||||
```
|
||||
# foremost -t jpg -i /dev/sda1 -o /home/gacanepa/rescued
|
||||
|
||||
```
|
||||
|
||||
where /home/gacanepa/rescued is a directory on a separate disk – keep in mind that recovering files on the same drive where the removed ones were located is not a wise move.
|
||||
|
||||
If, during the recovery, you occupy the same disk sectors where the removed files used to be, it may not be possible to recover anything. Additionally, it is essential to stop all your activities before performing the recovery.
|
||||
|
||||
After foremost has finished executing, the recovered file (if recovery was possible) will be found inside the /home/gacanepa/rescued/jpg directory.
|
||||
|
||||
##### Summary
|
||||
|
||||
In this article we have explained how to avoid removing a file accidentally and how to attempt to recover it if such an undesired event happens. Be warned, however, that foremost can take quite a while to run depending on the size of the partition.
|
||||
|
||||
As always, don’t hesitate to let us know if you have questions or comments. Feel free to drop us a note using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/recover-deleted-file-in-linux/
|
||||
|
||||
作者:[ Gabriel Cánepa][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2016/11/Active-Alias-in-Linux.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/11/Add-Alias-Permanently-in-Linux.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/11/Add-Alias-rm-Command.png
|
||||
[4]:http://www.tecmint.com/rename-multiple-files-in-linux/
|
||||
[5]:http://www.tecmint.com/progress-monitor-check-progress-of-linux-commands/
|
||||
[6]:http://www.tecmint.com/linux-find-command-to-search-multiple-filenames-extensions/
|
||||
@ -0,0 +1,107 @@
|
||||
translating by chenzhijun
|
||||
How To Update Wifi Network Password From Terminal In Arch Linux
|
||||
============================================================
|
||||

|
||||
|
||||
After changing the Wifi Network password in my Router, My Arch Linux test machine lost the Internet connection. So I wanted to update the new password from Terminal because my Arch Linux test box doesn’t have graphical desktop environment. Changing old wifi password to new password is pretty easy in GUI mode. I will simply open the network manager and update the new password to the wifi in few seconds. However, I am not aware of updating the wifi network password from command line in Arch Linux. So, I started to dig into Google and find a perfect solution from the Arch Linux forum. In case you ever been in the same situation, read on. It’s not that difficult.
|
||||
|
||||
|
||||
### Update Wifi Network Password From Terminal
|
||||
|
||||
After changing the password in Router, I ran _wifi-menu_ command to update the new password. But It kept throwing the following error.
|
||||
|
||||
```
|
||||
sudo wifi-menu
|
||||
```
|
||||
|
||||
It displayed the list of available wifi networks.
|
||||
|
||||
[
|
||||
|
||||
][2]
|
||||
|
||||
My wifi network name is Murugs9376. Then, I selected my network and hit OK button. Instead of asking the new password (I thought it was going to ask me if the password has been changed.), It showed the following error.
|
||||
|
||||
```
|
||||
Interface 'wlp9s0' is controlled by netctl-auto
|
||||
WPA association/authentication failed for interface 'wlp9s0'
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
I don’t have much experience in Arch based distributions. So I went thorough the Arch linux forum hoping for the solution. Thankfully, someone has posted the same problem and got the workaround from one of the fellow Arch user. Following is the solution to update the wifi network password from Terminal in Arch based distributions.
|
||||
|
||||
The network profiles is stored in the /etc/netctl/ folder. For example, here is my Arch Linux test box wifi network profile details.
|
||||
|
||||
```
|
||||
ls /etc/netctl/
|
||||
|
||||
Sample Output:
|
||||
|
||||
examples ostechnix 'wlp9s0-Chendhan Cell Service' wlp9s0-Pratheesh
|
||||
hooks wlp9s0 wlp9s0-Murugu9376
|
||||
interfaces wlp9s0-AndroidAP wlp9s0-none
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
All I need to update the new password is to delete the my wifi network profile (Ex. wlp9s0-Murugs9376) and re-run the _wifi-menu_ command to new password.
|
||||
|
||||
So, first let us delete the wifi profile using command:
|
||||
|
||||
```
|
||||
sudo rm /etc/netctl/wlp9s0-Murugu9376
|
||||
```
|
||||
|
||||
After deleting the profile, run wifi-menu command to update the new password.
|
||||
|
||||
```
|
||||
sudo wifi-menu
|
||||
```
|
||||
|
||||
Select the wifi-network and press ENTER.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Enter a name for the profile.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Finally, Enter the security key to the network profile and hit ENTER key.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
That’s it. Now, we have updated the password to the wifi network. As you can see, updating password from Terminal in Arch Linux is no big deal. Anyone could do it in a matter of seconds.
|
||||
|
||||
If you find this guide useful, please share it on your social networks and support us.
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/update-wifi-network-password-terminal-arch-linux/
|
||||
|
||||
作者:[ SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://ostechnix.tradepub.com/free/w_pacb38/prgm.cgi?a=1
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@sk_001-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@sk_002-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@sk_003-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@sk_004-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@sk_005-1.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@sk_006-1.png
|
||||
@ -0,0 +1,126 @@
|
||||
翻译中 by zky001
|
||||
How to check if port is in use on Linux or Unix
|
||||
============================================================
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
How do I determine if a port is in use under Linux or Unix-like system? How can I verify which ports are listening on Linux server?
|
||||
|
||||
It is important you verify which ports are listing on the server’s network interfaces. You need to pay attention to open ports to detect an intrusion. Apart from an intrusion, for troubleshooting purposes, it may be necessary to check if a port is already in use by a different application on your servers. For example, you may install Apache and Nginx server on the same system. So it is necessary to know if Apache or Nginx is using TCP port # 80/443\. This quick tutorial provides steps to use the netstat, nmap and lsof command to check the ports in use and view the application that is utilizing the port.
|
||||
|
||||
### How to check the listening ports and applications on Linux:
|
||||
|
||||
1. Open a terminal application i.e. shell prompt.
|
||||
2. Run any one of the following command:
|
||||
|
||||
```
|
||||
sudo lsof -i -P -n | grep LISTEN
|
||||
sudo netstat -tulpn | grep LISTEN
|
||||
sudo nmap -sTU -O IP-address-Here
|
||||
```
|
||||
|
||||
Let us see commands and its output in details.
|
||||
|
||||
### Option #1: lsof command
|
||||
|
||||
The syntax is:
|
||||
|
||||
```
|
||||
$ sudo lsof -i -P -n
|
||||
$ sudo lsof -i -P -n | grep LISTEN
|
||||
$ doas lsof -i -P -n | grep LISTEN
|
||||
```
|
||||
|
||||
### [OpenBSD] ###
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Fig.01: Check the listening ports and applications with lsof command
|
||||
|
||||
Consider the last line from above outputs:
|
||||
|
||||
```
|
||||
sshd 85379 root 3u IPv4 0xffff80000039e000 0t0 TCP 10.86.128.138:22 (LISTEN)
|
||||
```
|
||||
|
||||
- sshd is the name of the application.
|
||||
- 10.86.128.138 is the IP address to which sshd application bind to (LISTEN)
|
||||
- 22 is the TCP port that is being used (LISTEN)
|
||||
- 85379 is the process ID of the sshd process
|
||||
|
||||
### Option #2: netstat command
|
||||
|
||||
You can check the listening ports and applications with netstat as follows.
|
||||
|
||||
### Linux netstat syntax
|
||||
|
||||
```
|
||||
$ netstat -tulpn | grep LISTEN
|
||||
```
|
||||
|
||||
### FreeBSD/MacOS X netstat syntax
|
||||
|
||||
```
|
||||
$ netstat -anp tcp | grep LISTEN
|
||||
$ netstat -anp udp | grep LISTEN
|
||||
```
|
||||
|
||||
### OpenBSD netstat syntax
|
||||
|
||||
````
|
||||
$ netstat -na -f inet | grep LISTEN
|
||||
$ netstat -nat | grep LISTEN
|
||||
```
|
||||
|
||||
### Option #3: nmap command
|
||||
|
||||
The syntax is:
|
||||
|
||||
```
|
||||
$ sudo nmap -sT -O localhost
|
||||
$ sudo nmap -sU -O 192.168.2.13 ##[ list open UDP ports ]##
|
||||
$ sudo nmap -sT -O 192.168.2.13 ##[ list open TCP ports ]##
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
Fig.02: Determines which ports are listening for TCP connections using nmap
|
||||
|
||||
You can combine TCP/UDP scan in a single command:
|
||||
|
||||
`$ sudo nmap -sTU -O 192.168.2.13`
|
||||
|
||||
### A note about Windows users
|
||||
|
||||
You can check port usage from Windows operating system using following command:
|
||||
|
||||
```
|
||||
netstat -bano | more
|
||||
netstat -bano | grep LISTENING
|
||||
netstat -bano | findstr /R /C:"[LISTING]"
|
||||
````
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/
|
||||
|
||||
作者:[ VIVEK GITE][a]
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/
|
||||
[1]:https://www.cyberciti.biz/faq/category/linux/
|
||||
[2]:http://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/lsof-outputs/
|
||||
[3]:http://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/nmap-outputs/
|
||||
@ -0,0 +1,114 @@
|
||||
User Editorial: Steam Machines & SteamOS after a year in the wild
|
||||
====
|
||||
|
||||
|
||||
On this day, last year, [Valve released Steam Machines onto the world][2], after the typical Valve delays. While the state of the Linux desktop regarding gaming has improved, Steam Machines have not taken off as a platform, and SteamOS remains stagnant. What happened with these projects from Valve? Why were they created, why did they fail, and what could have been done to make them succeed?
|
||||
|
||||
**Context**
|
||||
|
||||
In 2012, when Windows 8 released, it included an app store, much like iOS and Android. With the new touch-friendly user interface Microsoft debuted, there was a new set of APIs available called “WinRT,” for creating these immersive touch-friendly applications in the UI language called “Metro.” Applications created with this new API, however, could only be distributed via the Windows Store, with Microsoft taking out a 30% cut, just like the other stores. To Gabe Newell, CEO of Valve, this was unacceptable, and he saw the risks of Microsoft using its position to push the Windows Store and Metro applications to crush Valve, like what they had done to Netscape using Internet Explorer.
|
||||
|
||||
To Valve, the strength of the PC running Windows was it that was an open platform, where anyone could run whatever they want without control over the operating system or hardware vendor. The alternative to these proprietary platforms closing in on third-party application stores like Steam was to push a truly open platform that grants freedoms to change, to everyone – Linux. Linux is just a kernel, but you can easily create an operating system with it and other software like the GNU core utilities and Gnome, such as Ubuntu. While pushing Ubuntu and other Linux distributions would allow Valve a sanctuary platform in case Microsoft or Apple turned hostile, Linux gave them possibilities to create a new platform.
|
||||
|
||||
**Conception**
|
||||
|
||||
Valve seemed to have found an opportunity in the console space, if we can call Steam Machines consoles. To achieve the user interface expectations of a console, being used on a large screen television from afar, Big Picture Mode was created. A core principle of the machines was openness; the software was able to be swapped out for Windows, as an example, and the CAD designs for the controller are available for people’s projects.
|
||||
|
||||
Originally, Valve had planned to create their own box as a “flagship” machine. However, these only shipped as prototypes to testers in 2013\. They would also let other OEMs like Dell create their own Steam Machines as well, and allow a variety of pricing and specification options. A company called “Xi3” showed their small box, small enough to fit into a palm, as a possible candidate to become a premiere Steam Machine, which created more hype around Steam Machines. Ultimately, Valve decided to only go with OEM partners to make and advertise Steam Machines, rather than doing it themselves.
|
||||
|
||||
More “out there” ideas were considered. Biometrics, gaze tracking, and motion controllers were considered for the controller. Of them, the released Steam Controller had a gyroscope, and the HTC Vive controllers had various tracking and motion features that may have been originally intended for the original controller concepts. The controller was also originally intended to be more radical in its approach, with a touchscreen in the middle that had customizable, context-sensitive actions. Ultimately, the launch controller was more conservative, but still had features like the dual trackpads and advanced software that gave it flexibility. Valve had also considered making a version of Steam Machines and SteamOS for smaller hardware like laptops. This ultimately never bore any fruit, though the “Smach Z” handheld could be compared to this.
|
||||
|
||||
In [September 2013][3], Valve had announced Steam Machines and SteamOS, with an expected release in the middle of 2014\. The aforementioned 300 prototype machines were released to testers in December, and in January, 2000 more machines were provided to developers. SteamOS was released for testers experienced with Linux to try out. With the feedback given, Valve had decided to delay the release until November 2015.
|
||||
|
||||
The late launch caused problems with partners; Dell’s Steam Machine was launched a year early running Windows as the Alienware Alpha, with extra software to improve usability with a controller.
|
||||
|
||||
**Launch**
|
||||
|
||||
With the launch, Valve and their OEM partners released their machines, and Valve also released the Steam Controller and the Steam Link. A retail presence was established with GameStop and other brick and mortar stores providing space. Before release, some OEMs pulled out of the launch; Origin PC and Falcon Northwest, two high-end boutique builders. They had claimed performance issues and limitations had made them decide not to ship SteamOS.
|
||||
|
||||
The machines had launched to mixed reviews. The Steam Link was praised and many had considered buying one for their existing PC instead of buying a Steam Machine for the living room. The Steam Controller reception was muddled, due to its rich feature set but high learning curve. The Steam Machines themselves ultimately launched to the muddiest reception, however. Reviewers like LinusTechTips noticed glaring defects with the SteamOS software, including performance issues. Many of the machines were criticized for their high price point and poor value, especially when compared to the option of building a PC from the perspective of a PC gamer, or the price in comparison to other consoles. The use of SteamOS was criticized over compatibility, bugs, and lower performance than Windows. Of the available options, the Alienware Steam Machine was considered to be the most interesting option due to its value relative to other machines and small form factor.
|
||||
|
||||
By using Debian Linux as the base, Valve had many “launch titles” for the platform, as they had a library of pre-existing Linux titles. The initial availability of games was seen as favourable over other consoles. However, many titles originally announced for the platform never came out, or came out much later. Rocket League and Mad Max only came out only recently after the initial announcements a year ago, and titles like The Witcher 3 and Batman: Arkham Knight never came for the platform, despite initial promises from Valve or publishers. In the case of The Witcher 3, the developer, CD Projekt Red, had denied they ever announced a port, despite their game appearing in a list of titles on sale that had or were announced to have Linux and SteamOS support. In addition, many “AAA” titles have not been ported; though this situation continues to improve over time.
|
||||
|
||||
**Neglect**
|
||||
|
||||
With the Steam Machines launched, developers at Valve had moved on to other projects. Of the projects being worked on, virtual reality was seen as the most important, with about a third of employees working on it as of June. Valve had seen virtual reality as something to develop, and Steam as the prime ecosystem for delivering VR. Using HTC to manufacture, they had designed their own virtual reality headset and controllers, and would continue to develop new revisions. However, Linux and Steam Machines had fallen to the wayside with this focus. SteamVR, until recently, did not support Linux (it's still not public yet, but it was shown off at SteamDevDays on Linux), which put into question Valve’s commitments to Steam Machines and Linux as an open platform with a future.
|
||||
|
||||
There has been little development to SteamOS itself. The last major update, SteamOS 2.0 was mostly synchronizing with upstream Debian and required a reinstallation, and continued patches simply continue synchronizing with upstream sources. While Valve has made improvements to projects like Mesa, which have improved performance for many users, it has done little with Steam Machines as a product.
|
||||
|
||||
Many features continue to go undeveloped. Steam’s built in functionality like chat and broadcasting continue to be weak, but this affects all platforms that Steam runs on. More pressingly, services like Netflix, Twitch, and Spotify are not integrated into the interface like most major consoles, but accessing them requires using the browser, which can be slow and clunky, if it even achieves what is wanted, or to bring in software from third-party sources, which requires using the terminal, and the software might not be very usable using a controller –this is a poor UX for what’s considered to be an appliance.
|
||||
|
||||
Valve put little effort into marketing the platform, preferring to leave this to OEMs. However, most OEMs were either boutique builders or makers or barebones builders. Of the OEMs, only Dell was the major player in the PC market, and the only one who pushed Steam Machines with advertisements.
|
||||
|
||||
Sales were not strong. With 500,000 controllers sold 7 months on (stated in June 2016), including those bundled with a Steam Machine. This puts retail Steam Machines, not counting machines people have installed SteamOS on, in the low hundred thousand mark. Compared to the existing PC and console install bases, this is low.
|
||||
|
||||
**Post-mortem thoughts**
|
||||
|
||||
So, with the story of what happened, can we identify why Steam Machines failed, and ways they could succeed in the future?
|
||||
|
||||
_Vision and purpose_
|
||||
|
||||
Steam Machines did not make clear what they were in the market, nor did any advantages particularly stand out. On the PC flank, building PCs had become popular and is a cheaper option with better upgrade and flexibility options. On the console flank, they were outflanked by consoles with low initial investment, despite a possibly higher TCO with game prices, and a far simpler user experience.
|
||||
|
||||
With PCs, flexibility is seen as a core asset, with users being able to use their machines beyond gaming, doing work and other tasks. While Steam Machines were just PCs running SteamOS with no restrictions, the SteamOS software and marketing had solidified their view as consoles to PC gamers, compounded by the price and lower flexibility in hardware with some options. In the living room where these machines could have made sense to PC gamers, the Steam Link offered a way to access content on a PC in another room, and small form factor hardware like NUCs and Mini-ITX motherboards allowed for custom built PCs that are more socially acceptable in living rooms. The SteamOS software was also available to “convert” these PCs into Steam Machines, but people seeking flexibility and compatibility often opted for a Linux or Windows desktop. Recent strides in Windows and desktop Linux have simplified maintenance tasks associated with desktop-experience computers, automating most of it.
|
||||
|
||||
With consoles, simplicity is a virtue. Even as they have expanded in their roles, with media features often a priority, they are still a plug and play experience where compatibility and experience are guaranteed, with a low barrier of entry. Consoles also have long life cycles, ranging from four to seven years, and the fixed hardware during this life cycle allow developers to target and optimize especially for their specifications and features. New mid-life upgrades like “Scorpio” and PlayStation 4 Pro may change the unified experience previously shared by users, but manufactures are requiring games to work on the original model consoles to avoid the most problematic aspects. To keep users attached to the systems, social networks and exclusive games are used. Games also come on discs that can be freely reused and resold, which is a positive for retailers and users. Steam Machines have none of these guarantees; they carry PC complexity and higher initial prices despite a living room friendly exterior.
|
||||
|
||||
_Reconciliation_
|
||||
|
||||
With this, Steam Machines could be seen as a “worst of both worlds” product, carrying the burdens of both kinds of product, without showing clearly as one or the other, or some kind of new product category. There also exist many deficiencies that neither party experiences, like lack of AAA titles that appear on consoles and Windows PCs, and lack of clients for services like Netflix. Despite this, Valve has shown little effort into improving the product or even trying to resolve the seemingly contradictory goals like the mutual distrust of PC and console gaming.
|
||||
|
||||
Some things may make it impossible to reconcile the two concepts into one category or the other, though. Things like graphics settings and mods may make it hard to create a foolproof experience, and the complexity of the underlying system appears from time to time.
|
||||
|
||||
One of the most complex parts is the concept of having a lineup – users need to evaluate not only the costs and specifications of a system, but its value and value relative to other systems. You need some way for the user to know that their hardware can run any given game, either by some automated benchmark system with comparison, or a grading system, though these need to be simple and need to support (almost) every game in the library. In addition, you also need to worry about how these systems and grades will age – what does a “2016 Grade A” machine mean three years from now?
|
||||
|
||||
_Valve, effort, and organization_
|
||||
|
||||
Valve’s organizational structure may be detrimental to creating platforms like Steam Machines, let alone maintaining services like Steam. Their mostly leaderless structure with people supposedly moving their desks to ad-hoc units working on projects that they alone decide to work on can be great for creative endeavours, as well as research and development. It’s said Valve only hires what they consider to be the “cream of the crop,” with very strict standards, tying them to what they deem more "worthy" work. This view may be inaccurate though; as cliques often exist, the word of Gabe Newell is more important than the “leaked” employee handbook lets on, and people hired and then fired as needed, as a form of contractor working on certain aspects.
|
||||
|
||||
However, this leaves projects that aren’t glamorous or interesting, but need persistent and often mundane work, to wither on the vine. Customer support for Valve has been a constant headache, with enraged users felt ignored, and Valve sometimes only acting when legally required to do so, like with the automated refund system that was forced into action by Australian and European legislation, or the Counter-Strike: Global Offensive item gambling site controversy involving the gambling commission of Washington State that’s still ongoing.
|
||||
|
||||
This has affected Steam Machines as a result. With the launch delayed by a year, some partners’ hands were forced, by Dell launching the Alienware Steam Machine a year earlier as the Alienware Alpha – causing the hardware to be outdated on launch. These delays may have also affected game availability as well. The opinions of developers and hardware partners as a result of the delayed and non-monumental launch are not clear. Valve’s platform for virtual reality simply wasn’t available on Linux, and as such, SteamOS, until recently, even as SteamVR was receiving significant developer effort.
|
||||
|
||||
The “long game”
|
||||
|
||||
Valve is seen as playing a “long game” with Steam Machines and SteamOS, though it appears as if there is no roadmap. An example of Valve aiming for the long term is with Steam, from its humble and initially reviled beginnings as a patching platform for their games to the popular distribution and social network it is today. It also helped that Steam was required to play Valve’s games like Half-Life 2 and Counter-Strike 1.6\. However, it doesn’t seem as if Valve is putting in the effort to Steam Machines as they did with Steam before. There is also entrenched competition that Steam in the early days never really dealt with. Their competition includes arguably Valve itself, with Steam on Windows.
|
||||
|
||||
_Gambit_
|
||||
|
||||
With the lack of developments in Steam Machines, one wonders if the platform was a bargaining chip of sorts. Steam Machines had been originally started over Valve’s Linux efforts took fruit because of concerns that Microsoft and Apple would have pushed them out of the market with native app stores, and Steam Machines grew so Valve would have a safe haven in case this happened, and a bargaining chip so Valve can remind the developers of its host platforms of possible independence. When these turned out to be non-threatening, Valve slowed down development. I don’t see this however; Valve has expended a lot of goodwill with hardware partners and developers trying to push this, only to halt it. You could say both Microsoft and Valve called each other’s bluffs – Microsoft with a locked-down Windows 8, and Valve’s capability as an independent player.
|
||||
|
||||
Even then, who is to say developers wouldn’t follow Microsoft with a locked-in platform, if they can offer superior deals to publishers, or better customer relationships? In addition, now Microsoft is pushing Xbox on Windows integration with cross-buy, Xbox Live integration, and Xbox exclusive games on Windows, all while preserving Windows as an open platform – arguably more a threat to Steam.
|
||||
|
||||
Another point you could argue is that all of this with Steam Machines was simply to push Linux adoption with PC gaming, and Steam Machines were simply to make it more palatable to publishers and developers by implying a large push and continued support. However, this made it an awfully expensive gambit, and developers continued to support Linux before and after Steam Machines, and could have backfired with developers pulling out of Linux due to the lack of the Promised Land of SteamOS coming.
|
||||
|
||||
**My opinions on what could have been done**
|
||||
|
||||
I think there’s an interesting product with Steam Machines, and that there is a market for it, but lack of interest and effort, as well as possible confusion in what it should have been has been damaging for it. I see Steam Machines as a way to cut out the complexity of PC gaming of worrying about parts, life cycles, and maintenance; while giving the advantages like cheap games, mods, and an open platform that can be fiddled with if the user desires. However, they need to get core aspects like pricing, marketing, lineup, and software right.
|
||||
|
||||
I think Steam Machines can make compromises on things like upgradability (Though it’s possible to preserve this – but it should be done with attention to user experience.) and choices, to reduce friction. PCs would still exist to these options. The paralysis of choice is a real dilemma, and the sheer amount of poorly valued options available with Steam Machines didn't help. Valve needs a flagship machine to lead Steam Machines. Arguably, the Alienware model was close, but it wasn’t made officially so. There’s good industrial design talent in Valve, and if they focused on their own machine, and with effort put in, it might be worth it. A company like Dell or HTC can manufacture for Valve, bringing their experience in. Defining life cycles and only having one or two specifications updated periodically would help, especially if they worked with developers to establish this is a baseline that should be supported. I’m not sure with OEMs; if Valve is putting their effort behind one machine, they might be made redundant and ultimately only hindering development of the platform.
|
||||
|
||||
Addressing the software issues is essential. The lack of integration with services like Netflix and Twitch that exist fluidly on console and easily put into place on PC, despite living room user interface issues, are holding Steam Machines back. Although Valve has slowly been acquiring movie licenses for distribution on Steam, people will use existing and trusted streaming sources. This needs to be addressed, especially as people use their consoles as parts of their home theatre. Fixing issues with the Steam client and platform are essential, and feature parity with other platforms is a good idea. Performance issues with Linux and its graphics stack are also a problem, but this is slowly improving. Getting ports of games will also be another issue. Game porting shops like Feral Interactive and Aspyr Media help the library, but they need to be contracted by publishers and developers, and they often use wrappers that add overhead. Valve has helped studios directly with porting, such as with Rocket League, but this has rarely happened and when it did, slowly at the typical Valve pace. The monolith of AAA games can’t be ignored either – the situation has improved dramatically, but studios like Bethesda are still reluctant to port, especially with a small user base, lack of support from Valve with Steam Machines even if Linux is doing relatively well, and the lack of extra DRM like Denuvo.
|
||||
|
||||
Valve also needs to put effort into the other bits beyond hardware and software. With one machine, they have an interest and can subsidize the hardware effectively. This would put it into parity with consoles, and possibly cheaper than custom built PCs. Efforts to marketing the product to market segments that would be interested in the machines are essential, whatever they are. (I myself would be interested in the machines. I don’t like the hassle of dealing with PC building or the premium on prebuilt machines, but consoles often lack the games I want to play, and I have an existing library of games on Steam I acquired cheaply.) Retail partners may not be effective, due to their interest in selling and reselling physical copies of games.
|
||||
|
||||
Even with my suggestions towards the platform and product, I’m not sure how effective it would be to help Steam Machines achieve their full potential and do well in the marketplace. Ultimately, learning from not just your own mistakes, but the mistakes of previous entrants like 3DO and Pippin who relied on an open platform or were descended from desktop-experience computing, which are relevant to Valve’s current situation, and the future of Nintendo's Switch, which steps into the realm of possible confusion between values.
|
||||
|
||||
_Note: Clearing up done by liamdawe, all thoughts are from the submitter._
|
||||
|
||||
This article was submitted by a guest, we encourage anyone to [submit their own articles][1].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.gamingonlinux.com/articles/user-editorial-steam-machines-steamos-after-a-year-in-the-wild.8474
|
||||
|
||||
作者:[calvin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.gamingonlinux.com/profiles/5163
|
||||
[1]:https://www.gamingonlinux.com/submit-article/
|
||||
[2]:https://www.gamingonlinux.com/articles/steam-machines-steam-link-steam-controller-officially-released-steamos-sale.6201
|
||||
[3]:https://www.gamingonlinux.com/articles/valve-announces-steam-machines-you-can-win-one-too.2469
|
||||
@ -0,0 +1,172 @@
|
||||
### [Can Linux containers save IoT from a security meltdown?][28]
|
||||
|
||||

|
||||
In this final IoT series post, Canonical and Resin.io champion Linux container technology as a solution to IoT security and interoperability challenges.
|
||||
|
||||
|
|
||||

|
||||
|
||||
**Artik 7** |
|
||||
|
||||
Despite growing security threats, the Internet of Things hype shows no sign of abating. Feeling the FoMo, companies are busily rearranging their roadmaps for IoT. The transition to IoT runs even deeper and broader than the mobile revolution. Everything gets swallowed in the IoT maw, including smartphones, which are often our windows on the IoT world, and sometimes our hubs or sensor endpoints.
|
||||
|
||||
New IoT focused processors and embedded boards continue to reshape the tech landscape. Since our [Linux and Open Source Hardware for IoT][5] story in September, we’ve seen [Intel Atom E3900][6] “Apollo Lake” SoCs aimed at IoT gateways, as well as [new Samsung Artik modules][7], including a Linux-driven, 64-bit Artik 7 COM for gateways and an RTOS-ready, Cortex-M4 Artik 0\. ARM announced [Cortex-M23 and Cortex-M33][8] cores for IoT endpoints featuring ARMv8-M and TrustZone security.
|
||||
|
||||
Security is a selling point for these products, and for good reason. The Mirai botnet that recently attacked the Dyn service and blacked out much of the U.S. Internet for a day brought Linux-based IoT into the forefront — and not in a good way. Just as IoT devices can be turned to the dark side via DDoS, the devices and their owners can also be the victimized directly by malicious attacks.
|
||||
|
||||
|
|
||||

|
||||
|
||||
**Cortex-M33 and -M23** |
|
||||
|
||||
The Dyn attack reinforced the view that IoT will more confidently move forward in more controlled and protected industrial environments rather than the home. It’s not that consumer [IoT security technology][9] is unavailable, but unless products are designed for security from scratch, as are many of the solutions in our [smart home hub story][10], security adds cost and complexity.
|
||||
|
||||
In this final, future-looking segment of our IoT series, we look at two Linux-based, Docker-oriented container technologies that are being proposed as solutions to IoT security. Containers might also help solve the ongoing issues of development complexity and barriers to interoperability that we explored in our story on [IoT frameworks][11].
|
||||
|
||||
We spoke with Canonical’s Oliver Ries, VP Engineering Ubuntu Client Platform about his company’s Ubuntu Core and its Docker-friendly, container-like Snaps package management technology. We also interviewed Resin.io CEO and co-founder Alexandros Marinos about his company’s new Docker-based ResinOS for IoT.
|
||||
|
||||
**Ubuntu Core Snaps to**
|
||||
|
||||
Canonical’s IoT-oriented [Snappy Ubuntu Core][12] version of Ubuntu is built around a container-like snap package management mechanism, and offers app store support. The snaps technology was recently [released on its own][13] for other Linux distributions. On November 3, Canonical released [Ubuntu Core 16][14], which improves white label app store and update control services.
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][15]
|
||||
**Classic Ubuntu (left) architecture vs. Ubuntu Core 16**
|
||||
(click image to enlarge)
|
||||
</center>
|
||||
|
||||
The snap mechanism offers automatic updates, and helps block unauthorized updates. Using transactional systems management, snaps ensure that updates either deploy as intended or not at all. In Ubuntu Core, security is further strengthened with AppArmor, and the fact that all application files are kept in separate silos, and are read-only.
|
||||
|
||||
|
|
||||

|
||||
|
||||
**LimeSDR** |
|
||||
|
||||
Ubuntu Core, which was part of our recent [survey of open source IoT OSes][16], now runs on Gumstix boards, Erle Robotics drones, Dell Edge Gateways, the [Nextcloud Box][17], LimeSDR, the Mycroft home hub, Intel’s Joule, and SBCs compliant with Linaro’s 96Boards spec. Canonical is also collaborating with the Linaro IoT and Embedded (LITE) Segment Group on its [96Boards IoT Edition][18]Initially, 96Boards IE is focused on Zephyr-driven Cortex-M4 boards like Seeed’s [BLE Carbon][19], but it will expand to gateway boards that can run Ubuntu Core.
|
||||
|
||||
“Ubuntu Core and snaps have relevance from edge to gateway to the cloud,” says Canonical’s Ries. “The ability to run snap packages on any major distribution, including Ubuntu Server and Ubuntu for Cloud, allows us to provide a coherent experience. Snaps can be upgraded in a failsafe manner using transactional updates, which is important in an IoT world moving to continuous updates for security, bug fixes, or new features.”
|
||||
|
||||
|
|
||||

|
||||
|
||||
**Nextcloud Box** |
|
||||
|
||||
Security and reliability are key points of emphasis, says Ries. “Snaps can run completely isolated from one another and from the OS, making it possible for two applications to securely run on a single gateway,” he says. “Snaps are read-only and authenticated, guaranteeing the integrity of the code.”
|
||||
|
||||
Ries also touts the technology for reducing development time. “Snap packages allow a developer to deliver the same binary package to any platform that supports it, thereby cutting down on development and testing costs, deployment time, and update speed,” says Ries. “With snap packages, the developer is in full control of the lifecycle, and can update immediately. Snap packages provide all required dependencies, so developers can choose which components they use.”
|
||||
|
||||
**ResinOS: Docker for IoT**
|
||||
|
||||
Resin.io, which makes the commercial IoT framework of the same name, recently spun off the framework’s Yocto Linux based [ResinOS 2.0][20]” target=”new”>ResinOS 2.0 as an open source project. Whereas Ubuntu Core runs Docker container engines within snap packages, ResinOS runs Docker on the host. The minimalist ResinOS abstracts the complexity of working with Yocto code, enabling developers to quickly deploy Docker containers.
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][21]
|
||||
**ResinOS 2.0 architecture**
|
||||
(click image to enlarge)
|
||||
</center>
|
||||
|
||||
Like the Linux-based CoreOS, ResinOS integrates systemd control services and a networking stack, enabling secure rollouts of updated applications over a heterogeneous network. However, it’s designed to run on resource constrained devices such as ARM hacker boards, whereas CoreOS and other Docker-oriented OSes like the Red Hat based Project Atomic are currently x86 only and prefer a resource-rich server platform. ResinOS can run on 20 Linux devices and counting, including the Raspberry Pi, BeagleBone, and Odroid-C1.
|
||||
|
||||
“We believe that Linux containers are even more important for embedded than for the cloud,” says Resin.io’s Marinos. “In the cloud, containers represent an optimization over previous processes, but in embedded they represent the long-delayed arrival of generic virtualization.”
|
||||
|
||||
|
|
||||

|
||||
|
||||
**BeagleBone
|
||||
Black** |
|
||||
|
||||
When applied to IoT, full enterprise virtual machines have performance issues and restrictions on direct hardware access, says Marinos. Mobile VMs like OSGi and Android’s Dalvik can been used for IoT, but they require Java among other limitations.
|
||||
|
||||
Using Docker may seem natural for enterprise developers, but how do you convince embedded hackers to move to an entirely new paradigm? “Rather than transferring practices from the cloud wholesale, ResinOS is optimized for embedded,” answers Marinos. In addition, he says, containers are better than typical IoT technologies at containing failure. “If there’s a software defect, the host OS can remain functional and even connected. To recover, you can either restart the container or push an update. The ability to update a device without rebooting it further removes failure opportunities.”
|
||||
|
||||
According to Marinos, other benefits accrue from better alignment with the cloud, such as access to a broader set of developers. Containers provide “a uniform paradigm across data center and edge, and a way to easily transfer technology, workflows, infrastructure, and even applications to the edge,” he adds.
|
||||
|
||||
The inherent security benefits in containers are being augmented with other technologies, says Marinos. “As the Docker community pushes to implement signed images and attestation, these naturally transfer to ResinOS,” he says. “Similar benefits accrue when the Linux kernel is hardened to improve container security, or gains the ability to better manage resources consumed by a container.”
|
||||
|
||||
Containers also fit in well with open source IoT frameworks, says Marinos. “Linux containers are easy to use in combination with an almost endless variety of protocols, applications, languages and libraries,” says Marinos. “Resin.io has participated in the AllSeen Alliance, and we have worked with partners who use IoTivity and Thread.”
|
||||
|
||||
**Future IoT: Smarter Gateways and Endpoints**
|
||||
|
||||
Marinos and Canonical’s Ries agree on several future trends in IoT. First, the original conception of IoT, in which MCU-based endpoints communicate directly with the cloud for processing, is quickly being replaced with a fog computing architecture. That calls for more intelligent gateways that do a lot more than aggregate data and translate between ZigBee and WiFi.
|
||||
|
||||
Second, gateways and smart edge devices are increasingly running multiple apps. Third, many of these devices will provide onboard analytics, which we’re seeing in the latest [smart home hubs][22]. Finally, rich media will soon become part of the IoT mix.
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][23] [
|
||||

|
||||
][24]
|
||||
**Some recent IoT gateways: Eurotech’s [ReliaGate 20-26][1] and Advantech’s [UBC-221][2]**
|
||||
(click images to enlarge)
|
||||
</center>
|
||||
|
||||
“Intelligent gateways are taking over a lot of the processing and control functions that were originally envisioned for the cloud,” says Marinos. “Accordingly, we’re seeing an increased push for containerization, so feature- and security-related improvements can be deployed with a cloud-like workflow. The decentralization is driven by factors such as the mobile data crunch, an evolving legal framework, and various physical limitations.”
|
||||
|
||||
Platforms like Ubuntu Core are enabling an “explosion of software becoming available for gateways,” says Canonical’s Ries. “The ability to run multiple applications on a single device is appealing both for users annoyed with the multitude of single-function devices, and for device owners, who can now generate ongoing software revenues.”
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][25] [
|
||||

|
||||
][26]
|
||||
**Two more IoT gateways: [MyOmega MYNXG IC2 Controller (left) and TechNexion’s ][3][LS1021A-IoT Gateway][4]**
|
||||
(click images to enlarge)
|
||||
</center>
|
||||
|
||||
It’s not only gateways — endpoints are getting smarter, too. “Reading a lot of IoT coverage, you get the impression that all endpoints run on microcontrollers,” says Marinos. “But we were surprised by the large amount of Linux endpoints out there like digital signage, drones, and industrial machinery, that perform tasks rather than operate as an intermediary. We call this the shadow IoT.”
|
||||
|
||||
Canonical’s Ries agrees that a single-minded focus on minimalist technology misses out on the emerging IoT landscape. “The notion of ‘lightweight’ is very short lived in an industry that’s developing as fast as IoT,” says Ries. “Today’s premium consumer hardware will be powering endpoints in a matter of months.”
|
||||
|
||||
While much of the IoT world will remain lightweight and “headless,” with sensors like accelerometers and temperature sensors communicating in whisper thin data streams, many of the newer IoT applications use rich media. “Media input/output is simply another type of peripheral,” says Marinos. “There’s always the issue of multiple containers competing for a limited resource, but it’s not much different than with sensor or Bluetooth antenna access.”
|
||||
|
||||
Ries sees a trend of “increasing smartness at the edge” in both industrial and home gateways. “We are seeing a large uptick in AI, machine learning, computer vision, and context awareness,” says Ries. “Why run face detection software in the cloud and incur delays and bandwidth and computing costs, when the same software could run at the edge?”
|
||||
|
||||
As we explored in our [opening story][27] of this IoT series, there are IoT issues related to security such as loss of privacy and the tradeoffs from living in a surveillance culture. There are also questions about the wisdom of relinquishing one’s decisions to AI agents that may be controlled by someone else. These won’t be fully solved by containers, snaps, or any other technology.
|
||||
|
||||
Perhaps we’d be happier if Alexa handled the details of our lives while we sweat the big stuff, and maybe there’s a way to balance privacy and utility. For now, we’re still exploring, and that’s all for the good.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
[1]:http://hackerboards.com/atom-based-gateway-taps-new-open-source-iot-cloud-platform/
|
||||
[2]:http://hackerboards.com/compact-iot-gateway-runs-yocto-linux-on-quark/
|
||||
[3]:http://hackerboards.com/wireless-crazed-customizable-iot-gateway-uses-arm-or-x86-coms/
|
||||
[4]:http://hackerboards.com/iot-gateway-runs-linux-on-qoriq-accepts-arduino-shields/
|
||||
[5]:http://hackerboards.com/linux-and-open-source-hardware-for-building-iot-devices/
|
||||
[6]:http://hackerboards.com/intel-launches-14nm-atom-e3900-and-spins-an-automotive-version/
|
||||
[7]:http://hackerboards.com/samsung-adds-first-64-bit-and-cortex-m4-based-artik-modules/
|
||||
[8]:http://hackerboards.com/new-cortex-m-chips-add-armv8-and-trustzone/
|
||||
[9]:http://hackerboards.com/exploring-security-challenges-in-linux-based-iot-devices/
|
||||
[10]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[11]:http://hackerboards.com/open-source-projects-for-the-internet-of-things-from-a-to-z/
|
||||
[12]:http://hackerboards.com/lightweight-snappy-ubuntu-core-os-targets-iot/
|
||||
[13]:http://hackerboards.com/canonical-pushes-snap-as-a-universal-linux-package-format/
|
||||
[14]:http://hackerboards.com/ubuntu-core-16-gets-smaller-goes-all-snaps/
|
||||
[15]:http://hackerboards.com/files/canonical_ubuntucore16_diagram.jpg
|
||||
[16]:http://hackerboards.com/open-source-oses-for-the-internet-of-things/
|
||||
[17]:http://hackerboards.com/private-cloud-server-and-iot-gateway-runs-ubuntu-snappy-on-rpi/
|
||||
[18]:http://hackerboards.com/linaro-beams-lite-at-internet-of-things-devices/
|
||||
[19]:http://hackerboards.com/96boards-goes-cortex-m4-with-iot-edition-and-carbon-sbc/
|
||||
[20]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/%3Ca%20href=
|
||||
[21]:http://hackerboards.com/files/resinio_resinos_arch.jpg
|
||||
[22]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[23]:http://hackerboards.com/files/eurotech_reliagate2026.jpg
|
||||
[24]:http://hackerboards.com/files/advantech_ubc221.jpg
|
||||
[25]:http://hackerboards.com/files/myomega_mynxg.jpg
|
||||
[26]:http://hackerboards.com/files/technexion_ls1021aiot_front.jpg
|
||||
[27]:http://hackerboards.com/an-open-source-perspective-on-the-internet-of-things-part-1/
|
||||
[28]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
@ -0,0 +1,233 @@
|
||||
Neofetch – Shows Linux System Information with Distribution Logo
|
||||
============================================================
|
||||
|
||||
Neoftech is a cross-platform and easy-to-use [system information command line script][3] that collects your Linux system information and display it on the terminal next to an image, it could be your distributions logo or any ascii art of your choice.
|
||||
|
||||
Neoftech is very similar to [ScreenFetch][4] or [Linux_Logo][5] utilities, but highly customizable and comes with some extra features as discussed below.
|
||||
|
||||
Its main features include: it’s fast, prints a full color image – your distributions logo in ASCII alongside your system information, it’s highly customizable in terms of which, where and when information is printed on the terminal and it can take a screenshot of your desktop when closing the script as enabled by a special flag.
|
||||
|
||||
#### Required Dependencies:
|
||||
|
||||
1. Bash 3.0+ with ncurses support.
|
||||
2. w3m-img (occasionally packaged with w3m) or iTerm2 or Terminology for printing images.
|
||||
3. [imagemagick][1] – for thumbnail creation.
|
||||
4. [Linux terminal emulator][2] should support \033[14t [3] or xdotool or xwininfo + xprop or xwininfo + xdpyinfo .
|
||||
5. On Linux, you need feh, nitrogen or gsettings for wallpaper support.
|
||||
|
||||
Important: You can read more about optional dependencies from the Neofetch Github repository to check if your [Linux terminal emulator][6] actually supports \033[14t or any extra dependencies for the script to work well on your distro.
|
||||
|
||||
### How To Install Neofetch in Linux
|
||||
|
||||
Neofetch can be easily installed from third-party repositories on almost all Linux distributions by following below respective installation instructions as per your distribution.
|
||||
|
||||
#### On Debian
|
||||
|
||||
```
|
||||
$ echo "deb http://dl.bintray.com/dawidd6/neofetch jessie main" | sudo tee -a /etc/apt/sources.list
|
||||
$ curl -L "https://bintray.com/user/downloadSubjectPublicKey?username=bintray" -o Release-neofetch.key && sudo apt-key add Release-neofetch.key && rm Release-neofetch.key
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install neofetch
|
||||
```
|
||||
|
||||
#### On Ubuntu and Linux Mint
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:dawidd0811/neofetch
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install neofetch
|
||||
```
|
||||
|
||||
#### On RHEL, CentOS and Fedora
|
||||
|
||||
You need to have dnf-plugins-core installed on your system, or else install it with the command below:
|
||||
|
||||
```
|
||||
$ sudo yum install dnf-plugins-core
|
||||
```
|
||||
|
||||
Enable COPR repository and install neofetch package.
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable konimex/neofetch
|
||||
$ sudo dnf install neofetch
|
||||
```
|
||||
|
||||
#### On Arch Linux
|
||||
|
||||
You can either install neofetch or neofetch-git from the AUR using packer or Yaourt.
|
||||
|
||||
```
|
||||
$ packer -S neofetch
|
||||
$ packer -S neofetch-git
|
||||
OR
|
||||
$ yaourt -S neofetch
|
||||
$ yaourt -S neofetch-git
|
||||
```
|
||||
|
||||
#### On Gentoo
|
||||
|
||||
Install app-misc/neofetch from Gentoo/Funtoo’s official repositories. However, in case you need the git version of the package, you can install =app-misc/neofetch-9999.
|
||||
|
||||
### How To Use Neofetch in Linux
|
||||
|
||||
Once you have installed the package, the general syntax for using it is:
|
||||
|
||||
```
|
||||
$ neofetch
|
||||
```
|
||||
|
||||
Note: If w3m-img or [imagemagick][7] is not installed on your system, [screenfetch][8] will be enabled by default and neofetch will display your [ASCII art logo][9] as in the image below.
|
||||
|
||||
#### Linux Mint Information
|
||||
|
||||
[
|
||||
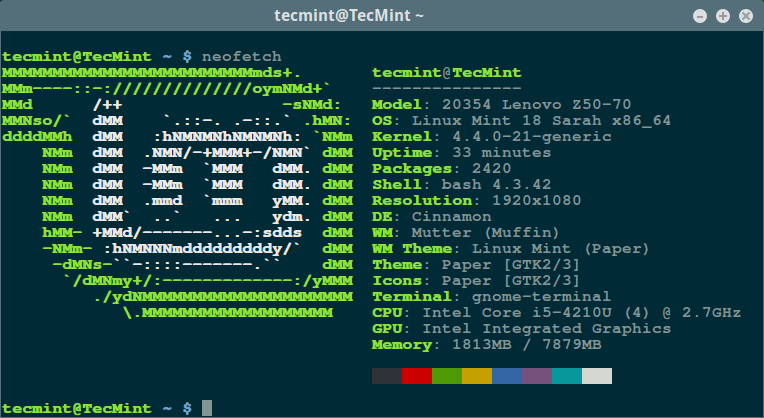
|
||||
][10]
|
||||
|
||||
Linux Mint System Information
|
||||
|
||||
#### Ubuntu Information
|
||||
|
||||
[
|
||||
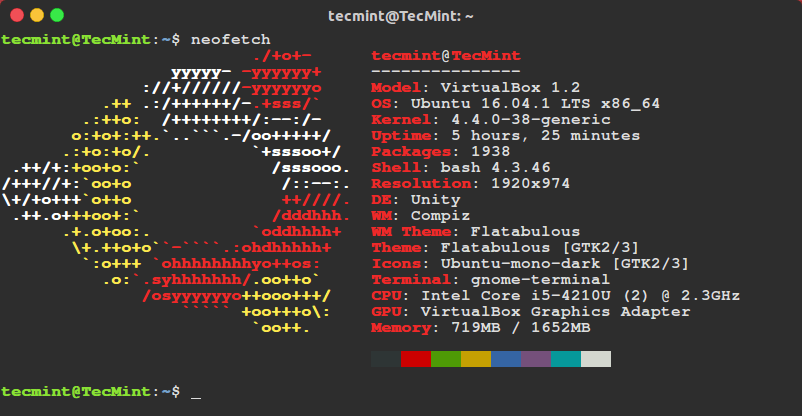
|
||||
][11]
|
||||
|
||||
Ubuntu System Information
|
||||
|
||||
If you want to display the default distribution logo as image, you should install w3m-img or imagemagickon your system as follows:
|
||||
|
||||
```
|
||||
$ sudo apt-get install w3m-img [On Debian/Ubuntu/Mint]
|
||||
$ sudo yum install w3m-img [On RHEL/CentOS/Fedora]
|
||||
```
|
||||
|
||||
Then run neofetch again, you will see the default wallpaper of your Linux distributions as the image.
|
||||
|
||||
```
|
||||
$ neofetch
|
||||
```
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
Ubuntu System Information with Logo
|
||||
|
||||
After running neofetch for the first time, it will create a configuration file with all options and settings: `$HOME/.config/neofetch/config`.
|
||||
|
||||
This configuration file will enable you through the `printinfo ()` function to alter the system information that you want to print on the terminal. You can type in new lines of information, modify the information lineup, delete certain lines and also tweak the script it using bash code to manage the information to be printed out.
|
||||
|
||||
You can open the configuration file using your favorite editor as follows:
|
||||
|
||||
```
|
||||
$ vi ~/.config/neofetch/config
|
||||
```
|
||||
|
||||
Below is an excerpt of the configuration file on my system showing the `printinfo ()` function.
|
||||
|
||||
Neofetch Configuration File
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
# vim:fdm=marker
|
||||
#
|
||||
# Neofetch config file
|
||||
# https://github.com/dylanaraps/neofetch
|
||||
|
||||
# Speed up script by not using unicode
|
||||
export LC_ALL=C
|
||||
export LANG=C
|
||||
|
||||
# Info Options {{{
|
||||
|
||||
# Info
|
||||
# See this wiki page for more info:
|
||||
# https://github.com/dylanaraps/neofetch/wiki/Customizing-Info
|
||||
printinfo() {
|
||||
info title
|
||||
info underline
|
||||
|
||||
info "Model" model
|
||||
info "OS" distro
|
||||
info "Kernel" kernel
|
||||
info "Uptime" uptime
|
||||
info "Packages" packages
|
||||
info "Shell" shell
|
||||
info "Resolution" resolution
|
||||
info "DE" de
|
||||
info "WM" wm
|
||||
info "WM Theme" wmtheme
|
||||
info "Theme" theme
|
||||
info "Icons" icons
|
||||
info "Terminal" term
|
||||
info "Terminal Font" termfont
|
||||
info "CPU" cpu
|
||||
info "GPU" gpu
|
||||
info "Memory" memory
|
||||
|
||||
# info "CPU Usage" cpu_usage
|
||||
# info "Disk" disk
|
||||
# info "Battery" battery
|
||||
# info "Font" font
|
||||
# info "Song" song
|
||||
# info "Local IP" localip
|
||||
# info "Public IP" publicip
|
||||
# info "Users" users
|
||||
# info "Birthday" birthday
|
||||
|
||||
info linebreak
|
||||
info cols
|
||||
info linebreak
|
||||
}
|
||||
.....
|
||||
```
|
||||
|
||||
Type the command below to view all flags and their configuration values you can use with neofetch script:
|
||||
|
||||
```
|
||||
$ neofetch --help
|
||||
```
|
||||
|
||||
To launch neofetch with all functions and flags enabled, employ the `--test` flag:
|
||||
|
||||
```
|
||||
$ neofetch --test
|
||||
```
|
||||
|
||||
You can enable the ASCII art logo again using the `--ascii` flag:
|
||||
|
||||
```
|
||||
$ neofetch --ascii
|
||||
```
|
||||
|
||||
In this article, we have covered a simple and highly configuration/customizable command line script that gathers your system information and displays it on the terminal.
|
||||
|
||||
Remember to get in touch with us via the feedback form below to ask any questions or give us your thoughts concerning the neofetch script.
|
||||
|
||||
Last but not least, if you know of any similar scripts out there, do not hesitate to let us know, we will be pleased to hear from you.
|
||||
|
||||
Visit the [neofetch Github repository][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/neofetch-shows-linux-system-information-with-logo
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/install-imagemagick-in-linux/
|
||||
[2]:http://www.tecmint.com/linux-terminal-emulators/
|
||||
[3]:http://www.tecmint.com/screenfetch-system-information-generator-for-linux/
|
||||
[4]:http://www.tecmint.com/screenfetch-system-information-generator-for-linux/
|
||||
[5]:http://www.tecmint.com/linux_logo-tool-to-print-color-ansi-logos-of-linux/
|
||||
[6]:http://www.tecmint.com/linux-terminal-emulators/
|
||||
[7]:http://www.tecmint.com/install-imagemagick-in-linux/
|
||||
[8]:http://www.tecmint.com/screenfetch-system-information-generator-for-linux/
|
||||
[9]:http://www.tecmint.com/linux_logo-tool-to-print-color-ansi-logos-of-linux/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/11/Linux-Mint-System-Information.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/11/Ubuntu-System-Information.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/11/Ubuntu-System-Information-with-Logo.png
|
||||
[13]:https://github.com/dylanaraps/neofetch
|
||||
@ -0,0 +1,233 @@
|
||||
OneNewLife translating
|
||||
|
||||
Apache Vs Nginx Vs Node.js And What It Means About The Performance Of WordPress Vs Ghost
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Ultimate battle of the giants: can the rising star Node.js prevail against the titans Apache and Nginx?
|
||||
|
||||
|
||||
Just like you, I too have read the various kinds of opinions / facts which are scattered all over the Internet throughout all sorts of sources, some of which I consider reliable, while others, perhaps shady or doubtful.
|
||||
|
||||
Many of the sources I read were quite contradicting, ahm – did someone say StackOverflow?[1][2], others showed a clear yet surprising results[3] thus having a crucial role in pushing me towards running my own tests and experiments.
|
||||
|
||||
At first, I did some thought experiments thinking I may avoid all the hassle of building and running physical tests of my own – I was drowning deep in those before I even knew it.
|
||||
|
||||
Nonetheless, looking backwards on it, it seem that my initial thoughts were quite accurate after all and have been reaffirmed by my tests; a fact which reminds me of what I learned back in school regarding Einstein and his photoelectric effect experiments where he faced a wave–particle duality and initially concluded that the experiments were affected by his state of mind, that is, when he expected the result would be a wave then so it was and vice versa.
|
||||
|
||||
That said, I’m pretty sure my results won’t prove to be a duality anytime in the near future, although my own state of mind probably did had an effect, to some extents, on them.
|
||||
|
||||
### About The Comparison
|
||||
|
||||
One of the sources I read came up with a revolutionary way, in my view, to deal with the natural subjectiveness and personal biases an author may have.
|
||||
|
||||
A way which I decided to embrace as-well, thus I declare the following in advance:
|
||||
|
||||
Developers spend many years honing their craft. Those who reach higher levels usually make their own choice based on a host of factors. It’s subjective; you’ll promote and defend your technology decision.
|
||||
|
||||
That said, the point of this comparison is not to become another “use whatever suits you, buddy” article. I will make recommendations based on my own experience, requirements and biases. You’ll agree with some points and disagree with others; that’s great — your comments will help others make an informed choice.
|
||||
|
||||
And thank you to Craig Buckler of [SitePoint][2] for re-enlightening me regarding the purpose of comparisons – a purpose I tend re-forgetting as I’m trying to please all visitors.
|
||||
|
||||
### About The Tests
|
||||
|
||||
All test were ran locally on an:
|
||||
|
||||
* Intel core i7-2600k machine of 4 cores and 8 threads.
|
||||
* **[Gentoo Linux][1]** is the operating system used to run the tests.
|
||||
|
||||
The tool used for benchmarking: ApacheBench, Version 2.3 <$Revision: 1748469 $>.
|
||||
|
||||
The tests included a series of benchmarks, starting from 1,000 to 10,000 requests and a concurrency of 100 to 1,000 – the results were quite surprising.
|
||||
|
||||
In addition, stress test to measure server function under high load was also issued.
|
||||
|
||||
As for the content, the main focus was about a static file containing a number of Lorem Ipsum verses with headings and an image.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Lorem Ipsum and ApacheBenchmark
|
||||
|
||||
The reason I decided to focus on static files is because they remove all sorts of rendering factors that may have an effect on the tests, such as: the speed of a programming language interpreter, how well is an interpreter integrated with the server, etc…
|
||||
|
||||
Also, based on my own experience, a substantial part of the average page load time is usually being spent on static content such as images for example, therefore in order to see which server could save us the most of that precious time it seem more realistic to focus on that part.
|
||||
|
||||
That aside, I also wanted to test a more real case scenario where I benchmarked each server upon running a dynamic page of different CMSs (more details about that later on).
|
||||
|
||||
### The Servers
|
||||
|
||||
As I’m running Gentoo Linux, you could say that either one of my HTTP servers is starting from an optimized state to begin with, since I built them using only the use-flags I actually needed. I.e there shouldn’t be any unnecessary code or module loading or running in the background while I ran my tests.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Apache vs Nginx vs Node.js use-flags
|
||||
|
||||
### Apache
|
||||
|
||||
`$: curl -i http://localhost/index.html
|
||||
HTTP/1.1 200 OK
|
||||
Date: Sun, 30 Oct 2016 15:35:44 GMT
|
||||
Server: Apache
|
||||
Last-Modified: Sun, 30 Oct 2016 14:13:36 GMT
|
||||
ETag: "2cf2-54015b280046d"
|
||||
Accept-Ranges: bytes
|
||||
Content-Length: 11506
|
||||
Cache-Control: max-age=600
|
||||
Expires: Sun, 30 Oct 2016 15:45:44 GMT
|
||||
Vary: Accept-Encoding
|
||||
Content-Type: text/html`
|
||||
|
||||
Apache was configured with “event mpm”.
|
||||
|
||||
### Nginx
|
||||
|
||||
`$: curl -i http://localhost/index.html
|
||||
HTTP/1.1 200 OK
|
||||
Server: nginx/1.10.1
|
||||
Date: Sun, 30 Oct 2016 14:17:30 GMT
|
||||
Content-Type: text/html
|
||||
Content-Length: 11506
|
||||
Last-Modified: Sun, 30 Oct 2016 14:13:36 GMT
|
||||
Connection: keep-alive
|
||||
Keep-Alive: timeout=20
|
||||
ETag: "58160010-2cf2"
|
||||
Accept-Ranges: bytes`
|
||||
|
||||
Nginx included various tweaks, among them: “sendfile on”, “tcp_nopush on” and “tcp_nodelay on”.
|
||||
|
||||
### Node.js
|
||||
|
||||
`$: curl -i http://127.0.0.1:8080
|
||||
HTTP/1.1 200 OK
|
||||
Content-Length: 11506
|
||||
Etag: 15
|
||||
Last-Modified: Thu, 27 Oct 2016 14:09:58 GMT
|
||||
Content-Type: text/html
|
||||
Date: Sun, 30 Oct 2016 16:39:47 GMT
|
||||
Connection: keep-alive`
|
||||
|
||||
The Node.js server used in the static tests was custom built from scratch, tailor made to be as lightweight and fast as possible – no external modules (outside of Node’s core) were used.
|
||||
|
||||
### The Results
|
||||
|
||||
Click on the images to enlarge:
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Apache vs Nginx vs Node: performance under requests load (per 100 concurrent users)
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Apache vs Nginx vs Node: performance under concurrent users load (per 1,000 requests)
|
||||
|
||||
### Stress Testing
|
||||
|
||||
[
|
||||
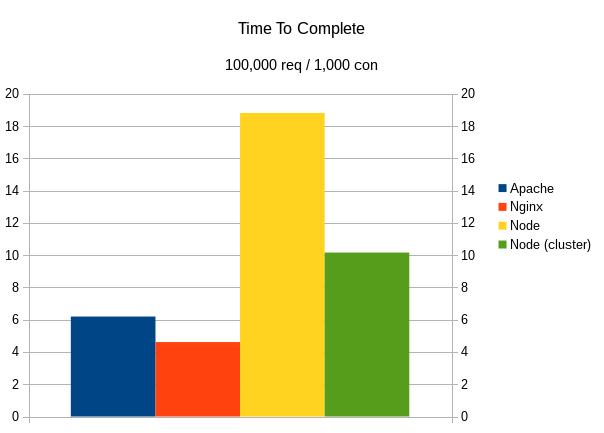
|
||||
][7]
|
||||
|
||||
Apache vs Nginx vs Node: time to complete 100,000 requests with concurrency of 1,000
|
||||
|
||||
### What Can We Learn From The Results?
|
||||
|
||||
Judging by the results above, it appears that Nginx can complete the highest amount of requests in the least amount of time, in other words, **Nginx** is the fastest HTTP server.
|
||||
|
||||
Another thing we can learn, which is quite surprising as a matter of fact, is that Node.js can be faster than Nginx and Apache in some cases, given the right amount of concurrent users and requests.
|
||||
|
||||
To those who wonder, the answer is NO, when the number of requests was raised during the concurrency test then Nginx would return to a leading position.
|
||||
|
||||
Unlike Apache and Nginx, Node.js, especially clustered Node, seem to be indifferent to the number of concurrent users hitting it. As the chart shows, clustered Node keeps a straight line at around 0.1 seconds while both Apache and Nginx suffer a variation of about 0.2 seconds.
|
||||
|
||||
A conclusion that can be drawn based on the above statistics is that the smaller the site is the less it matters which server it uses. However, as the site grows larger audience, the more apparent the impact an HTTP server has.
|
||||
|
||||
At the bottom line, when it comes to the raw speed of each server, as it’s depicted by the stress test, my sense is that the most crucial factor behind the performance is not some special algorithm but what it comes down to is actually the programming language each server is running.
|
||||
|
||||
As both Apache and Nginx are using C language – which is AOT (Ahead Of Time) compiled language, Node.js on the other hand is using JavaScript – which is an interpreted / JIT (Just In Time) compiled language. This means there’s additional work for the Node.js server on its way to execute a program.
|
||||
|
||||
This sense I base not only upon the results above but also upon further results, which you’ll see below, where I got pretty much the same performance parity even when using an optimized Node.js server built with the popular Express framework.
|
||||
|
||||
### The Bigger Picture
|
||||
|
||||
At the end of the day, an HTTP server is quite useless without the content it serves. Therefore when looking to compare web servers, a vital part we must take into account is the content we wish to run on top of it.
|
||||
|
||||
Although other function exists as well, the most widely popular use done with an HTTP server is running a website. Hence, to see the real life implications of each server’s performance I decided to compare WordPress – the most widely used CMS (Content Management System) in the world, with Ghost – a rising star with a gimmick of using JavaScript at its core.
|
||||
|
||||
Will a Ghost web-page based on JavaScript alone be able to outperform a WordPress page running on top of PHP and Apache / Nginx?
|
||||
|
||||
That’s an interesting question since Ghost has the advantage of using a single, coherent tool for its actions – no additional layers needed, whereas WordPress needs to rely on the integration between Apache / Nginx and PHP, an integration which might incur significant performance drawbacks.
|
||||
|
||||
Adding to that, there’s also a significant performance difference between PHP and Node.js in favor of the latter, which I’ll briefly talk about below, things might come out a bit differently than initially seemed.
|
||||
|
||||
### PHP Vs Node.js
|
||||
|
||||
In order to compare WordPress and Ghost we must first consider an essential component which affects both.
|
||||
|
||||
Essentially, WordPress is a PHP based CMS while Ghost is Node.js (JavaScript) based. Unlike PHP, Node.js enjoys the following advantages:
|
||||
|
||||
* Non-blocking I/O
|
||||
* Event driven
|
||||
* Modern, less legacy code encumbered
|
||||
|
||||
Since there are plenty of comparisons out there explaining and demonstrating Node.js raw speed over PHP (including PHP 7) I shall not elaborate further on the subject, Google it, I implore you.
|
||||
|
||||
So, given that Node.js outperforms PHP in general, will it be significant enough to make a Node.js website faster than Apache / Nginx with PHP?
|
||||
|
||||
### WordPress Vs Ghost
|
||||
|
||||
When comparing WordPress to Ghost some would say it’s like comparing apples to oranges and for the most part I’ll agree, as WordPress is a fully fledged CMS while Ghost is basically just a blogging platform at the moment.
|
||||
|
||||
However, the two still share many overlapping areas where both can be used to publish thoughts to the world.
|
||||
|
||||
Given that premise, how can we compare the 2 while one runs on totally different code base than the other, including themes and core features.
|
||||
|
||||
Indeed, a scientific lab-conditioned test would be hard to devise. However, in this comparison I’m interested in a more real life case scenario, where WordPress gets to keep its theme and so does Ghost. Thus, the goal here is to have both platform’s web-pages similar in size as possible and let PHP and Node.js do their magic behind the scenes.
|
||||
|
||||
Since the results were measured against different criteria and most importantly not exact same sizes, it wouldn’t be fair to display them side by side in a chart. Hence a table is used instead:
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Node vs Nginx vs Apache running WordPress & Ghost. Top 2 rows are WordPress, bottom 2 are Ghost
|
||||
|
||||
As you can see, despite the fact Ghost (Node.js) is loading a smaller sized page (you’d be surprised how much difference can 1kB make) it still remains slower than both WordPress with Nginx and with Apache.
|
||||
|
||||
Also, does preempting every Node server hit with Nginx proxy that serves as a load balancer actually contributes or detracts from performance?
|
||||
|
||||
Well, according to the table above, if it has any effect at all then it is a detracting one – which is a reasonable outcome as adding another layer should make things slower. However, the numbers above shows it just might be negligible.
|
||||
|
||||
But the most important thing the table above shows us is that even though Node.js is faster than PHP, the role an HTTP server has, may surpass the importance of what type of programming language a certain web platform uses.
|
||||
|
||||
Of course, on the other hand, if the page loaded was a lot more reliant on server-side script serving, then the results would of wind up a bit different, I suspect.
|
||||
|
||||
At the end of it, if a web platform really wants to beat WordPress at its own game, performance-wise that is, the conclusion rising from this comparison is it’ll have to have some sort of customized tool a-la PHP-FPM, that will communicate with JavaScript directly (instead of running it as a server) thus it could fully harness JS power to reach a better performance.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iwf1.com/apache-vs-nginx-vs-node-js-and-what-it-means-about-the-performance-of-wordpress-vs-ghost/
|
||||
|
||||
作者:[Liron][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iwf1.com/tag/linux
|
||||
[1]:http://iwf1.com/5-reasons-use-gentoo-linux/
|
||||
[2]:https://www.sitepoint.com/sitepoint-smackdown-php-vs-node-js/
|
||||
[3]:http://iwf1.com/wordpress/wp-content/uploads/2016/11/Lorem-Ipsum-and-ApacheBenchmark.jpg
|
||||
[4]:http://iwf1.com/wordpress/wp-content/uploads/2016/10/Apache-vs-Nginx-vs-Node.js-use-flags.jpg
|
||||
[5]:http://iwf1.com/wordpress/wp-content/uploads/2016/11/requests.jpg
|
||||
[6]:http://iwf1.com/wordpress/wp-content/uploads/2016/11/concurrency.jpg
|
||||
[7]:http://iwf1.com/wordpress/wp-content/uploads/2016/11/stress.jpg
|
||||
[8]:http://iwf1.com/wordpress/wp-content/uploads/2016/11/Node-vs-Nginx-vs-Apache-comparison-table.jpg
|
||||
@ -0,0 +1,42 @@
|
||||
Vic020
|
||||
|
||||
Introduction to Eclipse Che, a next-generation, web-based IDE
|
||||
============================================================
|
||||

|
||||
|
||||
>Image by : opensource.com
|
||||
|
||||
Correctly installing and configuring an integrated development environment, workspace, and build tools in order to contribute to a project can be a daunting or time consuming task, even for experienced developers. Tyler Jewell, CEO of [Codenvy][1], faced this problem when he was attempting to set up a simple Java project when he was working on getting his coding skills back after dealing with some health issues and having spent time in managerial positions. After multiple days of struggling, Jewell could not get the project to work, but inspiration struck him. He wanted to make it so that "anyone, anytime can contribute to a project with installing software."
|
||||
|
||||
It is this idea that lead to the development of [Eclipse Che][2].
|
||||
|
||||
Eclipse Che is a web-based integrated development environment (IDE) and workspace. Workspaces in Eclipse Che are bundled with an appropriate runtime stack and serve their own IDE, all in one tightly integrated bundle. A project in one of these workspaces has everything it needs to run without the developer having to do anything more than picking the correct stack when creating a workspace.
|
||||
|
||||
The ready-to-go bundled stacks included with Eclipse Che cover most of the modern popular languages. There are stacks for C++, Java, Go, PHP, Python, .NET, Node.js, Ruby on Rails, and Android development. A Stack Library provides even more options and if that is not enough, there is the option to create a custom stack that can provide specialized environments.
|
||||
|
||||
Eclipse Che is a full-featured IDE, not a simple web-based text editor. It is built on Orion and the JDT. Intellisense and debugging are both supported, and version control with both Git and Subversion is integrated. The IDE can even be shared by multiple users for paired programming. With just a web browser, a developer can write and debug their code. However, if a developer would prefer to use a desktop-based IDE, it is possible to connect to the workspace with a SSH connection.
|
||||
|
||||
One of the major technologies underlying Eclipse Che are [Linux containers][3], using Docker. Workspaces are built using Docker and installing a local copy of Eclipse Che requires nothing but Docker and a small script file. The first time `che.sh start` is run, the requisite Docker containers are downloaded and run. If setting up Docker to install Eclipse Che is too much work for you, Codenvy does offer online hosting options. They even provide 4GB workspaces for open source projects for any contributor to the project. Using Codenvy's hosting option or another online hosting method, it is possible to provide a url to potential contributors that will automatically create a workspace complete with a project's code, all with one click.
|
||||
|
||||
Beyond Codenvy, contributors to Eclipse Che include Microsoft, Red Hat, IBM, Samsung, and many others. Several of the contributors are working on customized versions of Eclipse Che for their own specific purposes. For example, Samsung's [Artik IDE][4] for IoT projects. A web-based IDE might turn some people off, but Eclipse Che has a lot to offer, and with so many big names in the industry involved, it is worth checking out.
|
||||
|
||||
* * *
|
||||
|
||||
If you are interested in learning more about Eclipse Che, [CheConf 2016][5] takes place on November 15\. CheConf 2016 is an online conference and registration is free. Sessions start at 11:00 am Eastern time (4:00 pm UTC) and end at 5:30 pm Eastern time (10:30 pm UTC).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/11/introduction-eclipse-che
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:http://codenvy.com/
|
||||
[2]:http://eclipse.org/che
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers
|
||||
[4]:http://eclipse.org/che/artik
|
||||
[5]:https://eclipse.org/che/checonf/
|
||||
@ -0,0 +1,175 @@
|
||||
Build, Deploy and Manage Custom Apps with IBM Bluemix
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
_IBM’s Bluemix affords developers an opportunity to build, deploy and manage custom apps. Bluemix is built on Cloud Foundry. It supports a number of programming languages as well as OpenWhisk, which allows developers to call any function without the need for resource management._
|
||||
|
||||
Bluemix is an open standards, cloud-based platform implemented by IBM. It has an open architecture which enables organisations to create, develop and manage their applications on the cloud. It is based on Cloud Foundry and hence can be considered as a Platform as a Service (PaaS). With Bluemix, developers need not worry about cloud configurations, but can concentrate on their applications. Cloud configurations will be done automatically by Bluemix.
|
||||
|
||||
Bluemix also provides a dashboard, with which developers can create, manage and view services and applications, while monitoring resource usage also.
|
||||
It supports the following programming languages:
|
||||
|
||||
* Java
|
||||
* Python
|
||||
* Ruby on Rails
|
||||
* PHP
|
||||
* Node.js
|
||||
|
||||
It also supports OpenWhisk (Function as a Service), which is also an IBM product that allows developers to call any function without requiring any resource management.
|
||||
|
||||

|
||||
|
||||
Figure 1: An Overview of IBM Bluemix
|
||||
|
||||

|
||||
|
||||
Figure 2: The IBM Bluemix architecture
|
||||
|
||||

|
||||
|
||||
Figure 3: Creating an organisation in IBM Bluemix
|
||||
|
||||
**How IBM Bluemix works**
|
||||
Bluemix is built on top of IBM’s SoftLayer IaaS (Infrastructure as a Service). It uses Cloud Foundry as an open source PaaS. It starts by pushing code through Cloud Foundry, which plays the role of combining the code and suitable runtime environment based on the programming language in which the application is written. IBM services, third party services or community built services can be used for different functionalities. Secure connectors can be used to connect to on-premise systems and the cloud.
|
||||
|
||||
|
||||
|
||||
Figure 4: Setting up Space in IBM Bluemix
|
||||
|
||||

|
||||
|
||||
Figure 5: The app template
|
||||
|
||||
|
||||
|
||||
Figure 6: IBM Bluemix supported programming languages
|
||||
|
||||
**Creating an app in Bluemix**
|
||||
In this article, we will create a sample ‘Hello World’ application in IBM Bluemix by using the Liberty for Java starter pack, in just a few simple steps.
|
||||
|
||||
1\. Go to [_https://console.ng.bluemix.net/registration/_][2].
|
||||
|
||||
2\. Confirm the Bluemix account.
|
||||
|
||||
3\. Click on the confirmation link in the mail to complete the sign up process.
|
||||
|
||||
4\. Give your email ID and click on _Continue_ to log in.
|
||||
|
||||
5\. Enter the password and click on _Log in._
|
||||
|
||||
6. _Set up_ and _Environment_ share resources in specific regions.
|
||||
|
||||
7\. Create Space to manage access and roll-back in Bluemix. We can map Spaces to development stages such as dev, test, uat, pre-prod and prod.
|
||||
|
||||

|
||||
|
||||
Figure 7: Naming the app
|
||||
|
||||

|
||||
|
||||
Figure 8: Knowing when the app is ready
|
||||
|
||||
|
||||
|
||||
Figure 9: The IBM Bluemix Java App
|
||||
|
||||
8\. Once this initial configuration is completed, click on_ I’m ready_. _Good to Go_!
|
||||
|
||||
9\. Verify the IBM Bluemix dashboard after successfully logging in, specifically sections such as Cloud Foundry Apps where 2GB is available and Virtual Server where 0 instances are available, as of now.
|
||||
|
||||
10\. Click on _Create app_. Choose the template for app creation. In our case, we will go for a Web app.
|
||||
|
||||
11\. How do you get started? Click on Liberty for Java, and then verify the description.
|
||||
|
||||
12\. Click on _Continue_.
|
||||
|
||||
13\. What do you want to name your new app? For this article, let’s use osfy-bluemix-tutorial and click on _Finish_.
|
||||
|
||||
14\. It will take some time to create resources and to host an application on Bluemix.
|
||||
|
||||
15\. In a few minutes, your app will be up and running. Note the URL of the application.
|
||||
|
||||
16\. Visit the application’s URL _http://osfy-bluemix-tutorial.au-syd.mybluemix.net/_. Bingo, our first Java application is up and running on IBM Bluemix.
|
||||
|
||||
17\. To verify the source code, click on _Files_ and navigate to different files and folders in the portal.
|
||||
|
||||
18\. The _Logs_ section provides all the activity logs, starting from the application’s creation.
|
||||
|
||||
19\. The _Environment Variables_ section provides details on all the environment variables of VCAP_Services as well as those that are user defined.
|
||||
|
||||
20\. To verify the application’s consumption of resources, go to the Liberty for Java section.
|
||||
|
||||
21\. The _Overview_ section of each application contains details regarding resources, the application’s health, and activity logs, by default.
|
||||
|
||||
22\. Open Eclipse, go to the Help menu and click on _Eclipse Marketplace_.
|
||||
|
||||
23\. Find _IBM Eclipse tools_ for _Bluemix_ and click on _Install_.
|
||||
|
||||
24\. Confirm the selected features and install them in Eclipse.
|
||||
|
||||
25\. Download the application starter code. Import it into Eclipse by clicking on _File Menu_, select _Import Existing Projects_ into _Workspace_ and start modifying the existing code.
|
||||
|
||||
|
||||
|
||||
Figure 10: The Java app source files
|
||||
|
||||
|
||||
|
||||
Figure 11: The Java app logs
|
||||
|
||||

|
||||
|
||||
Figure 12: Java app — Liberty for Java
|
||||
|
||||
**[
|
||||
][1]Why IBM Bluemix?**
|
||||
Here are some compelling reasons to use IBM Bluemix:
|
||||
|
||||
* Supports multiple languages and platforms
|
||||
* Free trial
|
||||
|
||||
1\. Minimal registration process
|
||||
|
||||
2\. No credit card required
|
||||
|
||||
3\. 30-days trial period – with quotas of 2GB of runtime, 20 services, 500 routes
|
||||
|
||||
4\. Unlimited access to standard support
|
||||
|
||||
5\. No production use limitations
|
||||
|
||||
* Pay only for the use of each runtime and service
|
||||
* Quick set-up – hence faster time to market
|
||||
* Continuous delivery of new features
|
||||
* Secure integration with on-premise resources
|
||||
* Use cases
|
||||
|
||||
1\. Web applications and mobile back-ends
|
||||
|
||||
2\. APIs and on-premise integration
|
||||
|
||||
* DevOps services are available as SaaS on the cloud and support continuous delivery of:
|
||||
|
||||
1\. Web IDE
|
||||
|
||||
2\. SCM
|
||||
|
||||
3\. Agile planning
|
||||
|
||||
4\. Delivery pipeline service
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensourceforu.com/2016/11/build-deploy-manage-custom-apps-ibm-bluemix/
|
||||
|
||||
作者:[MITESH_SONI][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensourceforu.com/author/mitesh_soni/
|
||||
[1]:http://opensourceforu.com/wp-content/uploads/2016/10/Figure-7-Naming-the-app.jpg
|
||||
[2]:https://console.ng.bluemix.net/registration/
|
||||
@ -1,59 +0,0 @@
|
||||
Training vs. hiring to meet the IT needs of today and tomorrow
|
||||
培训还是雇人,来满足当今和未来的 IT 需求
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
在数字化时代,由于企业需要不断跟上工具和技术更新换代的步伐,对 IT 技能的需求也稳定增长。对于企业来说,寻找和雇佣那些拥有令人垂涎能力的创新人才,是非常不容易的。同时,培训内部员工来使他们接受新的技能和挑战,需要一定的时间。而且,这也往往满足不了需求。
|
||||
|
||||
[Sandy Hill][1] 对多种 IT 学科涉及到的多项技术都很熟悉。她作为 [Pegasystems][2] 项目的 IT 主管,负责的 IT 团队涉及的领域从应用的部署到数据中心的运营。更重要的是,Pegasystems 开发应用来帮助销售,市场,服务以及运行团队简化操作,联系客户。这意味着她需要掌握和利用 IT 内部资源的最佳方法,面对公司客户遇到的 IT 挑战。
|
||||
|
||||

|
||||
|
||||
**企业家项目(TEP):这些年你是如何调整培训重心的?**
|
||||
|
||||
**Hill**:在过去的几十年中,我们经历了爆炸式的发展,所以现在我们要实现更多的全球化进程。随之而来的培训方面,将确保每个人都在同一起跑线上。
|
||||
|
||||
我们大多的关注点已经转移到培养员工使用新的产品和工具上,这些新产品和工具的实现,能够推动创新,并提高工作效率。例如,我们实现了资产管理系统; 以前我们是没有的。因此我们需要为全部员工做培训,而不是雇佣那些已经知道该产品的人。当我们正在发展的时候,我们也试图保持紧张的预算和稳定的职员总数。所以,我们更愿意在内部培训而不是雇佣新人。
|
||||
|
||||
**TEP:说说培训方法吧,你是怎样帮助你的员工发展他们的技能?**
|
||||
|
||||
**Hill**:我要求每一位员工制定一个技术性的和非技术性的训练目标。这作为他们绩效评估的一部分。他们的技术性目标需要与他们的工作职能相符,非技术行目标则着重发展一项软技能,或是学一些专业领域之外的东西。我每年对职员进行一次评估,看看差距和不足之处,以使团队保持全面发展。
|
||||
|
||||
**TEP:你的训练计划能够在多大程度上减轻招聘和保留职员的问题?**
|
||||
|
||||
**Hill**:使我们的职员对学习新的技术保持兴奋,让他们的技能更好。让职员知道我们重视他们并且让他们在擅长的领域成长和发展,以此激励他们。
|
||||
|
||||
**TEP:你有没有发现哪种培训是最有效的?**
|
||||
|
||||
**HILL**:我们使用几种不同的我们发现是有效的培训方法。当有新的或特殊的项目时,我们尝试加入一套由甲方(不会翻:乙方,卖方?)领导的培训课程,作为项目的一部分。要是这个方法不能实现,我们将进行异地培训。我们也会购买一些在线的培训课程。我也鼓励职员每年参加至少一次会议,以了解行业的动向。
|
||||
|
||||
**TEP:你有没有发现有哪些技能,雇佣新人要比培训现有员工要好?**
|
||||
|
||||
**Hill**:这和项目有关。有一个最近的计划,试图实现 OpenStack,而我们根本没有这方面的专家。所以我们与一家从事这一领域的咨询公司合作。我们利用他们的专业知识帮助我们运行项目,并现场培训我们的内部团队成员。让内部员工学习他们需要的技能,同时还要完成他们们天的工作,这是一项艰巨的任务。
|
||||
|
||||
顾问帮助我们确定我们需要的对某一技术熟练的的员工人数。这使我们能够对员工进行评估,看看是否存在缺口。如果存在人员上的缺口,我们还需要额外的培训或是员工招聘。我们也确实雇佣了一些承包商。另一个选择是让一些全职员工进行为期六至八周的培训,但我们的项目模式不容许这么做。
|
||||
|
||||
**TEP:想一下你最近雇佣的员工,他们的那些技能特别能够吸引到你?**
|
||||
|
||||
**Hill**:在最近的招聘中,我侧重于软技能。除了扎实的技术能力外,他们需要能够在团队中进行有效的沟通和工作,要有说服他人,谈判和解决冲突的能力。
|
||||
|
||||
IT 人一向独来独往。他们一般不是社交最多的人。现在,IT 越来越整合到组织中,它为其他业务部门提供有用的更新报告和状态报告的能力是至关重要的,这也表明 IT 是积极的存在,并将取得成功。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2016/6/training-vs-hiring-meet-it-needs-today-and-tomorrow
|
||||
|
||||
作者:[Paul Desmond][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://enterprisersproject.com/user/paul-desmond
|
||||
[1]: https://enterprisersproject.com/user/sandy-hill
|
||||
[2]: https://www.pega.com/pega-can?&utm_source=google&utm_medium=cpc&utm_campaign=900.US.Evaluate&utm_term=pegasystems&gloc=9009726&utm_content=smAXuLA4U|pcrid|102822102849|pkw|pegasystems|pmt|e|pdv|c|
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,57 +0,0 @@
|
||||
宽松开源许可证的崛起意味着什么
|
||||
====
|
||||
|
||||
为什么像 GNU GPL 这样的限制性许可证越来越不受青睐。
|
||||
|
||||
“如果你用了任何开源软件, 那么你软件的其他部分也必须开源。” 这是微软 CEO Steve Ballmer 2001 年说的, 尽管他说的不对, 还是引发了人们对自由软件的 FUD (恐惧, 不确定和怀疑)。 大概这才是他的意图。
|
||||
|
||||
对开源软件的这些 FUD 主要与开源许可有关。 现在有许多不同的许可证, 当中有些限制比其他的更严格(也有人称“更具保护性”)。 诸如 GNU 通用公共许可证 (GPL) 这样的限制性许可证使用了 copyleft 的概念。 copyleft 赋予人们自由发布软件副本和修改版的权力, 只要衍生工作给予人们同样的权力。 bash 和 GIMP 等开源项目就是使用了 GPL (v3)。 还有一个 Affero GPL 的许可证, 它为网络上的软件(如网络服务)提供了 copyleft 许可。
|
||||
|
||||
这意味着, 如果你使用了这种许可的代码, 然后加入了你自己的专有代码, 那么在一些情况下, 整个代码, 包括你的代码也就遵从这种限制性开源许可证。 Ballmer 说的大概就是这类的许可证。
|
||||
|
||||
但宽松许可证不同。 比如, 只要保留属性且不要求开发者承担责任, MIT 许可证允许任何人任意使用开源代码, 包括修改和出售。 另一个比较流行的宽松开源许可证, Apache 许可证 2.0 也把专利权从贡献者授予用户。 JQuery, .NET Core 和 Rails 使用了 MIT 许可证, 使用 Apache 许可证 2.0 的软件包括安卓, Apache 和 Swift。
|
||||
|
||||
两种许可证类型最终都是为了让软件更有用。 限制性许可证促进了参与和分享的开源理念, 使每个人从软件中得到最多的利益。 而宽松许可证通过允许人们任意使用软件来确保人们能从软件中得到最多的利益, 即使这意味着他们可以使用代码, 修改它, 据为己有,甚至以专有软件出售,而不做任何回报。
|
||||
|
||||
开源许可证管理公司 Black Duck Software 的数据显示, 去年使用最多的开源许可证是限制性许可证 GPL 2.0, 市占率大约 25%。 宽松许可证 MIT 和 Apache 2.0 次之, 市占率分别为 18% 和 16%, 再后面是 GPL 3.0, 市占率大约 10%。 这样来看, 限制性许可证占 35%, 宽松许可证占 34%, 几乎是平手。
|
||||
|
||||
但这个数据没有显示趋势。 Black Duck 的数据显示, 从 2009 年到 2015 年的六年间, MIT 许可证的市占率上升了 15.7%, Apache 的市占率上升了 12.4%。 在这段时期, GPL v2 和 v3 的市占率惊人地下降了 21.4%。 换言之, 在这段时期里, 大量市占率从限制性许可证移动到宽松许可证。
|
||||
|
||||
这个趋势还在继续。 Black Duck 的[最新数据][1]显示, MIT 现在的市占率为 26%, GPL v2 为 21%, Apache 2 为 16%, GPL v3 为 9%。 即 30% 的限制性许可证和 42% 的宽松许可证--与前一年的 35% 的限制许可证和 34% 的宽松许可证相比, 发生了重大的转变。 对 GitHub 上使用许可证的[调查研究][2]证实了这种转变。 它显示 MIT 以压倒性的 45% 占有率成为最流行的许可证, 与之相比, GPL v2 只有 13%, Apache 11%。
|
||||
|
||||

|
||||
|
||||
### 引领趋势
|
||||
|
||||
从限制性许可证到宽松许可证,这么大的转变背后是什么呢? 是公司害怕如果使用了限制性许可证的软件,他们就会像Ballmer说的那样,失去自己私有软件的控制权了吗? 事实上, 可能就是如此。 比如, Google [禁用了 Affero GPL 软件][3]。
|
||||
|
||||
[Instructional Media + Magic][4] 的主席 Jim Farmer, 是一个教育开源技术的开发者。 他作为很多公司为避开法律问题而不使用限制性许可证。 “问题就在于复杂性。 许可证的复杂性越高, 被人因为某此行为而告上法庭的可能性越高。 高复杂性更可能带来麻烦“, 他说。
|
||||
|
||||
他补充说, 这种对限制性许可证的恐惧正被律师们驱动着, 许多律师建议自己的客户使用 MIT 或 Apache 2.0 许可证的软件, 并明确反对使用 Affero 许可证的软件。
|
||||
|
||||
他说, 这会对软件开发者产生影响, 因为如果公司都避开限制性许可证软件的使用,开发者想要自己的软件被使用, 就更会把新的软件使用宽松许可证。
|
||||
|
||||
但 SalesAgility, 也就是开源 SuiteCRM 的那家公司,的 CEO Greg Soper 认为这种到宽松许可证的转变也由一些开发者驱动。 “看看像 Rocket.Chat 这样的应用。 开发者本可以选择 GPL 2.0 或 Affero 许可证, 但他们选择了宽松许可证,” 他说。 “这样可以给这个应用最大的机会, 因为专有软件厂商可以使用它, 不会伤害到他们的产品, 且不需要把他们的产品也使用开源许可证。 这样如果开发者想要让第三方应用使用他的应用的话, 他有理由选择宽松许可证。”
|
||||
|
||||
Soper 指出, 限制性许可证的设计,就是通过阻止开发者拿了别人的代码,做了修改,但不把结果回报给社区来帮助开源项目。 “ Affero 许可证对我们的产品很重要, 因为如果有人 fork 了,并做得比我们好, 却又不把代码回报回来, 就会杀死我们的产品,” 他说。 “ 对 Rocket.Chat 则不同, 因为如果它使用 Affero, 那么它会污染公司的 IP, 所以公司不会使用它。 不同的许可证有不同的使用案例。”
|
||||
|
||||
曾在 Gnome, 现在是 LibreOffice 的 OpenOffice 上工作的开源开发者 Michael Meeks 同意 Jim Farmer 的,许多公司确实出于对法律的担心,而选择使用宽松许可证的软件的观点。 “copyleft 许可证有风险, 但同样也有巨大的益处。 遗憾的是人们都听从律师, 而律师只是讲风险, 但从不告诉你有些事是安全的。”
|
||||
|
||||
Ballmer 发表他不正确的言论已经 15 年了, 但它产生的 FUD 还是有影响--即使从限制性许可证到宽松许可证的转变并不是他想要的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cio.com/article/3120235/open-source-tools/what-the-rise-of-permissive-open-source-licenses-means.html
|
||||
|
||||
作者:[Paul Rubens ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cio.com/author/Paul-Rubens/
|
||||
[1]: https://www.blackducksoftware.com/top-open-source-licenses
|
||||
[2]: https://github.com/blog/1964-open-source-license-usage-on-github-com
|
||||
[3]: http://www.theregister.co.uk/2011/03/31/google_on_open_source_licenses/
|
||||
[4]: http://immagic.com/
|
||||
|
||||
@ -0,0 +1,84 @@
|
||||
我们大学的机房使用 Fedora 系统
|
||||
==========
|
||||
|
||||

|
||||
|
||||
在[塞尔维亚共和国诺维萨德大学的自然科学系和数学与信息学系][5],我们教学生很多东西。从编程语言的入门到机器学习,所有开设的课程最终目的是让我们的学生能够像专业的开发者和软件工程师一样思考。课程时间紧凑而且学生众多,所以我们必须对现有可利用的资源进行合理调整以满足正常的教学。最终我们决定将机房电脑系统换为 Fedora。
|
||||
|
||||
### 以前的设置
|
||||
|
||||
我们过去的解决方案是在 Ubuntu 系统上面安装 Windows [虚拟机][4]并在虚拟机下安装好教学所需的开发软件。这在当时看起来是一个很不错的主意。然而,这种方法有很多弊端。首先,因为运行虚拟机导致了严重的计算机性能的浪费。因为运行虚拟机导致计算机性能利用率不高和操作系统的运行速度降低。此外,虚拟机有时候会在另一个用户会话里面同时运行。这会导致计算机工作效率的严重降低。我们有限的宝贵时间不应该花费在启动电脑和启动虚拟机上。最后,我们意识到我们的大部分教学所需软件都有对应的 Linux 版本。虚拟机不是必需的。我们不得不寻找一个更好的解决办法。
|
||||
|
||||
### 进入 Fedora!
|
||||
|
||||

|
||||
|
||||
默认运行 Fedora 工作站版本的一个机房的照片
|
||||
|
||||
我们思考过暂时替代以前的安装 Windows 虚拟机方案。我们最终决定使用 Fedora 有很多原因。
|
||||
|
||||
#### 发展的前沿
|
||||
|
||||
在我们所教授的课程中,我们会用到很多各种各样的开发工具。因此,我们能及时获取到最新的、最好用的开发工具很重要。在 Fedora 下,我们发现我们用到的开发工具有 95% 都能够在官方的软件仓库中找到。只有少量的一些工具,我们不得不手动安装。这在 Fedora 下很简单,因为你能获取到几乎所有的能开箱即用的开发工具。
|
||||
|
||||
我们意识到在这个过程中我们使用了大量自由、开源的软件和工具。这些软件总是能够及时更新并且可以用来做大量的工作而不仅仅局限于 Fedora 平台。
|
||||
|
||||
#### 硬件兼容性
|
||||
|
||||
我们选择 Fedora 用作机房的第二个原因是硬件兼容性。机房现在的电脑还是比较崭新的。过去比较低的内核版本总有些问题。在 Fedora 下,我们发现我们总能获得最新的内核版本。正如我们预期的那样,一切运行完美,没有任何差错。
|
||||
|
||||
我们决定我们最终会使用带有 [GNOME 桌面环境][2]的 Fedora [工作站版本][3]。学生群体通过使用这个版本的 Fedora 会发现很容易、直观、快速的上手。学生有一个简单舒适的环境对我们很重要,这样他们会更多的关注自己的任务和课程本身而不是一个复杂的或者运行缓慢的用户界面。
|
||||
|
||||
#### 自主的技术支持
|
||||
|
||||
最近,我们院系给予自由、开放源代码的软件很高的评价。通过使用这些软件,学生们即便在毕业后和工作的时候,仍然能够继续自由地使用它们。在这个过程中,他们通常也对 Fedora 和自由、开源的软件有一定了解。
|
||||
|
||||
### 转换机房
|
||||
|
||||
我们将机房的一台电脑完全手动安装。包括准备所有必要的脚本和软件,设置远程控制权限和一些其他的重要组成部分。我们也为每一门课程单独设置一个用户以方便学生存储他们的文件。
|
||||
|
||||
一台电脑安装配置好后,我们使用一个强大的、免费的、开源的叫做 [CloneZilla][1] 的工具。 CloneZilla 能够让我们为硬盘镜像做备份。镜像大小约为 11 G。我们用一些带有高速 USB 3.0 接口的闪存来还原磁盘镜像到剩余的电脑。我们仅仅利用若干个闪存设备花费了 75 分钟设置好剩余的 24 台电脑。
|
||||
|
||||
### 将来的工作
|
||||
|
||||
我们机房现在所有的电脑都完全使用 Fedora (没有虚拟机)。剩下的工作是设置一些管理脚本方便远程安装软件,电脑的开关等等。
|
||||
|
||||
我们由衷地感谢所有 Fedora 的维护人员,包制作人员和其他贡献者。我们希望我们的工作能够鼓励其他的学校和大学像我们一样将机房电脑的操作系统转向 Fedora。我们很高兴地确认了 Fedora 完全适合我们同时我们也担保 Fedora 同样适合你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-computer-lab-university/
|
||||
|
||||
作者:[Nemanja Milošević][a]
|
||||
|
||||
译者:[WangYueScream](https://github.com/WangYueScream)[LemonDemo](https://github.com/LemonDemo)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/nmilosev/
|
||||
[1]:http://clonezilla.org/
|
||||
[2]:https://www.gnome.org/
|
||||
[3]:https://getfedora.org/workstation/
|
||||
[4]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[5]:http://www.dmi.rs/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,55 @@
|
||||
# 你会考虑乘坐无人驾驶汽车吗?
|
||||
|
||||

|
||||
|
||||
科技在经历重大进展。最近我们经历的是如苹果手表及各种克隆,FitBit活动智能设备, 谷歌眼镜等可穿戴设备。看起来下一个就是人们研究了很长时间的无人驾驶汽车了。
|
||||
|
||||
这些汽车,有时也叫做自动汽车,自动驾驶汽车,或机器人汽车,确实可以依靠技术自己驾驶。它们能探测周边环境,如障碍物和标志,并使用 GPS 找到自己的路线。但是它们驾驶起来安全吗?我们请教我们的科技作者,“你会考虑乘坐无人驾驶汽车吗?”
|
||||
|
||||
### 我们的观点
|
||||
|
||||
**Derrik** 说他会乘坐无人驾驶汽车,因为 “_技术早就存在,而且很多聪明能干的人研究了很长时间。_” 他承认它们还是有些问题,但他相信很多事故的发生是因为有人的参与。如果不考虑人,他认为乘坐无人驾驶汽车会“_难以置信的安全_。”
|
||||
|
||||
对 **Phil**来说,这些汽车让他“紧张”,但他也承认这是他想象出的,因为他从没乘坐过。他同意 Derrik 这些技术是高度发达的观点,也知道它的原理,但仍然认为“_ 自己新技术接受缓慢,不会购买这类车_” 他甚至坦白说平时很少使用定速巡航。他认为依赖它太多的司机会让他感到不安全。
|
||||
|
||||

|
||||
|
||||
**Robert** 认为“_这个概念确实有点怪,_”但原则上他看不到汽车不向那个方向发展的理由。 他指出飞机已经走了那条路,而且变得更加安全, 他认为事故发生的主因是“_人们过于依赖科技手段,而当科技出现故障时不知所措而导致。_”
|
||||
|
||||
他是一个“焦虑型乘客”, 更喜欢控制整个局面。 对他来说,他的车子在哪里开很重要。如果是以低速在城市中驾驶他感觉还好,但如果是在“宽度不足两车道的弯弯曲曲的英国乡村道路”上,则绝不可以。他和 Phil 都认为英国道路与美国道路大大不同。他建议让别人去做小白鼠, 等到确定安全了再乘坐。
|
||||
|
||||
对 **Mahesh**来说, 他绝对会乘坐无人驾驶汽车,因为他知道这些汽车公司“ 拥有坚实的安全技术,决不会让他们的顾客去冒险。 ” 他承认安全与否还与车辆行驶的道路有关。
|
||||
|
||||
我的观点有些像这些观点的折中。虽然平时我会快速地投入到新科技中,但如果要拿生命去冒险,我不会那么做。我承认这些汽车发展了很久,应该很安全。而且坦率地说,很多司机比无人驾驶汽车危险得多。但和 Robert 一样,我想我会让其他人去做小白鼠,等到它更普遍了再去乘坐。
|
||||
|
||||
|
||||
### 你的观点
|
||||
|
||||
在这个问题上,你的观点是什么呢? 你会信任新生的科学技术呢,还是乘坐无人驾驶汽车时会紧张到不行? 你会考虑乘坐无人驾驶汽车吗? 在下面的评论里加入讨论吧。
|
||||
|
||||
<small style="box-sizing: inherit; font-size: 16px;">图片来自: [Steve Jurvetson][4] 和 [Steve Jurvetson at Wikimedia Commons][3]</small>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/riding-driverless-car/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[Laura Tucker][a]
|
||||
|
||||
译者:[willcoderwang](https://github.com/willcoderwang)
|
||||
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/lauratucker/
|
||||
[1]:https://www.maketecheasier.com/riding-driverless-car/#comments
|
||||
[2]:https://www.maketecheasier.com/author/lauratucker/
|
||||
[3]:https://commons.m.wikimedia.org/wiki/File:Inside_the_Google_RoboCar_today_with_PlanetLabs.jpg
|
||||
[4]:https://commons.m.wikimedia.org/wiki/File:Jurvetson_Google_driverless_car_trimmed.jpg
|
||||
[5]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[6]:https://www.maketecheasier.com/best-wordpress-video-plugins/
|
||||
[7]:https://www.maketecheasier.com/hidden-google-games/
|
||||
[8]:mailto:?subject=Would%20You%20Consider%20Riding%20in%20a%20Driverless%20Car?&body=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F
|
||||
[9]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F&text=Would+You+Consider+Riding+in+a+Driverless+Car%3F
|
||||
[10]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Friding-driverless-car%2F
|
||||
[11]:https://www.maketecheasier.com/category/opinion/
|
||||
@ -0,0 +1,68 @@
|
||||
Arch Linux: DIY用户的终结圣地
|
||||
|
||||

|
||||
|
||||
深入研究下Linux系统的新闻史,你会发现其中有一些鲜为人知的Linux发行版,而且关于这些操作系统的新闻报道的数量也十分惊人。
|
||||
|
||||
新发行版中的佼佼者,比如Elementary
|
||||
OS和Solus操作系统因其华丽的界面而被大家所关注,并且,任何搭载MATE桌面环境的操作系统都因其简洁性而被广泛报道。
|
||||
|
||||
感谢像《黑客军团》这样的电视节目,我确信关于Kali Linux系统的报道将会飙升。
|
||||
|
||||
尽管有很多关于Linux系统的报道,然而仍然有一个被广泛使用的Linux发行版几乎被大家完全遗忘了:Arch Linux系统。
|
||||
|
||||
关于Arch的新闻报道很少的原因有很多,其中最主要的原因是它很难安装,而且你还得熟练地在命令行下完成各种配置以使其正常运行。更可怕的是,大多数的用户认为最难的是配置系统,复杂的安装过程令无数的菜鸟们望而怯步。
|
||||
|
||||
这的确很遗憾,在我看来,实际上一旦安装完成后,Arch比我用过的其它Linux发行版更容易得多。
|
||||
|
||||
确实如此,Arch的安装过程很让人蛋疼。有些发行版的安装过程只需要点击“安装”后就可以放手地去干其它事了。Arch相对来说要花费更多的时间和精力去完成硬盘分区,手动挂载,生成fstab文件等。但是从Arch的安装过程中,我们学到很多。它掀开帷幕,让我们弄明白很多背后的东西。事实上,这个帷幕已经彻底消失了,在Arch的世界里,你就是帷幕背后的主宰。
|
||||
|
||||
除了大家所熟知的难安装外,Arch甚至没有自己默认的桌面环境,虽然这有些让人难以理解,但是Arch也因其可定制化而被广泛推崇。你可以自行决定在Arch的基础软件包上安装任何东西。
|
||||
|
||||

|
||||
你可以认为Arch是高度可定制化的,或者说它完全没有定制化。比如,不像Ubuntu系统那样,Arch几乎没有修改过或是定制开发后的软件包。Arch的开发者从始至终都使用上游开发者提供的软件包。对于部分用户来说,这种情况非常棒。比如,你可以使用纯粹的未定制化开发过的GNOME桌面环境。但是,在某些情况下,一些上游开发者未更新过的定制化软件包可能存在很多的缺陷。
|
||||
|
||||
由于Arch缺乏一些默认的应用程序和桌面系统,这完全不利于用户管理自己的桌面环境。我曾经使用最小化安装配置Openbox,tint2和dmenu桌面管理工具,但是安装后的效果却跟我很失望。因此,我更倾向于使用最新版的GNOME桌面系统。在使用Arch的过程中,我们会同时安装一个桌面环境,但是这给我们的体验是完全不一样的。对于任何发行版来说,这种做法是正确的,但是大多数的Linux系统都至少会使用一个默认的桌面环境。
|
||||
|
||||
然而Arch还是有很多共性的元素一起构成这个基本系统。比如说,我使用Arch系统的主要原因是因为它是一个滚动更新的发行版。这意味着两件事情。首先,Arch使用最新的稳定版内核。这就意味着我可以在Arch系统里完成在其它Linux发行版中很难完成的测试。滚动版最大的一个好处就是所有可用的软件更新包会被即时发布出来。这不只是说明软件包更新速度快,而且也没有太多的系统升级包会被拆分。
|
||||
|
||||
由于Arch是一个滚动更新的发行版,因此很多用户认为它是不稳定的。但是在我使用了9个多月之后,我并不赞同这种观点。
|
||||
|
||||
我在每一次升级系统的过程中,从未损坏过任何软件。有一次升级系统之后我不得不回滚,因为系统启动分区/boot无法挂载成功,但是后来我发现那完全是自己操作上的失误。一些基本的系统缺陷(比如我关于戴尔XPS笔记本触摸板相关的回归测试方面的问题)已经被修复,并且可用的软件包更新速度要比其它非滚动发行版快得多。总的来说,我认为Arch滚动更新的发布模式比其它我在用的发行版要稳定得多。唯一一点我要强调的是查阅维基上的资料,多关注你要更新的内容。
|
||||
|
||||
你必须要小心你正在做的操作,因为Arch也不是任你肆意胡来的。盲目的更新Arch系统是极其危险的。但是任何一个发行版的更新都有风险。在你别无选择的时候,你得根据实际情况,三思而后行。
|
||||
|
||||
Arch的哲学理念是我支持它的另外一个最主要的原因。我认为Arch最吸引用户的一点就是:Arch面向的是专业的Linux用户,或者是有“自己动手”的态度,并愿意查资料解决问题的任何人。
|
||||
|
||||
随着Linux逐渐成为主流的操作系统,开发者们更需要顺利地渡过每一个艰难的技术领域。那些晦涩难懂的专有软件方面的经验恰恰能反映出用户高深的技术能力。
|
||||
|
||||
尽管在这个时代听起来有些怪怪的,但是事实上我们大多数的用户更愿意自己动手装配一些东西。在这种情形下,Arch将会是Linux DIY用户的终结圣地。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: http://www.theregister.co.uk/2016/11/02/arch_linux_taster/
|
||||
|
||||
作者:[Scott
|
||||
Gilbertson][a]
|
||||
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由
|
||||
[LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/1785
|
||||
|
||||
[1]:https://wiki.archlinux.org/index.php/Arch_Linux
|
||||
|
||||
[2]:http://www.theregister.co.uk/Author/1785
|
||||
|
||||
[3]:https://www.linkedin.com/shareArticle?mini=true&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&summary=Last%20refuge%20for%20purists
|
||||
|
||||
[4]:http://twitter.com/share?text=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good&url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&via=theregister
|
||||
|
||||
[5]:http://www.reddit.com/submit?url=http://www.theregister.co.uk/2016/11/02/arch_linux_taster/&title=Arch%20Linux%3A%20In%20a%20world%20of%20polish%2C%20DIY%20never%20felt%20so%20good
|
||||
@ -1,101 +0,0 @@
|
||||
我成为一名软件工程师的原因和经历
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
1989 年乌干达首都,坎帕拉。
|
||||
|
||||
赞美我的父母,他们机智的把我送到叔叔的办公室,去学着用电脑,而非将我留在家里添麻烦。几日后,我和另外六、七个小孩,还有一台放置在与讲台相垂直课桌子上的崭新电脑,一起置身于 21 层楼高的狭小房间中。很明显我们还不够格去碰那家伙。在长达三周无趣的 DOS 命令学习后,终于迎来了这美妙的时光。终于轮到我来输 **copy doc.txt d:** 了。
|
||||
|
||||
那奇怪的声音其实是将一个简单文件写入五英寸软盘的声音,但听起来却像音乐般美妙。那段时间,这块软盘简直成为了我的至宝。我把所有我可以拷贝的东西都放在上面了。然而,1989 年的乌干达,人们的生活十分正经,相较而言捣鼓电脑,拷贝文件还有格式化磁盘就称不上正经。我不得不专注于自己的学业,这让我离开了计算机科学走入了建筑工程学。
|
||||
|
||||
在这些年里,我和同龄人一样,干过很多份工作也学到了许多技能。我教过幼儿园的小朋友,也教过大人如何使用软件,在服装店工作过,还在教堂中担任过付费招待。在我获取堪萨斯大学的学位时,我正在技术高管的手下做技术助理,其实也就听上去比较洋气,也就是搞搞学生数据库而已。
|
||||
|
||||
当我 2007 年毕业时,这些技术已经变得不可或缺。建筑工程学的方方面面都与计算机科学深深的交织在一起,所以我们也都在不经意间也都学了些简单的编程知识。我对于这方面一直很着迷。但由于我不得不成为一位正经的工程师,所以我发展了一项私人爱好:写科幻小说。
|
||||
|
||||
在我的故事中,我以我笔下的女英雄的形式存在。她们都是编程能力出众的科学家,总是在冒险的途中用自己的技术发明战胜那些渣渣们,有时发明要在战斗中进行。我想出的这些“新技术”,一般基于真实世界中的发明。也有些是从买来的科幻小说中读到的。这就意味着我需要了解这些技术的原理,而且我的研究使我有意无意的关注了许多有趣的 subreddit 和电子杂志
|
||||
|
||||
### 开源:巨大的宝库
|
||||
|
||||
在我的经历中,那几周花在 DOS 命令上的时间仍然记忆犹新,在一些偏门的项目上耗费心血,并占据了宝贵的学习时间。Geocities 一向所有 Yahoo! 用户开放,我就创建了一个网站,用于发布一些由我用小型数码相机拍摄的个人图片。这个网站是我随性而为的,用来帮助家人和朋友,解决一些他们所遇到的电脑问题。同时也为教堂搭建了一个图书馆数据库。
|
||||
|
||||
这意味着,我需要一直研究并尝试获取更多的信息,使它们变得更棒。上帝保佑,让互联网和开源砸在了我的面前。然后,30 天试用和 license 限制对我而言就变成了过去式。我可以完全不受这些限制,持续的使用 GIMP、Inkscape 和 OpenOffice。
|
||||
|
||||
### 是时候正经了
|
||||
|
||||
我很幸运,有商业伙伴看出了我故事中的奇妙。她也是个想象力丰富的人,对更高效、更便捷的互联这个世界,充满了各种美好的想法。我们根据我们以往成功道路中经历的痛点制定了解决方案,但执行却成了一个问题。我们都缺乏那种将产品带入生活的能力,每当我们试图将想法带到投资人面前时,都表现的尤为突出。
|
||||
|
||||
我们需要学习编程。所以在 2015 年的夏末,我们踏上了征途,来到了 Holberton 学校的阶前。那是一所座落于旧金山由社区推进,基于项目教学的学校。
|
||||
|
||||
我的商业伙伴一天早上找到我,并开始了一段充满她方式的对话,每当她有疯狂想法想要拉我入伙时。
|
||||
|
||||
**Zee**: Gloria,我想和你说点事,在拒绝前能先听我说完吗?
|
||||
|
||||
**Me**: 不行。
|
||||
|
||||
**Zee**: 我们想要申请一所学校的全栈工程师。
|
||||
|
||||
**Me**: 什么?
|
||||
|
||||
**Zee**: 就是这,看!就是这所学校,我们要申请这所学校学习编程。
|
||||
|
||||
**Me**: 我不明白。我们不是正在网上学 Python 和…
|
||||
|
||||
**Zee**: 这不一样。相信我。
|
||||
|
||||
**Me**: 那…
|
||||
|
||||
**Zee**: 还不相信吗?
|
||||
|
||||
**Me**: 好吧…我看看。
|
||||
|
||||
### 抛开偏见
|
||||
|
||||
我看到的和我们在网上听说的几乎差不多。这简直太棒了,以至于让人觉得不太真实,但我们还是决定尝试一下,双脚起跳,看看结果如何。
|
||||
|
||||
要成为学生,我们需要经历四个步骤,仅仅是针对才能和态度,无关学历和编程经历的筛选。筛选便是课程的开始,通过它我们开始学习与合作。
|
||||
|
||||
根据我和我合作伙伴的经验,相比 Holberton 学校的申请流程,其他的申请流程实在是太无聊了。就像场游戏。如果你完成了一项挑战,你就能通往下一关,在那里有别的有趣的挑战正等着你。我们创建了 Twitter 账号,在 Medium 上写博客,为了创建网站而学习 HTML 和 CSS, 打造了一个充满活力的社区,虽然在此之前我们并不知晓有谁会来。
|
||||
|
||||
在线社区最吸引人的就是我们使用电脑的经验是多种多样的,而我们的背景和性别并非创始人(我们私下里称他为“The Trinity(三位一体)”)做出选择的因素。大家只是喜欢聚在一块交流。我们都是通过学习编程来提升自己计算机技术的聪明人。
|
||||
|
||||
相较于其他的的申请流程,我们不需要泄露很多的身份信息。就像我的商业伙伴,她的名字里看不出她的性别和种族。直到最后一个步骤,在视频聊天的时候, The Trinity 才知道她是一位有色人种女性。迄今为止,促使她达到这个程度的只是她的热情和才华。肤色和性别,并没有妨碍或者帮助到她。还有比这更酷的吗?
|
||||
|
||||
那个我们获得录取通知书的晚上,我们知道我们的命运已经改变,我们获得了原先梦寐以求的生活。2016 年 1 月 22 日,我们来到北至巴特瑞大街 98 号,去见我们的小伙伴 [Hippokampoiers][2],这是我们的初次见面。很明显,在见面之前,“The Trinity”就已经开始做一些令人激动的事了。他们已经聚集了一批形形色色的人,他们都专注于成为全栈工程师,并为之乐此不疲。
|
||||
|
||||
这所大学有种与众不同的体验。感觉每天都是向编程的一次竭力的冲锋。我们着手的工程,并不会有很多指导,我们需要使用一切我们可以使用的资源找出解决方案。[Holberton 学校][1] 的办学宗旨便是向学员提供,相较于我们已知而言,更为多样的信息渠道。MOOCs(大型开放式课程)、教程、可用的开源软件和项目,以及线上社区层出不穷,将我们完成项目所需要的知识全都衔接了起来。加之宝贵的导师团队来指导我们制定解决方案,这所学校变得并不仅仅是一所学校;我们已经成为了求学者的社区。任何对软件工程感兴趣并对这种学习方法感兴趣的人,我都十分推荐这所学校。下次开课在 2016 年 10 月,并且会接受新的申请。虽然会让人有些悲喜交加,但是那真的很值得。
|
||||
|
||||
### 开源问题
|
||||
|
||||
我最早使用的开源系统是 [Fedora][3],一个 [Red Hat][4] 赞助的项目。在与 IRC 中一名成员一番惊慌失措的交流后,她推荐了这款免费的系统。 虽然在此之前,我还未独自安装过操作系统,但是这激起了我对开源的兴趣和日常使用计算机时对开源软件的依赖性。我们提倡为开源贡献代码,创造并使用开源的项目。我们的项目就在 Github 上,任何人都可以使用或是向它贡献出自己的力量。我们也会使用或以自己的方式为一些既存的开源项目做出贡献。在学校里,我们使用的大部分工具是开源的,例如 Fedora、[Vagrant][5]、[VirtualBox][6]、[GCC][7] 和 [Discourse][8],仅举几例。
|
||||
|
||||
重回软件工程师之路以后,我始终憧憬着有这样一个时刻——能为开源社区做出一份贡献,能与他人分享我所掌握的知识。
|
||||
|
||||
### Diversity Matters
|
||||
|
||||
站在教室里,在着 29 双明亮的眼睛关注下交流心得,真是令人陶醉。学员中有 40% 是女性,有 44% 的有色人种。当你是一位有色人种且为女性,并身处于这个以缺乏多样而著名的领域时,这些数字就变得非常重要了。那是高科技圣地麦加上的绿洲。我知道我做到了。
|
||||
|
||||
想要成为一个全栈的工程师是十分困难的,你甚至很难了解这意味着什么。这是一条充满挑战的路途,道路四周布满了对收获的未知。科技推动着未来飞速发展,而你也是美好未来很重要的一部分。虽然媒体在持续的关注解决科技公司的多样化的问题,但是如果能认清自己,了解自己,知道自己为什么想成为一名全栈工程师,这样你便能觅得一处生根发芽。
|
||||
|
||||
不过可能最重要的是,提醒人们女性在计算机的发展史上扮演着多么重要的角色,以帮助更多的女性回归到科技界,并使她们充满期待,而非对自己的性别与能力感到犹豫。她们的才能将会描绘出不仅仅是科技的未来,而是整个世界的未来。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-gloria-bwandungi
|
||||
|
||||
作者:[Gloria Bwandungi][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nappybrain
|
||||
[1]: https://www.holbertonschool.com/
|
||||
[2]: https://twitter.com/hippokampoiers
|
||||
[3]: https://en.wikipedia.org/wiki/Fedora_(operating_system)
|
||||
[4]: https://www.redhat.com/
|
||||
[5]: https://www.vagrantup.com/
|
||||
[6]: https://www.virtualbox.org/
|
||||
[7]: https://gcc.gnu.org/
|
||||
[8]: https://www.discourse.org/
|
||||
@ -1,148 +0,0 @@
|
||||
TOP 5 2016年LINUX最佳视频编辑软件
|
||||
=====================================================
|
||||
|
||||

|
||||
|
||||
概要: 在这篇文章中,Tiwo讨论了Linux下最佳视频编辑器的优缺点和基于Ubuntu-based发行版的安装方法。
|
||||
|
||||
在过去,我们已经在类似的文章中讨论了[Linux下最佳图片管理应用软件][1], [Linux下最佳代码编辑器][2]。今天,我们来看看Linux下的最佳视频编辑软件。
|
||||
当谈及免费的视频编辑软件,Windows Movie Maker和iMovie是大多数人经常推荐的。
|
||||
|
||||
不幸的是,它们在GNU/Linux下都是不可用的。但是你不必担心这个,因为我们已经为你收集了一系列最佳的视频编辑器。
|
||||
### Linux下最佳的视频编辑应用程序
|
||||
|
||||
接下来,让我们来看看Linux下排名前五的最佳视频编辑软件:
|
||||
|
||||
#### 1. KDENLIVE
|
||||
|
||||

|
||||
|
||||
[Kdenlive][3] 是一款来自于KDE的免费 [开源][4] 的视频编辑软件,它提供双视频监视器,多轨时间轴,剪辑列表,可自定义布局支持,基本效果和基本转换的功能。
|
||||
|
||||
它支持各种文件格式和各种摄像机和相机,包括低分辨率摄像机(Raw和AVI DV编辑),Mpeg2,mpeg4和h264 AVCHD(小型摄像机和摄像机),高分辨率摄像机文件,包括HDV和AVCHD摄像机 ,专业摄像机,包括XDCAM-HD TM流,IMX TM(D10)流,DVCAM(D10),DVCAM,DVCPRO TM,DVCPRO50 TM流和DNxHD TM流。
|
||||
|
||||
你可以在命令行下运行下面的命令安装 :
|
||||
|
||||
```
|
||||
sudo apt-get install kdenlive
|
||||
```
|
||||
|
||||
或者,打开Ubuntu软件中心,然后搜索Kdenlive。
|
||||
|
||||
#### 2. OPENSHOT
|
||||
|
||||

|
||||
|
||||
[OpenShot][5] 是我们的Linux视频编辑软件列表的第二选择。 OpenShot可以帮助您创建支持过渡,效果,调整音频电平的电影,当然,它也支持大多数格式和编解码器。
|
||||
|
||||
您还可以将电影导出到DVD,上传到YouTube,Vimeo,Xbox 360和许多其他常见的格式。 OpenShot比kdenlive更简单。 所以如果你需要一个简单UI的视频编辑器,OpenShot会是一个不错的选择。
|
||||
|
||||
最新的版本是2.0.7. 您可以从终端窗口运行以下命令安装OpenShot视频编辑器:
|
||||
|
||||
```
|
||||
sudo apt-get install openshot
|
||||
```
|
||||
|
||||
它需要下载25 MB,安装后需要70 MB硬盘空间。
|
||||
|
||||
#### 3. FLOWBLADE MOVIE EDITOR
|
||||
|
||||

|
||||
|
||||
[Flowblade Movie Editor][6] 是一个用于Linux的多轨非线性视频编辑器。 它是免费和开源的。 它配备了一个时尚而现代的用户界面。
|
||||
|
||||
|
||||
是用Python编写的,它旨在提供一个快速,精确的服务。 Flowblade致力于在Linux和其他免费平台上提供最好的体验。 所以现在没有Windows和OS X版本。
|
||||
|
||||
|
||||
要在Ubuntu和其他基于Ubuntu的系统上安装Flowblade,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt-get install flowblade
|
||||
```
|
||||
|
||||
#### 4. LIGHTWORKS
|
||||
|
||||

|
||||
|
||||
如果你要寻找一个有更多功能的视频编辑软件,这会是答案。 [Lightworks][7]是一个跨平台的专业的视频编辑器,在Linux,,Mac OS X和Windows系统下都可用。
|
||||
|
||||
它是一个获奖的专业的[非线性编辑] [8](NLE)软件,支持高达4K的分辨率以及SD和HD格式的视频。
|
||||
|
||||
|
||||
该应用程序有两个版本:Lightworks免费版和Lightworks专业版。虽然免费版本不支持Vimeo(H.264 / MPEG-4)和YouTube(H.264 / MPEG-4) - 高达2160p(4K UHD),蓝光和H.264 / MP4导出选项可配置的位速率设置,但是pro版本支持。
|
||||
|
||||
- Lightworks免费版
|
||||
- Lightworks专业版
|
||||
|
||||
专业版本有更多的功能,例如更高的分辨率支持,4K和Blu Ray支持等。
|
||||
|
||||
##### 怎么安装LIGHTWORKS?
|
||||
|
||||
不同于其他的视频编辑器,安装Lightwork不像运行单个命令那么直接。别担心,这不会很复杂。
|
||||
- 第1步 – 你可以从[Lightworks Downloads Page][9]下载安装包。这个安装包大约79.5MB。
|
||||
>请注意:这里
|
||||
没有Linux 32位的支持。
|
||||
|
||||
- 第2步 – 一旦下载,你可以使用[Gdebi package installer][10]来安装。Gdebi会自动下载依赖关系 :
|
||||
|
||||

|
||||
|
||||
- 第3步 – 现在你可以从Ubuntu仪表板或您的Linux发行版菜单中打开它。
|
||||
- 第4步 – 当你第一次使用它时,需要一个账号。点击未注册按钮来注册。别担心,它是免费的。
|
||||
- 第5步 – 在你的账号通过验证后,就可以登录了。
|
||||
现在,Lightworks可以使用了。
|
||||
|
||||
需要Lightworks的视频教程? 在[Lightworks video tutorials Page][11]得到它们。
|
||||
|
||||
#### 5. BLENDER
|
||||
|
||||

|
||||
|
||||
|
||||
Blender是一个专业的,行业级的开源,跨平台的视频编辑器。在3D作品的制作中,是非常受欢迎的。 Blender已被用于几部好莱坞电影的制作,包括蜘蛛侠系列。
|
||||
|
||||
|
||||
虽然最初是设计用于制作3D模型,但它也可以用于各种格式的视频编辑和输入能力。 该视频编辑器包括:
|
||||
|
||||
- 实时预览,亮度波形,色度矢量示波器和直方图显示
|
||||
- 音频混合,同步,擦除和波形可视化
|
||||
- 最多32个插槽用于添加视频,图像,音频,场景,面具和效果
|
||||
- 速度控制,调整图层,过渡,关键帧,过滤器等
|
||||
|
||||
最新的版本可以从[Blender Download Page][12]下载.
|
||||
|
||||
### 哪一个是最好的视频编辑软件?
|
||||
|
||||
如果你需要一个简单的视频编辑器, OpenShot, Kdenlive和 Flowblade是一个不错的选择。这些软件是适合初学者的,并且带有标准规范的系统。
|
||||
|
||||
如果你有一个高性能的计算机,并且需要高级功能,你可以使用Lightworks。如果你正在寻找更高级的功能,Blender可以帮助你。
|
||||
|
||||
这就是我写的5个最佳的视频编辑软件,它们可以在Ubuntu,Linux Mint,Elementary和其他Linux发行版下使用。 与我们分享您最喜欢的视频编辑器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-video-editing-software-linux/
|
||||
|
||||
作者:[Tiwo Satriatama][a]
|
||||
译者:[DockerChen](https://github.com/DockerChen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/tiwo/
|
||||
[1]: https://itsfoss.com/linux-photo-management-software/
|
||||
[2]: https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[3]: https://kdenlive.org/
|
||||
[4]: https://itsfoss.com/tag/open-source/
|
||||
[5]: http://www.openshot.org/
|
||||
[6]: http://jliljebl.github.io/flowblade/
|
||||
[7]: https://www.lwks.com/
|
||||
[8]: https://en.wikipedia.org/wiki/Non-linear_editing_system
|
||||
[9]: https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206
|
||||
[10]: https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[11]: https://www.lwks.com/videotutorials
|
||||
[12]: https://www.blender.org/download/
|
||||
|
||||
|
||||
|
||||
@ -1,190 +0,0 @@
|
||||
写一个比setTimeout更棒的javascript框架
|
||||
===================
|
||||
|
||||
这是JavaScript框架系列的第二章. 在这一章里, 我打算讲一下浏览器的异步代码不同执行方式. 你将了解定时器和事件循环直接的不同差异, 比如 setTimeout 和 Promises.
|
||||
|
||||
这个系列是一个开源的客户端框架, 叫做 NX. 在这个系列里, 我主要解释一下写该框架不得不客服的主要困难. 如果你对NX感兴趣可以参观我们的 [主页][1].
|
||||
|
||||
这个系列包含以下几个章节:
|
||||
|
||||
1. [项目结构][2]
|
||||
2. 定时执行 (当前章节)
|
||||
3. [沙箱代码评估][3]
|
||||
4. 数据绑定 (part 1)
|
||||
5. 数据绑定 (part 2)
|
||||
6. 自定义元素
|
||||
7. 客户端侧路由
|
||||
|
||||
### 异步代码执行
|
||||
|
||||
你可能比较熟悉 Promise, process.nextTick(), setTimeout() and maybe requestAnimationFrame() 这些作为异步执行的代码. 它们都是内部事件循环, 但是他们确实有一些不同.
|
||||
|
||||
在这一章里, 我将解释它们之间的不同, 然后给大家演示一个先进的定时系统框架, 像NX 这样的框架. 不用我们重新做一个,我们将使用原生的内部循环来达到我们的目的.
|
||||
|
||||
### 事件循环
|
||||
|
||||
事件循环甚至没有在ES6里提到. JavaScript只有jobs 和 job queues. 更加复杂的事件循环是在NodeJS 和HTML5里分别指定的. 我会在后面详细说明.
|
||||
|
||||
事件循环叫做一个理由的循环. 它不停的寻找新的任务来运行. 这个循环中的一次事件叫做tick. 运行tick期间的代码叫做task.
|
||||
|
||||
```
|
||||
while (eventLoop.waitForTask()) {
|
||||
eventLoop.processNextTask()
|
||||
}
|
||||
```
|
||||
|
||||
Tasks 是同步代码他可以在其它的循环中调用. 一个简单的调用新任务的方式是setTimeout(taskFn). 不管怎样, tasks可能有很多比如 用户事件, networking 或者 DOM 操作.
|
||||
|
||||

|
||||
|
||||
### 任务队列
|
||||
|
||||
简单来说, 事件循环可以有多个任务队列. 这里有两个约束条件,相同数据源的事件必须在相同的队列以及任务必须做插入顺序处理. 除此之外, 浏览器可以做任何他想做的事情. 例如, 它可以决定接下来处理哪个任务队列.
|
||||
|
||||
```
|
||||
while (eventLoop.waitForTask()) {
|
||||
const taskQueue = eventLoop.selectTaskQueue()
|
||||
if (taskQueue.hasNextTask()) {
|
||||
taskQueue.processNextTask()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
用这个模型, 我们不能精确的控制定时. 如果用setTimeout()浏览器可能决定先运行完其它几个队列才运行我们的队列.
|
||||
|
||||

|
||||
|
||||
### The microtask queue
|
||||
|
||||
幸运的是, 事件循环还提供了单个队列叫做microtask队列. 当前任务结束的时候microtask队列会清空每个tick里的任务.
|
||||
|
||||
|
||||
```
|
||||
while (eventLoop.waitForTask()) {
|
||||
const taskQueue = eventLoop.selectTaskQueue()
|
||||
if (taskQueue.hasNextTask()) {
|
||||
taskQueue.processNextTask()
|
||||
}
|
||||
|
||||
const microtaskQueue = eventLoop.microTaskQueue
|
||||
while (microtaskQueue.hasNextMicrotask()) {
|
||||
microtaskQueue.processNextMicrotask()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
最简单的调用microtask的方法是Promise.resolve().then(microtaskFn). Microtasks做插入顺序的处理, 并且由于仅存在一个microtask队列, 现在浏览器对于我们来说并不是杂乱无章的了.
|
||||
|
||||
此外, microtasks 可以安排新的 microtasks插入到相同的队列.
|
||||
|
||||

|
||||
|
||||
### 绘制
|
||||
|
||||
最后是绘制调度. 不同于事件处理和分解, 绘制并不是在后台任务完成的. 它是在每个循环tick结束时运行的算法.
|
||||
|
||||
在这里浏览器又有了许多自由: 他可能在每个任务以后绘制, 但是他也肯能在好几百个任务都执行了以后也不绘制.
|
||||
|
||||
幸运的是, 我们有 requestAnimationFrame(), 它表示在下一个绘制之前执行. 我们最终的模型像这样.
|
||||
|
||||
```
|
||||
while (eventLoop.waitForTask()) {
|
||||
const taskQueue = eventLoop.selectTaskQueue()
|
||||
if (taskQueue.hasNextTask()) {
|
||||
taskQueue.processNextTask()
|
||||
}
|
||||
|
||||
const microtaskQueue = eventLoop.microTaskQueue
|
||||
while (microtaskQueue.hasNextMicrotask()) {
|
||||
microtaskQueue.processNextMicrotask()
|
||||
}
|
||||
|
||||
if (shouldRender()) {
|
||||
applyScrollResizeAndCSS()
|
||||
runAnimationFrames()
|
||||
render()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
现在用我们所知道知识来创建定时系统!
|
||||
|
||||
### 利用事件循环
|
||||
|
||||
和大多数现代框架一样, NX 也是基于 DOM 操作和 后台数据绑定的.在批操作和异步执行方面有更好的性能表现. 基于以上理由我们用 Promises, MutationObservers and requestAnimationFrame().
|
||||
|
||||
我们所期望的定时器是这样的:
|
||||
|
||||
1. 代码来自于开发者
|
||||
2. 数据绑定和DOM操作由NX来执行
|
||||
3. developer定义HOOKS
|
||||
4. 浏览器进行绘制
|
||||
|
||||
#### 步骤 1
|
||||
|
||||
NX 寄存器对象基于ES6转变 以及 DOM转换基于MutationObserver(变动观测器)同步运行(下一节详细介绍). 它作为一个microtasks延迟直到步骤 2 执行以后才有反应. 这个延迟已经在 Promise.resolve().then(reaction) 进行了对象转换, 并且它将通过变动观测器自动运行.
|
||||
|
||||
#### 步骤 2
|
||||
|
||||
开发人员完成了代码(任务). NX的microtask反应注册器开始运行. 当它们进入队列运行. 注意我们仍然在同一个tick循环中.
|
||||
|
||||
#### 步骤 3
|
||||
|
||||
开发者通过requestAnimationFrame(hook)通知NX运行hooks. 这可能在tick循环后发生. 重要的是hooks运行在下一次绘制之前和所以数据操作之后, 并且DOM和CSS改变都已经完成 .
|
||||
|
||||
#### 步骤 4
|
||||
|
||||
浏览器绘制下一个视图. 这也有可能发生在tick循环之后, 但是绝对不会发生在步骤3的tick之前.
|
||||
|
||||
### 牢记在心里的事情
|
||||
|
||||
我们实现了一简单而有效的定时系统. 理论上讲它运行的很好, 但是还是很脆弱, 一个轻微的错误可能会导致很严重的BUG.
|
||||
|
||||
在一个复杂的系统当中, 最重要的就是建立一定的规则并在以后保持它们. 在NX中有以下规则.
|
||||
|
||||
1. 永远不用setTimeout(fn, 0)来进行内部操作
|
||||
2. 用相同的方法来注册microtasks
|
||||
3. microtasks仅供内部操作
|
||||
4. 不要干预开发者hook运行时间
|
||||
|
||||
#### 规则 1 和 2
|
||||
|
||||
序列化数据和DOM操作. 这样只要不混合就可以很好的延迟它们. 混合执行会出现莫名其妙的问题.
|
||||
|
||||
setTimeout(fn, 0) 完全不可预测. 使用不同的方法注册microtasks也会发生混乱. 例如 下面的例子中microtask2不会在 microtask1之前正确运行.
|
||||
|
||||
```
|
||||
Promise.resolve().then().then(microtask1)
|
||||
Promise.resolve().then(microtask2)
|
||||
```
|
||||
|
||||

|
||||
|
||||
#### 规则 3 和 4
|
||||
|
||||
分离开发者的代码执行和内部操作是非常重要的. 混合这两种行为会导致不可预测的事情发生, 并且它会迫使开发者了解框架内部. 我想很多前台开发者已经有过类似经历.
|
||||
|
||||
### 结论
|
||||
|
||||
如果你对 NX 框架感兴趣, 可以参观我们的主页. 还可以再GIT上找到我们的源代码 [NX source code][5] .
|
||||
|
||||
在下一节我们再见 [sandboxed code evaluation][4]!
|
||||
|
||||
你也可以给我们留言.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.risingstack.com/writing-a-javascript-framework-execution-timing-beyond-settimeout/?utm_source=javascriptweekly&utm_medium=email
|
||||
|
||||
作者:[Bertalan Miklos][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.risingstack.com/author/bertalan/
|
||||
[1]: http://nx-framework.com/
|
||||
[2]: https://blog.risingstack.com/writing-a-javascript-framework-project-structuring/
|
||||
[3]: https://blog.risingstack.com/writing-a-javascript-framework-sandboxed-code-evaluation/
|
||||
[4]: https://blog.risingstack.com/writing-a-javascript-framework-sandboxed-code-evaluation/
|
||||
[5]: https://github.com/RisingStack/nx-framework
|
||||
515
translated/tech/20161024 Getting Started with Webpack 2.md
Normal file
515
translated/tech/20161024 Getting Started with Webpack 2.md
Normal file
@ -0,0 +1,515 @@
|
||||
OneNewLife translated
|
||||
|
||||
# Webpack 2 入门
|
||||
|
||||

|
||||
|
||||
Webpack 2 即将退出测试,[一旦文档完成][26]。不过这不意味着你现在不能开始使用第 2 版,前提是你知道怎么配置它。
|
||||
|
||||
### Webpack 是什么
|
||||
|
||||
官方的说法是最简单的 —— Webpack 是一个 JavaScript 模块打包器。然而,自从它发布以来,它发展成为了你所有前端代码的管理工具(有意地或社区的意愿)。
|
||||
|
||||

|
||||
|
||||
任务运行器,例如 Gulp,可以处理许多不同的预处理器和转换器,但是在所有的情景下,它都需要一个输入源并将其压缩到一个编译好的输出文件中。然而,它是在个案基础上这样做的,不用担心整个系统。这是开发者的负担:找到任务运行器中断的地方,并找到适当的方式将所有这些模块在生产中联合在一起。
|
||||
|
||||
Webpack 试图通过提出一个大胆的想法来减轻开发者的负担:如果有一部分开发过程可以自动处理依赖关系会怎样?如果我们可以简单地写代码,让构建过程只基于最终需求管理自己会怎样?
|
||||
|
||||

|
||||
|
||||
如果你过去几年一直是 web 社区的一员,你已经知道解决问题的首选方法:使用 JavaScript 来构建。因此 Webpack 尝试通过 JavaScript 传递依赖关系使构建过程更加容易。不过这个设计真正的亮点不是简单的代码管理部分,而是管理层由 100% 有效的 JavaScript 实现(具有 Nodejs 特性)。Webpack 能够让你写有效的 JavaScript,更好更全面地了解系统。
|
||||
|
||||
换句话来说:你不需要为 Webpack 写代码。你只需要写项目代码。而且 Webpack 会持续工作(当然需要一些配置)。
|
||||
|
||||
简而言之,如果你曾经遇到过以下任何一种情况:
|
||||
|
||||
* 意外引入一些你不需要在生产中用上的样式表和 JS 库,使项目膨胀
|
||||
* 遇到作用域的问题 —— CSS 和 JavaScript 都会有
|
||||
* 找到一个好的构建系统让你在 JavaScript 中使用 Node/Bower 模块,或者依靠一个疯狂的后端配置来正确地使用这些模块
|
||||
* 需要优化资产交付,但担心你会弄坏一些东西
|
||||
|
||||
那么你可以从 Webpack 中收益了。它通过让 JavaScript 毫不费力地担心你的依赖关系和加载顺序,而不是开发者的大脑。最好的部分是?Webpack 甚至可以纯粹在服务器端运行,这意味着你还可以使用 Webpack 构建[渐进增强][25]的网站。
|
||||
|
||||
### 第一步
|
||||
|
||||
我们将在本教程中使用 [Yarn][24](运行命令 `brew install yarn`) 代替 `npm`,不过这完全取决于你,它们做同样的事情。在我们的项目文件夹中,我们将在终端窗口中运行以下代码,将 Webpack 2 添加到我们的全局软件包以及本地项目中:
|
||||
|
||||
```
|
||||
yarn global add webpack@2.1.0-beta.25 webpack-dev-server@2.1.0-beta.9
|
||||
yarn add --dev webpack@2.1.0-beta.25 webpack-dev-server@2.1.0-beta.9
|
||||
```
|
||||
|
||||
我们接着会通过项目根目录的一个 `webpack.config.js` 文件来声明 webpack 的配置:
|
||||
|
||||
```
|
||||
'use strict';
|
||||
|
||||
const webpack = require('webpack');
|
||||
|
||||
module.exports = {
|
||||
context: __dirname + '/src',
|
||||
entry: {
|
||||
app: './app.js',
|
||||
},
|
||||
output: {
|
||||
path: __dirname + '/dist',
|
||||
filename: '[name].bundle.js',
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
注意:`__dirname` 是指你的项目根目录
|
||||
|
||||
记住,Webpack “知道”你的项目发生了什么。它通过阅读你的代码来实现(别担心,它签署了一个 NDA 协议)。Webpack 基本上执行以下操作:
|
||||
|
||||
1. 从 `context` 文件夹开始...
|
||||
2. ...它查找 `entry` 的文件名...
|
||||
3. ...并读取内容。每一个 `import`([ES6][7])或 `require()`(Nodejs)的依赖会在它解析代码的时候找到,它会在最终构建的时候打包这些依赖项。然后,它会搜索那些依赖项以及那些依赖项所依赖的依赖项,直到它到达“树”的最底端 —— 只是打包它所需要的,没有其它东西。
|
||||
4. Webpack 从 `context` 文件夹打包所有东西到 `output.path` 文件夹,使用 `output.filename` 命名模板来为其命名(其中 `[name]` 被替换成来自 `entry` 的对象键)。
|
||||
|
||||
所以如果我们的 `src/app.js` 文件看起来像这样(假设我们事先运行了 `yarn add --dev moment`):
|
||||
|
||||
```
|
||||
'use strict';
|
||||
|
||||
import moment from 'moment';
|
||||
var rightNow = moment().format('MMMM Do YYYY, h:mm:ss a');
|
||||
console.log( rightNow );
|
||||
|
||||
// "October 23rd 2016, 9:30:24 pm"
|
||||
```
|
||||
|
||||
我们应该运行:
|
||||
|
||||
```
|
||||
webpack -p
|
||||
```
|
||||
|
||||
注意:`p` 标志表示“生产”模式,这会压缩输出文件。
|
||||
|
||||
它会输出一个 `dist/app.bundle.js`,这会将当前日期和时间打印到控制台。要注意 Webpack 会自动识别 `'moment'` 指代什么(虽然如果你有一个 `moment.js` 文件在你的目录,默认情况下 Webpack 会优先考虑你的 `moment` Node 模块)。
|
||||
|
||||
### 使用多个文件
|
||||
|
||||
你可以通过仅仅修改 `entry` 对象来指定任意数量的输入/输出点。
|
||||
|
||||
#### 打包多个文件
|
||||
|
||||
```
|
||||
`'use strict';
|
||||
|
||||
const webpack = require("webpack");
|
||||
|
||||
module.exports = {
|
||||
context: __dirname + "/src",
|
||||
entry: {
|
||||
app: ["./home.js", "./events.js", "./vendor.js"],
|
||||
},
|
||||
output: {
|
||||
path: __dirname + "/dist",
|
||||
filename: "[name].bundle.js",
|
||||
},
|
||||
};`
|
||||
```
|
||||
|
||||
所有文件都会按照数组的顺序一起被打包成一个 `dist/app.bundle.js` 文件。
|
||||
|
||||
#### 输出多个文件
|
||||
|
||||
```
|
||||
`const webpack = require("webpack");
|
||||
|
||||
module.exports = {
|
||||
context: __dirname + "/src",
|
||||
entry: {
|
||||
home: "./home.js",
|
||||
events: "./events.js",
|
||||
contact: "./contact.js",
|
||||
},
|
||||
output: {
|
||||
path: __dirname + "/dist",
|
||||
filename: "[name].bundle.js",
|
||||
},
|
||||
};`
|
||||
```
|
||||
|
||||
或者,你可以选择打包成多个 JS 文件以便于分割应用的某些模块。这将被打包成 3 个文件:`dist/home.bundle.js`,`dist/events.bundle.js` 和 `dist/contact.bundle.js`。
|
||||
|
||||
#### 高级打包自动化
|
||||
|
||||
如果你将你的应用分割成多个 `output` 输出项(如果你的应用的一部分有大量你不需要预加载的 JS,这会很有用),你可能会重用这些文件的代码,因为它将分别解析每个依赖关系。幸运的是,Webpack 有一个内置的 `CommonsChunk` 插件来处理这个:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
|
||||
plugins: [
|
||||
new webpack.optimize.CommonsChunkPlugin({
|
||||
name: "commons",
|
||||
filename: "commons.bundle.js",
|
||||
minChunks: 2,
|
||||
}),
|
||||
],
|
||||
|
||||
// …
|
||||
};
|
||||
```
|
||||
|
||||
现在,在你的 `output` 文件中,如果你有任何模块被加载 2 次以上(通过 `minChunks` 设置),它会把那个模块打包到 `common.js` 文件中,然后你可以将其缓存在客户端。这将生成一个额外的请求头,但是你防止了客户端多次下载同一个库。因此,在很多情景下,这会大大提升速度。
|
||||
|
||||
### 开发
|
||||
|
||||
Webpack actually has its own development server, so whether you’re developing a static site or are just prototyping your front-end, it’s perfect for either. To get that running, just add a `devServer` object to `webpack.config.js`:
|
||||
Webpack 实际上有自己的开发服务器,所以无论你是开发一个静态网站还是只是你的网站前端原型,它都是无可挑剔的。要运行那个服务器,只需要添加一个 `devServer` 对象到 `webpack.config.js`:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
context: __dirname + "/src",
|
||||
entry: {
|
||||
app: "./app.js",
|
||||
},
|
||||
output: {
|
||||
filename: "[name].bundle.js",
|
||||
path: __dirname + "/dist/assets",
|
||||
publicPath: "/assets", // New
|
||||
},
|
||||
devServer: {
|
||||
contentBase: __dirname + "/src", // New
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
现在创建一个包含以下代码的 `src/index.html` 文件:
|
||||
|
||||
```
|
||||
<script src="/assets/app.bundle.js"></script>
|
||||
```
|
||||
|
||||
... 在你的终端运行:
|
||||
|
||||
```
|
||||
webpack-dev-server
|
||||
```
|
||||
|
||||
你的服务器现在运行在 `localhost:8080`。注意 `script` 标签里面的 `/assets` 是怎么匹配到 `output.publicPath` 的 —— 你可以随意更改它的名称(如果你需要一个 CDN 的时候这会很有用)。
|
||||
|
||||
Webpack 会热加载所有 JavaScript 更改,而不需要刷新你的浏览器。但是,所有 `webpack.config.js` 文件里面的更改都需要重新启动服务器才能生效。
|
||||
|
||||
### 全局访问方法
|
||||
|
||||
需要在全局空间使用你的函数?在 `webpack.config.js` 里面简单地设置 `output.library`:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
output: {
|
||||
library: 'myClassName',
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
这会将你打包好的文件附加到一个 `window.myClassName` 实例。因此,使用该命名空间,你可以调用入口文件的可用方法(可以在[文档][23]中阅读有关此设置的更多信息)。
|
||||
|
||||
### 加载器
|
||||
|
||||
到目前为止,我们所做的一切只涉及 JavaScript。从一开始使用 JavaScript 是重要的,因为它是 Webpack 唯一支持的语言。事实上我们可以处理几乎所有文件类型,只要我们将其转换成 JavaScript。我们用加载器来实现这个功能。
|
||||
|
||||
加载器可以是 Sass 这样的预处理器,或者是 Babel 这样的转译器。在 NPM 上,它们通常被命名为 `*-loader`,例如 `sass-loader` 和 `babel-loader`。
|
||||
|
||||
#### Babel 和 ES6
|
||||
|
||||
如果我们想在项目中通过 [Babel][22] 来使用 ES6,我们首先需要在本地安装合适的加载器:
|
||||
|
||||
```
|
||||
yarn add --dev babel-loader babel-core babel-preset-es2015
|
||||
```
|
||||
|
||||
然后将它添加到 `webpack.config.js`,让 Webpack 知道在哪里使用它。
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.js$/,
|
||||
use: [{
|
||||
loader: "babel-loader",
|
||||
options: { presets: ["es2015"] }
|
||||
}],
|
||||
},
|
||||
|
||||
// Loaders for other file types can go here
|
||||
],
|
||||
},
|
||||
|
||||
// …
|
||||
};
|
||||
```
|
||||
|
||||
Webpack 1 的用户注意:加载器的核心概念没有任何改变,但是语法改进了。直到官方文档完成之前,这可能不是确切的首选语法。
|
||||
|
||||
`/\.js$/` 这个正则表达式查找所有以 `.js` 结尾的待通过 Babel 加载的文件。Webpack 依靠正则检查给予你完全的控制权 —— 它不限制你的文件扩展名或者假设你的代码必须以某种方式组织。例如:也许你的 `/my_legacy_code/` 文件夹下的内容不是用 ES6 写的。所以你可以修改上述的 `test` 为 `/^((?!my_legacy_folder).)\.js$/`,这将会排除那个特定的文件夹,不过会用 Babel 处理其余的文件。
|
||||
|
||||
#### CSS 和 Style 加载器
|
||||
|
||||
如果我们只想加载 CSS 作为我们的应用程序,我们也可以这样做。假设我们有一个 `index.js` 文件,我们将从那里引入:
|
||||
|
||||
```
|
||||
import styles from './assets/stylesheets/application.css';
|
||||
```
|
||||
|
||||
我们会得到以下错误:`你可能需要一个合适的加载器来处理这种类型的文件`。记住,Webpack 只能识别 JavaScript,所以我们必须安装合适的加载器:
|
||||
|
||||
```
|
||||
yarn add --dev css-loader style-loader
|
||||
```
|
||||
|
||||
然后添加一条规则到 `webpack.config.js`:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.css$/,
|
||||
use: ["style-loader", "css-loader"],
|
||||
},
|
||||
|
||||
// …
|
||||
],
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
加载器以数组的逆序处理。这意味着 `css-loader` 会比 `style-loader` 先执行。
|
||||
|
||||
你可能会注意到,即使在生产版本中,这实际上是将你的 CSS 和 JavaScript 打包在一起,`style-loader` 手动将你的样式写到 `<head>`。乍一看,它可能看起来有点怪异,但你仔细想想这就慢慢开始变得更加有意义了。你已经节省了一个头部请求 —— 节省了一些连接上的时间。如果你用 JavaScript 来加载你的 DOM,无论如何,这从本质上消除了 [FOUC][21]。
|
||||
|
||||
你还会注意到一个开箱即用的特性 —— Webpack 已经通过将这些文件打包在一起以自动解决你所有的 `@import` 查询(而不是依靠 CSS 默认的 import 方式,这会导致无谓的头部请求以及资源加载缓慢)。
|
||||
|
||||
从你的 JS 加载 CSS 是非常惊人的,因为你现在可以用一种新的强大的方式将你的 CSS 模块化。仅仅通过加载 `button.js` 来加载 `button.css`。这将意味着如果 `button.js` 从来没有真正使用过的话,它的 CSS 就不会膨胀我们的生产版本。如果你坚持面向组件的 CSS 实践,如 SMACSS 或 BEM,你会看到更紧密地结合你的 CSS 和你的标记 + JavaScript 的价值。
|
||||
|
||||
#### CSS 和 Node 模块
|
||||
|
||||
我们可以使用 Webpack 来利用 Node 的使用 `~` 前缀导入 Node 模块的优势。如果我们运行 `yarn add normalize.css`,我们可以使用:
|
||||
|
||||
```
|
||||
@import "~normalize.css";
|
||||
```
|
||||
|
||||
并且充分利用 NPM 来管理我们的第三方样式 —— 版本控制、没有任何副本和粘贴的部分。此外,让 Webpack 为我们打包 CSS 比起使用 CSS 的默认导入方式有明显的优势 —— 节省无谓的头部请求和加载时间。
|
||||
|
||||
更新:这一节和下面一节已经更新为准确的用法,不再使用 CSS 模块简单地导入 Node 模块。感谢 [Albert Fernández][20] 的帮助!
|
||||
|
||||
#### CSS 模块
|
||||
|
||||
你可能听说过 [CSS 模块][19],它消除了 CSS 的层叠性。通常它的最适用场景是只有当你使用 JavaScript 构建 DOM 的时候,但实质上,它神奇地将你的 CSS 类放置到加载它的 JavaScript 文件([在这里了解更多][18])。如果你打算使用它,CSS 模块已经与 `css-loader` 封装在一起(`yarn add --dev css-loader`):
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.css$/,
|
||||
use: [
|
||||
"style-loader",
|
||||
{ loader: "css-loader", options: { modules: true } }
|
||||
],
|
||||
},
|
||||
|
||||
// …
|
||||
],
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
注意:对于 `css-loader`,我们现在使用扩展对象语法来给它传递一个选项。你可以使用一个更为精简的字符串来取代默认选项,正如我们仍然使用了 `'style-loader'`。
|
||||
|
||||
* * *
|
||||
|
||||
值得注意的是,当允许导入 CSS 模块的时候(例如:`@import 'normalize.css';`),你完全可以删除掉 `~`。但是,当你 `@import` 你自己的 CSS 的时候,你可能会遇到构建错误。如果你遇到“无法找到 ____”的错误,尝试添加一个 `resolve` 对象到 `webpack.config.js`,让 Webpack 更好地理解你的模块加载顺序。
|
||||
|
||||
```
|
||||
const path = require("path");
|
||||
|
||||
module.exports = {
|
||||
//…
|
||||
|
||||
resolve: {
|
||||
modules: [path.resolve(__dirname, "src"), "node_modules"]
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
我们首先指定源目录,然后指定 `node_modules`。因此,Webpack 会更好地处理解析度,按照既定的顺序(分别用你的源目录和 Node 模块的目录替换 `'src'` 和 `'node_modules'`),首先查找我们的源目录,然后再查找已安装的 Node 模块。
|
||||
|
||||
#### Sass
|
||||
|
||||
需要使用 Sass?没问题。安装:
|
||||
|
||||
```
|
||||
yarn add --dev sass-loader node-sass
|
||||
```
|
||||
|
||||
并添加新的规则:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
// …
|
||||
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.(sass|scss)$/,
|
||||
use: [
|
||||
"style-loader",
|
||||
"css-loader",
|
||||
"sass-loader",
|
||||
]
|
||||
}
|
||||
|
||||
// …
|
||||
],
|
||||
},
|
||||
};
|
||||
```
|
||||
|
||||
然后当你的 Javascript 对一个 `.scss` 或 `.sass` 文件调用 `import` 方法的时候,Webpack 会处理的。
|
||||
|
||||
#### CSS 独立打包
|
||||
|
||||
或许你在处理渐进增强的问题;或许你因为其它原因需要一个单独的 CSS 文件。我们可以通过在我们的配置中用 `extract-text-webpack-plugin` 替换 `style-loader` 而轻易地做到这一点,这不需要更改任何代码。以我们的 `app.js` 文件为例:
|
||||
|
||||
```
|
||||
import styles from './assets/stylesheets/application.css';
|
||||
```
|
||||
|
||||
让我们安装这个插件到本地(我们需要 2016 年 10 月的 测试版本):
|
||||
|
||||
```
|
||||
yarn add --dev extract-text-webpack-plugin@2.0.0-beta.4
|
||||
```
|
||||
|
||||
并且添加到 `webpack.config.js`:
|
||||
|
||||
```
|
||||
const ExtractTextPlugin = require("extract-text-webpack-plugin");
|
||||
|
||||
module.exports = {
|
||||
// …
|
||||
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.css$/,
|
||||
use: [
|
||||
ExtractTextPlugin.extract("css"),
|
||||
{ loader: "css-loader", options: { modules: true } },
|
||||
],
|
||||
},
|
||||
|
||||
// …
|
||||
]
|
||||
},
|
||||
plugins: [
|
||||
new ExtractTextPlugin({
|
||||
filename: "[name].bundle.css",
|
||||
allChunks: true,
|
||||
}),
|
||||
],
|
||||
};
|
||||
```
|
||||
|
||||
现在当运行 `webpack -p` 的时候,你的 `output` 目录还会有一个 `app.bundle.css` 文件。只需要像往常一样简单地在你的 HTML 中向该文件添加一个 `<link>` 标签即可。
|
||||
|
||||
#### HTML
|
||||
|
||||
正如你可能已经猜到,Webpack 还有一个 `[html-loader][6]` 插件。但是,当我们用 JavaScript 加载 HTML 时,我们针对不同的场景分成了不同的方法,我无法想出一个单一的例子来为你计划下一步做什么。通常,你需要加载 HTML 以便于在更大的系统(如 [React][13]、[Angular][12]、[Vue][11] 或 [Ember][10])中使用 JavaScript 风格的标记,如 [JSX][16]、[Mustache][15] 或 [Handlebars][14]。
|
||||
|
||||
教程到此为止了:你可以用 Webpack 加载标记,但是进展到这一步的时候,关于你的架构,你将做出自己的决定,我和 Webpack 都无法左右你。不过参考以上的例子以及搜索 NPM 上适用的加载器应该足够你发展下去了。
|
||||
|
||||
### 从模块的角度思考
|
||||
|
||||
为了充分使用 Webpack,你必须从模块的角度来思考 —— 细粒度的、可复用的、用于高效处理每一件事的独立的处理程序。这意味着采取这样的方式:
|
||||
|
||||
```
|
||||
└── js/
|
||||
└── application.js // 300KB of spaghetti code
|
||||
```
|
||||
|
||||
将其转变成这样:
|
||||
|
||||
```
|
||||
└── js/
|
||||
├── components/
|
||||
│ ├── button.js
|
||||
│ ├── calendar.js
|
||||
│ ├── comment.js
|
||||
│ ├── modal.js
|
||||
│ ├── tab.js
|
||||
│ ├── timer.js
|
||||
│ ├── video.js
|
||||
│ └── wysiwyg.js
|
||||
│
|
||||
└── application.js // ~ 1KB of code; imports from ./components/
|
||||
```
|
||||
|
||||
结果呈现了整洁的、可复用的代码。每一个独立的组件依赖于 `import` 自身的依赖,并 `export` 它想要暴露给其它模块的部分。结合 Babel 和 ES6,你可以利用 [JavaScript 类][9] 来实现更强大的模块化,而不用考虑它的工作原理。
|
||||
|
||||
有关模块的更多信息,请参阅 Preethi Kasreddy [这篇优秀的文章][8].
|
||||
|
||||
* * *
|
||||
|
||||
### 延伸阅读
|
||||
|
||||
* [Webpack 2 的新特性][5]
|
||||
* [Webpack 配置文档][4]
|
||||
* [Webpack 范例][3]
|
||||
* [React + Webpack 入门套件][2]
|
||||
* [怎么使用 Webpack][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.madewithenvy.com/getting-started-with-webpack-2-ed2b86c68783#.oozfpppao
|
||||
|
||||
作者:[Drew Powers][a]
|
||||
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.madewithenvy.com/@an_ennui
|
||||
[1]:https://github.com/petehunt/webpack-howto
|
||||
[2]:https://github.com/kriasoft/react-starter-kit
|
||||
[3]:https://github.com/webpack/webpack/tree/master/examples
|
||||
[4]:https://webpack.js.org/configuration/
|
||||
[5]:https://gist.github.com/sokra/27b24881210b56bbaff7
|
||||
[6]:https://github.com/webpack/html-loader
|
||||
[7]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/import
|
||||
[8]:https://medium.freecodecamp.com/javascript-modules-a-beginner-s-guide-783f7d7a5fcc
|
||||
[9]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes
|
||||
[10]:http://emberjs.com/
|
||||
[11]:http://vuejs.org/
|
||||
[12]:https://angularjs.org/
|
||||
[13]:https://facebook.github.io/react/
|
||||
[14]:http://handlebarsjs.com/
|
||||
[15]:https://github.com/janl/mustache.js/
|
||||
[16]:https://jsx.github.io/
|
||||
[17]:https://github.com/webpack/html-loader
|
||||
[18]:https://github.com/css-modules/css-modules
|
||||
[19]:https://github.com/css-modules/css-modules
|
||||
[20]:https://medium.com/u/901a038e32e5
|
||||
[21]:https://en.wikipedia.org/wiki/Flash_of_unstyled_content
|
||||
[22]:https://babeljs.io/
|
||||
[23]:https://webpack.js.org/concepts/output/#output-library
|
||||
[24]:https://yarnpkg.com/
|
||||
[25]:https://www.smashingmagazine.com/2009/04/progressive-enhancement-what-it-is-and-how-to-use-it/
|
||||
[26]:https://github.com/webpack/webpack/issues/1545#issuecomment-255446425
|
||||
455
translated/tech/20161027 DTrace for Linux 2016.md
Normal file
455
translated/tech/20161027 DTrace for Linux 2016.md
Normal file
@ -0,0 +1,455 @@
|
||||
Linux 中的 DTrace
|
||||
===========
|
||||
|
||||

|
||||
|
||||
随着 BPF 追踪系统(基于时间采样)最后一个主要功能被合并至 Linux 4.9-rc1 版本的内核中,现在 Linux 内核拥有类似 DTrace 的原生追踪功能。DTrace 是 Solaris 系统中的高级追踪器。对于长期使用 DTrace 的用户和专家,这将是一个振奋人心的里程碑!在 Linux 系统上,现在你可以使用用安全的、低负载的定制追踪系统,通过执行时间的柱状图和频率统计等信息,分析应用的性能以及内核。
|
||||
|
||||
用于 Linux 的追踪工程有很多,但是最终被合并进 Linux 内核的技术从一开始就根本不是一个追踪项目:它是最开始是用于 Berkeley Packet Filter(BPF)的补丁。这些补丁允许 BPF 将软件包重定向,创建软件定义的网络。久而久之,支持追踪事件就被添加进来了,使得程序追踪可用于 Linux 系统。
|
||||
|
||||
尽管目前 BPF 没有像 DTrace 一样的高级语言,它所提供的前端已经足够让我创建很多 BPF 工具了,其中有些是基于我以前的 [DTraceToolkit][37]。这个帖子将告诉你怎么去用这些工具,BPF 提供的前端,以及畅谈这项技术将会何去何从。
|
||||
|
||||
### 截图
|
||||
|
||||
我已经将基于 BPF 的追踪工具添加到了开源的 [bcc][36] 项目里(感谢 PLUMgrid 公司的 Brenden Blanco 带领 bcc 项目的发展)。详见 [bcc 安装][35] 手册。它会在 /usr/share/bcc/tools 目录下添加一系列工具,包括接下来的那些工具。
|
||||
|
||||
捕获新进程:
|
||||
|
||||
```
|
||||
# **execsnoop**
|
||||
PCOMM PID RET ARGS
|
||||
bash 15887 0 /usr/bin/man ls
|
||||
preconv 15894 0 /usr/bin/preconv -e UTF-8
|
||||
man 15896 0 /usr/bin/tbl
|
||||
man 15897 0 /usr/bin/nroff -mandoc -rLL=169n -rLT=169n -Tutf8
|
||||
man 15898 0 /usr/bin/pager -s
|
||||
nroff 15900 0 /usr/bin/locale charmap
|
||||
nroff 15901 0 /usr/bin/groff -mtty-char -Tutf8 -mandoc -rLL=169n -rLT=169n
|
||||
groff 15902 0 /usr/bin/troff -mtty-char -mandoc -rLL=169n -rLT=169n -Tutf8
|
||||
groff 15903 0 /usr/bin/grotty
|
||||
|
||||
```
|
||||
|
||||
硬盘 I/O 延迟的柱状图:
|
||||
|
||||
```
|
||||
# **biolatency -m**
|
||||
Tracing block device I/O... Hit Ctrl-C to end.
|
||||
^C
|
||||
msecs : count distribution
|
||||
0 -> 1 : 96 |************************************ |
|
||||
2 -> 3 : 25 |********* |
|
||||
4 -> 7 : 29 |*********** |
|
||||
8 -> 15 : 62 |*********************** |
|
||||
16 -> 31 : 100 |**************************************|
|
||||
32 -> 63 : 62 |*********************** |
|
||||
64 -> 127 : 18 |****** |
|
||||
|
||||
```
|
||||
|
||||
追踪常见的 ext4 操作,稍慢于 5ms:
|
||||
|
||||
```
|
||||
# **ext4slower 5**
|
||||
Tracing ext4 operations slower than 5 ms
|
||||
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
21:49:45 supervise 3570 W 18 0 5.48 status.new
|
||||
21:49:48 supervise 12770 R 128 0 7.55 run
|
||||
21:49:48 run 12770 R 497 0 16.46 nsswitch.conf
|
||||
21:49:48 run 12770 R 1680 0 17.42 netflix_environment.sh
|
||||
21:49:48 run 12770 R 1079 0 9.53 service_functions.sh
|
||||
21:49:48 run 12772 R 128 0 17.74 svstat
|
||||
21:49:48 svstat 12772 R 18 0 8.67 status
|
||||
21:49:48 run 12774 R 128 0 15.76 stat
|
||||
21:49:48 run 12777 R 128 0 7.89 grep
|
||||
21:49:48 run 12776 R 128 0 8.25 ps
|
||||
21:49:48 run 12780 R 128 0 11.07 xargs
|
||||
21:49:48 ps 12776 R 832 0 12.02 libprocps.so.4.0.0
|
||||
21:49:48 run 12779 R 128 0 13.21 cut
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
追踪新建的 TCP 活跃连接(connect()):
|
||||
|
||||
```
|
||||
# **tcpconnect**
|
||||
PID COMM IP SADDR DADDR DPORT
|
||||
1479 telnet 4 127.0.0.1 127.0.0.1 23
|
||||
1469 curl 4 10.201.219.236 54.245.105.25 80
|
||||
1469 curl 4 10.201.219.236 54.67.101.145 80
|
||||
1991 telnet 6 ::1 ::1 23
|
||||
2015 ssh 6 fe80::2000:bff:fe82:3ac fe80::2000:bff:fe82:3ac 22
|
||||
|
||||
```
|
||||
|
||||
通过捕获 getaddrinfo()/gethostbyname() 库的调用来追踪 DNS 延迟:
|
||||
|
||||
```
|
||||
# **gethostlatency**
|
||||
TIME PID COMM LATms HOST
|
||||
06:10:24 28011 wget 90.00 www.iovisor.org
|
||||
06:10:28 28127 wget 0.00 www.iovisor.org
|
||||
06:10:41 28404 wget 9.00 www.netflix.com
|
||||
06:10:48 28544 curl 35.00 www.netflix.com.au
|
||||
06:11:10 29054 curl 31.00 www.plumgrid.com
|
||||
06:11:16 29195 curl 3.00 www.facebook.com
|
||||
06:11:25 29404 curl 72.00 foo
|
||||
06:11:28 29475 curl 1.00 foo
|
||||
|
||||
```
|
||||
|
||||
按类别划分 VFS 操作的时间间隔统计:
|
||||
|
||||
```
|
||||
# **vfsstat**
|
||||
TIME READ/s WRITE/s CREATE/s OPEN/s FSYNC/s
|
||||
18:35:32: 231 12 4 98 0
|
||||
18:35:33: 274 13 4 106 0
|
||||
18:35:34: 586 86 4 251 0
|
||||
18:35:35: 241 15 4 99 0
|
||||
|
||||
```
|
||||
|
||||
对一个给定的 PID,通过内核和用户堆栈轨迹来追踪 CPU 外的时间(由内核进行统计):
|
||||
|
||||
```
|
||||
# **offcputime -d -p 24347**
|
||||
Tracing off-CPU time (us) of PID 24347 by user + kernel stack... Hit Ctrl-C to end.
|
||||
^C
|
||||
[...]
|
||||
ffffffff810a9581 finish_task_switch
|
||||
ffffffff8185d385 schedule
|
||||
ffffffff81085672 do_wait
|
||||
ffffffff8108687b sys_wait4
|
||||
ffffffff81861bf6 entry_SYSCALL_64_fastpath
|
||||
--
|
||||
00007f6733a6b64a waitpid
|
||||
- bash (24347)
|
||||
4952
|
||||
|
||||
ffffffff810a9581 finish_task_switch
|
||||
ffffffff8185d385 schedule
|
||||
ffffffff81860c48 schedule_timeout
|
||||
ffffffff810c5672 wait_woken
|
||||
ffffffff8150715a n_tty_read
|
||||
ffffffff815010f2 tty_read
|
||||
ffffffff8122cd67 __vfs_read
|
||||
ffffffff8122df65 vfs_read
|
||||
ffffffff8122f465 sys_read
|
||||
ffffffff81861bf6 entry_SYSCALL_64_fastpath
|
||||
--
|
||||
00007f6733a969b0 read
|
||||
- bash (24347)
|
||||
1450908
|
||||
|
||||
```
|
||||
|
||||
追踪 MySQL 查询延迟(通过 USDT 探针):
|
||||
|
||||
```
|
||||
# **mysqld_qslower `pgrep -n mysqld`**
|
||||
Tracing MySQL server queries for PID 14371 slower than 1 ms...
|
||||
TIME(s) PID MS QUERY
|
||||
0.000000 18608 130.751 SELECT * FROM words WHERE word REGEXP '^bre.*n$'
|
||||
2.921535 18608 130.590 SELECT * FROM words WHERE word REGEXP '^alex.*$'
|
||||
4.603549 18608 24.164 SELECT COUNT(*) FROM words
|
||||
9.733847 18608 130.936 SELECT count(*) AS count FROM words WHERE word REGEXP '^bre.*n$'
|
||||
17.864776 18608 130.298 SELECT * FROM words WHERE word REGEXP '^bre.*n$' ORDER BY word
|
||||
|
||||
```
|
||||
|
||||
<!--Using the trace multi-tool to watch login requests, by instrumenting the pam library: -->
|
||||
检测 pam 库并使用多种追踪工具观察登陆请求:
|
||||
|
||||
```
|
||||
# **trace 'pam:pam_start "%s: %s", arg1, arg2'**
|
||||
TIME PID COMM FUNC -
|
||||
17:49:45 5558 sshd pam_start sshd: root
|
||||
17:49:47 5662 sudo pam_start sudo: root
|
||||
17:49:49 5727 login pam_start login: bgregg
|
||||
|
||||
```
|
||||
|
||||
bcc 项目里的很多工具都有帮助信息(-h 选项),并且都应该包含有示例的 man 页面和文本文件。
|
||||
|
||||
### 必要的
|
||||
|
||||
2014 年,Linux 追踪程序就有一些内核相关的特性(自 ftrace 和 pref_events),但是我们仍然要转储并报告进程数据,因为数十年的老技术会有很大规模的开销。你不能频繁地访问进程名,函数名,堆栈轨迹或内核中的其它任何数据。你不能在将变量保存到一个监测事件里,又在另一个事件里访问它们,这意味着你不能在自定义的地方计算延迟(或者说时间参数)。你也不能创建一个内核之内的延迟柱状图,也不能追踪 USDT 探针,甚至不能写自定义的程序。DTrace 可以做到这些,但仅限于 Solaris 或 BSD 系统。在 Linux 系统中,有些基于树的追踪器,像 SystemTap 就可以满足你的这些需求,但它也有自身的不足。(你可以写一个基于探针的内核模块来满足需求-但实际上没人这么做。)
|
||||
|
||||
2014 年我加入了 Netflix cloud performance 团队。做了这么久的 DTrace 方面的专家,转到 Linux 对我来说简直不可思议。但我确实这么做了,尤其是发现了严重的问题:Netflix cloud 会随着应用,微服务架构和分布式系统的快速变化,性能受到影响。有时要用到系统追踪,而我之前是用的 DTrace。在 Linux 系统上可没有 DTrace,我就开始用 Linux 内核内建的 ftrace 和 perf_events 工具,构建了一个追踪工具([perf-tools][34])。这些工具很有用,但有些工作还是没法完成,尤其是延迟柱状图图以及计算堆栈踪迹。我们需要的是内核追踪程序化。
|
||||
|
||||
### 发生了什么?
|
||||
|
||||
BPF 将程序化的功能添加到现有的内核追踪工具中(tracepoints, kprobes, uprobes)。在 Linux 4.x 系列的内核里,这些功能大大加强了。
|
||||
|
||||
时间采样是最主要的部分,它被 Linux 4.9-rc1 所采用([patchset][33])。十分感谢 Alexei Starovoitov(致力于 Facebook 中的 BPF 开发),改进 BPF 的主要开发者。
|
||||
|
||||
Linux 内核现在内建有以下这些特性(添加自 2.6 版本到 4.9 版本):
|
||||
|
||||
* 内核级的动态追踪(BPF 对 kprobes 的支持)
|
||||
* 用户级的动态追踪(BPF 对 uprobes 的支持)
|
||||
* 内核级的静态追踪(BPF 对 tracepoints 的支持)
|
||||
* 时间采样事件(BPF 的 pref_event_open)
|
||||
* PMC 事件(BPF 的 pref_event_open)
|
||||
* 过滤器(通过 BPF 程序)
|
||||
* 调试输出(bpf_trace_printk())
|
||||
* 事件输出(bpf_perf_event_output())
|
||||
* 基础变量(全局的和每个线程的变量,基于 BPF 映射)
|
||||
* 关联数组(通过 BPF 映射)
|
||||
* 频率计数(基于 BPF 映射)
|
||||
* 柱状图(power-of-2, 线性及自定义,基于 BPF 映射)
|
||||
* Timestamps and time deltas (bpf_ktime_get_ns(), and BPF programs)
|
||||
* 时间戳和时间参数(bpf_ktime_get_ns(),和 BPF 程序)
|
||||
* 内核态的堆栈轨迹(BPF stackmap 栈映射)
|
||||
* 用户态的堆栈轨迹 (BPF stackmap 栈映射)
|
||||
* 重写 ring 缓存(pref_event_attr.write_backward)
|
||||
|
||||
我们采用的前端是 bcc,它同时提供 Python 和 lua 接口。bcc 添加了:
|
||||
|
||||
* 用户级静态追踪(基于 uprobes 的 USDT 探针)
|
||||
* 调试输出(调用 BPF.trace_pipe() 和 BPF.trace_fields() 函数的 Python)
|
||||
* 所有事件输出(BPF_PERF_OUTPUT 宏和 BPF.open_perf_buffer())
|
||||
* 间隔输出(BPF.get_table() 和 table.clear())
|
||||
* 打印柱状图(table.print_log2_hist())
|
||||
* 内核级的 C 结构体导航(bcc 重写 bpf_probe_read() 函数的映射)
|
||||
* 内核级的符号解析(ksym(), ksymaddr())
|
||||
* 用户级的符号解析(usymaddr())
|
||||
* BPF tracepoint 支持(通过 TRACEPOINT_PROBE)
|
||||
* BPF 堆栈轨迹支持(包括针对堆栈框架的 walk 方法)
|
||||
* 其它各种助手宏和方法
|
||||
* 例子(位于 /examples 目录)
|
||||
* 工具(位于 /tools 目录)
|
||||
* 教程(/docs/tutorial*.md)
|
||||
* 参考手册(/docs/reference_guide.md)
|
||||
|
||||
直到最新也是最主要的特性被整合进来,我才开始写这篇文章,现在它在 4.9-rc1 内核中。我们还需要去完成一些次要的东西,还有另外一些事情要做,但是现在我们所拥有的已经值得欢呼了。现在 Linux 拥有内建的高级追踪能力。
|
||||
|
||||
### 安全性
|
||||
|
||||
设计 BPF 以及改进版时就考虑到产品安全,它被用在大范围的生产环境里。确信的话,你应该能找到一个挂起内核的方法。这个例子是偶然而不是必然,类似的漏洞会被快速修复,尤其是当 BPF 合并入了 Linux。因为 Linux 可是公众的焦点。
|
||||
|
||||
在开发过程中我们碰到了一些非 BPF 的漏洞,它们需要被修复:rcu 不可重入,这可能导致内核由于 funccount 挂起,在 4.6 内核版本中这个漏洞被 “bpf: map pre-alloc” 所修复,旧版本内核的漏洞暂时由 bcc 处理。还有一个是 uprobe 的内存计算问题,这导致 uprobe 分配内存失败,在 4.8 内核版本这个漏洞由 “uprobes: Fix the memcg accounting” 补丁所修复,并且该补丁还将被移植到之前版本的内核中(例如,它现在被移植到了 4.4.27 和 4.4.0-45.66 版本中)。
|
||||
|
||||
### 为什么 Linux 追踪很耗时?
|
||||
|
||||
首要任务被分到了若干追踪器中间:只有联合使用这些追踪器才能有作用。想要了解更多关于这个或其它方面的问题,可以看一看我在 2014 年写的 [tracing summit talk][32]。我忽视了计数器在部分方案中的效率:有些公司发现其它追踪器(SystemTap 和 LTTng)能满足他们的需求,尽管他们乐于听到 BPF 的开发进程,考虑到他们现有的解决方案,帮助 BPF 的开发就不那么重要了。
|
||||
|
||||
近两年里 BPF 仅在追踪领域得到加强。这一过程原本可以更快的,但早期缺少全职工作于 BPF 追踪的工程师。Alexei Starovoitov (BPF 领导者),Brenden Blanco (bcc 领导者),我还有其它一些开发者,都有其它的事情要做。我在 Netflix 公司花了大量时间(自由工作地),大概有 7% 的时间是花在 BPF 和 bcc 上。某种程度上这不是我的首要任务,因为我还有自己的工作(包括我的 perf-tools,一个工作在旧版本内核上的程序)。
|
||||
|
||||
BPF 追踪已经推出了,已经有科技公司开始关注 BPF 的特点了。但我还是推荐 [Netflix 公司][31]。(如果你为了 BPF 而要聘请我,那我还是十分乐于待在 Netflix 公司的!)
|
||||
|
||||
### 使用简单
|
||||
|
||||
DTrace 和 bcc/BPF 现在的最大区别就是哪个更好使用。这取决于你要用 BPF 追踪做什么了。如果你要
|
||||
|
||||
* **使用 BPF tools/metrics**:应该是没什么区别的。工具的表现都差不多,图形用户界面的访问也类似。大部分用户通过这种方式使用 BPF。
|
||||
* **开发 tools/metrics**:bcc 的开发可难多了。DTrace 有一套自己的简单语言,D 语音,和 awk 语言相似,而 bcc 使用已有的带有库的语言(C 语言,Python 和 lua)。一个用 C 和 Python 写的 bcc 工具与仅仅用 D 语言写出来的工具相比,可能要多十多倍行数的代码,或者更多。但是很多 DTrace 工具用 shell 包装来提供参数和差错,会让代码变得十分臃肿。编程的难处是不同的:重写 bcc 更需要巧妙性,这导致某些脚本更加难开发。(尤其是 bpf_probe_read() 这类的函数,需要了解更多 BPF 的内涵知识)。当计划改进 bcc 时,这一情形将得到改善。
|
||||
* **运行常见的命令**:十分相近。用 “dtrace” 命令,DTrace 能做很多事,但 bcc 有各种工具,trace,argdist,funccount,funclatency 等等。
|
||||
* **编写自定义的特殊命令**:使用 DTrace 的话,这就没有必要了。允许定制消息快速传递和系统快速响应,DTrace 的高级分析很快。而 bcc 现在受限于它的多种工具以及它们的适用范围。
|
||||
|
||||
简单来说,如果你只使用 BPF 工具的话,就不必关注这些差异了。如果你经验丰富,是个开发者(像我一样),目前 bcc 的使用是比较困难的。
|
||||
|
||||
举一个 bcc 的 Python 前端的例子,下面是追踪硬盘 I/O 和 打印 I/O 容量柱状图的代码:
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
from time import sleep
|
||||
|
||||
# load BPF program
|
||||
b = BPF(text="""
|
||||
#include <uapi/linux/ptrace.h>
|
||||
#include <linux/blkdev.h>
|
||||
|
||||
BPF_HISTOGRAM(dist);
|
||||
|
||||
int kprobe__blk_account_io_completion(struct pt_regs *ctx, struct request *req)
|
||||
{
|
||||
dist.increment(bpf_log2l(req->__data_len / 1024));
|
||||
return 0;
|
||||
}
|
||||
""")
|
||||
|
||||
# header
|
||||
print("Tracing... Hit Ctrl-C to end.")
|
||||
|
||||
# trace until Ctrl-C
|
||||
try:
|
||||
sleep(99999999)
|
||||
except KeyboardInterrupt:
|
||||
print
|
||||
|
||||
# output
|
||||
b["dist"].print_log2_hist("kbytes")
|
||||
|
||||
```
|
||||
|
||||
注意 Python 代码中嵌入的 C 语句(text=)。
|
||||
|
||||
这就完成了任务,但仍有改进的空间。好在我们有时间去做:人们使用 Linux 4.9 并能用上 BPF 还得好几个月呢,所以我们有时间来制造工具和前端。
|
||||
|
||||
### 高级语言
|
||||
|
||||
前端越简单,比如高级语言,所改进的可能就越不如你所期望的。绝大多数人使用封装好的工具(和 GUI),仅有少部分人能写出这些工具。但我不反对使用高级语言,比如 SystemTap,毕竟已经开发出来了。
|
||||
|
||||
```
|
||||
#!/usr/bin/stap
|
||||
/*
|
||||
* opensnoop.stp Trace file open()s. Basic version of opensnoop.
|
||||
*/
|
||||
|
||||
probe begin
|
||||
{
|
||||
printf("\n%6s %6s %16s %s\n", "UID", "PID", "COMM", "PATH");
|
||||
}
|
||||
|
||||
probe syscall.open
|
||||
{
|
||||
printf("%6d %6d %16s %s\n", uid(), pid(), execname(), filename);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
如果拥有整合了语言和脚本的 SystemTap 前端与高性能内核内建的 BPF 后端,会不会令人满意呢?RedHat 公司的 Richard Henderson 已经在进行相关工作了,并且发布了 [初代版本][30]!
|
||||
|
||||
这是 [ply][29],一个完全新颖的 BPF 高级语言:
|
||||
|
||||
```
|
||||
#!/usr/bin/env ply
|
||||
|
||||
kprobe:SyS_*
|
||||
{
|
||||
$syscalls[func].count()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这也是一份承诺。
|
||||
|
||||
尽管如此,我认为工具开发者的实际难题不是使用什么语言:而是要了解要用这些强大的工具做什么?
|
||||
|
||||
### 如何帮助我们
|
||||
|
||||
* **推广**:BPF 追踪目前还没有什么市场方面的进展。尽管有公司了解并在使用它(Facebook,Netflix,Github 和其它公司),但要广为人知尚需时日。分享关于 BPF 产业的文章和资源来帮助我们。
|
||||
* **教育**:你可以撰写文章,发表演讲,甚至参与 bcc 文档的编写。分享 BPF 如何解决实际问题以及为公司带来收益的实例。
|
||||
* **解决 bcc 的问题**:参考 [bcc issue list][19],这包含了错误和需要的特性。
|
||||
* **提交错误**:使用 bcc/BPF,提交你发现的错误。
|
||||
* **创造工具**:有很多可视化的工具需要开发,请不要太草率,因为大家会先花几个小时学习使用你做的工具,所以请尽量把工具做的直观好用(参考我的 [文档][18])。就像 Mike Muuss 提及到他自己的 [ping][17] 程序:“要是我早知道这是我一生中最出名的成就,我就多开发一两天,添加更多选项。”
|
||||
* **高级语言**:如果现有的 bcc 前端语言让你很困扰,或者你能弄门更好的语言。要是你想将这门语言内建到 bcc 里面,你需要使用 libbcc。或者你可以帮助进行 SystemTap BPF 或 ply 的工作。
|
||||
* **整合图形界面**:除了 bcc 可以使用的 CLI 命令行工具,怎么让这些信息可视呢?延迟关系,火焰图等等。
|
||||
|
||||
### 其它追踪器
|
||||
|
||||
那么 SystemTap,ktap,sysdig,LTTng 等追踪器怎么样呢?它们有个共同点,要么使用了 BPF,要么在自己的领域做得更好。会有单独的文章介绍它们自己。
|
||||
|
||||
至于 DTrace ?我们公司目前还在基于 FreeBSD 系统的 CDN 中使用它。
|
||||
|
||||
### 更多 bcc/BPF 的信息
|
||||
|
||||
我已经写了一篇 [bcc/BPF Tool End-User Tutorial][28],一篇 [bcc Python Developer's Tutorial][27],一篇 [bcc/BPF Reference Guide][26],和已经写好的有用的 [/tools][25],每一个工具都有一个 [example.txt][24] 文件和 [man page][23]。我之前写过的关于 bcc 和 BPF 的文章有:
|
||||
|
||||
* [eBPF: One Small Step][16] (以后就叫做 BPF)
|
||||
* [bcc: Taming Linux 4.3+ Tracing Superpowers][15]
|
||||
* [Linux eBPF Stack Trace Hack][14] (现在官方支持追踪堆栈了)
|
||||
* [Linux eBPF Off-CPU Flame Graph][13] (" " ")
|
||||
* [Linux Wakeup and Off-Wake Profiling][12] (" " ")
|
||||
* [Linux Chain Graph Prototype][11] (" " ")
|
||||
* [Linux eBPF/bcc uprobes][10]
|
||||
* [Linux BPF Superpowers][9]
|
||||
* [Ubuntu Xenial bcc/BPF][8]
|
||||
* [Linux bcc Tracing Security Capabilities][7]
|
||||
* [Linux MySQL Slow Query Tracing with bcc/BPF][6]
|
||||
* [Linux bcc ext4 Latency Tracing][5]
|
||||
* [Linux bcc/BPF Run Queue (Scheduler) Latency][4]
|
||||
* [Linux bcc/BPF Node.js USDT Tracing][3]
|
||||
* [Linux bcc tcptop][2]
|
||||
* [Linux 4.9's Efficient BPF-based Profiler][1]
|
||||
|
||||
我在 Facebook 的 Performance@Scale [Linux BPF Superpowers][22] 大会上发表过一次演讲。十二月份,我将在 Boston 发表关于 BPF/bcc 在 [USENIX LISA][21] 方面的演讲和教程。
|
||||
|
||||
### 致谢
|
||||
|
||||
* Van Jacobson and Steve McCanne,他是最早将 BPF 应用到包过滤的。
|
||||
* Barton P. Miller,Jeffrey K. Hollingsworth,and Jon Cargille,发明了动态追踪,并发表文章《Dynamic Program Instrumentation for Scalable Performance Tools》,可扩展高性能计算协议 (SHPCC),于田纳西州诺克斯维尔市,1994 年 5 月发表。
|
||||
* kerninst (ParaDyn, UW-Madison), an early dynamic tracing tool that showed the value of dynamic tracing (late 1990's).(早期的能够显示动态追踪数值的动态追踪工具,稍晚于 1990 年)
|
||||
* Mathieu Desnoyers (of LTTng),内核的主要开发者,主导 tracepoints 项目。
|
||||
* IBM 开发的作为 DProbes 一部分的 kprobes,DProbes 在 2000 年时曾与 LTT 一起提供 Linux 动态追踪,但没有整合到一起。
|
||||
* Bryan Cantrill, Mike Shapiro, and Adam Leventhal (Sun Microsystems),DTrace 的核心成员,DTrace 是一款很棒的动态追踪工具,安全而且简单(2004 年)。考虑到动态追踪的技术,DTrace 是科技的重要转折点:它很安全,默认安装在 Solaris 以及其它以可靠性著称的系统里。
|
||||
* 来自 Sun Microsystems 的各部门的许多员工,促进了 DTrace,为我们带来了高级系统追踪的意识。
|
||||
* Roland McGrath (at Red Hat),utrace 项目的主要开发者,utrace 变成了后来的 uprobes。
|
||||
* Alexei Starovoitov (PLUMgrid, then Facebook), 加强版 BPF(可编程内核容器)的主要开发者。
|
||||
* 那些帮助反馈,提交代码、测试以及针对增强版 BPF 补丁(搜索 BPF 的 lkml)的 Linux 内核工程师: Wang Nan, Daniel Borkmann, David S. Miller, Peter Zijlstra, 以及其它很多人。
|
||||
* Brenden Blanco (PLUMgrid),bcc 的主要开发者。
|
||||
* Sasha Goldshtein (Sela) 开发了 bcc 中可用的 tracepoint,和功能最强大的 bcc 工具 trace 及 argdist,帮助 USDT 项目的开发。
|
||||
* Vicent Martí 和其它 Github 上的工程师,为 bcc 编写了基于 lua 的前端,帮助 USDT 部分项目的开发。
|
||||
* Allan McAleavy, Mark Drayton,和其他的改进 bcc 的贡献者。
|
||||
|
||||
感觉 Netflix 提供环的境和支持,让我能够编写 BPF 和 bcc tracing 并完成它们。开发追踪工具(使用 TNF/prex, DTrace, SystemTap, ktap, ftrace, perf, and now bcc/BPF)和写书、博客以及评论,我已经编写了多年的追踪工具。
|
||||
|
||||
最后,感谢 [Deirdré][20] 编辑了另外一篇文章。
|
||||
|
||||
### 总结
|
||||
|
||||
Linux 没有 DTrace(语言),但它现在有了,或者说拥有了 DTraceTookit(工具)。
|
||||
|
||||
通过内核构建的 BPF 引擎补丁,Linux 4.9 内核有用来支持现代化追踪的最后一项功能。内核支持这一最难的部分已经做完了。今后的任务包括更多的命令行执行工具,可选的高级语言和图形用户界面。
|
||||
|
||||
对于性能分析产品的客户,这也是一件好事:你能查看延迟柱状图和热点图,CPU 运行和休眠的火焰图,拥有更好的时延断点和更低耗的工具。我们现在用的追踪和处理程序是没有效率的方式。
|
||||
|
||||
那么你什么时候会升级到 Linux 4.9 呢?一旦官方发布,新的性能测试工具就来了:`apt-get install bcc-tools` 。
|
||||
|
||||
开始享受它吧!
|
||||
|
||||
Brendan
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2016-10-27/dtrace-for-linux-2016.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com/
|
||||
[1]:http://www.brendangregg.com/blog/2016-10-21/linux-efficient-profiler.html
|
||||
[2]:http://www.brendangregg.com/blog/2016-10-15/linux-bcc-tcptop.html
|
||||
[3]:http://www.brendangregg.com/blog/2016-10-12/linux-bcc-nodejs-usdt.html
|
||||
[4]:http://www.brendangregg.com/blog/2016-10-08/linux-bcc-runqlat.html
|
||||
[5]:http://www.brendangregg.com/blog/2016-10-06/linux-bcc-ext4dist-ext4slower.html
|
||||
[6]:http://www.brendangregg.com/blog/2016-10-04/linux-bcc-mysqld-qslower.html
|
||||
[7]:http://www.brendangregg.com/blog/2016-10-01/linux-bcc-security-capabilities.html
|
||||
[8]:http://www.brendangregg.com/blog/2016-06-14/ubuntu-xenial-bcc-bpf.html
|
||||
[9]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[10]:http://www.brendangregg.com/blog/2016-02-08/linux-ebpf-bcc-uprobes.html
|
||||
[11]:http://www.brendangregg.com/blog/2016-02-05/ebpf-chaingraph-prototype.html
|
||||
[12]:http://www.brendangregg.com/blog/2016-02-01/linux-wakeup-offwake-profiling.html
|
||||
[13]:http://www.brendangregg.com/blog/2016-01-20/ebpf-offcpu-flame-graph.html
|
||||
[14]:http://www.brendangregg.com/blog/2016-01-18/ebpf-stack-trace-hack.html
|
||||
[15]:http://www.brendangregg.com/blog/2015-09-22/bcc-linux-4.3-tracing.html
|
||||
[16]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[17]:http://ftp.arl.army.mil/~mike/ping.html
|
||||
[18]:https://github.com/iovisor/bcc/blob/master/CONTRIBUTING-SCRIPTS.md
|
||||
[19]:https://github.com/iovisor/bcc/issues
|
||||
[20]:http://www.brendangregg.com/blog/2016-07-23/deirdre.html
|
||||
[21]:https://www.usenix.org/conference/lisa16
|
||||
[22]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[23]:https://github.com/iovisor/bcc/tree/master/man/man8
|
||||
[24]:https://github.com/iovisor/bcc/tree/master/tools
|
||||
[25]:https://github.com/iovisor/bcc/tree/master/tools
|
||||
[26]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[27]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[28]:https://github.com/iovisor/bcc/blob/master/docs/tutorial.md
|
||||
[29]:https://wkz.github.io/ply/
|
||||
[30]:https://lkml.org/lkml/2016/6/14/749
|
||||
[31]:http://www.brendangregg.com/blog/2016-03-30/working-at-netflix-2016.html
|
||||
[32]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux
|
||||
[33]:https://lkml.org/lkml/2016/9/1/831
|
||||
[34]:https://github.com/brendangregg/perf-tools
|
||||
[35]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[36]:https://github.com/iovisor/bcc
|
||||
[37]:https://github.com/opendtrace/toolkit
|
||||
[38]:https://raw.githubusercontent.com/brendangregg/bcc/master/images/bcc_tracing_tools_2016.png
|
||||
@ -0,0 +1,108 @@
|
||||
在Linux系统下提取和复制ISO镜像文件的3种方法
|
||||
============================================================
|
||||
|
||||
假设你的Linux服务器上有一个超大的ISO镜像文件,你想要打开它,然后提取或者复制其中的一个文件。你会怎么做呢?
|
||||
其实在Linux系统里,有很多方法来实现这个要求。
|
||||
|
||||
比如说,你可以使用传统的mount命令以只读方式把ISO镜像文件加载为loop设备,然后再把文件复制到另一个目录。
|
||||
|
||||
### 在Linux系统下提取ISO镜像文件
|
||||
|
||||
为了完成该测试,你得有一个ISO镜像文件(我使用ubuntu-16.10-server-amd64.iso系统镜像文件)以及用于挂载和提取ISO镜像文件的目录。
|
||||
|
||||
首先,使用如下命令创建一个挂载目录来挂载ISO镜像文件:
|
||||
|
||||
```
|
||||
$ sudo mkdir /mnt/iso
|
||||
```
|
||||
|
||||
目录创建完成后,你就可以运行如下命令很容易地挂载ubuntu-16.10-server-amd64.iso系统镜像文件并查看其中的内容。
|
||||
|
||||
```
|
||||
$ sudo mount -o loop ubuntu-16.10-server-amd64.iso /mnt/iso
|
||||
$ ls /mnt/iso/
|
||||
```
|
||||
[
|
||||
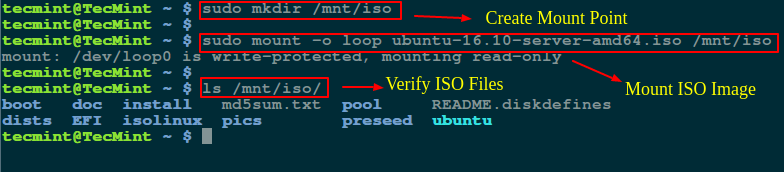
|
||||
][1]
|
||||
|
||||
在Linux系统里技巧ISO镜像
|
||||
|
||||
Now you can go inside the mounted directory (/mnt/iso) and access the files or copy the files to `/tmp`directory using [cp command][2].
|
||||
现在你就可以进入到挂载目录/mnt/iso里,查看文件或者使用cp命令把文件复制到/tmp目录了。
|
||||
|
||||
```
|
||||
$ cd /mnt/iso
|
||||
$ sudo cp md5sum.txt /tmp/
|
||||
$ sudo cp -r ubuntu /tmp/
|
||||
```
|
||||
[
|
||||
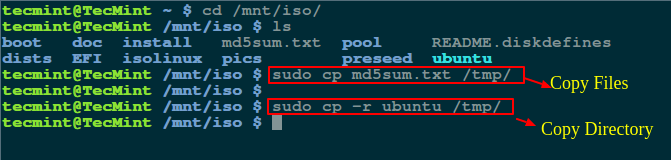
|
||||
][3]
|
||||
|
||||
|
||||
在Linux系统中复制ISO镜像里的文件
|
||||
|
||||
注意:-r选项用于递归复制目录里的内容。如有必要,你也可以监控复制命令的完成进度。
|
||||
|
||||
### 使用7zip命令提取ISO镜像里的内容
|
||||
|
||||
如果不想挂载ISO镜像,你可以简单地安装一个7zip工具,这是一个免费而且开源的解压缩软件,用于压缩或解压不同类型格式的文件,包括TAR,XZ,GZIP,ZIP,BZIP2等等。
|
||||
|
||||
```
|
||||
$ sudo apt-get install p7zip-full p7zip-rar [On Debian/Ubuntu systems]
|
||||
$ sudo yum install p7zip p7zip-plugins [On CentOS/RHEL systems]
|
||||
```
|
||||
|
||||
7zip软件安装完成后,你就可以使用7z命令提取ISO镜像文件里的内容了。
|
||||
|
||||
```
|
||||
$ 7z x ubuntu-16.10-server-amd64.iso
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
使用7zip工具在Linux系统下提取ISO镜像里的文件
|
||||
|
||||
注意:跟Linux的mount命令相比起来,7zip在压缩和解压缩任何格式的文件时速度更快,更智能。
|
||||
|
||||
### 使用isoinfo命令来提取ISO镜像文件内容
|
||||
|
||||
虽然isoinfo命令是用来以目录的形式列出iso9660镜像文件的内容,但是你也可以使用程序来提取文件。
|
||||
|
||||
我说过,isoinfo程序会显示目录列表,因此先列出ISO镜像文件的内容。
|
||||
|
||||
```
|
||||
$ isoinfo -i ubuntu-16.10-server-amd64.iso -l
|
||||
```
|
||||
[
|
||||
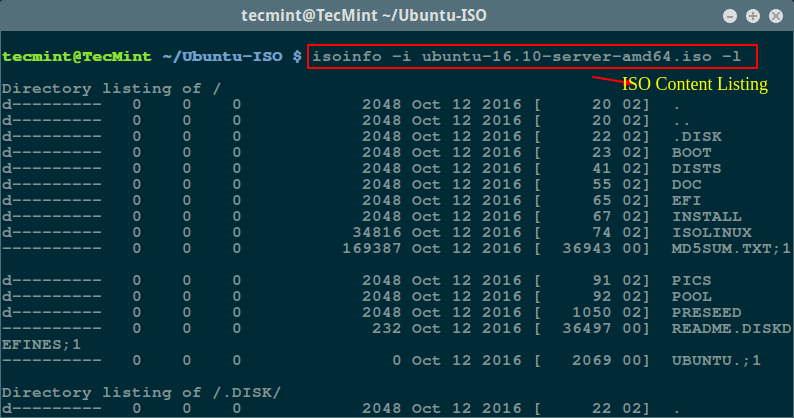
|
||||
][6]
|
||||
|
||||
Linux里列出ISO文件的内容
|
||||
|
||||
现在你可以按如下的方式从ISO镜像文件中提取单文件:
|
||||
|
||||
```
|
||||
$ isoinfo -i ubuntu-16.10-server-amd64.iso -x MD5SUM.TXT > MD5SUM.TXT
|
||||
```
|
||||
|
||||
注意:必须使用重定向参数 -x 来提取指定文件
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
从ISO镜像文件中提取单文件
|
||||
|
||||
就到这里吧,其实还有很多种方法来实现这个要求,如果你还知道其它有用的命令或工具来提取复制出ISO镜像文件中的文件,请在下面的评论中跟大家分享下。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/extract-files-from-iso-files-linux
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,88 +0,0 @@
|
||||
Ubuntu 14.04/16.04 与Windows 10周年版ubuntu Bash性能对比
|
||||
===========================
|
||||
|
||||
今年初,当Microsoft和Canonical发布[Windows 10 Bash 和Ubuntu用户空间][1],我尝试做了一些初步性能测试 [Ubuntu on Windows 10 对比 原生Ubuntu][2],这次我发布更多的,关于原生纯净Ubuntu和Base on Windows 10的基准对比。
|
||||
|
||||

|
||||
|
||||
Windows的Linux子系统测试在上周刚刚完成所有测试,并放出升级。 默认的Ubuntu用户空间还是Ubuntu 14.04,但是已经可以升级到16.04。所以测试首先在14.04测试,完成后将系统升级升级到16.04版本并重复所有测试。完成所有基于Windows的测试后,我删除了Ubuntu14.04.5和Ubuntu 16.04 LTS来对比查看性能
|
||||
|
||||
|
||||

|
||||
|
||||
配置为Intel i5 6600K Skylake框架, 16G内存和256东芝ssd, 所有测试都采用原生默认配置。
|
||||
|
||||
|
||||

|
||||
>点击放大查看
|
||||
|
||||
|
||||
这次Ubuntu/Bash on Windows和原生Ubuntu对比测试,采用开源软件Phoronix测试套件,完全自动化并可重复测试。
|
||||
|
||||

|
||||
|
||||
First up was the SQLite embedded database benchmark. The out-of-the-box Ubuntu/Bash on Windows performance was quite slow, but when switching that 14.04 environment to 16.04 LTS, the performance was much faster. However, for this disk-heavy workload the native Ubuntu Linux installations were almost twice as fast as relying upon the Windows Subsystem for Linux.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
The CompileBench test profile as additional disk-focused workloads show that this is the particular subsystem really straining the Ubuntu performance atop Windows 10 with it being up to multiple times slower.
|
||||
|
||||
Next up were some basic system memory speed tests with Stream.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Strangely, the Stream memory benchmarks show better performance with Ubuntu on Windows than Ubuntu itself! This happened on both the 14.04 and 16.04 based environments that the Windows results came out faster.
|
||||
|
||||
Next are more of the CPU-heavy tests,
|
||||
|
||||

|
||||
|
||||
With the Dolfyn scientific test, the performance between Ubuntu on Windows and Ubuntu installed bare metal was actually quite close. With Ubuntu 16.04 the performance is slower on both platforms due to the newer GCC compiler regressing the performance.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Fhourstones and John The Ripper show that the performance of Ubuntu running on Windows via the Windows Subsystem for Linux can be incredibly close to the bare metal Ubuntu Linux performance!
|
||||
|
||||

|
||||
|
||||
The x264 results were another strange case similar to Stream where the best performance was actually with Ubuntu on Windows 10 via WSL!
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
The timed compilation benchmarks were heavily in favor of the bare metal Ubuntu Linux installations outside of Windows. This is likely due to these large program compilations requiring plenty of disk reads and from the earlier disk-focused benchmarks showing that is the big area where the Windows Subsystem for Linux is slow.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Many of our other common open-source benchmarks show that for the strictly CPU-focused tests, the Windows Subsystem for Linux is close -- or even matches -- the native Ubuntu Linux performance running on the actual hardware.
|
||||
|
||||
These latest Windows Subsystem for Linux results are actually rather impressive. The big letdown is just the continued slow disk/file-system performance, but for CPU-bound workloads the results are very compelling. There's also the rare cases with x264 and Stream where the performance of the Ubuntu user-space on Windows appears to clearly outperform that of Ubuntu Linux running on the hardware by itself.
|
||||
|
||||
Overall the experience was actually quite pleasant and haven't run into any other bugs or annoyances while running with Ubuntu/Bash on Windows. If you're interested in more Windows vs. Linux benchmarks, please consider voicing yourself as a Phoronix Premium subscriber.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=article&item=windows10-anv-wsl&num=1
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.michaellarabel.com/
|
||||
[1]: http://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-User-Space-On-Win10
|
||||
[2]: http://www.phoronix.com/scan.php?page=article&item=windows-10-lxcore&num=1
|
||||
|
||||
Loading…
Reference in New Issue
Block a user