mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
981edb5ef7
@ -1,4 +0,0 @@
|
||||
# Linux中国翻译规范
|
||||
1. 翻译中出现的专有名词,可参见Dict.md中的翻译。
|
||||
2. 英文人名,如无中文对应译名,一般不译。
|
||||
2. 缩写词,一般不须翻译,可考虑旁注中文全名。
|
||||
110
README.md
110
README.md
@ -1,8 +1,8 @@
|
||||
|
||||

|
||||

|
||||

|
||||

|
||||
[](https://lctt.github.io/new)
|
||||
[](https://lctt.github.io/translating)
|
||||
[](https://github.com/LCTT/TranslateProject/tree/master/translated)
|
||||
[](https://github.com/LCTT/TranslateProject/tree/master/published)
|
||||
|
||||
[](https://travis-ci.com/LCTT/TranslateProject)
|
||||
[](https://github.com/LCTT/TranslateProject/graphs/contributors)
|
||||
@ -11,34 +11,30 @@
|
||||
简介
|
||||
-------------------------------
|
||||
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux 中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
|
||||
LCTT 已经拥有几百名活跃成员,并欢迎更多的 Linux 志愿者加入我们的团队。
|
||||
|
||||

|
||||

|
||||
|
||||
LCTT 的组成
|
||||
-------------------------------
|
||||
|
||||
**选题**,负责选择合适的内容,并将原文转换为 markdown 格式,提交到 LCTT 的 [TranslateProject](https://github.com/LCTT/TranslateProject) 库中。
|
||||
|
||||
**译者**,负责从选题中选择内容进行翻译。
|
||||
|
||||
**校对**,负责将初译的文章进行文字润色、技术校对等工作。
|
||||
|
||||
**发布**,负责将校对后的文章,排版进行发布。
|
||||
- LCTT 官网: [https://linux.cn/lctt/](https://linux.cn/lctt/)
|
||||
- LCTT 状态: [https://lctt.github.io/](https://lctt.github.io/)
|
||||
|
||||
加入我们
|
||||
-------------------------------
|
||||
|
||||
请首先加入翻译组的 QQ 群,群号是:198889102,加群时请说明是“志愿者”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
请首先加入翻译组的 QQ 群,群号是:**198889102**,加群时请说明是“*志愿者*”。
|
||||
|
||||
加入的成员,请先阅读 [WIKI 如何开始](https://github.com/LCTT/TranslateProject/wiki/01-如何开始)。
|
||||
加入的成员,请:
|
||||
|
||||
1. 修改你的 QQ 群名片为“译者-您的_GitHub_ID”。
|
||||
2. 阅读 [WIKI](http://lctt.github.io/wiki) 了解如何开始。
|
||||
3. 遇到不解之处,请在群内发问。
|
||||
|
||||
如何开始
|
||||
-------------------------------
|
||||
|
||||
请阅读 [WIKI](https://github.com/LCTT/TranslateProject/wiki)。
|
||||
请阅读 [WIKI](http://lctt.github.io/wiki)。如需要协助,请在群内发问。
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
@ -79,44 +75,52 @@ LCTT 的组成
|
||||
* 2018/08/17 提升 pityonline 为核心成员,担任校对,并接受他的建议采用 PR 审核模式。
|
||||
* 2018/09/10 [LCTT 五周年](https://linux.cn/article-9999-1.html)。
|
||||
* 2018/10/25 重构了 CI,感谢 vizv、lujun9972、bestony。
|
||||
* 2018/11/13 [成立了项目管理委员会(PMC)](https://linux.cn/article-10279-1.html),初始成员为:@wxy (主席)、@oska874、@lujun9972、@bestony、@pityonline、@geekpi、@qhwdw。
|
||||
|
||||
核心成员
|
||||
|
||||
项目管理委员及核心成员
|
||||
-------------------------------
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
LCTT 现由项目管理委员会(PMC)进行管理,成员如下:
|
||||
|
||||
- 组长 @wxy,
|
||||
- 选题 @oska874,
|
||||
- 选题 @lujun9972,
|
||||
- 技术 @bestony,
|
||||
- 校对 @jasminepeng,
|
||||
- 校对 @pityonline,
|
||||
- 钻石译者 @geekpi,
|
||||
- 钻石译者 @qhwdw,
|
||||
- 钻石译者 @GOLinux,
|
||||
- 核心成员 @GHLandy,
|
||||
- 核心成员 @martin2011qi,
|
||||
- 核心成员 @ictlyh,
|
||||
- 核心成员 @strugglingyouth,
|
||||
- 核心成员 @FSSlc,
|
||||
- 核心成员 @zpl1025,
|
||||
- 核心成员 @runningwater,
|
||||
- 核心成员 @bazz2,
|
||||
- 核心成员 @Vic020,
|
||||
- 核心成员 @alim0x,
|
||||
- 核心成员 @tinyeyeser,
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @MjSeven
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
- 前任校对 @carolinewuyan,
|
||||
- 功勋成员 @vito-L,
|
||||
- 功勋成员 @willqian,
|
||||
- 功勋成员 @vizv,
|
||||
- 功勋成员 @dongfengweixiao,
|
||||
- 🎩 主席 @wxy
|
||||
- 🎩 选题 @oska874
|
||||
- 🎩 选题 @lujun9972
|
||||
- 🎩 技术 @bestony
|
||||
- 🎩 校对 @pityonline
|
||||
- 🎩 译者 @geekpi
|
||||
- 🎩 译者 @qhwdw
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
|
||||
- ❤️ 核心成员 @vizv
|
||||
- ❤️ 核心成员 @zpl1025
|
||||
- ❤️ 核心成员 @runningwater
|
||||
- ❤️ 核心成员 @FSSlc
|
||||
- ❤️ 核心成员 @Vic020
|
||||
- ❤️ 核心成员 @alim0x
|
||||
- ❤️ 核心成员 @martin2011qi
|
||||
- ❤️ 核心成员 @Locez
|
||||
- ❤️ 核心成员 @ucasFL
|
||||
- ❤️ 核心成员 @MjSeven
|
||||
|
||||
曾经做出了巨大贡献的核心成员,被列入荣誉榜:
|
||||
|
||||
- 🏆 前任选题 @DeadFire
|
||||
- 🏆 前任校对 @reinoir222
|
||||
- 🏆 前任校对 @PurlingNayuki
|
||||
- 🏆 前任校对 @carolinewuyan
|
||||
- 🏆 前任校对 @jasminepeng
|
||||
- 🏆 功勋成员 @tinyeyeser
|
||||
- 🏆 功勋成员 @vito-L
|
||||
- 🏆 功勋成员 @willqian
|
||||
- 🏆 功勋成员 @GOLinux
|
||||
- 🏆 功勋成员 @bazz2
|
||||
- 🏆 功勋成员 @ictlyh
|
||||
- 🏆 功勋成员 @dongfengweixiao
|
||||
- 🏆 功勋成员 @strugglingyouth
|
||||
- 🏆 功勋成员 @GHLandy
|
||||
- 🏆 功勋成员 @rusking
|
||||
|
||||
全部成员列表请参见: https://linux.cn/lctt-list/ 。
|
||||
|
||||
|
||||
@ -0,0 +1,154 @@
|
||||
用 PGP 保护代码完整性(四):将主密钥移到离线存储中
|
||||
======
|
||||
> 如果开发者的 PGP 密钥被偷了,危害非常大。了解一下如何更安全。
|
||||
|
||||

|
||||
|
||||
在本系列教程中,我们为使用 PGP 提供了一个实用指南。你可以从下面的链接中查看前面的文章:
|
||||
|
||||
- [第一部分:基本概念和工具][1]
|
||||
- [第二部分:生成你的主密钥][2]
|
||||
- [第三部分:生成 PGP 子密钥][3]
|
||||
|
||||
这是本系列教程的第四部分,我们继续本教程,我们将谈一谈如何及为什么要将主密钥从你的家目录移到离线存储中。现在开始我们的教程。
|
||||
|
||||
#### 清单
|
||||
|
||||
* 准备一个加密的可移除的存储(必要)
|
||||
* 备份你的 GnuPG 目录(必要)
|
||||
* 从你的家目录中删除主密钥(推荐)
|
||||
* 从你的家目录中删除吊销证书(推荐)
|
||||
|
||||
#### 考虑事项
|
||||
|
||||
为什么要从你的家目录中删除你的主 [C] 密钥 ?这样做的主要原因是防止你的主密钥失窃或意外泄露。对于心怀不轨的人来说,私钥对他们具有很大的诱惑力 —— 我们知道有几个恶意软件成功地实现了扫描用户的家目录并将发现的私钥内容上传。
|
||||
|
||||
对于开发者来说,私钥失窃是非常危险的事情 —— 在自由软件的世界中,这无疑是身份证明失窃。从你的家目录中删除私钥将帮你防范这类事件的发生。
|
||||
|
||||
#### 备份你的 GnuPG 目录
|
||||
|
||||
**!!!绝对不要跳过这一步!!!**
|
||||
|
||||
备份你的 PGP 密钥将让你在需要的时候很容易地恢复它们,这很重要!(这与我们做的使用 paperkey 的灾难级备份是不一样的)。
|
||||
|
||||
#### 准备可移除的加密存储
|
||||
|
||||
我们从取得一个(最好是两个)小型的 USB “拇指“ 驱动器(可加密 U 盘)开始,我们将用它来做备份。你首先需要去加密它们:
|
||||
|
||||
加密密码可以使用与主密钥相同的密码。
|
||||
|
||||
#### 备份你的 GnuPG 目录
|
||||
|
||||
加密过程结束之后,重新插入 USB 驱动器并确保它能够正常挂载。你可以通过运行 `mount` 命令去找到设备挂载点的完全路径。(在 Linux 下,外置介质一般挂载在 `/media/disk` 下,Mac 一般在它的 `/Volumes` 下)
|
||||
|
||||
你知道了挂载点的全路径后,将你的整个 GnuPG 的目录复制进去:
|
||||
|
||||
```
|
||||
$ cp -rp ~/.gnupg [/media/disk/name]/gnupg-backup
|
||||
```
|
||||
|
||||
(注意:如果出现任何套接字不支持的错误,没有关系,直接忽略它们。)
|
||||
|
||||
现在,用如下的命令去测试一下,确保它们能够正常地工作:
|
||||
|
||||
```
|
||||
$ gpg --homedir=[/media/disk/name]/gnupg-backup --list-key [fpr]
|
||||
```
|
||||
|
||||
如果没有出现任何错误,说明一切正常。弹出这个 USB 驱动器并给它粘上一个明确的标签,以便于你下次需要它时能够很快找到它。接着,将它放到一个安全的 —— 但不要太远 —— 的地方,因为从现在起,你需要偶尔使用它来做一些像编辑身份信息、添加或吊销子证书、或签署其它人的密钥这样的事情。
|
||||
|
||||
#### 删除主密钥
|
||||
|
||||
我们家目录中的文件并没有像我们所想像的那样受到保护。它们可能会通过许多不同的方式被泄露或失窃:
|
||||
|
||||
* 通过快速复制来配置一个新工作站时的偶尔事故
|
||||
* 通过系统管理员的疏忽或恶意操作
|
||||
* 通过安全性欠佳的备份
|
||||
* 通过桌面应用中的恶意软件(浏览器、pdf 查看器等等)
|
||||
* 通过跨境胁迫
|
||||
|
||||
使用一个很好的密码来保护你的密钥是降低上述风险的一个很好方法,但是密码能够通过键盘记录器、背后窥视、或其它方式被发现。基于以上原因,我们建议去配置一个从你的家目录上可移除的主密钥,将它保存在一个离线存储中。
|
||||
|
||||
##### 删除你的主密钥
|
||||
|
||||
**请查看前面的节,确保你有完整的你的 GnuPG 目录的一个备份。如果你没有一个可用的备份,下面所做的操作将会使你的主密钥失效!!!**
|
||||
|
||||
首先,识别你的主密钥的 keygrip:
|
||||
|
||||
```
|
||||
$ gpg --with-keygrip --list-key [fpr]
|
||||
```
|
||||
|
||||
它的输出应该像下面这样:
|
||||
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
Keygrip = AAAA999988887777666655554444333322221111
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
sub rsa2048 2017-12-06 [E]
|
||||
Keygrip = BBBB999988887777666655554444333322221111
|
||||
sub rsa2048 2017-12-06 [S]
|
||||
Keygrip = CCCC999988887777666655554444333322221111
|
||||
```
|
||||
|
||||
找到 `pub` 行下方的 `Keygrip` 条目(就在主密钥指纹的下方)。它与你的家目录下 `.gnupg` 目录下的一个文件是一致的:
|
||||
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ ls
|
||||
AAAA999988887777666655554444333322221111.key
|
||||
BBBB999988887777666655554444333322221111.key
|
||||
CCCC999988887777666655554444333322221111.key
|
||||
```
|
||||
|
||||
现在你做的全部操作就是简单地删除与主密钥 keygrip 一致的 `.key` 文件:
|
||||
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ rm AAAA999988887777666655554444333322221111.key
|
||||
```
|
||||
|
||||
现在,如果运行 `--list-secret-keys` 命令将出现问题,它将显示主密钥丢失(`#` 表示不可用):
|
||||
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb rsa2048 2017-12-06 [E]
|
||||
ssb rsa2048 2017-12-06 [S]
|
||||
```
|
||||
|
||||
#### 删除吊销证书
|
||||
|
||||
你应该去删除的另一个文件是吊销证书(**删除之前,确保你的备份中有它**),它是使用你的主密钥自动创建的。吊销证书允许一些人去永久标记你的证书为吊销状态,这意味着它无论在任何用途中将不再被使用或信任。一般是使用它来吊销由于某些原因不再受控的一个密钥 —— 比如,你丢失了密钥密码。
|
||||
|
||||
与使用主密钥一样,如果一个吊销证书泄露到恶意者手中,他们能够使用它去破坏你的开发者数字身份,因此,最好是从你的家目录中删除它。
|
||||
|
||||
```
|
||||
cd ~/.gnupg/openpgp-revocs.d
|
||||
rm [fpr].rev
|
||||
```
|
||||
|
||||
在下一篇文章中,你将学习如何保护你的子密钥。敬请期待。
|
||||
|
||||
从来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][4] 中学习更多 Linux 知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://linux.cn/article-9524-1.html
|
||||
[2]:https://linux.cn/article-9529-1.html
|
||||
[3]:https://linux.cn/article-9607-1.html
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,78 @@
|
||||
Emacs 系列(一):抛掉一切,投入 Emacs 和 Org 模式的怀抱
|
||||
======
|
||||
|
||||
我必须承认,在使用了几十年的 vim 后, 我被 [Emacs][1] 吸引了。
|
||||
|
||||
长期以来,我一直对如何组织安排事情感到沮丧。我也有用过 [GTD][2] 和 [ZTD][3] 之类的方法,但是像邮件或是大型文件这样的事务真的很难来组织安排。
|
||||
|
||||
我一直在用 Asana 处理任务,用 Evernote 做笔记,用 Thunderbird 处理邮件,把 ikiwiki 和其他的一些项目组合作为个人知识库,而且还在电脑的归档了各种文件。当我的新工作需要将 Slack 也加入进来时,我终于忍无可忍了。
|
||||
|
||||
许多 TODO 管理工具与电子邮件集成的很差。当你想做“提醒我在一周内回复这个邮件”之类的事时,很多时候是不可能的,因为这个工具不能以一种能够轻松回复的方式存储邮件。而这个问题在 Slack 上更为严重。
|
||||
|
||||
就在那时,我偶然发现了 [Carsten Dominik 在 Google Talk 上关于 Org 模式的讲话][4]。Carsten 是 Org 模式的作者,即便是这个讲话已经有 10 年了,但它仍然很具有参考价值。
|
||||
|
||||
我之前有用过 [Org 模式][5],但是每次我都没有真正的深入研究它,
|
||||
因为我当时的反应是“一个大纲编辑器?但我需要的是待办事项列表”。我就这么错过了它。但实际上 Org 模式就是我所需要的。
|
||||
|
||||
### 什么是 Emacs?什么是 Org 模式?
|
||||
|
||||
Emacs 最初是一个文本编辑器,现在依然是一个文本编辑器,而且这种传统无疑贯穿始终。但是说 Emacs 是个编辑器是很不公平的。
|
||||
|
||||
Emacs 更像一个平台或是工具包。你不仅可以用它来编辑源代码,而且配置 Emacs 本身也是编程,里面有很多模式。就像编写一个 Firefox 插件一样简单,只要几行代码,然后,模式里的操作就改变了。
|
||||
|
||||
Org 模式也一样。确实,它是一个大纲编辑器,但它真正所包含的不止如此。它是一个信息组织平台。它的网站上写着,“你可以用纯文本来记录你的生活:你可以用 Org 模式来记笔记,处理待办事项,规划项目和使用快速有效的纯文本系统编写文档。”
|
||||
|
||||
### 捕获
|
||||
|
||||
如果你读过基于 GTD 的生产力指南,那么他们强调的一件事就是毫不费力地获取项目。这个想法是,当某件事突然出现在你的脑海里时,把它迅速输入一个受信任的系统,这样你就可以继续做你正在做的事情。Org 模式有一个专门的捕获系统。我可以在 Emacs 的任何地方按下 `C-c c` 键,它就会空出一个位置来记录我的笔记。最关键的是,自动嵌入到笔记中的链接可以链接到我按下 `C-c c` 键时正在编辑的那一行。如果我正在编辑文件,它会链回到那个文件和我所在的行。如果我正在浏览邮件,它就会链回到那封邮件(通过邮件的 Message-Id,这样它就可以在任何一个文件夹中找到邮件)。聊天时也一样,甚至是当你在另一个 Org 模式中也可也这样。
|
||||
|
||||
这样我就可以做一个笔记,它会提醒我在一周内回复某封邮件,当我点击这个笔记中的链接时,它会在我的邮件阅读器中弹出这封邮件 —— 即使我随后将它从收件箱中存档。
|
||||
|
||||
没错,这正是我要找的!
|
||||
|
||||
### 工具套件
|
||||
|
||||
一旦你开始使用 Org 模式,很快你就会想将所有的事情都集成到里面。有可以从网络上捕获内容的浏览器插件,也有多个 Emacs 邮件或新闻阅读器与之集成,ERC(IRC 客户端)也不错。所以我将自己从 Thunderbird 和 mairix + mutt (用于邮件归档)换到了 mu4e,从 xchat + slack 换到了 ERC。
|
||||
|
||||
你可能不明白,我喜欢这些基于 Emacs 的工具,而不是具有相同功能的单独的工具。
|
||||
|
||||
一个小花絮:我又在使用离线 IMAP 了!我甚至在很久以前就用过 GNUS。
|
||||
|
||||
### 用一个 Emacs 进程来管理
|
||||
|
||||
我以前也经常使用 Emacs,那时,Emacs 是一个“大”的程序(现在显示电源状态的小程序占用的内存要比 Emacs 多)。当时存在在启动时间过长的问题,但是现在已经有连接到一个正在运行的 Emacs 进程的解决方法。
|
||||
|
||||
我喜欢用 Mod-p(一个 [xmonad][6] 中 [dzen][7] 菜单栏的快捷方式,但是在大多数传统的桌面环境中该功能的快捷键是 `Alt-F2`)来启动程序(LCTT 译注:xmonad 是一种平铺桌面;dzen 是 X11 窗口下管理消息、提醒和菜单的程序)。这个设置在不运行多个<ruby>[emacs 们](https://www.emacswiki.org/emacs/Emacsen)<rt>emacsen</rt></ruby>时很方便,因为这样就不会在试图捕获另一个打开的文件时出问题。这中方法很简单:创建一个叫 `em` 的脚本并将它放到我自己的环境变量中。就像这样:
|
||||
|
||||
```
|
||||
#!/bin/bash exec emacsclient -c -a "" "$@"
|
||||
```
|
||||
|
||||
如果没有 emacs 进程存在的话,就会创建一个新的 emacs 进程,否则的话就直接使用已存在的进程。这样做还有一个好处:`-nw` 之类的参数工作的很好,它实际上就像在 shell 提示符下输入 `emacs` 一样。它很适合用于设置 `EDITOR` 环境变量。
|
||||
|
||||
### 下一篇
|
||||
|
||||
接下来我将讨论我的使用情况,并展示以下的配置:
|
||||
|
||||
* Org 模式,包括计算机之间的同步、捕获、日程和待办事项、文件、链接、关键字和标记、各种导出(幻灯片)等。
|
||||
* mu4e,用于电子邮件,包括多个账户,bbdb 集成
|
||||
* ERC,用于 IRC 和即时通讯
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://www.gnu.org/software/emacs/
|
||||
[2]:https://gettingthingsdone.com/
|
||||
[3]:https://zenhabits.net/zen-to-done-the-simple-productivity-e-book/
|
||||
[4]:https://www.youtube.com/watch?v=oJTwQvgfgMM
|
||||
[5]:https://orgmode.org/
|
||||
[6]:https://wiki.archlinux.org/index.php/Xmonad_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
|
||||
[7]:http://robm.github.io/dzen/
|
||||
@ -1,26 +1,34 @@
|
||||
DevOps应聘者应该准备回答的20个问题
|
||||
DevOps 应聘者应该准备回答的 20 个问题
|
||||
======
|
||||
|
||||
> 想要建立一个积极,富有成效的工作环境? 在招聘过程中要专注于寻找契合点。
|
||||
|
||||

|
||||
聘请一个不合适的人代价是很高的。根据Link人力资源的首席执行官Jörgen Sundberg的统计,招聘,雇佣一名新员工将会花费公司$240,000之多,当你进行了一次不合适的招聘:
|
||||
* 你失去了他们所知道的。
|
||||
* 你失去了他们认识的人
|
||||
|
||||
聘请一个不合适的人[代价是很高的][1]。根据 Link 人力资源的首席执行官 Jörgen Sundberg 的统计,招聘、雇佣一名新员工将会花费公司$240,000 之多,当你进行了一次不合适的招聘:
|
||||
|
||||
* 你失去了他们的知识技能。
|
||||
* 你失去了他们的人脉。
|
||||
* 你的团队将可能进入到一个组织发展的震荡阶段
|
||||
* 你的公司将会面临组织破裂的风险
|
||||
|
||||
当你失去一名员工的时候,你就像丢失了公司图谱中的一块。同样值得一提的是另一端的疼痛。应聘到一个错误工作岗位的员工会感受到很大的压力以及整个身心的不满意,甚至是健康问题。
|
||||
当你失去一名员工的时候,你就像丢失了公司版图中的一块。同样值得一提的是另一端的痛苦。应聘到一个错误工作岗位的员工会感受到很大的压力以及整个身心的不满意,甚至是健康问题。
|
||||
|
||||
另外一方面,当你招聘到合适的人时,新的员工将会:
|
||||
* 丰富公司现有的文化,使你的组织成为一个更好的工作场所。研究表明一个积极的工作文化能够帮助驱动一个更长久的财务业绩,而且如果你在一个欢快的环境中工 作,你更有可能在生活中做的更好。
|
||||
|
||||
* 丰富公司现有的文化,使你的组织成为一个更好的工作场所。研究表明一个积极的工作文化能够帮助更长久推动财务业绩增长,而且如果你在一个欢快的环境中工作,你更有可能在生活中做的更好。
|
||||
* 热爱和你的组织在一起工作。当人们热爱他们所在做的,他们会趋向于做的更好。
|
||||
|
||||
招聘适合的或者加强现有的文化在DevOps和敏捷团多中是必不可少的。也就是说雇佣到一个能够鼓励积极合作的人,以便来自不同背景,有着不同目标和工作方式的团队能够在一起有效的工作。你新雇佣的员工因应该能够帮助团队合作来充分发挥放大他们的价值同时也能够增加员工的满意度以及平衡组织目标的冲突。他或者她应该能够通过明智的选择工具和工作流来促进你的组织,文化就是一切。
|
||||
招聘以适合或加强现有的文化在 DevOps 和敏捷团多中是必不可少的。也就是说雇佣到一个能够鼓励积极合作的人,以便来自不同背景,有着不同目标和工作方式的团队能够在一起有效的工作。你新雇佣的员工应该能够帮助团队合作来充分发挥放大他们的价值,同时也能够增加员工的满意度以及平衡组织目标的冲突。他或者她应该能够通过明智的选择工具和工作流来促进你的组织,文化就是一切。
|
||||
|
||||
作为我们 2017 年 11 月发布的一篇文章 [DevOps 的招聘经理应该准备回答的 20 个问题][4] 的回应,这篇文章将会重点关注在如何招聘最适合的人。
|
||||
|
||||
作为我们2017年11月发布的一篇文章,[DevOps的招聘经理应该准备回答的20个问题][4],这篇文章将会重点关注在如何招聘最适合的人。
|
||||
### 为什么招聘走错了方向
|
||||
很多公司现在在用的典型的雇佣策略是基于人才过剩的基础上:
|
||||
|
||||
* 职位公告栏。
|
||||
* 关注和所需才能符合的应聘者。
|
||||
很多公司现在用的典型的雇佣策略是基于人才过剩的基础上:
|
||||
|
||||
* 在职位公告栏发布招聘。
|
||||
* 关注具有所需才能的应聘者。
|
||||
* 尽可能找多的候选者。
|
||||
* 通过面试淘汰弱者。
|
||||
* 通过正式的面试淘汰更多的弱者。
|
||||
@ -30,37 +38,48 @@ DevOps应聘者应该准备回答的20个问题
|
||||

|
||||
|
||||
职位公告栏是有成千上万失业者人才过剩的经济大萧条时期发明的。在今天的求职市场上已经没有人才过剩了,然而我们仍然在使用基于此的招聘策略。
|
||||
|
||||

|
||||
|
||||
### 雇佣最合适的人员:运用文化和情感
|
||||
在人才过剩雇佣策略背后的思想是去设计工作岗位然后将人员安排进去。
|
||||
相反,做相反的事情:寻找将会积极融入你的商业文化的人才,然后为他们寻找他们热爱的最合适的岗位。要想如此实现,你必须能够围绕他们热情为他们创造工作岗位。
|
||||
**谁正在寻找一份工作?** 根据一份2016年对美国50,000名开发者的调查显示,[85.7%的受访对象][5]要么对新的机会不感兴趣,要么对于寻找新工作没有积极性。在寻找工作的那部分中,有将近[28.3%的求职者][5]来自于朋友的推荐。如果你只是在那些在找工作的人中寻找人才,你将会错过高端的人才。
|
||||
**运用团队力量去发现和寻找潜力的雇员**。列如,戴安娜是你的团队中的一名开发者,她所提供的机会即使她已经从事编程很多年而且在期间已经结识了很多从事热爱他们所从事的工作的人。难道你不认为她所推荐的潜在员工在技能,知识和智慧上要比HR所寻找的要优秀吗?在要求戴安娜分享她同伴之前,通知她即将到来的使命任务,向她阐明你要雇佣潜在有探索精神的团队,描述在将来会需要的知识领域。
|
||||
**雇员想要什么?**一份来自千禧年,婴儿潮实时期出生的人的对比综合性研究显示,20% 的人所想要的是相同的:
|
||||
|
||||
在人才过剩雇佣策略背后的思想是设计工作岗位然后将人员安排进去。
|
||||
|
||||
反而应该反过来:寻找将会积极融入你的商业文化的人才,然后为他们寻找他们热爱的最合适的岗位。要想实现这样的目标,你必须能够围绕他们热情为他们创造工作岗位。
|
||||
|
||||
**谁正在寻找一份工作?** 根据一份 2016 年对美国 50000 名开发者的调查显示,[85.7% 的受访对象][5]要么对新的机会不感兴趣,要么对于寻找新工作没有积极性。在寻找工作的那部分中,有将近 [28.3% 的求职者][5]来自于朋友的推荐。如果你只是在那些在找工作的人中寻找人才,你将会错过高端的人才。
|
||||
|
||||
**运用团队力量去发现和寻找潜力的雇员**。例如,戴安娜是你的团队中的一名开发者,她所能提供的机会是,她已经[从事编程很多年][6]而且在期间已经结识了很多从事热爱他们所从事的工作的人。难道你不认为她所推荐的潜在员工在技能、知识和智慧上要比 HR 所寻找的要优秀吗?在要求戴安娜分享她同伴之前,通知她即将到来的使命任务,向她阐明你要雇佣潜在有探索精神的团队,描述在将来会需要的知识领域。
|
||||
|
||||
**雇员想要什么?**一份来自千禧年婴儿潮时期出生的人的对比综合性研究显示,20% 的人所想要的是相同的:
|
||||
|
||||
1. 对组织产生积极的影响
|
||||
2. 帮助解决社交或者环境上的挑战
|
||||
3. 和一群有动力的人一起工作
|
||||
|
||||
### 面试的挑战
|
||||
面试应该是招聘者和应聘者双方为了寻找最合适的人才进行的一次双方之间的对话。将面试聚焦在企业文化和情感对话两个问题上:这个应聘者将会丰富你的企业文化并且会热爱和你在一起工作吗?你能够在工作中帮他们取得成功吗?
|
||||
**对于招聘经理来说:** 每一次的面试都是你学习如何将自己的组织变得对未来的团队成员更有吸引力,并且每次积极的面试多都可能是你发现人才(即使你不会雇佣)的机会。每个人都将会记得积极有效的面试的经历。即使他们不会被雇佣,他们将会和他们的朋友谈论这次经历,你竟会得到一个被推荐的机会。这又很大的好处:如果你无法吸引到这个人才,你也将会从中学习吸取经验并且改善。
|
||||
**对面试者来说**:每次的面试都是你释放激情的机会
|
||||
|
||||
### 助你释放潜在雇员激情的20个问题
|
||||
面试应该是招聘者和应聘者双方为了寻找最合适的人才进行的一次双方之间的对话。将面试聚焦在企业文化和情感对话两个问题上:这个应聘者将会丰富你的企业文化并且会热爱和你在一起工作吗?你能够在工作中帮他们取得成功吗?
|
||||
|
||||
**对于招聘经理来说:** 每一次的面试都是你学习如何将自己的组织变得对未来的团队成员更有吸引力,并且每次积极的面试都可能是你发现人才(即使你不会雇佣)的机会。每个人都将会记得积极有效的面试的经历。即使他们不会被雇佣,他们将会和他们的朋友谈论这次经历,你会得到一个被推荐的机会。这有很大的好处:如果你无法吸引到这个人才,你也将会从中学习吸取经验并且改善。
|
||||
|
||||
**对面试者来说**:每次的面试都是你释放激情的机会。
|
||||
|
||||
### 助你释放潜在雇员激情的 20 个问题
|
||||
|
||||
1. 你热爱什么?
|
||||
2. “今天早晨我已经迫不及待的要去工作”你怎么看待这句话?
|
||||
2. “今天早晨我已经迫不及待的要去工作”,你怎么看待这句话?
|
||||
3. 你曾经最快乐的是什么?
|
||||
4. 你曾经解决问题的最典型的例子是什么,你是如何解决的?
|
||||
5. 你如何看待配对学习?
|
||||
6. 你到达办公室和离开办公室心里最先想到的是什么?
|
||||
7. 你如果你有一次改变你之前或者现在的共工作的一件事的机会,将会是什么事?
|
||||
8. 当你在这工作的时候,你最兴奋去学习什么?
|
||||
7. 你如果你有一次改变你之前或者现在的工作中的一件事的机会,将会是什么事?
|
||||
8. 当你在工作的时候,你最乐于去学习什么?
|
||||
9. 你的梦想是什么,你如何去实现?
|
||||
10. 你在学会如何去实现你的追求的时候想要或者需要什么?
|
||||
11. 你的价值观是什么?
|
||||
12. 你是如何坚守自己的价值观的?
|
||||
13. 平衡在你的生活中意味着什么?
|
||||
13. 在你的生活中平衡意味着什么?
|
||||
14. 你最引以为傲的工作交流能力是什么?为什么?
|
||||
15. 你最喜欢营造什么样的环境?
|
||||
16. 你喜欢别人怎样对待你?
|
||||
@ -70,14 +89,13 @@ DevOps应聘者应该准备回答的20个问题
|
||||
20. 如果你正在雇佣我,你将会问我什么问题?
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/questions-devops-employees-should-answer
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
构建满足用户需求的云环境的五个步骤
|
||||
======
|
||||
> 在投入时间和资金开发你的云环境之前,确认什么是你的用户所需要的。
|
||||
|
||||

|
||||
|
||||
无论你如何定义,云就是你的用户展现其在组织中的价值的另一个工具。当谈论新的范例或者技术(云是两者兼有)的时候很容易被它的新特性所分心。由一系列无止境的问题引发的对话能够很快的被发展为功能愿景清单,所有下面的这些都是你可能已经考虑到的:
|
||||
|
||||
* 是公有云、私有云还是混合云?
|
||||
* 会使用虚拟机还是容器,或者是两者?
|
||||
* 会提供自助服务吗?
|
||||
* 从开发到生产是完全自动的,还是它将需要手动操作?
|
||||
* 我们能以多块的速度做到?
|
||||
* 关于某某工具?
|
||||
|
||||
这样的清单还可以列举很多。
|
||||
|
||||
当开始 IT 现代化,或者数字转型,无论你是如何称呼的,通常方法是开始回答更高管理层的一些高层次问题,这种方法的结果是可以预想到的:失败。经过大范围的调研并且花费了数月的时间(如果不是几年的话)部署了这个最炫的新技术,而这个新的云技术却从未被使用过,而且陷入了荒废,直到它最终被丢弃或者遗忘在数据中心的一角和预算之中。
|
||||
|
||||
这是因为无论你交付的是什么工具,都不是用户所想要或者需要的。更加糟糕的是,它可能是一个单一的工具,而用户真正需要的是一系列工具 —— 能够随着时间推移,更换升级为更新的、更漂亮的工具,以更好地满足其需求。
|
||||
|
||||
### 专注于重要的事情
|
||||
|
||||
问题在于关注,传统上一直是关注于工具。但工具并不是要增加到组织价值中的东西;终端用户利用它做什么才是目的。你需要将你的注意力从创建云(例如技术和工具)转移到你的人员和用户身上。
|
||||
|
||||
事实上,除了使用工具的用户(而不是工具本身)是驱动价值的因素之外,聚焦注意力在用户身上也是有其它原因的。工具是给用户使用去解决他们的问题并允许他们创造价值的,所以这就导致了如果那些工具不能满足那些用户的需求,那么那些工具将不会被使用。如果你交付给你的用户的工具并不是他们喜欢的,他们将不会使用,这就是人类的人性行为。
|
||||
|
||||
数十年来,IT 产业只为用户提供一种解决方案,因为仅有一个或两个选择,用户是没有权力去改变的。现在情况已经不同了。我们现在生活在一个技术选择的世界中。不给用户一个选择的机会的情况将不会被接受的;他们在个人的科技生活中有选择,同时希望在工作中也有选择。现在的用户都是受过教育的并且知道将会有比你所提供的更好选择。
|
||||
|
||||
因此,在物理上的最安全的地点之外,没有能够阻止他们只做他们自己想要的东西的方法,我们称之为“影子 IT”。如果你的组织有如此严格的安全策略和承诺策略而不允许影子 IT,许多员工将会感到灰心丧气并且会离职去其他能提供更好机会的公司。
|
||||
|
||||
基于以上所有的原因,你必须牢记要首先和你的最终用户设计你的昂贵又费时的云项目。
|
||||
|
||||
### 创建满足用户需求的云五个步骤的过程
|
||||
|
||||
既然我们已经知道了为什么,接下来我们来讨论一下怎么做。你如何去为终端用户创建一个云?你怎样重新将你的注意力从技术转移到使用技术的用户身上?
|
||||
|
||||
根据以往的经验,我们知道最好的方法中包含两件重要的事情:从你的用户中得到及时的反馈,在创建中和用户进行更多的互动。
|
||||
|
||||
你的云环境将继续随着你的组织不断发展。下面的五个步骤将会帮助你创建满足用户需求的云环境。
|
||||
|
||||
#### 1、识别谁将是你的用户
|
||||
|
||||
在你开始询问用户问题之前,你首先必须识别谁将是你的新的云环境的用户。他们可能包括将在云上创建开发应用的开发者;也可能是运营、维护或者或者创建该云的运维团队;还可能是保护你的组织的安全团队。在第一次迭代时,将你的用户数量缩小至人数较少的小组防止你被大量的反馈所淹没,让你识别的每个小组指派两个代表(一个主要的一个辅助的)。这将使你的第一次交付在规模和时间上都很小。
|
||||
|
||||
#### 2、和你的用户面对面的交谈来收获有价值的输入。
|
||||
|
||||
获得反馈的最佳途径是和用户直接交谈。群发的邮件会自行挑选出受访者——如果你能收到回复的话。小组讨论会很有帮助的,但是当人们有个私密的、专注的对话者时,他们会比较的坦诚。
|
||||
|
||||
和你的第一批用户安排个面对面的个人的会谈,并且向他们询问以下的问题:
|
||||
|
||||
* 为了完成你的任务,你需要什么?
|
||||
* 为了完成你的任务,你想要什么?
|
||||
* 你现在最头疼的技术痛点是什么?
|
||||
* 你现在最头疼的政策或者流程痛点是哪个?
|
||||
* 关于解决你的需求、希望或痛点,你有什么建议?
|
||||
|
||||
这些问题只是指导性的,并不一定适合每个组织。你不应该只询问这些问题,他们应该导向更深层次的讨论。确保告诉用户他们任何所说的和被问的都被视作反馈,所有的反馈都是有帮助的,无论是消极的还是积极的。这些对话将会帮助你设置你的开发优先级。
|
||||
|
||||
收集这种个性化的反馈是保持初始用户群较小的另一个原因:这将会花费你大量的时间来和每个用户交流,但是我们已经发现这是相当值得付出的投入。
|
||||
|
||||
#### 3、设计并交付你的解决方案的第一个版本
|
||||
|
||||
一旦你收到初始用户的反馈,就是时候开始去设计并交付一部分的功能了。我们不推荐尝试一次性交付整个解决方案。设计和交付的时期要短;这可以避免你花费一年的时间去构建一个你*认为*正确的解决方案,而只会让你的用户拒绝它,因为对他们来说毫无用处。创建你的云所需要的工具取决于你的组织和它的特殊需求。只需确保你的解决方案是建立在用户的反馈的基础上的,你将功能小块化的交付并且要经常的去征求用户的反馈。
|
||||
|
||||
#### 4、询问用户对第一个版本的反馈
|
||||
|
||||
太棒了,现在你已经设计并向你的用户交付了你的炫酷的新的云环境的第一个版本!你并不是花费一整年去完成它而是将它处理成小的模块。为什么将其分为小的模块如此重要呢?因为你要回到你的用户组并且向他们收集关于你的设计和交付的功能。他们喜欢什么?不喜欢什么?你正确的处理了他们所关注的吗?是技术功能上很厉害,但系统进程或者策略方面仍然欠缺吗?
|
||||
|
||||
再重申一次,你要问的问题取决于你的组织;这里的关键是继续前一个阶段的讨论。毕竟你正在为用户创建云环境,所以确保它对用户来说是有用的并且能够有效利用每个人的时间。
|
||||
|
||||
#### 5、回到第一步。
|
||||
|
||||
这是一个迭代的过程。你的首次交付应该是快速而小规模的,而且以后的迭代也应该是这样的。不要期待仅仅按照这个流程完成了一次、两次甚至是三次就能完成。一旦你持续的迭代,你将会吸引更多的用户从而能够在这个过程中得到更好的回报。你将会从用户那里得到更多的支持。你能够迭代的更迅速并且更可靠。到最后,你将会通过改变你的流程来满足用户的需求。
|
||||
|
||||
用户是这个过程中最重要的一部分,但迭代是第二重要的因为它让你能够回到用户中进行持续沟通从而得到更多有用的信息。在每个阶段,记录哪些是有效的哪些没有起到应有的效果。要自省,要对自己诚实。我们所花费的时间提供了最有价值的了吗?如果不是,在下一个阶段尝试些不同的。在每次循环中不要花费太多时间的最重要的部分是,如果某部分在这次不起作用,你能够很容易的在下一次中调整它,直到你找到能够在你组织中起作用的方法。
|
||||
|
||||
### 这仅仅是开始
|
||||
|
||||
通过许多客户约见,从他们那里收集反馈,以及在这个领域的同行的经验,我们一次次的发现在创建云的时候最重要事就是和你的用户交谈。这似乎是很明显的,但很让人惊讶的是很多组织却偏离了这个方向去花费数月或者数年的时间去创建,然后最终发现它对终端用户甚至一点用处都没有。
|
||||
|
||||
现在你已经知道为什么你需要将你的注意力集中到终端用户身上并且在中心节点和用户一起的互动创建云。剩下的是我们所喜欢的部分,你自己去做的部分。
|
||||
|
||||
这篇文章是基于一篇作者在 [Red Hat Summit 2018][3] 上发表的文章“[为终端用户设计混合云,要么失败]”。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly
|
||||
|
||||
作者:[Cameron Wyatt][a], [Ian Teksbury][1]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cameronmwyatt
|
||||
[1]:https://opensource.com/users/itewk
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
@ -0,0 +1,139 @@
|
||||
如何在终端中浏览 Stack Overflow
|
||||
======
|
||||
|
||||

|
||||
|
||||
前段时间,我们写了一篇关于 [SoCLI][1] 的文章,它是一个从命令行搜索和浏览 Stack Overflow 网站的 python 脚本。今天,我们将讨论一个名为 “how2” 的类似工具。它是一个命令行程序,可以从终端浏览 Stack Overflow。你可以如你在 [Google 搜索][2]中那样直接用英语查询,然后它会使用 Google 和 Stackoverflow API 来搜索给定的查询。它是使用 NodeJS 编写的自由开源程序。
|
||||
|
||||
### 使用 how2 从终端浏览 Stack Overflow
|
||||
|
||||
由于 `how2` 是一个 NodeJS 包,我们可以使用 Npm 包管理器安装它。如果你尚未安装 Npm 和 NodeJS,请参考以下指南。
|
||||
|
||||
在安装 Npm 和 NodeJS 后,运行以下命令安装 how2。
|
||||
|
||||
```
|
||||
$ npm install -g how2
|
||||
```
|
||||
|
||||
现在让我们看下如何使用这个程序浏览 Stack Overflow。使用 `how2` 搜索 Stack Overflow 站点的典型用法是:
|
||||
|
||||
```
|
||||
$ how2 <search-query>
|
||||
```
|
||||
|
||||
例如,我将搜索如何创建 tgz 存档。
|
||||
|
||||
```
|
||||
$ how2 create archive tgz
|
||||
```
|
||||
|
||||
哎呀!我收到以下错误。
|
||||
|
||||
```
|
||||
/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59
|
||||
Transport.prototype.__proto__ = EventEmitter.prototype;
|
||||
^
|
||||
|
||||
TypeError: Cannot read property 'prototype' of undefined
|
||||
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59:46)
|
||||
at Module._compile (internal/modules/cjs/loader.js:654:30)
|
||||
at Object.Module._extensions..js (internal/modules/cjs/loader.js:665:10)
|
||||
at Module.load (internal/modules/cjs/loader.js:566:32)
|
||||
at tryModuleLoad (internal/modules/cjs/loader.js:506:12)
|
||||
at Function.Module._load (internal/modules/cjs/loader.js:498:3)
|
||||
at Module.require (internal/modules/cjs/loader.js:598:17)
|
||||
at require (internal/modules/cjs/helpers.js:11:18)
|
||||
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/stream.js:8:17)
|
||||
at Module._compile (internal/modules/cjs/loader.js:654:30)
|
||||
|
||||
```
|
||||
|
||||
我可能遇到了一个 bug。我希望它在未来版本中得到修复。但是,我在[这里][3]找到了一个临时方法。
|
||||
|
||||
|
||||
要临时修复此错误,你需要使用以下命令编辑 `transport.js`:
|
||||
|
||||
```
|
||||
$ vi /home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js
|
||||
```
|
||||
|
||||
此文件的实际路径将显示在错误输出中。用你自己的文件路径替换上述文件路径。然后找到以下行:
|
||||
|
||||
```
|
||||
var EventEmitter = process.EventEmitter;
|
||||
```
|
||||
|
||||
并用以下行替换它:
|
||||
|
||||
```
|
||||
var EventEmitter = require('events');
|
||||
```
|
||||
|
||||
按 `ESC` 并输入 `:wq` 以保存并退出文件。
|
||||
|
||||
现在再次搜索查询。
|
||||
|
||||
```
|
||||
$ how2 create archive tgz
|
||||
```
|
||||
|
||||
这是我的 Ubuntu 系统的示例输出。
|
||||
|
||||
![][5]
|
||||
|
||||
如果你要查找的答案未显示在上面的输出中,请按**空格键**键开始交互式搜索,你可以通过它查看 Stack Overflow 站点中的所有建议问题和答案。
|
||||
|
||||
![][6]
|
||||
|
||||
使用向上/向下箭头在结果之间移动。得到正确的答案/问题后,点击空格键或回车键在终端中打开它。
|
||||
|
||||
![][7]
|
||||
|
||||
要返回并退出,请按 `ESC`。
|
||||
|
||||
**搜索特定语言的答案**
|
||||
|
||||
如果你没有指定语言,它**默认为 Bash** unix 命令行,并立即为你提供最可能的答案。你还可以将结果缩小到特定语言,例如 perl、python、c、Java 等。
|
||||
|
||||
例如,使用 `-l` 标志仅搜索与 “Python” 语言相关的查询,如下所示。
|
||||
|
||||
```
|
||||
$ how2 -l python linked list
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
要获得快速帮助,请输入:
|
||||
|
||||
```
|
||||
$ how2 -h
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
`how2` 是一个基本的命令行程序,它可以快速搜索 Stack Overflow 中的问题和答案,而无需离开终端,并且它可以很好地完成这项工作。但是,它只是 Stack overflow 的 CLI 浏览器。对于一些高级功能,例如搜索投票最多的问题,使用多个标签搜索查询,彩色界面,提交新问题和查看问题统计信息等,**SoCLI** 做得更好。
|
||||
|
||||
就是这些了。希望这篇文章有用。我将很快写一篇新的指南。在此之前,请继续关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-browse-stack-overflow-from-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/search-browse-stack-overflow-website-commandline/
|
||||
[2]:https://www.ostechnix.com/google-search-navigator-enhance-keyboard-navigation-in-google-search/
|
||||
[3]:https://github.com/santinic/how2/issues/79
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-3.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-4.png
|
||||
@ -1,38 +1,38 @@
|
||||
Anbox:如何方便地安装 Google Play 商店以及启用 ARM(libhoudini) 支持
|
||||
如何在 Anbox 上安装 Google Play 商店及启用 ARM 支持
|
||||
======
|
||||
|
||||
|
||||
|
||||
**[Anbox][1] 或称为 Anroid in a Box 是一个免费的开源工具,它允许在 Linux 上运行 Android 应用程序**。它的工作原理是在 LXC 容器中运行 Android 运行时环境,重新创建 Android 的目录结构作为可挂载的 loop 镜像,同时使用本机 Linux 内核来执行应用。
|
||||
[Anbox][1] (Anroid in a Box)是一个自由开源工具,它允许你在 Linux 上运行 Android 应用程序。它的工作原理是在 LXC 容器中运行 Android 运行时环境,重新创建 Android 的目录结构作为可挂载的 loop 镜像,同时使用本机 Linux 内核来执行应用。
|
||||
|
||||
据其网站所述,它的主要特性是安全性、性能、集成和趋同(不同外形尺寸缩放)。
|
||||
|
||||
**使用 Anbox,每个 Android 应用或游戏就像系统应用一样都在一个单独的窗口中启动**,它们的行为或多或少类似于常规窗口,显示在启动器中,可以平铺等等。
|
||||
使用 Anbox,每个 Android 应用或游戏就像系统应用一样都在一个单独的窗口中启动,它们的行为或多或少类似于常规窗口,显示在启动器中,可以平铺等等。
|
||||
|
||||
默认情况下,Anbox 没有 Google Play 商店或 ARM 应用支持。要安装应用,你必须下载每个应用 APK 并使用 adb 手动安装。此外,默认情况下不能使用 Anbox 安装 ARM 应用或游戏 - 尝试安装 ARM 应用会显示以下错误:
|
||||
默认情况下,Anbox 没有 Google Play 商店或 ARM 应用支持。要安装应用,你必须下载每个应用的 APK 并使用 `adb` 手动安装。此外,默认情况下不能使用 Anbox 安装 ARM 应用或游戏 —— 尝试安装 ARM 应用会显示以下错误:
|
||||
|
||||
```
|
||||
Failed to install PACKAGE.NAME.apk: Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]
|
||||
|
||||
```
|
||||
|
||||
你可以在 Anbox 中手动设置 Google Play 商店和 ARM 应用支持(通过 libhoudini),但这是一个非常复杂的过程。**为了更容易地在 Anbox 上安装 Google Play 商店和 Google Play 服务,并让它支持 ARM 应用程序和游戏(使用 libhoudini),[geeks-r-us.de][2](文章是德语)上的人创建了一个自动执行这些任务的脚本**。
|
||||
你可以在 Anbox 中手动设置 Google Play 商店和 ARM 应用支持(通过 libhoudini),但这是一个非常复杂的过程。为了更容易地在 Anbox 上安装 Google Play 商店和 Google Play 服务,并让它支持 ARM 应用程序和游戏(使用 libhoudini),[geeks-r-us.de][2](文章是德语)上的人创建了一个自动执行这些任务的脚本。
|
||||
|
||||
在使用之前,我想明确指出,即使在集成 libhoudini 来支持 ARM 后,也并非所有 Android 应用和游戏都能在 Anbox 中运行。某些 Android 应用和游戏可能根本不会出现在 Google Play 商店中,而一些应用和游戏可能可以安装但无法使用。此外,某些应用可能无法使用某些功能。
|
||||
|
||||
### 安装 Google Play 商店并在 Anbox 上启用 ARM 应用/游戏支持(Android in a Box)
|
||||
### 安装 Google Play 商店并在 Anbox 上启用 ARM 应用/游戏支持
|
||||
|
||||
如果你的 Linux 桌面上尚未安装 Anbox,这些说明显然不起作用。如果你还没有,请按照[此处][7]的安装说明安装 Anbox。此外,请确保在安装 Anbox 之后,使用此脚本之前至少运行一次 `anbox.appmgr`,以避免遇到问题。另外,确保在执行下面的脚本时 Anbox 没有运行(我怀疑这是导致评论中提到的这个[问题][8]的原因)。
|
||||
|
||||
1\. 安装所需的依赖项(wget、lzip、unzip 和 squashfs-tools)。
|
||||
1、 安装所需的依赖项(wget、lzip、unzip 和 squashfs-tools)。
|
||||
|
||||
在 Debian、Ubuntu 或 Linux Mint 中,使用此命令安装所需的依赖项:
|
||||
|
||||
```
|
||||
sudo apt install wget lzip unzip squashfs-tools
|
||||
|
||||
```
|
||||
|
||||
2\. 下载并运行脚本,在 Anbox 上自动下载并安装 Google Play商店(和 Google Play 服务)和 libhoudini(用于 ARM 应用/游戏支持)。
|
||||
2、 下载并运行脚本,在 Anbox 上自动下载并安装 Google Play 商店(和 Google Play 服务)和 libhoudini(用于 ARM 应用/游戏支持)。
|
||||
|
||||
**警告:永远不要在不知道它做什么的情况下运行不是你写的脚本。在运行此脚本之前,请查看其[代码][4]。**
|
||||
|
||||
@ -42,25 +42,23 @@ sudo apt install wget lzip unzip squashfs-tools
|
||||
wget https://raw.githubusercontent.com/geeks-r-us/anbox-playstore-installer/master/install-playstore.sh
|
||||
chmod +x install-playstore.sh
|
||||
sudo ./install-playstore.sh
|
||||
|
||||
```
|
||||
|
||||
3\. 要让 Google Play 商店在 Anbox 中运行,你需要启用 Google Play 商店和 Google Play 服务的所有权限
|
||||
3、要让 Google Play 商店在 Anbox 中运行,你需要启用 Google Play 商店和 Google Play 服务的所有权限
|
||||
|
||||
为此,请运行Anbox:
|
||||
|
||||
```
|
||||
anbox.appmgr
|
||||
|
||||
```
|
||||
|
||||
然后进入`设置>应用> Google Play 服务>权限`并启用所有可用权限。对 Google Play 商店也一样!
|
||||
然后进入“设置 > 应用 > Google Play 服务 > 权限”并启用所有可用权限。对 Google Play 商店也一样!
|
||||
|
||||
|
||||
|
||||
你现在应该可以使用 Google 帐户登录 Google Play 商店了。
|
||||
|
||||
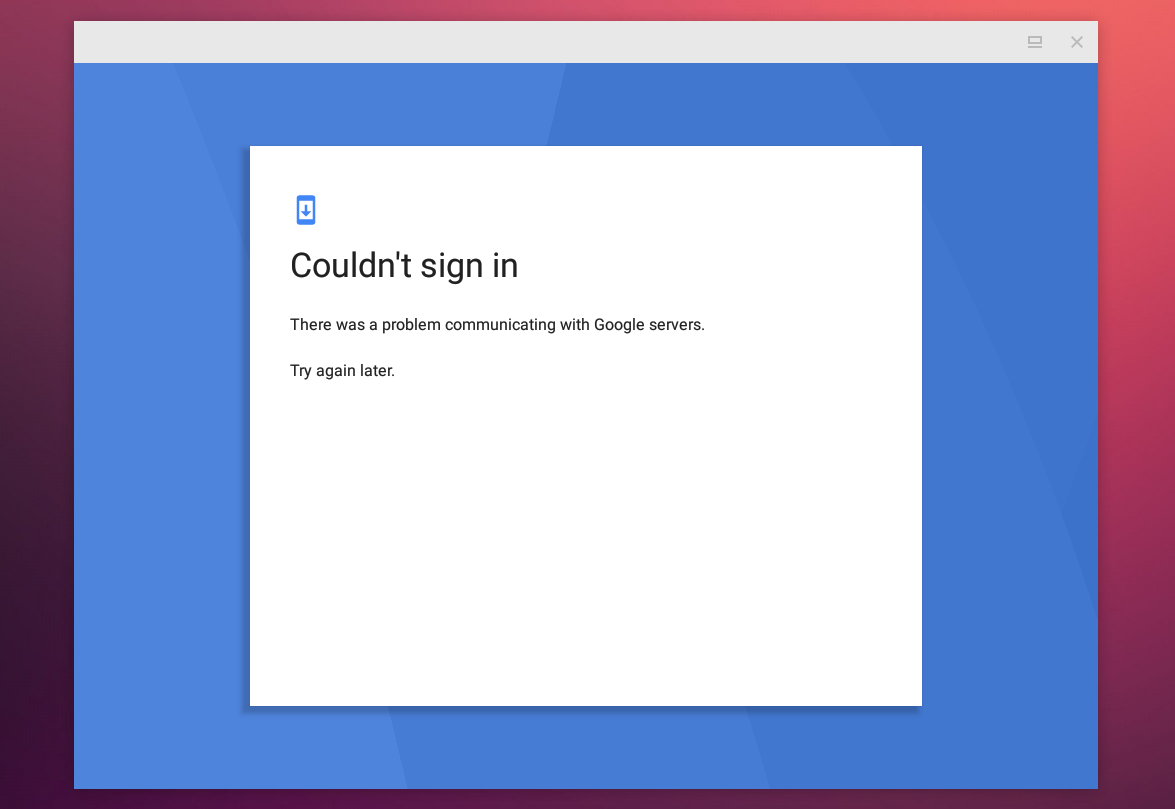
如果未启用 Google Play 商店和 Google Play 服务的所有权限,你可能会在尝试登录 Google 帐户时可能会遇到问题,并显示以下错误消息:“_Couldn't sign in. There was a problem communicating with Google servers. Try again later_ “,如你在下面的截图中看到的那样:
|
||||
如果未启用 Google Play 商店和 Google Play 服务的所有权限,你可能会在尝试登录 Google 帐户时可能会遇到问题,并显示以下错误消息:“Couldn't sign in. There was a problem communicating with Google servers. Try again later“,如你在下面的截图中看到的那样:
|
||||
|
||||
|
||||
|
||||
@ -68,23 +66,18 @@ anbox.appmgr
|
||||
|
||||
**如果你在 Anbox 上登录 Google 帐户时遇到一些连接问题**,请确保 `anbox-bride.sh` 正在运行:
|
||||
|
||||
* 启动它:
|
||||
|
||||
启动它:
|
||||
|
||||
```
|
||||
sudo /snap/anbox/current/bin/anbox-bridge.sh start
|
||||
|
||||
```
|
||||
|
||||
* 重启它:
|
||||
|
||||
重启它:
|
||||
|
||||
```
|
||||
sudo /snap/anbox/current/bin/anbox-bridge.sh restart
|
||||
|
||||
```
|
||||
|
||||
根据[此][9]用户的说法,如果 Anbox 仍然存在连接问题,你可能还需要安装 dnsmasq 包。但是在我的 Ubuntu 18.04 桌面上不需要这样做。
|
||||
根据[此用户][9]的说法,如果 Anbox 仍然存在连接问题,你可能还需要安装 dnsmasq 包。但是在我的 Ubuntu 18.04 桌面上不需要这样做。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -94,7 +87,7 @@ via: https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-stor
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -107,4 +100,4 @@ via: https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-stor
|
||||
[6]:https://github.com/anbox/anbox/issues/118#issuecomment-295270113
|
||||
[7]:https://github.com/anbox/anbox/blob/master/docs/install.md
|
||||
[8]:https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html?showComment=1533506821283#c4415289781078860898
|
||||
[9]:https://github.com/anbox/anbox/issues/118#issuecomment-295270113
|
||||
[9]:https://github.com/anbox/anbox/issues/118#issuecomment-295270113
|
||||
@ -0,0 +1,109 @@
|
||||
i3 窗口管理器使 Linux 更美好
|
||||
======
|
||||
|
||||
> 通过键盘操作的 i3 平铺窗口管理器使用 Linux 桌面。
|
||||
|
||||

|
||||
|
||||
Linux(和一般的开源软件)最美好的一点是自由 —— 可以在不同的替代方案中进行选择以满足我们的需求。
|
||||
|
||||
我使用 Linux 已经很长时间了,但我从来没有对可选用的桌面环境完全满意过。直到去年,[Xfce][1] 还是我认为在功能和性能之间的平和最接近满意的一个桌面环境。然后我发现了 [i3][2],这是一个改变了我的生活的惊人的软件。
|
||||
|
||||
i3 是一个平铺窗口管理器。窗口管理器的目标是控制窗口系统中窗口的外观和位置。窗口管理器通常用作功能齐全的桌面环境 (如 GONME 或 Xfce ) 的一部分,但也有一些可以用作独立的应用程序。
|
||||
|
||||
平铺式窗口管理器会自动排列窗口,以不重叠的方式占据整个屏幕。其他流行的平铺式窗口管理器还有 [wmii][3] 和 [xmonad][4] 。
|
||||
|
||||
![i3 tiled window manager screenshot][6]
|
||||
|
||||
*带有三个的 i3 屏幕截图*
|
||||
|
||||
为了获得更好的 Linux 桌面体验,以下是我使用和推荐 i3 窗口管理器的五个首要原因。
|
||||
|
||||
### 1、极简艺术
|
||||
|
||||
i3 速度很快。它既不冗杂、也不花哨。它的设计简单而高效。作为开发人员,我重视这些功能,因为我可以使用更多的功能以丰富我最喜欢的开发工具,或者使用容器或虚拟机在本地测试内容。
|
||||
|
||||
此外, i3 是一个窗口管理器,与功能齐全的桌面环境不同,它并不规定您应该使用的应用程序。您是否想使用 Xfce 的 Thunar 作为文件管理器?GNOME 的 gedit 去编辑文本? i3 并不在乎。选择对您的工作流最有意义的工具,i3 将以相同的方式管理它们。
|
||||
|
||||
### 2、屏幕实际使用面积
|
||||
|
||||
作为平铺式窗口管理器,i3 将自动 “平铺”,以不重叠的方式定位窗口,类似于在墙上放置瓷砖。因为您不需要担心窗口定位,i3 一般会更好地利用您的屏幕空间。它还可以让您更快地找到您需要的东西。
|
||||
|
||||
对于这种情况有很多有用的例子。例如,系统管理员可以打开多个终端来同时监视或在不同的远程系统上工作;开发人员可以使用他们最喜欢的 IDE 或编辑器和几个终端来测试他们的程序。
|
||||
|
||||
此外,i3 具有灵活性。如果您需要为特定窗口提供更多空间,请启用全屏模式或切换到其他布局,如堆叠或选项卡式(标签式)。
|
||||
|
||||
### 3、键盘式工作流程
|
||||
|
||||
i3 广泛使用键盘快捷键来控制环境的不同方面。其中包括打开终端和其他程序、调整大小和定位窗口、更改布局,甚至退出 i3。当您开始使用 i3 时,您需要记住其中的一些快捷方式才能使用,随着时间的推移,您会使用更多的快捷方式。
|
||||
|
||||
主要好处是,您不需要经常在键盘和鼠标之间切换。通过练习,您将提高工作流程的速度和效率。
|
||||
|
||||
例如, 要打开新的终端,请按 `<SUPER>+<ENTER>`。由于窗口是自动定位的,您可以立即开始键入命令。结合一个很好的终端文本编辑器(如 Vim)和一个以面向键盘的浏览器,形成一个完全由键盘驱动的工作流程。
|
||||
|
||||
在 i3 中,您可以为所有内容定义快捷方式。下面是一些示例:
|
||||
|
||||
* 打开终端
|
||||
* 打开浏览器
|
||||
* 更改布局
|
||||
* 调整窗口大小
|
||||
* 控制音乐播放器
|
||||
* 切换工作区
|
||||
|
||||
现在我已经习惯了这个工作形式,我已无法回到了常规的桌面环境。
|
||||
|
||||
### 4、灵活
|
||||
|
||||
i3 力求极简,使用很少的系统资源,但这并不意味着它不能变漂亮。i3 是灵活且可通过多种方式进行自定义以改善视觉体验。因为 i3 是一个窗口管理器,所以它没有提供启用自定义的工具,你需要外部工具来实现这一点。一些例子:
|
||||
|
||||
* 用 `feh` 定义桌面的背景图片。
|
||||
* 使用合成器管理器,如 `compton` 以启用窗口淡入淡出和透明度等效果。
|
||||
* 用 `dmenu` 或 `rofi` 以启用可从键盘快捷方式启动的可自定义菜单。
|
||||
* 用 `dunst` 用于桌面通知。
|
||||
|
||||
i3 是可完全配置的,您可以通过更新默认配置文件来控制它的各个方面。从更改所有键盘快捷键,到重新定义工作区的名称,再到修改状态栏,您都可以使 i3 以任何最适合您需要的方式运行。
|
||||
|
||||
![i3 with rofi menu and dunst desktop notifications][8]
|
||||
|
||||
*i3 与 `rofi` 菜单和 `dunst` 桌面通知。*
|
||||
|
||||
最后,对于更高级的用户,i3 提供了完整的进程间通信([IPC][9])接口,允许您使用偏好的语言来开发脚本或程序,以实现更多的自定义选项。
|
||||
|
||||
### 5、工作空间
|
||||
|
||||
在 i3 中,工作区是对窗口进行分组的一种简单方法。您可以根据您的工作流以不同的方式对它们进行分组。例如,您可以将浏览器放在一个工作区上,终端放在另一个工作区上,将电子邮件客户端放在第三个工作区上等等。您甚至可以更改 i3 的配置,以便始终将特定应用程序分配给它们自己的工作区。
|
||||
|
||||
切换工作区既快速又简单。像 i3 中的惯例,使用键盘快捷方式执行此操作。按 `<SUPER>+num` 切换到工作区 `num` 。如果您养成了始终将应用程序组的窗口分配到同一个工作区的习惯,则可以在它们之间快速切换,这使得工作区成为非常有用的功能。
|
||||
|
||||
此外,还可以使用工作区来控制多监视器环境,其中每个监视器都有个初始工作区。如果切换到该工作区,则切换到该监视器,而无需让手离开键盘。
|
||||
|
||||
最后,i3 中还有另一种特殊类型的工作空间:the scratchpad(便笺簿)。它是一个不可见的工作区,通过按快捷方式显示在其他工作区的中间。这是一种访问您经常使用的窗口或程序的方便方式,如电子邮件客户端或音乐播放器。
|
||||
|
||||
### 尝试一下吧
|
||||
|
||||
如果您重视简洁和效率,并且不惮于使用键盘,i3 就是您的窗口管理器。有人说是为高级用户准备的,但情况不一定如此。你需要学习一些基本的快捷方式来度过开始的阶段,不久就会越来越自然并且不假思索地使用它们。
|
||||
|
||||
这篇文章只是浅浅谈及了 i3 能做的事情。欲了解更多详情,请参阅 [i3 的文档][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/i3-tiling-window-manager
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lixinyuxx](https://github.com/lixinyuxx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rgerardi
|
||||
[1]:https://xfce.org/
|
||||
[2]:https://i3wm.org/
|
||||
[3]:https://code.google.com/archive/p/wmii/
|
||||
[4]:https://xmonad.org/
|
||||
[5]:/file/406476
|
||||
[6]:https://opensource.com/sites/default/files/uploads/i3_screenshot.png "i3 tiled window manager screenshot"
|
||||
[7]:/file/405161
|
||||
[8]:https://opensource.com/sites/default/files/uploads/rofi_dunst.png "i3 with rofi menu and dunst desktop notifications"
|
||||
[9]:https://i3wm.org/docs/ipc.html
|
||||
[10]:https://i3wm.org/docs/userguide.html
|
||||
File diff suppressed because it is too large
Load Diff
@ -3,11 +3,12 @@
|
||||
|
||||

|
||||
|
||||
越来越多的开发人员使用容器开发和部署他们的应用。这意味着可以轻松地测试容器也变得很重要。[Conu][1] (container utilities 的简写) 是一个Python库,让你编写容器测试变得简单。本文向你介绍如何使用它测试容器。
|
||||
越来越多的开发人员使用容器开发和部署他们的应用。这意味着可以轻松地测试容器也变得很重要。[Conu][1] (container utilities 的简写) 是一个 Python 库,让你编写容器测试变得简单。本文向你介绍如何使用它测试容器。
|
||||
|
||||
### 开始吧
|
||||
|
||||
首先,你需要一个容器程序来测试。为此,以下命令创建一个包含一个容器 Dockerfile 和一个被容器伺服的 Flask 应用程序的文件夹。
|
||||
首先,你需要一个容器程序来测试。为此,以下命令创建一个包含一个容器的 Dockerfile 和一个被容器伺服的 Flask 应用程序的文件夹。
|
||||
|
||||
```bash
|
||||
$ mkdir container_test
|
||||
$ cd container_test
|
||||
@ -15,22 +16,24 @@ $ touch Dockerfile
|
||||
$ touch app.py
|
||||
```
|
||||
|
||||
将以下代码复制到 app.py 文件中。这是惯常的基本 Flask 应用,它返回字符串“Hello Container World!”。
|
||||
将以下代码复制到 `app.py` 文件中。这是惯常的基本 Flask 应用,它返回字符串 “Hello Container World!”。
|
||||
|
||||
```python
|
||||
from flask import Flask
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route('/')
|
||||
def hello_world():
|
||||
return 'Hello Container World!'
|
||||
return 'Hello Container World!'
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True,host='0.0.0.0')
|
||||
app.run(debug=True,host='0.0.0.0')
|
||||
```
|
||||
|
||||
### 创建和构建测试容器
|
||||
|
||||
为了构建测试容器,将以下指令添加到 Dockerfile。
|
||||
|
||||
```dockerfile
|
||||
FROM registry.fedoraproject.org/fedora-minimal:latest
|
||||
RUN microdnf -y install python3-flask && microdnf clean all
|
||||
@ -39,6 +42,7 @@ CMD ["python3", "/srv/app.py"]
|
||||
```
|
||||
|
||||
然后使用 Docker CLI 工具构建容器。
|
||||
|
||||
```bash
|
||||
$ sudo dnf -y install docker
|
||||
$ sudo systemctl start docker
|
||||
@ -48,6 +52,7 @@ $ sudo docker build . -t flaskapp_container
|
||||
提示:只有在系统上未安装 Docker 时才需要前两个命令。
|
||||
|
||||
构建之后使用以下命令运行容器。
|
||||
|
||||
```bash
|
||||
$ sudo docker run -p 5000:5000 --rm flaskapp_container
|
||||
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
|
||||
@ -56,17 +61,19 @@ $ sudo docker run -p 5000:5000 --rm flaskapp_container
|
||||
* Debugger PIN: 473-505-51
|
||||
```
|
||||
|
||||
最后,使用 curl 检查 Flask 应用程序是否在容器内正确运行:
|
||||
最后,使用 `curl` 检查 Flask 应用程序是否在容器内正确运行:
|
||||
|
||||
```bash
|
||||
$ curl http://127.0.0.1:5000
|
||||
Hello Container World!
|
||||
```
|
||||
|
||||
现在,flaskapp_container 正在运行并准备好进行测试,你可以使用 Ctrl+C 将其停止。
|
||||
现在,flaskapp_container 正在运行并准备好进行测试,你可以使用 `Ctrl+C` 将其停止。
|
||||
|
||||
### 创建测试脚本
|
||||
|
||||
在编写测试脚本之前,必须安装 conu。在先前创建的 container_test 目录中,运行以下命令。
|
||||
在编写测试脚本之前,必须安装 `conu`。在先前创建的 `container_test` 目录中,运行以下命令。
|
||||
|
||||
```bash
|
||||
$ python3 -m venv .venv
|
||||
$ source .venv/bin/activate
|
||||
@ -75,48 +82,48 @@ $ source .venv/bin/activate
|
||||
$ touch test_container.py
|
||||
```
|
||||
|
||||
然后将以下脚本复制并保存在 test_container.py 文件中。
|
||||
然后将以下脚本复制并保存在 `test_container.py` 文件中。
|
||||
|
||||
```python
|
||||
import conu
|
||||
|
||||
PORT = 5000
|
||||
|
||||
with conu.DockerBackend() as backend:
|
||||
image = backend.ImageClass("flaskapp_container")
|
||||
options = ["-p", "5000:5000"]
|
||||
container = image.run_via_binary(additional_opts=options)
|
||||
image = backend.ImageClass("flaskapp_container")
|
||||
options = ["-p", "5000:5000"]
|
||||
container = image.run_via_binary(additional_opts=options)
|
||||
|
||||
try:
|
||||
# Check that the container is running and wait for the flask application to start.
|
||||
assert container.is_running()
|
||||
container.wait_for_port(PORT)
|
||||
|
||||
# Run a GET request on / port 5000.
|
||||
http_response = container.http_request(path="/", port=PORT)
|
||||
|
||||
# Check the response status code is 200
|
||||
assert http_response.ok
|
||||
|
||||
# Get the response content
|
||||
response_content = http_response.content.decode("utf-8")
|
||||
|
||||
try:
|
||||
# Check that the container is running and wait for the flask application to start.
|
||||
assert container.is_running()
|
||||
container.wait_for_port(PORT)
|
||||
# Check that the "Hello Container World!" string is served.
|
||||
assert "Hello Container World!" in response_content
|
||||
|
||||
# Run a GET request on / port 5000.
|
||||
http_response = container.http_request(path="/", port=PORT)
|
||||
|
||||
# Check the response status code is 200
|
||||
assert http_response.ok
|
||||
|
||||
# Get the response content
|
||||
response_content = http_response.content.decode("utf-8")
|
||||
|
||||
# Check that the "Hello Container World!" string is served.
|
||||
assert "Hello Container World!" in response_content
|
||||
|
||||
# Get the logs from the container
|
||||
logs = [line for line in container.logs()]
|
||||
# Check the the Flask application saw the GET request.
|
||||
assert b'"GET / HTTP/1.1" 200 -' in logs[-1]
|
||||
|
||||
finally:
|
||||
container.stop()
|
||||
container.delete()
|
||||
# Get the logs from the container
|
||||
logs = [line for line in container.logs()]
|
||||
# Check the the Flask application saw the GET request.
|
||||
assert b'"GET / HTTP/1.1" 200 -' in logs[-1]
|
||||
|
||||
finally:
|
||||
container.stop()
|
||||
container.delete()
|
||||
```
|
||||
|
||||
#### 测试设置
|
||||
|
||||
这个脚本首先设置 conu 使用 Docker 作为后端来运行容器。然后它设置容器镜像以使用你在本教程第一部分中构建的 flaskapp_container。
|
||||
这个脚本首先设置 `conu` 使用 Docker 作为后端来运行容器。然后它设置容器镜像以使用你在本教程第一部分中构建的 flaskapp_container。
|
||||
|
||||
下一步是配置运行容器所需的选项。在此示例中,Flask 应用在端口5000上提供内容。于是你需要暴露此端口并将其映射到主机上的同一端口。
|
||||
|
||||
@ -124,13 +131,13 @@ with conu.DockerBackend() as backend:
|
||||
|
||||
#### 测试方法
|
||||
|
||||
在测试容器之前,检查容器是否正在运行并准备就绪。示范脚本使用 container.is_running 和 container.wait_for_port。这些方法可确保容器正在运行,并且服务在预设端口上可用。
|
||||
在测试容器之前,检查容器是否正在运行并准备就绪。示范脚本使用 `container.is_running` 和 `container.wait_for_port`。这些方法可确保容器正在运行,并且服务在预设端口上可用。
|
||||
|
||||
container.http_request 是 [request][2] 库的包装器,可以方便地在测试期间发送 HTTP 请求。这个方法返回[requests.Responseobject][3],因此可以轻松地访问响应的内容以进行测试。
|
||||
`container.http_request` 是 [request][2] 库的包装器,可以方便地在测试期间发送 HTTP 请求。这个方法返回[requests.Responseobject][3],因此可以轻松地访问响应的内容以进行测试。
|
||||
|
||||
Conu 还可以访问容器日志。又一次,这在测试期间非常有用。在上面的示例中,container.logs 方法返回容器日志。你可以使用它们断言打印了特定日志,或者,例如在测试期间没有异常被引发。
|
||||
`conu` 还可以访问容器日志。又一次,这在测试期间非常有用。在上面的示例中,`container.logs` 方法返回容器日志。你可以使用它们断言打印了特定日志,或者,例如在测试期间没有异常被引发。
|
||||
|
||||
Conu 提供了许多与容器接合的有用方法。[文档][4]中提供了完整的 API 列表。你还可以参考 [GitHub][5] 上提供的示例。
|
||||
`conu` 提供了许多与容器接合的有用方法。[文档][4]中提供了完整的 API 列表。你还可以参考 [GitHub][5] 上提供的示例。
|
||||
|
||||
运行本教程所需的所有代码和文件也可以在 [GitHub][6] 上获得。 对于想要进一步采用这个例子的读者,你可以看看使用 [pytest][7] 来运行测试并构建一个容器测试套件。
|
||||
|
||||
@ -141,7 +148,7 @@ via: https://fedoramagazine.org/test-containers-python-conu/
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
222
published/201811/20180907 6.828 lab tools guide.md
Normal file
222
published/201811/20180907 6.828 lab tools guide.md
Normal file
@ -0,0 +1,222 @@
|
||||
Caffeinated 6.828:实验工具指南
|
||||
======
|
||||
|
||||
熟悉你的环境对高效率的开发和调试来说是至关重要的。本文将为你简单概述一下 JOS 环境和非常有用的 GDB 和 QEMU 命令。话虽如此,但你仍然应该去阅读 GDB 和 QEMU 手册,来理解这些强大的工具如何使用。
|
||||
|
||||
### 调试小贴士
|
||||
|
||||
#### 内核
|
||||
|
||||
GDB 是你的朋友。使用 `qemu-gdb target`(或它的变体 `qemu-gdb-nox`)使 QEMU 等待 GDB 去绑定。下面在调试内核时用到的一些命令,可以去查看 GDB 的资料。
|
||||
|
||||
如果你遭遇意外的中断、异常、或三重故障,你可以使用 `-d` 参数要求 QEMU 去产生一个详细的中断日志。
|
||||
|
||||
调试虚拟内存问题时,尝试 QEMU 的监视命令 `info mem`(提供内存高级概述)或 `info pg`(提供更多细节内容)。注意,这些命令仅显示**当前**页表。
|
||||
|
||||
(在实验 4 以后)去调试多个 CPU 时,使用 GDB 的线程相关命令,比如 `thread` 和 `info threads`。
|
||||
|
||||
#### 用户环境(在实验 3 以后)
|
||||
|
||||
GDB 也可以去调试用户环境,但是有些事情需要注意,因为 GDB 无法区分开多个用户环境或区分开用户环境与内核环境。
|
||||
|
||||
你可以使用 `make run-name`(或编辑 `kern/init.c` 目录)来指定 JOS 启动的用户环境,为使 QEMU 等待 GDB 去绑定,使用 `run-name-gdb` 的变体。
|
||||
|
||||
你可以符号化调试用户代码,就像调试内核代码一样,但是你要告诉 GDB,哪个符号表用到符号文件命令上,因为它一次仅能够使用一个符号表。提供的 `.gdbinit` 用于加载内核符号表 `obj/kern/kernel`。对于一个用户环境,这个符号表在它的 ELF 二进制文件中,因此你可以使用 `symbol-file obj/user/name` 去加载它。不要从任何 `.o` 文件中加载符号,因为它们不会被链接器迁移进去(库是静态链接进 JOS 用户二进制文件中的,因此这些符号已经包含在每个用户二进制文件中了)。确保你得到了正确的用户二进制文件;在不同的二进制文件中,库函数被链接为不同的 EIP,而 GDB 并不知道更多的内容!
|
||||
|
||||
(在实验 4 以后)因为 GDB 绑定了整个虚拟机,所以它可以将时钟中断看作为一种控制转移。这使得从底层上不可能实现步进用户代码,因为一个时钟中断无形中保证了片刻之后虚拟机可以再次运行。因此可以使用 `stepi` 命令,因为它阻止了中断,但它仅可以步进一个汇编指令。断点一般来说可以正常工作,但要注意,因为你可能在不同的环境(完全不同的一个二进制文件)上遇到同一个 EIP。
|
||||
|
||||
### 参考
|
||||
|
||||
#### JOS makefile
|
||||
|
||||
JOS 的 GNUmakefile 包含了在各种方式中运行的 JOS 的许多假目标。所有这些目标都配置 QEMU 去监听 GDB 连接(`*-gdb` 目标也等待这个连接)。要在运行中的 QEMU 上启动它,只需要在你的实验目录中简单地运行 `gdb ` 即可。我们提供了一个 `.gdbinit` 文件,它可以在 QEMU 中自动指向到 GDB、加载内核符号文件、以及在 16 位和 32 位模式之间切换。退出 GDB 将关闭 QEMU。
|
||||
|
||||
* `make qemu`
|
||||
|
||||
在一个新窗口中构建所有的东西并使用 VGA 控制台和你的终端中的串行控制台启动 QEMU。想退出时,既可以关闭 VGA 窗口,也可以在你的终端中按 `Ctrl-c` 或 `Ctrl-a x`。
|
||||
* `make qemu-nox`
|
||||
|
||||
和 `make qemu` 一样,但仅使用串行控制台来运行。想退出时,按下 `Ctrl-a x`。这种方式在通过 SSH 拨号连接到 Athena 上时非常有用,因为 VGA 窗口会占用许多带宽。
|
||||
* `make qemu-gdb`
|
||||
|
||||
和 `make qemu` 一样,但它与任意时间被动接受 GDB 不同,而是暂停第一个机器指令并等待一个 GDB 连接。
|
||||
* `make qemu-nox-gdb`
|
||||
|
||||
它是 `qemu-nox` 和 `qemu-gdb` 目标的组合。
|
||||
* `make run-nam`
|
||||
|
||||
(在实验 3 以后)运行用户程序 _name_。例如,`make run-hello` 运行 `user/hello.c`。
|
||||
* `make run-name-nox`,`run-name-gdb`, `run-name-gdb-nox`
|
||||
|
||||
(在实验 3 以后)与 `qemu` 目标变量对应的 `run-name` 的变体。
|
||||
|
||||
makefile 也接受几个非常有用的变量:
|
||||
|
||||
* `make V=1 …`
|
||||
|
||||
详细模式。输出正在运行的每个命令,包括参数。
|
||||
* `make V=1 grade`
|
||||
|
||||
在评级测试失败后停止,并将 QEMU 的输出放入 `jos.out` 文件中以备检查。
|
||||
* `make QEMUEXTRA=' _args_ ' …`
|
||||
|
||||
指定传递给 QEMU 的额外参数。
|
||||
|
||||
#### JOS obj/
|
||||
|
||||
在构建 JOS 时,makefile 也产生一些额外的输出文件,这些文件在调试时非常有用:
|
||||
|
||||
* `obj/boot/boot.asm`、`obj/kern/kernel.asm`、`obj/user/hello.asm`、等等。
|
||||
|
||||
引导加载器、内核、和用户程序的汇编代码列表。
|
||||
* `obj/kern/kernel.sym`、`obj/user/hello.sym`、等等。
|
||||
|
||||
内核和用户程序的符号表。
|
||||
* `obj/boot/boot.out`、`obj/kern/kernel`、`obj/user/hello`、等等。
|
||||
|
||||
内核和用户程序链接的 ELF 镜像。它们包含了 GDB 用到的符号信息。
|
||||
|
||||
#### GDB
|
||||
|
||||
完整的 GDB 命令指南请查看 [GDB 手册][1]。下面是一些在 6.828 课程中非常有用的命令,它们中的一些在操作系统开发之外的领域几乎用不到。
|
||||
|
||||
* `Ctrl-c`
|
||||
|
||||
在当前指令处停止机器并打断进入到 GDB。如果 QEMU 有多个虚拟的 CPU,所有的 CPU 都会停止。
|
||||
* `c`(或 `continue`)
|
||||
|
||||
继续运行,直到下一个断点或 `Ctrl-c`。
|
||||
* `si`(或 `stepi`)
|
||||
|
||||
运行一个机器指令。
|
||||
* `b function` 或 `b file:line`(或 `breakpoint`)
|
||||
|
||||
在给定的函数或行上设置一个断点。
|
||||
* `b * addr`(或 `breakpoint`)
|
||||
|
||||
在 EIP 的 addr 处设置一个断点。
|
||||
* `set print pretty`
|
||||
|
||||
启用数组和结构的美化输出。
|
||||
* `info registers`
|
||||
|
||||
输出通用寄存器 `eip`、`eflags`、和段选择器。更多更全的机器寄存器状态转储,查看 QEMU 自己的 `info registers` 命令。
|
||||
* `x/ N x addr`
|
||||
|
||||
以十六进制显示虚拟地址 addr 处开始的 N 个词的转储。如果 N 省略,默认为 1。addr 可以是任何表达式。
|
||||
* `x/ N i addr`
|
||||
|
||||
显示从 addr 处开始的 N 个汇编指令。使用 `$eip` 作为 addr 将显示当前指令指针寄存器中的指令。
|
||||
* `symbol-file file`
|
||||
|
||||
(在实验 3 以后)切换到符号文件 file 上。当 GDB 绑定到 QEMU 后,它并不是虚拟机中进程边界内的一部分,因此我们要去告诉它去使用哪个符号。默认情况下,我们配置 GDB 去使用内核符号文件 `obj/kern/kernel`。如果机器正在运行用户代码,比如是 `hello.c`,你就需要使用 `symbol-file obj/user/hello` 去切换到 hello 的符号文件。
|
||||
|
||||
QEMU 将每个虚拟 CPU 表示为 GDB 中的一个线程,因此你可以使用 GDB 中所有的线程相关的命令去查看或维护 QEMU 的虚拟 CPU。
|
||||
|
||||
* `thread n`
|
||||
|
||||
GDB 在一个时刻只关注于一个线程(即:CPU)。这个命令将关注的线程切换到 n,n 是从 0 开始编号的。
|
||||
* `info threads`
|
||||
|
||||
列出所有的线程(即:CPU),包括它们的状态(活动还是停止)和它们在什么函数中。
|
||||
|
||||
|
||||
#### QEMU
|
||||
|
||||
QEMU 包含一个内置的监视器,它能够有效地检查和修改机器状态。想进入到监视器中,在运行 QEMU 的终端中按入 `Ctrl-a c` 即可。再次按下 `Ctrl-a c` 将切换回串行控制台。
|
||||
|
||||
监视器命令的完整参考资料,请查看 [QEMU 手册][2]。下面是 6.828 课程中用到的一些有用的命令:
|
||||
|
||||
* `xp/ N x paddr`
|
||||
|
||||
显示从物理地址 paddr 处开始的 N 个词的十六进制转储。如果 N 省略,默认为 1。这是 GDB 的 `x` 命令模拟的物理内存。
|
||||
* `info registers`
|
||||
|
||||
显示机器内部寄存器状态的一个完整转储。实践中,对于段选择器,这将包含机器的 _隐藏_ 段状态和局部、全局、和中断描述符表加任务状态寄存器。隐藏状态是在加载段选择器后,虚拟的 CPU 从 GDT/LDT 中读取的信息。下面是实验 1 中 JOS 内核处于运行中时的 CS 信息和每个字段的含义:
|
||||
|
||||
```c
|
||||
CS =0008 10000000 ffffffff 10cf9a00 DPL=0 CS32 [-R-]
|
||||
```
|
||||
|
||||
* `CS =0008`
|
||||
|
||||
代码选择器可见部分。我们使用段 0x8。这也告诉我们参考全局描述符表(0x8&4=0),并且我们的 CPL(当前权限级别)是 0x8&3=0。
|
||||
* `10000000`
|
||||
|
||||
这是段基址。线性地址 = 逻辑地址 + 0x10000000。
|
||||
* `ffffffff`
|
||||
|
||||
这是段限制。访问线性地址 0xffffffff 以上将返回段违规异常。
|
||||
* `10cf9a00`
|
||||
|
||||
段的原始标志,QEMU 将在接下来的几个字段中解码这些对我们有用的标志。
|
||||
* `DPL=0`
|
||||
|
||||
段的权限级别。一旦代码以权限 0 运行,它将就能够加载这个段。
|
||||
* `CS32`
|
||||
|
||||
这是一个 32 位代码段。对于数据段(不要与 DS 寄存器混淆了),另外的值还包括 `DS`,而对于本地描述符表是 `LDT`。
|
||||
* `[-R-]`
|
||||
|
||||
这个段是只读的。
|
||||
|
||||
* `info mem`
|
||||
|
||||
(在实验 2 以后)显示映射的虚拟内存和权限。比如:
|
||||
|
||||
```
|
||||
ef7c0000-ef800000 00040000 urw
|
||||
efbf8000-efc00000 00008000 -rw
|
||||
```
|
||||
|
||||
这告诉我们从 0xef7c0000 到 0xef800000 的 0x00040000 字节的内存被映射为读取/写入/用户可访问,而映射在 0xefbf8000 到 0xefc00000 之间的内存权限是读取/写入,但是仅限于内核可访问。
|
||||
|
||||
* `info pg`
|
||||
|
||||
(在实验 2 以后)显示当前页表结构。它的输出类似于 `info mem`,但与页目录条目和页表条目是有区别的,并且为每个条目给了单独的权限。重复的 PTE 和整个页表被折叠为一个单行。例如:
|
||||
|
||||
```
|
||||
VPN range Entry Flags Physical page
|
||||
[00000-003ff] PDE[000] -------UWP
|
||||
[00200-00233] PTE[200-233] -------U-P 00380 0037e 0037d 0037c 0037b 0037a ..
|
||||
[00800-00bff] PDE[002] ----A--UWP
|
||||
[00800-00801] PTE[000-001] ----A--U-P 0034b 00349
|
||||
[00802-00802] PTE[002] -------U-P 00348
|
||||
```
|
||||
|
||||
这里各自显示了两个页目录条目、虚拟地址范围 0x00000000 到 0x003fffff 以及 0x00800000 到 0x00bfffff。 所有的 PDE 都存在于内存中、可写入、并且用户可访问,而第二个 PDE 也是可访问的。这些页表中的第二个映射了三个页、虚拟地址范围 0x00800000 到 0x00802fff,其中前两个页是存在于内存中的、可写入、并且用户可访问的,而第三个仅存在于内存中,并且用户可访问。这些 PTE 的第一个条目映射在物理页 0x34b 处。
|
||||
|
||||
QEMU 也有一些非常有用的命令行参数,使用 `QEMUEXTRA` 变量可以将参数传递给 JOS 的 makefile。
|
||||
|
||||
* `make QEMUEXTRA='-d int' ...`
|
||||
|
||||
记录所有的中断和一个完整的寄存器转储到 `qemu.log` 文件中。你可以忽略前两个日志条目、“SMM: enter” 和 “SMM: after RMS”,因为这些是在进入引导加载器之前生成的。在这之后的日志条目看起来像下面这样:
|
||||
|
||||
```
|
||||
4: v=30 e=0000 i=1 cpl=3 IP=001b:00800e2e pc=00800e2e SP=0023:eebfdf28 EAX=00000005
|
||||
EAX=00000005 EBX=00001002 ECX=00200000 EDX=00000000
|
||||
ESI=00000805 EDI=00200000 EBP=eebfdf60 ESP=eebfdf28
|
||||
...
|
||||
```
|
||||
|
||||
第一行描述了中断。`4:` 只是一个日志记录计数器。`v` 提供了十六进程的向量号。`e` 提供了错误代码。`i=1` 表示它是由一个 `int` 指令(相对一个硬件产生的中断而言)产生的。剩下的行的意思很明显。对于一个寄存器转储而言,接下来看到的就是寄存器信息。
|
||||
|
||||
注意:如果你运行的是一个 0.15 版本之前的 QEMU,日志将写入到 `/tmp` 目录,而不是当前目录下。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labguide.html
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://sourceware.org/gdb/current/onlinedocs/gdb/
|
||||
[2]: http://wiki.qemu.org/download/qemu-doc.html#pcsys_005fmonitor
|
||||
@ -1,34 +1,35 @@
|
||||
IssueHunt:一个新的开源软件打赏平台
|
||||
======
|
||||
许多开源开发者和公司都在努力解决的问题之一就是资金问题。社区中有一种假想,甚至是期望,必须免费提供自由和开源软件。但即使是 FOSS 也需要资金来继续开发。如果我们不建立让软件持续开发的系统,我们怎能期待更高质量的软件?
|
||||
|
||||
我们已经写了一篇关于[开源资金平台][1]的文章来试图解决这个缺点,截至今年 7 月,市场上出现了一个新的竞争者,旨在帮助填补这个空白:[IssueHunt][2] 。
|
||||
![IssueHunt][4]
|
||||
|
||||
许多开源开发者和公司都在努力解决的问题之一就是资金问题。社区中有一种假想,甚至是期望,必须免费提供自由开源软件(FOSS)。但即使是 FOSS 也需要资金来继续开发。如果我们不建立让软件持续开发的系统,我们怎能期待更高质量的软件?
|
||||
|
||||
我们已经写了一篇关于[开源资金平台][1]的文章来试图解决这个缺点,截至今年 7 月,市场上出现了一个新的竞争者,旨在帮助填补这个空白:[IssueHunt][2]。
|
||||
|
||||
### IssueHunt: 开源软件打赏平台
|
||||
|
||||
![IssueHunt website][3]
|
||||
|
||||
IssueHunt 提供了一种服务,支付自由开发者对开源代码的贡献。它通过所谓的赏金来实现:给予解决特定问题的任何人财务奖励。这些奖励的资金来自任何愿意捐赠以修复任何特定 bug 或添加功能的人。
|
||||
IssueHunt 提供了一种服务,对自由开发者的开源代码贡献进行支付。它通过所谓的赏金来实现:给予解决特定问题的任何人财务奖励。这些奖励的资金来自任何愿意捐赠以修复任何特定 bug 或添加功能的人。
|
||||
|
||||
如果你想修复的某个开源软件存在问题,你可以根据自己选择的方式提供奖励金额。
|
||||
|
||||
想要自己的产品被争抢解决么?在 IssueHunt 上向任何解决问题的人提供奖金就好了。就这么简单。
|
||||
|
||||
如果你是程序员,则可以浏览未解决的问题。解决这个问题(如果你可以的话),在 GitHub 存储库上提交 pull request,如果你的 pull request 被合并,那么你就会得到了钱。
|
||||
如果你是程序员,则可以浏览未解决的问题。解决这个问题(如果你可以的话),在 GitHub 存储库上提交拉取请求,如果你的拉取请求被合并,那么你就会得到了钱。
|
||||
|
||||
#### IssueHunt 最初是 Boostnote 的内部项目
|
||||
|
||||
![IssueHunt][4]
|
||||
|
||||
当笔记应用 [Boostnote][5] 背后的开发人员联系社区为他们的产品做出贡献时,该产品出现了。
|
||||
|
||||
在使用 IssueHunt 的前两年,Boostnote 通过数百名贡献者和压倒性的捐款收到了超过 8,400 个 Github star。
|
||||
|
||||
该产品非常成功,团队决定将其开放给社区的其他成员。
|
||||
|
||||
今天,[列表中在使用这个服务的项目][6]提供了数千美元的赏金。
|
||||
如今,[列表中在使用这个服务的项目][6]提供了数千美元的赏金。
|
||||
|
||||
Boostnote 号称有 [$2,800 的总赏金] [7],而 Settings Sync,以前称为 Visual Studio Code Settings Sync,提供了[超过 $1,600 的赏金][8]。
|
||||
Boostnote 号称有 [$2,800 的总赏金][7],而 Settings Sync,以前称为 Visual Studio Code Settings Sync,提供了[超过 $1,600 的赏金][8]。
|
||||
|
||||
还有其他服务提供类似于 IssueHunt 在此提供的内容。也许最引人注目的是 [Bountysource][9],它提供与 IssueHunt 类似的赏金服务,同时还提供类似于 [Librepay][10] 的订阅支付处理。
|
||||
|
||||
@ -36,7 +37,7 @@ Boostnote 号称有 [$2,800 的总赏金] [7],而 Settings Sync,以前称为
|
||||
|
||||
在撰写本文时,IssueHunt 还处于起步阶段,但我非常高兴看到这个项目在这些年里的成果。
|
||||
|
||||
我不了解你,但我非常乐意为 FOSS 付款。如果产品质量高,并为我的生活增添价值,那么我很乐意向开发者支付产品费用。特别是 FOSS 的开发者正在创造尊重我自由的产品。
|
||||
我不知道你会怎么看,但我非常乐意为 FOSS 付款。如果产品质量高,并为我的生活增添价值,那么我很乐意向开发者支付产品费用。特别是 FOSS 的开发者正在创造尊重我自由的产品。
|
||||
|
||||
话虽如此,我一定会关注 IssueHunt 的继续前进,我可以用自己的钱或者在需要贡献的地方传播这个它来支持社区。
|
||||
|
||||
@ -49,15 +50,15 @@ via: https://itsfoss.com/issuehunt/
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/phillip/
|
||||
[1]: https://itsfoss.com/open-source-funding-platforms/
|
||||
[2]: https://issuehunt.io
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/issuehunt-website.png
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/issuehunt.jpg
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/09/issuehunt-website.png?w=799&ssl=1
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/09/issuehunt.jpg?w=800&ssl=1
|
||||
[5]: https://itsfoss.com/boostnote-linux-review/
|
||||
[6]: https://issuehunt.io/repos
|
||||
[7]: https://issuehunt.io/repos/53266139
|
||||
@ -1,13 +1,13 @@
|
||||
使用 Pandoc 将你的书转换成网页和电子书
|
||||
======
|
||||
|
||||
通过 Markdown 和 Pandoc,可以做到编写一次,发布两次。
|
||||
> 通过 Markdown 和 Pandoc,可以做到编写一次,发布两次。
|
||||
|
||||

|
||||
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。在我的 [Pandoc 简介][1] 一文中,我演示了如何把 Markdown 编写的文本转换为网页、幻灯片和 PDF。
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。在我 [对 Pandoc 的简介][1] 一文中,我演示了如何把 Markdown 编写的文本转换为网页、幻灯片和 PDF。
|
||||
|
||||
在这篇后续文章中,我将深入探讨 [Pandoc][2],展示如何从同一 Markdown 源文件生成网页和 ePub 格式的电子书。我将使用我即将发布的电子书-- [面向对象思想的 GRASP 原则][3] 为例进行讲解,这本电子书正是通过以下过程创建的。
|
||||
在这篇后续文章中,我将深入探讨 [Pandoc][2],展示如何从同一个 Markdown 源文件生成网页和 ePub 格式的电子书。我将使用我即将发布的电子书《[面向对象思想的 GRASP 原则][3]》为例进行讲解,这本电子书正是通过以下过程创建的。
|
||||
|
||||
首先,我将解释这本书使用的文件结构,然后介绍如何使用 Pandoc 生成网页并将其部署在 GitHub 上;最后,我演示了如何生成对应的 ePub 格式电子书。
|
||||
|
||||
@ -15,7 +15,7 @@ Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为
|
||||
|
||||
### 设置图书结构
|
||||
|
||||
我用 Markdown 语法完成了所有的写作,你也可以使用 HTML,但是当 Pandoc 将 Markdown 转换为 ePub 文档时,引入的 HTML 越多,出现问题的风险就越高。我的书按照每章一个文件的形式进行组织,用 Markdown 的 `H1` 标记(`#`)声明每章的标题。你也可以在每个文件中放置多个章节,但将它们放在单独的文件中可以更轻松地查找内容并在以后进行更新。
|
||||
我用 Markdown 语法完成了所有的写作,你也可以使用 HTML 标记,但是当 Pandoc 将 Markdown 转换为 ePub 文档时,引入的 HTML 标记越多,出现问题的风险就越高。我的书按照每章一个文件的形式进行组织,用 Markdown 的 `H1` 标记(`#`)声明每章的标题。你也可以在每个文件中放置多个章节,但将它们放在单独的文件中可以更轻松地查找内容并在以后进行更新。
|
||||
|
||||
元信息遵循类似的模式,每种输出格式都有自己的元信息文件。元信息文件定义有关文档的信息,例如要添加到 HTML 中的文本或 ePub 的许可证。我将所有 Markdown 文档存储在名为 `parts` 的文件夹中(这对于用来生成网页和 ePub 的 Makefile 非常重要)。下面以一个例子进行说明,让我们看一下目录,前言和关于本书(分为 `toc.md`、`preface.md` 和 `about.md` 三个文件)这三部分,为清楚起见,我们将省略其余的章节。
|
||||
|
||||
@ -48,60 +48,60 @@ author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
header-includes:
|
||||
- |
|
||||
\```{=html}
|
||||
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
|
||||
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
|
||||
\```
|
||||
```{=html}
|
||||
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
|
||||
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
|
||||
```
|
||||
include-before:
|
||||
- |
|
||||
\```{=html}
|
||||
<p>If you like this book, please consider
|
||||
spreading the word or
|
||||
<a href="https://www.buymeacoffee.com/programming">
|
||||
buying me a coffee
|
||||
</a>
|
||||
</p>
|
||||
\```
|
||||
```{=html}
|
||||
<p>If you like this book, please consider
|
||||
spreading the word or
|
||||
<a href="https://www.buymeacoffee.com/programming">
|
||||
buying me a coffee
|
||||
</a>
|
||||
</p>
|
||||
```
|
||||
include-after:
|
||||
- |
|
||||
```{=html}
|
||||
<div class="footnotes">
|
||||
<hr>
|
||||
<div class="container">
|
||||
<nav class="pagination" role="pagination">
|
||||
<ul>
|
||||
<p>
|
||||
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
|
||||
</p>
|
||||
<p>
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
</p>
|
||||
</ul>
|
||||
</nav>
|
||||
</div>
|
||||
</div>
|
||||
\```
|
||||
---:
|
||||
```{=html}
|
||||
<div class="footnotes">
|
||||
<hr>
|
||||
<div class="container">
|
||||
<nav class="pagination" role="pagination">
|
||||
<ul>
|
||||
<p>
|
||||
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
|
||||
</p>
|
||||
<p>
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
</p>
|
||||
</ul>
|
||||
</nav>
|
||||
</div>
|
||||
</div>
|
||||
```
|
||||
---
|
||||
```
|
||||
|
||||
下面几个变量需要注意一下:
|
||||
|
||||
- `header-includes` 变量包含将要嵌入 `<head>` 标签的 HTML 文本。
|
||||
- 调用变量后的下一行必须是 `- |`。再往下一行必须以与`|`对齐的三个反引号开始,否则 Pandoc 将无法识别。`{= html}` 告诉 Pandoc 其中的内容是原始文本,不应该作为 Markdown 处理。(为此,需要检查 Pandoc 中的 `raw_attribute` 扩展是否已启用。要进行此检查,键入 `pandoc --list-extensions | grep raw` 并确保返回的列表包含名为 `+ raw_html` 的项目,加号表示已启用。)
|
||||
- 变量 `include-before` 在网页开头添加一些 HTML 文本,此处我要求读者帮忙宣传我的书或给我打赏。
|
||||
- 调用变量后的下一行必须是 `- |`。再往下一行必须以与 `|` 对齐的三个反引号开始,否则 Pandoc 将无法识别。`{= html}` 告诉 Pandoc 其中的内容是原始文本,不应该作为 Markdown 处理。(为此,需要检查 Pandoc 中的 `raw_attribute` 扩展是否已启用。要进行此检查,键入 `pandoc --list-extensions | grep raw` 并确保返回的列表包含名为 `+ raw_html` 的项目,加号表示已启用。)
|
||||
- 变量 `include-before` 在网页开头添加一些 HTML 文本,此处我请求读者帮忙宣传我的书或给我打赏。
|
||||
- `include-after` 变量在网页末尾添加原始 HTML 文本,同时显示我的图书许可证。
|
||||
|
||||
这些只是其中一部分可用的变量,查看 HTML 中的模板变量(我的文章 [Pandoc简介][1] 中介绍了如何查看 LaTeX 的模版变量,查看 HTML 模版变量的过程是相同的)对其余变量进行了解。
|
||||
|
||||
#### 将网页分成多章
|
||||
|
||||
网页可以作为一个整体生成,这会产生一个包含所有内容的长页面;也可以分成多章,我认为这样会更容易阅读。 我将解释如何将网页划分为多章,以便读者不会被长网页吓到。
|
||||
网页可以作为一个整体生成,这会产生一个包含所有内容的长页面;也可以分成多章,我认为这样会更容易阅读。我将解释如何将网页划分为多章,以便读者不会被长网页吓到。
|
||||
|
||||
为了使网页易于在 GitHub Pages 上部署,需要创建一个名为 `docs` 的根文件夹(这是 GitHub Pages 默认用于渲染网页的根文件夹)。然后我们需要为 `docs` 下的每一章创建文件夹,将 HTML 内容放在各自的文件夹中,将文件内容放在名为 `index.html` 的文件中。
|
||||
|
||||
例如,`about.md` 文件将转换成名为 `index.html` 的文件,该文件位于名为 `about`(`about/index.html`)的文件夹中。这样,当用户键入 `http://<your-website.com>/about/` 时,文件夹中的 `index.html` 文件将显示在其浏览器中。
|
||||
|
||||
下面的 Makefile 将执行上述所有操作:
|
||||
下面的 `Makefile` 将执行上述所有操作:
|
||||
|
||||
```
|
||||
# Your book files
|
||||
@ -149,6 +149,7 @@ clean:
|
||||
```
|
||||
make
|
||||
```
|
||||
|
||||
根文件夹现在应该包含如下所示的文件结构:
|
||||
|
||||
```
|
||||
@ -200,7 +201,7 @@ stylesheet: assets/epub.css
|
||||
...
|
||||
```
|
||||
|
||||
将以下内容添加到之前的 Makefile 中:
|
||||
将以下内容添加到之前的 `Makefile` 中:
|
||||
|
||||
```
|
||||
epub:
|
||||
@ -208,7 +209,7 @@ epub:
|
||||
$(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
用于产生 ePub 格式图书的命令从 HTML 版本获取所有依赖项(每章的名称),向它们添加 Markdown 扩展,并在它们前面加上每一章的文件夹路径,以便让 Pandoc 知道如何进行处理。例如,如果 `$(DEPENDENCIES` 变量只包含 “前言” 和 “关于本书” 两章,那么 Makefile 将会这样调用:
|
||||
用于产生 ePub 格式图书的命令从 HTML 版本获取所有依赖项(每章的名称),向它们添加 Markdown 扩展,并在它们前面加上每一章的文件夹路径,以便让 Pandoc 知道如何进行处理。例如,如果 `$(DEPENDENCIES` 变量只包含 “前言” 和 “关于本书” 两章,那么 `Makefile` 将会这样调用:
|
||||
|
||||
```
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
@ -226,18 +227,17 @@ Pandoc 将提取这两章的内容,然后进行组合,最后生成 ePub 格
|
||||
- HTML 图书:
|
||||
- 使用 Markdown 语法创建每章内容
|
||||
- 添加元信息
|
||||
- 创建一个 Makefile 将各个部分组合在一起
|
||||
- 创建一个 `Makefile` 将各个部分组合在一起
|
||||
- 设置 GitHub Pages
|
||||
- 部署
|
||||
- ePub 电子书:
|
||||
- 使用之前创建的每一章内容
|
||||
- 添加新的元信息文件
|
||||
- 创建一个 Makefile 以将各个部分组合在一起
|
||||
- 创建一个 `Makefile` 以将各个部分组合在一起
|
||||
- 设置 GitHub Pages
|
||||
- 部署
|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
|
||||
@ -245,12 +245,12 @@ via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kikofernandez
|
||||
[1]: https://opensource.com/article/18/9/intro-pandoc
|
||||
[1]: https://linux.cn/article-10228-1.html
|
||||
[2]: https://pandoc.org/
|
||||
[3]: https://www.programmingfightclub.com/
|
||||
[4]: https://github.com/kikofernandez/programmingfightclub
|
||||
@ -1,42 +1,42 @@
|
||||
|
||||
Greg Kroah-Hartman 解释内核社区如何保护 Linux
|
||||
============================================================
|
||||
Greg Kroah-Hartman 解释内核社区是如何使 Linux 安全的
|
||||
============
|
||||
|
||||

|
||||
内核维护者 Greg Kroah-Hartman 谈论内核社区如何保护 Linux 不遭受损害。[Creative Commons Zero][2]
|
||||
|
||||
由于 Linux 使用量持续扩大,内核社区去提高全世界最广泛使用的技术 — Linux 内核的安全性的重要程序越来越高。安全不仅对企业客户很重要,它对消费者也很重要,因为 80% 的移动设备都使用了 Linux。在本文中,Linux 内核维护者 Greg Kroah-Hartman 带我们了解内核社区如何应对威胁。
|
||||
> 内核维护者 Greg Kroah-Hartman 谈论内核社区如何保护 Linux 不遭受损害。
|
||||
|
||||
由于 Linux 使用量持续扩大,内核社区去提高这个世界上使用最广泛的技术 —— Linux 内核的安全性的重要性越来越高。安全不仅对企业客户很重要,它对消费者也很重要,因为 80% 的移动设备都使用了 Linux。在本文中,Linux 内核维护者 Greg Kroah-Hartman 带我们了解内核社区如何应对威胁。
|
||||
|
||||
### bug 不可避免
|
||||
|
||||
|
||||

|
||||
|
||||
Greg Kroah-Hartman [Linux 基金会][1]
|
||||
*Greg Kroah-Hartman [Linux 基金会][1]*
|
||||
|
||||
正如 Linus Torvalds 曾经说过,大多数安全问题都是 bug 造成的,而 bug 又是软件开发过程的一部分。是个软件就有 bug。
|
||||
正如 Linus Torvalds 曾经说过的,大多数安全问题都是 bug 造成的,而 bug 又是软件开发过程的一部分。是软件就有 bug。
|
||||
|
||||
Kroah-Hartman 说:“就算是 bug ,我们也不知道它是安全的 bug 还是不安全的 bug。我修复的一个著名 bug,在三年后才被 Red Hat 认定为安全漏洞“。
|
||||
Kroah-Hartman 说:“就算是 bug,我们也不知道它是安全的 bug 还是不安全的 bug。我修复的一个著名 bug,在三年后才被 Red Hat 认定为安全漏洞“。
|
||||
|
||||
在消除 bug 方面,内核社区没有太多的办法,只能做更多的测试来寻找 bug。内核社区现在已经有了自己的安全团队,它们是由熟悉内核核心的内核开发者组成。
|
||||
|
||||
Kroah Hartman 说:”当我们收到一个报告时,我们就让参与这个领域的核心开发者去修复它。在一些情况下,他们可能是同一个人,让他们进入安全团队可以更快地解决问题“。但他也强调,内核所有部分的开发者都必须清楚地了解这些问题,因为内核是一个可信环境,它必须被保护起来。
|
||||
Kroah-Hartman 说:”当我们收到一个报告时,我们就让参与这个领域的核心开发者去修复它。在一些情况下,他们可能是同一个人,让他们进入安全团队可以更快地解决问题“。但他也强调,内核所有部分的开发者都必须清楚地了解这些问题,因为内核是一个可信环境,它必须被保护起来。
|
||||
|
||||
Kroah Hartman 说:”一旦我们修复了它,我们就将它放到我们的栈分析规则中,以便于以后不再重新出现这个 bug。“
|
||||
Kroah-Hartman 说:”一旦我们修复了它,我们就将它放到我们的栈分析规则中,以便于以后不再重新出现这个 bug。“
|
||||
|
||||
除修复 bug 之外,内核社区也不断加固内核。Kroah Hartman 说:“我们意识到,我们需要一些主动的缓减措施。因此我们需要加固内核。”
|
||||
除修复 bug 之外,内核社区也不断加固内核。Kroah-Hartman 说:“我们意识到,我们需要一些主动的缓减措施,因此我们需要加固内核。”
|
||||
|
||||
Kees Cook 和其他一些人付出了巨大的努力,带来了一直在内核之外的加固特性,并将它们合并或适配到内核中。在每个内核发行后,Cook 都对所有新的加固特性做一个总结。但是只加固内核是不够的,供应商必须要启用这些新特性来让它们充分发挥作用。但他们并没有这么做。
|
||||
Kees Cook 和其他一些人付出了巨大的努力,带来了一直在内核之外的加固特性,并将它们合并或适配到内核中。在每个内核发行后,Cook 都对所有新的加固特性做一个总结。但是只加固内核是不够的,供应商们必须要启用这些新特性来让它们充分发挥作用,但他们并没有这么做。
|
||||
|
||||
Kroah-Hartman [每周发布一个稳定版内核][5],而为了长周期的支持,公司只从中挑选一个,以便于设备制造商能够利用它。但是,Kroah-Hartman 注意到,除了 Google Pixel 之外,大多数 Android 手机并不包含这些额外的安全加固特性,这就意味着,所有的这些手机都是有漏洞的。他说:“人们应该去启用这些加固特性”。
|
||||
Kroah-Hartman [每周发布一个稳定版内核][5],而为了长期的支持,公司们只从中挑选一个,以便于设备制造商能够利用它。但是,Kroah-Hartman 注意到,除了 Google Pixel 之外,大多数 Android 手机并不包含这些额外的安全加固特性,这就意味着,所有的这些手机都是有漏洞的。他说:“人们应该去启用这些加固特性”。
|
||||
|
||||
Kroah-Hartman 说:“我购买了基于 Linux 内核 4.4 的所有旗舰级手机,去查看它们中哪些确实升级了新特性。结果我发现只有一家公司升级了它们的内核”。“我在整个供应链中努力去解决这个问题,因为这是一个很棘手的问题。它涉及许多不同的组织 — SoC 制造商、运营商、等等。关键点是,需要他们把我们辛辛苦苦设计的内核去推送给大家。
|
||||
Kroah-Hartman 说:“我购买了基于 Linux 内核 4.4 的所有旗舰级手机,去查看它们中哪些确实升级了新特性。结果我发现只有一家公司升级了它们的内核。……我在整个供应链中努力去解决这个问题,因为这是一个很棘手的问题。它涉及许多不同的组织 —— SoC 制造商、运营商等等。关键点是,需要他们把我们辛辛苦苦设计的内核去推送给大家。”
|
||||
|
||||
好消息是,与消息电子产品不一样,像 Red Hat 和 SUSE 这样的大供应商,在企业环境中持续对内核进行更新。使用容器、pod、和虚拟化的现代系统做到这一点更容易了。无需停机就可以毫不费力地更新和重启。事实上,现在来保证系统安全相比过去容易多了。
|
||||
好消息是,与消费电子产品不一样,像 Red Hat 和 SUSE 这样的大供应商,在企业环境中持续对内核进行更新。使用容器、pod 和虚拟化的现代系统做到这一点更容易了。无需停机就可以毫不费力地更新和重启。事实上,现在来保证系统安全相比过去容易多了。
|
||||
|
||||
### Meltdown 和 Spectre
|
||||
|
||||
没有任何一个关于安全的讨论能够避免提及 Meltdown 和 Spectre。内核社区一直致力于修改新发现的和已查明的安全漏洞。不管怎样,Intel 已经因为这些事情改变了它们的策略。
|
||||
没有任何一个关于安全的讨论能够避免提及 Meltdown 和 Spectre 缺陷。内核社区一直致力于修改新发现的和已查明的安全漏洞。不管怎样,Intel 已经因为这些事情改变了它们的策略。
|
||||
|
||||
Kroah-Hartman 说:“他们已经重新研究如何处理安全 bug,以及如何与社区合作,因为他们知道他们做错了。内核已经修复了几乎所有大的 Spectre 问题,但是还有一些小问题仍在处理中”。
|
||||
|
||||
@ -57,7 +57,7 @@ via: https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-c
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[oska874][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||

|
||||
|
||||
几周前,Steam 宣布要给 Steam Play 增加一个新组件,用于支持在 Linux 平台上使用 Proton 来玩 Windows 的游戏,这个组件是 WINE 的一个分支。这个功能仍然处于测试阶段,且并非对所有游戏都有效。这里有一些关于 Steam 和 Proton 的细节。
|
||||
之前,Steam [宣布][1]要给 Steam Play 增加一个新组件,用于支持在 Linux 平台上使用 Proton 来玩 Windows 的游戏,这个组件是 WINE 的一个分支。这个功能仍然处于测试阶段,且并非对所有游戏都有效。这里有一些关于 Steam 和 Proton 的细节。
|
||||
|
||||
据 Steam 网站称,测试版本中有以下这些新功能:
|
||||
|
||||
@ -13,29 +13,27 @@
|
||||
* 改进了对游戏控制器的支持,游戏自动识别所有 Steam 支持的控制器,比起游戏的原始版本,能够获得更多开箱即用的控制器兼容性。
|
||||
* 和 vanilla WINE 比起来,游戏的多线程性能得到了极大的提高。
|
||||
|
||||
|
||||
|
||||
### 安装
|
||||
|
||||
如果你有兴趣,想尝试一下 Steam 和 Proton。请按照下面这些简单的步骤进行操作。(请注意,如果你已经安装了最新版本的 Steam,可以忽略启用 Steam 测试版这个第一步。在这种情况下,你不再需要通过 Steam 测试版来使用 Proton。)
|
||||
|
||||
打开 Steam 并登陆到你的帐户,这个截屏示例显示的是在使用 Proton 之前仅支持22个游戏。
|
||||
打开 Steam 并登陆到你的帐户,这个截屏示例显示的是在使用 Proton 之前仅支持 22 个游戏。
|
||||
|
||||
![][3]
|
||||
|
||||
现在点击客户端顶部的 Steam 选项,这会显示一个下拉菜单。然后选择设置。
|
||||
现在点击客户端顶部的 “Steam” 选项,这会显示一个下拉菜单。然后选择“设置”。
|
||||
|
||||
![][4]
|
||||
|
||||
现在弹出了设置窗口,选择账户选项,并在 Beta participation 旁边,点击更改。
|
||||
现在弹出了设置窗口,选择“账户”选项,并在 “参与 Beta 测试” 旁边,点击“更改”。
|
||||
|
||||
![][5]
|
||||
|
||||
现在将 None 更改为 Steam Beta Update。
|
||||
现在将 “None” 更改为 “Steam Beta Update”。
|
||||
|
||||
![][6]
|
||||
|
||||
点击确定,然后系统会提示你重新启动。
|
||||
点击“确定”,然后系统会提示你重新启动。
|
||||
|
||||
![][7]
|
||||
|
||||
@ -43,11 +41,11 @@
|
||||
|
||||
![][8]
|
||||
|
||||
在重新启动之后,返回到上面的设置窗口。这次你会看到一个新选项。确定有为提供支持的游戏使用 Stream Play 这个复选框,让所有的游戏都使用 Steam Play 进行运行,而不是 steam 中游戏特定的选项。兼容性工具应该是 Proton。
|
||||
在重新启动之后,返回到上面的设置窗口。这次你会看到一个新选项。确定勾选了“为提供支持的游戏使用 Stream Play” 、“让所有的游戏都使用 Steam Play 运行”,“使用这个工具替代 Steam 中游戏特定的选项”。这个兼容性工具应该就是 Proton。
|
||||
|
||||
![][9]
|
||||
|
||||
Steam 客户端会要求你重新启动,照做,然后重新登陆你的 Steam 账户,你的 Linux 的游戏库就能得到扩展了。
|
||||
Steam 客户端会要求你重新启动,照做,然后重新登录你的 Steam 账户,你的 Linux 的游戏库就能得到扩展了。
|
||||
|
||||
![][10]
|
||||
|
||||
@ -69,7 +67,7 @@ Steam 客户端会要求你重新启动,照做,然后重新登陆你的 Stea
|
||||
|
||||
![][16]
|
||||
|
||||
一些游戏可能会受到 Proton 测试性质的影响,在下面这个叫 Chantelise 游戏中,没有了声音并且帧率很低。请记住这个功能仍然在测试阶段,Fedora 不会对结果负责。如果你想要了解更多,社区已经创建了一个 Google 文档,这个文档里有已经测试过的游戏的列表。
|
||||
一些游戏可能会受到 Proton 测试性质的影响,在这个叫 Chantelise 游戏中,没有了声音并且帧率很低。请记住这个功能仍然在测试阶段,Fedora 不会对结果负责。如果你想要了解更多,社区已经创建了一个 Google 文档,这个文档里有已经测试过的游戏的列表。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -79,25 +77,25 @@ via: https://fedoramagazine.org/play-windows-games-steam-play-proton/
|
||||
作者:[Francisco J. Vergara Torres][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/patxi/
|
||||
[1]: https://steamcommunity.com/games/221410/announcements/detail/1696055855739350561
|
||||
[2]: https://fedoramagazine.org/third-party-repositories-fedora/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/09/listOfGamesLinux-300x197.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/09/1-300x169.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/09/2-300x196.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/09/4-300x272.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/09/6-300x237.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2018/09/7-300x126.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2018/09/10-300x237.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/09/12-300x196.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/09/13-300x196.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2018/09/14-300x195.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2018/09/15-300x196.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2018/09/16-300x195.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-14-59-300x169.png
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-19-34-300x169.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/09/listOfGamesLinux-768x505.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/09/1-768x432.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/09/2-768x503.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/09/4.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/09/6.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2018/09/7.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2018/09/10.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/09/12-768x503.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/09/13-768x501.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2018/09/14-768x498.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2018/09/15-768x501.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2018/09/16-768x500.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-14-59-768x432.png
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-19-34-768x432.png
|
||||
[17]: https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/edit#gid=1003113831
|
||||
@ -30,6 +30,8 @@ Lisp 是怎么成为上帝的编程语言的
|
||||
> 我知道,上帝偏爱那一门
|
||||
|
||||
> 名字是四个字母的语言。
|
||||
|
||||
(LCTT 译注:参见 “四个字母”,参见:[四字神名](https://zh.wikipedia.org/wiki/%E5%9B%9B%E5%AD%97%E7%A5%9E%E5%90%8D),致谢 [no1xsyzy](https://github.com/LCTT/TranslateProject/issues/11320))
|
||||
|
||||
以下这句话我实在不好在人前说;不过,我还是觉得,这样一种 “Lisp 是奥术魔法”的文化模因实在是有史以来最奇异、最迷人的东西。Lisp 是象牙塔的产物,是人工智能研究的工具;因此,它对于编程界的俗人而言总是陌生的,甚至是带有神秘色彩的。然而,当今的程序员们[开始怂恿彼此,“在你死掉之前至少试一试 Lisp”][4],就像这是一种令人恍惚入迷的致幻剂似的。尽管 Lisp 是广泛使用的编程语言中第二古老的(只比 Fortran 年轻一岁)[^1] ,程序员们也仍旧在互相怂恿。想象一下,如果你的工作是为某种组织或者团队推广一门新的编程语言的话,忽悠大家让他们相信你的新语言拥有神力难道不是绝佳的策略吗?—— 但你如何能够做到这一点呢?或者,换句话说,一门编程语言究竟是如何变成人们口中“隐晦知识的载体”的呢?
|
||||
|
||||
@ -83,7 +85,7 @@ SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日
|
||||
|
||||
*SICP 封面上的画作。*
|
||||
|
||||
说真的,这上面画的究竟是怎么一回事?为什么桌子会长着动物的腿?为什么这个女人指着桌子?墨水瓶又是干什么用的?我们是不是该说,这位巫师已经破译了宇宙的隐藏奥秘,而所有这些奥秘就蕴含在 eval/apply 循环和 Lambda 微积分之中?看似就是如此。单单是这张图片,就一定对人们如今谈论 Lisp 的方式产生了难以计量的影响。
|
||||
说真的,这上面画的究竟是怎么一回事?为什么桌子会长着动物的腿?为什么这个女人指着桌子?墨水瓶又是干什么用的?我们是不是该说,这位巫师已经破译了宇宙的隐藏奥秘,而所有这些奥秘就蕴含在 eval/apply 循环和 Lambda 演算之中?看似就是如此。单单是这张图片,就一定对人们如今谈论 Lisp 的方式产生了难以计量的影响。
|
||||
|
||||
然而,这本书的内容通常并不比封面正常多少。SICP 跟你读过的所有计算机科学教科书都不同。在引言中,作者们表示,这本书不只教你怎么用 Lisp 编程 —— 它是关于“现象的三个焦点:人的心智、复数的计算机程序,和计算机”的作品 [^19]。在之后,他们对此进行了解释,描述了他们对如下观点的坚信:编程不该被当作是一种计算机科学的训练,而应该是“<ruby>程序性认识论<rt>procedural epistemology</rt></ruby>”的一种新表达方式 [^20]。程序是将那些偶然被送入计算机的思想组织起来的全新方法。这本书的第一章简明地介绍了 Lisp,但是之后的绝大部分都在讲述更加抽象的概念。其中包括了对不同编程范式的讨论,对于面向对象系统中“时间”和“一致性”的讨论;在书中的某一处,还有关于通信的基本限制可能会如何带来同步问题的讨论 —— 而这些基本限制在通信中就像是光速不变在相对论中一样关键 [^21]。都是些高深难懂的东西。
|
||||
|
||||
@ -97,7 +99,7 @@ SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日
|
||||
|
||||
理所当然地,确定人们对 Lisp 重新燃起热情的具体时间并不可能;但这多半是保罗·格雷厄姆发表他那几篇声称 Lisp 是首选入门语言的短文之后的事了。保罗·格雷厄姆是 Y-Combinator 的联合创始人和《Hacker News》的创始者,他这几篇短文有很大的影响力。例如,在短文《<ruby>[胜于平庸][20]<rt>Beating the Averages</rt></ruby>》中,他声称 Lisp 宏使 Lisp 比其它语言更强。他说,因为他在自己创办的公司 Viaweb 中使用 Lisp,他得以比竞争对手更快地推出新功能。至少,[一部分程序员][21]被说服了。然而,庞大的主流程序员群体并未换用 Lisp。
|
||||
|
||||
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表理解。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种][22]。就如格雷厄姆之前在 2001 年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化” [^23]。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,麦卡锡写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优” [^24]。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
|
||||
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表推导式。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种][22]。就如格雷厄姆之前在 2001 年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化” [^23]。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,麦卡锡写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优” [^24]。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
什么是 SRE?它和 DevOps 是怎么关联的?
|
||||
=====
|
||||
|
||||
大型企业里 SRE 角色比较常见,不过小公司也需要 SRE。
|
||||
> 大型企业里 SRE 角色比较常见,不过小公司也需要 SRE。
|
||||
|
||||

|
||||
|
||||
虽然站点可靠性工程师(SRE)角色在近几年变得流行起来,但是很多人 —— 甚至是软件行业里的 —— 还不知道 SRE 是什么或者 SRE 都干些什么。为了搞清楚这些问题,这篇文章解释了 SRE 的含义,还有 SRE 怎样关联 DevOps,以及在工程师团队规模不大的组织里 SRE 该如何工作。
|
||||
虽然<ruby>站点可靠性工程师<rt>site reliability engineer</rt></ruby>(SRE)角色在近几年变得流行起来,但是很多人 —— 甚至是软件行业里的 —— 还不知道 SRE 是什么或者 SRE 都干些什么。为了搞清楚这些问题,这篇文章解释了 SRE 的含义,还有 SRE 怎样关联 DevOps,以及在工程师团队规模不大的组织里 SRE 该如何工作。
|
||||
|
||||
### 什么是站点可靠性工程?
|
||||
|
||||
谷歌的几个工程师写的《 [SRE:谷歌运维解密][1]》被认为是站点可靠性工程的权威书籍。谷歌的工程副总裁 Ben Treynor Sloss 在二十一世纪初[创造了这个术语][2]。他是这样定义的:“当你让软件工程师设计运维功能时,SRE 就产生了。”
|
||||
谷歌的几个工程师写的《[SRE:谷歌运维解密][1]》被认为是站点可靠性工程的权威书籍。谷歌的工程副总裁 Ben Treynor Sloss 在二十一世纪初[创造了这个术语][2]。他是这样定义的:“当你让软件工程师设计运维功能时,SRE 就产生了。”
|
||||
|
||||
虽然系统管理员从很久之前就在写代码,但是过去的很多时候系统管理团队是手动管理机器的。当时他们管理的机器可能有几十台或者上百台,不过当这个数字涨到了几千甚至几十万的时候,就不能简单的靠人去解决问题了。规模如此大的情况下,很明显应该用代码去管理机器(以及机器上运行的软件)。
|
||||
|
||||
@ -19,13 +19,13 @@
|
||||
|
||||
### SRE 和 DevOps
|
||||
|
||||
站点可靠性工程的核心,就是对 DevOps 范例的实践。[DevOps 的定义][3]有很多种方式。开发团队(“devs”)和运维(“ops”)团队相互分离的传统模式下,写代码的团队在服务交付给用户使用之后就不再对服务状态负责了。开发团队“把代码扔到墙那边”让运维团队去部署和支持。
|
||||
站点可靠性工程的核心,就是对 DevOps 范例的实践。[DevOps 的定义][3]有很多种方式。开发团队(“dev”)和运维(“ops”)团队相互分离的传统模式下,写代码的团队在将服务交付给用户使用之后就不再对服务状态负责了。开发团队“把代码扔到墙那边”让运维团队去部署和支持。
|
||||
|
||||
这种情况会导致大量失衡。开发和运维的目标总是不一致 —— 开发希望用户体验到“最新最棒”的代码,但是运维想要的是变更尽量少的稳定系统。运维是这样假定的,任何变更都可能引发不稳定,而不做任何变更的系统可以一直保持稳定。(减少软件的变更次数并不是避免故障的唯一因素,认识到这一点很重要。例如,虽然你的 web 应用保持不变,但是当用户数量涨到十倍时,服务可能就会以各种方式出问题。)
|
||||
|
||||
DevOps 理念认为通过合并这两个岗位就能够消灭争论。如果开发团队时刻都想把新代码部署上线,那么他们也必须对新代码引起的故障负责。就像亚马逊的 [Werner Vogels 说的][4]那样,“谁开发,谁运维”(生产环境)。但是开发人员已经有一大堆问题了。他们不断的被推动着去开发老板要的产品功能。再让他们去了解基础设施,包括如何部署、配置还有监控服务,这对他们的要求有点太多了。所以就需要 SRE 了。
|
||||
|
||||
开发一个 web 应用的时候经常是很多人一起参与。有用户界面设计师,图形设计师,前端工程师,后端工程师,还有许多其他工种(视技术选型的具体情况而定)。如何管理写好的代码也是需求之一(例如部署,配置,监控)—— 这是 SRE 的专业领域。但是,就像前端工程师受益于后端领域的知识一样(例如从数据库获取数据的方法),SRE 理解部署系统的工作原理,知道如何满足特定的代码或者项目的具体需求。
|
||||
开发一个 web 应用的时候经常是很多人一起参与。有用户界面设计师、图形设计师、前端工程师、后端工程师,还有许多其他工种(视技术选型的具体情况而定)。如何管理写好的代码也是需求之一(例如部署、配置、监控)—— 这是 SRE 的专业领域。但是,就像前端工程师受益于后端领域的知识一样(例如从数据库获取数据的方法),SRE 理解部署系统的工作原理,知道如何满足特定的代码或者项目的具体需求。
|
||||
|
||||
所以 SRE 不仅仅是“写代码的运维工程师”。相反,SRE 是开发团队的成员,他们有着不同的技能,特别是在发布部署、配置管理、监控、指标等方面。但是,就像前端工程师必须知道如何从数据库中获取数据一样,SRE 也不是只负责这些领域。为了提供更容易升级、管理和监控的产品,整个团队共同努力。
|
||||
|
||||
@ -37,7 +37,7 @@ DevOps 理念认为通过合并这两个岗位就能够消灭争论。如果开
|
||||
|
||||
让开发人员做 SRE 最显著的优点是,团队规模变大的时候也能很好的扩展。而且,开发人员将会全面地了解应用的特性。但是,许多初创公司的基础设施包含了各种各样的 SaaS 产品,这种多样性在基础设施上体现的最明显,因为连基础设施本身也是多种多样。然后你们在某个基础设施上引入指标系统、站点监控、日志分析、容器等等。这些技术解决了一部分问题,也增加了复杂度。开发人员除了要了解应用程序的核心技术(比如开发语言),还要了解上述所有技术和服务。最终,掌握所有的这些技术让人无法承受。
|
||||
|
||||
另一种方案是聘请专家专职做 SRE。他们专注于发布部署、配置管理、监控和指标,可以节省开发人员的时间。这种方案的缺点是,SRE 的时间必须分配给多个不同的应用(就是说 SRE 需要贯穿整个工程部门)。 这可能意味着 SRE 没时间对任何应用深入学习,然而他们可以站在一个能看到服务全貌的高度,知道各个部分是怎么组合在一起的。 这个“ 三万英尺高的视角”可以帮助 SRE 从系统整体上考虑,哪些薄弱环节需要优先修复。
|
||||
另一种方案是聘请专家专职做 SRE。他们专注于发布部署、配置管理、监控和指标,可以节省开发人员的时间。这种方案的缺点是,SRE 的时间必须分配给多个不同的应用(就是说 SRE 需要贯穿整个工程部门)。 这可能意味着 SRE 没时间对任何应用深入学习,然而他们可以站在一个能看到服务全貌的高度,知道各个部分是怎么组合在一起的。 这个“三万英尺高的视角”可以帮助 SRE 从系统整体上考虑,哪些薄弱环节需要优先修复。
|
||||
|
||||
有一个关键信息我还没提到:其他的工程师。他们可能很渴望了解发布部署的原理,也很想尽全力学会使用指标系统。而且,雇一个 SRE 可不是一件简单的事儿。因为你要找的是一个既懂系统管理又懂软件工程的人。(我之所以明确地说软件工程而不是说“能写代码”,是因为除了写代码之外软件工程还包括很多东西,比如编写良好的测试或文档。)
|
||||
|
||||
@ -54,7 +54,7 @@ via: https://opensource.com/article/18/10/sre-startup
|
||||
作者:[Craig Sebenik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[BeliteX](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,27 +1,27 @@
|
||||
让系统崩溃的黑天鹅分类
|
||||
======
|
||||
|
||||
在严重的故障发生之前,找到引起问题的异常事件,并修复它。
|
||||
> 在严重的故障发生之前,找到引起问题的异常事件,并修复它。
|
||||
|
||||

|
||||
|
||||
黑天鹅用来比喻造成严重影响的小概率事件(比如 2008 年的金融危机)。在生产环境的系统中,黑天鹅是指这样的事情:它引发了你不知道的问题,造成了重大影响,不能快速修复或回滚,也不能用值班说明书上的其他标准响应来解决。它是事发几年后你还在给新人说起的事件。
|
||||
<ruby>黑天鹅<rt>Black swan</rt></ruby>用来比喻造成严重影响的小概率事件(比如 2008 年的金融危机)。在生产环境的系统中,黑天鹅是指这样的事情:它引发了你不知道的问题,造成了重大影响,不能快速修复或回滚,也不能用值班说明书上的其他标准响应来解决。它是事发几年后你还在给新人说起的事件。
|
||||
|
||||
从定义上看,黑天鹅是不可预测的,不过有时候我们能找到其中的一些模式,针对有关联的某一类问题准备防御措施。
|
||||
|
||||
例如,大部分故障的直接原因是变更(代码、环境或配置)。虽然这种方式触发的 bug 是独特的,不可预测的,但是常见的金丝雀发布对避免这类问题有一定的作用,而且自动回滚已经成了一种标准止损策略。
|
||||
例如,大部分故障的直接原因是变更(代码、环境或配置)。虽然这种方式触发的 bug 是独特的、不可预测的,但是常见的金丝雀发布对避免这类问题有一定的作用,而且自动回滚已经成了一种标准止损策略。
|
||||
|
||||
随着我们的专业性不断成熟,一些其他的问题也正逐渐变得容易理解,被归类到某种风险并有普适的预防策略。
|
||||
|
||||
### 公布出来的黑天鹅事件
|
||||
|
||||
所有科技公司都有生产环境的故障,只不过并不是所有公司都会分享他们的事故分析。那些公开讨论事故的公司帮了我们的忙。下列事故都描述了某一类问题,但它们绝对不是只属于一个类别。我们的系统中都有黑天鹅在潜伏着,只是有些人还不知道而已。
|
||||
所有科技公司都有生产环境的故障,只不过并不是所有公司都会分享他们的事故分析。那些公开讨论事故的公司帮了我们的忙。下列事故都描述了某一类问题,但它们绝对不是只一个孤例。我们的系统中都有黑天鹅在潜伏着,只是有些人还不知道而已。
|
||||
|
||||
#### 达到上限
|
||||
|
||||
达到任何类型的限制都会引发严重事故。这类问题的一个典型例子是 2017 年 2 月 [Instapaper 的一次服务中断][1]。我把这份事故报告给任何一个运维工作者看,他们读完都会脊背发凉。Instapaper 生产环境的数据库所在的文件系统有 2 TB 的大小限制,但是数据库服务团队并不知情。在没有任何报错的情况下,数据库不再接受任何写入了。完全恢复需要好几天,而且还得迁移数据库。
|
||||
|
||||
资源限制有各式各样的触发场景。Sentry 遇到了 [Postgres 的最大事务 ID 限制][2]。Platform.sh 遇到了[管道缓冲区大小限制][3]。SparkPost [触发了 AWS 的 DDos 保护][4]。Foursquare 在他们的一个 [MongoDB 耗尽内存][5]时遭遇了性能骤降。
|
||||
资源限制有各式各样的触发场景。Sentry 遇到了 [Postgres 的最大事务 ID 限制][2]。Platform.sh 遇到了[管道缓冲区大小限制][3]。SparkPost [触发了 AWS 的 DDoS 保护][4]。Foursquare 在他们的一个 [MongoDB 耗尽内存][5]时遭遇了性能骤降。
|
||||
|
||||
提前了解系统限制的一个办法是定期做测试。好的压力测试(在生产环境的副本上做)应该包含写入事务,并且应该把每一种数据存储都写到超过当前生产环境的容量。压力测试时很容易忽略的是次要存储(比如 Zookeeper)。如果你是在测试时遇到了资源限制,那么你还有时间去解决问题。鉴于这种资源限制问题的解决方案可能涉及重大的变更(比如数据存储拆分),所以时间是非常宝贵的。
|
||||
|
||||
@ -32,7 +32,7 @@
|
||||
#### 扩散的慢请求
|
||||
|
||||
> “这个世界的关联性远比我们想象中更大。所以我们看到了更多 Nassim Taleb 所说的‘黑天鹅事件’ —— 即罕见事件以更高的频率离谱地发生了,因为世界是相互关联的”
|
||||
> — [Richard Thaler][6]
|
||||
> —— [Richard Thaler][6]
|
||||
|
||||
HostedGraphite 的负载均衡器并没有托管在 AWS 上,却[被 AWS 的服务中断给搞垮了][7],他们关于这次事故原因的分析报告很好地诠释了分布式计算系统之间存在多么大的关联。在这个事件里,负载均衡器的连接池被来自 AWS 上的客户访问占满了,因为这些连接很耗时。同样的现象还会发生在应用的线程、锁、数据库连接上 —— 任何能被慢操作占满的资源。
|
||||
|
||||
@ -40,7 +40,7 @@ HostedGraphite 的负载均衡器并没有托管在 AWS 上,却[被 AWS 的服
|
||||
|
||||
重试的间隔应该用指数退避来限制一下,并加入一些时间抖动。Square 有一次服务中断是 [Redis 存储的过载][9],原因是有一段代码对失败的事务重试了 500 次,没有任何重试退避的方案,也说明了过度重试的潜在风险。另外,针对这种情况,[断路器][10]设计模式也是有用的。
|
||||
|
||||
应该设计出监控仪表盘来清晰地展示所有资源的[使用率,饱和度和报错][11],这样才能快速发现问题。
|
||||
应该设计出监控仪表盘来清晰地展示所有资源的[使用率、饱和度和报错][11],这样才能快速发现问题。
|
||||
|
||||
#### 突发的高负载
|
||||
|
||||
@ -48,7 +48,7 @@ HostedGraphite 的负载均衡器并没有托管在 AWS 上,却[被 AWS 的服
|
||||
|
||||
在预定时刻同时发生的事件并不是突发大流量的唯一原因。Slack 经历过一次短时间内的[多次服务中断][12],原因是非常多的客户端断开连接后立即重连,造成了突发的大负载。 CircleCI 也经历过一次[严重的服务中断][13],当时 Gitlab 从故障中恢复了,所以数据库里积累了大量的构建任务队列,服务变得饱和而且缓慢。
|
||||
|
||||
几乎所有的服务都会受突发的高负载所影响。所以对这类可能出现的事情做应急预案——并测试一下预案能否正常工作——是必须的。客户端退避和[减载][14]通常是这些方案的核心。
|
||||
几乎所有的服务都会受突发的高负载所影响。所以对这类可能出现的事情做应急预案 —— 并测试一下预案能否正常工作 —— 是必须的。客户端退避和[减载][14]通常是这些方案的核心。
|
||||
|
||||
如果你的系统必须不间断地接收数据,并且数据不能被丢掉,关键是用可伸缩的方式把数据缓冲到队列中,后续再处理。
|
||||
|
||||
@ -57,7 +57,7 @@ HostedGraphite 的负载均衡器并没有托管在 AWS 上,却[被 AWS 的服
|
||||
> “复杂的系统本身就是有风险的系统”
|
||||
> —— [Richard Cook, MD][15]
|
||||
|
||||
过去几年里软件的运维操作趋势是更加自动化。任何可能降低系统容量的自动化操作(比如擦除磁盘,退役设备,关闭服务)都应该谨慎操作。这类自动化操作的故障(由于系统有 bug 或者有不正确的调用)能很快地搞垮你的系统,而且可能很难恢复。
|
||||
过去几年里软件的运维操作趋势是更加自动化。任何可能降低系统容量的自动化操作(比如擦除磁盘、退役设备、关闭服务)都应该谨慎操作。这类自动化操作的故障(由于系统有 bug 或者有不正确的调用)能很快地搞垮你的系统,而且可能很难恢复。
|
||||
|
||||
谷歌的 Christina Schulman 和 Etienne Perot 在[用安全规约协助保护你的数据中心][16]的演讲中给了一些例子。其中一次事故是将谷歌整个内部的内容分发网络(CDN)提交给了擦除磁盘的自动化系统。
|
||||
|
||||
@ -69,11 +69,11 @@ Schulman 和 Perot 建议使用一个中心服务来管理规约,限制破坏
|
||||
|
||||
### 防止黑天鹅事件
|
||||
|
||||
可能在等着击垮系统的黑天鹅可不止上面这些。有很多其他的严重问题是能通过一些技术来避免的,像金丝雀发布,压力测试,混沌工程,灾难测试和模糊测试——当然还有冗余性和弹性的设计。但是即使用了这些技术,有时候你的系统还是会有故障。
|
||||
可能在等着击垮系统的黑天鹅可不止上面这些。有很多其他的严重问题是能通过一些技术来避免的,像金丝雀发布、压力测试、混沌工程、灾难测试和模糊测试 —— 当然还有冗余性和弹性的设计。但是即使用了这些技术,有时候你的系统还是会有故障。
|
||||
|
||||
为了确保你的组织能有效地响应,在服务中断期间,请保证关键技术人员和领导层有办法沟通协调。例如,有一种你可能需要处理的烦人的事情,那就是网络完全中断。拥有故障时仍然可用的通信通道非常重要,这个通信通道要完全独立于你们自己的基础设施和基础设施的依赖。举个例子,假如你使用 AWS,那么把故障时可用的通信服务部署在 AWS 上就不明智了。在和你的主系统无关的地方,运行电话网桥或 IRC 服务器是比较好的方案。确保每个人都知道这个通信平台,并练习使用它。
|
||||
为了确保你的组织能有效地响应,在服务中断期间,请保证关键技术人员和领导层有办法沟通协调。例如,有一种你可能需要处理的烦人的事情,那就是网络完全中断。拥有故障时仍然可用的通信通道非常重要,这个通信通道要完全独立于你们自己的基础设施及对其的依赖。举个例子,假如你使用 AWS,那么把故障时可用的通信服务部署在 AWS 上就不明智了。在和你的主系统无关的地方,运行电话网桥或 IRC 服务器是比较好的方案。确保每个人都知道这个通信平台,并练习使用它。
|
||||
|
||||
另一个原则是,确保监控和运维工具对生产环境系统的依赖尽可能的少。将控制平面和数据平面分开,你才能在系统不健康的时候做变更。不要让数据处理和配置变更或监控使用同一个消息队列,比如——应该使用不同的消息队列实例。在 [SparkPost: DNS 挂掉的那一天][4] 这个演讲中,Jeremy Blosser 讲了一个这类例子,很关键的工具依赖了生产环境的 DNS 配置,但是生产环境的 DNS 出了问题。
|
||||
另一个原则是,确保监控和运维工具对生产环境系统的依赖尽可能的少。将控制平面和数据平面分开,你才能在系统不健康的时候做变更。不要让数据处理和配置变更或监控使用同一个消息队列,比如,应该使用不同的消息队列实例。在 [SparkPost: DNS 挂掉的那一天][4] 这个演讲中,Jeremy Blosser 讲了一个这类例子,很关键的工具依赖了生产环境的 DNS 配置,但是生产环境的 DNS 出了问题。
|
||||
|
||||
### 对抗黑天鹅的心理学
|
||||
|
||||
@ -83,7 +83,7 @@ Schulman 和 Perot 建议使用一个中心服务来管理规约,限制破坏
|
||||
|
||||
### 了解更多
|
||||
|
||||
关于黑天鹅(或者以前的黑天鹅)事件以及应对策略,还有很多其他的事情可以说。如果你想了解更多,我强烈推荐你去看这两本书,它们是关于生产环境中的弹性和稳定性的:Susan Fowler 写的[生产微服务][19],还有 Michael T. Nygard 的 [Release It!][20]。
|
||||
关于黑天鹅(或者以前的黑天鹅)事件以及应对策略,还有很多其他的事情可以说。如果你想了解更多,我强烈推荐你去看这两本书,它们是关于生产环境中的弹性和稳定性的:Susan Fowler 写的《[生产微服务][19]》,还有 Michael T. Nygard 的 《[Release It!][20]》。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -92,7 +92,7 @@ via: https://opensource.com/article/18/10/taxonomy-black-swans
|
||||
作者:[Laura Nolan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[BeliteX](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,40 +1,38 @@
|
||||
Android 9.0 概览
|
||||
======
|
||||
|
||||
> 第九代 Android 带来了更令人满意的用户体验。
|
||||
|
||||

|
||||
|
||||
我们来谈论一下 Android。尽管 Android 只是一款内核经过修改的 Linux,但经过多年的发展,Android 开发者们(或许包括正在阅读这篇文章的你)已经为这个平台的演变做出了很多值得称道的贡献。当然,可能很多人都已经知道,但我们还是要说,Android 并不完全开源,当你使用 Google 服务的时候,就已经接触到闭源的部分了。Google Play 商店就是其中之一,它不是一个开放的服务,不过这与 Android 是否开源没有太直接的联系,而是为了让你享用到美味、营养、高效、省电的馅饼(注:Android 9.0 代号为 Pie)。
|
||||
我们来谈论一下 Android。尽管 Android 只是一款内核经过修改的 Linux,但经过多年的发展,Android 开发者们(或许包括正在阅读这篇文章的你)已经为这个平台的演变做出了很多值得称道的贡献。当然,可能很多人都已经知道,但我们还是要说,Android 并不完全开源,当你使用 Google 服务的时候,就已经接触到闭源的部分了。Google Play 商店就是其中之一,它不是一个开放的服务。不过无论 Android 开源与否,这就是一个美味、营养、高效、省电的馅饼(LCTT 译注:Android 9.0 代号为 Pie)。
|
||||
|
||||
我在我的 Essential PH-1 手机上运行了 Android 9.0(我真的很喜欢这款手机,也很了解这家公司的境况并不好)。在我自己体验了一段时间之后,我认为它是会被大众接受的。那么 Android 9.0 到底好在哪里呢?下面我们就来深入探讨一下。我们的出发点是用户的角度,而不是开发人员的角度,因此我也不会深入探讨太底层的方面。
|
||||
我在我的 Essential PH-1 手机上运行了 Android 9.0(我真的很喜欢这款手机,也知道这家公司的境况并不好)。在我自己体验了一段时间之后,我认为它是会被大众接受的。那么 Android 9.0 到底好在哪里呢?下面我们就来深入探讨一下。我们的出发点是用户的角度,而不是开发人员的角度,因此我也不会深入探讨太底层的方面。
|
||||
|
||||
### 手势操作
|
||||
|
||||
Android 系统在新的手势操作方面投入了很多,但实际体验却不算太好。这个功能确实引起了我的兴趣。在这个功能发布之初,大家都对它了解甚少,纷纷猜测它会不会让用户使用多点触控的手势来浏览 Android 界面?又或者会不会是一个完全颠覆人们认知的东西?
|
||||
|
||||
实际上,手势操作比大多数人设想的要更加微妙和简单,因为很多功能都浓缩到了 Home 键上。打开手势操作功能之后,Recent 键的功能就合并到 Home 键上了。因此,如果需要查看最近打开的应用程序,就不能简单地通过 Recent 键来查看,而应该从 Home 键向上轻扫一下。(图1)
|
||||
实际上,手势操作比大多数人设想的要更加微妙而简单,因为很多功能都浓缩到了 Home 键上。打开手势操作功能之后,Recent 键的功能就合并到 Home 键上了。因此,如果需要查看最近打开的应用程序,就不能简单地通过 Recent 键来查看,而应该从 Home 键向上轻扫一下。(图 1)
|
||||
|
||||
![Android Pie][2]
|
||||
|
||||
图 1:Android 9.0 中的”最近的应用程序“界面。
|
||||
*图 1:Android 9.0 中的”最近的应用程序“界面。*
|
||||
|
||||
另一个不同的地方是 App Drawer。类似于查看最近打开的应用,需要在 Home 键向上滑动才能打开 App Drawer。
|
||||
|
||||
而后退按钮则没有去掉。在应用程序需要用到后退功能时,它就会出现在屏幕的左下方。有时候即使应用程序自己带有后退按钮,Android 的后退按钮也会出现。
|
||||
而后退按钮则没有去掉。在应用程序需要用到后退功能时,它就会出现在主屏幕的左下方。有时候即使应用程序自己带有后退按钮,Android 的后退按钮也会出现。
|
||||
|
||||
当然,如果你不喜欢使用手势操作,也可以禁用这个功能。只需要按照下列步骤操作:
|
||||
|
||||
|
||||
1. 打开”设置“
|
||||
|
||||
2. 向下滑动并进入 系统 > 手势
|
||||
|
||||
2. 向下滑动并进入“系统 > 手势”
|
||||
3. 从 Home 键向上滑动
|
||||
|
||||
4. 将 On/Off 滑块(图2)滑动至 Off 位置
|
||||
4. 将 On/Off 滑块(图 2)滑动至 Off 位置
|
||||
|
||||

|
||||
|
||||
图 2:关闭手势操作。
|
||||
*图 2:关闭手势操作。*
|
||||
|
||||
### 电池寿命
|
||||
|
||||
@ -42,25 +40,19 @@ Android 系统在新的手势操作方面投入了很多,但实际体验却不
|
||||
|
||||
对于这个功能的唯一一个警告是,如果人工智能出现问题并导致电池电量过早耗尽,就只能通过恢复出厂设置来解决这个问题了。尽管有这样的缺陷,在电池续航时间方面,Android 9.0 也比 Android 8.0 有所改善。
|
||||
|
||||
### 分屏功能
|
||||
### 分屏功能的变化
|
||||
|
||||
分屏对于 Android 来说不是一个新功能,但在 Android 9.0 上,它的使用方式和以往相比略有不同,而且只对于手势操作有影响,不使用手势操作的用户不受影响。要在 Android 9.0 上使用分屏功能,需要按照下列步骤操作:
|
||||
|
||||
1. 从 Home 键向上滑动,打开“最近的应用程序”。
|
||||
2. 找到需要放置在屏幕顶部的应用程序。
|
||||
3. 长按应用程序顶部的图标以显示新的弹出菜单。(图 3)
|
||||
4. 点击分屏,应用程序会在屏幕的上半部分打开。
|
||||
5. 找到要打开的第二个应用程序,然后点击它添加到屏幕的下半部分。
|
||||
|
||||
![Adding an app][5]
|
||||
|
||||
图 3:在 Android 9.0 上将应用添加到分屏模式中。
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
1. 从 Home 键向上滑动,打开“最近的应用程序”。
|
||||
|
||||
2. 找到需要放置在屏幕顶部的应用程序。
|
||||
|
||||
3. 长按应用程序顶部的图标以显示新的弹出菜单。(图 3)
|
||||
|
||||
4. 点击分屏,应用程序会在屏幕的上半部分打开。
|
||||
|
||||
5. 找到要打开的第二个应用程序,然后点击它添加到屏幕的下半部分。
|
||||
*图 3:在 Android 9.0 上将应用添加到分屏模式中。*
|
||||
|
||||
使用分屏功能关闭应用程序的方法和原来保持一致。
|
||||
|
||||
@ -72,7 +64,7 @@ Android 系统在新的手势操作方面投入了很多,但实际体验却不
|
||||
|
||||
![Actions][7]
|
||||
|
||||
图 4:Android 应用操作。
|
||||
*图 4:Android 应用操作。*
|
||||
|
||||
### 声音控制
|
||||
|
||||
@ -82,17 +74,17 @@ Android 9.0 这次优化针对的是设备上快速控制声音的按钮。如
|
||||
|
||||
![Sound control][9]
|
||||
|
||||
图 5:Android 9.0 上的声音控制。
|
||||
*图 5:Android 9.0 上的声音控制。*
|
||||
|
||||
### 屏幕截图
|
||||
|
||||
由于我要撰写关于 Android 的文章,所以我会常常需要进行屏幕截图。而 Android 9.0 有意向我最喜欢的更新,就是分享屏幕截图。Android 9.0 可以在截取屏幕截图后,直接共享、编辑,或者删除不喜欢的截图,而不需要像以前一样打开 Google 相册、找到要共享的屏幕截图、打开图像然后共享图像。
|
||||
由于我要撰写关于 Android 的文章,所以我会常常需要进行屏幕截图。而 Android 9.0 有一项我最喜欢的更新,就是分享屏幕截图。Android 9.0 可以在截取屏幕截图后,直接共享、编辑,或者删除不喜欢的截图,而不需要像以前一样打开 Google 相册、找到要共享的屏幕截图、打开图像然后共享图像。
|
||||
|
||||
如果你想分享屏幕截图,只需要在截图后等待弹出菜单,点击分享(图 6),从标准的 Android 分享菜单中分享即可。
|
||||
|
||||
![Sharing ][11]
|
||||
|
||||
图 6:共享屏幕截图变得更加容易。
|
||||
|
||||
如果你想分享屏幕截图,只需要在截图后等待弹出菜单,点击分享(图 6),从标准的 Android 分享菜单中分享即可。
|
||||
*图 6:共享屏幕截图变得更加容易。*
|
||||
|
||||
### 更令人满意的 Android 体验
|
||||
|
||||
@ -105,7 +97,7 @@ via: https://www.linux.com/learn/2018/10/overview-android-pie
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
如何从 Windows OS 7、8 和 10 创建可启动的 Linux USB 盘?
|
||||
如何从 Windows 7、8 和 10 创建可启动的 Linux USB 盘?
|
||||
======
|
||||
|
||||
如果你想了解 Linux,首先要做的是在你的系统上安装 Linux 系统。
|
||||
|
||||
它可以通过两种方式实现,使用 Virtualbox、VMWare 等虚拟化应用,或者在你的系统上安装 Linux。
|
||||
|
||||
如果你倾向从 Windows 系统迁移到 Linux 系统或计划在备用机上安装 Linux 系统,那么你须为此创建可启动的 USB 盘。
|
||||
如果你倾向于从 Windows 系统迁移到 Linux 系统或计划在备用机上安装 Linux 系统,那么你须为此创建可启动的 USB 盘。
|
||||
|
||||
我们已经写过许多[在 Linux 上创建可启动 USB 盘][1] 的文章,如 [BootISO][2]、[Etcher][3] 和 [dd 命令][4],但我们从来没有机会写一篇文章关于在 Windows 中创建 Linux 可启动 USB 盘的文章。不管怎样,我们今天有机会做这件事了。
|
||||
|
||||
@ -22,29 +23,32 @@
|
||||
|
||||
有许多程序可供使用,但我的首选是 [Universal USB Installer][6],它使用起来非常简单。只需访问 Universal USB Installer 页面并下载该程序即可。
|
||||
|
||||
### 步骤3:如何使用 Universal USB Installer 创建可启动的 Ubuntu ISO
|
||||
### 步骤3:创建可启动的 Ubuntu ISO
|
||||
|
||||
这个程序在使用上不复杂。首先连接 USB 盘,然后点击下载的 Universal USB Installer。启动后,你可以看到类似于我们的界面。
|
||||
|
||||
![][8]
|
||||
|
||||
* **`步骤 1:`** 选择Ubuntu 系统。
|
||||
* **`步骤 2:`** 选择 Ubuntu ISO 下载位置。
|
||||
* **`步骤 3:`** 默认它选择的是 USB 盘,但是要验证一下,接着勾选格式化选项。
|
||||
|
||||
|
||||
* 步骤 1:选择 Ubuntu 系统。
|
||||
* 步骤 2:选择 Ubuntu ISO 下载位置。
|
||||
* 步骤 3:它默认选择的是 USB 盘,但是要验证一下,接着勾选格式化选项。
|
||||
|
||||
![][9]
|
||||
|
||||
当你点击 `Create` 按钮时,它会弹出一个带有警告的窗口。不用担心,只需点击 `Yes` 继续进行此操作即可。
|
||||
当你点击 “Create” 按钮时,它会弹出一个带有警告的窗口。不用担心,只需点击 “Yes” 继续进行此操作即可。
|
||||
|
||||
![][10]
|
||||
|
||||
USB 盘分区正在进行中。
|
||||
|
||||
![][11]
|
||||
|
||||
要等待一会儿才能完成。如你您想将它移至后台,你可以点击 `Background` 按钮。
|
||||
要等待一会儿才能完成。如你您想将它移至后台,你可以点击 “Background” 按钮。
|
||||
|
||||
![][12]
|
||||
|
||||
好了,完成了。
|
||||
|
||||
![][13]
|
||||
|
||||
现在你可以进行[安装 Ubuntu 系统][14]了。但是,它也提供了一个 live 模式,如果你想在安装之前尝试,那么可以使用它。
|
||||
@ -56,7 +60,7 @@ via: https://www.2daygeek.com/create-a-bootable-live-usb-drive-from-windows-usin
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,67 +1,65 @@
|
||||
2018 重温 Unix 哲学
|
||||
======
|
||||
在现代微服务环境中,构建小型,集中应用程序的旧策略又再一次流行了起来。
|
||||
> 在现代微服务环境中,构建小型、单一的应用程序的旧策略又再一次流行了起来。
|
||||
|
||||

|
||||
|
||||
1984年,Rob Pike 和 Brian W 在 AT&T 贝尔实验室技术期刊上发表了名为 “[Unix 环境编程][1]” 的文章,其中他们使用 BSD 的 **cat -v** 例子来认证 Unix 哲学。简而言之,Unix 哲学是:构建小型,单一的应用程序——不管用什么语言——只做一件小而美的事情,用 **stdin** / **stdout** 进行通信,并通过管道进行连接。
|
||||
1984 年,Rob Pike 和 Brian W. Kernighan 在 AT&T 贝尔实验室技术期刊上发表了名为 “[Unix 环境编程][1]” 的文章,其中他们使用 BSD 的 `cat -v` 例子来认证 Unix 哲学。简而言之,Unix 哲学是:构建小型、单一的应用程序 —— 不管用什么语言 —— 只做一件小而美的事情,用 `stdin` / `stdout` 进行通信,并通过管道进行连接。
|
||||
|
||||
听起来是不是有点耳熟?
|
||||
|
||||
是的,我也这么认为。这就是 James Lewis 和 Martin Fowler 给出的 [微服务的定义][2] 。
|
||||
|
||||
> 简单来说,微服务架构的风格是将应用程序开发为一套单一,小型服务的方法,每个服务都运行在它的进程中,并用轻量级机制进行通信,通常是 HTTP 资源 API 。
|
||||
> 简单来说,微服务架构的风格是将单个 应用程序开发为一套小型服务的方法,每个服务都运行在它的进程中,并用轻量级机制进行通信,通常是 HTTP 资源 API 。
|
||||
|
||||
虽然一个 *nix 程序或者是一个微服务本身可能非常局限甚至不是很有趣,但是当这些独立工作的单元组合在一起的时候就显示出了它们真正的好处和强大。
|
||||
虽然一个 *nix 程序或者是一个微服务本身可能非常局限甚至不是很有用,但是当这些独立工作的单元组合在一起的时候就显示出了它们真正的好处和强大。
|
||||
|
||||
### *nix程序 vs 微服务
|
||||
|
||||
下面的表格对比了 *nix 环境中的程序(例如 **cat** 或 **lsof**)与微服务环境中的程序。
|
||||
下面的表格对比了 *nix 环境中的程序(例如 `cat` 或 `lsof`)与微服务环境中的程序。
|
||||
|
||||
| | *nix 程序 | 微服务 |
|
||||
| ----------------------------------- | -------------------------- | ---------------------------------- |
|
||||
| 执行单元 | 程序使用 `stdin/stdout` | 使用 HTTP 或 gRPC API |
|
||||
| 数据流 | 管道 | ? |
|
||||
| 可配置和参数化 | 命令行参数 | |
|
||||
| 环境变量和配置文件 | JSON/YAML 文档 | |
|
||||
| 发现 | 包管理器, man, make | DNS, 环境变量, OpenAPI |
|
||||
| | *nix 程序 | 微服务 |
|
||||
| ------------- | ------------------------- | ----------------------- |
|
||||
| 执行单元 | 程序使用 `stdin`/`stdout` | 使用 HTTP 或 gRPC API |
|
||||
| 数据流 | 管道 | ? |
|
||||
| 可配置和参数化 | 命令行参数、环境变量和配置文件 | JSON/YAML 文档 |
|
||||
| 发现 | 包管理器、man、make | DNS、环境变量、OpenAPI |
|
||||
|
||||
让我们详细的看看每一行。
|
||||
|
||||
#### 执行单元
|
||||
|
||||
*nix 系统(像 Linux)中的执行单元是一个可执行的文件(二进制或者是脚本),理想情况下,它们从 `stdin` 读取输入并将输出写入 `stdout`。而微服务通过暴露一个或多个通信接口来提供服务,比如 HTTP 和 gRPC APIs。在这两种情况下,你都会发现无状态示例(本质上是纯函数行为)和有状态示例,除了输入之外,还有一些内部(持久)状态决定发生了什么。
|
||||
*nix 系统(如 Linux)中的执行单元是一个可执行的文件(二进制或者是脚本),理想情况下,它们从 `stdin` 读取输入并将输出写入 `stdout`。而微服务通过暴露一个或多个通信接口来提供服务,比如 HTTP 和 gRPC API。在这两种情况下,你都会发现无状态示例(本质上是纯函数行为)和有状态示例,除了输入之外,还有一些内部(持久)状态决定发生了什么。
|
||||
|
||||
#### 数据流
|
||||
|
||||
传统的,*nix 程序能够通过管道进行通信。换名话说,我们要感谢 [Doug McIlroy][3],你不需要创建临时文件来传递,而可以在每个进程之间处理无穷无尽的数据流。据我所知,除了 [2017 年做的基于 `Apache Kafka` 小实验][4],没有什么能比得上管道化的微服务了。
|
||||
传统的,*nix 程序能够通过管道进行通信。换句话说,我们要感谢 [Doug McIlroy][3],你不需要创建临时文件来传递,而可以在每个进程之间处理无穷无尽的数据流。据我所知,除了我在 [2017 年做的基于 Apache Kafka 小实验][4],没有什么能比得上管道化的微服务了。
|
||||
|
||||
#### 可配置和参数化
|
||||
|
||||
你是如何配置程序或者服务的,无论是永久性的服务还是即时的服务?是的,在 *nix 系统上,你通常有三种方法:命令行参数,环境变量,或全面化的配置文件。在微服务架构中,典型的做法是用 YAML ( 或者甚至是worse,JSON ) 文档,定制好一个服务的布局和配置以及依赖的组件和通信,存储,和运行时配置。例如 [ Kubernetes 资源定义][5],[Nomad 工作规范][6],或 [Docker 组件][7] 文档。这些可能参数化也可能不参数化;也就是说,除非你知道一些模板语言,像 Kubernetes 中的 [Helm][8],否则你会发现你使用了很多 **sed -i** 这样的命令。
|
||||
你是如何配置程序或者服务的,无论是永久性的服务还是即时的服务?是的,在 *nix 系统上,你通常有三种方法:命令行参数、环境变量,或全面的配置文件。在微服务架构中,典型的做法是用 YAML(或者甚至是 JSON)文档,定制好一个服务的布局和配置以及依赖的组件和通信、存储和运行时配置。例如 [Kubernetes 资源定义][5]、[Nomad 工作规范][6] 或 [Docker 编排][7] 文档。这些可能参数化也可能不参数化;也就是说,除非你知道一些模板语言,像 Kubernetes 中的 [Helm][8],否则你会发现你使用了很多 `sed -i` 这样的命令。
|
||||
|
||||
#### 发现
|
||||
|
||||
你怎么知道有哪些程序和服务可用,以及如何使用它们?在 *nix 系统中通常都有一个包管理器和一个很好用的 man 页面;使用他们,应该能够回答你所有的问题。在微服务的设置中,在寻找一个服务的时候会相对更自动化一些。除了像 [Airbnb 的 SmartStack][9] 或 [Netflix 的 Eureka][10] 等可以定制以外,通常还有基于环境变量或基于 DNS 的[方法][11],允许您动态的发现服务。同样重要的是,事实上 [OpenAPI][12] 为 HTTP API 提供了一套标准文档和设计模式,[gRPC][13] 为一些耦合性强的高性能项目也做了同样的事情。最后非常重要的一点是,考虑到开发人员的经验(DX),应该从写一份好的 [Makefiles][14] 开始,并以编写符合 [**风格**][15] 的文档结束。
|
||||
你怎么知道有哪些程序和服务可用,以及如何使用它们?在 *nix 系统中通常都有一个包管理器和一个很好用的 man 页面;使用它们,应该能够回答你所有的问题。在微服务的设置中,在寻找一个服务的时候会相对更自动化一些。除了像 [Airbnb 的 SmartStack][9] 或 [Netflix 的 Eureka][10] 等可以定制以外,通常还有基于环境变量或基于 DNS 的[方法][11],允许您动态的发现服务。同样重要的是,事实上 [OpenAPI][12] 为 HTTP API 提供了一套标准文档和设计模式,[gRPC][13] 为一些耦合性强的高性能项目也做了同样的事情。最后非常重要的一点是,考虑到开发者经验(DX),应该从写一份好的 [Makefile][14] 开始,并以编写符合 [风格][15] 的文档结束。
|
||||
|
||||
### 优点和缺点
|
||||
|
||||
*nix 系统和微服务都提供了许多挑战和机遇
|
||||
*nix 系统和微服务都提供了许多挑战和机遇。
|
||||
|
||||
#### 模块性
|
||||
|
||||
设计一个简洁,有清晰的目的并且能够很好的和其它模块配合是很困难的。甚至是在不同版本中实现并引入相应的异常处理流程都很困难的。在微服务中,这意味着重试逻辑和超时机制,或者将这些功能外包到服务网格( service mesh )是不是一个更好的选择呢?这确实比较难,可如果你做好了,那它的可重用性是巨大的。
|
||||
要设计一个简洁、有清晰的目的,并且能够很好地和其它模块配合的某个东西是很困难的。甚至是在不同版本中实现并引入相应的异常处理流程都很困难的。在微服务中,这意味着重试逻辑和超时机制,或者将这些功能外包到<ruby>服务网格<rt>service mesh</rt></ruby>是不是一个更好的选择呢?这确实比较难,可如果你做好了,那它的可重用性是巨大的。
|
||||
|
||||
#### Observability
|
||||
#### 可观测性
|
||||
|
||||
#### 预测
|
||||
|
||||
在一个巨型(2018年)或是一个试图做任何事情的大型程序(1984)年,当事情开始变坏的时候,应当能够直接的找到问题的根源。但是在一个
|
||||
在一个<ruby>独石<rt>monolith</rt></ruby>(2018 年)或是一个试图做任何事情的大型程序(1984 年),当情况恶化的时候,应当能够直接的找到问题的根源。但是在一个
|
||||
|
||||
```
|
||||
yes | tr \\n x | head -c 450m | grep n
|
||||
```
|
||||
|
||||
或者在一个微服务设置中请求一个路径,例如,涉及20个服务,你怎么弄清楚是哪个服务的问题?幸运的是,我们有很多标准,特别是 [OpenCensus][16] 和 [OpenTracing][17]。如果您希望转向微服务,可预测性仍然可能是最大的问题。
|
||||
或者在一个微服务设置中请求一个路径,例如,涉及 20 个服务,你怎么弄清楚是哪个服务的问题?幸运的是,我们有很多标准,特别是 [OpenCensus][16] 和 [OpenTracing][17]。如果您希望转向微服务,可预测性仍然可能是最大的问题。
|
||||
|
||||
#### 全局状态
|
||||
|
||||
@ -77,8 +75,8 @@ via: https://opensource.com/article/18/11/revisiting-unix-philosophy-2018
|
||||
|
||||
作者:[Michael Hausenblas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Jamkr](https://github.com/Jamkr)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Jamskr](https://github.com/Jamskr)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user