mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-04 22:00:34 +08:00
commit
97e9285ed7
@ -0,0 +1,74 @@
|
||||
为什么 Arch Linux 如此“难弄”又有何优劣?
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Arch Linux][1] 于 **2002** 年发布,由 **Aaron Grifin** 领头,是当下最热门的 Linux 发行版之一。从设计上说,Arch Linux 试图给用户提供简单、最小化且优雅的体验,但它的目标用户群可不是怕事儿多的用户。Arch 鼓励参与社区建设,并且从设计上期待用户自己有学习操作系统的能力。
|
||||
|
||||
很多 Linux 老鸟对于 **Arch Linux** 会更了解,但电脑前的你可能只是刚开始打算把 Arch 当作日常操作系统来使用。虽然我也不是权威人士,但下面几点优劣是我认为你总会在使用中慢慢发现的。
|
||||
|
||||
### 1、优点: 定制属于你自己的 Linux 操作系统
|
||||
|
||||
大多数热门的 Linux 发行版(比如 **Ubuntu** 和 **Fedora**)很像一般我们会看到的预装系统,和 **Windows** 或者 **MacOS** 一样。但 Arch 则会更鼓励你去把操作系统配置的符合你的品味。如果你能顺利做到这点的话,你会得到一个每一个细节都如你所想的操作系统。
|
||||
|
||||
#### 缺点: 安装过程让人头疼
|
||||
|
||||
[Arch Linux 的安装 ][2] 别辟蹊径——因为你要花些时间来微调你的操作系统。你会在过程中了解到不少终端命令和组成你系统的各种软件模块——毕竟你要自己挑选安装什么。当然,你也知道这个过程少不了阅读一些文档/教程。
|
||||
|
||||
### 2、优点: 没有预装垃圾
|
||||
|
||||
鉴于 **Arch** 允许你在安装时选择你想要的系统部件,你再也不用烦恼怎么处理你不想要的一堆预装软件。作为对比,**Ubuntu** 会预装大量的软件和桌面应用——很多你不需要、甚至卸载之前都不知道它们存在的东西。
|
||||
|
||||
总而言之,**Arch Linux* 能省去大量的系统安装后时间。**Pacman**,是 Arch Linux 默认使用的优秀包管理组件。或者你也可以选择 [Pamac][3] 作为替代。
|
||||
|
||||
### 3、优点: 无需繁琐系统升级
|
||||
|
||||
**Arch Linux** 采用滚动升级模型,简直妙极了。这意味着你不需要操心升级了。一旦你用上了 Arch,持续的更新体验会让你和一会儿一个版本的升级说再见。只要你记得‘滚’更新(Arch 用语),你就一直会使用最新的软件包们。
|
||||
|
||||
#### 缺点: 一些升级可能会滚坏你的系统
|
||||
|
||||
虽然升级过程是完全连续的,你有时得留意一下你在更新什么。没人能知道所有软件的细节配置,也没人能替你来测试你的情况。所以如果你盲目更新,有时候你会滚坏你的系统。(LCTT 译注:别担心,你可以‘滚’回来 ;D )
|
||||
|
||||
### 4、优点: Arch 有一个社区基因
|
||||
|
||||
所有 Linux 用户通常有一个共同点:对独立自由的追求。虽然大多数 Linux 发行版和公司企业等挂钩极少,但也并非没有。比如 基于 **Ubuntu** 的衍生版本们不得不受到 Canonical 公司决策的影响。
|
||||
|
||||
如果你想让你的电脑更独立,那么 Arch Linux 是你的伙伴。不像大多数操作系统,Arch 完全没有商业集团的影响,完全由社区驱动。
|
||||
|
||||
### 5、优点: Arch Wiki 无敌
|
||||
|
||||
[Arch Wiki][4] 是一个无敌文档库,几乎涵盖了所有关于安装和维护 Arch 以及关于操作系统本身的知识。Arch Wiki 最厉害的一点可能是,不管你在用什么发行版,你多多少少可能都在 Arch Wiki 的页面里找到有用信息。这是因为 Arch 用户也会用别的发行版用户会用的东西,所以一些技巧和知识得以泛化。
|
||||
|
||||
### 6、优点: 别忘了 Arch 用户软件库 (AUR)
|
||||
|
||||
<ruby>[Arch 用户软件库][5]<rt>Arch User Repository</rt></ruby> (AUR)是一个来自社区的超大软件仓库。如果你找了一个还没有 Arch 的官方仓库里出现的软件,那你肯定能在 AUR 里找到社区为你准备好的包。
|
||||
|
||||
AUR 是由用户自发编译和维护的。Arch 用户也可以给每个包投票,这样后来者就能找到最有用的那些软件包了。
|
||||
|
||||
#### 最后: Arch Linux 适合你吗?
|
||||
|
||||
**Arch Linux** 优点多于缺点,也有很多优缺点我无法在此一一叙述。安装过程很长,对非 Linux 用户来说也可能偏有些技术,但只要你投入一些时间和善用 Wiki,你肯定能迈过这道坎。
|
||||
|
||||
**Arch Linux** 是一个非常优秀的发行版——尽管它有一些复杂性。同时它也很受那些知道自己想要什么的用户的欢迎——只要你肯做点功课,有些耐心。
|
||||
|
||||
当你从零开始搭建完 Arch 的时候,你会掌握很多 GNU/Linux 的内部细节,也再也不会对你的电脑内部运作方式一无所知了。
|
||||
|
||||
欢迎读者们在评论区讨论你使用 Arch Linux 的优缺点?以及你曾经遇到过的一些挑战。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
|
||||
[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
|
||||
[4]:https://wiki.archlinux.org/
|
||||
[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
@ -1,6 +1,8 @@
|
||||
系统管理员的一个网络管理指南
|
||||
面向系统管理员的网络管理指南
|
||||
======
|
||||
|
||||
> 一个使管理服务器和网络更轻松的 Linux 工具和命令的参考列表。
|
||||
|
||||

|
||||
|
||||
如果你是一位系统管理员,那么你的日常工作应该包括管理服务器和数据中心的网络。以下的 Linux 实用工具和命令 —— 从基础的到高级的 —— 将帮你更轻松地管理你的网络。
|
||||
@ -16,8 +18,6 @@
|
||||
* IPv4: `ping <ip address>/<fqdn>`
|
||||
* IPv6: `ping6 <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
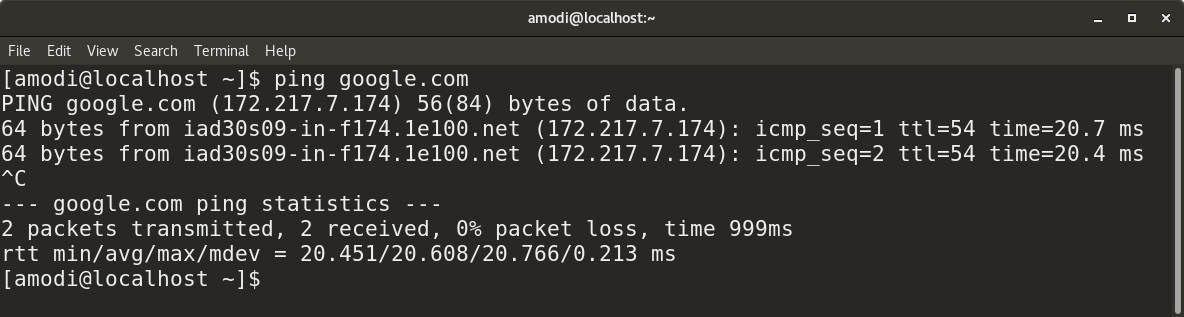
你也可以使用 `ping` 去解析出网站所对应的 IP 地址,如下图所示:
|
||||
|
||||
|
||||
@ -32,16 +32,12 @@
|
||||
|
||||
* `traceroute <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
### Telnet
|
||||
|
||||
**语法:**
|
||||
|
||||
* `telnet <ip address>/<fqdn>` 是用于 [telnet][3] 进入任何支持该协议的服务器。
|
||||
|
||||
|
||||
|
||||
### Netstat
|
||||
|
||||
这个网络统计(`netstat`)实用工具是用于去分析解决网络连接问题和检查接口/端口统计数据、路由表、协议状态等等的。它是任何管理员都应该必须掌握的工具。
|
||||
@ -69,20 +65,14 @@
|
||||
**语法:**
|
||||
|
||||
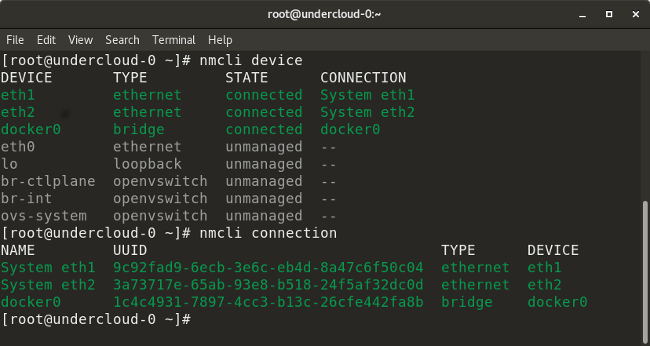
* `nmcli device` 列出网络上的所有设备。
|
||||
|
||||
* `nmcli device show <interface>` 显示指定接口的网络相关的详细情况。
|
||||
|
||||
* `nmcli connection` 检查设备的连接情况。
|
||||
|
||||
* `nmcli connection down <interface>` 关闭指定接口。
|
||||
|
||||
* `nmcli connection up <interface>` 打开指定接口。
|
||||
|
||||
* `nmcli con add type vlan con-name <connection-name> dev <interface> id <vlan-number> ipv4 <ip/cidr> gw4 <gateway-ip>` 在特定的接口上使用指定的 VLAN 号添加一个虚拟局域网(VLAN)接口、IP 地址、和网关。
|
||||
|
||||
|
||||
|
||||
|
||||
### 路由
|
||||
|
||||
检查和配置路由的命令很多。下面是其中一些比较有用的:
|
||||
@ -101,13 +91,13 @@
|
||||
|
||||
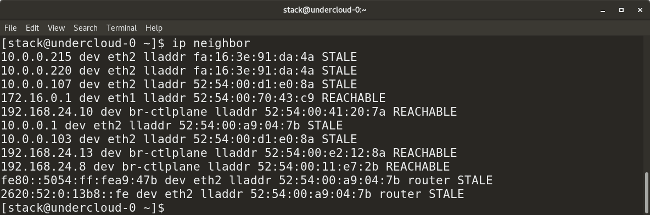
* `ip neighbor` 显示当前的邻接表和用于去添加、改变、或删除新的邻居。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
* `arp` (它的全称是 “地址解析协议”)类似于 `ip neighbor`。`arp` 映射一个系统的 IP 地址到它相应的 MAC(介质访问控制)地址。
|
||||
|
||||
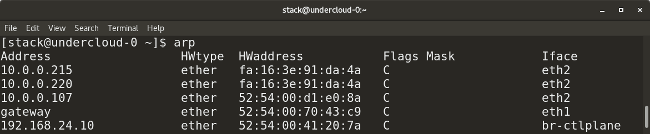
|
||||

|
||||
|
||||
### Tcpdump 和 Wireshark
|
||||
|
||||
@ -117,7 +107,7 @@ Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark`
|
||||
|
||||
* `tcpdump -i <interface-name>` 显示指定接口上实时通过的数据包。通过在命令中添加一个 `-w` 标志和输出文件的名字,可以将数据包保存到一个文件中。例如:`tcpdump -w <output-file.> -i <interface-name>`。
|
||||
|
||||
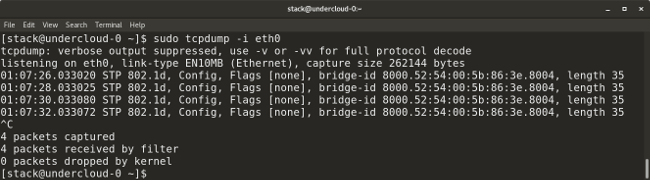
|
||||

|
||||
|
||||
* `tcpdump -i <interface> src <source-ip>` 从指定的源 IP 地址上捕获数据包。
|
||||
* `tcpdump -i <interface> dst <destination-ip>` 从指定的目标 IP 地址上捕获数据包。
|
||||
@ -135,22 +125,16 @@ Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark`
|
||||
* `iptables -L` 列出所有已存在的 `iptables` 规则。
|
||||
* `iptables -F` 删除所有已存在的规则。
|
||||
|
||||
|
||||
|
||||
下列命令允许流量从指定端口到指定接口:
|
||||
|
||||
* `iptables -A INPUT -i <interface> -p tcp –dport <port-number> -m state –state NEW,ESTABLISHED -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o <interface> -p tcp -sport <port-number> -m state – state ESTABLISHED -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
下列命令允许<ruby>环回<rt>loopback</rt></ruby>接口访问系统:
|
||||
|
||||
* `iptables -A INPUT -i lo -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o lo -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
### Nslookup
|
||||
|
||||
`nslookup` 工具是用于去获得一个网站或域名所映射的 IP 地址。它也能用于去获得你的 DNS 服务器的信息,比如,一个网站的所有 DNS 记录(具体看下面的示例)。与 `nslookup` 类似的一个工具是 `dig`(Domain Information Groper)实用工具。
|
||||
@ -161,7 +145,6 @@ Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark`
|
||||
* `nslookup -type=any <website-name.com>` 显示指定网站/域中所有可用记录。
|
||||
|
||||
|
||||
|
||||
### 网络/接口调试
|
||||
|
||||
下面是用于接口连通性或相关网络问题调试所需的命令和文件的汇总。
|
||||
@ -182,7 +165,6 @@ Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark`
|
||||
* `/etc/ntp.conf` 指定 NTP 服务器域名。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
|
||||
@ -190,7 +172,7 @@ via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,21 @@
|
||||
针对 Bash 的不完整路径展开(补全)
|
||||
针对 Bash 的不完整路径展开(补全)功能
|
||||
======
|
||||
|
||||
|
||||

|
||||
|
||||
[bash-complete-partial-path][1] 通过添加不完整的路径展开(类似于 Zsh)来增强 Bash(它在 Linux 上,macOS 使用 gnu-sed,Windows 使用 MSYS)中的路径补全。如果你想在 Bash 中使用这个省时特性,而不必切换到 Zsh,它将非常有用。
|
||||
|
||||
这是它如何工作的。当按下 `Tab` 键时,bash-complete-partial-path 假定每个部分都不完整并尝试展开它。假设你要进入 `/usr/share/applications` 。你可以输入 `cd /u/s/app`,按下 `Tab`,bash-complete-partial-path 应该把它展开成 `cd /usr/share/applications` 。如果存在冲突,那么按 `Tab` 仅补全没有冲突的路径。例如,Ubuntu 用户在 `/usr/share` 中应该有很多以 “app” 开头的文件夹,在这种情况下,输入 `cd /u/s/app` 只会展开 `/usr/share/` 部分。
|
||||
|
||||
这是更深层不完整文件路径展开的另一个例子。在Ubuntu系统上输入 `cd /u/s/f/t/u`,按下 `Tab`,它应该自动展开为 `cd /usr/share/fonts/truetype/ubuntu`。
|
||||
另一个更深层不完整文件路径展开的例子。在Ubuntu系统上输入 `cd /u/s/f/t/u`,按下 `Tab`,它应该自动展开为 `cd /usr/share/fonts/truetype/ubuntu`。
|
||||
|
||||
功能包括:
|
||||
|
||||
* 转义特殊字符
|
||||
|
||||
* 如果用户路径开头使用引号,则不转义字符转义,而是在展开路径后使用匹配字符结束引号
|
||||
|
||||
* 正确展开 ~ 表达式
|
||||
|
||||
* 如果 bash-completion 包正在使用,则此代码将安全地覆盖其 _filedir 函数。无需额外配置,只需确保在主 bash-completion 后 source 此项目。
|
||||
* 正确展开 `~` 表达式
|
||||
* 如果正在使用 bash-completion 包,则此代码将安全地覆盖其 `_filedir` 函数。无需额外配置,只需确保在主 bash-completion 后引入此项目。
|
||||
|
||||
查看[项目页面][2]以获取更多信息和演示截图。
|
||||
|
||||
@ -25,7 +23,7 @@
|
||||
|
||||
bash-complete-partial-path 安装说明指定直接下载 bash_completion 脚本。我更喜欢从 Git 仓库获取,这样我可以用一个简单的 `git pull` 来更新它,因此下面的说明将使用这种安装 bash-complete-partial-path。如果你喜欢,可以使用[官方][3]说明。
|
||||
|
||||
1. 安装 Git(需要克隆 bash-complete-partial-path 的 Git 仓库)。
|
||||
1、 安装 Git(需要克隆 bash-complete-partial-path 的 Git 仓库)。
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 等中,使用此命令安装 Git:
|
||||
|
||||
@ -33,13 +31,13 @@ bash-complete-partial-path 安装说明指定直接下载 bash_completion 脚本
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
2. 在 `~/.config/` 中克隆 bash-complete-partial-path 的 Git 仓库:
|
||||
2、 在 `~/.config/` 中克隆 bash-complete-partial-path 的 Git 仓库:
|
||||
|
||||
```
|
||||
cd ~/.config && git clone https://github.com/sio/bash-complete-partial-path
|
||||
```
|
||||
|
||||
3. 在 `~/.bashrc` 文件中 source `~/.config/bash-complete-partial-path/bash_completion`,
|
||||
3、 在 `~/.bashrc` 文件中 source `~/.config/bash-complete-partial-path/bash_completion`,
|
||||
|
||||
用文本编辑器打开 ~/.bashrc。例如你可以使用 Gedit:
|
||||
|
||||
@ -55,7 +53,7 @@ gedit ~/.bashrc
|
||||
|
||||
我提到在文件的末尾添加它,因为这需要包含在你的 `~/.bashrc` 文件的主 bash-completion 下面(之后)。因此,请确保不要将其添加到原始 bash-completion 之上,因为它会导致问题。
|
||||
|
||||
4\. Source `~/.bashrc`:
|
||||
4、 引入 `~/.bashrc`:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
@ -63,8 +61,6 @@ source ~/.bashrc
|
||||
|
||||
这样就好了,现在应该安装完 bash-complete-partial-path 并可以使用了。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/incomplete-path-expansion-completion.html
|
||||
@ -72,7 +68,7 @@ via: https://www.linuxuprising.com/2018/07/incomplete-path-expansion-completion.
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,185 @@
|
||||
How blockchain will influence open source
|
||||
======
|
||||
|
||||

|
||||
|
||||
What [Satoshi Nakamoto][1] started as Bitcoin a decade ago has found a lot of followers and turned into a movement for decentralization. For some, blockchain technology is a religion that will have the same impact on humanity as the Internet has had. For others, it is hype and technology suitable only for Ponzi schemes. While blockchain is still evolving and trying to find its place, one thing is for sure: It is a disruptive technology that will fundamentally transform certain industries. And I'm betting open source will be one of them.
|
||||
|
||||
### The open source model
|
||||
|
||||
Open source is a collaborative software development and distribution model that allows people with common interests to gather and produce something that no individual can create on their own. It allows the creation of value that is bigger than the sum of its parts. Open source is enabled by distributed collaboration tools (IRC, email, git, wiki, issue trackers, etc.), distributed and protected by an open source licensing model and often governed by software foundations such as the [Apache Software Foundation][2] (ASF), [Cloud Native Computing Foundation][3] (CNCF), etc.
|
||||
|
||||
One interesting aspect of the open source model is the lack of financial incentives in its core. Some people believe open source work should remain detached from money and remain a free and voluntary activity driven only by intrinsic motivators (such as "common purpose" and "for the greater good”). Others believe open source work should be rewarded directly or indirectly through extrinsic motivators (such as financial incentive). While the idea of open source projects prospering only through voluntary contributions is romantic, in reality, the majority of open source contributions are done through paid development. Yes, we have a lot of voluntary contributions, but these are on a temporary basis from contributors who come and go, or for exceptionally popular projects while they are at their peak. Creating and sustaining open source projects that are useful for enterprises requires developing, documenting, testing, and bug-fixing for prolonged periods, even when the software is no longer shiny and exciting. It is a boring activity that is best motivated through financial incentives.
|
||||
|
||||
### Commercial open source
|
||||
|
||||
Software foundations such as ASF survive on donations and other income streams such as sponsorships, conference fees, etc. But those funds are primarily used to run the foundations, to provide legal protection for the projects, and to ensure there are enough servers to run builds, issue trackers, mailing lists, etc.
|
||||
|
||||
Similarly, CNCF has member fees and other income streams, which are used to run the foundation and provide resources for the projects. These days, most software is not built on laptops; it is run and tested on hundreds of machines on the cloud, and that requires money. Creating marketing campaigns, brand designs, distributing stickers, etc. takes money, and some foundations can assist with that as well. At its core, foundations implement the right processes to interact with users, developers, and control mechanisms and ensure distribution of available financial resources to open source projects for the common good.
|
||||
|
||||
If users of open source projects can donate money and the foundations can distribute it in a fair way, what is missing?
|
||||
|
||||
What is missing is a direct, transparent, trusted, decentralized, automated bidirectional link for transfer of value between the open source producers and the open source consumer. Currently, the link is either unidirectional or indirect:
|
||||
|
||||
* **Unidirectional** : A developer (think of a "developer" as any role that is involved in the production, maintenance, and distribution of software) can use their brain juice and devote time to do a contribution and share that value with all open source users. But there is no reverse link.
|
||||
|
||||
* **Indirect** : If there is a bug that affects a specific user/company, the options are:
|
||||
|
||||
* To have in-house developers to fix the bug and do a pull request. That is ideal, but it not always possible to hire in-house developers who are knowledgeable about hundreds of open source projects used daily.
|
||||
|
||||
* To hire a freelancer specializing in that specific open source project and pay for the services. Ideally, the freelancer is also a committer for the open source project and can directly change the project code quickly. Otherwise, the fix might not ever make it to the project.
|
||||
|
||||
* To approach a company providing services around the open source project. Such companies typically employ open source committers to influence and gain credibility in the community and offer products, expertise, and professional services.
|
||||
|
||||
|
||||
|
||||
|
||||
The third option has been a successful [model][4] for sustaining many open source projects. Whether they provide services (training, consulting, workshops), support, packaging, open core, or SaaS, there are companies that employ hundreds of staff members who work on open source full time. There is a long [list of companies][5] that have managed to build a successful open source business model over the years, and that list is growing steadily.
|
||||
|
||||
The companies that back open source projects play an important role in the ecosystem: They are the catalyst between the open source projects and the users. The ones that add real value do more than just package software nicely; they can identify user needs and technology trends, and they create a full stack and even an ecosystem of open source projects to address these needs. They can take a boring project and support it for years. If there is a missing piece in the stack, they can start an open source project from scratch and build a community around it. They can acquire a closed source software company and open source the projects (here I got a little carried away, but yes, I'm talking about my employer, [Red Hat][6]).
|
||||
|
||||
To summarize, with the commercial open source model, projects are officially or unofficially managed and controlled by a very few individuals or companies that monetize them and give back to the ecosystem by ensuring the project is successful. It is a win-win-win for open source developers, managing companies, and end users. The alternative is inactive projects and expensive closed source software.
|
||||
|
||||
### Self-sustaining, decentralized open source
|
||||
|
||||
For a project to become part of a reputable foundation, it must conform to certain criteria. For example, ASF and CNCF require incubation and graduation processes, respectively, where apart from all the technical and formal requirements, a project must have a healthy number of active committer and users. And that is the essence of forming a sustainable open source project. Having source code on GitHub is not the same thing as having an active open source project. The latter requires committers who write the code and users who use the code, with both groups enforcing each other continuously by exchanging value and forming an ecosystem where everybody benefits. Some project ecosystems might be tiny and short-lived, and some may consist of multiple projects and competing service providers, with very complex interactions lasting for many years. But as long as there is an exchange of value and everybody benefits from it, the project is developed, maintained, and sustained.
|
||||
|
||||
If you look at ASF [Attic][7], you will find projects that have reached their end of life. When a project is no longer technologically fit for its purpose, it is usually its natural end. Similarly, in the ASF [Incubator][8], you will find tons of projects that never graduated but were instead retired. Typically, these projects were not able to build a large enough community because they are too specialized or there are better alternatives available.
|
||||
|
||||
But there are also cases where projects with high potential and superior technology cannot sustain themselves because they cannot form or maintain a functioning ecosystem for the exchange of value. The open source model and the foundations do not provide a framework and mechanisms for developers to get paid for their work or for users to get their requests heard. There isn’t a common value commitment framework for either party. As a result, some projects can sustain themselves only in the context of commercial open source, where a company acts as an intermediary and value adder between developers and users. That adds another constraint and requires a service provider company to sustain some open source projects. Ideally, users should be able to express their interest in a project and developers should be able to show their commitment to the project in a transparent and measurable way, which forms a community with common interest and intent for the exchange of value.
|
||||
|
||||
Imagine there is a model with mechanisms and tools that enable direct interaction between open source users and developers. This includes not only code contributions through pull requests, questions over the mailing lists, GitHub stars, and stickers on laptops, but also other ways that allow users to influence projects' destinies in a richer, more self-controlled and transparent manner.
|
||||
|
||||
This model could include incentives for actions such as:
|
||||
|
||||
* Funding open source projects directly rather than through software foundations
|
||||
|
||||
* Influencing the direction of projects through voting (by token holders)
|
||||
|
||||
* Feature requests driven by user needs
|
||||
|
||||
* On-time pull request merges
|
||||
|
||||
* Bounties for bug hunts
|
||||
|
||||
* Better test coverage incentives
|
||||
|
||||
* Up-to-date documentation rewards
|
||||
|
||||
* Long-term support guarantees
|
||||
|
||||
* Timely security fixes
|
||||
|
||||
* Expert assistance, support, and services
|
||||
|
||||
* Budget for evangelism and promotion of the projects
|
||||
|
||||
* Budget for regular boring activities
|
||||
|
||||
* Fast email and chat assistance
|
||||
|
||||
* Full visibility of the overall project findings, etc.
|
||||
|
||||
|
||||
|
||||
|
||||
If you haven't guessed, I'm talking about using blockchain and [smart contracts][9] to allow such interactions between users and developers—smart contracts that will give power to the hand of token holders to influence projects.
|
||||
|
||||
![blockchain_in_open_source_ecosystem.png][11]
|
||||
|
||||
The usage of blockchain in the open source ecosystem
|
||||
|
||||
Existing channels in the open source ecosystem provide ways for users to influence projects through financial commitments to service providers or other limited means through the foundations. But the addition of blockchain-based technology to the open source ecosystem could open new channels for interaction between users and developers. I'm not saying this will replace the commercial open source model; most companies working with open source do many things that cannot be replaced by smart contracts. But smart contracts can spark a new way of bootstrapping new open source projects, giving a second life to commodity projects that are a burden to maintain. They can motivate developers to apply boring pull requests, write documentation, get tests to pass, etc., providing a direct value exchange channel between users and open source developers. Blockchain can add new channels to help open source projects grow and become self-sustaining in the long term, even when company backing is not feasible. It can create a new complementary model for self-sustaining open source projects—a win-win.
|
||||
|
||||
### Tokenizing open source
|
||||
|
||||
There are already a number of initiatives aiming to tokenize open source. Some focus only on an open source model, and some are more generic but apply to open source development as well:
|
||||
|
||||
* [Gitcoin][12] \- grow open source, one of the most promising ones in this area.
|
||||
|
||||
* [Oscoin][13] \- cryptocurrency for open source
|
||||
|
||||
* [Open collective][14] \- a platform for supporting open source projects.
|
||||
|
||||
* [FundYourselfNow][15] \- Kickstarter and ICOs for projects.
|
||||
|
||||
* [Kauri][16] \- support for open source project documentation.
|
||||
|
||||
* [Liberapay][17] \- a recurrent donations platform.
|
||||
|
||||
* [FundRequest][18] \- a decentralized marketplace for open source collaboration.
|
||||
|
||||
* [CanYa][19] \- recently acquired [Bountysource][20], now the world’s largest open source P2P bounty platform.
|
||||
|
||||
* [OpenGift][21] \- a new model for open source monetization.
|
||||
|
||||
* [Hacken][22] \- a white hat token for hackers.
|
||||
|
||||
* [Coinlancer][23] \- a decentralized job market.
|
||||
|
||||
* [CodeFund][24] \- an open source ad platform.
|
||||
|
||||
* [IssueHunt][25] \- a funding platform for open source maintainers and contributors.
|
||||
|
||||
* [District0x 1Hive][26] \- a crowdfunding and curation platform.
|
||||
|
||||
* [District0x Fixit][27] \- github bug bounties.
|
||||
|
||||
|
||||
|
||||
|
||||
This list is varied and growing rapidly. Some of these projects will disappear, others will pivot, but a few will emerge as the [SourceForge][28], the ASF, the GitHub of the future. That doesn't necessarily mean they'll replace these platforms, but they'll complement them with token models and create a richer open source ecosystem. Every project can pick its distribution model (license), governing model (foundation), and incentive model (token). In all cases, this will pump fresh blood to the open source world.
|
||||
|
||||
### The future is open and decentralized
|
||||
|
||||
* Software is eating the world.
|
||||
|
||||
* Every company is a software company.
|
||||
|
||||
* Open source is where innovation happens.
|
||||
|
||||
|
||||
|
||||
|
||||
Given that, it is clear that open source is too big to fail and too important to be controlled by a few or left to its own destiny. Open source is a shared-resource system that has value to all, and more importantly, it must be managed as such. It is only a matter of time until every company on earth will want to have a stake and a say in the open source world. Unfortunately, we don't have the tools and the habits to do it yet. Such tools would allow anybody to show their appreciation or ignorance of software projects. It would create a direct and faster feedback loop between producers and consumers, between developers and users. It will foster innovation—innovation driven by user needs and expressed through token metrics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bibryam
|
||||
[1]:https://en.wikipedia.org/wiki/Satoshi_Nakamoto
|
||||
[2]:https://www.apache.org/
|
||||
[3]:https://www.cncf.io/
|
||||
[4]:https://medium.com/open-consensus/3-oss-business-model-progressions-dafd5837f2d
|
||||
[5]:https://docs.google.com/spreadsheets/d/17nKMpi_Dh5slCqzLSFBoWMxNvWiwt2R-t4e_l7LPLhU/edit#gid=0
|
||||
[6]:http://jobs.redhat.com/
|
||||
[7]:https://attic.apache.org/
|
||||
[8]:http://incubator.apache.org/
|
||||
[9]:https://en.wikipedia.org/wiki/Smart_contract
|
||||
[10]:/file/404421
|
||||
[11]:https://opensource.com/sites/default/files/uploads/blockchain_in_open_source_ecosystem.png (blockchain_in_open_source_ecosystem.png)
|
||||
[12]:https://gitcoin.co/
|
||||
[13]:http://oscoin.io/
|
||||
[14]:https://opencollective.com/opensource
|
||||
[15]:https://www.fundyourselfnow.com/page/about
|
||||
[16]:https://kauri.io/
|
||||
[17]:https://liberapay.com/
|
||||
[18]:https://fundrequest.io/
|
||||
[19]:https://canya.io/
|
||||
[20]:https://www.bountysource.com/
|
||||
[21]:https://opengift.io/pub/
|
||||
[22]:https://hacken.io/
|
||||
[23]:https://www.coinlancer.com/home
|
||||
[24]:https://codefund.io/
|
||||
[25]:https://issuehunt.io/
|
||||
[26]:https://blog.district0x.io/district-proposal-spotlight-1hive-283957f57967
|
||||
[27]:https://github.com/district0x/district-proposals/issues/177
|
||||
[28]:https://sourceforge.net/
|
||||
@ -1,3 +1,5 @@
|
||||
fuowang 翻译中
|
||||
|
||||
Arch Linux Applications Automatic Installation Script
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,172 @@
|
||||
BootISO – A Simple Bash Script To Securely Create A Bootable USB Device From ISO File
|
||||
======
|
||||
Most of us (including me) very often create a bootable USB device from ISO file for OS installation.
|
||||
|
||||
There are many applications freely available in Linux for this purpose. Even we wrote few of the utility in the past.
|
||||
|
||||
Every one uses different application and each application has their own features and functionality.
|
||||
|
||||
In that few of applications are belongs to CLI and few of them associated with GUI.
|
||||
|
||||
Today we are going to discuss about similar kind of utility called BootISO. It’s a simple bash script, which allow users to create a USB device from ISO file.
|
||||
|
||||
Many of the Linux admin uses dd command to create bootable ISO, which is one of the native and famous method but the same time, it’s one of the very dangerous command. So, be careful, when you performing any action with dd command.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [Etcher – Easy way to Create a bootable USB drive & SD card from an ISO image][1]
|
||||
**(#)** [Create a bootable USB drive from an ISO image using dd command on Linux][2]
|
||||
|
||||
### What IS BootISO
|
||||
|
||||
[BootIOS][3] is a simple bash script, which allow users to securely create a bootable USB device from one ISO file. It’s written in bash.
|
||||
|
||||
It doesn’t offer any GUI but in the same time it has vast of options, which allow newbies to create a bootable USB device in Linux without any issues. Since it’s a intelligent tool that automatically choose if any USB device is connected on the system.
|
||||
|
||||
It will print the list when the system has more than one USB device connected. When you choose manually another hard disk manually instead of USB, this will safely exit without writing anything on it.
|
||||
|
||||
This script will also check for dependencies and prompt user for installation, it works with all package managers such as apt-get, yum, dnf, pacman and zypper.
|
||||
|
||||
### BootISO Features
|
||||
|
||||
* It checks whether the selected ISO has the correct mime-type or not. If no then it exit.
|
||||
* BootISO will exit automatically, if you selected any other disks (local hard drive) except USB drives.
|
||||
* BootISO allow users to select the desired USB drives when you have more than one.
|
||||
* BootISO prompts the user for confirmation before erasing and paritioning USB device.
|
||||
* BootISO will handle any failure from a command properly and exit.
|
||||
* BootISO will call a cleanup routine on exit with trap.
|
||||
|
||||
|
||||
|
||||
### How To Install BootISO In Linux
|
||||
|
||||
There are few ways are available to install BootISO in Linux but i would advise users to install using the following method.
|
||||
```
|
||||
$ curl -L https://git.io/bootiso -O
|
||||
$ chmod +x bootiso
|
||||
$ sudo mv bootiso /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
Once BootISO installed, run the following command to list the available USB devices.
|
||||
```
|
||||
$ bootiso -l
|
||||
|
||||
Listing USB drives available in your system:
|
||||
NAME HOTPLUG SIZE STATE TYPE
|
||||
sdd 1 32G running disk
|
||||
|
||||
```
|
||||
|
||||
If you have only one USB device, then simple run the following command to create a bootable USB device from ISO file.
|
||||
```
|
||||
$ bootiso /path/to/iso file
|
||||
|
||||
$ bootiso /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
Granting root privileges for bootiso.
|
||||
Listing USB drives available in your system:
|
||||
NAME HOTPLUG SIZE STATE TYPE
|
||||
sdd 1 32G running disk
|
||||
Autoselecting `sdd' (only USB device candidate)
|
||||
The selected device `/dev/sdd' is connected through USB.
|
||||
Created ISO mount point at `/tmp/iso.vXo'
|
||||
`bootiso' is about to wipe out the content of device `/dev/sdd'.
|
||||
Are you sure you want to proceed? (y/n)>y
|
||||
Erasing contents of /dev/sdd...
|
||||
Creating FAT32 partition on `/dev/sdd1'...
|
||||
Created USB device mount point at `/tmp/usb.0j5'
|
||||
Copying files from ISO to USB device with `rsync'
|
||||
Synchronizing writes on device `/dev/sdd'
|
||||
`bootiso' took 250 seconds to write ISO to USB device with `rsync' method.
|
||||
ISO succesfully unmounted.
|
||||
USB device succesfully unmounted.
|
||||
USB device succesfully ejected.
|
||||
You can safely remove it !
|
||||
|
||||
```
|
||||
|
||||
Mention your device name, when you have more than one USB device using `--device` option.
|
||||
```
|
||||
$ bootiso -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
By default bootios uses `rsync` command to perform all the action and if you want to use `dd` command instead of, use the following format.
|
||||
```
|
||||
$ bootiso --dd -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
If you want to skip `mime-type` check, include the following option with bootios utility.
|
||||
```
|
||||
$ bootiso --no-mime-check -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
Add the below option with bootios to skip user for confirmation before erasing and partitioning USB device.
|
||||
```
|
||||
$ bootiso -y -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
Enable autoselecting USB devices in conjunction with -y option.
|
||||
```
|
||||
$ bootiso -y -a /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
|
||||
```
|
||||
|
||||
To know more all the available option for bootiso, run the following command.
|
||||
```
|
||||
$ bootiso -h
|
||||
Create a bootable USB from any ISO securely.
|
||||
Usage: bootiso [...]
|
||||
|
||||
Options
|
||||
|
||||
-h, --help, help Display this help message and exit.
|
||||
-v, --version Display version and exit.
|
||||
-d, --device Select block file as USB device.
|
||||
If is not connected through USB, `bootiso' will fail and exit.
|
||||
Device block files are usually situated in /dev/sXX or /dev/hXX.
|
||||
You will be prompted to select a device if you don't use this option.
|
||||
-b, --bootloader Install a bootloader with syslinux (safe mode) for non-hybrid ISOs. Does not work with `--dd' option.
|
||||
-y, --assume-yes `bootiso' won't prompt the user for confirmation before erasing and partitioning USB device.
|
||||
Use at your own risks.
|
||||
-a, --autoselect Enable autoselecting USB devices in conjunction with -y option.
|
||||
Autoselect will automatically select a USB drive device if there is exactly one connected to the system.
|
||||
Enabled by default when neither -d nor --no-usb-check options are given.
|
||||
-J, --no-eject Do not eject device after unmounting.
|
||||
-l, --list-usb-drives List available USB drives.
|
||||
-M, --no-mime-check `bootiso' won't assert that selected ISO file has the right mime-type.
|
||||
-s, --strict-mime-check Disallow loose application/octet-stream mime type in ISO file.
|
||||
-- POSIX end of options.
|
||||
--dd Use `dd' utility instead of mounting + `rsync'.
|
||||
Does not allow bootloader installation with syslinux.
|
||||
--no-usb-check `bootiso' won't assert that selected device is a USB (connected through USB bus).
|
||||
Use at your own risks.
|
||||
|
||||
Readme
|
||||
|
||||
Bootiso v2.5.2.
|
||||
Author: Jules Samuel Randolph
|
||||
Bugs and new features: https://github.com/jsamr/bootiso/issues
|
||||
If you like bootiso, please help the community by making it visible:
|
||||
* star the project at https://github.com/jsamr/bootiso
|
||||
* upvote those SE post: https://goo.gl/BNRmvm https://goo.gl/YDBvFe
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/
|
||||
[2]:https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/
|
||||
[3]:https://github.com/jsamr/bootiso
|
||||
@ -1,3 +1,4 @@
|
||||
[Moelf](https://github.com/moelf/) Translating
|
||||
Don’t Install Yaourt! Use These Alternatives for AUR in Arch Linux
|
||||
======
|
||||
**Brief: Yaourt had been the most popular AUR helper, but it is not being developed anymore. In this article, we list out some of the best alternatives to Yaourt for Arch based Linux distributions. **
|
||||
|
||||
@ -1,322 +0,0 @@
|
||||
BriFuture is translating
|
||||
|
||||
|
||||
Testing Node.js in 2018
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
[Stream][4] powers feeds for over 300+ million end users. With all of those users relying on our infrastructure, we’re very good about testing everything that gets pushed into production. Our primary codebase is written in Go, with some remaining bits of Python.
|
||||
|
||||
Our recent showcase application, [Winds 2.0][5], is built with Node.js and we quickly learned that our usual testing methods in Go and Python didn’t quite fit. Furthermore, creating a proper test suite requires a bit of upfront work in Node.js as the frameworks we are using don’t offer any type of built-in test functionality.
|
||||
|
||||
Setting up a good test framework can be tricky regardless of what language you’re using. In this post, we’ll uncover the hard parts of testing with Node.js, the various tooling we decided to utilize in Winds 2.0, and point you in the right direction for when it comes time for you to write your next set of tests.
|
||||
|
||||
### Why Testing is so Important
|
||||
|
||||
We’ve all pushed a bad commit to production and faced the consequences. It’s not a fun thing to have happen. Writing a solid test suite is not only a good sanity check, but it allows you to completely refactor code and feel confident that your codebase is still functional. This is especially important if you’ve just launched.
|
||||
|
||||
If you’re working with a team, it’s extremely important that you have test coverage. Without it, it’s nearly impossible for other developers on the team to know if their contributions will result in a breaking change (ouch).
|
||||
|
||||
Writing tests also encourage you and your teammates to split up code into smaller pieces. This makes it much easier to understand your code, and fix bugs along the way. The productivity gains are even bigger, due to the fact that you catch bugs early on.
|
||||
|
||||
Finally, without tests, your codebase might as well be a house of cards. There is simply zero certainty that your code is stable.
|
||||
|
||||
### The Hard Parts
|
||||
|
||||
In my opinion, most of the testing problems we ran into with Winds were specific to Node.js. The ecosystem is always growing. For example, if you are on macOS and run “brew upgrade” (with homebrew installed), your chances of seeing a new version of Node.js are quite high. With Node.js moving quickly and libraries following close behind, keeping up to date with the latest libraries is difficult.
|
||||
|
||||
Below are a few pain points that immediately come to mind:
|
||||
|
||||
1. Testing in Node.js is very opinionated and un-opinionated at the same time. Many people have different views on how a test infrastructure should be built and measured for success. The sad part is that there is no golden standard (yet) for how you should approach testing.
|
||||
|
||||
2. There are a large number of frameworks available to use in your application. However, they are generally minimal with no well-defined configuration or boot process. This leads to side effects that are very common, and yet hard to diagnose; so, you’ll likely end up writing your own test runner from scratch.
|
||||
|
||||
3. It’s almost guaranteed that you will be _required_ to write your own test runner (we’ll get to this in a minute).
|
||||
|
||||
The situations listed above are not ideal and it’s something that the Node.js community needs to address sooner rather than later. If other languages have figured it out, I think it’s time for Node.js, a widely adopted language, to figure it out as well.
|
||||
|
||||
### Writing Your Own Test Runner
|
||||
|
||||
So… you’re probably wondering what a test runner _is_ . To be honest, it’s not that complicated. A test runner is the highest component in the test suite. It allows for you to specify global configurations and environments, as well as import fixtures. One would assume this would be simple and easy to do… Right? Not so fast…
|
||||
|
||||
What we learned is that, although there is a solid number of test frameworks out there, not a single one for Node.js provides a unified way to construct your test runner. Sadly, it’s up to the developer to do so. Here’s a quick breakdown of the requirements for a test runner:
|
||||
|
||||
* Ability to load different configurations (e.g. local, test, development) and ensure that you _NEVER_ load a production configuration — you can guess what goes wrong when that happens.
|
||||
|
||||
* Lift and seed a database with dummy data for testing. This must work for various databases, whether it be MySQL, PostgreSQL, MongoDB, or any other, for that matter.
|
||||
|
||||
* Ability to load fixtures (files with seed data for testing in a development environment).
|
||||
|
||||
With Winds, we chose to use Mocha as our test runner. Mocha provides an easy and programmatic way to run tests on an ES6 codebase via command-line tools (integrated with Babel).
|
||||
|
||||
To kick off the tests, we register the Babel module loader ourselves. This provides us with finer grain greater control over which modules are imported before Babel overrides Node.js module loading process, giving us the opportunity to mock modules before any tests are run.
|
||||
|
||||
Additionally, we also use Mocha’s test runner feature to pre-assign HTTP handlers to specific requests. We do this because the normal initialization code is not run during tests (server interactions are mocked by the Chai HTTP plugin) and run some safety check to ensure we are not connecting to production databases.
|
||||
|
||||
While this isn’t part of the test runner, having a fixture loader is an important part of our test suite. We examined existing solutions; however, we settled on writing our own helper so that it was tailored to our requirements. With our solution, we can load fixtures with complex data-dependencies by following an easy ad-hoc convention when generating or writing fixtures by hand.
|
||||
|
||||
### Tooling for Winds
|
||||
|
||||
Although the process was cumbersome, we were able to find the right balance of tools and frameworks to make proper testing become a reality for our backend API. Here’s what we chose to go with:
|
||||
|
||||
### Mocha ☕
|
||||
|
||||
[Mocha][6], described as a “feature-rich JavaScript test framework running on Node.js”, was our immediate choice of tooling for the job. With well over 15k stars, many backers, sponsors, and contributors, we knew it was the right framework for the job.
|
||||
|
||||
### Chai 🥃
|
||||
|
||||
Next up was our assertion library. We chose to go with the traditional approach, which is what works best with Mocha — [Chai][7]. Chai is a BDD and TDD assertion library for Node.js. With a simple API, Chai was easy to integrate into our application and allowed for us to easily assert what we should _expect_ tobe returned from the Winds API. Best of all, writing tests feel natural with Chai. Here’s a short example:
|
||||
|
||||
```
|
||||
describe('retrieve user', () => {
|
||||
let user;
|
||||
|
||||
before(async () => {
|
||||
await loadFixture('user');
|
||||
user = await User.findOne({email: authUser.email});
|
||||
expect(user).to.not.be.null;
|
||||
});
|
||||
|
||||
after(async () => {
|
||||
await User.remove().exec();
|
||||
});
|
||||
|
||||
describe('valid request', () => {
|
||||
it('should return 200 and the user resource, including the email field, when retrieving the authenticated user', async () => {
|
||||
const response = await withLogin(request(api).get(`/users/${user._id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(user._id.toString());
|
||||
});
|
||||
|
||||
it('should return 200 and the user resource, excluding the email field, when retrieving another user', async () => {
|
||||
const anotherUser = await User.findOne({email: 'another_user@email.com'});
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${anotherUser.id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(anotherUser._id.toString());
|
||||
expect(response.body).to.not.have.an('email');
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
describe('invalid requests', () => {
|
||||
|
||||
it('should return 404 if requested user does not exist', async () => {
|
||||
const nonExistingId = '5b10e1c601e9b8702ccfb974';
|
||||
expect(await User.findOne({_id: nonExistingId})).to.be.null;
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${nonExistingId}`), authUser);
|
||||
expect(response).to.have.status(404);
|
||||
});
|
||||
});
|
||||
|
||||
});
|
||||
```
|
||||
|
||||
### Sinon 🧙
|
||||
|
||||
With the ability to work with any unit testing framework, [Sinon][8] was our first choice for a mocking library. Again, a super clean integration with minimal setup, Sinon turns mocking requests into a simple and easy process. Their website has an extremely friendly user experience and offers up easy steps to integrate Sinon with your test suite.
|
||||
|
||||
### Nock 🔮
|
||||
|
||||
For all external HTTP requests, we use [nock][9], a robust HTTP mocking library that really comes in handy when you have to communicate with a third party API (such as [Stream’s REST API][10]). There’s not much to say about this little library aside from the fact that it is awesome at what it does, and that’s why we like it. Here’s a quick example of us calling our [personalization][11] engine for Stream:
|
||||
|
||||
```
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
```
|
||||
|
||||
### Mock-require 🎩
|
||||
|
||||
The library [mock-require][12] allows dependencies on external code. In a single line of code, you can replace a module and mock-require will step in when some code attempts to import that module. It’s a small and minimalistic, but robust library, and we’re big fans.
|
||||
|
||||
### Istanbul 🔭
|
||||
|
||||
[Istanbul][13] is a JavaScript code coverage tool that computes statement, line, function and branch coverage with module loader hooks to transparently add coverage when running tests. Although we have similar functionality with CodeCov (see next section), this is a nice tool to have when running tests locally.
|
||||
|
||||
### The End Result — Working Tests
|
||||
|
||||
_With all of the libraries, including the test runner mentioned above, let’s have a look at what a full test looks like (you can have a look at our entire test suite _ [_here_][14] _):_
|
||||
|
||||
```
|
||||
import nock from 'nock';
|
||||
import { expect, request } from 'chai';
|
||||
|
||||
import api from '../../src/server';
|
||||
import Article from '../../src/models/article';
|
||||
import config from '../../src/config';
|
||||
import { dropDBs, loadFixture, withLogin } from '../utils.js';
|
||||
|
||||
describe('Article controller', () => {
|
||||
let article;
|
||||
|
||||
before(async () => {
|
||||
await dropDBs();
|
||||
await loadFixture('initial-data', 'articles');
|
||||
article = await Article.findOne({});
|
||||
expect(article).to.not.be.null;
|
||||
expect(article.rss).to.not.be.null;
|
||||
});
|
||||
|
||||
describe('get', () => {
|
||||
it('should return the right article via /articles/:articleId', async () => {
|
||||
let response = await withLogin(request(api).get(`/articles/${article.id}`));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('get parsed article', () => {
|
||||
it('should return the parsed version of the article', async () => {
|
||||
const response = await withLogin(
|
||||
request(api).get(`/articles/${article.id}`).query({ type: 'parsed' })
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list', () => {
|
||||
it('should return the list of articles', async () => {
|
||||
let response = await withLogin(request(api).get('/articles'));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list from personalization', () => {
|
||||
after(function () {
|
||||
nock.cleanAll();
|
||||
});
|
||||
|
||||
it('should return the list of articles', async () => {
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
|
||||
const response = await withLogin(
|
||||
request(api).get('/articles').query({
|
||||
type: 'recommended',
|
||||
})
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body.length).to.be.at.least(1);
|
||||
expect(response.body[0].url).to.eq(article.url);
|
||||
});
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
### Continuous Integration
|
||||
|
||||
There are a lot of continuous integration services available, but we like to use [Travis CI][15] because they love the open-source environment just as much as we do. Given that Winds is open-source, it made for a perfect fit.
|
||||
|
||||
Our integration is rather simple — we have a [.travis.yml][16] file that sets up the environment and kicks off our tests via a simple [npm][17] command. The coverage reports back to GitHub, where we have a clear picture of whether or not our latest codebase or PR passes our tests. The GitHub integration is great, as it is visible without us having to go to Travis CI to look at the results. Below is a screenshot of GitHub when viewing the PR (after tests):
|
||||
|
||||
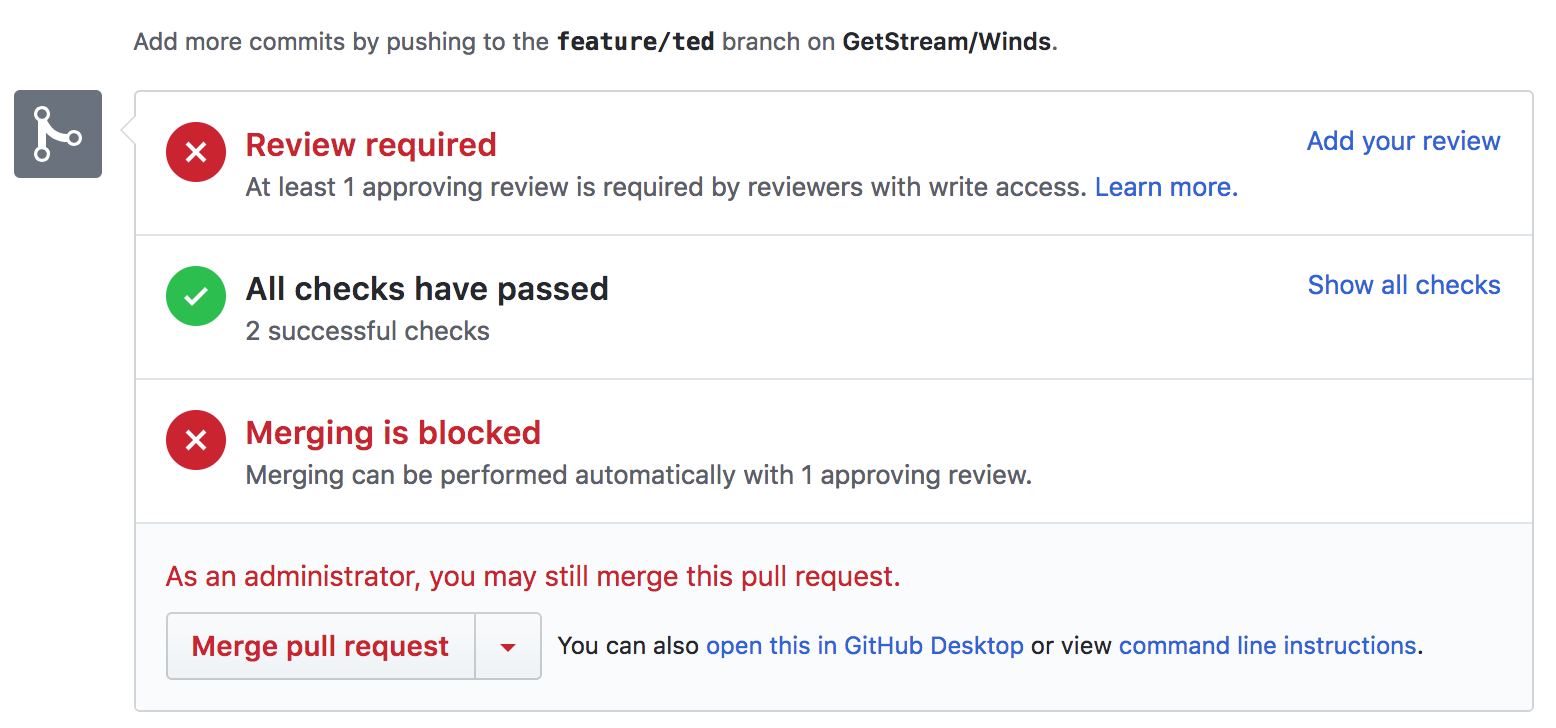
|
||||
|
||||
In addition to Travis CI, we use a tool called [CodeCov][18]. CodeCov is similar to [Istanbul][19], however, it’s a visualization tool that allows us to easily see code coverage, files changed, lines modified, and all sorts of other goodies. Though visualizing this data is possible without CodeCov, it’s nice to have everything in one spot.
|
||||
|
||||
### What We Learned
|
||||
|
||||
|
||||
|
||||
We learned a lot throughout the process of developing our test suite. With no “correct” way of doing things, we decided to set out and create our own test flow by sorting through the available libraries to find ones that were promising enough to add to our toolbox.
|
||||
|
||||
What we ultimately learned is that testing in Node.js is not as easy as it may sound. Hopefully, as Node.js continues to grow, the community will come together and build a rock solid library that handles everything test related in a “correct” manner.
|
||||
|
||||
Until then, we’ll continue to use our test suite, which is open-source on the [Winds GitHub repository][20].
|
||||
|
||||
### Limitations
|
||||
|
||||
#### No Easy Way to Create Fixtures
|
||||
|
||||
Frameworks and languages, such as Python’s Django, have easy ways to create fixtures. With Django, for example, you can use the following commands to automate the creation of fixtures by dumping data into a file:
|
||||
|
||||
The Following command will dump the whole database into a db.json file:
|
||||
./manage.py dumpdata > db.json
|
||||
|
||||
The Following command will dump only the content in django admin.logentry table:
|
||||
./manage.py dumpdata admin.logentry > logentry.json
|
||||
|
||||
The Following command will dump the content in django auth.user table: ./manage.py dumpdata auth.user > user.json
|
||||
|
||||
There’s no easy way to create a fixture in Node.js. What we ended up doing is using MongoDB Compass and exporting JSON from there. This resulted in a nice fixture, as shown below (however, it was a tedious process and prone to error):
|
||||
|
||||
|
||||
|
||||
|
||||
#### Unintuitive Module Loading When Using Babel, Mocked Modules, and Mocha Test-Runner
|
||||
|
||||
To support a broader variety of node versions and have access to latest additions to Javascript standard, we are using Babel to transpile our ES6 codebase to ES5\. Node.js module system is based on the CommonJS standard whereas the ES6 module system has different semantics.
|
||||
|
||||
Babel emulates ES6 module semantics on top of the Node.js module system, but because we are interfering with module loading by using mock-require, we are embarking on a journey through weird module loading corner cases, which seem unintuitive and can lead to multiple independent versions of the module imported and initialized and used throughout the codebase. This complicates mocking and global state management during testing.
|
||||
|
||||
#### Inability to Mock Functions Used Within the Module They Are Declared in When Using ES6 Modules
|
||||
|
||||
When a module exports multiple functions where one calls the other, it’s impossible to mock the function being used inside the module. The reason is that when you require an ES6 module you are presented with a separate set of references from the one used inside the module. Any attempt to rebind the references to point to new values does not really affect the code inside the module, which will continue to use the original function.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
Testing Node.js applications is a complicated process because the ecosystem is always evolving. It’s important to stay on top of the latest and greatest tools so you don’t fall behind.
|
||||
|
||||
There are so many outlets for JavaScript related news these days that it’s hard to keep up to date with all of them. Following email newsletters such as [JavaScript Weekly][21] and [Node Weekly][22] is a good start. Beyond that, joining a subreddit such as [/r/node][23] is a great idea. If you like to stay on top of the latest trends, [State of JS][24] does a great job at helping developers visualize trends in the testing world.
|
||||
|
||||
Lastly, here are a couple of my favorite blogs where articles often popup:
|
||||
|
||||
* [Hacker Noon][1]
|
||||
|
||||
* [Free Code Camp][2]
|
||||
|
||||
* [Bits and Pieces][3]
|
||||
|
||||
Think I missed something important? Let me know in the comments, or on Twitter – [@NickParsons][25].
|
||||
|
||||
Also, if you’d like to check out Stream, we have a great 5 minute tutorial on our website. Give it a shot [here][26].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nick Parsons
|
||||
|
||||
Dreamer. Doer. Engineer. Developer Evangelist https://getstream.io.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/testing-node-js-in-2018-10a04dd77391
|
||||
|
||||
作者:[Nick Parsons][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@nparsons08?source=post_header_lockup
|
||||
[1]:https://hackernoon.com/
|
||||
[2]:https://medium.freecodecamp.org/
|
||||
[3]:https://blog.bitsrc.io/
|
||||
[4]:https://getstream.io/
|
||||
[5]:https://getstream.io/winds
|
||||
[6]:https://github.com/mochajs/mocha
|
||||
[7]:http://www.chaijs.com/
|
||||
[8]:http://sinonjs.org/
|
||||
[9]:https://github.com/node-nock/nock
|
||||
[10]:https://getstream.io/docs_rest/
|
||||
[11]:https://getstream.io/personalization
|
||||
[12]:https://github.com/boblauer/mock-require
|
||||
[13]:https://github.com/gotwarlost/istanbul
|
||||
[14]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[15]:https://travis-ci.org/
|
||||
[16]:https://github.com/GetStream/Winds/blob/master/.travis.yml
|
||||
[17]:https://www.npmjs.com/
|
||||
[18]:https://codecov.io/#features
|
||||
[19]:https://github.com/gotwarlost/istanbul
|
||||
[20]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[21]:https://javascriptweekly.com/
|
||||
[22]:https://nodeweekly.com/
|
||||
[23]:https://www.reddit.com/r/node/
|
||||
[24]:https://stateofjs.com/2017/testing/results/
|
||||
[25]:https://twitter.com/@nickparsons
|
||||
[26]:https://getstream.io/try-the-api
|
||||
@ -1,90 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
4 cool new projects to try in COPR for July 2018
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here’s a set of new and interesting projects in COPR.
|
||||
|
||||
### Hledger
|
||||
|
||||
[Hledger][2] is a command-line program for tracking money or other commodities. It uses a simple, plain-text formatted journal for storing data and double-entry accounting. In addition to the command-line interface, hledger offers a terminal interface and a web client that can show graphs of balance on the accounts.
|
||||
![][3]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides hledger for Fedora 27, 28, and Rawhide. To install hledger, use these commands:
|
||||
```
|
||||
sudo dnf copr enable kefah/HLedger
|
||||
sudo dnf install hledger
|
||||
|
||||
```
|
||||
|
||||
### Neofetch
|
||||
|
||||
[Neofetch][4] is a command-line tool that displays information about the operating system, software, and hardware. Its main purpose is to show the data in a compact way to take screenshots. You can configure Neofetch to display exactly the way you want, by using both command-line flags and a configuration file.
|
||||
![][5]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Neofetch for Fedora 28. To install Neofetch, use these commands:
|
||||
```
|
||||
sudo dnf copr enable sysek/neofetch
|
||||
sudo dnf install neofetch
|
||||
|
||||
```
|
||||
|
||||
### Remarkable
|
||||
|
||||
[Remarkable][6] is a Markdown text editor that uses the GitHub-like flavor of Markdown. It offers a preview of the document, as well as the option to export to PDF and HTML. There are several styles available for the Markdown, including an option to create your own styles using CSS. In addition, Remarkable supports LaTeX syntax for writing equations and syntax highlighting for source code.
|
||||
![][7]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Remarkable for Fedora 28 and Rawhide. To install Remarkable, use these commands:
|
||||
```
|
||||
sudo dnf copr enable neteler/remarkable
|
||||
sudo dnf install remarkable
|
||||
|
||||
```
|
||||
|
||||
### Aha
|
||||
|
||||
[Aha][8] (or ANSI HTML Adapter) is a command-line tool that converts terminal escape sequences to HTML code. This allows you to share, for example, output of git diff or htop as a static HTML page.
|
||||
![][9]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][10] currently provides aha for Fedora 26, 27, 28, and Rawhide, EPEL 6 and 7, and other distributions. To install aha, use these commands:
|
||||
```
|
||||
sudo dnf copr enable scx/aha
|
||||
sudo dnf install aha
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-july-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://hledger.org/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/hledger.png
|
||||
[4]:https://github.com/dylanaraps/neofetch
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/neofetch.png
|
||||
[6]:https://remarkableapp.github.io/linux.html
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/remarkable.png
|
||||
[8]:https://github.com/theZiz/aha
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/aha.png
|
||||
[10]:https://copr.fedorainfracloud.org/coprs/scx/aha/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
The evolution of package managers
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,136 @@
|
||||
How To Use Pbcopy And Pbpaste Commands On Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Since Linux and Mac OS X are *Nix based systems, many commands would work on both platforms. However, some commands may not available in on both platforms, for example **pbcopy** and **pbpaste**. These commands are exclusively available only on Mac OS X platform. The Pbcopy command will copy the standard input into clipboard. You can then paste the clipboard contents using Pbpaste command wherever you want. Of course, there could be some Linux alternatives to the above commands, for example **Xclip**. The Xclip will do exactly same as Pbcopy. But, the distro-hoppers who switched to Linux from Mac OS would miss this command-pair and still prefer to use them. No worries! This brief tutorial describes how to use Pbcopy and Pbpaste commands on Linux.
|
||||
|
||||
### Install Xclip / Xsel
|
||||
|
||||
Like I already said, Pbcopy and Pbpaste commands are not available in Linux. However, we can replicate the functionality of pbcopy and pbpaste commands using Xclip and/or Xsel commands via shell aliasing. Both Xclip and Xsel packages available in the default repositories of most Linux distributions. Please note that you need not to install both utilities. Just install any one of the above utilities.
|
||||
|
||||
To install them on Arch Linux and its derivatives, run:
|
||||
```
|
||||
$ sudo pacman xclip xsel
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
$ sudo dnf xclip xsel
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt install xclip xsel
|
||||
|
||||
```
|
||||
|
||||
Once installed, you need create aliases for pbcopy and pbpaste commands. To do so, edit your **~/.bashrc** file:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
If you want to use Xclip, paste the following lines:
|
||||
```
|
||||
alias pbcopy='xclip -selection clipboard'
|
||||
alias pbpaste='xclip -selection clipboard -o'
|
||||
|
||||
```
|
||||
|
||||
If you want to use xsel, paste the following lines in your ~/.bashrc file.
|
||||
```
|
||||
alias pbcopy='xsel --clipboard --input'
|
||||
alias pbpaste='xsel --clipboard --output'
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Next, run the following command to update the changes in ~/.bashrc file.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
The ZSH users paste the above lines in **~/.zshrc** file.
|
||||
|
||||
### Use Pbcopy And Pbpaste Commands On Linux
|
||||
|
||||
Let us see some examples.
|
||||
|
||||
The pbcopy command will copy the text from stdin into clipboard buffer. For example, have a look at the following example.
|
||||
```
|
||||
$ echo "Welcome To OSTechNix!" | pbcopy
|
||||
|
||||
```
|
||||
|
||||
The above command will copy the text “Welcome To OSTechNix” into clipboard. You can access this content later and paste them anywhere you want using Pbpaste command like below.
|
||||
```
|
||||
$ echo `pbpaste`
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
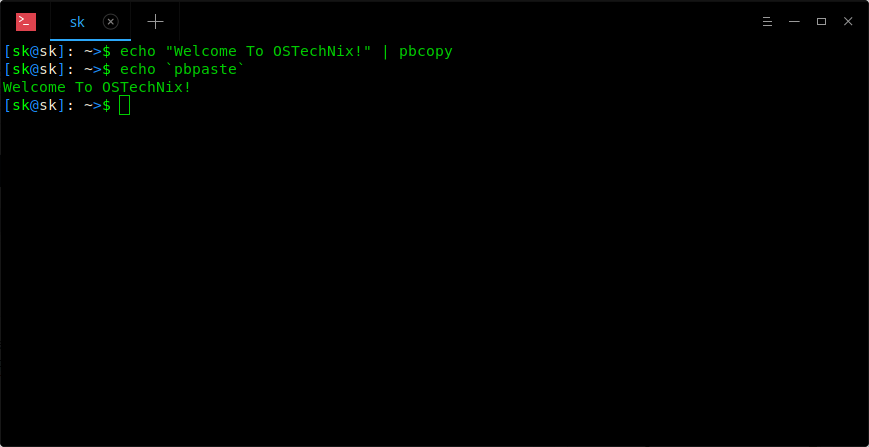
|
||||
|
||||
Here are some other use cases.
|
||||
|
||||
I have a file named **file.txt** with the following contents.
|
||||
```
|
||||
$ cat file.txt
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
You can directly copy the contents of a file into a clipboard as shown below.
|
||||
```
|
||||
$ pbcopy < file.txt
|
||||
|
||||
```
|
||||
|
||||
Now, the contents of the file is available in the clipboard as long as you updated with another file’s contents.
|
||||
|
||||
To retrieve the contents from clipboard, simply type:
|
||||
```
|
||||
$ pbpaste
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
You can also send the output of any Linux command to clip board using pipeline character. Have a look at the following example.
|
||||
```
|
||||
$ ps aux | pbcopy
|
||||
|
||||
```
|
||||
|
||||
Now, type “pbpaste” command at any time to display the output of “ps aux” command from the clipboard.
|
||||
```
|
||||
$ pbpaste
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
There is much more you can do with Pbcopy and Pbpaste commands. I hope you now got a basic idea about these commands.
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,64 @@
|
||||
What's in a container image: Meeting the legal challenges
|
||||
======
|
||||
|
||||
|
||||
[Container][1] technology has, for many years, been transforming how workloads in data centers are managed and speeding the cycle of application development and deployment.
|
||||
|
||||
In addition, container images are increasingly used as a distribution format, with container registries a mechanism for software distribution. Isn't this just like packages distributed using package management tools? Not quite. While container image distribution is similar to RPMs, DEBs, and other package management systems (for example, storing and distributing archives of files), the implications of container image distribution are more complicated. It is not the fault of container technology itself; rather, it's because container distribution is used differently than package management systems.
|
||||
|
||||
Talking about the challenges of license compliance for container images, [Dirk Hohndel][2], chief open source officer at VMware, pointed out that the content of a container image is more complex than most people expect, and many readily available images have been built in surprisingly cavalier ways. (See the [LWN.net article][3] by Jake Edge about a talk Dirk gave in April.)
|
||||
|
||||
Why is it hard to understand the licensing of container images? Shouldn't there just be a label for the image ("the license is X")? In the [Open Container Image Format Specification][4] , one of the pre-defined annotation keys is "org.opencontainers.image.licenses," which is described as "License(s) under which contained software is distributed as an SPDX License Expression." But that doesn't contemplate the complexity of a container image–while very simple images are built from tens of components, images are often built from hundreds of components. An [SPDX License Expression][5] is most frequently used to convey the licensing for a single source file. Such expressions can handle more than one license, such as "GPL-2.0 OR BSD-3-Clause" (see, for example, [Appendix IV][6] of version 2.1 of the SPDX specification). But the licensing for a typical container image is, typically, much more complicated.
|
||||
|
||||
In talking about container-related technology, the term "[container][7]" can lead to confusion. A container does not refer to the containment of files for storing or transferring. Rather, it refers to using features built into the kernel (such as cgroups and namespaces) to present a sort of "contained" experience to code running on the kernel. In other words, the containment to which "container" refers is an execution experience, not a distribution experience. The set of files to be laid out in a file system as the basis for an executing container is typically distributed in what is known as a "container image," sometimes confusingly referred to simply as a container, thereby awkwardly overloading the term "container."
|
||||
|
||||
In understanding software distribution via container images, I believe it is useful to consider two separate factors:
|
||||
|
||||
* **Diversity of content:** The basic unit of software distribution (a container image) includes a larger quantity and diversity of content than in the basic unit of distribution in typical software distribution mechanisms.
|
||||
* **Use model:** The nature of widely used tooling fosters the use of a registry, which is often publicly available, in the typical workflow.
|
||||
|
||||
|
||||
|
||||
### Diversity of content
|
||||
|
||||
When talking about a particular container image, the focus of attention is often on a particular software component (for example, a database or the code that implements one specific service). However, the container image includes a much larger collection of software. In fact, even the developer who created the image may have only a superficial understanding of and/or interest in most of the components in the image. With other distribution mechanisms, those other pieces of software would be identified as dependencies, and users of the software might be directed elsewhere for expertise on those components. In a container, the individual who acquires the container image isn't aware of those additional components that play supporting roles to the featured component.
|
||||
|
||||
#### The unit of distribution: user-driven vs. factory-driven
|
||||
|
||||
For container images, the distribution unit is user-driven, not factory-driven. Container images are a great tool for reducing the burden on software consumers. With a container image, the image's consumer can focus on the application of interest; the image's builder can take care of the dependencies and configuration. This simplification can be a huge benefit.
|
||||
|
||||
When the unit of software is driven by the "factory," the user bears a greater responsibility for building a platform on which to run the software of interest, assembling the correct versions of the dependencies, and getting all the configuration details right. The unit of distribution in a package management system is a modular unit, rather than a complete solution. This unit facilitates building and maintaining a flow of components that are flexible enough to be assembled into myriad solutions. Note that because of this unit, a package maintainer will typically be far more familiar with the content of the packages than someone who builds containers. A person building a container may have a detailed understanding of the container's featured components, but limited familiarity with the image's supporting components.
|
||||
|
||||
Packages, package management system tools, package maintenance processes, and package maintainers are incredibly underappreciated. They have been central to delivery of a large variety of software over the last two decades. While container images are playing a growing role, I don't expect the importance of package management systems to fade anytime soon. In fact, the bulk of the content in container images benefits from being built from such packages.
|
||||
|
||||
In understanding container images, it is important to appreciate how distribution via such images has different properties than distribution of packages. Much of the content in images is built from packages, but the image's consumer may not know what packages are included or other package-level information. In the future, a variety of techniques may be used to build containers, e.g., directly from source without involvement of a package maintainer.
|
||||
|
||||
### Use models
|
||||
|
||||
What about reports that so many container images are poorly built? In part, the volume of casually built images is because of container tools that facilitate a workflow to make images publicly available. When experimenting with container tools and moving to a workflow that extends beyond a laptop, the tools expect you to have a repository where multiple machines can pull container images (a container registry). You could spin up your own. Some widely used tools make it easy to use an existing registry that is available at no cost, provided the images are publicly available. This makes many casually built images visible, even those that were never intended to be maintained or updated.
|
||||
|
||||
By comparison, how often do you see developers publishing RPMs of their early explorations? RPMs resulting from experimentation by random developers are not ending up in the major package repositories.
|
||||
|
||||
Or consider someone experimenting with the latest machine learning frameworks. In the past, a researcher might have shared only analysis results. Now, they can share a full analytical software configuration by publishing a container image. This could be a great benefit to other researchers. However, those browsing a container registry could be confused by the ready-to-run nature of such images. It is important to distinguish between an image built for one individual's exploration and an image that was assembled and tested with broad use in mind.
|
||||
|
||||
Be aware that container images include supporting software, not just the featured software; a container image distributes a collection of software. If you are building upon or otherwise using images built by others, be aware of how that image was built and consider your level of confidence in the image's source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/whats-container-image-meeting-legal-challenges
|
||||
|
||||
作者:[Scott Peterson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/skpeterson
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers
|
||||
[2]:https://www.linkedin.com/in/dirkhohndel
|
||||
[3]:https://lwn.net/Articles/752982/
|
||||
[4]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[5]:https://spdx.org/
|
||||
[6]:https://spdx.org/spdx-specification-21-web-version#h.jxpfx0ykyb60
|
||||
[7]:https://opensource.com/bus/16/8/introduction-linux-containers-and-image-signing
|
||||
@ -0,0 +1,83 @@
|
||||
5 of the Best Linux Games to Play in 2018
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux may not be establishing itself as the gamer’s platform of choice any time soon – the lack of success with Valve’s Steam Machines seems a poignant reminder of that – but that doesn’t mean that the platform isn’t steadily growing with its fair share of great games.
|
||||
|
||||
From indie hits to glorious RPGs, 2018 has already been a solid year for Linux games. Here we’ve listed our five favourites so far.
|
||||
|
||||
Looking for great Linux games but don’t want to splash the cash? Look to our list of the best [free Linux games][1] for guidance!
|
||||
|
||||
### 1. Pillars of Eternity II: Deadfire
|
||||
|
||||
![best-linux-games-2018-pillars-of-eternity-2-deadfire][2]
|
||||
|
||||
One of the titles that best represents the cRPG revival of recent years makes your typical Bethesda RPG look like a facile action-adventure. The latest entry in the majestic Pillars of Eternity series has a more buccaneering slant as you sail with a crew around islands filled with adventures and peril.
|
||||
|
||||
Adding naval combat to the mix, Deadfire continues with the rich storytelling and excellent writing of its predecessor while building on those beautiful graphics and hand-painted backgrounds of the original game.
|
||||
|
||||
This is a deep and unquestionably hardcore RPG that may cause some to bounce off it, but those who take to it will be absorbed in its world for months.
|
||||
|
||||
### 2. Slay the Spire
|
||||
|
||||
![best-linux-games-2018-slay-the-spire][3]
|
||||
|
||||
Still in early access, but already one of the best games of the year, Slay the Spire is a deck-building card game that’s embellished by a vibrant visual style and rogue-like mechanics that’ll leave you coming back for more after each infuriating (but probably deserved) death.
|
||||
|
||||
With endless card combinations and a different layout each time you play, Slay the Spire feels like the realisation of all the best systems that have been rocking the indie scene in recent years – card games and a permadeath adventure rolled into one.
|
||||
|
||||
And we repeat that it’s still in early access, so it’s only going to get better!
|
||||
|
||||
### 3. Battletech
|
||||
|
||||
![best-linux-games-2018-battletech][4]
|
||||
|
||||
As close as we get on this list to a “blockbuster” game, Battletech is an intergalactic wargame (based on a tabletop game) where you load up a team of Mechs and guide them through a campaign of rich, turn-based battles.
|
||||
|
||||
The action takes place across a range of terrain – from frigid wastelands to golden sun-soaked climes – as you load your squad of four with hulking hot weaponry, taking on rival squads. If this sounds a little “MechWarrior” to you, then you’re thinking along the right track, albeit this one’s more focused on the tactics than outright action.
|
||||
|
||||
Alongside a campaign that sees you navigate your way through a cosmic conflict, the multiplayer mode is also likely to consume untold hours of your life.
|
||||
|
||||
### 4. Dead Cells
|
||||
|
||||
![best-linux-games-2018-dead-cells][5]
|
||||
|
||||
This one deserves highlighting as the combat-platformer of the year. With its rogue-lite structure, Dead Cells throws you into a dark (yet gorgeously coloured) world where you slash and dodge your way through procedurally-generated levels. It’s a bit like a 2D Dark Souls, if Dark Souls were saturated in vibrant neon colours.
|
||||
|
||||
Dead Cells can be merciless, but its precise and responsive controls ensure that you only ever have yourself to blame for failure, and its upgrades system that carries over between runs ensures that you always have some sense of progress.
|
||||
|
||||
Dead Cells is a zenith of pixel-game graphics, animations and mechanics, a timely reminder of just how much can be achieved without the excesses of 3D graphics.
|
||||
|
||||
### 5. Iconoclasts
|
||||
|
||||
![best-linux-games-2018-iconoclasts][6]
|
||||
|
||||
A little less known than some of the above, this is still a lovely game that could be seen as a less foreboding, more cutesy alternative to Dead Cells. It casts you as Robin, a girl who’s cast out as a fugitive after finding herself at the wrong end of the twisted politics of an alien world.
|
||||
|
||||
It’s a good plot, even though your role in it is mainly blasting your way through the non-linear levels. Robin acquires all kinds of imaginative upgrades, the most crucial of which is her wrench, which you use to do everything from deflecting projectiles to solving the clever little environmental puzzles.
|
||||
|
||||
Iconoclasts is a joyful, vibrant platformer, borrowing from greats like Megaman for its combat and Metroid for its exploration. You can do a lot worse than take inspiration from those two classics.
|
||||
|
||||
### Conclusion
|
||||
|
||||
That’s it for our picks of the best Linux games to have come out in 2018. Have you dug up any gaming gems that we’ve missed? Let us know in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-games/
|
||||
|
||||
作者:[Robert Zak][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/robzak/
|
||||
[1]:https://www.maketecheasier.com/open-source-linux-games/
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-pillars-of-eternity-2-deadfire.jpg (best-linux-games-2018-pillars-of-eternity-2-deadfire)
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-slay-the-spire.jpg (best-linux-games-2018-slay-the-spire)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-battletech.jpg (best-linux-games-2018-battletech)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-dead-cells.jpg (best-linux-games-2018-dead-cells)
|
||||
[6]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-iconoclasts.jpg (best-linux-games-2018-iconoclasts)
|
||||
53
sources/tech/20180801 Cross-Site Request Forgery.md
Normal file
53
sources/tech/20180801 Cross-Site Request Forgery.md
Normal file
@ -0,0 +1,53 @@
|
||||
Cross-Site Request Forgery
|
||||
======
|
||||

|
||||
Security is a major concern when designing web apps. And I am not talking about DDOS protection, using a strong password or 2 step verification. I am talking about the biggest threat to a web app. It is known as **CSRF** short for **Cross Site Resource Forgery**.
|
||||
|
||||
### What is CSRF?
|
||||
|
||||
[][1]
|
||||
|
||||
First thing first, **CSRF** is short for Cross Site Resource Forgery. It is commonly pronounced as sea-surf and often referred to as XSRF. CSRF is a type of attack where various actions are performed on the web app where the victim is logged in without the victim's knowledge. These actions could be anything ranging from simply liking or commenting on a social media post to sending abusive messages to people or even transferring money from the victim’s bank account.
|
||||
|
||||
### How CSRF works?
|
||||
|
||||
**CSRF** attacks try to bank upon a simple common vulnerability in all browsers. Every time, we authenticate or log in to a website, session cookies are stored in the browser. So whenever we make a request to the website these cookies are automatically sent to the server where the server identifies us by matching the cookie we sent with the server’s records. So that way it knows it’s us.
|
||||
|
||||
[][2]
|
||||
|
||||
This means that any request made by me, knowingly or unknowingly, will be fulfilled. Since the cookies are being sent and they will match the records on the server, the server thinks I am making that request.
|
||||
|
||||
|
||||
|
||||
CSRF attacks usually come in form of links. We may click them on other websites or receive them as email. On clicking these links, an unwanted request is made to the server. And as I previously said, the server thinks we made the request and authenticates it.
|
||||
|
||||
#### A Real World Example
|
||||
|
||||
To put things into perspective, imagine you are logged into your bank’s website. And you fill up a form on the page at **yourbank.com/transfer** . You fill in the account number of the receiver as 1234 and the amount of 5,000 and you click on the submit button. Now, a request will be made to **yourbank.com/transfer/send?to=1234&amount=5000** . So the server will act upon the request and make the transfer. Now just imagine you are on another website and you click on a link that opens up the above URL with the hacker’s account number. That money is now transferred to the hacker and the server thinks you made the transaction. Even though you didn’t.
|
||||
|
||||
[][3]
|
||||
|
||||
#### Protection against CSRF
|
||||
|
||||
CSRF protection is very easy to implement. It usually involves sending a token called the CSRF token to the webpage. This token is sent and verified on the server with every new request made. So malicious requests made by the server will pass cookie authentication but fail CSRF authentication. Most web frameworks provide out of the box support for preventing CSRF attacks and CSRF attacks are not as commonly seen today as they were some time back.
|
||||
|
||||
### Conclusion
|
||||
|
||||
CSRF attacks were a big thing 10 years back but today we don’t see too many of them. In the past, famous sites such as Youtube, The New York Times and Netflix have been vulnerable to CSRF. However, popularity and occurrence of CSRF attacks have decreased lately. Nevertheless, CSRF attacks are still a threat and it is important, you protect your website or app from it.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/understanding-csrf-cross-site-request-forgery
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-what-is-cross-site-forgery_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/cookies-set-by-website-chrome_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-hacking-bank-account_orig.jpg
|
||||
@ -0,0 +1,299 @@
|
||||
Getting started with Standard Notes for encrypted note-taking
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Standard Notes][1] is a simple, encrypted notes app that aims to make dealing with your notes the easiest thing you'll do all day. When you sign up for a free sync account, your notes are automatically encrypted and seamlessly synced with all your devices.
|
||||
|
||||
There are two key factors that differentiate Standard Notes from other, commercial software solutions:
|
||||
|
||||
1. The server and client are both completely open source.
|
||||
2. The company is built on sustainable business practices and focuses on product development.
|
||||
|
||||
|
||||
|
||||
When you combine open source with ethical business practices, you get a software product that has the potential to serve you for decades. You start to feel ownership in the product rather than feeling like just another transaction for an IPO-bound company.
|
||||
|
||||
In this article, I’ll describe how to deploy your own Standard Notes open source syncing server on a Linux machine. You’ll then be able to use your server with our published applications for Linux, Windows, Android, Mac, iOS, and the web.
|
||||
|
||||
If you don’t want to host your own server and are ready to start using Standard Notes right away, you can use our public syncing server. Simply head on over to [Standard Notes][1] to get started.
|
||||
|
||||
### Hosting your own Standard Notes server
|
||||
|
||||
Get the [Standard File Rails app][2] running on your Linux box and expose it via [NGINX][3] or any other web server.
|
||||
|
||||
### Getting started
|
||||
|
||||
These instructions are based on setting up our syncing server on a fresh [CentOS][4]-like installation. You can use a hosting service like [AWS][5] or [DigitalOcean][6] to launch your server, or even run it locally on your own machine.
|
||||
|
||||
1. Update your system:
|
||||
|
||||
```
|
||||
sudo yum update
|
||||
|
||||
```
|
||||
|
||||
2. Install [RVM][7] (Ruby Version Manager):
|
||||
|
||||
```
|
||||
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
|
||||
\curl -sSL https://get.rvm.io | bash -s stable
|
||||
|
||||
```
|
||||
|
||||
3. Begin using RVM in current session:
|
||||
```
|
||||
source /home/ec2-user/.rvm/scripts/rvm
|
||||
|
||||
```
|
||||
|
||||
4. Install [Ruby][8]:
|
||||
|
||||
```
|
||||
rvm install ruby
|
||||
|
||||
```
|
||||
|
||||
This should install the latest version of Ruby (2.3 at the time of this writing.)
|
||||
|
||||
Note that at least Ruby 2.2.2 is required for Rails 5.
|
||||
|
||||
5. Use Ruby:
|
||||
```
|
||||
rvm use ruby
|
||||
|
||||
```
|
||||
|
||||
6. Install [Bundler][9]:
|
||||
|
||||
```
|
||||
gem install bundler --no-ri --no-rdoc
|
||||
|
||||
```
|
||||
|
||||
7. Install [mysql-devel][10]:
|
||||
```
|
||||
sudo yum install mysql-devel
|
||||
|
||||
```
|
||||
|
||||
8. Install [MySQL][11] (optional; you can also use a hosted db through [Amazon RDS][12], which is recommended):
|
||||
```
|
||||
sudo yum install mysql56-server
|
||||
|
||||
sudo service mysqld start
|
||||
|
||||
sudo mysql_secure_installation
|
||||
|
||||
sudo chkconfig mysqld on
|
||||
|
||||
```
|
||||
|
||||
Create a database:
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
|
||||
> create database standard_file;
|
||||
|
||||
> quit;
|
||||
|
||||
```
|
||||
|
||||
9. Install [Passenger][13]:
|
||||
```
|
||||
sudo yum install rubygems
|
||||
|
||||
gem install rubygems-update --no-rdoc --no-ri
|
||||
|
||||
update_rubygems
|
||||
|
||||
gem install passenger --no-rdoc --no-ri
|
||||
|
||||
```
|
||||
|
||||
10. Remove system NGINX installation if installed (you’ll use Passenger’s instead):
|
||||
```
|
||||
sudo yum remove nginx
|
||||
sudo rm -rf /etc/nginx
|
||||
```
|
||||
|
||||
11. Configure Passenger:
|
||||
```
|
||||
sudo chmod o+x "/home/ec2-user"
|
||||
|
||||
sudo yum install libcurl-devel
|
||||
|
||||
rvmsudo passenger-install-nginx-module
|
||||
|
||||
rvmsudo passenger-config validate-install
|
||||
|
||||
```
|
||||
|
||||
12. Install Git:
|
||||
```
|
||||
sudo yum install git
|
||||
|
||||
```
|
||||
|
||||
13. Set up HTTPS/SSL for your server (free using [Let'sEncrypt][14]; required if using the secure client on [https://app.standardnotes.org][15]):
|
||||
```
|
||||
sudo chown ec2-user /opt
|
||||
|
||||
cd /opt
|
||||
|
||||
git clone https://github.com/letsencrypt/letsencrypt
|
||||
|
||||
cd letsencrypt
|
||||
|
||||
```
|
||||
|
||||
Run the setup wizard:
|
||||
```
|
||||
./letsencrypt-auto certonly --standalone --debug
|
||||
|
||||
```
|
||||
|
||||
Note the location of the certificates, typically `/etc/letsencrypt/live/domain.com/fullchain.pem`
|
||||
|
||||
14. Configure NGINX:
|
||||
```
|
||||
sudo vim /opt/nginx/conf/nginx.conf
|
||||
|
||||
```
|
||||
|
||||
Add this to the bottom of the file, inside the last curly brace:
|
||||
```
|
||||
server {
|
||||
|
||||
listen 443 ssl default_server;
|
||||
|
||||
ssl_certificate /etc/letsencrypt/live/domain.com/fullchain.pem;
|
||||
|
||||
ssl_certificate_key /etc/letsencrypt/live/domain.com/privkey.pem;
|
||||
|
||||
server_name domain.com;
|
||||
|
||||
passenger_enabled on;
|
||||
|
||||
passenger_app_env production;
|
||||
|
||||
root /home/ec2-user/ruby-server/public;
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
15. Make sure you are in your home directory and clone the Standard File [ruby-server][2] project:
|
||||
```
|
||||
cd ~
|
||||
|
||||
git clone https://github.com/standardfile/ruby-server.git
|
||||
|
||||
cd ruby-server
|
||||
|
||||
```
|
||||
|
||||
16. Set up project:
|
||||
```
|
||||
bundle install
|
||||
|
||||
bower install
|
||||
|
||||
rails assets:precompile
|
||||
|
||||
```
|
||||
|
||||
17. Create a .env file for your environment variables. The Rails app will automatically load these when it starts.
|
||||
|
||||
```
|
||||
vim .env
|
||||
|
||||
```
|
||||
|
||||
Insert:
|
||||
```
|
||||
RAILS_ENV=production
|
||||
|
||||
SECRET_KEY_BASE=use "bundle exec rake secret"
|
||||
|
||||
|
||||
|
||||
DB_HOST=localhost
|
||||
|
||||
DB_PORT=3306
|
||||
|
||||
DB_DATABASE=standard_file
|
||||
|
||||
DB_USERNAME=root
|
||||
|
||||
DB_PASSWORD=
|
||||
|
||||
```
|
||||
|
||||
18. Setup database:
|
||||
```
|
||||
rails db:migrate
|
||||
|
||||
```
|
||||
|
||||
19. Start NGINX:
|
||||
```
|
||||
sudo /opt/nginx/sbin/nginx
|
||||
|
||||
```
|
||||
|
||||
Tip: you will need to restart NGINX whenever you make changes to your environment variables or the NGINX configuration:
|
||||
```
|
||||
sudo /opt/nginx/sbin/nginx -s reload
|
||||
|
||||
```
|
||||
|
||||
20. You’re done!
|
||||
|
||||
|
||||
|
||||
|
||||
### Using your new server
|
||||
|
||||
Now that you have your server running, you can plug it into any of the Standard Notes applications and sign into it.
|
||||
|
||||
**On the Standard Notes web or desktop app:**
|
||||
|
||||
Click Account, then Register. Choose "Advanced Options" and you’ll see a field for Sync Server. Enter your server’s URL here.
|
||||
|
||||
**On the Standard Notes Android or iOS app:**
|
||||
|
||||
Open the Settings window, click "Advanced Options" when signing in or registering, and enter your server URL in the Sync Server field.
|
||||
|
||||
For help or questions with your Standard Notes server, join our [Slack group][16] in the #dev channel, or visit our [help page][17] for frequently asked questions and other topics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-standard-notes
|
||||
|
||||
作者:[Mo Bitar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mobitar
|
||||
[1]:https://standardnotes.org/
|
||||
[2]:https://github.com/standardfile/ruby-server
|
||||
[3]:https://www.nginx.com/
|
||||
[4]:https://www.centos.org/
|
||||
[5]:https://aws.amazon.com/
|
||||
[6]:https://www.digitalocean.com/
|
||||
[7]:https://rvm.io/
|
||||
[8]:https://www.ruby-lang.org/en/
|
||||
[9]:https://bundler.io/
|
||||
[10]:https://rpmfind.net/linux/rpm2html/search.php?query=mysql-devel
|
||||
[11]:https://www.mysql.com/
|
||||
[12]:https://aws.amazon.com/rds/
|
||||
[13]:https://www.phusionpassenger.com/
|
||||
[14]:https://letsencrypt.org/
|
||||
[15]:https://app.standardnotes.org/
|
||||
[16]:https://standardnotes.org/slack
|
||||
[17]:https://standardnotes.org/help
|
||||
@ -0,0 +1,114 @@
|
||||
Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange
|
||||
======
|
||||
Previously, I have written about the email services [Protonmail][1] and [Tutanota][2] on It’s FOSS. And though I liked both of those email providers very much, some of us couldn’t possibly use these email services exclusively. If you are like me and you have an email address provided for you by your work, then you understand what I am talking about.
|
||||
|
||||
Some of us use [Thunderbird][3] for these types of use cases, while others of us use something like [Geary][4] or even [Mailspring][5]. But for those of us who have to deal with [Microsoft Exchange Servers][6], none of these offer seamless solutions on Linux for our work needs.
|
||||
|
||||
This is where [Hiri][7] comes in. We have already featured Hiri on our list of [best email clients for Linux][8], but we thought it was about time for an in-depth review.
|
||||
|
||||
FYI, Hiri is neither free nor open source software.
|
||||
|
||||
### Reviewing Hiri email client on Linux
|
||||
|
||||
![Hiri email client review][9]
|
||||
|
||||
According to their website, Hiri not only supports Microsoft Exchange and Office 365 accounts, it was exclusively “built for the Microsoft email ecosystem.”
|
||||
|
||||
Based in Dublin, Ireland, Hiri has raised $2 million in funding. They have been in the business for almost five years but started supporting Linux only last year. The support for Linux has brought Hiri a considerable amount of success.
|
||||
|
||||
I have been using Hiri for a week as of yesterday, and I have to say, I have been very pleased with my experience…for the most part.
|
||||
|
||||
#### Hiri features
|
||||
|
||||
Some of the main features of Hiri are:
|
||||
|
||||
* Cross-platform application available for Linux, macOS and Windows
|
||||
* **Supports only Office 365, Outlook and Microsoft Exchange for now**
|
||||
* Clean and intuitive UI
|
||||
* Action filters
|
||||
* Reminders
|
||||
* [Skills][10]: Plugins to make you more productive with your emails
|
||||
* Office 365 and Exchange and other Calendar Sync
|
||||
* Compatible with [Active Directory][11]
|
||||
* Offline email access
|
||||
* Secure (it doesn’t send data to any third party server, it’s just an email client)
|
||||
* Compatible with Microsoft’s archiving tool
|
||||
|
||||
|
||||
|
||||
#### Taking a look at Hiri Features
|
||||
|
||||
![][12]
|
||||
|
||||
Hiri can either be compiled manually or [installed easily as Snap][13] and comes jam-packed with useful features. But, if you knew me at all, you would know that usually, a robust feature list is not a huge selling point for me. As a self-proclaimed minimalist, I tend to believe the simpler option is often the better option, and the less “fluff” there is surrounding a product, the easier it is to get to the part that really matters. Admittedly, this is not always the case. For example, KDE’s [Plasma][14] desktop is known for its excessive amount of tweaks and features and I am still a huge Plasma fan. But in Hiri’s case, it has what feels like the perfect feature set and in no way feels convoluted or confusing.
|
||||
|
||||
That is partially due to the way that Hiri works. If I had to put it into my own words, I would say that Hiri feels almost modular. It does this by utilizing what Hiri calls the Skill Center. Here you can add or remove functionality in Hiri at the flip of a switch. This includes the ability to add tasks, delegate action items to other people, set reminders, and even enables the user to create better subject lines. None of which are required, but each of which adds something to Hiri that no other email client has done as well.
|
||||
|
||||
Using these features can help you organize your email like never before. The Dashboard feature allows you to monitor your time spent working on emails, the Task List enables you to stay on track, the Action/FYI feature allows you to tag your emails as needed to help you cipher through a messy inbox, and the Zero Inbox feature helps the user keep their inbox count at a minimum once they have sorted through the nonsense. And as someone who is an avid Inbox Zeroer (if that is even a thing), this to me was incredibly useful.
|
||||
|
||||
Hiri also syncs with your associated calendars as you would expect, and it even allows a global search for all of the other accounts associated with your office. Need to email Frank Smith in Human Resources but can’t remember his email address? No big deal! Hiri will auto-fill the email address once you start typing in his name just like in a native Outlook client.
|
||||
|
||||
Multiple account support is also available in Hiri. The support for IMAP will be added in a few months.
|
||||
|
||||
In short, Hiri’s feature-set allows for what feels like a truly native Microsoft offering on Linux. It is clean, simple enough, and allows someone with my productivity workflow to thrive. I really dig what Hiri has to offer, and it’s as simple as that.
|
||||
|
||||
#### Experiencing the Hiri UI
|
||||
|
||||
As far as design goes, Hiri gets a solid A from me. I never felt like I was using something outdated looking like [Evolution][15] (I know people like Evolution a lot, but to say it is clean and modern is a lie), it never felt overly complicated like [KMail][16], and it felt less cramped than Thunderbird. Though I love Thunderbird dearly, the inbox list is just a little too small to feel like I can really cipher through my emails in a decent amount of time. Hiri seemingly fixes this but adds another issue that may be even worse.
|
||||
|
||||
![][17]
|
||||
|
||||
Geary is an email client that I think does layouts just right. It is spacious, but not in a wasteful way, it is clean, simple, and allows me to get from point A to point B quickly. Hiri, on the other hand, falls just shy of layout heaven. Though the inbox list looks fantastic, when you click to read an email it takes up the whole screen. Whereas Geary or Thunderbird can be set up to have the user’s list of emails on the left and opened emails in the same window on the right, which is my preferred way to read email, Hiri does not allow this functionality. The layout either looks and functions like it belongs on a mobile device, or the email preview is below the email list instead of to the right. This isn’t a make or break issue for me, but I will be honest and say I really don’t like it.
|
||||
|
||||
In my opinion, Hiri could work even better with a couple of tweaks. But that opinion is just that, an opinion. Hiri is modern, clean, and intuitive enough, I am just obnoxiously picky. Other than that, the color palette is beautiful, the soft edges are pretty stunning, and Hiri’s overall design language is a breath of fresh air in the, at times, outdated feel that is oh so common in the Linux application world.
|
||||
|
||||
Also, this isn’t Hiri’s fault but since I installed the Hiri snap it still has the same cursor theme issue that many other snaps suffer from, which drives me UP A WALL when I move in and out of the application, so there’s that.
|
||||
|
||||
#### How much does Hiri cost?
|
||||
|
||||
![Hiri is compatible with Microsoft Active Directory][18]
|
||||
|
||||
Hiri is neither free nor open source software. [Hiri costs][19] either up to $39 a year or $119 for a lifetime license. However, it does provide a free seven day trial period.
|
||||
|
||||
Considering the features it provides, Hiri is a good product even if you don’t have to deal with Microsoft Exchange Servers. Don’t take my word for it. Give Hiri a try for free for the seven day trial and see for yourself if it is worth paying or not.
|
||||
|
||||
And if you decide to purchase it, I have further good news for you. Hiri team has agreed to provide an exclusive 60% discount to It’s FOSS readers. All you have to do is to use coupon code ITSFOSS60 at checkout.
|
||||
|
||||
[Get 60% Off with ITSFOSS60 Coupon Code][20]
|
||||
|
||||
#### Conclusion
|
||||
|
||||
In the end, Hiri is an amazingly beautiful piece of software that checks so many boxes for me. That being said, the three marks that it misses for me are collectively too big to overlook: the layout, the cost, and the freedom (or lack thereof). If you are someone who is really in need of a native client, the layout does not bother you, you can justify spending some money, and you don’t want or need it to be FOSS, then you may have just found your new email client!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/hiri-email-review/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://itsfoss.com/protonmail/
|
||||
[2]:https://itsfoss.com/tutanota-review/
|
||||
[3]:https://www.thunderbird.net/en-US/
|
||||
[4]:https://wiki.gnome.org/Apps/Geary
|
||||
[5]:http://getmailspring.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Exchange_Server
|
||||
[7]:https://www.hiri.com/
|
||||
[8]:https://itsfoss.com/best-email-clients-linux/
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/hiri-email-client-review.jpeg
|
||||
[10]:https://www.hiri.com/skills/
|
||||
[11]:https://en.wikipedia.org/wiki/Active_Directory
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri2-e1533106054811.png
|
||||
[13]:https://snapcraft.io/hiri
|
||||
[14]:https://www.kde.org/plasma-desktop
|
||||
[15]:https://wiki.gnome.org/Apps/Evolution
|
||||
[16]:https://www.kde.org/applications/internet/kmail/
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri3-e1533106099642.png
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri1-e1533106238745.png
|
||||
[19]:https://www.hiri.com/pricing/
|
||||
[20]:https://www.hiri.com/download/
|
||||
77
sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
Normal file
77
sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
Normal file
@ -0,0 +1,77 @@
|
||||
Migrating Perl 5 code to Perl 6
|
||||
======
|
||||
|
||||

|
||||
|
||||
Whether you are a programmer who is taking the first steps to convert your Perl 5 code to Perl 6 and encountering some issues or you're just interested in learning about what might happen if you try to port Perl 5 programs to Perl 6, this article should answer your questions.
|
||||
|
||||
The [Perl 6 documentation][1] already contains most (if not all) the [documentation you need][2] to deal with the issues you will confront in migrating Perl 5 code to Perl 6. But, as documentation goes, the focus is on the factual differences. I will try to go a little more in-depth about specific issues and provide a little more hands-on information based on my experience porting quite a lot of Perl 5 code to Perl 6.
|
||||
|
||||
### How is Perl 6 anyway?
|
||||
|
||||
Very well, thank you! Since its first official release in December 2015, Rakudo Perl 6 has seen an order of magnitude of improvement and quite a few bug fixes (more than 14,000 commits in total). Seven books about Perl 6 have been published so far. [Learning Perl 6][3] by Brian D. Foy will soon be published by O'Reilly, having been re-worked from the seminal [Learning Perl][4] (aka "The Llama Book") that many people have come to know and love.
|
||||
|
||||
The user distribution [Rakudo Star][5] is on a three-month release cycle, and more than 1,100 modules are available in the [Perl 6 ecosystem][6]. The Rakudo Compiler Release is on a monthly release cycle and typically contains contributions by more than 30 people. Perl 6 modules are uploaded to the Perl programming Authors Upload Server ([PAUSE][7]) and distributed all over the world using the Comprehensive Perl Archive Network ([CPAN][8]).
|
||||
|
||||
The online [Perl 6 Introduction][9] document has been translated into 12 languages, teaching over 3 billion people about Perl 6 in their native language. The most recent incarnation of [Perl 6 Weekly][10] has been reporting on all things Perl 6 every week since February 2014.
|
||||
|
||||
[Cro][11], a microservices framework, uses all of Perl 6's features from the ground up, providing HTTP 1.1 persistent connections, HTTP 2.0 with request multiplexing, and HTTPS with optional certificate authority out of the box. And a [Perl 6 IDE][12] is now in (paid) beta (think of it as a Kickstarter with immediate deliverables).
|
||||
|
||||
### Using Perl 5 features in Perl 6
|
||||
|
||||
Perl 5 code can be seamlessly integrated with Perl 6 using the [`Inline::Perl5`][13] module, making all of [CPAN][14] available to any Perl 6 program. This could be considered cheating, as it will embed a Perl 5 interpreter and therefore continues to have a dependency on the `perl` (5) runtime. But it does make it easy to get your Perl 6 code running (if you need access to modules that have not yet been ported) simply by adding `:from<Perl5>` to your `use` statement, like `use DBI:from<Perl5>;`.
|
||||
|
||||
In January 2018, I proposed a [CPAN Butterfly Plan][15] to convert Perl 5 functionality to Perl 6 as closely as possible to the original API. I stated this as a goal because Perl 5 (as a programming language) is so much more than syntax alone. Ask anyone what Perl's unique selling point is, and they will most likely tell you it is CPAN. Therefore, I think it's time to move from this view of the Perl universe:
|
||||
|
||||
|
||||
|
||||
to a more modern view:
|
||||
|
||||
|
||||
|
||||
In other words: put CPAN, as the most important element of Perl, in the center.
|
||||
|
||||
### Converting semantics
|
||||
|
||||
To run Perl 5 code natively in Perl 6, you also need a lot of Perl 5 semantics. Having (optional) support for Perl 5 semantics available in Perl 6 lowers the conceptual threshold that Perl 5 programmers perceive when trying to program in Perl 6. It's easier to feel at home!
|
||||
|
||||
Since the publication of the CPAN Butterfly Plan, more than 100 built-in Perl 5 functions are now supported in Perl 6 with the same API. Many functions already exist in Perl 6 but have slightly different semantics, e.g., `shift` in Perl 5 magically shifts from `@_` (or `@ARGV`) if no parameter is specified; in Perl 6 the parameter is obligatory.
|
||||
|
||||
More than 50 Perl 5 CPAN distributions have also been ported to Perl 6 while adhering to the original Perl 5 API. These include core modules such as [Scalar::Util][16] and [List::Util][17], but also non-core modules such as [Text::CSV][18] and [Memoize][19]. Distributions that are upstream on the [River of CPAN][20] are targeted to have as much effect on the ecosystem as possible.
|
||||
|
||||
### Summary
|
||||
|
||||
Rakudo Perl 6 has matured in such a way that using Perl 6 is now a viable approach to creating new, interactive projects. Being able to use reliable and proven Perl 5 language components aids in lowering the threshold for developers to use Perl 6, and it builds towards a situation where the sum of Perl 5 and Perl 6 becomes greater than its parts.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/migrating-perl-5-perl-6
|
||||
|
||||
作者:[Elizabeth Mattijsen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/lizmat
|
||||
[1]:https://docs.perl6.org/
|
||||
[2]:https://docs.perl6.org/language/5to6-overview
|
||||
[3]:https://www.learningperl6.com
|
||||
[4]:http://shop.oreilly.com/product/0636920049517.do
|
||||
[5]:https://rakudo.org/files
|
||||
[6]:https://modules.perl6.org
|
||||
[7]:https://pause.perl.org/pause/query?ACTION=pause_04about
|
||||
[8]:https://www.cpan.org
|
||||
[9]:https://perl6intro.com
|
||||
[10]:https://p6weekly.wordpress.com
|
||||
[11]:https://cro.services
|
||||
[12]:https://commaide.com
|
||||
[13]:http://modules.perl6.org/dist/Inline::Perl5:cpan:NINE
|
||||
[14]:https://metacpan.org
|
||||
[15]:https://www.perl.com/article/an-open-letter-to-the-perl-community/
|
||||
[16]:https://modules.perl6.org/dist/Scalar::Util
|
||||
[17]:https://modules.perl6.org/dist/List::Util
|
||||
[18]:https://modules.perl6.org/dist/Text::CSV
|
||||
[19]:https://modules.perl6.org/dist/Memoize
|
||||
[20]:http://neilb.org/2015/04/20/river-of-cpan.html
|
||||
@ -0,0 +1,370 @@
|
||||
6 Easy Ways to Check User Name And Other Information in Linux
|
||||
======
|
||||
This is very basic topic, everyone knows how to find a user information in Linux using **id** command. Some of the users are filtering a user information from **/etc/passwd** file.
|
||||
|
||||
We also using these commands to get a user information.
|
||||
|
||||
You may ask, Why are you discussing this basic topic? Even i thought the same, there is no other ways except this two but we are having some good alternatives too.
|
||||
|
||||
Those are giving more detailed information compared with those two, which is very helpful for newbies.
|
||||
|
||||
This is one of the basic command which helps admin to find out a user information in Linux. Everything is file in Linux, even user information were stored in a file.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How To Check User Created Date On Linux][1]
|
||||
**(#)** [How To Check Which Groups A User Belongs To On Linux][2]
|
||||
**(#)** [How To Force User To Change Password On Next Login In Linux][3]
|
||||
|
||||
All the users are added in `/etc/passwd` file. This keep user name and other related details. Users details will be stored in /etc/passwd file when you created a user in Linux. The passwd file contain each/every user details as a single line with seven fields.
|
||||
|
||||
We can find a user information using the below six methods.
|
||||
|
||||
* `id :`Print user and group information for the specified username.
|
||||
* `getent :`Get entries from Name Service Switch libraries.
|
||||
* `/etc/passwd file :`The /etc/passwd file contain each/every user details as a single line with seven fields.
|
||||
* `finger :`User information lookup program
|
||||
* `lslogins :`lslogins display information about known users in the system
|
||||
* `compgen :`compgen is bash built-in command and it will show all available commands for the user.
|
||||
|
||||
|
||||
|
||||
### 1) Using id Command
|
||||
|
||||
id stands for identity. print real and effective user and group IDs. To print user and group information for the specified user, or for the current user.
|
||||
```
|
||||
# id daygeek
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information for the above output.
|
||||
|
||||
* **`uid (1000/daygeek):`** It displays user ID & Name
|
||||
* **`gid (1000/daygeek):`** It displays user’s primary group ID & Name
|
||||
* **`groups:`** It displays user’s secondary groups ID & Name
|
||||
|
||||
|
||||
|
||||
### 2) Using getent Command
|
||||
|
||||
The getent command displays entries from databases supported by the Name Service Switch libraries, which are configured in /etc/nsswitch.conf.
|
||||
|
||||
getent command shows user details similar to /etc/passwd file, it shows every user details as a single line with seven fields.
|
||||
```
|
||||
# getent passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
|
||||
sync:x:5:0:sync:/sbin:/bin/sync
|
||||
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
|
||||
halt:x:7:0:halt:/sbin:/sbin/halt
|
||||
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
|
||||
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
|
||||
operator:x:11:0:operator:/root:/sbin/nologin
|
||||
games:x:12:100:games:/usr/games:/sbin/nologin
|
||||
gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
|
||||
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
|
||||
nobody:x:99:99:Nobody:/:/sbin/nologin
|
||||
dbus:x:81:81:System message bus:/:/sbin/nologin
|
||||
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
|
||||
abrt:x:173:173::/etc/abrt:/sbin/nologin
|
||||
haldaemon:x:68:68:HAL daemon:/:/sbin/nologin
|
||||
ntp:x:38:38::/etc/ntp:/sbin/nologin
|
||||
saslauth:x:499:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin
|
||||
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
|
||||
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
|
||||
tcpdump:x:72:72::/:/sbin/nologin
|
||||
centos:x:500:500:Cloud User:/home/centos:/bin/bash
|
||||
prakash:x:501:501:2018/04/12:/home/prakash:/bin/bash
|
||||
apache:x:48:48:Apache:/var/www:/sbin/nologin
|
||||
nagios:x:498:498::/var/spool/nagios:/sbin/nologin
|
||||
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
|
||||
nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
|
||||
sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information about seven fields.
|
||||
```
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
* **`Username (magesh):`** Username of created user. Characters length should be between 1 to 32.
|
||||
* **`Password (x):`** It indicates that encrypted password is stored at /etc/shadow file.
|
||||
* **`User ID (UID-502):`** It indicates the user ID (UID) each user should be contain unique UID. UID (0-Zero) is reserved for root, UID (1-99) reserved for system users and UID (100-999) reserved for system accounts/groups
|
||||
* **`Group ID (GID-503):`** It indicates the group ID (GID) each group should be contain unique GID is stored at /etc/group file.
|
||||
* **`User ID Info (2g Admin - Magesh M):`** It indicates the command field. This field can be used to describe the user information.
|
||||
* **`Home Directory (/home/magesh):`** It indicates the user home directory.
|
||||
* **`shell (/bin/bash):`** It indicates the user’s bash shell.
|
||||
|
||||
|
||||
|
||||
If you would like to display only user names from the getent command output, use the below format.
|
||||
```
|
||||
# getent passwd | cut -d: -f1
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
uucp
|
||||
operator
|
||||
games
|
||||
gopher
|
||||
ftp
|
||||
nobody
|
||||
dbus
|
||||
vcsa
|
||||
abrt
|
||||
haldaemon
|
||||
ntp
|
||||
saslauth
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
centos
|
||||
prakash
|
||||
apache
|
||||
nagios
|
||||
rpc
|
||||
nrpe
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
To display only home directory users, use the below format.
|
||||
```
|
||||
# getent passwd | grep '/home' | cut -d: -f1
|
||||
centos
|
||||
prakash
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
### 3) Using /etc/passwd file
|
||||
|
||||
The `/etc/passwd` is a text file that contains each user information, which is necessary to login Linux system. It maintain useful information about users such as username, password, user ID, group ID, user ID info, home directory and shell. The /etc/passwd file contain every user details as a single line with seven fields as described below.
|
||||
```
|
||||
# cat /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
|
||||
sync:x:5:0:sync:/sbin:/bin/sync
|
||||
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
|
||||
halt:x:7:0:halt:/sbin:/sbin/halt
|
||||
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
|
||||
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
|
||||
operator:x:11:0:operator:/root:/sbin/nologin
|
||||
games:x:12:100:games:/usr/games:/sbin/nologin
|
||||
gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
|
||||
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
|
||||
nobody:x:99:99:Nobody:/:/sbin/nologin
|
||||
dbus:x:81:81:System message bus:/:/sbin/nologin
|
||||
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
|
||||
abrt:x:173:173::/etc/abrt:/sbin/nologin
|
||||
haldaemon:x:68:68:HAL daemon:/:/sbin/nologin
|
||||
ntp:x:38:38::/etc/ntp:/sbin/nologin
|
||||
saslauth:x:499:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin
|
||||
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
|
||||
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
|
||||
tcpdump:x:72:72::/:/sbin/nologin
|
||||
centos:x:500:500:Cloud User:/home/centos:/bin/bash
|
||||
prakash:x:501:501:2018/04/12:/home/prakash:/bin/bash
|
||||
apache:x:48:48:Apache:/var/www:/sbin/nologin
|
||||
nagios:x:498:498::/var/spool/nagios:/sbin/nologin
|
||||
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
|
||||
nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
|
||||
sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information about seven fields.
|
||||
```
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
* **`Username (magesh):`** Username of created user. Characters length should be between 1 to 32.
|
||||
* **`Password (x):`** It indicates that encrypted password is stored at /etc/shadow file.
|
||||
* **`User ID (UID-502):`** It indicates the user ID (UID) each user should be contain unique UID. UID (0-Zero) is reserved for root, UID (1-99) reserved for system users and UID (100-999) reserved for system accounts/groups
|
||||
* **`Group ID (GID-503):`** It indicates the group ID (GID) each group should be contain unique GID is stored at /etc/group file.
|
||||
* **`User ID Info (2g Admin - Magesh M):`** It indicates the command field. This field can be used to describe the user information.
|
||||
* **`Home Directory (/home/magesh):`** It indicates the user home directory.
|
||||
* **`shell (/bin/bash):`** It indicates the user’s bash shell.
|
||||
|
||||
|
||||
|
||||
If you would like to display only user names from the /etc/passwd file, use the below format.
|
||||
```
|
||||
# cut -d: -f1 /etc/passwd
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
uucp
|
||||
operator
|
||||
games
|
||||
gopher
|
||||
ftp
|
||||
nobody
|
||||
dbus
|
||||
vcsa
|
||||
abrt
|
||||
haldaemon
|
||||
ntp
|
||||
saslauth
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
centos
|
||||
prakash
|
||||
apache
|
||||
nagios
|
||||
rpc
|
||||
nrpe
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
To display only home directory users, use the below format.
|
||||
```
|
||||
# cat /etc/passwd | grep '/home' | cut -d: -f1
|
||||
centos
|
||||
prakash
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
### 4) Using finger Command
|
||||
|
||||
The finger comamnd displays information about the system users. It displays the user’s real name, terminal name and write status (as a ‘‘*’’ after the terminal name if write permission is denied), idle time and login time.
|
||||
```
|
||||
# finger magesh
|
||||
Login: magesh Name: 2g Admin - Magesh M
|
||||
Directory: /home/magesh Shell: /bin/bash
|
||||
Last login Tue Jul 17 22:46 (EDT) on pts/2 from 103.5.134.167
|
||||
No mail.
|
||||
No Plan.
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information for the above output.
|
||||
|
||||
* **`Login:`** User’s login name
|
||||
* **`Name:`** Additional/Other information about the user
|
||||
* **`Directory:`** User home directory information
|
||||
* **`Shell:`** User’s shell information
|
||||
* **`LAST-LOGIN:`** Date of last login and other information
|
||||
|
||||
|
||||
|
||||
### 5) Using lslogins Command
|
||||
|
||||
It displays information about known users in the system. By default it will list information about all the users in the system.
|
||||
|
||||
The lslogins utility is inspired by the logins utility, which first appeared in FreeBSD 4.10.
|
||||
```
|
||||
# lslogins -u
|
||||
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
|
||||
0 root 0 0 00:17:28 root
|
||||
500 centos 0 1 Cloud User
|
||||
501 prakash 0 0 Apr12/04:08 2018/04/12
|
||||
502 magesh 0 0 Jul17/22:46 2g Admin - Magesh M
|
||||
503 thanu 0 0 Jul18/00:40 2g Editor - Thanisha M
|
||||
504 sudha 0 0 Jul18/01:18 2g Editor - Sudha M
|
||||
|
||||
```
|
||||
|
||||
Below are the detailed information for the above output.
|
||||
|
||||
* **`UID:`** User id
|
||||
* **`USER:`** Name of the user
|
||||
* **`PWD-LOCK:`** password defined, but locked
|
||||
* **`PWD-DENY:`** login by password disabled
|
||||
* **`LAST-LOGIN:`** Date of last login
|
||||
* **`GECOS:`** Other information about the user
|
||||
|
||||
|
||||
|
||||
### 6) Using compgen Command
|
||||
|
||||
compgen is bash built-in command and it will show all available commands, aliases, and functions for you.
|
||||
```
|
||||
# compgen -u
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
uucp
|
||||
operator
|
||||
games
|
||||
gopher
|
||||
ftp
|
||||
nobody
|
||||
dbus
|
||||
vcsa
|
||||
abrt
|
||||
haldaemon
|
||||
ntp
|
||||
saslauth
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
centos
|
||||
prakash
|
||||
apache
|
||||
nagios
|
||||
rpc
|
||||
nrpe
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-easy-ways-to-check-user-name-and-other-information-in-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/how-to-check-user-created-date-on-linux/
|
||||
[2]:https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
[3]:https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/
|
||||
@ -0,0 +1,69 @@
|
||||
Getting started with Mu, a Python editor for beginners
|
||||
======
|
||||
|
||||

|
||||
|
||||
Mu is a Python editor for beginning programmers, designed to make the learning experience more pleasant. It gives students the ability to experience success early on, which is important anytime you're learning something new.
|
||||
|
||||
If you have ever tried to teach young people how to program, you will immediately grasp the importance of [Mu][1]. Most programming tools are written by developers for developers and aren't well-suited for beginning programmers, regardless of their age. Mu, however, was written by a teacher for students.
|
||||
|
||||
### Mu's origins
|
||||
|
||||
Mu is the brainchild of [Nicholas Tollervey][2] (who I heard speak at PyCon2018 in May). Nicholas is a classically trained musician who became interested in Python and development early in his career while working as a music teacher. He also wrote [Python in Education][3], a free book you can download from O'Reilly.
|
||||
|
||||
Nicholas was looking for a simpler interface for Python programming. He wanted something without the complexity of other editors—even the IDLE3 editor that comes with Python—so he worked with [Carrie Ann Philbin][4] , director of education at the Raspberry Pi Foundation (which sponsored his work), to develop Mu.
|
||||
|
||||
Mu is an open source application (licensed under [GNU GPLv3][5]) written in Python. It was originally developed to work with the [Micro:bit][6] mini-computer, but feedback and requests from other teachers spurred him to rewrite Mu into a generic Python editor.
|
||||
|
||||
### Inspired by music
|
||||
|
||||
Nicholas' inspiration for Mu came from his approach to teaching music. He wondered what would happen if we taught programming the way we teach music and immediately saw the disconnect. Unlike with programming, we don't have music boot camps and we don't learn to play an instrument from a book on, say, how to play the flute.
|
||||
|
||||
Nicholas says, Mu "aims to be the real thing," because no one can learn Python in 30 minutes. As he developed Mu, he worked with teachers, observed coding clubs, and watched secondary school students as they worked with Python. He found that less is more and keeping things simple improves the finished product's functionality. Mu is only about 3,000 lines of code, Nicholas says.
|
||||
|
||||
### Using Mu
|
||||
|
||||
To try it out, [download][7] Mu and follow the easy installation instructions for [Linux, Windows, and Mac OS][8]. If, like me, you want to [install it on Raspberry Pi][9], enter the following in the terminal:
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install mu
|
||||
|
||||
```
|
||||
|
||||
Launch Mu from the Programming menu. Then you'll have a choice about how you will use Mu.
|
||||
|
||||
|
||||
|
||||
I chose Python 3, which launches an environment to write code; the Python shell is directly below, which allows you to see the code execution.
|
||||
|
||||
|
||||
|
||||
The menu is very simple to use and understand, which achieves Mu's purpose—making coding easy for beginning programmers.
|
||||
|
||||
[Tutorials][10] and other resources are available on the Mu users' website. On the site, you can also see names of some of the [volunteers][11] who helped develop Mu. If you would like to become one of them and [contribute to Mu's development][12], you are most welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://codewith.mu
|
||||
[2]:https://us.pycon.org/2018/speaker/profile/194/
|
||||
[3]:https://www.oreilly.com/programming/free/python-in-education.csp
|
||||
[4]:https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7
|
||||
[5]:https://mu.readthedocs.io/en/latest/license.html
|
||||
[6]:http://microbit.org/
|
||||
[7]:https://codewith.mu/en/download
|
||||
[8]:https://codewith.mu/en/howto/install_with_python
|
||||
[9]:https://codewith.mu/en/howto/install_raspberry_pi
|
||||
[10]:https://codewith.mu/en/tutorials/
|
||||
[11]:https://codewith.mu/en/thanks
|
||||
[12]:https://mu.readthedocs.io/en/latest/contributing.html
|
||||
117
sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
Normal file
117
sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
Normal file
@ -0,0 +1,117 @@
|
||||
Walkthrough On How To Use GNOME Boxes
|
||||
======
|
||||
|
||||

|
||||
|
||||
Boxes or GNOME Boxes is a virtualization software for GNOME Desktop Environment. It is similar to Oracle VirtualBox but features a simple user interface. Boxes also pose some challenge for newbies and VirtualBox users, for instance, on VirtualBox, it is easy to install guest addition image through menu bar but the same is not true for Boxes. Rather, users are encouraged to install additional guest tools from the terminal program within the guest session.
|
||||
|
||||
This article will provide a walkthrough on how to use GNOME Boxes by installing the software and actually setting a guest session on the machine. It will also take you through the steps for installing the guest tools and provide some additional tips for Boxes configuration.
|
||||
|
||||
### Purpose of virtualization
|
||||
|
||||
If you are wondering what is the purpose of virtualization and why most computer experts and developers use them a lot. There is usually a common reason for this: **TESTING**.
|
||||
|
||||
Developers who use Linux and writes software for Windows has to test his program on an actual Windows environment before deploying it to the end users. Virtualization makes it possible for him to install and set up a Windows guest session on his Linux computer.
|
||||
|
||||
Virtualization is also used by ordinary users who wish to get hands-on with their favorite Linux distro that is still in beta release, without installing it on their physical computer. So in the event the virtual machine crashes, the host is not affected and the important files & documents stored on the physical disk remain intact.
|
||||
|
||||
Virtualization allows you to test a software built for another platform/architecture which may include ARM, MIPS, SPARC, etc on your computer equipped with another architecture such as Intel or AMD.
|
||||
|
||||
### Installing GNOME Boxes
|
||||
|
||||
Launch Ubuntu Software and key in " gnome boxes ". Click the application name to load its installer page and then select the Install button. [][1]
|
||||
|
||||
### Extra setup for Ubuntu 18.04
|
||||
|
||||
There's a bug in GNOME Boxes on Ubuntu 18.04; it fails to start the Virtual Machine (VM). To remedy that, perform the below two steps on a terminal program:
|
||||
|
||||
1. Add the line "group=kvm" to the qemu config file sudo gedit /etc/modprobe.d/qemu-system-x86.conf
|
||||
|
||||
2. Add your user account to kvm group sudo usermod -a -G kvm
|
||||
|
||||
[][2]
|
||||
|
||||
After that, logout and re-login again for the changes to take effect.
|
||||
|
||||
#### Downloading an image file
|
||||
|
||||
You can download an image file/Operating System (OS) from the Internet or within the GNOME Boxes setup itself. However, for this article we'll proceed with the realistic method ie., downloading an image file from the Internet. We'll be configuring Lubuntu on Boxes so head over to this website to download the Linux distro.
|
||||
|
||||
[Download][3]
|
||||
|
||||
#### To burn or not to burn
|
||||
|
||||
If you have no intention to distribute Lubuntu to your friends or install it on a physical machine then it's best not to burn the image file to a blank disc or portable USB drive. Instead just leave it as it is, we'll use it for creating a VM afterward.
|
||||
|
||||
#### Starting GNOME Boxes
|
||||
|
||||
Below is the interface of GNOME Boxes on Ubuntu - [][4]
|
||||
|
||||
The interface is simple and intuitive for newbies to get familiar right away without much effort. Boxes don't feature a menu bar or toolbar, unlike Oracle VirtualBox. On the top left is the New button to create a VM and on the right houses buttons for VM options; delete list or grid view, and configuration (they'll become available when a VM is created).
|
||||
|
||||
### Installing an Operating System
|
||||
|
||||
Click the New button and choose "Select a file". Select the downloaded Lubuntu image file on the Downloads library and then click Create button.
|
||||
|
||||
[][5]
|
||||
|
||||
In case this is your first time installing an OS on a VM, do not panic when the installer pops up a window asking you to erase the disk partition. It's safe, your physical computer hard drive won't be erased, only that the storage space would be allocated for your VM. So on a 1TB hard drive, if you allocate 30 GB for your VM, performing erase partition operation on Boxes would only erase that virtual 30 GB storage drive and not the physical storage.
|
||||
|
||||
_Usually, computer students find virtualization a useful tool for practicing advanced partitioning using UNIX based OS. You can too since there is no risk that would tamper the main OS files._
|
||||
|
||||
After installing Lubuntu, you'll be prompted to reboot the computer (VM) to finish the installation process and actually boot from the hard drive. Confirm the operation.
|
||||
|
||||
|
||||
|
||||
Sometimes, certain Linux distros hang in the reboot process after installation. The trick is to force shutdown the VM from the options button found on the top right side of the tile bar and then power it on again.
|
||||
|
||||
#### Set up Guest tools
|
||||
|
||||
By now you might have noticed Lubuntu's screen resolution is small with extra black spaces on the left and right side, and folder sharing is not enabled too. This brings up the need to install guest tools on Lubuntu.
|
||||
|
||||
|
||||
|
||||
Launch terminal program from the guest session (not your host terminal program) and install the guest tools using the below command:
|
||||
|
||||
sudo apt install spice-vdagent spice-webdavd
|
||||
|
||||
After that, reboot Lubuntu and the next boot will set the VM to its appropriate screen resolution; no more extra black spaces on the left and right side. You can resize Boxes window and the guest screen resolution will automatically resize itself.
|
||||
|
||||
[][6]
|
||||
|
||||
To share a folder between the host and guest, open Boxes options while the guest is still running and choose Properties. On the Devices & Shares category, click the + button and set up the name. By default, Public folder from the host will be shared with the guest OS. You can configure the directory of your choice. After that is done, launch Lubuntu's file manager program (it's called PCManFM) and click Go menu on the menu bar. Select Network and choose Spice Client Folder. The first time you try to open it a dialog box will pop up asking you which program should handle the network, select PCManFM under Accessories category and the network will be mounted on the desktop. Launch it and there you'll see your shared folder name.
|
||||
|
||||
Now you can share files and folders between host and guest computer. Subsequent launch of the network will directly open the shared folder so you don't have to open the folder manually the next time.
|
||||
|
||||
[][7]
|
||||
|
||||
#### Where's the OS installed?
|
||||
|
||||
Lubuntu is installed as a VM using **GNOME Boxes** but where does it store the disk image?
|
||||
|
||||
This question is of particular interest for those who wish to move the huge image file to another partition where there is sufficient storage. The trick is using symlinks which is efficient as it saves more space for Linux root partition and or home partition, depending on how the user set it up during installation. Boxes stores the disk image files to ~/.local/share/gnome-boxes/images folder
|
||||
|
||||
### Conclusion
|
||||
|
||||
We've successfully set up Lubuntu as a guest OS on our Ubuntu. You can try other variants of Ubuntu such as Kubuntu, Ubuntu MATE, Xubuntu, etc or some random Linux distros which in my opinion would be quite challenging due to varying package management. But there's no harm in wanting to :) You can also try installing other platforms like Microsoft Windows, OpenBSD, etc on your computer as a VM. And by the way, don't forget to leave your opinions in the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/walkthrough-on-how-to-use-gnome-boxes
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-gnome-boxes_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-boxes-extras-for-ubuntu-18-04_orig.jpg
|
||||
[3]:https://lubuntu.net/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-gnome-boxes_orig.jpg
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-os-on-ubuntu-guest-box_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/lubuntu-on-gnome-boxes_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-boxes-guest-addition_orig.jpg
|
||||
@ -1,73 +0,0 @@
|
||||
为什么 Arch Linux 如此'难弄'又有何优劣?
|
||||
======
|
||||
|
||||

|
||||
[Arch Linux][1] 于**2002**年发布,由** Aaron Grifin** 领头,是当下最热门的 Linux 发行版之一。从设计上说,Arch Linux 试图给用户提供简单,最小化且优雅的体验,但他的目标用户群可不是怕事儿多的用户。Arch 鼓励参与社区建设,并且从设计上期待用户自己有学习操作系统的能力。
|
||||
|
||||
很多 Linux 老鸟对于 **Arch Linux** 会更了解,但电脑前的你可能只是刚开始打算把 Arch 当作日常操作系统来使用。虽然我也不是权威人士,但下面几点优劣是我认为你总会在使用中慢慢发现的。
|
||||
|
||||
### 1\. Pro: 定制属于你自己的 Linux 操作系统
|
||||
|
||||
大多数热门的 Linux 发行版(比如**Ubuntu** 和 **Fedora**) 很像一般我们会看到的预装系统,和**Windows** 或者 **MacOS** 一样。但 Arch 则会更鼓励你去把操作系统配置到符合你的胃口。如果你能顺利做到这点的话,你会得到一个每一个细节都如你所想的操作系统。
|
||||
|
||||
#### Con: 安装过程让人头疼
|
||||
|
||||
[安装 Arch Linux][2] 是主流发行版里的一支独苗——因为你要花些时间来微调你的操作系统。你会在过程中学到不少终端命令,和组成你系统的各种软件模块——毕竟你要自己挑选安装什么。当然,你也知道这个过程少不了阅读一些文档/教程。
|
||||
|
||||
### 2\. Pro: 没有预装垃圾
|
||||
|
||||
介于 **Arch** 允许你在安装时选择你想要的系统部件,你再也不用烦恼怎么处理你不想要的一堆预装软件。作为对比,**Ubuntu** 会预装大量的软件和桌面应用——很多你不需要甚至卸载之前都不知道他们存在的东西。
|
||||
|
||||
长话短说,**Arch Linux* 能省去大量的系统安装后时间。**Pacman**,是 Arch Linux 默认使用的优秀包管理组件。或者你也可以选择 [Pamac][3] 作为替代。
|
||||
|
||||
### 3\. Pro: 无需繁琐系统升级
|
||||
|
||||
**Arch Linux** 采用滚动升级模型,妙极了。这意味着你不需要担心老是被升级打断。一旦你用上了 Arch,连续地更新体验会让你和一会儿一个版本的升级说再见。只要你记得‘滚’更新(Arch 用语),你就一直会使用最新的软件包们。
|
||||
|
||||
#### Con: 一些升级可能会滚坏你的系统
|
||||
|
||||
虽然升级过程是完全连续的,你有时得留意一下你在更新什么。没人能知道所有软件的细节配置,也没人能替你来测试你的情况。所以如果你盲目更新,有时候你会滚坏你的系统。(译者:别担心,你可以回滚)
|
||||
|
||||
### 4\. Pro: Arch 有一个社区基因
|
||||
|
||||
所有 Linux 用户通常有一个共同点:对独立自由的追求。虽然大多数 Linux 发行版和公司企业等挂钩极少,但有时候也不是不存在的。比如 基于 **Ubuntu** 的变化版本们不得不受到 Canonical 公司决策的影响。
|
||||
|
||||
如果你想让你的电脑更独立,那么 Arch Linux 是你的伙伴。不像大多数操作系统,Arch 完全没有商业集团的影响,完全由社区驱动。
|
||||
|
||||
### 5\. Pro: Arch Wiki 无敌
|
||||
|
||||
[Arch Wiki][4] 是一个无敌文档库,几乎涵盖了所有关于安装和维护 Arch 以及关于操作系统本身的知识。Arch Wiki 最厉害的一点可能是,不管你在用什么发行版,你多多少少可能都在 Arch Wiki 的页面里找到过有用信息。这是因为 Arch 用户也会用别的发行版用户会用的东西,所以一些技巧和知识得以泛化。
|
||||
|
||||
### 6\. Pro: 别忘了 Arch 用户软件库 (AUR)
|
||||
|
||||
[Arch User Repository (AUR)][5] 是一个来自社区的超大软件仓库。如果你找一个还没有 Arch 的官方仓库里出现的软件,你肯定能在 AUR 里找到社区为你准备好的包。
|
||||
|
||||
AUR 是由用户自发编译和维护的。Arch 用户也可以给每个包投票,这样后来者就能找到最有用的那些软件包了。
|
||||
|
||||
#### 最后: Arch Linux 适合你吗?
|
||||
|
||||
**Arch Linux** 优点多于缺点,也有很多优缺点我无法在此一一叙述。安装过程很长,对非 Linux 用户来说也可能偏有些技术,但只要你投入一些时间和善用 Wiki,你肯定能迈过这道坎。
|
||||
|
||||
**Arch Linux** 是一个非常优秀的发行版——尽管它有一些复杂性。同时它也很受那些知道自己想要什么的用户的欢迎——只要你肯做点功课,有些耐心。
|
||||
|
||||
当你从0搭安装完 Arch 的时候,你会掌握很多 GNU/Linux 的内部细节,也再也不会对你的电脑内部运作方式一无所知了。
|
||||
|
||||
欢迎读者们在评论区讨论你使用 Arch Linux 的优缺点?以及你曾经遇到过的一些挑战。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
|
||||
[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
|
||||
[4]:https://wiki.archlinux.org/
|
||||
[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
320
translated/tech/20180705 Testing Node.js in 2018.md
Normal file
320
translated/tech/20180705 Testing Node.js in 2018.md
Normal file
@ -0,0 +1,320 @@
|
||||
测试 Node.js,2018
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
超过 3 亿用户正在使用 [Stream][4]。这些用户全都依赖我们的框架,而我们十分擅长测试要放到生产环境中的任何东西。我们大部分的代码库是用 Go 语言编写的,剩下的部分则是用 Python 编写。
|
||||
|
||||
我们最新的展示应用,[Winds 2.0][5],是用 Node.js 构建的,很快我们就了解到测试 Go 和 Python 的常规方法并不适合它。而且,创造一个好的测试套件需要用 Node.js 做很多额外的工作,因为我们正在使用的框架没有提供任何内建的测试功能。
|
||||
|
||||
不论你用什么语言,要构建完好的测试框架可能都非常复杂。本文我们会展示在使用 Node.js 测试过程中的困难部分,以及我们在 Winds 2.0 中用到的各种工具,并且在你要编写下一个测试集合时为你指明正确的方向。
|
||||
|
||||
### 为什么测试如此重要
|
||||
|
||||
我们都向生产环境中推送过糟糕的提交,并且经历过结果。碰到这样的情况不是好事。编写一个稳固的测试套件不仅仅是一个明智的检测,而且它还让你能够自由的重构代码,重构之后的代码仍然正常运行会让你信心倍增。这在你刚刚开始编写代码的时候尤为重要。
|
||||
|
||||
如果你是与团队共事,达到测试覆盖率极其重要。没有它,团队中的其他开发者几乎不可能知道他们所做的工作是否导致重大变动(ouch)。
|
||||
|
||||
编写测试同时促进你和你的队友把代码分割成更小的片段。这让别人去理解你的代码和修改 bug 变得容易多了。产品收益变得更大,因为你能更早的发现 bug。
|
||||
|
||||
最后,没有测试,你的基本代码还不如一堆纸片。基本不能保证你的代码是稳定的。
|
||||
|
||||
### 困难的部分
|
||||
|
||||
在我看来,我们在 Winds 中遇到的大多数测试问题是 Node.js 中特有的。它的生态系统总是在变大。例如,如果你用的是 macOS,运行 "brew upgrade"(安装了 homebrew),你看到你一个新版本的 Node.js 的概率非常高。由于 Node.js 迭代频繁,相应的库也紧随其后,想要与最新的库保持同步非常困难。
|
||||
|
||||
以下是一些要记在心上的痛点:
|
||||
|
||||
1. 在 Node.js 中进行测试是固执又不是固执的。人们对于如何构建一个测试架构以及如何检验成功有不同的看法。沮丧的是还没有一个黄金准则规定你应该如何进行测试。
|
||||
|
||||
2. 有一堆框架能够在你的应用里使用。但是它们一般都很精简,没有完好的配置或者启动过程。这会导致非常常见的副作用,而且还很难检测到;所以你们最终会想要从零开始编写自己的测试执行平台。
|
||||
|
||||
3. 几乎能保证你 _需要_ 编写自己的测试执行平台(马上就会讲到这一节)。
|
||||
|
||||
以上列出的情况不是理想的,而且这是 Node.js 社区应该尽管处理的事情。如果其他语言解决了这些问题,我认为也是作为广泛使用的语言, Node.js 解决这些问题的时候。
|
||||
|
||||
### 编写你自己的测试执行平台
|
||||
|
||||
所以...你可能会好奇测试执行平台 _是_ 什么,它并不复杂。测试执行平台在测试套件中是最高层的容器。它允许你指定全局配置和环境,还可以导入配置。可能有人觉得做这个很简单,对吧?没那么快呢。
|
||||
|
||||
我们所学到的是,尽管现在就有足够数量的测试框架了,没有一个关于 Node.js 的测试框架提供标准的方式能构建你的测试执行平台。很难受,这需要开发者来完成。这里有个关于测试执行平台的需求的简单总结:
|
||||
|
||||
* 能够加载不同的配置(比如,本地的,测试的,开发的),能够确保你 _永远不会_ 加载一个生产环境的配置 —— 你能想象出那样会出什么问题。
|
||||
|
||||
* 支持数据库,生成种子数据库,产生用于测试的数据。必须要支持多种数据库,不论是 MySQL、PostgreSQL、MongoDB 或者其它任何一个数据库。
|
||||
|
||||
* 能够加载配置(带有用于开发环境的种子数据的文件)。
|
||||
|
||||
做 Winds 的时候,我们选择 Mocha 作为测试执行平台。Mocha 提供了简单并且可编程的方式,通过命令行工具(整合了 Babel)来运行 ES6 代码的测试。
|
||||
|
||||
为了进行测试,我们注册了自己的 Babel 模块引导器。这为我们提供了更细的粒度,更强大的控制,在 Babel 覆盖掉 Node.js 模块加载过程前,对导入的模块进行控制,让我们有机会在所有测试运行前对模块进行模拟。
|
||||
|
||||
此外,我们还使用了 Mocha 的测试执行平台特性,预先把特定的请求赋给 HTTP 管理器。我们这么做是因为常规的初始化代码在测试中不会运行(服务器交互是用 Chai HTTP 插件模拟的),还要做一些安全性检查来确保我们不会连接到生产环境数据库。
|
||||
|
||||
尽管这不是测试执行平台的一部分,有一个固定加载器也是我们测试套件中的重要的一部分。我们试验过已有的解决方案;然而,我们最终决定编写自己的助手,这样它就能贴合我们的需求。根据我们的解决方案,在生成或手动编写配置时,通过遵循简单专有的协议,我们就能加载数据依赖很复杂的配置。
|
||||
|
||||
### Winds 中用到的工具
|
||||
|
||||
尽管过程很冗长,我们还是能够合理使用框架和工具,使得针对后台 API 进行的适当测试变成现实。这里是我们选择使用的工具:
|
||||
|
||||
### Mocha ☕
|
||||
|
||||
[Mocha][6], 被称为 “在 Node.js 上运行的特性丰富的测试框架”,是我们完成任务的首选。拥有超过 15K 的 stars,很多支持者和贡献者,我们指定这是正确的框架。
|
||||
|
||||
### Chai 🥃
|
||||
|
||||
然后是我们的断言库。我们选择使用传统方法,也就是最适合配合 Mocha 使用的 —— [Chai][7]。Chai 是一个用于 Node.js,适合 BDD 和 TDD 模式的断言库。有简单的 API,Chai 很容易整合进我们的应用,让我们能够轻松地断言出我们 _期望_ 从 Winds API 中返回的应该是什么。最棒的地方在于,用 Chai 编写测试让人觉得很自然。这是一个简短的例子:
|
||||
|
||||
```
|
||||
describe('retrieve user', () => {
|
||||
let user;
|
||||
|
||||
before(async () => {
|
||||
await loadFixture('user');
|
||||
user = await User.findOne({email: authUser.email});
|
||||
expect(user).to.not.be.null;
|
||||
});
|
||||
|
||||
after(async () => {
|
||||
await User.remove().exec();
|
||||
});
|
||||
|
||||
describe('valid request', () => {
|
||||
it('should return 200 and the user resource, including the email field, when retrieving the authenticated user', async () => {
|
||||
const response = await withLogin(request(api).get(`/users/${user._id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(user._id.toString());
|
||||
});
|
||||
|
||||
it('should return 200 and the user resource, excluding the email field, when retrieving another user', async () => {
|
||||
const anotherUser = await User.findOne({email: 'another_user@email.com'});
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${anotherUser.id}`), authUser);
|
||||
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body._id).to.equal(anotherUser._id.toString());
|
||||
expect(response.body).to.not.have.an('email');
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
describe('invalid requests', () => {
|
||||
|
||||
it('should return 404 if requested user does not exist', async () => {
|
||||
const nonExistingId = '5b10e1c601e9b8702ccfb974';
|
||||
expect(await User.findOne({_id: nonExistingId})).to.be.null;
|
||||
|
||||
const response = await withLogin(request(api).get(`/users/${nonExistingId}`), authUser);
|
||||
expect(response).to.have.status(404);
|
||||
});
|
||||
});
|
||||
|
||||
});
|
||||
```
|
||||
|
||||
### Sinon 🧙
|
||||
|
||||
拥有与任何测试框架相适应的能力,[Sinon][8] 是模拟库的首选。而且,精简安装带来的超级整洁的整合,让 Sinon 把模拟请求变成简单的过程。它的网站有极其良好的用户体验,并且提供简单的步骤,供你将 Sinon 整合进自己的测试框架中。
|
||||
|
||||
### Nock 🔮
|
||||
|
||||
For all external HTTP requests, we use [nock][9], a robust HTTP mocking library that really comes in handy when you have to communicate with a third party API (such as [Stream’s REST API][10]). There’s not much to say about this little library aside from the fact that it is awesome at what it does, and that’s why we like it. Here’s a quick example of us calling our [personalization][11] engine for Stream:
|
||||
对于所有外部的 HTTP 请求,我们使用稳定的 HTTP 模拟库 [nock][9],在你要和第三方 API 交互时非常易用(比如说 [Stream's REST API][10])。它做的事情非常酷炫,这就是我们喜欢它的原因,除此之外关于这个精妙的库没有什么要多说的了。这是我们的速成示例,调用我们在 Stream 引擎中提供的 [personalization][11]:
|
||||
|
||||
```
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
```
|
||||
|
||||
### Mock-require 🎩
|
||||
|
||||
[mock-require][12] 库允许依赖外部代码。用一行代码,你就可以替换一个模块,并且当代码尝试导入这个库时,将会产生模拟请求。这是一个小巧但稳定的库,我们还是它的粉丝。
|
||||
|
||||
### Istanbul 🔭
|
||||
|
||||
[Istanbul][13] 是 JavaScript 代码覆盖工具,在运行测试的时候,通过模块钩子自动添加覆盖率,可以计算语句,行数,函数和分支覆盖率。尽管我们有相似功能的 CodeCov(见下一节),进行本地测试时,这仍然是一个很棒的工具。
|
||||
|
||||
### 最终结果 — 运行测试
|
||||
|
||||
_有了这些库,还有之前提过的测试执行平台,现在让我们看看什么是完整的测试(你可以在 [_这里_][14] 看看我们完整的测试套件):_
|
||||
|
||||
```
|
||||
import nock from 'nock';
|
||||
import { expect, request } from 'chai';
|
||||
|
||||
import api from '../../src/server';
|
||||
import Article from '../../src/models/article';
|
||||
import config from '../../src/config';
|
||||
import { dropDBs, loadFixture, withLogin } from '../utils.js';
|
||||
|
||||
describe('Article controller', () => {
|
||||
let article;
|
||||
|
||||
before(async () => {
|
||||
await dropDBs();
|
||||
await loadFixture('initial-data', 'articles');
|
||||
article = await Article.findOne({});
|
||||
expect(article).to.not.be.null;
|
||||
expect(article.rss).to.not.be.null;
|
||||
});
|
||||
|
||||
describe('get', () => {
|
||||
it('should return the right article via /articles/:articleId', async () => {
|
||||
let response = await withLogin(request(api).get(`/articles/${article.id}`));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('get parsed article', () => {
|
||||
it('should return the parsed version of the article', async () => {
|
||||
const response = await withLogin(
|
||||
request(api).get(`/articles/${article.id}`).query({ type: 'parsed' })
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list', () => {
|
||||
it('should return the list of articles', async () => {
|
||||
let response = await withLogin(request(api).get('/articles'));
|
||||
expect(response).to.have.status(200);
|
||||
});
|
||||
});
|
||||
|
||||
describe('list from personalization', () => {
|
||||
after(function () {
|
||||
nock.cleanAll();
|
||||
});
|
||||
|
||||
it('should return the list of articles', async () => {
|
||||
nock(config.stream.baseUrl)
|
||||
.get(/winds_article_recommendations/)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
|
||||
const response = await withLogin(
|
||||
request(api).get('/articles').query({
|
||||
type: 'recommended',
|
||||
})
|
||||
);
|
||||
expect(response).to.have.status(200);
|
||||
expect(response.body.length).to.be.at.least(1);
|
||||
expect(response.body[0].url).to.eq(article.url);
|
||||
});
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
### 持续集成
|
||||
|
||||
有很多可用的持续集成服务,但我们钟爱 [Travis CI][15],因为他们和我们一样喜爱开源环境。考虑到 Winds 是开源的,它再合适不过了。
|
||||
|
||||
我们的集成非常简单 —— 我们用 [.travis.yml] 文件设置环境,通过简单的 [npm][17] 命令进行测试。测试覆盖率反馈给 Github,在 Github 上我们通过明了的图片能够看出我们最新的代码或者 PR 是不是通过了测试。Github 集成很棒,因为它可以自动查询 Travis CI 获取结果。以下是一个在 Github 上查看 PR (经过测试)的简单截图:
|
||||
|
||||

|
||||
|
||||
除了 Travis CI,我们还用到了叫做 [CodeCov][18] 的工具。CodeCov 和 [Istanbul] 很像,但它是个可视化的工具,方便我们 查看代码覆盖率,文件变动,行数变化,还有其他各种小玩意儿。尽管不用 CodeCov 也可以可视化数据,但把所有东西囊括在一个地方也很不错。
|
||||
|
||||
### 我们学到了什么
|
||||
|
||||

|
||||
|
||||
在开发我们的测试套件的整个过程中,我们学到了很多东西。开发时没有“正确”的方法,我们决定开始创造自己的测试流程,通过理清楚可用的库,找到那些足够有用的东西添加到我们的工具箱中。
|
||||
|
||||
最终我们学到的是,在 Node.js 中进行测试不是听上去那么简单。还好,随着 Node.js 持续完善,社区将会聚集力量,构建一个坚固稳健的库,可以用“正确”的方式处理所有和测试相关的东西。
|
||||
|
||||
直到那时,我们还会接着用自己的测试套件,也就是开源的 [Winds Github repository][20]。
|
||||
|
||||
### 局限
|
||||
|
||||
#### 创建配置没有简单的方法
|
||||
|
||||
框架和语言,就如 Python 中的 Django,有简单的方式来创建配置。比如,你可以使用下面这些 Django 命令,把数据导出到文件中来自动化配置的创建过程:
|
||||
|
||||
以下命令会把整个数据库导出到 db.json 文件中:
|
||||
./manage.py dumpdata > db.json
|
||||
|
||||
以下命令仅导出 django 中 admin.logentry 表里的内容:
|
||||
./manage.py dumpdata admin.logentry > logentry.json
|
||||
|
||||
以下命令会导出 auth.user 表中的内容:
|
||||
./manage.py dumpdata auth.user > user.json
|
||||
|
||||
Node.js 里面没有简单的方式来创建配置。我们最后做的事情是用 MongoDB Compass 工具导出数据到 JSON 中。这生成了不错的配置,如下图(但是,这是个乏味的过程,肯定会出错):
|
||||
|
||||

|
||||
|
||||
#### 使用 Babel,模拟模块和 Mocha 测试执行平台时,模块加载不直观
|
||||
|
||||
为了支持多种 node 版本,能够获取 JavaScript 标准的最新附件,我们使用 Babel 把 ES6 代码转换成 ES5。Node.js 模块系统基于 CommonJS 标准,而 ES6 模块系统中有不同的语义。
|
||||
|
||||
Babel 在 Node.js 模块系统的顶层模拟 ES6 模块语义,但由于我们要使用模拟访问来介入模块的加载,所以我们干的是经历奇怪的模块加载边角情况,这看上去很不直观,而且能导致在整个代码中,导入的、初始化的和使用的模块有不同的版本。这使测试时的模拟过程和全局状态管理复杂化了。
|
||||
|
||||
#### 在使用 ES6 模块时声明的函数,模块内部的函数,都无法模拟
|
||||
|
||||
当一个模块导出多个函数,其中一个函数调用了其他的函数,就不可能模拟使用在模块内部的函数。原因在于当你引用一个 ES6 模块时,你得到的引用集合和模块内部的是不同的。任何重新绑定引用,将其指向新值的尝试都无法真正影响模块内部的函数,内部函数仍然使用的是原始的函数。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
测试 Node.js 应用是复杂的过程,因为它的生态系统总在发展。掌握最新和最好的工具很重要,这样你就不会掉队了。
|
||||
|
||||
如今有很多路径获取 JavaScript 相关的新闻,导致与时俱进很难。关注邮件新闻刊物如 [JavaScript Weekly][21] 和 [Node Weekly][22] 是良好的开始。还有,关注一些子模块如 [/r/node][23] 也不错。如果你喜欢了解最新的趋势,[State of JS][24] 在帮助开发者可视化测试世界的趋势方便就做的很好。
|
||||
|
||||
最后,这里是一些我喜欢的博客,我经常在这上面发文章:
|
||||
|
||||
* [Hacker Noon][1]
|
||||
|
||||
* [Free Code Camp][2]
|
||||
|
||||
* [Bits and Pieces][3]
|
||||
|
||||
觉得我遗漏了某些重要的东西?在评论区或者 Twitter [@NickParsons][25] 让我知道。
|
||||
|
||||
还有,如果你想要了解 Stream,我们的网站上有很棒的 5 分钟教程。点 [这里][26] 进行查看。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nick Parsons
|
||||
|
||||
Dreamer. Doer. Engineer. Developer Evangelist https://getstream.io.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/testing-node-js-in-2018-10a04dd77391
|
||||
|
||||
作者:[Nick Parsons][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@nparsons08?source=post_header_lockup
|
||||
[1]:https://hackernoon.com/
|
||||
[2]:https://medium.freecodecamp.org/
|
||||
[3]:https://blog.bitsrc.io/
|
||||
[4]:https://getstream.io/
|
||||
[5]:https://getstream.io/winds
|
||||
[6]:https://github.com/mochajs/mocha
|
||||
[7]:http://www.chaijs.com/
|
||||
[8]:http://sinonjs.org/
|
||||
[9]:https://github.com/node-nock/nock
|
||||
[10]:https://getstream.io/docs_rest/
|
||||
[11]:https://getstream.io/personalization
|
||||
[12]:https://github.com/boblauer/mock-require
|
||||
[13]:https://github.com/gotwarlost/istanbul
|
||||
[14]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[15]:https://travis-ci.org/
|
||||
[16]:https://github.com/GetStream/Winds/blob/master/.travis.yml
|
||||
[17]:https://www.npmjs.com/
|
||||
[18]:https://codecov.io/#features
|
||||
[19]:https://github.com/gotwarlost/istanbul
|
||||
[20]:https://github.com/GetStream/Winds/tree/master/api/test
|
||||
[21]:https://javascriptweekly.com/
|
||||
[22]:https://nodeweekly.com/
|
||||
[23]:https://www.reddit.com/r/node/
|
||||
[24]:https://stateofjs.com/2017/testing/results/
|
||||
[25]:https://twitter.com/@nickparsons
|
||||
[26]:https://getstream.io/try-the-api
|
||||
@ -0,0 +1,88 @@
|
||||
2018 年 7 月 COPR 中 4 个值得尝试很酷的新项目
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
### Hledger
|
||||
|
||||
[Hledger][2]是用于跟踪货币或其他商品的命令行程序。它使用简单的纯文本格式日志来存储数据和复式记帐。除了命令行界面,hledger 还提供终端界面和 Web 客户端,可以显示帐户余额图。
|
||||
![][3]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 27、28 和 Rawhide 提供了 hledger。要安装 hledger,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable kefah/HLedger
|
||||
sudo dnf install hledger
|
||||
|
||||
```
|
||||
|
||||
### Neofetch
|
||||
|
||||
[Neofetch][4] 是一个命令行工具,可显示有关操作系统、软件和硬件的信息。其主要目的是以紧凑的方式显示数据来截图。你可以使用命令行标志和配置文件将 Neofetch 配置为完全按照你希望的方式显示。
|
||||
![][5]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 28 提供 Neofetch。要安装 Neofetch,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable sysek/neofetch
|
||||
sudo dnf install neofetch
|
||||
|
||||
```
|
||||
|
||||
### Remarkable
|
||||
|
||||
[Remarkable][6]是 Markdown 文本编辑器,它使用类似 GitHub 的 Markdown 风格。它提供了文档的预览,以及导出为 PDF 和 HTML 的选项。Markdown 有几种可用的样式,包括使用 CSS 创建自己的样式的选项。此外,Remarkable 支持用于编写方程的 LaTeX 语法和源代码的语法高亮。
|
||||
![][7]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 28 和 Rawhide 提供 Remarkable。要安装 Remarkable,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable neteler/remarkable
|
||||
sudo dnf install remarkable
|
||||
|
||||
```
|
||||
|
||||
### Aha
|
||||
|
||||
[Aha][8](或 ANSI HTML Adapter)是一个命令行工具,可将终端转义成 HTML 代码。这允许你将 git diff 或 htop 的输出共享为静态 HTML 页面。
|
||||
![][9]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
[仓库][10] 目前为 Fedora 26、27、28 和 Rawhide、EPEL 6 和 7 以及其他发行版提供 aha。要安装 aha,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable scx/aha
|
||||
sudo dnf install aha
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-july-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://hledger.org/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/hledger.png
|
||||
[4]:https://github.com/dylanaraps/neofetch
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/neofetch.png
|
||||
[6]:https://remarkableapp.github.io/linux.html
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/remarkable.png
|
||||
[8]:https://github.com/theZiz/aha
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/aha.png
|
||||
[10]:https://copr.fedorainfracloud.org/coprs/scx/aha/
|
||||
Loading…
Reference in New Issue
Block a user